
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4ac69fc831867071de98dc9ac6dd084801928d0d
| 13,172 |
ipynb
|
Jupyter Notebook
|
Wi19_content/DSMCER/L12_Neural_Networks.ipynb
|
ShahResearchGroup/UWDIRECT.github.io
|
d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e
|
[
"BSD-3-Clause"
] | 1 |
2021-01-26T19:55:02.000Z
|
2021-01-26T19:55:02.000Z
|
Wi19_content/DSMCER/L12_Neural_Networks.ipynb
|
ShahResearchGroup/UWDIRECT.github.io
|
d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e
|
[
"BSD-3-Clause"
] | null | null | null |
Wi19_content/DSMCER/L12_Neural_Networks.ipynb
|
ShahResearchGroup/UWDIRECT.github.io
|
d4db958a6bfe151b6f7b1eb4772d8fd1b9bb0c3e
|
[
"BSD-3-Clause"
] | null | null | null | 26.826884 | 330 | 0.573261 |
[
[
[
"from keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.wrappers.scikit_learn import KerasRegressor\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.model_selection import KFold\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.pipeline import Pipeline\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Set our random seed so that all computations are deterministic",
"_____no_output_____"
]
],
[
[
"seed = 21899",
"_____no_output_____"
]
],
[
[
"Read in the raw data for the first 100K records of the HCEPDB into a pandas dataframe",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('https://github.com/UWDIRECT/UWDIRECT.github.io/blob/master/Wi18_content/DSMCER/HCEPD_100K.csv?raw=true')\ndf.head()",
"_____no_output_____"
]
],
[
[
"Separate out the predictors from the output\n",
"_____no_output_____"
]
],
[
[
"X = df[['mass', 'voc', 'jsc', 'e_homo_alpha', 'e_gap_alpha', \n 'e_lumo_alpha']].values\nY = df[['pce']].values",
"_____no_output_____"
]
],
[
[
"Let's create the test / train split for these data using 80/20. The `_pn` extension is related to the 'prenormalization' nature of the data.",
"_____no_output_____"
]
],
[
[
"X_train_pn, X_test_pn, y_train, y_test = train_test_split(X, Y,\n test_size=0.20,\n random_state=seed)",
"_____no_output_____"
]
],
[
[
"Now we need to `StandardScaler` the training data and apply that scale to the test data.",
"_____no_output_____"
]
],
[
[
"# create the scaler from the training data only and keep it for later use\nX_train_scaler = StandardScaler().fit(X_train_pn)\n# apply the scaler transform to the training data\nX_train = X_train_scaler.transform(X_train_pn)",
"_____no_output_____"
]
],
[
[
"Now let's reuse that scaler transform on the test set. This way we never contaminate the test data with the training data. We'll start with a histogram of the testing data just to prove to ourselves it is working.",
"_____no_output_____"
]
],
[
[
"plt.hist(X_test_pn[:,1])",
"_____no_output_____"
]
],
[
[
"OK, bnow apply the training scaler transform to the test and plot a histogram",
"_____no_output_____"
]
],
[
[
"X_test = X_train_scaler.transform(X_test_pn)",
"_____no_output_____"
],
[
"plt.hist(X_test[:,1])",
"_____no_output_____"
]
],
[
[
"### Let's create the neural network layout\n\nThis is a simple neural network with no hidden layers and just the inputs transitioned to the output.",
"_____no_output_____"
]
],
[
[
"def simple_model():\n # assemble the structure\n model = Sequential()\n model.add(Dense(6, input_dim=6, kernel_initializer='normal', activation='relu'))\n model.add(Dense(1, kernel_initializer='normal'))\n # compile the model\n model.compile(loss='mean_squared_error', optimizer='adam')\n return model",
"_____no_output_____"
]
],
[
[
"Train the neural network with the following",
"_____no_output_____"
]
],
[
[
"# initialize the andom seed as this is used to generate\n# the starting weights\nnp.random.seed(seed)\n# create the NN framework\nestimator = KerasRegressor(build_fn=simple_model,\n epochs=150, batch_size=25000, verbose=0)\nhistory = estimator.fit(X_train, y_train, validation_split=0.33, epochs=150, \n batch_size=10000, verbose=0)",
"_____no_output_____"
]
],
[
[
"The history object returned by the `fit` call contains the information in a fitting run.",
"_____no_output_____"
]
],
[
[
"print(history.history.keys())",
"_____no_output_____"
],
[
"print(\"final MSE for train is %.2f and for validation is %.2f\" % \n (history.history['loss'][-1], history.history['val_loss'][-1]))",
"_____no_output_____"
]
],
[
[
"Let's plot it!",
"_____no_output_____"
]
],
[
[
"# summarize history for loss\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'validation'], loc='upper left')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's get the MSE for the test set.",
"_____no_output_____"
]
],
[
[
"test_loss = estimator.model.evaluate(X_test, y_test)\nprint(\"test set mse is %.2f\" % test_loss)",
"_____no_output_____"
]
],
[
[
"## NEAT!\n\nSo our train mse is very similar to the training and validation at the final step!",
"_____no_output_____"
],
[
"### Let's look at another way to evaluate the set of models using cross validation\n\nUse 10 fold cross validation to evaluate the models generated from our training set. We'll use scikit-learn's tools for this. Remember, this is only assessing our training set. If you get negative values, to make `cross_val_score` behave as expected, we have to flip the signs on the results (incompatibility with keras).",
"_____no_output_____"
]
],
[
[
"kfold = KFold(n_splits=10, random_state=seed)\nresults = cross_val_score(estimator, X_train, y_train, cv=kfold)\nprint(\"Results: %.2f (%.2f) MSE\" % (-1 * results.mean(), results.std()))",
"_____no_output_____"
]
],
[
[
"#### Quick aside, `Pipeline`\n\nLet's use scikit learns `Pipeline` workflow to run a k-fold cross validation run on the learned model.\n\nWith this tool, we create a workflow using the `Pipeline` object. You provide a list of actions (as named tuples) to be performed. We do this with `StandardScaler` to eliminate the posibility of training leakage into the cross validation test set during normalization.",
"_____no_output_____"
]
],
[
[
"estimators = []\nestimators.append(('standardize', StandardScaler()))\nestimators.append(('mlp', KerasRegressor(build_fn=simple_model,\n epochs=150, batch_size=25000, verbose=0)))\npipeline = Pipeline(estimators)\nkfold = KFold(n_splits=10, random_state=seed)\nresults = cross_val_score(pipeline, X_train, y_train, cv=kfold)\nprint('MSE mean: %.4f ; std: %.4f' % (-1 * results.mean(), results.std()))",
"_____no_output_____"
]
],
[
[
"### Now, let's try a more sophisticated model\n\nLet's use a hidden layer this time.",
"_____no_output_____"
]
],
[
[
"def medium_model():\n # assemble the structure\n model = Sequential()\n model.add(Dense(6, input_dim=6, kernel_initializer='normal', activation='relu'))\n model.add(Dense(4, kernel_initializer='normal', activation='relu'))\n model.add(Dense(1, kernel_initializer='normal'))\n # compile the model\n model.compile(loss='mean_squared_error', optimizer='adam')\n return model",
"_____no_output_____"
],
[
"# initialize the andom seed as this is used to generate\n# the starting weights\nnp.random.seed(seed)\n# create the NN framework\nestimator = KerasRegressor(build_fn=medium_model,\n epochs=150, batch_size=25000, verbose=0)\nhistory = estimator.fit(X_train, y_train, validation_split=0.33, epochs=150, \n batch_size=10000, verbose=0)\nprint(\"final MSE for train is %.2f and for validation is %.2f\" % \n (history.history['loss'][-1], history.history['val_loss'][-1]))",
"_____no_output_____"
],
[
"# summarize history for loss\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'validation'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"test_loss = estimator.model.evaluate(X_test, y_test)\nprint(\"test set mse is %.2f\" % test_loss)",
"_____no_output_____"
]
],
[
[
"_So it appears our more complex model improved performance_",
"_____no_output_____"
],
[
"### Free time!\n\nFind example code for keras for the two following items:\n* L1 and L2 regularization (note in keras, this can be done by layer)\n* Dropout\n\n\n#### Regularization\nLet's start by adding L1 or L2 (or both) regularization to the hidden layer.\n\nHint: you need to define a new function that is the neural network model and add the correct parameters to the layer definition. Then retrain and plot as above. What parameters did you choose for your dropout? Did it improve training?",
"_____no_output_____"
],
[
"#### Dropout\n\nFind the approach to specifying dropout on a layer using your best friend `bing`. As with L1 and L2 above, this will involve defining a new network struction using a function and some new 'magical' dropout layers.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4ac6a8fc19e0042a7e3d36da54cd885a1e0520ba
| 5,027 |
ipynb
|
Jupyter Notebook
|
notebook/sample.ipynb
|
k-utsubo/japanese-pretrained-models
|
59cd04e94f5c80bdb7408874636e0a38d979b6ef
|
[
"Apache-2.0"
] | null | null | null |
notebook/sample.ipynb
|
k-utsubo/japanese-pretrained-models
|
59cd04e94f5c80bdb7408874636e0a38d979b6ef
|
[
"Apache-2.0"
] | null | null | null |
notebook/sample.ipynb
|
k-utsubo/japanese-pretrained-models
|
59cd04e94f5c80bdb7408874636e0a38d979b6ef
|
[
"Apache-2.0"
] | null | null | null | 28.241573 | 97 | 0.526358 |
[
[
[
"https://github.com/rinnakk/japanese-pretrained-models",
"_____no_output_____"
]
],
[
[
"import torch\r\nfrom transformers import T5Tokenizer, RobertaForMaskedLM\r\n\r\n# load tokenizer\r\ntokenizer = T5Tokenizer.from_pretrained(\"rinna/japanese-roberta-base\")\r\ntokenizer.do_lower_case = True # due to some bug of tokenizer config loading\r\n\r\n# load model\r\nmodel = RobertaForMaskedLM.from_pretrained(\"rinna/japanese-roberta-base\")\r\nmodel = model.eval()\r\n\r\n# original text\r\ntext = \"4年に1度オリンピックは開かれる。\"\r\n\r\n# prepend [CLS]\r\ntext = \"[CLS]\" + text\r\n\r\n# tokenize\r\ntokens = tokenizer.tokenize(text)\r\nprint(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', 'オリンピック', 'は', '開かれる', '。']']\r\n\r\n# mask a token\r\nmasked_idx = 5\r\ntokens[masked_idx] = tokenizer.mask_token\r\nprint(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', '[MASK]', 'は', '開かれる', '。']\r\n\r\n# convert to ids\r\ntoken_ids = tokenizer.convert_tokens_to_ids(tokens)\r\nprint(token_ids) # output: [4, 1602, 44, 24, 368, 6, 11, 21583, 8]\r\n\r\n# convert to tensor\r\ntoken_tensor = torch.tensor([token_ids])\r\n\r\n# get the top 10 predictions of the masked token\r\nwith torch.no_grad():\r\n outputs = model(token_tensor)\r\n predictions = outputs[0][0, masked_idx].topk(10)\r\n\r\nfor i, index_t in enumerate(predictions.indices):\r\n index = index_t.item()\r\n token = tokenizer.convert_ids_to_tokens([index])[0]\r\n print(i, token)",
"Downloading: 100%|██████████| 806k/806k [00:00<00:00, 15.2MB/s]\nDownloading: 100%|██████████| 153/153 [00:00<00:00, 37.4kB/s]\nDownloading: 100%|██████████| 259/259 [00:00<00:00, 263kB/s]\nDownloading: 100%|██████████| 663/663 [00:00<00:00, 332kB/s]\nDownloading: 100%|██████████| 443M/443M [00:10<00:00, 43.4MB/s]\n"
],
[
"from transformers import T5Tokenizer, AutoModelForCausalLM\r\nfrom transformers import GPT2Tokenizer, GPT2LMHeadModel\r\ntokenizer = T5Tokenizer.from_pretrained(\"rinna/japanese-gpt2-medium\")\r\ntokenizer.do_lower_case = True # due to some bug of tokenizer config loading\r\n\r\nmodel = AutoModelForCausalLM.from_pretrained(\"rinna/japanese-gpt2-medium\")",
"_____no_output_____"
],
[
"inputs=tokenizer(\"こんにちは,世界!\")\r\nprint(inputs)\r\n",
"{'input_ids': [9, 30442, 11, 83, 301, 543, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1]}\n"
],
[
"outputs = model.generate(input_ids=torch.tensor([inputs[\"input_ids\"]]))\r\ntext = tokenizer.decode(\r\n outputs[0].tolist(),\r\n skip_special_tokens=True,\r\n clean_up_tokenization_spaces=True,\r\n)\r\nprint(text)",
"Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ac6cc3f096e964b1453dfb344d77297438621fe
| 487,258 |
ipynb
|
Jupyter Notebook
|
ML_Testing.ipynb
|
daniella-patton/TennisDoctor
|
2524d5bd52d2c4676b3de820eee4695a46795a63
|
[
"MIT"
] | null | null | null |
ML_Testing.ipynb
|
daniella-patton/TennisDoctor
|
2524d5bd52d2c4676b3de820eee4695a46795a63
|
[
"MIT"
] | null | null | null |
ML_Testing.ipynb
|
daniella-patton/TennisDoctor
|
2524d5bd52d2c4676b3de820eee4695a46795a63
|
[
"MIT"
] | null | null | null | 125.711558 | 125,760 | 0.768184 |
[
[
[
"# Testing Various Machine Learning Models\n\nI would like to create model that can identify individuals at the greatest risk of injury three months prior to when it occurs. In order to do this, I will first complete feature selection using a step-forward approach to optimize recall. Then I will complete some basic EDA. How imablaneced is the data? Are the features selected correlated? Next, I tested various machine learnign models and balenced thate data using to oversampling",
"_____no_output_____"
]
],
[
[
"# Machine Learning Model Tests\n%load_ext nb_black",
"_____no_output_____"
],
[
"######FINAL COPY\n# ML 2010\n# Reading in the pachages used for this part of analysis\nimport pandas as pd\nimport numpy as np\nfrom numpy import cov\nfrom scipy.stats import pearsonr\nfrom datetime import date\nimport datetime\nfrom dateutil.relativedelta import relativedelta\nfrom dateutil import parser\nfrom collections import Counter\nfrom datetime import datetime\nfrom dateutil.parser import parse\nimport datetime\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import train_test_split\nimport seaborn as sns\nfrom dateutil import parser\nimport random\nimport os\nimport os.path\nfrom collections import Counter\nimport sklearn\n\nimport matplotlib.pyplot as plt\nfrom matplotlib import colors\nfrom matplotlib.ticker import PercentFormatter\n\nfrom pandas.plotting import scatter_matrix\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn import linear_model\n\nfrom xgboost import XGBClassifier\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import confusion_matrix, classification_report\n\nimport matplotlib.pyplot as plt\nfrom sklearn import model_selection\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.svm import SVC\nfrom sklearn.ensemble import RandomForestClassifier\nimport matplotlib.pyplot as plt\n\nfrom imblearn.over_sampling import SMOTE\nfrom imblearn.pipeline import make_pipeline\nfrom imblearn.over_sampling import ADASYN \nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom sklearn import preprocessing\nimport pickle\nfrom sklearn import preprocessing\n",
"_____no_output_____"
],
[
"# Change the Working Directory\nos.chdir(\"/Users/Owner/Desktop/InsightFellows/Daniella_Patton_Insight_Project/Raw_Data\")\nprint(os.getcwd()) # Prints the current working directory\nml_table2010 = pd.read_csv(\"ML_filtered_career.csv\")",
"/Users/Owner/Desktop/InsightFellows/Daniella_Patton_Insight_Project/Raw_Data\n"
],
[
"ml_table2010.head()\n\n\ndef ratio(ml_table2010):\n if ml_table2010.Month1DoublesMathces == 0:\n x = ml_table2010.Month1SinglesMathces\n else:\n x = ml_table2010.Month1SinglesMathces / ml_table2010.Month1DoublesMathces\n return x",
"_____no_output_____"
],
[
"# Hard Code in Yes or No for injury type\nml_table2010[\"Injured\"] = ml_table2010[\"Injured\"].replace(\"Y\", 1)\nml_table2010[\"Injured\"] = ml_table2010[\"Injured\"].replace(\"N\", 0)\n# Hard Code in\nml_table2010[\"Month1Injured\"] = ml_table2010[\"Month1Injured\"].replace(\"Y\", 1)\nml_table2010[\"Month1Injured\"] = ml_table2010[\"Month1Injured\"].replace(\"N\", 0)\n# Hard Code in\nml_table2010[\"Month3Injured\"] = ml_table2010[\"Month3Injured\"].replace(\"Y\", 1)\nml_table2010[\"Month3Injured\"] = ml_table2010[\"Month3Injured\"].replace(\"N\", 0)\n# Hard Code in\nml_table2010[\"Month6Injured\"] = ml_table2010[\"Month6Injured\"].replace(\"Y\", 1)\nml_table2010[\"Month6Injured\"] = ml_table2010[\"Month6Injured\"].replace(\"N\", 0)\n# Hard Code in\nml_table2010[\"CumInjured\"] = ml_table2010[\"CumInjured\"].replace(\"Y\", 1)\nml_table2010[\"CumInjured\"] = ml_table2010[\"CumInjured\"].replace(\"N\", 0)",
"_____no_output_____"
],
[
"# GET DUMMIES FOR THE REST\n# Drop the name\nml_table2010 = pd.get_dummies(\n ml_table2010,\n columns=[\n \"Country\",\n \"Month1InjuredType\",\n \"Month3InjuredType\",\n \"Month6InjuredType\",\n \"CumInjuredType\",\n ],\n)",
"_____no_output_____"
],
[
"ml_table2010 = ml_table2010.drop([\"EndDate\"], axis=1)\nml_table2010.dtypes",
"_____no_output_____"
],
[
"# Getting all of the data in the collumn filtered by startdate so\nml_table2010[\"StartDate\"] = ml_table2010[\"StartDate\"].apply(\n lambda x: parser.parse(x).date()\n)",
"_____no_output_____"
],
[
"# Chacked for Unbalenced Classes\nsns.catplot(x=\"Injured\", kind=\"count\", palette=\"ch:.25\", data=ml_table2010)\nprint(ml_table2010[\"Injured\"].value_counts())\nprint(2698 / 13687)",
"0 13687\n1 2698\nName: Injured, dtype: int64\n0.19712135603127054\n"
],
[
"# Use 2010 - 2018 data to train\nTraining = ml_table2010[ml_table2010[\"StartDate\"] < datetime.date(2018, 1, 1)]\nX_train = Training.drop([\"Injured\", \"StartDate\", \"PlayerName\"], axis=1)\nY_train = Training[\"Injured\"]\n\n# Use 2019 data to test how accurate the model predictions are\n# Testing Set\nTesting = ml_table2010[\n (ml_table2010[\"StartDate\"] >= datetime.date(2018, 1, 1))\n & (ml_table2010[\"StartDate\"] < datetime.date(2019, 6, 1))\n]\nX_test = Testing.drop([\"Injured\", \"StartDate\", \"PlayerName\"], axis=1)\nY_test = Testing[\"Injured\"]",
"_____no_output_____"
],
[
"ml_table2010.head()",
"_____no_output_____"
],
[
"# keep last duplicate value\ndf = ml_table2010.drop_duplicates(subset=[\"PlayerName\"], keep=\"last\")\n\ncsv_for_webapp = df[\n [\n \"PlayerName\",\n \"Month1Carpet\",\n \"CumInjured\",\n \"CumInjuredTimes\",\n \"CumInjuredGames\",\n \"Country_Argentina\",\n \"Country_Australia\",\n \"Country_Austria\",\n \"Country_Belarus\",\n \"Country_Brazil\",\n \"Country_Colombia\",\n \"Country_Egypt\",\n \"Country_Estonia\",\n \"Country_Israel\",\n \"Country_Kazakhstan\",\n \"Country_Latvia\",\n \"Country_Romania\",\n \"Country_Russia\",\n \"Country_Serbia\",\n \"Country_South Korea\",\n \"Country_Sweden\",\n \"Country_Switzerland\",\n \"Country_Thailand\",\n \"Country_Venezuela\",\n \"Month1InjuredType_Severe\",\n \"CumInjuredType_Moderate\",\n ]\n].copy()",
"_____no_output_____"
],
[
"csv_for_webapp.head()\ncsv_for_webapp.to_csv(\"Current_Player_Info.csv\")",
"_____no_output_____"
]
],
[
[
"# First Pass Random Forest with unbalenced data for model selections",
"_____no_output_____"
]
],
[
[
"from imblearn.pipeline import Pipeline, make_pipeline\nfrom sklearn.model_selection import KFold # import KFold\nfrom imblearn.over_sampling import SMOTE\n\n# Import the model we are using\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn import metrics\nfrom sklearn.model_selection import KFold, cross_val_score\n\n# Build RF classifier to use in feature selection\nfrom mlxtend.feature_selection import SequentialFeatureSelector as sfs",
"_____no_output_____"
],
[
"# First Pass Random Forest\nrf = RandomForestClassifier()\n\nrf.fit(X_train, Y_train)\n\ny_pred = rf.predict(X_test)\ny_pred = pd.Series(y_pred)\n# Train the model on training data\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\"Accuracy of random forest on test set: {:.2f}\".format(rf.score(X_test, Y_test)))\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.recall_score(Y_test, y_pred))\nprint(\"F1:\", metrics.f1_score(Y_test, y_pred))",
"[[1775 15]\n [ 394 10]]\nAccuracy of random forest on test set: 0.81\nPrecision: 0.4\nRecall: 0.024752475247524754\nF1: 0.046620046620046623\n"
],
[
"# Step Foward for Precision\nclf = RandomForestClassifier(n_estimators=100, n_jobs=-1)\n#clf = LogisticRegression(solver='liblinear', max_iter=1, class_weight='balanced')\n# Build step forward feature selection\nsfs = sfs(clf,\n k_features=25,\n forward=True,\n floating=False,\n verbose=2,\n scoring='recall',\n cv=5)\n\n# Perform SFFS\nsfs1 = sfs1.fit(X_train, Y_train)",
"[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 3.4s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 113 out of 113 | elapsed: 3.6min finished\n\n[2020-02-06 11:56:02] Features: 1/15 -- score: 0.12790608469148354[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.2s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 112 out of 112 | elapsed: 10.4min finished\n\n[2020-02-06 12:06:25] Features: 2/15 -- score: 0.19121684909144435[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.2s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 111 out of 111 | elapsed: 8.0min finished\n\n[2020-02-06 12:14:24] Features: 3/15 -- score: 0.20472966342851534[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.1s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 110 out of 110 | elapsed: 7.8min finished\n\n[2020-02-06 12:22:14] Features: 4/15 -- score: 0.21148250238624094[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.0s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 109 out of 109 | elapsed: 7.5min finished\n\n[2020-02-06 12:29:45] Features: 5/15 -- score: 0.21401325590315876[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.0s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 108 out of 108 | elapsed: 10.0min finished\n\n[2020-02-06 12:39:43] Features: 6/15 -- score: 0.21570012756353646[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 12.2s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 107 out of 107 | elapsed: 9.2min finished\n\n[2020-02-06 12:48:57] Features: 7/15 -- score: 0.22034058572180443[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.2s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 106 out of 106 | elapsed: 7.6min finished\n\n[2020-02-06 12:56:31] Features: 8/15 -- score: 0.22245207446855958[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.1s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 105 out of 105 | elapsed: 7.8min finished\n\n[2020-02-06 13:04:22] Features: 9/15 -- score: 0.21949670386526435[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.1s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 104 out of 104 | elapsed: 7.3min finished\n\n[2020-02-06 13:11:37] Features: 10/15 -- score: 0.22456713142612467[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.0s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 103 out of 103 | elapsed: 7.1min finished\n\n[2020-02-06 13:18:45] Features: 11/15 -- score: 0.2279480111684998[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.3s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 102 out of 102 | elapsed: 7.1min finished\n\n[2020-02-06 13:25:53] Features: 12/15 -- score: 0.22836816799136495[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.1s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 101 out of 101 | elapsed: 7.0min finished\n\n[2020-02-06 13:32:56] Features: 13/15 -- score: 0.2304823328962275[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.1s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 100 out of 100 | elapsed: 7.0min finished\n\n[2020-02-06 13:39:55] Features: 14/15 -- score: 0.23132086243655275[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 4.2s remaining: 0.0s\n[Parallel(n_jobs=1)]: Done 99 out of 99 | elapsed: 7.0min finished\n\n[2020-02-06 13:46:56] Features: 15/15 -- score: 0.2321665283984978"
],
[
"# Which features?\nfeat_cols = list(sfs1.k_feature_idx_)\n# Random Forest Classifired Index [37, 38, 47, 49, 51, 74, 84, 92, 96, 110]\n# Logistic Regression Index [10, 37, 38, 48, 56, 73, 75, 77, 84, 85, 92, 93, 98, 104, 111]",
"_____no_output_____"
],
[
"X_train.head(20)\n# colnames = X_train.columns[feat_cols]\n# print(colnames)\n\n\n# X_train.head()\n\n# X_train = X_train[colnames]\n# X_test = X_test[colnames]\n\nX_train = X_train[\n [\n \"Month1GamesPlayed\",\n \"Month1Carpet\",\n \"CumInjured\",\n \"CumInjuredTimes\",\n \"CumInjuredGames\",\n \"Country_Argentina\",\n \"Country_Australia\",\n \"Country_Austria\",\n \"Country_Belarus\",\n \"Country_Brazil\",\n \"Country_Colombia\",\n \"Country_Egypt\",\n \"Country_Estonia\",\n \"Country_Israel\",\n \"Country_Kazakhstan\",\n \"Country_Latvia\",\n \"Country_Romania\",\n \"Country_Russia\",\n \"Country_Serbia\",\n \"Country_South Korea\",\n \"Country_Sweden\",\n \"Country_Switzerland\",\n \"Country_Thailand\",\n \"Country_Venezuela\",\n \"Month1InjuredType_Severe\",\n \"CumInjuredType_Moderate\",\n ]\n]\n\n\nX_test = X_test[\n [\n \"Month1GamesPlayed\",\n \"Month1Carpet\",\n \"CumInjured\",\n \"CumInjuredTimes\",\n \"CumInjuredGames\",\n \"Country_Argentina\",\n \"Country_Australia\",\n \"Country_Austria\",\n \"Country_Belarus\",\n \"Country_Brazil\",\n \"Country_Colombia\",\n \"Country_Egypt\",\n \"Country_Estonia\",\n \"Country_Israel\",\n \"Country_Kazakhstan\",\n \"Country_Latvia\",\n \"Country_Romania\",\n \"Country_Russia\",\n \"Country_Serbia\",\n \"Country_South Korea\",\n \"Country_Sweden\",\n \"Country_Switzerland\",\n \"Country_Thailand\",\n \"Country_Venezuela\",\n \"Month1InjuredType_Severe\",\n \"CumInjuredType_Moderate\",\n ]\n]",
"_____no_output_____"
],
[
"# Instantiate model with 1000 decision trees\n# Imporvement to model, so using these variable movni foward\nrf = RandomForestClassifier(class_weight=\"balanced\")\nrf.fit(X_train, Y_train)\n\ny_pred = rf.predict(X_test)\ny_pred = pd.Series(y_pred)\n# Train the model on training data\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\"Accuracy of random forest on test set: {:.2f}\".format(rf.score(X_test, Y_test)))\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.recall_score(Y_test, y_pred))\nprint(\"F1:\", metrics.f1_score(Y_test, y_pred))",
"[[1694 96]\n [ 372 32]]\nAccuracy of random forest on test set: 0.79\nPrecision: 0.25\nRecall: 0.07920792079207921\nF1: 0.12030075187969924\n"
],
[
"# Corr Matrix test\ncorr_mt = X_train.copy()\ncorr_mt[\"Injured\"] = Y_train",
"_____no_output_____"
],
[
"# Need to Look at correlation matrix and remove highly correlated variables in the\n# order of most important variabes\n\nf = plt.figure(figsize=(19, 15))\nplt.matshow(corr_mt.corr(), fignum=f.number)\nplt.xticks(range(corr_mt.shape[1]), corr_mt.columns, fontsize=14, rotation=45)\nplt.yticks(range(corr_mt.shape[1]), corr_mt.columns, fontsize=14)\ncb = plt.colorbar()\ncb.ax.tick_params(labelsize=14)",
"_____no_output_____"
],
[
"# prepare configuration for cross validation test harness\nseed = 7\nkfold = 5\n# Ratio of injured to non-injured \n# 2682/13580 = 0.2 (5 x)\n\n# prepare models\nmodels = []\nmodels.append(('LR', LogisticRegression(solver='liblinear', max_iter=100, class_weight='balanced')))\nmodels.append(('LDA', LinearDiscriminantAnalysis()))\nmodels.append(('KNN', KNeighborsClassifier()))\nmodels.append(('CART', DecisionTreeClassifier(class_weight='balanced')))\nmodels.append(('NB', GaussianNB()))\nmodels.append(('SVM', SVC(class_weight='balanced')))\nmodels.append(('RF', RandomForestClassifier(class_weight='balanced')))\nmodels.append(('XGBoost', XGBClassifier(scale_pos_weight=4)))\n\n# evaluate each model in turn\nresults = []\nnames = []\nscoring='f1'\n\nprint('The results with balanced-weighting')\nfor name, model in models:\n kfold = model_selection.KFold(n_splits=5)\n cv_results = model_selection.cross_val_score(model, X_train, Y_train, cv=kfold, scoring=scoring)\n results.append(cv_results)\n names.append(name)\n msg = \"%s: %f (%f)\" % (name, cv_results.mean(), cv_results.std())\n print(msg)\n \n\nmodels = []\nmodels.append(('LR', LogisticRegression()))\nmodels.append(('LDA', LinearDiscriminantAnalysis()))\nmodels.append(('KNN', KNeighborsClassifier()))\nmodels.append(('CART', DecisionTreeClassifier()))\nmodels.append(('NB', GaussianNB()))\nmodels.append(('SVM', SVC()))\nmodels.append(('RF', RandomForestClassifier()))\nmodels.append(('XGBoost', XGBClassifier()))\n\n \nprint('The results with balanced data using SMOTE')\nresults_SMOTE = []\nnames_SMOTE = []\n\nfor name, model in models: \n kfold = model_selection.KFold(n_splits=5)\n imba_pipeline = make_pipeline(SMOTE(random_state=42), model)\n cv_results = cross_val_score(imba_pipeline, X_train, Y_train, scoring= scoring, cv=kfold)\n results_SMOTE.append(cv_results)\n names_SMOTE.append(name)\n msg = \"%s: %f (%f)\" % (name, cv_results.mean(), cv_results.std())\n print(msg)\n\n\nprint('The results with balanced data using ADASYN')\nresults_ADASYN = []\nnames_ADASYN = []\n\nfor name, model in models: \n kfold = model_selection.KFold(n_splits=5)\n imba_pipeline = make_pipeline(ADASYN(random_state=42), model)\n cv_results = cross_val_score(imba_pipeline, X_train, Y_train, scoring= scoring, cv=kfold)\n results_ADASYN.append(cv_results)\n names_ADASYN.append(name)\n msg = \"%s: %f (%f)\" % (name, cv_results.mean(), cv_results.std())\n print(msg)",
"_____no_output_____"
],
[
"X_scaled = preprocessing.scale(X_train)\n\n# prepare models\nmodels = []\nmodels.append(\n (\n \"LR\",\n LogisticRegression(solver=\"liblinear\", max_iter=100, class_weight=\"balanced\"),\n )\n)\nmodels.append((\"LDA\", LinearDiscriminantAnalysis()))\nmodels.append((\"KNN\", KNeighborsClassifier()))\nmodels.append((\"CART\", DecisionTreeClassifier(class_weight=\"balanced\")))\nmodels.append((\"NB\", GaussianNB()))\nmodels.append((\"SVM\", SVC(class_weight=\"balanced\")))\nmodels.append((\"RF\", RandomForestClassifier(class_weight=\"balanced\")))\nmodels.append((\"XGBoost\", XGBClassifier(scale_pos_weight=4)))\n\n# evaluate each model in turn\nresults = []\nnames = []\nscoring = \"f1\"\n\nprint(\"The results with balanced-weighting\")\nfor name, model in models:\n kfold = model_selection.KFold(n_splits=5)\n cv_results = model_selection.cross_val_score(\n model, X_scaled, Y_train, cv=kfold, scoring=scoring\n )\n results.append(cv_results)\n names.append(name)\n msg = \"%s: %f (%f)\" % (name, cv_results.mean(), cv_results.std())\n print(msg)\n\n\n\"\"\"\nThe results with balanced-weighting\nLR: 0.335936 (0.007798)\nLDA: 0.061024 (0.037630)\nKNN: 0.152377 (0.031906)\nCART: 0.223875 (0.018499)\nNB: 0.285749 (0.012118)\nSVM: 0.329350 (0.012078)\nRF: 0.237863 (0.016613)\nXGBoost: 0.329015 (0.014148)\n\"\"\"",
"The results with balanced-weighting\nLR: 0.338619 (0.008997)\nLDA: 0.072454 (0.035208)\n"
],
[
"# boxplot algorithm comparison\nfig = plt.figure()\nfig.suptitle(\"Balanced Algorithm Comparison\")\nax = fig.add_subplot(111)\nplt.boxplot(results)\nax.set_xticklabels(names)\nplt.show()",
"_____no_output_____"
],
[
"sns.set(font_scale=3)\nsns.set_style(\"whitegrid\")\n\nfig, ax = plt.subplots(figsize=(8, 8.27))\n\ntips = sns.load_dataset(\"tips\")\nax = sns.boxplot(x=names, y=results)\n\nplt.xticks(rotation=45)\n\n# Select which box you want to change\nmybox = ax.artists[0]\n\n# Change the appearance of that box\nmybox.set_facecolor(\"orangered\")\nmybox.set_edgecolor(\"black\")\n# mybox.set_linewidth(3)\n\n\nmybox = ax.artists[1]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[2]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[3]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[4]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[5]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[6]\nmybox.set_facecolor(\"lightblue\")\nmybox = ax.artists[7]\nmybox.set_facecolor(\"lightblue\")",
"_____no_output_____"
],
[
"# boxplot algorithm comparison\n\n\nsns.set(font_scale=3)\nsns.set_style(\"whitegrid\")\nfig, ax = plt.subplots(figsize=(8, 8.27))\n\n\ntips = sns.load_dataset(\"tips\")\nax = sns.boxplot(x=names_SMOTE, y=results_SMOTE)\n\nplt.xticks(rotation=45)\n\n# fig = plt.figure()\n# fig.suptitle('SMOTE Algorithm Comparison')\n# ax = fig.add_subplot(111)\n# plt.boxplot(results_SMOTE)\n# ax.set_xticklabels(names_SMOTE)\nplt.show()",
"_____no_output_____"
],
[
"# boxplot algorithm comparison\nsns.set(font_scale=3)\nsns.set_style(\"whitegrid\")\nfig, ax = plt.subplots(figsize=(8, 8.27))\n\ntips = sns.load_dataset(\"tips\")\nax = sns.boxplot(x=names, y=results)\nplt.xticks(rotation=45)\n# Select which box you want to change\nmybox = ax.artists[0]\n\n\n# fig = plt.figure()\n# fig.suptitle('ADYSONs Algorithm Comparison')\n# ax = fig.add_subplot(111)\n# plt.boxplot(results_ADASYN)\n# ax.set_xticklabels(names_ADASYN)\n# plt.show()",
"_____no_output_____"
],
[
"rf = LogisticRegression(class_weight=\"balanced\")\n\nrf.fit(X_train, Y_train)\n\ny_pred = rf.predict(X_test)\ny_pred = pd.Series(y_pred)\n# Train the model on training data\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\"Accuracy of random forest on test set: {:.2f}\".format(rf.score(X_test, Y_test)))\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.recall_score(Y_test, y_pred))\nprint(\"F1:\", metrics.f1_score(Y_test, y_pred))",
"[[910 880]\n [116 288]]\nAccuracy of random forest on test set: 0.55\nPrecision: 0.2465753424657534\nRecall: 0.7128712871287128\nF1: 0.366412213740458\n"
],
[
"from sklearn.model_selection import GridSearchCV\n\n# Create logistic regression\nlogistic = linear_model.LogisticRegression(\n solver=\"liblinear\", max_iter=1000, class_weight=\"balanced\"\n)\n# Create regularization penalty space\npenalty = [\"l1\", \"l2\"]\n# Create regularization hyperparameter space\nC = np.logspace(0, 4, 10)\n# Create hyperparameter options\nhyperparameters = dict(C=C, penalty=penalty)\n# Create grid search using 5-fold cross validation\nclf = GridSearchCV(logistic, hyperparameters, cv=5, verbose=0)\n# Fit grid search\nbest_model = clf.fit(X_train, Y_train)\n# View best hyperparameters\nprint(\"Best Penalty:\", best_model.best_estimator_.get_params()[\"penalty\"])\nprint(\"Best C:\", best_model.best_estimator_.get_params()[\"C\"])\n# Predict target vector\ny_pred = best_model.predict(X_test)\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\n \"Accuracy of random forest on test set: {:.2f}\".format(\n best_model.score(X_test, Y_test)\n )\n)\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"F1:\", metrics.f1_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.recall_score(Y_test, y_pred))",
"Best Penalty: l2\nBest C: 21.544346900318832\n[[917 873]\n [117 287]]\nAccuracy of random forest on test set: 0.55\nPrecision: 0.24741379310344827\nF1: 0.36700767263427114\nRecall: 0.7103960396039604\n"
],
[
"# Best Penalty: l2 Best C: 1.0\nlogistic = linear_model.LogisticRegression(\n solver=\"liblinear\", max_iter=1000, class_weight=\"balanced\", penalty=\"l2\"\n)\n\nlogistic.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"X_tester = X_test.iloc[\n 0:,\n]",
"_____no_output_____"
],
[
"X_tester",
"_____no_output_____"
],
[
"logistic.predict(X_tester)",
"_____no_output_____"
],
[
"filename = \"logistic_model.sav\"\npickle.dump(logistic, open(filename, \"wb\"))",
"_____no_output_____"
],
[
"coeff_list = logistic.coef_\ncoeff_list\n# Absolute or Square\n# Standardized B coefficients\nx = np.std(X_train, 0)\nprint(np.std(X_train, 0))",
"Month1GamesPlayed 97.512333\nMonth1Carpet 0.414798\nCumInjured 0.478958\nCumInjuredTimes 3.324430\nCumInjuredGames 3747.207088\nCountry_Argentina 0.111580\nCountry_Australia 0.204882\nCountry_Austria 0.115169\nCountry_Belarus 0.115169\nCountry_Brazil 0.084641\nCountry_Colombia 0.060894\nCountry_Egypt 0.048468\nCountry_Estonia 0.069011\nCountry_Israel 0.065658\nCountry_Kazakhstan 0.101479\nCountry_Latvia 0.065082\nCountry_Romania 0.187995\nCountry_Russia 0.289007\nCountry_Serbia 0.144026\nCountry_South Korea 0.080093\nCountry_Sweden 0.093054\nCountry_Switzerland 0.142757\nCountry_Thailand 0.079623\nCountry_Venezuela 0.049242\nMonth1InjuredType_Severe 0.105078\nCumInjuredType_Moderate 0.414487\ndtype: float64\n"
],
[
"x[0] * coeff_list[0:0]",
"_____no_output_____"
],
[
"print(len(coeff_list))\nprint(type(coeff_list))\n\nprint(len(X_train.columns))\nprint(type(X_train.columns))\n\n#coeff_list[10:] == shape 0,25\ncoeff_list.shape = (25,1)\n\n\n\n",
"1\n<class 'numpy.ndarray'>\n26\n<class 'pandas.core.indexes.base.Index'>\n"
],
[
"X_train.columns",
"_____no_output_____"
],
[
"# coeff_list = coeff_list.flatten\n\nflat_list = [item for sublist in coeff_list for item in sublist]\nprint(flat_list)",
"[0.001805080413358999, -0.1572769040388151, 0.6511616686803923, 0.10670978132118113, -5.7995937368536574e-05, 0.12780949020795246, 0.01858666490827254, 0.12163143899655078, 0.09641004291199745, -0.0808435450835756, -0.10540492277765569, -0.11847205760060109, -0.01067028033410488, -0.13049244089238063, 0.11126849203297087, 0.05512145826310445, 0.3597012673344866, 0.19641564515196355, -0.1904003017654783, -0.31296803649912763, -0.19724370137196598, 0.29954249541900485, -0.08583616281059572, -0.1875439590141722, -0.23386918123934514, 0.06006079447764746]\n"
],
[
"data = {'Var':X_train.columns,\n 'Coeff':flat_list,\n 'NP': x}\n\ncoeff_df = pd.DataFrame(data)",
"_____no_output_____"
],
[
"coeff_df.head()",
"_____no_output_____"
],
[
"# B standardizing the coefficients\n# (B - sd)/mean\nd_mean = []\nd_std = []\nfor column in X_train.columns:\n mean = X_train[column].mean()\n d_mean.append(mean)\n std = X_train[column].std()\n d_std.append(std)\n\n\ncoeff_df[\"Mean\"] = d_mean\ncoeff_df[\"Std\"] = d_std",
"_____no_output_____"
],
[
"coeff_df.head(12)",
"_____no_output_____"
],
[
"coeff_df['Standardized_B'] = (coeff_df['Coeff'] - coeff_df['Std'])/coeff_df['Mean']",
"_____no_output_____"
],
[
"# cols = ['Coeff']\ncoeff_df = coeff_df[abs(coeff_df.Coeff) > 0.08]\n\n\ncoeff_df",
"_____no_output_____"
],
[
"# standardize the data attributes\nX_train_2 = preprocessing.scale(X_train)\n\n# Create logistic regression\nlogistic = linear_model.LogisticRegression(\n solver=\"liblinear\", max_iter=1000, class_weight=\"balanced\"\n)\n# Create regularization penalty space\npenalty = [\"l1\", \"l2\"]\n# Create regularization hyperparameter space\nC = np.logspace(0, 4, 10)\n# Create hyperparameter options\nhyperparameters = dict(C=C, penalty=penalty)\n# Create grid search using 5-fold cross validation\nclf = GridSearchCV(logistic, hyperparameters, cv=5, verbose=0)\n# Fit grid search\nbest_model = clf.fit(X_train / np.std(X_train, 0), Y_train)\n# View best hyperparameters\nprint(\"Best Penalty:\", best_model.best_estimator_.get_params()[\"penalty\"])\nprint(\"Best C:\", best_model.best_estimator_.get_params()[\"C\"])\n# Predict target vector\ny_pred = best_model.predict(X_test / np.std(X_test, 0))\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# m.fit(X / np.std(X, 0), y)\n# print(m.coef_)\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\n \"Accuracy of random forest on test set: {:.2f}\".format(\n best_model.score(X_test, Y_test)\n )\n)\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"F1:\", metrics.f1_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.recall_score(Y_test, y_pred))\n\n\n# Best Penalty: l2 Best C: 1.0\nlogistic = linear_model.LogisticRegression(\n solver=\"liblinear\", max_iter=1000, class_weight=\"balanced\", penalty=\"l2\"\n)\n\nlogistic.fit(X_train / np.std(X_train, 0), Y_train)\n\n\n# coeff_list = coeff_list.flatten\ncoeff_list = logistic.coef_\nflat_list = [item for sublist in coeff_list for item in sublist]\nprint(flat_list)\n\ndata2 = {\"Var\": X_train.columns, \"Coeff\": flat_list}\n\ncoeff_df2 = pd.DataFrame(data2)\n\n\nplt.subplots(figsize=(8, 8.27))\n\ny_pos = np.arange(len(coeff_df2.Var))\n# Create horizontal bars\n# barlist = plt.barh(y_pos, coeff_df.Coeff)\n\nbarlist = plt.barh(y_pos, coeff_df.Var)\n\n# Create names on the y-axis\nplt.yticks(y_pos, coeff_df.Var)\n\n\n# plt.suptitle('Coefficient', fontsize=14, fontweight='bold')\n\n# Show graphic\nplt.yticks(fontsize=16)\nplt.xlabel(\"Coefficients\", fontsize=18)\nplt.xticks(fontsize=18)\nplt.show()",
"Best Penalty: l1\nBest C: 7.742636826811269\n[[ 505 1285]\n [ 41 363]]\nAccuracy of random forest on test set: 0.82\nPrecision: 0.22026699029126215\nF1: 0.35380116959064334\nRecall: 0.8985148514851485\n[0.17410449734595326, -0.06717428959904706, 0.31728165109038264, 0.3501976187326158, -0.21645758343423888, 0.015126202771072057, -0.002682983477153123, 0.015357157952462262, 0.012336867572791248, -0.011040836270745409, -0.024530607044654627, -0.03649700415773, -0.0018374279839064387, -0.027761925893840203, 0.01406169932374854, 0.00845084231170604, 0.047968315812437316, 0.04988017355351481, -0.02482473669194198, -0.06671038443577801, -0.03055752153698089, 0.03482018390975633, -0.013400978115314635, -0.3098983554854067, -0.029694667524065826, 0.012358360986046618]\n"
],
[
"# coeff_df.plot(kind='bar', color=coeff_df.Coeff.apply(lambda x: 'b' if x>0 else 'y'));\n# sns.set(font_scale=3)\n# sns.set_style(\"whitegrid\")\n# fig, ax = plt.subplots(figsize=(8, 8.27))\n# tips = sns.load_dataset(\"tips\")\n# ax = sns.boxplot(x= coeff_df.Var, y= coeff_df.Coeff)\n# plt.xticks(rotation=45)\n\nplt.subplots(figsize=(8, 8.27))\n\ny_pos = np.arange(len(coeff_df.Var))\n# Create horizontal bars\nbarlist = plt.barh(y_pos, coeff_df.Standardized_B)\n\n\nbarlist[0].set_color(\"r\")\nbarlist[8].set_color(\"r\")\nbarlist[9].set_color(\"r\")\nbarlist[10].set_color(\"r\")\nbarlist[11].set_color(\"r\")\nbarlist[12].set_color(\"r\")\nbarlist[13].set_color(\"r\")\nbarlist[17].set_color(\"r\")\nbarlist[18].set_color(\"r\")\nbarlist[19].set_color(\"r\")\nbarlist[21].set_color(\"r\")\nbarlist[22].set_color(\"r\")\nbarlist[23].set_color(\"r\")\n\n# Create names on the y-axis\nplt.yticks(y_pos, coeff_df.Var)\n\n\n# plt.suptitle('Coefficient', fontsize=14, fontweight='bold')\n\n# Show graphic\nplt.yticks(fontsize=16)\nplt.xlabel(\"Coefficients\", fontsize=18)\nplt.xticks(fontsize=18)\nplt.show()",
"_____no_output_____"
],
[
"logistic = linear_model.LogisticRegression(\n solver=\"liblinear\", max_iter=1000, class_weight=\"balanced\", penalty=\"l1\"\n)\n\nlogistic.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"import pickle\nfilename = 'logistic_model.sav'\npickle.dump(logistic, open(filename, 'wb'))",
"_____no_output_____"
],
[
"plt.subplots(figsize=(8, 8.27))\n\ny_pos = np.arange(len(coeff_df.Var))\n# Create horizontal bars\n# barlist = plt.barh(y_pos, coeff_df.Coeff)\n\nbarlist = plt.barh(y_pos, coeff_df.Standardized_B)\n\n\nbarlist[1].set_color(\"r\")\nbarlist[2].set_color(\"r\")\nbarlist[3].set_color(\"r\")\nbarlist[4].set_color(\"r\")\nbarlist[7].set_color(\"r\")\nbarlist[8].set_color(\"r\")\nbarlist[12].set_color(\"r\")\nbarlist[15].set_color(\"r\")\n\n\n# Create names on the y-axis\nplt.yticks(y_pos, coeff_df.Var)\n\n\n# plt.suptitle('Coefficient', fontsize=14, fontweight='bold')\n\n# Show graphic\nplt.yticks(fontsize=16)\nplt.xlabel(\"Coefficients\", fontsize=18)\nplt.xticks(fontsize=18)\nplt.show()",
"_____no_output_____"
],
[
"# The four best performers test against the test set\n\n# The results with balanced-weighting\n# SVM: 0.789121 (0.047093)\n# Instantiate model with 1000 decision trees\nrf = SVC(class_weight=\"balanced\")\nrf.fit(X_train, Y_train)\n\ny_pred = rf.predict(X_test)\ny_pred = pd.Series(y_pred)\n# Train the model on training data\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint(\"Accuracy of random forest on test set: {:.2f}\".format(rf.score(X_test, Y_test)))\nprint(\"Precision:\", metrics.precision_score(Y_test, y_pred))\nprint(\"Recall:\", metrics.f1_score(Y_test, y_pred))\nprint(\"F1:\", metrics.recall_score(Y_test, y_pred))",
"[[ 78 1712]\n [ 8 396]]\nAccuracy of random forest on test set: 0.22\nPrecision: 0.18785578747628084\nRecall: 0.31528662420382164\nF1: 0.9801980198019802\n"
],
[
"# Random Chance Model\n\nfrom sklearn.dummy import DummyClassifier\n\ndclf = DummyClassifier() \ndclf.fit(X_train, Y_train) \n\ny_pred = dclf.predict(X_test)\ny_pred = pd.Series(y_pred)\n# Train the model on training data\ncm = confusion_matrix(Y_test, y_pred)\nprint(cm)\n\n# First pass run is not awful, but courld use improvement and hyperperamter model\n# optimization\nprint('Accuracy of random forest on test set: {:.2f}'.format(dclf.score(X_test, Y_test)))\nprint(\"Precision:\",metrics.precision_score(Y_test, y_pred))\nprint(\"Recall:\",metrics.recall_score(Y_test, y_pred))\nprint(\"F1:\",metrics.f1_score(Y_test, y_pred)) \n\n\nscore = dclf.score(X_test, Y_test) \n\nscore \n\n\n#listofzeros = [0] * (2114 + 223)\n# Randomly replace value of zeroes\n# 0 2114\n# 1 336\n#Y_test.count()",
"[[1828 286]\n [ 289 47]]\nAccuracy of random forest on test set: 0.75\nPrecision: 0.14114114114114115\nRecall: 0.13988095238095238\nF1: 0.14050822122571005\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac6d2744a1279c35e2f8e3e59843481ff923464
| 614,315 |
ipynb
|
Jupyter Notebook
|
Daily/.ipynb_checkpoints/2020_12_11-checkpoint.ipynb
|
andrew-saydjari/DHC
|
4c544fd2f381f43ee02c6465a563d288b9e5a2a2
|
[
"MIT"
] | 3 |
2021-02-23T04:59:53.000Z
|
2021-05-30T16:52:05.000Z
|
Daily/.ipynb_checkpoints/2020_12_11-checkpoint.ipynb
|
andrew-saydjari/DHC
|
4c544fd2f381f43ee02c6465a563d288b9e5a2a2
|
[
"MIT"
] | 4 |
2021-02-28T14:00:07.000Z
|
2021-03-08T15:15:45.000Z
|
Daily/.ipynb_checkpoints/2020_12_11-checkpoint.ipynb
|
andrew-saydjari/DHC
|
4c544fd2f381f43ee02c6465a563d288b9e5a2a2
|
[
"MIT"
] | null | null | null | 100.312704 | 280 | 0.809498 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4ac6e54973516203c88a1d682f6e56db80dacb04
| 9,922 |
ipynb
|
Jupyter Notebook
|
examples/research/heart_disease_uci.ipynb
|
zakraicik/gretel-synthetics
|
e164132e7581aafdacfb2105e4e86ae2b8ffae48
|
[
"Apache-2.0"
] | null | null | null |
examples/research/heart_disease_uci.ipynb
|
zakraicik/gretel-synthetics
|
e164132e7581aafdacfb2105e4e86ae2b8ffae48
|
[
"Apache-2.0"
] | null | null | null |
examples/research/heart_disease_uci.ipynb
|
zakraicik/gretel-synthetics
|
e164132e7581aafdacfb2105e4e86ae2b8ffae48
|
[
"Apache-2.0"
] | null | null | null | 30.529231 | 121 | 0.560572 |
[
[
[
"#!pip install gretel-synthetics --upgrade\n#!pip install matplotlib\n#!pip install smart_open",
"_____no_output_____"
],
[
"# load source training set\nimport logging\nimport os\nimport sys\nimport pandas as pd\nfrom smart_open import open\n\nsource_file = \"https://gretel-public-website.s3-us-west-2.amazonaws.com/datasets/uci-heart-disease/train.csv\"\nannotated_file = \"./heart_annotated.csv\"\n\ndef annotate_dataset(df):\n df = df.fillna(\"\")\n df = df.replace(',', '[c]', regex=True)\n df = df.replace('\\r', '', regex=True)\n df = df.replace('\\n', ' ', regex=True)\n return df\n\n# Preprocess dataset, store annotated file to disk\n# Protip: Training set is very small, repeat so RNN can learn structure\ndf = annotate_dataset(pd.read_csv(source_file))\nwhile not len(df.index) > 15000:\n df = df.append(df)\n \n# Write annotated training data to disk\ndf.to_csv(annotated_file, index=False, header=False)\n\n# Preview dataset\ndf.head(15)",
"_____no_output_____"
],
[
"# Plot distribution\ncounts = df['sex'].value_counts().sort_values(ascending=False)\ncounts.rename({1:\"Male\", 0:\"Female\"}).plot.pie()",
"_____no_output_____"
],
[
"from pathlib import Path\n\nfrom gretel_synthetics.config import LocalConfig\n\n# Create a config that we can use for both training and generating, with CPU-friendly settings\n# The default values for ``max_chars`` and ``epochs`` are better suited for GPUs\nconfig = LocalConfig(\n max_lines=0, # read all lines (zero)\n epochs=15, # 15-30 epochs for production\n vocab_size=200, # tokenizer model vocabulary size\n character_coverage=1.0, # tokenizer model character coverage percent\n gen_chars=0, # the maximum number of characters possible per-generated line of text\n gen_lines=10000, # the number of generated text lines\n rnn_units=256, # dimensionality of LSTM output space\n batch_size=64, # batch size\n buffer_size=1000, # buffer size to shuffle the dataset\n dropout_rate=0.2, # fraction of the inputs to drop\n dp=True, # let's use differential privacy\n dp_learning_rate=0.015, # learning rate\n dp_noise_multiplier=1.1, # control how much noise is added to gradients\n dp_l2_norm_clip=1.0, # bound optimizer's sensitivity to individual training points\n dp_microbatches=256, # split batches into minibatches for parallelism\n checkpoint_dir=(Path.cwd() / 'checkpoints').as_posix(),\n save_all_checkpoints=False,\n field_delimiter=\",\",\n input_data_path=annotated_file # filepath or S3\n)",
"_____no_output_____"
],
[
"# Train a model\n# The training function only requires our config as a single arg\nfrom gretel_synthetics.train import train_rnn\n\ntrain_rnn(config)",
"_____no_output_____"
],
[
"# Let's generate some records!\n\nfrom collections import Counter\nfrom gretel_synthetics.generate import generate_text\n\n# Generate this many records\nrecords_to_generate = 111\n\n# Validate each generated record\n# Note: This custom validator verifies the record structure matches\n# the expected format for UCI healthcare data, and also that \n# generated records are Female (e.g. column 1 is 0)\n\ndef validate_record(line):\n rec = line.strip().split(\",\")\n if not int(rec[1]) == 0:\n raise Exception(\"record generated must be female\")\n if len(rec) == 14:\n int(rec[0])\n int(rec[2])\n int(rec[3])\n int(rec[4])\n int(rec[5])\n int(rec[6])\n int(rec[7])\n int(rec[8])\n float(rec[9])\n int(rec[10])\n int(rec[11])\n int(rec[12])\n int(rec[13])\n else:\n raise Exception('record not 14 parts')\n \n# Dataframe to hold synthetically generated records \nsynth_df = pd.DataFrame(columns=df.columns)\n\n\nfor idx, record in enumerate(generate_text(config, line_validator=validate_record)):\n status = record.valid\n \n # ensure all generated records are unique\n synth_df = synth_df.drop_duplicates()\n synth_cnt = len(synth_df.index)\n if synth_cnt > records_to_generate:\n break \n\n # if generated record passes validation, save it\n if status:\n print(f\"({synth_cnt}/{records_to_generate} : {status})\") \n print(f\"{line.text}\")\n data = line.values_as_list()\n synth_df = synth_df.append({k:v for k,v in zip(df.columns, data)}, ignore_index=True)\n ",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nfrom pathlib import Path\nimport seaborn as sns\n\n# Load model history from file\nhistory = pd.read_csv(f\"{(Path(config.checkpoint_dir) / 'model_history.csv').as_posix()}\")\n\n# Plot output\ndef plot_training_data(history: pd.DataFrame):\n sns.set(style=\"whitegrid\")\n fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(18,4))\n sns.lineplot(x=history['epoch'], y=history['loss'], ax=ax1, color='orange').set(title='Model training loss')\n history[['perplexity', 'epoch']].plot('epoch', ax=ax2, color='orange').set(title='Perplexity')\n history[['accuracy', 'epoch']].plot('epoch', ax=ax3, color='blue').set(title='% Accuracy')\n plt.show()\n\nplot_training_data(history)\n",
"_____no_output_____"
],
[
"# Preview the synthetic dataset\nsynth_df.head(10)",
"_____no_output_____"
],
[
"# As a final step, combine the original training data + \n# our synthetic records, and shuffle them to prepare for training\ntrain_df = annotate_dataset(pd.read_csv(source_file))\ncombined_df = synth_df.append(train_df).sample(frac=1)\n\n# Write our final training dataset to disk (download this for the Kaggle experiment!)\ncombined_df.to_csv('synthetic_train_shuffled.csv', index=False)\ncombined_df.head(10)",
"_____no_output_____"
],
[
"# Plot distribution\ncounts = combined_df['sex'].astype(int).value_counts().sort_values(ascending=False)\ncounts.rename({1:\"Male\", 0:\"Female\"}).plot.pie()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac6eb443c92c151a1d0ad8564143776039a96d0
| 913,352 |
ipynb
|
Jupyter Notebook
|
Approximation.ipynb
|
LukaszKrawczyk/bspline_heat_maps
|
5220a952094b605171f191bbea254aac86271843
|
[
"MIT"
] | null | null | null |
Approximation.ipynb
|
LukaszKrawczyk/bspline_heat_maps
|
5220a952094b605171f191bbea254aac86271843
|
[
"MIT"
] | null | null | null |
Approximation.ipynb
|
LukaszKrawczyk/bspline_heat_maps
|
5220a952094b605171f191bbea254aac86271843
|
[
"MIT"
] | null | null | null | 2,429.12766 | 240,136 | 0.951064 |
[
[
[
"# Heat map approximation",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"%autoreload\nimport heat_maps\nimport utils\nimport itertools\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n%matplotlib inline\nplt.style.use('ggplot')\nsns.set(color_codes=True)\n ",
"_____no_output_____"
]
],
[
[
"## Load sample data",
"_____no_output_____"
]
],
[
[
"hm = heat_maps.read('test_hm_1.bmp')\nprint hm.shape\n",
"(180, 320)\n"
],
[
"utils.draw_2d(hm, title='Heatmap')\n",
"_____no_output_____"
]
],
[
[
"## Fit B-spline surface",
"_____no_output_____"
]
],
[
[
"tck = heat_maps.fit(hm)\n",
"_____no_output_____"
]
],
[
[
"## Approximate heat map values",
"_____no_output_____"
]
],
[
[
"X, Y = np.arange(0.0, hm.shape[1], 1.0), np.arange(0.0, hm.shape[0], 1.0)\nhm_approx = heat_maps.approx(tck, X, Y)\nprint hm_approx.shape\n",
"(180, 320)\n"
],
[
"# approximate within area\nhm_area = hm[0:50, 0:50]\nprint hm_area.shape\n\nAX, AY= np.arange(0.0, 50.0, 1.0), np.arange(0.0, 50.0, 1.0)\nhm_approx_area = heat_maps.approx(tck, AX, AY)\nprint hm_approx_area.shape\n",
"(50, 50)\n(50, 50)\n"
],
[
"p = itertools.product(tck[0], tck[1]);\npoints = np.array(list(p))\n\nf, ax = plt.subplots(1, 2, figsize=(15, 6))\n\nm = min(len(tck[0]), len(tck[1]))\nax[0].scatter(tck[0][:m], tck[1][:m], c='r')\nax[0].set_xlabel('U')\nax[0].set_ylabel('V')\nax[0].set_title('Knots distribution')\n\nax[1].scatter(points[:,0], points[:, 1] , c='r')\nax[1].set_xlabel('U')\nax[1].set_ylabel('V')\nax[1].set_title('Knots distribution')\n",
"_____no_output_____"
],
[
"print 'Total size: {:} KB'.format((tck[0].nbytes + tck[1].nbytes + tck[2].nbytes) / 1024)\nprint 'Knots: {:} {:}'.format(len(tck[0]), len(tck[1]))\nprint 'Coefficients: {:}\\n'.format(len(tck[2]))\n\nprint 'Original:\\n{:}\\n'.format(hm[100:200, 100:200])\nprint 'Approximation:\\n{:}\\n'.format(np.round(hm_approx[100:200, 100:200]))\n",
"Total size: 13 KB\nKnots: 45 44\nCoefficients: 1640\n\nOriginal:\n[[ 29. 27. 27. ..., 12. 12. 11.]\n [ 28. 27. 28. ..., 11. 10. 10.]\n [ 30. 29. 28. ..., 10. 9. 8.]\n ..., \n [ 23. 22. 22. ..., 23. 24. 25.]\n [ 22. 22. 23. ..., 26. 27. 24.]\n [ 24. 24. 24. ..., 26. 27. 28.]]\n\nApproximation:\n[[ 28. 28. 27. ..., 12. 11. 11.]\n [ 28. 28. 28. ..., 11. 10. 10.]\n [ 29. 29. 28. ..., 10. 9. 9.]\n ..., \n [ 22. 22. 22. ..., 24. 25. 25.]\n [ 22. 23. 23. ..., 25. 26. 26.]\n [ 24. 24. 25. ..., 28. 28. 28.]]\n\n"
],
[
"utils.compare_2d(hm, hm_approx)\n",
"_____no_output_____"
],
[
"utils.err(hm, hm_approx)\n",
"_____no_output_____"
],
[
"utils.compare_3d(hm, hm_approx)\nutils.compare_3d(hm_area, hm_approx_area, stride=3, title_left='Heat map in area', title_right='Approximation in area')\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac70587c882806ad9881e7465edb5a908145c1c
| 11,575 |
ipynb
|
Jupyter Notebook
|
external_tools/ambient_color_camera/Camera ALS.ipynb
|
robert-wu-ms/WFH-Buddy
|
4c151c840aa714f893f6103f503222343de83d78
|
[
"MIT"
] | null | null | null |
external_tools/ambient_color_camera/Camera ALS.ipynb
|
robert-wu-ms/WFH-Buddy
|
4c151c840aa714f893f6103f503222343de83d78
|
[
"MIT"
] | 3 |
2020-10-06T19:36:42.000Z
|
2022-03-25T19:11:01.000Z
|
external_tools/ambient_color_camera/Camera ALS.ipynb
|
robert-wu-ms/WFH-Buddy
|
4c151c840aa714f893f6103f503222343de83d78
|
[
"MIT"
] | null | null | null | 28.370098 | 239 | 0.566825 |
[
[
[
"# Methods of Approximating Ambient Light Level Using Camera Output",
"_____no_output_____"
],
[
"## 1. Helper Functions\n\nThese helper functions can largely be ignored, but make sure to run each cell before using the algorithm section (Section 2).",
"_____no_output_____"
],
[
"### 1.1 Get Camera Capture\n\nGet capture from camera.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport cv2\n\ndef show_img(img):\n img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n plt.imshow(img)\n plt.show()\n\ndef get_capture():\n cap = cv2.VideoCapture(0, cv2.CAP_DSHOW)\n\n # Lower resolution to speed up processing\n cap.set(3, 640)\n cap.set(4, 480)\n\n ret, img = cap.read()\n\n if not ret:\n print(\"Failed to get video capture.\")\n raise ConnectionError\n else:\n return img\n\nimg = get_capture()\nshow_img(img)",
"_____no_output_____"
]
],
[
[
"### 1.2 Get Data Set\n\nLoad the camera frame to ALS lux reading into memory. The datasets are tuples where tuple[0] is the camera image and tuple[1] is the real lux value as read from the ALS.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport glob\nimport cv2\n\nDARK_SET_PATH = \"dataset\\dark_background\"\nLIGHT_D25_SET_PATH = \"dataset\\light_background_D25\"\nLIGHT_D90_SET_PATH = \"dataset\\light_background_D90\"\n\ndef get_num_samples(set_path):\n return len(glob.glob1(set_path, \"*.txt\"))\n\n\ndef get_real_lux_samples(set_path):\n samples = []\n for i in range(get_num_samples(set_path)):\n with open(\"{}\\{}.txt\".format(set_path, i), \"r\") as f:\n file_str = f.read()\n samples.append(float(file_str))\n return samples\n\ndef get_camera_frames(set_path):\n samples = []\n for i in range(get_num_samples(set_path)):\n image = cv2.imread(\"{}\\{}.png\".format(set_path, i))\n samples.append(image)\n return samples\n\ndef get_dataset(set_path):\n return list(zip(get_camera_frames(set_path), get_real_lux_samples(set_path)))\n\ndark_dataset = get_dataset(DARK_SET_PATH)\nlight_d25_dataset = get_dataset(LIGHT_D25_SET_PATH)\nlight_d90_dataset = get_dataset(LIGHT_D90_SET_PATH)",
"_____no_output_____"
]
],
[
[
"### 1.3 Map Operation\n\nDoes a map operation over a dataset. Usually the map operator is a function which takes in an image and then return the approximated lux level.",
"_____no_output_____"
]
],
[
[
"def map_data(dataset, map_op):\n def inner_map_op(data):\n img = data[0]\n real_lux = data[1]\n \n return map_op(img), real_lux\n \n return list(map(inner_map_op, dataset))",
"_____no_output_____"
]
],
[
[
"### 1.4 Plot Mapped Data\n\nTakes in the mapped data (usually from the map_data() function) which is a list of tuples that contain tuple[0] is the approximated lux and tuple[1] is the real ALS data. The function then creates a scatter plot of the two data sets.",
"_____no_output_____"
]
],
[
[
"from pylab import plot, title, xlabel, ylabel, savefig, legend, array\nfrom itertools import chain\n\ndef create_mapped_data_figure(title, mapped_data):\n approx_lux_list, real_lux_list = list(zip(*mapped_data))\n \n fig = plt.figure()\n ax1 = fig.add_subplot(111)\n\n fig.suptitle(title)\n ax1.scatter(list(range(len(approx_lux_list))), approx_lux_list, c='r', marker=\"s\", label='Approx Lux')\n ax1.scatter(list(range(len(real_lux_list))), real_lux_list, c='g', marker=\"s\", label='Real Lux')\n ax1.set_ylabel(\"Lux\")\n ax1.set_xlabel(\"Sample\")\n\n plt.legend(loc='upper right', bbox_to_anchor=(1.32, 1));",
"_____no_output_____"
]
],
[
[
"### 1.5 Uber Mapping Function\n\nUber function which:\n 1. Runs the lux estimation algorithm over each image in the loaded data set (where algo is f(img) -> lux).\n 2. Maps each data set into a figure.\n 3. Displays each mapping.\n \nThis is generally the function each algorithm should call to show its data.",
"_____no_output_____"
]
],
[
[
"def apply_and_show_algo(algo):\n light_d25_data_mapped = map_data(light_d25_dataset, get_avg_brightness)\n light_d90_data_mapped = map_data(light_d90_dataset, get_avg_brightness)\n dark_data_mapped = map_data(dark_dataset, get_avg_brightness)\n \n create_mapped_data_figure('Light Background D25 Light', light_d25_data_mapped)\n create_mapped_data_figure('Light Background D90 Light', light_d90_data_mapped)\n create_mapped_data_figure('Dark Background', dark_data_mapped)\n plt.show()",
"_____no_output_____"
]
],
[
[
"### 1.6 Get ALS Sample\n\nQuery the real lux value from the ALS sensor. There must be an ALS on the system, otherwise this function will throw.",
"_____no_output_____"
]
],
[
[
"import winrt.windows.devices.sensors as sensors\n\ndef get_als_sample():\n als = sensors.LightSensor.get_default()\n if not als:\n print(\"Can't read from ALS, none on system.\")\n raise ConnectionError\n return als.get_current_reading().illuminance_in_lux",
"_____no_output_____"
]
],
[
[
"## 1.7 Live Comparison\n\nGrabs a camera capture and runs the given lux estimation algorithm on it. The function will then query the ALS. The approx lux and real lux are returned as a tuple for comparison.",
"_____no_output_____"
]
],
[
[
"def live_compare(algo):\n img = get_capture()\n show_img(img)\n approx_lux = algo(img)\n real_lux = get_als_sample()\n return approx_lux, real_lux",
"_____no_output_____"
]
],
[
[
"## 2. (Option 1) Average Pixel Brightness\n\nConvert the RGB image in YUV color space, then take the mean value from the Y channel.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef get_avg_brightness(img):\n img_yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)\n y, u, v = cv2.split(img_yuv)\n return np.mean(y)",
"_____no_output_____"
]
],
[
[
"### 2.1 Average Pixel Brightness Dataset Performance\n\nRun the average pixel brightness algorithm over the datasets.",
"_____no_output_____"
]
],
[
[
"apply_and_show_algo(get_avg_brightness)",
"_____no_output_____"
]
],
[
[
"### 2.2 Average Pixel Brightness Live Sample\n\nRun the average pixel brightness algorithm on a live camera sample.",
"_____no_output_____"
]
],
[
[
"approx_lux, real_lux = live_compare(get_avg_brightness)\n\nprint('Approx Lux: {}'.format(approx_lux))\nprint('Real Lux: {}'.format(real_lux))",
"_____no_output_____"
]
],
[
[
"Run the average pixel brightness algorithm over time on a live camera sample",
"_____no_output_____"
]
],
[
[
"def collect_live_compare_over_time():\n MAX_ITER = 4\n data_list = []\n for i in range(MAX_ITER):\n print(\"Querying iteration {}\".format(i))\n data_list.append(live_compare(get_avg_brightness))\n create_mapped_data_figure(\"Live Samples\", data_list)\n plt.show()\n \ncollect_live_compare_over_time()",
"_____no_output_____"
]
],
[
[
"## 3. (Option 2) Use ML to Classify User Enviroment\n\nUse ML to classify what brightness enviroment the camera image is in.",
"_____no_output_____"
],
[
"## 4. (Option 3) Linear Regression\n\nGather a lot of camera data and the associate lux readings from a real ALS. Then run regression on the data set to find a more accurate lux approximation. This can be used with Option 1 to \"calibrate\" the readings.",
"_____no_output_____"
],
[
"## 5. Set Display Brightness Based On Camera",
"_____no_output_____"
]
],
[
[
"import wmi\n\ndef set_display_brightness(percent):\n print(\"Setting display brightness to {}%\".format(percent))\n wmi.WMI(namespace='wmi').WmiMonitorBrightnessMethods()[0].WmiSetBrightness(percent, 0)\n\napprox_lux, real_lux = live_compare(get_avg_brightness)\n\nprint('Approx Lux: {}'.format(approx_lux))\nprint('Real Lux: {}'.format(real_lux))\n\nif approx_lux > 200:\n print('Assuming user is in outdoor like enviroment')\n set_display_brightness(90)\nelse:\n print('Assuming user is in indoor like enviroment')\n set_display_brightness(40)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4ac70c2a3854710da05a30e370d89a45e9c2a896
| 176,386 |
ipynb
|
Jupyter Notebook
|
climate_starterapw.ipynb
|
awinston8089/sqlalchemy-challenge
|
c97c909618466421c7768a35a882ab5f48f711ac
|
[
"ADSL"
] | null | null | null |
climate_starterapw.ipynb
|
awinston8089/sqlalchemy-challenge
|
c97c909618466421c7768a35a882ab5f48f711ac
|
[
"ADSL"
] | null | null | null |
climate_starterapw.ipynb
|
awinston8089/sqlalchemy-challenge
|
c97c909618466421c7768a35a882ab5f48f711ac
|
[
"ADSL"
] | null | null | null | 268.881098 | 70,121 | 0.752163 |
[
[
[
"%matplotlib inline\nfrom matplotlib import style\nstyle.use('fivethirtyeight')\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"import datetime as dt",
"_____no_output_____"
]
],
[
[
"# Reflect Tables into SQLAlchemy ORM",
"_____no_output_____"
]
],
[
[
"# Python SQL toolkit and Object Relational Mapper\nimport sqlalchemy\nfrom sqlalchemy.ext.automap import automap_base\nfrom sqlalchemy.orm import Session\nfrom sqlalchemy import create_engine, func, inspect",
"_____no_output_____"
],
[
"engine = create_engine(\"sqlite:///Resources/hawaii.sqlite\")",
"_____no_output_____"
],
[
"# reflect an existing database into a new model # reflect the tables\nBase = automap_base()\nBase.prepare(engine, reflect=True)\nBase.classes.keys()\n\n",
"_____no_output_____"
],
[
"# We can view all of the classes that automap found;# Save references to each table\nMeasurement = Base.classes.measurement\nStation = Base.classes.station\n",
"_____no_output_____"
],
[
"# Create our session (link) from Python to the DB\nsession = Session(engine)",
"_____no_output_____"
]
],
[
[
"# Exploratory Climate Analysis\nStart of My Analysis.",
"_____no_output_____"
]
],
[
[
"# Find the tables...\ninspector = inspect(engine)\ninspector.get_table_names()\n",
"_____no_output_____"
],
[
"conn = engine.connect()\nmdata = pd.read_sql(\"select * from measurement\", conn)\nmdata\n",
"_____no_output_____"
],
[
"# Get a list of column names and types\ncolumns = inspector.get_columns('measurement')\nfor c in columns:\n print(c['name'], c[\"type\"])\n# columns",
"id INTEGER\nstation TEXT\ndate TEXT\nprcp FLOAT\ntobs FLOAT\n"
],
[
"# Get a list of column names and types\ncolumns = inspector.get_columns('station')\nfor c in columns:\n print(c['name'], c[\"type\"])\n# columns",
"id INTEGER\nstation TEXT\nname TEXT\nlatitude FLOAT\nlongitude FLOAT\nelevation FLOAT\n"
]
],
[
[
"#### Design a query to retrieve the last 12 months of precipitation data and plot the results\n\n\n",
"_____no_output_____"
]
],
[
[
"\nlast_date = session.query(Measurement.date).order_by(Measurement.date.desc()).first()\n\nlast_date\n# Calculate the date 1 year ago from the last data point in the database\n\nyear_ago = dt.date(2017, 8, 23) - dt.timedelta(days=365)\n\nyear_ago\n\n# Perform a query to retrieve the data and precipitation scores\nPrcp_results = session.query(Measurement.date, Measurement.prcp).\\\n filter(Measurement.date >= year_ago).all()\n \n\n# Save the query results as a Pandas DataFrame and set the index to the date column\nPrecipitation_inches_oneyear = pd.DataFrame(Prcp_results, columns = ['date', 'precipitation'])\nPrecipitation_inches_oneyear\n\n#Sort by date\nPrecipitation_inches_oneyear = Precipitation_inches_oneyear.sort_values(by=['date'])\n\n\n# Reindex the dataframe by date\nPrecipitation_inches_oneyear = Precipitation_inches_oneyear.set_index(['date'])\n\n\n\n# Use Pandas Plotting with Matplotlib to plot the data\nPrecipitation_inches_oneyear.plot(rot=90)\nplt.xlabel('date')\nplt.ylabel('inches')\n\n",
"_____no_output_____"
],
[
"# Use Pandas to calcualte the summary statistics for the precipitation data\n\nPrecipitation_inches_oneyear.describe()",
"_____no_output_____"
],
[
"# Design a query to show how many stations are available in this dataset?\nnum_station = session.query(Station.station).count()\nnum_station",
"_____no_output_____"
],
[
"# What are the most active stations? (i.e. what stations have the most rows)?\n# List the stations and the counts in descending order.\nactive_stations = session.query(Measurement.station,func.count(Measurement.station)).\\\n group_by(Measurement.station).order_by(func.count(Measurement.station).desc())\nmost_active_stations = session.query(Station.name).filter(Station.station==active_stations[0][0]).all()\n\nprint (f'The most active station is {active_stations[0]}, {most_active_stations[0]}\n\nfor station in active_stations:\n print (station)",
"('USC00519281', 2772)\n('USC00519397', 2724)\n('USC00513117', 2709)\n('USC00519523', 2669)\n('USC00516128', 2612)\n('USC00514830', 2202)\n('USC00511918', 1979)\n('USC00517948', 1372)\n('USC00518838', 511)\n"
],
[
"# Using the station id from the previous query, calculate the lowest temperature recorded, \n# highest temperature recorded, and average temperature of the most active station?\ntemp_station = session.query(func.min(Measurement.tobs),func.max(Measurement.tobs), func.avg(Measurement.tobs)).\\\n filter(Measurement.station==active_stations[0][0])\ntemp_station[0][0],temp_station[0][1],round(temp_station[0][2],2)",
"_____no_output_____"
],
[
"# Choose the station with the highest number of temperature observations.\n# Query the last 12 months of temperature observation data for this station and plot the results as a histogram\nactive_tobs = session.query(Measurement.date, Measurement.tobs).filter(Measurement.station==active_stations[0][0]).\\\n filter(Measurement.date>=year_ago).all()\nactive_tobs[:10]",
"_____no_output_____"
],
[
"active_tobs_df = pd.DataFrame(active_tobs)\nactive_tobs_df.head()",
"_____no_output_____"
],
[
"active_tobs_df.plot(kind=\"hist\",bins=12)\nplt.xlabel(\"Temperature\")\nplt.title(\"Distribution of Temperature Observation\")\nplt.savefig(\"Histogram.png\")",
"_____no_output_____"
]
],
[
[
"## Bonus Challenge Assignment",
"_____no_output_____"
]
],
[
[
"# This function called `calc_temps` will accept start date and end date in the format '%Y-%m-%d' \n# and return the minimum, average, and maximum temperatures for that range of dates\ndef calc_temps(start_date, end_date):\n \"\"\"TMIN, TAVG, and TMAX for a list of dates.\n \n Args:\n start_date (string): A date string in the format %Y-%m-%d\n end_date (string): A date string in the format %Y-%m-%d\n \n Returns:\n TMIN, TAVE, and TMAX\n \"\"\"\n \n return session.query(func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)).\\\n filter(Measurement.date >= start_date).filter(Measurement.date <= end_date).all()\n\n# function usage example\nprint(calc_temps('2012-02-28', '2012-03-05'))",
"_____no_output_____"
],
[
"# Use your previous function `calc_temps` to calculate the tmin, tavg, and tmax \n# for your trip using the previous year's data for those same dates.\n",
"_____no_output_____"
],
[
"# Plot the results from your previous query as a bar chart. \n# Use \"Trip Avg Temp\" as your Title\n# Use the average temperature for the y value\n# Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr)\n",
"_____no_output_____"
],
[
"# Calculate the total amount of rainfall per weather station for your trip dates using the previous year's matching dates.\n# Sort this in descending order by precipitation amount and list the station, name, latitude, longitude, and elevation\n\n",
"_____no_output_____"
],
[
"# Create a query that will calculate the daily normals \n# (i.e. the averages for tmin, tmax, and tavg for all historic data matching a specific month and day)\n\ndef daily_normals(date):\n \"\"\"Daily Normals.\n \n Args:\n date (str): A date string in the format '%m-%d'\n \n Returns:\n A list of tuples containing the daily normals, tmin, tavg, and tmax\n \n \"\"\"\n \n sel = [func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)]\n return session.query(*sel).filter(func.strftime(\"%m-%d\", Measurement.date) == date).all()\n \ndaily_normals(\"01-01\")",
"_____no_output_____"
],
[
"# calculate the daily normals for your trip\n# push each tuple of calculations into a list called `normals`\n\n# Set the start and end date of the trip\n\n# Use the start and end date to create a range of dates\n\n# Stip off the year and save a list of %m-%d strings\n\n# Loop through the list of %m-%d strings and calculate the normals for each date\n",
"_____no_output_____"
],
[
"# Load the previous query results into a Pandas DataFrame and add the `trip_dates` range as the `date` index\n",
"_____no_output_____"
],
[
"# Plot the daily normals as an area plot with `stacked=False`\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac71700223258eb8701e810f5b4f780a8e45226
| 11,540 |
ipynb
|
Jupyter Notebook
|
Set and Booleans.ipynb
|
Coslate/Python_Exercise
|
9c400aa99d65136398e6b2944bd3e7886953b090
|
[
"MIT"
] | null | null | null |
Set and Booleans.ipynb
|
Coslate/Python_Exercise
|
9c400aa99d65136398e6b2944bd3e7886953b090
|
[
"MIT"
] | null | null | null |
Set and Booleans.ipynb
|
Coslate/Python_Exercise
|
9c400aa99d65136398e6b2944bd3e7886953b090
|
[
"MIT"
] | null | null | null | 15.184211 | 82 | 0.425043 |
[
[
[
"x = set()",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"x.add(1)",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"x.add(2)\nx",
"_____no_output_____"
],
[
"x.add(1)\nx\nx.pop()\nx",
"_____no_output_____"
],
[
"l = [1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3, 4, 4]",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
],
[
"set(l)",
"_____no_output_____"
],
[
"#booleans",
"_____no_output_____"
],
[
"a = True",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"1>2",
"_____no_output_____"
],
[
"11>2",
"_____no_output_____"
],
[
"b = None",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"b = \"a\"",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"4**0.5 == 2",
"_____no_output_____"
],
[
"2.0 == 2",
"_____no_output_____"
],
[
"l = [3, 2 , 10, 9]",
"_____no_output_____"
],
[
"sorted(l)",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
],
[
"l.sort()",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
],
[
"my_list = [5, 5, 1, 2, 3, 3, 3, 10, 10, 10, 6, 2, 1]",
"_____no_output_____"
],
[
"set(my_list)",
"_____no_output_____"
],
[
"new_t = set(my_list)",
"_____no_output_____"
],
[
"type(new_t)",
"_____no_output_____"
],
[
"new_t",
"_____no_output_____"
],
[
"set(\"Helloops\")",
"_____no_output_____"
],
[
"a = None",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"type(a)",
"_____no_output_____"
],
[
"if(a == None) : print(\"yes\")",
"yes\n"
],
[
"#Place holder. Will assign value to the variable in the later of the code\na == None",
"_____no_output_____"
],
[
"my_list = [2, 1, 0]",
"_____no_output_____"
],
[
"my_list.sort()",
"_____no_output_____"
],
[
"my_list",
"_____no_output_____"
],
[
"if(my_list.sort() == None) : print(\"yes\")",
"yes\n"
],
[
"my_list.sort() == None",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac7214a61f60d85e600ce4c522b55e03d69931e
| 13,518 |
ipynb
|
Jupyter Notebook
|
equacao2grau.ipynb
|
DeBrites/calculo-numerico
|
7284f689421e08e821a955935d904e55a2310c97
|
[
"MIT"
] | null | null | null |
equacao2grau.ipynb
|
DeBrites/calculo-numerico
|
7284f689421e08e821a955935d904e55a2310c97
|
[
"MIT"
] | null | null | null |
equacao2grau.ipynb
|
DeBrites/calculo-numerico
|
7284f689421e08e821a955935d904e55a2310c97
|
[
"MIT"
] | null | null | null | 81.433735 | 10,502 | 0.850496 |
[
[
[
"% Função de segundo grau\nfunction [x1, x2] = eq2(a,b,c)\n x1 = (-b + sqrt(b^2-4*a*c)/(2*a));\n x2 = (-b - sqrt(b^2-4*a*c)/(2*a));\nend\na=1\nb=10\nc=8\n[x1,x2] = eq2(a,b,c)",
"a = 1\r\n"
],
[
"% definindo função para plotar num gráfico\nf = @(x) x.^2 - 4*x + 3\nf(5)",
"f =\r\n\r\n@(x) x .^ 2 - 4 * x + 3\r\n\r\n"
],
[
"% ';' faz com que não apareça os pontos x e y abaixo\nx = 0:0.1:4;\ny = f(x);\n",
"_____no_output_____"
],
[
"% em '-or' ele define retas no g´rafico com bolinhas marcados entre x e y, se tirar a letra o não aparece as bolinhas '-r'\nplot(x,y,'-or')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4ac723fd99927997d9775e6af60db5de6e9639d4
| 35,253 |
ipynb
|
Jupyter Notebook
|
HW4/MIDS261_MRjOB2.ipynb
|
maynard242/Machine-Learning-At-Scale
|
00406de025e3a94d3514d056a0ec7d46473444ef
|
[
"MIT"
] | 1 |
2021-10-03T07:52:32.000Z
|
2021-10-03T07:52:32.000Z
|
HW4/MIDS261_MRjOB2.ipynb
|
maynard242/Machine-Learning-At-Scale
|
00406de025e3a94d3514d056a0ec7d46473444ef
|
[
"MIT"
] | null | null | null |
HW4/MIDS261_MRjOB2.ipynb
|
maynard242/Machine-Learning-At-Scale
|
00406de025e3a94d3514d056a0ec7d46473444ef
|
[
"MIT"
] | 1 |
2020-01-30T02:59:50.000Z
|
2020-01-30T02:59:50.000Z
| 31.645422 | 128 | 0.531075 |
[
[
[
"## Homework 3 and 4 - Applications Using MRJob",
"_____no_output_____"
]
],
[
[
"# general imports\nimport os\nimport re\nimport sys\nimport time\nimport random\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n# tell matplotlib not to open a new window\n%matplotlib inline\n\n# automatically reload modules \n%reload_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"# print some configuration details for future replicability.\nprint 'Python Version: %s' % (sys.version.split('|')[0])\nhdfs_conf = !hdfs getconf -confKey fs.defaultFS ### UNCOMMENT ON DOCKER\n#hdfs_conf = !hdfs getconf -confKey fs.default.name ### UNCOMMENT ON ALTISCALE\nprint 'HDFS filesystem running at: \\n\\t %s' % (hdfs_conf[0])",
"Python Version: 2.7.14 \nHDFS filesystem running at: \n\t hdfs://quickstart.cloudera:8020\n"
],
[
"JAR_FILE = \"/usr/lib/hadoop-mapreduce/hadoop-streaming-2.6.0-cdh5.7.0.jar\"\nHDFS_DIR = \"/user/root/HW3\"\nHOME_DIR = \"/media/notebooks/SP18-1-maynard242\" # FILL IN HERE eg. /media/notebooks/w261-main/Assignments\n# save path for use in Hadoop jobs (-cmdenv PATH={PATH})\nfrom os import environ\nPATH = environ['PATH']",
"_____no_output_____"
],
[
"#!hdfs dfs -mkdir HW3\n!hdfs dfs -ls",
"Found 2 items\ndrwxr-xr-x - root supergroup 0 2018-02-12 07:08 HW5\ndrwxr-xr-x - root supergroup 0 2018-02-12 07:45 tmp\n"
],
[
"%%writefile example1.txt\nUnix,30\nSolaris,10\nLinux,25\nLinux,20\nHPUX,100\nAIX,25",
"Writing example1.txt\n"
],
[
"%%writefile example2.txt\nfoo foo quux labs foo bar jimi quux jimi jimi\nfoo jimi jimi\ndata mining is data science\n",
"Writing example2.txt\n"
],
[
"%%writefile WordCount.py\n\nfrom mrjob.job import MRJob\nimport re\n \nWORD_RE = re.compile(r\"[\\w']+\")\n \nclass MRWordFreqCount(MRJob):\n def mapper(self, _, line):\n for word in WORD_RE.findall(line):\n yield word.lower(), 1\n \n def combiner(self, word, counts):\n yield word, sum(counts)\n\n #hello, (1,1,1,1,1,1): using a combiner? NO and YEs\n def reducer(self, word, counts):\n yield word, sum(counts)\n\nif __name__ == '__main__':\n MRWordFreqCount.run()",
"Writing WordCount.py\n"
],
[
"!python WordCount.py -r hadoop --cmdenv PATH=/opt/anaconda/bin:$PATH example2.txt",
"No configs found; falling back on auto-configuration\nNo configs specified for hadoop runner\nLooking for hadoop binary in $PATH...\nFound hadoop binary: /usr/bin/hadoop\nUsing Hadoop version 2.6.0\nLooking for Hadoop streaming jar in /home/hadoop/contrib...\nLooking for Hadoop streaming jar in /usr/lib/hadoop-mapreduce...\nFound Hadoop streaming jar: /usr/lib/hadoop-mapreduce/hadoop-streaming.jar\nCreating temp directory /tmp/WordCount.root.20180213.151128.815364\nCopying local files to hdfs:///user/root/tmp/mrjob/WordCount.root.20180213.151128.815364/files/...\nRunning step 1 of 1...\n packageJobJar: [] [/usr/jars/hadoop-streaming-2.6.0-cdh5.7.0.jar] /tmp/streamjob3643071481984327907.jar tmpDir=null\n Connecting to ResourceManager at /0.0.0.0:8032\n Connecting to ResourceManager at /0.0.0.0:8032\n Total input paths to process : 1\n number of splits:2\n Submitting tokens for job: job_1518417280058_0043\n Submitted application application_1518417280058_0043\n The url to track the job: http://docker.w261:8088/proxy/application_1518417280058_0043/\n Running job: job_1518417280058_0043\n Job job_1518417280058_0043 running in uber mode : false\n map 0% reduce 0%\n map 50% reduce 0%\n map 100% reduce 0%\n map 100% reduce 100%\n Job job_1518417280058_0043 completed successfully\n Output directory: hdfs:///user/root/tmp/mrjob/WordCount.root.20180213.151128.815364/output\nCounters: 49\n\tFile Input Format Counters \n\t\tBytes Read=132\n\tFile Output Format Counters \n\t\tBytes Written=82\n\tFile System Counters\n\t\tFILE: Number of bytes read=127\n\t\tFILE: Number of bytes written=355519\n\t\tFILE: Number of large read operations=0\n\t\tFILE: Number of read operations=0\n\t\tFILE: Number of write operations=0\n\t\tHDFS: Number of bytes read=452\n\t\tHDFS: Number of bytes written=82\n\t\tHDFS: Number of large read operations=0\n\t\tHDFS: Number of read operations=9\n\t\tHDFS: Number of write operations=2\n\tJob Counters \n\t\tData-local map tasks=2\n\t\tLaunched map tasks=2\n\t\tLaunched reduce tasks=1\n\t\tTotal megabyte-seconds taken by all map tasks=5086208\n\t\tTotal megabyte-seconds taken by all reduce tasks=2483200\n\t\tTotal time spent by all map tasks (ms)=4967\n\t\tTotal time spent by all maps in occupied slots (ms)=4967\n\t\tTotal time spent by all reduce tasks (ms)=2425\n\t\tTotal time spent by all reduces in occupied slots (ms)=2425\n\t\tTotal vcore-seconds taken by all map tasks=4967\n\t\tTotal vcore-seconds taken by all reduce tasks=2425\n\tMap-Reduce Framework\n\t\tCPU time spent (ms)=1730\n\t\tCombine input records=18\n\t\tCombine output records=11\n\t\tFailed Shuffles=0\n\t\tGC time elapsed (ms)=47\n\t\tInput split bytes=320\n\t\tMap input records=3\n\t\tMap output bytes=160\n\t\tMap output materialized bytes=133\n\t\tMap output records=18\n\t\tMerged Map outputs=2\n\t\tPhysical memory (bytes) snapshot=929681408\n\t\tReduce input groups=9\n\t\tReduce input records=11\n\t\tReduce output records=9\n\t\tReduce shuffle bytes=133\n\t\tShuffled Maps =2\n\t\tSpilled Records=22\n\t\tTotal committed heap usage (bytes)=1513095168\n\t\tVirtual memory (bytes) snapshot=4258435072\n\tShuffle Errors\n\t\tBAD_ID=0\n\t\tCONNECTION=0\n\t\tIO_ERROR=0\n\t\tWRONG_LENGTH=0\n\t\tWRONG_MAP=0\n\t\tWRONG_REDUCE=0\nStreaming final output from hdfs:///user/root/tmp/mrjob/WordCount.root.20180213.151128.815364/output...\n\"bar\"\t1\n\"data\"\t2\n\"foo\"\t4\n\"is\"\t1\n\"jimi\"\t5\n\"labs\"\t1\n\"mining\"\t1\n\"quux\"\t2\n\"science\"\t1\nRemoving HDFS temp directory hdfs:///user/root/tmp/mrjob/WordCount.root.20180213.151128.815364...\nRemoving temp directory /tmp/WordCount.root.20180213.151128.815364...\n"
],
[
"from WordCount import MRWordFreqCount\nmr_job = MRWordFreqCount(args=['example2.txt'])\nwith mr_job.make_runner() as runner: \n runner.run()\n # stream_output: get access of the output \n for line in runner.stream_output():\n print mr_job.parse_output_line(line)",
"(u'jimi', 5)\n(u'quux', 2)\n(u'science', 1)\n(u'foo', 4)\n(u'bar', 1)\n(u'data', 2)\n(u'is', 1)\n(u'labs', 1)\n(u'mining', 1)\n"
],
[
"%%writefile AnotherWordCount.py\n\nfrom mrjob.job import MRJob\n\nclass MRAnotherWordCount(MRJob):\n \n def mapper (self,_,line):\n yield \"chars\", len(line)\n yield \"words\", len(line.split())\n yield 'lines', 1\n \n def reducer (self, key, values):\n yield key, sum(values)\n \nif __name__ == '__main__':\n MRAnotherWordCount.run()",
"Overwriting AnotherWordCount.py\n"
],
[
"!python AnotherWordCount.py example2.txt",
"No configs found; falling back on auto-configuration\nNo configs specified for inline runner\nRunning step 1 of 1...\nCreating temp directory /tmp/AnotherWordCount.root.20180203.141743.462604\nStreaming final output from /tmp/AnotherWordCount.root.20180203.141743.462604/output...\n\"words\"\t18\n\"chars\"\t86\n\"lines\"\t3\nRemoving temp directory /tmp/AnotherWordCount.root.20180203.141743.462604...\n"
],
[
"%%writefile AnotherWC3.py\n# Copyright 2009-2010 Yelp\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"An implementation of wc as an MRJob.\nThis is meant as an example of why mapper_final is useful.\"\"\"\nfrom mrjob.job import MRJob\n\n\nclass MRWordCountUtility(MRJob):\n\n def __init__(self, *args, **kwargs):\n super(MRWordCountUtility, self).__init__(*args, **kwargs)\n self.chars = 0\n self.words = 0\n self.lines = 0\n\n def mapper(self, _, line):\n # Don't actually yield anything for each line. Instead, collect them\n # and yield the sums when all lines have been processed. The results\n # will be collected by the reducer.\n self.chars += len(line) + 1 # +1 for newline\n self.words += sum(1 for word in line.split() if word.strip())\n self.lines += 1\n\n def mapper_final(self):\n yield('chars', self.chars)\n yield('words', self.words)\n yield('lines', self.lines)\n\n def reducer(self, key, values):\n yield(key, sum(values))\n\n\nif __name__ == '__main__':\n MRWordCountUtility.run()",
"Writing AnotherWC3.py\n"
],
[
"!python AnotherWC3.py -r hadoop --cmdenv PATH=/opt/anaconda/bin:$PATH example2.txt",
"No configs found; falling back on auto-configuration\nNo configs specified for hadoop runner\nLooking for hadoop binary in $PATH...\nFound hadoop binary: /usr/bin/hadoop\nUsing Hadoop version 2.6.0\nLooking for Hadoop streaming jar in /home/hadoop/contrib...\nLooking for Hadoop streaming jar in /usr/lib/hadoop-mapreduce...\nFound Hadoop streaming jar: /usr/lib/hadoop-mapreduce/hadoop-streaming.jar\nCreating temp directory /tmp/AnotherWC3.root.20180210.114605.598768\nCopying local files to hdfs:///user/root/tmp/mrjob/AnotherWC3.root.20180210.114605.598768/files/...\nRunning step 1 of 1...\n packageJobJar: [] [/usr/jars/hadoop-streaming-2.6.0-cdh5.7.0.jar] /tmp/streamjob6426766568329965202.jar tmpDir=null\n Connecting to ResourceManager at /0.0.0.0:8032\n Connecting to ResourceManager at /0.0.0.0:8032\n Total input paths to process : 1\n number of splits:2\n Submitting tokens for job: job_1518262877936_0001\n Submitted application application_1518262877936_0001\n The url to track the job: http://docker.w261:8088/proxy/application_1518262877936_0001/\n Running job: job_1518262877936_0001\n Job job_1518262877936_0001 running in uber mode : false\n map 0% reduce 0%\n map 50% reduce 0%\n map 100% reduce 0%\n map 100% reduce 100%\n Job job_1518262877936_0001 completed successfully\n Output directory: hdfs:///user/root/tmp/mrjob/AnotherWC3.root.20180210.114605.598768/output\nCounters: 49\n\tFile Input Format Counters \n\t\tBytes Read=132\n\tFile Output Format Counters \n\t\tBytes Written=32\n\tFile System Counters\n\t\tFILE: Number of bytes read=81\n\t\tFILE: Number of bytes written=354347\n\t\tFILE: Number of large read operations=0\n\t\tFILE: Number of read operations=0\n\t\tFILE: Number of write operations=0\n\t\tHDFS: Number of bytes read=454\n\t\tHDFS: Number of bytes written=32\n\t\tHDFS: Number of large read operations=0\n\t\tHDFS: Number of read operations=9\n\t\tHDFS: Number of write operations=2\n\tJob Counters \n\t\tData-local map tasks=2\n\t\tLaunched map tasks=2\n\t\tLaunched reduce tasks=1\n\t\tTotal megabyte-seconds taken by all map tasks=4611072\n\t\tTotal megabyte-seconds taken by all reduce tasks=2557952\n\t\tTotal time spent by all map tasks (ms)=4503\n\t\tTotal time spent by all maps in occupied slots (ms)=4503\n\t\tTotal time spent by all reduce tasks (ms)=2498\n\t\tTotal time spent by all reduces in occupied slots (ms)=2498\n\t\tTotal vcore-seconds taken by all map tasks=4503\n\t\tTotal vcore-seconds taken by all reduce tasks=2498\n\tMap-Reduce Framework\n\t\tCPU time spent (ms)=1470\n\t\tCombine input records=0\n\t\tCombine output records=0\n\t\tFailed Shuffles=0\n\t\tGC time elapsed (ms)=43\n\t\tInput split bytes=322\n\t\tMap input records=3\n\t\tMap output bytes=63\n\t\tMap output materialized bytes=87\n\t\tMap output records=6\n\t\tMerged Map outputs=2\n\t\tPhysical memory (bytes) snapshot=928542720\n\t\tReduce input groups=3\n\t\tReduce input records=6\n\t\tReduce output records=3\n\t\tReduce shuffle bytes=87\n\t\tShuffled Maps =2\n\t\tSpilled Records=12\n\t\tTotal committed heap usage (bytes)=1513095168\n\t\tVirtual memory (bytes) snapshot=4245602304\n\tShuffle Errors\n\t\tBAD_ID=0\n\t\tCONNECTION=0\n\t\tIO_ERROR=0\n\t\tWRONG_LENGTH=0\n\t\tWRONG_MAP=0\n\t\tWRONG_REDUCE=0\nStreaming final output from hdfs:///user/root/tmp/mrjob/AnotherWC3.root.20180210.114605.598768/output...\n\"chars\"\t89\n\"lines\"\t3\n\"words\"\t18\nRemoving HDFS temp directory hdfs:///user/root/tmp/mrjob/AnotherWC3.root.20180210.114605.598768...\nRemoving temp directory /tmp/AnotherWC3.root.20180210.114605.598768...\n"
],
[
"%%writefile AnotherWC2.py\n\nfrom mrjob.job import MRJob\nfrom mrjob.step import MRStep\nimport re\n\nWORD_RE = re.compile(r\"[\\w']+\")\n\n\nclass MRMostUsedWord(MRJob):\n\n def steps(self):\n return [\n MRStep(mapper=self.mapper_get_words,\n combiner=self.combiner_count_words,\n reducer=self.reducer_count_words),\n MRStep(reducer=self.reducer_find_max_word)\n ]\n\n def mapper_get_words(self, _, line):\n # yield each word in the line\n for word in WORD_RE.findall(line):\n self.increment_counter('group', 'counter_name', 1)\n yield (word.lower(), 1)\n\n def combiner_count_words(self, word, counts):\n # optimization: sum the words we've seen so far\n yield (word, sum(counts))\n\n def reducer_count_words(self, word, counts):\n # send all (num_occurrences, word) pairs to the same reducer.\n # num_occurrences is so we can easily use Python's max() function.\n yield None, (sum(counts), word)\n\n # discard the key; it is just None\n def reducer_find_max_word(self, _, word_count_pairs):\n # each item of word_count_pairs is (count, word),\n # so yielding one results in key=counts, value=word\n yield max(word_count_pairs)\n\n\nif __name__ == '__main__':\n MRMostUsedWord.run()",
"Overwriting AnotherWC2.py\n"
],
[
"!python WordCount.py example2.txt --output-dir mrJobOutput",
"No configs found; falling back on auto-configuration\nNo configs specified for inline runner\nRunning step 1 of 1...\nCreating temp directory /tmp/WordCount.root.20180203.150000.135247\nStreaming final output from mrJobOutput...\n\"labs\"\t1\n\"jimi\"\t5\n\"foo\"\t4\n\"science\"\t1\n\"quux\"\t2\n\"bar\"\t1\n\"mining\"\t1\n\"is\"\t1\n\"data\"\t2\nRemoving temp directory /tmp/WordCount.root.20180203.150000.135247...\n"
],
[
"!ls -las mrJobOutput/\n!cat mrJobOutput/part-0000*",
"total 44\n4 drwxr-xr-x 2 root root 4096 Feb 3 14:52 .\n4 drwxrwxr-x 4 1000 1000 4096 Feb 3 15:16 ..\n4 -rw-r--r-- 1 root root 8 Feb 3 15:22 part-00000\n4 -rw-r--r-- 1 root root 9 Feb 3 15:22 part-00001\n4 -rw-r--r-- 1 root root 8 Feb 3 15:22 part-00002\n4 -rw-r--r-- 1 root root 7 Feb 3 15:22 part-00003\n4 -rw-r--r-- 1 root root 9 Feb 3 15:22 part-00004\n4 -rw-r--r-- 1 root root 9 Feb 3 15:22 part-00005\n4 -rw-r--r-- 1 root root 11 Feb 3 15:22 part-00006\n4 -rw-r--r-- 1 root root 9 Feb 3 15:22 part-00007\n4 -rw-r--r-- 1 root root 12 Feb 3 15:22 part-00008\n0 -rw-r--r-- 1 root root 0 Feb 3 15:22 part-00009\n\"bar\"\t1\n\"data\"\t2\n\"foo\"\t4\n\"is\"\t1\n\"jimi\"\t5\n\"labs\"\t1\n\"mining\"\t1\n\"quux\"\t2\n\"science\"\t1\n"
],
[
"%%writefile WordCount2.py\n\nfrom mrjob.job import MRJob\nfrom mrjob.step import MRStep\nimport re\n \nWORD_RE = re.compile(r\"[\\w']+\")\n \nclass MRWordFreqCount(MRJob):\n SORT_VALUES = True\n def mapper(self, _, line):\n for word in WORD_RE.findall(line):\n self.increment_counter('group', 'mapper', 1)\n yield word.lower(), 1\n \n def jobconfqqqq(self): #assume we had second job to sort the word counts in decreasing order of counts\n orig_jobconf = super(MRWordFreqCount, self).jobconf() \n 'mapred.reduce.tasks': '1',\n }\n combined_jobconf = orig_jobconf\n combined_jobconf.update(custom_jobconf)\n self.jobconf = combined_jobconf\n return combined_jobconf custom_jobconf = { #key value pairs\n 'mapred.output.key.comparator.class': 'org.apache.hadoop.mapred.lib.KeyFieldBasedComparator',\n 'mapred.text.key.comparator.options': '-k2,2nr',\n \n\n\n def combiner(self, word, counts):\n self.increment_counter('group', 'combiner', 1)\n yield word, sum(counts)\n\n def reducer(self, word, counts):\n self.increment_counter('group', 'reducer', 1)\n yield word, sum(counts)\n\n def steps(self):\n return [MRStep(\n mapper = self.mapper, \n combiner = self.combiner,\n reducer = self.reducer,\n #,\n# jobconf = self.jobconfqqqq\n \n# jobconf = {'mapred.output.key.comparator.class': 'org.apache.hadoop.mapred.lib.KeyFieldBasedComparator',\n# 'mapred.text.key.comparator.options':'-k1r',\n# 'mapred.reduce.tasks' : 1} \n \n \n )]\n \n\n\nif __name__ == '__main__':\n MRWordFreqCount.run()",
"Overwriting WordCount2.py\n"
],
[
"!python WordCount2.py --jobconf numReduceTasks=1 example2.txt --output-dir mrJobOutput",
"No configs found; falling back on auto-configuration\nNo configs specified for inline runner\nRunning step 1 of 1...\nCreating temp directory /tmp/WordCount2.root.20180203.152437.411298\n\nCounters: 3\n\tgroup\n\t\tcombiner=11\n\t\tmapper=18\n\t\treducer=9\n\nStreaming final output from mrJobOutput...\n\"labs\"\t1\n\"jimi\"\t5\n\"foo\"\t4\n\"science\"\t1\n\"quux\"\t2\n\"bar\"\t1\n\"mining\"\t1\n\"is\"\t1\n\"data\"\t2\nRemoving temp directory /tmp/WordCount2.root.20180203.152437.411298...\n"
],
[
"!ls -las mrJobOutput/",
"total 44\n4 drwxr-xr-x 2 root root 4096 Feb 3 14:52 .\n4 drwxrwxr-x 4 1000 1000 4096 Feb 3 15:22 ..\n4 -rw-r--r-- 1 root root 8 Feb 3 15:23 part-00000\n4 -rw-r--r-- 1 root root 9 Feb 3 15:23 part-00001\n4 -rw-r--r-- 1 root root 8 Feb 3 15:23 part-00002\n4 -rw-r--r-- 1 root root 7 Feb 3 15:23 part-00003\n4 -rw-r--r-- 1 root root 9 Feb 3 15:23 part-00004\n4 -rw-r--r-- 1 root root 9 Feb 3 15:23 part-00005\n4 -rw-r--r-- 1 root root 11 Feb 3 15:23 part-00006\n4 -rw-r--r-- 1 root root 9 Feb 3 15:23 part-00007\n4 -rw-r--r-- 1 root root 12 Feb 3 15:23 part-00008\n0 -rw-r--r-- 1 root root 0 Feb 3 15:23 part-00009\n"
]
],
[
[
"### Calculate Relative Frequency and Sort by TOP and BOTTOM",
"_____no_output_____"
]
],
[
[
"%%writefile WordCount3.3.py\n\nfrom mrjob.job import MRJob\nfrom mrjob.step import MRStep\nimport re\n\nWORD_RE = re.compile(r\"[\\w']+\")\n\n\nclass MRWordCount33(MRJob):\n\n def steps(self):\n return [\n MRStep(mapper=self.mapper_get_words,\n combiner=self.combiner_count_words,\n reducer=self.reducer_count_words),\n MRStep(reducer=self.reducer_find_max_word)\n ]\n\n def mapper_get_words(self, _, line):\n for word in WORD_RE.findall(line):\n self.increment_counter('Process', 'Mapper', 1)\n yield (word.lower(), 1)\n\n def combiner_count_words(self, word, counts):\n # optimization: sum the words we've seen so far\n yield (word, sum(counts))\n\n def reducer_count_words(self, word, counts):\n # send all (num_occurrences, word) pairs to the same reducer.\n # num_occurrences is so we can easily use Python's max() function.\n yield None, (sum(counts), word)\n\n # discard the key; it is just None\n def reducer_find_max_word(self, _, word_count_pairs):\n # each item of word_count_pairs is (count, word),\n # so yielding one results in key=counts, value=word\n yield max(word_count_pairs)\n\n\nif __name__ == '__main__':\n MRMostUsedWord.run()",
"_____no_output_____"
],
[
"%%writefile top_pages.py\n\"\"\"Find Vroots with more than 400 visits.\n\nThis program will take a CSV data file and output tab-seperated lines of\n\n Vroot -> number of visits\n\nTo run:\n\n python top_pages.py anonymous-msweb.data\n\nTo store output:\n\n python top_pages.py anonymous-msweb.data > top_pages.out\n\"\"\"\nfrom mrjob.job import MRJob\nimport csv\n\ndef csv_readline(line):\n \"\"\"Given a sting CSV line, return a list of strings.\"\"\"\n for row in csv.reader([line]):\n return row\n\nclass TopPages(MRJob):\n\n def mapper(self, line_no, line):\n \"\"\"Extracts the Vroot that was visited\"\"\"\n cell = csv_readline(line)\n if cell[0] == 'V':\n yield ### FILL IN\n # What Key, Value do we want to output?\n\n def reducer(self, vroot, visit_counts):\n \"\"\"Sumarizes the visit counts by adding them together. If total visits\n is more than 400, yield the results\"\"\"\n total = ### FILL IN\n # How do we calculate the total visits from the visit_counts?\n if total > 400:\n yield ### FILL IN\n # What Key, Value do we want to output?\n \nif __name__ == '__main__':\n TopPages.run()",
"_____no_output_____"
],
[
"%reload_ext autoreload\n%autoreload 2\nfrom top_pages import TopPages\nimport csv\n\nmr_job = TopPages(args=['anonymous-msweb.data'])\nwith mr_job.make_runner() as runner:\n runner.run()\n for line in runner.stream_output():\n print mr_job.parse_output_line(line)",
"_____no_output_____"
],
[
"%%writefile TopPages.py\n\"\"\"Find Vroots with more than 400 visits.\n\nThis program will take a CSV data file and output tab-seperated lines of\n\n Vroot -> number of visits\n\nTo run:\n\n python top_pages.py anonymous-msweb.data\n\nTo store output:\n\n python top_pages.py anonymous-msweb.data > top_pages.out\n\"\"\"\n\nfrom mrjob.job import MRJob\nimport csv\n\ndef csv_readline(line):\n \"\"\"Given a sting CSV line, return a list of strings.\"\"\"\n for row in csv.reader([line]):\n return row\n\nclass TopPages(MRJob):\n\n def mapper(self, line_no, line):\n \"\"\"Extracts the Vroot that visit a page\"\"\"\n cell = csv_readline(line)\n if cell[0] == 'V':\n yield cell[1],1\n\n def reducer(self, vroot, visit_counts):\n \"\"\"Sumarizes the visit counts by adding them together. If total visits\n is more than 400, yield the results\"\"\"\n total = sum(i for i in visit_counts)\n if total > 400:\n yield vroot, total\n \nif __name__ == '__main__':\n TopPages.run()",
"Writing TopPages.py\n"
],
[
"%reload_ext autoreload\n%autoreload 2\nfrom TopPages import TopPages\nimport csv\n\nmr_job = TopPages(args=['anonymous-msweb.data'])\nwith mr_job.make_runner() as runner:\n runner.run()\n count = 0\n for line in runner.stream_output():\n print mr_job.parse_output_line(line)\n count += 1\n print 'Final count: ', count",
"(u'1009', 4628)\n(u'1020', 1087)\n(u'1024', 521)\n(u'1025', 2123)\n(u'1038', 1110)\n(u'1040', 1506)\n(u'1041', 1500)\n(u'1035', 1791)\n(u'1036', 759)\n(u'1037', 1160)\n(u'1026', 3220)\n(u'1027', 507)\n(u'1030', 1115)\n(u'1031', 574)\n(u'1032', 1446)\n(u'1004', 8463)\n(u'1000', 912)\n(u'1001', 4451)\n(u'1067', 548)\n(u'1070', 602)\n(u'1074', 584)\n(u'1034', 9383)\n(u'1002', 749)\n(u'1003', 2968)\n(u'1045', 474)\n(u'1046', 636)\n(u'1052', 842)\n(u'1007', 865)\n(u'1008', 10836)\n(u'1010', 698)\n(u'1014', 728)\n(u'1017', 5108)\n(u'1076', 444)\n(u'1078', 462)\n(u'1053', 670)\n(u'1058', 672)\n(u'1018', 5330)\n(u'1295', 716)\nFinal count: 38\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ac747c267c30b1f259878e374413a5901d9afb9
| 23,541 |
ipynb
|
Jupyter Notebook
|
FC/make_adjacency_matrix.ipynb
|
cnlab/cnlab_pipeline
|
979e2fcdfe9113deec1bc9bad17c2624c1e516bb
|
[
"MIT"
] | null | null | null |
FC/make_adjacency_matrix.ipynb
|
cnlab/cnlab_pipeline
|
979e2fcdfe9113deec1bc9bad17c2624c1e516bb
|
[
"MIT"
] | 1 |
2022-03-25T20:40:02.000Z
|
2022-03-25T20:40:02.000Z
|
FC/make_adjacency_matrix.ipynb
|
cnlab/cnlab_pipeline
|
979e2fcdfe9113deec1bc9bad17c2624c1e516bb
|
[
"MIT"
] | null | null | null | 43.433579 | 1,806 | 0.530734 |
[
[
[
"# Mega-Meta Functional Connectivity Pipeline\n\n_________\n```\nCHANGE LOG\n08/14 . -MJ changed \"dur = rel_events.loc[o,'durTR']\" to \"dur = rel_events.loc[i,'durTR'] -> 0 to i\n05/22/2019 - JMP initial commit\n05/28/2019 - JMP added 'rest' TR extration\n```\n\n#### Description\nextracts signal from Power ROI spheres (264) for a given task condition, as defined by a model spec file. Create condition specific adjacency matrix",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport os,glob,sys,pickle,json\n\nfrom IPython.display import Image\n\n\n# NIYPE FUNCTIONS\nimport nipype.interfaces.io as nio # Data i/o\nfrom nipype.interfaces.utility import IdentityInterface, Function # utility\nfrom nipype.pipeline.engine import Node\nfrom nipype.pipeline.engine.workflows import Workflow\n\n\nfrom nilearn import image, plotting, input_data\nfrom nilearn.connectome import ConnectivityMeasure\n%matplotlib inline",
"/usr/local/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:34: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n/usr/local/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 192 from C header, got 216 from PyObject\n return f(*args, **kwds)\n"
]
],
[
[
"# Nipype Setup",
"_____no_output_____"
],
[
"1. Infosource for iterating over subjects\n2. create subject information structure\n3. process confounds\n4. subset TR\n5. process signal\n6. correlation pairwise\n7. save function\n",
"_____no_output_____"
],
[
"### Infosource for iterating subjects",
"_____no_output_____"
]
],
[
[
"# set up infosource\ninfoSource = Node(IdentityInterface(fields = ['subject_id']),\n name = 'infosource')\n\ninfoSource.iterables = [('subject_id',SUBJECT_LIST)]\n",
"_____no_output_____"
]
],
[
[
"### Get subject information\nThis function finds those runs for a given subject that are complete (e.g. have motion, events and functional data). The function then creates the `subject_str` which is a modified `model_str` with subject specific information.",
"_____no_output_____"
]
],
[
[
"def get_subject_info(subject_id,model_str):\n \"\"\"\n checks what runs a given subject has all information for\n \"\"\"\n \n import numpy as np\n import os\n \n \n subPath = model_str['sub_path'].format(PROJECT=model_str['ProjectID'],PID=subject_id)\n \n Runs = []\n for r in model_str['Runs']:\n func = model_str['task_func_template'].format(PID=subject_id,\n TASK=model_str['TaskName'],\n RUN=r)\n motion = model_str['motion_template'].format(PID=subject_id,\n TASK=model_str['TaskName'],\n RUN=r)\n events = model_str['event_template'].format(PID=subject_id,\n TASK=model_str['TaskName'],\n RUN=r)\n\n # check if files exist\n if (os.path.isfile(os.path.join(subPath,func)) and \n os.path.isfile(os.path.join(subPath,motion)) and\n os.path.isfile(os.path.join(subPath,events))):\n Runs.append(r)\n \n # return a subject modified model_structure\n subj_str = model_str\n subj_str['subject_id'] = subject_id\n subj_str['Runs'] = Runs\n \n return subj_str\n \n \nget_sub_info = Node(Function(input_names=['subject_id','model_str'],\n output_names=['subj_str'],\n function = get_subject_info),\n name = \"get_subject_info\")\n\nget_sub_info.inputs.model_str = model_def",
"_____no_output_____"
]
],
[
[
"### Extract Confounds\nThis function extracts matter and motion confounds. Matter confounds include Global average signal (from grey matter mask), white matter, and CSF average signal. There are 24 motion parameters, as per Power (2012). These include all 6 motion regressors, their derivatives, the quadratic of the motion params, and the squared derivatives. ",
"_____no_output_____"
]
],
[
[
"def extract_confounds(subject_str):\n \"\"\"\n extract confounds for all available runs\n \"\"\"\n \n import numpy as np\n import glob\n import os\n from nilearn import image, input_data\n \n subPath = subject_str['sub_path'].format(PROJECT=subject_str['ProjectID'],PID=subject_str['subject_id'])\n struc_files = glob.glob(subject_str['anat_template'].format(PID=subject_str['subject_id'][4:]))\n \n print(struc_files)\n \n # make matter masks\n maskers = [input_data.NiftiLabelsMasker(labels_img=struc,standardize=True,memory='nilearn_cache') for struc in struc_files]\n\n confound = {}\n for r in subject_str['Runs']:\n \n func = subject_str['task_func_template'].format(PID=subject_str['subject_id'],\n TASK=subject_str['TaskName'],\n RUN=r)\n func_file = os.path.join(subPath,func)\n \n # high variance confounds\n hv_confounds = image.high_variance_confounds(func_file)\n \n # get This runs matter confounds (grand mean, white matter, CSF)\n matter_confounds = None\n for mask in maskers:\n mt = mask.fit_transform(func_file)\n mean_matter = np.nanmean(mt,axis=1) # get average signal\n \n if matter_confounds is None:\n matter_confounds = mean_matter\n else:\n matter_confounds = np.column_stack([matter_confounds,mean_matter])\n \n # Motion includes xyz,roll,pitch,yaw\n # their derivatives, the quadratic term, and qaudratic derivatives\n motion = subject_str['motion_template'].format(PID=subject_str['subject_id'],\n TASK=subject_str['TaskName'],\n RUN=r)\n \n motion = np.genfromtxt(os.path.join(subPath,motion),delimiter='\\t',skip_header=True)\n motion = motion[:,:6] # dont take framewise displacement\n \n # derivative of motion\n motion_deriv = np.concatenate([np.zeros([1,np.shape(motion)[1]]),np.diff(motion,axis=0)],axis=0)\n matter_deriv = np.concatenate([np.zeros([1,np.shape(matter_confounds)[1]]),np.diff(matter_confounds,axis=0)],axis=0)\n \n conf = np.concatenate([motion,motion**2,motion_deriv,motion_deriv**2,\n matter_confounds,matter_confounds**2,matter_deriv,matter_deriv**2,\n hv_confounds],axis=1)\n confound[r] = conf\n return confound\n \nconfounds = Node(Function(input_names=['subject_str'],\n output_names = ['confound'],\n function = extract_confounds),\n name = 'get_confounds')\n ",
"_____no_output_____"
]
],
[
[
"### Condition TR\nThis function finds those TR for a run that match the condition labels of a given model specification. The `condition` input argument must be set for a given pipeline.",
"_____no_output_____"
]
],
[
[
"def get_condition_TR(subject_str):\n \"\"\"\n Gets the TR list for condition of interest\n \"\"\"\n \n import numpy as np\n import os\n import pandas as pd\n \n subPath = subject_str['sub_path'].format(PROJECT=subject_str['ProjectID'],PID=subject_str['subject_id'])\n \n conditions = subject_str['Conditions'][subject_str['condition']]\n \n TRs = {}\n for r in subject_str['Runs']:\n \n ev = subject_str['event_template'].format(PID=subject_str['subject_id'],\n TASK=subject_str['TaskName'],\n RUN=r)\n \n events_df = pd.read_csv(os.path.join(subPath,ev),delimiter='\\t')\n \n \n rel_events = events_df.loc[events_df.trial_type.isin(conditions)].reset_index()\n \n rel_events['TR'] = (rel_events['onset']/subject_str['TR']).astype('int')\n rel_events['durTR'] = (rel_events['duration']/subject_str['TR']).astype('int')\n\n condition_TR = []\n \n for i,tr in enumerate(rel_events.TR):\n dur = rel_events.loc[i,'durTR']\n condition_TR.extend(list(range(tr,tr+dur)))\n TRs[r] = condition_TR\n \n return TRs\n\nevents = Node(Function(input_names=['subject_str'],\n output_names = ['TRs'],\n function = get_condition_TR),\n name = 'get_TRs')\n\n",
"_____no_output_____"
]
],
[
[
"### Get Signal\nThis is where things all come together. Data is masked and confounds are regressed from masked signal. Only those TR for the condition are then subset from the TR. Currently Power atlas is used as a masker (264 nodes). ",
"_____no_output_____"
]
],
[
[
"def get_signal(subject_str,confound,TRs,mask):\n \"\"\"\n gets task data, regresses confounds and subsets relevant TR\n \"\"\"\n \n from nilearn import image, input_data\n import numpy as np\n import os\n \n subPath = subject_str['sub_path'].format(PROJECT=subject_str['ProjectID'],PID=subject_str['subject_id'])\n \n signal = None\n for r in subject_str['Runs']:\n runTR = TRs[r]\n con = confound[r]\n func = subject_str['task_func_template'].format(PID=subject_str['subject_id'],\n TASK=subject_str['TaskName'],\n RUN=r)\n func_file = os.path.join(subPath,func)\n \n masked_fun = mask.fit_transform(func_file,con)\n \n condition_TR = [_ for _ in runTR if _ < masked_fun.shape[0]]\n \n # if condition is rest, take all TR that are unmodeled\n if subject_str['condition'] == 'rest':\n masked_condition = masked_fun[[i for i in range(masked_fun.shape[0]) if i not in condition_TR],:]\n else:\n masked_condition = masked_fun[condition_TR,:]\n \n if signal is None:\n signal = masked_condition\n else:\n signal = np.concatenate([signal,masked_condition],axis=0)\n \n return signal\n\n\nsignal = Node(Function(input_names=['subject_str','confound','TRs','mask'],\n output_names = ['signal'],\n function = get_signal),\n name = 'get_signal')\n\nsignal.inputs.mask = NODE_MASKER\n ",
"_____no_output_____"
]
],
[
[
"### Adjacency matrix\n\nThe final step of the pipeline. Data is pairwise correlated using pearson R and output is a 264X264 adjacency matrix.",
"_____no_output_____"
]
],
[
[
"def make_adj_matrix(signal):\n import numpy as np\n from scipy import stats\n signal[np.isnan(signal)] = 0\n \n features = signal.shape[1]\n \n r_adj = np.zeros([features,features])\n p_adj = np.zeros([features,features])\n for i in range(features):\n for i2 in range(features):\n r_adj[i,i2],p_adj[i,i2] = stats.pearsonr(signal[:,i],signal[:,i2])\n\n return r_adj,p_adj\n\nadj_matrix = Node(Function(input_names=['signal'],\n output_names = ['r_adj','p_adj'],\n function = make_adj_matrix),\n name = 'adjacency_matrix')",
"_____no_output_____"
]
],
[
[
"### Data output\nOutput is a json file containing \n* the subject ID\n* Project\n* Task name\n* Condition\n* Pearson r value adj matrix\n* p.value adj matrix",
"_____no_output_____"
]
],
[
[
"def data_out(subject_str,r_adj,p_adj):\n import pickle,os\n Output = {\"SubjectID\":subject_str['subject_id'],\n \"Project\":subject_str['ProjectID'],\n \"Task\":subject_str['TaskName'],\n \"Condition\":subject_str['condition'],\n 'r_adj':r_adj,\n 'p_adj':p_adj}\n \n subFile = '{PID}_task-{TASK}_condition-{CONDITION}_parcellation-POWER2011_desc-FCcorrelation_adj.pkl'.format(PID = subject_str['subject_id'],\n TASK = subject_str['TaskName'],\n CONDITION=subject_str['condition'])\n outFile = os.path.join(subject_str['output_dir'],subFile)\n \n with open(outFile,'wb') as outp:\n pickle.dump(Output,outp)\n\ndata_save = Node(Function(input_names=['subject_str','r_adj','p_adj'],\n function = data_out),\n name = 'data_out')\n ",
"_____no_output_____"
]
],
[
[
"______\n\n## WIRE UP",
"_____no_output_____"
]
],
[
[
"wfl = Workflow(name='workflow')\nwfl.base_dir = working_dir\n\nwfl.connect([(infoSource,get_sub_info,[(\"subject_id\",\"subject_id\")]),\n (get_sub_info, confounds,[(\"subj_str\",\"subject_str\")]),\n (get_sub_info, events,[('subj_str','subject_str')]),\n (get_sub_info,signal,[('subj_str','subject_str')]),\n (confounds,signal,[('confound','confound')]),\n (events,signal,[('TRs','TRs')]),\n (signal, adj_matrix,[('signal','signal')]),\n (get_sub_info,data_save,[('subj_str','subject_str')]),\n (adj_matrix, data_save,[('r_adj','r_adj'),('p_adj','p_adj')]),\n ])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac74ad017df542981051f62a141035f37157747
| 2,000 |
ipynb
|
Jupyter Notebook
|
case_studies/SVS/code/radar_chart.ipynb
|
ricrosales/honestnft-shenanigans
|
c5033902776783677bb4224ad3ddc965752322f7
|
[
"MIT"
] | 88 |
2021-10-25T23:57:36.000Z
|
2022-03-31T17:01:57.000Z
|
case_studies/SVS/code/radar_chart.ipynb
|
ricrosales/honestnft-shenanigans
|
c5033902776783677bb4224ad3ddc965752322f7
|
[
"MIT"
] | 14 |
2021-11-17T18:48:27.000Z
|
2022-03-10T15:57:13.000Z
|
case_studies/SVS/code/radar_chart.ipynb
|
ricrosales/honestnft-shenanigans
|
c5033902776783677bb4224ad3ddc965752322f7
|
[
"MIT"
] | 41 |
2021-10-30T16:20:53.000Z
|
2022-03-31T17:02:00.000Z
| 23.529412 | 92 | 0.4965 |
[
[
[
"import plotly.express as px\nimport pandas as pd\nfrom random import randint\n\nCOLLECTION_NAME = \"SVS\"\n\nFAIRNESS = 10\nGAS_EFFICIENCY = 7\nUX = 7\nTRUSTLESSNESS = 3\nAFFORDABILITY = 9\nSIMPLICITY = 7\nr = [FAIRNESS, GAS_EFFICIENCY, UX, TRUSTLESSNESS, AFFORDABILITY, SIMPLICITY]\n\ndf = pd.DataFrame(\n dict(\n r=r,\n theta=[\n \"Fairness\",\n \"Gas efficiency\",\n \"User Experience\",\n \"Trustlessness\",\n \"Affordability\",\n \"Simplicity\",\n ],\n )\n)\nfig = px.line_polar(df, r=\"r\", theta=\"theta\", line_close=True, range_r=[0, 10])\nfig.update_traces(fill=\"toself\")\nfig.update_layout(\n title_text=\"HonestNFT HonestScore - Sneaky Vampire Syndicate\", title_x=0.5\n)\n\nfig.write_image(\"../figures/honest_score.png\".format(COLLECTION_NAME))",
"43\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4ac752778d9ae825d1d6864e02d5e79390abf4f3
| 11,704 |
ipynb
|
Jupyter Notebook
|
tutorials/nasa_apps_oct_2019/answers/3 - Debugging.ipynb
|
gmarkall/numba-examples
|
0ea1b5855bdcf7545759bca55bfb0ac25274ee82
|
[
"BSD-2-Clause"
] | 140 |
2017-07-15T21:17:44.000Z
|
2022-03-19T00:56:05.000Z
|
tutorials/nasa_apps_oct_2019/answers/3 - Debugging.ipynb
|
stuartarchibald/numba-examples
|
ccf2351c26acafad9f5eca371ad608610450171f
|
[
"BSD-2-Clause"
] | 24 |
2017-07-24T16:25:35.000Z
|
2021-12-08T17:54:38.000Z
|
tutorials/nasa_apps_oct_2019/answers/3 - Debugging.ipynb
|
stuartarchibald/numba-examples
|
ccf2351c26acafad9f5eca371ad608610450171f
|
[
"BSD-2-Clause"
] | 50 |
2017-07-15T21:15:16.000Z
|
2021-12-12T15:27:05.000Z
| 32.692737 | 403 | 0.572112 |
[
[
[
"# Debugging Numba problems\n\n",
"_____no_output_____"
],
[
"## Common problems\n\nNumba is a compiler, if there's a problem, it could well be a \"compilery\" problem, the dynamic interpretation that comes with the Python interpreter is gone! As with any compiler toolchain there's a bit of a learning curve but once the basics are understood it becomes easy to write quite complex applications.",
"_____no_output_____"
]
],
[
[
"from numba import njit\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"### Type inference problems\n\nA very large set of problems can be classed as type inference problems. These are problems which appear when Numba can't work out the types of all the variables in your code. Here's an example:",
"_____no_output_____"
]
],
[
[
"@njit\ndef type_inference_problem():\n a = {}\n return a\n\ntype_inference_problem()",
"_____no_output_____"
]
],
[
[
"Things to note in the above, Numba has said that:\n \n 1. It has encountered a typing error.\n 2. It cannot infer (work out) the type of the variable named `a`.\n 3. It has an imprecise type for `a` of `DictType[undefined, undefined]`.\n 4. It's pointing to where the problem is in the source\n 5. It's giving you things to look at for help\n \nNumba's response is reasonable, how can it possibly compile a specialisation of an empty dictionary, it cannot work out what to use for a key or value type.",
"_____no_output_____"
],
[
"### Type unification problems\n\nAnother common issue is that of type unification, this is due to Numba needing the inferred variable types for the code it's compiling to be statically determined and type stable. What this usually means is something like the type of a variable is being changed in a loop or there's two (or more) possible return types. Example:",
"_____no_output_____"
]
],
[
[
"@njit\ndef foo(x):\n if x > 10:\n return (1,)\n else:\n return 1\n\nfoo(1)",
"_____no_output_____"
]
],
[
[
"Things to note in the above, Numba has said that:\n \n 1. It has encountered a typing error.\n 2. It cannot unify the return types and then lists the offending types.\n 3. It pointis to the locations in the source that are the cause of the problem.\n 4. It's giving you things to look at for help.\n \nNumba's response due to it not being possible to compile a function that returns a tuple or an integer? You couldn't do that in C/Fortran, same here!\n\n### Unsupported features\n\nNumba supports a subset of Python and NumPy, it's possible to run into something that hasn't been implemented. For example `str(int)` has not been written yet (this is a rather tricky thing to write :)). This is what it looks like:",
"_____no_output_____"
]
],
[
[
"@njit\ndef foo():\n return str(10)\n\nfoo()",
"_____no_output_____"
]
],
[
[
"Things to note in the above, Numba has said that:\n \n 1. It has encountered a typing error.\n 2. It's an invalid use of a `Function` of type `(<class 'str'>)` with argument(s) of type(s): `(Literal[int](10))`\n 3. It points to the location in the source that is the cause of the problem.\n 4. It's giving you things to look at for help.\n\n\nWhat's this bit about?\n```\n* parameterized\nIn definition 0:\n All templates rejected with literals.\nIn definition 1:\n All templates rejected without literals.\nIn definition 2:\n All templates rejected with literals.\nIn definition 3:\n All templates rejected without literals.\n```\n \nInternally Numba does something akin to \"template matching\" to try and find something to do the functionality requested with the types requested, it's looking through the definitions see if any match and reporting what they say (which in this case is \"rejected\").\n\nHere's a different one, Numba's `np.mean` implementation doesn't support `axis`:",
"_____no_output_____"
]
],
[
[
"@njit\ndef foo():\n x = np.arange(100).reshape((10, 10))\n return np.mean(x, axis=1)\n\nfoo()",
"_____no_output_____"
]
],
[
[
"Things to note in the above, Numba has said that:\n \n 1. It has encountered a typing error.\n 2. It's an invalid use of a `Function` \"mean\" with argument(s) of type(s): `(array(float64, 2d, C), axis=Literal[int](1))`\n 3. It's reporting what the various template defintions are responding with: e.g. \n \"TypingError: numba doesn't support kwarg for mean\", which is correct!\n 4. It points to the location in the source that is the cause of the problem.\n 5. It's giving you things to look at for help.\n \nA common workaround for the above is to just unroll the loop over the axis, for example:",
"_____no_output_____"
]
],
[
[
"@njit\ndef foo():\n x = np.arange(100).reshape((10, 10))\n lim, _ = x.shape\n buf = np.empty((lim,), x.dtype)\n for i in range(lim):\n buf[i] = np.mean(x[i])\n return buf\n \nfoo()",
"_____no_output_____"
]
],
[
[
"### Lowering errors\n\n\"Lowering\" is the process of translating the Numba IR to LLVM IR to machine code. Numba tries really hard to prevent lowering errors, but sometimes you might see them, if you do please tell us:\n \nhttps://github.com/numba/numba/issues/new\n\nA lowering error means that there's a problem in Numba internals. The most common cause is that it worked out that it could compile a function as all the variable types were statically determined, but when it tried to find an implementation for some operation in the function to translate to machine code, it couldn't find one.",
"_____no_output_____"
],
[
"<h3><span style=\"color:blue\"> Task 1: Debugging practice</span></h3>\n\nThe following code has a couple of issues, see if you can work them out and fix them.",
"_____no_output_____"
]
],
[
[
"x = np.arange(20.).reshape((4, 5))\n\n@njit\ndef problem_factory(x):\n nrm_x = np.linalg.norm(x, ord=2, axis=1) # axis not supported, manual unroll\n nrm_total = np.sum(nrm_x)\n ret = {} # dict type requires float->int cast, true branch is int and it sets the dict type\n if nrm_total > 87:\n ret[nrm_total] = 1\n else:\n ret[nrm_total] = nrm_total\n \n return ret\n\n\n# This is a fixed version\n@njit\ndef problem_factory_fixed(x):\n lim, _ = x.shape\n \n nrm_x = np.empty(lim, x.dtype)\n for i in range(lim):\n nrm_x[i] = np.linalg.norm(x[i])\n nrm_total = np.sum(nrm_x)\n\n ret = {}\n if nrm_total > 87:\n ret[nrm_total] = 1.0\n else:\n ret[nrm_total] = nrm_total\n \n return ret \n\nfixed = problem_factory_fixed(x)\nexpected = problem_factory.py_func(x)\n\n# will pass if \"fixed\" correctly\nfor k, v in zip(fixed.items(), expected.items()):\n np.testing.assert_allclose(k[0], k[1])\n np.testing.assert_allclose(v[0], v[1])",
"_____no_output_____"
]
],
[
[
"## Debugging compiled code\n\nIn Numba compiled code debugging typically takes one of a few forms.\n\n1. Temporarily disabling the JIT compiler so that the code just runs in Python and the usual Python debugging tools can be used. Either remove the Numba JIT decorators or set the environment variable `NUMBA_DISABLE_JIT`, to disable JIT compilation globally, [docs](http://numba.pydata.org/numba-doc/latest/reference/envvars.html#envvar-NUMBA_DISABLE_JIT).\n\n2. Traditional \"print-to-stdout\" debugging, Numba supports the use of `print()` (without interpolation!) so it's relatively easy to inspect values and control flow. e.g.",
"_____no_output_____"
]
],
[
[
"@njit\ndef demo_print(x):\n print(\"function entry\")\n if x > 1:\n print(\"branch 1, x = \", x)\n else:\n print(\"branch 2, x = \", x)\n print(\"function exit\")\n \ndemo_print(5)",
"_____no_output_____"
]
],
[
[
"3. Debugging with `gdb` (the GNU debugger). This is not going to be demonstrated here as it does not work with notebooks. However, the gist is to supply the Numba JIT decorator with the kwarg `debug=True` and then Numba has a special function `numba.gdb()` that can be used in your program to automatically launch and attach `gdb` at the call site. For example (and **remember not to run this!**):",
"_____no_output_____"
]
],
[
[
"from numba import gdb\n\n@njit(debug=True)\ndef _DO_NOT_RUN_gdb_demo(x):\n if x > 1:\n y = 3\n gdb()\n else:\n y = 5\n return y",
"_____no_output_____"
]
],
[
[
"Extensive documentation on using `gdb` with Numba is available [here](http://numba.pydata.org/numba-doc/latest/user/troubleshoot.html#debugging-jit-compiled-code-with-gdb).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac755af98bb76cb37deb3b226caa5312d8408fd
| 2,023 |
ipynb
|
Jupyter Notebook
|
Set Operations .ipynb
|
raj-laddha/myCapAI
|
19607304e6bbcce2d33bdb7e44b4181e5d40899d
|
[
"MIT"
] | null | null | null |
Set Operations .ipynb
|
raj-laddha/myCapAI
|
19607304e6bbcce2d33bdb7e44b4181e5d40899d
|
[
"MIT"
] | null | null | null |
Set Operations .ipynb
|
raj-laddha/myCapAI
|
19607304e6bbcce2d33bdb7e44b4181e5d40899d
|
[
"MIT"
] | null | null | null | 23.8 | 112 | 0.531389 |
[
[
[
"# Program to illustrate set operations",
"_____no_output_____"
]
],
[
[
"# creating two sets \nsetEven = {0, 2, 4, 6, 8, 10}\nsetNatural = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}",
"_____no_output_____"
],
[
"# Union Operation\nprint('Union of setEven and setNatural: ', setEven.union(setNatural) ,'\\n')\n\n# Intersection Opertaion\nprint('Intersection of setEven and setNatural: ', setEven.intersection(setNatural), '\\n')\n\n# Difference Opertaion\nprint('Difference of setNatural and setEven: ', setNatural.difference(setEven), '\\n')\n\n# Symmetric Difference Opertaion\nprint('Symmetric Difference of setNatural and setEven: ', setNatural.symmetric_difference(setEven), '\\n')",
"Union of setEven and setNatural: {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10} \n\nIntersection of setEven and setNatural: {2, 4, 6, 8, 10} \n\nDifference of setNatural and setEven: {1, 3, 5, 7, 9} \n\nSymmetric Difference of setNatural and setEven: {0, 1, 3, 5, 7, 9} \n\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
]
] |
4ac759872d9f5471b3a40bb2faa82c5bb0729ffa
| 11,590 |
ipynb
|
Jupyter Notebook
|
Intro Module/intro-strings.ipynb
|
ds-modules/GWS-101
|
10c011c33a9060be4dfcdfb04a7f5b85e8fd9bec
|
[
"MIT"
] | 1 |
2017-11-06T18:25:08.000Z
|
2017-11-06T18:25:08.000Z
|
Intro Module/intro-strings.ipynb
|
ds-modules/GWS-101
|
10c011c33a9060be4dfcdfb04a7f5b85e8fd9bec
|
[
"MIT"
] | null | null | null |
Intro Module/intro-strings.ipynb
|
ds-modules/GWS-101
|
10c011c33a9060be4dfcdfb04a7f5b85e8fd9bec
|
[
"MIT"
] | null | null | null | 29.717949 | 633 | 0.587403 |
[
[
[
"# Introduction to Strings\n---\n\nThis notebook covers the topic of strings and their importance in the world of programming. You will learn various methods that will help you manipulate these strings and make useful inferences with them. This notebook assumes that you have already completed the \"Introduction to Data Science\" notebook.\n\n*Estimated Time: 30 minutes*\n\n---\n\n**Topics Covered:**\n- Objects\n- String Concatenation\n- Loops\n- String Methods\n\n**Dependencies:**",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom datascience import *",
"_____no_output_____"
]
],
[
[
"## What Are Objects?",
"_____no_output_____"
],
[
"Objects are used everywhere when you're coding - even when you dont know it. But what really is an object? \n\nBy definition, an object is an **instance** of a **class**. They're an **abstraction**, so they can be used to manipulate data. That sounds complicated, doesn't it? Well, to simplify, think of this: a class is a huge general category of something which holds particular attributes (variables) and actions (functions). Let's assume that Mars has aliens called Xelhas and one of them visits Earth. The Xelha species would be a class, and the alien itself would be an *instance* of that class (or an object). By observing its behavior and mannerisms, we would be able to see how the rest of its species goes about doing things.\n\nStrings are objects too, of the *String* class, which has pre-defined methods that we use. But you don't need to worry about that yet. All you should know is that strings are **not** \"primitive\" data types, such as integers or booleans. That being said, let's delve right in.\n\nTry running the code cell below:\n",
"_____no_output_____"
]
],
[
[
"5 + \"5\"",
"_____no_output_____"
]
],
[
[
"Why did that happen?\n\nThis can be classified as a *type* error. As mentioned before, Strings are not primitive data types, like integers and booleans, so when you try to **add** a string to an integer, Python gets confused and throws an error. The important thing to note here is that a String is a String: no matter what its contents may be. If it's between two quotes, it has to be a String. \n\nBut what if we followed the \"same type\" rule and tried to add two Strings? Let's try it.\n",
"_____no_output_____"
]
],
[
[
"\"5\" + \"5\"",
"_____no_output_____"
]
],
[
[
"What?! How does 5 + 5 equal 55?\n\nThis is known as concatenation.",
"_____no_output_____"
],
[
"## Concatenation\n\n\"Concatenating\" two items means literally combining or joining them. \n\nWhen you put the + operator with two or more Strings, Python will take all of the content inside quotes and club it all together to make one String. This process is called **concatenation**.\n\nThe following examples illustrate how String concatenation works:",
"_____no_output_____"
]
],
[
[
"\"Berk\" + \"eley\"",
"_____no_output_____"
],
[
"\"B\" + \"e\" + \"r\" + \"k\" + \"e\" + \"l\" + \"e\" + \"y\"",
"_____no_output_____"
]
],
[
[
"Here's a small exercise for you, with a lot of variables. Try making the output \"today is a lovely day\".\n\n_Hint: Remember to add double quotes with spaces \" \" because Python literally clubs all text together._\n",
"_____no_output_____"
]
],
[
[
"a = \"oda\"\nb = \"is\"\nc = \"a\"\nd = \"l\"\ne = \"t\"\nf = \"y\"\ng = \"lo\"\nh = \"d\"\ni = \"ve\"\n\n# your expression here",
"_____no_output_____"
]
],
[
[
"## String methods",
"_____no_output_____"
],
[
"The String class is great for regular use because it comes equipped with a lot of built-in functions with useful properties. These functions, or **methods** can fundamentally transform Strings. Here are some common String methods that may prove to be helpful.\n\n### Replace\nFor example, the *replace* method replaces all instances of some part of a string with some replacement. A method is invoked on a string by placing a . after the string value, then the name of the method, and finally parentheses containing the arguments.\n\n <string>.<method name>(<argument>, <argument>, ...)\n\nTry to predict the output of these examples, then execute them.",
"_____no_output_____"
]
],
[
[
"# Replace one letter\n'Hello'.replace('e', 'i')",
"_____no_output_____"
],
[
"# Replace a sequence of letters, which appears twice\n'hitchhiker'.replace('hi', 'ma')",
"_____no_output_____"
]
],
[
[
"Once a name is bound to a string value, methods can be invoked on that name as well. The name doesn't change in this case, so a new name is needed to capture the result.\n\nRemember, a string method will replace **every** instance of where the replacement text is found.",
"_____no_output_____"
]
],
[
[
"sharp = 'edged'\nhot = sharp.replace('ed', 'ma')\nprint('sharp =', sharp)\nprint('hot =', hot)",
"_____no_output_____"
]
],
[
[
"Another very useful method is the **`split`** method. It takes in a \"separator string\" and splits up the original string into an array, with each element of the array being a separated portion of the string.\n\nHere are some examples:",
"_____no_output_____"
]
],
[
[
"\"Another very useful method is the split method\".split(\" \")",
"_____no_output_____"
],
[
"string_of_numbers = \"1, 2, 3, 4, 5, 6, 7\"\narr_of_strings = string_of_numbers.split(\", \")\nprint(arr_of_strings) # Remember, these elements are still strings!\narr_of_numbers = []\nfor s in arr_of_strings: # Loop through the array, converting each string to an int\n arr_of_numbers.append(int(s))\nprint(arr_of_numbers)",
"_____no_output_____"
]
],
[
[
"As you can see, the `split` function can be very handy when cleaning up and organizing data (a process known as _parsing_).",
"_____no_output_____"
],
[
"## Loops",
"_____no_output_____"
],
[
"What do you do when you have to do the same task repetitively? Let's say you have to say Hi to someone five times. Would that require 5 lines of \"print('hi')\"? No! This is why coding is beautiful. It allows for automation and takes care of all the hard work. \n\nLoops, in the literal meaning of the term, can be used to repeat tasks over and over, until you get your desired output. They are also called \"iterators\", and they are defined using a variable which changes (either increases or decreases) with each loop, to keep a track of the number of times you're looping.\n\nThe most useful loop to know for the scope of this course is the **for** loop.\n\nA for statement begins with the word *for*, followed by a name we want to give each item in the sequence, followed by the word *in*, and ending with an expression that evaluates to a sequence. The indented body of the for statement is executed once for each item in that sequence.\n\n for *variable* in *np.arange(0,5)*:\n \nDon't worry about the np.arange() part yet. Just remember that this expression produces a sequence, and Strings are sequences too! So let's try our loop with Strings!\n \n for each_character in \"John Doenero\":\n *do something*\n \nInteresting! Let's put our code to test.\n",
"_____no_output_____"
]
],
[
[
"for each_character in \"John Doenero\":\n print(each_character)",
"_____no_output_____"
]
],
[
[
"Cool, right? Now let's do something more useful. \n\nWrite a for loop that iterates through the sentence \"Hi, I am a quick brown fox and I jump over the lazy dog\" and checks if each letter is an *a*. Print out the number of a's in the sentence.\n\n_Hint: try combining what you've learnt from conditions and use a counter._",
"_____no_output_____"
]
],
[
[
"# your code here\nfor ...\n ",
"_____no_output_____"
]
],
[
[
"## Conclusion\n---\nCongratulations! You have learned the basics of String manipulation in Python.",
"_____no_output_____"
],
[
"## Bibliography\n---\nSome examples adapted from the UC Berkeley Data 8 textbook, <a href=\"https://www.inferentialthinking.com\">*Inferential Thinking*</a>.\n\nAuthors:\n- Shriya Vohra\n- Scott Lee\n- Pancham Yadav",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4ac765a26dfd914695da56af30179179dfa3c251
| 3,942 |
ipynb
|
Jupyter Notebook
|
2020/day5.ipynb
|
yttrian/advent
|
3bd83366f6c459ac8a6bb6f7fff5edee5fcd0b75
|
[
"MIT"
] | null | null | null |
2020/day5.ipynb
|
yttrian/advent
|
3bd83366f6c459ac8a6bb6f7fff5edee5fcd0b75
|
[
"MIT"
] | null | null | null |
2020/day5.ipynb
|
yttrian/advent
|
3bd83366f6c459ac8a6bb6f7fff5edee5fcd0b75
|
[
"MIT"
] | null | null | null | 19.229268 | 110 | 0.47311 |
[
[
[
"# Advent of Code Day 5",
"_____no_output_____"
]
],
[
[
"import java.io.*",
"_____no_output_____"
],
[
"val day5 = File(\"day5.txt\").readLines()\nday5.take(5)",
"_____no_output_____"
],
[
"fun find(path: String, lower: String, upper: String, min: Int, max: Int): Int = when (path.take(1)) {\n lower -> if (path.length > 1) find(path.drop(1), lower, upper, min, (max + min) / 2) else min\n upper -> if (path.length > 1) find(path.drop(1), lower, upper, (max + min + 1) / 2, max) else max\n else -> throw IllegalArgumentException()\n}\nfun findRow(path: String) = find(path, \"F\", \"B\", 0, 127)\nfun findColumn(path: String) = find(path, \"L\", \"R\", 0, 7)",
"_____no_output_____"
],
[
"fun seatId(path: String) = findRow(path.take(7)) * 8 + findColumn(path.drop(7))",
"_____no_output_____"
],
[
"seatId(\"BFFFBBFRRR\")",
"_____no_output_____"
],
[
"seatId(\"FFFBBBFRRR\")",
"_____no_output_____"
],
[
"seatId(\"BBFFBBFRLL\")",
"_____no_output_____"
],
[
"day5.map(::seatId).max()",
"_____no_output_____"
],
[
"val takenSeats = day5.map(::seatId).toSet()\n(seatId(\"FFFFFFFLLL\")..seatId(\"BBBBBBBRRR\")).first { \n (it !in takenSeats) && (it + 1 in takenSeats) && (it - 1 in takenSeats) \n}",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac77b8cc672e8914fac25a543ee0334c14575a0
| 5,949 |
ipynb
|
Jupyter Notebook
|
examples/cifar.ipynb
|
Garfounkel/fastai
|
3dae8a4bf292b98efbb89ec370fd1a4a13aeb3cf
|
[
"Apache-2.0"
] | null | null | null |
examples/cifar.ipynb
|
Garfounkel/fastai
|
3dae8a4bf292b98efbb89ec370fd1a4a13aeb3cf
|
[
"Apache-2.0"
] | null | null | null |
examples/cifar.ipynb
|
Garfounkel/fastai
|
3dae8a4bf292b98efbb89ec370fd1a4a13aeb3cf
|
[
"Apache-2.0"
] | null | null | null | 33.421348 | 120 | 0.486132 |
[
[
[
"%reload_ext autoreload\n%autoreload 2\n\nfrom fastai import *\nfrom fastai.vision import *\nfrom fastai.vision.models.wrn import wrn_22\n\ntorch.backends.cudnn.benchmark = True",
"_____no_output_____"
],
[
"untar_data(Paths.CIFAR)",
"_____no_output_____"
],
[
"ds_tfms = ([*rand_pad(4, 32), flip_lr(p=0.5)], [])\ndata = image_data_from_folder(Paths.CIFAR, valid='test', ds_tfms=ds_tfms, tfms=cifar_norm, bs=512)",
"_____no_output_____"
],
[
"learn = Learner(data, wrn_22(), metrics=accuracy).to_fp16()\nlearn.fit_one_cycle(30, 3e-3, wd=0.4, div_factor=10, pct_start=0.5)",
"_____no_output_____"
]
],
[
[
"With mixup",
"_____no_output_____"
]
],
[
[
"learn = Learner(data, wrn_22(), metrics=accuracy).to_fp16().mixup()\nlearn.fit_one_cycle(24, 3e-3, wd=0.2, div_factor=10, pct_start=0.5)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac780c99a632028f78f300a83cba6bb694f6325
| 54,457 |
ipynb
|
Jupyter Notebook
|
kinases-in-chembl/kinases_in_chembl.ipynb
|
schallerdavid/kinodata
|
78b62fa5fb7be1868cba06272e64f86b01702b02
|
[
"MIT"
] | null | null | null |
kinases-in-chembl/kinases_in_chembl.ipynb
|
schallerdavid/kinodata
|
78b62fa5fb7be1868cba06272e64f86b01702b02
|
[
"MIT"
] | null | null | null |
kinases-in-chembl/kinases_in_chembl.ipynb
|
schallerdavid/kinodata
|
78b62fa5fb7be1868cba06272e64f86b01702b02
|
[
"MIT"
] | null | null | null | 34.510139 | 341 | 0.392401 |
[
[
[
"# Find UniProt IDs in ChEMBL targets",
"_____no_output_____"
],
[
"Ultimately, we are interested in getting [activity data from ChEMBl](/chembl-27/query_local_chembl-27.ipynb) we need to account for three components:\n\n* The compound being measured\n* The target the compound binds to\n* The assay where this measurement took place\n\nSo, to find all activity data stored in ChEMBL that refers to kinases, we have to query for those assays annotated with a certain target.\n\nEach of those three components have a unique ChEMBL ID, but so far we only have obtained Uniprot IDs in the `human-kinases` notebook. We need a way to connect Uniprot IDs to ChEMBL target IDs. Fortunately, ChEMBL maintains such a map in their FTP releases. We will parse that file and convert it into a dataframe for easy manipulation.",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\nimport urllib.request\n\nimport pandas as pd",
"_____no_output_____"
],
[
"REPO = (Path(_dh[-1]) / \"..\").resolve()\nDATA = REPO / 'data'",
"_____no_output_____"
],
[
"CHEMBL_VERSION = 28\nurl = fr\"ftp://ftp.ebi.ac.uk/pub/databases/chembl/ChEMBLdb/releases/chembl_{CHEMBL_VERSION}/chembl_uniprot_mapping.txt\"",
"_____no_output_____"
],
[
"with urllib.request.urlopen(url) as response:\n uniprot_map = pd.read_csv(response, sep=\"\\t\", skiprows=[0], names=[\"UniprotID\", \"chembl_targets\", \"description\", \"type\"])\nuniprot_map",
"_____no_output_____"
]
],
[
[
"We join this new information to the human kinases aggregated list from `human-kinases` (all of them, regardless the source):",
"_____no_output_____"
]
],
[
[
"kinases = pd.read_csv(DATA / \"human_kinases.aggregated.csv\", index_col=0)\nkinases",
"_____no_output_____"
]
],
[
[
"We are only interested in those kinases present in these datasets:\n\n* KinHub\n* KLIFS\n* PKinFam\n* Dunbrack's MSA",
"_____no_output_____"
]
],
[
[
"kinases_subset = kinases[kinases[[\"kinhub\", \"klifs\", \"pkinfam\", \"dunbrack_msa\"]].sum(axis=1) > 0]\nkinases_subset",
"_____no_output_____"
]
],
[
[
"We would also like to preserve the provenance of the Uniprot assignment, so we will group the provenance columns in a single one now.",
"_____no_output_____"
]
],
[
[
"kinases_subset[\"origin\"] = kinases_subset.apply(lambda s: '|'.join([k for k in [\"kinhub\", \"klifs\", \"pkinfam\", \"reviewed_uniprot\", \"dunbrack_msa\"] if s[k]]), axis=1)\nkinases_subset",
"_____no_output_____"
]
],
[
[
"We can now merge the needed columns based on the `UniprotID` key.",
"_____no_output_____"
]
],
[
[
"merged = pd.merge(kinases_subset[[\"UniprotID\", \"Name\", \"origin\"]], uniprot_map[[\"UniprotID\", \"chembl_targets\", \"type\"]], how=\"inner\", on='UniprotID')[[\"UniprotID\", \"Name\", \"chembl_targets\", \"type\", \"origin\"]]\nmerged",
"_____no_output_____"
]
],
[
[
"How is this possible? 969 targets (ChEMBL 28)?!\n\nApparently, there's not 1:1 correspondence between UniprotID and ChEMBL ID! Some Uniprot IDs are included in several ChEMBL targets:",
"_____no_output_____"
]
],
[
[
"merged.UniprotID.value_counts()",
"_____no_output_____"
],
[
"merged[merged.UniprotID == \"P11802\"]",
"_____no_output_____"
]
],
[
[
"... and some ChEMBL targets include several kinases (e.g. chimeric proteins):",
"_____no_output_____"
]
],
[
[
"merged[merged.chembl_targets == \"CHEMBL2096618\"]",
"_____no_output_____"
]
],
[
[
"This is due to the different `type` values:",
"_____no_output_____"
]
],
[
[
"merged.type.value_counts()",
"_____no_output_____"
]
],
[
[
"If we focus on `SINGLE PROTEIN` types:",
"_____no_output_____"
]
],
[
[
"merged[merged.type == \"SINGLE PROTEIN\"]",
"_____no_output_____"
]
],
[
[
"... we end up with a total of 491 targets (ChEMBL 28), which is more acceptable.\n\nFor that reason, we will only save records corresponding to `type == SINGLE PROTEIN`",
"_____no_output_____"
]
],
[
[
"merged[merged.type == \"SINGLE PROTEIN\"].to_csv(DATA / f\"human_kinases_and_chembl_targets.chembl_{CHEMBL_VERSION}.csv\", index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac7a39e5c6ef657fb1f53a0ae54e57f06700d08
| 158,300 |
ipynb
|
Jupyter Notebook
|
Jupyter_Notebooks/ROC_Using_Predict_Proba.ipynb
|
bkommineni/Activity-Recognition-Using-Sensordata
|
94effff8295e5314ac097a777b01013e540c75de
|
[
"BSD-4-Clause-UC"
] | null | null | null |
Jupyter_Notebooks/ROC_Using_Predict_Proba.ipynb
|
bkommineni/Activity-Recognition-Using-Sensordata
|
94effff8295e5314ac097a777b01013e540c75de
|
[
"BSD-4-Clause-UC"
] | null | null | null |
Jupyter_Notebooks/ROC_Using_Predict_Proba.ipynb
|
bkommineni/Activity-Recognition-Using-Sensordata
|
94effff8295e5314ac097a777b01013e540c75de
|
[
"BSD-4-Clause-UC"
] | null | null | null | 261.221122 | 74,304 | 0.911472 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"from pathlib import Path\nfrom pandas import DataFrame,Series\nfrom pandas.plotting import scatter_matrix\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import tree\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.metrics import accuracy_score\nimport pandas as pd\nfrom matplotlib.colors import ListedColormap\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import confusion_matrix\nimport numpy as np\nimport scipy.stats as stats\nimport pylab as pl\nfrom random import sample",
"_____no_output_____"
],
[
"#Description of features\n#Average[3]: Average acceleration (for each axis)\n#Standard Deviation[3]: Standard deviation (for each axis)\n#Average Absolute Difference[3]: Average absolute\n#difference between the value of each of the 200 readings\n#within the ED and the mean value over those 200 values\n#(for each axis)\n#Average Resultant Acceleration[1]: Average of the square\n#roots of the sum of the values of each axis squared\n#over the ED\n#Time Between Peaks[3]: Time in milliseconds between\n#peaks in the sinusoidal waves associated with most\n#activities (for each axis)\n#Binned Distribution[30]: We determine the range of values\n#for each axis (maximum – minimum), divide this range into\n#10 equal sized bins, and then record what fraction of the\n#200 values fell within each of the bins. ",
"_____no_output_____"
],
[
"my_file = Path(\"/Users/bharu/CS690-PROJECTS/ActivityAnalyzer/activity_analyzer/DecisionTreeClassifier/FeaturesCsvFile/featuresfile.csv\")\ndf = pd.read_csv(my_file)\ndf.head()\ndf.shape#(no of rows, no of columns)",
"_____no_output_____"
],
[
"df['color'] = Series([(0 if x == \"walking\" else 1) for x in df['Label']])\nmy_color_map = ListedColormap(['skyblue','coral'],'mycolormap')\n#0,red,walking\n#1,green,running\n\ndf_unique = df.drop_duplicates(subset=['User', 'Timestamp'])\ndf_unique.head()\ndf_unique.shape",
"_____no_output_____"
],
[
"X_train = df_unique.values[:,2:45]\nY_train = df_unique.values[:,45]",
"_____no_output_____"
],
[
"test_file = Path(\"/Users/bharu/CS690-PROJECTS/ActivityAnalyzer/activity_analyzer/DecisionTreeClassifier/FeaturesCsvFile/featuresfile_10.csv\")\ndf_test = pd.read_csv(test_file)\ndf_test.head()\ndf_test.shape#(no of rows, no of columns)",
"_____no_output_____"
],
[
"df_test['color'] = Series([(0 if x == \"walking\" else 1) for x in df_test['Label']])",
"_____no_output_____"
],
[
"df_unique_test = df_test.drop_duplicates(subset=['User', 'Timestamp'])\ndf_unique_test.head()\ndf_unique_test.shape",
"_____no_output_____"
],
[
"#Predicting using test data\n#taking size of test data 10% of training data\ntest_small = df_unique_test.iloc[sample(range(len(df_unique_test)), 40), :]\nX_test_small = test_small.values[:,2:45]\nY_test_small = test_small.values[:,45]",
"_____no_output_____"
],
[
"df_gini = DecisionTreeClassifier(criterion = 'gini')",
"_____no_output_____"
],
[
"df_gini.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"#Predicting using test data\nY_predict_gini = df_gini.predict(X_test_small)",
"_____no_output_____"
],
[
"#Calculating accuracy score\nscore = accuracy_score(Y_test_small,Y_predict_gini)\nscore",
"_____no_output_____"
],
[
"#Predicting using test data\nY_predict_gini_probas = df_gini.predict_proba(X_test_small)\nprint (Y_predict_gini_probas[:,0])\nprint (Y_predict_gini_probas[:,1])\nprint(len(Y_predict_gini_probas))",
"[ 1. 0. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 1. 1. 1. 0. 0. 1.\n 1. 1. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1. 0. 1. 1. 1. 0.\n 1. 0. 1. 1.]\n[ 0. 1. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 1. 1. 0.\n 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 1.\n 0. 1. 0. 0.]\n40\n"
],
[
"import numpy as np\nfrom sklearn import metrics\nimport matplotlib.pyplot as plt\n\n\ndef plot_roc_curve(Y_predict_gini,Y_test,name_graph):\n num_labels = []\n for i in range(0,len(Y_test)):\n if Y_test[i] == \"walking\":\n num_labels.append(0)\n else:\n num_labels.append(1)\n\n labels = np.array(num_labels)\n fpr, tpr, thresholds = metrics.roc_curve(labels,Y_predict_gini)\n roc_auc = metrics.auc(fpr, tpr)\n plt.title('Area under ROC Curve')\n plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)\n plt.legend(loc = 'lower right')\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0, 1])\n plt.ylim([0, 1])\n plt.ylabel('True Positive Rate')\n plt.xlabel('False Positive Rate')\n plt.savefig('./../Data-Visualization/images/' + name_graph +'.png',dpi=1000)",
"_____no_output_____"
],
[
"plot_roc_curve(Y_predict_gini_probas[:,0],Y_test_small,\"DecisionTree_ROC_using_predict_proba\")",
"_____no_output_____"
],
[
"df_3_10 = pd.concat([df_unique,df_unique_test])\ndf_3_10.shape",
"_____no_output_____"
],
[
"X = df_3_10.values[:,2:45]\ny = df_3_10.values[:,45]",
"_____no_output_____"
],
[
"X_train,X_test,Y_train,Y_test = train_test_split(X,y,test_size=0.5)",
"_____no_output_____"
],
[
"df_gini.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"#Predicting using test data\nY_predict_gini_3_10 = df_gini.predict(X_test)",
"_____no_output_____"
],
[
"#Calculating accuracy score\nscore = accuracy_score(Y_test,Y_predict_gini_3_10)\nscore",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedKFold\n\ncv = StratifiedKFold(n_splits=10)\n\nj = 0\nfor train, test in cv.split(X, y):\n probas_ = df_gini.fit(X[train], y[train]).predict_proba(X[test])\n \n num_labels = []\n for i in range(0,len(y[test])):\n if y[test][i] == \"walking\":\n num_labels.append(0)\n else:\n num_labels.append(1)\n\n labels = np.array(num_labels)\n \n # Compute ROC curve and area the curve\n fpr, tpr, thresholds = metrics.roc_curve(labels, probas_[:, 0])\n roc_auc = metrics.auc(fpr, tpr)\n plt.plot(fpr, tpr, lw=1, alpha=0.3,\n label='ROC fold %d (AUC = %0.2f)' % (j, roc_auc))\n j += 1\n \nplt.plot([0, 1], [0, 1], linestyle='--', lw=2, color='r',label='Luck', alpha=.8)\nplt.xlim([0, 1])\nplt.ylim([0, 1])\nplt.xlabel('False Positive Rate')\nplt.ylabel('True Positive Rate')\nplt.title('Receiver operating characteristic example')\nplt.legend(loc=\"lower right\")\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedKFold\n\ncv = StratifiedKFold(n_splits=20)\n\ntprs = []\naucs = []\nmean_fpr = np.linspace(0, 1, 100)\n\nj = 0\nfor train, test in cv.split(X, y):\n probas_ = df_gini.fit(X[train], y[train]).predict_proba(X[test])\n \n num_labels = []\n for i in range(0,len(y[test])):\n if y[test][i] == \"walking\":\n num_labels.append(0)\n else:\n num_labels.append(1)\n\n labels = np.array(num_labels)\n \n # Compute ROC curve and area the curve\n fpr, tpr, thresholds = metrics.roc_curve(labels, probas_[:, 0])\n tprs.append(np.interp(mean_fpr, fpr, tpr))\n tprs[-1][0] = 0.0\n roc_auc = metrics.auc(fpr, tpr)\n aucs.append(roc_auc)\n plt.plot(fpr, tpr, lw=1, alpha=0.3,\n label='ROC fold %d (AUC = %0.2f)' % (j, roc_auc))\n j += 1\n \n\n\nmean_tpr = np.mean(tprs, axis=0)\nmean_tpr[-1] = 1.0\nmean_auc = metrics.auc(mean_fpr, mean_tpr)\nstd_auc = np.std(aucs)\nplt.plot(mean_fpr, mean_tpr, color='b',\n label=r'Mean ROC (AUC = %0.2f $\\pm$ %0.2f)' % (mean_auc, std_auc),\n lw=2, alpha=.8)\n\nstd_tpr = np.std(tprs, axis=0)\ntprs_upper = np.minimum(mean_tpr + std_tpr, 1)\ntprs_lower = np.maximum(mean_tpr - std_tpr, 0)\nplt.fill_between(mean_fpr, tprs_lower, tprs_upper, color='grey', alpha=.2,\n label=r'$\\pm$ 1 std. dev.')\n\nplt.xlim([0, 1])\nplt.ylim([0, 1])\nplt.xlabel('False Positive Rate')\nplt.ylabel('True Positive Rate')\nplt.title('Receiver operating characteristic example')\nplt.legend(loc=\"lower right\")\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac7a5b863f6cf1699986eda00e483e2a10bbb21
| 64,526 |
ipynb
|
Jupyter Notebook
|
tf/train_and_evaluate.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | 1 |
2021-11-25T15:52:01.000Z
|
2021-11-25T15:52:01.000Z
|
tf/train_and_evaluate.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | null | null | null |
tf/train_and_evaluate.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | 1 |
2020-06-23T07:43:49.000Z
|
2020-06-23T07:43:49.000Z
| 32.40884 | 236 | 0.590506 |
[
[
[
"##### Copyright 2020 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Training & evaluation with the built-in methods",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/guide/keras/train_and_evaluate\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/keras-team/keras-io/blob/master/tf/train_and_evaluate.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/keras-team/keras-io/blob/master/guides/training_with_built_in_methods.py\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/keras-io/tf/train_and_evaluate.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"## Setup",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers",
"_____no_output_____"
]
],
[
[
"## Introduction\n\nThis guide covers training, evaluation, and prediction (inference) models\nwhen using built-in APIs for training & validation (such as `model.fit()`,\n`model.evaluate()`, `model.predict()`).\n\nIf you are interested in leveraging `fit()` while specifying your\nown training step function, see the guide\n[\"customizing what happens in `fit()`\"](https://www.tensorflow.org/guide/keras/customizing_what_happens_in_fit/).\n\nIf you are interested in writing your own training & evaluation loops from\nscratch, see the guide\n[\"writing a training loop from scratch\"](https://www.tensorflow.org/guide/keras/writing_a_training_loop_from_scratch/).\n\nIn general, whether you are using built-in loops or writing your own, model training &\nevaluation works strictly in the same way across every kind of Keras model --\nSequential models, models built with the Functional API, and models written from\nscratch via model subclassing.\n\nThis guide doesn't cover distributed training. For distributed training, see\nour [guide to multi-gpu & distributed training](/guides/distributed_training/).",
"_____no_output_____"
],
[
"## API overview: a first end-to-end example\n\nWhen passing data to the built-in training loops of a model, you should either use\n**NumPy arrays** (if your data is small and fits in memory) or **`tf.data Dataset`\nobjects**. In the next few paragraphs, we'll use the MNIST dataset as NumPy arrays, in\norder to demonstrate how to use optimizers, losses, and metrics.\n\nLet's consider the following model (here, we build in with the Functional API, but it\ncould be a Sequential model or a subclassed model as well):",
"_____no_output_____"
]
],
[
[
"inputs = keras.Input(shape=(784,), name=\"digits\")\nx = layers.Dense(64, activation=\"relu\", name=\"dense_1\")(inputs)\nx = layers.Dense(64, activation=\"relu\", name=\"dense_2\")(x)\noutputs = layers.Dense(10, activation=\"softmax\", name=\"predictions\")(x)\n\nmodel = keras.Model(inputs=inputs, outputs=outputs)",
"_____no_output_____"
]
],
[
[
"Here's what the typical end-to-end workflow looks like, consisting of:\n\n- Training\n- Validation on a holdout set generated from the original training data\n- Evaluation on the test data\n\nWe'll use MNIST data for this example.",
"_____no_output_____"
]
],
[
[
"(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()\n\n# Preprocess the data (these are NumPy arrays)\nx_train = x_train.reshape(60000, 784).astype(\"float32\") / 255\nx_test = x_test.reshape(10000, 784).astype(\"float32\") / 255\n\ny_train = y_train.astype(\"float32\")\ny_test = y_test.astype(\"float32\")\n\n# Reserve 10,000 samples for validation\nx_val = x_train[-10000:]\ny_val = y_train[-10000:]\nx_train = x_train[:-10000]\ny_train = y_train[:-10000]",
"_____no_output_____"
]
],
[
[
"We specify the training configuration (optimizer, loss, metrics):",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(), # Optimizer\n # Loss function to minimize\n loss=keras.losses.SparseCategoricalCrossentropy(),\n # List of metrics to monitor\n metrics=[keras.metrics.SparseCategoricalAccuracy()],\n)",
"_____no_output_____"
]
],
[
[
"We call `fit()`, which will train the model by slicing the data into \"batches\" of size\n\"batch_size\", and repeatedly iterating over the entire dataset for a given number of\n\"epochs\".",
"_____no_output_____"
]
],
[
[
"print(\"Fit model on training data\")\nhistory = model.fit(\n x_train,\n y_train,\n batch_size=64,\n epochs=2,\n # We pass some validation for\n # monitoring validation loss and metrics\n # at the end of each epoch\n validation_data=(x_val, y_val),\n)",
"_____no_output_____"
]
],
[
[
"The returned \"history\" object holds a record of the loss values and metric values\nduring training:",
"_____no_output_____"
]
],
[
[
"history.history",
"_____no_output_____"
]
],
[
[
"We evaluate the model on the test data via `evaluate()`:",
"_____no_output_____"
]
],
[
[
"# Evaluate the model on the test data using `evaluate`\nprint(\"Evaluate on test data\")\nresults = model.evaluate(x_test, y_test, batch_size=128)\nprint(\"test loss, test acc:\", results)\n\n# Generate predictions (probabilities -- the output of the last layer)\n# on new data using `predict`\nprint(\"Generate predictions for 3 samples\")\npredictions = model.predict(x_test[:3])\nprint(\"predictions shape:\", predictions.shape)",
"_____no_output_____"
]
],
[
[
"Now, let's review each piece of this workflow in detail.",
"_____no_output_____"
],
[
"## The `compile()` method: specifying a loss, metrics, and an optimizer\n\nTo train a model with `fit()`, you need to specify a loss function, an optimizer, and\noptionally, some metrics to monitor.\n\nYou pass these to the model as arguments to the `compile()` method:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),\n loss=keras.losses.SparseCategoricalCrossentropy(),\n metrics=[keras.metrics.SparseCategoricalAccuracy()],\n)",
"_____no_output_____"
]
],
[
[
"The `metrics` argument should be a list -- your model can have any number of metrics.\n\nIf your model has multiple outputs, you can specify different losses and metrics for\neach output, and you can modulate the contribution of each output to the total loss of\nthe model. You will find more details about this in the section **\"Passing data to\nmulti-input, multi-output models\"**.\n\nNote that if you're satisfied with the default settings, in many cases the optimizer,\nloss, and metrics can be specified via string identifiers as a shortcut:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=\"rmsprop\",\n loss=\"sparse_categorical_crossentropy\",\n metrics=[\"sparse_categorical_accuracy\"],\n)",
"_____no_output_____"
]
],
[
[
"For later reuse, let's put our model definition and compile step in functions; we will\ncall them several times across different examples in this guide.",
"_____no_output_____"
]
],
[
[
"def get_uncompiled_model():\n inputs = keras.Input(shape=(784,), name=\"digits\")\n x = layers.Dense(64, activation=\"relu\", name=\"dense_1\")(inputs)\n x = layers.Dense(64, activation=\"relu\", name=\"dense_2\")(x)\n outputs = layers.Dense(10, activation=\"softmax\", name=\"predictions\")(x)\n model = keras.Model(inputs=inputs, outputs=outputs)\n return model\n\n\ndef get_compiled_model():\n model = get_uncompiled_model()\n model.compile(\n optimizer=\"rmsprop\",\n loss=\"sparse_categorical_crossentropy\",\n metrics=[\"sparse_categorical_accuracy\"],\n )\n return model\n",
"_____no_output_____"
]
],
[
[
"### Many built-in optimizers, losses, and metrics are available\n\nIn general, you won't have to create from scratch your own losses, metrics, or\noptimizers, because what you need is likely already part of the Keras API:\n\nOptimizers:\n\n- `SGD()` (with or without momentum)\n- `RMSprop()`\n- `Adam()`\n- etc.\n\nLosses:\n\n- `MeanSquaredError()`\n- `KLDivergence()`\n- `CosineSimilarity()`\n- etc.\n\nMetrics:\n\n- `AUC()`\n- `Precision()`\n- `Recall()`\n- etc.",
"_____no_output_____"
],
[
"### Custom losses\n\nThere are two ways to provide custom losses with Keras. The first example creates a\nfunction that accepts inputs `y_true` and `y_pred`. The following example shows a loss\nfunction that computes the mean squared error between the real data and the\npredictions:",
"_____no_output_____"
]
],
[
[
"def custom_mean_squared_error(y_true, y_pred):\n return tf.math.reduce_mean(tf.square(y_true - y_pred))\n\n\nmodel = get_uncompiled_model()\nmodel.compile(optimizer=keras.optimizers.Adam(), loss=custom_mean_squared_error)\n\n# We need to one-hot encode the labels to use MSE\ny_train_one_hot = tf.one_hot(y_train, depth=10)\nmodel.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"If you need a loss function that takes in parameters beside `y_true` and `y_pred`, you\ncan subclass the `tf.keras.losses.Loss` class and implement the following two methods:\n\n- `__init__(self)`: accept parameters to pass during the call of your loss function\n- `call(self, y_true, y_pred)`: use the targets (y_true) and the model predictions\n(y_pred) to compute the model's loss\n\nLet's say you want to use mean squared error, but with an added term that\nwill de-incentivize prediction values far from 0.5 (we assume that the categorical\ntargets are one-hot encoded and take values between 0 and 1). This\ncreates an incentive for the model not to be too confident, which may help\nreduce overfitting (we won't know if it works until we try!).\n\nHere's how you would do it:",
"_____no_output_____"
]
],
[
[
"class CustomMSE(keras.losses.Loss):\n def __init__(self, regularization_factor=0.1, name=\"custom_mse\"):\n super().__init__(name=name)\n self.regularization_factor = regularization_factor\n\n def call(self, y_true, y_pred):\n mse = tf.math.reduce_mean(tf.square(y_true - y_pred))\n reg = tf.math.reduce_mean(tf.square(0.5 - y_pred))\n return mse + reg * self.regularization_factor\n\n\nmodel = get_uncompiled_model()\nmodel.compile(optimizer=keras.optimizers.Adam(), loss=CustomMSE())\n\ny_train_one_hot = tf.one_hot(y_train, depth=10)\nmodel.fit(x_train, y_train_one_hot, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"### Custom metrics\n\nIf you need a metric that isn't part of the API, you can easily create custom metrics\nby subclassing the `tf.keras.metrics.Metric` class. You will need to implement 4\nmethods:\n\n- `__init__(self)`, in which you will create state variables for your metric.\n- `update_state(self, y_true, y_pred, sample_weight=None)`, which uses the targets\ny_true and the model predictions y_pred to update the state variables.\n- `result(self)`, which uses the state variables to compute the final results.\n- `reset_states(self)`, which reinitializes the state of the metric.\n\nState update and results computation are kept separate (in `update_state()` and\n`result()`, respectively) because in some cases, results computation might be very\nexpensive, and would only be done periodically.\n\nHere's a simple example showing how to implement a `CategoricalTruePositives` metric,\nthat counts how many samples were correctly classified as belonging to a given class:",
"_____no_output_____"
]
],
[
[
"class CategoricalTruePositives(keras.metrics.Metric):\n def __init__(self, name=\"categorical_true_positives\", **kwargs):\n super(CategoricalTruePositives, self).__init__(name=name, **kwargs)\n self.true_positives = self.add_weight(name=\"ctp\", initializer=\"zeros\")\n\n def update_state(self, y_true, y_pred, sample_weight=None):\n y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))\n values = tf.cast(y_true, \"int32\") == tf.cast(y_pred, \"int32\")\n values = tf.cast(values, \"float32\")\n if sample_weight is not None:\n sample_weight = tf.cast(sample_weight, \"float32\")\n values = tf.multiply(values, sample_weight)\n self.true_positives.assign_add(tf.reduce_sum(values))\n\n def result(self):\n return self.true_positives\n\n def reset_states(self):\n # The state of the metric will be reset at the start of each epoch.\n self.true_positives.assign(0.0)\n\n\nmodel = get_uncompiled_model()\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),\n loss=keras.losses.SparseCategoricalCrossentropy(),\n metrics=[CategoricalTruePositives()],\n)\nmodel.fit(x_train, y_train, batch_size=64, epochs=3)",
"_____no_output_____"
]
],
[
[
"### Handling losses and metrics that don't fit the standard signature\n\nThe overwhelming majority of losses and metrics can be computed from `y_true` and\n`y_pred`, where `y_pred` is an output of your model. But not all of them. For\ninstance, a regularization loss may only require the activation of a layer (there are\nno targets in this case), and this activation may not be a model output.\n\nIn such cases, you can call `self.add_loss(loss_value)` from inside the call method of\na custom layer. Losses added in this way get added to the \"main\" loss during training\n(the one passed to `compile()`). Here's a simple example that adds activity\nregularization (note that activity regularization is built-in in all Keras layers --\nthis layer is just for the sake of providing a concrete example):",
"_____no_output_____"
]
],
[
[
"class ActivityRegularizationLayer(layers.Layer):\n def call(self, inputs):\n self.add_loss(tf.reduce_sum(inputs) * 0.1)\n return inputs # Pass-through layer.\n\n\ninputs = keras.Input(shape=(784,), name=\"digits\")\nx = layers.Dense(64, activation=\"relu\", name=\"dense_1\")(inputs)\n\n# Insert activity regularization as a layer\nx = ActivityRegularizationLayer()(x)\n\nx = layers.Dense(64, activation=\"relu\", name=\"dense_2\")(x)\noutputs = layers.Dense(10, name=\"predictions\")(x)\n\nmodel = keras.Model(inputs=inputs, outputs=outputs)\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n)\n\n# The displayed loss will be much higher than before\n# due to the regularization component.\nmodel.fit(x_train, y_train, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"You can do the same for logging metric values, using `add_metric()`:",
"_____no_output_____"
]
],
[
[
"class MetricLoggingLayer(layers.Layer):\n def call(self, inputs):\n # The `aggregation` argument defines\n # how to aggregate the per-batch values\n # over each epoch:\n # in this case we simply average them.\n self.add_metric(\n keras.backend.std(inputs), name=\"std_of_activation\", aggregation=\"mean\"\n )\n return inputs # Pass-through layer.\n\n\ninputs = keras.Input(shape=(784,), name=\"digits\")\nx = layers.Dense(64, activation=\"relu\", name=\"dense_1\")(inputs)\n\n# Insert std logging as a layer.\nx = MetricLoggingLayer()(x)\n\nx = layers.Dense(64, activation=\"relu\", name=\"dense_2\")(x)\noutputs = layers.Dense(10, name=\"predictions\")(x)\n\nmodel = keras.Model(inputs=inputs, outputs=outputs)\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n)\nmodel.fit(x_train, y_train, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"In the [Functional API](https://www.tensorflow.org/guide/keras/functional/),\nyou can also call `model.add_loss(loss_tensor)`,\nor `model.add_metric(metric_tensor, name, aggregation)`.\n\nHere's a simple example:",
"_____no_output_____"
]
],
[
[
"inputs = keras.Input(shape=(784,), name=\"digits\")\nx1 = layers.Dense(64, activation=\"relu\", name=\"dense_1\")(inputs)\nx2 = layers.Dense(64, activation=\"relu\", name=\"dense_2\")(x1)\noutputs = layers.Dense(10, name=\"predictions\")(x2)\nmodel = keras.Model(inputs=inputs, outputs=outputs)\n\nmodel.add_loss(tf.reduce_sum(x1) * 0.1)\n\nmodel.add_metric(keras.backend.std(x1), name=\"std_of_activation\", aggregation=\"mean\")\n\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n)\nmodel.fit(x_train, y_train, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"Note that when you pass losses via `add_loss()`, it becomes possible to call\n`compile()` without a loss function, since the model already has a loss to minimize.\n\nConsider the following `LogisticEndpoint` layer: it takes as inputs\ntargets & logits, and it tracks a crossentropy loss via `add_loss()`. It also\ntracks classification accuracy via `add_metric()`.",
"_____no_output_____"
]
],
[
[
"class LogisticEndpoint(keras.layers.Layer):\n def __init__(self, name=None):\n super(LogisticEndpoint, self).__init__(name=name)\n self.loss_fn = keras.losses.BinaryCrossentropy(from_logits=True)\n self.accuracy_fn = keras.metrics.BinaryAccuracy()\n\n def call(self, targets, logits, sample_weights=None):\n # Compute the training-time loss value and add it\n # to the layer using `self.add_loss()`.\n loss = self.loss_fn(targets, logits, sample_weights)\n self.add_loss(loss)\n\n # Log accuracy as a metric and add it\n # to the layer using `self.add_metric()`.\n acc = self.accuracy_fn(targets, logits, sample_weights)\n self.add_metric(acc, name=\"accuracy\")\n\n # Return the inference-time prediction tensor (for `.predict()`).\n return tf.nn.softmax(logits)\n",
"_____no_output_____"
]
],
[
[
"You can use it in a model with two inputs (input data & targets), compiled without a\n`loss` argument, like this:",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ninputs = keras.Input(shape=(3,), name=\"inputs\")\ntargets = keras.Input(shape=(10,), name=\"targets\")\nlogits = keras.layers.Dense(10)(inputs)\npredictions = LogisticEndpoint(name=\"predictions\")(logits, targets)\n\nmodel = keras.Model(inputs=[inputs, targets], outputs=predictions)\nmodel.compile(optimizer=\"adam\") # No loss argument!\n\ndata = {\n \"inputs\": np.random.random((3, 3)),\n \"targets\": np.random.random((3, 10)),\n}\nmodel.fit(data)",
"_____no_output_____"
]
],
[
[
"For more information about training multi-input models, see the section **Passing data\nto multi-input, multi-output models**.",
"_____no_output_____"
],
[
"### Automatically setting apart a validation holdout set\n\nIn the first end-to-end example you saw, we used the `validation_data` argument to pass\na tuple of NumPy arrays `(x_val, y_val)` to the model for evaluating a validation loss\nand validation metrics at the end of each epoch.\n\nHere's another option: the argument `validation_split` allows you to automatically\nreserve part of your training data for validation. The argument value represents the\nfraction of the data to be reserved for validation, so it should be set to a number\nhigher than 0 and lower than 1. For instance, `validation_split=0.2` means \"use 20% of\nthe data for validation\", and `validation_split=0.6` means \"use 60% of the data for\nvalidation\".\n\nThe way the validation is computed is by taking the last x% samples of the arrays\nreceived by the fit call, before any shuffling.\n\nNote that you can only use `validation_split` when training with NumPy data.",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\nmodel.fit(x_train, y_train, batch_size=64, validation_split=0.2, epochs=1)",
"_____no_output_____"
]
],
[
[
"## Training & evaluation from tf.data Datasets\n\nIn the past few paragraphs, you've seen how to handle losses, metrics, and optimizers,\nand you've seen how to use the `validation_data` and `validation_split` arguments in\nfit, when your data is passed as NumPy arrays.\n\nLet's now take a look at the case where your data comes in the form of a\n`tf.data.Dataset` object.\n\nThe `tf.data` API is a set of utilities in TensorFlow 2.0 for loading and preprocessing\ndata in a way that's fast and scalable.\n\nFor a complete guide about creating `Datasets`, see the\n[tf.data documentation](https://www.tensorflow.org/guide/data).\n\nYou can pass a `Dataset` instance directly to the methods `fit()`, `evaluate()`, and\n`predict()`:",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\n# First, let's create a training Dataset instance.\n# For the sake of our example, we'll use the same MNIST data as before.\ntrain_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))\n# Shuffle and slice the dataset.\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\n# Now we get a test dataset.\ntest_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))\ntest_dataset = test_dataset.batch(64)\n\n# Since the dataset already takes care of batching,\n# we don't pass a `batch_size` argument.\nmodel.fit(train_dataset, epochs=3)\n\n# You can also evaluate or predict on a dataset.\nprint(\"Evaluate\")\nresult = model.evaluate(test_dataset)\ndict(zip(model.metrics_names, result))",
"_____no_output_____"
]
],
[
[
"Note that the Dataset is reset at the end of each epoch, so it can be reused of the\nnext epoch.\n\nIf you want to run training only on a specific number of batches from this Dataset, you\ncan pass the `steps_per_epoch` argument, which specifies how many training steps the\nmodel should run using this Dataset before moving on to the next epoch.\n\nIf you do this, the dataset is not reset at the end of each epoch, instead we just keep\ndrawing the next batches. The dataset will eventually run out of data (unless it is an\ninfinitely-looping dataset).",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\n# Prepare the training dataset\ntrain_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\n# Only use the 100 batches per epoch (that's 64 * 100 samples)\nmodel.fit(train_dataset, epochs=3, steps_per_epoch=100)",
"_____no_output_____"
]
],
[
[
"### Using a validation dataset\n\nYou can pass a `Dataset` instance as the `validation_data` argument in `fit()`:",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\n# Prepare the training dataset\ntrain_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\n# Prepare the validation dataset\nval_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))\nval_dataset = val_dataset.batch(64)\n\nmodel.fit(train_dataset, epochs=1, validation_data=val_dataset)",
"_____no_output_____"
]
],
[
[
"At the end of each epoch, the model will iterate over the validation dataset and\ncompute the validation loss and validation metrics.\n\nIf you want to run validation only on a specific number of batches from this dataset,\nyou can pass the `validation_steps` argument, which specifies how many validation\nsteps the model should run with the validation dataset before interrupting validation\nand moving on to the next epoch:",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\n# Prepare the training dataset\ntrain_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\n# Prepare the validation dataset\nval_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))\nval_dataset = val_dataset.batch(64)\n\nmodel.fit(\n train_dataset,\n epochs=1,\n # Only run validation using the first 10 batches of the dataset\n # using the `validation_steps` argument\n validation_data=val_dataset,\n validation_steps=10,\n)",
"_____no_output_____"
]
],
[
[
"Note that the validation dataset will be reset after each use (so that you will always\nbe evaluating on the same samples from epoch to epoch).\n\nThe argument `validation_split` (generating a holdout set from the training data) is\nnot supported when training from `Dataset` objects, since this features requires the\nability to index the samples of the datasets, which is not possible in general with\nthe `Dataset` API.",
"_____no_output_____"
],
[
"## Other input formats supported\n\nBesides NumPy arrays, eager tensors, and TensorFlow `Datasets`, it's possible to train\na Keras model using Pandas dataframes, or from Python generators that yield batches of\ndata & labels.\n\nIn particular, the `keras.utils.Sequence` class offers a simple interface to build\nPython data generators that are multiprocessing-aware and can be shuffled.\n\nIn general, we recommend that you use:\n\n- NumPy input data if your data is small and fits in memory\n- `Dataset` objects if you have large datasets and you need to do distributed training\n- `Sequence` objects if you have large datasets and you need to do a lot of custom\nPython-side processing that cannot be done in TensorFlow (e.g. if you rely on external libraries\nfor data loading or preprocessing).\n\n\n## Using a `keras.utils.Sequence` object as input\n\n`keras.utils.Sequence` is a utility that you can subclass to obtain a Python generator with\ntwo important properties:\n\n- It works well with multiprocessing.\n- It can be shuffled (e.g. when passing `shuffle=True` in `fit()`).\n\nA `Sequence` must implement two methods:\n\n- `__getitem__`\n- `__len__`\n\nThe method `__getitem__` should return a complete batch.\nIf you want to modify your dataset between epochs, you may implement `on_epoch_end`.\n\nHere's a quick example:\n\n```python\nfrom skimage.io import imread\nfrom skimage.transform import resize\nimport numpy as np\n\n# Here, `filenames` is list of path to the images\n# and `labels` are the associated labels.\n\nclass CIFAR10Sequence(Sequence):\n def __init__(self, filenames, labels, batch_size):\n self.filenames, self.labels = filenames, labels\n self.batch_size = batch_size\n\n def __len__(self):\n return int(np.ceil(len(self.filenames) / float(self.batch_size)))\n\n def __getitem__(self, idx):\n batch_x = self.filenames[idx * self.batch_size:(idx + 1) * self.batch_size]\n batch_y = self.labels[idx * self.batch_size:(idx + 1) * self.batch_size]\n return np.array([\n resize(imread(filename), (200, 200))\n for filename in batch_x]), np.array(batch_y)\n\nsequence = CIFAR10Sequence(filenames, labels, batch_size)\nmodel.fit(sequence, epochs=10)\n```",
"_____no_output_____"
],
[
"## Using sample weighting and class weighting\n\nWith the default settings the weight of a sample is decided by its frequency\nin the dataset. There are two methods to weight the data, independent of\nsample frequency:\n\n* Class weights\n* Sample weights",
"_____no_output_____"
],
[
"### Class weights\n\nThis is set by passing a dictionary to the `class_weight` argument to\n`Model.fit()`. This dictionary maps class indices to the weight that should\nbe used for samples belonging to this class.\n\nThis can be used to balance classes without resampling, or to train a\nmodel that has a gives more importance to a particular class.\n\nFor instance, if class \"0\" is half as represented as class \"1\" in your data,\nyou could use `Model.fit(..., class_weight={0: 1., 1: 0.5})`.",
"_____no_output_____"
],
[
"Here's a NumPy example where we use class weights or sample weights to\ngive more importance to the correct classification of class #5 (which\nis the digit \"5\" in the MNIST dataset).",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nclass_weight = {\n 0: 1.0,\n 1: 1.0,\n 2: 1.0,\n 3: 1.0,\n 4: 1.0,\n # Set weight \"2\" for class \"5\",\n # making this class 2x more important\n 5: 2.0,\n 6: 1.0,\n 7: 1.0,\n 8: 1.0,\n 9: 1.0,\n}\n\nprint(\"Fit with class weight\")\nmodel = get_compiled_model()\nmodel.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"### Sample weights\n\nFor fine grained control, or if you are not building a classifier,\nyou can use \"sample weights\".\n\n- When training from NumPy data: Pass the `sample_weight`\n argument to `Model.fit()`.\n- When training from `tf.data` or any other sort of iterator:\n Yield `(input_batch, label_batch, sample_weight_batch)` tuples.\n\nA \"sample weights\" array is an array of numbers that specify how much weight\neach sample in a batch should have in computing the total loss. It is commonly\nused in imbalanced classification problems (the idea being to give more weight\nto rarely-seen classes).\n\nWhen the weights used are ones and zeros, the array can be used as a *mask* for\nthe loss function (entirely discarding the contribution of certain samples to\nthe total loss).",
"_____no_output_____"
]
],
[
[
"sample_weight = np.ones(shape=(len(y_train),))\nsample_weight[y_train == 5] = 2.0\n\nprint(\"Fit with sample weight\")\nmodel = get_compiled_model()\nmodel.fit(x_train, y_train, sample_weight=sample_weight, batch_size=64, epochs=1)",
"_____no_output_____"
]
],
[
[
"Here's a matching `Dataset` example:",
"_____no_output_____"
]
],
[
[
"sample_weight = np.ones(shape=(len(y_train),))\nsample_weight[y_train == 5] = 2.0\n\n# Create a Dataset that includes sample weights\n# (3rd element in the return tuple).\ntrain_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train, sample_weight))\n\n# Shuffle and slice the dataset.\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\nmodel = get_compiled_model()\nmodel.fit(train_dataset, epochs=1)",
"_____no_output_____"
]
],
[
[
"## Passing data to multi-input, multi-output models\n\nIn the previous examples, we were considering a model with a single input (a tensor of\nshape `(764,)`) and a single output (a prediction tensor of shape `(10,)`). But what\nabout models that have multiple inputs or outputs?\n\nConsider the following model, which has an image input of shape `(32, 32, 3)` (that's\n`(height, width, channels)`) and a timeseries input of shape `(None, 10)` (that's\n`(timesteps, features)`). Our model will have two outputs computed from the\ncombination of these inputs: a \"score\" (of shape `(1,)`) and a probability\ndistribution over five classes (of shape `(5,)`).",
"_____no_output_____"
]
],
[
[
"image_input = keras.Input(shape=(32, 32, 3), name=\"img_input\")\ntimeseries_input = keras.Input(shape=(None, 10), name=\"ts_input\")\n\nx1 = layers.Conv2D(3, 3)(image_input)\nx1 = layers.GlobalMaxPooling2D()(x1)\n\nx2 = layers.Conv1D(3, 3)(timeseries_input)\nx2 = layers.GlobalMaxPooling1D()(x2)\n\nx = layers.concatenate([x1, x2])\n\nscore_output = layers.Dense(1, name=\"score_output\")(x)\nclass_output = layers.Dense(5, activation=\"softmax\", name=\"class_output\")(x)\n\nmodel = keras.Model(\n inputs=[image_input, timeseries_input], outputs=[score_output, class_output]\n)",
"_____no_output_____"
]
],
[
[
"Let's plot this model, so you can clearly see what we're doing here (note that the\nshapes shown in the plot are batch shapes, rather than per-sample shapes).",
"_____no_output_____"
]
],
[
[
"keras.utils.plot_model(model, \"multi_input_and_output_model.png\", show_shapes=True)",
"_____no_output_____"
]
],
[
[
"At compilation time, we can specify different losses to different outputs, by passing\nthe loss functions as a list:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],\n)",
"_____no_output_____"
]
],
[
[
"If we only passed a single loss function to the model, the same loss function would be\napplied to every output (which is not appropriate here).\n\nLikewise for metrics:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],\n metrics=[\n [\n keras.metrics.MeanAbsolutePercentageError(),\n keras.metrics.MeanAbsoluteError(),\n ],\n [keras.metrics.CategoricalAccuracy()],\n ],\n)",
"_____no_output_____"
]
],
[
[
"Since we gave names to our output layers, we could also specify per-output losses and\nmetrics via a dict:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss={\n \"score_output\": keras.losses.MeanSquaredError(),\n \"class_output\": keras.losses.CategoricalCrossentropy(),\n },\n metrics={\n \"score_output\": [\n keras.metrics.MeanAbsolutePercentageError(),\n keras.metrics.MeanAbsoluteError(),\n ],\n \"class_output\": [keras.metrics.CategoricalAccuracy()],\n },\n)",
"_____no_output_____"
]
],
[
[
"We recommend the use of explicit names and dicts if you have more than 2 outputs.\n\nIt's possible to give different weights to different output-specific losses (for\ninstance, one might wish to privilege the \"score\" loss in our example, by giving to 2x\nthe importance of the class loss), using the `loss_weights` argument:",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss={\n \"score_output\": keras.losses.MeanSquaredError(),\n \"class_output\": keras.losses.CategoricalCrossentropy(),\n },\n metrics={\n \"score_output\": [\n keras.metrics.MeanAbsolutePercentageError(),\n keras.metrics.MeanAbsoluteError(),\n ],\n \"class_output\": [keras.metrics.CategoricalAccuracy()],\n },\n loss_weights={\"score_output\": 2.0, \"class_output\": 1.0},\n)",
"_____no_output_____"
]
],
[
[
"You could also chose not to compute a loss for certain outputs, if these outputs meant\nfor prediction but not for training:",
"_____no_output_____"
]
],
[
[
"# List loss version\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss=[None, keras.losses.CategoricalCrossentropy()],\n)\n\n# Or dict loss version\nmodel.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss={\"class_output\": keras.losses.CategoricalCrossentropy()},\n)",
"_____no_output_____"
]
],
[
[
"Passing data to a multi-input or multi-output model in fit works in a similar way as\nspecifying a loss function in compile: you can pass **lists of NumPy arrays** (with\n1:1 mapping to the outputs that received a loss function) or **dicts mapping output\nnames to NumPy arrays**.",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer=keras.optimizers.RMSprop(1e-3),\n loss=[keras.losses.MeanSquaredError(), keras.losses.CategoricalCrossentropy()],\n)\n\n# Generate dummy NumPy data\nimg_data = np.random.random_sample(size=(100, 32, 32, 3))\nts_data = np.random.random_sample(size=(100, 20, 10))\nscore_targets = np.random.random_sample(size=(100, 1))\nclass_targets = np.random.random_sample(size=(100, 5))\n\n# Fit on lists\nmodel.fit([img_data, ts_data], [score_targets, class_targets], batch_size=32, epochs=1)\n\n# Alternatively, fit on dicts\nmodel.fit(\n {\"img_input\": img_data, \"ts_input\": ts_data},\n {\"score_output\": score_targets, \"class_output\": class_targets},\n batch_size=32,\n epochs=1,\n)",
"_____no_output_____"
]
],
[
[
"Here's the `Dataset` use case: similarly as what we did for NumPy arrays, the `Dataset`\nshould return a tuple of dicts.",
"_____no_output_____"
]
],
[
[
"train_dataset = tf.data.Dataset.from_tensor_slices(\n (\n {\"img_input\": img_data, \"ts_input\": ts_data},\n {\"score_output\": score_targets, \"class_output\": class_targets},\n )\n)\ntrain_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)\n\nmodel.fit(train_dataset, epochs=1)",
"_____no_output_____"
]
],
[
[
"## Using callbacks\n\nCallbacks in Keras are objects that are called at different point during training (at\nthe start of an epoch, at the end of a batch, at the end of an epoch, etc.) and which\ncan be used to implement behaviors such as:\n\n- Doing validation at different points during training (beyond the built-in per-epoch\nvalidation)\n- Checkpointing the model at regular intervals or when it exceeds a certain accuracy\nthreshold\n- Changing the learning rate of the model when training seems to be plateauing\n- Doing fine-tuning of the top layers when training seems to be plateauing\n- Sending email or instant message notifications when training ends or where a certain\nperformance threshold is exceeded\n- Etc.\n\nCallbacks can be passed as a list to your call to `fit()`:",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\ncallbacks = [\n keras.callbacks.EarlyStopping(\n # Stop training when `val_loss` is no longer improving\n monitor=\"val_loss\",\n # \"no longer improving\" being defined as \"no better than 1e-2 less\"\n min_delta=1e-2,\n # \"no longer improving\" being further defined as \"for at least 2 epochs\"\n patience=2,\n verbose=1,\n )\n]\nmodel.fit(\n x_train,\n y_train,\n epochs=20,\n batch_size=64,\n callbacks=callbacks,\n validation_split=0.2,\n)",
"_____no_output_____"
]
],
[
[
"### Many built-in callbacks are available\n\n- `ModelCheckpoint`: Periodically save the model.\n- `EarlyStopping`: Stop training when training is no longer improving the validation\nmetrics.\n- `TensorBoard`: periodically write model logs that can be visualized in\n[TensorBoard](https://www.tensorflow.org/tensorboard) (more details in the section\n\"Visualization\").\n- `CSVLogger`: streams loss and metrics data to a CSV file.\n- etc.\n\nSee the [callbacks documentation](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/) for the complete list.\n\n### Writing your own callback\n\nYou can create a custom callback by extending the base class\n`keras.callbacks.Callback`. A callback has access to its associated model through the\nclass property `self.model`.\n\nMake sure to read the\n[complete guide to writing custom callbacks](https://www.tensorflow.org/guide/keras/custom_callback/).\n\nHere's a simple example saving a list of per-batch loss values during training:",
"_____no_output_____"
]
],
[
[
"class LossHistory(keras.callbacks.Callback):\n def on_train_begin(self, logs):\n self.per_batch_losses = []\n\n def on_batch_end(self, batch, logs):\n self.per_batch_losses.append(logs.get(\"loss\"))\n",
"_____no_output_____"
]
],
[
[
"## Checkpointing models\n\nWhen you're training model on relatively large datasets, it's crucial to save\ncheckpoints of your model at frequent intervals.\n\nThe easiest way to achieve this is with the `ModelCheckpoint` callback:",
"_____no_output_____"
]
],
[
[
"model = get_compiled_model()\n\ncallbacks = [\n keras.callbacks.ModelCheckpoint(\n # Path where to save the model\n # The two parameters below mean that we will overwrite\n # the current checkpoint if and only if\n # the `val_loss` score has improved.\n # The saved model name will include the current epoch.\n filepath=\"mymodel_{epoch}\",\n save_best_only=True, # Only save a model if `val_loss` has improved.\n monitor=\"val_loss\",\n verbose=1,\n )\n]\nmodel.fit(\n x_train, y_train, epochs=2, batch_size=64, callbacks=callbacks, validation_split=0.2\n)",
"_____no_output_____"
]
],
[
[
"The `ModelCheckpoint` callback can be used to implement fault-tolerance:\nthe ability to restart training from the last saved state of the model in case training\ngets randomly interrupted. Here's a basic example:",
"_____no_output_____"
]
],
[
[
"import os\n\n# Prepare a directory to store all the checkpoints.\ncheckpoint_dir = \"./ckpt\"\nif not os.path.exists(checkpoint_dir):\n os.makedirs(checkpoint_dir)\n\n\ndef make_or_restore_model():\n # Either restore the latest model, or create a fresh one\n # if there is no checkpoint available.\n checkpoints = [checkpoint_dir + \"/\" + name for name in os.listdir(checkpoint_dir)]\n if checkpoints:\n latest_checkpoint = max(checkpoints, key=os.path.getctime)\n print(\"Restoring from\", latest_checkpoint)\n return keras.models.load_model(latest_checkpoint)\n print(\"Creating a new model\")\n return get_compiled_model()\n\n\nmodel = make_or_restore_model()\ncallbacks = [\n # This callback saves a SavedModel every 100 batches.\n # We include the training loss in the saved model name.\n keras.callbacks.ModelCheckpoint(\n filepath=checkpoint_dir + \"/ckpt-loss={loss:.2f}\", save_freq=100\n )\n]\nmodel.fit(x_train, y_train, epochs=1, callbacks=callbacks)",
"_____no_output_____"
]
],
[
[
"You call also write your own callback for saving and restoring models.\n\nFor a complete guide on serialization and saving, see the\n[guide to saving and serializing Models](https://www.tensorflow.org/guide/keras/save_and_serialize/).",
"_____no_output_____"
],
[
"## Using learning rate schedules\n\nA common pattern when training deep learning models is to gradually reduce the learning\nas training progresses. This is generally known as \"learning rate decay\".\n\nThe learning decay schedule could be static (fixed in advance, as a function of the\ncurrent epoch or the current batch index), or dynamic (responding to the current\nbehavior of the model, in particular the validation loss).\n\n### Passing a schedule to an optimizer\n\nYou can easily use a static learning rate decay schedule by passing a schedule object\nas the `learning_rate` argument in your optimizer:",
"_____no_output_____"
]
],
[
[
"initial_learning_rate = 0.1\nlr_schedule = keras.optimizers.schedules.ExponentialDecay(\n initial_learning_rate, decay_steps=100000, decay_rate=0.96, staircase=True\n)\n\noptimizer = keras.optimizers.RMSprop(learning_rate=lr_schedule)",
"_____no_output_____"
]
],
[
[
"Several built-in schedules are available: `ExponentialDecay`, `PiecewiseConstantDecay`,\n`PolynomialDecay`, and `InverseTimeDecay`.\n\n### Using callbacks to implement a dynamic learning rate schedule\n\nA dynamic learning rate schedule (for instance, decreasing the learning rate when the\nvalidation loss is no longer improving) cannot be achieved with these schedule objects\nsince the optimizer does not have access to validation metrics.\n\nHowever, callbacks do have access to all metrics, including validation metrics! You can\nthus achieve this pattern by using a callback that modifies the current learning rate\non the optimizer. In fact, this is even built-in as the `ReduceLROnPlateau` callback.",
"_____no_output_____"
],
[
"## Visualizing loss and metrics during training\n\nThe best way to keep an eye on your model during training is to use\n[TensorBoard](https://www.tensorflow.org/tensorboard), a browser-based application\nthat you can run locally that provides you with:\n\n- Live plots of the loss and metrics for training and evaluation\n- (optionally) Visualizations of the histograms of your layer activations\n- (optionally) 3D visualizations of the embedding spaces learned by your `Embedding`\nlayers\n\nIf you have installed TensorFlow with pip, you should be able to launch TensorBoard\nfrom the command line:\n\n```\ntensorboard --logdir=/full_path_to_your_logs\n```",
"_____no_output_____"
],
[
"### Using the TensorBoard callback\n\nThe easiest way to use TensorBoard with a Keras model and the fit method is the\n`TensorBoard` callback.\n\nIn the simplest case, just specify where you want the callback to write logs, and\nyou're good to go:",
"_____no_output_____"
]
],
[
[
"keras.callbacks.TensorBoard(\n log_dir=\"/full_path_to_your_logs\",\n histogram_freq=0, # How often to log histogram visualizations\n embeddings_freq=0, # How often to log embedding visualizations\n update_freq=\"epoch\",\n) # How often to write logs (default: once per epoch)",
"_____no_output_____"
]
],
[
[
"For more information, see the\n[documentation for the `TensorBoard` callback](https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/tensorboard/).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac7c25418d3a7fcb8df1f491e02adab1c5a6bb8
| 10,176 |
ipynb
|
Jupyter Notebook
|
python/example/dl-ner/ner.ipynb
|
picachu93/spark-nlp
|
2c65924aa6f626b9a2f95d1e5663daef326eb2f6
|
[
"Apache-2.0"
] | null | null | null |
python/example/dl-ner/ner.ipynb
|
picachu93/spark-nlp
|
2c65924aa6f626b9a2f95d1e5663daef326eb2f6
|
[
"Apache-2.0"
] | null | null | null |
python/example/dl-ner/ner.ipynb
|
picachu93/spark-nlp
|
2c65924aa6f626b9a2f95d1e5663daef326eb2f6
|
[
"Apache-2.0"
] | 1 |
2019-11-01T00:46:39.000Z
|
2019-11-01T00:46:39.000Z
| 26.638743 | 218 | 0.54717 |
[
[
[
"<img src=\"https://nlp.johnsnowlabs.com/assets/images/logo.png\" width=\"180\" height=\"50\" style=\"float: left;\">",
"_____no_output_____"
],
[
"## Deep Learning NER\n\nIn the following example, we walk-through a LSTM NER model training and prediction. This annotator is implemented on top of TensorFlow.\n\nThis annotator will take a series of word embedding vectors, training CoNLL dataset, plus a validation dataset. We include our own predefined Tensorflow Graphs, but it will train all layers during fit() stage.\n\nDL NER will compute several layers of BI-LSTM in order to auto generate entity extraction, and it will leverage batch-based distributed calls to native TensorFlow libraries during prediction. ",
"_____no_output_____"
],
[
"### Spark `2.4` and Spark NLP `2.0.1`",
"_____no_output_____"
],
[
"#### 1. Call necessary imports and set the resource folder path.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nsys.path.append('../../')\n\nfrom pyspark.sql import SparkSession\nfrom pyspark.ml import Pipeline\n\nfrom sparknlp.annotator import *\nfrom sparknlp.common import *\nfrom sparknlp.base import *\n\nimport time\nimport zipfile\n#Setting location of resource Directory\nresource_path= \"../../../src/test/resources/\"",
"_____no_output_____"
]
],
[
[
"#### 2. Download CoNLL 2003 data if not present",
"_____no_output_____"
]
],
[
[
"# Download CoNLL 2003 Dataset\nimport os\nfrom pathlib import Path\nimport urllib.request\nurl = \"https://github.com/patverga/torch-ner-nlp-from-scratch/raw/master/data/conll2003/\"\nfile_train=\"eng.train\"\nfile_testa= \"eng.testa\"\nfile_testb= \"eng.testb\"\n# https://github.com/patverga/torch-ner-nlp-from-scratch/tree/master/data/conll2003\nif not Path(file_train).is_file(): \n print(\"Downloading \"+file_train)\n urllib.request.urlretrieve(url+file_train, file_train)\nif not Path(file_testa).is_file():\n print(\"Downloading \"+file_testa)\n urllib.request.urlretrieve(url+file_testa, file_testa)\n\nif not Path(file_testb).is_file():\n print(\"Downloading \"+file_testb)\n urllib.request.urlretrieve(url+file_testb, file_testb)",
"_____no_output_____"
]
],
[
[
"#### 3. Download Glove embeddings and unzip, if not present",
"_____no_output_____"
]
],
[
[
"# Download Glove Word Embeddings\nfile = \"glove.6B.zip\"\nif not Path(\"glove.6B.zip\").is_file():\n url = \"http://nlp.stanford.edu/data/glove.6B.zip\"\n print(\"Start downoading Glove Word Embeddings. It will take some time, please wait...\")\n urllib.request.urlretrieve(url, \"glove.6B.zip\")\n print(\"Downloading finished\")\nelse:\n print(\"Glove data present.\")\n \nif not Path(\"glove.6B.100d.txt\").is_file():\n zip_ref = zipfile.ZipFile(file, 'r')\n zip_ref.extractall(\"./\")\n zip_ref.close()",
"_____no_output_____"
]
],
[
[
"#### 4. Create the spark session",
"_____no_output_____"
]
],
[
[
"spark = SparkSession.builder \\\n .appName(\"DL-NER\")\\\n .master(\"local[*]\")\\\n .config(\"spark.driver.memory\",\"8G\")\\\n .config(\"spark.jars.packages\", \"JohnSnowLabs:spark-nlp:2.0.1\")\\\n .config(\"spark.kryoserializer.buffer.max\", \"500m\")\\\n .getOrCreate()",
"_____no_output_____"
]
],
[
[
"#### 6. Load parquet dataset and cache into memory",
"_____no_output_____"
]
],
[
[
"from sparknlp.training import CoNLL\n\nconll = CoNLL(\n documentCol=\"document\",\n sentenceCol=\"sentence\",\n tokenCol=\"token\",\n posCol=\"pos\"\n)\n\ntraining_data = conll.readDataset(spark, './eng.train')\ntraining_data.show()",
"_____no_output_____"
]
],
[
[
"#### 5. Create annotator components with appropriate params and in the right order. The finisher will output only NER. Put everything in Pipeline",
"_____no_output_____"
]
],
[
[
"glove = WordEmbeddings()\\\n .setInputCols([\"sentence\", \"token\"])\\\n .setOutputCol(\"glove\")\\\n .setEmbeddingsSource(\"/home/saif/Downloads/glove.6B.100d.txt\", 100, 2)\n\nnerTagger = NerDLApproach()\\\n .setInputCols([\"sentence\", \"token\", \"glove\"])\\\n .setLabelColumn(\"label\")\\\n .setOutputCol(\"ner\")\\\n .setMaxEpochs(1)\\\n .setRandomSeed(0)\\\n .setVerbose(0)\n\nconverter = NerConverter()\\\n .setInputCols([\"sentence\", \"token\", \"ner\"])\\\n .setOutputCol(\"ner_span\")\n \nfinisher = Finisher() \\\n .setInputCols([\"sentence\", \"token\", \"ner\", \"ner_span\"]) \\\n .setIncludeMetadata(True)\n\nner_pipeline = Pipeline(\n stages = [\n glove,\n nerTagger,\n converter,\n finisher\n ])\n",
"_____no_output_____"
]
],
[
[
"#### 7. Train the pipeline. (This will take some time)",
"_____no_output_____"
]
],
[
[
"start = time.time()\nprint(\"Start fitting\")\nner_model = ner_pipeline.fit(training_data)\nprint(\"Fitting is ended\")\nprint (time.time() - start)",
"_____no_output_____"
]
],
[
[
"#### 8. Lets predict with the model",
"_____no_output_____"
]
],
[
[
"document = DocumentAssembler()\\\n .setInputCol(\"text\")\\\n .setOutputCol(\"document\")\n\nsentence = SentenceDetector()\\\n .setInputCols(['document'])\\\n .setOutputCol('sentence')\n\ntoken = Tokenizer()\\\n .setInputCols(['sentence'])\\\n .setOutputCol('token')\n\nprediction_pipeline = Pipeline(\n stages = [\n document,\n sentence,\n token,\n ner_model\n ]\n)",
"_____no_output_____"
],
[
"prediction_data = spark.createDataFrame([[\"Germany is a nice place\"]]).toDF(\"text\")\nprediction_data.show()",
"_____no_output_____"
],
[
"prediction_model = prediction_pipeline.fit(prediction_data)\nprediction_model.transform(prediction_data).show()",
"_____no_output_____"
],
[
"# We can be fast!\n\nlp = LightPipeline(prediction_model)\nresult = lp.annotate(\"International Business Machines Corporation (IBM) is an American multinational information technology company headquartered in Armonk.\")\nlist(zip(result['token'], result['ner']))",
"_____no_output_____"
]
],
[
[
"#### 9. Save both pipeline and single model once trained, on disk",
"_____no_output_____"
]
],
[
[
"prediction_pipeline.write().overwrite().save(\"./prediction_dl_pipeline\")\nprediction_model.write().overwrite().save(\"./prediction_dl_model\")",
"_____no_output_____"
]
],
[
[
"#### 10. Load both again, deserialize from disk",
"_____no_output_____"
]
],
[
[
"from pyspark.ml import PipelineModel, Pipeline\n\nloaded_prediction_pipeline = Pipeline.read().load(\"./prediction_dl_pipeline\")\nloaded_prediction_model = PipelineModel.read().load(\"./prediction_dl_model\")",
"_____no_output_____"
],
[
"loaded_prediction_model.transform(prediction_data).show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4ac7c8fc4808830653bae898481b87b8598d93a7
| 10,917 |
ipynb
|
Jupyter Notebook
|
sem 5/machine learning/ml practicals/Naive Bayes Classifier.ipynb
|
ashish-3916/academic_nsut
|
7817c979d4d2c25707b1873cf27390b745e790ef
|
[
"MIT"
] | 1 |
2021-10-17T15:57:33.000Z
|
2021-10-17T15:57:33.000Z
|
sem 5/machine learning/ml practicals/Naive Bayes Classifier.ipynb
|
ashish-3916/academic_nsut
|
7817c979d4d2c25707b1873cf27390b745e790ef
|
[
"MIT"
] | null | null | null |
sem 5/machine learning/ml practicals/Naive Bayes Classifier.ipynb
|
ashish-3916/academic_nsut
|
7817c979d4d2c25707b1873cf27390b745e790ef
|
[
"MIT"
] | null | null | null | 27.08933 | 125 | 0.398644 |
[
[
[
"# Naive Bayes Classifier (Self Made)",
"_____no_output_____"
],
[
"### 1. Importing Libraries",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport os\nimport pandas as pd\nfrom sklearn.metrics import r2_score\nfrom sklearn.datasets import load_boston\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import preprocessing\nfrom sklearn import metrics\nfrom sklearn.metrics import confusion_matrix\nfrom collections import defaultdict",
"_____no_output_____"
]
],
[
[
"### 2. Data Preprocessing",
"_____no_output_____"
]
],
[
[
"pima = pd.read_csv(\"diabetes.csv\")\n\npima.head()",
"_____no_output_____"
],
[
"pima.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 768 entries, 0 to 767\nData columns (total 9 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Pregnancies 768 non-null int64 \n 1 Glucose 768 non-null int64 \n 2 BloodPressure 768 non-null int64 \n 3 SkinThickness 768 non-null int64 \n 4 Insulin 768 non-null int64 \n 5 BMI 768 non-null float64\n 6 DiabetesPedigreeFunction 768 non-null float64\n 7 Age 768 non-null int64 \n 8 Outcome 768 non-null int64 \ndtypes: float64(2), int64(7)\nmemory usage: 54.1 KB\n"
],
[
"#normalizing the dataset\nscalar = preprocessing.MinMaxScaler()\npima = scalar.fit_transform(pima)\n\n#split dataset in features and target variable\n\nX = pima[:,:8]\ny = pima[:, 8]\n\nX_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.3, random_state=42)\n\n\nprint(X_train.shape, X_test.shape, Y_train.shape, Y_test.shape)\n",
"(537, 8) (231, 8) (537,) (231,)\n"
]
],
[
[
"### 3. Required Functions",
"_____no_output_____"
]
],
[
[
"\ndef normal_distr(x, mean, dev):\n \n #finding the value through the normal distribution formula\n return (1/(np.sqrt(2 * np.pi) * dev)) * (np.exp(- (((x - mean) / dev) ** 2) / 2))\n\ndef finding_mean(X):\n \n return np.mean(X)\n\ndef finding_std_dev(X):\n \n return np.std(X)\n\n#def pred(X_test):\n \n\ndef train(X_train,Y_train):\n \n labels = set(Y_train)\n \n cnt_table = defaultdict(list)\n \n for row in range(X_train.shape[0]):\n \n for col in range(X_train.shape[1]):\n \n cnt_table[(col, Y_train[row])].append(X_train[row][col])\n \n \n lookup_list = defaultdict(list)\n \n for item in cnt_table.items():\n \n X_category = np.asarray(item[1])\n \n lookup_list[(item[0][0], item[0][1])].append(finding_mean(X_category))\n lookup_list[(item[0][0], item[0][1])].append(finding_std_dev(X_category))\n \n \n return lookup_list\n\n\ndef pred(X_test, lookup_list):\n \n Y_pred = []\n \n \n for row in range(X_test.shape[0]):\n \n prob_yes = 1\n prob_no = 1\n for col in range(X_test.shape[1]):\n \n prob_yes = prob_yes * normal_distr(X_test[row][col], lookup_list[(col, 1)][0], lookup_list[(col, 1)][1])\n prob_no = prob_no * normal_distr(X_test[row][col], lookup_list[(col, 0)][0], lookup_list[(col, 1)][1])\n \n if(prob_yes >= prob_no):\n \n Y_pred.append(1)\n \n else:\n \n Y_pred.append(0)\n \n \n return np.asarray(Y_pred)\n\n\ndef score(Y_pred, Y_test):\n \n correct_pred = np.sum(Y_pred == Y_test)\n \n return correct_pred / Y_pred.shape[0]\n\n\ndef naive_bayes(X_train,Y_train, X_test, Y_test):\n \n lookup_list = train(X_train, Y_train)\n \n Y_pred = pred(X_test, lookup_list)\n \n return score(Y_pred, Y_test)\n \n ",
"_____no_output_____"
],
[
"score = naive_bayes(X_train, Y_train, X_test, Y_test)",
"_____no_output_____"
],
[
"print(\"The accuracy of the model is : {0}\".format(score))",
"The accuracy of the model is : 0.6926406926406926\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac7cd7170f42608345313f32e778c0cc5154512
| 63,970 |
ipynb
|
Jupyter Notebook
|
experiments/plot_tradeoff.ipynb
|
almostExactMatch/basicFLAME
|
e9028c6efc959f1fdd9be6216734794633450411
|
[
"MIT"
] | 1 |
2019-02-22T21:27:01.000Z
|
2019-02-22T21:27:01.000Z
|
experiments/.ipynb_checkpoints/plot_tradeoff-checkpoint.ipynb
|
almostExactMatch/basicFLAME
|
e9028c6efc959f1fdd9be6216734794633450411
|
[
"MIT"
] | 1 |
2019-02-22T21:47:21.000Z
|
2019-02-22T21:47:21.000Z
|
experiments/plot_tradeoff.ipynb
|
almostExactMatch/basicFLAME
|
e9028c6efc959f1fdd9be6216734794633450411
|
[
"MIT"
] | null | null | null | 242.310606 | 21,616 | 0.902157 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport pickle\nimport time\nimport itertools\n\nimport matplotlib\nmatplotlib.rcParams.update({'font.size': 17.5})\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\nimport sys\nimport os.path\nsys.path.append( os.path.abspath(os.path.join( os.path.dirname('..') , os.path.pardir )) )",
"_____no_output_____"
],
[
"from FLAMEdb import *\nfrom FLAMEbit import *",
"_____no_output_____"
],
[
"# data generation, tune the tradeoff_param to generation to generate different plots\n\nd = data_generation_gradual_decrease_imbalance( 10000 , 10000 , 20 )\ndf = d[0] \nholdout,_ = data_generation_gradual_decrease_imbalance( 10000 , 10000, 20 )\nres = run_bit(df, holdout, range(20), [2]*20, tradeoff_param = 0.5)",
"[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 18, 19]\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 17, 18, 19]\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 16, 17, 19]\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 14, 16, 17, 19]\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 2, 3, 4, 6, 7, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 2, 3, 4, 6, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 2, 3, 4, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 2, 3, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 2, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 8, 9, 11, 14, 16, 17, 19]\n[0, 1, 9, 11, 14, 16, 17, 19]\n[0, 9, 11, 14, 16, 17, 19]\n[9, 11, 14, 16, 17, 19]\n[11, 14, 16, 17, 19]\n[14, 16, 17, 19]\n[16, 17, 19]\n[17, 19]\n"
],
[
"def bubble_plot(res):\n sizes = []\n effects = []\n \n for i in range(min(len(res),21)):\n r = res[i]\n if (r is None):\n effects.append([0])\n sizes.append([0])\n continue\n effects.append(list( r['effect'] ) )\n sizes.append(list(r['size'] ) )\n return sizes, effects",
"_____no_output_____"
],
[
"# plot percent of units matched, figure 4\n\nmatplotlib.rcParams.update({'font.size': 17.5})\n\n#res = pickle.load(open('__thePickleFile__', 'rb'))[1]\n \nss, es = bubble_plot(res[1])\n\ns = []\nfor i in ss:\n s.append(np.sum(i)/float(20000))\n \npct = [sum(s[:i+1]) for i in range(len(s))]\n\nplt.figure(figsize=(5,5)) \n\nplt.plot(pct, alpha = 0.6 , color = 'blue')\n\nplt.xticks(range(len(ss)), [str(20-i) if i%5==0 else '' for i in range(20) ] ) \n\nplt.ylabel('% of units matched')\nplt.xlabel('number of covariates remaining')\n\nplt.ylim([0,1])\n\nplt.tight_layout()",
"_____no_output_____"
],
[
"# plot the CATE on each level, figure 5\n\nss, es = bubble_plot(res[1])\n\nplt.figure(figsize=(5,5)) \n\nfor i in range(len(ss)):\n plt.scatter([i]*len(es[i]), es[i], s = ss[i], alpha = 0.6 , color = 'blue')\n\nplt.xticks(range(len(ss)), [str(20-i) if i%5==0 else '' for i in range(20) ] ) \n\nplt.ylabel('estimated treatment effect')\nplt.xlabel('number of covariates remaining')\n\nplt.ylim([8,14])\n\nplt.tight_layout()\n\n#plt.savefig('tradeoff01.png', dpi = 300)",
"_____no_output_____"
],
[
"# figure 6\n\nunits_matched = []\nCATEs = []\n\nfor i in range(len(res[1])):\n r = res[1][i]\n units_matched.append( np.sum(r['size']) )\n l = list(res[1][i]['effect'])\n CATEs.append( l )\n\nPCTs = []\n\nfor i in range(len(units_matched)):\n PCTs.append( np.sum(units_matched[:i+1])/30000 )\n\nfor i in range(len(PCTs)):\n CATE = CATEs[i]\n if len(CATE) > 0:\n plt.scatter( [PCTs[i]] * len(CATE), CATE, alpha = 0.6, color = 'b' )\n\nplt.xlabel('% of Units Matched')\nplt.ylabel('Estimated Treatment Effect')\n#plt.ylim([8,14])\nplt.xlim([-0.1,1])\n\nplt.tight_layout()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac7ec6e5a269a7c4f23f808b4487845bdba865a
| 6,787 |
ipynb
|
Jupyter Notebook
|
carga-diccionario.ipynb
|
gdsa-upc/2018-Equip2
|
9892c059126d314ff21d29fd88c7d1cd67c03eb8
|
[
"MIT"
] | null | null | null |
carga-diccionario.ipynb
|
gdsa-upc/2018-Equip2
|
9892c059126d314ff21d29fd88c7d1cd67c03eb8
|
[
"MIT"
] | null | null | null |
carga-diccionario.ipynb
|
gdsa-upc/2018-Equip2
|
9892c059126d314ff21d29fd88c7d1cd67c03eb8
|
[
"MIT"
] | 1 |
2022-02-15T18:59:18.000Z
|
2022-02-15T18:59:18.000Z
| 23.648084 | 138 | 0.536172 |
[
[
[
"from keras.applications.vgg19 import VGG19\nfrom keras.models import Model\nfrom keras.applications.vgg19 import preprocess_input\nfrom keras.preprocessing import image\nimport numpy as np\nimport pickle\nimport os",
"_____no_output_____"
],
[
"val = []",
"_____no_output_____"
],
[
"# Leemos el archivo annotation.txt y guardamos los datos en un vector (por palabras)\nwith open('/home/exla24/TB2018/val/annotation.txt','r') as f:\n archivo = f.readlines()",
"_____no_output_____"
],
[
"archivo.sort()",
"_____no_output_____"
],
[
"for line in archivo:\n for word in line.split():\n val.append(word)",
"_____no_output_____"
],
[
"archivo_val = []\netiqueta_val = []\n\ni = 0\nfor i in range (len(val)):\n if (i%2 == 0): # Sabemos que las palabras pares del vector a serán las de archivo y las impares serán las etiquetas\n archivo_val.append(val[i])\n else:\n etiqueta_val.append(val[i])",
"_____no_output_____"
],
[
"# Ya tenemos en el vector archivos y etiquetas ordenados todo lo que necesitamos. Ahora crearemos el diccionario\nval_dict = dict()\nj=0\nfor j in range (len(etiqueta_val)):\n val_dict[j] = dict(archivos = archivo_val[j], etiquetas = etiqueta_val[j])",
"_____no_output_____"
],
[
"# Haremos lo mismo con la carpeta train\ntrain = []",
"_____no_output_____"
],
[
"# Leemos el archivo annotation.txt y guardamos los datos en un vector (por palabras)\nwith open('/home/exla24/TB2018/train/annotation.txt','r') as f:\n archivo1 = f.readlines()",
"_____no_output_____"
],
[
"archivo1.sort()",
"_____no_output_____"
],
[
"for line in archivo1:\n for word in line.split():\n train.append(word)",
"_____no_output_____"
],
[
"archivo_train = []\netiqueta_train = []\n\ni = 0\nfor i in range (len(train)):\n if (i%2 == 0): # Sabemos que las palabras pares del vector a serán las de archivo y las impares serán las etiquetas\n archivo_train.append(train[i])\n else:\n etiqueta_train.append(train[i])",
"_____no_output_____"
],
[
"# Ya tenemos en el vector archivos y etiquetas ordenados todo lo que necesitamos. Ahora crearemos el diccionario\ntrain_dict = dict()\nj=0\nfor j in range (len(etiqueta_train)):\n train_dict[j] = dict(archivos = archivo_train[j], etiquetas = etiqueta_train[j])",
"_____no_output_____"
],
[
"# Haremos lo mismo con la carpeta test\ntest = []",
"_____no_output_____"
],
[
"# Leemos el archivo annotation.txt y guardamos los datos en un vector (por palabras)\nwith open('/home/exla24/TB2018/test/annotation.txt','r') as f:\n archivo2 = f.readlines()",
"_____no_output_____"
],
[
"archivo2.sort()",
"_____no_output_____"
],
[
"for line in archivo2:\n for word in line.split():\n test.append(word)",
"_____no_output_____"
],
[
"archivo_test = []\netiqueta_test = []\n\ni = 0\nfor i in range (len(test)):\n if (i%2 == 0): # Sabemos que las palabras pares del vector a serán las de archivo y las impares serán las etiquetas\n archivo_test.append(test[i])\n else:\n etiqueta_test.append(test[i])",
"_____no_output_____"
],
[
"# Ya tenemos en el vector archivos y etiquetas ordenados todo lo que necesitamos. Ahora crearemos el diccionario\ntest_dict = dict()\nj=0\nfor j in range (len(etiqueta_test)):\n test_dict[j] = dict(archivos = archivo_test[j],etiquetas = etiqueta_test[j])",
"_____no_output_____"
],
[
"pickle.dump(val_dict, open(\"/home/jupyter/Pickles/Etiquetas/diccionario_validacion\", \"wb\"))",
"_____no_output_____"
],
[
"pickle.dump(train_dict, open(\"/home/jupyter/Pickles/Etiquetas/diccionario_entrenamiento\", \"wb\"))",
"_____no_output_____"
],
[
"pickle.dump(test_dict, open(\"/home/jupyter/Pickles/Etiquetas/diccionario_test\", \"wb\"))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac7f3d682a2fde89b76ee7b1fd448e332991635
| 56,150 |
ipynb
|
Jupyter Notebook
|
notebooks/Hindcast_201704/ComparisonOfSalinityToVENUSData.ipynb
|
SalishSeaCast/analysis-susan
|
52633f4fe82af6d7c69dff58f69f0da4f7933f48
|
[
"Apache-2.0"
] | null | null | null |
notebooks/Hindcast_201704/ComparisonOfSalinityToVENUSData.ipynb
|
SalishSeaCast/analysis-susan
|
52633f4fe82af6d7c69dff58f69f0da4f7933f48
|
[
"Apache-2.0"
] | null | null | null |
notebooks/Hindcast_201704/ComparisonOfSalinityToVENUSData.ipynb
|
SalishSeaCast/analysis-susan
|
52633f4fe82af6d7c69dff58f69f0da4f7933f48
|
[
"Apache-2.0"
] | null | null | null | 78.973277 | 21,904 | 0.784577 |
[
[
[
"import arrow as arw\nimport matplotlib.pyplot as plt\nimport netCDF4 as nc\nimport numpy as np\nimport pandas as pd\nimport xarray as xr\n\nfrom salishsea_tools import places, teos_tools\n\n%matplotlib inline",
"_____no_output_____"
],
[
"hindcast_dataset = xr.open_dataset(\n 'https://salishsea.eos.ubc.ca/erddap/griddap/ubcSSg3DTracerFields1hV17-02')",
"_____no_output_____"
],
[
"nowcastv1_dataset = xr.open_dataset(\n 'https://salishsea.eos.ubc.ca/erddap/griddap/ubcSSn3DTracerFields1hV1')",
"_____no_output_____"
],
[
"nowcastv2_dataset = xr.open_dataset(\n 'https://salishsea.eos.ubc.ca/erddap/griddap/ubcSSn3DTracerFields1hV16-10')",
"_____no_output_____"
],
[
"def _prep_plot_data(xr_dataset, variable, place, weight1, weight2, poss1, poss2, state_day, end_day, factor=1):\n time_slice = slice(start_day.date(), end_day.replace(days=+1).date(), 1)\n grid_y, grid_x = places.PLACES[place]['NEMO grid ji']\n var_result1 = (\n xr_dataset[variable]\n .sel(time=time_slice)\n .isel(depth=poss1, gridX=grid_x, gridY=grid_y))\n var_result2 = (\n xr_dataset[variable]\n .sel(time=time_slice)\n .isel(depth=poss2, gridX=grid_x, gridY=grid_y))\n return (weight1*var_result1+weight2*var_result2)*factor",
"_____no_output_____"
],
[
"def make_plot(use_title, \n sal_obs,\n hindcast_ts_2014, hindcast_ts_2015, hindcast_ts_2016, hindcast_ts_2017,\n nowcastv2_ts_2016, nowcastv2_ts_2017, \n nowcastv1_ts_2014, nowcastv1_ts_2015, nowcastv1_ts_2016):\n\n fig, ax = plt.subplots(1, 1, figsize=(15, 5))\n sal_obs_hourly = sal_obs.resample('1H').mean()\n nowcastv2_ts_2017.plot(ax=ax, color='b', label='')\n sal_obs_hourly.plot(ax=ax, color='g', label='Observations')\n hindcast_ts_2014.plot(ax=ax, color='r', label='Hindcast')\n hindcast_ts_2015.plot(ax=ax, color='r', label='')\n hindcast_ts_2016.plot(ax=ax, color='r', label='')\n hindcast_ts_2017.plot(ax=ax, color='r', label='')\n nowcastv2_ts_2016.plot(ax=ax, color='b', label='Nowcast-V2')\n nowcastv1_ts_2014.plot(ax=ax, color='teal', label='Nowcast-V1')\n nowcastv1_ts_2015.plot(ax=ax, color='teal', label='')\n nowcastv1_ts_2016.plot(ax=ax, color='teal', label='')\n ax.legend()\n ax.set_ylabel('Reference Salinity (g/kg)')\n ax.set_xlabel('Date (UTC)')\n ax.set_title(use_title)\n",
"_____no_output_____"
]
],
[
[
"## Central Node ##",
"_____no_output_____"
]
],
[
[
"place = 'Central node'\nposs1 = 34 -1\ndepth1 = 280\nposs2 = poss1 + 1\ndepth2 = 307\ndepth = 294\nweight1 = (depth2 - depth)/(depth2 - depth1)\nweight2 = 1 - weight1\nuse_title = 'Salinity at VENUS Central'\n",
"_____no_output_____"
],
[
"observations_dataset = nc.Dataset('https://salishsea.eos.ubc.ca/erddap/tabledap/ubcONCSCVIPCTD15mV1')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1, figsize=(15, 5)) \nsal_obs_hourly = sal_obs.resample('1H').mean()\nsal_obs_hourly.plot(ax=ax, color='g', label='Observations') \nax.legend()\nax.set_ylabel('Reference Salinity (g/kg)')\nax.set_xlabel('Date (UTC)')\nax.set_title(use_title)\nax.set_xlim('20160601', '20160831')\nax.grid(which='both')",
"_____no_output_____"
]
],
[
[
"## These Cells need to be Run individually Rather than in a Function ##",
"_____no_output_____"
]
],
[
[
"sals = observations_dataset.variables['s.salinity']\ntimes = observations_dataset.variables['s.time']\njd = nc.num2date(times[:], times.units)\nunits_sav = times.units\nsal_obs = pd.Series(sals[:], index=jd)\nsal_obs.plot()",
"_____no_output_____"
],
[
"# for cases without units (aka BBL)\nsals = observations_dataset.variables['s.salinity']\ntimes = observations_dataset.variables['s.time']\nprint(times)\n#jd = nc.num2date(times[:], 'seconds since 1970-01-01T00:00:00Z')\nsal_obs = pd.Series(sals[:], index=times)",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get(hindcast_dataset.time_coverage_start)\nend_day = arw.get('2014-12-31T23:59:59')\nhindcast_ts_2014 = _prep_plot_data(hindcast_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2014-12-31T23:59:59')\nend_day = arw.get('2015-12-31T23:59:59')\nhindcast_ts_2015 = _prep_plot_data(hindcast_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2015-12-31T23:59:59')\nend_day = arw.get('2016-12-31T23:59:59')\nhindcast_ts_2016 = _prep_plot_data(hindcast_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2016-12-31T23:59:59')\nend_day = arw.get(hindcast_dataset.time_coverage_end)\nhindcast_ts_2017 = _prep_plot_data(hindcast_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get(nowcastv2_dataset.time_coverage_start)\nend_day = arw.get('2016-12-31T23:59:59')\nnowcastv2_ts_2016 = _prep_plot_data(nowcastv2_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2016-12-31T23:59:59')\nend_day = arw.get(nowcastv2_dataset.time_coverage_end)\nnowcastv2_ts_2017 = _prep_plot_data(nowcastv2_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day)\n",
"_____no_output_____"
],
[
"print(place)\nfactor = teos_tools.PSU_TEOS\nstart_day = arw.get(nowcastv1_dataset.time_coverage_start)\nend_day = arw.get('2014-12-31T23:59:59')\nnowcastv1_ts_2014 = _prep_plot_data(nowcastv1_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day, factor)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2014-12-31T23:59:59')\nend_day = arw.get('2015-12-31T23:59:59')\nnowcastv1_ts_2015 = _prep_plot_data(nowcastv1_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day, factor)\n",
"_____no_output_____"
],
[
"print(place)\nstart_day = arw.get('2015-12-31T23:59:59')\nend_day = arw.get('2016-12-31T23:59:59')\nnowcastv1_ts_2016 = _prep_plot_data(nowcastv1_dataset, 'salinity', place, weight1, weight2, poss1, poss2, start_day, end_day, factor)\n",
"_____no_output_____"
]
],
[
[
"## East Node ##",
"_____no_output_____"
]
],
[
[
"place = 'East node'\nposs1 = 29 -1\ndepth1 = 147\nposs2 = poss1 + 1\ndepth2 = 173\ndepth = 164\nweight1 = (depth2 - depth)/(depth2 - depth1)\nweight2 = 1 - weight1\nuse_title = 'Salinity at VENUS East'\n",
"_____no_output_____"
],
[
"observations_dataset = nc.Dataset('https://salishsea.eos.ubc.ca/erddap/tabledap/ubcONCSEVIPCTD15mV1')",
"_____no_output_____"
]
],
[
[
"### run all the ts cells one at a time and then plot",
"_____no_output_____"
]
],
[
[
"make_plot(use_title, \n sal_obs,\n hindcast_ts_2014, hindcast_ts_2015, hindcast_ts_2016, hindcast_ts_2017,\n nowcastv2_ts_2016, nowcastv2_ts_2017, \n nowcastv1_ts_2014, nowcastv1_ts_2015, nowcastv1_ts_2016)",
"_____no_output_____"
]
],
[
[
"## Delta BBL Node ##",
"_____no_output_____"
]
],
[
[
"place = 'Delta BBL node'\nposs1 = 28 -1\ndepth1 = 122\nposs2 = poss1 + 1\ndepth2 = 147\ndepth = 143\nweight1 = (depth2 - depth)/(depth2 - depth1)\nweight2 = 1 - weight1\n\nuse_title = 'Salinity at VENUS Delta BBL'",
"_____no_output_____"
],
[
"observations_dataset = nc.Dataset('https://salishsea.eos.ubc.ca/erddap/tabledap/ubcONCLSBBLCTD15mV1.nc')#?time,salinity,temperature,temperature_std_dev,salinity_std_dev,salinity_sample_count,temperature_sample_count,latitude,longitude,depth')",
"_____no_output_____"
]
],
[
[
"### run all the ts cells one at a time and then plot",
"_____no_output_____"
]
],
[
[
"make_plot(use_title, \n sal_obs,\n hindcast_ts_2014, hindcast_ts_2015, hindcast_ts_2016, hindcast_ts_2017,\n nowcastv2_ts_2016, nowcastv2_ts_2017, \n nowcastv1_ts_2014, nowcastv1_ts_2015, nowcastv1_ts_2016)\nprint(place)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1, figsize=(15, 5))\nsal_obs_hourly = sal_obs.resample('1H').mean()\nnowcastv2_ts_2017.plot(ax=ax, color='b', label='')\nsal_obs_hourly.plot(ax=ax, color='k', label='Observations') \n# hindcast_ts_2014.plot(ax=ax, color='g', label='Hindcast')\n# hindcast_ts_2015.plot(ax=ax, color='g', label='') \n# hindcast_ts_2016.plot(ax=ax, color='g', label='') \n# hindcast_ts_2017.plot(ax=ax, color='g', label='') \nnowcastv2_ts_2016.plot(ax=ax, color='b', label='Nowcast-V2')\nnowcastv1_ts_2014.plot(ax=ax, color='teal', label='Nowcast-V1')\nnowcastv1_ts_2015.plot(ax=ax, color='teal', label='')\nnowcastv1_ts_2016.plot(ax=ax, color='teal', label='')\nax.legend()\nax.set_ylabel('Reference Salinity (g/kg)')\nax.set_xlabel('Date (UTC)')\nax.set_title(use_title)",
"_____no_output_____"
]
],
[
[
"## Delta DDL node ##",
"_____no_output_____"
]
],
[
[
"place = 'Delta DDL node'\nposs1 = 27 -1\ndepth1 = 98\nposs2 = poss1 + 1\ndepth2 = 122\ndepth = 107\nweight1 = (depth2 - depth)/(depth2 - depth1)\nweight2 = 1 - weight1",
"_____no_output_____"
],
[
"observations_dataset = xr.open_dataset('https://salishsea.eos.ubc.ca/erddap/tabledap/ubcONCUSDDLCTD15mV1')",
"_____no_output_____"
],
[
"observations_sal = observations_dataset['s.salinity']\nobservations_time = observations_dataset['s.time']",
"_____no_output_____"
],
[
"hindcast_ts = _prep_plot_data(hindcast_dataset, 'salinity', place, weight1, weight2, poss1, poss2)",
"_____no_output_____"
],
[
"nowcastv2_ts = _prep_plot_data(nowcastv2_dataset, 'salinity', place, weight1, weight2, poss1, poss2)",
"_____no_output_____"
],
[
"factor = teos_tools.PSU_TEOS\nnowcastv1_ts = _prep_plot_data(nowcastv1_dataset, 'salinity', place, weight1, weight2, poss1, poss2, factor)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1, figsize=(15, 5))\nax.plot(observations_time, observations_sal, 'g', label='Observations')\nhindcast_ts.plot(ax=ax, color='r', label='Hindcast')\nnowcastv2_ts.plot(ax=ax, label='Nowcast-V2')\nnowcastv1_ts.plot(ax=ax, label='Nowcast-V1')\nax.legend()\nax.set_ylabel('Reference Salinity (g/kg)')\nax.set_xlabel('Date (UTC)')\nax.set_title('Salinity at VENUS Delta DDL')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac7f4dde08b0b6fb8a5f0a0201c4ef382a95b13
| 58,418 |
ipynb
|
Jupyter Notebook
|
14 plotting a bloch sphere.ipynb
|
jayakumarksrit/Qiskit-Certification
|
1d9da57111bd3d1cafbda714317091032a626b3a
|
[
"Apache-2.0"
] | null | null | null |
14 plotting a bloch sphere.ipynb
|
jayakumarksrit/Qiskit-Certification
|
1d9da57111bd3d1cafbda714317091032a626b3a
|
[
"Apache-2.0"
] | null | null | null |
14 plotting a bloch sphere.ipynb
|
jayakumarksrit/Qiskit-Certification
|
1d9da57111bd3d1cafbda714317091032a626b3a
|
[
"Apache-2.0"
] | null | null | null | 177.56231 | 48,564 | 0.904636 |
[
[
[
"import numpy as np\n\n# Importing standard Qiskit libraries\nfrom qiskit import QuantumCircuit, transpile, Aer, IBMQ, assemble\nfrom qiskit.tools.jupyter import *\nfrom qiskit.visualization import *\nfrom ibm_quantum_widgets import *\nfrom qiskit.providers.aer import QasmSimulator\n\n# Loading your IBM Quantum account(s)\nprovider = IBMQ.load_account()",
"ibmqfactory.load_account:WARNING:2022-01-19 21:49:33,143: Credentials are already in use. The existing account in the session will be replaced.\n"
],
[
"from qiskit import qiskit\nfrom qiskit.visualization import plot_bloch_multivector\nqc=QuantumCircuit(1,1)\nqc.h(0)\n\nsimulator=Aer.get_backend('statevector_simulator')\njob=qiskit.execute(qc,simulator)\nresult=job.result()\noutput_state=result.get_statevector(qc)\nplot_bloch_multivector(output_state)\n\n\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4ac7f4ec9dd6fe138c02193188f775737e552306
| 87,302 |
ipynb
|
Jupyter Notebook
|
tests/practice/tflive_dense_sentiment_classifier.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | 1 |
2019-05-10T09:16:23.000Z
|
2019-05-10T09:16:23.000Z
|
tests/practice/tflive_dense_sentiment_classifier.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | null | null | null |
tests/practice/tflive_dense_sentiment_classifier.ipynb
|
gopala-kr/ds-notebooks
|
bc35430ecdd851f2ceab8f2437eec4d77cb59423
|
[
"MIT"
] | 1 |
2019-05-10T09:17:28.000Z
|
2019-05-10T09:17:28.000Z
| 34.547685 | 7,812 | 0.486415 |
[
[
[
"# Dense Sentiment Classifier",
"_____no_output_____"
],
[
"In this notebook, we build a dense neural net to classify IMDB movie reviews by their sentiment.",
"_____no_output_____"
]
],
[
[
"#load watermark\n%load_ext watermark\n%watermark -a 'Gopala KR' -u -d -v -p watermark,numpy,pandas,matplotlib,nltk,sklearn,tensorflow,theano,mxnet,chainer,seaborn,keras,tflearn,bokeh,gensim",
"WARNING (theano.configdefaults): install mkl with `conda install mkl-service`: No module named 'mkl'\n/opt/conda/lib/python3.6/site-packages/urllib3/contrib/pyopenssl.py:46: DeprecationWarning: OpenSSL.rand is deprecated - you should use os.urandom instead\n import OpenSSL.SSL\nUsing TensorFlow backend.\n/opt/conda/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py:211: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() or inspect.getfullargspec()\n arg_spec = inspect.getargspec(func)\n/opt/conda/lib/python3.6/site-packages/tensorflow/contrib/labeled_tensor/python/ops/_typecheck.py:233: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() or inspect.getfullargspec()\n spec = inspect.getargspec(f)\n/opt/conda/lib/python3.6/site-packages/tensorflow/python/framework/function.py:810: DeprecationWarning: inspect.getargspec() is deprecated, use inspect.signature() or inspect.getfullargspec()\n argspec = inspect.getargspec(func)\n"
]
],
[
[
"#### Load dependencies",
"_____no_output_____"
]
],
[
[
"import keras\nfrom keras.datasets import imdb\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Flatten, Dropout\nfrom keras.layers import Embedding # new!\nfrom keras.callbacks import ModelCheckpoint # new! \nimport os # new! \nfrom sklearn.metrics import roc_auc_score, roc_curve # new!\nimport pandas as pd\nimport matplotlib.pyplot as plt # new!\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"#### Set hyperparameters",
"_____no_output_____"
]
],
[
[
"# output directory name:\noutput_dir = 'model_output/dense'\n\n# training:\nepochs = 4\nbatch_size = 128\n\n# vector-space embedding: \nn_dim = 64\nn_unique_words = 5000 # as per Maas et al. (2011); may not be optimal\nn_words_to_skip = 50 # ditto\nmax_review_length = 100\npad_type = trunc_type = 'pre'\n\n# neural network architecture: \nn_dense = 64\ndropout = 0.5",
"_____no_output_____"
]
],
[
[
"#### Load data",
"_____no_output_____"
],
[
"For a given data set: \n\n* the Keras text utilities [here](https://keras.io/preprocessing/text/) quickly preprocess natural language and convert it into an index\n* the `keras.preprocessing.text.Tokenizer` class may do everything you need in one line:\n * tokenize into words or characters\n * `num_words`: maximum unique tokens\n * filter out punctuation\n * lower case\n * convert words to an integer index",
"_____no_output_____"
]
],
[
[
"(x_train, y_train), (x_valid, y_valid) = imdb.load_data(num_words=n_unique_words, skip_top=n_words_to_skip) ",
"_____no_output_____"
],
[
"x_train[0:6] # 0 reserved for padding; 1 would be starting character; 2 is unknown; 3 is most common word, etc.",
"_____no_output_____"
],
[
"for x in x_train[0:6]:\n print(len(x))",
"218\n189\n141\n550\n147\n43\n"
],
[
"y_train[0:6]",
"_____no_output_____"
],
[
"len(x_train), len(x_valid)",
"_____no_output_____"
]
],
[
[
"#### Restoring words from index",
"_____no_output_____"
]
],
[
[
"word_index = keras.datasets.imdb.get_word_index()\nword_index = {k:(v+3) for k,v in word_index.items()}\nword_index[\"PAD\"] = 0\nword_index[\"START\"] = 1\nword_index[\"UNK\"] = 2",
"Downloading data from https://s3.amazonaws.com/text-datasets/imdb_word_index.json\n1515520/1641221 [==========================>...] - ETA: 0s"
],
[
"word_index",
"_____no_output_____"
],
[
"index_word = {v:k for k,v in word_index.items()}",
"_____no_output_____"
],
[
"x_train[0]",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in x_train[0])",
"_____no_output_____"
],
[
"(all_x_train,_),(all_x_valid,_) = imdb.load_data() ",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in all_x_train[0])",
"_____no_output_____"
]
],
[
[
"#### Preprocess data",
"_____no_output_____"
]
],
[
[
"x_train = pad_sequences(x_train, maxlen=max_review_length, padding=pad_type, truncating=trunc_type, value=0)\nx_valid = pad_sequences(x_valid, maxlen=max_review_length, padding=pad_type, truncating=trunc_type, value=0)",
"_____no_output_____"
],
[
"x_train[0:6]",
"_____no_output_____"
],
[
"for x in x_train[0:6]:\n print(len(x))",
"100\n100\n100\n100\n100\n100\n"
],
[
"' '.join(index_word[id] for id in x_train[0])",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in x_train[5])",
"_____no_output_____"
]
],
[
[
"#### Design neural network architecture",
"_____no_output_____"
]
],
[
[
"model = Sequential()\nmodel.add(Embedding(n_unique_words, n_dim, input_length=max_review_length))\nmodel.add(Flatten())\nmodel.add(Dense(n_dense, activation='relu'))\nmodel.add(Dropout(dropout))\n# model.add(Dense(n_dense, activation='relu'))\n# model.add(Dropout(dropout))\nmodel.add(Dense(1, activation='sigmoid')) # mathematically equivalent to softmax with two classes",
"_____no_output_____"
],
[
"model.summary() # so many parameters!",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_1 (Embedding) (None, 100, 64) 320000 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 6400) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 64) 409664 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 64) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 1) 65 \n=================================================================\nTotal params: 729,729\nTrainable params: 729,729\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# embedding layer dimensions and parameters: \nn_dim, n_unique_words, n_dim*n_unique_words",
"_____no_output_____"
],
[
"# ...flatten:\nmax_review_length, n_dim, n_dim*max_review_length",
"_____no_output_____"
],
[
"# ...dense:\nn_dense, n_dim*max_review_length*n_dense + n_dense # weights + biases",
"_____no_output_____"
],
[
"# ...and output:\nn_dense + 1 ",
"_____no_output_____"
]
],
[
[
"#### Configure model",
"_____no_output_____"
]
],
[
[
"model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])",
"_____no_output_____"
],
[
"modelcheckpoint = ModelCheckpoint(filepath=output_dir+\"/weights.{epoch:02d}.hdf5\")",
"_____no_output_____"
],
[
"if not os.path.exists(output_dir):\n os.makedirs(output_dir)",
"_____no_output_____"
]
],
[
[
"#### Train!",
"_____no_output_____"
]
],
[
[
"# 84.7% validation accuracy in epoch 2\nmodel.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_valid, y_valid), callbacks=[modelcheckpoint])",
"Train on 25000 samples, validate on 25000 samples\nEpoch 1/4\n25000/25000 [==============================] - 5s - loss: 0.5359 - acc: 0.7068 - val_loss: 0.3667 - val_acc: 0.8368\nEpoch 2/4\n25000/25000 [==============================] - 5s - loss: 0.2699 - acc: 0.8940 - val_loss: 0.3502 - val_acc: 0.8467\nEpoch 3/4\n25000/25000 [==============================] - 5s - loss: 0.1092 - acc: 0.9678 - val_loss: 0.4354 - val_acc: 0.8307\nEpoch 4/4\n25000/25000 [==============================] - 5s - loss: 0.0243 - acc: 0.9962 - val_loss: 0.5281 - val_acc: 0.8335\n"
]
],
[
[
"#### Evaluate",
"_____no_output_____"
]
],
[
[
"model.load_weights(output_dir+\"/weights.01.hdf5\") # zero-indexed",
"_____no_output_____"
],
[
"y_hat = model.predict_proba(x_valid)",
"24736/25000 [============================>.] - ETA: 0s"
],
[
"len(y_hat)",
"_____no_output_____"
],
[
"y_hat[0]",
"_____no_output_____"
],
[
"plt.hist(y_hat)\n_ = plt.axvline(x=0.5, color='orange')",
"_____no_output_____"
],
[
"pct_auc = roc_auc_score(y_valid, y_hat)*100.0",
"_____no_output_____"
],
[
"\"{:0.2f}\".format(pct_auc)",
"_____no_output_____"
],
[
"float_y_hat = []\nfor y in y_hat:\n float_y_hat.append(y[0])",
"_____no_output_____"
],
[
"ydf = pd.DataFrame(list(zip(float_y_hat, y_valid)), columns=['y_hat', 'y'])",
"_____no_output_____"
],
[
"ydf.head(10)",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in all_x_valid[0])",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in all_x_valid[6]) ",
"_____no_output_____"
],
[
"ydf[(ydf.y == 0) & (ydf.y_hat > 0.9)].head(10)",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in all_x_valid[489]) ",
"_____no_output_____"
],
[
"ydf[(ydf.y == 1) & (ydf.y_hat < 0.1)].head(10)",
"_____no_output_____"
],
[
"' '.join(index_word[id] for id in all_x_valid[927]) ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac8038734f56712e09f118579fbde6041923169
| 374,239 |
ipynb
|
Jupyter Notebook
|
evaluation_onset.ipynb
|
mcferrenm/musicinformationretrieval.com
|
2d889a3a4712fb189cec7c5cd35568ec5bfefcb5
|
[
"MIT"
] | 636 |
2018-07-02T09:33:08.000Z
|
2022-03-30T12:50:42.000Z
|
evaluation_onset.ipynb
|
aospinab/musicinformationretrieval.com
|
2d889a3a4712fb189cec7c5cd35568ec5bfefcb5
|
[
"MIT"
] | 20 |
2016-01-14T14:22:58.000Z
|
2018-04-17T01:04:42.000Z
|
evaluation_onset.ipynb
|
aospinab/musicinformationretrieval.com
|
2d889a3a4712fb189cec7c5cd35568ec5bfefcb5
|
[
"MIT"
] | 272 |
2018-07-01T15:37:07.000Z
|
2022-03-29T03:18:01.000Z
| 1,130.63142 | 226,628 | 0.950617 |
[
[
[
"%matplotlib inline\nimport mir_eval, librosa, librosa.display, numpy, matplotlib.pyplot as plt, IPython.display as ipd",
"_____no_output_____"
],
[
"plt.style.use('seaborn-muted')\nplt.rcParams['figure.figsize'] = (14, 5)\nplt.rcParams['axes.grid'] = True\nplt.rcParams['axes.spines.left'] = False\nplt.rcParams['axes.spines.right'] = False\nplt.rcParams['axes.spines.bottom'] = False\nplt.rcParams['axes.spines.top'] = False\nplt.rcParams['axes.xmargin'] = 0\nplt.rcParams['axes.ymargin'] = 0\nplt.rcParams['image.cmap'] = 'gray'\nplt.rcParams['image.interpolation'] = None",
"_____no_output_____"
]
],
[
[
"[← Back to Index](index.html)",
"_____no_output_____"
],
[
"# Evaluation Example: Onset Detection",
"_____no_output_____"
],
[
"[Documentation: `mir_eval.onset`](http://craffel.github.io/mir_eval/#module-mir_eval.onset)",
"_____no_output_____"
],
[
"Evaluation method: determine which estimated onsets are “correct”, where correctness is defined as being within a small window of a reference onset.",
"_____no_output_____"
],
[
"`mir_eval` finds the largest feasible set of matches using the [Hopcroft-Karp algorithm](https://en.wikipedia.org/wiki/Hopcroft%E2%80%93Karp_algorithm). (See [`_bipartite_match`](https://github.com/craffel/mir_eval/blob/master/mir_eval/util.py#L547).)",
"_____no_output_____"
],
[
"Let's evaluate an onset detector on the following audio:",
"_____no_output_____"
]
],
[
[
"y, sr = librosa.load('audio/simple_piano.wav')",
"_____no_output_____"
],
[
"ipd.Audio(y, rate=sr)",
"_____no_output_____"
]
],
[
[
"## Detect Onsets",
"_____no_output_____"
],
[
"Estimate the onsets in the signal using `onset_detect`:",
"_____no_output_____"
]
],
[
[
"est_onsets = librosa.onset.onset_detect(y=y, sr=sr, units='time')",
"_____no_output_____"
],
[
"est_onsets",
"_____no_output_____"
]
],
[
[
"Load a fictional reference annotation.",
"_____no_output_____"
]
],
[
[
"ref_onsets = numpy.array([0, 0.270, 0.510, 1.02,\n 1.50, 2.02, 2.53, 3.01])",
"_____no_output_____"
]
],
[
[
"Plot the estimated and reference onsets together.",
"_____no_output_____"
]
],
[
[
"librosa.display.waveplot(y, sr=sr, alpha=0.5)\nplt.vlines(est_onsets, -1, 1, color='r')\nplt.scatter(ref_onsets, numpy.zeros_like(ref_onsets), color='k', s=100)\nplt.legend(['Waveform', 'Estimated onsets', 'Reference onsets']);",
"_____no_output_____"
]
],
[
[
"## Evaluate",
"_____no_output_____"
],
[
"Evaluate using [`mir_eval.onset.evaluate`](https://github.com/craffel/mir_eval/blob/master/mir_eval/onset.py#L101):",
"_____no_output_____"
]
],
[
[
"mir_eval.onset.evaluate(ref_onsets, est_onsets)",
"_____no_output_____"
]
],
[
[
"Out of a possible 8 reference onsets, 7 estimated onsets matched, i.e. recall = 7/8 = 0.875.",
"_____no_output_____"
],
[
"Out of a possible 14 estimated onsets, 7 reference onsets matched, i.e. precision = 7/14 = 0.5.",
"_____no_output_____"
],
[
"The default matching tolerance is 50 milliseconds. To reduce the matching tolerance, adjust the `window` keyword parameter:",
"_____no_output_____"
]
],
[
[
"mir_eval.onset.evaluate(ref_onsets, est_onsets, window=0.002)",
"_____no_output_____"
]
],
[
[
"[← Back to Index](index.html)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac81b499e3998dd045bb43e0dd0b5bae0c74fd4
| 34,084 |
ipynb
|
Jupyter Notebook
|
notebooks/tensor01/04. tf.function.ipynb
|
mmercan/study_python
|
1170116d57aecf331b4d8d5dd78ac1c6abe5003a
|
[
"MIT"
] | null | null | null |
notebooks/tensor01/04. tf.function.ipynb
|
mmercan/study_python
|
1170116d57aecf331b4d8d5dd78ac1c6abe5003a
|
[
"MIT"
] | null | null | null |
notebooks/tensor01/04. tf.function.ipynb
|
mmercan/study_python
|
1170116d57aecf331b4d8d5dd78ac1c6abe5003a
|
[
"MIT"
] | null | null | null | 26.690681 | 1,363 | 0.531188 |
[
[
[
"import time\nimport warnings\nimport logging\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"### Decorate functions with tf.function\n\nFunctions can be faster than eager code, especially for graphs with many small ops. But for graphs with a few expensive ops (like convolutions), you may not see much speedup.",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef add(a, b):\n return a + b\n\[email protected]\ndef sub(a, b):\n return a - b\n\[email protected]\ndef mul(a, b):\n return a * b\n\[email protected]\ndef div(a, b):\n return a / b",
"_____no_output_____"
],
[
"print(add(tf.constant(5), tf.constant(2)))",
"tf.Tensor(7, shape=(), dtype=int32)\n"
],
[
"print(sub(tf.constant(5), tf.constant(2)))",
"tf.Tensor(3, shape=(), dtype=int32)\n"
],
[
"print(mul(tf.constant(5), tf.constant(2)))",
"tf.Tensor(10, shape=(), dtype=int32)\n"
],
[
"print(div(tf.constant(5), tf.constant(2)))",
"tf.Tensor(2.5, shape=(), dtype=float64)\n"
]
],
[
[
"### Operate on variables and tensors, invoke nested functions",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef matmul(a, b):\n return tf.matmul(a, b)",
"_____no_output_____"
],
[
"@tf.function\ndef linear(m, x, c):\n return add(matmul(m, x), c)",
"_____no_output_____"
],
[
"m = tf.constant([[4.0, 5.0, 6.0]], tf.float32)\n\nm",
"_____no_output_____"
],
[
"x = tf.Variable([[100.0], [100.0], [100.0]], tf.float32)\n\nx",
"_____no_output_____"
],
[
"c = tf.constant([[1.0]], tf.float32)\n\nc",
"_____no_output_____"
],
[
"linear(m, x, c)",
"_____no_output_____"
]
],
[
[
"### Convert regular Python code to TensorFlow constructs\n\nTo help users avoid having to rewrite their code when adding @tf.function, AutoGraph converts a subset of Python constructs into their TensorFlow equivalents.\n\nMay use data-dependent control flow, including if, for, while break, continue and return statements",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef pos_neg_check(x):\n reduce_sum = tf.reduce_sum(x)\n\n if reduce_sum > 0:\n return tf.constant(1)\n\n elif reduce_sum == 0:\n return tf.constant(0)\n \n else:\n return tf.constant(-1)",
"_____no_output_____"
],
[
"pos_neg_check(tf.constant([100, 100]))",
"_____no_output_____"
],
[
"pos_neg_check(tf.constant([100, -100]))",
"_____no_output_____"
],
[
"pos_neg_check(tf.constant([-100, -100]))",
"_____no_output_____"
]
],
[
[
"### Operations with side effects\n\nMay also use ops with side effects, such as tf.print, tf.Variable and others.",
"_____no_output_____"
]
],
[
[
"num = tf.Variable(7)",
"_____no_output_____"
],
[
"@tf.function\ndef add_times(x):\n for i in tf.range(x):\n num.assign_add(x)",
"_____no_output_____"
],
[
"add_times(5)",
"_____no_output_____"
],
[
"print(num)",
"<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=42>\n"
]
],
[
[
"### In-order code execution\n\nDependencies in the code are automatically resolved based on the order in which the code is written",
"_____no_output_____"
]
],
[
[
"a = tf.Variable(1.0)\n\nb = tf.Variable(2.0)",
"_____no_output_____"
],
[
"@tf.function\ndef f(x, y):\n \n a.assign(y * b)\n \n b.assign_add(x * a)\n \n return a + b",
"_____no_output_____"
],
[
"f(1, 2)",
"_____no_output_____"
]
],
[
[
"### Polymorphism and tracing\n\nPython's dynamic typing means that you can call functions with a variety of argument types, and Python will do something different in each scenario.\n\nOn the other hand, TensorFlow graphs require static dtypes and shape dimensions. tf.function bridges this gap by retracing the function when necessary to generate the correct graphs. Most of the subtlety of tf.function usage stems from this retracing behavior.",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef square(a):\n print(\"Input a: \", a)\n return a * a",
"_____no_output_____"
]
],
[
[
"Trace a new graph with floating point inputs",
"_____no_output_____"
]
],
[
[
"x = tf.Variable([[2, 2], [2, 2]], dtype = tf.float32)\n\nsquare(x)",
"Input a: <tf.Variable 'Variable:0' shape=(2, 2) dtype=float32>\n"
]
],
[
[
"Re-trace the graph, now the inputs are of type integer",
"_____no_output_____"
]
],
[
[
"y = tf.Variable([[2, 2], [2, 2]], dtype = tf.int32)\n\nsquare(y)",
"Input a: <tf.Variable 'Variable:0' shape=(2, 2) dtype=int32>\n"
]
],
[
[
"This time the graph for floating point inputs is not traced, it is simply executed. This means that the print() statement is not executed. Since that is a Python side-effect. Python side-effects are executed only when the graph is traced",
"_____no_output_____"
]
],
[
[
"z = tf.Variable([[3, 3], [3, 3]], dtype = tf.float32)\n\nsquare(z)",
"_____no_output_____"
]
],
[
[
"### Use get_concrete_function() to get a concrete trace for a particular type of function",
"_____no_output_____"
]
],
[
[
"concrete_int_square_fn = square.get_concrete_function(tf.TensorSpec(shape=None, dtype=tf.int32))\n\nconcrete_int_square_fn",
"_____no_output_____"
],
[
"concrete_float_square_fn = square.get_concrete_function(tf.TensorSpec(shape=None, dtype=tf.float32))\n\nconcrete_float_square_fn",
"_____no_output_____"
],
[
"concrete_int_square_fn(tf.constant([[2, 2], [2, 2]], dtype = tf.int32))",
"_____no_output_____"
],
[
"concrete_float_square_fn(tf.constant([[2.1, 2.1], [2.1, 2.1]], dtype = tf.float32))",
"_____no_output_____"
],
[
"concrete_float_square_fn(tf.constant([[2, 2], [2, 2]], dtype = tf.int32))",
"_____no_output_____"
]
],
[
[
"### Python side effects only happen during tracing\n\nIn general, Python side effects (like printing or mutating objects) only happen during tracing. ",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef f(x):\n print(\"Python execution: \", x)\n tf.print(\"Graph execution: \", x)",
"_____no_output_____"
],
[
"f(1)",
"Python execution: 1\nGraph execution: 1\n"
],
[
"f(1)",
"Graph execution: 1\n"
],
[
"f(\"Hello tf.function!\")",
"Python execution: Hello tf.function!\nGraph execution: Hello tf.function!\n"
]
],
[
[
"Appending to Python lists is also a Python side-effect",
"_____no_output_____"
]
],
[
[
"arr = []\n\[email protected]\ndef f(x):\n for i in range(len(x)):\n arr.append(x[i]) ",
"_____no_output_____"
],
[
"f(tf.constant([10, 20, 30]))",
"_____no_output_____"
],
[
"arr",
"_____no_output_____"
],
[
"@tf.function\ndef f(x):\n tensor_arr = tf.TensorArray(dtype = tf.int32, size = 0, dynamic_size = True)\n \n for i in range(len(x)):\n tensor_arr = tensor_arr.write(i, x[i])\n \n return tensor_arr.stack()",
"_____no_output_____"
],
[
"result_arr = f(tf.constant([10, 20, 30]))\n\nresult_arr",
"_____no_output_____"
]
],
[
[
"### Use the tf.py_function() exit hatch to execute side effects",
"_____no_output_____"
]
],
[
[
"external_list = []\n\ndef side_effect(x):\n print('Python side effect')\n external_list.append(x)\n\[email protected]\ndef fn_with_side_effects(x):\n tf.py_function(side_effect, inp=[x], Tout=[])",
"_____no_output_____"
],
[
"fn_with_side_effects(1)",
"Python side effect\n"
],
[
"fn_with_side_effects(2)",
"Python side effect\n"
],
[
"external_list",
"_____no_output_____"
]
],
[
[
"### Control flow works\n\nfor/while --> tf.while_loop (break and continue are supported)",
"_____no_output_____"
]
],
[
[
"@tf.function\n\ndef some_tanh_fn(x):\n while tf.reduce_sum(x) > 1:\n x = tf.tanh(x)\n \n return x",
"_____no_output_____"
],
[
"some_tanh_fn(tf.random.uniform([10]))",
"_____no_output_____"
]
],
[
[
"#### Converting a function in eager mode to its Graph representation",
"_____no_output_____"
],
[
"Converting a function that works in eager mode to its Graph representation requires to think about the Graph even though we are working in eager mode",
"_____no_output_____"
]
],
[
[
"def fn_with_variable_init_eager():\n\n a = tf.constant([[10,10],[11.,1.]])\n x = tf.constant([[1.,0.],[0.,1.]])\n b = tf.Variable(12.)\n \n y = tf.matmul(a, x) + b\n\n tf.print(\"tf_print: \", y)\n \n return y",
"_____no_output_____"
],
[
"fn_with_variable_init_eager()",
"tf_print: [[22 22]\n [23 13]]\n"
],
[
"@tf.function\ndef fn_with_variable_init_autograph():\n\n a = tf.constant([[10,10],[11.,1.]])\n x = tf.constant([[1.,0.],[0.,1.]])\n b = tf.Variable(12.)\n \n y = tf.matmul(a, x) + b\n\n tf.print(\"tf_print: \", y)\n \n return y",
"_____no_output_____"
],
[
"fn_with_variable_init_autograph()",
"_____no_output_____"
],
[
"class F():\n def __init__(self):\n self._b = None\n\n @tf.function\n def __call__(self):\n a = tf.constant([[10, 10], [11., 1.]])\n x = tf.constant([[1., 0.], [0., 1.]])\n \n if self._b is None:\n self._b = tf.Variable(12.)\n \n y = tf.matmul(a, x) + self._b\n print(y)\n\n tf.print(\"tf_print: \", y)\n return y\n\nfn_with_variable_init_autograph = F()\nfn_with_variable_init_autograph()",
"Tensor(\"add:0\", shape=(2, 2), dtype=float32)\nTensor(\"add:0\", shape=(2, 2), dtype=float32)\ntf_print: [[22 22]\n [23 13]]\n"
],
[
"def f(x):\n if x > 0:\n x *= x\n return x\n \nprint(tf.autograph.to_code(f)) ",
"def tf__f(x):\n do_return = False\n retval_ = ag__.UndefinedReturnValue()\n with ag__.FunctionScope('f', 'fscope', ag__.ConversionOptions(recursive=True, user_requested=True, optional_features=(), internal_convert_user_code=True)) as fscope:\n\n def get_state():\n return ()\n\n def set_state(loop_vars):\n pass\n\n def if_true():\n (x_1,) = (x,)\n x_1 *= x_1\n return x_1\n\n def if_false():\n return x\n cond = (x > 0)\n x = ag__.if_stmt(cond, if_true, if_false, get_state, set_state, ('x',), ())\n try:\n do_return = True\n retval_ = fscope.mark_return_value(x)\n except:\n do_return = False\n raise\n (do_return,)\n return ag__.retval(retval_)\n\n"
]
],
[
[
"#### AutoGraph is highly optimized and works well when the input is a tf.Tensor object",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef g(x):\n return x\n\nstart = time.time()\nfor i in tf.range(2000):\n g(i)\nend = time.time()\n\nprint(\"tf.Tensor time elapsed: \", (end-start))",
"tf.Tensor time elapsed: 0.5737230777740479\n"
],
[
"warnings.filterwarnings('ignore')\nlogging.getLogger('tensorflow').disabled = True",
"_____no_output_____"
],
[
"start = time.time()\nfor i in range(2000):\n g(i)\nend = time.time()\n\nprint(\"Native type time elapsed: \", (end-start))",
"Native type time elapsed: 12.941787004470825\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac82089252dd302fa592407dbb1dcb4c141d4e1
| 11,250 |
ipynb
|
Jupyter Notebook
|
nbs/061_callback.noisy_student.ipynb
|
duyniem/tsai
|
18ea05f6077fe011fb9e3f206311abe4c0f3105c
|
[
"Apache-2.0"
] | null | null | null |
nbs/061_callback.noisy_student.ipynb
|
duyniem/tsai
|
18ea05f6077fe011fb9e3f206311abe4c0f3105c
|
[
"Apache-2.0"
] | null | null | null |
nbs/061_callback.noisy_student.ipynb
|
duyniem/tsai
|
18ea05f6077fe011fb9e3f206311abe4c0f3105c
|
[
"Apache-2.0"
] | 1 |
2021-08-12T20:45:07.000Z
|
2021-08-12T20:45:07.000Z
| 36.173633 | 325 | 0.517956 |
[
[
[
"# default_exp callback.noisy_student",
"_____no_output_____"
]
],
[
[
"# Noisy student\n\n> Callback to apply noisy student self-training (a semi-supervised learning approach) based on: Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020). Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10687-10698).",
"_____no_output_____"
]
],
[
[
"#export \nfrom tsai.imports import *\nfrom tsai.utils import *\nfrom tsai.data.preprocessing import *\nfrom tsai.data.transforms import *\nfrom tsai.models.layers import *\nfrom fastai.callback.all import *",
"_____no_output_____"
],
[
"#export\nimport torch.multiprocessing\ntorch.multiprocessing.set_sharing_strategy('file_system')",
"_____no_output_____"
],
[
"#export\n\n# This is an unofficial implementation of noisy student based on:\n# Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020). Self-training with noisy student improves imagenet classification. \n# In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10687-10698).\n# Official tensorflow implementation available in https://github.com/google-research/noisystudent\n\n\nclass NoisyStudent(Callback):\n \"\"\"A callback to implement the Noisy Student approach. In the original paper this was used in combination with noise: \n - stochastic depth: .8\n - RandAugment: N=2, M=27\n - dropout: .5\n \n Steps:\n 1. Build the dl you will use as a teacher\n 2. Create dl2 with the pseudolabels (either soft or hard preds)\n 3. Pass any required batch_tfms to the callback\n \n \"\"\"\n \n def __init__(self, dl2:DataLoader, bs:Optional[int]=None, l2pl_ratio:int=1, batch_tfms:Optional[list]=None, do_setup:bool=True, \n pseudolabel_sample_weight:float=1., verbose=False): \n r'''\n Args:\n dl2: dataloader with the pseudolabels\n bs: batch size of the new, combined dataloader. If None, it will pick the bs from the labeled dataloader.\n l2pl_ratio: ratio between labels and pseudolabels in the combined batch\n batch_tfms: transforms applied to the combined batch. If None, it will pick the batch_tfms from the labeled dataloader (if any)\n do_setup: perform a transform setup on the labeled dataset.\n pseudolabel_sample_weight: weight of each pseudolabel sample relative to the labeled one of the loss.\n '''\n \n self.dl2, self.bs, self.l2pl_ratio, self.batch_tfms, self.do_setup, self.verbose = dl2, bs, l2pl_ratio, batch_tfms, do_setup, verbose\n self.pl_sw = pseudolabel_sample_weight\n \n def before_fit(self):\n if self.batch_tfms is None: self.batch_tfms = self.dls.train.after_batch\n self.old_bt = self.dls.train.after_batch # Remove and store dl.train.batch_tfms\n self.old_bs = self.dls.train.bs\n self.dls.train.after_batch = noop \n\n if self.do_setup and self.batch_tfms:\n for bt in self.batch_tfms: \n bt.setup(self.dls.train)\n\n if self.bs is None: self.bs = self.dls.train.bs\n self.dl2.bs = min(len(self.dl2.dataset), int(self.bs / (1 + self.l2pl_ratio)))\n self.dls.train.bs = self.bs - self.dl2.bs\n pv(f'labels / pseudolabels per training batch : {self.dls.train.bs} / {self.dl2.bs}', self.verbose)\n rel_weight = (self.dls.train.bs/self.dl2.bs) * (len(self.dl2.dataset)/len(self.dls.train.dataset))\n pv(f'relative labeled/ pseudolabel sample weight in dataset: {rel_weight:.1f}', self.verbose)\n self.dl2iter = iter(self.dl2)\n \n self.old_loss_func = self.learn.loss_func\n self.learn.loss_func = self.loss\n \n def before_batch(self):\n if self.training:\n X, y = self.x, self.y\n try: X2, y2 = next(self.dl2iter)\n except StopIteration:\n self.dl2iter = iter(self.dl2)\n X2, y2 = next(self.dl2iter)\n if y.ndim == 1 and y2.ndim == 2: y = torch.eye(self.learn.dls.c)[y].to(device) # ensure both \n \n X_comb, y_comb = concat(X, X2), concat(y, y2)\n \n if self.batch_tfms is not None: \n X_comb = compose_tfms(X_comb, self.batch_tfms, split_idx=0)\n y_comb = compose_tfms(y_comb, self.batch_tfms, split_idx=0)\n self.learn.xb = (X_comb,)\n self.learn.yb = (y_comb,)\n pv(f'\\nX: {X.shape} X2: {X2.shape} X_comb: {X_comb.shape}', self.verbose)\n pv(f'y: {y.shape} y2: {y2.shape} y_comb: {y_comb.shape}', self.verbose)\n \n def loss(self, output, target): \n if target.ndim == 2: _, target = target.max(dim=1)\n if self.training and self.pl_sw != 1: \n loss = (1 - self.pl_sw) * self.old_loss_func(output[:self.dls.train.bs], target[:self.dls.train.bs])\n loss += self.pl_sw * self.old_loss_func(output[self.dls.train.bs:], target[self.dls.train.bs:])\n return loss \n else: \n return self.old_loss_func(output, target)\n \n def after_fit(self):\n self.dls.train.after_batch = self.old_bt\n self.learn.loss_func = self.old_loss_func\n self.dls.train.bs = self.old_bs\n self.dls.bs = self.old_bs",
"_____no_output_____"
],
[
"from tsai.data.all import *\nfrom tsai.models.all import *\nfrom tsai.tslearner import *\ndsid = 'NATOPS'\nX, y, splits = get_UCR_data(dsid, return_split=False)",
"_____no_output_____"
],
[
"pseudolabeled_data = X\nsoft_preds = True\n\npseudolabels = ToNumpyCategory()(y) if soft_preds else OneHot()(y)\ndsets2 = TSDatasets(pseudolabeled_data, pseudolabels)\ndl2 = TSDataLoader(dsets2, num_workers=0)\nnoisy_student_cb = NoisyStudent(dl2, bs=256, l2pl_ratio=2, verbose=True)\nlearn = TSClassifier(X, y, splits=splits, batch_tfms=[TSStandardize(), TSRandomSize(.5)], cbs=noisy_student_cb)\nlearn.fit_one_cycle(1)",
"labels / pseudolabels per training batch : 171 / 85\nrelative labeled/ pseudolabel sample weight in dataset: 4.0\n"
],
[
"pseudolabeled_data = X\nsoft_preds = False\n\npseudolabels = ToNumpyCategory()(y) if soft_preds else OneHot()(y)\ndsets2 = TSDatasets(pseudolabeled_data, pseudolabels)\ndl2 = TSDataLoader(dsets2, num_workers=0)\nnoisy_student_cb = NoisyStudent(dl2, bs=256, l2pl_ratio=2, verbose=True)\nlearn = TSClassifier(X, y, splits=splits, batch_tfms=[TSStandardize(), TSRandomSize(.5)], cbs=noisy_student_cb)\nlearn.fit_one_cycle(1)",
"labels / pseudolabels per training batch : 171 / 85\nrelative labeled/ pseudolabel sample weight in dataset: 4.0\n"
],
[
"#hide\nout = create_scripts(); beep(out)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac82324638d7683aa7acf2af34d0a29bb4073e5
| 104,742 |
ipynb
|
Jupyter Notebook
|
notebooks/test.ipynb
|
rmcd-mscb/pySB
|
8ba858fc5a40052df5b2b90ced67b5489f184ff4
|
[
"MIT"
] | null | null | null |
notebooks/test.ipynb
|
rmcd-mscb/pySB
|
8ba858fc5a40052df5b2b90ced67b5489f184ff4
|
[
"MIT"
] | null | null | null |
notebooks/test.ipynb
|
rmcd-mscb/pySB
|
8ba858fc5a40052df5b2b90ced67b5489f184ff4
|
[
"MIT"
] | null | null | null | 463.460177 | 39,464 | 0.948932 |
[
[
[
"%matplotlib inline\nimport sys\nsys.executable",
"_____no_output_____"
],
[
"sys.path.append(r'C:\\Users\\rmcd\\GitRepos\\Python Projects')\nimport numpy as np\n\nfrom pyFM.Utils.COGridGen import COGridGen\nfrom pyFM.Utils.mapper import mapper\nfrom shapely.geometry import shape\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"print(\"The excutable is {}\".format(sys.executable))\n\ngrid = COGridGen(r\"..\\data\\GreenRiver\\centerline.shp\", nx=25, ny=11, width=350)\n\nprint(grid.description())\n\n",
"The excutable is C:\\Users\\rmcd\\AppData\\Local\\Continuum\\anaconda3\\envs\\pyviz-vtk\\python.exe\nUses centerline ..\\data\\GreenRiver\\centerline.shp and width 350 with nx = 25 and ny = 11 to generate curvilinear orthogonal grid\n"
],
[
"x, y = grid.cl.getpoints()\n# print(x)\nxo, yo = grid.cl.getinterppts(grid.nx)\n# print(xo)\n\nxgrid, ygrid = grid.getXYGrid()\n# print(xgrid)\n\nplt.scatter(xgrid,ygrid)\nplt.plot(x,y)\nplt.plot(xo, yo)\nplt.show()\n",
"_____no_output_____"
],
[
"map = mapper(grid, 'Elevation', 60, 5, 1, r\"..\\data\\GreenRiver\\channeltopoz.shp\", shp_has_geo=True)\nxd, yd, zd = map.getData()\nplt.scatter(xd, yd, s = 0.25, c=zd)\nplt.scatter(xgrid, ygrid, s=1, c='black')\nplt.show()",
"_____no_output_____"
],
[
"map.MapwCLTemplate()\ntmp = 1000\nprint(tmp)\nmap.plotmapgrid()\ngrid.plotmapgrid('Elevation')",
"(275,)\n1000\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac830d66b49e9a22765ca1513d93f34b2f381e0
| 982,381 |
ipynb
|
Jupyter Notebook
|
Customer Churn Prediction.ipynb
|
jaysmitjadhav/Churn-Prediction-and-Survival-Analysis
|
6fea7fb3eb346466e2eda4d65aa74abb2e85b4b2
|
[
"Apache-2.0"
] | null | null | null |
Customer Churn Prediction.ipynb
|
jaysmitjadhav/Churn-Prediction-and-Survival-Analysis
|
6fea7fb3eb346466e2eda4d65aa74abb2e85b4b2
|
[
"Apache-2.0"
] | null | null | null |
Customer Churn Prediction.ipynb
|
jaysmitjadhav/Churn-Prediction-and-Survival-Analysis
|
6fea7fb3eb346466e2eda4d65aa74abb2e85b4b2
|
[
"Apache-2.0"
] | null | null | null | 472.525734 | 252,627 | 0.810842 |
[
[
[
"# Customer Churn Prediction",
"_____no_output_____"
]
],
[
[
"# Importing necessary libraries\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('darkgrid')\n\n#import warnings\n#warnings.simplefilter(\"ignore\")",
"_____no_output_____"
]
],
[
[
"### Data Preparation based on EDA",
"_____no_output_____"
]
],
[
[
"def datapreparation(filepath):\n \n df = pd.read_csv(filepath)\n df.drop([\"customerID\"], inplace = True, axis = 1)\n \n df.TotalCharges = df.TotalCharges.replace(\" \",np.nan)\n df.TotalCharges.fillna(0, inplace = True)\n df.TotalCharges = df.TotalCharges.astype(float)\n \n cols1 = ['Partner', 'Dependents', 'PaperlessBilling', 'Churn', 'PhoneService']\n for col in cols1:\n df[col] = df[col].apply(lambda x: 0 if x == \"No\" else 1)\n \n df.gender = df.gender.apply(lambda x: 0 if x == \"Male\" else 1)\n df.MultipleLines = df.MultipleLines.map({'No phone service': 0, 'No': 0, 'Yes': 1})\n \n cols2 = ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']\n for col in cols2:\n df[col] = df[col].map({'No internet service': 0, 'No': 0, 'Yes': 1})\n \n df = pd.get_dummies(df, columns=['InternetService', 'Contract', 'PaymentMethod'], drop_first=True)\n \n return df",
"_____no_output_____"
],
[
"telco = datapreparation(filepath = \"./Data/Telco_Customer_Churn.csv\")\ntelco.head()",
"_____no_output_____"
],
[
"telco.isnull().any().any()",
"_____no_output_____"
]
],
[
[
"The dataframe has no null values",
"_____no_output_____"
],
[
"### Model building",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score\nfrom sklearn.metrics import confusion_matrix, accuracy_score, classification_report\nfrom sklearn.metrics import roc_auc_score, roc_curve, precision_score, recall_score, f1_score\nfrom imblearn.over_sampling import SMOTE\nfrom sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"train, test = train_test_split(telco, test_size=0.2, random_state=111, stratify = telco.Churn)",
"_____no_output_____"
],
[
"x = telco.columns[telco.columns!=\"Churn\"]\ny = \"Churn\"\ntrain_x = train[x]\ntrain_y = train[y]\ntest_x = test[x]\ntest_y = test[y]",
"_____no_output_____"
],
[
"#function for model fitting\ndef churn_prediction(algo, training_x, training_y, testing_x, testing_y, cols, cf = 'coefficients'):\n algo.fit(training_x,training_y)\n predictions = algo.predict(testing_x)\n probabilities = algo.predict_proba(testing_x)[:,1]\n \n #coeffs\n if cf == \"coefficients\":\n coefficients = pd.DataFrame(algo.coef_.ravel())\n elif cf == \"features\":\n coefficients = pd.DataFrame(algo.feature_importances_)\n \n column_df = pd.DataFrame(cols)\n coef_sumry = (pd.merge(coefficients, column_df, left_index= True, right_index= True, how = \"left\"))\n coef_sumry.columns = [\"coefficients\",\"features\"]\n coef_sumry = coef_sumry.sort_values(by = \"coefficients\",ascending = False)\n \n print (algo)\n print (\"\\n Classification report : \\n\",classification_report(testing_y,predictions))\n print (\"Accuracy Score : \",accuracy_score(testing_y,predictions))\n \n #confusion matrix\n conf_matrix = confusion_matrix(testing_y,predictions)\n plt.figure(figsize=(12,12))\n plt.subplot(221)\n sns.heatmap(conf_matrix, fmt = \"d\",annot=True, cmap='Blues')\n plt.title('Confuion Matrix')\n plt.ylabel('True Values')\n plt.xlabel('Predicted Values')\n \n #roc_auc_score\n model_roc_auc = roc_auc_score(testing_y,probabilities) \n print (\"Area under curve : \",model_roc_auc,\"\\n\")\n fpr,tpr,thresholds = roc_curve(testing_y,probabilities)\n \n plt.subplot(222)\n plt.plot(fpr, tpr, color='darkorange', lw=1, label = \"Auc : %.3f\" %model_roc_auc)\n plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')\n plt.xlim([0.0, 1.0])\n plt.ylim([0.0, 1.05])\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title('Receiver operating characteristic')\n plt.legend(loc=\"lower right\")\n \n plt.subplot(212)\n sns.barplot(x = coef_sumry[\"features\"] ,y = coef_sumry[\"coefficients\"])\n plt.title('Feature Importances')\n plt.xticks(rotation=\"vertical\")\n \n plt.show()",
"_____no_output_____"
]
],
[
[
"### Hyperparameter Tuning\n\n#### Grid 1: Selecting class weight and estimators",
"_____no_output_____"
]
],
[
[
"param_grid1 = {'max_features':['auto', 'sqrt', 'log2', None],\n 'n_estimators':[300, 500, 700, 900, 1100, 1300]}\n\nrf_model = RandomForestClassifier()\ngrid1 = GridSearchCV(estimator=rf_model, param_grid=param_grid1, n_jobs=-1, cv=3, verbose=1, scoring = 'f1')\ngrid1.fit(train_x, train_y)",
"Fitting 3 folds for each of 24 candidates, totalling 72 fits\n"
],
[
"grid1.best_params_",
"_____no_output_____"
],
[
"dt = pd.DataFrame(grid1.cv_results_)\ndt.param_max_features = dt.param_max_features.astype(str)\ndt.param_n_estimators = dt.param_n_estimators.astype(str)\n\ntable = pd.pivot_table(dt, values='mean_test_score', index='param_n_estimators', \n columns='param_max_features')\n \nsns.heatmap(table)",
"_____no_output_____"
],
[
"grid1.best_score_",
"_____no_output_____"
]
],
[
[
"#### Grid 2: Selecting max depth and split criterion",
"_____no_output_____"
]
],
[
[
"param_grid2 = {'max_features':['log2'],\n 'n_estimators':[800, 900, 1000],\n 'criterion': ['entropy', 'gini'],\n 'max_depth': [7, 9, 11, 13, 15, None]}\n\nrf_model = RandomForestClassifier()\ngrid2 = GridSearchCV(estimator=rf_model, param_grid=param_grid2, n_jobs=-1, cv=3, verbose=1, scoring = 'f1')\ngrid2.fit(train_x, train_y)",
"Fitting 3 folds for each of 36 candidates, totalling 108 fits\n"
],
[
"grid2.best_params_",
"_____no_output_____"
],
[
"dt = pd.DataFrame(grid2.cv_results_)\ntable = pd.pivot_table(dt, values='mean_test_score', index='param_max_depth', columns='param_criterion') \nsns.heatmap(table)",
"_____no_output_____"
],
[
"table = pd.pivot_table(dt, values='mean_test_score', index='param_max_depth', columns='param_n_estimators')\nsns.heatmap(table)",
"_____no_output_____"
],
[
"grid2.best_score_",
"_____no_output_____"
]
],
[
[
"Checking if other depth and estimator value results better score",
"_____no_output_____"
]
],
[
[
"param_grid2_2 = {'max_features':['log2'],\n 'n_estimators':[950, 1000, 1050],\n 'criterion': ['gini'],\n 'max_depth': [10, 11, 12]}\n\nrf_model = RandomForestClassifier()\ngrid2_2 = GridSearchCV(estimator=rf_model, param_grid=param_grid2, n_jobs=-1, cv=3, verbose=1, scoring = 'f1')\ngrid2_2.fit(train_x, train_y)",
"Fitting 3 folds for each of 36 candidates, totalling 108 fits\n"
],
[
"grid2_2.best_params_",
"_____no_output_____"
],
[
"grid2_2.best_score_",
"_____no_output_____"
]
],
[
[
"#### Grid 3: Selecting minimum samples leaf and split",
"_____no_output_____"
]
],
[
[
"param_grid3 = {'max_features':['log2'],\n 'n_estimators':[1000],\n 'criterion': ['gini'],\n 'max_depth': [11],\n 'min_samples_leaf': [1, 3, 5, 7],\n 'min_samples_split': [2, 4, 6, 8]}\n\nrf_model = RandomForestClassifier()\ngrid3 = GridSearchCV(estimator=rf_model, param_grid=param_grid3, n_jobs=-1, cv=3, verbose=1, scoring = 'f1')\ngrid3.fit(train_x, train_y)",
"Fitting 3 folds for each of 16 candidates, totalling 48 fits\n"
],
[
"grid3.best_params_",
"_____no_output_____"
],
[
"dt = pd.DataFrame(grid3.cv_results_)\ntable = pd.pivot_table(dt, values='mean_test_score', index='param_min_samples_leaf', columns='param_min_samples_split') \nsns.heatmap(table)",
"_____no_output_____"
],
[
"grid3.best_score_",
"_____no_output_____"
]
],
[
[
"#### Grid 4: Selecting class weight",
"_____no_output_____"
]
],
[
[
"param_grid4 = {'class_weight':[{0:1, 1:1}, {0:1, 1:2}, {0:1, 1:3}],\n 'max_features':['log2'],\n 'n_estimators':[1000],\n 'criterion': ['gini'],\n 'max_depth': [11],\n 'min_samples_leaf': [3],\n 'min_samples_split': [8]}\n\nrf_model = RandomForestClassifier()\ngrid4 = GridSearchCV(estimator=rf_model, param_grid=param_grid4, n_jobs=-1, cv=3, verbose=1, scoring = 'f1')\ngrid4.fit(train_x, train_y)",
"Fitting 3 folds for each of 3 candidates, totalling 9 fits\n"
],
[
"grid4.best_params_",
"_____no_output_____"
],
[
"dt = pd.DataFrame(grid4.cv_results_)\ndt.param_class_weight = dt.param_class_weight.astype(str)\ntable = pd.pivot_table(dt, values='mean_test_score', index='param_class_weight')\n \nsns.heatmap(table)",
"_____no_output_____"
],
[
"grid4.best_score_",
"_____no_output_____"
]
],
[
[
"#### Final Model",
"_____no_output_____"
]
],
[
[
"model = RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight={0: 1, 1: 3},\n criterion='gini', max_depth=11, max_features='log2',\n max_leaf_nodes=None, max_samples=None,\n min_impurity_decrease=0.0, min_impurity_split=None,\n min_samples_leaf=3, min_samples_split=8,\n min_weight_fraction_leaf=0.0, n_estimators=1000,\n n_jobs=None, oob_score=False, random_state=None,\n verbose=0, warm_start=False)",
"_____no_output_____"
],
[
"churn_prediction(model, train_x, train_y, test_x, test_y, x,\"features\")",
"RandomForestClassifier(class_weight={0: 1, 1: 3}, max_depth=11,\n max_features='log2', min_samples_leaf=3,\n min_samples_split=8, n_estimators=1000)\n\n Classification report : \n precision recall f1-score support\n\n 0 0.88 0.80 0.84 1035\n 1 0.56 0.70 0.62 374\n\n accuracy 0.78 1409\n macro avg 0.72 0.75 0.73 1409\nweighted avg 0.80 0.78 0.78 1409\n\nAccuracy Score : 0.7750177430801988\nArea under curve : 0.8480043400759514 \n\n"
]
],
[
[
"Checking the model's performance on train data itself",
"_____no_output_____"
]
],
[
[
"train_scores = cross_val_score(model, train_x, train_y, cv = 5, scoring='f1')\ntrain_scores",
"_____no_output_____"
],
[
"np.mean(train_scores)",
"_____no_output_____"
]
],
[
[
"As we can see that the performance of the model on test data is same as training data. So, we can conclude that there is no overfitting or underfitting.",
"_____no_output_____"
],
[
"#### Saving model",
"_____no_output_____"
]
],
[
[
"import pickle\npickle.dump(model, open('churnmodel.pkl','wb'))",
"_____no_output_____"
]
],
[
[
"## Model Interpretability",
"_____no_output_____"
],
[
"#### ELI5",
"_____no_output_____"
]
],
[
[
"import eli5\nfrom eli5.sklearn import PermutationImportance",
"Using TensorFlow backend.\n"
],
[
"perm = PermutationImportance(model, random_state=1).fit(test_x, test_y)\neli5.show_weights(perm, feature_names = test_x.columns.tolist())",
"_____no_output_____"
]
],
[
[
"Visualizing how the partial dependance plots look for top features",
"_____no_output_____"
]
],
[
[
"from pdpbox import pdp, info_plots\n\npdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, \n feature='InternetService_Fiber optic')\npdp.pdp_plot(pdp_p, 'InternetService_Fiber optic')\nplt.show()",
"_____no_output_____"
],
[
"pdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, \n feature='PaymentMethod_Mailed check')\npdp.pdp_plot(pdp_p, 'PaymentMethod_Mailed check')\nplt.show()",
"_____no_output_____"
],
[
"pdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, feature='MonthlyCharges')\npdp.pdp_plot(pdp_p, 'MonthlyCharges')\nplt.show()",
"_____no_output_____"
],
[
"pdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, feature='TotalCharges')\npdp.pdp_plot(pdp_p, 'TotalCharges')\nplt.show()",
"_____no_output_____"
],
[
"pdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, \n feature='Contract_Two year')\npdp.pdp_plot(pdp_p, 'Contract_Two year')\nplt.show()",
"_____no_output_____"
],
[
"pdp_p = pdp.pdp_isolate(model=model, dataset=test_x, model_features=test_x.columns.values, \n feature='tenure')\npdp.pdp_plot(pdp_p, 'tenure')\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### SHAP",
"_____no_output_____"
]
],
[
[
"import shap \nshap.initjs()\n\nimport joblib",
"_____no_output_____"
],
[
"explainer = shap.TreeExplainer(model)\n\nshap_values = explainer.shap_values(np.array(test_x.iloc[0]))\nshap.force_plot(explainer.expected_value[1], shap_values[1], test_x.iloc[0])",
"_____no_output_____"
],
[
"# Saving Explainer\nex_filename = 'explainer.bz2'\njoblib.dump(explainer, filename=ex_filename, compress=('bz2', 9))",
"_____no_output_____"
],
[
"explainer = joblib.load(filename=\"explainer.bz2\")\nshap_values = explainer.shap_values(np.array(test_x.iloc[0]))\nshap.force_plot(explainer.expected_value[1], shap_values[1], list(test_x.columns), matplotlib = True, show = False).savefig('static/images/shap.png', bbox_inches=\"tight\")",
"_____no_output_____"
]
],
[
[
"#### Gauge Chart",
"_____no_output_____"
]
],
[
[
"from matplotlib.patches import Circle, Wedge, Rectangle\n\ndef degree_range(n): \n start = np.linspace(0,180,n+1, endpoint=True)[0:-1]\n end = np.linspace(0,180,n+1, endpoint=True)[1::]\n mid_points = start + ((end-start)/2.)\n return np.c_[start, end], mid_points\n\ndef rot_text(ang): \n rotation = np.degrees(np.radians(ang) * np.pi / np.pi - np.radians(90))\n return rotation\n\ndef gauge(labels=['LOW','MEDIUM','HIGH','EXTREME'], \\\n colors=['#00FF00','#FFFF00','#FF7700','#FF0000'], Probability=1, fname=False): \n \n N = len(labels)\n colors = colors[::-1]\n\n \"\"\"\n begins the plotting\n \"\"\"\n \n fig, ax = plt.subplots()\n\n ang_range, mid_points = degree_range(4)\n\n labels = labels[::-1]\n \n \"\"\"\n plots the sectors and the arcs\n \"\"\"\n patches = []\n for ang, c in zip(ang_range, colors): \n # sectors\n patches.append(Wedge((0.,0.), .4, *ang, facecolor='w', lw=2))\n # arcs\n patches.append(Wedge((0.,0.), .4, *ang, width=0.10, facecolor=c, lw=2, alpha=0.5))\n \n [ax.add_patch(p) for p in patches]\n\n \n \"\"\"\n set the labels (e.g. 'LOW','MEDIUM',...)\n \"\"\"\n\n for mid, lab in zip(mid_points, labels): \n\n ax.text(0.35 * np.cos(np.radians(mid)), 0.35 * np.sin(np.radians(mid)), lab, \\\n horizontalalignment='center', verticalalignment='center', fontsize=14, \\\n fontweight='bold', rotation = rot_text(mid))\n\n \"\"\"\n set the bottom banner and the title\n \"\"\"\n r = Rectangle((-0.4,-0.1),0.8,0.1, facecolor='w', lw=2)\n ax.add_patch(r)\n \n ax.text(0, -0.05, 'Churn Probability ' + np.round(Probability,2).astype(str), horizontalalignment='center', \\\n verticalalignment='center', fontsize=22, fontweight='bold')\n\n \"\"\"\n plots the arrow now\n \"\"\"\n \n pos = (1-Probability)*180\n ax.arrow(0, 0, 0.225 * np.cos(np.radians(pos)), 0.225 * np.sin(np.radians(pos)), \\\n width=0.04, head_width=0.09, head_length=0.1, fc='k', ec='k')\n \n ax.add_patch(Circle((0, 0), radius=0.02, facecolor='k'))\n ax.add_patch(Circle((0, 0), radius=0.01, facecolor='w', zorder=11))\n\n \"\"\"\n removes frame and ticks, and makes axis equal and tight\n \"\"\"\n \n ax.set_frame_on(False)\n ax.axes.set_xticks([])\n ax.axes.set_yticks([])\n ax.axis('equal')\n plt.tight_layout()\n if fname:\n fig.savefig(fname, dpi=200)",
"_____no_output_____"
],
[
"gauge(Probability=model.predict_proba(test_x.iloc[0:1])[0,1])",
"_____no_output_____"
],
[
"# final features\ntest_x.columns",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac832553c880e4009e101d9e97d5bd5f9856870
| 94,779 |
ipynb
|
Jupyter Notebook
|
src/数据分析篇/工具介绍/numpy和scipy/窗口函数与卷积.ipynb
|
hsz1273327/TutorialForDataScience
|
1d8e72c033a264297e80f43612cd44765365b09e
|
[
"MIT"
] | null | null | null |
src/数据分析篇/工具介绍/numpy和scipy/窗口函数与卷积.ipynb
|
hsz1273327/TutorialForDataScience
|
1d8e72c033a264297e80f43612cd44765365b09e
|
[
"MIT"
] | 3 |
2020-03-31T03:36:05.000Z
|
2020-03-31T03:36:21.000Z
|
src/数据分析篇/工具介绍/numpy和scipy/窗口函数与卷积.ipynb
|
hsz1273327/TutorialForDataScience
|
1d8e72c033a264297e80f43612cd44765365b09e
|
[
"MIT"
] | null | null | null | 277.131579 | 17,900 | 0.932401 |
[
[
[
"# 窗口函数与卷积\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## 窗口函数\n\n在信号处理中,窗函数(window function)是一种除在给定区间之外取值均为0的实函数.譬如:在给定区间内为常数而在区间外为0的窗函数被形象地称为矩形窗.任何函数与窗函数之积仍为窗函数,所以相乘的结果就像透过窗口\"看\"其他函数一样.窗函数在频谱分析,滤波器设计,波束形成,以及音频数据压缩(如在Ogg Vorbis音频格式中)等方面有广泛的应用.\n\nnumpy中提供了几种常见的窗函数\n\n函数|说明\n---|---\nbartlett(M)\t|Bartlett窗口函数\nblackman(M)\t|Blackman 窗口函数\nhamming(M)\t|Hamming窗口函数\nhanning(M)\t|Hanning窗口函数\nkaiser(M, beta)\t|Kaiser窗口函数",
"_____no_output_____"
],
[
"### bartlett窗\n\n$$ w(n)=\\frac{2}{N-1}\\cdot\\left(\\frac{N-1}{2}-\\left |n-\\frac{N-1}{2}\\right |\\right)\\, $$",
"_____no_output_____"
]
],
[
[
"window = np.bartlett(51)\nplt.plot(window)\nplt.title(\"Bartlett window\")\nplt.ylabel(\"Amplitude\")\nplt.xlabel(\"Sample\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Blackman窗\n\n$$ \nw(n)=a_0 - a_1 \\cos \\left ( \\frac{2 \\pi n}{N-1} \\right) + a_2 \\cos \\left ( \\frac{4 \\pi n}{N-1} \\right)\n$$\n$$\n{\\displaystyle a_{0}=0.42;\\quad a_{1}=0.5;\\quad a_{2}=0.08\\,} a_0=0.42;\\quad a_1=0.5;\\quad a_2=0.08\\,\n$$",
"_____no_output_____"
]
],
[
[
"window = np.blackman(51)\nplt.plot(window)\nplt.title(\"Blackman window\")\nplt.ylabel(\"Amplitude\")\nplt.xlabel(\"Sample\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Hamming窗\n\n$$ w(n)=0.53836 - 0.46164\\; \\cos \\left ( \\frac{2 \\pi n}{N-1} \\right) $$",
"_____no_output_____"
]
],
[
[
"window = np.hamming(51)\nplt.plot(window)\nplt.title(\"Hamming window\")\nplt.ylabel(\"Amplitude\")\nplt.xlabel(\"Sample\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Hanning窗\n\n$$ w(n)= 0.5\\; \\left(1 - \\cos \\left ( \\frac{2 \\pi n}{N-1} \\right) \\right) $$",
"_____no_output_____"
]
],
[
[
"window = np.hanning(51)\nplt.plot(window)\nplt.title(\"Hanning window\")\nplt.ylabel(\"Amplitude\")\nplt.xlabel(\"Sample\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Kaiser窗\n\n$$ w(n)=\\frac{I_0\\Bigg (\\pi\\alpha \\sqrt{1 - (\\begin{matrix} \\frac{2 n}{N-1} \\end{matrix}-1)^2}\\Bigg )} {I_0(\\pi\\alpha)} $$",
"_____no_output_____"
]
],
[
[
"window = np.kaiser(51, 14)\nplt.plot(window)\nplt.title(\"Kaiser window\")\nplt.ylabel(\"Amplitude\")\nplt.xlabel(\"Sample\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 卷积\n\n卷积运算符经常出现在信号处理中,其中它模拟线性时不变系统对信号的影响.在概率理论中,两个独立随机变量的和根据它们各自的分布的卷积来分布.\n**离散**卷积运算定义为:\n\n$$ (a * v)[n] = \\sum_{m = -\\infty}^{\\infty} a[m] v[n - m] $$\n\nnumpy提供了通用的卷积操作`convolve(a, v, mode='full')`\n\n\n其中前两个参数都是一维的输入向量,而mode则提供了可选的三种运算规则,它可以有3种选项\n\n+ full\n 默认情况下,模式为\"full\".这在每个重叠点处返回卷积,其输出形状为(N M-1,).在卷积的端点,信号不完全重叠,并且可以看到边界效应.\n \n+ same\n 模式same返回长度max(M,N)的输出.边界效应仍然可见.\n \n+ valid\n 模式'valid'返回长度为max(M,N)-min(M,N)+1.卷积产物仅针对信号完全重叠的点给出.信号边界外的值没有效果.",
"_____no_output_____"
]
],
[
[
"np.convolve([1, 2, 3], [0, 1, 0.5])\n\n# a相当于[...0,0,1,2, 3 ,0,0,...]\n# v相当于[...0,0,0,1,0.5,0,0,...]\n# [0*0.5+0*1+1*0+2*0+3*0,\n# 0*0.5+1*1+2*0+3*0,\n# 1*0.5+2*1+3*0,\n# 1*0+2*0.5+3*1+0*0,\n# 1*0+2*0+3*0.5+0*1+0*0]",
"_____no_output_____"
],
[
"np.convolve([1,2,3],[0,1,0.5], 'same')",
"_____no_output_____"
],
[
"np.convolve([1,2,3],[0,1,0.5], 'valid')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac838d4183e5404a66aa58a9d232a1bf51907e1
| 75,905 |
ipynb
|
Jupyter Notebook
|
6_dynamics/4_wavepackets/2_dvr_basics/tutorial.ipynb
|
langerest/Tutorials_Libra
|
f0f079b0817e627e94cd916a47ad1e497378c94e
|
[
"CC0-1.0"
] | 8 |
2020-06-19T10:29:11.000Z
|
2021-12-22T09:04:04.000Z
|
6_dynamics/4_wavepackets/2_dvr_basics/tutorial.ipynb
|
langerest/Tutorials_Libra
|
f0f079b0817e627e94cd916a47ad1e497378c94e
|
[
"CC0-1.0"
] | 3 |
2020-05-06T14:49:06.000Z
|
2020-05-06T15:30:26.000Z
|
6_dynamics/4_wavepackets/2_dvr_basics/tutorial.ipynb
|
langerest/Tutorials_Libra
|
f0f079b0817e627e94cd916a47ad1e497378c94e
|
[
"CC0-1.0"
] | 14 |
2020-04-14T17:28:49.000Z
|
2022-01-12T22:13:32.000Z
| 45.80869 | 661 | 0.599104 |
[
[
[
"# Basics of the DVR calculations with Libra",
"_____no_output_____"
],
[
"## Table of Content <a name=\"TOC\"></a>\n\n1. [General setups](#setups)\n2. [Mapping points on multidimensional grids ](#mapping)\n3. [Functions of the Wfcgrid2 class](#wfcgrid2)\n4. [Showcase: computing energies of the HO eigenstates](#ho_showcase)\n5. [Dynamics: computed with SOFT method](#soft_dynamics)",
"_____no_output_____"
],
[
"### A. Learning objectives\n\n- to map sequential numbers of the grid points to the multi-dimensional index and vice versa\n- to define the Wfcgrid2 class objects for DVR calculations\n- to initialize wavefunctions of the grids\n- to compute various properties of the wavefunctions defined on the grid\n- to set up and conduct the quantum dynamics of the DVR of wavefunctions\n\n### B. Use cases\n\n- [Compute energies of the DVR wavefunctions](#energy-use-case)\n- [Numerically exact solution of the TD-SE](#tdse-solution)\n\n### C. Functions\n\n- `liblibra::libdyn::libwfcgrid` \n - [`compute_mapping`](#compute_mapping-1)\n - [`compute_imapping`](#compute_imapping-1)\n\n### D. Classes and class members\n\n- `liblibra::libdyn::libwfcgrid2`\n - [`Wfcgrid2`](#Wfcgrid2-1) | [also here](#Wfcgrid2-2) \n - [`nstates`](#nstates-1)\n - [`ndof`](#ndof-1) \n \n - [`Npts`](#Npts-1) \n - [`npts`](#npts-1) \n - [`rmin`](#rmin-1) \n - [`rmax`](#rmax-1) \n - [`dr`](#dr-1) \n - [`kmin`](#kmin-1) \n - [`dk`](#dk-1) \n \n - [`gmap`](#gmap-1) | [also here](#gmap-2)\n - [`imap`](#imap-1) | [also here](#imap-2) \n \n - [`PSI_dia`](#PSI_dia-1) \n - [`reciPSI_dia`](#reciPSI_dia-1) \n - [`PSI_adi`](#PSI_adi-1) \n - [`reciPSI_adi`](#reciPSI_adi-1) \n \n - [`Hdia`](#Hdia-1) \n - [`U`](#U-1) \n \n - [`add_wfc_Gau`](#add_wfc_Gau-1)\n - [`add_wfc_HO`](#add_wfc_HO-1) | [also here](#add_wfc_HO-2)\n - [`add_wfc_ARB`](#add_wfc_ARB-1)\n \n - [`norm`](#norm-1) | [also here](#norm-2)\n - [`e_kin`](#e_kin-1) | [also here](#e_kin-2)\n - [`e_pot`](#e_pot-1) | [also here](#e_pot-2)\n - [`e_tot`](#e_tot-1) | [also here](#e_tot-2)\n - [`get_pow_q`](#get_pow_q-1) \n - [`get_pow_p`](#get_pow_p-1) | [also here](#e_kin-2)\n - [`get_den_mat`](#get_den_mat-1)\n - [`get_pops`](#get_pops-1) | [also here](#get_pops-2)\n \n - [`update_propagator_H`](#update_propagator_H-1) | [also here](#update_propagator_H-2)\n - [`update_propagator_K`](#update_propagator_K-1)\n - [`SOFT_propagate`](#SOFT_propagate-1)\n \n - [`update_reciprocal`](#update_reciprocal-1) | [also here](#update_reciprocal-2) \n \n - [`normalize`](#normalize-1) | [also here](#normalize-2)\n \n - [`update_Hamiltonian`](#update_Hamiltonian-1) | [also here](#update_Hamiltonian-2)\n - [`update_adiabatic`](#update_adiabatic-1)\n ",
"_____no_output_____"
],
[
"## 1. General setups \n<a name=\"setups\"></a>[Back to TOC](#TOC)\n\nFirst, import all the necessary libraries:\n* liblibra_core - for general data types from Libra\n\nThe output of the cell below will throw a bunch of warnings, but this is not a problem nothing really serios. So just disregard them.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport math\nif sys.platform==\"cygwin\":\n from cyglibra_core import *\nelif sys.platform==\"linux\" or sys.platform==\"linux2\":\n from liblibra_core import *\nfrom libra_py import data_outs\n",
"/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for std::vector<std::vector<int, std::allocator<int> >, std::allocator<std::vector<int, std::allocator<int> > > > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for boost::python::detail::container_element<std::vector<std::vector<int, std::allocator<int> >, std::allocator<std::vector<int, std::allocator<int> > > >, unsigned long, boost::python::detail::final_vector_derived_policies<std::vector<std::vector<int, std::allocator<int> >, std::allocator<std::vector<int, std::allocator<int> > > >, false> > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for std::vector<std::vector<float, std::allocator<float> >, std::allocator<std::vector<float, std::allocator<float> > > > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for boost::python::detail::container_element<std::vector<std::vector<float, std::allocator<float> >, std::allocator<std::vector<float, std::allocator<float> > > >, unsigned long, boost::python::detail::final_vector_derived_policies<std::vector<std::vector<float, std::allocator<float> >, std::allocator<std::vector<float, std::allocator<float> > > >, false> > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for std::vector<std::vector<double, std::allocator<double> >, std::allocator<std::vector<double, std::allocator<double> > > > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for boost::python::detail::container_element<std::vector<std::vector<double, std::allocator<double> >, std::allocator<std::vector<double, std::allocator<double> > > >, unsigned long, boost::python::detail::final_vector_derived_policies<std::vector<std::vector<double, std::allocator<double> >, std::allocator<std::vector<double, std::allocator<double> > > >, false> > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for std::vector<std::vector<std::complex<double>, std::allocator<std::complex<double> > >, std::allocator<std::vector<std::complex<double>, std::allocator<std::complex<double> > > > > already registered; second conversion method ignored.\n return f(*args, **kwds)\n/home/alexey/miniconda2/envs/py37/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: to-Python converter for boost::python::detail::container_element<std::vector<std::vector<std::complex<double>, std::allocator<std::complex<double> > >, std::allocator<std::vector<std::complex<double>, std::allocator<std::complex<double> > > > >, unsigned long, boost::python::detail::final_vector_derived_policies<std::vector<std::vector<std::complex<double>, std::allocator<std::complex<double> > >, std::allocator<std::vector<std::complex<double>, std::allocator<std::complex<double> > > > >, false> > already registered; second conversion method ignored.\n return f(*args, **kwds)\n"
]
],
[
[
"Also, lets import matplotlib for plotting and define all the plotting parameters: sizes, colors, etc.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt # plots\n\nplt.rc('axes', titlesize=38) # fontsize of the axes title\nplt.rc('axes', labelsize=38) # fontsize of the x and y labels\nplt.rc('legend', fontsize=38) # legend fontsize\nplt.rc('xtick', labelsize=38) # fontsize of the tick labels\nplt.rc('ytick', labelsize=38) # fontsize of the tick labels\n\nplt.rc('figure.subplot', left=0.2)\nplt.rc('figure.subplot', right=0.95)\nplt.rc('figure.subplot', bottom=0.13)\nplt.rc('figure.subplot', top=0.88)\n\ncolors = {}\n\ncolors.update({\"11\": \"#8b1a0e\"}) # red \ncolors.update({\"12\": \"#FF4500\"}) # orangered \ncolors.update({\"13\": \"#B22222\"}) # firebrick \ncolors.update({\"14\": \"#DC143C\"}) # crimson \n\ncolors.update({\"21\": \"#5e9c36\"}) # green\ncolors.update({\"22\": \"#006400\"}) # darkgreen \ncolors.update({\"23\": \"#228B22\"}) # forestgreen\ncolors.update({\"24\": \"#808000\"}) # olive \n\ncolors.update({\"31\": \"#8A2BE2\"}) # blueviolet\ncolors.update({\"32\": \"#00008B\"}) # darkblue \n\ncolors.update({\"41\": \"#2F4F4F\"}) # darkslategray\n\nclrs_index = [\"11\", \"21\", \"31\", \"41\", \"12\", \"22\", \"32\", \"13\",\"23\", \"14\", \"24\"]",
"_____no_output_____"
]
],
[
[
"We'll use these auxiliary functions later:",
"_____no_output_____"
]
],
[
[
"class tmp:\n pass\n\ndef harmonic1D(q, params):\n \"\"\"\n 1D Harmonic potential \n \"\"\"\n \n x = q.get(0)\n k = params[\"k\"]\n \n obj = tmp()\n obj.ham_dia = CMATRIX(1,1) \n obj.ham_dia.set(0,0, 0.5*k*x**2)\n\n return obj\n \n\ndef harmonic2D(q, params):\n \"\"\"\n 2D Harmonic potential \n \"\"\"\n \n x = q.get(0)\n y = q.get(1)\n kx = params[\"kx\"]\n ky = params[\"ky\"]\n \n obj = tmp()\n obj.ham_dia = CMATRIX(1,1) \n obj.ham_dia.set(0, 0, (0.5*kx*x**2 + 0.5*ky*y**2)*(1.0+0.0j) )\n\n return obj\n \n",
"_____no_output_____"
]
],
[
[
"## 2. Mapping points on multidimensional grids \n<a name=\"mapping\"></a>[Back to TOC](#TOC)\n\n\nImagine a 3D grid with:\n * 3 points in the 1-st dimension\n * 2 points in the 2-nd dimension \n * 4 points in the 3-rd dimension\n\nSo there are 3 x 2 x 4 = 24 points \n \nHowever, we can still store all of them in 1D array, which is more efficient way. However, to refer to the points, we need a function that does the mapping.\n\nThis example demonstrates the functions:\n\n`vector<vector<int> > compute_mapping(vector<vector<int> >& inp, vector<int>& npts)`\n\n`int compute_imapping(vector<int>& inp, vector<int>& npts)`\n\ndefined in: dyn/wfcgrid/Grid_functions.h\n<a name=\"compute_mapping-1\"></a>",
"_____no_output_____"
]
],
[
[
"inp = intList2()\nnpts = Py2Cpp_int([3,2,4])\n\nres = compute_mapping(inp, npts);\n\nprint(\"The number of points = \", len(res) )\nprint(\"The number of dimensions = \", len(res[0]) )\n",
"The number of points = 24\nThe number of dimensions = 3\n"
]
],
[
[
"And the inverse of that mapping\n<a name=\"compute_imapping-1\"></a>",
"_____no_output_____"
]
],
[
[
"cnt = 0\nfor i in res:\n print(\"point # \", cnt, Cpp2Py(i) )\n print(\"index of that point in the global array =\", compute_imapping(i, Py2Cpp_int([3,2,4])) )\n cnt +=1",
"point # 0 [0, 0, 0]\nindex of that point in the global array = 0\npoint # 1 [0, 0, 1]\nindex of that point in the global array = 1\npoint # 2 [0, 0, 2]\nindex of that point in the global array = 2\npoint # 3 [0, 0, 3]\nindex of that point in the global array = 3\npoint # 4 [0, 1, 0]\nindex of that point in the global array = 4\npoint # 5 [0, 1, 1]\nindex of that point in the global array = 5\npoint # 6 [0, 1, 2]\nindex of that point in the global array = 6\npoint # 7 [0, 1, 3]\nindex of that point in the global array = 7\npoint # 8 [1, 0, 0]\nindex of that point in the global array = 8\npoint # 9 [1, 0, 1]\nindex of that point in the global array = 9\npoint # 10 [1, 0, 2]\nindex of that point in the global array = 10\npoint # 11 [1, 0, 3]\nindex of that point in the global array = 11\npoint # 12 [1, 1, 0]\nindex of that point in the global array = 12\npoint # 13 [1, 1, 1]\nindex of that point in the global array = 13\npoint # 14 [1, 1, 2]\nindex of that point in the global array = 14\npoint # 15 [1, 1, 3]\nindex of that point in the global array = 15\npoint # 16 [2, 0, 0]\nindex of that point in the global array = 16\npoint # 17 [2, 0, 1]\nindex of that point in the global array = 17\npoint # 18 [2, 0, 2]\nindex of that point in the global array = 18\npoint # 19 [2, 0, 3]\nindex of that point in the global array = 19\npoint # 20 [2, 1, 0]\nindex of that point in the global array = 20\npoint # 21 [2, 1, 1]\nindex of that point in the global array = 21\npoint # 22 [2, 1, 2]\nindex of that point in the global array = 22\npoint # 23 [2, 1, 3]\nindex of that point in the global array = 23\n"
]
],
[
[
"## 3. Functions of the Wfcgrid2 class\n<a name=\"wfcgrid2\"></a>[Back to TOC](#TOC)\n\nThis example demonstrates the functions of the class `Wfcgrid2`\n \n defined in: `dyn/wfcgrid2/Wfcgrid2.h`\n\n\nHere, we test simple Harmonic oscillator eigenfunctions and will \ncompare the energies as computed by Libra to the analytic results\n\n### 3.1. Initialize the grid and do the mappings (internally):\n\n`Wfcgrid2(vector<double>& rmin_, vector<double>& rmax_, vector<double>& dr_, int nstates_)`\n<a name=\"Wfcgrid2-1\"></a>",
"_____no_output_____"
]
],
[
[
"num_el_st = 1\nwfc = Wfcgrid2(Py2Cpp_double([-15.0]), Py2Cpp_double([15.0]), Py2Cpp_double([0.01]), num_el_st)",
"_____no_output_____"
]
],
[
[
"The key descriptors are stored in the `wfc` object:\n<a name=\"nstates-1\"></a> <a name=\"ndof-1\"></a> <a name=\"Npts-1\"></a> <a name=\"npts-1\"></a> \n<a name=\"rmin-1\"></a> <a name=\"rmax-1\"></a> <a name=\"dr-1\"></a> <a name=\"kmin-1\"></a> <a name=\"dk-1\"></a>",
"_____no_output_____"
]
],
[
[
"print(F\"number of quantum states: {wfc.nstates}\")\nprint(F\"number of nuclear degrees of freedom: {wfc.ndof}\")\nprint(F\"the total number of grid points: {wfc.Npts}\")\nprint(F\"the number of grid points in each dimension: {Cpp2Py(wfc.npts)}\")\nprint(F\"the lower boundary of the real-space grid in each dimension: {Cpp2Py(wfc.rmin)}\")\nprint(F\"the upper boundary of the real-space grid in each dimension: {Cpp2Py(wfc.rmax)}\")\nprint(F\"the real-space grid-step in each dimension: {Cpp2Py(wfc.dr)}\")\nprint(F\"the lower boundary of the reciprocal-space grid in each dimension: {Cpp2Py(wfc.kmin)}\")\nprint(F\"the reciprocal-space grid-step in each dimension: {Cpp2Py(wfc.dk)}\")",
"number of quantum states: 1\nnumber of nuclear degrees of freedom: 1\nthe total number of grid points: 4096\nthe number of grid points in each dimension: [4096]\nthe lower boundary of the real-space grid in each dimension: [-15.0]\nthe upper boundary of the real-space grid in each dimension: [15.0]\nthe real-space grid-step in each dimension: [0.01]\nthe lower boundary of the reciprocal-space grid in each dimension: [-50.0]\nthe reciprocal-space grid-step in each dimension: [0.0244140625]\n"
]
],
[
[
"### Exercise 1:\n\nWhat is the upper boundary of reciprocal space?",
"_____no_output_____"
],
[
"Grid mapping : the wavefunctions are stored in a consecutive order.\n\nTo convert the single integer (which is just an order of the point in a real or reciprocal space) from \nthe indices of the point on the 1D grid in each dimensions, we use the mapping below:\ne.g. igmap[1] = [0, 1, 0, 0] means that the second (index 1) entry in the PSI array below corresponds to\na grid point that is first (lower boundary) in dimensions 0, 2, and 3, but is second (index 1) in the \ndimension 1. Same for the reciprocal space\n\n<a name=\"gmap-1\"></a>",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"the point {i} corresponds to the grid indices = {Cpp2Py(wfc.gmap[i]) }\")",
"the point 0 corresponds to the grid indices = [0]\nthe point 1 corresponds to the grid indices = [1]\nthe point 2 corresponds to the grid indices = [2]\nthe point 3 corresponds to the grid indices = [3]\nthe point 4 corresponds to the grid indices = [4]\nthe point 5 corresponds to the grid indices = [5]\nthe point 6 corresponds to the grid indices = [6]\nthe point 7 corresponds to the grid indices = [7]\nthe point 8 corresponds to the grid indices = [8]\nthe point 9 corresponds to the grid indices = [9]\n"
]
],
[
[
"Analogously, the inverse mapping of the indices of the point on the axes of all dimensions to the sequentian number:\n<a name=\"imap-1\"></a>",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"the point {i} corresponds to the grid indices = { wfc.imap( Py2Cpp_int([i]) ) }\")",
"the point 0 corresponds to the grid indices = 0\nthe point 1 corresponds to the grid indices = 1\nthe point 2 corresponds to the grid indices = 2\nthe point 3 corresponds to the grid indices = 3\nthe point 4 corresponds to the grid indices = 4\nthe point 5 corresponds to the grid indices = 5\nthe point 6 corresponds to the grid indices = 6\nthe point 7 corresponds to the grid indices = 7\nthe point 8 corresponds to the grid indices = 8\nthe point 9 corresponds to the grid indices = 9\n"
]
],
[
[
"### 3.2. Let's run the above examples for a 2D case:\n\n<a name=\"Wfcgrid2-2\"></a> <a name=\"gmap-2\"></a> <a name=\"imap-2\"></a>",
"_____no_output_____"
]
],
[
[
"wfc2 = Wfcgrid2(Py2Cpp_double([-15.0, -15.0]), Py2Cpp_double([15.0, 15.0]), Py2Cpp_double([1, 1]), num_el_st)\n\n\nprint(F\"number of quantum states: {wfc2.nstates}\")\nprint(F\"number of nuclear degrees of freedom: {wfc2.ndof}\")\nprint(F\"the total number of grid points: {wfc2.Npts}\")\nprint(F\"the number of grid points in each dimension: {Cpp2Py(wfc2.npts)}\")\nprint(F\"the lower boundary of the real-space grid in each dimension: {Cpp2Py(wfc2.rmin)}\")\nprint(F\"the upper boundary of the real-space grid in each dimension: {Cpp2Py(wfc2.rmax)}\")\nprint(F\"the real-space grid-step in each dimension: {Cpp2Py(wfc2.dr)}\")\nprint(F\"the lower boundary of the reciprocal-space grid in each dimension: {Cpp2Py(wfc2.kmin)}\")\nprint(F\"the reciprocal-space grid-step in each dimension: {Cpp2Py(wfc2.dk)}\")\n\nfor i in range(10):\n print(F\"the point {i} corresponds to the grid indices = {Cpp2Py(wfc2.gmap[i]) }\")\n \nfor i in range(10):\n print(F\"the point {i} corresponds to the grid indices = { wfc2.imap( Py2Cpp_int([i, i]) ) }\") ",
"number of quantum states: 1\nnumber of nuclear degrees of freedom: 2\nthe total number of grid points: 1024\nthe number of grid points in each dimension: [32, 32]\nthe lower boundary of the real-space grid in each dimension: [-15.0, -15.0]\nthe upper boundary of the real-space grid in each dimension: [15.0, 15.0]\nthe real-space grid-step in each dimension: [1.0, 1.0]\nthe lower boundary of the reciprocal-space grid in each dimension: [-0.5, -0.5]\nthe reciprocal-space grid-step in each dimension: [0.03125, 0.03125]\nthe point 0 corresponds to the grid indices = [0, 0]\nthe point 1 corresponds to the grid indices = [0, 1]\nthe point 2 corresponds to the grid indices = [0, 2]\nthe point 3 corresponds to the grid indices = [0, 3]\nthe point 4 corresponds to the grid indices = [0, 4]\nthe point 5 corresponds to the grid indices = [0, 5]\nthe point 6 corresponds to the grid indices = [0, 6]\nthe point 7 corresponds to the grid indices = [0, 7]\nthe point 8 corresponds to the grid indices = [0, 8]\nthe point 9 corresponds to the grid indices = [0, 9]\nthe point 0 corresponds to the grid indices = 0\nthe point 1 corresponds to the grid indices = 33\nthe point 2 corresponds to the grid indices = 66\nthe point 3 corresponds to the grid indices = 99\nthe point 4 corresponds to the grid indices = 132\nthe point 5 corresponds to the grid indices = 165\nthe point 6 corresponds to the grid indices = 198\nthe point 7 corresponds to the grid indices = 231\nthe point 8 corresponds to the grid indices = 264\nthe point 9 corresponds to the grid indices = 297\n"
]
],
[
[
"### 3.3. Add a wavefunction to the grid\n\nThis can be done by sequentially adding either Gaussian wavepackets or the Harmonic osccillator eigenfunctions to the grid with the corresponding weights.\n\nAdding of such functions is done with for instance:\n\n`void add_wfc_HO(vector<double>& x0, vector<double>& px0, vector<double>& alpha, int init_state, vector<int>& nu, complex<double> weight, int rep)`\n\nHere,\n\n* `x0` - is the center of the added function\n* `p0` - it's initial momentum (if any)\n* `alpha` - the exponent parameters \n* `init_state` - specialization of the initial electronic state\n* `nu` - the selector of the HO eigenstate to be added\n* `weight` - the amplitude with which the added function enters the superpositions, doesn't have to lead to a normalized function, the norm is included when computing the properties\n* `rep` - representation\n\nThe variables x0, p0, etc. should have the dimensionality comparable to that of the grid. \n\nFor instance, in the example below we add the wavefunction (single HO eigenstate) to the 1D grid\n<a name=\"add_wfc_HO-1\"></a> <a name=\"norm-1\"></a>",
"_____no_output_____"
]
],
[
[
"x0 = Py2Cpp_double([0.0]) \np0 = Py2Cpp_double([0.0]) \nalphas = Py2Cpp_double([1.0])\nnu = Py2Cpp_int([0])\nel_st = 0\nrep = 0 \n\nweight = 1.0+0.0j\nwfc.add_wfc_HO(x0, p0, alphas, el_st, nu, weight, rep)\n\nprint(F\" norm of the diabatic wfc = {wfc.norm(0)} and norm of the adiabatic wfc = {wfc.norm(1)}\")",
" norm of the diabatic wfc = 0.9999999999999986 and norm of the adiabatic wfc = 0.0\n"
]
],
[
[
"We can see that the wavefunction is pretty much normalized - this is becasue we have only added a single wavefunction which is already normalized.\n\nAlso, note how the norm of the diabatic wavefunction is 1.0, but that of the adiabatic is zero - this is because we have added the wavefunction only in the diabatic representation (`rep = 0`) and haven't yet run any calculations to do any updates of the other (adiabatic) representation",
"_____no_output_____"
],
[
"### Exercise 2\n<a name=\"add_wfc_Gau-1\"></a>\nUse the `add_wfc_Gau` function to add several Gaussians to the grid.",
"_____no_output_____"
],
[
"### Exercise 3\n\nInitialize the wavefunction as the superposition: $|0> - 0.5 |1> + 0.25i |2 >$\n\nIs the resulting wavefunction normalized?\n\nUse the `normalize()` method of the `Wfcgrid2` class to normalize it\n<a name=\"normalize-1\"></a>",
"_____no_output_____"
],
[
"### 3.4. A more advanced example: adding an arbitrary wavefunctions \n\nusing the `add_wfc_ARB` method\n\nAll we need to do is to set up a Python function that would take `vector<double>` as the input for coordinates, a Python dictionary for parameters, and it would return a `CMATRIX(nstates, 1)` object containing energies of all states as the function of the multidimensional coordinate. \n\nLet's define the one:",
"_____no_output_____"
]
],
[
[
"def my_2D_sin(q, params):\n \"\"\"\n 2D sine potential \n \"\"\"\n \n x = q.get(0,0)\n y = q.get(1,0)\n A = params[\"A\"]\n alpha = params[\"alpha\"]\n omega = params[\"omega\"]\n \n res = CMATRIX(1,1) \n res.set(0,0, 0.5* A * math.sin(omega*(x**2 + y**2)) * math.exp(-alpha*(x**2 + y**2)) )\n\n return res\n",
"_____no_output_____"
]
],
[
[
"Now, we can add the wavefunction to that grid using:\n\n`void add_wfc_ARB(bp::object py_funct, bp::object params, int rep)`\n<a name=\"add_wfc_ARB-1\"></a>",
"_____no_output_____"
]
],
[
[
"rep = 0 \nwfc2.add_wfc_ARB(my_2D_sin, {\"A\":1, \"alpha\":1.0, \"omega\":1.0}, rep)\n\nprint(F\" norm of the diabatic wfc = {wfc2.norm(0)} and norm of the adiabatic wfc = {wfc2.norm(1)}\")",
" norm of the diabatic wfc = 0.11124683022492163 and norm of the adiabatic wfc = 0.0\n"
]
],
[
[
"As we can see, this wavefunction is not normalized.\n\nWe can normalize it using `normalize(int rep)` method with `rep = 0` since we are working with the diabatic representation\n<a name=\"normalize-2\"></a>",
"_____no_output_____"
]
],
[
[
"wfc2.normalize(0)\nprint(F\" norm of the diabatic wfc = {wfc2.norm(0)} and norm of the adiabatic wfc = {wfc2.norm(1)}\")",
" norm of the diabatic wfc = 0.9999999999999994 and norm of the adiabatic wfc = 0.0\n"
]
],
[
[
"### 3.5. Accessing wavefunction and the internal data\n\nNow that we have initialized the wavefunction, we can access the wavefunction \n<a name=\"PSI_dia-1\"></a> <a name=\"PSI_adi-1\"></a>",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"diabatic wfc = {wfc.PSI_dia[500+i].get(0,0) } adiabatic wfc = {wfc.PSI_adi[500+i].get(0,0) }\")",
"diabatic wfc = (1.4487332796885729e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (1.6010178358670647e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (1.7691329616726924e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (1.954705561969595e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (2.159527773482247e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (2.3855735423596517e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (2.6350168440629746e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (2.91025170616495e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (3.2139142101365356e-22+0j) adiabatic wfc = 0j\ndiabatic wfc = (3.5489066651617274e-22+0j) adiabatic wfc = 0j\n"
]
],
[
[
"We can also see what the reciprocal of the wavefunctions are. \n<a name=\"reciPSI_dia-1\"></a> <a name=\"reciPSI_adi-1\"></a>",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"diabatic wfc = {wfc.reciPSI_dia[500+i].get(0,0) } adiabatic wfc = {wfc.reciPSI_adi[500+i].get(0,0) }\")",
"diabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\ndiabatic wfc = 0j adiabatic wfc = 0j\n"
]
],
[
[
"### 3.6. Update the reciprocal of the initial wavefunction\n\nThis is needed for computing some properties, and also as the initialization of the dynamics\n<a name=\"update_reciprocal-1\"></a>",
"_____no_output_____"
]
],
[
[
"wfc.update_reciprocal(rep)",
"_____no_output_____"
]
],
[
[
"Now, since we have computed the reciprocal of the wavefunction (by doing an FFT of the real-space wfc), we can access those numbers (still in the diabatic representation only)",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"diabatic wfc = {wfc.reciPSI_dia[500+i].get(0,0) } adiabatic wfc = {wfc.reciPSI_adi[500+i].get(0,0) }\")",
"diabatic wfc = (-7.938581813042437e-16-3.292442409596794e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-1.0534997694888374e-15-4.3324393460622627e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-1.344645905336897e-15-5.169367280259415e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-1.5875806328520155e-15-6.733472460693432e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-1.9543907628057097e-15-8.294333772218843e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-2.4186289504751935e-15-9.33707190095722e-16j) adiabatic wfc = 0j\ndiabatic wfc = (-2.872689724086602e-15-1.1414549034631344e-15j) adiabatic wfc = 0j\ndiabatic wfc = (-3.1856187839746186e-15-1.3084149947233198e-15j) adiabatic wfc = 0j\ndiabatic wfc = (-3.578929217190932e-15-1.5015963563073512e-15j) adiabatic wfc = 0j\ndiabatic wfc = (-3.923212091435534e-15-1.4885132888172904e-15j) adiabatic wfc = 0j\n"
]
],
[
[
"### 3.4. Compute the Hamiltonian on the grid\n\nThe nice thing is - we can define any Hamiltonian function right in Python (this is done in [section 1]() ) and pass that function, together with the dictionary of the corresponding parameters to the `update_Hamiltonian` method.\n\nHere, we define the force constant of the potential to be consistent with the alpha of the initial Gaussian wavepacket and the mass of the particle, as is done in any Quantum chemistry textbooks.\n<a name=\"update_Hamiltonian-1\"></a> ",
"_____no_output_____"
]
],
[
[
"masses = Py2Cpp_double([2000.0])\nomega = alphas[0]/masses[0]\nk = masses[0] * omega**2\n\nwfc.update_Hamiltonian(harmonic1D, {\"k\": k}, rep)",
"_____no_output_____"
]
],
[
[
"After this step, the internal storage will also contain the Hamitonians computed at the grid points:\n<a name=\"Hdia-1\"></a> ",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"diabatic Hamiltonian (potential only) = {wfc.Hdia[500+i].get(0,0) } \")",
"diabatic Hamiltonian (potential only) = (0.025+0j) \ndiabatic Hamiltonian (potential only) = (0.024950025+0j) \ndiabatic Hamiltonian (potential only) = (0.0249001+0j) \ndiabatic Hamiltonian (potential only) = (0.024850224999999997+0j) \ndiabatic Hamiltonian (potential only) = (0.024800400000000004+0j) \ndiabatic Hamiltonian (potential only) = (0.024750624999999995+0j) \ndiabatic Hamiltonian (potential only) = (0.024700899999999998+0j) \ndiabatic Hamiltonian (potential only) = (0.024651225000000002+0j) \ndiabatic Hamiltonian (potential only) = (0.0246016+0j) \ndiabatic Hamiltonian (potential only) = (0.024552025+0j) \n"
]
],
[
[
"### 3.5. Computing properties\n\nNow, when the Hamiltonian is evaluated on the grid, we can compute various properties.\n\nIn this example, we use the wavefunction represented in the diabatic basis\n<a name=\"norm-2\"></a> <a name=\"e_kin-1\"></a> <a name=\"e_pot-1\"></a> <a name=\"e_tot-1\"></a> <a name=\"get_pow_p-1\"></a> ",
"_____no_output_____"
]
],
[
[
"rep = 0\nprint( \"Norm = \", wfc.norm(rep) )\nprint( \"Ekin = \", wfc.e_kin(masses, rep) )\nprint( \"Expected kinetic energy = \", 0.5*alphas[0]/(2.0*masses[0]) )\nprint( \"Epot = \", wfc.e_pot(rep) )\nprint( \"Expected potential energy = \", (0.5*k/alphas[0])*(0.5 + nu[0]) )\nprint( \"Etot = \", wfc.e_tot(masses, rep) )\nprint( \"Expected total energy = \", omega*(0.5 + nu[0]) )\n\np2 = wfc.get_pow_p(0, 2);\nprint( \"p2 = \", p2.get(0).real )\nprint( \"p2/2*m = \", p2.get(0).real/(2.0 * masses[0]) )",
"Norm = 0.9999999999999986\nEkin = 0.00012499999999999567\nExpected kinetic energy = 0.000125\nEpot = 0.00012499999999999987\nExpected potential energy = 0.000125\nEtot = 0.00024999999999999556\nExpected total energy = 0.00025\np2 = 0.49999999999998224\np2/2*m = 0.00012499999999999556\n"
]
],
[
[
"We can also compute the populations of all states and resolve it by the spatial region too:\n\n<a name=\"get_pops-1\"></a> <a name=\"get_pops-2\"></a> ",
"_____no_output_____"
]
],
[
[
"p = wfc.get_pops(0).get(0,0)\nprint(F\" population of diabatic state 0 of wfc in the whole region {p}\")\n\nleft, right = Py2Cpp_double([-15.0]), Py2Cpp_double([0.0])\np = wfc.get_pops(0, left, right).get(0,0)\nprint(F\" population of diabatic state 0 of wfc in the half of the original region {p}\")\n",
" population of diabatic state 0 of wfc in the whole region 0.9999999999999986\n population of diabatic state 0 of wfc in the half of the original region 0.5028209479177388\n"
]
],
[
[
"### 3.6. Converting between diabatic and adiabatic representations\n\nThe transformation matrix `wfc.U` is computed when we compute the real-space propagator `wfc.update_propagator_H` \n\nFor the purposes of the adi-to-dia transformation, it doesn't matter what value for dt is used in that function.\n\n<a name=\"update_propagator_H-1\"></a> ",
"_____no_output_____"
]
],
[
[
"wfc.update_propagator_H(0.0)",
"_____no_output_____"
]
],
[
[
"Now, we can access the transformation matrix - one for each grid point. \n\nNote, in this tutorial we deal with the 1 electronic state, so all the transformation matrices are just the identity ones\n<a name=\"U-1\"></a> ",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"dia-to-adi transformation matrix at point {500+i}\\n\")\n data_outs.print_matrix(wfc.U[500+i])",
"dia-to-adi transformation matrix at point 500\n\n(1+0j) \ndia-to-adi transformation matrix at point 501\n\n(1+0j) \ndia-to-adi transformation matrix at point 502\n\n(1+0j) \ndia-to-adi transformation matrix at point 503\n\n(1+0j) \ndia-to-adi transformation matrix at point 504\n\n(1+0j) \ndia-to-adi transformation matrix at point 505\n\n(1+0j) \ndia-to-adi transformation matrix at point 506\n\n(1+0j) \ndia-to-adi transformation matrix at point 507\n\n(1+0j) \ndia-to-adi transformation matrix at point 508\n\n(1+0j) \ndia-to-adi transformation matrix at point 509\n\n(1+0j) \n"
]
],
[
[
"Now, we can update the real-space adiabatic wavefunction and then its reciprocal for the adiabatic representation (`rep = 1`):\n\n<a name=\"update_adiabatic-1\"></a> <a name=\"update_reciprocal-1\"></a> ",
"_____no_output_____"
]
],
[
[
"wfc.update_adiabatic()\nwfc.update_reciprocal(1)",
"_____no_output_____"
]
],
[
[
"And compute the properties but now in the adiabatic basis",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n print(F\"diabatic wfc = {wfc.PSI_dia[500+i].get(0,0) } adiabatic wfc = {wfc.PSI_adi[500+i].get(0,0) }\")",
"diabatic wfc = (1.4487332796885729e-22+0j) adiabatic wfc = (1.4487332796885729e-22+0j)\ndiabatic wfc = (1.6010178358670647e-22+0j) adiabatic wfc = (1.6010178358670647e-22+0j)\ndiabatic wfc = (1.7691329616726924e-22+0j) adiabatic wfc = (1.7691329616726924e-22+0j)\ndiabatic wfc = (1.954705561969595e-22+0j) adiabatic wfc = (1.954705561969595e-22+0j)\ndiabatic wfc = (2.159527773482247e-22+0j) adiabatic wfc = (2.159527773482247e-22+0j)\ndiabatic wfc = (2.3855735423596517e-22+0j) adiabatic wfc = (2.3855735423596517e-22+0j)\ndiabatic wfc = (2.6350168440629746e-22+0j) adiabatic wfc = (2.6350168440629746e-22+0j)\ndiabatic wfc = (2.91025170616495e-22+0j) adiabatic wfc = (2.91025170616495e-22+0j)\ndiabatic wfc = (3.2139142101365356e-22+0j) adiabatic wfc = (3.2139142101365356e-22+0j)\ndiabatic wfc = (3.5489066651617274e-22+0j) adiabatic wfc = (3.5489066651617274e-22+0j)\n"
],
[
"for i in range(10):\n print(F\"diabatic wfc = {wfc.reciPSI_dia[500+i].get(0,0) } adiabatic wfc = {wfc.reciPSI_adi[500+i].get(0,0) }\")",
"diabatic wfc = (-7.938581813042437e-16-3.292442409596794e-16j) adiabatic wfc = (-7.938581813042437e-16-3.292442409596794e-16j)\ndiabatic wfc = (-1.0534997694888374e-15-4.3324393460622627e-16j) adiabatic wfc = (-1.0534997694888374e-15-4.3324393460622627e-16j)\ndiabatic wfc = (-1.344645905336897e-15-5.169367280259415e-16j) adiabatic wfc = (-1.344645905336897e-15-5.169367280259415e-16j)\ndiabatic wfc = (-1.5875806328520155e-15-6.733472460693432e-16j) adiabatic wfc = (-1.5875806328520155e-15-6.733472460693432e-16j)\ndiabatic wfc = (-1.9543907628057097e-15-8.294333772218843e-16j) adiabatic wfc = (-1.9543907628057097e-15-8.294333772218843e-16j)\ndiabatic wfc = (-2.4186289504751935e-15-9.33707190095722e-16j) adiabatic wfc = (-2.4186289504751935e-15-9.33707190095722e-16j)\ndiabatic wfc = (-2.872689724086602e-15-1.1414549034631344e-15j) adiabatic wfc = (-2.872689724086602e-15-1.1414549034631344e-15j)\ndiabatic wfc = (-3.1856187839746186e-15-1.3084149947233198e-15j) adiabatic wfc = (-3.1856187839746186e-15-1.3084149947233198e-15j)\ndiabatic wfc = (-3.578929217190932e-15-1.5015963563073512e-15j) adiabatic wfc = (-3.578929217190932e-15-1.5015963563073512e-15j)\ndiabatic wfc = (-3.923212091435534e-15-1.4885132888172904e-15j) adiabatic wfc = (-3.923212091435534e-15-1.4885132888172904e-15j)\n"
],
[
"print( \"Norm = \", wfc.norm(1) )\nprint( \"Ekin = \", wfc.e_kin(masses, 1) )\nprint( \"Expected kinetic energy = \", 0.5*alphas[0]/(2.0*masses[0]) )\nprint( \"Epot = \", wfc.e_pot(1) )\nprint( \"Expected potential energy = \", (0.5*k/alphas[0])*(0.5 + nu[0]) )\nprint( \"Etot = \", wfc.e_tot(masses, 1) )\nprint( \"Expected total energy = \", omega*(0.5 + nu[0]) )\n\np2 = wfc.get_pow_p(1, 2);\nprint( \"p2 = \", p2.get(0).real )\nprint( \"p2/2*m = \", p2.get(0).real/(2.0 * masses[0]) )",
"Norm = 0.9999999999999986\nEkin = 0.00012499999999999567\nExpected kinetic energy = 0.000125\nEpot = 0.00012499999999999987\nExpected potential energy = 0.000125\nEtot = 0.00024999999999999556\nExpected total energy = 0.00025\np2 = 0.49999999999998224\np2/2*m = 0.00012499999999999556\n"
],
[
"p = wfc.get_pops(1).get(0,0)\nprint(F\" population of adiabatic state 0 of wfc in the whole region {p}\")\n\nleft, right = Py2Cpp_double([-15.0]), Py2Cpp_double([0.0])\np = wfc.get_pops(1, left, right).get(0,0)\nprint(F\" population of adiabatic state 0 of wfc in the half of the original region {p}\")\n",
" population of adiabatic state 0 of wfc in the whole region 0.9999999999999986\n population of adiabatic state 0 of wfc in the half of the original region 0.5028209479177388\n"
]
],
[
[
"## 4. Showcase: computing energies of the HO eigenstates\n<a name=\"ho_showcase\"></a>[Back to TOC](#TOC)\n<a name=\"energy-use-case\"></a>\n\nWe, of course, know all the properties of the HO eigenstates analytically. Namely, the energies should be:\n\n\\\\[ E_n = \\hbar \\omega (n + \\frac{1}{2}) \\\\]\n\nLet's see if we can also get them numerically",
"_____no_output_____"
]
],
[
[
"for n in [0, 1, 2, 3, 10, 20]:\n\n wfc = Wfcgrid2(Py2Cpp_double([-15.0]), Py2Cpp_double([15.0]), Py2Cpp_double([0.01]), num_el_st)\n \n nu = Py2Cpp_int([n]) \n wfc.add_wfc_HO(x0, p0, alphas, el_st, nu, 1.0+0.0j, rep)\n\n wfc.update_reciprocal(rep)\n wfc.update_Hamiltonian(harmonic1D, {\"k\": k}, rep)\n\n print( \"========== State %i ==============\" % (n) )\n print( \"Etot = \", wfc.e_tot(masses, rep) )\n print( \"Expected total energy = \", omega*(0.5 + nu[0]) )\n\n",
"========== State 0 ==============\nEtot = 0.00024999999999999556\nExpected total energy = 0.00025\n========== State 1 ==============\nEtot = 0.000749999999999987\nExpected total energy = 0.00075\n========== State 2 ==============\nEtot = 0.00124999999999998\nExpected total energy = 0.00125\n========== State 3 ==============\nEtot = 0.0017499999999999684\nExpected total energy = 0.00175\n========== State 10 ==============\nEtot = 0.0052499999999999075\nExpected total energy = 0.00525\n========== State 20 ==============\nEtot = 0.01024999999999985\nExpected total energy = 0.01025\n"
]
],
[
[
"## 5. Dynamics: computed with SOFT method\n<a name=\"soft_dynamics\"></a>[Back to TOC](#TOC)\n<a name=\"tdse-solution\"></a>\n\n### 5.1. Initialization\n\nAs usual, let's initialize the grid and populate it with some wavefunction\n\nIn this case, we start with a superposition of 2 HO eigenstates, so the initial wavefunction is not stationary with respect ot the chosen potential (or we won't be able to see any dynamics)\n\nAs in the axamples above, we update the reciprocal wavefunction and then the Hamiltonian\n\n<a name=\"add_wfc_HO-2\"></a> <a name=\"update_reciprocal-2\"> <a name=\"update_Hamiltonian-2\"></a>",
"_____no_output_____"
]
],
[
[
"wfc = Wfcgrid2(Py2Cpp_double([-15.0]), Py2Cpp_double([15.0]), Py2Cpp_double([0.01]), num_el_st)\n \nwfc.add_wfc_HO(x0, p0, alphas, el_st, Py2Cpp_int([0]) , 1.0+0.0j, rep)\nwfc.add_wfc_HO(x0, p0, alphas, el_st, Py2Cpp_int([1]) , 1.0+0.0j, rep)\n\nwfc.update_reciprocal(rep)\nwfc.update_Hamiltonian(harmonic1D, {\"k\": k}, rep)",
"_____no_output_____"
]
],
[
[
"### 5.2. Update the propagators \n\nTo compute the quantum dynamics on the grid, all we need to do is first to compute the propagators - the matrices that advances the wavefunction in real and reciprocal spaces.\n\nThe split-operator Fourier-transform (SOFT) method dates back to Kosloff & Kosloff and is basically the following:\n\nIf the Hamiltonian is given by:\n\n\\\\[ H = K + V \\\\]\n\nThen, the solution of the TD-SE:\n\n\\\\[ i \\hbar \\frac{\\partial \\psi}{\\partial t} = H \\psi \\\\]\n\nis given by:\n\n\\\\[ \\psi(t) = exp(-i \\frac{H t}{\\hbar} ) \\psi(0) \\\\]\n\nOf course, in practice we compute the state advancement by only small time increment \\\\[ \\Delta t \\\\] as:\n\n\\\\[ \\psi(t + \\Delta t) = exp(-i \\frac{H \\Delta t}{\\hbar} ) \\psi(t) \\\\]\n\nSo it all boils down to the computing the propagator \n\n\\\\[ exp(-i \\frac{H \\Delta t}{\\hbar} ) \\\\]\n\nThis is then done by the Trotter splitting technique:\n\n\\\\[ exp(-i \\frac{H \\Delta t}{\\hbar} ) \\approx exp(-i \\frac{V \\Delta t}{2 \\hbar} ) exp(-i \\frac{K \\Delta t}{\\hbar} ) exp(-i \\frac{V \\Delta t}{2 \\hbar} ) \\\\]\n\n\nIn the end, we need to compute the operators $ exp(-i \\frac{V \\Delta t}{2 \\hbar} ) $ and \n$exp(-i \\frac{K \\Delta t}{\\hbar} )$\n\nThis is done by:\n\n<a name=\"update_propagator_H-2\"></a> <a name=\"update_propagator_K-1\"></a>",
"_____no_output_____"
]
],
[
[
"dt = 10.0 \nwfc.update_propagator_H(0.5*dt)\nwfc.update_propagator_K(dt, masses)",
"_____no_output_____"
]
],
[
[
"### 5.3. Compute the dynamics\n\nThe propagators in real and reciprocal spaces are stored in the class object, so we can now simply apply them many times to our starting wavefunction:\n\nThis is done with the `SOFT_propagate()` function.\n\nNote how we use the following functions to compute the corresponding properties:\n\n* `get_pow_q` - for \\<q\\>\n* `get_pow_p` - for \\<p\\>\n* `get_den_mat` - for $\\rho_{ij} = |i><j|$\nand so on\n\n\nBy default, the dynamics is executed in the diabatic representation, so for us to access the adiabatic properties (e.g. populations of the adiabatic states), we convert the propagated wavefunctions to the adiabatic representation with\n\n* `update_adiabatic`\n\n<a name=\"get_pow_q-1\"></a> <a name=\"get_pow_p-2\"></a> <a name=\"get_den_mat-1\"></a> \n<a name=\"e_kin-2\"></a> <a name=\"e_pot-2\"></a> <a name=\"e_tot-2\"></a> <a name=\"SOFT_propagate-1\"> </a>",
"_____no_output_____"
]
],
[
[
"nsteps = 100\nfor step in range(nsteps):\n wfc.SOFT_propagate()\n q = wfc.get_pow_q(0, 1).get(0).real\n p = wfc.get_pow_p(0, 1).get(0).real\n \n # Diabatic is the rep used for propagation, so we need to \n # convert wfcs into adiabatic one\n wfc.update_adiabatic()\n\n Ddia = wfc.get_den_mat(0) # diabatic density matrix\n Dadi = wfc.get_den_mat(1) # adiabatic density matrix\n\n p0_dia = Ddia.get(0,0).real\n p0_adi = Dadi.get(0,0).real\n print(\"step= \", step, \" Ekin= \", wfc.e_kin(masses, rep), \n \" Epot= \", wfc.e_pot(rep), \" Etot= \", wfc.e_tot(masses, rep), \n \" q= \", q, \" p= \", p, \" p0_dia= \", p0_dia, \" p0_adi= \", p0_adi )",
"step= 0 Ekin= 0.00025000156250001165 Epot= 0.00025000000003912 Etot= 0.0005000015625391317 q= 0.7070979423518663 p= -0.0017677669529488457 p0_dia= 1.0 p0_adi= 1.0\nstep= 1 Ekin= 0.00025000156242188827 Epot= 0.00025000000015636153 Etot= 0.0005000015625782497 q= 0.7070714260686285 p= -0.005303256664678722 p0_dia= 1.0 p0_adi= 1.0\nstep= 2 Ekin= 0.0002500015622656477 Epot= 0.0002500000003517117 Etot= 0.0005000015626173594 q= 0.7070272329997399 p= -0.008838613794993148 p0_dia= 1.0 p0_adi= 1.0\nstep= 3 Ekin= 0.00025000156203130715 Epot= 0.0002500000006251523 Etot= 0.0005000015626564594 q= 0.7069653642500252 p= -0.012373749959962675 p0_dia= 1.0 p0_adi= 1.0\nstep= 4 Ekin= 0.00025000156171888855 Epot= 0.00025000000097665496 Etot= 0.0005000015626955435 q= 0.7068858213662036 p= -0.01590857678118353 p0_dia= 1.0 p0_adi= 1.0\nstep= 5 Ekin= 0.0002500015613284251 Epot= 0.0002500000014061854 Etot= 0.0005000015627346106 q= 0.7067886063368511 p= -0.01944300588798536 p0_dia= 1.0 p0_adi= 1.0\nstep= 6 Ekin= 0.0002500015608599548 Epot= 0.00025000000191370005 Etot= 0.0005000015627736549 q= 0.7066737215923383 p= -0.02297694891964037 p0_dia= 1.0 p0_adi= 1.0\nstep= 7 Ekin= 0.00025000156031352357 Epot= 0.00025000000249914776 Etot= 0.0005000015628126714 q= 0.7065411700047862 p= -0.02651031752757296 p0_dia= 1.0 p0_adi= 1.0\nstep= 8 Ekin= 0.00025000155968918787 Epot= 0.00025000000316247165 Etot= 0.0005000015628516595 q= 0.7063909548879852 p= -0.030043023377567632 p0_dia= 1.0 p0_adi= 1.0\nstep= 9 Ekin= 0.0002500015589870089 Epot= 0.00025000000390360433 Etot= 0.0005000015628906132 q= 0.7062230799973127 p= -0.03357497815197839 p0_dia= 1.0 p0_adi= 1.0\nstep= 10 Ekin= 0.0002500015582070569 Epot= 0.00025000000472247106 Etot= 0.000500001562929528 q= 0.7060375495296392 p= -0.03710609355193575 p0_dia= 1.0 p0_adi= 1.0\nstep= 11 Ekin= 0.0002500015573494101 Epot= 0.0002500000056189901 Etot= 0.0005000015629684001 q= 0.705834368123228 p= -0.040636281299554614 p0_dia= 1.0 p0_adi= 1.0\nstep= 12 Ekin= 0.0002500015564141549 Epot= 0.00025000000659307375 Etot= 0.0005000015630072286 q= 0.7056135408576153 p= -0.04416545314014116 p0_dia= 1.0 p0_adi= 1.0\nstep= 13 Ekin= 0.0002500015554013841 Epot= 0.00025000000764462203 Etot= 0.0005000015630460061 q= 0.7053750732534821 p= -0.04769352084440014 p0_dia= 1.0 p0_adi= 1.0\nstep= 14 Ekin= 0.000250001554311199 Epot= 0.0002500000087735311 Etot= 0.0005000015630847301 q= 0.7051189712725154 p= -0.05122039621063817 p0_dia= 1.0 p0_adi= 1.0\nstep= 15 Ekin= 0.00025000155314370897 Epot= 0.000250000009979688 Etot= 0.000500001563123397 q= 0.7048452413172687 p= -0.05474599106697135 p0_dia= 1.0 p0_adi= 1.0\nstep= 16 Ekin= 0.00025000155189903057 Epot= 0.00025000001126297195 Etot= 0.0005000015631620025 q= 0.704553890230989 p= -0.05827021727352828 p0_dia= 1.0 p0_adi= 1.0\nstep= 17 Ekin= 0.00025000155057728815 Epot= 0.00025000001262325504 Etot= 0.0005000015632005432 q= 0.7042449252974535 p= -0.061792986724653824 p0_dia= 1.0 p0_adi= 1.0\nstep= 18 Ekin= 0.0002500015491786138 Epot= 0.0002500000140603999 Etot= 0.0005000015632390137 q= 0.7039183542407861 p= -0.06531421135111176 p0_dia= 1.0 p0_adi= 1.0\nstep= 19 Ekin= 0.00025000154770314794 Epot= 0.0002500000155742644 Etot= 0.0005000015632774123 q= 0.7035741852252627 p= -0.0688338031222861 p0_dia= 1.0 p0_adi= 1.0\nstep= 20 Ekin= 0.000250001546151037 Epot= 0.00025000001716469583 Etot= 0.0005000015633157328 q= 0.703212426855109 p= -0.072351674048383 p0_dia= 1.0 p0_adi= 1.0\nstep= 21 Ekin= 0.00025000154452243807 Epot= 0.00025000001883153687 Etot= 0.0005000015633539749 q= 0.7028330881742846 p= -0.0758677361826292 p0_dia= 1.0 p0_adi= 1.0\nstep= 22 Ekin= 0.00025000154281751237 Epot= 0.0002500000205746193 Etot= 0.0005000015633921317 q= 0.7024361786662567 p= -0.07938190162347127 p0_dia= 1.0 p0_adi= 1.0\nstep= 23 Ekin= 0.0002500015410364309 Epot= 0.00025000002239376946 Etot= 0.0005000015634302004 q= 0.702021708253762 p= -0.08289408251677306 p0_dia= 1.0 p0_adi= 1.0\nstep= 24 Ekin= 0.00025000153917937234 Epot= 0.0002500000242888055 Etot= 0.0005000015634681779 q= 0.7015896872985622 p= -0.08640419105801246 p0_dia= 1.0 p0_adi= 1.0\nstep= 25 Ekin= 0.00025000153724652127 Epot= 0.00025000002625953757 Etot= 0.0005000015635060588 q= 0.7011401266011813 p= -0.08991213949447603 p0_dia= 1.0 p0_adi= 1.0\nstep= 26 Ekin= 0.00025000153523807193 Epot= 0.0002500000283057693 Etot= 0.0005000015635438413 q= 0.700673037400633 p= -0.09341784012745238 p0_dia= 1.0 p0_adi= 1.0\nstep= 27 Ekin= 0.00025000153315422435 Epot= 0.0002500000304272944 Etot= 0.0005000015635815188 q= 0.70018843137415 p= -0.09692120531442594 p0_dia= 1.0 p0_adi= 1.0\nstep= 28 Ekin= 0.00025000153099518805 Epot= 0.0002500000326239025 Etot= 0.0005000015636190906 q= 0.6996863206368836 p= -0.10042214747126764 p0_dia= 1.0 p0_adi= 1.0\nstep= 29 Ekin= 0.0002500015287611773 Epot= 0.0002500000348953724 Etot= 0.0005000015636565497 q= 0.6991667177416017 p= -0.10392057907442231 p0_dia= 1.0 p0_adi= 1.0\nstep= 30 Ekin= 0.0002500015264524168 Epot= 0.0002500000372414787 Etot= 0.0005000015636938955 q= 0.698629635678378 p= -0.10741641266310081 p0_dia= 1.0 p0_adi= 1.0\nstep= 31 Ekin= 0.0002500015240691374 Epot= 0.00025000003966198643 Etot= 0.0005000015637311238 q= 0.6980750878742608 p= -0.11090956084146308 p0_dia= 1.0 p0_adi= 1.0\nstep= 32 Ekin= 0.0002500015216115774 Epot= 0.0002500000421566523 Etot= 0.0005000015637682297 q= 0.697503088192947 p= -0.11439993628080534 p0_dia= 1.0 p0_adi= 1.0\nstep= 33 Ekin= 0.0002500015190799814 Epot= 0.0002500000447252272 Etot= 0.0005000015638052086 q= 0.6969136509344295 p= -0.11788745172174027 p0_dia= 1.0 p0_adi= 1.0\nstep= 34 Ekin= 0.00025000151647460404 Epot= 0.0002500000473674556 Etot= 0.0005000015638420597 q= 0.6963067908346414 p= -0.1213720199763831 p0_dia= 1.0 p0_adi= 1.0\nstep= 35 Ekin= 0.00025000151379570495 Epot= 0.00025000005008307165 Etot= 0.0005000015638787766 q= 0.6956825230650773 p= -0.12485355393052677 p0_dia= 1.0 p0_adi= 1.0\nstep= 36 Ekin= 0.00025000151104355233 Epot= 0.00025000005287180465 Etot= 0.000500001563915357 q= 0.6950408632324391 p= -0.12833196654582263 p0_dia= 1.0 p0_adi= 1.0\nstep= 37 Ekin= 0.0002500015082184216 Epot= 0.00025000005573337555 Etot= 0.0005000015639517971 q= 0.694381827378222 p= -0.13180717086195562 p0_dia= 1.0 p0_adi= 1.0\nstep= 38 Ekin= 0.00025000150532059507 Epot= 0.0002500000586674984 Etot= 0.0005000015639880934 q= 0.6937054319783195 p= -0.13527907999881725 p0_dia= 1.0 p0_adi= 1.0\nstep= 39 Ekin= 0.00025000150235036255 Epot= 0.00025000006167388025 Etot= 0.0005000015640242428 q= 0.6930116939426177 p= -0.13874760715867948 p0_dia= 1.0 p0_adi= 1.0\nstep= 40 Ekin= 0.0002500014993080207 Epot= 0.000250000064752219 Etot= 0.0005000015640602396 q= 0.692300630614569 p= -0.1422126656283631 p0_dia= 1.0 p0_adi= 1.0\nstep= 41 Ekin= 0.0002500014961938745 Epot= 0.0002500000679022077 Etot= 0.0005000015640960822 q= 0.6915722597707545 p= -0.1456741687814068 p0_dia= 1.0 p0_adi= 1.0\nstep= 42 Ekin= 0.0002500014930082346 Epot= 0.0002500000711235313 Etot= 0.000500001564131766 q= 0.6908265996204463 p= -0.14913203008023115 p0_dia= 1.0 p0_adi= 1.0\nstep= 43 Ekin= 0.00025000148975142 Epot= 0.0002500000744158676 Etot= 0.0005000015641672877 q= 0.6900636688051474 p= -0.15258616307830386 p0_dia= 1.0 p0_adi= 1.0\nstep= 44 Ekin= 0.00025000148642375633 Epot= 0.0002500000777788876 Etot= 0.0005000015642026439 q= 0.6892834863981302 p= -0.1560364814223001 p0_dia= 1.0 p0_adi= 1.0\nstep= 45 Ekin= 0.0002500014830255765 Epot= 0.00025000008121225497 Etot= 0.0005000015642378315 q= 0.6884860719039512 p= -0.15948289885426167 p0_dia= 1.0 p0_adi= 1.0\n"
]
],
[
[
"### Exercise 4\n\nWrite the scripts to visualize various quantities computed by the dynamics",
"_____no_output_____"
],
[
"### Exercise 5\n\nCompute the population in a certain region of space and observe how it evolves during the dynamics",
"_____no_output_____"
],
[
"### Exercise 6\n\nCompute the dynamics of the 2D wavepacked we set up in the above examples.",
"_____no_output_____"
],
[
"### Exercise 7\n\nExplore the behavior of the dynamics (e.g. conservation of energy, etc.) as you vary the initial conditions (e.g. the parameters of the initial wavefunction), the integration parameters (e.g. dt), and the grid properties (grid spacing and the boundaries)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ac84281fe7ae2c88b0de972c0309d75feea1daf
| 378,106 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/movies-checkpoint.ipynb
|
AprilYoungs/analyze_basic
|
b6b68e47c7da574021429e8f18cc1b1ff187ed27
|
[
"Apache-2.0"
] | null | null | null |
.ipynb_checkpoints/movies-checkpoint.ipynb
|
AprilYoungs/analyze_basic
|
b6b68e47c7da574021429e8f18cc1b1ff187ed27
|
[
"Apache-2.0"
] | null | null | null |
.ipynb_checkpoints/movies-checkpoint.ipynb
|
AprilYoungs/analyze_basic
|
b6b68e47c7da574021429e8f18cc1b1ff187ed27
|
[
"Apache-2.0"
] | null | null | null | 49.464417 | 25,416 | 0.480807 |
[
[
[
"> **提示**:欢迎参加“调查数据集”项目!引用段会添加这种提示,帮助你制定调查方法。提交项目之前,最后浏览一下报告,将这一段删除,以保持报告简洁。首先,需要双击这个 Markdown 框,将标题更改为与数据集和调查相关的标题。\n\n# 项目:TMDB电影集调查\n\n## 目录\n<ul>\n<li><a href=\"#intro\">简介</a></li>\n<li><a href=\"#wrangling\">数据整理</a></li>\n<li><a href=\"#eda\">探索性数据分析</a></li>\n<li><a href=\"#conclusions\">结论</a></li>\n</ul>\n\n<a id='intro'></a>\n## 简介\n\n> 本数据集中包含 1 万条电影信息,信息来源为“电影数据库”(TMDb,The Movie Database),包括用户评分和票房。“演职人员 (cast)”、“电影类别 (genres)”等数据列包含由竖线字符(|)分隔的多个数值。“演职人员 (cast) ”列中有一些奇怪的字符。先不要清洁它们,你可以保持原样,不去管它们。\n\n> **提示**:在这一段报告中对你选择进行分析的数据集进行简要介绍。在本段末尾,对你计划在报告过程中探索的问题进行描述。自己尝试建立至少一个因变量和三个自变量的分析报告。如果你不确定要问什么问题,务必熟悉数据集、数据集变量以及数据集上下文,以便确定要探索的问题。\n\n> 如果尚未选择和下载数据,务必先进行这一步,再回到这里。如需在这个工作区中处理数据,还需要将其上传到工作区。因此,请单击左上角的 jupyter 图标,回到工作区目录。右上角有一个‘上传’按钮,可以将你的数据文件添加到工作区。然后单击 .ipynb 文件名,回到这里。",
"_____no_output_____"
]
],
[
[
"# import packages\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('darkgrid')\n\n%matplotlib inline\n%config InlineBackend.fig_format = 'retina'",
"_____no_output_____"
]
],
[
[
"<a id='wrangling'></a>\n## 数据整理\n\n> **提示**:在这一段报告中载入数据,检查简洁度,然后整理和清理数据集,以进行分析。务必将步骤仔细归档,并确定清理决策是否正确。\n\n### 常规属性",
"_____no_output_____"
]
],
[
[
"# 导入数据,预览数据\ndf = pd.read_csv('tmdb-movies.csv')\ndf.head(2)",
"_____no_output_____"
],
[
"# 数据类型\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10866 entries, 0 to 10865\nData columns (total 21 columns):\nid 10866 non-null int64\nimdb_id 10856 non-null object\npopularity 10866 non-null float64\nbudget 10866 non-null int64\nrevenue 10866 non-null int64\noriginal_title 10866 non-null object\ncast 10790 non-null object\nhomepage 2936 non-null object\ndirector 10822 non-null object\ntagline 8042 non-null object\nkeywords 9373 non-null object\noverview 10862 non-null object\nruntime 10866 non-null int64\ngenres 10843 non-null object\nproduction_companies 9836 non-null object\nrelease_date 10866 non-null object\nvote_count 10866 non-null int64\nvote_average 10866 non-null float64\nrelease_year 10866 non-null int64\nbudget_adj 10866 non-null float64\nrevenue_adj 10866 non-null float64\ndtypes: float64(4), int64(6), object(11)\nmemory usage: 1.7+ MB\n"
],
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"> **提示**:_不应_在每个框中进行太多操作。可以自由创建框,进行数据探索。在这个项目中,可以在初始 notebook 中进行大量探索操作。不要求对其进行组织,但务必仔细阅读备注,理解每个代码框的用途。完成分析之后,可以创建 notebook 副本,在其中去除多余数据,组织步骤,从而形成结构连贯、紧密的报告。\n\n> **提示**:务必向你的读者告知你在调查中采取的步骤。在每个代码框或每组相关代码框后面,用 markdown 框对前面的框中的调查结果向读者进行说明。尽量做到这一点,以便读者理解后续框中的内容。\n\n### 数据整理",
"_____no_output_____"
],
[
" 观察数据,可以看出大多数电影没有 `homepage`,而且具体数据,我不关心,我只关注有和没有",
"_____no_output_____"
]
],
[
[
"# 添加一栏,有无homepage\ndf['has_homepage'] = df.homepage.notnull()\ndf['has_homepage'].sum()",
"_____no_output_____"
]
],
[
[
"删除对分析问题没帮助的描述性栏目",
"_____no_output_____"
]
],
[
[
"# 删除 id, imdb_id, homepage, tagline, overview \ndf.drop(['id', 'imdb_id', 'homepage', 'tagline', 'overview'], axis=1,inplace=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10866 entries, 0 to 10865\nData columns (total 17 columns):\npopularity 10866 non-null float64\nbudget 10866 non-null int64\nrevenue 10866 non-null int64\noriginal_title 10866 non-null object\ncast 10790 non-null object\ndirector 10822 non-null object\nkeywords 9373 non-null object\nruntime 10866 non-null int64\ngenres 10843 non-null object\nproduction_companies 9836 non-null object\nrelease_date 10866 non-null object\nvote_count 10866 non-null int64\nvote_average 10866 non-null float64\nrelease_year 10866 non-null int64\nbudget_adj 10866 non-null float64\nrevenue_adj 10866 non-null float64\nhas_homepage 10866 non-null bool\ndtypes: bool(1), float64(4), int64(5), object(7)\nmemory usage: 1.3+ MB\n"
]
],
[
[
"把发布时间转化成pandas的时间格式",
"_____no_output_____"
]
],
[
[
"def trans_to_datetime(row):\n '''把数据集中的release_date转化成时间戳格式\n '''\n (month, day, _) = row['release_date'].split('/')\n year = row['release_year']\n \n return pd.datetime(int(year), int(month), int(day))",
"_____no_output_____"
],
[
"df.release_date = df.apply(trans_to_datetime, axis=1)",
"_____no_output_____"
],
[
"df.release_date.min(), df.release_date.max()",
"_____no_output_____"
]
],
[
[
"转换成功,都在合理的范围内",
"_____no_output_____"
],
[
"统一 budget 和 revenue 单位为 `int`",
"_____no_output_____"
]
],
[
[
"df.budget_adj = df.budget_adj.astype(int)\ndf.revenue_adj = df.revenue_adj.astype(int)\ntype(df.budget_adj[1]), type(df.revenue_adj[0])",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df.head(3)",
"_____no_output_____"
]
],
[
[
"比较一下调整后的实际预算 和 初期的预算的比例 (用百分比显示x坐标)",
"_____no_output_____"
]
],
[
[
"((df.budget_adj - df.budget)/df.budget).hist(bins = 100);",
"_____no_output_____"
]
],
[
[
"比较一下调整后的实际收入 和 初期的预估收入的比例 (用百分比显示x坐标)",
"_____no_output_____"
]
],
[
[
"((df.revenue_adj - df.revenue)/df.revenue).hist(bins = 100);",
"_____no_output_____"
]
],
[
[
"发现有大量预算为 0 的电影",
"_____no_output_____"
]
],
[
[
"df.query('budget == 0')",
"_____no_output_____"
]
],
[
[
"# 删除 budget == 0 的数据",
"_____no_output_____"
],
[
"调整数据排序,按发布时间排序",
"_____no_output_____"
]
],
[
[
"df.sort_values('release_date',ascending=False,inplace=True)\ndf",
"_____no_output_____"
]
],
[
[
"调整 列标签的顺序",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
],
[
"df.set_index(['original_title', 'director', 'cast', 'production_companies', 'genres', 'keywords', 'runtime',\n 'release_date', 'release_year', 'budget', 'budget_adj', 'revenue', 'revenue_adj',\n 'vote_count', 'vote_average', 'popularity', 'has_homepage'], inplace=True)\n\ndf.head()",
"_____no_output_____"
]
],
[
[
"保存整理后的数据",
"_____no_output_____"
]
],
[
[
"df.to_csv('clean_movies.csv')",
"_____no_output_____"
],
[
"df_clean = pd.read_csv('clean_movies.csv')\ndf_clean.head()",
"_____no_output_____"
],
[
"df_clean.dtypes",
"_____no_output_____"
],
[
"df_clean.release_date = pd.to_datetime(df_clean.release_date, infer_datetime_format=True)",
"_____no_output_____"
],
[
"df_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10866 entries, 0 to 10865\nData columns (total 17 columns):\noriginal_title 10866 non-null object\ndirector 10822 non-null object\ncast 10790 non-null object\nproduction_companies 9836 non-null object\ngenres 10843 non-null object\nkeywords 9373 non-null object\nruntime 10866 non-null int64\nrelease_date 10866 non-null datetime64[ns]\nrelease_year 10866 non-null int64\nbudget 10866 non-null int64\nbudget_adj 10866 non-null int64\nrevenue 10866 non-null int64\nrevenue_adj 10866 non-null int64\nvote_count 10866 non-null int64\nvote_average 10866 non-null float64\npopularity 10866 non-null float64\nhas_homepage 10866 non-null bool\ndtypes: bool(1), datetime64[ns](1), float64(2), int64(7), object(6)\nmemory usage: 1.3+ MB\n"
]
],
[
[
"<a id='eda'></a>\n## 探索性数据分析\n\n> **提示**:整理和清理数据之后,现在可以进行探索。计算统计值,创建视图,解决你在简介段提出的研究问题。建议采用系统化方法。一次探索一个变量,然后探索变量之间的关系。\n\n",
"_____no_output_____"
],
[
"数据探索",
"_____no_output_____"
],
[
"每个栏目的唯一值",
"_____no_output_____"
]
],
[
[
"for c in df_clean.columns:\n print('{} has {} different value'.format(c,len(df_clean[c].unique())))",
"original_title has 10571 different value\ndirector has 5068 different value\ncast has 10720 different value\nproduction_companies has 7446 different value\ngenres has 2040 different value\nkeywords has 8805 different value\nruntime has 247 different value\nrelease_date has 5909 different value\nrelease_year has 56 different value\nbudget has 557 different value\nbudget_adj has 2600 different value\nrevenue has 4702 different value\nrevenue_adj has 4831 different value\nvote_count has 1289 different value\nvote_average has 72 different value\npopularity has 10814 different value\nhas_homepage has 2 different value\n"
],
[
"# 有多少年份的数据\nyears = df_clean.release_year.unique()\nprint('从{}年到{}年,总共有{}个年份的电影'.format(min(years), max(years), len(years)))",
"从1960年到2015年,总共有56个年份的电影\n"
]
],
[
[
"投票得分 和 受欢迎程度 的关系?",
"_____no_output_____"
]
],
[
[
"# 绘制评分和受欢迎程度的散点图\nplt.scatter(df_clean.vote_average,df_clean.popularity)\nplt.xlabel('vote_average')\nplt.ylabel('popularity')\nplt.title('scatter of vote_average and popularity');",
"_____no_output_____"
]
],
[
[
"可以看出 评分 和 受欢迎 程正相关,但有一些比较奇怪的数据,\n- 右上角有三个异常受欢迎的电影\n- 还有评分高于8.5的电影好像都不怎么受欢迎",
"_____no_output_____"
]
],
[
[
"# 绘制投票数 和 受欢迎程度的散点图\nplt.scatter(df_clean.vote_count, df_clean.popularity)\nplt.xlabel('vote_count')\nplt.ylabel('popularity')\nplt.title('scatter of vote_count and popularity');",
"_____no_output_____"
]
],
[
[
"投票数 和 受欢迎程度 也是正相关,不过仍然有三个很显眼的数据",
"_____no_output_____"
],
[
"查找 受欢迎程度 大于20的电影",
"_____no_output_____"
]
],
[
[
"df_clean.query('popularity > 20')",
"_____no_output_____"
]
],
[
[
"三部电影都是 科幻 和 冒险 类电影",
"_____no_output_____"
],
[
"### 每年最受欢迎的电影类别是哪些?",
"_____no_output_____"
],
[
"求出每年最受欢迎的值",
"_____no_output_____"
]
],
[
[
"max_popular_of_the_year = df_clean.groupby('release_year', as_index=False)['popularity'].max()\nmax_popular_of_the_year",
"_____no_output_____"
]
],
[
[
"重命名,并把数集进行合并",
"_____no_output_____"
]
],
[
[
"max_popular_of_the_year=max_popular_of_the_year.rename(index=str, columns={'popularity':'popularity_max'})\nmax_popular_of_the_year.head(2)",
"_____no_output_____"
],
[
"df_clean = df_clean.merge(max_popular_of_the_year,on='release_year')\ndf_clean.head(2)",
"_____no_output_____"
]
],
[
[
"把 popularity_max 转化成bool值方便查询",
"_____no_output_____"
]
],
[
[
"df_clean.popularity_max = df_clean.popularity == df_clean.popularity_max\ndf_clean.popularity_max.dtype",
"_____no_output_____"
]
],
[
[
"### 查询到每一年最受欢迎的电影",
"_____no_output_____"
]
],
[
[
"df_clean.query('popularity_max == True')",
"_____no_output_____"
]
],
[
[
"### 票房高的电影有哪些特点? ",
"_____no_output_____"
]
],
[
[
"# 继续探索数据,解决你的附加研究问题。\n# 如果有其它问题要调查,\n# 请根据需要添加更多标题。\n",
"_____no_output_____"
]
],
[
[
"<a id='conclusions'></a>\n## 结论\n\n> **提示**:最后,总结你的调查结果。确保了解探索结果的限制。如果尚未进行任何统计检验,不要做出任何统计结论。切记不要根据相互关系推导出因果关系!\n\n> **提示**:如果对报告满意,应将其副本保存为 HTML 或 PDF 形式。导出报告之前请检查一遍,确保报告流程完整。应删除所有类似的“提示”引用段,以保持报告简洁。还需要查看课程结尾的项目提交页的项目审阅规范。\n\n> 如需将报告导出到工作区,应运行下面的代码框。如果正确,会返回代码 0,工作区目录下会生成 .html 文件(单击左上角的 jupyter 图标)。也可以通过 **文件** > **下载为** 子菜单下载 html 报告,然后手动上传到工作区目录。完成之后,可以单击右下角的“提交项目”,提交你的项目。恭喜!",
"_____no_output_____"
]
],
[
[
"from subprocess import call\ncall(['python', '-m', 'nbconvert', 'Investigate_a_Dataset.ipynb'])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac84c971a8eca1f5a41cc96f75bf3a4c6970d78
| 1,071 |
ipynb
|
Jupyter Notebook
|
011-Python 案例/003-九九乘法表.ipynb
|
imcda/Python-Tutorial-for-Humans
|
e19b6516a85ea07c3b13c0182e22169906f7e4d7
|
[
"MIT"
] | 19 |
2020-01-09T11:04:49.000Z
|
2021-08-11T20:43:56.000Z
|
011-Python 案例/003-九九乘法表.ipynb
|
DavidFnck/Python-Tutorial-for-Humans
|
e19b6516a85ea07c3b13c0182e22169906f7e4d7
|
[
"MIT"
] | 1 |
2020-03-18T12:29:27.000Z
|
2020-03-18T12:29:27.000Z
|
011-Python 案例/003-九九乘法表.ipynb
|
DavidFnck/Python-Tutorial-for-Humans
|
e19b6516a85ea07c3b13c0182e22169906f7e4d7
|
[
"MIT"
] | 8 |
2020-03-24T12:06:48.000Z
|
2021-06-06T02:36:18.000Z
| 16.734375 | 42 | 0.480859 |
[
[
[
"# 九九乘法表\n基于「程序打印输出、字符串格式化、字符串方法、嵌套循环、占位语句」\n\n如何打印九九乘法表,这里面涉及到的 5 点知识",
"_____no_output_____"
]
],
[
[
"\n\"%s是一种%s\"%(\"python\",\"对的\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
4ac85469a5f6bfd3d598131612c32b092c89ac6e
| 9,413 |
ipynb
|
Jupyter Notebook
|
Section-4 Array Shape Manipulation/Array Shape Manipulation.ipynb
|
praneethmetuku/Colaberry-PracticalDataScience
|
e1b8224412869cdfa4066f55291b0d3582f139e6
|
[
"MIT"
] | null | null | null |
Section-4 Array Shape Manipulation/Array Shape Manipulation.ipynb
|
praneethmetuku/Colaberry-PracticalDataScience
|
e1b8224412869cdfa4066f55291b0d3582f139e6
|
[
"MIT"
] | null | null | null |
Section-4 Array Shape Manipulation/Array Shape Manipulation.ipynb
|
praneethmetuku/Colaberry-PracticalDataScience
|
e1b8224412869cdfa4066f55291b0d3582f139e6
|
[
"MIT"
] | null | null | null | 19.054656 | 228 | 0.452672 |
[
[
[
"",
"_____no_output_____"
],
[
"# Array Shape Flattening ",
"_____no_output_____"
],
[
"For flattening, ravel() function is used. This function returns a flattened one-dimensional array. A copy is made only if needed. The returned array will have the same type as that of the input array",
"_____no_output_____"
]
],
[
[
"import numpy as np\na=np.array([[1,2,3],[4,5,6],[7,8,9]])\na",
"_____no_output_____"
],
[
"#array flattening\nnp.ravel(a)",
"_____no_output_____"
]
],
[
[
"## Resizing ",
"_____no_output_____"
],
[
"Sometimes it required to shrink or expand the current array, this is called resizing. Resizing of an array can be changed with nparray.resize()\n\n",
"_____no_output_____"
]
],
[
[
"b=np.arange(0,5)\nb",
"_____no_output_____"
],
[
"b=np.arange(0,5)\nb.resize(9)\nb",
"_____no_output_____"
],
[
"b=np.arange(0,5)\nb.resize((3,3))\nb\n",
"_____no_output_____"
]
],
[
[
"## Adding new dimension ",
"_____no_output_____"
],
[
"Indexing with the np.newaxis object allows us to add an axis to an array. Simply put, the newaxis is used to increase the dimension of the existing array by one more dimension, when used once. Thus,\n\n1D array will become 2D array\n\n2D array will become 3D array\n\n3D array will become 4D array and so on..",
"_____no_output_____"
]
],
[
[
"a=np.array([1,2,3,4,5])\na",
"_____no_output_____"
],
[
"a[:,np.newaxis]",
"_____no_output_____"
]
],
[
[
"## Transpose of an array ",
"_____no_output_____"
]
],
[
[
"In python, transpose of an array can be achienved by using transpose() function. This function permutes the dimension of the given array. It returns a view wherever possible. The function takes the following parameters.\n\nnumpy.transpose(arr, axes)\n\narr: The array to be transposed\naxes: List of ints, corresponding to the dimensions. By default, the dimensions are reversed",
"_____no_output_____"
]
],
[
[
"a=np.arange(9).reshape(3,3)\na",
"_____no_output_____"
],
[
"a.transpose()",
"_____no_output_____"
],
[
"a.T",
"_____no_output_____"
],
[
"#swapping axis\na.swapaxes(1,1)",
"_____no_output_____"
]
],
[
[
"## Array processing ",
"_____no_output_____"
]
],
[
[
"a",
"_____no_output_____"
],
[
"#Saving array on disk in binary format (file extension .npy)\nnp.save('my_array',a)",
"_____no_output_____"
],
[
"#loading the saved copy\nnp.load('my_array.npy')",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"#Saving multiple arrays into a zip file\nnp.savez('two_arrays.npz',x=a,y=b)",
"_____no_output_____"
],
[
"#loading the saved two_array copy\nnp.load('two_arrays.npz')['y']",
"_____no_output_____"
],
[
"#Now saving and loading text files\n\narr = np.array([[1,2,3],[4,5,6]])\nnp.savetxt('my_test_text.txt',arr,delimiter=',')\narr = np.loadtxt('my_test_text.txt',delimiter = ',')\narr",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac860b7cbe1e1195c6cf11f7876da17d261b432
| 7,574 |
ipynb
|
Jupyter Notebook
|
code/misc/yml_generator.ipynb
|
at-crx/xqtl-pipeline
|
eedb2a74eeb75dd8a415a27c289a274f5f56c56f
|
[
"MIT"
] | null | null | null |
code/misc/yml_generator.ipynb
|
at-crx/xqtl-pipeline
|
eedb2a74eeb75dd8a415a27c289a274f5f56c56f
|
[
"MIT"
] | null | null | null |
code/misc/yml_generator.ipynb
|
at-crx/xqtl-pipeline
|
eedb2a74eeb75dd8a415a27c289a274f5f56c56f
|
[
"MIT"
] | null | null | null | 39.041237 | 191 | 0.621468 |
[
[
[
"## Allele filp QC YML generator\nThis module takes in a table of sumstat, with the columns: #chr, theme1, theme2, theme3 and each rows as 1 chr and the sumstat of corresponding chr and generate a list of yml to be used",
"_____no_output_____"
]
],
[
[
"[global]\n# List of path to the index of sumstat, each correspond to 1 recipe file documenting the path to the sumstat of each chromosome.\nparameter: sumstat_list = paths\n# List of names that corresponding to each of the studies\nparameter: name = list\nparameter: cwd = path\nimport pandas as pd\ninput_list = sumstat_list\nsumstat_list = pd.read_csv(input_list[0],sep = \"\\t\")\nsumstat_list = sumstat_list.sort_values('#chr')\nfor x in range(1,len(input_list)):\n sumstat_list = sumstat_list.merge(pd.read_csv(input_list[x],sep = \"\\t\"), on = \"#chr\")\n\nsumstat_meta = sumstat_list.filter(regex='column').iloc[0].values.tolist()\nsumstat_list = sumstat_list.drop(sumstat_list.filter(regex='column').columns,axis = 1)\nsumstat_list.columns = [\"#chr\"] + name\nsumstat_inv = sumstat_list.values.tolist()\nnames = \"_\".join(name)\n## The target vcf file, with GENE,CHR,POS,A0,A1 as columns, should contains all snps\nparameter: TARGET_list = path(\"./\")\nif TARGET_list.is_file():\n TARGET_list = sumstat_list.merge(pd.read_csv(TARGET_list,sep = \"\\t\"), on = \"#chr\" )[[\"TARGET\"]].values.tolist()\n## Assuming all the input sumstat are using the same header\nparameter: CHR = \"chrom\"\nparameter: POS = \"pos\"\nparameter: A0 = \"ref\" \nparameter: A1 = \"alt\"\nparameter: SNP = \"variant_id\"\nparameter: STAT = \"beta\"\nparameter: SE = \"se\"\nparameter: P = \"pval\"\nparameter: KEEP_AMBIGUOUS = \"True\"\nparameter: GENE = \"phenotype_id\"\nparameter: container = \"\"",
"_____no_output_____"
],
[
"[yml_generator]\ninput: for_each = \"sumstat_inv\",group_with = \"TARGET_list\"\noutput: f'{cwd:a}/{names}.{_sumstat_inv[0]}/{names}.{_sumstat_inv[0]}.yml'\npython: expand = \"$[ ]\", stderr = f'{_output}.stderr', stdout = f'{_output}.stdout' , container = container\n import os\n import yaml\n import pandas as pd\n output = dict()\n ## Input dict\n output[\"INPUT\"] = [pd.read_csv(y,\"\\t\",index_col = 0,names = [x],header = 0 ).to_dict() for x,y in zip($[_sumstat_inv[1:len(_sumstat_inv)]],$[sumstat_meta])] \n ## Target dict\n output[\"TARGET\"] = [\"$[_TARGET_list if _TARGET_list.is_file() else _sumstat_inv[1]]\"] ## Allow for both external TARGET file or using one of the sumstat as TARGET\n ## Output dict\n output[\"OUTPUT\"] = [$[_output:dr]]\n with open($[_output:ar], 'w') as f:\n yaml.dump(output,f,sort_keys = False)",
"_____no_output_____"
],
[
"[yml_list]\ninput: output_from(\"yml_generator\"),group_by = \"all\"\noutput: f'{cwd:a}/yml_list.txt', f'{cwd:a}/qced_sumstat_list.txt'\nimport pandas as pd\nyml_df = pd.DataFrame({\"#chr\" : sumstat_list[\"#chr\"].values.tolist() , \"dir\" : _input})\nyml_df.to_csv(_output[0],sep = \"\\t\",index = 0)\ndata_dir_tmp = pd.Series(_input)\ndata_dir = [f'{x:d}' for x in data_dir_tmp ]\ntheme = sumstat_list.columns.values.tolist()[1:]\nfor i in theme:\n sumstat_list = sumstat_list.assign(**{i : data_dir+ pd.Series([f'/{path(x):b}' for x in sumstat_list[i].values.tolist()]) } )\nsumstat_list.to_csv(_output[1],sep = \"\\t\", index = 0)",
"_____no_output_____"
],
[
"#chr TARGET\n1 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr1.txt\n10 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr10.txt\n11 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr11.txt\n12 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr12.txt\n13 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr13.txt\n14 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr14.txt\n15 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr15.txt\n16 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr16.txt\n17 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr17.txt\n18 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr18.txt\n19 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr19.txt\n2 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr2.txt\n20 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr20.txt\n21 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr21.txt\n22 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr22.txt\n3 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr3.txt\n4 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr4.txt\n5 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr5.txt\n6 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr6.txt\n7 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr7.txt\n8 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr8.txt\n9 /mnt/mfs/statgen/snuc_pseudo_bulk/eight_tissue_analysis/8test/TARGET_ref_chr9.txt",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ac865ce84d1180525ce168841e8dd14a78a315e
| 134,026 |
ipynb
|
Jupyter Notebook
|
src/Match Outcome Prediction with IPL Data (Data Mining and Features).ipynb
|
XInterns/IPL-T2
|
a358ad8877c9e7acf9e645c6dab0ed8ca19e2b31
|
[
"MIT"
] | 1 |
2020-11-23T19:54:18.000Z
|
2020-11-23T19:54:18.000Z
|
src/Match Outcome Prediction with IPL Data (Data Mining and Features).ipynb
|
XInterns/IPL-T2
|
a358ad8877c9e7acf9e645c6dab0ed8ca19e2b31
|
[
"MIT"
] | null | null | null |
src/Match Outcome Prediction with IPL Data (Data Mining and Features).ipynb
|
XInterns/IPL-T2
|
a358ad8877c9e7acf9e645c6dab0ed8ca19e2b31
|
[
"MIT"
] | 1 |
2017-08-31T05:15:26.000Z
|
2017-08-31T05:15:26.000Z
| 89.950336 | 16,698 | 0.770201 |
[
[
[
"# Predicting the Outcome of Cricket Matches",
"_____no_output_____"
],
[
"## Introduction\n\nIn this project, we shall build a model which predicts the outcome of cricket matches in the Indian Premier League using data about matches and deliveries.\n\n### Data Mining:\n\n * Season : 2008 - 2015 (8 Seasons)\n * Teams : DD, KKR, MI, RCB, KXIP, RR, CSK (7 Teams)\n * Neglect matches that have inconsistencies such as No Result, Tie, D/L Method, etc.\n\n### Features:\n\n * Average Batsman Rating (Strike Rate)\n * Average Bowler Rating (Wickets per Run)\n * Player of the Match Awards \n * Previous Encounters - Win by runs, Win by Wickets \n * Recent form\n \n### Prediction Model\n\n * Logistic Regression using sklearn\n * K-Nearest Neighbors using sklearn\n \n ",
"_____no_output_____"
]
],
[
[
"%matplotlib inline \nimport numpy as np # imports a fast numerical programming library\nimport matplotlib.pyplot as plt #sets up plotting under plt\nimport pandas as pd #lets us handle data as dataframes\n#sets up pandas table display\npd.set_option('display.width', 500)\npd.set_option('display.max_columns', 100)\npd.set_option('display.notebook_repr_html', True)\nimport seaborn as sns\nsns.set(style=\"whitegrid\", color_codes=True)\nfrom __future__ import division",
"_____no_output_____"
]
],
[
[
"## Data Mining\n ",
"_____no_output_____"
]
],
[
[
"# Reading in the data\nallmatches = pd.read_csv(\"../data/matches.csv\")\nalldeliveries = pd.read_csv(\"../data/deliveries.csv\")\nallmatches.head(10)",
"_____no_output_____"
],
[
"# Selecting Seasons 2008 - 2015\nmatches_seasons = allmatches.loc[allmatches['season'] != 2016]\ndeliveries_seasons = alldeliveries.loc[alldeliveries['match_id'] < 518]",
"_____no_output_____"
],
[
"# Selecting teams DD, KKR, MI, RCB, KXIP, RR, CSK\nmatches_teams = matches_seasons.loc[(matches_seasons['team1'].isin(['Kolkata Knight Riders', \\\n'Royal Challengers Bangalore', 'Delhi Daredevils', 'Chennai Super Kings', 'Rajasthan Royals', \\\n'Mumbai Indians', 'Kings XI Punjab'])) & (matches_seasons['team2'].isin(['Kolkata Knight Riders', \\\n'Royal Challengers Bangalore', 'Delhi Daredevils', 'Chennai Super Kings', 'Rajasthan Royals', \\\n'Mumbai Indians', 'Kings XI Punjab']))]\nmatches_team_matchids = matches_teams.id.unique()\ndeliveries_teams = deliveries_seasons.loc[deliveries_seasons['match_id'].isin(matches_team_matchids)]\nprint \"Teams selected:\\n\"\nfor team in matches_teams.team1.unique():\n print team",
"Teams selected:\n\nKolkata Knight Riders\nChennai Super Kings\nRajasthan Royals\nMumbai Indians\nKings XI Punjab\nRoyal Challengers Bangalore\nDelhi Daredevils\n"
],
[
"# Neglect matches with inconsistencies like 'No Result' or 'D/L Applied'\nmatches = matches_teams.loc[(matches_teams['result'] == 'normal') & (matches_teams['dl_applied'] == 0)]\nmatches_matchids = matches.id.unique()\ndeliveries = deliveries_teams.loc[deliveries_teams['match_id'].isin(matches_matchids)]\n# Verifying consistency between datasets\n(matches.id.unique() == deliveries.match_id.unique()).all()",
"_____no_output_____"
]
],
[
[
"## Building Features",
"_____no_output_____"
]
],
[
[
"# Batsman Strike Rate Calculation\n# Team 1: Batting First; Team 2: Fielding First\n\ndef getMatchDeliveriesDF(match_id):\n return deliveries.loc[deliveries['match_id'] == match_id]\n\ndef getInningsOneBatsmen(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 1].batsman.unique()[0:5]\n\ndef getInningsTwoBatsmen(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 2].batsman.unique()[0:5]\n\ndef getBatsmanStrikeRate(batsman, match_id):\n onstrikedeliveries = deliveries.loc[(deliveries['match_id'] < match_id) & (deliveries['batsman'] == batsman)]\n total_runs = onstrikedeliveries['batsman_runs'].sum()\n total_balls = onstrikedeliveries.shape[0]\n if total_balls != 0: \n return (total_runs/total_balls) * 100\n else:\n return None\n\ndef getTeamStrikeRate(batsmen, match_id):\n strike_rates = []\n for batsman in batsmen:\n bsr = getBatsmanStrikeRate(batsman, match_id)\n if bsr != None:\n strike_rates.append(bsr)\n return np.mean(strike_rates)\n\ndef getAverageStrikeRates(match_id):\n match_deliveries = getMatchDeliveriesDF(match_id)\n innOneBatsmen = getInningsOneBatsmen(match_deliveries)\n innTwoBatsmen = getInningsTwoBatsmen(match_deliveries)\n teamOneSR = getTeamStrikeRate(innOneBatsmen, match_id)\n teamTwoSR = getTeamStrikeRate(innTwoBatsmen, match_id)\n return teamOneSR, teamTwoSR",
"_____no_output_____"
],
[
"# Testing Functionality\ngetAverageStrikeRates(517)",
"_____no_output_____"
],
[
"# Bowler Rating : Wickets/Run (Higher the Better)\n# Team 1: Batting First; Team 2: Fielding First\n\ndef getInningsOneBowlers(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 1].bowler.unique()[0:4]\n\ndef getInningsTwoBowlers(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 2].bowler.unique()[0:4]\n\ndef getBowlerWPR(bowler, match_id):\n balls = deliveries.loc[(deliveries['match_id'] < match_id) & (deliveries['bowler'] == bowler)]\n total_runs = balls['total_runs'].sum()\n total_wickets = balls.loc[balls['dismissal_kind'].isin(['caught', 'bowled', 'lbw', \\\n 'caught and bowled', 'stumped'])].shape[0]\n if balls.shape[0] > 0:\n return (total_wickets/total_runs) * 100\n else:\n return None\n\ndef getTeamWPR(bowlers, match_id):\n WPRs = []\n for bowler in bowlers:\n bwpr = getBowlerWPR(bowler, match_id)\n if bwpr != None:\n WPRs.append(bwpr)\n return np.mean(WPRs)\n\ndef getAverageWPR(match_id):\n match_deliveries = getMatchDeliveriesDF(match_id)\n innOneBowlers = getInningsOneBowlers(match_deliveries)\n innTwoBowlers = getInningsTwoBowlers(match_deliveries)\n teamOneWPR = getTeamWPR(innTwoBowlers, match_id)\n teamTwoWPR = getTeamWPR(innOneBowlers, match_id)\n return teamOneWPR, teamTwoWPR",
"_____no_output_____"
],
[
"# testing functionality\ngetAverageWPR(517)",
"_____no_output_____"
],
[
"# MVP Score (Total number of Player of the Match awards in a squad)\n\ndef getAllInningsOneBatsmen(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 1].batsman.unique()\n\ndef getAllInningsTwoBatsmen(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 2].batsman.unique()\n\ndef getAllInningsOneBowlers(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 1].bowler.unique()\n\ndef getAllInningsTwoBowlers(match_deliveries):\n return match_deliveries.loc[match_deliveries['inning'] == 2].bowler.unique()\n\ndef makeSquad(batsmen, bowlers):\n p = []\n p = np.append(p, batsmen)\n for i in bowlers:\n if i not in batsmen:\n p = np.append(p, i)\n return p\n\ndef getPlayerMVPAwards(player, match_id):\n return matches.loc[(matches['player_of_match'] == player) & (matches['id'] < match_id)].shape[0]\n\ndef getTeamMVPAwards(squad, match_id):\n num_awards = 0\n for player in squad:\n num_awards += getPlayerMVPAwards(player, match_id)\n return num_awards\n\ndef compareMVPAwards(match_id):\n match_deliveries = getMatchDeliveriesDF(match_id)\n innOneBatsmen = getAllInningsOneBatsmen(match_deliveries)\n innTwoBatsmen = getAllInningsTwoBatsmen(match_deliveries)\n innOneBowlers = getAllInningsOneBowlers(match_deliveries)\n innTwoBowlers = getAllInningsTwoBowlers(match_deliveries)\n teamOneSquad = makeSquad(innOneBatsmen, innTwoBowlers)\n teamTwoSquad = makeSquad(innTwoBatsmen, innOneBowlers)\n teamOneAwards = getTeamMVPAwards(teamOneSquad, match_id)\n teamTwoAwards = getTeamMVPAwards(teamTwoSquad, match_id)\n return teamOneAwards, teamTwoAwards",
"_____no_output_____"
],
[
"compareMVPAwards(517)",
"_____no_output_____"
],
[
"# Prints a comparison between two teams based on squad attributes\n\ndef generateSquadRating(match_id):\n gameday_teams = deliveries.loc[(deliveries['match_id'] == match_id)].batting_team.unique()\n teamOne = gameday_teams[0]\n teamTwo = gameday_teams[1]\n teamOneSR, teamTwoSR = getAverageStrikeRates(match_id)\n teamOneWPR, teamTwoWPR = getAverageWPR(match_id)\n teamOneMVPs, teamTwoMVPs = compareMVPAwards(match_id)\n print \"Comparing squads for {} vs {}\".format(teamOne,teamTwo)\n print \"\\nAverage Strike Rate for Batsmen in {} : {}\".format(teamOne,teamOneSR)\n print \"\\nAverage Strike Rate for Batsmen in {} : {}\".format(teamTwo,teamTwoSR)\n print \"\\nBowler Rating (W/R) for {} : {}\".format(teamOne,teamOneWPR)\n print \"\\nBowler Rating (W/R) for {} : {}\".format(teamTwo,teamTwoWPR)\n print \"\\nNumber of MVP Awards in {} : {}\".format(teamOne,teamOneMVPs)\n print \"\\nNumber of MVP Awards in {} : {}\".format(teamTwo,teamTwoMVPs) ",
"_____no_output_____"
],
[
"#Testing Functionality\ngenerateSquadRating(517)",
"Comparing squads for Mumbai Indians vs Chennai Super Kings\n\nAverage Strike Rate for Batsmen in Mumbai Indians : 126.980245232\n\nAverage Strike Rate for Batsmen in Chennai Super Kings : 128.555795104\n\nBowler Rating (W/R) for Mumbai Indians : 2.76418065941\n\nBowler Rating (W/R) for Chennai Super Kings : 4.4721111768\n\nNumber of MVP Awards in Mumbai Indians : 28\n\nNumber of MVP Awards in Chennai Super Kings : 52\n"
],
[
"## 2nd Feature : Previous Encounter\n# Won by runs and won by wickets (Higher the better)\n\ndef getTeam1(match_id):\n return matches.loc[matches[\"id\"] == match_id].team1.unique()\n\ndef getTeam2(match_id):\n return matches.loc[matches[\"id\"] == match_id].team2.unique()\n\ndef getPreviousEncDF(match_id):\n team1 = getTeam1(match_id)\n team2 = getTeam2(match_id)\n return matches.loc[(matches[\"id\"] < match_id) & (((matches[\"team1\"].isin(team1)) & (matches[\"team2\"].isin(team2))) | ((matches[\"team1\"].isin(team2)) & (matches[\"team2\"].isin(team1))))]\n\ndef getTeamWBR(match_id, team):\n WBR = 0\n DF = getPreviousEncDF(match_id)\n winnerDF = DF.loc[DF[\"winner\"] == team]\n WBR = winnerDF['win_by_runs'].sum() \n return WBR\n\n\ndef getTeamWBW(match_id, team):\n WBW = 0 \n DF = getPreviousEncDF(match_id)\n winnerDF = DF.loc[DF[\"winner\"] == team]\n WBW = winnerDF['win_by_wickets'].sum()\n return WBW \n \ndef getTeamWinPerc(match_id):\n dF = getPreviousEncDF(match_id)\n timesPlayed = dF.shape[0]\n team1 = getTeam1(match_id)[0].strip(\"[]\")\n timesWon = dF.loc[dF[\"winner\"] == team1].shape[0]\n if timesPlayed != 0:\n winPerc = (timesWon/timesPlayed) * 100\n else:\n winPerc = 0\n return winPerc\n\ndef getBothTeamStats(match_id):\n DF = getPreviousEncDF(match_id)\n team1 = getTeam1(match_id)[0].strip(\"[]\")\n team2 = getTeam2(match_id)[0].strip(\"[]\")\n timesPlayed = DF.shape[0]\n timesWon = DF.loc[DF[\"winner\"] == team1].shape[0]\n WBRTeam1 = getTeamWBR(match_id, team1)\n WBRTeam2 = getTeamWBR(match_id, team2)\n WBWTeam1 = getTeamWBW(match_id, team1)\n WBWTeam2 = getTeamWBW(match_id, team2)\n\n print \"Out of {} times in the past {} have won {} times({}%) from {}\".format(timesPlayed, team1, timesWon, getTeamWinPerc(match_id), team2)\n print \"{} won by {} total runs and {} total wickets.\".format(team1, WBRTeam1, WBWTeam1)\n print \"{} won by {} total runs and {} total wickets.\".format(team2, WBRTeam2, WBWTeam2)\n",
"_____no_output_____"
],
[
"#Testing functionality \ngetBothTeamStats(517)",
"Out of 21 times in the past Mumbai Indians have won 11 times(52.380952381%) from Chennai Super Kings\nMumbai Indians won by 144 total runs and 30 total wickets.\nChennai Super Kings won by 138 total runs and 31 total wickets.\n"
],
[
"# 3rd Feature: Recent Form (Win Percentage of 3 previous matches of a team in the same season)\n# Higher the better\n\ndef getMatchYear(match_id):\n return matches.loc[matches[\"id\"] == match_id].season.unique()\n\ndef getTeam1DF(match_id, year):\n team1 = getTeam1(match_id)\n return matches.loc[(matches[\"id\"] < match_id) & (matches[\"season\"] == year) & ((matches[\"team1\"].isin(team1)) | (matches[\"team2\"].isin(team1)))].tail(3)\n\ndef getTeam2DF(match_id, year):\n team2 = getTeam2(match_id)\n return matches.loc[(matches[\"id\"] < match_id) & (matches[\"season\"] == year) & ((matches[\"team1\"].isin(team2)) | (matches[\"team2\"].isin(team2)))].tail(3)\n\ndef getTeamWinPercentage(match_id):\n year = int(getMatchYear(match_id))\n team1 = getTeam1(match_id)[0].strip(\"[]\")\n team2 = getTeam2(match_id)[0].strip(\"[]\")\n team1DF = getTeam1DF(match_id, year)\n team2DF = getTeam2DF(match_id, year)\n team1TotalMatches = team1DF.shape[0]\n team1WinMatches = team1DF.loc[team1DF[\"winner\"] == team1].shape[0]\n team2TotalMatches = team2DF.shape[0]\n team2WinMatches = team2DF.loc[team2DF[\"winner\"] == team2].shape[0]\n if (team1TotalMatches != 0) and (team2TotalMatches !=0):\n winPercTeam1 = ((team1WinMatches / team1TotalMatches) * 100) \n winPercTeam2 = ((team2WinMatches / team2TotalMatches) * 100) \n elif (team1TotalMatches != 0) and (team2TotalMatches ==0):\n winPercTeam1 = ((team1WinMatches / team1TotalMatches) * 100) \n winPercTeam2 = 0\n elif (team1TotalMatches == 0) and (team2TotalMatches !=0):\n winPercTeam1 = 0\n winPercTeam2 = ((team2WinMatches / team2TotalMatches) * 100) \n else:\n winPercTeam1 = 0\n winPercTeam2 = 0\n return winPercTeam1, winPercTeam2",
"_____no_output_____"
],
[
"#Testing Functionality\ngetTeamWinPercentage(517)",
"_____no_output_____"
],
[
"#Function to implement all features\ndef getAllFeatures(match_id):\n generateSquadRating(match_id)\n print (\"\\n\")\n getBothTeamStats(match_id)\n print(\"\\n\")\n getTeamWinPercentage(match_id)\n",
"_____no_output_____"
],
[
"#Testing Functionality\ngetAllFeatures(517)",
"Comparing squads for Mumbai Indians vs Chennai Super Kings\n\nAverage Strike Rate for Batsmen in Mumbai Indians : 126.980245232\n\nAverage Strike Rate for Batsmen in Chennai Super Kings : 128.555795104\n\nBowler Rating (W/R) for Mumbai Indians : 2.76418065941\n\nBowler Rating (W/R) for Chennai Super Kings : 4.4721111768\n\nNumber of MVP Awards in Mumbai Indians : 28\n\nNumber of MVP Awards in Chennai Super Kings : 52\n\n\nOut of 21 times in the past Mumbai Indians have won 11 times(52.380952381%) from Chennai Super Kings\nMumbai Indians won by 144 total runs and 30 total wickets.\nChennai Super Kings won by 138 total runs and 31 total wickets.\n\n\n"
]
],
[
[
"## Adding New Columns for Features in Matches DataFrame",
"_____no_output_____"
]
],
[
[
"#Create Column for Team 1 Winning Status (1 = Won, 0 = Lost)\n\nmatches['team1Winning'] = np.where(matches['team1'] == matches['winner'], 1, 0)",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n"
],
[
"# New Column for Difference of Average Strike rates (First Team SR - Second Team SR) \n# [Negative value means Second team is better]\n\nfirstTeamSR = []\nsecondTeamSR = []\nfor i in matches['id'].unique():\n P, Q = getAverageStrikeRates(i)\n firstTeamSR.append(P), secondTeamSR.append(Q)\nfirstSRSeries = pd.Series(firstTeamSR)\nsecondSRSeries = pd.Series(secondTeamSR)\nmatches[\"Avg_SR_Difference\"] = firstSRSeries.values - secondSRSeries.values ",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/numpy/core/fromnumeric.py:2889: RuntimeWarning: Mean of empty slice.\n out=out, **kwargs)\n/Users/gursahej/anaconda2/lib/python2.7/site-packages/numpy/core/_methods.py:80: RuntimeWarning: invalid value encountered in double_scalars\n ret = ret.dtype.type(ret / rcount)\n/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:11: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n # This is added back by InteractiveShellApp.init_path()\n"
],
[
"# New Column for Difference of Wickets Per Run (First Team WPR - Second Team WPR) \n# [Negative value means Second team is better]\n\nfirstTeamWPR = []\nsecondTeamWPR = []\nfor i in matches['id'].unique():\n R, S = getAverageWPR(i)\n firstTeamWPR.append(R), secondTeamWPR.append(S)\nfirstWPRSeries = pd.Series(firstTeamWPR)\nsecondWPRSeries = pd.Series(secondTeamWPR)\nmatches[\"Avg_WPR_Difference\"] = firstWPRSeries.values - secondWPRSeries.values ",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:11: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n # This is added back by InteractiveShellApp.init_path()\n"
],
[
"# New column for difference of MVP Awards \n# (Negative value means Second team is better)\n\nfirstTeamMVP = []\nsecondTeamMVP = []\nfor i in matches['id'].unique():\n T, U = compareMVPAwards(i)\n firstTeamMVP.append(T), secondTeamMVP.append(U)\nfirstMVPSeries = pd.Series(firstTeamMVP)\nsecondMVPSeries = pd.Series(secondTeamMVP)\nmatches[\"Total_MVP_Difference\"] = firstMVPSeries.values - secondMVPSeries.values ",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:11: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n # This is added back by InteractiveShellApp.init_path()\n"
],
[
"# New column for Win Percentage of Team 1 in previous encounters\n\nfirstTeamWP = []\nfor i in matches['id'].unique():\n WP = getTeamWinPerc(i)\n firstTeamWP.append(WP)\nfirstWPSeries = pd.Series(firstTeamWP)\nmatches[\"Prev_Enc_Team1_WinPerc\"] = firstWPSeries.values",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:8: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"# New column for Recent form(Win Percentage in the current season) of 1st Team compared to 2nd Team\n# (Negative means 2nd team has higher win percentage)\n\nfirstTeamRF = []\nsecondTeamRF = []\nfor i in matches['id'].unique():\n K, L = getTeamWinPercentage(i)\n firstTeamRF.append(K), secondTeamRF.append(L)\nfirstRFSeries = pd.Series(firstTeamRF)\nsecondRFSeries = pd.Series(secondTeamRF)\nmatches[\"Total_RF_Difference\"] = firstRFSeries.values - secondRFSeries.values ",
"/Users/gursahej/anaconda2/lib/python2.7/site-packages/ipykernel_launcher.py:11: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n # This is added back by InteractiveShellApp.init_path()\n"
],
[
"#Testing \nmatches.tail()",
"_____no_output_____"
]
],
[
[
"## Visualizations for Features vs. Response",
"_____no_output_____"
]
],
[
[
"# Graph for Average Strike Rate Difference\nmatches.boxplot(column = 'Avg_SR_Difference', by='team1Winning', showfliers= False)",
"_____no_output_____"
],
[
"# Graph for Average WPR(Wickets per Run) Difference\nmatches.boxplot(column = 'Avg_WPR_Difference', by='team1Winning', showfliers= False)",
"_____no_output_____"
],
[
"# Graph for MVP Difference\nmatches.boxplot(column = 'Total_MVP_Difference', by='team1Winning', showfliers= False)",
"_____no_output_____"
],
[
"#Graph for Previous encounters Win Percentage of Team #1\nmatches.boxplot(column = 'Prev_Enc_Team1_WinPerc', by='team1Winning', showfliers= False)",
"_____no_output_____"
],
[
"# Graph for Recent form(Win Percentage in the same season)\nmatches.boxplot(column = 'Total_RF_Difference', by='team1Winning', showfliers= False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ac873ed4ca34af81ac1f9e15ab6f46fdb12ae8d
| 6,528 |
ipynb
|
Jupyter Notebook
|
notebooks/keras_tuning_cnn.ipynb
|
cgm616/hackholyoke
|
0b6b995147b13efeb5420ba7b5a5818b731e0e32
|
[
"MIT"
] | 1 |
2021-12-11T13:29:38.000Z
|
2021-12-11T13:29:38.000Z
|
notebooks/keras_tuning_cnn.ipynb
|
cgm616/hackholyoke
|
0b6b995147b13efeb5420ba7b5a5818b731e0e32
|
[
"MIT"
] | null | null | null |
notebooks/keras_tuning_cnn.ipynb
|
cgm616/hackholyoke
|
0b6b995147b13efeb5420ba7b5a5818b731e0e32
|
[
"MIT"
] | 1 |
2020-10-11T06:04:26.000Z
|
2020-10-11T06:04:26.000Z
| 27.661017 | 332 | 0.57644 |
[
[
[
"Let's load the data from the csv just as in `dataset.ipynb`.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nraw_data_file_name = \"../dataset/fer2013.csv\"\nraw_data = pd.read_csv(raw_data_file_name)",
"_____no_output_____"
]
],
[
[
"Now, we separate and clean the data a little bit. First, we create an array of only the training data. Then, we create an array of only the private test data (referred to in the code with the prefix `first_test`). The `reset_index` call re-aligns the `first_test_data` to index from 0 instead of wherever it starts in the set.",
"_____no_output_____"
]
],
[
[
"train_data = raw_data[raw_data[\"Usage\"] == \"Training\"]\n\nfirst_test_data = raw_data[raw_data[\"Usage\"] == \"PrivateTest\"]\nfirst_test_data.reset_index(inplace=True)\n\nsecond_test_data = raw_data[raw_data[\"Usage\"] == \"PublicTest\"]\nsecond_test_data.reset_index(inplace=True)",
"_____no_output_____"
],
[
"import keras\n\ntrain_expected = keras.utils.to_categorical(train_data[\"emotion\"], num_classes=7, dtype='int32')\nfirst_test_expected = keras.utils.to_categorical(first_test_data[\"emotion\"], num_classes=7, dtype='int32')\nsecond_test_expected = keras.utils.to_categorical(second_test_data[\"emotion\"], num_classes=7, dtype='int32')",
"_____no_output_____"
],
[
"def process_pixels(array_input):\n output = np.empty([int(len(array_input)), 2304])\n for index, item in enumerate(output):\n item[:] = array_input[index].split(\" \")\n output /= 255\n return output",
"_____no_output_____"
],
[
"train_pixels = process_pixels(train_data[\"pixels\"])\ntrain_pixels = train_pixels.reshape(train_pixels.shape[0], 48, 48, 1)",
"_____no_output_____"
],
[
"first_test_pixels = process_pixels(first_test_data[\"pixels\"])\nfirst_test_pixels = first_test_pixels.reshape(first_test_pixels.shape[0], 48, 48, 1)",
"_____no_output_____"
],
[
"second_test_pixels = process_pixels(second_test_data[\"pixels\"])\nsecond_test_pixels = second_test_pixels.reshape(second_test_pixels.shape[0], 48, 48, 1)",
"_____no_output_____"
],
[
"from keras.preprocessing.image import ImageDataGenerator\n\ndatagen = ImageDataGenerator(\n featurewise_center=False,\n featurewise_std_normalization=False,\n rotation_range=10,\n width_shift_range=0.1,\n height_shift_range=0.1,\n horizontal_flip=True\n)",
"_____no_output_____"
]
],
[
[
"Here, we create our own top-level network to load on top of VGG16.",
"_____no_output_____"
]
],
[
[
"from keras.models import Sequential\nfrom keras.layers import Dense, Dropout, MaxPooling2D, Conv2D, Flatten\nfrom keras.optimizers import Adam\n\ndef gen_model(size):\n model = Sequential()\n model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape = (48, 48, 1)))\n model.add(MaxPooling2D(pool_size=(2, 2)))\n model.add(Dropout(0.2))\n\n model.add(Flatten())\n\n model.add(Dense(size, activation='relu'))\n model.add(Dense(7, activation='softmax'))\n\n optimizer = Adam(learning_rate=0.0009)\n model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])\n \n return model",
"_____no_output_____"
],
[
"from keras.callbacks.callbacks import EarlyStopping, ReduceLROnPlateau\n\nearly_stop = EarlyStopping('val_loss', patience=50)\nreduce_lr = ReduceLROnPlateau('val_loss', factor=0.1, patience=int(50/4), verbose=1)\ncallbacks = [early_stop, reduce_lr]",
"_____no_output_____"
],
[
"sizes = [32, 64, 128, 256]\nresults = [None] * len(sizes)\n\nfor i in range(len(sizes)):\n model = gen_model(sizes[i])\n model.fit_generator(datagen.flow(train_pixels, train_expected, batch_size=32),\n steps_per_epoch=len(train_pixels) / 32,\n epochs=10, verbose=1, callbacks=callbacks,\n validation_data=(first_test_pixels,first_test_expected))\n results[i] = model.evaluate(second_test_pixels, second_test_pixels, batch_size=32)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac881f5fba3d2e77512b735b54c55e6f8eb65a4
| 258,053 |
ipynb
|
Jupyter Notebook
|
experiments/tuned_1v2/oracle.run2_limited/trials/2/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tuned_1v2/oracle.run2_limited/trials/2/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tuned_1v2/oracle.run2_limited/trials/2/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null | 84.083741 | 73,776 | 0.770694 |
[
[
[
"# PTN Template\nThis notebook serves as a template for single dataset PTN experiments \nIt can be run on its own by setting STANDALONE to True (do a find for \"STANDALONE\" to see where) \nBut it is intended to be executed as part of a *papermill.py script. See any of the \nexperimentes with a papermill script to get started with that workflow. ",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n \nimport os, json, sys, time, random\nimport numpy as np\nimport torch\nfrom torch.optim import Adam\nfrom easydict import EasyDict\nimport matplotlib.pyplot as plt\n\nfrom steves_models.steves_ptn import Steves_Prototypical_Network\n\nfrom steves_utils.lazy_iterable_wrapper import Lazy_Iterable_Wrapper\nfrom steves_utils.iterable_aggregator import Iterable_Aggregator\nfrom steves_utils.ptn_train_eval_test_jig import PTN_Train_Eval_Test_Jig\nfrom steves_utils.torch_sequential_builder import build_sequential\nfrom steves_utils.torch_utils import get_dataset_metrics, ptn_confusion_by_domain_over_dataloader\nfrom steves_utils.utils_v2 import (per_domain_accuracy_from_confusion, get_datasets_base_path)\nfrom steves_utils.PTN.utils import independent_accuracy_assesment\n\nfrom steves_utils.stratified_dataset.episodic_accessor import Episodic_Accessor_Factory\n\nfrom steves_utils.ptn_do_report import (\n get_loss_curve,\n get_results_table,\n get_parameters_table,\n get_domain_accuracies,\n)\n\nfrom steves_utils.transforms import get_chained_transform",
"_____no_output_____"
]
],
[
[
"# Required Parameters\nThese are allowed parameters, not defaults\nEach of these values need to be present in the injected parameters (the notebook will raise an exception if they are not present)\n\nPapermill uses the cell tag \"parameters\" to inject the real parameters below this cell.\nEnable tags to see what I mean",
"_____no_output_____"
]
],
[
[
"required_parameters = {\n \"experiment_name\",\n \"lr\",\n \"device\",\n \"seed\",\n \"dataset_seed\",\n \"labels_source\",\n \"labels_target\",\n \"domains_source\",\n \"domains_target\",\n \"num_examples_per_domain_per_label_source\",\n \"num_examples_per_domain_per_label_target\",\n \"n_shot\",\n \"n_way\",\n \"n_query\",\n \"train_k_factor\",\n \"val_k_factor\",\n \"test_k_factor\",\n \"n_epoch\",\n \"patience\",\n \"criteria_for_best\",\n \"x_transforms_source\",\n \"x_transforms_target\",\n \"episode_transforms_source\",\n \"episode_transforms_target\",\n \"pickle_name\",\n \"x_net\",\n \"NUM_LOGS_PER_EPOCH\",\n \"BEST_MODEL_PATH\",\n \"torch_default_dtype\"\n}",
"_____no_output_____"
],
[
"\n\nstandalone_parameters = {}\nstandalone_parameters[\"experiment_name\"] = \"STANDALONE PTN\"\nstandalone_parameters[\"lr\"] = 0.0001\nstandalone_parameters[\"device\"] = \"cuda\"\n\nstandalone_parameters[\"seed\"] = 1337\nstandalone_parameters[\"dataset_seed\"] = 1337\n\n\nstandalone_parameters[\"num_examples_per_domain_per_label_source\"]=100\nstandalone_parameters[\"num_examples_per_domain_per_label_target\"]=100\n\nstandalone_parameters[\"n_shot\"] = 3\nstandalone_parameters[\"n_query\"] = 2\nstandalone_parameters[\"train_k_factor\"] = 1\nstandalone_parameters[\"val_k_factor\"] = 2\nstandalone_parameters[\"test_k_factor\"] = 2\n\n\nstandalone_parameters[\"n_epoch\"] = 100\n\nstandalone_parameters[\"patience\"] = 10\nstandalone_parameters[\"criteria_for_best\"] = \"target_accuracy\"\n\nstandalone_parameters[\"x_transforms_source\"] = [\"unit_power\"]\nstandalone_parameters[\"x_transforms_target\"] = [\"unit_power\"]\nstandalone_parameters[\"episode_transforms_source\"] = []\nstandalone_parameters[\"episode_transforms_target\"] = []\n\nstandalone_parameters[\"torch_default_dtype\"] = \"torch.float32\" \n\n\n\nstandalone_parameters[\"x_net\"] = [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\":[-1, 1, 2, 256]}},\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":1, \"out_channels\":256, \"kernel_size\":(1,7), \"bias\":False, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":256, \"out_channels\":80, \"kernel_size\":(2,7), \"bias\":True, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 80*256, \"out_features\": 256}}, # 80 units per IQ pair\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n]\n\n# Parameters relevant to results\n# These parameters will basically never need to change\nstandalone_parameters[\"NUM_LOGS_PER_EPOCH\"] = 10\nstandalone_parameters[\"BEST_MODEL_PATH\"] = \"./best_model.pth\"\n\n# uncomment for CORES dataset\nfrom steves_utils.CORES.utils import (\n ALL_NODES,\n ALL_NODES_MINIMUM_1000_EXAMPLES,\n ALL_DAYS\n)\n\n\nstandalone_parameters[\"labels_source\"] = ALL_NODES\nstandalone_parameters[\"labels_target\"] = ALL_NODES\n\nstandalone_parameters[\"domains_source\"] = [1]\nstandalone_parameters[\"domains_target\"] = [2,3,4,5]\n\nstandalone_parameters[\"pickle_name\"] = \"cores.stratified_ds.2022A.pkl\"\n\n\n# Uncomment these for ORACLE dataset\n# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n# standalone_parameters[\"labels_source\"] = ALL_SERIAL_NUMBERS\n# standalone_parameters[\"labels_target\"] = ALL_SERIAL_NUMBERS\n# standalone_parameters[\"domains_source\"] = [8,20, 38,50]\n# standalone_parameters[\"domains_target\"] = [14, 26, 32, 44, 56]\n# standalone_parameters[\"pickle_name\"] = \"oracle.frame_indexed.stratified_ds.2022A.pkl\"\n# standalone_parameters[\"num_examples_per_domain_per_label_source\"]=1000\n# standalone_parameters[\"num_examples_per_domain_per_label_target\"]=1000\n\n# Uncomment these for Metahan dataset\n# standalone_parameters[\"labels_source\"] = list(range(19))\n# standalone_parameters[\"labels_target\"] = list(range(19))\n# standalone_parameters[\"domains_source\"] = [0]\n# standalone_parameters[\"domains_target\"] = [1]\n# standalone_parameters[\"pickle_name\"] = \"metehan.stratified_ds.2022A.pkl\"\n# standalone_parameters[\"n_way\"] = len(standalone_parameters[\"labels_source\"])\n# standalone_parameters[\"num_examples_per_domain_per_label_source\"]=200\n# standalone_parameters[\"num_examples_per_domain_per_label_target\"]=100\n\n\nstandalone_parameters[\"n_way\"] = len(standalone_parameters[\"labels_source\"])",
"_____no_output_____"
],
[
"# Parameters\nparameters = {\n \"experiment_name\": \"tuned_1v2:oracle.run2_limited\",\n \"device\": \"cuda\",\n \"lr\": 0.0001,\n \"labels_source\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"labels_target\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"episode_transforms_source\": [],\n \"episode_transforms_target\": [],\n \"domains_source\": [8, 32, 50],\n \"domains_target\": [14, 20, 26, 38, 44],\n \"num_examples_per_domain_per_label_source\": 2000,\n \"num_examples_per_domain_per_label_target\": 2000,\n \"n_shot\": 3,\n \"n_way\": 16,\n \"n_query\": 2,\n \"train_k_factor\": 3,\n \"val_k_factor\": 2,\n \"test_k_factor\": 2,\n \"torch_default_dtype\": \"torch.float32\",\n \"n_epoch\": 50,\n \"patience\": 3,\n \"criteria_for_best\": \"target_accuracy\",\n \"x_net\": [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\": [-1, 1, 2, 256]}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 1,\n \"out_channels\": 256,\n \"kernel_size\": [1, 7],\n \"bias\": False,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 256}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 256,\n \"out_channels\": 80,\n \"kernel_size\": [2, 7],\n \"bias\": True,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 20480, \"out_features\": 256}},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\": 256}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n ],\n \"NUM_LOGS_PER_EPOCH\": 10,\n \"BEST_MODEL_PATH\": \"./best_model.pth\",\n \"pickle_name\": \"oracle.Run2_10kExamples_stratified_ds.2022A.pkl\",\n \"x_transforms_source\": [\"unit_mag\"],\n \"x_transforms_target\": [\"unit_mag\"],\n \"dataset_seed\": 1337,\n \"seed\": 1337,\n}\n",
"_____no_output_____"
],
[
"# Set this to True if you want to run this template directly\nSTANDALONE = False\nif STANDALONE:\n print(\"parameters not injected, running with standalone_parameters\")\n parameters = standalone_parameters\n\nif not 'parameters' in locals() and not 'parameters' in globals():\n raise Exception(\"Parameter injection failed\")\n\n#Use an easy dict for all the parameters\np = EasyDict(parameters)\n\nsupplied_keys = set(p.keys())\n\nif supplied_keys != required_parameters:\n print(\"Parameters are incorrect\")\n if len(supplied_keys - required_parameters)>0: print(\"Shouldn't have:\", str(supplied_keys - required_parameters))\n if len(required_parameters - supplied_keys)>0: print(\"Need to have:\", str(required_parameters - supplied_keys))\n raise RuntimeError(\"Parameters are incorrect\")\n\n",
"_____no_output_____"
],
[
"###################################\n# Set the RNGs and make it all deterministic\n###################################\nnp.random.seed(p.seed)\nrandom.seed(p.seed)\ntorch.manual_seed(p.seed)\n\ntorch.use_deterministic_algorithms(True) ",
"_____no_output_____"
],
[
"###########################################\n# The stratified datasets honor this\n###########################################\ntorch.set_default_dtype(eval(p.torch_default_dtype))",
"_____no_output_____"
],
[
"###################################\n# Build the network(s)\n# Note: It's critical to do this AFTER setting the RNG\n# (This is due to the randomized initial weights)\n###################################\nx_net = build_sequential(p.x_net)",
"_____no_output_____"
],
[
"start_time_secs = time.time()",
"_____no_output_____"
],
[
"###################################\n# Build the dataset\n###################################\n\nif p.x_transforms_source == []: x_transform_source = None\nelse: x_transform_source = get_chained_transform(p.x_transforms_source) \n\nif p.x_transforms_target == []: x_transform_target = None\nelse: x_transform_target = get_chained_transform(p.x_transforms_target)\n\nif p.episode_transforms_source == []: episode_transform_source = None\nelse: raise Exception(\"episode_transform_source not implemented\")\n\nif p.episode_transforms_target == []: episode_transform_target = None\nelse: raise Exception(\"episode_transform_target not implemented\")\n\n\neaf_source = Episodic_Accessor_Factory(\n labels=p.labels_source,\n domains=p.domains_source,\n num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_source,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),\n x_transform_func=x_transform_source,\n example_transform_func=episode_transform_source,\n \n)\ntrain_original_source, val_original_source, test_original_source = eaf_source.get_train(), eaf_source.get_val(), eaf_source.get_test()\n\n\neaf_target = Episodic_Accessor_Factory(\n labels=p.labels_target,\n domains=p.domains_target,\n num_examples_per_domain_per_label=p.num_examples_per_domain_per_label_target,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n pickle_path=os.path.join(get_datasets_base_path(), p.pickle_name),\n x_transform_func=x_transform_target,\n example_transform_func=episode_transform_target,\n)\ntrain_original_target, val_original_target, test_original_target = eaf_target.get_train(), eaf_target.get_val(), eaf_target.get_test()\n\n\ntransform_lambda = lambda ex: ex[1] # Original is (<domain>, <episode>) so we strip down to episode only\n\ntrain_processed_source = Lazy_Iterable_Wrapper(train_original_source, transform_lambda)\nval_processed_source = Lazy_Iterable_Wrapper(val_original_source, transform_lambda)\ntest_processed_source = Lazy_Iterable_Wrapper(test_original_source, transform_lambda)\n\ntrain_processed_target = Lazy_Iterable_Wrapper(train_original_target, transform_lambda)\nval_processed_target = Lazy_Iterable_Wrapper(val_original_target, transform_lambda)\ntest_processed_target = Lazy_Iterable_Wrapper(test_original_target, transform_lambda)\n\ndatasets = EasyDict({\n \"source\": {\n \"original\": {\"train\":train_original_source, \"val\":val_original_source, \"test\":test_original_source},\n \"processed\": {\"train\":train_processed_source, \"val\":val_processed_source, \"test\":test_processed_source}\n },\n \"target\": {\n \"original\": {\"train\":train_original_target, \"val\":val_original_target, \"test\":test_original_target},\n \"processed\": {\"train\":train_processed_target, \"val\":val_processed_target, \"test\":test_processed_target}\n },\n})",
"_____no_output_____"
],
[
"# Some quick unit tests on the data\nfrom steves_utils.transforms import get_average_power, get_average_magnitude\n\nq_x, q_y, s_x, s_y, truth = next(iter(train_processed_source))\n\nassert q_x.dtype == eval(p.torch_default_dtype)\nassert s_x.dtype == eval(p.torch_default_dtype)\n\nprint(\"Visually inspect these to see if they line up with expected values given the transforms\")\nprint('x_transforms_source', p.x_transforms_source)\nprint('x_transforms_target', p.x_transforms_target)\nprint(\"Average magnitude, source:\", get_average_magnitude(q_x[0].numpy()))\nprint(\"Average power, source:\", get_average_power(q_x[0].numpy()))\n\nq_x, q_y, s_x, s_y, truth = next(iter(train_processed_target))\nprint(\"Average magnitude, target:\", get_average_magnitude(q_x[0].numpy()))\nprint(\"Average power, target:\", get_average_power(q_x[0].numpy()))\n",
"Visually inspect these to see if they line up with expected values given the transforms\nx_transforms_source ['unit_mag']\nx_transforms_target ['unit_mag']\nAverage magnitude, source: 1.0\nAverage power, source: 1.2461352\n"
],
[
"###################################\n# Build the model\n###################################\nmodel = Steves_Prototypical_Network(x_net, device=p.device, x_shape=(2,256))\noptimizer = Adam(params=model.parameters(), lr=p.lr)",
"(2, 256)\n"
],
[
"###################################\n# train\n###################################\njig = PTN_Train_Eval_Test_Jig(model, p.BEST_MODEL_PATH, p.device)\n\njig.train(\n train_iterable=datasets.source.processed.train,\n source_val_iterable=datasets.source.processed.val,\n target_val_iterable=datasets.target.processed.val,\n num_epochs=p.n_epoch,\n num_logs_per_epoch=p.NUM_LOGS_PER_EPOCH,\n patience=p.patience,\n optimizer=optimizer,\n criteria_for_best=p.criteria_for_best,\n)",
"epoch: 1, [batch: 1 / 2520], examples_per_second: 128.3243, train_label_loss: 2.7755, \n"
],
[
"total_experiment_time_secs = time.time() - start_time_secs",
"_____no_output_____"
],
[
"###################################\n# Evaluate the model\n###################################\nsource_test_label_accuracy, source_test_label_loss = jig.test(datasets.source.processed.test)\ntarget_test_label_accuracy, target_test_label_loss = jig.test(datasets.target.processed.test)\n\nsource_val_label_accuracy, source_val_label_loss = jig.test(datasets.source.processed.val)\ntarget_val_label_accuracy, target_val_label_loss = jig.test(datasets.target.processed.val)\n\nhistory = jig.get_history()\n\ntotal_epochs_trained = len(history[\"epoch_indices\"])\n\nval_dl = Iterable_Aggregator((datasets.source.original.val,datasets.target.original.val))\n\nconfusion = ptn_confusion_by_domain_over_dataloader(model, p.device, val_dl)\nper_domain_accuracy = per_domain_accuracy_from_confusion(confusion)\n\n# Add a key to per_domain_accuracy for if it was a source domain\nfor domain, accuracy in per_domain_accuracy.items():\n per_domain_accuracy[domain] = {\n \"accuracy\": accuracy,\n \"source?\": domain in p.domains_source\n }\n\n# Do an independent accuracy assesment JUST TO BE SURE!\n# _source_test_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.test, p.device)\n# _target_test_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.test, p.device)\n# _source_val_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.val, p.device)\n# _target_val_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.val, p.device)\n\n# assert(_source_test_label_accuracy == source_test_label_accuracy)\n# assert(_target_test_label_accuracy == target_test_label_accuracy)\n# assert(_source_val_label_accuracy == source_val_label_accuracy)\n# assert(_target_val_label_accuracy == target_val_label_accuracy)\n\nexperiment = {\n \"experiment_name\": p.experiment_name,\n \"parameters\": dict(p),\n \"results\": {\n \"source_test_label_accuracy\": source_test_label_accuracy,\n \"source_test_label_loss\": source_test_label_loss,\n \"target_test_label_accuracy\": target_test_label_accuracy,\n \"target_test_label_loss\": target_test_label_loss,\n \"source_val_label_accuracy\": source_val_label_accuracy,\n \"source_val_label_loss\": source_val_label_loss,\n \"target_val_label_accuracy\": target_val_label_accuracy,\n \"target_val_label_loss\": target_val_label_loss,\n \"total_epochs_trained\": total_epochs_trained,\n \"total_experiment_time_secs\": total_experiment_time_secs,\n \"confusion\": confusion,\n \"per_domain_accuracy\": per_domain_accuracy,\n },\n \"history\": history,\n \"dataset_metrics\": get_dataset_metrics(datasets, \"ptn\"),\n}",
"_____no_output_____"
],
[
"ax = get_loss_curve(experiment)\nplt.show()",
"_____no_output_____"
],
[
"get_results_table(experiment)",
"_____no_output_____"
],
[
"get_domain_accuracies(experiment)",
"_____no_output_____"
],
[
"print(\"Source Test Label Accuracy:\", experiment[\"results\"][\"source_test_label_accuracy\"], \"Target Test Label Accuracy:\", experiment[\"results\"][\"target_test_label_accuracy\"])\nprint(\"Source Val Label Accuracy:\", experiment[\"results\"][\"source_val_label_accuracy\"], \"Target Val Label Accuracy:\", experiment[\"results\"][\"target_val_label_accuracy\"])",
"Source Test Label Accuracy: 0.6025173611111111 Target Test Label Accuracy: 0.4956770833333333\nSource Val Label Accuracy: 0.6120659722222223 Target Val Label Accuracy: 0.5025\n"
],
[
"json.dumps(experiment)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac88b222e32a48836ce2201c261f8f2008d9e1f
| 325,933 |
ipynb
|
Jupyter Notebook
|
examples/timeseries.ipynb
|
a-mitani/pfilter
|
2feb021e8086f964b4ec1160e9ff68da6c92ae0d
|
[
"MIT"
] | null | null | null |
examples/timeseries.ipynb
|
a-mitani/pfilter
|
2feb021e8086f964b4ec1160e9ff68da6c92ae0d
|
[
"MIT"
] | null | null | null |
examples/timeseries.ipynb
|
a-mitani/pfilter
|
2feb021e8086f964b4ec1160e9ff68da6c92ae0d
|
[
"MIT"
] | null | null | null | 776.030952 | 87,264 | 0.950287 |
[
[
[
"## 1 Simple time series\nSimple time series example: tracking state with linear dynamics",
"_____no_output_____"
]
],
[
[
"from pfilter import ParticleFilter, independent_sample, squared_error\nfrom scipy.stats import norm, gamma, uniform \nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport numpy as np\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Utility function to filter a time series offline and return results as a dictionary of states:",
"_____no_output_____"
]
],
[
[
"def apply_filter(pf, ys, inputs=None):\n \"\"\"Apply filter pf to a series of observations (time_steps, h) and return a dictionary: \n particles: an array of particles (time_steps, n, d)\n weights: an array of weights (time_steps,) \n \"\"\"\n\n states = []\n pf.init_filter() # reset\n for i,y in enumerate(ys):\n if inputs is None:\n pf.update(y)\n else:\n pf.update(y, **inputs[i])\n \n states.append([pf.transformed_particles, np.array(pf.weights)])\n return {\n name: np.array([s[i] for s in states])\n for i, name in enumerate([\"particles\", \"weights\"])\n }",
"_____no_output_____"
],
[
"def plot_particles(x, y, yn, states):\n \"\"\"Plot a 1D tracking result as a line graph with overlaid\n scatterplot of particles. Particles are sized according to\n normalised weight at each step.\n \n x: time values\n y: original (uncorrupted) values\n yn: noisy (observed) values\n states: dictionary return from apply_pfilter \n \"\"\"\n fig, ax = plt.subplots()\n ax.plot(x, y, label='True', lw=1)\n ax.plot(x, yn, label='Noisy', lw=2)\n \n particles = states[\"particles\"]\n ws = states[\"weights\"] \n means = np.sum(particles[:,:,0] * ws, axis=1)\n \n dev = (means - (particles[:,:,0]).T).T**2\n var = np.sum(ws * dev, axis=1) / 1-np.sum(ws**2) # unbiased variance\n stds = np.sqrt(var)\n \n ax.plot(x, means, 'C4', label='Mean est.', lw=4)\n ax.fill_between(x, means-stds, means+stds, color='C4', alpha=0.5, label='Std.')\n ax.scatter(np.tile(x, (len(particles[0]),1)).ravel(), particles[:,:,0].T, s=ws*1000/np.sqrt(len(ws)),\n alpha=0.15, label='Particles')\n ax.set_xlabel(\"Time\")\n ax.set_ylabel(\"Observed\")\n ax.legend()\n \ndef filter_plot(x, y, yn, pf, inputs=None):\n \"\"\"Apply a filter to yn, and plot the results using plot_particles()\"\"\"\n states = apply_filter(pf, yn, inputs)\n plot_particles(x, y, yn, states)\n",
"_____no_output_____"
]
],
[
[
"## (a) Tracking a 1D sinewave",
"_____no_output_____"
],
[
"### Data\nWe generate a noisy (co)sine wave with a linear trend, and Gaussian noise added:",
"_____no_output_____"
]
],
[
[
"# Noisy sine wave data\nx = np.linspace(0, 100, 100)\ny = np.cos(x/4.0) + x * 0.05\nyn = y + np.random.normal(0,0.5,x.shape)\n\n\nfig, ax = plt.subplots()\nax.plot(x, y, label='True', lw=1)\nax.plot(x, yn, label='Noisy', lw=1)",
"_____no_output_____"
]
],
[
[
"### Purely stochastic dynamics (random walk)",
"_____no_output_____"
]
],
[
[
"# No dynamics\n# just diffusion on x\nprior_fn = lambda n: np.random.normal(0,1,(n,1))\ndt = 0.05\nnoise = 0.15\nsigma = 1.5\n\npf = ParticleFilter(prior_fn = prior_fn, \n observe_fn = lambda x: x, \n dynamics_fn=lambda x: x ,\n n_particles=250, \n noise_fn = lambda x: x + np.random.normal(0, noise, x.shape),\n weight_fn = lambda x,y : squared_error(x, y, sigma=sigma),\n resample_proportion=0.01)\n\nfilter_plot(x, y, yn, pf)",
"c:\\local\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:21: RuntimeWarning: invalid value encountered in sqrt\n"
]
],
[
[
"### Simple linear dynamics",
"_____no_output_____"
]
],
[
[
"# Linear dynamics\n# x, dx, ddx\nprior_fn = lambda n: np.random.normal(0,1,(n,3))\ndt = 0.25\nnoise = 0.125\nsigma = 1.0\n\n# linear dynamics\nD = np.array([[1, dt, 0.5*dt**2],\n [0, 1, dt],\n [0, 0, 1]])\n\nO = np.array([[1, 0, 0]])\npf = ParticleFilter(prior_fn = prior_fn, \n observe_fn = lambda x: x @ O.T, \n dynamics_fn=lambda x: x @ D.T ,\n n_particles=200, \n noise_fn = lambda x: x + np.random.normal(0, noise, x.shape),\n weight_fn = lambda x,y : squared_error(x, y, sigma=sigma),\n resample_proportion=0.02)\n\nfilter_plot(x, y, yn, pf)\n",
"c:\\local\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:21: RuntimeWarning: invalid value encountered in sqrt\n"
]
],
[
[
"### Linear dynamics with missing values",
"_____no_output_____"
]
],
[
[
"# Missing values; randomly delete 25% of the observations\ny_missing = np.array([yt if np.random.uniform()>0.25 else None for yt in yn])\nfilter_plot(x, y, y_missing, pf)\n",
"c:\\local\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:21: RuntimeWarning: invalid value encountered in sqrt\n"
]
],
[
[
"### Latent variable estimation (cosine model)",
"_____no_output_____"
]
],
[
[
"# Cosine estimation\n# x = a cos(wt + p) + kt\n# state = [a,w,p,k]\n\nprior_fn = lambda n: np.random.uniform(0,1,(n,4)) * [1.0, 0.25, np.pi*2.0, 0.1]\nnoise = 0.0005\nsigma = 0.5\n\ndef cos_observe(x, t): \n return x[:,0] * np.cos(t * x[:,1] + x[:,2] ) + x[:,3] * t\n\nts = [{\"t\":t} for t in x]\n\npf = ParticleFilter(prior_fn = prior_fn, \n observe_fn = cos_observe, \n dynamics_fn = lambda x, **kwargs:x ,\n n_particles=200, \n n_eff_threshold=1.0,\n noise_fn = lambda x, **kwargs: x + np.random.normal(0, noise, x.shape) ,\n weight_fn = lambda x,y, **kwargs: squared_error(x, y, sigma=sigma),\n transform_fn = lambda x, weights, **kwargs: cos_observe(x, kwargs['t'])[:,None],\n resample_proportion=0.01)\n\nfilter_plot(x, y, yn, pf, inputs=ts)\n",
"c:\\local\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:21: RuntimeWarning: invalid value encountered in sqrt\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac88f4b42b7149e47720a77b45ac07015cfdc36
| 171,313 |
ipynb
|
Jupyter Notebook
|
CaseOfOracleOpenWorld2018/2-OOW2018 Session Catalog - Wrangling I - one single, refined, reshaped file.ipynb
|
aamst/DataAnalytics--IntroductionDataWrangling-JupyterNotebooks
|
06bac89ee1cc8b28fe8d9a9b7aa1df00517ed8f1
|
[
"MIT"
] | 7 |
2019-05-09T10:04:03.000Z
|
2021-04-11T07:59:16.000Z
|
CaseOfOracleOpenWorld2018/2-OOW2018 Session Catalog - Wrangling I - one single, refined, reshaped file.ipynb
|
aamst/DataAnalytics--IntroductionDataWrangling-JupyterNotebooks
|
06bac89ee1cc8b28fe8d9a9b7aa1df00517ed8f1
|
[
"MIT"
] | 1 |
2019-02-16T08:52:37.000Z
|
2019-02-16T08:52:37.000Z
|
CaseOfOracleOpenWorld2018/2-OOW2018 Session Catalog - Wrangling I - one single, refined, reshaped file.ipynb
|
aamst/DataAnalytics--IntroductionDataWrangling-JupyterNotebooks
|
06bac89ee1cc8b28fe8d9a9b7aa1df00517ed8f1
|
[
"MIT"
] | 15 |
2019-02-14T06:53:21.000Z
|
2021-10-04T14:58:34.000Z
| 40.38496 | 610 | 0.465487 |
[
[
[
"# Step 2 - Data Wrangling Raw Data in Local Data Lake to Digestable Data \nLoading, merging, cleansing, unifying and wrangling Oracle OpenWorld & CodeOne Session Data from still fairly raw JSON files in the local datalake. \n\nThe gathering of raw data from the (semi-)public API for the Session Catalog into a local data lake was discussed and performed in <a href=\"./1-OOW2018 Session Catalog - retrieving raw session data in JSON files.ipynb\">Notebook 1-OOW2018 Session Catalog - retrieving raw session data in JSON files</a>. The current notebook starts from the 44 raw JSON files in local directory `./data`.\n\nThis notebook describes how to load, combine and wrangle the data from these files. This notebook shows for example how to load and merge data from dozens of (same formatted) JSON files, discard undesired attributes, deduplicate the record set, derive attributes for easier business intelligence & machine learning and write the resulting data set to a single JSON file.\n\nSteps in this notebook:\n* Load and Merge from raw JSON\n * <a href=\"#deduplicate\">discard redundant columns</a>\n * <a href=\"#deduplicate\">deduplication</a> \n* <a href=\"#explore\">Explore Data Frame</a>\n* <a href=\"#enriching\">Enrich Data</a>\n* <a href=\"publish\">Publish Wrangle Results</a>\n\nThe deliverable from this notebook is a single file `oow2018-sessions-wrangled.json` in the `datawarehouse` folder. This file contains unique, filtered, enriched data that is in a poper shape to perform further analysis on.",
"_____no_output_____"
],
[
"# Load and merge data from raw JSON files\nThis first section describes how the session data from Oracle OpenWorld 2018 is loaded from over 40 individual files with the raw JSON session data. These files are organized by session type and event (oow and codeone) - and have been produced by a different notebook (<a href=\"./1-OOW2018 Session Catalog - retrieving raw session data in JSON files.ipynb\">Notebook 1-OOW2018 Session Catalog - retrieving raw session data in JSON files</a>) from the Oracle OpenWorld Session Catalog API.\n\nThe files are read into individual Pandas Data Frame objects. These Data Frames are concatenated. The end result from reading 44 files is a single Pandas Data Frame - called *ss* (session schedule).\n\nLet's start with reading the session information from a single file into a Pandas Data Frame - to get a feel for how that works and what it results in.",
"_____no_output_____"
]
],
[
[
"#read a single session data file and parse the JSON content into a Pandas Data Frame\nimport pandas as pd\nimport json\n\ndataLake = \"datalake/\" # file system directory used for storing the gathered data\n\n#as a test, try to load data from one of the generated files \nconference = 'oow' # could also be codeone\nsessionType = 'TRN' # could also be one of 21 other values such as TUT, DEV, GEN, BOF, HOL, ...\nss = pd.read_json(\"{0}oow2018-sessions_{1}_{2}.json\".format(dataLake, conference, sessionType))\n# add an additional column to the Data Frame to specify the conference catalog of origin of these sessions; in this case oow\nss = ss.assign(catalog=conference)\n\nss.head(3)\n",
"_____no_output_____"
],
[
"#as a test, try to load data from another file ; same sessionType but different conference \n\nconference = 'codeone' \nsessionType = 'TRN'\nss2 = pd.read_json(\"{0}oow2018-sessions_{1}_{2}.json\".format(dataLake, conference, sessionType))\n# add an additional column to the Data Frame to specify the conference catalog of origin of these sessions; in this case codeone\nss2 = ss2.assign(catalog='codeone')\n\nss2.head(3)\n",
"_____no_output_____"
]
],
[
[
"All session data is to be merged into a single data frame. We will use `ss` as the sink - the data frame into which all sessions records are to be loaded. We use the Pandas concat operation to merge two Data Frames, as is done below for the two data frames with session records for session type TRN.",
"_____no_output_____"
]
],
[
[
"#add ss and ss2 together\n#see https://pandas.pydata.org/pandas-docs/stable/merging.html\nss = pd.concat([ss,ss2], ignore_index=True , sort=True)\nss.head(8)",
"_____no_output_____"
]
],
[
[
"Overhead, two files were loaded, parsed into a Data Frame and added together into a single Data Frame. The next step is to load the session data from the raw JSON file for all 44 files - for the two events and for all session types. The session types are defined in the Dict object *sessionTypes* . The code loops over the keys in this Dict and reads the corresponding JSON file for each of the two events.",
"_____no_output_____"
]
],
[
[
"sessionTypes = {'BOF': '1518466139979001dQkv'\n , 'BQS': 'bqs'\n , 'BUS': '1519240082595001EpMm'\n , 'CAS': 'casestudy'\n , 'DEV': '1522435540042001BxTD'\n , 'ESS': 'ess'\n , 'FLP': 'flp'\n , 'GEN': 'general'\n , 'HOL': 'hol'\n , 'HOM': 'hom'\n , 'IGN': 'ignite'\n , 'KEY': 'option_1508950285425'\n , 'MTE':'1523906206279002QAu9'\n , 'PKN': '1527614217434001RBfj'\n , 'PRO': '1518464344082003KVWZ'\n , 'PRM': '1518464344082002KM3k'\n , 'TRN': '1518464344082001KHky'\n , 'SIG': 'sig'\n , 'THT': 'ts'\n , 'TLD': '1537894888625001RriS'\n , 'TIP': '1517517756579001F3CR'\n , 'TUT': 'tutorial'\n#commented out because TRN is dealt with earlier on, 'TRN': '1518464344082001KHky'\n}\n#loop over all session types and read the corresponding files for both events codeone and oow\nfor key,value in sessionTypes.items():\n sessionType = key\n conference = 'oow' \n ssoow = pd.read_json(\"{0}oow2018-sessions_{1}_{2}.json\".format(dataLake, conference, sessionType))\n # add an additional column to the Data Frame to specify the conference catalog of origin of these sessions\n ssoow = ssoow.assign(catalog=conference)\n \n conference = 'codeone' \n sscodeone = pd.read_json(\"{0}oow2018-sessions_{1}_{2}.json\".format(dataLake, conference, sessionType))\n sscodeone = sscodeone.assign(catalog=conference)\n \n # merge data for sessions of type session type for both oow and codeone into a master set in ss\n ss = pd.concat([ss,ssoow,sscodeone], ignore_index=True, sort=True)\n \nprint(\"Done - all data is merged into one data frame\") ",
"Done - all data is merged into one data frame\n"
]
],
[
[
"### Some key metrics on the merged Sessions Set\nThe shape function on the data frame returns the dimensions of the frame: the number of rows by the number of columns:",
"_____no_output_____"
]
],
[
[
"ss.shape",
"_____no_output_____"
],
[
"# total memory usage\nss.memory_usage(index=True, deep=True).sum()",
"_____no_output_____"
],
[
"#list all columns in the Dataframe\nss.columns",
"_____no_output_____"
],
[
"# data types for the columns in the data frame\nss.dtypes",
"_____no_output_____"
],
[
"ss.groupby(['event','type'])['event'].count()",
"_____no_output_____"
]
],
[
[
"<a name=\"discard\" />",
"_____no_output_____"
],
[
"## Discard unneeded attributes\nEarly inspection of the JSON document and the session catalog website has provided insight in the available attributes and their relevance. Below, you will see an overview of all columns in the Data Frame - corresponding with the top level items in the JSON document. The subsequent step removes from the Data Frame all columns that seem irrelevant for our task at hand. \n\nThese columns seem relevant for the web frontend developers, for planned but not realized objectives or for unknown purposes. In order to not carry more weight than necessary - because of performance, resource usage and lurking complexity we get rid of columns that seem irrelevant. If we need them after all, they are still available in the data lake. ",
"_____no_output_____"
],
[
"Remove the unwanted columns from the Dataframe\n(allowDoubleBooking .'codeParts', 'code_id', 'es_metadata_id',type_displayorder\ttype_displayorder_string\tuseDoubleBooking\tuseWaitingList\tvideos\tviewAccess\tviewAccessPublic, ...)\n",
"_____no_output_____"
]
],
[
[
"# remove columns\n# Note that the original 'data' object is changed when inplace=True\nss.drop([\n 'allowDoubleBooking'\n ,'codeParts', 'code_id', 'es_metadata_id','type_displayorder'\n ,'type_displayorder_string', 'useDoubleBooking'\n ,'useWaitingList', 'videos'\n , 'viewAccess', 'viewAccessPublic','viewFileAccess', 'waitlistAccess', 'waitlistLimit'\n , 'eventId','eventName','featured_value','publicViewPrivateSchedule','published', 'scheduleAccess','sessionID','status'\n ,'externalID','highlight','abbreviation'\n ]\n , axis=1, inplace=True) ",
"_____no_output_____"
]
],
[
[
"<a name=\"deduplicate\" />",
"_____no_output_____"
],
[
"## Deduplicate\nSome sessions are included in the catalog for both events - Oracle OpenWorld and CodeOne - even though they are associated with one of the two. The exact same session - with only a different value for attribute catalog - occurs twice in our data set for these sessions. We should get rid of duplicates. However, we should not do so before we capture the fact that a session is part of the catalogs of both events in the record that is retained. \n\nNote: it seems there are some sessions that occur multiple times in the data set but are not included in both event catalogs. This seems to be just some form of data pollution.\n\nLet's first see how many events are part of both events' catalogs. ",
"_____no_output_____"
]
],
[
[
"# The code feature is supposed to be the unique identifier of sessions\n# Let's see at the multifold occurrence of individual code values\n\ncounts = ss['code'].value_counts()\ncounts.head(13)",
"_____no_output_____"
]
],
[
[
"We have found quite a few code values that occur multiple times in the data frame. Each code should be in the data frame only once. Let's further look into these sessions.",
"_____no_output_____"
]
],
[
[
"# let's create a data frame with all sessions whose code occurs more than one in the data frame\nduplicates = ss[ss['code'].isin(counts.index[counts > 1])]\n# show the first ten records of these 'candidate duplicates'\nduplicates[['code','title','event','catalog' ]].sort_values('code').head(10)",
"_____no_output_____"
],
[
"#are duplicates indeed associated with both events?\n# some are - but not all of them:\nduplicates.loc[duplicates['code']=='BOF4977']\n",
"_____no_output_____"
]
],
[
[
"The next step is a little bit complex: we want to record the fact that certain sessions (actually session codes) are associated with both catalogs. We join the sessions in `ss` with the sessions that occur multiple times in `duplicates` and we join records in `ss` with their counterparts (same session code) that have a different catalog origin.\n\nThis gives us a data frame with all session codes associated with both catalogs.",
"_____no_output_____"
]
],
[
[
"# find all sessions that occur in both catalogs: set their catalog attribute to both\n# set catalog=\"both\" if session in duplicates with a different catalog value than the session's own catalog value\ndoubleCatalogSessions = pd.merge(ss, duplicates, on=['code'], how='inner').query('catalog_y != catalog_x')\ndoubleCatalogSessions[['code','catalog_x', 'catalog_y']] .head(20)\n\n",
"_____no_output_____"
]
],
[
[
"The master dataset is still `ss`. All sessions in this data frame whose session code appears in `doubleCatalogSessions` will get their *catalog* attribute updated to *both*. The cell will then show the values in catalog and the number of their occurrences.",
"_____no_output_____"
]
],
[
[
"# all sessions in doubleCatalogSessions occur in both oow and code one session catalog\n# time to update column catalog for all sessions in ss that have a code that occurs in doubleCatalogSessions['code']\nss.loc[ss['code'].isin(doubleCatalogSessions['code']),'catalog']='both'\nss['catalog'].value_counts()",
"_____no_output_____"
]
],
[
[
"If we now drop any duplicate records - any sessions whose session code occurs more than once - we will reduce our data frame to the unique set of sessions that actually took place, without the ghost duplicates introduced in our data set because a session appeared in more than one catalog.",
"_____no_output_____"
]
],
[
[
"#Drop duplicates - identifying rows by their code\nss.drop_duplicates(subset=['code'], keep='first', inplace=True)",
"_____no_output_____"
],
[
"#hpw many sessions appear in each and in both catalogs?\nss['catalog'].value_counts()",
"_____no_output_____"
]
],
[
[
"<a name=\"explore\" />",
"_____no_output_____"
],
[
"# Exploring the Data\nLet's briefly look at the data we now have in the Pandas Data Frame. What does the data look like? What values do we have in the columns? And what complexity is hiding in some columns with nested values, such as participants, attributevalues and files.\n\nNote: https://morphocode.com/pandas-cheat-sheet/ provides a quick overview of commands used for inspecting and manipulating the data frame.",
"_____no_output_____"
]
],
[
[
"#an overview of the current contents of the data frame\nss.head(6)\n",
"_____no_output_____"
],
[
"# and this overview of the rows and columns in the data frame.\nprint(ss.info())",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 2052 entries, 0 to 2338\nData columns (total 14 columns):\nabstract 2052 non-null object\nattributevalues 2052 non-null object\ncatalog 2052 non-null object\ncode 2052 non-null object\nevent 2052 non-null object\neventCode 2052 non-null object\nfiles 1399 non-null object\nlength 2052 non-null float64\nparticipants 2052 non-null object\nsponsors 238 non-null object\ntimes 2051 non-null object\ntitle 2052 non-null object\ntitle_sort 2052 non-null object\ntype 2052 non-null object\ndtypes: float64(1), object(13)\nmemory usage: 240.5+ KB\nNone\n"
],
[
"#let's look at all different values for length (the duration of each session in minutes)\nss['length'].unique()\n# yes - it is that simple!",
"_____no_output_____"
],
[
"# and what about (session) type?\nss['type'].unique()",
"_____no_output_____"
]
],
[
[
"Some of the columns in the data frame contain complex, nested values. For example the `attributevalues` column. It contains a JSON array - a list of objects that each describe some attribute for the session. Examples of session attributes that are defined in this somewhat convoluted wat are *(target Experience) Level*, *Track*, *Day* , *Role*. A little later on, we will create new, proper features in the data frame based on values extracted from this complex attributevalues colunmn - in order to make it possible to make good use of this information for visualization, analysis and machine learning.",
"_____no_output_____"
]
],
[
[
"# some of the columns or attributes have nested values. It seems useful to take a closer look at them. \n# show nested array attributevalues for first record in Dataframe - this is an attribute which contains an array of objects that each define a specific characteristic of the session, \n# such as date and time, track, topic, level, role, company market size, \n\nss['attributevalues'][10]",
"_____no_output_____"
]
],
[
[
"The *participants* column also contains a complex object. This column too contains a JSON array with the people associated with a session as speaker. The array contains a nested object for each speaker. This object has a lot of data in it - from name and biography and special designations (titles) for the speaker to company, job title, URL to a picture and details on all (other) sessions the speaker is involved in.\n\nLet's take a look at an example.",
"_____no_output_____"
]
],
[
[
"#show nested array participants for 11th record in the Dataframe\nss['participants'][10]\n",
"_____no_output_____"
]
],
[
[
"The *files* column too contains a JSON array. This array contains entries for files associated with the session. These files provide the slides or other supporting content for the session. Each session is supposed to have exactly one files associated with it. Some do not - for example because the speaker(s) forgot to upload their slides. \n\nLet's inspect the JSON contents of the *files* column. It contains the name of the file and the URL from where it can be downloaded.",
"_____no_output_____"
]
],
[
[
"#show nested array files\nss['files'][0]",
"_____no_output_____"
]
],
[
[
"<a name=\"enriching\" />",
"_____no_output_____"
],
[
"# Enriching the data\nIn this section we are engineering the data to produce some attributes or features that are easier to work with once we start doing data science activities such as business intelligence or machine learning. In this section we are not yet actually bringing in external data sources to add information we not already have in our set. However, we are making the data we already have more accessible and thereby more valuable. So in that sense, this too can be called *enriching*. \n\nThe enrichments performed on the session data in the data frame :\n* set a flag at session level to indicate whether the session is an Oracle session (with Oracle staff among the speakers- speaker has Oracle in companyName attribute)\n* set a flag at session level to indicate whether a file has been uploaded for the session\n* set a flag at session level to indicate whether one of the speakers has Java Rockstar, Java Champion, Developer Champion/Groundbreaker Ambassador, ACE or ACE Director\n* set attribute level (based on attributevalues array) - beginner, all, ...\n* derive track(s?) from attributevalues array (where attribute_id=Track or attribute_id=CodeOneTracks )\n* set attribute with number of speakers on session\n* number of instances of the session ",
"_____no_output_____"
],
[
"### Oracle Speaker and File Uploaded\nThese functions `oracle_speaker` and `file_flag` are invoked for every record in the data frame. They are used to derive new, first class attributes to indicate whether or not at least one speaker working for Oracle is associated with a session (Y or N) and if a file has been upload (presumably with slides) for the session. The information represented by these two new attributes already exists in the data frame - but in a way that makes it quite unaccessible to the data analyst.",
"_____no_output_____"
]
],
[
[
"#function to derive Oracle flag from participants\ndef oracle_speaker(session):\n result = \"N\"\n # loop over speakers; if for any of them, companyName contains the word Oracle, the result =Y \n for x in session[\"participants\"][:]:\n if (\"oracle\" in x.get('companyName','x').lower()):\n result='Y'\n return result",
"_____no_output_____"
]
],
[
[
"New columns `oracle_speaker` and `file_flag` are added to the data frame with values derived for each record by applying the functions with corresponding names. ",
"_____no_output_____"
]
],
[
[
"#set oracle_speaker flag\n#apply function oracle_speaker to every row in the data frame to derive values for the new column oracle_speaker\nss['oracle_speaker'] = ss.apply(oracle_speaker, axis=1)\n# show the values and the number of occurrences for the new column oracle_speaker\nss['oracle_speaker'].value_counts()\n",
"_____no_output_____"
],
[
"#function to derive file flag from files\ndef file_flag(session):\n result = \"N\"\n if isinstance(session.get(\"files\",None),list) :\n # loop over files; if any exist, then result = Y\n for x in session[\"files\"][:]:\n if x['fileId']:\n result='Y'\n break\n return result",
"_____no_output_____"
],
[
"#set file_flag\n#apply function file_flag to every row in the data frame to derive values for the new column file_flag\nss['file_flag'] = ss.apply(file_flag, axis=1)\nss['file_flag'].value_counts()\n",
"_____no_output_____"
]
],
[
[
"### Speaker Designations\nMany of the speakers are special - in the sense that they have been awarded community awards and titles, such as (Oracle) Java Champion, Oracle ACE Directory, JavaOne Rockstar and Groundbreaker Ambassador. These designations can be found for speakers (a nested JSON object) in their *attributevalues* feature - which happens to be another nested JSON object.\n\nThe next function *speaker_designation* finds out for a session if it has at least one speaker associated with it who has the requested designation.",
"_____no_output_____"
]
],
[
[
"#function to derive designation flag from speakers\n# values for designation: JavaOne Rockstar, Oracle ACE Director, Oracle Java Champion, Groundbreaker Ambassador, \ndef speaker_designation(session, designation):\n result = \"N\"\n # loop over speakers and their attributevalues; if any exist with attribute_id == specialdesignations and value == JavaOne Rockstar\n for x in session[\"participants\"][:]:\n if \"attributevalues\" in x: \n for y in x[\"attributevalues\"][:]:\n if \"attribute_id\" in y: \n if y[\"attribute_id\"]==\"specialdesignations\":\n if y[\"value\"]== designation:\n result=\"Y\"\n return result",
"_____no_output_____"
]
],
[
[
"The next cell iterates over four major `designations` and derives for each designation a new column in the data frame that contain Y or N, depending on whether a speaker with the designation will present in the session. ",
"_____no_output_____"
]
],
[
[
"#set flags for designations\ndesignations = ['JavaOne Rockstar', 'Oracle ACE Director', 'Oracle Java Champion', 'Groundbreaker Ambassador']\nfor d in designations:\n ss[d] = ss.apply(speaker_designation, args=(d,), axis=1) ",
"_____no_output_____"
]
],
[
[
"Let's check the newly created columns: what values do they contain and how often does each value occur?",
"_____no_output_____"
]
],
[
[
"ss[['JavaOne Rockstar','Oracle ACE Director' , 'Oracle Java Champion', 'Groundbreaker Ambassador']].apply(pd.value_counts).fillna(0)",
"_____no_output_____"
]
],
[
[
"### Level\nEach session can be described as suitable for one or more levels of experience: Beginner, Intermediate or Advaned. Each session can be associated with all levels - or a subset of them. This level indication is somewhat hidden away, in the attributevalues object. The next function `session_level` will unearth for a given session whether it is associated with the specified level, Y or N.",
"_____no_output_____"
]
],
[
[
"#function to derive level flag for a session\ndef session_level(session, level):\n result = \"N\"\n # loop over attributevalues; if any exist with attribute_id == \"SessionsbyExperienceLevel\", and value == level\n for x in session[\"attributevalues\"][:]:\n if \"attribute_id\" in x: \n if x[\"attribute_id\"]==\"SessionsbyExperienceLevel\":\n if x[\"value\"]== level:\n result=\"Y\"\n break # no point in continuing if we have found what we are looking for\n return result",
"_____no_output_____"
]
],
[
[
"This cell runs through all three level values and creates a new column in the data frame for each level. It will set a Y or N for each session in the new columns, depending on whether session is associated with the level, or not.",
"_____no_output_____"
]
],
[
[
"#set flags for designations\nlevels = ['Intermediate', 'Beginner', 'Advanced']\nfor l in levels:\n ss[l] = ss.apply(session_level, args=(l,), axis=1) \nprint(\"Assigned Level Flags (Advanced, Intermediate, Beginner)\")",
"Assigned Level Flags (Advanced, Intermediate, Beginner)\n"
]
],
[
[
"Next we will derive values for a new column 'All' that indicates whether a session has been associated with all levels - even though I am not sure what exactly that means.",
"_____no_output_____"
]
],
[
[
"def isAll(session):\n return 'Y' if session['Beginner'] == 'Y' and session['Intermediate'] == 'Y' and session['Advanced'] == 'Y'else 'N'\n\nss['All'] = ss.apply( isAll, axis=1) ",
"_____no_output_____"
],
[
"ss[['Intermediate', 'Beginner', 'Advanced', 'All']].apply(pd.value_counts).fillna(0)",
"_____no_output_____"
]
],
[
[
"### Track\nAll sessions are assigned to one or more tracks. These tracks are categories that help attendees identify and assess sessions. Some examples of tracks are: Core Java Platform, Development Tools, Oracle Cloud Platform, MySQL, Containers, Serverless, and Cloud, Emerging Technologies, Modern Web, Application Development, Infrastructure Technologies (Data Center).\n\nDepending on whether a session originates from the Oracle OpenWorld or CodeOne catalog, the track(s) are found in the nested object *attributevalues* under the attribute_id *CodeOneTracks* or just *Track*.\n\nThe next function is created to return a String array for a session with all the tracks associated with the session.",
"_____no_output_____"
]
],
[
[
"#function to derive track flag for a session\ndef session_track(session):\n result = ['abc'] \n # loop over attributevalues; if any exist with attribute_id == \"SessionsbyExperienceLevel\", and value == level\n for x in session[\"attributevalues\"][:]:\n if \"attribute_id\" in x: \n if x[\"attribute_id\"]==\"CodeOneTracks\":\n result.append( x[\"value\"])\n if x[\"attribute_id\"]==\"Track\": \n result.append( x[\"value\"])\n del result[0] \n return result",
"_____no_output_____"
]
],
[
[
"The next cell uses the function `session_track` to produce the value for each session for the track. The cell then prints out the tracks for a sample of sessions.",
"_____no_output_____"
]
],
[
[
"# add column track with a value derived from the session record\nss[\"track\"] = ss.apply(session_track, axis=1) \nprint(\"Assigned Track\")\nss[['title','catalog','track']].tail(10)",
"Assigned Track\n"
]
],
[
[
"### Number of Speakers per Session\nThe number of speakers making an appearance in a session is another fact that while not readily available is also hiding in our data frame. We will turn this piece of information into an explicit feature. The next cell counts the number of elements in the participants array - and assigns it to the speaker_count attribute of each session record.",
"_____no_output_____"
]
],
[
[
"#set number of speakers for each session by taking the length of the list in the participants column\nss[\"speaker_count\"] = ss['participants'].apply(lambda x: len(x))\n# list the values in the new speaker_count column and the number of occurrences. 12 participants in one session?\nss['speaker_count'].value_counts()",
"_____no_output_____"
]
],
[
[
"### Number of instances per session\nMost sessions are scheduled just once. However, some sessions are executed multiple times. This can be derived from the *times* column in the data frame, simply by taking the number of elements in the JSON array in that column.\n\nThe next cell adds a column to the data frame, with for each session the number of times that session takes place.",
"_____no_output_____"
]
],
[
[
"#set number of instancesfor each session by taking the length of the list in the times column\nss[\"instance_count\"] = ss['times'].apply(lambda x: len(x) if x else None)\nss['instance_count'].value_counts()",
"_____no_output_____"
]
],
[
[
"### Session Room Capacity\nThe session records have a *times* feature - a JSON array with all the instances of the session. The elements contain the *capacity* attribute that gives the size or capcity of the room in which the session is scheduled. Because most sessions occur only once it seems acceptable to set a room_capacity feature on all session records in the data frame derived from the capacity found first element in the times feature. Likewise, we can derive the value for room itself.",
"_____no_output_____"
]
],
[
[
"#set the room capacity based on the capacity of the room of the first entry in the times list\n# note: when the session is scheduled multiple times, not all rooms may have the same capacity; that detail gets lost\nss[\"room_capacity\"]= ss['times'].apply(lambda x:x[0]['capacity'] if x else None)\nss[\"room\"]= ss['times'].apply(lambda x:x[0]['room'] if x else None)",
"_____no_output_____"
]
],
[
[
"### Session Slot - Day and Time\nAs discussed in the preceding section, the session records have a *times* feature - a JSON array with all the instances of the session. The elements contain attributes *dayName* and *time* that mark the slot in which the session is scehduled. Because most sessions occur only once it seems acceptable to set a session day and time feature from the values for time and day found first element in the times feature. Likewise, we can derive the Python DateTime value for the starting timestamp of the session.",
"_____no_output_____"
]
],
[
[
"#likewise derive day, time and room - from the first occurrence of the session\nss[\"day\"]= ss['times'].apply(lambda x:x[0]['dayName'] if x else None)\nss[\"time\"]= ss['times'].apply(lambda x:x[0]['time'] if x else None)\n\nss[['day','time']].apply(pd.value_counts).fillna(0)",
"_____no_output_____"
]
],
[
[
"The columns `day` and `time` are just strings. It may be useful for the data analysts further downstream in the data science pipeline to also have a real DateTime object to work with. The next cell introduces the `session_timestamp` column, set to the real timestamp derived from day and time. Note that we make use of one external piece of data not found in the datalake: the fact that Sunday in this case means 21st October 2018. ",
"_____no_output_____"
]
],
[
[
"import datetime\n# see https://stackabuse.com/converting-strings-to-datetime-in-python/\n\n#Sunday means 21st October 2018; monday through thursday are the days following the 21st\ndayMap = {'Sunday': '21', 'Monday': '22', 'Tuesday':'23', 'Wednesday':'24', 'Thursday':'25'}\n\n\ndef create_timestamp(day, timestr):\n if not timestr:\n return None\n if not day:\n return None\n dtString = '2018-10-'+ dayMap[day] +' '+ timestr\n return datetime.datetime.strptime(dtString, '%Y-%m-%d %H:%M')\n\ndef create_session_timestamp(session):\n return create_timestamp(session['day'], session['time'])\n\nss['session_timestamp'] = ss.apply(create_session_timestamp, axis=1) ",
"_____no_output_____"
],
[
"ss[['day','time','session_timestamp'] ].head(10)",
"_____no_output_____"
]
],
[
[
"<a name=\"publish\" />",
"_____no_output_____"
],
[
"## Persist Pandas Dataframe - as single, consolidated, reshaped, enriched JSON file",
"_____no_output_____"
],
[
"One thing we want to be able to do with the data we gather, is to persist it for future use by data analists, data scientists and other stakeholders. We could store the data in a NoSQL database, a cloud storage service or simply as a local file. For now, let's do the latter: store the cleansed and reshaped data in a local JSON file for further enrichment, visualization and machine learning purposes.\n\nThe file is called `oow2018-sessions-wrangled.json` and it will be stored in the `datawarehouse` folder.",
"_____no_output_____"
]
],
[
[
"dataWarehouse = \"datawarehouse/\" # file system directory used for storing the wrangled data\nss.to_json(\"{0}oow2018-sessions-wrangled.json\".format(dataWarehouse), force_ascii=False)",
"_____no_output_____"
]
],
[
[
"A quick check to see whether the wrangled session data was successfully written to disk - and can be read again. If we can read it, than we can safely assume that in the next phase in the data analytics flow the same will succeed.",
"_____no_output_____"
]
],
[
[
"dubss = pd.read_json(\"{0}oow2018-sessions-wrangled.json\".format(dataWarehouse))\ndubss.head(10)",
"_____no_output_____"
]
],
[
[
"If and when the previous cell lists session records correctly, then the data warehouse has been populated with the consolidated file *oow2018-sessions-wrangled.json* with all sessions - cleansed, deduplicated, enriched and ready for further processing.\n\nThe wrangled data set no longer contains many of the attributes not conceivably useful for further analysis. It has been extended with (derived) attributes that will probably be useful for next data analytics tasks. Additionally, the record set has been deduplicated to only the uniqe sessions. ",
"_____no_output_____"
]
],
[
[
"# a quick list of all columns\ndubss.columns",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac88f5108528fbe01284361184532e6ccb9cf76
| 294,601 |
ipynb
|
Jupyter Notebook
|
model3.ipynb
|
team-eda-datathon/datathon2020
|
4ca5224da5fe3cdb51df31e3ebf48979f718ba02
|
[
"MIT"
] | null | null | null |
model3.ipynb
|
team-eda-datathon/datathon2020
|
4ca5224da5fe3cdb51df31e3ebf48979f718ba02
|
[
"MIT"
] | null | null | null |
model3.ipynb
|
team-eda-datathon/datathon2020
|
4ca5224da5fe3cdb51df31e3ebf48979f718ba02
|
[
"MIT"
] | null | null | null | 64.662204 | 1,112 | 0.621437 |
[
[
[
"pip install scipy==1.1.0",
"Defaulting to user installation because normal site-packages is not writeable\nCollecting scipy==1.1.0\n Using cached scipy-1.1.0.tar.gz (15.6 MB)\nBuilding wheels for collected packages: scipy\n Building wheel for scipy (setup.py) ... \u001b[?25lerror\n\u001b[31m ERROR: Command errored out with exit status 1:\n command: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"'; __file__='\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"';f=getattr(tokenize, '\"'\"'open'\"'\"', open)(__file__);code=f.read().replace('\"'\"'\\r\\n'\"'\"', '\"'\"'\\n'\"'\"');f.close();exec(compile(code, __file__, '\"'\"'exec'\"'\"'))' bdist_wheel -d /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-wheel-rtp5zbfe\n cwd: /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/\n Complete output (3653 lines):\n lapack_opt_info:\n lapack_mkl_info:\n customize UnixCCompiler\n C compiler: xcrun -sdk macosx clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -iwithsysroot/System/Library/Frameworks/System.framework/PrivateHeaders -iwithsysroot/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.8/Headers -arch arm64 -arch x86_64\n \n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var/folders\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var/folders/wq\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b\n compile options: '-MMD -MF /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/file.c.d -c'\n xcrun: /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpbt0lv64b/file.c\n libraries mkl_rt not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_lapack_info:\n libraries openblas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_clapack_info:\n libraries openblas,lapack not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n flame_info:\n libraries flame not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_threads_info:\n Setting PTATLAS=ATLAS\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries tatlas,tatlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries tatlas,tatlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries tatlas,tatlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_3_10_threads_info'>\n NOT AVAILABLE\n \n atlas_3_10_info:\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries satlas,satlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries satlas,satlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries satlas,satlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_3_10_info'>\n NOT AVAILABLE\n \n atlas_threads_info:\n Setting PTATLAS=ATLAS\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries ptf77blas,ptcblas,atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries ptf77blas,ptcblas,atlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries ptf77blas,ptcblas,atlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_threads_info'>\n NOT AVAILABLE\n \n atlas_info:\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries f77blas,cblas,atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries f77blas,cblas,atlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries f77blas,cblas,atlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_info'>\n NOT AVAILABLE\n \n accelerate_info:\n libraries accelerate not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n Library accelerate was not found. Ignoring\n libraries veclib not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n Library veclib was not found. Ignoring\n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n Running from scipy source directory.\n Splitting linalg.interpolative Fortran source files\n /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/distutils/system_info.py:820: UserWarning: Specified path /Users/school/Library/Python/3.8/include/python3.8 is invalid.\n return self.get_paths(self.section, key)\n /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/distutils/system_info.py:820: UserWarning: Specified path /usr/local/include/python3.8 is invalid.\n return self.get_paths(self.section, key)\n blas_opt_info:\n blas_mkl_info:\n libraries mkl_rt not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n blis_info:\n libraries blis not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_info:\n libraries openblas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_blas_threads_info:\n Setting PTATLAS=ATLAS\n libraries tatlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_blas_info:\n libraries satlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_blas_threads_info:\n Setting PTATLAS=ATLAS\n libraries ptf77blas,ptcblas,atlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_blas_info:\n libraries f77blas,cblas,atlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n non-existing path in 'scipy/signal/windows': 'tests'\n non-existing path in 'scipy/sparse': 'sparsetools/sparsetools_impl.h'\n non-existing path in 'scipy/sparse': 'sparsetools/bsr_impl.h'\n non-existing path in 'scipy/sparse': 'sparsetools/csc_impl.h'\n non-existing path in 'scipy/sparse': 'sparsetools/csr_impl.h'\n non-existing path in 'scipy/sparse': 'sparsetools/other_impl.h'\n [makenpz] scipy/special/tests/data/boost.npz not rebuilt\n [makenpz] scipy/special/tests/data/gsl.npz not rebuilt\n [makenpz] scipy/special/tests/data/local.npz not rebuilt\n running bdist_wheel\n running build\n running config_cc\n unifing config_cc, config, build_clib, build_ext, build commands --compiler options\n running config_fc\n unifing config_fc, config, build_clib, build_ext, build commands --fcompiler options\n running build_src\n build_src\n building py_modules sources\n creating build\n creating build/src.macosx-10.14.6-x86_64-3.8\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy\n building library \"dfftpack\" sources\n building library \"fftpack\" sources\n building library \"mach\" sources\n building library \"quadpack\" sources\n building library \"lsoda\" sources\n building library \"vode\" sources\n building library \"dop\" sources\n building library \"fitpack\" sources\n building library \"fwrappers\" sources\n building library \"odrpack\" sources\n building library \"minpack\" sources\n building library \"rootfind\" sources\n building library \"superlu_src\" sources\n building library \"arpack_scipy\" sources\n building library \"sc_c_misc\" sources\n building library \"sc_cephes\" sources\n building library \"sc_mach\" sources\n building library \"sc_amos\" sources\n building library \"sc_cdf\" sources\n building library \"sc_specfun\" sources\n building library \"statlib\" sources\n building extension \"scipy.cluster._vq\" sources\n building extension \"scipy.cluster._hierarchy\" sources\n building extension \"scipy.cluster._optimal_leaf_ordering\" sources\n building extension \"scipy.fftpack._fftpack\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/src\n conv_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/src/dct.c\n conv_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/src/dst.c\n f2py options: []\n f2py: scipy/fftpack/fftpack.pyf\n Reading fortran codes...\n \tReading file 'scipy/fftpack/fftpack.pyf' (format:free)\n Post-processing...\n \tBlock: _fftpack\n \t\t\tBlock: zfft\n \t\t\tBlock: drfft\n \t\t\tBlock: zrfft\n \t\t\tBlock: zfftnd\n \t\t\tBlock: destroy_zfft_cache\n \t\t\tBlock: destroy_zfftnd_cache\n \t\t\tBlock: destroy_drfft_cache\n \t\t\tBlock: cfft\n \t\t\tBlock: rfft\n \t\t\tBlock: crfft\n \t\t\tBlock: cfftnd\n \t\t\tBlock: destroy_cfft_cache\n \t\t\tBlock: destroy_cfftnd_cache\n \t\t\tBlock: destroy_rfft_cache\n \t\t\tBlock: ddct1\n \t\t\tBlock: ddct2\n \t\t\tBlock: ddct3\n \t\t\tBlock: dct1\n \t\t\tBlock: dct2\n \t\t\tBlock: dct3\n \t\t\tBlock: destroy_ddct2_cache\n \t\t\tBlock: destroy_ddct1_cache\n \t\t\tBlock: destroy_dct2_cache\n \t\t\tBlock: destroy_dct1_cache\n \t\t\tBlock: ddst1\n \t\t\tBlock: ddst2\n \t\t\tBlock: ddst3\n \t\t\tBlock: dst1\n \t\t\tBlock: dst2\n \t\t\tBlock: dst3\n \t\t\tBlock: destroy_ddst2_cache\n \t\t\tBlock: destroy_ddst1_cache\n \t\t\tBlock: destroy_dst2_cache\n \t\t\tBlock: destroy_dst1_cache\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_fftpack\"...\n \t\tConstructing wrapper function \"zfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"drfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = drfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"zrfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zrfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"zfftnd\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zfftnd(x,[s,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"destroy_zfft_cache\"...\n \t\t destroy_zfft_cache()\n \t\tConstructing wrapper function \"destroy_zfftnd_cache\"...\n \t\t destroy_zfftnd_cache()\n \t\tConstructing wrapper function \"destroy_drfft_cache\"...\n \t\t destroy_drfft_cache()\n \t\tConstructing wrapper function \"cfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = cfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"rfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = rfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"crfft\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = crfft(x,[n,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"cfftnd\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = cfftnd(x,[s,direction,normalize,overwrite_x])\n \t\tConstructing wrapper function \"destroy_cfft_cache\"...\n \t\t destroy_cfft_cache()\n \t\tConstructing wrapper function \"destroy_cfftnd_cache\"...\n \t\t destroy_cfftnd_cache()\n \t\tConstructing wrapper function \"destroy_rfft_cache\"...\n \t\t destroy_rfft_cache()\n \t\tConstructing wrapper function \"ddct1\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddct1(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"ddct2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddct2(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"ddct3\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddct3(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dct1\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dct1(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dct2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dct2(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dct3\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dct3(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"destroy_ddct2_cache\"...\n \t\t destroy_ddct2_cache()\n \t\tConstructing wrapper function \"destroy_ddct1_cache\"...\n \t\t destroy_ddct1_cache()\n \t\tConstructing wrapper function \"destroy_dct2_cache\"...\n \t\t destroy_dct2_cache()\n \t\tConstructing wrapper function \"destroy_dct1_cache\"...\n \t\t destroy_dct1_cache()\n \t\tConstructing wrapper function \"ddst1\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddst1(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"ddst2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddst2(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"ddst3\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ddst3(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dst1\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dst1(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dst2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dst2(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"dst3\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dst3(x,[n,normalize,overwrite_x])\n \t\tConstructing wrapper function \"destroy_ddst2_cache\"...\n \t\t destroy_ddst2_cache()\n \t\tConstructing wrapper function \"destroy_ddst1_cache\"...\n \t\t destroy_ddst1_cache()\n \t\tConstructing wrapper function \"destroy_dst2_cache\"...\n \t\t destroy_dst2_cache()\n \t\tConstructing wrapper function \"destroy_dst1_cache\"...\n \t\t destroy_dst1_cache()\n \tWrote C/API module \"_fftpack\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/_fftpackmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n building extension \"scipy.fftpack.convolve\" sources\n f2py options: []\n f2py: scipy/fftpack/convolve.pyf\n Reading fortran codes...\n \tReading file 'scipy/fftpack/convolve.pyf' (format:free)\n Post-processing...\n \tBlock: convolve__user__routines\n \t\t\tBlock: kernel_func\n \tBlock: convolve\n \t\t\tBlock: init_convolution_kernel\n In: scipy/fftpack/convolve.pyf:convolve:unknown_interface:init_convolution_kernel\n get_useparameters: no module convolve__user__routines info used by init_convolution_kernel\n \t\t\tBlock: destroy_convolve_cache\n \t\t\tBlock: convolve\n \t\t\tBlock: convolve_z\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_kernel_func_in_convolve__user__routines\"\n \t def kernel_func(k): return kernel_func\n \tBuilding module \"convolve\"...\n \t\tConstructing wrapper function \"init_convolution_kernel\"...\n \t\t omega = init_convolution_kernel(n,kernel_func,[d,zero_nyquist,kernel_func_extra_args])\n \t\tConstructing wrapper function \"destroy_convolve_cache\"...\n \t\t destroy_convolve_cache()\n \t\tConstructing wrapper function \"convolve\"...\n \t\t y = convolve(x,omega,[swap_real_imag,overwrite_x])\n \t\tConstructing wrapper function \"convolve_z\"...\n \t\t y = convolve_z(x,omega_real,omega_imag,[overwrite_x])\n \tWrote C/API module \"convolve\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/convolvemodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack' to include_dirs.\n building extension \"scipy.integrate._quadpack\" sources\n building extension \"scipy.integrate._odepack\" sources\n building extension \"scipy.integrate.vode\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate\n f2py options: []\n f2py: scipy/integrate/vode.pyf\n Reading fortran codes...\n \tReading file 'scipy/integrate/vode.pyf' (format:free)\n Post-processing...\n \tBlock: dvode__user__routines\n \t\tBlock: dvode_user_interface\n \t\t\tBlock: f\n \t\t\tBlock: jac\n \tBlock: zvode__user__routines\n \t\tBlock: zvode_user_interface\n \t\t\tBlock: f\n \t\t\tBlock: jac\n \tBlock: vode\n \t\t\tBlock: dvode\n In: scipy/integrate/vode.pyf:vode:unknown_interface:dvode\n get_useparameters: no module dvode__user__routines info used by dvode\n \t\t\tBlock: zvode\n In: scipy/integrate/vode.pyf:vode:unknown_interface:zvode\n get_useparameters: no module zvode__user__routines info used by zvode\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_f_in_dvode__user__routines\"\n \t def f(t,y): return ydot\n \tConstructing call-back function \"cb_jac_in_dvode__user__routines\"\n \t def jac(t,y): return jac\n \tConstructing call-back function \"cb_f_in_zvode__user__routines\"\n \t def f(t,y): return ydot\n \tConstructing call-back function \"cb_jac_in_zvode__user__routines\"\n \t def jac(t,y): return jac\n \tBuilding module \"vode\"...\n \t\tConstructing wrapper function \"dvode\"...\n warning: callstatement is defined without callprotoargument\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y,t,istate = dvode(f,jac,y,t,tout,rtol,atol,itask,istate,rwork,iwork,mf,[f_extra_args,jac_extra_args,overwrite_y])\n \t\tConstructing wrapper function \"zvode\"...\n warning: callstatement is defined without callprotoargument\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y,t,istate = zvode(f,jac,y,t,tout,rtol,atol,itask,istate,zwork,rwork,iwork,mf,[f_extra_args,jac_extra_args,overwrite_y])\n \tWrote C/API module \"vode\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/vodemodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate\n building extension \"scipy.integrate.lsoda\" sources\n f2py options: []\n f2py: scipy/integrate/lsoda.pyf\n Reading fortran codes...\n \tReading file 'scipy/integrate/lsoda.pyf' (format:free)\n Post-processing...\n \tBlock: lsoda__user__routines\n \t\tBlock: lsoda_user_interface\n \t\t\tBlock: f\n \t\t\tBlock: jac\n \tBlock: lsoda\n \t\t\tBlock: lsoda\n In: scipy/integrate/lsoda.pyf:lsoda:unknown_interface:lsoda\n get_useparameters: no module lsoda__user__routines info used by lsoda\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_f_in_lsoda__user__routines\"\n \t def f(t,y): return ydot\n \tConstructing call-back function \"cb_jac_in_lsoda__user__routines\"\n \t def jac(t,y): return jac\n \tBuilding module \"lsoda\"...\n \t\tConstructing wrapper function \"lsoda\"...\n warning: callstatement is defined without callprotoargument\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y,t,istate = lsoda(f,y,t,tout,rtol,atol,itask,istate,rwork,iwork,jac,jt,[f_extra_args,overwrite_y,jac_extra_args])\n \tWrote C/API module \"lsoda\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/lsodamodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n building extension \"scipy.integrate._dop\" sources\n f2py options: []\n f2py: scipy/integrate/dop.pyf\n Reading fortran codes...\n \tReading file 'scipy/integrate/dop.pyf' (format:free)\n Post-processing...\n \tBlock: __user__routines\n \t\t\tBlock: fcn\n \t\t\tBlock: solout\n \tBlock: _dop\n \t\t\tBlock: dopri5\n In: scipy/integrate/dop.pyf:_dop:unknown_interface:dopri5\n get_useparameters: no module __user__routines info used by dopri5\n \t\t\tBlock: dop853\n In: scipy/integrate/dop.pyf:_dop:unknown_interface:dop853\n get_useparameters: no module __user__routines info used by dop853\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_fcn_in___user__routines\"\n \t def fcn(x,y): return f\n \tConstructing call-back function \"cb_solout_in___user__routines\"\n \t def solout(nr,xold,x,y,con,icomp,[nd]): return irtn\n \tBuilding module \"_dop\"...\n \t\tConstructing wrapper function \"dopri5\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y,iwork,idid = dopri5(fcn,x,y,xend,rtol,atol,solout,iout,work,iwork,[fcn_extra_args,overwrite_y,solout_extra_args])\n \t\tConstructing wrapper function \"dop853\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y,iwork,idid = dop853(fcn,x,y,xend,rtol,atol,solout,iout,work,iwork,[fcn_extra_args,overwrite_y,solout_extra_args])\n \tWrote C/API module \"_dop\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_dopmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n building extension \"scipy.integrate._test_multivariate\" sources\n building extension \"scipy.integrate._test_odeint_banded\" sources\n f2py options: []\n f2py:> build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_test_odeint_bandedmodule.c\n Reading fortran codes...\n \tReading file 'scipy/integrate/tests/banded5x5.f' (format:fix,strict)\n Post-processing...\n \tBlock: _test_odeint_banded\n \t\t\tBlock: jacobian\n \t\t\tBlock: getbands\n \t\t\tBlock: banded5x5\n \t\t\tBlock: banded5x5_jac\n \t\t\tBlock: banded5x5_bjac\n \t\t\tBlock: banded5x5_solve\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_test_odeint_banded\"...\n \t\tConstructing wrapper function \"getbands\"...\n \t\t jac = getbands()\n \t\tConstructing wrapper function \"banded5x5\"...\n \t\t banded5x5(t,y,f,[n])\n \t\tConstructing wrapper function \"banded5x5_jac\"...\n \t\t banded5x5_jac(t,y,ml,mu,jac,[n,nrowpd])\n \t\tConstructing wrapper function \"banded5x5_bjac\"...\n \t\t banded5x5_bjac(t,y,ml,mu,bjac,[n,nrowpd])\n \t\tConstructing wrapper function \"banded5x5_solve\"...\n \t\t nst,nfe,nje = banded5x5_solve(y,nsteps,dt,jt)\n \t\tConstructing COMMON block support for \"jac\"...\n \t\t bands\n \tWrote C/API module \"_test_odeint_banded\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_test_odeint_bandedmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_test_odeint_banded-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_test_odeint_banded-f2pywrappers.f' to sources.\n building extension \"scipy.interpolate.interpnd\" sources\n building extension \"scipy.interpolate._ppoly\" sources\n building extension \"scipy.interpolate._bspl\" sources\n building extension \"scipy.interpolate._fitpack\" sources\n building extension \"scipy.interpolate.dfitpack\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src\n f2py options: []\n f2py: scipy/interpolate/src/fitpack.pyf\n Reading fortran codes...\n \tReading file 'scipy/interpolate/src/fitpack.pyf' (format:free)\n Post-processing...\n \tBlock: dfitpack\n \t\t\tBlock: fpchec\n \t\t\tBlock: splev\n \t\t\tBlock: splder\n \t\t\tBlock: splint\n \t\t\tBlock: sproot\n \t\t\tBlock: spalde\n \t\t\tBlock: curfit\n \t\t\tBlock: percur\n \t\t\tBlock: parcur\n \t\t\tBlock: fpcurf0\n \t\t\tBlock: fpcurf1\n \t\t\tBlock: fpcurfm1\n \t\t\tBlock: bispev\n \t\t\tBlock: parder\n \t\t\tBlock: bispeu\n \t\t\tBlock: pardeu\n \t\t\tBlock: surfit_smth\n \t\t\tBlock: surfit_lsq\n \t\t\tBlock: spherfit_smth\n \t\t\tBlock: spherfit_lsq\n \t\t\tBlock: regrid_smth\n \t\t\tBlock: regrid_smth_spher\n \t\t\tBlock: dblint\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"dfitpack\"...\n \t\tConstructing wrapper function \"fpchec\"...\n \t\t ier = fpchec(x,t,k)\n \t\tConstructing wrapper function \"splev\"...\n \t\t y = splev(t,c,k,x,[e])\n \t\tConstructing wrapper function \"splder\"...\n \t\t y = splder(t,c,k,x,[nu,e])\n \t\tCreating wrapper for Fortran function \"splint\"(\"splint\")...\n \t\tConstructing wrapper function \"splint\"...\n \t\t splint = splint(t,c,k,a,b)\n \t\tConstructing wrapper function \"sproot\"...\n \t\t zero,m,ier = sproot(t,c,[mest])\n \t\tConstructing wrapper function \"spalde\"...\n \t\t d,ier = spalde(t,c,k,x)\n \t\tConstructing wrapper function \"curfit\"...\n \t\t n,c,fp,ier = curfit(iopt,x,y,w,t,wrk,iwrk,[xb,xe,k,s])\n \t\tConstructing wrapper function \"percur\"...\n \t\t n,c,fp,ier = percur(iopt,x,y,w,t,wrk,iwrk,[k,s])\n \t\tConstructing wrapper function \"parcur\"...\n \t\t n,c,fp,ier = parcur(iopt,ipar,idim,u,x,w,ub,ue,t,wrk,iwrk,[k,s])\n \t\tConstructing wrapper function \"fpcurf0\"...\n \t\t x,y,w,xb,xe,k,s,n,t,c,fp,fpint,nrdata,ier = fpcurf0(x,y,k,[w,xb,xe,s,nest])\n \t\tConstructing wrapper function \"fpcurf1\"...\n \t\t x,y,w,xb,xe,k,s,n,t,c,fp,fpint,nrdata,ier = fpcurf1(x,y,w,xb,xe,k,s,n,t,c,fp,fpint,nrdata,ier,[overwrite_x,overwrite_y,overwrite_w,overwrite_t,overwrite_c,overwrite_fpint,overwrite_nrdata])\n \t\tConstructing wrapper function \"fpcurfm1\"...\n \t\t x,y,w,xb,xe,k,s,n,t,c,fp,fpint,nrdata,ier = fpcurfm1(x,y,k,t,[w,xb,xe,overwrite_t])\n \t\tConstructing wrapper function \"bispev\"...\n \t\t z,ier = bispev(tx,ty,c,kx,ky,x,y)\n \t\tConstructing wrapper function \"parder\"...\n \t\t z,ier = parder(tx,ty,c,kx,ky,nux,nuy,x,y)\n \t\tConstructing wrapper function \"bispeu\"...\n \t\t z,ier = bispeu(tx,ty,c,kx,ky,x,y)\n \t\tConstructing wrapper function \"pardeu\"...\n \t\t z,ier = pardeu(tx,ty,c,kx,ky,nux,nuy,x,y)\n \t\tConstructing wrapper function \"surfit_smth\"...\n \t\t nx,tx,ny,ty,c,fp,wrk1,ier = surfit_smth(x,y,z,[w,xb,xe,yb,ye,kx,ky,s,nxest,nyest,eps,lwrk2])\n \t\tConstructing wrapper function \"surfit_lsq\"...\n \t\t tx,ty,c,fp,ier = surfit_lsq(x,y,z,tx,ty,[w,xb,xe,yb,ye,kx,ky,eps,lwrk2,overwrite_tx,overwrite_ty])\n \t\tConstructing wrapper function \"spherfit_smth\"...\n \t\t nt,tt,np,tp,c,fp,ier = spherfit_smth(teta,phi,r,[w,s,eps])\n \t\tConstructing wrapper function \"spherfit_lsq\"...\n \t\t tt,tp,c,fp,ier = spherfit_lsq(teta,phi,r,tt,tp,[w,eps,overwrite_tt,overwrite_tp])\n \t\tConstructing wrapper function \"regrid_smth\"...\n \t\t nx,tx,ny,ty,c,fp,ier = regrid_smth(x,y,z,[xb,xe,yb,ye,kx,ky,s])\n \t\tConstructing wrapper function \"regrid_smth_spher\"...\n \t\t nu,tu,nv,tv,c,fp,ier = regrid_smth_spher(iopt,ider,u,v,r,[r0,r1,s])\n \t\tCreating wrapper for Fortran function \"dblint\"(\"dblint\")...\n \t\tConstructing wrapper function \"dblint\"...\n \t\t dblint = dblint(tx,ty,c,kx,ky,xb,xe,yb,ye)\n \tWrote C/API module \"dfitpack\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/dfitpackmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/dfitpack-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/dfitpack-f2pywrappers.f' to sources.\n building extension \"scipy.interpolate._interpolate\" sources\n building extension \"scipy.io._test_fortran\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/io\n f2py options: []\n f2py: scipy/io/_test_fortran.pyf\n Reading fortran codes...\n \tReading file 'scipy/io/_test_fortran.pyf' (format:free)\n Post-processing...\n \tBlock: _test_fortran\n \t\t\tBlock: read_unformatted_double\n \t\t\tBlock: read_unformatted_int\n \t\t\tBlock: read_unformatted_mixed\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_test_fortran\"...\n \t\tConstructing wrapper function \"read_unformatted_double\"...\n \t\t a = read_unformatted_double(m,n,k,filename)\n \t\tConstructing wrapper function \"read_unformatted_int\"...\n \t\t a = read_unformatted_int(m,n,k,filename)\n \t\tConstructing wrapper function \"read_unformatted_mixed\"...\n \t\t a,b = read_unformatted_mixed(m,n,k,filename)\n \tWrote C/API module \"_test_fortran\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/io/_test_fortranmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io\n building extension \"scipy.io.matlab.streams\" sources\n building extension \"scipy.io.matlab.mio_utils\" sources\n building extension \"scipy.io.matlab.mio5_utils\" sources\n building extension \"scipy.linalg._fblas\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fblas.pyf\n Including file scipy/linalg/fblas_l1.pyf.src\n Including file scipy/linalg/fblas_l2.pyf.src\n Including file scipy/linalg/fblas_l3.pyf.src\n Mismatch in number of replacements (base <prefix=s,d,c,z>) for <__l1=->. Ignoring.\n Mismatch in number of replacements (base <prefix6=s,d,c,z,c,z>) for <prefix=s,d,c,z>. Ignoring.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n f2py options: []\n f2py: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fblas.pyf\n Reading fortran codes...\n \tReading file 'build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fblas.pyf' (format:free)\n Post-processing...\n \tBlock: _fblas\n \t\t\tBlock: srotg\n \t\t\tBlock: drotg\n \t\t\tBlock: crotg\n \t\t\tBlock: zrotg\n \t\t\tBlock: srotmg\n \t\t\tBlock: drotmg\n \t\t\tBlock: srot\n \t\t\tBlock: drot\n \t\t\tBlock: csrot\n \t\t\tBlock: zdrot\n \t\t\tBlock: srotm\n \t\t\tBlock: drotm\n \t\t\tBlock: sswap\n \t\t\tBlock: dswap\n \t\t\tBlock: cswap\n \t\t\tBlock: zswap\n \t\t\tBlock: sscal\n \t\t\tBlock: dscal\n \t\t\tBlock: cscal\n \t\t\tBlock: zscal\n \t\t\tBlock: csscal\n \t\t\tBlock: zdscal\n \t\t\tBlock: scopy\n \t\t\tBlock: dcopy\n \t\t\tBlock: ccopy\n \t\t\tBlock: zcopy\n \t\t\tBlock: saxpy\n \t\t\tBlock: daxpy\n \t\t\tBlock: caxpy\n \t\t\tBlock: zaxpy\n \t\t\tBlock: sdot\n \t\t\tBlock: ddot\n \t\t\tBlock: cdotu\n \t\t\tBlock: zdotu\n \t\t\tBlock: cdotc\n \t\t\tBlock: zdotc\n \t\t\tBlock: snrm2\n \t\t\tBlock: scnrm2\n \t\t\tBlock: dnrm2\n \t\t\tBlock: dznrm2\n \t\t\tBlock: sasum\n \t\t\tBlock: scasum\n \t\t\tBlock: dasum\n \t\t\tBlock: dzasum\n \t\t\tBlock: isamax\n \t\t\tBlock: idamax\n \t\t\tBlock: icamax\n \t\t\tBlock: izamax\n \t\t\tBlock: sgemv\n \t\t\tBlock: dgemv\n \t\t\tBlock: cgemv\n \t\t\tBlock: zgemv\n \t\t\tBlock: sgbmv\n \t\t\tBlock: dgbmv\n \t\t\tBlock: cgbmv\n \t\t\tBlock: zgbmv\n \t\t\tBlock: ssbmv\n \t\t\tBlock: dsbmv\n \t\t\tBlock: chbmv\n \t\t\tBlock: zhbmv\n \t\t\tBlock: sspmv\n \t\t\tBlock: dspmv\n \t\t\tBlock: cspmv\n \t\t\tBlock: zspmv\n \t\t\tBlock: chpmv\n \t\t\tBlock: zhpmv\n \t\t\tBlock: ssymv\n \t\t\tBlock: dsymv\n \t\t\tBlock: chemv\n \t\t\tBlock: zhemv\n \t\t\tBlock: sger\n \t\t\tBlock: dger\n \t\t\tBlock: cgeru\n \t\t\tBlock: zgeru\n \t\t\tBlock: cgerc\n \t\t\tBlock: zgerc\n \t\t\tBlock: ssyr\n \t\t\tBlock: dsyr\n \t\t\tBlock: csyr\n \t\t\tBlock: zsyr\n \t\t\tBlock: cher\n \t\t\tBlock: zher\n \t\t\tBlock: ssyr2\n \t\t\tBlock: dsyr2\n \t\t\tBlock: cher2\n \t\t\tBlock: zher2\n \t\t\tBlock: sspr\n \t\t\tBlock: dspr\n \t\t\tBlock: cspr\n \t\t\tBlock: zspr\n \t\t\tBlock: chpr\n \t\t\tBlock: zhpr\n \t\t\tBlock: sspr2\n \t\t\tBlock: dspr2\n \t\t\tBlock: chpr2\n \t\t\tBlock: zhpr2\n \t\t\tBlock: stbsv\n \t\t\tBlock: dtbsv\n \t\t\tBlock: ctbsv\n \t\t\tBlock: ztbsv\n \t\t\tBlock: stpsv\n \t\t\tBlock: dtpsv\n \t\t\tBlock: ctpsv\n \t\t\tBlock: ztpsv\n \t\t\tBlock: strmv\n \t\t\tBlock: dtrmv\n \t\t\tBlock: ctrmv\n \t\t\tBlock: ztrmv\n \t\t\tBlock: strsv\n \t\t\tBlock: dtrsv\n \t\t\tBlock: ctrsv\n \t\t\tBlock: ztrsv\n \t\t\tBlock: stbmv\n \t\t\tBlock: dtbmv\n \t\t\tBlock: ctbmv\n \t\t\tBlock: ztbmv\n \t\t\tBlock: stpmv\n \t\t\tBlock: dtpmv\n \t\t\tBlock: ctpmv\n \t\t\tBlock: ztpmv\n \t\t\tBlock: sgemm\n \t\t\tBlock: dgemm\n \t\t\tBlock: cgemm\n \t\t\tBlock: zgemm\n \t\t\tBlock: ssymm\n \t\t\tBlock: dsymm\n \t\t\tBlock: csymm\n \t\t\tBlock: zsymm\n \t\t\tBlock: chemm\n \t\t\tBlock: zhemm\n \t\t\tBlock: ssyrk\n \t\t\tBlock: dsyrk\n \t\t\tBlock: csyrk\n \t\t\tBlock: zsyrk\n \t\t\tBlock: cherk\n \t\t\tBlock: zherk\n \t\t\tBlock: ssyr2k\n \t\t\tBlock: dsyr2k\n \t\t\tBlock: csyr2k\n \t\t\tBlock: zsyr2k\n \t\t\tBlock: cher2k\n \t\t\tBlock: zher2k\n \t\t\tBlock: strmm\n \t\t\tBlock: dtrmm\n \t\t\tBlock: ctrmm\n \t\t\tBlock: ztrmm\n \t\t\tBlock: strsm\n \t\t\tBlock: dtrsm\n \t\t\tBlock: ctrsm\n \t\t\tBlock: ztrsm\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_fblas\"...\n \t\tConstructing wrapper function \"srotg\"...\n \t\t c,s = srotg(a,b)\n \t\tConstructing wrapper function \"drotg\"...\n \t\t c,s = drotg(a,b)\n \t\tConstructing wrapper function \"crotg\"...\n \t\t c,s = crotg(a,b)\n \t\tConstructing wrapper function \"zrotg\"...\n \t\t c,s = zrotg(a,b)\n \t\tConstructing wrapper function \"srotmg\"...\n \t\t param = srotmg(d1,d2,x1,y1)\n \t\tConstructing wrapper function \"drotmg\"...\n \t\t param = drotmg(d1,d2,x1,y1)\n \t\tConstructing wrapper function \"srot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = srot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"drot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = drot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"csrot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = csrot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"zdrot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = zdrot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"srotm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = srotm(x,y,param,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"drotm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = drotm(x,y,param,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"sswap\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = sswap(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"dswap\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = dswap(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"cswap\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = cswap(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"zswap\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,y = zswap(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"sscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = sscal(a,x,[n,offx,incx])\n \t\tConstructing wrapper function \"dscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = dscal(a,x,[n,offx,incx])\n \t\tConstructing wrapper function \"cscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = cscal(a,x,[n,offx,incx])\n \t\tConstructing wrapper function \"zscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = zscal(a,x,[n,offx,incx])\n \t\tConstructing wrapper function \"csscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = csscal(a,x,[n,offx,incx,overwrite_x])\n \t\tConstructing wrapper function \"zdscal\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = zdscal(a,x,[n,offx,incx,overwrite_x])\n \t\tConstructing wrapper function \"scopy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = scopy(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"dcopy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dcopy(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"ccopy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ccopy(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"zcopy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zcopy(x,y,[n,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"saxpy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t z = saxpy(x,y,[n,a,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"daxpy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t z = daxpy(x,y,[n,a,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"caxpy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t z = caxpy(x,y,[n,a,offx,incx,offy,incy])\n \t\tConstructing wrapper function \"zaxpy\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t z = zaxpy(x,y,[n,a,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"sdot\"(\"wsdot \")...\n \t\tConstructing wrapper function \"sdot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = sdot(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"ddot\"(\"ddot\")...\n \t\tConstructing wrapper function \"ddot\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = ddot(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"cdotu\"(\"wcdotu \")...\n \t\tConstructing wrapper function \"cdotu\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = cdotu(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"zdotu\"(\"wzdotu \")...\n \t\tConstructing wrapper function \"zdotu\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = zdotu(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"cdotc\"(\"wcdotc \")...\n \t\tConstructing wrapper function \"cdotc\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = cdotc(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"zdotc\"(\"wzdotc \")...\n \t\tConstructing wrapper function \"zdotc\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xy = zdotc(x,y,[n,offx,incx,offy,incy])\n \t\tCreating wrapper for Fortran function \"snrm2\"(\"wsnrm2 \")...\n \t\tConstructing wrapper function \"snrm2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t n2 = snrm2(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"scnrm2\"(\"wscnrm2 \")...\n \t\tConstructing wrapper function \"scnrm2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t n2 = scnrm2(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"dnrm2\"(\"dnrm2\")...\n \t\tConstructing wrapper function \"dnrm2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t n2 = dnrm2(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"dznrm2\"(\"dznrm2\")...\n \t\tConstructing wrapper function \"dznrm2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t n2 = dznrm2(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"sasum\"(\"wsasum \")...\n \t\tConstructing wrapper function \"sasum\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t s = sasum(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"scasum\"(\"wscasum \")...\n \t\tConstructing wrapper function \"scasum\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t s = scasum(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"dasum\"(\"dasum\")...\n \t\tConstructing wrapper function \"dasum\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t s = dasum(x,[n,offx,incx])\n \t\tCreating wrapper for Fortran function \"dzasum\"(\"dzasum\")...\n \t\tConstructing wrapper function \"dzasum\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t s = dzasum(x,[n,offx,incx])\n \t\tConstructing wrapper function \"isamax\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t k = isamax(x,[n,offx,incx])\n \t\tConstructing wrapper function \"idamax\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t k = idamax(x,[n,offx,incx])\n \t\tConstructing wrapper function \"icamax\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t k = icamax(x,[n,offx,incx])\n \t\tConstructing wrapper function \"izamax\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t k = izamax(x,[n,offx,incx])\n \t\tConstructing wrapper function \"sgemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = sgemv(alpha,a,x,[beta,y,offx,incx,offy,incy,trans,overwrite_y])\n \t\tConstructing wrapper function \"dgemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dgemv(alpha,a,x,[beta,y,offx,incx,offy,incy,trans,overwrite_y])\n \t\tConstructing wrapper function \"cgemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = cgemv(alpha,a,x,[beta,y,offx,incx,offy,incy,trans,overwrite_y])\n \t\tConstructing wrapper function \"zgemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zgemv(alpha,a,x,[beta,y,offx,incx,offy,incy,trans,overwrite_y])\n \t\tConstructing wrapper function \"sgbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = sgbmv(m,n,kl,ku,alpha,a,x,[incx,offx,beta,y,incy,offy,trans,overwrite_y])\n \t\tConstructing wrapper function \"dgbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = dgbmv(m,n,kl,ku,alpha,a,x,[incx,offx,beta,y,incy,offy,trans,overwrite_y])\n \t\tConstructing wrapper function \"cgbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = cgbmv(m,n,kl,ku,alpha,a,x,[incx,offx,beta,y,incy,offy,trans,overwrite_y])\n \t\tConstructing wrapper function \"zgbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = zgbmv(m,n,kl,ku,alpha,a,x,[incx,offx,beta,y,incy,offy,trans,overwrite_y])\n \t\tConstructing wrapper function \"ssbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = ssbmv(k,alpha,a,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"dsbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = dsbmv(k,alpha,a,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"chbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = chbmv(k,alpha,a,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"zhbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = zhbmv(k,alpha,a,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"sspmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = sspmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"dspmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = dspmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"cspmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = cspmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"zspmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = zspmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"chpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = chpmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"zhpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t yout = zhpmv(n,alpha,ap,x,[incx,offx,beta,y,incy,offy,lower,overwrite_y])\n \t\tConstructing wrapper function \"ssymv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = ssymv(alpha,a,x,[beta,y,offx,incx,offy,incy,lower,overwrite_y])\n \t\tConstructing wrapper function \"dsymv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = dsymv(alpha,a,x,[beta,y,offx,incx,offy,incy,lower,overwrite_y])\n \t\tConstructing wrapper function \"chemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = chemv(alpha,a,x,[beta,y,offx,incx,offy,incy,lower,overwrite_y])\n \t\tConstructing wrapper function \"zhemv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t y = zhemv(alpha,a,x,[beta,y,offx,incx,offy,incy,lower,overwrite_y])\n \t\tConstructing wrapper function \"sger\"...\n \t\t a = sger(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"dger\"...\n \t\t a = dger(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"cgeru\"...\n \t\t a = cgeru(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"zgeru\"...\n \t\t a = zgeru(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"cgerc\"...\n \t\t a = cgerc(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"zgerc\"...\n \t\t a = zgerc(alpha,x,y,[incx,incy,a,overwrite_x,overwrite_y,overwrite_a])\n \t\tConstructing wrapper function \"ssyr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = ssyr(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"dsyr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = dsyr(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"csyr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = csyr(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"zsyr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = zsyr(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"cher\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = cher(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"zher\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = zher(alpha,x,[lower,incx,offx,n,a,overwrite_a])\n \t\tConstructing wrapper function \"ssyr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = ssyr2(alpha,x,y,[lower,incx,offx,incy,offy,n,a,overwrite_a])\n \t\tConstructing wrapper function \"dsyr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = dsyr2(alpha,x,y,[lower,incx,offx,incy,offy,n,a,overwrite_a])\n \t\tConstructing wrapper function \"cher2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = cher2(alpha,x,y,[lower,incx,offx,incy,offy,n,a,overwrite_a])\n \t\tConstructing wrapper function \"zher2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t a = zher2(alpha,x,y,[lower,incx,offx,incy,offy,n,a,overwrite_a])\n \t\tConstructing wrapper function \"sspr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = sspr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"dspr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = dspr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"cspr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = cspr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"zspr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = zspr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"chpr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = chpr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"zhpr\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = zhpr(n,alpha,x,ap,[incx,offx,lower,overwrite_ap])\n \t\tConstructing wrapper function \"sspr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = sspr2(n,alpha,x,y,ap,[incx,offx,incy,offy,lower,overwrite_ap])\n \t\tConstructing wrapper function \"dspr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = dspr2(n,alpha,x,y,ap,[incx,offx,incy,offy,lower,overwrite_ap])\n \t\tConstructing wrapper function \"chpr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = chpr2(n,alpha,x,y,ap,[incx,offx,incy,offy,lower,overwrite_ap])\n \t\tConstructing wrapper function \"zhpr2\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t apu = zhpr2(n,alpha,x,y,ap,[incx,offx,incy,offy,lower,overwrite_ap])\n \t\tConstructing wrapper function \"stbsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = stbsv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtbsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = dtbsv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctbsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ctbsv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztbsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ztbsv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"stpsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = stpsv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtpsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = dtpsv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctpsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ctpsv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztpsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ztpsv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"strmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = strmv(a,x,[offx,incx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtrmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = dtrmv(a,x,[offx,incx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctrmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = ctrmv(a,x,[offx,incx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztrmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = ztrmv(a,x,[offx,incx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"strsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = strsv(a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtrsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = dtrsv(a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctrsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ctrsv(a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztrsv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ztrsv(a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"stbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = stbmv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = dtbmv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ctbmv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztbmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ztbmv(k,a,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"stpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = stpmv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"dtpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = dtpmv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ctpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ctpmv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"ztpmv\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t xout = ztpmv(n,ap,x,[incx,offx,lower,trans,diag,overwrite_x])\n \t\tConstructing wrapper function \"sgemm\"...\n \t\t c = sgemm(alpha,a,b,[beta,c,trans_a,trans_b,overwrite_c])\n \t\tConstructing wrapper function \"dgemm\"...\n \t\t c = dgemm(alpha,a,b,[beta,c,trans_a,trans_b,overwrite_c])\n \t\tConstructing wrapper function \"cgemm\"...\n \t\t c = cgemm(alpha,a,b,[beta,c,trans_a,trans_b,overwrite_c])\n \t\tConstructing wrapper function \"zgemm\"...\n \t\t c = zgemm(alpha,a,b,[beta,c,trans_a,trans_b,overwrite_c])\n \t\tConstructing wrapper function \"ssymm\"...\n \t\t c = ssymm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"dsymm\"...\n \t\t c = dsymm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"csymm\"...\n \t\t c = csymm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"zsymm\"...\n \t\t c = zsymm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"chemm\"...\n \t\t c = chemm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"zhemm\"...\n \t\t c = zhemm(alpha,a,b,[beta,c,side,lower,overwrite_c])\n \t\tConstructing wrapper function \"ssyrk\"...\n \t\t c = ssyrk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"dsyrk\"...\n \t\t c = dsyrk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"csyrk\"...\n \t\t c = csyrk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"zsyrk\"...\n \t\t c = zsyrk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"cherk\"...\n \t\t c = cherk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"zherk\"...\n \t\t c = zherk(alpha,a,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"ssyr2k\"...\n \t\t c = ssyr2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"dsyr2k\"...\n \t\t c = dsyr2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"csyr2k\"...\n \t\t c = csyr2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"zsyr2k\"...\n \t\t c = zsyr2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"cher2k\"...\n \t\t c = cher2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"zher2k\"...\n \t\t c = zher2k(alpha,a,b,[beta,c,trans,lower,overwrite_c])\n \t\tConstructing wrapper function \"strmm\"...\n \t\t b = strmm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"dtrmm\"...\n \t\t b = dtrmm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"ctrmm\"...\n \t\t b = ctrmm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"ztrmm\"...\n \t\t b = ztrmm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"strsm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = strsm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"dtrsm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = dtrsm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"ctrsm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = ctrsm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \t\tConstructing wrapper function \"ztrsm\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x = ztrsm(alpha,a,b,[side,lower,trans_a,diag,overwrite_b])\n \tWrote C/API module \"_fblas\" to file \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_fblasmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_fblas-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_fblas-f2pywrappers.f' to sources.\n building extension \"scipy.linalg._flapack\" sources\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf\n Including file scipy/linalg/flapack_user.pyf.src\n f2py options: []\n f2py: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf\n Reading fortran codes...\n \tReading file 'build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf' (format:free)\n Post-processing...\n \tBlock: _flapack\n \t\t\tBlock: gees__user__routines\n \t\t\t\t\tBlock: sselect\n \t\t\t\t\tBlock: dselect\n \t\t\t\t\tBlock: cselect\n \t\t\t\t\tBlock: zselect\n \t\t\tBlock: gges__user__routines\n \t\t\t\t\tBlock: cselect\n \t\t\t\t\tBlock: zselect\n \t\t\t\t\tBlock: sselect\n \t\t\t\t\tBlock: dselect\n \t\t\tBlock: stgsen\n \t\t\tBlock: dtgsen\n \t\t\tBlock: ctgsen\n \t\t\tBlock: ztgsen\n \t\t\tBlock: sgges\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:sgges\n get_useparameters: no module gges__user__routines info used by sgges\n \t\t\tBlock: dgges\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:dgges\n get_useparameters: no module gges__user__routines info used by dgges\n \t\t\tBlock: cgges\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:cgges\n get_useparameters: no module gges__user__routines info used by cgges\n \t\t\tBlock: zgges\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:zgges\n get_useparameters: no module gges__user__routines info used by zgges\n \t\t\tBlock: spbtrf\n \t\t\tBlock: dpbtrf\n \t\t\tBlock: cpbtrf\n \t\t\tBlock: zpbtrf\n \t\t\tBlock: spbtrs\n \t\t\tBlock: dpbtrs\n \t\t\tBlock: cpbtrs\n \t\t\tBlock: zpbtrs\n \t\t\tBlock: strtrs\n \t\t\tBlock: dtrtrs\n \t\t\tBlock: ctrtrs\n \t\t\tBlock: ztrtrs\n \t\t\tBlock: spbsv\n \t\t\tBlock: dpbsv\n \t\t\tBlock: cpbsv\n \t\t\tBlock: zpbsv\n \t\t\tBlock: sptsv\n \t\t\tBlock: dptsv\n \t\t\tBlock: cptsv\n \t\t\tBlock: zptsv\n \t\t\tBlock: sgebal\n \t\t\tBlock: dgebal\n \t\t\tBlock: cgebal\n \t\t\tBlock: zgebal\n \t\t\tBlock: sgehrd\n \t\t\tBlock: dgehrd\n \t\t\tBlock: cgehrd\n \t\t\tBlock: zgehrd\n \t\t\tBlock: sgehrd_lwork\n \t\t\tBlock: dgehrd_lwork\n \t\t\tBlock: cgehrd_lwork\n \t\t\tBlock: zgehrd_lwork\n \t\t\tBlock: sorghr\n \t\t\tBlock: dorghr\n \t\t\tBlock: sorghr_lwork\n \t\t\tBlock: dorghr_lwork\n \t\t\tBlock: cunghr\n \t\t\tBlock: zunghr\n \t\t\tBlock: cunghr_lwork\n \t\t\tBlock: zunghr_lwork\n \t\t\tBlock: sgbsv\n \t\t\tBlock: dgbsv\n \t\t\tBlock: cgbsv\n \t\t\tBlock: zgbsv\n \t\t\tBlock: sgtsv\n \t\t\tBlock: dgtsv\n \t\t\tBlock: cgtsv\n \t\t\tBlock: zgtsv\n \t\t\tBlock: sgesv\n \t\t\tBlock: dgesv\n \t\t\tBlock: cgesv\n \t\t\tBlock: zgesv\n \t\t\tBlock: sgesvx\n \t\t\tBlock: dgesvx\n \t\t\tBlock: cgesvx\n \t\t\tBlock: zgesvx\n \t\t\tBlock: sgecon\n \t\t\tBlock: dgecon\n \t\t\tBlock: cgecon\n \t\t\tBlock: zgecon\n \t\t\tBlock: ssytf2\n \t\t\tBlock: dsytf2\n \t\t\tBlock: csytf2\n \t\t\tBlock: zsytf2\n \t\t\tBlock: ssygst\n \t\t\tBlock: dsygst\n \t\t\tBlock: ssytrf\n \t\t\tBlock: dsytrf\n \t\t\tBlock: csytrf\n \t\t\tBlock: zsytrf\n \t\t\tBlock: ssytrf_lwork\n \t\t\tBlock: dsytrf_lwork\n \t\t\tBlock: csytrf_lwork\n \t\t\tBlock: zsytrf_lwork\n \t\t\tBlock: ssysv\n \t\t\tBlock: dsysv\n \t\t\tBlock: csysv\n \t\t\tBlock: zsysv\n \t\t\tBlock: ssysv_lwork\n \t\t\tBlock: dsysv_lwork\n \t\t\tBlock: csysv_lwork\n \t\t\tBlock: zsysv_lwork\n \t\t\tBlock: ssysvx\n \t\t\tBlock: dsysvx\n \t\t\tBlock: csysvx\n \t\t\tBlock: zsysvx\n \t\t\tBlock: ssysvx_lwork\n \t\t\tBlock: dsysvx_lwork\n \t\t\tBlock: csysvx_lwork\n \t\t\tBlock: zsysvx_lwork\n \t\t\tBlock: ssycon\n \t\t\tBlock: dsycon\n \t\t\tBlock: csycon\n \t\t\tBlock: zsycon\n \t\t\tBlock: checon\n \t\t\tBlock: zhecon\n \t\t\tBlock: chegst\n \t\t\tBlock: zhegst\n \t\t\tBlock: chetrf\n \t\t\tBlock: zhetrf\n \t\t\tBlock: chetrf_lwork\n \t\t\tBlock: zhetrf_lwork\n \t\t\tBlock: chesv\n \t\t\tBlock: zhesv\n \t\t\tBlock: chesv_lwork\n \t\t\tBlock: zhesv_lwork\n \t\t\tBlock: chesvx\n \t\t\tBlock: zhesvx\n \t\t\tBlock: chesvx_lwork\n \t\t\tBlock: zhesvx_lwork\n \t\t\tBlock: sgetrf\n \t\t\tBlock: dgetrf\n \t\t\tBlock: cgetrf\n \t\t\tBlock: zgetrf\n \t\t\tBlock: ssytrd\n \t\t\tBlock: dsytrd\n \t\t\tBlock: ssytrd_lwork\n \t\t\tBlock: dsytrd_lwork\n \t\t\tBlock: chetrd\n \t\t\tBlock: zhetrd\n \t\t\tBlock: chetrd_lwork\n \t\t\tBlock: zhetrd_lwork\n \t\t\tBlock: sgetrs\n \t\t\tBlock: dgetrs\n \t\t\tBlock: cgetrs\n \t\t\tBlock: zgetrs\n \t\t\tBlock: sgetri\n \t\t\tBlock: dgetri\n \t\t\tBlock: cgetri\n \t\t\tBlock: zgetri\n \t\t\tBlock: sgetri_lwork\n \t\t\tBlock: dgetri_lwork\n \t\t\tBlock: cgetri_lwork\n \t\t\tBlock: zgetri_lwork\n \t\t\tBlock: sgesdd\n \t\t\tBlock: dgesdd\n \t\t\tBlock: sgesdd_lwork\n \t\t\tBlock: dgesdd_lwork\n \t\t\tBlock: cgesdd\n \t\t\tBlock: zgesdd\n \t\t\tBlock: cgesdd_lwork\n \t\t\tBlock: zgesdd_lwork\n \t\t\tBlock: sgesvd\n \t\t\tBlock: dgesvd\n \t\t\tBlock: sgesvd_lwork\n \t\t\tBlock: dgesvd_lwork\n \t\t\tBlock: cgesvd\n \t\t\tBlock: zgesvd\n \t\t\tBlock: cgesvd_lwork\n \t\t\tBlock: zgesvd_lwork\n \t\t\tBlock: sgels\n \t\t\tBlock: dgels\n \t\t\tBlock: cgels\n \t\t\tBlock: zgels\n \t\t\tBlock: sgels_lwork\n \t\t\tBlock: dgels_lwork\n \t\t\tBlock: cgels_lwork\n \t\t\tBlock: zgels_lwork\n \t\t\tBlock: sgelss\n \t\t\tBlock: dgelss\n \t\t\tBlock: sgelss_lwork\n \t\t\tBlock: dgelss_lwork\n \t\t\tBlock: cgelss\n \t\t\tBlock: zgelss\n \t\t\tBlock: slasd4\n \t\t\tBlock: dlasd4\n \t\t\tBlock: cgelss_lwork\n \t\t\tBlock: zgelss_lwork\n \t\t\tBlock: sgelsy\n \t\t\tBlock: dgelsy\n \t\t\tBlock: sgelsy_lwork\n \t\t\tBlock: dgelsy_lwork\n \t\t\tBlock: cgelsy\n \t\t\tBlock: zgelsy\n \t\t\tBlock: cgelsy_lwork\n \t\t\tBlock: zgelsy_lwork\n \t\t\tBlock: sgelsd\n \t\t\tBlock: dgelsd\n \t\t\tBlock: sgelsd_lwork\n \t\t\tBlock: dgelsd_lwork\n \t\t\tBlock: cgelsd\n \t\t\tBlock: zgelsd\n \t\t\tBlock: cgelsd_lwork\n \t\t\tBlock: zgelsd_lwork\n \t\t\tBlock: sgeqp3\n \t\t\tBlock: dgeqp3\n \t\t\tBlock: cgeqp3\n \t\t\tBlock: zgeqp3\n \t\t\tBlock: sgeqrf\n \t\t\tBlock: dgeqrf\n \t\t\tBlock: cgeqrf\n \t\t\tBlock: zgeqrf\n \t\t\tBlock: sgerqf\n \t\t\tBlock: dgerqf\n \t\t\tBlock: cgerqf\n \t\t\tBlock: zgerqf\n \t\t\tBlock: sorgqr\n \t\t\tBlock: dorgqr\n \t\t\tBlock: cungqr\n \t\t\tBlock: zungqr\n \t\t\tBlock: sormqr\n \t\t\tBlock: dormqr\n \t\t\tBlock: cunmqr\n \t\t\tBlock: zunmqr\n \t\t\tBlock: sorgrq\n \t\t\tBlock: dorgrq\n \t\t\tBlock: cungrq\n \t\t\tBlock: zungrq\n \t\t\tBlock: sgeev\n \t\t\tBlock: dgeev\n \t\t\tBlock: sgeev_lwork\n \t\t\tBlock: dgeev_lwork\n \t\t\tBlock: cgeev\n \t\t\tBlock: zgeev\n \t\t\tBlock: cgeev_lwork\n \t\t\tBlock: zgeev_lwork\n \t\t\tBlock: sgegv\n \t\t\tBlock: dgegv\n \t\t\tBlock: cgegv\n \t\t\tBlock: zgegv\n \t\t\tBlock: ssyev\n \t\t\tBlock: dsyev\n \t\t\tBlock: cheev\n \t\t\tBlock: zheev\n \t\t\tBlock: ssyevd\n \t\t\tBlock: dsyevd\n \t\t\tBlock: cheevd\n \t\t\tBlock: zheevd\n \t\t\tBlock: sposv\n \t\t\tBlock: dposv\n \t\t\tBlock: cposv\n \t\t\tBlock: zposv\n \t\t\tBlock: sposvx\n \t\t\tBlock: dposvx\n \t\t\tBlock: cposvx\n \t\t\tBlock: zposvx\n \t\t\tBlock: spocon\n \t\t\tBlock: dpocon\n \t\t\tBlock: cpocon\n \t\t\tBlock: zpocon\n \t\t\tBlock: spotrf\n \t\t\tBlock: dpotrf\n \t\t\tBlock: cpotrf\n \t\t\tBlock: zpotrf\n \t\t\tBlock: spotrs\n \t\t\tBlock: dpotrs\n \t\t\tBlock: cpotrs\n \t\t\tBlock: zpotrs\n \t\t\tBlock: spotri\n \t\t\tBlock: dpotri\n \t\t\tBlock: cpotri\n \t\t\tBlock: zpotri\n \t\t\tBlock: slauum\n \t\t\tBlock: dlauum\n \t\t\tBlock: clauum\n \t\t\tBlock: zlauum\n \t\t\tBlock: strtri\n \t\t\tBlock: dtrtri\n \t\t\tBlock: ctrtri\n \t\t\tBlock: ztrtri\n \t\t\tBlock: strsyl\n \t\t\tBlock: dtrsyl\n \t\t\tBlock: ctrsyl\n \t\t\tBlock: ztrsyl\n \t\t\tBlock: slaswp\n \t\t\tBlock: dlaswp\n \t\t\tBlock: claswp\n \t\t\tBlock: zlaswp\n \t\t\tBlock: cgees\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:cgees\n get_useparameters: no module gees__user__routines info used by cgees\n \t\t\tBlock: zgees\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:zgees\n get_useparameters: no module gees__user__routines info used by zgees\n \t\t\tBlock: sgees\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:sgees\n get_useparameters: no module gees__user__routines info used by sgees\n \t\t\tBlock: dgees\n In: build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/flapack.pyf:_flapack:unknown_interface:dgees\n get_useparameters: no module gees__user__routines info used by dgees\n \t\t\tBlock: sggev\n \t\t\tBlock: dggev\n \t\t\tBlock: cggev\n \t\t\tBlock: zggev\n \t\t\tBlock: ssbev\n \t\t\tBlock: dsbev\n \t\t\tBlock: ssbevd\n \t\t\tBlock: dsbevd\n \t\t\tBlock: ssbevx\n \t\t\tBlock: dsbevx\n \t\t\tBlock: sstebz\n \t\t\tBlock: dstebz\n \t\t\tBlock: ssterf\n \t\t\tBlock: dsterf\n \t\t\tBlock: sstein\n \t\t\tBlock: dstein\n \t\t\tBlock: sstemr\n \t\t\tBlock: dstemr\n \t\t\tBlock: sstemr_lwork\n \t\t\tBlock: dstemr_lwork\n \t\t\tBlock: sstev\n \t\t\tBlock: dstev\n \t\t\tBlock: chbevd\n \t\t\tBlock: zhbevd\n \t\t\tBlock: chbevx\n \t\t\tBlock: zhbevx\n \t\t\tBlock: dlamch\n \t\t\tBlock: slamch\n \t\t\tBlock: sgbtrf\n \t\t\tBlock: dgbtrf\n \t\t\tBlock: cgbtrf\n \t\t\tBlock: zgbtrf\n \t\t\tBlock: sgbtrs\n \t\t\tBlock: dgbtrs\n \t\t\tBlock: cgbtrs\n \t\t\tBlock: zgbtrs\n \t\t\tBlock: ssyevr\n \t\t\tBlock: dsyevr\n \t\t\tBlock: cheevr\n \t\t\tBlock: zheevr\n \t\t\tBlock: ssygv\n \t\t\tBlock: dsygv\n \t\t\tBlock: chegv\n \t\t\tBlock: zhegv\n \t\t\tBlock: ssygvd\n \t\t\tBlock: dsygvd\n \t\t\tBlock: chegvd\n \t\t\tBlock: zhegvd\n \t\t\tBlock: ssygvx\n \t\t\tBlock: dsygvx\n \t\t\tBlock: chegvx\n \t\t\tBlock: zhegvx\n \t\t\tBlock: sgglse\n \t\t\tBlock: dgglse\n \t\t\tBlock: cgglse\n \t\t\tBlock: zgglse\n \t\t\tBlock: sgglse_lwork\n \t\t\tBlock: dgglse_lwork\n \t\t\tBlock: cgglse_lwork\n \t\t\tBlock: zgglse_lwork\n \t\t\tBlock: slange\n \t\t\tBlock: dlange\n \t\t\tBlock: clange\n \t\t\tBlock: zlange\n \t\t\tBlock: slarfg\n \t\t\tBlock: dlarfg\n \t\t\tBlock: clarfg\n \t\t\tBlock: zlarfg\n \t\t\tBlock: slarf\n \t\t\tBlock: dlarf\n \t\t\tBlock: clarf\n \t\t\tBlock: zlarf\n \t\t\tBlock: slartg\n \t\t\tBlock: dlartg\n \t\t\tBlock: clartg\n \t\t\tBlock: zlartg\n \t\t\tBlock: crot\n \t\t\tBlock: zrot\n \t\t\tBlock: ilaver\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_sselect_in_gees__user__routines\"\n \t def sselect(arg1,arg2): return sselect\n \tConstructing call-back function \"cb_dselect_in_gees__user__routines\"\n \t def dselect(arg1,arg2): return dselect\n \tConstructing call-back function \"cb_cselect_in_gees__user__routines\"\n \t def cselect(arg): return cselect\n \tConstructing call-back function \"cb_zselect_in_gees__user__routines\"\n \t def zselect(arg): return zselect\n \tConstructing call-back function \"cb_cselect_in_gges__user__routines\"\n \t def cselect(alpha,beta): return cselect\n \tConstructing call-back function \"cb_zselect_in_gges__user__routines\"\n \t def zselect(alpha,beta): return zselect\n \tConstructing call-back function \"cb_sselect_in_gges__user__routines\"\n \t def sselect(alphar,alphai,beta): return sselect\n \tConstructing call-back function \"cb_dselect_in_gges__user__routines\"\n \t def dselect(alphar,alphai,beta): return dselect\n \tBuilding module \"_flapack\"...\n \t\tConstructing wrapper function \"stgsen\"...\n \t\t a,b,alphar,alphai,beta,q,z,m,pl,pr,dif,work,iwork,info = stgsen(select,a,b,q,z,[lwork,liwork,overwrite_a,overwrite_b,overwrite_q,overwrite_z])\n \t\tConstructing wrapper function \"dtgsen\"...\n \t\t a,b,alphar,alphai,beta,q,z,m,pl,pr,dif,work,iwork,info = dtgsen(select,a,b,q,z,[lwork,liwork,overwrite_a,overwrite_b,overwrite_q,overwrite_z])\n \t\tConstructing wrapper function \"ctgsen\"...\n \t\t a,b,alpha,beta,q,z,m,pl,pr,dif,work,iwork,info = ctgsen(select,a,b,q,z,[lwork,liwork,overwrite_a,overwrite_b,overwrite_q,overwrite_z])\n \t\tConstructing wrapper function \"ztgsen\"...\n \t\t a,b,alpha,beta,q,z,m,pl,pr,dif,work,iwork,info = ztgsen(select,a,b,q,z,[lwork,liwork,overwrite_a,overwrite_b,overwrite_q,overwrite_z])\n \t\tConstructing wrapper function \"sgges\"...\n \t\t a,b,sdim,alphar,alphai,beta,vsl,vsr,work,info = sgges(sselect,a,b,[jobvsl,jobvsr,sort_t,ldvsl,ldvsr,lwork,sselect_extra_args,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgges\"...\n \t\t a,b,sdim,alphar,alphai,beta,vsl,vsr,work,info = dgges(dselect,a,b,[jobvsl,jobvsr,sort_t,ldvsl,ldvsr,lwork,dselect_extra_args,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgges\"...\n \t\t a,b,sdim,alpha,beta,vsl,vsr,work,info = cgges(cselect,a,b,[jobvsl,jobvsr,sort_t,ldvsl,ldvsr,lwork,cselect_extra_args,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgges\"...\n \t\t a,b,sdim,alpha,beta,vsl,vsr,work,info = zgges(zselect,a,b,[jobvsl,jobvsr,sort_t,ldvsl,ldvsr,lwork,zselect_extra_args,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"spbtrf\"...\n \t\t c,info = spbtrf(ab,[lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"dpbtrf\"...\n \t\t c,info = dpbtrf(ab,[lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"cpbtrf\"...\n \t\t c,info = cpbtrf(ab,[lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"zpbtrf\"...\n \t\t c,info = zpbtrf(ab,[lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"spbtrs\"...\n \t\t x,info = spbtrs(ab,b,[lower,ldab,overwrite_b])\n \t\tConstructing wrapper function \"dpbtrs\"...\n \t\t x,info = dpbtrs(ab,b,[lower,ldab,overwrite_b])\n \t\tConstructing wrapper function \"cpbtrs\"...\n \t\t x,info = cpbtrs(ab,b,[lower,ldab,overwrite_b])\n \t\tConstructing wrapper function \"zpbtrs\"...\n \t\t x,info = zpbtrs(ab,b,[lower,ldab,overwrite_b])\n \t\tConstructing wrapper function \"strtrs\"...\n \t\t x,info = strtrs(a,b,[lower,trans,unitdiag,lda,overwrite_b])\n \t\tConstructing wrapper function \"dtrtrs\"...\n \t\t x,info = dtrtrs(a,b,[lower,trans,unitdiag,lda,overwrite_b])\n \t\tConstructing wrapper function \"ctrtrs\"...\n \t\t x,info = ctrtrs(a,b,[lower,trans,unitdiag,lda,overwrite_b])\n \t\tConstructing wrapper function \"ztrtrs\"...\n \t\t x,info = ztrtrs(a,b,[lower,trans,unitdiag,lda,overwrite_b])\n \t\tConstructing wrapper function \"spbsv\"...\n \t\t c,x,info = spbsv(ab,b,[lower,ldab,overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"dpbsv\"...\n \t\t c,x,info = dpbsv(ab,b,[lower,ldab,overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"cpbsv\"...\n \t\t c,x,info = cpbsv(ab,b,[lower,ldab,overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"zpbsv\"...\n \t\t c,x,info = zpbsv(ab,b,[lower,ldab,overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"sptsv\"...\n \t\t d,du,x,info = sptsv(d,e,b,[overwrite_d,overwrite_e,overwrite_b])\n \t\tConstructing wrapper function \"dptsv\"...\n \t\t d,du,x,info = dptsv(d,e,b,[overwrite_d,overwrite_e,overwrite_b])\n \t\tConstructing wrapper function \"cptsv\"...\n \t\t d,du,x,info = cptsv(d,e,b,[overwrite_d,overwrite_e,overwrite_b])\n \t\tConstructing wrapper function \"zptsv\"...\n \t\t d,du,x,info = zptsv(d,e,b,[overwrite_d,overwrite_e,overwrite_b])\n \t\tConstructing wrapper function \"sgebal\"...\n \t\t ba,lo,hi,pivscale,info = sgebal(a,[scale,permute,overwrite_a])\n \t\tConstructing wrapper function \"dgebal\"...\n \t\t ba,lo,hi,pivscale,info = dgebal(a,[scale,permute,overwrite_a])\n \t\tConstructing wrapper function \"cgebal\"...\n \t\t ba,lo,hi,pivscale,info = cgebal(a,[scale,permute,overwrite_a])\n \t\tConstructing wrapper function \"zgebal\"...\n \t\t ba,lo,hi,pivscale,info = zgebal(a,[scale,permute,overwrite_a])\n \t\tConstructing wrapper function \"sgehrd\"...\n \t\t ht,tau,info = sgehrd(a,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgehrd\"...\n \t\t ht,tau,info = dgehrd(a,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgehrd\"...\n \t\t ht,tau,info = cgehrd(a,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgehrd\"...\n \t\t ht,tau,info = zgehrd(a,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgehrd_lwork\"...\n \t\t work,info = sgehrd_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"dgehrd_lwork\"...\n \t\t work,info = dgehrd_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"cgehrd_lwork\"...\n \t\t work,info = cgehrd_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"zgehrd_lwork\"...\n \t\t work,info = zgehrd_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"sorghr\"...\n \t\t ht,info = sorghr(a,tau,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dorghr\"...\n \t\t ht,info = dorghr(a,tau,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sorghr_lwork\"...\n \t\t work,info = sorghr_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"dorghr_lwork\"...\n \t\t work,info = dorghr_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"cunghr\"...\n \t\t ht,info = cunghr(a,tau,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zunghr\"...\n \t\t ht,info = zunghr(a,tau,[lo,hi,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cunghr_lwork\"...\n \t\t work,info = cunghr_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"zunghr_lwork\"...\n \t\t work,info = zunghr_lwork(n,[lo,hi])\n \t\tConstructing wrapper function \"sgbsv\"...\n \t\t lub,piv,x,info = sgbsv(kl,ku,ab,b,[overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"dgbsv\"...\n \t\t lub,piv,x,info = dgbsv(kl,ku,ab,b,[overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"cgbsv\"...\n \t\t lub,piv,x,info = cgbsv(kl,ku,ab,b,[overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"zgbsv\"...\n \t\t lub,piv,x,info = zgbsv(kl,ku,ab,b,[overwrite_ab,overwrite_b])\n \t\tConstructing wrapper function \"sgtsv\"...\n \t\t du2,d,du,x,info = sgtsv(dl,d,du,b,[overwrite_dl,overwrite_d,overwrite_du,overwrite_b])\n \t\tConstructing wrapper function \"dgtsv\"...\n \t\t du2,d,du,x,info = dgtsv(dl,d,du,b,[overwrite_dl,overwrite_d,overwrite_du,overwrite_b])\n \t\tConstructing wrapper function \"cgtsv\"...\n \t\t du2,d,du,x,info = cgtsv(dl,d,du,b,[overwrite_dl,overwrite_d,overwrite_du,overwrite_b])\n \t\tConstructing wrapper function \"zgtsv\"...\n \t\t du2,d,du,x,info = zgtsv(dl,d,du,b,[overwrite_dl,overwrite_d,overwrite_du,overwrite_b])\n \t\tConstructing wrapper function \"sgesv\"...\n \t\t lu,piv,x,info = sgesv(a,b,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgesv\"...\n \t\t lu,piv,x,info = dgesv(a,b,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgesv\"...\n \t\t lu,piv,x,info = cgesv(a,b,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgesv\"...\n \t\t lu,piv,x,info = zgesv(a,b,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgesvx\"...\n \t\t as,lu,ipiv,equed,rs,cs,bs,x,rcond,ferr,berr,info = sgesvx(a,b,[fact,trans,af,ipiv,equed,r,c,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgesvx\"...\n \t\t as,lu,ipiv,equed,rs,cs,bs,x,rcond,ferr,berr,info = dgesvx(a,b,[fact,trans,af,ipiv,equed,r,c,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgesvx\"...\n \t\t as,lu,ipiv,equed,rs,cs,bs,x,rcond,ferr,berr,info = cgesvx(a,b,[fact,trans,af,ipiv,equed,r,c,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgesvx\"...\n \t\t as,lu,ipiv,equed,rs,cs,bs,x,rcond,ferr,berr,info = zgesvx(a,b,[fact,trans,af,ipiv,equed,r,c,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgecon\"...\n \t\t rcond,info = sgecon(a,anorm,[norm])\n \t\tConstructing wrapper function \"dgecon\"...\n \t\t rcond,info = dgecon(a,anorm,[norm])\n \t\tConstructing wrapper function \"cgecon\"...\n \t\t rcond,info = cgecon(a,anorm,[norm])\n \t\tConstructing wrapper function \"zgecon\"...\n \t\t rcond,info = zgecon(a,anorm,[norm])\n \t\tConstructing wrapper function \"ssytf2\"...\n \t\t ldu,ipiv,info = ssytf2(a,[lower,overwrite_a])\n \t\tConstructing wrapper function \"dsytf2\"...\n \t\t ldu,ipiv,info = dsytf2(a,[lower,overwrite_a])\n \t\tConstructing wrapper function \"csytf2\"...\n \t\t ldu,ipiv,info = csytf2(a,[lower,overwrite_a])\n \t\tConstructing wrapper function \"zsytf2\"...\n \t\t ldu,ipiv,info = zsytf2(a,[lower,overwrite_a])\n \t\tConstructing wrapper function \"ssygst\"...\n \t\t c,info = ssygst(a,b,[itype,lower,overwrite_a])\n \t\tConstructing wrapper function \"dsygst\"...\n \t\t c,info = dsygst(a,b,[itype,lower,overwrite_a])\n \t\tConstructing wrapper function \"ssytrf\"...\n \t\t ldu,ipiv,info = ssytrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dsytrf\"...\n \t\t ldu,ipiv,info = dsytrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"csytrf\"...\n \t\t ldu,ipiv,info = csytrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zsytrf\"...\n \t\t ldu,ipiv,info = zsytrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"ssytrf_lwork\"...\n \t\t work,info = ssytrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"dsytrf_lwork\"...\n \t\t work,info = dsytrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"csytrf_lwork\"...\n \t\t work,info = csytrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"zsytrf_lwork\"...\n \t\t work,info = zsytrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"ssysv\"...\n \t\t udut,ipiv,x,info = ssysv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dsysv\"...\n \t\t udut,ipiv,x,info = dsysv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"csysv\"...\n \t\t udut,ipiv,x,info = csysv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zsysv\"...\n \t\t udut,ipiv,x,info = zsysv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssysv_lwork\"...\n \t\t work,info = ssysv_lwork(n,[lower])\n \t\tConstructing wrapper function \"dsysv_lwork\"...\n \t\t work,info = dsysv_lwork(n,[lower])\n \t\tConstructing wrapper function \"csysv_lwork\"...\n \t\t work,info = csysv_lwork(n,[lower])\n \t\tConstructing wrapper function \"zsysv_lwork\"...\n \t\t work,info = zsysv_lwork(n,[lower])\n \t\tConstructing wrapper function \"ssysvx\"...\n \t\t a_s,udut,ipiv,b_s,x,rcond,ferr,berr,info = ssysvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dsysvx\"...\n \t\t a_s,udut,ipiv,b_s,x,rcond,ferr,berr,info = dsysvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"csysvx\"...\n \t\t a_s,udut,ipiv,b_s,x,rcond,ferr,berr,info = csysvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zsysvx\"...\n \t\t a_s,udut,ipiv,b_s,x,rcond,ferr,berr,info = zsysvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssysvx_lwork\"...\n \t\t work,info = ssysvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"dsysvx_lwork\"...\n \t\t work,info = dsysvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"csysvx_lwork\"...\n \t\t work,info = csysvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"zsysvx_lwork\"...\n \t\t work,info = zsysvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"ssycon\"...\n \t\t rcond,info = ssycon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"dsycon\"...\n \t\t rcond,info = dsycon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"csycon\"...\n \t\t rcond,info = csycon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"zsycon\"...\n \t\t rcond,info = zsycon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"checon\"...\n \t\t rcond,info = checon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"zhecon\"...\n \t\t rcond,info = zhecon(a,ipiv,anorm,[lower])\n \t\tConstructing wrapper function \"chegst\"...\n \t\t c,info = chegst(a,b,[itype,lower,overwrite_a])\n \t\tConstructing wrapper function \"zhegst\"...\n \t\t c,info = zhegst(a,b,[itype,lower,overwrite_a])\n \t\tConstructing wrapper function \"chetrf\"...\n \t\t ldu,ipiv,info = chetrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zhetrf\"...\n \t\t ldu,ipiv,info = zhetrf(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"chetrf_lwork\"...\n \t\t work,info = chetrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"zhetrf_lwork\"...\n \t\t work,info = zhetrf_lwork(n,[lower])\n \t\tConstructing wrapper function \"chesv\"...\n \t\t uduh,ipiv,x,info = chesv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zhesv\"...\n \t\t uduh,ipiv,x,info = zhesv(a,b,[lwork,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"chesv_lwork\"...\n \t\t work,info = chesv_lwork(n,[lower])\n \t\tConstructing wrapper function \"zhesv_lwork\"...\n \t\t work,info = zhesv_lwork(n,[lower])\n \t\tConstructing wrapper function \"chesvx\"...\n \t\t uduh,ipiv,x,rcond,ferr,berr,info = chesvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zhesvx\"...\n \t\t uduh,ipiv,x,rcond,ferr,berr,info = zhesvx(a,b,[af,ipiv,lwork,factored,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"chesvx_lwork\"...\n \t\t work,info = chesvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"zhesvx_lwork\"...\n \t\t work,info = zhesvx_lwork(n,[lower])\n \t\tConstructing wrapper function \"sgetrf\"...\n \t\t lu,piv,info = sgetrf(a,[overwrite_a])\n \t\tConstructing wrapper function \"dgetrf\"...\n \t\t lu,piv,info = dgetrf(a,[overwrite_a])\n \t\tConstructing wrapper function \"cgetrf\"...\n \t\t lu,piv,info = cgetrf(a,[overwrite_a])\n \t\tConstructing wrapper function \"zgetrf\"...\n \t\t lu,piv,info = zgetrf(a,[overwrite_a])\n \t\tConstructing wrapper function \"ssytrd\"...\n \t\t c,d,e,tau,info = ssytrd(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dsytrd\"...\n \t\t c,d,e,tau,info = dsytrd(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"ssytrd_lwork\"...\n \t\t work,info = ssytrd_lwork(n,[lower])\n \t\tConstructing wrapper function \"dsytrd_lwork\"...\n \t\t work,info = dsytrd_lwork(n,[lower])\n \t\tConstructing wrapper function \"chetrd\"...\n \t\t c,d,e,tau,info = chetrd(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zhetrd\"...\n \t\t c,d,e,tau,info = zhetrd(a,[lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"chetrd_lwork\"...\n \t\t work,info = chetrd_lwork(n,[lower])\n \t\tConstructing wrapper function \"zhetrd_lwork\"...\n \t\t work,info = zhetrd_lwork(n,[lower])\n \t\tConstructing wrapper function \"sgetrs\"...\n \t\t x,info = sgetrs(lu,piv,b,[trans,overwrite_b])\n \t\tConstructing wrapper function \"dgetrs\"...\n \t\t x,info = dgetrs(lu,piv,b,[trans,overwrite_b])\n \t\tConstructing wrapper function \"cgetrs\"...\n \t\t x,info = cgetrs(lu,piv,b,[trans,overwrite_b])\n \t\tConstructing wrapper function \"zgetrs\"...\n \t\t x,info = zgetrs(lu,piv,b,[trans,overwrite_b])\n \t\tConstructing wrapper function \"sgetri\"...\n \t\t inv_a,info = sgetri(lu,piv,[lwork,overwrite_lu])\n \t\tConstructing wrapper function \"dgetri\"...\n \t\t inv_a,info = dgetri(lu,piv,[lwork,overwrite_lu])\n \t\tConstructing wrapper function \"cgetri\"...\n \t\t inv_a,info = cgetri(lu,piv,[lwork,overwrite_lu])\n \t\tConstructing wrapper function \"zgetri\"...\n \t\t inv_a,info = zgetri(lu,piv,[lwork,overwrite_lu])\n \t\tConstructing wrapper function \"sgetri_lwork\"...\n \t\t work,info = sgetri_lwork(n)\n \t\tConstructing wrapper function \"dgetri_lwork\"...\n \t\t work,info = dgetri_lwork(n)\n \t\tConstructing wrapper function \"cgetri_lwork\"...\n \t\t work,info = cgetri_lwork(n)\n \t\tConstructing wrapper function \"zgetri_lwork\"...\n \t\t work,info = zgetri_lwork(n)\n \t\tConstructing wrapper function \"sgesdd\"...\n \t\t u,s,vt,info = sgesdd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgesdd\"...\n \t\t u,s,vt,info = dgesdd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgesdd_lwork\"...\n \t\t work,info = sgesdd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"dgesdd_lwork\"...\n \t\t work,info = dgesdd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"cgesdd\"...\n \t\t u,s,vt,info = cgesdd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgesdd\"...\n \t\t u,s,vt,info = zgesdd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgesdd_lwork\"...\n \t\t work,info = cgesdd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"zgesdd_lwork\"...\n \t\t work,info = zgesdd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"sgesvd\"...\n \t\t u,s,vt,info = sgesvd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgesvd\"...\n \t\t u,s,vt,info = dgesvd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgesvd_lwork\"...\n \t\t work,info = sgesvd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"dgesvd_lwork\"...\n \t\t work,info = dgesvd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"cgesvd\"...\n \t\t u,s,vt,info = cgesvd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgesvd\"...\n \t\t u,s,vt,info = zgesvd(a,[compute_uv,full_matrices,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgesvd_lwork\"...\n \t\t work,info = cgesvd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"zgesvd_lwork\"...\n \t\t work,info = zgesvd_lwork(m,n,[compute_uv,full_matrices])\n \t\tConstructing wrapper function \"sgels\"...\n \t\t lqr,x,info = sgels(a,b,[trans,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgels\"...\n \t\t lqr,x,info = dgels(a,b,[trans,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgels\"...\n \t\t lqr,x,info = cgels(a,b,[trans,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgels\"...\n \t\t lqr,x,info = zgels(a,b,[trans,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgels_lwork\"...\n \t\t work,info = sgels_lwork(m,n,nrhs,[trans])\n \t\tConstructing wrapper function \"dgels_lwork\"...\n \t\t work,info = dgels_lwork(m,n,nrhs,[trans])\n \t\tConstructing wrapper function \"cgels_lwork\"...\n \t\t work,info = cgels_lwork(m,n,nrhs,[trans])\n \t\tConstructing wrapper function \"zgels_lwork\"...\n \t\t work,info = zgels_lwork(m,n,nrhs,[trans])\n \t\tConstructing wrapper function \"sgelss\"...\n \t\t v,x,s,rank,work,info = sgelss(a,b,[cond,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgelss\"...\n \t\t v,x,s,rank,work,info = dgelss(a,b,[cond,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgelss_lwork\"...\n \t\t work,info = sgelss_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"dgelss_lwork\"...\n \t\t work,info = dgelss_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"cgelss\"...\n \t\t v,x,s,rank,work,info = cgelss(a,b,[cond,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgelss\"...\n \t\t v,x,s,rank,work,info = zgelss(a,b,[cond,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"slasd4\"...\n \t\t delta,sigma,work,info = slasd4(i,d,z,[rho])\n \t\tConstructing wrapper function \"dlasd4\"...\n \t\t delta,sigma,work,info = dlasd4(i,d,z,[rho])\n \t\tConstructing wrapper function \"cgelss_lwork\"...\n \t\t work,info = cgelss_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"zgelss_lwork\"...\n \t\t work,info = zgelss_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"sgelsy\"...\n \t\t v,x,j,rank,info = sgelsy(a,b,jptv,cond,lwork,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgelsy\"...\n \t\t v,x,j,rank,info = dgelsy(a,b,jptv,cond,lwork,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgelsy_lwork\"...\n \t\t work,info = sgelsy_lwork(m,n,nrhs,cond,[lwork])\n \t\tConstructing wrapper function \"dgelsy_lwork\"...\n \t\t work,info = dgelsy_lwork(m,n,nrhs,cond,[lwork])\n \t\tConstructing wrapper function \"cgelsy\"...\n \t\t v,x,j,rank,info = cgelsy(a,b,jptv,cond,lwork,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgelsy\"...\n \t\t v,x,j,rank,info = zgelsy(a,b,jptv,cond,lwork,[overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgelsy_lwork\"...\n \t\t work,info = cgelsy_lwork(m,n,nrhs,cond,[lwork])\n \t\tConstructing wrapper function \"zgelsy_lwork\"...\n \t\t work,info = zgelsy_lwork(m,n,nrhs,cond,[lwork])\n \t\tConstructing wrapper function \"sgelsd\"...\n \t\t x,s,rank,info = sgelsd(a,b,lwork,size_iwork,[cond,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgelsd\"...\n \t\t x,s,rank,info = dgelsd(a,b,lwork,size_iwork,[cond,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgelsd_lwork\"...\n \t\t work,iwork,info = sgelsd_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"dgelsd_lwork\"...\n \t\t work,iwork,info = dgelsd_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"cgelsd\"...\n \t\t x,s,rank,info = cgelsd(a,b,lwork,size_rwork,size_iwork,[cond,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgelsd\"...\n \t\t x,s,rank,info = zgelsd(a,b,lwork,size_rwork,size_iwork,[cond,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgelsd_lwork\"...\n \t\t work,rwork,iwork,info = cgelsd_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"zgelsd_lwork\"...\n \t\t work,rwork,iwork,info = zgelsd_lwork(m,n,nrhs,[cond,lwork])\n \t\tConstructing wrapper function \"sgeqp3\"...\n \t\t qr,jpvt,tau,work,info = sgeqp3(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgeqp3\"...\n \t\t qr,jpvt,tau,work,info = dgeqp3(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgeqp3\"...\n \t\t qr,jpvt,tau,work,info = cgeqp3(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgeqp3\"...\n \t\t qr,jpvt,tau,work,info = zgeqp3(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgeqrf\"...\n \t\t qr,tau,work,info = sgeqrf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgeqrf\"...\n \t\t qr,tau,work,info = dgeqrf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgeqrf\"...\n \t\t qr,tau,work,info = cgeqrf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgeqrf\"...\n \t\t qr,tau,work,info = zgeqrf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgerqf\"...\n \t\t qr,tau,work,info = sgerqf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgerqf\"...\n \t\t qr,tau,work,info = dgerqf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgerqf\"...\n \t\t qr,tau,work,info = cgerqf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgerqf\"...\n \t\t qr,tau,work,info = zgerqf(a,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"sorgqr\"...\n \t\t q,work,info = sorgqr(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"dorgqr\"...\n \t\t q,work,info = dorgqr(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"cungqr\"...\n \t\t q,work,info = cungqr(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"zungqr\"...\n \t\t q,work,info = zungqr(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"sormqr\"...\n \t\t cq,work,info = sormqr(side,trans,a,tau,c,lwork,[overwrite_c])\n \t\tConstructing wrapper function \"dormqr\"...\n \t\t cq,work,info = dormqr(side,trans,a,tau,c,lwork,[overwrite_c])\n \t\tConstructing wrapper function \"cunmqr\"...\n \t\t cq,work,info = cunmqr(side,trans,a,tau,c,lwork,[overwrite_c])\n \t\tConstructing wrapper function \"zunmqr\"...\n \t\t cq,work,info = zunmqr(side,trans,a,tau,c,lwork,[overwrite_c])\n \t\tConstructing wrapper function \"sorgrq\"...\n \t\t q,work,info = sorgrq(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"dorgrq\"...\n \t\t q,work,info = dorgrq(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"cungrq\"...\n \t\t q,work,info = cungrq(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"zungrq\"...\n \t\t q,work,info = zungrq(a,tau,[lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgeev\"...\n \t\t wr,wi,vl,vr,info = sgeev(a,[compute_vl,compute_vr,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dgeev\"...\n \t\t wr,wi,vl,vr,info = dgeev(a,[compute_vl,compute_vr,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sgeev_lwork\"...\n \t\t work,info = sgeev_lwork(n,[compute_vl,compute_vr])\n \t\tConstructing wrapper function \"dgeev_lwork\"...\n \t\t work,info = dgeev_lwork(n,[compute_vl,compute_vr])\n \t\tConstructing wrapper function \"cgeev\"...\n \t\t w,vl,vr,info = cgeev(a,[compute_vl,compute_vr,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zgeev\"...\n \t\t w,vl,vr,info = zgeev(a,[compute_vl,compute_vr,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cgeev_lwork\"...\n \t\t work,info = cgeev_lwork(n,[compute_vl,compute_vr])\n \t\tConstructing wrapper function \"zgeev_lwork\"...\n \t\t work,info = zgeev_lwork(n,[compute_vl,compute_vr])\n \t\tConstructing wrapper function \"sgegv\"...\n \t\t alphar,alphai,beta,vl,vr,info = sgegv(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dgegv\"...\n \t\t alphar,alphai,beta,vl,vr,info = dgegv(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cgegv\"...\n \t\t alpha,beta,vl,vr,info = cgegv(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zgegv\"...\n \t\t alpha,beta,vl,vr,info = zgegv(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssyev\"...\n \t\t w,v,info = ssyev(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dsyev\"...\n \t\t w,v,info = dsyev(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cheev\"...\n \t\t w,v,info = cheev(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zheev\"...\n \t\t w,v,info = zheev(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"ssyevd\"...\n \t\t w,v,info = ssyevd(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dsyevd\"...\n \t\t w,v,info = dsyevd(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cheevd\"...\n \t\t w,v,info = cheevd(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zheevd\"...\n \t\t w,v,info = zheevd(a,[compute_v,lower,lwork,overwrite_a])\n \t\tConstructing wrapper function \"sposv\"...\n \t\t c,x,info = sposv(a,b,[lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dposv\"...\n \t\t c,x,info = dposv(a,b,[lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cposv\"...\n \t\t c,x,info = cposv(a,b,[lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zposv\"...\n \t\t c,x,info = zposv(a,b,[lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sposvx\"...\n \t\t a_s,lu,equed,s,b_s,x,rcond,ferr,berr,info = sposvx(a,b,[fact,af,equed,s,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dposvx\"...\n \t\t a_s,lu,equed,s,b_s,x,rcond,ferr,berr,info = dposvx(a,b,[fact,af,equed,s,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cposvx\"...\n \t\t a_s,lu,equed,s,b_s,x,rcond,ferr,berr,info = cposvx(a,b,[fact,af,equed,s,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zposvx\"...\n \t\t a_s,lu,equed,s,b_s,x,rcond,ferr,berr,info = zposvx(a,b,[fact,af,equed,s,lower,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"spocon\"...\n \t\t rcond,info = spocon(a,anorm,[uplo])\n \t\tConstructing wrapper function \"dpocon\"...\n \t\t rcond,info = dpocon(a,anorm,[uplo])\n \t\tConstructing wrapper function \"cpocon\"...\n \t\t rcond,info = cpocon(a,anorm,[uplo])\n \t\tConstructing wrapper function \"zpocon\"...\n \t\t rcond,info = zpocon(a,anorm,[uplo])\n \t\tConstructing wrapper function \"spotrf\"...\n \t\t c,info = spotrf(a,[lower,clean,overwrite_a])\n \t\tConstructing wrapper function \"dpotrf\"...\n \t\t c,info = dpotrf(a,[lower,clean,overwrite_a])\n \t\tConstructing wrapper function \"cpotrf\"...\n \t\t c,info = cpotrf(a,[lower,clean,overwrite_a])\n \t\tConstructing wrapper function \"zpotrf\"...\n \t\t c,info = zpotrf(a,[lower,clean,overwrite_a])\n \t\tConstructing wrapper function \"spotrs\"...\n \t\t x,info = spotrs(c,b,[lower,overwrite_b])\n \t\tConstructing wrapper function \"dpotrs\"...\n \t\t x,info = dpotrs(c,b,[lower,overwrite_b])\n \t\tConstructing wrapper function \"cpotrs\"...\n \t\t x,info = cpotrs(c,b,[lower,overwrite_b])\n \t\tConstructing wrapper function \"zpotrs\"...\n \t\t x,info = zpotrs(c,b,[lower,overwrite_b])\n \t\tConstructing wrapper function \"spotri\"...\n \t\t inv_a,info = spotri(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"dpotri\"...\n \t\t inv_a,info = dpotri(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"cpotri\"...\n \t\t inv_a,info = cpotri(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"zpotri\"...\n \t\t inv_a,info = zpotri(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"slauum\"...\n \t\t a,info = slauum(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"dlauum\"...\n \t\t a,info = dlauum(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"clauum\"...\n \t\t a,info = clauum(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"zlauum\"...\n \t\t a,info = zlauum(c,[lower,overwrite_c])\n \t\tConstructing wrapper function \"strtri\"...\n \t\t inv_c,info = strtri(c,[lower,unitdiag,overwrite_c])\n \t\tConstructing wrapper function \"dtrtri\"...\n \t\t inv_c,info = dtrtri(c,[lower,unitdiag,overwrite_c])\n \t\tConstructing wrapper function \"ctrtri\"...\n \t\t inv_c,info = ctrtri(c,[lower,unitdiag,overwrite_c])\n \t\tConstructing wrapper function \"ztrtri\"...\n \t\t inv_c,info = ztrtri(c,[lower,unitdiag,overwrite_c])\n \t\tConstructing wrapper function \"strsyl\"...\n \t\t x,scale,info = strsyl(a,b,c,[trana,tranb,isgn,overwrite_c])\n \t\tConstructing wrapper function \"dtrsyl\"...\n \t\t x,scale,info = dtrsyl(a,b,c,[trana,tranb,isgn,overwrite_c])\n \t\tConstructing wrapper function \"ctrsyl\"...\n \t\t x,scale,info = ctrsyl(a,b,c,[trana,tranb,isgn,overwrite_c])\n \t\tConstructing wrapper function \"ztrsyl\"...\n \t\t x,scale,info = ztrsyl(a,b,c,[trana,tranb,isgn,overwrite_c])\n \t\tConstructing wrapper function \"slaswp\"...\n \t\t a = slaswp(a,piv,[k1,k2,off,inc,overwrite_a])\n \t\tConstructing wrapper function \"dlaswp\"...\n \t\t a = dlaswp(a,piv,[k1,k2,off,inc,overwrite_a])\n \t\tConstructing wrapper function \"claswp\"...\n \t\t a = claswp(a,piv,[k1,k2,off,inc,overwrite_a])\n \t\tConstructing wrapper function \"zlaswp\"...\n \t\t a = zlaswp(a,piv,[k1,k2,off,inc,overwrite_a])\n \t\tConstructing wrapper function \"cgees\"...\n \t\t t,sdim,w,vs,work,info = cgees(cselect,a,[compute_v,sort_t,lwork,cselect_extra_args,overwrite_a])\n \t\tConstructing wrapper function \"zgees\"...\n \t\t t,sdim,w,vs,work,info = zgees(zselect,a,[compute_v,sort_t,lwork,zselect_extra_args,overwrite_a])\n \t\tConstructing wrapper function \"sgees\"...\n \t\t t,sdim,wr,wi,vs,work,info = sgees(sselect,a,[compute_v,sort_t,lwork,sselect_extra_args,overwrite_a])\n \t\tConstructing wrapper function \"dgees\"...\n \t\t t,sdim,wr,wi,vs,work,info = dgees(dselect,a,[compute_v,sort_t,lwork,dselect_extra_args,overwrite_a])\n \t\tConstructing wrapper function \"sggev\"...\n \t\t alphar,alphai,beta,vl,vr,work,info = sggev(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dggev\"...\n \t\t alphar,alphai,beta,vl,vr,work,info = dggev(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"cggev\"...\n \t\t alpha,beta,vl,vr,work,info = cggev(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zggev\"...\n \t\t alpha,beta,vl,vr,work,info = zggev(a,b,[compute_vl,compute_vr,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssbev\"...\n \t\t w,z,info = ssbev(ab,[compute_v,lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"dsbev\"...\n \t\t w,z,info = dsbev(ab,[compute_v,lower,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"ssbevd\"...\n \t\t w,z,info = ssbevd(ab,[compute_v,lower,ldab,liwork,overwrite_ab])\n \t\tConstructing wrapper function \"dsbevd\"...\n \t\t w,z,info = dsbevd(ab,[compute_v,lower,ldab,liwork,overwrite_ab])\n \t\tConstructing wrapper function \"ssbevx\"...\n \t\t w,z,m,ifail,info = ssbevx(ab,vl,vu,il,iu,[ldab,compute_v,range,lower,abstol,mmax,overwrite_ab])\n \t\tConstructing wrapper function \"dsbevx\"...\n \t\t w,z,m,ifail,info = dsbevx(ab,vl,vu,il,iu,[ldab,compute_v,range,lower,abstol,mmax,overwrite_ab])\n \t\tConstructing wrapper function \"sstebz\"...\n \t\t m,w,iblock,isplit,info = sstebz(d,e,range,vl,vu,il,iu,tol,order)\n \t\tConstructing wrapper function \"dstebz\"...\n \t\t m,w,iblock,isplit,info = dstebz(d,e,range,vl,vu,il,iu,tol,order)\n \t\tConstructing wrapper function \"ssterf\"...\n \t\t vals,info = ssterf(d,e,[overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"dsterf\"...\n \t\t vals,info = dsterf(d,e,[overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"sstein\"...\n \t\t z,info = sstein(d,e,w,iblock,isplit)\n \t\tConstructing wrapper function \"dstein\"...\n \t\t z,info = dstein(d,e,w,iblock,isplit)\n \t\tConstructing wrapper function \"sstemr\"...\n \t\t m,w,z,info = sstemr(d,e,range,vl,vu,il,iu,[compute_v,lwork,liwork,overwrite_d])\n \t\tConstructing wrapper function \"dstemr\"...\n \t\t m,w,z,info = dstemr(d,e,range,vl,vu,il,iu,[compute_v,lwork,liwork,overwrite_d])\n \t\tConstructing wrapper function \"sstemr_lwork\"...\n \t\t work,iwork,info = sstemr_lwork(d,e,range,vl,vu,il,iu,[compute_v,overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"dstemr_lwork\"...\n \t\t work,iwork,info = dstemr_lwork(d,e,range,vl,vu,il,iu,[compute_v,overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"sstev\"...\n \t\t vals,z,info = sstev(d,e,[compute_v,overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"dstev\"...\n \t\t vals,z,info = dstev(d,e,[compute_v,overwrite_d,overwrite_e])\n \t\tConstructing wrapper function \"chbevd\"...\n \t\t w,z,info = chbevd(ab,[compute_v,lower,ldab,lrwork,liwork,overwrite_ab])\n \t\tConstructing wrapper function \"zhbevd\"...\n \t\t w,z,info = zhbevd(ab,[compute_v,lower,ldab,lrwork,liwork,overwrite_ab])\n \t\tConstructing wrapper function \"chbevx\"...\n \t\t w,z,m,ifail,info = chbevx(ab,vl,vu,il,iu,[ldab,compute_v,range,lower,abstol,mmax,overwrite_ab])\n \t\tConstructing wrapper function \"zhbevx\"...\n \t\t w,z,m,ifail,info = zhbevx(ab,vl,vu,il,iu,[ldab,compute_v,range,lower,abstol,mmax,overwrite_ab])\n \t\tCreating wrapper for Fortran function \"dlamch\"(\"dlamch\")...\n \t\tConstructing wrapper function \"dlamch\"...\n \t\t dlamch = dlamch(cmach)\n \t\tCreating wrapper for Fortran function \"slamch\"(\"wslamch \")...\n \t\tConstructing wrapper function \"slamch\"...\n \t\t slamch = slamch(cmach)\n \t\tConstructing wrapper function \"sgbtrf\"...\n \t\t lu,ipiv,info = sgbtrf(ab,kl,ku,[m,n,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"dgbtrf\"...\n \t\t lu,ipiv,info = dgbtrf(ab,kl,ku,[m,n,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"cgbtrf\"...\n \t\t lu,ipiv,info = cgbtrf(ab,kl,ku,[m,n,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"zgbtrf\"...\n \t\t lu,ipiv,info = zgbtrf(ab,kl,ku,[m,n,ldab,overwrite_ab])\n \t\tConstructing wrapper function \"sgbtrs\"...\n \t\t x,info = sgbtrs(ab,kl,ku,b,ipiv,[trans,n,ldab,ldb,overwrite_b])\n \t\tConstructing wrapper function \"dgbtrs\"...\n \t\t x,info = dgbtrs(ab,kl,ku,b,ipiv,[trans,n,ldab,ldb,overwrite_b])\n \t\tConstructing wrapper function \"cgbtrs\"...\n \t\t x,info = cgbtrs(ab,kl,ku,b,ipiv,[trans,n,ldab,ldb,overwrite_b])\n \t\tConstructing wrapper function \"zgbtrs\"...\n \t\t x,info = zgbtrs(ab,kl,ku,b,ipiv,[trans,n,ldab,ldb,overwrite_b])\n \t\tConstructing wrapper function \"ssyevr\"...\n \t\t w,z,info = ssyevr(a,[jobz,range,uplo,il,iu,lwork,overwrite_a])\n \t\tConstructing wrapper function \"dsyevr\"...\n \t\t w,z,info = dsyevr(a,[jobz,range,uplo,il,iu,lwork,overwrite_a])\n \t\tConstructing wrapper function \"cheevr\"...\n \t\t w,z,info = cheevr(a,[jobz,range,uplo,il,iu,lwork,overwrite_a])\n \t\tConstructing wrapper function \"zheevr\"...\n \t\t w,z,info = zheevr(a,[jobz,range,uplo,il,iu,lwork,overwrite_a])\n \t\tConstructing wrapper function \"ssygv\"...\n \t\t a,w,info = ssygv(a,b,[itype,jobz,uplo,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dsygv\"...\n \t\t a,w,info = dsygv(a,b,[itype,jobz,uplo,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"chegv\"...\n \t\t a,w,info = chegv(a,b,[itype,jobz,uplo,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zhegv\"...\n \t\t a,w,info = zhegv(a,b,[itype,jobz,uplo,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssygvd\"...\n \t\t a,w,info = ssygvd(a,b,[itype,jobz,uplo,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dsygvd\"...\n \t\t a,w,info = dsygvd(a,b,[itype,jobz,uplo,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"chegvd\"...\n \t\t a,w,info = chegvd(a,b,[itype,jobz,uplo,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zhegvd\"...\n \t\t a,w,info = zhegvd(a,b,[itype,jobz,uplo,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"ssygvx\"...\n \t\t w,z,ifail,info = ssygvx(a,b,iu,[itype,jobz,uplo,il,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"dsygvx\"...\n \t\t w,z,ifail,info = dsygvx(a,b,iu,[itype,jobz,uplo,il,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"chegvx\"...\n \t\t w,z,ifail,info = chegvx(a,b,iu,[itype,jobz,uplo,il,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"zhegvx\"...\n \t\t w,z,ifail,info = zhegvx(a,b,iu,[itype,jobz,uplo,il,lwork,overwrite_a,overwrite_b])\n \t\tConstructing wrapper function \"sgglse\"...\n \t\t t,r,res,x,info = sgglse(a,b,c,d,[lwork,overwrite_a,overwrite_b,overwrite_c,overwrite_d])\n \t\tConstructing wrapper function \"dgglse\"...\n \t\t t,r,res,x,info = dgglse(a,b,c,d,[lwork,overwrite_a,overwrite_b,overwrite_c,overwrite_d])\n \t\tConstructing wrapper function \"cgglse\"...\n \t\t t,r,res,x,info = cgglse(a,b,c,d,[lwork,overwrite_a,overwrite_b,overwrite_c,overwrite_d])\n \t\tConstructing wrapper function \"zgglse\"...\n \t\t t,r,res,x,info = zgglse(a,b,c,d,[lwork,overwrite_a,overwrite_b,overwrite_c,overwrite_d])\n \t\tConstructing wrapper function \"sgglse_lwork\"...\n \t\t work,info = sgglse_lwork(m,n,p)\n \t\tConstructing wrapper function \"dgglse_lwork\"...\n \t\t work,info = dgglse_lwork(m,n,p)\n \t\tConstructing wrapper function \"cgglse_lwork\"...\n \t\t work,info = cgglse_lwork(m,n,p)\n \t\tConstructing wrapper function \"zgglse_lwork\"...\n \t\t work,info = zgglse_lwork(m,n,p)\n \t\tCreating wrapper for Fortran function \"slange\"(\"wslange \")...\n \t\tConstructing wrapper function \"slange\"...\n \t\t n2 = slange(norm,a)\n \t\tCreating wrapper for Fortran function \"dlange\"(\"dlange \")...\n \t\tConstructing wrapper function \"dlange\"...\n \t\t n2 = dlange(norm,a)\n \t\tCreating wrapper for Fortran function \"clange\"(\"wclange \")...\n \t\tConstructing wrapper function \"clange\"...\n \t\t n2 = clange(norm,a)\n \t\tCreating wrapper for Fortran function \"zlange\"(\"zlange \")...\n \t\tConstructing wrapper function \"zlange\"...\n \t\t n2 = zlange(norm,a)\n \t\tConstructing wrapper function \"slarfg\"...\n \t\t alpha,x,tau = slarfg(n,alpha,x,[incx,overwrite_x])\n \t\tConstructing wrapper function \"dlarfg\"...\n \t\t alpha,x,tau = dlarfg(n,alpha,x,[incx,overwrite_x])\n \t\tConstructing wrapper function \"clarfg\"...\n \t\t alpha,x,tau = clarfg(n,alpha,x,[incx,overwrite_x])\n \t\tConstructing wrapper function \"zlarfg\"...\n \t\t alpha,x,tau = zlarfg(n,alpha,x,[incx,overwrite_x])\n \t\tConstructing wrapper function \"slarf\"...\n \t\t c = slarf(v,tau,c,work,[side,incv,overwrite_c])\n \t\tConstructing wrapper function \"dlarf\"...\n \t\t c = dlarf(v,tau,c,work,[side,incv,overwrite_c])\n \t\tConstructing wrapper function \"clarf\"...\n \t\t c = clarf(v,tau,c,work,[side,incv,overwrite_c])\n \t\tConstructing wrapper function \"zlarf\"...\n \t\t c = zlarf(v,tau,c,work,[side,incv,overwrite_c])\n \t\tConstructing wrapper function \"slartg\"...\n \t\t cs,sn,r = slartg(f,g)\n \t\tConstructing wrapper function \"dlartg\"...\n \t\t cs,sn,r = dlartg(f,g)\n \t\tConstructing wrapper function \"clartg\"...\n \t\t cs,sn,r = clartg(f,g)\n \t\tConstructing wrapper function \"zlartg\"...\n \t\t cs,sn,r = zlartg(f,g)\n \t\tConstructing wrapper function \"crot\"...\n \t\t x,y = crot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"zrot\"...\n \t\t x,y = zrot(x,y,c,s,[n,offx,incx,offy,incy,overwrite_x,overwrite_y])\n \t\tConstructing wrapper function \"ilaver\"...\n \t\t major,minor,patch = ilaver()\n \tWrote C/API module \"_flapack\" to file \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flapackmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flapack-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flapack-f2pywrappers.f' to sources.\n building extension \"scipy.linalg._flinalg\" sources\n f2py options: []\n f2py:> build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flinalgmodule.c\n Reading fortran codes...\n \tReading file 'scipy/linalg/src/det.f' (format:fix,strict)\n \tReading file 'scipy/linalg/src/lu.f' (format:fix,strict)\n Post-processing...\n \tBlock: _flinalg\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:ddet_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: ddet_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:ddet_r\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: ddet_r\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:sdet_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: sdet_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:sdet_r\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: sdet_r\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:zdet_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: zdet_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:zdet_r\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: zdet_r\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:cdet_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: cdet_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/det.f:cdet_r\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: cdet_r\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/lu.f:dlu_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: dlu_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/lu.f:zlu_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: zlu_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/lu.f:slu_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: slu_c\n {'attrspec': ['intent(out)']}\n In: :_flinalg:scipy/linalg/src/lu.f:clu_c\n vars2fortran: No typespec for argument \"info\".\n \t\t\tBlock: clu_c\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_flinalg\"...\n \t\tConstructing wrapper function \"ddet_c\"...\n \t\t det,info = ddet_c(a,[overwrite_a])\n \t\tConstructing wrapper function \"ddet_r\"...\n \t\t det,info = ddet_r(a,[overwrite_a])\n \t\tConstructing wrapper function \"sdet_c\"...\n \t\t det,info = sdet_c(a,[overwrite_a])\n \t\tConstructing wrapper function \"sdet_r\"...\n \t\t det,info = sdet_r(a,[overwrite_a])\n \t\tConstructing wrapper function \"zdet_c\"...\n \t\t det,info = zdet_c(a,[overwrite_a])\n \t\tConstructing wrapper function \"zdet_r\"...\n \t\t det,info = zdet_r(a,[overwrite_a])\n \t\tConstructing wrapper function \"cdet_c\"...\n \t\t det,info = cdet_c(a,[overwrite_a])\n \t\tConstructing wrapper function \"cdet_r\"...\n \t\t det,info = cdet_r(a,[overwrite_a])\n \t\tConstructing wrapper function \"dlu_c\"...\n \t\t p,l,u,info = dlu_c(a,[permute_l,overwrite_a])\n \t\tConstructing wrapper function \"zlu_c\"...\n \t\t p,l,u,info = zlu_c(a,[permute_l,overwrite_a])\n \t\tConstructing wrapper function \"slu_c\"...\n \t\t p,l,u,info = slu_c(a,[permute_l,overwrite_a])\n \t\tConstructing wrapper function \"clu_c\"...\n \t\t p,l,u,info = clu_c(a,[permute_l,overwrite_a])\n \tWrote C/API module \"_flinalg\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flinalgmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg\n building extension \"scipy.linalg._interpolative\" sources\n f2py options: []\n f2py: scipy/linalg/interpolative.pyf\n Reading fortran codes...\n \tReading file 'scipy/linalg/interpolative.pyf' (format:free)\n Post-processing...\n \tBlock: _interpolative\n \t\t\tBlock: id_srand\n \t\t\tBlock: idd_frm\n \t\t\tBlock: idd_sfrm\n \t\t\tBlock: idd_frmi\n \t\t\tBlock: idd_sfrmi\n \t\t\tBlock: iddp_id\n \t\t\tBlock: iddr_id\n \t\t\tBlock: idd_reconid\n \t\t\tBlock: idd_reconint\n \t\t\tBlock: idd_copycols\n \t\t\tBlock: idd_id2svd\n \t\t\tBlock: idd_snorm\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idd_snorm\n get_useparameters: no module idd__user__routines info used by idd_snorm\n \t\t\tBlock: idd_diffsnorm\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idd_diffsnorm\n get_useparameters: no module idd__user__routines info used by idd_diffsnorm\n \t\t\tBlock: iddr_svd\n \t\t\tBlock: iddp_svd\n \t\t\tBlock: iddp_aid\n \t\t\tBlock: idd_estrank\n \t\t\tBlock: iddp_asvd\n \t\t\tBlock: iddp_rid\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:iddp_rid\n get_useparameters: no module idd__user__routines info used by iddp_rid\n \t\t\tBlock: idd_findrank\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idd_findrank\n get_useparameters: no module idd__user__routines info used by idd_findrank\n \t\t\tBlock: iddp_rsvd\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:iddp_rsvd\n get_useparameters: no module idd__user__routines info used by iddp_rsvd\n \t\t\tBlock: iddr_aid\n \t\t\tBlock: iddr_aidi\n \t\t\tBlock: iddr_asvd\n \t\t\tBlock: iddr_rid\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:iddr_rid\n get_useparameters: no module idd__user__routines info used by iddr_rid\n \t\t\tBlock: iddr_rsvd\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:iddr_rsvd\n get_useparameters: no module idd__user__routines info used by iddr_rsvd\n \t\t\tBlock: idz_frm\n \t\t\tBlock: idz_sfrm\n \t\t\tBlock: idz_frmi\n \t\t\tBlock: idz_sfrmi\n \t\t\tBlock: idzp_id\n \t\t\tBlock: idzr_id\n \t\t\tBlock: idz_reconid\n \t\t\tBlock: idz_reconint\n \t\t\tBlock: idz_copycols\n \t\t\tBlock: idz_id2svd\n \t\t\tBlock: idz_snorm\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idz_snorm\n get_useparameters: no module idz__user__routines info used by idz_snorm\n \t\t\tBlock: idz_diffsnorm\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idz_diffsnorm\n get_useparameters: no module idz__user__routines info used by idz_diffsnorm\n \t\t\tBlock: idzr_svd\n \t\t\tBlock: idzp_svd\n \t\t\tBlock: idzp_aid\n \t\t\tBlock: idz_estrank\n \t\t\tBlock: idzp_asvd\n \t\t\tBlock: idzp_rid\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idzp_rid\n get_useparameters: no module idz__user__routines info used by idzp_rid\n \t\t\tBlock: idz_findrank\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idz_findrank\n get_useparameters: no module idz__user__routines info used by idz_findrank\n \t\t\tBlock: idzp_rsvd\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idzp_rsvd\n get_useparameters: no module idz__user__routines info used by idzp_rsvd\n \t\t\tBlock: idzr_aid\n \t\t\tBlock: idzr_aidi\n \t\t\tBlock: idzr_asvd\n \t\t\tBlock: idzr_rid\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idzr_rid\n get_useparameters: no module idz__user__routines info used by idzr_rid\n \t\t\tBlock: idzr_rsvd\n In: scipy/linalg/interpolative.pyf:_interpolative:unknown_interface:idzr_rsvd\n get_useparameters: no module idz__user__routines info used by idzr_rsvd\n \tBlock: idd__user__routines\n \t\tBlock: idd_user_interface\n \t\t\tBlock: matvect\n \t\t\tBlock: matvec\n \t\t\tBlock: matvect2\n \t\t\tBlock: matvec2\n \tBlock: idz__user__routines\n \t\tBlock: idz_user_interface\n \t\t\tBlock: matveca\n \t\t\tBlock: matvec\n \t\t\tBlock: matveca2\n \t\t\tBlock: matvec2\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_matvect_in_idd__user__routines\"\n \t def matvect(x,[m,n,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matvec_in_idd__user__routines\"\n \t def matvec(x,[n,m,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matvect2_in_idd__user__routines\"\n \t def matvect2(x,[m,n,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matvec2_in_idd__user__routines\"\n \t def matvec2(x,[n,m,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matveca_in_idz__user__routines\"\n \t def matveca(x,[m,n,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matvec_in_idz__user__routines\"\n \t def matvec(x,[n,m,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matveca2_in_idz__user__routines\"\n \t def matveca2(x,[m,n,p1,p2,p3,p4]): return y\n \tConstructing call-back function \"cb_matvec2_in_idz__user__routines\"\n \t def matvec2(x,[n,m,p1,p2,p3,p4]): return y\n \tBuilding module \"_interpolative\"...\n \t\tConstructing wrapper function \"id_srand\"...\n \t\t r = id_srand(n)\n \t\tConstructing wrapper function \"id_srandi\"...\n \t\t id_srandi(t)\n \t\tConstructing wrapper function \"id_srando\"...\n \t\t id_srando()\n \t\tConstructing wrapper function \"idd_frm\"...\n \t\t y = idd_frm(n,w,x,[m])\n \t\tConstructing wrapper function \"idd_sfrm\"...\n \t\t y = idd_sfrm(l,n,w,x,[m])\n \t\tConstructing wrapper function \"idd_frmi\"...\n \t\t n,w = idd_frmi(m)\n \t\tConstructing wrapper function \"idd_sfrmi\"...\n \t\t n,w = idd_sfrmi(l,m)\n \t\tConstructing wrapper function \"iddp_id\"...\n \t\t krank,list,rnorms = iddp_id(eps,a,[m,n])\n \t\tConstructing wrapper function \"iddr_id\"...\n \t\t list,rnorms = iddr_id(a,krank,[m,n])\n \t\tConstructing wrapper function \"idd_reconid\"...\n \t\t approx = idd_reconid(col,list,proj,[m,krank,n])\n \t\tConstructing wrapper function \"idd_reconint\"...\n \t\t p = idd_reconint(list,proj,[n,krank])\n \t\tConstructing wrapper function \"idd_copycols\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t col = idd_copycols(a,krank,list,[m,n])\n \t\tConstructing wrapper function \"idd_id2svd\"...\n \t\t u,v,s,ier = idd_id2svd(b,list,proj,[m,krank,n,w])\n \t\tConstructing wrapper function \"idd_snorm\"...\n \t\t snorm,v = idd_snorm(m,n,matvect,matvec,its,[p1t,p2t,p3t,p4t,p1,p2,p3,p4,u,matvect_extra_args,matvec_extra_args])\n \t\tConstructing wrapper function \"idd_diffsnorm\"...\n \t\t snorm = idd_diffsnorm(m,n,matvect,matvect2,matvec,matvec2,its,[p1t,p2t,p3t,p4t,p1t2,p2t2,p3t2,p4t2,p1,p2,p3,p4,p12,p22,p32,p42,w,matvect_extra_args,matvect2_extra_args,matvec_extra_args,matvec2_extra_args])\n \t\tConstructing wrapper function \"iddr_svd\"...\n \t\t u,v,s,ier = iddr_svd(a,krank,[m,n,r])\n \t\tConstructing wrapper function \"iddp_svd\"...\n \t\t krank,iu,iv,is,w,ier = iddp_svd(eps,a,[m,n])\n \t\tConstructing wrapper function \"iddp_aid\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,list,proj = iddp_aid(eps,a,work,proj,[m,n])\n \t\tConstructing wrapper function \"idd_estrank\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,ra = idd_estrank(eps,a,w,ra,[m,n])\n \t\tConstructing wrapper function \"iddp_asvd\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,iu,iv,is,w,ier = iddp_asvd(eps,a,winit,w,[m,n])\n \t\tConstructing wrapper function \"iddp_rid\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,list,proj,ier = iddp_rid(eps,m,n,matvect,proj,[p1,p2,p3,p4,matvect_extra_args])\n \t\tConstructing wrapper function \"idd_findrank\"...\n \t\t krank,ra,ier = idd_findrank(eps,m,n,matvect,[p1,p2,p3,p4,w,matvect_extra_args])\n \t\tConstructing wrapper function \"iddp_rsvd\"...\n \t\t krank,iu,iv,is,w,ier = iddp_rsvd(eps,m,n,matvect,matvec,[p1t,p2t,p3t,p4t,p1,p2,p3,p4,matvect_extra_args,matvec_extra_args])\n \t\tConstructing wrapper function \"iddr_aid\"...\n \t\t list,proj = iddr_aid(a,krank,w,[m,n])\n \t\tConstructing wrapper function \"iddr_aidi\"...\n \t\t w = iddr_aidi(m,n,krank)\n \t\tConstructing wrapper function \"iddr_asvd\"...\n \t\t u,v,s,ier = iddr_asvd(a,krank,w,[m,n])\n \t\tConstructing wrapper function \"iddr_rid\"...\n \t\t list,proj = iddr_rid(m,n,matvect,krank,[p1,p2,p3,p4,matvect_extra_args])\n \t\tConstructing wrapper function \"iddr_rsvd\"...\n \t\t u,v,s,ier = iddr_rsvd(m,n,matvect,matvec,krank,[p1t,p2t,p3t,p4t,p1,p2,p3,p4,w,matvect_extra_args,matvec_extra_args])\n \t\tConstructing wrapper function \"idz_frm\"...\n \t\t y = idz_frm(n,w,x,[m])\n \t\tConstructing wrapper function \"idz_sfrm\"...\n \t\t y = idz_sfrm(l,n,w,x,[m])\n \t\tConstructing wrapper function \"idz_frmi\"...\n \t\t n,w = idz_frmi(m)\n \t\tConstructing wrapper function \"idz_sfrmi\"...\n \t\t n,w = idz_sfrmi(l,m)\n \t\tConstructing wrapper function \"idzp_id\"...\n \t\t krank,list,rnorms = idzp_id(eps,a,[m,n])\n \t\tConstructing wrapper function \"idzr_id\"...\n \t\t list,rnorms = idzr_id(a,krank,[m,n])\n \t\tConstructing wrapper function \"idz_reconid\"...\n \t\t approx = idz_reconid(col,list,proj,[m,krank,n])\n \t\tConstructing wrapper function \"idz_reconint\"...\n \t\t p = idz_reconint(list,proj,[n,krank])\n \t\tConstructing wrapper function \"idz_copycols\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t col = idz_copycols(a,krank,list,[m,n])\n \t\tConstructing wrapper function \"idz_id2svd\"...\n \t\t u,v,s,ier = idz_id2svd(b,list,proj,[m,krank,n,w])\n \t\tConstructing wrapper function \"idz_snorm\"...\n \t\t snorm,v = idz_snorm(m,n,matveca,matvec,its,[p1a,p2a,p3a,p4a,p1,p2,p3,p4,u,matveca_extra_args,matvec_extra_args])\n \t\tConstructing wrapper function \"idz_diffsnorm\"...\n \t\t snorm = idz_diffsnorm(m,n,matveca,matveca2,matvec,matvec2,its,[p1a,p2a,p3a,p4a,p1a2,p2a2,p3a2,p4a2,p1,p2,p3,p4,p12,p22,p32,p42,w,matveca_extra_args,matveca2_extra_args,matvec_extra_args,matvec2_extra_args])\n \t\tConstructing wrapper function \"idzr_svd\"...\n \t\t u,v,s,ier = idzr_svd(a,krank,[m,n,r])\n \t\tConstructing wrapper function \"idzp_svd\"...\n \t\t krank,iu,iv,is,w,ier = idzp_svd(eps,a,[m,n])\n \t\tConstructing wrapper function \"idzp_aid\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,list,proj = idzp_aid(eps,a,work,proj,[m,n])\n \t\tConstructing wrapper function \"idz_estrank\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,ra = idz_estrank(eps,a,w,ra,[m,n])\n \t\tConstructing wrapper function \"idzp_asvd\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,iu,iv,is,w,ier = idzp_asvd(eps,a,winit,w,[m,n])\n \t\tConstructing wrapper function \"idzp_rid\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t krank,list,proj,ier = idzp_rid(eps,m,n,matveca,proj,[p1,p2,p3,p4,matveca_extra_args])\n \t\tConstructing wrapper function \"idz_findrank\"...\n \t\t krank,ra,ier = idz_findrank(eps,m,n,matveca,[p1,p2,p3,p4,w,matveca_extra_args])\n \t\tConstructing wrapper function \"idzp_rsvd\"...\n \t\t krank,iu,iv,is,w,ier = idzp_rsvd(eps,m,n,matveca,matvec,[p1a,p2a,p3a,p4a,p1,p2,p3,p4,matveca_extra_args,matvec_extra_args])\n \t\tConstructing wrapper function \"idzr_aid\"...\n \t\t list,proj = idzr_aid(a,krank,w,[m,n])\n \t\tConstructing wrapper function \"idzr_aidi\"...\n \t\t w = idzr_aidi(m,n,krank)\n \t\tConstructing wrapper function \"idzr_asvd\"...\n \t\t u,v,s,ier = idzr_asvd(a,krank,w,[m,n])\n \t\tConstructing wrapper function \"idzr_rid\"...\n \t\t list,proj = idzr_rid(m,n,matveca,krank,[p1,p2,p3,p4,matveca_extra_args])\n \t\tConstructing wrapper function \"idzr_rsvd\"...\n \t\t u,v,s,ier = idzr_rsvd(m,n,matveca,matvec,krank,[p1a,p2a,p3a,p4a,p1,p2,p3,p4,w,matveca_extra_args,matvec_extra_args])\n \tWrote C/API module \"_interpolative\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_interpolativemodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n building extension \"scipy.linalg._solve_toeplitz\" sources\n building extension \"scipy.linalg.cython_blas\" sources\n building extension \"scipy.linalg.cython_lapack\" sources\n building extension \"scipy.linalg._decomp_update\" sources\n building extension \"scipy.odr.__odrpack\" sources\n building extension \"scipy.optimize._minpack\" sources\n building extension \"scipy.optimize._zeros\" sources\n building extension \"scipy.optimize._lbfgsb\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb\n f2py options: []\n f2py: scipy/optimize/lbfgsb/lbfgsb.pyf\n Reading fortran codes...\n \tReading file 'scipy/optimize/lbfgsb/lbfgsb.pyf' (format:free)\n Post-processing...\n \tBlock: _lbfgsb\n \t\t\tBlock: setulb\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_lbfgsb\"...\n \t\tConstructing wrapper function \"setulb\"...\n \t\t setulb(m,x,l,u,nbd,f,g,factr,pgtol,wa,iwa,task,iprint,csave,lsave,isave,dsave,maxls,[n])\n \tWrote C/API module \"_lbfgsb\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb/_lbfgsbmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb\n building extension \"scipy.optimize.moduleTNC\" sources\n building extension \"scipy.optimize._cobyla\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla\n f2py options: []\n f2py: scipy/optimize/cobyla/cobyla.pyf\n Reading fortran codes...\n \tReading file 'scipy/optimize/cobyla/cobyla.pyf' (format:free)\n Post-processing...\n \tBlock: _cobyla__user__routines\n \t\tBlock: _cobyla_user_interface\n \t\t\tBlock: calcfc\n \tBlock: _cobyla\n \t\t\tBlock: minimize\n In: scipy/optimize/cobyla/cobyla.pyf:_cobyla:unknown_interface:minimize\n get_useparameters: no module _cobyla__user__routines info used by minimize\n Post-processing (stage 2)...\n Building modules...\n \tConstructing call-back function \"cb_calcfc_in__cobyla__user__routines\"\n \t def calcfc(x,con): return f\n \tBuilding module \"_cobyla\"...\n \t\tConstructing wrapper function \"minimize\"...\n \t\t x,dinfo = minimize(calcfc,m,x,rhobeg,rhoend,dinfo,[iprint,maxfun,calcfc_extra_args])\n \tWrote C/API module \"_cobyla\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla/_cobylamodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla\n building extension \"scipy.optimize.minpack2\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2\n f2py options: []\n f2py: scipy/optimize/minpack2/minpack2.pyf\n Reading fortran codes...\n \tReading file 'scipy/optimize/minpack2/minpack2.pyf' (format:free)\n Post-processing...\n \tBlock: minpack2\n \t\t\tBlock: dcsrch\n \t\t\tBlock: dcstep\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"minpack2\"...\n \t\tConstructing wrapper function \"dcsrch\"...\n \t\t stp,f,g,task = dcsrch(stp,f,g,ftol,gtol,xtol,task,stpmin,stpmax,isave,dsave)\n \t\tConstructing wrapper function \"dcstep\"...\n \t\t stx,fx,dx,sty,fy,dy,stp,brackt = dcstep(stx,fx,dx,sty,fy,dy,stp,fp,dp,brackt,stpmin,stpmax)\n \tWrote C/API module \"minpack2\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2/minpack2module.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2\n building extension \"scipy.optimize._slsqp\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp\n f2py options: []\n f2py: scipy/optimize/slsqp/slsqp.pyf\n Reading fortran codes...\n \tReading file 'scipy/optimize/slsqp/slsqp.pyf' (format:free)\n Post-processing...\n \tBlock: _slsqp\n \t\t\tBlock: slsqp\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_slsqp\"...\n \t\tConstructing wrapper function \"slsqp\"...\n \t\t slsqp(m,meq,x,xl,xu,f,c,g,a,acc,iter,mode,w,jw,[la,n,l_w,l_jw])\n \tWrote C/API module \"_slsqp\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp/_slsqpmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp\n building extension \"scipy.optimize._nnls\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls\n f2py options: []\n f2py: scipy/optimize/nnls/nnls.pyf\n Reading fortran codes...\n \tReading file 'scipy/optimize/nnls/nnls.pyf' (format:free)\n Post-processing...\n \tBlock: _nnls\n \t\t\tBlock: nnls\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_nnls\"...\n \t\tConstructing wrapper function \"nnls\"...\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n getarrdims:warning: assumed shape array, using 0 instead of '*'\n \t\t x,rnorm,mode = nnls(a,m,n,b,w,zz,index_bn,maxiter,[mda,overwrite_a,overwrite_b])\n \tWrote C/API module \"_nnls\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls/_nnlsmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls\n building extension \"scipy.optimize._group_columns\" sources\n building extension \"scipy.optimize._lsq.givens_elimination\" sources\n building extension \"scipy.optimize._trlib._trlib\" sources\n building extension \"scipy.signal.sigtools\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/signal\n conv_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/signal/lfilter.c\n conv_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/signal/correlate_nd.c\n building extension \"scipy.signal._spectral\" sources\n building extension \"scipy.signal._max_len_seq_inner\" sources\n building extension \"scipy.signal._peak_finding_utils\" sources\n building extension \"scipy.signal._upfirdn_apply\" sources\n building extension \"scipy.signal.spline\" sources\n building extension \"scipy.sparse.linalg.isolve._iterative\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/getbreak.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/BiCGREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/BiCGSTABREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/CGREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/CGSREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/GMRESREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/QMRREVCOM.f\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/_iterative.pyf\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative\n f2py options: []\n f2py: build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/_iterative.pyf\n Reading fortran codes...\n \tReading file 'build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/_iterative.pyf' (format:free)\n Post-processing...\n \tBlock: _iterative\n \t\t\tBlock: sbicgrevcom\n \t\t\tBlock: dbicgrevcom\n \t\t\tBlock: cbicgrevcom\n \t\t\tBlock: zbicgrevcom\n \t\t\tBlock: sbicgstabrevcom\n \t\t\tBlock: dbicgstabrevcom\n \t\t\tBlock: cbicgstabrevcom\n \t\t\tBlock: zbicgstabrevcom\n \t\t\tBlock: scgrevcom\n \t\t\tBlock: dcgrevcom\n \t\t\tBlock: ccgrevcom\n \t\t\tBlock: zcgrevcom\n \t\t\tBlock: scgsrevcom\n \t\t\tBlock: dcgsrevcom\n \t\t\tBlock: ccgsrevcom\n \t\t\tBlock: zcgsrevcom\n \t\t\tBlock: sqmrrevcom\n \t\t\tBlock: dqmrrevcom\n \t\t\tBlock: cqmrrevcom\n \t\t\tBlock: zqmrrevcom\n \t\t\tBlock: sgmresrevcom\n \t\t\tBlock: dgmresrevcom\n \t\t\tBlock: cgmresrevcom\n \t\t\tBlock: zgmresrevcom\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_iterative\"...\n \t\tConstructing wrapper function \"sbicgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = sbicgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"dbicgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dbicgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"cbicgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = cbicgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"zbicgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zbicgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"sbicgstabrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = sbicgstabrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"dbicgstabrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dbicgstabrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"cbicgstabrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = cbicgstabrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"zbicgstabrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zbicgstabrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"scgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = scgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"dcgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dcgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"ccgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = ccgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"zcgrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zcgrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"scgsrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = scgsrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"dcgsrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dcgsrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"ccgsrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = ccgsrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"zcgsrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zcgsrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"sqmrrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = sqmrrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"dqmrrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dqmrrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"cqmrrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = cqmrrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"zqmrrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zqmrrevcom(b,x,work,iter,resid,info,ndx1,ndx2,ijob)\n \t\tConstructing wrapper function \"sgmresrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = sgmresrevcom(b,x,restrt,work,work2,iter,resid,info,ndx1,ndx2,ijob,tol)\n \t\tConstructing wrapper function \"dgmresrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = dgmresrevcom(b,x,restrt,work,work2,iter,resid,info,ndx1,ndx2,ijob,tol)\n \t\tConstructing wrapper function \"cgmresrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = cgmresrevcom(b,x,restrt,work,work2,iter,resid,info,ndx1,ndx2,ijob,tol)\n \t\tConstructing wrapper function \"zgmresrevcom\"...\n \t\t x,iter,resid,info,ndx1,ndx2,sclr1,sclr2,ijob = zgmresrevcom(b,x,restrt,work,work2,iter,resid,info,ndx1,ndx2,ijob,tol)\n \tWrote C/API module \"_iterative\" to file \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/_iterativemodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative\n building extension \"scipy.sparse.linalg.dsolve._superlu\" sources\n building extension \"scipy.sparse.linalg.eigen.arpack._arpack\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n from_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/arpack.pyf\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n f2py options: []\n f2py: build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/arpack.pyf\n Reading fortran codes...\n \tReading file 'build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/arpack.pyf' (format:free)\n Post-processing...\n \tBlock: _arpack\n \t\t\tBlock: ssaupd\n \t\t\tBlock: dsaupd\n \t\t\tBlock: sseupd\n \t\t\tBlock: dseupd\n \t\t\tBlock: snaupd\n \t\t\tBlock: dnaupd\n \t\t\tBlock: sneupd\n \t\t\tBlock: dneupd\n \t\t\tBlock: cnaupd\n \t\t\tBlock: znaupd\n \t\t\tBlock: cneupd\n \t\t\tBlock: zneupd\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"_arpack\"...\n \t\tConstructing wrapper function \"ssaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = ssaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"dsaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = dsaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"sseupd\"...\n \t\t d,z,info = sseupd(rvec,howmny,select,sigma,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"dseupd\"...\n \t\t d,z,info = dseupd(rvec,howmny,select,sigma,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"snaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = snaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"dnaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = dnaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"sneupd\"...\n \t\t dr,di,z,info = sneupd(rvec,howmny,select,sigmar,sigmai,workev,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"dneupd\"...\n \t\t dr,di,z,info = dneupd(rvec,howmny,select,sigmar,sigmai,workev,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"cnaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = cnaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,rwork,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"znaupd\"...\n \t\t ido,tol,resid,v,iparam,ipntr,info = znaupd(ido,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,rwork,info,[n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"cneupd\"...\n \t\t d,z,info = cneupd(rvec,howmny,select,sigma,workev,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,rwork,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing wrapper function \"zneupd\"...\n \t\t d,z,info = zneupd(rvec,howmny,select,sigma,workev,bmat,which,nev,tol,resid,v,iparam,ipntr,workd,workl,rwork,info,[ldz,n,ncv,ldv,lworkl])\n \t\tConstructing COMMON block support for \"debug\"...\n \t\t logfil,ndigit,mgetv0,msaupd,msaup2,msaitr,mseigt,msapps,msgets,mseupd,mnaupd,mnaup2,mnaitr,mneigh,mnapps,mngets,mneupd,mcaupd,mcaup2,mcaitr,mceigh,mcapps,mcgets,mceupd\n \t\tConstructing COMMON block support for \"timing\"...\n \t\t nopx,nbx,nrorth,nitref,nrstrt,tsaupd,tsaup2,tsaitr,tseigt,tsgets,tsapps,tsconv,tnaupd,tnaup2,tnaitr,tneigh,tngets,tnapps,tnconv,tcaupd,tcaup2,tcaitr,tceigh,tcgets,tcapps,tcconv,tmvopx,tmvbx,tgetv0,titref,trvec\n \tWrote C/API module \"_arpack\" to file \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/_arpackmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/_arpack-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/_arpack-f2pywrappers.f' to sources.\n building extension \"scipy.sparse.csgraph._shortest_path\" sources\n building extension \"scipy.sparse.csgraph._traversal\" sources\n building extension \"scipy.sparse.csgraph._min_spanning_tree\" sources\n building extension \"scipy.sparse.csgraph._reordering\" sources\n building extension \"scipy.sparse.csgraph._tools\" sources\n building extension \"scipy.sparse._csparsetools\" sources\n building extension \"scipy.sparse._sparsetools\" sources\n [generate_sparsetools] generating 'scipy/sparse/sparsetools/bsr_impl.h'\n [generate_sparsetools] generating 'scipy/sparse/sparsetools/csr_impl.h'\n [generate_sparsetools] generating 'scipy/sparse/sparsetools/csc_impl.h'\n [generate_sparsetools] generating 'scipy/sparse/sparsetools/other_impl.h'\n [generate_sparsetools] generating 'scipy/sparse/sparsetools/sparsetools_impl.h'\n building extension \"scipy.spatial.qhull\" sources\n building extension \"scipy.spatial.ckdtree\" sources\n building extension \"scipy.spatial._distance_wrap\" sources\n building extension \"scipy.spatial._voronoi\" sources\n building extension \"scipy.spatial._hausdorff\" sources\n building extension \"scipy.special.specfun\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/special\n f2py options: ['--no-wrap-functions']\n f2py: scipy/special/specfun.pyf\n Reading fortran codes...\n \tReading file 'scipy/special/specfun.pyf' (format:free)\n Post-processing...\n \tBlock: specfun\n \t\t\tBlock: clqmn\n \t\t\tBlock: lqmn\n \t\t\tBlock: clpmn\n \t\t\tBlock: jdzo\n \t\t\tBlock: bernob\n \t\t\tBlock: bernoa\n \t\t\tBlock: lpmns\n \t\t\tBlock: eulera\n \t\t\tBlock: clqn\n \t\t\tBlock: airyzo\n \t\t\tBlock: eulerb\n \t\t\tBlock: cva1\n \t\t\tBlock: lqnb\n \t\t\tBlock: lamv\n \t\t\tBlock: lagzo\n \t\t\tBlock: legzo\n \t\t\tBlock: pbdv\n \t\t\tBlock: cerzo\n \t\t\tBlock: lamn\n \t\t\tBlock: clpn\n \t\t\tBlock: lqmns\n \t\t\tBlock: chgm\n \t\t\tBlock: lpmn\n \t\t\tBlock: fcszo\n \t\t\tBlock: aswfb\n \t\t\tBlock: lqna\n \t\t\tBlock: cpbdn\n \t\t\tBlock: lpn\n \t\t\tBlock: fcoef\n \t\t\tBlock: rcty\n \t\t\tBlock: lpni\n \t\t\tBlock: cyzo\n \t\t\tBlock: othpl\n \t\t\tBlock: klvnzo\n \t\t\tBlock: jyzo\n \t\t\tBlock: rctj\n \t\t\tBlock: herzo\n \t\t\tBlock: pbvv\n \t\t\tBlock: segv\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"specfun\"...\n \t\tConstructing wrapper function \"clqmn\"...\n \t\t cqm,cqd = clqmn(m,n,z)\n \t\tConstructing wrapper function \"lqmn\"...\n \t\t qm,qd = lqmn(m,n,x)\n \t\tConstructing wrapper function \"clpmn\"...\n \t\t cpm,cpd = clpmn(m,n,x,y,ntype)\n \t\tConstructing wrapper function \"jdzo\"...\n \t\t n,m,pcode,zo = jdzo(nt)\n \t\tConstructing wrapper function \"bernob\"...\n \t\t bn = bernob(n)\n \t\tConstructing wrapper function \"bernoa\"...\n \t\t bn = bernoa(n)\n \t\tConstructing wrapper function \"lpmns\"...\n \t\t pm,pd = lpmns(m,n,x)\n \t\tConstructing wrapper function \"eulera\"...\n \t\t en = eulera(n)\n \t\tConstructing wrapper function \"clqn\"...\n \t\t cqn,cqd = clqn(n,z)\n \t\tConstructing wrapper function \"airyzo\"...\n \t\t xa,xb,xc,xd = airyzo(nt,[kf])\n \t\tConstructing wrapper function \"eulerb\"...\n \t\t en = eulerb(n)\n \t\tConstructing wrapper function \"cva1\"...\n \t\t cv = cva1(kd,m,q)\n \t\tConstructing wrapper function \"lqnb\"...\n \t\t qn,qd = lqnb(n,x)\n \t\tConstructing wrapper function \"lamv\"...\n \t\t vm,vl,dl = lamv(v,x)\n \t\tConstructing wrapper function \"lagzo\"...\n \t\t x,w = lagzo(n)\n \t\tConstructing wrapper function \"legzo\"...\n \t\t x,w = legzo(n)\n \t\tConstructing wrapper function \"pbdv\"...\n \t\t dv,dp,pdf,pdd = pbdv(v,x)\n \t\tConstructing wrapper function \"cerzo\"...\n \t\t zo = cerzo(nt)\n \t\tConstructing wrapper function \"lamn\"...\n \t\t nm,bl,dl = lamn(n,x)\n \t\tConstructing wrapper function \"clpn\"...\n \t\t cpn,cpd = clpn(n,z)\n \t\tConstructing wrapper function \"lqmns\"...\n \t\t qm,qd = lqmns(m,n,x)\n \t\tConstructing wrapper function \"chgm\"...\n \t\t hg = chgm(a,b,x)\n \t\tConstructing wrapper function \"lpmn\"...\n \t\t pm,pd = lpmn(m,n,x)\n \t\tConstructing wrapper function \"fcszo\"...\n \t\t zo = fcszo(kf,nt)\n \t\tConstructing wrapper function \"aswfb\"...\n \t\t s1f,s1d = aswfb(m,n,c,x,kd,cv)\n \t\tConstructing wrapper function \"lqna\"...\n \t\t qn,qd = lqna(n,x)\n \t\tConstructing wrapper function \"cpbdn\"...\n \t\t cpb,cpd = cpbdn(n,z)\n \t\tConstructing wrapper function \"lpn\"...\n \t\t pn,pd = lpn(n,x)\n \t\tConstructing wrapper function \"fcoef\"...\n \t\t fc = fcoef(kd,m,q,a)\n \t\tConstructing wrapper function \"rcty\"...\n \t\t nm,ry,dy = rcty(n,x)\n \t\tConstructing wrapper function \"lpni\"...\n \t\t pn,pd,pl = lpni(n,x)\n \t\tConstructing wrapper function \"cyzo\"...\n \t\t zo,zv = cyzo(nt,kf,kc)\n \t\tConstructing wrapper function \"othpl\"...\n \t\t pl,dpl = othpl(kf,n,x)\n \t\tConstructing wrapper function \"klvnzo\"...\n \t\t zo = klvnzo(nt,kd)\n \t\tConstructing wrapper function \"jyzo\"...\n \t\t rj0,rj1,ry0,ry1 = jyzo(n,nt)\n \t\tConstructing wrapper function \"rctj\"...\n \t\t nm,rj,dj = rctj(n,x)\n \t\tConstructing wrapper function \"herzo\"...\n \t\t x,w = herzo(n)\n \t\tConstructing wrapper function \"pbvv\"...\n \t\t vv,vp,pvf,pvd = pbvv(v,x)\n \t\tConstructing wrapper function \"segv\"...\n \t\t cv,eg = segv(m,n,c,kd)\n \tWrote C/API module \"specfun\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/special/specfunmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special\n building extension \"scipy.special._ufuncs\" sources\n conv_template:> build/src.macosx-10.14.6-x86_64-3.8/scipy/special/_logit.c\n building extension \"scipy.special._ufuncs_cxx\" sources\n building extension \"scipy.special._ellip_harm_2\" sources\n building extension \"scipy.special.cython_special\" sources\n building extension \"scipy.special._comb\" sources\n building extension \"scipy.special._test_round\" sources\n building extension \"scipy.stats.statlib\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/stats\n f2py options: ['--no-wrap-functions']\n f2py: scipy/stats/statlib.pyf\n Reading fortran codes...\n \tReading file 'scipy/stats/statlib.pyf' (format:free)\n Post-processing...\n \tBlock: statlib\n \t\t\tBlock: swilk\n \t\t\tBlock: gscale\n \t\t\tBlock: prho\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"statlib\"...\n \t\tConstructing wrapper function \"swilk\"...\n \t\t a,w,pw,ifault = swilk(x,a,[init,n1])\n \t\tConstructing wrapper function \"gscale\"...\n \t\t astart,a1,ifault = gscale(test,other)\n \t\tConstructing wrapper function \"prho\"...\n \t\t ifault = prho(n,is)\n \tWrote C/API module \"statlib\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/statlibmodule.c\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats' to include_dirs.\n creating build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.c -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/f2py/src/fortranobject.h -> build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats\n building extension \"scipy.stats._stats\" sources\n building extension \"scipy.stats.mvn\" sources\n f2py options: []\n f2py: scipy/stats/mvn.pyf\n Reading fortran codes...\n \tReading file 'scipy/stats/mvn.pyf' (format:free)\n Post-processing...\n \tBlock: mvn\n \t\t\tBlock: mvnun\n \t\t\tBlock: mvndst\n Post-processing (stage 2)...\n Building modules...\n \tBuilding module \"mvn\"...\n \t\tConstructing wrapper function \"mvnun\"...\n \t\t value,inform = mvnun(lower,upper,means,covar,[maxpts,abseps,releps])\n \t\tConstructing wrapper function \"mvndst\"...\n \t\t error,value,inform = mvndst(lower,upper,infin,correl,[maxpts,abseps,releps])\n \t\tConstructing COMMON block support for \"dkblck\"...\n \t\t ivls\n \tWrote C/API module \"mvn\" to file \"build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/mvnmodule.c\"\n \tFortran 77 wrappers are saved to \"build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/mvn-f2pywrappers.f\"\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/mvn-f2pywrappers.f' to sources.\n building extension \"scipy.ndimage._nd_image\" sources\n building extension \"scipy.ndimage._ni_label\" sources\n building extension \"scipy.ndimage._ctest\" sources\n building extension \"scipy.ndimage._ctest_oldapi\" sources\n building extension \"scipy.ndimage._cytest\" sources\n building extension \"scipy._lib._ccallback_c\" sources\n building extension \"scipy._lib._test_ccallback\" sources\n building extension \"scipy._lib._fpumode\" sources\n building extension \"scipy._lib.messagestream\" sources\n creating build/src.macosx-10.14.6-x86_64-3.8/scipy/_lib\n Could not locate executable gfortran\n Could not locate executable f95\n Could not locate executable f90\n Could not locate executable f77\n Could not locate executable xlf90\n Could not locate executable xlf\n Could not locate executable ifort\n Could not locate executable ifc\n Could not locate executable g77\n Could not locate executable g95\n Could not locate executable pgfortran\n don't know how to compile Fortran code on platform 'posix'\n building data_files sources\n build_src: building npy-pkg config files\n running build_py\n creating build/lib.macosx-10.14.6-x86_64-3.8\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying scipy/conftest.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying scipy/version.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying scipy/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying scipy/_distributor_init.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying scipy/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying build/src.macosx-10.14.6-x86_64-3.8/scipy/__config__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/cluster\n copying scipy/cluster/vq.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/cluster\n copying scipy/cluster/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/cluster\n copying scipy/cluster/hierarchy.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/cluster\n copying scipy/cluster/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/cluster\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/constants\n copying scipy/constants/constants.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/constants\n copying scipy/constants/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/constants\n copying scipy/constants/codata.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/constants\n copying scipy/constants/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/constants\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/pseudo_diffs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/realtransforms.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/basic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n copying scipy/fftpack/helper.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/fftpack\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/_ode.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/quadrature.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/quadpack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/_bvp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n copying scipy/integrate/odepack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/bdf.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/ivp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/common.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/radau.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/lsoda.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/rk.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n copying scipy/integrate/_ivp/base.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/integrate/_ivp\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/_cubic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/polyint.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/ndgriddata.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/_bsplines.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/fitpack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/rbf.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/interpnd_info.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/_pade.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/interpolate.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/_fitpack_impl.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/fitpack2.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n copying scipy/interpolate/interpolate_wrapper.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/interpolate\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/wavfile.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/idl.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/netcdf.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/_fortran.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n copying scipy/io/mmio.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/miobase.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/mio5_params.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/byteordercodes.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/mio.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/mio4.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n copying scipy/io/matlab/mio5.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/matlab\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/arff\n copying scipy/io/arff/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/arff\n copying scipy/io/arff/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/arff\n copying scipy/io/arff/arffread.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/arff\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/harwell_boeing\n copying scipy/io/harwell_boeing/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/harwell_boeing\n copying scipy/io/harwell_boeing/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/harwell_boeing\n copying scipy/io/harwell_boeing/_fortran_format_parser.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/harwell_boeing\n copying scipy/io/harwell_boeing/hb.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/io/harwell_boeing\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp_qr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_matfuncs_inv_ssq.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/misc.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_sketches.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp_cholesky.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_testutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp_lu.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp_svd.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_procrustes.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_matfuncs_sqrtm.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/matfuncs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_generate_pyx.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_solvers.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_interpolative_backend.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/flinalg.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/basic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_decomp_polar.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/interpolative.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/blas.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_cython_signature_generator.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/special_matrices.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_decomp_ldl.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/decomp_schur.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_decomp_qz.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/_expm_frechet.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/linalg_version.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n copying scipy/linalg/lapack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/linalg\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n copying scipy/misc/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n copying scipy/misc/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n copying scipy/misc/common.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n copying scipy/misc/pilutil.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n copying scipy/misc/doccer.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/misc\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n copying scipy/odr/models.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n copying scipy/odr/add_newdocs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n copying scipy/odr/odrpack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n copying scipy/odr/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n copying scipy/odr/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/odr\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/tnc.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/optimize.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_linprog_ip.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/linesearch.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/nonlin.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_root.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/lbfgsb.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/zeros.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/slsqp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_trustregion_ncg.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_minimize.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/minpack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/nnls.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_basinhopping.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_linprog.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_hessian_update_strategy.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_hungarian.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/cobyla.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_tstutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_spectral.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_differentiable_functions.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_trustregion_krylov.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_trustregion.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_trustregion_dogleg.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_trustregion_exact.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_constraints.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_differentialevolution.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_remove_redundancy.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n copying scipy/optimize/_numdiff.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/least_squares.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/dogbox.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/trf_linear.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/common.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/lsq_linear.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/bvls.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n copying scipy/optimize/_lsq/trf.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_lsq\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trlib\n copying scipy/optimize/_trlib/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trlib\n copying scipy/optimize/_trlib/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trlib\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/equality_constrained_sqp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/tr_interior_point.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/qp_subproblem.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/minimize_trustregion_constr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/projections.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/report.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n copying scipy/optimize/_trustregion_constr/canonical_constraint.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/optimize/_trustregion_constr\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/waveforms.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/_savitzky_golay.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/signaltools.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/bsplines.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/_arraytools.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/_max_len_seq.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/wavelets.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/lti_conversion.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/_peak_finding.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/filter_design.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/spectral.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/_upfirdn.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/ltisys.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n copying scipy/signal/fir_filter_design.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal/windows\n copying scipy/signal/windows/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal/windows\n copying scipy/signal/windows/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal/windows\n copying scipy/signal/windows/windows.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/signal/windows\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/csc.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/generate_sparsetools.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/sparsetools.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/dok.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/coo.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/compressed.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/dia.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/spfuncs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/lil.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/sputils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/bsr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/_matrix_io.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/csr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/construct.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/extract.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/base.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n copying scipy/sparse/data.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/matfuncs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/interface.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/_expm_multiply.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/_norm.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n copying scipy/sparse/linalg/_onenormest.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/lsqr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/iterative.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/utils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/_gcrotmk.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/minres.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/lsmr.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n copying scipy/sparse/linalg/isolve/lgmres.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/dsolve\n copying scipy/sparse/linalg/dsolve/_add_newdocs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/dsolve\n copying scipy/sparse/linalg/dsolve/linsolve.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/dsolve\n copying scipy/sparse/linalg/dsolve/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/dsolve\n copying scipy/sparse/linalg/dsolve/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/dsolve\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n copying scipy/sparse/linalg/eigen/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n copying scipy/sparse/linalg/eigen/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n copying scipy/sparse/linalg/eigen/arpack/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n copying scipy/sparse/linalg/eigen/arpack/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n copying scipy/sparse/linalg/eigen/arpack/arpack.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/lobpcg\n copying scipy/sparse/linalg/eigen/lobpcg/lobpcg.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/lobpcg\n copying scipy/sparse/linalg/eigen/lobpcg/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/lobpcg\n copying scipy/sparse/linalg/eigen/lobpcg/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/lobpcg\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/csgraph\n copying scipy/sparse/csgraph/_laplacian.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/csgraph\n copying scipy/sparse/csgraph/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/csgraph\n copying scipy/sparse/csgraph/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/csgraph\n copying scipy/sparse/csgraph/_validation.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/sparse/csgraph\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/_spherical_voronoi.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/_procrustes.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/distance.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/kdtree.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n copying scipy/spatial/_plotutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/spatial\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/spfun_stats.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_testutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/sf_error.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/add_newdocs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_spherical_bessel.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_mptestutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_ellip_harm.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_generate_pyx.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/basic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/lambertw.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/orthogonal.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n copying scipy/special/_logsumexp.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/expn_asy.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/zetac.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/struve_convergence.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/loggamma.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/gammainc_asy.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/gammainc_data.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/utils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n copying scipy/special/_precompute/lambertw.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/special/_precompute\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_multivariate.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_constants.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_binned_statistic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_distr_params.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_tukeylambda_stats.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_stats_mstats_common.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/kde.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/mstats_extras.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_discrete_distns.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/distributions.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/mstats.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_distn_infrastructure.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/stats.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/_continuous_distns.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/morestats.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/mstats_basic.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/contingency.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n copying scipy/stats/vonmises.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/stats\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/_ni_support.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/interpolation.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/io.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/_ni_docstrings.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/morphology.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/fourier.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/filters.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n copying scipy/ndimage/measurements.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/ndimage\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/_build_utils\n copying scipy/_build_utils/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_build_utils\n copying scipy/_build_utils/_fortran.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_build_utils\n creating build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_testutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_version.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/decorator.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/__init__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_ccallback.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_threadsafety.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/setup.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_tmpdirs.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_numpy_compat.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_util.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/six.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n copying scipy/_lib/_gcutils.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy/_lib\n running build_clib\n customize UnixCCompiler\n C compiler: xcrun -sdk macosx clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -iwithsysroot/System/Library/Frameworks/System.framework/PrivateHeaders -iwithsysroot/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.8/Headers -arch arm64 -arch x86_64\n \n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var/folders\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var/folders/wq\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq\n compile options: '-MMD -MF /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/file.c.d -c'\n xcrun: /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmpg19ulotq/file.c\n customize UnixCCompiler using build_clib\n building 'dfftpack' library\n error: library dfftpack has Fortran sources but no Fortran compiler found\n ----------------------------------------\u001b[0m\n\u001b[31m ERROR: Failed building wheel for scipy\u001b[0m\n\u001b[?25h Running setup.py clean for scipy\n\u001b[31m ERROR: Command errored out with exit status 1:\n command: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"'; __file__='\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"';f=getattr(tokenize, '\"'\"'open'\"'\"', open)(__file__);code=f.read().replace('\"'\"'\\r\\n'\"'\"', '\"'\"'\\n'\"'\"');f.close();exec(compile(code, __file__, '\"'\"'exec'\"'\"'))' clean --all\n cwd: /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy\n Complete output (9 lines):\n \n `setup.py clean` is not supported, use one of the following instead:\n \n - `git clean -xdf` (cleans all files)\n - `git clean -Xdf` (cleans all versioned files, doesn't touch\n files that aren't checked into the git repo)\n \n Add `--force` to your command to use it anyway if you must (unsupported).\n \n ----------------------------------------\u001b[0m\n\u001b[31m ERROR: Failed cleaning build dir for scipy\u001b[0m\nFailed to build scipy\nInstalling collected packages: scipy\n Attempting uninstall: scipy\n Found existing installation: scipy 1.5.2\n Uninstalling scipy-1.5.2:\n Successfully uninstalled scipy-1.5.2\n Running setup.py install for scipy ... \u001b[?25lerror\n\u001b[31m ERROR: Command errored out with exit status 1:\n command: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"'; __file__='\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"';f=getattr(tokenize, '\"'\"'open'\"'\"', open)(__file__);code=f.read().replace('\"'\"'\\r\\n'\"'\"', '\"'\"'\\n'\"'\"');f.close();exec(compile(code, __file__, '\"'\"'exec'\"'\"'))' install --record /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-record-8zxnhqrw/install-record.txt --single-version-externally-managed --user --prefix= --compile --install-headers /Users/school/Library/Python/3.8/include/python3.8/scipy\n cwd: /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/\n Complete output (361 lines):\n \n Note: if you need reliable uninstall behavior, then install\n with pip instead of using `setup.py install`:\n \n - `pip install .` (from a git repo or downloaded source\n release)\n - `pip install scipy` (last SciPy release on PyPI)\n \n \n lapack_opt_info:\n lapack_mkl_info:\n customize UnixCCompiler\n C compiler: xcrun -sdk macosx clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -iwithsysroot/System/Library/Frameworks/System.framework/PrivateHeaders -iwithsysroot/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.8/Headers -arch arm64 -arch x86_64\n \n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var/folders\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var/folders/wq\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud\n compile options: '-MMD -MF /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/file.c.d -c'\n xcrun: /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmphthxxcud/file.c\n libraries mkl_rt not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_lapack_info:\n libraries openblas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_clapack_info:\n libraries openblas,lapack not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n flame_info:\n libraries flame not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_threads_info:\n Setting PTATLAS=ATLAS\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries tatlas,tatlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries tatlas,tatlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries tatlas,tatlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_3_10_threads_info'>\n NOT AVAILABLE\n \n atlas_3_10_info:\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries satlas,satlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries satlas,satlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries satlas,satlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_3_10_info'>\n NOT AVAILABLE\n \n atlas_threads_info:\n Setting PTATLAS=ATLAS\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries ptf77blas,ptcblas,atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries ptf77blas,ptcblas,atlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries ptf77blas,ptcblas,atlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_threads_info'>\n NOT AVAILABLE\n \n atlas_info:\n libraries lapack_atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries f77blas,cblas,atlas not found in /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib\n libraries lapack_atlas not found in /usr/local/lib\n libraries f77blas,cblas,atlas not found in /usr/local/lib\n libraries lapack_atlas not found in /usr/lib\n libraries f77blas,cblas,atlas not found in /usr/lib\n <class 'numpy.distutils.system_info.atlas_info'>\n NOT AVAILABLE\n \n accelerate_info:\n libraries accelerate not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n Library accelerate was not found. Ignoring\n libraries veclib not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n Library veclib was not found. Ignoring\n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n Running from scipy source directory.\n Splitting linalg.interpolative Fortran source files\n /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/distutils/system_info.py:820: UserWarning: Specified path /Users/school/Library/Python/3.8/include/python3.8 is invalid.\n return self.get_paths(self.section, key)\n /Users/school/Library/Python/3.8/lib/python/site-packages/numpy/distutils/system_info.py:820: UserWarning: Specified path /usr/local/include/python3.8 is invalid.\n return self.get_paths(self.section, key)\n blas_opt_info:\n blas_mkl_info:\n libraries mkl_rt not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n blis_info:\n libraries blis not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n openblas_info:\n libraries openblas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_blas_threads_info:\n Setting PTATLAS=ATLAS\n libraries tatlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_3_10_blas_info:\n libraries satlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_blas_threads_info:\n Setting PTATLAS=ATLAS\n libraries ptf77blas,ptcblas,atlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n atlas_blas_info:\n libraries f77blas,cblas,atlas not found in ['/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib', '/usr/local/lib', '/usr/lib']\n NOT AVAILABLE\n \n FOUND:\n extra_compile_args = ['-msse3', '-I/System/Library/Frameworks/vecLib.framework/Headers']\n extra_link_args = ['-Wl,-framework', '-Wl,Accelerate']\n define_macros = [('NO_ATLAS_INFO', 3), ('HAVE_CBLAS', None)]\n \n non-existing path in 'scipy/signal/windows': 'tests'\n [makenpz] scipy/special/tests/data/boost.npz not rebuilt\n [makenpz] scipy/special/tests/data/gsl.npz not rebuilt\n [makenpz] scipy/special/tests/data/local.npz not rebuilt\n running install\n running build\n running config_cc\n unifing config_cc, config, build_clib, build_ext, build commands --compiler options\n running config_fc\n unifing config_fc, config, build_clib, build_ext, build commands --fcompiler options\n running build_src\n build_src\n building py_modules sources\n building library \"dfftpack\" sources\n building library \"fftpack\" sources\n building library \"mach\" sources\n building library \"quadpack\" sources\n building library \"lsoda\" sources\n building library \"vode\" sources\n building library \"dop\" sources\n building library \"fitpack\" sources\n building library \"fwrappers\" sources\n building library \"odrpack\" sources\n building library \"minpack\" sources\n building library \"rootfind\" sources\n building library \"superlu_src\" sources\n building library \"arpack_scipy\" sources\n building library \"sc_c_misc\" sources\n building library \"sc_cephes\" sources\n building library \"sc_mach\" sources\n building library \"sc_amos\" sources\n building library \"sc_cdf\" sources\n building library \"sc_specfun\" sources\n building library \"statlib\" sources\n building extension \"scipy.cluster._vq\" sources\n building extension \"scipy.cluster._hierarchy\" sources\n building extension \"scipy.cluster._optimal_leaf_ordering\" sources\n building extension \"scipy.fftpack._fftpack\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack' to include_dirs.\n building extension \"scipy.fftpack.convolve\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/fftpack' to include_dirs.\n building extension \"scipy.integrate._quadpack\" sources\n building extension \"scipy.integrate._odepack\" sources\n building extension \"scipy.integrate.vode\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n building extension \"scipy.integrate.lsoda\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n building extension \"scipy.integrate._dop\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n building extension \"scipy.integrate._test_multivariate\" sources\n building extension \"scipy.integrate._test_odeint_banded\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/integrate/_test_odeint_banded-f2pywrappers.f' to sources.\n building extension \"scipy.interpolate.interpnd\" sources\n building extension \"scipy.interpolate._ppoly\" sources\n building extension \"scipy.interpolate._bspl\" sources\n building extension \"scipy.interpolate._fitpack\" sources\n building extension \"scipy.interpolate.dfitpack\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/interpolate/src/dfitpack-f2pywrappers.f' to sources.\n building extension \"scipy.interpolate._interpolate\" sources\n building extension \"scipy.io._test_fortran\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/io' to include_dirs.\n building extension \"scipy.io.matlab.streams\" sources\n building extension \"scipy.io.matlab.mio_utils\" sources\n building extension \"scipy.io.matlab.mio5_utils\" sources\n building extension \"scipy.linalg._fblas\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_fblas-f2pywrappers.f' to sources.\n building extension \"scipy.linalg._flapack\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/_flapack-f2pywrappers.f' to sources.\n building extension \"scipy.linalg._flinalg\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n building extension \"scipy.linalg._interpolative\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/linalg' to include_dirs.\n building extension \"scipy.linalg._solve_toeplitz\" sources\n building extension \"scipy.linalg.cython_blas\" sources\n building extension \"scipy.linalg.cython_lapack\" sources\n building extension \"scipy.linalg._decomp_update\" sources\n building extension \"scipy.odr.__odrpack\" sources\n building extension \"scipy.optimize._minpack\" sources\n building extension \"scipy.optimize._zeros\" sources\n building extension \"scipy.optimize._lbfgsb\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/lbfgsb' to include_dirs.\n building extension \"scipy.optimize.moduleTNC\" sources\n building extension \"scipy.optimize._cobyla\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/cobyla' to include_dirs.\n building extension \"scipy.optimize.minpack2\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/minpack2' to include_dirs.\n building extension \"scipy.optimize._slsqp\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/slsqp' to include_dirs.\n building extension \"scipy.optimize._nnls\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/optimize/nnls' to include_dirs.\n building extension \"scipy.optimize._group_columns\" sources\n building extension \"scipy.optimize._lsq.givens_elimination\" sources\n building extension \"scipy.optimize._trlib._trlib\" sources\n building extension \"scipy.signal.sigtools\" sources\n building extension \"scipy.signal._spectral\" sources\n building extension \"scipy.signal._max_len_seq_inner\" sources\n building extension \"scipy.signal._peak_finding_utils\" sources\n building extension \"scipy.signal._upfirdn_apply\" sources\n building extension \"scipy.signal.spline\" sources\n building extension \"scipy.sparse.linalg.isolve._iterative\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/isolve/iterative' to include_dirs.\n building extension \"scipy.sparse.linalg.dsolve._superlu\" sources\n building extension \"scipy.sparse.linalg.eigen.arpack._arpack\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/sparse/linalg/eigen/arpack/_arpack-f2pywrappers.f' to sources.\n building extension \"scipy.sparse.csgraph._shortest_path\" sources\n building extension \"scipy.sparse.csgraph._traversal\" sources\n building extension \"scipy.sparse.csgraph._min_spanning_tree\" sources\n building extension \"scipy.sparse.csgraph._reordering\" sources\n building extension \"scipy.sparse.csgraph._tools\" sources\n building extension \"scipy.sparse._csparsetools\" sources\n building extension \"scipy.sparse._sparsetools\" sources\n [generate_sparsetools] 'scipy/sparse/sparsetools/bsr_impl.h' already up-to-date\n [generate_sparsetools] 'scipy/sparse/sparsetools/csr_impl.h' already up-to-date\n [generate_sparsetools] 'scipy/sparse/sparsetools/csc_impl.h' already up-to-date\n [generate_sparsetools] 'scipy/sparse/sparsetools/other_impl.h' already up-to-date\n [generate_sparsetools] 'scipy/sparse/sparsetools/sparsetools_impl.h' already up-to-date\n building extension \"scipy.spatial.qhull\" sources\n building extension \"scipy.spatial.ckdtree\" sources\n building extension \"scipy.spatial._distance_wrap\" sources\n building extension \"scipy.spatial._voronoi\" sources\n building extension \"scipy.spatial._hausdorff\" sources\n building extension \"scipy.special.specfun\" sources\n f2py options: ['--no-wrap-functions']\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/special' to include_dirs.\n building extension \"scipy.special._ufuncs\" sources\n building extension \"scipy.special._ufuncs_cxx\" sources\n building extension \"scipy.special._ellip_harm_2\" sources\n building extension \"scipy.special.cython_special\" sources\n building extension \"scipy.special._comb\" sources\n building extension \"scipy.special._test_round\" sources\n building extension \"scipy.stats.statlib\" sources\n f2py options: ['--no-wrap-functions']\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats' to include_dirs.\n building extension \"scipy.stats._stats\" sources\n building extension \"scipy.stats.mvn\" sources\n f2py options: []\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/fortranobject.c' to sources.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/build/src.macosx-10.14.6-x86_64-3.8/scipy/stats' to include_dirs.\n adding 'build/src.macosx-10.14.6-x86_64-3.8/scipy/stats/mvn-f2pywrappers.f' to sources.\n building extension \"scipy.ndimage._nd_image\" sources\n building extension \"scipy.ndimage._ni_label\" sources\n building extension \"scipy.ndimage._ctest\" sources\n building extension \"scipy.ndimage._ctest_oldapi\" sources\n building extension \"scipy.ndimage._cytest\" sources\n building extension \"scipy._lib._ccallback_c\" sources\n building extension \"scipy._lib._test_ccallback\" sources\n building extension \"scipy._lib._fpumode\" sources\n building extension \"scipy._lib.messagestream\" sources\n Could not locate executable gfortran\n Could not locate executable f95\n Could not locate executable f90\n Could not locate executable f77\n Could not locate executable xlf90\n Could not locate executable xlf\n Could not locate executable ifort\n Could not locate executable ifc\n Could not locate executable g77\n Could not locate executable g95\n Could not locate executable pgfortran\n don't know how to compile Fortran code on platform 'posix'\n building data_files sources\n build_src: building npy-pkg config files\n running build_py\n copying scipy/version.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n copying build/src.macosx-10.14.6-x86_64-3.8/scipy/__config__.py -> build/lib.macosx-10.14.6-x86_64-3.8/scipy\n running build_clib\n customize UnixCCompiler\n C compiler: xcrun -sdk macosx clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -iwithsysroot/System/Library/Frameworks/System.framework/PrivateHeaders -iwithsysroot/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.8/Headers -arch arm64 -arch x86_64\n \n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var/folders\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var/folders/wq\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T\n creating /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86\n compile options: '-MMD -MF /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/file.c.d -c'\n xcrun: /var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/tmp2_c1xr86/file.c\n customize UnixCCompiler using build_clib\n building 'dfftpack' library\n error: library dfftpack has Fortran sources but no Fortran compiler found\n ----------------------------------------\u001b[0m\n\u001b[?25h Rolling back uninstall of scipy\n Moving to /Users/school/Library/Caches/com.apple.python/Users/school/Library/Python/3.8/lib/python/site-packages/scipy/\n from /Users/school/Library/Caches/com.apple.python/Users/school/Library/Python/3.8/lib/python/site-packages/~cipy\n Moving to /Users/school/Library/Python/3.8/lib/python/site-packages/scipy-1.5.2.dist-info/\n from /Users/school/Library/Python/3.8/lib/python/site-packages/~cipy-1.5.2.dist-info\n Moving to /Users/school/Library/Python/3.8/lib/python/site-packages/scipy/\n from /Users/school/Library/Python/3.8/lib/python/site-packages/~cipy\n\u001b[31mERROR: Command errored out with exit status 1: /Library/Developer/CommandLineTools/usr/bin/python3 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"'; __file__='\"'\"'/private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-install-0cuparmt/scipy/setup.py'\"'\"';f=getattr(tokenize, '\"'\"'open'\"'\"', open)(__file__);code=f.read().replace('\"'\"'\\r\\n'\"'\"', '\"'\"'\\n'\"'\"');f.close();exec(compile(code, __file__, '\"'\"'exec'\"'\"'))' install --record /private/var/folders/wq/3skt395n3k1dt_twqdv2514m0000gp/T/pip-record-8zxnhqrw/install-record.txt --single-version-externally-managed --user --prefix= --compile --install-headers /Users/school/Library/Python/3.8/include/python3.8/scipy Check the logs for full command output.\u001b[0m\nNote: you may need to restart the kernel to use updated packages.\n"
],
[
"pip install pandas==0.21.3",
"Defaulting to user installation because normal site-packages is not writeable\n\u001b[31mERROR: Could not find a version that satisfies the requirement pandas==0.21.3 (from versions: 0.1, 0.2b0, 0.2b1, 0.2, 0.3.0b0, 0.3.0b2, 0.3.0, 0.4.0, 0.4.1, 0.4.2, 0.4.3, 0.5.0, 0.6.0, 0.6.1, 0.7.0rc1, 0.7.0, 0.7.1, 0.7.2, 0.7.3, 0.8.0rc1, 0.8.0rc2, 0.8.0, 0.8.1, 0.9.0, 0.9.1, 0.10.0, 0.10.1, 0.11.0, 0.12.0, 0.13.0, 0.13.1, 0.14.0, 0.14.1, 0.15.0, 0.15.1, 0.15.2, 0.16.0, 0.16.1, 0.16.2, 0.17.0, 0.17.1, 0.18.0, 0.18.1, 0.19.0rc1, 0.19.0, 0.19.1, 0.19.2, 0.20.0rc1, 0.20.0, 0.20.1, 0.20.2, 0.20.3, 0.21.0rc1, 0.21.0, 0.21.1, 0.22.0, 0.23.0rc2, 0.23.0, 0.23.1, 0.23.2, 0.23.3, 0.23.4, 0.24.0rc1, 0.24.0, 0.24.1, 0.24.2, 0.25.0rc0, 0.25.0, 0.25.1, 0.25.2, 0.25.3, 1.0.0rc0, 1.0.0, 1.0.1, 1.0.2, 1.0.3, 1.0.4, 1.0.5, 1.1.0rc0, 1.1.0, 1.1.1, 1.1.2)\u001b[0m\n\u001b[31mERROR: No matching distribution found for pandas==0.21.3\u001b[0m\nNote: you may need to restart the kernel to use updated packages.\n"
],
[
"#pip install numpy==1.18.1",
"_____no_output_____"
],
[
"from keras.models import Sequential\nfrom keras.layers.core import Dense, Dropout, Activation\nfrom keras.utils import np_utils\nfrom keras.preprocessing.text import Tokenizer\nfrom keras import metrics\nfrom keras.layers.embeddings import Embedding\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.preprocessing.text import one_hot\nfrom keras.layers import Flatten\n\nfrom nltk import word_tokenize, pos_tag, chunk\nfrom pprint import pprint\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import RegexpTokenizer\nfrom nltk.stem import WordNetLemmatizer\n\nfrom pprint import pprint\nimport pandas as pd\nimport numpy as np\n\nfrom keras import optimizers\nfrom keras.layers import Dense\nfrom sklearn.model_selection import GridSearchCV\nfrom keras.wrappers.scikit_learn import KerasClassifier\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import LabelBinarizer\nfrom keras.constraints import maxnorm\nfrom keras.layers import Dropout\nimport os",
"_____no_output_____"
],
[
"df = pd.read_csv('data.csv')",
"_____no_output_____"
],
[
"selected_df = df[['job_description','job_title','category']]\nselected_df = selected_df.dropna()",
"_____no_output_____"
],
[
"train, test = train_test_split(selected_df ,test_size = 0.2)\ntrain_descs = train['job_description']\ntrain_labels = train['category']\n#train_labels = train['job_title']\n \ntest_descs = test['job_description']\ntest_labels = test['category']",
"_____no_output_____"
],
[
"num_labels = len(train_labels.unique().tolist())\nvocab_size = 1000\nbatch_size = 32\nnb_epoch = 50\n\n# define Tokenizer with Vocab Size\ntokenizer = Tokenizer(num_words=vocab_size)\ntokenizer.fit_on_texts(train_descs)\nx_train = tokenizer.texts_to_matrix(train_descs, mode='tfidf')\nx_test = tokenizer.texts_to_matrix(test_descs, mode='tfidf')\n \nencoder = LabelBinarizer()\nencoder.fit(train_labels)\ny_train = encoder.transform(train_labels)\ny_test = encoder.transform(test_labels)",
"_____no_output_____"
],
[
"model = Sequential()\nmodel.add(Dense(4096, input_shape=(vocab_size,), activation = 'relu', kernel_initializer = 'glorot_normal', kernel_constraint=maxnorm(2)))\nmodel.add(Dropout(0.1))\nmodel.add(Dense(1024, kernel_initializer = 'glorot_normal', activation= 'relu'))\nmodel.add(Dropout(0.1))\nmodel.add(Dense(num_labels))\nmodel.add(Activation('softmax'))\n \n # Compile model\nmodel.compile(loss = 'categorical_crossentropy',\n optimizer = 'sgd',\n metrics = [metrics.categorical_accuracy, 'accuracy'])",
"_____no_output_____"
],
[
"history = model.fit(x_train, y_train,\n batch_size=batch_size,\n epochs=nb_epoch,\n verbose=1,\n validation_split=0.1)",
"_____no_output_____"
],
[
"score = model.evaluate(x_test, y_test,\n batch_size=batch_size, verbose=1)\n \nprint('\\nTest categorical_crossentropy:', score[0])\nprint('Categorical accuracy:', score[1])\nprint('Accuracy:', score[2])",
"_____no_output_____"
],
[
"with open('resume.txt','r') as f:\n resume = f.read()\nimport re\nresume = re.sub('\\s+',' ',resume)\nresume = pd.Series(resume)\ntokenizer_resume = tokenizer.texts_to_matrix(resume, mode='tfidf')",
"_____no_output_____"
],
[
"pred = model.predict(tokenizer_resume)",
"_____no_output_____"
],
[
"print('The suggested work is', (encoder.inverse_transform(pred))[0])",
"_____no_output_____"
]
],
[
[
"next step: batch inputs, thousand input resumes (pdf format) to text, then make prediction\n\n3 functions needs:\n\n\n\n1. pdf converter: pdf to txt [[resume1],[resume2],....,[resumen]]\n2. function for multiple predictions?\n3. fuction to tokenizer all resumes\n\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ac8ada73dcd2357b0f1e0e9afc9fe255f4b6455
| 29,968 |
ipynb
|
Jupyter Notebook
|
tensorflow1_ipynb/mechanics/file-queues.ipynb
|
NeoGitCrt1/deeplearning-models
|
35aba5dc03c43bc29af5304ac248fc956e1361bf
|
[
"MIT"
] | 16,182 |
2019-06-05T17:56:01.000Z
|
2022-03-31T16:07:10.000Z
|
tensorflow1_ipynb/mechanics/file-queues.ipynb
|
ShirleyGao1023/deeplearning-models
|
6816908a3567ff7da539d9a2931047313c3f20dc
|
[
"MIT"
] | 41 |
2019-06-06T09:42:38.000Z
|
2022-02-27T23:59:04.000Z
|
tensorflow1_ipynb/mechanics/file-queues.ipynb
|
ShirleyGao1023/deeplearning-models
|
6816908a3567ff7da539d9a2931047313c3f20dc
|
[
"MIT"
] | 3,917 |
2019-06-05T18:03:40.000Z
|
2022-03-31T06:07:34.000Z
| 46.75195 | 6,558 | 0.630072 |
[
[
[
"Deep Learning Models -- A collection of various deep learning architectures, models, and tips for TensorFlow and PyTorch in Jupyter Notebooks.\n- Author: Sebastian Raschka\n- GitHub Repository: https://github.com/rasbt/deeplearning-models",
"_____no_output_____"
]
],
[
[
"%load_ext watermark\n%watermark -a 'Sebastian Raschka' -v -p tensorflow,numpy",
"Sebastian Raschka \n\nCPython 3.6.1\nIPython 6.1.0\n\ntensorflow 1.1.0\nnumpy 1.12.1\n"
]
],
[
[
"# Using Queue Runners to Feed Images Directly from Disk",
"_____no_output_____"
],
[
"TensorFlow provides users with multiple options for providing data to the model. One of the probably most common methods is to define placeholders in the TensorFlow graph and feed the data from the current Python session into the TensorFlow `Session` using the `feed_dict` parameter. Using this approach, a large dataset that does not fit into memory is most conveniently and efficiently stored using NumPy archives as explained in [Chunking an Image Dataset for Minibatch Training using NumPy NPZ Archives](image-data-chunking-npz.ipynb) or HDF5 data base files ([Storing an Image Dataset for Minibatch Training using HDF5](image-data-chunking-hdf5.ipynb)).\n\nAnother approach, which is often preferred when it comes to computational efficiency, is to do the \"data loading\" directly in the graph using input queues from so-called TFRecords files, which is illustrated in the [Using Input Pipelines to Read Data from TFRecords Files](tfrecords.ipynb) notebook. \n\nThis notebook will introduce an alternative approach which is similar to the TFRecords approach as we will be using input queues to load the data directly on the graph. However, here we are going to read the images directly from JPEG files, which is a useful approach if disk space is a concern and we don't want to create a large TFRecords file from our \"large\" image database.\n\nBeyond the examples in this notebook, you are encouraged to read more in TensorFlow's \"[Reading Data](https://www.tensorflow.org/programmers_guide/reading_data)\" guide.",
"_____no_output_____"
],
[
"## 0. The Dataset",
"_____no_output_____"
],
[
"Let's pretend we have a directory of images containing two subdirectories with images for training, validation, and testing. The following function will create such a dataset of images in JPEG format locally for demonstration purposes.",
"_____no_output_____"
]
],
[
[
"# Note that executing the following code \n# cell will download the MNIST dataset\n# and save all the 60,000 images as separate JPEG\n# files. This might take a few minutes depending\n# on your machine.\n\nimport numpy as np\n\n# load utilities from ../helper.py\nimport sys\nsys.path.insert(0, '..') \nfrom helper import mnist_export_to_jpg\n\nnp.random.seed(123)\nmnist_export_to_jpg(path='./')",
"Extracting ./train-images-idx3-ubyte.gz\nExtracting ./train-labels-idx1-ubyte.gz\nExtracting ./t10k-images-idx3-ubyte.gz\nExtracting ./t10k-labels-idx1-ubyte.gz\n"
]
],
[
[
"The `mnist_export_to_jpg` function called above creates 3 directories, mnist_train, mnist_test, and mnist_validation. Note that the names of the subdirectories correspond directly to the class label of the images that are stored under it:",
"_____no_output_____"
]
],
[
[
"import os\n\nfor i in ('train', 'valid', 'test'): \n dirs = [d for d in os.listdir('mnist_%s' % i) if not d.startswith('.')]\n print('mnist_%s subdirectories' % i, dirs)",
"mnist_train subdirectories ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\nmnist_valid subdirectories ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\nmnist_test subdirectories ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\n"
]
],
[
[
"To make sure that the images look okay, the snippet below plots an example image from the subdirectory `mnist_train/9/`:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.image as mpimg\nimport matplotlib.pyplot as plt\nimport os\n\nsome_img = os.path.join('./mnist_train/9/', os.listdir('./mnist_train/9/')[0])\n\nimg = mpimg.imread(some_img)\nprint(img.shape)\nplt.imshow(img, cmap='binary');",
"(28, 28)\n"
]
],
[
[
"Note: The JPEG format introduces a few artifacts that we can see in the image above. In this case, we use JPEG instead of PNG. Here, JPEG is used for demonstration purposes since that's still format many image datasets are stored in.",
"_____no_output_____"
],
[
"# 1. Reading",
"_____no_output_____"
],
[
"This section provides an example of how to use the [`tf.WholeFileReader`](https://www.tensorflow.org/api_docs/python/tf/WholeFileReader) and a filename queue to read in the images from the `mnist_train` directory. Also, we will be extracting the class labels directly from the file paths and convert the images to a one-hot encoded format that we will use in the later sections to train a multilayer neural network.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\n\ng = tf.Graph()\nwith g.as_default():\n \n filename_queue = tf.train.string_input_producer(\n tf.train.match_filenames_once('mnist_train/*/*.jpg'),\n seed=123,\n shuffle=True)\n\n image_reader = tf.WholeFileReader()\n\n file_name, image_raw = image_reader.read(filename_queue)\n file_name = tf.identity(file_name, name='file_name')\n image = tf.image.decode_jpeg(image_raw, name='image')\n image = tf.cast(image, tf.float32)\n label = tf.string_split([file_name], '/').values[1]\n label = tf.string_to_number(label, tf.int32, name='label')\n onehot_label = tf.one_hot(indices=label, \n depth=10, \n name='onehot_label')\n\n \n\nwith tf.Session(graph=g) as sess:\n\n sess.run(tf.local_variables_initializer())\n\n coord = tf.train.Coordinator()\n threads = tf.train.start_queue_runners(sess=sess,\n coord=coord)\n \n image_tensor, file_name, class_label, ohe_label =\\\n sess.run(['image:0', \n 'file_name:0', \n 'label:0',\n 'onehot_label:0'])\n\n print('Image shape:', image_tensor.shape)\n print('File name:', file_name) \n print('Class label:', class_label) \n print('One-hot class label:', ohe_label) \n\n coord.request_stop()\n coord.join(threads)",
"Image shape: (28, 28, 1)\nFile name: b'mnist_train/6/22340.jpg'\nClass label: 6\nOne-hot class label: [ 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]\n"
]
],
[
[
"- The `tf.train.string_input_producer` produces a filename queue that we iterate over in the session. Note that we need to call `sess.run(tf.local_variables_initializer())` for our filename queue. y.\" \n\n- The `tf.train.start_queue_runners` function uses a queue runner that uses a separate thread to load the filenames from the `queue` that we defined in the graph without blocking the reader.",
"_____no_output_____"
],
[
"Note that it is important to shuffle the dataset so that we can later make use of TensorFlow's [`tf.train.shuffle_batch`](https://www.tensorflow.org/api_docs/python/tf/train/shuffle_batch) function and don't need to load the whole dataset into memory to shuffle epochs.",
"_____no_output_____"
],
[
"## 2. Reading in batches",
"_____no_output_____"
],
[
"While the previous section illustrated how we can use input pipelines to read images one by one, we rarely (want to) train neural networks with one datapoint at a time but use minibatches instead. TensorFlow also has some really convenient utility functions to do the batching conveniently. In the following code example, we will use the [`tf.train.shuffle_batch`](https://www.tensorflow.org/api_docs/python/tf/train/shuffle_batch) function to load the images and labels in batches of size 64.\n\nAlso, let us put the code for processing the images and labels into a function, `read_images_from_disk`, that we can reuse later.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\n\ndef read_images_from_disk(filename_queue, image_dimensions, normalize=True):\n\n image_reader = tf.WholeFileReader()\n file_name, image_raw = image_reader.read(filename_queue)\n file_name = tf.identity(file_name, name='file_name')\n image = tf.image.decode_jpeg(image_raw, name='image')\n image.set_shape(image_dimensions)\n image = tf.cast(image, tf.float32)\n\n if normalize:\n # normalize to [0, 1] range\n image = image / 255.\n \n label = tf.string_split([file_name], '/').values[1]\n label = tf.string_to_number(label, tf.int32)\n onehot_label = tf.one_hot(indices=label,\n depth=10, \n name='onehot_label')\n return image, onehot_label\n \n \n \n\ng = tf.Graph()\nwith g.as_default():\n \n\n filename_queue = tf.train.string_input_producer(\n tf.train.match_filenames_once('mnist_train/*/*.jpg'),\n seed=123)\n \n image, label = read_images_from_disk(filename_queue,\n image_dimensions=[28, 28, 1])\n \n \n image_batch, label_batch = tf.train.shuffle_batch([image, label], \n batch_size=64,\n capacity=2000,\n min_after_dequeue=1000,\n num_threads=1,\n seed=123)\n\n\n \nwith tf.Session(graph=g) as sess:\n\n sess.run(tf.local_variables_initializer())\n\n coord = tf.train.Coordinator()\n threads = tf.train.start_queue_runners(sess=sess,\n coord=coord)\n \n multipe_images, multiple_labels = sess.run([image_batch, label_batch])\n print('Image batch shape:', multipe_images.shape)\n print('Label batch shape:', label_batch.shape)\n\n coord.request_stop()\n coord.join(threads)",
"Image batch shape: (64, 28, 28, 1)\nLabel batch shape: (64, 10)\n"
]
],
[
[
"The other relevant arguments we provided to `tf.train.shuffle_batch` are described below:\n\n- `capacity`: An integer that defines the maximum number of elements in the queue.\n- `min_after_dequeue`: The minimum number elements in the queue after a dequeue, which is used to ensure that a minimum number of data points have been loaded for shuffling.\n- `num_threads`: The number of threads for enqueuing.",
"_____no_output_____"
],
[
"## 3. Use queue runners to train a neural network",
"_____no_output_____"
],
[
"In this section, we will take the concepts that were introduced in the previous sections and train a multilayer perceptron using the concepts introduced in the previous sections: the `read_images_from_disk` function, a filename queue, and the `tf.train.shuffle_batch` function.\n ",
"_____no_output_____"
]
],
[
[
"##########################\n### SETTINGS\n##########################\n\n# Hyperparameters\nlearning_rate = 0.1\nbatch_size = 128\nn_epochs = 15\nn_iter = n_epochs * (45000 // batch_size)\n\n# Architecture\nn_hidden_1 = 128\nn_hidden_2 = 256\nheight, width = 28, 28\nn_classes = 10\n\n\n\n##########################\n### GRAPH DEFINITION\n##########################\n\ng = tf.Graph()\nwith g.as_default():\n \n tf.set_random_seed(123)\n\n # Input data\n filename_queue = tf.train.string_input_producer(\n tf.train.match_filenames_once('mnist_train/*/*.jpg'),\n seed=123)\n \n image, label = read_images_from_disk(filename_queue,\n image_dimensions=[28, 28, 1])\n image = tf.reshape(image, (width*height,))\n \n \n image_batch, label_batch = tf.train.shuffle_batch([image, label], \n batch_size=batch_size,\n capacity=2000,\n min_after_dequeue=1000,\n num_threads=1,\n seed=123)\n \n tf_images = tf.placeholder_with_default(image_batch,\n shape=[None, 784], \n name='images')\n tf_labels = tf.placeholder_with_default(label_batch, \n shape=[None, 10], \n name='labels')\n\n # Model parameters\n weights = {\n 'h1': tf.Variable(tf.truncated_normal([height*width, n_hidden_1], stddev=0.1)),\n 'h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2], stddev=0.1)),\n 'out': tf.Variable(tf.truncated_normal([n_hidden_2, n_classes], stddev=0.1))\n }\n biases = {\n 'b1': tf.Variable(tf.zeros([n_hidden_1])),\n 'b2': tf.Variable(tf.zeros([n_hidden_2])),\n 'out': tf.Variable(tf.zeros([n_classes]))\n }\n\n # Multilayer perceptron\n layer_1 = tf.add(tf.matmul(tf_images, weights['h1']), biases['b1'])\n layer_1 = tf.nn.relu(layer_1)\n layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])\n layer_2 = tf.nn.relu(layer_2)\n out_layer = tf.matmul(layer_2, weights['out']) + biases['out']\n\n # Loss and optimizer\n loss = tf.nn.softmax_cross_entropy_with_logits(logits=out_layer, labels=tf_labels)\n cost = tf.reduce_mean(loss, name='cost')\n optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)\n train = optimizer.minimize(cost, name='train')\n\n # Prediction\n prediction = tf.argmax(out_layer, 1, name='prediction')\n correct_prediction = tf.equal(tf.argmax(label_batch, 1), tf.argmax(out_layer, 1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='accuracy')\n \n \n \nwith tf.Session(graph=g) as sess:\n sess.run(tf.local_variables_initializer())\n sess.run(tf.global_variables_initializer())\n saver0 = tf.train.Saver()\n \n coord = tf.train.Coordinator()\n threads = tf.train.start_queue_runners(sess=sess, coord=coord)\n \n avg_cost = 0.\n iter_per_epoch = n_iter // n_epochs\n epoch = 0\n\n for i in range(n_iter):\n _, cost = sess.run(['train', 'cost:0'])\n avg_cost += cost\n \n if not i % iter_per_epoch:\n epoch += 1\n avg_cost /= iter_per_epoch\n print(\"Epoch: %03d | AvgCost: %.3f\" % (epoch, avg_cost))\n avg_cost = 0.\n \n \n coord.request_stop()\n coord.join(threads)\n \n saver0.save(sess, save_path='./mlp')",
"Epoch: 001 | AvgCost: 0.007\nEpoch: 002 | AvgCost: 0.481\nEpoch: 003 | AvgCost: 0.234\nEpoch: 004 | AvgCost: 0.180\nEpoch: 005 | AvgCost: 0.147\nEpoch: 006 | AvgCost: 0.125\nEpoch: 007 | AvgCost: 0.108\nEpoch: 008 | AvgCost: 0.094\nEpoch: 009 | AvgCost: 0.084\nEpoch: 010 | AvgCost: 0.075\nEpoch: 011 | AvgCost: 0.067\nEpoch: 012 | AvgCost: 0.061\nEpoch: 013 | AvgCost: 0.055\nEpoch: 014 | AvgCost: 0.049\nEpoch: 015 | AvgCost: 0.046\n"
]
],
[
[
"After looking at the graph above, you probably wondered why we used [`tf.placeholder_with_default`](https://www.tensorflow.org/api_docs/python/tf/placeholder_with_default) to define the two placeholders:\n\n```python\ntf_images = tf.placeholder_with_default(image_batch,\n shape=[None, 784], \n name='images')\ntf_labels = tf.placeholder_with_default(label_batch, \n shape=[None, 10], \n name='labels')\n``` \n\nIn the training session above, these placeholders are being ignored if we don't feed them via a session's `feed_dict`, or in other words \"[A `tf.placeholder_with_default` is a] placeholder op that passes through input when its output is not fed\" (https://www.tensorflow.org/api_docs/python/tf/placeholder_with_default).\n\nHowever, these placeholders are useful if we want to feed new data to the graph and make predictions after training as in a real-world application, which we will see in the next section.",
"_____no_output_____"
],
[
"## 4. Feeding new datapoints through placeholders",
"_____no_output_____"
],
[
"To demonstrate how we can feed new data points to the network that are not part of the training queue, let's use the test dataset and load the images into Python and pass it to the graph using a `feed_dict`:",
"_____no_output_____"
]
],
[
[
"import matplotlib.image as mpimg\nimport numpy as np\nimport glob\n\n\nimg_paths = np.array([p for p in glob.iglob('mnist_test/*/*.jpg')])\nlabels = np.array([int(path.split('/')[1]) for path in img_paths])\n\n\nwith tf.Session() as sess:\n \n saver1 = tf.train.import_meta_graph('./mlp.meta')\n saver1.restore(sess, save_path='./mlp')\n \n num_correct = 0\n cnt = 0\n for path, lab in zip(img_paths, labels):\n cnt += 1\n image = mpimg.imread(path)\n image = image.reshape(1, -1)\n \n pred = sess.run('prediction:0', \n feed_dict={'images:0': image})\n\n num_correct += int(lab == pred[0])\n acc = num_correct / cnt * 100\n\nprint('Test accuracy: %.1f%%' % acc)",
"INFO:tensorflow:Restoring parameters from ./mlp\nTest accuracy: 97.1%\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4ac8b5d2abdcf1e6123aca59687a04c3358d1065
| 25,789 |
ipynb
|
Jupyter Notebook
|
notebooks/petfinder.ipynb
|
korolm/kaggle-petfinder
|
a841508f28df7b0a3839f9a97f7798ce30a6a935
|
[
"MIT"
] | null | null | null |
notebooks/petfinder.ipynb
|
korolm/kaggle-petfinder
|
a841508f28df7b0a3839f9a97f7798ce30a6a935
|
[
"MIT"
] | null | null | null |
notebooks/petfinder.ipynb
|
korolm/kaggle-petfinder
|
a841508f28df7b0a3839f9a97f7798ce30a6a935
|
[
"MIT"
] | null | null | null | 84.832237 | 563 | 0.651402 |
[
[
[
"!kg download -u [email protected] -p okneffdr -c microsoft-malware-prediction",
"\"ls\" не является внутренней или внешней\nкомандой, исполняемой программой или пакетным файлом.\n"
],
[
"!pip install kaggle-cli",
"Collecting kaggle-cli\n Downloading https://files.pythonhosted.org/packages/67/61/710d02460bc4367ffd1f5e71cd9c031fb278f78aa0e8e32ca9dd99a2add8/kaggle-cli-0.12.13.tar.gz\nCollecting cliff<2.9,>=2.8.0 (from kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/c2/ba/f45621f885ecd8527142811c279740367eb6c552ceb8debfdb7c5fca0677/cliff-2.8.2.tar.gz (72kB)\nCollecting MechanicalSoup<0.9,>=0.7.0 (from kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/5c/2e/f63ed26b51e36efa4cc22cad18187fcb0a253f756d548c96bb931f13de98/MechanicalSoup-0.8.0-py2.py3-none-any.whl\nCollecting lxml<4.1,>=4.0.0 (from kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/07/76/9f14811d3fb91ed7973a798ded15eda416070bbcb1aadc6a5af9d691d993/lxml-4.0.0.tar.gz (4.2MB)\nCollecting cssselect<1.1,>=1.0.1 (from kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/7b/44/25b7283e50585f0b4156960691d951b05d061abf4a714078393e51929b30/cssselect-1.0.3-py2.py3-none-any.whl\nRequirement already satisfied: configparser in c:\\users\\mi\\anaconda3\\lib\\site-packages (from kaggle-cli) (3.5.0)\nCollecting progressbar2<3.35,>=3.34.3 (from kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/87/31/b984e17bcc7491c1baeda3906fe3abc14cb5cd5dbd046ab46d9fc7a2edfd/progressbar2-3.34.3-py2.py3-none-any.whl\nRequirement already satisfied: beautifulsoup4<4.7,>=4.6.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from kaggle-cli) (4.6.3)\nCollecting pbr!=2.1.0,>=2.0.0 (from cliff<2.9,>=2.8.0->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/f3/04/fddc1c2dd75b256eda4d360024692231a2c19a0c61ad7f4a162407c1ab58/pbr-5.1.1-py2.py3-none-any.whl (106kB)\nCollecting cmd2>=0.6.7 (from cliff<2.9,>=2.8.0->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/36/cf/25c3151c531f13988605e6792922152bd5d0dc0e907d02006767ca7668ed/cmd2-0.9.7-py3-none-any.whl (86kB)\nCollecting PrettyTable<0.8,>=0.7.1 (from cliff<2.9,>=2.8.0->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/ef/30/4b0746848746ed5941f052479e7c23d2b56d174b82f4fd34a25e389831f5/prettytable-0.7.2.tar.bz2\nRequirement already satisfied: pyparsing>=2.1.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cliff<2.9,>=2.8.0->kaggle-cli) (2.2.0)\nRequirement already satisfied: six>=1.9.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cliff<2.9,>=2.8.0->kaggle-cli) (1.11.0)\nCollecting stevedore>=1.20.0 (from cliff<2.9,>=2.8.0->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/35/fa/8683fab2a6e15ecfe107996e56fab91e52fe3ec0b40ca9440a0e1ffe6892/stevedore-1.30.0-py2.py3-none-any.whl (42kB)\nRequirement already satisfied: PyYAML>=3.10.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cliff<2.9,>=2.8.0->kaggle-cli) (3.13)\nRequirement already satisfied: requests>=2.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from MechanicalSoup<0.9,>=0.7.0->kaggle-cli) (2.19.1)\nCollecting python-utils>=2.1.0 (from progressbar2<3.35,>=3.34.3->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/eb/a0/19119d8b7c05be49baf6c593f11c432d571b70d805f2fe94c0585e55e4c8/python_utils-2.3.0-py2.py3-none-any.whl\nRequirement already satisfied: wcwidth>=0.1.7 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cmd2>=0.6.7->cliff<2.9,>=2.8.0->kaggle-cli) (0.1.7)\nCollecting pyperclip>=1.5.27 (from cmd2>=0.6.7->cliff<2.9,>=2.8.0->kaggle-cli)\n Downloading https://files.pythonhosted.org/packages/2d/0f/4eda562dffd085945d57c2d9a5da745cfb5228c02bc90f2c74bbac746243/pyperclip-1.7.0.tar.gz\nRequirement already satisfied: attrs>=16.3.0 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cmd2>=0.6.7->cliff<2.9,>=2.8.0->kaggle-cli) (18.2.0)\nRequirement already satisfied: colorama in c:\\users\\mi\\anaconda3\\lib\\site-packages (from cmd2>=0.6.7->cliff<2.9,>=2.8.0->kaggle-cli) (0.3.9)\nCollecting pyreadline; sys_platform == \"win32\" (from cmd2>=0.6.7->cliff<2.9,>=2.8.0->kaggle-cli)\n Using cached https://files.pythonhosted.org/packages/bc/7c/d724ef1ec3ab2125f38a1d53285745445ec4a8f19b9bb0761b4064316679/pyreadline-2.1.zip\nRequirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from requests>=2.0->MechanicalSoup<0.9,>=0.7.0->kaggle-cli) (3.0.4)\nRequirement already satisfied: urllib3<1.24,>=1.21.1 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from requests>=2.0->MechanicalSoup<0.9,>=0.7.0->kaggle-cli) (1.23)\nRequirement already satisfied: idna<2.8,>=2.5 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from requests>=2.0->MechanicalSoup<0.9,>=0.7.0->kaggle-cli) (2.7)\nRequirement already satisfied: certifi>=2017.4.17 in c:\\users\\mi\\anaconda3\\lib\\site-packages (from requests>=2.0->MechanicalSoup<0.9,>=0.7.0->kaggle-cli) (2018.8.24)\nBuilding wheels for collected packages: kaggle-cli, cliff, lxml, PrettyTable, pyperclip, pyreadline\n Running setup.py bdist_wheel for kaggle-cli: started\n Running setup.py bdist_wheel for kaggle-cli: finished with status 'done'\n Stored in directory: C:\\Users\\mi\\AppData\\Local\\pip\\Cache\\wheels\\d5\\bb\\10\\c1dd1b08c7433c943cb55c46367ae3f891415e8a37300ff8a7\n Running setup.py bdist_wheel for cliff: started\n Running setup.py bdist_wheel for cliff: finished with status 'done'\n Stored in directory: C:\\Users\\mi\\AppData\\Local\\pip\\Cache\\wheels\\02\\22\\09\\66f8c243f9c68dee7e6456a0fd6c117439a64394fdaf02d965\n Running setup.py bdist_wheel for lxml: started\n Running setup.py bdist_wheel for lxml: finished with status 'error'\n Complete output from command c:\\users\\mi\\anaconda3\\python.exe -u -c \"import setuptools, tokenize;__file__='C:\\\\Users\\\\mi\\\\AppData\\\\Local\\\\Temp\\\\pip-install-c_k003km\\\\lxml\\\\setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\\r\\n', '\\n');f.close();exec(compile(code, __file__, 'exec'))\" bdist_wheel -d C:\\Users\\mi\\AppData\\Local\\Temp\\pip-wheel-sbvos4r2 --python-tag cp37:\n Building lxml version 4.0.0.\n Building without Cython.\n ERROR: b'\"xslt-config\" \\xed\\xe5 \\xff\\xe2\\xeb\\xff\\xe5\\xf2\\xf1\\xff \\xe2\\xed\\xf3\\xf2\\xf0\\xe5\\xed\\xed\\xe5\\xe9 \\xe8\\xeb\\xe8 \\xe2\\xed\\xe5\\xf8\\xed\\xe5\\xe9\\r\\n\\xea\\xee\\xec\\xe0\\xed\\xe4\\xee\\xe9, \\xe8\\xf1\\xef\\xee\\xeb\\xed\\xff\\xe5\\xec\\xee\\xe9 \\xef\\xf0\\xee\\xe3\\xf0\\xe0\\xec\\xec\\xee\\xe9 \\xe8\\xeb\\xe8 \\xef\\xe0\\xea\\xe5\\xf2\\xed\\xfb\\xec \\xf4\\xe0\\xe9\\xeb\\xee\\xec.\\r\\n'\n ** make sure the development packages of libxml2 and libxslt are installed **\n \n Using build configuration of libxslt\n running bdist_wheel\n running build\n running build_py\n creating build\n creating build\\lib.win-amd64-3.7\n creating build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\builder.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\cssselect.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\doctestcompare.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\ElementInclude.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\pyclasslookup.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\sax.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\usedoctest.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\_elementpath.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\n creating build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\includes\n creating build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\builder.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\clean.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\defs.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\diff.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\ElementSoup.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\formfill.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\html5parser.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\soupparser.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\usedoctest.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_diffcommand.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_html5builder.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_setmixin.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\html\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\n copying src\\lxml\\isoschematron\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\n copying src\\lxml\\etree.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\etree_api.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\lxml.etree.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\lxml.etree_api.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\includes\\c14n.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\config.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\dtdvalid.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\etreepublic.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\htmlparser.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\relaxng.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\schematron.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\tree.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\uri.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xinclude.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlerror.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlparser.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlschema.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xpath.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xslt.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\__init__.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\etree_defs.h -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\lxml-version.h -> build\\lib.win-amd64-3.7\\lxml\\includes\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\rng\n copying src\\lxml\\isoschematron\\resources\\rng\\iso-schematron.rng -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\rng\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n copying src\\lxml\\isoschematron\\resources\\xsl\\RNG2Schtrn.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n copying src\\lxml\\isoschematron\\resources\\xsl\\XSD2Schtrn.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_abstract_expand.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_dsdl_include.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_schematron_message.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_schematron_skeleton_for_xslt1.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_svrl_for_xslt1.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\readme.txt -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n running build_ext\n building 'lxml.etree' extension\n error: Microsoft Visual C++ 14.0 is required. Get it with \"Microsoft Visual C++ Build Tools\": https://visualstudio.microsoft.com/downloads/\n \n ----------------------------------------\n Running setup.py clean for lxml\n Running setup.py bdist_wheel for PrettyTable: started\n Running setup.py bdist_wheel for PrettyTable: finished with status 'done'\n Stored in directory: C:\\Users\\mi\\AppData\\Local\\pip\\Cache\\wheels\\80\\34\\1c\\3967380d9676d162cb59513bd9dc862d0584e045a162095606\n Running setup.py bdist_wheel for pyperclip: started\n Running setup.py bdist_wheel for pyperclip: finished with status 'done'\n Stored in directory: C:\\Users\\mi\\AppData\\Local\\pip\\Cache\\wheels\\92\\f0\\ac\\2ba2972034e98971c3654ece337ac61e546bdeb34ca960dc8c\n Running setup.py bdist_wheel for pyreadline: started\n Running setup.py bdist_wheel for pyreadline: finished with status 'done'\n Stored in directory: C:\\Users\\mi\\AppData\\Local\\pip\\Cache\\wheels\\70\\66\\59\\590265c96902c7616243300c8f0d8ffe7800253ad55dfa9aa1\nSuccessfully built kaggle-cli cliff PrettyTable pyperclip pyreadline\nFailed to build lxml\nInstalling collected packages: pbr, pyperclip, pyreadline, cmd2, PrettyTable, stevedore, cliff, MechanicalSoup, lxml, cssselect, python-utils, progressbar2, kaggle-cli\n Found existing installation: lxml 4.2.5\n Uninstalling lxml-4.2.5:\n Successfully uninstalled lxml-4.2.5\n Running setup.py install for lxml: started\n Running setup.py install for lxml: finished with status 'error'\n Complete output from command c:\\users\\mi\\anaconda3\\python.exe -u -c \"import setuptools, tokenize;__file__='C:\\\\Users\\\\mi\\\\AppData\\\\Local\\\\Temp\\\\pip-install-c_k003km\\\\lxml\\\\setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\\r\\n', '\\n');f.close();exec(compile(code, __file__, 'exec'))\" install --record C:\\Users\\mi\\AppData\\Local\\Temp\\pip-record-jcsztoej\\install-record.txt --single-version-externally-managed --compile:\n Building lxml version 4.0.0.\n Building without Cython.\n ERROR: b'\"xslt-config\" \\xed\\xe5 \\xff\\xe2\\xeb\\xff\\xe5\\xf2\\xf1\\xff \\xe2\\xed\\xf3\\xf2\\xf0\\xe5\\xed\\xed\\xe5\\xe9 \\xe8\\xeb\\xe8 \\xe2\\xed\\xe5\\xf8\\xed\\xe5\\xe9\\r\\n\\xea\\xee\\xec\\xe0\\xed\\xe4\\xee\\xe9, \\xe8\\xf1\\xef\\xee\\xeb\\xed\\xff\\xe5\\xec\\xee\\xe9 \\xef\\xf0\\xee\\xe3\\xf0\\xe0\\xec\\xec\\xee\\xe9 \\xe8\\xeb\\xe8 \\xef\\xe0\\xea\\xe5\\xf2\\xed\\xfb\\xec \\xf4\\xe0\\xe9\\xeb\\xee\\xec.\\r\\n'\n ** make sure the development packages of libxml2 and libxslt are installed **\n \n Using build configuration of libxslt\n running install\n running build\n running build_py\n creating build\n creating build\\lib.win-amd64-3.7\n creating build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\builder.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\cssselect.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\doctestcompare.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\ElementInclude.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\pyclasslookup.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\sax.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\usedoctest.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\_elementpath.py -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\n creating build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\includes\n creating build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\builder.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\clean.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\defs.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\diff.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\ElementSoup.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\formfill.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\html5parser.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\soupparser.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\usedoctest.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_diffcommand.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_html5builder.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\_setmixin.py -> build\\lib.win-amd64-3.7\\lxml\\html\n copying src\\lxml\\html\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\html\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\n copying src\\lxml\\isoschematron\\__init__.py -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\n copying src\\lxml\\etree.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\etree_api.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\lxml.etree.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\lxml.etree_api.h -> build\\lib.win-amd64-3.7\\lxml\n copying src\\lxml\\includes\\c14n.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\config.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\dtdvalid.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\etreepublic.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\htmlparser.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\relaxng.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\schematron.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\tree.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\uri.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xinclude.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlerror.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlparser.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xmlschema.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xpath.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\xslt.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\__init__.pxd -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\etree_defs.h -> build\\lib.win-amd64-3.7\\lxml\\includes\n copying src\\lxml\\includes\\lxml-version.h -> build\\lib.win-amd64-3.7\\lxml\\includes\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\rng\n copying src\\lxml\\isoschematron\\resources\\rng\\iso-schematron.rng -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\rng\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n copying src\\lxml\\isoschematron\\resources\\xsl\\RNG2Schtrn.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n copying src\\lxml\\isoschematron\\resources\\xsl\\XSD2Schtrn.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\n creating build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_abstract_expand.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_dsdl_include.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_schematron_message.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_schematron_skeleton_for_xslt1.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\iso_svrl_for_xslt1.xsl -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n copying src\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\\readme.txt -> build\\lib.win-amd64-3.7\\lxml\\isoschematron\\resources\\xsl\\iso-schematron-xslt1\n running build_ext\n building 'lxml.etree' extension\n error: Microsoft Visual C++ 14.0 is required. Get it with \"Microsoft Visual C++ Build Tools\": https://visualstudio.microsoft.com/downloads/\n \n ----------------------------------------\n Rolling back uninstall of lxml\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4ac8bb448b418cf25d4eb507f87ad9a5b09e3190
| 2,790 |
ipynb
|
Jupyter Notebook
|
notebooks/30-DataWorkflow.ipynb
|
fmaussion/scipro_ws2018
|
0030f8e6bdbc48ec6a97fb2e9656d6b0b3cc1c41
|
[
"CC-BY-4.0"
] | null | null | null |
notebooks/30-DataWorkflow.ipynb
|
fmaussion/scipro_ws2018
|
0030f8e6bdbc48ec6a97fb2e9656d6b0b3cc1c41
|
[
"CC-BY-4.0"
] | null | null | null |
notebooks/30-DataWorkflow.ipynb
|
fmaussion/scipro_ws2018
|
0030f8e6bdbc48ec6a97fb2e9656d6b0b3cc1c41
|
[
"CC-BY-4.0"
] | null | null | null | 26.571429 | 653 | 0.572401 |
[
[
[
"# The scientific data analysis workflow",
"_____no_output_____"
],
[
"In this lecture I will write down some basic principles which might come handy when analyzing data of any kind in your thesis or any class project.\n\nIt's not ready yet, though ;-)",
"_____no_output_____"
],
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#The-scientific-data-analysis-workflow\" data-toc-modified-id=\"The-scientific-data-analysis-workflow-30\"><span class=\"toc-item-num\">30 </span>The scientific data analysis workflow</a></span><ul class=\"toc-item\"><li><span><a href=\"#A-typical-workflow\" data-toc-modified-id=\"A-typical-workflow-30.1\"><span class=\"toc-item-num\">30.1 </span>A typical workflow</a></span></li><li><span><a href=\"#What's-next?\" data-toc-modified-id=\"What's-next?-30.2\"><span class=\"toc-item-num\">30.2 </span>What's next?</a></span></li></ul></li></ul></div>",
"_____no_output_____"
],
[
"## A typical workflow",
"_____no_output_____"
],
[
"Almost all data analysis workflows are done with the same scheme:\n1. read the data\n2. cleanse it\n3. process it (add value to the data, e.g. diagnostics)\n4. reduce it\n5. plot it\n6. happy? Stop. Not happy? Repeat from step 2.",
"_____no_output_____"
],
[
"## What's next? ",
"_____no_output_____"
],
[
"Back to the [table of contents](00-Introduction.ipynb#ctoc).",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ac8c5fb0f1f781aeb013a52bfb5c35eb454ccaf
| 12,746 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/SqlToKql.ipynb
|
grantv9/msticpy
|
adafb326ac03fbf550af6ce2f2434acb7ea9dd1a
|
[
"MIT"
] | 16 |
2019-02-25T01:34:49.000Z
|
2019-05-05T16:55:21.000Z
|
docs/notebooks/SqlToKql.ipynb
|
grantv9/msticpy
|
adafb326ac03fbf550af6ce2f2434acb7ea9dd1a
|
[
"MIT"
] | null | null | null |
docs/notebooks/SqlToKql.ipynb
|
grantv9/msticpy
|
adafb326ac03fbf550af6ce2f2434acb7ea9dd1a
|
[
"MIT"
] | 1 |
2019-02-27T10:26:42.000Z
|
2019-02-27T10:26:42.000Z
| 30.420048 | 130 | 0.565118 |
[
[
[
"# SQL TO KQL Conversion (Experimental)\n\nThe `sql_to_kql` module is a simple converter to KQL based on [moz_sql_parser](https://github.com/DrDonk/moz-sql-parser).\nIt is an experimental feature built to help us convert a few queries but we\nthought that it was useful enough to include in MSTICPy.\n\nYou must have msticpy installed along with the moz_sql_parser package to run this notebook:\n```\n%pip install --upgrade msticpy[sql2kql]\n```\n\nIt supports a subset of ANSI SQL-92 which includes the following:\n- SELECT (including column renaming and functions)\n- FROM (including from subquery)\n- WHERE (common string and int operations, LIKE, some common functions)\n- LIMIT\n- UNION, UNION ALL\n- JOIN - only tested for relatively simple join expressions\n- GROUP BY\n- SQL Comments (ignored)\n\nIt does not support HAVING, multiple SQL statements or anything complex like Common Table Expressions.\n\nIt does support a few additional Spark SQL extensions like RLIKE.\n\n## Caveat Emptor!\nThis module is included in MSTICPy in the hope that it might be useful to others.\nWe do not intend to expand its capabilities.\n\nIt is also not guaranteed to produce perfectly-executing KQL - there will likely\nbe things that you have to fix up in the output query. \nYou will, for example, nearly always need change\nthe names of the fields used since the source data tables are unlikely\nto exactly match the schema of your Kusto/Azure Sentinel target.\n\nThe module does include an elementary table name mapping function that we\ndemonstrate below.\n",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\nimport os\nimport sys\nimport warnings\nfrom IPython.display import display, HTML, Markdown\n \nfrom msticpy.nbtools import nbinit\nnbinit.init_notebook(namespace=globals())\n\nfrom msticpy.data.sql_to_kql import sql_to_kql",
"Processing imports....\nChecking configuration....\nNo errors found.\nNo warnings found.\nSetting notebook options....\n"
]
],
[
[
"## Simple SQL Query",
"_____no_output_____"
]
],
[
[
"sql = \"\"\"\nSELECT DISTINCT Message, Otherfield\nFROM apt29Host\nWHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID BETWEEN 1 AND 10\n AND LOWER(ParentImage) LIKE '%explorer.exe'\n AND EventID IN ('4', '5', '6')\n AND LOWER(Image) LIKE \"3aka3%\"\nLIMIT 10\n\"\"\"\n\nkql = sql_to_kql(sql)\nprint(kql)",
"apt29Host\n| where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID between (1 .. 10)\n and tolower(ParentImage) endswith 'explorer.exe'\n and EventID in ('4', '5', '6')\n and tolower(Image) startswith '3aka3'\n| project Message, Otherfield\n| distinct Message, Otherfield\n| limit 10\n"
]
],
[
[
"## SQL Joins",
"_____no_output_____"
]
],
[
[
"sql=\"\"\"\nSELECT DISTINCT Message, Otherfield, COUNT(DISTINCT EventID)\nFROM (SELECT EventID, ParentImage, Image, Message, Otherfield FROM apt29Host) as A\n--FROM A\nINNER JOIN (Select Message, evt_id FROM MyTable ) on MyTable.Message == A.Message and MyTable.evt_id == A.EventID\nWHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(ParentImage) LIKE \"%explorer.exe\"\n AND LOWER(Image) RLIKE \".*3aka3%\"\nGROUP BY EventID\nORDER BY Message DESC, Otherfield\nLIMIT 10\n\"\"\"\n\nkql = sql_to_kql(sql)\nprint(kql)",
"apt29Host\n| project EventID, ParentImage, Image, Message, Otherfield\n| join kind=inner (MyTable\n | project Message, evt_id) on $right.Message == $left.Message\n and $right.evt_id == $left.EventID\n| where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(ParentImage) endswith 'explorer.exe'\n and tolower(Image) startswith '.*3aka3'\n| summarize any(Message), any(Otherfield), dcount(EventID) by EventID\n| order by Message desc, Otherfield\n| limit 10\n"
]
],
[
[
"## Table Renaming",
"_____no_output_____"
]
],
[
[
"sql=\"\"\"\nSELECT DISTINCT Message, Otherfield, COUNT(DISTINCT EventID)\nFROM (SELECT EventID, ParentImage, Image, Message, Otherfield FROM apt29Host) as A\nINNER JOIN (Select Message, evt_id FROM MyTable ) on MyTable.Message == A.Message and MyTable.evt_id == A.EventID\nWHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(ParentImage) LIKE \"%explorer.exe\"\n AND LOWER(Image) RLIKE \".*3aka3%\"\nGROUP BY EventID\nORDER BY Message DESC, Otherfield\nLIMIT 10\n\"\"\"\n\ntable_map = {\"apt29Host\": \"SecurityEvent\", \"MyTable\": \"SigninLogs\"}\n\nkql = sql_to_kql(sql, table_map)\nprint(kql)",
"SecurityEvent\n| project EventID, ParentImage, Image, Message, Otherfield\n| join kind=inner (SigninLogs\n | project Message, evt_id) on $right.Message == $left.Message\n and $right.evt_id == $left.EventID\n| where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(ParentImage) endswith 'explorer.exe'\n and tolower(Image) startswith '.*3aka3'\n| summarize any(Message), any(Otherfield), dcount(EventID) by EventID\n| order by Message desc, Otherfield\n| limit 10\n"
]
],
[
[
"## Join with Aliases",
"_____no_output_____"
]
],
[
[
"sql=\"\"\"\nSELECT Message\nFROM apt29Host a\nINNER JOIN (\n SELECT ProcessGuid\n FROM apt29Host\n WHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(ParentImage) RLIKE '.*partial_string.*'\n AND LOWER(Image) LIKE '%cmd.exe'\n) b\nON a.ParentProcessGuid = b.ProcessGuid\nWHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(Image) LIKE '%powershell.exe'\n\"\"\"\n\nkql = sql_to_kql(sql, table_map)\nprint(kql)",
"SecurityEvent\n| join kind=inner (SecurityEvent\n | where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(ParentImage) matches regex '.*partial.string.*'\n and tolower(Image) endswith 'cmd.exe'\n | project ProcessGuid) on $left.ParentProcessGuid == $right.ProcessGuid\n| where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(Image) endswith 'powershell.exe'\n| project Message\n"
]
],
[
[
"## Unions and Group By",
"_____no_output_____"
]
],
[
[
"sql=\"\"\"\nSELECT DISTINCT Message, COUNT(Otherfield)\nFROM (SELECT *\n FROM (SELECT EventID, ParentImage, Image, Message, Otherfield FROM apt29Host)\n\n UNION\n SELECT DISTINCT Message, Otherfield, EventID\n FROM (SELECT EventID, ParentImage, Image, Message, Otherfield FROM apt29Host) as A\n INNER JOIN MyTable on MyTable.mssg = A.Message\n WHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(ParentImage) LIKE \"%explorer.exe\"\n AND LOWER(Image) RLIKE \".*3aka3%\"\n LIMIT 10\n )\nGROUP BY Message\nORDER BY Message DESC, Otherfield\n\"\"\"\n\nkql = sql_to_kql(sql, table_map)\nprint(kql)",
"SecurityEvent\n| project EventID, ParentImage, Image, Message, Otherfield\n| union (SecurityEvent\n | project EventID, ParentImage, Image, Message, Otherfield\n | join kind=inner (SigninLogs) on $right.mssg == $left.Message\n | where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(ParentImage) endswith 'explorer.exe'\n and tolower(Image) startswith '.*3aka3'\n | project Message, Otherfield, EventID\n | distinct Message, Otherfield, EventID\n)\n| distinct *\n| limit 10\n| summarize any(Message), count(Otherfield) by Message\n| order by Message desc, Otherfield\n"
]
],
[
[
"## Aliased and Calculated Select Columns",
"_____no_output_____"
]
],
[
[
"sql=\"\"\"\nSELECT DISTINCT Message as mssg, COUNT(Otherfield)\nFROM (SELECT EventID as ID, ParentImage, Image, Message,\n ParentImage + Message as ParentMessage,\n LOWER(Otherfield) FROM apt29Host\n )\nWHERE Channel = \"Microsoft-Windows-Sysmon/Operational\"\n AND EventID = 1\n AND LOWER(ParentImage) LIKE \"%explorer.exe\"\n\"\"\"\nkql = sql_to_kql(sql, table_map)\nprint(kql)",
"SecurityEvent\n| extend ParentMessage = ParentImage + Message, Otherfield = tolower(Otherfield)\n| project ID = EventID, ParentImage, Image, Message, ParentMessage, Otherfield\n| where Channel == 'Microsoft-Windows-Sysmon/Operational'\n and EventID == 1\n and tolower(ParentImage) endswith 'explorer.exe'\n| extend Otherfield = count(Otherfield)\n| project mssg = Message, Otherfield\n| distinct *\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac8ca17ebb02803f0bc57e8e0011a4f5147f8d6
| 156,363 |
ipynb
|
Jupyter Notebook
|
notebooks/Ofer_Spacy_NLP.ipynb
|
BloomTech-Labs/tally-ai-ds
|
09d7a207bf5e6f9de2d615ad078cebb8340abcd8
|
[
"MIT"
] | 8 |
2020-01-08T18:16:20.000Z
|
2020-06-30T23:49:38.000Z
|
notebooks/Ofer_Spacy_NLP.ipynb
|
Lambda-School-Labs/tally-ai-ds
|
09d7a207bf5e6f9de2d615ad078cebb8340abcd8
|
[
"MIT"
] | 5 |
2021-03-30T13:48:15.000Z
|
2021-09-22T19:11:46.000Z
|
notebooks/Ofer_Spacy_NLP.ipynb
|
BloomTech-Labs/tally-ai-ds
|
09d7a207bf5e6f9de2d615ad078cebb8340abcd8
|
[
"MIT"
] | 5 |
2020-02-02T04:27:26.000Z
|
2020-06-05T05:12:28.000Z
| 56.612238 | 2,074 | 0.400274 |
[
[
[
"<a href=\"https://colab.research.google.com/github/oferbaharav/tally-ai-ds/blob/eda/Ofer_Spacy_NLP.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import boto3\nimport dask.dataframe as dd\n#from sagemaker import get_execution_role\nimport pandas as pd\n!pip install fastparquet\nfrom fastparquet import ParquetFile\n\n\n#role = get_execution_role()\nbucket='tally-ai-dspt3'\nfolder = 'yelp-kaggle-raw-data'\n\npd.set_option('display.max_columns', None)\n\nprint(f\"S3 Bucket is {bucket}, and Folder is {folder}\")",
"Collecting fastparquet\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/20/65/557177ac29fa2afe05cf8734283ae297e601e8063509b8305ff6153be7e6/fastparquet-0.4.0.tar.gz (152kB)\n\u001b[K |████████████████████████████████| 153kB 4.8MB/s \n\u001b[?25hRequirement already satisfied: pandas>=0.19 in /usr/local/lib/python3.6/dist-packages (from fastparquet) (1.0.4)\nRequirement already satisfied: numba>=0.28 in /usr/local/lib/python3.6/dist-packages (from fastparquet) (0.48.0)\nRequirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from fastparquet) (1.18.4)\nCollecting thrift>=0.11.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/97/1e/3284d19d7be99305eda145b8aa46b0c33244e4a496ec66440dac19f8274d/thrift-0.13.0.tar.gz (59kB)\n\u001b[K |████████████████████████████████| 61kB 7.2MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from fastparquet) (1.12.0)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.19->fastparquet) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.19->fastparquet) (2018.9)\nRequirement already satisfied: llvmlite<0.32.0,>=0.31.0dev0 in /usr/local/lib/python3.6/dist-packages (from numba>=0.28->fastparquet) (0.31.0)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from numba>=0.28->fastparquet) (47.1.1)\nBuilding wheels for collected packages: fastparquet, thrift\n Building wheel for fastparquet (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for fastparquet: filename=fastparquet-0.4.0-cp36-cp36m-linux_x86_64.whl size=251896 sha256=920745982966d5ed3db75a5b381e854c4b5ae3156b704a93f52540c0f2f7b141\n Stored in directory: /root/.cache/pip/wheels/2f/1d/6f/d10f8d2688469c279b71799a457a1fd8f35e5ba06e91b7d993\n Building wheel for thrift (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for thrift: filename=thrift-0.13.0-cp36-cp36m-linux_x86_64.whl size=345200 sha256=93fe62a552139bb37dc3b5af249fce037f6dc4d55e743b816e832f13b111f63e\n Stored in directory: /root/.cache/pip/wheels/02/a2/46/689ccfcf40155c23edc7cdbd9de488611c8fdf49ff34b1706e\nSuccessfully built fastparquet thrift\nInstalling collected packages: thrift, fastparquet\nSuccessfully installed fastparquet-0.4.0 thrift-0.13.0\nS3 Bucket is tally-ai-dspt3, and Folder is yelp-kaggle-raw-data\n"
],
[
"#Loading data\ndata = 'final_combined.parquet.gzip'\ndata_location = 'https://s3.amazonaws.com/{}/{}/{}'.format(bucket, folder, data)\ndf = dd.read_parquet(data_location)\ndf.head()",
"_____no_output_____"
],
[
"from flask import Flask, render_template, request, jsonify\nimport json\nimport warnings\nimport pandas as pd\nimport spacy\n!pip install scattertext\nimport scattertext as st\nfrom lxml import html\nfrom requests import Session\nfrom concurrent.futures import ThreadPoolExecutor as Executor\nimport requests\n# from flask_cors import CORS\n# from decouple import config\nimport re",
"Collecting scattertext\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/18/bb/6c73ee4b109b017e0ba458436f67aa25c0e963bd8682e28c75d7864222e8/scattertext-0.0.2.64-py3-none-any.whl (6.9MB)\n\u001b[K |████████████████████████████████| 6.9MB 3.8MB/s \n\u001b[?25hRequirement already satisfied: statsmodels in /usr/local/lib/python3.6/dist-packages (from scattertext) (0.10.2)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from scattertext) (1.0.4)\nCollecting mock\n Downloading https://files.pythonhosted.org/packages/cd/74/d72daf8dff5b6566db857cfd088907bb0355f5dd2914c4b3ef065c790735/mock-4.0.2-py3-none-any.whl\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from scattertext) (1.12.0)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from scattertext) (1.4.1)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from scattertext) (1.18.4)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from scattertext) (0.22.2.post1)\nRequirement already satisfied: patsy>=0.4.0 in /usr/local/lib/python3.6/dist-packages (from statsmodels->scattertext) (0.5.1)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas->scattertext) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas->scattertext) (2018.9)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->scattertext) (0.15.1)\nInstalling collected packages: mock, scattertext\nSuccessfully installed mock-4.0.2 scattertext-0.0.2.64\n"
],
[
"nlp = spacy.load(\"en_core_web_sm\")#if you run into problems here, 'Restart Runtime' and run all, it might fix things.",
"_____no_output_____"
],
[
"def customtokensize(text):\n return re.findall(\"[\\w']+\", str(text))\n\ndf['tokenized_text'] = df['text'].apply(customtokensize)\ndf.head(2)",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('text', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"stopwords = ['ve',\"n't\",'check-in','=','= =','u','want', 'u want', 'cuz','him',\"i've\",'on', 'her','told','ins', '1 check','I', 'i\"m', 'i', ' ', 'it', \"it's\", 'it.','they', 'the', 'this','its', 'l','-','they','this',\"don't\",'the ', ' the', 'it', 'i\"ve', 'i\"m', '!', '1','2','3','4', '5','6','7','8','9','0','/','.',',']\n\ndef filter_stopwords(text):\n nonstopwords = []\n for i in text:\n if i not in stopwords:\n nonstopwords.append(i)\n return nonstopwords\ndf['tokenized_text'] = df['tokenized_text'].apply(filter_stopwords)\ndf['parts_of_speech_reference'] = df['tokenized_text'].apply(filter_stopwords)\ndf['parts_of_speech_reference'] = df['parts_of_speech_reference'].str.join(' ')\ndf.head(2)",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('tokenized_text', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"def find_part_of_speech(x):\n \"\"\"Use spacy's entity recognition to recogize if word is noun, verb, adjective, etc.\"\"\"\n part_of_speech = []\n doc = nlp(str(x))\n for token in doc:\n part_of_speech.append(token.pos_)\n return part_of_speech\n\ndf['parts_of_speech'] = df['parts_of_speech_reference'].apply(find_part_of_speech)\ndf.head(2)",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('parts_of_speech_reference', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"#Useless?\ndef extract_adjective_indexes(text):\n \"\"\"Get the indexes of Adjectives and delete the occurrence\n of adjectives in order to persistently find new adjective \n occurrences. In the future, add words occurring before and after\"\"\"\n adjective_indexes = []\n for i in text:\n if i == 'ADJ':\n adj_index = text.index('ADJ')\n adjective_indexes.append(adj_index)\n text.remove(i)\n return adjective_indexes\n\ndf['adjective_positions'] = df['parts_of_speech'].apply(extract_adjective_indexes)\ndf.head(2)\n",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('parts_of_speech', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"def find_adj(x):\n \"\"\"Get Just the Adjectives\"\"\"\n adj_list = []\n doc = nlp(str(x))\n for token in doc:\n if token.pos_ == 'ADJ':\n adj_list.append(token)\n return adj_list\n\ndf['adj_list'] = df['parts_of_speech_reference'].apply(find_adj)\ndf.head(2)",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('parts_of_speech_reference', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"def find_phrases(x):\n \"\"\"Create a list where adjectives come immediately before nouns for each review\"\"\"\n adj_list = []\n doc = nlp(str(x))\n try:\n for token in range(len(doc)):\n sub_list = []\n if (doc[token].pos_ == 'ADJ'and doc[token+1].pos_ =='NOUN') or (doc[token].pos_ == 'VERB'and doc[token+1].pos_ =='NOUN'):\n sub_list.append(doc[token])\n sub_list.append(doc[token+1])\n elif (doc[token].pos_ == 'ADJ'and doc[token+1].pos_ == 'ADJ'and doc[token+2].pos_ =='NOUN')or (doc[token].pos_ == 'ADJ'and doc[token+1].pos_ =='VERB'and doc[token+2].pos_ =='NOUN')or (doc[token].pos_ == 'ADJ'and doc[token+1].pos_ == 'NOUN'and doc[token+2].pos_ =='NOUN'):\n sub_list.append(doc[token])\n sub_list.append(doc[token+1]) \n sub_list.append(doc[token+2])\n if (doc[token].lemma_ == 'wait'):\n sub_list.append(doc[token-2]) \n sub_list.append(doc[token-1])\n sub_list.append(doc[token])\n sub_list.append(doc[token+1])\n sub_list.append(doc[token+2])\n sub_list.append(doc[token+3])\n if (doc[token].lemma_ == 'service'):\n sub_list.append(doc[token-2]) \n sub_list.append(doc[token-1])\n sub_list.append(doc[token])\n sub_list.append(doc[token+1])\n sub_list.append(doc[token+2])\n sub_list.append(doc[token+3])\n if len(sub_list) != 0:\n adj_list.append(sub_list)\n return adj_list\n except IndexError as e:\n pass\n\ndf['adj_noun_phrases'] = df['parts_of_speech_reference'].apply(find_phrases)\n",
"_____no_output_____"
],
[
"df['adj_noun_phrases'].head(10)",
"_____no_output_____"
],
[
"doc = nlp(\"Apple is looking at buying U.K. startup for $1 billion\")\n\nfor ent in doc.ents:\n print(ent.text, ent.start_char, ent.end_char, ent.label_)",
"Apple 0 5 ORG\nU.K. 27 31 GPE\n$1 billion 44 54 MONEY\n"
],
[
"def find_money(x):\n \"\"\"Create a list where adjectives come immediately before nouns for each review\"\"\"\n money_list = []\n doc = nlp(str(x))\n for ent in doc.ents:\n if ent.label_ == 'MONEY':\n money_list.append(ent)\n return money_list\n\ndf['money_list'] = df['parts_of_speech_reference'].apply(find_money)\n",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('parts_of_speech_reference', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"df.head(2)",
"_____no_output_____"
],
[
"def find_noun_chunks(x):\n \"\"\"Create a list where adjectives come immediately before nouns for each review\"\"\"\n noun_list = []\n doc = nlp(str(x))\n for chunk in doc.noun_chunks:\n noun_list.append(chunk)\n return noun_list\n\ndf['noun_chunks'] = df['parts_of_speech_reference'].apply(find_noun_chunks)\n",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:3073: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=('parts_of_speech_reference', 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"doc = nlp(\"Autonomous cars shift insurance liability toward manufacturers\")\nfor token in doc:\n print(token.text, token.dep_, token.head.text, token.head.pos_,\n [child for child in token.children])",
"Autonomous amod cars NOUN []\ncars nsubj shift VERB [Autonomous]\nshift ROOT shift VERB [cars, liability]\ninsurance compound liability NOUN []\nliability dobj shift VERB [insurance, toward]\ntoward prep liability NOUN [manufacturers]\nmanufacturers pobj toward ADP []\n"
],
[
"for token in doc:\n print(token.text, token.dep_, token.head.text, token.head.pos_,\n [child for child in token.children])",
"Autonomous amod cars NOUN []\ncars nsubj shift VERB [Autonomous]\nshift ROOT shift VERB [cars, liability]\ninsurance compound liability NOUN []\nliability dobj shift VERB [insurance, toward]\ntoward prep liability NOUN [manufacturers]\nmanufacturers pobj toward ADP []\n"
],
[
"corpus = st.CorpusFromPandas(df, \n category_col='stars_review', \n text_col='text',\n nlp=nlp).build()\n\nterm_freq_df = corpus.get_term_freq_df()\nterm_freq_df['highratingscore'] = corpus.get_scaled_f_scores('5')\n\nterm_freq_df['poorratingscore'] = corpus.get_scaled_f_scores('1')\ndh = term_freq_df.sort_values(by= 'highratingscore', ascending = False)\ndh = dh[['highratingscore', 'poorratingscore']]\ndh = dh.reset_index(drop=False)",
"/usr/local/lib/python3.6/dist-packages/dask/dataframe/core.py:4150: UserWarning: \nYou did not provide metadata, so Dask is running your function on a small dataset to guess output types. It is possible that Dask will guess incorrectly.\nTo provide an explicit output types or to silence this message, please provide the `meta=` keyword, as described in the map or apply function that you are using.\n Before: .apply(func)\n After: .apply(func, meta=(None, 'object'))\n\n warnings.warn(meta_warning(meta))\n"
],
[
"dh = dh.rename(columns={'highratingscore':'score'})\ndh = dh.drop(columns='poorratingscore')\npositive_df = dh.head(10)\nnegative_df = dh.tail(10)\n# word_df = pd.concat([positive_df, negative_df])\n# word_df",
"_____no_output_____"
],
[
"results = {'positive': [{'term': pos_term, 'score': pos_score} for pos_term, pos_score in zip(positive_df['term'], positive_df['score'])], 'negative': [{'term': neg_term, 'score': neg_score} for neg_term, neg_score in zip(negative_df['term'], negative_df['score'])]}",
"_____no_output_____"
],
[
"results",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac8e693c4b6f7b1211832dd62fd34b1b5f70689
| 5,818 |
ipynb
|
Jupyter Notebook
|
nbs/74_callback.azureml.ipynb
|
mmichelli/fastai
|
08a639548fd82ff22b7a72db9519f82b176511d7
|
[
"Apache-2.0"
] | 1 |
2021-07-26T13:56:08.000Z
|
2021-07-26T13:56:08.000Z
|
nbs/74_callback.azureml.ipynb
|
mmichelli/fastai
|
08a639548fd82ff22b7a72db9519f82b176511d7
|
[
"Apache-2.0"
] | 1 |
2021-05-20T16:10:19.000Z
|
2021-05-20T16:10:19.000Z
|
nbs/74_callback.azureml.ipynb
|
mmichelli/fastai
|
08a639548fd82ff22b7a72db9519f82b176511d7
|
[
"Apache-2.0"
] | 1 |
2021-03-27T02:12:30.000Z
|
2021-03-27T02:12:30.000Z
| 32.502793 | 249 | 0.557924 |
[
[
[
"#hide\n#skip\n! [ -e /content ] && pip install -Uqq fastai # upgrade fastai on colab",
"_____no_output_____"
],
[
"#all_slow",
"_____no_output_____"
],
[
"#export\nfrom fastai.basics import *\nfrom fastai.learner import Callback",
"_____no_output_____"
],
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"#default_exp callback.azureml",
"_____no_output_____"
]
],
[
[
"# AzureML Callback\n\nTrack fastai experiments with the azure machine learning plattform.\n\n## Prerequisites\n\nInstall the azureml SDK:\n\n```python\npip install azureml-core\n```\n\n## How to use it?\n\nImport and use `AzureMLCallback` during model fitting.\n\nIf you are submitting your training run with azureml SDK [ScriptRunConfig](https://docs.microsoft.com/en-us/azure/machine-learning/how-to-set-up-training-targets), the callback will automatically detect the run and log metrics. For example:\n\n```python\nfrom fastai.callback.azureml import AzureMLCallback\nlearn.fit_one_cycle(epoch, lr, cbs=AzureMLCallback())\n```\n\nIf you are running an experiment manually and just want to have interactive logging of the run, use azureml's `Experiment.start_logging` to create the interactive `run`, and pass that into `AzureMLCallback`. For example:\n\n```python\nfrom azureml.core import Experiment\nexperiment = Experiment(workspace=ws, name='experiment_name')\nrun = experiment.start_logging(outputs=None, snapshot_directory=None)\n\nfrom fastai.callback.azureml import AzureMLCallback\nlearn.fit_one_cycle(epoch, lr, cbs=AzureMLCallback(run))\n```\n\nIf you are running an experiment on your local machine (i.e. not using `ScriptRunConfig` and not passing an azureml `run` into the callback), it will recognize that there is no AzureML run to log to, and print the log attempts instead.\n\nTo save the model weights, use the usual fastai methods and save the model to the `outputs` folder, which is a \"special\" (for Azure) folder that is automatically tracked in AzureML.\n\nAs it stands, note that if you pass the callback into your `Learner` directly, e.g.:\n```python\nlearn = Learner(dls, model, cbs=AzureMLCallback())\n```\n…some `Learner` methods (e.g. `learn.show_results()`) might add unwanted logging into your azureml experiment runs. Adding further checks into the callback should help eliminate this – another PR needed.",
"_____no_output_____"
]
],
[
[
"#export\nfrom azureml.core.run import Run",
"_____no_output_____"
],
[
"# export\nclass AzureMLCallback(Callback):\n \"Log losses, metrics, model architecture summary to AzureML\"\n order = Recorder.order+1\n\n def __init__(self, azurerun=None):\n if azurerun:\n self.azurerun = azurerun\n else:\n self.azurerun = Run.get_context()\n\n def before_fit(self):\n self.azurerun.log(\"n_epoch\", self.learn.n_epoch)\n self.azurerun.log(\"model_class\", str(type(self.learn.model)))\n\n try:\n summary_file = Path(\"outputs\") / 'model_summary.txt'\n with summary_file.open(\"w\") as f:\n f.write(repr(self.learn.model))\n except:\n print('Did not log model summary. Check if your model is PyTorch model.')\n\n def after_batch(self):\n # log loss and opt.hypers\n if self.learn.training:\n self.azurerun.log('batch__loss', self.learn.loss.item())\n self.azurerun.log('batch__train_iter', self.learn.train_iter)\n for i, h in enumerate(self.learn.opt.hypers):\n for k, v in h.items():\n self.azurerun.log(f'batch__opt.hypers.{k}', v)\n\n def after_epoch(self):\n # log metrics\n for n, v in zip(self.learn.recorder.metric_names, self.learn.recorder.log):\n if n not in ['epoch', 'time']:\n self.azurerun.log(f'epoch__{n}', v)\n if n == 'time':\n # split elapsed time string, then convert into 'seconds' to log\n m, s = str(v).split(':')\n elapsed = int(m)*60 + int(s)\n self.azurerun.log(f'epoch__{n}', elapsed)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4ac8e70061664771c5e281cca791cf2cd65333d5
| 944,657 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/2 initial visuals-checkpoint.ipynb
|
Serenitea/CRISP_DM-StackOverflow-Survey
|
0ac3f6186d1b5fbb60fca398723057500e4014c1
|
[
"CNRI-Python"
] | null | null | null |
.ipynb_checkpoints/2 initial visuals-checkpoint.ipynb
|
Serenitea/CRISP_DM-StackOverflow-Survey
|
0ac3f6186d1b5fbb60fca398723057500e4014c1
|
[
"CNRI-Python"
] | null | null | null |
.ipynb_checkpoints/2 initial visuals-checkpoint.ipynb
|
Serenitea/CRISP_DM-StackOverflow-Survey
|
0ac3f6186d1b5fbb60fca398723057500e4014c1
|
[
"CNRI-Python"
] | null | null | null | 241.7239 | 89,960 | 0.861474 |
[
[
[
"# import libraries here; add more as necessary\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n%matplotlib inline",
"_____no_output_____"
],
[
"df2019 = pd.read_csv('./2019survey_results_public.csv', header = 0)\ndf2019.head()",
"_____no_output_____"
],
[
"df2019.describe()",
"_____no_output_____"
],
[
"def compare_plt(column, n, df):\n fig, axs = plt.subplots(n,2, figsize=(15, 10))\n fig.subplots_adjust(hspace =2 , wspace=.2)\n axs = axs.ravel()\n for i in range(n):\n plt.subplot(121)\n sns.countplot(x = column, data = df).set_title('Few missing')\n plt.subplot(122)\n sns.countplot(x = column, data = df).set_title('High missing')",
"_____no_output_____"
],
[
"sns.countplot(x = df2019['MainBranch'].value_counts(), data = df2019['MainBranch'])",
"_____no_output_____"
],
[
"interested_var = ['MainBranch', 'YearsCodePro', 'Age1stCode', 'CareerSat', 'ConvertedComp', 'WorkWeekHrs', 'Age', 'EdLevel']\nfor var in interested_var:\n sns.countplot(x = var, data = df2019)",
"_____no_output_____"
],
[
"df2019.hist(figsize = (10, 10))",
"_____no_output_____"
],
[
"sns.heatmap(df2019.corr(), annot = True, fmt = '.2f')",
"_____no_output_____"
]
],
[
[
"To do:\n- filtering out ",
"_____no_output_____"
]
],
[
[
"df2019_rows, df2019_cols = df2019.shape\ndf2019_col_names = df2019.columns\nprint(df2019_col_names)\n\ncol_to_keep = ['MainBranch', 'Hobbyist', 'Employment', 'Country', 'Student', 'EdLevel', 'UndergradMajor', 'DevType', 'YearsCodePro', 'CareerSat', 'ConvertedComp', 'WorkWeekHrs', 'LanguageWorkedWith', 'LanguageDesireNextYear', 'DatabaseWorkedWith''DatabaseDesireNextYear', 'PlatformWorkedWith',\n 'PlatformDesireNextYear', 'WebFrameWorkedWith',\n 'WebFrameDesireNextYear', 'MiscTechWorkedWith',\n 'MiscTechDesireNextYear', 'DevEnviron', 'OpSys', 'Containers', 'Age', 'Gender', 'Ethnicity']",
"Index(['Respondent', 'MainBranch', 'Hobbyist', 'OpenSourcer', 'OpenSource',\n 'Employment', 'Country', 'Student', 'EdLevel', 'UndergradMajor',\n 'EduOther', 'OrgSize', 'DevType', 'YearsCode', 'Age1stCode',\n 'YearsCodePro', 'CareerSat', 'JobSat', 'MgrIdiot', 'MgrMoney',\n 'MgrWant', 'JobSeek', 'LastHireDate', 'LastInt', 'FizzBuzz',\n 'JobFactors', 'ResumeUpdate', 'CurrencySymbol', 'CurrencyDesc',\n 'CompTotal', 'CompFreq', 'ConvertedComp', 'WorkWeekHrs', 'WorkPlan',\n 'WorkChallenge', 'WorkRemote', 'WorkLoc', 'ImpSyn', 'CodeRev',\n 'CodeRevHrs', 'UnitTests', 'PurchaseHow', 'PurchaseWhat',\n 'LanguageWorkedWith', 'LanguageDesireNextYear', 'DatabaseWorkedWith',\n 'DatabaseDesireNextYear', 'PlatformWorkedWith',\n 'PlatformDesireNextYear', 'WebFrameWorkedWith',\n 'WebFrameDesireNextYear', 'MiscTechWorkedWith',\n 'MiscTechDesireNextYear', 'DevEnviron', 'OpSys', 'Containers',\n 'BlockchainOrg', 'BlockchainIs', 'BetterLife', 'ITperson', 'OffOn',\n 'SocialMedia', 'Extraversion', 'ScreenName', 'SOVisit1st',\n 'SOVisitFreq', 'SOVisitTo', 'SOFindAnswer', 'SOTimeSaved',\n 'SOHowMuchTime', 'SOAccount', 'SOPartFreq', 'SOJobs', 'EntTeams',\n 'SOComm', 'WelcomeChange', 'SONewContent', 'Age', 'Gender', 'Trans',\n 'Sexuality', 'Ethnicity', 'Dependents', 'SurveyLength', 'SurveyEase'],\n dtype='object')\n"
],
[
"#schema2019 = pd.read_csv('./2019survey_results_schema.csv', header = 0)\n#schema2019.head()",
"_____no_output_____"
],
[
"print(df2019.shape)\nprint(df2019.info())",
"(88883, 85)\n<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 88883 entries, 0 to 88882\nData columns (total 85 columns):\nRespondent 88883 non-null int64\nMainBranch 88331 non-null object\nHobbyist 88883 non-null object\nOpenSourcer 88883 non-null object\nOpenSource 86842 non-null object\nEmployment 87181 non-null object\nCountry 88751 non-null object\nStudent 87014 non-null object\nEdLevel 86390 non-null object\nUndergradMajor 75614 non-null object\nEduOther 84260 non-null object\nOrgSize 71791 non-null object\nDevType 81335 non-null object\nYearsCode 87938 non-null object\nAge1stCode 87634 non-null object\nYearsCodePro 74331 non-null object\nCareerSat 72847 non-null object\nJobSat 70988 non-null object\nMgrIdiot 61159 non-null object\nMgrMoney 61157 non-null object\nMgrWant 61232 non-null object\nJobSeek 80555 non-null object\nLastHireDate 79854 non-null object\nLastInt 67155 non-null object\nFizzBuzz 71344 non-null object\nJobFactors 79371 non-null object\nResumeUpdate 77877 non-null object\nCurrencySymbol 71392 non-null object\nCurrencyDesc 71392 non-null object\nCompTotal 55945 non-null float64\nCompFreq 63268 non-null object\nConvertedComp 55823 non-null float64\nWorkWeekHrs 64503 non-null float64\nWorkPlan 68914 non-null object\nWorkChallenge 68141 non-null object\nWorkRemote 70284 non-null object\nWorkLoc 70055 non-null object\nImpSyn 71779 non-null object\nCodeRev 70390 non-null object\nCodeRevHrs 49790 non-null float64\nUnitTests 62668 non-null object\nPurchaseHow 61108 non-null object\nPurchaseWhat 62029 non-null object\nLanguageWorkedWith 87569 non-null object\nLanguageDesireNextYear 84088 non-null object\nDatabaseWorkedWith 76026 non-null object\nDatabaseDesireNextYear 69147 non-null object\nPlatformWorkedWith 80714 non-null object\nPlatformDesireNextYear 77443 non-null object\nWebFrameWorkedWith 65022 non-null object\nWebFrameDesireNextYear 62944 non-null object\nMiscTechWorkedWith 59586 non-null object\nMiscTechDesireNextYear 64511 non-null object\nDevEnviron 87317 non-null object\nOpSys 87851 non-null object\nContainers 85366 non-null object\nBlockchainOrg 48175 non-null object\nBlockchainIs 60165 non-null object\nBetterLife 86269 non-null object\nITperson 87141 non-null object\nOffOn 86663 non-null object\nSocialMedia 84437 non-null object\nExtraversion 87305 non-null object\nScreenName 80486 non-null object\nSOVisit1st 83877 non-null object\nSOVisitFreq 88263 non-null object\nSOVisitTo 88086 non-null object\nSOFindAnswer 87816 non-null object\nSOTimeSaved 86344 non-null object\nSOHowMuchTime 68378 non-null object\nSOAccount 87828 non-null object\nSOPartFreq 74692 non-null object\nSOJobs 88066 non-null object\nEntTeams 87841 non-null object\nSOComm 88131 non-null object\nWelcomeChange 85855 non-null object\nSONewContent 69560 non-null object\nAge 79210 non-null float64\nGender 85406 non-null object\nTrans 83607 non-null object\nSexuality 76147 non-null object\nEthnicity 76668 non-null object\nDependents 83059 non-null object\nSurveyLength 86984 non-null object\nSurveyEase 87081 non-null object\ndtypes: float64(5), int64(1), object(79)\nmemory usage: 57.6+ MB\nNone\n"
],
[
"for col in df2019.columns:\n print(df2019[col].name, df2019[col].unique())\n print('-----------------------------------------------------')",
"Respondent [ 1 2 3 ... 88802 88816 88863]\n-----------------------------------------------------\nMainBranch ['I am a student who is learning to code'\n 'I am not primarily a developer, but I write code sometimes as part of my work'\n 'I am a developer by profession' 'I code primarily as a hobby'\n 'I used to be a developer by profession, but no longer am' nan]\n-----------------------------------------------------\nHobbyist ['Yes' 'No']\n-----------------------------------------------------\nOpenSourcer ['Never' 'Less than once per year' 'Once a month or more often'\n 'Less than once a month but more than once per year']\n-----------------------------------------------------\nOpenSource ['The quality of OSS and closed source software is about the same'\n 'OSS is, on average, of HIGHER quality than proprietary / closed source software'\n nan\n 'OSS is, on average, of LOWER quality than proprietary / closed source software']\n-----------------------------------------------------\nEmployment ['Not employed, and not looking for work'\n 'Not employed, but looking for work' 'Employed full-time'\n 'Independent contractor, freelancer, or self-employed' nan\n 'Employed part-time' 'Retired']\n-----------------------------------------------------\nCountry ['United Kingdom' 'Bosnia and Herzegovina' 'Thailand' 'United States'\n 'Ukraine' 'Canada' 'India' 'New Zealand' 'Antigua and Barbuda' 'Germany'\n 'Australia' 'Russian Federation' 'Brazil' 'Lithuania' 'Israel'\n 'South Africa' 'Colombia' 'Turkey' 'Switzerland' 'Argentina' 'Sri Lanka'\n 'Czech Republic' 'Denmark' 'Malaysia' 'Bangladesh' 'Spain' 'Serbia'\n 'Poland' 'Sweden' 'China' 'France' 'Netherlands' 'Italy' 'Philippines'\n 'Ireland' 'Pakistan' 'Azerbaijan' 'Austria' 'Estonia' 'Croatia'\n 'South Korea' 'Greece' 'Japan' 'Romania' 'Finland' 'Bulgaria' 'Viet Nam'\n 'Slovenia' 'Iran' 'Belarus' 'Hungary' 'Latvia' 'Hong Kong (S.A.R.)'\n 'United Arab Emirates' 'Portugal' 'Nigeria' 'Norway' 'Nicaragua'\n 'Zimbabwe' 'Egypt' 'Mexico' 'Dominican Republic' 'Guatemala' 'Chile'\n 'Ecuador' 'Ghana' 'Uganda' 'Cambodia' 'Mauritius' 'Nepal' 'Singapore'\n 'Sierra Leone' 'Republic of Moldova' 'Belgium' 'Armenia' 'Afghanistan'\n 'Bahrain' 'Mongolia' 'Georgia' 'Cyprus' 'Kenya' 'Luxembourg'\n 'Saudi Arabia' 'Cape Verde' 'Peru' 'Burundi' 'Iraq' 'Slovakia' 'Algeria'\n 'Taiwan' 'Yemen' 'Indonesia' 'Morocco' 'Libyan Arab Jamahiriya' 'Belize'\n 'Mali' 'Trinidad and Tobago' 'Venezuela, Bolivarian Republic of...'\n 'Panama' 'Lebanon' 'Tunisia' 'Kuwait' 'Andorra' \"Côte d'Ivoire\"\n 'Syrian Arab Republic' 'El Salvador' 'Cameroon' 'Malta' 'Turkmenistan'\n 'Brunei Darussalam' 'Other Country (Not Listed Above)' 'Costa Rica'\n 'Jordan' 'Albania' 'Uzbekistan' 'Sudan' 'Kazakhstan'\n 'The former Yugoslav Republic of Macedonia' 'Ethiopia' 'Paraguay'\n 'Myanmar' 'Somalia' 'Guyana' 'Honduras' 'Qatar' 'Jamaica' 'Fiji' 'Haiti'\n 'Democratic Republic of the Congo' 'Benin' 'Namibia' 'Montenegro'\n 'Rwanda' 'Tajikistan' 'Uruguay' 'Mauritania' 'Bolivia' 'Gabon'\n 'Liechtenstein' 'United Republic of Tanzania' 'Kyrgyzstan'\n \"Lao People's Democratic Republic\" 'Madagascar' 'Guinea'\n 'Republic of Korea' 'Cuba' 'Maldives' 'Monaco' 'North Korea' 'Senegal'\n 'Angola' 'Iceland' 'Togo' 'Swaziland' 'Congo, Republic of the...'\n 'Zambia' 'Oman' 'Timor-Leste' 'Tonga' 'Djibouti'\n \"Democratic People's Republic of Korea\" 'Niger' 'Mozambique' 'Botswana'\n 'Dominica' 'Papua New Guinea' 'Barbados' 'Seychelles' 'Lesotho' 'Bahamas'\n 'Burkina Faso' 'Saint Kitts and Nevis' 'Malawi' 'Liberia' 'Bhutan'\n 'Saint Vincent and the Grenadines' 'San Marino' 'Sao Tome and Principe'\n 'Chad' nan]\n-----------------------------------------------------\nStudent ['No' 'Yes, full-time' nan 'Yes, part-time']\n-----------------------------------------------------\nEdLevel ['Primary/elementary school'\n 'Secondary school (e.g. American high school, German Realschule or Gymnasium, etc.)'\n 'Bachelor’s degree (BA, BS, B.Eng., etc.)'\n 'Some college/university study without earning a degree'\n 'Master’s degree (MA, MS, M.Eng., MBA, etc.)'\n 'Other doctoral degree (Ph.D, Ed.D., etc.)' nan 'Associate degree'\n 'Professional degree (JD, MD, etc.)'\n 'I never completed any formal education']\n-----------------------------------------------------\nUndergradMajor [nan 'Web development or web design'\n 'Computer science, computer engineering, or software engineering'\n 'Mathematics or statistics'\n 'Another engineering discipline (ex. civil, electrical, mechanical)'\n 'Information systems, information technology, or system administration'\n 'A business discipline (ex. accounting, finance, marketing)'\n 'A natural science (ex. biology, chemistry, physics)'\n 'A social science (ex. anthropology, psychology, political science)'\n 'A humanities discipline (ex. literature, history, philosophy)'\n 'Fine arts or performing arts (ex. graphic design, music, studio art)'\n 'A health science (ex. nursing, pharmacy, radiology)'\n 'I never declared a major']\n-----------------------------------------------------\nEduOther ['Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n nan 'Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Received on-the-job training in software development'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a hackathon;Contributed to open source software'\n 'Received on-the-job training in software development;Participated in a hackathon'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a hackathon'\n 'Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development'\n 'Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD)'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in a hackathon'\n 'Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD)'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder)'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Taught yourself a new language, framework, or tool without taking a formal course;Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Participated in a full-time developer training program or bootcamp;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken an online course in programming or software development (e.g. a MOOC);Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon;Contributed to open source software'\n 'Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Contributed to open source software'\n 'Participated in a full-time developer training program or bootcamp;Received on-the-job training in software development;Participated in online coding competitions (e.g. HackerRank, CodeChef, TopCoder);Participated in a hackathon'\n 'Participated in a full-time developer training program or bootcamp;Taken a part-time in-person course in programming or software development;Completed an industry certification program (e.g. MCPD);Received on-the-job training in software development;Participated in a hackathon;Contributed to open source software']\n-----------------------------------------------------\nOrgSize [nan '100 to 499 employees' '10,000 or more employees'\n 'Just me - I am a freelancer, sole proprietor, etc.' '10 to 19 employees'\n '20 to 99 employees' '1,000 to 4,999 employees' '2-9 employees'\n '500 to 999 employees' '5,000 to 9,999 employees']\n-----------------------------------------------------\nDevType [nan 'Developer, desktop or enterprise applications;Developer, front-end'\n 'Designer;Developer, back-end;Developer, front-end;Developer, full-stack'\n ...\n 'Developer, full-stack;Developer, game or graphics;Developer, mobile;Marketing or sales professional;Product manager'\n 'Data or business analyst;Data scientist or machine learning specialist;Developer, full-stack;DevOps specialist;Engineer, data;Engineer, site reliability;Student'\n 'Developer, QA or test;Student;System administrator']\n-----------------------------------------------------\nYearsCode ['4' nan '3' '16' '13' '6' '8' '12' '2' '5' '17' '10' '14' '35' '7'\n 'Less than 1 year' '30' '9' '26' '40' '19' '15' '20' '28' '25' '1' '22'\n '11' '33' '50' '41' '18' '34' '24' '23' '42' '27' '21' '36' '32' '39'\n '38' '31' '37' 'More than 50 years' '29' '44' '45' '48' '46' '43' '47'\n '49']\n-----------------------------------------------------\nAge1stCode ['10' '17' '22' '16' '14' '15' '11' '20' '13' '18' '12' '19' '21' '8' '35'\n '6' '9' '29' '7' '5' '23' '30' nan '27' '24' 'Younger than 5 years' '33'\n '25' '26' '39' '36' '38' '28' '31' 'Older than 85' '32' '37' '50' '65'\n '42' '34' '40' '67' '43' '44' '60' '46' '45' '49' '51' '41' '55' '83'\n '48' '53' '54' '47' '56' '79' '61' '68' '77' '66' '52' '80' '62' '84'\n '57' '58' '63']\n-----------------------------------------------------\nYearsCodePro [nan '1' 'Less than 1 year' '9' '3' '4' '10' '8' '2' '13' '18' '5' '14'\n '22' '23' '19' '35' '20' '25' '7' '15' '27' '6' '48' '12' '31' '11' '17'\n '16' '21' '29' '30' '26' '33' '28' '37' '40' '34' '24' '39' '38' '36'\n '32' '41' '45' '43' 'More than 50 years' '44' '42' '46' '49' '50' '47']\n-----------------------------------------------------\nCareerSat [nan 'Slightly satisfied' 'Very satisfied' 'Very dissatisfied'\n 'Slightly dissatisfied' 'Neither satisfied nor dissatisfied']\n-----------------------------------------------------\nJobSat [nan 'Slightly satisfied' 'Slightly dissatisfied'\n 'Neither satisfied nor dissatisfied' 'Very satisfied' 'Very dissatisfied']\n-----------------------------------------------------\nMgrIdiot [nan 'Not at all confident' 'Very confident' 'Somewhat confident'\n \"I don't have a manager\"]\n-----------------------------------------------------\nMgrMoney [nan 'Not sure' 'No' 'Yes']\n-----------------------------------------------------\nMgrWant [nan 'Not sure' 'No' 'Yes' 'I am already a manager']\n-----------------------------------------------------\nJobSeek [nan 'I am actively looking for a job'\n 'I’m not actively looking, but I am open to new opportunities'\n 'I am not interested in new job opportunities']\n-----------------------------------------------------\nLastHireDate [nan \"I've never had a job\" '1-2 years ago' 'Less than a year ago'\n 'NA - I am an independent contractor or self employed' '3-4 years ago'\n 'More than 4 years ago']\n-----------------------------------------------------\nLastInt [nan 'Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Complete a take-home project;Interview with people in senior / management roles'\n 'Write any code'\n 'Write any code;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Complete a take-home project;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Interview with people in senior / management roles'\n 'Complete a take-home project;Interview with people in senior / management roles'\n 'Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Interview with people in senior / management roles'\n 'Complete a take-home project'\n 'Write code by hand (e.g., on a whiteboard);Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Complete a take-home project;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write code by hand (e.g., on a whiteboard);Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Complete a take-home project'\n 'Write code by hand (e.g., on a whiteboard)'\n 'Write any code;Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard)'\n 'Write any code;Complete a take-home project;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in senior / management roles'\n 'Write any code;Interview with people in senior / management roles'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle'\n 'Write any code;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project'\n 'Write any code;Solve a brain-teaser style puzzle'\n 'Solve a brain-teaser style puzzle'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in senior / management roles'\n 'Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Complete a take-home project;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Interview with people in peer roles'\n 'Complete a take-home project;Solve a brain-teaser style puzzle'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles;Interview with people in senior / management roles'\n 'Write any code;Complete a take-home project;Solve a brain-teaser style puzzle'\n 'Write any code;Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Interview with people in peer roles'\n 'Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in senior / management roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle'\n 'Write any code;Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write any code;Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write any code;Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles'\n 'Write code by hand (e.g., on a whiteboard);Complete a take-home project;Solve a brain-teaser style puzzle;Interview with people in peer roles']\n-----------------------------------------------------\nFizzBuzz [nan 'No' 'Yes']\n-----------------------------------------------------\nJobFactors [nan\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with\"\n \"Languages, frameworks, and other technologies I'd be working with;Remote work options;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture;Opportunities for professional development\"\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;Flex time or a flexible schedule\"\n 'Financial performance or funding status of the company or organization;Opportunities for professional development;How widely used or impactful my work output would be'\n 'Remote work options;Opportunities for professional development;Flex time or a flexible schedule'\n 'Financial performance or funding status of the company or organization;Office environment or company culture;How widely used or impactful my work output would be'\n 'Financial performance or funding status of the company or organization;Office environment or company culture;Opportunities for professional development'\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development\"\n 'Remote work options;How widely used or impactful my work output would be;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with\"\n 'Opportunities for professional development;How widely used or impactful my work output would be;Flex time or a flexible schedule'\n 'Office environment or company culture;Remote work options;Opportunities for professional development'\n 'Remote work options;Diversity of the company or organization;How widely used or impactful my work output would be'\n 'Financial performance or funding status of the company or organization;Remote work options;Flex time or a flexible schedule'\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture;Remote work options\"\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;Flex time or a flexible schedule\"\n \"Specific department or team I'd be working on;Office environment or company culture;Remote work options\"\n \"Specific department or team I'd be working on;Office environment or company culture;Flex time or a flexible schedule\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;Office environment or company culture\"\n 'Office environment or company culture;Diversity of the company or organization;Flex time or a flexible schedule'\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture;How widely used or impactful my work output would be\"\n 'Office environment or company culture;Remote work options;Flex time or a flexible schedule'\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with\"\n 'Opportunities for professional development;Diversity of the company or organization;How widely used or impactful my work output would be'\n 'Financial performance or funding status of the company or organization;How widely used or impactful my work output would be;Flex time or a flexible schedule'\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development\"\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;Office environment or company culture\"\n 'Office environment or company culture;How widely used or impactful my work output would be;Flex time or a flexible schedule'\n 'Office environment or company culture;Opportunities for professional development;Flex time or a flexible schedule'\n 'Remote work options;Opportunities for professional development;How widely used or impactful my work output would be'\n \"Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development;How widely used or impactful my work output would be\"\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Remote work options\"\n 'Office environment or company culture;Opportunities for professional development;How widely used or impactful my work output would be'\n \"Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with;Remote work options;Opportunities for professional development\"\n \"Languages, frameworks, and other technologies I'd be working with;How widely used or impactful my work output would be;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with\"\n \"Languages, frameworks, and other technologies I'd be working with;Remote work options\"\n \"Specific department or team I'd be working on;Remote work options;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Office environment or company culture;How widely used or impactful my work output would be\"\n \"Industry that I'd be working in;Opportunities for professional development;How widely used or impactful my work output would be\"\n 'Office environment or company culture;Remote work options'\n \"Industry that I'd be working in;Specific department or team I'd be working on;Opportunities for professional development\"\n \"Industry that I'd be working in;Opportunities for professional development;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Office environment or company culture;Opportunities for professional development\"\n 'Diversity of the company or organization;How widely used or impactful my work output would be;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Office environment or company culture;Flex time or a flexible schedule\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization\"\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;How widely used or impactful my work output would be\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;Remote work options\"\n \"Industry that I'd be working in;Office environment or company culture;Remote work options\"\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;Remote work options\"\n \"Languages, frameworks, and other technologies I'd be working with;Remote work options;How widely used or impactful my work output would be\"\n \"Specific department or team I'd be working on;Opportunities for professional development;Flex time or a flexible schedule\"\n \"Specific department or team I'd be working on;Office environment or company culture;Diversity of the company or organization\"\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Opportunities for professional development\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;How widely used or impactful my work output would be\"\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;Remote work options\"\n \"Specific department or team I'd be working on;Opportunities for professional development;How widely used or impactful my work output would be\"\n \"Industry that I'd be working in;Specific department or team I'd be working on;Diversity of the company or organization\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;How widely used or impactful my work output would be\"\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development\"\n 'Financial performance or funding status of the company or organization;Diversity of the company or organization;How widely used or impactful my work output would be'\n 'Financial performance or funding status of the company or organization;Office environment or company culture;Flex time or a flexible schedule'\n \"Specific department or team I'd be working on;Remote work options;Opportunities for professional development\"\n \"Languages, frameworks, and other technologies I'd be working with;Remote work options;Diversity of the company or organization\"\n 'Office environment or company culture;Remote work options;How widely used or impactful my work output would be'\n \"Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization;How widely used or impactful my work output would be\"\n 'Financial performance or funding status of the company or organization;Remote work options;Opportunities for professional development'\n \"Industry that I'd be working in;Remote work options;Opportunities for professional development\"\n 'Office environment or company culture'\n 'Remote work options;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization\"\n 'Opportunities for professional development;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with;Office environment or company culture\"\n \"Specific department or team I'd be working on;Office environment or company culture;Opportunities for professional development\"\n 'Office environment or company culture;Diversity of the company or organization;How widely used or impactful my work output would be'\n 'Financial performance or funding status of the company or organization;Opportunities for professional development;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Opportunities for professional development\"\n \"Industry that I'd be working in;Specific department or team I'd be working on;How widely used or impactful my work output would be\"\n \"Industry that I'd be working in;Remote work options;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Specific department or team I'd be working on;Office environment or company culture\"\n 'Office environment or company culture;Remote work options;Diversity of the company or organization'\n 'Office environment or company culture;Opportunities for professional development;Diversity of the company or organization'\n 'Remote work options;Diversity of the company or organization;Flex time or a flexible schedule'\n 'Opportunities for professional development;Diversity of the company or organization;Flex time or a flexible schedule'\n 'Financial performance or funding status of the company or organization;Office environment or company culture;Remote work options'\n 'Financial performance or funding status of the company or organization;Remote work options;How widely used or impactful my work output would be'\n \"Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development;Diversity of the company or organization\"\n 'Financial performance or funding status of the company or organization;Remote work options;Diversity of the company or organization'\n \"Industry that I'd be working in;Specific department or team I'd be working on;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with\"\n 'Remote work options'\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;How widely used or impactful my work output would be\"\n 'Opportunities for professional development'\n \"Specific department or team I'd be working on;Office environment or company culture;How widely used or impactful my work output would be\"\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Office environment or company culture\"\n \"Industry that I'd be working in\" 'Flex time or a flexible schedule'\n 'How widely used or impactful my work output would be'\n \"Specific department or team I'd be working on\"\n \"Specific department or team I'd be working on;Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization\"\n 'Remote work options;Opportunities for professional development;Diversity of the company or organization'\n \"Specific department or team I'd be working on;How widely used or impactful my work output would be;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture;Diversity of the company or organization\"\n 'Financial performance or funding status of the company or organization;Office environment or company culture;Diversity of the company or organization'\n 'Remote work options;How widely used or impactful my work output would be'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Office environment or company culture\"\n \"Languages, frameworks, and other technologies I'd be working with;Office environment or company culture\"\n 'Diversity of the company or organization'\n \"Industry that I'd be working in;Opportunities for professional development;Diversity of the company or organization\"\n \"Specific department or team I'd be working on;Diversity of the company or organization;Flex time or a flexible schedule\"\n \"Specific department or team I'd be working on;Opportunities for professional development;Diversity of the company or organization\"\n 'Office environment or company culture;Opportunities for professional development'\n \"Specific department or team I'd be working on;How widely used or impactful my work output would be\"\n \"Industry that I'd be working in;Remote work options;Diversity of the company or organization\"\n \"Specific department or team I'd be working on;Remote work options;How widely used or impactful my work output would be\"\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Opportunities for professional development\"\n \"Specific department or team I'd be working on;Office environment or company culture\"\n \"Industry that I'd be working in;How widely used or impactful my work output would be;Flex time or a flexible schedule\"\n 'Financial performance or funding status of the company or organization;Diversity of the company or organization;Flex time or a flexible schedule'\n \"Languages, frameworks, and other technologies I'd be working with;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Office environment or company culture;Diversity of the company or organization\"\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Flex time or a flexible schedule\"\n 'Remote work options;Opportunities for professional development'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Remote work options\"\n \"Languages, frameworks, and other technologies I'd be working with;Opportunities for professional development\"\n 'Financial performance or funding status of the company or organization'\n \"Industry that I'd be working in;Remote work options;How widely used or impactful my work output would be\"\n \"Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization;Flex time or a flexible schedule\"\n 'Financial performance or funding status of the company or organization;Diversity of the company or organization'\n \"Specific department or team I'd be working on;Remote work options\"\n \"Industry that I'd be working in;Remote work options\"\n \"Specific department or team I'd be working on;Diversity of the company or organization;How widely used or impactful my work output would be\"\n 'Office environment or company culture;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Specific department or team I'd be working on\"\n \"Industry that I'd be working in;Diversity of the company or organization;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Diversity of the company or organization;How widely used or impactful my work output would be\"\n 'Opportunities for professional development;How widely used or impactful my work output would be'\n 'Diversity of the company or organization;How widely used or impactful my work output would be'\n \"Financial performance or funding status of the company or organization;Languages, frameworks, and other technologies I'd be working with\"\n 'Financial performance or funding status of the company or organization;Flex time or a flexible schedule'\n \"Specific department or team I'd be working on;Remote work options;Diversity of the company or organization\"\n \"Industry that I'd be working in;Office environment or company culture\"\n 'Financial performance or funding status of the company or organization;Opportunities for professional development;Diversity of the company or organization'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Flex time or a flexible schedule\"\n \"Languages, frameworks, and other technologies I'd be working with;How widely used or impactful my work output would be\"\n 'Financial performance or funding status of the company or organization;Opportunities for professional development'\n \"Industry that I'd be working in;Flex time or a flexible schedule\"\n \"Specific department or team I'd be working on;Flex time or a flexible schedule\"\n \"Industry that I'd be working in;Languages, frameworks, and other technologies I'd be working with\"\n 'Financial performance or funding status of the company or organization;Office environment or company culture'\n \"Industry that I'd be working in;Specific department or team I'd be working on;Remote work options\"\n \"Specific department or team I'd be working on;Opportunities for professional development\"\n 'Office environment or company culture;How widely used or impactful my work output would be'\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;How widely used or impactful my work output would be\"\n 'How widely used or impactful my work output would be;Flex time or a flexible schedule'\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization;Diversity of the company or organization\"\n \"Industry that I'd be working in;Financial performance or funding status of the company or organization\"\n \"Industry that I'd be working in;Diversity of the company or organization\"\n 'Financial performance or funding status of the company or organization;Remote work options'\n \"Languages, frameworks, and other technologies I'd be working with;Diversity of the company or organization\"\n \"Industry that I'd be working in;Specific department or team I'd be working on\"\n 'Office environment or company culture;Diversity of the company or organization'\n 'Remote work options;Diversity of the company or organization'\n 'Opportunities for professional development;Diversity of the company or organization'\n 'Financial performance or funding status of the company or organization;How widely used or impactful my work output would be'\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on;Diversity of the company or organization\"\n \"Industry that I'd be working in;How widely used or impactful my work output would be\"\n \"Financial performance or funding status of the company or organization;Specific department or team I'd be working on\"\n \"Specific department or team I'd be working on;Diversity of the company or organization\"\n 'Diversity of the company or organization;Flex time or a flexible schedule']\n-----------------------------------------------------\nResumeUpdate [nan 'Something else changed (education, award, media, etc.)'\n 'I was preparing for a job search'\n 'I heard about a job opportunity (from a recruiter, online job posting, etc.)'\n 'My job status changed (promotion, new job, etc.)'\n 'I had a negative experience or interaction at work'\n 'Re-entry into the workforce']\n-----------------------------------------------------\nCurrencySymbol [nan 'THB' 'USD' 'UAH' 'CAD' 'NZD' 'INR' 'EUR' 'GBP' 'AUD' 'RUB' 'BRL'\n 'ILS' 'ZAR' 'TRY' 'CHF' 'CZK' 'MYR' 'PLN' 'SEK' 'CNY' 'ARS' 'PHP' 'PKR'\n 'AZN' 'HRK' 'KRW' 'BGN' 'VND' 'IRR' 'HUF' 'HKD' 'AED' 'NGN' 'NOK' 'DKK'\n 'JPY' 'XPF' 'MXN' 'EGP' 'MUR' 'UGX' 'SAR' 'SLL' 'NIO' 'SGD' 'NPR' 'AMD'\n 'RON' 'AFN' 'BHD' 'MNT' 'CLP' 'GEL' 'KES' 'DOP' 'BDT' 'CVE' 'RSD' 'BIF'\n 'LKR' 'IQD' 'COP' 'GTQ' 'TWD' 'YER' 'IDR' 'BYN' 'LYD' 'AOA' 'ALL' 'LBP'\n 'KWD' 'MDL' 'DZD' 'BAM' 'SYP' 'XOF' 'MAD' 'XAF' 'BND' 'MKD' 'JOD' 'TTD'\n 'ZMW' 'CRC' 'GHS' 'PYG' 'MMK' 'PEN' 'UZS' 'TND' 'HNL' 'QAR' 'RWF' 'KZT'\n 'TJS' 'UYU' 'TMT' 'TZS' 'KGS' 'SDG' 'ANG' 'SOS' 'GNF' 'ETB' 'KHR' 'CUP'\n 'MRU' 'BWP' 'BOB' 'ISK' 'DJF' 'VES' 'BZD' 'JMD' 'MVR' 'non' 'WST' 'MZN'\n 'XDR' 'BBD' 'HTG' 'LSL' 'SZL' 'GYD' 'MGA' 'FKP' 'FJD' 'BMD' 'VUV' 'GGP'\n 'XCD' 'BSD' 'AWG' 'OMR' 'BTN' 'IMP' 'SRD' 'LAK' 'SCR' 'MWK' 'KYD' 'CDF']\n-----------------------------------------------------\nCurrencyDesc [nan 'Thai baht' 'United States dollar' 'Ukrainian hryvnia'\n 'Canadian dollar' 'New Zealand dollar' 'Indian rupee' 'European Euro'\n 'Pound sterling' 'Australian dollar' 'Russian ruble' 'Brazilian real'\n 'Israeli new shekel' 'South African rand' 'Turkish lira' 'Swiss franc'\n 'Czech koruna' 'Malaysian ringgit' 'Polish zloty' 'Swedish krona'\n 'Chinese Yuan Renminbi' 'Argentine peso' 'Philippine peso'\n 'Pakistani rupee' 'Azerbaijan manat' 'Croatian kuna' 'South Korean won'\n 'Bulgarian lev' 'Vietnamese dong' 'Iranian rial' 'Hungarian forint'\n 'Hong Kong dollar' 'United Arab Emirates dirham' 'Nigerian naira'\n 'Norwegian krone' 'Danish krone' 'Japanese yen' 'CFP franc'\n 'Mexican peso' 'Egyptian pound' 'Mauritian rupee' 'Ugandan shilling'\n 'Saudi Arabian riyal' 'Sierra Leonean leone' 'Nicaraguan cordoba'\n 'Singapore dollar' 'Nepalese rupee' 'Armenian dram' 'Romanian leu'\n 'Afghan afghani' 'Bahraini dinar' 'Mongolian tugrik' 'Chilean peso'\n 'Georgian lari' 'Kenyan shilling' 'Dominican peso' 'Bangladeshi taka'\n 'Cape Verdean escudo' 'Serbian dinar' 'Burundi franc' 'Sri Lankan rupee'\n 'Iraqi dinar' 'Colombian peso' 'Guatemalan quetzal' 'New Taiwan dollar'\n 'Yemeni rial' 'Indonesian rupiah' 'Belarusian ruble' 'Libyan dinar'\n 'Angolan kwanza' 'Albanian lek' 'Lebanese pound' 'Kuwaiti dinar'\n 'Moldovan leu' 'Algerian dinar' 'Bosnia and Herzegovina convertible mark'\n 'Syrian pound' 'West African CFA franc' 'Moroccan dirham'\n 'Central African CFA franc' 'Brunei dollar' 'Macedonian denar'\n 'Jordanian dinar' 'Trinidad and Tobago dollar' 'Zambian kwacha'\n 'Costa Rican colon' 'Ghanaian cedi' 'Paraguayan guarani' 'Myanmar kyat'\n 'Peruvian sol' 'Uzbekistani som' 'Tunisian dinar' 'Honduran lempira'\n 'Qatari riyal' 'Rwandan franc' 'Kazakhstani tenge' 'Tajikistani somoni'\n 'Uruguayan peso' 'Turkmen manat' 'Tanzanian shilling' 'Kyrgyzstani som'\n 'Sudanese pound' 'Netherlands Antillean guilder' 'Somali shilling'\n 'Guinean franc' 'Ethiopian birr' 'Cambodian riel' 'Cuban peso'\n 'Mauritanian ouguiya' 'Botswana pula' 'Bolivian boliviano'\n 'Icelandic krona' 'Djiboutian franc' 'Venezuelan bolivar' 'Belize dollar'\n 'Jamaican dollar' 'Maldivian rufiyaa' 'e\\tCook Islands dollar'\n 'Samoan tala' 'Mozambican metical' 'SDR (Special Drawing Right)'\n 'Barbadian dollar' 'Haitian gourde' 'Lesotho loti' 'Swazi lilangeni'\n 'Guyanese dollar' 'Malagasy ariary' 'Falkland Islands pound'\n 'Fijian dollar' 'Bermudian dollar' 'Vanuatu vatu' 'Guernsey Pound'\n 'East Caribbean dollar' 'Bahamian dollar' 'Aruban florin' 'Omani rial'\n 'Bhutanese ngultrum' 'Manx pound' 'Surinamese dollar' 'Lao kip'\n 'e\\tFaroese krona' 'Seychellois rupee' 'Malawian kwacha'\n 'Cayman Islands dollar' 'Congolese franc']\n-----------------------------------------------------\nCompTotal [ nan 23000. 61000. ... 723800. 4752. 42768.]\n-----------------------------------------------------\nCompFreq [nan 'Monthly' 'Yearly' 'Weekly']\n-----------------------------------------------------\nConvertedComp [ nan 8820. 61000. ... 38766. 13272. 588012.]\n-----------------------------------------------------\nWorkWeekHrs [ nan 4.000000e+01 8.000000e+01 5.500000e+01 1.500000e+01\n 3.200000e+01 7.000000e+01 4.500000e+01 8.000000e+00 1.400000e+02\n 5.000000e+01 3.600000e+01 3.700000e+01 3.500000e+01 3.800000e+01\n 3.900000e+01 4.200000e+01 7.000000e+00 4.600000e+01 4.800000e+01\n 2.500000e+01 4.400000e+01 6.000000e+00 1.200000e+01 7.500000e+01\n 3.000000e+01 1.600000e+02 6.000000e+01 3.850000e+02 3.750000e+01\n 3.400000e+01 9.800000e+01 3.100000e+01 9.000000e+00 4.300000e+01\n 1.100000e+01 2.800000e+01 5.400000e+01 1.000000e+01 2.000000e+01\n 2.400000e+01 1.000000e+02 3.750000e+02 2.100000e+01 4.100000e+01\n 1.000000e+00 3.850000e+01 4.250000e+01 3.675000e+01 1.600000e+01\n 5.200000e+01 1.300000e+02 8.500000e+00 1.800000e+01 1.680000e+02\n 1.400000e+01 3.300000e+01 3.620000e+01 4.700000e+01 1.300000e+01\n 4.900000e+01 9.000000e+01 4.000000e+00 6.500000e+01 4.750000e+02\n 7.250000e+00 3.350000e+01 5.600000e+01 5.800000e+01 5.000000e+00\n 5.300000e+01 7.200000e+01 3.625000e+01 9.250000e+00 3.650000e+01\n 7.600000e+01 3.000000e+00 2.220000e+01 6.200000e+01 5.100000e+01\n 4.150000e+01 6.300000e+01 1.500000e+02 8.500000e+01 8.400000e+01\n 4.350000e+01 1.700000e+01 2.200000e+01 7.500000e+00 3.500000e+00\n 1.012000e+03 4.750000e+01 2.900000e+01 1.130000e+02 4.550000e+01\n 3.950000e+02 3.725000e+01 3.250000e+01 6.600000e+01 5.700000e+01\n 6.400000e+01 4.120000e+01 3.550000e+02 4.050000e+01 3.680000e+01\n 8.800000e+00 2.700000e+01 9.500000e+01 3.150000e+01 7.900000e+01\n 1.050000e+02 1.450000e+02 2.000000e+00 1.200000e+02 9.500000e+00\n 1.100000e+02 3.950000e+01 1.900000e+01 2.740000e+01 6.300000e+00\n 2.300000e+01 3.775000e+01 3.450000e+01 8.900000e+01 1.670000e+02\n 7.400000e+01 8.800000e+01 4.125000e+03 4.250000e+02 1.150000e+02\n 1.875000e+01 2.250000e+01 9.600000e+00 1.650000e+02 8.200000e+00\n 7.250000e+01 2.150000e+01 8.250000e+00 6.100000e+01 2.600000e+01\n 1.280000e+02 7.700000e+01 1.000005e+00 2.560000e+01 1.650000e+01\n 6.400000e+00 1.440000e+02 9.600000e+01 1.850000e+01 3.550000e+01\n 8.833000e+01 3.875000e+03 6.900000e+01 6.700000e+01 3.875000e+01\n 7.800000e+01 8.100000e+01 4.450000e+01 3.360000e+01 1.120000e+02\n 3.760000e+01 8.300000e+00 9.300000e+00 7.220000e+00 3.830000e+01\n 1.620000e+02 4.340000e+01 6.800000e+01 3.575000e+01 6.250000e+01\n 4.150000e+02 3.975000e+01 3.110000e+01 3.910000e+01 7.300000e+01\n 4.850000e+03 1.350000e+02 4.950000e+01 3.751450e+01 6.500000e+00\n 8.100000e+00 1.080000e+02 8.230000e+01 3.225000e+01 6.650000e+01\n 3.780000e+01 8.200000e+01 3.730000e+01 8.150000e+00 5.250000e+01\n 5.750000e+01 4.725000e+01 1.550000e+02 8.400000e+00 1.925000e+01\n 4.075000e+01 1.950000e+01 5.950000e+01 1.375000e+02 4.650000e+01\n 1.640000e+02 3.250000e+02 2.550000e+01 3.925000e+01 3.980000e+01\n 2.625000e+01 4.125000e+01 2.750000e+01]\n-----------------------------------------------------\nWorkPlan [nan\n \"There's no schedule or spec; I work on what seems most important or urgent\"\n 'There is a schedule and/or spec (made by me or by a colleague), and I follow it very closely'\n 'There is a schedule and/or spec (made by me or by a colleague), and my work somewhat aligns']\n-----------------------------------------------------\nWorkChallenge [nan\n 'Distracting work environment;Inadequate access to necessary tools;Lack of support from management'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Distracting work environment;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Not enough people for the workload'\n 'Meetings;Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Being tasked with non-development work;Not enough people for the workload'\n 'Being tasked with non-development work;Distracting work environment;Meetings'\n 'Distracting work environment;Meetings;Time spent commuting'\n 'Distracting work environment;Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Being tasked with non-development work;Meetings;Not enough people for the workload'\n 'Distracting work environment;Meetings;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Meetings;Time spent commuting'\n 'Distracting work environment;Inadequate access to necessary tools'\n 'Distracting work environment;Lack of support from management'\n 'Inadequate access to necessary tools;Meetings;Toxic work environment'\n 'Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Inadequate access to necessary tools;Lack of support from management;Not enough people for the workload'\n 'Distracting work environment;Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Distracting work environment;Inadequate access to necessary tools'\n 'Distracting work environment;Inadequate access to necessary tools;Not enough people for the workload'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Meetings'\n 'Being tasked with non-development work;Meetings;Toxic work environment'\n 'Meetings;Not enough people for the workload'\n 'Meetings;Time spent commuting'\n 'Distracting work environment;Lack of support from management;Not enough people for the workload'\n 'Being tasked with non-development work;Distracting work environment'\n 'Meetings;Not enough people for the workload;Time spent commuting'\n 'Lack of support from management;Meetings;Toxic work environment'\n 'Being tasked with non-development work;Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Inadequate access to necessary tools;Not enough people for the workload'\n 'Not enough people for the workload;Time spent commuting'\n 'Inadequate access to necessary tools;Lack of support from management;Toxic work environment'\n 'Distracting work environment;Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment'\n 'Meetings;Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Lack of support from management;Not enough people for the workload;Toxic work environment'\n 'Distracting work environment;Inadequate access to necessary tools;Time spent commuting'\n 'Distracting work environment;Not enough people for the workload'\n 'Being tasked with non-development work;Meetings'\n 'Not enough people for the workload;Time spent commuting;Toxic work environment'\n 'Being tasked with non-development work;Distracting work environment;Time spent commuting'\n 'Being tasked with non-development work;Inadequate access to necessary tools'\n 'Inadequate access to necessary tools;Toxic work environment'\n 'Toxic work environment'\n 'Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Distracting work environment;Toxic work environment'\n 'Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Lack of support from management'\n 'Meetings;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Lack of support from management;Meetings'\n 'Meetings'\n 'Lack of support from management;Not enough people for the workload;Time spent commuting'\n 'Distracting work environment;Inadequate access to necessary tools;Toxic work environment'\n 'Inadequate access to necessary tools'\n 'Distracting work environment;Meetings'\n 'Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Meetings;Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment'\n 'Being tasked with non-development work;Lack of support from management;Not enough people for the workload'\n 'Being tasked with non-development work;Not enough people for the workload;Time spent commuting'\n 'Being tasked with non-development work;Not enough people for the workload;Toxic work environment'\n 'Inadequate access to necessary tools;Meetings'\n 'Distracting work environment;Inadequate access to necessary tools;Meetings'\n 'Being tasked with non-development work;Lack of support from management'\n 'Not enough people for the workload'\n 'Meetings;Not enough people for the workload;Toxic work environment'\n 'Being tasked with non-development work'\n 'Being tasked with non-development work;Time spent commuting'\n 'Being tasked with non-development work;Distracting work environment;Not enough people for the workload'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Time spent commuting'\n 'Distracting work environment;Not enough people for the workload;Time spent commuting'\n 'Distracting work environment;Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Distracting work environment'\n 'Lack of support from management;Not enough people for the workload'\n 'Meetings;Time spent commuting;Toxic work environment'\n 'Distracting work environment;Not enough people for the workload;Toxic work environment'\n 'Distracting work environment;Lack of support from management;Meetings'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Distracting work environment;Meetings;Not enough people for the workload'\n 'Inadequate access to necessary tools;Time spent commuting'\n 'Distracting work environment;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Distracting work environment;Lack of support from management'\n 'Distracting work environment;Time spent commuting;Toxic work environment'\n 'Lack of support from management;Time spent commuting'\n 'Being tasked with non-development work;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Distracting work environment;Lack of support from management;Toxic work environment'\n 'Lack of support from management'\n 'Being tasked with non-development work;Meetings;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload;Toxic work environment'\n 'Being tasked with non-development work;Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Distracting work environment;Meetings;Toxic work environment'\n 'Time spent commuting'\n 'Not enough people for the workload;Toxic work environment'\n 'Lack of support from management;Meetings;Time spent commuting'\n 'Being tasked with non-development work;Lack of support from management;Toxic work environment'\n 'Distracting work environment;Lack of support from management;Time spent commuting'\n 'Lack of support from management;Toxic work environment'\n 'Inadequate access to necessary tools;Not enough people for the workload;Toxic work environment'\n 'Inadequate access to necessary tools;Not enough people for the workload;Time spent commuting'\n 'Inadequate access to necessary tools;Meetings;Time spent commuting'\n 'Being tasked with non-development work;Toxic work environment'\n 'Inadequate access to necessary tools;Meetings;Not enough people for the workload'\n 'Lack of support from management;Meetings'\n 'Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Time spent commuting;Toxic work environment'\n 'Lack of support from management;Meetings;Not enough people for the workload'\n 'Being tasked with non-development work;Time spent commuting;Toxic work environment'\n 'Being tasked with non-development work;Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload'\n 'Inadequate access to necessary tools;Lack of support from management'\n 'Meetings;Toxic work environment'\n 'Being tasked with non-development work;Lack of support from management;Time spent commuting'\n 'Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment'\n 'Distracting work environment;Toxic work environment'\n 'Being tasked with non-development work;Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment'\n 'Time spent commuting;Toxic work environment'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Not enough people for the workload;Time spent commuting'\n 'Inadequate access to necessary tools;Time spent commuting;Toxic work environment'\n 'Distracting work environment;Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Being tasked with non-development work;Inadequate access to necessary tools;Toxic work environment'\n 'Lack of support from management;Meetings;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Distracting work environment;Time spent commuting'\n 'Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment'\n 'Inadequate access to necessary tools;Lack of support from management;Meetings'\n 'Lack of support from management;Time spent commuting;Toxic work environment'\n 'Inadequate access to necessary tools;Lack of support from management;Time spent commuting'\n 'Inadequate access to necessary tools;Meetings;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Inadequate access to necessary tools;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Inadequate access to necessary tools;Lack of support from management;Non-work commitments (parenting, school work, hobbies, etc.)'\n 'Non-work commitments (parenting, school work, hobbies, etc.);Toxic work environment']\n-----------------------------------------------------\nWorkRemote [nan 'Less than once per month / Never' 'A few days each month'\n \"All or almost all the time (I'm full-time remote)\"\n 'More than half, but not all, the time'\n 'Less than half the time, but at least one day each week'\n 'About half the time' \"It's complicated\"]\n-----------------------------------------------------\nWorkLoc [nan 'Home' 'Office' 'Other place, such as a coworking space or cafe']\n-----------------------------------------------------\nImpSyn [nan 'Average' 'A little below average' 'A little above average'\n 'Far above average' 'Far below average']\n-----------------------------------------------------\nCodeRev [nan 'No' 'Yes, because I see value in code review'\n 'Yes, because I was told to do so']\n-----------------------------------------------------\nCodeRevHrs [ nan 6.000e+00 1.200e+01 4.000e+00 5.000e+00 5.000e-01 3.000e+00\n 1.000e+00 8.000e+00 2.000e+00 1.000e+01 1.500e+01 2.000e+01 0.000e+00\n 2.500e+00 7.000e+00 1.600e+01 5.000e-02 9.000e+00 1.300e+01 3.000e+01\n 2.500e-01 5.000e+01 1.500e+00 2.500e+01 2.200e+01 4.000e+01 1.800e+01\n 1.400e+01 4.800e+01 1.000e-01 5.400e+01 7.190e+00 2.400e+01 3.500e+00\n 1.700e+01 7.500e+00 4.200e+01 4.000e-01 1.000e-02 2.000e-01 3.500e+01\n 5.500e+01 2.100e+01 8.400e+01 3.600e+01 9.900e+01 9.800e+01 3.000e-01\n 8.500e+00 6.000e+01 4.250e+01 4.500e+00 1.100e+01 4.500e+01 5.500e+00\n 8.000e+01 6.500e+00 3.200e+01 7.200e+01 9.000e+01 2.800e+01 5.200e+01\n 1.370e+00 7.000e+01 9.890e+01 6.500e+01 7.700e+01 3.800e+00 2.600e+01\n 3.800e-01 9.500e+01 9.600e+01 6.000e-01 3.900e+01 1.019e+01 5.100e+01\n 5.600e+01 2.570e+00 8.400e+00 6.700e+00 2.700e-01 3.750e+01 3.300e+01\n 2.300e+01 1.800e+00 3.600e+00 9.700e+01 4.900e+01 2.700e+01 8.200e+01\n 3.140e+00 2.000e-02]\n-----------------------------------------------------\nUnitTests [nan 'No, but I think we should' \"Yes, it's part of our process\"\n \"Yes, it's not part of our process but the developers do it on their own\"\n \"No, and I'm glad we don't\"]\n-----------------------------------------------------\nPurchaseHow [nan 'Not sure'\n 'Developers typically have the most influence on purchasing new technology'\n 'Developers and management have nearly equal input into purchasing new technology'\n 'The CTO, CIO, or other management purchase new technology typically without the involvement of developers']\n-----------------------------------------------------\nPurchaseWhat [nan 'I have little or no influence' 'I have some influence'\n 'I have a great deal of influence']\n-----------------------------------------------------\nLanguageWorkedWith ['HTML/CSS;Java;JavaScript;Python' 'C++;HTML/CSS;Python' 'HTML/CSS' ...\n 'Bash/Shell/PowerShell;C++;Python;Ruby;Other(s):'\n 'Assembly;C++;HTML/CSS;VBA'\n 'Assembly;Bash/Shell/PowerShell;C;C#;HTML/CSS;Java;JavaScript;PHP;SQL;Other(s):']\n-----------------------------------------------------\n"
],
[
"def assess_missing_col(df):\n df_rows, df_cols = df.shape\n missing_num = pd.Series(df.isnull().sum(), name = 'Number of Missing')\n #all columns\n missing_per = pd.Series(missing_num/(df_rows)*100, name = '% NaN Missing')\n\n #only columns with missing data\n missing_data = pd.Series(missing_num[missing_num > 0]/df_rows*100, name = '% NaN Missing')\n missing_data.sort_values(inplace = True)\n print(missing_data)\n \n plt.hist(missing_data, bins = 50)\n plt.xlabel('Nan % in a column (%)')\n plt.ylabel('Counts')\n #plt.title('Histogram of missing value counts for each column')\n plt.grid(True)\n plt.minorticks_on()\n plt.grid(b=True, which='minor', alpha=0.2)\n plt.show()\n\n return missing_data, plt.show()",
"_____no_output_____"
],
[
"missing_data, plot = assess_missing_col(df2019)",
"Country 0.148510\nMainBranch 0.621041\nSOVisitFreq 0.697546\nSOComm 0.846056\nSOVisitTo 0.896684\n ... \nMiscTechWorkedWith 32.961309\nCompTotal 37.057705\nConvertedComp 37.194964\nCodeRevHrs 43.982539\nBlockchainOrg 45.799534\nName: % NaN Missing, Length: 82, dtype: float64\n"
],
[
"#Investigate missing data using different thresholds of %NaN missing.\ndef investigate_nan_threshold(df, interval, start):\n '''\nThis function finds how many columns have more than a certain percentage \nof data missing.\n\nINPUTS:\n start - the initial threshold percentage of data missing to be analyzed\n interval - the amount of increase in the analysis threshold \n if the previous threshold has at least 1 column remaining\n\nOUTPUTS:\n Prints the names of the columns that have more than the threshold % of \n data missing as well as the current threshold.\n '''\n\n n = start\n df_rows, df_cols = df.shape\n missing_list = [1]\n while len(missing_list) > 0:\n missing_list = [col for col in df.columns if (df[col].isnull().sum()/df_rows)*100 > n]\n if len(missing_list) > 0:\n print('There are {} columns with more than {}% of data missing.'.format(len(missing_list), n))\n print(missing_list)\n print('--------------------------------------')\n n = n+interval\n else:\n break\n",
"_____no_output_____"
],
[
"investigate_nan_threshold(df2019, 10, 5)",
"There are 54 columns with more than 5% of data missing.\n['UndergradMajor', 'EduOther', 'OrgSize', 'DevType', 'YearsCodePro', 'CareerSat', 'JobSat', 'MgrIdiot', 'MgrMoney', 'MgrWant', 'JobSeek', 'LastHireDate', 'LastInt', 'FizzBuzz', 'JobFactors', 'ResumeUpdate', 'CurrencySymbol', 'CurrencyDesc', 'CompTotal', 'CompFreq', 'ConvertedComp', 'WorkWeekHrs', 'WorkPlan', 'WorkChallenge', 'WorkRemote', 'WorkLoc', 'ImpSyn', 'CodeRev', 'CodeRevHrs', 'UnitTests', 'PurchaseHow', 'PurchaseWhat', 'LanguageDesireNextYear', 'DatabaseWorkedWith', 'DatabaseDesireNextYear', 'PlatformWorkedWith', 'PlatformDesireNextYear', 'WebFrameWorkedWith', 'WebFrameDesireNextYear', 'MiscTechWorkedWith', 'MiscTechDesireNextYear', 'BlockchainOrg', 'BlockchainIs', 'SocialMedia', 'ScreenName', 'SOVisit1st', 'SOHowMuchTime', 'SOPartFreq', 'SONewContent', 'Age', 'Trans', 'Sexuality', 'Ethnicity', 'Dependents']\n--------------------------------------\nThere are 35 columns with more than 15% of data missing.\n['OrgSize', 'YearsCodePro', 'CareerSat', 'JobSat', 'MgrIdiot', 'MgrMoney', 'MgrWant', 'LastInt', 'FizzBuzz', 'CurrencySymbol', 'CurrencyDesc', 'CompTotal', 'CompFreq', 'ConvertedComp', 'WorkWeekHrs', 'WorkPlan', 'WorkChallenge', 'WorkRemote', 'WorkLoc', 'ImpSyn', 'CodeRev', 'CodeRevHrs', 'UnitTests', 'PurchaseHow', 'PurchaseWhat', 'DatabaseDesireNextYear', 'WebFrameWorkedWith', 'WebFrameDesireNextYear', 'MiscTechWorkedWith', 'MiscTechDesireNextYear', 'BlockchainOrg', 'BlockchainIs', 'SOHowMuchTime', 'SOPartFreq', 'SONewContent']\n--------------------------------------\nThere are 17 columns with more than 25% of data missing.\n['MgrIdiot', 'MgrMoney', 'MgrWant', 'CompTotal', 'CompFreq', 'ConvertedComp', 'WorkWeekHrs', 'CodeRevHrs', 'UnitTests', 'PurchaseHow', 'PurchaseWhat', 'WebFrameWorkedWith', 'WebFrameDesireNextYear', 'MiscTechWorkedWith', 'MiscTechDesireNextYear', 'BlockchainOrg', 'BlockchainIs']\n--------------------------------------\nThere are 4 columns with more than 35% of data missing.\n['CompTotal', 'ConvertedComp', 'CodeRevHrs', 'BlockchainOrg']\n--------------------------------------\nThere are 1 columns with more than 45% of data missing.\n['BlockchainOrg']\n--------------------------------------\n"
],
[
"#Visualize all columns.\nmissing_data.plot(kind='barh', figsize = (7,15))\nplt.xlabel('Nan % in a column (%)')\nplt.ylabel('Feature')\n#plt.title('Bar graph of missing value counts')\nplt.grid(True)\nplt.show()",
"_____no_output_____"
],
[
"#function for dropping all columns above a certain % threshold and\n#returns it as a new df called df_dropped\ndef drop_missing_cols(df, threshold):\n most_missing_cols = list(df.columns[df.isnull().mean()*100 > threshold])\n df_dropped = df.copy()\n for col in most_missing_cols:\n df_dropped.drop(col, axis = 1, inplace = True)\n return df_dropped",
"_____no_output_____"
],
[
"df2019_dropped = drop_missing_cols(df2019, 40)\ndf2019_dropped.head()",
"_____no_output_____"
],
[
"#currently useless\ndf2019_dropped['JobSat'].isnull().mean()",
"_____no_output_____"
],
[
"df2019['ConvertedComp'].hist(bins = 50, figsize = (10, 6))",
"_____no_output_____"
],
[
"df2019_convertedcomp = df2019.groupby(['ConvertedComp']).mean()\n\n#ConvertedComp 55823 non-null float64\n#WorkWeekHrs\nprint(df2019_convertedcomp)",
" Respondent CompTotal WorkWeekHrs CodeRevHrs Age\nConvertedComp \n0.0 40051.663317 3.834673e+01 42.881283 9.561594 31.342391\n1.0 53639.666667 1.000000e+00 17.333333 3.000000 22.333333\n2.0 40064.500000 2.650000e+03 38.000000 10.000000 21.000000\n4.0 29962.666667 1.006667e+03 53.333333 3.000000 38.333333\n5.0 18947.000000 5.700000e+02 40.000000 8.000000 27.000000\n... ... ... ... ... ...\n1872000.0 31984.000000 1.560000e+05 43.000000 1.000000 30.000000\n1920000.0 53687.000000 1.600000e+05 45.000000 3.000000 43.250000\n1965600.0 25797.000000 3.931200e+04 40.000000 NaN 20.000000\n1980000.0 37110.250000 1.650000e+05 46.250000 2.333333 35.000000\n2000000.0 45725.994358 2.820875e+13 42.944397 4.592301 32.618871\n\n[9162 rows x 5 columns]\n"
],
[
"#WHY DOESN'T THIS WORK\ndf2019.groupby(['Hobbyist']).mean()['JobSat']\ndf2019.groupby(['Hobbyist']).mean()['YearsCode'].sort_values()",
"_____no_output_____"
],
[
"#only works for simple, mutually exclusive categories\ndef evaluate_col(df, col, plot_type):\n col_num = df[df[col].isnull() == 0].shape[0]\n col_vals = pd.Series(df[col].value_counts())\n print(col_vals)\n (col_vals/col_num*100).plot(kind = plot_type)",
"_____no_output_____"
],
[
"evaluate_col(df2019, 'UndergradMajor', 'bar')",
"Computer science, computer engineering, or software engineering 47214\nAnother engineering discipline (ex. civil, electrical, mechanical) 6222\nInformation systems, information technology, or system administration 5253\nWeb development or web design 3422\nA natural science (ex. biology, chemistry, physics) 3232\nMathematics or statistics 2975\nA business discipline (ex. accounting, finance, marketing) 1841\nA humanities discipline (ex. literature, history, philosophy) 1571\nA social science (ex. anthropology, psychology, political science) 1352\nFine arts or performing arts (ex. graphic design, music, studio art) 1233\nI never declared a major 976\nA health science (ex. nursing, pharmacy, radiology) 323\nName: UndergradMajor, dtype: int64\n"
],
[
"def eval_complex_col(df, col, plot_type):\n col_num = df[df[col].isnull() == 0].shape[0]\n \n col_df = df[col].value_counts().reset_index()\n col_df.rename(columns={'index': col, col:'count'}, inplace = True)\n col_series = pd.Series(col_df[col].unique()).dropna()\n clean_list = col_series.str.split(pat = ';').tolist()\n \n flat_list = []\n for sublist in clean_list:\n for item in sublist:\n flat_list.append(item)\n clean_series = pd.DataFrame(flat_list)\n col_vals = clean_series[0].unique()\n cat_count = clean_series[0].value_counts()\n \n \n \n print('Unique Categories: ', col_vals)\n print(cat_count)\n\n (cat_count/col_num*100).plot(kind = plot_type, figsize = (7,10))\n plt.xlabel('Proportion (%)')\n plt.ylabel(col)\n plt.grid(True)\n plt.show() \n'''\n\n\n\n'''",
"_____no_output_____"
],
[
"eval_complex_col(df2019, 'LanguageWorkedWith', 'bar')",
"Unique Categories: ['HTML/CSS' 'JavaScript' 'PHP' 'SQL' 'C#' 'TypeScript' 'Java' 'Python'\n 'Bash/Shell/PowerShell' 'Kotlin' 'Objective-C' 'Swift' 'C++' 'Ruby'\n 'Other(s):' 'C' 'R' 'VBA' 'Assembly' 'Go' 'Scala' 'Clojure' 'Dart' 'F#'\n 'Elixir' 'Erlang' 'Rust' 'WebAssembly']\nJavaScript 13868\nHTML/CSS 12880\nSQL 11445\nPython 11151\nJava 10910\nBash/Shell/PowerShell 10315\nC++ 8206\nC 7859\nC# 7555\nPHP 6403\nTypeScript 5865\nGo 4253\nRuby 3741\nAssembly 3477\nOther(s): 3447\nSwift 3328\nKotlin 3141\nObjective-C 2686\nR 2557\nRust 2253\nVBA 2216\nScala 2033\nDart 1323\nElixir 1007\nClojure 947\nWebAssembly 881\nF# 728\nErlang 693\nName: 0, dtype: int64\n"
],
[
"eval_complex_col(df2019, 'PlatformWorkedWith', 'bar')",
"Unique Categories: ['Windows' 'Linux' 'Android' 'Microsoft Azure' 'Docker' 'WordPress' 'iOS'\n 'AWS' 'Other(s):' 'MacOS' 'Raspberry Pi' 'Heroku' 'Slack' 'Arduino'\n 'Kubernetes' 'Google Cloud Platform' 'IBM Cloud or Watson']\nLinux 5576\nDocker 4751\nWindows 4637\nAWS 4269\nAndroid 4175\nSlack 4110\nMacOS 4014\nRaspberry Pi 3421\nGoogle Cloud Platform 3399\nWordPress 3010\niOS 2816\nHeroku 2805\nArduino 2608\nMicrosoft Azure 2591\nKubernetes 2089\nIBM Cloud or Watson 1048\nOther(s): 809\nName: 0, dtype: int64\n"
],
[
"eval_complex_col(df2019, 'LastInt', 'bar')",
"Unique Categories: ['Interview with people in peer roles'\n 'Interview with people in senior / management roles' 'Write any code'\n 'Write code by hand (e.g., on a whiteboard)'\n 'Complete a take-home project' 'Solve a brain-teaser style puzzle']\nSolve a brain-teaser style puzzle 32\nWrite any code 32\nInterview with people in peer roles 32\nComplete a take-home project 32\nWrite code by hand (e.g., on a whiteboard) 32\nInterview with people in senior / management roles 32\nName: 0, dtype: int64\n"
],
[
"eval_complex_col(df2019, '', 'bar')",
"_____no_output_____"
],
[
"evaluate_col(df2019, 'SocialMedia', 'bar')",
"Reddit 14374\nYouTube 13830\nWhatsApp 13347\nFacebook 13178\nTwitter 11398\nInstagram 6261\nI don't use social media 5554\nLinkedIn 4501\nWeChat 微信 667\nSnapchat 628\nVK ВКонта́кте 603\nWeibo 新浪微博 56\nYouku Tudou 优酷 21\nHello 19\nName: SocialMedia, dtype: int64\n"
],
[
"evaluate_col(df2019, 'EdLevel', 'bar')",
"Bachelor’s degree (BA, BS, B.Eng., etc.) 39134\nMaster’s degree (MA, MS, M.Eng., MBA, etc.) 19569\nSome college/university study without earning a degree 10502\nSecondary school (e.g. American high school, German Realschule or Gymnasium, etc.) 8642\nAssociate degree 2938\nOther doctoral degree (Ph.D, Ed.D., etc.) 2432\nPrimary/elementary school 1422\nProfessional degree (JD, MD, etc.) 1198\nI never completed any formal education 553\nName: EdLevel, dtype: int64\n"
],
[
"evaluate_col(df2019, 'Gender', 'bar')",
"Man 77919\nWoman 6344\nNon-binary, genderqueer, or gender non-conforming 597\nMan;Non-binary, genderqueer, or gender non-conforming 181\nWoman;Non-binary, genderqueer, or gender non-conforming 163\nWoman;Man 132\nWoman;Man;Non-binary, genderqueer, or gender non-conforming 70\nName: Gender, dtype: int64\n"
],
[
"evaluate_col(df2019, 'CareerSat', 'bar')",
"Very satisfied 29173\nSlightly satisfied 25018\nSlightly dissatisfied 7670\nNeither satisfied nor dissatisfied 7252\nVery dissatisfied 3734\nName: CareerSat, dtype: int64\n"
],
[
"evaluate_col(df2019, 'JobSat', 'bar')",
"Slightly satisfied 24207\nVery satisfied 22452\nSlightly dissatisfied 10752\nNeither satisfied nor dissatisfied 8720\nVery dissatisfied 4857\nName: JobSat, dtype: int64\n"
],
[
"evaluate_col(df2019, 'Ethnicity', 'pie')",
"White or of European descent 50929\nSouth Asian 8373\nEast Asian 3510\nHispanic or Latino/Latina 3474\nMiddle Eastern 2580\n ... \nBlack or of African descent;East Asian;Hispanic or Latino/Latina;Middle Eastern;South Asian;White or of European descent;Biracial;Multiracial 1\nBlack or of African descent;East Asian;Middle Eastern;Native American, Pacific Islander, or Indigenous Australian;White or of European descent;Multiracial 1\nBlack or of African descent;Hispanic or Latino/Latina;South Asian;White or of European descent;Biracial 1\nEast Asian;South Asian;White or of European descent;Biracial 1\nHispanic or Latino/Latina;Native American, Pacific Islander, or Indigenous Australian;South Asian;White or of European descent 1\nName: Ethnicity, Length: 196, dtype: int64\n"
],
[
"evaluate_col(df2019, 'WorkWeekHrs', 'hist')",
"40.00 30131\n45.00 6352\n50.00 4656\n35.00 3159\n37.50 1662\n ... \n7.22 1\n415.00 1\n8.15 1\n27.40 1\n35.75 1\nName: WorkWeekHrs, Length: 207, dtype: int64\n"
],
[
"eval_complex_col(df2019, 'WebFrameWorkedWith', 'bar')",
"Unique Categories: ['jQuery' 'ASP.NET' 'React.js' 'Spring' 'Angular/Angular.js' 'Other(s):'\n 'Flask' 'Django' 'Express' 'Laravel' 'Ruby on Rails' 'Vue.js' 'Drupal']\njQuery 1279\nReact.js 1089\nAngular/Angular.js 1085\nExpress 967\nVue.js 919\nDjango 839\nFlask 771\nLaravel 764\nASP.NET 747\nSpring 716\nRuby on Rails 708\nDrupal 521\nOther(s): 493\nName: 0, dtype: int64\n"
],
[
"eval_complex_col(df2019, 'MiscTechWorkedWith', 'bar')",
"Unique Categories: ['Node.js' '.NET' '.NET Core' 'React Native' 'Pandas' 'Ansible' 'Unity 3D'\n 'Other(s):' 'Cordova' 'Xamarin' 'TensorFlow' 'Apache Spark' 'Flutter'\n 'Torch/PyTorch' 'Hadoop' 'Puppet' 'Chef' 'Unreal Engine' 'CryEngine']\nNode.js 1603\n.NET 1186\nTensorFlow 1071\nUnity 3D 937\n.NET Core 914\nPandas 903\nReact Native 809\nAnsible 689\nApache Spark 689\nCordova 678\nHadoop 673\nXamarin 616\nUnreal Engine 550\nTorch/PyTorch 512\nFlutter 467\nChef 408\nPuppet 390\nOther(s): 355\nCryEngine 179\nName: 0, dtype: int64\n"
],
[
"evaluate_col(df2019, 'Student', 'pie')",
"No 65816\nYes, full-time 15769\nYes, part-time 5429\nName: Student, dtype: int64\n"
],
[
"eval_complex_col(df2019, 'DevType', 'bar')",
"Unique Categories: ['Developer, full-stack' 'Developer, back-end' 'Developer, front-end'\n 'Developer, mobile' 'Student'\n 'Developer, desktop or enterprise applications'\n 'Developer, embedded applications or devices'\n 'Data scientist or machine learning specialist' 'Developer, QA or test'\n 'Data or business analyst' 'Engineering manager' 'DevOps specialist'\n 'Designer' 'Engineer, data' 'Academic researcher' 'System administrator'\n 'Senior executive/VP' 'Developer, game or graphics'\n 'Database administrator' 'Product manager' 'Scientist' 'Educator'\n 'Engineer, site reliability' 'Marketing or sales professional']\nDeveloper, back-end 8680\nDeveloper, full-stack 7888\nDeveloper, front-end 6289\nDeveloper, desktop or enterprise applications 5274\nDatabase administrator 4659\nSystem administrator 4315\nDeveloper, mobile 4294\nDesigner 4050\nDevOps specialist 3383\nStudent 3340\nData or business analyst 3164\nDeveloper, embedded applications or devices 3069\nDeveloper, QA or test 3015\nEngineer, data 2943\nAcademic researcher 2870\nData scientist or machine learning specialist 2790\nEducator 2580\nProduct manager 2543\nDeveloper, game or graphics 2116\nEngineering manager 2097\nScientist 1936\nEngineer, site reliability 1603\nSenior executive/VP 1352\nMarketing or sales professional 697\nName: 0, dtype: int64\n"
],
[
"#divide the data into two subsets based on the number of missing values in each row\n\nrow_threshold = 45\ndf2019_lowmiss = df2019_dropped[df2019_dropped.isnull().sum(axis=1) < row_threshold].reset_index(drop=True)\n\ndf2019_highmiss = df2019_dropped[df2019_dropped.isnull().sum(axis=1) >= row_threshold].reset_index(drop=True)",
"_____no_output_____"
],
[
"print(df2019_lowmiss.shape)\nprint(df2019_highmiss.shape)\nrowmissing_per = int(df2019_highmiss.shape[0]/df2019_dropped.shape[0]*100)\nprint('{}% of the rows have 8 or more missing values'.format(rowmissing_per))",
"(88028, 83)\n(855, 83)\n0% of the rows have 8 or more missing values\n"
],
[
"def compare_plt(column, n, df):\n fig, axs = plt.subplots(n,2, figsize=(10, 5))\n fig.subplots_adjust(hspace =2 , wspace=.2)\n axs = axs.ravel()\n for i in range(n):\n plt.subplot(121)\n sns.countplot(x = column, data = df).set_title('Few missing')\n plt.subplot(122)\n sns.countplot(x = column, data = df).set_title('High missing')",
"_____no_output_____"
]
],
[
[
"# Questions\nis educational level related to salary?\nWhat are the biggest factors relating to salary?\nLanguages related to salary?\nType of developer related to salary?\n\nWhat languages, platforms, etc are people using?\nWhat languages are people likely to learn together?\n\n\n\n# Variables of interest:\nConvertedComp - annual compensation\nWorkWeekHrs - hours/week worked\nLanguageWorkedWith\nDatabaseWorkedWith\nPlatformWorkedWith\nWebFrameWorkedWith\nMiscTechWorkedWith\nDevEnviron\nOpSys\n\nLastInt - \"In your most recent successful job interview (resulting in a job offer), you were asked to... (check all that apply)\"\n\nJobSat\nCareerSat\nYearsCodePro - How many years have you coded professionally (as a part of your work)?\nDevType\nOrgSize\nEduOther\nUndergradMajor\nEdLevel\nCountry\nAge\nGender\nEthnicity\n",
"_____no_output_____"
]
],
[
[
"for x in schema2019['QuestionText']:\n print(x)",
"_____no_output_____"
]
],
[
[
"Randomized respondent ID number (not in order of survey response time)\nWhich of the following options best describes you today? Here, by \"developer\" we mean \"someone who writes code.\"\nDo you code as a hobby?\nHow often do you contribute to open source?\nHow do you feel about the quality of open source software (OSS)?\n\n\nWhich of the following best describes your current employment status?\nIn which country do you currently reside?\n\n\nAre you currently enrolled in a formal, degree-granting college or university program?\nWhich of the following best describes the highest level of formal education that you’ve completed?\n\n\nWhat was your main or most important field of study?\nWhich of the following types of non-degree education have you used or participated in? Please select all that apply.\nApproximately how many people are employed by the company or organization you work for?\nWhich of the following describe you? Please select all that apply.\nIncluding any education, how many years have you been coding?\n\nAt what age did you write your first line of code or program? (E.g., webpage, Hello World, Scratch project)\nHow many years have you coded professionally (as a part of your work)?\n\n\nOverall, how satisfied are you with your career thus far?\nHow satisfied are you with your current job? (If you work multiple jobs, answer for the one you spend the most hours on.)\n\n\nHow confident are you that your manager knows what they’re doing?\nDo you believe that you need to be a manager to make more money?\nDo you want to become a manager yourself in the future?\n\n\nWhich of the following best describes your current job-seeking status?\nWhen was the last time that you took a job with a new employer?\nIn your most recent successful job interview (resulting in a job offer), you were asked to... (check all that apply)\nHave you ever been asked to solve FizzBuzz in an interview?\nImagine that you are deciding between two job offers with the same compensation, benefits, and location. Of the following factors, which 3 are MOST important to you?\nThink back to the last time you updated your resumé, CV, or an online profile on a job site. What is the PRIMARY reason that you did so?\n\n\nWhich currency do you use day-to-day? If your answer is complicated, please pick the one you're most comfortable estimating in.\nWhich currency do you use day-to-day? If your answer is complicated, please pick the one you're most comfortable estimating in.\n\nWhat is your current total compensation (salary, bonuses, and perks, before taxes and deductions), in `CurrencySymbol`? Please enter a whole number in the box below, without any punctuation. If you are paid hourly, please estimate an equivalent weekly, monthly, or yearly salary. If you prefer not to answer, please leave the box empty.\nIs that compensation weekly, monthly, or yearly?\n\nSalary converted to annual USD salaries using the exchange rate on 2019-02-01, assuming 12 working months and 50 working weeks.\n\n\nOn average, how many hours per week do you work?\nHow structured or planned is your work?\n\n\nOf these options, what are your greatest challenges to productivity as a developer? Select up to 3:\nHow often do you work remotely?\nWhere would you prefer to work?\nFor the specific work you do, and the years of experience you have, how do you rate your own level of competence?\nDo you review code as part of your work?\nOn average, how many hours per week do you spend on code review?\n\n\n\nDoes your company regularly employ unit tests in the development of their products?\nHow does your company make decisions about purchasing new technology (cloud, AI, IoT, databases)?\nWhat level of influence do you, personally, have over new technology purchases at your organization?\n\n\nWhich of the following programming, scripting, and markup languages have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the language and want to continue to do so, please check both boxes in that row.)\nWhich of the following programming, scripting, and markup languages have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the language and want to continue to do so, please check both boxes in that row.)\nWhich of the following database environments have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the database and want to continue to do so, please check both boxes in that row.)\nWhich of the following database environments have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the database and want to continue to do so, please check both boxes in that row.)\nWhich of the following platforms have you done extensive development work for over the past year? (If you both developed for the platform and want to continue to do so, please check both boxes in that row.)\nWhich of the following platforms have you done extensive development work for over the past year? (If you both developed for the platform and want to continue to do so, please check both boxes in that row.)\nWhich of the following web frameworks have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the framework and want to continue to do so, please check both boxes in that row.)\nWhich of the following web frameworks have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the framework and want to continue to do so, please check both boxes in that row.)\nWhich of the following other frameworks, libraries, and tools have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the technology and want to continue to do so, please check both boxes in that row.)\nWhich of the following other frameworks, libraries, and tools have you done extensive development work in over the past year, and which do you want to work in over the next year? (If you both worked with the technology and want to continue to do so, please check both boxes in that row.)\nWhich development environment(s) do you use regularly? Please check all that apply.\nWhat is the primary operating system in which you work?\n\n\nHow do you use containers (Docker, Open Container Initiative (OCI), etc.)?\nHow is your organization thinking about or implementing blockchain technology?\nBlockchain / cryptocurrency technology is primarily:\n\n\nDo you think people born today will have a better life than their parents?\nAre you the \"IT support person\" for your family?\n\n\nHave you tried turning it off and on again?\nWhat social media site do you use the most?\nDo you prefer online chat or IRL conversations?\nWhat do you call it?\n\n\nTo the best of your memory, when did you first visit Stack Overflow?\nHow frequently would you say you visit Stack Overflow?\nI visit Stack Overflow to... (check all that apply)\nOn average, how many times a week do you find (and use) an answer on Stack Overflow?\nThink back to the last time you solved a coding problem using Stack Overflow, as well as the last time you solved a problem using a different resource. Which was faster?\nAbout how much time did you save? If you're not sure, please use your best estimate.\n\nDo you have a Stack Overflow account?\nHow frequently would you say you participate in Q&A on Stack Overflow? By participate we mean ask, answer, vote for, or comment on questions.\nHave you ever used or visited Stack Overflow Jobs?\nHave you ever used Stack Overflow for Enterprise or Stack Overflow for Teams?\nDo you consider yourself a member of the Stack Overflow community?\nCompared to last year, how welcome do you feel on Stack Overflow?\nWould you like to see any of the following on Stack Overflow? Check all that apply.\n\n\nWhat is your age (in years)? If you prefer not to answer, you may leave this question blank.\nWhich of the following do you currently identify as? Please select all that apply. If you prefer not to answer, you may leave this question blank.\nDo you identify as transgender?\nWhich of the following do you currently identify as? Please select all that apply. If you prefer not to answer, you may leave this question blank.\nWhich of the following do you identify as? Please check all that apply. If you prefer not to answer, you may leave this question blank.\nDo you have any dependents (e.g., children, elders, or others) that you care for?\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac909421eefdcf4dd6423f321758de14d5315b0
| 188,598 |
ipynb
|
Jupyter Notebook
|
XgboostRegressor/Flight Fare.ipynb
|
golesuman/Regression_problems
|
f6f65f9daf14d524558e44379f045f11163c8435
|
[
"MIT"
] | 2 |
2021-06-01T05:04:05.000Z
|
2021-06-09T07:06:35.000Z
|
XgboostRegressor/Flight Fare.ipynb
|
golesuman/Regression_problems
|
f6f65f9daf14d524558e44379f045f11163c8435
|
[
"MIT"
] | null | null | null |
XgboostRegressor/Flight Fare.ipynb
|
golesuman/Regression_problems
|
f6f65f9daf14d524558e44379f045f11163c8435
|
[
"MIT"
] | null | null | null | 49.631053 | 27,880 | 0.549608 |
[
[
[
"#Importing necessary dependencies\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\npd.set_option('display.max_columns',None)",
"_____no_output_____"
],
[
"df=pd.read_excel('Data_Train.xlsx')\ndf.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
],
[
[
"## Exploratory data analysis \nFirst we will try to find the missing values and we will try to find relationship between different features and we will also visualize the data and see the relationship between them.\n",
"_____no_output_____"
]
],
[
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10683 entries, 0 to 10682\nData columns (total 11 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Airline 10683 non-null object\n 1 Date_of_Journey 10683 non-null object\n 2 Source 10683 non-null object\n 3 Destination 10683 non-null object\n 4 Route 10682 non-null object\n 5 Dep_Time 10683 non-null object\n 6 Arrival_Time 10683 non-null object\n 7 Duration 10683 non-null object\n 8 Total_Stops 10682 non-null object\n 9 Additional_Info 10683 non-null object\n 10 Price 10683 non-null int64 \ndtypes: int64(1), object(10)\nmemory usage: 918.2+ KB\n"
],
[
"#Describe the data\ndf.describe()",
"_____no_output_____"
]
],
[
[
"Since there is only one numerical feature we will try to analyze the categorical data and see the relationship with the price",
"_____no_output_____"
]
],
[
[
"feature_categorical=[feature for feature in df.columns if df[feature].dtypes=='O']\nfeature_categorical",
"_____no_output_____"
],
[
"df.dropna(inplace=True)",
"_____no_output_____"
]
],
[
[
"## Lets change the date time format",
"_____no_output_____"
]
],
[
[
"#train_data[\"Journey_day\"] = pd.to_datetime(train_data.Date_of_Journey, format=\"%d/%m/%Y\").dt.day\ndf['Day_of_Journey']=pd.to_datetime(df['Date_of_Journey']).dt.day\ndf['Journey_Month']=pd.to_datetime(df['Date_of_Journey']).dt.month",
"_____no_output_____"
],
[
"# Now we will extract the hour and minutes in Arrival time\ndf[\"Arrival_hour\"]=pd.to_datetime(df['Arrival_Time']).dt.hour\ndf['Arrival_minute']=pd.to_datetime(df['Arrival_Time']).dt.minute\ndf.head()",
"_____no_output_____"
],
[
"df.drop(['Date_of_Journey','Arrival_Time'],axis=1,inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"df['Dep_hour']=pd.to_datetime(df['Dep_Time']).dt.hour\ndf['Dep_min']=pd.to_datetime(df['Dep_Time']).dt.minute\ndf.drop(['Dep_Time'],inplace=True,axis=1)\ndf.head()",
"_____no_output_____"
],
[
"duration=list(df['Duration'])\nduration[0].split(\" \")",
"_____no_output_____"
],
[
"for num in range(len(duration)):\n if len(duration[num].split(\" \"))!=2:\n if 'h' in duration[num]:\n duration[num]=duration[num].strip()+'0m'\n else:\n duration[num]='0h'+duration[num]\n \nduration_hour=[]\nduration_min=[]\nfor num in range(len(duration)):\n duration_hour.append(int(duration[num].split(\"h\")[0]))\n duration_min.append(int(duration[num].split(\"h\")[1].split('m')[0].strip()))",
"_____no_output_____"
],
[
"df['Duration_hour']=duration_hour\ndf['Duration_min']=duration_min\ndf.drop('Duration',axis=1,inplace=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"# Handling the categorical data",
"_____no_output_____"
]
],
[
[
"airway=df['Airline']",
"_____no_output_____"
],
[
"df['Airline'].value_counts()",
"_____no_output_____"
],
[
"plt.figure(figsize=(18,8))\nsns.boxplot(x='Airline',y='Price',data=df.sort_values('Price',ascending=False))\n\n",
"_____no_output_____"
]
],
[
[
"# Encoding categorical data into numerical\nSince the airlines are not ordinal we will one hot encode the data using get dummies function in pandas",
"_____no_output_____"
]
],
[
[
"Airline=pd.get_dummies(df['Airline'],drop_first=True)\nAirline.head()",
"_____no_output_____"
],
[
"df['Source'].value_counts()",
"_____no_output_____"
],
[
"# Source vs Price\nplt.figure(figsize=(14,8))\nsns.boxplot(x='Source',y='Price',data=df.sort_values('Price',ascending=False))",
"_____no_output_____"
],
[
"# Now we one hot encode the source feature using same method used above\nSource=df['Source']\nSource=pd.get_dummies(Source,drop_first=False)\nSource.head()",
"_____no_output_____"
],
[
"Destination=df['Destination']\nDestination=pd.get_dummies(Destination,drop_first=False)",
"_____no_output_____"
],
[
"Destination=Destination.rename(columns={\"Banglore\":\"Dest_Banglore\",'Cochin':'Dest_Cochin',\"Delhi\":'Dest_Delhi','Hyderabad':'Dest_Hyderabad',\"Kolkata\":'Dest_Kolkata','New Delhi':'Dest_NewDelhi'})",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df[\"Route\"].head()",
"_____no_output_____"
],
[
"df['Total_Stops'].value_counts()",
"_____no_output_____"
],
[
"# Since the route is related to no of stops we can drop that feature\n# Now we can change no of stops using ordinal encoding since it is ordinal data\ndf['Total_Stops'].replace({'non-stop':0,'1 stop':1,'2 stops':2,'3 stops':3,'4 stops':4},inplace=True)",
"_____no_output_____"
],
[
"# Since the Airline, Source and Destination are one hot encoded and\n# we can determine the route by seeing the no of stops we can drop those features\ndf.drop(['Airline','Source','Destination','Route'],inplace=True,axis=1)\ndf.head()",
"_____no_output_____"
],
[
"df['Additional_Info'].value_counts()",
"_____no_output_____"
]
],
[
[
"## Since the Addtional_info has lot of no info we can actually drop this feature",
"_____no_output_____"
]
],
[
[
"df.drop('Additional_Info',axis=1,inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"df_concat=pd.concat([df,Airline,Source,Destination],axis=1)\ndf_concat.head()",
"_____no_output_____"
]
],
[
[
"# Let's repeat above for the test data",
"_____no_output_____"
]
],
[
[
"df_test=pd.read_excel('Test_set.xlsx')\ndf_test.head()",
"_____no_output_____"
],
[
"# duration=list(df['Duration'])\n# duration[0].split(\" \")\n# for num in range(len(duration)):\n# if len(duration[num].split(\" \"))!=2:\n# if 'h' in duration[num]:\n# duration[num]=duration[num].strip()+'0m'\n# else:\n# duration[num]='0h'+duration[num]\n \n# duration_hour=[]\n# duration_min=[]\n# for num in range(len(duration)):\n# duration_hour.append(int(duration[num].split(\"h\")[0]))\n# duration_min.append(int(duration[num].split(\"h\")[1].split('m')[0].strip()))\n \n# df_test['Duration_hour']=duration_hour\n# df_test['Duration_min']=duration_min\n# df_test.drop('Duration',axis=1,inplace=True)\n# Airline=pd.get_dummies(df_test['Airline'],drop_first=True)\n# # Now we one hot encode the source feature using same method used above\n# Source=df_test['Source']\n# Source=pd.get_dummies(Source,drop_first=False)\n# Destination=df['Destination']\n# Destination=pd.get_dummies(Destination,drop_first=False)\n# Since the route is related to no of stops we can drop that feature\n# Now we can change no of stops using ordinal encoding since it is ordinal data\n# df_test['Total_Stops'].replace({'non-stop':0,'1 stop':1,'2 stops':2,'3 stops':3,'4 stops':4},inplace=True)\n# df_test.drop(['Airline','Source','Destination','Route'],inplace=True,axis=1)\n# df_test.drop('Additional_Info',axis=1,inplace=True)\n# df_concat1=pd.concat([df_test,Airline,Source,Destination],axis=1)",
"_____no_output_____"
],
[
"df_test['Day_of_Journey']=pd.to_datetime(df_test['Date_of_Journey']).dt.day\ndf_test['Journey_Month']=pd.to_datetime(df_test['Date_of_Journey']).dt.month\n# Now we will extract the hour and minutes in Arrival time\ndf_test[\"Arrival_hour\"]=pd.to_datetime(df_test['Arrival_Time']).dt.hour\ndf_test['Arrival_minute']=pd.to_datetime(df_test['Arrival_Time']).dt.minute\ndf_test.drop(['Date_of_Journey','Arrival_Time'],axis=1,inplace=True)\ndf_test['Dep_hour']=pd.to_datetime(df_test['Dep_Time']).dt.hour\ndf_test['Dep_min']=pd.to_datetime(df_test['Dep_Time']).dt.minute\nduration=list(df_test['Duration'])\nduration[0].split(\" \")\nfor num in range(len(duration)):\n if len(duration[num].split(\" \"))!=2:\n if 'h' in duration[num]:\n duration[num]=duration[num].strip()+'0m'\n else:\n duration[num]='0h'+duration[num]\n \nduration_hour=[]\nduration_min=[]\nfor num in range(len(duration)):\n duration_hour.append(int(duration[num].split(\"h\")[0]))\n duration_min.append(int(duration[num].split(\"h\")[1].split('m')[0].strip()))\n \ndf_test['Duration_hour']=duration_hour\ndf_test['Duration_min']=duration_min\ndf_test.drop('Duration',axis=1,inplace=True)\nAirline=pd.get_dummies(df_test['Airline'],drop_first=True)\n# Now we one hot encode the source feature using same method used above\nSource=df_test['Source']\nSource=pd.get_dummies(Source,drop_first=False)\nDestination=df_test['Destination']\nDestination=pd.get_dummies(Destination,drop_first=False)\nDestination=Destination.rename(columns={\"Banglore\":\"Dest_Banglore\",'Cochin':'Dest_Cochin',\"Delhi\":'Dest_Delhi','Hyderabad':'Dest_Hyderabad',\"Kolkata\":'Dest_Kolkata','New Delhi':'Dest_NewDelhi'})\n# Since the route is related to no of stops we can drop that feature\n# Now we can change no of stops using ordinal encoding since it is ordinal data\ndf_test['Total_Stops'].replace({'non-stop':0,'1 stop':1,'2 stops':2,'3 stops':3,'4 stops':4},inplace=True)\ndf_test.drop(['Airline','Source','Destination','Route'],inplace=True,axis=1)\ndf_test.drop(['Additional_Info','Dep_Time'],axis=1,inplace=True)\ndf_concat1=pd.concat([df_test,Airline,Source,Destination],axis=1)",
"_____no_output_____"
],
[
"df_concat1.head()",
"_____no_output_____"
],
[
"df_concat.head()",
"_____no_output_____"
],
[
"df_concat1.head()",
"_____no_output_____"
],
[
"df_concat.shape",
"_____no_output_____"
],
[
"df_test['Dep_min']",
"_____no_output_____"
],
[
"Xtr=df_concat.drop(['Price','Trujet'],axis=1)\nYtr=df[\"Price\"]\nfrom sklearn.model_selection import train_test_split\nx_train,x_test,y_train,y_test=train_test_split(Xtr,Ytr,test_size=0.2,random_state=5)\nx_test.shape",
"_____no_output_____"
],
[
"print(x_train.shape)\nprint(x_test.shape)\nprint(y_train.shape)",
"(8545, 30)\n(2137, 30)\n(8545,)\n"
],
[
"from xgboost import XGBRegressor\nmodel=XGBRegressor()",
"_____no_output_____"
],
[
"model.fit(x_train,y_train)",
"_____no_output_____"
],
[
"y_pre=model.predict(x_test)\ny_pre",
"_____no_output_____"
],
[
"y_test",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nr2_score(y_test,y_pred=y_pre)",
"_____no_output_____"
],
[
"model.predict(df_concat1)",
"_____no_output_____"
],
[
"plt.figure(figsize=(14,8))\nplt.scatter(y_test,y_pre,color='g')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac90df039372fea55d299a6e70a1a68834b9e06
| 4,110 |
ipynb
|
Jupyter Notebook
|
notebooks/week_7/part1_merging_unique_id.ipynb
|
staeiou/COMM106E_S22
|
7edd6d4dad564de13233c6215c8ad016495f2fe9
|
[
"MIT"
] | null | null | null |
notebooks/week_7/part1_merging_unique_id.ipynb
|
staeiou/COMM106E_S22
|
7edd6d4dad564de13233c6215c8ad016495f2fe9
|
[
"MIT"
] | null | null | null |
notebooks/week_7/part1_merging_unique_id.ipynb
|
staeiou/COMM106E_S22
|
7edd6d4dad564de13233c6215c8ad016495f2fe9
|
[
"MIT"
] | null | null | null | 19.295775 | 170 | 0.526034 |
[
[
[
"!pip install pandas openpyxl",
"_____no_output_____"
]
],
[
[
"# Merging or joining two datasets with a unique identifier",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"data1 = pd.read_excel(\"supermarket_marketing.xlsx\")\ndata2 = pd.read_excel(\"drugstore_pregnancy.xlsx\")",
"_____no_output_____"
],
[
"data1.describe()",
"_____no_output_____"
],
[
"data2.describe()",
"_____no_output_____"
],
[
"data1.sample(3).T",
"_____no_output_____"
],
[
"data2.sample(3).T",
"_____no_output_____"
]
],
[
[
"# Merging\n\n<img src = \"https://cdn.mindmajix.com/blog/images/db-01_2119.png\" width=50%>\n\n## Inner merge: only keep if the unique identifier is found in both datasets",
"_____no_output_____"
]
],
[
[
"data_merged_inner = pd.merge(data1, data2, on='phone', how='inner')",
"_____no_output_____"
],
[
"data_merged_inner",
"_____no_output_____"
],
[
"data_merged_inner.sample(3).T",
"_____no_output_____"
]
],
[
[
"## Left merge: show the entire first/left dataset; if unique identifier matches in second/right dataset, add variables for the matching row; if not, leave blank/NaN",
"_____no_output_____"
]
],
[
[
"data_merged_left = pd.merge(data1, data2, on='phone', how='left')",
"_____no_output_____"
],
[
"data_merged_left",
"_____no_output_____"
],
[
"data_merged_left.sample(5).T",
"_____no_output_____"
]
],
[
[
"# Export to file",
"_____no_output_____"
]
],
[
[
"data_merged_inner.to_excel(\"supermarket_drugstore_inner_merge.xlsx\")\ndata_merged_left.to_excel(\"supermarket_drugstore_left_merge.xlsx\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac915bbf3e63d11e114cd07b88549a2291164c2
| 158,526 |
ipynb
|
Jupyter Notebook
|
notebooks/benchmark/speed_benchmark_rule_count.ipynb
|
Hezelius/pyARC
|
057d8dc49bf41b22ad2fcc3c7cbc9f05dc739ec7
|
[
"MIT"
] | null | null | null |
notebooks/benchmark/speed_benchmark_rule_count.ipynb
|
Hezelius/pyARC
|
057d8dc49bf41b22ad2fcc3c7cbc9f05dc739ec7
|
[
"MIT"
] | null | null | null |
notebooks/benchmark/speed_benchmark_rule_count.ipynb
|
Hezelius/pyARC
|
057d8dc49bf41b22ad2fcc3c7cbc9f05dc739ec7
|
[
"MIT"
] | null | null | null | 73.801676 | 27,040 | 0.664257 |
[
[
[
"%run ../../main.py\n%matplotlib inline",
"_____no_output_____"
],
[
"import pandas as pd\n\nfrom cba.algorithms import M1Algorithm, M2Algorithm, top_rules, createCARs \nfrom cba.data_structures import TransactionDB\nimport sklearn.metrics as skmetrics",
"_____no_output_____"
],
[
"df = pd.read_csv(\"c:/code/python/machine_learning/assoc_rules/train/lymph0.csv\")\n\nlen(df)",
"_____no_output_____"
],
[
"#\n#\n# =========================\n# Oveření běhu v závislosti na vložených pravidlech / instancích\n# =========================\n#\n#\n#\n\nimport time\n\ntarget_rule_count = 50\n\nbenchmark_data = {\n \"rule_count\": [],\n \"M1_duration\": [],\n \"M2_duration\": [],\n \"M1_accuracy\": [],\n \"M2_accuracy\": [],\n \"M1_output_rules\": [],\n \"M2_output_rules\": []\n}\n\nnumber_of_iterations = 10\n\ndirectory = \"c:/code/python/machine_learning/assoc_rules\"\n\n\nfor sequence in [*range(10, 20), *range(20, 100, 10), *range(200, 1000, 100), *range(2000, 10000, 1000), *range(20000, 100000, 10000)]:\n target_rule_count = sequence\n\n dataset_name_benchmark = \"lymph0\"\n \n pd_ds = pd.read_csv(\"c:/code/python/machine_learning/assoc_rules/train/{}.csv\".format(dataset_name_benchmark))\n pd_ds_test = pd.read_csv(\"c:/code/python/machine_learning/assoc_rules/test/{}.csv\".format(dataset_name_benchmark))\n \n \n txns = TransactionDB.from_DataFrame(pd_ds, unique_transactions=True)\n txns_test = TransactionDB.from_DataFrame(pd_ds_test)\n actual = list(map(lambda i: i.value, txns_test.class_labels))\n \n rules = top_rules(txns.string_representation, appearance=txns.appeardict)\n\n cars = createCARs(rules)\n \n if len(cars) > target_rule_count:\n cars = cars[:target_rule_count]\n \n \n\n m1t1 = time.time()\n m1accs = []\n m1rules = []\n for _ in range(number_of_iterations):\n m1 = M1Algorithm(cars, txns)\n clf = m1.build()\n pred = clf.predict_all(txns_test)\n acc = skmetrics.accuracy_score(pred, actual)\n \n m1rules.append(len(clf.rules) + 1)\n m1accs.append(acc)\n \n m1t2 = time.time()\n \n \n m2t1 = time.time()\n m2accs = []\n m2rules = []\n for _ in range(number_of_iterations):\n m2 = M2Algorithm(cars, txns)\n clf = m2.build()\n pred = clf.predict_all(txns_test)\n acc = skmetrics.accuracy_score(pred, actual)\n \n m2rules.append(len(clf.rules) + 1)\n m2accs.append(acc)\n \n \n m2t2 = time.time()\n \n \n m1duration = (m1t2 - m1t1) / number_of_iterations\n m2duration = (m2t2 - m2t1) / number_of_iterations\n m1acc = sum(m1accs) / len(m1accs)\n m2acc = sum(m2accs) / len(m2accs)\n m1rules = sum(m1rules) / number_of_iterations\n m2rules = sum(m2rules) / number_of_iterations\n \n benchmark_data[\"rule_count\"].append(target_rule_count)\n benchmark_data[\"M1_duration\"].append(m1duration)\n benchmark_data[\"M2_duration\"].append(m2duration)\n benchmark_data[\"M1_accuracy\"].append(m1acc)\n benchmark_data[\"M2_accuracy\"].append(m2acc)\n benchmark_data[\"M1_output_rules\"].append(m1rules)\n benchmark_data[\"M2_output_rules\"].append(m2rules)\n \n print(\"target rule count:\", target_rule_count)\n print(\"M1 duration:\", m1duration)\n print(\"M2 duration:\", m2duration)\n print(\"M1 acc:\", m1acc)\n print(\"M2 acc:\", m2acc)\n print(\"M1 clf len:\", m1rules)\n print(\"M2 clf len:\", m2rules)\n \n print(\"\\n\\n\")",
"Running apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 10\nM1 duration: 0.0024516105651855467\nM2 duration: 0.010109353065490722\nM1 acc: 0.611111111111\nM2 acc: 0.522222222222\nM1 clf len: 10.0\nM2 clf len: 10.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 11\nM1 duration: 0.002500152587890625\nM2 duration: 0.009957122802734374\nM1 acc: 0.611111111111\nM2 acc: 0.522222222222\nM1 clf len: 10.0\nM2 clf len: 10.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 12\nM1 duration: 0.0027002811431884764\nM2 duration: 0.009156250953674316\nM1 acc: 0.611111111111\nM2 acc: 0.522222222222\nM1 clf len: 10.0\nM2 clf len: 10.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 13\nM1 duration: 0.002649950981140137\nM2 duration: 0.009556865692138672\nM1 acc: 0.611111111111\nM2 acc: 0.522222222222\nM1 clf len: 11.0\nM2 clf len: 11.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 14\nM1 duration: 0.0029038190841674805\nM2 duration: 0.01170675754547119\nM1 acc: 0.666666666667\nM2 acc: 0.577777777778\nM1 clf len: 12.0\nM2 clf len: 12.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 15\nM1 duration: 0.0031003475189208983\nM2 duration: 0.011710286140441895\nM1 acc: 0.666666666667\nM2 acc: 0.577777777778\nM1 clf len: 13.0\nM2 clf len: 13.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 16\nM1 duration: 0.00460348129272461\nM2 duration: 0.013459300994873047\nM1 acc: 0.666666666667\nM2 acc: 0.577777777778\nM1 clf len: 13.0\nM2 clf len: 13.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 17\nM1 duration: 0.006304383277893066\nM2 duration: 0.012859082221984864\nM1 acc: 0.722222222222\nM2 acc: 0.633333333333\nM1 clf len: 14.0\nM2 clf len: 14.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 18\nM1 duration: 0.004703736305236817\nM2 duration: 0.012108111381530761\nM1 acc: 0.722222222222\nM2 acc: 0.633333333333\nM1 clf len: 14.0\nM2 clf len: 14.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 19\nM1 duration: 0.004753327369689942\nM2 duration: 0.015260887145996094\nM1 acc: 0.722222222222\nM2 acc: 0.633333333333\nM1 clf len: 14.0\nM2 clf len: 14.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 20\nM1 duration: 0.0037008047103881834\nM2 duration: 0.013309669494628907\nM1 acc: 0.722222222222\nM2 acc: 0.633333333333\nM1 clf len: 14.0\nM2 clf len: 14.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 30\nM1 duration: 0.008206033706665039\nM2 duration: 0.015810942649841307\nM1 acc: 0.722222222222\nM2 acc: 0.677777777778\nM1 clf len: 17.0\nM2 clf len: 17.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 40\nM1 duration: 0.004953575134277344\nM2 duration: 0.020264244079589842\nM1 acc: 0.777777777778\nM2 acc: 0.733333333333\nM1 clf len: 18.0\nM2 clf len: 18.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 50\nM1 duration: 0.006806588172912598\nM2 duration: 0.016962003707885743\nM1 acc: 0.777777777778\nM2 acc: 0.733333333333\nM1 clf len: 18.0\nM2 clf len: 18.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 60\nM1 duration: 0.006206154823303223\nM2 duration: 0.01871340274810791\nM1 acc: 0.777777777778\nM2 acc: 0.733333333333\nM1 clf len: 18.0\nM2 clf len: 18.8\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 70\nM1 duration: 0.006955099105834961\nM2 duration: 0.020616316795349122\nM1 acc: 0.777777777778\nM2 acc: 0.733333333333\nM1 clf len: 18.0\nM2 clf len: 18.8\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 80\nM1 duration: 0.011307930946350098\nM2 duration: 0.025067877769470216\nM1 acc: 0.777777777778\nM2 acc: 0.733333333333\nM1 clf len: 20.0\nM2 clf len: 20.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 90\nM1 duration: 0.00865640640258789\nM2 duration: 0.025119471549987792\nM1 acc: 0.833333333333\nM2 acc: 0.744444444444\nM1 clf len: 23.0\nM2 clf len: 23.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 200\nM1 duration: 0.017062163352966307\nM2 duration: 0.04268028736114502\nM1 acc: 0.888888888889\nM2 acc: 0.8\nM1 clf len: 31.0\nM2 clf len: 31.0\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 300\nM1 duration: 0.03009793758392334\nM2 duration: 0.072853422164917\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 400\nM1 duration: 0.02616865634918213\nM2 duration: 0.10257329940795898\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 500\nM1 duration: 0.020664525032043458\nM2 duration: 0.14710466861724852\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 600\nM1 duration: 0.028670239448547363\nM2 duration: 0.16151511669158936\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 700\nM1 duration: 0.02326676845550537\nM2 duration: 0.14610674381256103\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\ntarget rule count: 800\nM1 duration: 0.022616267204284668\nM2 duration: 0.12914319038391114\nM1 acc: 0.888888888889\nM2 acc: 0.844444444444\nM1 clf len: 33.0\nM2 clf len: 36.6\n\n\n\nRunning apriori with setting: confidence=0.5, support=0.0, minlen=2, maxlen=3, MAX_RULE_LEN=19\nRule count: 2266, Iteration: 1\nTarget rule count satisfied: 1000\n"
],
[
"import matplotlib.pyplot as plt\n\nbenchmark_data_pd = pd.DataFrame(benchmark_data)\n\nbenchmark_data_pd.plot(x=[\"rule_count\"], y=[\"M1_duration\", \"M2_duration\"])\n\nplt.savefig(\"../data/m1_m2_podrobne.PNG\")",
"_____no_output_____"
],
[
"arc_rule_sensitivity = pd.read_csv(\"../data/arc-rule-sensitivity.csv\")\n\n#times_arc = arc_rule_sensitivity[[\"input rules\", \"time_rcba\", \"time_arc\", \"time_acba\"]]\ntimes_arc = arc_rule_sensitivity\n\ntimes_arc = times_arc.astype({\"input rules\": int})\n\ntimes_arc = times_arc.set_index(\"input rules\")\n\ntimes_arc.head()",
"_____no_output_____"
],
[
"benchmark_data_pd.head()",
"_____no_output_____"
],
[
"benchmark_data_pd.columns = [\"acc_pyARC_m1\", \"time_pyARC_m1\", \"output_rules_pyARC_m1\", \"acc_pyARC_m2\", \"time_pyARC_m2\", \"output_rules_pyARC_m2\", \"input rules\"]\n\nbenchmark_data_pd = benchmark_data_pd.set_index(\"input rules\")",
"_____no_output_____"
],
[
"times_df = benchmark_data_pd.join(times_arc)\ntimes_df",
"_____no_output_____"
],
[
"times_df[\"input rules\"] = times_df.index\n\nlabels = [\"pyARC - m1\", \"pyARC - m2\", \"arc\", \"rCBA\", \"arulesCBA\"]",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nax = times_df.plot(x=[\"input rules\"], y=[\"time_pyARC_m1\", \"time_pyARC_m2\", \"time_arc\", \"time_rcba\", \"time_acba\"])\nax.legend(labels)\n\nplt.savefig('../data/rule_sensitivity_plot.png')",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nax = times_df.plot(subplots=True, sharey=True, sharex=True, figsize=(5, 10), x=[\"input rules\"], y=[\"acc_pyARC_m1\", \"acc_pyARC_m2\", \"acc_arc\", \"acc_rcba\", \"acc_acba\"])\n\n\n\nplt.savefig('../data/rule_sensitivity_plot_accuracy.png')",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\n\ntimes_df.plot(subplots=True, sharey=True, sharex=True, figsize=(5, 10), x=[\"input rules\"], y=[\"output_rules_pyARC_m1\", \"output_rules_pyARC_m2\", \"output_rules_arc\", \"output_rules_rcba\", \"output_rules_acba\"])\n\n\n\n\nplt.savefig('../data/rule_sensitivity_plot_output_rules.png')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac926d6ad7b256df6cd1b143e8c419798dd9704
| 46,412 |
ipynb
|
Jupyter Notebook
|
09_Time_Series/Apple_Stock/Exercises.ipynb
|
NazmiDere/pandas_exercises
|
eb0d7334a44239c646059e47aa96a14f4d289347
|
[
"BSD-3-Clause"
] | null | null | null |
09_Time_Series/Apple_Stock/Exercises.ipynb
|
NazmiDere/pandas_exercises
|
eb0d7334a44239c646059e47aa96a14f4d289347
|
[
"BSD-3-Clause"
] | null | null | null |
09_Time_Series/Apple_Stock/Exercises.ipynb
|
NazmiDere/pandas_exercises
|
eb0d7334a44239c646059e47aa96a14f4d289347
|
[
"BSD-3-Clause"
] | null | null | null | 75.100324 | 30,584 | 0.773679 |
[
[
[
"# Apple Stock",
"_____no_output_____"
],
[
"### Introduction:\n\nWe are going to use Apple's stock price.\n\n\n### Step 1. Import the necessary libraries",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/09_Time_Series/Apple_Stock/appl_1980_2014.csv)",
"_____no_output_____"
]
],
[
[
"url = 'https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/09_Time_Series/Apple_Stock/appl_1980_2014.csv'",
"_____no_output_____"
]
],
[
[
"### Step 3. Assign it to a variable apple",
"_____no_output_____"
]
],
[
[
"apple = pd.read_csv(url)",
"_____no_output_____"
]
],
[
[
"### Step 4. Check out the type of the columns",
"_____no_output_____"
]
],
[
[
"apple.dtypes",
"_____no_output_____"
]
],
[
[
"### Step 5. Transform the Date column as a datetime type",
"_____no_output_____"
]
],
[
[
"apple['Date'] = pd.to_datetime(apple['Date'])",
"_____no_output_____"
]
],
[
[
"### Step 6. Set the date as the index",
"_____no_output_____"
]
],
[
[
"apple.set_index('Date', inplace=True)",
"_____no_output_____"
],
[
"apple.head()",
"_____no_output_____"
]
],
[
[
"### Step 7. Is there any duplicate dates?",
"_____no_output_____"
]
],
[
[
"apple.index.is_unique",
"_____no_output_____"
]
],
[
[
"### Step 8. Ops...it seems the index is from the most recent date. Make the first entry the oldest date.",
"_____no_output_____"
]
],
[
[
"apple.sort_index(inplace=True)",
"_____no_output_____"
]
],
[
[
"### Step 9. Get the last business day of each month",
"_____no_output_____"
]
],
[
[
"apple.resample('BM').mean()",
"_____no_output_____"
]
],
[
[
"### Step 10. What is the difference in days between the first day and the oldest",
"_____no_output_____"
]
],
[
[
"(apple.index[-1]-apple.index[0]).days",
"_____no_output_____"
]
],
[
[
"### Step 11. How many months in the data we have?",
"_____no_output_____"
]
],
[
[
"len(apple.resample('M'))",
"_____no_output_____"
]
],
[
[
"### Step 12. Plot the 'Adj Close' value. Set the size of the figure to 13.5 x 9 inches",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(13.5,9))\nplt.plot(apple['Adj Close'])",
"_____no_output_____"
]
],
[
[
"### BONUS: Create your own question and answer it.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac92e1601d3e2133bdd973c718955e90926e7fc
| 624,677 |
ipynb
|
Jupyter Notebook
|
content/ch-gates/multiple-qubits-entangled-states.ipynb
|
t-imamichi/qiskit-textbook
|
1d10b491b6e59526c7346f6c54b6cc8152928037
|
[
"Apache-2.0"
] | 4 |
2020-04-02T06:03:30.000Z
|
2020-09-02T23:23:30.000Z
|
content/ch-gates/multiple-qubits-entangled-states.ipynb
|
t-imamichi/qiskit-textbook
|
1d10b491b6e59526c7346f6c54b6cc8152928037
|
[
"Apache-2.0"
] | 19 |
2020-01-23T03:27:35.000Z
|
2021-01-21T01:07:32.000Z
|
content/ch-gates/multiple-qubits-entangled-states.ipynb
|
t-imamichi/qiskit-textbook
|
1d10b491b6e59526c7346f6c54b6cc8152928037
|
[
"Apache-2.0"
] | 46 |
2020-01-22T00:24:31.000Z
|
2021-01-26T08:28:25.000Z
| 41.606301 | 808 | 0.516052 |
[
[
[
"# Multiple Qubits & Entangled States",
"_____no_output_____"
],
[
"Single qubits are interesting, but individually they offer no computational advantage. We will now look at how we represent multiple qubits, and how these qubits can interact with each other. We have seen how we can represent the state of a qubit using a 2D-vector, now we will see how we can represent the state of multiple qubits.",
"_____no_output_____"
],
[
"## Contents\n1. [Representing Multi-Qubit States](#represent) \n 1.1 [Exercises](#ex1)\n2. [Single Qubit Gates on Multi-Qubit Statevectors](#single-qubit-gates) \n 2.1 [Exercises](#ex2)\n3. [Multi-Qubit Gates](#multi-qubit-gates) \n 3.1 [The CNOT-gate](#cnot) \n 3.2 [Entangled States](#entangled) \n 3.3 [Visualizing Entangled States](#visual) \n 3.4 [Exercises](#ex3)\n\n\n## 1. Representing Multi-Qubit States <a id=\"represent\"></a>\n\nWe saw that a single bit has two possible states, and a qubit state has two complex amplitudes. Similarly, two bits have four possible states:\n\n`00` `01` `10` `11`\n\nAnd to describe the state of two qubits requires four complex amplitudes. We store these amplitudes in a 4D-vector like so:\n\n$$ |a\\rangle = a_{00}|00\\rangle + a_{01}|01\\rangle + a_{10}|10\\rangle + a_{11}|11\\rangle = \\begin{bmatrix} a_{00} \\\\ a_{01} \\\\ a_{10} \\\\ a_{11} \\end{bmatrix} $$\n\nThe rules of measurement still work in the same way:\n\n$$ p(|00\\rangle) = |\\langle 00 | a \\rangle |^2 = |a_{00}|^2$$\n\nAnd the same implications hold, such as the normalisation condition:\n\n$$ |a_{00}|^2 + |a_{01}|^2 + |a_{10}|^2 + |a_{11}|^2 = 1$$\n\nIf we have two separated qubits, we can describe their collective state using the tensor product:\n\n$$ |a\\rangle = \\begin{bmatrix} a_0 \\\\ a_1 \\end{bmatrix}, \\quad |b\\rangle = \\begin{bmatrix} b_0 \\\\ b_1 \\end{bmatrix} $$\n\n$$ \n|ba\\rangle = |b\\rangle \\otimes |a\\rangle = \\begin{bmatrix} b_0 \\times \\begin{bmatrix} a_0 \\\\ a_1 \\end{bmatrix} \\\\ b_1 \\times \\begin{bmatrix} a_0 \\\\ a_1 \\end{bmatrix} \\end{bmatrix} = \\begin{bmatrix} b_0 a_0 \\\\ b_0 a_1 \\\\ b_1 a_0 \\\\ b_1 a_1 \\end{bmatrix}\n$$\n\nAnd following the same rules, we can use the tensor product to describe the collective state of any number of qubits. Here is an example with three qubits:\n\n$$ \n|cba\\rangle = \\begin{bmatrix} c_0 b_0 a_0 \\\\ c_0 b_0 a_1 \\\\ c_0 b_1 a_0 \\\\ c_0 b_1 a_1 \\\\\n c_1 b_0 a_0 \\\\ c_1 b_0 a_1 \\\\ c_1 b_1 a_0 \\\\ c_1 b_1 a_1 \\\\\n \\end{bmatrix}\n$$\n\nIf we have $n$ qubits, we will need to keep track of $2^n$ complex amplitudes. As we can see, these vectors grow exponentially with the number of qubits. This is the reason quantum computers with large numbers of qubits are so difficult to simulate. A modern laptop can easily simulate a general quantum state of around 20 qubits, but simulating 100 qubits is too difficult for the largest supercomputers.\n\nLet's look at an example circuit:",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumCircuit, Aer, assemble\nfrom math import pi\nimport numpy as np\nfrom qiskit.visualization import plot_histogram, plot_bloch_multivector",
"_____no_output_____"
],
[
"qc = QuantumCircuit(3)\n# Apply H-gate to each qubit:\nfor qubit in range(3):\n qc.h(qubit)\n# See the circuit:\nqc.draw()",
"_____no_output_____"
]
],
[
[
"Each qubit is in the state $|+\\rangle$, so we should see the vector:\n\n$$ \n|{+++}\\rangle = \\frac{1}{\\sqrt{8}}\\begin{bmatrix} 1 \\\\ 1 \\\\ 1 \\\\ 1 \\\\\n 1 \\\\ 1 \\\\ 1 \\\\ 1 \\\\\n \\end{bmatrix}\n$$",
"_____no_output_____"
]
],
[
[
"# Let's see the result\nsvsim = Aer.get_backend('statevector_simulator')\nqobj = assemble(qc)\nfinal_state = svsim.run(qobj).result().get_statevector()\n\n# In Jupyter Notebooks we can display this nicely using Latex.\n# If not using Jupyter Notebooks you may need to remove the \n# array_to_latex function and use print(final_state) instead.\nfrom qiskit_textbook.tools import array_to_latex\narray_to_latex(final_state, pretext=\"\\\\text{Statevector} = \")",
"_____no_output_____"
]
],
[
[
"And we have our expected result.",
"_____no_output_____"
],
[
"### 1.2 Quick Exercises: <a id=\"ex1\"></a>\n\n1.\tWrite down the tensor product of the qubits: \n a)\t$|0\\rangle|1\\rangle$ \n b)\t$|0\\rangle|+\\rangle$ \n c)\t$|+\\rangle|1\\rangle$ \n d)\t$|-\\rangle|+\\rangle$ \n2.\tWrite the state:\n $|\\psi\\rangle = \\tfrac{1}{\\sqrt{2}}|00\\rangle + \\tfrac{i}{\\sqrt{2}}|01\\rangle $\n as two separate qubits.\n\n\n## 2. Single Qubit Gates on Multi-Qubit Statevectors <a id=\"single-qubit-gates\"></a>\n\nWe have seen that an X-gate is represented by the matrix:\n\n$$\nX = \\begin{bmatrix} 0 & 1 \\\\ 1 & 0 \\end{bmatrix}\n$$\n\nAnd that it acts on the state $|0\\rangle$ as so:\n\n$$\nX|0\\rangle = \\begin{bmatrix} 0 & 1 \\\\ 1 & 0 \\end{bmatrix}\\begin{bmatrix} 1 \\\\ 0 \\end{bmatrix} = \\begin{bmatrix} 0 \\\\ 1\\end{bmatrix}\n$$\n\nbut it may not be clear how an X-gate would act on a qubit in a multi-qubit vector. Fortunately, the rule is quite simple; just as we used the tensor product to calculate multi-qubit statevectors, we use the tensor product to calculate matrices that act on these statevectors. For example, in the circuit below:",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(2)\nqc.h(0)\nqc.x(1)\nqc.draw()",
"_____no_output_____"
]
],
[
[
"we can represent the simultaneous operations (H & X) using their tensor product:\n\n$$\nX|q_1\\rangle \\otimes H|q_0\\rangle = (X\\otimes H)|q_1 q_0\\rangle\n$$\n\nThe operation looks like this:\n\n$$\nX\\otimes H = \\begin{bmatrix} 0 & 1 \\\\ 1 & 0 \\end{bmatrix} \\otimes \\tfrac{1}{\\sqrt{2}}\\begin{bmatrix} 1 & 1 \\\\ 1 & -1 \\end{bmatrix} = \\frac{1}{\\sqrt{2}}\n\\begin{bmatrix} 0 \\times \\begin{bmatrix} 1 & 1 \\\\ 1 & -1 \\end{bmatrix}\n & 1 \\times \\begin{bmatrix} 1 & 1 \\\\ 1 & -1 \\end{bmatrix}\n \\\\ \n 1 \\times \\begin{bmatrix} 1 & 1 \\\\ 1 & -1 \\end{bmatrix}\n & 0 \\times \\begin{bmatrix} 1 & 1 \\\\ 1 & -1 \\end{bmatrix}\n\\end{bmatrix} = \\frac{1}{\\sqrt{2}}\n\\begin{bmatrix} 0 & 0 & 1 & 1 \\\\\n 0 & 0 & 1 & -1 \\\\\n 1 & 1 & 0 & 0 \\\\\n 1 & -1 & 0 & 0 \\\\\n\\end{bmatrix}\n$$\n\nWhich we can then apply to our 4D statevector $|q_1 q_0\\rangle$. This can become quite messy, you will often see the clearer notation:\n\n$$\nX\\otimes H = \n\\begin{bmatrix} 0 & H \\\\\n H & 0\\\\\n\\end{bmatrix}\n$$\n\nInstead of calculating this by hand, we can use Qiskit’s `unitary_simulator` to calculate this for us. The unitary simulator multiplies all the gates in our circuit together to compile a single unitary matrix that performs the whole quantum circuit:",
"_____no_output_____"
]
],
[
[
"usim = Aer.get_backend('unitary_simulator')\nqobj = assemble(qc)\nunitary = usim.run(qobj).result().get_unitary()",
"_____no_output_____"
]
],
[
[
"and view the results:",
"_____no_output_____"
]
],
[
[
"# In Jupyter Notebooks we can display this nicely using Latex.\n# If not using Jupyter Notebooks you may need to remove the \n# array_to_latex function and use print(unitary) instead.\nfrom qiskit_textbook.tools import array_to_latex\narray_to_latex(unitary, pretext=\"\\\\text{Circuit = }\\n\")",
"_____no_output_____"
]
],
[
[
"If we want to apply a gate to only one qubit at a time (such as in the circuit below), we describe this using tensor product with the identity matrix, e.g.:\n\n$$ X \\otimes I $$",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(2)\nqc.x(1)\nqc.draw()",
"_____no_output_____"
],
[
"# Simulate the unitary\nusim = Aer.get_backend('unitary_simulator')\nqobj = assemble(qc)\nunitary = usim.run(qobj).result().get_unitary()\n# Display the results:\narray_to_latex(unitary, pretext=\"\\\\text{Circuit = } \")",
"_____no_output_____"
]
],
[
[
"We can see Qiskit has performed the tensor product:\n$$\nX \\otimes I =\n\\begin{bmatrix} 0 & I \\\\\n I & 0\\\\\n\\end{bmatrix} = \n\\begin{bmatrix} 0 & 0 & 1 & 0 \\\\\n 0 & 0 & 0 & 1 \\\\\n 1 & 0 & 0 & 0 \\\\\n 0 & 1 & 0 & 0 \\\\\n\\end{bmatrix}\n$$\n\n### 2.1 Quick Exercises: <a id=\"ex2\"></a>\n\n1. Calculate the single qubit unitary ($U$) created by the sequence of gates: $U = XZH$. Use Qiskit's unitary simulator to check your results.\n2. Try changing the gates in the circuit above. Calculate their tensor product, and then check your answer using the unitary simulator.\n\n**Note:** Different books, softwares and websites order their qubits differently. This means the tensor product of the same circuit can look very different. Try to bear this in mind when consulting other sources. \n",
"_____no_output_____"
],
[
"## 3. Multi-Qubit Gates <a id=\"multi-qubit-gates\"></a>\n\nNow we know how to represent the state of multiple qubits, we are now ready to learn how qubits interact with each other. An important two-qubit gate is the CNOT-gate.\n\n### 3.1 The CNOT-Gate <a id=\"cnot\"></a>\n\nYou have come across this gate before in _[The Atoms of Computation](../ch-states/atoms-computation.html)._ This gate is a conditional gate that performs an X-gate on the second qubit (target), if the state of the first qubit (control) is $|1\\rangle$. The gate is drawn on a circuit like this, with `q0` as the control and `q1` as the target:",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(2)\n# Apply CNOT\nqc.cx(0,1)\n# See the circuit:\nqc.draw()",
"_____no_output_____"
]
],
[
[
"When our qubits are not in superposition of $|0\\rangle$ or $|1\\rangle$ (behaving as classical bits), this gate is very simple and intuitive to understand. We can use the classical truth table:\n\n| Input (t,c) | Output (t,c) |\n|:-----------:|:------------:|\n| 00 | 00 |\n| 01 | 11 |\n| 10 | 10 |\n| 11 | 01 |\n\nAnd acting on our 4D-statevector, it has one of the two matrices:\n\n$$\n\\text{CNOT} = \\begin{bmatrix} 1 & 0 & 0 & 0 \\\\\n 0 & 0 & 0 & 1 \\\\\n 0 & 0 & 1 & 0 \\\\\n 0 & 1 & 0 & 0 \\\\\n \\end{bmatrix}, \\quad\n\\text{CNOT} = \\begin{bmatrix} 1 & 0 & 0 & 0 \\\\\n 0 & 1 & 0 & 0 \\\\\n 0 & 0 & 0 & 1 \\\\\n 0 & 0 & 1 & 0 \\\\\n \\end{bmatrix}\n$$\n\ndepending on which qubit is the control and which is the target. Different books, simulators and papers order their qubits differently. In our case, the left matrix corresponds to the CNOT in the circuit above. This matrix swaps the amplitudes of $|01\\rangle$ and $|11\\rangle$ in our statevector:\n\n$$ \n|a\\rangle = \\begin{bmatrix} a_{00} \\\\ a_{01} \\\\ a_{10} \\\\ a_{11} \\end{bmatrix}, \\quad \\text{CNOT}|a\\rangle = \\begin{bmatrix} a_{00} \\\\ a_{11} \\\\ a_{10} \\\\ a_{01} \\end{bmatrix} \\begin{matrix} \\\\ \\leftarrow \\\\ \\\\ \\leftarrow \\end{matrix}\n$$\n\nWe have seen how this acts on classical states, but let’s now see how it acts on a qubit in superposition. We will put one qubit in the state $|+\\rangle$:",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(2)\n# Apply H-gate to the first:\nqc.h(0)\nqc.draw()",
"_____no_output_____"
],
[
"# Let's see the result:\nsvsim = Aer.get_backend('statevector_simulator')\nqobj = assemble(qc)\nfinal_state = svsim.run(qobj).result().get_statevector()\n# Print the statevector neatly:\narray_to_latex(final_state, pretext=\"\\\\text{Statevector = }\")",
"_____no_output_____"
]
],
[
[
"As expected, this produces the state $|0\\rangle \\otimes |{+}\\rangle = |0{+}\\rangle$:\n\n$$\n|0{+}\\rangle = \\tfrac{1}{\\sqrt{2}}(|00\\rangle + |01\\rangle)\n$$\n\nAnd let’s see what happens when we apply the CNOT gate:",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(2)\n# Apply H-gate to the first:\nqc.h(0)\n# Apply a CNOT:\nqc.cx(0,1)\nqc.draw()",
"_____no_output_____"
],
[
"# Let's get the result:\nqobj = assemble(qc)\nresult = svsim.run(qobj).result()\n# Print the statevector neatly:\nfinal_state = result.get_statevector()\narray_to_latex(final_state, pretext=\"\\\\text{Statevector = }\")",
"_____no_output_____"
]
],
[
[
"We see we have the state:\n\n$$\n\\text{CNOT}|0{+}\\rangle = \\tfrac{1}{\\sqrt{2}}(|00\\rangle + |11\\rangle)\n$$ \n\nThis state is very interesting to us, because it is _entangled._ This leads us neatly on to the next section.",
"_____no_output_____"
],
[
"### 3.2 Entangled States <a id=\"entangled\"></a>\n\nWe saw in the previous section we could create the state:\n\n$$\n\\tfrac{1}{\\sqrt{2}}(|00\\rangle + |11\\rangle)\n$$ \n\nThis is known as a _Bell_ state. We can see that this state has 50% probability of being measured in the state $|00\\rangle$, and 50% chance of being measured in the state $|11\\rangle$. Most interestingly, it has a **0%** chance of being measured in the states $|01\\rangle$ or $|10\\rangle$. We can see this in Qiskit:",
"_____no_output_____"
]
],
[
[
"plot_histogram(result.get_counts())",
"_____no_output_____"
]
],
[
[
"This combined state cannot be written as two separate qubit states, which has interesting implications. Although our qubits are in superposition, measuring one will tell us the state of the other and collapse its superposition. For example, if we measured the top qubit and got the state $|1\\rangle$, the collective state of our qubits changes like so:\n\n$$\n\\tfrac{1}{\\sqrt{2}}(|00\\rangle + |11\\rangle) \\quad \\xrightarrow[]{\\text{measure}} \\quad |11\\rangle\n$$\n\nEven if we separated these qubits light-years away, measuring one qubit collapses the superposition and appears to have an immediate effect on the other. This is the [‘spooky action at a distance’](https://en.wikipedia.org/wiki/Quantum_nonlocality) that upset so many physicists in the early 20th century.\n\nIt’s important to note that the measurement result is random, and the measurement statistics of one qubit are **not** affected by any operation on the other qubit. Because of this, there is **no way** to use shared quantum states to communicate. This is known as the no-communication theorem.[1]",
"_____no_output_____"
],
[
"### 3.3 Visualizing Entangled States<a id=\"visual\"></a>\n\nWe have seen that this state cannot be written as two separate qubit states, this also means we lose information when we try to plot our state on separate Bloch spheres:",
"_____no_output_____"
]
],
[
[
"plot_bloch_multivector(final_state)",
"_____no_output_____"
]
],
[
[
"Given how we defined the Bloch sphere in the earlier chapters, it may not be clear how Qiskit even calculates the Bloch vectors with entangled qubits like this. In the single-qubit case, the position of the Bloch vector along an axis nicely corresponds to the expectation value of measuring in that basis. If we take this as _the_ rule of plotting Bloch vectors, we arrive at this conclusion above. This shows us there is _no_ single-qubit measurement basis for which a specific measurement is guaranteed. This contrasts with our single qubit states, in which we could always pick a single-qubit basis. Looking at the individual qubits in this way, we miss the important effect of correlation between the qubits. We cannot distinguish between different entangled states. For example, the two states:\n\n$$\\tfrac{1}{\\sqrt{2}}(|01\\rangle + |10\\rangle) \\quad \\text{and} \\quad \\tfrac{1}{\\sqrt{2}}(|00\\rangle + |11\\rangle)$$\n\nwill both look the same on these separate Bloch spheres, despite being very different states with different measurement outcomes.\n\nHow else could we visualize this statevector? This statevector is simply a collection of four amplitudes (complex numbers), and there are endless ways we can map this to an image. One such visualization is the _Q-sphere,_ here each amplitude is represented by a blob on the surface of a sphere. The size of the blob is proportional to the magnitude of the amplitude, and the colour is proportional to the phase of the amplitude. The amplitudes for $|00\\rangle$ and $|11\\rangle$ are equal, and all other amplitudes are 0:",
"_____no_output_____"
]
],
[
[
"from qiskit.visualization import plot_state_qsphere\nplot_state_qsphere(final_state)",
"_____no_output_____"
]
],
[
[
"Here we can clearly see the correlation between the qubits. The Q-sphere's shape has no significance, it is simply a nice way of arranging our blobs; the number of `0`s in the state is proportional to the states position on the Z-axis, so here we can see the amplitude of $|00\\rangle$ is at the top pole of the sphere, and the amplitude of $|11\\rangle$ is at the bottom pole of the sphere.",
"_____no_output_____"
],
[
"### 3.4 Exercise: <a id=\"ex3\"></a>\n1. Create a quantum circuit that produces the Bell state: $\\tfrac{1}{\\sqrt{2}}(|01\\rangle + |10\\rangle)$.\n Use the statevector simulator to verify your result.\n \n2. The circuit you created in question 1 transforms the state $|00\\rangle$ to $\\tfrac{1}{\\sqrt{2}}(|01\\rangle + |10\\rangle)$, calculate the unitary of this circuit using Qiskit's simulator. Verify this unitary does in fact perform the correct transformation.\n\n3. Think about other ways you could represent a statevector visually. Can you design an interesting visualization from which you can read the magnitude and phase of each amplitude?",
"_____no_output_____"
],
[
"## 4. References\n\n[1] Asher Peres, Daniel R. Terno, _Quantum Information and Relativity Theory,_ 2004, https://arxiv.org/abs/quant-ph/0212023",
"_____no_output_____"
]
],
[
[
"import qiskit\nqiskit.__qiskit_version__",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4ac9341bbe28e2b4a574e9adb216cde3254a6fda
| 9,552 |
ipynb
|
Jupyter Notebook
|
8QUEEN_Problem.ipynb
|
aditya270520/100Daysofpython
|
a70d72bb8663947ccad1cc0cb6252f3d3624fb44
|
[
"MIT"
] | 4 |
2020-12-12T11:49:02.000Z
|
2021-02-09T14:10:17.000Z
|
8QUEEN_Problem.ipynb
|
aditya270520/100Daysofpython
|
a70d72bb8663947ccad1cc0cb6252f3d3624fb44
|
[
"MIT"
] | null | null | null |
8QUEEN_Problem.ipynb
|
aditya270520/100Daysofpython
|
a70d72bb8663947ccad1cc0cb6252f3d3624fb44
|
[
"MIT"
] | null | null | null | 57.890909 | 239 | 0.257747 |
[
[
[
"<a href=\"https://colab.research.google.com/github/aditya270520/100Daysofpython/blob/main/8QUEEN_Problem.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"BOARD_SIZE = 8\n\ndef under_attack(col, queens):\n left = right = col\n\n for r, c in reversed(queens):\n left, right = left - 1, right + 1\n\n if c in (left, col, right):\n return True\n return False\n\ndef solve(n):\n if n == 0:\n return [[]]\n\n smaller_solutions = solve(n - 1)\n\n return [solution+[(n,i+1)]\n for i in range(BOARD_SIZE)\n for solution in smaller_solutions\n if not under_attack(i+1, solution)]\nfor answer in solve(BOARD_SIZE):\n print (answer)",
"[(1, 4), (2, 2), (3, 7), (4, 3), (5, 6), (6, 8), (7, 5), (8, 1)]\n[(1, 5), (2, 2), (3, 4), (4, 7), (5, 3), (6, 8), (7, 6), (8, 1)]\n[(1, 3), (2, 5), (3, 2), (4, 8), (5, 6), (6, 4), (7, 7), (8, 1)]\n[(1, 3), (2, 6), (3, 4), (4, 2), (5, 8), (6, 5), (7, 7), (8, 1)]\n[(1, 5), (2, 7), (3, 1), (4, 3), (5, 8), (6, 6), (7, 4), (8, 2)]\n[(1, 4), (2, 6), (3, 8), (4, 3), (5, 1), (6, 7), (7, 5), (8, 2)]\n[(1, 3), (2, 6), (3, 8), (4, 1), (5, 4), (6, 7), (7, 5), (8, 2)]\n[(1, 5), (2, 3), (3, 8), (4, 4), (5, 7), (6, 1), (7, 6), (8, 2)]\n[(1, 5), (2, 7), (3, 4), (4, 1), (5, 3), (6, 8), (7, 6), (8, 2)]\n[(1, 4), (2, 1), (3, 5), (4, 8), (5, 6), (6, 3), (7, 7), (8, 2)]\n[(1, 3), (2, 6), (3, 4), (4, 1), (5, 8), (6, 5), (7, 7), (8, 2)]\n[(1, 4), (2, 7), (3, 5), (4, 3), (5, 1), (6, 6), (7, 8), (8, 2)]\n[(1, 6), (2, 4), (3, 2), (4, 8), (5, 5), (6, 7), (7, 1), (8, 3)]\n[(1, 6), (2, 4), (3, 7), (4, 1), (5, 8), (6, 2), (7, 5), (8, 3)]\n[(1, 1), (2, 7), (3, 4), (4, 6), (5, 8), (6, 2), (7, 5), (8, 3)]\n[(1, 6), (2, 8), (3, 2), (4, 4), (5, 1), (6, 7), (7, 5), (8, 3)]\n[(1, 6), (2, 2), (3, 7), (4, 1), (5, 4), (6, 8), (7, 5), (8, 3)]\n[(1, 4), (2, 7), (3, 1), (4, 8), (5, 5), (6, 2), (7, 6), (8, 3)]\n[(1, 5), (2, 8), (3, 4), (4, 1), (5, 7), (6, 2), (7, 6), (8, 3)]\n[(1, 4), (2, 8), (3, 1), (4, 5), (5, 7), (6, 2), (7, 6), (8, 3)]\n[(1, 2), (2, 7), (3, 5), (4, 8), (5, 1), (6, 4), (7, 6), (8, 3)]\n[(1, 1), (2, 7), (3, 5), (4, 8), (5, 2), (6, 4), (7, 6), (8, 3)]\n[(1, 2), (2, 5), (3, 7), (4, 4), (5, 1), (6, 8), (7, 6), (8, 3)]\n[(1, 4), (2, 2), (3, 7), (4, 5), (5, 1), (6, 8), (7, 6), (8, 3)]\n[(1, 5), (2, 7), (3, 1), (4, 4), (5, 2), (6, 8), (7, 6), (8, 3)]\n[(1, 6), (2, 4), (3, 1), (4, 5), (5, 8), (6, 2), (7, 7), (8, 3)]\n[(1, 5), (2, 1), (3, 4), (4, 6), (5, 8), (6, 2), (7, 7), (8, 3)]\n[(1, 5), (2, 2), (3, 6), (4, 1), (5, 7), (6, 4), (7, 8), (8, 3)]\n[(1, 6), (2, 3), (3, 7), (4, 2), (5, 8), (6, 5), (7, 1), (8, 4)]\n[(1, 2), (2, 7), (3, 3), (4, 6), (5, 8), (6, 5), (7, 1), (8, 4)]\n[(1, 7), (2, 3), (3, 1), (4, 6), (5, 8), (6, 5), (7, 2), (8, 4)]\n[(1, 5), (2, 1), (3, 8), (4, 6), (5, 3), (6, 7), (7, 2), (8, 4)]\n[(1, 1), (2, 5), (3, 8), (4, 6), (5, 3), (6, 7), (7, 2), (8, 4)]\n[(1, 3), (2, 6), (3, 8), (4, 1), (5, 5), (6, 7), (7, 2), (8, 4)]\n[(1, 6), (2, 3), (3, 1), (4, 7), (5, 5), (6, 8), (7, 2), (8, 4)]\n[(1, 7), (2, 5), (3, 3), (4, 1), (5, 6), (6, 8), (7, 2), (8, 4)]\n[(1, 7), (2, 3), (3, 8), (4, 2), (5, 5), (6, 1), (7, 6), (8, 4)]\n[(1, 5), (2, 3), (3, 1), (4, 7), (5, 2), (6, 8), (7, 6), (8, 4)]\n[(1, 2), (2, 5), (3, 7), (4, 1), (5, 3), (6, 8), (7, 6), (8, 4)]\n[(1, 3), (2, 6), (3, 2), (4, 5), (5, 8), (6, 1), (7, 7), (8, 4)]\n[(1, 6), (2, 1), (3, 5), (4, 2), (5, 8), (6, 3), (7, 7), (8, 4)]\n[(1, 8), (2, 3), (3, 1), (4, 6), (5, 2), (6, 5), (7, 7), (8, 4)]\n[(1, 2), (2, 8), (3, 6), (4, 1), (5, 3), (6, 5), (7, 7), (8, 4)]\n[(1, 5), (2, 7), (3, 2), (4, 6), (5, 3), (6, 1), (7, 8), (8, 4)]\n[(1, 3), (2, 6), (3, 2), (4, 7), (5, 5), (6, 1), (7, 8), (8, 4)]\n[(1, 6), (2, 2), (3, 7), (4, 1), (5, 3), (6, 5), (7, 8), (8, 4)]\n[(1, 3), (2, 7), (3, 2), (4, 8), (5, 6), (6, 4), (7, 1), (8, 5)]\n[(1, 6), (2, 3), (3, 7), (4, 2), (5, 4), (6, 8), (7, 1), (8, 5)]\n[(1, 4), (2, 2), (3, 7), (4, 3), (5, 6), (6, 8), (7, 1), (8, 5)]\n[(1, 7), (2, 1), (3, 3), (4, 8), (5, 6), (6, 4), (7, 2), (8, 5)]\n[(1, 1), (2, 6), (3, 8), (4, 3), (5, 7), (6, 4), (7, 2), (8, 5)]\n[(1, 3), (2, 8), (3, 4), (4, 7), (5, 1), (6, 6), (7, 2), (8, 5)]\n[(1, 6), (2, 3), (3, 7), (4, 4), (5, 1), (6, 8), (7, 2), (8, 5)]\n[(1, 7), (2, 4), (3, 2), (4, 8), (5, 6), (6, 1), (7, 3), (8, 5)]\n[(1, 4), (2, 6), (3, 8), (4, 2), (5, 7), (6, 1), (7, 3), (8, 5)]\n[(1, 2), (2, 6), (3, 1), (4, 7), (5, 4), (6, 8), (7, 3), (8, 5)]\n[(1, 2), (2, 4), (3, 6), (4, 8), (5, 3), (6, 1), (7, 7), (8, 5)]\n[(1, 3), (2, 6), (3, 8), (4, 2), (5, 4), (6, 1), (7, 7), (8, 5)]\n[(1, 6), (2, 3), (3, 1), (4, 8), (5, 4), (6, 2), (7, 7), (8, 5)]\n[(1, 8), (2, 4), (3, 1), (4, 3), (5, 6), (6, 2), (7, 7), (8, 5)]\n[(1, 4), (2, 8), (3, 1), (4, 3), (5, 6), (6, 2), (7, 7), (8, 5)]\n[(1, 2), (2, 6), (3, 8), (4, 3), (5, 1), (6, 4), (7, 7), (8, 5)]\n[(1, 7), (2, 2), (3, 6), (4, 3), (5, 1), (6, 4), (7, 8), (8, 5)]\n[(1, 3), (2, 6), (3, 2), (4, 7), (5, 1), (6, 4), (7, 8), (8, 5)]\n[(1, 4), (2, 7), (3, 3), (4, 8), (5, 2), (6, 5), (7, 1), (8, 6)]\n[(1, 4), (2, 8), (3, 5), (4, 3), (5, 1), (6, 7), (7, 2), (8, 6)]\n[(1, 3), (2, 5), (3, 8), (4, 4), (5, 1), (6, 7), (7, 2), (8, 6)]\n[(1, 4), (2, 2), (3, 8), (4, 5), (5, 7), (6, 1), (7, 3), (8, 6)]\n[(1, 5), (2, 7), (3, 2), (4, 4), (5, 8), (6, 1), (7, 3), (8, 6)]\n[(1, 7), (2, 4), (3, 2), (4, 5), (5, 8), (6, 1), (7, 3), (8, 6)]\n[(1, 8), (2, 2), (3, 4), (4, 1), (5, 7), (6, 5), (7, 3), (8, 6)]\n[(1, 7), (2, 2), (3, 4), (4, 1), (5, 8), (6, 5), (7, 3), (8, 6)]\n[(1, 5), (2, 1), (3, 8), (4, 4), (5, 2), (6, 7), (7, 3), (8, 6)]\n[(1, 4), (2, 1), (3, 5), (4, 8), (5, 2), (6, 7), (7, 3), (8, 6)]\n[(1, 5), (2, 2), (3, 8), (4, 1), (5, 4), (6, 7), (7, 3), (8, 6)]\n[(1, 3), (2, 7), (3, 2), (4, 8), (5, 5), (6, 1), (7, 4), (8, 6)]\n[(1, 3), (2, 1), (3, 7), (4, 5), (5, 8), (6, 2), (7, 4), (8, 6)]\n[(1, 8), (2, 2), (3, 5), (4, 3), (5, 1), (6, 7), (7, 4), (8, 6)]\n[(1, 3), (2, 5), (3, 2), (4, 8), (5, 1), (6, 7), (7, 4), (8, 6)]\n[(1, 3), (2, 5), (3, 7), (4, 1), (5, 4), (6, 2), (7, 8), (8, 6)]\n[(1, 5), (2, 2), (3, 4), (4, 6), (5, 8), (6, 3), (7, 1), (8, 7)]\n[(1, 6), (2, 3), (3, 5), (4, 8), (5, 1), (6, 4), (7, 2), (8, 7)]\n[(1, 5), (2, 8), (3, 4), (4, 1), (5, 3), (6, 6), (7, 2), (8, 7)]\n[(1, 4), (2, 2), (3, 5), (4, 8), (5, 6), (6, 1), (7, 3), (8, 7)]\n[(1, 4), (2, 6), (3, 1), (4, 5), (5, 2), (6, 8), (7, 3), (8, 7)]\n[(1, 6), (2, 3), (3, 1), (4, 8), (5, 5), (6, 2), (7, 4), (8, 7)]\n[(1, 5), (2, 3), (3, 1), (4, 6), (5, 8), (6, 2), (7, 4), (8, 7)]\n[(1, 4), (2, 2), (3, 8), (4, 6), (5, 1), (6, 3), (7, 5), (8, 7)]\n[(1, 6), (2, 3), (3, 5), (4, 7), (5, 1), (6, 4), (7, 2), (8, 8)]\n[(1, 6), (2, 4), (3, 7), (4, 1), (5, 3), (6, 5), (7, 2), (8, 8)]\n[(1, 4), (2, 7), (3, 5), (4, 2), (5, 6), (6, 1), (7, 3), (8, 8)]\n[(1, 5), (2, 7), (3, 2), (4, 6), (5, 3), (6, 1), (7, 4), (8, 8)]\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
4ac9373ab27d4bb511cb068441d31272fa64e14f
| 214,247 |
ipynb
|
Jupyter Notebook
|
_notebooks/2021-01-02-transformer-lm-from-scratch.ipynb
|
arampacha/thoughtsamples
|
3a12b2b2c7874799105e3c0456ac2c76f12b4c5e
|
[
"Apache-2.0"
] | 2 |
2021-01-24T18:58:08.000Z
|
2021-01-25T22:17:58.000Z
|
_notebooks/2021-01-02-transformer-lm-from-scratch.ipynb
|
arampacha/thoughtsamples
|
3a12b2b2c7874799105e3c0456ac2c76f12b4c5e
|
[
"Apache-2.0"
] | 3 |
2021-05-20T23:15:32.000Z
|
2022-02-26T10:26:57.000Z
|
_notebooks/2021-01-02-transformer-lm-from-scratch.ipynb
|
arampacha/thoughtsamples
|
3a12b2b2c7874799105e3c0456ac2c76f12b4c5e
|
[
"Apache-2.0"
] | null | null | null | 45.633014 | 15,224 | 0.672747 |
[
[
[
"# A Transformer based Language Model from scratch\n> Building transformer with simple building blocks\n\n- toc: true\n- branch: master\n- badges: true\n- comments: true\n- author: Arto\n- categories: [fastai, pytorch]",
"_____no_output_____"
]
],
[
[
"#hide\nimport sys\nif 'google.colab' in sys.modules:\n !pip install -Uqq fastai",
"_____no_output_____"
]
],
[
[
"In this notebook i'm going to construct transformer based language model from scratch starting with the simplest building blocks. This is inspired by Chapter 12 of [Deep Learning for Coders book](https://www.amazon.com/Deep-Learning-Coders-fastai-PyTorch/dp/1492045527) in which it's demonstrated how to create a Recurrent Neural Network. It provides a strong intuition of how RNNs relate to regular feed-forward neural nets and why certain design choices were made. Here we aim to aquire similar kind of intuition about Transfomer based architectures.\n\nBut as always we should start with the data to be modeled, 'cause without data any model makes no particular sense.",
"_____no_output_____"
],
[
"## Data",
"_____no_output_____"
],
[
"Similar to authors of the book I'll use simple Human numbers dataset which is specifically designed to prototyping model fast and straightforward. For more details on the data one can refer to the aforemantioned book chapter which is also available for free as [a notebook](https://github.com/fastai/fastbook/blob/master/12_nlp_dive.ipynb) (isn't that awesome?!)",
"_____no_output_____"
]
],
[
[
"from fastai.text.all import *\npath = untar_data(URLs.HUMAN_NUMBERS)\nPath.BASE_PATH = path\npath.ls()",
"_____no_output_____"
]
],
[
[
"The data consists of consecutive numbers from 1 to 9999 inclusive spelled as words.",
"_____no_output_____"
]
],
[
[
"lines = L()\nwith open(path/'train.txt') as f: lines += L(*f.readlines())\nwith open(path/'valid.txt') as f: lines += L(*f.readlines())\nlines",
"_____no_output_____"
],
[
"text = ' . '.join([l.strip() for l in lines])\ntokens = text.split(' ')\ntokens[:10]",
"_____no_output_____"
],
[
"vocab = L(*tokens).unique()\nvocab",
"_____no_output_____"
],
[
"word2idx = {w:i for i,w in enumerate(vocab)}\nnums = L(word2idx[i] for i in tokens)\nnums",
"_____no_output_____"
]
],
[
[
"The task will be to predict subsequent token given preceding three. This kind of tasks when the goal is to predict next token from previous ones is called autoregresive language modeling.",
"_____no_output_____"
]
],
[
[
"L((tokens[i:i+3], tokens[i+3]) for i in range(0,len(tokens)-4,3))",
"_____no_output_____"
],
[
"seqs = L((tensor(nums[i:i+3]), nums[i+3]) for i in range(0,len(nums)-4,3))\nseqs",
"_____no_output_____"
],
[
"bs = 64\ncut = int(len(seqs) * 0.8)\ndls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], bs=64, shuffle=False)",
"_____no_output_____"
],
[
"x, y = dls.one_batch()\nx.shape, y.shape",
"_____no_output_____"
]
],
[
[
"## Dot product attention",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"The core idea behind Transformers is Attention. Since the release of famous paper [Attention is All You Need](https://arxiv.org/abs/1706.03762) transformers has become most popular architecture for language modelling. \n\nThere are a lot of great resourses explaining transformers architecture. I'll list some of those I found useful and comprehensive:\n1. [The Annotated Transformer](http://nlp.seas.harvard.edu/2018/04/03/attention.html) completes the original paper with code\n2. [Encoder-Decoder Model](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb) notebook by huggingface gives mathemetically grounded explanation of how transformer encoder-decoder models work\n3. [The Illustrated GPT-2](https://jalammar.github.io/illustrated-gpt2/) one of the great blogposts by Jay Alammar visualizing generative language modelling on exaple of GPT-2\n4. [minGPT](https://github.com/karpathy/minGPT) cool repo by A. Karpathy providing clear minimal implementation of GPT model\n\nThere exist multiple attention mechanisms. The particular one used in the original transformer paper is Scaled Dot Product attention.\nGiven query vector for particular token we will compare it with a key vector for each token in a sequence and decide how much value vectors of those will effect resulting representetion of the token of interest. One way to view this from a linguistic prospective is: a key is a question each word respondes to, value is information that word represent and a query is related to what every word was looking to combine with.\n\nMathemetically we can compute attention for all _q_, _k_, _v_ in a matrix form:\n\n$$\\textbf {Attention}(Q,K,V) = \\textbf {softmax}({QK^T\\over\\sqrt d_k})V $$\n\nNote that dot product $QK^T$ results in matrix of shape (seq_len x seq_len). Then it is devided by $ \\sqrt d_k$ to compensate the fact, that longer sequences will have larger dot product. $ \\textbf{softmax}$ is applied to rescale the attention matrix to be betwin 0 and 1. When multiplied by $V$ it produces a matrix of the same shape as $V$ (seq_len x dv).\n\nSo where those _q_, _k_, _v_ come from. Well that's fairly straitforward queries are culculated from the embeddings of tokens we want to find representation for by simple linear projection. Keys and values are calculated from the embeddings of context tokens. In case of self attention all of them come from the original sequence.",
"_____no_output_____"
]
],
[
[
"class SelfAttention(Module):\n def __init__(self, d_in, d_qk, d_v=None):\n d_v = ifnone(d_v, d_qk)\n self.iq = nn.Linear(d_in, d_qk)\n self.ik = nn.Linear(d_in, d_qk)\n self.iv = nn.Linear(d_in, d_v)\n self.out = nn.Linear(d_v, d_in)\n self.scale = d_qk**-0.5\n def forward(self, x):\n q, k, v = self.iq(x), self.ik(x), self.iv(x)\n q *= self.scale\n return self.out(F.softmax([email protected](-2,-1), -1)@v)",
"_____no_output_____"
]
],
[
[
"Even though self attention mechanism is extremely useful it posseses limited expressive power. Essentially we are computing weighted some of the input modified by single affine transformation, shared across the whole sequence. To add more computational power to the model we can introduce fully connected feedforward network on top of the SelfAttention layer.\n\nCurious reader can find detailed formal analysis of the roles of SelfAttention and FeedForward layers in transformer architecture in [this paper](https://arxiv.org/pdf/1912.10077.pdf) by C. Yun et al.\nIn brief the authors state that SelfAttention layers compute precise contextual maps and FeedForward layers then assign the results of these contextual maps to the desired output values.",
"_____no_output_____"
]
],
[
[
"class FeedForward(Module):\n def __init__(self, d_in, d_ff):\n self.lin1 = nn.Linear(d_in, d_ff)\n self.lin2 = nn.Linear(d_ff, d_in)\n self.act = nn.ReLU()\n \n def forward(self, x):\n out = self.lin2(self.act(self.lin1(x)))\n return out",
"_____no_output_____"
]
],
[
[
"The output would be of shape (bs, seq_len, d) which then may be mapped to (bs, seq_len, vocab_sz) using linear layer. But we have only one target. To adress this issue we can simply do average pooling over seq_len dimention.\n\nThe resulting model is fairly simple:",
"_____no_output_____"
]
],
[
[
"class Model1(Module):\n def __init__(self, vocab_sz, d_model, d_qk, d_ff):\n self.emb = Embedding(vocab_sz, d_model)\n self.attn = SelfAttention(d_model, d_qk)\n self.ff = FeedForward(d_model, d_ff)\n self.out = nn.Linear(d_model, vocab_sz)\n def forward(self, x):\n x = self.emb(x)\n x = self.ff(self.attn(x))\n x = x.mean(1)\n return self.out(x)",
"_____no_output_____"
],
[
"model = Model1(len(vocab), 64, 64, 128)\nout = model(x)\nout.shape",
"_____no_output_____"
],
[
"learn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=accuracy)\nlearn.lr_find()",
"_____no_output_____"
],
[
"learn.fit_one_cycle(5, 5e-3)",
"_____no_output_____"
]
],
[
[
"To evaluete the model performance we need to compare it to some baseline. Let's see what would be the accuracy if of the model which would always predict most common token.",
"_____no_output_____"
]
],
[
[
"n,counts = 0,torch.zeros(len(vocab))\nfor x,y in dls.valid:\n n += y.shape[0]\n for i in range_of(vocab): counts[i] += (y==i).long().sum()\nidx = torch.argmax(counts)\nidx, vocab[idx.item()], counts[idx].item()/n",
"_____no_output_____"
]
],
[
[
"As you can see, always predicting \"thousand\" which turn out to be the most common token in the dataset would result in ~15% accuracy. Our simple transformer does much better then that. It feels promising, so let's try to improve the architecture and check if we can get better results.",
"_____no_output_____"
],
[
"### Multihead attention",
"_____no_output_____"
],
[
"A structured sequence may comprise multiple distinctive kinds of relationships. Our model is forced to learn only one way in which queries, keys and values are constructed from the original token embedding. To remove this limitation we can modify attention layer include multiple heads which would correspond to extracting different kinds of relationships between tokens. The MultiHeadAttention layer consits of several heads each of those is similar to SelfAttention layer we made before. To keep computational cost of the multi-head layer we set $d_k = d_v = d_{model}/n_h$, where $n_h$ is number of heads.",
"_____no_output_____"
]
],
[
[
"class SelfAttention(Module):\n def __init__(self, d_in, d_qk, d_v=None):\n d_v = ifnone(d_v, d_qk)\n self.iq = nn.Linear(d_in, d_qk)\n self.ik = nn.Linear(d_in, d_qk)\n self.iv = nn.Linear(d_in, d_v)\n self.scale = d_qk**-0.5\n def forward(self, x):\n q, k, v = self.iq(x), self.ik(x), self.iv(x)\n return F.softmax([email protected](-2,-1)*self.scale, -1)@v",
"_____no_output_____"
],
[
"class MultiHeadAttention(Module):\n def __init__(self, d_model, n_heads, d_qk=None, d_v=None):\n d_qk = ifnone(d_qk, d_model//n_heads)\n d_v = ifnone(d_v, d_qk)\n self.heads = nn.ModuleList([SelfAttention(d_model, d_qk) for _ in range(n_heads)])\n self.out = nn.Linear(d_v*n_heads, d_model)\n \n def forward(self, x):\n out = [m(x) for m in self.heads]\n return self.out(torch.cat(out, -1))",
"_____no_output_____"
],
[
"inp = torch.randn(8, 10, 64)\nmha = MultiHeadAttention(64, 8)\nout = mha(inp)\nout.shape",
"_____no_output_____"
],
[
"class Model2(Module):\n def __init__(self, vocab_sz, d_model=64, n_heads=4, d_ff=64*4):\n self.emb = nn.Embedding(vocab_sz, d_model)\n self.attn = MultiHeadAttention(d_model, n_heads)\n self.ff = FeedForward(d_model, d_ff)\n self.out = nn.Linear(d_model, vocab_sz)\n def forward(self, x):\n x = self.emb(x)\n x = self.ff(self.attn(x))\n x = x.mean(1)\n return self.out(x)",
"_____no_output_____"
],
[
"learn = Learner(dls, Model2(len(vocab)), loss_func=CrossEntropyLossFlat(), metrics=accuracy)\nlearn.fit_one_cycle(5, 5e-4)",
"_____no_output_____"
]
],
[
[
"### MultiHead Attention Refactor",
"_____no_output_____"
],
[
"Python `for` loops are slow, therefore it is better to refactor the MultiHeadAttention module to compute Q, K, V for all heads in batch.",
"_____no_output_____"
]
],
[
[
"class MultiHeadAttention(Module):\n def __init__(self, d_model, n_heads):\n assert d_model%n_heads == 0\n self.n_heads = n_heads\n #d_qk, d_v = d_model//n_heads, d_model//n_heads\n self.iq = nn.Linear(d_model, d_model, bias=False)\n self.ik = nn.Linear(d_model, d_model, bias=False)\n self.iv = nn.Linear(d_model, d_model, bias=False)\n self.out = nn.Linear(d_model, d_model, bias=False)\n self.scale = d_model//n_heads\n \n def forward(self, x):\n bs, seq_len, d = x.size()\n # (bs,sl,d) -> (bs,sl,nh,dh) -> (bs,nh,sl,dh)\n q = self.iq(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n k = self.ik(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n v = self.iv(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n q*= self.scale\n att = F.softmax([email protected](-2,-1), -1)\n out = att @ v # (bs, nh, sl, sl) x (bs, nh, sl, dh) -> (bs, nh, sl, dh)\n out = out.transpose(1, 2).contiguous().view(bs, seq_len, d) # back to original shape\n return self.out(out)",
"_____no_output_____"
],
[
"learn = Learner(dls, Model2(len(vocab)), loss_func=CrossEntropyLossFlat(), metrics=accuracy)\nlearn.fit_one_cycle(5, 1e-3)",
"_____no_output_____"
]
],
[
[
"Note that some speedup is observed even on such a tiny dataset and small model.",
"_____no_output_____"
],
[
"## More signal",
"_____no_output_____"
],
[
"Similarly to the RNN case considered in the book, we can take the next step and create more signal for the model to learn from. To adapt to the modified objective we need to make couple of steps. First let's rearrange data to proper input-target pairs for the new task.",
"_____no_output_____"
],
[
"### Arranging data",
"_____no_output_____"
],
[
"Unlike RNN the tranformer is not a stateful model. This means it treats each sequence indepently and can only attend within fixed length context. This limitation was addressed by authors of [Transformer-XL paper](https://arxiv.org/abs/1901.02860) where adding a segment-level recurrence mechanism and a novel positional encoding scheme were proposed to enable capturing long-term dependencies. I will not go into details of TransformerXL architecture here. As we shell see stateless transformer can also learn a lot about the structure of our data.\n\nOne thing to note in this case is that we don't need to maintain the structure of the data outside of the sequences, so we can shuffle the sequences randomly in the dataloader.",
"_____no_output_____"
]
],
[
[
"sl = 16\nseqs = L((tensor(nums[i:i+sl]), tensor(nums[i+1:i+sl+1]))\n for i in range(0,len(nums)-sl-1,sl))\ncut = int(len(seqs) * 0.8)\ndls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:],\n bs=bs, drop_last=True, shuffle=True)\nxb, yb = dls.one_batch()\nxb.shape, yb.shape",
"_____no_output_____"
],
[
"[L(vocab[o] for o in s) for s in seqs[0]]",
"_____no_output_____"
]
],
[
[
"### Positional encoding",
"_____no_output_____"
],
[
"Before we did average pooling over seq_len dimension. Our model didn't care about the order of the tokens at all. But actually order of the tokens in a sentence matter a lot. In our case `one hundred two` and `two hundred one` are pretty different and `hundred one two` doesn't make sense.\n\nTo encorporate positional information into the model authors of the transformer architecture proposed to use positional encodings in addition to regular token embeddings. Positional encodings may be learned, but it's also possible to use hardcoded encodings. For instance encodings may be composed of sin and cos.\nIn this way each position in a sequence will get unique vector associated with it.",
"_____no_output_____"
]
],
[
[
"class PositionalEncoding(Module):\n def __init__(self, d):\n self.register_buffer('freq', 1/(10000 ** (torch.arange(0., d, 2.)/d)))\n self.scale = d**0.5\n def forward(self, x):\n device = x.device\n pos_enc = torch.cat([torch.sin(torch.outer(torch.arange(x.size(1), device=device), self.freq)),\n torch.cos(torch.outer(torch.arange(x.size(1), device=device), self.freq))],\n axis=-1)\n return x*self.scale + pos_enc",
"_____no_output_____"
],
[
"#collapse-hide\nx = torch.zeros(1, 16, 64)\nencs = PositionalEncoding(64)(x)\nplt.matshow(encs.squeeze())\nplt.xlabel('Embedding size')\nplt.ylabel('Sequence length')\nplt.show()",
"_____no_output_____"
],
[
"class TransformerEmbedding(Module):\n def __init__(self, emb_sz, d_model):\n self.emb = nn.Embedding(emb_sz, d_model)\n self.pos_enc = PositionalEncoding(d_model)\n def forward(self, x):\n return self.pos_enc(self.emb(x))",
"_____no_output_____"
],
[
"class Model3(Module):\n def __init__(self, vocab_sz, d_model=64, n_heads=4, d_ff=64*4):\n self.emb = TransformerEmbedding(vocab_sz, d_model)\n self.attn = MultiHeadAttention(d_model, n_heads)\n self.ff = FeedForward(d_model, d_ff)\n self.out = nn.Linear(d_model, vocab_sz)\n def forward(self, x):\n x = self.emb(x)\n x = self.ff(self.attn(x))\n return self.out(x)",
"_____no_output_____"
],
[
"model = Model3(len(vocab))\nout = model(xb)\nout.shape",
"_____no_output_____"
],
[
"def loss_func(inp, targ):\n return F.cross_entropy(inp.view(-1, len(vocab)), targ.view(-1))",
"_____no_output_____"
],
[
"learn = Learner(dls, Model3(len(vocab)), loss_func=loss_func, metrics=accuracy)\nlearn.fit_one_cycle(5, 1e-2)",
"_____no_output_____"
]
],
[
[
"Wow! That's a great accuracy! So the problem is solved and we only needed one attention layer and 2 layer deep feed-forward block? Don't you feel somewhat skeptical about this result?\n\nWell, you should be! Think about what we did here: the goal was to predict a target sequence, say `['.','two','.','three','.','four']` from an input `['one','.','two','.','three','.']`. These two sequences intersect on all positions except the first and the last one. So models needs to learn simply to copy input tokens starting from the second one to the outputs. In our case this will result in 15 correct predictions of total 16 positions, that's almost 94% accuracy. This makes the task very simple but not very useful to learn. To train proper autoregressive language model, as we did with RNNs, a concept of masking is to be introduced.",
"_____no_output_____"
],
[
"### Causal Masking",
"_____no_output_____"
],
[
"So we want to allow the model for each token to attend only to itself and those prior to it. To acomplish this we can set all the values of attention matrix above the main diagonal to $-\\infty$. After softmax this values will effectively turn to 0 thus disabling attention to the \"future\".",
"_____no_output_____"
]
],
[
[
"def get_subsequent_mask(x):\n sz = x.size(1)\n mask = (torch.triu(torch.ones(sz, sz, device=x.device)) == 1).transpose(0, 1)\n mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))\n return mask",
"_____no_output_____"
],
[
"inp = torch.randn(8, 10, 64)\nmask = get_subsequent_mask(inp)\nplt.matshow(mask);",
"_____no_output_____"
],
[
"q, k = torch.rand(1,10,32), torch.randn(1,10,32)\natt_ = F.softmax(([email protected](0,2,1)+mask), -1)\nplt.matshow(att_[0].detach());",
"_____no_output_____"
]
],
[
[
"We should also modify the attention layer to accept mask:",
"_____no_output_____"
]
],
[
[
"class MultiHeadAttention(Module):\n def __init__(self, d_model, n_heads):\n assert d_model%n_heads == 0\n self.n_heads = n_heads\n d_qk, d_v = d_model//n_heads, d_model//n_heads\n self.iq = nn.Linear(d_model, d_model, bias=False)\n self.ik = nn.Linear(d_model, d_model, bias=False)\n self.iv = nn.Linear(d_model, d_model, bias=False)\n self.scale = d_qk**-0.5\n self.out = nn.Linear(d_model, d_model, bias=False)\n \n def forward(self, x, mask=None):\n bs, seq_len, d = x.size()\n mask = ifnone(mask, 0)\n q = self.iq(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n k = self.ik(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n v = self.iv(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n q*= self.scale\n att = F.softmax([email protected](-2,-1) + mask, -1)\n \n out = att @ v # (bs, nh, sl, sl) x (bs, nh, sl, dh) -> (bs, nh, sl, dh)\n out = out.transpose(1, 2).contiguous().view(bs, seq_len, d) # back to original shape\n\n return self.out(out)",
"_____no_output_____"
],
[
"class Model4(Module):\n def __init__(self, vocab_sz, d_model=64, n_heads=8, d_ff=64*4):\n self.emb = TransformerEmbedding(vocab_sz, d_model)\n self.attn = MultiHeadAttention(d_model, n_heads)\n self.ff = FeedForward(d_model, d_ff)\n self.out = nn.Linear(d_model, vocab_sz)\n def forward(self, x):\n x = self.emb(x)\n mask = get_subsequent_mask(x)\n x = self.ff(self.attn(x, mask))\n return self.out(x)",
"_____no_output_____"
],
[
"learn = Learner(dls, Model4(len(vocab)), loss_func=loss_func, metrics=accuracy)\nlearn.fit_one_cycle(5, 3e-3)",
"_____no_output_____"
]
],
[
[
"Now we get somewhat lower accuracy, which is expected given that the task has become more difficult. Also training loss is significantly lower than validation loss, which means the model is overfitting. Let's see if the same approaches as was applied to RNNs can help.",
"_____no_output_____"
],
[
"### Multilayer transformer",
"_____no_output_____"
],
[
"To solve a more difficult task we ussualy need a deeper model. For convenience let's make a TransformerLayer which will combine self-attention and feed-forward blocks.",
"_____no_output_____"
]
],
[
[
"class TransformerLayer(Module):\n def __init__(self, d_model, n_heads=8, d_ff=None, causal=True):\n d_ff = ifnone(d_ff, 4*d_model)\n self.attn = MultiHeadAttention(d_model, n_heads)\n self.ff = FeedForward(d_model, d_ff)\n self.causal = causal\n def forward(self, x, mask=None):\n if self.causal:\n mask = get_subsequent_mask(x)\n return self.ff(self.attn(x, mask))",
"_____no_output_____"
],
[
"class Model5(Module):\n def __init__(self, vocab_sz, d_model=64, n_layer=4, n_heads=8):\n self.emb = TransformerEmbedding(vocab_sz, d_model)\n self.encoder = nn.Sequential(*[TransformerLayer(d_model, n_heads) for _ in range(n_layer)])\n self.out = nn.Linear(d_model, vocab_sz)\n def forward(self, x):\n x = self.emb(x)\n x = self.encoder(x)\n return self.out(x)",
"_____no_output_____"
],
[
"learn = Learner(dls, Model5(len(vocab), n_layer=4), loss_func=loss_func, metrics=accuracy)\nlearn.fit_one_cycle(5, 1e-2)",
"_____no_output_____"
]
],
[
[
"That's not good! 4 layer deep Transformer strugles to learn anything. But there are good news, this problem has been already resolved in the original transformer.",
"_____no_output_____"
],
[
"### Residual connections and Regularization",
"_____no_output_____"
],
[
"If you are familiar with ResNets the proposed solution will not surprise you much. The idea is simple yet very effective. Instead of returning modified output $f(x)$ each transformer sublayer will return $x + f(x)$. This allows the original input to propagate freely through the model. So the model learns not an entirely new representation of $x$ but how to modify $x$ to add some useful information to the original representation.\n\nAs we modify layers to include the residual connections let's also add some regularization by inserting Dropout layers.",
"_____no_output_____"
]
],
[
[
"class TransformerEmbedding(Module):\n def __init__(self, emb_sz, d_model, p=0.1):\n self.emb = Embedding(emb_sz, d_model)\n nn.init.trunc_normal_(self.emb.weight, std=d_model**-0.5)\n self.pos_enc = PositionalEncoding(d_model)\n self.drop = nn.Dropout(p)\n def forward(self, x):\n return self.drop(self.pos_enc(self.emb(x)))",
"_____no_output_____"
]
],
[
[
"Another modification is to add layer normalization which is intended to improve learning dynamics of the network by reparametrising data statistics and is generally used in transformer based architectures.",
"_____no_output_____"
]
],
[
[
"class FeedForward(Module):\n def __init__(self, d_model, d_ff, p=0.2):\n self.lin1 = nn.Linear(d_model, d_ff)\n self.lin2 = nn.Linear(d_ff, d_model)\n self.act = nn.ReLU()\n self.norm = nn.LayerNorm(d_model)\n self.drop = nn.Dropout(p)\n def forward(self, x):\n x = self.norm(x)\n out = self.act(self.lin1(x))\n out = self.lin2(out)\n return x + self.drop(out)",
"_____no_output_____"
],
[
"class MultiHeadAttention(Module):\n def __init__(self, d_model, n_heads, p=0.1):\n assert d_model%n_heads == 0\n self.n_heads = n_heads\n d_qk, d_v = d_model//n_heads, d_model//n_heads\n self.iq = nn.Linear(d_model, d_model, bias=False)\n self.ik = nn.Linear(d_model, d_model, bias=False)\n self.iv = nn.Linear(d_model, d_model, bias=False)\n self.scale = d_qk**0.5\n self.out = nn.Linear(d_model, d_model, bias=False)\n self.norm = nn.LayerNorm(d_model)\n self.drop = nn.Dropout(p)\n def forward(self, x, mask=None):\n bs, seq_len, d = x.size()\n mask = ifnone(mask, 0)\n x = self.norm(x)\n k = self.ik(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n q = self.iq(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n v = self.iv(x).view(bs, seq_len, self.n_heads, d//self.n_heads).transpose(1, 2)\n att = F.softmax([email protected](-2,-1)/self.scale + mask, -1)\n \n out = att @ v # (bs, nh, sl, sl) x (bs, nh, sl, dh) -> (bs, nh, sl, dh)\n out = out.transpose(1, 2).contiguous().view(bs, seq_len, d) # back to original shape\n\n return x + self.drop(self.out(out))",
"_____no_output_____"
],
[
"class TransformerLayer(Module):\n def __init__(self, d_model, n_heads=8, d_ff=None, causal=True,\n p_att=0.1, p_ff=0.1):\n d_ff = ifnone(d_ff, 4*d_model)\n self.attn = MultiHeadAttention(d_model, n_heads)\n self.ff = FeedForward(d_model, d_ff, p=p_ff)\n self.causal = causal\n self._init()\n def forward(self, x, mask=None):\n if self.causal:\n mask = get_subsequent_mask(x)\n return self.ff(self.attn(x, mask))\n def _init(self):\n for p in self.parameters():\n if p.dim()>1: nn.init.xavier_uniform_(p)",
"_____no_output_____"
],
[
"class Model6(Module):\n def __init__(self, vocab_sz, d_model=64, n_layer=4, n_heads=8, \n p_emb=0.1, p_att=0.1, p_ff=0.2, tie_weights=True):\n self.emb = TransformerEmbedding(vocab_sz, d_model, p=p_emb)\n self.encoder = nn.Sequential(*[TransformerLayer(d_model, n_heads,\n p_att=p_att, p_ff=p_ff)\n for _ in range(n_layer)],\n nn.LayerNorm(d_model))\n self.out = nn.Linear(d_model, vocab_sz)\n if tie_weights: self.out.weight = self.emb.emb.weight\n def forward(self, x):\n x = self.emb(x)\n x = self.encoder(x)\n return self.out(x)",
"_____no_output_____"
],
[
"learn = Learner(dls, Model6(len(vocab), n_layer=2), loss_func=loss_func, metrics=accuracy)\nlearn.fit_one_cycle(8, 1e-2)",
"_____no_output_____"
]
],
[
[
"## Bonus - Generation example",
"_____no_output_____"
]
],
[
[
"#hide\nfrom google.colab import drive\n\ndrive.mount('/content/drive')\npath = Path('/content/drive/MyDrive/char_model')",
"Mounted at /content/drive\n"
]
],
[
[
"Learning to predict numbers is great, but let's try something more entertaining. We can train a language model to generate texts. For example let's try to generate some text in style of Lewis Carroll. For this we'll fit a language model on \"Alice in Wonderland\" and \"Through the looking glass\".",
"_____no_output_____"
]
],
[
[
"#collapse-hide\ndef parse_txt(fns):\n txts = []\n for fn in fns:\n with open(fn) as f:\n tmp = ''\n for line in f.readlines():\n line = line.strip('\\n')\n if line:\n tmp += ' ' + line\n elif tmp:\n txts.append(tmp.strip())\n tmp = ''\n return txts",
"_____no_output_____"
],
[
"texts = parse_txt([path/'11-0.txt', path/'12-0.txt'])",
"_____no_output_____"
],
[
"len(texts)",
"_____no_output_____"
],
[
"texts[0:2]",
"_____no_output_____"
],
[
"#collapse-hide\nclass CharTokenizer(Transform):\n \"Simple charecter level tokenizer\"\n def __init__(self, vocab=None):\n self.vocab = ifnone(vocab, ['', 'xxbos', 'xxeos'] + list(string.printable))\n self.c2i = defaultdict(int, [(c,i) for i, c in enumerate(self.vocab)])\n def encodes(self, s, add_bos=False, add_eos=False):\n strt = [self.c2i['xxbos']] if add_bos else []\n end = [self.c2i['xxeos']] if add_eos else []\n return LMTensorText(strt + [self.c2i[c] for c in s] + end)\n def decodes(self, s, remove_special=False):\n return TitledStr(''.join([self.decode_one(i) for i in s]))\n def decode_one(self, i):\n if i == 2: return '\\n'\n elif i == 1: return ''\n else: return self.vocab[i]\n @property\n def vocab_sz(self):\n return len(self.vocab)\n",
"_____no_output_____"
],
[
"tok = CharTokenizer()",
"_____no_output_____"
],
[
"def add_bos_eos(x:list, bos_id=1, eos_id=2):\n return [bos_id] + x + [eos_id]",
"_____no_output_____"
],
[
"nums = [add_bos_eos(tok(t.lower()).tolist()) for t in texts]",
"_____no_output_____"
],
[
"len(nums)",
"_____no_output_____"
],
[
"all_nums = []\nfor n in nums: all_nums.extend(n)",
"_____no_output_____"
],
[
"all_nums[:15]",
"_____no_output_____"
],
[
"print(tok.decode(all_nums[:100]))",
"chapter i. down the rabbit-hole\nalice was beginning to get very tired of sitting by her sister on\n"
],
[
"sl = 512\nseqs = L((tensor(all_nums[i:i+sl]), tensor(all_nums[i+1:i+sl+1]))\n for i in range(0,len(all_nums)-sl-1,sl))\ncut = int(len(seqs) * 0.8)\ndls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], device='cuda',\n bs=8, drop_last=True, shuffle=True)\nxb, yb = dls.one_batch()\nxb.shape, yb.shape",
"_____no_output_____"
],
[
"model = Model6(tok.vocab_sz, 512, 6, p_emb=0.1, p_ff=0.1, tie_weights=True)\nlearn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=[accuracy, perplexity]).to_native_fp16()\nlearn.lr_find()",
"_____no_output_____"
],
[
"#collapse_output\nlearn.fit_one_cycle(50, 5e-4, cbs=EarlyStoppingCallback(patience=5))",
"_____no_output_____"
]
],
[
[
"### Text generation\n\nText generation is a big topic on it's own. One can refer to great posts [by Patrick von Platen from HuggingFace](https://huggingface.co/blog/how-to-generate) and [Lilian Weng](https://lilianweng.github.io/lil-log/2021/01/02/controllable-neural-text-generation.html) for more details on various approaches. Here I will use nucleus sampling. This method rallies on sampling from candidates compounding certain value of probability mass. Intuitively this approach should work for character level generation: when there is only one grammatically correct option for continuation we always want to select it, but when starting a new word some diversity in outputs is desirable.",
"_____no_output_____"
]
],
[
[
"#collapse-hide\ndef expand_dim1(x):\n if len(x.shape) == 1:\n return x[None, :]\n else: return x\n\ndef top_p_filter(logits, top_p=0.9):\n sorted_logits, sorted_indices = torch.sort(logits, descending=True)\n cum_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)\n\n sorted_indices_to_remove = cum_probs > top_p\n sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()\n sorted_indices_to_remove[..., 0] = 0\n indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)\n logits[indices_to_remove] = float('-inf')\n return logits\n\[email protected]_grad()\ndef generate(model, inp,\n max_len=50,\n temperature=1.,\n top_k = 20,\n top_p = 0.9,\n early_stopping=False, #need eos_idx to work\n eos_idx=None):\n model.to(inp.device)\n model.eval()\n thresh = top_p\n inp = expand_dim1(inp)\n b, t = inp.shape\n out = inp\n for _ in range(max_len):\n x = out\n\n logits = model(x)[:, -1, :]\n filtered_logits = top_p_filter(logits)\n probs = F.softmax(filtered_logits / temperature, dim=-1)\n sample = torch.multinomial(probs, 1)\n\n out = torch.cat((out, sample), dim=-1)\n\n if early_stopping and (sample == eos_idx).all():\n break\n return out",
"_____no_output_____"
],
[
"out = generate(learn.model, tok('Alice said '), max_len=200, early_stopping=True, eos_idx=tok.c2i['xxeos'])",
"_____no_output_____"
],
[
"print(tok.decode(out[0]))",
"Alice said in a minute turn, only purind his with it migut at in musible. i cant elp out my why yested it to like thought: i know i did it wish indeed it hope?\n\n"
]
],
[
[
"Our relatively simple model learned to generate mostly grammatically plausible text, but it's not entirely coherent. But it would be too much to ask from the model to learn language from scratch by \"reading\" only two novels (however great those novels are). To get more from the model let's feed it larger corpus of data.",
"_____no_output_____"
],
[
"### Pretraining on larger dataset",
"_____no_output_____"
]
],
[
[
"#hide\nimport sys\nif 'google.colab' in sys.modules:\n !pip install -Uqq datasets\n\nfrom datasets import load_dataset",
"\u001b[K |████████████████████████████████| 163kB 14.0MB/s \n\u001b[K |████████████████████████████████| 17.7MB 207kB/s \n\u001b[K |████████████████████████████████| 245kB 54.7MB/s \n\u001b[?25h"
]
],
[
[
"For this purpose I will use a sample from [bookcorpus dataset](https://huggingface.co/datasets/bookcorpus). ",
"_____no_output_____"
]
],
[
[
"#hide_ouput\ndataset = load_dataset(\"bookcorpus\", split='train')",
"_____no_output_____"
],
[
"df = pd.DataFrame(dataset[:10_000_000])\ndf.head()",
"_____no_output_____"
],
[
"df['len'] = df['text'].str.len()",
"_____no_output_____"
],
[
"cut = int(len(df)*0.8)\nsplits = range_of(df)[:cut], range_of(df[cut:])\ntfms = Pipeline([ColReader('text'), tok])\ndsets = Datasets(df, tfms=tfms, dl_type=LMDataLoader, splits=splits)",
"_____no_output_____"
],
[
"#collapse\n@patch\ndef create_item(self:LMDataLoader, seq):\n if seq>=self.n: raise IndexError\n sl = self.last_len if seq//self.bs==self.n_batches-1 else self.seq_len\n st = (seq%self.bs)*self.bl + (seq//self.bs)*self.seq_len\n txt = self.chunks[st : st+sl+1] \n return LMTensorText(txt[:-1]),txt[1:]",
"_____no_output_____"
],
[
"%%time\ndl_kwargs = [{'lens':df['len'].values[splits[0]]}, {'val_lens':df['len'].values[splits[1]]}]\ndls = dsets.dataloaders(bs=32, seq_len=512, dl_kwargs=dl_kwargs, shuffle_train=True, num_workers=2)",
"CPU times: user 13min 29s, sys: 13 s, total: 13min 42s\nWall time: 13min 35s\n"
],
[
"dls.show_batch(max_n=2)",
"_____no_output_____"
],
[
"model = Model6(tok.vocab_sz, 512, 8, p_emb=0.1, p_ff=0.1, tie_weights=True)\nlearn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=[accuracy, perplexity]).to_native_fp16()\nlearn.lr_find()",
"_____no_output_____"
],
[
"learn = learn.load(path/'char_bookcorpus_10m')",
"_____no_output_____"
],
[
"learn.fit_one_cycle(1, 1e-4)",
"_____no_output_____"
],
[
"learn.save(path/'char_bookcorpus_10m')",
"_____no_output_____"
]
],
[
[
"### Finetune on Carrolls' books\n\nFinally we can finetune the pretrained bookcorpus model on Carroll's books. This will determine the style of generated text.",
"_____no_output_____"
]
],
[
[
"sl = 512\nseqs = L((tensor(all_nums[i:i+sl]), tensor(all_nums[i+1:i+sl+1]))\n for i in range(0,len(all_nums)-sl-1,sl))\ncut = int(len(seqs) * 0.8)\ndls = DataLoaders.from_dsets(seqs[:cut], seqs[cut:], device='cuda',\n bs=16, drop_last=True, shuffle=True)",
"_____no_output_____"
],
[
"model = Model6(tok.vocab_sz, 512, 8, p_emb=0.1, p_ff=0.1, tie_weights=True)\nlearn = Learner(dls, model, loss_func=CrossEntropyLossFlat(), metrics=[accuracy, perplexity]).to_native_fp16()",
"_____no_output_____"
],
[
"learn = learn.load(path/'char_bookcorpus_10m')\nlearn.lr_find()",
"_____no_output_____"
],
[
"learn.fit_one_cycle(10, 1e-4)",
"_____no_output_____"
]
],
[
[
"As you see pretraining model on large corpus followed by finetuning helped to reduce validation loss from arount 1.53 to 1.037 and improve accuracy in predicting next character to 68% (compared to 56.7% before). Let's see how it effects sampled text:",
"_____no_output_____"
]
],
[
[
"out = generate(learn.model, tok('Alice said '), max_len=200, early_stopping=True, eos_idx=tok.c2i['xxeos'])",
"_____no_output_____"
],
[
"#collapse-hide\nprint(tok.decode(out[0]))",
"Alice said what you want is, why, if you cant see a little rather from people to bed their moment, when birds began drinking from behind, and offering the cart to say something, and dripping off a strange mou\n"
],
[
"#hide\nlearn.save(path/'char_alice')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ac946aab29c01758e1b44d1461c19a6dccca42c
| 12,918 |
ipynb
|
Jupyter Notebook
|
notebooks/eda.ipynb
|
ttimbers/demo-tests-ds-analysis
|
8789f31df9a8b6112f3af283c825e56af662c336
|
[
"MIT"
] | null | null | null |
notebooks/eda.ipynb
|
ttimbers/demo-tests-ds-analysis
|
8789f31df9a8b6112f3af283c825e56af662c336
|
[
"MIT"
] | null | null | null |
notebooks/eda.ipynb
|
ttimbers/demo-tests-ds-analysis
|
8789f31df9a8b6112f3af283c825e56af662c336
|
[
"MIT"
] | null | null | null | 54.050209 | 485 | 0.548305 |
[
[
[
"## Demo of sourcing an R function from a script\n\nHere we demonstrate how we can use the `source` function to read in a function stored in another R script contained within this repository. The function in the file `../R/count_classes.R` is named `count_classes` (it doesn't have to have the same name as the file, but it often makes sense to do this), and sourcing the file allows us to access the function in this notebook. We will demonstrate using it below to calculate the number of observations in each class of a data set.",
"_____no_output_____"
]
],
[
[
"options(repr.matrix.max.rows = 6)\nlibrary(tidyverse)\nsource(\"../R/count_classes.R\")",
"── \u001b[1mAttaching packages\u001b[22m ─────────────────────────────────────── tidyverse 1.3.1 ──\n\n\u001b[32m✔\u001b[39m \u001b[34mggplot2\u001b[39m 3.3.5 \u001b[32m✔\u001b[39m \u001b[34mpurrr \u001b[39m 0.3.4\n\u001b[32m✔\u001b[39m \u001b[34mtibble \u001b[39m 3.1.6 \u001b[32m✔\u001b[39m \u001b[34mdplyr \u001b[39m 1.0.7\n\u001b[32m✔\u001b[39m \u001b[34mtidyr \u001b[39m 1.2.0 \u001b[32m✔\u001b[39m \u001b[34mstringr\u001b[39m 1.4.0\n\u001b[32m✔\u001b[39m \u001b[34mreadr \u001b[39m 2.1.2 \u001b[32m✔\u001b[39m \u001b[34mforcats\u001b[39m 0.5.1\n\n── \u001b[1mConflicts\u001b[22m ────────────────────────────────────────── tidyverse_conflicts() ──\n\u001b[31m✖\u001b[39m \u001b[34mdplyr\u001b[39m::\u001b[32mfilter()\u001b[39m masks \u001b[34mstats\u001b[39m::filter()\n\u001b[31m✖\u001b[39m \u001b[34mdplyr\u001b[39m::\u001b[32mlag()\u001b[39m masks \u001b[34mstats\u001b[39m::lag()\n\n"
]
],
[
[
"Here's some data (the Wisconsin Breast Cancer data set, originally from the [UCI machine learning repository](https://archive-beta.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+diagnostic)) where we would like to calculate the number of observations in each class:",
"_____no_output_____"
]
],
[
[
"cancer <- read_csv(\"https://github.com/UBC-DSCI/introduction-to-datascience/raw/master/data/wdbc.csv\")\ncancer",
"\u001b[1mRows: \u001b[22m\u001b[34m569\u001b[39m \u001b[1mColumns: \u001b[22m\u001b[34m12\u001b[39m\n\u001b[36m──\u001b[39m \u001b[1mColumn specification\u001b[22m \u001b[36m────────────────────────────────────────────────────────\u001b[39m\n\u001b[1mDelimiter:\u001b[22m \",\"\n\u001b[31mchr\u001b[39m (1): Class\n\u001b[32mdbl\u001b[39m (11): ID, Radius, Texture, Perimeter, Area, Smoothness, Compactness, Con...\n\n\u001b[36mℹ\u001b[39m Use \u001b[30m\u001b[47m\u001b[30m\u001b[47m`spec()`\u001b[47m\u001b[30m\u001b[49m\u001b[39m to retrieve the full column specification for this data.\n\u001b[36mℹ\u001b[39m Specify the column types or set \u001b[30m\u001b[47m\u001b[30m\u001b[47m`show_col_types = FALSE`\u001b[47m\u001b[30m\u001b[49m\u001b[39m to quiet this message.\n"
]
],
[
[
"To calculate the number observations of each class, we will use the `count_classes` function from the `../R/count_classes.R` file that we sourced in the first code cell of this notebook:",
"_____no_output_____"
]
],
[
[
"count_classes(cancer, Class)",
"_____no_output_____"
]
],
[
[
"Ta da! Now isn't that easier to read for a human trying to understand the analysis, compared to if we included the source code for that function in this notebook?",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ac9683eb287b0d25499349fd0b53e690cd1618c
| 157,812 |
ipynb
|
Jupyter Notebook
|
data_files/data_eng_data_accuracy_analysis_roster_match.ipynb
|
sojackyso/match_source_data
|
34a32ae587caf779591f81d54597660dd7eee922
|
[
"MIT"
] | null | null | null |
data_files/data_eng_data_accuracy_analysis_roster_match.ipynb
|
sojackyso/match_source_data
|
34a32ae587caf779591f81d54597660dd7eee922
|
[
"MIT"
] | null | null | null |
data_files/data_eng_data_accuracy_analysis_roster_match.ipynb
|
sojackyso/match_source_data
|
34a32ae587caf779591f81d54597660dd7eee922
|
[
"MIT"
] | null | null | null | 41.59515 | 699 | 0.400077 |
[
[
[
"%%bash\nhead /Users/jackyso/Desktop/data_files/source_data.json",
"{\"doctor\":{\"first_name\":\"Dean\",\"last_name\":\"Israel\",\"npi\":\"85103080143784778415\"},\"practices\":[{\"street\":\"271 Annabelle Fort\",\"street_2\":\"Apt. 404\",\"zip\":\"53549\",\"city\":\"Port Demetris\",\"state\":\"LA\",\"lat\":\"-79.8757664338564\",\"lon\":\"84.31253504872467\"}]}\n{\"doctor\":{\"first_name\":\"Quinton\",\"last_name\":\"Mollie\",\"npi\":\"36233383542350521233\"},\"practices\":[{\"street\":\"8496 Kennedi Inlet\",\"street_2\":\"Suite 815\",\"zip\":\"52665-6811\",\"city\":\"Nealville\",\"state\":\"OR\",\"lat\":\"81.37417480720865\",\"lon\":\"-95.33450729432164\"},{\"street\":\"29483 Nader Wall\",\"street_2\":\"Apt. 748\",\"zip\":\"46006-3437\",\"city\":\"Rashadborough\",\"state\":\"UT\",\"lat\":\"69.84837521604314\",\"lon\":\"87.36942972635728\"},{\"street\":\"2122 Wintheiser Valleys\",\"street_2\":\"Suite 855\",\"zip\":\"99372\",\"city\":\"South Daronland\",\"state\":\"AK\",\"lat\":\"84.90377842497296\",\"lon\":\"177.28706015725533\"}]}\n{\"doctor\":{\"first_name\":\"Vincent\",\"last_name\":\"Abbie\",\"npi\":\"68951826121607537145\"},\"practices\":[{\"street\":\"210 Walsh Island\",\"street_2\":\"Suite 839\",\"zip\":\"59104\",\"city\":\"West Lonnieberg\",\"state\":\"GA\",\"lat\":\"52.12502086274685\",\"lon\":\"109.12414094328233\"},{\"street\":\"460 Ortiz Points\",\"street_2\":\"Suite 609\",\"zip\":\"60776-9928\",\"city\":\"Port Angieborough\",\"state\":\"KY\",\"lat\":\"89.41473074638557\",\"lon\":\"-38.22151510102702\"},{\"street\":\"13810 Pfannerstill Pike\",\"street_2\":\"Apt. 165\",\"zip\":\"71167-1710\",\"city\":\"Nyasiaburgh\",\"state\":\"NH\",\"lat\":\"0.7514069044332956\",\"lon\":\"93.56993517086102\"}]}\n{\"doctor\":{\"first_name\":\"Gerardo\",\"last_name\":\"Piper\",\"npi\":\"92442805782715742535\"},\"practices\":[{\"street\":\"1262 O'Keefe Ford\",\"street_2\":\"Apt. 790\",\"zip\":\"39283\",\"city\":\"Grantborough\",\"state\":\"MN\",\"lat\":\"78.53231427000821\",\"lon\":\"12.229188372184922\"},{\"street\":\"591 Gretchen Fields\",\"street_2\":\"Apt. 523\",\"zip\":\"15472\",\"city\":\"East Ozella\",\"state\":\"PA\",\"lat\":\"25.541057391873352\",\"lon\":\"-32.342152333557465\"}]}\n{\"doctor\":{\"first_name\":\"Dean\",\"last_name\":\"Francesco\",\"npi\":\"83029151715578341587\"},\"practices\":[{\"street\":\"98764 Mante Trafficway\",\"street_2\":\"Suite 356\",\"zip\":\"43570\",\"city\":\"New Fredy\",\"state\":\"IL\",\"lat\":\"-4.541598251928605\",\"lon\":\"-41.46795232079714\"},{\"street\":\"43586 Roberto Harbor\",\"street_2\":\"Apt. 875\",\"zip\":\"37340\",\"city\":\"D'Amoreview\",\"state\":\"DE\",\"lat\":\"34.926103897363646\",\"lon\":\"89.45264216496582\"}]}\n{\"doctor\":{\"first_name\":\"Marshall\",\"last_name\":\"Cole\",\"npi\":\"18233577393219566041\"},\"practices\":[{\"street\":\"729 Reuben Stream\",\"street_2\":\"Apt. 314\",\"zip\":\"85355\",\"city\":\"Lake Sheila\",\"state\":\"AZ\",\"lat\":\"67.8952178905721\",\"lon\":\"-71.54982356539455\"},{\"street\":\"59944 Adaline Harbor\",\"street_2\":\"Apt. 862\",\"zip\":\"94189-5965\",\"city\":\"Keelingstad\",\"state\":\"AL\",\"lat\":\"-84.7669879597025\",\"lon\":\"134.0653096213187\"},{\"street\":\"920 Hester Drive\",\"street_2\":\"Apt. 759\",\"zip\":\"86170-5877\",\"city\":\"South Vesta\",\"state\":\"IA\",\"lat\":\"-80.29587184932748\",\"lon\":\"-156.78993611303167\"}]}\n{\"doctor\":{\"first_name\":\"Lawson\",\"last_name\":\"Lilliana\",\"npi\":\"78792788275411915642\"},\"practices\":[{\"street\":\"36175 Amina Mount\",\"street_2\":\"Apt. 256\",\"zip\":\"30997-4476\",\"city\":\"North Daija\",\"state\":\"DE\",\"lat\":\"-5.6687886642665575\",\"lon\":\"-78.53360129963642\"}]}\n{\"doctor\":{\"first_name\":\"Coty\",\"last_name\":\"Brad\",\"npi\":\"50391514247237749255\"},\"practices\":[{\"street\":\"45963 Karli Square\",\"street_2\":\"Apt. 942\",\"zip\":\"53565\",\"city\":\"West Calistaside\",\"state\":\"ND\",\"lat\":\"-58.29709418783973\",\"lon\":\"-90.33104012263043\"},{\"street\":\"88315 Hilma Rapid\",\"street_2\":\"Suite 795\",\"zip\":\"40956-7199\",\"city\":\"South Breanahaven\",\"state\":\"NY\",\"lat\":\"35.61319092049271\",\"lon\":\"-40.85256575227882\"},{\"street\":\"46952 Purdy Greens\",\"street_2\":\"Suite 133\",\"zip\":\"21329-5225\",\"city\":\"Turcotteborough\",\"state\":\"ME\",\"lat\":\"-26.725359700401064\",\"lon\":\"147.06704213574403\"}]}\n{\"doctor\":{\"first_name\":\"Billy\",\"last_name\":\"Gennaro\",\"npi\":\"10032670447666263763\"},\"practices\":[{\"street\":\"441 Marge Turnpike\",\"street_2\":\"Apt. 734\",\"zip\":\"81096-8100\",\"city\":\"West Penelope\",\"state\":\"OK\",\"lat\":\"-26.051512799700845\",\"lon\":\"-142.5655398712161\"}]}\n{\"doctor\":{\"first_name\":\"Deion\",\"last_name\":\"Mae\",\"npi\":\"36556623055822736995\"},\"practices\":[{\"street\":\"91801 Jamel Port\",\"street_2\":\"Apt. 482\",\"zip\":\"58023\",\"city\":\"Streichchester\",\"state\":\"AZ\",\"lat\":\"14.435512034467493\",\"lon\":\"-17.361548051772843\"}]}\n"
],
[
"\"\"\"\nclean and prep data for matching:\nlowercase everything, take only first 5 digits of zip, pop out each address from each doctor, make all string to preserve zip and npi values\n\ncolumns = ['first_name','last_name','npi','street','street_2','zip','city','state']\naddress = [['street'],['street_2'],['zip'],['city'],['state']]\ndoctor = ['first_name','last_name','npi']\npractices = [address]\n\"\"\"\nimport pandas as pd\nimport json\nimport csv\nimport numpy as np\n# set view width to fit entire row\npd.set_option('max_colwidth',-1)\n\ncsvFile = '/Users/jackyso/Desktop/data_files/match_file.csv'\njsonFile = '/Users/jackyso/Desktop/data_files/source_data.json'\n\n# read in csv and turn into dataframe, make it string to preserve values \ndf_match = pd.read_csv(csvFile, header = 0, dtype = str)\n# take only first 5 chars of zip to standardize\ndf_match['zip'] = df_match['zip'].str[:5]\n# make all lowercase to standardize using apply astype\n# df_match=df_match.apply(lambda x:x.astype(str).str.lower())\ndf_match = df_match.fillna('').astype(str).apply(lambda x: x.str.lower())\n# remove punctuations from street_2 column\ndf_match['street_2'] = df_match['street_2'].str.replace('[^\\w\\s]','')\n\n# need to convert empty string or whitespace into NaN so we can do pandas notna/isna string compare\ndf_match=df_match.astype(str).apply(lambda x: x.str.strip()).replace('', np.nan)\n# df_match[df_match['npi'].notna()].head(10)\n\n#view top 10 results\ndf_match[0:10]",
"_____no_output_____"
],
[
"# read in json, values already in string but need to orient as columns\n# already declared jsonFile path above\ndf_source = pd.read_json(jsonFile, orient='columns', lines=True)\n# view top\ndf_source.head()",
"_____no_output_____"
],
[
"# view doctor returns doctor, dtype: object\ndf_source['doctor'].head()",
"_____no_output_____"
],
[
"# view array of practices\ndf_source['practices'].head()",
"_____no_output_____"
],
[
"\"\"\"\none doctor can be at many addresses, so \"practices\" is an array of addresses\npop out each address so you can see doctor-practice individual association\nneed to define the dictionary. for every row in the data, key is \"doctor\" and many addresses can be tied to one doctor\n\nPRO-TIP:\nlowercase data to standardize. If do this before popping out addresses from array, it will give you error because str.lower will give you an object.\nthen you are trying to make a dataframe out of a list of tuples. easier to lowercase after popping out addresses separately.\n> df_source = df_source.apply(lambda x:x.astype(str).str.lower())\n\"\"\"\ndf_source = pd.DataFrame([dict(y,doctor = i) for i,x in df_source.values.tolist() for y in x])\n# to view\ndf_source.head()",
"_____no_output_____"
],
[
"# unpack tuples doctor column to individual columns\n# take dict, make a new dataframe\nd = df_source['doctor'].to_dict()\n\n# transpose it, redefine it\ndf_source_d = pd.DataFrame.from_dict(d).transpose()\n\n# view new dataframe\ndf_source_d.head()",
"_____no_output_____"
],
[
"# drop doctor column\ndf_source = df_source.drop(columns='doctor')\ndf_source.head()",
"_____no_output_____"
],
[
"# add new columns from new dataframe via concat\ndf_good = pd.concat([df_source, df_source_d], join = 'outer', sort = False, axis = 1)\n\ndf_good.head()",
"_____no_output_____"
],
[
"# after popping everything out, now do lowercase data to standardize.\n# df_source = df_source.apply(lambda x:x.astype(str).str.lower())\ndf_good = df_good.fillna('').astype(str).apply(lambda x: x.str.lower())\ndf_good.head()",
"_____no_output_____"
],
[
"# standardize zip with first 5 chars for addresses from json file\ndf_good['zip'] = df_good['zip'].str[:5]\ndf_good.head()",
"_____no_output_____"
],
[
"# null check\n# df_good[df_good['npi'].notna()]\n\n# remove punctuations from street_2 column\ndf_good['street_2'] = df_good['street_2'].str.replace('[^\\w\\s]','')\ndf_good.head()",
"_____no_output_____"
],
[
"# recall that dataframe01 = df_match\n# dataframe02 = df_good\n# select distinct npi from dataframe01 where exists(select 1 from dataframe02 where dataframe02.npi = dataframe01.npi)\n# merge does inner join by default\n# SELECT * FROM df1 INNER JOIN df2 ON df1.key = df2.key\ndf_npi = pd.merge(df_match, df_good, on='npi')\n# df_npi.head()\nlen(df_npi['npi'].unique())\n# 864 unique npis in both sets",
"_____no_output_____"
],
[
"# group by\n# inner join to find only same ones in both\n# left join gets you match data in despite whether it matches or not\n# pandas merge full reference: http://pandas.pydata.org/pandas-docs/version/0.19.1/generated/pandas.DataFrame.merge.html\ndf_fullname_npi = pd.merge(df_match, df_good, on=['npi','first_name','last_name'])\n# new_df = pd.merge(A_df, B_df, how='left', left_on=['A_c1','c2'], right_on = ['B_c1','c2'])\nlen(df_fullname_npi['npi'].unique())",
"_____no_output_____"
],
[
"# name and address match = 799\ndf_name_address = pd.merge(df_match, df_good, on=['first_name','last_name','street','street_2','zip','city','state'])\n# new_df = pd.merge(A_df, B_df, how='left', left_on=['A_c1','c2'], right_on = ['B_c1','c2'])\nlen(df_name_address['first_name'].unique())",
"_____no_output_____"
],
[
"# address match = 921\ndf_address = pd.merge(df_match, df_good, on=['street','street_2','zip','city','state'])\nlen(df_address['street'].unique())",
"_____no_output_____"
],
[
"# left-excluding join to get unmatched data.\n# join csv df to source df with left. matches get mapped to source that includes lat, lon. those without get NaN lat lon and get dropped.\n# add indicator column to see how it was merged. \"left_only\" means only in csv. \"both\" means it appears in both files.\ndf_unmatched = pd.merge(df_match,df_good, how='left', indicator=True)\ndf_unmatched\n# csv only had 1265 rows. json had over 11k rows but over 22k practices. thus, only 1265 are attempting matches.\n# unmatched check displays results for the 1265 rows.",
"_____no_output_____"
],
[
"df_unmatched_results = df_unmatched[df_unmatched['_merge'].eq('left_only')]\n# .drop(['df_good','_merge'],axis=1)\ndf_unmatched_results\n# returns 574 rows but does not account for any possible doctor-address matches, only all matches of dr, npi, and address",
"_____no_output_____"
],
[
"\"\"\"\ndataframe01 = df_match\ndataframe02 = df_good\n1) \n\"df_compare.shape[0]\" will tell you how many rows were evaluated\n\"df_compare.count()\" will give you the breakdown of values found in each column, but it will exclude NaN\n\n2)\ndf_npi = pd.merge(df_match, df_good, on='npi')\nlen(df_npi['npi'].unique())\n# returns 864\n\n3) \ndf_name_address = pd.merge(df_match, df_good, on=['first_name','last_name','street','street_2','zip','city','state'])\n# new_df = pd.merge(A_df, B_df, how='left', left_on=['A_c1','c2'], right_on = ['B_c1','c2'])\nlen(df_name_address['first_name'].unique())\n# returns 799\n\n4)\ndf_address = pd.merge(df_match, df_good, on=['street','street_2','zip','city','state'])\nlen(df_address['street'].unique())\n# returns 921\n\n5) total unmatched - return unmatched from each of above, and throw in total from left-excluding join, too\n\n# left-excluding join to get unmatched data.\n# join csv df to source df with left. matches get mapped to source that includes lat, lon. those without get NaN lat lon and get dropped.\n# add indicator column to see how it was merged. \"left_only\" means only in csv. \"both\" means it appears in both files.\ndf_unmatched = pd.merge(df_match,df_good, how='left', indicator=True)\ndf_unmatched\n# csv only had 1265 rows. json had over 11k rows but over 22k practices. thus, only 1265 are attempting matches.\n# unmatched check displays results for the 1265 rows.\ndf_unmatched_results = df_unmatched[df_unmatched['_merge'].eq('left_only')]\n# .drop(['df_good','_merge'],axis=1)\ndf_unmatched_results\n# returns 574 rows but does not account for any possible doctor-address matches, only all matches of dr, npi, and address\n# spot check or view sample to compare between and test\n\"\"\"\ndf_compare = pd.merge(df_match,df_good, how='left', indicator=True)\n# would be great to do a left join on this and use the indicator column to select for records in both or not in both, but would need to drop duplicates\n# merge will inner join by default, which is what we want for only the npis in both data sets\ndf_npi = pd.merge(df_match,df_good, on='npi')\ndf_name_address = pd.merge(df_match, df_good, on=['first_name','last_name','street','street_2','zip','city','state'])\n# only unique addresses, do left merge so can use it later for unmatched addresses\ndf_address = pd.merge(df_match, df_good, how = 'left', on=['street','street_2','zip','city','state'], indicator = True)\n# len(df_name_address['first_name'].unique())\n\ndf_matched_results = pd.merge(df_match,df_good, how='left', indicator=True)\ndf_all_unmatched_columns_result = df_matched_results[df_matched_results['_merge'].eq('left_only')]\n\ndf_not_npi = pd.merge(df_match, df_good, how='left', on='npi', indicator=True).drop_duplicates(keep='first')\n# df_not_npi.query('_merge != \"both\"')\ndf_not_name_address = pd.merge(df_match, df_good, how='left', on=['first_name','last_name','street','street_2','zip','city','state'], indicator=True)\n\nprint(\"*****Breakdown of Total Number of Documents Scanned:*****\\n\\n\", df_compare.count())\nprint(\"\\n*****MATCHED DOCUMENTS BREAKDOWN:*****\\n\")\nprint(\"\\n*Number of Doctors Matched with NPI:\\n\", len(df_npi['npi'].unique()))\nprint(\"\\n*Number of Doctors Matched with Name + Address:\\n\", len(df_name_address['first_name'].unique()))\nprint(\"\\n*Number of Practices Matched with Address:\\n\", len(df_address.query('_merge == \"both\"')))\n# unmatches are interesting, because you can find a practice that exists and is missing a doctor, so the doctor might need to be appended to it later\nprint(\"\\n*****UNMATCHED DOCUMENTS BREAKDOWN:*****\\n\")\n# npis not matched\nprint(\"*Number of Unmatched NPIs:\\n\", len(df_not_npi.query('_merge != \"both\"')))\n# doctor name and address not matched\nprint(\"\\n*Number of Unmatched Doctors by Name + Address:\\n\", len(df_not_name_address.query('_merge != \"both\"')))\n# practices not matched\nprint(\"\\n*Number of Unmatched Practices by Address:\\n\", len(df_address.query('_merge != \"both\"')))\n\n# for kicks, doctors that did not match by all given fields: name, address, and npi\n# this is interesting, because you can have a doctor who does not match by all fields due to missing npi, but they have the same name and one of their many addresses\nprint(\"\\n*Number of Unmatched Doctors by Name, Address, and NPI:\\n\", len(df_all_unmatched_columns_result.query('_merge != \"both\"')))\nprint(\"\\n*****Breakdown of Total Number of Unmatched Doctors by Name, Address, and NPI:*****\\n\\n\", df_all_unmatched_columns_result.count())\n\nprint(\"\\n*****EDGE CASES TO CONSIDER:*****\\n- practice matches but does not have doctor, consider appending as \\\"new doctor\\\" to practice\\n- doctor name and address match with NaN npi, consider assumption that doctor is same person\")\n\n# for extra kicks, write all the unmatched data to a csv so you can share it with interested parties or have it for reference later\n# import os\n# \"\"\"change filepath as you wish\"\"\"\n# file = 'matched_results.csv'\n# df_matched_results.to_csv(file, header=True, index=False)\n\n\"\"\"uncomment these for each result csv, depending on what you want to compare.\\\"both\" means matched fields appear in both, \\\"left_only\" means matched fields not found in source data as is\"\"\"\nimport os\ndf_matched_results.to_csv('matched_results.csv', header=True, index=False)\ndf_name_address.to_csv('name_address.csv', header=True, index=False)\ndf_address.to_csv('practice_match.csv', header=True, index=False)\n\nprint(\"\\nMAGICAL DATA! THANK YOU FOR EXPLORING WITH ME!\")\nprint(\"\"\"\n\\\n \\\\\n \\%, ,' , ,.\n \\%\\,';/J,\";\";\";;,,.\n ~.------------\\%;((`);)));`;;,.,-----------,~\n ~~: ,`;@)((;`,`((;(;;);;,` :~~\n ~~ : ;`(@```))`~ ``; );(;));;, : ~~\n ~~ : `X `(( `), (;;);;;;` : ~~\n ~~~~ : / `) `` /;~ `;;;;;;;);, : ~~~~\n~~~~ : / , ` ,/` / (`;;(;;;;, : ~~~~\n ~~~ : (o /]_/` / ,);;;`;;;;;`,, : ~~~\n ~~ : `~` `~` ` ``;, ``;\" ';, : ~~\n ~~: YAY! `' `' `' :~~\n ~`-----------------------------------------`~\n\n\"\"\")",
"*****Breakdown of Total Number of Documents Scanned:*****\n\n first_name 1265\nlast_name 1265\nnpi 978 \nstreet 1035\nstreet_2 1035\ncity 1035\nstate 1035\nzip 1035\nlat 691 \nlon 691 \n_merge 1265\ndtype: int64\n\n*****MATCHED DOCUMENTS BREAKDOWN:*****\n\n\n*Number of Doctors Matched with NPI:\n 864\n\n*Number of Doctors Matched with Name + Address:\n 799\n\n*Number of Practices Matched with Address:\n 921\n\n*****UNMATCHED DOCUMENTS BREAKDOWN:*****\n\n*Number of Unmatched NPIs:\n 401\n\n*Number of Unmatched Doctors by Name + Address:\n 344\n\n*Number of Unmatched Practices by Address:\n 344\n\n*Number of Unmatched Doctors by Name, Address, and NPI:\n 574\n\n*****Breakdown of Total Number of Unmatched Doctors by Name, Address, and NPI:*****\n\n first_name 574\nlast_name 574\nnpi 287\nstreet 344\nstreet_2 344\ncity 344\nstate 344\nzip 344\nlat 0 \nlon 0 \n_merge 574\ndtype: int64\n\n*****EDGE CASES TO CONSIDER:*****\n- practice matches but does not have doctor, consider appending as \"new doctor\" to practice\n- doctor name and address match with NaN npi, consider assumption that doctor is same person\n\nMAGICAL DATA! THANK YOU FOR EXPLORING WITH ME!\n\n \\\n \\%, ,' , ,.\n \\%\\,';/J,\";\";\";;,,.\n ~.------------\\%;((`);)));`;;,.,-----------,~\n ~~: ,`;@)((;`,`((;(;;);;,` :~~\n ~~ : ;`(@```))`~ ``; );(;));;, : ~~\n ~~ : `X `(( `), (;;);;;;` : ~~\n ~~~~ : / `) `` /;~ `;;;;;;;);, : ~~~~\n~~~~ : / , ` ,/` / (`;;(;;;;, : ~~~~\n ~~~ : (o /]_/` / ,);;;`;;;;;`,, : ~~~\n ~~ : `~` `~` ` ``;, ``;\" ';, : ~~\n ~~: YAY! `' `' `' :~~\n ~`-----------------------------------------`~\n\n\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac977cab8ae30691f52e6bb1f64fda4820bbfe3
| 274,057 |
ipynb
|
Jupyter Notebook
|
2.Improving Deep Neural Networks/Week 1/Regularization_v2a.ipynb
|
thesauravkarmakar/deeplearning.ai
|
1758daed135e187f545e0ead6dbad5a44e5c3165
|
[
"MIT"
] | null | null | null |
2.Improving Deep Neural Networks/Week 1/Regularization_v2a.ipynb
|
thesauravkarmakar/deeplearning.ai
|
1758daed135e187f545e0ead6dbad5a44e5c3165
|
[
"MIT"
] | null | null | null |
2.Improving Deep Neural Networks/Week 1/Regularization_v2a.ipynb
|
thesauravkarmakar/deeplearning.ai
|
1758daed135e187f545e0ead6dbad5a44e5c3165
|
[
"MIT"
] | null | null | null | 241.886143 | 56,104 | 0.891216 |
[
[
[
"# Regularization\n\nWelcome to the second assignment of this week. Deep Learning models have so much flexibility and capacity that **overfitting can be a serious problem**, if the training dataset is not big enough. Sure it does well on the training set, but the learned network **doesn't generalize to new examples** that it has never seen!\n\n**You will learn to:** Use regularization in your deep learning models.\n\nLet's first import the packages you are going to use.",
"_____no_output_____"
],
[
"### <font color='darkblue'> Updates to Assignment <font>\n\n#### If you were working on a previous version\n* The current notebook filename is version \"2a\". \n* You can find your work in the file directory as version \"2\".\n* To see the file directory, click on the Coursera logo at the top left of the notebook.\n\n#### List of Updates\n* Clarified explanation of 'keep_prob' in the text description.\n* Fixed a comment so that keep_prob and 1-keep_prob add up to 100%\n* Updated print statements and 'expected output' for easier visual comparisons.",
"_____no_output_____"
]
],
[
[
"# import packages\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec\nfrom reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters\nimport sklearn\nimport sklearn.datasets\nimport scipy.io\nfrom testCases import *\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'",
"_____no_output_____"
]
],
[
[
"**Problem Statement**: You have just been hired as an AI expert by the French Football Corporation. They would like you to recommend positions where France's goal keeper should kick the ball so that the French team's players can then hit it with their head. \n\n<img src=\"images/field_kiank.png\" style=\"width:600px;height:350px;\">\n<caption><center> <u> **Figure 1** </u>: **Football field**<br> The goal keeper kicks the ball in the air, the players of each team are fighting to hit the ball with their head </center></caption>\n\n\nThey give you the following 2D dataset from France's past 10 games.",
"_____no_output_____"
]
],
[
[
"train_X, train_Y, test_X, test_Y = load_2D_dataset()",
"_____no_output_____"
]
],
[
[
"Each dot corresponds to a position on the football field where a football player has hit the ball with his/her head after the French goal keeper has shot the ball from the left side of the football field.\n- If the dot is blue, it means the French player managed to hit the ball with his/her head\n- If the dot is red, it means the other team's player hit the ball with their head\n\n**Your goal**: Use a deep learning model to find the positions on the field where the goalkeeper should kick the ball.",
"_____no_output_____"
],
[
"**Analysis of the dataset**: This dataset is a little noisy, but it looks like a diagonal line separating the upper left half (blue) from the lower right half (red) would work well. \n\nYou will first try a non-regularized model. Then you'll learn how to regularize it and decide which model you will choose to solve the French Football Corporation's problem. ",
"_____no_output_____"
],
[
"## 1 - Non-regularized model\n\nYou will use the following neural network (already implemented for you below). This model can be used:\n- in *regularization mode* -- by setting the `lambd` input to a non-zero value. We use \"`lambd`\" instead of \"`lambda`\" because \"`lambda`\" is a reserved keyword in Python. \n- in *dropout mode* -- by setting the `keep_prob` to a value less than one\n\nYou will first try the model without any regularization. Then, you will implement:\n- *L2 regularization* -- functions: \"`compute_cost_with_regularization()`\" and \"`backward_propagation_with_regularization()`\"\n- *Dropout* -- functions: \"`forward_propagation_with_dropout()`\" and \"`backward_propagation_with_dropout()`\"\n\nIn each part, you will run this model with the correct inputs so that it calls the functions you've implemented. Take a look at the code below to familiarize yourself with the model.",
"_____no_output_____"
]
],
[
[
"def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True, lambd = 0, keep_prob = 1):\n \"\"\"\n Implements a three-layer neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.\n \n Arguments:\n X -- input data, of shape (input size, number of examples)\n Y -- true \"label\" vector (1 for blue dot / 0 for red dot), of shape (output size, number of examples)\n learning_rate -- learning rate of the optimization\n num_iterations -- number of iterations of the optimization loop\n print_cost -- If True, print the cost every 10000 iterations\n lambd -- regularization hyperparameter, scalar\n keep_prob - probability of keeping a neuron active during drop-out, scalar.\n \n Returns:\n parameters -- parameters learned by the model. They can then be used to predict.\n \"\"\"\n \n grads = {}\n costs = [] # to keep track of the cost\n m = X.shape[1] # number of examples\n layers_dims = [X.shape[0], 20, 3, 1]\n \n # Initialize parameters dictionary.\n parameters = initialize_parameters(layers_dims)\n\n # Loop (gradient descent)\n\n for i in range(0, num_iterations):\n\n # Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.\n if keep_prob == 1:\n a3, cache = forward_propagation(X, parameters)\n elif keep_prob < 1:\n a3, cache = forward_propagation_with_dropout(X, parameters, keep_prob)\n \n # Cost function\n if lambd == 0:\n cost = compute_cost(a3, Y)\n else:\n cost = compute_cost_with_regularization(a3, Y, parameters, lambd)\n \n # Backward propagation.\n assert(lambd==0 or keep_prob==1) # it is possible to use both L2 regularization and dropout, \n # but this assignment will only explore one at a time\n if lambd == 0 and keep_prob == 1:\n grads = backward_propagation(X, Y, cache)\n elif lambd != 0:\n grads = backward_propagation_with_regularization(X, Y, cache, lambd)\n elif keep_prob < 1:\n grads = backward_propagation_with_dropout(X, Y, cache, keep_prob)\n \n # Update parameters.\n parameters = update_parameters(parameters, grads, learning_rate)\n \n # Print the loss every 10000 iterations\n if print_cost and i % 10000 == 0:\n print(\"Cost after iteration {}: {}\".format(i, cost))\n if print_cost and i % 1000 == 0:\n costs.append(cost)\n \n # plot the cost\n plt.plot(costs)\n plt.ylabel('cost')\n plt.xlabel('iterations (x1,000)')\n plt.title(\"Learning rate =\" + str(learning_rate))\n plt.show()\n \n return parameters",
"_____no_output_____"
]
],
[
[
"Let's train the model without any regularization, and observe the accuracy on the train/test sets.",
"_____no_output_____"
]
],
[
[
"parameters = model(train_X, train_Y)\nprint (\"On the training set:\")\npredictions_train = predict(train_X, train_Y, parameters)\nprint (\"On the test set:\")\npredictions_test = predict(test_X, test_Y, parameters)",
"Cost after iteration 0: 0.6557412523481002\nCost after iteration 10000: 0.16329987525724213\nCost after iteration 20000: 0.13851642423253263\n"
]
],
[
[
"The train accuracy is 94.8% while the test accuracy is 91.5%. This is the **baseline model** (you will observe the impact of regularization on this model). Run the following code to plot the decision boundary of your model.",
"_____no_output_____"
]
],
[
[
"plt.title(\"Model without regularization\")\naxes = plt.gca()\naxes.set_xlim([-0.75,0.40])\naxes.set_ylim([-0.75,0.65])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"_____no_output_____"
]
],
[
[
"The non-regularized model is obviously overfitting the training set. It is fitting the noisy points! Lets now look at two techniques to reduce overfitting.",
"_____no_output_____"
],
[
"## 2 - L2 Regularization\n\nThe standard way to avoid overfitting is called **L2 regularization**. It consists of appropriately modifying your cost function, from:\n$$J = -\\frac{1}{m} \\sum\\limits_{i = 1}^{m} \\large{(}\\small y^{(i)}\\log\\left(a^{[L](i)}\\right) + (1-y^{(i)})\\log\\left(1- a^{[L](i)}\\right) \\large{)} \\tag{1}$$\nTo:\n$$J_{regularized} = \\small \\underbrace{-\\frac{1}{m} \\sum\\limits_{i = 1}^{m} \\large{(}\\small y^{(i)}\\log\\left(a^{[L](i)}\\right) + (1-y^{(i)})\\log\\left(1- a^{[L](i)}\\right) \\large{)} }_\\text{cross-entropy cost} + \\underbrace{\\frac{1}{m} \\frac{\\lambda}{2} \\sum\\limits_l\\sum\\limits_k\\sum\\limits_j W_{k,j}^{[l]2} }_\\text{L2 regularization cost} \\tag{2}$$\n\nLet's modify your cost and observe the consequences.\n\n**Exercise**: Implement `compute_cost_with_regularization()` which computes the cost given by formula (2). To calculate $\\sum\\limits_k\\sum\\limits_j W_{k,j}^{[l]2}$ , use :\n```python\nnp.sum(np.square(Wl))\n```\nNote that you have to do this for $W^{[1]}$, $W^{[2]}$ and $W^{[3]}$, then sum the three terms and multiply by $ \\frac{1}{m} \\frac{\\lambda}{2} $.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost_with_regularization\n\ndef compute_cost_with_regularization(A3, Y, parameters, lambd):\n \"\"\"\n Implement the cost function with L2 regularization. See formula (2) above.\n \n Arguments:\n A3 -- post-activation, output of forward propagation, of shape (output size, number of examples)\n Y -- \"true\" labels vector, of shape (output size, number of examples)\n parameters -- python dictionary containing parameters of the model\n \n Returns:\n cost - value of the regularized loss function (formula (2))\n \"\"\"\n m = Y.shape[1]\n W1 = parameters[\"W1\"]\n W2 = parameters[\"W2\"]\n W3 = parameters[\"W3\"]\n \n cross_entropy_cost = compute_cost(A3, Y) # This gives you the cross-entropy part of the cost\n \n ### START CODE HERE ### (approx. 1 line)\n L2_regularization_cost = lambd/(m*2)*(np.sum(np.square(W1))+np.sum(np.square(W2))+np.sum(np.square(W3)))\n ### END CODER HERE ###\n \n cost = cross_entropy_cost + L2_regularization_cost\n \n return cost",
"_____no_output_____"
],
[
"A3, Y_assess, parameters = compute_cost_with_regularization_test_case()\n\nprint(\"cost = \" + str(compute_cost_with_regularization(A3, Y_assess, parameters, lambd = 0.1)))",
"cost = 1.78648594516\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr>\n <td>\n **cost**\n </td>\n <td>\n 1.78648594516\n </td>\n \n </tr>\n\n</table> ",
"_____no_output_____"
],
[
"Of course, because you changed the cost, you have to change backward propagation as well! All the gradients have to be computed with respect to this new cost. \n\n**Exercise**: Implement the changes needed in backward propagation to take into account regularization. The changes only concern dW1, dW2 and dW3. For each, you have to add the regularization term's gradient ($\\frac{d}{dW} ( \\frac{1}{2}\\frac{\\lambda}{m} W^2) = \\frac{\\lambda}{m} W$).",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: backward_propagation_with_regularization\n\ndef backward_propagation_with_regularization(X, Y, cache, lambd):\n \"\"\"\n Implements the backward propagation of our baseline model to which we added an L2 regularization.\n \n Arguments:\n X -- input dataset, of shape (input size, number of examples)\n Y -- \"true\" labels vector, of shape (output size, number of examples)\n cache -- cache output from forward_propagation()\n lambd -- regularization hyperparameter, scalar\n \n Returns:\n gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables\n \"\"\"\n \n m = X.shape[1]\n (Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache\n \n dZ3 = A3 - Y\n \n ### START CODE HERE ### (approx. 1 line)\n dW3 = 1./m * np.dot(dZ3, A2.T) + lambd/m*W3\n ### END CODE HERE ###\n db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)\n \n dA2 = np.dot(W3.T, dZ3)\n dZ2 = np.multiply(dA2, np.int64(A2 > 0))\n ### START CODE HERE ### (approx. 1 line)\n dW2 = 1./m * np.dot(dZ2, A1.T) + lambd/m*W2\n ### END CODE HERE ###\n db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)\n \n dA1 = np.dot(W2.T, dZ2)\n dZ1 = np.multiply(dA1, np.int64(A1 > 0))\n ### START CODE HERE ### (approx. 1 line)\n dW1 = 1./m * np.dot(dZ1, X.T) + lambd/m*W1\n ### END CODE HERE ###\n db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)\n \n gradients = {\"dZ3\": dZ3, \"dW3\": dW3, \"db3\": db3,\"dA2\": dA2,\n \"dZ2\": dZ2, \"dW2\": dW2, \"db2\": db2, \"dA1\": dA1, \n \"dZ1\": dZ1, \"dW1\": dW1, \"db1\": db1}\n \n return gradients",
"_____no_output_____"
],
[
"X_assess, Y_assess, cache = backward_propagation_with_regularization_test_case()\n\ngrads = backward_propagation_with_regularization(X_assess, Y_assess, cache, lambd = 0.7)\nprint (\"dW1 = \\n\"+ str(grads[\"dW1\"]))\nprint (\"dW2 = \\n\"+ str(grads[\"dW2\"]))\nprint (\"dW3 = \\n\"+ str(grads[\"dW3\"]))",
"dW1 = \n[[-0.25604646 0.12298827 -0.28297129]\n [-0.17706303 0.34536094 -0.4410571 ]]\ndW2 = \n[[ 0.79276486 0.85133918]\n [-0.0957219 -0.01720463]\n [-0.13100772 -0.03750433]]\ndW3 = \n[[-1.77691347 -0.11832879 -0.09397446]]\n"
]
],
[
[
"**Expected Output**:\n\n```\ndW1 = \n[[-0.25604646 0.12298827 -0.28297129]\n [-0.17706303 0.34536094 -0.4410571 ]]\ndW2 = \n[[ 0.79276486 0.85133918]\n [-0.0957219 -0.01720463]\n [-0.13100772 -0.03750433]]\ndW3 = \n[[-1.77691347 -0.11832879 -0.09397446]]\n```",
"_____no_output_____"
],
[
"Let's now run the model with L2 regularization $(\\lambda = 0.7)$. The `model()` function will call: \n- `compute_cost_with_regularization` instead of `compute_cost`\n- `backward_propagation_with_regularization` instead of `backward_propagation`",
"_____no_output_____"
]
],
[
[
"parameters = model(train_X, train_Y, lambd = 0.7)\nprint (\"On the train set:\")\npredictions_train = predict(train_X, train_Y, parameters)\nprint (\"On the test set:\")\npredictions_test = predict(test_X, test_Y, parameters)",
"Cost after iteration 0: 0.6974484493131264\nCost after iteration 10000: 0.2684918873282239\nCost after iteration 20000: 0.26809163371273015\n"
]
],
[
[
"Congrats, the test set accuracy increased to 93%. You have saved the French football team!\n\nYou are not overfitting the training data anymore. Let's plot the decision boundary.",
"_____no_output_____"
]
],
[
[
"plt.title(\"Model with L2-regularization\")\naxes = plt.gca()\naxes.set_xlim([-0.75,0.40])\naxes.set_ylim([-0.75,0.65])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"_____no_output_____"
]
],
[
[
"**Observations**:\n- The value of $\\lambda$ is a hyperparameter that you can tune using a dev set.\n- L2 regularization makes your decision boundary smoother. If $\\lambda$ is too large, it is also possible to \"oversmooth\", resulting in a model with high bias.\n\n**What is L2-regularization actually doing?**:\n\nL2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes. \n\n<font color='blue'>\n**What you should remember** -- the implications of L2-regularization on:\n- The cost computation:\n - A regularization term is added to the cost\n- The backpropagation function:\n - There are extra terms in the gradients with respect to weight matrices\n- Weights end up smaller (\"weight decay\"): \n - Weights are pushed to smaller values.",
"_____no_output_____"
],
[
"## 3 - Dropout\n\nFinally, **dropout** is a widely used regularization technique that is specific to deep learning. \n**It randomly shuts down some neurons in each iteration.** Watch these two videos to see what this means!\n\n<!--\nTo understand drop-out, consider this conversation with a friend:\n- Friend: \"Why do you need all these neurons to train your network and classify images?\". \n- You: \"Because each neuron contains a weight and can learn specific features/details/shape of an image. The more neurons I have, the more featurse my model learns!\"\n- Friend: \"I see, but are you sure that your neurons are learning different features and not all the same features?\"\n- You: \"Good point... Neurons in the same layer actually don't talk to each other. It should be definitly possible that they learn the same image features/shapes/forms/details... which would be redundant. There should be a solution.\"\n!--> \n\n\n<center>\n<video width=\"620\" height=\"440\" src=\"images/dropout1_kiank.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n<br>\n<caption><center> <u> Figure 2 </u>: Drop-out on the second hidden layer. <br> At each iteration, you shut down (= set to zero) each neuron of a layer with probability $1 - keep\\_prob$ or keep it with probability $keep\\_prob$ (50% here). The dropped neurons don't contribute to the training in both the forward and backward propagations of the iteration. </center></caption>\n\n<center>\n<video width=\"620\" height=\"440\" src=\"images/dropout2_kiank.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n\n<caption><center> <u> Figure 3 </u>: Drop-out on the first and third hidden layers. <br> $1^{st}$ layer: we shut down on average 40% of the neurons. $3^{rd}$ layer: we shut down on average 20% of the neurons. </center></caption>\n\n\nWhen you shut some neurons down, you actually modify your model. The idea behind drop-out is that at each iteration, you train a different model that uses only a subset of your neurons. With dropout, your neurons thus become less sensitive to the activation of one other specific neuron, because that other neuron might be shut down at any time. \n\n### 3.1 - Forward propagation with dropout\n\n**Exercise**: Implement the forward propagation with dropout. You are using a 3 layer neural network, and will add dropout to the first and second hidden layers. We will not apply dropout to the input layer or output layer. \n\n**Instructions**:\nYou would like to shut down some neurons in the first and second layers. To do that, you are going to carry out 4 Steps:\n1. In lecture, we dicussed creating a variable $d^{[1]}$ with the same shape as $a^{[1]}$ using `np.random.rand()` to randomly get numbers between 0 and 1. Here, you will use a vectorized implementation, so create a random matrix $D^{[1]} = [d^{[1](1)} d^{[1](2)} ... d^{[1](m)}] $ of the same dimension as $A^{[1]}$.\n2. Set each entry of $D^{[1]}$ to be 1 with probability (`keep_prob`), and 0 otherwise.\n\n**Hint:** Let's say that keep_prob = 0.8, which means that we want to keep about 80% of the neurons and drop out about 20% of them. We want to generate a vector that has 1's and 0's, where about 80% of them are 1 and about 20% are 0.\nThis python statement: \n`X = (X < keep_prob).astype(int)` \n\nis conceptually the same as this if-else statement (for the simple case of a one-dimensional array) :\n\n```\nfor i,v in enumerate(x):\n if v < keep_prob:\n x[i] = 1\n else: # v >= keep_prob\n x[i] = 0\n```\nNote that the `X = (X < keep_prob).astype(int)` works with multi-dimensional arrays, and the resulting output preserves the dimensions of the input array.\n\nAlso note that without using `.astype(int)`, the result is an array of booleans `True` and `False`, which Python automatically converts to 1 and 0 if we multiply it with numbers. (However, it's better practice to convert data into the data type that we intend, so try using `.astype(int)`.)\n\n3. Set $A^{[1]}$ to $A^{[1]} * D^{[1]}$. (You are shutting down some neurons). You can think of $D^{[1]}$ as a mask, so that when it is multiplied with another matrix, it shuts down some of the values.\n4. Divide $A^{[1]}$ by `keep_prob`. By doing this you are assuring that the result of the cost will still have the same expected value as without drop-out. (This technique is also called inverted dropout.)",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation_with_dropout\n\ndef forward_propagation_with_dropout(X, parameters, keep_prob = 0.5):\n \"\"\"\n Implements the forward propagation: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.\n \n Arguments:\n X -- input dataset, of shape (2, number of examples)\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", \"W2\", \"b2\", \"W3\", \"b3\":\n W1 -- weight matrix of shape (20, 2)\n b1 -- bias vector of shape (20, 1)\n W2 -- weight matrix of shape (3, 20)\n b2 -- bias vector of shape (3, 1)\n W3 -- weight matrix of shape (1, 3)\n b3 -- bias vector of shape (1, 1)\n keep_prob - probability of keeping a neuron active during drop-out, scalar\n \n Returns:\n A3 -- last activation value, output of the forward propagation, of shape (1,1)\n cache -- tuple, information stored for computing the backward propagation\n \"\"\"\n \n np.random.seed(1)\n \n # retrieve parameters\n W1 = parameters[\"W1\"]\n b1 = parameters[\"b1\"]\n W2 = parameters[\"W2\"]\n b2 = parameters[\"b2\"]\n W3 = parameters[\"W3\"]\n b3 = parameters[\"b3\"]\n \n # LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID\n Z1 = np.dot(W1, X) + b1\n A1 = relu(Z1)\n ### START CODE HERE ### (approx. 4 lines) # Steps 1-4 below correspond to the Steps 1-4 described above. \n D1 = np.random.rand(A1.shape[0],A1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...)\n D1 = (D1 < keep_prob).astype(int) # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)\n A1 *= D1 # Step 3: shut down some neurons of A1\n A1 /= keep_prob # Step 4: scale the value of neurons that haven't been shut down\n ### END CODE HERE ###\n Z2 = np.dot(W2, A1) + b2\n A2 = relu(Z2)\n ### START CODE HERE ### (approx. 4 lines)\n D2 = np.random.rand(A2.shape[0],A2.shape[1]) # Step 1: initialize matrix D2 = np.random.rand(..., ...)\n D2 = (D2 < keep_prob).astype(int) # Step 2: convert entries of D2 to 0 or 1 (using keep_prob as the threshold)\n A2 *= D2 # Step 3: shut down some neurons of A2\n A2 /= keep_prob # Step 4: scale the value of neurons that haven't been shut down\n ### END CODE HERE ###\n Z3 = np.dot(W3, A2) + b3\n A3 = sigmoid(Z3)\n \n cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)\n \n return A3, cache",
"_____no_output_____"
],
[
"X_assess, parameters = forward_propagation_with_dropout_test_case()\n\nA3, cache = forward_propagation_with_dropout(X_assess, parameters, keep_prob = 0.7)\nprint (\"A3 = \" + str(A3))",
"A3 = [[ 0.36974721 0.00305176 0.04565099 0.49683389 0.36974721]]\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr>\n <td>\n **A3**\n </td>\n <td>\n [[ 0.36974721 0.00305176 0.04565099 0.49683389 0.36974721]]\n </td>\n \n </tr>\n\n</table> ",
"_____no_output_____"
],
[
"### 3.2 - Backward propagation with dropout\n\n**Exercise**: Implement the backward propagation with dropout. As before, you are training a 3 layer network. Add dropout to the first and second hidden layers, using the masks $D^{[1]}$ and $D^{[2]}$ stored in the cache. \n\n**Instruction**:\nBackpropagation with dropout is actually quite easy. You will have to carry out 2 Steps:\n1. You had previously shut down some neurons during forward propagation, by applying a mask $D^{[1]}$ to `A1`. In backpropagation, you will have to shut down the same neurons, by reapplying the same mask $D^{[1]}$ to `dA1`. \n2. During forward propagation, you had divided `A1` by `keep_prob`. In backpropagation, you'll therefore have to divide `dA1` by `keep_prob` again (the calculus interpretation is that if $A^{[1]}$ is scaled by `keep_prob`, then its derivative $dA^{[1]}$ is also scaled by the same `keep_prob`).\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: backward_propagation_with_dropout\n\ndef backward_propagation_with_dropout(X, Y, cache, keep_prob):\n \"\"\"\n Implements the backward propagation of our baseline model to which we added dropout.\n \n Arguments:\n X -- input dataset, of shape (2, number of examples)\n Y -- \"true\" labels vector, of shape (output size, number of examples)\n cache -- cache output from forward_propagation_with_dropout()\n keep_prob - probability of keeping a neuron active during drop-out, scalar\n \n Returns:\n gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables\n \"\"\"\n \n m = X.shape[1]\n (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache\n \n dZ3 = A3 - Y\n dW3 = 1./m * np.dot(dZ3, A2.T)\n db3 = 1./m * np.sum(dZ3, axis=1, keepdims = True)\n dA2 = np.dot(W3.T, dZ3)\n ### START CODE HERE ### (≈ 2 lines of code)\n dA2 *= D2 # Step 1: Apply mask D2 to shut down the same neurons as during the forward propagation\n dA2 /= keep_prob # Step 2: Scale the value of neurons that haven't been shut down\n ### END CODE HERE ###\n dZ2 = np.multiply(dA2, np.int64(A2 > 0))\n dW2 = 1./m * np.dot(dZ2, A1.T)\n db2 = 1./m * np.sum(dZ2, axis=1, keepdims = True)\n \n dA1 = np.dot(W2.T, dZ2)\n ### START CODE HERE ### (≈ 2 lines of code)\n dA1 *= D1 # Step 1: Apply mask D1 to shut down the same neurons as during the forward propagation\n dA1 /= keep_prob # Step 2: Scale the value of neurons that haven't been shut down\n ### END CODE HERE ###\n dZ1 = np.multiply(dA1, np.int64(A1 > 0))\n dW1 = 1./m * np.dot(dZ1, X.T)\n db1 = 1./m * np.sum(dZ1, axis=1, keepdims = True)\n \n gradients = {\"dZ3\": dZ3, \"dW3\": dW3, \"db3\": db3,\"dA2\": dA2,\n \"dZ2\": dZ2, \"dW2\": dW2, \"db2\": db2, \"dA1\": dA1, \n \"dZ1\": dZ1, \"dW1\": dW1, \"db1\": db1}\n \n return gradients",
"_____no_output_____"
],
[
"X_assess, Y_assess, cache = backward_propagation_with_dropout_test_case()\n\ngradients = backward_propagation_with_dropout(X_assess, Y_assess, cache, keep_prob = 0.8)\n\nprint (\"dA1 = \\n\" + str(gradients[\"dA1\"]))\nprint (\"dA2 = \\n\" + str(gradients[\"dA2\"]))",
"dA1 = \n[[ 0.36544439 0. -0.00188233 0. -0.17408748]\n [ 0.65515713 0. -0.00337459 0. -0. ]]\ndA2 = \n[[ 0.58180856 0. -0.00299679 0. -0.27715731]\n [ 0. 0.53159854 -0. 0.53159854 -0.34089673]\n [ 0. 0. -0.00292733 0. -0. ]]\n"
]
],
[
[
"**Expected Output**: \n\n```\ndA1 = \n[[ 0.36544439 0. -0.00188233 0. -0.17408748]\n [ 0.65515713 0. -0.00337459 0. -0. ]]\ndA2 = \n[[ 0.58180856 0. -0.00299679 0. -0.27715731]\n [ 0. 0.53159854 -0. 0.53159854 -0.34089673]\n [ 0. 0. -0.00292733 0. -0. ]]\n```",
"_____no_output_____"
],
[
"Let's now run the model with dropout (`keep_prob = 0.86`). It means at every iteration you shut down each neurons of layer 1 and 2 with 14% probability. The function `model()` will now call:\n- `forward_propagation_with_dropout` instead of `forward_propagation`.\n- `backward_propagation_with_dropout` instead of `backward_propagation`.",
"_____no_output_____"
]
],
[
[
"parameters = model(train_X, train_Y, keep_prob = 0.86, learning_rate = 0.3)\n\nprint (\"On the train set:\")\npredictions_train = predict(train_X, train_Y, parameters)\nprint (\"On the test set:\")\npredictions_test = predict(test_X, test_Y, parameters)",
"Cost after iteration 0: 0.6543912405149825\n"
]
],
[
[
"Dropout works great! The test accuracy has increased again (to 95%)! Your model is not overfitting the training set and does a great job on the test set. The French football team will be forever grateful to you! \n\nRun the code below to plot the decision boundary.",
"_____no_output_____"
]
],
[
[
"plt.title(\"Model with dropout\")\naxes = plt.gca()\naxes.set_xlim([-0.75,0.40])\naxes.set_ylim([-0.75,0.65])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"_____no_output_____"
]
],
[
[
"**Note**:\n- A **common mistake** when using dropout is to use it both in training and testing. You should use dropout (randomly eliminate nodes) only in training. \n- Deep learning frameworks like [tensorflow](https://www.tensorflow.org/api_docs/python/tf/nn/dropout), [PaddlePaddle](http://doc.paddlepaddle.org/release_doc/0.9.0/doc/ui/api/trainer_config_helpers/attrs.html), [keras](https://keras.io/layers/core/#dropout) or [caffe](http://caffe.berkeleyvision.org/tutorial/layers/dropout.html) come with a dropout layer implementation. Don't stress - you will soon learn some of these frameworks.\n\n<font color='blue'>\n**What you should remember about dropout:**\n- Dropout is a regularization technique.\n- You only use dropout during training. Don't use dropout (randomly eliminate nodes) during test time.\n- Apply dropout both during forward and backward propagation.\n- During training time, divide each dropout layer by keep_prob to keep the same expected value for the activations. For example, if keep_prob is 0.5, then we will on average shut down half the nodes, so the output will be scaled by 0.5 since only the remaining half are contributing to the solution. Dividing by 0.5 is equivalent to multiplying by 2. Hence, the output now has the same expected value. You can check that this works even when keep_prob is other values than 0.5. ",
"_____no_output_____"
],
[
"## 4 - Conclusions",
"_____no_output_____"
],
[
"**Here are the results of our three models**: \n\n<table> \n <tr>\n <td>\n **model**\n </td>\n <td>\n **train accuracy**\n </td>\n <td>\n **test accuracy**\n </td>\n\n </tr>\n <td>\n 3-layer NN without regularization\n </td>\n <td>\n 95%\n </td>\n <td>\n 91.5%\n </td>\n <tr>\n <td>\n 3-layer NN with L2-regularization\n </td>\n <td>\n 94%\n </td>\n <td>\n 93%\n </td>\n </tr>\n <tr>\n <td>\n 3-layer NN with dropout\n </td>\n <td>\n 93%\n </td>\n <td>\n 95%\n </td>\n </tr>\n</table> ",
"_____no_output_____"
],
[
"Note that regularization hurts training set performance! This is because it limits the ability of the network to overfit to the training set. But since it ultimately gives better test accuracy, it is helping your system. ",
"_____no_output_____"
],
[
"Congratulations for finishing this assignment! And also for revolutionizing French football. :-) ",
"_____no_output_____"
],
[
"<font color='blue'>\n**What we want you to remember from this notebook**:\n- Regularization will help you reduce overfitting.\n- Regularization will drive your weights to lower values.\n- L2 regularization and Dropout are two very effective regularization techniques.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ac98dae1da488d7b32878e426c2b1d633b25230
| 49,382 |
ipynb
|
Jupyter Notebook
|
funnelweb/tables/create-destroy-testing.ipynb
|
mikeireland/funnelweb
|
1d0f30e7a0009597fb3b789d3cc199fea0fd6741
|
[
"MIT"
] | null | null | null |
funnelweb/tables/create-destroy-testing.ipynb
|
mikeireland/funnelweb
|
1d0f30e7a0009597fb3b789d3cc199fea0fd6741
|
[
"MIT"
] | null | null | null |
funnelweb/tables/create-destroy-testing.ipynb
|
mikeireland/funnelweb
|
1d0f30e7a0009597fb3b789d3cc199fea0fd6741
|
[
"MIT"
] | null | null | null | 145.241176 | 1,645 | 0.682293 |
[
[
[
"## First test tables notebook: Create and destroy tables in Postgres using psycopg2\n### Using GALAH data to test because they have full fits headers",
"_____no_output_____"
]
],
[
[
"# imports\nimport os\nfrom astropy.io import fits\nimport sqlalchemy\nfrom sqlalchemy import create_engine, Table, Column, Integer, String, Float, MetaData, ForeignKey",
"_____no_output_____"
],
[
"# do some setup\n\n# detect current location\npath1=os.getcwd()\n\n# path to local data stash (input by user)\ndatapath='/Users/sarah/active/programs/FunnelWeb/computing/test-data/'\n\n",
"_____no_output_____"
],
[
"# create a new database\nengine=create_engine(\"postgresql://sarah:imoLonae@localhost/db1\")\n# this isn't currently working (but errors out silently) - set up the database directly in Postgres?",
"_____no_output_____"
],
[
"metadata=MetaData()",
"_____no_output_____"
],
[
"# create the observation table: includes all exposures\n# the extend_existing=True allows updates to an existing Table definition\nobservationtable=Table('observationtable',metadata,\n Column('obsid',String,primary_key=True),\n Column('configfile',String),\n Column('mjd',String),\n Column('date',Integer),\n Column('filename',String),\n Column('telra',Float),\n Column('teldec',Float),\n Column('obstype',String),\n Column('exptime',Float),\n Column('camera',Integer)\n ,extend_existing=True)",
"_____no_output_____"
],
[
"# create one table that's been defined, but only if it doesn't already exist (default behaviour)\nobservationtable.create(engine,checkfirst=True)\n\n# create all tables that were defined, whether or not they already exist \n# not sure what happens when there's a clash)\n#metadata.create_all(engine, checkfirst=False)",
"_____no_output_____"
],
[
"# drop one particular table, but only if it exists (default behaviour)\nobservationtable.drop(engine,checkfirst=True)\n\n# drop all tables, whether or not they exist \n# not sure what happens if they don't exist\nmetadata.drop_all(engine)",
"_____no_output_____"
],
[
"# find all local data files, loop through and concatenate the header information into a list of dictionaries\nupdatelist=[]\nfor root,dirs,files in os.walk(datapath):\n for name in files:\n fitspath=os.path.join(root,name)\n header = fits.getheader(fitspath)\n updatelist.append({'obsid':header['FILEORIG'][-9:-5]\n ,'configfile':header['CFG_FILE']\n ,'mjd':header['UTMJD']\n ,'date':int((header['UTDATE'].replace(':',''))[2:])\n ,'filename':(header['FILEORIG'].split('/'))[-1]\n ,'telra':header['MEANRA']\n ,'teldec':header['MEANDEC']\n ,'obstype':header['OBSTYPE']\n ,'exptime':header['EXPOSED']})",
"_____no_output_____"
],
[
"updatelist",
"_____no_output_____"
],
[
"# populate the table we just created by inserting values into columns\n# add one row to the table\n#ins = observationtable.insert()\n#conn.execute(ins, obsid='0012', configfile='field1324tile3.txt')\n\n# add many rows to the table: feed in a list of dictionaries\nconn.execute(observationtable.insert(),updatelist)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac994b4c1e0d9576e50b88d08f0b763dd966e6f
| 15,913 |
ipynb
|
Jupyter Notebook
|
talks/uc2018/IntegratingMLandDeepLearning/1_TensorFlow/1 - Webcam Person Detection.ipynb
|
nitz21/arcpy
|
36074b5d448c9cfdba166332e99100afb3390824
|
[
"Apache-2.0"
] | 2 |
2020-11-23T23:06:04.000Z
|
2020-11-23T23:06:07.000Z
|
talks/uc2018/IntegratingMLandDeepLearning/1_TensorFlow/1 - Webcam Person Detection.ipynb
|
josemartinsgeo/arcgis-python-api
|
4c10bb1ce900060959829f7ac6c58d4d67037d56
|
[
"Apache-2.0"
] | null | null | null |
talks/uc2018/IntegratingMLandDeepLearning/1_TensorFlow/1 - Webcam Person Detection.ipynb
|
josemartinsgeo/arcgis-python-api
|
4c10bb1ce900060959829f7ac6c58d4d67037d56
|
[
"Apache-2.0"
] | 1 |
2020-06-06T21:21:18.000Z
|
2020-06-06T21:21:18.000Z
| 28.114841 | 298 | 0.583297 |
[
[
[
"## <span style=\"color:purple\">ArcGIS API for Python: Real-time Person Detection</span>\n<img src=\"../img/webcam_detection.PNG\" style=\"width: 100%\"></img>\n\n\n## Integrating ArcGIS with TensorFlow Deep Learning using the ArcGIS API for Python",
"_____no_output_____"
],
[
"This notebook provides an example of integration between ArcGIS and deep learning frameworks like TensorFlow using the ArcGIS API for Python.\n\n<img src=\"../img/ArcGIS_ML_Integration.png\" style=\"width: 75%\"></img>\n\nWe will leverage a model to detect objects on your device's video camera, and use these to update a feature service on a web GIS in real-time. As people are detected on your camera, the feature will be updated to reflect the detection. ",
"_____no_output_____"
],
[
"### Notebook Requirements: ",
"_____no_output_____"
],
[
"#### 1. TensorFlow and Object Detection API",
"_____no_output_____"
],
[
"This demonstration is designed to run using the TensorFlow Object Detection API (https://github.com/tensorflow/models/tree/master/research/object_detection)\n\nPlease follow the instructions found in that repository to install TensorFlow, clone the repository, and test a pre-existing model. \n\nOnce you have followed those instructions, this notebook should be placed within the \"object_detection\" folder of that repository. Alternatively, you may leverage this notebook from another location but reference paths to the TensorFlow model paths and utilities will need to be adjusted. ",
"_____no_output_____"
],
[
"#### 2. Access to ArcGIS Online or ArcGIS Enterprise ",
"_____no_output_____"
],
[
"This notebook will make a connection to an ArcGIS Enterprise or ArcGIS Online organization to provide updates to a target feature service.\n\nPlease ensure you have access to an ArcGIS Enterprise or ArcGIS Online account with a feature service to serve as the target of your detection updates. The feature service should have a record with an boolean attribute (i.e. column with True or False possible options) named \"Person_Found\".",
"_____no_output_____"
],
[
"# Import needed modules",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport os\nimport six.moves.urllib as urllib\nimport sys\nimport tarfile\nimport tensorflow as tf\nimport zipfile\n\nfrom collections import defaultdict\nfrom io import StringIO\nfrom matplotlib import pyplot as plt\nfrom PIL import Image\n\nimport cv2",
"_____no_output_____"
]
],
[
[
"We will use VideoCapture to connect to the device's web camera feed. The cv2 module helps here. ",
"_____no_output_____"
]
],
[
[
"# Set our caption \ncap = cv2.VideoCapture(0)",
"_____no_output_____"
],
[
"# This is needed since the notebook is meant to be run in the object_detection folder.\nsys.path.append(\"..\")",
"_____no_output_____"
]
],
[
[
"## Object detection imports\nHere are the imports from the object detection module.",
"_____no_output_____"
]
],
[
[
"from utils import label_map_util\n\nfrom utils import visualization_utils as vis_util",
"_____no_output_____"
]
],
[
[
"# Model preparation ",
"_____no_output_____"
],
[
"## Variables\n\nAny model exported using the `export_inference_graph.py` tool can be loaded here simply by changing `PATH_TO_CKPT` to point to a new .pb file. \n\nBy default we use an \"SSD with Mobilenet\" model here. See the [detection model zoo](https://github.com/tensorflow/models/blob/master/object_detection/g3doc/detection_model_zoo.md) for a list of other models that can be run out-of-the-box with varying speeds and accuracies.",
"_____no_output_____"
]
],
[
[
"# What model to download.\nMODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017'\nMODEL_FILE = MODEL_NAME + '.tar.gz'\nDOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'\n\n# Path to frozen detection graph. This is the actual model that is used for the object detection.\nPATH_TO_CKPT = MODEL_NAME + '/frozen_inference_graph.pb'\n\n# List of the strings that is used to add correct label for each box.\nPATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')\n\nNUM_CLASSES = 90",
"_____no_output_____"
]
],
[
[
"## Download Model",
"_____no_output_____"
]
],
[
[
"opener = urllib.request.URLopener()\nopener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)\ntar_file = tarfile.open(MODEL_FILE)\nfor file in tar_file.getmembers():\n file_name = os.path.basename(file.name)\n if 'frozen_inference_graph.pb' in file_name:\n tar_file.extract(file, os.getcwd())",
"_____no_output_____"
]
],
[
[
"## Load a (frozen) Tensorflow model into memory.",
"_____no_output_____"
]
],
[
[
"detection_graph = tf.Graph()\nwith detection_graph.as_default():\n od_graph_def = tf.GraphDef()\n with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:\n serialized_graph = fid.read()\n od_graph_def.ParseFromString(serialized_graph)\n tf.import_graph_def(od_graph_def, name='')",
"_____no_output_____"
]
],
[
[
"## Loading label map\nLabel maps map indices to category names, so that when our convolution network predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility functions, but anything that returns a dictionary mapping integers to appropriate string labels would be fine",
"_____no_output_____"
]
],
[
[
"label_map = label_map_util.load_labelmap(PATH_TO_LABELS)\ncategories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)\ncategory_index = label_map_util.create_category_index(categories)",
"_____no_output_____"
],
[
"category_index",
"_____no_output_____"
]
],
[
[
"## Helper code",
"_____no_output_____"
]
],
[
[
"def load_image_into_numpy_array(image):\n (im_width, im_height) = image.size\n return np.array(image.getdata()).reshape(\n (im_height, im_width, 3)).astype(np.uint8)",
"_____no_output_____"
]
],
[
[
"This is a helper function that takes the detection graph output tensor (np arrays), stacks the classes and scores, and determines if the class for a person (1) is available within a certain score and within a certain amount of objects",
"_____no_output_____"
]
],
[
[
"def person_in_image(classes_arr, scores_arr, obj_thresh=5, score_thresh=0.5):\n stacked_arr = np.stack((classes_arr, scores_arr), axis=-1)\n person_found_flag = False\n for ix in range(obj_thresh):\n if 1.00000000e+00 in stacked_arr[ix]:\n if stacked_arr[ix][1] >= score_thresh:\n person_found_flag = True\n \n return person_found_flag",
"_____no_output_____"
]
],
[
[
"# Establish Connection to GIS via ArcGIS API for Python",
"_____no_output_____"
],
[
"### Authenticate",
"_____no_output_____"
]
],
[
[
"import arcgis",
"_____no_output_____"
],
[
"gis_url = \"\" # Replace with gis URL\nusername = \"\" # Replace with username",
"_____no_output_____"
],
[
"gis = arcgis.gis.GIS(gis_url, username)",
"_____no_output_____"
]
],
[
[
"### Retrieve the Object Detection Point Layer",
"_____no_output_____"
]
],
[
[
"target_service_name = \"\" # Replace with name of target service",
"_____no_output_____"
],
[
"object_point_srvc = gis.content.search(target_service_name)[0]\nobject_point_srvc",
"_____no_output_____"
],
[
"# Convert our existing service into a pandas dataframe\nobject_point_lyr = object_point_srvc.layers[0]\nobj_fset = object_point_lyr.query() #querying without any conditions returns all the features\nobj_df = obj_fset.df\nobj_df.head()",
"_____no_output_____"
],
[
"all_features = obj_fset.features\nall_features",
"_____no_output_____"
],
[
"from copy import deepcopy\n\noriginal_feature = all_features[0]\nfeature_to_be_updated = deepcopy(original_feature)\nfeature_to_be_updated",
"_____no_output_____"
]
],
[
[
"### Test of Manual Update",
"_____no_output_____"
]
],
[
[
"feature_to_be_updated.attributes['Person_Found']",
"_____no_output_____"
],
[
"features_for_update = []\nfeature_to_be_updated.attributes['Person_Found'] = \"False\"\nfeatures_for_update.append(feature_to_be_updated)",
"_____no_output_____"
],
[
"object_point_lyr.edit_features(updates=features_for_update)",
"_____no_output_____"
]
],
[
[
"# Detection",
"_____no_output_____"
]
],
[
[
"with detection_graph.as_default():\n with tf.Session(graph=detection_graph) as sess:\n # Definite input and output Tensors for detection_graph\n image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')\n # Each box represents a part of the image where a particular object was detected.\n detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')\n # Each score represent how level of confidence for each of the objects.\n # Score is shown on the result image, together with the class label.\n detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')\n detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')\n num_detections = detection_graph.get_tensor_by_name('num_detections:0')\n while True:\n ret, image_np = cap.read()\n # Expand dimensions since the model expects images to have shape: [1, None, None, 3]\n image_np_expanded = np.expand_dims(image_np, axis=0)\n # Actual detection.\n (boxes, scores, classes, num) = sess.run(\n [detection_boxes, detection_scores, detection_classes, num_detections],\n feed_dict={image_tensor: image_np_expanded})\n # Visualization of the results of a detection.\n vis_util.visualize_boxes_and_labels_on_image_array(\n image_np,\n np.squeeze(boxes),\n np.squeeze(classes).astype(np.int32),\n np.squeeze(scores),\n category_index,\n use_normalized_coordinates=True,\n line_thickness=8, min_score_thresh=0.5)\n \n cv2.imshow('object detection', cv2.resize(image_np, (800,600)))\n if cv2.waitKey(25) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n break\n \n person_found = person_in_image(np.squeeze(classes).astype(np.int32), \n np.squeeze(scores), \n obj_thresh=2)\n \n features_for_update = []\n feature_to_be_updated.attributes['Person_Found'] = str(person_found)\n features_for_update.append(feature_to_be_updated)\n object_point_lyr.edit_features(updates=features_for_update)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ac9a16c4819b96e68bb43669a3ed057f9986972
| 140,024 |
ipynb
|
Jupyter Notebook
|
ARIMA.ipynb
|
Meet953/TUS-Engineering-Team-Project
|
4cf50d8fad737d3c5157f7f21058da74f4d2a16c
|
[
"Apache-2.0"
] | null | null | null |
ARIMA.ipynb
|
Meet953/TUS-Engineering-Team-Project
|
4cf50d8fad737d3c5157f7f21058da74f4d2a16c
|
[
"Apache-2.0"
] | null | null | null |
ARIMA.ipynb
|
Meet953/TUS-Engineering-Team-Project
|
4cf50d8fad737d3c5157f7f21058da74f4d2a16c
|
[
"Apache-2.0"
] | null | null | null | 181.143596 | 22,970 | 0.826037 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Meet953/TUS-Engineering-Team-Project/blob/main/ARIMA.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"def test_stationarity(timeseries):\n import matplotlib.pyplot as plt\n rolmean = timeseries.rolling(window=5).mean()\n rolstd = timeseries.rolling(window=5).std()\n\n orig = plt.plot(timeseries, label = 'Original')\n mean = plt.plot(rolmean, label='Rolling mean')\n std = plt.plot(rolstd, label='Rolling std')\n\n plt.legend(loc='best')\n plt.title('Timeseries data with rolling mean and std. deviation')\n plt.show()\n\n\n from statsmodels.tsa.stattools import adfuller\n\n dftest = adfuller(timeseries)\n dfoutput = pd.Series(dftest[0:4], index = ['Test Statistics', 'Mackinnons approx p-value', 'used lags','NOBS'])\n print(dfoutput)",
"_____no_output_____"
],
[
"url = 'https://raw.githubusercontent.com/SimonMcLain/TUS-Engineering-Team-Project/main/Data/HSE/COVID-19_HPSC_County_Statistics_Historic_Data.csv'\n\nimport pandas as pd\n\ncovid_19_dataset = pd.read_csv(url)\n\ncovid_19_dataset.head()\n\ncovid_19_dataset.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 18590 entries, 0 to 18589\nData columns (total 16 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 OBJECTID 18590 non-null int64 \n 1 ORIGID 18590 non-null int64 \n 2 CountyName 18590 non-null object \n 3 PopulationCensus16 18590 non-null int64 \n 4 TimeStamp 18590 non-null object \n 5 IGEasting 18590 non-null int64 \n 6 IGNorthing 18590 non-null int64 \n 7 Lat 18590 non-null float64\n 8 Long 18590 non-null float64\n 9 UGI 18590 non-null object \n 10 ConfirmedCovidCases 18590 non-null int64 \n 11 PopulationProportionCovidCases 18538 non-null float64\n 12 ConfirmedCovidDeaths 0 non-null float64\n 13 ConfirmedCovidRecovered 0 non-null float64\n 14 Shape__Area 18590 non-null float64\n 15 Shape__Length 18590 non-null float64\ndtypes: float64(7), int64(6), object(3)\nmemory usage: 2.3+ MB\n"
],
[
"covid_19_dataset['TimeStamp'] = pd.to_datetime(covid_19_dataset['TimeStamp'], infer_datetime_format=True)\n\nindexed_covid_19_dataset = covid_19_dataset.set_index(['TimeStamp'])\n\nindexed_covid_19_dataset.head()",
"_____no_output_____"
],
[
"covid_19_confirmed_case_dataset = indexed_covid_19_dataset['ConfirmedCovidCases']\n\ncovid_19_confirmed_agg_dataset = covid_19_confirmed_case_dataset.groupby('TimeStamp').sum()\n\ntest_stationarity(covid_19_confirmed_agg_dataset)",
"_____no_output_____"
],
[
"import numpy as np\n\ncovid_19_confirmed_agg_dataset_log_scaled = np.log(covid_19_confirmed_agg_dataset)\n \ncovid_19_confirmed_agg_dataset_log_scaled = covid_19_confirmed_agg_dataset_log_scaled[covid_19_confirmed_agg_dataset_log_scaled > 0]\n\ntest_stationarity(covid_19_confirmed_agg_dataset_log_scaled)",
"_____no_output_____"
],
[
"ma = covid_19_confirmed_agg_dataset_log_scaled.rolling(window=6).mean()\n\ncovid_19_confirmed_agg_dataset_log_scaled_minus_ma = covid_19_confirmed_agg_dataset_log_scaled - ma\n\ncovid_19_confirmed_agg_dataset_log_scaled_minus_ma.dropna(inplace = True)\n\ntest_stationarity(covid_19_confirmed_agg_dataset_log_scaled_minus_ma)\n",
"_____no_output_____"
],
[
"covid_19_confirmed_agg_dataset_log_scaled_ps = covid_19_confirmed_agg_dataset_log_scaled.diff(periods=6)\n\ncovid_19_confirmed_agg_dataset_log_scaled_ps.dropna(inplace = True)\n\ntest_stationarity(covid_19_confirmed_agg_dataset_log_scaled_ps)",
"_____no_output_____"
],
[
"from statsmodels.tsa.stattools import acf\nfrom statsmodels.tsa.stattools import pacf\n\nfrom statsmodels.graphics.tsaplots import plot_acf\nfrom statsmodels.graphics.tsaplots import plot_pacf\n\nimport matplotlib.pyplot as plt\n\nlag_acf = acf(covid_19_confirmed_agg_dataset_log_scaled_ps, nlags = 32)\nlag_pacf = pacf(covid_19_confirmed_agg_dataset_log_scaled_ps, nlags = 16)\n\nfig,ax = plt.subplots(1,2,figsize=(20,5))\n\nplot_acf(lag_acf, ax = ax[0])\nplot_pacf(lag_pacf, lags = 7, ax = ax[1])\n\nplt.show()",
"/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/stattools.py:541: FutureWarning: fft=True will become the default in a future version of statsmodels. To suppress this warning, explicitly set fft=False.\n warnings.warn(msg, FutureWarning)\n"
],
[
"def predict(timeseries,p,d,q):\n\n from statsmodels.tsa.arima_model import ARIMA\n\n from sklearn.model_selection import train_test_split\n\n timeseries.dropna(inplace = True)\n\n train, test = train_test_split(timeseries, test_size = 0.20, shuffle = False)\n\n model_arima = ARIMA(train, order=(p,d,q))\n\n model_arima_fit = model_arima.fit()\n\n predictions = model_arima_fit.predict(start='2021-08-14', end = '2021-12-22')\n\n from sklearn.metrics import mean_squared_error\n\n error = mean_squared_error(test, predictions)\n\n print('Test MSE %.5f' % error)\n\n predict = np.exp(predictions)\n test_set = np.exp(test)\n\n plt.plot(test_set)\n plt.plot(predict, color='red')\n plt.show()\n\n from pandas import DataFrame\n\n residual = DataFrame(model_arima_fit.resid)\n\n residual.plot(kind='kde')\n\n\n",
"_____no_output_____"
],
[
"predict(covid_19_confirmed_agg_dataset_log_scaled_minus_ma, 10,2,3)",
"/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/base/tsa_model.py:165: ValueWarning: No frequency information was provided, so inferred frequency D will be used.\n % freq, ValueWarning)\n/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/base/tsa_model.py:165: ValueWarning: No frequency information was provided, so inferred frequency D will be used.\n % freq, ValueWarning)\n/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/tsatools.py:668: RuntimeWarning: overflow encountered in exp\n newparams = ((1-np.exp(-params))/(1+np.exp(-params))).copy()\n/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/tsatools.py:668: RuntimeWarning: invalid value encountered in true_divide\n newparams = ((1-np.exp(-params))/(1+np.exp(-params))).copy()\n/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/tsatools.py:669: RuntimeWarning: overflow encountered in exp\n tmp = ((1-np.exp(-params))/(1+np.exp(-params))).copy()\n/usr/local/lib/python3.7/dist-packages/statsmodels/tsa/tsatools.py:669: RuntimeWarning: invalid value encountered in true_divide\n tmp = ((1-np.exp(-params))/(1+np.exp(-params))).copy()\n/usr/local/lib/python3.7/dist-packages/statsmodels/base/model.py:492: HessianInversionWarning: Inverting hessian failed, no bse or cov_params available\n 'available', HessianInversionWarning)\n/usr/local/lib/python3.7/dist-packages/statsmodels/base/model.py:512: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals\n \"Check mle_retvals\", ConvergenceWarning)\n"
],
[
"from sklearn.model_selection import train_test_split\n\ncovid_19_confirmed_agg_dataset_log_scaled_ps.dropna(inplace = True)\n\ntrain, test= train_test_split(covid_19_confirmed_agg_dataset_log_scaled_ps,test_size = 0.20, shuffle = False)\ntest.head()\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac9b27a9224cd8e49b7ae55d043ee2dbc84ba27
| 201,400 |
ipynb
|
Jupyter Notebook
|
Notebooks/Notebooks_extra/Chapter_2_sec_3.1_3.5.ipynb
|
citizenkrank/ISLR-python
|
1de89811856ee770fcd3c12668db4306c6b08d89
|
[
"MIT"
] | null | null | null |
Notebooks/Notebooks_extra/Chapter_2_sec_3.1_3.5.ipynb
|
citizenkrank/ISLR-python
|
1de89811856ee770fcd3c12668db4306c6b08d89
|
[
"MIT"
] | null | null | null |
Notebooks/Notebooks_extra/Chapter_2_sec_3.1_3.5.ipynb
|
citizenkrank/ISLR-python
|
1de89811856ee770fcd3c12668db4306c6b08d89
|
[
"MIT"
] | null | null | null | 92.512632 | 75,944 | 0.818227 |
[
[
[
"# This is the Python Code for Chapter2 ''Statistical Learning\"",
"_____no_output_____"
],
[
"## 2.3.1 Basic Commands",
"_____no_output_____"
]
],
[
[
"import numpy as np # for calculation purpose, let use np.array \nimport random # for the random \n\nx = np.array([1, 3, 2, 5])\nprint(x)",
"[1 3 2 5]\n"
],
[
"x = np.array([1, 6, 2])\nprint(x)\ny = [1, 4, 3]",
"[1 6 2]\n"
]
],
[
[
"### use len() to find length of a vector",
"_____no_output_____"
]
],
[
[
"len(x) ",
"_____no_output_____"
],
[
"len(y)",
"_____no_output_____"
],
[
"print(x + y) # please note that we define x and y a little bit differently, but we still can do the calculation \ny = np.array([1, 4, 3])",
"[ 2 10 5]\n"
],
[
"whos",
"Variable Type Data/Info\n-------------------------------\nnp module <module 'numpy' from '/ho<...>kages/numpy/__init__.py'>\nrandom module <module 'random' from '/h<...>lib/python3.6/random.py'>\nx ndarray 3: 3 elems, type `int64`, 24 bytes\ny ndarray 3: 3 elems, type `int64`, 24 bytes\n"
],
[
"del x # reset_selective x",
"_____no_output_____"
],
[
"%whos",
"Variable Type Data/Info\n-------------------------------\nnp module <module 'numpy' from '/ho<...>kages/numpy/__init__.py'>\nrandom module <module 'random' from '/h<...>lib/python3.6/random.py'>\ny ndarray 3: 3 elems, type `int64`, 24 bytes\n"
],
[
"reset?",
"_____no_output_____"
],
[
"x = [[1,2],[3, 4]]\nprint (x)",
"[[1, 2], [3, 4]]\n"
],
[
"x = np.array([1, 2, 3, 4])",
"_____no_output_____"
],
[
"x = np.reshape(x, [2,2])\nprint(x)",
"[[1 2]\n [3 4]]\n"
],
[
"np.sqrt(x)",
"_____no_output_____"
],
[
"x**2\nnp.square(x)",
"_____no_output_____"
],
[
"mu, sigma = 0, 1\nx = np.random.normal(mu, sigma, 50)\ny = x + np.random.normal(50, 0.1, 50)\nprint( x, y)",
"[-1.11330146 0.17333015 -0.83817908 -0.34416826 1.45695885 -1.29066983\n -1.88914083 0.77601056 0.75374139 -0.58118128 0.86448042 0.68623428\n 1.45714366 0.83061637 1.84927013 0.77529365 -0.32502206 -0.36110087\n -0.5289383 0.71969056 -1.60081924 0.19714617 -0.2324194 -1.55215464\n 0.88046085 0.85399221 -0.39633995 -0.94504659 -0.02878268 -0.31564805\n -1.43614558 -0.17993546 0.66801294 1.22697392 -0.11762423 0.12406038\n 0.75099322 -1.28704529 -1.3494753 0.29994702 1.36893807 -0.24163683\n -0.70479902 -0.31562023 0.7024766 -1.97554785 -0.49308469 -0.15038975\n -1.54841198 1.04313762] [ 48.62834742 50.15327256 49.30996293 49.49149611 51.28980977\n 48.82970554 48.16569728 50.74076592 50.59654308 49.4857515\n 50.70761993 50.83439285 51.44724806 50.77533274 51.89119507\n 50.86677842 49.68501719 49.73077947 49.49630462 50.77017439\n 48.48763331 50.04463643 49.76748305 48.46663893 50.91813111\n 50.80103914 49.76436688 49.00816486 49.92725696 49.65239017\n 48.49543256 49.81201792 50.73063847 51.28864834 49.90410862\n 50.21688627 50.69776516 48.77997255 48.74814371 50.33958716\n 51.50665978 49.767955 49.46368203 49.62030975 50.72490379\n 48.23424311 49.42384104 49.77754179 48.43059038 51.04749535]\n"
],
[
"np.corrcoef(x, y) ",
"_____no_output_____"
]
],
[
[
"### Above will return the correlation matrix ",
"_____no_output_____"
]
],
[
[
"np.corrcoef(x, y)[0,1]",
"_____no_output_____"
],
[
"import random \nrandom.seed(2333)",
"_____no_output_____"
],
[
"np.random.normal(mu, sigma, 50) # after set up the seed, this should genernate the same result",
"_____no_output_____"
],
[
"y = np.random.normal(mu, sigma, 100)",
"_____no_output_____"
],
[
"print (np.mean(y))",
"0.113611414571\n"
],
[
"print (np.var(y))",
"1.27169618541\n"
],
[
"print (np.sqrt(np.var(y)))\nprint (np.std(y))",
"1.12769507643\n1.12769507643\n"
]
],
[
[
"### if we raise the number of sample to a larger number, the mean and std will be more close to (0, 1)",
"_____no_output_____"
]
],
[
[
"y = np.random.normal(mu, sigma, 5000)\nprint (np.mean(y))\nprint (np.std(y))",
"-0.00242010847682\n1.01887668187\n"
]
],
[
[
"## 2.3.2 Graphics",
"_____no_output_____"
]
],
[
[
"import numpy as np # for calculation purpose, let use np.array \nimport random # for the random \n\nx = np.random.normal(0, 1, 100)\ny = np.random.normal(0, 1, 100)\n\n# In python, matplotlib is the most used library for plot \n# matplotlib.pyplot is a collection of command style functions that make matplotlib work like MATLAB.\nimport matplotlib.pyplot as plt\n\nplt.figure()\nplt.plot(x, y, 'bo') # please use plt.plot? to look at more options \nplt.ylabel(\"this is the y-axis\")\nplt.xlabel(\"this is the x-axis\")\nplt.title(\"Plot of X vs Y\")\nplt.savefig('Figure.pdf') # use plt.savefig function to save images\nplt.show() \n",
"_____no_output_____"
],
[
"x = np.arange(1, 11) # note the arange excludes right end of rande specification \nprint (x )\n\n",
"[ 1 2 3 4 5 6 7 8 9 10]\n"
]
],
[
[
"### note: this actually can result in unexpected results; check np.arange(0.2, 0.6, 0.4) vs np.arange(0.2, 1.6, 1.4);",
"_____no_output_____"
]
],
[
[
"print(np.arange(0.2,0.6,0.4))\nprint(np.arange(0.2,1.6,1.4))",
"[ 0.2]\n[ 0.2 1.6]\n"
],
[
"# in order to use Pi, math module needs to loaded first\nimport math\nx = np.linspace(-math.pi, math.pi, num = 50)\nprint (x)",
"[-3.14159265 -3.01336438 -2.88513611 -2.75690784 -2.62867957 -2.5004513\n -2.37222302 -2.24399475 -2.11576648 -1.98753821 -1.85930994 -1.73108167\n -1.60285339 -1.47462512 -1.34639685 -1.21816858 -1.08994031 -0.96171204\n -0.83348377 -0.70525549 -0.57702722 -0.44879895 -0.32057068 -0.19234241\n -0.06411414 0.06411414 0.19234241 0.32057068 0.44879895 0.57702722\n 0.70525549 0.83348377 0.96171204 1.08994031 1.21816858 1.34639685\n 1.47462512 1.60285339 1.73108167 1.85930994 1.98753821 2.11576648\n 2.24399475 2.37222302 2.5004513 2.62867957 2.75690784 2.88513611\n 3.01336438 3.14159265]\n"
],
[
"import matplotlib.cm as cm\nimport matplotlib.mlab as mlab\ny = x\nX, Y = np.meshgrid(x,y)",
"_____no_output_____"
],
[
"whos",
"Variable Type Data/Info\n-------------------------------\nX ndarray 50x50: 2500 elems, type `float64`, 20000 bytes\nY ndarray 50x50: 2500 elems, type `float64`, 20000 bytes\ncm module <module 'matplotlib.cm' f<...>ckages/matplotlib/cm.py'>\nmath module <module 'math' from '/hom<...>36m-x86_64-linux-gnu.so'>\nmlab module <module 'matplotlib.mlab'<...>ages/matplotlib/mlab.py'>\nmu int 0\nnp module <module 'numpy' from '/ho<...>kages/numpy/__init__.py'>\nplt module <module 'matplotlib.pyplo<...>es/matplotlib/pyplot.py'>\nrandom module <module 'random' from '/h<...>lib/python3.6/random.py'>\nsigma int 1\nx ndarray 50: 50 elems, type `float64`, 400 bytes\ny ndarray 50: 50 elems, type `float64`, 400 bytes\n"
],
[
"plt.figure()\nf = np.cos(Y)/(1 + np.square(X))\nCS = plt.contour(X, Y, f)\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"### same as above, use plt.contour? to explore the options",
"_____no_output_____"
]
],
[
[
"fa = (f - f.T)/2 #f.T for transpose or tranpose(f)\nplt.imshow(fa, extent=(x[0], x[-1], y[0], y[-1])) \nplt.show()",
"_____no_output_____"
]
],
[
[
"### I think imshow looks nicer for heatmap, use 'extent =' fix the x, y axis",
"_____no_output_____"
]
],
[
[
"from mpl_toolkits.mplot3d import axes3d\nfig = plt.figure()\nax = fig.add_subplot(111, projection='3d')\nax.plot_wireframe(X, Y, fa)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 2.3.3 Indexing Data",
"_____no_output_____"
]
],
[
[
"A = np.arange(1,17,1).reshape(4, 4).transpose()\nprint(A)",
"[[ 1 5 9 13]\n [ 2 6 10 14]\n [ 3 7 11 15]\n [ 4 8 12 16]]\n"
],
[
"A[2, 3]",
"_____no_output_____"
]
],
[
[
"### try the same index as the book, but we got different number. The reason is R starts the index from 1 (Matlab too), but Python starts the index from 0. To select the same number (10) as the book did, we reduce the index by 1",
"_____no_output_____"
]
],
[
[
"A[1, 2]",
"_____no_output_____"
]
],
[
[
"### to select a submatrix, need the non-singleton dimension of your indexing array to be aligned with the axis you're indexing into, e.g. for an n x m 2D subarray: A[n by 1 array,1 by m array]",
"_____no_output_____"
]
],
[
[
"A[[[0],[2]], [1,3]]",
"_____no_output_____"
],
[
"A[0:3:1, 1:4:1] # this is another way of doing it",
"_____no_output_____"
],
[
"A[0:2,:]",
"_____no_output_____"
],
[
"A[:,0:2]",
"_____no_output_____"
]
],
[
[
"### The last two examples include either no index for the columns or no index for the rows. These indicate that Python should include all columns or all rows, respectively",
"_____no_output_____"
]
],
[
[
"A[0,:]",
"_____no_output_____"
]
],
[
[
"### '-' sign has a different meaning in Python. This means index from the end, -1 means the last element ",
"_____no_output_____"
]
],
[
[
"A[-1, -1] ",
"_____no_output_____"
]
],
[
[
"### There are quite a few ways to let Python keep all rows except certain index. Here boolean was used.",
"_____no_output_____"
]
],
[
[
"ind = np.ones((4,), bool)\nind[[0,2]] = False",
"_____no_output_____"
],
[
"ind",
"_____no_output_____"
],
[
"A[ind,:]",
"_____no_output_____"
],
[
"A[ind]",
"_____no_output_____"
],
[
"A.shape",
"_____no_output_____"
]
],
[
[
"## 2.3.4 Loading Data",
"_____no_output_____"
],
[
"### In Python, Pandas is a common used module to read from file into a data frame. I downloaded the Auto.csv from the book website. First, take a look at the csv file. There are headers, missing value is marked by '?' .",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nAuto = pd.read_csv('data/Auto.csv', header=0, na_values='?')",
"_____no_output_____"
]
],
[
[
"### check one record with missing value, and make sure the missing value is correctly imported ",
"_____no_output_____"
]
],
[
[
"Auto.iloc[32]",
"_____no_output_____"
]
],
[
[
"### Use the same function as in ndarray to find out the dimension of the data frame ",
"_____no_output_____"
]
],
[
[
"Auto.shape",
"_____no_output_____"
],
[
"Auto[:4]",
"_____no_output_____"
],
[
"Auto.iloc[:4, :2]",
"_____no_output_____"
],
[
"list(Auto)",
"_____no_output_____"
]
],
[
[
"### Use .isnull and .sum to find out how many NaNs in each variables",
"_____no_output_____"
]
],
[
[
"Auto.isnull().sum()",
"_____no_output_____"
]
],
[
[
"### after the previous steps, there are 397 obs in the data and only 5 with missing values. We can just drop the ones with missing values ",
"_____no_output_____"
]
],
[
[
"Auto = Auto.dropna()",
"_____no_output_____"
],
[
"Auto.shape",
"_____no_output_____"
]
],
[
[
"## 2.3.5 Additional Graphical and Numerical Summaries",
"_____no_output_____"
],
[
"### refer a column of data frame by name, by using a '.'. Ref the options in plt.plot for more.",
"_____no_output_____"
]
],
[
[
"plt.plot(Auto.cylinders, Auto.mpg, 'ro')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Use .hist to get the histogram of certain variables. column = to specify which variable",
"_____no_output_____"
]
],
[
[
"Auto.hist(column = ['cylinders', 'mpg'])\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Use the .describe() to get a summary of the data frame. Use .describe ( include = 'all' ) for mix types, use describe(include = [np.number]) for numerical columns, use describe(include = ['O']) for objects.",
"_____no_output_____"
]
],
[
[
"Auto.describe()",
"_____no_output_____"
]
],
[
[
"### We can change type of certain variable(s). Here changed the cylinders into categorical variable ",
"_____no_output_____"
]
],
[
[
"Auto['cylinders'] = Auto['cylinders'].astype('category')",
"_____no_output_____"
],
[
"Auto.describe()",
"_____no_output_____"
],
[
"Auto.describe(include= 'all')",
"_____no_output_____"
]
],
[
[
"## Exercises",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ac9cb2a80199887eb5080af1c17fc5e29ece360
| 892,090 |
ipynb
|
Jupyter Notebook
|
Notebooks/CH day-ahead prices.ipynb
|
invveritas/green_charging_emobility
|
ac95f67a2b733a3558da12f58a0c68becb1b0e1c
|
[
"MIT"
] | null | null | null |
Notebooks/CH day-ahead prices.ipynb
|
invveritas/green_charging_emobility
|
ac95f67a2b733a3558da12f58a0c68becb1b0e1c
|
[
"MIT"
] | 10 |
2021-09-24T11:40:23.000Z
|
2021-09-25T09:50:15.000Z
|
Notebooks/CH day-ahead prices.ipynb
|
invveritas/green_charging_emobility
|
ac95f67a2b733a3558da12f58a0c68becb1b0e1c
|
[
"MIT"
] | 1 |
2021-09-24T11:45:31.000Z
|
2021-09-24T11:45:31.000Z
| 1,425.063898 | 109,884 | 0.956266 |
[
[
[
"from pathlib import Path\nimport pandas as pd\nimport numpy as np\nfrom import_clean_data import load_annotated_meter_data, load_co2_data\nfrom load_dayahead_prices import load_dayahead_prices\nimport warnings\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"DATA_DIR = (Path.cwd() / \"..\" / \"Data\").resolve()",
"_____no_output_____"
],
[
"dayahead_2020_filename = \"Day-ahead Prices_202001010000-202101010000.csv\"\ndayahead_2021_filename = \"Day-ahead Prices_202101010000-202201010000.csv\"",
"_____no_output_____"
],
[
"dayahead_2020 = load_dayahead_prices(DATA_DIR / dayahead_2020_filename)\ndayahead_2021 = load_dayahead_prices(DATA_DIR / dayahead_2021_filename)",
"_____no_output_____"
],
[
"dayahead_2020",
"_____no_output_____"
],
[
"dayahead = pd.concat([dayahead_2020, dayahead_2021])",
"_____no_output_____"
],
[
"dayahead.drop([\"BZN|CH\"], axis=1, inplace=True)",
"_____no_output_____"
],
[
"dayahead = dayahead[dayahead['Day-ahead Price [EUR/MWh]'].notna()]",
"_____no_output_____"
],
[
"dayahead.dtypes",
"_____no_output_____"
],
[
"mondays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 0]\ntuesdays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 1]\nwednesdays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 2]\nthursdays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 3]\nfridays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 4]\nsaturdays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 5]\nsundays = dayahead.loc[dayahead['datetime'].dt.dayofweek == 6]",
"_____no_output_____"
],
[
"# Calculate price per hour of average weekday\ndays = [mondays, tuesdays, wednesdays, thursdays, fridays, saturdays, sundays]\nresult = {}\n\nj = 0\nfor day in days:\n hours = []\n \n for i in range(24):\n thishour = day.loc[day['datetime'].dt.hour == i]\n number = len(thishour.index)\n avg = thishour['Day-ahead Price [EUR/MWh]'].sum() / number\n hours.append(avg)\n \n result[str(j)] = hours\n j += 1",
"_____no_output_____"
],
[
"plt.figure(figsize=(14, 8))\nplt.plot(result['0'], label=\"Monday\")\nplt.plot(result['1'], label=\"Tuesday\")\nplt.plot(result['2'], label=\"Wednesdays\")\nplt.plot(result['3'], label=\"Thursday\")\nplt.plot(result['4'], label=\"Friday\")\nplt.plot(result['5'], label=\"Saturday\")\nplt.plot(result['6'], label=\"Sunday\")\nplt.title(\"Average energy price per hour of weekday\")\nplt.ylabel(\"day-ahead price (EUR / MWh)\")\nplt.xlabel(\"hour of day [UTC]\")\nplt.legend()\nplt.savefig(\"daily_dayahead_price.png\", dpi=300)",
"_____no_output_____"
],
[
"# per month\nJan = dayahead.loc[dayahead['datetime'].dt.month == 1]\nFeb = dayahead.loc[dayahead['datetime'].dt.month == 2]\nMar = dayahead.loc[dayahead['datetime'].dt.month == 3]\nApr = dayahead.loc[dayahead['datetime'].dt.month == 4]\nMai = dayahead.loc[dayahead['datetime'].dt.month == 5]\nJun = dayahead.loc[dayahead['datetime'].dt.month == 6]\nJul = dayahead.loc[dayahead['datetime'].dt.month == 7]\nAug = dayahead.loc[dayahead['datetime'].dt.month == 8]\nSep = dayahead.loc[dayahead['datetime'].dt.month == 9]\nOkt = dayahead.loc[dayahead['datetime'].dt.month == 10]\nNov = dayahead.loc[dayahead['datetime'].dt.month == 11]\nDez = dayahead.loc[dayahead['datetime'].dt.month == 12]",
"_____no_output_____"
],
[
"# Calculate average price per month\nmonths = [Jan, Feb, Mar, Apr, Mai, Jun, Jul, Aug, Sep, Okt, Nov, Dez]\nresult = {}\n\nj = 0\nfor month in months:\n hours = []\n \n for i in range(24):\n thishour = month.loc[month['datetime'].dt.hour == i]\n number = len(thishour.index)\n avg = thishour['Day-ahead Price [EUR/MWh]'].sum() / number\n hours.append(avg)\n \n result[str(j)] = hours\n j += 1",
"_____no_output_____"
],
[
"plt.plot(result['0'], label=\"Jan\")\nplt.plot(result['1'], label=\"Feb\")\nplt.plot(result['2'], label=\"Mar\")\nplt.plot(result['3'], label=\"Apr\")\nplt.plot(result['4'], label=\"Mai\")\nplt.plot(result['5'], label=\"Jun\")\nplt.plot(result['6'], label=\"Jul\")\nplt.plot(result['7'], label=\"Aug\")\nplt.plot(result['8'], label=\"Sep\")\nplt.plot(result['9'], label=\"Okt\")\nplt.plot(result['10'], label=\"Nov\")\nplt.plot(result['11'], label=\"Dez\")\nplt.title(\"Average electricity price per hour of months\")\nplt.ylabel(\"day-ahead price (EUR / MWh)\")\nplt.xlabel(\"hour of day [UTC]\")\nplt.legend();",
"_____no_output_____"
],
[
"# for every weekday, plot all months\nmonthcount = 1\n\nfor month in months:\n mondays = month.loc[month['datetime'].dt.dayofweek == 0]\n tuesdays = month.loc[month['datetime'].dt.dayofweek == 1]\n wednesdays = month.loc[month['datetime'].dt.dayofweek == 2]\n thursdays = month.loc[month['datetime'].dt.dayofweek == 3]\n fridays = month.loc[month['datetime'].dt.dayofweek == 4]\n saturdays = month.loc[month['datetime'].dt.dayofweek == 5]\n sundays = month.loc[month['datetime'].dt.dayofweek == 6]\n \n # Calculate average co2_intensity per weekday\n days = [mondays, tuesdays, wednesdays, thursdays, fridays, saturdays, sundays]\n result = {}\n\n j = 0\n for day in days:\n hours = []\n\n for i in range(24):\n thishour = day.loc[day['datetime'].dt.hour == i]\n number = len(thishour.index)\n avg = thishour['Day-ahead Price [EUR/MWh]'].sum() / number\n hours.append(avg)\n\n result[str(j)] = hours\n j += 1\n \n # plot\n plt.figure()\n plt.plot(result['0'], label=\"Monday\")\n plt.plot(result['1'], label=\"Tuesday\")\n plt.plot(result['2'], label=\"Wednesdays\")\n plt.plot(result['3'], label=\"Thursday\")\n plt.plot(result['4'], label=\"Friday\")\n plt.plot(result['5'], label=\"Saturday\")\n plt.plot(result['6'], label=\"Sunday\")\n plt.title(\"Average electricity price per hour of weekday in month \" + str(monthcount))\n plt.ylabel(\"Day-ahead Price [EUR/MWh]\")\n plt.xlabel(\"hour of day [UTC]\")\n plt.legend()\n \n monthcount += 1\n \nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac9e33b93b08134983f0452116ca595ac96635c
| 4,772 |
ipynb
|
Jupyter Notebook
|
np_data_type.ipynb
|
ftconan/numpy_tutorial
|
0cca229357e975e3a30fe099f2d1a3158b1712ca
|
[
"MIT"
] | null | null | null |
np_data_type.ipynb
|
ftconan/numpy_tutorial
|
0cca229357e975e3a30fe099f2d1a3158b1712ca
|
[
"MIT"
] | null | null | null |
np_data_type.ipynb
|
ftconan/numpy_tutorial
|
0cca229357e975e3a30fe099f2d1a3158b1712ca
|
[
"MIT"
] | null | null | null | 18.21374 | 253 | 0.469405 |
[
[
[
"import numpy as np",
"_____no_output_____"
],
[
"x = np.float32(1.0)\nx",
"_____no_output_____"
],
[
"y = np.int_([1,2,4])\ny",
"_____no_output_____"
],
[
"z = np.arange(3, dtype=np.uint8)\nz",
"_____no_output_____"
],
[
"np.array([1,2,3], dtype='f')",
"_____no_output_____"
],
[
"z.astype(float)",
"_____no_output_____"
],
[
"np.int8(z)",
"_____no_output_____"
],
[
"z.dtype",
"_____no_output_____"
],
[
"d = np.dtype(int)\nd",
"_____no_output_____"
],
[
"np.issubdtype(d, int)",
"/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:1: FutureWarning: Conversion of the second argument of issubdtype from `int` to `np.signedinteger` is deprecated. In future, it will be treated as `np.int64 == np.dtype(int).type`.\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"np.issubdtype(d, float)",
"/usr/local/lib/python3.5/dist-packages/ipykernel_launcher.py:1: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n \"\"\"Entry point for launching an IPython kernel.\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ac9fd85bfd35de3e901ef2621a3c77fdf9e8731
| 508,475 |
ipynb
|
Jupyter Notebook
|
scripts/model_selection.ipynb
|
szczurek-lab/hydramp
|
be4eb6defe227fe3fef4fe9882a85a0b717301c6
|
[
"MIT"
] | 4 |
2022-03-04T15:57:24.000Z
|
2022-03-24T11:13:01.000Z
|
scripts/model_selection.ipynb
|
szczurek-lab/hydramp
|
be4eb6defe227fe3fef4fe9882a85a0b717301c6
|
[
"MIT"
] | null | null | null |
scripts/model_selection.ipynb
|
szczurek-lab/hydramp
|
be4eb6defe227fe3fef4fe9882a85a0b717301c6
|
[
"MIT"
] | 1 |
2022-03-07T16:44:11.000Z
|
2022-03-07T16:44:11.000Z
| 171.203704 | 44,992 | 0.89486 |
[
[
[
"import tensorflow as tf\nconfig = tf.compat.v1.ConfigProto(\n gpu_options = tf.compat.v1.GPUOptions(per_process_gpu_memory_fraction=0.8),\n)\nconfig.gpu_options.allow_growth = True\nsession = tf.compat.v1.Session(config=config)\ntf.compat.v1.keras.backend.set_session(session)",
"_____no_output_____"
],
[
"import os\nimport warnings\nwarnings.filterwarnings('ignore')\n\nimport numpy as np\nimport pandas as pd\nimport sklearn\nfrom sklearn.model_selection import train_test_split\nfrom pathlib import Path\nfrom keras import backend, layers, activations, Model\n\nfrom amp.utils.basic_model_serializer import load_master_model_components\nfrom amp.models.decoders import amp_expanded_decoder\nfrom amp.models.encoders import amp_expanded_encoder\nfrom amp.models.master import master\nfrom amp.utils import basic_model_serializer\nimport amp.data_utils.data_loader as data_loader\nfrom amp.data_utils.sequence import pad, to_one_hot\n\n\n\nfrom tqdm import tqdm\nfrom joblib import dump, load\nfrom sklearn.decomposition import PCA\n\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nparams = {'axes.labelsize': 16,\n 'axes.titlesize': 24,\n 'xtick.labelsize':14,\n 'ytick.labelsize': 14}\nplt.rcParams.update(params)\nplt.rc('text', usetex=False)\nsns.set_style('whitegrid', {'grid.color': '.95', 'axes.spines.right': False, 'axes.spines.top': False})\nsns.set_context(\"notebook\")",
"Using TensorFlow backend.\n"
],
[
"seed = 7\nnp.random.seed(seed)",
"_____no_output_____"
],
[
"from amp.config import MIN_LENGTH, MAX_LENGTH, LATENT_DIM, MIN_KL, RCL_WEIGHT, HIDDEN_DIM, MAX_TEMPERATURE\n\ninput_to_encoder = layers.Input(shape=(MAX_LENGTH,))\ninput_to_decoder = layers.Input(shape=(LATENT_DIM+2,))",
"_____no_output_____"
],
[
"def translate_generated_peptide(encoded_peptide):\n alphabet = list('ACDEFGHIKLMNPQRSTVWY')\n return ''.join([alphabet[el - 1] if el != 0 else \"\" for el in encoded_peptide[0].argmax(axis=1)])\n\ndef translate_peptide(encoded_peptide):\n alphabet = list('ACDEFGHIKLMNPQRSTVWY')\n return ''.join([alphabet[el-1] if el != 0 else \"\" for el in encoded_peptide])",
"_____no_output_____"
],
[
"models = [\n 'HydrAMP',\n 'PepCVAE',\n 'Basic',\n]\n\nmodel_labels = [\n 'HydrAMP',\n 'PepCVAE',\n 'Basic',\n]",
"_____no_output_____"
],
[
"bms = basic_model_serializer.BasicModelSerializer()\namp_classifier = bms.load_model('../models/amp_classifier')\namp_classifier_model = amp_classifier()\nmic_classifier = bms.load_model('../models/mic_classifier/')\nmic_classifier_model = mic_classifier() ",
"_____no_output_____"
]
],
[
[
"# Get validation data",
"_____no_output_____"
]
],
[
[
"data_manager = data_loader.AMPDataManager(\n '../data/unlabelled_positive.csv',\n '../data/unlabelled_negative.csv',\n min_len=MIN_LENGTH,\n max_len=MAX_LENGTH)\n\namp_x, amp_y = data_manager.get_merged_data()\namp_x_train, amp_x_test, amp_y_train, amp_y_test = train_test_split(amp_x, amp_y, test_size=0.1, random_state=36)\namp_x_train, amp_x_val, amp_y_train, amp_y_val = train_test_split(amp_x_train, amp_y_train, test_size=0.2, random_state=36)",
"_____no_output_____"
],
[
"# Restrict the length\necoli_df = pd.read_csv('../data/mic_data.csv')\nmask = (ecoli_df['sequence'].str.len() <= MAX_LENGTH) & (ecoli_df['sequence'].str.len() >= MIN_LENGTH)\necoli_df = ecoli_df.loc[mask]\nmic_x = pad(to_one_hot(ecoli_df['sequence']))\nmic_y = ecoli_df.value\n\nmic_x_train, mic_x_test, mic_y_train, mic_y_test = train_test_split(mic_x, mic_y, test_size=0.1, random_state=36)\nmic_x_train, mic_x_val, mic_y_train, mic_y_val = train_test_split(mic_x_train, mic_y_train, test_size=0.2, random_state=36)",
"_____no_output_____"
],
[
"pos = np.vstack([amp_x_val[amp_y_val == 1], mic_x_val[mic_y_val < 1.5]])\nneg = np.vstack([amp_x_val[amp_y_val == 0], mic_x_val[mic_y_val > 1.5]])",
"_____no_output_____"
],
[
"neg.shape, pos.shape",
"_____no_output_____"
],
[
"pos_amp = amp_classifier_model.predict(pos, verbose=1).reshape(len(pos))\nneg_mic = mic_classifier_model.predict(neg, verbose=1).reshape(len(neg))\nneg_amp = amp_classifier_model.predict(neg, verbose=1).reshape(len(neg))\npos_mic = mic_classifier_model.predict(pos, verbose=1).reshape(len(pos))",
"2404/2404 [==============================] - 2s 762us/step\n2223/2223 [==============================] - 0s 172us/step\n2223/2223 [==============================] - 0s 161us/step\n2404/2404 [==============================] - 0s 44us/step\n"
],
[
"fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(12, 4), sharex=True, sharey=True) \nax1.hist(pos_amp)\nax1.set_ylabel('AMP')\nax1.set_title('Positives')\nax2.hist(neg_amp)\nax2.set_title('Negatives')\n\nax3.hist(pos_mic)\nax3.set_ylabel('MIC')\nax4.hist(neg_mic)\nplt.show()",
"_____no_output_____"
],
[
"pos = np.vstack([pos] * 64).reshape(-1, 25)\npos_amp = np.vstack([pos_amp] * 64).reshape(-1, 1)\npos_mic = np.vstack([pos_mic] * 64).reshape(-1, 1)\nneg = np.vstack([neg] * 64).reshape(-1, 25)\nneg_amp = np.vstack([neg_amp] * 64).reshape(-1, 1)\nneg_mic = np.vstack([neg_mic] * 64).reshape(-1, 1)",
"_____no_output_____"
],
[
"def improve(x, model, epoch, mode):\n if mode == 'pos':\n amp = pos_amp\n mic = pos_mic\n else:\n amp = neg_mic\n mic = neg_mic\n \n encoded = encoder_model.predict(x, batch_size=5000)\n conditioned = np.hstack([\n encoded,\n np.ones((len(x), 1)),\n np.ones((len(x), 1)),\n ])\n decoded = decoder_model.predict(conditioned, batch_size=5000)\n new_peptides = np.argmax(decoded, axis=2)\n new_amp = amp_classifier_model.predict(new_peptides, batch_size=5000)\n new_mic = mic_classifier_model.predict(new_peptides, batch_size=5000) \n \n # RELATIVE\n rel_better = new_amp > amp.reshape(-1, 1)\n rel_better = rel_better & (new_mic > mic.reshape(-1, 1))\n rel_better = np.logical_or.reduce(rel_better, axis=1)\n rel_improved = new_peptides[np.where(rel_better), :].reshape(-1, 25)\n before_rel_improve = x[np.where(rel_better), :].reshape(-1, 25)\n \n # ABSOLUTE\n abs_better = new_amp >= 0.8\n abs_better = abs_better & (new_mic > 0.5)\n abs_better = np.logical_or.reduce(abs_better, axis=1)\n abs_improved = new_peptides[np.where(abs_better), :].reshape(-1, 25)\n before_abs_improve = x[np.where(abs_better), :].reshape(-1, 25)\n \n return {\n 'new_peptides': new_peptides,\n 'rel_improved': rel_improved,\n 'abs_improved': abs_improved,\n 'before_rel_improve': before_rel_improve,\n 'before_abs_improve': before_abs_improve, \n 'new_amp': new_amp,\n 'new_mic': new_mic,\n } ",
"_____no_output_____"
]
],
[
[
"# HydrAMP improve",
"_____no_output_____"
]
],
[
[
"from keras.models import Model\nmodel = models[0]\ncurrent_model_pos = {epoch: [] for epoch in range(40)} \ncurrent_model_neg = {epoch: [] for epoch in range(40)} \nfor epoch in tqdm(range(40)):\n AMPMaster = bms.load_model(f'../models/{model}/{epoch}')\n encoder_model = AMPMaster.encoder(input_to_encoder)\n decoder_model = AMPMaster.decoder(input_to_decoder) \n current_model_pos[epoch] = improve(pos, model, epoch, 'pos')\n current_model_neg[epoch] = improve(neg, model, epoch, 'neg')\ndump(current_model_pos, f'../results/improvement_PosVal_{model}.joblib') \ndump(current_model_neg, f'../results/improvement_NegVal_{model}.joblib') \n",
"\r 0%| | 0/40 [00:00<?, ?it/s]"
]
],
[
[
"# PepCVAE improve",
"_____no_output_____"
]
],
[
[
"from keras.models import Model\nmodel = models[1]\ncurrent_model_pos = {epoch: [] for epoch in range(40)} \ncurrent_model_neg = {epoch: [] for epoch in range(40)} \nfor epoch in tqdm(range(40)):\n AMPMaster = bms.load_model(f'../models/{model}/{epoch}')\n encoder_model = AMPMaster.encoder(input_to_encoder)\n decoder_model = AMPMaster.decoder(input_to_decoder)\n new_act = layers.TimeDistributed(\n layers.Activation(activations.softmax),\n name='decoder_time_distribute_activation')\n decoder_model.layers.pop()\n x = new_act(decoder_model.layers[-1].output)\n decoder_model = Model(input=decoder_model.input, output=[x]) \n current_model_pos[epoch] = improve(pos, model, epoch, 'pos')\n current_model_neg[epoch] = improve(neg, model, epoch, 'neg')\ndump(current_model_pos, f'../results/improvement_PosVal_{model}.joblib') \ndump(current_model_neg, f'../results/improvement_NegVal_{model}.joblib') \n",
"\r 0%| | 0/40 [00:00<?, ?it/s]"
]
],
[
[
"# Basic improvement",
"_____no_output_____"
]
],
[
[
"from keras.models import Model\nmodel = models[2]\ncurrent_model_pos = {epoch: [] for epoch in range(40)} \ncurrent_model_neg = {epoch: [] for epoch in range(40)} \nfor epoch in tqdm(range(40)):\n AMPMaster = bms.load_model(f'../models/{model}/{epoch}')\n encoder_model = AMPMaster.encoder(input_to_encoder)\n decoder_model = AMPMaster.decoder(input_to_decoder)\n new_act = layers.TimeDistributed(\n layers.Activation(activations.softmax),\n name='decoder_time_distribute_activation')\n decoder_model.layers.pop()\n x = new_act(decoder_model.layers[-1].output)\n decoder_model = Model(input=decoder_model.input, output=[x]) \n current_model_pos[epoch] = improve(pos, model, epoch, 'pos')\n current_model_neg[epoch] = improve(neg, model, epoch, 'neg')\ndump(current_model_pos, f'../results/improvement_PosVal_{model}.joblib') \ndump(current_model_neg, f'../results/improvement_NegVal_{model}.joblib') \n",
"\r 0%| | 0/40 [00:00<?, ?it/s]"
]
],
[
[
"# Collect results",
"_____no_output_____"
]
],
[
[
"pos_final_results = {model: {epoch: \n {'absolute improvement':0,\n 'relative improvement':0,\n } for epoch in range(40)} for model in models}\nneg_final_results = {model: {epoch: \n {'absolute improvement':0,\n 'relative improvement':0,\n } for epoch in range(40)} for model in models}",
"_____no_output_____"
],
[
"for model in models:\n if model in ['PepCVAE', 'Basic']:\n model_results = load(f'../results/improvement_PosVal_{model}.joblib')\n else:\n model_results = load(f'../results/improvement_PosVal_{model}.joblib')\n for epoch in range(40):\n pos_final_results[model][epoch]['relative improvement'] = np.unique(\n model_results[epoch]['rel_improved'], axis=0).shape[0]\n pos_final_results[model][epoch]['absolute improvement'] = np.unique(\n model_results[epoch]['abs_improved'], axis=0).shape[0]\n pos_final_results[model][epoch]['before relative improvement'] = np.unique(\n model_results[epoch]['before_rel_improve'], axis=0).shape[0]\n pos_final_results[model][epoch]['before absolute improvement'] = np.unique(\n model_results[epoch]['before_abs_improve'], axis=0).shape[0]\n \n ",
"_____no_output_____"
],
[
"for model in models:\n if model in ['PepCVAE', 'Basic']:\n model_results = load(f'../results/improvement_NegVal_{model}.joblib')\n else:\n model_results = load(f'../results/improvement_NegVal_{model}.joblib')\n for epoch in range(40):\n neg_final_results[model][epoch]['relative improvement'] = np.unique(\n model_results[epoch]['rel_improved'], axis=0).shape[0]\n neg_final_results[model][epoch]['absolute improvement'] = np.unique(\n model_results[epoch]['abs_improved'], axis=0).shape[0]\n neg_final_results[model][epoch]['before relative improvement'] = np.unique(\n model_results[epoch]['before_rel_improve'], axis=0).shape[0]\n neg_final_results[model][epoch]['before absolute improvement'] = np.unique(\n model_results[epoch]['before_abs_improve'], axis=0).shape[0]",
"_____no_output_____"
],
[
"hydra_metrics = pd.read_csv('../models/HydrAMP/metrics.csv')\npepcvae_metrics = pd.read_csv('../models/PepCVAE/metrics.csv')\nbasic_metrics = pd.read_csv('../models/Basic/metrics.csv')\n",
"_____no_output_____"
],
[
"plt.title('Relative improved')\nplt.plot([pos_final_results[models[0]][epoch]['relative improvement'] for epoch in range(10, 40)], c='red', label='HydrAMP')\nplt.plot([pos_final_results[models[1]][epoch]['relative improvement'] for epoch in range(10, 40)], c='orange', label='PepCVAE')\nplt.plot([pos_final_results[models[2]][epoch]['relative improvement'] for epoch in range(10, 40)], c='blue', label='Basic')\n\nplt.legend(bbox_to_anchor=(1.1, 0.5))\nplt.show()",
"_____no_output_____"
],
[
"plt.title('Absolute improved')\nplt.plot([pos_final_results[models[0]][epoch]['absolute improvement'] for epoch in range(10, 40)], c='red', label='HydrAMP')\nplt.plot([pos_final_results[models[1]][epoch]['absolute improvement'] for epoch in range(10, 40)], c='orange', label='PepCVAE')\nplt.plot([pos_final_results[models[2]][epoch]['absolute improvement'] for epoch in range(10, 40)], c='blue', label='Basic')\n\nplt.legend(bbox_to_anchor=(1.1, 0.5))\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,5))\nplt.plot([float(x) for x in hydra_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='red', label='HydrAMP', linestyle='--')\nplt.plot([float(x) for x in pepcvae_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='orange', label='PepCVAE', linestyle='--')\nplt.plot([float(x) for x in basic_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='blue', label='Basic', linestyle='--')\n\n\n\nplt.title('How many petides were susceptible to (relative) improvement out of 2404 known AMPs? ')\nplt.plot([pos_final_results[models[0]][epoch]['before relative improvement']/2404 for epoch in range(10, 40)], c='red')\nplt.plot([pos_final_results[models[1]][epoch]['before relative improvement']/2404 for epoch in range(10, 40)], c='orange')\nplt.plot([pos_final_results[models[2]][epoch]['before relative improvement']/2404 for epoch in range(10, 40)], c='blue')\n\nplt.legend(bbox_to_anchor=(1.1, 0.5))\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,5))\nplt.plot([float(x) for x in hydra_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='red', label='HydrAMP', linestyle='--')\nplt.plot([float(x) for x in pepcvae_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='orange', label='PepCVAE', linestyle='--')\nplt.plot([float(x) for x in basic_metrics['val_vae_loss_1__amino_acc'].tolist()[10:40]],\n c='blue', label='Basic', linestyle='--')\n\n\nplt.title('How many petides were susceptible to (absolute) improvement out of 2404 known AMPs? ')\nplt.plot([pos_final_results[models[0]][epoch]['before absolute improvement']/2404 for epoch in range(10, 40)], c='red')\nplt.plot([pos_final_results[models[1]][epoch]['before absolute improvement']/2404 for epoch in range(10, 40)], c='orange')\nplt.plot([pos_final_results[models[2]][epoch]['before absolute improvement']/2404 for epoch in range(10, 40)], c='blue')\n\nplt.legend(bbox_to_anchor=(1.1, 0.5))\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Model selection",
"_____no_output_____"
]
],
[
[
"def choose_best_epoch(model):\n model_metrics = pd.read_csv(f'../models/{model}/metrics.csv')\n good_epochs = model_metrics.iloc[10:40][model_metrics['val_vae_loss_1__amino_acc'].astype(float) > 0.95].epoch_no.tolist()\n improved_peptides = [pos_final_results[model][epoch]['before relative improvement']/2404 + \\\n neg_final_results[model][epoch]['before absolute improvement']/2223 \\\n for epoch in good_epochs]\n return good_epochs[np.argmax(improved_peptides)], np.max(improved_peptides) ",
"_____no_output_____"
],
[
"best_epochs = {model: [] for model in models}\n\nfor model in models:\n best_epochs[model] = choose_best_epoch(model)\n",
"_____no_output_____"
],
[
"best_epochs",
"_____no_output_____"
],
[
"ax = sns.barplot(\n x=model_labels,\n y=[\n pos_final_results[model][int(best_epochs[model][0])]['before relative improvement']/2404 + \\\n neg_final_results[model][int(best_epochs[model][0])]['before absolute improvement']/2223 \\\n for model in models\n ]\n)\n\nax.set_title('VALIDATION SET\\n % of relatively improved positives + % of absolutely improved negatives')\nax.set_xticklabels(model_labels, rotation=90)\nplt.show()\n ",
"_____no_output_____"
],
[
"\n\nmetrics_to_consider = [\n 'before relative improvement',\n 'before absolute improvement',\n 'relative improvement',\n 'absolute improvement',\n]\n\nmetrics_labels = [\n 'How many petides were susceptible to (relative) improvement?',\n 'How many petides were susceptible to (absolute) improvement?',\n 'Number of uniquely generated peptides during relative improvement procedure (64 attempts per peptide)',\n 'Number of uniquely generated peptides during absolute improvement procedure (64 attempts per peptide)',\n]",
"_____no_output_____"
],
[
"for metric, metric_label in zip(metrics_to_consider, metrics_labels): \n fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), sharex=True)\n plt.suptitle(metric_label, y=1.1)\n sns.barplot(x=model_labels, y=[pos_final_results[model][int(best_epochs[model][0])][metric] for model in models], ax=ax1)\n sns.barplot(x=model_labels, y=[neg_final_results[model][int(best_epochs[model][0])][metric] for model in models], ax=ax2)\n\n ax1.set_title('2404 positives (validation set)')\n ax2.set_title('2223 negatives (validation set)')\n ax1.set_xticklabels(model_labels, rotation=90)\n ax2.set_xticklabels(model_labels, rotation=90)\n plt.show()\n ",
"_____no_output_____"
]
],
[
[
"# Test set ",
"_____no_output_____"
]
],
[
[
"best_epochs = {\n 'HydrAMP': 37,\n 'PepCVAE': 35,\n 'Basic': 15,\n}",
"_____no_output_____"
],
[
"pos = np.vstack([amp_x_test[amp_y_test == 1], mic_x_test[mic_y_test < 1.5]])\nneg = np.vstack([amp_x_test[amp_y_test == 0], mic_x_test[mic_y_test > 1.5]])\n\nprint(pos.shape, neg.shape)\n\npos_amp = amp_classifier_model.predict(pos, verbose=1).reshape(len(pos))\nneg_mic = mic_classifier_model.predict(neg, verbose=1).reshape(len(neg))\nneg_amp = amp_classifier_model.predict(neg, verbose=1).reshape(len(neg))\npos_mic = amp_classifier_model.predict(pos, verbose=1).reshape(len(pos))\n\npos = np.vstack([pos] * 64).reshape(-1, 25)\npos_amp = np.vstack([pos_amp] * 64).reshape(-1, 1)\npos_mic = np.vstack([pos_mic] * 64).reshape(-1, 1)\nneg = np.vstack([neg] * 64).reshape(-1, 25)\nneg_amp = np.vstack([neg_amp] * 64).reshape(-1, 1)\nneg_mic = np.vstack([neg_mic] * 64).reshape(-1, 1)",
"(1319, 25) (1253, 25)\n1319/1319 [==============================] - 0s 159us/step\n1253/1253 [==============================] - 0s 48us/step\n1253/1253 [==============================] - 0s 165us/step\n1319/1319 [==============================] - 0s 169us/step\n"
],
[
"final_pos_results = {}\nfinal_neg_results = {}",
"_____no_output_____"
],
[
"for model in tqdm(models):\n epoch = int(best_epochs[model])\n AMPMaster = bms.load_model(f'../models/{model}/{epoch}')\n encoder_model = AMPMaster.encoder(input_to_encoder)\n decoder_model = AMPMaster.decoder(input_to_decoder)\n if model in ['PepCVAE', 'Basic']:\n new_act = layers.TimeDistributed(\n layers.Activation(activations.softmax),\n name='decoder_time_distribute_activation')\n decoder_model.layers.pop()\n x = new_act(decoder_model.layers[-1].output)\n decoder_model = Model(input=decoder_model.input, output=[x]) \n final_pos_results[model] = improve(pos, model, epoch, 'pos')\n final_neg_results[model] = improve(neg, model, epoch, 'neg')\n \ndump(final_pos_results, f'../results/improvement_PosTest.joblib') \ndump(final_neg_results, f'../results/improvement_NegTest.joblib') \n\n",
"\r 0%| | 0/3 [00:00<?, ?it/s]"
],
[
"pos_final_results = {models: {} for models in models}\nneg_final_results = {models: {} for models in models}",
"_____no_output_____"
],
[
"for model in models:\n pos_final_results[model]['relative improvement'] = np.unique(\n final_pos_results[model]['rel_improved'], axis=0).shape[0]\n pos_final_results[model]['absolute improvement'] = np.unique(\n final_pos_results[model]['abs_improved'], axis=0).shape[0]\n pos_final_results[model]['before relative improvement'] = np.unique(\n final_pos_results[model]['before_rel_improve'], axis=0).shape[0]\n pos_final_results[model]['before absolute improvement'] = np.unique(\n final_pos_results[model]['before_abs_improve'], axis=0).shape[0]\n \n neg_final_results[model]['relative improvement'] = np.unique(\n final_neg_results[model]['rel_improved'], axis=0).shape[0]\n neg_final_results[model]['absolute improvement'] = np.unique(\n final_neg_results[model]['abs_improved'], axis=0).shape[0]\n neg_final_results[model]['before relative improvement'] = np.unique(\n final_neg_results[model]['before_rel_improve'], axis=0).shape[0]\n neg_final_results[model]['before absolute improvement'] = np.unique(\n final_neg_results[model]['before_abs_improve'], axis=0).shape[0] ",
"_____no_output_____"
],
[
"ax = sns.barplot(\n x=model_labels,\n y=[\n pos_final_results[model]['before relative improvement']/1319 + \\\n neg_final_results[model]['before absolute improvement']/1253 \\\n for model in models])\n\nax.set_title('Before relative improvement (positives) + before absolute improvement (negatives)')\nax.set_xticklabels(model_labels, rotation=90)\nplt.show()\n ",
"_____no_output_____"
],
[
"for metric, metric_label in zip(metrics_to_consider, metrics_labels): \n fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(12, 4), sharex=True)\n plt.suptitle(metric_label, y=1.1)\n sns.barplot(x=model_labels, y=[pos_final_results[model][metric] for model in models], ax=ax1)\n sns.barplot(x=model_labels, y=[neg_final_results[model][metric] for model in models], ax=ax2)\n\n ax1.set_title('1319 positives (test set)')\n ax2.set_title('1253 negatives (test set)')\n ax1.set_xticklabels(model_labels, rotation=90)\n ax2.set_xticklabels(model_labels, rotation=90)\n plt.show()\n ",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca0114a80f2e6873f72b70804376fc8010718a
| 5,566 |
ipynb
|
Jupyter Notebook
|
proje02_2.ipynb
|
senemcelik0835/hu-bby162-2022
|
764e7185ac7a6bd2aeab55d51620f46e87b1e666
|
[
"MIT"
] | null | null | null |
proje02_2.ipynb
|
senemcelik0835/hu-bby162-2022
|
764e7185ac7a6bd2aeab55d51620f46e87b1e666
|
[
"MIT"
] | null | null | null |
proje02_2.ipynb
|
senemcelik0835/hu-bby162-2022
|
764e7185ac7a6bd2aeab55d51620f46e87b1e666
|
[
"MIT"
] | null | null | null | 37.608108 | 1,153 | 0.510061 |
[
[
[
"<a href=\"https://colab.research.google.com/github/senemcelik0835/hu-bby162-2022/blob/main/proje02_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"\n\nfrom random import choice\nadamCan = []\nkelimeler =[]\n\n# Seviye Basit\ncan1= 10\nliste1 = ['random', 'bulut', 'vakum','artvin']\n\n#Seviye Orta\ncan2 =5\nliste2 = ['gökyüzü', 'güvenlik', 'hoşgörü','karınca']\n\n#Seviye Zor\ncan3 =3\nliste3= ['müzikçalar', 'edebiyatçı', 'fabrikatör','çayırçimen']\n\nsecilenKelime = choice[kelimeler]\nprint(secilenKelime)\ndizilenKelime=[]\nfor diz in secilenKelime :\n dizilenKelime.append(\"_\")\nprint(dizilenKelime)\nwhile adamCan>0:\n adiniz = input(\"lütfen adınızı giriniz :\")\n print(\"merhaba \" + adiniz + \" seninle bir oyun oynayacağız\")\n print(\"1)basit - 2)orta - 3)ileri - 4)Çıkış\")\n seviye = input(\"lütfen oynamak istediğiniz seviyeyi seçiniz: 1/2/3/4\")\n seviye = str(seviye)\nkelimeler =[]\nif seviye == \"basit\": \n print('sahip olduğunuz can sayısı:10')\n adamCan= can1\n kelimeler = liste1\n\nelif seviye == \"orta\": \n print('sahip olduğunuz can sayısı:5')\n adamCan= can2\n kelimeler = liste2\n\nelif seviye == \"ileri\": \n print('sahip olduğunuz can sayısı:3')\n adamCan= can3\n kelimeler = liste3\n\nelse:\n print(\"çıkış yapmak üzeresiniz\")\n\n \n girilenHarf =input(\"Bir harf giriniz: \")\n canKontrol = girilenHarf in secilenKelime\n if canKontrol == False:\n adamCan -=1\n i=0\n for kontrol in secilenKelime:\n if secilenKelime [i] == girilenHarf:\n dizilenKelime [i] = girilenHarf\n i+=1\n print(dizilenKelime)\n print(\"Kalan can: \" +str(adamCan))\n print(secilenKelime == dizilenKelime)\n for girilenHarf in dizilenKelime:\n print(kontrol)\n if secilenKelime == kontrol:\n print(\"Tebrikler\")\n break\n\n\n\n",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aca24a0376e0e53a3a5ee818ed2038c23675072
| 24,995 |
ipynb
|
Jupyter Notebook
|
application_arXiv.ipynb
|
willyrv/nplm
|
1ab35a1aa447572f35704787c3765f00fe3280f6
|
[
"MIT"
] | null | null | null |
application_arXiv.ipynb
|
willyrv/nplm
|
1ab35a1aa447572f35704787c3765f00fe3280f6
|
[
"MIT"
] | null | null | null |
application_arXiv.ipynb
|
willyrv/nplm
|
1ab35a1aa447572f35704787c3765f00fe3280f6
|
[
"MIT"
] | null | null | null | 76.671779 | 13,888 | 0.809202 |
[
[
[
"import numpy as np\nfrom nplm.data_manipulation import create_training_dataset_arXiv\nimport nplm.neurnetmodel as Neur\nfrom nplm.data_manipulation import one_hot_encode_matrix\nfrom nplm.minimizers import train_model",
"_____no_output_____"
],
[
"PATH2FILE = \"./arxiv_articles_sample.csv\"\nCONTEXT_SIZE = 4\nDICT_SIZE = 1000",
"_____no_output_____"
],
[
"# This takes a while, depending the size of the dataset and the size of the dictionary\ndataset, dictionary = create_training_dataset_arXiv(PATH2FILE, CONTEXT_SIZE, DICT_SIZE)",
"_____no_output_____"
],
[
"dataset[:10]",
"_____no_output_____"
]
],
[
[
"## The Neural Network model",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\nNB_FEATURES = 200\nH = 100 # The number of hidden units\nBATCH_SIZE = 100\nN = Neur.Network([Neur.ProjectVectors(DICT_SIZE, NB_FEATURES),\n Neur.ConcatProjections(), \n Neur.Dense(NB_FEATURES * (CONTEXT_SIZE-1), H), \n Neur.Tanh(), Neur.Dense(H, DICT_SIZE)])\n#N_a=Neur.Network([N,Neur.Ilogit_and_KL(y)])",
"_____no_output_____"
],
[
"N.get_params()\nprint(len(N.get_params()))",
"361100\n"
],
[
"D = np.array(dataset)\nX = D[:5000, :3]\nY = D[:5000, -1:]",
"_____no_output_____"
],
[
"costs = train_model(N, X, Y, DICT_SIZE, batch_size=300, nb_epochs=100, alpha=1e-3)",
"Epoch 0 completed. Cost function = 154902.59317606725\nEpoch 1 completed. Cost function = 137557.11178860517\nEpoch 2 completed. Cost function = 126427.37265589312\nEpoch 3 completed. Cost function = 118345.34505901579\nEpoch 4 completed. Cost function = 112071.32430031362\nEpoch 5 completed. Cost function = 106863.03131045282\nEpoch 6 completed. Cost function = 102647.71398602768\nEpoch 7 completed. Cost function = 98977.73528909426\nEpoch 8 completed. Cost function = 95699.85605577378\nEpoch 9 completed. Cost function = 92960.91706971741\nEpoch 10 completed. Cost function = 90398.6215337231\nEpoch 11 completed. Cost function = 88047.50160744504\nEpoch 12 completed. Cost function = 85833.78256970418\nEpoch 13 completed. Cost function = 83789.68463981508\nEpoch 14 completed. Cost function = 81860.40785016875\nEpoch 15 completed. Cost function = 80117.23636271946\nEpoch 16 completed. Cost function = 78476.87428738092\nEpoch 17 completed. Cost function = 76907.00661424258\nEpoch 18 completed. Cost function = 75434.319414976\nEpoch 19 completed. Cost function = 74022.48027107095\nEpoch 20 completed. Cost function = 72674.2751357106\nEpoch 21 completed. Cost function = 71365.40170272307\nEpoch 22 completed. Cost function = 70105.63614278479\nEpoch 23 completed. Cost function = 68890.4621232783\nEpoch 24 completed. Cost function = 67718.14789557972\nEpoch 25 completed. Cost function = 66576.14150489376\nEpoch 26 completed. Cost function = 65497.837810689714\nEpoch 27 completed. Cost function = 64437.748828458534\nEpoch 28 completed. Cost function = 63449.039083661024\nEpoch 29 completed. Cost function = 62423.00075382177\nEpoch 30 completed. Cost function = 61427.137508541025\nEpoch 31 completed. Cost function = 60466.72807573887\nEpoch 32 completed. Cost function = 59572.74257710053\nEpoch 33 completed. Cost function = 58673.94783761989\nEpoch 34 completed. Cost function = 57843.89399351025\nEpoch 35 completed. Cost function = 56983.99995013907\nEpoch 36 completed. Cost function = 56150.80516966771\nEpoch 37 completed. Cost function = 55352.21086946724\nEpoch 38 completed. Cost function = 54582.04967663062\nEpoch 39 completed. Cost function = 53810.21298664639\nEpoch 40 completed. Cost function = 53060.05487118349\nEpoch 41 completed. Cost function = 52308.69842299608\nEpoch 42 completed. Cost function = 51606.08690407075\nEpoch 43 completed. Cost function = 50909.31357543137\nEpoch 44 completed. Cost function = 50209.34140069892\nEpoch 45 completed. Cost function = 49517.790215472676\nEpoch 46 completed. Cost function = 48827.95204351767\nEpoch 47 completed. Cost function = 48159.85841918727\nEpoch 48 completed. Cost function = 47536.23633891985\nEpoch 49 completed. Cost function = 46925.76198237951\nEpoch 50 completed. Cost function = 46307.183988301185\nEpoch 51 completed. Cost function = 45710.77394022206\nEpoch 52 completed. Cost function = 45142.57211209364\nEpoch 53 completed. Cost function = 44555.73667486408\nEpoch 54 completed. Cost function = 43997.24597302302\nEpoch 55 completed. Cost function = 43405.480292354514\nEpoch 56 completed. Cost function = 42863.204005387\nEpoch 57 completed. Cost function = 42334.16008606967\nEpoch 58 completed. Cost function = 41816.723875376854\nEpoch 59 completed. Cost function = 41307.52889636052\nEpoch 60 completed. Cost function = 40807.49258071437\nEpoch 61 completed. Cost function = 40324.29204439277\nEpoch 62 completed. Cost function = 39840.000655884935\nEpoch 63 completed. Cost function = 39379.39369077081\nEpoch 64 completed. Cost function = 38915.00266990775\nEpoch 65 completed. Cost function = 38455.19704599045\nEpoch 66 completed. Cost function = 38039.611300627694\nEpoch 67 completed. Cost function = 37582.52937612386\nEpoch 68 completed. Cost function = 37139.62386139235\nEpoch 69 completed. Cost function = 36703.67208995084\nEpoch 70 completed. Cost function = 36302.67989447354\nEpoch 71 completed. Cost function = 35891.58627295107\nEpoch 72 completed. Cost function = 35490.66230614724\nEpoch 73 completed. Cost function = 35100.63731850011\nEpoch 74 completed. Cost function = 34696.84814698237\nEpoch 75 completed. Cost function = 34308.91348425638\nEpoch 76 completed. Cost function = 33930.79914033103\nEpoch 77 completed. Cost function = 33564.745440545244\nEpoch 78 completed. Cost function = 33203.888913353854\nEpoch 79 completed. Cost function = 32837.333599696125\nEpoch 80 completed. Cost function = 32472.48385838763\nEpoch 81 completed. Cost function = 32141.259316297113\nEpoch 82 completed. Cost function = 31784.580047956573\nEpoch 83 completed. Cost function = 31445.792854140334\nEpoch 84 completed. Cost function = 31095.75946753762\nEpoch 85 completed. Cost function = 30761.71568137397\nEpoch 86 completed. Cost function = 30432.086706529484\nEpoch 87 completed. Cost function = 30090.260804037316\nEpoch 88 completed. Cost function = 29785.878737958876\nEpoch 89 completed. Cost function = 29463.222751546233\nEpoch 90 completed. Cost function = 29134.46004442496\nEpoch 91 completed. Cost function = 28821.877501733492\nEpoch 92 completed. Cost function = 28505.37580388709\nEpoch 93 completed. Cost function = 28197.818553626224\nEpoch 94 completed. Cost function = 27912.056559445256\nEpoch 95 completed. Cost function = 27613.97261672828\nEpoch 96 completed. Cost function = 27330.80629659633\nEpoch 97 completed. Cost function = 27038.913390380072\nEpoch 98 completed. Cost function = 26757.785663307957\nEpoch 99 completed. Cost function = 26490.631941577365\n"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"plt.plot(costs)",
"_____no_output_____"
],
[
"# Save the trained network (this can be improved)\nimport pickle",
"_____no_output_____"
],
[
"with open(\"./trained_nplm.pickle\", 'wb') as f:\n pickle.dump(N, f)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca2e51ad59b03ac7ad993408e5ad2226cec295
| 56,679 |
ipynb
|
Jupyter Notebook
|
notebooks-notworking/subsetting.ipynb
|
Ouranosinc/PAVICS-e2e-workflow-tests-
|
f8e5141bb85698ddc1ec62953494cc9701872571
|
[
"Apache-2.0"
] | 1 |
2020-04-03T18:05:59.000Z
|
2020-04-03T18:05:59.000Z
|
notebooks-notworking/subsetting.ipynb
|
Ouranosinc/PAVICS-e2e-workflow-tests-
|
f8e5141bb85698ddc1ec62953494cc9701872571
|
[
"Apache-2.0"
] | 66 |
2019-06-03T16:29:40.000Z
|
2022-03-18T19:24:36.000Z
|
notebooks-notworking/subsetting.ipynb
|
Ouranosinc/PAVICS-e2e-workflow-tests-
|
f8e5141bb85698ddc1ec62953494cc9701872571
|
[
"Apache-2.0"
] | 2 |
2019-09-27T12:59:07.000Z
|
2019-12-09T08:55:23.000Z
| 289.178571 | 28,124 | 0.929656 |
[
[
[
"%matplotlib inline\nimport xarray as xr\nimport numpy as np\nfrom matplotlib import pyplot as plt\n# The dodsC link for the test file\ndap = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/dodsC/'\nncfile = 'birdhouse/testdata/flyingpigeon/cmip5/tasmax_Amon_MPI-ESM-MR_rcp45_r1i1p1_200601-200612.nc'\n\n# Here we open the file and subset it using xarray fonctionality, which communicates directly with \n# the OPeNDAP server to retrieve only the data needed. \nds = xr.open_dataset(dap+ncfile)\ntas = ds.tasmax\nsubtas = tas.sel(time=slice('2006-01-01', '2006-03-01'), lon=slice(188,330), lat=slice(6, 70))\nsubtas.isel(time=0).plot()\nplt.show()",
"_____no_output_____"
],
[
"from birdy import WPSClient\nurl = 'https://pavics.ouranos.ca/twitcher/ows/proxy/flyingpigeon/wps'\nfp = WPSClient(url)",
"/usr/local/anaconda/anaconda2/envs/birdy/lib/python2.7/site-packages/birdhouse_birdy-0.5.1-py2.7.egg/birdy/dependencies.py:20: IPythonWarning: Jupyter Notebook is not supported. Please install *ipywidgets*.\n warnings.warn('Jupyter Notebook is not supported. Please install *ipywidgets*.', IPythonWarning)\n"
],
[
"help(fp.subset_continents)",
"Help on method subset_continents in module birdy.client.base:\n\nsubset_continents(self, region='Africa', mosaic=None, resource=None) method of birdy.client.base.WPSClient instance\n Return the data whose grid cells intersect the selected continents for each input dataset.\n \n Parameters\n ----------\n region : {'Africa', 'Asia', 'Australia', 'North America', 'Oceania', 'South America', 'Antarctica', 'Europe'}string\n Continent name.\n mosaic : boolean\n If True, selected regions will be merged into a single geometry.\n resource : ComplexData:mimetype:`application/x-netcdf`, :mimetype:`application/x-tar`, :mimetype:`application/zip`\n NetCDF Files or archive (tar/zip) containing netCDF files.\n \n Returns\n -------\n output : ComplexData:mimetype:`application/x-tar`\n Tar archive of the subsetted netCDF files.\n ncout : ComplexData:mimetype:`application/x-netcdf`\n NetCDF file with subset for one dataset.\n output_log : ComplexData:mimetype:`text/plain`\n Collected logs during process run.\n\n"
],
[
"thredds = 'https://pavics.ouranos.ca/twitcher/ows/proxy/thredds/fileServer/'\nncfile = 'birdhouse/testdata/flyingpigeon/cmip5/tasmax_Amon_MPI-ESM-MR_rcp45_r1i1p1_200601-200612.nc'\nresp = fp.subset_continents(resource=thredds+ncfile, region='Africa')",
"_____no_output_____"
],
[
"resp.get()\ntar_out, nc_out, log = resp.get(asobj=True)",
"/usr/local/anaconda/anaconda2/envs/birdy/lib/python2.7/site-packages/birdhouse_birdy-0.5.1-py2.7.egg/birdy/client/outputs.py:65: UserWarning: No converter was found for mime type: application/x-tar\n warnings.warn(UserWarning(\"No converter was found for mime type: {}\".format(output.mimeType)))\n"
],
[
"import xarray as xr\nds = xr.open_dataset(xr.backends.NetCDF4DataStore(nc_out))\nds.tasmax.isel(time=0).plot()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca2ec3f2c559c719a48c68665b38f287715a0a
| 104,813 |
ipynb
|
Jupyter Notebook
|
results_display.ipynb
|
alanmitchell/heat-pump-calc
|
fd3efab5a956ce8ef68b5a7f35f3d0a1bd58565b
|
[
"Apache-2.0"
] | 4 |
2018-03-19T17:37:47.000Z
|
2021-08-10T19:32:48.000Z
|
results_display.ipynb
|
alanmitchell/heat-pump-calc
|
fd3efab5a956ce8ef68b5a7f35f3d0a1bd58565b
|
[
"Apache-2.0"
] | null | null | null |
results_display.ipynb
|
alanmitchell/heat-pump-calc
|
fd3efab5a956ce8ef68b5a7f35f3d0a1bd58565b
|
[
"Apache-2.0"
] | 1 |
2021-03-11T23:57:11.000Z
|
2021-03-11T23:57:11.000Z
| 33.337468 | 206 | 0.402145 |
[
[
[
"# Notebook to be used to Develop Display of Results",
"_____no_output_____"
]
],
[
[
"from importlib import reload\nimport pandas as pd\nimport numpy as np\nfrom IPython.display import Markdown",
"_____no_output_____"
],
[
"# If one of the modules changes and you need to reimport it,\n# execute this cell again.\nimport heatpump.hp_model\nreload(heatpump.hp_model)\nimport heatpump.home_heat_model\nreload(heatpump.home_heat_model)\nimport heatpump.library as lib\nreload(lib)",
"_____no_output_____"
],
[
"# Anchorage large home inputs\nutil = lib.util_from_id(1)\ninputs1 = dict(\n city_id=1,\n utility=util,\n pce_limit=500.0,\n co2_lbs_per_kwh=1.1,\n exist_heat_fuel_id=2,\n exist_unit_fuel_cost=0.97852,\n exist_fuel_use=1600,\n exist_heat_effic=.8,\n exist_kwh_per_mmbtu=8,\n includes_dhw=True,\n includes_dryer=True,\n includes_cooking=False,\n occupant_count=3,\n elec_use_jan=550,\n elec_use_may=400,\n hp_model_id=575,\n low_temp_cutoff=5,\n garage_stall_count=2,\n garage_heated_by_hp=False,\n bldg_floor_area=3600,\n indoor_heat_setpoint=70,\n insul_level=3, \n pct_exposed_to_hp=0.46,\n doors_open_to_adjacent=False,\n bedroom_temp_tolerance=2,\n capital_cost=4500,\n rebate_dol=500,\n pct_financed=0.5,\n loan_term=10,\n loan_interest=0.05,\n hp_life=14,\n op_cost_chg=10,\n sales_tax=0.02,\n discount_rate=0.05,\n inflation_rate=0.02,\n fuel_esc_rate=0.03,\n elec_esc_rate=0.02,\n)",
"_____no_output_____"
],
[
"# Ambler Home inputs\nutil = lib.util_from_id(202)\ninputs2 = dict(\n city_id=45,\n utility=util,\n pce_limit=500.0,\n co2_lbs_per_kwh=1.6,\n exist_heat_fuel_id=4,\n exist_unit_fuel_cost=8.0,\n exist_fuel_use=450,\n exist_heat_effic=.86,\n exist_kwh_per_mmbtu=8,\n includes_dhw=False,\n includes_dryer=False,\n includes_cooking=False,\n occupant_count=3,\n elec_use_jan=550,\n elec_use_may=300,\n hp_model_id=575,\n low_temp_cutoff=5,\n garage_stall_count=0,\n garage_heated_by_hp=False,\n bldg_floor_area=800,\n indoor_heat_setpoint=70,\n insul_level=2, \n pct_exposed_to_hp=1.0,\n doors_open_to_adjacent=False,\n bedroom_temp_tolerance=3,\n capital_cost=6500,\n rebate_dol=0,\n pct_financed=0.0,\n loan_term=10,\n loan_interest=0.05,\n hp_life=14,\n op_cost_chg=0,\n sales_tax=0.00,\n discount_rate=0.05,\n inflation_rate=0.02,\n fuel_esc_rate=0.03,\n elec_esc_rate=0.02,\n)",
"_____no_output_____"
],
[
"inputs2",
"_____no_output_____"
],
[
"# Change from **inputs1 to **inputs2 to run the two cases.\nmod = heatpump.hp_model.HP_model(**inputs2)\nmod.run()\n\n# Pull out the results from the model object.\n# Use these variable names in your display of outputs.\nsmy = mod.summary\ndf_cash_flow = mod.df_cash_flow\ndf_mo_en_base = mod.df_mo_en_base\ndf_mo_en_hp = mod.df_mo_en_hp\ndf_mo_dol_base = mod.df_mo_dol_base\ndf_mo_dol_hp = mod.df_mo_dol_hp",
"_____no_output_____"
],
[
"# This is a dictionary containing summary output.\n# The 'fuel_use_xxx' values are annual totals in physical units\n# like gallons. 'elec_use_xxx' are kWh. 'hp_max_capacity' is the\n# maximum output of the heat pump at 5 deg F. 'max_hp_reached' \n# indicates whether the heat pump ever used all of its capacity\n# at some point during the year.\nsmy",
"_____no_output_____"
],
[
"md = f\"Design Heat Load: **{smy['design_heat_load']:,.0f} Btu/hour** at {smy['design_heat_temp']:.0f} degrees F outdoors\"\nmd",
"_____no_output_____"
],
[
"# You can get a string that is in Markdown format rendered properly\n# by using the Markdown class.\nMarkdown(md)",
"_____no_output_____"
],
[
"# Or, this might be a case where f-strings are not the cleanest.\n# Here is another way:\nmd = 'Design Heat Load of Entire Building: **{design_heat_load:,.0f} Btu/hour** at {design_heat_temp:.0f} degrees F outdoors \\n(required output of heating system, no safety margin)'.format(**smy)\nMarkdown(md)",
"_____no_output_____"
],
[
"# Cash Flow over the life of the heat pump.\n# Negative values are costs and positive values are benefits.\n# When displaying this table delete the two columns that don't apply,\n# depending on whether you are showing the PCE or no PCE case.\ndf_cash_flow",
"_____no_output_____"
],
[
"# The Base case and w/ Heat Pump monthly energy results.\ndf_mo_en_base",
"_____no_output_____"
],
[
"df_mo_en_hp",
"_____no_output_____"
],
[
"# The monthly dollar flows with and without the heat pump\n# The PCE and no PCE case are included in this one table\ndf_mo_dol_base",
"_____no_output_____"
],
[
"df_mo_dol_hp",
"_____no_output_____"
],
[
"list(df_mo_en_base.columns.values)",
"_____no_output_____"
],
[
"import plotly\n\nplotly.tools.set_credentials_file(username='dustin_cchrc', api_key='yzYaFYf93PQ7D0VUZKGy')\n\nimport plotly.plotly as py\nimport plotly.graph_objs as go",
"_____no_output_____"
]
],
[
[
"## Monthly Heating Load",
"_____no_output_____"
]
],
[
[
"data = [go.Bar(x=df_mo_en_base.index,\n y=df_mo_en_base.secondary_load_mmbtu, \n name='Monthly Heating Load')]\n\nlayout = go.Layout(title='Monthly Heating Load',\n xaxis=dict(title='Month'),\n yaxis=dict(title='Total Estimated Heat Load (MMBTU)', hoverformat='.1f')\n )\n\nfig = go.Figure(data=data, layout=layout)\n\npy.iplot(fig, filename='estimated_heat_load', fileopt='overwrite')",
"_____no_output_____"
]
],
[
[
"## Heating Cost Comparison",
"_____no_output_____"
]
],
[
[
"df_mo_dol_chg = df_mo_dol_hp - df_mo_dol_base\n\ndf_mo_dol_chg['cost_savings'] = np.where(\n df_mo_dol_chg.total_dol < 0.0,\n -df_mo_dol_chg.total_dol,\n 0.0\n)\n\n# Note: we make these negative values so bars extend downwards\ndf_mo_dol_chg['cost_increases'] = np.where(\n df_mo_dol_chg.total_dol >= 0.0,\n -df_mo_dol_chg.total_dol,\n 0.0\n)\n\ndf_mo_dol_chg",
"_____no_output_____"
],
[
"# calculate the change in dollars between the base scenario and the heat\n# pump scenario.\nhp_cost = go.Bar(\n x=df_mo_dol_hp.index,\n y=df_mo_dol_hp.total_dol,\n name='', \n marker=dict(color='#377eb8'),\n hoverinfo = 'y',\n)\n\ncost_savings = go.Bar(\n x=df_mo_dol_chg.index,\n y=df_mo_dol_chg.cost_savings,\n name='Cost Savings',\n marker=dict(color='#4daf4a'),\n hoverinfo = 'y',\n)\n\ncost_increases = go.Bar(\n x=df_mo_dol_chg.index,\n y=df_mo_dol_chg.cost_increases,\n name='Cost Increases',\n marker=dict(color='#e41a1c'),\n hoverinfo = 'y',\n)\n\nno_hp_costs = go.Scatter(\n x=df_mo_dol_base.index,\n y=df_mo_dol_base.total_dol,\n name='Baseline Energy Costs',\n mode='markers',\n marker=dict(color='#000000', size=12),\n hoverinfo = 'y',\n)\n\ndata = [hp_cost, cost_savings, cost_increases, no_hp_costs]\n\nlayout = go.Layout(\n title='Energy Costs: Heat Pump vs. Baseline',\n xaxis=dict(title='Month', fixedrange=True,),\n yaxis=dict(\n title='Total Energy Costs', \n hoverformat='$,.0f',\n fixedrange=True,\n tickformat='$,.0f',\n ),\n barmode='stack',\n hovermode= 'closest',\n)\n\nfig = go.Figure(data=data, layout=layout)\n\npy.iplot(fig, filename='heatpump_costs', fileopt='overwrite')",
"_____no_output_____"
]
],
[
[
"## Monthly Heat Pump Efficiency",
"_____no_output_____"
]
],
[
[
"efficiency = [go.Scatter(x=df_mo_en_hp.index,\n y=df_mo_en_hp.cop, \n name='COP',\n mode='lines+markers')]\n\nlayout = go.Layout(title='Monthly Heat Pump Efficiency',\n xaxis=dict(title='Month'),\n yaxis=dict(title='COP'))\n\nfig = go.Figure(data=efficiency, layout=layout)\n\npy.iplot(fig, layout=layout, filename='cop', fileopt='overwrite')",
"_____no_output_____"
]
],
[
[
"## Energy Use Comparison",
"_____no_output_____"
]
],
[
[
"list(df_mo_en_base.columns.values)",
"_____no_output_____"
],
[
"list(df_mo_dol_base.columns.values)",
"_____no_output_____"
],
[
"list(df_mo_dol_hp.columns.values)",
"_____no_output_____"
],
[
"from plotly import tools\n\nelec_no_hp = go.Scatter(x=df_mo_dol_base.index,\n y=df_mo_dol_base.elec_kwh,\n name='Monthly kWh (no Heat Pump)',\n line=dict(color='#92c5de',\n width=2,\n dash='dash')\n )\n\nelec_w_hp = go.Scatter(x=df_mo_dol_hp.index,\n y=df_mo_dol_hp.elec_kwh,\n name='Monthly kWh (with Heat Pump)',\n mode='lines',\n marker=dict(color='#0571b0')\n )\n\nfuel_no_hp = go.Scatter(x=df_mo_dol_base.index,\n y=df_mo_dol_base.secondary_fuel_units,\n name='Monthly Fuel Usage (no Heat Pump)',\n line=dict(color='#f4a582',\n width = 2,\n dash = 'dash')\n )\n\nfuel_w_hp = go.Scatter(x=df_mo_dol_hp.index,\n y=df_mo_dol_hp.secondary_fuel_units,\n name='Monthly Fuel Usage (with Heat Pump)',\n mode='lines',\n marker=dict(color='#ca0020'))\n\nfig = tools.make_subplots(rows=2, cols=1)\n\nfig.append_trace(elec_no_hp, 1, 1)\nfig.append_trace(elec_w_hp, 1, 1)\nfig.append_trace(fuel_no_hp, 2, 1)\nfig.append_trace(fuel_w_hp, 2, 1)\n\nfig['layout'].update(title='Energy Usage: Heat Pump vs. Baseline')\n\nfig['layout']['xaxis1'].update(title='Month')\nfig['layout']['xaxis2'].update(title='Month')\nfig['layout']['yaxis1'].update(title='Electricity Use (kWh)', hoverformat='.0f')\nyaxis2_title = 'Heating Fuel Use (%s)' % (smy['fuel_unit'])\nfig['layout']['yaxis2'].update(title=yaxis2_title, hoverformat='.1f')\n\npy.iplot(fig, filename='heatpump_energy_usage', fileopt='overwrite')",
"This is the format of your plot grid:\n[ (1,1) x1,y1 ]\n[ (2,1) x2,y2 ]\n\n"
]
],
[
[
"## Cash Flow Visualization",
"_____no_output_____"
]
],
[
[
"df_cash_flow",
"_____no_output_____"
],
[
"df_cash_flow['negative_flow'] = np.where(df_cash_flow.cash_flow < 0, df_cash_flow.cash_flow, 0)\ndf_cash_flow['positive_flow'] = np.where(df_cash_flow.cash_flow > 0, df_cash_flow.cash_flow, 0)",
"_____no_output_____"
],
[
"negative_flow = go.Bar(x=df_cash_flow.index,\n y=df_cash_flow.negative_flow,\n name='Cash Flow', \n marker=dict(color='#d7191c'))\n\npositive_flow = go.Bar(x=df_cash_flow.index,\n y=df_cash_flow.positive_flow,\n name='Cash Flow', \n marker=dict(color='#000000'))\n\ndata = [negative_flow, positive_flow]\n\nlayout = go.Layout(title='Heat Pump Cash Flow',\n xaxis=dict(title='Year'),\n yaxis=dict(title='Annual Cash Flow ($)', hoverformat='dol,.0f')\n )\n\nfig = go.Figure(data=data, layout=layout)\n\npy.iplot(fig, filename='cash_flow', fileopt='overwrite')",
"_____no_output_____"
]
],
[
[
"## Cumulative Discounted Cash Flow",
"_____no_output_____"
]
],
[
[
"df_cash_flow",
"_____no_output_____"
],
[
"df_cash_flow['cum_negative_flow'] = np.where(df_cash_flow.cum_disc_cash_flow < 0, df_cash_flow.cum_disc_cash_flow, 0)\ndf_cash_flow['cum_positive_flow'] = np.where(df_cash_flow.cum_disc_cash_flow > 0, df_cash_flow.cum_disc_cash_flow, 0)",
"_____no_output_____"
],
[
"negative_cash_flow = go.Scatter(x=df_cash_flow.index,\n y=df_cash_flow.cum_negative_flow,\n name='Cash Flow ($)',\n fill='tozeroy',\n fillcolor='#d7191c',\n line=dict(color='#ffffff')\n )\n\npositive_cash_flow = go.Scatter(x=df_cash_flow.index,\n y=df_cash_flow.cum_positive_flow,\n name='Cash Flow ($)',\n fill='tozeroy',\n fillcolor='#000000',\n line=dict(color='#ffffff')\n )\n\ndata = [negative_cash_flow, positive_cash_flow]\n\nlayout = go.Layout(title='Heat Pump Lifetime Cumulative Discounted Cash Flow',\n xaxis=dict(title='Year'),\n yaxis=dict(title='Annual Discounted Cash Flow ($)', hoverformat='.0f'),\n )\n\nfig = go.Figure(data=data, layout=layout)\n\npy.iplot(fig, filename='cumulative_discounted_heatpump_cash_flow', fileopt='overwrite')",
"_____no_output_____"
]
],
[
[
"## Markdown Display of Results",
"_____no_output_____"
]
],
[
[
"## Need to account for NaN internal rate of return (hide somehow)",
"_____no_output_____"
]
],
[
[
"### With PCE",
"_____no_output_____"
]
],
[
[
"md_results = '''# Results\n\n## Heat Pump Cost Effectiveness\n\n### Net Present Value: **\\${:,.0f}**\nThe Net Present Value of installing an air-source heat pump is estimated to be **\\${:,.0f}**. \nThis means that over the course of the life of the equipment you will {} **\\${:,.0f}** in today's dollars.\n\n### Internal Rate of Return: **{:.1f}%**\nThe internal rate of return on the investment is estimated to be **{:.1f}%**. Compare this tax-free investment to your other investment options.\n\n### Cash Flow\nThis is how your cash flow will be affected by installing a heat pump:\n\n\n## Greenhouse Gas Emissions\n\nInstalling a heat pump is predicted to save {:,.0f} pounds of CO2 emissions annually, or {:,.0f} pounds over the life of the equipment.\nThis is equivalent to a reduction of {:,.0f} miles driven by an average passenger vehicle annually, or {:,.0f} over the equipment's life. \n'''",
"_____no_output_____"
],
[
"def npv_indicator(summary, pce_indicator):\n if pce_indicator == 1:\n if summary['npv'] > 0:\n return 'earn'\n else:\n return 'lose'\n else: \n if summary['npv_no_pce'] > 0:\n return 'earn'\n else:\n return 'lose'",
"_____no_output_____"
],
[
"smy",
"_____no_output_____"
],
[
"smy['npv']",
"_____no_output_____"
],
[
"md = md_results.format(smy['npv'],\n smy['npv'],\n npv_indicator(smy, 1),\n abs(smy['npv']),\n smy['irr']*100,\n smy['irr']*100,\n smy['co2_lbs_saved'],\n smy['co2_lbs_saved'] * 12,\n smy['co2_driving_miles_saved'],\n smy['co2_driving_miles_saved'] * 12)\nMarkdown(md)",
"_____no_output_____"
],
[
"from textwrap import dedent\ninputs = {'hp_life': 14}",
"_____no_output_____"
],
[
"sumd = smy.copy()\nsumd['npv_abs'] = abs(sumd['npv'])\nsumd['irr'] *= 100. # convert to %\nsumd['npv_indicator'] = 'earn' if sumd['npv'] >= 0 else 'lose'\nsumd['co2_lbs_saved_life'] = sumd['co2_lbs_saved'] * inputs['hp_life']\nsumd['co2_driving_miles_saved_life'] = sumd['co2_driving_miles_saved'] * inputs['hp_life']\n\nmd_tmpl = dedent('''\n# Results\n\n## Heat Pump Cost Effectiveness\n\n### Net Present Value: **\\${npv:,.0f}**\n\nThe Net Present Value of installing an air-source heat pump is estimated to \nbe **\\${npv:,.0f}**. This means that over the course of the life of the equipment you \nwill {npv_indicator} **\\${npv_abs:,.0f}** in today's dollars.\n\n### Internal Rate of Return: **{irr:.1f}%**\n\nThe internal rate of return on the investment is estimated to be **{irr:.1f}%**. \nCompare this tax-free investment to your other investment options.\n\n### Cash Flow\n\nThis is how your cash flow will be affected by installing a heat pump:\n\n## Greenhouse Gas Emissions\n\nInstalling a heat pump is predicted to save {co2_lbs_saved:,.0f} pounds of CO2 emissions annually, \nor {co2_lbs_saved_life:,.0f} pounds over the life of the equipment. This is equivalent to a reduction \nof {co2_driving_miles_saved:,.0f} miles driven by an average passenger vehicle annually, \nor {co2_driving_miles_saved_life:,.0f} miles over the equipment's life. \n''')\n\nmd = md_tmpl.format(**sumd)\nMarkdown(md)",
"_____no_output_____"
],
[
"sumd",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca2ed19be148e8938af9c29b0c8a6841de09d5
| 2,065 |
ipynb
|
Jupyter Notebook
|
papermill/tests/notebooks/collection/result1.ipynb
|
wsavran/papermill
|
a28ffe536bb23029169a02c0fd06fe7adf3e1801
|
[
"BSD-3-Clause"
] | 1 |
2019-02-28T21:36:21.000Z
|
2019-02-28T21:36:21.000Z
|
papermill/tests/notebooks/collection/result1.ipynb
|
wsavran/papermill
|
a28ffe536bb23029169a02c0fd06fe7adf3e1801
|
[
"BSD-3-Clause"
] | 1 |
2022-03-21T09:23:29.000Z
|
2022-03-21T09:23:29.000Z
|
papermill/tests/notebooks/collection/result1.ipynb
|
wsavran/papermill
|
a28ffe536bb23029169a02c0fd06fe7adf3e1801
|
[
"BSD-3-Clause"
] | null | null | null | 17.208333 | 46 | 0.445036 |
[
[
[
"# Parameters\nfoo = 1\nbar = \"hello\"\n",
"_____no_output_____"
],
[
"import papermill as pm\n\npm.record(\"number\", 1)\npm.record(\"list\", [1,2,3])\npm.record(\"dict\", dict(a=1, b=2))\n\npm.display(\"output\", \"Hello World!\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4aca3abf8f4949636200ce2b89d52a40885d0fa2
| 29,676 |
ipynb
|
Jupyter Notebook
|
EHR_Only/BART/Death_No.ipynb
|
shreyaskar123/EHR-Discontinuity
|
8d2becfd784b9cbe697f8308d60023701971ef5d
|
[
"MIT"
] | null | null | null |
EHR_Only/BART/Death_No.ipynb
|
shreyaskar123/EHR-Discontinuity
|
8d2becfd784b9cbe697f8308d60023701971ef5d
|
[
"MIT"
] | null | null | null |
EHR_Only/BART/Death_No.ipynb
|
shreyaskar123/EHR-Discontinuity
|
8d2becfd784b9cbe697f8308d60023701971ef5d
|
[
"MIT"
] | null | null | null | 41.446927 | 1,187 | 0.609314 |
[
[
[
"import pandas as pd\nmedicare = pd.read_csv(\"/netapp2/home/se197/data/CMS/Data/medicare.csv\")",
"_____no_output_____"
],
[
"train_set = medicare[medicare.Hospital != 'BWH'] # MGH\nvalidation_set = medicare[medicare.Hospital == 'BWH'] # BWH and Neither \nimport numpy as np\n\nfifty_perc_EHR_cont = np.percentile(medicare['Cal_MPEC_R0'],50)\ntrain_set_high = train_set[train_set.Cal_MPEC_R0 >= fifty_perc_EHR_cont]\ntrain_set_low= train_set[train_set.Cal_MPEC_R0 < fifty_perc_EHR_cont]\n\nvalidation_set_high = validation_set[validation_set.Cal_MPEC_R0 >= fifty_perc_EHR_cont]\nvalidation_set_low = validation_set[validation_set.Cal_MPEC_R0 < fifty_perc_EHR_cont]",
"_____no_output_____"
],
[
"predictor_variable = [\n 'Co_CAD_R0', 'Co_Embolism_R0', 'Co_DVT_R0', 'Co_PE_R0', 'Co_AFib_R0',\n 'Co_Hypertension_R0', 'Co_Hyperlipidemia_R0', 'Co_Atherosclerosis_R0',\n 'Co_HF_R0', 'Co_HemoStroke_R0', 'Co_IscheStroke_R0', 'Co_OthStroke_R0',\n 'Co_TIA_R0', 'Co_COPD_R0', 'Co_Asthma_R0', 'Co_Pneumonia_R0', 'Co_Alcoholabuse_R0',\n 'Co_Drugabuse_R0', 'Co_Epilepsy_R0', 'Co_Cancer_R0', 'Co_MorbidObesity_R0',\n 'Co_Dementia_R0', 'Co_Depression_R0', 'Co_Bipolar_R0', 'Co_Psychosis_R0',\n 'Co_Personalitydisorder_R0', 'Co_Adjustmentdisorder_R0', 'Co_Anxiety_R0',\n 'Co_Generalizedanxiety_R0', 'Co_OldMI_R0', 'Co_AcuteMI_R0', 'Co_PUD_R0',\n 'Co_UpperGIbleed_R0', 'Co_LowerGIbleed_R0', 'Co_Urogenitalbleed_R0',\n 'Co_Othbleed_R0', 'Co_PVD_R0', 'Co_LiverDisease_R0', 'Co_MRI_R0',\n 'Co_ESRD_R0', 'Co_Obesity_R0', 'Co_Sepsis_R0', 'Co_Osteoarthritis_R0',\n 'Co_RA_R0', 'Co_NeuroPain_R0', 'Co_NeckPain_R0', 'Co_OthArthritis_R0',\n 'Co_Osteoporosis_R0', 'Co_Fibromyalgia_R0', 'Co_Migraine_R0', 'Co_Headache_R0',\n 'Co_OthPain_R0', 'Co_GeneralizedPain_R0', 'Co_PainDisorder_R0',\n 'Co_Falls_R0', 'Co_CoagulationDisorder_R0', 'Co_WhiteBloodCell_R0', 'Co_Parkinson_R0',\n 'Co_Anemia_R0', 'Co_UrinaryIncontinence_R0', 'Co_DecubitusUlcer_R0',\n 'Co_Oxygen_R0', 'Co_Mammography_R0', 'Co_PapTest_R0', 'Co_PSATest_R0',\n 'Co_Colonoscopy_R0', 'Co_FecalOccultTest_R0', 'Co_FluShot_R0', 'Co_PneumococcalVaccine_R0', 'Co_RenalDysfunction_R0', 'Co_Valvular_R0', 'Co_Hosp_Prior30Days_R0',\n 'Co_RX_Antibiotic_R0', 'Co_RX_Corticosteroid_R0', 'Co_RX_Aspirin_R0', 'Co_RX_Dipyridamole_R0',\n 'Co_RX_Clopidogrel_R0', 'Co_RX_Prasugrel_R0', 'Co_RX_Cilostazol_R0', 'Co_RX_Ticlopidine_R0',\n 'Co_RX_Ticagrelor_R0', 'Co_RX_OthAntiplatelet_R0', 'Co_RX_NSAIDs_R0',\n 'Co_RX_Opioid_R0', 'Co_RX_Antidepressant_R0', 'Co_RX_AAntipsychotic_R0', 'Co_RX_TAntipsychotic_R0',\n 'Co_RX_Anticonvulsant_R0', 'Co_RX_PPI_R0', 'Co_RX_H2Receptor_R0', 'Co_RX_OthGastro_R0',\n 'Co_RX_ACE_R0', 'Co_RX_ARB_R0', 'Co_RX_BBlocker_R0', 'Co_RX_CCB_R0', 'Co_RX_Thiazide_R0',\n 'Co_RX_Loop_R0', 'Co_RX_Potassium_R0', 'Co_RX_Nitrates_R0', 'Co_RX_Aliskiren_R0',\n 'Co_RX_OthAntihypertensive_R0', 'Co_RX_Antiarrhythmic_R0', 'Co_RX_OthAnticoagulant_R0',\n 'Co_RX_Insulin_R0', 'Co_RX_Noninsulin_R0', 'Co_RX_Digoxin_R0', 'Co_RX_Statin_R0',\n 'Co_RX_Lipid_R0', 'Co_RX_Lithium_R0', 'Co_RX_Benzo_R0', 'Co_RX_ZDrugs_R0',\n 'Co_RX_OthAnxiolytic_R0', 'Co_RX_Barbiturate_R0', 'Co_RX_Dementia_R0', 'Co_RX_Hormone_R0',\n 'Co_RX_Osteoporosis_R0', 'Co_N_Drugs_R0', 'Co_N_Hosp_R0', 'Co_Total_HospLOS_R0',\n 'Co_N_MDVisit_R0', 'Co_RX_AnyAspirin_R0', 'Co_RX_AspirinMono_R0', 'Co_RX_ClopidogrelMono_R0',\n 'Co_RX_AspirinClopidogrel_R0', 'Co_RX_DM_R0', 'Co_RX_Antipsychotic_R0'\n]\n\n\nco_train_gpop = train_set[predictor_variable]\nco_train_high = train_set_high[predictor_variable]\nco_train_low = train_set_low[predictor_variable]\n\nco_validation_gpop = validation_set[predictor_variable]\nco_validation_high = validation_set_high[predictor_variable]\nco_validation_low = validation_set_low[predictor_variable]\nlen(predictor_variable)\n\n",
"_____no_output_____"
],
[
"out_train_death_gpop = train_set['ehr_claims_death']\nout_train_death_high = train_set_high['ehr_claims_death']\nout_train_death_low = train_set_low['ehr_claims_death']\n\nout_validation_death_gpop = validation_set['ehr_claims_death']\nout_validation_death_high = validation_set_high['ehr_claims_death']\nout_validation_death_low = validation_set_low['ehr_claims_death']",
"_____no_output_____"
],
[
"def bart(X_train, y_train):\n from bartpy.sklearnmodel import SklearnModel\n from sklearn.model_selection import GridSearchCV\n from bartpy.data import Data\n from bartpy.sigma import Sigma\n param_grid = [{\n 'n_trees': [10,30,50] #\n }]\n model = SklearnModel()\n clf = GridSearchCV(estimator = model, param_grid = param_grid, n_jobs = 10, verbose = True)\n best_clf = clf.fit(X_train, y_train.to_numpy())\n print(best_clf)\n return best_clf ",
"_____no_output_____"
],
[
"def scores(X_train,y_train, best_clf):\n from sklearn.metrics import accuracy_score\n from sklearn.metrics import f1_score\n from sklearn.metrics import fbeta_score\n from sklearn.metrics import roc_auc_score \n from sklearn.metrics import log_loss\n import numpy as np\n pred = np.round(best_clf.predict(X_train))\n print(pred)\n actual = y_train\n print(accuracy_score(actual,pred))\n print(f1_score(actual,pred))\n print(fbeta_score(actual,pred, average = 'macro', beta = 2))\n print(roc_auc_score(actual, best_clf.predict(X_train)))\n print(log_loss(actual,best_clf.predict(X_train)))",
"_____no_output_____"
],
[
"def cross_val(X,y):\n from sklearn.model_selection import KFold\n from sklearn.model_selection import cross_validate\n from sklearn.metrics import log_loss\n from sklearn.metrics import roc_auc_score\n from sklearn.metrics import fbeta_score\n import sklearn\n import numpy as np\n cv = KFold(n_splits=5, random_state=1, shuffle=True)\n log_loss = [] \n auc = [] \n accuracy = []\n f1 = []\n f2 = [] \n for train_index, test_index in cv.split(X):\n X_train, X_test, y_train, y_test = X.iloc[train_index], X.iloc[test_index], y.iloc[train_index], y.iloc[test_index]\n model = bart(X_train, y_train)\n prob = model.predict(X_test) # prob is a vector of probabilities \n pred = np.round(model.predict(X_test)) # pred is the rounded predictions \n log_loss.append(sklearn.metrics.log_loss(y_test, prob))\n auc.append(sklearn.metrics.roc_auc_score(y_test, prob))\n accuracy.append(sklearn.metrics.accuracy_score(y_test, pred))\n f1.append(sklearn.metrics.f1_score(y_test, pred, average = 'macro'))\n f2.append(fbeta_score(y_test,pred, average = 'macro', beta = 2))\n print(np.mean(accuracy))\n print(np.mean(f1))\n print(np.mean(f2))\n print(np.mean(auc))\n print(np.mean(log_loss))",
"_____no_output_____"
],
[
"import datetime\nbegin_time = datetime.datetime.now()\n\nbest_clf = bart(co_train_gpop,out_train_death_gpop)\ncross_val(co_train_gpop,out_train_death_gpop)\nprint()\nscores(co_validation_gpop,out_validation_death_gpop, best_clf)\n\nprint(datetime.datetime.now() - begin_time)",
"Fitting 5 folds for each of 3 candidates, totalling 15 fits\n"
],
[
"scores(co_validation_gpop,out_validation_death_gpop, best_clf)\n",
"[ 0. -0. 0. ... 0. 0. 0.]\n0.8968887116074991\n0.020833333333333332\n0.4951062823157546\n0.7865797967466328\n0.30089140439944767\n"
],
[
"pip install knockknock",
"Collecting knockknock\n Downloading knockknock-0.1.8.1-py3-none-any.whl (28 kB)\nCollecting matrix-client\n Downloading matrix_client-0.4.0-py2.py3-none-any.whl (43 kB)\n\u001b[K |████████████████████████████████| 43 kB 217 kB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: keyring in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from knockknock) (22.3.0)\nCollecting yagmail>=0.11.214\n Downloading yagmail-0.14.256-py2.py3-none-any.whl (15 kB)\nCollecting twilio\n Downloading twilio-6.63.0.tar.gz (488 kB)\n\u001b[K |████████████████████████████████| 488 kB 3.1 MB/s eta 0:00:01\n\u001b[?25hCollecting python-telegram-bot\n Downloading python_telegram_bot-13.7-py3-none-any.whl (490 kB)\n\u001b[K |████████████████████████████████| 490 kB 9.5 MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: requests in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from knockknock) (2.25.1)\nCollecting premailer\n Downloading premailer-3.10.0-py2.py3-none-any.whl (19 kB)\nRequirement already satisfied: SecretStorage>=3.2 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from keyring->knockknock) (3.3.1)\nRequirement already satisfied: jeepney>=0.4.2 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from keyring->knockknock) (0.6.0)\nRequirement already satisfied: cryptography>=2.0 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from SecretStorage>=3.2->keyring->knockknock) (3.4.7)\nRequirement already satisfied: cffi>=1.12 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from cryptography>=2.0->SecretStorage>=3.2->keyring->knockknock) (1.14.5)\nRequirement already satisfied: pycparser in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from cffi>=1.12->cryptography>=2.0->SecretStorage>=3.2->keyring->knockknock) (2.20)\nRequirement already satisfied: urllib3~=1.21 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from matrix-client->knockknock) (1.26.4)\nRequirement already satisfied: certifi>=2017.4.17 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from requests->knockknock) (2020.12.5)\nRequirement already satisfied: chardet<5,>=3.0.2 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from requests->knockknock) (4.0.0)\nRequirement already satisfied: idna<3,>=2.5 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from requests->knockknock) (2.10)\nCollecting cssutils\n Downloading cssutils-2.3.0-py3-none-any.whl (404 kB)\n\u001b[K |████████████████████████████████| 404 kB 11.3 MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: lxml in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from premailer->yagmail>=0.11.214->knockknock) (4.6.3)\nCollecting cssselect\n Downloading cssselect-1.1.0-py2.py3-none-any.whl (16 kB)\nRequirement already satisfied: cachetools in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from premailer->yagmail>=0.11.214->knockknock) (4.2.2)\nCollecting APScheduler==3.6.3\n Downloading APScheduler-3.6.3-py2.py3-none-any.whl (58 kB)\n\u001b[K |████████████████████████████████| 58 kB 926 kB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: tornado>=6.1 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from python-telegram-bot->knockknock) (6.1)\nRequirement already satisfied: pytz>=2018.6 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from python-telegram-bot->knockknock) (2021.1)\nRequirement already satisfied: tzlocal>=1.2 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from APScheduler==3.6.3->python-telegram-bot->knockknock) (2.1)\nRequirement already satisfied: setuptools>=0.7 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from APScheduler==3.6.3->python-telegram-bot->knockknock) (52.0.0.post20210125)\nRequirement already satisfied: six>=1.4.0 in /netapp2/home/se197/anaconda3/lib/python3.8/site-packages (from APScheduler==3.6.3->python-telegram-bot->knockknock) (1.15.0)\nCollecting PyJWT==1.7.1\n Downloading PyJWT-1.7.1-py2.py3-none-any.whl (18 kB)\nBuilding wheels for collected packages: twilio\n Building wheel for twilio (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for twilio: filename=twilio-6.63.0-py2.py3-none-any.whl size=1290602 sha256=37986b5993ae1031018b7a8b32a9e43871608b6d9d555605f53750cc8c8bff87\n Stored in directory: /netapp2/home/se197/.cache/pip/wheels/c3/a0/62/a106e75c16a842a1ef3ab9793f31cfa4d7f6ede5d41748aa3b\nSuccessfully built twilio\nInstalling collected packages: cssutils, cssselect, PyJWT, premailer, APScheduler, yagmail, twilio, python-telegram-bot, matrix-client, knockknock\n Attempting uninstall: PyJWT\n Found existing installation: PyJWT 2.1.0\n Uninstalling PyJWT-2.1.0:\n Successfully uninstalled PyJWT-2.1.0\nSuccessfully installed APScheduler-3.6.3 PyJWT-1.7.1 cssselect-1.1.0 cssutils-2.3.0 knockknock-0.1.8.1 matrix-client-0.4.0 premailer-3.10.0 python-telegram-bot-13.7 twilio-6.63.0 yagmail-0.14.256\nNote: you may need to restart the kernel to use updated packages.\n"
],
[
"import datetime\nbegin_time = datetime.datetime.now()\n\nbest_clf = bart(co_train_low,out_train_death_low)\ncross_val(co_train_low,out_train_death_low)\nprint()\nscores(co_validation_low,out_validation_death_low, best_clf)\n\nprint(datetime.datetime.now() - begin_time)",
"Fitting 5 folds for each of 3 candidates, totalling 15 fits\n"
],
[
"import datetime\nbegin_time = datetime.datetime.now()\n\nbest_clf = bart(co_train_high,out_train_death_high)\ncross_val(co_train_high,out_train_death_high)\nprint()\nscores(co_validation_high,out_validation_death_high, best_clf)\n\nprint(datetime.datetime.now() - begin_time)",
"Fitting 5 folds for each of 3 candidates, totalling 15 fits\n"
],
[
"\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca6d19134f1058f2c80bfd6f004a745a678eb6
| 7,881 |
ipynb
|
Jupyter Notebook
|
Mathematics/CVX101-HW-with-python/HW5/dinner_problem.ipynb
|
YunyaoCheng/Books
|
8196417fdc86128f9a8e1f012ca801a07d2984d2
|
[
"BSD-2-Clause"
] | 2 |
2020-10-01T08:38:42.000Z
|
2020-10-04T02:13:12.000Z
|
Mathematics/CVX101-HW-with-python/HW5/dinner_problem.ipynb
|
YunyaoCheng/books
|
8196417fdc86128f9a8e1f012ca801a07d2984d2
|
[
"BSD-2-Clause"
] | null | null | null |
Mathematics/CVX101-HW-with-python/HW5/dinner_problem.ipynb
|
YunyaoCheng/books
|
8196417fdc86128f9a8e1f012ca801a07d2984d2
|
[
"BSD-2-Clause"
] | null | null | null | 27.082474 | 124 | 0.388276 |
[
[
[
"# Boolean LP dinner problem\nplanning dinner with 2 more couples turned out to be a `boolean linear program` problem",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport cvxpy as cvx\nimport pandas as pd\n\nnumber_of_households = 3\nfood_dict = {\"meat\":100, \"wine1\":40, \"first_meal\":45,\"dessert\":50,\"side_dish\":30, 'soup':22,\"wine2\":40}\nfood_cost = pd.DataFrame(list(food_dict.values()),index=food_dict.keys(), columns=[\"price $\"])\nfood_cost",
"_____no_output_____"
],
[
"C = np.array(food_cost[\"price $\"]) # food costs\nA = cvx.Variable(shape=(C.shape[0],number_of_households), boolean =True) # \nconstraints = [A * np.ones((number_of_households,1)) == 1\n , A <=1\n , A >= 0]\nobj = cvx.Minimize(cvx.sum_squares(C * A))\nprob = cvx.Problem(obj, constraints)\nprob.solve()\nassignment = pd.DataFrame(np.abs(np.round(A.value))\n ,columns=[\"household 1\",\"household 2\",\"household 3\"], index=food_cost.index)\nassignment.append(pd.DataFrame({\"total expenses\":(C[:,None]*A.value).sum(axis=0)},index=assignment.columns).T)",
"_____no_output_____"
]
],
[
[
"> total expenses with `minmax` cost where $95,100,70$",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4aca6e11e73e673f0dd0f65d7c9dca77a0d944d1
| 6,075 |
ipynb
|
Jupyter Notebook
|
examples/notebook/contrib/lectures.ipynb
|
MaximilianAzendorf/wasm-or-tools
|
f16c3efc13ad5d41c7a65338434ea88ed908c398
|
[
"Apache-2.0"
] | null | null | null |
examples/notebook/contrib/lectures.ipynb
|
MaximilianAzendorf/wasm-or-tools
|
f16c3efc13ad5d41c7a65338434ea88ed908c398
|
[
"Apache-2.0"
] | null | null | null |
examples/notebook/contrib/lectures.ipynb
|
MaximilianAzendorf/wasm-or-tools
|
f16c3efc13ad5d41c7a65338434ea88ed908c398
|
[
"Apache-2.0"
] | null | null | null | 30.994898 | 246 | 0.552757 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4aca7457e97551b9b834b52dc9d8791f949e42c6
| 89,247 |
ipynb
|
Jupyter Notebook
|
Cls5-Dimentionality Reduction/542_m5_assign_sol_3_v1.0.ipynb
|
tuhinssam/MLResources
|
5410ce33bc6f3a951b0f94c32bf82748a8c5bd6c
|
[
"MIT"
] | 1 |
2020-01-31T06:18:30.000Z
|
2020-01-31T06:18:30.000Z
|
Cls5-Dimentionality Reduction/542_m5_assign_sol_3_v1.0.ipynb
|
tuhinssam/MLResources
|
5410ce33bc6f3a951b0f94c32bf82748a8c5bd6c
|
[
"MIT"
] | null | null | null |
Cls5-Dimentionality Reduction/542_m5_assign_sol_3_v1.0.ipynb
|
tuhinssam/MLResources
|
5410ce33bc6f3a951b0f94c32bf82748a8c5bd6c
|
[
"MIT"
] | null | null | null | 91.441598 | 61,478 | 0.806526 |
[
[
[
"# Module 5 -- Dimensionality Reduction -- Case Study",
"_____no_output_____"
],
[
"# Import Libraries\n\n**Import the usual libraries **",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nimport seaborn as sns\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Data Set : Cancer Data Set\nFeatures are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image. n the 3-dimensional space is that described in: [K. P. Bennett and O. L. Mangasarian: \"Robust Linear Programming Discrimination of Two Linearly Inseparable Sets\", Optimization Methods and Software 1, 1992, 23-34].\n\nThis database is also available through the UW CS ftp server: ftp ftp.cs.wisc.edu cd math-prog/cpo-dataset/machine-learn/WDBC/\n\nAlso can be found on UCI Machine Learning Repository: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29\n\nAttribute Information:\n\n1) ID number 2) Diagnosis (M = malignant, B = benign) 3-32)\n\nTen real-valued features are computed for each cell nucleus:\n\na) radius (mean of distances from center to points on the perimeter) b) texture (standard deviation of gray-scale values) c) perimeter d) area e) smoothness (local variation in radius lengths) f) compactness (perimeter^2 / area - 1.0) g) concavity (severity of concave portions of the contour) h) concave points (number of concave portions of the contour) i) symmetry j) fractal dimension (\"coastline approximation\" - 1)\n\nThe mean, standard error and \"worst\" or largest (mean of the three largest values) of these features were computed for each image, resulting in 30 features. For instance, field 3 is Mean Radius, field 13 is Radius SE, field 23 is Worst Radius.\n\nAll feature values are recoded with four significant digits.\n\nMissing attribute values: none\n\nClass distribution: 357 benign, 212 malignant",
"_____no_output_____"
],
[
"## Get the Data\n\n** Use pandas to read data as a dataframe called df.**",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('breast-cancer-data.csv')\ndf.head()\n",
"_____no_output_____"
],
[
"# Check the data , there should be no missing values \ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 569 entries, 0 to 568\nData columns (total 32 columns):\nid 569 non-null int64\ndiagnosis 569 non-null object\nradius_mean 569 non-null float64\ntexture_mean 569 non-null float64\nperimeter_mean 569 non-null float64\narea_mean 569 non-null float64\nsmoothness_mean 569 non-null float64\ncompactness_mean 569 non-null float64\nconcavity_mean 569 non-null float64\nconcave points_mean 569 non-null float64\nsymmetry_mean 569 non-null float64\nfractal_dimension_mean 569 non-null float64\nradius_se 569 non-null float64\ntexture_se 569 non-null float64\nperimeter_se 569 non-null float64\narea_se 569 non-null float64\nsmoothness_se 569 non-null float64\ncompactness_se 569 non-null float64\nconcavity_se 569 non-null float64\nconcave points_se 569 non-null float64\nsymmetry_se 569 non-null float64\nfractal_dimension_se 569 non-null float64\nradius_worst 569 non-null float64\ntexture_worst 569 non-null float64\nperimeter_worst 569 non-null float64\narea_worst 569 non-null float64\nsmoothness_worst 569 non-null float64\ncompactness_worst 569 non-null float64\nconcavity_worst 569 non-null float64\nconcave points_worst 569 non-null float64\nsymmetry_worst 569 non-null float64\nfractal_dimension_worst 569 non-null float64\ndtypes: float64(30), int64(1), object(1)\nmemory usage: 142.3+ KB\n"
],
[
"feature_names = np.array(['mean radius' 'mean texture' 'mean perimeter' 'mean area'\n 'mean smoothness' 'mean compactness' 'mean concavity'\n 'mean concave points' 'mean symmetry' 'mean fractal dimension'\n 'radius error' 'texture error' 'perimeter error' 'area error'\n 'smoothness error' 'compactness error' 'concavity error'\n 'concave points error' 'symmetry error' 'fractal dimension error'\n 'worst radius' 'worst texture' 'worst perimeter' 'worst area'\n 'worst smoothness' 'worst compactness' 'worst concavity'\n 'worst concave points' 'worst symmetry' 'worst fractal dimension'])",
"_____no_output_____"
]
],
[
[
"#### Convert diagnosis column to 1/0 and store in new column target\n",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import LabelEncoder",
"_____no_output_____"
],
[
"# # Encode label diagnosis\n# # M -> 1\n# # B -> 0",
"_____no_output_____"
],
[
"# Get All rows, but only last column\ntarget_data=df[\"diagnosis\"]\n\n\nencoder = LabelEncoder()\ntarget_data = encoder.fit_transform(target_data)",
"_____no_output_____"
]
],
[
[
"#### Store the encoded column in dataframe and drop the diagnosis column for simpilcity",
"_____no_output_____"
]
],
[
[
"df.drop([\"diagnosis\"],axis = 1, inplace = True)",
"_____no_output_____"
]
],
[
[
"## Principal Component Analysis -- PCA\n\nLets use PCA to find the first two principal components, and visualize the data in this new, two-dimensional space, with a single scatter-plot",
"_____no_output_____"
],
[
"Scale data so that each feature has a single unit variance.",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler",
"_____no_output_____"
],
[
"scaler = StandardScaler()\nscaler.fit(df)",
"_____no_output_____"
],
[
"scaled_data = scaler.transform(df)",
"_____no_output_____"
]
],
[
[
"Now we can transform this data to its first 2 principal components.",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import PCA",
"_____no_output_____"
],
[
"pca = PCA(n_components=2)",
"_____no_output_____"
],
[
"pca.fit(scaled_data)",
"_____no_output_____"
],
[
"x_pca = pca.transform(scaled_data)",
"_____no_output_____"
],
[
"scaled_data.shape",
"_____no_output_____"
],
[
"x_pca.shape",
"_____no_output_____"
]
],
[
[
"#### Reduced 30 dimensions to just 2! Let's plot these two dimensions out!",
"_____no_output_____"
],
[
"** Q1. Plot scatter for 2 components. What inference can you draw from this data? **",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(9,6))\nplt.scatter(x_pca[:,0],x_pca[:,1],c=target_data,cmap='viridis')\nplt.xlabel('First Principal Component')\nplt.ylabel('Second Principal Component')",
"_____no_output_____"
]
],
[
[
"## Interpreting the components \n\nUnfortunately, with this great power of dimensionality reduction, comes the cost of being able to easily understand what these components represent.\n\nThe components correspond to combinations of the original features, the components themselves are stored as an attribute of the fitted PCA object:",
"_____no_output_____"
]
],
[
[
"pca.components_",
"_____no_output_____"
]
],
[
[
"# Explained Variance\nThe explained variance tells you how much information (variance) can be attributed to each of the principal components. This is important as you can convert n dimensional space to 2 dimensional space, you lose some of the variance (information).",
"_____no_output_____"
],
[
"** Q2. What is the variance attributed by 1st and 2nd Components? **",
"_____no_output_____"
],
[
"** Q3 Ideally the sum above should be 100%. What happened to the remaining variance ? **",
"_____no_output_____"
]
],
[
[
"pca.explained_variance_ratio_",
"_____no_output_____"
]
],
[
[
"## Lets try with 3 Principal Components",
"_____no_output_____"
]
],
[
[
"pca_3 = PCA(n_components=3)\npca_3.fit(scaled_data)\nx_pca_3 = pca_3.transform(scaled_data)",
"_____no_output_____"
]
],
[
[
"In this numpy matrix array, each row represents a principal component, and each column relates back to the original features. we can visualize this relationship with a heatmap:",
"_____no_output_____"
]
],
[
[
"x_pca_3.shape",
"_____no_output_____"
]
],
[
[
"** Q4. What is the total variance attributed by three Components? **",
"_____no_output_____"
]
],
[
[
"pca_3.explained_variance_ratio_",
"_____no_output_____"
]
],
[
[
"### Lets check the accuracy for 2 vs. 3 components",
"_____no_output_____"
],
[
"** Q5. What is accuracy for component count 2 vs. 3 ?**",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"train_data, test_data, train_output, test_output = train_test_split( df, target_data, test_size=0.3, random_state=101)",
"_____no_output_____"
],
[
"train_data = scaler.transform(train_data)\ntest_data = scaler.transform(test_data)",
"_____no_output_____"
],
[
"train_data = pca.transform(train_data)\ntest_data = pca.transform(test_data)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression\nlogisticRegr = LogisticRegression(solver = 'lbfgs')\nlogisticRegr.fit(train_data, train_output)\n",
"_____no_output_____"
],
[
"logisticRegr.score(test_data, test_output)",
"_____no_output_____"
]
],
[
[
"Score for 3 components",
"_____no_output_____"
]
],
[
[
"train_data, test_data, train_output, test_output = train_test_split( df, target_data, test_size=0.3, random_state=101)\ntrain_data = scaler.transform(train_data)\ntest_data = scaler.transform(test_data)\n\ntrain_data = pca_3.transform(train_data)\ntest_data = pca_3.transform(test_data)\nlogisticRegr = LogisticRegression(solver = 'lbfgs')\n\nlogisticRegr.fit(train_data, train_output)\nlogisticRegr.score(test_data, test_output)",
"_____no_output_____"
]
],
[
[
"# End of Case Study",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aca79f8a4e8aa51b69daf2d8a8ee2891ac450a3
| 434,150 |
ipynb
|
Jupyter Notebook
|
AI2_project2.ipynb
|
pavlosapostolatos/AI2
|
cd794d0a49f3b53d4e35fe2be57ceb2c73f30104
|
[
"MIT"
] | 1 |
2022-03-22T19:12:22.000Z
|
2022-03-22T19:12:22.000Z
|
AI2_project2.ipynb
|
pavlosapostolatos/AI2
|
cd794d0a49f3b53d4e35fe2be57ceb2c73f30104
|
[
"MIT"
] | null | null | null |
AI2_project2.ipynb
|
pavlosapostolatos/AI2
|
cd794d0a49f3b53d4e35fe2be57ceb2c73f30104
|
[
"MIT"
] | null | null | null | 256.589835 | 207,129 | 0.884462 |
[
[
[
"## Τα Στοιχεία μου\nΤΥΠΑΛΔΟΣ-ΠΑΥΛΟΣ ΑΠΟΣΤΟΛΑΤΟΣ 1115201800009\n\n",
"_____no_output_____"
],
[
"# Initialisation",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import figure\nimport numpy as np\nfrom sklearn.preprocessing import PolynomialFeatures\nimport nltk\nimport re\nfrom gensim.models import Word2Vec\nfrom sklearn.metrics import f1_score,recall_score,precision_score,confusion_matrix,classification_report\nfrom gensim.parsing.preprocessing import remove_stopwords\nimport urllib.request\nfrom scipy import spatial\nfrom sklearn.manifold import TSNE\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom google.colab import drive\ndrive.mount('/content/drive')\npath = \"/content/drive/MyDrive/AI2/\" #update this\n#path = \"C:/Users/Pavlos/Desktop/AI2/\" #update this\nimport sys, os\nfrom statistics import mean\nfrom sklearn.metrics import roc_curve, auc\nfrom sklearn.preprocessing import label_binarize\nfrom sklearn.metrics import roc_auc_score\nfrom scipy import interp\nfrom itertools import cycle",
"Mounted at /content/drive\n"
],
[
"train_df = pd.read_csv(path + \"vaccine_train_set.csv\",index_col=0)\nvalidation_set = pd.read_csv(path + \"vaccine_validation_set.csv\",index_col=0) # and this. only those 2 needed to run your own test csv\nprint(train_df)\nprint(validation_set)\n# print(validation_set.iat[0,0])",
" tweet label\n0 Sip N Shop Come thru right now #Marjais #Popul... 0\n1 I don't know about you but My family and I wil... 1\n2 @MSignorile Immunizations should be mandatory.... 2\n3 President Obama spoke in favor of vaccination ... 0\n4 \"@myfoxla: Arizona monitoring hundreds for mea... 0\n... ... ...\n15971 @Salon if u believe the anti-vax nutcases caus... 1\n15972 How do you feel about parents who don't #vacci... 0\n15973 70 Preschoolers Tested for Measles in Simi Val... 0\n15974 Finance Minister: Budget offers room to procur... 0\n15975 Are you up to date on vaccines? Take CDC’s vac... 2\n\n[15976 rows x 2 columns]\n tweet label\n0 @user They had a massive surge in with covid d... 1\n1 Required vaccines for school: Parents and guar... 0\n2 “@KCStar: Two more Johnson County children hav... 0\n3 NV can do better. Which states are the best (a... 2\n4 Nothing like killing ourselves w/ our own fear... 2\n... ... ...\n2277 RT @abc7: Number of measles cases reported in ... 0\n2278 Evidence points to the idea that \"measles affe... 0\n2279 Where's @SavedYouAClick \"@voxdotcom: Why you s... 2\n2280 Some of my favorite people have autism. If tha... 2\n2281 Coronavirus: The married couple behind the suc... 0\n\n[2282 rows x 2 columns]\n"
]
],
[
[
"# Προεπεξεργασία δεδομένων\nκανω ολες τις λεξεις lowercase ετσι ωστε να μην θεωρουνται διαφορετικες λογω ενος κεφαλαιου αρχικου γραμματος και βγαζω σημεια στιξης\n\n#Σε αντίθεση με την ασκηση 1\nδεν εκτελω τις 2 τελευταιες γραμμες γιατι καταργουν χαρακτηριστικα των tweets που συνυπολογιζονται στο κελί \n\"Optimisation των λεξεων μας για το Twitter\"\n\nγενικα η χρήση αυτου του κελιού είναι up to debate. θεωρητικα θα βοηθήσει το word2vec γιατι θα μετατρέψει το κειμενο με απλες λεξεις για τις οποιες μπόρει να εκπαιδευτεί αλλα θα εμποδίσει το GloVe γιατί του καταργεί την ιδιατερότητα",
"_____no_output_____"
]
],
[
[
"train_df['tweet'] = train_df['tweet'].apply(lambda x: x.lower())\n# train_df['tweet'] = train_df['tweet'].apply(lambda x: re.sub(r'\\W', ' ', x))\n# train_df['tweet'] = train_df['tweet'].apply(lambda x:re.sub(r'\\s+', ' ', x))\n\nvalidation_set['tweet'] = validation_set['tweet'].apply(lambda x: x.lower())\n# validation_set['tweet'] = validation_set['tweet'].apply(lambda x: re.sub(r'\\W', ' ', x))\n# validation_set['tweet'] = validation_set['tweet'].apply(lambda x:re.sub(r'\\s+', ' ', x))\n",
"_____no_output_____"
],
[
"train_df = train_df.drop(train_df[train_df.tweet.str.len() < 2].index)\nvalidation_set = validation_set.drop(validation_set[validation_set.tweet.str.len() < 2].index)",
"_____no_output_____"
]
],
[
[
"## Αφαίρεση stopwords\ni.e “a”, “the”, “is” etc",
"_____no_output_____"
]
],
[
[
"\ntrain_df['tweet'] = train_df['tweet'].apply(lambda x: remove_stopwords(x))\nvalidation_set['tweet'] = validation_set['tweet'].apply(lambda x: remove_stopwords(x))\n",
"_____no_output_____"
]
],
[
[
"# Οπτικοποίηση Δεδομένων",
"_____no_output_____"
]
],
[
[
"print(\"test set Examples:\")\npd.DataFrame(train_df['tweet']).head(10)",
"test set Examples:\n"
],
[
"print(\"validation set Examples:\")\npd.DataFrame(validation_set['tweet']).head(10)\n# values, counts = np.unique(validation_set['label'], return_counts=True)\n# print(values, counts )",
"validation set Examples:\n"
]
],
[
[
"##Optimisation των λεξεων μας για το Twitter\nοι λεξεις του twitter εχουν διαφορες ιδιαιτεροτητες οπως emojies hashtags user tags κλπ. αυτο το script που συνισταται απο την ιστοσελίδα του glover μας επιτρεπει να αναγνωριζουμε αυτα τα χαρακτηριστικα στις λεξεις των αρχειων μας και να συνυπολογίζουμε την σημασία τους στα vector της καθε λεξης.\n\nη μέθοδος ειναι οτι οταν ανιχνευσει ενα χαρακτηριστικο προσθετει στην προταση την λεξη <χαρακτηριστικο> η οποία υπάρχει στο vocabulary txt αρχειο και μας δινει ένα εκπαιδευμένο vector\n\nπχ τα allcaps συχνά δείχνουν θυμό και αρνητικότητα(μήπως θα μας ωθήσει σε anti-vax πρόβλεψη??)",
"_____no_output_____"
]
],
[
[
"\"\"\"\npreprocess-twitter.py\n\npython preprocess-twitter.py \"Some random text with #hashtags, @mentions and http://t.co/kdjfkdjf (links). :)\"\n\nScript for preprocessing tweets by Romain Paulus\nwith small modifications by Jeffrey Pennington\nwith translation to Python by Motoki Wu (github.com/tokestermw)\n\nTranslation of Ruby script to create features for GloVe vectors for Twitter data.\nhttp://nlp.stanford.edu/projects/glove/preprocess-twitter.rb\n\nthis version from gist.github.com/ppope > preprocess_twitter.py\n\nlight edits by amackcrane, mostly inspired by the test case given at bottom\n\"\"\"\n\nimport sys\nimport regex as re\n\nFLAGS = re.MULTILINE | re.DOTALL\n\ndef hashtag(text):\n text = text.group()\n hashtag_body = text[1:]\n if hashtag_body.isupper():\n result = \"<hashtag> {} <allcaps>\".format(hashtag_body.lower())\n else:\n result = \" \".join([\"<hashtag>\"] + re.split(r\"(?=[A-Z])\", hashtag_body, flags=FLAGS))\n return result\n\ndef allcaps(text):\n text = text.group()\n return text.lower() + \" <allcaps> \" # amackcrane added trailing space\n\n\ndef tokenize(text):\n # Different regex parts for smiley faces\n eyes = r\"[8:=;]\"\n nose = r\"['`\\-]?\"\n\n # function so code less repetitive\n def re_sub(pattern, repl):\n return re.sub(pattern, repl, text, flags=FLAGS)\n\n text = re_sub(r\"https?:\\/\\/\\S+\\b|www\\.(\\w+\\.)+\\S*\", \"<url>\")\n text = re_sub(r\"@\\w+\", \"<user>\")\n text = re_sub(r\"{}{}[)dD]+|[)dD]+{}{}\".format(eyes, nose, nose, eyes), \"<smile>\")\n text = re_sub(r\"{}{}p+\".format(eyes, nose), \"<lolface>\")\n text = re_sub(r\"{}{}\\(+|\\)+{}{}\".format(eyes, nose, nose, eyes), \"<sadface>\")\n text = re_sub(r\"{}{}[\\/|l*]\".format(eyes, nose), \"<neutralface>\")\n text = re_sub(r\"/\",\" / \")\n text = re_sub(r\"<3\",\"<heart>\")\n text = re_sub(r\"[-+]?[.\\d]*[\\d]+[:,.\\d]*\", \"<number>\")\n text = re_sub(r\"#\\w+\", hashtag) # amackcrane edit\n text = re_sub(r\"([!?.]){2,}\", r\"\\1 <repeat>\")\n text = re_sub(r\"\\b(\\S*?)(.)\\2{2,}\\b\", r\"\\1\\2 <elong>\")\n \n\n ## -- I just don't understand why the Ruby script adds <allcaps> to everything so I limited the selection.\n # text = re_sub(r\"([^a-z0-9()<>'`\\-]){2,}\", allcaps)\n #text = re_sub(r\"([A-Z]){2,}\", allcaps) # moved below -amackcrane\n\n # amackcrane additions\n text = re_sub(r\"([a-zA-Z<>()])([?!.:;,])\", r\"\\1 \\2\")\n text = re_sub(r\"\\(([a-zA-Z<>]+)\\)\", r\"( \\1 )\")\n text = re_sub(r\" \", r\" \")\n text = re_sub(r\" ([A-Z]){2,} \", allcaps)\n \n return text.lower()\n\nif __name__ == '__main__':\n #_, text = sys.argv # kaggle envt breaks this -amackcrane\n #if text == \"test\":\n text = \"I TEST alllll kinds of #hashtags and #HASHTAGS, @mentions and 3000 (http://t.co/dkfjkdf). w/ <3 :) haha!!!!!\"\n text2 = \"TEStiNg some *tough* #CASES\" # couple extra tests -amackcrane\n tokens = tokenize(text)\n print(tokens)\n print(tokenize(text2))\n",
"i test <allcaps> al <elong> kinds of <hashtag> hashtags and <hashtag> hashtags <allcaps> , <user> and <number> ( <url> ) . w / <heart> <smile> haha ! <repeat>\ntesting some *tough* <hashtag> cases <allcaps>\n"
]
],
[
[
"# Classification",
"_____no_output_____"
],
[
"##Confusion Matrix\n\nιδια υλοποίση με αυτη τη στην εργασία 1",
"_____no_output_____"
]
],
[
[
"def ConfusionMatrix(test_label,ypred):\n C = confusion_matrix(test_label,ypred)\n confusionMatrix = pd.DataFrame(data = C, index=['neutral(0), true','anti-vax(1), true','pro-vax(2), true'], columns = ['neutral(0), predicted','anti-vax(1), predicted','pro-vax(2), predicted'])\n confusionMatrix.loc['sum'] = confusionMatrix.sum()\n confusionMatrix['sum'] = confusionMatrix.sum(axis=1)\n # print(confusionMatrix.to_string())\n confMx = confusionMatrix.values[0:3,0:3]\n plt.matshow(confMx, cmap=plt.cm.gray)\n plt.show()\n\ndef MetricReport(test_label,ypred):\n print(classification_report(test_label, y_pred, digits=3))\n\n\n",
"_____no_output_____"
]
],
[
[
"#Φόρτωση GloVe λεξιλογείου Twitter\n\nχρησιμοποίω το μεγαλύτερο txt λεξιλογείου για μεγαλύτερη ακρίβεια. αν δεν ειναι η πρώτη φορα που τρέχετε το notebook παραλείπτε αυτο το βημα γιατι απλά κατεβαζει το αρχειο.\n\nαν θέλετε το αρχείο να κατεβει καπου αλλου και οχι στο path που ειναι τα csv αλλαχτε το $path πχ\n!unzip \"/content/glove.6B.zip\" -d \"/content/\"\n",
"_____no_output_____"
]
],
[
[
"urllib.request.urlretrieve('https://nlp.stanford.edu/data/glove.twitter.27B.zip','glove.27B.zip') #i load the largest vocabulary for the most accuracy\n!unzip \"/content/glove.27B.zip\" -d $path\n",
"Archive: /content/glove.27B.zip\n inflating: /content/drive/MyDrive/AI2/glove.twitter.27B.25d.txt \n inflating: /content/drive/MyDrive/AI2/glove.twitter.27B.50d.txt \n inflating: /content/drive/MyDrive/AI2/glove.twitter.27B.100d.txt \n inflating: /content/drive/MyDrive/AI2/glove.twitter.27B.200d.txt \n"
]
],
[
[
"αντιστοιχώ κάθε λεξη με εναν vector. ουσιαστικά μεταφόρα απο αρχείο txt σε μνήμη.αν θέλετε αρχείο με άλλο πλήθος features αλλάξτε το d. εγώ επιλέγω το μέγιστο για καλύτερη απόδοση",
"_____no_output_____"
]
],
[
[
"emmbed_dict = {}\nd=200\nwith open(path + 'glove.twitter.27B.' + str(d) + 'd.txt','r', encoding=\"utf8\") as f:\n for line in f:\n values = line.split()\n word = values[0]\n vector = np.asarray(values[1:],'float32')\n emmbed_dict[word]=vector",
"_____no_output_____"
],
[
"def find_similar_word(emmbedes):\n nearest = sorted(emmbed_dict.keys(), key=lambda word: spatial.distance.euclidean(emmbed_dict[word], emmbedes))\n return nearest\nemmbed_dict.get(\"river\", 0.000)\n# np.zeros((200,), dtype=float)",
"_____no_output_____"
]
],
[
[
"# Classification with Word2Vec & GloVe\nτο GloVe εχει έτοιμο λεξιλόγιο και vectors για αυτο ενω το Word2Vec το παράγει απο τα csv δεδόμενων μας.\n\nστο glove οταν δεν υπάρχει μια λεξη στο λεξιλόγιο της αναθέτω εναν μηδενικο vector για να μην έχει αντίκτυπο στο classification\n\nμια προταση πρεπει να εχει ενα 1xN πινακα οπου N=200 για το GloVe και 100 γία το Word2Vec. μια πρόταση εχει πολλες λεξεις που γυρνανε 1xN vector φτιαχνοντας εναν MxN πίνακα. για να τον κάνω 1xN παίρω τον μέσο ορο των M γραμμων\n",
"_____no_output_____"
]
],
[
[
"trainlabel = torch.tensor(train_df['label'])#extract true-false label\ntestlabel=torch.tensor(validation_set['label'])\nsentences = pd.concat([train_df.tweet,validation_set.tweet],ignore_index=True)\nnltk.download('punkt')\n# simple tokenization\ntokens = [nltk.word_tokenize(sentence) for sentence in sentences]\n\nw2vmodel = Word2Vec(tokens,\n seed=32,\n negative=5,\n sg=0,\n min_count=1,\n window=1)\n\nw2vmodel.build_vocab(tokens, update=True) # prepare the model vocabulary\nw2vmodel.train(tokens, total_examples=len(tokens), epochs=2)\ntrain_tokens = [nltk.word_tokenize(sentences) for sentences in train_df.tweet ]\ntest_tokens = [nltk.word_tokenize(sentences) for sentences in validation_set.tweet]",
"[nltk_data] Downloading package punkt to /root/nltk_data...\n[nltk_data] Unzipping tokenizers/punkt.zip.\n"
],
[
"test_result = 0.0\ntrain_result = 0.0\ntest_results = []\ntrain_results = []\ntest_learning_curve = []\ntrain_learning_curve = []\nprint(\"Word2Vec\")\nw2v_traindata = torch.tensor( [np.array([w2vmodel.wv.get_vector(word) for word in record]).mean(axis=0) for record in train_tokens], dtype=torch.float)\nw2v_testdata = torch.tensor([np.array([w2vmodel.wv.get_vector(word) for word in record]).mean(axis=0) for record in test_tokens], dtype=torch.float)\n# print(traindata)\n\n# Classiefiers()#this arguement doesnt matter here\n\nprint()\n\nprint(\"Glove\")\nglv_traindata = torch.tensor([np.array([emmbed_dict.get(tokenize(word),np.zeros((200,), dtype=float)) for word in record]).mean(axis=0) for record in train_tokens], dtype=torch.float)\nglv_testdata = torch.tensor([np.array([emmbed_dict.get(tokenize(word),np.zeros((200,), dtype=float)) for word in record]).mean(axis=0) for record in test_tokens], dtype=torch.float)\n# Classiefiers()#this arguement doesnt matter here\n# print(traindata)\n",
"Word2Vec\n"
]
],
[
[
"##GPU\n\nεγώ δούλεψα κυρίως σε google colab αλλα μεταφέρω τους tensors στην gpu για να υποστηρίξω τοπική χρήση pytorch. στον δικο μου υπολογιστή είδα γυρω στο 10% μείωση ταχύτητας",
"_____no_output_____"
]
],
[
[
"def accuracy(outputs, labels):\n _, preds = torch.max(outputs, dim=1)\n return torch.tensor(torch.sum(preds == labels).item() / len(preds))\ndef get_default_device():\n \"\"\"Pick GPU if available, else CPU\"\"\"\n if torch.cuda.is_available():\n return torch.device('cuda')\n else:\n return torch.device('cpu')\n \ndef to_device(data, device):\n \"\"\"Move tensor(s) to chosen device\"\"\"\n if isinstance(data, (list,tuple)):\n return [to_device(x, device) for x in data]\n return data.to(device, non_blocking=True)\n\nclass DeviceDataLoader():\n \"\"\"Wrap a dataloader to move data to a device\"\"\"\n def __init__(self, dl, device):\n self.dl = dl\n self.device = device\n \n def __iter__(self):\n \"\"\"Yield a batch of data after moving it to device\"\"\"\n for b in self.dl: \n yield to_device(b, self.device)\n\n def __len__(self):\n \"\"\"Number of batches\"\"\"\n return len(self.dl)\n# train_loader = DeviceDataLoader(train_loader, device)\n# val_loader = DeviceDataLoader(val_loader, device)\ndevice = get_default_device()\ndevice\ncpudevice =torch.device('cpu')",
"_____no_output_____"
]
],
[
[
"##NEURAL NETWORKS",
"_____no_output_____"
],
[
"Εδω βλεπουμε 3 μοντέλα που με 3 η 2 Hidden layers προσπαθουν απο καθε layer(μαζι με τα Layer εισοσου και εξόδου) να συμπίεσουν τον vector μια λέξης (vector μηκους 100 η 200) στην διάσταση(πλήθος Units) του επόμενου layer Μεχρι που το Layer της εξόδου θα ειναι μια αποτίμηση για τις 3 κλασσεις μας δηλαδη 3 floats που δειχνουν ποσο ταιριάζει ενα tweet σε καθε κλάσση αντίστοιχα.\n\nεκτελώ την τελικη activation function που μου δίνει τις τελικές πιθανότητες και argmax που επιλέγει την κλασση με την μεγαλύτερη πιθανότητα μετατρέποντας ετσι τον 3 μελη vector σε πρόβλεψη μετα την εκτέλεση της forward.\n\nτα μοντέλα βασίστηκαν στο φροντηστήριο μας και παραδείγματα βιβλιογραφείων της pytorch\nhttps://pytorch.org/tutorials/beginner/basics/optimization_tutorial.html\n\nhttps://github.com/pytorch/examples/blob/master/mnist/main.py",
"_____no_output_____"
]
],
[
[
"class Net(nn.Module):\n def __init__(self, D_in, H1, H2, H3, D_out):\n super(Net, self).__init__()\n self.flatten = nn.Flatten()\n self.linear_relu_stack = nn.Sequential(\n nn.Linear(D_in, H1),\n nn.ReLU(),\n nn.Linear(H1, H2),\n nn.ReLU(),\n nn.Linear(H2, H3),\n nn.ReLU(),\n nn.Linear(H3, D_out),\n )\n\n def forward(self, x):\n x = self.flatten(x)\n logits = self.linear_relu_stack(x)\n return logits\nclass Net2(nn.Module):\n def __init__(self, D_in, H1, H2, H3, D_out):\n super(Net2, self).__init__()\n self.linear1 = nn.Linear(D_in, H1)\n self.linear2 = nn.Linear(H1, H2)\n self.linear3 = nn.Linear(H2, H3)\n self.linear4 = nn.Linear(H3, D_out)\n \n def forward(self, x):\n h1 = self.linear1(x)\n h2 = self.linear2(h1)\n h3 = self.linear3(h2)\n out = self.linear4(h3)\n return out\nclass Net3(nn.Module):\n def __init__(self, D_in, H1, H2, D_out):\n super(Net3, self).__init__()\n self.conv1 = nn.Linear(D_in, H1)\n self.dropout1 = nn.Dropout(0.25)\n self.dropout2 = nn.Dropout(0.5)\n self.fc1 = nn.Linear(H1, H2)\n self.fc2 = nn.Linear(H2, D_out)\n\n def forward(self, x):\n x = self.conv1(x)\n x = F.relu(x)\n x = self.dropout1(x)\n x = torch.flatten(x, 1)\n x = self.fc1(x)\n x = F.relu(x)\n x = self.dropout2(x)\n x = self.fc2(x)\n return x",
"_____no_output_____"
]
],
[
[
"θα δειτε στην 1 σειρα τα διαγράματα του W2vec και στη 2η του GloVe.αριστερά με το class net1 και δεξιά με το net2",
"_____no_output_____"
]
],
[
[
"\n\n#Initialize dataloader\n# plt.subplot(2,2,1)\nfig, ax = plt.subplots(2,2)\nk=0\nfor embd,(traindata,testdata) in enumerate(zip([w2v_traindata,glv_traindata],[w2v_testdata,glv_testdata])):#pick word embedding\n to_device(traindata,device)\n to_device(testdata,device)\n trainset = torch.utils.data.TensorDataset(traindata, trainlabel)\n trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)#here we shuffle the dataset so the neural network doesnt optimise itself for a specific portion of the dataset(earlier or later) so in each execution the 64 tweets will be different\n testset = torch.utils.data.TensorDataset(testdata, testlabel)#this way we ensure a result isn't dependant on the luck of the order of the tweets\n testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)\n trainloader = DeviceDataLoader(trainloader, device)#move data loader and their contents to your preffered device\n testloader = DeviceDataLoader(testloader, device)\n D_in = traindata.shape[1]\n print(D_in)\n H1 = 128#hyperparameters\n H2 = 64\n H3 = 32\n D_out = 3\n\n #Define Hyperparameters\n learning_rate = 1e-4\n #Initialize model, loss, optimizer\n for i , model in enumerate([Net(D_in, H1, H2, H3, D_out),Net2(D_in, H1, H2, H3, D_out)]):\n to_device(model,device)\n for j, (loss_func,optimizer) in enumerate(zip([F.cross_entropy],[torch.optim.Adam(model.parameters(), lr=learning_rate)])):#picks a loss and optimiser i use different ones later for to avoid making this convoluted\n train_losses=[]\n test_losses=[]\n final_output=[]\n final_ypred = []\n final_label= []\n for epoch in range(100):\n model.train()#train mode allows for gradient and hyper parameter optimisation.torch.optim takes model.parameters() so it can know which parameters to tweak and which not\n batch_losses = []\n for x_batch, y_batch in trainloader:\n output = model(x_batch)\n pred_probab = nn.Softmax(dim=1)(output)#activation function\n y_pred = pred_probab.argmax(1)\n loss = loss_func(output, y_batch) #models always output a one hot vector while y_batch is class number i.e 0 1 2\n batch_losses.append(loss.item())\n \n #Delete previously stored gradients\n optimizer.zero_grad()\n #Perform backpropagation starting from the loss calculated in this epoch\n loss.backward()\n #Update model's weights based on the gradients calculated during backprop\n optimizer.step()\n \n # print(f\"Epoch {epoch:3}: Loss = {sum(batch_losses)/len(trainloader):.5f}\")\n train_losses.append(sum(batch_losses)/len(trainloader))\n model.eval()#this eval/test mode will stop the model from training itself for the test dataset by locking down the model parameters and not doing backward probagation\n # scores=[]\n batch_losses = []\n for x_batch, y_batch in testloader:\n output = model(x_batch)\n pred_probab = nn.Softmax(dim=1)(output)\n y_pred = pred_probab.argmax(1)\n if epoch==99:#for the final epoch combine the results and store them(the final epoch will have the best results)\n final_output += output\n final_ypred += y_pred\n final_label += y_batch\n loss = loss_func(output, y_batch)\n batch_losses.append(loss.item())\n test_losses.append(sum(batch_losses)/len(testloader))\n k=k+1\n for metric,metric_name in zip([f1_score(torch.tensor(final_label),torch.tensor(final_ypred),average='macro' ),recall_score (torch.tensor(final_label),torch.tensor(final_ypred),average='macro' ) ,precision_score(torch.tensor(final_label),torch.tensor(final_ypred),average='macro' )], [\"F measure =\",\"recall score =\",\"precision score =\"]):\n ax[embd][i].scatter([100], [metric])\n ax[embd][i].annotate(metric_name, (100, metric))\n ax[embd][i].plot(range(100), train_losses)\n ax[embd][i].plot(range(100), test_losses)\n ax[embd][i].legend(['train', 'test'])\n ax[embd][i].set_xlabel(\"epochs\")\n ax[embd][i].set_ylabel(\"Loss\")\n ax[embd][i].title.set_text(\"Loss vs epochs\")#plot loss vs epochs graph and point the prediction accuracy scores\nfig.set_figwidth(10)\nfig.set_figheight(4*2)\nplt.tight_layout()\nplt.show()",
"100\n200\n"
]
],
[
[
"# Το καλύτερο μου μοντέλο\nεδω χρησιμοποιω το Net3 που λιγο πιο φορτωμένο με MSE_LOSS function kai SGD optimiser. loss functions εκτος του cross entropy & MSE_LOSS εκαναν το μοντέλο να εχει απαίσα ακρίβεια προβλέψεων το ιδιο και η αλλαγη optimiser. ετρεξα με nll_loss HingeEmbeddingLoss LBFGS SGD. Άλλαξα την activation function σε SIGMOID και τώρα έβαλα 2 Hidden layers με μικρότερο αριθμό units. δεν χειροτέρευσε την ακρίβεια\n\n#ΠΑΡΑΔΟΧΗ\nαυτο το κελι δε θα τρέξει σε τοπικό υπολογιστη,τουλαχιστον όχι στον δικό μου.Τρέχτε το μονο στο colab. Δυστυχως δεν βρήκα κανένα τρόπο να κανω την mseloss να μεταλγωτιστεί, υποψιάζομαι λογω Python version. αν δεν τρέξετε αυτο το κελι τα παρακάτω θα τρέξουν με τα αποτελέσματα του πάνω κελιου με net1,2 cross entropy και adam",
"_____no_output_____"
]
],
[
[
"k=0\nfor embd,(traindata,testdata) in enumerate(zip([w2v_traindata,glv_traindata],[w2v_testdata,glv_testdata])):\n trainset = torch.utils.data.TensorDataset(traindata, trainlabel)\n trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)\n testset = torch.utils.data.TensorDataset(testdata, testlabel)\n testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)\n D_in = traindata.shape[1]\n print(D_in)\n H1 = 120\n H2 = 50#changed the number of hidden layers and the number of their units\n D_out = 3\n #Define Hyperparameters\n learning_rate = 1e-4\n #Initialize model, loss, optimizer\n for i , model in enumerate([Net3(D_in, H1, H2, D_out)]):\n for j, (loss_func,optimizer) in enumerate(zip([F.mse_loss ],[torch.optim.RMSprop(model.parameters(), lr=learning_rate)])):\n train_losses=[]\n test_losses=[]\n final_output=[]\n final_ypred = []\n final_label= []\n for epoch in range(100):\n batch_losses = []\n model.train()\n for x_batch, y_batch in trainloader:\n output = model(x_batch)\n pred_probab = nn.Sigmoid()(output)\n y_pred = pred_probab.argmax(1)\n loss = loss_func(output.float(), torch.tensor(label_binarize(y_batch, classes=[0, 1, 2])).float())\n batch_losses.append(loss.item())\n \n #Delete previously stored gradients\n optimizer.zero_grad()\n #Perform backpropagation starting from the loss calculated in this epoch\n loss.backward()\n #Update model's weights based on the gradients calculated during backprop\n optimizer.step()\n \n # print(f\"Epoch {epoch:3}: Loss = {sum(batch_losses)/len(trainloader):.5f}\")\n train_losses.append(sum(batch_losses)/len(trainloader))\n model.eval()\n # scores=[]\n batch_losses = []\n for x_batch, y_batch in testloader:\n output = model(x_batch)\n # print(x_batch.shape[0])\n # print(y_batch)\n pred_probab = nn.Sigmoid()(output)##changed activation function\n y_pred = pred_probab.argmax(1)\n if epoch==99:\n final_output += output\n final_ypred += y_pred\n final_label += y_batch\n loss = loss_func(output.float(),torch.tensor(label_binarize(y_batch, classes=[0, 1, 2])).float())\n batch_losses.append(loss.item())\n test_losses.append(sum(batch_losses)/len(testloader))\n confusion_matrix(final_label,final_ypred)\n k=k+1\n plt.subplot(1, 2, k)\n for metric,metric_name in zip([f1_score(torch.tensor(final_label),torch.tensor(final_ypred),average='macro' ),recall_score (torch.tensor(final_label),torch.tensor(final_ypred),average='macro' ) ,precision_score(torch.tensor(final_label),torch.tensor(final_ypred),average='macro' )], [\"F measure =\",\"recall score =\",\"precision score =\"]):\n plt.scatter([100], [metric])\n plt.annotate(metric_name, (100, metric))\n plt.plot(range(100), train_losses)\n plt.plot(range(100), test_losses)\n plt.legend(['train', 'test'])\n plt.xlabel(\"epochs\")\n plt.ylabel(\"Loss\")\n plt.title(\"Loss vs epochs\")\n# figure. set_figswidth(10)\n# figure.set_figheight(4*2)\nplt.tight_layout()\nplt.show()",
"100\n200\n"
]
],
[
[
"αυτο δειχνει για το GloV embedding σε net3 αφου ηταν η τελευταια εκτελεση",
"_____no_output_____"
]
],
[
[
"#make data compatible with roc_curve function\nf =[o.tolist() for o in final_output]\nf\nfn = np.array(f)\nfn",
"_____no_output_____"
],
[
"fpr = dict()\ntpr = dict()\nroc_auc = dict()\ny_test=label_binarize(final_label, classes=[0, 1, 2])# roc curve function requires one-hot vectors\ny_score=fn\nn_classes=D_out\nfor i in range(n_classes):\n print(y_test[:, i])#oi ploiades poy einai pragmati tis classis i exoyn 1/true\n print(y_score[:, i])#oi ploiades poy NOMIZOYN oti einai tis classis i exoyn 1/true\n fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])\n roc_auc[i] = auc(fpr[i], tpr[i])\n\n# Compute micro-average ROC curve and ROC area\nfpr[\"micro\"], tpr[\"micro\"], _ = roc_curve(y_test.ravel(), y_score.ravel())\nroc_auc[\"micro\"] = auc(fpr[\"micro\"], tpr[\"micro\"])",
"[1 1 1 ... 0 0 0]\n[0.78387153 0.93916595 0.95754254 ... 0.1700906 0.04485992 0.49797651]\n[0 0 0 ... 0 0 1]\n[0.05677056 0.04919791 0.02026488 ... 0.12816623 0.10415281 0.39618403]\n[0 0 0 ... 1 1 0]\n[0.15458657 0.01838425 0.02429202 ... 0.70040381 0.84977782 0.10388252]\n"
],
[
"plt.figure()\nlw = 2\nplt.plot(\n fpr[2],\n tpr[2],\n color=\"darkorange\",\n lw=lw,\n label=\"ROC curve (area = %0.2f)\" % roc_auc[2],\n)\nplt.plot([0, 1], [0, 1], color=\"navy\", lw=lw, linestyle=\"--\")\nplt.xlim([0.0, 1.0])\nplt.ylim([0.0, 1.05])\nplt.xlabel(\"False Positive Rate\")\nplt.ylabel(\"True Positive Rate\")\nplt.title(\"Receiver operating characteristic example\")\nplt.legend(loc=\"lower right\")\nplt.show()",
"_____no_output_____"
],
[
"# First aggregate all false positive rates\nall_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))\n\n# Then interpolate all ROC curves at this points\nmean_tpr = np.zeros_like(all_fpr)\nfor i in range(n_classes):\n mean_tpr += interp(all_fpr, fpr[i], tpr[i])\n\n# Finally average it and compute AUC\nmean_tpr /= n_classes\n\nfpr[\"macro\"] = all_fpr\ntpr[\"macro\"] = mean_tpr\nroc_auc[\"macro\"] = auc(fpr[\"macro\"], tpr[\"macro\"])\n\n# Plot all ROC curves\nplt.figure()\nplt.plot(\n fpr[\"micro\"],\n tpr[\"micro\"],\n label=\"micro-average ROC curve (area = {0:0.2f})\".format(roc_auc[\"micro\"]),\n color=\"deeppink\",\n linestyle=\":\",\n linewidth=4,\n)\n\nplt.plot(\n fpr[\"macro\"],\n tpr[\"macro\"],\n label=\"macro-average ROC curve (area = {0:0.2f})\".format(roc_auc[\"macro\"]),\n color=\"navy\",\n linestyle=\":\",\n linewidth=4,\n)\n\ncolors = cycle([\"aqua\", \"darkorange\", \"cornflowerblue\"])\nfor i, color in zip(range(n_classes), colors):\n plt.plot(\n fpr[i],\n tpr[i],\n color=color,\n lw=lw,\n label=\"ROC curve of class {0} (area = {1:0.2f})\".format(i, roc_auc[i]),\n )\n\nplt.plot([0, 1], [0, 1], \"k--\", lw=lw)\nplt.xlim([0.0, 1.0])\nplt.ylim([0.0, 1.05])\nplt.xlabel(\"False Positive Rate\")\nplt.ylabel(\"True Positive Rate\")\nplt.title(\"Some extension of Receiver operating characteristic to multiclass\")\nplt.legend(loc=\"lower right\")\nplt.show()",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:7: DeprecationWarning: scipy.interp is deprecated and will be removed in SciPy 2.0.0, use numpy.interp instead\n import sys\n"
]
],
[
[
"Τo anti-vax συνεχίζει να είναι η αδυναμία των μοντέλων μου οπως στην ασκηση 1 λόγω μικρου sample(15% του ολικου dataset)",
"_____no_output_____"
]
],
[
[
"print(classification_report(final_label, final_ypred, digits=3,target_names=['neutral(0)','anti-vax(1)','pro-vax(2)']))",
" precision recall f1-score support\n\n neutral(0) 0.773 0.801 0.787 1065\n anti-vax(1) 0.561 0.297 0.389 296\n pro-vax(2) 0.670 0.743 0.704 921\n\n accuracy 0.712 2282\n macro avg 0.668 0.614 0.626 2282\nweighted avg 0.704 0.712 0.702 2282\n\n"
]
],
[
[
"#Συμπερασματα\n\nΤα μοντελα έχουν φθίνουσα πορεία(με εξαιρεση μερικά του GloVE) με μεγάλη κυρτότητα στην αρχη που σημαίνει πως ο optimiser και η loss function μου με κινουν γρήγορα μακριά απο κακές αποφάσεις. με την ίδια εξαίρεση εφόσον η καμπυλες του train και test loss ακολουθούν σχεδόν ίδια πορεία πιστεύω δεν εχω Over η underfitting\n\nτο ROC curve μου ειναι αρκέτα ικανοποιητικό με το βέλτιστο σημειο των άλλων 2 κλάσσεων ειναι στο ~0.2-0.3 false positive rate γιατι αρχίζει το true positive rate να εχει φθίνουσα βελτίωση. θέλουμε ενα roc curve να καμπυλώνει αποτομα προς τα πάνω αγκαλιάζοντας το αξονα y μακρια απο την μαύρη διαγωνιο που ενωνει την αρχή και το τέλος της\n\nγενικά η ακρίβεια πρόβλεψης ειναι σχεδον ακριβώς ίση με αυτή της εργασίας 1 και νευρωνικών της sklearn οπως [MLPClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html) .((πειραματιστηκα με αυτο γιατί έκανα στην αρχή το λαθος να νομίζω οτι παλι sklearn μοντέλα απαιτουσε η εργασια)). Αυτο το θεωρώ επιτυχία γιατί αυτά τα μοντέλα είναι Pre-trained προϊοντα μαζικής χρήσης αν και ομολογουμένως πολυ γενικευμένα για αυτον ακριβώς τον λογο\n\nΥ.Γ δοκίμασα επίσης να αυξήσω το batch_size γιατι το 64 θεωρείται μικρό και κατάφερε να κάνει την καμπύλη του πρώτου συνδλυασμού με GloVe λιγότερο ανοδική.Πιστεύω έκανε καλύτερο generalisation ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aca7dd3ca6f1826175ffa67ffecdab274c22ad3
| 32,115 |
ipynb
|
Jupyter Notebook
|
module5/2_introduction_to_complex_network_analysis_2/2_introduction_to_complex_network_analysis_2.ipynb
|
ruyuanzhang/ccnss2018_students
|
978b2414ade6116da01c19a945304f9c514fb93f
|
[
"CC-BY-4.0"
] | 12 |
2018-07-01T10:51:09.000Z
|
2021-11-15T22:57:17.000Z
|
module5/2_introduction_to_complex_network_analysis_2/2_introduction_to_complex_network_analysis_2.ipynb
|
marcelomattar/ccnss2018_students
|
978b2414ade6116da01c19a945304f9c514fb93f
|
[
"CC-BY-4.0"
] | null | null | null |
module5/2_introduction_to_complex_network_analysis_2/2_introduction_to_complex_network_analysis_2.ipynb
|
marcelomattar/ccnss2018_students
|
978b2414ade6116da01c19a945304f9c514fb93f
|
[
"CC-BY-4.0"
] | 13 |
2018-05-15T02:54:07.000Z
|
2021-11-15T22:57:19.000Z
| 37.561404 | 561 | 0.519788 |
[
[
[
"## CCNSS 2018 Module 5: Whole-Brain Dynamics and Cognition\n# Tutorial 2: Introduction to Complex Network Analysis (II)\n",
"_____no_output_____"
],
[
"*Please execute the cell bellow in order to initialize the notebook environment*",
"_____no_output_____"
]
],
[
[
"!rm -rf data ccnss2018_students\n!if [ ! -d data ]; then git clone https://github.com/ccnss/ccnss2018_students; \\\n cp -rf ccnss2018_students/module5/2_introduction_to_complex_network_analysis_2/data ./; \\\n cp ccnss2018_students/module5/net_tool.py ./; fi",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt # import matplotlib\nimport numpy as np # import numpy\nimport math # import basic math functions\nimport random # import basic random number generator functions\nimport csv # import CSV(Comma Separated Values) file reading and writing\nimport scipy as sp # import scipy\nfrom scipy import sparse # import sparse module from scipy\nfrom scipy import signal # import signal module from scipy\nimport os # import basic os functions\nimport time # import time to measure real time\nimport collections # import collections\nimport networkx as nx # import networkx\n\nimport sys\nsys.path.append('../')\nimport net_tool as net # import net_tool, a network analysis toolbox from tutorial #1 \n\ndata_folder = 'data'\n\nprint('Available data files:\\n'+'\\n'.join(sorted(os.listdir(data_folder))))\n\ndata_file_1 = os.path.join(data_folder, 'george_baseline_44.txt')\ndata_file_2 = os.path.join(data_folder, 'george_propofol.txt')\ndata_file_3 = os.path.join(data_folder, 'george_ketamin.txt')\ndata_file_4 = os.path.join(data_folder, 'george_medetomidine.txt')",
"_____no_output_____"
]
],
[
[
"# Objectives\n\nIn this notebook we will construct a fuctional network from a given time series. Following up on the powerpoint tutorial, we will first construct a functional network from the brain signals, and compare functional network properties for different states of the brain.",
"_____no_output_____"
],
[
"\n## Background\n\nNetwork theory (graph theory) measures can be applied to any kind of network, including the brain. Structural networks of various species are good examples. We can also construct fuctional networks from time series data we observe using various techniques such as fMRI, EEG, ECoG, and MEG.\n\nUsing an ECoG data from a macaque as an example, We will go through the following steps:\n\n* Appy a measure (PLI: phase lag index) to two time series, and construct a PLI matrix.\n* Construct a network from the PLI matrix, by applying a threshold.\n* Apply various network measures to the resulting network.\n* Construct the functional networks for different brain states, and compare how they differ from each other.\n* (Optional) Divide the time series into small time windows, and construct functional network for each time window.\n\n",
"_____no_output_____"
],
[
"The example we will analyze is a thirty second - segment of whole brain ECoG data of a macaque monkey named George, from an eyes closed resting state. The sampling freqeuncy is 1000 Hz, resulting in total of 30,000 time points for each channel. The data consists of signals coming from 106 areas that cover the left hemisphere. The data is preprocessed, by applying a band path filter to remove the alpha wave component (7-13 Hz) from the signal. Alpha waves are correlated with global interactions of the brain for many instances of the brain states.",
"_____no_output_____"
]
],
[
[
"george_base = [ row for row in csv.reader(open(data_file_1,'r'),delimiter='\\t')]\ngeorge_base = np.array(george_base).astype(np.float32)",
"_____no_output_____"
],
[
"george_propofol = [ row for row in csv.reader(open(data_file_2,'r'),delimiter='\\t')]\ngeorge_propofol = np.array(george_propofol).astype(np.float32)",
"_____no_output_____"
]
],
[
[
"**EXERCISE 0: Calculating* i)* the phases of oscillating signals, and* ii)* the differences between the phases from two signals. Read through and understand the code, which will be used in later exercises (Exercise #4).\n**\n\n\n$i)$ Every oscillating signal $S_j$ can be represented by its amplitude and its phase:\n\n$$ S_j(t) = r_j(t) e^{i \\theta_j(t) } = r_j(t) ( \\cos \\theta_j(t) + i \\ \\sin \\theta_j(t) ) .\\\\$$\n\nUsing this representation, we could assign $phase$ $\\theta_j$ to the signal at every time point $t$. One way of computing the phase of a signal for each time point is using the ***Hilbert transform***. \n\n• We can obtain the signal in the form of above representation by `sp.hilbert`($S_j$). After that, we could use `np.angle()` to get the angle at each time point $t$: `np.angle(sp.hilbert`( $S_j$ ) `).` \n\n$$ $$\n\n$ii)$ After getting the angle $\\theta_j$ of each signal $S_j$, we can calculate the differences between phases:\n\n$$ \\Delta \\theta_{jk}(t) = \\theta_j(t) - \\theta_k(t) \\\\$$\n\nBest way to calculate the phase difference, again is to calculate it in the exponent form:\n\n$$ e^{i \\Delta \\theta_{jk} (t)} = e^{i ( \\theta_j (t) - \\theta_k (t) ) },\\\\ $$\n\nthen take the angle of $ e^{i \\Delta \\theta_{jk} (t)} $:\n\n$$ \\Delta \\theta_{jk} (t) = arg ( e^{i \\Delta \\theta_{jk} (t)} ) .\\\\ $$\n\nWe can obtain the angle by using `np.angle()`.\n\nThis phase difference gives a valuable information about the \"directionality\" between pair of oscillators.\n\n• Calculate the $\\theta_{ij}$ between all pairs of time series, and build a phase-difference matrix. Each elements of the matrix containing time averaged phase difference $\\langle \\theta_{ij} \\rangle _t$ between $i$ and $j$. The resulting matrix will be anti-symmetric.\n\n• From the phase-difference matrix we constructed, compute the average phase-difference for each node. Calculate the row-sum of the matrix:\n\n$$ \\theta_i = \\frac{1}{N} \\sum_{j=1}^{N} \\langle \\theta_{ij} \\rangle _t,$$\n\nthen we can have a vector of averaged phase-differences, each element of the vector corresponding for each node.\n\nThis average phase-difference for each node will tell us whether one node is phase-leading or phase-lagging with respect to other nodes over a given period of time.",
"_____no_output_____"
]
],
[
[
"# getting the phases from the signals, using np.angle and sp.signal.hilbert\n\ngeorge_base_angle = np.angle(sp.signal.hilbert( george_base,axis=0) )\nprint(\"size of george_base_angle is:\" , george_base_angle.shape )",
"_____no_output_____"
],
[
"def phase_diff_mat(theta):\n \n # theta must has dimension TxN, where T is the length of time points and N is the number of nodes\n \n N_len = theta.shape[1]\n \n PDiff_mat= np.zeros((N_len,N_len)) \n for ch1 in range(N_len):\n for ch2 in range(ch1+1,N_len):\n PDiff=theta[:,ch1]-theta[:,ch2] # theta_ch1 - theta_ch2\n PDiff_exp_angle = np.angle( np.exp(1j*PDiff) ) # angle of exp (1i * (theta_ch1-theta_ch2) )\n PDiff_exp_mean = np.mean(PDiff_exp_angle) # mean of the angle with respect to time\n PDiff_mat[ch1,ch2] = PDiff_exp_mean # put the mean into the matrix\n PDiff_mat[ch2,ch1] = -1*PDiff_exp_mean # the matrix will be anti-symmetric\n \n PDiff_mean = np.mean(PDiff_mat,axis=1) # calculate the mean for each node, with respect to all the other nodes\n \n #alternative code\n #arr = np.array([np.roll(theta, i, axis=1) for i in range(N_len)])\n #PDiff_mat = theta[None, :] - arr\n #PDiff_mean = PDiff_mat.mean(1)\n \n return PDiff_mean,PDiff_mat",
"_____no_output_____"
]
],
[
[
"**EXERCISE 1: Calculating the PLI for two given time series**\n\nThe data is in a form of 30,000x106 (# of time points x # of channels) sized matrix. We will measure $PLI$s between all possible pairs of channels.\n\nWe now define $dPLI$ (directed phase-lag index) as the following:\n\n$$ dPLI_{ij} = \\frac{1}{T}\\sum_{t=1}^{T} sign ( \\Delta \\theta_{ij} (t) ) \\, $$\n\nwhere\n\n$$ \\Delta \\theta_{ij} = \\theta_i - \\theta_j ,$$\n\nand \n\n$$ sign ( \\theta_i - \\theta_j ) = \n\\begin{cases}\n1 & if \\ \\Delta \\theta_{ij} > 0 \\\\ \n0 & if \\ \\Delta \\theta_{ij} = 0 \\\\\n-1 & if \\ \\Delta \\theta_{ij} < 0. \\\\\n\\end{cases} \\\\ $$\n\n$dPLI$ will range from 1 to -1, and give us information about which signal is leading another. \\\n\nIf we take absolute value of $dPLI$, we get $PLI$ (phase lag index):\n\n$$\\\\ PLI_{ij} =|dPLI_{ij}| = | \\langle sign ( \\Delta \\theta_{ij} ) \\rangle_t | .\\\\$$\n\n\n$PLI$ will range from 0 to 1, and give us information about whether two signals have consistent phase-lead/lag relationship with each other over given period of time.\n\n• Plot the time series for the first 3 channels of `george_base` (first 500 time points)\n\n• Plot the time series for the first 3 channels of `george_base_angle` (first 500 time points).\n\n• Compute $PLI_{ij}$ for all pairs of $i$ and $j$, and make $PLI$ matrix. The resulting matrix will be symmetric. You can use `np.sign()`.",
"_____no_output_____"
]
],
[
[
"# Write your code for plotting time series ",
"_____no_output_____"
]
],
[
[
"**EXPECTED OUTPUT**\n\n",
"_____no_output_____"
]
],
[
[
"def cal_dPLI_PLI(theta):\n \n # insert your code for calculating dPLI and PLI\n # theta must has dimension TxN, where T is the length of time points and N is the number of nodes\n # outputs PLI matrix containing PLIs between all pairs of channels, and dPLI matrix containg dPLIs between all pairs of channels\n\n \n return PLI,dPLI",
"_____no_output_____"
],
[
"george_base_PLI, george_base_dPLI = cal_dPLI_PLI(george_base_angle)\nprint(george_base_dPLI[:5,:5])",
"_____no_output_____"
]
],
[
[
"**EXPECTED OUTPUT**\n```\n[[ 0. -0.09446667 0.0348 -0.05666667 0.28 ]\n [ 0.09446667 0. 0.04926667 0.00693333 0.341 ]\n [-0.0348 -0.04926667 0. -0.0614 0.2632 ]\n [ 0.05666667 -0.00693333 0.0614 0. 0.3316 ]\n [-0.28 -0.341 -0.2632 -0.3316 0. ]]\n ```\n",
"_____no_output_____"
],
[
"**EXERCISE 2: Constructing network connectivity matrix**\n\nWe can construct a network from the above PLI matrix. Two approaches are possible. We can apply a threshold value for the PLI matrix and turn it into a binary network. Or, we can take the PLI value as is, and turn the matrix into a weighted network. We will take the first approach.\n\n• Binary network approach: one must determine a right threshold value for the matrix. For example, you can choose a value such that highest 30% of the PLI values between nodes will turn into connection.\n\n• (Optional) Weighted network approach: we can take the PLI value itself as the weighted link between two nodes.\n\n",
"_____no_output_____"
]
],
[
[
"def cal_mat_thresholded(data_mat, threshold):\n \n \n # insert your code here\n # input is the original matrix with threshold\n # output is the thresholded matrix. It would be symmetric.\n\n return data_mat_binary",
"_____no_output_____"
],
[
"threshold = 0.3\ngeorge_base_PLI_p3 = cal_mat_thresholded(george_base_PLI,threshold)\nprint(\"sum of george_base_PLI_p3:\", np.sum(george_base_PLI_p3))",
"_____no_output_____"
]
],
[
[
"**EXPECTED OUTPUT**\n```\nsum of george_base_PLI_p3: 3372.0\n```",
"_____no_output_____"
],
[
"**EXERCISE 3: Applying network measure to the functional network**\n\nWe now have a resulting functional network from a macaque ECoG data. Now we can apply network measures to this network.\n\n• Apply network measures to this network, such as $C, L, E$ and $b$ (clustering coefficient, characteristic path length, efficiency, and betweenness centrality).\n\n(If you prefer, you can use functions that we provide in net.py. Ask tutors for the details.)\n",
"_____no_output_____"
]
],
[
[
"# insert your code here",
"_____no_output_____"
]
],
[
[
"**EXPECTED OUTPUT**\n```\nC: 0.4405029623271814\nE and L: 1.735130278526505 0.6451332734351602\nb: 38.594339622641506\n```",
"_____no_output_____"
],
[
"**EXERCISE 4: Computing phase measures for the functional network**\n\nWe can define a mean of $PLI_i$ over all other nodes as follows:\n\n$$ PLI_i = \\frac{1}{N-1} \\sum_{j=1,\\ j \\neq i }^{N} PLI_{ij} ,$$\n\nThis quantity will tell us how persistantly a node is locked with respect to other nodes, over a given period of time. Usually, the node with high $PLI_i$ is the one with high degree in a network: the $k_i$ and $PLI_i$ of a node $i$ is correlated.\n\nWe can also define a mean of $dPLI_i$ over all other nodes as follows:\n\n$$ dPLI_i = \\frac{1}{N-1} \\sum_{j=1,\\ j \\neq i}^{N} dPLI_{ij} ,$$\n\nThis quantity will tell us how persistantly a node is phase-leadaing or phase-lagging with respect to other nodes, over a given period of time. This quantity is correlated with the average phase-difference $\\theta_i$ which we defined in earlier exercise.\n\n• Do a scatterplot of the mean PLI and mean dPLI. Is there any pattern between these two quantities? Calculate the Pearson correlation coefficient between these two vectors.\n\n• Also, you can do a scatterplot of degree of each node vs. average phase-difference. Do they resemble above the scatter plot?",
"_____no_output_____"
]
],
[
[
"# insert your code for calculating mean dPLI and PLI, mean phase, and degree of the network \n\ngeorge_base_PLI_mean = \ngeorge_base_dPLI_mean = \ngeorge_base_phase_diff_mean,_ = phase_diff_mat(george_base_angle)\ngeorge_base_PLI_p3_degree = ",
"_____no_output_____"
],
[
"plt.figure()\nfor i in range(len(george_base_PLI_mean)):\n plt.plot(george_base_PLI_mean[i],george_base_dPLI_mean[i],'C0s')\n plt.text(george_base_PLI_mean[i],george_base_dPLI_mean[i],str(i))\n plt.xlabel('PLI')\n plt.ylabel('dPLI')\n plt.title('dPLI vs PLI')\nplt.show()\n\ncorr_PLI_dPLI = np.corrcoef(george_base_PLI_mean,george_base_dPLI_mean)\nprint(\"corr. of PLI and dPLI is:\", corr_PLI_dPLI[1,0])\n\nplt.figure()\nfor i in range(len(george_base_PLI_p3_degree)):\n plt.plot(george_base_PLI_p3_degree[i] , george_base_phase_diff_mean[i],'C0s' )\n plt.text(george_base_PLI_p3_degree[i] , george_base_phase_diff_mean[i],str(i))\n plt.xlabel('k')\n plt.ylabel('theta')\n plt.title('theta vs k')\nplt.show()\n\ncorr_degree_phase = np.corrcoef(george_base_PLI_p3_degree , george_base_phase_diff_mean)\nprint(\"corr. of degree and phase is:\", corr_degree_phase[1,0])\n",
"_____no_output_____"
]
],
[
[
"**EXPECTED OUTPUT**\n\n\n```\ncorr. of PLI and dPLI is: -0.5848065158893657\n\n```\n\n```\ncorr. of degree and phase is: -0.5082925792988023\n```",
"_____no_output_____"
],
[
"**EXERCISE 5: Dividing the data into moving time windows (optional)**\n\nSometimes the time length of the data is large. Or, one wants to investigate the changes that occurs in finer time resolution. For example, we can apply a time window of 2 seconds with an overlap of 1 second to the data, dividing the data into 29 time segments of size 2000x106 matrix.\n\n\n\n• Write a code for a function that divide a given time series into moving time windows.\n\n• Using the codes from Exercise 1 and 2, construct a connectivity matrix for each time window.\n\n• We can now apply network measures to the resulting connectivity matrices.",
"_____no_output_____"
]
],
[
[
"win_len = 2000\nwin_start = 10000\noverlap = 1000\n\nPLI_win = []\ndPLI_win = []\n\nfor idx in range(0, george_base_angle.shape[0], overlap):\n \n temp = cal_dPLI_PLI(george_base_angle[idx:idx+win_len])\n PLI_win += [temp[0]]\n dPLI_win += [temp[1]]\n \nPLI_win = np.array(PLI_win[:-1])\ndPLI_win = np.array(dPLI_win[:-1])",
"_____no_output_____"
]
],
[
[
"**EXERCISE 6: Comparison between two different states of brain (optional, possible for mini projects)**\n\nThe above analysis can be repeated to different states of the brain. For example, we can construct the network from anesthesized unconcious states. The provided data is from anesthetized George, induced with propofol. We can construct the connectivity network and apply network measure.\n\n• Repeat the processes in Exercise 1 and 2 to construct the resulting fuctional network.\n\n• Apply network measures as in Exercise 3, and phase measures as in Exercise 4. Compare the result with the resting state network. How are they different from each other?\n",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"**EXERCISE 7: Phase coherence (optional, possible for mini projects)**\n\nThere are many measures which can be applied to construct functional connectivity matrix. One measure is phase coherence $(PC)$. Phase coherence $PC$ between two time-series $a$ and $b$ is defined as the following:\n\n$$ PC_{ab} = \\lvert {R e^{i \\Theta_{ab}}} \\rvert = \\left| \\frac{1}{T} \\sum_{t=1}^{T} e^{i \\theta_{ab}(t)} \\right| , \\\\ $$\n\nwhere $\\theta_{ab}(t)$ is difference of phases of time-series $a$ and $b$ at time $t$:\n\n$$ \\theta_{ab}(t) = \\theta_a(t) - \\theta_b(t) \\\\ $$\n\n\n• Construct a code for a function that computes $PC_{ij}$ for given time-series $i$ and $j$.\n\n• Construct a code for a function that constructs $PC$ matrix which contain $PC_{ij}$ for all possible pairs of time_series.\n\n• Use the codes to construct connectivity matrix as in Exercise 2.\n\n• After the construction, we can proceed to apply the measures as in Exercise 3.\n\n",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"** EXERCISE 8: Pearson correlation coefficients (optional, possible for mini projects)**\n\n• Another measure which can be used to construct connectivity matrix is Pearson correlation coefficient $c$. Measure *Pearson* correlation coefficients ($c$) between all possible pairs, and contruct a correlation matrix with the coefficients as its element. The resulting matrix will be a symmetric matrix. The pearson correlation coefficient $c_{xy}$ between two data set $x=\\{x_1, x_2, x_3, ..., x_n \\}$ and $y=\\{y_1, y_2, y_3, ..., y_n \\}$ is defined as the following: \n\n$$ c_{xy} = \\frac { \\sum_{i=1}^{n} (x_i - \\bar x) (y_i - \\bar y) } { \\sqrt { \\sum_{i=1}^{n} (x_i - \\bar x )^2 } \\sqrt {\\sum_{i=1}^{n} (y_i - \\bar y)^2 } } $$ \n\nwhere $\\bar x$ and $\\bar y$ are the mean of $x$ and $y$.\n\nAlternatively, we can rewrite in the following way:\n\n$$ c_{xy} = \\frac { cov(x,y) } { \\sqrt { var(x) \\ var(y) } } $$\n\n\n\nwhere\n\n$$ cov(x,y) = \\langle (x_i - \\bar x) (y_i - \\bar y) \\rangle _i \\\\\nvar(x,y) = \\langle x_i - \\bar x \\rangle _i.$$\n\n• You can construct a code for a function that computes $c_{ij}$ for given time-series $i$ and $j$, or you can use a numpy function, `np.corrcoef()`.\n\n• Construct a code for a function that constructs correlation coefficient $c$ matrix which contain $c_{ij}$ for all possible pairs of time series.\n\n• Use the codes to construct connectivity matrix as in Exercise 2.\n\n• After the construction, we can proceed to Exercise 3. ",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aca828d8e7a6f07ed95878064409a0b29f91c9f
| 1,321 |
ipynb
|
Jupyter Notebook
|
g3median_gcn-syme.ipynb
|
Paeans/phylognn
|
45048d2e68af7c9114ada7e3ede9e765d10fe0a1
|
[
"MIT"
] | null | null | null |
g3median_gcn-syme.ipynb
|
Paeans/phylognn
|
45048d2e68af7c9114ada7e3ede9e765d10fe0a1
|
[
"MIT"
] | null | null | null |
g3median_gcn-syme.ipynb
|
Paeans/phylognn
|
45048d2e68af7c9114ada7e3ede9e765d10fe0a1
|
[
"MIT"
] | null | null | null | 23.175439 | 73 | 0.580621 |
[
[
[
"import time\n\nimport torch\nfrom torch.optim.lr_scheduler import ReduceLROnPlateau\n\nfrom torch_geometric.nn import VGAE\nfrom torch_geometric.loader import DataLoader\nfrom torch_geometric.utils import (degree, negative_sampling, \n add_self_loops, to_undirected)\n\nfrom torch.utils.tensorboard import SummaryWriter\n\nfrom gene_graph_dataset import G3MedianDataset\nfrom phylognn_model import G3Median_GCNConv",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4aca87b3bdf52d616c4fed0ffcbd42a9c303313a
| 8,404 |
ipynb
|
Jupyter Notebook
|
All_figures/PV_watts/Wasilla-Palmer_tilt_loss.ipynb
|
acep-uaf/ACEP_solar
|
3ae25d011cdacd660e3e65e8044be24f9f6679cf
|
[
"MIT"
] | null | null | null |
All_figures/PV_watts/Wasilla-Palmer_tilt_loss.ipynb
|
acep-uaf/ACEP_solar
|
3ae25d011cdacd660e3e65e8044be24f9f6679cf
|
[
"MIT"
] | null | null | null |
All_figures/PV_watts/Wasilla-Palmer_tilt_loss.ipynb
|
acep-uaf/ACEP_solar
|
3ae25d011cdacd660e3e65e8044be24f9f6679cf
|
[
"MIT"
] | null | null | null | 35.459916 | 174 | 0.545574 |
[
[
[
"#import the needed package\nimport requests\nimport pandas as pd\nimport numpy as np\nfrom bokeh.plotting import figure, output_file, show, output_notebook\nfrom bokeh.models import NumeralTickFormatter\nfrom bokeh.io import show\nfrom bokeh.layouts import column\nfrom bokeh.models import ColumnDataSource, CustomJS, Select\nfrom bokeh.plotting import figure",
"_____no_output_____"
],
[
"# # Call the PV Watts to get the data (prediction)\n# nrel_long_tilt_tmy2 = []\n\n# # We choose the tilt at the below degree, and the Fairbanks lon & lat are (64.82,-147.87)\n# tilts = [5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90]\n# for i in range(len(tilts)):\n# list_parameters = {\"formt\": 'JSON', \"api_key\": \"spJFj2l5ghY5jwk7dNfVYs3JHbpR6BOGHQNO8Y9Z\", \"system_capacity\": 4, \"module_type\": 0, \"losses\": 14.08,\n# \"array_type\": 0, \"tilt\": tilts[i], \"azimuth\": 180, \"lat\": 61.58, \"lon\": -149.44, \"dataset\": 'tmy2'}\n# json_response = requests.get(\"https://developer.nrel.gov/api/pvwatts/v6\", params = list_parameters).json()\n# new_dataframe = pd.DataFrame(data = json_response['outputs'])\n# nrel_long_tilt_tmy2.append(new_dataframe)\n\n# Call the PV Watts to get the data (prediction)\nnrel_long_tilt_tmy3 = []\n\n# We choose the tilt at the below degree, and the Fairbanks lon & lat are (64.82,-147.87)\ntilts = [5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90]\nfor i in range(len(tilts)):\n list_parameters = {\"formt\": 'JSON', \"api_key\": \"spJFj2l5ghY5jwk7dNfVYs3JHbpR6BOGHQNO8Y9Z\", \"system_capacity\": 4, \"module_type\": 0, \"losses\": 14.08,\n \"array_type\": 0, \"tilt\": tilts[i], \"azimuth\": 180, \"lat\": 61.58, \"lon\": -149.44, \"dataset\": 'tmy3'}\n json_response = requests.get(\"https://developer.nrel.gov/api/pvwatts/v6\", params = list_parameters).json()\n new_dataframe = pd.DataFrame(data = json_response['outputs'])\n nrel_long_tilt_tmy3.append(new_dataframe)",
"_____no_output_____"
],
[
"json_response",
"_____no_output_____"
],
[
"annual_production_tmy2 = []\nfor i in range(len(tilts)):\n annual_production_tmy2.append(nrel_long_tilt_tmy2[i]['ac_annual'][2])\n \nannual_production_tmy3 = []\nfor i in range(len(tilts)):\n annual_production_tmy3.append(nrel_long_tilt_tmy3[i]['ac_annual'][2])\n\nd_tmy2 = {'Tilts':tilts,'Annual_production':annual_production_tmy2}\ndf_tmy2 = pd.DataFrame(d_tmy2)\n\nd_tmy3 = {'Tilts':tilts,'Annual_production':annual_production_tmy3}\ndf_tmy3 = pd.DataFrame(d_tmy3)\n\n#Then find out the max production raw\nmax_tilt_tmy2 = int(df_tmy2[['Annual_production']].idxmax().values)\nmax_tilt_tmy3 = int(df_tmy3[['Annual_production']].idxmax().values)\n\n\n#Then calculate the other tilts' lose compared with the max annual production\nlose_tmy2 = []\nfor index, row in df_tmy2.iterrows():\n tilt_loss = 1- row['Annual_production']/df_tmy2['Annual_production'][max_tilt_tmy2]\n lose_tmy2.append(tilt_loss)\n\ndf_tmy2['loss']=lose_tmy2\n\nlose_tmy3 = []\nfor index, row in df_tmy3.iterrows():\n tilt_loss = 1- row['Annual_production']/df_tmy3['Annual_production'][max_tilt_tmy3]\n lose_tmy3.append(tilt_loss)\n\ndf_tmy3['loss']=lose_tmy3\n\noutput_file(\"Wasilla-Palmer_tilts_loss.html\")\n\np = figure(x_axis_label='Tilts', y_axis_label='loss (%)',plot_width=500, plot_height=250)\n\n# add a line renderer\np.line(tilts, df_tmy2['loss'], line_width=2,color='red',legend=\"TMY2\")\np.line(tilts,df_tmy3['loss'],line_width=2,color='blue',legend=\"TMY3\")\np.xaxis.ticker = [10,20,30,40,50,60,70,80,90]\np.yaxis.formatter = NumeralTickFormatter(format='0 %')\np.title.text = \"Annual Production loss of different tilts\"\np.title.align = \"center\"\np.title.text_color = \"olive\"\np.title.text_font = \"times\"\np.title.text_font_style = \"italic\"\np.title.text_font_size = '12pt'\n\n\n\nshow(p)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4aca9647e5e15447e780fbab4572fde3677a9a39
| 20,481 |
ipynb
|
Jupyter Notebook
|
content/courses/deeplearning/notebooks/new/3The_ultimate_guide_to_Encoder_Decoder_Models_3_4.ipynb
|
dlmacedo/starter-academic
|
3867254e23c3eae3dd76eaadb42510cdea5ae430
|
[
"MIT"
] | 14 |
2020-09-22T04:22:48.000Z
|
2021-12-28T21:15:02.000Z
|
content/courses/deeplearning/notebooks/new/3The_ultimate_guide_to_Encoder_Decoder_Models_3_4.ipynb
|
dlmacedo/starter-academic
|
3867254e23c3eae3dd76eaadb42510cdea5ae430
|
[
"MIT"
] | 24 |
2020-09-22T18:23:39.000Z
|
2021-03-20T14:54:24.000Z
|
content/courses/deeplearning/notebooks/new/3The_ultimate_guide_to_Encoder_Decoder_Models_3_4.ipynb
|
dlmacedo/starter-academic
|
3867254e23c3eae3dd76eaadb42510cdea5ae430
|
[
"MIT"
] | 1 |
2020-11-14T08:30:15.000Z
|
2020-11-14T08:30:15.000Z
| 92.674208 | 1,079 | 0.673014 |
[
[
[
"<a href=\"https://colab.research.google.com/github/dlmacedo/starter-academic/blob/master/3The_ultimate_guide_to_Encoder_Decoder_Models_3_4.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"%%capture\n!pip install -qq git+https://github.com/huggingface/transformers.git",
"_____no_output_____"
]
],
[
[
"# **Transformer-based Encoder-Decoder Models**\n\n\n\n",
"_____no_output_____"
],
[
"The *transformer-based* encoder-decoder model was introduced by Vaswani et al. in the famous [Attention is all you need paper](https://arxiv.org/abs/1706.03762) and is today the *de-facto* standard encoder-decoder architecture in natural language processing (NLP).\n\nRecently, there has been a lot of research on different *pre-training* objectives for transformer-based encoder-decoder models, *e.g.* T5, Bart, Pegasus, ProphetNet, Marge, *etc*..., but the model architecture has stayed largely the same.\n\nThe goal of the blog post is to give an **in-detail** explanation of **how** the transformer-based encoder-decoder architecture models *sequence-to-sequence* problems. We will focus on the mathematical model defined by the architecture and how the model can be used in inference. Along the way, we will give some background on sequence-to-sequence models in NLP and break down the *transformer-based* encoder-decoder architecture into its **encoder** and **decoder** part. We provide many illustrations and establish the link\nbetween the theory of *transformer-based* encoder-decoder models and their practical usage in 🤗Transformers for inference.\nNote that this blog post does *not* explain how such models can be trained - this will be the topic of a future blog post.\n\nTransformer-based encoder-decoder models are the result of years of research on *representation learning* and *model architectures*. \nThis notebook provides a short summary of the history of neural encoder-decoder models. For more context, the reader is advised to read this awesome [blog post](https://ruder.io/a-review-of-the-recent-history-of-nlp/) by Sebastion Ruder. Additionally, a basic understanding of the *self-attention architecture* is recommended. \nThe following blog post by Jay Alammar serves as a good refresher on the original Transformer model [here](http://jalammar.github.io/illustrated-transformer/).\n\nAt the time of writing this notebook, 🤗Transformers comprises the encoder-decoder models *T5*, *Bart*, *MarianMT*, and *Pegasus*, which are summarized in the docs under [model summaries](https://huggingface.co/transformers/model_summary.html#sequence-to-sequence-models).\n\nThe notebook is divided into four parts:\n\n- **Background** - *A short history of neural encoder-decoder models is given with a focus on on RNN-based models.* - [click here](https://colab.research.google.com/drive/18ZBlS4tSqSeTzZAVFxfpNDb_SrZfAOMf?usp=sharing)\n- **Encoder-Decoder** - *The transformer-based encoder-decoder model is presented and it is explained how the model is used for inference.* - [click here](https://colab.research.google.com/drive/1XpKHijllH11nAEdPcQvkpYHCVnQikm9G?usp=sharing)\n- **Encoder** - *The encoder part of the model is explained in detail.*\n- **Decoder** - *The decoder part of the model is explained in detail.* - to be published on *Thursday, 08.10.2020*\n\nEach part builds upon the previous part, but can also be read on its own. ",
"_____no_output_____"
],
[
"## **Encoder**\n\nAs mentioned in the previous section, the *transformer-based* encoder maps the input sequence to a contextualized encoding sequence:\n\n$$ f_{\\theta_{\\text{enc}}}: \\mathbf{X}_{1:n} \\to \\mathbf{\\overline{X}}_{1:n}. $$\n\nTaking a closer look at the architecture, the transformer-based encoder is a stack of residual *encoder blocks*.\nEach encoder block consists of a **bi-directional** self-attention layer, followed by two feed-forward layers. For simplicity, we disregard the normalization layers in this notebook. Also, we will not further discuss the role of the two feed-forward layers, but simply see it as a final vector-to-vector mapping required in each encoder block ${}^1$.\nThe bi-directional self-attention layer puts each input vector $\\mathbf{x'}_j, \\forall j \\in \\{1, \\ldots, n\\}$ into relation with all input vectors $\\mathbf{x'}_1, \\ldots, \\mathbf{x'}_n$ and by doing so transforms the input vector $\\mathbf{x'}_j$ to a more \"refined\" contextual representation of itself, defined as $\\mathbf{x''}_j$.\nThereby, the first encoder block transforms each input vector of the input sequence $\\mathbf{X}_{1:n}$ (shown in light green below) from a *context-independent* vector representation to a *context-dependent* vector representation, and the following encoder blocks further refine this contextual representation until the last encoder block outputs the final contextual encoding $\\mathbf{\\overline{X}}_{1:n}$ (shown in darker green below).\n\nLet's visualize how the encoder processes the input sequence \"I want to buy a car EOS\" to a contextualized encoding sequence. Similar to RNN-based encoders, transformer-based encoders also add a special \"end-of-sequence\" input vector to the input sequence to hint to the model that the input vector sequence is finished ${}^2$.\n\n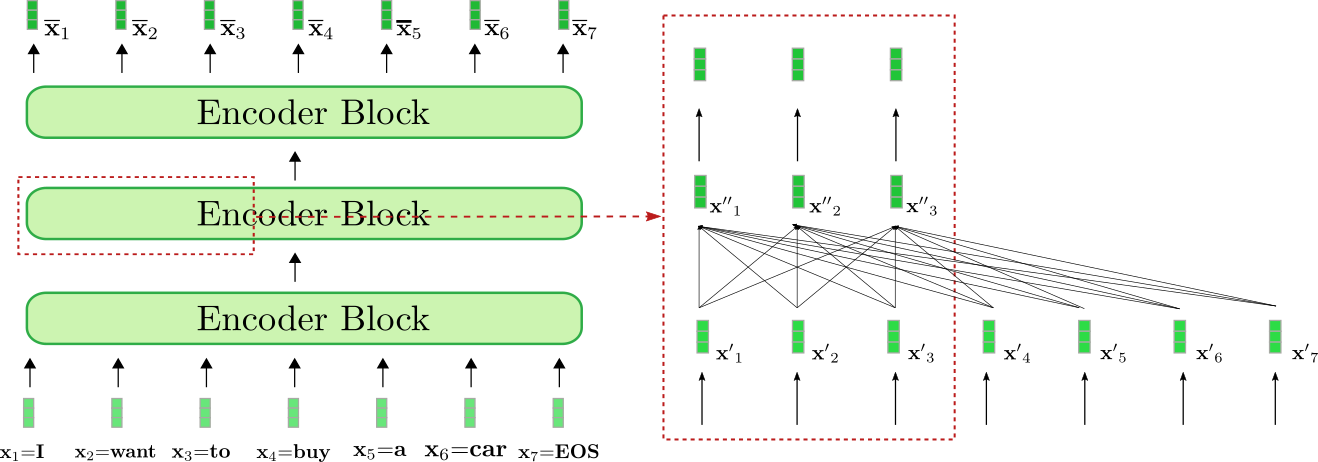\n\nOur exemplary *transformer-based* encoder is composed of three encoder blocks, whereas the second encoder block is shown in more detail in the red box on the right for the first three input vectors $\\mathbf{x}_1, \\mathbf{x}_2 and \\mathbf{x}_3$.\nThe bi-directional self-attention mechanism is illustrated by the fully-connected graph in the lower part of the red box and the two feed-forward layers are shown in the upper part of the red box. As stated before, we will focus only on the bi-directional self-attention mechanism.\n\nAs can be seen each output vector of the self-attention layer $\\mathbf{x''}_i, \\forall i \\in \\{1, \\ldots, 7\\}$ depends *directly* on *all* input vectors $\\mathbf{x'}_1, \\ldots, \\mathbf{x'}_7$. This means, *e.g.* that the input vector representation of the word \"want\", *i.e.* $\\mathbf{x'}_2$, is put into direct relation with the word \"buy\", *i.e.* $\\mathbf{x'}_4$, but also with the word \"I\",*i.e.* $\\mathbf{x'}_1$. The output vector representation of \"want\", *i.e.* $\\mathbf{x''}_2$, thus represents a more refined contextual representation for the word \"want\".\n\nLet's take a deeper look at how bi-directional self-attention works.\nEach input vector $\\mathbf{x'}_i$ of an input sequence $\\mathbf{X'}_{1:n}$ of an encoder block is projected to a key vector $\\mathbf{k}_i$, value vector $\\mathbf{v}_i$ and query vector $\\mathbf{q}_i$ (shown in orange, blue, and purple respectively below) through three trainable weight matrices $\\mathbf{W}_q, \\mathbf{W}_v, \\mathbf{W}_k$:\n\n$$ \\mathbf{q}_i = \\mathbf{W}_q \\mathbf{x'}_i,$$\n$$ \\mathbf{v}_i = \\mathbf{W}_v \\mathbf{x'}_i,$$ \n$$ \\mathbf{k}_i = \\mathbf{W}_k \\mathbf{x'}_i, $$\n$$ \\forall i \\in \\{1, \\ldots n \\}.$$\n\nNote, that the **same** weight matrices are applied to each input vector $\\mathbf{x}_i, \\forall i \\in \\{i, \\ldots, n\\}$. After projecting each input vector $\\mathbf{x}_i$ to a query, key, and value vector, each query vector $\\mathbf{q}_j, \\forall j \\in \\{1, \\ldots, n\\}$ is compared to all key vectors $\\mathbf{k}_1, \\ldots, \\mathbf{k}_n$. The more similar one of the key vectors $\\mathbf{k}_1, \\ldots \\mathbf{k}_n$ is to a query vector $\\mathbf{q}_j$, the more important is the corresponding value vector $\\mathbf{v}_j$ for the output vector $\\mathbf{x''}_j$. More specifically, an output vector $\\mathbf{x''}_j$ is defined as the weighted sum of all value vectors $\\mathbf{v}_1, \\ldots, \\mathbf{v}_n$ plus the input vector $\\mathbf{x'}_j$. Thereby, the weights are proportional to the cosine similarity between $\\mathbf{q}_j$ and the respective key vectors $\\mathbf{k}_1, \\ldots, \\mathbf{k}_n$, which is mathematically expressed by $\\textbf{Softmax}(\\mathbf{K}_{1:n}^\\intercal \\mathbf{q}_j)$ as illustrated in the equation below.\nFor a complete description of the self-attention layer, the reader is advised to take a look at [this](http://jalammar.github.io/illustrated-transformer/) blog post or the original [paper](https://arxiv.org/abs/1706.03762).\n\nAlright, this sounds quite complicated. Let's illustrate the bi-directional self-attention layer for one of the query vectors of our example above. For simplicity, it is assumed that our exemplary *transformer-based* decoder uses only a single attention head `config.num_heads = 1` and that no normalization is applied.\n\n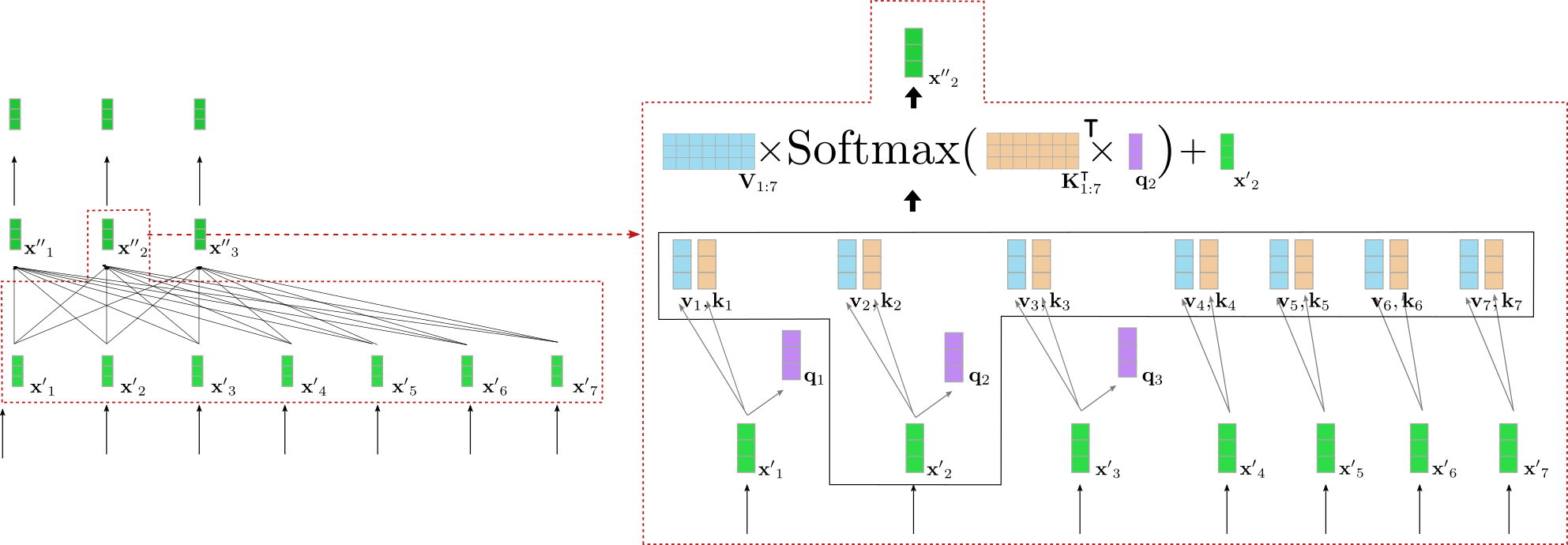\n\nOn the left, the previously illustrated second encoder block is shown again and on the right, an in detail visualization of the bi-directional self-attention mechanism is given for the second input vector $\\mathbf{x'}_2$ that corresponds to the input word \"want\".\nAt first all input vectors $\\mathbf{x'}_1, \\ldots, \\mathbf{x'}_7$ are projected to their respective query vectors $\\mathbf{q}_1, \\ldots, \\mathbf{q}_7$ (only the first three query vectors are shown in purple above), value vectors $\\mathbf{v}_1, \\ldots, \\mathbf{v}_7$ (shown in blue), and key vectors $\\mathbf{k}_1, \\ldots, \\mathbf{k}_7$ (shown in orange). The query vector $\\mathbf{q}_2$ is then multiplied by the transpose of all key vectors, *i.e.* $\\mathbf{K}_{1:7}^{\\intercal}$ followed by the softmax operation to yield the *self-attention weights*. The self-attention weights are finally multiplied by the respective value vectors and the input vector $\\mathbf{x'}_2$ is added to output the \"refined\" representation of the word \"want\", *i.e.* $\\mathbf{x''}_2$ (shown in dark green on the right).\nThe whole equation is illustrated in the upper part of the box on the right.\nThe multiplication of $\\mathbf{K}_{1:7}^{\\intercal}$ and $\\mathbf{q}_2$ thereby makes it possible to compare the vector representation of \"want\" to all other input vector representations \"I\", \"to\", \"buy\", \"a\", \"car\", \"EOS\" so that the self-attention weights mirror the importance each of the other input vector representations $\\mathbf{x'}_j \\text{, with } j \\ne 2$ for the refined representation $\\mathbf{x''}_2$ of the word \"want\".\n\nTo further understand the implications of the bi-directional self-attention layer, let's assume the following sentence is processed: \"*The house is beautiful and well located in the middle of the city where it is easily accessible by public transport*\". The word \"it\" refers to \"house\", which is 12 \"positions away\". In transformer-based encoders, the bi-directional self-attention layer performs a single mathematical operation to put the input vector of \"house\" into relation with the input vector of \"it\" (compare to the first illustration of this section). In contrast, in an RNN-based encoder, a word that is 12 \"positions away\", would require at least 12 mathematical operations meaning that in an RNN-based encoder a linear number of mathematical operations are required. This makes it much harder for an RNN-based encoder to model long-range contextual representations.\nAlso, it becomes clear that a transformer-based encoder is much less prone to lose important information than an RNN-based encoder-decoder model because the sequence length of the encoding is kept the same, *i.e.* $\\textbf{len}(\\mathbf{X}_{1:n}) = \\textbf{len}(\\mathbf{\\overline{X}}_{1:n}) = n$, while an RNN compresses the length from $\\textbf{len}((\\mathbf{X}_{1:n}) = n$ to just $\\textbf{len}(\\mathbf{c}) = 1$, which makes it very difficult for RNNs to effectively encode long-range dependencies between input words.\n\nIn addition to making long-range dependencies more easily learnable, we can see that the Transformer architecture is able to process text in parallel.Mathematically, this can easily be shown by writing the self-attention formula as a product of query, key, and value matrices:\n\n$$\\mathbf{X''}_{1:n} = \\mathbf{V}_{1:n} \\text{Softmax}(\\mathbf{Q}_{1:n}^\\intercal \\mathbf{K}_{1:n}) + \\mathbf{X'}_{1:n}. $$\n\nThe output $\\mathbf{X''}_{1:n} = \\mathbf{x''}_1, \\ldots, \\mathbf{x''}_n$ is computed via a series of matrix multiplications and a softmax operation, which can be parallelized effectively. \nNote, that in an RNN-based encoder model, the computation of the hidden state $\\mathbf{c}$ has to be done sequentially: Compute hidden state of the first input vector $\\mathbf{x}_1$, then compute the hidden state of the second input vector that depends on the hidden state of the first hidden vector, etc. The sequential nature of RNNs prevents effective parallelization and makes them much more inefficient compared to transformer-based encoder models on modern GPU hardware.\n\nGreat, now we should have a better understanding of a) how transformer-based encoder models effectively model long-range contextual representations and b) how they efficiently process long sequences of input vectors. \n\nNow, let's code up a short example of the encoder part of our `MarianMT` encoder-decoder models to verify that the explained theory holds in practice.\n\n---\n${}^1$ An in-detail explanation of the role the feed-forward layers play in transformer-based models is out-of-scope for this notebook. It is argued in [Yun et. al, (2017)](https://arxiv.org/pdf/1912.10077.pdf) that feed-forward layers are crucial to map each contextual vector $\\mathbf{x'}_i$ individually to the desired output space, which the *self-attention* layer does not manage to do on its own. It should be noted here, that each output token $\\mathbf{x'}$ is processed by the same feed-forward layer. For more detail, the reader is advised to read the paper.\n\n${}^2$ However, the EOS input vector does not have to be appended to the input sequence, but has been shown to improve performance in many cases. In contrast to the *0th* $\\text{BOS}$ target vector of the transformer-based decoder is required as a starting input vector to predict a first target vector.\n\n",
"_____no_output_____"
]
],
[
[
"%%capture\nfrom transformers import MarianMTModel, MarianTokenizer\nimport torch\n\ntokenizer = MarianTokenizer.from_pretrained(\"Helsinki-NLP/opus-mt-en-de\")\nmodel = MarianMTModel.from_pretrained(\"Helsinki-NLP/opus-mt-en-de\")\n",
"_____no_output_____"
],
[
"embeddings = model.get_input_embeddings()\n\n# create ids of encoded input vectors\ninput_ids = tokenizer(\"I want to buy a car\", return_tensors=\"pt\").input_ids\n\n# pass input_ids to encoder\nencoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state\n\n# change the input slightly and pass to encoder\ninput_ids_perturbed = tokenizer(\"I want to buy a house\", return_tensors=\"pt\").input_ids\nencoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state\n\n# compare shape and encoding of first vector\nprint(f\"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}\")\n\n# compare values of word embedding of \"I\" for input_ids and perturbed input_ids\nprint(\"Is encoding for `I` equal to its perturbed version?: \", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))",
"Length of input embeddings 7. Length of encoder_hidden_states 7\nIs encoding for `I` equal to its perturbed version?: False\n"
]
],
[
[
"We compare the length of the input word embeddings, *i.e.* `embeddings(input_ids)` corresponding to $\\mathbf{X}_{1:n}$, with the length of the `encoder_hidden_states`, corresponding to $\\mathbf{\\overline{X}}_{1:n}$.\nAlso, we have forwarded the word sequence \"I want to buy a car\" and a slightly perturbated version \"I want to buy a house\" through the encoder to check if the first output encoding, corresponding to \"I\", differs when only the last word is changed in the input sequence.\n\nAs expected the output length of the input word embeddings and encoder output encodings, *i.e.* $\\textbf{len}(\\mathbf{X}_{1:n})$ and $\\textbf{len}(\\mathbf{\\overline{X}}_{1:n})$, is equal.\nSecond, it can be noted that the values of the encoded output vector of $\\mathbf{\\overline{x}}_1 = \\text{\"I\"}$ are different when the last word is changed from \"car\" to \"house\". This however should not come as a surprise if one has understood bi-directional self-attention.\n\nOn a side-note, *autoencoding* models, such as BERT, have the exact same architecture as *transformer-based* encoder models. *Autoencoding* models leverage this architecture for massive self-supervised pre-training on open-domain text data so that they can map any word sequence to a deep bi-directional representation. In [Devlin et al. (2018)](https://arxiv.org/abs/1810.04805), the authors show that a pre-trained BERT model with a single task-specific classification layer on top can achieve SOTA results on eleven NLP tasks. All *autoencoding* models of 🤗Transformers can be found [here](https://huggingface.co/transformers/model_summary.html#autoencoding-models).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4aca9aa182eb999d7cd6f63cbd850055bea0c085
| 27,348 |
ipynb
|
Jupyter Notebook
|
_notebooks/2022-01-23-bpr-movie.ipynb
|
recohut/notebook
|
610670666a1c3d8ef430d42f712ff72ecdbd8f86
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2022-01-23-bpr-movie.ipynb
|
recohut/notebook
|
610670666a1c3d8ef430d42f712ff72ecdbd8f86
|
[
"Apache-2.0"
] | 1 |
2022-01-12T05:40:57.000Z
|
2022-01-12T05:40:57.000Z
|
_notebooks/2022-01-23-bpr-movie.ipynb
|
recohut/notebook
|
610670666a1c3d8ef430d42f712ff72ecdbd8f86
|
[
"Apache-2.0"
] | null | null | null | 27,348 | 27,348 | 0.629808 |
[
[
[
"# BPR on ML-1m in Tensorflow",
"_____no_output_____"
]
],
[
[
"!pip install tensorflow==2.5.0",
"_____no_output_____"
],
[
"!wget -q --show-progress https://files.grouplens.org/datasets/movielens/ml-1m.zip\n!unzip ml-1m.zip",
"ml-1m.zip 100%[===================>] 5.64M 16.7MB/s in 0.3s \nArchive: ml-1m.zip\n creating: ml-1m/\n inflating: ml-1m/movies.dat \n inflating: ml-1m/ratings.dat \n inflating: ml-1m/README \n inflating: ml-1m/users.dat \n"
],
[
"import os\nimport pandas as pd\nimport numpy as np\nimport random\nfrom time import time\nfrom tqdm.notebook import tqdm\nfrom collections import defaultdict\n\nimport tensorflow as tf\nfrom tensorflow.keras import Model\nfrom tensorflow.keras.optimizers import Adam\nfrom tensorflow.keras.layers import Embedding, Input\nfrom tensorflow.keras.regularizers import l2",
"_____no_output_____"
],
[
"!pip install -q watermark\n%reload_ext watermark\n%watermark -m -iv -u -t -d",
"_____no_output_____"
],
[
"os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nos.environ['CUDA_VISIBLE_DEVICES'] = '0'\n\nfile = 'ml-1m/ratings.dat'\ntrans_score = 1\ntest_neg_num = 100\n\nembed_dim = 64\nmode = 'inner' # dist\nembed_reg = 1e-6 # 1e-6\nK = 10 # top-k\n\nlearning_rate = 0.001\nepochs = 20\nbatch_size = 512",
"_____no_output_____"
],
[
"def sparseFeature(feat, feat_num, embed_dim=4):\n \"\"\"\n create dictionary for sparse feature\n :param feat: feature name\n :param feat_num: the total number of sparse features that do not repeat\n :param embed_dim: embedding dimension\n :return:\n \"\"\"\n return {'feat': feat, 'feat_num': feat_num, 'embed_dim': embed_dim}",
"_____no_output_____"
],
[
"def create_ml_1m_dataset(file, trans_score=2, embed_dim=8, test_neg_num=100):\n \"\"\"\n :param file: A string. dataset path.\n :param trans_score: A scalar. Greater than it is 1, and less than it is 0.\n :param embed_dim: A scalar. latent factor.\n :param test_neg_num: A scalar. The number of test negative samples\n :return: user_num, item_num, train_df, test_df\n \"\"\"\n print('==========Data Preprocess Start=============')\n data_df = pd.read_csv(file, sep=\"::\", engine='python',\n names=['user_id', 'item_id', 'label', 'Timestamp'])\n # filtering\n data_df['item_count'] = data_df.groupby('item_id')['item_id'].transform('count')\n data_df = data_df[data_df.item_count >= 5]\n # trans score\n data_df = data_df[data_df.label >= trans_score]\n # sort\n data_df = data_df.sort_values(by=['user_id', 'Timestamp'])\n # split dataset and negative sampling\n print('============Negative Sampling===============')\n train_data, val_data, test_data = defaultdict(list), defaultdict(list), defaultdict(list)\n item_id_max = data_df['item_id'].max()\n for user_id, df in tqdm(data_df[['user_id', 'item_id']].groupby('user_id')):\n pos_list = df['item_id'].tolist()\n\n def gen_neg():\n neg = pos_list[0]\n while neg in set(pos_list):\n neg = random.randint(1, item_id_max)\n return neg\n\n neg_list = [gen_neg() for i in range(len(pos_list) + test_neg_num)]\n for i in range(1, len(pos_list)):\n hist_i = pos_list[:i]\n if i == len(pos_list) - 1:\n test_data['user_id'].append(user_id)\n test_data['pos_id'].append(pos_list[i])\n test_data['neg_id'].append(neg_list[i:])\n elif i == len(pos_list) - 2:\n val_data['user_id'].append(user_id)\n val_data['pos_id'].append(pos_list[i])\n val_data['neg_id'].append(neg_list[i])\n else:\n train_data['user_id'].append(user_id)\n train_data['pos_id'].append(pos_list[i])\n train_data['neg_id'].append(neg_list[i])\n # feature columns\n user_num, item_num = data_df['user_id'].max() + 1, data_df['item_id'].max() + 1\n feat_col = [sparseFeature('user_id', user_num, embed_dim),\n sparseFeature('item_id', item_num, embed_dim)]\n # shuffle\n random.shuffle(train_data)\n random.shuffle(val_data)\n train = [np.array(train_data['user_id']), np.array(train_data['pos_id']),\n np.array(train_data['neg_id'])]\n val = [np.array(val_data['user_id']), np.array(val_data['pos_id']),\n np.array(val_data['neg_id'])]\n test = [np.array(test_data['user_id']), np.array(test_data['pos_id']),\n np.array(test_data['neg_id'])]\n print('============Data Preprocess End=============')\n return feat_col, train, val, test",
"_____no_output_____"
],
[
"class BPR(Model):\n def __init__(self, feature_columns, mode='inner', embed_reg=1e-6):\n \"\"\"\n BPR\n :param feature_columns: A list. user feature columns + item feature columns\n :mode: A string. 'inner' or 'dist'.\n :param embed_reg: A scalar. The regularizer of embedding.\n \"\"\"\n super(BPR, self).__init__()\n # feature columns\n self.user_fea_col, self.item_fea_col = feature_columns\n # mode\n self.mode = mode\n # user embedding\n self.user_embedding = Embedding(input_dim=self.user_fea_col['feat_num'],\n input_length=1,\n output_dim=self.user_fea_col['embed_dim'],\n mask_zero=False,\n embeddings_initializer='random_normal',\n embeddings_regularizer=l2(embed_reg))\n # item embedding\n self.item_embedding = Embedding(input_dim=self.item_fea_col['feat_num'],\n input_length=1,\n output_dim=self.item_fea_col['embed_dim'],\n mask_zero=True,\n embeddings_initializer='random_normal',\n embeddings_regularizer=l2(embed_reg))\n\n def call(self, inputs):\n user_inputs, pos_inputs, neg_inputs = inputs # (None, 1), (None, 1)\n # user info\n user_embed = self.user_embedding(user_inputs) # (None, 1, dim)\n # item\n pos_embed = self.item_embedding(pos_inputs) # (None, 1, dim)\n neg_embed = self.item_embedding(neg_inputs) # (None, 1, dim)\n if self.mode == 'inner':\n # calculate positive item scores and negative item scores\n pos_scores = tf.reduce_sum(tf.multiply(user_embed, pos_embed), axis=-1) # (None, 1)\n neg_scores = tf.reduce_sum(tf.multiply(user_embed, neg_embed), axis=-1) # (None, 1)\n # add loss. Computes softplus: log(exp(features) + 1)\n # self.add_loss(tf.reduce_mean(tf.math.softplus(neg_scores - pos_scores)))\n self.add_loss(tf.reduce_mean(-tf.math.log(tf.nn.sigmoid(pos_scores - neg_scores))))\n else:\n # clip by norm\n # user_embed = tf.clip_by_norm(user_embed, 1, -1)\n # pos_embed = tf.clip_by_norm(pos_embed, 1, -1)\n # neg_embed = tf.clip_by_norm(neg_embed, 1, -1)\n pos_scores = tf.reduce_sum(tf.square(user_embed - pos_embed), axis=-1)\n neg_scores = tf.reduce_sum(tf.square(user_embed - neg_embed), axis=-1)\n self.add_loss(tf.reduce_sum(tf.nn.relu(pos_scores - neg_scores + 0.5)))\n logits = tf.concat([pos_scores, neg_scores], axis=-1)\n return logits\n\n def summary(self):\n user_inputs = Input(shape=(1, ), dtype=tf.int32)\n pos_inputs = Input(shape=(1, ), dtype=tf.int32)\n neg_inputs = Input(shape=(1, ), dtype=tf.int32)\n Model(inputs=[user_inputs, pos_inputs, neg_inputs],\n outputs=self.call([user_inputs, pos_inputs, neg_inputs])).summary()",
"_____no_output_____"
],
[
"def test_model():\n user_features = {'feat': 'user_id', 'feat_num': 100, 'embed_dim': 8}\n item_features = {'feat': 'item_id', 'feat_num': 100, 'embed_dim': 8}\n features = [user_features, item_features]\n model = BPR(features)\n model.summary()",
"_____no_output_____"
],
[
"def evaluate_model(model, test, K):\n \"\"\"\n evaluate model\n :param model: model\n :param test: test set\n :param K: top K\n :return: hit rate, ndcg\n \"\"\"\n if model.mode == 'inner':\n pred_y = - model.predict(test)\n else:\n pred_y = model.predict(test)\n rank = pred_y.argsort().argsort()[:, 0]\n hr, ndcg = 0.0, 0.0\n for r in rank:\n if r < K:\n hr += 1\n ndcg += 1 / np.log2(r + 2)\n return hr / len(rank), ndcg / len(rank)",
"_____no_output_____"
],
[
"# ========================== Create dataset =======================\nfeature_columns, train, val, test = create_ml_1m_dataset(file, trans_score, embed_dim, test_neg_num)\n\n# ============================Build Model==========================\nmirrored_strategy = tf.distribute.MirroredStrategy()\nwith mirrored_strategy.scope():\n model = BPR(feature_columns, mode, embed_reg)\n model.summary()\n # =========================Compile============================\n model.compile(optimizer=Adam(learning_rate=learning_rate))\n\nresults = []\nfor epoch in range(1, epochs + 1):\n # ===========================Fit==============================\n t1 = time()\n model.fit(\n train,\n None,\n validation_data=(val, None),\n epochs=1,\n batch_size=batch_size,\n )\n # ===========================Test==============================\n t2 = time()\n if epoch % 5 == 0:\n hit_rate, ndcg = evaluate_model(model, test, K)\n print('Iteration %d Fit [%.1f s], Evaluate [%.1f s]: HR = %.4f, NDCG = %.4f'\n % (epoch, t2 - t1, time() - t2, hit_rate, ndcg))\n results.append([epoch, t2 - t1, time() - t2, hit_rate, ndcg])\n# ========================== Write Log ===========================\npd.DataFrame(results, columns=['Iteration', 'fit_time', 'evaluate_time', 'hit_rate', 'ndcg'])\\\n .to_csv('BPR_log_dim_{}_mode_{}_K_{}.csv'.format(embed_dim, mode, K), index=False)",
"==========Data Preprocess Start=============\n============Negative Sampling===============\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aca9c141a52ea340239cf73499778905ea1b34e
| 5,094 |
ipynb
|
Jupyter Notebook
|
notebooks/curve_interface_v1_batch.ipynb
|
yizaochen/bentDNA
|
2841ac1276eb5103ab9ab387f7b2b6d6d7839046
|
[
"MIT"
] | 1 |
2021-12-10T09:23:28.000Z
|
2021-12-10T09:23:28.000Z
|
notebooks/curve_interface_v1_batch.ipynb
|
yizaochen/bentdna
|
1707421345d2c1444be555a7f038341c8f4170a5
|
[
"MIT"
] | null | null | null |
notebooks/curve_interface_v1_batch.ipynb
|
yizaochen/bentdna
|
1707421345d2c1444be555a7f038341c8f4170a5
|
[
"MIT"
] | null | null | null | 26.952381 | 207 | 0.591284 |
[
[
[
"from os import path, system\nfrom bentdna.PDB import PDBReader, PDBWriter\nfrom bentdna.find_haxis_curve import FindHelixAgent, PrepareHelix\nfind_helix_folder = '/home/yizaochen/codes/dna_rna/length_effect/find_helical_axis'",
"_____no_output_____"
]
],
[
[
"### Part 1: Batch Running",
"_____no_output_____"
]
],
[
[
"hosts = ['tat_21mer', 'g_tract_21mer']\nn_bp = 21\nfor host in hosts:\n prep_helix = PrepareHelix(find_helix_folder, host, n_bp)\n #f_agent = FindHelixAgent(prep_helix.workfolder, prep_helix.pdb_modi, prep_helix.dcd_out, n_bp)\n #f_agent.extract_pdb_allatoms()\n #f_agent.curveplus_find_haxis()",
"_____no_output_____"
],
[
"hosts = ['gcgc_21mer', 'tat_1_21mer', 'tat_2_21mer', 'tat_3_21mer', 'atat_21mer']\nn_bp = 21\nfor host in hosts:\n prep_helix = PrepareHelix(find_helix_folder, host, n_bp)\n f_agent = FindHelixAgent(prep_helix.workfolder, prep_helix.pdb_modi, prep_helix.dcd_out, n_bp)\n #f_agent.extract_pdb_allatoms()\n #f_agent.curveplus_find_haxis()",
"_____no_output_____"
]
],
[
[
"### Part 2: After Curve+, Use VMD to show",
"_____no_output_____"
]
],
[
[
"host = 'tat_3_21mer'\nn_bp = 21\nprep_helix = PrepareHelix(find_helix_folder, host, n_bp)",
"/home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/input exists\n/home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/output exists\n"
],
[
"haxis_folder = path.join(prep_helix.workfolder, 'pdbs_haxis')\ncmd = f'cd {haxis_folder}'\nprint(cmd)\n\ncmd = 'vmd'\nprint(cmd)\n\nhaxis_tcl = '/home/yizaochen/codes/na_mechanics/make_haxis.tcl'\ncmd = f'source {haxis_tcl}'\nprint(cmd)\n\nstart = 0\nend = prep_helix.lastframe\ncmd = f'read_all_pdb_files {start} {end}'\nprint(cmd)\n\nhaxis_dcd = path.join(prep_helix.output_folder, 'haxis.dcd')\ncmd = f'animate write dcd {haxis_dcd} beg {start} end {end} waitfor all'\nprint(cmd)",
"cd /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/pdbs_haxis\nvmd\nsource /home/yizaochen/codes/na_mechanics/make_haxis.tcl\nread_all_pdb_files 0 50000\nanimate write dcd /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/output/haxis.dcd beg 0 end 50000 waitfor all\n"
],
[
"pdb_ref = path.join(prep_helix.workfolder, 'pdbs_haxis', 'haxis.0.pdb')\ncmd = f'vmd -pdb {pdb_ref} {haxis_dcd}'\nprint(cmd)\n\ncmd = f'mol new {prep_helix.pdb_modi}'\nprint(cmd)\n\ncmd = f'mol addfile {prep_helix.dcd_out} 1 waitfor 1' \nprint(cmd)",
"vmd -pdb /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/pdbs_haxis/haxis.0.pdb /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/output/haxis.dcd\nmol new /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/input/bdna_modi.pdb\nmol addfile /home/yizaochen/codes/dna_rna/length_effect/find_helical_axis/tat_3_21mer/input/bdna+bdna.0_5000ns.50000frames.dcd 1 waitfor 1\n"
]
],
[
[
"### Useful commands",
"_____no_output_____"
],
[
"- cat 0.pdb | grep 'ATOM 1'",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4acab9edea911cc69edba3a8b247c74696246bb7
| 229,134 |
ipynb
|
Jupyter Notebook
|
Annual_Sales_Analysis_and_Visualization.ipynb
|
daiphuongngo/Annual_Sales_Python_Analysis_and_Tableau_Visualization
|
23e750c3ed35642eaf85bfe93da8694291d99afe
|
[
"MIT"
] | null | null | null |
Annual_Sales_Analysis_and_Visualization.ipynb
|
daiphuongngo/Annual_Sales_Python_Analysis_and_Tableau_Visualization
|
23e750c3ed35642eaf85bfe93da8694291d99afe
|
[
"MIT"
] | null | null | null |
Annual_Sales_Analysis_and_Visualization.ipynb
|
daiphuongngo/Annual_Sales_Python_Analysis_and_Tableau_Visualization
|
23e750c3ed35642eaf85bfe93da8694291d99afe
|
[
"MIT"
] | null | null | null | 70.611402 | 41,390 | 0.679541 |
[
[
[
"## 1: Import packages and Load data",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport os\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"df = pd.read_csv('/content/drive/My Drive/Colab Notebooks/CoTAI/Data Science Internship CoTAI 2021/Sales Analysis/Data/sales2019_3.csv')\ndf.head()",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
]
],
[
[
"## 2: Clean and Preprocess data",
"_____no_output_____"
],
[
"### 2.1: Merge 12-month data",
"_____no_output_____"
]
],
[
[
"path = '/content/drive/My Drive/Colab Notebooks/CoTAI/Data Science Internship CoTAI 2021/Sales Analysis/Data/'\n\nframes = [] # List of all files' names \nall_length = []\nfor file in os.listdir(path): # Get all directory of each file\n if file.endswith('.csv'): # Get only files with .csv\n filepath = path + file\n df1 = pd.read_csv(filepath)\n frames.append(df1) \n result = pd.concat(frames) # Merge all dataframes into a master dataframe\n length_1month = len(df1.index)\n all_length.append(length_1month) # Find sum of length of all dataframes' rows\n\nresult.to_csv('annualSales2019.csv', index=False) # Save the original data, the first Index column is unnecessary so it can be removed",
"_____no_output_____"
],
[
"df = result\ndf",
"_____no_output_____"
],
[
"print(sum(all_length))",
"186850\n"
]
],
[
[
"The total number of all_length is now proven to match the number of all rows in the master data frame.",
"_____no_output_____"
],
[
"### 2.2: Add 'Month' column",
"_____no_output_____"
],
[
"The Month column's type is mm/dd/yy so only 2 first indices are needed.",
"_____no_output_____"
]
],
[
[
"df['Month'] = df['Order Date'].str[0:2]\ndf.head()",
"_____no_output_____"
]
],
[
[
"### 2.3: Get rid of 'NaN' and 'Or' value",
"_____no_output_____"
],
[
"Print all unique values in Month by using set",
"_____no_output_____"
]
],
[
[
"print(set(df['Month']))",
"{nan, '10', '11', '03', '12', '01', '02', '08', '04', '07', '06', 'Or', '09', '05'}\n"
]
],
[
[
"Now remove Nan and Or",
"_____no_output_____"
]
],
[
[
"df = df.dropna(how='all') # Remove NaN\ndf = df[df['Month'] != 'Or'] # Keep rows of Month with values different from 'Or\ndf",
"_____no_output_____"
]
],
[
[
"## 3: Reporting",
"_____no_output_____"
],
[
"### 3.1: What was the best month for Sales? How much was earned on that month?",
"_____no_output_____"
],
[
"To calculate or multiply successfully, let's check the types of 2 needed variables Quantity Ordered and Price Each.\n\n\n",
"_____no_output_____"
]
],
[
[
"print(df['Quantity Ordered'].dtypes)\nprint(df['Price Each'].dtypes)",
"object\nobject\n"
]
],
[
[
"Convert the object type into interger and float types",
"_____no_output_____"
]
],
[
[
"df['Quantity Ordered'] = pd.to_numeric(df['Quantity Ordered'], downcast='integer')\ndf['Price Each'] = pd.to_numeric(df['Price Each'], downcast='float')",
"_____no_output_____"
]
],
[
[
"Let's check their types again",
"_____no_output_____"
]
],
[
[
"print(df['Quantity Ordered'].dtypes)\nprint(df['Price Each'].dtypes)",
"int8\nfloat32\n"
]
],
[
[
"Create a new Sales column from Quantity Ordered and Price each",
"_____no_output_____"
]
],
[
[
"df['Sales'] = df['Quantity Ordered'] * df['Price Each']",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"print(df['Sales'].dtypes)",
"float32\n"
]
],
[
[
"Sales in now visible in the master data frame. But it is placed at the last column and it might be hard to see or find. We shoud then create a new data frame 'moving_colum' as a temporary data frame. The purpose of this step is to add all variables of moving_columns into the master data and place Sales variable at the index 4.",
"_____no_output_____"
]
],
[
[
"moving_column = df.pop('Sales')\ndf.insert(4, 'Sales', moving_column)\ndf.head()",
"_____no_output_____"
]
],
[
[
"Filter data grouped by Month with each month's total Sales",
"_____no_output_____"
]
],
[
[
"sales_value = df.groupby('Month').sum()['Sales']\nsales_value",
"_____no_output_____"
],
[
"months = range(1,13)\nmonths",
"_____no_output_____"
]
],
[
[
"Find the highest Sales value of 12 months",
"_____no_output_____"
]
],
[
[
"sales_value.max()",
"_____no_output_____"
]
],
[
[
"Months will have 12 bar charts on X axis. Sales values will be on Y axis.",
"_____no_output_____"
]
],
[
[
"plt.bar(x=months, height=sales_value)\nplt.xticks(months)\nplt.xlabel('Months')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"It can be easily seen that December had the highest Sales Value at US$ 4,613,443.5. \n\nTo dive deeper into why December had the highest Sales Value. We can analyze further by the following hypotheses. \n- Holiday season (for example Christmas, New Year, etc.) might affect and have a positive correlation with the highest sales of the year, namely in December.\n- Electronics corporations launch new products in Quarter 4 so people tend to spend more in December.",
"_____no_output_____"
],
[
"### 3.2: Which city had the best Sales of the year?",
"_____no_output_____"
],
[
"Create a new column City. First, we have to get the city name from Purchase Address which is between 2 commas. Then we will split each of its value by comma, and get the values of the city name at index 1.",
"_____no_output_____"
]
],
[
[
"address_to_city = lambda address:address.split(',')[1]\naddress_to_city",
"_____no_output_____"
]
],
[
[
"After that, we will apply this method to all values of Purchase Address and create a new variable City to contain all new values.",
"_____no_output_____"
]
],
[
[
"df['City'] = df['Purchase Address'].apply(address_to_city)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"We will use the previous method of grouping the master data frame by City with each city's total sales value.",
"_____no_output_____"
]
],
[
[
"df.groupby('City').sum()['Sales']",
"_____no_output_____"
]
],
[
[
"Find the best sales by City",
"_____no_output_____"
]
],
[
[
"sales_value_city = df.groupby('City').sum()['Sales']\nsales_value_city.max()",
"_____no_output_____"
]
],
[
[
"Print all unique city names",
"_____no_output_____"
]
],
[
[
"cities = df['City'].unique()\nprint(cities)",
"[' New York City' ' San Francisco' ' Atlanta' ' Portland' ' Dallas'\n ' Los Angeles' ' Boston' ' Austin' ' Seattle']\n"
],
[
"plt.bar(x=cities, height=sales_value_city)\nplt.xticks(cities)\nplt.xlabel('Cities')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"At this stage, we can visualize City by Sales. However, we can enhance its format for a better look.",
"_____no_output_____"
]
],
[
[
"plt.bar(x=cities, height=sales_value_city)\nplt.xticks(cities, rotation=90, size=8)\nplt.xlabel('Cities')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"To make sure that the order of cities aligns with that of sales_value_city. Let's print them out.",
"_____no_output_____"
]
],
[
[
"print(cities)\nprint(sales_value_city)",
"[' New York City' ' San Francisco' ' Atlanta' ' Portland' ' Dallas'\n ' Los Angeles' ' Boston' ' Austin' ' Seattle']\nCity\n Atlanta 2795498.50\n Austin 1819581.75\n Boston 3661642.00\n Dallas 2767975.50\n Los Angeles 5452571.00\n New York City 4664317.50\n Portland 2320490.50\n San Francisco 8262204.00\n Seattle 2747755.50\nName: Sales, dtype: float32\n"
]
],
[
[
"Their city values do not align with each other. We now have to use the order of sales_value_city to get the correct order. And we will apply list comprehension to cities from sales_value_city.",
"_____no_output_____"
]
],
[
[
"cities = [city for city, sales in sales_value_city.items()]",
"_____no_output_____"
],
[
"plt.bar(x=cities, height=sales_value_city)\nplt.xticks(cities, rotation=90, size=8)\nplt.xlabel('Cities')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"It now shows accurately that San Francisco had the highest Sales at US$ 8,262,204.\n\nTo dive deeper into why San Franciso has the highest Sales Value. We can analyze further by the following hypotheses. \n- Silicon Valley is based in San Francisco.\n- There is a density of engineers in San Franciso with high income. Therefore, they tend to spend more in this city, especially on hi-tech products.",
"_____no_output_____"
],
[
"### 3.3: When was the most efficient time to display ads to maximize/optimize the possibility of customers' decisions to buy products?",
"_____no_output_____"
]
],
[
[
"print(df['Order Date'].dtypes)",
"object\n"
]
],
[
[
"Convert Order Data into datetime type as this type has many already-built-in functions for faster and more coding efficiency.",
"_____no_output_____"
]
],
[
[
"df['Order Date'] = pd.to_datetime(df['Order Date'])",
"_____no_output_____"
],
[
"print(df['Order Date'].dtypes)",
"datetime64[ns]\n"
]
],
[
[
"We just need only the hour values from Order Date and create a new variable Hours to contain these values.",
"_____no_output_____"
]
],
[
[
"df['Hours'] = df['Order Date'].dt.hour\ndf.head()",
"_____no_output_____"
]
],
[
[
"We repeat the same method as the previous question.",
"_____no_output_____"
]
],
[
[
"sales_value_hours = df.groupby('Hours').sum()['Sales']\nhours = [hour for hour, sales in sales_value_hours.items()]",
"_____no_output_____"
],
[
"plt.plot(hours, sales_value_hours)\nplt.grid()\nplt.xticks(hours, rotation=90, size=8)\nplt.xlabel('Hours')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"We are using Sum for the Sales, which means we can obtain the Total Sales within the hour. It is different from the Total Orders within the hour. Therefore, the Total Orders within the hour have more sense to be used to get an answer since we are trying to find the best hour to optimizing the number of Orders.\n\nSo for this chart, we will visualize by using count instead.",
"_____no_output_____"
]
],
[
[
"sales_value_hours = df.groupby('Hours').count()['Sales']\nhours = [hour for hour, sales in sales_value_hours.items()]",
"_____no_output_____"
],
[
"plt.plot(hours, sales_value_hours)\nplt.grid()\nplt.xticks(hours, rotation=90, size=8)\nplt.xlabel('Hours')\nplt.ylabel('Sales in USD')\nplt.show()",
"_____no_output_____"
]
],
[
[
"After using count, the illustration of the line chart does not change much. But the most important thing here is to understand the question and our data.\n\nThe peak of placing Orders was at 11 AM and 12 PM (during lunch break), and at 7 PM, when people got home after work. Therefore, running an ad within 30-60 minutes before these two periods can be recommended to get the most viewers.",
"_____no_output_____"
]
],
[
[
"df_dup = df[df['Order ID'].duplicated(keep=False)]\ngroupProduct = lambda product: ', '.join(product)\ndf_dup['All Products'] = df_dup.groupby('Order ID')['Product'].transform(groupProduct)\ndf_dup = df_dup[['Order ID', 'All Products']].drop_duplicates()\ndf_dup['All Products'].value_counts().head(10)",
"_____no_output_____"
]
],
[
[
"### 3.4: Which products were most sold together?",
"_____no_output_____"
],
[
"First, we will find items ordered on the same day, at the same time and/or with the same Order ID to obtain the items of the same Order. Now, we find the duplicated Item.",
"_____no_output_____"
]
],
[
[
"df_dup = df[df['Order ID'].duplicated(keep=False)]\ndf_dup.head()",
"_____no_output_____"
]
],
[
[
"We group all rows by Order ID and join all rows of Product by ','.\n\nIf using pandas apply(), the first parameter must be a function, then we will create a new function by using lambda to get all product values into groupProduct.",
"_____no_output_____"
]
],
[
[
"groupProduct = lambda product: ', '.join(product)",
"_____no_output_____"
]
],
[
[
"However, pandas apply() returns a DataFrame while we need a return of Series to input to a new column All Products. Then, we use pandas transform() instead to return/obtain a Series.",
"_____no_output_____"
]
],
[
[
"df_dup['All Products'] = df_dup.groupby('Order ID')['Product'].transform(groupProduct)\ndf_dup.head()",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
]
],
[
[
"Since we don't need to use other variables, except Order ID and All Products, we will delete the rest of the unnecessary variables and duplicated rows.",
"_____no_output_____"
]
],
[
[
"df_dup = df_dup[['Order ID', 'All Products']].drop_duplicates()\ndf_dup",
"_____no_output_____"
]
],
[
[
"Print the top 10 of best-selling products by using value_counts()",
"_____no_output_____"
]
],
[
[
"df_dup['All Products'].value_counts().head(10)",
"_____no_output_____"
]
],
[
[
"It returns the top-selling products which were sold at the same time within the same order. Then we can identify the best sellers and the other less sold items. Companies can sell their products in a combo to push sales for both best sellers and the less common items. Or they can place promotion on a combo while keeping the regular price of their single purchased product to raise demand for buying a combo rather than a single item.",
"_____no_output_____"
],
[
"### 3.5: Which product was sold the most? Why do you think it was the best-selling product?",
"_____no_output_____"
],
[
"This is simply handled by grouping the data frame by Product with each product's total Quantity Ordered.",
"_____no_output_____"
]
],
[
[
"all_products = df.groupby('Product').sum()['Quantity Ordered']\nall_products",
"_____no_output_____"
]
],
[
[
"We repeat the same method on prices and products list.",
"_____no_output_____"
]
],
[
[
"prices = df.groupby('Product').mean()['Price Each']\nprices",
"_____no_output_____"
],
[
"products_ls = [product for product, quant in all_products.items()]\nproducts_ls",
"_____no_output_____"
],
[
"x = products_ls\ny1 = all_products\ny2 = prices\n\nfig, ax1 = plt.subplots()\n\nax2 = ax1.twinx()\nax1.bar(x, y1, color='g')\nax2.plot(x, y2, 'b-')\n\nax1.set_xticklabels(products_ls, rotation=90, size=8)\nax1.set_xlabel('Products')\nax1.set_ylabel('Quantity Ordered', color='g')\nax2.set_ylabel('Price Each', color='b')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Instead of plotting on bar charts of Products and Quantity Order, we will add a line chart of Price of each product to demonstrate the correlation between Products, Quantity and Price.\n\nLook at the plot, we can see a correlation between the Products' Prices and their Volumes. The AA and AAA Batteries have the highest Volumes Ordered while other pricey products have both low quantities and revenues.\n\nAs we do not have other data of other factors or criteria such as brand quality to research and analyze further, so far that is the sum-up of our conclusion.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4acabd1220670215ae6ff407c486135e37d1aede
| 956 |
ipynb
|
Jupyter Notebook
|
chapters/analysis.ipynb
|
giswqs/geebook
|
ba4dd993b699685b0e14dcb3c10a06e27cc47e0b
|
[
"CC-BY-4.0"
] | 16 |
2021-04-02T23:16:13.000Z
|
2022-03-27T12:55:11.000Z
|
chapters/analysis.ipynb
|
giswqs/geebook
|
ba4dd993b699685b0e14dcb3c10a06e27cc47e0b
|
[
"CC-BY-4.0"
] | null | null | null |
chapters/analysis.ipynb
|
giswqs/geebook
|
ba4dd993b699685b0e14dcb3c10a06e27cc47e0b
|
[
"CC-BY-4.0"
] | 2 |
2021-04-03T07:04:38.000Z
|
2021-11-10T05:16:37.000Z
| 16.482759 | 34 | 0.502092 |
[
[
[
"# Geospatial Data Analysis",
"_____no_output_____"
],
[
"## Zonal Statistics",
"_____no_output_____"
],
[
"## Time-series Analysis",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
]
] |
4acad0e23c16853768baae5924f0851a1f44493f
| 9,289 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Create_Python_Script-checkpoint.ipynb
|
Dhananjayyy/smart_queuing-system-at-edge-using-intel-openvino
|
bd3c2fb61aa46bd2956ec4f011b843b604edb8f7
|
[
"MIT"
] | 2 |
2020-12-20T11:18:44.000Z
|
2022-01-31T07:17:24.000Z
|
.ipynb_checkpoints/Create_Python_Script-checkpoint.ipynb
|
Dhananjayyy/smart_queuing-system-at-edge-using-intel-openvino
|
bd3c2fb61aa46bd2956ec4f011b843b604edb8f7
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Create_Python_Script-checkpoint.ipynb
|
Dhananjayyy/smart_queuing-system-at-edge-using-intel-openvino
|
bd3c2fb61aa46bd2956ec4f011b843b604edb8f7
|
[
"MIT"
] | null | null | null | 38.226337 | 238 | 0.533965 |
[
[
[
"# Step1: Create the Python Script\n\nIn the cell below, you will need to complete the Python script and run the cell to generate the file using the magic `%%writefile` command. Your main task is to complete the following methods for the `PersonDetect` class:\n* `load_model`\n* `predict`\n* `draw_outputs`\n* `preprocess_outputs`\n* `preprocess_inputs`\n\nFor your reference, here are all the arguments used for the argument parser in the command line:\n* `--model`: The file path of the pre-trained IR model, which has been pre-processed using the model optimizer. There is automated support built in this argument to support both FP32 and FP16 models targeting different hardware.\n* `--device`: The type of hardware you want to load the model on (CPU, GPU, MYRIAD, HETERO:FPGA,CPU)\n* `--video`: The file path of the input video.\n* `--output_path`: The location where the output stats and video file with inference needs to be stored (results/[device]).\n* `--max_people`: The max number of people in queue before directing a person to another queue.\n* `--threshold`: The probability threshold value for the person detection. Optional arg; default value is 0.60.",
"_____no_output_____"
]
],
[
[
"%%writefile person_detect.py\n\nimport numpy as np\nimport time\nfrom openvino.inference_engine import IENetwork, IECore\nimport os\nimport cv2\nimport argparse\nimport sys\n\n\nclass Queue:\n '''\n Class for dealing with queues\n '''\n def __init__(self):\n self.queues=[]\n\n def add_queue(self, points):\n self.queues.append(points)\n\n def get_queues(self, image):\n for q in self.queues:\n x_min, y_min, x_max, y_max=q\n frame=image[y_min:y_max, x_min:x_max]\n yield frame\n \n def check_coords(self, coords):\n d={k+1:0 for k in range(len(self.queues))}\n for coord in coords:\n for i, q in enumerate(self.queues):\n if coord[0]>q[0] and coord[2]<q[2]:\n d[i+1]+=1\n return d\n\n\nclass PersonDetect:\n '''\n Class for the Person Detection Model.\n '''\n\n def __init__(self, model_name, device, threshold=0.60):\n self.model_weights=model_name+'.bin'\n self.model_structure=model_name+'.xml'\n self.device=device\n self.threshold=threshold\n\n try:\n self.model=IENetwork(self.model_structure, self.model_weights)\n except Exception as e:\n raise ValueError(\"Could not Initialise the network. Have you enterred the correct model path?\")\n\n self.input_name=next(iter(self.model.inputs))\n self.input_shape=self.model.inputs[self.input_name].shape\n self.output_name=next(iter(self.model.outputs))\n self.output_shape=self.model.outputs[self.output_name].shape\n\n def load_model(self):\n '''\n TODO: This method needs to be completed by you\n '''\n raise NotImplementedError\n \n def predict(self, image):\n '''\n TODO: This method needs to be completed by you\n '''\n raise NotImplementedError\n \n def draw_outputs(self, coords, image):\n '''\n TODO: This method needs to be completed by you\n '''\n raise NotImplementedError\n\n def preprocess_outputs(self, outputs):\n '''\n TODO: This method needs to be completed by you\n '''\n raise NotImplementedError\n\n def preprocess_input(self, image):\n '''\n TODO: This method needs to be completed by you\n '''\n raise NotImplementedError\n\n\ndef main(args):\n model=args.model\n device=args.device\n video_file=args.video\n max_people=args.max_people\n threshold=args.threshold\n output_path=args.output_path\n\n start_model_load_time=time.time()\n pd= PersonDetect(model, device, threshold)\n pd.load_model()\n total_model_load_time = time.time() - start_model_load_time\n\n queue=Queue()\n \n try:\n queue_param=np.load(args.queue_param)\n for q in queue_param:\n queue.add_queue(q)\n except:\n print(\"error loading queue param file\")\n\n try:\n cap=cv2.VideoCapture(video_file)\n except FileNotFoundError:\n print(\"Cannot locate video file: \"+ video_file)\n except Exception as e:\n print(\"Something else went wrong with the video file: \", e)\n \n initial_w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))\n initial_h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))\n video_len = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n fps = int(cap.get(cv2.CAP_PROP_FPS))\n out_video = cv2.VideoWriter(os.path.join(output_path, 'output_video.mp4'), cv2.VideoWriter_fourcc(*'avc1'), fps, (initial_w, initial_h), True)\n \n counter=0\n start_inference_time=time.time()\n\n try:\n while cap.isOpened():\n ret, frame=cap.read()\n if not ret:\n break\n counter+=1\n \n coords, image= pd.predict(frame)\n num_people= queue.check_coords(coords)\n print(f\"Total People in frame = {len(coords)}\")\n print(f\"Number of people in queue = {num_people}\")\n out_text=\"\"\n y_pixel=25\n \n for k, v in num_people.items():\n out_text += f\"No. of People in Queue {k} is {v} \"\n if v >= int(max_people):\n out_text += f\" Queue full; Please move to next Queue \"\n cv2.putText(image, out_text, (15, y_pixel), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)\n out_text=\"\"\n y_pixel+=40\n out_video.write(image)\n \n total_time=time.time()-start_inference_time\n total_inference_time=round(total_time, 1)\n fps=counter/total_inference_time\n\n with open(os.path.join(output_path, 'stats.txt'), 'w') as f:\n f.write(str(total_inference_time)+'\\n')\n f.write(str(fps)+'\\n')\n f.write(str(total_model_load_time)+'\\n')\n\n cap.release()\n cv2.destroyAllWindows()\n except Exception as e:\n print(\"Could not run Inference: \", e)\n\nif __name__=='__main__':\n parser=argparse.ArgumentParser()\n parser.add_argument('--model', required=True)\n parser.add_argument('--device', default='CPU')\n parser.add_argument('--video', default=None)\n parser.add_argument('--queue_param', default=None)\n parser.add_argument('--output_path', default='/results')\n parser.add_argument('--max_people', default=2)\n parser.add_argument('--threshold', default=0.60)\n \n args=parser.parse_args()\n\n main(args)",
"_____no_output_____"
]
],
[
[
"# Next Step\n\nNow that you've run the above cell and created your Python script, you will create your job submission shell script in the next workspace.\n\n**Note**: As a reminder, if you need to make any changes to the Python script, you can come back to this workspace to edit and run the above cell to overwrite the file with your changes.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4acae1a3cfd372eb8138d746cdacd5c810f7e20d
| 139,093 |
ipynb
|
Jupyter Notebook
|
eurosat-allbands.ipynb
|
fatimacodes2001/multilabel-classification-eurosat
|
8cc5b92d7131614dfaf65458110db4b64b82dcae
|
[
"MIT"
] | null | null | null |
eurosat-allbands.ipynb
|
fatimacodes2001/multilabel-classification-eurosat
|
8cc5b92d7131614dfaf65458110db4b64b82dcae
|
[
"MIT"
] | null | null | null |
eurosat-allbands.ipynb
|
fatimacodes2001/multilabel-classification-eurosat
|
8cc5b92d7131614dfaf65458110db4b64b82dcae
|
[
"MIT"
] | null | null | null | 54.269606 | 187 | 0.523873 |
[
[
[
"import os\nimport matplotlib.pyplot as plt\nfrom tqdm import tqdm\nimport shutil\nimport PIL\nimport pandas as pd\nfrom libtiff import TIFF\nimport numpy as np\nimport re\nfrom tifffile import tifffile\n\nfrom sklearn.model_selection import StratifiedShuffleSplit, train_test_split\nfrom keras.preprocessing.image import ImageDataGenerator\nimport pandas as pd\nimport tensorflow as tf\nfrom keras.models import Model\nfrom keras.layers import Dense, Dropout, Flatten\nfrom keras.callbacks import ModelCheckpoint, EarlyStopping, ReduceLROnPlateau\nfrom keras.optimizers import Adam\nfrom keras.applications import ResNet50\nfrom keras.utils import to_categorical\n",
"_____no_output_____"
],
[
"import os\nimport numpy as np\nfrom tqdm import tqdm\nfrom tifffile import imread, imwrite\n\nDATA_DIR= \"/home/fatima_tuz_zehra/Dataset/eurosat-all\"\nmodel_dir = \"/home/fatima_tuz_zehra/Dataset/euro-rgb-new\"\nms_dir = \"/home/fatima_tuz_zehra/Dataset/euro-all-assets\"\ndata_path = \"/home/fatima_tuz_zehra/Dataset\"\n\n#ds_sizes = {label: len(os.listdir(os.path.join(DATA_DIR,label))) for label in classes}\n\nif not os.path.isdir(os.path.join(data_path,'ms_and_ind')):\n os.mkdir(os.path.join(data_path,'ms_and_ind'))\nfor land_class in classes:\n class_path = os.path.join(os.path.join(data_path,'ms_and_ind'), land_class)\n if not os.path.isdir(class_path):\n os.mkdir(class_path)\n\n\n\n",
"_____no_output_____"
],
[
"reject = [0, 11, 12]\naccept = [i for i in range(13) if i not in reject]\n\nfor land_class in tqdm(classes):\n class_path = os.path.join(DATA_DIR, land_class)\n image_fps = [os.path.join(class_path, img_name) for img_name in os.listdir(class_path)]\n for path in tqdm(image_fps):\n img = imread(path)\n req_bands = img[accept]\n # indices = get_indices(img)\n #result = np.vstack((req_bands, indices))\n res_path = os.path.join('ms_and_ind', land_class, path.split('/')[-1])\n imwrite(res_path, req_bands)",
" 0%| | 0/10 [00:00<?, ?it/s]\n 0%| | 0/3000 [00:00<?, ?it/s]\u001b[A\n 0%| | 11/3000 [00:00<00:30, 98.30it/s]\u001b[A\n 2%|▏ | 50/3000 [00:00<00:23, 126.27it/s]\u001b[A\n 3%|▎ | 92/3000 [00:00<00:18, 158.87it/s]\u001b[A\n 4%|▍ | 125/3000 [00:00<00:15, 182.47it/s]\u001b[A\n 5%|▍ | 149/3000 [00:00<00:17, 163.39it/s]\u001b[A\n 6%|▌ | 170/3000 [00:00<00:16, 170.81it/s]\u001b[A\n 6%|▋ | 190/3000 [00:00<00:15, 177.45it/s]\u001b[A\n 7%|▋ | 216/3000 [00:01<00:16, 164.64it/s]\u001b[A\n 8%|▊ | 235/3000 [00:01<00:17, 158.09it/s]\u001b[A\n 8%|▊ | 252/3000 [00:01<00:17, 156.87it/s]\u001b[A\n 9%|▉ | 283/3000 [00:01<00:14, 183.44it/s]\u001b[A\n 10%|█ | 314/3000 [00:01<00:13, 205.71it/s]\u001b[A\n 11%|█▏ | 339/3000 [00:01<00:16, 161.64it/s]\u001b[A\n 13%|█▎ | 382/3000 [00:01<00:13, 194.25it/s]\u001b[A\n 14%|█▍ | 413/3000 [00:01<00:11, 217.02it/s]\u001b[A\n 15%|█▍ | 446/3000 [00:02<00:10, 241.23it/s]\u001b[A\n 16%|█▌ | 475/3000 [00:02<00:13, 181.44it/s]\u001b[A\n 17%|█▋ | 512/3000 [00:02<00:11, 213.94it/s]\u001b[A\n 18%|█▊ | 550/3000 [00:02<00:10, 244.16it/s]\u001b[A\n 19%|█▉ | 581/3000 [00:02<00:09, 255.18it/s]\u001b[A\n 20%|██ | 611/3000 [00:02<00:12, 195.39it/s]\u001b[A\n 22%|██▏ | 650/3000 [00:02<00:10, 229.19it/s]\u001b[A\n 24%|██▎ | 706/3000 [00:03<00:08, 270.66it/s]\u001b[A\n 25%|██▍ | 741/3000 [00:03<00:09, 236.61it/s]\u001b[A\n 26%|██▌ | 771/3000 [00:03<00:11, 188.05it/s]\u001b[A\n 27%|██▋ | 812/3000 [00:03<00:09, 224.44it/s]\u001b[A\n 28%|██▊ | 842/3000 [00:03<00:12, 174.77it/s]\u001b[A\n 29%|██▉ | 869/3000 [00:03<00:12, 177.26it/s]\u001b[A\n 30%|██▉ | 892/3000 [00:04<00:11, 183.31it/s]\u001b[A\n 31%|███ | 922/3000 [00:04<00:10, 207.06it/s]\u001b[A\n 32%|███▏ | 947/3000 [00:04<00:10, 189.28it/s]\u001b[A\n 32%|███▏ | 972/3000 [00:04<00:09, 203.44it/s]\u001b[A\n 33%|███▎ | 1002/3000 [00:04<00:10, 197.11it/s]\u001b[A\n 34%|███▍ | 1027/3000 [00:04<00:09, 209.91it/s]\u001b[A\n 35%|███▌ | 1050/3000 [00:04<00:09, 204.79it/s]\u001b[A\n 36%|███▌ | 1072/3000 [00:05<00:15, 125.19it/s]\u001b[A\n 36%|███▋ | 1089/3000 [00:05<00:14, 135.79it/s]\u001b[A\n 37%|███▋ | 1121/3000 [00:05<00:11, 163.85it/s]\u001b[A\n 38%|███▊ | 1143/3000 [00:05<00:11, 159.22it/s]\u001b[A\n 39%|███▉ | 1182/3000 [00:05<00:09, 189.59it/s]\u001b[A\n 40%|████ | 1206/3000 [00:05<00:10, 169.62it/s]\u001b[A\n 41%|████▏ | 1239/3000 [00:05<00:09, 195.08it/s]\u001b[A\n 42%|████▏ | 1263/3000 [00:06<00:08, 195.70it/s]\u001b[A\n 43%|████▎ | 1286/3000 [00:06<00:10, 155.83it/s]\u001b[A\n 44%|████▎ | 1305/3000 [00:06<00:10, 161.70it/s]\u001b[A\n 44%|████▍ | 1334/3000 [00:06<00:09, 184.87it/s]\u001b[A\n 46%|████▌ | 1368/3000 [00:06<00:07, 212.90it/s]\u001b[A\n 46%|████▋ | 1393/3000 [00:06<00:08, 197.68it/s]\u001b[A\n 47%|████▋ | 1419/3000 [00:06<00:07, 212.95it/s]\u001b[A\n 48%|████▊ | 1453/3000 [00:06<00:06, 237.37it/s]\u001b[A\n 49%|████▉ | 1480/3000 [00:07<00:07, 215.50it/s]\u001b[A\n 50%|█████ | 1510/3000 [00:07<00:06, 234.18it/s]\u001b[A\n 51%|█████▏ | 1542/3000 [00:07<00:05, 254.64it/s]\u001b[A\n 52%|█████▏ | 1570/3000 [00:07<00:06, 217.21it/s]\u001b[A\n 53%|█████▎ | 1594/3000 [00:07<00:07, 196.60it/s]\u001b[A\n 54%|█████▍ | 1616/3000 [00:07<00:07, 180.45it/s]\u001b[A\n 55%|█████▍ | 1639/3000 [00:07<00:07, 192.38it/s]\u001b[A\n 55%|█████▌ | 1660/3000 [00:08<00:07, 171.07it/s]\u001b[A\n 56%|█████▌ | 1683/3000 [00:08<00:07, 184.79it/s]\u001b[A\n 57%|█████▋ | 1703/3000 [00:08<00:07, 164.02it/s]\u001b[A\n 58%|█████▊ | 1727/3000 [00:08<00:07, 181.12it/s]\u001b[A\n 58%|█████▊ | 1747/3000 [00:08<00:08, 153.90it/s]\u001b[A\n 59%|█████▉ | 1765/3000 [00:08<00:08, 139.04it/s]\u001b[A\n 60%|█████▉ | 1786/3000 [00:08<00:07, 154.07it/s]\u001b[A\n 60%|██████ | 1803/3000 [00:08<00:08, 139.21it/s]\u001b[A\n 61%|██████ | 1835/3000 [00:09<00:06, 167.05it/s]\u001b[A\n 62%|██████▏ | 1856/3000 [00:09<00:07, 153.35it/s]\u001b[A\n 63%|██████▎ | 1876/3000 [00:09<00:07, 155.96it/s]\u001b[A\n 63%|██████▎ | 1894/3000 [00:09<00:06, 159.02it/s]\u001b[A\n 64%|██████▎ | 1912/3000 [00:09<00:07, 138.99it/s]\u001b[A\n 65%|██████▍ | 1946/3000 [00:09<00:06, 168.59it/s]\u001b[A\n 66%|██████▌ | 1967/3000 [00:09<00:06, 162.76it/s]\u001b[A\n 66%|██████▋ | 1988/3000 [00:09<00:06, 166.81it/s]\u001b[A\n 67%|██████▋ | 2007/3000 [00:10<00:05, 166.15it/s]\u001b[A\n 68%|██████▊ | 2041/3000 [00:10<00:04, 194.69it/s]\u001b[A\n 69%|██████▉ | 2064/3000 [00:10<00:05, 186.33it/s]\u001b[A\n 70%|██████▉ | 2085/3000 [00:10<00:05, 175.70it/s]\u001b[A\n 70%|███████ | 2105/3000 [00:10<00:05, 165.61it/s]\u001b[A\n 71%|███████ | 2123/3000 [00:10<00:05, 148.68it/s]\u001b[A\n 71%|███████▏ | 2140/3000 [00:10<00:06, 135.05it/s]\u001b[A\n 72%|███████▏ | 2168/3000 [00:11<00:05, 149.04it/s]\u001b[A\n 73%|███████▎ | 2194/3000 [00:11<00:04, 169.89it/s]\u001b[A\n 74%|███████▍ | 2213/3000 [00:11<00:04, 165.27it/s]\u001b[A\n 74%|███████▍ | 2231/3000 [00:11<00:04, 163.56it/s]\u001b[A\n 75%|███████▌ | 2259/3000 [00:11<00:03, 185.99it/s]\u001b[A\n 76%|███████▌ | 2280/3000 [00:11<00:04, 178.01it/s]\u001b[A\n 77%|███████▋ | 2310/3000 [00:11<00:03, 185.62it/s]\u001b[A\n 78%|███████▊ | 2334/3000 [00:11<00:03, 197.82it/s]\u001b[A\n 78%|███████▊ | 2355/3000 [00:12<00:03, 180.40it/s]\u001b[A\n 79%|███████▉ | 2374/3000 [00:12<00:03, 173.40it/s]\u001b[A\n 80%|████████ | 2400/3000 [00:12<00:03, 190.25it/s]\u001b[A\n 81%|████████ | 2421/3000 [00:12<00:03, 182.79it/s]\u001b[A\n 81%|████████▏ | 2441/3000 [00:12<00:03, 182.35it/s]\u001b[A\n 82%|████████▏ | 2468/3000 [00:12<00:02, 196.95it/s]\u001b[A\n 83%|████████▎ | 2500/3000 [00:12<00:02, 217.45it/s]\u001b[A\n 84%|████████▍ | 2523/3000 [00:12<00:02, 196.64it/s]\u001b[A\n 85%|████████▍ | 2544/3000 [00:12<00:02, 191.57it/s]\u001b[A\n 86%|████████▌ | 2565/3000 [00:13<00:02, 192.28it/s]\u001b[A\n 86%|████████▌ | 2585/3000 [00:13<00:02, 189.89it/s]\u001b[A\n 87%|████████▋ | 2605/3000 [00:13<00:02, 182.89it/s]\u001b[A\n 87%|████████▋ | 2624/3000 [00:13<00:02, 166.50it/s]\u001b[A\n 88%|████████▊ | 2643/3000 [00:13<00:02, 172.30it/s]\u001b[A\n 89%|████████▉ | 2674/3000 [00:13<00:01, 198.46it/s]\u001b[A\n 90%|█████████ | 2712/3000 [00:13<00:01, 220.31it/s]\u001b[A\n 91%|█████████ | 2736/3000 [00:14<00:01, 158.83it/s]\u001b[A\n 92%|█████████▏| 2766/3000 [00:14<00:01, 184.71it/s]\u001b[A\n 94%|█████████▎| 2805/3000 [00:14<00:00, 218.56it/s]\u001b[A\n 95%|█████████▍| 2841/3000 [00:14<00:00, 246.89it/s]\u001b[A\n 96%|█████████▌| 2871/3000 [00:14<00:00, 186.33it/s]\u001b[A\n 97%|█████████▋| 2896/3000 [00:14<00:00, 190.72it/s]\u001b[A\n 98%|█████████▊| 2925/3000 [00:14<00:00, 212.52it/s]\u001b[A\n 99%|█████████▊| 2956/3000 [00:14<00:00, 229.54it/s]\u001b[A\n100%|██████████| 3000/3000 [00:15<00:00, 195.79it/s]\u001b[A\n 10%|█ | 1/10 [00:15<02:19, 15.45s/it]\n 0%| | 0/2500 [00:00<?, ?it/s]\u001b[A\n 1%| | 17/2500 [00:00<00:15, 161.39it/s]\u001b[A\n 2%|▏ | 48/2500 [00:00<00:13, 187.07it/s]\u001b[A\n 3%|▎ | 84/2500 [00:00<00:11, 218.38it/s]\u001b[A\n 5%|▌ | 128/2500 [00:00<00:09, 254.67it/s]\u001b[A\n 6%|▌ | 155/2500 [00:00<00:09, 246.02it/s]\u001b[A\n 7%|▋ | 183/2500 [00:00<00:09, 246.29it/s]\u001b[A\n 8%|▊ | 208/2500 [00:00<00:09, 242.10it/s]\u001b[A\n 9%|▉ | 233/2500 [00:00<00:11, 203.04it/s]\u001b[A\n 10%|█ | 258/2500 [00:01<00:11, 197.83it/s]\u001b[A\n 11%|█▏ | 286/2500 [00:01<00:10, 216.43it/s]\u001b[A\n 12%|█▏ | 309/2500 [00:01<00:10, 211.87it/s]\u001b[A\n 13%|█▎ | 332/2500 [00:01<00:10, 203.13it/s]\u001b[A\n 14%|█▍ | 353/2500 [00:01<00:11, 185.22it/s]\u001b[A\n 16%|█▌ | 389/2500 [00:01<00:09, 216.48it/s]\u001b[A\n 17%|█▋ | 414/2500 [00:01<00:10, 190.56it/s]\u001b[A\n 17%|█▋ | 436/2500 [00:02<00:14, 144.22it/s]\u001b[A\n 18%|█▊ | 461/2500 [00:02<00:12, 162.94it/s]\u001b[A\n 20%|█▉ | 491/2500 [00:02<00:10, 185.37it/s]\u001b[A\n 21%|██ | 513/2500 [00:02<00:11, 173.32it/s]\u001b[A\n 22%|██▏ | 550/2500 [00:02<00:09, 200.09it/s]\u001b[A\n 24%|██▎ | 593/2500 [00:02<00:08, 237.05it/s]\u001b[A\n 25%|██▍ | 622/2500 [00:02<00:08, 232.33it/s]\u001b[A\n 26%|██▌ | 653/2500 [00:02<00:07, 251.07it/s]\u001b[A\n 27%|██▋ | 682/2500 [00:03<00:07, 229.62it/s]\u001b[A\n 28%|██▊ | 708/2500 [00:03<00:08, 206.25it/s]\u001b[A\n 30%|██▉ | 742/2500 [00:03<00:08, 214.89it/s]\u001b[A\n 31%|███ | 766/2500 [00:03<00:08, 192.87it/s]\u001b[A\n 31%|███▏ | 787/2500 [00:03<00:09, 184.34it/s]\u001b[A\n 33%|███▎ | 832/2500 [00:03<00:08, 205.59it/s]\u001b[A\n 34%|███▍ | 855/2500 [00:03<00:08, 184.29it/s]\u001b[A\n 36%|███▌ | 889/2500 [00:04<00:07, 213.28it/s]\u001b[A\n 37%|███▋ | 914/2500 [00:04<00:08, 187.35it/s]\u001b[A\n 38%|███▊ | 952/2500 [00:04<00:07, 220.68it/s]\u001b[A\n 39%|███▉ | 979/2500 [00:04<00:07, 197.62it/s]\u001b[A\n 41%|████ | 1014/2500 [00:04<00:07, 197.94it/s]\u001b[A\n 41%|████▏ | 1037/2500 [00:04<00:11, 127.96it/s]\u001b[A\n 43%|████▎ | 1075/2500 [00:05<00:08, 159.61it/s]\u001b[A\n 45%|████▍ | 1123/2500 [00:05<00:06, 199.30it/s]\u001b[A\n 46%|████▋ | 1161/2500 [00:05<00:05, 232.42it/s]\u001b[A\n 48%|████▊ | 1194/2500 [00:05<00:05, 235.71it/s]\u001b[A\n 49%|████▉ | 1225/2500 [00:05<00:06, 193.83it/s]\u001b[A\n 50%|█████ | 1251/2500 [00:05<00:06, 188.99it/s]\u001b[A\n 51%|█████ | 1275/2500 [00:05<00:06, 176.66it/s]\u001b[A\n 52%|█████▏ | 1297/2500 [00:06<00:06, 183.02it/s]\u001b[A\n 53%|█████▎ | 1318/2500 [00:06<00:07, 167.36it/s]\u001b[A\n 53%|█████▎ | 1337/2500 [00:06<00:06, 168.73it/s]\u001b[A\n 54%|█████▍ | 1360/2500 [00:06<00:06, 181.91it/s]\u001b[A\n 55%|█████▌ | 1382/2500 [00:06<00:05, 191.20it/s]\u001b[A\n 56%|█████▌ | 1403/2500 [00:06<00:06, 175.34it/s]\u001b[A\n 58%|█████▊ | 1439/2500 [00:06<00:05, 187.75it/s]\u001b[A\n 58%|█████▊ | 1459/2500 [00:06<00:06, 169.38it/s]\u001b[A\n 60%|█████▉ | 1488/2500 [00:07<00:05, 192.79it/s]\u001b[A\n 60%|██████ | 1510/2500 [00:07<00:05, 174.49it/s]\u001b[A\n 61%|██████▏ | 1533/2500 [00:07<00:05, 188.01it/s]\u001b[A\n 62%|██████▏ | 1554/2500 [00:07<00:05, 186.43it/s]\u001b[A\n 63%|██████▎ | 1578/2500 [00:07<00:05, 154.73it/s]\u001b[A\n 64%|██████▍ | 1603/2500 [00:07<00:05, 170.85it/s]\u001b[A\n 65%|██████▍ | 1622/2500 [00:07<00:05, 165.69it/s]\u001b[A\n 67%|██████▋ | 1668/2500 [00:07<00:04, 204.75it/s]\u001b[A\n 68%|██████▊ | 1695/2500 [00:08<00:04, 180.45it/s]\u001b[A\n 69%|██████▊ | 1718/2500 [00:08<00:04, 165.49it/s]\u001b[A\n 70%|██████▉ | 1746/2500 [00:08<00:04, 188.50it/s]\u001b[A\n 71%|███████ | 1769/2500 [00:08<00:04, 179.59it/s]\u001b[A\n 72%|███████▏ | 1802/2500 [00:08<00:03, 187.85it/s]\u001b[A\n 73%|███████▎ | 1827/2500 [00:08<00:03, 202.65it/s]\u001b[A\n 74%|███████▍ | 1849/2500 [00:08<00:03, 194.78it/s]\u001b[A\n 75%|███████▍ | 1874/2500 [00:09<00:03, 186.64it/s]\u001b[A\n 76%|███████▌ | 1901/2500 [00:09<00:03, 195.98it/s]\u001b[A\n 77%|███████▋ | 1922/2500 [00:09<00:03, 179.18it/s]\u001b[A\n 78%|███████▊ | 1948/2500 [00:09<00:02, 197.43it/s]\u001b[A\n 79%|███████▉ | 1969/2500 [00:09<00:03, 143.91it/s]\u001b[A\n 80%|███████▉ | 1991/2500 [00:09<00:03, 160.20it/s]\u001b[A\n 81%|████████ | 2021/2500 [00:09<00:02, 185.32it/s]\u001b[A\n 82%|████████▏ | 2043/2500 [00:10<00:02, 180.86it/s]\u001b[A\n 83%|████████▎ | 2081/2500 [00:10<00:01, 209.67it/s]\u001b[A\n 84%|████████▍ | 2106/2500 [00:10<00:01, 215.82it/s]\u001b[A\n 85%|████████▌ | 2130/2500 [00:10<00:01, 195.20it/s]\u001b[A\n 86%|████████▋ | 2159/2500 [00:10<00:01, 195.71it/s]\u001b[A\n 88%|████████▊ | 2188/2500 [00:10<00:01, 216.65it/s]\u001b[A\n 88%|████████▊ | 2212/2500 [00:10<00:01, 193.42it/s]\u001b[A\n 90%|████████▉ | 2242/2500 [00:10<00:01, 216.38it/s]\u001b[A\n 91%|█████████ | 2266/2500 [00:11<00:01, 207.83it/s]\u001b[A\n 92%|█████████▏| 2304/2500 [00:11<00:00, 235.19it/s]\u001b[A\n 93%|█████████▎| 2331/2500 [00:11<00:00, 244.00it/s]\u001b[A\n 94%|█████████▍| 2358/2500 [00:11<00:00, 246.87it/s]\u001b[A\n 95%|█████████▌| 2384/2500 [00:11<00:00, 186.04it/s]\u001b[A\n 97%|█████████▋| 2422/2500 [00:11<00:00, 208.56it/s]\u001b[A\n 98%|█████████▊| 2449/2500 [00:11<00:00, 223.48it/s]\u001b[A\n100%|██████████| 2500/2500 [00:11<00:00, 209.29it/s]\u001b[A\n 20%|██ | 2/10 [00:27<01:55, 14.42s/it]\n 0%| | 0/3000 [00:00<?, ?it/s]\u001b[A\n 1%| | 16/3000 [00:00<00:22, 134.67it/s]\u001b[A\n 1%|▏ | 39/3000 [00:00<00:19, 153.64it/s]\u001b[A\n 2%|▏ | 63/3000 [00:00<00:18, 160.57it/s]\u001b[A\n 3%|▎ | 89/3000 [00:00<00:16, 180.82it/s]\u001b[A\n 4%|▎ | 106/3000 [00:00<00:19, 146.17it/s]\u001b[A\n 5%|▍ | 136/3000 [00:00<00:16, 172.65it/s]\u001b[A\n 6%|▌ | 169/3000 [00:00<00:14, 200.51it/s]\u001b[A\n 6%|▋ | 192/3000 [00:00<00:15, 181.42it/s]\u001b[A\n 8%|▊ | 229/3000 [00:01<00:12, 213.71it/s]\u001b[A\n 9%|▉ | 268/3000 [00:01<00:11, 246.43it/s]\u001b[A\n 10%|▉ | 298/3000 [00:01<00:15, 172.94it/s]\u001b[A\n 11%|█ | 324/3000 [00:01<00:14, 188.78it/s]\u001b[A\n 12%|█▏ | 361/3000 [00:01<00:12, 216.76it/s]\u001b[A\n 13%|█▎ | 396/3000 [00:01<00:12, 207.75it/s]\u001b[A\n 14%|█▍ | 421/3000 [00:02<00:13, 196.06it/s]\u001b[A\n 15%|█▌ | 452/3000 [00:02<00:11, 217.48it/s]\u001b[A\n 16%|█▌ | 484/3000 [00:02<00:10, 238.47it/s]\u001b[A\n 17%|█▋ | 513/3000 [00:02<00:09, 251.04it/s]\u001b[A\n 18%|█▊ | 540/3000 [00:02<00:12, 195.19it/s]\u001b[A\n 19%|█▉ | 563/3000 [00:02<00:15, 160.17it/s]\u001b[A\n 20%|█▉ | 598/3000 [00:02<00:12, 190.32it/s]\u001b[A\n 21%|██ | 622/3000 [00:02<00:12, 193.52it/s]\u001b[A\n 22%|██▏ | 645/3000 [00:03<00:13, 178.81it/s]\u001b[A\n 23%|██▎ | 676/3000 [00:03<00:11, 204.58it/s]\u001b[A\n 23%|██▎ | 700/3000 [00:03<00:12, 178.16it/s]\u001b[A\n 24%|██▍ | 733/3000 [00:03<00:11, 205.97it/s]\u001b[A\n 26%|██▌ | 765/3000 [00:03<00:10, 206.45it/s]\u001b[A\n 26%|██▋ | 790/3000 [00:03<00:10, 215.46it/s]\u001b[A\n 27%|██▋ | 814/3000 [00:03<00:11, 195.03it/s]\u001b[A\n 29%|██▊ | 862/3000 [00:04<00:09, 234.17it/s]\u001b[A\n 30%|██▉ | 891/3000 [00:04<00:09, 211.40it/s]\u001b[A\n 31%|███ | 916/3000 [00:04<00:09, 208.77it/s]\u001b[A\n 32%|███▏ | 945/3000 [00:04<00:09, 227.50it/s]\u001b[A\n 32%|███▏ | 971/3000 [00:04<00:09, 210.73it/s]\u001b[A\n 33%|███▎ | 998/3000 [00:04<00:09, 214.62it/s]\u001b[A\n 34%|███▍ | 1021/3000 [00:04<00:09, 208.24it/s]\u001b[A\n 35%|███▌ | 1051/3000 [00:04<00:08, 224.93it/s]\u001b[A\n 36%|███▌ | 1075/3000 [00:05<00:09, 199.10it/s]\u001b[A\n 37%|███▋ | 1103/3000 [00:05<00:08, 217.08it/s]\u001b[A\n 38%|███▊ | 1127/3000 [00:05<00:10, 186.90it/s]\u001b[A\n 39%|███▊ | 1159/3000 [00:05<00:09, 197.00it/s]\u001b[A\n 39%|███▉ | 1181/3000 [00:05<00:10, 181.33it/s]\u001b[A\n 40%|████ | 1210/3000 [00:05<00:08, 204.15it/s]\u001b[A\n 41%|████ | 1233/3000 [00:05<00:08, 197.04it/s]\u001b[A\n 42%|████▏ | 1255/3000 [00:05<00:09, 192.45it/s]\u001b[A\n 43%|████▎ | 1283/3000 [00:06<00:08, 211.72it/s]\u001b[A\n 44%|████▎ | 1306/3000 [00:06<00:09, 181.22it/s]\u001b[A\n 44%|████▍ | 1331/3000 [00:06<00:08, 193.99it/s]\u001b[A\n 45%|████▌ | 1352/3000 [00:06<00:09, 170.75it/s]\u001b[A\n 46%|████▌ | 1371/3000 [00:06<00:09, 169.88it/s]\u001b[A\n 47%|████▋ | 1401/3000 [00:06<00:08, 186.88it/s]\u001b[A\n 48%|████▊ | 1432/3000 [00:06<00:07, 204.08it/s]\u001b[A\n 48%|████▊ | 1454/3000 [00:06<00:07, 197.80it/s]\u001b[A\n 49%|████▉ | 1484/3000 [00:07<00:07, 216.43it/s]\u001b[A\n 50%|█████ | 1507/3000 [00:07<00:07, 200.79it/s]\u001b[A\n 51%|█████▏ | 1541/3000 [00:07<00:06, 228.63it/s]\u001b[A\n 52%|█████▏ | 1566/3000 [00:07<00:07, 194.03it/s]\u001b[A\n 53%|█████▎ | 1588/3000 [00:07<00:07, 188.36it/s]\u001b[A\n 54%|█████▎ | 1609/3000 [00:07<00:08, 160.73it/s]\u001b[A\n 54%|█████▍ | 1627/3000 [00:07<00:09, 151.86it/s]\u001b[A\n 55%|█████▌ | 1664/3000 [00:08<00:07, 184.15it/s]\u001b[A\n 57%|█████▋ | 1699/3000 [00:08<00:06, 213.10it/s]\u001b[A\n 58%|█████▊ | 1738/3000 [00:08<00:05, 246.27it/s]\u001b[A\n 59%|█████▉ | 1768/3000 [00:08<00:06, 201.29it/s]\u001b[A\n 60%|██████ | 1802/3000 [00:08<00:05, 228.84it/s]\u001b[A\n 61%|██████ | 1833/3000 [00:08<00:06, 179.30it/s]\u001b[A\n 62%|██████▏ | 1859/3000 [00:08<00:05, 194.46it/s]\u001b[A\n 63%|██████▎ | 1897/3000 [00:09<00:04, 221.20it/s]\u001b[A\n 64%|██████▍ | 1924/3000 [00:09<00:05, 196.52it/s]\u001b[A\n 65%|██████▌ | 1950/3000 [00:09<00:05, 200.87it/s]\u001b[A\n 66%|██████▌ | 1976/3000 [00:09<00:04, 208.23it/s]\u001b[A\n 67%|██████▋ | 2001/3000 [00:09<00:04, 215.81it/s]\u001b[A\n 68%|██████▊ | 2031/3000 [00:09<00:04, 235.12it/s]\u001b[A\n 69%|██████▊ | 2056/3000 [00:09<00:04, 202.77it/s]\u001b[A\n 69%|██████▉ | 2079/3000 [00:09<00:04, 187.99it/s]\u001b[A\n 70%|███████ | 2114/3000 [00:10<00:04, 215.78it/s]\u001b[A\n 71%|███████▏ | 2139/3000 [00:10<00:04, 195.26it/s]\u001b[A\n 72%|███████▏ | 2170/3000 [00:10<00:03, 219.49it/s]\u001b[A\n 73%|███████▎ | 2195/3000 [00:10<00:03, 207.04it/s]\u001b[A\n 74%|███████▍ | 2218/3000 [00:10<00:03, 208.63it/s]\u001b[A\n 75%|███████▌ | 2262/3000 [00:10<00:02, 247.48it/s]\u001b[A\n 76%|███████▋ | 2291/3000 [00:10<00:03, 185.43it/s]\u001b[A\n 78%|███████▊ | 2332/3000 [00:11<00:03, 221.57it/s]\u001b[A\n 79%|███████▊ | 2361/3000 [00:11<00:03, 190.56it/s]\u001b[A\n 80%|████████ | 2414/3000 [00:11<00:02, 234.83it/s]\u001b[A\n 82%|████████▏ | 2447/3000 [00:11<00:02, 184.54it/s]\u001b[A\n 82%|████████▏ | 2474/3000 [00:11<00:03, 161.59it/s]\u001b[A\n 84%|████████▎ | 2512/3000 [00:11<00:02, 192.04it/s]\u001b[A\n 85%|████████▍ | 2538/3000 [00:12<00:02, 183.65it/s]\u001b[A\n 85%|████████▌ | 2562/3000 [00:12<00:02, 195.41it/s]\u001b[A\n 86%|████████▋ | 2595/3000 [00:12<00:01, 222.57it/s]\u001b[A\n 87%|████████▋ | 2622/3000 [00:12<00:01, 201.77it/s]\u001b[A\n 88%|████████▊ | 2649/3000 [00:12<00:01, 215.21it/s]\u001b[A\n 89%|████████▉ | 2673/3000 [00:12<00:01, 184.22it/s]\u001b[A\n 90%|████████▉ | 2694/3000 [00:12<00:01, 179.09it/s]\u001b[A\n 91%|█████████ | 2723/3000 [00:12<00:01, 202.13it/s]\u001b[A\n 92%|█████████▏| 2746/3000 [00:13<00:01, 197.52it/s]\u001b[A\n 93%|█████████▎| 2787/3000 [00:13<00:00, 215.96it/s]\u001b[A\n 94%|█████████▎| 2811/3000 [00:13<00:00, 213.88it/s]\u001b[A\n 94%|█████████▍| 2834/3000 [00:13<00:00, 212.19it/s]\u001b[A\n 95%|█████████▌| 2859/3000 [00:13<00:00, 221.63it/s]\u001b[A\n 96%|█████████▋| 2889/3000 [00:13<00:00, 215.90it/s]\u001b[A\n 97%|█████████▋| 2921/3000 [00:13<00:00, 239.09it/s]\u001b[A\n 98%|█████████▊| 2947/3000 [00:13<00:00, 213.01it/s]\u001b[A\n100%|██████████| 3000/3000 [00:14<00:00, 211.49it/s]\u001b[A\n 30%|███ | 3/10 [00:41<01:40, 14.36s/it]\n 0%| | 0/3000 [00:00<?, ?it/s]\u001b[A\n 1%| | 37/3000 [00:00<00:08, 364.97it/s]\u001b[A\n 2%|▏ | 63/3000 [00:00<00:09, 323.93it/s]\u001b[A\n 3%|▎ | 93/3000 [00:00<00:09, 309.08it/s]\u001b[A\n 4%|▍ | 113/3000 [00:00<00:14, 196.98it/s]\u001b[A\n 5%|▍ | 145/3000 [00:00<00:14, 201.86it/s]\u001b[A\n 6%|▌ | 172/3000 [00:00<00:13, 214.11it/s]\u001b[A\n 7%|▋ | 199/3000 [00:00<00:12, 224.92it/s]\u001b[A\n 7%|▋ | 221/3000 [00:00<00:13, 201.40it/s]\u001b[A\n 8%|▊ | 242/3000 [00:01<00:15, 183.11it/s]\u001b[A\n 10%|▉ | 290/3000 [00:01<00:12, 224.12it/s]\u001b[A\n 11%|█ | 328/3000 [00:01<00:11, 241.87it/s]\u001b[A\n 12%|█▏ | 356/3000 [00:01<00:12, 207.40it/s]\u001b[A\n 13%|█▎ | 384/3000 [00:01<00:11, 224.51it/s]\u001b[A\n 14%|█▍ | 416/3000 [00:01<00:10, 245.89it/s]\u001b[A\n 15%|█▍ | 444/3000 [00:01<00:10, 251.64it/s]\u001b[A\n 16%|█▌ | 472/3000 [00:02<00:13, 191.57it/s]\u001b[A\n 16%|█▋ | 495/3000 [00:02<00:13, 188.01it/s]\u001b[A\n 18%|█▊ | 531/3000 [00:02<00:11, 218.02it/s]\u001b[A\n 19%|█▉ | 571/3000 [00:02<00:09, 247.68it/s]\u001b[A\n 20%|██ | 600/3000 [00:02<00:09, 253.50it/s]\u001b[A\n 21%|██ | 629/3000 [00:02<00:10, 215.85it/s]\u001b[A\n 22%|██▏ | 660/3000 [00:02<00:12, 185.32it/s]\u001b[A\n 23%|██▎ | 697/3000 [00:03<00:10, 212.30it/s]\u001b[A\n 25%|██▍ | 739/3000 [00:03<00:09, 235.54it/s]\u001b[A\n 26%|██▌ | 766/3000 [00:03<00:11, 196.07it/s]\u001b[A\n 26%|██▋ | 789/3000 [00:03<00:14, 152.96it/s]\u001b[A\n 27%|██▋ | 818/3000 [00:03<00:12, 176.70it/s]\u001b[A\n 29%|██▊ | 859/3000 [00:03<00:10, 212.81it/s]\u001b[A\n 30%|██▉ | 898/3000 [00:03<00:08, 245.78it/s]\u001b[A\n 31%|███ | 929/3000 [00:04<00:11, 173.83it/s]\u001b[A\n 32%|███▏ | 974/3000 [00:04<00:09, 211.07it/s]\u001b[A\n 34%|███▍ | 1021/3000 [00:04<00:07, 252.55it/s]\u001b[A\n 35%|███▌ | 1056/3000 [00:04<00:07, 250.61it/s]\u001b[A\n 36%|███▋ | 1088/3000 [00:04<00:10, 186.85it/s]\u001b[A\n 37%|███▋ | 1122/3000 [00:04<00:08, 211.92it/s]\u001b[A\n 39%|███▊ | 1156/3000 [00:05<00:08, 219.50it/s]\u001b[A\n 39%|███▉ | 1183/3000 [00:05<00:10, 178.98it/s]\u001b[A\n 41%|████ | 1223/3000 [00:05<00:08, 214.18it/s]\u001b[A\n 42%|████▏ | 1264/3000 [00:05<00:07, 221.32it/s]\u001b[A\n 43%|████▎ | 1291/3000 [00:05<00:07, 226.15it/s]\u001b[A\n 44%|████▍ | 1317/3000 [00:05<00:08, 194.78it/s]\u001b[A\n 45%|████▍ | 1342/3000 [00:05<00:08, 197.46it/s]\u001b[A\n 46%|████▌ | 1367/3000 [00:06<00:07, 210.21it/s]\u001b[A\n 47%|████▋ | 1410/3000 [00:06<00:06, 244.18it/s]\u001b[A\n 48%|████▊ | 1443/3000 [00:06<00:05, 262.75it/s]\u001b[A\n 49%|████▉ | 1472/3000 [00:06<00:07, 217.96it/s]\u001b[A\n 50%|████▉ | 1497/3000 [00:06<00:06, 223.25it/s]\u001b[A\n 51%|█████ | 1531/3000 [00:06<00:05, 248.48it/s]\u001b[A\n 52%|█████▏ | 1559/3000 [00:06<00:07, 189.18it/s]\u001b[A\n 53%|█████▎ | 1588/3000 [00:07<00:06, 209.62it/s]\u001b[A\n 54%|█████▍ | 1629/3000 [00:07<00:05, 233.92it/s]\u001b[A\n 55%|█████▌ | 1656/3000 [00:07<00:07, 174.62it/s]\u001b[A\n 56%|█████▌ | 1687/3000 [00:07<00:06, 191.67it/s]\u001b[A\n 57%|█████▋ | 1717/3000 [00:07<00:05, 214.51it/s]\u001b[A\n 58%|█████▊ | 1750/3000 [00:07<00:05, 234.90it/s]\u001b[A\n 60%|█████▉ | 1786/3000 [00:07<00:04, 261.78it/s]\u001b[A\n 61%|██████ | 1816/3000 [00:08<00:05, 209.76it/s]\u001b[A\n 62%|██████▏ | 1859/3000 [00:08<00:04, 247.64it/s]\u001b[A\n 63%|██████▎ | 1898/3000 [00:08<00:03, 277.41it/s]\u001b[A\n 64%|██████▍ | 1931/3000 [00:08<00:04, 219.67it/s]\u001b[A\n 65%|██████▌ | 1959/3000 [00:08<00:06, 166.21it/s]\u001b[A\n 66%|██████▋ | 1993/3000 [00:08<00:05, 195.33it/s]\u001b[A\n 68%|██████▊ | 2032/3000 [00:09<00:05, 181.00it/s]\u001b[A\n 69%|██████▊ | 2056/3000 [00:09<00:04, 194.99it/s]\u001b[A\n 70%|██████▉ | 2096/3000 [00:09<00:03, 230.12it/s]\u001b[A\n 71%|███████ | 2124/3000 [00:09<00:03, 241.97it/s]\u001b[A\n 72%|███████▏ | 2155/3000 [00:09<00:03, 256.11it/s]\u001b[A\n 73%|███████▎ | 2184/3000 [00:09<00:03, 242.66it/s]\u001b[A\n 74%|███████▎ | 2211/3000 [00:09<00:03, 211.23it/s]\u001b[A\n 74%|███████▍ | 2235/3000 [00:09<00:04, 188.29it/s]\u001b[A\n 76%|███████▌ | 2268/3000 [00:10<00:03, 215.47it/s]\u001b[A\n 76%|███████▋ | 2293/3000 [00:10<00:03, 193.04it/s]\u001b[A\n 77%|███████▋ | 2317/3000 [00:10<00:03, 204.03it/s]\u001b[A\n 78%|███████▊ | 2340/3000 [00:10<00:03, 201.26it/s]\u001b[A\n 79%|███████▊ | 2362/3000 [00:10<00:03, 182.76it/s]\u001b[A\n 80%|███████▉ | 2394/3000 [00:10<00:03, 197.02it/s]\u001b[A\n 80%|████████ | 2415/3000 [00:10<00:03, 152.85it/s]\u001b[A\n 81%|████████▏ | 2441/3000 [00:11<00:03, 174.26it/s]\u001b[A\n 82%|████████▏ | 2462/3000 [00:11<00:03, 171.18it/s]\u001b[A\n 83%|████████▎ | 2483/3000 [00:11<00:02, 179.76it/s]\u001b[A\n 84%|████████▍ | 2516/3000 [00:11<00:02, 187.55it/s]\u001b[A\n 85%|████████▍ | 2539/3000 [00:11<00:02, 198.33it/s]\u001b[A\n 86%|████████▌ | 2574/3000 [00:11<00:01, 227.54it/s]\u001b[A\n 87%|████████▋ | 2599/3000 [00:11<00:02, 199.75it/s]\u001b[A\n 88%|████████▊ | 2625/3000 [00:11<00:01, 213.94it/s]\u001b[A\n 88%|████████▊ | 2649/3000 [00:12<00:01, 186.30it/s]\u001b[A\n 89%|████████▉ | 2672/3000 [00:12<00:01, 187.02it/s]\u001b[A\n 90%|████████▉ | 2697/3000 [00:12<00:01, 191.72it/s]\u001b[A\n 91%|█████████ | 2718/3000 [00:12<00:01, 171.25it/s]\u001b[A\n 92%|█████████▏| 2748/3000 [00:12<00:01, 192.42it/s]\u001b[A\n 92%|█████████▏| 2769/3000 [00:12<00:01, 176.70it/s]\u001b[A\n 94%|█████████▍| 2817/3000 [00:12<00:00, 199.71it/s]\u001b[A\n 95%|█████████▍| 2839/3000 [00:12<00:00, 204.54it/s]\u001b[A\n 95%|█████████▌| 2861/3000 [00:13<00:00, 196.15it/s]\u001b[A\n 96%|█████████▌| 2886/3000 [00:13<00:00, 205.96it/s]\u001b[A\n 97%|█████████▋| 2908/3000 [00:13<00:00, 205.44it/s]\u001b[A\n 98%|█████████▊| 2947/3000 [00:13<00:00, 238.88it/s]\u001b[A\n 99%|█████████▉| 2974/3000 [00:13<00:00, 184.83it/s]\u001b[A\n100%|██████████| 3000/3000 [00:13<00:00, 217.60it/s]\u001b[A\n 40%|████ | 4/10 [00:55<01:25, 14.20s/it]\n 0%| | 0/2500 [00:00<?, ?it/s]\u001b[A\n 1%| | 20/2500 [00:00<00:17, 139.25it/s]\u001b[A\n 2%|▏ | 47/2500 [00:00<00:15, 162.88it/s]\u001b[A\n 3%|▎ | 83/2500 [00:00<00:12, 194.75it/s]\u001b[A\n 4%|▍ | 102/2500 [00:00<00:13, 174.62it/s]\u001b[A\n 5%|▌ | 131/2500 [00:00<00:11, 198.12it/s]\u001b[A\n 7%|▋ | 165/2500 [00:00<00:10, 225.80it/s]\u001b[A\n 8%|▊ | 190/2500 [00:00<00:13, 176.26it/s]\u001b[A\n 9%|▉ | 229/2500 [00:00<00:10, 209.75it/s]\u001b[A\n 10%|█ | 261/2500 [00:01<00:09, 233.22it/s]\u001b[A\n 12%|█▏ | 289/2500 [00:01<00:13, 168.70it/s]\u001b[A\n 13%|█▎ | 314/2500 [00:01<00:11, 186.29it/s]\u001b[A\n 14%|█▍ | 346/2500 [00:01<00:10, 212.69it/s]\u001b[A\n 16%|█▌ | 388/2500 [00:01<00:08, 246.63it/s]\u001b[A\n 17%|█▋ | 424/2500 [00:01<00:08, 244.59it/s]\u001b[A\n 18%|█▊ | 453/2500 [00:02<00:12, 170.25it/s]\u001b[A\n 19%|█▉ | 476/2500 [00:02<00:12, 156.44it/s]\u001b[A\n 21%|██ | 516/2500 [00:02<00:10, 190.69it/s]\u001b[A\n 22%|██▏ | 546/2500 [00:02<00:09, 210.18it/s]\u001b[A\n 23%|██▎ | 573/2500 [00:02<00:08, 219.91it/s]\u001b[A\n 24%|██▍ | 599/2500 [00:02<00:10, 184.33it/s]\u001b[A\n 25%|██▌ | 627/2500 [00:02<00:09, 205.25it/s]\u001b[A\n 26%|██▌ | 656/2500 [00:03<00:08, 223.98it/s]\u001b[A\n 28%|██▊ | 688/2500 [00:03<00:07, 244.15it/s]\u001b[A\n 29%|██▊ | 715/2500 [00:03<00:10, 176.82it/s]\u001b[A\n 30%|██▉ | 748/2500 [00:03<00:08, 205.09it/s]\u001b[A\n 31%|███ | 774/2500 [00:03<00:09, 178.42it/s]\u001b[A\n 32%|███▏ | 804/2500 [00:03<00:08, 200.44it/s]\u001b[A\n 33%|███▎ | 828/2500 [00:03<00:09, 184.67it/s]\u001b[A\n 34%|███▍ | 855/2500 [00:04<00:08, 203.30it/s]\u001b[A\n 35%|███▌ | 878/2500 [00:04<00:09, 173.98it/s]\u001b[A\n 36%|███▌ | 903/2500 [00:04<00:08, 189.95it/s]\u001b[A\n 37%|███▋ | 925/2500 [00:04<00:10, 154.84it/s]\u001b[A\n 38%|███▊ | 957/2500 [00:04<00:08, 182.70it/s]\u001b[A\n 39%|███▉ | 980/2500 [00:04<00:10, 143.48it/s]\u001b[A\n 40%|███▉ | 999/2500 [00:04<00:10, 139.12it/s]\u001b[A\n 42%|████▏ | 1047/2500 [00:05<00:08, 175.41it/s]\u001b[A\n 43%|████▎ | 1087/2500 [00:05<00:06, 210.55it/s]\u001b[A\n 45%|████▍ | 1117/2500 [00:05<00:06, 218.88it/s]\u001b[A\n 46%|████▌ | 1145/2500 [00:05<00:06, 198.05it/s]\u001b[A\n 47%|████▋ | 1172/2500 [00:05<00:06, 207.80it/s]\u001b[A\n 48%|████▊ | 1202/2500 [00:05<00:05, 224.24it/s]\u001b[A\n 49%|████▉ | 1228/2500 [00:05<00:07, 174.48it/s]\u001b[A\n 50%|█████ | 1255/2500 [00:06<00:06, 191.38it/s]\u001b[A\n 51%|█████▏ | 1286/2500 [00:06<00:05, 214.58it/s]\u001b[A\n 52%|█████▏ | 1311/2500 [00:06<00:06, 184.08it/s]\u001b[A\n 53%|█████▎ | 1335/2500 [00:06<00:05, 196.53it/s]\u001b[A\n 54%|█████▍ | 1359/2500 [00:06<00:05, 207.53it/s]\u001b[A\n 55%|█████▌ | 1382/2500 [00:06<00:05, 188.56it/s]\u001b[A\n 57%|█████▋ | 1418/2500 [00:06<00:04, 219.83it/s]\u001b[A\n 58%|█████▊ | 1444/2500 [00:06<00:04, 228.39it/s]\u001b[A\n 59%|█████▉ | 1470/2500 [00:07<00:06, 159.43it/s]\u001b[A\n 60%|█████▉ | 1492/2500 [00:07<00:05, 172.70it/s]\u001b[A\n 61%|██████ | 1518/2500 [00:07<00:05, 191.47it/s]\u001b[A\n 62%|██████▏ | 1547/2500 [00:07<00:04, 212.60it/s]\u001b[A\n 63%|██████▎ | 1572/2500 [00:07<00:04, 192.20it/s]\u001b[A\n 64%|██████▍ | 1599/2500 [00:07<00:04, 209.36it/s]\u001b[A\n 65%|██████▌ | 1625/2500 [00:07<00:03, 221.61it/s]\u001b[A\n 66%|██████▌ | 1649/2500 [00:08<00:04, 174.42it/s]\u001b[A\n 67%|██████▋ | 1675/2500 [00:08<00:04, 192.01it/s]\u001b[A\n 69%|██████▊ | 1715/2500 [00:08<00:04, 189.25it/s]\u001b[A\n 69%|██████▉ | 1736/2500 [00:08<00:04, 178.51it/s]\u001b[A\n 71%|███████ | 1778/2500 [00:08<00:03, 215.56it/s]\u001b[A\n 72%|███████▏ | 1804/2500 [00:08<00:03, 222.15it/s]\u001b[A\n 73%|███████▎ | 1830/2500 [00:08<00:04, 157.46it/s]\u001b[A\n 75%|███████▍ | 1863/2500 [00:09<00:03, 186.58it/s]\u001b[A\n 76%|███████▌ | 1897/2500 [00:09<00:02, 212.91it/s]\u001b[A\n 77%|███████▋ | 1924/2500 [00:09<00:02, 215.15it/s]\u001b[A\n 78%|███████▊ | 1950/2500 [00:09<00:02, 195.08it/s]\u001b[A\n 79%|███████▉ | 1976/2500 [00:09<00:02, 209.94it/s]\u001b[A\n 80%|████████ | 2000/2500 [00:09<00:04, 118.16it/s]\u001b[A\n 81%|████████ | 2019/2500 [00:10<00:03, 124.47it/s]\u001b[A\n 82%|████████▏ | 2041/2500 [00:10<00:03, 142.06it/s]\u001b[A\n 83%|████████▎ | 2079/2500 [00:10<00:02, 171.54it/s]\u001b[A\n 84%|████████▍ | 2109/2500 [00:10<00:01, 196.78it/s]\u001b[A\n 85%|████████▌ | 2134/2500 [00:10<00:02, 158.50it/s]\u001b[A\n 86%|████████▋ | 2159/2500 [00:10<00:01, 176.32it/s]\u001b[A\n 87%|████████▋ | 2181/2500 [00:10<00:01, 163.91it/s]\u001b[A\n 88%|████████▊ | 2201/2500 [00:11<00:01, 168.59it/s]\u001b[A\n 89%|████████▉ | 2220/2500 [00:11<00:01, 164.69it/s]\u001b[A\n 90%|████████▉ | 2245/2500 [00:11<00:01, 176.51it/s]\u001b[A\n 91%|█████████ | 2264/2500 [00:11<00:01, 174.91it/s]\u001b[A\n 92%|█████████▏| 2288/2500 [00:11<00:01, 189.51it/s]\u001b[A\n 92%|█████████▏| 2311/2500 [00:11<00:00, 196.33it/s]\u001b[A\n 93%|█████████▎| 2332/2500 [00:11<00:00, 177.69it/s]\u001b[A\n 94%|█████████▍| 2354/2500 [00:11<00:00, 184.24it/s]\u001b[A\n 95%|█████████▍| 2374/2500 [00:12<00:00, 152.95it/s]\u001b[A\n 96%|█████████▌| 2391/2500 [00:12<00:00, 154.26it/s]\u001b[A\n 96%|█████████▋| 2408/2500 [00:12<00:00, 147.03it/s]\u001b[A\n 98%|█████████▊| 2438/2500 [00:12<00:00, 163.18it/s]\u001b[A\n 98%|█████████▊| 2456/2500 [00:12<00:00, 159.98it/s]\u001b[A\n 99%|█████████▉| 2473/2500 [00:12<00:00, 125.49it/s]\u001b[A\n100%|██████████| 2500/2500 [00:12<00:00, 194.32it/s]\u001b[A\n 50%|█████ | 5/10 [01:08<01:08, 13.80s/it]\n 0%| | 0/2000 [00:00<?, ?it/s]\u001b[A\n 1%| | 17/2000 [00:00<00:11, 166.12it/s]\u001b[A\n 3%|▎ | 54/2000 [00:00<00:09, 196.67it/s]\u001b[A\n 4%|▍ | 75/2000 [00:00<00:09, 194.81it/s]\u001b[A\n 5%|▍ | 93/2000 [00:00<00:10, 188.99it/s]\u001b[A\n 6%|▋ | 126/2000 [00:00<00:08, 213.10it/s]\u001b[A\n 7%|▋ | 149/2000 [00:00<00:08, 215.33it/s]\u001b[A\n 9%|▊ | 172/2000 [00:00<00:08, 217.89it/s]\u001b[A\n 10%|▉ | 194/2000 [00:00<00:09, 189.79it/s]\u001b[A\n 11%|█ | 223/2000 [00:00<00:08, 211.33it/s]\u001b[A\n 12%|█▏ | 246/2000 [00:01<00:09, 190.83it/s]\u001b[A\n 14%|█▍ | 281/2000 [00:01<00:07, 217.20it/s]\u001b[A\n 15%|█▌ | 305/2000 [00:01<00:08, 194.87it/s]\u001b[A\n 17%|█▋ | 333/2000 [00:01<00:07, 213.93it/s]\u001b[A\n 18%|█▊ | 367/2000 [00:01<00:06, 240.44it/s]\u001b[A\n 20%|█▉ | 394/2000 [00:01<00:07, 210.11it/s]\u001b[A\n 21%|██ | 418/2000 [00:01<00:08, 178.12it/s]\u001b[A\n 22%|██▏ | 445/2000 [00:02<00:08, 193.78it/s]\u001b[A\n 23%|██▎ | 469/2000 [00:02<00:07, 200.69it/s]\u001b[A\n 25%|██▌ | 503/2000 [00:02<00:06, 222.28it/s]\u001b[A\n 26%|██▋ | 528/2000 [00:02<00:07, 196.99it/s]\u001b[A\n 28%|██▊ | 562/2000 [00:02<00:06, 223.92it/s]\u001b[A\n 29%|██▉ | 587/2000 [00:02<00:06, 213.71it/s]\u001b[A\n 31%|███ | 615/2000 [00:02<00:06, 210.23it/s]\u001b[A\n 32%|███▏ | 642/2000 [00:02<00:06, 221.71it/s]\u001b[A\n 33%|███▎ | 667/2000 [00:03<00:06, 207.27it/s]\u001b[A\n 35%|███▍ | 694/2000 [00:03<00:05, 222.07it/s]\u001b[A\n 36%|███▌ | 718/2000 [00:03<00:05, 219.06it/s]\u001b[A\n 37%|███▋ | 742/2000 [00:03<00:05, 223.44it/s]\u001b[A\n 39%|███▊ | 772/2000 [00:03<00:05, 240.93it/s]\u001b[A\n 41%|████ | 812/2000 [00:03<00:04, 271.04it/s]\u001b[A\n 43%|████▎ | 853/2000 [00:03<00:05, 227.24it/s]\u001b[A\n 44%|████▍ | 887/2000 [00:03<00:04, 246.63it/s]\u001b[A\n 46%|████▌ | 924/2000 [00:04<00:03, 270.27it/s]\u001b[A\n 48%|████▊ | 954/2000 [00:04<00:05, 198.87it/s]\u001b[A\n 50%|████▉ | 994/2000 [00:04<00:04, 229.70it/s]\u001b[A\n 51%|█████ | 1022/2000 [00:04<00:05, 181.03it/s]\u001b[A\n 52%|█████▏ | 1046/2000 [00:04<00:04, 191.63it/s]\u001b[A\n 54%|█████▍ | 1080/2000 [00:04<00:04, 195.64it/s]\u001b[A\n 55%|█████▌ | 1107/2000 [00:05<00:04, 212.99it/s]\u001b[A\n 57%|█████▋ | 1133/2000 [00:05<00:04, 213.46it/s]\u001b[A\n 58%|█████▊ | 1156/2000 [00:05<00:04, 200.25it/s]\u001b[A\n 59%|█████▉ | 1184/2000 [00:05<00:03, 218.60it/s]\u001b[A\n 60%|██████ | 1208/2000 [00:05<00:04, 189.29it/s]\u001b[A\n 62%|██████▏ | 1241/2000 [00:05<00:03, 216.17it/s]\u001b[A\n 63%|██████▎ | 1266/2000 [00:05<00:03, 224.31it/s]\u001b[A\n 65%|██████▍ | 1291/2000 [00:05<00:03, 207.88it/s]\u001b[A\n 66%|██████▌ | 1317/2000 [00:05<00:03, 220.42it/s]\u001b[A\n 67%|██████▋ | 1341/2000 [00:06<00:03, 213.49it/s]\u001b[A\n 69%|██████▉ | 1377/2000 [00:06<00:02, 212.91it/s]\u001b[A\n 70%|███████ | 1403/2000 [00:06<00:02, 224.56it/s]\u001b[A\n 71%|███████▏ | 1427/2000 [00:06<00:02, 206.25it/s]\u001b[A\n 73%|███████▎ | 1455/2000 [00:06<00:02, 208.82it/s]\u001b[A\n 74%|███████▍ | 1477/2000 [00:06<00:03, 138.62it/s]\u001b[A\n 75%|███████▍ | 1495/2000 [00:07<00:03, 143.74it/s]\u001b[A\n 76%|███████▋ | 1530/2000 [00:07<00:02, 173.24it/s]\u001b[A\n 78%|███████▊ | 1552/2000 [00:07<00:02, 156.46it/s]\u001b[A\n 79%|███████▉ | 1582/2000 [00:07<00:02, 166.94it/s]\u001b[A\n 80%|████████ | 1605/2000 [00:07<00:02, 181.78it/s]\u001b[A\n 81%|████████▏ | 1628/2000 [00:07<00:02, 183.16it/s]\u001b[A\n 83%|████████▎ | 1668/2000 [00:07<00:01, 215.65it/s]\u001b[A\n 85%|████████▍ | 1693/2000 [00:07<00:01, 210.71it/s]\u001b[A\n 86%|████████▌ | 1717/2000 [00:08<00:01, 192.98it/s]\u001b[A\n 87%|████████▋ | 1746/2000 [00:08<00:01, 213.53it/s]\u001b[A\n 88%|████████▊ | 1770/2000 [00:08<00:01, 205.19it/s]\u001b[A\n 90%|████████▉ | 1793/2000 [00:08<00:01, 194.11it/s]\u001b[A\n 91%|█████████ | 1821/2000 [00:08<00:00, 211.93it/s]\u001b[A\n 92%|█████████▏| 1844/2000 [00:08<00:00, 201.75it/s]\u001b[A\n 93%|█████████▎| 1866/2000 [00:08<00:00, 189.21it/s]\u001b[A\n 95%|█████████▍| 1898/2000 [00:08<00:00, 199.44it/s]\u001b[A\n 96%|█████████▋| 1926/2000 [00:09<00:00, 217.80it/s]\u001b[A\n 97%|█████████▋| 1949/2000 [00:09<00:00, 189.21it/s]\u001b[A\n 99%|█████████▉| 1977/2000 [00:09<00:00, 209.59it/s]\u001b[A\n100%|██████████| 2000/2000 [00:09<00:00, 211.83it/s]\u001b[A\n 60%|██████ | 6/10 [01:17<00:50, 12.52s/it]\n 0%| | 0/2500 [00:00<?, ?it/s]\u001b[A\n 0%| | 4/2500 [00:00<01:06, 37.37it/s]\u001b[A\n 1%| | 26/2500 [00:00<00:49, 49.61it/s]\u001b[A\n 2%|▏ | 46/2500 [00:00<00:39, 62.11it/s]\u001b[A\n 3%|▎ | 68/2500 [00:00<00:30, 79.11it/s]\u001b[A\n 3%|▎ | 82/2500 [00:00<00:29, 82.54it/s]\u001b[A\n 5%|▌ | 126/2500 [00:00<00:21, 109.10it/s]\u001b[A\n 6%|▌ | 156/2500 [00:00<00:17, 131.18it/s]\u001b[A\n 7%|▋ | 179/2500 [00:01<00:18, 123.88it/s]\u001b[A\n 8%|▊ | 199/2500 [00:01<00:17, 128.44it/s]\u001b[A\n 9%|▉ | 223/2500 [00:01<00:15, 148.89it/s]\u001b[A\n 10%|█ | 253/2500 [00:01<00:12, 173.19it/s]\u001b[A\n 11%|█ | 275/2500 [00:01<00:14, 157.03it/s]\u001b[A\n 13%|█▎ | 321/2500 [00:01<00:11, 195.59it/s]\u001b[A\n 14%|█▍ | 357/2500 [00:01<00:11, 183.24it/s]\u001b[A\n 15%|█▌ | 381/2500 [00:02<00:12, 171.99it/s]\u001b[A\n 17%|█▋ | 418/2500 [00:02<00:10, 204.76it/s]\u001b[A\n 18%|█▊ | 444/2500 [00:02<00:10, 190.13it/s]\u001b[A\n 19%|█▊ | 468/2500 [00:02<00:13, 154.70it/s]\u001b[A\n 20%|█▉ | 498/2500 [00:02<00:11, 172.79it/s]\u001b[A\n 21%|██▏ | 535/2500 [00:02<00:09, 205.42it/s]\u001b[A\n 23%|██▎ | 568/2500 [00:02<00:09, 214.41it/s]\u001b[A\n 24%|██▍ | 594/2500 [00:03<00:09, 200.37it/s]\u001b[A\n 25%|██▍ | 617/2500 [00:03<00:09, 194.03it/s]\u001b[A\n 26%|██▌ | 639/2500 [00:03<00:09, 195.72it/s]\u001b[A\n 27%|██▋ | 679/2500 [00:03<00:07, 231.04it/s]\u001b[A\n 28%|██▊ | 706/2500 [00:03<00:09, 195.63it/s]\u001b[A\n 30%|██▉ | 738/2500 [00:03<00:08, 200.25it/s]\u001b[A\n 31%|███ | 771/2500 [00:03<00:07, 226.37it/s]\u001b[A\n 32%|███▏ | 797/2500 [00:03<00:08, 196.13it/s]\u001b[A\n 33%|███▎ | 822/2500 [00:04<00:08, 207.83it/s]\u001b[A\n 34%|███▍ | 845/2500 [00:04<00:08, 195.65it/s]\u001b[A\n 35%|███▍ | 870/2500 [00:04<00:07, 207.50it/s]\u001b[A\n 36%|███▌ | 893/2500 [00:04<00:07, 211.42it/s]\u001b[A\n 37%|███▋ | 921/2500 [00:04<00:07, 199.73it/s]\u001b[A\n 38%|███▊ | 948/2500 [00:04<00:07, 206.79it/s]\u001b[A\n 39%|███▉ | 970/2500 [00:04<00:08, 187.33it/s]\u001b[A\n 40%|████ | 1011/2500 [00:04<00:06, 222.85it/s]\u001b[A\n 41%|████▏ | 1037/2500 [00:05<00:07, 200.70it/s]\u001b[A\n 43%|████▎ | 1069/2500 [00:05<00:06, 208.41it/s]\u001b[A\n 44%|████▎ | 1092/2500 [00:05<00:07, 186.95it/s]\u001b[A\n 45%|████▍ | 1123/2500 [00:05<00:06, 209.76it/s]\u001b[A\n 46%|████▌ | 1147/2500 [00:05<00:06, 196.21it/s]\u001b[A\n 47%|████▋ | 1174/2500 [00:05<00:06, 213.43it/s]\u001b[A\n 48%|████▊ | 1197/2500 [00:05<00:06, 212.18it/s]\u001b[A\n 49%|████▉ | 1231/2500 [00:05<00:05, 238.53it/s]\u001b[A\n 50%|█████ | 1257/2500 [00:06<00:05, 209.29it/s]\u001b[A\n 51%|█████ | 1280/2500 [00:06<00:05, 209.07it/s]\u001b[A\n 52%|█████▏ | 1309/2500 [00:06<00:05, 228.07it/s]\u001b[A\n 53%|█████▎ | 1336/2500 [00:06<00:05, 204.34it/s]\u001b[A\n 54%|█████▍ | 1358/2500 [00:06<00:06, 181.76it/s]\u001b[A\n 56%|█████▌ | 1393/2500 [00:06<00:05, 212.21it/s]\u001b[A\n 57%|█████▋ | 1418/2500 [00:06<00:05, 191.22it/s]\u001b[A\n 58%|█████▊ | 1448/2500 [00:07<00:04, 212.96it/s]\u001b[A\n 59%|█████▉ | 1472/2500 [00:07<00:05, 173.28it/s]\u001b[A\n 60%|██████ | 1509/2500 [00:07<00:04, 202.92it/s]\u001b[A\n 61%|██████▏ | 1534/2500 [00:07<00:05, 162.03it/s]\u001b[A\n 62%|██████▏ | 1555/2500 [00:07<00:05, 165.93it/s]\u001b[A\n 63%|██████▎ | 1582/2500 [00:07<00:05, 176.41it/s]\u001b[A\n 64%|██████▍ | 1608/2500 [00:07<00:04, 194.77it/s]\u001b[A\n 65%|██████▌ | 1630/2500 [00:08<00:04, 185.07it/s]\u001b[A\n 66%|██████▌ | 1654/2500 [00:08<00:04, 185.47it/s]\u001b[A\n 67%|██████▋ | 1680/2500 [00:08<00:04, 200.22it/s]\u001b[A\n 68%|██████▊ | 1709/2500 [00:08<00:03, 220.58it/s]\u001b[A\n 70%|██████▉ | 1748/2500 [00:08<00:02, 251.03it/s]\u001b[A\n 71%|███████ | 1776/2500 [00:08<00:02, 258.52it/s]\u001b[A\n 72%|███████▏ | 1804/2500 [00:08<00:03, 190.19it/s]\u001b[A\n 73%|███████▎ | 1827/2500 [00:08<00:03, 192.01it/s]\u001b[A\n 74%|███████▍ | 1856/2500 [00:09<00:03, 213.58it/s]\u001b[A\n 76%|███████▌ | 1889/2500 [00:09<00:02, 231.28it/s]\u001b[A\n 77%|███████▋ | 1932/2500 [00:09<00:02, 258.44it/s]\u001b[A\n 78%|███████▊ | 1961/2500 [00:09<00:03, 175.58it/s]\u001b[A\n 80%|███████▉ | 1994/2500 [00:09<00:02, 203.48it/s]\u001b[A\n 81%|████████ | 2022/2500 [00:09<00:02, 214.60it/s]\u001b[A\n 82%|████████▏ | 2048/2500 [00:09<00:02, 191.72it/s]\u001b[A\n 83%|████████▎ | 2086/2500 [00:10<00:01, 224.79it/s]\u001b[A\n 85%|████████▍ | 2124/2500 [00:10<00:01, 252.17it/s]\u001b[A\n 86%|████████▋ | 2157/2500 [00:10<00:01, 270.05it/s]\u001b[A\n 88%|████████▊ | 2188/2500 [00:10<00:01, 205.36it/s]\u001b[A\n 89%|████████▊ | 2214/2500 [00:10<00:01, 198.64it/s]\u001b[A\n 90%|████████▉ | 2238/2500 [00:10<00:01, 169.81it/s]\u001b[A\n 91%|█████████ | 2271/2500 [00:10<00:01, 198.37it/s]\u001b[A\n 92%|█████████▏| 2307/2500 [00:11<00:00, 228.63it/s]\u001b[A\n 94%|█████████▎| 2342/2500 [00:11<00:00, 255.10it/s]\u001b[A\n 95%|█████████▍| 2372/2500 [00:11<00:00, 200.56it/s]\u001b[A\n 96%|█████████▌| 2399/2500 [00:11<00:00, 215.61it/s]\u001b[A\n 97%|█████████▋| 2426/2500 [00:11<00:00, 188.52it/s]\u001b[A\n 98%|█████████▊| 2451/2500 [00:11<00:00, 198.72it/s]\u001b[A\n 99%|█████████▉| 2474/2500 [00:11<00:00, 181.02it/s]\u001b[A\n100%|██████████| 2500/2500 [00:12<00:00, 207.74it/s]\u001b[A\n 70%|███████ | 7/10 [01:29<00:37, 12.39s/it]\n 0%| | 0/2500 [00:00<?, ?it/s]\u001b[A\n 1%| | 19/2500 [00:00<00:13, 185.98it/s]\u001b[A\n 2%|▏ | 49/2500 [00:00<00:11, 207.50it/s]\u001b[A\n 3%|▎ | 71/2500 [00:00<00:15, 158.30it/s]\u001b[A\n 4%|▍ | 112/2500 [00:00<00:12, 190.02it/s]\u001b[A\n 5%|▌ | 131/2500 [00:00<00:14, 163.78it/s]\u001b[A\n 6%|▌ | 148/2500 [00:00<00:15, 155.79it/s]\u001b[A\n 7%|▋ | 180/2500 [00:00<00:12, 183.00it/s]\u001b[A\n 8%|▊ | 212/2500 [00:01<00:10, 209.00it/s]\u001b[A\n 9%|▉ | 236/2500 [00:01<00:11, 189.39it/s]\u001b[A\n 11%|█ | 276/2500 [00:01<00:09, 223.44it/s]\u001b[A\n 12%|█▏ | 303/2500 [00:01<00:09, 232.05it/s]\u001b[A\n 13%|█▎ | 335/2500 [00:01<00:08, 250.87it/s]\u001b[A\n 15%|█▍ | 363/2500 [00:01<00:12, 166.60it/s]\u001b[A\n 16%|█▌ | 404/2500 [00:01<00:10, 202.18it/s]\u001b[A\n 18%|█▊ | 438/2500 [00:02<00:09, 216.39it/s]\u001b[A\n 19%|█▊ | 466/2500 [00:02<00:09, 213.48it/s]\u001b[A\n 20%|█▉ | 492/2500 [00:02<00:10, 195.62it/s]\u001b[A\n 21%|██ | 515/2500 [00:02<00:10, 186.19it/s]\u001b[A\n 22%|██▏ | 557/2500 [00:02<00:08, 221.45it/s]\u001b[A\n 23%|██▎ | 586/2500 [00:02<00:08, 232.78it/s]\u001b[A\n 25%|██▍ | 618/2500 [00:02<00:07, 253.44it/s]\u001b[A\n 26%|██▌ | 647/2500 [00:03<00:11, 168.02it/s]\u001b[A\n 28%|██▊ | 688/2500 [00:03<00:09, 201.23it/s]\u001b[A\n 29%|██▉ | 723/2500 [00:03<00:07, 225.56it/s]\u001b[A\n 31%|███ | 767/2500 [00:03<00:06, 252.62it/s]\u001b[A\n 32%|███▏ | 798/2500 [00:03<00:07, 226.26it/s]\u001b[A\n 33%|███▎ | 832/2500 [00:03<00:09, 176.75it/s]\u001b[A\n 35%|███▍ | 869/2500 [00:04<00:08, 203.31it/s]\u001b[A\n 36%|███▋ | 908/2500 [00:04<00:06, 235.93it/s]\u001b[A\n 38%|███▊ | 942/2500 [00:04<00:06, 259.60it/s]\u001b[A\n 39%|███▉ | 973/2500 [00:04<00:07, 193.15it/s]\u001b[A\n 40%|████ | 1002/2500 [00:04<00:07, 213.73it/s]\u001b[A\n 41%|████ | 1028/2500 [00:04<00:08, 177.76it/s]\u001b[A\n 42%|████▏ | 1059/2500 [00:04<00:07, 200.23it/s]\u001b[A\n 43%|████▎ | 1083/2500 [00:05<00:08, 173.42it/s]\u001b[A\n 45%|████▍ | 1115/2500 [00:05<00:06, 198.12it/s]\u001b[A\n 46%|████▌ | 1145/2500 [00:05<00:06, 215.27it/s]\u001b[A\n 47%|████▋ | 1170/2500 [00:05<00:10, 124.32it/s]\u001b[A\n 48%|████▊ | 1192/2500 [00:05<00:10, 122.21it/s]\u001b[A\n 49%|████▊ | 1215/2500 [00:05<00:09, 141.81it/s]\u001b[A\n 49%|████▉ | 1234/2500 [00:06<00:09, 132.24it/s]\u001b[A\n 51%|█████ | 1266/2500 [00:06<00:07, 160.20it/s]\u001b[A\n 52%|█████▏ | 1297/2500 [00:06<00:06, 185.58it/s]\u001b[A\n 53%|█████▎ | 1329/2500 [00:06<00:05, 211.21it/s]\u001b[A\n 54%|█████▍ | 1355/2500 [00:06<00:05, 197.14it/s]\u001b[A\n 55%|█████▌ | 1379/2500 [00:06<00:05, 186.84it/s]\u001b[A\n 56%|█████▌ | 1401/2500 [00:06<00:06, 180.10it/s]\u001b[A\n 57%|█████▋ | 1424/2500 [00:06<00:05, 191.46it/s]\u001b[A\n 58%|█████▊ | 1445/2500 [00:07<00:05, 178.42it/s]\u001b[A\n 59%|█████▉ | 1478/2500 [00:07<00:05, 195.52it/s]\u001b[A\n 60%|█████▉ | 1499/2500 [00:07<00:06, 155.24it/s]\u001b[A\n 61%|██████▏ | 1532/2500 [00:07<00:05, 183.29it/s]\u001b[A\n 62%|██████▏ | 1554/2500 [00:07<00:05, 163.02it/s]\u001b[A\n 63%|██████▎ | 1574/2500 [00:07<00:06, 143.75it/s]\u001b[A\n 64%|██████▍ | 1596/2500 [00:07<00:05, 160.13it/s]\u001b[A\n 65%|██████▍ | 1615/2500 [00:08<00:05, 151.18it/s]\u001b[A\n 66%|██████▌ | 1651/2500 [00:08<00:04, 182.75it/s]\u001b[A\n 67%|██████▋ | 1674/2500 [00:08<00:04, 168.78it/s]\u001b[A\n 68%|██████▊ | 1702/2500 [00:08<00:04, 175.87it/s]\u001b[A\n 69%|██████▉ | 1722/2500 [00:08<00:05, 150.55it/s]\u001b[A\n 70%|███████ | 1755/2500 [00:08<00:04, 179.52it/s]\u001b[A\n 71%|███████ | 1777/2500 [00:08<00:04, 163.75it/s]\u001b[A\n 72%|███████▏ | 1802/2500 [00:09<00:04, 167.73it/s]\u001b[A\n 74%|███████▎ | 1838/2500 [00:09<00:03, 199.71it/s]\u001b[A\n 75%|███████▍ | 1863/2500 [00:09<00:03, 188.43it/s]\u001b[A\n 75%|███████▌ | 1885/2500 [00:09<00:03, 180.48it/s]\u001b[A\n 77%|███████▋ | 1920/2500 [00:09<00:03, 187.71it/s]\u001b[A\n 78%|███████▊ | 1958/2500 [00:09<00:02, 220.93it/s]\u001b[A\n 79%|███████▉ | 1984/2500 [00:09<00:02, 204.85it/s]\u001b[A\n 80%|████████ | 2008/2500 [00:10<00:02, 202.84it/s]\u001b[A\n 81%|████████▏ | 2034/2500 [00:10<00:02, 213.34it/s]\u001b[A\n 83%|████████▎ | 2069/2500 [00:10<00:01, 241.19it/s]\u001b[A\n 84%|████████▍ | 2096/2500 [00:10<00:02, 156.96it/s]\u001b[A\n 85%|████████▍ | 2124/2500 [00:10<00:02, 180.15it/s]\u001b[A\n 86%|████████▌ | 2147/2500 [00:10<00:02, 176.21it/s]\u001b[A\n 87%|████████▋ | 2170/2500 [00:10<00:01, 189.29it/s]\u001b[A\n 88%|████████▊ | 2192/2500 [00:11<00:01, 170.55it/s]\u001b[A\n 89%|████████▉ | 2226/2500 [00:11<00:01, 200.43it/s]\u001b[A\n 90%|█████████ | 2256/2500 [00:11<00:01, 217.99it/s]\u001b[A\n 91%|█████████ | 2281/2500 [00:11<00:01, 192.99it/s]\u001b[A\n 93%|█████████▎| 2314/2500 [00:11<00:00, 217.14it/s]\u001b[A\n 94%|█████████▍| 2348/2500 [00:11<00:00, 243.21it/s]\u001b[A\n 95%|█████████▌| 2377/2500 [00:11<00:00, 253.19it/s]\u001b[A\n 96%|█████████▌| 2405/2500 [00:12<00:00, 172.86it/s]\u001b[A\n 97%|█████████▋| 2430/2500 [00:12<00:00, 188.88it/s]\u001b[A\n 99%|█████████▉| 2469/2500 [00:12<00:00, 222.28it/s]\u001b[A\n100%|██████████| 2500/2500 [00:12<00:00, 202.52it/s]\u001b[A\n 80%|████████ | 8/10 [01:42<00:24, 12.40s/it]\n 0%| | 0/3000 [00:00<?, ?it/s]\u001b[A\n 0%| | 15/3000 [00:00<00:28, 105.32it/s]\u001b[A\n 1%|▏ | 41/3000 [00:00<00:23, 126.86it/s]\u001b[A\n 3%|▎ | 84/3000 [00:00<00:18, 159.17it/s]\u001b[A\n 4%|▍ | 116/3000 [00:00<00:15, 180.76it/s]\u001b[A\n 5%|▍ | 137/3000 [00:00<00:18, 155.56it/s]\u001b[A\n 5%|▌ | 156/3000 [00:00<00:19, 148.53it/s]\u001b[A\n 6%|▌ | 174/3000 [00:00<00:18, 149.36it/s]\u001b[A\n 7%|▋ | 200/3000 [00:01<00:16, 170.55it/s]\u001b[A\n 8%|▊ | 235/3000 [00:01<00:14, 196.85it/s]\u001b[A\n 9%|▉ | 265/3000 [00:01<00:12, 217.88it/s]\u001b[A\n 10%|▉ | 290/3000 [00:01<00:14, 181.62it/s]\u001b[A\n 11%|█ | 317/3000 [00:01<00:13, 199.49it/s]\u001b[A\n 11%|█▏ | 340/3000 [00:01<00:14, 182.73it/s]\u001b[A\n 12%|█▏ | 364/3000 [00:01<00:14, 176.37it/s]\u001b[A\n 13%|█▎ | 384/3000 [00:01<00:16, 159.59it/s]\u001b[A\n 13%|█▎ | 402/3000 [00:02<00:15, 163.46it/s]\u001b[A\n 14%|█▍ | 432/3000 [00:02<00:13, 187.40it/s]\u001b[A\n 15%|█▌ | 453/3000 [00:02<00:14, 175.31it/s]\u001b[A\n 16%|█▌ | 473/3000 [00:02<00:14, 169.64it/s]\u001b[A\n 17%|█▋ | 509/3000 [00:02<00:13, 186.16it/s]\u001b[A\n 18%|█▊ | 537/3000 [00:02<00:12, 203.28it/s]\u001b[A\n 19%|█▊ | 559/3000 [00:02<00:13, 175.34it/s]\u001b[A\n 19%|█▉ | 579/3000 [00:03<00:19, 121.95it/s]\u001b[A\n 20%|█▉ | 596/3000 [00:03<00:18, 132.57it/s]\u001b[A\n 21%|██ | 631/3000 [00:03<00:14, 160.73it/s]\u001b[A\n 22%|██▏ | 662/3000 [00:03<00:12, 187.25it/s]\u001b[A\n 23%|██▎ | 696/3000 [00:03<00:10, 210.28it/s]\u001b[A\n 24%|██▍ | 726/3000 [00:03<00:09, 230.58it/s]\u001b[A\n 25%|██▌ | 753/3000 [00:03<00:11, 196.32it/s]\u001b[A\n 26%|██▌ | 777/3000 [00:04<00:12, 179.89it/s]\u001b[A\n 27%|██▋ | 800/3000 [00:04<00:11, 191.49it/s]\u001b[A\n 27%|██▋ | 822/3000 [00:04<00:11, 192.31it/s]\u001b[A\n 28%|██▊ | 843/3000 [00:04<00:12, 177.49it/s]\u001b[A\n 29%|██▊ | 862/3000 [00:04<00:15, 139.47it/s]\u001b[A\n 29%|██▉ | 879/3000 [00:04<00:21, 99.99it/s] \u001b[A\n 30%|██▉ | 893/3000 [00:05<00:21, 95.98it/s]\u001b[A\n 30%|███ | 908/3000 [00:05<00:20, 101.90it/s]\u001b[A\n 31%|███ | 922/3000 [00:05<00:18, 110.51it/s]\u001b[A\n 32%|███▏ | 954/3000 [00:05<00:14, 136.71it/s]\u001b[A\n 32%|███▏ | 973/3000 [00:05<00:13, 148.71it/s]\u001b[A\n 33%|███▎ | 992/3000 [00:05<00:15, 127.43it/s]\u001b[A\n 34%|███▍ | 1018/3000 [00:05<00:13, 149.81it/s]\u001b[A\n 35%|███▍ | 1048/3000 [00:05<00:11, 175.84it/s]\u001b[A\n 36%|███▌ | 1070/3000 [00:06<00:10, 175.76it/s]\u001b[A\n 36%|███▋ | 1091/3000 [00:06<00:10, 177.28it/s]\u001b[A\n 37%|███▋ | 1122/3000 [00:06<00:09, 202.24it/s]\u001b[A\n 38%|███▊ | 1145/3000 [00:06<00:09, 194.15it/s]\u001b[A\n 39%|███▉ | 1167/3000 [00:06<00:10, 181.71it/s]\u001b[A\n 40%|███▉ | 1195/3000 [00:06<00:09, 187.01it/s]\u001b[A\n 40%|████ | 1215/3000 [00:06<00:10, 166.73it/s]\u001b[A\n 41%|████▏ | 1243/3000 [00:06<00:10, 169.69it/s]\u001b[A\n 42%|████▏ | 1261/3000 [00:07<00:10, 158.34it/s]\u001b[A\n 43%|████▎ | 1283/3000 [00:07<00:09, 172.55it/s]\u001b[A\n 44%|████▍ | 1319/3000 [00:07<00:08, 203.96it/s]\u001b[A\n 45%|████▍ | 1343/3000 [00:07<00:09, 183.80it/s]\u001b[A\n 46%|████▌ | 1379/3000 [00:07<00:07, 215.29it/s]\u001b[A\n 47%|████▋ | 1405/3000 [00:07<00:07, 201.52it/s]\u001b[A\n 48%|████▊ | 1428/3000 [00:07<00:08, 189.67it/s]\u001b[A\n 48%|████▊ | 1450/3000 [00:07<00:09, 171.67it/s]\u001b[A\n 49%|████▉ | 1480/3000 [00:08<00:07, 196.29it/s]\u001b[A\n 50%|█████ | 1503/3000 [00:08<00:08, 183.18it/s]\u001b[A\n 51%|█████ | 1524/3000 [00:08<00:07, 188.68it/s]\u001b[A\n 52%|█████▏ | 1545/3000 [00:08<00:08, 181.08it/s]\u001b[A\n 52%|█████▏ | 1565/3000 [00:08<00:08, 176.74it/s]\u001b[A\n 53%|█████▎ | 1584/3000 [00:08<00:08, 170.11it/s]\u001b[A\n 54%|█████▎ | 1609/3000 [00:08<00:07, 187.52it/s]\u001b[A\n 54%|█████▍ | 1629/3000 [00:08<00:07, 186.68it/s]\u001b[A\n 55%|█████▍ | 1649/3000 [00:09<00:07, 181.61it/s]\u001b[A\n 56%|█████▌ | 1669/3000 [00:09<00:07, 186.37it/s]\u001b[A\n 57%|█████▋ | 1696/3000 [00:09<00:06, 200.49it/s]\u001b[A\n 57%|█████▋ | 1717/3000 [00:09<00:06, 195.04it/s]\u001b[A\n 58%|█████▊ | 1752/3000 [00:09<00:05, 219.27it/s]\u001b[A\n 59%|█████▉ | 1776/3000 [00:09<00:06, 193.62it/s]\u001b[A\n 60%|██████ | 1804/3000 [00:09<00:05, 212.79it/s]\u001b[A\n 61%|██████ | 1827/3000 [00:09<00:05, 205.56it/s]\u001b[A\n 62%|██████▏ | 1849/3000 [00:09<00:06, 188.92it/s]\u001b[A\n 62%|██████▏ | 1869/3000 [00:10<00:06, 181.69it/s]\u001b[A\n 64%|██████▎ | 1906/3000 [00:10<00:05, 214.40it/s]\u001b[A\n 64%|██████▍ | 1931/3000 [00:10<00:05, 208.51it/s]\u001b[A\n 65%|██████▌ | 1954/3000 [00:10<00:06, 160.98it/s]\u001b[A\n 66%|██████▌ | 1985/3000 [00:10<00:05, 185.23it/s]\u001b[A\n 67%|██████▋ | 2009/3000 [00:10<00:05, 191.72it/s]\u001b[A\n 68%|██████▊ | 2031/3000 [00:10<00:05, 188.19it/s]\u001b[A\n 68%|██████▊ | 2052/3000 [00:11<00:05, 183.79it/s]\u001b[A\n 69%|██████▉ | 2079/3000 [00:11<00:04, 194.41it/s]\u001b[A\n 70%|███████ | 2101/3000 [00:11<00:04, 200.67it/s]\u001b[A\n 71%|███████ | 2131/3000 [00:11<00:03, 221.26it/s]\u001b[A\n 72%|███████▏ | 2155/3000 [00:11<00:04, 208.91it/s]\u001b[A\n 73%|███████▎ | 2187/3000 [00:11<00:03, 231.47it/s]\u001b[A\n 74%|███████▍ | 2217/3000 [00:11<00:03, 244.20it/s]\u001b[A\n 75%|███████▍ | 2243/3000 [00:11<00:03, 196.65it/s]\u001b[A\n 76%|███████▌ | 2265/3000 [00:11<00:03, 198.54it/s]\u001b[A\n 77%|███████▋ | 2303/3000 [00:12<00:03, 206.09it/s]\u001b[A\n 78%|███████▊ | 2330/3000 [00:12<00:03, 217.60it/s]\u001b[A\n 78%|███████▊ | 2353/3000 [00:12<00:03, 187.16it/s]\u001b[A\n 79%|███████▉ | 2377/3000 [00:12<00:03, 199.90it/s]\u001b[A\n 80%|████████ | 2401/3000 [00:12<00:02, 206.14it/s]\u001b[A\n 81%|████████ | 2436/3000 [00:12<00:02, 228.98it/s]\u001b[A\n 82%|████████▏ | 2461/3000 [00:12<00:02, 215.14it/s]\u001b[A\n 83%|████████▎ | 2484/3000 [00:12<00:02, 204.07it/s]\u001b[A\n 84%|████████▍ | 2525/3000 [00:13<00:02, 222.19it/s]\u001b[A\n 85%|████████▌ | 2551/3000 [00:13<00:01, 226.31it/s]\u001b[A\n 86%|████████▌ | 2576/3000 [00:13<00:01, 228.51it/s]\u001b[A\n 87%|████████▋ | 2612/3000 [00:13<00:01, 234.35it/s]\u001b[A\n 88%|████████▊ | 2638/3000 [00:13<00:01, 235.69it/s]\u001b[A\n 89%|████████▊ | 2662/3000 [00:13<00:01, 187.21it/s]\u001b[A\n 90%|████████▉ | 2694/3000 [00:13<00:01, 212.41it/s]\u001b[A\n 91%|█████████ | 2718/3000 [00:14<00:01, 212.32it/s]\u001b[A\n 91%|█████████▏| 2744/3000 [00:14<00:01, 222.66it/s]\u001b[A\n 92%|█████████▏| 2768/3000 [00:14<00:01, 192.34it/s]\u001b[A\n 93%|█████████▎| 2798/3000 [00:14<00:00, 215.22it/s]\u001b[A\n 94%|█████████▍| 2828/3000 [00:14<00:00, 215.37it/s]\u001b[A\n 95%|█████████▌| 2855/3000 [00:14<00:00, 223.99it/s]\u001b[A\n 96%|█████████▌| 2879/3000 [00:14<00:00, 197.72it/s]\u001b[A\n 97%|█████████▋| 2908/3000 [00:14<00:00, 190.93it/s]\u001b[A\n 98%|█████████▊| 2935/3000 [00:15<00:00, 204.13it/s]\u001b[A\n 99%|█████████▊| 2957/3000 [00:15<00:00, 189.43it/s]\u001b[A\n100%|██████████| 3000/3000 [00:15<00:00, 193.68it/s]\u001b[A\n 90%|█████████ | 9/10 [01:57<00:13, 13.34s/it]\n 0%| | 0/3000 [00:00<?, ?it/s]\u001b[A\n 0%| | 8/3000 [00:00<00:41, 71.82it/s]\u001b[A\n 1%| | 37/3000 [00:00<00:32, 92.03it/s]\u001b[A\n 2%|▏ | 72/3000 [00:00<00:25, 114.62it/s]\u001b[A\n 3%|▎ | 92/3000 [00:00<00:22, 127.02it/s]\u001b[A\n 4%|▍ | 117/3000 [00:00<00:19, 148.35it/s]\u001b[A\n 5%|▍ | 148/3000 [00:00<00:18, 158.28it/s]\u001b[A\n 6%|▌ | 174/3000 [00:00<00:15, 179.03it/s]\u001b[A\n 6%|▋ | 195/3000 [00:00<00:16, 169.35it/s]\u001b[A\n 7%|▋ | 221/3000 [00:01<00:14, 186.08it/s]\u001b[A\n 9%|▊ | 258/3000 [00:01<00:12, 212.59it/s]\u001b[A\n 9%|▉ | 282/3000 [00:01<00:13, 203.68it/s]\u001b[A\n 10%|█ | 305/3000 [00:01<00:13, 195.95it/s]\u001b[A\n 11%|█▏ | 340/3000 [00:01<00:11, 225.25it/s]\u001b[A\n 13%|█▎ | 384/3000 [00:01<00:09, 261.66it/s]\u001b[A\n 14%|█▍ | 415/3000 [00:01<00:09, 259.59it/s]\u001b[A\n 15%|█▍ | 444/3000 [00:02<00:14, 172.80it/s]\u001b[A\n 16%|█▌ | 481/3000 [00:02<00:12, 205.49it/s]\u001b[A\n 17%|█▋ | 512/3000 [00:02<00:11, 223.88it/s]\u001b[A\n 18%|█▊ | 540/3000 [00:02<00:12, 189.81it/s]\u001b[A\n 19%|█▉ | 564/3000 [00:02<00:14, 164.15it/s]\u001b[A\n 20%|█▉ | 598/3000 [00:02<00:12, 190.47it/s]\u001b[A\n 21%|██ | 628/3000 [00:02<00:11, 209.41it/s]\u001b[A\n 22%|██▏ | 659/3000 [00:03<00:10, 222.72it/s]\u001b[A\n 23%|██▎ | 684/3000 [00:03<00:14, 158.79it/s]\u001b[A\n 24%|██▎ | 705/3000 [00:03<00:14, 159.55it/s]\u001b[A\n 25%|██▍ | 737/3000 [00:03<00:12, 187.59it/s]\u001b[A\n 26%|██▌ | 768/3000 [00:03<00:10, 212.69it/s]\u001b[A\n 27%|██▋ | 805/3000 [00:03<00:09, 239.78it/s]\u001b[A\n 28%|██▊ | 837/3000 [00:03<00:10, 201.33it/s]\u001b[A\n 29%|██▉ | 869/3000 [00:04<00:09, 221.82it/s]\u001b[A\n 30%|██▉ | 895/3000 [00:04<00:12, 169.96it/s]\u001b[A\n 31%|███ | 917/3000 [00:04<00:12, 172.63it/s]\u001b[A\n 31%|███▏ | 944/3000 [00:04<00:10, 191.52it/s]\u001b[A\n 32%|███▏ | 970/3000 [00:04<00:10, 195.10it/s]\u001b[A\n 33%|███▎ | 994/3000 [00:04<00:09, 202.38it/s]\u001b[A\n 34%|███▍ | 1017/3000 [00:04<00:12, 162.00it/s]\u001b[A\n 35%|███▍ | 1039/3000 [00:05<00:11, 173.26it/s]\u001b[A\n 36%|███▌ | 1067/3000 [00:05<00:10, 190.74it/s]\u001b[A\n 36%|███▋ | 1088/3000 [00:05<00:10, 184.10it/s]\u001b[A\n 37%|███▋ | 1116/3000 [00:05<00:09, 204.92it/s]\u001b[A\n 38%|███▊ | 1139/3000 [00:05<00:09, 193.54it/s]\u001b[A\n 39%|███▉ | 1182/3000 [00:05<00:07, 230.09it/s]\u001b[A\n 40%|████ | 1209/3000 [00:05<00:08, 205.90it/s]\u001b[A\n 41%|████ | 1233/3000 [00:05<00:08, 198.89it/s]\u001b[A\n 42%|████▏ | 1256/3000 [00:06<00:09, 177.60it/s]\u001b[A\n 43%|████▎ | 1297/3000 [00:06<00:07, 213.31it/s]\u001b[A\n 44%|████▍ | 1323/3000 [00:06<00:07, 214.68it/s]\u001b[A\n 45%|████▍ | 1348/3000 [00:06<00:08, 204.07it/s]\u001b[A\n 46%|████▌ | 1377/3000 [00:06<00:07, 223.21it/s]\u001b[A\n 47%|████▋ | 1402/3000 [00:06<00:07, 206.65it/s]\u001b[A\n 48%|████▊ | 1425/3000 [00:06<00:09, 168.85it/s]\u001b[A\n 48%|████▊ | 1445/3000 [00:07<00:09, 169.38it/s]\u001b[A\n 49%|████▉ | 1465/3000 [00:07<00:08, 177.48it/s]\u001b[A\n 50%|████▉ | 1493/3000 [00:07<00:07, 199.04it/s]\u001b[A\n 50%|█████ | 1515/3000 [00:07<00:07, 186.91it/s]\u001b[A\n 51%|█████ | 1537/3000 [00:07<00:07, 194.51it/s]\u001b[A\n 52%|█████▏ | 1566/3000 [00:07<00:06, 215.76it/s]\u001b[A\n 53%|█████▎ | 1590/3000 [00:07<00:07, 198.93it/s]\u001b[A\n 55%|█████▍ | 1636/3000 [00:07<00:06, 219.00it/s]\u001b[A\n 55%|█████▌ | 1660/3000 [00:07<00:06, 205.44it/s]\u001b[A\n 56%|█████▌ | 1682/3000 [00:08<00:07, 168.28it/s]\u001b[A\n 57%|█████▋ | 1703/3000 [00:08<00:07, 177.75it/s]\u001b[A\n 58%|█████▊ | 1733/3000 [00:08<00:06, 201.62it/s]\u001b[A\n 59%|█████▊ | 1756/3000 [00:08<00:06, 197.40it/s]\u001b[A\n 60%|█████▉ | 1786/3000 [00:08<00:06, 199.90it/s]\u001b[A\n 61%|██████ | 1822/3000 [00:08<00:05, 230.49it/s]\u001b[A\n 62%|██████▏ | 1848/3000 [00:08<00:05, 205.61it/s]\u001b[A\n 62%|██████▏ | 1871/3000 [00:09<00:05, 198.99it/s]\u001b[A\n 64%|██████▎ | 1909/3000 [00:09<00:04, 231.46it/s]\u001b[A\n 65%|██████▍ | 1936/3000 [00:09<00:05, 203.28it/s]\u001b[A\n 65%|██████▌ | 1960/3000 [00:09<00:05, 192.80it/s]\u001b[A\n 67%|██████▋ | 1998/3000 [00:09<00:04, 225.77it/s]\u001b[A\n 68%|██████▊ | 2025/3000 [00:09<00:04, 204.75it/s]\u001b[A\n 68%|██████▊ | 2049/3000 [00:09<00:04, 203.93it/s]\u001b[A\n 69%|██████▉ | 2072/3000 [00:10<00:05, 164.32it/s]\u001b[A\n 71%|███████ | 2117/3000 [00:10<00:04, 201.95it/s]\u001b[A\n 71%|███████▏ | 2144/3000 [00:10<00:04, 175.31it/s]\u001b[A\n 73%|███████▎ | 2185/3000 [00:10<00:03, 208.49it/s]\u001b[A\n 74%|███████▍ | 2213/3000 [00:10<00:03, 225.14it/s]\u001b[A\n 75%|███████▍ | 2249/3000 [00:10<00:02, 252.89it/s]\u001b[A\n 76%|███████▌ | 2279/3000 [00:10<00:03, 202.09it/s]\u001b[A\n 77%|███████▋ | 2304/3000 [00:10<00:03, 212.22it/s]\u001b[A\n 78%|███████▊ | 2329/3000 [00:11<00:03, 192.69it/s]\u001b[A\n 78%|███████▊ | 2352/3000 [00:11<00:03, 181.96it/s]\u001b[A\n 80%|███████▉ | 2388/3000 [00:11<00:02, 210.10it/s]\u001b[A\n 81%|████████ | 2424/3000 [00:11<00:02, 232.47it/s]\u001b[A\n 82%|████████▏ | 2456/3000 [00:11<00:02, 241.14it/s]\u001b[A\n 83%|████████▎ | 2483/3000 [00:11<00:02, 208.94it/s]\u001b[A\n 84%|████████▎ | 2507/3000 [00:11<00:02, 192.20it/s]\u001b[A\n 85%|████████▍ | 2540/3000 [00:12<00:02, 219.70it/s]\u001b[A\n 86%|████████▌ | 2565/3000 [00:12<00:01, 226.56it/s]\u001b[A\n 86%|████████▋ | 2590/3000 [00:12<00:02, 171.05it/s]\u001b[A\n 87%|████████▋ | 2620/3000 [00:12<00:01, 195.93it/s]\u001b[A\n 88%|████████▊ | 2653/3000 [00:12<00:01, 219.99it/s]\u001b[A\n 90%|████████▉ | 2687/3000 [00:12<00:01, 232.49it/s]\u001b[A\n 90%|█████████ | 2713/3000 [00:12<00:01, 192.55it/s]\u001b[A\n 91%|█████████ | 2736/3000 [00:12<00:01, 196.98it/s]\u001b[A\n 92%|█████████▏| 2765/3000 [00:13<00:01, 216.89it/s]\u001b[A\n 93%|█████████▎| 2789/3000 [00:13<00:01, 189.73it/s]\u001b[A\n 94%|█████████▍| 2815/3000 [00:13<00:01, 121.23it/s]\u001b[A\n 95%|█████████▍| 2842/3000 [00:13<00:01, 144.78it/s]\u001b[A\n 96%|█████████▌| 2877/3000 [00:13<00:00, 175.31it/s]\u001b[A\n 97%|█████████▋| 2902/3000 [00:13<00:00, 188.27it/s]\u001b[A\n 98%|█████████▊| 2936/3000 [00:14<00:00, 216.09it/s]\u001b[A\n 99%|█████████▉| 2963/3000 [00:14<00:00, 208.21it/s]\u001b[A\n100%|██████████| 3000/3000 [00:14<00:00, 208.06it/s]\u001b[A\n100%|██████████| 10/10 [02:12<00:00, 13.24s/it]\n"
],
[
"print(tf.test.is_gpu_available())",
"WARNING:tensorflow:From <ipython-input-109-ae932be897c3>:1: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.config.list_physical_devices('GPU')` instead.\nTrue\n"
],
[
"path = os.path.join(data_path, \"ms_and_ind\")\n#path = \"/home/fatima_tuz_zehra/Dataset/eurosat-all\"\n\nlabels = os.listdir(path)\nlabels",
"_____no_output_____"
],
[
"data = dict()\nfor label in labels:\n imgs = os.listdir(os.path.join(DATA_DIR,label))\n for img in imgs:\n data[os.path.join(DATA_DIR,label,img)] = label\n \ndata = pd.DataFrame(data.items())\ny = data[1]\nX_train, X_test, y_train, y_test = train_test_split(data, y, test_size=0.2, random_state=42,shuffle=True)",
"_____no_output_____"
],
[
"X_train.to_csv(os.path.join(ms_dir,\"train.csv\"),index = False)\nX_test.to_csv(os.path.join(ms_dir,\"test.csv\"),index = False)",
"_____no_output_____"
],
[
"tr = pd.read_csv(os.path.join(ms_dir,\"train.csv\"))\nts = pd.read_csv(os.path.join(ms_dir,\"test.csv\"))",
"_____no_output_____"
],
[
"tr[0:6]['0']",
"_____no_output_____"
],
[
"for each in tr[0:6]['0']:\n print(each)",
"/home/fatima_tuz_zehra/Dataset/eurosat-all/Pasture/Pasture_1456.tif\n/home/fatima_tuz_zehra/Dataset/eurosat-all/Industrial/Industrial_173.tif\n/home/fatima_tuz_zehra/Dataset/eurosat-all/HerbaceousVegetation/HerbaceousVegetation_2696.tif\n/home/fatima_tuz_zehra/Dataset/eurosat-all/SeaLake/SeaLake_2051.tif\n/home/fatima_tuz_zehra/Dataset/eurosat-all/Industrial/Industrial_1148.tif\n/home/fatima_tuz_zehra/Dataset/eurosat-all/SeaLake/SeaLake_287.tif\n"
],
[
"def data_generator(file = \"train\", batch_size = 32):\n \n batch_Y= []\n idx = 0\n \n if file == \"train\":\n df = pd.read_csv(os.path.join(ms_dir,\"train.csv\"))\n y = pd.get_dummies(df['1'])\n else:\n df = pd.read_csv(os.path.join(ms_dir,\"test.csv\"))\n y = pd.get_dummies(df['1'])\n \n num_records = len(df)\n i = 0\n \n while i != -1:\n batch_X = []\n \n idx += batch_size\n if idx < len(df)-1:\n samples = df[idx-batch_size:idx]['0']\n batch_Y = y[idx-batch_size:idx]\n \n else:\n i = -1\n samples = df[idx-batch_size:len(df)]['0']\n batch_Y = y[idx-batch_size:len(df)]\n \n \n \n \n for sample in samples:\n image = tifffile.imread(sample)\n x = np.moveaxis(image,0,-1)\n batch_X.append(x)\n \n \n \n yield [np.array(batch_X)], batch_Y.to_numpy()\n \n return\n \n\n \n \n \n \n ",
"_____no_output_____"
],
[
"def get_model(lr, tune = None):\n resnet = ResNet50(include_top=False,\n weights=None ,\n input_shape=(64,64,10))\n model = resnet.output\n model = Flatten()(model)\n model = Dense(2048, activation='relu')(model)\n model = Dropout(0.3)(model)\n\n output = Dense(10, activation='softmax')(model)\n\n model = Model(inputs=resnet.input, outputs=output)\n \n if(tune == 0):\n for layer in resnet.layers:\n layer.trainable = True\n \n else:\n for layer in resnet.layers:\n layer.trainable = False\n \n\n model.compile(optimizer=Adam(lr = lr), loss='categorical_crossentropy',\n metrics=['categorical_accuracy'])\n return model",
"_____no_output_____"
],
[
"rgb_model = tf.keras.models.load_model(os.path.join(model_dir,\"best.hdf5\"))",
"_____no_output_____"
],
[
"model = get_model(lr = 1e-3,tune=0)",
"_____no_output_____"
],
[
"for layer in rgb_model.layers:\n print(layer)\n weights = layer.get_weights()\n for i in range(len(weights)):\n print(weights[i].shape)",
"<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7fdd4cd2cfd0>\n<tensorflow.python.keras.layers.convolutional.ZeroPadding2D object at 0x7fdd4cd31750>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd31850>\n(7, 7, 3, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cd31710>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cd367d0>\n<tensorflow.python.keras.layers.convolutional.ZeroPadding2D object at 0x7fdd4cd36910>\n<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fdd4cd2cf50>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd36cd0>\n(1, 1, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cd3a750>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cd31b10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd3aed0>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cd3f610>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cd3fc10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd3fd50>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccc6510>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccc6b90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd7461ca10>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4ccca610>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccca750>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cccaa10>\n(1, 1, 256, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cdf8990>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccd0790>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccd08d0>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccd0fd0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccd6690>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccd67d0>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccd6f50>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cccaed0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccda6d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccda990>\n(1, 1, 256, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccd6fd0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cce0710>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cce0850>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cce0fd0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cce5610>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cce5750>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cce5ed0>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4ccdae50>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cce9650>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cce9910>\n(1, 1, 256, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cce9fd0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccf1690>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccf17d0>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccf1f50>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cce5f90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccf66d0>\n(1, 1, 256, 512)\n(512,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccf6e50>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccfd510>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccfdb10>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4ccf1fd0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc83250>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc83510>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc83c50>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccfdfd0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc893d0>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc89b50>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc83fd0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc8d2d0>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc8da50>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc8dfd0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc921d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc92490>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc92bd0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc89fd0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc98350>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc98ad0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc98f90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc9d250>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc9d990>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc9df90>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc9df10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cca4390>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cdf8110>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cca4f50>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccaa150>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccaa8d0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccaaed0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccaaf90>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccb0790>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4ccb0d90>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccb0ed0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccb51d0>\n(1, 1, 512, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccb5910>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccb5f10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccb5fd0>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccb9810>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4ccb9e10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccb9f50>\n(1, 1, 512, 1024)\n(1024,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4ccbf710>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccbfd50>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc92fd0>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc46990>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc46ad0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc46d90>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc4a510>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc4ab10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc4ac50>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc51410>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc51a10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc51b50>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc57310>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc57910>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc57a50>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc57d10>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc5b490>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc5ba90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc5bbd0>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc61390>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc61990>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc61ad0>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4ccbfe10>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc66890>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc669d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc66c90>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc6a410>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc6aa10>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc6ab50>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc74310>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc74910>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc74a50>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc61fd0>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc78810>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc78950>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc78c10>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc7e390>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc7e990>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc7ead0>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc74f50>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc02890>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc029d0>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc7efd0>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc07790>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc078d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc07b90>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc0d310>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc0d910>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc0da50>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc02ed0>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc13810>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc13950>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc0df50>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc16710>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc16850>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc16b10>\n(1, 1, 1024, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc13e50>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc1f890>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc1f9d0>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc16fd0>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc23790>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc238d0>\n(1, 1, 1024, 2048)\n(2048,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc23fd0>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc28710>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc28d10>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc1fed0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc2e490>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc2e750>\n(1, 1, 2048, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc2ee90>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc28dd0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc33610>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc33d90>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc2ef50>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc3a510>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc3ac90>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cc33e50>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc3f410>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cc3f6d0>\n(1, 1, 2048, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cc3fe10>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc3ad50>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cbc3590>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cbc3d10>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cc3fed0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cbcc490>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cbccc10>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cbc3dd0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cbd2390>\n<tensorflow.python.keras.layers.core.Flatten object at 0x7fdd4cbd2650>\n<tensorflow.python.keras.layers.core.Dense object at 0x7fdd4cbd2990>\n(8192, 2048)\n(2048,)\n<tensorflow.python.keras.layers.core.Dropout object at 0x7fdd4cbd2dd0>\n<tensorflow.python.keras.layers.core.Dense object at 0x7fdd4cbd2f50>\n(2048, 10)\n(10,)\n"
],
[
"for layer in model.layers:\n print(layer)\n weights = layer.get_weights()\n for i in range(len(weights)):\n print(weights[i].shape)",
"<tensorflow.python.keras.engine.input_layer.InputLayer object at 0x7fdd4c0e8d50>\n<tensorflow.python.keras.layers.convolutional.ZeroPadding2D object at 0x7fdd4c0e8f90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c1a7fd0>\n(7, 7, 10, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c033b10>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cdafc50>\n<tensorflow.python.keras.layers.convolutional.ZeroPadding2D object at 0x7fdd4cdb2690>\n<tensorflow.python.keras.layers.pooling.MaxPooling2D object at 0x7fdd4c0ffe90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd00050>\n(1, 1, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4cd4f2d0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cd582d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4cd59810>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30d47ad0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4cd5fb90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c0ebc90>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30d5b190>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c0efcd0>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30d77f90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4c003090>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30d615d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c002dd0>\n(1, 1, 256, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c041690>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4c047310>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c047ed0>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c079a90>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4c083350>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c087890>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c0b0b10>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4c08dc10>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4c0bc250>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c0bc350>\n(1, 1, 256, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30d24cd0>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30d28510>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30d2d490>\n(3, 3, 64, 64)\n(64,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30cd9710>\n(64,)\n(64,)\n(64,)\n(64,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30cdb550>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30cdbed0>\n(1, 1, 64, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30c87a90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30c8f350>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30c918d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30c45550>\n(1, 1, 256, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30c6cfd0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30c79310>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30c79ed0>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30c24ad0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30c2a350>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30c91950>\n(1, 1, 256, 512)\n(512,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30c2f890>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30c3fcd0>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30bd9b10>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30c34c10>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30be5250>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30be5350>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30b90cd0>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30b95550>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30b924d0>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30b46750>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30b4a110>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30b4af50>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30b74b10>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30afb3d0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30afe950>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30afe9d0>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30b2cd10>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30b32590>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30b37b10>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30ae4950>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30ae1050>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30aed550>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30a9b7d0>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30a9eed0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30aa3890>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30aa3090>\n(1, 1, 512, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30a52990>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30a5e150>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30aab350>\n(3, 3, 128, 128)\n(128,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30a02e10>\n(128,)\n(128,)\n(128,)\n(128,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30a091d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30a0fb90>\n(1, 1, 128, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30a399d0>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd309bd050>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd309c3610>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd309f6bd0>\n(1, 1, 512, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd309a02d0>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd309a85d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd309acb50>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30959990>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3095f050>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd309c3690>\n(1, 1, 512, 1024)\n(1024,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30963590>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd309f0fd0>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd3090e810>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30913f10>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd309158d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd309150d0>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd308c79d0>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd308cc250>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd308d5090>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd308d5550>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3087c790>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30881b90>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd308ada10>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd308b2090>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd308b7650>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd308b76d0>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30864990>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30869290>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd3086c810>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd3081ba90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30872b90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30825190>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd307cbf90>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd307d2090>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd307d7c90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd307d7d10>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30789690>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3078c310>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd3078ced0>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd307b8a90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3073e350>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30742890>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30770b10>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30748bd0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30779590>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30779390>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30726c90>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3072d510>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30731490>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd306dc750>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd306e1110>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd306e1f50>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd3068bb10>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd306943d0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30699950>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd306999d0>\n(1, 1, 1024, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30644d10>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3064c590>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30650b10>\n(3, 3, 256, 256)\n(256,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd305fc950>\n(256,)\n(256,)\n(256,)\n(256,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30601050>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30607550>\n(1, 1, 256, 1024)\n(1024,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd306357d0>\n(1024,)\n(1024,)\n(1024,)\n(1024,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30638ed0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd305bd890>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd3057b150>\n(1, 1, 1024, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd3059a710>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd305a2550>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd305a64d0>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30551790>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30557e90>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd305bd090>\n(1, 1, 1024, 2048)\n(2048,)\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd30557fd0>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd305ea990>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30501b90>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd30509450>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd3050c9d0>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd305317d0>\n(1, 1, 2048, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30539d90>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd304c0150>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd304c4b90>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd304f19d0>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd304f6050>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd3047b610>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd304a8890>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd304b8110>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd304b3810>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd304b3090>\n(1, 1, 2048, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd30460a50>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd304b8410>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd3046b190>\n(3, 3, 512, 512)\n(512,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd3040df90>\n(512,)\n(512,)\n(512,)\n(512,)\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd30416090>\n<tensorflow.python.keras.layers.convolutional.Conv2D object at 0x7fdd4c1a4710>\n(1, 1, 512, 2048)\n(2048,)\n<tensorflow.python.keras.layers.normalization_v2.BatchNormalization object at 0x7fdd4c1a6210>\n(2048,)\n(2048,)\n(2048,)\n(2048,)\n<tensorflow.python.keras.layers.merge.Add object at 0x7fdd4cdad4d0>\n<tensorflow.python.keras.layers.core.Activation object at 0x7fdd4c142310>\n<tensorflow.python.keras.layers.core.Flatten object at 0x7fdd4cddddd0>\n<tensorflow.python.keras.layers.core.Dense object at 0x7fdd4efa5510>\n(8192, 2048)\n(2048,)\n<tensorflow.python.keras.layers.core.Dropout object at 0x7fdd4eee45d0>\n<tensorflow.python.keras.layers.core.Dense object at 0x7fdd4d857610>\n(2048, 10)\n(10,)\n"
],
[
"channel_weights = rgb_model.layers[2].get_weights()\ndiff_w = channel_weights[0]\n\nmulti_channel_weights = model.layers[2].get_weights()\nrep_w = multi_channel_weights[0]\n\nfor i in range(10):\n if i < 3 :\n rep_w[:,:,i,:] = diff_w[:,:,i,:]\n else:\n rep_w[:,:,i,:] = diff_w[:,:,0,:]\nrep_single = rgb_model.layers[2].get_weights()[1]\narr_weights = [rep_w, rep_single]\n\nfor i in range(len(model.layers)):\n if i == 2:\n model.layers[i].set_weights(arr_weights)\n else:\n model.layers[i].set_weights(rgb_model.layers[i].get_weights())\n\nmodel.save(os.path.join(model_dir,\"loaded-ms.hdf5\")) ",
"_____no_output_____"
],
[
"pretrained = tf.keras.models.load_model(os.path.join(model_dir,\"loaded-ms.hdf5\"))",
"_____no_output_____"
],
[
"checkpoint = ModelCheckpoint(filepath = ms_dir + '/all-bands.hdf5',\n monitor='val_categorical_accuracy',\n save_best_only=True,\n verbose=1)\n\nfor i in range(10):\n train_gen = data_generator(file = \"train\", batch_size = 32)\n test_gen = data_generator(file = \"test\", batch_size = 16)\n pretrained.fit(train_gen, steps_per_epoch=len(tr)//32, epochs=1, validation_data=test_gen,validation_steps=len(ts)//16,callbacks=[checkpoint])",
"675/675 [==============================] - ETA: 0s - loss: 1.0770 - categorical_accuracy: 0.7908\nEpoch 00001: val_categorical_accuracy improved from -inf to 0.74017, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 313s 463ms/step - loss: 1.0770 - categorical_accuracy: 0.7908 - val_loss: 0.8833 - val_categorical_accuracy: 0.7402\n675/675 [==============================] - ETA: 0s - loss: 0.4324 - categorical_accuracy: 0.8858\nEpoch 00001: val_categorical_accuracy improved from 0.74017 to 0.84996, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 71s 105ms/step - loss: 0.4324 - categorical_accuracy: 0.8858 - val_loss: 0.4759 - val_categorical_accuracy: 0.8500\n675/675 [==============================] - ETA: 0s - loss: 0.3554 - categorical_accuracy: 0.9104\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 68s 101ms/step - loss: 0.3554 - categorical_accuracy: 0.9104 - val_loss: 0.6462 - val_categorical_accuracy: 0.8249\n675/675 [==============================] - ETA: 0s - loss: 0.2772 - categorical_accuracy: 0.9269\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 67s 99ms/step - loss: 0.2772 - categorical_accuracy: 0.9269 - val_loss: 20.6082 - val_categorical_accuracy: 0.5453\n675/675 [==============================] - ETA: 0s - loss: 0.2934 - categorical_accuracy: 0.9234\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 67s 100ms/step - loss: 0.2934 - categorical_accuracy: 0.9234 - val_loss: 0.6520 - val_categorical_accuracy: 0.7947\n675/675 [==============================] - ETA: 0s - loss: 0.1920 - categorical_accuracy: 0.9460\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 69s 101ms/step - loss: 0.1920 - categorical_accuracy: 0.9460 - val_loss: 0.5776 - val_categorical_accuracy: 0.8414\n675/675 [==============================] - ETA: 0s - loss: 1.0779 - categorical_accuracy: 0.7102\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 68s 101ms/step - loss: 1.0779 - categorical_accuracy: 0.7102 - val_loss: 1.8591 - val_categorical_accuracy: 0.5903\n675/675 [==============================] - ETA: 0s - loss: 0.5754 - categorical_accuracy: 0.8167\nEpoch 00001: val_categorical_accuracy did not improve from 0.84996\n675/675 [==============================] - 68s 100ms/step - loss: 0.5754 - categorical_accuracy: 0.8167 - val_loss: 1.0169 - val_categorical_accuracy: 0.7174\n675/675 [==============================] - ETA: 0s - loss: 0.3646 - categorical_accuracy: 0.8819\nEpoch 00001: val_categorical_accuracy improved from 0.84996 to 0.90393, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 73s 108ms/step - loss: 0.3646 - categorical_accuracy: 0.8819 - val_loss: 0.2803 - val_categorical_accuracy: 0.9039\n675/675 [==============================] - ETA: 0s - loss: 0.2850 - categorical_accuracy: 0.9073\nEpoch 00001: val_categorical_accuracy improved from 0.90393 to 0.92044, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 73s 109ms/step - loss: 0.2850 - categorical_accuracy: 0.9073 - val_loss: 0.2449 - val_categorical_accuracy: 0.9204\n"
],
[
"for i in range(3):\n train_gen = data_generator(file = \"train\", batch_size = 32)\n test_gen = data_generator(file = \"test\", batch_size = 16)\n pretrained.fit(train_gen, steps_per_epoch=len(tr)//32, epochs=1, validation_data=test_gen,validation_steps=len(ts)//16,callbacks=[checkpoint])",
"675/675 [==============================] - ETA: 0s - loss: 0.2340 - categorical_accuracy: 0.9234\nEpoch 00001: val_categorical_accuracy did not improve from 0.92044\n675/675 [==============================] - 70s 103ms/step - loss: 0.2340 - categorical_accuracy: 0.9234 - val_loss: 0.2617 - val_categorical_accuracy: 0.9162\n675/675 [==============================] - ETA: 0s - loss: 0.2107 - categorical_accuracy: 0.9314\nEpoch 00001: val_categorical_accuracy did not improve from 0.92044\n675/675 [==============================] - 79s 117ms/step - loss: 0.2107 - categorical_accuracy: 0.9314 - val_loss: 0.4728 - val_categorical_accuracy: 0.8531\n675/675 [==============================] - ETA: 0s - loss: 0.2052 - categorical_accuracy: 0.9332\nEpoch 00001: val_categorical_accuracy did not improve from 0.92044\n675/675 [==============================] - 68s 101ms/step - loss: 0.2052 - categorical_accuracy: 0.9332 - val_loss: 0.9372 - val_categorical_accuracy: 0.7342\n"
],
[
"pretrained.load_weights(ms_dir + '/all-bands.hdf5')\npretrained.optimizer.lr = 0.0001\nfor i in range(10):\n train_gen = data_generator(file = \"train\", batch_size = 32)\n test_gen = data_generator(file = \"test\", batch_size = 16)\n pretrained.fit(train_gen, steps_per_epoch=len(tr)//32, epochs=1, validation_data=test_gen,validation_steps=len(ts)//16,callbacks=[checkpoint])",
"675/675 [==============================] - ETA: 0s - loss: 0.1589 - categorical_accuracy: 0.9488\nEpoch 00001: val_categorical_accuracy improved from 0.92044 to 0.94881, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 78s 115ms/step - loss: 0.1589 - categorical_accuracy: 0.9488 - val_loss: 0.1549 - val_categorical_accuracy: 0.9488\n675/675 [==============================] - ETA: 0s - loss: 0.1252 - categorical_accuracy: 0.9601\nEpoch 00001: val_categorical_accuracy did not improve from 0.94881\n675/675 [==============================] - 68s 101ms/step - loss: 0.1252 - categorical_accuracy: 0.9601 - val_loss: 0.1836 - val_categorical_accuracy: 0.9395\n675/675 [==============================] - ETA: 0s - loss: 0.1045 - categorical_accuracy: 0.9658\nEpoch 00001: val_categorical_accuracy did not improve from 0.94881\n675/675 [==============================] - 69s 102ms/step - loss: 0.1045 - categorical_accuracy: 0.9658 - val_loss: 0.1851 - val_categorical_accuracy: 0.9423\n675/675 [==============================] - ETA: 0s - loss: 0.0874 - categorical_accuracy: 0.9718\nEpoch 00001: val_categorical_accuracy improved from 0.94881 to 0.95215, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 73s 108ms/step - loss: 0.0874 - categorical_accuracy: 0.9718 - val_loss: 0.1683 - val_categorical_accuracy: 0.9522\n675/675 [==============================] - ETA: 0s - loss: 0.0709 - categorical_accuracy: 0.9757\nEpoch 00001: val_categorical_accuracy did not improve from 0.95215\n675/675 [==============================] - 69s 102ms/step - loss: 0.0709 - categorical_accuracy: 0.9757 - val_loss: 0.2189 - val_categorical_accuracy: 0.9388\n675/675 [==============================] - ETA: 0s - loss: 0.0572 - categorical_accuracy: 0.9812\nEpoch 00001: val_categorical_accuracy did not improve from 0.95215\n675/675 [==============================] - 68s 101ms/step - loss: 0.0572 - categorical_accuracy: 0.9812 - val_loss: 0.2402 - val_categorical_accuracy: 0.9397\n675/675 [==============================] - ETA: 0s - loss: 0.0451 - categorical_accuracy: 0.9850\nEpoch 00001: val_categorical_accuracy did not improve from 0.95215\n675/675 [==============================] - 70s 103ms/step - loss: 0.0451 - categorical_accuracy: 0.9850 - val_loss: 0.2329 - val_categorical_accuracy: 0.9470\n675/675 [==============================] - ETA: 0s - loss: 0.0394 - categorical_accuracy: 0.9868\nEpoch 00001: val_categorical_accuracy improved from 0.95215 to 0.95475, saving model to /home/fatima_tuz_zehra/Dataset/euro-rgb-new/all-bands.hdf5\n675/675 [==============================] - 74s 110ms/step - loss: 0.0394 - categorical_accuracy: 0.9868 - val_loss: 0.2203 - val_categorical_accuracy: 0.9547\n675/675 [==============================] - ETA: 0s - loss: 0.0318 - categorical_accuracy: 0.9897\nEpoch 00001: val_categorical_accuracy did not improve from 0.95475\n675/675 [==============================] - 69s 103ms/step - loss: 0.0318 - categorical_accuracy: 0.9897 - val_loss: 0.2417 - val_categorical_accuracy: 0.9533\n675/675 [==============================] - ETA: 0s - loss: 0.0241 - categorical_accuracy: 0.9923\nEpoch 00001: val_categorical_accuracy did not improve from 0.95475\n675/675 [==============================] - 70s 104ms/step - loss: 0.0241 - categorical_accuracy: 0.9923 - val_loss: 0.3108 - val_categorical_accuracy: 0.9405\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4acae390409e4f526249a9a9fce480da8af6d51c
| 3,408 |
ipynb
|
Jupyter Notebook
|
notebooks/Plot Ocean Pole Tide Map.ipynb
|
bludka/pyTMD
|
2f866508f743b8b130b21c5379c400b39f73d3f0
|
[
"MIT"
] | 47 |
2019-09-29T07:46:39.000Z
|
2022-03-17T08:41:49.000Z
|
notebooks/Plot Ocean Pole Tide Map.ipynb
|
bludka/pyTMD
|
2f866508f743b8b130b21c5379c400b39f73d3f0
|
[
"MIT"
] | 54 |
2020-06-11T08:51:34.000Z
|
2022-03-29T01:58:24.000Z
|
notebooks/Plot Ocean Pole Tide Map.ipynb
|
bludka/pyTMD
|
2f866508f743b8b130b21c5379c400b39f73d3f0
|
[
"MIT"
] | 13 |
2019-11-03T05:38:01.000Z
|
2022-03-28T07:35:49.000Z
| 28.881356 | 159 | 0.606514 |
[
[
[
"## Plot Ocean Pole Tide Map\nPlots maps of the real and imaginary geocentric pole tide admittance functions from [Desai et al. (2002)](https://doi.org/10.1029/2001JC001224)\n\n- [IERS map of ocean pole tide coefficients](ftp://maia.usno.navy.mil/conventions/2010/2010_update/chapter7/additional_info/opoleloadcoefcmcor.txt.gz)\n\n#### Python Dependencies\n - [numpy: Scientific Computing Tools For Python](https://www.numpy.org) \n - [matplotlib: Python 2D plotting library](http://matplotlib.org/) \n - [cartopy: Python package designed for geospatial data processing](https://scitools.org.uk/cartopy/docs/latest/) \n\n#### Program Dependencies\n\n- `utilities.py`: Download and management utilities for files\n- `read_ocean_pole_tide.py`: Read ocean pole load tide map from IERS",
"_____no_output_____"
],
[
"#### Load modules",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport cartopy.crs as ccrs\nfrom pyTMD.utilities import get_data_path\nfrom pyTMD.read_ocean_pole_tide import read_ocean_pole_tide",
"_____no_output_____"
]
],
[
[
"#### Read ocean pole tide coefficient maps",
"_____no_output_____"
]
],
[
[
"# read ocean pole tide map from Desai (2002)\nocean_pole_tide_file = get_data_path(['data','opoleloadcoefcmcor.txt.gz'])\niur,iun,iue,ilon,ilat = read_ocean_pole_tide(ocean_pole_tide_file)",
"_____no_output_____"
]
],
[
[
"#### Plot ocean pole tide maps",
"_____no_output_____"
]
],
[
[
"fig,(ax1,ax2) = plt.subplots(ncols=2,sharex=True,sharey=True,figsize=(10,4),\n subplot_kw=dict(projection=ccrs.PlateCarree()))\nax1.imshow(iur.real.T,extent=(ilon[0],ilon[-1],ilat[0],ilat[-1]),origin='lower')\nax2.imshow(iur.imag.T,extent=(ilon[0],ilon[-1],ilat[0],ilat[-1]),origin='lower')\nax1.set_title('Radial Ocean Pole Tide (real component)')\nax2.set_title('Radial Ocean Pole Tide (imaginary component)')\nax1.coastlines(); ax2.coastlines()\nfig.subplots_adjust(left=0.01, right=0.99, bottom=0.10, top=0.95, wspace=0.05)\nplt.show()\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4acb0ddc0b05bf879c7706b1bebcaf1e2d9f010d
| 264,477 |
ipynb
|
Jupyter Notebook
|
code/soln/chap03soln.ipynb
|
flothesof/ThinkBayes2
|
c56895e57fdecc17389bc9980f5db4eeb3b8c1df
|
[
"MIT"
] | 1 |
2021-08-14T05:08:54.000Z
|
2021-08-14T05:08:54.000Z
|
code/soln/chap03soln.ipynb
|
flothesof/ThinkBayes2
|
c56895e57fdecc17389bc9980f5db4eeb3b8c1df
|
[
"MIT"
] | null | null | null |
code/soln/chap03soln.ipynb
|
flothesof/ThinkBayes2
|
c56895e57fdecc17389bc9980f5db4eeb3b8c1df
|
[
"MIT"
] | 1 |
2021-08-14T05:08:55.000Z
|
2021-08-14T05:08:55.000Z
| 171.404407 | 27,304 | 0.90744 |
[
[
[
"# Think Bayes\n\nSecond Edition\n\nCopyright 2020 Allen B. Downey\n\nLicense: [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)",
"_____no_output_____"
]
],
[
[
"# If we're running on Colab, install empiricaldist\n# https://pypi.org/project/empiricaldist/\n\nimport sys\nIN_COLAB = 'google.colab' in sys.modules\n\nif IN_COLAB:\n !pip install empiricaldist",
"_____no_output_____"
],
[
"# Get utils.py and create directories\n\nimport os\n\nif not os.path.exists('utils.py'):\n !wget https://github.com/AllenDowney/ThinkBayes2/raw/master/code/soln/utils.py\n \nif not os.path.exists('figs'):\n !mkdir figs\n \nif not os.path.exists('tables'):\n !mkdir tables",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nfrom empiricaldist import Pmf\nfrom utils import decorate, savefig",
"_____no_output_____"
]
],
[
[
"## The Euro Problem\n\nIn *Information Theory, Inference, and Learning Algorithms*, David MacKay poses this problem:\n\n\"A statistical statement appeared in *The Guardian* on Friday January 4, 2002:\n\n>When spun on edge 250 times, a Belgian one-euro coin came\n up heads 140 times and tails 110. 'It looks very suspicious\n to me,' said Barry Blight, a statistics lecturer at the London\n School of Economics. 'If the coin were unbiased, the chance of\n getting a result as extreme as that would be less than 7\\%.'\n\n\"But [MacKay asks] do these data give evidence that the coin is biased rather than fair?\"\n\nTo answer that question, we'll proceed in two steps.\nFirst we'll use the binomial distribution to see where that 7% came from; then we'll use Bayes's Theorem to estimate the probability that this coin comes up heads.\n",
"_____no_output_____"
],
[
"## The binomial distribution\n\nSuppose I tell you that a coin is \"fair\", that is, the probability of heads is 50%. If you spin it twice, there are four outcomes: `HH`, `HT`, `TH`, and `TT`. All four outcomes have the same probability, 25%. \n\nIf we add up the total number of heads, there are three possible outcomes: 0, 1, or 2. The probability of 0 and 2 is 25%, and the probability of 1 is 50%.\n\nMore generally, suppose the probability of heads is `p` and we spin the coin `n` times. What is the probability that we get a total of `k` heads?\n\nThe answer is given by the binomial distribution:\n\n$P(k; n, p) = \\binom{n}{k} p^k (1-p)^{n-k}$\n\nwhere $\\binom{n}{k}$ is the [binomial coefficient](https://en.wikipedia.org/wiki/Binomial_coefficient), usually pronounced \"n choose k\".\n\nWe can compute the binomial distribution ourselves, but we can also use the SciPy function `binom.pmf`:",
"_____no_output_____"
]
],
[
[
"from scipy.stats import binom\n\nn = 2\np = 0.5\nks = np.arange(n+1)\n\na = binom.pmf(ks, n, p)\na",
"_____no_output_____"
]
],
[
[
"If we put this array in a `Pmf`, the result is the distribution of `k` for the given values of `n` and `p`.",
"_____no_output_____"
]
],
[
[
"pmf_k = Pmf(a, ks)\npmf_k",
"_____no_output_____"
],
[
"from utils import write_pmf\nwrite_pmf(pmf_k, 'table03-01')",
"_____no_output_____"
]
],
[
[
"The following function computes the binomial distribution for given values of `n` and `p`:",
"_____no_output_____"
]
],
[
[
"def make_binomial(n, p):\n \"\"\"Make a binomial PMF.\n \n n: number of spins\n p: probability of heads\n \n returns: Pmf representing the distribution\n \"\"\"\n ks = np.arange(n+1)\n a = binom.pmf(ks, n, p)\n return Pmf(a, ks)",
"_____no_output_____"
]
],
[
[
"And here's what it looks like with `n=250` and `p=0.5`:",
"_____no_output_____"
]
],
[
[
"pmf_k = make_binomial(n=250, p=0.5)\npmf_k.plot(label='n=250, p=0.5')\n\ndecorate(xlabel='Number of heads (k)',\n ylabel='PMF',\n title='Binomial distribution')\n\nsavefig('fig03-01')",
"_____no_output_____"
]
],
[
[
"The most likely value in this distribution is 125:",
"_____no_output_____"
]
],
[
[
"pmf_k.max_prob()",
"_____no_output_____"
]
],
[
[
"But even though it is the most likely value, the probability that we get exactly 125 heads is only about 5%.",
"_____no_output_____"
]
],
[
[
"pmf_k[125]",
"_____no_output_____"
]
],
[
[
"In MacKay's example, we got 140 heads, which is less likely than 125:",
"_____no_output_____"
]
],
[
[
"pmf_k[140]",
"_____no_output_____"
]
],
[
[
"In the article MacKay quotes, the statistician says, ‘If the coin were unbiased the chance of getting a result as extreme as that would be less than 7%’.\n\nWe can use the binomial distribution to check his math. The following function takes a PMF and computes the total probability of values greater than or equal to `threshold`. ",
"_____no_output_____"
]
],
[
[
"def ge_dist(pmf, threshold):\n \"\"\"Probability of values greater than a threshold.\n \n pmf: Series representing a PMF\n threshold: value to compare to\n \n returns: probability\n \"\"\"\n ge = (pmf.index >= threshold)\n total = pmf[ge].sum()\n return total",
"_____no_output_____"
]
],
[
[
"Here's the probability of getting 140 heads or more:",
"_____no_output_____"
]
],
[
[
"ge_dist(pmf_k, 140)",
"_____no_output_____"
]
],
[
[
"`Pmf` provides a method that does the same computation.",
"_____no_output_____"
]
],
[
[
"pmf_k.ge_dist(140)",
"_____no_output_____"
]
],
[
[
"The result is about 3.3%, which is less than 7%. The reason is that the statistician includes all values \"as extreme as\" 140, which includes values less than or equal to 110, because 140 exceeds the expected value by 15 and 110 falls short by 15.",
"_____no_output_____"
]
],
[
[
"pmf_k.le_dist(110)",
"_____no_output_____"
]
],
[
[
"The probability of values less than or equal to 110 is also 3.3%,\nso the total probability of values \"as extreme\" as 140 is 6.6%.\n\nThe point of this calculation is that these extreme values are unlikely if the coin is fair.\n\nThat's interesting, but it doesn't answer MacKay's question. Let's see if we can.",
"_____no_output_____"
],
[
"## The Euro problem\n",
"_____no_output_____"
],
[
"Any given coin has some probability of landing heads up when spun\non edge; I'll call this probability `x`.\n\nIt seems reasonable to believe that `x` depends\non physical characteristics of the coin, like the distribution\nof weight.\n\nIf a coin is perfectly balanced, we expect `x` to be close to 50%, but\nfor a lopsided coin, `x` might be substantially different. We can use\nBayes's theorem and the observed data to estimate `x`.\n\nFor simplicity, I'll start with a uniform prior, which assume that all values of `x` are equally likely.\nThat might not be a reasonable assumption, so we'll come back and consider other priors later.\n\nWe can make a uniform prior like this:",
"_____no_output_____"
]
],
[
[
"hypos = np.linspace(0, 1, 101)\nprior = Pmf(1, hypos)",
"_____no_output_____"
]
],
[
[
"I'll use a dictionary to store the likelihoods for `H` and `T`:",
"_____no_output_____"
]
],
[
[
"likelihood = {\n 'H': hypos,\n 'T': 1 - hypos\n}",
"_____no_output_____"
]
],
[
[
"I'll use a string to represent the dataset:\n",
"_____no_output_____"
]
],
[
[
"dataset = 'H' * 140 + 'T' * 110",
"_____no_output_____"
]
],
[
[
"The following function does the update.",
"_____no_output_____"
]
],
[
[
"def update_euro(pmf, dataset):\n \"\"\"Updates the Suite with the given number of heads and tails.\n\n pmf: Pmf representing the prior\n data: tuple of heads and tails\n \"\"\"\n for data in dataset:\n pmf *= likelihood[data]\n\n pmf.normalize()",
"_____no_output_____"
]
],
[
[
"And here's how we use it.",
"_____no_output_____"
]
],
[
[
"posterior = prior.copy()\nupdate_euro(posterior, dataset)",
"_____no_output_____"
]
],
[
[
"Here's what the posterior looks like.",
"_____no_output_____"
]
],
[
[
"def decorate_euro(title):\n decorate(xlabel='Proportion of heads (x)',\n ylabel='Probability',\n title=title)",
"_____no_output_____"
],
[
"posterior.plot(label='140 heads out of 250')\ndecorate_euro(title='Posterior distribution of x')\nsavefig('fig03-02')",
"_____no_output_____"
]
],
[
[
"The peak of the posterior is at 56%, which is the proportion of heads in the dataset.",
"_____no_output_____"
]
],
[
[
"posterior.max_prob()",
"_____no_output_____"
]
],
[
[
"## Different priors\n\nLet's see how that looks with different priors. Here's the uniform prior again.",
"_____no_output_____"
]
],
[
[
"uniform = Pmf(1, hypos, name='uniform')\nuniform.normalize()",
"_____no_output_____"
]
],
[
[
"And here's a triangle-shaped prior.",
"_____no_output_____"
]
],
[
[
"ramp_up = np.arange(50)\nramp_down = np.arange(50, -1, -1)\n\na = np.append(ramp_up, ramp_down)\n\ntriangle = Pmf(a, hypos, name='triangle')\ntriangle.normalize()",
"_____no_output_____"
]
],
[
[
"Here's what they look like:",
"_____no_output_____"
]
],
[
[
"uniform.plot()\ntriangle.plot()\ndecorate_euro(title='Uniform and triangle prior distributions')\n\nsavefig('fig03-03')",
"_____no_output_____"
]
],
[
[
"If we update them both with the same data:",
"_____no_output_____"
]
],
[
[
"update_euro(uniform, dataset)\nupdate_euro(triangle, dataset)",
"_____no_output_____"
]
],
[
[
"Here are the posteriors.",
"_____no_output_____"
]
],
[
[
"uniform.plot()\ntriangle.plot()\ndecorate_euro(title='Posterior distributions')\nsavefig('fig03-04')",
"_____no_output_____"
]
],
[
[
"The results are almost identical; the remaining difference is unlikely to matter in practice.",
"_____no_output_____"
],
[
"## The binomial likelihood function\n\nWe can make the Euro class more efficient by computing the likelihood of the entire dataset at once, rather than one coin toss at a time.\n\nIf the probability of heads is `p`, we can compute the probability of `k=140` heads in `n=250` tosses using the binomial PMF.",
"_____no_output_____"
]
],
[
[
"from scipy.stats import binom\n\ndef update_binomial(pmf, data):\n \"\"\"Update the PMF using the binomial distribution.\n \n pmf: Pmf representing the prior\n data: tuple of integers k and n\n \"\"\"\n k, n = data\n xs = pmf.qs\n likelihood = binom.pmf(k, n, xs)\n pmf *= likelihood\n pmf.normalize()",
"_____no_output_____"
]
],
[
[
"The data are represented with a tuple of values for `k` and `n`, rather than a long string of outcomes.\n\nHere's the update.",
"_____no_output_____"
]
],
[
[
"uniform2 = Pmf(1, hypos, name='uniform2')\ndata = 140, 250\nupdate_binomial(uniform2, data)",
"_____no_output_____"
]
],
[
[
"Here's what the posterior looks like.",
"_____no_output_____"
]
],
[
[
"uniform.plot()\nuniform2.plot()\ndecorate_euro(title='Posterior distributions computed two ways')",
"_____no_output_____"
]
],
[
[
"The results are the same, within floating-point error.",
"_____no_output_____"
]
],
[
[
"np.max(np.abs(uniform-uniform2))",
"_____no_output_____"
]
],
[
[
"## Exercises\n",
"_____no_output_____"
],
[
"**Exercise:** In Major League Baseball, most players have a batting average between 200 and 330, which means that the probability of getting a hit is between 0.2 and 0.33.\n\nSuppose a new player appearing in his first game gets 3 hits out of 3 attempts. What is the posterior distribution for his probability of getting a hit?\n\nFor this exercise, I will construct the prior distribution by starting with a uniform distribution and updating it with imaginary data until it has a shape that reflects my background knowledge of batting averages.",
"_____no_output_____"
]
],
[
[
"hypos = np.linspace(0.1, 0.4, 101)\nprior = Pmf(1, hypos)",
"_____no_output_____"
],
[
"likelihood = {\n 'Y': hypos,\n 'N': 1-hypos\n}",
"_____no_output_____"
],
[
"dataset = 'Y' * 25 + 'N' * 75",
"_____no_output_____"
],
[
"for data in dataset:\n prior *= likelihood[data]\n\nprior.normalize()",
"_____no_output_____"
],
[
"prior.plot(label='prior')\ndecorate(xlabel='Probability of getting a hit',\n ylabel='PMF')",
"_____no_output_____"
]
],
[
[
"This distribution indicates that most players have a batting average near 250, with only a few players below 175 or above 350. I'm not sure how accurately this prior reflects the distribution of batting averages in Major League Baseball, but it is good enough for this exercise.\n\nNow update this distribution with the data and plot the posterior. What is the most likely value in the posterior distribution?",
"_____no_output_____"
]
],
[
[
"# Solution\n\nposterior = prior.copy()\n\nfor data in 'YYY':\n posterior *= likelihood[data]\n\nposterior.normalize()",
"_____no_output_____"
],
[
"# Solution\n\nprior.plot(label='prior')\nposterior.plot(label='posterior ')\ndecorate(xlabel='Probability of getting a hit',\n ylabel='PMF')",
"_____no_output_____"
],
[
"# Solution\n\nprior.max_prob()",
"_____no_output_____"
],
[
"# Solution\n\nposterior.max_prob()",
"_____no_output_____"
]
],
[
[
"**Exercise:** Whenever you survey people about sensitive issues, you have to deal with [social desirability bias](https://en.wikipedia.org/wiki/Social_desirability_bias), which is the tendency of people to shade their answers to show themselves in the most positive light.\n\nOne of the ways to improve the accuracy of the results is [randomized response](https://en.wikipedia.org/wiki/Randomized_response).\n\nAs an example, suppose you ask 100 people to flip a coin and:\n\n* If they get heads, they report YES.\n\n* If they get tails, they honestly answer the question \"Do you cheat on your taxes?\"\n\nAnd suppose you get 80 YESes and 20 NOs. Based on this data, what is the posterior distribution for the fraction of people who cheat on their taxes? What is the most likely value in the posterior distribution?",
"_____no_output_____"
]
],
[
[
"# Solution\n\nhypos = np.linspace(0, 1, 101)\nprior = Pmf(1, hypos)",
"_____no_output_____"
],
[
"# Solution\n\nlikelihood = {\n 'Y': 0.5 + hypos/2,\n 'N': (1-hypos)/2\n}",
"_____no_output_____"
],
[
"# Solution\n\ndataset = 'Y' * 80 + 'N' * 20\n\nposterior = prior.copy()\n\nfor data in dataset:\n posterior *= likelihood[data]\n\nposterior.normalize()",
"_____no_output_____"
],
[
"# Solution\n\nposterior.plot(label='80 YES, 20 NO')\ndecorate(xlabel='Proportion of cheaters',\n ylabel='PMF')",
"_____no_output_____"
],
[
"# Solution\n\nposterior.idxmax()",
"_____no_output_____"
]
],
[
[
"**Exercise:** Suppose that instead of observing coin spins directly, you measure the outcome using an instrument that is not always correct. Specifically, suppose the probability is `y=0.2` that an actual heads is reported\nas tails, or actual tails reported as heads.\n\nIf we spin a coin 250 times and the instrument reports 140 heads, what is the posterior distribution of `x`?\n\nWhat happens as you vary the value of `y`?",
"_____no_output_____"
]
],
[
[
"# Solution\n\ndef update_unreliable(pmf, dataset, y):\n \n likelihood = {\n 'H': (1-y) * hypos + y * (1-hypos),\n 'T': y * hypos + (1-y) * (1-hypos)\n }\n for data in dataset:\n pmf *= likelihood[data]\n\n pmf.normalize()",
"_____no_output_____"
],
[
"# Solution\n\nhypos = np.linspace(0, 1, 101)\nprior = Pmf(1, hypos)\ndataset = 'H' * 140 + 'T' * 110\n\nposterior00 = prior.copy()\nupdate_unreliable(posterior00, dataset, 0.0)\n\nposterior02 = prior.copy()\nupdate_unreliable(posterior02, dataset, 0.2)\n\nposterior04 = prior.copy()\nupdate_unreliable(posterior04, dataset, 0.4)",
"_____no_output_____"
],
[
"# Solution\n\nposterior00.plot(label='y = 0.0')\nposterior02.plot(label='y = 0.2')\nposterior04.plot(label='y = 0.4')\ndecorate(xlabel='Proportion of heads',\n ylabel='PMF')",
"_____no_output_____"
],
[
"# Solution\n\nposterior00.idxmax(), posterior02.idxmax(), posterior04.idxmax()",
"_____no_output_____"
]
],
[
[
"**Exercise:** In preparation for an alien invasion, the Earth Defense League (EDL) has been working on new missiles to shoot down space invaders. Of course, some missile designs are better than others; let's assume that each design has some probability of hitting an alien ship, `x`.\n\nBased on previous tests, the distribution of `x` in the population of designs is approximately uniform between 0.1 and 0.4.\n\nNow suppose the new ultra-secret Alien Blaster 9000 is being tested. In a press conference, an EDL general reports that the new design has been tested twice, taking two shots during each test. The results of the test are confidential, so the general won't say how many targets were hit, but they report: \"The same number of targets were hit in the two tests, so we have reason to think this new design is consistent.\"\n\nIs this data good or bad; that is, does it increase or decrease your estimate of `x` for the Alien Blaster 9000?\n\nHint: If the probability of hitting each target is $x$, the probability of hitting one target in both tests is $[2x(1-x)]^2$.",
"_____no_output_____"
]
],
[
[
"# Solution\n\nhypos = np.linspace(0.1, 0.4, 101)\nprior = Pmf(1, hypos)",
"_____no_output_____"
],
[
"# Solution\n\n# specific version for n=2 shots\nx = hypos\nlikes = [(1-x)**4, (2*x*(1-x))**2, x**4]\nlikelihood = np.sum(likes, axis=0)",
"_____no_output_____"
],
[
"# Solution\n\n# general version for any n shots per test\n\nfrom scipy.stats import binom\n\nn = 2\nlikes2 = [binom.pmf(k, n, x)**2 for k in range(n+1)]\nlikelihood2 = np.sum(likes2, axis=0)",
"_____no_output_____"
],
[
"# Solution\n\nplt.plot(x, likelihood, label='special case')\nplt.plot(x, likelihood2, label='general formula')\ndecorate(xlabel='Probability of hitting the target',\n ylabel='Likelihood',\n title='Likelihood of getting the same result')",
"_____no_output_____"
],
[
"# Solution\n\nposterior = prior * likelihood\nposterior.normalize()",
"_____no_output_____"
],
[
"# Solution\n\nposterior.plot(label='Two tests, two shots, same outcome')\ndecorate(xlabel='Probability of hitting the target',\n ylabel='PMF',\n title='Posterior distribution',\n ylim=[0, 0.015])",
"_____no_output_____"
],
[
"# Solution\n\n# Getting the same result in both tests is more likely for \n# extreme values of `x` and least likely when `x=0.5`.\n\n# In this example, the prior suggests that `x` is less than 0.5,\n# and the update gives more weight to extreme values.\n\n# So the data makes lower values of `x` more likely.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4acb33adbb5c54eb32f8dfbbaf46255dc1f42279
| 41,782 |
ipynb
|
Jupyter Notebook
|
day4.ipynb
|
beaes/dw_matrix_car
|
4e421fc6fd0b57943377b5f03f2b3e0f76765236
|
[
"MIT"
] | null | null | null |
day4.ipynb
|
beaes/dw_matrix_car
|
4e421fc6fd0b57943377b5f03f2b3e0f76765236
|
[
"MIT"
] | null | null | null |
day4.ipynb
|
beaes/dw_matrix_car
|
4e421fc6fd0b57943377b5f03f2b3e0f76765236
|
[
"MIT"
] | null | null | null | 41,782 | 41,782 | 0.584917 |
[
[
[
"!pip install --upgrade tables\n!pip install eli5\n!pip install xgboost",
"Collecting tables\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/ed/c3/8fd9e3bb21872f9d69eb93b3014c86479864cca94e625fd03713ccacec80/tables-3.6.1-cp36-cp36m-manylinux1_x86_64.whl (4.3MB)\n\u001b[K |████████████████████████████████| 4.3MB 2.8MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: numpy>=1.9.3 in /usr/local/lib/python3.6/dist-packages (from tables) (1.17.5)\nRequirement already satisfied, skipping upgrade: numexpr>=2.6.2 in /usr/local/lib/python3.6/dist-packages (from tables) (2.7.1)\nInstalling collected packages: tables\n Found existing installation: tables 3.4.4\n Uninstalling tables-3.4.4:\n Successfully uninstalled tables-3.4.4\nSuccessfully installed tables-3.6.1\nCollecting eli5\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/97/2f/c85c7d8f8548e460829971785347e14e45fa5c6617da374711dec8cb38cc/eli5-0.10.1-py2.py3-none-any.whl (105kB)\n\u001b[K |████████████████████████████████| 112kB 2.8MB/s \n\u001b[?25hRequirement already satisfied: tabulate>=0.7.7 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.8.6)\nRequirement already satisfied: attrs>16.0.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (19.3.0)\nRequirement already satisfied: scikit-learn>=0.18 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.22.1)\nRequirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from eli5) (0.10.1)\nRequirement already satisfied: jinja2 in /usr/local/lib/python3.6/dist-packages (from eli5) (2.11.1)\nRequirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (1.17.5)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from eli5) (1.4.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from eli5) (1.12.0)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.18->eli5) (0.14.1)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.6/dist-packages (from jinja2->eli5) (1.1.1)\nInstalling collected packages: eli5\nSuccessfully installed eli5-0.10.1\nRequirement already satisfied: xgboost in /usr/local/lib/python3.6/dist-packages (0.90)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from xgboost) (1.4.1)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from xgboost) (1.17.5)\n"
],
[
"import pandas as pd\nimport numpy as np\n\nfrom sklearn.dummy import DummyRegressor\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\n\nimport xgboost as xgb\n\nfrom sklearn.metrics import mean_absolute_error as mae\nfrom sklearn.model_selection import cross_val_score, KFold\n\nimport eli5\nfrom eli5.sklearn import PermutationImportance",
"_____no_output_____"
],
[
"cd \"/content/drive/My Drive/Colab Notebooks/dw_matrix/dw_matrix_car\"",
"/content/drive/My Drive/Colab Notebooks/dw_matrix/dw_matrix_car\n"
],
[
"df = pd.read_hdf('data/car.h5')\ndf.shape",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"## Feature Enginnering",
"_____no_output_____"
]
],
[
[
"SUFFIX_CAT = '_cat'\nfor feat in df.columns:\n if isinstance (df[feat][0], list):continue\n\n factorized_values = df[feat].factorize()[0]\n if SUFFIX_CAT in feat:\n df[feat] = factorized_values\n else:\n df[feat + SUFFIX_CAT] = factorized_values",
"_____no_output_____"
],
[
"cat_feats = [x for x in df.columns if SUFFIX_CAT in x ]\ncat_feats = [x for x in cat_feats if 'price' not in x ]\nlen(cat_feats)",
"_____no_output_____"
],
[
"x = df[cat_feats].values\ny = df['price_value'].values\n\nmodel = DecisionTreeRegressor(max_depth=5)\nscores = cross_val_score(model, x, y, cv=3, scoring='neg_mean_absolute_error')\nnp.mean(scores), np.std(scores)",
"_____no_output_____"
],
[
"def run_model(model, feats):\n x = df[feats].values\n y = df['price_value'].values\n\n scores = cross_val_score(model, x, y, cv=3, scoring='neg_mean_absolute_error')\n return np.mean(scores), np.std(scores)\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"## DecisionTree",
"_____no_output_____"
]
],
[
[
"run_model( DecisionTreeRegressor(max_depth=5), cat_feats )",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"## RandomForest",
"_____no_output_____"
]
],
[
[
"model = RandomForestRegressor(max_depth=5, n_estimators=50, random_state=0)\nrun_model( model, cat_feats )",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"## XGBoost",
"_____no_output_____"
]
],
[
[
"xgb_params = {\n 'max_depth':5,\n 'n_estimators':50,\n 'learning_rate':0.1,\n 'seed':0\n}\n\nrun_model(xgb.XGBRegressor(**xgb_params), cat_feats )",
"[11:18:36] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:18:55] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:19:15] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"m = xgb.XGBRegressor(max_depth=5, n_estimators=50, learning_rate=0.1, seed=0)\nm.fit(x,y)\n\nimp = PermutationImportance(m, random_state=0).fit(x,y)\neli5.show_weights(imp, feature_names=cat_feats)",
"[11:24:20] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"len(cat_feats)",
"_____no_output_____"
],
[
"feats = ['param_napęd_cat','param_rok-produkcji_cat','param_stan_cat','param_skrzynia-biegów_cat','param_faktura-vat_cat','param_moc_cat','param_marka-pojazdu_cat','feature_kamera-cofania_cat','param_typ_cat','param_pojemność-skokowa_cat','seller_name_cat','feature_wspomaganie-kierownicy_cat','param_model-pojazdu_cat','param_wersja_cat','param_kod-silnika_cat','feature_system-start-stop_cat','feature_asystent-pasa-ruchu_cat','feature_czujniki-parkowania-przednie_cat','feature_łopatki-zmiany-biegów_cat','feature_regulowane-zawieszenie_cat']\nlen(feats)",
"_____no_output_____"
],
[
"feats = ['param_napęd_cat','param_rok-produkcji_cat','param_stan_cat','param_skrzynia-biegów_cat','param_faktura-vat_cat','param_moc_cat','param_marka-pojazdu_cat','feature_kamera-cofania_cat','param_typ_cat','param_pojemność-skokowa_cat','seller_name_cat','feature_wspomaganie-kierownicy_cat','param_model-pojazdu_cat','param_wersja_cat','param_kod-silnika_cat','feature_system-start-stop_cat','feature_asystent-pasa-ruchu_cat','feature_czujniki-parkowania-przednie_cat','feature_łopatki-zmiany-biegów_cat','feature_regulowane-zawieszenie_cat']\nrun_model(xgb.XGBRegressor(**xgb_params), feats )",
"[11:47:05] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:47:09] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:47:13] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"df['param_napęd'].unique()",
"_____no_output_____"
],
[
"df['param_rok-produkcji'].unique()",
"_____no_output_____"
],
[
"df['param_rok-produkcji'] = df['param_rok-produkcji'].map(lambda x:-1 if str(x)=='None' else int(x))\n\nfeats = ['param_napęd_cat','param_rok-produkcji','param_stan_cat','param_skrzynia-biegów_cat','param_faktura-vat_cat','param_moc_cat','param_marka-pojazdu_cat','feature_kamera-cofania_cat','param_typ_cat','param_pojemność-skokowa_cat','seller_name_cat','feature_wspomaganie-kierownicy_cat','param_model-pojazdu_cat','param_wersja_cat','param_kod-silnika_cat','feature_system-start-stop_cat','feature_asystent-pasa-ruchu_cat','feature_czujniki-parkowania-przednie_cat','feature_łopatki-zmiany-biegów_cat','feature_regulowane-zawieszenie_cat']\nrun_model(xgb.XGBRegressor(**xgb_params), feats )",
"[11:54:53] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:54:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[11:55:01] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"df['param_moc'].unique()",
"_____no_output_____"
],
[
"df['param_moc'].map(lambda x: -1 if str(x) == 'None' else int(x.split(' ')[0]))",
"_____no_output_____"
],
[
"df['param_moc'] = df['param_moc'].map(lambda x: -1 if str(x) == 'None' else int(x.split(' ')[0]))\n\ndf['param_rok-produkcji'] = df['param_rok-produkcji'].map(lambda x:-1 if str(x)=='None' else int(x))\n\nfeats = ['param_napęd_cat','param_rok-produkcji','param_stan_cat','param_skrzynia-biegów_cat','param_faktura-vat_cat','param_moc','param_marka-pojazdu_cat','feature_kamera-cofania_cat','param_typ_cat','param_pojemność-skokowa_cat','seller_name_cat','feature_wspomaganie-kierownicy_cat','param_model-pojazdu_cat','param_wersja_cat','param_kod-silnika_cat','feature_system-start-stop_cat','feature_asystent-pasa-ruchu_cat','feature_czujniki-parkowania-przednie_cat','feature_łopatki-zmiany-biegów_cat','feature_regulowane-zawieszenie_cat']\nrun_model(xgb.XGBRegressor(**xgb_params), feats )",
"[12:08:32] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[12:08:36] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[12:08:40] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"df['param_pojemność-skokowa'].unique()",
"_____no_output_____"
],
[
"df['param_pojemność-skokowa'] = df['param_pojemność-skokowa'].map(lambda x: -1 if str(x) == 'None' else int( str(x).split('cm')[0].replace(' ', '')))\n\nfeats = ['param_napęd_cat','param_rok-produkcji','param_stan_cat','param_skrzynia-biegów_cat','param_faktura-vat_cat','param_moc','param_marka-pojazdu_cat','feature_kamera-cofania_cat','param_typ_cat','param_pojemność-skokowa','seller_name_cat','feature_wspomaganie-kierownicy_cat','param_model-pojazdu_cat','param_wersja_cat','param_kod-silnika_cat','feature_system-start-stop_cat','feature_asystent-pasa-ruchu_cat','feature_czujniki-parkowania-przednie_cat','feature_łopatki-zmiany-biegów_cat','feature_regulowane-zawieszenie_cat']\nrun_model(xgb.XGBRegressor(**xgb_params), feats )",
"[12:23:26] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[12:23:30] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[12:23:34] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4acb34c07188992d60b21b3e094247809fb9a05f
| 11,032 |
ipynb
|
Jupyter Notebook
|
cifar10_transformation_with_pca/cifar-10-pca-cpp.ipynb
|
tomjpsun/examples
|
a09e3cca3881bfce04724aeb2fc4ce16f020e8d0
|
[
"BSD-3-Clause"
] | 1 |
2020-12-18T13:33:34.000Z
|
2020-12-18T13:33:34.000Z
|
cifar10_transformation_with_pca/cifar-10-pca-cpp.ipynb
|
GauravSarkar/examples
|
93f9aacc155572c3affc73920354b5c55601807a
|
[
"BSD-3-Clause"
] | null | null | null |
cifar10_transformation_with_pca/cifar-10-pca-cpp.ipynb
|
GauravSarkar/examples
|
93f9aacc155572c3affc73920354b5c55601807a
|
[
"BSD-3-Clause"
] | 1 |
2021-05-12T21:51:40.000Z
|
2021-05-12T21:51:40.000Z
| 41.946768 | 1,507 | 0.558194 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4acb46939d7d538f20c0b296fd64351f4e448265
| 242 |
ipynb
|
Jupyter Notebook
|
book_rethinking2/01_sr2ed_ch1.ipynb
|
pydatawrangler/biwp
|
da8b504b98d1210499a3463b521680376b5163a8
|
[
"MIT"
] | null | null | null |
book_rethinking2/01_sr2ed_ch1.ipynb
|
pydatawrangler/biwp
|
da8b504b98d1210499a3463b521680376b5163a8
|
[
"MIT"
] | null | null | null |
book_rethinking2/01_sr2ed_ch1.ipynb
|
pydatawrangler/biwp
|
da8b504b98d1210499a3463b521680376b5163a8
|
[
"MIT"
] | null | null | null | 12.1 | 27 | 0.487603 |
[
[
[
"# Chapter 1 Notes",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4acb4f7629e86ae0f49ad4a0c34a7d213050c5ef
| 18,897 |
ipynb
|
Jupyter Notebook
|
sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
|
vikramelango/amazon-sagemaker-examples
|
9a3b8de17c253fc18fc089120885afc6ff36111d
|
[
"Apache-2.0"
] | null | null | null |
sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
|
vikramelango/amazon-sagemaker-examples
|
9a3b8de17c253fc18fc089120885afc6ff36111d
|
[
"Apache-2.0"
] | 1 |
2022-03-15T20:04:30.000Z
|
2022-03-15T20:04:30.000Z
|
sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
|
vivekmadan2/amazon-sagemaker-examples
|
4ccb050067c5305a50db750df3444dbc85600d5f
|
[
"Apache-2.0"
] | 1 |
2022-03-19T17:04:30.000Z
|
2022-03-19T17:04:30.000Z
| 32.581034 | 532 | 0.588083 |
[
[
[
"# Run a SageMaker Experiment with MNIST Handwritten Digits Classification\n\nThis demo shows how you can use the [SageMaker Experiments Python SDK](https://sagemaker-experiments.readthedocs.io/en/latest/) to organize, track, compare, and evaluate your machine learning (ML) model training experiments.\n\nYou can track artifacts for experiments, including data sets, algorithms, hyperparameters, and metrics. Experiments executed on SageMaker such as SageMaker Autopilot jobs and training jobs are automatically tracked. You can also track artifacts for additional steps within an ML workflow that come before or after model training, such as data pre-processing or post-training model evaluation.\n\nThe APIs also let you search and browse your current and past experiments, compare experiments, and identify best-performing models.\n\nWe demonstrate these capabilities through an MNIST handwritten digits classification example. The experiment is organized as follows:\n\n1. Download and prepare the MNIST dataset.\n2. Train a Convolutional Neural Network (CNN) Model. Tune the hyperparameter that configures the number of hidden channels in the model. Track the parameter configurations and resulting model accuracy using the SageMaker Experiments Python SDK.\n3. Finally use the search and analytics capabilities of the SDK to search, compare and evaluate the performance of all model versions generated from model tuning in Step 2.\n4. We also show an example of tracing the complete lineage of a model version: the collection of all the data pre-processing and training configurations and inputs that went into creating that model version.\n\nMake sure you select the `Python 3 (Data Science)` kernel in Studio, or `conda_pytorch_p36` in a notebook instance.\n\n## Runtime\n\nThis notebook takes approximately 25 minutes to run.\n\n## Contents\n\n1. [Install modules](#Install-modules)\n1. [Setup](#Setup)\n1. [Download the dataset](#Download-the-dataset)\n1. [Step 1: Set up the Experiment](#Step-1:-Set-up-the-Experiment)\n1. [Step 2: Track Experiment](#Step-2:-Track-Experiment)\n1. [Deploy an endpoint for the best training job / trial component](#Deploy-an-endpoint-for-the-best-training-job-/-trial-component)\n1. [Cleanup](#Cleanup)\n1. [Contact](#Contact)",
"_____no_output_____"
],
[
"## Install modules",
"_____no_output_____"
]
],
[
[
"import sys",
"_____no_output_____"
]
],
[
[
"### Install the SageMaker Experiments Python SDK",
"_____no_output_____"
]
],
[
[
"!{sys.executable} -m pip install sagemaker-experiments==0.1.35",
"_____no_output_____"
]
],
[
[
"### Install PyTorch",
"_____no_output_____"
]
],
[
[
"# PyTorch version needs to be the same in both the notebook instance and the training job container\n# https://github.com/pytorch/pytorch/issues/25214\n!{sys.executable} -m pip install torch==1.1.0\n!{sys.executable} -m pip install torchvision==0.2.2\n!{sys.executable} -m pip install pillow==6.2.2\n!{sys.executable} -m pip install --upgrade sagemaker",
"_____no_output_____"
]
],
[
[
"## Setup",
"_____no_output_____"
]
],
[
[
"import time\n\nimport boto3\nimport numpy as np\nimport pandas as pd\nfrom IPython.display import set_matplotlib_formats\nfrom matplotlib import pyplot as plt\nfrom torchvision import datasets, transforms\n\nimport sagemaker\nfrom sagemaker import get_execution_role\nfrom sagemaker.session import Session\nfrom sagemaker.analytics import ExperimentAnalytics\n\nfrom smexperiments.experiment import Experiment\nfrom smexperiments.trial import Trial\nfrom smexperiments.trial_component import TrialComponent\nfrom smexperiments.tracker import Tracker\n\nset_matplotlib_formats(\"retina\")",
"_____no_output_____"
],
[
"sm_sess = sagemaker.Session()\nsess = sm_sess.boto_session\nsm = sm_sess.sagemaker_client\nrole = get_execution_role()",
"_____no_output_____"
]
],
[
[
"## Download the dataset\nWe download the MNIST handwritten digits dataset, and then apply a transformation on each image.",
"_____no_output_____"
]
],
[
[
"bucket = sm_sess.default_bucket()\nprefix = \"DEMO-mnist\"\nprint(\"Using S3 location: s3://\" + bucket + \"/\" + prefix + \"/\")\n\ndatasets.MNIST.urls = [\n \"https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/train-images-idx3-ubyte.gz\",\n \"https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/train-labels-idx1-ubyte.gz\",\n \"https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/t10k-images-idx3-ubyte.gz\",\n \"https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/t10k-labels-idx1-ubyte.gz\",\n]\n\n# Download the dataset to the ./mnist folder, and load and transform (normalize) them\ntrain_set = datasets.MNIST(\n \"mnist\",\n train=True,\n transform=transforms.Compose(\n [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]\n ),\n download=True,\n)\n\ntest_set = datasets.MNIST(\n \"mnist\",\n train=False,\n transform=transforms.Compose(\n [transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]\n ),\n download=False,\n)",
"_____no_output_____"
]
],
[
[
"View an example image from the dataset.",
"_____no_output_____"
]
],
[
[
"plt.imshow(train_set.data[2].numpy())",
"_____no_output_____"
]
],
[
[
"After transforming the images in the dataset, we upload it to S3.",
"_____no_output_____"
]
],
[
[
"inputs = sagemaker.Session().upload_data(path=\"mnist\", bucket=bucket, key_prefix=prefix)",
"_____no_output_____"
]
],
[
[
"Now let's track the parameters from the data pre-processing step.",
"_____no_output_____"
]
],
[
[
"with Tracker.create(display_name=\"Preprocessing\", sagemaker_boto_client=sm) as tracker:\n tracker.log_parameters(\n {\n \"normalization_mean\": 0.1307,\n \"normalization_std\": 0.3081,\n }\n )\n # We can log the S3 uri to the dataset we just uploaded\n tracker.log_input(name=\"mnist-dataset\", media_type=\"s3/uri\", value=inputs)",
"_____no_output_____"
]
],
[
[
"## Step 1: Set up the Experiment\n\nCreate an experiment to track all the model training iterations. Experiments are a great way to organize your data science work. You can create experiments to organize all your model development work for: [1] a business use case you are addressing (e.g. create experiment named “customer churn prediction”), or [2] a data science team that owns the experiment (e.g. create experiment named “marketing analytics experiment”), or [3] a specific data science and ML project. Think of it as a “folder” for organizing your “files”.",
"_____no_output_____"
],
[
"### Create an Experiment",
"_____no_output_____"
]
],
[
[
"mnist_experiment = Experiment.create(\n experiment_name=f\"mnist-hand-written-digits-classification-{int(time.time())}\",\n description=\"Classification of mnist hand-written digits\",\n sagemaker_boto_client=sm,\n)\nprint(mnist_experiment)",
"_____no_output_____"
]
],
[
[
"## Step 2: Track Experiment\n### Now create a Trial for each training run to track its inputs, parameters, and metrics.\nWhile training the CNN model on SageMaker, we experiment with several values for the number of hidden channel in the model. We create a Trial to track each training job run. We also create a TrialComponent from the tracker we created before, and add to the Trial. This enriches the Trial with the parameters we captured from the data pre-processing stage.",
"_____no_output_____"
]
],
[
[
"from sagemaker.pytorch import PyTorch, PyTorchModel",
"_____no_output_____"
],
[
"hidden_channel_trial_name_map = {}",
"_____no_output_____"
]
],
[
[
"If you want to run the following five training jobs in parallel, you may need to increase your resource limit. Here we run them sequentially.",
"_____no_output_____"
]
],
[
[
"preprocessing_trial_component = tracker.trial_component",
"_____no_output_____"
],
[
"for i, num_hidden_channel in enumerate([2, 5, 10, 20, 32]):\n # Create trial\n trial_name = f\"cnn-training-job-{num_hidden_channel}-hidden-channels-{int(time.time())}\"\n cnn_trial = Trial.create(\n trial_name=trial_name,\n experiment_name=mnist_experiment.experiment_name,\n sagemaker_boto_client=sm,\n )\n hidden_channel_trial_name_map[num_hidden_channel] = trial_name\n\n # Associate the proprocessing trial component with the current trial\n cnn_trial.add_trial_component(preprocessing_trial_component)\n\n # All input configurations, parameters, and metrics specified in\n # the estimator definition are automatically tracked\n estimator = PyTorch(\n py_version=\"py3\",\n entry_point=\"./mnist.py\",\n role=role,\n sagemaker_session=sagemaker.Session(sagemaker_client=sm),\n framework_version=\"1.1.0\",\n instance_count=1,\n instance_type=\"ml.c4.xlarge\",\n hyperparameters={\n \"epochs\": 2,\n \"backend\": \"gloo\",\n \"hidden_channels\": num_hidden_channel,\n \"dropout\": 0.2,\n \"kernel_size\": 5,\n \"optimizer\": \"sgd\",\n },\n metric_definitions=[\n {\"Name\": \"train:loss\", \"Regex\": \"Train Loss: (.*?);\"},\n {\"Name\": \"test:loss\", \"Regex\": \"Test Average loss: (.*?),\"},\n {\"Name\": \"test:accuracy\", \"Regex\": \"Test Accuracy: (.*?)%;\"},\n ],\n enable_sagemaker_metrics=True,\n )\n\n cnn_training_job_name = \"cnn-training-job-{}\".format(int(time.time()))\n\n # Associate the estimator with the Experiment and Trial\n estimator.fit(\n inputs={\"training\": inputs},\n job_name=cnn_training_job_name,\n experiment_config={\n \"TrialName\": cnn_trial.trial_name,\n \"TrialComponentDisplayName\": \"Training\",\n },\n wait=True,\n )\n\n # Wait two seconds before dispatching the next training job\n time.sleep(2)",
"_____no_output_____"
]
],
[
[
"### Compare the model training runs for an experiment\n\nNow we use the analytics capabilities of the Experiments SDK to query and compare the training runs for identifying the best model produced by our experiment. You can retrieve trial components by using a search expression.",
"_____no_output_____"
],
[
"### Some Simple Analyses",
"_____no_output_____"
]
],
[
[
"search_expression = {\n \"Filters\": [\n {\n \"Name\": \"DisplayName\",\n \"Operator\": \"Equals\",\n \"Value\": \"Training\",\n }\n ],\n}",
"_____no_output_____"
],
[
"trial_component_analytics = ExperimentAnalytics(\n sagemaker_session=Session(sess, sm),\n experiment_name=mnist_experiment.experiment_name,\n search_expression=search_expression,\n sort_by=\"metrics.test:accuracy.max\",\n sort_order=\"Descending\",\n metric_names=[\"test:accuracy\"],\n parameter_names=[\"hidden_channels\", \"epochs\", \"dropout\", \"optimizer\"],\n)",
"_____no_output_____"
],
[
"trial_component_analytics.dataframe()",
"_____no_output_____"
]
],
[
[
"To isolate and measure the impact of change in hidden channels on model accuracy, we vary the number of hidden channel and fix the value for other hyperparameters.\n\nNext let's look at an example of tracing the lineage of a model by accessing the data tracked by SageMaker Experiments for the `cnn-training-job-2-hidden-channels` trial.",
"_____no_output_____"
]
],
[
[
"lineage_table = ExperimentAnalytics(\n sagemaker_session=Session(sess, sm),\n search_expression={\n \"Filters\": [\n {\n \"Name\": \"Parents.TrialName\",\n \"Operator\": \"Equals\",\n \"Value\": hidden_channel_trial_name_map[2],\n }\n ]\n },\n sort_by=\"CreationTime\",\n sort_order=\"Ascending\",\n)",
"_____no_output_____"
],
[
"lineage_table.dataframe()",
"_____no_output_____"
]
],
[
[
"## Deploy an endpoint for the best training job / trial component\n\nNow we take the best model and deploy it to an endpoint so it is available to perform inference.",
"_____no_output_____"
]
],
[
[
"# Pulling best based on sort in the analytics/dataframe, so first is best....\nbest_trial_component_name = trial_component_analytics.dataframe().iloc[0][\"TrialComponentName\"]\nbest_trial_component = TrialComponent.load(best_trial_component_name)\n\nmodel_data = best_trial_component.output_artifacts[\"SageMaker.ModelArtifact\"].value\nenv = {\n \"hidden_channels\": str(int(best_trial_component.parameters[\"hidden_channels\"])),\n \"dropout\": str(best_trial_component.parameters[\"dropout\"]),\n \"kernel_size\": str(int(best_trial_component.parameters[\"kernel_size\"])),\n}\nmodel = PyTorchModel(\n model_data,\n role,\n \"./mnist.py\",\n py_version=\"py3\",\n env=env,\n sagemaker_session=sagemaker.Session(sagemaker_client=sm),\n framework_version=\"1.1.0\",\n name=best_trial_component.trial_component_name,\n)\n\npredictor = model.deploy(instance_type=\"ml.m5.xlarge\", initial_instance_count=1)",
"_____no_output_____"
]
],
[
[
"## Cleanup\n\nOnce we're done, clean up the endpoint to prevent unnecessary billing.",
"_____no_output_____"
]
],
[
[
"predictor.delete_endpoint()",
"_____no_output_____"
]
],
[
[
"Trial components can exist independently of trials and experiments. You might want keep them if you plan on further exploration. If not, delete all experiment artifacts.",
"_____no_output_____"
]
],
[
[
"mnist_experiment.delete_all(action=\"--force\")",
"_____no_output_____"
]
],
[
[
"## Contact\nSubmit any questions or issues to https://github.com/aws/sagemaker-experiments/issues or mention @aws/sagemakerexperimentsadmin ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4acb574afd0242283d4d7b66f639645ab87242d2
| 657,651 |
ipynb
|
Jupyter Notebook
|
1_mosaic_data_attention_experiments/3_stage_wise_training/alternate_minimization/effect on interpretability/blob_with_sparse_regulariser/10runs_entropy_005_every1_what_where.ipynb
|
lnpandey/DL_explore_synth_data
|
0a5d8b417091897f4c7f358377d5198a155f3f24
|
[
"MIT"
] | 2 |
2019-08-24T07:20:35.000Z
|
2020-03-27T08:16:59.000Z
|
1_mosaic_data_attention_experiments/3_stage_wise_training/alternate_minimization/effect on interpretability/blob_with_sparse_regulariser/10runs_entropy_005_every1_what_where.ipynb
|
lnpandey/DL_explore_synth_data
|
0a5d8b417091897f4c7f358377d5198a155f3f24
|
[
"MIT"
] | null | null | null |
1_mosaic_data_attention_experiments/3_stage_wise_training/alternate_minimization/effect on interpretability/blob_with_sparse_regulariser/10runs_entropy_005_every1_what_where.ipynb
|
lnpandey/DL_explore_synth_data
|
0a5d8b417091897f4c7f358377d5198a155f3f24
|
[
"MIT"
] | 3 |
2019-06-21T09:34:32.000Z
|
2019-09-19T10:43:07.000Z
| 107.109283 | 31,086 | 0.566445 |
[
[
[
" import numpy as np\nimport pandas as pd\n\nimport torch\nimport torchvision\nfrom torch.utils.data import Dataset, DataLoader\nfrom torchvision import transforms, utils\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\n\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nfrom scipy.stats import entropy",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"path=\"/content/drive/MyDrive/Research/alternate_minimisation/\"",
"_____no_output_____"
],
[
"name=\"_50_50_10runs_entropy\"",
"_____no_output_____"
],
[
"# mu1 = np.array([3,3,3,3,0])\n# sigma1 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu2 = np.array([4,4,4,4,0])\n# sigma2 = np.array([[16,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu3 = np.array([10,5,5,10,0])\n# sigma3 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu4 = np.array([-10,-10,-10,-10,0])\n# sigma4 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu5 = np.array([-21,4,4,-21,0])\n# sigma5 = np.array([[16,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu6 = np.array([-10,18,18,-10,0])\n# sigma6 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu7 = np.array([4,20,4,20,0])\n# sigma7 = np.array([[16,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu8 = np.array([4,-20,-20,4,0])\n# sigma8 = np.array([[16,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu9 = np.array([20,20,20,20,0])\n# sigma9 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n# mu10 = np.array([20,-10,-10,20,0])\n# sigma10 = np.array([[1,1,1,1,1],[1,16,1,1,1],[1,1,1,1,1],[1,1,1,1,1],[1,1,1,1,1]])\n\n\n\n# sample1 = np.random.multivariate_normal(mean=mu1,cov= sigma1,size=500)\n# sample2 = np.random.multivariate_normal(mean=mu2,cov= sigma2,size=500)\n# sample3 = np.random.multivariate_normal(mean=mu3,cov= sigma3,size=500)\n# sample4 = np.random.multivariate_normal(mean=mu4,cov= sigma4,size=500)\n# sample5 = np.random.multivariate_normal(mean=mu5,cov= sigma5,size=500)\n# sample6 = np.random.multivariate_normal(mean=mu6,cov= sigma6,size=500)\n# sample7 = np.random.multivariate_normal(mean=mu7,cov= sigma7,size=500)\n# sample8 = np.random.multivariate_normal(mean=mu8,cov= sigma8,size=500)\n# sample9 = np.random.multivariate_normal(mean=mu9,cov= sigma9,size=500)\n# sample10 = np.random.multivariate_normal(mean=mu10,cov= sigma10,size=500)\n",
"_____no_output_____"
],
[
"# X = np.concatenate((sample1,sample2,sample3,sample4,sample5,sample6,sample7,sample8,sample9,sample10),axis=0)\n# Y = np.concatenate((np.zeros((500,1)),np.ones((500,1)),2*np.ones((500,1)),3*np.ones((500,1)),4*np.ones((500,1)),\n# 5*np.ones((500,1)),6*np.ones((500,1)),7*np.ones((500,1)),8*np.ones((500,1)),9*np.ones((500,1))),axis=0).astype(int)\n# print(X.shape,Y.shape)\n# # plt.scatter(sample1[:,0],sample1[:,1],label=\"class_0\")\n# # plt.scatter(sample2[:,0],sample2[:,1],label=\"class_1\")\n# # plt.scatter(sample3[:,0],sample3[:,1],label=\"class_2\")\n# # plt.scatter(sample4[:,0],sample4[:,1],label=\"class_3\")\n# # plt.scatter(sample5[:,0],sample5[:,1],label=\"class_4\")\n# # plt.scatter(sample6[:,0],sample6[:,1],label=\"class_5\")\n# # plt.scatter(sample7[:,0],sample7[:,1],label=\"class_6\")\n# # plt.scatter(sample8[:,0],sample8[:,1],label=\"class_7\")\n# # plt.scatter(sample9[:,0],sample9[:,1],label=\"class_8\")\n# # plt.scatter(sample10[:,0],sample10[:,1],label=\"class_9\")\n# # plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')",
"_____no_output_____"
],
[
"# class SyntheticDataset(Dataset):\n# \"\"\"MosaicDataset dataset.\"\"\"\n\n# def __init__(self, x, y):\n# \"\"\"\n# Args:\n# csv_file (string): Path to the csv file with annotations.\n# root_dir (string): Directory with all the images.\n# transform (callable, optional): Optional transform to be applied\n# on a sample.\n# \"\"\"\n# self.x = x\n# self.y = y\n# #self.fore_idx = fore_idx\n \n# def __len__(self):\n# return len(self.y)\n\n# def __getitem__(self, idx):\n# return self.x[idx] , self.y[idx] #, self.fore_idx[idx]",
"_____no_output_____"
],
[
"# trainset = SyntheticDataset(X,Y)\n\n\n# # testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)",
"_____no_output_____"
],
[
"# classes = ('zero','one','two','three','four','five','six','seven','eight','nine')\n\n# foreground_classes = {'zero','one','two'}\n# fg_used = '012'\n# fg1, fg2, fg3 = 0,1,2\n\n\n# all_classes = {'zero','one','two','three','four','five','six','seven','eight','nine'}\n# background_classes = all_classes - foreground_classes\n# background_classes",
"_____no_output_____"
],
[
"# trainloader = torch.utils.data.DataLoader(trainset, batch_size=100, shuffle=True)",
"_____no_output_____"
],
[
"# dataiter = iter(trainloader)\n# background_data=[]\n# background_label=[]\n# foreground_data=[]\n# foreground_label=[]\n# batch_size=100\n\n# for i in range(50):\n# images, labels = dataiter.next()\n# for j in range(batch_size):\n# if(classes[labels[j]] in background_classes):\n# img = images[j].tolist()\n# background_data.append(img)\n# background_label.append(labels[j])\n# else:\n# img = images[j].tolist()\n# foreground_data.append(img)\n# foreground_label.append(labels[j])\n \n# foreground_data = torch.tensor(foreground_data)\n# foreground_label = torch.tensor(foreground_label)\n# background_data = torch.tensor(background_data)\n# background_label = torch.tensor(background_label)",
"_____no_output_____"
],
[
"# def create_mosaic_img(bg_idx,fg_idx,fg): \n# \"\"\"\n# bg_idx : list of indexes of background_data[] to be used as background images in mosaic\n# fg_idx : index of image to be used as foreground image from foreground data\n# fg : at what position/index foreground image has to be stored out of 0-8\n# \"\"\"\n# image_list=[]\n# j=0\n# for i in range(9):\n# if i != fg:\n# image_list.append(background_data[bg_idx[j]])\n# j+=1\n# else: \n# image_list.append(foreground_data[fg_idx])\n# label = foreground_label[fg_idx] - fg1 # minus fg1 because our fore ground classes are fg1,fg2,fg3 but we have to store it as 0,1,2\n# #image_list = np.concatenate(image_list ,axis=0)\n# image_list = torch.stack(image_list) \n# return image_list,label",
"_____no_output_____"
],
[
"# desired_num = 3000\n# mosaic_list_of_images =[] # list of mosaic images, each mosaic image is saved as list of 9 images\n# fore_idx =[] # list of indexes at which foreground image is present in a mosaic image i.e from 0 to 9 \n# mosaic_label=[] # label of mosaic image = foreground class present in that mosaic\n# list_set_labels = [] \n# for i in range(desired_num):\n# set_idx = set()\n# np.random.seed(i)\n# bg_idx = np.random.randint(0,3500,8)\n# set_idx = set(background_label[bg_idx].tolist())\n# fg_idx = np.random.randint(0,1500)\n# set_idx.add(foreground_label[fg_idx].item())\n# fg = np.random.randint(0,9)\n# fore_idx.append(fg)\n# image_list,label = create_mosaic_img(bg_idx,fg_idx,fg)\n# mosaic_list_of_images.append(image_list)\n# mosaic_label.append(label)\n# list_set_labels.append(set_idx)",
"_____no_output_____"
],
[
"# def create_avg_image_from_mosaic_dataset(mosaic_dataset,labels,foreground_index,dataset_number):\n# \"\"\"\n# mosaic_dataset : mosaic_dataset contains 9 images 32 x 32 each as 1 data point\n# labels : mosaic_dataset labels\n# foreground_index : contains list of indexes where foreground image is present so that using this we can take weighted average\n# dataset_number : will help us to tell what ratio of foreground image to be taken. for eg: if it is \"j\" then fg_image_ratio = j/9 , bg_image_ratio = (9-j)/8*9\n# \"\"\"\n# avg_image_dataset = []\n# for i in range(len(mosaic_dataset)):\n# img = torch.zeros([5], dtype=torch.float64)\n# for j in range(9):\n# if j == foreground_index[i]:\n# img = img + mosaic_dataset[i][j]*dataset_number/9\n# else :\n# img = img + mosaic_dataset[i][j]*(9-dataset_number)/(8*9)\n \n# avg_image_dataset.append(img)\n \n# return torch.stack(avg_image_dataset) , torch.stack(labels) , foreground_index",
"_____no_output_____"
],
[
"class MosaicDataset1(Dataset):\n \"\"\"MosaicDataset dataset.\"\"\"\n\n def __init__(self, mosaic_list, mosaic_label,fore_idx):\n \"\"\"\n Args:\n csv_file (string): Path to the csv file with annotations.\n root_dir (string): Directory with all the images.\n transform (callable, optional): Optional transform to be applied\n on a sample.\n \"\"\"\n self.mosaic = mosaic_list\n self.label = mosaic_label\n self.fore_idx = fore_idx\n \n def __len__(self):\n return len(self.label)\n\n def __getitem__(self, idx):\n return self.mosaic[idx] , self.label[idx] , self.fore_idx[idx]",
"_____no_output_____"
],
[
"# data = [{\"mosaic_list\":mosaic_list_of_images, \"mosaic_label\": mosaic_label, \"fore_idx\":fore_idx}]\n# np.save(\"mosaic_data.npy\",data)",
"_____no_output_____"
],
[
"data = np.load(path+\"mosaic_data.npy\",allow_pickle=True)",
"_____no_output_____"
],
[
"mosaic_list_of_images = data[0][\"mosaic_list\"]\nmosaic_label = data[0][\"mosaic_label\"]\nfore_idx = data[0][\"fore_idx\"]",
"_____no_output_____"
],
[
"batch = 250\nmsd = MosaicDataset1(mosaic_list_of_images, mosaic_label, fore_idx)\ntrain_loader = DataLoader( msd,batch_size= batch ,shuffle=True)",
"_____no_output_____"
]
],
[
[
"**Focus Net**",
"_____no_output_____"
]
],
[
[
"class Focus_deep(nn.Module):\n '''\n deep focus network averaged at zeroth layer\n input : elemental data\n '''\n def __init__(self,inputs,output,K,d):\n super(Focus_deep,self).__init__()\n self.inputs = inputs\n self.output = output\n self.K = K\n self.d = d\n self.linear1 = nn.Linear(self.inputs,50) #,self.output)\n self.linear2 = nn.Linear(50,self.output) \n def forward(self,z):\n batch = z.shape[0]\n x = torch.zeros([batch,self.K],dtype=torch.float64)\n y = torch.zeros([batch,self.d], dtype=torch.float64)\n x,y = x.to(\"cuda\"),y.to(\"cuda\")\n for i in range(self.K):\n x[:,i] = self.helper(z[:,i] )[:,0] # self.d*i:self.d*i+self.d\n log_x = F.log_softmax(x,dim=1) # log alpha to calculate entropy\n x = F.softmax(x,dim=1) # alphas\n \n x1 = x[:,0]\n for i in range(self.K):\n x1 = x[:,i] \n y = y+torch.mul(x1[:,None],z[:,i]) # self.d*i:self.d*i+self.d\n return y , x,log_x \n def helper(self,x):\n x = F.relu(self.linear1(x))\n x = self.linear2(x)\n return x\n",
"_____no_output_____"
]
],
[
[
"**Classification Net**",
"_____no_output_____"
]
],
[
[
"class Classification_deep(nn.Module):\n '''\n input : elemental data\n deep classification module data averaged at zeroth layer\n '''\n def __init__(self,inputs,output):\n super(Classification_deep,self).__init__()\n self.inputs = inputs\n self.output = output\n self.linear1 = nn.Linear(self.inputs,50)\n self.linear2 = nn.Linear(50,self.output)\n\n def forward(self,x):\n x = F.relu(self.linear1(x))\n x = self.linear2(x)\n return x ",
"_____no_output_____"
],
[
"criterion = nn.CrossEntropyLoss()\ndef my_cross_entropy(x, y,alpha,log_alpha,k):\n # log_prob = -1.0 * F.log_softmax(x, 1)\n # loss = log_prob.gather(1, y.unsqueeze(1))\n # loss = loss.mean()\n loss = criterion(x,y)\n \n #alpha = torch.clamp(alpha,min=1e-10) \n \n b = -1.0* alpha * log_alpha\n b = torch.mean(torch.sum(b,dim=1))\n closs = loss\n entropy = b \n loss = (1-k)*loss + ((k)*b)\n return loss,closs,entropy",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"def calculate_attn_loss(dataloader,what,where,criter,k):\n what.eval()\n where.eval()\n r_loss = 0\n cc_loss = 0\n cc_entropy = 0\n alphas = []\n lbls = []\n pred = []\n fidices = []\n with torch.no_grad():\n for i, data in enumerate(dataloader, 0):\n inputs, labels,fidx = data\n lbls.append(labels)\n fidices.append(fidx)\n inputs = inputs.double()\n inputs, labels = inputs.to(\"cuda\"),labels.to(\"cuda\")\n avg,alpha,log_alpha = where(inputs)\n outputs = what(avg)\n _, predicted = torch.max(outputs.data, 1)\n pred.append(predicted.cpu().numpy())\n alphas.append(alpha.cpu().numpy())\n\n #ent = np.sum(entropy(alpha.cpu().detach().numpy(), base=2, axis=1))/batch\n # mx,_ = torch.max(alpha,1)\n # entropy = np.mean(-np.log2(mx.cpu().detach().numpy()))\n # print(\"entropy of batch\", entropy)\n\n #loss = (1-k)*criter(outputs, labels) + k*ent\n loss,closs,entropy = my_cross_entropy(outputs,labels,alpha,log_alpha,k)\n r_loss += loss.item()\n cc_loss += closs.item()\n cc_entropy += entropy.item()\n\n alphas = np.concatenate(alphas,axis=0)\n pred = np.concatenate(pred,axis=0)\n lbls = np.concatenate(lbls,axis=0)\n fidices = np.concatenate(fidices,axis=0)\n #print(alphas.shape,pred.shape,lbls.shape,fidices.shape) \n analysis = analyse_data(alphas,lbls,pred,fidices)\n return r_loss/i,cc_loss/i,cc_entropy/i,analysis",
"_____no_output_____"
],
[
"def analyse_data(alphas,lbls,predicted,f_idx):\n '''\n analysis data is created here\n '''\n batch = len(predicted)\n amth,alth,ftpt,ffpt,ftpf,ffpf = 0,0,0,0,0,0\n for j in range (batch):\n focus = np.argmax(alphas[j])\n if(alphas[j][focus] >= 0.5):\n amth +=1\n else:\n alth +=1\n if(focus == f_idx[j] and predicted[j] == lbls[j]):\n ftpt += 1\n elif(focus != f_idx[j] and predicted[j] == lbls[j]):\n ffpt +=1\n elif(focus == f_idx[j] and predicted[j] != lbls[j]):\n ftpf +=1\n elif(focus != f_idx[j] and predicted[j] != lbls[j]):\n ffpf +=1\n #print(sum(predicted==lbls),ftpt+ffpt)\n return [ftpt,ffpt,ftpf,ffpf,amth,alth]",
"_____no_output_____"
],
[
"number_runs = 10\nfull_analysis =[]\nFTPT_analysis = pd.DataFrame(columns = [\"FTPT\",\"FFPT\", \"FTPF\",\"FFPF\"])\nk = 0.005\n\nevery_what_epoch = 1\n\nfor n in range(number_runs):\n print(\"--\"*40)\n \n # instantiate focus and classification Model\n torch.manual_seed(n)\n where = Focus_deep(5,1,9,5).double()\n torch.manual_seed(n)\n what = Classification_deep(5,3).double()\n where = where.to(\"cuda\")\n what = what.to(\"cuda\")\n\n\n\n # instantiate optimizer\n optimizer_where = optim.Adam(where.parameters(),lr =0.01)\n optimizer_what = optim.Adam(what.parameters(), lr=0.01)\n #criterion = nn.CrossEntropyLoss()\n acti = []\n analysis_data = []\n loss_curi = []\n epochs = 2000\n\n\n # calculate zeroth epoch loss and FTPT values\n running_loss ,_,_,anlys_data= calculate_attn_loss(train_loader,what,where,criterion,k)\n loss_curi.append(running_loss)\n analysis_data.append(anlys_data)\n\n print('epoch: [%d ] loss: %.3f' %(0,running_loss)) \n\n # training starts \n for epoch in range(epochs): # loop over the dataset multiple times\n ep_lossi = []\n running_loss = 0.0\n what.train()\n where.train()\n if ((epoch) % (every_what_epoch*2) ) <= every_what_epoch-1 :\n print(epoch+1,\"updating what_net, where_net is freezed\")\n print(\"--\"*40)\n elif ((epoch) % (every_what_epoch*2)) > every_what_epoch-1 :\n print(epoch+1,\"updating where_net, what_net is freezed\")\n print(\"--\"*40)\n for i, data in enumerate(train_loader, 0):\n # get the inputs\n inputs, labels,_ = data\n inputs = inputs.double()\n inputs, labels = inputs.to(\"cuda\"),labels.to(\"cuda\")\n\n # zero the parameter gradients\n optimizer_where.zero_grad()\n optimizer_what.zero_grad()\n \n # forward + backward + optimize\n avg, alpha,log_alpha = where(inputs)\n outputs = what(avg)\n\n my_loss,_,_ = my_cross_entropy(outputs,labels,alpha,log_alpha,k)\n\n # print statistics\n running_loss += my_loss.item()\n my_loss.backward()\n\n if ((epoch) % (every_what_epoch*2) ) <= every_what_epoch-1 :\n optimizer_what.step()\n elif ( (epoch) % (every_what_epoch*2)) > every_what_epoch-1 :\n optimizer_where.step()\n \n # optimizer_where.step()\n # optimizer_what.step()\n #break\n running_loss,ccloss,ccentropy,anls_data = calculate_attn_loss(train_loader,what,where,criterion,k)\n analysis_data.append(anls_data)\n print('epoch: [%d] loss: %.3f celoss: %.3f entropy: %.3f' %(epoch + 1,running_loss,ccloss,ccentropy)) \n loss_curi.append(running_loss) #loss per epoch\n if running_loss<=0.001:\n break\n print('Finished Training run ' +str(n))\n #break\n analysis_data = np.array(analysis_data)\n FTPT_analysis.loc[n] = analysis_data[-1,:4]/30\n full_analysis.append((epoch, analysis_data))\n correct = 0\n total = 0\n with torch.no_grad():\n for data in train_loader:\n images, labels,_ = data\n images = images.double()\n images, labels = images.to(\"cuda\"), labels.to(\"cuda\")\n avg, alpha,log_alpha = where(images)\n outputs = what(avg)\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\n print('Accuracy of the network on the 3000 train images: %d %%' % ( 100 * correct / total))\n ",
"\u001b[1;30;43mStreaming output truncated to the last 5000 lines.\u001b[0m\n293 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [293] loss: 0.003 celoss: 0.000 entropy: 0.549\n294 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [294] loss: 0.003 celoss: 0.000 entropy: 0.542\n295 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [295] loss: 0.003 celoss: 0.000 entropy: 0.542\n296 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [296] loss: 0.003 celoss: 0.000 entropy: 0.547\n297 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [297] loss: 0.003 celoss: 0.000 entropy: 0.547\n298 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [298] loss: 0.003 celoss: 0.000 entropy: 0.548\n299 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [299] loss: 0.003 celoss: 0.000 entropy: 0.548\n300 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [300] loss: 0.003 celoss: 0.000 entropy: 0.535\n301 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [301] loss: 0.003 celoss: 0.000 entropy: 0.535\n302 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [302] loss: 0.003 celoss: 0.000 entropy: 0.547\n303 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [303] loss: 0.003 celoss: 0.000 entropy: 0.547\n304 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [304] loss: 0.003 celoss: 0.000 entropy: 0.534\n305 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [305] loss: 0.003 celoss: 0.000 entropy: 0.534\n306 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [306] loss: 0.003 celoss: 0.000 entropy: 0.569\n307 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [307] loss: 0.003 celoss: 0.000 entropy: 0.569\n308 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [308] loss: 0.003 celoss: 0.000 entropy: 0.550\n309 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [309] loss: 0.003 celoss: 0.000 entropy: 0.550\n310 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [310] loss: 0.003 celoss: 0.000 entropy: 0.530\n311 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [311] loss: 0.003 celoss: 0.000 entropy: 0.530\n312 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [312] loss: 0.003 celoss: 0.000 entropy: 0.542\n313 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [313] loss: 0.003 celoss: 0.000 entropy: 0.542\n314 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [314] loss: 0.003 celoss: 0.000 entropy: 0.522\n315 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [315] loss: 0.003 celoss: 0.000 entropy: 0.522\n316 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [316] loss: 0.003 celoss: 0.000 entropy: 0.530\n317 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [317] loss: 0.003 celoss: 0.000 entropy: 0.530\n318 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [318] loss: 0.003 celoss: 0.000 entropy: 0.525\n319 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [319] loss: 0.003 celoss: 0.000 entropy: 0.525\n320 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [320] loss: 0.003 celoss: 0.000 entropy: 0.519\n321 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [321] loss: 0.003 celoss: 0.000 entropy: 0.519\n322 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [322] loss: 0.003 celoss: 0.000 entropy: 0.518\n323 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [323] loss: 0.003 celoss: 0.000 entropy: 0.518\n324 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [324] loss: 0.003 celoss: 0.000 entropy: 0.516\n325 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [325] loss: 0.003 celoss: 0.000 entropy: 0.516\n326 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [326] loss: 0.003 celoss: 0.000 entropy: 0.527\n327 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [327] loss: 0.003 celoss: 0.000 entropy: 0.527\n328 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [328] loss: 0.003 celoss: 0.000 entropy: 0.507\n329 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [329] loss: 0.003 celoss: 0.000 entropy: 0.507\n330 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [330] loss: 0.003 celoss: 0.000 entropy: 0.522\n331 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [331] loss: 0.003 celoss: 0.000 entropy: 0.522\n332 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [332] loss: 0.003 celoss: 0.000 entropy: 0.509\n333 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [333] loss: 0.003 celoss: 0.000 entropy: 0.509\n334 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [334] loss: 0.003 celoss: 0.000 entropy: 0.507\n335 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [335] loss: 0.003 celoss: 0.000 entropy: 0.507\n336 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [336] loss: 0.003 celoss: 0.000 entropy: 0.516\n337 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [337] loss: 0.003 celoss: 0.000 entropy: 0.516\n338 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [338] loss: 0.003 celoss: 0.000 entropy: 0.501\n339 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [339] loss: 0.003 celoss: 0.000 entropy: 0.501\n340 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [340] loss: 0.003 celoss: 0.000 entropy: 0.502\n341 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [341] loss: 0.003 celoss: 0.000 entropy: 0.502\n342 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [342] loss: 0.003 celoss: 0.000 entropy: 0.502\n343 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [343] loss: 0.003 celoss: 0.000 entropy: 0.502\n344 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [344] loss: 0.003 celoss: 0.000 entropy: 0.495\n345 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [345] loss: 0.003 celoss: 0.000 entropy: 0.495\n346 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [346] loss: 0.003 celoss: 0.000 entropy: 0.498\n347 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [347] loss: 0.003 celoss: 0.000 entropy: 0.498\n348 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [348] loss: 0.003 celoss: 0.000 entropy: 0.495\n349 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [349] loss: 0.003 celoss: 0.000 entropy: 0.495\n350 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [350] loss: 0.003 celoss: 0.000 entropy: 0.498\n351 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [351] loss: 0.003 celoss: 0.000 entropy: 0.498\n352 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [352] loss: 0.003 celoss: 0.000 entropy: 0.496\n353 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [353] loss: 0.003 celoss: 0.000 entropy: 0.496\n354 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [354] loss: 0.003 celoss: 0.000 entropy: 0.491\n355 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [355] loss: 0.003 celoss: 0.000 entropy: 0.491\n356 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [356] loss: 0.003 celoss: 0.000 entropy: 0.492\n357 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [357] loss: 0.003 celoss: 0.000 entropy: 0.492\n358 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [358] loss: 0.003 celoss: 0.000 entropy: 0.492\n359 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [359] loss: 0.003 celoss: 0.000 entropy: 0.492\n360 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [360] loss: 0.003 celoss: 0.000 entropy: 0.488\n361 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [361] loss: 0.003 celoss: 0.000 entropy: 0.488\n362 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [362] loss: 0.004 celoss: 0.001 entropy: 0.487\n363 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [363] loss: 0.003 celoss: 0.001 entropy: 0.487\n364 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [364] loss: 0.003 celoss: 0.001 entropy: 0.536\n365 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [365] loss: 0.003 celoss: 0.000 entropy: 0.536\n366 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [366] loss: 0.505 celoss: 0.507 entropy: 0.088\n367 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [367] loss: 0.201 celoss: 0.201 entropy: 0.088\n368 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [368] loss: 0.156 celoss: 0.156 entropy: 0.007\n369 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [369] loss: 0.086 celoss: 0.086 entropy: 0.007\n370 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [370] loss: 0.019 celoss: 0.019 entropy: 0.000\n371 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [371] loss: 0.010 celoss: 0.010 entropy: 0.000\n372 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [372] loss: 0.010 celoss: 0.010 entropy: 0.000\n373 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [373] loss: 0.008 celoss: 0.009 entropy: 0.000\n374 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [374] loss: 0.008 celoss: 0.009 entropy: 0.000\n375 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [375] loss: 0.006 celoss: 0.006 entropy: 0.000\n376 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [376] loss: 0.006 celoss: 0.006 entropy: 0.000\n377 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [377] loss: 0.005 celoss: 0.005 entropy: 0.000\n378 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [378] loss: 0.005 celoss: 0.005 entropy: 0.000\n379 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [379] loss: 0.005 celoss: 0.005 entropy: 0.000\n380 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [380] loss: 0.005 celoss: 0.005 entropy: 0.000\n381 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [381] loss: 0.004 celoss: 0.004 entropy: 0.000\n382 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [382] loss: 0.004 celoss: 0.004 entropy: 0.000\n383 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [383] loss: 0.004 celoss: 0.004 entropy: 0.000\n384 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [384] loss: 0.004 celoss: 0.004 entropy: 0.000\n385 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [385] loss: 0.004 celoss: 0.004 entropy: 0.000\n386 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [386] loss: 0.004 celoss: 0.004 entropy: 0.000\n387 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [387] loss: 0.003 celoss: 0.003 entropy: 0.000\n388 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [388] loss: 0.003 celoss: 0.003 entropy: 0.000\n389 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [389] loss: 0.003 celoss: 0.003 entropy: 0.000\n390 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [390] loss: 0.003 celoss: 0.003 entropy: 0.000\n391 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [391] loss: 0.003 celoss: 0.003 entropy: 0.000\n392 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [392] loss: 0.003 celoss: 0.003 entropy: 0.000\n393 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [393] loss: 0.003 celoss: 0.003 entropy: 0.000\n394 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [394] loss: 0.003 celoss: 0.003 entropy: 0.000\n395 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [395] loss: 0.003 celoss: 0.003 entropy: 0.000\n396 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [396] loss: 0.003 celoss: 0.003 entropy: 0.000\n397 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [397] loss: 0.002 celoss: 0.002 entropy: 0.000\n398 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [398] loss: 0.002 celoss: 0.002 entropy: 0.000\n399 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [399] loss: 0.002 celoss: 0.002 entropy: 0.000\n400 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [400] loss: 0.002 celoss: 0.002 entropy: 0.000\n401 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [401] loss: 0.002 celoss: 0.002 entropy: 0.000\n402 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [402] loss: 0.002 celoss: 0.002 entropy: 0.000\n403 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [403] loss: 0.002 celoss: 0.002 entropy: 0.000\n404 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [404] loss: 0.002 celoss: 0.002 entropy: 0.000\n405 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [405] loss: 0.002 celoss: 0.002 entropy: 0.000\n406 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [406] loss: 0.002 celoss: 0.002 entropy: 0.000\n407 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [407] loss: 0.002 celoss: 0.002 entropy: 0.000\n408 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [408] loss: 0.002 celoss: 0.002 entropy: 0.000\n409 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [409] loss: 0.002 celoss: 0.002 entropy: 0.000\n410 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [410] loss: 0.002 celoss: 0.002 entropy: 0.000\n411 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [411] loss: 0.002 celoss: 0.002 entropy: 0.000\n412 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [412] loss: 0.002 celoss: 0.002 entropy: 0.000\n413 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [413] loss: 0.002 celoss: 0.002 entropy: 0.000\n414 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [414] loss: 0.002 celoss: 0.002 entropy: 0.000\n415 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [415] loss: 0.002 celoss: 0.002 entropy: 0.000\n416 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [416] loss: 0.002 celoss: 0.002 entropy: 0.000\n417 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [417] loss: 0.002 celoss: 0.002 entropy: 0.000\n418 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [418] loss: 0.002 celoss: 0.002 entropy: 0.000\n419 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [419] loss: 0.002 celoss: 0.002 entropy: 0.000\n420 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [420] loss: 0.002 celoss: 0.002 entropy: 0.000\n421 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [421] loss: 0.001 celoss: 0.001 entropy: 0.000\n422 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [422] loss: 0.001 celoss: 0.001 entropy: 0.000\n423 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [423] loss: 0.001 celoss: 0.001 entropy: 0.000\n424 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [424] loss: 0.001 celoss: 0.001 entropy: 0.000\n425 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [425] loss: 0.001 celoss: 0.001 entropy: 0.000\n426 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [426] loss: 0.001 celoss: 0.001 entropy: 0.000\n427 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [427] loss: 0.001 celoss: 0.001 entropy: 0.000\n428 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [428] loss: 0.001 celoss: 0.001 entropy: 0.000\n429 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [429] loss: 0.001 celoss: 0.001 entropy: 0.000\n430 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [430] loss: 0.001 celoss: 0.001 entropy: 0.000\n431 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [431] loss: 0.001 celoss: 0.001 entropy: 0.000\n432 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [432] loss: 0.001 celoss: 0.001 entropy: 0.000\n433 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [433] loss: 0.001 celoss: 0.001 entropy: 0.000\n434 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [434] loss: 0.001 celoss: 0.001 entropy: 0.000\n435 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [435] loss: 0.001 celoss: 0.001 entropy: 0.000\n436 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [436] loss: 0.001 celoss: 0.001 entropy: 0.000\n437 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [437] loss: 0.001 celoss: 0.001 entropy: 0.000\n438 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [438] loss: 0.001 celoss: 0.001 entropy: 0.000\n439 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [439] loss: 0.001 celoss: 0.001 entropy: 0.000\n440 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [440] loss: 0.001 celoss: 0.001 entropy: 0.000\n441 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [441] loss: 0.001 celoss: 0.001 entropy: 0.000\n442 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [442] loss: 0.001 celoss: 0.001 entropy: 0.000\n443 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [443] loss: 0.001 celoss: 0.001 entropy: 0.000\n444 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [444] loss: 0.001 celoss: 0.001 entropy: 0.000\n445 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [445] loss: 0.001 celoss: 0.001 entropy: 0.000\nFinished Training run 6\nAccuracy of the network on the 3000 train images: 100 %\n--------------------------------------------------------------------------------\nepoch: [0 ] loss: 2.560\n1 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1] loss: 1.264 celoss: 1.263 entropy: 1.472\n2 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [2] loss: 1.228 celoss: 1.230 entropy: 0.726\n3 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [3] loss: 1.212 celoss: 1.214 entropy: 0.726\n4 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [4] loss: 1.211 celoss: 1.213 entropy: 0.669\n5 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [5] loss: 1.194 celoss: 1.197 entropy: 0.669\n6 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [6] loss: 1.192 celoss: 1.195 entropy: 0.530\n7 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [7] loss: 1.212 celoss: 1.215 entropy: 0.530\n8 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [8] loss: 1.211 celoss: 1.214 entropy: 0.530\n9 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [9] loss: 1.231 celoss: 1.234 entropy: 0.530\n10 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [10] loss: 1.227 celoss: 1.231 entropy: 0.421\n11 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [11] loss: 1.194 celoss: 1.197 entropy: 0.421\n12 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [12] loss: 1.192 celoss: 1.196 entropy: 0.377\n13 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [13] loss: 1.185 celoss: 1.189 entropy: 0.377\n14 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [14] loss: 1.184 celoss: 1.188 entropy: 0.372\n15 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [15] loss: 1.179 celoss: 1.183 entropy: 0.372\n16 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [16] loss: 1.178 celoss: 1.182 entropy: 0.365\n17 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [17] loss: 1.208 celoss: 1.212 entropy: 0.365\n18 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [18] loss: 1.206 celoss: 1.210 entropy: 0.398\n19 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [19] loss: 1.187 celoss: 1.191 entropy: 0.398\n20 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [20] loss: 1.180 celoss: 1.183 entropy: 0.677\n21 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [21] loss: 1.173 celoss: 1.175 entropy: 0.677\n22 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [22] loss: 1.169 celoss: 1.172 entropy: 0.536\n23 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [23] loss: 1.174 celoss: 1.177 entropy: 0.536\n24 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [24] loss: 1.173 celoss: 1.176 entropy: 0.513\n25 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [25] loss: 1.178 celoss: 1.182 entropy: 0.513\n26 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [26] loss: 1.175 celoss: 1.179 entropy: 0.459\n27 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [27] loss: 1.200 celoss: 1.203 entropy: 0.459\n28 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [28] loss: 1.198 celoss: 1.201 entropy: 0.452\n29 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [29] loss: 1.175 celoss: 1.179 entropy: 0.452\n30 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [30] loss: 1.178 celoss: 1.182 entropy: 0.444\n31 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [31] loss: 1.164 celoss: 1.168 entropy: 0.444\n32 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [32] loss: 1.162 celoss: 1.166 entropy: 0.447\n33 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [33] loss: 1.157 celoss: 1.161 entropy: 0.447\n34 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [34] loss: 1.160 celoss: 1.163 entropy: 0.439\n35 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [35] loss: 1.149 celoss: 1.153 entropy: 0.439\n36 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [36] loss: 1.157 celoss: 1.161 entropy: 0.416\n37 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [37] loss: 1.164 celoss: 1.168 entropy: 0.416\n38 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [38] loss: 1.187 celoss: 1.191 entropy: 0.405\n39 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [39] loss: 1.202 celoss: 1.206 entropy: 0.405\n40 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [40] loss: 1.199 celoss: 1.203 entropy: 0.403\n41 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [41] loss: 1.166 celoss: 1.170 entropy: 0.403\n42 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [42] loss: 1.166 celoss: 1.170 entropy: 0.412\n43 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [43] loss: 1.167 celoss: 1.171 entropy: 0.412\n44 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [44] loss: 1.167 celoss: 1.171 entropy: 0.411\n45 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [45] loss: 1.178 celoss: 1.182 entropy: 0.411\n46 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [46] loss: 1.174 celoss: 1.178 entropy: 0.407\n47 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [47] loss: 1.164 celoss: 1.167 entropy: 0.407\n48 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [48] loss: 1.159 celoss: 1.163 entropy: 0.390\n49 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [49] loss: 1.156 celoss: 1.160 entropy: 0.390\n50 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [50] loss: 1.153 celoss: 1.157 entropy: 0.384\n51 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [51] loss: 1.145 celoss: 1.148 entropy: 0.384\n52 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [52] loss: 1.143 celoss: 1.146 entropy: 0.386\n53 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [53] loss: 1.156 celoss: 1.160 entropy: 0.386\n54 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [54] loss: 1.157 celoss: 1.161 entropy: 0.385\n55 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [55] loss: 1.141 celoss: 1.145 entropy: 0.385\n56 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [56] loss: 1.143 celoss: 1.147 entropy: 0.384\n57 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [57] loss: 1.135 celoss: 1.139 entropy: 0.384\n58 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [58] loss: 1.055 celoss: 1.059 entropy: 0.262\n59 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [59] loss: 1.019 celoss: 1.023 entropy: 0.262\n60 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [60] loss: 1.086 celoss: 1.091 entropy: 0.212\n61 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [61] loss: 1.068 celoss: 1.072 entropy: 0.212\n62 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [62] loss: 1.035 celoss: 1.039 entropy: 0.183\n63 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [63] loss: 1.037 celoss: 1.041 entropy: 0.183\n64 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [64] loss: 1.019 celoss: 1.024 entropy: 0.170\n65 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [65] loss: 0.985 celoss: 0.989 entropy: 0.170\n66 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [66] loss: 0.959 celoss: 0.963 entropy: 0.099\n67 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [67] loss: 0.915 celoss: 0.919 entropy: 0.099\n68 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [68] loss: 0.909 celoss: 0.913 entropy: 0.072\n69 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [69] loss: 0.900 celoss: 0.904 entropy: 0.072\n70 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [70] loss: 0.900 celoss: 0.904 entropy: 0.067\n71 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [71] loss: 0.899 celoss: 0.903 entropy: 0.067\n72 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [72] loss: 0.899 celoss: 0.903 entropy: 0.066\n73 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [73] loss: 0.899 celoss: 0.903 entropy: 0.066\n74 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [74] loss: 0.899 celoss: 0.903 entropy: 0.065\n75 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [75] loss: 0.888 celoss: 0.892 entropy: 0.065\n76 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [76] loss: 0.888 celoss: 0.892 entropy: 0.065\n77 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [77] loss: 0.868 celoss: 0.872 entropy: 0.065\n78 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [78] loss: 0.868 celoss: 0.872 entropy: 0.065\n79 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [79] loss: 0.861 celoss: 0.865 entropy: 0.065\n80 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [80] loss: 0.861 celoss: 0.865 entropy: 0.064\n81 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [81] loss: 0.867 celoss: 0.871 entropy: 0.064\n82 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [82] loss: 0.867 celoss: 0.871 entropy: 0.064\n83 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [83] loss: 0.865 celoss: 0.869 entropy: 0.064\n84 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [84] loss: 0.865 celoss: 0.869 entropy: 0.064\n85 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [85] loss: 0.850 celoss: 0.854 entropy: 0.064\n86 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [86] loss: 0.850 celoss: 0.854 entropy: 0.064\n87 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [87] loss: 0.854 celoss: 0.858 entropy: 0.064\n88 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [88] loss: 0.854 celoss: 0.858 entropy: 0.064\n89 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [89] loss: 0.875 celoss: 0.879 entropy: 0.064\n90 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [90] loss: 0.875 celoss: 0.879 entropy: 0.064\n91 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [91] loss: 0.854 celoss: 0.858 entropy: 0.064\n92 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [92] loss: 0.854 celoss: 0.858 entropy: 0.064\n93 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [93] loss: 0.849 celoss: 0.853 entropy: 0.064\n94 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [94] loss: 0.849 celoss: 0.853 entropy: 0.063\n95 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [95] loss: 0.853 celoss: 0.857 entropy: 0.063\n96 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [96] loss: 0.853 celoss: 0.857 entropy: 0.063\n97 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [97] loss: 0.859 celoss: 0.863 entropy: 0.063\n98 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [98] loss: 0.859 celoss: 0.863 entropy: 0.063\n99 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [99] loss: 0.852 celoss: 0.856 entropy: 0.063\n100 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [100] loss: 0.852 celoss: 0.856 entropy: 0.063\n101 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [101] loss: 0.852 celoss: 0.856 entropy: 0.063\n102 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [102] loss: 0.852 celoss: 0.856 entropy: 0.063\n103 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [103] loss: 0.845 celoss: 0.849 entropy: 0.063\n104 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [104] loss: 0.845 celoss: 0.849 entropy: 0.063\n105 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [105] loss: 0.846 celoss: 0.850 entropy: 0.063\n106 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [106] loss: 0.846 celoss: 0.850 entropy: 0.063\n107 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [107] loss: 0.844 celoss: 0.848 entropy: 0.063\n108 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [108] loss: 0.844 celoss: 0.848 entropy: 0.062\n109 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [109] loss: 0.847 celoss: 0.851 entropy: 0.062\n110 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [110] loss: 0.847 celoss: 0.851 entropy: 0.062\n111 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [111] loss: 0.846 celoss: 0.850 entropy: 0.062\n112 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [112] loss: 0.846 celoss: 0.850 entropy: 0.062\n113 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [113] loss: 0.848 celoss: 0.852 entropy: 0.062\n114 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [114] loss: 0.848 celoss: 0.852 entropy: 0.062\n115 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [115] loss: 0.846 celoss: 0.850 entropy: 0.062\n116 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [116] loss: 0.846 celoss: 0.850 entropy: 0.062\n117 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [117] loss: 0.847 celoss: 0.851 entropy: 0.062\n118 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [118] loss: 0.847 celoss: 0.851 entropy: 0.061\n119 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [119] loss: 0.844 celoss: 0.848 entropy: 0.061\n120 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [120] loss: 0.844 celoss: 0.848 entropy: 0.061\n121 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [121] loss: 0.844 celoss: 0.848 entropy: 0.061\n122 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [122] loss: 0.844 celoss: 0.848 entropy: 0.061\n123 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [123] loss: 0.844 celoss: 0.848 entropy: 0.061\n124 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [124] loss: 0.844 celoss: 0.848 entropy: 0.061\n125 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [125] loss: 0.843 celoss: 0.847 entropy: 0.061\n126 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [126] loss: 0.843 celoss: 0.847 entropy: 0.061\n127 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [127] loss: 0.843 celoss: 0.847 entropy: 0.061\n128 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [128] loss: 0.843 celoss: 0.847 entropy: 0.060\n129 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [129] loss: 0.844 celoss: 0.848 entropy: 0.060\n130 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [130] loss: 0.844 celoss: 0.848 entropy: 0.060\n131 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [131] loss: 0.848 celoss: 0.852 entropy: 0.060\n132 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [132] loss: 0.848 celoss: 0.851 entropy: 0.059\n133 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [133] loss: 0.857 celoss: 0.861 entropy: 0.059\n134 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [134] loss: 0.857 celoss: 0.861 entropy: 0.059\n135 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [135] loss: 0.845 celoss: 0.849 entropy: 0.059\n136 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [136] loss: 0.844 celoss: 0.848 entropy: 0.058\n137 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [137] loss: 0.842 celoss: 0.846 entropy: 0.058\n138 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [138] loss: 0.842 celoss: 0.846 entropy: 0.057\n139 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [139] loss: 0.841 celoss: 0.845 entropy: 0.057\n140 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [140] loss: 0.823 celoss: 0.827 entropy: 0.066\n141 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [141] loss: 0.829 celoss: 0.832 entropy: 0.066\n142 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [142] loss: 0.068 celoss: 0.068 entropy: 0.036\n143 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [143] loss: 0.061 celoss: 0.061 entropy: 0.036\n144 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [144] loss: 0.014 celoss: 0.014 entropy: 0.022\n145 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [145] loss: 0.010 celoss: 0.010 entropy: 0.022\n146 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [146] loss: 0.005 celoss: 0.005 entropy: 0.003\n147 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [147] loss: 0.003 celoss: 0.003 entropy: 0.003\n148 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [148] loss: 0.003 celoss: 0.003 entropy: 0.000\n149 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [149] loss: 0.003 celoss: 0.003 entropy: 0.000\n150 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [150] loss: 0.003 celoss: 0.003 entropy: 0.000\n151 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [151] loss: 0.002 celoss: 0.002 entropy: 0.000\n152 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [152] loss: 0.002 celoss: 0.002 entropy: 0.000\n153 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [153] loss: 0.002 celoss: 0.002 entropy: 0.000\n154 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [154] loss: 0.002 celoss: 0.002 entropy: 0.000\n155 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [155] loss: 0.002 celoss: 0.002 entropy: 0.000\n156 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [156] loss: 0.002 celoss: 0.002 entropy: 0.000\n157 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [157] loss: 0.002 celoss: 0.002 entropy: 0.000\n158 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [158] loss: 0.002 celoss: 0.002 entropy: 0.000\n159 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [159] loss: 0.001 celoss: 0.001 entropy: 0.000\n160 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [160] loss: 0.001 celoss: 0.001 entropy: 0.000\n161 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [161] loss: 0.001 celoss: 0.001 entropy: 0.000\n162 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [162] loss: 0.001 celoss: 0.001 entropy: 0.000\n163 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [163] loss: 0.001 celoss: 0.001 entropy: 0.000\n164 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [164] loss: 0.001 celoss: 0.001 entropy: 0.000\n165 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [165] loss: 0.001 celoss: 0.001 entropy: 0.000\n166 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [166] loss: 0.001 celoss: 0.001 entropy: 0.000\n167 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [167] loss: 0.001 celoss: 0.001 entropy: 0.000\n168 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [168] loss: 0.001 celoss: 0.001 entropy: 0.000\n169 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [169] loss: 0.001 celoss: 0.001 entropy: 0.000\nFinished Training run 7\nAccuracy of the network on the 3000 train images: 100 %\n--------------------------------------------------------------------------------\nepoch: [0 ] loss: 2.577\n1 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1] loss: 1.224 celoss: 1.224 entropy: 1.236\n2 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [2] loss: 1.223 celoss: 1.225 entropy: 0.735\n3 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [3] loss: 1.216 celoss: 1.218 entropy: 0.735\n4 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [4] loss: 1.210 celoss: 1.213 entropy: 0.611\n5 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [5] loss: 1.206 celoss: 1.209 entropy: 0.611\n6 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [6] loss: 1.205 celoss: 1.209 entropy: 0.567\n7 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [7] loss: 1.192 celoss: 1.195 entropy: 0.567\n8 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [8] loss: 1.189 celoss: 1.192 entropy: 0.611\n9 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [9] loss: 1.186 celoss: 1.189 entropy: 0.611\n10 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [10] loss: 1.184 celoss: 1.187 entropy: 0.644\n11 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [11] loss: 1.184 celoss: 1.187 entropy: 0.644\n12 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [12] loss: 1.178 celoss: 1.180 entropy: 0.765\n13 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [13] loss: 1.188 celoss: 1.190 entropy: 0.765\n14 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [14] loss: 0.897 celoss: 0.897 entropy: 0.741\n15 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [15] loss: 0.786 celoss: 0.786 entropy: 0.741\n16 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [16] loss: 0.633 celoss: 0.634 entropy: 0.393\n17 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [17] loss: 0.401 celoss: 0.401 entropy: 0.393\n18 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [18] loss: 0.370 celoss: 0.370 entropy: 0.390\n19 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [19] loss: 0.258 celoss: 0.257 entropy: 0.390\n20 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [20] loss: 0.246 celoss: 0.246 entropy: 0.352\n21 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [21] loss: 0.173 celoss: 0.172 entropy: 0.352\n22 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [22] loss: 0.171 celoss: 0.171 entropy: 0.339\n23 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [23] loss: 0.135 celoss: 0.134 entropy: 0.339\n24 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [24] loss: 0.136 celoss: 0.135 entropy: 0.322\n25 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [25] loss: 0.109 celoss: 0.108 entropy: 0.322\n26 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [26] loss: 0.108 celoss: 0.107 entropy: 0.332\n27 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [27] loss: 0.090 celoss: 0.089 entropy: 0.332\n28 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [28] loss: 0.090 celoss: 0.089 entropy: 0.306\n29 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [29] loss: 0.077 celoss: 0.076 entropy: 0.306\n30 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [30] loss: 0.077 celoss: 0.076 entropy: 0.267\n31 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [31] loss: 0.067 celoss: 0.066 entropy: 0.267\n32 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [32] loss: 0.066 celoss: 0.065 entropy: 0.253\n33 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [33] loss: 0.063 celoss: 0.062 entropy: 0.253\n34 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [34] loss: 0.062 celoss: 0.061 entropy: 0.263\n35 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [35] loss: 0.051 celoss: 0.050 entropy: 0.263\n36 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [36] loss: 0.051 celoss: 0.050 entropy: 0.257\n37 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [37] loss: 0.046 celoss: 0.045 entropy: 0.257\n38 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [38] loss: 0.046 celoss: 0.045 entropy: 0.253\n39 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [39] loss: 0.039 celoss: 0.038 entropy: 0.253\n40 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [40] loss: 0.039 celoss: 0.037 entropy: 0.251\n41 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [41] loss: 0.034 celoss: 0.033 entropy: 0.251\n42 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [42] loss: 0.034 celoss: 0.033 entropy: 0.253\n43 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [43] loss: 0.030 celoss: 0.029 entropy: 0.253\n44 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [44] loss: 0.030 celoss: 0.028 entropy: 0.252\n45 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [45] loss: 0.026 celoss: 0.025 entropy: 0.252\n46 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [46] loss: 0.026 celoss: 0.025 entropy: 0.252\n47 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [47] loss: 0.024 celoss: 0.023 entropy: 0.252\n48 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [48] loss: 0.024 celoss: 0.022 entropy: 0.252\n49 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [49] loss: 0.024 celoss: 0.023 entropy: 0.252\n50 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [50] loss: 0.023 celoss: 0.022 entropy: 0.272\n51 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [51] loss: 0.020 celoss: 0.019 entropy: 0.272\n52 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [52] loss: 0.020 celoss: 0.019 entropy: 0.271\n53 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [53] loss: 0.018 celoss: 0.017 entropy: 0.271\n54 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [54] loss: 0.018 celoss: 0.017 entropy: 0.241\n55 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [55] loss: 0.017 celoss: 0.015 entropy: 0.241\n56 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [56] loss: 0.016 celoss: 0.015 entropy: 0.265\n57 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [57] loss: 0.015 celoss: 0.014 entropy: 0.265\n58 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [58] loss: 0.015 celoss: 0.013 entropy: 0.262\n59 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [59] loss: 0.014 celoss: 0.012 entropy: 0.262\n60 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [60] loss: 0.014 celoss: 0.012 entropy: 0.251\n61 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [61] loss: 0.013 celoss: 0.012 entropy: 0.251\n62 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [62] loss: 0.013 celoss: 0.011 entropy: 0.257\n63 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [63] loss: 0.012 celoss: 0.011 entropy: 0.257\n64 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [64] loss: 0.012 celoss: 0.010 entropy: 0.260\n65 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [65] loss: 0.011 celoss: 0.010 entropy: 0.260\n66 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [66] loss: 0.011 celoss: 0.010 entropy: 0.250\n67 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [67] loss: 0.010 celoss: 0.009 entropy: 0.250\n68 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [68] loss: 0.010 celoss: 0.009 entropy: 0.243\n69 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [69] loss: 0.010 celoss: 0.009 entropy: 0.243\n70 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [70] loss: 0.010 celoss: 0.009 entropy: 0.222\n71 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [71] loss: 0.009 celoss: 0.008 entropy: 0.222\n72 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [72] loss: 0.009 celoss: 0.008 entropy: 0.238\n73 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [73] loss: 0.009 celoss: 0.008 entropy: 0.238\n74 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [74] loss: 0.009 celoss: 0.008 entropy: 0.238\n75 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [75] loss: 0.008 celoss: 0.007 entropy: 0.238\n76 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [76] loss: 0.008 celoss: 0.007 entropy: 0.228\n77 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [77] loss: 0.008 celoss: 0.007 entropy: 0.228\n78 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [78] loss: 0.008 celoss: 0.007 entropy: 0.235\n79 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [79] loss: 0.007 celoss: 0.006 entropy: 0.235\n80 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [80] loss: 0.007 celoss: 0.006 entropy: 0.240\n81 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [81] loss: 0.007 celoss: 0.006 entropy: 0.240\n82 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [82] loss: 0.007 celoss: 0.006 entropy: 0.233\n83 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [83] loss: 0.007 celoss: 0.006 entropy: 0.233\n84 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [84] loss: 0.007 celoss: 0.006 entropy: 0.239\n85 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [85] loss: 0.006 celoss: 0.005 entropy: 0.239\n86 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [86] loss: 0.006 celoss: 0.005 entropy: 0.230\n87 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [87] loss: 0.006 celoss: 0.005 entropy: 0.230\n88 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [88] loss: 0.006 celoss: 0.005 entropy: 0.222\n89 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [89] loss: 0.006 celoss: 0.005 entropy: 0.222\n90 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [90] loss: 0.006 celoss: 0.005 entropy: 0.226\n91 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [91] loss: 0.006 celoss: 0.005 entropy: 0.226\n92 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [92] loss: 0.006 celoss: 0.005 entropy: 0.221\n93 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [93] loss: 0.005 celoss: 0.004 entropy: 0.221\n94 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [94] loss: 0.005 celoss: 0.004 entropy: 0.225\n95 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [95] loss: 0.005 celoss: 0.004 entropy: 0.225\n96 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [96] loss: 0.005 celoss: 0.004 entropy: 0.224\n97 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [97] loss: 0.005 celoss: 0.004 entropy: 0.224\n98 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [98] loss: 0.005 celoss: 0.004 entropy: 0.214\n99 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [99] loss: 0.005 celoss: 0.004 entropy: 0.214\n100 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [100] loss: 0.005 celoss: 0.004 entropy: 0.225\n101 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [101] loss: 0.005 celoss: 0.004 entropy: 0.225\n102 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [102] loss: 0.005 celoss: 0.004 entropy: 0.217\n103 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [103] loss: 0.005 celoss: 0.004 entropy: 0.217\n104 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [104] loss: 0.005 celoss: 0.004 entropy: 0.216\n105 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [105] loss: 0.004 celoss: 0.003 entropy: 0.216\n106 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [106] loss: 0.004 celoss: 0.003 entropy: 0.216\n107 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [107] loss: 0.004 celoss: 0.003 entropy: 0.216\n108 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [108] loss: 0.004 celoss: 0.003 entropy: 0.212\n109 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [109] loss: 0.004 celoss: 0.003 entropy: 0.212\n110 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [110] loss: 0.004 celoss: 0.003 entropy: 0.199\n111 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [111] loss: 0.004 celoss: 0.003 entropy: 0.199\n112 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [112] loss: 0.004 celoss: 0.003 entropy: 0.204\n113 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [113] loss: 0.004 celoss: 0.003 entropy: 0.204\n114 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [114] loss: 0.004 celoss: 0.003 entropy: 0.212\n115 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [115] loss: 0.004 celoss: 0.003 entropy: 0.212\n116 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [116] loss: 0.004 celoss: 0.003 entropy: 0.202\n117 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [117] loss: 0.004 celoss: 0.003 entropy: 0.202\n118 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [118] loss: 0.004 celoss: 0.003 entropy: 0.209\n119 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [119] loss: 0.004 celoss: 0.003 entropy: 0.209\n120 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [120] loss: 0.004 celoss: 0.003 entropy: 0.201\n121 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [121] loss: 0.003 celoss: 0.002 entropy: 0.201\n122 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [122] loss: 0.003 celoss: 0.002 entropy: 0.204\n123 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [123] loss: 0.003 celoss: 0.002 entropy: 0.204\n124 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [124] loss: 0.003 celoss: 0.002 entropy: 0.201\n125 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [125] loss: 0.003 celoss: 0.002 entropy: 0.201\n126 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [126] loss: 0.003 celoss: 0.002 entropy: 0.197\n127 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [127] loss: 0.003 celoss: 0.002 entropy: 0.197\n128 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [128] loss: 0.003 celoss: 0.002 entropy: 0.194\n129 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [129] loss: 0.003 celoss: 0.002 entropy: 0.194\n130 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [130] loss: 0.003 celoss: 0.002 entropy: 0.195\n131 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [131] loss: 0.003 celoss: 0.002 entropy: 0.195\n132 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [132] loss: 0.003 celoss: 0.002 entropy: 0.193\n133 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [133] loss: 0.003 celoss: 0.002 entropy: 0.193\n134 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [134] loss: 0.003 celoss: 0.002 entropy: 0.191\n135 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [135] loss: 0.003 celoss: 0.002 entropy: 0.191\n136 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [136] loss: 0.003 celoss: 0.002 entropy: 0.189\n137 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [137] loss: 0.003 celoss: 0.002 entropy: 0.189\n138 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [138] loss: 0.003 celoss: 0.002 entropy: 0.194\n139 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [139] loss: 0.003 celoss: 0.002 entropy: 0.194\n140 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [140] loss: 0.003 celoss: 0.002 entropy: 0.197\n141 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [141] loss: 0.003 celoss: 0.002 entropy: 0.197\n142 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [142] loss: 0.003 celoss: 0.002 entropy: 0.191\n143 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [143] loss: 0.003 celoss: 0.002 entropy: 0.191\n144 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [144] loss: 0.003 celoss: 0.002 entropy: 0.191\n145 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [145] loss: 0.003 celoss: 0.002 entropy: 0.191\n146 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [146] loss: 0.003 celoss: 0.002 entropy: 0.187\n147 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [147] loss: 0.003 celoss: 0.002 entropy: 0.187\n148 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [148] loss: 0.003 celoss: 0.002 entropy: 0.187\n149 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [149] loss: 0.003 celoss: 0.002 entropy: 0.187\n150 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [150] loss: 0.003 celoss: 0.002 entropy: 0.190\n151 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [151] loss: 0.002 celoss: 0.002 entropy: 0.190\n152 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [152] loss: 0.002 celoss: 0.002 entropy: 0.185\n153 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [153] loss: 0.002 celoss: 0.002 entropy: 0.185\n154 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [154] loss: 0.002 celoss: 0.002 entropy: 0.179\n155 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [155] loss: 0.002 celoss: 0.002 entropy: 0.179\n156 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [156] loss: 0.002 celoss: 0.001 entropy: 0.184\n157 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [157] loss: 0.002 celoss: 0.001 entropy: 0.184\n158 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [158] loss: 0.002 celoss: 0.001 entropy: 0.182\n159 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [159] loss: 0.002 celoss: 0.001 entropy: 0.182\n160 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [160] loss: 0.002 celoss: 0.001 entropy: 0.183\n161 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [161] loss: 0.002 celoss: 0.001 entropy: 0.183\n162 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [162] loss: 0.002 celoss: 0.001 entropy: 0.176\n163 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [163] loss: 0.002 celoss: 0.001 entropy: 0.176\n164 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [164] loss: 0.002 celoss: 0.001 entropy: 0.183\n165 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [165] loss: 0.002 celoss: 0.001 entropy: 0.183\n166 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [166] loss: 0.002 celoss: 0.001 entropy: 0.180\n167 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [167] loss: 0.002 celoss: 0.001 entropy: 0.180\n168 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [168] loss: 0.002 celoss: 0.001 entropy: 0.174\n169 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [169] loss: 0.002 celoss: 0.001 entropy: 0.174\n170 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [170] loss: 0.002 celoss: 0.001 entropy: 0.179\n171 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [171] loss: 0.002 celoss: 0.001 entropy: 0.179\n172 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [172] loss: 0.002 celoss: 0.001 entropy: 0.174\n173 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [173] loss: 0.002 celoss: 0.001 entropy: 0.174\n174 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [174] loss: 0.002 celoss: 0.001 entropy: 0.179\n175 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [175] loss: 0.002 celoss: 0.001 entropy: 0.179\n176 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [176] loss: 0.002 celoss: 0.001 entropy: 0.172\n177 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [177] loss: 0.002 celoss: 0.001 entropy: 0.172\n178 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [178] loss: 0.002 celoss: 0.001 entropy: 0.173\n179 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [179] loss: 0.002 celoss: 0.001 entropy: 0.173\n180 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [180] loss: 0.002 celoss: 0.001 entropy: 0.177\n181 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [181] loss: 0.002 celoss: 0.001 entropy: 0.177\n182 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [182] loss: 0.002 celoss: 0.001 entropy: 0.172\n183 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [183] loss: 0.002 celoss: 0.001 entropy: 0.172\n184 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [184] loss: 0.002 celoss: 0.001 entropy: 0.168\n185 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [185] loss: 0.002 celoss: 0.001 entropy: 0.168\n186 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [186] loss: 0.002 celoss: 0.001 entropy: 0.170\n187 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [187] loss: 0.002 celoss: 0.001 entropy: 0.170\n188 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [188] loss: 0.002 celoss: 0.001 entropy: 0.169\n189 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [189] loss: 0.002 celoss: 0.001 entropy: 0.169\n190 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [190] loss: 0.002 celoss: 0.001 entropy: 0.169\n191 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [191] loss: 0.002 celoss: 0.001 entropy: 0.169\n192 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [192] loss: 0.002 celoss: 0.001 entropy: 0.169\n193 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [193] loss: 0.002 celoss: 0.001 entropy: 0.169\n194 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [194] loss: 0.002 celoss: 0.001 entropy: 0.167\n195 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [195] loss: 0.002 celoss: 0.001 entropy: 0.167\n196 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [196] loss: 0.002 celoss: 0.001 entropy: 0.166\n197 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [197] loss: 0.002 celoss: 0.001 entropy: 0.166\n198 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [198] loss: 0.002 celoss: 0.001 entropy: 0.164\n199 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [199] loss: 0.002 celoss: 0.001 entropy: 0.164\n200 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [200] loss: 0.002 celoss: 0.001 entropy: 0.164\n201 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [201] loss: 0.002 celoss: 0.001 entropy: 0.164\n202 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [202] loss: 0.002 celoss: 0.001 entropy: 0.162\n203 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [203] loss: 0.002 celoss: 0.001 entropy: 0.162\n204 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [204] loss: 0.002 celoss: 0.001 entropy: 0.165\n205 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [205] loss: 0.002 celoss: 0.001 entropy: 0.165\n206 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [206] loss: 0.002 celoss: 0.001 entropy: 0.166\n207 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [207] loss: 0.002 celoss: 0.001 entropy: 0.166\n208 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [208] loss: 0.002 celoss: 0.001 entropy: 0.161\n209 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [209] loss: 0.002 celoss: 0.001 entropy: 0.161\n210 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [210] loss: 0.002 celoss: 0.001 entropy: 0.161\n211 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [211] loss: 0.002 celoss: 0.001 entropy: 0.161\n212 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [212] loss: 0.002 celoss: 0.001 entropy: 0.164\n213 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [213] loss: 0.002 celoss: 0.001 entropy: 0.164\n214 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [214] loss: 0.002 celoss: 0.001 entropy: 0.161\n215 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [215] loss: 0.002 celoss: 0.001 entropy: 0.161\n216 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [216] loss: 0.002 celoss: 0.001 entropy: 0.159\n217 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [217] loss: 0.002 celoss: 0.001 entropy: 0.159\n218 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [218] loss: 0.002 celoss: 0.001 entropy: 0.158\n219 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [219] loss: 0.002 celoss: 0.001 entropy: 0.158\n220 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [220] loss: 0.002 celoss: 0.001 entropy: 0.158\n221 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [221] loss: 0.001 celoss: 0.001 entropy: 0.158\n222 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [222] loss: 0.001 celoss: 0.001 entropy: 0.156\n223 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [223] loss: 0.001 celoss: 0.001 entropy: 0.156\n224 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [224] loss: 0.001 celoss: 0.001 entropy: 0.155\n225 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [225] loss: 0.001 celoss: 0.001 entropy: 0.155\n226 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [226] loss: 0.001 celoss: 0.001 entropy: 0.154\n227 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [227] loss: 0.001 celoss: 0.001 entropy: 0.154\n228 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [228] loss: 0.001 celoss: 0.001 entropy: 0.152\n229 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [229] loss: 0.001 celoss: 0.001 entropy: 0.152\n230 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [230] loss: 0.001 celoss: 0.001 entropy: 0.154\n231 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [231] loss: 0.001 celoss: 0.001 entropy: 0.154\n232 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [232] loss: 0.001 celoss: 0.001 entropy: 0.153\n233 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [233] loss: 0.001 celoss: 0.001 entropy: 0.153\n234 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [234] loss: 0.001 celoss: 0.001 entropy: 0.152\n235 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [235] loss: 0.001 celoss: 0.001 entropy: 0.152\n236 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [236] loss: 0.001 celoss: 0.001 entropy: 0.150\n237 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [237] loss: 0.001 celoss: 0.001 entropy: 0.150\n238 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [238] loss: 0.001 celoss: 0.001 entropy: 0.151\n239 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [239] loss: 0.001 celoss: 0.001 entropy: 0.151\n240 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [240] loss: 0.001 celoss: 0.001 entropy: 0.149\n241 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [241] loss: 0.001 celoss: 0.001 entropy: 0.149\n242 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [242] loss: 0.001 celoss: 0.001 entropy: 0.148\n243 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [243] loss: 0.001 celoss: 0.001 entropy: 0.148\n244 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [244] loss: 0.001 celoss: 0.001 entropy: 0.148\n245 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [245] loss: 0.001 celoss: 0.001 entropy: 0.148\n246 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [246] loss: 0.001 celoss: 0.001 entropy: 0.146\n247 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [247] loss: 0.001 celoss: 0.001 entropy: 0.146\n248 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [248] loss: 0.001 celoss: 0.001 entropy: 0.146\n249 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [249] loss: 0.001 celoss: 0.001 entropy: 0.146\n250 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [250] loss: 0.001 celoss: 0.001 entropy: 0.145\n251 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [251] loss: 0.001 celoss: 0.001 entropy: 0.145\n252 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [252] loss: 0.001 celoss: 0.001 entropy: 0.145\n253 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [253] loss: 0.001 celoss: 0.001 entropy: 0.145\n254 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [254] loss: 0.001 celoss: 0.001 entropy: 0.145\n255 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [255] loss: 0.001 celoss: 0.001 entropy: 0.145\n256 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [256] loss: 0.001 celoss: 0.001 entropy: 0.143\n257 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [257] loss: 0.001 celoss: 0.001 entropy: 0.143\n258 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [258] loss: 0.001 celoss: 0.001 entropy: 0.142\n259 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [259] loss: 0.001 celoss: 0.001 entropy: 0.142\n260 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [260] loss: 0.001 celoss: 0.001 entropy: 0.141\n261 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [261] loss: 0.001 celoss: 0.000 entropy: 0.141\n262 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [262] loss: 0.001 celoss: 0.000 entropy: 0.140\n263 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [263] loss: 0.001 celoss: 0.000 entropy: 0.140\n264 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [264] loss: 0.001 celoss: 0.000 entropy: 0.140\n265 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [265] loss: 0.001 celoss: 0.000 entropy: 0.140\n266 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [266] loss: 0.001 celoss: 0.000 entropy: 0.138\n267 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [267] loss: 0.001 celoss: 0.000 entropy: 0.138\n268 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [268] loss: 0.001 celoss: 0.000 entropy: 0.137\n269 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [269] loss: 0.001 celoss: 0.000 entropy: 0.137\n270 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [270] loss: 0.001 celoss: 0.000 entropy: 0.136\n271 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [271] loss: 0.001 celoss: 0.000 entropy: 0.136\n272 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [272] loss: 0.001 celoss: 0.000 entropy: 0.135\n273 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [273] loss: 0.001 celoss: 0.000 entropy: 0.135\n274 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [274] loss: 0.001 celoss: 0.000 entropy: 0.134\n275 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [275] loss: 0.001 celoss: 0.000 entropy: 0.134\n276 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [276] loss: 0.001 celoss: 0.000 entropy: 0.134\n277 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [277] loss: 0.001 celoss: 0.000 entropy: 0.134\n278 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [278] loss: 0.001 celoss: 0.000 entropy: 0.132\n279 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [279] loss: 0.001 celoss: 0.000 entropy: 0.132\n280 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [280] loss: 0.001 celoss: 0.000 entropy: 0.131\n281 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [281] loss: 0.001 celoss: 0.000 entropy: 0.131\n282 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [282] loss: 0.001 celoss: 0.000 entropy: 0.130\n283 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [283] loss: 0.001 celoss: 0.000 entropy: 0.130\n284 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [284] loss: 0.001 celoss: 0.000 entropy: 0.130\n285 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [285] loss: 0.001 celoss: 0.000 entropy: 0.130\n286 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [286] loss: 0.001 celoss: 0.000 entropy: 0.129\n287 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [287] loss: 0.001 celoss: 0.000 entropy: 0.129\n288 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [288] loss: 0.001 celoss: 0.000 entropy: 0.129\n289 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [289] loss: 0.001 celoss: 0.000 entropy: 0.129\n290 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [290] loss: 0.001 celoss: 0.000 entropy: 0.127\n291 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [291] loss: 0.001 celoss: 0.000 entropy: 0.127\n292 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [292] loss: 0.001 celoss: 0.000 entropy: 0.127\n293 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [293] loss: 0.001 celoss: 0.000 entropy: 0.127\n294 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [294] loss: 0.001 celoss: 0.000 entropy: 0.125\n295 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [295] loss: 0.001 celoss: 0.000 entropy: 0.125\n296 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [296] loss: 0.001 celoss: 0.000 entropy: 0.124\n297 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [297] loss: 0.001 celoss: 0.000 entropy: 0.124\n298 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [298] loss: 0.001 celoss: 0.000 entropy: 0.123\n299 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [299] loss: 0.001 celoss: 0.000 entropy: 0.123\nFinished Training run 8\nAccuracy of the network on the 3000 train images: 100 %\n--------------------------------------------------------------------------------\nepoch: [0 ] loss: 2.701\n1 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1] loss: 1.545 celoss: 1.547 entropy: 1.079\n2 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [2] loss: 1.399 celoss: 1.400 entropy: 1.084\n3 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [3] loss: 1.269 celoss: 1.270 entropy: 1.084\n4 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [4] loss: 1.250 celoss: 1.251 entropy: 1.104\n5 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [5] loss: 1.208 celoss: 1.209 entropy: 1.104\n6 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [6] loss: 1.198 celoss: 1.199 entropy: 1.037\n7 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [7] loss: 1.182 celoss: 1.183 entropy: 1.037\n8 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [8] loss: 1.175 celoss: 1.177 entropy: 0.767\n9 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [9] loss: 1.152 celoss: 1.154 entropy: 0.767\n10 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [10] loss: 1.136 celoss: 1.138 entropy: 0.640\n11 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [11] loss: 1.116 celoss: 1.119 entropy: 0.640\n12 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [12] loss: 1.116 celoss: 1.119 entropy: 0.582\n13 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [13] loss: 1.092 celoss: 1.095 entropy: 0.582\n14 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [14] loss: 1.082 celoss: 1.085 entropy: 0.605\n15 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [15] loss: 1.078 celoss: 1.080 entropy: 0.605\n16 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [16] loss: 1.067 celoss: 1.069 entropy: 0.613\n17 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [17] loss: 1.060 celoss: 1.062 entropy: 0.613\n18 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [18] loss: 1.060 celoss: 1.062 entropy: 0.582\n19 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [19] loss: 1.038 celoss: 1.040 entropy: 0.582\n20 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [20] loss: 1.038 celoss: 1.040 entropy: 0.603\n21 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [21] loss: 1.073 celoss: 1.076 entropy: 0.603\n22 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [22] loss: 1.074 celoss: 1.076 entropy: 0.603\n23 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [23] loss: 1.089 celoss: 1.092 entropy: 0.603\n24 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [24] loss: 1.093 celoss: 1.095 entropy: 0.593\n25 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [25] loss: 1.106 celoss: 1.108 entropy: 0.593\n26 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [26] loss: 1.108 celoss: 1.110 entropy: 0.593\n27 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [27] loss: 1.031 celoss: 1.034 entropy: 0.593\n28 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [28] loss: 1.048 celoss: 1.050 entropy: 0.586\n29 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [29] loss: 1.048 celoss: 1.050 entropy: 0.586\n30 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [30] loss: 1.079 celoss: 1.082 entropy: 0.554\n31 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [31] loss: 1.030 celoss: 1.033 entropy: 0.554\n32 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [32] loss: 1.024 celoss: 1.027 entropy: 0.569\n33 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [33] loss: 1.042 celoss: 1.045 entropy: 0.569\n34 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [34] loss: 1.042 celoss: 1.044 entropy: 0.585\n35 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [35] loss: 1.051 celoss: 1.053 entropy: 0.585\n36 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [36] loss: 1.050 celoss: 1.052 entropy: 0.575\n37 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [37] loss: 1.023 celoss: 1.025 entropy: 0.575\n38 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [38] loss: 1.022 celoss: 1.024 entropy: 0.601\n39 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [39] loss: 1.021 celoss: 1.023 entropy: 0.601\n40 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [40] loss: 1.021 celoss: 1.023 entropy: 0.582\n41 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [41] loss: 1.023 celoss: 1.025 entropy: 0.582\n42 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [42] loss: 1.032 celoss: 1.034 entropy: 0.589\n43 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [43] loss: 1.045 celoss: 1.048 entropy: 0.589\n44 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [44] loss: 1.069 celoss: 1.072 entropy: 0.525\n45 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [45] loss: 1.035 celoss: 1.037 entropy: 0.525\n46 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [46] loss: 1.033 celoss: 1.036 entropy: 0.594\n47 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [47] loss: 1.042 celoss: 1.045 entropy: 0.594\n48 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [48] loss: 1.034 celoss: 1.036 entropy: 0.562\n49 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [49] loss: 1.020 celoss: 1.022 entropy: 0.562\n50 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [50] loss: 1.029 celoss: 1.032 entropy: 0.560\n51 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [51] loss: 1.061 celoss: 1.064 entropy: 0.560\n52 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [52] loss: 1.065 celoss: 1.068 entropy: 0.558\n53 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [53] loss: 1.020 celoss: 1.023 entropy: 0.558\n54 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [54] loss: 1.017 celoss: 1.019 entropy: 0.530\n55 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [55] loss: 1.037 celoss: 1.040 entropy: 0.530\n56 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [56] loss: 1.037 celoss: 1.039 entropy: 0.533\n57 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [57] loss: 1.017 celoss: 1.020 entropy: 0.533\n58 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [58] loss: 1.027 celoss: 1.029 entropy: 0.554\n59 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [59] loss: 1.053 celoss: 1.056 entropy: 0.554\n60 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [60] loss: 1.056 celoss: 1.058 entropy: 0.576\n61 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [61] loss: 1.016 celoss: 1.018 entropy: 0.576\n62 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [62] loss: 1.015 celoss: 1.017 entropy: 0.552\n63 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [63] loss: 1.039 celoss: 1.041 entropy: 0.552\n64 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [64] loss: 1.038 celoss: 1.040 entropy: 0.530\n65 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [65] loss: 1.047 celoss: 1.050 entropy: 0.530\n66 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [66] loss: 1.043 celoss: 1.045 entropy: 0.527\n67 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [67] loss: 1.026 celoss: 1.028 entropy: 0.527\n68 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [68] loss: 1.024 celoss: 1.026 entropy: 0.542\n69 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [69] loss: 1.051 celoss: 1.054 entropy: 0.542\n70 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [70] loss: 1.053 celoss: 1.056 entropy: 0.530\n71 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [71] loss: 1.018 celoss: 1.020 entropy: 0.530\n72 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [72] loss: 1.017 celoss: 1.019 entropy: 0.535\n73 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [73] loss: 1.012 celoss: 1.014 entropy: 0.535\n74 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [74] loss: 1.017 celoss: 1.019 entropy: 0.555\n75 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [75] loss: 1.004 celoss: 1.006 entropy: 0.555\n76 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [76] loss: 1.013 celoss: 1.016 entropy: 0.551\n77 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [77] loss: 1.034 celoss: 1.037 entropy: 0.551\n78 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [78] loss: 1.031 celoss: 1.033 entropy: 0.553\n79 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [79] loss: 1.003 celoss: 1.006 entropy: 0.553\n80 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [80] loss: 1.001 celoss: 1.003 entropy: 0.542\n81 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [81] loss: 1.003 celoss: 1.006 entropy: 0.542\n82 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [82] loss: 1.000 celoss: 1.003 entropy: 0.554\n83 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [83] loss: 1.011 celoss: 1.013 entropy: 0.554\n84 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [84] loss: 1.008 celoss: 1.011 entropy: 0.539\n85 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [85] loss: 0.991 celoss: 0.993 entropy: 0.539\n86 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [86] loss: 0.990 celoss: 0.993 entropy: 0.549\n87 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [87] loss: 1.005 celoss: 1.007 entropy: 0.549\n88 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [88] loss: 1.006 celoss: 1.008 entropy: 0.542\n89 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [89] loss: 0.999 celoss: 1.001 entropy: 0.542\n90 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [90] loss: 1.002 celoss: 1.005 entropy: 0.556\n91 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [91] loss: 1.004 celoss: 1.006 entropy: 0.556\n92 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [92] loss: 0.993 celoss: 0.995 entropy: 0.541\n93 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [93] loss: 0.989 celoss: 0.992 entropy: 0.541\n94 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [94] loss: 0.984 celoss: 0.986 entropy: 0.557\n95 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [95] loss: 1.001 celoss: 1.003 entropy: 0.557\n96 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [96] loss: 1.011 celoss: 1.014 entropy: 0.543\n97 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [97] loss: 1.012 celoss: 1.014 entropy: 0.543\n98 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [98] loss: 1.003 celoss: 1.006 entropy: 0.539\n99 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [99] loss: 0.986 celoss: 0.988 entropy: 0.539\n100 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [100] loss: 0.984 celoss: 0.986 entropy: 0.563\n101 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [101] loss: 0.978 celoss: 0.980 entropy: 0.563\n102 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [102] loss: 0.975 celoss: 0.977 entropy: 0.562\n103 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [103] loss: 0.979 celoss: 0.981 entropy: 0.562\n104 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [104] loss: 0.980 celoss: 0.982 entropy: 0.570\n105 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [105] loss: 0.969 celoss: 0.971 entropy: 0.570\n106 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [106] loss: 0.980 celoss: 0.983 entropy: 0.530\n107 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [107] loss: 0.969 celoss: 0.971 entropy: 0.530\n108 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [108] loss: 0.972 celoss: 0.974 entropy: 0.568\n109 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [109] loss: 0.977 celoss: 0.979 entropy: 0.568\n110 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [110] loss: 0.965 celoss: 0.967 entropy: 0.545\n111 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [111] loss: 0.955 celoss: 0.957 entropy: 0.545\n112 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [112] loss: 0.997 celoss: 1.000 entropy: 0.521\n113 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [113] loss: 0.967 celoss: 0.970 entropy: 0.521\n114 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [114] loss: 0.955 celoss: 0.958 entropy: 0.478\n115 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [115] loss: 0.946 celoss: 0.949 entropy: 0.478\n116 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [116] loss: 0.921 celoss: 0.923 entropy: 0.478\n117 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [117] loss: 0.923 celoss: 0.926 entropy: 0.478\n118 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [118] loss: 0.908 celoss: 0.910 entropy: 0.491\n119 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [119] loss: 0.896 celoss: 0.898 entropy: 0.491\n120 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [120] loss: 0.903 celoss: 0.905 entropy: 0.491\n121 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [121] loss: 0.892 celoss: 0.894 entropy: 0.491\n122 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [122] loss: 0.883 celoss: 0.885 entropy: 0.471\n123 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [123] loss: 0.872 celoss: 0.874 entropy: 0.471\n124 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [124] loss: 0.883 celoss: 0.885 entropy: 0.426\n125 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [125] loss: 0.885 celoss: 0.887 entropy: 0.426\n126 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [126] loss: 0.879 celoss: 0.881 entropy: 0.419\n127 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [127] loss: 0.864 celoss: 0.866 entropy: 0.419\n128 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [128] loss: 0.864 celoss: 0.866 entropy: 0.418\n129 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [129] loss: 0.859 celoss: 0.861 entropy: 0.418\n130 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [130] loss: 0.858 celoss: 0.860 entropy: 0.417\n131 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [131] loss: 0.858 celoss: 0.860 entropy: 0.417\n132 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [132] loss: 0.858 celoss: 0.860 entropy: 0.420\n133 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [133] loss: 0.860 celoss: 0.862 entropy: 0.420\n134 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [134] loss: 0.860 celoss: 0.862 entropy: 0.407\n135 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [135] loss: 0.864 celoss: 0.866 entropy: 0.407\n136 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [136] loss: 0.865 celoss: 0.867 entropy: 0.400\n137 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [137] loss: 0.854 celoss: 0.857 entropy: 0.400\n138 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [138] loss: 0.855 celoss: 0.857 entropy: 0.401\n139 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [139] loss: 0.858 celoss: 0.860 entropy: 0.401\n140 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [140] loss: 0.859 celoss: 0.861 entropy: 0.408\n141 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [141] loss: 0.859 celoss: 0.862 entropy: 0.408\n142 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [142] loss: 0.861 celoss: 0.863 entropy: 0.397\n143 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [143] loss: 0.853 celoss: 0.855 entropy: 0.397\n144 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [144] loss: 0.853 celoss: 0.855 entropy: 0.392\n145 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [145] loss: 0.853 celoss: 0.855 entropy: 0.392\n146 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [146] loss: 0.853 celoss: 0.855 entropy: 0.389\n147 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [147] loss: 0.855 celoss: 0.858 entropy: 0.389\n148 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [148] loss: 0.855 celoss: 0.858 entropy: 0.390\n149 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [149] loss: 0.852 celoss: 0.855 entropy: 0.390\n150 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [150] loss: 0.852 celoss: 0.855 entropy: 0.390\n151 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [151] loss: 0.860 celoss: 0.862 entropy: 0.390\n152 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [152] loss: 0.861 celoss: 0.863 entropy: 0.378\n153 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [153] loss: 0.856 celoss: 0.859 entropy: 0.378\n154 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [154] loss: 0.856 celoss: 0.858 entropy: 0.388\n155 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [155] loss: 0.851 celoss: 0.854 entropy: 0.388\n156 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [156] loss: 0.851 celoss: 0.854 entropy: 0.379\n157 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [157] loss: 0.849 celoss: 0.852 entropy: 0.379\n158 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [158] loss: 0.849 celoss: 0.852 entropy: 0.384\n159 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [159] loss: 0.849 celoss: 0.851 entropy: 0.384\n160 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [160] loss: 0.849 celoss: 0.851 entropy: 0.374\n161 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [161] loss: 0.849 celoss: 0.851 entropy: 0.374\n162 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [162] loss: 0.849 celoss: 0.851 entropy: 0.380\n163 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [163] loss: 0.848 celoss: 0.851 entropy: 0.380\n164 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [164] loss: 0.848 celoss: 0.851 entropy: 0.374\n165 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [165] loss: 0.848 celoss: 0.850 entropy: 0.374\n166 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [166] loss: 0.848 celoss: 0.850 entropy: 0.369\n167 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [167] loss: 0.848 celoss: 0.851 entropy: 0.369\n168 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [168] loss: 0.848 celoss: 0.850 entropy: 0.371\n169 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [169] loss: 0.852 celoss: 0.854 entropy: 0.371\n170 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [170] loss: 0.852 celoss: 0.854 entropy: 0.371\n171 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [171] loss: 0.848 celoss: 0.850 entropy: 0.371\n172 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [172] loss: 0.848 celoss: 0.850 entropy: 0.364\n173 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [173] loss: 0.849 celoss: 0.851 entropy: 0.364\n174 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [174] loss: 0.849 celoss: 0.851 entropy: 0.367\n175 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [175] loss: 0.851 celoss: 0.854 entropy: 0.367\n176 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [176] loss: 0.851 celoss: 0.854 entropy: 0.370\n177 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [177] loss: 0.854 celoss: 0.856 entropy: 0.370\n178 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [178] loss: 0.855 celoss: 0.857 entropy: 0.372\n179 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [179] loss: 0.852 celoss: 0.854 entropy: 0.372\n180 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [180] loss: 0.851 celoss: 0.853 entropy: 0.372\n181 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [181] loss: 0.851 celoss: 0.854 entropy: 0.372\n182 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [182] loss: 0.852 celoss: 0.855 entropy: 0.358\n183 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [183] loss: 0.851 celoss: 0.853 entropy: 0.358\n184 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [184] loss: 0.850 celoss: 0.853 entropy: 0.363\n185 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [185] loss: 0.848 celoss: 0.850 entropy: 0.363\n186 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [186] loss: 0.848 celoss: 0.850 entropy: 0.365\n187 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [187] loss: 0.847 celoss: 0.849 entropy: 0.365\n188 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [188] loss: 0.847 celoss: 0.849 entropy: 0.364\n189 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [189] loss: 0.847 celoss: 0.850 entropy: 0.364\n190 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [190] loss: 0.847 celoss: 0.850 entropy: 0.363\n191 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [191] loss: 0.850 celoss: 0.852 entropy: 0.363\n192 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [192] loss: 0.850 celoss: 0.852 entropy: 0.359\n193 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [193] loss: 0.849 celoss: 0.851 entropy: 0.359\n194 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [194] loss: 0.849 celoss: 0.851 entropy: 0.358\n195 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [195] loss: 0.847 celoss: 0.850 entropy: 0.358\n196 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [196] loss: 0.848 celoss: 0.850 entropy: 0.365\n197 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [197] loss: 0.847 celoss: 0.849 entropy: 0.365\n198 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [198] loss: 0.847 celoss: 0.849 entropy: 0.361\n199 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [199] loss: 0.847 celoss: 0.849 entropy: 0.361\n200 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [200] loss: 0.847 celoss: 0.849 entropy: 0.357\n201 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [201] loss: 0.848 celoss: 0.851 entropy: 0.357\n202 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [202] loss: 0.848 celoss: 0.851 entropy: 0.352\n203 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [203] loss: 0.847 celoss: 0.850 entropy: 0.352\n204 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [204] loss: 0.847 celoss: 0.850 entropy: 0.352\n205 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [205] loss: 0.848 celoss: 0.851 entropy: 0.352\n206 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [206] loss: 0.849 celoss: 0.852 entropy: 0.343\n207 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [207] loss: 0.849 celoss: 0.852 entropy: 0.343\n208 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [208] loss: 0.849 celoss: 0.851 entropy: 0.364\n209 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [209] loss: 0.850 celoss: 0.852 entropy: 0.364\n210 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [210] loss: 0.850 celoss: 0.852 entropy: 0.360\n211 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [211] loss: 0.848 celoss: 0.850 entropy: 0.360\n212 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [212] loss: 0.848 celoss: 0.851 entropy: 0.352\n213 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [213] loss: 0.846 celoss: 0.849 entropy: 0.352\n214 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [214] loss: 0.846 celoss: 0.849 entropy: 0.354\n215 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [215] loss: 0.846 celoss: 0.848 entropy: 0.354\n216 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [216] loss: 0.846 celoss: 0.848 entropy: 0.351\n217 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [217] loss: 0.845 celoss: 0.848 entropy: 0.351\n218 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [218] loss: 0.845 celoss: 0.848 entropy: 0.349\n219 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [219] loss: 0.845 celoss: 0.848 entropy: 0.349\n220 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [220] loss: 0.845 celoss: 0.848 entropy: 0.343\n221 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [221] loss: 0.845 celoss: 0.848 entropy: 0.343\n222 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [222] loss: 0.845 celoss: 0.847 entropy: 0.343\n223 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [223] loss: 0.845 celoss: 0.848 entropy: 0.343\n224 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [224] loss: 0.845 celoss: 0.848 entropy: 0.340\n225 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [225] loss: 0.845 celoss: 0.848 entropy: 0.340\n226 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [226] loss: 0.845 celoss: 0.848 entropy: 0.338\n227 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [227] loss: 0.846 celoss: 0.848 entropy: 0.338\n228 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [228] loss: 0.846 celoss: 0.848 entropy: 0.335\n229 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [229] loss: 0.845 celoss: 0.848 entropy: 0.335\n230 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [230] loss: 0.845 celoss: 0.848 entropy: 0.335\n231 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [231] loss: 0.845 celoss: 0.847 entropy: 0.335\n232 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [232] loss: 0.845 celoss: 0.847 entropy: 0.331\n233 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [233] loss: 0.845 celoss: 0.847 entropy: 0.331\n234 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [234] loss: 0.845 celoss: 0.847 entropy: 0.332\n235 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [235] loss: 0.845 celoss: 0.848 entropy: 0.332\n236 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [236] loss: 0.845 celoss: 0.848 entropy: 0.328\n237 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [237] loss: 0.846 celoss: 0.848 entropy: 0.328\n238 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [238] loss: 0.845 celoss: 0.848 entropy: 0.329\n239 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [239] loss: 0.844 celoss: 0.847 entropy: 0.329\n240 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [240] loss: 0.844 celoss: 0.847 entropy: 0.324\n241 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [241] loss: 0.845 celoss: 0.848 entropy: 0.324\n242 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [242] loss: 0.845 celoss: 0.848 entropy: 0.327\n243 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [243] loss: 0.845 celoss: 0.848 entropy: 0.327\n244 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [244] loss: 0.845 celoss: 0.848 entropy: 0.330\n245 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [245] loss: 0.846 celoss: 0.848 entropy: 0.330\n246 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [246] loss: 0.846 celoss: 0.848 entropy: 0.331\n247 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [247] loss: 0.845 celoss: 0.848 entropy: 0.331\n248 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [248] loss: 0.845 celoss: 0.848 entropy: 0.333\n249 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [249] loss: 0.845 celoss: 0.848 entropy: 0.333\n250 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [250] loss: 0.845 celoss: 0.848 entropy: 0.330\n251 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [251] loss: 0.846 celoss: 0.848 entropy: 0.330\n252 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [252] loss: 0.846 celoss: 0.848 entropy: 0.331\n253 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [253] loss: 0.845 celoss: 0.848 entropy: 0.331\n254 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [254] loss: 0.845 celoss: 0.848 entropy: 0.327\n255 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [255] loss: 0.846 celoss: 0.848 entropy: 0.327\n256 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [256] loss: 0.846 celoss: 0.849 entropy: 0.325\n257 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [257] loss: 0.845 celoss: 0.848 entropy: 0.325\n258 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [258] loss: 0.846 celoss: 0.849 entropy: 0.337\n259 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [259] loss: 0.846 celoss: 0.848 entropy: 0.337\n260 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [260] loss: 0.846 celoss: 0.849 entropy: 0.324\n261 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [261] loss: 0.846 celoss: 0.849 entropy: 0.324\n262 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [262] loss: 0.846 celoss: 0.849 entropy: 0.327\n263 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [263] loss: 0.846 celoss: 0.848 entropy: 0.327\n264 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [264] loss: 0.845 celoss: 0.848 entropy: 0.325\n265 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [265] loss: 0.847 celoss: 0.850 entropy: 0.325\n266 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [266] loss: 0.847 celoss: 0.850 entropy: 0.327\n267 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [267] loss: 0.845 celoss: 0.848 entropy: 0.327\n268 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [268] loss: 0.845 celoss: 0.848 entropy: 0.324\n269 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [269] loss: 0.845 celoss: 0.847 entropy: 0.324\n270 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [270] loss: 0.845 celoss: 0.847 entropy: 0.322\n271 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [271] loss: 0.845 celoss: 0.847 entropy: 0.322\n272 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [272] loss: 0.845 celoss: 0.847 entropy: 0.319\n273 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [273] loss: 0.845 celoss: 0.847 entropy: 0.319\n274 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [274] loss: 0.845 celoss: 0.847 entropy: 0.323\n275 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [275] loss: 0.844 celoss: 0.847 entropy: 0.323\n276 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [276] loss: 0.845 celoss: 0.847 entropy: 0.313\n277 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [277] loss: 0.844 celoss: 0.847 entropy: 0.313\n278 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [278] loss: 0.845 celoss: 0.847 entropy: 0.308\n279 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [279] loss: 0.844 celoss: 0.847 entropy: 0.308\n280 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [280] loss: 0.844 celoss: 0.847 entropy: 0.318\n281 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [281] loss: 0.844 celoss: 0.847 entropy: 0.318\n282 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [282] loss: 0.844 celoss: 0.847 entropy: 0.304\n283 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [283] loss: 0.845 celoss: 0.847 entropy: 0.304\n284 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [284] loss: 0.844 celoss: 0.847 entropy: 0.317\n285 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [285] loss: 0.844 celoss: 0.847 entropy: 0.317\n286 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [286] loss: 0.844 celoss: 0.847 entropy: 0.311\n287 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [287] loss: 0.845 celoss: 0.847 entropy: 0.311\n288 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [288] loss: 0.844 celoss: 0.847 entropy: 0.317\n289 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [289] loss: 0.844 celoss: 0.847 entropy: 0.317\n290 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [290] loss: 0.844 celoss: 0.847 entropy: 0.311\n291 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [291] loss: 0.844 celoss: 0.847 entropy: 0.311\n292 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [292] loss: 0.844 celoss: 0.847 entropy: 0.314\n293 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [293] loss: 0.844 celoss: 0.847 entropy: 0.314\n294 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [294] loss: 0.844 celoss: 0.847 entropy: 0.309\n295 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [295] loss: 0.844 celoss: 0.847 entropy: 0.309\n296 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [296] loss: 0.844 celoss: 0.847 entropy: 0.308\n297 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [297] loss: 0.844 celoss: 0.847 entropy: 0.308\n298 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [298] loss: 0.844 celoss: 0.847 entropy: 0.305\n299 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [299] loss: 0.845 celoss: 0.847 entropy: 0.305\n300 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [300] loss: 0.845 celoss: 0.847 entropy: 0.308\n301 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [301] loss: 0.845 celoss: 0.847 entropy: 0.308\n302 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [302] loss: 0.845 celoss: 0.847 entropy: 0.308\n303 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [303] loss: 0.844 celoss: 0.847 entropy: 0.308\n304 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [304] loss: 0.844 celoss: 0.847 entropy: 0.307\n305 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [305] loss: 0.845 celoss: 0.847 entropy: 0.307\n306 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [306] loss: 0.845 celoss: 0.847 entropy: 0.304\n307 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [307] loss: 0.844 celoss: 0.847 entropy: 0.304\n308 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [308] loss: 0.844 celoss: 0.847 entropy: 0.304\n309 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [309] loss: 0.844 celoss: 0.847 entropy: 0.304\n310 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [310] loss: 0.844 celoss: 0.847 entropy: 0.300\n311 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [311] loss: 0.844 celoss: 0.847 entropy: 0.300\n312 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [312] loss: 0.844 celoss: 0.847 entropy: 0.303\n313 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [313] loss: 0.844 celoss: 0.847 entropy: 0.303\n314 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [314] loss: 0.844 celoss: 0.847 entropy: 0.300\n315 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [315] loss: 0.845 celoss: 0.847 entropy: 0.300\n316 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [316] loss: 0.844 celoss: 0.847 entropy: 0.299\n317 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [317] loss: 0.844 celoss: 0.847 entropy: 0.299\n318 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [318] loss: 0.844 celoss: 0.847 entropy: 0.300\n319 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [319] loss: 0.844 celoss: 0.847 entropy: 0.300\n320 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [320] loss: 0.844 celoss: 0.847 entropy: 0.299\n321 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [321] loss: 0.844 celoss: 0.847 entropy: 0.299\n322 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [322] loss: 0.844 celoss: 0.847 entropy: 0.299\n323 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [323] loss: 0.844 celoss: 0.847 entropy: 0.299\n324 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [324] loss: 0.844 celoss: 0.847 entropy: 0.297\n325 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [325] loss: 0.844 celoss: 0.846 entropy: 0.297\n326 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [326] loss: 0.844 celoss: 0.846 entropy: 0.297\n327 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [327] loss: 0.844 celoss: 0.847 entropy: 0.297\n328 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [328] loss: 0.844 celoss: 0.847 entropy: 0.295\n329 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [329] loss: 0.844 celoss: 0.846 entropy: 0.295\n330 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [330] loss: 0.844 celoss: 0.846 entropy: 0.296\n331 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [331] loss: 0.843 celoss: 0.846 entropy: 0.296\n332 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [332] loss: 0.843 celoss: 0.846 entropy: 0.294\n333 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [333] loss: 0.844 celoss: 0.846 entropy: 0.294\n334 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [334] loss: 0.844 celoss: 0.846 entropy: 0.294\n335 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [335] loss: 0.843 celoss: 0.846 entropy: 0.294\n336 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [336] loss: 0.843 celoss: 0.846 entropy: 0.290\n337 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [337] loss: 0.844 celoss: 0.846 entropy: 0.290\n338 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [338] loss: 0.844 celoss: 0.846 entropy: 0.292\n339 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [339] loss: 0.844 celoss: 0.846 entropy: 0.292\n340 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [340] loss: 0.844 celoss: 0.846 entropy: 0.291\n341 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [341] loss: 0.843 celoss: 0.846 entropy: 0.291\n342 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [342] loss: 0.843 celoss: 0.846 entropy: 0.284\n343 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [343] loss: 0.844 celoss: 0.846 entropy: 0.284\n344 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [344] loss: 0.844 celoss: 0.846 entropy: 0.290\n345 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [345] loss: 0.843 celoss: 0.846 entropy: 0.290\n346 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [346] loss: 0.843 celoss: 0.846 entropy: 0.286\n347 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [347] loss: 0.843 celoss: 0.846 entropy: 0.286\n348 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [348] loss: 0.843 celoss: 0.846 entropy: 0.290\n349 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [349] loss: 0.843 celoss: 0.846 entropy: 0.290\n350 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [350] loss: 0.843 celoss: 0.846 entropy: 0.287\n351 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [351] loss: 0.843 celoss: 0.846 entropy: 0.287\n352 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [352] loss: 0.843 celoss: 0.846 entropy: 0.286\n353 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [353] loss: 0.844 celoss: 0.846 entropy: 0.286\n354 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [354] loss: 0.844 celoss: 0.847 entropy: 0.278\n355 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [355] loss: 0.844 celoss: 0.847 entropy: 0.278\n356 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [356] loss: 0.844 celoss: 0.847 entropy: 0.284\n357 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [357] loss: 0.844 celoss: 0.846 entropy: 0.284\n358 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [358] loss: 0.844 celoss: 0.846 entropy: 0.286\n359 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [359] loss: 0.844 celoss: 0.847 entropy: 0.286\n360 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [360] loss: 0.844 celoss: 0.847 entropy: 0.282\n361 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [361] loss: 0.844 celoss: 0.847 entropy: 0.282\n362 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [362] loss: 0.849 celoss: 0.852 entropy: 0.268\n363 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [363] loss: 0.850 celoss: 0.853 entropy: 0.268\n364 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [364] loss: 0.868 celoss: 0.871 entropy: 0.284\n365 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [365] loss: 0.861 celoss: 0.864 entropy: 0.284\n366 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [366] loss: 0.964 celoss: 0.968 entropy: 0.258\n367 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [367] loss: 0.891 celoss: 0.895 entropy: 0.258\n368 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [368] loss: 0.873 celoss: 0.876 entropy: 0.151\n369 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [369] loss: 0.864 celoss: 0.868 entropy: 0.151\n370 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [370] loss: 0.864 celoss: 0.868 entropy: 0.105\n371 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [371] loss: 0.857 celoss: 0.861 entropy: 0.105\n372 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [372] loss: 0.857 celoss: 0.861 entropy: 0.096\n373 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [373] loss: 0.851 celoss: 0.855 entropy: 0.096\n374 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [374] loss: 0.851 celoss: 0.855 entropy: 0.094\n375 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [375] loss: 0.849 celoss: 0.853 entropy: 0.094\n376 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [376] loss: 0.849 celoss: 0.853 entropy: 0.092\n377 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [377] loss: 0.849 celoss: 0.852 entropy: 0.092\n378 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [378] loss: 0.849 celoss: 0.852 entropy: 0.092\n379 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [379] loss: 0.847 celoss: 0.851 entropy: 0.092\n380 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [380] loss: 0.847 celoss: 0.851 entropy: 0.091\n381 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [381] loss: 0.846 celoss: 0.850 entropy: 0.091\n382 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [382] loss: 0.846 celoss: 0.850 entropy: 0.091\n383 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [383] loss: 0.846 celoss: 0.850 entropy: 0.091\n384 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [384] loss: 0.846 celoss: 0.850 entropy: 0.090\n385 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [385] loss: 0.845 celoss: 0.849 entropy: 0.090\n386 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [386] loss: 0.845 celoss: 0.849 entropy: 0.090\n387 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [387] loss: 0.846 celoss: 0.850 entropy: 0.090\n388 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [388] loss: 0.846 celoss: 0.850 entropy: 0.090\n389 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [389] loss: 0.850 celoss: 0.854 entropy: 0.090\n390 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [390] loss: 0.850 celoss: 0.854 entropy: 0.089\n391 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [391] loss: 0.847 celoss: 0.851 entropy: 0.089\n392 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [392] loss: 0.847 celoss: 0.851 entropy: 0.089\n393 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [393] loss: 0.844 celoss: 0.848 entropy: 0.089\n394 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [394] loss: 0.844 celoss: 0.848 entropy: 0.088\n395 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [395] loss: 0.844 celoss: 0.848 entropy: 0.088\n396 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [396] loss: 0.844 celoss: 0.848 entropy: 0.088\n397 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [397] loss: 0.844 celoss: 0.848 entropy: 0.088\n398 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [398] loss: 0.844 celoss: 0.848 entropy: 0.088\n399 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [399] loss: 0.843 celoss: 0.847 entropy: 0.088\n400 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [400] loss: 0.843 celoss: 0.847 entropy: 0.087\n401 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [401] loss: 0.844 celoss: 0.848 entropy: 0.087\n402 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [402] loss: 0.844 celoss: 0.848 entropy: 0.087\n403 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [403] loss: 0.845 celoss: 0.849 entropy: 0.087\n404 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [404] loss: 0.845 celoss: 0.849 entropy: 0.087\n405 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [405] loss: 0.845 celoss: 0.848 entropy: 0.087\n406 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [406] loss: 0.845 celoss: 0.848 entropy: 0.086\n407 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [407] loss: 0.844 celoss: 0.848 entropy: 0.086\n408 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [408] loss: 0.844 celoss: 0.848 entropy: 0.086\n409 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [409] loss: 0.844 celoss: 0.847 entropy: 0.086\n410 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [410] loss: 0.844 celoss: 0.847 entropy: 0.085\n411 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [411] loss: 0.843 celoss: 0.847 entropy: 0.085\n412 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [412] loss: 0.843 celoss: 0.847 entropy: 0.085\n413 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [413] loss: 0.843 celoss: 0.847 entropy: 0.085\n414 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [414] loss: 0.843 celoss: 0.847 entropy: 0.085\n415 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [415] loss: 0.842 celoss: 0.846 entropy: 0.085\n416 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [416] loss: 0.842 celoss: 0.846 entropy: 0.084\n417 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [417] loss: 0.843 celoss: 0.846 entropy: 0.084\n418 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [418] loss: 0.843 celoss: 0.846 entropy: 0.084\n419 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [419] loss: 0.842 celoss: 0.846 entropy: 0.084\n420 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [420] loss: 0.842 celoss: 0.846 entropy: 0.084\n421 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [421] loss: 0.842 celoss: 0.846 entropy: 0.084\n422 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [422] loss: 0.842 celoss: 0.846 entropy: 0.084\n423 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [423] loss: 0.842 celoss: 0.846 entropy: 0.084\n424 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [424] loss: 0.842 celoss: 0.846 entropy: 0.083\n425 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [425] loss: 0.842 celoss: 0.846 entropy: 0.083\n426 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [426] loss: 0.842 celoss: 0.846 entropy: 0.083\n427 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [427] loss: 0.842 celoss: 0.846 entropy: 0.083\n428 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [428] loss: 0.842 celoss: 0.846 entropy: 0.082\n429 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [429] loss: 0.842 celoss: 0.846 entropy: 0.082\n430 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [430] loss: 0.842 celoss: 0.846 entropy: 0.082\n431 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [431] loss: 0.842 celoss: 0.846 entropy: 0.082\n432 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [432] loss: 0.842 celoss: 0.846 entropy: 0.081\n433 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [433] loss: 0.842 celoss: 0.846 entropy: 0.081\n434 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [434] loss: 0.842 celoss: 0.846 entropy: 0.081\n435 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [435] loss: 0.842 celoss: 0.845 entropy: 0.081\n436 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [436] loss: 0.842 celoss: 0.845 entropy: 0.080\n437 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [437] loss: 0.842 celoss: 0.845 entropy: 0.080\n438 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [438] loss: 0.842 celoss: 0.845 entropy: 0.080\n439 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [439] loss: 0.842 celoss: 0.845 entropy: 0.080\n440 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [440] loss: 0.842 celoss: 0.845 entropy: 0.080\n441 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [441] loss: 0.842 celoss: 0.846 entropy: 0.080\n442 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [442] loss: 0.842 celoss: 0.846 entropy: 0.079\n443 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [443] loss: 0.842 celoss: 0.846 entropy: 0.079\n444 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [444] loss: 0.842 celoss: 0.846 entropy: 0.079\n445 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [445] loss: 0.842 celoss: 0.846 entropy: 0.079\n446 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [446] loss: 0.842 celoss: 0.846 entropy: 0.078\n447 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [447] loss: 0.842 celoss: 0.845 entropy: 0.078\n448 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [448] loss: 0.842 celoss: 0.845 entropy: 0.078\n449 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [449] loss: 0.842 celoss: 0.845 entropy: 0.078\n450 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [450] loss: 0.842 celoss: 0.845 entropy: 0.077\n451 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [451] loss: 0.842 celoss: 0.845 entropy: 0.077\n452 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [452] loss: 0.842 celoss: 0.845 entropy: 0.077\n453 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [453] loss: 0.842 celoss: 0.846 entropy: 0.077\n454 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [454] loss: 0.842 celoss: 0.846 entropy: 0.077\n455 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [455] loss: 0.842 celoss: 0.845 entropy: 0.077\n456 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [456] loss: 0.842 celoss: 0.845 entropy: 0.076\n457 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [457] loss: 0.841 celoss: 0.845 entropy: 0.076\n458 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [458] loss: 0.841 celoss: 0.845 entropy: 0.076\n459 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [459] loss: 0.841 celoss: 0.845 entropy: 0.076\n460 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [460] loss: 0.841 celoss: 0.845 entropy: 0.075\n461 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [461] loss: 0.842 celoss: 0.845 entropy: 0.075\n462 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [462] loss: 0.842 celoss: 0.845 entropy: 0.075\n463 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [463] loss: 0.841 celoss: 0.845 entropy: 0.075\n464 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [464] loss: 0.841 celoss: 0.845 entropy: 0.075\n465 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [465] loss: 0.842 celoss: 0.845 entropy: 0.075\n466 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [466] loss: 0.842 celoss: 0.845 entropy: 0.075\n467 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [467] loss: 0.841 celoss: 0.845 entropy: 0.075\n468 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [468] loss: 0.841 celoss: 0.845 entropy: 0.074\n469 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [469] loss: 0.841 celoss: 0.845 entropy: 0.074\n470 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [470] loss: 0.841 celoss: 0.845 entropy: 0.074\n471 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [471] loss: 0.842 celoss: 0.845 entropy: 0.074\n472 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [472] loss: 0.842 celoss: 0.845 entropy: 0.074\n473 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [473] loss: 0.841 celoss: 0.845 entropy: 0.074\n474 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [474] loss: 0.841 celoss: 0.845 entropy: 0.074\n475 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [475] loss: 0.841 celoss: 0.845 entropy: 0.074\n476 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [476] loss: 0.841 celoss: 0.845 entropy: 0.073\n477 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [477] loss: 0.841 celoss: 0.845 entropy: 0.073\n478 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [478] loss: 0.841 celoss: 0.845 entropy: 0.073\n479 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [479] loss: 0.841 celoss: 0.845 entropy: 0.073\n480 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [480] loss: 0.841 celoss: 0.845 entropy: 0.073\n481 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [481] loss: 0.841 celoss: 0.845 entropy: 0.073\n482 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [482] loss: 0.841 celoss: 0.845 entropy: 0.073\n483 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [483] loss: 0.841 celoss: 0.845 entropy: 0.073\n484 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [484] loss: 0.841 celoss: 0.845 entropy: 0.072\n485 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [485] loss: 0.841 celoss: 0.845 entropy: 0.072\n486 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [486] loss: 0.841 celoss: 0.845 entropy: 0.072\n487 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [487] loss: 0.842 celoss: 0.845 entropy: 0.072\n488 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [488] loss: 0.842 celoss: 0.845 entropy: 0.072\n489 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [489] loss: 0.841 celoss: 0.845 entropy: 0.072\n490 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [490] loss: 0.841 celoss: 0.845 entropy: 0.072\n491 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [491] loss: 0.841 celoss: 0.845 entropy: 0.072\n492 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [492] loss: 0.841 celoss: 0.845 entropy: 0.071\n493 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [493] loss: 0.841 celoss: 0.845 entropy: 0.071\n494 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [494] loss: 0.841 celoss: 0.845 entropy: 0.071\n495 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [495] loss: 0.841 celoss: 0.845 entropy: 0.071\n496 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [496] loss: 0.841 celoss: 0.845 entropy: 0.071\n497 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [497] loss: 0.841 celoss: 0.845 entropy: 0.071\n498 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [498] loss: 0.841 celoss: 0.845 entropy: 0.070\n499 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [499] loss: 0.841 celoss: 0.845 entropy: 0.070\n500 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [500] loss: 0.841 celoss: 0.845 entropy: 0.070\n501 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [501] loss: 0.842 celoss: 0.846 entropy: 0.070\n502 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [502] loss: 0.842 celoss: 0.846 entropy: 0.070\n503 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [503] loss: 0.842 celoss: 0.845 entropy: 0.070\n504 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [504] loss: 0.842 celoss: 0.845 entropy: 0.070\n505 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [505] loss: 0.841 celoss: 0.845 entropy: 0.070\n506 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [506] loss: 0.841 celoss: 0.845 entropy: 0.069\n507 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [507] loss: 0.841 celoss: 0.845 entropy: 0.069\n508 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [508] loss: 0.841 celoss: 0.845 entropy: 0.069\n509 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [509] loss: 0.841 celoss: 0.845 entropy: 0.069\n510 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [510] loss: 0.841 celoss: 0.845 entropy: 0.068\n511 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [511] loss: 0.842 celoss: 0.845 entropy: 0.068\n512 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [512] loss: 0.842 celoss: 0.845 entropy: 0.068\n513 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [513] loss: 0.841 celoss: 0.845 entropy: 0.068\n514 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [514] loss: 0.841 celoss: 0.845 entropy: 0.068\n515 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [515] loss: 0.841 celoss: 0.845 entropy: 0.068\n516 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [516] loss: 0.841 celoss: 0.845 entropy: 0.067\n517 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [517] loss: 0.841 celoss: 0.845 entropy: 0.067\n518 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [518] loss: 0.841 celoss: 0.845 entropy: 0.067\n519 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [519] loss: 0.841 celoss: 0.845 entropy: 0.067\n520 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [520] loss: 0.841 celoss: 0.845 entropy: 0.067\n521 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [521] loss: 0.841 celoss: 0.845 entropy: 0.067\n522 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [522] loss: 0.841 celoss: 0.845 entropy: 0.066\n523 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [523] loss: 0.841 celoss: 0.845 entropy: 0.066\n524 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [524] loss: 0.841 celoss: 0.845 entropy: 0.066\n525 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [525] loss: 0.841 celoss: 0.845 entropy: 0.066\n526 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [526] loss: 0.841 celoss: 0.845 entropy: 0.065\n527 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [527] loss: 0.841 celoss: 0.845 entropy: 0.065\n528 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [528] loss: 0.841 celoss: 0.845 entropy: 0.065\n529 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [529] loss: 0.841 celoss: 0.845 entropy: 0.065\n530 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [530] loss: 0.841 celoss: 0.845 entropy: 0.065\n531 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [531] loss: 0.841 celoss: 0.845 entropy: 0.065\n532 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [532] loss: 0.841 celoss: 0.845 entropy: 0.064\n533 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [533] loss: 0.841 celoss: 0.845 entropy: 0.064\n534 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [534] loss: 0.841 celoss: 0.845 entropy: 0.064\n535 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [535] loss: 0.841 celoss: 0.845 entropy: 0.064\n536 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [536] loss: 0.841 celoss: 0.845 entropy: 0.064\n537 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [537] loss: 0.841 celoss: 0.845 entropy: 0.064\n538 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [538] loss: 0.841 celoss: 0.845 entropy: 0.063\n539 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [539] loss: 0.841 celoss: 0.845 entropy: 0.063\n540 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [540] loss: 0.841 celoss: 0.845 entropy: 0.063\n541 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [541] loss: 0.841 celoss: 0.845 entropy: 0.063\n542 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [542] loss: 0.841 celoss: 0.845 entropy: 0.063\n543 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [543] loss: 0.842 celoss: 0.846 entropy: 0.063\n544 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [544] loss: 0.842 celoss: 0.846 entropy: 0.063\n545 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [545] loss: 0.841 celoss: 0.845 entropy: 0.063\n546 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [546] loss: 0.841 celoss: 0.845 entropy: 0.062\n547 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [547] loss: 0.841 celoss: 0.845 entropy: 0.062\n548 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [548] loss: 0.841 celoss: 0.845 entropy: 0.062\n549 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [549] loss: 0.841 celoss: 0.845 entropy: 0.062\n550 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [550] loss: 0.841 celoss: 0.845 entropy: 0.062\n551 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [551] loss: 0.841 celoss: 0.845 entropy: 0.062\n552 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [552] loss: 0.841 celoss: 0.845 entropy: 0.061\n553 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [553] loss: 0.841 celoss: 0.845 entropy: 0.061\n554 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [554] loss: 0.841 celoss: 0.845 entropy: 0.061\n555 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [555] loss: 0.840 celoss: 0.844 entropy: 0.061\n556 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [556] loss: 0.840 celoss: 0.844 entropy: 0.061\n557 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [557] loss: 0.841 celoss: 0.845 entropy: 0.061\n558 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [558] loss: 0.841 celoss: 0.845 entropy: 0.061\n559 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [559] loss: 0.840 celoss: 0.844 entropy: 0.061\n560 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [560] loss: 0.840 celoss: 0.844 entropy: 0.061\n561 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [561] loss: 0.840 celoss: 0.844 entropy: 0.061\n562 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [562] loss: 0.840 celoss: 0.844 entropy: 0.060\n563 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [563] loss: 0.840 celoss: 0.844 entropy: 0.060\n564 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [564] loss: 0.840 celoss: 0.844 entropy: 0.060\n565 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [565] loss: 0.840 celoss: 0.844 entropy: 0.060\n566 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [566] loss: 0.840 celoss: 0.844 entropy: 0.060\n567 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [567] loss: 0.840 celoss: 0.844 entropy: 0.060\n568 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [568] loss: 0.840 celoss: 0.844 entropy: 0.059\n569 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [569] loss: 0.840 celoss: 0.844 entropy: 0.059\n570 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [570] loss: 0.840 celoss: 0.844 entropy: 0.059\n571 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [571] loss: 0.840 celoss: 0.844 entropy: 0.059\n572 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [572] loss: 0.840 celoss: 0.844 entropy: 0.059\n573 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [573] loss: 0.840 celoss: 0.844 entropy: 0.059\n574 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [574] loss: 0.840 celoss: 0.844 entropy: 0.058\n575 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [575] loss: 0.840 celoss: 0.844 entropy: 0.058\n576 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [576] loss: 0.840 celoss: 0.844 entropy: 0.058\n577 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [577] loss: 0.840 celoss: 0.844 entropy: 0.058\n578 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [578] loss: 0.840 celoss: 0.844 entropy: 0.058\n579 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [579] loss: 0.840 celoss: 0.844 entropy: 0.058\n580 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [580] loss: 0.840 celoss: 0.844 entropy: 0.058\n581 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [581] loss: 0.840 celoss: 0.844 entropy: 0.058\n582 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [582] loss: 0.840 celoss: 0.844 entropy: 0.057\n583 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [583] loss: 0.840 celoss: 0.844 entropy: 0.057\n584 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [584] loss: 0.840 celoss: 0.844 entropy: 0.057\n585 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [585] loss: 0.841 celoss: 0.845 entropy: 0.057\n586 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [586] loss: 0.841 celoss: 0.845 entropy: 0.057\n587 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [587] loss: 0.841 celoss: 0.845 entropy: 0.057\n588 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [588] loss: 0.841 celoss: 0.845 entropy: 0.057\n589 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [589] loss: 0.841 celoss: 0.845 entropy: 0.057\n590 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [590] loss: 0.841 celoss: 0.845 entropy: 0.057\n591 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [591] loss: 0.841 celoss: 0.845 entropy: 0.057\n592 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [592] loss: 0.841 celoss: 0.845 entropy: 0.057\n593 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [593] loss: 0.840 celoss: 0.844 entropy: 0.057\n594 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [594] loss: 0.840 celoss: 0.844 entropy: 0.057\n595 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [595] loss: 0.840 celoss: 0.844 entropy: 0.057\n596 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [596] loss: 0.840 celoss: 0.844 entropy: 0.056\n597 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [597] loss: 0.840 celoss: 0.844 entropy: 0.056\n598 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [598] loss: 0.840 celoss: 0.844 entropy: 0.056\n599 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [599] loss: 0.840 celoss: 0.844 entropy: 0.056\n600 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [600] loss: 0.840 celoss: 0.844 entropy: 0.056\n601 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [601] loss: 0.840 celoss: 0.844 entropy: 0.056\n602 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [602] loss: 0.840 celoss: 0.844 entropy: 0.056\n603 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [603] loss: 0.840 celoss: 0.844 entropy: 0.056\n604 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [604] loss: 0.840 celoss: 0.844 entropy: 0.055\n605 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [605] loss: 0.840 celoss: 0.844 entropy: 0.055\n606 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [606] loss: 0.840 celoss: 0.844 entropy: 0.055\n607 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [607] loss: 0.840 celoss: 0.844 entropy: 0.055\n608 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [608] loss: 0.840 celoss: 0.844 entropy: 0.056\n609 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [609] loss: 0.840 celoss: 0.844 entropy: 0.056\n610 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [610] loss: 0.840 celoss: 0.844 entropy: 0.056\n611 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [611] loss: 0.840 celoss: 0.844 entropy: 0.056\n612 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [612] loss: 0.840 celoss: 0.844 entropy: 0.056\n613 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [613] loss: 0.840 celoss: 0.844 entropy: 0.056\n614 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [614] loss: 0.840 celoss: 0.844 entropy: 0.055\n615 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [615] loss: 0.840 celoss: 0.844 entropy: 0.055\n616 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [616] loss: 0.840 celoss: 0.844 entropy: 0.055\n617 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [617] loss: 0.840 celoss: 0.844 entropy: 0.055\n618 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [618] loss: 0.840 celoss: 0.844 entropy: 0.055\n619 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [619] loss: 0.840 celoss: 0.844 entropy: 0.055\n620 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [620] loss: 0.840 celoss: 0.844 entropy: 0.055\n621 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [621] loss: 0.840 celoss: 0.844 entropy: 0.055\n622 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [622] loss: 0.840 celoss: 0.844 entropy: 0.055\n623 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [623] loss: 0.844 celoss: 0.848 entropy: 0.055\n624 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [624] loss: 0.844 celoss: 0.848 entropy: 0.055\n625 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [625] loss: 0.849 celoss: 0.853 entropy: 0.055\n626 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [626] loss: 0.849 celoss: 0.853 entropy: 0.055\n627 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [627] loss: 0.842 celoss: 0.846 entropy: 0.055\n628 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [628] loss: 0.842 celoss: 0.846 entropy: 0.054\n629 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [629] loss: 0.841 celoss: 0.845 entropy: 0.054\n630 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [630] loss: 0.841 celoss: 0.845 entropy: 0.054\n631 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [631] loss: 0.840 celoss: 0.844 entropy: 0.054\n632 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [632] loss: 0.840 celoss: 0.844 entropy: 0.054\n633 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [633] loss: 0.840 celoss: 0.844 entropy: 0.054\n634 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [634] loss: 0.840 celoss: 0.844 entropy: 0.054\n635 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [635] loss: 0.840 celoss: 0.844 entropy: 0.054\n636 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [636] loss: 0.840 celoss: 0.844 entropy: 0.054\n637 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [637] loss: 0.840 celoss: 0.844 entropy: 0.054\n638 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [638] loss: 0.840 celoss: 0.844 entropy: 0.053\n639 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [639] loss: 0.841 celoss: 0.845 entropy: 0.053\n640 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [640] loss: 0.841 celoss: 0.845 entropy: 0.053\n641 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [641] loss: 0.840 celoss: 0.844 entropy: 0.053\n642 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [642] loss: 0.840 celoss: 0.844 entropy: 0.053\n643 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [643] loss: 0.841 celoss: 0.845 entropy: 0.053\n644 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [644] loss: 0.841 celoss: 0.845 entropy: 0.053\n645 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [645] loss: 0.841 celoss: 0.845 entropy: 0.053\n646 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [646] loss: 0.841 celoss: 0.845 entropy: 0.053\n647 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [647] loss: 0.841 celoss: 0.845 entropy: 0.053\n648 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [648] loss: 0.841 celoss: 0.845 entropy: 0.053\n649 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [649] loss: 0.841 celoss: 0.845 entropy: 0.053\n650 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [650] loss: 0.841 celoss: 0.845 entropy: 0.053\n651 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [651] loss: 0.840 celoss: 0.844 entropy: 0.053\n652 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [652] loss: 0.840 celoss: 0.844 entropy: 0.053\n653 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [653] loss: 0.840 celoss: 0.844 entropy: 0.053\n654 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [654] loss: 0.840 celoss: 0.844 entropy: 0.052\n655 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [655] loss: 0.841 celoss: 0.845 entropy: 0.052\n656 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [656] loss: 0.841 celoss: 0.845 entropy: 0.052\n657 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [657] loss: 0.841 celoss: 0.845 entropy: 0.052\n658 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [658] loss: 0.841 celoss: 0.845 entropy: 0.052\n659 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [659] loss: 0.841 celoss: 0.845 entropy: 0.052\n660 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [660] loss: 0.841 celoss: 0.845 entropy: 0.052\n661 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [661] loss: 0.841 celoss: 0.845 entropy: 0.052\n662 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [662] loss: 0.841 celoss: 0.845 entropy: 0.052\n663 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [663] loss: 0.840 celoss: 0.844 entropy: 0.052\n664 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [664] loss: 0.840 celoss: 0.844 entropy: 0.051\n665 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [665] loss: 0.840 celoss: 0.844 entropy: 0.051\n666 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [666] loss: 0.840 celoss: 0.844 entropy: 0.051\n667 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [667] loss: 0.840 celoss: 0.844 entropy: 0.051\n668 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [668] loss: 0.840 celoss: 0.844 entropy: 0.051\n669 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [669] loss: 0.841 celoss: 0.845 entropy: 0.051\n670 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [670] loss: 0.841 celoss: 0.845 entropy: 0.051\n671 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [671] loss: 0.840 celoss: 0.844 entropy: 0.051\n672 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [672] loss: 0.840 celoss: 0.844 entropy: 0.051\n673 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [673] loss: 0.840 celoss: 0.844 entropy: 0.051\n674 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [674] loss: 0.840 celoss: 0.844 entropy: 0.051\n675 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [675] loss: 0.840 celoss: 0.844 entropy: 0.051\n676 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [676] loss: 0.840 celoss: 0.844 entropy: 0.051\n677 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [677] loss: 0.841 celoss: 0.845 entropy: 0.051\n678 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [678] loss: 0.841 celoss: 0.845 entropy: 0.051\n679 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [679] loss: 0.841 celoss: 0.845 entropy: 0.051\n680 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [680] loss: 0.841 celoss: 0.845 entropy: 0.050\n681 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [681] loss: 0.841 celoss: 0.845 entropy: 0.050\n682 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [682] loss: 0.841 celoss: 0.845 entropy: 0.050\n683 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [683] loss: 0.841 celoss: 0.845 entropy: 0.050\n684 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [684] loss: 0.841 celoss: 0.845 entropy: 0.050\n685 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [685] loss: 0.840 celoss: 0.844 entropy: 0.050\n686 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [686] loss: 0.840 celoss: 0.844 entropy: 0.050\n687 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [687] loss: 0.840 celoss: 0.844 entropy: 0.050\n688 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [688] loss: 0.840 celoss: 0.844 entropy: 0.049\n689 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [689] loss: 0.841 celoss: 0.845 entropy: 0.049\n690 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [690] loss: 0.841 celoss: 0.845 entropy: 0.050\n691 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [691] loss: 0.841 celoss: 0.845 entropy: 0.050\n692 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [692] loss: 0.841 celoss: 0.844 entropy: 0.049\n693 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [693] loss: 0.840 celoss: 0.844 entropy: 0.049\n694 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [694] loss: 0.840 celoss: 0.844 entropy: 0.049\n695 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [695] loss: 0.840 celoss: 0.844 entropy: 0.049\n696 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [696] loss: 0.840 celoss: 0.844 entropy: 0.049\n697 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [697] loss: 0.840 celoss: 0.844 entropy: 0.049\n698 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [698] loss: 0.840 celoss: 0.844 entropy: 0.049\n699 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [699] loss: 0.840 celoss: 0.844 entropy: 0.049\n700 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [700] loss: 0.840 celoss: 0.844 entropy: 0.049\n701 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [701] loss: 0.840 celoss: 0.844 entropy: 0.049\n702 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [702] loss: 0.840 celoss: 0.844 entropy: 0.049\n703 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [703] loss: 0.841 celoss: 0.845 entropy: 0.049\n704 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [704] loss: 0.841 celoss: 0.845 entropy: 0.049\n705 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [705] loss: 0.841 celoss: 0.845 entropy: 0.049\n706 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [706] loss: 0.841 celoss: 0.845 entropy: 0.049\n707 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [707] loss: 0.841 celoss: 0.845 entropy: 0.049\n708 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [708] loss: 0.841 celoss: 0.845 entropy: 0.048\n709 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [709] loss: 0.840 celoss: 0.844 entropy: 0.048\n710 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [710] loss: 0.840 celoss: 0.844 entropy: 0.048\n711 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [711] loss: 0.840 celoss: 0.844 entropy: 0.048\n712 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [712] loss: 0.840 celoss: 0.844 entropy: 0.048\n713 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [713] loss: 0.840 celoss: 0.844 entropy: 0.048\n714 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [714] loss: 0.840 celoss: 0.844 entropy: 0.048\n715 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [715] loss: 0.840 celoss: 0.844 entropy: 0.048\n716 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [716] loss: 0.840 celoss: 0.844 entropy: 0.048\n717 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [717] loss: 0.840 celoss: 0.844 entropy: 0.048\n718 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [718] loss: 0.840 celoss: 0.844 entropy: 0.048\n719 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [719] loss: 0.840 celoss: 0.844 entropy: 0.048\n720 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [720] loss: 0.840 celoss: 0.844 entropy: 0.047\n721 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [721] loss: 0.840 celoss: 0.844 entropy: 0.047\n722 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [722] loss: 0.840 celoss: 0.844 entropy: 0.048\n723 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [723] loss: 0.840 celoss: 0.844 entropy: 0.048\n724 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [724] loss: 0.840 celoss: 0.844 entropy: 0.048\n725 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [725] loss: 0.840 celoss: 0.844 entropy: 0.048\n726 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [726] loss: 0.840 celoss: 0.844 entropy: 0.048\n727 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [727] loss: 0.840 celoss: 0.844 entropy: 0.048\n728 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [728] loss: 0.840 celoss: 0.844 entropy: 0.047\n729 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [729] loss: 0.841 celoss: 0.845 entropy: 0.047\n730 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [730] loss: 0.841 celoss: 0.845 entropy: 0.047\n731 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [731] loss: 0.841 celoss: 0.845 entropy: 0.047\n732 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [732] loss: 0.841 celoss: 0.845 entropy: 0.047\n733 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [733] loss: 0.841 celoss: 0.845 entropy: 0.047\n734 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [734] loss: 0.841 celoss: 0.845 entropy: 0.047\n735 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [735] loss: 0.840 celoss: 0.844 entropy: 0.047\n736 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [736] loss: 0.840 celoss: 0.844 entropy: 0.047\n737 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [737] loss: 0.841 celoss: 0.844 entropy: 0.047\n738 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [738] loss: 0.841 celoss: 0.844 entropy: 0.047\n739 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [739] loss: 0.840 celoss: 0.844 entropy: 0.047\n740 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [740] loss: 0.840 celoss: 0.844 entropy: 0.047\n741 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [741] loss: 0.840 celoss: 0.844 entropy: 0.047\n742 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [742] loss: 0.840 celoss: 0.844 entropy: 0.047\n743 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [743] loss: 0.840 celoss: 0.844 entropy: 0.047\n744 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [744] loss: 0.840 celoss: 0.844 entropy: 0.047\n745 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [745] loss: 0.840 celoss: 0.844 entropy: 0.047\n746 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [746] loss: 0.840 celoss: 0.844 entropy: 0.046\n747 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [747] loss: 0.840 celoss: 0.844 entropy: 0.046\n748 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [748] loss: 0.840 celoss: 0.844 entropy: 0.046\n749 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [749] loss: 0.840 celoss: 0.844 entropy: 0.046\n750 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [750] loss: 0.840 celoss: 0.844 entropy: 0.047\n751 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [751] loss: 0.841 celoss: 0.845 entropy: 0.047\n752 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [752] loss: 0.841 celoss: 0.845 entropy: 0.047\n753 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [753] loss: 0.841 celoss: 0.845 entropy: 0.047\n754 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [754] loss: 0.841 celoss: 0.845 entropy: 0.047\n755 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [755] loss: 0.841 celoss: 0.845 entropy: 0.047\n756 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [756] loss: 0.841 celoss: 0.845 entropy: 0.047\n757 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [757] loss: 0.840 celoss: 0.844 entropy: 0.047\n758 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [758] loss: 0.840 celoss: 0.844 entropy: 0.046\n759 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [759] loss: 0.840 celoss: 0.844 entropy: 0.046\n760 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [760] loss: 0.840 celoss: 0.844 entropy: 0.046\n761 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [761] loss: 0.840 celoss: 0.844 entropy: 0.046\n762 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [762] loss: 0.840 celoss: 0.844 entropy: 0.045\n763 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [763] loss: 0.840 celoss: 0.844 entropy: 0.045\n764 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [764] loss: 0.840 celoss: 0.844 entropy: 0.045\n765 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [765] loss: 0.840 celoss: 0.844 entropy: 0.045\n766 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [766] loss: 0.840 celoss: 0.844 entropy: 0.045\n767 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [767] loss: 0.840 celoss: 0.844 entropy: 0.045\n768 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [768] loss: 0.840 celoss: 0.844 entropy: 0.045\n769 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [769] loss: 0.840 celoss: 0.844 entropy: 0.045\n770 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [770] loss: 0.840 celoss: 0.844 entropy: 0.045\n771 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [771] loss: 0.840 celoss: 0.844 entropy: 0.045\n772 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [772] loss: 0.840 celoss: 0.844 entropy: 0.044\n773 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [773] loss: 0.840 celoss: 0.844 entropy: 0.044\n774 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [774] loss: 0.840 celoss: 0.844 entropy: 0.044\n775 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [775] loss: 0.840 celoss: 0.844 entropy: 0.044\n776 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [776] loss: 0.840 celoss: 0.844 entropy: 0.044\n777 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [777] loss: 0.840 celoss: 0.844 entropy: 0.044\n778 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [778] loss: 0.840 celoss: 0.844 entropy: 0.045\n779 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [779] loss: 0.840 celoss: 0.844 entropy: 0.045\n780 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [780] loss: 0.840 celoss: 0.844 entropy: 0.045\n781 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [781] loss: 0.840 celoss: 0.844 entropy: 0.045\n782 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [782] loss: 0.840 celoss: 0.844 entropy: 0.044\n783 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [783] loss: 0.840 celoss: 0.844 entropy: 0.044\n784 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [784] loss: 0.840 celoss: 0.844 entropy: 0.044\n785 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [785] loss: 0.840 celoss: 0.844 entropy: 0.044\n786 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [786] loss: 0.840 celoss: 0.844 entropy: 0.044\n787 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [787] loss: 0.840 celoss: 0.844 entropy: 0.044\n788 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [788] loss: 0.840 celoss: 0.844 entropy: 0.044\n789 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [789] loss: 0.840 celoss: 0.844 entropy: 0.044\n790 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [790] loss: 0.840 celoss: 0.844 entropy: 0.044\n791 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [791] loss: 0.841 celoss: 0.845 entropy: 0.044\n792 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [792] loss: 0.841 celoss: 0.845 entropy: 0.044\n793 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [793] loss: 0.840 celoss: 0.844 entropy: 0.044\n794 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [794] loss: 0.840 celoss: 0.844 entropy: 0.044\n795 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [795] loss: 0.840 celoss: 0.844 entropy: 0.044\n796 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [796] loss: 0.840 celoss: 0.844 entropy: 0.043\n797 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [797] loss: 0.841 celoss: 0.845 entropy: 0.043\n798 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [798] loss: 0.841 celoss: 0.845 entropy: 0.043\n799 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [799] loss: 0.840 celoss: 0.844 entropy: 0.043\n800 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [800] loss: 0.840 celoss: 0.844 entropy: 0.043\n801 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [801] loss: 0.840 celoss: 0.844 entropy: 0.043\n802 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [802] loss: 0.840 celoss: 0.844 entropy: 0.044\n803 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [803] loss: 0.840 celoss: 0.844 entropy: 0.044\n804 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [804] loss: 0.840 celoss: 0.844 entropy: 0.044\n805 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [805] loss: 0.840 celoss: 0.844 entropy: 0.044\n806 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [806] loss: 0.840 celoss: 0.844 entropy: 0.044\n807 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [807] loss: 0.840 celoss: 0.844 entropy: 0.044\n808 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [808] loss: 0.840 celoss: 0.844 entropy: 0.043\n809 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [809] loss: 0.840 celoss: 0.844 entropy: 0.043\n810 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [810] loss: 0.840 celoss: 0.844 entropy: 0.043\n811 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [811] loss: 0.840 celoss: 0.844 entropy: 0.043\n812 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [812] loss: 0.840 celoss: 0.844 entropy: 0.042\n813 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [813] loss: 0.840 celoss: 0.844 entropy: 0.042\n814 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [814] loss: 0.840 celoss: 0.844 entropy: 0.042\n815 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [815] loss: 0.840 celoss: 0.844 entropy: 0.042\n816 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [816] loss: 0.840 celoss: 0.844 entropy: 0.042\n817 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [817] loss: 0.840 celoss: 0.844 entropy: 0.042\n818 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [818] loss: 0.840 celoss: 0.844 entropy: 0.042\n819 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [819] loss: 0.840 celoss: 0.844 entropy: 0.042\n820 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [820] loss: 0.840 celoss: 0.844 entropy: 0.041\n821 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [821] loss: 0.840 celoss: 0.844 entropy: 0.041\n822 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [822] loss: 0.840 celoss: 0.844 entropy: 0.042\n823 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [823] loss: 0.840 celoss: 0.844 entropy: 0.042\n824 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [824] loss: 0.840 celoss: 0.844 entropy: 0.042\n825 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [825] loss: 0.840 celoss: 0.845 entropy: 0.042\n826 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [826] loss: 0.840 celoss: 0.845 entropy: 0.042\n827 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [827] loss: 0.840 celoss: 0.844 entropy: 0.042\n828 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [828] loss: 0.840 celoss: 0.844 entropy: 0.041\n829 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [829] loss: 0.840 celoss: 0.844 entropy: 0.041\n830 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [830] loss: 0.840 celoss: 0.844 entropy: 0.042\n831 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [831] loss: 0.840 celoss: 0.844 entropy: 0.042\n832 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [832] loss: 0.840 celoss: 0.844 entropy: 0.041\n833 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [833] loss: 0.840 celoss: 0.844 entropy: 0.041\n834 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [834] loss: 0.840 celoss: 0.844 entropy: 0.041\n835 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [835] loss: 0.840 celoss: 0.844 entropy: 0.041\n836 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [836] loss: 0.840 celoss: 0.844 entropy: 0.041\n837 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [837] loss: 0.840 celoss: 0.844 entropy: 0.041\n838 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [838] loss: 0.840 celoss: 0.844 entropy: 0.041\n839 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [839] loss: 0.840 celoss: 0.844 entropy: 0.041\n840 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [840] loss: 0.840 celoss: 0.844 entropy: 0.041\n841 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [841] loss: 0.841 celoss: 0.845 entropy: 0.041\n842 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [842] loss: 0.841 celoss: 0.845 entropy: 0.040\n843 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [843] loss: 0.841 celoss: 0.845 entropy: 0.040\n844 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [844] loss: 0.841 celoss: 0.845 entropy: 0.040\n845 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [845] loss: 0.841 celoss: 0.845 entropy: 0.040\n846 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [846] loss: 0.841 celoss: 0.845 entropy: 0.040\n847 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [847] loss: 0.840 celoss: 0.844 entropy: 0.040\n848 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [848] loss: 0.840 celoss: 0.844 entropy: 0.040\n849 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [849] loss: 0.840 celoss: 0.844 entropy: 0.040\n850 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [850] loss: 0.840 celoss: 0.844 entropy: 0.040\n851 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [851] loss: 0.840 celoss: 0.844 entropy: 0.040\n852 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [852] loss: 0.840 celoss: 0.844 entropy: 0.040\n853 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [853] loss: 0.840 celoss: 0.844 entropy: 0.040\n854 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [854] loss: 0.840 celoss: 0.844 entropy: 0.040\n855 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [855] loss: 0.840 celoss: 0.844 entropy: 0.040\n856 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [856] loss: 0.840 celoss: 0.844 entropy: 0.040\n857 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [857] loss: 0.840 celoss: 0.844 entropy: 0.040\n858 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [858] loss: 0.840 celoss: 0.844 entropy: 0.040\n859 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [859] loss: 0.841 celoss: 0.845 entropy: 0.040\n860 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [860] loss: 0.841 celoss: 0.845 entropy: 0.039\n861 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [861] loss: 0.840 celoss: 0.844 entropy: 0.039\n862 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [862] loss: 0.840 celoss: 0.844 entropy: 0.039\n863 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [863] loss: 0.840 celoss: 0.844 entropy: 0.039\n864 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [864] loss: 0.840 celoss: 0.844 entropy: 0.039\n865 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [865] loss: 0.840 celoss: 0.844 entropy: 0.039\n866 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [866] loss: 0.840 celoss: 0.844 entropy: 0.039\n867 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [867] loss: 0.840 celoss: 0.844 entropy: 0.039\n868 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [868] loss: 0.840 celoss: 0.844 entropy: 0.039\n869 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [869] loss: 0.840 celoss: 0.844 entropy: 0.039\n870 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [870] loss: 0.840 celoss: 0.844 entropy: 0.039\n871 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [871] loss: 0.840 celoss: 0.844 entropy: 0.039\n872 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [872] loss: 0.840 celoss: 0.844 entropy: 0.040\n873 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [873] loss: 0.840 celoss: 0.844 entropy: 0.040\n874 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [874] loss: 0.840 celoss: 0.844 entropy: 0.040\n875 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [875] loss: 0.840 celoss: 0.844 entropy: 0.040\n876 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [876] loss: 0.840 celoss: 0.844 entropy: 0.039\n877 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [877] loss: 0.840 celoss: 0.844 entropy: 0.039\n878 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [878] loss: 0.840 celoss: 0.844 entropy: 0.039\n879 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [879] loss: 0.840 celoss: 0.844 entropy: 0.039\n880 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [880] loss: 0.840 celoss: 0.844 entropy: 0.039\n881 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [881] loss: 0.840 celoss: 0.844 entropy: 0.039\n882 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [882] loss: 0.840 celoss: 0.844 entropy: 0.040\n883 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [883] loss: 0.840 celoss: 0.844 entropy: 0.040\n884 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [884] loss: 0.840 celoss: 0.844 entropy: 0.039\n885 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [885] loss: 0.840 celoss: 0.844 entropy: 0.039\n886 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [886] loss: 0.840 celoss: 0.844 entropy: 0.039\n887 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [887] loss: 0.840 celoss: 0.844 entropy: 0.039\n888 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [888] loss: 0.840 celoss: 0.844 entropy: 0.039\n889 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [889] loss: 0.840 celoss: 0.844 entropy: 0.039\n890 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [890] loss: 0.840 celoss: 0.844 entropy: 0.039\n891 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [891] loss: 0.840 celoss: 0.844 entropy: 0.039\n892 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [892] loss: 0.840 celoss: 0.844 entropy: 0.039\n893 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [893] loss: 0.840 celoss: 0.844 entropy: 0.039\n894 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [894] loss: 0.840 celoss: 0.844 entropy: 0.039\n895 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [895] loss: 0.840 celoss: 0.844 entropy: 0.039\n896 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [896] loss: 0.840 celoss: 0.844 entropy: 0.038\n897 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [897] loss: 0.840 celoss: 0.844 entropy: 0.038\n898 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [898] loss: 0.840 celoss: 0.844 entropy: 0.038\n899 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [899] loss: 0.841 celoss: 0.845 entropy: 0.038\n900 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [900] loss: 0.841 celoss: 0.845 entropy: 0.038\n901 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [901] loss: 0.840 celoss: 0.844 entropy: 0.038\n902 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [902] loss: 0.840 celoss: 0.844 entropy: 0.038\n903 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [903] loss: 0.840 celoss: 0.844 entropy: 0.038\n904 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [904] loss: 0.840 celoss: 0.844 entropy: 0.038\n905 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [905] loss: 0.840 celoss: 0.844 entropy: 0.038\n906 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [906] loss: 0.840 celoss: 0.844 entropy: 0.038\n907 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [907] loss: 0.840 celoss: 0.844 entropy: 0.038\n908 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [908] loss: 0.840 celoss: 0.844 entropy: 0.037\n909 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [909] loss: 0.840 celoss: 0.844 entropy: 0.037\n910 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [910] loss: 0.840 celoss: 0.844 entropy: 0.037\n911 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [911] loss: 0.840 celoss: 0.844 entropy: 0.037\n912 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [912] loss: 0.840 celoss: 0.844 entropy: 0.037\n913 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [913] loss: 0.840 celoss: 0.844 entropy: 0.037\n914 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [914] loss: 0.840 celoss: 0.844 entropy: 0.038\n915 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [915] loss: 0.840 celoss: 0.844 entropy: 0.038\n916 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [916] loss: 0.840 celoss: 0.844 entropy: 0.037\n917 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [917] loss: 0.840 celoss: 0.844 entropy: 0.037\n918 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [918] loss: 0.840 celoss: 0.844 entropy: 0.037\n919 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [919] loss: 0.840 celoss: 0.844 entropy: 0.037\n920 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [920] loss: 0.840 celoss: 0.844 entropy: 0.037\n921 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [921] loss: 0.840 celoss: 0.844 entropy: 0.037\n922 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [922] loss: 0.840 celoss: 0.844 entropy: 0.037\n923 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [923] loss: 0.840 celoss: 0.844 entropy: 0.037\n924 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [924] loss: 0.840 celoss: 0.844 entropy: 0.037\n925 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [925] loss: 0.840 celoss: 0.844 entropy: 0.037\n926 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [926] loss: 0.840 celoss: 0.844 entropy: 0.036\n927 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [927] loss: 0.840 celoss: 0.844 entropy: 0.036\n928 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [928] loss: 0.840 celoss: 0.844 entropy: 0.036\n929 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [929] loss: 0.840 celoss: 0.844 entropy: 0.036\n930 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [930] loss: 0.840 celoss: 0.844 entropy: 0.036\n931 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [931] loss: 0.840 celoss: 0.844 entropy: 0.036\n932 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [932] loss: 0.840 celoss: 0.844 entropy: 0.036\n933 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [933] loss: 0.840 celoss: 0.844 entropy: 0.036\n934 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [934] loss: 0.840 celoss: 0.844 entropy: 0.036\n935 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [935] loss: 0.840 celoss: 0.844 entropy: 0.036\n936 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [936] loss: 0.840 celoss: 0.844 entropy: 0.036\n937 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [937] loss: 0.840 celoss: 0.844 entropy: 0.036\n938 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [938] loss: 0.840 celoss: 0.844 entropy: 0.036\n939 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [939] loss: 0.840 celoss: 0.844 entropy: 0.036\n940 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [940] loss: 0.840 celoss: 0.844 entropy: 0.035\n941 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [941] loss: 0.840 celoss: 0.844 entropy: 0.035\n942 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [942] loss: 0.840 celoss: 0.844 entropy: 0.036\n943 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [943] loss: 0.840 celoss: 0.844 entropy: 0.036\n944 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [944] loss: 0.840 celoss: 0.844 entropy: 0.036\n945 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [945] loss: 0.840 celoss: 0.844 entropy: 0.036\n946 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [946] loss: 0.840 celoss: 0.844 entropy: 0.036\n947 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [947] loss: 0.841 celoss: 0.845 entropy: 0.036\n948 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [948] loss: 0.841 celoss: 0.845 entropy: 0.035\n949 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [949] loss: 0.840 celoss: 0.845 entropy: 0.035\n950 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [950] loss: 0.840 celoss: 0.845 entropy: 0.035\n951 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [951] loss: 0.840 celoss: 0.844 entropy: 0.035\n952 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [952] loss: 0.840 celoss: 0.844 entropy: 0.035\n953 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [953] loss: 0.840 celoss: 0.844 entropy: 0.035\n954 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [954] loss: 0.840 celoss: 0.844 entropy: 0.035\n955 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [955] loss: 0.840 celoss: 0.844 entropy: 0.035\n956 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [956] loss: 0.840 celoss: 0.844 entropy: 0.035\n957 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [957] loss: 0.840 celoss: 0.844 entropy: 0.035\n958 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [958] loss: 0.840 celoss: 0.844 entropy: 0.035\n959 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [959] loss: 0.840 celoss: 0.844 entropy: 0.035\n960 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [960] loss: 0.840 celoss: 0.844 entropy: 0.035\n961 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [961] loss: 0.840 celoss: 0.844 entropy: 0.035\n962 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [962] loss: 0.840 celoss: 0.844 entropy: 0.035\n963 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [963] loss: 0.840 celoss: 0.844 entropy: 0.035\n964 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [964] loss: 0.840 celoss: 0.844 entropy: 0.035\n965 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [965] loss: 0.841 celoss: 0.845 entropy: 0.035\n966 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [966] loss: 0.841 celoss: 0.845 entropy: 0.035\n967 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [967] loss: 0.840 celoss: 0.845 entropy: 0.035\n968 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [968] loss: 0.840 celoss: 0.845 entropy: 0.035\n969 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [969] loss: 0.840 celoss: 0.844 entropy: 0.035\n970 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [970] loss: 0.840 celoss: 0.844 entropy: 0.035\n971 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [971] loss: 0.841 celoss: 0.845 entropy: 0.035\n972 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [972] loss: 0.841 celoss: 0.845 entropy: 0.035\n973 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [973] loss: 0.840 celoss: 0.844 entropy: 0.035\n974 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [974] loss: 0.840 celoss: 0.844 entropy: 0.035\n975 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [975] loss: 0.841 celoss: 0.845 entropy: 0.035\n976 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [976] loss: 0.841 celoss: 0.845 entropy: 0.035\n977 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [977] loss: 0.840 celoss: 0.844 entropy: 0.035\n978 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [978] loss: 0.840 celoss: 0.844 entropy: 0.034\n979 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [979] loss: 0.840 celoss: 0.844 entropy: 0.034\n980 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [980] loss: 0.840 celoss: 0.844 entropy: 0.034\n981 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [981] loss: 0.840 celoss: 0.844 entropy: 0.034\n982 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [982] loss: 0.840 celoss: 0.844 entropy: 0.034\n983 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [983] loss: 0.840 celoss: 0.844 entropy: 0.034\n984 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [984] loss: 0.840 celoss: 0.844 entropy: 0.035\n985 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [985] loss: 0.840 celoss: 0.844 entropy: 0.035\n986 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [986] loss: 0.840 celoss: 0.844 entropy: 0.035\n987 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [987] loss: 0.840 celoss: 0.844 entropy: 0.035\n988 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [988] loss: 0.840 celoss: 0.844 entropy: 0.034\n989 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [989] loss: 0.840 celoss: 0.844 entropy: 0.034\n990 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [990] loss: 0.840 celoss: 0.844 entropy: 0.034\n991 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [991] loss: 0.840 celoss: 0.844 entropy: 0.034\n992 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [992] loss: 0.840 celoss: 0.844 entropy: 0.034\n993 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [993] loss: 0.840 celoss: 0.844 entropy: 0.034\n994 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [994] loss: 0.840 celoss: 0.844 entropy: 0.034\n995 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [995] loss: 0.840 celoss: 0.844 entropy: 0.034\n996 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [996] loss: 0.840 celoss: 0.844 entropy: 0.034\n997 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [997] loss: 0.840 celoss: 0.844 entropy: 0.034\n998 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [998] loss: 0.840 celoss: 0.844 entropy: 0.033\n999 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [999] loss: 0.840 celoss: 0.844 entropy: 0.033\n1000 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1000] loss: 0.840 celoss: 0.844 entropy: 0.033\n1001 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1001] loss: 0.840 celoss: 0.844 entropy: 0.033\n1002 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1002] loss: 0.840 celoss: 0.844 entropy: 0.034\n1003 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1003] loss: 0.841 celoss: 0.845 entropy: 0.034\n1004 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1004] loss: 0.841 celoss: 0.845 entropy: 0.034\n1005 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1005] loss: 0.840 celoss: 0.844 entropy: 0.034\n1006 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1006] loss: 0.840 celoss: 0.844 entropy: 0.033\n1007 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1007] loss: 0.840 celoss: 0.844 entropy: 0.033\n1008 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1008] loss: 0.840 celoss: 0.844 entropy: 0.033\n1009 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1009] loss: 0.840 celoss: 0.844 entropy: 0.033\n1010 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1010] loss: 0.840 celoss: 0.844 entropy: 0.033\n1011 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1011] loss: 0.840 celoss: 0.844 entropy: 0.033\n1012 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1012] loss: 0.840 celoss: 0.844 entropy: 0.034\n1013 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1013] loss: 0.841 celoss: 0.845 entropy: 0.034\n1014 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1014] loss: 0.841 celoss: 0.845 entropy: 0.034\n1015 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1015] loss: 0.840 celoss: 0.844 entropy: 0.034\n1016 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1016] loss: 0.840 celoss: 0.844 entropy: 0.034\n1017 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1017] loss: 0.840 celoss: 0.844 entropy: 0.034\n1018 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1018] loss: 0.840 celoss: 0.844 entropy: 0.033\n1019 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1019] loss: 0.840 celoss: 0.844 entropy: 0.033\n1020 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1020] loss: 0.840 celoss: 0.844 entropy: 0.033\n1021 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1021] loss: 0.840 celoss: 0.844 entropy: 0.033\n1022 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1022] loss: 0.840 celoss: 0.844 entropy: 0.033\n1023 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1023] loss: 0.840 celoss: 0.844 entropy: 0.033\n1024 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1024] loss: 0.840 celoss: 0.844 entropy: 0.033\n1025 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1025] loss: 0.840 celoss: 0.844 entropy: 0.033\n1026 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1026] loss: 0.987 celoss: 0.992 entropy: 0.035\n1027 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1027] loss: 1.069 celoss: 1.074 entropy: 0.035\n1028 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1028] loss: 1.849 celoss: 1.857 entropy: 0.108\n1029 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1029] loss: 1.047 celoss: 1.052 entropy: 0.108\n1030 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1030] loss: 0.960 celoss: 0.964 entropy: 0.137\n1031 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1031] loss: 0.926 celoss: 0.930 entropy: 0.137\n1032 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1032] loss: 0.927 celoss: 0.931 entropy: 0.166\n1033 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1033] loss: 0.900 celoss: 0.904 entropy: 0.166\n1034 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1034] loss: 0.897 celoss: 0.900 entropy: 0.173\n1035 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1035] loss: 0.897 celoss: 0.901 entropy: 0.173\n1036 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1036] loss: 0.046 celoss: 0.046 entropy: 0.006\n1037 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1037] loss: 0.017 celoss: 0.017 entropy: 0.006\n1038 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1038] loss: 0.002 celoss: 0.002 entropy: 0.000\n1039 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1039] loss: 0.001 celoss: 0.001 entropy: 0.000\n1040 updating where_net, what_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1040] loss: 0.001 celoss: 0.001 entropy: 0.000\n1041 updating what_net, where_net is freezed\n--------------------------------------------------------------------------------\nepoch: [1041] loss: 0.001 celoss: 0.001 entropy: 0.000\nFinished Training run 9\nAccuracy of the network on the 3000 train images: 100 %\n"
],
[
"a,b= full_analysis[0]\nprint(a)",
"288\n"
],
[
"cnt=1\nfor epoch, analysis_data in full_analysis:\n analysis_data = np.array(analysis_data)\n # print(\"=\"*20+\"run \",cnt,\"=\"*20)\n \n plt.figure(figsize=(6,6))\n plt.plot(np.arange(0,epoch+2,1),analysis_data[:,0],label=\"ftpt\")\n plt.plot(np.arange(0,epoch+2,1),analysis_data[:,1],label=\"ffpt\")\n plt.plot(np.arange(0,epoch+2,1),analysis_data[:,2],label=\"ftpf\")\n plt.plot(np.arange(0,epoch+2,1),analysis_data[:,3],label=\"ffpf\")\n\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n plt.title(\"Training trends for run \"+str(cnt))\n plt.savefig(path+\"50_50_10runs_entropy/every1/run\"+str(cnt)+\".png\",bbox_inches=\"tight\")\n plt.savefig(path+\"50_50_10runs_entropy/every1/run\"+str(cnt)+\".pdf\",bbox_inches=\"tight\")\n cnt+=1\n",
"_____no_output_____"
],
[
"np.mean(np.array(FTPT_analysis),axis=0) #array([87.85333333, 5.92 , 0. , 6.22666667])",
"_____no_output_____"
],
[
"FTPT_analysis.to_csv(path+\"50_50_10runs_entropy/FTPT_analysis_every1\"+name+\".csv\",index=False)",
"_____no_output_____"
],
[
"FTPT_analysis",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4acb577383f92876b50e3c9d9de476aa88bde783
| 817 |
ipynb
|
Jupyter Notebook
|
2020 Осенний семестр/Практическое задание 1/Пшеничников_Задание1.ipynb
|
mosalov/Notebook_For_AI_Main
|
a693d29bf0bdcf824cb4f1eca86ff54b67ba7428
|
[
"MIT"
] | 6 |
2021-09-20T10:28:18.000Z
|
2022-03-14T18:39:17.000Z
|
2020 Осенний семестр/Практическое задание 1/Пшеничников_Задание1.ipynb
|
mosalov/Notebook_For_AI_Main
|
a693d29bf0bdcf824cb4f1eca86ff54b67ba7428
|
[
"MIT"
] | 122 |
2020-09-07T11:57:57.000Z
|
2022-03-22T06:47:03.000Z
|
2020 Осенний семестр/Практическое задание 1/Пшеничников_Задание1.ipynb
|
mosalov/Notebook_For_AI_Main
|
a693d29bf0bdcf824cb4f1eca86ff54b67ba7428
|
[
"MIT"
] | 97 |
2020-09-07T11:32:19.000Z
|
2022-03-31T10:27:38.000Z
| 18.568182 | 40 | 0.500612 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport sklearn as sk\n\na = \"Иван\"\nb = \"Пшеничников\"\nc = a +\" \"+ b\n\nprint(c)\nprint(len(c))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4acb650dac1f84f6264672c5118b7c22647689fa
| 6,749 |
ipynb
|
Jupyter Notebook
|
001-MIMO-experiment.ipynb
|
kmtusher97/MIMO-for-pattern-recodnition
|
05f3027a73b65b396beaef1068e94ee7a4e83028
|
[
"MIT"
] | 1 |
2021-03-04T17:23:32.000Z
|
2021-03-04T17:23:32.000Z
|
001-MIMO-experiment.ipynb
|
kmtusher97/MIMO-for-pattern-recodnition
|
05f3027a73b65b396beaef1068e94ee7a4e83028
|
[
"MIT"
] | null | null | null |
001-MIMO-experiment.ipynb
|
kmtusher97/MIMO-for-pattern-recodnition
|
05f3027a73b65b396beaef1068e94ee7a4e83028
|
[
"MIT"
] | null | null | null | 24.103571 | 263 | 0.443177 |
[
[
[
"import cmath\nimport numpy as np\n\nnp.set_printoptions(precision=3)\n\nx = np.matrix(np.arange(12).reshape((3,4)))\n\nz = x - 1j*x",
"_____no_output_____"
],
[
"y = z.getH()\nprint(y)",
"[[ 0. -0.j 4. +4.j 8. +8.j]\n [ 1. +1.j 5. +5.j 9. +9.j]\n [ 2. +2.j 6. +6.j 10.+10.j]\n [ 3. +3.j 7. +7.j 11.+11.j]]\n"
],
[
"x = np.matrix([[complex(0.2, 0.4)], \n [complex(1.1, -0.6)], \n [complex(0.45, -0.34)], \n [complex(1.2, 1.4)]])",
"_____no_output_____"
],
[
"n = np.matrix([[complex(0.001, 0.02)], \n [complex(0.003, -0.005)], \n [complex(0.04, -0.003)], \n [complex(0.0012, -0.003)]])",
"_____no_output_____"
],
[
"H = np.matrix([[complex(0.23, -0.12), complex(-0.612, 0.09), complex(-0.71, 0.12), complex(0.32, 0.11)], \n [complex(0.112, -0.098), complex(0.16, 0.23), complex(0.154, -0.22), complex(0.32, -0.23)],\n [complex(-0.53, -0.12), complex(0.321, -0.25), complex(0.56, -0.076), complex(0.71, -0.22)],\n [complex(0.86, -0.23), complex(-0.887, -0.099), complex(0.23, 0.76), complex(0.45, -0.42)]])",
"_____no_output_____"
],
[
"r = H * x + n\nprint(r)",
"[[-0.573+1.43j ]\n [ 1.079+0.198j]\n [ 1.571-0.201j]\n [ 0.72 +1.108j]]\n"
],
[
"H_ct = H.getH()\nprint(H_ct)",
"[[ 0.23 +0.12j 0.112+0.098j -0.53 +0.12j 0.86 +0.23j ]\n [-0.612-0.09j 0.16 -0.23j 0.321+0.25j -0.887+0.099j]\n [-0.71 -0.12j 0.154+0.22j 0.56 +0.076j 0.23 -0.76j ]\n [ 0.32 -0.11j 0.32 +0.23j 0.71 +0.22j 0.45 +0.42j ]]\n"
],
[
"Q1 = H * H_ct\nprint(Q1)",
"[[ 1.083+0.j -0.098+0.135j -0.53 +0.129j 0.785+0.56j ]\n [-0.098-0.135j 0.328+0.j 0.327-0.025j 0.063-0.383j]\n [-0.53 -0.129j 0.327+0.025j 1.333+0.j -0.205-0.215j]\n [ 0.785-0.56j 0.063+0.383j -0.205+0.215j 2.598+0.j ]]\n"
],
[
"from numpy import linalg as LA\n\nD1, U = LA.eig(Q1)\n\nprint(U)",
"[[ 0.362+0.262j -0.232+0.037j 0.838+0.j -0.205+0.019j]\n [-0.003-0.156j 0.177-0.1j 0.326+0.067j 0.907+0.j ]\n [-0.168-0.214j 0.854+0.j 0.3 +0.055j -0.316-0.063j]\n [ 0.838+0.j 0.242-0.34j -0.274+0.136j 0.006-0.174j]]\n"
],
[
"print(D1)",
"[3.281-4.807e-17j 1.409-1.211e-17j 0.488+7.744e-18j 0.164-3.075e-18j]\n"
],
[
"Q2 = H_ct * H\nprint(Q2)",
"[[ 1.177+0.j -1.036-0.129j -0.404+0.747j 0.252+0.013j]\n [-1.036+0.129j 1.423+0.j 0.339-0.616j -0.262+0.317j]\n [-0.404-0.747j 0.339+0.616j 1.54 +0.j 0.085-0.589j]\n [ 0.252-0.013j -0.262-0.317j 0.085+0.589j 1.201+0.j ]]\n"
],
[
"D2, V = LA.eig(Q2)\nprint(V)",
"[[-0.242+0.481j -0.186-0.088j 0.703+0.j 0.414-0.043j]\n [ 0.175-0.528j 0.285+0.354j 0.574-0.201j -0.02 +0.337j]\n [ 0.567+0.j 0.377-0.227j -0.113+0.241j 0.644+0.j ]\n [-0.106+0.26j 0.747+0.j 0.182+0.179j -0.379-0.394j]]\n"
],
[
"D = np.sqrt(D1)\nprint(D)",
"[1.811-1.327e-17j 1.187-5.101e-18j 0.698+5.545e-18j 0.406-3.791e-18j]\n"
],
[
"np = U.getH() * n\nxp = V.getH() * x\nrp = U.getH() * r",
"_____no_output_____"
],
[
"print(np)\nprint(\"------------------\")\nprint(xp)\nprint(\"------------------\")\nprint(rp)",
"[[ 0.001+0.014j]\n [ 0.037-0.008j]\n [ 0.013+0.012j]\n [-0.009-0.005j]]\n------------------\n[[ 1.146-0.371j]\n [ 1.171+0.402j]\n [ 1.228+0.128j]\n [-0.875-0.461j]]\n------------------\n[[0.516+2.135j]\n [1.496+0.173j]\n [0.299+0.641j]\n [0.452+0.191j]]\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4acb7f8511091314ba9071a3c8e4517319d51c67
| 4,307 |
ipynb
|
Jupyter Notebook
|
Images/PNTJy.ipynb
|
hebamohamed8/Assignment_6_answers
|
a25eed70ea407f2d4886d744724f0fb09580d63a
|
[
"MIT"
] | null | null | null |
Images/PNTJy.ipynb
|
hebamohamed8/Assignment_6_answers
|
a25eed70ea407f2d4886d744724f0fb09580d63a
|
[
"MIT"
] | null | null | null |
Images/PNTJy.ipynb
|
hebamohamed8/Assignment_6_answers
|
a25eed70ea407f2d4886d744724f0fb09580d63a
|
[
"MIT"
] | null | null | null | 24.611429 | 376 | 0.467611 |
[
[
[
"import os\nimport random\nimport string",
"_____no_output_____"
],
[
"def get_image(location):\n images = os.listdir(location)\n return images\nimage_list = get_image('../Images')\nimage_list",
"_____no_output_____"
],
[
"image_list_renamed = []\ndef rename_images(name):\n for image in image_list:\n image_name = os.path.splitext(image)[0]\n image_ext = os.path.splitext(image)[1]\n old_name = image_name + image_ext\n new_name = ''.join(random.choice(string.ascii_letters+string.digits) for i in range (5))+ image_ext\n os.rename(old_name,new_name)\n \nrename_images(image_list)",
"[None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]\n"
],
[
"for image in image_list:\n new_name = ''.join(random.choice(string.ascii_letters+string.digits) for i in range (5))+ image_ext\n print(new_name)",
"_____no_output_____"
],
[
"image_renamed = os.rename(old_name,new_name)\nprint(image_renamed)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
4acb880b9bf7dd539c7cc6f4483f3525ffcfbb3b
| 839 |
ipynb
|
Jupyter Notebook
|
example-code/.ipynb_checkpoints/clean_census_data-checkpoint.ipynb
|
mixerupper/2020-hackathon
|
162ca997d2c3dcd7fea4baf7a8d6e9b34ea8d926
|
[
"MIT"
] | 2 |
2020-02-07T16:00:49.000Z
|
2020-02-07T16:00:58.000Z
|
example-code/.ipynb_checkpoints/clean_census_data-checkpoint.ipynb
|
mixerupper/2020-hackathon
|
162ca997d2c3dcd7fea4baf7a8d6e9b34ea8d926
|
[
"MIT"
] | null | null | null |
example-code/.ipynb_checkpoints/clean_census_data-checkpoint.ipynb
|
mixerupper/2020-hackathon
|
162ca997d2c3dcd7fea4baf7a8d6e9b34ea8d926
|
[
"MIT"
] | 1 |
2020-02-07T17:27:46.000Z
|
2020-02-07T17:27:46.000Z
| 17.851064 | 40 | 0.529201 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport math as math",
"_____no_output_____"
],
[
"census = pd.read_csv('census.csv')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.