
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4ad0087a2abfe1077db890a04c64ae57af500956
| 280,833 |
ipynb
|
Jupyter Notebook
|
StackflowSatisfaction.ipynb
|
superring/stackoverflow
|
73cfdbb9b495170d2b781dce0241657b1d1718bc
|
[
"CNRI-Python"
] | null | null | null |
StackflowSatisfaction.ipynb
|
superring/stackoverflow
|
73cfdbb9b495170d2b781dce0241657b1d1718bc
|
[
"CNRI-Python"
] | null | null | null |
StackflowSatisfaction.ipynb
|
superring/stackoverflow
|
73cfdbb9b495170d2b781dce0241657b1d1718bc
|
[
"CNRI-Python"
] | null | null | null | 206.646799 | 173,404 | 0.86853 |
[
[
[
"## Business Understanding\nNow let's look at the 2nd question of interest. That is - What part of the StackOverflow affects the users satisfaction towards StackOverflow?\nI use the data from the Stack Overflow survey answered by more than 64,000 reviewers, with the personal information, coding experience, attitude towards coding and etc.\n\nTo answer this question we need to use the data related to the StackOverflow satisfaction such as the answers to question regarding the StackOverflow's service, moderation, community and etc.\n\n## Data Understanding\nTo get started let's read in the necessary libraries and take a look at some of our columns of interest.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nfrom sklearn.metrics import r2_score, mean_squared_error\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\ndf = pd.read_csv('./survey_results_public.csv')\ndf.head()",
"_____no_output_____"
],
[
"# Pick the questionaire answers related to StackOverflow services.\nrel_col = [\n 'StackOverflowSatisfaction', 'StackOverflowDescribes', 'StackOverflowDevices', \n 'StackOverflowFoundAnswer', 'StackOverflowCopiedCode', 'StackOverflowJobListing', 'StackOverflowCompanyPage',\n 'StackOverflowJobSearch','StackOverflowNewQuestion', 'StackOverflowAnswer', 'StackOverflowMetaChat', \n 'StackOverflowAdsRelevant', 'StackOverflowAdsDistracting', 'StackOverflowModeration',\n 'StackOverflowCommunity', 'StackOverflowHelpful'\n ]\ndf_rel = df[rel_col]",
"_____no_output_____"
]
],
[
[
"Let's look into the quantative variables first, from the description below it seems the only quantative variable is StackOverflowSatisfaction and it has null values.",
"_____no_output_____"
]
],
[
[
"print('Total rows:', len(df_rel))\ndf_rel.describe()",
"Total rows: 51392\n"
]
],
[
[
"Great, seems many people likes StackOverflow.Let's also check what the categorical variables look like.",
"_____no_output_____"
]
],
[
[
"# Check what kinds of values do the categorical variables contain \nfor col in df_rel.select_dtypes(include = ['object']).columns:\n print(col)\n print(df_rel[col].value_counts())\n print()",
"StackOverflowDescribes\nI have a login for Stack Overflow, but haven't created a CV or Developer Story 19696\nI have created a CV or Developer Story on Stack Overflow 8906\nI've visited Stack Overflow, but haven't logged in/created an account 8012\nI'd never heard of Stack Overflow before today 196\nI've heard of Stack Overflow, but have never visited 122\nName: StackOverflowDescribes, dtype: int64\n\nStackOverflowDevices\nDesktop 16516\nDesktop; Android browser 7640\nDesktop; iOS browser 3688\nDesktop; Android browser; Android app 2001\nDesktop; Android app 1503\nDesktop; iOS browser; iOS app 1008\nDesktop; iOS browser; Android browser 790\nDesktop; Other phone browser 596\nDesktop; iOS app 573\nDesktop; Android browser; Other phone browser 182\nDesktop; iOS browser; iOS app; Android browser; Android app 128\nDesktop; iOS browser; Android browser; Android app 91\nDesktop; Android browser; Android app; Other phone browser 51\nDesktop; iOS browser; Other phone browser 47\nDesktop; iOS app; Android app 45\nDesktop; iOS browser; Android app 41\nDesktop; iOS browser; Android browser; Other phone browser 39\nDesktop; iOS browser; iOS app; Android browser; Android app; Other phone browser 37\nAndroid browser 32\nDesktop; iOS browser; iOS app; Android browser 28\niOS browser 25\nDesktop; Android app; Other phone browser 20\nOther phone browser 18\nDesktop; iOS app; Android browser 14\niOS app 13\nDesktop; iOS browser; iOS app; Other phone browser 13\niOS browser; iOS app 11\nAndroid app 10\nDesktop; iOS app; Android browser; Android app 7\nAndroid browser; Android app 6\nDesktop; iOS browser; iOS app; Android app 5\nDesktop; iOS browser; Android browser; Android app; Other phone browser 5\nDesktop; iOS browser; iOS app; Android browser; Other phone browser 3\niOS browser; Android browser 2\nAndroid browser; Other phone browser 2\niOS app; Android app; Other phone browser 2\nDesktop; iOS app; Other phone browser 1\nAndroid app; Other phone browser 1\niOS app; Other phone browser 1\nDesktop; iOS app; Android browser; Other phone browser 1\niOS browser; Other phone browser 1\niOS app; Android browser; Android app 1\niOS browser; Android browser; Android app 1\niOS browser; iOS app; Android browser 1\niOS browser; Android app 1\niOS browser; iOS app; Android browser; Android app 1\niOS app; Android browser 1\nName: StackOverflowDevices, dtype: int64\n\nStackOverflowFoundAnswer\nAt least once each week 13090\nSeveral times 12441\nAt least once each day 5279\nOnce or twice 2861\nHaven't done at all 619\nName: StackOverflowFoundAnswer, dtype: int64\n\nStackOverflowCopiedCode\nOnce or twice 10400\nSeveral times 10239\nHaven't done at all 8433\nAt least once each week 3811\nAt least once each day 1026\nName: StackOverflowCopiedCode, dtype: int64\n\nStackOverflowJobListing\nHaven't done at all 19640\nOnce or twice 7916\nSeveral times 4477\nAt least once each week 1156\nAt least once each day 279\nName: StackOverflowJobListing, dtype: int64\n\nStackOverflowCompanyPage\nHaven't done at all 26263\nOnce or twice 4323\nSeveral times 2201\nAt least once each week 512\nAt least once each day 136\nName: StackOverflowCompanyPage, dtype: int64\n\nStackOverflowJobSearch\nHaven't done at all 24202\nOnce or twice 5492\nSeveral times 2719\nAt least once each week 803\nAt least once each day 199\nName: StackOverflowJobSearch, dtype: int64\n\nStackOverflowNewQuestion\nHaven't done at all 20914\nOnce or twice 8338\nSeveral times 3804\nAt least once each week 431\nAt least once each day 131\nName: StackOverflowNewQuestion, dtype: int64\n\nStackOverflowAnswer\nHaven't done at all 19394\nOnce or twice 7732\nSeveral times 4683\nAt least once each week 1318\nAt least once each day 429\nName: StackOverflowAnswer, dtype: int64\n\nStackOverflowMetaChat\nHaven't done at all 28257\nOnce or twice 3236\nSeveral times 1312\nAt least once each week 377\nAt least once each day 225\nName: StackOverflowMetaChat, dtype: int64\n\nStackOverflowAdsRelevant\nSomewhat agree 13660\nDisagree 8193\nAgree 5292\nStrongly disagree 2733\nStrongly agree 939\nName: StackOverflowAdsRelevant, dtype: int64\n\nStackOverflowAdsDistracting\nDisagree 17701\nStrongly disagree 5953\nSomewhat agree 5523\nAgree 1771\nStrongly agree 789\nName: StackOverflowAdsDistracting, dtype: int64\n\nStackOverflowModeration\nDisagree 17733\nSomewhat agree 5156\nStrongly disagree 4952\nAgree 1534\nStrongly agree 754\nName: StackOverflowModeration, dtype: int64\n\nStackOverflowCommunity\nSomewhat agree 10829\nDisagree 9069\nAgree 7212\nStrongly disagree 2668\nStrongly agree 2632\nName: StackOverflowCommunity, dtype: int64\n\nStackOverflowHelpful\nAgree 16502\nStrongly agree 13902\nSomewhat agree 3272\nDisagree 192\nStrongly disagree 78\nName: StackOverflowHelpful, dtype: int64\n\n"
]
],
[
[
"It seems some of the question has too many irregular answers and need to be cleaned.",
"_____no_output_____"
],
[
"## Prepare Data\nLet's begin cleaning the variables. For StackOverflowSatisfaction just delete the null values since it has only a small portion.\n",
"_____no_output_____"
]
],
[
[
"# delete the NaN in StackOverflowSatisfaction\ndf_rel = df_rel[df_rel['StackOverflowSatisfaction'].notna()]",
"_____no_output_____"
]
],
[
[
"Also note that for the StackOverflowDevices, almost all the users use desktop, so it might be meaningless to use StackOverflowDevices for modeling.",
"_____no_output_____"
]
],
[
[
"# remove StackOverflowDevices since almost all users use desktops\ndf_rel = df_rel.drop('StackOverflowDevices', axis=1)",
"_____no_output_____"
],
[
"# Check what kinds of values do the categorical variables contain after the cleaning\nfor col in df_rel.select_dtypes(include = ['object']).columns:\n print(col)\n print(df_rel[col].value_counts())\n print()",
"StackOverflowDescribes\nI have a login for Stack Overflow, but haven't created a CV or Developer Story 19686\nI have created a CV or Developer Story on Stack Overflow 8901\nI've visited Stack Overflow, but haven't logged in/created an account 8005\nName: StackOverflowDescribes, dtype: int64\n\nStackOverflowFoundAnswer\nAt least once each week 13090\nSeveral times 12441\nAt least once each day 5279\nOnce or twice 2861\nHaven't done at all 619\nName: StackOverflowFoundAnswer, dtype: int64\n\nStackOverflowCopiedCode\nOnce or twice 10400\nSeveral times 10239\nHaven't done at all 8433\nAt least once each week 3811\nAt least once each day 1026\nName: StackOverflowCopiedCode, dtype: int64\n\nStackOverflowJobListing\nHaven't done at all 19640\nOnce or twice 7916\nSeveral times 4477\nAt least once each week 1156\nAt least once each day 279\nName: StackOverflowJobListing, dtype: int64\n\nStackOverflowCompanyPage\nHaven't done at all 26263\nOnce or twice 4323\nSeveral times 2201\nAt least once each week 512\nAt least once each day 136\nName: StackOverflowCompanyPage, dtype: int64\n\nStackOverflowJobSearch\nHaven't done at all 24202\nOnce or twice 5492\nSeveral times 2719\nAt least once each week 803\nAt least once each day 199\nName: StackOverflowJobSearch, dtype: int64\n\nStackOverflowNewQuestion\nHaven't done at all 20914\nOnce or twice 8338\nSeveral times 3804\nAt least once each week 431\nAt least once each day 131\nName: StackOverflowNewQuestion, dtype: int64\n\nStackOverflowAnswer\nHaven't done at all 19394\nOnce or twice 7732\nSeveral times 4683\nAt least once each week 1318\nAt least once each day 429\nName: StackOverflowAnswer, dtype: int64\n\nStackOverflowMetaChat\nHaven't done at all 28257\nOnce or twice 3236\nSeveral times 1312\nAt least once each week 377\nAt least once each day 225\nName: StackOverflowMetaChat, dtype: int64\n\nStackOverflowAdsRelevant\nSomewhat agree 13660\nDisagree 8193\nAgree 5292\nStrongly disagree 2733\nStrongly agree 939\nName: StackOverflowAdsRelevant, dtype: int64\n\nStackOverflowAdsDistracting\nDisagree 17701\nStrongly disagree 5953\nSomewhat agree 5523\nAgree 1771\nStrongly agree 789\nName: StackOverflowAdsDistracting, dtype: int64\n\nStackOverflowModeration\nDisagree 17733\nSomewhat agree 5156\nStrongly disagree 4952\nAgree 1534\nStrongly agree 754\nName: StackOverflowModeration, dtype: int64\n\nStackOverflowCommunity\nSomewhat agree 10829\nDisagree 9069\nAgree 7212\nStrongly disagree 2668\nStrongly agree 2632\nName: StackOverflowCommunity, dtype: int64\n\nStackOverflowHelpful\nAgree 16502\nStrongly agree 13902\nSomewhat agree 3272\nDisagree 192\nStrongly disagree 78\nName: StackOverflowHelpful, dtype: int64\n\n"
]
],
[
[
"Since all explainatory variables are categorical, get dummys and use random forest model",
"_____no_output_____"
]
],
[
[
"# Define the function to clean data: create dummies for \n# catagorical variables, and return df\ndef add_dummies(df):\n '''\n INPUT\n df - the dataframe to be added dummy variables\n \n OUTPUT\n df - the dataframe output with all the categorical variables\n converted to dummy variables\n '''\n # Dummy the categorical variables\n cat_vars = df.select_dtypes(include=['object']).copy().columns\n for var in cat_vars:\n # for each cat add dummy var, drop original column\n df = pd.concat([df.drop(var, axis=1), pd.get_dummies(df[var], prefix=var, prefix_sep='_', drop_first=True)], axis=1)\n \n return df\n\ndf_rel = add_dummies(df_rel)",
"_____no_output_____"
]
],
[
[
"## Data Modeling\nUse randomforest instead of linear model since all the explainatory variables are categorical.",
"_____no_output_____"
]
],
[
[
"### Use randomforest instead of linear model\nfrom sklearn.ensemble import RandomForestRegressor\n\n### Let's see what be the best number of features to use based on the test set performance\ndef find_optimal_rf_mod(X, y, cutoffs, test_size = .30, random_state=42, plot=True):\n '''\n INPUT\n X - pandas dataframe, X matrix\n y - pandas dataframe, response variable\n cutoffs - list of ints, cutoff for number of non-zero values in dummy categorical vars\n test_size - float between 0 and 1, default 0.3, determines the proportion of data as test data\n random_state - int, default 42, controls random state for train_test_split\n plot - boolean, default 0.3, True to plot result\n kwargs - include the arguments you want to pass to the rf model\n \n OUTPUT\n r2_scores_test - list of floats of r2 scores on the test data\n r2_scores_train - list of floats of r2 scores on the train data\n rf_model - model object from sklearn\n X_train, X_test, y_train, y_test - output from sklearn train test split used for optimal model\n '''\n r2_scores_test, r2_scores_train, num_feats, results = [], [], [], dict()\n for cutoff in cutoffs:\n \n #reduce X matrix\n reduce_X = X.iloc[:, np.where((X.sum() > cutoff) == True)[0]]\n num_feats.append(reduce_X.shape[1])\n\n #split the data into train and test\n X_train, X_test, y_train, y_test = train_test_split(reduce_X, y, test_size = test_size, random_state=random_state)\n\n #fit the model and obtain pred response\n\n rf_model = RandomForestRegressor() #no normalizing here, but could tune other hyperparameters\n rf_model.fit(X_train, y_train)\n y_test_preds = rf_model.predict(X_test)\n y_train_preds = rf_model.predict(X_train)\n \n #append the r2 value from the test set\n r2_scores_test.append(r2_score(y_test, y_test_preds))\n r2_scores_train.append(r2_score(y_train, y_train_preds))\n results[str(cutoff)] = r2_score(y_test, y_test_preds)\n \n if plot:\n plt.plot(num_feats, r2_scores_test, label=\"Test\", alpha=.5)\n plt.plot(num_feats, r2_scores_train, label=\"Train\", alpha=.5)\n plt.xlabel('Number of Features')\n plt.ylabel('Rsquared')\n plt.title('Rsquared by Number of Features')\n plt.legend(loc=1)\n plt.show()\n \n best_cutoff = max(results, key=results.get)\n \n #reduce X matrix\n reduce_X = X.iloc[:, np.where((X.sum() > int(best_cutoff)) == True)[0]]\n num_feats.append(reduce_X.shape[1])\n\n #split the data into train and test\n X_train, X_test, y_train, y_test = train_test_split(reduce_X, y, test_size = test_size, random_state=random_state)\n\n #fit the model\n rf_model = RandomForestRegressor() \n rf_model.fit(X_train, y_train)\n \n return r2_scores_test, r2_scores_train, rf_model, X_train, X_test, y_train, y_test",
"_____no_output_____"
]
],
[
[
"## Evaluation\nEvaluate the model performance, from the result below you can see the model is underfit and needs improvement.",
"_____no_output_____"
]
],
[
[
"X = df_rel.drop('StackOverflowSatisfaction', axis=1)\ny = df_rel['StackOverflowSatisfaction']\n\n\ncutoffs = [5000, 3500, 2500, 1000, 100, 50, 30, 20, 10, 5]\nr2_test, r2_train, rf_model, X_train, X_test, y_train, y_test = find_optimal_rf_mod(X, y, cutoffs)",
"_____no_output_____"
],
[
"y_test_preds = rf_model.predict(X_test)\n\npreds_vs_act = pd.DataFrame(np.hstack([y_test.values.reshape(y_test.size,1), y_test_preds.reshape(y_test.size,1)]))\npreds_vs_act.columns = ['actual', 'preds']\npreds_vs_act['diff'] = preds_vs_act['actual'] - preds_vs_act['preds']\n\nplt.plot(preds_vs_act['preds'], preds_vs_act['diff'], 'bo');\nplt.xlabel('predicted');\nplt.ylabel('difference');",
"_____no_output_____"
]
],
[
[
"## Model improvement\nUse GridSearchCV to search for optimal hyper parameters.",
"_____no_output_____"
]
],
[
[
"# use GridSearchCV to search for optimal hyper parameters\n\nfrom sklearn.model_selection import GridSearchCV\n\n### Let's see what be the best number of features to use based on the test set performance\ndef find_optimal_rf_mod(X, y, cutoffs, test_size = .30, random_state=42, plot=True, param_grid=None):\n '''\n INPUT\n X - pandas dataframe, X matrix\n y - pandas dataframe, response variable\n cutoffs - list of ints, cutoff for number of non-zero values in dummy categorical vars\n test_size - float between 0 and 1, default 0.3, determines the proportion of data as test data\n random_state - int, default 42, controls random state for train_test_split\n plot - boolean, default 0.3, True to plot result\n kwargs - include the arguments you want to pass to the rf model\n \n OUTPUT\n r2_scores_test - list of floats of r2 scores on the test data\n r2_scores_train - list of floats of r2 scores on the train data\n rf_model - model object from sklearn\n X_train, X_test, y_train, y_test - output from sklearn train test split used for optimal model\n '''\n\n r2_scores_test, r2_scores_train, num_feats, results = [], [], [], dict()\n for cutoff in cutoffs:\n\n #reduce X matrix\n reduce_X = X.iloc[:, np.where((X.sum() > cutoff) == True)[0]]\n num_feats.append(reduce_X.shape[1])\n\n #split the data into train and test\n X_train, X_test, y_train, y_test = train_test_split(reduce_X, y, test_size = test_size, random_state=random_state)\n\n #fit the model and obtain pred response\n if param_grid==None:\n rf_model = RandomForestRegressor() #no normalizing here, but could tune other hyperparameters\n\n else:\n rf_inst = RandomForestRegressor(n_jobs=-1, verbose=1)\n rf_model = GridSearchCV(rf_inst, param_grid, n_jobs=-1) \n \n rf_model.fit(X_train, y_train)\n y_test_preds = rf_model.predict(X_test)\n y_train_preds = rf_model.predict(X_train)\n\n #append the r2 value from the test set\n r2_scores_test.append(r2_score(y_test, y_test_preds))\n r2_scores_train.append(r2_score(y_train, y_train_preds))\n results[str(cutoff)] = r2_score(y_test, y_test_preds)\n\n if plot:\n plt.plot(num_feats, r2_scores_test, label=\"Test\", alpha=.5)\n plt.plot(num_feats, r2_scores_train, label=\"Train\", alpha=.5)\n plt.xlabel('Number of Features')\n plt.ylabel('Rsquared')\n plt.title('Rsquared by Number of Features')\n plt.legend(loc=1)\n plt.show()\n \n best_cutoff = max(results, key=results.get)\n\n #reduce X matrix\n reduce_X = X.iloc[:, np.where((X.sum() > int(best_cutoff)) == True)[0]]\n num_feats.append(reduce_X.shape[1])\n\n #split the data into train and test\n X_train, X_test, y_train, y_test = train_test_split(reduce_X, y, test_size = test_size, random_state=random_state)\n\n #fit the model\n if param_grid==None:\n rf_model = RandomForestRegressor() #no normalizing here, but could tune other hyperparameters\n\n else:\n rf_inst = RandomForestRegressor(n_jobs=-1, verbose=1)\n rf_model = GridSearchCV(rf_inst, param_grid, n_jobs=-1) \n rf_model.fit(X_train, y_train)\n \n return r2_scores_test, r2_scores_train, rf_model, X_train, X_test, y_train, y_test",
"_____no_output_____"
]
],
[
[
"### Evaluation\nLooks better than before.",
"_____no_output_____"
]
],
[
[
"cutoffs = [5000, 3500, 2500, 1000, 100, 50, 30, 20, 10, 5]\nparams = {'n_estimators': [10, 100, 1000], 'max_depth': [1, 5, 10, 100]}\nr2_test, r2_train, rf_model, X_train, X_test, y_train, y_test = find_optimal_rf_mod(X, y, cutoffs, param_grid=params)",
"[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.1s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 0.6s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 1.5s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 2.8s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 3.6s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 0.8s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.0s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 3.6s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 4.7s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 1.0s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.4s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 4.2s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 5.4s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 1.0s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.5s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 4.4s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 5.7s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 1.1s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.6s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 4.7s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 6.1s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 1.1s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.6s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 4.7s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 6.1s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.3s finished\n[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=-1)]: Done 18 tasks | elapsed: 0.2s\n[Parallel(n_jobs=-1)]: Done 168 tasks | elapsed: 1.1s\n[Parallel(n_jobs=-1)]: Done 418 tasks | elapsed: 2.6s\n[Parallel(n_jobs=-1)]: Done 768 tasks | elapsed: 4.8s\n[Parallel(n_jobs=-1)]: Done 1000 out of 1000 | elapsed: 6.1s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 768 tasks | elapsed: 0.2s\n[Parallel(n_jobs=16)]: Done 1000 out of 1000 | elapsed: 0.2s finished\n[Parallel(n_jobs=16)]: Using backend ThreadingBackend with 16 concurrent workers.\n[Parallel(n_jobs=16)]: Done 18 tasks | elapsed: 0.0s\n[Parallel(n_jobs=16)]: Done 168 tasks | elapsed: 0.1s\n[Parallel(n_jobs=16)]: Done 418 tasks | elapsed: 0.1s\n"
]
],
[
[
"Let's check the importance of features.",
"_____no_output_____"
]
],
[
[
"features = X_train.columns\nimportances = rf_model.best_estimator_.feature_importances_\nindices = np.argsort(importances)\nplt.figure(figsize=(10,20))\nplt.title('Feature Importances')\nplt.barh(range(len(indices)), importances[indices], color='b', align='center')\nplt.yticks(range(len(indices)), [features[i] for i in indices])\nplt.xlabel('Relative Importance')\nplt.show()",
"_____no_output_____"
]
],
[
[
"We can see that the top 3 facter affecting the satisfaction of StackOverflow is whether it's helpful, whether the moderation is fair, and whether the community is strong, so StackOverflow should keep or improve mainly from the usability, the moderation and the community.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad01b325973d7ce2a747dcf0ac6521d1efad2f0
| 6,436 |
ipynb
|
Jupyter Notebook
|
Computer_Science/Algorithm/Algorithm Learning/LeetCode/algorithm/TC551.ipynb
|
kevinkda/KnowTech_Learning
|
378afcc4a0900bca047f51583f6e5f2030015cbe
|
[
"MIT"
] | 1 |
2022-01-25T15:56:49.000Z
|
2022-01-25T15:56:49.000Z
|
Computer_Science/Algorithm/Algorithm Learning/LeetCode/algorithm/TC551.ipynb
|
kevinkda/KnowTech_Learning
|
378afcc4a0900bca047f51583f6e5f2030015cbe
|
[
"MIT"
] | null | null | null |
Computer_Science/Algorithm/Algorithm Learning/LeetCode/algorithm/TC551.ipynb
|
kevinkda/KnowTech_Learning
|
378afcc4a0900bca047f51583f6e5f2030015cbe
|
[
"MIT"
] | null | null | null | 24.849421 | 85 | 0.469702 |
[
[
[
"# LeetCode Algorithm Test Case 551\n\n## (学生出勤记录 I)[https://leetcode-cn.com/problems/student-attendance-record-i/]\n\n[TOC]\n\n给你一个字符串 s 表示一个学生的出勤记录,其中的每个字符用来标记当天的出勤情况(缺勤、迟到、到场)。记录中只含下面三种字符:\n\n1. 'A':Absent,缺勤\n2. 'L':Late,迟到\n3. 'P':Present,到场\n\n如果学生能够 同时 满足下面两个条件,则可以获得出勤奖励:\n1. 按 总出勤 计,学生缺勤('A')严格 少于两天。\n2. 学生 不会 存在 连续 3 天或 3 天以上的迟到('L')记录。\n\n如果学生可以获得出勤奖励,返回 true ;否则,返回 false 。\n\n> 示例 1:\n> 输入: s = \"PPALLP\"\n> 输出: true\n> 解释: 学生缺勤次数少于 2 次,且不存在 3 天或以上的连续迟到记录。\n\n> 示例 2:\n> 输入: s = \"PPALLL\"\n> 输出: false\n> 解释: 学生最后三天连续迟到,所以不满足出勤奖励的条件。\n\n> 提示:\n> - `1 <= s.length <= 1000`\n> - `s[i]` 为 `A`、`L` 或 `P`",
"_____no_output_____"
],
[
"### Type A: Violent Enumeration Solution - Scheme I\n> 2021/08/17 Kevin Tang",
"_____no_output_____"
]
],
[
[
"from typing import List\n\n\ndef checkRecord_TypeA_Scheme_A(s: str) -> bool:\n \"\"\"\n :param nums:\n :param target:\n :return:\n\n >>> ic(checkRecord_TypeA_Scheme_A(s=\"PPALLP\"))\n True\n >>> ic(checkRecord_TypeA_Scheme_A(s=\"PPALLL\"))\n False\n >>> ic(checkRecord_TypeA_Scheme_A(s=\"AA\"))\n False\n \"\"\"\n absent, late, present = 0, 0, 0\n lateContinuousCount = 0\n for i in s:\n if i == 'L':\n late += 1\n lateContinuousCount += 1\n elif i == 'A':\n absent += 1\n lateContinuousCount = 0\n elif i == 'P':\n present += 1\n lateContinuousCount = 0\n if absent >= 2 or lateContinuousCount >= 3:\n return False\n return True",
"_____no_output_____"
]
],
[
[
"### Type A: Violent Enumeration Solution - Scheme II\n> 2021/08/17 Kevin Tang",
"_____no_output_____"
]
],
[
[
"from typing import List\n\n\ndef checkRecord_TypeA_Scheme_B(s: str) -> bool:\n \"\"\"\n :param nums:\n :param target:\n :return:\n\n >>> ic(checkRecord_TypeA_Scheme_B(s=\"PPALLP\"))\n True\n >>> ic(checkRecord_TypeA_Scheme_B(s=\"PPALLL\"))\n False\n >>> ic(checkRecord_TypeA_Scheme_B(s=\"AA\"))\n False\n \"\"\"\n absent: int = 0\n lateContinuousCount = 0\n for i in s:\n if i == 'A':\n absent += 1\n if absent >= 2:\n return False\n if i == 'L':\n lateContinuousCount += 1\n if lateContinuousCount >= 3:\n return False\n else:\n lateContinuousCount = 0\n return True",
"_____no_output_____"
]
],
[
[
"### Type B: Built in Function Solution - Scheme I\n> 2021/08/19 Kevin Tang",
"_____no_output_____"
]
],
[
[
"from typing import List\n\n\ndef checkRecord_TypeB_Scheme_A(s: str) -> bool:\n \"\"\"\n :param nums:\n :param target:\n :return:\n\n >>> ic(checkRecord_TypeB_Scheme_A(s=\"PPALLP\"))\n True\n >>> ic(checkRecord_TypeB_Scheme_A(s=\"PPALLL\"))\n False\n >>> ic(checkRecord_TypeB_Scheme_A(s=\"AA\"))\n False\n >>> ic(checkRecord_TypeB_Scheme_A(s=\"LPLPLPLPLPL\"))\n True\n \"\"\"\n return (s.find('A') == s.rfind('A')) and ('LLL' not in s)",
"_____no_output_____"
]
],
[
[
"### Test Script",
"_____no_output_____"
]
],
[
[
"import doctest\nfrom icecream import ic\n\nic(doctest.testmod())",
"ic| checkRecord_TypeA_Scheme_A(s=\"PPALLP\"): True\nic| checkRecord_TypeA_Scheme_A(s=\"PPALLL\"): False\nic| checkRecord_TypeA_Scheme_A(s=\"AA\"): False\nic| checkRecord_TypeA_Scheme_B(s=\"PPALLP\"): True\nic| checkRecord_TypeA_Scheme_B(s=\"PPALLL\"): False\nic| checkRecord_TypeA_Scheme_B(s=\"AA\"): False\nic| checkRecord_TypeB_Scheme_A(s=\"PPALLP\"): True\nic| checkRecord_TypeB_Scheme_A(s=\"PPALLL\"): False\nic| checkRecord_TypeB_Scheme_A(s=\"AA\"): False\nic| checkRecord_TypeB_Scheme_A(s=\"LPLPLPLPLPL\"): True\nic| doctest.testmod(): TestResults(failed=0, attempted=10)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad02bd7293f243f3923defecb944898e43f642c
| 8,443 |
ipynb
|
Jupyter Notebook
|
Draft/Homework4.ipynb
|
Upward-Spiral-Science/claritycontrol
|
3da44a35f4eb8746c408ad34e7f433d14c031323
|
[
"Apache-2.0"
] | 2 |
2016-02-04T20:32:20.000Z
|
2016-02-21T15:44:01.000Z
|
rough/Homework4.ipynb
|
Upward-Spiral-Science/claritycontrol
|
3da44a35f4eb8746c408ad34e7f433d14c031323
|
[
"Apache-2.0"
] | 6 |
2016-02-04T20:24:34.000Z
|
2016-04-28T10:08:32.000Z
|
rough/Homework4.ipynb
|
Upward-Spiral-Science/claritycontrol
|
3da44a35f4eb8746c408ad34e7f433d14c031323
|
[
"Apache-2.0"
] | null | null | null | 29.013746 | 341 | 0.576572 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4ad02cb7d3e8b2f62381b2cf825ff89a4a62d920
| 4,567 |
ipynb
|
Jupyter Notebook
|
05-Object Oriented Programming/04-OOP Challenge.ipynb
|
PseudoCodeNerd/learning-python
|
1aa02a5c0a5d2f194c20a56a68088012fbfa5da3
|
[
"MIT"
] | null | null | null |
05-Object Oriented Programming/04-OOP Challenge.ipynb
|
PseudoCodeNerd/learning-python
|
1aa02a5c0a5d2f194c20a56a68088012fbfa5da3
|
[
"MIT"
] | null | null | null |
05-Object Oriented Programming/04-OOP Challenge.ipynb
|
PseudoCodeNerd/learning-python
|
1aa02a5c0a5d2f194c20a56a68088012fbfa5da3
|
[
"MIT"
] | null | null | null | 20.949541 | 138 | 0.501861 |
[
[
[
"# Object Oriented Programming Challenge\n\nFor this challenge, create a bank account class that has two attributes:\n\n* owner\n* balance\n\nand two methods:\n\n* deposit\n* withdraw\n\nAs an added requirement, withdrawals may not exceed the available balance.\n\nInstantiate your class, make several deposits and withdrawals, and test to make sure the account can't be overdrawn.",
"_____no_output_____"
]
],
[
[
"class Account:\n def __init__(self, owner, balance=0):\n self.owner = owner\n self.balance = balance\n \n def __str__(self):\n return f\"Account owner: {self.owner}\\nAccount Balance: {self.balance}\"\n \n def deposit(self, dep_amount):\n self.balance += dep_amount\n print('Deposit Accepted')\n \n def withdraw(self, with_amount):\n if with_amount > self.balance:\n return f\"\"\"You do not have enough funds to withdraw {with_amount} ! Please deposit or cancel the transaction\"\"\"\n else:\n self.balance -= with_amount\n return f\"Withdrawal Accepted\\nCurrent State\\nAccount Balance: {self.balance}\"\n ",
"_____no_output_____"
],
[
"# 1. Instantiate the class\nacct1 = Account('Jose',100)",
"_____no_output_____"
],
[
"# 2. Print the object\nprint(acct1)",
"Account owner: Jose\nAccount Balance: 100\n"
],
[
"# 3. Show the account owner attribute\nacct1.owner",
"_____no_output_____"
],
[
"# 4. Show the account balance attribute\nacct1.balance",
"_____no_output_____"
],
[
"# 5. Make a series of deposits and withdrawals\nacct1.deposit(50)",
"Deposit Accepted\n"
],
[
"acct1.withdraw(75)",
"_____no_output_____"
],
[
"# 6. Make a withdrawal that exceeds the available balance\nacct1.withdraw(500)",
"_____no_output_____"
]
],
[
[
"## Good job!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ad031cc546a9f423d5fb4b4f573559216cc35b6
| 664,362 |
ipynb
|
Jupyter Notebook
|
notebooks/2018-07-24-Adsorption on solid surfaces.ipynb
|
fraricci/matgenb
|
436269046302dc7d8e5545e5d48f208ca2275a92
|
[
"BSD-3-Clause"
] | 132 |
2017-03-11T02:27:06.000Z
|
2022-02-19T17:45:38.000Z
|
notebooks/2018-07-24-Adsorption on solid surfaces.ipynb
|
fraricci/matgenb
|
436269046302dc7d8e5545e5d48f208ca2275a92
|
[
"BSD-3-Clause"
] | 15 |
2017-11-30T22:49:15.000Z
|
2022-02-27T15:10:23.000Z
|
notebooks/2018-07-24-Adsorption on solid surfaces.ipynb
|
fraricci/matgenb
|
436269046302dc7d8e5545e5d48f208ca2275a92
|
[
"BSD-3-Clause"
] | 107 |
2017-03-11T01:02:57.000Z
|
2022-03-01T08:18:18.000Z
| 929.177622 | 140,210 | 0.71755 |
[
[
[
"\n# Supplemental Information\n\nThis notebook is intended to serve as a supplement to the manuscript \"High-throughput workflows for determining adsorption energies on solid surfaces.\" It outlines basic use of the code and workflow software that has been developed for processing surface slabs and placing adsorbates according to symmetrically distinct sites on surface facets.\n\n## Installation\n\nTo use this notebook, we recommend installing python via [Anaconda](https://www.continuum.io/downloads), which includes jupyter and the associated iPython notebook software.\n\nThe code used in this project primarily makes use of two packages, pymatgen and atomate, which are installable via pip or the matsci channel on conda (e. g. `conda install -c matsci pymatgen atomate`). Development versions with editable code may be installed by cloning the repositories and using `python setup.py develop`.",
"_____no_output_____"
],
[
"## Example 1: AdsorbateSiteFinder (pymatgen)\n\nAn example using the the AdsorbateSiteFinder class in pymatgen is shown below. We begin with an import statement for the necessay modules. To use the MP RESTful interface, you must provide your own API key either in the MPRester call i.e. ```mpr=MPRester(\"YOUR_API_KEY\")``` or provide in in your .pmgrc.yaml configuration file. API keys can be accessed at materialsproject.org under your \"Dashboard.\"",
"_____no_output_____"
]
],
[
[
"# Import statements\nfrom pymatgen import Structure, Lattice, MPRester, Molecule\nfrom pymatgen.analysis.adsorption import *\nfrom pymatgen.core.surface import generate_all_slabs\nfrom pymatgen.symmetry.analyzer import SpacegroupAnalyzer\nfrom matplotlib import pyplot as plt\n%matplotlib inline\n# Note that you must provide your own API Key, which can\n# be accessed via the Dashboard at materialsproject.org\nmpr = MPRester()",
"_____no_output_____"
]
],
[
[
"We create a simple fcc structure, generate it's distinct slabs, and select the slab with a miller index of (1, 1, 1).",
"_____no_output_____"
]
],
[
[
"fcc_ni = Structure.from_spacegroup(\"Fm-3m\", Lattice.cubic(3.5), [\"Ni\"], [[0, 0, 0]])\nslabs = generate_all_slabs(fcc_ni, max_index=1, min_slab_size=8.0,\n min_vacuum_size=10.0)\nni_111 = [slab for slab in slabs if slab.miller_index==(1,1,1)][0]",
"_____no_output_____"
]
],
[
[
"We make an instance of the AdsorbateSiteFinder and use it to find the relevant adsorption sites.",
"_____no_output_____"
]
],
[
[
"asf_ni_111 = AdsorbateSiteFinder(ni_111)\nads_sites = asf_ni_111.find_adsorption_sites()\nprint(ads_sites)\nassert len(ads_sites) == 4",
"{'ontop': [array([1.23743687, 0.71443451, 9.0725408 ])], 'bridge': [array([-0.61871843, 1.78608627, 9.0725408 ])], 'hollow': [array([4.27067681e-16, 7.39702921e-16, 9.07254080e+00]), array([8.80455477e-16, 1.42886902e+00, 9.07254080e+00])], 'all': [array([1.23743687, 0.71443451, 9.0725408 ]), array([-0.61871843, 1.78608627, 9.0725408 ]), array([4.27067681e-16, 7.39702921e-16, 9.07254080e+00]), array([1.63125081e-15, 1.42886902e+00, 9.07254080e+00])]}\n"
]
],
[
[
"We visualize the sites using a tool from pymatgen.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = fig.add_subplot(111)\nplot_slab(ni_111, ax, adsorption_sites=True)",
"_____no_output_____"
]
],
[
[
"Use the `AdsorbateSiteFinder.generate_adsorption_structures` method to generate structures of adsorbates.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = fig.add_subplot(111)\nadsorbate = Molecule(\"H\", [[0, 0, 0]])\nads_structs = asf_ni_111.generate_adsorption_structures(adsorbate, \n repeat=[1, 1, 1])\nplot_slab(ads_structs[0], ax, adsorption_sites=False, decay=0.09)",
"_____no_output_____"
]
],
[
[
"## Example 2: AdsorbateSiteFinder for various surfaces\n\nIn this example, the AdsorbateSiteFinder is used to find adsorption sites on different structures and miller indices.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\naxes = [fig.add_subplot(2, 3, i) for i in range(1, 7)]\nmats = {\"mp-23\":(1, 0, 0), # FCC Ni\n \"mp-2\":(1, 1, 0), # FCC Au\n \"mp-13\":(1, 1, 0), # BCC Fe\n \"mp-33\":(0, 0, 1), # HCP Ru\n \"mp-30\": (2, 1, 1),\n \"mp-5229\":(1, 0, 0),\n } # Cubic SrTiO3\n #\"mp-2133\":(0, 1, 1)} # Wurtzite ZnO\n\nfor n, (mp_id, m_index) in enumerate(mats.items()):\n struct = mpr.get_structure_by_material_id(mp_id)\n struct = SpacegroupAnalyzer(struct).get_conventional_standard_structure()\n slabs = generate_all_slabs(struct, 1, 5.0, 2.0, center_slab=True)\n slab_dict = {slab.miller_index:slab for slab in slabs}\n asf = AdsorbateSiteFinder.from_bulk_and_miller(struct, m_index, undercoord_threshold=0.10)\n plot_slab(asf.slab, axes[n])\n ads_sites = asf.find_adsorption_sites()\n sop = get_rot(asf.slab)\n ads_sites = [sop.operate(ads_site)[:2].tolist()\n for ads_site in ads_sites[\"all\"]]\n axes[n].plot(*zip(*ads_sites), color='k', marker='x', \n markersize=10, mew=1, linestyle='', zorder=10000)\n mi_string = \"\".join([str(i) for i in m_index])\n axes[n].set_title(\"{}({})\".format(struct.composition.reduced_formula, mi_string))\n axes[n].set_xticks([])\n axes[n].set_yticks([])\n \naxes[4].set_xlim(-2, 5)\naxes[4].set_ylim(-2, 5)\nfig.savefig('slabs.png', dpi=200)",
"_____no_output_____"
],
[
"!open slabs.png",
"_____no_output_____"
]
],
[
[
"## Example 3: Generating a workflow from atomate\n\nIn this example, we demonstrate how MatMethods may be used to generate a full workflow for the determination of DFT-energies from which adsorption energies may be calculated. Note that this requires a working instance of [FireWorks](https://pythonhosted.org/FireWorks/index.html) and its dependency, [MongoDB](https://www.mongodb.com/). Note that MongoDB can be installed via [Anaconda](https://anaconda.org/anaconda/mongodb).",
"_____no_output_____"
]
],
[
[
"from fireworks import LaunchPad\nlpad = LaunchPad()",
"_____no_output_____"
],
[
"lpad.reset('', require_password=False)",
"2018-07-24 09:56:31,982 INFO Performing db tune-up\n2018-07-24 09:56:31,995 INFO LaunchPad was RESET.\n"
]
],
[
[
"Import the necessary workflow-generating function from atomate:",
"_____no_output_____"
]
],
[
[
"from atomate.vasp.workflows.base.adsorption import get_wf_surface, get_wf_surface_all_slabs",
"_____no_output_____"
]
],
[
[
"Adsorption configurations take the form of a dictionary with the miller index as a string key and a list of pymatgen Molecule instances as the values.",
"_____no_output_____"
]
],
[
[
"co = Molecule(\"CO\", [[0, 0, 0], [0, 0, 1.23]])\nh = Molecule(\"H\", [[0, 0, 0]])",
"_____no_output_____"
]
],
[
[
"Workflows are generated using the a slab a list of molecules.",
"_____no_output_____"
]
],
[
[
"struct = mpr.get_structure_by_material_id(\"mp-23\") # fcc Ni\nstruct = SpacegroupAnalyzer(struct).get_conventional_standard_structure()\nslabs = generate_all_slabs(struct, 1, 5.0, 2.0, center_slab=True)\nslab_dict = {slab.miller_index:slab for slab in slabs}\n\nni_slab_111 = slab_dict[(1, 1, 1)]\nwf = get_wf_surface([ni_slab_111], molecules=[co, h])\nlpad.add_wf(wf)",
"2018-07-24 09:56:33,057 INFO Added a workflow. id_map: {-9: 1, -8: 2, -7: 3, -6: 4, -5: 5, -4: 6, -3: 7, -2: 8, -1: 9}\n"
]
],
[
[
"The workflow may be inspected as below. Note that there are 9 optimization tasks correponding the slab, and 4 distinct adsorption configurations for each of the 2 adsorbates. Details on running FireWorks, including [singleshot launching](https://pythonhosted.org/FireWorks/worker_tutorial.html#launch-a-rocket-on-a-worker-machine-fireworker), [queue submission](https://pythonhosted.org/FireWorks/queue_tutorial.html#), [workflow management](https://pythonhosted.org/FireWorks/defuse_tutorial.html), and more can be found in the [FireWorks documentation](https://pythonhosted.org/FireWorks/index.html).",
"_____no_output_____"
]
],
[
[
"lpad.get_wf_summary_dict(1)",
"_____no_output_____"
]
],
[
[
"Note also that running FireWorks via atomate may require system specific tuning (e. g. for VASP parameters). More information is available in the [atomate documentation](http://pythonhosted.org/atomate/).",
"_____no_output_____"
],
[
"## Example 4 - Screening of oxygen evolution electrocatalysts on binary oxides",
"_____no_output_____"
],
[
"This final example is intended to demonstrate how to use the MP API and the adsorption workflow to do an initial high-throughput study of oxygen evolution electrocatalysis on binary oxides of transition metals.",
"_____no_output_____"
]
],
[
[
"from pymatgen.core.periodic_table import *\nfrom pymatgen.core.surface import get_symmetrically_distinct_miller_indices\nimport tqdm\n\nlpad.reset('', require_password=False)",
"2018-07-24 09:56:33,079 INFO Performing db tune-up\n2018-07-24 09:56:33,088 INFO LaunchPad was RESET.\n"
]
],
[
[
"For oxygen evolution, a common metric for the catalytic activity of a given catalyst is the theoretical overpotential corresponding to the mechanism that proceeds through OH\\*, O\\*, and OOH\\*. So we can define our adsorbates:",
"_____no_output_____"
]
],
[
[
"OH = Molecule(\"OH\", [[0, 0, 0], [-0.793, 0.384, 0.422]])\nO = Molecule(\"O\", [[0, 0, 0]])\nOOH = Molecule(\"OOH\", [[0, 0, 0], [-1.067, -0.403, 0.796], \n [-0.696, -0.272, 1.706]])\nadsorbates = [OH, O, OOH]",
"_____no_output_____"
]
],
[
[
"Then we can retrieve the structures using the MP rest interface, and write a simple for loop which creates all of the workflows corresponding to every slab and every adsorption site for each material. The code below will take ~15 minutes. This could be parallelized to be more efficient, but is not for simplicity in this case.",
"_____no_output_____"
]
],
[
[
"elements = [Element.from_Z(i) for i in range(1, 103)]\ntrans_metals = [el for el in elements if el.is_transition_metal]\n# tqdm adds a progress bar so we can see the progress of the for loop\nfor metal in tqdm.tqdm_notebook(trans_metals):\n # Get relatively stable structures with small unit cells\n data = mpr.get_data(\"{}-O\".format(metal.symbol))\n data = [datum for datum in data if datum[\"e_above_hull\"] < 0.05]\n data = sorted(data, key = lambda x: x[\"nsites\"])\n struct = Structure.from_str(data[0][\"cif\"], fmt='cif')\n # Put in conventional cell settings\n struct = SpacegroupAnalyzer(struct).get_conventional_standard_structure()\n # Get distinct miller indices for low-index facets\n wf = get_wf_surface_all_slabs(struct, adsorbates)\n lpad.add_wf(wf)\n print(\"Processed: {}\".format(struct.formula))",
"_____no_output_____"
]
],
[
[
"Ultimately, running this code produces workflows that contain many (tens of thousands) of calculations, all of which can be managed using FireWorks and queued on supercomputing resources. Limitations on those resources might necessitate a more selective approach towards choosing surface facets or representative materials. Nevertheless, this approach represents a way to provide for a complete and structurally accurate way of screening materials for adsorption properties than can be managed using fireworks.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad03388e7330eddd2c03983d65048ddbed11f6f
| 3,220 |
ipynb
|
Jupyter Notebook
|
slides/2_7/mlp-gluon.ipynb
|
yang-chenyu104/berkeley-stat-157
|
327f77db7ecdc02001f8b7be8c1fcaf0607694c0
|
[
"Apache-2.0"
] | 2,709 |
2018-12-29T18:15:20.000Z
|
2022-03-31T13:24:29.000Z
|
slides/2_7/mlp-gluon.ipynb
|
zemooooo/berkeley-stat-157
|
82e700596f986191ecde38f5829fb40d50a98ab4
|
[
"Apache-2.0"
] | 7 |
2018-12-27T04:56:20.000Z
|
2021-02-18T04:43:11.000Z
|
slides/2_7/mlp-gluon.ipynb
|
zemooooo/berkeley-stat-157
|
82e700596f986191ecde38f5829fb40d50a98ab4
|
[
"Apache-2.0"
] | 1,250 |
2019-01-07T05:51:39.000Z
|
2022-03-31T13:24:18.000Z
| 22.836879 | 85 | 0.530435 |
[
[
[
"# Multilayer Perceptron in Gluon",
"_____no_output_____"
]
],
[
[
"import d2l\nfrom mxnet import gluon, init\nfrom mxnet.gluon import loss as gloss, nn",
"_____no_output_____"
]
],
[
[
"## The Model",
"_____no_output_____"
]
],
[
[
"net = nn.Sequential()\nnet.add(nn.Dense(256, activation='relu'))\nnet.add(nn.Dense(10))\nnet.initialize(init.Normal(sigma=0.01))",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"batch_size = 256\ntrain_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)\n\nloss = gloss.SoftmaxCrossEntropyLoss()\ntrainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.5})\nnum_epochs = 10\nd2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,\n None, None, trainer)",
"epoch 1, loss 0.8333, train acc 0.688, test acc 0.817\nepoch 2, loss 0.5031, train acc 0.815, test acc 0.829\nepoch 3, loss 0.4303, train acc 0.842, test acc 0.860\nepoch 4, loss 0.3942, train acc 0.855, test acc 0.857\nepoch 5, loss 0.3694, train acc 0.864, test acc 0.873\nepoch 6, loss 0.3534, train acc 0.869, test acc 0.864\nepoch 7, loss 0.3410, train acc 0.873, test acc 0.875\nepoch 8, loss 0.3221, train acc 0.880, test acc 0.883\nepoch 9, loss 0.3158, train acc 0.884, test acc 0.882\nepoch 10, loss 0.3083, train acc 0.885, test acc 0.885\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad035b326a75411a1852b06e8a8add84de4c9fb
| 8,297 |
ipynb
|
Jupyter Notebook
|
notebooks/OLD/A_Retrieving_data_from_PATSTAT.ipynb
|
amc-econ/nlp-emerging-technologies
|
0f584d5e8d290fb4a24f644269722e902bc4a7fd
|
[
"MIT"
] | null | null | null |
notebooks/OLD/A_Retrieving_data_from_PATSTAT.ipynb
|
amc-econ/nlp-emerging-technologies
|
0f584d5e8d290fb4a24f644269722e902bc4a7fd
|
[
"MIT"
] | null | null | null |
notebooks/OLD/A_Retrieving_data_from_PATSTAT.ipynb
|
amc-econ/nlp-emerging-technologies
|
0f584d5e8d290fb4a24f644269722e902bc4a7fd
|
[
"MIT"
] | null | null | null | 29.845324 | 1,548 | 0.581053 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4ad05d2dc3131a72cd630f6136082f3b5990e805
| 349,742 |
ipynb
|
Jupyter Notebook
|
notebooks/example_iss_tile.ipynb
|
milana-gataric/postcode
|
0f2a4f7f1e463c06984e7eeee4df901f0dc636c9
|
[
"MIT"
] | 1 |
2022-02-27T18:27:22.000Z
|
2022-02-27T18:27:22.000Z
|
notebooks/example_iss_tile.ipynb
|
lbgbox/postcode
|
0f2a4f7f1e463c06984e7eeee4df901f0dc636c9
|
[
"MIT"
] | null | null | null |
notebooks/example_iss_tile.ipynb
|
lbgbox/postcode
|
0f2a4f7f1e463c06984e7eeee4df901f0dc636c9
|
[
"MIT"
] | 2 |
2022-02-15T12:54:12.000Z
|
2022-02-27T18:27:18.000Z
| 853.029268 | 163,720 | 0.948691 |
[
[
[
"# Decoding specified ISS tile(s)\nThis notebook provides an exampe how to decode an ISS tile from the mouse brain dataset used in the PoSTcode paper that is stored at local directory ``postcode/example-iss-tile-data/``.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nfrom pandas import read_csv\nimport matplotlib.pyplot as plt\nimport pickle\nimport os",
"_____no_output_____"
],
[
"from postcode.decoding_functions import *\nfrom postcode.spot_detection_functions import *\nfrom postcode.reading_data_functions import *",
"_____no_output_____"
],
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"* Specify directory location ``data_path`` with channel_info.csv and taglist.csv",
"_____no_output_____"
]
],
[
[
"dataset_name = 'NT_ISS_KR0018'\ndata_path = os.path.dirname(os.getcwd()) + '/example-iss-tile-data/' + dataset_name + '/' ",
"_____no_output_____"
]
],
[
[
"* Read channel_info.csv and taglist.csv files",
"_____no_output_____"
]
],
[
[
"barcodes_01, K, R, C, gene_names, channels_info = read_taglist_and_channel_info(data_path)",
"_____no_output_____"
]
],
[
[
"## Spot detection",
"_____no_output_____"
],
[
"* Input parameters for spot detection via trackpy should be specified in dictionary ``spots_params``, which has to contain value for key ``'trackpy_spot_diam'`` indicating spot diameter in pixels.",
"_____no_output_____"
]
],
[
[
"spots_params = {'trackpy_spot_diam':5} #parameters for spot detection: spot diameter must to be specified\nspots_params['trackpy_prc'] = 0 #by default this parameter is set to 64, decrease it to select more spots\nspots_params['trackpy_sep'] = 2 #by default this paramerer is set to 'trackpy_spot_diam'+1\ntifs_path = data_path + 'selected-tiles/'\ntile_names = read_csv(data_path + 'tile_names.csv')\nx_min, x_max, y_min, y_max = find_xy_range_of_tile_names(tile_names['selected_tile_names'])\ntiles_info = {'tile_size':1000, 'y_max_size':1000, 'x_max_size':1000, 'filename_prefix':'out_opt_flow_registered_', 'y_max':y_max, 'x_max':x_max}\ntiles_to_load = {'y_start':1, 'y_end':1, 'x_start':12, 'x_end':12} #tile(s) to load (only 'X12_Y1' tile of size 1000x1000 is stored locally)\nspots_out = load_tiles_to_extract_spots(tifs_path, channels_info, C, R, tile_names, tiles_info, tiles_to_load, spots_params, \n anchors_cy_ind_for_spot_detect=0, compute_also_without_tophat=False, return_anchors=True) ",
"100%|██████████| 1/1 [00:06<00:00, 6.24s/it]\n"
],
[
"print('In total {} spots were detected.'.format(spots_out['spots'].shape[0]))",
"In total 2416 spots were detected.\n"
]
],
[
[
"## Spot decoding",
"_____no_output_____"
],
[
"* Estimate model parameters and compute class probabilities",
"_____no_output_____"
]
],
[
[
"out = decoding_function(spots_out['spots'], barcodes_01, print_training_progress=True)",
"100%|██████████| 60/60 [00:02<00:00, 29.37it/s]\n100%|██████████| 257/257 [00:00<00:00, 2892.85it/s]\n"
]
],
[
[
"* Create a data frame from the decoding output",
"_____no_output_____"
]
],
[
[
"df_class_names = np.concatenate((gene_names,['infeasible','background','nan']))\ndf_class_codes = np.concatenate((channels_info['barcodes_AGCT'],['inf','0000','NA']))\ndecoded_spots_df = decoding_output_to_dataframe(out, df_class_names, df_class_codes)\ndecoded_df = pd.concat([decoded_spots_df, spots_out['spots_loc']], axis=1) ",
"_____no_output_____"
]
],
[
[
"## Visualizing decoding results",
"_____no_output_____"
],
[
"* Plot loss, estimated activation parameters and covariance: loss should decrease, $\\hat\\alpha+\\hat\\beta$ shoud be separated from $\\hat\\alpha$, covariance matrix should have a checkerboard pattern",
"_____no_output_____"
]
],
[
[
"fig, (ax1, ax2, ax3) = plt.subplots(1, 3, gridspec_kw={'width_ratios': [1, 3, 1]}, figsize=(14, 2.5), dpi=100, facecolor='w', edgecolor='k')\nchannel_base = np.array(channels_info['channel_base'])[np.where(np.array(channels_info['coding_chs']) == True)[0]]\nactivation = (out['params']['codes_tr_v_star']+out['params']['codes_tr_consts_v_star'])[0,:].numpy() #corresponding to the channel activation (code=1)\nno_activation = out['params']['codes_tr_consts_v_star'][0,:].numpy() # (code=0)\nchannel_activation=np.stack((no_activation,activation))\nax1.plot(np.arange(0,len(out['params']['losses'])),(1/out['class_probs'].shape[0]*np.asarray(out['params']['losses'])))\nax1.annotate(np.round(1/out['class_probs'].shape[0]*out['params']['losses'][-1],4),(-2+len(out['params']['losses']),0.2+1/out['class_probs'].shape[0]*out['params']['losses'][-1]),size=6)\nax1.set_title('Loss over iterations')\nax2.scatter(np.arange(1,1+R*C),activation,c='green',label=r'$\\hat{\\alpha}+\\hat{\\beta}$ (channel active)') \nax2.scatter(np.arange(1,1+R*C),no_activation,c='orange',label=r'$\\hat{\\alpha}$ (channel not active)') \nax2.legend(loc=9)\nax2.vlines(np.arange(0.5,R*C+.8,C), out['params']['codes_tr_consts_v_star'].min(), (out['params']['codes_tr_v_star']+out['params']['codes_tr_consts_v_star']).max(), linestyles='dashed')\nax2.set_xticks(np.arange(1,1+R*C))\nax2.set_xticklabels(np.tile(channel_base,R))\nax2.set_title('Parameters of the barcode transformation as activation / no activation')\ncovim = ax3.imshow(out['params']['sigma_star'])\nax3.set_xticks(np.arange(0,R*C))\nax3.set_xticklabels(np.tile(channel_base,R))\nax3.set_yticks(np.arange(0,R*C))\nax3.set_yticklabels(np.tile(channel_base,R))\nax3.set_title('Estimated covariance')\nplt.colorbar(covim, ax=ax3, fraction=0.02)\nplt.show()",
"_____no_output_____"
]
],
[
[
"* Plot histogram of barcode assignments",
"_____no_output_____"
]
],
[
[
"thr=0.7\ndf = pd.concat([decoded_df.Name[decoded_df.Probability>thr].value_counts(), decoded_df.Name[decoded_df.Probability <=thr].replace(np.unique(decoded_df.Name),'thr').value_counts()]).sort_index(axis=0)#.sort_values(ascending=False)\nfig, ax = plt.subplots(1, 1, figsize=(14,3), dpi=100, facecolor='w', edgecolor='k')\ndf.plot(kind='bar',width=0.7,rot=90,logy=True,fontsize=6,ax=ax)\nnum_decoded_barcodes = sum((decoded_df.Name!='background')&(decoded_df.Name!='infeasible')&(decoded_df.Name!='NaN')&(decoded_df.Probability>thr))\nfor p in ax.patches:\n ax.annotate(str(p.get_height()), (p.get_x() * 1.005, p.get_height() * 1.005),size=6) \nplt.title('Histogram of decoded barcodes afther thresholding with {}: \\n in total {} spots detected while {} spots decoded ({:.02f}%)'.format(thr,decoded_df.shape[0], num_decoded_barcodes, 100*num_decoded_barcodes/decoded_df.shape[0]), fontsize=10) \nplt.show()",
"_____no_output_____"
]
],
[
[
"* Plot spatial patterns of a few selected barcodes over the whole tile ",
"_____no_output_____"
]
],
[
[
"names = ['Cux2','Rorb','Grin3a','infeasible','background']\nlog_scale = True\nfig, ax = plt.subplots(1, len(names), figsize=(3*len(names), 3), dpi=100, facecolor='w', edgecolor='k')\nfor i in range(len(names)):\n im = heatmap_pattern(decoded_df, names[i], grid=10, thr=0.7, plot_probs=True)\n if log_scale:\n ims = ax[i].imshow(np.log2(1+im),cmap='jet')\n else:\n ims = ax[i].imshow(im)\n ax[i].axis('off')\n plt.colorbar(ims, ax=ax[i], fraction=0.02)\n ax[i].set_title('{} (barcode: {})'.format(names[i],df_class_codes[df_class_names==names[i]][0]),fontsize=8)\nfig.suptitle('Spatial patterns in logaritmic scale')\nplt.show()",
"_____no_output_____"
]
],
[
[
"* Plot all detected / decoded spots and a selected barcode over a zoom of the anchor channel",
"_____no_output_____"
]
],
[
[
"x00 = 600; y00 = 350 #coordinates of the zoom (between 0--1000)\ndelta = 200 #size of the zoom in each axis (up to 1000)\nanchor_zoom = spots_out['anchors'][y00:y00+delta,x00:x00+delta] #anchor of the last loaded tile\n#in case multiple tiles were used, find coordinates corresponding to the last one loaded\ny00 = y00+(int(decoded_df.Tile.iloc[-1][-2:].replace('Y',''))-tiles_to_load['y_start'])*tiles_info['tile_size']\nx00 = x00+(int(decoded_df.Tile.iloc[-1][1:3].replace('_',''))-tiles_to_load['x_start'])*tiles_info['tile_size']\n\nplt.figure(num=None, figsize=(12, 4), dpi=100, facecolor='w', edgecolor='k')\nplt.subplot(1,3,1)\nplt.imshow(np.log(0.06+anchor_zoom/anchor_zoom.max()),cmap='gray')\ny0 = np.around(decoded_df.Y.to_numpy()).astype(np.int32)-y00; x0 = np.around(decoded_df.X.to_numpy()).astype(np.int32)-x00\ny = y0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]; x = x0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]\nplt.scatter(x,y,s=13,marker='.',c='orange') \nplt.title('Detected spots',fontsize=10)\nplt.axis('off') \n\nfrom matplotlib import cm\nfrom matplotlib.lines import Line2D\nmarkers = list(Line2D.markers.keys()); markersL = markers[1:20]*(int(K/20)+1)\nhsv_cols = cm.get_cmap('hsv', K+1); colL=hsv_cols(range(2*K)); colL=np.concatenate((colL[::2,],colL[1::2,]))\nplt.subplot(1,3,2)\nplt.imshow(np.log(0.06+anchor_zoom/anchor_zoom.max()),cmap='gray')\nfor name in gene_names:\n col = colL[np.where(gene_names==name)[0][0],:]; mar = markersL[np.where(gene_names==name)[0][0]]\n x0 = np.around(decoded_df.X[(decoded_df.Name == name) & (decoded_df.Probability >thr)].to_numpy()).astype(np.int32)-x00\n y0 = np.around(decoded_df.Y[(decoded_df.Name == name) & (decoded_df.Probability >thr)].to_numpy()).astype(np.int32)-y00\n y = y0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]; x = x0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]\n plt.scatter(x,y,s=13,marker=mar,c=np.repeat(col.reshape((1,4)),x.shape[0],axis=0)) \nplt.title('Decoded barcodes',fontsize=10)\nplt.axis('off') \n\nplt.subplot(1,3,3)\nplt.imshow(np.log(0.06+anchor_zoom/anchor_zoom.max()),cmap='gray')\nname = 'Cux2'; thr=0.7\nx0 = np.around(decoded_df.X[(decoded_df.Name == name) & (decoded_df.Probability >thr)].to_numpy()).astype(np.int32)-x00\ny0 = np.around(decoded_df.Y[(decoded_df.Name == name) & (decoded_df.Probability >thr)].to_numpy()).astype(np.int32)-y00\ny = y0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]; x = x0[(y0>=0)&(y0<delta)&(x0>=0)&(x0<delta)]\nplt.scatter(x,y,s=13,marker='.',c='cyan') \nplt.title('{} ({})'.format(name,decoded_df.Code[decoded_df.Name==name].to_numpy()[0]),fontsize=10)\nplt.axis('off') \n\nplt.suptitle('Zoomed section of the anchor channel used for spot detection')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad062cdac82447512025a219e60df93c433699c
| 22,191 |
ipynb
|
Jupyter Notebook
|
ALL_NEWSPAPERS_ARTICLES_EXTRACTION_13th_Jan_2022.ipynb
|
Gaurav7004/NEWS_ARTICLES_DEPLOYMENT
|
4b566918940b882808d499a49d125bb2f8d8ad16
|
[
"Apache-2.0"
] | null | null | null |
ALL_NEWSPAPERS_ARTICLES_EXTRACTION_13th_Jan_2022.ipynb
|
Gaurav7004/NEWS_ARTICLES_DEPLOYMENT
|
4b566918940b882808d499a49d125bb2f8d8ad16
|
[
"Apache-2.0"
] | null | null | null |
ALL_NEWSPAPERS_ARTICLES_EXTRACTION_13th_Jan_2022.ipynb
|
Gaurav7004/NEWS_ARTICLES_DEPLOYMENT
|
4b566918940b882808d499a49d125bb2f8d8ad16
|
[
"Apache-2.0"
] | null | null | null | 39.068662 | 2,100 | 0.438556 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Gaurav7004/NEWS_ARTICLES_DEPLOYMENT/blob/main/ALL_NEWSPAPERS_ARTICLES_EXTRACTION_13th_Jan_2022.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from bs4 import BeautifulSoup\nimport requests\nimport pandas as pd\nimport re",
"_____no_output_____"
],
[
"url='https://www.financialexpress.com/economy/page/'\nagent = {\"User-Agent\":'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}\npage=requests.get(url,headers=agent)\nsoup=BeautifulSoup(page.text,'html.parser')",
"_____no_output_____"
],
[
"page_links=[]\n\nfor page_num in range(1,5):\n page_url=url+str(page_num)\n page_links.append(page_url)",
"_____no_output_____"
],
[
"page_links[0:4]",
"_____no_output_____"
],
[
"str_for_search = []\n\n# importing modules\nimport urllib.request \n\nfor url in page_links:\n # opening the url for reading\n html = urllib.request.urlopen(url) \n\n # parsing the html file\n htmlParse = BeautifulSoup(html, 'html.parser')\n\n # print(htmlParse)\n \n # getting all the paragraphs\n for para in htmlParse.find_all('div', class_='entry-title'):\n lis = para.find_all('a')\n str_for_search.append(lis)",
"_____no_output_____"
],
[
"str(str_for_search[0])",
"_____no_output_____"
],
[
"Final_LIST = []\n\n## Extracting required News Articles Link\nfor i in range(len(str_for_search)):\n regex=\"(?P<url>https?://[^\\s]+)\"\n\n matches = re.findall(regex, str(str_for_search[i]))\n Final_LIST.append(matches[0])\n",
"_____no_output_____"
],
[
"Final_LIST[0]",
"_____no_output_____"
],
[
"## Lists to get dates and news articles\nList_articles = []\nList_date = []\nList_month = []\nList_year = []\n\nfor i in range(len(Final_LIST)):\n # opening the url for reading\n html = urllib.request.urlopen(str(Final_LIST[i]))\n\n # parsing the html file\n htmlParse = BeautifulSoup(html, 'html.parser')\n \n # getting all the paragraphs of articles\n for para in htmlParse.find_all(['div'], class_='entry-content wp-block-post-content'):\n # txt = para.find_all('p')\n List_articles.append(para.get_text())\n\n # Getting respective month, date, year the article published\n for det in htmlParse.find_all('div', class_='ie-network-post-meta-date'):\n dt = det.get_text()\n dt = dt.split(' ')\n List_month.append(dt[0])\n List_date.append(dt[1])\n List_year.append(dt[2])\n",
"_____no_output_____"
],
[
"List_articles[109]",
"_____no_output_____"
],
[
"List_date[109]",
"_____no_output_____"
],
[
"## Newspaper Name\nNewspaper_Name = ['The Financial Express'] * len(List_articles)",
"_____no_output_____"
],
[
"df = pd.DataFrame(list(zip(Newspaper_Name, List_articles, List_year, List_month, List_date)), columns =['Newspaper Name', 'Article', 'Year', 'Month', 'Date'])\ndf.to_excel('News_Articles_Scraped_Data.xlsx')",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad074e611aa7c07a23f7df3806458fe068cc827
| 25,103 |
ipynb
|
Jupyter Notebook
|
implementations/dcgan/self_dcgan.ipynb
|
HighCWu/SelfGAN
|
0b3fbd41c0ca8a42c59afcbd503f25447a1c2198
|
[
"MIT"
] | 5 |
2019-02-26T13:27:19.000Z
|
2021-04-26T08:58:13.000Z
|
implementations/dcgan/self_dcgan.ipynb
|
HighCWu/SelfGAN
|
0b3fbd41c0ca8a42c59afcbd503f25447a1c2198
|
[
"MIT"
] | 2 |
2019-04-11T09:34:57.000Z
|
2019-06-10T15:47:15.000Z
|
implementations/dcgan/self_dcgan.ipynb
|
HighCWu/SelfGAN
|
0b3fbd41c0ca8a42c59afcbd503f25447a1c2198
|
[
"MIT"
] | null | null | null | 38.739198 | 247 | 0.460104 |
[
[
[
"# Self DCGAN\n\n<table class=\"tfo-notebook-buttons\" align=\"left\" >\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/HighCWu/SelfGAN/blob/master/implementations/dcgan/self_dcgan.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/HighCWu/SelfGAN/blob/master/implementations/dcgan/self_dcgan.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"## Datasets",
"_____no_output_____"
]
],
[
[
"import glob\nimport random\nimport os\nimport numpy as np\n\nfrom torch.utils.data import Dataset\nfrom PIL import Image\nimport torchvision.transforms as transforms\n\nclass ImageDataset(Dataset):\n def __init__(self, root, transforms_=None):\n self.transform = transforms.Compose(transforms_)\n\n self.files = sorted(glob.glob(root + '/**/*.*', recursive=True))\n\n def __getitem__(self, index):\n\n img = Image.open(self.files[index % len(self.files)]).convert('RGB')\n w, h = img.size\n\n img = self.transform(img)\n\n return img\n\n def __len__(self):\n return len(self.files)",
"_____no_output_____"
]
],
[
[
"## Prepare",
"_____no_output_____"
]
],
[
[
"import argparse\nimport os\nimport sys\nimport numpy as np\nimport math\n\nimport torchvision.transforms as transforms\nfrom torchvision.utils import save_image\n\nfrom torch.utils.data import DataLoader\nfrom torchvision import datasets\nfrom torch.autograd import Variable\n\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch\n\nos.makedirs('images', exist_ok=True)\nos.makedirs('images_normal', exist_ok=True)",
"_____no_output_____"
],
[
"parser = argparse.ArgumentParser()\nparser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')\nparser.add_argument('--batch_size', type=int, default=64, help='size of the batches')\nparser.add_argument('--lr', type=float, default=2e-4, help='adam: learning rate')\nparser.add_argument('--b1', type=float, default=0.5, help='adam: decay of first order momentum of gradient')\nparser.add_argument('--b2', type=float, default=0.999, help='adam: decay of first order momentum of gradient')\nparser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')\nparser.add_argument('--latent_dim', type=int, default=100, help='dimensionality of the latent space')\nparser.add_argument('--img_size', type=int, default=64, help='size of each image dimension')\nparser.add_argument('--channels', type=int, default=3, help='number of image channels')\nparser.add_argument('--sample_interval', type=int, default=200, help='interval betwen image samples')\nparser.add_argument('--data_use', type=str, default='bedroom', help='datasets:[mnist]/[bedroom]')\n\nopt, _ = parser.parse_known_args()\nif opt.data_use == 'mnist':\n opt.img_size = 32\n opt.channels = 1\nprint(opt)",
"_____no_output_____"
],
[
"import os, zipfile\nfrom google.colab import files\n\nif opt.data_use == 'bedroom':\n os.makedirs('data/bedroom', exist_ok=True)\n print('Please upload your kaggle api json.')\n files.upload()\n\n ! mkdir /root/.kaggle\n ! mv ./kaggle.json /root/.kaggle\n ! chmod 600 /root/.kaggle/kaggle.json\n ! kaggle datasets download -d jhoward/lsun_bedroom\n\n out_fname = 'lsun_bedroom.zip'\n zip_ref = zipfile.ZipFile(out_fname)\n zip_ref.extractall('./')\n zip_ref.close()\n os.remove(out_fname)\n\n out_fname = 'sample.zip'\n zip_ref = zipfile.ZipFile(out_fname)\n zip_ref.extractall('data/bedroom/')\n zip_ref.close()\n os.remove(out_fname)\nelse:\n os.makedirs('data/mnist', exist_ok=True)",
"_____no_output_____"
],
[
"img_shape = (opt.channels, opt.img_size, opt.img_size)\n\ncuda = True if torch.cuda.is_available() else False",
"_____no_output_____"
],
[
"def weights_init_normal(m):\n classname = m.__class__.__name__\n if classname.find('Conv') != -1:\n torch.nn.init.normal_(m.weight.data, 0.0, 0.02)\n elif classname.find('BatchNorm2d') != -1:\n torch.nn.init.normal_(m.weight.data, 1.0, 0.02)\n torch.nn.init.constant_(m.bias.data, 0.0)\n\nclass Generator(nn.Module):\n def __init__(self):\n super(Generator, self).__init__()\n\n self.init_size = opt.img_size // 4\n self.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128*self.init_size**2))\n\n self.conv_blocks = nn.Sequential(\n nn.BatchNorm2d(128),\n nn.Upsample(scale_factor=2),\n nn.Conv2d(128, 128, 3, stride=1, padding=1),\n nn.BatchNorm2d(128, 0.8),\n nn.LeakyReLU(0.2, inplace=True),\n nn.Upsample(scale_factor=2),\n nn.Conv2d(128, 64, 3, stride=1, padding=1),\n nn.BatchNorm2d(64, 0.8),\n nn.LeakyReLU(0.2, inplace=True),\n nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),\n nn.Tanh()\n )\n\n def forward(self, z):\n out = self.l1(z)\n out = out.view(out.shape[0], 128, self.init_size, self.init_size)\n img = self.conv_blocks(out)\n return img\n\nclass Discriminator(nn.Module):\n def __init__(self):\n super(Discriminator, self).__init__()\n\n def discriminator_block(in_filters, out_filters, bn=True):\n block = [ nn.Conv2d(in_filters, out_filters, 3, 2, 1),\n nn.LeakyReLU(0.2, inplace=True),\n nn.Dropout2d(0.25)]\n if bn:\n block.append(nn.BatchNorm2d(out_filters, 0.8))\n return block\n\n self.model = nn.Sequential(\n *discriminator_block(opt.channels, 16, bn=False),\n *discriminator_block(16, 32),\n *discriminator_block(32, 64),\n *discriminator_block(64, 128),\n )\n\n # The height and width of downsampled image\n ds_size = opt.img_size // 2**4\n self.adv_layer = nn.Sequential( nn.Linear(128*ds_size**2, 1),\n nn.Sigmoid())\n\n def forward(self, img):\n out = self.model(img)\n out = out.view(out.shape[0], -1)\n validity = self.adv_layer(out)\n\n return validity\n \nclass SelfGAN(nn.Module):\n def __init__(self):\n super(SelfGAN, self).__init__()\n\n # Initialize generator and discriminator\n self.generator = Generator()\n self.discriminator = Discriminator()\n\n def forward(self, z, real_img, fake_img):\n gen_img = self.generator(z)\n validity_gen = self.discriminator(gen_img)\n validity_real = self.discriminator(real_img)\n validity_fake = self.discriminator(fake_img)\n\n return gen_img, validity_gen, validity_real, validity_fake",
"_____no_output_____"
]
],
[
[
"## SelfGAN Part",
"_____no_output_____"
]
],
[
[
"# Loss function\nadversarial_loss = torch.nn.BCELoss()\nshard_adversarial_loss = torch.nn.BCELoss(reduction='none')\n\n# Initialize SelfGAN model\nself_gan = SelfGAN()\n\nif cuda:\n self_gan.cuda()\n adversarial_loss.cuda()\n shard_adversarial_loss.cuda()\n\n# Initialize weights\nself_gan.apply(weights_init_normal) \n\n# Configure data loader\ndataloader = torch.utils.data.DataLoader(\n ImageDataset('data/bedroom',\n transforms_=[\n transforms.Resize((opt.img_size, opt.img_size)),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ]) if opt.data_use == 'bedroom' else\n datasets.MNIST('data/mnist', train=True, download=True,\n transform=transforms.Compose([\n transforms.Resize(opt.img_size),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ])),\n batch_size=opt.batch_size, shuffle=True, drop_last=True)\n\n# Optimizers\noptimizer = torch.optim.Adam(self_gan.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))\n\nTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor\n\nlast_imgs = Tensor(opt.batch_size, *img_shape)*0.0",
"_____no_output_____"
]
],
[
[
"### Standard performance on the GPU",
"_____no_output_____"
]
],
[
[
"# ----------\n# Training\n# ----------\n\nfor epoch in range(opt.n_epochs):\n for i, imgs in enumerate(dataloader):\n \n if opt.data_use != 'bedroom':\n imgs = imgs[0]\n \n # Adversarial ground truths\n valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)\n fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)\n\n # Configure input\n real_imgs = Variable(imgs.type(Tensor))\n\n # -----------------\n # Train SelfGAN\n # -----------------\n\n optimizer.zero_grad()\n\n # Sample noise as generator input\n z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))\n\n # Generate a batch of images\n gen_imgs, validity_gen, validity_real, validity_fake = self_gan(z, real_imgs, last_imgs)\n\n # Loss measures generator's ability to fool the discriminator and measure discriminator's ability to classify real from generated samples at the same time\n gen_loss = adversarial_loss(validity_gen, valid)\n real_loss = adversarial_loss(validity_real, valid)\n fake_loss = adversarial_loss(validity_fake, fake)\n v_g = 1 - torch.mean(validity_gen)\n v_f = torch.mean(validity_fake)\n s_loss = (real_loss + v_g*gen_loss*0.1 + v_f*fake_loss*0.9) / 2\n\n s_loss.backward()\n optimizer.step()\n \n last_imgs = gen_imgs.detach()\n \n sys.stdout.flush()\n print (\"\\r[Epoch %d/%d] [Batch %d/%d] [S loss: %f R loss: %f F loss: %f G loss: %f]\" % (epoch, opt.n_epochs, i, len(dataloader),\n s_loss.item(), real_loss.item(), fake_loss.item(), gen_loss.item()),\n end='')\n\n batches_done = epoch * len(dataloader) + i\n if batches_done % opt.sample_interval == 0:\n save_image(gen_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)",
"_____no_output_____"
]
],
[
[
"### Running on the GPU with similar performance of running on the TPU (Maybe)",
"_____no_output_____"
]
],
[
[
"# ----------\n# Training\n# ----------\n\nfor epoch in range(opt.n_epochs):\n for i, imgs in enumerate(dataloader):\n \n if opt.data_use != 'bedroom':\n imgs = imgs[0]\n\n # Adversarial ground truths\n valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)\n fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)\n\n # Configure input\n real_imgs = Variable(imgs.type(Tensor))\n\n # -----------------\n # Train SelfGAN\n # -----------------\n\n optimizer.zero_grad()\n\n # Sample noise as generator input\n z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))\n\n s = opt.batch_size//8\n for k in range(8):\n # Generate a batch of images\n gen_imgs, validity_gen, validity_real, validity_fake = self_gan(z[k*s:k*s+s], real_imgs[k*s:k*s+s], last_imgs[k*s:k*s+s])\n\n # Loss measures generator's ability to fool the discriminator and measure discriminator's ability to classify real from generated samples at the same time\n gen_loss = shard_adversarial_loss(validity_gen, valid[k*s:k*s+s])\n real_loss = shard_adversarial_loss(validity_real, valid[k*s:k*s+s])\n fake_loss = shard_adversarial_loss(validity_fake, fake[k*s:k*s+s])\n v_g = 1 - torch.mean(validity_gen)\n v_r = 1 - torch.mean(validity_real)\n v_f = torch.mean(validity_fake)\n v_sum = v_g + v_r + v_f\n s_loss = v_r*real_loss/v_sum + v_g*gen_loss/v_sum + v_f*fake_loss/v_sum\n \n gen_loss = torch.mean(gen_loss)\n real_loss = torch.mean(real_loss)\n fake_loss = torch.mean(fake_loss)\n s_loss = torch.mean(s_loss)\n\n s_loss.backward()\n last_imgs[k*s:k*s+s] = gen_imgs.detach()\n \n optimizer.step()\n \n sys.stdout.flush()\n print (\"\\r[Epoch %d/%d] [Batch %d/%d] [S loss: %f R loss: %f F loss: %f G loss: %f]\" % (epoch, opt.n_epochs, i, len(dataloader),\n s_loss.item(), real_loss.item(), fake_loss.item(), gen_loss.item()),\n end='')\n\n batches_done = epoch * len(dataloader) + i\n if batches_done % opt.sample_interval == 0:\n save_image(last_imgs.data[:25], 'images/%d.png' % batches_done, nrow=5, normalize=True)",
"_____no_output_____"
]
],
[
[
"## Normal GAN Part",
"_____no_output_____"
]
],
[
[
"# Loss function\nadversarial_loss = torch.nn.BCELoss()\n\n# Initialize generator and discriminator\ngenerator = Generator()\ndiscriminator = Discriminator()\n\nif cuda:\n generator.cuda()\n discriminator.cuda()\n adversarial_loss.cuda()\n\n# Initialize weights\ngenerator.apply(weights_init_normal)\ndiscriminator.apply(weights_init_normal) \n \n# Configure data loader\ndataloader = torch.utils.data.DataLoader(\n ImageDataset('data/bedroom',\n transforms_=[\n transforms.Resize((opt.img_size, opt.img_size)),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ]) if opt.data_use == 'bedroom' else\n datasets.MNIST('data/mnist', train=True, download=True,\n transform=transforms.Compose([\n transforms.Resize(opt.img_size),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n ])),\n batch_size=opt.batch_size, shuffle=True)\n\n# Optimizers\noptimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))\noptimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))\n\nTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor",
"_____no_output_____"
],
[
"# ----------\n# Training\n# ----------\n\nfor epoch in range(opt.n_epochs):\n for i, imgs in enumerate(dataloader):\n \n if opt.data_use != 'bedroom':\n imgs = imgs[0]\n\n # Adversarial ground truths\n valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)\n fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)\n\n # Configure input\n real_imgs = Variable(imgs.type(Tensor))\n\n # -----------------\n # Train Generator\n # -----------------\n\n optimizer_G.zero_grad()\n\n # Sample noise as generator input\n z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))\n\n # Generate a batch of images\n gen_imgs = generator(z)\n\n # Loss measures generator's ability to fool the discriminator\n g_loss = adversarial_loss(discriminator(gen_imgs), valid)\n\n g_loss.backward()\n optimizer_G.step()\n\n # ---------------------\n # Train Discriminator\n # ---------------------\n\n optimizer_D.zero_grad()\n\n # Measure discriminator's ability to classify real from generated samples\n real_loss = adversarial_loss(discriminator(real_imgs), valid)\n fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)\n d_loss = (real_loss + fake_loss) / 2\n\n d_loss.backward()\n optimizer_D.step()\n \n sys.stdout.flush()\n print (\"\\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]\" % (epoch, opt.n_epochs, i, len(dataloader),\n d_loss.item(), g_loss.item()), \n end='')\n\n batches_done = epoch * len(dataloader) + i\n if batches_done % opt.sample_interval == 0:\n save_image(gen_imgs.data[:25], 'images_normal/%d.png' % batches_done, nrow=5, normalize=True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4ad0d27c80f426ad09b1141703659a752c0402a1
| 70,075 |
ipynb
|
Jupyter Notebook
|
bert_content_20e_maxseq400.ipynb
|
marquis08/programmers_nlp
|
8214426ec281f81a76600170cd7d857747b6d5eb
|
[
"Apache-2.0"
] | null | null | null |
bert_content_20e_maxseq400.ipynb
|
marquis08/programmers_nlp
|
8214426ec281f81a76600170cd7d857747b6d5eb
|
[
"Apache-2.0"
] | null | null | null |
bert_content_20e_maxseq400.ipynb
|
marquis08/programmers_nlp
|
8214426ec281f81a76600170cd7d857747b6d5eb
|
[
"Apache-2.0"
] | null | null | null | 81.482558 | 20,235 | 0.585487 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport gc\nfrom time import time\nimport math\nimport random\n\nimport datetime\nimport pkg_resources\n#import seaborn as sns\nimport scipy.stats as stats\nimport gc\nimport re\nimport operator \nimport sys\nfrom sklearn import metrics\nfrom sklearn import model_selection\nimport torch\nimport torch.nn as nn\nimport torch.utils.data\nimport torch.nn.functional as F\nfrom torch.utils.data import TensorDataset, Subset, DataLoader\nfrom torch.optim import Optimizer\n\n#from nltk.stem import PorterStemmer\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn.metrics import roc_auc_score\n#%load_ext autoreload\n#%autoreload 2\n#%matplotlib inline\nfrom tqdm import tqdm, tqdm_notebook\nimport os\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\nimport warnings\nwarnings.filterwarnings(action='once')\nimport pickle\n#from apex import amp\nimport shutil\n",
"_____no_output_____"
],
[
"device=torch.device('cuda')",
"_____no_output_____"
],
[
"def seed_everything(seed=123):\n random.seed(seed)\n os.environ['PYTHONHASHSEED'] = str(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.backends.cudnn.deterministic = True\n \ndef sigmoid(x):\n return 1 / (1 + np.exp(-x))\n\nclass AdamW(Optimizer):\n \"\"\"Implements AdamW algorithm.\n\n It has been proposed in `Fixing Weight Decay Regularization in Adam`_.\n\n Arguments:\n params (iterable): iterable of parameters to optimize or dicts defining\n parameter groups\n lr (float, optional): learning rate (default: 1e-3)\n betas (Tuple[float, float], optional): coefficients used for computing\n running averages of gradient and its square (default: (0.9, 0.999))\n eps (float, optional): term added to the denominator to improve\n numerical stability (default: 1e-8)\n weight_decay (float, optional): weight decay (L2 penalty) (default: 0)\n\n .. Fixing Weight Decay Regularization in Adam:\n https://arxiv.org/abs/1711.05101\n \"\"\"\n\n def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8,\n weight_decay=0):\n defaults = dict(lr=lr, betas=betas, eps=eps,\n weight_decay=weight_decay)\n super(AdamW, self).__init__(params, defaults)\n\n def step(self, closure=None):\n \"\"\"Performs a single optimization step.\n\n Arguments:\n closure (callable, optional): A closure that reevaluates the model\n and returns the loss.\n \"\"\"\n loss = None\n if closure is not None:\n loss = closure()\n\n for group in self.param_groups:\n for p in group['params']:\n if p.grad is None:\n continue\n grad = p.grad.data\n if grad.is_sparse:\n raise RuntimeError('AdamW does not support sparse gradients, please consider SparseAdam instead')\n\n state = self.state[p]\n\n # State initialization\n if len(state) == 0:\n state['step'] = 0\n # Exponential moving average of gradient values\n state['exp_avg'] = torch.zeros_like(p.data)\n # Exponential moving average of squared gradient values\n state['exp_avg_sq'] = torch.zeros_like(p.data)\n\n exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']\n beta1, beta2 = group['betas']\n\n state['step'] += 1\n\n # according to the paper, this penalty should come after the bias correction\n # if group['weight_decay'] != 0:\n # grad = grad.add(group['weight_decay'], p.data)\n\n # Decay the first and second moment running average coefficient\n exp_avg.mul_(beta1).add_(1 - beta1, grad)\n exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)\n\n denom = exp_avg_sq.sqrt().add_(group['eps'])\n\n bias_correction1 = 1 - beta1 ** state['step']\n bias_correction2 = 1 - beta2 ** state['step']\n step_size = group['lr'] * math.sqrt(bias_correction2) / bias_correction1\n\n p.data.addcdiv_(-step_size, exp_avg, denom)\n\n if group['weight_decay'] != 0:\n p.data.add_(-group['weight_decay'], p.data)\n\n return loss\n",
"_____no_output_____"
],
[
"MAX_SEQUENCE_LENGTH = 295 \nSEED = 42\nEPOCHS = 20\nData_dir=\"../job_nlp/\"\nWORK_DIR = \"../job_nlp/working/\"\n#num_to_load=100000 #Train size to match time limit\n#valid_size= 50000 #Validation Size\nTARGET = 'smishing'",
"_____no_output_____"
],
[
"# https://www.kaggle.com/matsuik/ppbert\npackage_dir_a = \"../job_nlp/ppbert/pytorch-pretrained-bert/pytorch-pretrained-BERT\"\nsys.path.insert(0, package_dir_a)",
"_____no_output_____"
],
[
"from pytorch_pretrained_bert import convert_tf_checkpoint_to_pytorch\nfrom pytorch_pretrained_bert import BertTokenizer, BertForSequenceClassification,BertAdam",
"/home/yilgukseo/anaconda3/envs/pytorch/lib/python3.7/importlib/_bootstrap.py:219: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility. Expected 216, got 192\n return f(*args, **kwds)\n/home/yilgukseo/anaconda3/envs/pytorch/lib/python3.7/importlib/_bootstrap.py:219: ImportWarning: can't resolve package from __spec__ or __package__, falling back on __name__ and __path__\n return f(*args, **kwds)\n/home/yilgukseo/anaconda3/envs/pytorch/lib/python3.7/site-packages/tensorflow_core/python/keras/backend.py:5879: ResourceWarning: unclosed file <_io.TextIOWrapper name='/home/yilgukseo/.keras/keras.json' mode='r' encoding='UTF-8'>\n _config = json.load(open(_config_path))\nResourceWarning: Enable tracemalloc to get the object allocation traceback\n"
],
[
"# Translate model from tensorflow to pytorch\nBERT_MODEL_PATH = '../job_nlp/bert-pretrained-models/uncased_L-12_H-768_A-12/uncased_L-12_H-768_A-12/'\nconvert_tf_checkpoint_to_pytorch.convert_tf_checkpoint_to_pytorch(\n BERT_MODEL_PATH + 'bert_model.ckpt',\nBERT_MODEL_PATH + 'bert_config.json',\nWORK_DIR + 'pytorch_model.bin')\n\nshutil.copyfile(BERT_MODEL_PATH + 'bert_config.json', WORK_DIR + 'bert_config.json')",
"erNorm/beta with shape [768]\nLoading TF weight bert/encoder/layer_9/output/LayerNorm/gamma with shape [768]\nLoading TF weight bert/encoder/layer_9/output/dense/bias with shape [768]\nLoading TF weight bert/encoder/layer_9/output/dense/kernel with shape [3072, 768]\nLoading TF weight bert/pooler/dense/bias with shape [768]\nLoading TF weight bert/pooler/dense/kernel with shape [768, 768]\nLoading TF weight cls/predictions/output_bias with shape [30522]\nLoading TF weight cls/predictions/transform/LayerNorm/beta with shape [768]\nLoading TF weight cls/predictions/transform/LayerNorm/gamma with shape [768]\nLoading TF weight cls/predictions/transform/dense/bias with shape [768]\nLoading TF weight cls/predictions/transform/dense/kernel with shape [768, 768]\nLoading TF weight cls/seq_relationship/output_bias with shape [2]\nLoading TF weight cls/seq_relationship/output_weights with shape [2, 768]\nInitialize PyTorch weight ['bert', 'embeddings', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'embeddings', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'embeddings', 'position_embeddings']\nInitialize PyTorch weight ['bert', 'embeddings', 'token_type_embeddings']\nInitialize PyTorch weight ['bert', 'embeddings', 'word_embeddings']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_0', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_1', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_10', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_11', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_2', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_3', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_4', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_5', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_6', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_7', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_8', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'key', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'key', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'query', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'query', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'value', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'attention', 'self', 'value', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'intermediate', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'intermediate', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'output', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'output', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'output', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'encoder', 'layer_9', 'output', 'dense', 'kernel']\nInitialize PyTorch weight ['bert', 'pooler', 'dense', 'bias']\nInitialize PyTorch weight ['bert', 'pooler', 'dense', 'kernel']\nInitialize PyTorch weight ['cls', 'predictions', 'output_bias']\nInitialize PyTorch weight ['cls', 'predictions', 'transform', 'LayerNorm', 'beta']\nInitialize PyTorch weight ['cls', 'predictions', 'transform', 'LayerNorm', 'gamma']\nInitialize PyTorch weight ['cls', 'predictions', 'transform', 'dense', 'bias']\nInitialize PyTorch weight ['cls', 'predictions', 'transform', 'dense', 'kernel']\nInitialize PyTorch weight ['cls', 'seq_relationship', 'output_bias']\nInitialize PyTorch weight ['cls', 'seq_relationship', 'output_weights']\nSave PyTorch model to ../job_nlp/working/pytorch_model.bin\n"
],
[
"# This is the Bert configuration file\nfrom pytorch_pretrained_bert import BertConfig\n\nbert_config = BertConfig('../job_nlp/bert-pretrained-models/uncased_L-12_H-768_A-12/uncased_L-12_H-768_A-12/'+'bert_config.json')",
"_____no_output_____"
],
[
"bert_config",
"_____no_output_____"
],
[
"# Converting the lines to BERT format\n# Thanks to https://www.kaggle.com/httpwwwfszyc/bert-in-keras-taming\ndef convert_lines(example, max_seq_length,tokenizer):\n max_seq_length -=2\n all_tokens = []\n longer = 0\n for text in tqdm_notebook(example):\n tokens_a = tokenizer.tokenize(text)\n if len(tokens_a)>max_seq_length:\n tokens_a = tokens_a[:max_seq_length]\n longer += 1\n one_token = tokenizer.convert_tokens_to_ids([\"[CLS]\"]+tokens_a+[\"[SEP]\"])+[0] * (max_seq_length - len(tokens_a))\n all_tokens.append(one_token)\n print(longer)\n return np.array(all_tokens)",
"_____no_output_____"
],
[
"BERT_MODEL_PATH = '../job_nlp/bert-pretrained-models/uncased_L-12_H-768_A-12/uncased_L-12_H-768_A-12/'",
"_____no_output_____"
],
[
"tokenizer = BertTokenizer.from_pretrained(BERT_MODEL_PATH, cache_dir=None,do_lower_case=True)",
"_____no_output_____"
],
[
"%%time\ntrain_df = pd.read_csv(os.path.join(Data_dir,\"train.csv\"))\ntest_df = pd.read_csv(os.path.join(Data_dir,\"test.csv\"))",
"CPU times: user 31.1 ms, sys: 2.45 ms, total: 33.6 ms\nWall time: 33.3 ms\n"
],
[
"train_df.label.value_counts(normalize=True)",
"_____no_output_____"
],
[
"# replace NaN\nprint(train_df.iloc[2400,:])\ntrain_df.iloc[2400,1] = \"@@@\"",
"title [$$$] 재귀함수를 처리하면서 setTimeout으로 딜레이를 주면 읽는 순서가 ...\ncontent NaN\nlabel 4\nName: 2400, dtype: object\n"
],
[
"%%time\ntrain_df['text'] = train_df[['title', 'content']].apply(lambda x: ' '.join(x), axis = 1)\ntest_df['text'] = test_df[['title', 'content']].apply(lambda x: ' '.join(x), axis = 1) ",
"CPU times: user 38.1 ms, sys: 0 ns, total: 38.1 ms\nWall time: 37.7 ms\n"
],
[
"train_df.head()",
"_____no_output_____"
],
[
"len(train_df.iloc[0,0])",
"_____no_output_____"
],
[
"len(train_df.iloc[0,1])",
"_____no_output_____"
],
[
"len(train_df.iloc[0,3])",
"_____no_output_____"
],
[
"train_df['t_length'] = train_df['title'].apply(lambda x: len(x))\ntrain_df['c_length'] = train_df['content'].apply(lambda x: len(x))\ntrain_df['text_length'] = train_df['text'].apply(lambda x: len(x))\n\ntest_df['t_length'] = test_df['title'].apply(lambda x: len(x))\ntest_df['c_length'] = test_df['content'].apply(lambda x: len(x))\ntest_df['text_length'] = test_df['text'].apply(lambda x: len(x))",
"_____no_output_____"
],
[
"train_df.describe()",
"_____no_output_____"
],
[
"test_df.describe()",
"_____no_output_____"
],
[
"MAX_SEQUENCE_LENGTH = 400",
"_____no_output_____"
]
],
[
[
"### Tokenizing",
"_____no_output_____"
]
],
[
[
"#%%time\ntokenizer = BertTokenizer.from_pretrained(BERT_MODEL_PATH, cache_dir=None,do_lower_case=True)\n#train_df = pd.read_csv(os.path.join(Data_dir,\"train.csv\"))#.sample(num_to_load+valid_size,random_state=SEED)\nprint('loaded %d records' % len(train_df))\n# Make sure all comment_text values are strings\ntrain_df['content'] = train_df['content'].astype(str) \nx_train = convert_lines(train_df[\"content\"].fillna(\"DUMMY_VALUE\"),MAX_SEQUENCE_LENGTH,tokenizer)\nprint(\"X_train : {}\".format(len(x_train)))\n\n#test_df = pd.read_csv(os.path.join(Data_dir,\"public_test.csv\"))#.sample(num_to_load+valid_size,random_state=SEED)\nprint('loaded %d records' % len(test_df))\ntest_df['content'] = test_df['content'].astype(str) \nx_test = convert_lines(test_df[\"content\"].fillna(\"DUMMY_VALUE\"),MAX_SEQUENCE_LENGTH,tokenizer)\nprint(\"X_test : {}\".format(len(x_test)))\n\ntrain_df=train_df.fillna(0)",
"loaded 2592 records\n/home/yilgukseo/anaconda3/envs/pytorch/lib/python3.7/site-packages/ipykernel_launcher.py:7: TqdmDeprecationWarning: This function will be removed in tqdm==5.0.0\nPlease use `tqdm.notebook.tqdm` instead of `tqdm.tqdm_notebook`\n import sys\n"
],
[
"# above not working in linux ?? these x_train & x_test are obtained from windows\n#x_train = np.loadtxt('../job_nlp/x_train.csv', delimiter=',')\n#x_test = np.loadtxt('../job_nlp/x_test.csv', delimiter=',')",
"_____no_output_____"
],
[
"seed_everything(SEED)\noutput_model_file = \"bert_pytorch.bin\"\n\nlr=2e-5\nbatch_size = 8\naccumulation_steps=2\nn_labels = 2\n\ncriterion = nn.CrossEntropyLoss()\n\nTARGET = 'label'",
"_____no_output_____"
],
[
"train_df[TARGET] = train_df[TARGET]-1",
"_____no_output_____"
],
[
"#x_train = train_df['text']\ny_train = torch.tensor(train_df[TARGET])#.long()\ny_train",
"_____no_output_____"
],
[
"y_train[:5]",
"_____no_output_____"
],
[
"def to_numpy(x):\n return x.cpu().detach().numpy()",
"_____no_output_____"
],
[
"test_dataset = TensorDataset(torch.tensor(x_test, dtype = torch.long)) #TensorDataset(X_valid, valid_length, torch.tensor(Y_valid))\ntest_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)",
"_____no_output_____"
],
[
"model = BertForSequenceClassification.from_pretrained(\"../job_nlp/working\",cache_dir=None, num_labels=5)",
"_____no_output_____"
],
[
"%%time\nbest_epoch_list = []\nbest_val_acc_list = []\nstart_time = time()\nn_splits = 5\n\nsplits = list(StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=SEED).split(x_train, y_train))\nfor fold in [0, 1, 2, 3, 4]:\n\n print(\"================ ༼ つ ◕_◕ ༽つ {}/{} fold training starts!\".format(fold+1, n_splits))\n \n fold_num = str(fold + 1)\n\n trn_index, val_index = splits[fold]\n\n X_train, X_valid = x_train[trn_index], x_train[val_index]\n #train_length, valid_length = lengths[trn_index], lengths[val_index]\n Y_train, Y_valid = y_train[trn_index], y_train[val_index]\n\n train_dataset = TensorDataset(torch.tensor(X_train, dtype = torch.long), torch.tensor(Y_train, dtype=torch.long)) #TensorDataset(X_train, train_length, torch.tensor(Y_train))\n valid_dataset = TensorDataset(torch.tensor(X_valid, dtype = torch.long), torch.tensor(Y_valid, dtype=torch.long)) #TensorDataset(X_valid, valid_length, torch.tensor(Y_valid))\n \n model = BertForSequenceClassification.from_pretrained(\"../job_nlp/working\",cache_dir=None, num_labels=5)\n model.zero_grad()\n model = model.to(device)\n #optimizer = BertAdam(optimizer_grouped_parameters,\n # lr=lr,\n # warmup=0.05,\n # t_total=num_train_optimization_steps)\n #scheduler = StepLR(optimizer, step_size=5, gamma=0.5)\n \n param_optimizer = list(model.named_parameters())\n no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']\n optimizer_grouped_parameters = [\n {'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},\n {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}\n ]\n #train = train_dataset\n\n num_train_optimization_steps = int(EPOCHS*len(train_dataset)/batch_size/accumulation_steps)\n\n #optimizer = BertAdam(optimizer_grouped_parameters,\n # lr=lr,\n # warmup=0.05,\n # t_total=np.ceil(num_train_optimization_steps))\n\n optimizer = AdamW(model.parameters(), lr, weight_decay=0.000025)\n \n train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)\n valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)\n \n best_valid_score = 0\n best_val_acc = 0\n \n #tq = tqdm_notebook(range(EPOCHS))\n #model, optimizer = amp.initialize(model, optimizer, opt_level=\"O1\",verbosity=0)\n for epoch in range(1, EPOCHS + 1):\n \n #start_time = time.time()\n train_loss = 0\n train_total_correct = 0\n model.train()\n optimizer.zero_grad()\n #tk0 = tqdm_notebook(enumerate(train_loader),total=len(train_loader),leave=False)\n \n for i, (x_batch, y_batch) in enumerate(train_loader):\n preds = model(x_batch.to(device), attention_mask = (x_batch>0).to(device), labels=None)\n loss = criterion(preds, y_batch.to(device))\n loss.backward()\n \n if (i+1) % accumulation_steps == 0: # Wait for several backward steps\n optimizer.step() # Now we can do an optimizer step\n optimizer.zero_grad()\n else:\n optimizer.step()\n optimizer.zero_grad()\n\n train_loss += loss.item()/len(train_loader)\n \n # Validation Starts\n model.eval()\n val_loss = 0\n valid_total_correct = 0\n \n #valid_preds = np.zeros(len(valid_dataset),5)\n #valid_targets = np.zeros(len(valid_dataset),5)\n \n with torch.no_grad():\n for i, (x_batch, y_batch) in enumerate(valid_loader):\n #valid_targets[i*batch_size: (i+1)*batch_size] = y_batch.numpy().copy()\n \n preds = model(x_batch.to(device), attention_mask = (x_batch>0).to(device), labels=None)\n \n loss = criterion(preds, y_batch.to(device))\n \n output_prob = F.softmax(preds, dim=1)\n\n predict_vector = np.argmax(to_numpy(output_prob), axis=1)\n label_vector = to_numpy(y_batch)\n #valid_preds[i*batch_size: (i+1)*batch_size] = np.argmax(preds_prob.detach().cpu().squeeze().numpy())\n bool_vector = predict_vector == label_vector\n \n val_loss += loss.item()/len(valid_loader)\n valid_total_correct += bool_vector.sum()\n \n #val_score = roc_auc_score(valid_targets, valid_preds)\n\n elapsed = time() - start_time\n val_acc = valid_total_correct / len(valid_loader.dataset)\n \n if val_acc > best_val_acc:\n best_val_acc = val_acc\n best_epoch = epoch\n print(\"val_acc has improved !! \")\n best_epoch_list.append(best_epoch)\n best_val_acc_list.append(best_val_acc)\n \n torch.save(model.state_dict(), '../job_nlp/Bert_content_20e_maxseq400_fold_{}.pt'.format(fold))\n #print(\"================ ༼ つ ◕_◕ ༽つ BEST epoch : {}, Accuracy : {} \".format(epoch, best_val_acc))\n \n #lr = [_['lr'] for _ in optimizer.param_g] # or optimizer\n print(\"================ ༼ つ ◕_◕ ༽つ Epoch {} - train_loss: {:.5f} val_loss: {:.5f} val_acc: {:.5f} elapsed: {:.0f}m {:.0f}s\".format(epoch, train_loss, val_loss, best_val_acc, elapsed // 60, elapsed % 60))\n print(\"============== ༼ つ ◕_◕ ༽つ BEST epoch : {}, Accuracy : {} ====================================\".format(epoch, best_val_acc))\n #best_epoch_list.append(best_epoch)\n #best_val_acc_list.append(best_val_acc)\n \n #---- Inference ----\n #batch_size = 8\n\n print(\"========================== ༼ つ ◕_◕ ༽つ Model Load {}_th FOLD =================================\".format(fold))\n model.load_state_dict(torch.load('Bert_content_20e_maxseq400_fold_{}.pt'.format(fold)))\n model.eval()\n predictions = np.zeros((len(test_loader.dataset),5))\n with torch.no_grad():\n for i, (x_batch, ) in enumerate(test_loader):\n preds = model(x_batch.to(device), attention_mask = (x_batch>0).to(device), labels=None)\n \n predictions[i*batch_size: (i+1)*batch_size] = to_numpy(preds)\n print(\"predict values check : \",predictions[0])\n np.savetxt(\"../job_nlp/bert_raw_submission/bert_content_20e_maxseq400_fold_{}.csv\".format(fold), predictions, delimiter=\",\") ",
"================ ༼ つ ◕_◕ ༽つ 1/5 fold training starts!\n/home/yilgukseo/anaconda3/envs/pytorch/lib/python3.7/site-packages/ipykernel_launcher.py:19: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 1 - train_loss: 1.26997 val_loss: 0.95356 val_acc: 0.64162 elapsed: 1m 28s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 2 - train_loss: 0.86164 val_loss: 0.72513 val_acc: 0.74952 elapsed: 2m 54s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 3 - train_loss: 0.59586 val_loss: 0.65616 val_acc: 0.77264 elapsed: 4m 23s\n================ ༼ つ ◕_◕ ༽つ Epoch 4 - train_loss: 0.46959 val_loss: 0.69946 val_acc: 0.77264 elapsed: 5m 52s\n================ ༼ つ ◕_◕ ༽つ Epoch 5 - train_loss: 0.33286 val_loss: 0.67387 val_acc: 0.77264 elapsed: 7m 18s\n================ ༼ つ ◕_◕ ༽つ Epoch 6 - train_loss: 0.24191 val_loss: 0.94004 val_acc: 0.77264 elapsed: 8m 44s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 7 - train_loss: 0.17543 val_loss: 0.83540 val_acc: 0.77457 elapsed: 10m 10s\n================ ༼ つ ◕_◕ ༽つ Epoch 8 - train_loss: 0.12882 val_loss: 0.93321 val_acc: 0.77457 elapsed: 11m 39s\n================ ༼ つ ◕_◕ ༽つ Epoch 9 - train_loss: 0.12237 val_loss: 0.94471 val_acc: 0.77457 elapsed: 13m 4s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 10 - train_loss: 0.09056 val_loss: 0.87780 val_acc: 0.78035 elapsed: 14m 30s\n================ ༼ つ ◕_◕ ༽つ Epoch 11 - train_loss: 0.09019 val_loss: 0.89897 val_acc: 0.78035 elapsed: 15m 59s\n================ ༼ つ ◕_◕ ༽つ Epoch 12 - train_loss: 0.09022 val_loss: 0.95272 val_acc: 0.78035 elapsed: 17m 25s\n================ ༼ つ ◕_◕ ༽つ Epoch 13 - train_loss: 0.08153 val_loss: 0.98328 val_acc: 0.78035 elapsed: 18m 51s\n================ ༼ つ ◕_◕ ༽つ Epoch 14 - train_loss: 0.07197 val_loss: 1.16162 val_acc: 0.78035 elapsed: 20m 17s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 15 - train_loss: 0.05762 val_loss: 1.02941 val_acc: 0.78998 elapsed: 21m 42s\n================ ༼ つ ◕_◕ ༽つ Epoch 16 - train_loss: 0.06961 val_loss: 1.15094 val_acc: 0.78998 elapsed: 23m 11s\n================ ༼ つ ◕_◕ ༽つ Epoch 17 - train_loss: 0.05915 val_loss: 1.11618 val_acc: 0.78998 elapsed: 24m 37s\n================ ༼ つ ◕_◕ ༽つ Epoch 18 - train_loss: 0.05215 val_loss: 1.12977 val_acc: 0.78998 elapsed: 26m 3s\n================ ༼ つ ◕_◕ ༽つ Epoch 19 - train_loss: 0.05726 val_loss: 1.03090 val_acc: 0.78998 elapsed: 27m 29s\n================ ༼ つ ◕_◕ ༽つ Epoch 20 - train_loss: 0.07749 val_loss: 1.07535 val_acc: 0.78998 elapsed: 28m 55s\n============== ༼ つ ◕_◕ ༽つ BEST epoch : 20, Accuracy : 0.789980732177264 ====================================\n========================== ༼ つ ◕_◕ ༽つ Model Load 0_th FOLD =================================\npredict values check : [-1.33655119 -1.64948583 -1.99604511 -1.74130619 6.22682905]\n================ ༼ つ ◕_◕ ༽つ 2/5 fold training starts!\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 1 - train_loss: 1.31722 val_loss: 1.00038 val_acc: 0.66281 elapsed: 30m 28s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 2 - train_loss: 0.82660 val_loss: 0.66793 val_acc: 0.77264 elapsed: 31m 54s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 3 - train_loss: 0.56479 val_loss: 0.66947 val_acc: 0.78035 elapsed: 33m 23s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 4 - train_loss: 0.42481 val_loss: 0.65005 val_acc: 0.78805 elapsed: 34m 51s\n================ ༼ つ ◕_◕ ༽つ Epoch 5 - train_loss: 0.31143 val_loss: 0.69951 val_acc: 0.78805 elapsed: 36m 20s\n================ ༼ つ ◕_◕ ༽つ Epoch 6 - train_loss: 0.24120 val_loss: 0.73232 val_acc: 0.78805 elapsed: 37m 46s\n================ ༼ つ ◕_◕ ༽つ Epoch 7 - train_loss: 0.17967 val_loss: 0.99080 val_acc: 0.78805 elapsed: 39m 12s\n================ ༼ つ ◕_◕ ༽つ Epoch 8 - train_loss: 0.16717 val_loss: 0.79054 val_acc: 0.78805 elapsed: 40m 38s\n================ ༼ つ ◕_◕ ༽つ Epoch 9 - train_loss: 0.11300 val_loss: 0.85392 val_acc: 0.78805 elapsed: 42m 4s\n================ ༼ つ ◕_◕ ༽つ Epoch 10 - train_loss: 0.11132 val_loss: 1.04922 val_acc: 0.78805 elapsed: 43m 30s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 11 - train_loss: 0.13431 val_loss: 0.83856 val_acc: 0.79191 elapsed: 44m 56s\n================ ༼ つ ◕_◕ ༽つ Epoch 12 - train_loss: 0.08946 val_loss: 1.05974 val_acc: 0.79191 elapsed: 46m 25s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 13 - train_loss: 0.08668 val_loss: 0.97704 val_acc: 0.79576 elapsed: 47m 51s\n================ ༼ つ ◕_◕ ༽つ Epoch 14 - train_loss: 0.02919 val_loss: 1.11555 val_acc: 0.79576 elapsed: 49m 20s\n================ ༼ つ ◕_◕ ༽つ Epoch 15 - train_loss: 0.03958 val_loss: 0.98772 val_acc: 0.79576 elapsed: 50m 45s\n================ ༼ つ ◕_◕ ༽つ Epoch 16 - train_loss: 0.08741 val_loss: 1.12351 val_acc: 0.79576 elapsed: 52m 11s\n================ ༼ つ ◕_◕ ༽つ Epoch 17 - train_loss: 0.12820 val_loss: 1.03809 val_acc: 0.79576 elapsed: 53m 37s\n================ ༼ つ ◕_◕ ༽つ Epoch 18 - train_loss: 0.07281 val_loss: 1.00135 val_acc: 0.79576 elapsed: 55m 3s\n================ ༼ つ ◕_◕ ༽つ Epoch 19 - train_loss: 0.05741 val_loss: 1.05405 val_acc: 0.79576 elapsed: 56m 29s\n================ ༼ つ ◕_◕ ༽つ Epoch 20 - train_loss: 0.03647 val_loss: 1.04437 val_acc: 0.79576 elapsed: 57m 55s\n============== ༼ つ ◕_◕ ༽つ BEST epoch : 20, Accuracy : 0.7957610789980732 ====================================\n========================== ༼ つ ◕_◕ ༽つ Model Load 1_th FOLD =================================\npredict values check : [-1.29721546 -1.60733271 -1.11734426 -1.99168658 6.62477732]\n================ ༼ つ ◕_◕ ༽つ 3/5 fold training starts!\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 1 - train_loss: 1.35356 val_loss: 1.03713 val_acc: 0.59846 elapsed: 59m 28s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 2 - train_loss: 0.91478 val_loss: 0.94048 val_acc: 0.68533 elapsed: 60m 54s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 3 - train_loss: 0.66772 val_loss: 0.80805 val_acc: 0.72394 elapsed: 62m 23s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 4 - train_loss: 0.47075 val_loss: 0.65813 val_acc: 0.76641 elapsed: 63m 52s\n================ ༼ つ ◕_◕ ༽つ Epoch 5 - train_loss: 0.36629 val_loss: 0.85477 val_acc: 0.76641 elapsed: 65m 21s\n================ ༼ つ ◕_◕ ༽つ Epoch 6 - train_loss: 0.30021 val_loss: 0.82802 val_acc: 0.76641 elapsed: 66m 46s\n================ ༼ つ ◕_◕ ༽つ Epoch 7 - train_loss: 0.23044 val_loss: 0.95205 val_acc: 0.76641 elapsed: 68m 12s\n================ ༼ つ ◕_◕ ༽つ Epoch 8 - train_loss: 0.18205 val_loss: 1.00494 val_acc: 0.76641 elapsed: 69m 38s\n================ ༼ つ ◕_◕ ༽つ Epoch 9 - train_loss: 0.14957 val_loss: 0.97451 val_acc: 0.76641 elapsed: 71m 4s\n================ ༼ つ ◕_◕ ༽つ Epoch 10 - train_loss: 0.15032 val_loss: 0.95657 val_acc: 0.76641 elapsed: 72m 30s\n================ ༼ つ ◕_◕ ༽つ Epoch 11 - train_loss: 0.11209 val_loss: 1.12512 val_acc: 0.76641 elapsed: 73m 56s\n================ ༼ つ ◕_◕ ༽つ Epoch 12 - train_loss: 0.11358 val_loss: 1.21408 val_acc: 0.76641 elapsed: 75m 21s\n================ ༼ つ ◕_◕ ༽つ Epoch 13 - train_loss: 0.10051 val_loss: 1.08425 val_acc: 0.76641 elapsed: 76m 47s\n================ ༼ つ ◕_◕ ༽つ Epoch 14 - train_loss: 0.08168 val_loss: 1.29008 val_acc: 0.76641 elapsed: 78m 13s\n================ ༼ つ ◕_◕ ༽つ Epoch 15 - train_loss: 0.08096 val_loss: 1.17141 val_acc: 0.76641 elapsed: 79m 39s\n================ ༼ つ ◕_◕ ༽つ Epoch 16 - train_loss: 0.07379 val_loss: 1.21000 val_acc: 0.76641 elapsed: 81m 5s\n================ ༼ つ ◕_◕ ༽つ Epoch 17 - train_loss: 0.10559 val_loss: 1.24898 val_acc: 0.76641 elapsed: 82m 30s\n================ ༼ つ ◕_◕ ༽つ Epoch 18 - train_loss: 0.06274 val_loss: 1.20185 val_acc: 0.76641 elapsed: 83m 56s\n================ ༼ つ ◕_◕ ༽つ Epoch 19 - train_loss: 0.05998 val_loss: 1.25338 val_acc: 0.76641 elapsed: 85m 22s\n================ ༼ つ ◕_◕ ༽つ Epoch 20 - train_loss: 0.04911 val_loss: 1.22630 val_acc: 0.76641 elapsed: 86m 48s\n============== ༼ つ ◕_◕ ༽つ BEST epoch : 20, Accuracy : 0.7664092664092664 ====================================\n========================== ༼ つ ◕_◕ ༽つ Model Load 2_th FOLD =================================\npredict values check : [-0.81744957 -1.65529895 -1.04801464 0.11835536 3.89325619]\n================ ༼ つ ◕_◕ ༽つ 4/5 fold training starts!\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 1 - train_loss: 1.24524 val_loss: 0.88960 val_acc: 0.68340 elapsed: 88m 21s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 2 - train_loss: 0.81533 val_loss: 0.76428 val_acc: 0.73166 elapsed: 89m 47s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 3 - train_loss: 0.56177 val_loss: 0.70380 val_acc: 0.77027 elapsed: 91m 16s\n================ ༼ つ ◕_◕ ༽つ Epoch 4 - train_loss: 0.41233 val_loss: 0.73184 val_acc: 0.77027 elapsed: 92m 45s\n================ ༼ つ ◕_◕ ༽つ Epoch 5 - train_loss: 0.28578 val_loss: 0.88065 val_acc: 0.77027 elapsed: 94m 11s\n================ ༼ つ ◕_◕ ༽つ Epoch 6 - train_loss: 0.22031 val_loss: 0.87194 val_acc: 0.77027 elapsed: 95m 37s\n================ ༼ つ ◕_◕ ༽つ Epoch 7 - train_loss: 0.15033 val_loss: 0.89508 val_acc: 0.77027 elapsed: 97m 2s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 8 - train_loss: 0.14656 val_loss: 0.98294 val_acc: 0.77220 elapsed: 98m 28s\n================ ༼ つ ◕_◕ ༽つ Epoch 9 - train_loss: 0.10391 val_loss: 1.02709 val_acc: 0.77220 elapsed: 99m 57s\n================ ༼ つ ◕_◕ ༽つ Epoch 10 - train_loss: 0.10149 val_loss: 1.04623 val_acc: 0.77220 elapsed: 101m 23s\n================ ༼ つ ◕_◕ ༽つ Epoch 11 - train_loss: 0.09065 val_loss: 1.11266 val_acc: 0.77220 elapsed: 102m 49s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 12 - train_loss: 0.07500 val_loss: 1.05743 val_acc: 0.77606 elapsed: 104m 15s\n================ ༼ つ ◕_◕ ༽つ Epoch 13 - train_loss: 0.08861 val_loss: 1.16476 val_acc: 0.77606 elapsed: 105m 44s\n================ ༼ つ ◕_◕ ༽つ Epoch 14 - train_loss: 0.08551 val_loss: 1.17960 val_acc: 0.77606 elapsed: 107m 10s\n================ ༼ つ ◕_◕ ༽つ Epoch 15 - train_loss: 0.08847 val_loss: 1.19570 val_acc: 0.77606 elapsed: 108m 35s\n================ ༼ つ ◕_◕ ༽つ Epoch 16 - train_loss: 0.06440 val_loss: 1.07245 val_acc: 0.77606 elapsed: 110m 1s\n================ ༼ つ ◕_◕ ༽つ Epoch 17 - train_loss: 0.06107 val_loss: 1.08461 val_acc: 0.77606 elapsed: 111m 27s\n================ ༼ つ ◕_◕ ༽つ Epoch 18 - train_loss: 0.05304 val_loss: 1.19353 val_acc: 0.77606 elapsed: 112m 53s\n================ ༼ つ ◕_◕ ༽つ Epoch 19 - train_loss: 0.02879 val_loss: 1.30685 val_acc: 0.77606 elapsed: 114m 19s\n================ ༼ つ ◕_◕ ༽つ Epoch 20 - train_loss: 0.05603 val_loss: 1.34832 val_acc: 0.77606 elapsed: 115m 45s\n============== ༼ つ ◕_◕ ༽つ BEST epoch : 20, Accuracy : 0.7760617760617761 ====================================\n========================== ༼ つ ◕_◕ ༽つ Model Load 3_th FOLD =================================\npredict values check : [-1.54165888 -1.53146303 -2.406703 -0.97923213 6.23691416]\n================ ༼ つ ◕_◕ ༽つ 5/5 fold training starts!\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 1 - train_loss: 1.25060 val_loss: 0.97384 val_acc: 0.62741 elapsed: 117m 18s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 2 - train_loss: 0.83962 val_loss: 0.81059 val_acc: 0.68533 elapsed: 118m 44s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 3 - train_loss: 0.61084 val_loss: 0.75072 val_acc: 0.72587 elapsed: 120m 13s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 4 - train_loss: 0.44675 val_loss: 0.68672 val_acc: 0.75869 elapsed: 121m 41s\n================ ༼ つ ◕_◕ ༽つ Epoch 5 - train_loss: 0.32167 val_loss: 0.91745 val_acc: 0.75869 elapsed: 123m 10s\n================ ༼ つ ◕_◕ ༽つ Epoch 6 - train_loss: 0.26213 val_loss: 0.91354 val_acc: 0.75869 elapsed: 124m 36s\n================ ༼ つ ◕_◕ ༽つ Epoch 7 - train_loss: 0.20572 val_loss: 0.88650 val_acc: 0.75869 elapsed: 126m 2s\n================ ༼ つ ◕_◕ ༽つ Epoch 8 - train_loss: 0.15177 val_loss: 0.94716 val_acc: 0.75869 elapsed: 127m 28s\n================ ༼ つ ◕_◕ ༽つ Epoch 9 - train_loss: 0.11900 val_loss: 1.01129 val_acc: 0.75869 elapsed: 128m 54s\n================ ༼ つ ◕_◕ ༽つ Epoch 10 - train_loss: 0.13787 val_loss: 1.09601 val_acc: 0.75869 elapsed: 130m 20s\n================ ༼ つ ◕_◕ ༽つ Epoch 11 - train_loss: 0.12032 val_loss: 1.14737 val_acc: 0.75869 elapsed: 131m 46s\n================ ༼ つ ◕_◕ ༽つ Epoch 12 - train_loss: 0.08636 val_loss: 1.12600 val_acc: 0.75869 elapsed: 133m 11s\nval_acc has improved !! \n================ ༼ つ ◕_◕ ༽つ Epoch 13 - train_loss: 0.05441 val_loss: 1.12678 val_acc: 0.76255 elapsed: 134m 37s\n================ ༼ つ ◕_◕ ༽つ Epoch 14 - train_loss: 0.04466 val_loss: 1.24464 val_acc: 0.76255 elapsed: 136m 6s\n================ ༼ つ ◕_◕ ༽つ Epoch 15 - train_loss: 0.07197 val_loss: 1.34421 val_acc: 0.76255 elapsed: 137m 32s\n================ ༼ つ ◕_◕ ༽つ Epoch 16 - train_loss: 0.06006 val_loss: 1.23416 val_acc: 0.76255 elapsed: 138m 58s\n================ ༼ つ ◕_◕ ༽つ Epoch 17 - train_loss: 0.07172 val_loss: 1.27671 val_acc: 0.76255 elapsed: 140m 24s\n================ ༼ つ ◕_◕ ༽つ Epoch 18 - train_loss: 0.07090 val_loss: 1.27837 val_acc: 0.76255 elapsed: 141m 49s\n================ ༼ つ ◕_◕ ༽つ Epoch 19 - train_loss: 0.04806 val_loss: 1.36582 val_acc: 0.76255 elapsed: 143m 15s\n================ ༼ つ ◕_◕ ༽つ Epoch 20 - train_loss: 0.04454 val_loss: 1.50119 val_acc: 0.76255 elapsed: 144m 41s\n============== ༼ つ ◕_◕ ༽つ BEST epoch : 20, Accuracy : 0.7625482625482626 ====================================\n========================== ༼ つ ◕_◕ ༽つ Model Load 4_th FOLD =================================\npredict values check : [-1.09749067 -1.85101628 -1.88581681 -1.1021055 7.09595823]\nCPU times: user 2h 16min 48s, sys: 7min 20s, total: 2h 24min 8s\nWall time: 2h 24min 47s\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad0e6e310f1a89dea0a8d0512e7ac91caffcdb3
| 129,622 |
ipynb
|
Jupyter Notebook
|
standard normal.ipynb
|
fja05680/BFS_Sequences
|
9c9a1ee0e78fbfc32dee4253fc89ff02e5a0dcfe
|
[
"MIT"
] | 3 |
2019-08-05T20:16:09.000Z
|
2021-07-13T05:04:09.000Z
|
standard normal.ipynb
|
fja05680/BFS_Sequences
|
9c9a1ee0e78fbfc32dee4253fc89ff02e5a0dcfe
|
[
"MIT"
] | null | null | null |
standard normal.ipynb
|
fja05680/BFS_Sequences
|
9c9a1ee0e78fbfc32dee4253fc89ff02e5a0dcfe
|
[
"MIT"
] | 1 |
2019-10-20T20:40:02.000Z
|
2019-10-20T20:40:02.000Z
| 63.230244 | 24,279 | 0.656725 |
[
[
[
"# Standard Normal N(0,1)\n\nGenerate a total of 2000 i.i.d. standard normals N(0,1) using each method. Test the normality of the standard normals obtained from each method, using the Anderson-Darling test. Which data set is closer to the normal distribution? (Consult the paper by Stephens - filename 2008 Stephens.pdf on Canvas - to find the appropriate critical points for the Anderson-Darling statistic. Clearly identify those percentiles in your soultion.)",
"_____no_output_____"
]
],
[
[
"# imports\nimport random\nimport math\nimport numpy\nimport matplotlib.pyplot as plt\nfrom scipy.stats import anderson\nfrom mpl_toolkits.mplot3d import axes3d\n%matplotlib notebook\n\n# project imports\nimport rand\nimport halton\nimport bfs\nimport box_muller\nimport beasley_springer_moro",
"_____no_output_____"
]
],
[
[
"### Generate a total of 2000 i.i.d. standard normals N (0, 1) using Box Muller",
"_____no_output_____"
]
],
[
[
"# generate 1000 2-dim vectors, then flatten to create 2000 standard normals\nN = 1000\ns = 2\nseq = rand.rand_seq\nseq = halton.halton_seq\n#seq = bfs.bfs_seq",
"_____no_output_____"
],
[
"l = box_muller.box_muller_seq(s, N, seq=seq)\n# print the first 20\nprint(l[:10])\n# flatten the sequence into 1 dimension\nflattened = [item for sublist in l for item in sublist]\nnums = flattened\nprint(nums[:20])",
"[(0.7443300850272079, -0.6113446172758047), (0.22750250323107185, 1.3746076837154961), (-0.2494802853218258, -0.44280186764434915), (1.6558473350849008, 0.01741370677972137), (-0.3827115346426496, 0.647064691400064), (0.21543958611815975, -1.1509103496429351), (2.532576610273044, 2.170874557206201), (-1.7154082878285117, 0.6040055310970016), (-0.712862863490848, -0.4796718958687281), (1.1489490697564084, -0.5619728901777015)]\n[0.7443300850272079, -0.6113446172758047, 0.22750250323107185, 1.3746076837154961, -0.2494802853218258, -0.44280186764434915, 1.6558473350849008, 0.01741370677972137, -0.3827115346426496, 0.647064691400064, 0.21543958611815975, -1.1509103496429351, 2.532576610273044, 2.170874557206201, -1.7154082878285117, 0.6040055310970016, -0.712862863490848, -0.4796718958687281, 1.1489490697564084, -0.5619728901777015]\n"
]
],
[
[
"### Sort the sequence",
"_____no_output_____"
]
],
[
[
"nums = numpy.array(nums)\nnums = sorted(nums)",
"_____no_output_____"
],
[
"print(nums[:20])",
"[-3.5409431816696766, -3.1398610496653436, -2.9805243083534694, -2.9368656765203136, -2.9183735528681174, -2.749374931759913, -2.696584045082842, -2.673434038789564, -2.6637133132283606, -2.602326318987692, -2.590178545528447, -2.5814016358470764, -2.515685310747461, -2.453941617556857, -2.452827867160038, -2.4113719915033367, -2.3938365329485434, -2.3420632093356692, -2.3329943092852723, -2.276147668551989]\n"
]
],
[
[
"### Compute the sample mean and standard deviation",
"_____no_output_____"
]
],
[
[
"nums = numpy.array(nums)\nmean = numpy.mean(nums)\nvar = numpy.var(nums)\nstd = numpy.std(nums)\n\nprint('mean = {}'.format(mean))\nprint('variance = {}'.format(var))\nprint('standard deviation = {}'.format(std))",
"mean = 0.0014995686420993478\nvariance = 0.9935254197054167\nstandard deviation = 0.996757452796525\n"
],
[
"# plot the histogram\nplt.hist(nums, density=True, bins=30)\nplt.ylabel('Standard Normal - Box Muller');",
"_____no_output_____"
]
],
[
[
"### Anderson Darling Test\n\nreference:\nhttps://en.wikipedia.org/wiki/Anderson%E2%80%93Darling_test#Test_for_normality\n\nreference:\n2008 Stephens.pdf pg. 4, \"1.3 Modificatons for a test for normality, u, and sigma^2 unknown\"",
"_____no_output_____"
]
],
[
[
"# normality test using scipy.stats\nresult = anderson(nums)\nprint('Statistic: %.3f' % result.statistic)\np = 0\nfor i in range(len(result.critical_values)):\n sl, cv = result.significance_level[i], result.critical_values[i]\n if result.statistic < result.critical_values[i]:\n print('%.3f: %.3f, data looks normal (fail to reject H0)' % (sl, cv))\n else:\n print('%.3f: %.3f, data does not look normal (reject H0)' % (sl, cv))",
"Statistic: 0.041\n15.000: 0.575, data looks normal (fail to reject H0)\n10.000: 0.655, data looks normal (fail to reject H0)\n5.000: 0.785, data looks normal (fail to reject H0)\n2.500: 0.916, data looks normal (fail to reject H0)\n1.000: 1.090, data looks normal (fail to reject H0)\n"
]
],
[
[
"### Generate a total of 2000 i.i.d. standard normals N (0, 1) using Beasley-Springer-Moro",
"_____no_output_____"
]
],
[
[
"N=2000\ns=1\n\nl = beasley_springer_moro.beasley_springer_moro_seq(s=s, N=N, seq=seq)\n# print the first 20\nprint(l[:20])\n# flatten the sequence into 1 dimension\nflattened = [item for sublist in l for item in sublist]\nnums = flattened\nprint(nums[:20])",
"[(-0.45354220491354497,), (-1.4389723392670315,), (0.18932048542646718,), (1.6456218388230586,), (-0.1254613002624064,), (-0.841338444465769,), (0.5246282553188133,), (1.2137540974782643,), (-0.2856341307724526,), (-1.0912603031903014,), (0.35199549745081987,), (-2.238962442870265,), (0.031536554447300705,), (-0.6354141211428904,), (0.714623629180169,), (1.0639714340786743,), (-0.3682881880881213,), (-1.2462888763124396,), (0.2697642345248874,), (2.0820090832222746,)]\n[-0.45354220491354497, -1.4389723392670315, 0.18932048542646718, 1.6456218388230586, -0.1254613002624064, -0.841338444465769, 0.5246282553188133, 1.2137540974782643, -0.2856341307724526, -1.0912603031903014, 0.35199549745081987, -2.238962442870265, 0.031536554447300705, -0.6354141211428904, 0.714623629180169, 1.0639714340786743, -0.3682881880881213, -1.2462888763124396, 0.2697642345248874, 2.0820090832222746]\n"
]
],
[
[
"### Sort the sequence",
"_____no_output_____"
]
],
[
[
"nums = numpy.array(nums)\nnums = sorted(nums)",
"_____no_output_____"
],
[
"print(nums[:20])",
"[-3.3727194621923373, -3.1346044221532785, -3.000267898341195, -2.90487610870623, -2.830292443600595, -2.7687540302075453, -2.7161964314970097, -2.6702165174341346, -2.6292716619518317, -2.5923108117998117, -2.5585846646267565, -2.5275396610714904, -2.498754904793903, -2.4719026739584775, -2.446722653047625, -2.42300452486657, -2.4005758596607176, -2.3792934740686174, -2.3590371290895824, -2.339704844677499]\n"
]
],
[
[
"### Compute the sample mean and standard deviation",
"_____no_output_____"
]
],
[
[
"nums = numpy.array(nums)\nmean = numpy.mean(nums)\nvar = numpy.var(nums)\nstd = numpy.std(nums)\n\nprint('mean = {}'.format(mean))\nprint('variance = {}'.format(var))\nprint('standard deviation = {}'.format(std))",
"mean = 0.00017262607399879925\nvariance = 0.9995629114486932\nstandard deviation = 0.999781431838326\n"
],
[
"# plot the histogram\nfig = plt.figure()\nax = fig.add_subplot(111)\nax.hist(nums, density=True, bins=30)\nax.set_ylabel('Standard Normal - Beasley-Springer-Moro');",
"_____no_output_____"
],
[
"# normality test using scipy.stats\nresult = anderson(nums)\nprint('Statistic: %.3f' % result.statistic)\np = 0\nfor i in range(len(result.critical_values)):\n sl, cv = result.significance_level[i], result.critical_values[i]\n if result.statistic < result.critical_values[i]:\n print('%.3f: %.3f, data looks normal (fail to reject H0)' % (sl, cv))\n else:\n print('%.3f: %.3f, data does not look normal (reject H0)' % (sl, cv))",
"Statistic: 0.002\n15.000: 0.575, data looks normal (fail to reject H0)\n10.000: 0.655, data looks normal (fail to reject H0)\n5.000: 0.785, data looks normal (fail to reject H0)\n2.500: 0.916, data looks normal (fail to reject H0)\n1.000: 1.090, data looks normal (fail to reject H0)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad0f8ff02086a6f90941a0220e0c3866a9b8bfc
| 18,637 |
ipynb
|
Jupyter Notebook
|
site/en-snapshot/lite/performance/post_training_integer_quant_16x8.ipynb
|
leeyspaul/docs-l10n
|
0e2f1a4d1c507b8a71be6b506b275ab2c83ca359
|
[
"Apache-2.0"
] | 2 |
2020-09-29T07:31:21.000Z
|
2020-10-13T08:16:18.000Z
|
site/en-snapshot/lite/performance/post_training_integer_quant_16x8.ipynb
|
leeyspaul/docs-l10n
|
0e2f1a4d1c507b8a71be6b506b275ab2c83ca359
|
[
"Apache-2.0"
] | null | null | null |
site/en-snapshot/lite/performance/post_training_integer_quant_16x8.ipynb
|
leeyspaul/docs-l10n
|
0e2f1a4d1c507b8a71be6b506b275ab2c83ca359
|
[
"Apache-2.0"
] | null | null | null | 31.534687 | 507 | 0.539947 |
[
[
[
"##### Copyright 2020 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Post-training integer quantization with int16 activations",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/lite/performance/post_training_quant_16x8\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quant_16x8.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/performance/post_training_quant_16x8.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/tensorflow/lite/g3doc/performance/post_training_quant_16x8.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"## Overview\n\n[TensorFlow Lite](https://www.tensorflow.org/lite/) now supports\nconverting activations to 16-bit integer values and weights to 8-bit integer values during model conversion from TensorFlow to TensorFlow Lite's flat buffer format. We refer to this mode as the \"16x8 quantization mode\". This mode can improve accuracy of the quantized model significantly, when activations are sensitive to the quantization, while still achieving almost 3-4x reduction in model size. Moreover, this fully quantized model can be consumed by integer-only hardware accelerators. \n\nSome examples of models that benefit from this mode of the post-training quantization include: \n* super-resolution, \n* audio signal processing such\nas noise cancelling and beamforming, \n* image de-noising, \n* HDR reconstruction\nfrom a single image\n\nIn this tutorial, you train an MNIST model from scratch, check its accuracy in TensorFlow, and then convert the model into a Tensorflow Lite flatbuffer using this mode. At the end you check the accuracy of the converted model and compare it to the original float32 model. Note that this example demonstrates the usage of this mode and doesn't show benefits over other available quantization techniques in TensorFlow Lite.",
"_____no_output_____"
],
[
"## Build an MNIST model",
"_____no_output_____"
],
[
"### Setup",
"_____no_output_____"
]
],
[
[
"import logging\nlogging.getLogger(\"tensorflow\").setLevel(logging.DEBUG)\n\nimport tensorflow as tf\nfrom tensorflow import keras\nimport numpy as np\nimport pathlib",
"_____no_output_____"
]
],
[
[
"Check that the 16x8 quantization mode is available ",
"_____no_output_____"
]
],
[
[
"tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8",
"_____no_output_____"
]
],
[
[
"### Train and export the model",
"_____no_output_____"
]
],
[
[
"# Load MNIST dataset\nmnist = keras.datasets.mnist\n(train_images, train_labels), (test_images, test_labels) = mnist.load_data()\n\n# Normalize the input image so that each pixel value is between 0 to 1.\ntrain_images = train_images / 255.0\ntest_images = test_images / 255.0\n\n# Define the model architecture\nmodel = keras.Sequential([\n keras.layers.InputLayer(input_shape=(28, 28)),\n keras.layers.Reshape(target_shape=(28, 28, 1)),\n keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation=tf.nn.relu),\n keras.layers.MaxPooling2D(pool_size=(2, 2)),\n keras.layers.Flatten(),\n keras.layers.Dense(10)\n])\n\n# Train the digit classification model\nmodel.compile(optimizer='adam',\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])\nmodel.fit(\n train_images,\n train_labels,\n epochs=1,\n validation_data=(test_images, test_labels)\n)",
"_____no_output_____"
]
],
[
[
"For the example, you trained the model for just a single epoch, so it only trains to ~96% accuracy.",
"_____no_output_____"
],
[
"### Convert to a TensorFlow Lite model\n\nUsing the Python [TFLiteConverter](https://www.tensorflow.org/lite/convert/python_api), you can now convert the trained model into a TensorFlow Lite model.\n\nNow, convert the model using `TFliteConverter` into default float32 format:",
"_____no_output_____"
]
],
[
[
"converter = tf.lite.TFLiteConverter.from_keras_model(model)\ntflite_model = converter.convert()",
"_____no_output_____"
]
],
[
[
"Write it out to a `.tflite` file:",
"_____no_output_____"
]
],
[
[
"tflite_models_dir = pathlib.Path(\"/tmp/mnist_tflite_models/\")\ntflite_models_dir.mkdir(exist_ok=True, parents=True)",
"_____no_output_____"
],
[
"tflite_model_file = tflite_models_dir/\"mnist_model.tflite\"\ntflite_model_file.write_bytes(tflite_model)",
"_____no_output_____"
]
],
[
[
"To instead quantize the model to 16x8 quantization mode, first set the `optimizations` flag to use default optimizations. Then specify that 16x8 quantization mode is the required supported operation in the target specification:",
"_____no_output_____"
]
],
[
[
"converter.optimizations = [tf.lite.Optimize.DEFAULT]\nconverter.target_spec.supported_ops = [tf.lite.OpsSet.EXPERIMENTAL_TFLITE_BUILTINS_ACTIVATIONS_INT16_WEIGHTS_INT8]",
"_____no_output_____"
]
],
[
[
"As in the case of int8 post-training quantization, it is possible to produce a fully integer quantized model by setting converter options `inference_input(output)_type` to tf.int16.",
"_____no_output_____"
],
[
"Set the calibration data:",
"_____no_output_____"
]
],
[
[
"mnist_train, _ = tf.keras.datasets.mnist.load_data()\nimages = tf.cast(mnist_train[0], tf.float32) / 255.0\nmnist_ds = tf.data.Dataset.from_tensor_slices((images)).batch(1)\ndef representative_data_gen():\n for input_value in mnist_ds.take(100):\n # Model has only one input so each data point has one element.\n yield [input_value]\nconverter.representative_dataset = representative_data_gen",
"_____no_output_____"
]
],
[
[
"Finally, convert the model as usual. Note, by default the converted model will still use float input and outputs for invocation convenience.",
"_____no_output_____"
]
],
[
[
"tflite_16x8_model = converter.convert()\ntflite_model_16x8_file = tflite_models_dir/\"mnist_model_quant_16x8.tflite\"\ntflite_model_16x8_file.write_bytes(tflite_16x8_model)",
"_____no_output_____"
]
],
[
[
"Note how the resulting file is approximately `1/3` the size.",
"_____no_output_____"
]
],
[
[
"!ls -lh {tflite_models_dir}",
"_____no_output_____"
]
],
[
[
"## Run the TensorFlow Lite models",
"_____no_output_____"
],
[
"Run the TensorFlow Lite model using the Python TensorFlow Lite Interpreter.",
"_____no_output_____"
],
[
"### Load the model into the interpreters",
"_____no_output_____"
]
],
[
[
"interpreter = tf.lite.Interpreter(model_path=str(tflite_model_file))\ninterpreter.allocate_tensors()",
"_____no_output_____"
],
[
"interpreter_16x8 = tf.lite.Interpreter(model_path=str(tflite_model_16x8_file))\ninterpreter_16x8.allocate_tensors()",
"_____no_output_____"
]
],
[
[
"### Test the models on one image",
"_____no_output_____"
]
],
[
[
"test_image = np.expand_dims(test_images[0], axis=0).astype(np.float32)\n\ninput_index = interpreter.get_input_details()[0][\"index\"]\noutput_index = interpreter.get_output_details()[0][\"index\"]\n\ninterpreter.set_tensor(input_index, test_image)\ninterpreter.invoke()\npredictions = interpreter.get_tensor(output_index)",
"_____no_output_____"
],
[
"import matplotlib.pylab as plt\n\nplt.imshow(test_images[0])\ntemplate = \"True:{true}, predicted:{predict}\"\n_ = plt.title(template.format(true= str(test_labels[0]),\n predict=str(np.argmax(predictions[0]))))\nplt.grid(False)",
"_____no_output_____"
],
[
"test_image = np.expand_dims(test_images[0], axis=0).astype(np.float32)\n\ninput_index = interpreter_16x8.get_input_details()[0][\"index\"]\noutput_index = interpreter_16x8.get_output_details()[0][\"index\"]\n\ninterpreter_16x8.set_tensor(input_index, test_image)\ninterpreter_16x8.invoke()\npredictions = interpreter_16x8.get_tensor(output_index)",
"_____no_output_____"
],
[
"plt.imshow(test_images[0])\ntemplate = \"True:{true}, predicted:{predict}\"\n_ = plt.title(template.format(true= str(test_labels[0]),\n predict=str(np.argmax(predictions[0]))))\nplt.grid(False)",
"_____no_output_____"
]
],
[
[
"### Evaluate the models",
"_____no_output_____"
]
],
[
[
"# A helper function to evaluate the TF Lite model using \"test\" dataset.\ndef evaluate_model(interpreter):\n input_index = interpreter.get_input_details()[0][\"index\"]\n output_index = interpreter.get_output_details()[0][\"index\"]\n\n # Run predictions on every image in the \"test\" dataset.\n prediction_digits = []\n for test_image in test_images:\n # Pre-processing: add batch dimension and convert to float32 to match with\n # the model's input data format.\n test_image = np.expand_dims(test_image, axis=0).astype(np.float32)\n interpreter.set_tensor(input_index, test_image)\n\n # Run inference.\n interpreter.invoke()\n\n # Post-processing: remove batch dimension and find the digit with highest\n # probability.\n output = interpreter.tensor(output_index)\n digit = np.argmax(output()[0])\n prediction_digits.append(digit)\n\n # Compare prediction results with ground truth labels to calculate accuracy.\n accurate_count = 0\n for index in range(len(prediction_digits)):\n if prediction_digits[index] == test_labels[index]:\n accurate_count += 1\n accuracy = accurate_count * 1.0 / len(prediction_digits)\n\n return accuracy",
"_____no_output_____"
],
[
"print(evaluate_model(interpreter))",
"_____no_output_____"
]
],
[
[
"Repeat the evaluation on the 16x8 quantized model:",
"_____no_output_____"
]
],
[
[
"# NOTE: This quantization mode is an experimental post-training mode,\n# it does not have any optimized kernels implementations or\n# specialized machine learning hardware accelerators. Therefore,\n# it could be slower than the float interpreter.\nprint(evaluate_model(interpreter_16x8))",
"_____no_output_____"
]
],
[
[
"In this example, you have quantized a model to 16x8 with no difference in the accuracy, but with the 3x reduced size.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad11965baf35bab77de0ce00b3e9b153620ea0d
| 94,689 |
ipynb
|
Jupyter Notebook
|
Python/diagramas.ipynb
|
shm-unesp/MecSol
|
fef0a1b15668b8e79a756e44afbecfd2e325fd55
|
[
"CC0-1.0"
] | 1 |
2021-12-05T02:04:28.000Z
|
2021-12-05T02:04:28.000Z
|
Python/diagramas.ipynb
|
shm-unesp/MecSol
|
fef0a1b15668b8e79a756e44afbecfd2e325fd55
|
[
"CC0-1.0"
] | null | null | null |
Python/diagramas.ipynb
|
shm-unesp/MecSol
|
fef0a1b15668b8e79a756e44afbecfd2e325fd55
|
[
"CC0-1.0"
] | null | null | null | 364.188462 | 43,428 | 0.932748 |
[
[
[
"# Diagramas de Cortante e Momento em Vigas\n\nExemplo disponível em https://youtu.be/MNW1-rB46Ig\n\n<img src=\"viga1.jpg\">",
"_____no_output_____"
]
],
[
[
"import numpy as np \nimport matplotlib.pyplot as plt\nimport matplotlib.font_manager as font_manager\nfrom matplotlib import rc\n\n# Set the font dictionaries (for plot title and axis titles)\nrc('font', **{'family': 'serif', 'serif': ['Computer Modern'],'size': '18'})\nrc('text', usetex=True)",
"_____no_output_____"
],
[
"q = 10\nL = 1\nN=10\n\n# Reações de Apoio\nVA=3*q*L/4\nVB=q*L/4\nprint(\"Reação de Apoio em A (kN) =\",VA)\nprint(\"Reação de Apoio em B (kN) =\",VB)",
"Reação de Apoio em A (kN) = 7.5\nReação de Apoio em B (kN) = 2.5\n"
]
],
[
[
"Cálculo da Cortante pela integração do carregamento usando a Regra do Trapézio",
"_____no_output_____"
]
],
[
[
"def Cortante(q,x,V0):\n # Entro com o carregamento, comprimento do trecho e cortante em x[0]\n V = np.zeros(len(x)) # inicializa\n dx=x[1] # passo\n V[0]=V0 # Valor inicial da cortante\n for i in range(1,N):\n V[i]=V[i-1]+dx*(q[i-1]+q[i])/2\n return np.array(V)",
"_____no_output_____"
]
],
[
[
"Cálculo do Momento Fletor pela integração do carregamento usando a Regra do Trapézio",
"_____no_output_____"
]
],
[
[
"def Momento(V,x,M0):\n # Entro com a cortante, comprimento do trecho e momento em x[0]\n M = np.zeros(len(x)) # inicializa\n dx=x[1] # passo\n M[0]=M0 # Valor inicial da cortante\n for i in range(1,N):\n M[i]=M0+M[i-1]+dx*(V[i-1]+V[i])/2\n return np.array(M)",
"_____no_output_____"
],
[
"carregamento1 = q*np.ones(N)\ncarregamento2 =0*np.ones(N)\nx1=np.linspace(0,L,N)\nx2=np.linspace(L,2*L,N)\n\n# Carregamento\nplt.figure(figsize=(15,5))\nplt.plot(x1,carregamento1,color='r',linewidth=2)\nplt.fill_between(x1,carregamento1, facecolor='b', alpha=0.5)\nplt.plot(x2,carregamento2,color='r',linewidth=2)\nplt.fill_between(x2,carregamento2, facecolor='b', alpha=0.5)\nplt.xlabel(\"Comprimento (m)\")\nplt.ylabel(\"Carregamento (kN/m)\")\nplt.grid(which='major', axis='both')\nplt.title(\"Carregamento\")\nplt.show()",
"_____no_output_____"
],
[
"# Trecho I - 0<x<L\nV1=-q*x1+VA # Cortante Teórica\nM1=VA*x1-q*(x1*x1)/2 # Momento Teórico\n# por integração numérica\nV1int = Cortante(-carregamento1,x1,VA)\nM1int = Momento(V1int,x1,0)\n\n# Trecho II - L<x<2L\nV2=VA-q*np.ones(N)*L # Cortante Teórico\nM2=VA*x2-q*L*(x2-L/2) # Momento Teórico\n# por integração numérica\nV2int=Cortante(-carregamento2,x2,V1int[N-1])\nM2int=Momento(V2int,x2,M1int[N-1])",
"_____no_output_____"
],
[
"# Cortante\nplt.figure(figsize=(15,5))\nplt.plot(x1,V1,color='r',linewidth=2)\nplt.fill_between(x1, V1, facecolor='b', alpha=0.5)\nplt.plot(x2,V2,color='r',linewidth=2,label=\"Método das Seções\")\nplt.fill_between(x2, V2, facecolor='b', alpha=0.5)\nplt.plot(x1,V1int,color='k',linestyle = 'dotted', linewidth=5,label=\"Integração\")\nplt.plot(x2,V2int,color='k',linestyle = 'dotted', linewidth=5)\nplt.legend(loc =\"upper right\")\nplt.xlabel(\"Comprimento (m)\")\nplt.ylabel(\"Cortante (kN)\")\nplt.grid(which='major', axis='both')\nplt.title(\"Diagrama de Cortante\")\nplt.show()",
"_____no_output_____"
],
[
"# Momento Fletor\nplt.figure(figsize=(15,5))\nplt.plot(x1,M1,color='r',linewidth=2)\nplt.fill_between(x1, M1, facecolor='b', alpha=0.5)\nplt.plot(x2,M2,color='r',linewidth=2,label=\"Método das Seções\")\nplt.fill_between(x2, M2, facecolor='b', alpha=0.5)\nplt.plot(x1,M1int,color='k',linestyle = 'dotted', linewidth=5,label=\"Integração\")\nplt.plot(x2,M2int,color='k',linestyle = 'dotted', linewidth=5)\nplt.legend(loc =\"upper right\")\nplt.xlabel(\"Comprimento (m)\")\nplt.ylabel(\"Momento (kN.m)\")\nplt.grid(which='major', axis='both')\nplt.title(\"Diagrama de Momento Fletor\")\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ad11c298f22587a4d9133c2cc7f74d44865f4fc
| 6,302 |
ipynb
|
Jupyter Notebook
|
Python Functions, Packages, Input_Output, Exception Handling and Debugging/3_function_arguments.ipynb
|
sauravraghuvanshi/AI-and-ML-Complete-Learning
|
6b2f6c02015ad479118d326d21be298c84088891
|
[
"MIT"
] | 2 |
2020-05-18T13:59:26.000Z
|
2020-09-24T08:56:21.000Z
|
Python Functions, Packages, Input_Output, Exception Handling and Debugging/3_function_arguments.ipynb
|
sauravraghuvanshi/AI-and-ML-Complete-Learning
|
6b2f6c02015ad479118d326d21be298c84088891
|
[
"MIT"
] | null | null | null |
Python Functions, Packages, Input_Output, Exception Handling and Debugging/3_function_arguments.ipynb
|
sauravraghuvanshi/AI-and-ML-Complete-Learning
|
6b2f6c02015ad479118d326d21be298c84088891
|
[
"MIT"
] | 1 |
2021-07-18T17:55:18.000Z
|
2021-07-18T17:55:18.000Z
| 23.961977 | 556 | 0.514281 |
[
[
[
"# Function Arguments\n",
"_____no_output_____"
]
],
[
[
"def greet(name, msg):\n \"\"\"\n This function greets to person with the provided message\n \"\"\"\n print(\"Hello {0} , {1}\".format(name, msg))\n\n#call the function with arguments\ngreet(\"satish\", \"Good Morning\")\n",
"Hello satish , Good Morning\n"
],
[
"#suppose if we pass one argument\n\ngreet(\"satish\") #will get an error\n",
"_____no_output_____"
]
],
[
[
"# Different Forms of Arguments",
"_____no_output_____"
],
[
"# 1. Default Arguments",
"_____no_output_____"
],
[
"We can provide a default value to an argument by using the assignment operator (=). ",
"_____no_output_____"
]
],
[
[
"def greet(name, msg=\"Good Morning\"):\n \"\"\"\n This function greets to person with the provided message\n if message is not provided, it defaults to \"Good Morning\"\n \"\"\"\n print(\"Hello {0} , {1}\".format(name, msg))\n\ngreet(\"satish\", \"Good Night\")\n",
"Hello satish , Good Night\n"
],
[
"#with out msg argument\ngreet(\"satish\")\n",
"Hello satish , Good Morning\n"
]
],
[
[
"Once we have a default argument, all the arguments to its right must also have default values.",
"_____no_output_____"
],
[
"def greet(msg=\"Good Morning\", name) \n\n#will get a SyntaxError : non-default argument follows default argument",
"_____no_output_____"
],
[
"# 2. Keyword Arguments",
"_____no_output_____"
],
[
"kwargs allows you to pass keyworded variable length of arguments to a function. You should use **kwargs if you want to handle named arguments in a function",
"_____no_output_____"
],
[
"# Example:",
"_____no_output_____"
]
],
[
[
"def greet(**kwargs):\n \"\"\"\n This function greets to person with the provided message\n \"\"\"\n if kwargs:\n print(\"Hello {0} , {1}\".format(kwargs['name'], kwargs['msg']))\ngreet(name=\"satish\", msg=\"Good Morning\")\n",
"Hello satish , Good Morning\n"
]
],
[
[
"# 3. Arbitary Arguments",
"_____no_output_____"
],
[
"Sometimes, we do not know in advance the number of arguments that will be passed into a function.Python allows us to handle this kind of situation through function calls with arbitrary number of arguments.",
"_____no_output_____"
],
[
"# Example:",
"_____no_output_____"
]
],
[
[
"def greet(*names):\n \"\"\"\n This function greets all persons in the names tuple \n \"\"\"\n print(names)\n \n for name in names:\n print(\"Hello, {0} \".format(name))\n\ngreet(\"satish\", \"murali\", \"naveen\", \"srikanth\")\n",
"('satish', 'murali', 'naveen', 'srikanth')\nHello, satish \nHello, murali \nHello, naveen \nHello, srikanth \n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4ad11f81f147abb900f8b7b553c0ebc8e1d31c57
| 101,921 |
ipynb
|
Jupyter Notebook
|
notebooks_completos/015-NumPy-EntradaSalida.ipynb
|
rrendon502/AeroPython
|
c4bbcf67ac4787717a49232666b63c50c6a76218
|
[
"CC-BY-4.0"
] | null | null | null |
notebooks_completos/015-NumPy-EntradaSalida.ipynb
|
rrendon502/AeroPython
|
c4bbcf67ac4787717a49232666b63c50c6a76218
|
[
"CC-BY-4.0"
] | null | null | null |
notebooks_completos/015-NumPy-EntradaSalida.ipynb
|
rrendon502/AeroPython
|
c4bbcf67ac4787717a49232666b63c50c6a76218
|
[
"CC-BY-4.0"
] | null | null | null | 196.001923 | 85,260 | 0.884548 |
[
[
[
"<img src=\"../images/Boeing_full_logo.png\" alt=\"Boeing\" style=\"width: 400px;\"/>\n\n<br/>\n\n<img src=\"../images/aeropython_logo.png\" alt=\"AeroPython\" style=\"width: 200px;\"/>",
"_____no_output_____"
],
[
"# NumPy: Entrada/Salida",
"_____no_output_____"
],
[
"Con E/S (I/O en inglés) entendemos leer y escribir datos archivos. Es algo que necesitaremos hacer con relativa frecuencia, y en NumPy es muy sencillo de hacer. Para el caso de la **lectura** se usa la función `np.loadtxt`.",
"_____no_output_____"
],
[
"## Ejemplo con datos de temperaturas ",
"_____no_output_____"
],
[
"Para practicar, vamos a leer el archivo `temperaturas.csv` que contiene datos diarios de temperaturas en Nueva York entre el 1 de enero de 2013 y el 1 de enero de 2014, obtenidos gratuitamente de http://ncdc.noaa.gov/. Como los hemos descargado en formato CSV habrá que tener algunas precauciones a la hora de leer el archivo.",
"_____no_output_____"
]
],
[
[
"!head ../data/temperaturas.csv",
"STATION,DATE,TMAX,TMIN\r\nGHCND:USW00094728,20130101,44,-33\r\nGHCND:USW00094728,20130102,6,-56\r\nGHCND:USW00094728,20130103,0,-44\r\nGHCND:USW00094728,20130104,28,-11\r\nGHCND:USW00094728,20130105,56,0\r\nGHCND:USW00094728,20130106,78,11\r\nGHCND:USW00094728,20130107,72,28\r\nGHCND:USW00094728,20130108,89,17\r\nGHCND:USW00094728,20130109,94,39\r\n"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"datos = np.loadtxt(\"../data/temperaturas.csv\",\n skiprows=1, # Saltamos una línea\n usecols=(1, 2, 3), # Solo columnas 2, 3 y 4\n delimiter=',') # Separados por comas",
"_____no_output_____"
],
[
"datos[:9]",
"_____no_output_____"
]
],
[
[
"La primera columna es un entero con formato \"AAAAMMDD\" que vamos a ignorar. Las temperaturas están medidas en décimas de grado Celsius, así que hay que pasarlas a grados Celsius. Vamos a calcular también la temperatura media.",
"_____no_output_____"
]
],
[
[
"Tmax = datos[:, 1] / 10\nTmin = datos[:, 2] / 10\nTavg = (Tmax + Tmin) / 2",
"_____no_output_____"
]
],
[
[
"Como vamos a ignorar la columna de las fechas tenemos que crear un dominio para el eje x. Simplemente construiremos un array de enteros desde 0 hasta 365.",
"_____no_output_____"
]
],
[
[
"x = np.arange(366)",
"_____no_output_____"
]
],
[
[
"Supongamos que ahora queremos guardar nuestra tabla de datos en un archivo txt, para poder cargarlo ya modificado más adelante. Una manera fácil de hacerlo sería con otra función de NumPy: `np.savetxt`. Lo usaremos con los argumentos opcionales `fmt='%.5f', newline = '\\r\\n'` para obtener un fichero *bonito* que podamos entender de un vistazo.",
"_____no_output_____"
]
],
[
[
"matriz_datos = np.zeros([366, 4])\nmatriz_datos[:, 0] = x\nmatriz_datos[:, 1] = Tmax\nmatriz_datos[:, 2] = Tmin\nmatriz_datos[:, 3] = Tavg\n\nprint(matriz_datos[:10])\n\n# np.savetxt('archivo_datos.txt', matriz_datos, fmt='%.5f', newline = '\\r\\n')",
"[[ 0. 4.4 -3.3 0.55]\n [ 1. 0.6 -5.6 -2.5 ]\n [ 2. 0. -4.4 -2.2 ]\n [ 3. 2.8 -1.1 0.85]\n [ 4. 5.6 0. 2.8 ]\n [ 5. 7.8 1.1 4.45]\n [ 6. 7.2 2.8 5. ]\n [ 7. 8.9 1.7 5.3 ]\n [ 8. 9.4 3.9 6.65]\n [ 9. 8.3 4.4 6.35]]\n"
]
],
[
[
"##### Ejercicio",
"_____no_output_____"
],
[
"Y ahora representamos la evolución de la temperatura media (por ejemplo de color negro), indicando \"Daily summaries\" en el título, \"Days\" en el eje x y \"Temperature (C)\" en el eje y, usando la interfaz orientada a objetos de matplotlib (función `plt.subplots`). Podemos crear una zona rellena entre la máxima y la mínima con la función `fill_between(x, max, min)` (por ejemplo de color #4f88b1). Si los límites del eje x no quedan como queremos podemos usar la función `set_xlim(xmin, xmax)`.",
"_____no_output_____"
]
],
[
[
"# aeropython: preserve\n%matplotlib inline\nimport matplotlib.pyplot as plt\n\nfig, ax = plt.subplots()\n\nax.plot(x, Tavg, 'k')\nax.set_xlim(0, 366)\nax.fill_between(x, Tmin, Tmax, facecolor='#4f88b1', edgecolor='none')\nax.set_title(\"Resúmenes diarios\")\nax.set_xlabel(\"Días\")\nax.set_ylabel(\"Temperatura (°C)\")",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"_Ya hemos aprendido a efectuar algunas operaciones útiles con NumPy e incluso hemos hecho nuestro primer ejercicio de lectura de datos. Estamos en condiciones de empezar a escribir programas más interesantes, pero aún queda lo mejor._\n\nSi quieres saber más sobre lectura y escritura de ficheros en Python, puedes consultar al documentación oficial:\n\nhttps://docs.python.org/3.5/tutorial/inputoutput.html#reading-and-writing-files",
"_____no_output_____"
],
[
"---\n<br/>\n#### <h4 align=\"right\">¡Síguenos en Twitter!\n<br/>\n###### <a href=\"https://twitter.com/AeroPython\" class=\"twitter-follow-button\" data-show-count=\"false\">Follow @AeroPython</a> <script>!function(d,s,id){var js,fjs=d.getElementsByTagName(s)[0],p=/^http:/.test(d.location)?'http':'https';if(!d.getElementById(id)){js=d.createElement(s);js.id=id;js.src=p+'://platform.twitter.com/widgets.js';fjs.parentNode.insertBefore(js,fjs);}}(document, 'script', 'twitter-wjs');</script> \n<br/>\n###### Este notebook ha sido realizado por: Juan Luis Cano, Mabel Delgado y Álex Sáez \n<br/>\n##### <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/deed.es\"><img alt=\"Licencia Creative Commons\" style=\"border-width:0\" src=\"http://i.creativecommons.org/l/by/4.0/88x31.png\" /></a><br /><span xmlns:dct=\"http://purl.org/dc/terms/\" property=\"dct:title\">Curso AeroPython</span> por <span xmlns:cc=\"http://creativecommons.org/ns#\" property=\"cc:attributionName\">Juan Luis Cano Rodriguez y Alejandro Sáez Mollejo</span> se distribuye bajo una <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/deed.es\">Licencia Creative Commons Atribución 4.0 Internacional</a>.",
"_____no_output_____"
],
[
"---\n_Las siguientes celdas contienen configuración del Notebook_\n\n_Para visualizar y utlizar los enlaces a Twitter el notebook debe ejecutarse como [seguro](http://ipython.org/ipython-doc/dev/notebook/security.html)_\n\n File > Trusted Notebook",
"_____no_output_____"
]
],
[
[
"# Esta celda da el estilo al notebook\nfrom IPython.core.display import HTML\ncss_file = '../styles/aeropython.css'\nHTML(open(css_file, \"r\").read())",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4ad12767a083c89f401808c46f6cb9eadc49b59e
| 15,559 |
ipynb
|
Jupyter Notebook
|
notebook_gallery/other_experiments/explore-models/modelinterpretation/treeinterpreter/random_forest_intepretation_treeinterpreter.ipynb
|
pramitchoudhary/Experiments
|
71c251dbb2a7af801d9afab2bfb93d6a55caa7da
|
[
"Unlicense"
] | 3 |
2017-02-20T08:00:10.000Z
|
2017-08-27T03:28:09.000Z
|
notebook_gallery/other_experiments/explore-models/modelinterpretation/treeinterpreter/random_forest_intepretation_treeinterpreter.ipynb
|
pramitchoudhary/Experiments
|
71c251dbb2a7af801d9afab2bfb93d6a55caa7da
|
[
"Unlicense"
] | null | null | null |
notebook_gallery/other_experiments/explore-models/modelinterpretation/treeinterpreter/random_forest_intepretation_treeinterpreter.ipynb
|
pramitchoudhary/Experiments
|
71c251dbb2a7af801d9afab2bfb93d6a55caa7da
|
[
"Unlicense"
] | null | null | null | 28.186594 | 223 | 0.453307 |
[
[
[
"# Reference: https://github.com/andosa/treeinterpreter\n# Blog: http://blog.datadive.net/random-forest-interpretation-with-scikit-learn/\n\nfrom treeinterpreter import treeinterpreter as ti\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"from sklearn.datasets import load_boston\nboston = load_boston()\nrf = RandomForestRegressor()\nprint(len(boston.feature_names))",
"13\n"
],
[
"print(boston.DESCR)",
"Boston House Prices dataset\n===========================\n\nNotes\n------\nData Set Characteristics: \n\n :Number of Instances: 506 \n\n :Number of Attributes: 13 numeric/categorical predictive\n \n :Median Value (attribute 14) is usually the target\n\n :Attribute Information (in order):\n - CRIM per capita crime rate by town\n - ZN proportion of residential land zoned for lots over 25,000 sq.ft.\n - INDUS proportion of non-retail business acres per town\n - CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)\n - NOX nitric oxides concentration (parts per 10 million)\n - RM average number of rooms per dwelling\n - AGE proportion of owner-occupied units built prior to 1940\n - DIS weighted distances to five Boston employment centres\n - RAD index of accessibility to radial highways\n - TAX full-value property-tax rate per $10,000\n - PTRATIO pupil-teacher ratio by town\n - B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town\n - LSTAT % lower status of the population\n - MEDV Median value of owner-occupied homes in $1000's\n\n :Missing Attribute Values: None\n\n :Creator: Harrison, D. and Rubinfeld, D.L.\n\nThis is a copy of UCI ML housing dataset.\nhttp://archive.ics.uci.edu/ml/datasets/Housing\n\n\nThis dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.\n\nThe Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic\nprices and the demand for clean air', J. Environ. Economics & Management,\nvol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics\n...', Wiley, 1980. N.B. Various transformations are used in the table on\npages 244-261 of the latter.\n\nThe Boston house-price data has been used in many machine learning papers that address regression\nproblems. \n \n**References**\n\n - Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.\n - Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.\n - many more! (see http://archive.ics.uci.edu/ml/datasets/Housing)\n\n"
],
[
"pd.DataFrame(boston.data[:300,]).head()",
"_____no_output_____"
],
[
"rf = RandomForestRegressor()\n# Selecting 300 sample rows from the data set\nfit1 = rf.fit(boston.data[:300], boston.target[:300])",
"_____no_output_____"
],
[
"fit1",
"_____no_output_____"
],
[
"# Randomly pick 2 instances\ninstances = boston.data[[300, 309]]\nprint(pd.DataFrame(instances))\nprint \"Instance 0 prediction:\", rf.predict(instances[0].reshape(1,13))\nprint \"Instance 1 prediction:\", rf.predict(instances[1].reshape(1,13))",
" 0 1 2 3 4 5 6 7 8 9 10 \\\n0 0.04417 70.0 2.24 0.0 0.400 6.871 47.4 7.8278 5.0 358.0 14.8 \n1 0.34940 0.0 9.90 0.0 0.544 5.972 76.7 3.1025 4.0 304.0 18.4 \n\n 11 12 \n0 390.86 6.07 \n1 396.24 9.97 \nInstance 0 prediction: [ 29.08]\nInstance 1 prediction: [ 22.64]\n"
],
[
"# It uses feature response from multiple tree path \nprediction, bias, contributions = ti.predict(rf, instances)",
"_____no_output_____"
],
[
"for i in range(len(instances)):\n print \"Instance\", i\n print \"Bias (trainset mean)\", bias[i]\n print \"Feature contributions:\"\n for c, feature in sorted(zip(contributions[i], \n boston.feature_names), \n key=lambda x: -abs(x[0])):\n print feature, round(c, 2)\n print \"-\"*20",
"Instance 0\nBias (trainset mean) 25.5101\nFeature contributions:\nRM 2.62\nLSTAT 1.95\nTAX -0.92\nINDUS 0.46\nPTRATIO 0.45\nNOX -0.33\nZN -0.28\nDIS -0.26\nB -0.2\nCRIM -0.16\nRAD 0.13\nAGE 0.1\nCHAS 0.0\n--------------------\nInstance 1\nBias (trainset mean) 25.5101\nFeature contributions:\nRM -5.98\nLSTAT 2.7\nCRIM 0.9\nAGE -0.34\nB -0.17\nPTRATIO 0.14\nTAX -0.12\nNOX 0.11\nRAD -0.07\nDIS -0.06\nZN 0.02\nINDUS 0.01\nCHAS 0.0\n--------------------\n"
],
[
"#print prediction\n#print(contributions[0])\nprint(bias[0] + np.sum(contributions[0]))\nprint(bias[1] + np.sum(contributions[1]))",
"29.08\n22.64\n"
],
[
"np.sum(contributions, axis=1)",
"_____no_output_____"
],
[
"# the basic feature importance feature provided by sklearn\nfit1.feature_importances_",
"_____no_output_____"
],
[
"# treeinterpreter uses the apply function to retrieve the leave indicies with the help of which, \n# the tree path is retrieves\nrf.apply",
"_____no_output_____"
],
[
"rf.apply(instances)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad12973c9a40833dba122173847f7243ee39e38
| 13,959 |
ipynb
|
Jupyter Notebook
|
docs/memo/notebooks/data/eventvestor.shareholder_meetings/notebook.ipynb
|
zhangshoug/czipline
|
6bce0abd4772443547f44669c0adb2b5c63f64db
|
[
"Apache-2.0"
] | 9 |
2019-05-18T10:44:48.000Z
|
2022-01-01T15:12:49.000Z
|
docs/memo/notebooks/data/eventvestor.shareholder_meetings/notebook.ipynb
|
yuanyichuangzhi/czipline
|
6bce0abd4772443547f44669c0adb2b5c63f64db
|
[
"Apache-2.0"
] | null | null | null |
docs/memo/notebooks/data/eventvestor.shareholder_meetings/notebook.ipynb
|
yuanyichuangzhi/czipline
|
6bce0abd4772443547f44669c0adb2b5c63f64db
|
[
"Apache-2.0"
] | 10 |
2019-05-18T10:58:55.000Z
|
2022-03-24T13:37:17.000Z
| 34.213235 | 311 | 0.493087 |
[
[
[
"# EventVestor: Shareholder Meetings\n\nIn this notebook, we'll take a look at EventVestor's *Shareholder Meetings* dataset, available on the [Quantopian Store](https://www.quantopian.com/store). This dataset spans January 01, 2007 through the current day, and documents companies' annual and special shareholder meetings calendars.\n\n### Blaze\nBefore we dig into the data, we want to tell you about how you generally access Quantopian Store data sets. These datasets are available through an API service known as [Blaze](http://blaze.pydata.org). Blaze provides the Quantopian user with a convenient interface to access very large datasets.\n\nBlaze provides an important function for accessing these datasets. Some of these sets are many millions of records. Bringing that data directly into Quantopian Research directly just is not viable. So Blaze allows us to provide a simple querying interface and shift the burden over to the server side.\n\nIt is common to use Blaze to reduce your dataset in size, convert it over to Pandas and then to use Pandas for further computation, manipulation and visualization.\n\nHelpful links:\n* [Query building for Blaze](http://blaze.pydata.org/en/latest/queries.html)\n* [Pandas-to-Blaze dictionary](http://blaze.pydata.org/en/latest/rosetta-pandas.html)\n* [SQL-to-Blaze dictionary](http://blaze.pydata.org/en/latest/rosetta-sql.html).\n\nOnce you've limited the size of your Blaze object, you can convert it to a Pandas DataFrames using:\n> `from odo import odo` \n> `odo(expr, pandas.DataFrame)`\n\n### Free samples and limits\nOne other key caveat: we limit the number of results returned from any given expression to 10,000 to protect against runaway memory usage. To be clear, you have access to all the data server side. We are limiting the size of the responses back from Blaze.\n\nThere is a *free* version of this dataset as well as a paid one. The free one includes about three years of historical data, though not up to the current day.\n\nWith preamble in place, let's get started:",
"_____no_output_____"
]
],
[
[
"# import the dataset\nfrom quantopian.interactive.data.eventvestor import shareholder_meetings\n# or if you want to import the free dataset, use:\n# from quantopian.data.eventvestor import shareholder_meetings_free\n\n# import data operations\nfrom odo import odo\n# import other libraries we will use\nimport pandas as pd",
"_____no_output_____"
],
[
"# Let's use blaze to understand the data a bit using Blaze dshape()\nshareholder_meetings.dshape",
"_____no_output_____"
],
[
"# And how many rows are there?\n# N.B. we're using a Blaze function to do this, not len()\nshareholder_meetings.count()",
"_____no_output_____"
],
[
"# Let's see what the data looks like. We'll grab the first three rows.\nshareholder_meetings[:3]",
"_____no_output_____"
]
],
[
[
"Let's go over the columns:\n- **event_id**: the unique identifier for this event.\n- **asof_date**: EventVestor's timestamp of event capture.\n- **symbol**: stock ticker symbol of the affected company.\n- **event_headline**: a brief description of the event\n- **meeting_type**: types include *annual meeting, special meeting, proxy contest*.\n- **record_date**: record date to be eligible for proxy vote\n- **meeting_date**: shareholder meeting date\n- **timestamp**: this is our timestamp on when we registered the data.\n- **sid**: the equity's unique identifier. Use this instead of the symbol.",
"_____no_output_____"
],
[
"We've done much of the data processing for you. Fields like `timestamp` and `sid` are standardized across all our Store Datasets, so the datasets are easy to combine. We have standardized the `sid` across all our equity databases.\n\nWe can select columns and rows with ease. Below, we'll fetch Tesla's 2013 and 2014 meetings.",
"_____no_output_____"
]
],
[
[
"# get tesla's sid first\ntesla_sid = symbols('TSLA').sid\nmeetings = shareholder_meetings[('2012-12-31' < shareholder_meetings['asof_date']) & \n (shareholder_meetings['asof_date'] <'2015-01-01') & \n (shareholder_meetings.sid == tesla_sid)]\n# When displaying a Blaze Data Object, the printout is automatically truncated to ten rows.\nmeetings.sort('asof_date')",
"_____no_output_____"
]
],
[
[
"Now suppose we want a DataFrame of the Blaze Data Object above, but only want the `record_date, meeting_date`, and `sid`.",
"_____no_output_____"
]
],
[
[
"df = odo(meetings, pd.DataFrame)\ndf = df[['record_date','meeting_date','sid']]\ndf",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad135b74f5f109b23b4aad60f2d9577c7255817
| 7,124 |
ipynb
|
Jupyter Notebook
|
Chapter12/Exercise12.03/export_pmml.ipynb
|
jeroenzwiers/The-Artificial-Intelligence-Infrastructure-Workshop
|
f30ee8abc36aaf47cb04174391e7c789a91bbbd4
|
[
"MIT"
] | 18 |
2020-04-06T19:19:06.000Z
|
2022-02-07T09:31:00.000Z
|
Chapter12/Exercise12.03/export_pmml.ipynb
|
jeroenzwiers/The-Artificial-Intelligence-Infrastructure-Workshop
|
f30ee8abc36aaf47cb04174391e7c789a91bbbd4
|
[
"MIT"
] | 7 |
2020-04-29T18:30:08.000Z
|
2022-01-04T16:42:58.000Z
|
Chapter12/Exercise12.03/export_pmml.ipynb
|
jeroenzwiers/The-Artificial-Intelligence-Infrastructure-Workshop
|
f30ee8abc36aaf47cb04174391e7c789a91bbbd4
|
[
"MIT"
] | 22 |
2020-03-03T17:48:40.000Z
|
2022-02-14T18:07:04.000Z
| 43.705521 | 195 | 0.613419 |
[
[
[
"# copy the trained model for predicting whether a person would have survived the Titanic disaster\n!cp ../Exercise12.01/model.pkl .",
"_____no_output_____"
],
[
"!pip install sklearn2pmml",
"Collecting sklearn2pmml\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/29/13/921daa2a87e19dc7579865f0990984b66cd9ad521bb43218d165a3d885d8/sklearn2pmml-0.55.4.tar.gz (5.6MB)\n\u001b[K |████████████████████████████████| 5.6MB 422kB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: joblib>=0.13.0 in /usr/local/anaconda3/lib/python3.7/site-packages (from sklearn2pmml) (0.13.2)\nRequirement already satisfied: scikit-learn>=0.18.0 in /usr/local/anaconda3/lib/python3.7/site-packages (from sklearn2pmml) (0.21.3)\nCollecting sklearn-pandas>=0.0.10 (from sklearn2pmml)\n Downloading https://files.pythonhosted.org/packages/1f/48/4e1461d828baf41d609efaa720d20090ac6ec346b5daad3c88e243e2207e/sklearn_pandas-1.8.0-py2.py3-none-any.whl\nRequirement already satisfied: scipy>=0.17.0 in /usr/local/anaconda3/lib/python3.7/site-packages (from scikit-learn>=0.18.0->sklearn2pmml) (1.3.1)\nRequirement already satisfied: numpy>=1.11.0 in /usr/local/anaconda3/lib/python3.7/site-packages (from scikit-learn>=0.18.0->sklearn2pmml) (1.17.2)\nRequirement already satisfied: pandas>=0.11.0 in /usr/local/anaconda3/lib/python3.7/site-packages (from sklearn-pandas>=0.0.10->sklearn2pmml) (0.25.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/anaconda3/lib/python3.7/site-packages (from pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (2019.3)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/anaconda3/lib/python3.7/site-packages (from pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (2.8.0)\nRequirement already satisfied: six>=1.5 in /usr/local/anaconda3/lib/python3.7/site-packages (from python-dateutil>=2.6.1->pandas>=0.11.0->sklearn-pandas>=0.0.10->sklearn2pmml) (1.12.0)\nBuilding wheels for collected packages: sklearn2pmml\n Building wheel for sklearn2pmml (setup.py) ... \u001b[?25ldone\n\u001b[?25h Created wheel for sklearn2pmml: filename=sklearn2pmml-0.55.4-cp37-none-any.whl size=5639649 sha256=c23d4072bd29d0373a4aad2742d559f7d9eeb0e80ff369a9c8328b7c716a753b\n Stored in directory: /Users/bas/Library/Caches/pip/wheels/09/59/21/0d21d626166a52114f645f7eb675b51d947a32811f6e5198bf\nSuccessfully built sklearn2pmml\nInstalling collected packages: sklearn-pandas, sklearn2pmml\nSuccessfully installed sklearn-pandas-1.8.0 sklearn2pmml-0.55.4\n"
],
[
"from sklearn2pmml import sklearn2pmml, make_pmml_pipeline\nimport pickle",
"_____no_output_____"
],
[
"# load the model from pickle file\nfile = open('model.pkl', 'rb') # read bytes\nmodel = pickle.load(file)\nfile.close()",
"_____no_output_____"
],
[
"pmml_pipeline = make_pmml_pipeline(model)\nsklearn2pmml(pmml_pipeline, 'titanic.pmml')",
"_____no_output_____"
],
[
"!cat titanic.pmml",
"<?xml version=\"1.0\" encoding=\"UTF-8\" standalone=\"yes\"?>\r\n<PMML xmlns=\"http://www.dmg.org/PMML-4_3\" xmlns:data=\"http://jpmml.org/jpmml-model/InlineTable\" version=\"4.3\">\r\n\t<Header>\r\n\t\t<Application name=\"JPMML-SkLearn\" version=\"1.5.35\"/>\r\n\t\t<Timestamp>2020-04-16T07:19:01Z</Timestamp>\r\n\t</Header>\r\n\t<DataDictionary>\r\n\t\t<DataField name=\"y\" optype=\"categorical\" dataType=\"integer\">\r\n\t\t\t<Value value=\"0\"/>\r\n\t\t\t<Value value=\"1\"/>\r\n\t\t</DataField>\r\n\t\t<DataField name=\"x1\" optype=\"continuous\" dataType=\"double\"/>\r\n\t\t<DataField name=\"x2\" optype=\"continuous\" dataType=\"double\"/>\r\n\t\t<DataField name=\"x3\" optype=\"continuous\" dataType=\"double\"/>\r\n\t\t<DataField name=\"x4\" optype=\"continuous\" dataType=\"double\"/>\r\n\t\t<DataField name=\"x5\" optype=\"continuous\" dataType=\"double\"/>\r\n\t\t<DataField name=\"x6\" optype=\"continuous\" dataType=\"double\"/>\r\n\t</DataDictionary>\r\n\t<RegressionModel functionName=\"classification\" normalizationMethod=\"logit\">\r\n\t\t<MiningSchema>\r\n\t\t\t<MiningField name=\"y\" usageType=\"target\"/>\r\n\t\t\t<MiningField name=\"x1\"/>\r\n\t\t\t<MiningField name=\"x2\"/>\r\n\t\t\t<MiningField name=\"x3\"/>\r\n\t\t\t<MiningField name=\"x4\"/>\r\n\t\t\t<MiningField name=\"x5\"/>\r\n\t\t\t<MiningField name=\"x6\"/>\r\n\t\t</MiningSchema>\r\n\t\t<Output>\r\n\t\t\t<OutputField name=\"probability(0)\" optype=\"continuous\" dataType=\"double\" feature=\"probability\" value=\"0\"/>\r\n\t\t\t<OutputField name=\"probability(1)\" optype=\"continuous\" dataType=\"double\" feature=\"probability\" value=\"1\"/>\r\n\t\t</Output>\r\n\t\t<RegressionTable intercept=\"1.7352745860996108\" targetCategory=\"1\">\r\n\t\t\t<NumericPredictor name=\"x1\" coefficient=\"-0.9542728806698173\"/>\r\n\t\t\t<NumericPredictor name=\"x2\" coefficient=\"2.6453670750923477\"/>\r\n\t\t\t<NumericPredictor name=\"x3\" coefficient=\"-0.03428781881627483\"/>\r\n\t\t\t<NumericPredictor name=\"x4\" coefficient=\"-0.3292077169124686\"/>\r\n\t\t\t<NumericPredictor name=\"x5\" coefficient=\"-0.10430754556461452\"/>\r\n\t\t\t<NumericPredictor name=\"x6\" coefficient=\"0.003925071564013619\"/>\r\n\t\t</RegressionTable>\r\n\t\t<RegressionTable intercept=\"0.0\" targetCategory=\"0\"/>\r\n\t</RegressionModel>\r\n</PMML>\r\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad16ae161705f7d6a6be0442a31f07c5c61ca73
| 97,033 |
ipynb
|
Jupyter Notebook
|
stack-overflow-developers-survey-analysis.ipynb
|
shahad-bit/Stack-Overflow-Survey-2019
|
1035b293c537a0e4f5cc80c627de1f1d5d2e6e21
|
[
"CNRI-Python"
] | null | null | null |
stack-overflow-developers-survey-analysis.ipynb
|
shahad-bit/Stack-Overflow-Survey-2019
|
1035b293c537a0e4f5cc80c627de1f1d5d2e6e21
|
[
"CNRI-Python"
] | null | null | null |
stack-overflow-developers-survey-analysis.ipynb
|
shahad-bit/Stack-Overflow-Survey-2019
|
1035b293c537a0e4f5cc80c627de1f1d5d2e6e21
|
[
"CNRI-Python"
] | null | null | null | 108.538031 | 44,364 | 0.825214 |
[
[
[
"# Stack Overflow Survey 2019 Analysis ",
"_____no_output_____"
],
[
"\n## Business Understanding\n\nI am interested in finding the answers to the following questions related to career satisfaction. \n\n- Are Developers satisfied with thier career?\n\n- Who are the most satisfied developers?\n\n- Is there is a significant relationship between compensation and career satisfaction?\n",
"_____no_output_____"
]
],
[
[
"#Imports\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Data Understanding",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('.\\data\\survey_results_public.csv')\ndata.shape",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
]
],
[
[
"## Q1: Are developers satisfied with thier career?",
"_____no_output_____"
],
[
"### Prepare Data",
"_____no_output_____"
],
[
"Our focus is on career satisfaction of full-time developers (people who writes code), we'll filter the data accordingly and remove all na values in career satisfaction column in order to get more accurate results. ",
"_____no_output_____"
]
],
[
[
"careerSat_data = data[(~ data['CareerSat'].isna()) \n & (data['Employment'] == 'Employed full-time') \n & (data['MainBranch'] == 'I am a developer by profession')]\ncareerSat_data.shape",
"_____no_output_____"
]
],
[
[
"### Model Data",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(1,1,figsize =(15,6))\n\nax.title.set_text('Career Satisfaction')\nsns.countplot(careerSat_data['CareerSat'] ,order=['Very satisfied', \n 'Slightly satisfied', \n 'Neither satisfied nor dissatisfied',\n 'Slightly dissatisfied',\n 'Very dissatisfied'], ax = ax)\n\n",
"_____no_output_____"
],
[
"satisfaied_devs_perc = careerSat_data[careerSat_data['CareerSat'].isin(\n ['Very satisfied', 'Slightly satisfied'])].shape[0] / careerSat_data.shape[0] * 100\nsatisfaied_devs_perc",
"_____no_output_____"
]
],
[
[
"### Result",
"_____no_output_____"
],
[
"From the above plot we can till that most developers are satisfied with career path, to validate the result we calculated the percentage of satisfied developers over the whole sample, thus we can say that most developers are satisfied with thier career.",
"_____no_output_____"
],
[
"## Q2: who are the most satisfied ones? (job titles)",
"_____no_output_____"
],
[
"### Prepare Data",
"_____no_output_____"
],
[
"We will encode the values into 0 1 encoding in order to be able to calculate the satisfaction mean. For this reason we need to deal with NA values first. The devType column can have multiple combinations of devTypes which means if we impute it, more than one hot encoded column could be affected. Thus, we would rather drop them and then convert it to multiple ont hot encoded columns.",
"_____no_output_____"
]
],
[
[
"jobs_data = careerSat_data[~ careerSat_data['DevType'].isna()].copy()\nDevTyps = ['Academic researcher', 'Data or business analyst', \n 'Data scientist or machine learning specialist','Database administrator', \n 'Designer', 'Developer, back-end', 'Developer, desktop or enterprise applications',\n 'Developer, embedded applications or devices', 'Developer, front-end',\n 'Developer, full-stack', 'Developer, game or graphics', 'Developer, mobile', \n 'Developer, QA or test','DevOps specialist','Educator', 'Engineer, data',\n 'Engineer, site reliability','Engineering manager', 'Marketing or sales professional',\n 'Product manager', 'Scientist', 'Senior executive/VP', 'Student', 'System administrator']\nfor devType in DevTyps:\n jobs_data[devType]=0\nfor i, row in jobs_data.iterrows():\n for value in row['DevType'].split(';'):\n if value != 'Other':\n jobs_data.loc[i, value] = 1\n ",
"_____no_output_____"
],
[
"satisfaction_dict = {'Very satisfied':2, \n 'Slightly satisfied':1, \n 'Neither satisfied nor dissatisfied':0, \n 'Slightly dissatisfied':-1,\n 'Very dissatisfied':-2}\njobs_data['CareerSat']= jobs_data['CareerSat'].apply(lambda x : satisfaction_dict[x])",
"_____no_output_____"
]
],
[
[
"### Model Data",
"_____no_output_____"
]
],
[
[
"def get_careerSat_mean(df):\n \"\"\"\n Returns the mean of career satisfaction in the recieved dataset.\n Args:\n df: pandas dataframe that contains CareerSat column.\n Returns:\n Career satisfaction mean.\n \"\"\"\n return df['CareerSat'].mean()",
"_____no_output_____"
],
[
"sat_list = pd.Series()\nfor devType in DevTyps:\n sat_list[devType] = get_careerSat_mean(jobs_data[jobs_data[devType] == 1])\nsat_list = sat_list.sort_values(ascending = False )",
"_____no_output_____"
],
[
"plt.subplots(1,1,figsize =(15,3))\nsat_list.plot.bar()",
"_____no_output_____"
],
[
"#Top 3\nsat_list.sort_values(ascending=False)[:3]",
"_____no_output_____"
]
],
[
[
"### Result",
"_____no_output_____"
],
[
"By calculating the satisfaction mean, we find that most of the people working excutive and managerial levels are satisfied with thier career.",
"_____no_output_____"
],
[
"### Q3: Is compensation is the reason of career satisfaction?",
"_____no_output_____"
],
[
"### Prepare Data",
"_____no_output_____"
],
[
"First we'll unify compensation frequency. And since the number of NA values is small we'll drop them to make sure we don't lose the integrity of the data.",
"_____no_output_____"
]
],
[
[
"jobs_data = jobs_data[(~jobs_data['CompFreq'].isna()) & (~jobs_data['CompTotal'].isna())]",
"_____no_output_____"
],
[
"for i, row in jobs_data.iterrows():\n if row['CompFreq'] == \"Yearly\":\n jobs_data.loc[i, 'MonthlyCompTotal'] = row['CompTotal']/12\n elif row['CompFreq'] == \"Weekly\":\n jobs_data.loc[i, 'MonthlyCompTotal'] = row['CompTotal']* 4\n else :\n jobs_data.loc[i, 'MonthlyCompTotal'] = row['CompTotal']",
"_____no_output_____"
]
],
[
[
"### Model Data",
"_____no_output_____"
],
[
"Null Hypothesis: There is no relationship between career satisfaction and compensation.\n\nAlternative Hypothesis: There is a high correlation between career satisfaction and compensation.\n\nIn order to test the hypothesis, we will extracted 2 subsets of the data based on monthly compensation values, one for those with low compensation(less than 75% of the population) and the other one for the developers with high compensation (above than 75% of the developers). ",
"_____no_output_____"
]
],
[
[
"q1 = jobs_data['MonthlyCompTotal'].quantile(0.25)\nq3 = jobs_data['MonthlyCompTotal'].quantile(0.75)\n\nlow_comp = jobs_data[jobs_data['MonthlyCompTotal']< q1]\nhigh_comp = jobs_data[jobs_data['MonthlyCompTotal'] > q3]",
"_____no_output_____"
],
[
"# Calculate the observed difference on average Career Satisfaction rating between the two subsets\ns1_mean = get_careerSat_mean(low_comp)\ns2_mean = get_careerSat_mean(high_comp)\nobs_diff = s2_mean - s1_mean\nobs_diff",
"_____no_output_____"
],
[
"# Bootstrapping (simulating null distibution)\nrand_diffs = []\nsize = 5000\nfor i in range(10000):\n sample1 = jobs_data.sample(size)\n sample2 = jobs_data.sample(size)\n sample1_mean = get_careerSat_mean(sample1)\n sample2_mean = get_careerSat_mean(sample2)\n rand_diffs.append(sample1_mean - sample2_mean)\nrand_diffs = np.array(rand_diffs)",
"_____no_output_____"
],
[
"rand_diffs.mean()",
"_____no_output_____"
],
[
"# Plot the null distibution\nplt.hist(rand_diffs, bins=50)\nplt.axvline(obs_diff, c='red')\nplt.title('Null distibution with the observed mean')\n\n",
"_____no_output_____"
],
[
"# p-value\n(rand_diffs > obs_diff).mean()",
"_____no_output_____"
]
],
[
[
"### Result",
"_____no_output_____"
],
[
"Since the observed difference was significatly larger than random and since to the calculated p value is smaller than 0.05, we can say that compensation is significatly related to career satisfaction.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4ad18815be023ef15daf7a70a51af356902c00e3
| 15,816 |
ipynb
|
Jupyter Notebook
|
example/rnn/char-rnn.ipynb
|
vkuznet/mxnet
|
afb6fadf10942de9334a2f60bf1fc611c06aab75
|
[
"Apache-2.0"
] | 9 |
2018-06-12T12:12:56.000Z
|
2020-11-26T01:45:15.000Z
|
example/rnn/char-rnn.ipynb
|
vkuznet/mxnet
|
afb6fadf10942de9334a2f60bf1fc611c06aab75
|
[
"Apache-2.0"
] | null | null | null |
example/rnn/char-rnn.ipynb
|
vkuznet/mxnet
|
afb6fadf10942de9334a2f60bf1fc611c06aab75
|
[
"Apache-2.0"
] | 14 |
2016-11-18T07:21:41.000Z
|
2019-09-30T08:48:22.000Z
| 28.756364 | 1,204 | 0.5533 |
[
[
[
"import mxnet as mx\nimport numpy as np\nimport random\nimport bisect",
"_____no_output_____"
],
[
"# set up logging\nimport logging\nreload(logging)\nlogging.basicConfig(format='%(asctime)s %(levelname)s:%(message)s', level=logging.DEBUG, datefmt='%I:%M:%S')",
"_____no_output_____"
]
],
[
[
"# A Glance of LSTM structure and embedding layer\n\nWe will build a LSTM network to learn from char only. At each time, input is a char. We will see this LSTM is able to learn words and grammers from sequence of chars.\n\nThe following figure is showing an unrolled LSTM network, and how we generate embedding of a char. The one-hot to embedding operation is a special case of fully connected network.\n",
"_____no_output_____"
],
[
"<img src=\"http://data.dmlc.ml/mxnet/data/char-rnn_1.png\">\n",
"_____no_output_____"
],
[
"<img src=\"http://data.dmlc.ml/mxnet/data/char-rnn_2.png\">",
"_____no_output_____"
]
],
[
[
"from lstm import lstm_unroll, lstm_inference_symbol\nfrom bucket_io import BucketSentenceIter\nfrom rnn_model import LSTMInferenceModel",
"_____no_output_____"
],
[
"# Read from doc\ndef read_content(path):\n with open(path) as ins:\n content = ins.read()\n return content\n\n# Build a vocabulary of what char we have in the content\ndef build_vocab(path):\n content = read_content(path)\n content = list(content)\n idx = 1 # 0 is left for zero-padding\n the_vocab = {}\n for word in content:\n if len(word) == 0:\n continue\n if not word in the_vocab:\n the_vocab[word] = idx\n idx += 1\n return the_vocab\n\n# We will assign each char with a special numerical id\ndef text2id(sentence, the_vocab):\n words = list(sentence)\n words = [the_vocab[w] for w in words if len(w) > 0]\n return words",
"_____no_output_____"
],
[
"# Evaluation \ndef Perplexity(label, pred):\n label = label.T.reshape((-1,))\n loss = 0.\n for i in range(pred.shape[0]):\n loss += -np.log(max(1e-10, pred[i][int(label[i])]))\n return np.exp(loss / label.size)",
"_____no_output_____"
]
],
[
[
"# Get Data",
"_____no_output_____"
]
],
[
[
"import os\ndata_url = \"http://data.dmlc.ml/mxnet/data/lab_data.zip\"\nos.system(\"wget %s\" % data_url)\nos.system(\"unzip -o lab_data.zip\")",
"_____no_output_____"
]
],
[
[
"Sample training data:\n```\nall to Renewal Keynote Address Call to Renewal Pt 1Call to Renewal Part 2 TOPIC: Our Past, Our Future & Vision for America June\n28, 2006 Call to Renewal' Keynote Address Complete Text Good morning. I appreciate the opportunity to speak here at the Call to R\nenewal's Building a Covenant for a New America conference. I've had the opportunity to take a look at your Covenant for a New Ame\nrica. It is filled with outstanding policies and prescriptions for much of what ails this country. So I'd like to congratulate yo\nu all on the thoughtful presentations you've given so far about poverty and justice in America, and for putting fire under the fe\net of the political leadership here in Washington.But today I'd like to talk about the connection between religion and politics a\nnd perhaps offer some thoughts about how we can sort through some of the often bitter arguments that we've been seeing over the l\nast several years.I do so because, as you all know, we can affirm the importance of poverty in the Bible; and we can raise up and\n pass out this Covenant for a New America. We can talk to the press, and we can discuss the religious call to address poverty and\n environmental stewardship all we want, but it won't have an impact unless we tackle head-on the mutual suspicion that sometimes\n```",
"_____no_output_____"
],
[
"# LSTM Hyperparameters",
"_____no_output_____"
]
],
[
[
"# The batch size for training\nbatch_size = 32\n# We can support various length input\n# For this problem, we cut each input sentence to length of 129\n# So we only need fix length bucket\nbuckets = [129]\n# hidden unit in LSTM cell\nnum_hidden = 512\n# embedding dimension, which is, map a char to a 256 dim vector\nnum_embed = 256\n# number of lstm layer\nnum_lstm_layer = 3",
"_____no_output_____"
],
[
"# we will show a quick demo in 2 epoch\n# and we will see result by training 75 epoch\nnum_epoch = 2\n# learning rate \nlearning_rate = 0.01\n# we will use pure sgd without momentum\nmomentum = 0.0",
"_____no_output_____"
],
[
"# we can select multi-gpu for training\n# for this demo we only use one\ndevs = [mx.context.gpu(i) for i in range(1)]",
"_____no_output_____"
],
[
"# build char vocabluary from input\nvocab = build_vocab(\"./obama.txt\")",
"_____no_output_____"
],
[
"# generate symbol for a length\ndef sym_gen(seq_len):\n return lstm_unroll(num_lstm_layer, seq_len, len(vocab) + 1,\n num_hidden=num_hidden, num_embed=num_embed,\n num_label=len(vocab) + 1, dropout=0.2)",
"_____no_output_____"
],
[
"# initalize states for LSTM\ninit_c = [('l%d_init_c'%l, (batch_size, num_hidden)) for l in range(num_lstm_layer)]\ninit_h = [('l%d_init_h'%l, (batch_size, num_hidden)) for l in range(num_lstm_layer)]\ninit_states = init_c + init_h",
"_____no_output_____"
],
[
"# we can build an iterator for text\ndata_train = BucketSentenceIter(\"./obama.txt\", vocab, buckets, batch_size,\n init_states, seperate_char='\\n',\n text2id=text2id, read_content=read_content)",
"Summary of dataset ==================\nbucket of len 129 : 8290 samples\n"
],
[
"# the network symbol\nsymbol = sym_gen(buckets[0])",
"_____no_output_____"
]
],
[
[
"# Train model",
"_____no_output_____"
]
],
[
[
"# Train a LSTM network as simple as feedforward network\nmodel = mx.model.FeedForward(ctx=devs,\n symbol=symbol,\n num_epoch=num_epoch,\n learning_rate=learning_rate,\n momentum=momentum,\n wd=0.0001,\n initializer=mx.init.Xavier(factor_type=\"in\", magnitude=2.34))",
"_____no_output_____"
],
[
"# Fit it\nmodel.fit(X=data_train,\n eval_metric = mx.metric.np(Perplexity),\n batch_end_callback=mx.callback.Speedometer(batch_size, 50),\n epoch_end_callback=mx.callback.do_checkpoint(\"obama\"))",
"05:01:35 INFO:Start training with [gpu(0)]\n"
]
],
[
[
"# Inference from model",
"_____no_output_____"
]
],
[
[
"# helper strcuture for prediction\ndef MakeRevertVocab(vocab):\n dic = {}\n for k, v in vocab.items():\n dic[v] = k\n return dic",
"_____no_output_____"
],
[
"# make input from char\ndef MakeInput(char, vocab, arr):\n idx = vocab[char]\n tmp = np.zeros((1,))\n tmp[0] = idx\n arr[:] = tmp",
"_____no_output_____"
],
[
"# helper function for random sample \ndef _cdf(weights):\n total = sum(weights)\n result = []\n cumsum = 0\n for w in weights:\n cumsum += w\n result.append(cumsum / total)\n return result\n\ndef _choice(population, weights):\n assert len(population) == len(weights)\n cdf_vals = _cdf(weights)\n x = random.random()\n idx = bisect.bisect(cdf_vals, x)\n return population[idx]\n\n# we can use random output or fixed output by choosing largest probability\ndef MakeOutput(prob, vocab, sample=False, temperature=1.):\n if sample == False:\n idx = np.argmax(prob, axis=1)[0]\n else:\n fix_dict = [\"\"] + [vocab[i] for i in range(1, len(vocab) + 1)]\n scale_prob = np.clip(prob, 1e-6, 1 - 1e-6)\n rescale = np.exp(np.log(scale_prob) / temperature)\n rescale[:] /= rescale.sum()\n return _choice(fix_dict, rescale[0, :])\n try:\n char = vocab[idx]\n except:\n char = ''\n return char",
"_____no_output_____"
],
[
"# load from check-point\n_, arg_params, __ = mx.model.load_checkpoint(\"obama\", 75)",
"_____no_output_____"
],
[
"# build an inference model\nmodel = LSTMInferenceModel(num_lstm_layer, len(vocab) + 1,\n num_hidden=num_hidden, num_embed=num_embed,\n num_label=len(vocab) + 1, arg_params=arg_params, ctx=mx.gpu(), dropout=0.2)",
"_____no_output_____"
],
[
"# generate a sequence of 1200 chars\n\nseq_length = 1200\ninput_ndarray = mx.nd.zeros((1,))\nrevert_vocab = MakeRevertVocab(vocab)\n# Feel free to change the starter sentence\noutput ='The joke'\nrandom_sample = True\nnew_sentence = True\n\nignore_length = len(output)\n\nfor i in range(seq_length):\n if i <= ignore_length - 1:\n MakeInput(output[i], vocab, input_ndarray)\n else:\n MakeInput(output[-1], vocab, input_ndarray)\n prob = model.forward(input_ndarray, new_sentence)\n new_sentence = False\n next_char = MakeOutput(prob, revert_vocab, random_sample)\n if next_char == '':\n new_sentence = True\n if i >= ignore_length - 1:\n output += next_char\n\n ",
"_____no_output_____"
],
[
"# Let's see what we can learned from char in Obama's speech.\nprint(output)",
"The joke learning to be struggle for our daughter. We are the ones who can't pay their relationship. The Judiciary Commencement ce designed to deficit to the party of almost unemployment instead, just to look at home, little proof for America, Carguin are showing struggle against our pride. That if you came from tharger by a party that would increase the pervasive sense of new global warming against the challenge of governments - to get a corporation.As a highealth care, your own retirement security information about his family decided to get a job or aspect what will allow cannot simply by sagging high school system and stin twenty-five years. But led my faith designed to leave all their buddets and responsibility. But I sund this dangerous weapons, explain withdrawal oful -clears axdication in Iraq.What is the time for American policy became their efforts, and given them that a man doesn't make sure that that my own, you'll be faced with you. Four years, reforms illness all that kind of choose to understand is a broadeary. You instills in search of a reducithis recision, of us, with public services from using that barealies, but that must continue to limb line, they know th\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad18a5de612fb0621130b173956028abbc20c18
| 509,428 |
ipynb
|
Jupyter Notebook
|
mobilebert_mlm_shakespeare_fedclientadam.ipynb
|
ronaldseoh/BERTerated
|
57a7714c0cc491400eea2342e43ff3641e8c721d
|
[
"Apache-2.0"
] | null | null | null |
mobilebert_mlm_shakespeare_fedclientadam.ipynb
|
ronaldseoh/BERTerated
|
57a7714c0cc491400eea2342e43ff3641e8c721d
|
[
"Apache-2.0"
] | null | null | null |
mobilebert_mlm_shakespeare_fedclientadam.ipynb
|
ronaldseoh/BERTerated
|
57a7714c0cc491400eea2342e43ff3641e8c721d
|
[
"Apache-2.0"
] | null | null | null | 58.764333 | 256 | 0.660466 |
[
[
[
"# Further Pre-training MobileBERT MLM with Client-side Adam (Shakepeare)",
"_____no_output_____"
]
],
[
[
"# Copyright 2020, The TensorFlow Federated Authors.\n# Copyright 2020, Ronald Seoh\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"### Google Colab settings",
"_____no_output_____"
]
],
[
[
"# Use Google Colab\nuse_colab = True\n\n# Is this notebook running on Colab?\n# If so, then google.colab package (github.com/googlecolab/colabtools)\n# should be available in this environment\n\n# Previous version used importlib, but we could do the same thing with\n# just attempting to import google.colab\ntry:\n from google.colab import drive\n colab_available = True\nexcept:\n colab_available = False\n\nif use_colab and colab_available:\n # Mount Google Drive root directory\n drive.mount('/content/drive')\n\n # cd to the appropriate working directory under my Google Drive\n %cd '/content/drive/My Drive/Colab Notebooks/BERTerated'\n \n # List the directory contents\n !ls",
"_____no_output_____"
]
],
[
[
"### CUDA Multi GPU",
"_____no_output_____"
]
],
[
[
"# Use this code snippet to use specific GPUs\nimport os\n\nos.environ[\"CUDA_DEVICE_ORDER\"]=\"PCI_BUS_ID\"\n\n# os.environ[\"CUDA_VISIBLE_DEVICES\"]=\"1,2,3\"",
"_____no_output_____"
],
[
"# IPython reloading magic\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"# Install required packages\n# !pip install -r requirements.txt",
"_____no_output_____"
]
],
[
[
"## Import packages",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf",
"_____no_output_____"
],
[
"tf_physical_devices_gpu = tf.config.list_physical_devices('GPU')\n\n# Allow the growth of GPU memory consumption to take place incrementally\nif tf_physical_devices_gpu:\n for gpu in tf_physical_devices_gpu:\n tf.config.experimental.set_memory_growth(gpu, True)",
"_____no_output_____"
],
[
"import os\nimport sys\nimport random\nimport datetime\nimport json\nimport pathlib\nimport itertools\nimport time\n\nimport numpy as np\nimport tensorflow_federated as tff\nimport tensorflow_text as tf_text\nimport tensorflow_addons as tfa\nimport transformers\n\nimport nest_asyncio\nnest_asyncio.apply()\n\nimport fedavg\nimport fedavg_client\nimport datasets\nimport utils\n\n\n# Random seed settings\nrandom_seed = 692\nrandom.seed(random_seed) # Python\nnp.random.seed(random_seed) # NumPy\ntf.random.set_seed(random_seed) # TensorFlow\n\n# Test if TFF is working\ntff.federated_computation(lambda: 'Hello, World!')()",
"_____no_output_____"
],
[
"# Print version information\nprint(\"Python version: \" + sys.version)\nprint(\"NumPy version: \" + np.__version__)\nprint(\"TensorFlow version: \" + tf.__version__)\nprint(\"TensorFlow Federated version: \" + tff.__version__)\nprint(\"Transformers version: \" + transformers.__version__)",
"Python version: 3.6.9 (default, Jul 17 2020, 12:50:27) \n[GCC 8.4.0]\nNumPy version: 1.18.4\nTensorFlow version: 2.3.1\nTensorFlow Federated version: 0.17.0\nTransformers version: 3.4.0\n"
],
[
"!nvidia-smi",
"Sat Nov 28 21:14:16 2020 \r\n+-----------------------------------------------------------------------------+\r\n| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |\r\n|-------------------------------+----------------------+----------------------+\r\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\r\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\r\n|===============================+======================+======================|\r\n| 0 GeForce GTX 1080 On | 00000000:03:00.0 Off | N/A |\r\n| 0% 52C P2 48W / 205W | 231MiB / 8118MiB | 0% Default |\r\n+-------------------------------+----------------------+----------------------+\r\n \r\n+-----------------------------------------------------------------------------+\r\n| Processes: GPU Memory |\r\n| GPU PID Type Process name Usage |\r\n|=============================================================================|\r\n+-----------------------------------------------------------------------------+\r\n"
],
[
"tf_logical_devices_cpu = tf.config.list_logical_devices('CPU')\ntf_logical_devices_gpu = tf.config.list_logical_devices('GPU')",
"_____no_output_____"
]
],
[
[
"## Experiment Settings",
"_____no_output_____"
]
],
[
[
"EXPERIMENT_CONFIG = {}\n\nEXPERIMENT_CONFIG['HUGGINGFACE_MODEL_NAME'] = 'google/mobilebert-uncased'\nEXPERIMENT_CONFIG['HUGGINGFACE_CACHE_DIR'] = os.path.join('.', 'transformers_cache')\n\nEXPERIMENT_CONFIG['TOTAL_ROUNDS'] = 50 # Number of total training rounds\nEXPERIMENT_CONFIG['ROUNDS_PER_EVAL'] = 1 # How often to evaluate\n\nEXPERIMENT_CONFIG['TRAIN_CLIENTS_PER_ROUND'] = 10 # How many clients to sample per round.\nEXPERIMENT_CONFIG['CLIENT_EPOCHS_PER_ROUND'] = 3\n\nEXPERIMENT_CONFIG['BATCH_SIZE'] = 8 # Batch size used on the client.\nEXPERIMENT_CONFIG['TEST_BATCH_SIZE'] = 16 # Minibatch size of test data.\n\n# Maximum length of input token sequence for BERT.\nEXPERIMENT_CONFIG['BERT_MAX_SEQ_LENGTH'] = 128\n\n# Optimizer configuration\nEXPERIMENT_CONFIG['SERVER_LEARNING_RATE'] = 1.0 # Server learning rate.\nEXPERIMENT_CONFIG['CLIENT_LEARNING_RATE'] = 5e-5 # Client learning rate\n\n# Client dataset setting\nEXPERIMENT_CONFIG['TRAIN_NUM_CLIENT_LIMIT'] = -1\nEXPERIMENT_CONFIG['TEST_NUM_CLIENT_LIMIT'] = -1\n\n# Path to save trained weights and logs\nEXPERIMENT_CONFIG['RESULTS_DIRECTORY'] = os.path.join(\n '.', 'results',\n 'mobilebert_mlm_shakespeare_fedadam',\n datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\n)\n\nEXPERIMENT_CONFIG['RESULTS_LOG'] = os.path.join(EXPERIMENT_CONFIG['RESULTS_DIRECTORY'], \"logs\")\nEXPERIMENT_CONFIG['RESULTS_MODEL'] = os.path.join(EXPERIMENT_CONFIG['RESULTS_DIRECTORY'], \"model\")\nEXPERIMENT_CONFIG['RESULTS_CONFIG'] = os.path.join(EXPERIMENT_CONFIG['RESULTS_DIRECTORY'], \"config\")",
"_____no_output_____"
],
[
"# Dump all the configuration into a json file\npathlib.Path(EXPERIMENT_CONFIG['RESULTS_CONFIG']).mkdir(parents=True, exist_ok=True)\n\nwith open(os.path.join(EXPERIMENT_CONFIG['RESULTS_CONFIG'], \"config.json\"), 'w') as config_file:\n json.dump(EXPERIMENT_CONFIG, config_file, indent=6)",
"_____no_output_____"
],
[
"# TFF executor factory settings\n# Reference: https://www.tensorflow.org/federated/api_docs/python/tff/backends/native/set_local_execution_context\ntff.backends.native.set_local_execution_context(\n num_clients=EXPERIMENT_CONFIG['TRAIN_CLIENTS_PER_ROUND'],\n max_fanout=100,\n clients_per_thread=1,\n server_tf_device=tf_logical_devices_cpu[0],\n client_tf_devices=tf_logical_devices_cpu,\n)",
"_____no_output_____"
]
],
[
[
"## Dataset",
"_____no_output_____"
],
[
"### Dataset loader",
"_____no_output_____"
]
],
[
[
"train_client_data, test_client_data = tff.simulation.datasets.shakespeare.load_data(cache_dir='./tff_cache')",
"_____no_output_____"
]
],
[
[
"### Tokenizer",
"_____no_output_____"
]
],
[
[
"bert_tokenizer = transformers.AutoTokenizer.from_pretrained(\n EXPERIMENT_CONFIG['HUGGINGFACE_MODEL_NAME'], cache_dir=EXPERIMENT_CONFIG['HUGGINGFACE_CACHE_DIR'])",
"_____no_output_____"
],
[
"# Imitate transformers tokenizer with TF.Text Tokenizer\ntokenizer_tf_text, vocab_lookup_table, special_ids_mask_table = \\\ndatasets.preprocessing_for_bert.convert_huggingface_tokenizer(bert_tokenizer)",
"_____no_output_____"
]
],
[
[
"### Preprocessing",
"_____no_output_____"
]
],
[
[
"def check_empty_snippet(x):\n return tf.strings.length(x['snippets']) > 0\n\ndef tokenizer_and_mask_wrapped(x):\n\n masked, labels = datasets.preprocessing_for_bert.tokenize_and_mask(tf.reshape(x['snippets'], shape=[1]),\n max_seq_length=EXPERIMENT_CONFIG['BERT_MAX_SEQ_LENGTH'],\n bert_tokenizer_tf_text=tokenizer_tf_text,\n vocab_lookup_table=vocab_lookup_table,\n special_ids_mask_table=special_ids_mask_table,\n cls_token_id=bert_tokenizer.cls_token_id,\n sep_token_id=bert_tokenizer.sep_token_id,\n pad_token_id=bert_tokenizer.pad_token_id,\n mask_token_id=bert_tokenizer.mask_token_id)\n\n return (masked, labels)\n\ndef preprocess_for_train(train_dataset):\n return (\n train_dataset\n # Tokenize each samples using MobileBERT tokenizer\n #.map(tokenizer_and_mask_wrapped, num_parallel_calls=tf.data.experimental.AUTOTUNE, deterministic=False)\n .map(tokenizer_and_mask_wrapped, num_parallel_calls=24, deterministic=False)\n # Shuffle\n .shuffle(100000)\n # Form minibatches\n # Use drop_remainder=True to force the batch size to be exactly BATCH_SIZE\n # and make the shape **exactly** (BATCH_SIZE, SEQ_LENGTH)\n .batch(EXPERIMENT_CONFIG['BATCH_SIZE'])#, drop_remainder=True)\n # Repeat to make each client train multiple epochs\n .repeat(count=EXPERIMENT_CONFIG['CLIENT_EPOCHS_PER_ROUND'])\n )\n \ndef preprocess_for_test(test_dataset):\n return (\n test_dataset\n # Tokenize each samples using MobileBERT tokenizer\n #.map(tokenizer_and_mask_wrapped, num_parallel_calls=tf.data.experimental.AUTOTUNE, deterministic=False)\n .map(tokenizer_and_mask_wrapped, num_parallel_calls=24, deterministic=False)\n # Shuffle\n .shuffle(100000)\n # Form minibatches\n # Use drop_remainder=True to force the batch size to be exactly TEST_BATCH_SIZE\n # and make the shape **exactly** (TEST_BATCH_SIZE, SEQ_LENGTH)\n .batch(EXPERIMENT_CONFIG['TEST_BATCH_SIZE'])\n ) ",
"_____no_output_____"
]
],
[
[
"### Training set",
"_____no_output_____"
]
],
[
[
"# Since the dataset is pretty large, we randomly select TRAIN_NUM_CLIENT_LIMIT number of clients.\nall_train_client_ids = train_client_data.client_ids\n\nrandom.shuffle(all_train_client_ids)\n\nif EXPERIMENT_CONFIG['TRAIN_NUM_CLIENT_LIMIT'] > 0:\n selected_train_client_ids = all_train_client_ids[0:EXPERIMENT_CONFIG['TRAIN_NUM_CLIENT_LIMIT']]\nelse:\n selected_train_client_ids = all_train_client_ids",
"_____no_output_____"
],
[
"train_client_data = train_client_data.preprocess(preprocess_fn=lambda x: x.filter(check_empty_snippet))",
"_____no_output_____"
],
[
"train_client_data = train_client_data.preprocess(preprocess_fn=preprocess_for_train)",
"WARNING:tensorflow:From /root/BERTerated/datasets/preprocessing_for_bert.py:76: Bernoulli.__init__ (from tensorflow.python.ops.distributions.bernoulli) is deprecated and will be removed after 2019-01-01.\nInstructions for updating:\nThe TensorFlow Distributions library has moved to TensorFlow Probability (https://github.com/tensorflow/probability). You should update all references to use `tfp.distributions` instead of `tf.distributions`.\n"
],
[
"print(train_client_data.element_type_structure)",
"(TensorSpec(shape=(None, 128), dtype=tf.int32, name=None), TensorSpec(shape=(None, 128), dtype=tf.int32, name=None))\n"
],
[
"train_client_states = {}\n\n# Initialize client states for all clients (selected for the entire simulation)\nfor i, client_id in enumerate(selected_train_client_ids):\n train_client_states[client_id] = fedavg_client.ClientState(\n client_serial=i, num_processed=0, optimizer_options=utils.OptimizerOptions())",
"_____no_output_____"
]
],
[
[
"### Test set",
"_____no_output_____"
]
],
[
[
"test_client_data_all_merged = test_client_data.create_tf_dataset_for_client(\n test_client_data.client_ids[0]).filter(check_empty_snippet)\n\nif len(test_client_data.client_ids) > 1:\n for i in range(1, len(test_client_data.client_ids)):\n test_client_data_all_merged = test_client_data_all_merged.concatenate(\n test_client_data.create_tf_dataset_for_client(test_client_data.client_ids[i]).filter(check_empty_snippet))",
"_____no_output_____"
],
[
"test_client_data_all_merged = preprocess_for_test(test_client_data_all_merged)",
"_____no_output_____"
],
[
"test_client_data_all_merged = test_client_data_all_merged.cache()",
"_____no_output_____"
],
[
"print(test_client_data_all_merged.element_spec)",
"(TensorSpec(shape=(None, 128), dtype=tf.int32, name=None), TensorSpec(shape=(None, 128), dtype=tf.int32, name=None))\n"
]
],
[
[
"## Model",
"_____no_output_____"
]
],
[
[
"bert_model = transformers.TFAutoModelForPreTraining.from_pretrained(\n EXPERIMENT_CONFIG['HUGGINGFACE_MODEL_NAME'], cache_dir=EXPERIMENT_CONFIG['HUGGINGFACE_CACHE_DIR'])",
"All model checkpoint layers were used when initializing TFMobileBertForPreTraining.\n\nAll the layers of TFMobileBertForPreTraining were initialized from the model checkpoint at google/mobilebert-uncased.\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use TFMobileBertForPreTraining for predictions without further training.\n"
],
[
"print(bert_model.config)",
"MobileBertConfig {\n \"_name_or_path\": \"google/mobilebert-uncased\",\n \"attention_probs_dropout_prob\": 0.1,\n \"classifier_activation\": false,\n \"embedding_size\": 128,\n \"hidden_act\": \"relu\",\n \"hidden_dropout_prob\": 0.0,\n \"hidden_size\": 512,\n \"initializer_range\": 0.02,\n \"intermediate_size\": 512,\n \"intra_bottleneck_size\": 128,\n \"key_query_shared_bottleneck\": true,\n \"layer_norm_eps\": 1e-12,\n \"max_position_embeddings\": 512,\n \"model_type\": \"mobilebert\",\n \"normalization_type\": \"no_norm\",\n \"num_attention_heads\": 4,\n \"num_feedforward_networks\": 4,\n \"num_hidden_layers\": 24,\n \"pad_token_id\": 0,\n \"trigram_input\": true,\n \"true_hidden_size\": 128,\n \"type_vocab_size\": 2,\n \"use_bottleneck\": true,\n \"use_bottleneck_attention\": false,\n \"vocab_size\": 30522\n}\n\n"
],
[
"# Due to the limitations with Keras subclasses, we can only use the main layer part from pretrained models\n# and add output heads by ourselves\nbert_keras_converted = utils.convert_huggingface_mlm_to_keras(\n huggingface_model=bert_model,\n max_seq_length=EXPERIMENT_CONFIG['BERT_MAX_SEQ_LENGTH'],\n)",
"_____no_output_____"
],
[
"# Use lists of NumPy arrays to backup pretained weights\nbert_pretrained_trainable_weights = []\nbert_pretrained_non_trainable_weights = []\n\nfor w in bert_keras_converted.trainable_weights:\n bert_pretrained_trainable_weights.append(w.numpy())\n\nfor w in bert_keras_converted.non_trainable_weights:\n bert_pretrained_non_trainable_weights.append(w.numpy())",
"_____no_output_____"
],
[
"def tff_model_fn():\n \"\"\"Constructs a fully initialized model for use in federated averaging.\"\"\"\n\n loss = utils.MaskedLMCrossEntropy()\n\n model_wrapped = utils.KerasModelWrapper(\n tf.keras.models.clone_model(bert_keras_converted),\n train_client_data.element_type_structure, loss)\n\n return model_wrapped",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
],
[
"### Training setups",
"_____no_output_____"
]
],
[
[
"summary_writer = tf.summary.create_file_writer(EXPERIMENT_CONFIG['RESULTS_LOG'])",
"_____no_output_____"
],
[
"def server_optimizer_fn():\n return tf.keras.optimizers.SGD(learning_rate=EXPERIMENT_CONFIG['SERVER_LEARNING_RATE'])\n\ndef client_optimizer_fn():\n return transformers.AdamWeightDecay(\n learning_rate=EXPERIMENT_CONFIG['CLIENT_LEARNING_RATE'],\n weight_decay_rate=0.01,\n )",
"_____no_output_____"
],
[
"%%time\n\niterative_process = fedavg.build_federated_averaging_process(\n model_fn=tff_model_fn,\n model_input_spec=train_client_data.element_type_structure,\n initial_trainable_weights=bert_pretrained_trainable_weights,\n initial_non_trainable_weights=bert_pretrained_non_trainable_weights,\n server_optimizer_fn=server_optimizer_fn, \n client_optimizer_fn=client_optimizer_fn)",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/autograph/operators/control_flow.py:565: get_next_as_optional (from tensorflow.python.data.ops.iterator_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Iterator.get_next_as_optional()` instead.\n"
],
[
"%%time\n\nserver_state = iterative_process.initialize()",
"CPU times: user 22.2 s, sys: 3.74 s, total: 25.9 s\nWall time: 25.7 s\n"
],
[
"metric_eval = tfa.metrics.MeanMetricWrapper(fn=utils.calculate_masked_lm_cross_entropy, name='ce')",
"_____no_output_____"
],
[
"# The model for calculating validation loss only\n# (This happens outside FedAvg)\nmodel_final = utils.KerasModelWrapper(\n tf.keras.models.clone_model(bert_keras_converted),\n train_client_data.element_type_structure,\n utils.MaskedLMCrossEntropy(),\n tf_device_identifier=\"/GPU:0\")",
"_____no_output_____"
]
],
[
[
"### Training loop",
"_____no_output_____"
]
],
[
[
"%%time\n\nwith summary_writer.as_default():\n for round_num in range(1, EXPERIMENT_CONFIG['TOTAL_ROUNDS'] + 1): \n # FedAvg\n print(f'Round {round_num} start!')\n\n # Training client selection\n sampled_client_serials = np.random.choice(\n len(selected_train_client_ids),\n size=EXPERIMENT_CONFIG['TRAIN_CLIENTS_PER_ROUND'],\n replace=False)\n\n sampled_train_data = [\n train_client_data.create_tf_dataset_for_client(selected_train_client_ids[client_serial])\n for client_serial in sampled_client_serials\n ]\n \n sampled_client_states = [\n train_client_states[selected_train_client_ids[client_serial]]\n for client_serial in sampled_client_serials\n ]\n \n print(\"Selected client serials:\", sampled_client_serials)\n\n current_round_start_time = time.time()\n \n server_state, new_client_states, train_loss = iterative_process.next(\n server_state, sampled_client_states, sampled_train_data)\n \n current_round_end_time = time.time()\n \n currnt_round_running_time = current_round_end_time - current_round_start_time\n\n print(f'Round {round_num} training loss: {train_loss}')\n print(f'Round {round_num} execution time: {currnt_round_running_time}')\n \n # Record the current round's training loss to the log\n tf.summary.scalar('train_loss', train_loss, step=round_num)\n tf.summary.scalar('train_running_time', currnt_round_running_time, step=round_num)\n \n print()\n \n # Update client states\n print(\"Updating client states.\")\n\n for state in new_client_states:\n train_client_states[selected_train_client_ids[state.client_serial]] = state\n\n print()\n \n print(\"Recording client statistics:\")\n \n for client_id in selected_train_client_ids:\n state = train_client_states[client_id]\n \n tf.summary.scalar(\n 'client_' + str(int(state.client_serial)) + '_num_processed',\n int(state.num_processed), step=round_num)\n\n print()\n\n # Evaluation\n if round_num % EXPERIMENT_CONFIG['ROUNDS_PER_EVAL'] == 0:\n model_final.from_weights(server_state.model_weights)\n\n # Test dataset generation for this round\n print(\"Calculating validation metric:\")\n\n current_round_validation_start_time = time.time()\n \n current_round_validation_metric = utils.keras_evaluate(\n model_final.keras_model, test_client_data_all_merged, metric_eval, \"/GPU:0\")\n \n current_round_validation_end_time = time.time()\n \n current_round_validation_runnning_time = current_round_validation_end_time - current_round_validation_start_time\n\n print(f'Round {round_num} validation metric: {current_round_validation_metric}')\n print(f'Round {round_num} validation time: {current_round_validation_runnning_time}')\n \n # Write down train_metrics to the log\n tf.summary.scalar('validation_metric', current_round_validation_metric, step=round_num)\n tf.summary.scalar('validation_running_time', current_round_validation_runnning_time, step=round_num)\n \n print()",
"Round 1 start!\nSelected client serials: [267 191 488 146 82 205 384 38 86 78]\nAnonymous client 146 : updated the model with server message.\nAnonymous client 146 : training start.\nAnonymous client 146 : batch 1 , 1 examples processed\nAnonymous client 146 : batch 2 , 2 examples processed\nAnonymous client 146 : batch 3 , 3 examples processed\nAnonymous client 146 : training finished. 3 examples processed, loss: 10.3245993\nAnonymous client 488 : updated the model with server message.\nAnonymous client 488 : training start.\nAnonymous client 488 : batch 1 , 8 examples processed\nAnonymous client 205 : updated the model with server message.\nAnonymous client 205 : training start.\nAnonymous client 205 : batch 1 , 2 examples processed\nAnonymous client 488 : batch 2 , 16 examples processed\nAnonymous client 205 : batch 2 , 4 examples processed\nAnonymous client 205 : batch 3 , 6 examples processed\nAnonymous client 488 : batch 3 , 24 examples processed\nAnonymous client 205 : training finished. 6 examples processed, loss: 10.3104439\nAnonymous client 488 : batch 4 , 32 examples processed\nAnonymous client 488 : batch 5 , 40 examples processed\nAnonymous client 191 : updated the model with server message.\nAnonymous client 191 : training start.\nAnonymous client 191 : batch 1 , 8 examples processed\nAnonymous client 488 : batch 6 , 48 examples processed\nAnonymous client 191 : batch 2 , 10 examples processed\nAnonymous client 488 : batch 7 , 52 examples processed\nAnonymous client 384 : updated the model with server message.\nAnonymous client 488 : batch 8 , 60 examples processed\nAnonymous client 384 : training start.\nAnonymous client 384 : batch 1 , 8 examples processed\nAnonymous client 488 : batch 9 , 68 examples processed\nAnonymous client 191 : batch 3 , 18 examples processed\nAnonymous client 384 : batch 2 , 16 examples processed\nAnonymous client 488 : batch 10 , 76 examples processed\nAnonymous client 191 : batch 4 , 20 examples processed\nAnonymous client 191 : batch 5 , 28 examples processed\nAnonymous client 384 : batch 3 , 24 examples processed\nAnonymous client 488 : batch 11 , 84 examples processed\nAnonymous client 191 : batch 6 , 30 examples processed\nAnonymous client 384 : batch 4 , 27 examples processed\nAnonymous client 488 : batch 12 , 92 examples processed\nAnonymous client 191 : training finished. 30 examples processed, loss: 10.3131609\nAnonymous client 384 : batch 5 , 35 examples processed\nAnonymous client 488 : batch 13 , 100 examples processed\nAnonymous client 384 : batch 6 , 43 examples processed\nAnonymous client 488 : batch 14 , 104 examples processed\nAnonymous client 384 : batch 7 , 51 examples processed\nAnonymous client 488 : batch 15 , 112 examples processed\nAnonymous client 384 : batch 8 , 54 examples processed\nAnonymous client 488 : batch 16 , 120 examples processed\nAnonymous client 384 : batch 9 , 62 examples processed\nAnonymous client 488 : batch 17 , 128 examples processed\nAnonymous client 384 : batch 10 , 70 examples processed\nAnonymous client 488 : batch 18 , 136 examples processed\nAnonymous client 384 : batch 11 , 78 examples processed\nAnonymous client 488 : batch 19 , 144 examples processed\nAnonymous client 384 : batch 12 , 81 examples processed\nAnonymous client 488 : batch 20 , 152 examples processed\nAnonymous client 384 : training finished. 81 examples processed, loss: 10.2556782\nAnonymous client 38 : updated the model with server message.\nAnonymous client 38 : training start.\nAnonymous client 78 : updated the model with server message.\nAnonymous client 78 : training start.\nAnonymous client 488 : batch 21 , 156 examples processed\nAnonymous client 38 : batch 1 , 8 examples processed\nAnonymous client 78 : batch 1 , 8 examples processed\nAnonymous client 82 : updated the model with server message.\nAnonymous client 82 : training start.\nAnonymous client 488 : training finished. 156 examples processed, loss: 10.1645241\nAnonymous client 78 : batch 2 , 16 examples processed\nAnonymous client 82 : batch 1 , 8 examples processed\nAnonymous client 38 : batch 2 , 16 examples processed\nAnonymous client 82 : batch 2 , 16 examples processed\nAnonymous client 78 : batch 3 , 19 examples processed\nAnonymous client 38 : batch 3 , 24 examples processed\nAnonymous client 82 : batch 3 , 24 examples processed\nAnonymous client 78 : batch 4 , 27 examples processed\nAnonymous client 38 : training finished. 24 examples processed, loss: 10.3124046\nAnonymous client 78 : batch 5 , 35 examples processed\nAnonymous client 82 : batch 4 , 32 examples processed\nAnonymous client 267 : updated the model with server message.\nAnonymous client 267 : training start.\nAnonymous client 267 : batch 1 , 1 examples processed\nAnonymous client 267 : batch 2 , 2 examples processed\nAnonymous client 78 : batch 6 , 38 examples processed\nAnonymous client 82 : batch 5 , 40 examples processed\nAnonymous client 86 : updated the model with server message.\nAnonymous client 86 : training start.\nAnonymous client 267 : batch 3 , 3 examples processed\nAnonymous client 78 : batch 7 , 46 examples processed\nAnonymous client 267 : training finished. 3 examples processed, loss: 10.3236561\nAnonymous client 82 : batch 6 , 44 examples processed\nAnonymous client 86 : batch 1 , 8 examples processed\nAnonymous client 78 : batch 8 , 54 examples processed\nAnonymous client 82 : batch 7 , 52 examples processed\nAnonymous client 86 : batch 2 , 16 examples processed\nAnonymous client 78 : batch 9 , 57 examples processed\nAnonymous client 82 : batch 8 , 60 examples processed\nAnonymous client 86 : batch 3 , 24 examples processed\nAnonymous client 78 : training finished. 57 examples processed, loss: 10.2828646\nAnonymous client 82 : batch 9 , 68 examples processed\nAnonymous client 86 : batch 4 , 29 examples processed\nAnonymous client 82 : batch 10 , 76 examples processed\nAnonymous client 86 : batch 5 , 37 examples processed\nAnonymous client 82 : batch 11 , 84 examples processed\nAnonymous client 86 : batch 6 , 45 examples processed\nAnonymous client 82 : batch 12 , 88 examples processed\nAnonymous client 86 : batch 7 , 53 examples processed\nAnonymous client 82 : batch 13 , 96 examples processed\nAnonymous client 86 : batch 8 , 58 examples processed\nAnonymous client 82 : batch 14 , 104 examples processed\nAnonymous client 86 : batch 9 , 66 examples processed\nAnonymous client 82 : batch 15 , 112 examples processed\nAnonymous client 86 : batch 10 , 74 examples processed\nAnonymous client 82 : batch 16 , 120 examples processed\nAnonymous client 86 : batch 11 , 82 examples processed\nAnonymous client 82 : batch 17 , 128 examples processed\nAnonymous client 86 : batch 12 , 87 examples processed\nAnonymous client 86 : training finished. 87 examples processed, loss: 10.2675657\nAnonymous client 82 : batch 18 , 132 examples processed\nAnonymous client 82 : training finished. 132 examples processed, loss: 10.1899986\nRound 1 training loss: 10.227214813232422\nRound 1 execution time: 1257.1640684604645\n\nUpdating client states.\n\nRecording client statistics:\n\nCalculating validation metric:\nRound 1 validation metric: 10.123824119567871\nRound 1 validation time: 63.56597375869751\n\nRound 2 start!\nSelected client serials: [295 629 660 601 714 292 547 161 232 647]\nAnonymous client 161 : updated the model with server message.\nAnonymous client 161 : training start.\nAnonymous client 660 : updated the model with server message.\nAnonymous client 660 : training start.\nAnonymous client 232 : updated the model with server message.\nAnonymous client 232 : training start.\nAnonymous client 295 : updated the model with server message.\nAnonymous client 295 : training start.\nAnonymous client 629 : updated the model with server message.\nAnonymous client 629 : training start.\nAnonymous client 647 : updated the model with server message.\nAnonymous client 647 : training start.\nAnonymous client 601 : updated the model with server message.\nAnonymous client 601 : training start.\nAnonymous client 292 : updated the model with server message.\nAnonymous client 292 : training start.\nAnonymous client 547 : updated the model with server message.\nAnonymous client 547 : training start.\nAnonymous client 161 : batch 1 , 1 examples processed\nAnonymous client 232 : batch 1 , 6 examples processed\n"
]
],
[
[
"### Save the trained model",
"_____no_output_____"
]
],
[
[
"model_final.keras_model.save(EXPERIMENT_CONFIG['RESULTS_MODEL'])",
"WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/tracking/tracking.py:111: Model.state_updates (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis property should not be used in TensorFlow 2.0, as updates are applied automatically.\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad18c3774526cc0ea46a8f26b02c90c79abafd0
| 4,383 |
ipynb
|
Jupyter Notebook
|
Assignment 4/Mystery.ipynb
|
ksopan/Edx_Machine_Learning_DSE220x
|
88841bbe7e400f05eeee25e52f2780082ec99f74
|
[
"MIT"
] | null | null | null |
Assignment 4/Mystery.ipynb
|
ksopan/Edx_Machine_Learning_DSE220x
|
88841bbe7e400f05eeee25e52f2780082ec99f74
|
[
"MIT"
] | null | null | null |
Assignment 4/Mystery.ipynb
|
ksopan/Edx_Machine_Learning_DSE220x
|
88841bbe7e400f05eeee25e52f2780082ec99f74
|
[
"MIT"
] | null | null | null | 24.762712 | 132 | 0.522473 |
[
[
[
"# Standard includes\n%matplotlib inline\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\n# Routines for linear regression\nfrom sklearn import linear_model\nfrom sklearn.metrics import mean_squared_error",
"_____no_output_____"
],
[
"data = np.genfromtxt('mystery.dat', delimiter=',')",
"_____no_output_____"
],
[
"x = data[:,0:99]\ny = data[:,100]",
"_____no_output_____"
],
[
"def feature_subset_regression(x,y,flist):\n if len(flist) < 1:\n print(\"Need at least one feature\")\n return\n for f in flist:\n if (f < 0) or (f > 100):\n print(\"Feature index is out of bounds\")\n return\n regr = linear_model.LinearRegression()\n regr.fit(x[:,flist], y)\n return mean_squared_error(y, regr.predict(x[:,flist]))",
"_____no_output_____"
],
[
"feature_list=[[0,4,6,18,43],[1,2,12,16,28],[2,6,12,18,43],[4,22,23,50,60]] #We are subtracting 1 from every index\n#feature_list=[[1,7,5,19,44],[2,3,13,27,29],[3,7,13,19,44],[5,23,24,51,61]] #We are subtracting 1 from every index\nfor features in feature_list:\n print(feature_subset_regression(x,y,features))",
"6.666805964795619\n5.931005043656825\n6.711275934495151\n7.497074872393358\n"
]
],
[
[
"#### Provides correct answer. Let's try single features to get top 10 features with lowest MSE",
"_____no_output_____"
]
],
[
[
"def one_feature_regression(x,y,f):\n if (f < 0) or (f > 99):\n print(\"Feature index is out of bounds\")\n return 0\n regr = linear_model.LinearRegression()\n x1 = x[:,[f]]\n regr.fit(x1, y)\n # Make predictions using the model\n y_pred = regr.predict(x1)\n #print(\"Mean squared error: \", mean_squared_error(y, y_pred))\n return mean_squared_error(y, y_pred)",
"_____no_output_____"
],
[
"def top_ten_singled_features(x,y):\n ls=[]\n indices=[]\n for i in range(0,99):\n ls.append(one_feature_regression(x,y,i))\n sorted_ls=sorted(ls)\n #[i+1 for i,x in enumerate(ls) if x=min(ls)]\n for x in sorted_ls:\n indices.append(ls.index(x))\n return indices[0:10]",
"_____no_output_____"
],
[
"indices= top_ten_singled_features(x,y)\nprint(\"We get MSE for\",indices,\"features as \",feature_subset_regression(x,y,indices)) # Add 1 to relate with answers given",
"We get MSE for [16, 10, 18, 22, 12, 25, 4, 80, 6, 1] features as 2.135608858468031\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad1a026931cec1905bff00942b1ba14bbfaf9a1
| 86,877 |
ipynb
|
Jupyter Notebook
|
Notebooks/yolov4_tl.ipynb
|
adriankjaerran/TDT17
|
81ad329c918ebbaf501d29e66b53fc0e6a433f82
|
[
"MIT"
] | null | null | null |
Notebooks/yolov4_tl.ipynb
|
adriankjaerran/TDT17
|
81ad329c918ebbaf501d29e66b53fc0e6a433f82
|
[
"MIT"
] | null | null | null |
Notebooks/yolov4_tl.ipynb
|
adriankjaerran/TDT17
|
81ad329c918ebbaf501d29e66b53fc0e6a433f82
|
[
"MIT"
] | null | null | null | 83.056405 | 29,634 | 0.613546 |
[
[
[
"### Some helper functions",
"_____no_output_____"
]
],
[
[
"# define helper functions\ndef imShow(path):\n import cv2\n import matplotlib.pyplot as plt\n %matplotlib inline\n\n image = cv2.imread(path)\n height, width = image.shape[:2]\n resized_image = cv2.resize(image,(3*width, 3*height), interpolation = cv2.INTER_CUBIC)\n\n fig = plt.gcf()\n fig.set_size_inches(18, 10)\n plt.axis(\"off\")\n plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB))\n plt.show()\n\n# use this to upload files\ndef upload():\n from google.colab import files\n uploaded = files.upload() \n for name, data in uploaded.items():\n with open(name, 'wb') as f:\n f.write(data)\n print ('saved file', name)\n\n# use this to download a file \ndef download(path):\n from google.colab import files\n files.download(path)",
"_____no_output_____"
]
],
[
[
"### Cloning and building DarkNet",
"_____no_output_____"
]
],
[
[
"# clone darknet repo\n!git clone https://github.com/AlexeyAB/darknet\n\n# change makefile to have GPU and OPENCV enabled\n%cd darknet\n!sed -i 's/OPENCV=0/OPENCV=1/' Makefile\n!sed -i 's/GPU=0/GPU=1/' Makefile\n!sed -i 's/CUDNN=0/CUDNN=1/' Makefile\n!sed -i 's/CUDNN_HALF=0/CUDNN_HALF=1/' Makefile",
"Cloning into 'darknet'...\nremote: Enumerating objects: 15376, done.\u001b[K\nremote: Total 15376 (delta 0), reused 0 (delta 0), pack-reused 15376\u001b[K\nReceiving objects: 100% (15376/15376), 13.98 MiB | 17.21 MiB/s, done.\nResolving deltas: 100% (10341/10341), done.\n/content/darknet\n"
],
[
"# verify CUDA\n!/usr/local/cuda/bin/nvcc --version",
"nvcc: NVIDIA (R) Cuda compiler driver\nCopyright (c) 2005-2020 NVIDIA Corporation\nBuilt on Mon_Oct_12_20:09:46_PDT_2020\nCuda compilation tools, release 11.1, V11.1.105\nBuild cuda_11.1.TC455_06.29190527_0\n"
],
[
"# make darknet (builds darknet so that you can then use the darknet executable file to run or train object detectors)\n!make",
"make: *** No targets specified and no makefile found. Stop.\n"
]
],
[
[
"### Importing our own data",
"_____no_output_____"
]
],
[
[
"%cd ..\nfrom google.colab import drive\ndrive.mount('/content/drive')",
"/content\nMounted at /content/drive\n"
],
[
"# Own stored folder\n!ls drive/MyDrive/TDT17/Data/training_data",
"all_data_tfrecords ambient_data.zip intensity_data.zip test_data.zip\nambient_data\t intensity_data test_data\t\t train\n"
],
[
"# copy over both datasets into the root directory of the Colab VM (comment out test.zip if you are not using a validation dataset)\n!cp drive/MyDrive/TDT17/Data/training_data/ambient_data.zip /content/darknet/data\n!cp drive/MyDrive/TDT17/Data/training_data/intensity_data.zip /content/darknet/data\n!cp drive/MyDrive/TDT17/Data/training_data/test_data.zip /content/darknet/data",
"_____no_output_____"
],
[
"!ls",
"darknet drive\tsample_data\n"
],
[
"# unzip the datasets and their contents so that they are now in /darknet/data/ folder\n!unzip /content/darknet/data/ambient_data.zip -d /content/darknet/data\n!unzip /content/darknet/data/intensity_data.zip -d /content/darknet/data\n!unzip /content/darknet/data/test_data.zip -d /content/darknet/data",
"_____no_output_____"
]
],
[
[
"### Configuring training files\n- Config file\n- obj.names and obj.data\n- generating train.txt and test.txt\n",
"_____no_output_____"
]
],
[
[
"# download cfg to google drive and change its name\n!cp content/darknet/cfg/yolov4-custom.cfg /content/drive/MyDrive/TDT17/yolov4-obj.cfg",
"cp: cannot stat 'content/darknet/cfg/yolov4-custom.cfg': No such file or directory\n"
],
[
"download('/content/drive/MyDrive/TDT17/yolov4-obj.cfg')",
"_____no_output_____"
],
[
"# upload the custom .cfg back to cloud VM from Google Drive\n!cp /content/drive/MyDrive/TDT17/yolov4-obj.cfg ./cfg",
"cp: cannot stat '/content/drive/MyDrive/TDT17/yolov4-obj.cfg': No such file or directory\n"
],
[
"#%cd darknet\n!ls data/",
"9k.tree\t\t eagle.jpg\t\t intensity_data\tscream.jpg\nambient_data\t giraffe.jpg\t\t intensity_data.zip\ttest_data\nambient_data.zip goal.txt\t\t labels\t\ttest_data.zip\ncoco9k.map\t horses.jpg\t\t __MACOSX\t\tvoc.names\ncoco.names\t imagenet.labels.list\t openimages.names\ndog.jpg\t\t imagenet.shortnames.list person.jpg\n"
],
[
"# Creating correct .data files with pointer to backup location",
"_____no_output_____"
],
[
"# Replacing .data files with the one we created earlier, which points to correct backup location\n!rm -f /content/darknet/data/ambient_data/ambient.data\n!rm -f /content/darknet/data/intensity_data/intensity.data\n!cp /content/drive/MyDrive/TDT17/Data/training_data/ambient_data/ambient.data /content/darknet/data/ambient_data/ambient.data\n!cp /content/drive/MyDrive/TDT17/Data/training_data/intensity_data/intensity.data /content/darknet/data/intensity_data/intensity.data\n",
"_____no_output_____"
]
],
[
[
"### Note: Possible error with data formatting",
"_____no_output_____"
],
[
"### Downloading pre-trained weights for convolutional-layers",
"_____no_output_____"
]
],
[
[
"!wget https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137",
"--2021-11-22 19:34:08-- https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137\nResolving github.com (github.com)... 140.82.112.3\nConnecting to github.com (github.com)|140.82.112.3|:443... connected.\nHTTP request sent, awaiting response... 302 Found\nLocation: https://github-releases.githubusercontent.com/75388965/48bfe500-889d-11ea-819e-c4d182fcf0db?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20211122%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20211122T193408Z&X-Amz-Expires=300&X-Amz-Signature=c53a1f4abdbb3a041404395e336e5d22d7f7a8ba5d1ef212719ff3f6563f64a8&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=75388965&response-content-disposition=attachment%3B%20filename%3Dyolov4.conv.137&response-content-type=application%2Foctet-stream [following]\n--2021-11-22 19:34:08-- https://github-releases.githubusercontent.com/75388965/48bfe500-889d-11ea-819e-c4d182fcf0db?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20211122%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20211122T193408Z&X-Amz-Expires=300&X-Amz-Signature=c53a1f4abdbb3a041404395e336e5d22d7f7a8ba5d1ef212719ff3f6563f64a8&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=75388965&response-content-disposition=attachment%3B%20filename%3Dyolov4.conv.137&response-content-type=application%2Foctet-stream\nResolving github-releases.githubusercontent.com (github-releases.githubusercontent.com)... 185.199.108.154, 185.199.109.154, 185.199.110.154, ...\nConnecting to github-releases.githubusercontent.com (github-releases.githubusercontent.com)|185.199.108.154|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 170038676 (162M) [application/octet-stream]\nSaving to: ‘yolov4.conv.137’\n\nyolov4.conv.137 100%[===================>] 162.16M 91.6MB/s in 1.8s \n\n2021-11-22 19:34:10 (91.6 MB/s) - ‘yolov4.conv.137’ saved [170038676/170038676]\n\n"
],
[
"obj_data_path = \"/content/darknet/data/intensity_data\"\nconfig_path = \"/content/drive/MyDrive/TDT17/Data/yolov4-obj.cfg\"",
"_____no_output_____"
]
],
[
[
"## Fixing train and test datasets.. ",
"_____no_output_____"
]
],
[
[
"# We dont need to alter the folder/data/names structure, we just have to convert ambient.txt into main.txt, with correct pointers",
"_____no_output_____"
],
[
"def fix_files(name):\n import os\n base_path = f\"/content/darknet/data/{name}_data\"\n txt_path = f\"{base_path}/{name}.txt\"\n with open(txt_path, \"r\") as f:\n filenames = f.read().split(\"\\n\")\n print(filenames)\n \n add_str = \"/content/darknet/data/\"\n filenames_fixed = [f\"{add_str}{f}\" for f in filenames]\n os.rename(txt_path, f\"{txt_path.replace('.txt', '')}_OLD.txt\")\n #txt_path = \"/content/darknet/data/intensity_data/intensity_new.txt\"\n with open(txt_path, \"w\") as f:\n for l in filenames_fixed:\n f.write(l + \"\\n\")\n \n\nfix_files(\"intensity\")",
"['intensity_data/data/intensity_video_00_frame_000000.PNG', 'intensity_data/data/intensity_video_00_frame_000001.PNG', 'intensity_data/data/intensity_video_00_frame_000002.PNG', 'intensity_data/data/intensity_video_00_frame_000003.PNG', 'intensity_data/data/intensity_video_00_frame_000004.PNG', 'intensity_data/data/intensity_video_00_frame_000005.PNG', 'intensity_data/data/intensity_video_00_frame_000006.PNG', 'intensity_data/data/intensity_video_00_frame_000007.PNG', 'intensity_data/data/intensity_video_00_frame_000008.PNG', 'intensity_data/data/intensity_video_00_frame_000009.PNG', 'intensity_data/data/intensity_video_00_frame_000010.PNG', 'intensity_data/data/intensity_video_00_frame_000011.PNG', 'intensity_data/data/intensity_video_00_frame_000012.PNG', 'intensity_data/data/intensity_video_00_frame_000013.PNG', 'intensity_data/data/intensity_video_00_frame_000014.PNG', 'intensity_data/data/intensity_video_00_frame_000015.PNG', 'intensity_data/data/intensity_video_00_frame_000016.PNG', 'intensity_data/data/intensity_video_00_frame_000017.PNG', 'intensity_data/data/intensity_video_00_frame_000018.PNG', 'intensity_data/data/intensity_video_00_frame_000019.PNG', 'intensity_data/data/intensity_video_00_frame_000020.PNG', 'intensity_data/data/intensity_video_00_frame_000021.PNG', 'intensity_data/data/intensity_video_00_frame_000022.PNG', 'intensity_data/data/intensity_video_00_frame_000023.PNG', 'intensity_data/data/intensity_video_00_frame_000024.PNG', 'intensity_data/data/intensity_video_00_frame_000025.PNG', 'intensity_data/data/intensity_video_00_frame_000026.PNG', 'intensity_data/data/intensity_video_00_frame_000027.PNG', 'intensity_data/data/intensity_video_00_frame_000028.PNG', 'intensity_data/data/intensity_video_00_frame_000029.PNG', 'intensity_data/data/intensity_video_00_frame_000030.PNG', 'intensity_data/data/intensity_video_00_frame_000031.PNG', 'intensity_data/data/intensity_video_00_frame_000032.PNG', 'intensity_data/data/intensity_video_00_frame_000033.PNG', 'intensity_data/data/intensity_video_00_frame_000034.PNG', 'intensity_data/data/intensity_video_00_frame_000035.PNG', 'intensity_data/data/intensity_video_00_frame_000036.PNG', 'intensity_data/data/intensity_video_00_frame_000037.PNG', 'intensity_data/data/intensity_video_00_frame_000038.PNG', 'intensity_data/data/intensity_video_00_frame_000039.PNG', 'intensity_data/data/intensity_video_00_frame_000040.PNG', 'intensity_data/data/intensity_video_00_frame_000041.PNG', 'intensity_data/data/intensity_video_00_frame_000042.PNG', 'intensity_data/data/intensity_video_00_frame_000043.PNG', 'intensity_data/data/intensity_video_00_frame_000044.PNG', 'intensity_data/data/intensity_video_00_frame_000045.PNG', 'intensity_data/data/intensity_video_00_frame_000046.PNG', 'intensity_data/data/intensity_video_00_frame_000047.PNG', 'intensity_data/data/intensity_video_00_frame_000048.PNG', 'intensity_data/data/intensity_video_00_frame_000049.PNG', 'intensity_data/data/intensity_video_00_frame_000050.PNG', 'intensity_data/data/intensity_video_00_frame_000051.PNG', 'intensity_data/data/intensity_video_00_frame_000052.PNG', 'intensity_data/data/intensity_video_00_frame_000053.PNG', 'intensity_data/data/intensity_video_00_frame_000054.PNG', 'intensity_data/data/intensity_video_00_frame_000055.PNG', 'intensity_data/data/intensity_video_00_frame_000056.PNG', 'intensity_data/data/intensity_video_00_frame_000057.PNG', 'intensity_data/data/intensity_video_00_frame_000058.PNG', 'intensity_data/data/intensity_video_00_frame_000059.PNG', 'intensity_data/data/intensity_video_00_frame_000060.PNG', 'intensity_data/data/intensity_video_00_frame_000061.PNG', 'intensity_data/data/intensity_video_00_frame_000062.PNG', 'intensity_data/data/intensity_video_00_frame_000063.PNG', 'intensity_data/data/intensity_video_00_frame_000064.PNG', 'intensity_data/data/intensity_video_00_frame_000065.PNG', 'intensity_data/data/intensity_video_00_frame_000066.PNG', 'intensity_data/data/intensity_video_00_frame_000067.PNG', 'intensity_data/data/intensity_video_00_frame_000068.PNG', 'intensity_data/data/intensity_video_00_frame_000069.PNG', 'intensity_data/data/intensity_video_00_frame_000070.PNG', 'intensity_data/data/intensity_video_00_frame_000071.PNG', 'intensity_data/data/intensity_video_00_frame_000072.PNG', 'intensity_data/data/intensity_video_00_frame_000073.PNG', 'intensity_data/data/intensity_video_00_frame_000074.PNG', 'intensity_data/data/intensity_video_00_frame_000075.PNG', 'intensity_data/data/intensity_video_00_frame_000076.PNG', 'intensity_data/data/intensity_video_00_frame_000077.PNG', 'intensity_data/data/intensity_video_00_frame_000078.PNG', 'intensity_data/data/intensity_video_00_frame_000079.PNG', 'intensity_data/data/intensity_video_00_frame_000080.PNG', 'intensity_data/data/intensity_video_00_frame_000081.PNG', 'intensity_data/data/intensity_video_00_frame_000082.PNG', 'intensity_data/data/intensity_video_00_frame_000083.PNG', 'intensity_data/data/intensity_video_00_frame_000084.PNG', 'intensity_data/data/intensity_video_00_frame_000085.PNG', 'intensity_data/data/intensity_video_00_frame_000086.PNG', 'intensity_data/data/intensity_video_00_frame_000087.PNG', 'intensity_data/data/intensity_video_00_frame_000088.PNG', 'intensity_data/data/intensity_video_00_frame_000089.PNG', 'intensity_data/data/intensity_video_00_frame_000090.PNG', 'intensity_data/data/intensity_video_00_frame_000091.PNG', 'intensity_data/data/intensity_video_00_frame_000092.PNG', 'intensity_data/data/intensity_video_00_frame_000093.PNG', 'intensity_data/data/intensity_video_00_frame_000094.PNG', 'intensity_data/data/intensity_video_00_frame_000095.PNG', 'intensity_data/data/intensity_video_00_frame_000096.PNG', 'intensity_data/data/intensity_video_00_frame_000097.PNG', 'intensity_data/data/intensity_video_00_frame_000098.PNG', 'intensity_data/data/intensity_video_00_frame_000099.PNG', 'intensity_data/data/intensity_video_01_frame_000000.PNG', 'intensity_data/data/intensity_video_01_frame_000001.PNG', 'intensity_data/data/intensity_video_01_frame_000002.PNG', 'intensity_data/data/intensity_video_01_frame_000003.PNG', 'intensity_data/data/intensity_video_01_frame_000004.PNG', 'intensity_data/data/intensity_video_01_frame_000005.PNG', 'intensity_data/data/intensity_video_01_frame_000006.PNG', 'intensity_data/data/intensity_video_01_frame_000007.PNG', 'intensity_data/data/intensity_video_01_frame_000008.PNG', 'intensity_data/data/intensity_video_01_frame_000009.PNG', 'intensity_data/data/intensity_video_01_frame_000010.PNG', 'intensity_data/data/intensity_video_01_frame_000011.PNG', 'intensity_data/data/intensity_video_01_frame_000012.PNG', 'intensity_data/data/intensity_video_01_frame_000013.PNG', 'intensity_data/data/intensity_video_01_frame_000014.PNG', 'intensity_data/data/intensity_video_01_frame_000015.PNG', 'intensity_data/data/intensity_video_01_frame_000016.PNG', 'intensity_data/data/intensity_video_01_frame_000017.PNG', 'intensity_data/data/intensity_video_01_frame_000018.PNG', 'intensity_data/data/intensity_video_01_frame_000019.PNG', 'intensity_data/data/intensity_video_01_frame_000020.PNG', 'intensity_data/data/intensity_video_01_frame_000021.PNG', 'intensity_data/data/intensity_video_01_frame_000022.PNG', 'intensity_data/data/intensity_video_01_frame_000023.PNG', 'intensity_data/data/intensity_video_01_frame_000024.PNG', 'intensity_data/data/intensity_video_01_frame_000025.PNG', 'intensity_data/data/intensity_video_01_frame_000026.PNG', 'intensity_data/data/intensity_video_01_frame_000027.PNG', 'intensity_data/data/intensity_video_01_frame_000028.PNG', 'intensity_data/data/intensity_video_01_frame_000029.PNG', 'intensity_data/data/intensity_video_01_frame_000030.PNG', 'intensity_data/data/intensity_video_01_frame_000031.PNG', 'intensity_data/data/intensity_video_01_frame_000032.PNG', 'intensity_data/data/intensity_video_01_frame_000033.PNG', 'intensity_data/data/intensity_video_01_frame_000034.PNG', 'intensity_data/data/intensity_video_01_frame_000035.PNG', 'intensity_data/data/intensity_video_01_frame_000036.PNG', 'intensity_data/data/intensity_video_01_frame_000037.PNG', 'intensity_data/data/intensity_video_01_frame_000038.PNG', 'intensity_data/data/intensity_video_01_frame_000039.PNG', 'intensity_data/data/intensity_video_01_frame_000040.PNG', 'intensity_data/data/intensity_video_01_frame_000041.PNG', 'intensity_data/data/intensity_video_01_frame_000042.PNG', 'intensity_data/data/intensity_video_01_frame_000043.PNG', 'intensity_data/data/intensity_video_01_frame_000044.PNG', 'intensity_data/data/intensity_video_01_frame_000045.PNG', 'intensity_data/data/intensity_video_01_frame_000046.PNG', 'intensity_data/data/intensity_video_01_frame_000047.PNG', 'intensity_data/data/intensity_video_01_frame_000048.PNG', 'intensity_data/data/intensity_video_01_frame_000049.PNG', 'intensity_data/data/intensity_video_01_frame_000050.PNG', 'intensity_data/data/intensity_video_01_frame_000051.PNG', 'intensity_data/data/intensity_video_01_frame_000052.PNG', 'intensity_data/data/intensity_video_01_frame_000053.PNG', 'intensity_data/data/intensity_video_01_frame_000054.PNG', 'intensity_data/data/intensity_video_01_frame_000055.PNG', 'intensity_data/data/intensity_video_01_frame_000056.PNG', 'intensity_data/data/intensity_video_01_frame_000057.PNG', 'intensity_data/data/intensity_video_01_frame_000058.PNG', 'intensity_data/data/intensity_video_01_frame_000059.PNG', 'intensity_data/data/intensity_video_01_frame_000060.PNG', 'intensity_data/data/intensity_video_01_frame_000061.PNG', 'intensity_data/data/intensity_video_01_frame_000062.PNG', 'intensity_data/data/intensity_video_01_frame_000063.PNG', 'intensity_data/data/intensity_video_01_frame_000064.PNG', 'intensity_data/data/intensity_video_01_frame_000065.PNG', 'intensity_data/data/intensity_video_01_frame_000066.PNG', 'intensity_data/data/intensity_video_01_frame_000067.PNG', 'intensity_data/data/intensity_video_01_frame_000068.PNG', 'intensity_data/data/intensity_video_01_frame_000069.PNG', 'intensity_data/data/intensity_video_01_frame_000070.PNG', 'intensity_data/data/intensity_video_01_frame_000071.PNG', 'intensity_data/data/intensity_video_01_frame_000072.PNG', 'intensity_data/data/intensity_video_01_frame_000073.PNG', 'intensity_data/data/intensity_video_01_frame_000074.PNG', 'intensity_data/data/intensity_video_01_frame_000075.PNG', 'intensity_data/data/intensity_video_01_frame_000076.PNG', 'intensity_data/data/intensity_video_01_frame_000077.PNG', 'intensity_data/data/intensity_video_01_frame_000078.PNG', 'intensity_data/data/intensity_video_01_frame_000079.PNG', 'intensity_data/data/intensity_video_01_frame_000080.PNG', 'intensity_data/data/intensity_video_01_frame_000081.PNG', 'intensity_data/data/intensity_video_01_frame_000082.PNG', 'intensity_data/data/intensity_video_01_frame_000083.PNG', 'intensity_data/data/intensity_video_01_frame_000084.PNG', 'intensity_data/data/intensity_video_01_frame_000085.PNG', 'intensity_data/data/intensity_video_01_frame_000086.PNG', 'intensity_data/data/intensity_video_01_frame_000087.PNG', 'intensity_data/data/intensity_video_01_frame_000088.PNG', 'intensity_data/data/intensity_video_01_frame_000089.PNG', 'intensity_data/data/intensity_video_01_frame_000090.PNG', 'intensity_data/data/intensity_video_01_frame_000091.PNG', 'intensity_data/data/intensity_video_01_frame_000092.PNG', 'intensity_data/data/intensity_video_01_frame_000093.PNG', 'intensity_data/data/intensity_video_01_frame_000094.PNG', 'intensity_data/data/intensity_video_01_frame_000095.PNG', 'intensity_data/data/intensity_video_01_frame_000096.PNG', 'intensity_data/data/intensity_video_01_frame_000097.PNG', 'intensity_data/data/intensity_video_01_frame_000098.PNG', 'intensity_data/data/intensity_video_01_frame_000099.PNG', 'intensity_data/data/intensity_video_01_frame_000100.PNG', 'intensity_data/data/intensity_video_02_frame_000000.PNG', 'intensity_data/data/intensity_video_02_frame_000001.PNG', 'intensity_data/data/intensity_video_02_frame_000002.PNG', 'intensity_data/data/intensity_video_02_frame_000003.PNG', 'intensity_data/data/intensity_video_02_frame_000004.PNG', 'intensity_data/data/intensity_video_02_frame_000005.PNG', 'intensity_data/data/intensity_video_02_frame_000006.PNG', 'intensity_data/data/intensity_video_02_frame_000007.PNG', 'intensity_data/data/intensity_video_02_frame_000008.PNG', 'intensity_data/data/intensity_video_02_frame_000009.PNG', 'intensity_data/data/intensity_video_02_frame_000010.PNG', 'intensity_data/data/intensity_video_02_frame_000011.PNG', 'intensity_data/data/intensity_video_02_frame_000012.PNG', 'intensity_data/data/intensity_video_02_frame_000013.PNG', 'intensity_data/data/intensity_video_02_frame_000014.PNG', 'intensity_data/data/intensity_video_02_frame_000015.PNG', 'intensity_data/data/intensity_video_02_frame_000016.PNG', 'intensity_data/data/intensity_video_02_frame_000017.PNG', 'intensity_data/data/intensity_video_02_frame_000018.PNG', 'intensity_data/data/intensity_video_02_frame_000019.PNG', 'intensity_data/data/intensity_video_02_frame_000020.PNG', 'intensity_data/data/intensity_video_02_frame_000021.PNG', 'intensity_data/data/intensity_video_02_frame_000022.PNG', 'intensity_data/data/intensity_video_02_frame_000023.PNG', 'intensity_data/data/intensity_video_02_frame_000024.PNG', 'intensity_data/data/intensity_video_02_frame_000025.PNG', 'intensity_data/data/intensity_video_02_frame_000026.PNG', 'intensity_data/data/intensity_video_02_frame_000027.PNG', 'intensity_data/data/intensity_video_02_frame_000028.PNG', 'intensity_data/data/intensity_video_02_frame_000029.PNG', 'intensity_data/data/intensity_video_02_frame_000030.PNG', 'intensity_data/data/intensity_video_02_frame_000031.PNG', 'intensity_data/data/intensity_video_02_frame_000032.PNG', 'intensity_data/data/intensity_video_02_frame_000033.PNG', 'intensity_data/data/intensity_video_02_frame_000034.PNG', 'intensity_data/data/intensity_video_02_frame_000035.PNG', 'intensity_data/data/intensity_video_02_frame_000036.PNG', 'intensity_data/data/intensity_video_02_frame_000037.PNG', 'intensity_data/data/intensity_video_02_frame_000038.PNG', 'intensity_data/data/intensity_video_02_frame_000039.PNG', 'intensity_data/data/intensity_video_02_frame_000040.PNG', 'intensity_data/data/intensity_video_02_frame_000041.PNG', 'intensity_data/data/intensity_video_02_frame_000042.PNG', 'intensity_data/data/intensity_video_02_frame_000043.PNG', 'intensity_data/data/intensity_video_02_frame_000044.PNG', 'intensity_data/data/intensity_video_02_frame_000045.PNG', 'intensity_data/data/intensity_video_02_frame_000046.PNG', 'intensity_data/data/intensity_video_02_frame_000047.PNG', 'intensity_data/data/intensity_video_02_frame_000048.PNG', 'intensity_data/data/intensity_video_02_frame_000049.PNG', 'intensity_data/data/intensity_video_02_frame_000050.PNG', 'intensity_data/data/intensity_video_02_frame_000051.PNG', 'intensity_data/data/intensity_video_02_frame_000052.PNG', 'intensity_data/data/intensity_video_02_frame_000053.PNG', 'intensity_data/data/intensity_video_02_frame_000054.PNG', 'intensity_data/data/intensity_video_02_frame_000055.PNG', 'intensity_data/data/intensity_video_02_frame_000056.PNG', 'intensity_data/data/intensity_video_02_frame_000057.PNG', 'intensity_data/data/intensity_video_02_frame_000058.PNG', 'intensity_data/data/intensity_video_02_frame_000059.PNG', 'intensity_data/data/intensity_video_02_frame_000060.PNG', 'intensity_data/data/intensity_video_02_frame_000061.PNG', 'intensity_data/data/intensity_video_02_frame_000062.PNG', 'intensity_data/data/intensity_video_02_frame_000063.PNG', 'intensity_data/data/intensity_video_02_frame_000064.PNG', 'intensity_data/data/intensity_video_02_frame_000065.PNG', 'intensity_data/data/intensity_video_02_frame_000066.PNG', 'intensity_data/data/intensity_video_02_frame_000067.PNG', 'intensity_data/data/intensity_video_02_frame_000068.PNG', 'intensity_data/data/intensity_video_02_frame_000069.PNG', 'intensity_data/data/intensity_video_02_frame_000070.PNG', 'intensity_data/data/intensity_video_02_frame_000071.PNG', 'intensity_data/data/intensity_video_02_frame_000072.PNG', 'intensity_data/data/intensity_video_02_frame_000073.PNG', 'intensity_data/data/intensity_video_02_frame_000074.PNG', 'intensity_data/data/intensity_video_02_frame_000075.PNG', 'intensity_data/data/intensity_video_02_frame_000076.PNG', 'intensity_data/data/intensity_video_02_frame_000077.PNG', 'intensity_data/data/intensity_video_02_frame_000078.PNG', 'intensity_data/data/intensity_video_02_frame_000079.PNG', 'intensity_data/data/intensity_video_02_frame_000080.PNG', 'intensity_data/data/intensity_video_02_frame_000081.PNG', 'intensity_data/data/intensity_video_02_frame_000082.PNG', 'intensity_data/data/intensity_video_02_frame_000083.PNG', 'intensity_data/data/intensity_video_02_frame_000084.PNG', 'intensity_data/data/intensity_video_02_frame_000085.PNG', 'intensity_data/data/intensity_video_02_frame_000086.PNG', 'intensity_data/data/intensity_video_02_frame_000087.PNG', 'intensity_data/data/intensity_video_02_frame_000088.PNG', 'intensity_data/data/intensity_video_02_frame_000089.PNG', 'intensity_data/data/intensity_video_02_frame_000090.PNG', 'intensity_data/data/intensity_video_02_frame_000091.PNG', 'intensity_data/data/intensity_video_02_frame_000092.PNG', 'intensity_data/data/intensity_video_02_frame_000093.PNG', 'intensity_data/data/intensity_video_02_frame_000094.PNG', 'intensity_data/data/intensity_video_02_frame_000095.PNG', 'intensity_data/data/intensity_video_02_frame_000096.PNG', 'intensity_data/data/intensity_video_02_frame_000097.PNG', 'intensity_data/data/intensity_video_02_frame_000098.PNG', 'intensity_data/data/intensity_video_02_frame_000099.PNG', 'intensity_data/data/intensity_video_02_frame_000100.PNG', 'intensity_data/data/intensity_video_17_frame_000000.PNG', 'intensity_data/data/intensity_video_17_frame_000001.PNG', 'intensity_data/data/intensity_video_17_frame_000002.PNG', 'intensity_data/data/intensity_video_17_frame_000003.PNG', 'intensity_data/data/intensity_video_17_frame_000004.PNG', 'intensity_data/data/intensity_video_17_frame_000005.PNG', 'intensity_data/data/intensity_video_17_frame_000006.PNG', 'intensity_data/data/intensity_video_17_frame_000007.PNG', 'intensity_data/data/intensity_video_17_frame_000008.PNG', 'intensity_data/data/intensity_video_17_frame_000009.PNG', 'intensity_data/data/intensity_video_17_frame_000010.PNG', 'intensity_data/data/intensity_video_17_frame_000011.PNG', 'intensity_data/data/intensity_video_17_frame_000012.PNG', 'intensity_data/data/intensity_video_17_frame_000013.PNG', 'intensity_data/data/intensity_video_17_frame_000014.PNG', 'intensity_data/data/intensity_video_17_frame_000015.PNG', 'intensity_data/data/intensity_video_17_frame_000016.PNG', 'intensity_data/data/intensity_video_17_frame_000017.PNG', 'intensity_data/data/intensity_video_17_frame_000018.PNG', 'intensity_data/data/intensity_video_17_frame_000019.PNG', 'intensity_data/data/intensity_video_17_frame_000020.PNG', 'intensity_data/data/intensity_video_17_frame_000021.PNG', 'intensity_data/data/intensity_video_17_frame_000022.PNG', 'intensity_data/data/intensity_video_17_frame_000023.PNG', 'intensity_data/data/intensity_video_17_frame_000024.PNG', 'intensity_data/data/intensity_video_17_frame_000025.PNG', 'intensity_data/data/intensity_video_17_frame_000026.PNG', 'intensity_data/data/intensity_video_17_frame_000027.PNG', 'intensity_data/data/intensity_video_17_frame_000028.PNG', 'intensity_data/data/intensity_video_17_frame_000029.PNG', 'intensity_data/data/intensity_video_17_frame_000030.PNG', 'intensity_data/data/intensity_video_17_frame_000031.PNG', 'intensity_data/data/intensity_video_17_frame_000032.PNG', 'intensity_data/data/intensity_video_17_frame_000033.PNG', 'intensity_data/data/intensity_video_17_frame_000034.PNG', 'intensity_data/data/intensity_video_17_frame_000035.PNG', 'intensity_data/data/intensity_video_17_frame_000036.PNG', 'intensity_data/data/intensity_video_17_frame_000037.PNG', 'intensity_data/data/intensity_video_17_frame_000038.PNG', 'intensity_data/data/intensity_video_17_frame_000039.PNG', 'intensity_data/data/intensity_video_17_frame_000040.PNG', 'intensity_data/data/intensity_video_17_frame_000041.PNG', 'intensity_data/data/intensity_video_17_frame_000042.PNG', 'intensity_data/data/intensity_video_17_frame_000043.PNG', 'intensity_data/data/intensity_video_17_frame_000044.PNG', 'intensity_data/data/intensity_video_17_frame_000045.PNG', 'intensity_data/data/intensity_video_17_frame_000046.PNG', 'intensity_data/data/intensity_video_17_frame_000047.PNG', 'intensity_data/data/intensity_video_17_frame_000048.PNG', 'intensity_data/data/intensity_video_17_frame_000049.PNG', 'intensity_data/data/intensity_video_17_frame_000050.PNG', 'intensity_data/data/intensity_video_17_frame_000051.PNG', 'intensity_data/data/intensity_video_17_frame_000052.PNG', 'intensity_data/data/intensity_video_17_frame_000053.PNG', 'intensity_data/data/intensity_video_17_frame_000054.PNG', 'intensity_data/data/intensity_video_17_frame_000055.PNG', 'intensity_data/data/intensity_video_17_frame_000056.PNG', 'intensity_data/data/intensity_video_17_frame_000057.PNG', 'intensity_data/data/intensity_video_17_frame_000058.PNG', 'intensity_data/data/intensity_video_17_frame_000059.PNG', 'intensity_data/data/intensity_video_17_frame_000060.PNG', 'intensity_data/data/intensity_video_17_frame_000061.PNG', 'intensity_data/data/intensity_video_17_frame_000062.PNG', 'intensity_data/data/intensity_video_17_frame_000063.PNG', 'intensity_data/data/intensity_video_17_frame_000064.PNG', 'intensity_data/data/intensity_video_17_frame_000065.PNG', 'intensity_data/data/intensity_video_17_frame_000066.PNG', 'intensity_data/data/intensity_video_17_frame_000067.PNG', 'intensity_data/data/intensity_video_17_frame_000068.PNG', 'intensity_data/data/intensity_video_17_frame_000069.PNG', 'intensity_data/data/intensity_video_17_frame_000070.PNG', 'intensity_data/data/intensity_video_17_frame_000071.PNG', 'intensity_data/data/intensity_video_17_frame_000072.PNG', 'intensity_data/data/intensity_video_17_frame_000073.PNG', 'intensity_data/data/intensity_video_17_frame_000074.PNG', 'intensity_data/data/intensity_video_17_frame_000075.PNG', 'intensity_data/data/intensity_video_17_frame_000076.PNG', 'intensity_data/data/intensity_video_17_frame_000077.PNG', 'intensity_data/data/intensity_video_17_frame_000078.PNG', 'intensity_data/data/intensity_video_17_frame_000079.PNG', 'intensity_data/data/intensity_video_17_frame_000080.PNG', 'intensity_data/data/intensity_video_17_frame_000081.PNG', 'intensity_data/data/intensity_video_17_frame_000082.PNG', 'intensity_data/data/intensity_video_17_frame_000083.PNG', 'intensity_data/data/intensity_video_17_frame_000084.PNG', 'intensity_data/data/intensity_video_17_frame_000085.PNG', 'intensity_data/data/intensity_video_17_frame_000086.PNG', 'intensity_data/data/intensity_video_17_frame_000087.PNG', 'intensity_data/data/intensity_video_17_frame_000088.PNG', 'intensity_data/data/intensity_video_17_frame_000089.PNG', 'intensity_data/data/intensity_video_17_frame_000090.PNG', 'intensity_data/data/intensity_video_17_frame_000091.PNG', 'intensity_data/data/intensity_video_17_frame_000092.PNG', 'intensity_data/data/intensity_video_17_frame_000093.PNG', 'intensity_data/data/intensity_video_17_frame_000094.PNG', 'intensity_data/data/intensity_video_17_frame_000095.PNG', 'intensity_data/data/intensity_video_17_frame_000096.PNG', 'intensity_data/data/intensity_video_17_frame_000097.PNG', 'intensity_data/data/intensity_video_17_frame_000098.PNG', 'intensity_data/data/intensity_video_17_frame_000099.PNG', 'intensity_data/data/intensity_video_18_frame_000000.PNG', 'intensity_data/data/intensity_video_18_frame_000001.PNG', 'intensity_data/data/intensity_video_18_frame_000002.PNG', 'intensity_data/data/intensity_video_18_frame_000003.PNG', 'intensity_data/data/intensity_video_18_frame_000004.PNG', 'intensity_data/data/intensity_video_18_frame_000005.PNG', 'intensity_data/data/intensity_video_18_frame_000006.PNG', 'intensity_data/data/intensity_video_18_frame_000007.PNG', 'intensity_data/data/intensity_video_18_frame_000008.PNG', 'intensity_data/data/intensity_video_18_frame_000009.PNG', 'intensity_data/data/intensity_video_18_frame_000010.PNG', 'intensity_data/data/intensity_video_18_frame_000011.PNG', 'intensity_data/data/intensity_video_18_frame_000012.PNG', 'intensity_data/data/intensity_video_18_frame_000013.PNG', 'intensity_data/data/intensity_video_18_frame_000014.PNG', 'intensity_data/data/intensity_video_18_frame_000015.PNG', 'intensity_data/data/intensity_video_18_frame_000016.PNG', 'intensity_data/data/intensity_video_18_frame_000017.PNG', 'intensity_data/data/intensity_video_18_frame_000018.PNG', 'intensity_data/data/intensity_video_18_frame_000019.PNG', 'intensity_data/data/intensity_video_18_frame_000020.PNG', 'intensity_data/data/intensity_video_18_frame_000021.PNG', 'intensity_data/data/intensity_video_18_frame_000022.PNG', 'intensity_data/data/intensity_video_18_frame_000023.PNG', 'intensity_data/data/intensity_video_18_frame_000024.PNG', 'intensity_data/data/intensity_video_18_frame_000025.PNG', 'intensity_data/data/intensity_video_18_frame_000026.PNG', 'intensity_data/data/intensity_video_18_frame_000027.PNG', 'intensity_data/data/intensity_video_18_frame_000028.PNG', 'intensity_data/data/intensity_video_18_frame_000029.PNG', 'intensity_data/data/intensity_video_18_frame_000030.PNG', 'intensity_data/data/intensity_video_18_frame_000031.PNG', 'intensity_data/data/intensity_video_18_frame_000032.PNG', 'intensity_data/data/intensity_video_18_frame_000033.PNG', 'intensity_data/data/intensity_video_18_frame_000034.PNG', 'intensity_data/data/intensity_video_18_frame_000035.PNG', 'intensity_data/data/intensity_video_18_frame_000036.PNG', 'intensity_data/data/intensity_video_18_frame_000037.PNG', 'intensity_data/data/intensity_video_18_frame_000038.PNG', 'intensity_data/data/intensity_video_18_frame_000039.PNG', 'intensity_data/data/intensity_video_18_frame_000040.PNG', 'intensity_data/data/intensity_video_18_frame_000041.PNG', 'intensity_data/data/intensity_video_18_frame_000042.PNG', 'intensity_data/data/intensity_video_18_frame_000043.PNG', 'intensity_data/data/intensity_video_18_frame_000044.PNG', 'intensity_data/data/intensity_video_18_frame_000045.PNG', 'intensity_data/data/intensity_video_18_frame_000046.PNG', 'intensity_data/data/intensity_video_18_frame_000047.PNG', 'intensity_data/data/intensity_video_18_frame_000048.PNG', 'intensity_data/data/intensity_video_18_frame_000049.PNG', 'intensity_data/data/intensity_video_18_frame_000050.PNG', 'intensity_data/data/intensity_video_18_frame_000051.PNG', 'intensity_data/data/intensity_video_18_frame_000052.PNG', 'intensity_data/data/intensity_video_18_frame_000053.PNG', 'intensity_data/data/intensity_video_18_frame_000054.PNG', 'intensity_data/data/intensity_video_18_frame_000055.PNG', 'intensity_data/data/intensity_video_18_frame_000056.PNG', 'intensity_data/data/intensity_video_18_frame_000057.PNG', 'intensity_data/data/intensity_video_18_frame_000058.PNG', 'intensity_data/data/intensity_video_18_frame_000059.PNG', 'intensity_data/data/intensity_video_18_frame_000060.PNG', 'intensity_data/data/intensity_video_18_frame_000061.PNG', 'intensity_data/data/intensity_video_18_frame_000062.PNG', 'intensity_data/data/intensity_video_18_frame_000063.PNG', 'intensity_data/data/intensity_video_18_frame_000064.PNG', 'intensity_data/data/intensity_video_18_frame_000065.PNG', 'intensity_data/data/intensity_video_18_frame_000066.PNG', 'intensity_data/data/intensity_video_18_frame_000067.PNG', 'intensity_data/data/intensity_video_18_frame_000068.PNG', 'intensity_data/data/intensity_video_18_frame_000069.PNG', 'intensity_data/data/intensity_video_18_frame_000070.PNG', 'intensity_data/data/intensity_video_18_frame_000071.PNG', 'intensity_data/data/intensity_video_18_frame_000072.PNG', 'intensity_data/data/intensity_video_18_frame_000073.PNG', 'intensity_data/data/intensity_video_18_frame_000074.PNG', 'intensity_data/data/intensity_video_18_frame_000075.PNG', 'intensity_data/data/intensity_video_18_frame_000076.PNG', 'intensity_data/data/intensity_video_18_frame_000077.PNG', 'intensity_data/data/intensity_video_18_frame_000078.PNG', 'intensity_data/data/intensity_video_18_frame_000079.PNG', 'intensity_data/data/intensity_video_18_frame_000080.PNG', 'intensity_data/data/intensity_video_18_frame_000081.PNG', 'intensity_data/data/intensity_video_18_frame_000082.PNG', 'intensity_data/data/intensity_video_18_frame_000083.PNG', 'intensity_data/data/intensity_video_18_frame_000084.PNG', 'intensity_data/data/intensity_video_18_frame_000085.PNG', 'intensity_data/data/intensity_video_18_frame_000086.PNG', 'intensity_data/data/intensity_video_18_frame_000087.PNG', 'intensity_data/data/intensity_video_18_frame_000088.PNG', 'intensity_data/data/intensity_video_18_frame_000089.PNG', 'intensity_data/data/intensity_video_18_frame_000090.PNG', 'intensity_data/data/intensity_video_18_frame_000091.PNG', 'intensity_data/data/intensity_video_18_frame_000092.PNG', 'intensity_data/data/intensity_video_18_frame_000093.PNG', 'intensity_data/data/intensity_video_18_frame_000094.PNG', 'intensity_data/data/intensity_video_18_frame_000095.PNG', 'intensity_data/data/intensity_video_18_frame_000096.PNG', 'intensity_data/data/intensity_video_18_frame_000097.PNG', 'intensity_data/data/intensity_video_18_frame_000098.PNG', 'intensity_data/data/intensity_video_18_frame_000099.PNG']\n"
]
],
[
[
"## Starting training \n- old weights: /content/drive/MyDrive/TDT17/backup/yolov4-obj_last.weights",
"_____no_output_____"
]
],
[
[
"# Training from Yolo weights:\n#!./darknet detector train /content/darknet/data/intensity_data/intensity.data /content/drive/MyDrive/TDT17/Data/yolov4-obj.cfg yolov4.conv.137 -dont_show \n\n# Training from backup weights\n!./darknet detector train /content/darknet/data/intensity_data/intensity.data /content/drive/MyDrive/TDT17/Data/yolov4-obj.cfg /content/drive/MyDrive/TDT17/backup/yolov4-obj_last.weights -dont_show \n",
" CUDA-version: 11010 (11020), cuDNN: 7.6.5, CUDNN_HALF=1, GPU count: 1 \n CUDNN_HALF=1 \n OpenCV version: 3.2.0\nvalid: Using default 'intensity_data/intensity.txt'\nyolov4-obj\n 0 : compute_capability = 370, cudnn_half = 0, GPU: Tesla K80 \nnet.optimized_memory = 0 \nmini_batch = 4, batch = 64, time_steps = 1, train = 1 \n layer filters size/strd(dil) input output\n 0 Create CUDA-stream - 0 \n Create cudnn-handle 0 \nconv 32 3 x 3/ 1 1024 x 128 x 3 -> 1024 x 128 x 32 0.226 BF\n 1 conv 64 3 x 3/ 2 1024 x 128 x 32 -> 512 x 64 x 64 1.208 BF\n 2 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 3 route 1 \t\t -> 512 x 64 x 64 \n 4 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 5 conv 32 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 32 0.134 BF\n 6 conv 64 3 x 3/ 1 512 x 64 x 32 -> 512 x 64 x 64 1.208 BF\n 7 Shortcut Layer: 4, wt = 0, wn = 0, outputs: 512 x 64 x 64 0.002 BF\n 8 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 9 route 8 2 \t -> 512 x 64 x 128 \n 10 conv 64 1 x 1/ 1 512 x 64 x 128 -> 512 x 64 x 64 0.537 BF\n 11 conv 128 3 x 3/ 2 512 x 64 x 64 -> 256 x 32 x 128 1.208 BF\n 12 conv 64 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 64 0.134 BF\n 13 route 11 \t\t -> 256 x 32 x 128 \n 14 conv 64 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 64 0.134 BF\n 15 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 16 conv 64 3 x 3/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.604 BF\n 17 Shortcut Layer: 14, wt = 0, wn = 0, outputs: 256 x 32 x 64 0.001 BF\n 18 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 19 conv 64 3 x 3/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.604 BF\n 20 Shortcut Layer: 17, wt = 0, wn = 0, outputs: 256 x 32 x 64 0.001 BF\n 21 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 22 route 21 12 \t -> 256 x 32 x 128 \n 23 conv 128 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 128 0.268 BF\n 24 conv 256 3 x 3/ 2 256 x 32 x 128 -> 128 x 16 x 256 1.208 BF\n 25 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 26 route 24 \t\t -> 128 x 16 x 256 \n 27 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 28 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 29 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 30 Shortcut Layer: 27, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 31 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 32 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 33 Shortcut Layer: 30, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 34 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 35 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 36 Shortcut Layer: 33, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 37 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 38 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 39 Shortcut Layer: 36, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 40 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 41 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 42 Shortcut Layer: 39, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 43 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 44 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 45 Shortcut Layer: 42, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 46 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 47 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 48 Shortcut Layer: 45, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 49 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 50 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 51 Shortcut Layer: 48, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 52 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 53 route 52 25 \t -> 128 x 16 x 256 \n 54 conv 256 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 256 0.268 BF\n 55 conv 512 3 x 3/ 2 128 x 16 x 256 -> 64 x 8 x 512 1.208 BF\n 56 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 57 route 55 \t\t -> 64 x 8 x 512 \n 58 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 59 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 60 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 61 Shortcut Layer: 58, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 62 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 63 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 64 Shortcut Layer: 61, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 65 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 66 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 67 Shortcut Layer: 64, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 68 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 69 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 70 Shortcut Layer: 67, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 71 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 72 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 73 Shortcut Layer: 70, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 74 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 75 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 76 Shortcut Layer: 73, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 77 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 78 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 79 Shortcut Layer: 76, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 80 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 81 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 82 Shortcut Layer: 79, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 83 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 84 route 83 56 \t -> 64 x 8 x 512 \n 85 conv 512 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 512 0.268 BF\n 86 conv 1024 3 x 3/ 2 64 x 8 x 512 -> 32 x 4 x1024 1.208 BF\n 87 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 88 route 86 \t\t -> 32 x 4 x1024 \n 89 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 90 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 91 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 92 Shortcut Layer: 89, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 93 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 94 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 95 Shortcut Layer: 92, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 96 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 97 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 98 Shortcut Layer: 95, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 99 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 100 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 101 Shortcut Layer: 98, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 102 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 103 route 102 87 \t -> 32 x 4 x1024 \n 104 conv 1024 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x1024 0.268 BF\n 105 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 106 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 107 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 108 max 5x 5/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.002 BF\n 109 route 107 \t\t -> 32 x 4 x 512 \n 110 max 9x 9/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.005 BF\n 111 route 107 \t\t -> 32 x 4 x 512 \n 112 max 13x13/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.011 BF\n 113 route 112 110 108 107 \t -> 32 x 4 x2048 \n 114 conv 512 1 x 1/ 1 32 x 4 x2048 -> 32 x 4 x 512 0.268 BF\n 115 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 116 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 117 conv 256 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 256 0.034 BF\n 118 upsample 2x 32 x 4 x 256 -> 64 x 8 x 256\n 119 route 85 \t\t -> 64 x 8 x 512 \n 120 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 121 route 120 118 \t -> 64 x 8 x 512 \n 122 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 123 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 124 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 125 ^C\n"
],
[
"imShow('chart.png')",
"_____no_output_____"
]
],
[
[
"### Checking MaP",
"_____no_output_____"
]
],
[
[
"!./darknet detector recall /content/darknet/data/intensity_data/intensity.names /content/drive/MyDrive/TDT17/Data/yolov4-obj_INFERENCE.cfg /content/drive/MyDrive/TDT17/backup/yolov4-obj_last.weights -dont_show",
" CUDA-version: 11010 (11020), cuDNN: 7.6.5, CUDNN_HALF=1, GPU count: 1 \n CUDNN_HALF=1 \n OpenCV version: 3.2.0\n 0 : compute_capability = 370, cudnn_half = 0, GPU: Tesla K80 \nnet.optimized_memory = 0 \nmini_batch = 1, batch = 1, time_steps = 1, train = 0 \n layer filters size/strd(dil) input output\n 0 Create CUDA-stream - 0 \n Create cudnn-handle 0 \nconv 32 3 x 3/ 1 1024 x 128 x 3 -> 1024 x 128 x 32 0.226 BF\n 1 conv 64 3 x 3/ 2 1024 x 128 x 32 -> 512 x 64 x 64 1.208 BF\n 2 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 3 route 1 \t\t -> 512 x 64 x 64 \n 4 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 5 conv 32 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 32 0.134 BF\n 6 conv 64 3 x 3/ 1 512 x 64 x 32 -> 512 x 64 x 64 1.208 BF\n 7 Shortcut Layer: 4, wt = 0, wn = 0, outputs: 512 x 64 x 64 0.002 BF\n 8 conv 64 1 x 1/ 1 512 x 64 x 64 -> 512 x 64 x 64 0.268 BF\n 9 route 8 2 \t -> 512 x 64 x 128 \n 10 conv 64 1 x 1/ 1 512 x 64 x 128 -> 512 x 64 x 64 0.537 BF\n 11 conv 128 3 x 3/ 2 512 x 64 x 64 -> 256 x 32 x 128 1.208 BF\n 12 conv 64 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 64 0.134 BF\n 13 route 11 \t\t -> 256 x 32 x 128 \n 14 conv 64 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 64 0.134 BF\n 15 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 16 conv 64 3 x 3/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.604 BF\n 17 Shortcut Layer: 14, wt = 0, wn = 0, outputs: 256 x 32 x 64 0.001 BF\n 18 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 19 conv 64 3 x 3/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.604 BF\n 20 Shortcut Layer: 17, wt = 0, wn = 0, outputs: 256 x 32 x 64 0.001 BF\n 21 conv 64 1 x 1/ 1 256 x 32 x 64 -> 256 x 32 x 64 0.067 BF\n 22 route 21 12 \t -> 256 x 32 x 128 \n 23 conv 128 1 x 1/ 1 256 x 32 x 128 -> 256 x 32 x 128 0.268 BF\n 24 conv 256 3 x 3/ 2 256 x 32 x 128 -> 128 x 16 x 256 1.208 BF\n 25 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 26 route 24 \t\t -> 128 x 16 x 256 \n 27 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 28 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 29 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 30 Shortcut Layer: 27, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 31 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 32 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 33 Shortcut Layer: 30, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 34 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 35 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 36 Shortcut Layer: 33, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 37 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 38 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 39 Shortcut Layer: 36, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 40 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 41 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 42 Shortcut Layer: 39, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 43 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 44 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 45 Shortcut Layer: 42, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 46 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 47 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 48 Shortcut Layer: 45, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 49 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 50 conv 128 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.604 BF\n 51 Shortcut Layer: 48, wt = 0, wn = 0, outputs: 128 x 16 x 128 0.000 BF\n 52 conv 128 1 x 1/ 1 128 x 16 x 128 -> 128 x 16 x 128 0.067 BF\n 53 route 52 25 \t -> 128 x 16 x 256 \n 54 conv 256 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 256 0.268 BF\n 55 conv 512 3 x 3/ 2 128 x 16 x 256 -> 64 x 8 x 512 1.208 BF\n 56 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 57 route 55 \t\t -> 64 x 8 x 512 \n 58 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 59 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 60 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 61 Shortcut Layer: 58, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 62 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 63 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 64 Shortcut Layer: 61, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 65 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 66 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 67 Shortcut Layer: 64, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 68 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 69 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 70 Shortcut Layer: 67, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 71 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 72 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 73 Shortcut Layer: 70, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 74 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 75 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 76 Shortcut Layer: 73, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 77 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 78 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 79 Shortcut Layer: 76, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 80 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 81 conv 256 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.604 BF\n 82 Shortcut Layer: 79, wt = 0, wn = 0, outputs: 64 x 8 x 256 0.000 BF\n 83 conv 256 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 256 0.067 BF\n 84 route 83 56 \t -> 64 x 8 x 512 \n 85 conv 512 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 512 0.268 BF\n 86 conv 1024 3 x 3/ 2 64 x 8 x 512 -> 32 x 4 x1024 1.208 BF\n 87 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 88 route 86 \t\t -> 32 x 4 x1024 \n 89 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 90 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 91 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 92 Shortcut Layer: 89, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 93 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 94 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 95 Shortcut Layer: 92, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 96 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 97 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 98 Shortcut Layer: 95, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 99 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 100 conv 512 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.604 BF\n 101 Shortcut Layer: 98, wt = 0, wn = 0, outputs: 32 x 4 x 512 0.000 BF\n 102 conv 512 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.067 BF\n 103 route 102 87 \t -> 32 x 4 x1024 \n 104 conv 1024 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x1024 0.268 BF\n 105 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 106 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 107 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 108 max 5x 5/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.002 BF\n 109 route 107 \t\t -> 32 x 4 x 512 \n 110 max 9x 9/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.005 BF\n 111 route 107 \t\t -> 32 x 4 x 512 \n 112 max 13x13/ 1 32 x 4 x 512 -> 32 x 4 x 512 0.011 BF\n 113 route 112 110 108 107 \t -> 32 x 4 x2048 \n 114 conv 512 1 x 1/ 1 32 x 4 x2048 -> 32 x 4 x 512 0.268 BF\n 115 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 116 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 117 conv 256 1 x 1/ 1 32 x 4 x 512 -> 32 x 4 x 256 0.034 BF\n 118 upsample 2x 32 x 4 x 256 -> 64 x 8 x 256\n 119 route 85 \t\t -> 64 x 8 x 512 \n 120 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 121 route 120 118 \t -> 64 x 8 x 512 \n 122 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 123 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 124 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 125 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 126 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 127 conv 128 1 x 1/ 1 64 x 8 x 256 -> 64 x 8 x 128 0.034 BF\n 128 upsample 2x 64 x 8 x 128 -> 128 x 16 x 128\n 129 route 54 \t\t -> 128 x 16 x 256 \n 130 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 131 route 130 128 \t -> 128 x 16 x 256 \n 132 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 133 conv 256 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 256 1.208 BF\n 134 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 135 conv 256 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 256 1.208 BF\n 136 conv 128 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 128 0.134 BF\n 137 conv 256 3 x 3/ 1 128 x 16 x 128 -> 128 x 16 x 256 1.208 BF\n 138 conv 39 1 x 1/ 1 128 x 16 x 256 -> 128 x 16 x 39 0.041 BF\n 139 yolo\n[yolo] params: iou loss: ciou (4), iou_norm: 0.07, obj_norm: 1.00, cls_norm: 1.00, delta_norm: 1.00, scale_x_y: 1.20\nnms_kind: greedynms (1), beta = 0.600000 \n 140 route 136 \t\t -> 128 x 16 x 128 \n 141 conv 256 3 x 3/ 2 128 x 16 x 128 -> 64 x 8 x 256 0.302 BF\n 142 route 141 126 \t -> 64 x 8 x 512 \n 143 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 144 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 145 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 146 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 147 conv 256 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 256 0.134 BF\n 148 conv 512 3 x 3/ 1 64 x 8 x 256 -> 64 x 8 x 512 1.208 BF\n 149 conv 39 1 x 1/ 1 64 x 8 x 512 -> 64 x 8 x 39 0.020 BF\n 150 yolo\n[yolo] params: iou loss: ciou (4), iou_norm: 0.07, obj_norm: 1.00, cls_norm: 1.00, delta_norm: 1.00, scale_x_y: 1.10\nnms_kind: greedynms (1), beta = 0.600000 \n 151 route 147 \t\t -> 64 x 8 x 256 \n 152 conv 512 3 x 3/ 2 64 x 8 x 256 -> 32 x 4 x 512 0.302 BF\n 153 route 152 116 \t -> 32 x 4 x1024 \n 154 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 155 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 156 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 157 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 158 conv 512 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 512 0.134 BF\n 159 conv 1024 3 x 3/ 1 32 x 4 x 512 -> 32 x 4 x1024 1.208 BF\n 160 conv 39 1 x 1/ 1 32 x 4 x1024 -> 32 x 4 x 39 0.010 BF\n 161 yolo\n[yolo] params: iou loss: ciou (4), iou_norm: 0.07, obj_norm: 1.00, cls_norm: 1.00, delta_norm: 1.00, scale_x_y: 1.05\nnms_kind: greedynms (1), beta = 0.600000 \nTotal BFLOPS 45.151 \navg_outputs = 371653 \n Allocate additional workspace_size = 37.75 MB \nLoading weights from /content/drive/MyDrive/TDT17/backup/yolov4-obj_last.weights...\n seen 64, trained: 57 K-images (0 Kilo-batches_64) \nDone! Loaded 162 layers from weights-file \nvalid: Using default 'data/train.txt'\nCouldn't open file: data/train.txt\n"
]
],
[
[
"### Precting on single instance",
"_____no_output_____"
]
],
[
[
"# Copying config file\n!cp /content/drive/MyDrive/TDT17/Data/yolov4-obj.cfg /content/drive/MyDrive/TDT17/Data/yolov4-obj_INFERENCE.cfg\n\n# need to set our custom cfg to test mode \n!sed -i 's/batch=64/batch=1/' /content/drive/MyDrive/TDT17/Data/yolov4-obj_INFERENCE.cfg\n!sed -i 's/subdivisions=16/subdivisions=1/' /content/drive/MyDrive/TDT17/Data/yolov4-obj_INFERENCE.cfg\n",
"_____no_output_____"
],
[
"# run your custom detector with this command (upload an image to your google drive to test, thresh flag sets accuracy that detection must be in order to show it)\n!./darknet detector test /content/darknet/data/intensity_data/intensity.data /content/drive/MyDrive/TDT17/Data/yolov4-obj_INFERENCE.cfg /content/drive/MyDrive/TDT17/backup/yolov4-obj_last.weights /content/darknet/data/test_data/data/ambient_video_03_frame_000000.PNG -thresh 0.1\nimShow('predictions.jpg')",
"/bin/bash: ./darknet: Is a directory\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad1b1e9483ebcf0621f68a008343f1c316329b0
| 4,106 |
ipynb
|
Jupyter Notebook
|
tinkerforge/fetchfix.ipynb
|
hydrophyl/studienprojekt
|
43ef19ca3e0f5d09939094a441e047f3a440e3d5
|
[
"MIT"
] | null | null | null |
tinkerforge/fetchfix.ipynb
|
hydrophyl/studienprojekt
|
43ef19ca3e0f5d09939094a441e047f3a440e3d5
|
[
"MIT"
] | null | null | null |
tinkerforge/fetchfix.ipynb
|
hydrophyl/studienprojekt
|
43ef19ca3e0f5d09939094a441e047f3a440e3d5
|
[
"MIT"
] | null | null | null | 27.931973 | 86 | 0.517535 |
[
[
[
"#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nHOST = \"localhost\"\nPORT = 4223\nUID = \"LdW\" # Change XYZ to the UID of your Particulate Matter Bricklet\n\nfrom tinkerforge.ip_connection import IPConnection\nfrom tinkerforge.bricklet_particulate_matter import BrickletParticulateMatter\n\n#setting up packages\nimport os\nfrom os.path import exists\nimport pandas as pd\nimport datetime\nfrom time import strftime,localtime\n\ntime_only = datetime.datetime.now().time().strftime(\"%H:%M:%S\")\ndate_local = strftime(\"%d%m%Y\", localtime())\ndf = pd.DataFrame({'Datum': [],\n 'Zeit': [],\n 'PM10': [],\n 'PM25': [],\n 'PM100': []})\n\n# Callback function for PM concentration callback\ndef cb_pm_concentration(pm10, pm25, pm100):\n #Wiederholungen\n time_only = datetime.datetime.now().time().strftime(\"%H:%M:%S\")\n date_local = strftime(\"%d%m%Y\", localtime())\n #Erstellung ein pandas dataframe\n path = \"./\" + date_local + \".csv\"\n file_exists = exists(path)\n if file_exists == False:\n df.pop('Datum')\n df.pop('Zeit')\n df.pop('PM10')\n df.pop('PM25')\n df.pop('PM100')\n df['Datum'] = ''\n df['Zeit'] = ''\n df['PM10'] = ''\n df['PM25'] = ''\n df['PM100'] = ''\n \n df.loc[len(df.index)] = [date_local,time_only,pm10,pm25,pm100]\n df.to_csv(filename, index=False, encoding='utf8')\n\n ",
"_____no_output_____"
],
[
" #Check if go to next day already?\nfiles = os.listdir()\nfilename = date_local + \".csv\"\nfile_exists = exists(filename)\n\nprint(file_exists)",
"False\n"
],
[
"ipcon = IPConnection() # Create IP connection\npm = BrickletParticulateMatter(UID, ipcon) # Create device object\n\nipcon.connect(HOST, PORT) # Connect to brickd\n# Don't use device before ipcon is connected\n\n# Register PM concentration callback to function cb_pm_concentration\npm.register_callback(pm.CALLBACK_PM_CONCENTRATION, cb_pm_concentration)\n\n# Set period for PM concentration callback to 1s (1000ms)\npm.set_pm_concentration_callback_configuration(1000, False)\n\ninput(\"Press key to exit\\n\") # Use raw_input() in Python 2\nipcon.disconnect()",
"Press key to exit\n \n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4ad1b243c597f602eb8e671135baeace813ce53a
| 137,758 |
ipynb
|
Jupyter Notebook
|
Analysis.ipynb
|
stencilman/DeepLabv3FineTuning
|
c770903a05742969929a3ab4123498e279a0ab7b
|
[
"MIT"
] | null | null | null |
Analysis.ipynb
|
stencilman/DeepLabv3FineTuning
|
c770903a05742969929a3ab4123498e279a0ab7b
|
[
"MIT"
] | null | null | null |
Analysis.ipynb
|
stencilman/DeepLabv3FineTuning
|
c770903a05742969929a3ab4123498e279a0ab7b
|
[
"MIT"
] | null | null | null | 306.128889 | 69,036 | 0.897095 |
[
[
[
"import torch\nimport matplotlib.pyplot as plt\nimport cv2\nimport pandas as pd",
"_____no_output_____"
],
[
"# Load the trained model \nmodel = torch.load('./NutExp/weights.pt')\n# Set the model to evaluate mode\nmodel.eval()",
"_____no_output_____"
],
[
"# Read the log file using pandas into a dataframe\ndf = pd.read_csv('./NutExp/log.csv')",
"_____no_output_____"
]
],
[
[
"### Training and testing loss, f1_score and auroc values for the model trained on the CrackForest dataset",
"_____no_output_____"
]
],
[
[
"# Plot all the values with respect to the epochs\ndf.plot(x='epoch',figsize=(15,8));",
"_____no_output_____"
],
[
"print(df[['Train_auroc','Test_auroc']].max())",
"Train_auroc 0.962523\nTest_auroc 0.873000\ndtype: float64\n"
]
],
[
[
"### Sample Prediction",
"_____no_output_____"
]
],
[
[
"ino = 2\nimgname = 'test16-10-3-Colour.png'\n# Read a sample image and mask from the data-set\nimg = cv2.imread(f'./NutDataset/Images/' + imgname).transpose(2,0,1).reshape(1,3,240,255)\nmask = cv2.imread(f'./NutDataset/Masks/' + imgname)\nwith torch.no_grad():\n a = model(torch.from_numpy(img).type(torch.cuda.FloatTensor)/255)",
"_____no_output_____"
],
[
"# Plot histogram of the prediction to find a suitable threshold. From the histogram a 0.1 looks like a good choice.\nplt.hist(a['out'].data.cpu().numpy().flatten())",
"_____no_output_____"
],
[
"# Plot the input image, ground truth and the predicted output\nplt.figure(figsize=(10,10));\nplt.subplot(141);\nplt.imshow(img[0,...].transpose(1,2,0));\nplt.title('Image')\nplt.axis('off');\nplt.subplot(142);\nplt.imshow(mask);\nplt.title('Ground Truth')\nplt.axis('off');\nplt.subplot(143);\nplt.imshow(a['out'].cpu().detach().numpy()[0][0] > .1);\nplt.title('Segmentation Output')\nplt.subplot(144);\nplt.imshow(a['out'].cpu().detach().numpy()[0][0]);\nplt.title('Probability Mask')\nplt.axis('off');\nplt.savefig('./NutExp/SegmentationOutput.png',bbox_inches='tight')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad1b6fa0d18802c6a93307e6107cd43afe3e08d
| 8,192 |
ipynb
|
Jupyter Notebook
|
notebooks/generators-cvhull-depths.ipynb
|
chudur-budur/pviz-bench
|
aa4071ab14900e3421b550251b5411a1948abcfa
|
[
"Apache-2.0"
] | null | null | null |
notebooks/generators-cvhull-depths.ipynb
|
chudur-budur/pviz-bench
|
aa4071ab14900e3421b550251b5411a1948abcfa
|
[
"Apache-2.0"
] | null | null | null |
notebooks/generators-cvhull-depths.ipynb
|
chudur-budur/pviz-bench
|
aa4071ab14900e3421b550251b5411a1948abcfa
|
[
"Apache-2.0"
] | null | null | null | 39.574879 | 534 | 0.470337 |
[
[
[
"## Depth Contours\n\n### Generate depth-contours of all the Pareto-optimal data sets.\n\nThis notebook can be used to generate tradeoff values from all the Pareto-optimal data point files hard-coded in the dictionary `pfs`. Currently this notebook processes these Pareto-optimal fronts.\n\n- DTLZ2 ($m$-Sphere) Problem\n- DEBMDK (Knee) Problem\n- CDEBMDK (Constrained Knee) Problem\n- C0-DTLZ2 (A split $𝑚$-sphere with a small isolated cluster at $f_m$-axis)\n- C2-DTLZ2 Problem\n- DTLZ8 Problem (A 3-dimensional line and an 𝑚 -dimensional hypersurface)\n- GAA Problem (A 10-objective and 18-constraint general aviation design problem)\n\n**Note:** Sometimes, it might happen that `simple_shape.depth_contours()` function does not work for data points if the points are very sparse or they being on a fully convex surface (or on the same hyperplane). In that case, there will be only one layer. We solve this problem by approximating the depth-contours from another set of data points with similar shape and dimentions where the depth-contours are available. Please refer to `cvhull-approximation-test.ipynb` note book. Also note that, this is not a general solution.",
"_____no_output_____"
]
],
[
[
"%reload_ext autoreload\n%autoreload 2\n\nimport sys\nimport os\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\n\nplt.rcParams.update({'figure.max_open_warning': 0})",
"_____no_output_____"
]
],
[
[
"### Generate and save the depth contours\n\nIn this case we are computing the depth-contours from the convex-hulls. So we are using the `tda.simple_shape` module.",
"_____no_output_____"
]
],
[
[
"from viz.tda import simple_shape\nfrom viz.utils import io\n\npfs = {'dtlz2': ['3d', '4d', '8d'], \\\n 'dtlz2-nbi': ['3d', '4d', '8d'], \\\n 'debmdk': ['3d', '4d', '8d'], \\\n 'debmdk-nbi': ['3d', '4d', '8d'], \\\n 'debmdk-all': ['3d', '4d', '8d'], \\\n 'debmdk-all-nbi': ['3d', '4d', '8d'], \\\n 'dtlz8': ['3d', '4d', '6d', '8d'], \\\n 'dtlz8-nbi': ['3d', '4d', '6d', '8d'], \\\n 'c2dtlz2': ['3d', '4d', '5d', '8d'], \\\n 'c2dtlz2-nbi': ['3d', '4d', '5d', '8d'], \\\n 'cdebmdk': ['3d', '4d', '8d'], \\\n 'cdebmdk-nbi': ['3d', '4d', '8d'], \\\n 'c0dtlz2': ['3d', '4d', '8d'], \\\n 'c0dtlz2-nbi': ['3d', '4d', '8d'], \\\n 'crash-nbi': ['3d'], \\\n 'crash-c1-nbi': ['3d'], \\\n 'crash-c2-nbi': ['3d'], \\\n 'carside-nbi': ['3d'], \\\n 'gaa': ['10d'], \\\n 'gaa-nbi': ['10d']}\n\nfor pf in list(pfs.keys())[-2:]:\n for dim in pfs[pf]:\n fullpathf = \"../data/{0:s}/{1:s}/f.csv\".format(pf, dim)\n if os.path.exists(fullpathf):\n path, filenamef = os.path.split(fullpathf)\n dirs = path.split('/')\n frontname = dirs[-2]\n\n F = np.loadtxt(fullpathf, delimiter=',')\n print(fullpathf, F.shape, dirs, frontname)\n \n # test simple_shape.depth_contour function\n # it looks like these PFs are better displayed if project_collapse=False\n if pf in ['dtlz8', 'dtlz8-nbi', 'crash-nbi', 'crash-c1-nbi', 'crash-c2-nbi']:\n L = simple_shape.depth_contours(F, project_collapse=False)\n elif pf in ['gaa', 'gaa-nbi']:\n L = simple_shape.depth_contours(F, verbose=True)\n else:\n L = simple_shape.depth_contours(F)\n # save the layers\n io.savetxt(os.path.join(path, \"depth-cont-cvhull.csv\"), L, fmt='{:d}', delimiter=',')\n \n # We are not using this since it's exrtemely slow and also doesn't give\n # layers if all the points are on a fully convex surface.\n # print(\"Generating depth-contours (project_collapse=False) for \" + frontname)\n # # test ss.depth_contour function without projection and collapse\n # L = ss.depth_contours(F, project_collapse = False)\n # save the layers\n # io.savetxt(os.path.join(path, \"depth-cont-cvhull.csv\"), L, fmt = '{:d}', delimiter = ',')",
"_____no_output_____"
]
],
[
[
"### Plot and verify",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom viz.utils import io\n\npfs = {'dtlz2': ['3d', '4d', '8d'], \\\n 'dtlz2-nbi': ['3d', '4d', '8d'], \\\n 'debmdk': ['3d', '4d', '8d'], \\\n 'debmdk-nbi': ['3d', '4d', '8d'], \\\n 'debmdk-all': ['3d', '4d', '8d'], \\\n 'debmdk-all-nbi': ['3d', '4d', '8d'], \\\n 'dtlz8': ['3d', '4d', '6d', '8d'], \\\n 'dtlz8-nbi': ['3d', '4d', '6d', '8d'], \\\n 'c2dtlz2': ['3d', '4d', '5d', '8d'], \\\n 'c2dtlz2-nbi': ['3d', '4d', '5d', '8d'], \\\n 'cdebmdk': ['3d', '4d', '8d'], \\\n 'cdebmdk-nbi': ['3d', '4d', '8d'], \\\n 'c0dtlz2': ['3d', '4d', '8d'], \\\n 'c0dtlz2-nbi': ['3d', '4d', '8d'], \\\n 'crash-nbi': ['3d'], 'crash-c1-nbi': ['3d'], 'crash-c2-nbi': ['3d'], \\\n 'gaa': ['10d'], \\\n 'gaa-nbi': ['10d']}\n\nfor pf in list(pfs.keys()):\n for dim in pfs[pf]:\n fullpathf = \"../data/{0:s}/{1:s}/f.csv\".format(pf, dim)\n if os.path.exists(fullpathf):\n path, filenamef = os.path.split(fullpathf)\n dirs = path.split('/')\n frontname = dirs[-2]\n \n F = np.loadtxt(fullpathf, delimiter = ',')\n print(fullpathf, F.shape, dirs, frontname)\n \n layerpathf = os.path.join(path, \"depth-cont-cvhull.csv\")\n if os.path.exists(layerpathf):\n L = io.loadtxt(layerpathf, dtype=int, delimiter=',')\n if F.shape[1] == 2:\n fig = plt.figure()\n ax = fig.gca()\n for l in L:\n ax.scatter(F[l.astype(int),0], F[l.astype(int),1], s=1)\n plt.show()\n else:\n fig = plt.figure()\n ax = Axes3D(fig)\n for l in L:\n ax.scatter(F[l.astype(int),0], F[l.astype(int),1], F[l.astype(int),2], s=1)\n plt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad1c58b068727dca05c29c94db1c5afecdb942d
| 18,008 |
ipynb
|
Jupyter Notebook
|
figure/source/2019-11-12-pyjanitor/try-pyjanitor.ipynb
|
changhsinlee/changhsinlee.github.io
|
73e84a41d51f53362ed17a534a46f1629a57e3f9
|
[
"MIT"
] | 10 |
2018-12-04T05:43:15.000Z
|
2022-03-26T19:47:25.000Z
|
figure/source/2019-11-12-pyjanitor/try-pyjanitor.ipynb
|
changhsinlee/changhsinlee.github.io
|
73e84a41d51f53362ed17a534a46f1629a57e3f9
|
[
"MIT"
] | null | null | null |
figure/source/2019-11-12-pyjanitor/try-pyjanitor.ipynb
|
changhsinlee/changhsinlee.github.io
|
73e84a41d51f53362ed17a534a46f1629a57e3f9
|
[
"MIT"
] | 19 |
2018-05-28T03:55:05.000Z
|
2022-03-26T19:47:26.000Z
| 24.838621 | 180 | 0.407041 |
[
[
[
"Why do method chaining? Because data cleaning is essentially a graph. \n\nInstead of jumping back and forth, it is easier if all cleaning of one dataset happens in one place. However, due to the lack of easy-to-use custom methods, it is cumbersome.",
"_____no_output_____"
],
[
"## Basic cleaning",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"from janitor import then",
"_____no_output_____"
],
[
"from functools import partial",
"_____no_output_____"
]
],
[
[
"## The dataset",
"_____no_output_____"
]
],
[
[
"raw_avocados = pd.read_csv('avocado-prices.zip', index_col=0)",
"_____no_output_____"
],
[
"raw_avocados.sample(5)",
"_____no_output_____"
]
],
[
[
"## Using `janitor.then()`",
"_____no_output_____"
]
],
[
[
"def get_yearly_sum_by_PID(df, PID):\n output = (\n df\n [['year', str(PID)]]\n .groupby(['year'], as_index=False)\n .agg({\n str(PID): 'sum'\n })\n .sort_values('year')\n )\n return output",
"_____no_output_____"
],
[
"from janitor import then\nfrom functools import partial\n\ndf_by_pid = (\n raw_avocados\n .then(partial(get_yearly_sum_by_PID, PID=4770))\n)",
"_____no_output_____"
],
[
"df_by_pid",
"_____no_output_____"
]
],
[
[
"## Comparison with normal pandas\n\nWhat I would do if there is no pyjanitor?",
"_____no_output_____"
],
[
"[janitor.remove_columns](https://pyjanitor.readthedocs.io/reference/janitor.functions/janitor.remove_columns.html#janitor.remove_columns)",
"_____no_output_____"
]
],
[
[
"drop_cols = ['Small Bags', 'Large Bags', 'XLarge Bags']\n# pandas style\ndf_no_bags_pd = raw_avocados.drop(drop_cols, axis=1)\n# pyjanitor style\ndf_no_bags = raw_avocados.remove_columns(drop_cols)\ndf_no_bags.equals(df_no_bags_pd)",
"_____no_output_____"
]
],
[
[
"[janitor.to_datetime](https://pyjanitor.readthedocs.io/reference/janitor.functions/janitor.to_datetime.html#janitor.to_datetime)",
"_____no_output_____"
]
],
[
[
"# pandas style\ndf_dt = raw_avocados.assign(Date=lambda _df: pd.to_datetime(_df['Date']))\n# pyjanitor style\ndf_dt2 = raw_avocados.to_datetime('Date')\ndf_dt.equals(df_dt2)",
"_____no_output_____"
],
[
"df_dt[['Date']].dtypes",
"_____no_output_____"
]
],
[
[
"[janitor.dropnotnull](https://pyjanitor.readthedocs.io/reference/janitor.functions/janitor.dropnotnull.html#janitor.dropnotnull)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nnan = np.nan",
"_____no_output_____"
],
[
"test_df = pd.DataFrame({\n 'a': [1, nan, 3],\n 'b': ['x', 'y', 'z']\n})",
"_____no_output_____"
],
[
"test_df",
"_____no_output_____"
],
[
"test_out1 = test_df.dropnotnull('a')\ntest_out2 = test_df[lambda _df: pd.isnull(_df['a'])]\ntest_out1.equals(test_out2)",
"_____no_output_____"
]
],
[
[
"## Custom chaining function",
"_____no_output_____"
]
],
[
[
"import pandas_flavor as pf",
"_____no_output_____"
]
],
[
[
"@pf.register_dataframe_method\ndef then(df: pd.DataFrame, func, *args, **kwargs) -> pd.DataFrame:\n \"\"\"\n Add an arbitrary function to run in the ``pyjanitor`` method chain.\n\n This method does not mutate the original DataFrame.\n\n :param df: A pandas dataframe.\n :param func: A function you would like to run in the method chain.\n It should take one parameter and return one parameter, each being the\n DataFrame object. After that, do whatever you want in the middle.\n Go crazy.\n :returns: A pandas DataFrame.\n \"\"\"\n df = func(df, *args, **kwargs)\n return df",
"_____no_output_____"
]
],
[
[
"## Use with other package e.g. great_expectations",
"_____no_output_____"
]
],
[
[
"import great_expectations as ge",
"_____no_output_____"
],
[
"ge_avocados = ge.read_csv('avocado.csv')",
"_____no_output_____"
],
[
"df_ge = (\n ge_avocados\n .then(partial(get_yearly_sum_by_PID, PID=4046))\n)\ndf_ge",
"_____no_output_____"
],
[
"type(df_ge)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ad1d008a416bb43de51317a0073b81ed493ff10
| 85,099 |
ipynb
|
Jupyter Notebook
|
docs/memo/notebooks/lectures/p-Hacking_and_Multiple_Comparisons_Bias/notebook.ipynb
|
hebpmo/zipline
|
396469b29e7e0daea4fe1e8a1c18f6c7eeb92780
|
[
"Apache-2.0"
] | 4 |
2018-11-17T20:04:53.000Z
|
2021-12-10T14:47:30.000Z
|
docs/memo/notebooks/lectures/p-Hacking_and_Multiple_Comparisons_Bias/notebook.ipynb
|
t330883522/zipline
|
396469b29e7e0daea4fe1e8a1c18f6c7eeb92780
|
[
"Apache-2.0"
] | null | null | null |
docs/memo/notebooks/lectures/p-Hacking_and_Multiple_Comparisons_Bias/notebook.ipynb
|
t330883522/zipline
|
396469b29e7e0daea4fe1e8a1c18f6c7eeb92780
|
[
"Apache-2.0"
] | 3 |
2018-11-17T20:04:50.000Z
|
2020-03-01T11:11:41.000Z
| 83.104492 | 21,572 | 0.790256 |
[
[
[
"# p-Hacking and Multiple Comparisons Bias\n\nBy Delaney Mackenzie and Maxwell Margenot.\n\nPart of the Quantopian Lecture Series:\n\n* [www.quantopian.com/lectures](https://www.quantopian.com/lectures)\n* [github.com/quantopian/research_public](https://github.com/quantopian/research_public)\n\nNotebook released under the Creative Commons Attribution 4.0 License.\n\n---\n\nMultiple comparisons bias is a pervasive problem in statistics, data science, and in general forecasting/predictions. The short explanation is that the more tests you run, the more likely you are to get an outcome that you want/expect. If you ignore the multitude of tests that failed, you are clearly setting yourself up for failure by misinterpreting what's going on in your data.\n\nA particularly common example of this is when looking for relationships in large data sets comprising of many indepedent series or variables. In this case you run a test each time you evaluate whether a relationship exists between a set of variables.\n\n\n## Statistics Merely Illuminates This Issue\n\nMost folks also fall prey to multiple comparisons bias in real life. Any time you make a decision you are effectively taking an action based on an hypothesis. That hypothesis is often tested. You can end up unknowingly making many tests in your daily life.\n\nAn example might be deciding which medicine is helping cure a cold you have. Many people will take multiple medicines at once to try and get rid of symptoms. You may think that a certain medicine worked, when in reality none did and the cold just happened to start getting better at some point.\n\nThe point here is that this problem doesn't stem from statistical testing and p-values. Rather, these techniques give us much more information about the problem and when it might be occuring.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport scipy.stats as stats\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### Refresher: Spearman Rank Correlation\n\nPlease refer to [this lecture](https://www.quantopian.com/lectures/spearman-rank-correlation) for more full info, but here is a very brief refresher on Spearman Rank Correlation.\n\nIt's a variation of correlation that takes into account the ranks of the data. This can help with weird distributions or outliers that would confuse other measures. The test also returns a p-value, which is key here.",
"_____no_output_____"
],
[
"A higher coefficient means a stronger estimated relationship.",
"_____no_output_____"
]
],
[
[
"X = pd.Series(np.random.normal(0, 1, 100))\nY = X\n\nr_s = stats.spearmanr(Y, X)\nprint 'Spearman Rank Coefficient: ', r_s[0]\nprint 'p-value: ', r_s[1]",
"Spearman Rank Coefficient: 1.0\np-value: 0.0\n"
]
],
[
[
"If we add some noise our coefficient will drop.",
"_____no_output_____"
]
],
[
[
"X = pd.Series(np.random.normal(0, 1, 100))\nY = X + np.random.normal(0, 1, 100)\n\nr_s = stats.spearmanr(Y, X)\nprint 'Spearman Rank Coefficient: ', r_s[0]\nprint 'p-value: ', r_s[1]",
"Spearman Rank Coefficient: 0.701278127813\np-value: 4.47737717228e-16\n"
]
],
[
[
"### p-value Refresher\n\nFor more info on p-values see [this lecture](https://www.quantopian.com/lectures/hypothesis-testing). What's important to remember is they're used to test a hypothesis given some data. Here we are testing the hypothesis that a relationship exists between two series given the series values.\n\n####IMPORTANT: p-values must be treated as binary.\n\nA common mistake is that p-values are treated as more or less significant. This is bad practice as it allows for what's known as [p-hacking](https://en.wikipedia.org/wiki/Data_dredging) and will result in more false positives than you expect. Effectively, you will be too likely to convince yourself that relationships exist in your data.\n\nTo treat p-values as binary, a cutoff must be set in advance. Then the p-value must be compared with the cutoff and treated as significant/not signficant. Here we'll show this.\n\n### The Cutoff is our Significance Level\n\nWe can refer to the cutoff as our significance level because a lower cutoff means that results which pass it are significant at a higher level of confidence. So if you have a cutoff of 0.05, then even on random data 5% of tests will pass based on chance. A cutoff of 0.01 reduces this to 1%, which is a more stringent test. We can therefore have more confidence in our results.",
"_____no_output_____"
]
],
[
[
"# Setting a cutoff of 5% means that there is a 5% chance\n# of us getting a significant p-value given no relationship\n# in our data (false positive).\n# NOTE: This is only true if the test's assumptions have been\n# satisfied and the test is therefore properly calibrated.\n# All tests have different assumptions.\ncutoff = 0.05\n\nX = pd.Series(np.random.normal(0, 1, 100))\nY = X + np.random.normal(0, 1, 100)\n\nr_s = stats.spearmanr(Y, X)\nprint 'Spearman Rank Coefficient: ', r_s[0]\nif r_s[1] < cutoff:\n print 'There is significant evidence of a relationship.'\nelse:\n print 'There is not significant evidence of a relationship.'",
"Spearman Rank Coefficient: 0.712859285929\nThere is significant evidence of a relationship.\n"
]
],
[
[
"## Experiment - Running Many Tests\n\nWe'll start by defining a data frame.",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame()",
"_____no_output_____"
]
],
[
[
"Now we'll populate it by adding `N` randomly generated timeseries of length `T`.",
"_____no_output_____"
]
],
[
[
"N = 20\nT = 100\n\nfor i in range(N):\n X = np.random.normal(0, 1, T)\n X = pd.Series(X)\n name = 'X%s' % i\n df[name] = X",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"Now we'll run a test on all pairs within our data looking for instances where our p-value is below our defined cutoff of 5%.",
"_____no_output_____"
]
],
[
[
"cutoff = 0.05\n\nsignificant_pairs = []\n\nfor i in range(N):\n for j in range(i+1, N):\n Xi = df.iloc[:, i]\n Xj = df.iloc[:, j]\n \n results = stats.spearmanr(Xi, Xj)\n \n pvalue = results[1]\n \n if pvalue < cutoff:\n significant_pairs.append((i, j))",
"_____no_output_____"
]
],
[
[
"Before we check how many significant results we got, let's run out some math to check how many we'd expect. The formula for the number of pairs given N series is\n\n$$\\frac{N(N-1)}{2}$$\n\nThere are no relationships in our data as it's all randomly generated. If our test is properly calibrated we should expect a false positive rate of 5% given our 5% cutoff. Therefore we should expect the following number of pairs that achieved significance based on pure random chance.",
"_____no_output_____"
]
],
[
[
"(N * (N-1) / 2) * 0.05",
"_____no_output_____"
]
],
[
[
"Now let's compare to how many we actually found.",
"_____no_output_____"
]
],
[
[
"len(significant_pairs)",
"_____no_output_____"
]
],
[
[
"We shouldn't expect the numbers to match too closely here on a consistent basis as we've only run one experiment. If we run many of these experiments we should see a convergence to what we'd expect.",
"_____no_output_____"
],
[
"### Repeating the Experiment\n\n",
"_____no_output_____"
]
],
[
[
"def do_experiment(N, T, cutoff=0.05):\n df = pd.DataFrame()\n\n # Make random data\n for i in range(N):\n X = np.random.normal(0, 1, T)\n X = pd.Series(X)\n name = 'X%s' % i\n df[name] = X\n\n significant_pairs = []\n\n # Look for relationships\n for i in range(N):\n for j in range(i+1, N):\n Xi = df.iloc[:, i]\n Xj = df.iloc[:, j]\n\n results = stats.spearmanr(Xi, Xj)\n\n pvalue = results[1]\n\n if pvalue < cutoff:\n significant_pairs.append((i, j))\n \n return significant_pairs\n\n\nnum_experiments = 100\n\nresults = np.zeros((num_experiments,))\n\nfor i in range(num_experiments):\n # Run a single experiment\n result = do_experiment(20, 100, cutoff=0.05)\n \n # Count how many pairs\n n = len(result)\n \n # Add to array\n results[i] = n",
"_____no_output_____"
]
],
[
[
"The average over many experiments should be closer.",
"_____no_output_____"
]
],
[
[
"np.mean(results)",
"_____no_output_____"
]
],
[
[
"## Visualizing What's Going On\n\nWhat's happening here is that p-values should be uniformly distributed, given no signal in the underlying data. Basically, they carry no information whatsoever and will be equally likely to be 0.01 as 0.99. Because they're popping out randomly, you will expect a certain percentage of p-values to be underneath any threshold you choose. The lower the threshold the fewer will pass your test.\n\nLet's visualize this by making a modified function that returns p-values.",
"_____no_output_____"
]
],
[
[
"def get_pvalues_from_experiment(N, T):\n df = pd.DataFrame()\n\n # Make random data\n for i in range(N):\n X = np.random.normal(0, 1, T)\n X = pd.Series(X)\n name = 'X%s' % i\n df[name] = X\n\n pvalues = []\n\n # Look for relationships\n for i in range(N):\n for j in range(i+1, N):\n Xi = df.iloc[:, i]\n Xj = df.iloc[:, j]\n\n results = stats.spearmanr(Xi, Xj)\n\n pvalue = results[1]\n\n pvalues.append(pvalue)\n \n return pvalues\n",
"_____no_output_____"
]
],
[
[
"We'll now collect a bunch of pvalues. As in any case we'll want to collect quite a number of p-values to start getting a sense of how the underlying distribution looks. If we only collect few, it will be noisy like this:",
"_____no_output_____"
]
],
[
[
"pvalues = get_pvalues_from_experiment(10, 100)\nplt.hist(pvalues)\nplt.ylabel('Frequency')\nplt.title('Observed p-value');",
"_____no_output_____"
]
],
[
[
"Let's dial up our `N` parameter to get a better sense. Keep in mind that the number of p-values will increase at a rate of\n\n$$\\frac{N (N-1)}{2}$$\n\nor approximately quadratically. Therefore we don't need to increase `N` by much.",
"_____no_output_____"
]
],
[
[
"pvalues = get_pvalues_from_experiment(50, 100)\nplt.hist(pvalues)\nplt.ylabel('Frequency')\nplt.title('Observed p-value');",
"_____no_output_____"
]
],
[
[
"Starting to look pretty flat, as we expected. Lastly, just to visualize the process of drawing a cutoff, we'll draw two artificial lines.",
"_____no_output_____"
]
],
[
[
"pvalues = get_pvalues_from_experiment(50, 100)\nplt.vlines(0.01, 0, 150, colors='r', linestyle='--', label='0.01 Cutoff')\nplt.vlines(0.05, 0, 150, colors='r', label='0.05 Cutoff')\nplt.hist(pvalues, label='P-Value Distribution')\nplt.legend()\nplt.ylabel('Frequency')\nplt.title('Observed p-value');",
"_____no_output_____"
]
],
[
[
"We can see that with a lower cutoff we should expect to get fewer false positives. Let's check that with our above experiment.",
"_____no_output_____"
]
],
[
[
"num_experiments = 100\n\nresults = np.zeros((num_experiments,))\n\nfor i in range(num_experiments):\n # Run a single experiment\n result = do_experiment(20, 100, cutoff=0.01)\n \n # Count how many pairs\n n = len(result)\n \n # Add to array\n results[i] = n",
"_____no_output_____"
],
[
"np.mean(results)",
"_____no_output_____"
]
],
[
[
"And finally compare it to what we expected.",
"_____no_output_____"
]
],
[
[
"(N * (N-1) / 2) * 0.01",
"_____no_output_____"
]
],
[
[
"## Sensitivity / Specificity Tradeoff\n\nAs with any adjustment of p-value cutoff, we have a tradeoff. A lower cutoff decreases the rate of false positives, but also decreases the chance we find a real relationship (true positive). So you can't just decrease your cutoff to solve this problem.\n\nhttps://en.wikipedia.org/wiki/Sensitivity_and_specificity\n\n## Reducing Multiple Comparisons Bias\n\nYou can't really eliminate multiple comparisons bias, but you can reduce how much it impacts you. To do so we have two options.\n\n### Option 1: Run fewer tests.\n\nThis is often the best option. Rather than just sweeping around hoping you hit an interesting signal, use your expert knowledge of the system to develop a great hypothesis and test that. This process of exploring the data, coming up with a hypothesis, then gathering more data and testing the hypothesis on the new data is considered the gold standard in statistical and scientific research. It's crucial that the data set on which you develop your hypothesis is not the one on which you test it. Because you found the effect while exploring, the test will likely pass and not really tell you anything. What you want to know is how consistent the effect is. Moving to new data and testing there will not only mean you only run one test, but will be an 'unbiased estimator' of whether your hypothesis is true. We discuss this a lot in other lectures.\n\n### Option 2: Adjustment Factors and Bon Ferroni Correction\n\n#### WARNING: This section gets a little technical. Unless you're comfortable with significance levels, we recommend looking at the code examples first and maybe reading the linked articles before fully diving into the text.\n\nIf you must run many tests, try to correct your p-values. This means applying a correction factor to the cutoff you desire to obtain the one actually used when determining whether p-values are significant. The most conservative and common correction factor is Bon Ferroni.",
"_____no_output_____"
],
[
"### Example: Bon Ferroni Correction\n\nThe concept behind Bon Ferroni is quite simple. It just says that if we run $m$ tests, and we have a significance level/cutoff of $a$, then we should use $a/m$ as our new cutoff when determining significance. The math works out because of the following.\n\nLet's say we run $m$ tests. We should expect to see $ma$ false positives based on random chance that pass out cutoff. If we instead use $a/m$ as our cutoff, then we should expect to see $ma/m = a$ tests that pass our cutoff. Therefore we are back to our desired false positive rate of $a$.\n\nLet's try it on our experiment above.",
"_____no_output_____"
]
],
[
[
"num_experiments = 100\n\nresults = np.zeros((num_experiments,))\n\nN = 20\n\nT = 100\n\ndesired_level = 0.05\n\nnum_tests = N * (N - 1) / 2\n\nnew_cutoff = desired_level / num_tests\n\nfor i in range(num_experiments):\n # Run a single experiment\n result = do_experiment(20, 100, cutoff=new_cutoff)\n \n # Count how many pairs\n n = len(result)\n \n # Add to array\n results[i] = n",
"_____no_output_____"
],
[
"np.mean(results)",
"_____no_output_____"
]
],
[
[
"As you can see, our number of significant results is now far lower on average. Which is good because the data was random to begin with.",
"_____no_output_____"
],
[
"### These are Often Overly Conservative\n\nBecause Bon Ferroni is so stringent, you can often end up passing over real relationships. There is a good example in the following article\n\nhttps://en.wikipedia.org/wiki/Multiple_comparisons_problem\n\nEffectively, it assumes that all the tests you are running are independent, and doesn't take into account any structure in your data. You may be able to design a more finely tuned correction factor, but this is adding a layer of complexity and therefore a point of failure to your research. In general any time you relax your stringency, you need to be very careful not to make a mistake.\n\nBecause of the over-zealousness of Bon Ferroni, often running fewer tests is the better option. Or, if you must run many tests, reserve multiple sets of data so your candidate signals can undergo an out-of-sample round of testing. For example, you might have the following flow:\n\n * Let's say there are 100,000 possible relationships.\n * Run a test on each possible relationship, and pick those that passed the test.\n * With these candidates, run a test on a new out-of-sample set of data. Because you have many fewer candidates, you can now apply a Bon Ferroni correction to these p-values, or if necessary repeat another round of out-of-sample testing.",
"_____no_output_____"
],
[
"# What is p-Hacking?\n\np-hacking is just intentional or accidental abuse of multiple comparisons bias. It is surprisingly common, even in academic literature. The excellent statistical news website FiveThirtyEight has a great visualization here:\n\nhttps://fivethirtyeight.com/features/science-isnt-broken/\n\nWikipedia's article is also informative:\n\nhttps://en.wikipedia.org/wiki/Data_dredging\n\nIn general, the concept is simple. By running many tests or experiments and then focusing only on the ones that worked, you can present false positives as real results. Keep in mind that this also applies to running many different models or different types of experiments and on different data sets. Imagine that you spend a summer researching a new model to forecast corn future prices. You try 50 different models until finally one succeeds. Is this just luck at this point? Certainly you would want to be more careful about validating that model and testing it out-of-sample on new data before believing that it works.",
"_____no_output_____"
],
[
"# Final Notes\n\n## You can never eliminate, only reduce risk.\n\nIn general you can never completely eliminate multiple comparisons bias, you can only reduce the risk of false positives using techniques we described above. At the end of the day most ideas tried in research don't work, so you'll end up testing many different hypotheses over time. Just try to be careful and use common sense about whether there is sufficient evidence that a hypothesis is true, or that you just happened to get lucky on this iteration.\n\n## Use Out-of-Sample Testing\n\nAs mentioned above, out-of-sample testing is one of the best ways to reduce your risk. You should always use it, no matter the circumstances. Often one of the ways that false positives make it through your workflow is a lack of an out-of-sample test at the end.",
"_____no_output_____"
],
[
"####Sources\n\n * https://en.wikipedia.org/wiki/Multiple_comparisons_problem\n * https://en.wikipedia.org/wiki/Sensitivity_and_specificity\n * https://en.wikipedia.org/wiki/Bonferroni_correction\n * https://fivethirtyeight.com/features/science-isnt-broken/",
"_____no_output_____"
],
[
"*This presentation is for informational purposes only and does not constitute an offer to sell, a solicitation to buy, or a recommendation for any security; nor does it constitute an offer to provide investment advisory or other services by Quantopian, Inc. (\"Quantopian\"). Nothing contained herein constitutes investment advice or offers any opinion with respect to the suitability of any security, and any views expressed herein should not be taken as advice to buy, sell, or hold any security or as an endorsement of any security or company. In preparing the information contained herein, Quantopian, Inc. has not taken into account the investment needs, objectives, and financial circumstances of any particular investor. Any views expressed and data illustrated herein were prepared based upon information, believed to be reliable, available to Quantopian, Inc. at the time of publication. Quantopian makes no guarantees as to their accuracy or completeness. All information is subject to change and may quickly become unreliable for various reasons, including changes in market conditions or economic circumstances.*",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ad1d9ad410e04f54ae2497089ace47ae72d1c64
| 13,494 |
ipynb
|
Jupyter Notebook
|
notebooks/rolldecay/studies/03.3_maa_roll_decay_test_system_identification_many.ipynb
|
martinlarsalbert/rolldecay
|
bee335c27e6519bd32ed9488751bc13e7f6fa9b3
|
[
"MIT"
] | null | null | null |
notebooks/rolldecay/studies/03.3_maa_roll_decay_test_system_identification_many.ipynb
|
martinlarsalbert/rolldecay
|
bee335c27e6519bd32ed9488751bc13e7f6fa9b3
|
[
"MIT"
] | 6 |
2021-02-02T23:07:50.000Z
|
2022-01-13T03:27:41.000Z
|
notebooks/rolldecay/studies/03.3_maa_roll_decay_test_system_identification_many.ipynb
|
martinlarsalbert/rolldecay
|
bee335c27e6519bd32ed9488751bc13e7f6fa9b3
|
[
"MIT"
] | null | null | null | 24.759633 | 146 | 0.54854 |
[
[
[
"# Roll decay test parameter sensitivity many\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\npd.set_option(\"display.max_rows\", 200)\nimport matplotlib.pyplot as plt\n\nfrom pylab import rcParams\nrcParams['figure.figsize'] = 15, 7\n\nimport os\nimport copy\nfrom scipy.optimize import curve_fit\n\nfrom rolldecay.simulation import simulate\n#import rolldecay.parameter_identification as parameter_identification\nimport rolldecay.read_funky_ascii\nimport inspect\nfrom rolldecayestimators.direct_estimator import DirectEstimator\nfrom rolldecayestimators.direct_linear_estimator import DirectLinearEstimator\nfrom rolldecayestimators.norwegian_estimator import NorwegianEstimator\nfrom rolldecayestimators.transformers import CutTransformer, LowpassFilterDerivatorTransformer, ScaleFactorTransformer, OffsetTransformer\n#from rolldecay.equations_lambdify import calculate_acceleration, calculate_velocity\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"122/(19*2*3.14)",
"_____no_output_____"
],
[
"exclude_files = ['20084871055k.06.asc','20084871055k.03.asc'\n ]\nacii_directory_path = os.path.join(rolldecay.data_path,'project1','Ascii files')\nfile_names = []\nfor file_name in os.listdir(acii_directory_path):\n file_names.append(file_name)\n \nfile_names = list(set(file_names) - set(exclude_files))\n",
"_____no_output_____"
],
[
"exclude_files = ['20084871055k.06.asc','20084871055k.03.asc'\n ]\nacii_directory_path = os.path.join(rolldecay.data_path,'project1','Ascii files')\nfile_names = []\nfor file_name in os.listdir(acii_directory_path):\n file_names.append(file_name)\n \nfile_names = list(set(file_names) - set(exclude_files))\n",
"_____no_output_____"
],
[
"def fit(pipeline):\n \n pipelines = {}\n \n for file_name in file_names:\n \n ascii_file_path = os.path.join(acii_directory_path,file_name)\n df_raw = rolldecay.read_funky_ascii.read(ascii_path=ascii_file_path)[['phi']]\n \n # Exclude tests where roll is not big enough:\n if ((df_raw['phi'].max() < np.deg2rad(1)) |\n (df_raw['phi'].min() > -np.deg2rad(1))):\n continue\n \n \n pipeline = copy.deepcopy(pipeline)\n pipeline.fit(X=df_raw)\n pipelines[file_name] = pipeline\n \n return pipelines",
"_____no_output_____"
],
[
"def predict(pipelines):\n \n df = pd.DataFrame()\n \n for file_name, pipeline in pipelines.items():\n \n estimator = pipeline[-1]\n s = pd.Series(estimator.parameters, name=file_name)\n s['score'] = estimator.score(X=estimator.X)\n s['mean_damping'] = estimator.calculate_average_linear_damping()\n df = df.append(s)\n \n return df",
"_____no_output_____"
]
],
[
[
"## Direct",
"_____no_output_____"
]
],
[
[
"lowpass_filter = LowpassFilterDerivatorTransformer(cutoff=0.4)\nscaler = ScaleFactorTransformer(scale_factor=29.565)\ncutter = CutTransformer(phi_max=np.deg2rad(15), phi_min=np.deg2rad(1))\noffset_transformer = OffsetTransformer()\nbounds = {\n 'zeta':(0,np.inf), # Only positive damping\n 'd':(0,np.inf), # Only positive damping\n}\ndirect_estimator = DirectEstimator(bounds=bounds)\n\nsteps = [\n('filter',lowpass_filter),\n('scaler',scaler),\n('cutter', cutter), \n('offset_transformer',offset_transformer),\n('direct_estimator', direct_estimator)]\n \npipeline_direct = Pipeline(steps) # define the pipeline object.",
"_____no_output_____"
],
[
"pipeline_directs = fit(pipeline=pipeline_direct)",
"_____no_output_____"
],
[
"pipeline = pipeline_directs['20084871051k.01.asc']",
"_____no_output_____"
],
[
"df_direct = predict(pipelines=pipeline_directs)",
"_____no_output_____"
]
],
[
[
"## Norwegian",
"_____no_output_____"
]
],
[
[
"norwegian_estimator = NorwegianEstimator(bounds=bounds)\n\nsteps = [\n ('filter',lowpass_filter),\n ('scaler',scaler),\n ('cutter', cutter), \n ('offset_transformer',offset_transformer),\n ('norwegian_estimator', norwegian_estimator)]\n \npipeline_norwegian = Pipeline(steps) # define the pipeline object. ",
"_____no_output_____"
],
[
"pipeline_norwegians = fit(pipeline=pipeline_norwegian)",
"_____no_output_____"
],
[
"df_norwegian = predict(pipelines=pipeline_norwegians)",
"_____no_output_____"
]
],
[
[
"## Linear method",
"_____no_output_____"
]
],
[
[
"direct_linear_estimator = DirectLinearEstimator()\n\nsteps = [\n ('filter',lowpass_filter),\n ('scaler',scaler),\n ('cutter', cutter), \n ('offset_transformer',offset_transformer),\n ('norwegian_estimator', direct_linear_estimator)]\n \npipeline_direct_linear = Pipeline(steps) # define the pipeline object. ",
"_____no_output_____"
],
[
"pipeline_direct_linears = fit(pipeline=pipeline_direct_linear)",
"_____no_output_____"
],
[
"df_direct_linear = predict(pipelines=pipeline_direct_linears)\ndf_direct_linear['d']=0",
"_____no_output_____"
],
[
"mask = df_direct['score'] > 0.90\ndf_direct_good = df_direct.loc[mask].copy()\ndf_direct_linear_good = df_direct_linear.loc[mask].copy()\ndf_norwegian_good = df_norwegian.loc[mask].copy()\n\n",
"_____no_output_____"
],
[
"df1 = df_direct_good.sort_values(by='score', ascending=False).iloc[-10:]\n#df1 = df_direct_good.sort_values(by='score', ascending=False).iloc[0:10]\nindex = df1.index.copy()\ndf1.reset_index(inplace=True)\n\ndf1['method'] = 'direct'\ndf2 = df_direct_linear_good.loc[index].reset_index()\ndf2['method'] = 'direct linear'\ndf3 = df_norwegian_good.loc[index].reset_index()\ndf3['method'] = 'norwegian'\n\n\ndf_comparison = pd.concat([df1,df2,df3], sort=False)",
"_____no_output_____"
],
[
"df_comparison.isnull().any()",
"_____no_output_____"
],
[
"for column in ['zeta','d','omega0','mean_damping','score']:\n fig,ax = plt.subplots()\n \n df = df_comparison.pivot(index='method',columns='index', values=column).transpose()\n df.plot(kind='bar', ax=ax)\n ylim = ax.get_ylim()\n ax.set_ylim(df.min().min(),df.max().max())\n ax.set_title(column)\n",
"_____no_output_____"
],
[
"file = df_direct_good.iloc[0].name\nfile",
"_____no_output_____"
],
[
"#file = df_direct_good.iloc[0].name\nfile = '20084871056k.08.asc'\n\n\npipelines = [pipeline_directs, pipeline_direct_linears, pipeline_norwegians]\n\nfig,ax = plt.subplots()\nfor p in pipelines:\n\n pipeline = p[file]\n estimator = pipeline[-1]\n estimator.plot_fit(ax=ax, model_test=False)\n print('%s:%s' % (estimator.__class__.__name__,estimator.score(X=estimator.X)))\n\nestimator.X.plot(y='phi', label='Model test', ax=ax, style='k--');\nax.legend()\n",
"_____no_output_____"
],
[
"pipeline = pipeline_norwegians[file]\nestimator = pipeline[-1]\nestimator.plot_damping()",
"_____no_output_____"
],
[
"#file = df_direct_good.iloc[0].name\n#file = '20084871056k.08.asc'\n\n\npipelines = [pipeline_directs, pipeline_direct_linears, pipeline_norwegians]\n\nfig,ax = plt.subplots()\nfor p in pipelines:\n\n pipeline = p[file]\n estimator = pipeline[-1]\n estimator.plot_error(ax=ax)\n print('%s:%s' % (estimator.__class__.__name__,estimator.score(X=estimator.X)))\n",
"_____no_output_____"
],
[
"estimator.X.plot(y='phi')",
"_____no_output_____"
],
[
"df_direct_good.describe()",
"_____no_output_____"
],
[
"df_norwegian_good.describe()",
"_____no_output_____"
]
],
[
[
"## The linear model is performing as good as the two quadratic for the present data\nNeed to investigate more ships to see if this changes...",
"_____no_output_____"
]
],
[
[
"df_direct_linear_good.describe()",
"_____no_output_____"
],
[
"pipeline = pipeline_directs['20084871056k.14.asc']\nestimator = pipeline[-1]\nestimator.X_amplitudes.plot(x='phi',y='omega0',style='.')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4ad1db0f8a89dbb17f056626a6d883232cf53c42
| 134,358 |
ipynb
|
Jupyter Notebook
|
RNN_project.ipynb
|
StMight/aind2-rnn
|
36e7db4cb99c8fa18f136c11848a12129b6507cc
|
[
"MIT"
] | null | null | null |
RNN_project.ipynb
|
StMight/aind2-rnn
|
36e7db4cb99c8fa18f136c11848a12129b6507cc
|
[
"MIT"
] | null | null | null |
RNN_project.ipynb
|
StMight/aind2-rnn
|
36e7db4cb99c8fa18f136c11848a12129b6507cc
|
[
"MIT"
] | null | null | null | 88.161417 | 39,824 | 0.777274 |
[
[
[
"# Artificial Intelligence Nanodegree\n## Recurrent Neural Network Projects\n\nWelcome to the Recurrent Neural Network Project in the Artificial Intelligence Nanodegree! In this notebook, some template code has already been provided for you, and you will need to implement additional functionality to successfully complete this project. You will not need to modify the included code beyond what is requested. Sections that begin with **'Implementation'** in the header indicate that the following block of code will require additional functionality which you must provide. Instructions will be provided for each section and the specifics of the implementation are marked in the code block with a 'TODO' statement. Please be sure to read the instructions carefully!\n\n>**Note:** Code and Markdown cells can be executed using the **Shift + Enter** keyboard shortcut. In addition, Markdown cells can be edited by typically double-clicking the cell to enter edit mode.",
"_____no_output_____"
],
[
"### Implementation TODOs in this notebook\n\nThis notebook contains two problems, cut into a variety of TODOs. Make sure to complete each section containing a TODO marker throughout the notebook. For convenience we provide links to each of these sections below.\n\n[TODO #1: Implement a function to window time series](#TODO_1)\n\n[TODO #2: Create a simple RNN model using keras to perform regression](#TODO_2)\n\n[TODO #3: Finish cleaning a large text corpus](#TODO_3)\n\n[TODO #4: Implement a function to window a large text corpus](#TODO_4)\n\n[TODO #5: Create a simple RNN model using keras to perform multiclass classification](#TODO_5)\n\n[TODO #6: Generate text using a fully trained RNN model and a variety of input sequences](#TODO_6)\n",
"_____no_output_____"
],
[
"# Problem 1: Perform time series prediction \n\nIn this project you will perform time series prediction using a Recurrent Neural Network regressor. In particular you will re-create the figure shown in the notes - where the stock price of Apple was forecasted (or predicted) 7 days in advance. In completing this exercise you will learn how to construct RNNs using Keras, which will also aid in completing the second project in this notebook.\n\nThe particular network architecture we will employ for our RNN is known as [Long Term Short Memory (LSTM)](https://en.wikipedia.org/wiki/Long_short-term_memory), which helps significantly avoid technical problems with optimization of RNNs. ",
"_____no_output_____"
],
[
"## 1.1 Getting started\n\nFirst we must load in our time series - a history of around 140 days of Apple's stock price. Then we need to perform a number of pre-processing steps to prepare it for use with an RNN model. First off, it is good practice to normalize time series - by normalizing its range. This helps us avoid serious numerical issues associated how common activation functions (like tanh) transform very large (positive or negative) numbers, as well as helping us to avoid related issues when computing derivatives.\n\nHere we normalize the series to lie in the range [0,1] [using this scikit function](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html), but it is also commonplace to normalize by a series standard deviation.",
"_____no_output_____"
]
],
[
[
"### Load in necessary libraries for data input and normalization\n%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n%load_ext autoreload\n%autoreload 2\n\nfrom my_answers import *\n\n%load_ext autoreload\n%autoreload 2\n\nfrom my_answers import *\n\n### load in and normalize the dataset\ndataset = np.loadtxt('datasets/normalized_apple_prices.csv')",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
]
],
[
[
"Lets take a quick look at the (normalized) time series we'll be performing predictions on.",
"_____no_output_____"
]
],
[
[
"# lets take a look at our time series\nplt.plot(dataset)\nplt.xlabel('time period')\nplt.ylabel('normalized series value')",
"_____no_output_____"
]
],
[
[
"## 1.2 Cutting our time series into sequences\n\nRemember, our time series is a sequence of numbers that we can represent in general mathematically as \n\n$$s_{0},s_{1},s_{2},...,s_{P}$$\n\nwhere $s_{p}$ is the numerical value of the time series at time period $p$ and where $P$ is the total length of the series. In order to apply our RNN we treat the time series prediction problem as a regression problem, and so need to use a sliding window to construct a set of associated input/output pairs to regress on. This process is animated in the gif below.\n\n<img src=\"images/timeseries_windowing_training.gif\" width=600 height=600/>\n\nFor example - using a window of size T = 5 (as illustrated in the gif above) we produce a set of input/output pairs like the one shown in the table below\n\n$$\\begin{array}{c|c}\n\\text{Input} & \\text{Output}\\\\\n\\hline \\color{CornflowerBlue} {\\langle s_{1},s_{2},s_{3},s_{4},s_{5}\\rangle} & \\color{Goldenrod}{ s_{6}} \\\\\n\\ \\color{CornflowerBlue} {\\langle s_{2},s_{3},s_{4},s_{5},s_{6} \\rangle } & \\color{Goldenrod} {s_{7} } \\\\\n\\color{CornflowerBlue} {\\vdots} & \\color{Goldenrod} {\\vdots}\\\\\n\\color{CornflowerBlue} { \\langle s_{P-5},s_{P-4},s_{P-3},s_{P-2},s_{P-1} \\rangle } & \\color{Goldenrod} {s_{P}}\n\\end{array}$$\n\nNotice here that each input is a sequence (or vector) of length 5 (and in general has length equal to the window size T) while each corresponding output is a scalar value. Notice also how given a time series of length P and window size T = 5 as shown above, we created P - 5 input/output pairs. More generally, for a window size T we create P - T such pairs.",
"_____no_output_____"
],
[
"Now its time for you to window the input time series as described above! \n\n<a id='TODO_1'></a>\n\n**TODO:** Implement the function called **window_transform_series** in my_answers.py so that it runs a sliding window along the input series and creates associated input/output pairs. Note that this function should input a) the series and b) the window length, and return the input/output subsequences. Make sure to format returned input/output as generally shown in table above (where window_size = 5), and make sure your returned input is a numpy array.\n\n-----",
"_____no_output_____"
],
[
"You can test your function on the list of odd numbers given below",
"_____no_output_____"
]
],
[
[
"odd_nums = np.array([1,3,5,7,9,11,13])",
"_____no_output_____"
]
],
[
[
"Here is a hard-coded solution for odd_nums. You can compare its results with what you get from your **window_transform_series** implementation.",
"_____no_output_____"
]
],
[
[
"# run a window of size 2 over the odd number sequence and display the results\nwindow_size = 2\n\nX = []\nX.append(odd_nums[0:2])\nX.append(odd_nums[1:3])\nX.append(odd_nums[2:4])\nX.append(odd_nums[3:5])\nX.append(odd_nums[4:6])\n\ny = odd_nums[2:]\n\nX = np.asarray(X)\ny = np.asarray(y)\ny = np.reshape(y, (len(y),1)) #optional\n\nassert(type(X).__name__ == 'ndarray')\nassert(type(y).__name__ == 'ndarray')\nassert(X.shape == (5,2))\nassert(y.shape in [(5,1), (5,)])\n\n# print out input/output pairs --> here input = X, corresponding output = y\nprint ('--- the input X will look like ----')\nprint (X)\n\nprint ('--- the associated output y will look like ----')\nprint (y)",
"--- the input X will look like ----\n[[ 1 3]\n [ 3 5]\n [ 5 7]\n [ 7 9]\n [ 9 11]]\n--- the associated output y will look like ----\n[[ 5]\n [ 7]\n [ 9]\n [11]\n [13]]\n"
]
],
[
[
"Again - you can check that your completed **window_transform_series** function works correctly by trying it on the odd_nums sequence - you should get the above output.",
"_____no_output_____"
]
],
[
[
"### TODO: implement the function window_transform_series in the file my_answers.py\nfrom my_answers import window_transform_series",
"_____no_output_____"
]
],
[
[
"With this function in place apply it to the series in the Python cell below. We use a window_size = 7 for these experiments.",
"_____no_output_____"
]
],
[
[
"# window the data using your windowing function\nwindow_size = 7\nX,y = window_transform_series(series = dataset,window_size = window_size)\n\nprint(X[:2])\nprint(y[:2])",
"[[-0.70062339 -0.82088484 -0.93938305 -0.9471652 -0.68785527 -0.84325902\n -0.80532018]\n [-0.82088484 -0.93938305 -0.9471652 -0.68785527 -0.84325902 -0.80532018\n -0.82058073]]\n[[-0.82058073]\n [-0.92023124]]\n"
]
],
[
[
"## 1.3 Splitting into training and testing sets\n\nIn order to perform proper testing on our dataset we will lop off the last 1/3 of it for validation (or testing). This is that once we train our model we have something to test it on (like any regression problem!). This splitting into training/testing sets is done in the cell below.\n\nNote how here we are **not** splitting the dataset *randomly* as one typically would do when validating a regression model. This is because our input/output pairs *are related temporally*. We don't want to validate our model by training on a random subset of the series and then testing on another random subset, as this simulates the scenario that we receive new points *within the timeframe of our training set*. \n\nWe want to train on one solid chunk of the series (in our case, the first full 2/3 of it), and validate on a later chunk (the last 1/3) as this simulates how we would predict *future* values of a time series.",
"_____no_output_____"
]
],
[
[
"# split our dataset into training / testing sets\ntrain_test_split = int(np.ceil(2*len(y)/float(3))) # set the split point\n\n# partition the training set\nX_train = X[:train_test_split,:]\ny_train = y[:train_test_split]\n\n# keep the last chunk for testing\nX_test = X[train_test_split:,:]\ny_test = y[train_test_split:]\n\n# NOTE: to use keras's RNN LSTM module our input must be reshaped to [samples, window size, stepsize] \nX_train = np.asarray(np.reshape(X_train, (X_train.shape[0], window_size, 1)))\nX_test = np.asarray(np.reshape(X_test, (X_test.shape[0], window_size, 1)))",
"_____no_output_____"
]
],
[
[
"<a id='TODO_2'></a>\n\n## 1.4 Build and run an RNN regression model\n\nHaving created input/output pairs out of our time series and cut this into training/testing sets, we can now begin setting up our RNN. We use Keras to quickly build a two hidden layer RNN of the following specifications\n\n- layer 1 uses an LSTM module with 5 hidden units (note here the input_shape = (window_size,1))\n- layer 2 uses a fully connected module with one unit\n- the 'mean_squared_error' loss should be used (remember: we are performing regression here)\n\nThis can be constructed using just a few lines - see e.g., the [general Keras documentation](https://keras.io/getting-started/sequential-model-guide/) and the [LSTM documentation in particular](https://keras.io/layers/recurrent/) for examples of how to quickly use Keras to build neural network models. Make sure you are initializing your optimizer given the [keras-recommended approach for RNNs](https://keras.io/optimizers/) \n\n(given in the cell below). (remember to copy your completed function into the script *my_answers.py* function titled *build_part1_RNN* before submitting your project)",
"_____no_output_____"
]
],
[
[
"### TODO: create required RNN model\n# import keras network libraries\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nimport keras\n\n# given - fix random seed - so we can all reproduce the same results on our default time series\nnp.random.seed(0)\n\n\n# TODO: implement build_part1_RNN in my_answers.py\nfrom my_answers import build_part1_RNN\nmodel = build_part1_RNN(window_size)\n\n# build model using keras documentation recommended optimizer initialization\noptimizer = keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)\n\n# compile the model\nmodel.compile(loss='mean_squared_error', optimizer=optimizer)",
"_____no_output_____"
]
],
[
[
"With your model built you can now fit the model by activating the cell below! Note: the number of epochs (np_epochs) and batch_size are preset (so we can all produce the same results). You can choose to toggle the verbose parameter - which gives you regular updates on the progress of the algorithm - on and off by setting it to 1 or 0 respectively.",
"_____no_output_____"
]
],
[
[
"# run your model!\nmodel.fit(X_train, y_train, epochs=1000, batch_size=50, verbose=0)",
"_____no_output_____"
]
],
[
[
"## 1.5 Checking model performance\n\nWith your model fit we can now make predictions on both our training and testing sets.",
"_____no_output_____"
]
],
[
[
"# generate predictions for training\ntrain_predict = model.predict(X_train)\ntest_predict = model.predict(X_test)",
"_____no_output_____"
]
],
[
[
"In the next cell we compute training and testing errors using our trained model - you should be able to achieve at least\n\n*training_error* < 0.02\n\nand \n\n*testing_error* < 0.02\n\nwith your fully trained model. \n\nIf either or both of your accuracies are larger than 0.02 re-train your model - increasing the number of epochs you take (a maximum of around 1,000 should do the job) and/or adjusting your batch_size.",
"_____no_output_____"
]
],
[
[
"# print out training and testing errors\ntraining_error = model.evaluate(X_train, y_train, verbose=0)\nprint('training error = ' + str(training_error))\n\ntesting_error = model.evaluate(X_test, y_test, verbose=0)\nprint('testing error = ' + str(testing_error))",
"training error = 0.0160044296221\ntesting error = 0.0139837288406\n"
]
],
[
[
"Activating the next cell plots the original data, as well as both predictions on the training and testing sets. ",
"_____no_output_____"
]
],
[
[
"### Plot everything - the original series as well as predictions on training and testing sets\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n# plot original series\nplt.plot(dataset,color = 'k')\n\n# plot training set prediction\nsplit_pt = train_test_split + window_size \nplt.plot(np.arange(window_size,split_pt,1),train_predict,color = 'b')\n\n# plot testing set prediction\nplt.plot(np.arange(split_pt,split_pt + len(test_predict),1),test_predict,color = 'r')\n\n# pretty up graph\nplt.xlabel('day')\nplt.ylabel('(normalized) price of Apple stock')\nplt.legend(['original series','training fit','testing fit'],loc='center left', bbox_to_anchor=(1, 0.5))\nplt.show()",
"_____no_output_____"
]
],
[
[
"**Note:** you can try out any time series for this exercise! If you would like to try another see e.g., [this site containing thousands of time series](https://datamarket.com/data/list/?q=provider%3Atsdl) and pick another one!",
"_____no_output_____"
],
[
"# Problem 2: Create a sequence generator",
"_____no_output_____"
],
[
"## 2.1 Getting started\n\nIn this project you will implement a popular Recurrent Neural Network (RNN) architecture to create an English language sequence generator capable of building semi-coherent English sentences from scratch by building them up character-by-character. This will require a substantial amount amount of parameter tuning on a large training corpus (at least 100,000 characters long). In particular for this project we will be using a complete version of Sir Arthur Conan Doyle's classic book The Adventures of Sherlock Holmes.\n\nHow can we train a machine learning model to generate text automatically, character-by-character? *By showing the model many training examples so it can learn a pattern between input and output.* With this type of text generation each input is a string of valid characters like this one\n\n*dogs are grea*\n\nwhile the corresponding output is the next character in the sentence - which here is 't' (since the complete sentence is 'dogs are great'). We need to show a model many such examples in order for it to make reasonable predictions.\n\n**Fun note:** For those interested in how text generation is being used check out some of the following fun resources:\n\n- [Generate wacky sentences](http://www.cs.toronto.edu/~ilya/rnn.html) with this academic RNN text generator\n\n- Various twitter bots that tweet automatically generated text like[this one](http://tweet-generator-alex.herokuapp.com/).\n\n- the [NanoGenMo](https://github.com/NaNoGenMo/2016) annual contest to automatically produce a 50,000+ novel automatically\n\n- [Robot Shakespeare](https://github.com/genekogan/RobotShakespeare) a text generator that automatically produces Shakespear-esk sentences",
"_____no_output_____"
],
[
"## 2.2 Preprocessing a text dataset\n\nOur first task is to get a large text corpus for use in training, and on it we perform a several light pre-processing tasks. The default corpus we will use is the classic book Sherlock Holmes, but you can use a variety of others as well - so long as they are fairly large (around 100,000 characters or more). ",
"_____no_output_____"
]
],
[
[
"# read in the text, transforming everything to lower case\ntext = open('datasets/holmes.txt').read().lower()\nprint('our original text has ' + str(len(text)) + ' characters')",
"our original text has 581864 characters\n"
]
],
[
[
"Next, lets examine a bit of the raw text. Because we are interested in creating sentences of English words automatically by building up each word character-by-character, we only want to train on valid English words. In other words - we need to remove all of the other characters that are not part of English words.",
"_____no_output_____"
]
],
[
[
"### print out the first 1000 characters of the raw text to get a sense of what we need to throw out\ntext[:2000]",
"_____no_output_____"
]
],
[
[
"Wow - there's a lot of junk here (i.e., weird uncommon character combinations - as this first character chunk contains the title and author page, as well as table of contents)! To keep things simple, we want to train our RNN on a large chunk of more typical English sentences - we don't want it to start thinking non-english words or strange characters are valid! - so lets clean up the data a bit.\n\nFirst, since the dataset is so large and the first few hundred characters contain a lot of junk, lets cut it out. Lets also find-and-replace those newline tags with empty spaces.",
"_____no_output_____"
]
],
[
[
"### find and replace '\\n' and '\\r' symbols - replacing them \ntext = text[1302:]\ntext = text.replace('\\n',' ') # replacing '\\n' with '' simply removes the sequence\ntext = text.replace('\\r',' ')",
"_____no_output_____"
]
],
[
[
"Lets see how the first 1000 characters of our text looks now!",
"_____no_output_____"
]
],
[
[
"### print out the first 1000 characters of the raw text to get a sense of what we need to throw out\ntext[:1000]",
"_____no_output_____"
]
],
[
[
"<a id='TODO_3'></a>\n\n#### TODO: finish cleaning the text\n\nLets make sure we haven't left any other atypical characters (commas, periods, etc., are ok) lurking around in the depths of the text. You can do this by enumerating all the text's unique characters, examining them, and then replacing any unwanted characters with empty spaces! Once we find all of the text's unique characters, we can remove all of the atypical ones in the next cell. Note: don't remove the punctuation marks given in my_answers.py.",
"_____no_output_____"
]
],
[
[
"### TODO: implement cleaned_text in my_answers.py\nfrom my_answers import cleaned_text\n\ntext = cleaned_text(text)\n\n# shorten any extra dead space created above\ntext = text.replace(' ',' ')",
"_____no_output_____"
]
],
[
[
"With your chosen characters removed print out the first few hundred lines again just to double check that everything looks good.",
"_____no_output_____"
]
],
[
[
"### print out the first 2000 characters of the raw text to get a sense of what we need to throw out\ntext[:2000]",
"_____no_output_____"
]
],
[
[
"Now that we have thrown out a good number of non-English characters/character sequences lets print out some statistics about the dataset - including number of total characters and number of unique characters.",
"_____no_output_____"
]
],
[
[
"# count the number of unique characters in the text\nchars = sorted(list(set(text)))\n\n# print some of the text, as well as statistics\nprint (\"this corpus has \" + str(len(text)) + \" total number of characters\")\nprint (\"this corpus has \" + str(len(chars)) + \" unique characters\")",
"this corpus has 573681 total number of characters\nthis corpus has 33 unique characters\n"
]
],
[
[
"## 2.3 Cutting data into input/output pairs\n\nNow that we have our text all cleaned up, how can we use it to train a model to generate sentences automatically? First we need to train a machine learning model - and in order to do that we need a set of input/output pairs for a model to train on. How can we create a set of input/output pairs from our text to train on?\n\nRemember in part 1 of this notebook how we used a sliding window to extract input/output pairs from a time series? We do the same thing here! We slide a window of length $T$ along our giant text corpus - everything in the window becomes one input while the character following becomes its corresponding output. This process of extracting input/output pairs is illustrated in the gif below on a small example text using a window size of T = 5.\n\n<img src=\"images/text_windowing_training.gif\" width=400 height=400/>\n\nNotice one aspect of the sliding window in this gif that does not mirror the analogous gif for time series shown in part 1 of the notebook - we do not need to slide the window along one character at a time but can move by a fixed step size $M$ greater than 1 (in the gif indeed $M = 1$). This is done with large input texts (like ours which has over 500,000 characters!) when sliding the window along one character at a time we would create far too many input/output pairs to be able to reasonably compute with.\n\nMore formally lets denote our text corpus - which is one long string of characters - as follows\n\n$$s_{0},s_{1},s_{2},...,s_{P}$$\n\nwhere $P$ is the length of the text (again for our text $P \\approx 500,000!$). Sliding a window of size T = 5 with a step length of M = 1 (these are the parameters shown in the gif above) over this sequence produces the following list of input/output pairs\n\n\n$$\\begin{array}{c|c}\n\\text{Input} & \\text{Output}\\\\\n\\hline \\color{CornflowerBlue} {\\langle s_{1},s_{2},s_{3},s_{4},s_{5}\\rangle} & \\color{Goldenrod}{ s_{6}} \\\\\n\\ \\color{CornflowerBlue} {\\langle s_{2},s_{3},s_{4},s_{5},s_{6} \\rangle } & \\color{Goldenrod} {s_{7} } \\\\\n\\color{CornflowerBlue} {\\vdots} & \\color{Goldenrod} {\\vdots}\\\\\n\\color{CornflowerBlue} { \\langle s_{P-5},s_{P-4},s_{P-3},s_{P-2},s_{P-1} \\rangle } & \\color{Goldenrod} {s_{P}}\n\\end{array}$$\n\nNotice here that each input is a sequence (or vector) of 5 characters (and in general has length equal to the window size T) while each corresponding output is a single character. We created around P total number of input/output pairs (for general step size M we create around ceil(P/M) pairs).",
"_____no_output_____"
],
[
"<a id='TODO_4'></a>\n\nNow its time for you to window the input time series as described above! \n\n**TODO:** Create a function that runs a sliding window along the input text and creates associated input/output pairs. A skeleton function has been provided for you. Note that this function should input a) the text b) the window size and c) the step size, and return the input/output sequences. Note: the return items should be *lists* - not numpy arrays.\n\n(remember to copy your completed function into the script *my_answers.py* function titled *window_transform_text* before submitting your project)",
"_____no_output_____"
]
],
[
[
"### TODO: implement window_transform_series in my_answers.py\nfrom my_answers import window_transform_series",
"_____no_output_____"
]
],
[
[
"With our function complete we can now use it to produce input/output pairs! We employ the function in the next cell, where the window_size = 50 and step_size = 5.",
"_____no_output_____"
]
],
[
[
"# run your text window-ing function \nwindow_size = 100\nstep_size = 5\ninputs, outputs = window_transform_text(text,window_size,step_size)",
"_____no_output_____"
]
],
[
[
"Lets print out a few input/output pairs to verify that we have made the right sort of stuff!",
"_____no_output_____"
]
],
[
[
"# print out a few of the input/output pairs to verify that we've made the right kind of stuff to learn from\nprint('input = ' + inputs[2])\nprint('output = ' + outputs[2])\nprint('--------------')\nprint('input = ' + inputs[100])\nprint('output = ' + outputs[100])",
"input = e eclipses and predominates the whole of her sex. it was not that he felt any emotion akin to love f\noutput = o\n--------------\ninput = er excellent for drawing the veil from men s motives and actions. but for the trained reasoner to ad\noutput = m\n"
]
],
[
[
"Looks good!",
"_____no_output_____"
],
[
"## 2.4 Wait, what kind of problem is text generation again?\n\nIn part 1 of this notebook we used the same pre-processing technique - the sliding window - to produce a set of training input/output pairs to tackle the problem of time series prediction *by treating the problem as one of regression*. So what sort of problem do we have here now, with text generation? Well, the time series prediction was a regression problem because the output (one value of the time series) was a continuous value. Here - for character-by-character text generation - each output is a *single character*. This isn't a continuous value - but a distinct class - therefore **character-by-character text generation is a classification problem**. \n\nHow many classes are there in the data? Well, the number of classes is equal to the number of unique characters we have to predict! How many of those were there in our dataset again? Lets print out the value again.",
"_____no_output_____"
]
],
[
[
"# print out the number of unique characters in the dataset\nchars = sorted(list(set(text)))\nprint (\"this corpus has \" + str(len(chars)) + \" unique characters\")\nprint ('and these characters are ')\nprint (chars)",
"this corpus has 33 unique characters\nand these characters are \n[' ', '!', ',', '.', ':', ';', '?', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']\n"
]
],
[
[
"Rockin' - so we have a multiclass classification problem on our hands!",
"_____no_output_____"
],
[
"## 2.5 One-hot encoding characters\n\nThe last issue we have to deal with is representing our text data as numerical data so that we can use it as an input to a neural network. One of the conceptually simplest ways of doing this is via a 'one-hot encoding' scheme. Here's how it works.\n\nWe transform each character in our inputs/outputs into a vector with length equal to the number of unique characters in our text. This vector is all zeros except one location where we place a 1 - and this location is unique to each character type. e.g., we transform 'a', 'b', and 'c' as follows\n\n$$a\\longleftarrow\\left[\\begin{array}{c}\n1\\\\\n0\\\\\n0\\\\\n\\vdots\\\\\n0\\\\\n0\n\\end{array}\\right]\\,\\,\\,\\,\\,\\,\\,b\\longleftarrow\\left[\\begin{array}{c}\n0\\\\\n1\\\\\n0\\\\\n\\vdots\\\\\n0\\\\\n0\n\\end{array}\\right]\\,\\,\\,\\,\\,c\\longleftarrow\\left[\\begin{array}{c}\n0\\\\\n0\\\\\n1\\\\\n\\vdots\\\\\n0\\\\\n0 \n\\end{array}\\right]\\cdots$$\n\nwhere each vector has 32 entries (or in general: number of entries = number of unique characters in text).",
"_____no_output_____"
],
[
"The first practical step towards doing this one-hot encoding is to form a dictionary mapping each unique character to a unique integer, and one dictionary to do the reverse mapping. We can then use these dictionaries to quickly make our one-hot encodings, as well as re-translate (from integers to characters) the results of our trained RNN classification model.",
"_____no_output_____"
]
],
[
[
"# this dictionary is a function mapping each unique character to a unique integer\nchars_to_indices = dict((c, i) for i, c in enumerate(chars)) # map each unique character to unique integer\n\n# this dictionary is a function mapping each unique integer back to a unique character\nindices_to_chars = dict((i, c) for i, c in enumerate(chars)) # map each unique integer back to unique character",
"_____no_output_____"
]
],
[
[
"Now we can transform our input/output pairs - consisting of characters - to equivalent input/output pairs made up of one-hot encoded vectors. In the next cell we provide a function for doing just this: it takes in the raw character input/outputs and returns their numerical versions. In particular the numerical input is given as $\\bf{X}$, and numerical output is given as the $\\bf{y}$",
"_____no_output_____"
]
],
[
[
"# transform character-based input/output into equivalent numerical versions\ndef encode_io_pairs(text,window_size,step_size):\n # number of unique chars\n chars = sorted(list(set(text)))\n num_chars = len(chars)\n \n # cut up text into character input/output pairs\n inputs, outputs = window_transform_text(text,window_size,step_size)\n \n # create empty vessels for one-hot encoded input/output\n X = np.zeros((len(inputs), window_size, num_chars), dtype=np.bool)\n y = np.zeros((len(inputs), num_chars), dtype=np.bool)\n \n # loop over inputs/outputs and transform and store in X/y\n for i, sentence in enumerate(inputs):\n for t, char in enumerate(sentence):\n X[i, t, chars_to_indices[char]] = 1\n y[i, chars_to_indices[outputs[i]]] = 1\n \n return X,y",
"_____no_output_____"
]
],
[
[
"Now run the one-hot encoding function by activating the cell below and transform our input/output pairs!",
"_____no_output_____"
]
],
[
[
"# use your function\nwindow_size = 100\nstep_size = 5\nX,y = encode_io_pairs(text,window_size,step_size)",
"_____no_output_____"
]
],
[
[
"<a id='TODO_5'></a>\n\n## 2.6 Setting up our RNN\n\nWith our dataset loaded and the input/output pairs extracted / transformed we can now begin setting up our RNN for training. Again we will use Keras to quickly build a single hidden layer RNN - where our hidden layer consists of LSTM modules.\n\nTime to get to work: build a 3 layer RNN model of the following specification\n\n- layer 1 should be an LSTM module with 200 hidden units --> note this should have input_shape = (window_size,len(chars)) where len(chars) = number of unique characters in your cleaned text\n- layer 2 should be a linear module, fully connected, with len(chars) hidden units --> where len(chars) = number of unique characters in your cleaned text\n- layer 3 should be a softmax activation ( since we are solving a *multiclass classification*)\n- Use the **categorical_crossentropy** loss \n\nThis network can be constructed using just a few lines - as with the RNN network you made in part 1 of this notebook. See e.g., the [general Keras documentation](https://keras.io/getting-started/sequential-model-guide/) and the [LSTM documentation in particular](https://keras.io/layers/recurrent/) for examples of how to quickly use Keras to build neural network models.",
"_____no_output_____"
]
],
[
[
"### necessary functions from the keras library\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Activation, LSTM\nfrom keras.optimizers import RMSprop\nfrom keras.utils.data_utils import get_file\nimport keras\nimport random\n\n# TODO implement build_part2_RNN in my_answers.py\nfrom my_answers import build_part2_RNN\n\nmodel = build_part2_RNN(window_size, len(chars))\n\n# initialize optimizer\noptimizer = keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)\n\n# compile model --> make sure initialized optimizer and callbacks - as defined above - are used\nmodel.compile(loss='categorical_crossentropy', optimizer=optimizer)",
"_____no_output_____"
]
],
[
[
"## 2.7 Training our RNN model for text generation\n\nWith our RNN setup we can now train it! Lets begin by trying it out on a small subset of the larger version. In the next cell we take the first 10,000 input/output pairs from our training database to learn on.",
"_____no_output_____"
]
],
[
[
"# a small subset of our input/output pairs\nXsmall = X[:10000,:,:]\nysmall = y[:10000,:]",
"_____no_output_____"
]
],
[
[
"Now lets fit our model!",
"_____no_output_____"
]
],
[
[
"# train the model\nmodel.fit(Xsmall, ysmall, batch_size=500, epochs=40,verbose = 1)\n\n# save weights\nmodel.save_weights('model_weights/best_RNN_small_textdata_weights.hdf5')",
"Epoch 1/40\n10000/10000 [==============================] - 4s - loss: 3.0197 \nEpoch 2/40\n10000/10000 [==============================] - 4s - loss: 2.8836 \nEpoch 3/40\n10000/10000 [==============================] - 4s - loss: 2.8612 \nEpoch 4/40\n10000/10000 [==============================] - 4s - loss: 2.8277 \nEpoch 5/40\n10000/10000 [==============================] - 4s - loss: 2.7626 \nEpoch 6/40\n10000/10000 [==============================] - 4s - loss: 2.6909 \nEpoch 7/40\n10000/10000 [==============================] - 4s - loss: 2.6168 \nEpoch 8/40\n10000/10000 [==============================] - 4s - loss: 2.5521 \nEpoch 9/40\n10000/10000 [==============================] - 4s - loss: 2.4911 \nEpoch 10/40\n10000/10000 [==============================] - 4s - loss: 2.4433 \nEpoch 11/40\n10000/10000 [==============================] - 4s - loss: 2.4036 \nEpoch 12/40\n10000/10000 [==============================] - 4s - loss: 2.3703 \nEpoch 13/40\n10000/10000 [==============================] - 4s - loss: 2.3310 \nEpoch 14/40\n10000/10000 [==============================] - 4s - loss: 2.3028 \nEpoch 15/40\n10000/10000 [==============================] - 4s - loss: 2.2771 \nEpoch 16/40\n10000/10000 [==============================] - 4s - loss: 2.2593 \nEpoch 17/40\n10000/10000 [==============================] - 4s - loss: 2.2284 \nEpoch 18/40\n10000/10000 [==============================] - 4s - loss: 2.2113 \nEpoch 19/40\n10000/10000 [==============================] - 4s - loss: 2.1898 \nEpoch 20/40\n10000/10000 [==============================] - 4s - loss: 2.1697 \nEpoch 21/40\n10000/10000 [==============================] - 4s - loss: 2.1512 \nEpoch 22/40\n10000/10000 [==============================] - 4s - loss: 2.1341 \nEpoch 23/40\n10000/10000 [==============================] - 4s - loss: 2.1164 \nEpoch 24/40\n10000/10000 [==============================] - 4s - loss: 2.0980 \nEpoch 25/40\n10000/10000 [==============================] - 4s - loss: 2.0745 \nEpoch 26/40\n10000/10000 [==============================] - 4s - loss: 2.0617 \nEpoch 27/40\n10000/10000 [==============================] - 4s - loss: 2.0431 \nEpoch 28/40\n10000/10000 [==============================] - 4s - loss: 2.0222 \nEpoch 29/40\n10000/10000 [==============================] - 4s - loss: 2.0048 \nEpoch 30/40\n10000/10000 [==============================] - 4s - loss: 1.9900 \nEpoch 31/40\n10000/10000 [==============================] - 4s - loss: 1.9688 \nEpoch 32/40\n10000/10000 [==============================] - 4s - loss: 1.9471 \nEpoch 33/40\n10000/10000 [==============================] - 4s - loss: 1.9263 \nEpoch 34/40\n10000/10000 [==============================] - 4s - loss: 1.9072 \nEpoch 35/40\n10000/10000 [==============================] - 4s - loss: 1.8859 \nEpoch 36/40\n10000/10000 [==============================] - 4s - loss: 1.8652 \nEpoch 37/40\n10000/10000 [==============================] - 4s - loss: 1.8409 \nEpoch 38/40\n10000/10000 [==============================] - 4s - loss: 1.8180 \nEpoch 39/40\n10000/10000 [==============================] - 4s - loss: 1.7936 \nEpoch 40/40\n10000/10000 [==============================] - 4s - loss: 1.7712 \n"
]
],
[
[
"How do we make a given number of predictions (characters) based on this fitted model? \n\nFirst we predict the next character after following any chunk of characters in the text of length equal to our chosen window size. Then we remove the first character in our input sequence and tack our prediction onto the end. This gives us a slightly changed sequence of inputs that still has length equal to the size of our window. We then feed in this updated input sequence into the model to predict the another character. Together then we have two predicted characters following our original input sequence. Repeating this process N times gives us N predicted characters.\n\nIn the next Python cell we provide you with a completed function that does just this - it makes predictions when given a) a trained RNN model, b) a subset of (window_size) characters from the text, and c) a number of characters to predict (to follow our input subset).",
"_____no_output_____"
]
],
[
[
"# function that uses trained model to predict a desired number of future characters\ndef predict_next_chars(model,input_chars,num_to_predict): \n # create output\n predicted_chars = ''\n for i in range(num_to_predict):\n # convert this round's predicted characters to numerical input \n x_test = np.zeros((1, window_size, len(chars)))\n for t, char in enumerate(input_chars):\n x_test[0, t, chars_to_indices[char]] = 1.\n\n # make this round's prediction\n test_predict = model.predict(x_test,verbose = 0)[0]\n\n # translate numerical prediction back to characters\n r = np.argmax(test_predict) # predict class of each test input\n d = indices_to_chars[r] \n\n # update predicted_chars and input\n predicted_chars+=d\n input_chars+=d\n input_chars = input_chars[1:]\n return predicted_chars",
"_____no_output_____"
]
],
[
[
"<a id='TODO_6'></a>\n\nWith your trained model try a few subsets of the complete text as input - note the length of each must be exactly equal to the window size. For each subset use the function above to predict the next 100 characters that follow each input.",
"_____no_output_____"
]
],
[
[
"# TODO: choose an input sequence and use the prediction function in the previous Python cell to predict 100 characters following it\n# get an appropriately sized chunk of characters from the text\nstart_inds = [150]\n\n# load in weights\nmodel.load_weights('model_weights/best_RNN_small_textdata_weights.hdf5')\nfor s in start_inds:\n start_index = s\n input_chars = text[start_index: start_index + window_size]\n\n # use the prediction function\n predict_input = predict_next_chars(model,input_chars,num_to_predict = 100)\n\n # print out input characters\n print('------------------')\n input_line = 'input chars = ' + '\\n' + input_chars + '\"' + '\\n'\n print(input_line)\n\n # print out predicted characters\n line = 'predicted chars = ' + '\\n' + predict_input + '\"' + '\\n'\n print(line)",
"------------------\ninput chars = \nne particularly, were abhorrent to his cold, precise but admirably balanced mind. he was, i take it,\"\n\npredicted chars = \n and the mand dore ou the with whe has bere be be the gat the wast of the come the was was be the si\"\n\n"
]
],
[
[
"This looks ok, but not great. Now lets try the same experiment with a larger chunk of the data - with the first 100,000 input/output pairs. \n\nTuning RNNs for a typical character dataset like the one we will use here is a computationally intensive endeavour and thus timely on a typical CPU. Using a reasonably sized cloud-based GPU can speed up training by a factor of 10. Also because of the long training time it is highly recommended that you carefully write the output of each step of your process to file. This is so that all of your results are saved even if you close the web browser you're working out of, as the processes will continue processing in the background but variables/output in the notebook system will not update when you open it again.\n\nIn the next cell we show you how to create a text file in Python and record data to it. This sort of setup can be used to record your final predictions.",
"_____no_output_____"
]
],
[
[
"### A simple way to write output to file\nf = open('my_test_output.txt', 'w') # create an output file to write too\nf.write('this is only a test ' + '\\n') # print some output text\nx = 2\nf.write('the value of x is ' + str(x) + '\\n') # record a variable value\nf.close() \n\n# print out the contents of my_test_output.txt\nf = open('my_test_output.txt', 'r') # create an output file to write too\nf.read()",
"_____no_output_____"
]
],
[
[
"With this recording devices we can now more safely perform experiments on larger portions of the text. In the next cell we will use the first 100,000 input/output pairs to train our RNN model.",
"_____no_output_____"
],
[
"First we fit our model to the dataset, then generate text using the trained model in precisely the same generation method applied before on the small dataset.\n\n**Note:** your generated words should be - by and large - more realistic than with the small dataset, but you won't be able to generate perfect English sentences even with this amount of data. A rule of thumb: your model is working well if you generate sentences that largely contain real English words.",
"_____no_output_____"
]
],
[
[
"# a small subset of our input/output pairs\nXlarge = X[:100000,:,:]\nylarge = y[:100000,:]\n\n# TODO: fit to our larger dataset\nmodel.fit(Xlarge, ylarge, batch_size=500, epochs=30, verbose=1)\n\n# save weights\nmodel.save_weights('model_weights/best_RNN_large_textdata_weights.hdf5')",
"Epoch 1/30\n100000/100000 [==============================] - 44s - loss: 2.0253 \nEpoch 2/30\n100000/100000 [==============================] - 44s - loss: 1.9340 \nEpoch 3/30\n100000/100000 [==============================] - 44s - loss: 1.8689 \nEpoch 4/30\n100000/100000 [==============================] - 44s - loss: 1.8149 \nEpoch 5/30\n100000/100000 [==============================] - 44s - loss: 1.7677 \nEpoch 6/30\n100000/100000 [==============================] - 44s - loss: 1.7239 \nEpoch 7/30\n100000/100000 [==============================] - 44s - loss: 1.6839 \nEpoch 8/30\n100000/100000 [==============================] - 44s - loss: 1.6475 \nEpoch 9/30\n100000/100000 [==============================] - 44s - loss: 1.6112 \nEpoch 10/30\n100000/100000 [==============================] - 44s - loss: 1.5781 \nEpoch 11/30\n100000/100000 [==============================] - 44s - loss: 1.5451 \nEpoch 12/30\n100000/100000 [==============================] - 44s - loss: 1.5139 \nEpoch 13/30\n100000/100000 [==============================] - 44s - loss: 1.4834 \nEpoch 14/30\n100000/100000 [==============================] - 44s - loss: 1.4536 \nEpoch 15/30\n100000/100000 [==============================] - 44s - loss: 1.4242 \nEpoch 16/30\n100000/100000 [==============================] - 44s - loss: 1.3954 \nEpoch 17/30\n100000/100000 [==============================] - 44s - loss: 1.3663 \nEpoch 18/30\n100000/100000 [==============================] - 44s - loss: 1.3376 \nEpoch 19/30\n100000/100000 [==============================] - 44s - loss: 1.3089 \nEpoch 20/30\n100000/100000 [==============================] - 44s - loss: 1.2795 \nEpoch 21/30\n100000/100000 [==============================] - 44s - loss: 1.2508 \nEpoch 22/30\n100000/100000 [==============================] - 44s - loss: 1.2222 \nEpoch 23/30\n100000/100000 [==============================] - 44s - loss: 1.1943 \nEpoch 24/30\n100000/100000 [==============================] - 44s - loss: 1.1652 \nEpoch 25/30\n100000/100000 [==============================] - 44s - loss: 1.1368 \nEpoch 26/30\n100000/100000 [==============================] - 44s - loss: 1.1103 \nEpoch 27/30\n100000/100000 [==============================] - 44s - loss: 1.0826 \nEpoch 28/30\n100000/100000 [==============================] - 44s - loss: 1.0560 \nEpoch 29/30\n100000/100000 [==============================] - 44s - loss: 1.0298 \nEpoch 30/30\n100000/100000 [==============================] - 44s - loss: 1.0037 \n"
],
[
"# TODO: choose an input sequence and use the prediction function in the previous Python cell to predict 100 characters following it\n# get an appropriately sized chunk of characters from the text\nstart_inds = [150, 200, 300, 15000]\n\n# save output\nf = open('text_gen_output/RNN_large_textdata_output.txt', 'w') # create an output file to write too\n\n# load weights\nmodel.load_weights('model_weights/best_RNN_large_textdata_weights.hdf5')\nfor s in start_inds:\n start_index = s\n input_chars = text[start_index: start_index + window_size]\n\n # use the prediction function\n predict_input = predict_next_chars(model,input_chars,num_to_predict = 100)\n\n # print out input characters\n line = '-------------------' + '\\n'\n print(line)\n f.write(line)\n\n input_line = 'input chars = ' + '\\n' + input_chars + '\"' + '\\n'\n print(input_line)\n f.write(input_line)\n\n # print out predicted characters\n predict_line = 'predicted chars = ' + '\\n' + predict_input + '\"' + '\\n'\n print(predict_line)\n f.write(predict_line)\nf.close()",
"-------------------\n\ninput chars = \nne particularly, were abhorrent to his cold, precise but admirably balanced mind. he was, i take it,\"\n\npredicted chars = \n and me. i was about y upped minutes. it was the same to me. the look of me of has sutt s can fore\"\n\n-------------------\n\ninput chars = \nse but admirably balanced mind. he was, i take it, the most perfect reasoning and observing machine \"\n\npredicted chars = \nto me this manting of the street. i dad not know when i have a shat his reas to be a siden stoot and\"\n\n-------------------\n\ninput chars = \nthat the world has seen, but as a lover he would have placed himself in a false position. he never s\"\n\npredicted chars = \nhould been a shall can upon better the strace use as the wholl came the consedsed. what is the sitt\"\n\n-------------------\n\ninput chars = \n see! said holmes. hum! born in new jersey in the year . contralto hum! la scala, hum! prima donna\"\n\npredicted chars = \n der that the consery of the same which were in the door of the little the collers of the correming \"\n\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4ad1e18e9b3bb9bc0fc867814c4585728dca5ab2
| 41,800 |
ipynb
|
Jupyter Notebook
|
VacationPy/VacationPy.ipynb
|
patelveronica/Python-API-Challenge
|
dd29f5b1cb644f488d0e3b01bad4fa723311a2ea
|
[
"ADSL"
] | null | null | null |
VacationPy/VacationPy.ipynb
|
patelveronica/Python-API-Challenge
|
dd29f5b1cb644f488d0e3b01bad4fa723311a2ea
|
[
"ADSL"
] | null | null | null |
VacationPy/VacationPy.ipynb
|
patelveronica/Python-API-Challenge
|
dd29f5b1cb644f488d0e3b01bad4fa723311a2ea
|
[
"ADSL"
] | null | null | null | 33.764136 | 160 | 0.358038 |
[
[
[
"# VacationPy\n----\n\n#### Note\n* Keep an eye on your API usage. Use https://developers.google.com/maps/reporting/gmp-reporting as reference for how to monitor your usage and billing.\n\n* Instructions have been included for each segment. You do not have to follow them exactly, but they are included to help you think through the steps.",
"_____no_output_____"
]
],
[
[
"# Dependencies and Setup\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport json\nimport numpy as np\nimport requests\nimport gmaps\nimport os\n# Import API key\nfrom api_keys import (weather_api_key, g_key)\n",
"_____no_output_____"
]
],
[
[
"### Store Part I results into DataFrame\n* Load the csv exported in Part I to a DataFrame",
"_____no_output_____"
]
],
[
[
"# import the weather data for the cities from WeatherPy homework\n# Load the csv exported in Part I to a DataFrame\nweather_cities_data = pd.read_csv(\"../WeatherPy/weather_data.csv\")\nweather_cities_data\n",
"_____no_output_____"
]
],
[
[
"### Humidity Heatmap\n* Configure gmaps.\n* Use the Lat and Lng as locations and Humidity as the weight.\n* Add Heatmap layer to map.",
"_____no_output_____"
]
],
[
[
"# Configure the gmaps\ngmaps.configure(api_key = g_key)\n\n# Store the Latitude and Longitude in Locations\nlocations = weather_cities_data[[\"Latitude\", \"Longitude\"]]\nweight = weather_cities_data[\"Humidity\"]\n\n# create heat layer\nfig = gmaps.figure()\nheat_layer = gmaps.heatmap_layer(locations, weights = weight,\n dissipating=False, max_intensity=100,\n point_radius = 1)\n# add layer\nfig.add_layer(heat_layer)\n\nfig",
"_____no_output_____"
]
],
[
[
"### Create new DataFrame fitting weather criteria\n* Narrow down the cities to fit weather conditions.\n* Drop any rows will null values.",
"_____no_output_____"
]
],
[
[
"# Create new DataFrame fitting weather criteria\n# Narrow down the cities to fit weather conditions.\n# Drop any rows will null values\nnew_city_df = weather_cities_data.loc[(weather_cities_data[\"Wind Speed\"] <= 10) & (weather_cities_data[\"Clouds\"] == 0) & \\\n (weather_cities_data[\"Max Temperature\"] >= 70) & (weather_cities_data[\"Max Temperature\"] <= 80)].dropna()\nnew_city_df.dropna(inplace = True) \nnew_city_df",
"_____no_output_____"
]
],
[
[
"### Hotel Map\n* Store into variable named `hotel_df`.\n* Add a \"Hotel Name\" column to the DataFrame.\n* Set parameters to search for hotels with 5000 meters.\n* Hit the Google Places API for each city's coordinates.\n* Store the first Hotel result into the DataFrame.\n* Plot markers on top of the heatmap.",
"_____no_output_____"
]
],
[
[
"# create hotel_df \nhotel_df = new_city_df.loc[:, [\"City\", \"Country\", \"Latitude\", \"Longitude\"]]\n# add hotel name to hotel_df\nhotel_df[\"Hotel Name\"] = \"\"\n\nhotel_df",
"_____no_output_____"
],
[
"# print the name of the hotel for each city\n# base url\nbase_url = \"https://maps.googleapis.com/maps/api/place/nearbysearch/json\"\n# set up a parameteres dictonary\nparams = {\"type\": \"hotel\",\n \"Keyword\": \"hotel\",\n \"radius\": 5000,\n \"Key\": g_key \n}\n# loop through the hotel_df and run a lat/long search for each city\nfor index, row in hotel_df.iterrows(): \n #get the city name, lat, and longtitude from df\n latitude = row[\"Latitude\"]\n longitude = row[\"Longitude\"]\n city_name = row[\"City\"]\n# add ketword to params dict\n params[\"Location\"] = f\"{latitude},{longitude}\"\n# create url and make API calls\n print(f\"Retriving Results for Index {index}: {city_name}.\")\n# get the response\n response = requests.get(base_url, params=params).json()\n# get the results from the response\n results = response[\"results\"]\n \n try:\n print(f\"Closet hotel in {city_name} is {results[0]['name']}.\")\n hotel_df.loc[index, \"Hotel Name\"] = results[0]['name']\n except (KeyError, IndexError):\n print(\"Missing field/result ..... skipping.\")\n \n print(\"-----------\")\nprint(\"--------End of Search ----------\")\n \n",
"Retriving Results for Index 1: East London.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 51: Umeå.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 65: Province of Vibo Valentia.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 124: Tiznit Province.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 159: Ankara.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 178: Aichach.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 205: Kushikino.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 230: Zaozyornoye.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 341: Zharkent.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 348: Pimentel.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 397: Salamiyah.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 422: Severnyy.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 427: La Libertad.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 556: Boysun.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 590: Gorodishche.\nMissing field/result ..... skipping.\n-----------\nRetriving Results for Index 593: Xinyu.\nMissing field/result ..... skipping.\n-----------\n--------End of Search ----------\n"
],
[
"hotel_df",
"_____no_output_____"
],
[
"# NOTE: Do not change any of the code in this cell\n\n# Using the template add the hotel marks to the heatmap\ninfo_box_template = \"\"\"\n<dl>\n<dt>Name</dt><dd>{Hotel Name}</dd>\n<dt>City</dt><dd>{City}</dd>\n<dt>Country</dt><dd>{Country}</dd>\n</dl>\n\"\"\"\n# Store the DataFrame Row\n# NOTE: be sure to update with your DataFrame name\nhotel_info = [info_box_template.format(**row) for index, row in hotel_df.iterrows()]\nlocations = hotel_df[[\"Latitude\", \"Longitude\"]]",
"_____no_output_____"
],
[
"# Add marker layer ontop of heat map\nmarkers = gmaps.marker_layer(locations, info_box_content = hotel_info)\n\n# Add the layer to the map\nfig.add_layer(markers)\n# Display figure\nfig",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ad1fd7a4baea7bdd354a6acba4a6f52daef377a
| 30,694 |
ipynb
|
Jupyter Notebook
|
3sat.ipynb
|
David-Drexlin/Fun-with-Quantum
|
7b2c50078a8fa80f76a346d312658779d06f9ce3
|
[
"Apache-2.0"
] | 31 |
2020-04-08T11:34:08.000Z
|
2021-09-21T00:08:55.000Z
|
3sat.ipynb
|
David-Drexlin/Fun-with-Quantum
|
7b2c50078a8fa80f76a346d312658779d06f9ce3
|
[
"Apache-2.0"
] | 4 |
2021-03-09T14:00:57.000Z
|
2021-05-05T13:09:10.000Z
|
3sat.ipynb
|
David-Drexlin/Fun-with-Quantum
|
7b2c50078a8fa80f76a346d312658779d06f9ce3
|
[
"Apache-2.0"
] | 17 |
2020-03-04T10:44:04.000Z
|
2021-10-21T01:44:20.000Z
| 80.140992 | 16,808 | 0.792142 |
[
[
[
"# Simple Quantum Implementation using Qiskit Aqua for Boolean satisfiability problems\n\n\n\nThis Jupyter notebook demonstrates how easy it is to use quantum algorithms from [Qiskit Aqua](https://qiskit.org/aqua) to solve Boolean satisfiability problems [(SAT)](https://en.wikipedia.org/wiki/Boolean_satisfiability_problem). \n\nIt is based on the Qiskit tutorial [Using Grover search for 3-SAT problems](https://github.com/Qiskit/qiskit-tutorials/blob/master/community/aqua/optimization/grover.ipynb) by [Jay Gambetta](https://github.com/jaygambetta) and [Richard Chen](https://github.com/chunfuchen) and a hands-on workshop by David Mesterhazy.\n\nImplemented by [Jan-R. Lahmann](http://twitter.com/JanLahmann) using Qiskit, binder and RISE.",
"_____no_output_____"
],
[
"## Boolean Satisfiabilty problems (SAT)\n\nThe Boolean satisfiability problem [(SAT)](https://en.wikipedia.org/wiki/Boolean_satisfiability_problem) considers a Boolean expression with N boolean variables involving negation (NOT, $\\neg$), conjunction (AND, $\\wedge$) and disjunction (OR, $\\vee$), as in the following (simple) example: \n$$ f(x_1, x_2) = (x_1 \\vee x_2) \\wedge (x_1 \\vee \\neg x_2) . $$\n\nThe problem is to determine whether there is any assignment of values (TRUE, FALSE) to the Boolean variables which makes the formula true. \n\nIt's something like trying to flip a bunch of switches to find the setting that makes a light bulb turn on. \nSAT is of central importance in many areas of computer science, including complexity theory, algorithmics, cryptography, artificial intelligence, circuit design, and automatic theorem proving.",
"_____no_output_____"
],
[
"SAT was the first problem proven to be NP-complete. \nThis means that all problems in the [complexity class NP](https://en.wikipedia.org/wiki/NP_(complexity)) are at most as difficult to solve as SAT. \n\nThere is no known classical algorithm that efficiently solves each SAT problem, and it is generally believed that no such algorithm exists. \nWhether Boolean satisfiability problems have a classical algorithm that is polynomial in time is equivalent to the [P vs. NP problem](https://en.wikipedia.org/wiki/P_versus_NP_problem). \n\n\nWhile [Grover's quantum search algorithm](https://en.wikipedia.org/wiki/Grover's_algorithm) does not provide exponential speed-up to this problem, it may nevertheless provide some speed-up in contrast to classical black-box search strategies.\n\n",
"_____no_output_____"
],
[
"### Basic definitions and terminology\n\n\nA *literal* is either a variable, or the negation of a variable. \nA *clause* is a disjunction (OR, $\\vee$) of literals, or a single literal. \nA formula is in *conjunctive normal form* [(CNF)](https://en.wikipedia.org/wiki/Conjunctive_normal_form) if it is a conjunction (AND, $\\wedge$) of clauses, or a single clause. \n\nA problem in conjunctive normal form is called *3-SAT* if each clause is limited to at most three literals. \n3-SAT is also NP-complete.\n\nExample for 3-SAT: $ (x_1 ∨ ¬x_2) ∧ (¬x_1 ∨ x_2 ∨ x_3) ∧ ¬x_1 $.\n",
"_____no_output_____"
],
[
"## Solving 3-SAT using Qiskit Aqua \n\nWe will show how to solve a 3-SAT problem using quantum algorithms from [Qiskit Aqua](https://qiskit.org/aqua).\n\nLet us consider three Boolean variables $x_1, x_2, x_3$ and a Boolean function $f$ given by:\n\n\\begin{align*} \nf(x_1, x_2, x_3) \\;= &\\;\\;\\;\\;\n\\;(\\neg x_1 \\vee \\neg x_2 \\vee \\neg x_3) \\\\\n&\\;\\; \\wedge \\; ( x_1 \\vee \\neg x_2 \\vee x_3) \\\\\n&\\;\\; \\wedge \\;( x_1 \\vee x_2 \\vee \\neg x_3) \\\\\n&\\;\\; \\wedge \\;( x_1 \\vee \\neg x_2 \\vee \\neg x_3) \\\\\n&\\;\\; \\wedge \\;(\\neg x_1 \\vee x_2 \\vee x_3) \n\\end{align*}\n",
"_____no_output_____"
],
[
"It is common, to state 3-SAT problems in [DIMACS CNF format](https://people.sc.fsu.edu/~jburkardt/data/cnf/cnf.html):\n\n1. The file may begin with comment lines. \n* The \"problem\" line begins with \"p\", followed by the problem type \"cnf\", the number of variables and the number of clauses.\n* The remainder of the file contains lines defining the clauses.\n* A clause is defined by listing the index of each positive literal, and the negative index of each negative literal. \n\n",
"_____no_output_____"
]
],
[
[
"# import the problem in DIMACS CNF format\nimport os\nimport wget\nif not '3sat3-5.cnf' in os.listdir():\n wget.download('https://raw.githubusercontent.com/Qiskit/qiskit-tutorials/master/community/aqua/optimization/3sat3-5.cnf')\n\nwith open('3sat3-5.cnf', 'r') as f:\n sat_cnf = f.read()\nprint(sat_cnf)",
"c This is an example DIMACS 3-sat file with 3 satisfying solutions: 1 -2 3 0, -1 -2 -3 0, 1 2 -3 0\np cnf 3 5\n-1 -2 -3 0\n1 -2 3 0\n1 2 -3 0\n1 -2 -3 0\n-1 2 3 0\n\n"
]
],
[
[
"To apply a quantum algorithm from Qiskit Aqua to this problem, we simply need to import the Qiskit libraries and run the algorithm with the appropriate parameters.",
"_____no_output_____"
]
],
[
[
"# import Qiskit quantum libraries\nfrom qiskit import BasicAer\nfrom qiskit.visualization import plot_histogram\nfrom qiskit.aqua import QuantumInstance\nfrom qiskit.aqua.algorithms import Grover\nfrom qiskit.aqua.components.oracles import LogicalExpressionOracle, TruthTableOracle",
"/Users/majl/anaconda3/envs/Qiskitenv/lib/python3.7/site-packages/marshmallow/schema.py:364: ChangedInMarshmallow3Warning: strict=False is not recommended. In marshmallow 3.0, schemas will always be strict. See https://marshmallow.readthedocs.io/en/latest/upgrading.html#schemas-are-always-strict\n ChangedInMarshmallow3Warning\n"
],
[
"oracle = LogicalExpressionOracle(sat_cnf)\ngrover = Grover(oracle)\nbackend = BasicAer.get_backend('qasm_simulator')\nquantum_instance = QuantumInstance(backend, shots=200)\nresult = grover.run(quantum_instance)\nplot_histogram(result['measurement'])",
"/Users/majl/anaconda3/envs/Qiskitenv/lib/python3.7/site-packages/marshmallow/schema.py:364: ChangedInMarshmallow3Warning: strict=False is not recommended. In marshmallow 3.0, schemas will always be strict. See https://marshmallow.readthedocs.io/en/latest/upgrading.html#schemas-are-always-strict\n ChangedInMarshmallow3Warning\n"
]
],
[
[
"The result shows that the assignments $000, 101, 110$ for $x_1 x_2 x_3$ are potential solutions to the problem. \nWhether or not these are correct solutions to the problem can be verified efficiently, as 3-SAT is in NP. \nNote that the variables in the histogram are in reverse order: $x_3, x_2, x_1$ instead of $x_1, x_2, x_3$.\n",
"_____no_output_____"
],
[
"## Classical brute force algorithm\n\nThe solutions to the problem can also be derived with a classical (non-quantum) algorithm by simply trying every possible combination of input values $x_1, x_2, x_3$of $f$.\n\nWe find again, that the solutions for the given 3-SAT problem are the assignments $000, 101, 110$ for $x_1 x_2 x_3$. ",
"_____no_output_____"
]
],
[
[
"from IPython.display import HTML, display\nimport tabulate\n\nnbr = 3 # number of Boolean variables in Boolean function\n\ntable = []\nfor i in range(2**nbr):\n x1, x2, x3 = [int(x) for x in '{0:03b}'.format(i)] # Boolean variables\n \n # define clauses \n c1 = [not x1, not x2, not x3] # -1 -2 -3\n c2 = [ x1, not x2, x3] # 1 -2 3\n c3 = [ x1, x2, not x3] # 1 2 -3\n c4 = [ x1, not x2, not x3] # 1 -2 -3\n c5 = [not x1, x2, x3] # -1 2 3\n \n f = all([any(c1), any(c2), any(c3), any(c4), any(c5)]) # Boolean function\n table.append([x1, x2, x3, f])\n \ndisplay(HTML(tabulate.tabulate(table, tablefmt = 'html', \n headers = ['$x_1$', '$x_2$', '$x_3$', '$f$'])))",
"_____no_output_____"
]
],
[
[
"Remark: this is obviously not the most efficient classical algorithm that exists. Heuristic SAT-algorithms are able to solve problem instances involving tens of thousands of variables and formulas consisting of millions of symbols, which is sufficient for many practical SAT problems.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad205ce6cda8a1c18ea528cb3fc4a8fc33ee058
| 29,526 |
ipynb
|
Jupyter Notebook
|
m_theory/dim4/so8_supergravity_extrema/colab/so8_supergravity.ipynb
|
ojInc/google-research
|
9929c88b664800a25b8716c22068dd77d80bd5ee
|
[
"Apache-2.0"
] | 23,901 |
2018-10-04T19:48:53.000Z
|
2022-03-31T21:27:42.000Z
|
m_theory/dim4/so8_supergravity_extrema/colab/so8_supergravity.ipynb
|
MitchellTesla/google-research
|
393e60a28e676992af1e7cb4f93e5c2d4e0cf517
|
[
"Apache-2.0"
] | 891 |
2018-11-10T06:16:13.000Z
|
2022-03-31T10:42:34.000Z
|
m_theory/dim4/so8_supergravity_extrema/colab/so8_supergravity.ipynb
|
MitchellTesla/google-research
|
393e60a28e676992af1e7cb4f93e5c2d4e0cf517
|
[
"Apache-2.0"
] | 6,047 |
2018-10-12T06:31:02.000Z
|
2022-03-31T13:59:28.000Z
| 45.494607 | 98 | 0.488451 |
[
[
[
"Copyright 2020 Google LLC\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n https://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.",
"_____no_output_____"
]
],
[
[
"# Let us explicitly ask for TensorFlow2.\n# This installs a lot of stuff - and will take a while.\n!pip3 install tensorflow==2.0.1",
"_____no_output_____"
],
[
"import base64\nimport collections\nimport dataclasses\nimport hashlib\nimport itertools\nimport math\nimport numpy\nimport pprint\nimport scipy.optimize\nimport sys\n\nimport tensorflow as tf\n\n\nprint('TF version is:', tf.__version__)\nprint('NumPy version is:', numpy.__version__)\n\n\[email protected](frozen=True)\nclass Solution(object):\n potential: float\n stationarity: float\n pos: numpy.ndarray\n\n\ndef np_esum(spec, *arrays, optimize='greedy'):\n \"\"\"Numpy einsum with default greedy optimization.\"\"\"\n return numpy.einsum(spec, *arrays, optimize=optimize)\n\n\ndef get_onb_transform(k_ab):\n if not numpy.allclose(k_ab, k_ab.real) or not numpy.allclose(k_ab, k_ab.T):\n raise ValueError('Bad Gramian.')\n eigvals, eigvecsT = numpy.linalg.eigh(k_ab)\n if not all(v * eigvals[0] > 0 for v in eigvals):\n raise ValueError('Non-definite Gramian.')\n onb_transform = numpy.einsum('a,na->an', eigvals**(-.5), eigvecsT)\n g = np_esum('ab,Aa,Bb->AB', k_ab, onb_transform, onb_transform)\n assert numpy.allclose(\n g, numpy.eye(g.shape[0]) * ((-1, 1)[int(eigvals[0] > 0)])\n ), 'Bad ONB-transform.'\n return onb_transform, numpy.linalg.inv(onb_transform)\n\n\ndef numpy_signature(a, digits=3):\n \"\"\"Produces a signature-fingerprint of a numpy array.\"\"\"\n # Hack to ensure that -0.0 gets consistently shown as 0.0.\n minus_zero_hack = 1e-100+1e-100j\n return base64.b64encode(\n hashlib.sha256(\n str((a.shape,\n ','.join(repr(x)\n for x in numpy.round(a + minus_zero_hack, digits).flat))\n ).encode('utf-8')\n ).digest()).decode('utf-8').strip('\\n=')\n\n\ndef tformat(array,\n name=None,\n elem_filter=lambda x: abs(x) > 1e-8,\n fmt='%s',\n max_rows=numpy.inf,\n cols=120):\n \"\"\"Formats a numpy-array in human readable table form.\"\"\"\n # Leading row will be replaced if caller asked for a name-row.\n dim_widths = [\n max(1, int(math.ceil(math.log(dim + 1e-100, 10))))\n for dim in array.shape]\n format_str = '%s: %s' % (' '.join('%%%dd' % w for w in dim_widths), fmt)\n rows = []\n for indices in itertools.product(*[range(dim) for dim in array.shape]):\n v = array[indices]\n if elem_filter(v):\n rows.append(format_str % (indices + (v, )))\n num_entries = len(rows)\n if num_entries > max_rows:\n rows = rows[:max_rows]\n if cols is not None:\n width = max(map(len, rows))\n num_cols = max(1, cols // (3 + width))\n num_xrows = int(math.ceil(len(rows) / num_cols))\n padded = [('%%-%ds' % width) % s\n for s in rows + [''] * (num_cols * num_xrows - len(rows))]\n table = numpy.array(padded, dtype=object).reshape(num_cols, num_xrows).T\n xrows = [' | '.join(row) for row in table]\n else:\n xrows = rows\n if name is not None:\n return '\\n'.join(\n ['=== %s, shape=%r, %d%s / %d non-small entries ===' % (\n name, array.shape,\n num_entries,\n '' if num_entries == len(rows) else '(%d shown)' % num_entries,\n array.size)] +\n [r.strip() for r in xrows])\n return '\\n'.join(xrows)\n\n\ndef tprint(array, sep=' ', end='\\n', file=sys.stdout, **tformat_kwargs):\n \"\"\"Prints a numpy array in human readable table form.\"\"\"\n print(tformat(array, **tformat_kwargs), sep=sep, end=end, file=file)\n\n\n### Lie Algebra definitions for Spin(8), SU(8), E7.\n\ndef permutation_sign(p):\n q = [x for x in p] # Copy to list.\n parity = 1\n for n in range(len(p)):\n while n != q[n]:\n qn = q[n]\n q[n], q[qn] = q[qn], q[n] # Swap to make q[qn] = qn.\n parity = -parity\n return parity\n\n\ndef asymm2(a, einsum_spec):\n \"\"\"Antisymmetrizes.\"\"\"\n return 0.5 * (a - numpy.einsum(einsum_spec, a))\n\n\nclass Spin8(object):\n \"\"\"Container class for Spin(8) tensor invariants.\"\"\"\n\n def __init__(self):\n r8 = range(8)\n self.gamma_vsc = gamma_vsc = self._get_gamma_vsc()\n #\n # The gamma^{ab}_{alpha beta} tensor that translates between antisymmetric\n # matrices over vectors [ij] and antisymmetric matrices over spinors [sS].\n self.gamma_vvss = asymm2(\n numpy.einsum('isc,jSc->ijsS', gamma_vsc, gamma_vsc), 'ijsS->jisS')\n # The gamma^{ab}_{alpha* beta*} tensor that translates between antisymmetric\n # matrices over vectors [ij] and antisymmetric matrices over cospinors [cC].\n self.gamma_vvcc = asymm2(\n numpy.einsum('isc,jsC->ijcC', gamma_vsc, gamma_vsc), 'ijcC->jicC')\n #\n # The gamma^{ijkl}_{alpha beta} tensor that translates between antisymmetric\n # 4-forms [ijkl] and symmetric traceless matrices over the spinors (sS).\n g_ijsS = numpy.einsum('isc,jSc->ijsS', self.gamma_vsc, self.gamma_vsc)\n g_ijcC = numpy.einsum('isc,jsC->ijcC', self.gamma_vsc, self.gamma_vsc)\n g_ijklsS = numpy.einsum('ijst,kltS->ijklsS', g_ijsS, g_ijsS)\n g_ijklcC = numpy.einsum('ijcd,kldC->ijklcC', g_ijcC, g_ijcC)\n gamma_vvvvss = numpy.zeros([8] * 6)\n gamma_vvvvcc = numpy.zeros([8] * 6)\n for perm in itertools.permutations(range(4)):\n perm_ijkl = ''.join('ijkl'[p] for p in perm)\n sign = permutation_sign(perm)\n gamma_vvvvss += sign * numpy.einsum(perm_ijkl + 'sS->ijklsS', g_ijklsS)\n gamma_vvvvcc += sign * numpy.einsum(perm_ijkl + 'cC->ijklcC', g_ijklcC)\n self.gamma_vvvvss = gamma_vvvvss / 24.0\n self.gamma_vvvvcc = gamma_vvvvcc / 24.0\n\n def _get_gamma_vsc(self):\n \"\"\"Computes SO(8) gamma-matrices.\"\"\"\n # Conventions match Green, Schwarz, Witten's, but with index-counting\n # starting at zero.\n entries = (\n \"007+ 016- 025- 034+ 043- 052+ 061+ 070- \"\n \"101+ 110- 123- 132+ 145+ 154- 167- 176+ \"\n \"204+ 215- 226+ 237- 240- 251+ 262- 273+ \"\n \"302+ 313+ 320- 331- 346- 357- 364+ 375+ \"\n \"403+ 412- 421+ 430- 447+ 456- 465+ 474- \"\n \"505+ 514+ 527+ 536+ 541- 550- 563- 572- \"\n \"606+ 617+ 624- 635- 642+ 653+ 660- 671- \"\n \"700+ 711+ 722+ 733+ 744+ 755+ 766+ 777+\")\n ret = numpy.zeros([8, 8, 8])\n for ijkc in entries.split():\n ijk = tuple(map(int, ijkc[:-1]))\n ret[ijk] = +1 if ijkc[-1] == '+' else -1\n return ret\n\n\nclass SU8(object):\n \"\"\"Container class for su(8) tensor invariants.\"\"\"\n\n def __init__(self):\n # Tensor that translates between adjoint indices 'a' and\n # (vector) x (vector) indices 'ij'\n ij_map = [(i, j) for i in range(8) for j in range(8) if i < j]\n #\n # We also need the mapping between 8 x 8 and 35 representations, using\n # common conventions for a basis of the 35-representation, and likewise\n # for 8 x 8 and 28.\n m_35_8_8 = numpy.zeros([35, 8, 8], dtype=numpy.complex128)\n m_28_8_8 = numpy.zeros([28, 8, 8], dtype=numpy.complex128)\n for n in range(7):\n m_35_8_8[n, n, n] = +1.0\n m_35_8_8[n, n + 1, n + 1] = -1.0\n for a, (m, n) in enumerate(ij_map):\n m_35_8_8[a + 7, m, n] = m_35_8_8[a + 7, n, m] = 1.0\n m_28_8_8[a, m, n] = 1.0\n m_28_8_8[a, n, m] = -1.0\n #\n # The su8 'Generator Matrices'.\n t_aij = numpy.zeros([63, 8, 8], dtype=numpy.complex128)\n t_aij[:35, :, :] = 1.0j * m_35_8_8\n for a, (i, j) in enumerate(ij_map):\n t_aij[a + 35, i, j] = -1.0\n t_aij[a + 35, j, i] = 1.0\n self.ij_map = ij_map\n self.m_35_8_8 = m_35_8_8\n self.m_28_8_8 = m_28_8_8\n self.t_aij = t_aij\n\n\nclass E7(object):\n \"\"\"Container class for e7 tensor invariants.\"\"\"\n\n def __init__(self, spin8, su8):\n self._spin8 = spin8\n self._su8 = su8\n ij_map = su8.ij_map\n t_a_ij_kl = numpy.zeros([133, 56, 56], dtype=numpy.complex128)\n t_a_ij_kl[:35, 28:, :28] = (1 / 8.0) * (\n np_esum('ijklsS,qsS,Iij,Kkl->qIK',\n spin8.gamma_vvvvss, su8.m_35_8_8, su8.m_28_8_8, su8.m_28_8_8))\n t_a_ij_kl[:35, :28, 28:] = t_a_ij_kl[:35, 28:, :28]\n t_a_ij_kl[35:70, 28:, :28] = (1.0j / 8.0) * (\n np_esum('ijklcC,qcC,Iij,Kkl->qIK',\n spin8.gamma_vvvvcc, su8.m_35_8_8, su8.m_28_8_8, su8.m_28_8_8))\n t_a_ij_kl[35:70, :28, 28:] = -t_a_ij_kl[35:70, 28:, :28]\n #\n # We need to find the action of the su(8) algebra on the\n # 28-representation.\n su8_28 = 2 * np_esum('aij,mn,Iim,Jjn->aIJ',\n su8.t_aij,\n numpy.eye(8, dtype=numpy.complex128),\n su8.m_28_8_8, su8.m_28_8_8)\n t_a_ij_kl[70:, :28, :28] = su8_28\n t_a_ij_kl[70:, 28:, 28:] = su8_28.conjugate()\n self.t_a_ij_kl = t_a_ij_kl\n #\n self.k_ab = numpy.einsum('aMN,bNM->ab', t_a_ij_kl, t_a_ij_kl)\n self.v70_as_sc8x8 = numpy.einsum('sc,xab->sxcab',\n numpy.eye(2),\n su8.m_35_8_8).reshape(70, 2, 8, 8)\n # For e7, there actually is a better orthonormal basis:\n # the sd/asd 4-forms. The approach used here however readily generalizes\n # to all other groups.\n self.v70_onb_onbinv = get_onb_transform(self.k_ab[:70, :70])\n\n\ndef get_proj_35_8888(want_selfdual=True):\n \"\"\"Computes the (35, 8, 8, 8, 8)-projector to the (anti)self-dual 4-forms.\"\"\"\n # We first need some basis for the 35 self-dual 4-forms.\n # Our convention is that we lexicographically list those 8-choose-4\n # combinations that contain the index 0.\n sign_selfdual = 1 if want_selfdual else -1\n ret = numpy.zeros([35, 8, 8, 8, 8], dtype=numpy.float64)\n #\n def get_selfdual(ijkl):\n mnpq = tuple(n for n in range(8) if n not in ijkl)\n return (sign_selfdual * permutation_sign(ijkl + mnpq),\n ijkl, mnpq)\n selfduals = [get_selfdual(ijkl)\n for ijkl in itertools.combinations(range(8), 4)\n if 0 in ijkl]\n for num_sd, (sign_sd, ijkl, mnpq) in enumerate(selfduals):\n for abcd in itertools.permutations(range(4)):\n sign_abcd = permutation_sign(abcd)\n ret[num_sd,\n ijkl[abcd[0]],\n ijkl[abcd[1]],\n ijkl[abcd[2]],\n ijkl[abcd[3]]] = sign_abcd\n ret[num_sd,\n mnpq[abcd[0]],\n mnpq[abcd[1]],\n mnpq[abcd[2]],\n mnpq[abcd[3]]] = sign_abcd * sign_sd\n return ret / 24.0\n\n\nspin8 = Spin8()\nsu8 = SU8()\ne7 = E7(spin8, su8)\n\n\nassert (numpy_signature(e7.t_a_ij_kl) ==\n 'MMExYjC6Qr6gunZIYfRLLgM2PDtwUDYujBNzAIukAVY'), 'Bad E7(7) definitions.'\n",
"_____no_output_____"
],
[
"### SO(p, 8-p) gaugings\n\ndef get_so_pq_E(p=8):\n if p == 8 or p == 0:\n return numpy.eye(56, dtype=complex)\n q = 8 - p\n pq_ratio = p / q\n x88 = numpy.diag([-1.0] * p + [1.0 * pq_ratio] * q)\n t = 0.25j * numpy.pi / (1 + pq_ratio)\n k_ab = numpy.einsum('aij,bij->ab', su8.m_35_8_8, su8.m_35_8_8)\n v35 = numpy.einsum('mab,ab,mM->M', su8.m_35_8_8, x88, numpy.linalg.inv(k_ab))\n gen_E = numpy.einsum(\n 'aMN,a->NM',\n e7.t_a_ij_kl,\n numpy.pad(v35, [(0, 133 - 35)], 'constant'))\n return scipy.linalg.expm(-t * gen_E)",
"_____no_output_____"
],
[
"### Supergravity.\n\[email protected](frozen=True)\nclass SUGRATensors(object):\n v70: tf.Tensor\n vielbein: tf.Tensor\n tee_tensor: tf.Tensor\n a1: tf.Tensor\n a2: tf.Tensor\n potential: tf.Tensor\n\n\ndef get_tf_stationarity(fn_potential, **fn_potential_kwargs):\n \"\"\"Returns a @tf.function that computes |grad potential|^2.\"\"\"\n @tf.function\n def stationarity(pos):\n tape = tf.GradientTape()\n with tape:\n tape.watch(pos)\n potential = fn_potential(pos, **fn_potential_kwargs)\n grad_potential = tape.gradient(potential, pos)\n return tf.reduce_sum(grad_potential * grad_potential)\n return stationarity\n\n\[email protected]\ndef dwn_stationarity(t_a1, t_a2):\n \"\"\"Computes the de Wit-Nicolai stationarity-condition tensor.\"\"\"\n # See: https://arxiv.org/pdf/1302.6219.pdf, text after (3.2).\n t_x0 = (\n +4.0 * tf.einsum('mi,mjkl->ijkl', t_a1, t_a2)\n -3.0 * tf.einsum('mnij,nklm->ijkl', t_a2, t_a2))\n t_x0_real = tf.math.real(t_x0)\n t_x0_imag = tf.math.imag(t_x0)\n tc_sd = tf.constant(get_proj_35_8888(True))\n tc_asd = tf.constant(get_proj_35_8888(False))\n t_x_real_sd = tf.einsum('aijkl,ijkl->a', tc_sd, t_x0_real)\n t_x_imag_asd = tf.einsum('aijkl,ijkl->a', tc_asd, t_x0_imag)\n return (tf.einsum('a,a->', t_x_real_sd, t_x_real_sd) +\n tf.einsum('a,a->', t_x_imag_asd, t_x_imag_asd))\n\n\ndef tf_sugra_tensors(t_v70, compute_masses, t_lhs_vielbein, t_rhs_E):\n \"\"\"Returns key tensors for D=4 supergravity.\"\"\"\n tc_28_8_8 = tf.constant(su8.m_28_8_8)\n t_e7_generator_v70 = tf.einsum(\n 'v,vIJ->JI',\n tf.complex(t_v70, tf.constant([0.0] * 70, dtype=tf.float64)),\n tf.constant(e7.t_a_ij_kl[:70, :, :], dtype=tf.complex128))\n t_complex_vielbein0 = tf.linalg.expm(t_e7_generator_v70) @ t_rhs_E\n if compute_masses:\n t_complex_vielbein = t_lhs_vielbein @ t_complex_vielbein0\n else:\n t_complex_vielbein = t_complex_vielbein0\n @tf.function\n def expand_ijkl(t_ab):\n return 0.5 * tf.einsum(\n 'ijB,BIJ->ijIJ',\n tf.einsum('AB,Aij->ijB', t_ab, tc_28_8_8),\n tc_28_8_8)\n #\n t_u_ijIJ = expand_ijkl(t_complex_vielbein[:28, :28])\n t_u_klKL = expand_ijkl(t_complex_vielbein[28:, 28:])\n t_v_ijKL = expand_ijkl(t_complex_vielbein[:28, 28:])\n t_v_klIJ = expand_ijkl(t_complex_vielbein[28:, :28])\n #\n t_uv = t_u_klKL + t_v_klIJ\n t_uuvv = (tf.einsum('lmJK,kmKI->lkIJ', t_u_ijIJ, t_u_klKL) -\n tf.einsum('lmJK,kmKI->lkIJ', t_v_ijKL, t_v_klIJ))\n t_T = tf.einsum('ijIJ,lkIJ->lkij', t_uv, t_uuvv)\n t_A1 = (-4.0 / 21.0) * tf.linalg.trace(tf.einsum('mijn->ijmn', t_T))\n t_A2 = (-4.0 / (3 * 3)) * (\n # Antisymmetrize in last 3 indices, taking into account antisymmetry\n # in last two indices.\n t_T\n + tf.einsum('lijk->ljki', t_T)\n + tf.einsum('lijk->lkij', t_T))\n t_A1_real = tf.math.real(t_A1)\n t_A1_imag = tf.math.imag(t_A1)\n t_A2_real = tf.math.real(t_A2)\n t_A2_imag = tf.math.imag(t_A2)\n t_A1_potential = (-3.0 / 4) * (\n tf.einsum('ij,ij->', t_A1_real, t_A1_real) +\n tf.einsum('ij,ij->', t_A1_imag, t_A1_imag))\n t_A2_potential = (1.0 / 24) * (\n tf.einsum('ijkl,ijkl->', t_A2_real, t_A2_real) +\n tf.einsum('ijkl,ijkl->', t_A2_imag, t_A2_imag))\n t_potential = t_A1_potential + t_A2_potential\n #\n return t_v70, t_complex_vielbein, t_T, t_A1, t_A2, t_potential\n\n\ndef so8_sugra_tensors(t_v70, tc_rhs_E):\n t_v70, t_complex_vielbein, t_T, t_A1, t_A2, t_potential = (\n tf_sugra_tensors(t_v70, False, 0.0, tc_rhs_E))\n return SUGRATensors(\n v70=t_v70,\n vielbein=t_complex_vielbein,\n tee_tensor=t_T,\n a1=t_A1,\n a2=t_A2,\n potential=t_potential)\n\n\ndef so8_sugra_scalar_masses(v70, so_pq_p):\n # Note: In some situations, small deviations in the input give quite\n # noticeable deviations in the scalar mass-spectrum.\n # Getting reliable numbers here really requires satisfying\n # the stationarity-condition to high accuracy.\n tc_rhs_E = tf.constant(get_so_pq_E(so_pq_p), dtype=tf.complex128)\n tc_e7_onb = tf.constant(e7.v70_onb_onbinv[0], dtype=tf.complex128)\n tc_e7_taMN = tf.constant(e7.t_a_ij_kl[:70, :, :], dtype=tf.complex128)\n t_v70 = tf.constant(v70, dtype=tf.float64)\n #\n def tf_grad_potential_lhs_onb(t_d_v70_onb):\n tape = tf.GradientTape()\n with tape:\n tape.watch(t_d_v70_onb)\n t_d_gen_e7 = tf.einsum(\n 'a,aMN->NM',\n tf.einsum('Aa,A->a',\n tc_e7_onb,\n tf.complex(t_d_v70_onb, tf.zeros_like(t_d_v70_onb))),\n tc_e7_taMN)\n t_lhs_vielbein = (tf.eye(56, dtype=tf.complex128) +\n t_d_gen_e7 + 0.5 * t_d_gen_e7 @ t_d_gen_e7)\n t_potential = (\n tf_sugra_tensors(t_v70,\n tf.constant(True),\n t_lhs_vielbein,\n tc_rhs_E))[-1]\n return tape.gradient(t_potential, t_d_v70_onb)\n #\n t_d_v70_onb = tf.Variable(numpy.zeros(70), dtype=tf.float64)\n tape = tf.GradientTape(persistent=True)\n with tape:\n tape.watch(t_d_v70_onb)\n grad_potential = tf.unstack(tf_grad_potential_lhs_onb(t_d_v70_onb))\n\n t_mm = tf.stack([tape.gradient(grad_potential[k], t_d_v70_onb)\n for k in range(70)], axis=1)\n stensors = so8_sugra_tensors(t_v70, tc_rhs_E)\n return (t_mm * (36.0 / tf.abs(stensors.potential))).numpy()\n\n\n### Scanning\n\ndef scanner(\n use_dwn_stationarity=True,\n so_pq_p=8,\n seed=1,\n scale=0.15,\n stationarity_threshold=1e-4,\n relu_coordinate_threshold=3.0,\n gtol=1e-4,\n f_squashed=tf.math.asinh):\n \"\"\"Scans for critical points in the scalar potential.\n\n Args:\n use_dwn_stationarity: Whether to use the explicit stationarity condition\n from `dwn_stationarity`.\n so_pq_p: SO(p, 8-p) non-compact form of the gauge group to use.\n seed: Random number generator seed for generating starting points.\n scale: Scale for normal-distributed search starting point coordinates.\n stationarity_threshold: Upper bound on permissible post-optimization\n stationarity for a solution to be considered good.\n relu_coordinate_threshold: Threshold for any coordinate-value at which\n a ReLU-term kicks in, in order to move coordinates back to near zero.\n (This is relevant for noncompact gaugings with flat directions,\n where solutions can move 'very far out'.)\n gtol: `gtol` parameter for scipy.optimize.fmin_bfgs.\n f_squashed: Squashing-function for stationarity.\n Should be approximately linear near zero, monotonic, and not growing\n faster than logarithmic.\n Yields:\n `Solution` numerical solutions.\n \"\"\"\n # Use a seeded random number generator for better reproducibility\n # (but note that scipy's optimizers may themselves use independent\n # and not-easily-controllable random state).\n rng = numpy.random.RandomState(seed=seed)\n def get_x0():\n return rng.normal(scale=scale, size=70)\n #\n tc_rhs_E = tf.constant(get_so_pq_E(so_pq_p), dtype=tf.complex128)\n def f_potential(scalars):\n return so8_sugra_tensors(tf.constant(scalars), tc_rhs_E).potential.numpy()\n #\n f_grad_pot_sq_stationarity = (\n None if use_dwn_stationarity\n else get_tf_stationarity(\n lambda t_pos: so8_sugra_tensors(t_pos, tc_rhs_E).potential))\n #\n def f_t_stationarity(t_pos):\n if use_dwn_stationarity:\n stensors = so8_sugra_tensors(t_pos, tc_rhs_E)\n stationarity = dwn_stationarity(stensors.a1, stensors.a2)\n else:\n stationarity = f_grad_pot_sq_stationarity(t_pos)\n eff_stationarity = stationarity + tf.reduce_sum(\n tf.nn.relu(abs(t_pos) - relu_coordinate_threshold))\n return eff_stationarity\n #\n def f_opt(pos):\n t_pos = tf.constant(pos)\n t_stationarity = f_squashed(f_t_stationarity(t_pos))\n return t_stationarity.numpy()\n #\n def fprime_opt(pos):\n t_pos = tf.constant(pos)\n tape = tf.GradientTape()\n with tape:\n tape.watch(t_pos)\n t_stationarity = f_squashed(f_t_stationarity(t_pos))\n t_grad_opt = tape.gradient(t_stationarity, t_pos)\n return t_grad_opt.numpy()\n #\n while True:\n opt = scipy.optimize.fmin_bfgs(\n f_opt, get_x0(), fprime=fprime_opt, gtol=gtol, maxiter=10**4, disp=0)\n opt_pot = f_potential(opt)\n opt_stat = f_opt(opt)\n if numpy.isnan(opt_pot) or not opt_stat < stationarity_threshold:\n continue # Optimization ran into a bad solution.\n solution = Solution(potential=opt_pot,\n stationarity=opt_stat,\n pos=opt)\n yield solution\n",
"_____no_output_____"
],
[
"### Demo.\n\ndef demo(seed=0,\n scale=0.2,\n use_dwn_stationarity=True,\n so_pq_p=8,\n num_solutions=5,\n f_squashed=tf.math.asinh):\n solutions_iter = scanner(scale=scale, seed=seed,\n use_dwn_stationarity=use_dwn_stationarity,\n so_pq_p=so_pq_p, f_squashed=f_squashed)\n for num_solution in range(num_solutions):\n sol = next(solutions_iter)\n print('=== Solution ===')\n pprint.pprint(sol)\n mm0 = so8_sugra_scalar_masses(sol.pos, so_pq_p)\n print('\\nScalar Masses for: V/g^2=%s:' % sol.potential)\n print(sorted(collections.Counter(\n numpy.round(numpy.linalg.eigh(mm0)[0], 3)).items()))\n\ndemo()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ad20f2eabd92bb257e3b3f106da568568e51539
| 106,508 |
ipynb
|
Jupyter Notebook
|
notebooks/Assign3.ipynb
|
mmendiet/Reinforcement-Learning-Basics
|
bd14293f484a34dffec28d00cb0f8728756b7f9b
|
[
"MIT"
] | null | null | null |
notebooks/Assign3.ipynb
|
mmendiet/Reinforcement-Learning-Basics
|
bd14293f484a34dffec28d00cb0f8728756b7f9b
|
[
"MIT"
] | null | null | null |
notebooks/Assign3.ipynb
|
mmendiet/Reinforcement-Learning-Basics
|
bd14293f484a34dffec28d00cb0f8728756b7f9b
|
[
"MIT"
] | null | null | null | 169.598726 | 32,740 | 0.862639 |
[
[
[
"$\n\\DeclareMathOperator{\\E}{\\mathbb{E}}\n\\DeclareMathOperator{\\R}{\\mathcal{R}}\n\\DeclareMathOperator{\\wv}{\\mathbf{w}}\n\\newcommand{\\bm}{\\boldsymbol}\n$\n\n# ITCS 6010: Assignment #3 (V1)\n\n<font color=\"red\">(Due: 11 pm on Dec 3rd) </font>",
"_____no_output_____"
],
[
"### 1. The value of an action, $Q^\\pi(s,a)$, depends on the expected next reward and the expected sum of the remaining rewards. Again we can think of this in terms of a small backup diagram, this one rooted at an action (state–action pair) and branching to the possible next states:\n\n\n\n### Give the equation corresponding to this intuition and diagram for the value at the root node, $V^\\pi(s)$, in terms of the value at the expected leaf node, $Q^\\pi(s,a)$, given $s_t =s$. This expectation dpends on the policy, $\\pi$. Then give a second equation in which the expected value is written out explicitly in terms of $\\pi(a|s)$ such that no expected value notation appears in the equation.",
"_____no_output_____"
],
[
"$$V^{\\pi}(s)=\\mathbb{E}_{\\pi}[Q^{\\pi}(s, a)~|~s_t=s]$$<br>\n$$V^{\\pi}(s)=\\sum_{a} \\pi(a | s)Q^{\\pi}(s, a)$$",
"_____no_output_____"
],
[
"### 2. The compatible function approximation theorem states that the value function approximator is compatible to the policy, i.e., $\\nabla_{\\wv} Q_{\\wv}(s,a) = \\nabla_{\\bm\\theta} \\log \\pi_{\\bm\\theta}(s,a)$, and its parameter $\\wv$ minimizes the mean-square error, $\\E_{\\pi_{\\bm\\theta}} \\big[\\big(Q^{\\pi_\\theta}(s,a) - Q_{\\wv}(s,a) \\big)^2 \\big]$. Then the policy gradient is exact, $ \\nabla_{\\bm\\theta} J(\\bm\\theta) = \\E_{\\pi_{\\bm\\theta}} \\big[ \\nabla_{\\bm\\theta} \\log \\pi(a | s, \\bm\\theta) Q_{\\wv} (s, a) \\big]$. Show your proof.",
"_____no_output_____"
],
[
"If we minimize parameters $\\bf{w}$ with repect to the mean squared error:\n$$m = \\E_{\\pi_{\\bm\\theta}} \\big[\\big(Q^{\\pi_\\theta}(s,a) - Q_{\\wv}(s,a) \\big)^2 \\big]$$\nThen we are moving in the direction where:\n$$\\nabla_{\\bf{w}} m=0$$\nAs such, we rewrite the expectation:\n$$\\mathbb{E}_{\\pi_{\\theta}}\\left[\\left(Q^{\\pi_\\theta}(s, a)-Q_{\\bf{w}}(s, a)\\right) \\nabla_{\\bf{w}} Q_{\\bf{w}}(s, a)\\right]=0$$\n$$\\mathbb{E}_{\\pi_{\\theta}}\\left[\\left(Q^{\\pi_\\theta}(s, a)-Q_{\\bf{w}}(s, a)\\right) \\nabla_{\\theta} \\log \\pi_{\\theta}(s, a)\\right]=0$$\n$$\\mathbb{E}_{\\pi_{\\theta}}\\left[Q^{\\pi_\\theta}(s, a) \\nabla_{\\theta} \\log \\pi_{\\theta}(s, a)\\right]=\\mathbb{E}_{\\pi_{\\theta}}\\left[Q_{\\bf{w}}(s, a) \\nabla_{\\theta} \\log \\pi_{\\theta}(s, a)\\right]$$\n<br>Therefore, we can then substitute $Q^{\\pi_\\theta}(s, a)$ with $Q_{\\wv} (s, a)$ in the policy gradient:\n$$\\nabla_{\\bm\\theta} J(\\bm\\theta) = \\E_{\\pi_{\\bm\\theta}} \\big[ \\nabla_{\\bm\\theta} \\log \\pi(a | s, \\bm\\theta) Q_{\\wv} (s, a) \\big]$$",
"_____no_output_____"
],
[
"### 3. (Programming) \n1) Implement REINFORCE with Baseline (Value function for advantage) with neural network policy approximation to solve the Maze problem. \n\n2) Now, implement AC Methods with NN approximators for both actor and critic to solve the Maze problem. How are the solutions different each other?",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
],
[
"#### Maze Problem (Practice)",
"_____no_output_____"
]
],
[
[
"import collections\nimport numpy as np\nimport matplotlib\nfrom matplotlib import pyplot as plt\nimport sys\nfrom collections import defaultdict\nimport random\nimport math\nimport torch\nfrom statistics import mean\nimport torch.nn.functional as F",
"_____no_output_____"
]
],
[
[
"### Sample Grid Environment File\n\nSimple text file with three characters, 'O', 'H', and 'G'.\n- 'O': open space\n- 'H': Wall or obstacles\n- 'G': Goal location ",
"_____no_output_____"
]
],
[
[
"%%bash \ncat ../grid.txt",
"OOOHOOOOO\nOOOHOOHOO\nOOOOOOHOO\nOOOOHHHOO\nOOHOOOOOH\nOOHOOOGOO\nOOOOOOOOO\n"
]
],
[
[
"### GridWorld Class\n",
"_____no_output_____"
]
],
[
[
"# maze example\n#This environment is from the course material at: \n#https://nbviewer.jupyter.org/url/webpages.uncc.edu/mlee173/teach/itcs6010/notebooks/assign/Assign3.ipynb\nclass GridWorld:\n \"\"\" Grid World environment\n there are four actions (left, right, up, and down) to move an agent\n In a grid, if it reaches a goal, it get 30 points of reward.\n If it falls in a hole or moves out of the grid world, it gets -5.\n Each step costs -1 point. \n\n to test GridWorld, run the following sample codes:\n\n env = GridWorld('grid.txt')\n\n env.print_map()\n print [2,3], env.check_state([2,3])\n print [0,0], env.check_state([0,0])\n print [3,4], env.check_state([3,4])\n print [10,3], env.check_state([10,3])\n\n env.init([0,0])\n print env.next(1) # right\n print env.next(3) # down\n print env.next(0) # left\n print env.next(2) # up\n print env.next(2) # up\n\n Parameters\n ==========\n _map ndarray\n string array read from a file input\n _size 1d array\n the size of _map in ndarray\n goal_pos tuple\n the index for the goal location\n _actions list\n list of actions for 4 actions\n _s 1d array\n current state\n \"\"\"\n def __init__(self, fn):\n # read a map from a file\n self._map = self.read_map(fn)\n self._size = np.asarray(self._map.shape)\n self.goal_pos = np.where(self._map == 'G')\n\n # definition of actions (left, right, up, and down repectively)\n self._actions = [[0, -1], [0, 1], [-1, 0], [1, 0]]\n self._s = None\n\n def get_cur_state(self):\n return self._s\n\n def get_size(self):\n return self._size\n\n def read_map(self, fn):\n grid = []\n with open(fn) as f:\n for line in f:\n grid.append(list(line.strip()))\n return np.asarray(grid)\n\n def print_map(self):\n print( self._map )\n\n def check_state(self, s):\n if isinstance(s, collections.Iterable) and len(s) == 2:\n if s[0] < 0 or s[1] < 0 or\\\n s[0] >= self._size[0] or s[1] >= self._size[1]:\n return 'N'\n return self._map[tuple(s)].upper()\n else:\n return 'F' # wrong input\n\n def init(self, state=None):\n if state is None:\n s = [0, 0]\n else:\n s = state\n\n if self.check_state(s) == 'O':\n self._s = np.asarray(state)\n else:\n raise ValueError(\"Invalid state for init\")\n\n def next(self, a):\n s1 = self._s + self._actions[a]\n # state transition\n curr = self.check_state(s1)\n \n if curr == 'H' or curr == 'N':\n return -5\n elif curr == 'F':\n warnings.warn(\"invalid state \" + str(s1))\n return -5\n elif curr == 'G':\n self._s = s1\n return 30\n else:\n self._s = s1\n return -1\n \n def is_goal(self):\n return self.check_state(self._s) == 'G'\n \n def get_actions(self):\n return self._actions",
"_____no_output_____"
],
[
"# top-left to (0,0)\ndef coord_convert(s, sz):\n return [s[1], sz[0]-s[0]-1]",
"_____no_output_____"
],
[
"class Policy(torch.nn.Module):\n def __init__(self,input_size, hidden_size, output_size):\n super(Policy, self).__init__()\n #input:state\n self.l1 = torch.nn.Linear(input_size, hidden_size)\n self.relu = torch.nn.ReLU()\n self.l3 = torch.nn.Linear(hidden_size, output_size)\n self.out = torch.nn.Softmax(dim=0)\n #output: action probabilities\n \n def forward(self, x):\n x = torch.from_numpy(x).float()\n x = self.l1(x)\n x = self.relu(x)\n x = self.l3(x)\n x = self.out(x)\n return x\n\n def update(self, advantage, action_prob, optimizer):\n #policy_net.update(advantage, action_prob)\n loss = -(torch.log(action_prob)*advantage).mean()\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\ndef policy_init(input_size, hidden_size, output_size, lr):\n model = Policy(input_size, hidden_size, output_size)\n optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=5e-4)\n #optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)\n return model, optimizer",
"_____no_output_____"
],
[
"class Value(torch.nn.Module): \n def __init__(self,input_size, hidden_size, output_size):\n super(Value, self).__init__()\n #input:state\n self.l1 = torch.nn.Linear(input_size, hidden_size)\n self.relu = torch.nn.ReLU()\n self.l3 = torch.nn.Linear(hidden_size, output_size)\n #output: value\n \n def forward(self, x):\n x = torch.from_numpy(x).float()\n x = self.l1(x)\n x = self.relu(x)\n x = self.l3(x)\n return x\n\n def update(self, advantage, optimizer):\n #value_net.update(baseline_value, G_t)\n loss = advantage.pow(2).mean()\n optimizer.zero_grad()\n loss.backward(retain_graph=True)\n optimizer.step()\n\ndef value_init(input_size, hidden_size, output_size, lr):\n model = Value(input_size, hidden_size, output_size)\n optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=5e-4)\n #optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)\n return model, optimizer",
"_____no_output_____"
],
[
"def policy_gradient(num_episodes=20000, epsilon=1, final_epsilon=0.1, gamma=0.9, lr=0.002, algo='rf'):\n terminal_state_indicators = [\"H\",\"N\",\"F\",\"G\"]\n\n policy_net, pol_opt = policy_init(2,20,len(env._actions),lr)\n policy_net.train()\n value_net, val_opt = value_init(2,20,1,lr)\n value_net.train()\n \n epsilon_decay = np.exp(np.log(final_epsilon) / num_episodes)\n\n all_Gt = []\n all_avg = []\n for ep in range(0, num_episodes):\n reward_sum = 0\n episode = []\n #Randon Starts\n start_row = random.randint(0,env._size[0])\n start_col = random.randint(0,env._size[1])\n if(env.check_state([start_row,start_col]) == 'O' and (np.random.rand() < epsilon)):\n env.init([start_row,start_col])\n else:\n env.init([0,0])\n done = 0\n for steps in range(0,100):\n state = env.get_cur_state()\n action_probs = policy_net.forward(state)\n action = np.random.choice(np.arange(len(action_probs)), p=action_probs.detach().numpy())\n\n reward = env.next(action)\n reward_sum += reward\n next_state = env._s\n curr = env.check_state(next_state)\n if(curr in terminal_state_indicators):\n done = 1 \n #store experience\n episode.append((state, action, reward, action_probs[action], next_state))\n #if done, break\n if done:\n break\n state = next_state\n\n all_Gt.append(reward_sum)\n step_count = 0\n advantages = []\n picked_actp = []\n for traj in episode:\n state = traj[0]\n action = traj[1]\n action_prob = traj[3]\n next_state = traj[4]\n if(algo=='rf'):\n G_t = 0\n for i in range(step_count, len(episode)):\n reward = episode[i][2]\n G_t += reward*(gamma**(i-step_count))\n elif(algo=='ac'):\n reward = traj[2]\n G_t = reward + gamma*value_net.forward(next_state).detach()\n else:\n print(\"Invalid algorithm: Use 'rf' or 'ac'\")\n baseline_value = value_net.forward(state)\n advantage = G_t - baseline_value\n advantages.append(advantage)\n picked_actp.append(action_prob)\n step_count += 1\n value_net.update(torch.stack(advantages), val_opt)\n policy_net.update(torch.stack(advantages), torch.stack(picked_actp), pol_opt)\n epsilon *= epsilon_decay\n avg = mean(all_Gt[max(-50,-len(all_Gt)):])\n all_avg.append(avg)\n if ep>50 and avg > 20:\n print('Converged in episode '+str(ep))\n break\n return policy_net, all_Gt, all_avg",
"_____no_output_____"
],
[
"def print_policy(policy):\n print_value = np.zeros((env._size[0],env._size[1]))\n bad_state_indicators = [\"H\",\"N\",\"F\"]\n policy.eval()\n for row in range(0,env._size[0]):\n for col in range(0,env._size[1]):\n state = np.asarray([row,col])\n\n action_probs = policy.forward(state)\n action = np.random.choice(np.arange(len(action_probs)), p=action_probs.detach().numpy())\n curr = env.check_state(state)\n if(curr in bad_state_indicators):\n print_value[tuple(state)] = 0\n elif(curr in \"G\"):\n print_value[tuple(state)] = 9\n else:\n print_value[tuple(state)] = int(action)+1\n print(\"0: Hole 1: Left 2: Right 3: Up 4: Down 9: Goal\")\n print(print_value)",
"_____no_output_____"
],
[
"np.set_printoptions(suppress=True)\nenv = GridWorld(\"../grid.txt\")\nenv.print_map()",
"[['O' 'O' 'O' 'H' 'O' 'O' 'O' 'O' 'O']\n ['O' 'O' 'O' 'H' 'O' 'O' 'H' 'O' 'O']\n ['O' 'O' 'O' 'O' 'O' 'O' 'H' 'O' 'O']\n ['O' 'O' 'O' 'O' 'H' 'H' 'H' 'O' 'O']\n ['O' 'O' 'H' 'O' 'O' 'O' 'O' 'O' 'H']\n ['O' 'O' 'H' 'O' 'O' 'O' 'G' 'O' 'O']\n ['O' 'O' 'O' 'O' 'O' 'O' 'O' 'O' 'O']]\n"
],
[
"#******************* REINFORCE with Baseline ********************************\npolicy, all_reward, avg_reward = policy_gradient(num_episodes=20000, epsilon=1,\n final_epsilon=0.8,gamma=0.99, lr=0.002, algo='rf')\nprint_policy(policy)\nplt.plot(avg_reward)\nplt.title('REINFORCE with Baseline', fontsize=24)\nplt.ylabel('Running Average Reward', fontsize=18)\nplt.xlabel('Episodes', fontsize=18)\nprint(\"Final Average Reward: \" + str(avg_reward[-1]))\nplt.show()",
"Converged in episode 13772\n0: Hole 1: Left 2: Right 3: Up 4: Down 9: Goal\n[[4. 4. 4. 0. 4. 4. 4. 4. 4.]\n [4. 4. 1. 0. 4. 4. 0. 4. 4.]\n [2. 4. 4. 4. 4. 4. 0. 1. 4.]\n [2. 2. 4. 4. 0. 0. 0. 1. 4.]\n [3. 2. 0. 2. 4. 4. 4. 1. 0.]\n [3. 3. 0. 2. 2. 2. 9. 4. 1.]\n [3. 3. 2. 2. 2. 2. 2. 2. 3.]]\nFinal Average Reward: 20.02\n"
],
[
"#******************* Actor-Critic ********************************\npolicy, all_reward, avg_reward = policy_gradient(num_episodes=20000, epsilon=0.5,\n final_epsilon=0.1, gamma=0.99, lr=0.002, algo='ac')\nprint_policy(policy)\nplt.plot(avg_reward)\nplt.title('Actor-Critic', fontsize=24)\nplt.ylabel('Running Average Reward', fontsize=18)\nplt.xlabel('Episodes', fontsize=18)\nprint(\"Final Average Reward: \" + str(avg_reward[-1]))\nplt.show()",
"Converged in episode 17573\n0: Hole 1: Left 2: Right 3: Up 4: Down 9: Goal\n[[4. 4. 4. 0. 4. 4. 4. 4. 4.]\n [4. 4. 4. 0. 4. 4. 0. 4. 4.]\n [2. 2. 4. 4. 4. 4. 0. 4. 4.]\n [2. 2. 2. 4. 0. 0. 0. 4. 4.]\n [2. 2. 0. 2. 2. 4. 4. 4. 0.]\n [2. 2. 0. 2. 2. 2. 9. 4. 4.]\n [2. 2. 2. 2. 2. 2. 2. 2. 4.]]\nFinal Average Reward: 20.1\n"
]
],
[
[
"The generic policy update for REINFORCE with Baseline is shown in the follwing equation:<br><br>\n$$\\theta_{t+1}= \\theta_t + \\alpha\\left(G_{t}-\\hat{V}\\left(s_{t}\\right)\\right) \\nabla_{\\theta} \\log \\pi_{\\theta}\\left(s_{t}, a_{t}\\right)$$\nWhere $\\alpha$ is the learning rate, and $\\theta$ represents the policy function parameters.\n\nHere, we see that REINFORCE with Baseline takes the true return $G_t$, and subtracts the approximated value $\\hat{V}\\left(s_{t}\\right)$ as the baseline. This forms its advantage, which is used to push the gradient with respect to the difference in the true return and approximated state value.<br><br>\n\nBasic Actor-Critic is different than REINFORCE with Baseline in its advantage, as shown in the following equation:<br>\n\n$$\\theta_{t+1}= \\theta_t + \\alpha\\left(r + \\gamma \\hat{V}\\left(s_{t+1}\\right)-\\hat{V}\\left(s_{t}\\right)\\right) \\nabla_{\\theta} \\log \\pi_{\\theta}\\left(s_{t}, a_{t}\\right)$$\n\nHere, we can see that the advantage is calculated with the TD error using the value function approximate for the next state, rather than the full return used by REINFORCE.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ad21046388c9a769de4ae27e16908e5fc749c1c
| 28,283 |
ipynb
|
Jupyter Notebook
|
deploy-aks-with-controlled-rollout.ipynb
|
felipemoz/tdc_2021_content
|
6fd01c86de860a78dd90aac8dc05347e328daa5a
|
[
"MIT"
] | 2 |
2021-06-09T21:47:03.000Z
|
2021-06-14T14:10:01.000Z
|
deploy-aks-with-controlled-rollout.ipynb
|
felipemoz/tdc_2021_content
|
6fd01c86de860a78dd90aac8dc05347e328daa5a
|
[
"MIT"
] | null | null | null |
deploy-aks-with-controlled-rollout.ipynb
|
felipemoz/tdc_2021_content
|
6fd01c86de860a78dd90aac8dc05347e328daa5a
|
[
"MIT"
] | 1 |
2021-06-09T21:47:04.000Z
|
2021-06-09T21:47:04.000Z
| 52.375926 | 3,248 | 0.643531 |
[
[
[
"Copyright (c) Microsoft Corporation. All rights reserved.\n\nLicensed under the MIT License.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"# Deploy models to Azure Kubernetes Service (AKS) using controlled roll out\nThis notebook will show you how to deploy mulitple AKS webservices with the same scoring endpoint and how to roll out your models in a controlled manner by configuring % of scoring traffic going to each webservice. If you are using a Notebook VM, you are all set. Otherwise, go through the [configuration notebook](../../../configuration.ipynb) to install the Azure Machine Learning Python SDK and create an Azure ML Workspace.",
"_____no_output_____"
]
],
[
[
"# Check for latest version\nimport azureml.core\nprint(azureml.core.VERSION)",
"1.22.0\n"
]
],
[
[
"## Initialize workspace\nCreate a [Workspace](https://docs.microsoft.com/python/api/azureml-core/azureml.core.workspace%28class%29?view=azure-ml-py) object from your persisted configuration.",
"_____no_output_____"
]
],
[
[
"from azureml.core.workspace import Workspace\n\nws = Workspace.from_config()\nprint(ws.name, ws.resource_group, ws.location, ws.subscription_id, sep = '\\n')",
"fmoz-workspace\nml\nwestus2\n421b563f-a977-42aa-8934-f41ca5664b73\n"
]
],
[
[
"## Register the model\nRegister a file or folder as a model by calling [Model.register()](https://docs.microsoft.com/python/api/azureml-core/azureml.core.model.model?view=azure-ml-py#register-workspace--model-path--model-name--tags-none--properties-none--description-none--datasets-none--model-framework-none--model-framework-version-none--child-paths-none-).\nIn addition to the content of the model file itself, your registered model will also store model metadata -- model description, tags, and framework information -- that will be useful when managing and deploying models in your workspace. Using tags, for instance, you can categorize your models and apply filters when listing models in your workspace.",
"_____no_output_____"
]
],
[
[
"from azureml.core import Model\n\nmodel = Model.register(workspace=ws,\n model_name='sklearn_regression_model.pkl', # Name of the registered model in your workspace.\n model_path='./sklearn_regression_model.pkl', # Local file to upload and register as a model.\n model_framework=Model.Framework.SCIKITLEARN, # Framework used to create the model.\n model_framework_version='0.19.1', # Version of scikit-learn used to create the model.\n description='Ridge regression model to predict diabetes progression.',\n tags={'area': 'diabetes', 'type': 'regression'})\n\nprint('Name:', model.name)\nprint('Version:', model.version)",
"Registering model sklearn_regression_model.pkl\nName: sklearn_regression_model.pkl\nVersion: 4\n"
]
],
[
[
"## Register an environment (for all models)\n\nIf you control over how your model is run, or if it has special runtime requirements, you can specify your own environment and scoring method.\n\nSpecify the model's runtime environment by creating an [Environment](https://docs.microsoft.com/python/api/azureml-core/azureml.core.environment%28class%29?view=azure-ml-py) object and providing the [CondaDependencies](https://docs.microsoft.com/python/api/azureml-core/azureml.core.conda_dependencies.condadependencies?view=azure-ml-py) needed by your model.",
"_____no_output_____"
]
],
[
[
"from azureml.core import Environment\nfrom azureml.core.conda_dependencies import CondaDependencies\n\nenvironment=Environment('my-sklearn-environment')\nenvironment.python.conda_dependencies = CondaDependencies.create(pip_packages=[\n 'azureml-defaults',\n 'inference-schema[numpy-support]',\n 'numpy',\n 'scikit-learn==0.19.1',\n 'scipy'\n])",
"_____no_output_____"
]
],
[
[
"When using a custom environment, you must also provide Python code for initializing and running your model. An example script is included with this notebook.",
"_____no_output_____"
]
],
[
[
"with open('score.py') as f:\n print(f.read())",
"import pickle\nimport json\nimport numpy\nfrom sklearn.externals import joblib\nfrom sklearn.linear_model import Ridge\nfrom azureml.core.model import Model\n\n\ndef init():\n global model\n # note here \"sklearn_regression_model.pkl\" is the name of the model registered under\n # this is a different behavior than before when the code is run locally, even though the code is the same.\n model_path = Model.get_model_path('sklearn_regression_model.pkl')\n # deserialize the model file back into a sklearn model\n model = joblib.load(model_path)\n\n\n# note you can pass in multiple rows for scoring\ndef run(raw_data):\n try:\n data = json.loads(raw_data)['data']\n data = numpy.array(data)\n result = model.predict(data)\n # you can return any data type as long as it is JSON-serializable\n return result.tolist()\n except Exception as e:\n error = str(e)\n return error\n\n"
]
],
[
[
"## Create the InferenceConfig\nCreate the inference configuration to reference your environment and entry script during deployment",
"_____no_output_____"
]
],
[
[
"from azureml.core.model import InferenceConfig\n\ninference_config = InferenceConfig(entry_script='score.py', \n source_directory='.',\n environment=environment)\n",
"_____no_output_____"
]
],
[
[
"## Provision the AKS Cluster\nIf you already have an AKS cluster attached to this workspace, skip the step below and provide the name of the cluster.",
"_____no_output_____"
]
],
[
[
"from azureml.core.compute import AksCompute\nfrom azureml.core.compute import ComputeTarget\n# Use the default configuration (can also provide parameters to customize)\nprov_config = AksCompute.provisioning_configuration()\n\naks_name = 'my-aks' \n# Create the cluster\naks_target = ComputeTarget.create(workspace = ws, \n name = aks_name, \n provisioning_configuration = prov_config) \naks_target.wait_for_completion(show_output=True)",
"Creating................................................................................\nSucceededProvisioning operation finished, operation \"Succeeded\"\n"
]
],
[
[
"## Create an Endpoint and add a version (AKS service)\nThis creates a new endpoint and adds a version behind it. By default the first version added is the default version. You can specify the traffic percentile a version takes behind an endpoint. \n",
"_____no_output_____"
]
],
[
[
"# deploying the model and create a new endpoint\nfrom azureml.core.webservice import AksEndpoint\n# from azureml.core.compute import ComputeTarget\n\n#select a created compute\ncompute = ComputeTarget(ws, 'my-aks')\nnamespace_name=\"endpointnamespace\"\n# define the endpoint name\nendpoint_name = \"myendpoint2\"\n# define the service name\nversion_name= \"versiona\"\n\nendpoint_deployment_config = AksEndpoint.deploy_configuration(tags = {'modelVersion':'firstversion', 'department':'finance'}, \n description = \"my first version\", namespace = namespace_name, \n version_name = version_name, traffic_percentile = 40)\n\nendpoint = Model.deploy(ws, endpoint_name, [model], inference_config, endpoint_deployment_config, compute)\nendpoint.wait_for_deployment(True)",
"_____no_output_____"
],
[
"endpoint.get_logs()",
"_____no_output_____"
]
],
[
[
"## Add another version of the service to an existing endpoint\nThis adds another version behind an existing endpoint. You can specify the traffic percentile the new version takes. If no traffic_percentile is specified then it defaults to 0. All the unspecified traffic percentile (in this example 50) across all versions goes to default version.",
"_____no_output_____"
]
],
[
[
"# Adding a new version to an existing Endpoint.\nversion_name_add=\"versionb\" \n\nendpoint.create_version(version_name = version_name_add, inference_config=inference_config, models=[model], tags = {'modelVersion':'secondversion', 'department':'finance'}, \n description = \"my second version\", traffic_percentile = 50)\nendpoint.wait_for_deployment(True)",
"Tips: You can try get_logs(): https://aka.ms/debugimage#dockerlog or local deployment: https://aka.ms/debugimage#debug-locally to debug if deployment takes longer than 10 minutes.\nRunning..............\nSucceeded\nAKSENDPOINT service creation operation finished, operation \"Succeeded\"\n"
]
],
[
[
"## Update an existing version in an endpoint\nThere are two types of versions: control and treatment. An endpoint contains one or more treatment versions but only one control version. This categorization helps compare the different versions against the defined control version.",
"_____no_output_____"
]
],
[
[
"endpoint.update_version(version_name=endpoint.versions[version_name_add].name, description=\"my second version update\", traffic_percentile=40, is_default=True, is_control_version_type=True)\nendpoint.wait_for_deployment(True)",
"Tips: You can try get_logs(): https://aka.ms/debugimage#dockerlog or local deployment: https://aka.ms/debugimage#debug-locally to debug if deployment takes longer than 10 minutes.\nRunning......\nSucceeded\nAKSENDPOINT service creation operation finished, operation \"Succeeded\"\n"
]
],
[
[
"## Test the web service using run method\nTest the web sevice by passing in data. Run() method retrieves API keys behind the scenes to make sure that call is authenticated.",
"_____no_output_____"
]
],
[
[
"# Scoring on endpoint\nimport json\ntest_sample = json.dumps({'data': [\n [1,2,3,4,5,6,7,8,9,10], \n [10,9,8,7,6,5,4,3,2,1]\n]})\n\ntest_sample_encoded = bytes(test_sample, encoding='utf8')\nprediction = endpoint.run(input_data=test_sample_encoded)\nprint(prediction)",
"[5215.1981315798685, 3726.995485938578]\n"
]
],
[
[
"## Delete Resources",
"_____no_output_____"
]
],
[
[
"# deleting a version in an endpoint\nendpoint.delete_version(version_name=version_name)\nendpoint.wait_for_deployment(True)",
"Tips: You can try get_logs(): https://aka.ms/debugimage#dockerlog or local deployment: https://aka.ms/debugimage#debug-locally to debug if deployment takes longer than 10 minutes.\nRunning...\nSucceeded\nAKSENDPOINT service creation operation finished, operation \"Succeeded\"\n"
],
[
"# deleting an endpoint, this will delete all versions in the endpoint and the endpoint itself\n#endpoint.delete()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4ad2228a6539bce7b7ea11c0dcf2a1a8bb161f49
| 135,436 |
ipynb
|
Jupyter Notebook
|
sliderule_dsi_inferential_statistics_exercise_2.ipynb
|
anonyXmous/CapstoneProject
|
12f596a9ddf63e6ea152bca0471c49c71b01fc45
|
[
"Unlicense"
] | 1 |
2017-09-02T22:52:47.000Z
|
2017-09-02T22:52:47.000Z
|
sliderule_dsi_inferential_statistics_exercise_2.ipynb
|
anonyXmous/CapstoneProject
|
12f596a9ddf63e6ea152bca0471c49c71b01fc45
|
[
"Unlicense"
] | null | null | null |
sliderule_dsi_inferential_statistics_exercise_2.ipynb
|
anonyXmous/CapstoneProject
|
12f596a9ddf63e6ea152bca0471c49c71b01fc45
|
[
"Unlicense"
] | null | null | null | 215.319555 | 84,176 | 0.867672 |
[
[
[
"# Examining Racial Discrimination in the US Job Market\n\n### Background\nRacial discrimination continues to be pervasive in cultures throughout the world. Researchers examined the level of racial discrimination in the United States labor market by randomly assigning identical résumés to black-sounding or white-sounding names and observing the impact on requests for interviews from employers.\n\n### Data\nIn the dataset provided, each row represents a resume. The 'race' column has two values, 'b' and 'w', indicating black-sounding and white-sounding. The column 'call' has two values, 1 and 0, indicating whether the resume received a call from employers or not.\n\nNote that the 'b' and 'w' values in race are assigned randomly to the resumes when presented to the employer.",
"_____no_output_____"
],
[
"<div class=\"span5 alert alert-info\">\n### Exercises\nYou will perform a statistical analysis to establish whether race has a significant impact on the rate of callbacks for resumes.\n\nAnswer the following questions **in this notebook below and submit to your Github account**. \n\n 1. What test is appropriate for this problem? Does CLT apply?\n 2. What are the null and alternate hypotheses?\n 3. Compute margin of error, confidence interval, and p-value.\n 4. Write a story describing the statistical significance in the context or the original problem.\n 5. Does your analysis mean that race/name is the most important factor in callback success? Why or why not? If not, how would you amend your analysis?\n\nYou can include written notes in notebook cells using Markdown: \n - In the control panel at the top, choose Cell > Cell Type > Markdown\n - Markdown syntax: http://nestacms.com/docs/creating-content/markdown-cheat-sheet\n\n\n#### Resources\n+ Experiment information and data source: http://www.povertyactionlab.org/evaluation/discrimination-job-market-united-states\n+ Scipy statistical methods: http://docs.scipy.org/doc/scipy/reference/stats.html \n+ Markdown syntax: http://nestacms.com/docs/creating-content/markdown-cheat-sheet\n</div>\n****",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport pandas as pd\nimport numpy as np\nfrom scipy import stats\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom statsmodels.stats.proportion import proportions_ztest\n",
"_____no_output_____"
],
[
"# read the data\ndata = pd.io.stata.read_stata('data/us_job_market_discrimination.dta')\n\n# split data into black and nonblack sounding names\ndfblack = data[data.race=='b']\ndfnonblack = data[data.race!='b']\n\n# display some basic statistics\ndata.describe()\n\n",
"_____no_output_____"
],
[
"# count the number of blacks and nonblack sounding names and calls / noncalls\nblack_call=sum(dfblack.call)\nblack_nocall=len(dfblack)-black_call\nnonblack_call=sum(dfnonblack.call)\nnonblack_nocall=len(dfnonblack)-nonblack_call\n\n# number of callbacks for black and non black-sounding names\nprint(\"callbacks for black-sounding names\", black_call)\nprint(\"noncallbacks for black-sounding names\", black_nocall)\nprint(\"callbacks for non black-sounding names\", nonblack_call)\nprint(\"noncallbacks for non black-sounding names\", nonblack_nocall)\n\n#\n# create bar chart\n#\ncall = (black_call, nonblack_call)\nnoncall = (black_nocall, nonblack_nocall)\nfig, ax = plt.subplots()\nindex = np.arange(2)\nbar_width = 0.35\n\nopacity = 0.4\nerror_config = {'ecolor': '0.3'}\n\nrects1 = plt.bar(index, call, bar_width,\n alpha=opacity,\n color='b',\n error_kw=error_config,\n label='call')\n\nrects2 = plt.bar(index + bar_width, noncall, bar_width,\n alpha=opacity,\n color='r',\n error_kw=error_config,\n label='noncall')\n\n# put labels to bar chart\nplt.xlabel('Race')\nplt.ylabel('Calls')\nplt.title('Number of calls by race')\nplt.xticks(index + bar_width / 2, ('black sounding name', 'nonblack sounding name'))\nplt.legend()\nplt.tight_layout()\n\n#\n# create pie chart\n#\nlabels = 'Black sounding name', 'nonBlack sounding name'\nsizes = [black_call, nonblack_call]\nfig1, ax1 = plt.subplots()\nax1.pie(sizes, labels=labels, autopct='%1.0f%%')\nax1.axis('equal') \n\nplt.show()\n",
"callbacks for black-sounding names 157.0\nnoncallbacks for black-sounding names 2278.0\ncallbacks for non black-sounding names 235.0\nnoncallbacks for non black-sounding names 2200.0\n"
],
[
"# measure the proportions\nn1 = len(dfblack)\nn2 = len(dfnonblack)\np1 = black_call / n1\np2 = nonblack_call / n2\n\ncount_call = np.array([black_call, nonblack_call])\nnobs_array = np.array([n1, n2])\nls = .05\nstat, pval = proportions_ztest(count=count_call, nobs=nobs_array, value=ls)\n\n# standard error and confidence interval (CI)\nse = np.sqrt(p1*(1-p1)/n1 + p1*(1-p2)/n2)\nprint('margin of error=', se)\nprint('conf interval=', (p1-p2-1.96*se, p1-p2+1.96*se))\nprint('p-value=', pval)\n\n# print chi-square test \nchi_value = stats.chi2_contingency(np.array([[black_call, black_nocall],[nonblack_call, nonblack_nocall]]))\nprint('chi_sq p-value=', chi_value[1])\n\n#t-test on education, ofjobs and yearsexp and occupspecific and occupbroad\nprint('education p-value=', stats.ttest_ind(dfblack['education'], dfnonblack['education'], equal_var = False)[1])\nprint('ofjobs p-value=', stats.ttest_ind(dfblack['ofjobs'], dfnonblack['ofjobs'], equal_var = False)[1])\nprint('yearsexp p-value=', stats.ttest_ind(dfblack['yearsexp'], dfnonblack['yearsexp'], equal_var = False)[1])\nprint('occupspecific p-value=', stats.ttest_ind(dfblack['occupspecific'], dfnonblack['occupspecific'], equal_var = False)[1])\nprint('occupbroad p-value=', stats.ttest_ind(dfblack['occupbroad'], dfnonblack['occupbroad'], equal_var = False)[1])\n#proportion test on honors\tvolunteer\tmilitary\tempholes and workinschool\nprint('honors p-value=', proportions_ztest(count=np.array([sum(dfblack.honors), \\\n sum(dfnonblack.honors)]),nobs=np.array([n1, n2]), value=ls)[1])\nprint('volunteer p-value=', proportions_ztest(count=np.array([sum(dfblack.volunteer), \\\n sum(dfnonblack.volunteer)]),nobs=np.array([n1, n2]), value=ls)[1])\nprint('military p-value=', proportions_ztest(count=np.array([sum(dfblack.military), \\\n sum(dfnonblack.military)]),nobs=np.array([n1, n2]), value=ls)[1])\nprint('empholes p-value=', proportions_ztest(count=np.array([sum(dfblack.empholes), \\\n sum(dfnonblack.empholes)]),nobs=np.array([n1, n2]), value=ls)[1])\nprint('workinschool p-value=', proportions_ztest(count=np.array([sum(dfblack.workinschool), \\\n sum(dfnonblack.workinschool)]),nobs=np.array([n1, n2]), value=ls)[1])\nprint('computerskills p-value=', proportions_ztest(count=np.array([sum(dfblack.computerskills), \\\n sum(dfnonblack.computerskills)]),nobs=np.array([n1, n2]), value=ls)[1])\n",
"margin of error= 0.00697820016119\nconf interval= (-0.045710126525379105, -0.018355581893512069)\np-value= 6.89730455562e-26\nchi_sq p-value= 4.99757838996e-05\neducation p-value= 0.809972058063\nofjobs p-value= 0.860071151129\nyearsexp p-value= 0.853535019664\noccupspecific p-value= 0.601989729691\noccupbroad p-value= 0.827482690832\nhonors p-value= 1.55908916658e-16\nvolunteer p-value= 0.00170348780718\nmilitary p-value= 1.76596251695e-06\nempholes p-value= 0.000146806674725\nworkinschool p-value= 0.000925559566219\ncomputerskills p-value= 0.0172870962453\n"
],
[
"corrmat = data.corr()\n# Set up the matplotlib figure\nf, ax = plt.subplots(figsize=(12, 9))\n \n# Draw the heatmap using seaborn\nsns.heatmap(corrmat, vmax=.8, square=True)\nf.tight_layout()\n",
"_____no_output_____"
]
],
[
[
"<div class=\"span5 alert alert-info\">\n### ANSWERS:\n\n 1. What test is appropriate for this problem? <b> Comparison of two proportions </b>\n Does CLT apply? <b> Yes, since np and n(1-p) where n is number of samples and p is the probability that an applicant is called, is more than 10, it can approximate the normal distribution.</b>\n 2. What are the null and alternate hypotheses? <b> H<sub>o</sub>= the call back for black and non-blacks are the same while H<sub>a</sub>= the call back for black and non-blacks are not the same </b>\n 3. Compute margin of error, confidence interval, and p-value. <b> margin of error= 0.00697820016119\nconf interval= (-0.045710126525379105, -0.018355581893512069)\np-value= 2.36721263361e-25 </b>\n 4. Write a story describing the statistical significance in the context or the original problem.\n <h3> Discrimination in Job Market on Black sounding names </h3>\n > Black sounding names have 2% to 4% average less callbacks compared to non-black sounding names.\n \n > Education, years experience and number of previous jobs have no significant difference.\n \n > However, differences are found in honors achieved, military and volunteer work, employment holes, work in school and computer skills.\n \n There is a discrimination in the job market for black sounding names. A study of 4870 job applicants in 2000 to 2002 shows that there is a difference between the number of callbacks for black sounding names compared to non-black sounding names. The study also shows that education, years experience and number of previous jobs are the same between the two groups. Meanwhile, there is a difference shown in honors achieved, military and volunteer work, employment holes, work in school and computer skills.\n \n 5. Does your analysis mean that race/name is the most important factor in callback success? Why or why not? If not, how would you amend your analysis?\n <b> Race is not the most important factor in callback success. In fact there are differences between black and nonblack sounding names in terms of honors achieved, military and volunteer work, employment holes, work in school and computer skills. These are the reasons why there is a difference on the callbacks between the two groups</b>\n\n\n#### Resources\n+ Experiment information and data source: http://www.povertyactionlab.org/evaluation/discrimination-job-market-united-states\n+ Scipy statistical methods: http://docs.scipy.org/doc/scipy/reference/stats.html \n</div>\n****",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ad2289445b7121cccf79374eddef9e79012d8b1
| 10,563 |
ipynb
|
Jupyter Notebook
|
modules/machinegendomains/DgaProg1.ipynb
|
daisecpace/website
|
acc1a02bcfcd1a99b31fc05a29bb298c0319e7c8
|
[
"MIT"
] | 1 |
2019-11-30T05:49:35.000Z
|
2019-11-30T05:49:35.000Z
|
modules/machinegendomains/DgaProg1.ipynb
|
daisecpace/daisecpace.github.io
|
acc1a02bcfcd1a99b31fc05a29bb298c0319e7c8
|
[
"MIT"
] | null | null | null |
modules/machinegendomains/DgaProg1.ipynb
|
daisecpace/daisecpace.github.io
|
acc1a02bcfcd1a99b31fc05a29bb298c0319e7c8
|
[
"MIT"
] | null | null | null | 10,563 | 10,563 | 0.713339 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('alexa.csv', header=None,encoding='utf-8' )",
"_____no_output_____"
],
[
"df.shape[0]",
"_____no_output_____"
],
[
"df.head(n=10)",
"_____no_output_____"
],
[
"df.columns.tolist()",
"_____no_output_____"
],
[
"df.columns=['domain']",
"_____no_output_____"
],
[
"df1=pd.DataFrame(df.domain.str.split('.').tolist()).add_prefix('domain_') ",
"_____no_output_____"
],
[
"df1.columns.tolist()",
"_____no_output_____"
],
[
"df1.head(n=10)",
"_____no_output_____"
],
[
"df1['label']='0'",
"_____no_output_____"
],
[
"df2=df1[['domain_0', 'label']].copy()",
"_____no_output_____"
],
[
"df2.columns=['domain','label']",
"_____no_output_____"
],
[
"df2.head(n=5)",
"_____no_output_____"
],
[
"df2.to_csv('legit.csv', encoding='utf-8', index=False)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad234ac2fd02adb048094b903352fbb886df9a1
| 840,405 |
ipynb
|
Jupyter Notebook
|
notebooks/02-full_model_fit.ipynb
|
widdowquinn/SI_Holmes_etal_2017
|
72dc0c3e537b6d940cb9f2ced4d4de19187c14ac
|
[
"MIT"
] | null | null | null |
notebooks/02-full_model_fit.ipynb
|
widdowquinn/SI_Holmes_etal_2017
|
72dc0c3e537b6d940cb9f2ced4d4de19187c14ac
|
[
"MIT"
] | null | null | null |
notebooks/02-full_model_fit.ipynb
|
widdowquinn/SI_Holmes_etal_2017
|
72dc0c3e537b6d940cb9f2ced4d4de19187c14ac
|
[
"MIT"
] | 1 |
2019-04-24T01:42:31.000Z
|
2019-04-24T01:42:31.000Z
| 249.45236 | 180,136 | 0.888069 |
[
[
[
"<img src=\"images/JHI_STRAP_Web.png\" style=\"width: 150px; float: right;\">\n\n# Supplementary Information: Holmes *et al.* 2020\n\n# 2. Full model fitting\n\nThis notebook describes fitting of a Bayesian hierarchical model of the effects of control (growth) and treatment (passage) on individual genes from *E. coli* DH10B (carrier) and Sakai (BAC load), to data obtained using a multi-*E. coli* microarray.\n\nMuch of the code for the visualisation, analysis and data manipulation of the fitting results is found in the associated Python module `tools.py`, which should also be present in this directory.\n\nThe model fit can be downloaded directly from the [Zenodo](https://zenodo.org) repository, for use in this notebook:\n\n[](https://doi.org/10.5281/zenodo.269638)\n\nA code cell in the notebook below will attempt to make this download for you if the file does not already exist.\n\n## Table of Contents\n\n 1. [Experiment summary and interpretation](#summary)\n 2. [Building the model](#building)\n 1. [Stan model construction](#build_stan)\n 2. [Define and fit the Stan model](#fit_stan) \n 3. [Extract the fit](#extract_stan)\n 3. [Inspecting the fit](#inspect_fit)\n 1. [Median parameter estimates](#median_estimates)\n 4. [Identifying locus tags that confer an advantage under treatment](#locus_tags)\n 1. [Plotting distribution of effects](#plot_effects)\n 2. [Identifying candidates](#candidates)\n 5. [Manuscript Figure 1](#figure_1)",
"_____no_output_____"
],
[
"## Experiment summary and interpretation <a id=\"summary\"></a>\n\nThe experiment involves measuring changes in microarray probe intensity before and after a pool of bacteria is subjected to one of two processes:\n\n1. a sample from the pool is grown in media to a defined OD, then subsampled. This growth/subsample process is repeated *n* times. [*control*]\n2. a sample from the pool is applied to plant leaves, subsampled, and that subsample grown in media to a defined OD, then subsampled. This passage/subsample/growth/subsample process is repeated *n* times. [*treatment*]\n\nIn a single replicate, the microarray is exposed to genomic DNA extracted from the pool (i) before the experiment begins, and (ii) after the experiment concludes. Three replicates are performed.\n\n<br /><div class=\"alert-success\">\n<b>All genes in all samples go through the *growth and subsampling* part of the experiment, and we wish to estimate the effect of *passage and subsampling* on individual genes.</b>\n</div>\n\nThe pool of bacteria comprises *E. coli* DH10B as a carrier organism. The pool is heterogeneous, in that individual cells also contain BACs encoding random stretches of the *E. coli* Sakai chromosome. We therefore expect carrier organism genes to be unaffected by passage (treatment), and for any effects to be detectable only for genes that originate from *E. coli* Sakai.\n\n<br /><div class=\"alert-success\">\n<b>We expect that genes conferring a phenotypic/selective advantage only for association with the plant should be enriched at the end of the treatment experiment, but not at the end of the control experiment. Sakai genes that are enriched in both treatment and control experiments may be generally advantageous for growth, but those giving a selective advantage on passage through the plant could be specifically adaptive in an environmental context.</b> \n</div>\n\n<br /><div class=\"alert-danger\">\n<b>As the BACs describe contiguous regions of the *E. coli* Sakai genome, there is the possibility that linkage disequilibrium could result in some genes that do not confer an advantage by themselves apparently displaying enrichment after treatment.</b>\n</div>\n\nIf the biological function conferring an advantage during passage is encoded by a suite of coregulated genes in an operon, we might expect all members of this suite to show evidence of enrichment after passage. It is likely that clusters of enrichment for operons or regulons post-passage will be seen in the results. Although we are not accounting for this clustering or association by operon directly in this model, it is a possible additional hierarchical term in future iterations of the model.\n\nWe should expect there to be a selective burden to the carriage of additional non-functional gDNA as BACs, so we might also anticipate a slightly negative effect on recovery under *control* conditions.",
"_____no_output_____"
],
[
"## Python imports",
"_____no_output_____"
]
],
[
[
"%pylab inline\n\nimport os\nimport pickle\nimport warnings; warnings.filterwarnings('ignore')\n\nimport numpy as np\nimport pandas as pd\nimport pystan\nimport scipy\nimport seaborn as sns; sns.set_context('notebook')\n\nfrom Bio import SeqIO\n\nimport tools",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"## Building the model <a id=\"building\"></a>\n\nWe assume that each array probe $i$ (array probes take a unique values of $i$ in the context of the entire experiment; that is, $i$ is unique for probe X replicate X treatment) measures hybridisation of genomic DNA (gDNA) in the sample that corresponds to a single gene $j[i]$, and that the measured intensity of probe $i$ relates directly to the corresponding amount of gDNA in the sample. There may be multiple probes relating to a single gene, so it is possible that $j[p] = j[q], p \\neq q$. \n\n<div class=\"alert-success\">\n<b>This establishes a basis for pooling probe-level effects as samples of the gene-level effect.</b>\n</div>",
"_____no_output_____"
],
[
"We define the (input) measurement of a probe before an experiment as $x_i$, and the (output) measurement of that probe after the experiment as $y_i$. We assume that the measurement of each probe is subject to random experimental/measurement error that is normally-distributed with mean zero and variance $\\sigma_y^2$. The actual quantity of DNA measured after the experiment can then be represented as $\\hat{y}$, and the irreducible error in this experiment as $\\epsilon$ ($\\epsilon_i$ serves to include the irreducible errors in measuring both $x_i$ and $y_i$; all errors are assumed to be Normal, so their linear combinations are also Normal).\n\n$$y_i = \\hat{y_i} + \\epsilon_i$$\n$$\\epsilon_i \\sim N(0, \\sigma_y^2) \\implies y_i \\sim N(\\hat{y_i}, \\sigma_y^2)$$\n\nThe relationship between the input and output DNA quantities measured by a single probe can be represented as $\\hat{y_i} = f(x_i)$. That is to say, that the measured input DNA quantity $x_i$ is a *predictor* of the output quantity. This relationship will be modelled as the sum of two linear effects:\n\n$$\\textrm{control effect} = \\alpha + \\beta x$$\n$$\\textrm{treatment effect} = \\gamma + \\delta x$$\n$$\\hat{y_i} = \\textrm{control effect}(x_i) + \\textrm{treatment effect}(x_i) = \\alpha + \\beta x_i + \\gamma + \\delta x_i$$\n\nAs these are linear effects, we have intercept/offset parameters ($\\alpha$, $\\gamma$) and gradient/slope parameters ($\\beta$, $\\delta$). \n\n<div class=\"alert-success\">\n<b>Where $\\beta$ or $\\delta$ are large, they would indicate large $x_i$-dependent effects of the control (growth) and treatment (passage) parts of the experiment respectively.</b>\n</div>\n\nAs formulated above, the four parameters would be identical for all probes, but we are interested in estimating the control and treatment effects for individual genes, so we require a set of parameters for each gene (as it corresponds to probe $i$): $j[i]$. This is appropriate for the effects of growth/treatment that are specific to the levels of a single gene: $\\beta$ and $\\delta$.\n\nThe remaining parameters $\\alpha$ and $\\gamma$, the offsets from zero for each probe, could be considered to be constant across each replicate of both control and treatment experiments. They are possibly more realistically considered to be different for each array (i.e. each combination of replicate and treatment).\n\n<div class=\"alert-success\">\n<b>The offset for any particular array can be hierarchically modelled as being drawn from a distribution representing all arrays, and we require one parameter for each of the arrays, so that for probe $i$ the corresponding array for that experiment is $k[i]$.</b>\n</div>",
"_____no_output_____"
],
[
"\nAs a result, we estimate $\\alpha_{k[i]}$, $\\beta_{j[i]}$, $\\gamma_{k[i]}$, $\\delta_{j[i]}$, and the relationship for each probe is modelled as:\n\n$$\\hat{y_i} = \\textrm{control effect}_{j[i]}(x_i) + \\textrm{treatment effect}_{j[i]}(x_i) = \\alpha_{k[i]} + \\beta_{j[i]} x_i + \\gamma_{k[i]} + \\delta_{j[i]} x_i$$\n\nThe parameters $\\alpha_{k[i]}$, $\\beta_{j[i]}$, $\\gamma_{k[i]}$, $\\delta_{j[i]}$ (and $\\epsilon_i$) are to be estimated by the model fit. \n\n<br /><div class=\"alert-success\">\n<b>We assume that the values of each parameter, e.g. $\\alpha_{k[i]}$, are drawn from a single *pooled distribution* for that parameter, $\\alpha \\sim \\textrm{some distribution}$.</b>\n</div>\n\nThis pooling ensures that our fits are not completely pooled as a single estimate $\\alpha_{k[i]} = \\alpha$, which would imply that all parameter estimates are constant for all genes/arrays, a situation that would be completely uninformative for our goal to identify gene-level effects, and which would *underfit* our model. It also means that our estimates are not completely unpooled, which would allow all parameter estimates to vary independently. That situation would be equivalent to simultaneously fitting independent linear relationships to each gene, and so risk *overfitting* our model to the measured data.\n",
"_____no_output_____"
],
[
"<br /><div class=\"alert-warning\">\n<b>NOTE: By using a *pooled distribution*, we allow a parameter estimate for each gene to influence the estimates of that parameter for all other genes in the experiment, constrained by an expected distribution of that parameter's values. To do this, we define a *prior distribution* for each parameter, but we do not specify its mean or variance, allowing the parameters of these *pooled distributions* also to be estimated when fitting our model.</b>\n</div>\n\nFor each parameter's *prior* we choose a Cauchy distribution, because it has fat tails and infinite variance. This does not constrain outlying and extreme values (those we are interested in) so much as other distributions (e.g. Normal or Student's *t*):\n\n$$\\alpha_{k[i]} \\sim Cauchy(\\mu_{\\alpha}, \\sigma_{\\alpha}^2)$$\n$$\\beta_{j[i]} \\sim Cauchy(\\mu_{\\beta}, \\sigma_{\\beta}^2)$$\n$$\\gamma_{k[i]} \\sim Cauchy(\\mu_{\\gamma}, \\sigma_{\\gamma}^2)$$\n$$\\delta_{j[i]} \\sim Cauchy(\\mu_{\\delta}, \\sigma_{\\delta}^2)$$\n\nEach parameter's prior distribution requires a fit of both its mean and variance, and these also become parameters in our model. The means are free to vary, but we assume that the variance of each parameter's prior can be drawn from a Uniform distribution on the range (0, 100):\n\n$$\\sigma_{\\alpha} \\sim U(0, 100)$$\n$$\\sigma_{\\beta} \\sim U(0, 100)$$\n$$\\sigma_{\\gamma} \\sim U(0, 100)$$\n$$\\sigma_{\\delta} \\sim U(0, 100)$$",
"_____no_output_____"
],
[
"<div class=\"alert-success\">\n<b>We therefore construct the following model of the experiment:</b>\n\n$$\\hat{y_i} = \\alpha_{k[i]} + \\beta_{j[i]} x_i + \\gamma_{k[i]} t_i + \\delta_{j[i]} t_i x_i$$\n$$y_i \\sim N(\\hat{y_i}, \\sigma_y^2)$$\n$$\\alpha_{k[i]} \\sim Cauchy(\\mu_{\\alpha}, \\sigma_{\\alpha}^2)$$\n$$\\beta_{j[i]} \\sim Cauchy(\\mu_{\\beta}, \\sigma_{\\beta}^2)$$\n$$\\gamma_{k[i]} \\sim Cauchy(\\mu_{\\gamma}, \\sigma_{\\gamma}^2)$$\n$$\\delta_{j[i]} \\sim Cauchy(\\mu_{\\delta}, \\sigma_{\\delta}^2)$$\n$$\\sigma_{\\alpha} \\sim U(0, 100)$$\n$$\\sigma_{\\beta} \\sim U(0, 100)$$\n$$\\sigma_{\\gamma} \\sim U(0, 100)$$\n$$\\sigma_{\\delta} \\sim U(0, 100)$$\n$$\\sigma_y \\sim U(0, \\infty)$$\n\n<ul>\n<li> $y_i$: measured intensity output on the array for probe $i$ (specific to each replicate)\n<li> $\\hat{y_i}$: actual probe intensity for probe $i$ (specific to each replicate)\n<li> $x_i$: measured intensity input on the array for probe $i$ (specific to each replicate)\n<li> $t_i$: 0/1 pseudovariable indicating whether the probe $i$ was measured in a control (0) or treatment (1) experiment\n<li> $\\alpha_{k[i]}$: control effect offset for treatment X replicate $k$ (used for probe $i$)\n<li> $\\mu_{\\alpha}$: mean control effect offset for all arrays\n<li> $\\sigma_{\\alpha}$: control effect offset variance for all arrays\n<li> $\\beta_{j[i]}$: control effect slope for gene $[j[i]$\n<li> $\\mu_{\\beta}$: mean control effect slope for all genes\n<li> $\\sigma_{\\beta}$: control effect slope variance for all genes\n<li> $\\gamma_{k[i]}$: treatment effect offset for treatment X replicate $k$ (used for probe $i$)\n<li> $\\mu_{\\gamma}$: mean treatment effect offset for all arrays\n<li> $\\sigma_{\\gamma}$: treatment effect offset variance for all arrays\n<li> $\\delta_{j[i]}$: treatment effect slope for gene $j[i]$\n<li> $\\mu_{\\delta}$: mean treatment effect slope for all genes\n<li> $\\sigma_{\\delta}$: treatment effect slope variance for all genes\n<li> $\\sigma_y$: variance in measurement due to irreducible error\n</ul>\n</div>",
"_____no_output_____"
],
[
"### Load input data for fit\n\nIn the cells below we load in the data to be fit, and define useful variables for inspecting/analysing the data later:\n\n* `locus_tags`: the unique locus tags represented in the dataset\n* `ntags`: the number of unique locus tags\n* `arrays`: the arrays (combinations of replicate X treatment) used in the experiment\n* `narrays`: the number of arrays used\n* `outdir`: path to the directory in which to place model fit output\n* `outfile`: path to the model fit output file (pickled dataframe)",
"_____no_output_____"
]
],
[
[
"# load clean, normalised, indexed data\ndata = pd.read_csv(os.path.join(\"datasets\", \"normalised_array_data.tab\"), sep=\"\\t\") # full dataset\n#data = pd.read_csv(\"datasets/reduced_locus_data.tab\", sep=\"\\t\") # reduced dataset\n#data = data[:100] # uncomment this for debugging\n\n# useful values\nlocus_tags = data['locus_tag'].unique()\nntags = len(locus_tags)\narrays = data['repXtrt'].unique()\nnarrays = len(arrays)",
"_____no_output_____"
],
[
"# Create output directory and filename to hold the fitted model\noutdir = \"model_fits\"\nos.makedirs(outdir, exist_ok=True)\noutfile = os.path.join(outdir, 'full_model_fit.pkl')",
"_____no_output_____"
]
],
[
[
"### Stan model construction <a id=\"build_stan\"></a>\n\nWe need to define `data`, `parameters` and our `model` for [`Stan`](http://mc-stan.org/).\n\n<div class=\"alert-success\">\nIn the `data` block, we have:\n\n<ul>\n<li> `N`: `int`, the number of data points\n<li> `J`: `int`, the number of unique locus tags (`J` < `N`)\n<li> `K`: `int`, the number of unique treatment X replicate combinations (arrays)\n<li> `array`: `int[N]`, an index list of arrays\n<li> `tag`: `int[N]`, an index list of locus tags\n<li> `t`: `vector[N]`, 0/1 control/treatment values for each probe\n<li> `x`: `vector[N]`, the input log(intensity) values\n<li> `y`: `vector[N]`, the output log(intensity) values\n</ul>\n\nIn the `parameter` block, we have:\n\n<ul>\n<li> `a`: `real vector[K]`, estimated offset effect on log(intensity) of the *control* for each array\n<li> `mu_a`: `real`, an unconstrained value to be fit that represents the mean of the Cauchy distribution for the *control* effect offset, for all arrays\n<li> `sigma_a`: `real<lower=0,upper=100>`, standard deviation of the Cauchy distribution for the *control* effect offset, for all arrays\n<li> `b`: `real vector[J]`, estimated slope effect on log(intensity) of the *control* for each locus tag/gene\n<li> `mu_b`: `real`, an unconstrained value to be fit that represents the mean of the Cauchy distribution for the *control* effect slope, for all locus tags\n<li> `sigma_b`: `real<lower=0,upper=100>`, standard deviation of the Cauchy distribution for the *control* effect slope, for all locus tags\n<li> `g`: `real vector[K]`, estimate of the influence of treatment on the output measured intensity (offset) for array\n<li> `mu_g`: `real`, an unconstrained value to be fit that represents the mean of the Cauchy distribution for the offset for all arrays due to *treatment*\n<li> `sigma_g`: `real<lower=0,upper=100>`, standard deviation of the Cauchy distribution for the offset for all arrays due to *treatment*\n<li> `d`: `real vector[J]`, estimate of the influence of treatment on the output measured intensity (slope) for each locus tag/gene\n<li> `mu_d`: `real`, an unconstrained value to be fit that represents the mean of the Cauchy distribution for the slope for all locus tags due to *treatment*\n<li> `sigma_d`: `real<lower=0,upper=100>`, standard deviation of the Cauchy distribution for the slope for all locus tags due to *treatment*\n<li> `sigma`: `real<lower=0>`, the irreducible error in the experiment/model\n</ul>\n\nWe also define a `transformed parameter`:\n\n<ul>\n<li> `y_hat[i] <- b[tag[i]] * x[i] + a[array[i]] + g[tag[i]] * t[i] + d[array[i]] * t[i] * x[i]`: the linear relationship describing $\\hat{y}$, our estimate of experimental output intensity, which is subject to variance `sigma`.\n</ul>\n</div>",
"_____no_output_____"
],
[
"### Define and fit the Stan model <a id=\"fit_stan\"></a>\n\nIn the cells below we define the model to be fit, in the Stan language, conduct the fit, and save the fit out to a pickled dataframe (or load it in from one, depending on which code is commented out).",
"_____no_output_____"
]
],
[
[
"# define unpooled stan model\ntreatment_model = \"\"\"\ndata {\n int<lower=0> N;\n int<lower=0> J;\n int<lower=0> K; \n int<lower=1, upper=J> tag[N];\n int<lower=1, upper=K> array[N]; \n vector[N] t;\n vector[N] x;\n vector[N] y;\n}\nparameters {\n vector[K] a;\n vector[J] b;\n vector[K] g;\n vector[J] d;\n real mu_a;\n real mu_b;\n real mu_g;\n real mu_d;\n real<lower=0> sigma;\n real<lower=0,upper=100> sigma_a;\n real<lower=0,upper=100> sigma_b;\n real<lower=0,upper=100> sigma_g;\n real<lower=0,upper=100> sigma_d;\n}\ntransformed parameters{\n vector[N] y_hat;\n\n for (i in 1:N)\n y_hat[i] = a[array[i]] + b[tag[i]] * x[i] + g[array[i]] * t[i] + d[tag[i]] * t[i] * x[i];\n}\nmodel {\n sigma_a ~ uniform(0, 100);\n a ~ cauchy(mu_a, sigma_a);\n\n sigma_b ~ uniform(0, 100);\n b ~ cauchy(mu_b, sigma_b);\n\n sigma_g ~ uniform(0, 100);\n g ~ cauchy(mu_g, sigma_g);\n\n sigma_d ~ uniform(0, 100);\n d ~ cauchy(mu_d, sigma_d);\n\n y ~ normal(y_hat, sigma);\n}\n\"\"\"",
"_____no_output_____"
],
[
"# relate python variables to stan variables\ntreatment_data_dict = {'N': len(data),\n 'J': ntags,\n 'K': narrays,\n 'tag': data['locus_tag_index'] + 1,\n 'array': data['repXtrt_index'] + 1,\n 't': data['treatment'],\n 'x': data['log_input'],\n 'y': data['log_output']}",
"_____no_output_____"
]
],
[
[
"<div class=\"alert-danger\">\n<b>At this point, you have two options to obtain the model fit data</b>\n</div>\n\n1. Run the model fit 'live' in the notebook. This may take several hours. **USE CELL (1)**\n 1. (optionally) save the newly-generated model fit to a local file. **USE CELL (2)**\n2. Load the model fit from a local file. **USE CELL (4)**\n 1. If you have not generated the data locally, then you can download it from Zenodo **USE CELL (3) FIRST**.\n \nIt may be quicker to download the data from Zenodo using the button below, than to use cell (3), but be sure to place the downloaded file in the correct location as specified in the variable `outfile`.\n\n[](https://doi.org/10.5281/zenodo.269638)",
"_____no_output_____"
]
],
[
[
"# (1) USE THIS CELL TO RUN THE STAN FIT - takes a few hours on my laptop\n#treatment_fit = pystan.stan(model_code=treatment_model,\n# data=treatment_data_dict,\n# iter=1000, chains=2,\n# seed=tools.SEED)",
"_____no_output_____"
],
[
"# (2) USE THIS CELL TO SAVE THE STAN FIT TO A PICKLE FILE\n#unpermutedChains = treatment_fit.extract()\n#unpermutedChains_df = pd.DataFrame([dict(unpermutedChains)])\n#pickle.dump(unpermutedChains_df, open(outfile, 'wb'))",
"_____no_output_____"
],
[
"# (3) USE THIS CELL TO DOWNLOAD THE STAN FIT FROM ZENODO: DOI:10.5281/zenodo.269638\n# The file will not be downloaded if it already exists locally.\n# The file is 0.5GB in size, so may take some time to download\nimport urllib.request\nif not os.path.isfile(outfile):\n zenodo_url = \"https://zenodo.org/record/269638/files/full_model_fit.pkl\"\n response = urllib.request.urlretrieve(zenodo_url, outfile)",
"_____no_output_____"
],
[
"# (4) USE THIS CELL TO LOAD THE STAN FIT FROM A PICKLE FILE\n# Import the previously-fit model\ntreatment_fit = pd.read_pickle(open(outfile, 'rb'))",
"_____no_output_____"
]
],
[
[
"### Extract the fit <a id=\"extract_stan\"></a>\n\n<br /><div class=\"alert-warning\">\n<b>In the cells below we load in the contents of the pickled output (if the fit has already been run), and then extract useful summary information about mean, median, variance, and credibility intervals for the parameter estimates.</b>\n</div>\n\n<div class=\"alert-success\">\n<ul>\n<li> parameters $\\alpha$, $\\beta$, $\\gamma$ and $\\delta$ are represented by their Roman letter equivalents `a`, `b`, `g` and `d`.\n<li> `*_mean` and `*_median` are the mean and median estimates for the parameter over the ensemble\n<li> `*_sem` is the standard deviation for the parameter estimate over the ensemble\n<li> `*_Npc` is the *N*th percentile for the parameter estimate, over the ensemble. These can be combined to obtain credibility intervals (e.g. the range `a_25pc`..`a_75pc` constitutes the 50% CI for $\\alpha_{j[i]}$.\n</div>",
"_____no_output_____"
]
],
[
[
"# Get summary data for parameter estimates\n# use 'fit' for the model fit directly, and 'df'for loaded pickled data\n(estimates_by_probe, estimates) = tools.extract_variable_summaries(treatment_fit, 'df',\n ['a', 'b', 'g', 'd'],\n [arrays, locus_tags, arrays, locus_tags],\n data)",
"_____no_output_____"
],
[
"# Inspect the data, one row per experiment probe\nestimates_by_probe.head()",
"_____no_output_____"
],
[
"# Inspect the data, one row per locus tag\nestimates.head()",
"_____no_output_____"
],
[
"# Separate estimates for Sakai and DH10B into two different dataframes\nsakai_estimates = tools.split_estimates(estimates, 'sakai')\ndh10b_estimates = tools.split_estimates(estimates, 'dh10b')",
"_____no_output_____"
]
],
[
[
"## Inspecting the fit <a id=\"inspect_fit\"></a>\n\nIn the cells below, we visualise the fitted estimates for each of the parameters $\\alpha$, $\\beta$, $\\gamma$, and $\\delta$ as:\n\n* box plots of median estimates for each locus tag\n* relationship between control and treatment effects in Sakai\n* plots of 50% credibility interval range and median estimate for each locus tag to identify locus tags with a possible selective advantage",
"_____no_output_____"
],
[
"### Median parameter estimates <a id=\"median_estimates\"></a>\n\nWe first inspect the range of fitted estimates to get an overview of the relationships for the data as a whole, and then examine whether this relationship varies by *E. coli* isolate.\n\nMaking boxplots for the full set of fitted parameter estimates, for both isolates:",
"_____no_output_____"
]
],
[
[
"# Visualise median values for parameter estimates of alpha and gamma\ntools.boxplot_medians(estimates_by_probe, ['a', 'g'])",
"_____no_output_____"
],
[
"# Visualise median values for parameter estimates of beta and delta\ntools.boxplot_medians(estimates, ['b', 'd'])",
"_____no_output_____"
]
],
[
[
"<div class=\"alert-success\">\nFor this fit we can see that the estimates are all, in the main, tightly-distributed. Most estimated (median) values of $\\alpha$ (control intercept), $\\gamma$ (treatment intercept), and $\\delta$ (treatment slope) are close to zero. Most estimated values of $\\beta$ are close to (but slightly less than) unity. \n\n<b>This implies that:</b>\n\n<ul>\n<li> <b>The linear relationship between input and output intensity due to the control effects (growth only) is, for most genes in the experiment, a slight reduction of output intensity with respect to input intensity value, and on the whole the effect of the control/growth is neutral [median $\\alpha$ ≈ 0, median $\\beta$ ≈ 1]</b>\n<li> <b>For most genes in the experiment there is no treatment effect due to exposure to the plant [median $\\gamma$ ≈ 0, median $\\delta$ ≈ 0]</b>\n</ul>\n</div>\n\n<br /><div class=\"alert-warning\">\n<b>There are, however, a considerable number of outlying median values for each parameter, which suggests that a number of genes have associated parameter values that are affected by either control (growth) or treatment (passage).</b>\n</div>",
"_____no_output_____"
],
[
"#### DH10B\n\nConsidering boxplots of estimated $\\beta_{j[i]}$ and $\\delta_{j[i]}$ for the DH10B (carrier) isolate only:",
"_____no_output_____"
]
],
[
[
"# Visualise median values for Sakai parameter estimates\ntools.boxplot_medians(dh10b_estimates, ['b', 'd'])",
"_____no_output_____"
]
],
[
[
"it is clear that the median parameter estimates for DH10B are extremely restricted in their range:\n\n* $0.93 < \\beta < 0.98$\n* $-0.065 < \\delta < 0.045$\n\n<div class=\"alert-success\">\nThe control effect appears to be essentially *neutral*, in that the output intensity is almost a 1:1 linear relationship with the input intensity, but it is striking that the median estimates of $\\gamma$ and $\\delta$ are very close to zero, suggesting that passage (treatment) has almost no effect on this relationship, for any DH10B locus tag.\n\n<b>This is exactly what would be expected for DH10B as the carrier isolate.</b>\n</div>",
"_____no_output_____"
],
[
"#### Sakai\n\nConsidering the Sakai isolate parameter estimates for $\\beta_{j[i]}$ and $\\gamma_{j[i]}$ only:",
"_____no_output_____"
]
],
[
[
"# Visualise median values for Sakai parameter estimates\ntools.boxplot_medians(sakai_estimates, ['b', 'd'])",
"_____no_output_____"
]
],
[
[
"By contrast to the results for DH10B, the median parameter estimates for Sakai have many large value outliers, though the bulk of estimates are close to the values seen for DH10B:\n\n* $0.2 < \\beta < 1.4$\n* $-1.5 < \\delta < 0.5$\n\n<div class=\"alert-success\">\nThis indicates that we see the expected result, that strong variability of control and treatment effects are effectively confined to the Sakai BAC fragments.\n\n<b>It is expected that some genes/operons may be relatively advantageous in either growth (control) or passage (treatment) conditions, or both.</b>\n</div>",
"_____no_output_____"
],
[
"We can visualise the relationships between parameter estimates for control and treatment effects in a scatterplot of control effect ($\\beta$) against treatment effect ($\\delta) for each locus tag. This plot can be considered in four quadrants, which are delineated by the bulk of the data which describes orthogonal effects of locus tags on growth and treatment:\n\n<br /><div class=\"alert-success\">\n<b>(i.e. for most locus tags, there is *either* an effect on treatment or control, but *not both*)</b>\n</div>\n\n* (upper left) positive effect on growth, negative effect for treatment: may be related to ability to use growth medium more efficiently\n* (upper right) positive effect on both growth and treatment: no locus tags display this characteristic\n* (lower right) positive effect on treatment, negative effect for control: may be related to ability to use/exploit the plant, that is suppressive in the medium\n* (lower left) negative effect on both growth and treatment: most locus tags that display an interaction lie in this group",
"_____no_output_____"
]
],
[
[
"# Plot estimated parameters for treatment effects against control effects for Sakai\nfig, ax = plt.subplots(1, 1, figsize=(6,6))\nax.scatter(sakai_estimates['d_median'], sakai_estimates['b_median'], alpha=0.2)\nax.set_xlabel('delta (median)')\nax.set_ylabel('beta (median)');",
"_____no_output_____"
]
],
[
[
"<br /><div class=\"alert-warning\">\nThe strong cross-like distribution indicates that most parameter estimates of $\\beta$ or $\\delta$ that vary from those of the bulk do so orthogonally in either *treatment* or *control* conditions, but not both. \n<br /><br />\n<b>Where Sakai genes have an estimated effect under both conditions, this is typically negative for both treatment and control (lower left quadrant).</b>\n</div>",
"_____no_output_____"
],
[
"## Identifying locus tags that confer an advantage under treatment and/or control <a id=\"locus_tags\"></a>\n\nWe use a 50% credibility interval to determine whether the effect of a gene on passage is likely to be positive. Under this assumption, we identify locus tags for which the median estimate of $\\delta$ is positive, and the central 50% of the parameter estimates for $\\delta$ (the 50% credibility interval) does not include zero. We label these locus tags as `trt_pos` in the dataframe.\n\n<br /><div class=\"alert-success\">\nThese locus tags correspond to the genes that we should believe confer a selective advantage in passage/*treatment* (i.e. we require our estimate to be credibly positive). \n</div>\n\nLikewise, we use a 50% credibility interval to determine whether the effect of a gene on surviving growth (control) is positive. If the 50% CI for $\\beta$ does not include the 97.5 percentile for all estimates of $\\beta$ (as an upper estimate of overall dataset centrality for this dataset), and the median value of $\\beta$ is greater than this value, we consider that the effect of the gene on surviving growth conditions is positive. We label these locus tags as `ctl_pos` in the dataframe.",
"_____no_output_____"
]
],
[
[
"# Label locus tags with positive effects for control and treatment\nsakai_estimates = tools.label_positive_effects(sakai_estimates)",
"_____no_output_____"
]
],
[
[
"We can count the number of locus_tags in each of the groups:",
"_____no_output_____"
]
],
[
[
"# Count locus tags in each of the positive groups\ncounts = [sum(sakai_estimates[col]) for col in ('trt_pos', 'ctl_pos', 'combined')]\nprint(\"treatment positive: {0}\\ncontrol positive: {1}\\nboth: {2}\".format(*counts))",
"treatment positive: 115\ncontrol positive: 65\nboth: 0\n"
]
],
[
[
"which indicates, with these assumptions, that:\n\n<div class=\"alert-success\">\n<ul>\n<b>\n<li> 115 genes have a credible positive effect on passage (treatment)\n<li> 65 genes have a credible positive effect in the growth (control) step\n<li> no genes have a credible positive effect for both growth and treatment.\n</b>\n</ul>\n</div>\n\n(this confirms our observation in the earlier scatterplot)",
"_____no_output_____"
],
[
"### Plotting distribution of effects on the Sakai genome <a id=\"plot_effects\"></a>\n\nWe can show the estimated effects, and our confidence in those estimates, on a rough representation of the genome by plotting those values for each locus tag, sorted in order on the genome.\n\nIn the plots that follow, parameter estimates for each locus tag are rendered as points (the median estimate), with the 50% credibility interval for the estimate indicated as a vertical line. If the 50% CI includes a threshold value - the median value for the bulk parameter estimate of $\\beta$ or $\\delta$ - then we consider that there is not strong evidence of an effect on survival due to that gene (compared to the bulk), and the interval is coloured blue.\n\nIf the interval does not include the corresponding threshold value, then it is coloured either green for a *positive* effect, or magenta for a *negative* effect.",
"_____no_output_____"
],
[
"#### Sakai",
"_____no_output_____"
],
[
"We split the Sakai estimates into groups: one for the chromosome, and one for each plasmid pOSAK and pO157, on the basis of the locus tag prefixes, annotating them with their start position on the parent molecule.",
"_____no_output_____"
]
],
[
[
"sakai_chromosome = sakai_estimates.loc[sakai_estimates['locus_tag'].str.startswith('ECs')]\nsakai_pOSAK = sakai_estimates.loc[sakai_estimates['locus_tag'].str.startswith('pOSAK1')]\nsakai_pO157 = sakai_estimates.loc[(sakai_estimates['locus_tag'].str.startswith('pO157')) |\n (sakai_estimates['locus_tag'].str.startswith('ECp'))]",
"_____no_output_____"
],
[
"# Sakai chromosome\nsakai_chromosome_annotated = tools.annotate_locus_tags(sakai_chromosome,\n os.path.join('..', 'data', 'Sakai',\n 'GCF_000008865.1_ASM886v1_genomic.gbff'))\nsakai_chromosome_annotated.sort_values('startpos', inplace=True)\n#sakai_chromosome_annotated.head(15)",
"_____no_output_____"
],
[
"# pOSAK1\nsakai_pOSAK_annotated = tools.annotate_locus_tags(sakai_pOSAK,\n os.path.join('..', 'data', 'Sakai',\n 'GCF_000008865.1_ASM886v1_genomic.gbff'))\nsakai_pOSAK_annotated.sort_values('startpos', inplace=True)\n#sakai_pOSAK_annotated.head(15)",
"_____no_output_____"
],
[
"# pECp\nsakai_pO157_annotated = tools.annotate_locus_tags(sakai_pO157,\n os.path.join('..', 'data', 'Sakai',\n 'GCF_000008865.1_ASM886v1_genomic.gbff'))\nsakai_pO157_annotated.sort_values('startpos', inplace=True)\n#sakai_pO157_annotated.head(15)",
"_____no_output_____"
],
[
"# Regions of interest\nregions = [('S-loop 71', 'ECs1276', 'ECs1288', 1.3),\n ('SpLE1', 'ECs1299', 'ECs1410', 1.5),\n ('S-loop 225', 'ECs4325', 'ECs4341', 1.5),\n ('S-loop 231', 'ECs4379', 'ECs4387', 1.3)]\nannotations = {k:(tools.get_lt_index(v0, sakai_chromosome_annotated),\n tools.get_lt_index(v1, sakai_chromosome_annotated), v2) for\n k, v0, v1, v2 in regions}",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of beta for Sakai and mark values that don't include the median beta in 50% CI\nbeta_thresh = np.median(sakai_chromosome_annotated['b_median']) \n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of beta for Sakai chromosome'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\n# Plot on the figure axes\ntools.plot_parameter(sakai_chromosome_annotated, ax, 'b', beta_thresh, annotations=annotations);",
"_____no_output_____"
],
[
"# Regions of interest\nregions = [('S-loop 71', 'ECs1276', 'ECs1288', 1),\n ('SpLE1', 'ECs1299', 'ECs1410', 1.8),\n ('S-loop 225', 'ECs4325', 'ECs4341', 1.8),\n ('S-loop 231', 'ECs4379', 'ECs4387', 1)]\nannotations = {k:(tools.get_lt_index(v0, sakai_chromosome_annotated),\n tools.get_lt_index(v1, sakai_chromosome_annotated), v2) for\n k, v0, v1, v2 in regions}",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of delta for Sakai and mark values that don't include zero in 50%CI\ndelta_thresh = np.median(sakai_chromosome_annotated['d_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of delta for Sakai chromosome'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, delta_thresh))\n\ntools.plot_parameter(sakai_chromosome_annotated, ax, 'd', delta_thresh, annotations=annotations)",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of beta for Sakai and mark values that don't include the median beta in 50% CI\nbeta_thresh = np.median(sakai_pOSAK_annotated['b_median']) \n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of beta for Sakai plasmid pOSAK'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(sakai_pOSAK_annotated, ax, 'b', beta_thresh)",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of delta for Sakai and mark values that don't include zero in 50% CI\ndelta_thresh = np.median(sakai_pOSAK_annotated['d_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of delta for Sakai plasmid pOSAK'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(sakai_pOSAK_annotated, ax, 'd', delta_thresh)",
"_____no_output_____"
],
[
"# Regions of interest\nregions = [('StcE', 'pO157p01', 'pO157p01', 0.98),\n ('etp T2SS', 'pO157p02', 'pO157p14', 1)]\nannotations = {k:(tools.get_lt_index(v0, sakai_pO157_annotated),\n tools.get_lt_index(v1, sakai_pO157_annotated), v2) for\n k, v0, v1, v2 in regions}",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of beta for Sakai and mark values that don't include the median beta in 50% CI\nbeta_thresh = np.median(sakai_pO157_annotated['b_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of beta for Sakai plasmid p0157'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(sakai_pO157_annotated, ax, 'b', beta_thresh, annotations=annotations)",
"_____no_output_____"
],
[
"# Regions of interest\nregions = [('StcE', 'pO157p01', 'pO157p01', 0.13),\n ('etp T2SS', 'pO157p02', 'pO157p14', 0.19)]\nannotations = {k:(tools.get_lt_index(v0, sakai_pO157_annotated),\n tools.get_lt_index(v1, sakai_pO157_annotated), v2) for\n k, v0, v1, v2 in regions}",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of delta for Sakai and mark values that don't include zero in 50% CI\ndelta_thresh = np.median(sakai_pO157_annotated['d_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of delta for Sakai plasmid pO157'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(sakai_pO157_annotated, ax, 'd', delta_thresh, annotations=annotations)",
"_____no_output_____"
]
],
[
[
"<div class=\"alert-success\">\nThese plots indicate that most Sakai genes do not produce parameter estimates that are indicative of credible effects in the control or treatment, in either direction.\n<br /><br />\nWhere effects are seen they tend to cluster on the genome, which is as would be expected if operons or gene clusters with common function were responsible for producing an effect. This is suggestive that we are measuring a biological effect, rather than noise.\n<br /><br />\n<b>In general, several clusters of both positive and negative effects appear in the chromosome and pO157 plots for effects due to control ($\\beta$) and treatment ($\\delta$).</b>\n</div>",
"_____no_output_____"
],
[
"#### DH10B\n\nWe plot similar representations for the DH10B isolate as a control, and see that all parameter estimates for this isolate's locus tags are very similar.\n\n<br /><div class=\"alert-warning\">\nThere is a weak sinusoidal pattern of fitted estimates. As no gene ordering information is available to the model fit, and there is an apparent symmetry to this pattern, it may reflect a real underlying biological process or structure.\n</div>",
"_____no_output_____"
]
],
[
[
"# Annotate the DH10B results\ndh10b_annotated = tools.annotate_locus_tags(dh10b_estimates,\n os.path.join('..', 'data', 'DH10B',\n 'GCF_000019425.1_ASM1942v1_genomic.gbff'))\ndh10b_annotated.sort_values('startpos', inplace=True)",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of beta for DH10B\nbeta_thresh = np.median(dh10b_estimates['b_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of beta for DH10B', \nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(dh10b_estimates, ax, 'b', beta_thresh)",
"_____no_output_____"
],
[
"# Plot genome-wide estimates of delta for DH10B\ndelta_thresh = np.median(dh10b_estimates['d_median'])\n\n# Create figure with title to hold the plotted axis\nfig = plt.figure(figsize=(20, 8)) \nax = fig.add_subplot(1, 1, 1)\ntitle = 'Estimates of delta for DH10B'\nplt.title(\"{0} [threshold: {1:.2f}]\".format(title, beta_thresh))\n\ntools.plot_parameter(dh10b_estimates, ax, 'd', delta_thresh)",
"_____no_output_____"
]
],
[
[
"### Identifying Sakai candidates <a id=\"candidates\"></a>\n\nFrom the information above, we can list the 180 Sakai genes/locus tags that appear to impart a positive selective effect on treatment/passage (the green points/bars in the plots immediately above).",
"_____no_output_____"
]
],
[
[
"# Generate list of candidates with a positive effect under control or treatment.\ncandidates = sakai_estimates[sakai_estimates['ctl_pos'] | sakai_estimates['trt_pos']]\ncandidates = candidates[['locus_tag',\n 'b_median', 'ctl_pos',\n 'd_median', 'trt_pos']].sort_values(['ctl_pos', 'trt_pos', 'locus_tag'])\ncandidates.shape",
"_____no_output_____"
],
[
"# Inspect the data\ncandidates.head()",
"_____no_output_____"
]
],
[
[
"We restrict this set to those genes that only have a credible effect on treatment/passage, identifying 115 genes with positive $\\delta$ where the 50% CI does not include zero:",
"_____no_output_____"
]
],
[
[
"# Restrict candidates only to those with an effect on treatment/passage.\ntrt_only_positive = candidates.loc[candidates['trt_pos'] & ~candidates['ctl_pos']]\ntrt_only_positive.shape",
"_____no_output_____"
]
],
[
[
"We add a column with the functional annotation of each of the candidates that appear to have a positive selective effect under treatment conditions:",
"_____no_output_____"
]
],
[
[
"# Annotated locus tags with functions from NCBI GenBank files\nannotated = tools.annotate_locus_tags(trt_only_positive,\n os.path.join('..', 'data', 'Sakai',\n 'GCF_000008865.1_ASM886v1_genomic.gbff'))\npd.options.display.max_rows = 115 # force to show all rows\nannotated",
"_____no_output_____"
]
],
[
[
"Finally, we write this data out in tab-separated format",
"_____no_output_____"
]
],
[
[
"# Write data to file in tab-separated format\noutfile_annotated = os.path.join('datasets', 'trt_positive.tab')\nannotated.to_csv(outfile_annotated, sep=\"\\t\")",
"_____no_output_____"
]
],
[
[
"<a id=\"figure_1\"></a>\n## Manuscript Figure 1\n\nThe code in the cell below will reproduce figure 1 from the manuscript.",
"_____no_output_____"
]
],
[
[
"# Create figure with no title or xticks to hold the plotted axes\nfig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(20, 26)) \n\n# Add subplot for each result\n\n# 1) Sakai chromosome\nregions = [('S-loop 71', 'ECs1276', 'ECs1288', 1),\n ('SpLE1', 'ECs1299', 'ECs1410', 1.8),\n ('S-loop 225', 'ECs4325', 'ECs4341', 1.8),\n ('S-loop 231', 'ECs4379', 'ECs4387', 1)]\nannotations = {k:(tools.get_lt_index(v0, sakai_chromosome_annotated),\n tools.get_lt_index(v1, sakai_chromosome_annotated), v2) for\n k, v0, v1, v2 in regions}\ndelta_thresh = np.median(sakai_chromosome_annotated['d_median'])\ntools.plot_parameter(sakai_chromosome_annotated, ax1, 'd', delta_thresh, annotations=annotations,\n label=\"a) Sakai chromosome\")\n\n# 2) pO157 plasmid\nregions = [('StcE', 'pO157p01', 'pO157p01', 0.13),\n ('etp T2SS', 'pO157p02', 'pO157p14', 0.19)]\nannotations = {k:(tools.get_lt_index(v0, sakai_pO157_annotated),\n tools.get_lt_index(v1, sakai_pO157_annotated), v2) for\n k, v0, v1, v2 in regions}\ndelta_thresh = np.median(sakai_pO157_annotated['d_median'])\ntools.plot_parameter(sakai_pO157_annotated, ax2, 'd', delta_thresh, annotations=annotations,\n label=\"b) Sakai pO157\")\n\n# 3) DH10B chromosome\ndelta_thresh = np.median(dh10b_estimates['d_median'])\ntools.plot_parameter(dh10b_estimates, ax3, 'd', delta_thresh, label=\"c) DH10B chromosome\")\n\n# Save figure as pdf\nplt.savefig(\"figure_1.pdf\");",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad23b1b2f560697701077902a7c7213e1dea58c
| 86,032 |
ipynb
|
Jupyter Notebook
|
Emotion Detection Through Facial Recognition Using CNN.ipynb
|
AbdullahKhan47/Deep-Learning-with-Python
|
a2dee855ce7c97f742451d545ed9e71f46224fc0
|
[
"MIT"
] | 2 |
2021-03-20T08:09:07.000Z
|
2021-03-20T08:09:56.000Z
|
Emotion Detection Through Facial Recognition Using CNN.ipynb
|
AbdullahKhan47/Deep-Learning-with-Python
|
a2dee855ce7c97f742451d545ed9e71f46224fc0
|
[
"MIT"
] | null | null | null |
Emotion Detection Through Facial Recognition Using CNN.ipynb
|
AbdullahKhan47/Deep-Learning-with-Python
|
a2dee855ce7c97f742451d545ed9e71f46224fc0
|
[
"MIT"
] | 1 |
2021-03-20T09:37:02.000Z
|
2021-03-20T09:37:02.000Z
| 47.795556 | 12,036 | 0.585736 |
[
[
[
"import pandas as pd\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"expression_df=pd.read_csv(\"C:/Users/user/Desktop/New folder/icml_face_data.csv\")",
"_____no_output_____"
],
[
"expression_df.head()",
"_____no_output_____"
],
[
"expression_df[' Usage'].unique()",
"_____no_output_____"
],
[
"expression_df['emotion'].unique()",
"_____no_output_____"
],
[
"import collections",
"_____no_output_____"
],
[
"collections.Counter(np.array(expression_df['emotion']))",
"_____no_output_____"
],
[
"expression_df[' pixels'][0]",
"_____no_output_____"
],
[
"img=expression_df[' pixels'][920]",
"_____no_output_____"
],
[
"img=np.array(img.split(' ')).reshape(48,48,1).astype('float32')",
"_____no_output_____"
],
[
"img.shape",
"_____no_output_____"
],
[
"plt.imshow(img.squeeze(),cmap='gray')",
"_____no_output_____"
],
[
"images_list=np.zeros((len(expression_df),48,48,1))",
"_____no_output_____"
],
[
"images_list.shape",
"_____no_output_____"
],
[
"images_label=pd.get_dummies(expression_df['emotion'])",
"_____no_output_____"
],
[
"images_label",
"_____no_output_____"
],
[
"for idx in range(len(expression_df)):\n single_pic=np.array(expression_df[' pixels'][idx].split(' ')).reshape(48,48,1)\n images_list[idx]=single_pic",
"_____no_output_____"
],
[
"images_list.shape",
"_____no_output_____"
],
[
"images_list[35886].shape",
"_____no_output_____"
],
[
"expression_df['emotion'].value_counts()",
"_____no_output_____"
],
[
"expression_df['emotion'].value_counts().index",
"_____no_output_____"
],
[
"import seaborn as sns\nsns.barplot(x=expression_df['emotion'].value_counts().index,y=expression_df['emotion'].value_counts())\nplt.title('Number of images per emotion')",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train,X_Test,y_train,y_Test=train_test_split(images_list,images_label,test_size=0.20,shuffle=True)\nX_val,X_Test,y_val,y_Test=train_test_split(X_Test,y_Test,test_size=0.5, shuffle=True)",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"X_Test.shape",
"_____no_output_____"
],
[
"X_val.shape",
"_____no_output_____"
],
[
"X_train",
"_____no_output_____"
]
],
[
[
"# Normalizing",
"_____no_output_____"
]
],
[
[
"X_train=X_train/255\nX_val=X_val/255\nX_Test=X_Test/255",
"_____no_output_____"
],
[
"from keras.preprocessing.image import ImageDataGenerator\ndatagen=ImageDataGenerator(\n featurewise_center=False,\n samplewise_std_normalization=False,\n zca_whitening=False,\n featurewise_std_normalization=True,\n rotation_range=30,\n width_shift_range=0.1,\n height_shift_range=0.1,\n zoom_range=0.2)\n\ndatagen.fit(X_train)",
"Using TensorFlow backend.\nC:\\Users\\user\\AppData\\Roaming\\Python\\Python37\\site-packages\\keras_preprocessing\\image\\image_data_generator.py:348: UserWarning: This ImageDataGenerator specifies `featurewise_std_normalization`, which overrides setting of `featurewise_center`.\n warnings.warn('This ImageDataGenerator specifies '\n"
],
[
"input_reshape=(48,48,1)\nepochs=10\nbatch_size=128\nhidden_num_units=256\noutput_num_units=7",
"_____no_output_____"
],
[
"pool_size=(2,2)",
"_____no_output_____"
],
[
"import tensorflow.keras as keras",
"_____no_output_____"
],
[
"from tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense, Activation, Dropout,Convolution2D,Flatten,MaxPooling2D, Reshape,InputLayer\nfrom keras.layers.normalization import BatchNormalization\nfrom tensorflow.keras.preprocessing.image import load_img",
"_____no_output_____"
],
[
"model=Sequential([\n Convolution2D(32,(3,3),activation='relu',input_shape=input_reshape),\n \n Convolution2D(64,(3,3),activation='relu'),\n MaxPooling2D((2,2)),\n \n Convolution2D(64,(3,3),activation='relu'),\n MaxPooling2D((2,2)),\n \n\n Convolution2D(64,(3,3),activation='relu'),\n Flatten(),\n \n Dense(64,'relu'),\n Dense(7,'softmax')\n \n])",
"_____no_output_____"
],
[
"model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])\ntrained_model_cov=model.fit(X_train,y_train, epochs=epochs,batch_size=batch_size, validation_data=(X_val,y_val))",
"Train on 28709 samples, validate on 3589 samples\nEpoch 1/10\n28709/28709 [==============================] - 359s 12ms/sample - loss: 1.7036 - accuracy: 0.3199 - val_loss: 1.5382 - val_accuracy: 0.4166\nEpoch 2/10\n28709/28709 [==============================] - 323s 11ms/sample - loss: 1.4495 - accuracy: 0.4410 - val_loss: 1.3710 - val_accuracy: 0.4817\nEpoch 3/10\n28709/28709 [==============================] - 315s 11ms/sample - loss: 1.2987 - accuracy: 0.5052 - val_loss: 1.2750 - val_accuracy: 0.5130\nEpoch 4/10\n28709/28709 [==============================] - 314s 11ms/sample - loss: 1.2048 - accuracy: 0.5438 - val_loss: 1.2265 - val_accuracy: 0.5458\nEpoch 5/10\n28709/28709 [==============================] - 316s 11ms/sample - loss: 1.1307 - accuracy: 0.5724 - val_loss: 1.2168 - val_accuracy: 0.5444\nEpoch 6/10\n28709/28709 [==============================] - 319s 11ms/sample - loss: 1.0693 - accuracy: 0.5964 - val_loss: 1.1976 - val_accuracy: 0.5548\nEpoch 7/10\n28709/28709 [==============================] - 316s 11ms/sample - loss: 1.0048 - accuracy: 0.6226 - val_loss: 1.2069 - val_accuracy: 0.5567\nEpoch 8/10\n28709/28709 [==============================] - 345s 12ms/sample - loss: 0.9439 - accuracy: 0.6474 - val_loss: 1.2180 - val_accuracy: 0.5651\nEpoch 9/10\n28709/28709 [==============================] - 343s 12ms/sample - loss: 0.8771 - accuracy: 0.6748 - val_loss: 1.2279 - val_accuracy: 0.5614\nEpoch 10/10\n28709/28709 [==============================] - 345s 12ms/sample - loss: 0.8203 - accuracy: 0.6957 - val_loss: 1.2621 - val_accuracy: 0.5561\n"
],
[
"model.predict_classes(X_Test[1000].reshape(1,48,48,1))",
"_____no_output_____"
],
[
"plt.imshow(images_list[1000].squeeze(),cmap='gray')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad23f5a9a1e9111270924fb06bd5fe99aa97a82
| 9,818 |
ipynb
|
Jupyter Notebook
|
notebooks/02.c_csv_and_collections.ipynb
|
zyzllik/advanced_python_2021-22_HD
|
8562fc2a3fe11ef40829072a493bc090606c2a8f
|
[
"CC0-1.0"
] | null | null | null |
notebooks/02.c_csv_and_collections.ipynb
|
zyzllik/advanced_python_2021-22_HD
|
8562fc2a3fe11ef40829072a493bc090606c2a8f
|
[
"CC0-1.0"
] | 1 |
2021-11-15T13:55:23.000Z
|
2021-11-15T13:55:23.000Z
|
notebooks/02.c_csv_and_collections.ipynb
|
zyzllik/advanced_python_2021-22_HD
|
8562fc2a3fe11ef40829072a493bc090606c2a8f
|
[
"CC0-1.0"
] | 9 |
2021-11-08T12:53:30.000Z
|
2021-11-10T13:08:45.000Z
| 23.431981 | 241 | 0.55164 |
[
[
[
"import course;course.header()",
"_____no_output_____"
]
],
[
[
"# The csv module",
"_____no_output_____"
],
[
"\nThere are several ways to interact with files that contain data in a \"comma separated value\" format.\n\nWe cover the [basic csv module](https://docs.python.org/3/library/csv.html), as it is sometimes really helpful to retain only a fraction of the information of a csv to avoid memory overflow.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open(\"../data/amino_acid_properties.csv\") as aap:\n aap_reader = csv.DictReader(aap, delimiter=\",\") \n for line_dict in aap_reader:\n print(line_dict)\n break",
"_____no_output_____"
]
],
[
[
"Print not always very readable - use pretty print! :)",
"_____no_output_____"
]
],
[
[
"import pprint\npprint.pprint(line_dict)",
"_____no_output_____"
]
],
[
[
"The hydropathy index is the energy released or required ot transfer the amino acid from water to a hydrophobic environment.\n\n - Arg: +4.5 kcal/mol\n - Ile: -4.5 kcal/mol",
"_____no_output_____"
],
[
"We can also use the csv module to write csvs, or tab separated value files if we change the delimiter to \"\\t\"",
"_____no_output_____"
]
],
[
[
"with open(\"../data/test.csv\", \"w\") as output:\n aap_writer = csv.DictWriter(output, fieldnames=[\"Name\", \"3-letter code\"]) \n aap_writer.writeheader()\n aap_writer.writerow({\"Name\": \"Alanine\", \"3-letter code\": \"Ala\", \"1-letter code\": \"A\"})",
"_____no_output_____"
],
[
"!cat ../data/test.csv",
"_____no_output_____"
]
],
[
[
"## Fix it!",
"_____no_output_____"
]
],
[
[
"# fix it\nwith open(\"c\", \"w\") as output:\n aap_writer = csv.DictWriter(output, fieldnames=[\"Name\", \"3-letter code\"], extrasaction='ignore')\n aap_writer.writeheader()\n aap_writer.writerow({\"Name\": \"Alanine\", \"3-letter code\": \"Ala\", \"1-letter code\": \"A\"})",
"_____no_output_____"
]
],
[
[
"# Collections - high performance containers ... sorta",
"_____no_output_____"
],
[
"## [collections.Counter](https://docs.python.org/3.7/library/collections.html#counter-objects)\nA counter tool is provided to support convenient and rapid tallies. For example",
"_____no_output_____"
]
],
[
[
"from collections import Counter\ns = \"\"\"\nMQRLMMLLATSGACLGLLAVAAVAAAGANPAQRDTHSLLPTHRRQKRDWIWNQMHIDEEK\nNTSLPHHVGKIKSSVSRKNAKYLLKGEYVGKVFRVDAETGDVFAIERLDRENISEYHLTA\nVIVDKDTGENLETPSSFTIKVHDVNDNWPVFTHRLFNASVPESSAVGTSVISVTAVDADD\nPTVGDHASVMYQILKGKEYFAIDNSGRIITITKSLDREKQARYEIVVEARDAQGLRGDSG\nTATVLVTLQDINDNFPFFTQTKYTFVVPEDTRVGTSVGSLFVEDPDEPQNRMTKYSILRG\nDYQDAFTIETNPAHNEGIIKPMKPLDYEYIQQYSFIVEATDPTIDL RYMSPPAGNRAQVI\n\"\"\"\nCounter(s)",
"_____no_output_____"
],
[
"# Counter objects can be added together\nCounter(\"AABB\") + Counter(\"BBCC\")",
"_____no_output_____"
],
[
"# Works with any type of object that are comparable\nCounter([(1, 1), (1, 2), (2, 1), (1, 1)])",
"_____no_output_____"
]
],
[
[
"## [collections.deque](https://docs.python.org/3.7/library/collections.html#deque-objects)\nDeque \\[deck\\] or double-ended queue can be used for many tasks, e.g. building a sliding window",
"_____no_output_____"
]
],
[
[
"from collections import deque\ns = \"\"\"MQRLMMLLATSGACLGLLAVAAVAAAGANPAQRDTHSLLPTHRRQKRDWIWNQMHIDEEKNTSLPHHVGKIKSSVSRKNAKYLLKGEYVGKVFRVDAETGDVFAIERLDRENISEYHLTA\"\"\"\nwindow = deque([], maxlen=5)",
"_____no_output_____"
],
[
"for pos, aa in enumerate(s):\n window.append(aa)\n print(window)\n if pos > 7:\n break",
"_____no_output_____"
],
[
"Counter(window)",
"_____no_output_____"
]
],
[
[
"## [collections.defaultdicts](https://docs.python.org/3.7/library/collections.html#defaultdict-objects)\nDefaultdicts are like dicts yet they treat missing values not with an error, thus testing if key exists is not neccessary and makes life easier :) Ofcourse, one needs to define the default value that is taken if a key is not existent. ",
"_____no_output_____"
],
[
"\nI use it a lot for counting \n```python\ncounter[\"error\"] += 1\n```\nor collecting elements in lists\n```python\nsorter[\"typeA\"].append({\"name\": \"John\"})\n```\n\nNo more, let's check if I have the key and if not I need to initialize.",
"_____no_output_____"
]
],
[
[
"from collections import defaultdict\n\nddict_int = defaultdict(int)\n# ^---- default factory\nddict_list = defaultdict(list)",
"_____no_output_____"
],
[
"ddict_int[10] += 10\nddict_int",
"_____no_output_____"
],
[
"ddict_int[0]",
"_____no_output_____"
],
[
"def default_factory_with_prefilled_dictionary():\n return {\"__name\": \"our custom dict\", \"errors\": 0}\nddict_custom = defaultdict(default_factory_with_prefilled_dictionary)\n",
"_____no_output_____"
]
],
[
[
"Does that work?",
"_____no_output_____"
]
],
[
[
"ddict_custom[10] += 10",
"_____no_output_____"
],
[
"ddict_custom[\"what_ever_key\"]",
"_____no_output_____"
],
[
"ddict_custom[10]['errors'] += 10",
"_____no_output_____"
],
[
"ddict_custom",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ad240aa3a913a8ed22ce1cf372b716e1f1d64b7
| 12,598 |
ipynb
|
Jupyter Notebook
|
Projekat/FMIndexImproved.ipynb
|
ralle97/genomska_informatika_zadaci
|
9c939cbd91ab3999408581605aa8f65fa7bc1b5b
|
[
"MIT"
] | null | null | null |
Projekat/FMIndexImproved.ipynb
|
ralle97/genomska_informatika_zadaci
|
9c939cbd91ab3999408581605aa8f65fa7bc1b5b
|
[
"MIT"
] | null | null | null |
Projekat/FMIndexImproved.ipynb
|
ralle97/genomska_informatika_zadaci
|
9c939cbd91ab3999408581605aa8f65fa7bc1b5b
|
[
"MIT"
] | null | null | null | 31.813131 | 315 | 0.490157 |
[
[
[
"import time\nimport psutil\nimport os",
"_____no_output_____"
],
[
"%run BurrowsWheelerTransformImproved.ipynb",
"_____no_output_____"
],
[
"class FMIndexImproved():\n @staticmethod\n def SampleSuffixArray(suffixArray, step = 32):\n sampledSA = {}\n for index, suffix in enumerate(suffixArray):\n if suffix % step == 0:\n sampledSA[index] = suffix\n return sampledSA\n \n def __init__(self, seq, suffixArray = None, checkpointStep = 128, sampledSAStep = 32):\n if seq[-1] != '$':\n seq += '$'\n if suffixArray == None:\n suffixArray = SuffixArrayImprovedSort(seq)\n self.bwt = BWTViaSAImprovedDict(seq, suffixArray)\n self.sampledSA = self.SampleSuffixArray(suffixArray, sampledSAStep)\n self.length = len(self.bwt)\n \n self.CreateCheckpoints(checkpointStep)\n \n tots = dict()\n for c in self.bwt:\n tots[c] = tots.get(c, 0) + 1\n \n self.first = {}\n totc = 0\n for c, count in sorted(tots.items()):\n self.first[c] = totc\n totc += count\n \n def CreateCheckpoints(self, checkpointStep = 128):\n self.checkpoints = {}\n self.checkpointStep = checkpointStep\n tally = {}\n \n for char in self.bwt:\n if char not in tally:\n tally[char] = 0\n self.checkpoints[char] = []\n \n for index, char in enumerate(self.bwt):\n tally[char] += 1\n if index % checkpointStep == 0:\n for c in tally.keys():\n self.checkpoints[c].append(tally[c])\n \n def Rank(self, bwt, char, row):\n if row < 0 or char not in self.checkpoints:\n return 0\n index, numOccurences = row, 0\n \n while index % self.checkpointStep != 0:\n if bwt[index] == char:\n numOccurences += 1\n index -= 1\n return self.checkpoints[char][index // self.checkpointStep] + numOccurences\n \n def Range(self, pattern):\n left, right = 0, self.length - 1\n for i in range(len(pattern) - 1, -1, -1):\n left = self.Rank(self.bwt, pattern[i], left - 1) + self.Count(pattern[i])\n right = self.Rank(self.bwt, pattern[i], right) + self.Count(pattern[i]) - 1\n if right < left:\n break\n return left, right + 1\n \n def Resolve(self, row):\n def StepLeft(row):\n char = self.bwt[row]\n return self.Rank(self.bwt, char, row - 1) + self.Count(char)\n \n numSteps = 0\n while row not in self.sampledSA:\n row = StepLeft(row)\n numSteps += 1\n return self.sampledSA[row] + numSteps\n \n def Count(self, char):\n if char not in self.first:\n for cc in sorted(self.first.keys()):\n if char < cc:\n return self.first[cc]\n return self.first[cc]\n else:\n return self.first[char]\n \n def HasSubstring(self, pattern):\n left, right = self.Range(pattern)\n return right > left\n \n def HasSuffix(self, pattern):\n left, right = self.Range(pattern)\n if left >= self.length:\n return False\n offset = self.Resolve(left)\n return right > left and offset + len(pattern) == self.length - 1\n \n def Search(self, pattern):\n left, right = self.Range(pattern)\n return [self.Resolve(x) for x in range(left, right)]",
"_____no_output_____"
],
[
"dataSet = [\n {\"file\" : \"./data/13443_ref_Cara_1.0_chr1c.fa\",\n \"patterns\" : [\n \"ATGCATG\",\n \"TCTCTCTA\",\n \"TTCACTACTCTCA\"\n ]},\n {\"file\" : \"./data/10093_ref_PAHARI_EIJ_v1.1_chrX.fa\",\n \"patterns\" : [\n \"ATGATG\",\n \"CTCTCTA\",\n \"TCACTACTCTCA\"\n ]},\n {\"file\" : \"./data/144034_ref_Pbar_UMD_V03_chrUn.fa\",\n \"patterns\": [\n \"CGCGAG\",\n \"GTCGAAT\",\n \"GGGCGTCATCGCGCG\"\n ]}\n]",
"_____no_output_____"
],
[
"for data in dataSet:\n file = data.get(\"file\")\n genome = GetWholeGenomeFromFile(file)\n patterns = data.get(\"patterns\")\n \n for pattern in patterns:\n startTime = time.time()\n fm = FMIndexImproved(genome)\n fm.Search(pattern)\n endTime = time.time()\n duration = endTime - startTime\n print(f\"{file} : {pattern} executed in {duration}\")\n del fm\n \n del file\n del genome\n del patterns",
"D:\\Anaconda\\lib\\site-packages\\pydivsufsort\\divsufsort.py:76: UserWarning: converting str argument uses more memory\n warnings.warn(\"converting str argument uses more memory\")\n"
],
[
"file = dataSet[0].get(\"file\")\ngenome = GetWholeGenomeFromFile(file)\npattern = dataSet[0].get(\"patterns\")[1]\n \nstartTime = time.time()\nfm = FMIndexImproved(genome)\nfor f in fm.first:\n print()\nfm.Search(pattern)\nendTime = time.time()\nduration = endTime - startTime\nprint(f\"{file} : {pattern} executed in {duration}\")\ndel fm\n \ndel file\ndel genome\ndel pattern",
"D:\\Anaconda\\lib\\site-packages\\pydivsufsort\\divsufsort.py:76: UserWarning: converting str argument uses more memory\n warnings.warn(\"converting str argument uses more memory\")\n"
],
[
"seq = GetWholeGenomeFromFile(dataSet[0].get(\"file\"))\n\ntots = dict()\nfor c in seq:\n tots[c] = tots.get(c, 0) + 1\n\nbwt = \"\"\n#with open(\"./data/bwt\" + str(1) + \".txt\", \"a\") as f:\nfor char, count in sorted(tots.items()):\n index = 0\n toAdd = list()\n while count > 0:\n if seq[index] == char:\n toAdd.append(seq[index:] + seq[:index])\n count -= 1\n index += 1\n toWrite = ''.join(map(lambda x: x[-1], sorted(toAdd)))\n# for rotation in sorted(toAdd):\n# toWrite += rotation[-1]\n bwt += toWrite\n# f.write(toWrite)\n print(toWrite)\n del toWrite\n del toAdd\n# f.close()\ndel tots",
"T\n"
],
[
"!python \"./memTest/FMIndexImprovedFirstFile.py\" 128 32 \"ATGCATG\"\n!python \"./memTest/FMIndexImprovedFirstFile.py\" 128 32 \"TCTCTCTA\"\n!python \"./memTest/FMIndexImprovedFirstFile.py\" 128 32 \"TTCACTACTCTCA\"",
"Used this much memory: 1898.84765625 Mb\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad24cab186566b983e2ae5ab16a7d3d3fe02656
| 33,792 |
ipynb
|
Jupyter Notebook
|
lessons/python/ep3-lists.ipynb
|
mariakna/2019-12-03-intro-to-python-workshop
|
7039eae75ebf44520e52d2aa543adb5cba7b2793
|
[
"MIT"
] | null | null | null |
lessons/python/ep3-lists.ipynb
|
mariakna/2019-12-03-intro-to-python-workshop
|
7039eae75ebf44520e52d2aa543adb5cba7b2793
|
[
"MIT"
] | null | null | null |
lessons/python/ep3-lists.ipynb
|
mariakna/2019-12-03-intro-to-python-workshop
|
7039eae75ebf44520e52d2aa543adb5cba7b2793
|
[
"MIT"
] | null | null | null | 27.789474 | 494 | 0.516098 |
[
[
[
"# Programming with Python\n\n## Episode 3 - Storing Multiple Values in Lists\n\nTeaching: 30 min, \nExercises: 30 min ",
"_____no_output_____"
],
[
"## Objectives\n- Explain what a list is.\n- Create and index lists of simple values.\n- Change the values of individual elements\n- Append values to an existing list\n- Reorder and slice list elements\n- Create and manipulate nested lists",
"_____no_output_____"
],
[
"#### How can I store many values together?\nJust as a `for loop` is a way to do operations many times, a list is a way to store many values. Unlike NumPy arrays, lists are built into the language (so we don't have to load a library to use them). We create a list by putting values inside square brackets and separating the values with commas:\n```\nodds = [1, 3, 5, 7]\nprint('odds are:', odds)\n```",
"_____no_output_____"
]
],
[
[
"odds = [1, 3, 5, 7]\nprint('odds are:', odds)\n\nprint(odds[0])\n\n# lists are mutable\nodds[1] = 'a'\nprint(odds[1])",
"odds are: [1, 3, 5, 7]\n1\na\n"
]
],
[
[
"We can access elements of a list using indices – numbered positions of elements in the list. These positions are numbered starting at 0, so the first element has an index of 0.\n```\nprint('first element:', odds[0])\nprint('last element:', odds[3])\nprint('\"-1\" element:', odds[-1])\n```",
"_____no_output_____"
]
],
[
[
"print('first element:', odds[0])\nprint('last element:', odds[3])\n# negatives count from the back, -2 element is 5, -1 element is 7\nprint('\"-1\" element:', odds[-1])",
"first element: 1\nlast element: 7\n\"-1\" element: 7\n"
]
],
[
[
"Yes, we can use negative numbers as indices in Python. When we do so, the index `-1` gives us the last element in the list, `-2` the second to last, and so on. \n\nBecause of this, `odds[3]` and `odds[-1]` point to the same element here.\n\nIf we loop over a list, the loop variable is assigned elements one at a time:\n\nfor number in odds:\n print(number)",
"_____no_output_____"
]
],
[
[
"odds = [1, 3, 5, 7]\nfor number in odds:\n print(number)",
"1\n3\n5\n7\n"
]
],
[
[
"There is one important difference between lists and strings: we can change the values in a list, but we cannot change individual characters in a string. For example:\n```\nnames = ['Curie', 'Darwing', 'Turing'] # typo in Darwin's name\nprint('names is originally:', names)\nnames[1] = 'Darwin' # correct the name\nprint('final value of names:', names)\n```",
"_____no_output_____"
]
],
[
[
"names = ['Curie', 'Darwing', 'Turing'] # typo in Darwin's name\nprint('names is originally:', names)\nnames[1] = 'Darwin' # correct the name\nprint('final value of names:', names)",
"names is originally: ['Curie', 'Darwing', 'Turing']\nfinal value of names: ['Curie', 'Darwin', 'Turing']\n"
]
],
[
[
"works, but:\n```\nname = 'Darwin'\nname[0] = 'd'\n```\n\ndoesn't.",
"_____no_output_____"
],
[
"### Ch-Ch-Ch-Ch-Changes\nData which can be modified in place is called *mutable*, while data which cannot be modified is called *immutable*. Strings and numbers are immutable. This does not mean that variables with string or number values are constants, but when we want to change the value of a string or number variable, we can only replace the old value with a completely new value.\n\nLists and arrays, on the other hand, are mutable: we can modify them after they have been created. We can change individual elements, append new elements, or reorder the whole list. For some operations, like sorting, we can choose whether to use a function that modifies the data in-place or a function that returns a modified copy and leaves the original unchanged.\n\nBe careful when modifying data in-place. If two variables refer to the same list, and you modify the list value, it will change for both variables!\n```\nsalsa = ['peppers', 'onions', 'cilantro', 'tomatoes']\nmy_salsa = salsa # <-- my_salsa and salsa point to the *same* list data in memory\nsalsa[0] = 'hot peppers'\nprint('Ingredients in salsa:', salsa)\nprint('Ingredients in my salsa:', my_salsa)\n```",
"_____no_output_____"
]
],
[
[
"salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']\nmy_salsa = salsa # <-- my_salsa and salsa point to the *same* list data in memory\nsalsa[0] = 'hot peppers'\nprint('Ingredients in salsa:', salsa)\nprint('Ingredients in my salsa:', my_salsa)",
"Ingredients in salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']\nIngredients in my salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']\n"
]
],
[
[
"If you want variables with mutable values to be independent, you must make a copy of the value when you assign it.\n```\nsalsa = ['peppers', 'onions', 'cilantro', 'tomatoes']\nmy_salsa = list(salsa) # <-- makes a *copy* of the list\nsalsa[0] = 'hot peppers'\nprint('Ingredients in salsa:', salsa)\nprint('Ingredients in my salsa:', my_salsa)\n```",
"_____no_output_____"
]
],
[
[
"salsa = ['peppers', 'onions', 'cilantro', 'tomatoes']\nmy_salsa = list(salsa) # <-- makes a *copy* of the list\nsalsa[0] = 'hot peppers'\nprint('Ingredients in salsa:', salsa)\nprint('Ingredients in my salsa:', my_salsa)",
"Ingredients in salsa: ['hot peppers', 'onions', 'cilantro', 'tomatoes']\nIngredients in my salsa: ['peppers', 'onions', 'cilantro', 'tomatoes']\n"
]
],
[
[
"Because of pitfalls like this, code which modifies data in place can be more difficult to understand. However, it is often far more efficient to modify a large data structure in place than to create a modified copy for every small change. You should consider both of these aspects when writing your code.",
"_____no_output_____"
],
[
"### Nested Lists\nSince lists can contain any Python variable type, it can even contain other lists.\n\nFor example, we could represent the products in the shelves of a small grocery shop:\n```\nshop = [['pepper', 'zucchini', 'onion'],\n ['cabbage', 'lettuce', 'garlic'],\n ['apple', 'pear', 'banana']]\n```",
"_____no_output_____"
]
],
[
[
"shop = [['pepper', 'zucchini', 'onion'],\n ['cabbage', 'lettuce', 'garlic'],\n ['apple', 'pear', 'banana']]\n\nprint(shop)",
"[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n"
]
],
[
[
"Here is an example of how indexing a list of lists works:\n\nThe first element of our list is another list representing the first shelf:\n```\nprint(shop[0])\n```",
"_____no_output_____"
]
],
[
[
"print(shop[0])",
"['pepper', 'zucchini', 'onion']\n"
]
],
[
[
"to reference a particular item on a particular shelf (e.g. the third item on the second shelf - i.e. the `garlic`) we'd use extra `[` `]`'s\n\n```\nprint(shop[1][2])\n```\n\ndon't forget the zero index thing ...",
"_____no_output_____"
]
],
[
[
"# these indexes are calles subscripts\nprint(shop[1][2])",
"garlic\n"
],
[
"# list of items of different types\nanother_shop = [['pepper', 'zucchini', 'onion'],\n ['cabbage', 'lettuce', 'garlic'],\n ['apple', 'pear', 'banana'],\n 42.5, 45.6, 39.8, 3]\n\nprint(another_shop)\nprint(another_shop[3]) # print(another_shop[3][0]) is not possible\nprint(another_shop[5])",
"[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana'], 42.5, 45.6, 39.8, 3]\n42.5\n39.8\n"
]
],
[
[
"### Heterogeneous Lists\nLists in Python can contain elements of different types. Example:\n```\nsample_ages = [10, 12.5, 'Unknown']\n```",
"_____no_output_____"
]
],
[
[
"sample_ages = [10, 12.5, 'Unknown']",
"_____no_output_____"
]
],
[
[
"There are many ways to change the contents of lists besides assigning new values to individual elements:\n```\nodds.append(11)\nprint('odds after adding a value:', odds)\n\ndel odds[0]\nprint('odds after removing the first element:', odds)\n\nodds.reverse()\nprint('odds after reversing:', odds)\n```",
"_____no_output_____"
]
],
[
[
"odds.append(11)\nprint('odds after adding a value:', odds)",
"odds after adding a value: [1, 3, 5, 7, 11]\n"
],
[
"del odds[0]\nprint('odds after removing the first element:', odds)",
"odds after removing the first element: [3, 5, 7, 11]\n"
],
[
"odds.reverse()\nprint('odds after reversing:', odds)",
"odds after reversing: [11, 7, 5, 3]\n"
],
[
"# gives info about the object \"odds\"\nodds?\n# do odds. and press tab > shows a documentation for all possible functions that can be used with this variable\nodds.",
"_____no_output_____"
]
],
[
[
"While modifying in place, it is useful to remember that Python treats lists in a slightly counter-intuitive way.\n\nIf we make a list and (attempt to) copy it then modify in place, we can cause all sorts of trouble:\n```\nodds = [1, 3, 5, 7]\nprimes = odds\nprimes.append(2)\nprint('primes:', primes)\nprint('odds:', odds)\nprimes: [1, 3, 5, 7, 2]\nodds: [1, 3, 5, 7, 2]\n```",
"_____no_output_____"
]
],
[
[
"odds = [1, 3, 5, 7]\nprimes = odds\nprimes.append(2)\nprint('primes:', primes)\nprint('odds:', odds)\n# primes: [1, 3, 5, 7, 2]\n# odds: [1, 3, 5, 7, 2]",
"primes: [1, 3, 5, 7, 2]\nodds: [1, 3, 5, 7, 2]\n"
]
],
[
[
"This is because Python stores a list in memory, and then can use multiple names to refer to the same list. If all we want to do is copy a (simple) list, we can use the list function, so we do not modify a list we did not mean to:\n```\nodds = [1, 3, 5, 7]\nprimes = list(odds)\nprimes.append(2)\nprint('primes:', primes)\nprint('odds:', odds)\nprimes: [1, 3, 5, 7, 2]\nodds: [1, 3, 5, 7]\n```",
"_____no_output_____"
]
],
[
[
"odds = [1, 3, 5, 7]\nprimes = list(odds)\nprimes.append(2)\nprint('primes:', primes)\nprint('odds:', odds)\n# primes: [1, 3, 5, 7, 2]\n# odds: [1, 3, 5, 7]\n\n# another way to copy is to create a new slice\n# here, we slice from the beginning to the end\nprimes = odds[:]\n\n# another option\nprimes = odds.copy()",
"primes: [1, 3, 5, 7, 2]\nodds: [1, 3, 5, 7]\n"
],
[
"shop = [['pepper', 'zucchini', 'onion'],\n ['cabbage', 'lettuce', 'garlic'],\n ['apple', 'pear', 'banana']]\n\nprint(shop)\n\n# a copy only makes a copy of the top level. this is calles a shallow copy\nanother_shop = shop.copy()\nprint(another_shop)\ndel shop[2]\n\nprint(shop)\nprint(another_shop)\n\n# the deeper structure is not copied, it's still stored in one place and is referenced by two variables\nshop[0][1] = 'carrot'\nprint(shop)\nprint(another_shop)",
"[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic']]\n[['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n[['pepper', 'carrot', 'onion'], ['cabbage', 'lettuce', 'garlic']]\n[['pepper', 'carrot', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n"
],
[
"# create a deep copy\nimport copy\n\nshop = [['pepper', 'zucchini', 'onion'],\n ['cabbage', 'lettuce', 'garlic'],\n ['apple', 'pear', 'banana']]\n\nthird_shop = copy.deepcopy(shop)\n\nprint('original shop:', shop)\ndel shop[2]\nprint('original shop minus element 2:', shop)\nprint('deep copy of shop:', third_shop)\n\nshop[0][1] = 'carrot'\nprint('original shop with carrot and minus element 2:', shop)\nprint('deep copy of shop:', third_shop)",
"original shop: [['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\noriginal shop minus element 2: [['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic']]\ndeep copy of shop: [['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\noriginal shop with carrot and minus element 2: [['pepper', 'carrot', 'onion'], ['cabbage', 'lettuce', 'garlic']]\ndeep copy of shop: [['pepper', 'zucchini', 'onion'], ['cabbage', 'lettuce', 'garlic'], ['apple', 'pear', 'banana']]\n"
]
],
[
[
"### Turn a String Into a List\nUse a `for loop` to convert the string \"hello\" into a list of letters: `[\"h\", \"e\", \"l\", \"l\", \"o\"]`\n\nHint: You can create an empty list like this:\n\nmy_list = []",
"_____no_output_____"
]
],
[
[
"my_list = []\nfor letter in 'hello':\n my_list.append(letter)\nprint(my_list)",
"['h', 'e', 'l', 'l', 'o']\n"
],
[
"# if you want to put a new item in a specific location, use insert\nodds = [1,3,5,7]\nprimes = odds.copy()\nprimes.insert(1,2)\nprint(primes)\n\n# if you insert it past the last position, it inserts it in the end\nprimes.insert(10,2)\nprint(primes)",
"[1, 2, 3, 5, 7]\n[1, 2, 3, 5, 7, 2]\n"
]
],
[
[
"Subsets of lists and strings can be accessed by specifying ranges of values in brackets, similar to how we accessed ranges of positions in a NumPy array. This is commonly referred to as *slicing* the list/string.\n```\nbinomial_name = \"Drosophila melanogaster\"\ngroup = binomial_name[0:10]\nprint(\"group:\", group)\n\nspecies = binomial_name[11:24]\nprint(\"species:\", species)\n\nchromosomes = [\"X\", \"Y\", \"2\", \"3\", \"4\"]\nautosomes = chromosomes[2:5]\nprint(\"autosomes:\", autosomes)\n\nlast = chromosomes[-1]\nprint(\"last:\", last)\n```",
"_____no_output_____"
]
],
[
[
"binomial_name = \"Drosophila melanogaster\"\n# the last character (10) is not included\ngroup = binomial_name[0:10]\nprint(\"group:\", group)",
"group: Drosophila\n"
],
[
"species = binomial_name[11:24]\nprint(\"species:\", species)\n# or\nprint(\"species:\", binomial_name[11:])\n\n# to reverse the string\nprint(binomial_name[::-1])\n\n# to leave out some specific characters\nprint(binomial_name[:-5])\n\n# find an index for a specific element\nprint(binomial_name.index(' '))\n\n# break up by a specific character\nprint(binomial_name.split(' '))\n\n# split after every letter\nprint(list(binomial_name))",
"species: melanogaster\nspecies: melanogaster\nretsagonalem alihposorD\nDrosophila melanog\n10\n['Drosophila', 'melanogaster']\n['D', 'r', 'o', 's', 'o', 'p', 'h', 'i', 'l', 'a', ' ', 'm', 'e', 'l', 'a', 'n', 'o', 'g', 'a', 's', 't', 'e', 'r']\n"
],
[
"chromosomes = [\"X\", \"Y\", \"2\", \"3\", \"4\"]\nautosomes = chromosomes[2:5]\nprint(\"autosomes:\", autosomes)",
"autosomes: ['2', '3', '4']\n"
]
],
[
[
"### Slicing From the End\nUse slicing to access only the last four characters of a string or entries of a list.\n```\nstring_for_slicing = \"Observation date: 02-Feb-2013\"\nlist_for_slicing = [[\"fluorine\", \"F\"],\n [\"chlorine\", \"Cl\"],\n [\"bromine\", \"Br\"],\n [\"iodine\", \"I\"],\n [\"astatine\", \"At\"]]\n```\nWould your solution work regardless of whether you knew beforehand the length of the string or list (e.g. if you wanted to apply the solution to a set of lists of different lengths)? If not, try to change your approach to make it more robust.\n\nHint: Remember that indices can be negative as well as positive\n",
"_____no_output_____"
]
],
[
[
"string_for_slicing = \"Observation date: 02-Feb-2013\"\nlist_for_slicing = [[\"fluorine\", \"F\"],\n [\"chlorine\", \"Cl\"],\n [\"bromine\", \"Br\"],\n [\"iodine\", \"I\"],\n [\"astatine\", \"At\"]]\n\nprint(string_for_slicing[-4:])\nprint(list_for_slicing[-4:])\nprint(list_for_slicing[-1][1:])",
"2013\n[['chlorine', 'Cl'], ['bromine', 'Br'], ['iodine', 'I'], ['astatine', 'At']]\n['At']\n"
]
],
[
[
"### Non-Continuous Slices\nSo far we've seen how to use slicing to take single blocks of successive entries from a sequence. But what if we want to take a subset of entries that aren't next to each other in the sequence?\n\nYou can achieve this by providing a third argument to the range within the brackets, called the step size. The example below shows how you can take every third entry in a list:\n```\nprimes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]\nsubset = primes[0:12:3]\nprint(\"subset\", subset)\n```",
"_____no_output_____"
]
],
[
[
"primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]\nsubset = primes[0:12:3]\nprint(\"subset\", subset)",
"subset [2, 7, 17, 29]\n"
]
],
[
[
"Notice that the slice taken begins with the first entry in the range, followed by entries taken at equally-spaced intervals (the steps) thereafter. If you wanted to begin the subset with the third entry, you would need to specify that as the starting point of the sliced range:\n```\nprimes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]\nsubset = primes[2:12:3]\nprint(\"subset\", subset)\n```",
"_____no_output_____"
]
],
[
[
"primes = [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37]\nsubset = primes[2:12:3]\nprint(\"subset\", subset)",
"subset [5, 13, 23, 37]\n"
]
],
[
[
"Use the step size argument to create a new string that contains only every second character in the string \"In an octopus's garden in the shade\"\n\nStart with:\n```\nbeatles = \"In an octopus's garden in the shade\"\n```\nand print:\n```\nI notpssgre ntesae\n```",
"_____no_output_____"
]
],
[
[
"beatles = \"In an octopus's garden in the shade\"\nnew = beatles[0:len(beatles):2]\nprint(\"new string:\", new)\n\n# or easier:\nnew = beatles[0::2]",
"new string: I notpssgre ntesae\n"
]
],
[
[
"If you want to take a slice from the beginning of a sequence, you can omit the first index in the range:\n```\ndate = \"Monday 4 January 2016\"\nday = date[0:6]\nprint(\"Using 0 to begin range:\", day)\nday = date[:6]\nprint(\"Omitting beginning index:\", day)\n```",
"_____no_output_____"
]
],
[
[
"date = \"Monday 4 January 2016\"\nday = date[0:6]\nprint(\"Using 0 to begin range:\", day)\nday = date[:6]\nprint(\"Omitting beginning index:\", day)",
"Using 0 to begin range: Monday\nOmitting beginning index: Monday\n"
]
],
[
[
"And similarly, you can omit the ending index in the range to take a slice to the end of the sequence:\n```\nmonths = [\"jan\", \"feb\", \"mar\", \"apr\", \"may\", \"jun\", \"jul\", \"aug\", \"sep\", \"oct\", \"nov\", \"dec\"]\nq4 = months[8:12]\nprint(\"With specified start and end position:\", q4)\nq4 = months[8:len(months)]\nprint(\"Using len() to get last entry:\", q4)\nq4 = months[8:]\nprint(\"Omitting ending index:\", q4)\n```\n",
"_____no_output_____"
]
],
[
[
"months = [\"jan\", \"feb\", \"mar\", \"apr\", \"may\", \"jun\", \"jul\", \"aug\", \"sep\", \"oct\", \"nov\", \"dec\"]\nq4 = months[8:12]\nprint(\"With specified start and end position:\", q4)\nq4 = months[8:len(months)]\nprint(\"Using len() to get last entry:\", q4)\nq4 = months[8:]\nprint(\"Omitting ending index:\", q4)",
"With specified start and end position: ['sep', 'oct', 'nov', 'dec']\nUsing len() to get last entry: ['sep', 'oct', 'nov', 'dec']\nOmitting ending index: ['sep', 'oct', 'nov', 'dec']\n"
]
],
[
[
"### Overloading\n`+` usually means addition, but when used on strings or lists, it means \"concatenate\". Given that, what do you think the multiplication operator * does on lists? In particular, what will be the output of the following code?\n```\ncounts = [2, 4, 6, 8, 10]\nrepeats = counts * 2\nprint(repeats)\n```\n\nThe technical term for this is operator overloading. A single operator, like `+` or `*`, can do different things depending on what it's applied to.",
"_____no_output_____"
]
],
[
[
"counts = [2, 4, 6, 8, 10]\nrepeats = counts * 2\nprint(repeats)",
"[2, 4, 6, 8, 10, 2, 4, 6, 8, 10]\n"
]
],
[
[
"is this the same as:\n```\ncounts + counts\n```\nand what might:\n```\ncounts / 2\n```\nmean ?",
"_____no_output_____"
]
],
[
[
"# lists can't be divided, need slice if you want a half\ndouble_counts = counts*2\ndouble_counts[:int(len(double_counts)/2)]",
"_____no_output_____"
]
],
[
[
"## Key Points\n- [value1, value2, value3, ...] creates a list.\n- Lists can contain any Python object, including lists (i.e., list of lists).\n- Lists are indexed and sliced with square brackets (e.g., list[0] and list[2:9]), in the same way as strings and arrays.\n- Lists are mutable (i.e., their values can be changed in place).\n- Strings are immutable (i.e., the characters in them cannot be changed).",
"_____no_output_____"
],
[
"### Save, and version control your changes\n\n- save your work: `File -> Save`\n- add all your changes to your local repository: `Terminal -> git add .`\n- commit your updates a new Git version: `Terminal -> git commit -m \"End of Episode 3\"`\n- push your latest commits to GitHub: `Terminal -> git push`",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4ad2531126943ce56783a2eaacf6d0830403a178
| 12,124 |
ipynb
|
Jupyter Notebook
|
tutorial/transport/R_transport_ret.ipynb
|
danielhuppmann/ixmp
|
1f1dc5e49bd49f5732a367c6ce6866a674b80101
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
tutorial/transport/R_transport_ret.ipynb
|
danielhuppmann/ixmp
|
1f1dc5e49bd49f5732a367c6ce6866a674b80101
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
tutorial/transport/R_transport_ret.ipynb
|
danielhuppmann/ixmp
|
1f1dc5e49bd49f5732a367c6ce6866a674b80101
|
[
"Apache-2.0",
"CC-BY-4.0"
] | 1 |
2020-06-01T08:26:43.000Z
|
2020-06-01T08:26:43.000Z
| 29.144231 | 365 | 0.558232 |
[
[
[
"# Tutorial 1 for R\n\n## Solve Dantzig's Transport Problem using the *ix modeling platform* (ixmp)\n\n<img style=\"float: right; height: 80px;\" src=\"_static/R_logo.png\">\n\n### Aim and scope of the tutorial\n\nThis tutorial takes you through the steps to import the data for a very simple optimization model\nand solve it using the ``ixmp``-GAMS interface.\n\nWe use Dantzig's transport problem, which is also used as the standard GAMS tutorial.\nThis problem finds a least cost shipping schedule that meets requirements at markets and supplies at factories.\nIf you are not familiar with GAMS, please take a minute to look at the [transport.gms](transport.gms) code.\n\nFor reference of the transport problem, see:\n> Dantzig, G B, Chapter 3.3. In Linear Programming and Extensions. \n> Princeton University Press, Princeton, New Jersey, 1963.\n\n> This formulation is described in detail in: \n> Rosenthal, R E, Chapter 2: A GAMS Tutorial. \n> In GAMS: A User's Guide. The Scientific Press, Redwood City, California, 1988.\n\n> see http://www.gams.com/mccarl/trnsport.gms\n\nThe steps in the tutorial are the following:\n\n0. Launch an ixmp.Platform instance and initialize a new ixmp.Scenario.\n0. Define the sets and parameters in the scenario, and commit the data to the platform\n0. Check out the scenario and initialize variables and equations (necessary for ``ixmp`` to import the solution)\n0. Solve the model (export to GAMS input gdx, execute, read solution from output gdx)\n0. Display the solution (variables and equation)",
"_____no_output_____"
],
[
"### Launching the platform and initializing a new scenario\n\nWe launch a platform instance and initialize a new scenario. This will be used to store all data required to solve Dantzig's transport problem as well as the solution after solving it in GAMS.",
"_____no_output_____"
]
],
[
[
"# load the rixmp package source code\nlibrary(\"retixmp\")\nixmp <- import('ixmp')",
"_____no_output_____"
],
[
"# launch the ix modeling platform using a local HSQL database instance\nmp <- ixmp$Platform(dbtype=\"HSQLDB\")",
"_____no_output_____"
],
[
"# details for creating a new scenario in the ix modeling platform \nmodel <- \"transport problem\" \nscenario <- \"standard\"\nannot <- \"Dantzig's transportation problem for illustration and testing\" \n\n# initialize a new ixmp.Scenario\n# the parameter version='new' indicates that this is a new scenario instance\nscen <- mp$Scenario(model, scenario, \"new\", annotation=annot)",
"_____no_output_____"
]
],
[
[
"### Defining the sets in the scenario\n\nBelow, we first show the data as they would be written in the GAMS tutorial ([transport.gms](transport.gms) in this folder). \nThen, we show how this can be implemented in the R ``ixmp`` notation, and display the elements of set ``i`` as an R list.",
"_____no_output_____"
]
],
[
[
"Sets\n i canning plants / seattle, san-diego /\n j markets / new-york, chicago, topeka / ;",
"_____no_output_____"
]
],
[
[
"# define the sets of locations of canning plants \nscen$init_set(\"i\")\ni.set = c(\"seattle\",\"san-diego\")\nscen$add_set(\"i\", i.set )\n\n### markets set\nscen$init_set(\"j\")\nj.set = c(\"new-york\",\"chicago\",\"topeka\")\nscen$add_set(\"j\", j.set )",
"_____no_output_____"
],
[
"# display the set 'i'\nscen$set('i')",
"_____no_output_____"
]
],
[
[
"### Defining parameters in the scenario\n\nNext, we define the production capacity and demand parameters, and display the demand parameter as a DataFrame.\nThen, we add the two-dimensional distance parameter and the transport cost scalar.",
"_____no_output_____"
]
],
[
[
"Parameters\n a(i) capacity of plant i in cases\n / seattle 350\n san-diego 600 /\n b(j) demand at market j in cases\n / new-york 325\n chicago 300\n topeka 275 / ;",
"_____no_output_____"
]
],
[
[
"# capacity of plant i in cases \nscen$init_par(\"a\", c(\"i\"))\na.df = data.frame( i = i.set, value = c(350 , 600) , unit = 'cases')\nscen$add_par(\"a\", adapt_to_ret(a.df))\n#scen$add_par(\"a\", \"san-diego\", 600, \"cases\")\n\n# demand at market j in cases\nscen$init_par(\"b\", c(\"j\"))\nb.df = data.frame( j = j.set, value = c(325 , 300, 275) , unit = 'cases')\nscen$add_par(\"b\", adapt_to_ret(b.df))",
"_____no_output_____"
],
[
"# display the parameter 'b'\nscen$par('b')",
"_____no_output_____"
]
],
[
[
"Table d(i,j) distance in thousands of miles\n new-york chicago topeka\n seattle 2.5 1.7 1.8\n san-diego 2.5 1.8 1.4 ;",
"_____no_output_____"
]
],
[
[
"# distance in thousands of miles\nscen$init_par(\"d\", c(\"i\",\"j\"))\nd.df = data.frame(expand.grid(i = i.set,j = j.set), value = c(2.5,2.5,1.7,1.8,1.8,1.4), unit = 'km')\nscen$add_par(\"d\", adapt_to_ret(d.df))",
"_____no_output_____"
]
],
[
[
"Scalar f freight in dollars per case per thousand miles /90/ ; ",
"_____no_output_____"
]
],
[
[
"# cost per case per 1000 miles\n# initialize scalar with a value and a unit (and optionally a comment)\nscen$init_scalar(\"f\", 90.0, \"USD/km\")",
"_____no_output_____"
]
],
[
[
"### Committing the scenario to the ixmp database instance",
"_____no_output_____"
]
],
[
[
"# commit new scenario to the database\n# no changes can then be made to the scenario data until a check-out is performed\ncomment = \"importing Dantzig's transport problem for illustration of the R interface\"\nscen$commit(comment)\n\n# set this new scenario as the default version for the model/scenario name\nscen$set_as_default()",
"_____no_output_____"
]
],
[
[
"### Defining variables and equations in the scenario\n\nThe levels and marginals of these variables and equations will be imported to the scenario when reading the gdx solution file.",
"_____no_output_____"
]
],
[
[
"Variables\n x(i,j) shipment quantities in cases\n z total transportation costs in thousands of dollars ;\n \nEquations\n cost define objective function\n supply(i) observe supply limit at plant i\n demand(j) satisfy demand at market j ;",
"_____no_output_____"
]
],
[
[
"# perform a check_out to make further changes\nscen$check_out()\n\n# initialize the decision variables and equations\nscen$init_var(\"z\", NULL, NULL)\nscen$init_var(\"x\", idx_sets=c(\"i\", \"j\"))\nscen$init_equ(\"demand\", idx_sets=c(\"j\"))\n\n# commit changes to the scenario (save changes in ixmp database instance)\nchange_comment = \"inialize the model variables and equations\"\nscen$commit(change_comment)",
"_____no_output_____"
]
],
[
[
"### Solve the scenario\n\nThe ``solve()`` function exports the scenario to a GAMS gdx file, executes GAMS, and then imports the solution from an output GAMS gdx file to the database.\n\nFor the model equations and the GAMS workflow (reading the data from gdx, solving the model, writing the results to gdx), see ``transport_ixmp.gms``.",
"_____no_output_____"
]
],
[
[
"scen$solve(model=\"transport_ixmp\")",
"_____no_output_____"
]
],
[
[
"### Display and analyze the results",
"_____no_output_____"
]
],
[
[
"# display the objective value of the solution\nscen$var(\"z\")",
"_____no_output_____"
],
[
"# display the quantities transported from canning plants to demand locations\nscen$var(\"x\")",
"_____no_output_____"
],
[
"# display the quantities and marginals (=shadow prices) of the demand balance constraints\nscen$equ(\"demand\")",
"_____no_output_____"
]
],
[
[
"### Close the database connection of the ix modeling platform\n\nClosing the database connection is recommended when working with the local file-based database, i.e., ``dbtype='HSQLDB'``. This command closes the database files and removes temporary data. This is necessary so that other notebooks or ``ixmp`` instances can access the database file, or so that the database files can be copied to a different folder or drive.",
"_____no_output_____"
]
],
[
[
"# close the connection of the platform instance to the local database files\nmp$close_db()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"raw",
"code",
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code",
"code"
],
[
"raw"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad26c47e5c5a5dc6a6dc18b0aa52d6e0f5c3e7b
| 7,867 |
ipynb
|
Jupyter Notebook
|
tutorials/6_unsupervised_learning_with_graphsage.ipynb
|
varinic/GraphScope
|
b8cb7c404ed38841d46bf2cd35d8fe3fa812bf21
|
[
"Apache-2.0"
] | null | null | null |
tutorials/6_unsupervised_learning_with_graphsage.ipynb
|
varinic/GraphScope
|
b8cb7c404ed38841d46bf2cd35d8fe3fa812bf21
|
[
"Apache-2.0"
] | null | null | null |
tutorials/6_unsupervised_learning_with_graphsage.ipynb
|
varinic/GraphScope
|
b8cb7c404ed38841d46bf2cd35d8fe3fa812bf21
|
[
"Apache-2.0"
] | null | null | null | 33.054622 | 351 | 0.552307 |
[
[
[
"# Unsupervised Graph Learning with GraphSage\n\n\nGraphScope provides the capability to process learning tasks. In this tutorial, we demostrate how GraphScope trains a model with GraphSage.\n\nThe task is link prediction, which estimates the probability of links between nodes in a graph.\n\nIn this task, we use our implementation of GraphSAGE algorithm to build a model that predicts protein-protein links in the [PPI](https://humgenomics.biomedcentral.com/articles/10.1186/1479-7364-3-3-291) dataset. In which every node represents a protein. The task can be treated as a unsupervised link prediction on a homogeneous link network.\n\nIn this task, GraphSage algorithm would compress both structural and attribute information in the graph into low-dimensional embedding vectors on each node. These embeddings can be further used to predict links between nodes.\n\nThis tutorial has following steps:\n- Creating session and loading graph\n- Launching the learning engine and attaching to loaded graph.\n- Defining train process with builtin GraphSage model and hyperparameters\n- Training and evaluating\n",
"_____no_output_____"
],
[
"First, let's create a session and load the dataset as a graph.",
"_____no_output_____"
]
],
[
[
"import os\nimport graphscope\n\nk8s_volumes = {\n \"data\": {\n \"type\": \"hostPath\",\n \"field\": {\n \"path\": \"/testingdata\",\n \"type\": \"Directory\"\n },\n \"mounts\": {\n \"mountPath\": \"/home/jovyan/datasets\",\n \"readOnly\": True\n }\n }\n}\n\n# create session\ngraphscope.set_option(show_log=True)\nsess = graphscope.session(k8s_volumes=k8s_volumes)\n\n# loading ppi graph\ngraph = graphscope.Graph(sess)\ngraph = graph.add_vertices(\"/home/jovyan/datasets/ppi/node.csv\", \"protein\")\ngraph = graph.add_edges(\"/home/jovyan/datasets/ppi/edge.csv\", \"link\")",
"_____no_output_____"
]
],
[
[
"## Launch learning engine \nThen, we need to define a feature list for training. The training feature list should be seleted from the vertex properties. In this case, we choose all the properties prefix with \"feat-\" as the training features.\n\nWith the featrue list, next we launch a learning engine with the learning method of session. (You may find the detail of the method on [Session](https://graphscope.io/docs/reference/session.html).)\n\nIn this case, we specify the GCN training over `protein` nodes and `link` edges.\n\nWith gen_labels, we take protein nodes as training set.\n",
"_____no_output_____"
]
],
[
[
"# define the features for learning\npaper_features = []\nfor i in range(50):\n paper_features.append(\"feat-\" + str(i))\n\n# launch a learning engine.\nlg = sess.learning(graph, nodes=[(\"protein\", paper_features)],\n edges=[(\"protein\", \"link\", \"protein\")],\n gen_labels=[\n (\"train\", \"protein\", 100, (0, 100)),\n ])",
"_____no_output_____"
]
],
[
[
"\nWe use the builtin GraphSage model to define the training process. You can find more detail about all the builtin learning models on [Graph Learning Model](https://graphscope.io/docs/learning_engine.html#data-model)\n\nIn the example, we use tensorflow as NN backend trainer.\n",
"_____no_output_____"
]
],
[
[
"\nimport numpy as np\nfrom graphscope.learning.examples import GraphSage\nfrom graphscope.learning.graphlearn.python.model.tf.trainer import LocalTFTrainer\nfrom graphscope.learning.graphlearn.python.model.tf.optimizer import get_tf_optimizer\n\n# unsupervised GraphSage.\n\ndef train(config, graph):\n def model_fn():\n return GraphSage(\n graph,\n config[\"class_num\"],\n config[\"features_num\"],\n config[\"batch_size\"],\n categorical_attrs_desc=config[\"categorical_attrs_desc\"],\n hidden_dim=config[\"hidden_dim\"],\n in_drop_rate=config[\"in_drop_rate\"],\n neighs_num=config[\"neighs_num\"],\n hops_num=config[\"hops_num\"],\n node_type=config[\"node_type\"],\n edge_type=config[\"edge_type\"],\n full_graph_mode=config[\"full_graph_mode\"],\n unsupervised=config['unsupervised'],\n )\n trainer = LocalTFTrainer(\n model_fn,\n epoch=config[\"epoch\"],\n optimizer=get_tf_optimizer(\n config[\"learning_algo\"], config[\"learning_rate\"], config[\"weight_decay\"]\n ),\n )\n trainer.train()\n embs = trainer.get_node_embedding()\n np.save(config['emb_save_dir'], embs)\n\n# define hyperparameters\nconfig = {\n \"class_num\": 128, # output dimension\n \"features_num\": 50,\n \"batch_size\": 512,\n \"categorical_attrs_desc\": \"\",\n \"hidden_dim\": 128,\n \"in_drop_rate\": 0.5,\n \"hops_num\": 2,\n \"neighs_num\": [5, 5],\n \"full_graph_mode\": False,\n \"agg_type\": \"gcn\", # mean, sum\n \"learning_algo\": \"adam\",\n \"learning_rate\": 0.01,\n \"weight_decay\": 0.0005,\n 'unsupervised': True,\n \"epoch\": 1,\n 'emb_save_dir': './id_emb',\n \"node_type\": \"protein\",\n \"edge_type\": \"link\",\n}",
"_____no_output_____"
]
],
[
[
"## Run training process\n\nAfter define training process and hyperparameters,\n\nNow we can start the traning process with learning engine `lg` and the hyperparameters configurations.",
"_____no_output_____"
]
],
[
[
"train(config, lg)",
"_____no_output_____"
]
],
[
[
"Finally, don't forget to close the session.",
"_____no_output_____"
]
],
[
[
"sess.close()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad27fbca9b7c61440aee00119d0320e39debd0b
| 875,334 |
ipynb
|
Jupyter Notebook
|
module2-convolutional-neural-networks/LS_DS_432_Convolutional_Neural_Networks_Lecture(updated).ipynb
|
Scott-Huston/DS-Unit-4-Sprint-3-Deep-Learning
|
79080abe14fca0e188850e80c74771a810b027fc
|
[
"MIT"
] | null | null | null |
module2-convolutional-neural-networks/LS_DS_432_Convolutional_Neural_Networks_Lecture(updated).ipynb
|
Scott-Huston/DS-Unit-4-Sprint-3-Deep-Learning
|
79080abe14fca0e188850e80c74771a810b027fc
|
[
"MIT"
] | null | null | null |
module2-convolutional-neural-networks/LS_DS_432_Convolutional_Neural_Networks_Lecture(updated).ipynb
|
Scott-Huston/DS-Unit-4-Sprint-3-Deep-Learning
|
79080abe14fca0e188850e80c74771a810b027fc
|
[
"MIT"
] | null | null | null | 869.249255 | 315,293 | 0.954283 |
[
[
[
"Lambda School Data Science\n\n*Unit 4, Sprint 3, Module 2*\n\n---",
"_____no_output_____"
],
[
"# Convolutional Neural Networks (Prepare)\n\n> Convolutional networks are simply neural networks that use convolution in place of general matrix multiplication in at least one of their layers. *Goodfellow, et al.*",
"_____no_output_____"
],
[
"## Learning Objectives\n- <a href=\"#p1\">Part 1: </a>Describe convolution and pooling\n- <a href=\"#p2\">Part 2: </a>Apply a convolutional neural network to a classification task\n- <a href=\"#p3\">Part 3: </a>Use a pre-trained convolution neural network for object detection\n\nModern __computer vision__ approaches rely heavily on convolutions as both a dimensinoality reduction and feature extraction method. Before we dive into convolutions, let's talk about some of the common computer vision applications: \n* Classification [(Hot Dog or Not Dog)](https://www.youtube.com/watch?v=ACmydtFDTGs)\n* Object Detection [(YOLO)](https://www.youtube.com/watch?v=MPU2HistivI)\n* Pose Estimation [(PoseNet)](https://ai.googleblog.com/2019/08/on-device-real-time-hand-tracking-with.html)\n* Facial Recognition [Emotion Detection](https://www.cbronline.com/wp-content/uploads/2018/05/Mona-lIsa-test-570x300.jpg)\n* and *countless* more \n\nWe are going to focus on classification and pre-trained object detection today. What are some of the applications of object detection?",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('MPU2HistivI', width=600, height=400)",
"_____no_output_____"
]
],
[
[
"# Convolution & Pooling (Learn)\n<a id=\"p1\"></a>",
"_____no_output_____"
],
[
"## Overview\n\nLike neural networks themselves, CNNs are inspired by biology - specifically, the receptive fields of the visual cortex.\n\nPut roughly, in a real brain the neurons in the visual cortex *specialize* to be receptive to certain regions, shapes, colors, orientations, and other common visual features. In a sense, the very structure of our cognitive system transforms raw visual input, and sends it to neurons that specialize in handling particular subsets of it.\n\nCNNs imitate this approach by applying a convolution. A convolution is an operation on two functions that produces a third function, showing how one function modifies another. Convolutions have a [variety of nice mathematical properties](https://en.wikipedia.org/wiki/Convolution#Properties) - commutativity, associativity, distributivity, and more. Applying a convolution effectively transforms the \"shape\" of the input.\n\nOne common confusion - the term \"convolution\" is used to refer to both the process of computing the third (joint) function and the process of applying it. In our context, it's more useful to think of it as an application, again loosely analogous to the mapping from visual field to receptive areas of the cortex in a real animal.",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('IOHayh06LJ4', width=600, height=400)",
"_____no_output_____"
]
],
[
[
"## Follow Along\n\nLet's try to do some convolutions in `Keras`.",
"_____no_output_____"
],
[
"### Convolution - an example\n\nConsider blurring an image - assume the image is represented as a matrix of numbers, where each number corresponds to the color value of a pixel.",
"_____no_output_____"
]
],
[
[
"import imageio\nimport matplotlib.pyplot as plt\nfrom skimage import color, io\nfrom skimage.exposure import rescale_intensity\n\nausten = io.imread('https://dl.airtable.com/S1InFmIhQBypHBL0BICi_austen.jpg')\nausten_grayscale = rescale_intensity(color.rgb2gray(austen))\nausten_grayscale",
"_____no_output_____"
],
[
"plt.imshow(austen_grayscale, cmap=\"gray\");",
"_____no_output_____"
],
[
"austen_grayscale.shape",
"_____no_output_____"
],
[
"import numpy as np\nimport scipy.ndimage as nd\n\nhorizontal_edge_convolution = np.array([[1,1,1,1,1],\n [0,0,0,0,0],\n [0,0,0,0,0],\n [0,0,0,0,0],\n [-1,-1,-1,-1,-1]])\n\nvertical_edge_convolution = np.array([[1, 0, 0, 0, -1],\n [1, 0, 0, 0, -1],\n [1, 0, 0, 0, -1],\n [1, 0, 0, 0, -1],\n [1, 0, 0, 0, -1]])\n\nausten_edges = nd.convolve(austen_grayscale, horizontal_edge_convolution)\nausten_edges.shape",
"_____no_output_____"
],
[
"plt.imshow(austen_edges, cmap=\"gray\");",
"_____no_output_____"
]
],
[
[
"## Challenge\n\nYou will be expected to be able to describe convolution. ",
"_____no_output_____"
],
[
"# CNNs for Classification (Learn)",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"### Typical CNN Architecture\n\n\n\nThe first stage of a CNN is, unsurprisingly, a convolution - specifically, a transformation that maps regions of the input image to neurons responsible for receiving them. The convolutional layer can be visualized as follows:\n\n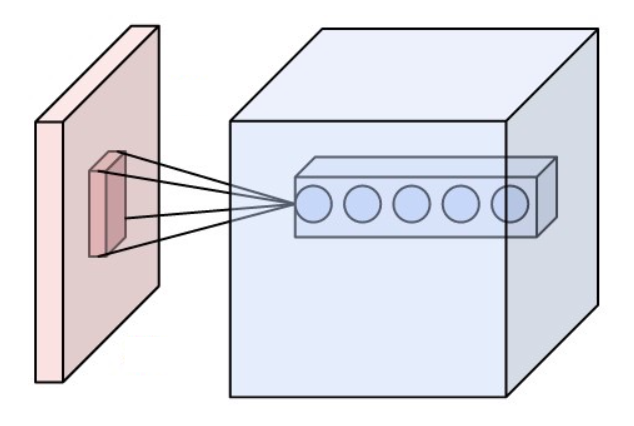\n\nThe red represents the original input image, and the blue the neurons that correspond.\n\nAs shown in the first image, a CNN can have multiple rounds of convolutions, [downsampling](https://en.wikipedia.org/wiki/Downsampling_(signal_processing)) (a digital signal processing technique that effectively reduces the information by passing through a filter), and then eventually a fully connected neural network and output layer. Typical output layers for a CNN would be oriented towards classification or detection problems - e.g. \"does this picture contain a cat, a dog, or some other animal?\"\n\nWhy are CNNs so popular?\n1. Compared to prior image learning techniques, they require relatively little image preprocessing (cropping/centering, normalizing, etc.)\n2. Relatedly, they are *robust* to all sorts of common problems in images (shifts, lighting, etc.)\n\nActually training a cutting edge image classification CNN is nontrivial computationally - the good news is, with transfer learning, we can get one \"off-the-shelf\"!",
"_____no_output_____"
],
[
"## Follow Along",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras import datasets\nfrom tensorflow.keras.models import Sequential, Model # <- May Use\nfrom tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten",
"_____no_output_____"
],
[
"(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()",
"_____no_output_____"
],
[
"train_images.max()",
"_____no_output_____"
],
[
"(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()\n\n# Normalize pixel values to be between 0 and 1\ntrain_images, test_images = train_images / 255.0, test_images / 255.0",
"Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz\n170500096/170498071 [==============================] - 48s 0us/step\n"
],
[
"class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',\n 'dog', 'frog', 'horse', 'ship', 'truck']\n\nplt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid(False)\n plt.imshow(train_images[i], cmap=plt.cm.binary)\n # The CIFAR labels happen to be arrays, \n # which is why you need the extra index\n plt.xlabel(class_names[train_labels[i][0]])\nplt.show()",
"_____no_output_____"
],
[
"train_images[0].shape",
"_____no_output_____"
],
[
"32*32*3",
"_____no_output_____"
],
[
"# Setup Architecture\n\nmodel = Sequential()\nmodel.add(Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)))\nmodel.add(MaxPooling2D((2,2)))\nmodel.add(Conv2D(64, (3,3), activation='relu'))\nmodel.add(MaxPooling2D((2,2)))\nmodel.add(Conv2D(64, (3,3), activation='relu'))\nmodel.add(Flatten())\nmodel.add(Dense(64, activation='relu'))\nmodel.add(Dense(10, activation='softmax'))\n\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d (Conv2D) (None, 30, 30, 32) 896 \n_________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 13, 13, 64) 18496 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 4, 4, 64) 36928 \n_________________________________________________________________\nflatten (Flatten) (None, 1024) 0 \n_________________________________________________________________\ndense (Dense) (None, 64) 65600 \n_________________________________________________________________\ndense_1 (Dense) (None, 10) 650 \n=================================================================\nTotal params: 122,570\nTrainable params: 122,570\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# Compile Model\n\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"print(type(test_labels))",
"<class 'numpy.ndarray'>\n"
],
[
"# Fit Model\nmodel.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))",
"Train on 50000 samples, validate on 10000 samples\nEpoch 1/10\n50000/50000 [==============================] - 43s 859us/sample - loss: 1.5203 - accuracy: 0.4448 - val_loss: 1.2410 - val_accuracy: 0.5498\nEpoch 2/10\n50000/50000 [==============================] - 41s 824us/sample - loss: 1.1562 - accuracy: 0.5903 - val_loss: 1.0852 - val_accuracy: 0.6094\nEpoch 3/10\n50000/50000 [==============================] - 37s 748us/sample - loss: 1.0153 - accuracy: 0.6443 - val_loss: 0.9633 - val_accuracy: 0.6612\nEpoch 4/10\n50000/50000 [==============================] - 38s 769us/sample - loss: 0.9234 - accuracy: 0.6761 - val_loss: 0.9613 - val_accuracy: 0.6633\nEpoch 5/10\n50000/50000 [==============================] - 39s 782us/sample - loss: 0.8479 - accuracy: 0.7025 - val_loss: 0.9722 - val_accuracy: 0.6613\nEpoch 6/10\n50000/50000 [==============================] - 42s 833us/sample - loss: 0.7862 - accuracy: 0.7258 - val_loss: 0.9456 - val_accuracy: 0.6703\nEpoch 7/10\n50000/50000 [==============================] - 44s 883us/sample - loss: 0.7297 - accuracy: 0.7436 - val_loss: 0.8979 - val_accuracy: 0.6948\nEpoch 8/10\n50000/50000 [==============================] - 44s 889us/sample - loss: 0.6852 - accuracy: 0.7592 - val_loss: 0.9226 - val_accuracy: 0.6918\nEpoch 9/10\n50000/50000 [==============================] - 41s 827us/sample - loss: 0.6458 - accuracy: 0.7743 - val_loss: 0.8872 - val_accuracy: 0.6990\nEpoch 10/10\n50000/50000 [==============================] - 42s 831us/sample - loss: 0.6003 - accuracy: 0.7899 - val_loss: 0.8644 - val_accuracy: 0.7113\n"
],
[
"# Evaluate Model\n\ntest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)",
"10000/10000 - 3s - loss: 0.8644 - accuracy: 0.7113\n"
]
],
[
[
"## Challenge\n\nYou will apply CNNs to a classification task in the module project.",
"_____no_output_____"
],
[
"# CNNs for Object Detection (Learn)",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"### Transfer Learning - TensorFlow Hub\n\n\"A library for reusable machine learning modules\"\n\nThis lets you quickly take advantage of a model that was trained with thousands of GPU hours. It also enables transfer learning - reusing a part of a trained model (called a module) that includes weights and assets, but also training the overall model some yourself with your own data. The advantages are fairly clear - you can use less training data, have faster training, and have a model that generalizes better.\n\nhttps://www.tensorflow.org/hub/\n\n**WARNING** - Dragons ahead!\n\n\n\nTensorFlow Hub is very bleeding edge, and while there's a good amount of documentation out there, it's not always updated or consistent. You'll have to use your problem-solving skills if you want to use it!",
"_____no_output_____"
],
[
"## Follow Along",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nfrom tensorflow.keras.applications.resnet50 import ResNet50\nfrom tensorflow.keras.preprocessing import image\nfrom tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions\n\ndef process_img_path(img_path):\n return image.load_img(img_path, target_size=(224, 224))\n\ndef img_contains_banana(img):\n x = image.img_to_array(img)\n x = np.expand_dims(x, axis=0)\n x = preprocess_input(x)\n model = ResNet50(weights='imagenet')\n features = model.predict(x)\n results = decode_predictions(features, top=3)[0]\n print(results)\n for entry in results:\n if entry[1] == 'banana':\n return entry[2]\n return 0.0",
"_____no_output_____"
],
[
"import requests\n\nimage_urls = [\"https://github.com/LambdaSchool/ML-YouOnlyLookOnce/raw/master/sample_data/negative_examples/example11.jpeg\",\n \"https://github.com/LambdaSchool/ML-YouOnlyLookOnce/raw/master/sample_data/positive_examples/example0.jpeg\"]\n\nfor _id,img in enumerate(image_urls): \n r = requests.get(img)\n with open(f'example{_id}.jpg', 'wb') as f:\n f.write(r.content)",
"_____no_output_____"
],
[
"from IPython.display import Image\nImage(filename='./example0.jpg', width=600)",
"_____no_output_____"
],
[
"img_contains_banana(process_img_path('example0.jpg'))",
"[('n04037443', 'racer', 0.90904015), ('n04285008', 'sports_car', 0.08587643), ('n04461696', 'tow_truck', 0.0025079146)]\n"
],
[
"Image(filename='example1.jpg', width=600)",
"_____no_output_____"
],
[
"img_contains_banana(process_img_path('example1.jpg'))",
"[('n07753592', 'banana', 0.06412234), ('n03532672', 'hook', 0.060046483), ('n03498962', 'hatchet', 0.058439624)]\n"
]
],
[
[
"Notice that, while it gets it right, the confidence for the banana image is fairly low. That's because so much of the image is \"not-banana\"! How can this be improved? Bounding boxes to center on items of interest.",
"_____no_output_____"
],
[
"## Challenge\n\nYou will be expected to apply a pretrained model to a classificaiton problem today. ",
"_____no_output_____"
],
[
"# Review\n\n- <a href=\"#p1\">Part 1: </a>Describe convolution and pooling\n * A Convolution is a function applied to another function to produce a third function\n * Convolutional Kernels are typically 'learned' during the process of training a Convolution Neural Network\n * Pooling is a dimensionality reduction technique that uses either Max or Average of a feature map region to downsample data\n- <a href=\"#p2\">Part 2: </a>Apply a convolutional neural network to a classification task\n * Keras has layers for convolutions :) \n- <a href=\"#p3\">Part 3: </a>Use a pre-trained convolution neural network for object detection\n * Check out both pretinaed models available in Keras & TensorFlow Hub",
"_____no_output_____"
],
[
"# Sources\n\n- *_Deep Learning_*. Goodfellow *et al.*\n- [Keras CNN Tutorial](https://www.tensorflow.org/tutorials/images/cnn)\n- [Tensorflow + Keras](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Conv2D)\n- [Convolution Wiki](https://en.wikipedia.org/wiki/Convolution)\n- [Keras Conv2D: Working with CNN 2D Convolutions in Keras](https://missinglink.ai/guides/keras/keras-conv2d-working-cnn-2d-convolutions-keras/)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ad2896b99c57e7f7070242a2996f89e74bb5494
| 72,306 |
ipynb
|
Jupyter Notebook
|
IBMCourse/course1week4_pcaexample.ipynb
|
kyle-gao/PySpark_Exercises_from_IBM_Course
|
697fef1a1131998997221d7d89513e4abbbb5526
|
[
"Apache-2.0"
] | 1 |
2020-09-21T22:36:00.000Z
|
2020-09-21T22:36:00.000Z
|
IBMCourse/course1week4_pcaexample.ipynb
|
kyle-gao/PySpark_Exercises_from_IBM_Course
|
697fef1a1131998997221d7d89513e4abbbb5526
|
[
"Apache-2.0"
] | null | null | null |
IBMCourse/course1week4_pcaexample.ipynb
|
kyle-gao/PySpark_Exercises_from_IBM_Course
|
697fef1a1131998997221d7d89513e4abbbb5526
|
[
"Apache-2.0"
] | null | null | null | 36,153 | 72,305 | 0.916729 |
[
[
[
"This notebook is designed to run in a IBM Watson Studio default runtime (NOT the Watson Studio Apache Spark Runtime as the default runtime with 1 vCPU is free of charge). Therefore, we install Apache Spark in local mode for test purposes only. Please don't use it in production.\n\nIn case you are facing issues, please read the following two documents first:\n\nhttps://github.com/IBM/skillsnetwork/wiki/Environment-Setup\n\nhttps://github.com/IBM/skillsnetwork/wiki/FAQ\n\nThen, please feel free to ask:\n\nhttps://coursera.org/learn/machine-learning-big-data-apache-spark/discussions/all\n\nPlease make sure to follow the guidelines before asking a question:\n\nhttps://github.com/IBM/skillsnetwork/wiki/FAQ#im-feeling-lost-and-confused-please-help-me\n\n\nIf running outside Watson Studio, this should work as well. In case you are running in an Apache Spark context outside Watson Studio, please remove the Apache Spark setup in the first notebook cells.",
"_____no_output_____"
]
],
[
[
"from IPython.display import Markdown, display\ndef printmd(string):\n display(Markdown('# <span style=\"color:red\">'+string+'</span>'))\n\n\nif ('sc' in locals() or 'sc' in globals()):\n printmd('<<<<<!!!!! It seems that you are running in a IBM Watson Studio Apache Spark Notebook. Please run it in an IBM Watson Studio Default Runtime (without Apache Spark) !!!!!>>>>>')\n",
"_____no_output_____"
],
[
"!pip install pyspark==2.4.5",
"_____no_output_____"
],
[
"try:\n from pyspark import SparkContext, SparkConf\n from pyspark.sql import SparkSession\nexcept ImportError as e:\n printmd('<<<<<!!!!! Please restart your kernel after installing Apache Spark !!!!!>>>>>')",
"_____no_output_____"
],
[
"sc = SparkContext.getOrCreate(SparkConf().setMaster(\"local[*]\"))\n\nspark = SparkSession \\\n .builder \\\n .getOrCreate()",
"_____no_output_____"
]
],
[
[
"# Exercise 3.2\nWelcome to the last exercise of this course. This is also the most advanced one because it somehow glues everything together you've learned. \n\nThese are the steps you will do:\n- load a data frame from cloudant/ApacheCouchDB\n- perform feature transformation by calculating minimal and maximal values of different properties on time windows (we'll explain what a time windows is later in here)\n- reduce these now twelve dimensions to three using the PCA (Principal Component Analysis) algorithm of SparkML (Spark Machine Learning) => We'll actually make use of SparkML a lot more in the next course\n- plot the dimensionality reduced data set",
"_____no_output_____"
],
[
"Now it is time to grab a PARQUET file and create a dataframe out of it. Using SparkSQL you can handle it like a database. ",
"_____no_output_____"
]
],
[
[
"!wget https://github.com/IBM/coursera/blob/master/coursera_ds/washing.parquet?raw=true\n!mv washing.parquet?raw=true washing.parquet",
"_____no_output_____"
],
[
"df = spark.read.parquet('washing.parquet')\ndf.createOrReplaceTempView('washing')\ndf.show()",
"_____no_output_____"
]
],
[
[
"This is the feature transformation part of this exercise. Since our table is mixing schemas from different sensor data sources we are creating new features. In other word we use existing columns to calculate new ones. We only use min and max for now, but using more advanced aggregations as we've learned in week three may improve the results. We are calculating those aggregations over a sliding window \"w\". This window is defined in the SQL statement and basically reads the table by a one by one stride in direction of increasing timestamp. Whenever a row leaves the window a new one is included. Therefore this window is called sliding window (in contrast to tubling, time or count windows). More on this can be found here: https://flink.apache.org/news/2015/12/04/Introducing-windows.html\n\n",
"_____no_output_____"
]
],
[
[
"result = spark.sql(\"\"\"\nSELECT * from (\n SELECT\n min(temperature) over w as min_temperature,\n max(temperature) over w as max_temperature, \n min(voltage) over w as min_voltage,\n max(voltage) over w as max_voltage,\n min(flowrate) over w as min_flowrate,\n max(flowrate) over w as max_flowrate,\n min(frequency) over w as min_frequency,\n max(frequency) over w as max_frequency,\n min(hardness) over w as min_hardness,\n max(hardness) over w as max_hardness,\n min(speed) over w as min_speed,\n max(speed) over w as max_speed\n FROM washing \n WINDOW w AS (ORDER BY ts ROWS BETWEEN CURRENT ROW AND 10 FOLLOWING) \n)\nWHERE min_temperature is not null \nAND max_temperature is not null\nAND min_voltage is not null\nAND max_voltage is not null\nAND min_flowrate is not null\nAND max_flowrate is not null\nAND min_frequency is not null\nAND max_frequency is not null\nAND min_hardness is not null\nAND min_speed is not null\nAND max_speed is not null \n\"\"\")",
"_____no_output_____"
]
],
[
[
"Since this table contains null values also our window might contain them. In case for a certain feature all values in that window are null we obtain also null. As we can see here (in my dataset) this is the case for 9 rows.",
"_____no_output_____"
]
],
[
[
"df.count()-result.count()",
"_____no_output_____"
]
],
[
[
"Now we import some classes from SparkML. PCA for the actual algorithm. Vectors for the data structure expected by PCA and VectorAssembler to transform data into these vector structures.",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import PCA\nfrom pyspark.ml.linalg import Vectors\nfrom pyspark.ml.feature import VectorAssembler",
"_____no_output_____"
]
],
[
[
"Let's define a vector transformation helper class which takes all our input features (result.columns) and created one additional column called \"features\" which contains all our input features as one single column wrapped in \"DenseVector\" objects",
"_____no_output_____"
]
],
[
[
"assembler = VectorAssembler(inputCols=result.columns, outputCol=\"features\") ###columns of n features into a column of n_d row vector",
"_____no_output_____"
]
],
[
[
"Now we actually transform the data, note that this is highly optimized code and runs really fast in contrast if we had implemented it.",
"_____no_output_____"
]
],
[
[
"features = assembler.transform(result)",
"_____no_output_____"
]
],
[
[
"Let's have a look at how this new additional column \"features\" looks like:",
"_____no_output_____"
]
],
[
[
"features.rdd.map(lambda r : r.features).take(10)",
"_____no_output_____"
]
],
[
[
"Since the source data set has been prepared as a list of DenseVectors we can now apply PCA. Note that the first line again only prepares the algorithm by finding the transformation matrices (fit method)",
"_____no_output_____"
]
],
[
[
"pca = PCA(k=3, inputCol=\"features\", outputCol=\"pcaFeatures\") ###computes the transformation matrix\nmodel = pca.fit(features)",
"_____no_output_____"
]
],
[
[
"Now we can actually transform the data. Let's have a look at the first 20 rows",
"_____no_output_____"
]
],
[
[
"result_pca = model.transform(features).select(\"pcaFeatures\") ###performs the transformation\nresult_pca.show(truncate=False)",
"+-----------------------------------------------------------+\n|pcaFeatures |\n+-----------------------------------------------------------+\n|[1459.9789705814187,-18.745237781780922,70.78430794796873] |\n|[1459.995481828676,-19.11343146165273,70.72738871425986] |\n|[1460.0895843561282,-20.969471062922928,70.75630600322052] |\n|[1469.6993929419532,-20.403124647615513,62.013569674880955]|\n|[1469.7159041892107,-20.771318327487293,61.95665044117209] |\n|[1469.7128317338704,-20.790751117222456,61.896106678330966]|\n|[1478.3530264572928,-20.294557029728722,71.67550104809607] |\n|[1478.3530264572928,-20.294557029728722,71.67550104809607] |\n|[1478.3686036138165,-20.260626897636314,71.63355353606426] |\n|[1478.3686036138165,-20.260626897636314,71.63355353606426] |\n|[1483.5412027684088,-20.006222577501354,66.82710394284209] |\n|[1483.5171090223353,-20.867020421583753,66.86707301954084] |\n|[1483.4224268542928,-19.87574823665505,66.93027077913985] |\n|[1483.4224268542928,-19.87574823665505,66.93027077913985] |\n|[1488.103073547271,-19.311848573386925,72.1626182636411] |\n|[1488.1076926849646,-19.311945711095063,72.27621605605316] |\n|[1488.0135901575127,-17.455906109824838,72.2472987670925] |\n|[1488.026374556614,-17.47632766649086,72.2214703423] |\n|[1465.1644738447062,-17.50333829280811,47.06072898272612] |\n|[1465.1644738447062,-17.50333829280811,47.06072898272612] |\n+-----------------------------------------------------------+\nonly showing top 20 rows\n\n"
]
],
[
[
"So we obtained three completely new columns which we can plot now. Let run a final check if the number of rows is the same.",
"_____no_output_____"
]
],
[
[
"result_pca.count()",
"_____no_output_____"
]
],
[
[
"Cool, this works as expected. Now we obtain a sample and read each of the three columns into a python list",
"_____no_output_____"
]
],
[
[
"rdd = result_pca.rdd.sample(False,0.8)",
"_____no_output_____"
],
[
"x = rdd.map(lambda a : a.pcaFeatures).map(lambda a : a[0]).collect()",
"_____no_output_____"
],
[
"y = rdd.map(lambda a : a.pcaFeatures).map(lambda a : a[1]).collect()",
"_____no_output_____"
],
[
"z = rdd.map(lambda a : a.pcaFeatures).map(lambda a : a[2]).collect()",
"_____no_output_____"
]
],
[
[
"Finally we plot the three lists and name each of them as dimension 1-3 in the plot",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\n\n\nfig = plt.figure()\nax = fig.add_subplot(111, projection='3d')\n\n\n\n\nax.scatter(x,y,z, c='r', marker='o')\n\nax.set_xlabel('dimension1')\nax.set_ylabel('dimension2')\nax.set_zlabel('dimension3')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Congratulations, we are done! We can see two clusters in the data set. We can also see a third cluster which either can be outliers or a real cluster. In the next course we will actually learn how to compute clusters automatically. For now we know that the data indicates that there are two semi-stable states of the machine and sometime we see some anomalies since those data points don't fit into one of the two clusters.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad299e6204b97a49a54d2a3f9011059f3008a4d
| 1,008,008 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Testing with Fastq files-checkpoint.ipynb
|
ericmjl/flu-assembler
|
853f58c51f4e324662dafc4fa2892028093365a3
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Testing with Fastq files-checkpoint.ipynb
|
ericmjl/flu-assembler
|
853f58c51f4e324662dafc4fa2892028093365a3
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Testing with Fastq files-checkpoint.ipynb
|
ericmjl/flu-assembler
|
853f58c51f4e324662dafc4fa2892028093365a3
|
[
"MIT"
] | null | null | null | 18.57908 | 7,454 | 0.256933 |
[
[
[
"from Bio import SeqIO\n\nimport os\nimport numpy as np\nfrom collections import Counter\nimport matplotlib.pyplot as plt\n\nimport networkx as nx\n\n%matplotlib inline\n\n",
"_____no_output_____"
]
],
[
[
"Note: Used `usearch` by drive5 to filter reads.",
"_____no_output_____"
]
],
[
[
"DATA_PATH = \"/Users/ericmjl/Dropbox (MIT)/Research Projects/Runstadler Lab/Data/20150918141407_RUNC_nextgen_data\"\nFASTQ = 'giv3_RUNC_61923_final.fastq'\nFASTQ_FILTERED = 'full_iontorrent_dataset_giv3_RUNC_61923_final.filtered.fastq'\nFASTA = 'full_iontorrent_dataset_giv3_RUNC_61923_final.fasta'\n\nfastq = os.path.join(DATA_PATH, FASTQ)\nfasta = os.path.join(DATA_PATH, FASTA)\nfiltered = os.path.join(DATA_PATH, FASTQ_FILTERED)",
"_____no_output_____"
],
[
"# Find the minimum length\nmin_length = np.inf\nlen_counts = Counter()\nfor s in SeqIO.parse(fastq, 'fastq'):\n if len(s.seq) < min_length:\n min_length = len(s.seq)\n len_counts[len(s.seq)] += 1",
"_____no_output_____"
],
[
"min_length",
"_____no_output_____"
],
[
"sum(len_counts.values())",
"_____no_output_____"
],
[
"plt.bar(len_counts.keys(), len_counts.values())",
"_____no_output_____"
],
[
"# Check that exactly 2 vertices have odd degree. This makes sure that we have an\n# Eulerian graph.\n",
"_____no_output_____"
],
[
"testG.edges(data=True)",
"_____no_output_____"
],
[
"# Try implementing the eulerian path around the sequence.\n\n",
"_____no_output_____"
],
[
"stack = [n]\ntravG = testG.copy()\nsequence = stack[-1]\nfrom random import choice\nwhile stack:\n n = stack[-1]\n print(n)\n print(travG.successors(n))\n if travG.successors(n):\n s = testG.successors(n)[-1] # assuming only one successor\n sequence += s[-1]\n if travG.edge[n][s]['count'] == 0:\n pass\n if travG.edge[n][s]['count'] > 0:\n stack.pop(-1)\n stack.append(s)\n testG.edge[n][s]['count'] += -1\n if not travG.successors(n):\n break\n \n \nprint(sequence)\nprint(original)",
"GCT\n['CTA']\nCTA\n['TAG']\nTAG\n['AGT']\nAGT\n['GTT']\nGTT\n['TTT']\nTTT\n['TTA']\nTTA\n['TAC']\nTAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']\nACG\n['CGC', 'CGT']\nCGT\n['GTC']\nGTC\n['TCA']\nTCA\n['CAA', 'CAC']\nCAC\n['ACG']"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad2ab26d9ffb7a5c4b54d1815c1a4870a40d76a
| 1,000 |
ipynb
|
Jupyter Notebook
|
01_INRIX_data_preprocessing_ifac17/INRIX_data_preprocessing_26_flow_conservation_adjustment_LS_ext_for_inserted_links_Oct.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null |
01_INRIX_data_preprocessing_ifac17/INRIX_data_preprocessing_26_flow_conservation_adjustment_LS_ext_for_inserted_links_Oct.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null |
01_INRIX_data_preprocessing_ifac17/INRIX_data_preprocessing_26_flow_conservation_adjustment_LS_ext_for_inserted_links_Oct.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null | 18.181818 | 116 | 0.545 |
[
[
[
"%run ../Python_files/load_dicts.py\n%run ../Python_files/INRIX_data_preprocessing_30_flow_conservation_adjustment_LS_ext_for_inserted_links_Oct.py",
"1025.07800094\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4ad2ad66d3766ab583e151f494faf0ac077287e2
| 27,134 |
ipynb
|
Jupyter Notebook
|
wechat_tool/lesson_2.ipynb
|
telescopeuser/workshop_blog
|
3680173f5f22c564700f24a8def2a231cf1a0ccc
|
[
"MIT"
] | 226 |
2017-04-23T07:37:25.000Z
|
2022-01-06T05:22:02.000Z
|
wechat_tool/lesson_2.ipynb
|
telescopeuser/workshop_blog
|
3680173f5f22c564700f24a8def2a231cf1a0ccc
|
[
"MIT"
] | 4 |
2017-07-27T13:47:02.000Z
|
2019-04-11T03:31:07.000Z
|
wechat_tool/lesson_2.ipynb
|
telescopeuser/workshop_blog
|
3680173f5f22c564700f24a8def2a231cf1a0ccc
|
[
"MIT"
] | 71 |
2017-04-22T12:19:33.000Z
|
2021-03-07T10:19:56.000Z
| 34.565605 | 368 | 0.480172 |
[
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('FPgo-hI7OiE')",
"_____no_output_____"
]
],
[
[
"# 如何使用和开发微信聊天机器人的系列教程\n# A workshop to develop & use an intelligent and interactive chat-bot in WeChat",
"_____no_output_____"
],
[
"### WeChat is a popular social media app, which has more than 800 million monthly active users.\n\n<img src='http://www.kudosdata.com/wp-content/uploads/2016/11/cropped-KudosLogo1.png' width=30% style=\"float: right;\">\n<img src='reference/WeChat_SamGu_QR.png' width=10% style=\"float: right;\">\n\n### http://www.KudosData.com\n\nby: [email protected]\n\n\nMay 2017 ========== Scan the QR code to become trainer's friend in WeChat ========>>",
"_____no_output_____"
],
[
"### 第二课:图像识别和处理\n### Lesson 2: Image Recognition & Processing\n\n* 识别图片消息中的物体名字 (Recognize objects in image)\n [1] 物体名 (General Object)\n [2] 地标名 (Landmark Object)\n [3] 商标名 (Logo Object)\n\n* 识别图片消息中的文字 (OCR: Extract text from image)\n 包含简单文本翻译 (Call text translation API)\n \n* 识别人脸 (Recognize human face)\n 基于人脸的表情来识别喜怒哀乐等情绪 (Identify sentiment and emotion from human face)\n\n* 不良内容识别 (Explicit Content Detection)\n",
"_____no_output_____"
],
[
"### Using Google Cloud Platform's Machine Learning APIs",
"_____no_output_____"
],
[
"From the same API console, choose \"Dashboard\" on the left-hand menu and \"Enable API\".\n\nEnable the following APIs for your project (search for them) if they are not already enabled:\n<ol>\n<li> Google Translate API </li>\n<li> Google Cloud Vision API </li>\n<li> Google Natural Language API </li>\n<li> Google Cloud Speech API </li>\n</ol>\n\nFinally, because we are calling the APIs from Python (clients in many other languages are available), let's install the Python package (it's not installed by default on Datalab)",
"_____no_output_____"
]
],
[
[
"# Copyright 2016 Google Inc.\n# Licensed under the Apache License, Version 2.0 (the \"License\"); \n# !pip install --upgrade google-api-python-client",
"_____no_output_____"
]
],
[
[
"### 导入需要用到的一些功能程序库:",
"_____no_output_____"
]
],
[
[
"import io, os, subprocess, sys, time, datetime, requests, itchat\nfrom itchat.content import *\nfrom googleapiclient.discovery import build",
"█\r"
]
],
[
[
"### Using Google Cloud Platform's Machine Learning APIs\n\nFirst, visit <a href=\"http://console.cloud.google.com/apis\">API console</a>, choose \"Credentials\" on the left-hand menu. Choose \"Create Credentials\" and generate an API key for your application. You should probably restrict it by IP address to prevent abuse, but for now, just leave that field blank and delete the API key after trying out this demo.\n\nCopy-paste your API Key here:",
"_____no_output_____"
]
],
[
[
"# Here I read in my own API_KEY from a file, which is not shared in Github repository:\n# with io.open('../../API_KEY.txt') as fp: \n# for line in fp: APIKEY = line\n\n# You need to un-comment below line and replace 'APIKEY' variable with your own GCP API key:\nAPIKEY='AIzaSyCvxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'",
"_____no_output_____"
],
[
"# Below is for GCP Language Tranlation API\nservice = build('translate', 'v2', developerKey=APIKEY)",
"_____no_output_____"
]
],
[
[
"### 图片二进制base64码转换 (Define image pre-processing functions)",
"_____no_output_____"
]
],
[
[
"# Import the base64 encoding library.\nimport base64\n# Pass the image data to an encoding function.\ndef encode_image(image_file):\n with open(image_file, \"rb\") as image_file:\n image_content = image_file.read()\n return base64.b64encode(image_content)",
"_____no_output_____"
]
],
[
[
"### 机器智能API接口控制参数 (Define control parameters for API)",
"_____no_output_____"
]
],
[
[
"# control parameter for Image API:\nparm_image_maxResults = 10 # max objects or faces to be extracted from image analysis\n\n# control parameter for Language Translation API:\nparm_translation_origin_language = '' # original language in text: to be overwriten by TEXT_DETECTION\nparm_translation_target_language = 'zh' # target language for translation: Chinese",
"_____no_output_____"
]
],
[
[
"### * 识别图片消息中的物体名字 (Recognize objects in image) \n [1] 物体名 (General Object)",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'LABEL_DETECTION'\ndef KudosData_LABEL_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 物体识别 ]\\n'\n # 'LABEL_DETECTION'\n if responses['responses'][0] != {}:\n for i in range(len(responses['responses'][0]['labelAnnotations'])):\n image_analysis_reply += responses['responses'][0]['labelAnnotations'][i]['description'] \\\n + '\\n( confidence ' + str(responses['responses'][0]['labelAnnotations'][i]['score']) + ' )\\n'\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n \n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### * 识别图片消息中的物体名字 (Recognize objects in image) \n [2] 地标名 (Landmark Object)",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'LANDMARK_DETECTION'\ndef KudosData_LANDMARK_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 地标识别 ]\\n'\n # 'LANDMARK_DETECTION'\n if responses['responses'][0] != {}:\n for i in range(len(responses['responses'][0]['landmarkAnnotations'])):\n image_analysis_reply += responses['responses'][0]['landmarkAnnotations'][i]['description'] \\\n + '\\n( confidence ' + str(responses['responses'][0]['landmarkAnnotations'][i]['score']) + ' )\\n'\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n \n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### * 识别图片消息中的物体名字 (Recognize objects in image) \n [3] 商标名 (Logo Object)",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'LOGO_DETECTION'\ndef KudosData_LOGO_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 商标识别 ]\\n'\n # 'LOGO_DETECTION'\n if responses['responses'][0] != {}:\n for i in range(len(responses['responses'][0]['logoAnnotations'])):\n image_analysis_reply += responses['responses'][0]['logoAnnotations'][i]['description'] \\\n + '\\n( confidence ' + str(responses['responses'][0]['logoAnnotations'][i]['score']) + ' )\\n'\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n \n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### * 识别图片消息中的文字 (OCR: Extract text from image)",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'TEXT_DETECTION'\ndef KudosData_TEXT_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 文字提取 ]\\n'\n # 'TEXT_DETECTION'\n if responses['responses'][0] != {}:\n image_analysis_reply += u'----- Start Original Text -----\\n'\n image_analysis_reply += u'( Original Language 原文: ' + responses['responses'][0]['textAnnotations'][0]['locale'] \\\n + ' )\\n' \n image_analysis_reply += responses['responses'][0]['textAnnotations'][0]['description'] + '----- End Original Text -----\\n'\n\n ##############################################################################################################\n # translation of detected text #\n ##############################################################################################################\n parm_translation_origin_language = responses['responses'][0]['textAnnotations'][0]['locale']\n # Call translation if parm_translation_origin_language is not parm_translation_target_language\n if parm_translation_origin_language != parm_translation_target_language:\n inputs=[responses['responses'][0]['textAnnotations'][0]['description']] # TEXT_DETECTION OCR results only\n outputs = service.translations().list(source=parm_translation_origin_language, \n target=parm_translation_target_language, q=inputs).execute()\n image_analysis_reply += u'\\n----- Start Translation -----\\n'\n image_analysis_reply += u'( Target Language 译文: ' + parm_translation_target_language + ' )\\n'\n image_analysis_reply += outputs['translations'][0]['translatedText'] + '\\n' + '----- End Translation -----\\n'\n print('Compeleted: Translation API ...')\n ##############################################################################################################\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n \n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### * 识别人脸 (Recognize human face)\n### * 基于人脸的表情来识别喜怒哀乐等情绪 (Identify sentiment and emotion from human face)",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'FACE_DETECTION'\ndef KudosData_FACE_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 面部表情 ]\\n'\n # 'FACE_DETECTION'\n if responses['responses'][0] != {}:\n for i in range(len(responses['responses'][0]['faceAnnotations'])):\n image_analysis_reply += u'----- No.' + str(i+1) + ' Face -----\\n'\n \n image_analysis_reply += u'>>> Joy 喜悦: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'joyLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> Anger 愤怒: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'angerLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> Sorrow 悲伤: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'sorrowLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> Surprise 惊奇: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'surpriseLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> Headwear 头饰: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'headwearLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> Blurred 模糊: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'blurredLikelihood'] + '\\n'\n \n image_analysis_reply += u'>>> UnderExposed 欠曝光: \\n' \\\n + responses['responses'][0]['faceAnnotations'][i][u'underExposedLikelihood'] + '\\n'\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n \n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### * 不良内容识别 (Explicit Content Detection)\n\nDetect explicit content like adult content or violent content within an image.",
"_____no_output_____"
]
],
[
[
"# Running Vision API\n# 'SAFE_SEARCH_DETECTION'\ndef KudosData_SAFE_SEARCH_DETECTION(image_base64, API_type, maxResults):\n vservice = build('vision', 'v1', developerKey=APIKEY)\n request = vservice.images().annotate(body={\n 'requests': [{\n 'image': {\n# 'source': {\n# 'gcs_image_uri': IMAGE\n# }\n \"content\": image_base64\n },\n 'features': [{\n 'type': API_type,\n 'maxResults': maxResults,\n }]\n }],\n })\n responses = request.execute(num_retries=3)\n image_analysis_reply = u'\\n[ ' + API_type + u' 不良内容 ]\\n'\n # 'SAFE_SEARCH_DETECTION'\n if responses['responses'][0] != {}:\n image_analysis_reply += u'>>> Adult 成人: \\n' + responses['responses'][0]['safeSearchAnnotation'][u'adult'] + '\\n'\n image_analysis_reply += u'>>> Violence 暴力: \\n' + responses['responses'][0]['safeSearchAnnotation'][u'violence'] + '\\n'\n image_analysis_reply += u'>>> Spoof 欺骗: \\n' + responses['responses'][0]['safeSearchAnnotation'][u'spoof'] + '\\n'\n image_analysis_reply += u'>>> Medical 医疗: \\n' + responses['responses'][0]['safeSearchAnnotation'][u'medical'] + '\\n'\n else:\n image_analysis_reply += u'[ Nill 无结果 ]\\n'\n return image_analysis_reply",
"_____no_output_____"
]
],
[
[
"### 用微信App扫QR码图片来自动登录",
"_____no_output_____"
]
],
[
[
"itchat.auto_login(hotReload=True) # hotReload=True: 退出程序后暂存登陆状态。即使程序关闭,一定时间内重新开启也可以不用重新扫码。\n# itchat.auto_login(enableCmdQR=-2) # enableCmdQR=-2: 命令行显示QR图片",
"Getting uuid of QR code.\nDownloading QR code.\nPlease scan the QR code to log in.\n"
],
[
"# @itchat.msg_register([PICTURE], isGroupChat=True)\[email protected]_register([PICTURE])\ndef download_files(msg):\n parm_translation_origin_language = 'zh' # will be overwriten by TEXT_DETECTION\n msg.download(msg.fileName)\n print('\\nDownloaded image file name is: %s' % msg['FileName'])\n image_base64 = encode_image(msg['FileName'])\n \n ##############################################################################################################\n # call image analysis APIs #\n ##############################################################################################################\n \n image_analysis_reply = u'[ Image Analysis 图像分析结果 ]\\n'\n\n # 1. LABEL_DETECTION:\n image_analysis_reply += KudosData_LABEL_DETECTION(image_base64, 'LABEL_DETECTION', parm_image_maxResults)\n # 2. LANDMARK_DETECTION:\n image_analysis_reply += KudosData_LANDMARK_DETECTION(image_base64, 'LANDMARK_DETECTION', parm_image_maxResults)\n # 3. LOGO_DETECTION:\n image_analysis_reply += KudosData_LOGO_DETECTION(image_base64, 'LOGO_DETECTION', parm_image_maxResults)\n # 4. TEXT_DETECTION:\n image_analysis_reply += KudosData_TEXT_DETECTION(image_base64, 'TEXT_DETECTION', parm_image_maxResults)\n # 5. FACE_DETECTION:\n image_analysis_reply += KudosData_FACE_DETECTION(image_base64, 'FACE_DETECTION', parm_image_maxResults)\n # 6. SAFE_SEARCH_DETECTION:\n image_analysis_reply += KudosData_SAFE_SEARCH_DETECTION(image_base64, 'SAFE_SEARCH_DETECTION', parm_image_maxResults)\n\n print('Compeleted: Image Analysis API ...')\n \n return image_analysis_reply",
"_____no_output_____"
],
[
"itchat.run()",
"Start auto replying.\n"
],
[
"# interupt kernel, then logout\nitchat.logout() # 安全退出",
"_____no_output_____"
]
],
[
[
"### 恭喜您!已经完成了:\n### 第二课:图像识别和处理\n### Lesson 2: Image Recognition & Processing\n\n* 识别图片消息中的物体名字 (Recognize objects in image)\n [1] 物体名 (General Object)\n [2] 地标名 (Landmark Object)\n [3] 商标名 (Logo Object)\n\n* 识别图片消息中的文字 (OCR: Extract text from image)\n 包含简单文本翻译 (Call text translation API)\n \n* 识别人脸 (Recognize human face)\n 基于人脸的表情来识别喜怒哀乐等情绪 (Identify sentiment and emotion from human face)\n\n* 不良内容识别 (Explicit Content Detection)\n",
"_____no_output_____"
],
[
"### 下一课是:\n### 第三课:自然语言处理:语音合成和识别\n### Lesson 3: Natural Language Processing 1\n* 消息文字转成语音 (Speech synthesis: text to voice)\n* 语音转换成消息文字 (Speech recognition: voice to text)\n* 消息文字的多语言互译 (Text based language translation)",
"_____no_output_____"
],
[
"<img src='http://www.kudosdata.com/wp-content/uploads/2016/11/cropped-KudosLogo1.png' width=30% style=\"float: right;\">\n<img src='reference/WeChat_SamGu_QR.png' width=10% style=\"float: left;\">\n\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4ad2aff260b9694e84cfa673bd43a323969bddc9
| 15,973 |
ipynb
|
Jupyter Notebook
|
syllabus.ipynb
|
versae/DH2304B
|
9d7ab894b4515fec2a4450cb7733fe518e260a6b
|
[
"MIT"
] | null | null | null |
syllabus.ipynb
|
versae/DH2304B
|
9d7ab894b4515fec2a4450cb7733fe518e260a6b
|
[
"MIT"
] | null | null | null |
syllabus.ipynb
|
versae/DH2304B
|
9d7ab894b4515fec2a4450cb7733fe518e260a6b
|
[
"MIT"
] | 1 |
2022-02-09T21:44:38.000Z
|
2022-02-09T21:44:38.000Z
| 42.823056 | 791 | 0.634446 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4ad2b75200b406181df9eaa2820bad070fef7c50
| 4,262 |
ipynb
|
Jupyter Notebook
|
src/user_guide/kill_purge.ipynb
|
andrewrocks/sos-docs
|
fb742052f761e6c3532d8e849a8d07167bc2b4ef
|
[
"MIT"
] | null | null | null |
src/user_guide/kill_purge.ipynb
|
andrewrocks/sos-docs
|
fb742052f761e6c3532d8e849a8d07167bc2b4ef
|
[
"MIT"
] | null | null | null |
src/user_guide/kill_purge.ipynb
|
andrewrocks/sos-docs
|
fb742052f761e6c3532d8e849a8d07167bc2b4ef
|
[
"MIT"
] | null | null | null | 22.791444 | 381 | 0.529564 |
[
[
[
"# How to kill and purge local and remote tasks",
"_____no_output_____"
],
[
"* **Difficulty level**: easy\n* **Time need to lean**: 10 minutes or less\n* **Key points**:\n\n ",
"_____no_output_____"
],
[
"### `sos kill` ",
"_____no_output_____"
],
[
"Command\n\n```bash\nsos kill [tasks] [-q queue]\n```\n\nkills specified or all tasks on specified job queue `queue`. Because the same job could be executed on different queues (you have have done so), you will have to specify the correct queue name to kill the job on different queues.\n",
"_____no_output_____"
],
[
"### `sos execute`",
"_____no_output_____"
],
[
"Command \n````\nsos execute [tasks] [-q queue]\n```\n\nis the command that is used internally by `sos run` to execute tasks but you could use this command to execute tasks externally. For example, if a task failed on a server, you could use command\n\n```\nsos execute task_id -q server\n```\n\nto execute the command on another server. Note that `task_id` specifies a local task with local paths. The task will be converted to a remote task (with path names converted for that host) if `server` specifies a remote host. This makes it easy for you to re-submit tasks to the same server after changing server configuration, or submit the same task to a different server. ",
"_____no_output_____"
],
[
"### `sos purge`",
"_____no_output_____"
],
[
"Command `sos purge` is used to clear completed or failed tasks. You can remove all tasks related to current project (default), tasks by age (`--age`) or status (option `--status`) from local or remote host (option `-q`). For example, command\n\n```\nsos purge -q cluster\n```\nremoves all tasks related to current project from a remote cluster,\n\n```\nsos purge --age 2d\n```\nremoves all tasks that are created more than 2 days ago, and\n\n```\nsos purge -q cluster -s completed\n```\nremoves all completed tasks from the remote cluster.\n\nYou can also specify the IDs of tasks to be removed, e.g.\n\n```\nsos purge 38ef\n```\n\nremoves all tasks with ID starting with `38ef`.\n\nFinally, if you would like to remove all tasks related information, including tasks that are not generated by workflows from the current project (directory), you can use command\n\n```\nsos purge --all\n```\nto clear all information.",
"_____no_output_____"
],
[
"## Further reading\n\n* ",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ad2c2c9ac14fe9060bcd9a30f8e1577239bfa38
| 71,108 |
ipynb
|
Jupyter Notebook
|
monte_carlo.ipynb
|
gauravsofat/btp-archive
|
94617171547959e483c69cdb340b0c3c44068ac1
|
[
"MIT"
] | null | null | null |
monte_carlo.ipynb
|
gauravsofat/btp-archive
|
94617171547959e483c69cdb340b0c3c44068ac1
|
[
"MIT"
] | null | null | null |
monte_carlo.ipynb
|
gauravsofat/btp-archive
|
94617171547959e483c69cdb340b0c3c44068ac1
|
[
"MIT"
] | null | null | null | 105.189349 | 47,506 | 0.820878 |
[
[
[
"# Monte-Carlo Method",
"_____no_output_____"
],
[
"## Install External Libraries",
"_____no_output_____"
]
],
[
[
"!pip install PyPortfolioOpt\n!pip install yfinance",
"_____no_output_____"
]
],
[
[
"## Import Dependencies",
"_____no_output_____"
]
],
[
[
"import matplotlib\nimport pypfopt\nimport datetime\nimport math\n\nimport pandas as pd\nimport numpy as np\nimport yfinance as yf\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## Set Local Variables",
"_____no_output_____"
]
],
[
[
"risk_free_rate = 0.06501 # Risk-free rate of return, 10Yr Treasury Bond Yield\ntrading_days = 240 # No of trading days in a year\n\nstart_date = datetime.date(2000, 1, 1) # Oldest date to be considered for price analysis\ninvestment_date = datetime.date(2019, 1, 1) # Date when funds are invested \ninvestment_end = datetime.date(2020, 5, 1) # Date of end of investment period",
"_____no_output_____"
],
[
"asset_universe = ['HDFC.BO', 'BAJFINANCE.BO', 'SBIN.BO', 'TITAN.BO', 'HDFCBANK.BO', \n 'HEROMOTOCO.BO', 'INFY.BO', 'KOTAKBANK.BO', 'ONGC.BO', 'RELIANCE.BO',\n 'TATASTEEL.BO', 'LT.BO', 'M&M.BO', 'HINDUNILVR.BO', 'NESTLEIND.BO',\n 'ASIANPAINT.BO', 'ITC.BO', 'SUNPHARMA.BO', 'ICICIBANK.BO', 'INDUSINDBK.BO',\n 'AXISBANK.BO', 'HCLTECH.BO', 'BHARTIARTL.BO', 'MARUTI.BO','ULTRACEMCO.BO',\n 'TCS.BO', 'NTPC.BO', 'TECHM.BO', 'POWERGRID.BO','BAJAJ-AUTO.BO'\n]",
"_____no_output_____"
]
],
[
[
"## Process Historical Data",
"_____no_output_____"
]
],
[
[
"# Download historical closing prices\nsensex30_history = yf.download(asset_universe, start=start_date, end=investment_end, auto_adjust=True).loc[:, 'Close']\nsensex_history = yf.download('^BSESN', start=start_date, end=investment_end, auto_adjust=True).loc[:, 'Close']",
"[*********************100%***********************] 30 of 30 completed\n[*********************100%***********************] 1 of 1 completed\n"
],
[
"# Rename data columns\nrename_col_dict = dict()\nfor ticker in sensex30_history.columns:\n rename_col_dict[ticker] = ticker[:-3]\n\nsensex30_history = sensex30_history.rename(columns=rename_col_dict)",
"_____no_output_____"
]
],
[
[
"## Compute and Plot Expected Returns",
"_____no_output_____"
]
],
[
[
"# Compute expected returns\nsensex30_prices = sensex30_history.loc[start_date:investment_date , :].copy()\n\n# Compute annualised mean daily returns of 30 stocks using data since 2009\nmean_daily_returns = sensex30_prices.pct_change().dropna(how=\"all\").mean()\n\n# Annualise mean daily returns via compounding\nexpected_returns = (1 + mean_daily_returns) ** trading_days - 1\n# print(type(expected_returns))",
"_____no_output_____"
],
[
"# Plot Expected Returns\nplt.style.use(\"seaborn-whitegrid\")\nax = expected_returns.plot(kind=\"barh\")\nstart, end = ax.get_xlim()\nax.xaxis.set_ticks(np.arange(start, end, 0.5))\nplt.grid(True)\nplt.ylabel(\"Stock Tickers\")\nplt.xlabel(\"Expected Return\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Compute and Plot Co-variance Matrix",
"_____no_output_____"
]
],
[
[
"# Compute Covariance Matrix\ncov_matrix = pypfopt.risk_models.CovarianceShrinkage(sensex30_prices, frequency=trading_days).ledoit_wolf(shrinkage_target=\"constant_correlation\")\n\n# Convert Covariance Matrix to Correlation Matrix\ninv_diag = np.diag(1 / np.sqrt(np.diag(cov_matrix)))\ncorr_matrix = pd.DataFrame(np.dot(inv_diag, np.dot(cov_matrix, inv_diag)), index=cov_matrix.index, columns=cov_matrix.columns)",
"_____no_output_____"
],
[
"# Plot Covariance Matrix Heatmap\n\nplt.style.use(\"default\")\nfig, ax = plt.subplots()\n\ncorr_ax = ax.imshow(corr_matrix, cmap='magma')\n\nfig.colorbar(corr_ax)\nax.set_xticks(np.arange(0, corr_matrix.shape[0], 1))\nax.set_xticklabels(corr_matrix.index)\nax.set_yticks(np.arange(0, corr_matrix.shape[0], 1))\nax.set_yticklabels(corr_matrix.index)\nplt.xticks(rotation=90)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Monte-Carlo Simulations",
"_____no_output_____"
]
],
[
[
"num_iterations = 1000000 # Number of simulations to be run\nsimulation_results = np.zeros((33 , num_iterations)) # Array to store the simulation results",
"_____no_output_____"
],
[
"# Simulate random weights and normalize them to ensure their aggregate is 1\n\nfor i in range(num_iterations):\n weights = np.array(np.random.random(30))\n weights /= np.sum(weights)\n portfolio_return = np.sum(expected_returns * weights)\n portfolio_stddev = np.sqrt(np.dot(weights.T,np.dot(cov_matrix, weights)))\n simulation_results[0,i] = portfolio_return\n simulation_results[1,i] = portfolio_stddev\n simulation_results[2,i] = simulation_results[0,i] / simulation_results[1,i]\n for j in range(len(weights)):\n simulation_results[j+3,i] = weights[j]",
"_____no_output_____"
],
[
"stock_list = list(sensex30_history.columns)\ncolumns = ['return','stdev','sharpe'] + stock_list\n\nsimulation_df = pd.DataFrame(simulation_results.T, columns=columns)",
"_____no_output_____"
]
],
[
[
"## Optimal Portfolio: Maximum Sharpe Ratio",
"_____no_output_____"
]
],
[
[
"max_sharpe_portfolio = simulation_df.iloc[simulation_df['sharpe'].idxmax()]\n\nmax_sharpe_nonzero_wts = dict()\nfor key, val in max_sharpe_portfolio.iloc[3:].items():\n if val != 0:\n max_sharpe_nonzero_wts[key] = val\nprint(max_sharpe_nonzero_wts)\n\n# max_sharpe_nonzero_wts = {'ASIANPAINT': 0.07343238490348997, 'AXISBANK': 0.008612974885070648, 'BAJAJ-AUTO': 0.03813084499118751, 'BAJFINANCE': 0.061185912560794316, 'BHARTIARTL': 0.004593054770775295, 'HCLTECH': 0.02086067944574963, 'HDFC': 0.03605937751872655, 'HDFCBANK': 0.040425363142332506, 'HEROMOTOCO': 0.06362023999177947, 'HINDUNILVR': 0.0013520625386036853, 'ICICIBANK': 0.043585316890703024, 'INDUSINDBK': 0.004503803481489264, 'INFY': 0.08042114124561395, 'ITC': 0.053653646551070425, 'KOTAKBANK': 0.024905588185587458, 'LT': 0.00534836152674258, 'M&M': 0.02682813480887665, 'MARUTI': 0.002167708621866709, 'NESTLEIND': 0.06076848889180933, 'NTPC': 0.015182944531474951, 'ONGC': 0.05442929888657013, 'POWERGRID': 0.03257005691129782, 'RELIANCE': 0.015565039461076551, 'SBIN': 0.05649540175373632, 'SUNPHARMA': 0.04901544405907509, 'TATASTEEL': 0.007102437112315602, 'TCS': 0.06347439598854171, 'TECHM': 0.024771014628683825, 'TITAN': 0.0016933222736356726, 'ULTRACEMCO': 0.02924555944132324}",
"_____no_output_____"
],
[
"# Plot Maximum Sharpe Ratio Portfolio\n\nplt.style.use(\"default\")\nplt.pie(max_sharpe_nonzero_wts.values(), labels=max_sharpe_nonzero_wts.keys(), autopct=\"%.2f%%\", pctdistance=0.8)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Optimal Portfolio: Min Volatility",
"_____no_output_____"
]
],
[
[
"min_volatility_portfolio = simulation_df.iloc[simulation_df['stdev'].idxmin()]\n\nmin_volatility_nonzero_wts = dict()\nfor key, val in min_volatility_portfolio.iloc[3:].items():\n if val != 0:\n min_volatility_nonzero_wts[key] = val\nprint(min_volatility_nonzero_wts)\n\n# min_volatility_nonzero_wts = {'ASIANPAINT': 0.01965804063580751, 'AXISBANK': 0.07921900481905146, 'BAJAJ-AUTO': 0.04732795120160519, 'BAJFINANCE': 0.006120193243540219, 'BHARTIARTL': 0.06385857271334033, 'HCLTECH': 0.020179076198290534, 'HDFC': 0.020976476571361927, 'HDFCBANK': 0.0031102360667119348, 'HEROMOTOCO': 0.06424486152873407, 'HINDUNILVR': 0.0835648551821641, 'ICICIBANK': 0.02450419620045124, 'INDUSINDBK': 0.0023788405507441305, 'INFY': 0.0349505328171844, 'ITC': 0.005338397125845731, 'KOTAKBANK': 0.015183855668722742, 'LT': 0.02607057640222921, 'M&M': 0.007845254228140591, 'MARUTI': 0.04593207681819233, 'NESTLEIND': 0.051963769101888095, 'NTPC': 0.04613073193245974, 'ONGC': 0.016806068861266624, 'POWERGRID': 0.04827795057037961, 'RELIANCE': 0.06797010969697301, 'SBIN': 0.01728353751669665, 'SUNPHARMA': 0.06417051300273635, 'TATASTEEL': 0.010970783283510551, 'TCS': 0.008782654701519997, 'TECHM': 0.02575905660883659, 'TITAN': 0.00041541287572671064, 'ULTRACEMCO': 0.0710064138758882}",
"_____no_output_____"
],
[
"# Plot Minimum Volatility Ratio Portfolio\n\nplt.style.use(\"default\")\nplt.pie(min_volatility_nonzero_wts.values(), labels=min_volatility_nonzero_wts.keys(), autopct=\"%.2f%%\", pctdistance=0.8)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Scatter Plot For Simulated Portfolios",
"_____no_output_____"
]
],
[
[
"# Plot Scatter Plot For Monte-Carlo Simulated Portfolio\n\nplt.style.use(\"seaborn-whitegrid\")\nplt.xlabel('Standard Deviation')\nplt.ylabel('Returns')\n\nplt.scatter(simulation_df['stdev']**2, simulation_df['return'], c=simulation_df['sharpe'], cmap=\"gray\")\n\nmax_sharpe_pt = plt.scatter(max_sharpe_portfolio[1]**2, max_sharpe_portfolio[0],color='r', s=100)\nmin_volatility_pt = plt.scatter(min_volatility_portfolio[1]**2, min_volatility_portfolio[0], color='b', s=100)\nplt.grid(True)\n\nplt.legend((max_sharpe_pt, min_volatility_pt), ('Max Sharpe', 'Min Volatility'), loc='best')\nplt.ylabel(\"Expected Returns\")\nplt.xlabel(\"Risk\")\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Performance Analysis of Monte Carlo Method",
"_____no_output_____"
]
],
[
[
"# Slice price datasets to required time-ranges\nsensex_prices = sensex_history.loc[investment_date:investment_end].copy()\nsensex30_prices = sensex30_history.loc[investment_date:investment_end].copy()",
"_____no_output_____"
],
[
"# Create dataframe to analyse portfolio performance\nportfolio_performance = pd.DataFrame(index=sensex_prices.index)\n\n# Import Sensex benchmark price value data\nportfolio_performance['Sensex'] = sensex_prices",
"_____no_output_____"
],
[
"# Import Max Sharpe portfolio price value\n# max_sharpe_nonzero_wts = {'ASIANPAINT': 0.07343238490348997, 'AXISBANK': 0.008612974885070648, 'BAJAJ-AUTO': 0.03813084499118751, 'BAJFINANCE': 0.061185912560794316, 'BHARTIARTL': 0.004593054770775295, 'HCLTECH': 0.02086067944574963, 'HDFC': 0.03605937751872655, 'HDFCBANK': 0.040425363142332506, 'HEROMOTOCO': 0.06362023999177947, 'HINDUNILVR': 0.0013520625386036853, 'ICICIBANK': 0.043585316890703024, 'INDUSINDBK': 0.004503803481489264, 'INFY': 0.08042114124561395, 'ITC': 0.053653646551070425, 'KOTAKBANK': 0.024905588185587458, 'LT': 0.00534836152674258, 'M&M': 0.02682813480887665, 'MARUTI': 0.002167708621866709, 'NESTLEIND': 0.06076848889180933, 'NTPC': 0.015182944531474951, 'ONGC': 0.05442929888657013, 'POWERGRID': 0.03257005691129782, 'RELIANCE': 0.015565039461076551, 'SBIN': 0.05649540175373632, 'SUNPHARMA': 0.04901544405907509, 'TATASTEEL': 0.007102437112315602, 'TCS': 0.06347439598854171, 'TECHM': 0.024771014628683825, 'TITAN': 0.0016933222736356726, 'ULTRACEMCO': 0.02924555944132324}\n\nmax_sharpe_val = pd.Series(index=sensex30_prices.index)\n\nfor index in sensex30_prices.index:\n val = 0\n for stock, wt in max_sharpe_nonzero_wts.items():\n val = val + wt * sensex30_prices.loc[index, stock]\n max_sharpe_val[index] = val\n\nportfolio_performance['Max Sharpe'] = max_sharpe_val",
"_____no_output_____"
],
[
"# Import Min Volatility portfolio price value\n# min_volatility_nonzero_wts = {'ASIANPAINT': 0.01965804063580751, 'AXISBANK': 0.07921900481905146, 'BAJAJ-AUTO': 0.04732795120160519, 'BAJFINANCE': 0.006120193243540219, 'BHARTIARTL': 0.06385857271334033, 'HCLTECH': 0.020179076198290534, 'HDFC': 0.020976476571361927, 'HDFCBANK': 0.0031102360667119348, 'HEROMOTOCO': 0.06424486152873407, 'HINDUNILVR': 0.0835648551821641, 'ICICIBANK': 0.02450419620045124, 'INDUSINDBK': 0.0023788405507441305, 'INFY': 0.0349505328171844, 'ITC': 0.005338397125845731, 'KOTAKBANK': 0.015183855668722742, 'LT': 0.02607057640222921, 'M&M': 0.007845254228140591, 'MARUTI': 0.04593207681819233, 'NESTLEIND': 0.051963769101888095, 'NTPC': 0.04613073193245974, 'ONGC': 0.016806068861266624, 'POWERGRID': 0.04827795057037961, 'RELIANCE': 0.06797010969697301, 'SBIN': 0.01728353751669665, 'SUNPHARMA': 0.06417051300273635, 'TATASTEEL': 0.010970783283510551, 'TCS': 0.008782654701519997, 'TECHM': 0.02575905660883659, 'TITAN': 0.00041541287572671064, 'ULTRACEMCO': 0.0710064138758882}\n\nmin_volatility_val = pd.Series(index=sensex30_prices.index)\n\nfor index in sensex30_prices.index:\n val = 0\n for stock, wt in min_volatility_nonzero_wts.items():\n val = val + wt * sensex30_prices.loc[index, stock]\n min_volatility_val[index] = val\n\nportfolio_performance['Min Volatility'] = min_volatility_val",
"_____no_output_____"
],
[
"# Compute and Plot Relative Portfolio Performance\nportfolio_performance = portfolio_performance.pct_change()\n\n# Normalise data to measure relative percentage change over time\nfor label, content in portfolio_performance.iteritems():\n for index, value in content.iteritems():\n if math.isnan(value):\n portfolio_performance.loc[index, label] = 100\n prev_index = index\n else:\n portfolio_performance.loc[index, label] = portfolio_performance.loc[prev_index, label] * (1 + value)\n prev_index = index",
"_____no_output_____"
],
[
"# Plot Relative Performance Graph\nplt.style.use('seaborn-whitegrid')\nportfolio_performance.plot(grid=True)\nplt.ylabel(\"Relative Value\")\nplt.show()",
"_____no_output_____"
],
[
"# Print LaTeX-friendly portfolio composition\n\nfor ticker in sensex30_prices.columns.values:\n print(ticker + ' & ' + \n (str(round(max_sharpe_nonzero_wts[ticker]*100, 2)) if ticker in max_sharpe_nonzero_wts else 0.00) \n + '\\% & ' \n + (str(round(min_volatility_nonzero_wts[ticker]*100, 2)) if ticker in min_volatility_nonzero_wts else 0.00)\n + '\\% \\\\\\\\' )",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad2df567d90793a886d96c87f4f2d30f8dc9b4c
| 17,630 |
ipynb
|
Jupyter Notebook
|
test/suli/A6-hungeo.ipynb
|
csaladenes/csaladenes.github.io
|
b585ab399df169189a16164bc37d51ccd6cd5ef4
|
[
"MIT"
] | 2 |
2018-11-15T09:59:50.000Z
|
2020-01-01T09:35:20.000Z
|
test/suli/A6-hungeo.ipynb
|
csaladenes/csaladenes.github.io
|
b585ab399df169189a16164bc37d51ccd6cd5ef4
|
[
"MIT"
] | 1 |
2017-04-21T01:54:52.000Z
|
2017-04-21T01:56:55.000Z
|
test/suli/A6-hungeo.ipynb
|
csaladenes/csaladenes.github.io
|
b585ab399df169189a16164bc37d51ccd6cd5ef4
|
[
"MIT"
] | 2 |
2017-11-06T15:29:32.000Z
|
2021-03-30T15:49:38.000Z
| 32.83054 | 288 | 0.5654 |
[
[
[
"import pandas as pd\nimport json\nimport numpy as np",
"_____no_output_____"
],
[
"megye={'Fehér':'ALBA', 'Arad':'ARAD', 'Bukarest':'B', 'Bákó':'BACAU', 'Bihar':'BIHOR', 'Beszterce-Naszód':'BISTRITA-NASAUD',\n 'Brassó':'BRASOV', 'Kolozs':'CLUJ', 'Kovászna':'COVASNA', 'Krassó-Szörény':'CARAS-SEVERIN', 'Hunyad':'HUNEDOARA',\n 'Hargita':'HARGHITA', 'Máramaros':'MARAMURES', 'Maros':'MURES', 'Szeben':'SIBIU', 'Szatmár':'SATU MARE', 'Szilágy':'SALAJ',\n 'Temes':'TIMIS'}",
"_____no_output_____"
],
[
"ro={'Ă':'A','Ş':'S','Â':'A','Ș':'S','Ț':'T','Â':'A','Î':'I','Ă':'A','Ţ':'T','-':' ','SC.GEN.':'','I VIII':''}\ndef roman(s):\n return replacer(s,ro)",
"_____no_output_____"
]
],
[
[
"Load processed geocoded db",
"_____no_output_____"
]
],
[
[
"data=pd.read_excel('data/clean/erdely6.xlsx').drop('Unnamed: 0',axis=1)",
"_____no_output_____"
],
[
"data['guess_scores']=abs(data['guess_scores']).replace(0,50)",
"_____no_output_____"
],
[
"data.index=data['Denumire'].astype(str)+' '+data['Localitate'].astype(str)+', '+data['Localitate superioară'].astype(str)+', '+\\\n data['Stradă'].astype(str)+' nr. '+data['Număr'].astype(str)+', '+data['Cod poștal'].astype(str).str[:-2]+', '+\\\n data['Judet'].astype(str)+', ROMANIA'",
"_____no_output_____"
],
[
"geo=pd.read_excel('data/clean/geo.xlsx').drop('Unnamed: 0',axis=1).set_index('index')\ngeo['telepules_g']=geo['telepules']\ngeo=geo.drop('telepules',axis=1)",
"_____no_output_____"
],
[
"data=data.join(geo)",
"_____no_output_____"
],
[
"hun_city={i:i for i in np.sort(list(data['varos'].unique()))}",
"_____no_output_____"
],
[
"open('data/geo/hun_city.json','w',encoding='utf8').write(json.dumps(hun_city,ensure_ascii=False))",
"_____no_output_____"
],
[
"pd.DataFrame(data['varos'].unique()).to_excel('data/geo/geo.xlsx')\n# pd.DataFrame(data['varos'].unique()).to_excel('data/geo/geo_manual.xlsx')",
"_____no_output_____"
]
],
[
[
"Manually edit and fix, then load back",
"_____no_output_____"
]
],
[
[
"geom=list(pd.read_excel('data/geo/geo_manual.xlsx').drop('Unnamed: 0',axis=1)[0].unique())",
"_____no_output_____"
],
[
"geom=data[['telepules','varos']].set_index('varos').loc[geom].reset_index().set_index('telepules')\ngeom.columns=['varos_geo']",
"_____no_output_____"
],
[
"#can't join, no judet",
"_____no_output_____"
]
],
[
[
"Geocode from Szekelydata DB",
"_____no_output_____"
]
],
[
[
"hun=json.loads(open('data/geo/hun2.json','r').read())",
"_____no_output_____"
],
[
"hdf=pd.DataFrame(hun).stack().reset_index().set_index('level_1').join(pd.DataFrame(megye,index=['level_1']).T.reset_index().reset_index().set_index('level_1').drop('level_0',axis=1))\nhdf.columns=['telepules','telepules_hun','Megye']",
"_____no_output_____"
],
[
"hdf.index=hdf['Megye']+'+'+hdf['telepules']\ndata.index=data['Megye']+'+'+data['telepules']",
"_____no_output_____"
],
[
"data=data.join(hdf['telepules_hun'])",
"_____no_output_____"
],
[
"data['telepules_hun']=data[['varos','telepules_hun']].T.ffill().T['telepules_hun']",
"_____no_output_____"
],
[
"gata=data[['ID','Év','Megye', 'telepules','telepules_hun','guessed_names2', 'guess_scores','Név','Típus', 'Profil',\n 'Óvodás csoportok összesen',\n 'Óvodások összesen', 'Kiscsoportok száma', 'Kiscsoportosok',\n 'Középcsoportok száma', 'Középcsoportosok', 'Nagycsoportok száma',\n 'Nagycsoportosok', 'Vegyes csoportok száma', 'Vegyescsoportosok',\n 'Tanítók összesen', 'Képzett tanítók', 'Képzetlen tanítók',\n 'Elemi osztályok összesen', 'Elemisek összesen',\n 'Előkészítő osztályok száma', 'Előkészítő osztályosok',\n '1. osztályok száma', '1. osztályosok', '2. osztályok száma',\n '2. osztályosok', '3. osztályok száma', '3. osztályosok',\n '4. osztályok száma', '4. osztályosok', 'Általános osztályok összesen',\n 'Általánososok összesen', '5. osztályok száma', '5. osztályosok',\n '6. osztályok száma', '6. osztályosok', '7. osztályok száma',\n '7. osztályosok', '8. osztályok száma', '8. osztályosok',\n 'Középiskolai osztályok összesen', 'Középiskolások összesen',\n '9. osztályok száma', '9. osztályosok', '10. osztályok száma',\n '10. osztályosok', '11. osztályok száma', '11. osztályosok',\n '12. osztályok száma', '12. osztályosok', '13. osztályok száma',\n '13. osztályosok', '14. osztályok száma', '14. osztályosok','Továbbtanulás', 'Iskolabusz', \n 'Cod SIIIR', 'Cod SIRUES', 'Denumire scurtă', 'Denumire', 'Localitate',\n 'Localitate superioară', 'Stradă', 'Număr', 'Cod poștal', 'Statut',\n 'Tip unitate', 'Unitate PJ', 'Mod funcționare', 'Formă de finanțare',\n 'Formă de proprietate', 'Cod fiscal', 'Judet', 'Data modificării',\n 'Data acreditării', 'Data intrării în vigoare', 'Data închiderii',\n 'Telefon', 'Fax', 'Adresa email', 'nev', 'telepules_g','varos','cim', 'koordinata', 'telefon', 'web', 'maps', 'kep', \n \n ]]",
"_____no_output_____"
],
[
"gata.columns=['ID','Év','Megye', 'Település (eredeti)','Település (magyar VÁZLAT)','Név (normalizált)', 'Adatok megbízhatósága',\n 'Név (eredeti)','Típus (VÁZLAT)', 'Profil (VÁZLAT)',\n 'Óvodás csoportok összesen',\n 'Óvodások összesen', 'Kiscsoportok száma', 'Kiscsoportosok',\n 'Középcsoportok száma', 'Középcsoportosok', 'Nagycsoportok száma',\n 'Nagycsoportosok', 'Vegyes csoportok száma', 'Vegyescsoportosok',\n 'Tanítók összesen', 'Képzett tanítók', 'Képzetlen tanítók',\n 'Elemi osztályok összesen', 'Elemisek összesen',\n 'Előkészítő osztályok száma', 'Előkészítő osztályosok',\n '1. osztályok száma', '1. osztályosok', '2. osztályok száma',\n '2. osztályosok', '3. osztályok száma', '3. osztályosok',\n '4. osztályok száma', '4. osztályosok', 'Általános osztályok összesen',\n 'Általánososok összesen', '5. osztályok száma', '5. osztályosok',\n '6. osztályok száma', '6. osztályosok', '7. osztályok száma',\n '7. osztályosok', '8. osztályok száma', '8. osztályosok',\n 'Középiskolai osztályok összesen', 'Középiskolások összesen',\n '9. osztályok száma', '9. osztályosok', '10. osztályok száma',\n '10. osztályosok', '11. osztályok száma', '11. osztályosok',\n '12. osztályok száma', '12. osztályosok', '13. osztályok száma',\n '13. osztályosok', '14. osztályok száma', '14. osztályosok','Továbbtanulás (VÁZLAT)', 'Iskolabusz (VÁZLAT)', \n 'RSH SIIIR kód', 'RSH SIRUES kód', 'RSH Rövid név', 'RSH Név', 'RSH Település',\n 'RSH Község', 'RSH Cím/Utca', 'RSH Cím/Szám', 'RSH Cím/Irányítószám', 'RSH Jogi forma',\n 'RSH Egység típusa', 'RSH Anyaintézmény', 'RSH Működési forma', 'RSH Finanszírozás',\n 'RSH Tulajdonviszony', 'RSH Adószám', 'RSH Megye', 'RSH Módosítva',\n 'RSH Akkreditálva', 'RSH Működés kezdete', 'RSH Bezárás ideje',\n 'RSH Telefon', 'RSH Fax', 'RSH Email', 'GOOGLE Név', 'GOOGLE Település', 'GOOGLE Község', 'GOOGLE Cím', \n 'GOOGLE koordináta', 'GOOGLE Telefon', 'GOOGLE weboldal', 'GOOGLE térkép', 'GOOGLE fénykép', \n ]",
"_____no_output_____"
],
[
"gata['Név (normalizált)']=gata['Név (normalizált)']\\\n.str.replace('SGMZ','ÁLTALÁNOS ISKOLA')\\\n.str.replace('SPRM','ELEMI ISKOLA')\\\n.str.replace('SPSTL','POSZTLÍCEUM')\\\n.str.replace('LICTEH','SZAKLÍCEUM')\\\n.str.replace('LISPRT','SPORTISKOLA')\\\n.str.replace('CLBCOP','GYEREK-KLUB')\\\n.str.replace('LITEOR','ELMÉLETI LÍCEUM')\\\n.str.replace('LIPDGA','TANÍTÓKÉPZŐ')\\\n.str.replace('LITOLX','TEOLÓGIAI LÍCEUM')\\\n.str.replace('LIARTE','MŰVÉSZETI LÍCEUM')\\\n.str.replace('COLGNAT','NEMZETI KOLLÉGIUM')\\\n.str.replace('GRDNRM','ÓVODA')\\\n.str.replace('GRDPLG','NAPKÖZI-OTTHON')\\\n.str.replace('INSPSCJ','TANFELÜGYELŐSÉG')\\\n.str.replace('SCSPC','SPECIÁLIS ISKOLA')",
"C:\\ProgramData\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:16: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n app.launch_new_instance()\n"
],
[
"hata=gata.set_index('ID').sort_values(['Év','Megye','Település (eredeti)','Név (normalizált)'])",
"_____no_output_____"
],
[
"hata.to_excel('data/output/Erdely_draft_output.xlsx')",
"_____no_output_____"
]
],
[
[
"DEPRECATED - google cant translate place names\nFinish up the rest with `googletrans`",
"_____no_output_____"
]
],
[
[
"# !pip install googletrans",
"_____no_output_____"
],
[
"from googletrans import Translator\ntranslator = Translator()\nt=translator.translate('scoala',src='ro',dest='hu')",
"_____no_output_____"
],
[
"to_translate=list((data['telepules']+', judetul '+data['Judet']+', ROMANIA').unique())[:20]",
"_____no_output_____"
],
[
"to_translate=list((data['Denumire'].astype(str)+' '+data['Localitate'].astype(str)+', '+data['Localitate superioară'].astype(str)+', '+\\\n data['Stradă'].astype(str)+' nr. '+data['Număr'].astype(str)+', '+data['Cod poștal'].astype(str).str[:-2]+', '+\\\n data['Judet'].astype(str)+', ROMANIA').unique())[:10]",
"_____no_output_____"
],
[
"translated={}",
"_____no_output_____"
],
[
"translations = translator.translate(to_translate, src='ro', dest='hu')\nfor translation in translations:\n translated[translation.origin]=translation.text",
"_____no_output_____"
],
[
"translated",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad2e892e8306b6992b395d1de11510d93150655
| 2,788 |
ipynb
|
Jupyter Notebook
|
Final_Project.ipynb
|
khangnngo12/Possible-Suggestion
|
e08ff61e74ab1e0962524176d1c3ab53e95a08d0
|
[
"MIT"
] | null | null | null |
Final_Project.ipynb
|
khangnngo12/Possible-Suggestion
|
e08ff61e74ab1e0962524176d1c3ab53e95a08d0
|
[
"MIT"
] | 1 |
2020-12-04T08:27:29.000Z
|
2020-12-08T13:59:35.000Z
|
Final_Project.ipynb
|
khangnngo12/Possible-Suggestion
|
e08ff61e74ab1e0962524176d1c3ab53e95a08d0
|
[
"MIT"
] | null | null | null | 29.041667 | 103 | 0.560258 |
[
[
[
"#import all the needed libraries\n%matplotlib inline \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy import random \n\n#limit of integration\na = 0\nb = 1.75\n\n#number of samples \nN = 20000\n\n#define the function\ndef func(x): \n return np.cos(x)\n\n#define the values of cosine from 0 to 1.75\nx_of_cos = np.linspace(0,1.75,10000)\ny_of_cos = func(x_of_cos)\n\n#define the min and max \nmin_of_cos = min(y_of_cos)\nmax_of_cos = max(y_of_cos)\n\n#creating random values\nx_random = np.random.uniform(a,b,N)\ny_random = np.random.uniform(min_of_cos,max_of_cos,N)\n\n#classify where the point is\ninside = np.where(np.cos(x_random)/y_random>1)[0]\noutside = np.where(np.cos(x_random)/y_random<=1)[0]\n\n#answer of the integral by just integrating cosine\nintegral_of_cos = float(np.sin(b) - np.sin(a))\n\n#plotting the figure\nfigure = plt.figure()\nplt.grid()\nplt.xlim([a,b])\nplt.ylim([min_of_cos,max_of_cos])\nplt.xlabel(\"X\")\nplt.ylabel(\"Y\")\nplt.title(\"F(0,1.75) = \" + str(integral_of_cos))\nplt.plot(x_random[inside],y_random[inside],\".\",color=\"blue\",label=\"Points below f(x)\")\nplt.plot(x_random[outside],y_random[outside],\".\",color=\"grey\",label=\"Points above f(x)\")\nplt.plot(x_of_cos,y_of_cos,color=\"red\",label=\"f(x)\")\nplt.legend()\n\n#estimating the value of the integral \ny_dimension = abs(min_of_cos - max_of_cos)\nx_dimension = b - a \narea = y_dimension * x_dimension\nvalue_of_integral = area*(len(inside)/float(N))\n\n#calculating the error\nerror = (value_of_integral - np.sin(1.75))/np.sin(1.75)\n\n#printing information\nprint(\"Number of samples: \",N)\nprint(\"Approximate value of the integral: \",value_of_integral)\nprint(\"Error in the approximation: \",error)\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4ad2f4b2dfc7da38495141c21fb5c5b676edd69e
| 3,317 |
ipynb
|
Jupyter Notebook
|
Classifier Performance Comparision.ipynb
|
vaidhin/Machine-learnig-Examples
|
c0caa2cb91add6bd82bfa07b03f841d4927ee9f6
|
[
"Apache-2.0"
] | null | null | null |
Classifier Performance Comparision.ipynb
|
vaidhin/Machine-learnig-Examples
|
c0caa2cb91add6bd82bfa07b03f841d4927ee9f6
|
[
"Apache-2.0"
] | null | null | null |
Classifier Performance Comparision.ipynb
|
vaidhin/Machine-learnig-Examples
|
c0caa2cb91add6bd82bfa07b03f841d4927ee9f6
|
[
"Apache-2.0"
] | null | null | null | 30.431193 | 118 | 0.576424 |
[
[
[
"#This example compares the performance of various classifiers available in Scikit learn\n#Here we define our own data set for male and female classification with three attributes each\n#Finally we print the classifier name which has the best performance\n\nfrom sklearn import tree\nfrom sklearn.svm import SVC\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.metrics import accuracy_score\nimport numpy as np\n\n# Data and labels\nX = [[181, 80, 44], [177, 70, 43], [160, 60, 38], [154, 54, 37], [166, 65, 40], [190, 90, 47], [175, 64, 39],\n [177, 70, 40], [159, 55, 37], [171, 75, 42], [181, 85, 43]]\n\nY = ['male', 'male', 'female', 'female', 'male', 'male', 'female', 'female', 'female', 'male', 'male']\n\n# Classifiers\n# using the default values for all the hyperparameters\nclf_tree = tree.DecisionTreeClassifier()\nclf_svm = SVC()\nclf_perceptron = Perceptron()\nclf_KNN = KNeighborsClassifier()\n\n# Training the models\nclf_tree.fit(X, Y)\nclf_svm.fit(X, Y)\nclf_perceptron.fit(X, Y)\nclf_KNN.fit(X, Y)\n\n# Testing using the same data\npred_tree = clf_tree.predict(X)\nacc_tree = accuracy_score(Y, pred_tree) * 100\nprint('Accuracy for DecisionTree: {}'.format(acc_tree))\n\npred_svm = clf_svm.predict(X)\nacc_svm = accuracy_score(Y, pred_svm) * 100\nprint('Accuracy for SVM: {}'.format(acc_svm))\n\npred_per = clf_perceptron.predict(X)\nacc_per = accuracy_score(Y, pred_per) * 100\nprint('Accuracy for perceptron: {}'.format(acc_per))\n\npred_KNN = clf_KNN.predict(X)\nacc_KNN = accuracy_score(Y, pred_KNN) * 100\nprint('Accuracy for KNN: {}'.format(acc_KNN))\n\n# The best classifier from svm, per, KNN\nindex = np.argmax([acc_svm, acc_per, acc_KNN])\nclassifiers = {0: 'SVM', 1: 'Perceptron', 2: 'KNN'}\nprint('Best gender classifier is {}'.format(classifiers[index]))",
"Accuracy for DecisionTree: 100.0\nAccuracy for SVM: 100.0\nAccuracy for perceptron: 54.5454545455\nAccuracy for KNN: 72.7272727273\nBest gender classifier is SVM\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4ad2f756cbf417ec50b028224cb913eb4afd3409
| 4,323 |
ipynb
|
Jupyter Notebook
|
HydrologyTermPaperII/HydrologyTPCodebase/ML_Models/models/HydroTool-Decision_Tree.ipynb
|
NiharikaVadlamudi/Hydrological-modelling-and-Software-Development
|
ee526636f38cdb0938aa82c06c1f8fb662cc6419
|
[
"MIT"
] | null | null | null |
HydrologyTermPaperII/HydrologyTPCodebase/ML_Models/models/HydroTool-Decision_Tree.ipynb
|
NiharikaVadlamudi/Hydrological-modelling-and-Software-Development
|
ee526636f38cdb0938aa82c06c1f8fb662cc6419
|
[
"MIT"
] | null | null | null |
HydrologyTermPaperII/HydrologyTPCodebase/ML_Models/models/HydroTool-Decision_Tree.ipynb
|
NiharikaVadlamudi/Hydrological-modelling-and-Software-Development
|
ee526636f38cdb0938aa82c06c1f8fb662cc6419
|
[
"MIT"
] | null | null | null | 21.40099 | 110 | 0.517927 |
[
[
[
"# Decision_Tree",
"_____no_output_____"
]
],
[
[
"# Importing libraries\nimport os \nimport csv\nimport pandas as pd \nimport matplotlib.pyplot as plt \nimport numpy as np\nimport joblib \nimport sklearn \nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import mean_squared_error as MSE\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.tree import DecisionTreeRegressor as DTR\nfrom sklearn.ensemble import AdaBoostRegressor as ABR",
"_____no_output_____"
],
[
"# Main file to be loaded ...\ntestFile='./data/testF.csv'\ndf=pd.read_csv('./data/trainComb.csv')\nprint(df.shape)",
"(10748, 13)\n"
],
[
"def preProcessing(dataframe):\n #Split into X,y \n #Scale them\n df1=dataframe[['cp','lsp','swvl1','ro','sd','dis']]\n X = df1.iloc[:,:5].values.astype(float)\n y = df1.iloc[:,-1].values.astype(float)\n X=np.reshape(X,(-1,5))\n y=np.reshape(y,(-1,1))\n sc_X = StandardScaler()\n sc_y = StandardScaler()\n X = sc_X.fit_transform(X)\n y = sc_y.fit_transform(y)\n return(X,y,sc_X,sc_y)",
"_____no_output_____"
],
[
"# Training it on the file.\nX,y,sx,sy=preProcessing(df)\nprint(X.shape)\nprint(y.shape)",
"(10748, 5)\n(10748, 1)\n"
],
[
"# Testing \nX_test,y_test,sxt,syt=preProcessing(pd.read_csv(testFile))\nprint(X_test.shape)\nprint(y_test.shape)\n",
"(1461, 5)\n(1461, 1)\n"
]
],
[
[
"# Training..",
"_____no_output_____"
]
],
[
[
"# Model\nregressor = ABR(DTR(random_state=1,splitter='best',max_depth=8,min_samples_split=2),n_estimators=150)\nmodel=regressor.fit(X,y.ravel())\nmodelParams=model.get_params(deep=True)",
"_____no_output_____"
],
[
"#Testing..\n# Loss Generation. \ny_pred_test = sy.inverse_transform((model.predict(X_test)))\nloss=1/1461*(MSE(sy.inverse_transform(y_test),y_pred_test))\nprint(loss)",
"1975.9187664009587\n"
],
[
"# Storing the files \njoblib.dump(model,str('./model_files/Decision_Tree')+'.sav')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad31554184215543fd8b86a0ff8de139e545f60
| 632 |
ipynb
|
Jupyter Notebook
|
_build/jupyter_execute/notebooks/diagnostics.ipynb
|
mgrover1/cesm-workflow
|
46fc6166bf10a21a4f54649c272f39e53099a64a
|
[
"Apache-2.0"
] | null | null | null |
_build/jupyter_execute/notebooks/diagnostics.ipynb
|
mgrover1/cesm-workflow
|
46fc6166bf10a21a4f54649c272f39e53099a64a
|
[
"Apache-2.0"
] | null | null | null |
_build/jupyter_execute/notebooks/diagnostics.ipynb
|
mgrover1/cesm-workflow
|
46fc6166bf10a21a4f54649c272f39e53099a64a
|
[
"Apache-2.0"
] | null | null | null | 19.151515 | 92 | 0.558544 |
[
[
[
"# Diagnostics\nThis will include an example diagnostics workflow, making use of intake-esm catalog(s)",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4ad318ea27e6d75f49643e0a9ea5be4df71b005b
| 100,254 |
ipynb
|
Jupyter Notebook
|
notebook/chap02.ipynb
|
tsahara/python_stat
|
d9953ada172efff83c342dd1b61403a73a001d2f
|
[
"BSD-3-Clause"
] | null | null | null |
notebook/chap02.ipynb
|
tsahara/python_stat
|
d9953ada172efff83c342dd1b61403a73a001d2f
|
[
"BSD-3-Clause"
] | null | null | null |
notebook/chap02.ipynb
|
tsahara/python_stat
|
d9953ada172efff83c342dd1b61403a73a001d2f
|
[
"BSD-3-Clause"
] | null | null | null | 46.694923 | 26,024 | 0.698376 |
[
[
[
"# 1次元のデータの整理",
"_____no_output_____"
],
[
"## データの中心の指標",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\n\n# Jupyter Notebookの出力を小数点以下3桁に抑える\n%precision 3\n# Dataframeの出力を小数点以下3桁に抑える\npd.set_option('precision', 3)",
"_____no_output_____"
],
[
"df = pd.read_csv('../data/ch2_scores_em.csv',\n index_col='生徒番号')\n# dfの最初の5行を表示。df.head(3) にすれば3行。\ndf.head()",
"_____no_output_____"
],
[
"# df['英語'] は Pamdas の Series だった。\nscores = np.array(df['英語'])[:10]\nscores",
"_____no_output_____"
],
[
"# scores に、「生徒」という名前のインデックスをつけて、また DataFrame を作る。\nscores_df = pd.DataFrame({'点数':scores},\n index=pd.Index(['A', 'B', 'C', 'D', 'E',\n 'F', 'G', 'H', 'I', 'J'],\n name='生徒'))\nscores_df",
"_____no_output_____"
]
],
[
[
"### 平均値",
"_____no_output_____"
]
],
[
[
"sum(scores) / len(scores)",
"_____no_output_____"
],
[
"np.mean(scores)",
"_____no_output_____"
],
[
"scores_df.mean()",
"_____no_output_____"
]
],
[
[
"### 中央値",
"_____no_output_____"
]
],
[
[
"sorted_scores = np.sort(scores)\nsorted_scores",
"_____no_output_____"
],
[
"n = len(sorted_scores)\nif n % 2 == 0:\n m0 = sorted_scores[n//2 - 1]\n m1 = sorted_scores[n//2]\n median = (m0 + m1) / 2\nelse:\n median = sorted_scores[(n+1)//2 - 1]\nmedian",
"_____no_output_____"
],
[
"# データの個数が偶数なので、56,57 の平均値である 56.5 が中央値となる。\nnp.median(scores)",
"_____no_output_____"
],
[
"scores_df.median()",
"_____no_output_____"
]
],
[
[
"### 最頻値",
"_____no_output_____"
]
],
[
[
"pd.Series([1, 1, 1, 2, 2, 3]).mode()",
"_____no_output_____"
],
[
"pd.Series([1, 2, 3, 4, 5]).mode()",
"_____no_output_____"
]
],
[
[
"## データのばらつきの指標",
"_____no_output_____"
],
[
"### 分散と標準偏差",
"_____no_output_____"
],
[
"#### 偏差",
"_____no_output_____"
]
],
[
[
"mean = np.mean(scores)\n# np.array から値を引き算している(!)。NumPy の「ブロードキャスト」という機能で実現されている。\ndeviation = scores - mean\ndeviation",
"_____no_output_____"
],
[
"another_scores = [50, 60, 58, 54, 51, 56, 57, 53, 52, 59]\nanother_mean = np.mean(another_scores)\nanother_deviation = another_scores - another_mean\nanother_deviation",
"_____no_output_____"
],
[
"np.mean(deviation)",
"_____no_output_____"
],
[
"np.mean(another_deviation)",
"_____no_output_____"
],
[
"summary_df = scores_df.copy()\nsummary_df['偏差'] = deviation\nsummary_df",
"_____no_output_____"
],
[
"summary_df.mean()",
"_____no_output_____"
]
],
[
[
"#### 分散",
"_____no_output_____"
]
],
[
[
"np.mean(deviation ** 2)",
"_____no_output_____"
],
[
"# NumPy なので標本分散が計算される。\nnp.var(scores)",
"_____no_output_____"
],
[
"# こちらは Pandas なので不偏分散。なお引数に ddof=0 を入れると標本分散になる。\nscores_df.var()",
"_____no_output_____"
],
[
"summary_df['偏差二乗'] = np.square(deviation)\nsummary_df",
"_____no_output_____"
],
[
"# 偏差の二乗をとってその平均値を作ると傾向が見える。\nsummary_df.mean()",
"_____no_output_____"
]
],
[
[
"#### 標準偏差",
"_____no_output_____"
]
],
[
[
"np.sqrt(np.var(scores, ddof=0))",
"_____no_output_____"
],
[
"np.std(scores, ddof=0)",
"_____no_output_____"
]
],
[
[
"### 範囲と四分位範囲",
"_____no_output_____"
],
[
"#### 範囲",
"_____no_output_____"
]
],
[
[
"np.max(scores) - np.min(scores)",
"_____no_output_____"
]
],
[
[
"#### 四分位範囲",
"_____no_output_____"
]
],
[
[
"scores_Q1 = np.percentile(scores, 25)\nscores_Q3 = np.percentile(scores, 75)\nscores_IQR = scores_Q3 - scores_Q1\nscores_IQR",
"_____no_output_____"
]
],
[
[
"### データの指標のまとめ",
"_____no_output_____"
]
],
[
[
"pd.Series(scores).describe()",
"_____no_output_____"
]
],
[
[
"## データの正規化",
"_____no_output_____"
],
[
"### 標準化",
"_____no_output_____"
]
],
[
[
"z = (scores - np.mean(scores)) / np.std(scores)\nz",
"_____no_output_____"
],
[
"np.mean(z), np.std(z, ddof=0)",
"_____no_output_____"
]
],
[
[
"### 偏差値",
"_____no_output_____"
]
],
[
[
"z = 50 + 10 * (scores - np.mean(scores)) / np.std(scores)",
"_____no_output_____"
],
[
"scores_df['偏差値'] = z\nscores_df",
"_____no_output_____"
]
],
[
[
"## データの視覚化",
"_____no_output_____"
]
],
[
[
"# 50人分の英語の点数のarray\nenglish_scores = np.array(df['英語'])\n# Seriesに変換してdescribeを表示\npd.Series(english_scores).describe()",
"_____no_output_____"
]
],
[
[
"### 度数分布表",
"_____no_output_____"
]
],
[
[
"freq, _ = np.histogram(english_scores, bins=10, range=(0, 100))\nfreq",
"_____no_output_____"
],
[
"# 0~10, 10~20, ... といった文字列のリストを作成\nfreq_class = [f'{i}~{i+10}' for i in range(0, 100, 10)]\n# freq_classをインデックスにしてfreqでDataFrameを作成\nfreq_dist_df = pd.DataFrame({'度数':freq},\n index=pd.Index(freq_class,\n name='階級'))\nfreq_dist_df",
"_____no_output_____"
],
[
"class_value = [(i+(i+10))//2 for i in range(0, 100, 10)]\nclass_value",
"_____no_output_____"
],
[
"rel_freq = freq / freq.sum()\nrel_freq",
"_____no_output_____"
],
[
"cum_rel_freq = np.cumsum(rel_freq)\ncum_rel_freq",
"_____no_output_____"
],
[
"freq_dist_df['階級値'] = class_value\nfreq_dist_df['相対度数'] = rel_freq\nfreq_dist_df['累積相対度数'] = cum_rel_freq\nfreq_dist_df = freq_dist_df[['階級値', '度数',\n '相対度数', '累積相対度数']]\n\nfreq_dist_df",
"_____no_output_____"
]
],
[
[
"#### 最頻値ふたたび",
"_____no_output_____"
]
],
[
[
"freq_dist_df.loc[freq_dist_df['度数'].idxmax(), '階級値']",
"_____no_output_____"
]
],
[
[
"### ヒストグラム",
"_____no_output_____"
]
],
[
[
"# Matplotlibのpyplotモジュールをpltという名前でインポート\nimport matplotlib.pyplot as plt\n\n# グラフがnotebook上に表示されるようにする\n%matplotlib inline",
"_____no_output_____"
],
[
"# キャンバスを作る\n# figsizeで横・縦の大きさを指定\nfig = plt.figure(figsize=(10, 6))\n# キャンバス上にグラフを描画するための領域を作る\n# 引数は領域を1×1個作り、1つめの領域に描画することを意味する\nax = fig.add_subplot(111)\n\n# 階級数を10にしてヒストグラムを描画\nfreq, _, _ = ax.hist(english_scores, bins=10, range=(0, 100))\n# X軸にラベルをつける\n#ax.set_xlabel('点数')\nax.set_xlabel('点数')\n# Y軸にラベルをつける\nax.set_ylabel('人数')\n# X軸に0, 10, 20, ..., 100の目盛りをふる\nax.set_xticks(np.linspace(0, 100, 10+1))\n# Y軸に0, 1, 2, ...の目盛りをふる\nax.set_yticks(np.arange(0, freq.max()+1))\n# グラフの表示\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(10, 6))\nax = fig.add_subplot(111)\n\nfreq, _ , _ = ax.hist(english_scores, bins=25, range=(0, 100))\nax.set_xlabel('点数')\nax.set_ylabel('人数')\nax.set_xticks(np.linspace(0, 100, 25+1))\nax.set_yticks(np.arange(0, freq.max()+1))\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(10, 6))\nax1 = fig.add_subplot(111)\n# Y軸のスケールが違うグラフをax1と同じ領域上に書けるようにする\nax2 = ax1.twinx()\n\n# 相対度数のヒストグラムにするためには、度数をデータの数で割る必要がある\n# これはhistの引数weightを指定することで実現できる\nweights = np.ones_like(english_scores) / len(english_scores)\nrel_freq, _, _ = ax1.hist(english_scores, bins=25,\n range=(0, 100), weights=weights)\n\ncum_rel_freq = np.cumsum(rel_freq)\nclass_value = [(i+(i+4))//2 for i in range(0, 100, 4)]\n# 折れ線グラフの描画\n# 引数lsを'--'にすることで線が点線に\n# 引数markerを'o'にすることでデータ点を丸に\n# 引数colorを'gray'にすることで灰色に\nax2.plot(class_value, cum_rel_freq,\n ls='--', marker='o', color='gray')\n# 折れ線グラフの罫線を消去\nax2.grid(visible=False)\n\nax1.set_xlabel('点数')\nax1.set_ylabel('相対度数')\nax2.set_ylabel('累積相対度数')\nax1.set_xticks(np.linspace(0, 100, 25+1))\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 箱ひげ図",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(5, 6))\nax = fig.add_subplot(111)\nax.boxplot(english_scores, labels=['英語'])\n\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad3191e4c4e6706ad75b1411a51b60f5411924c
| 62,293 |
ipynb
|
Jupyter Notebook
|
Data Science Professional/6 - Machine Learning With Python/5.2 Collaborative Filtering on Movies.ipynb
|
2series/DataScience-Courses
|
5ee71305721a61dfc207d8d7de67a9355530535d
|
[
"MIT"
] | 1 |
2020-02-23T07:40:39.000Z
|
2020-02-23T07:40:39.000Z
|
Data Science Professional/6 - Machine Learning With Python/5.2 Collaborative Filtering on Movies.ipynb
|
2series/DataScience-Courses
|
5ee71305721a61dfc207d8d7de67a9355530535d
|
[
"MIT"
] | null | null | null |
Data Science Professional/6 - Machine Learning With Python/5.2 Collaborative Filtering on Movies.ipynb
|
2series/DataScience-Courses
|
5ee71305721a61dfc207d8d7de67a9355530535d
|
[
"MIT"
] | 3 |
2019-12-05T11:04:58.000Z
|
2020-02-26T10:42:08.000Z
| 29.862416 | 2,822 | 0.486844 |
[
[
[
"## RIHAD VARIAWA, Data Scientist - Who has fun LEARNING, EXPLORING & GROWING\n<h1 align=\"center\"><font size=\"5\">COLLABORATIVE FILTERING</font></h1>",
"_____no_output_____"
],
[
"Recommendation systems are a collection of algorithms used to recommend items to users based on information taken from the user. These systems have become ubiquitous can be commonly seen in online stores, movies databases and job finders. In this notebook, we will explore recommendation systems based on Collaborative Filtering and implement simple version of one using Python and the Pandas library.",
"_____no_output_____"
],
[
"<h1>Table of contents</h1>\n\n<div class=\"alert alert-block alert-info\" style=\"margin-top: 20px\">\n <ol>\n <li><a href=\"#ref1\">Acquiring the Data</a></li>\n <li><a href=\"#ref2\">Preprocessing</a></li>\n <li><a href=\"#ref3\">Collaborative Filtering</a></li>\n </ol>\n</div>\n<br>\n<hr>",
"_____no_output_____"
],
[
"\n\n<a id=\"ref1\"></a>\n# Acquiring the Data",
"_____no_output_____"
],
[
"To acquire and extract the data, simply run the following Bash scripts: \nDataset acquired from [GroupLens](http://grouplens.org/datasets/movielens/). Lets download the dataset. To download the data, we will use **`!wget`** to download it from IBM Object Storage. \n__Did you know?__ When it comes to Machine Learning, you will likely be working with large datasets. As a business, where can you host your data? IBM is offering a unique opportunity for businesses, with 10 Tb of IBM Cloud Object Storage: [Sign up now for free](http://cocl.us/ML0101EN-IBM-Offer-CC)",
"_____no_output_____"
]
],
[
[
"!wget -O moviedataset.zip https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/moviedataset.zip\nprint('unziping ...')\n!unzip -o -j moviedataset.zip ",
"--2019-01-22 10:16:36-- https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/moviedataset.zip\nResolving s3-api.us-geo.objectstorage.softlayer.net (s3-api.us-geo.objectstorage.softlayer.net)... 67.228.254.193\nConnecting to s3-api.us-geo.objectstorage.softlayer.net (s3-api.us-geo.objectstorage.softlayer.net)|67.228.254.193|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 160301210 (153M) [application/zip]\nSaving to: ‘moviedataset.zip’\n\nmoviedataset.zip 100%[=====================>] 152.88M 34.7MB/s in 4.3s \n\n2019-01-22 10:16:41 (35.3 MB/s) - ‘moviedataset.zip’ saved [160301210/160301210]\n\nunziping ...\nArchive: moviedataset.zip\n inflating: links.csv \n inflating: movies.csv \n inflating: ratings.csv \n inflating: README.txt \n inflating: tags.csv \n"
]
],
[
[
"Now you're ready to start working with the data!",
"_____no_output_____"
],
[
"<hr>\n\n<a id=\"ref2\"></a>\n# Preprocessing",
"_____no_output_____"
],
[
"First, let's get all of the imports out of the way:",
"_____no_output_____"
]
],
[
[
"#Dataframe manipulation library\nimport pandas as pd\n#Math functions, we'll only need the sqrt function so let's import only that\nfrom math import sqrt\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Now let's read each file into their Dataframes:",
"_____no_output_____"
]
],
[
[
"#Storing the movie information into a pandas dataframe\nmovies_df = pd.read_csv('_datasets/movies.csv')\n#Storing the user information into a pandas dataframe\nratings_df = pd.read_csv('_datasets/ratings.csv')",
"_____no_output_____"
]
],
[
[
"Let's also take a peek at how each of them are organized:",
"_____no_output_____"
]
],
[
[
"#Head is a function that gets the first N rows of a dataframe. N's default is 5.\nmovies_df.head()",
"_____no_output_____"
]
],
[
[
"So each movie has a unique ID, a title with its release year along with it (Which may contain unicode characters) and several different genres in the same field. Let's remove the year from the title column and place it into its own one by using the handy [extract](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.str.extract.html#pandas.Series.str.extract) function that Pandas has.",
"_____no_output_____"
],
[
"Let's remove the year from the __title__ column by using pandas' replace function and store in a new __year__ column.",
"_____no_output_____"
]
],
[
[
"#Using regular expressions to find a year stored between parentheses\n#We specify the parantheses so we don't conflict with movies that have years in their titles\nmovies_df['year'] = movies_df.title.str.extract('(\\(\\d\\d\\d\\d\\))',expand=False)\n#Removing the parentheses\nmovies_df['year'] = movies_df.year.str.extract('(\\d\\d\\d\\d)',expand=False)\n#Removing the years from the 'title' column\nmovies_df['title'] = movies_df.title.str.replace('(\\(\\d\\d\\d\\d\\))', '')\n#Applying the strip function to get rid of any ending whitespace characters that may have appeared\nmovies_df['title'] = movies_df['title'].apply(lambda x: x.strip())",
"_____no_output_____"
]
],
[
[
"Let's look at the result!",
"_____no_output_____"
]
],
[
[
"movies_df.head()",
"_____no_output_____"
]
],
[
[
"With that, let's also drop the genres column since we won't need it for this particular recommendation system.",
"_____no_output_____"
]
],
[
[
"#Dropping the genres column\nmovies_df = movies_df.drop('genres', 1)",
"_____no_output_____"
]
],
[
[
"Here's the final movies dataframe:",
"_____no_output_____"
]
],
[
[
"movies_df.head()",
"_____no_output_____"
]
],
[
[
"<br>",
"_____no_output_____"
],
[
"Next, let's look at the ratings dataframe.",
"_____no_output_____"
]
],
[
[
"ratings_df.head()",
"_____no_output_____"
]
],
[
[
"Every row in the ratings dataframe has a user id associated with at least one movie, a rating and a timestamp showing when they reviewed it. We won't be needing the timestamp column, so let's drop it to save on memory.",
"_____no_output_____"
]
],
[
[
"#Drop removes a specified row or column from a dataframe\nratings_df = ratings_df.drop('timestamp', 1)",
"_____no_output_____"
]
],
[
[
"Here's how the final ratings Dataframe looks like:",
"_____no_output_____"
]
],
[
[
"ratings_df.head()",
"_____no_output_____"
]
],
[
[
"<hr>\n\n<a id=\"ref3\"></a>\n# Collaborative Filtering",
"_____no_output_____"
],
[
"Now, time to start our work on recommendation systems. \n\nThe first technique we're going to take a look at is called __Collaborative Filtering__, which is also known as __User-User Filtering__. As hinted by its alternate name, this technique uses other users to recommend items to the input user. It attempts to find users that have similar preferences and opinions as the input and then recommends items that they have liked to the input. There are several methods of finding similar users (Even some making use of Machine Learning), and the one we will be using here is going to be based on the __Pearson Correlation Function__.\n\n<img src=\"https://ibm.box.com/shared/static/1ql8cbwhtkmbr6nge5e706ikzm5mua5w.png\" width=800px>\n\n\nThe process for creating a User Based recommendation system is as follows:\n- Select a user with the movies the user has watched\n- Based on his rating to movies, find the top X neighbours \n- Get the watched movie record of the user for each neighbour.\n- Calculate a similarity score using some formula\n- Recommend the items with the highest score\n\n\nLet's begin by creating an input user to recommend movies to:\n\nNotice: To add more movies, simply increase the amount of elements in the userInput. Feel free to add more in! Just be sure to write it in with capital letters and if a movie starts with a \"The\", like \"The Matrix\" then write it in like this: 'Matrix, The' .",
"_____no_output_____"
]
],
[
[
"userInput = [\n {'title':'Breakfast Club, The', 'rating':5},\n {'title':'Toy Story', 'rating':3.5},\n {'title':'Jumanji', 'rating':2},\n {'title':\"Pulp Fiction\", 'rating':5},\n {'title':'Akira', 'rating':4.5}\n ] \ninputMovies = pd.DataFrame(userInput)\ninputMovies",
"_____no_output_____"
]
],
[
[
"#### Add movieId to input user\nWith the input complete, let's extract the input movies's ID's from the movies dataframe and add them into it.\n\nWe can achieve this by first filtering out the rows that contain the input movies' title and then merging this subset with the input dataframe. We also drop unnecessary columns for the input to save memory space.",
"_____no_output_____"
]
],
[
[
"#Filtering out the movies by title\ninputId = movies_df[movies_df['title'].isin(inputMovies['title'].tolist())]\n#Then merging it so we can get the movieId. It's implicitly merging it by title.\ninputMovies = pd.merge(inputId, inputMovies)\n#Dropping information we won't use from the input dataframe\ninputMovies = inputMovies.drop('year', 1)\n#Final input dataframe\n#If a movie you added in above isn't here, then it might not be in the original \n#dataframe or it might spelled differently, please check capitalisation.\ninputMovies",
"_____no_output_____"
]
],
[
[
"#### The users who has seen the same movies\nNow with the movie ID's in our input, we can now get the subset of users that have watched and reviewed the movies in our input.\n",
"_____no_output_____"
]
],
[
[
"#Filtering out users that have watched movies that the input has watched and storing it\nuserSubset = ratings_df[ratings_df['movieId'].isin(inputMovies['movieId'].tolist())]\nuserSubset.head()",
"_____no_output_____"
]
],
[
[
"We now group up the rows by user ID.",
"_____no_output_____"
]
],
[
[
"#Groupby creates several sub dataframes where they all have the same value in the column specified as the parameter\nuserSubsetGroup = userSubset.groupby(['userId'])",
"_____no_output_____"
]
],
[
[
"lets look at one of the users, e.g. the one with userID=1130",
"_____no_output_____"
]
],
[
[
"userSubsetGroup.get_group(1130)",
"_____no_output_____"
]
],
[
[
"Let's also sort these groups so the users that share the most movies in common with the input have higher priority. This provides a richer recommendation since we won't go through every single user.",
"_____no_output_____"
]
],
[
[
"#Sorting it so users with movie most in common with the input will have priority\nuserSubsetGroup = sorted(userSubsetGroup, key=lambda x: len(x[1]), reverse=True)",
"_____no_output_____"
]
],
[
[
"Now lets look at the first user",
"_____no_output_____"
]
],
[
[
"userSubsetGroup[0:3]",
"_____no_output_____"
]
],
[
[
"#### Similarity of users to input user\nNext, we are going to compare all users (not really all !!!) to our specified user and find the one that is most similar. \nwe're going to find out how similar each user is to the input through the __Pearson Correlation Coefficient__. It is used to measure the strength of a linear association between two variables. The formula for finding this coefficient between sets X and Y with N values can be seen in the image below. \n\nWhy Pearson Correlation?\n\nPearson correlation is invariant to scaling, i.e. multiplying all elements by a nonzero constant or adding any constant to all elements. For example, if you have two vectors X and Y,then, pearson(X, Y) == pearson(X, 2 * Y + 3). This is a pretty important property in recommendation systems because for example two users might rate two series of items totally different in terms of absolute rates, but they would be similar users (i.e. with similar ideas) with similar rates in various scales .\n\n\n\nThe values given by the formula vary from r = -1 to r = 1, where 1 forms a direct correlation between the two entities (it means a perfect positive correlation) and -1 forms a perfect negative correlation. \n\nIn our case, a 1 means that the two users have similar tastes while a -1 means the opposite.",
"_____no_output_____"
],
[
"We will select a subset of users to iterate through. This limit is imposed because we don't want to waste too much time going through every single user.",
"_____no_output_____"
]
],
[
[
"userSubsetGroup = userSubsetGroup[0:100]",
"_____no_output_____"
]
],
[
[
"Now, we calculate the Pearson Correlation between input user and subset group, and store it in a dictionary, where the key is the user Id and the value is the coefficient\n",
"_____no_output_____"
]
],
[
[
"#Store the Pearson Correlation in a dictionary, where the key is the user Id and the value is the coefficient\npearsonCorrelationDict = {}\n\n#For every user group in our subset\nfor name, group in userSubsetGroup:\n #Let's start by sorting the input and current user group so the values aren't mixed up later on\n group = group.sort_values(by='movieId')\n inputMovies = inputMovies.sort_values(by='movieId')\n #Get the N for the formula\n nRatings = len(group)\n #Get the review scores for the movies that they both have in common\n temp_df = inputMovies[inputMovies['movieId'].isin(group['movieId'].tolist())]\n #And then store them in a temporary buffer variable in a list format to facilitate future calculations\n tempRatingList = temp_df['rating'].tolist()\n #Let's also put the current user group reviews in a list format\n tempGroupList = group['rating'].tolist()\n #Now let's calculate the pearson correlation between two users, so called, x and y\n Sxx = sum([i**2 for i in tempRatingList]) - pow(sum(tempRatingList),2)/float(nRatings)\n Syy = sum([i**2 for i in tempGroupList]) - pow(sum(tempGroupList),2)/float(nRatings)\n Sxy = sum( i*j for i, j in zip(tempRatingList, tempGroupList)) - sum(tempRatingList)*sum(tempGroupList)/float(nRatings)\n \n #If the denominator is different than zero, then divide, else, 0 correlation.\n if Sxx != 0 and Syy != 0:\n pearsonCorrelationDict[name] = Sxy/sqrt(Sxx*Syy)\n else:\n pearsonCorrelationDict[name] = 0\n",
"_____no_output_____"
],
[
"pearsonCorrelationDict.items()",
"_____no_output_____"
],
[
"pearsonDF = pd.DataFrame.from_dict(pearsonCorrelationDict, orient='index')\npearsonDF.columns = ['similarityIndex']\npearsonDF['userId'] = pearsonDF.index\npearsonDF.index = range(len(pearsonDF))\npearsonDF.head()",
"_____no_output_____"
]
],
[
[
"#### The top x similar users to input user\nNow let's get the top 50 users that are most similar to the input.",
"_____no_output_____"
]
],
[
[
"topUsers=pearsonDF.sort_values(by='similarityIndex', ascending=False)[0:50]\ntopUsers.head()",
"_____no_output_____"
]
],
[
[
"Now, let's start recommending movies to the input user.\n\n#### Rating of selected users to all movies\nWe're going to do this by taking the weighted average of the ratings of the movies using the Pearson Correlation as the weight. But to do this, we first need to get the movies watched by the users in our __pearsonDF__ from the ratings dataframe and then store their correlation in a new column called _similarityIndex\". This is achieved below by merging of these two tables.",
"_____no_output_____"
]
],
[
[
"topUsersRating=topUsers.merge(ratings_df, left_on='userId', right_on='userId', how='inner')\ntopUsersRating.head()",
"_____no_output_____"
]
],
[
[
"Now all we need to do is simply multiply the movie rating by its weight (The similarity index), then sum up the new ratings and divide it by the sum of the weights.\n\nWe can easily do this by simply multiplying two columns, then grouping up the dataframe by movieId and then dividing two columns:\n\nIt shows the idea of all similar users to candidate movies for the input user:",
"_____no_output_____"
]
],
[
[
"#Multiplies the similarity by the user's ratings\ntopUsersRating['weightedRating'] = topUsersRating['similarityIndex']*topUsersRating['rating']\ntopUsersRating.head()",
"_____no_output_____"
],
[
"#Applies a sum to the topUsers after grouping it up by userId\ntempTopUsersRating = topUsersRating.groupby('movieId').sum()[['similarityIndex','weightedRating']]\ntempTopUsersRating.columns = ['sum_similarityIndex','sum_weightedRating']\ntempTopUsersRating.head()",
"_____no_output_____"
],
[
"#Creates an empty dataframe\nrecommendation_df = pd.DataFrame()\n#Now we take the weighted average\nrecommendation_df['weighted average recommendation score'] = tempTopUsersRating['sum_weightedRating']/tempTopUsersRating['sum_similarityIndex']\nrecommendation_df['movieId'] = tempTopUsersRating.index\nrecommendation_df.head()",
"_____no_output_____"
]
],
[
[
"Now let's sort it and see the top 20 movies that the algorithm recommended!",
"_____no_output_____"
]
],
[
[
"recommendation_df = recommendation_df.sort_values(by='weighted average recommendation score', ascending=False)\nrecommendation_df.head(10)",
"_____no_output_____"
],
[
"movies_df.loc[movies_df['movieId'].isin(recommendation_df.head(10)['movieId'].tolist())]",
"_____no_output_____"
]
],
[
[
"### Advantages and Disadvantages of Collaborative Filtering\n\n##### Advantages\n* Takes other user's ratings into consideration\n* Doesn't need to study or extract information from the recommended item\n* Adapts to the user's interests which might change over time\n\n##### Disadvantages\n* Approximation function can be slow\n* There might be a low of amount of users to approximate\n* Privacy issues when trying to learn the user's preferences",
"_____no_output_____"
],
[
"<h2>Want to learn more?</h2>\n\nIBM SPSS Modeler is a comprehensive analytics platform that has many machine learning algorithms. It has been designed to bring predictive intelligence to decisions made by individuals, by groups, by systems – by your enterprise as a whole. A free trial is available through this course, available here: <a href=\"http://cocl.us/ML0101EN-SPSSModeler\">SPSS Modeler</a>\n\nAlso, you can use Watson Studio to run these notebooks faster with bigger datasets. Watson Studio is IBM's leading cloud solution for data scientists, built by data scientists. With Jupyter notebooks, RStudio, Apache Spark and popular libraries pre-packaged in the cloud, Watson Studio enables data scientists to collaborate on their projects without having to install anything. Join the fast-growing community of Watson Studio users today with a free account at <a href=\"https://cocl.us/ML0101EN_DSX\">Watson Studio</a>\n\n<h3>Thanks for completing this lesson!</h3>\n\n<h4>Author: <a href=\"https://ca.linkedin.com/in/saeedaghabozorgi\">Saeed Aghabozorgi</a></h4>\n<p><a href=\"https://ca.linkedin.com/in/saeedaghabozorgi\">Saeed Aghabozorgi</a>, PhD is a Data Scientist in IBM with a track record of developing enterprise level applications that substantially increases clients’ ability to turn data into actionable knowledge. He is a researcher in data mining field and expert in developing advanced analytic methods like machine learning and statistical modelling on large datasets.</p>\n\n<hr>\n\n<p>Copyright © 2018 <a href=\"https://cocl.us/DX0108EN_CC\">Cognitive Class</a>. This notebook and its source code are released under the terms of the <a href=\"https://bigdatauniversity.com/mit-license/\">MIT License</a>.</p>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4ad326cd2222f088388f54d29d45c95c29e624d9
| 100,582 |
ipynb
|
Jupyter Notebook
|
fractal/both__inception_resnet_v2___combine__multiply.nbconvert.ipynb
|
amyshenin/masters-thesis---melanoma-analysis-with-fnn
|
b4fb76ae0a0a8c370dc67da4bc09b41cd264e927
|
[
"MIT"
] | null | null | null |
fractal/both__inception_resnet_v2___combine__multiply.nbconvert.ipynb
|
amyshenin/masters-thesis---melanoma-analysis-with-fnn
|
b4fb76ae0a0a8c370dc67da4bc09b41cd264e927
|
[
"MIT"
] | null | null | null |
fractal/both__inception_resnet_v2___combine__multiply.nbconvert.ipynb
|
amyshenin/masters-thesis---melanoma-analysis-with-fnn
|
b4fb76ae0a0a8c370dc67da4bc09b41cd264e927
|
[
"MIT"
] | null | null | null | 51.23892 | 35,108 | 0.707751 |
[
[
[
"# Melanoma analysis with fractal neural networks",
"_____no_output_____"
],
[
"This notebook shows how good is [Fractal neural network](#Fractal-neural-network) for [melanoma](#Melanoma) analysis.",
"_____no_output_____"
]
],
[
[
"import os\nimport datetime\nimport numpy as np\nimport tensorflow as tf\nimport tensorflow_hub as hub\nimport tensorflow_addons as tfa\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import roc_curve, auc",
"_____no_output_____"
]
],
[
[
"Check if a GPU is available.",
"_____no_output_____"
]
],
[
[
"tf.config.list_physical_devices('GPU')",
"_____no_output_____"
]
],
[
[
"Remove excessive logging. ",
"_____no_output_____"
]
],
[
[
"tf.get_logger().setLevel('ERROR')",
"_____no_output_____"
]
],
[
[
"# Melanoma",
"_____no_output_____"
],
[
"__Melanoma__, also redundantly known as __malignant melanoma__, is a type of skin cancer that develops from the pigment-producing cells known as melanocytes. Melanomas typically occur in the skin, but may rarely occur in the mouth, intestines, or eye (uveal melanoma). In women, they most commonly occur on the legs, while in men, they most commonly occur on the back. About 25% of melanomas develop from moles. Changes in a mole that can indicate melanoma include an increase in size, irregular edges, change in color, itchiness, or skin breakdown.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"<div style=\"text-align: center; font-weight: bold\">Pic.1. A melanoma of approximately 2.5 cm (1 in) by 1.5 cm (0.6 in)</div>",
"_____no_output_____"
],
[
"The primary cause of melanoma is ultraviolet light (UV) exposure in those with low levels of the skin pigment melanin. The UV light may be from the sun or other sources, such as tanning devices. Those with many moles, a history of affected family members, and poor immune function are at greater risk. A number of rare genetic conditions, such as xeroderma pigmentosum, also increase the risk. Diagnosis is by biopsy and analysis of any skin lesion that has signs of being potentially cancerous.",
"_____no_output_____"
],
[
"Melanoma is the most dangerous type of skin cancer. Globally, in 2012, it newly occurred in 232,000 people. In 2015, 3.1 million people had active disease, which resulted in 59,800 deaths. Australia and New Zealand have the highest rates of melanoma in the world. High rates also occur in Northern Europe and North America, while it is less common in Asia, Africa, and Latin America. In the United States, melanoma occurs about 1.6 times more often in men than women. Melanoma has become more common since the 1960s in areas mostly populated by people of European descent.",
"_____no_output_____"
],
[
"# Fractal neural network",
"_____no_output_____"
],
[
"We propose an ensemble model based on handcrafted fractal features and deep learning that consists of combining the classification of two CNNs by applying the sum rule. We apply feature extraction to obtain 300 fractal features from different\ndermoscopy datasets. These features are reshaped into a 10 × 10 × 3 matrix to compose an artificial image that\nis given as input to the first CNN. The second CNN model receives as input the correspondent original image.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"<div style=\"text-align: center; font-weight: bold\">Pic.2. Overview of the proposed FNN model.</div>",
"_____no_output_____"
],
[
"If you want to learn more about fractal neural networks, read [here](https://www.sciencedirect.com/science/article/abs/pii/S0957417420308563).",
"_____no_output_____"
],
[
"## Dividing images into patches.",
"_____no_output_____"
],
[
"According to the acticle:\n> One of the approaches available in the literature for multiscale analysis is the gliding-box algorithm (Ivanovici & Richard, 2011). The main advantage of this approach is that it can be applied on datasets containing images with different resolutions since the output features are given in relation to the scale instead of being absolute values. This algorithm consists in placing a box $\\beta_{i}$ sized $𝐿 × 𝐿$ on the left superior corner of the image, wherein 𝐿 is given in pixels. This box glides through the image, one column and then one row at a time. After reaching the end of the image, the box is repositioned at the starting point and the value of 𝐿 is increased by 2.",
"_____no_output_____"
],
[
"The gliding-box method will not be used since it consumes too much RAM. We'll employ a box-counting approach, which basically means we'll partition the images into non-overlapping chunks.",
"_____no_output_____"
]
],
[
[
"class Patchify(tf.keras.layers.Layer):\n def __init__(self, patch_size):\n super(Patchify, self).__init__()\n \n self.patch_size = patch_size\n \n def call(self, inputs):\n outputs = tf.image.extract_patches(\n inputs,\n sizes=(1, self.patch_size, self.patch_size, 1),\n strides=(1, self.patch_size, self.patch_size, 1),\n rates=(1, 1, 1, 1),\n padding='SAME'\n )\n \n _, rows, cols, _ = tf.unstack(tf.shape(outputs))\n outputs = tf.reshape(outputs, shape=(-1, rows * cols, self.patch_size, self.patch_size, 3))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Creating an array of binary values from image patches using the Chebyshev colour distance function applied to the patch centre and each pixel.",
"_____no_output_____"
],
[
"According to the article:\n> For each time the box $\\beta_{i}$ is moved, a multidimensional analysis of colour similarity is performed for every pixel inside it. This is done by assigning the centre pixel to a vector $𝑓_{c} = 𝑟_{c}, 𝑔_{c}, 𝑏_{c}$, where $𝑟_{c}, 𝑔_{c}$ and $𝑏_{c}$ correspond to the colour intensities for each of the RGB colour channels of given pixel. The other pixels in the box are assigned to a vector $𝑓_{i} = 𝑟_{i}, 𝑔_{i}, 𝑏_{i}$ and compared to the centre pixel by calculating a colour distance $\\Delta$. On the proposed approach, the Chebyshev ($\\Delta_{h}$) ...",
"_____no_output_____"
],
[
"The following equation is used to compute the Chebyshev distance.",
"_____no_output_____"
],
[
"$$\n\\Delta_{h} = max(|f_{i}(k_{i}) - f_{c}(k_{c})|), k \\in r, g, b. \n$$ ",
"_____no_output_____"
]
],
[
[
"class Chebyshev(tf.keras.layers.Layer):\n def __init__(self):\n super(Chebyshev, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size, channels = tf.unstack(tf.shape(inputs))\n outputs = tf.reshape(inputs, shape=(-1, patch_number, patch_size, channels)) \n \n centers = tf.image.resize_with_crop_or_pad(outputs, 1, 1)\n\n outputs = tf.math.subtract(outputs, centers)\n outputs = tf.math.abs(outputs)\n outputs = tf.math.reduce_max(outputs, axis=3)\n outputs = tf.math.less_equal(outputs, tf.cast(patch_size, dtype=tf.float32))\n outputs = tf.cast(outputs, dtype=tf.int32)\n outputs = tf.reshape(outputs, shape=(-1, patch_number, patch_size, patch_size))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Creating an array of binary values from image patches using the Euclidean colour distance function applied to the patch centre and each pixel.",
"_____no_output_____"
],
[
"According to the article:\n> For each time the box $\\beta_{i}$ is moved, a multidimensional analysis of colour similarity is performed for every pixel inside it. This is done by assigning the centre pixel to a vector $𝑓_{c} = 𝑟_{c}, 𝑔_{c}, 𝑏_{c}$, where $𝑟_{c}, 𝑔_{c}$ and $𝑏_{c}$ correspond to the colour intensities for each of the RGB colour channels of given pixel. The other pixels in the box are assigned to a vector $𝑓_{i} = 𝑟_{i}, 𝑔_{i}, 𝑏_{i}$ and compared to the centre pixel by calculating a colour distance $\\Delta$. On the proposed approach, ... the Euclidean ($\\Delta_{e}$) ...",
"_____no_output_____"
],
[
"$$\n\\Delta_{e} = \\sqrt{\\sum_{k} (f_{i}(k_{i}) - f_{c}(k_{c}))^2}, k \\in r, g, b\n$$",
"_____no_output_____"
]
],
[
[
"class Euclidean(tf.keras.layers.Layer):\n def __init__(self):\n super(Euclidean, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size, channels = tf.unstack(tf.shape(inputs))\n outputs = tf.reshape(inputs, shape=(-1, patch_number, patch_size, channels))\n \n centers = tf.image.resize_with_crop_or_pad(outputs, 1, 1)\n\n outputs = tf.math.subtract(outputs, centers)\n outputs = tf.math.pow(outputs, 2)\n outputs = tf.math.reduce_sum(outputs, axis=3)\n outputs = tf.math.pow(outputs, 0.5)\n outputs = tf.math.less_equal(outputs, tf.cast(patch_size, dtype=tf.float32))\n outputs = tf.cast(outputs, dtype=tf.int32)\n outputs = tf.reshape(outputs, shape=(-1, patch_number, patch_size, patch_size))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Creating an array of binary values from image patches using the Manhattan colour distance function applied to the patch centre and each pixel.",
"_____no_output_____"
],
[
"According to the article:\n> For each time the box $\\beta_{i}$ is moved, a multidimensional analysis of colour similarity is performed for every pixel inside it. This is done by assigning the centre pixel to a vector $𝑓_{c} = 𝑟_{c}, 𝑔_{c}, 𝑏_{c}$, where $𝑟_{c}, 𝑔_{c}$ and $𝑏_{c}$ correspond to the colour intensities for each of the RGB colour channels of given pixel. The other pixels in the box are assigned to a vector $𝑓_{i} = 𝑟_{i}, 𝑔_{i}, 𝑏_{i}$ and compared to the centre pixel by calculating a colour distance $\\Delta$. On the proposed approach, ... the Manhattan ($\\Delta_{m}$) ...",
"_____no_output_____"
],
[
"$$\n\\Delta_{m} = \\sum_{k} |f_{i}(k_{i}) - f_{c}(k_{c})|, k \\in r, g, b\n$$",
"_____no_output_____"
]
],
[
[
"class Manhattan(tf.keras.layers.Layer):\n def __init__(self):\n super(Manhattan, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size, channels = tf.unstack(tf.shape(inputs))\n outputs = tf.reshape(inputs, shape=(-1, patch_number, patch_size, channels))\n \n centers = tf.image.resize_with_crop_or_pad(outputs, 1, 1)\n\n outputs = tf.math.subtract(outputs, centers)\n outputs = tf.math.abs(outputs)\n outputs = tf.math.reduce_sum(outputs, axis=3)\n outputs = tf.math.less_equal(outputs, tf.cast(patch_size, dtype=tf.float32))\n outputs = tf.cast(outputs, dtype=tf.int32)\n outputs = tf.reshape(outputs, shape=(-1, patch_number, patch_size, patch_size))\n \n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating probability matrices",
"_____no_output_____"
],
[
"According to the article:\n> After performing this conversion for every box of every given 𝐿 scale, a structure known as probability matrix is generated. Each element of the matrix corresponds to the probability 𝑃 that 𝑚 pixels on a scale 𝐿 are labelled as 1 on each box. ... The matrix is normalized in a way that the sum of the elements in a column is equal to 1, as showed here:",
"_____no_output_____"
],
[
"$$\n\\sum_{m=1}^{L^2} P(m, L) = 1, \\forall L\n$$",
"_____no_output_____"
]
],
[
[
"class Probability(tf.keras.layers.Layer):\n def __init__(self):\n super(Probability, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size = tf.unstack(tf.shape(inputs))\n \n outputs = tf.math.reduce_sum(inputs, axis=(2, 3))\n outputs = tf.vectorized_map(lambda image: tf.math.bincount(image, minlength=patch_size ** 2 + 1), outputs)\n outputs = tf.math.divide(outputs, patch_number) \n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating fractal dimensions",
"_____no_output_____"
],
[
"According to the article:\n> FD is the most common technique to evaluate the fractal properties of an image. This is a measure for evaluating the irregularity and the complexity of a fractal. To obtain local FD features from the probability\nmatrix, for each value of 𝐿, the FD denominated 𝐷(𝐿) is calculated according to",
"_____no_output_____"
],
[
"$$\nD(L) = \\sum_{m=1}^{L^2} \\frac{P(m, L)}{m}\n$$",
"_____no_output_____"
]
],
[
[
"class FractalDimension(tf.keras.layers.Layer):\n def __init__(self):\n super(FractalDimension, self).__init__()\n \n def call(self, inputs):\n batch_size, _len = tf.unstack(tf.shape(inputs))\n numbers = tf.reshape(\n tf.concat(\n [tf.constant([1], dtype=tf.float32), tf.range(1, _len, dtype=tf.float32)], \n axis=0\n ), \n shape=(1, -1)\n )\n \n outputs = tf.math.divide(inputs, numbers)\n outputs = tf.math.reduce_sum(outputs, axis=1)\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating lacunarity",
"_____no_output_____"
],
[
"According to the article:\n> LAC is a measure complementary to FD and allows to evaluate how the space of a fractal is filled (Ivanovici & Richard, 2009). From the probability matrix, first and second-order moments are calculated with",
"_____no_output_____"
],
[
"$$\n\\mu(L) = \\sum_{m=1}^{L^2} mP(m, L)\n$$",
"_____no_output_____"
],
[
"$$\n\\mu^2(L) = \\sum_{m=1}^{L^2} m^{2}P(m, L)\n$$",
"_____no_output_____"
],
[
"> The LAC value for a scale $L$ is given by $\\Lambda$(𝐿), which is obtained according to",
"_____no_output_____"
],
[
"$$\n\\Lambda(L) = \\frac{\\mu^{2}(L) - (\\mu(L))^{2}}{(\\mu(L))^{2}}\n$$",
"_____no_output_____"
]
],
[
[
"class Lacunarity(tf.keras.layers.Layer):\n def __init__(self):\n super(Lacunarity, self).__init__()\n \n def call(self, inputs):\n batch_size, _len = tf.unstack(tf.shape(inputs))\n numbers = tf.reshape(\n tf.concat(\n [tf.constant([1], dtype=tf.float32), tf.range(1, _len, dtype=tf.float32)], \n axis=0\n ), \n shape=(1, -1)\n )\n \n mu_first_2 = tf.math.multiply(inputs, numbers)\n mu_first_2 = tf.math.reduce_sum(mu_first_2, axis=1)\n mu_first_2 = tf.math.pow(mu_first_2, 2)\n\n mu_second = tf.math.pow(numbers, 2)\n mu_second = tf.math.multiply(inputs, mu_second)\n mu_second = tf.math.reduce_sum(mu_second, axis=1)\n\n outputs = tf.math.divide(\n tf.math.subtract(mu_second, mu_first_2),\n mu_first_2\n )\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating percolation Q - the average occurrence of percolation on a scale L",
"_____no_output_____"
],
[
"According to the article:\n> We can also verify whether a box $\\beta_{i}$ is percolating. This can be achieved due to a property that states a percolation threshold for different types of structures. In squared matrices (digital images), this threshold has the value of $p = 0.59275$, which means that if the ratio between pixels labelled as 1 and pixels labelled as 0 is greater or equal than $p$, the matrix is considered as percolating. Let $\\Omega_{i}$ be the number of pixels labelled as 1 in a box $\\beta_{i}$ with size $L \\times L $ , we determine whether such box is percolating according to",
"_____no_output_____"
],
[
"$$\nq_{i} = \n\\begin{cases}\n1, & \\frac{\\Omega_{i}}{L^2} \\ge 0.59275 \\\\\n0, & \\frac{\\Omega_{i}}{L^2} < 0.59275\n\\end{cases}\n$$",
"_____no_output_____"
],
[
"> This results in a binary value for $q_{i}$, wherein 1 indicates that thebox is percolating. The feature $Q(L)$ regards the average occurrence of percolation on a scale $L$ and can be obtained by",
"_____no_output_____"
],
[
"$$\nQ(L) = \\frac{\\sum_{i=1}^{T(L)} q_{i}}{T(L)}\n$$",
"_____no_output_____"
]
],
[
[
"class PercolationQ(tf.keras.layers.Layer):\n def __init__(self, threshold=0.59275):\n super(PercolationQ, self).__init__()\n \n self.threshold = threshold\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size = tf.unstack(tf.shape(inputs))\n \n outputs = tf.math.reduce_sum(inputs, axis=(2, 3))\n outputs = tf.math.divide(outputs, patch_size ** 2)\n outputs = tf.math.greater_equal(outputs, self.threshold)\n outputs = tf.cast(outputs, dtype=tf.float32)\n outputs = tf.math.reduce_mean(outputs, axis=1)\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Clustering values in binarized patches ",
"_____no_output_____"
],
[
"The next two layers, which calculate percolation C and M, work with value clusters. We clustorize values in a separate layer to speed up calculations.",
"_____no_output_____"
]
],
[
[
"class Clusterize(tf.keras.layers.Layer):\n def __init__(self):\n super(Clusterize, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size = tf.unstack(tf.shape(inputs))\n \n outputs = tf.reshape(inputs, shape=(-1, patch_size, patch_size))\n outputs = tfa.image.connected_components(outputs)\n outputs = tf.reshape(outputs, shape=(-1, patch_number, patch_size, patch_size))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating percolation C - the average number of clusters per box on a scale L",
"_____no_output_____"
],
[
"According to the article:\n> Let $c_{i}$ be the number of clusters on a box $\\beta_{i}$, the feature $C(L)$ that represents the average number of clusters per box on a scale $L$ is given by",
"_____no_output_____"
],
[
"$$\nC(L) = \\frac{\\sum_{i=1}^{T(L)} c_{i}}{T(L)}\n$$",
"_____no_output_____"
]
],
[
[
"class PercolationC(tf.keras.layers.Layer):\n def __init__(self):\n super(PercolationC, self).__init__()\n \n def call(self, inputs):\n outputs = tf.cast(inputs, dtype=tf.float32)\n outputs = tf.math.reduce_max(outputs, axis=(2, 3))\n outputs = tf.math.reduce_mean(outputs, axis=1)\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Calculating percolation M - the average coverage area of the largest cluster on a scale L",
"_____no_output_____"
],
[
"According to the article:\n>Another feature that can be obtained is the average coverage area of the largest cluster in a box and is given by $M(L)$. Let $m_{i}$ be the size in pixels of the largest cluster of the box $\\beta_{i}$. The feature $M(L)$ is givenaccording to",
"_____no_output_____"
],
[
"$$\nM(L) = \\frac{\\sum_{i=1}^{T(L)} \\frac{m_{i}}{L^2}}{T(L)}\n$$",
"_____no_output_____"
]
],
[
[
"class PercolationM(tf.keras.layers.Layer):\n def __init__(self):\n super(PercolationM, self).__init__()\n \n def call(self, inputs):\n batch_size, patch_number, patch_size, patch_size = tf.unstack(tf.shape(inputs))\n \n outputs = tf.reshape(inputs, shape=(-1, patch_number, patch_size ** 2))\n outputs = tf.map_fn(lambda image: tf.math.reduce_max(tf.math.bincount(image)), outputs)\n outputs = tf.cast(outputs, dtype=tf.float32)\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Assembling fractal features into an image channel",
"_____no_output_____"
],
[
"According to the article:\n> To serve as input for the incoming CNN classification, the feature vectors generated on the previous layers of the network must be converted into feature matrices. To do so, the 100 features obtained by each distance $\\Delta$ are rearranged as a $10 \\times 10 \\times 10$ matrix. The matrices generated by $\\Delta_{h}$, $\\Delta_{e}$ and $\\Delta_{m}$ correspond to the R, G and B colour channels, respectively. ... Since each of the functions $C(L), Q(L), M(L), \\Lambda(L)$ and $D(L)$, obtained from a specific $\\Delta$, generate 20 features, each function is fit exactly into 2 columns of the matrix.\n\n>Since each of the functions $C(L), Q(L), M(L), \\Lambda(L)$ and $D(L)$, obtained from a specific $\\Delta$, generate 20 features, each function is fit exactly into 2 columns of the matrix.",
"_____no_output_____"
]
],
[
[
"class AssembleChannel(tf.keras.layers.Layer):\n def __init__(self):\n super(AssembleChannel, self).__init__()\n \n def call(self, inputs):\n fractal_dimension = tf.convert_to_tensor(inputs[0])\n fractal_dimension = tf.transpose(fractal_dimension, perm=(1, 0))\n \n lacunarity = tf.convert_to_tensor(inputs[1])\n lacunarity = tf.transpose(lacunarity, perm=(1, 0))\n \n percolation_q = tf.convert_to_tensor(inputs[2])\n percolation_q = tf.transpose(percolation_q, perm=(1, 0))\n \n percolation_c = tf.convert_to_tensor(inputs[3])\n percolation_c = tf.transpose(percolation_c, perm=(1, 0))\n \n percolation_m = tf.convert_to_tensor(inputs[4])\n percolation_m = tf.transpose(percolation_m, perm=(1, 0))\n \n outputs = tf.concat([\n percolation_c,\n percolation_q,\n percolation_m,\n lacunarity,\n fractal_dimension\n ], axis=1)\n outputs = tf.reshape(outputs, shape=(-1, 10, 10))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Organising fractal feature extraction into layers",
"_____no_output_____"
],
[
"We move feature extraction to layers to simplify and clarify the code.",
"_____no_output_____"
],
[
"### based on Chebyshev distance",
"_____no_output_____"
]
],
[
[
"class ChebyshevFeatures(tf.keras.layers.Layer):\n def __init__(self):\n super(ChebyshevFeatures, self).__init__()\n \n self.chebyshev = Chebyshev()\n self.probability = Probability()\n self.clusterize = Clusterize()\n \n self.fractal_dimension = FractalDimension()\n self.lacunarity = Lacunarity()\n self.percolation_q = PercolationQ()\n self.percolation_c = PercolationC()\n self.percolation_m = PercolationM()\n \n self.assemble_channel = AssembleChannel()\n \n def call(self, inputs):\n chebyshevs = [self.chebyshev(i) for i in inputs]\n \n probability = [self.probability(ch) for ch in chebyshevs]\n cluster = [self.clusterize(ch) for ch in chebyshevs]\n \n fractal_dimension = [self.fractal_dimension(ch) for ch in probability]\n lacunarity = [self.lacunarity(ch) for ch in probability] \n percolation_q = [self.percolation_q(ch) for ch in chebyshevs]\n percolation_c = [self.percolation_c(ch) for ch in cluster]\n percolation_m = [self.percolation_m(ch) for ch in cluster]\n \n features = self.assemble_channel([\n fractal_dimension,\n lacunarity,\n percolation_q,\n percolation_c,\n percolation_m\n ])\n \n return features",
"_____no_output_____"
]
],
[
[
"### based on Euclidean distance",
"_____no_output_____"
]
],
[
[
"class EuclideanFeatures(tf.keras.layers.Layer):\n def __init__(self):\n super(EuclideanFeatures, self).__init__()\n \n self.euclidean = Euclidean()\n self.probability = Probability()\n self.clusterize = Clusterize()\n \n self.fractal_dimension = FractalDimension()\n self.lacunarity = Lacunarity()\n self.percolation_q = PercolationQ()\n self.percolation_c = PercolationC()\n self.percolation_m = PercolationM()\n \n self.assemble_channel = AssembleChannel()\n \n def call(self, inputs):\n euclideans = [self.euclidean(i) for i in inputs]\n \n probability = [self.probability(eu) for eu in euclideans]\n cluster = [self.clusterize(eu) for eu in euclideans]\n \n fractal_dimension = [self.fractal_dimension(eu) for eu in probability]\n lacunarity = [self.lacunarity(eu) for eu in probability] \n percolation_q = [self.percolation_q(eu) for eu in euclideans]\n percolation_c = [self.percolation_c(eu) for eu in cluster]\n percolation_m = [self.percolation_m(eu) for eu in cluster]\n \n features = self.assemble_channel([\n fractal_dimension,\n lacunarity,\n percolation_q,\n percolation_c,\n percolation_m\n ])\n \n return features",
"_____no_output_____"
]
],
[
[
"### based on Manhattan distance",
"_____no_output_____"
]
],
[
[
"class ManhattanFeatures(tf.keras.layers.Layer):\n def __init__(self):\n super(ManhattanFeatures, self).__init__()\n \n self.manhattan = Manhattan()\n self.probability = Probability()\n self.clusterize = Clusterize()\n \n self.fractal_dimension = FractalDimension()\n self.lacunarity = Lacunarity()\n self.percolation_q = PercolationQ()\n self.percolation_c = PercolationC()\n self.percolation_m = PercolationM()\n \n self.assemble_channel = AssembleChannel()\n \n def call(self, inputs):\n manhattans = [self.manhattan(i) for i in inputs]\n \n probability = [self.probability(mh) for mh in manhattans]\n cluster = [self.clusterize(mh) for mh in manhattans]\n \n fractal_dimension = [self.fractal_dimension(mh) for mh in probability]\n lacunarity = [self.lacunarity(mh) for mh in probability] \n percolation_q = [self.percolation_q(mh) for mh in manhattans]\n percolation_c = [self.percolation_c(mh) for mh in cluster]\n percolation_m = [self.percolation_m(mh) for mh in cluster]\n \n features = self.assemble_channel([\n fractal_dimension,\n lacunarity,\n percolation_q,\n percolation_c,\n percolation_m\n ])\n \n return features",
"_____no_output_____"
]
],
[
[
"## Assembling fractal features into images",
"_____no_output_____"
],
[
"We assemble fractal features into images, such that each set of fractal features corresponds to a colour channel (R, G, B).",
"_____no_output_____"
]
],
[
[
"class AssembleImage(tf.keras.layers.Layer):\n def __init__(self):\n super(AssembleImage, self).__init__()\n \n def call(self, inputs):\n outputs = tf.stack(inputs)\n outputs = tf.transpose(outputs, perm=(1, 2, 3, 0))\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Organising the fractal feature extraction layers into the single, fractal image layer",
"_____no_output_____"
],
[
"To further simplify the code, we will gather the fractal feature extraction into the single layer, which generates artificial fractal image.",
"_____no_output_____"
]
],
[
[
"class FractalImage(tf.keras.layers.Layer):\n def __init__(self):\n super(FractalImage, self).__init__()\n \n self.patchifies = [Patchify(patch_size) for patch_size in range(3, 41 + 1, 2)]\n \n self.chebyshev_features = ChebyshevFeatures()\n self.euclidean_features = EuclideanFeatures()\n self.manhattan_features = ManhattanFeatures()\n \n self.assemble_image = AssembleImage()\n \n def call(self, inputs):\n patchifies = [patchify(inputs) for patchify in self.patchifies]\n \n chebyshev_features = self.chebyshev_features(patchifies)\n euclidean_features = self.euclidean_features(patchifies)\n manhattan_features = self.manhattan_features(patchifies)\n \n outputs = self.assemble_image([\n chebyshev_features,\n euclidean_features,\n manhattan_features\n ])\n \n return outputs",
"_____no_output_____"
]
],
[
[
"## Assembling the fractal neural network",
"_____no_output_____"
],
[
"So, here we are assembling the fractal neural network from the pieces mentioned above.",
"_____no_output_____"
]
],
[
[
"class FractalNeuralNetwork(tf.keras.Model):\n TARGET_WIDTH = 299\n TARGET_HEIGHT = 299\n \n def __init__(self, class_number):\n super(FractalNeuralNetwork, self).__init__()\n \n self.fractal_image = FractalImage()\n self.resize = tf.keras.layers.Resizing(width=self.TARGET_WIDTH, height=self.TARGET_HEIGHT)\n self.rescale_original = tf.keras.layers.Rescaling(scale=1./255)\n self.rescale_fractal = tf.keras.layers.Lambda(lambda x: tf.math.divide(x, tf.math.reduce_max(x)))\n self.model = hub.KerasLayer(\n \"https://tfhub.dev/google/imagenet/inception_resnet_v2/feature_vector/5\",\n trainable=False\n )\n self.combine = tf.keras.layers.Multiply()\n self.score = tf.keras.layers.Dense(class_number, activation='softmax')\n \n def call(self, inputs):\n fractal_outputs = self.fractal_image(inputs)\n fractal_outputs = self.resize(fractal_outputs)\n fractal_outputs = self.rescale_fractal(fractal_outputs)\n fractal_outputs = self.model(fractal_outputs)\n \n original_outputs = self.rescale_original(inputs)\n original_outputs = self.model(original_outputs)\n \n outputs = self.combine([fractal_outputs, original_outputs])\n outputs = self.score(outputs)\n \n return outputs",
"_____no_output_____"
]
],
[
[
"# Data loading",
"_____no_output_____"
],
[
"## Data source",
"_____no_output_____"
],
[
"As a data source, we use the ISIC Archive.",
"_____no_output_____"
],
[
"The ISIC Archive is an open source platform with publicly available images of skin lesions under Creative Commons licenses. The images are associated with ground-truth diagnoses and other clinical metadata. Images can be queried using faceted search and downloaded individually or in batches. The initial focus of the archive has been on dermoscopy images of individual skin lesions, as these images are inherently standardized by the use of a specialized acquisition device and devoid of many of the privacy challenges associated with clinical images. To date, the images have been provided by specialized melanoma centers from around the world. The archive is designed to accept contributions from new sources under the Terms of Use and welcomes new contributors. There are ongoing efforts to supplement the dermoscopy images in the archive with close-up clinical images and a broader representation of skin types. The images in the Archive are used to support educational efforts through linkage with Dermoscopedia and are used for Grand Challenges and Live Challenges to engage the computer science community for the development of diagnostic AI.",
"_____no_output_____"
],
[
"For more information, go to [ISIC Archive web site](https://www.isic-archive.com/)",
"_____no_output_____"
]
],
[
[
"generator = tf.keras.preprocessing.image.ImageDataGenerator(\n rotation_range=180,\n horizontal_flip=True,\n vertical_flip=True,\n brightness_range=(0.2, 1.5),\n validation_split=0.2,\n)\n\n\ntraining_set = generator.flow_from_directory(\n f\"{os.environ['SCRATCH']}/data10000\",\n target_size=(299, 299), \n batch_size=32, \n class_mode='categorical', \n subset='training'\n)\nvalidation_set = generator.flow_from_directory(\n f\"{os.environ['SCRATCH']}/data10000\", \n target_size=(299, 299), \n batch_size=32, \n class_mode='categorical', \n subset='validation'\n)",
"Found 7881 images belonging to 9 classes.\nFound 1964 images belonging to 9 classes.\n"
],
[
"CLASS_NUMBER = len(training_set.class_indices)",
"_____no_output_____"
]
],
[
[
"# Model training",
"_____no_output_____"
],
[
"## Preparing TensorFlow callbacks",
"_____no_output_____"
],
[
"For our convenience, we create a few TensorFlow callbacks.",
"_____no_output_____"
],
[
"### The TensorBoard callback",
"_____no_output_____"
],
[
"We want to see how the training is going. We add the callback, which will log the metrics to TensorBoard.",
"_____no_output_____"
]
],
[
[
"log_dir = '../logs/fit/' + datetime.datetime.now().strftime('both__inception_resnet_v2___combine__multiply')\ntensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)",
"_____no_output_____"
]
],
[
[
"### The EarlyStopping callback",
"_____no_output_____"
],
[
"This callback stops training when the metrics (e.g. validation loss) are not improving,",
"_____no_output_____"
]
],
[
[
"early_stop_callback = tf.keras.callbacks.EarlyStopping(\n monitor=\"val_loss\", \n min_delta=0.01, \n patience=5, \n restore_best_weights=True\n)",
"_____no_output_____"
]
],
[
[
"### The ModelCheckpoint callback",
"_____no_output_____"
],
[
"This callback saves the model with the best metrics during training.",
"_____no_output_____"
]
],
[
[
"checkpoint_path = 'checkpoints/both__inception_resnet_v2___combine__multiply.ckpt'\n\ncheckpoint_callback = tf.keras.callbacks.ModelCheckpoint(\n checkpoint_path,\n monitor='val_loss',\n verbose=1,\n save_best_only=True,\n save_weights_only=False,\n save_freq='epoch',\n mode='auto'\n)",
"_____no_output_____"
]
],
[
[
"## Actual training",
"_____no_output_____"
]
],
[
[
"model = FractalNeuralNetwork(class_number=CLASS_NUMBER)\nmodel.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])\nmodel.fit(\n training_set, \n validation_data=validation_set, \n epochs=10,\n callbacks=[\n tensorboard_callback,\n early_stop_callback,\n checkpoint_callback\n ]\n)",
"Epoch 1/10\n247/247 [==============================] - ETA: 0s - loss: 0.7032 - accuracy: 0.8087 \nEpoch 1: val_loss improved from inf to 0.52978, saving model to checkpoints/both__inception_resnet_v2___combine__multiply.ckpt\n"
]
],
[
[
"# Model validation",
"_____no_output_____"
],
[
"## Loading the model from the checkpoint",
"_____no_output_____"
]
],
[
[
"model = FractalNeuralNetwork(class_number=CLASS_NUMBER)",
"_____no_output_____"
],
[
"model.load_weights('./checkpoints/both__inception_resnet_v2___combine__multiply.ckpt')",
"_____no_output_____"
]
],
[
[
"## Loading the test data",
"_____no_output_____"
]
],
[
[
"testing_set = generator.flow_from_directory(\n f\"{os.environ['SCRATCH']}/data10000-test\",\n target_size=(299, 299),\n batch_size=32,\n class_mode='categorical'\n)",
"Found 9843 images belonging to 9 classes.\n"
]
],
[
[
"## Making diagnoses",
"_____no_output_____"
]
],
[
[
"true_labels = np.concatenate([testing_set[i][1] for i in range(len(testing_set))], axis=0)",
"_____no_output_____"
],
[
"predicted_labels = model.predict(testing_set)",
"_____no_output_____"
]
],
[
[
"## Plot the ROC Curve",
"_____no_output_____"
]
],
[
[
"fpr = dict()\ntpr = dict()\nauc_metric = dict()\n\ndiagnosis_index_dict = {v: k for k, v in testing_set.class_indices.items()}\n\nfor i in range(CLASS_NUMBER):\n diagnosis = diagnosis_index_dict[i]\n fpr[diagnosis], tpr[diagnosis], _ = roc_curve(true_labels[:, i], predicted_labels[:, i])\n auc_metric[diagnosis] = auc(fpr[diagnosis], tpr[diagnosis])",
"_____no_output_____"
],
[
"%matplotlib inline \nfor diagnosis in testing_set.class_indices:\n plt.plot(fpr[diagnosis], tpr[diagnosis], label=diagnosis)\n \nplt.plot([0, 1], [0, 1], 'k--')\nplt.xlabel('False Positive Rate')\nplt.ylabel('True Positive Rate')\nplt.title('Receiver operating characteristic')\nplt.legend(loc=\"lower right\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Show AUC",
"_____no_output_____"
]
],
[
[
"auc_metric",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad36403840854ad68256ca238cda75920589246
| 3,850 |
ipynb
|
Jupyter Notebook
|
notebooks/4-rnn/1-lstm-basics.ipynb
|
data-science-workshops/deep-learning
|
6f7c4c6aa2cc3cbf781a89e85137ebfc65faa80a
|
[
"MIT"
] | 1 |
2019-02-14T14:58:58.000Z
|
2019-02-14T14:58:58.000Z
|
notebooks/4-rnn/1-lstm-basics.ipynb
|
data-science-workshops/deep-learning
|
6f7c4c6aa2cc3cbf781a89e85137ebfc65faa80a
|
[
"MIT"
] | null | null | null |
notebooks/4-rnn/1-lstm-basics.ipynb
|
data-science-workshops/deep-learning
|
6f7c4c6aa2cc3cbf781a89e85137ebfc65faa80a
|
[
"MIT"
] | 2 |
2018-07-06T16:39:53.000Z
|
2018-10-09T17:29:17.000Z
| 21.751412 | 111 | 0.555844 |
[
[
[
"# Long Short Term Memory Networks",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"* Each line carries an entire vector\n* The pink circles represent pointwise operations (e.g. vector addition)\n* The yellow boxes are learned neural network layers\n* Lines merging denote concatenation\n* A line forking denote its content being copied",
"_____no_output_____"
],
[
"## The Core Idea Behind LSTMs",
"_____no_output_____"
],
[
"### Cell State",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"* The special thing about LSTMs is the cell status (`C`) (horizontal line)\n* The cell status runs straight down the entire chain\n* The LSTM has the ability to remove or add information to the cell state",
"_____no_output_____"
],
[
"### Gates",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"* Gates are a way to optionally let information through\n* They are composed out of a sigmoid neural net layer and a pointwise multiplication operation.\n* The sigmoid layer outputs numbers between zero and one\n * Zero means \"let nothing through\"\n * One means \"let everything through\"\n* An LSTM has three of these gates",
"_____no_output_____"
],
[
"## Step-by-Step LSTM Walk Through",
"_____no_output_____"
],
[
"### The \"forget gate layer\"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"### Decide what new information we’re going to store in the cell state",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"### Update the cell state",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"### Decide what we’re going to output",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Source: [Understanding LSTM Networks](http://colah.github.io/posts/2015-08-Understanding-LSTMs/)",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ad36a51dce9f922467b157d9f245c210af787b8
| 90,473 |
ipynb
|
Jupyter Notebook
|
notebooks/12.ipynb
|
noahbjohnson/senior-project
|
6353b7f5aeab6d7bcb3457e77dd1d816af7ee240
|
[
"MIT"
] | null | null | null |
notebooks/12.ipynb
|
noahbjohnson/senior-project
|
6353b7f5aeab6d7bcb3457e77dd1d816af7ee240
|
[
"MIT"
] | 1 |
2019-04-29T13:13:59.000Z
|
2019-04-30T03:06:18.000Z
|
notebooks/12.ipynb
|
noahbjohnson/senior-project
|
6353b7f5aeab6d7bcb3457e77dd1d816af7ee240
|
[
"MIT"
] | null | null | null | 38.190376 | 113 | 0.314989 |
[
[
[
"# Dataset Joining",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n%matplotlib inline\npd.set_option('display.float_format', lambda x: '%.3f' % x)\npd.set_option('display.max_columns', None)",
"_____no_output_____"
]
],
[
[
"## Load The Files",
"_____no_output_____"
]
],
[
[
"Tourism = pd.read_pickle('../data/processed/Tourism.pickle')\nInequality_WIID = pd.read_pickle('../data/processed/Inequality_WIID.pickle')\nInequality_WDI = pd.read_pickle('../data/processed/Inequality_WDI.pickle')\nGeneral_WDI = pd.read_pickle('../data/processed/General_WDI.pickle')\nEconomic_WDI = pd.read_pickle('../data/processed/Economic_WDI.pickle')\nEconomic_MADDISON = pd.read_pickle('../data/processed/Economic_MADDISON.pickle')\nEducation_WDI = pd.read_pickle('../data/processed/Education_WDI.pickle')\nLabor_WDI = pd.read_pickle('../data/processed/Labor_WDI.pickle')\nUrbanization_UNPD = pd.read_pickle('../data/processed/Urbanization_UNPD.pickle')",
"_____no_output_____"
]
],
[
[
"## Join By Subject",
"_____no_output_____"
],
[
"### Inequality",
"_____no_output_____"
]
],
[
[
"Inequality = Tourism.join(Inequality_WDI).join(Inequality_WIID)",
"_____no_output_____"
],
[
"Inequality.sample(5)",
"_____no_output_____"
]
],
[
[
"### General",
"_____no_output_____"
]
],
[
[
"General = Tourism.join(General_WDI)",
"_____no_output_____"
],
[
"General.sample(5)",
"_____no_output_____"
]
],
[
[
"### Economic",
"_____no_output_____"
]
],
[
[
"Economic = Tourism.join(Economic_MADDISON).join(Economic_WDI)",
"_____no_output_____"
],
[
"Economic.sample(5)",
"_____no_output_____"
]
],
[
[
"### Education",
"_____no_output_____"
]
],
[
[
"Education = Tourism.join(Education_WDI)",
"_____no_output_____"
],
[
"Education.sample(5)",
"_____no_output_____"
]
],
[
[
"### Labor",
"_____no_output_____"
]
],
[
[
"Labor = Tourism.join(Labor_WDI)",
"_____no_output_____"
],
[
"Labor.sample(5)",
"_____no_output_____"
]
],
[
[
"### Urbanization",
"_____no_output_____"
]
],
[
[
"Urbanization = Tourism.join(Urbanization_UNPD)",
"_____no_output_____"
],
[
"Urbanization.sample(5)",
"_____no_output_____"
]
],
[
[
"## Full Dataset Join",
"_____no_output_____"
]
],
[
[
"Full = Tourism.join([\n Inequality_WIID,\n Inequality_WDI,\n General_WDI,\n Economic_MADDISON,\n Education_WDI,\n Labor_WDI,\n Urbanization_UNPD],how=\"left\").join(Economic_WDI.drop(['SI.POV.GINI', 'SI.POV.NAGP'],axis='columns'))",
"_____no_output_____"
]
],
[
[
"## Save Files",
"_____no_output_____"
]
],
[
[
"General.to_csv(\"../data/processed/General.csv\")\nLabor.to_csv(\"../data/processed/Labor.csv\")\nUrbanization.to_csv(\"../data/processed/Urbanization.csv\")\nEducation.to_csv(\"../data/processed/Education.csv\")\nInequality.to_csv(\"../data/processed/Inequality.csv\")\nEconomic.to_csv(\"../data/processed/Economic.csv\")\nFull.to_csv(\"../data/processed/Full.csv\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad36df602521d124d02b71d6d92d280a2c98e36
| 9,845 |
ipynb
|
Jupyter Notebook
|
tutorials/hubbard_gp_opti.ipynb
|
scikit-quant/scikit-quant
|
397ab0b6287f3815e9bcadbfadbe200edbee5a23
|
[
"BSD-3-Clause-LBNL"
] | 31 |
2019-02-05T16:39:18.000Z
|
2022-03-11T23:14:11.000Z
|
tutorials/hubbard_gp_opti.ipynb
|
scikit-quant/scikit-quant
|
397ab0b6287f3815e9bcadbfadbe200edbee5a23
|
[
"BSD-3-Clause-LBNL"
] | 20 |
2020-04-13T09:22:53.000Z
|
2021-08-16T16:14:13.000Z
|
tutorials/hubbard_gp_opti.ipynb
|
scikit-quant/scikit-quant
|
397ab0b6287f3815e9bcadbfadbe200edbee5a23
|
[
"BSD-3-Clause-LBNL"
] | 6 |
2020-04-21T17:43:47.000Z
|
2021-03-10T04:12:34.000Z
| 36.872659 | 515 | 0.634129 |
[
[
[
"# Let's apply the GP-based optimizer to our small Hubbard model.\n\nMake sure your jupyter path is the same as your virtual environment that you used to install all your packages. \nIf nopt, do something like this in your terminal:\n\n`$ ipython kernel install --user --name TUTORIAL --display-name \"Python 3.9\"`",
"_____no_output_____"
]
],
[
[
"# check your python\nfrom platform import python_version\n\nprint(python_version())",
"_____no_output_____"
]
],
[
[
"Gaussian Process (GP) models were introduced in the __[Gaussian Process Models](optimization.ipynb)__ notebook. The GP-based optimizer uses these techniques as implemented in the included __[opti_by_gp.py](opti_by_gp.py)__ module, which also provides helpers for plotting results. Note that this module uses the ImFil optimizer underneath, a choice that can not currently be changed.\n\nAs a first step, create once more a __[Hubbard Model](hubbard_model_intro.ipynb)__ setup.",
"_____no_output_____"
]
],
[
[
"import hubbard as hb\nimport logging\nimport noise_model as noise\nimport numpy as np\nimport opti_by_gp as obg\nfrom IPython.display import Image\n\nlogging.getLogger('hubbard').setLevel(logging.INFO)",
"_____no_output_____"
],
[
"# Select a model appropriate for the machine used:\n# laptop -> use small model\n# server -> use medium model\n\nMODEL = hb.small_model\n#MODEL = hb.medium_model\n\n# Hubbard model for fermions (Fermi-Hubbard) required parameters\nxdim, ydim, t, U, chem, magf, periodic, spinless = MODEL()\n\n# Number of electrons to add to the system\nn_electrons_up = 1\nn_electrons_down = 1\nn_electrons = n_electrons_up + n_electrons_down\n\n# Total number of \"sites\", with each qubit representing occupied or not\nspinfactor = spinless and 1 or 2\nn_qubits = n_sites = xdim * ydim * spinfactor\n\n# Create the Hubbard Model for use with Qiskit\nhubbard_op = hb.hamiltonian_qiskit(\n x_dimension = xdim,\n y_dimension = ydim,\n tunneling = t,\n coulomb = U,\n chemical_potential = chem,\n magnetic_field = magf,\n periodic = periodic,\n spinless = spinless)",
"_____no_output_____"
]
],
[
[
"The GP modeling needs persistent access to the evaluated points, so tell the objective to save them. Otherwise, the objective is the same as before. Choose the maximum number of objective evaluations, the initial and set the bounds. Then run the optimization using GP (as mentioned before, this uses ImFil underneath).",
"_____no_output_____"
]
],
[
[
"# noise-free objective with enough Trotter steps to get an accurate result\nobjective = hb.EnergyObjective(hubbard_op, n_electrons_up, n_electrons_down,\n trotter_steps=3, save_evals=True)\n\n# initial and bounds (set good=True to get tighter bounds)\ninitial_amplitudes, bounds = MODEL.initial(\n n_electrons_up, n_electrons_down, objective.npar(), good=False)\n\n# max number of allowed function evals\nmaxevals = 100",
"_____no_output_____"
],
[
"result = obg.opti_by_gp(objective.npar(), bounds, objective, maxevals)",
"_____no_output_____"
],
[
"print('Results with GP:')\nprint(\"Estimated energy: %.5f\" % result[1])\nprint(\"Parameters: \", result[0])\nprint(\"Number of iters: \", result[2])",
"_____no_output_____"
]
],
[
[
"Now let's analyze the results be looking at the sample evaluations and convergence plot.",
"_____no_output_____"
]
],
[
[
"Image(filename='samples.png')",
"_____no_output_____"
]
],
[
[
"The left plot shows:\n1) the points sampled with GP (pink squares): you can see that we have some points everywhere in the space, but a denser pink square cloud where the function has its minimum\n\n2) yellow circles (5) -- these are the points from which the local search with ImFil starts: we choose the best point found by the GP, and another 4 points based on their function value and distance to already selected start points. 5 is a parameter, if you want to do only one local search, you can just start from the best point found by the GP iterations. Also: not all 5 points will necessarily be used for ImFil, the optimization stops when the maximum number of allowed evaluations has been reached. \n\n3) the green squares are the points ImFil decided to sample -- you can see that they cover most of the space. Wouldn't it be nice to force ImFil to search only a smaller radius?!\n\n4) the red dot indicates the best point found during optimization\n\n5) the contours are created by using a GP model and all sample information that we collected - so this is not the true contours, but the best guess of what the true contours may look like\n\nThe right plot shows the GP approximation of the energy surface - again, not the true surface, just our best guess based on training a GP on all input-output pairs",
"_____no_output_____"
]
],
[
[
"Image(filename='progress.png')",
"_____no_output_____"
]
],
[
[
"This plot shows the progress we are making with respect to improving the energy versus the number of function evaluations. \nWe show the best energy value found so far, thus, the graph is monotonically decreasing and has a step-like shape. whenever the graph is flat, it means that during these iterations no energy improvements were found. If you were to plot simply the energy at each function evaluation, the graph would go up and down because we use sampling based algorithms and not gradient-based algorithms. Thus, not in every iteration we find an improvement. \nThere is a large down-step in the beginning - this is due to our random space filling sampling initially. We can also see that ImFil does not make much progress here. The GP-based sampling is used until 30 evaluations. ",
"_____no_output_____"
],
[
"Note that the GP based optimizer has parameters, including the size of the initial experimental design, the number of iterations that we want to apply the GP (here 30), the maximum number of local searches with ImFil after the GP is done, .... see the __[opti_by_gp.py](opti_by_gp.py)__ module (or run the cell below to load).",
"_____no_output_____"
]
],
[
[
"%load 'opti_by_gp.py'",
"_____no_output_____"
]
],
[
[
"**Exercise:** redo the above analysis using a noisy objective. If time is limited, consider only using sampling noise, e.g. by setting `shots=8192` (see the notebook on __[noise](hubbard_vqe_noise.ipynb)__ for more examples), and using tight bounds.\n\n**Optional Exercise:** for comparison purposes, follow-up with an optimization run that does not use GP and try in particular what happens when using only few function evaluations (20, say, if using tight bounds). Try different optimizers (but consider that some, such as SPSA, will take more evalations per iteration; and consider that optimizers that do not respect bounds are at a severe disadvantage).",
"_____no_output_____"
]
],
[
[
"# Pull in a couple of optimizers to play with\nfrom qiskit.algorithms.optimizers import COBYLA, SPSA\ntry:\n from qiskit.algorithms.optimizers import IMFIL, SNOBFIT\nexcept ImportError:\n print(\"install scikit-quant to use IMFIL and SNOBFIT\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad38372db6a2200f3e5108a06f5d55e4e61c03f
| 7,138 |
ipynb
|
Jupyter Notebook
|
01.Algorithm/bruteforceok.ipynb
|
HenryPaik1/Study
|
deaa1df746587c3dc7fa3b7b73107035a704131b
|
[
"MIT"
] | 2 |
2018-11-02T14:57:12.000Z
|
2018-11-06T14:36:22.000Z
|
01.Algorithm/bruteforceok.ipynb
|
HenryPaik1/study
|
deaa1df746587c3dc7fa3b7b73107035a704131b
|
[
"MIT"
] | null | null | null |
01.Algorithm/bruteforceok.ipynb
|
HenryPaik1/study
|
deaa1df746587c3dc7fa3b7b73107035a704131b
|
[
"MIT"
] | null | null | null | 20.570605 | 149 | 0.375736 |
[
[
[
"# 브루트 포스\n가능한 모든 경우 시행\n- 순서\n - 가능한 모든 경우의 수 계산\n - 모든 방법 다 만들어보고(경우의 수가 아니라) <- 코딩 필요\n - 모든 경우 빠짐없이\n - for/순열/재귀호출/비트마스크\n - 각 방법 모두 사용해보자",
"_____no_output_____"
],
[
"### 예제: 일곱난쟁이\n- https://www.acmicpc.net/problem/2309\n- 난쟁이 N -> 2명고르면 O(N^2) -> 나머지 합 O(N) -> 전체 복잡도: O(N^3)\n- 아래 실제는 O(N^2): 마지막 print 구문은 +N",
"_____no_output_____"
]
],
[
[
"# 답\nimport sys\nn = 9\na = [int(input()) for _ in range(n)]\na.sort()\ntotal = sum(a)\nfor i in range(0, n):\n for j in range(i+1, n):\n if total - a[i] - a[j] == 100:\n for k in range(0, n):\n if i == k or j == k:\n continue\n print(a[k])\n sys.exit(0)",
"100\n0\n0\n0\n0\n0\n0\n0\n0\n0\n0\n0\n0\n0\n0\n100\n"
],
[
"a = [1,2,3,6,7,8,2]\nsorted(a)\na.sort()\na",
"_____no_output_____"
],
[
"## 답\n\ndef sol():\n n = 9; a = [int(input()) for _ in range(n)]\n total = sum(a)\n a.sort()\n for i in range(n):\n for j in range(i+1, n):\n if total - a[i] - a[j] == 100:\n # 아래는 한번만 반복됨\n for k in range(n):\n if k != i and k != j:\n print(a[k])\n return\nsol()",
"100\n1\n0\n0\n0\n0\n0\n0\n0\n100\n0\n0\n0\n0\n0\n0\n"
]
],
[
[
"### 예제: 날짜 계산(3가지 방식)\n- https://www.acmicpc.net/problem/1476\n- 총 경우의 수: 15 * 28 * 19\n- year mod (15, 28, 19) 검산\n- 중국인의 나머지 정리",
"_____no_output_____"
]
],
[
[
"# 예시답안\ndef sol():\n E, S, M = map(int, input().split())\n e, s, m = 1, 1, 1\n year = 1\n while True:\n if e == E and s == S and m == M:\n print(year)\n return\n \n e += 1\n s += 1\n m += 1\n if e == 16:\n e = 1\n if s == 29:\n s = 1\n if m == 20:\n m = 1\n year += 1\nsol()",
"1 16 16\n16\n"
],
[
"# 내 풀이\n# 나머지 범위가 0 ~ 14 vs 1 ~ 15 이기 때문에 우선 (실제수-1)을 나누고, 그 나머지에 다시 +1\n## 원래 1, 2, 3, ..., 15 -> 0, 1, 2, ..., 14 -> +1 복원가능\ndef sol():\n e, s, m = list(map(int, input().split()))\n ans = e - 1\n \n while True:\n if ans % 28 + 1 == s and ans % 19 + 1 == m:\n return ans + 1\n ans += 15\nsol()\n",
"1 16 16\nans: 0\nans: 15\n"
]
],
[
[
"### 예제: 테트로미노(pass)\n- (N * M)",
"_____no_output_____"
]
],
[
[
"[list(map(int. ))]",
"_____no_output_____"
],
[
"a = [[1, 2],\n[2, 3],\n[4, 5]]\na[1][1]",
"_____no_output_____"
],
[
"#일자\ndef sol1(n, m):\n MAX = 0\n # case1: i start point\n for i in range(0, n-4+1):\n for j in range(0, m):\n if sum(array[j, i:i+3]) > MAX:\n MAX = sum(array[j, i:i+3])\n \n for i in range(0, n):\n for j in range(0, m-4+1):\n if sum(array[])\n return Max",
"_____no_output_____"
],
[
"for i in range(n):\n for j in range(m):\n for block in blocks:\n ok = True\n s = a[i][j]\n for dx, dy in block",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ad383ce8f3f4df56ce210b74056ad75e3525854
| 5,488 |
ipynb
|
Jupyter Notebook
|
1. Performance analysis at system-level.ipynb
|
softvis-research/SSP2020
|
61c5c9bd1d44eff5434fcb79ec1ff9758843067d
|
[
"Apache-2.0"
] | null | null | null |
1. Performance analysis at system-level.ipynb
|
softvis-research/SSP2020
|
61c5c9bd1d44eff5434fcb79ec1ff9758843067d
|
[
"Apache-2.0"
] | null | null | null |
1. Performance analysis at system-level.ipynb
|
softvis-research/SSP2020
|
61c5c9bd1d44eff5434fcb79ec1ff9758843067d
|
[
"Apache-2.0"
] | null | null | null | 33.463415 | 109 | 0.564504 |
[
[
[
"# Performance analysis at system-level\n",
"_____no_output_____"
],
[
"## Reproduce line chart for CPU utiliztion\n",
"_____no_output_____"
]
],
[
[
"import py2neo\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\ngraph = py2neo.Graph(bolt=True, host='localhost', user='neo4j', password = 'neo4j')\n\n# query for CPU measurements\ncpu_query = \"\"\"\nMATCH (r:Record)-[:CONTAINS]->(c:CpuUtilization)\nWHERE r.fileName =~ '.*/1-MemoryLeak-5/kieker-logs/kieker-20150820-064855519-UTC-middletier2-KIEKER'\nRETURN c.timestamp AS timestamp, c.cpuID AS cpuID, c.totalUtilization * 100 AS cpuUtilization\nORDER BY timestamp\n\"\"\"\ndf = pd.DataFrame(graph.run(cpu_query).data())\n# drop first and last measurements to sanitize data\ndf.drop(df.head(3).index, inplace=True)\ndf.drop(df.tail(5).index, inplace=True)\n\n# cast to datetime and round up to the nearest second\ndf['timestamp'] = pd.to_datetime(df['timestamp'])\ndf['timestamp'] = df['timestamp'].dt.round('1s')\ndf['CPU ID'] = pd.to_numeric(df['cpuID'])\n# get the mean utilization of every CPU core\ndf = df.groupby(['timestamp']).mean()\ndf = df.drop('CPU ID', 1)\n\n# get the average of 7 measurements to sanitize the data\ndf_cpu_plot = df.rolling(7).mean()\ndf_cpu_plot = df_cpu_plot.iloc[::7, :]\n\n# label and style the plot\nplt.plot_date(df_cpu_plot.index, df_cpu_plot['cpuUtilization'], fmt='-', color='#00035b')\nplt.title('CPU utilization (%)')\nplt.ylim(-2.5, 102.5)\nplt.grid(linestyle=':')\n\n# fill in the data\ndate_list = pd.date_range(start=df.index[0], end=df.index[-1], periods=7).tolist()\n# As we don't know the time zone, we choose the time that makes the most sense\nplt.xticks(date_list + ['2015-08-20 08:05'], ['', '', '', '', '', '', '', '4:05 PM'])\nplt.yticks([0.0, 20.0, 40.0, 60.0, 80.0, 100.0], ['0.0', '', '', '', '', '100.0'])\nplt.axvline('2015-08-20 08:05', color='black', label='4:05 PM', linestyle='--')\nplt.setp(plt.gca().xaxis.get_majorticklabels(), 'rotation', 0)\n# uncomment to save the plot as a pdf\n# plt.savefig('cpu_plot.pdf')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Reproduce line chart for memory utilization\n",
"_____no_output_____"
]
],
[
[
"# query for memory measurements\nmem_query = \"\"\"\nMATCH (r:Record)-[:CONTAINS]->(m:MemSwapUsage)\nWHERE r.fileName =~ '.*/1-MemoryLeak-5/kieker-logs/kieker-20150820-064855519-UTC-middletier2-KIEKER'\nRETURN m.timestamp AS timestamp, toFloat(m.memUsed)*100.0 / toFloat(m.memTotal) AS memoryUtilization\nORDER BY timestamp\n\"\"\"\ndf_mem = pd.DataFrame(graph.run(mem_query).data())\n# drop first and last measurements to sanitize data\ndf_mem.drop(df_mem.head(3).index, inplace=True)\ndf_mem.drop(df_mem.tail(5).index, inplace=True)\n\n# cast to datetime and round up to the nearest second\ndf_mem['timestamp'] = pd.to_datetime(df_mem['timestamp'])\ndf_mem['timestamp'] = df_mem['timestamp'].dt.round('1s')\ndf_mem.set_index('timestamp', inplace=True)\n\n# get the average of 10 measurements to sanitize the data\ndf_mem_plot = df_mem.rolling(7).mean()\ndf_mem_plot = df_mem_plot.iloc[::7, :]\n\n# label and style the plot\nplt.plot_date(df_mem_plot.index, df_mem_plot['memoryUtilization'], fmt='-', color='#00035b')\nplt.title('Memory utilization (%)')\nplt.ylim(-2.5, 102.5)\nplt.grid(linestyle=':')\n\n# fill in the data\ndate_list = pd.date_range(start=df.index[0], end=df.index[-1], periods=7).tolist()\nplt.xticks(date_list + ['2015-08-20 07:55'], ['', '', '', '', '', '', '', '3:55 PM'])\nplt.yticks([0.0, 20.0, 40.0, 60.0, 80.0, 100.0], ['0.0', '', '', '', '', '100.0'])\nplt.axvline('2015-08-20 07:55', color='black', label='3:55 PM', linestyle='--')\nplt.setp(plt.gca().xaxis.get_majorticklabels(), 'rotation', 0)\n# uncomment to save the plot as a pdf\n# plt.savefig('mem_plot.pdf')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad38a580734e87334553483f4e2a6948470abc7
| 8,706 |
ipynb
|
Jupyter Notebook
|
decomposition/nonnegative-matrix/topic-modelling.ipynb
|
SeptumCapital/Machine-Learning-Numpy
|
ae8f9266a87ffd3f67471a97bf183b82740b7deb
|
[
"MIT"
] | 89 |
2018-11-22T02:57:40.000Z
|
2022-03-10T09:17:19.000Z
|
decomposition/nonnegative-matrix/topic-modelling.ipynb
|
IronOnet/Machine-Learning-Numpy
|
ae8f9266a87ffd3f67471a97bf183b82740b7deb
|
[
"MIT"
] | 1 |
2019-02-25T15:23:42.000Z
|
2019-06-24T00:46:18.000Z
|
decomposition/nonnegative-matrix/topic-modelling.ipynb
|
IronOnet/Machine-Learning-Numpy
|
ae8f9266a87ffd3f67471a97bf183b82740b7deb
|
[
"MIT"
] | 57 |
2018-11-22T02:57:35.000Z
|
2022-03-29T00:14:36.000Z
| 38.866071 | 107 | 0.597404 |
[
[
[
"import re, random\nimport numpy as np",
"_____no_output_____"
],
[
"with open('kerajaan','r') as fopen:\n kerajaan = list(filter(None, fopen.read().split('\\n')))",
"_____no_output_____"
],
[
"def clearstring(string):\n string = re.sub('[^A-Za-z0-9 ]+', '', string)\n string = string.split(' ')\n string = filter(None, string)\n string = [y.strip() for y in string]\n string = ' '.join(string)\n return string.lower()\n\nkerajaan = [clearstring(i) for i in kerajaan]",
"_____no_output_____"
],
[
"def penalty(M, mu):\n return np.where(M>=mu,0, np.min(M - mu, 0))\n\ndef grads(M, W, H, lam, mu):\n R = W.dot(H) - M\n return R.dot(H.T) + penalty(W, mu)*lam, W.T.dot(R) + penalty(H, mu)*lam\n\ndef upd(M, W, H, lr, lam, mu):\n dW,dH = grads(M,W,H,lam,mu)\n W -= lr*dW\n H -= lr*dH\n \ndef tfidf(corpus):\n vocabulary = list(set(' '.join(corpus).split()))\n idf = {}\n for i in vocabulary:\n idf[i] = 0\n for k in corpus:\n if i in k.split():\n idf[i] += 1\n idf[i] = np.log(idf[i] / len(corpus))\n tfidf = np.zeros((len(corpus),len(vocabulary)))\n for no, i in enumerate(corpus):\n for text in i.split():\n tfidf[no, vocabulary.index(text)] += 1\n for text in i.split():\n tfidf[no, vocabulary.index(text)] = tfidf[no, vocabulary.index(text)] * idf[text]\n return vocabulary, tfidf\n\ndef bow(corpus):\n vocabulary = list(set(' '.join(corpus).split()))\n bow = np.zeros((len(corpus),len(vocabulary)))\n for no, i in enumerate(corpus):\n for text in i.split():\n bow[no, vocabulary.index(text)] += 1\n return vocabulary, bow",
"_____no_output_____"
],
[
"def show_topics(corpus, count=10, k_words=10, use_tfidf=True, penalty=1e-6, learning_rate=1e-6,\n lam=1e3,epoch=50):\n if use_tfidf:\n vocab, vectors = tfidf(corpus)\n else:\n vocab, vectors = bow(corpus)\n print('vectors shape:',vectors.shape)\n m, n = vectors.shape\n W = np.abs(np.random.normal(scale=0.01, size=(m,count)))\n H = np.abs(np.random.normal(scale=0.01, size=(count,n)))\n for i in range(epoch):\n upd(vectors,W,H,learning_rate,lam,penalty)\n print('epoch:',i, W.min(), H.min())\n top_words = lambda t: [vocab[i] for i in np.argsort(t)[:-k_words-1:-1]]\n topic_words = ([top_words(t) for t in H])\n return [' '.join(t) for t in topic_words]",
"_____no_output_____"
],
[
"show_topics(kerajaan)",
"vectors shape: (6957, 16212)\nepoch: 0 -4.1044924381583935e-07 -2.90772193167458e-06\nepoch: 1 -7.8695576390063e-06 -6.253696457086038e-06\nepoch: 2 -3.4228037418379374e-05 -9.596089298466051e-06\nepoch: 3 -6.055980410656732e-05 -1.3333561301495036e-05\nepoch: 4 -8.686499916818119e-05 -2.0944640100188828e-05\nepoch: 5 -0.00011314376380983153 -2.8547641497971757e-05\nepoch: 6 -0.00013939623898103027 -3.6142573639530124e-05\nepoch: 7 -0.00016562256537509216 -4.3729444662373384e-05\nepoch: 8 -0.0001918228834300349 -5.130826269686379e-05\nepoch: 9 -0.00021799733332947895 -5.887903586627732e-05\nepoch: 10 -0.0002441460550035473 -6.64417722868597e-05\nepoch: 11 -0.00027026918812976373 -7.39964800678866e-05\nepoch: 12 -0.0002963668721339562 -8.154316731171842e-05\nepoch: 13 -0.00032243924619115133 -8.908184211389151e-05\nepoch: 14 -0.0003484864492264663 -9.661251256313463e-05\nepoch: 15 -0.0003745086199160063 -0.00010413518674145421\nepoch: 16 -0.0004005058966877604 -0.00011164987272422302\nepoch: 17 -0.0004264784177225016 -0.0001279288940378729\nepoch: 18 -0.00045242632095455104 -0.00017022687973194478\nepoch: 19 -0.00047834974407267184 -0.00021248205910133673\nepoch: 20 -0.0005042488245209668 -0.0002546946584620727\nepoch: 21 -0.000530123699499772 -0.00029686490371796215\nepoch: 22 -0.0005559745059665528 -0.00033899302036178805\nepoch: 23 -0.0005818013806368022 -0.000381079233476807\nepoch: 24 -0.0006076044599849372 -0.0004231237677380898\nepoch: 25 -0.0006333838802451981 -0.0004651268474141948\nepoch: 26 -0.0006591397774125548 -0.0005070886963683779\nepoch: 27 -0.0006848722872435997 -0.0005490095380599262\nepoch: 28 -0.0007105815452574472 -0.0005908895955454773\nepoch: 29 -0.0007362676867366378 -0.0006327290914810896\nepoch: 30 -0.0007619308467280407 -0.0006745282481228718\nepoch: 31 -0.0007875711600437581 -0.000716287287328728\nepoch: 32 -0.0008173509272152328 -0.000758006430559504\nepoch: 33 -0.0008513582303096573 -0.0007996858988820443\nepoch: 34 -0.0008853325305552274 -0.0008413259129674747\nepoch: 35 -0.0009192739276010804 -0.0008829266930953532\nepoch: 36 -0.0009531825209330819 -0.0009244884591534525\nepoch: 37 -0.0009870584098742618 -0.0009660114306396433\nepoch: 38 -0.0010209016935852234 -0.001007495826662702\nepoch: 39 -0.00105471247106459 -0.0010489418659462102\nepoch: 40 -0.0010884908411494078 -0.0010903497668260733\nepoch: 41 -0.0011222369025156147 -0.0011317197472553127\nepoch: 42 -0.001155950753678441 -0.0011730520248030844\nepoch: 43 -0.0011896324929928487 -0.0012143468166576255\nepoch: 44 -0.0012232822186539999 -0.0012556043396279525\nepoch: 45 -0.0012569000286976662 -0.0012968248101398491\nepoch: 46 -0.001290486021000694 -0.0013380084442423039\nepoch: 47 -0.0013240402932814404 -0.0013791554576082045\nepoch: 48 -0.0013575629431002358 -0.0014202660655350163\nepoch: 49 -0.0013910540678598402 -0.001461340482947894\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad38e08966ddbec6eb940aa396973e5a10728f0
| 381,102 |
ipynb
|
Jupyter Notebook
|
KNN, Decision Tree, SVM, and Logistic Regression.ipynb
|
hrishipoola/KNN_DecisionTree_SVM_Logistic_Loan_Status
|
39152edb3a432209f81abf863353e28d5e219bc0
|
[
"MIT"
] | null | null | null |
KNN, Decision Tree, SVM, and Logistic Regression.ipynb
|
hrishipoola/KNN_DecisionTree_SVM_Logistic_Loan_Status
|
39152edb3a432209f81abf863353e28d5e219bc0
|
[
"MIT"
] | null | null | null |
KNN, Decision Tree, SVM, and Logistic Regression.ipynb
|
hrishipoola/KNN_DecisionTree_SVM_Logistic_Loan_Status
|
39152edb3a432209f81abf863353e28d5e219bc0
|
[
"MIT"
] | null | null | null | 290.252856 | 115,344 | 0.739275 |
[
[
[
"# KNN, Decision Tree, SVM, and Logistic Regression Classifiers to Predict Loan Status ",
"_____no_output_____"
],
[
"Today, we'll look into the question: will a new bank customer default on his or her loan? We'll optimize, train, make predictions with, and evaluate four classification models - K Nearest Neighbor (KNN), Decision Tree, Support Vector Machine (SVM), and logistic regression - for loan status of new customers. We'll work with a bank data set of 346 customers with key variables such as loan status, principal, terms, effective date, due date, age, education, and gender. A bank's department head, for example, could apply a predictive model to better structure loans and tailor terms to various target customers. Let's break it down:\n\n**Part 1**: Cleaning and wrangling, including converting data types, using .to_datetime, and replacing values\n<br>**Part 2**: Exploratory analysis, including plotting stratified histograms, working with groupby, creating new relevant variables, and making observations to determine key features\n<br>**Part 3**: One hot encoding to convert categorical variables with multiple categories to binary variables using pd.get_dummies and adding new features using pd.concat\n<br>**Part 4**: Feature selection of predictors (X) and labeled target (y)\n<br>**Part 5**: Normalizing feature set using scikit learn's preprocessing.StandardScaler.fit.transform\n<br>**Part 6**: KNN, including determining and plotting optimal k value, training model and making predictions on test set, generating a confusion matrix heatmap and report, evaluating jaccard and F1 scores \n<br>**Part 7**: Decision Tree, including determining and plotting optimal max depth, training model and making predictions on test set, visualizing decision tree using pydotplus and graphviz, generating a confusion matrix heatmap and report, evaluating jaccard and F1 scores\n<br>**Part 8**: SVM, including determining and plotting optimal kernel function, training model and making predictions on test set, generating a confusion matrix heatmap and report, evaluating jaccard and F1 scores\n<br>**Part 9**: Logistic Regression, including determining and plotting optimal regularization and numerical solver, training model and making predictions on test set, calculating probability, generating a confusion matrix heatmap and report, evaluating jaccard, F1, and log loss scores\n<br>**Part 10**: Evaluating model performance head-to-head by creating a dataframe of accuracy scores for KNN, Decision Tree, SVM, and Logistic Regression models to make comparisons \n\nWe'll cover cleaning, wrangling, and visualizing techniques, apply important scikit learn libraries to develop, optimize, train, and make predictions, and walk through evaluating and comparing models. Let's dig in.",
"_____no_output_____"
]
],
[
[
"# Import relevant libraries\nimport itertools\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import NullFormatter\nimport pandas as pd\nimport numpy as np\nimport matplotlib.ticker as ticker\nimport seaborn as sns\n\n# Scikit learn libraries\nfrom sklearn import preprocessing\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import metrics\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.tree import DecisionTreeClassifier \nfrom sklearn import tree\nimport scipy.optimize as opt\nfrom sklearn.svm import SVC \nfrom sklearn import svm\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import classification_report, confusion_matrix\nfrom sklearn.metrics import jaccard_similarity_score\nfrom sklearn.metrics import f1_score\nfrom sklearn.metrics import log_loss\n\n# Visualizing Decision Tree\n!pip install graphviz\n!pip install pydotplus\nimport graphviz \nimport pydotplus",
"Collecting graphviz\n Downloading https://files.pythonhosted.org/packages/83/cc/c62100906d30f95d46451c15eb407da7db201e30f42008f3643945910373/graphviz-0.14-py2.py3-none-any.whl\nInstalling collected packages: graphviz\nSuccessfully installed graphviz-0.14\nCollecting pydotplus\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/60/bf/62567830b700d9f6930e9ab6831d6ba256f7b0b730acb37278b0ccdffacf/pydotplus-2.0.2.tar.gz (278kB)\n\u001b[K |████████████████████████████████| 286kB 7.4MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: pyparsing>=2.0.1 in /opt/conda/envs/Python36/lib/python3.6/site-packages (from pydotplus) (2.3.1)\nBuilding wheels for collected packages: pydotplus\n Building wheel for pydotplus (setup.py) ... \u001b[?25ldone\n\u001b[?25h Stored in directory: /home/dsxuser/.cache/pip/wheels/35/7b/ab/66fb7b2ac1f6df87475b09dc48e707b6e0de80a6d8444e3628\nSuccessfully built pydotplus\nInstalling collected packages: pydotplus\nSuccessfully installed pydotplus-2.0.2\n"
]
],
[
[
"## Part 1: Cleaning and Wrangling",
"_____no_output_____"
]
],
[
[
"# Read in data\npd.set_option(\"display.max_columns\", 100)\ndf = pd.read_csv('https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/ML0101ENv3/labs/loan_train.csv')",
"_____no_output_____"
],
[
"# Check first few rows\ndf.head()",
"_____no_output_____"
],
[
"# Check dimensions of dataframe\ndf.shape",
"_____no_output_____"
],
[
"# Check number of null values. We see there are no null values\ndf.isnull().sum().to_frame()",
"_____no_output_____"
],
[
"# Check datatypes. Several key variables are objects, let's convert them to numerical values\ndf.dtypes",
"_____no_output_____"
],
[
"# Convert gender strings 'Male' to 0 and 'Female' to 1\ndf['Gender'].replace(to_replace=['male','female'], value=[0,1],inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"# Convert effective data and due date columns into date time object\ndf['due_date'] = pd.to_datetime(df['due_date'])\ndf['effective_date'] = pd.to_datetime(df['effective_date'])\ndf.head()",
"_____no_output_____"
],
[
"# Under column education, \"Bachelor\" is mispelled, let's replace it with the correct spelling\ndf['education']=df['education'].str.replace('Bechalor', 'Bachelor')\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Part 2: Exploratory Analysis",
"_____no_output_____"
]
],
[
[
"# As we'll be plotting with seaborn, let's set the style to darkgrid\nsns.set_style(\"darkgrid\")",
"_____no_output_____"
],
[
"# Check loan status split. We have 260 loans paied, and 86 that defaulted.\ndf['loan_status'].value_counts().to_frame()",
"_____no_output_____"
]
],
[
[
"Let's check how loan status looks by gender. In our sample, from our plot, there are fewer women applying for and receiving loans (and thus fewer defaulting). Grouping our data by gender using groupby we see that 27% of men defaulted while 13% of women defaulted. ",
"_____no_output_____"
]
],
[
[
"# Plot histogram of age stratified by gender and loan status\nbins = np.linspace(df.age.min(), df.age.max(), 10)\ng = sns.FacetGrid(df, col=\"Gender\", hue=\"loan_status\", palette=\"Set2\", col_wrap=2)\ng.map(plt.hist, 'age', bins=bins, ec=\"k\")\ng.axes[-1].legend()\nplt.show()",
"_____no_output_____"
],
[
"# Check percentage of loan status as collection by day of week \ndf.groupby(['Gender'])['loan_status'].value_counts(normalize=True).to_frame()",
"_____no_output_____"
]
],
[
[
"Let's see if loan status differs by education status. From our plot and grouped data below, it looks like there's not too much of a difference among different education categories, though people who are college-educated have a slightly lower default rate (24%) than those who have an education level of high school or below (26%). We also see that there are only 2 people who have an education level of master or above in our sample, let's exclude this group later when we build our feature set. ",
"_____no_output_____"
]
],
[
[
"# Plot histogram of age stratified by education and loan status\nbins = np.linspace(df.age.min(), df.age.max(), 10)\ng = sns.FacetGrid(df, col=\"education\", hue=\"loan_status\", palette=\"Set2\", col_wrap=4)\ng.map(plt.hist, 'age', bins=bins, ec=\"k\")\ng.axes[-1].legend()\nplt.show()",
"_____no_output_____"
],
[
"# Check percentage of loan status as collection by day of week \ndf.groupby(['education'])['loan_status'].value_counts(normalize=True).to_frame()",
"_____no_output_____"
],
[
"# We confirm that 'Master or Above' only has 2 observations, let's delete these observations when we do our feature selection\nlen(df[df.education=='Master or Above'])",
"_____no_output_____"
]
],
[
[
"Let's see if loan status differs by the day of the week of the loan. Below, we create a variable 'dayofweek' by applying the .dt.dayofweek function to our effective date variable. \n\nIn our sample, from our plot, people receiving loans on Fridays, Saturdays, and Sundays are more likely to default than those doing so earlier in the week. If we group the data by day of week using groupby, we see that 45% and 39% of people receiving a loan on Saturday and Sunday, respectively, defaulted, while only 3% of people receiving a loan on Monday defaulted. ",
"_____no_output_____"
]
],
[
[
"# Convert effective date to a day of the week using .dt.dayofweek\ndf['dayofweek'] = df['effective_date'].dt.dayofweek\n\n# Plot histogram of day of week stratified by loan status and gender. \nbins = np.linspace(df.dayofweek.min(), df.dayofweek.max(), 10)\ng = sns.FacetGrid(df, col = \"loan_status\", hue =\"Gender\", palette=\"Set2\", col_wrap=2)\ng.map(plt.hist, 'dayofweek', bins=bins, ec=\"k\")\ng.axes[-1].legend()\nplt.show()",
"_____no_output_____"
],
[
"# Check percentage of loan status as collection by day of week \ndf.groupby(['dayofweek'])['loan_status'].value_counts(normalize=True).to_frame()",
"_____no_output_____"
]
],
[
[
"As weekend loans seem to be a significant feature in our data set, let's create a variable 'weekend' for loans given on days 4, 5, and 6 (Friday, Saturday, and Sunday). ",
"_____no_output_____"
]
],
[
[
"# Create variable 'weekend' for any 'dayofweek' above 3\ndf['weekend'] = df['dayofweek'].apply(lambda x: 1 if (x>3) else 0)\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Part 3: One Hot Encoding",
"_____no_output_____"
],
[
"For our feature set (predictors), let's select 'Principal', 'terms', 'age', 'Gender', 'weekend', and 'education'. Since our education variable is categorical with multiple categories, let's use one hot encoding to convert them to binary variables using pd.get_dummies and append them to our dataframe using pd.concat. As we saw before, let's drop education level 'Master or Above' as there were only two observations. ",
"_____no_output_____"
]
],
[
[
"# Create a numpy array for the features we'll be selecting. We use double brackets to create the numpy array, which is required for the scikit learn alogrithms later. \nfeatures = df[['Principal','terms','age','Gender','weekend']]\n\n# Apply pd.get_dummies for one hot encoding and add new features to array using pd.concat\nfeatures = pd.concat([features, pd.get_dummies(df['education'])], axis=1)\nfeatures.drop(['Master or Above'], axis = 1,inplace=True)\nfeatures[0:5]",
"_____no_output_____"
]
],
[
[
"## Part 4: Feature Selection",
"_____no_output_____"
],
[
"Let's select our predictors, feature set X.",
"_____no_output_____"
]
],
[
[
"X = features\nX[0:5]",
"_____no_output_____"
]
],
[
[
"Let's select our labeled target as loan status, y.",
"_____no_output_____"
]
],
[
[
"y = df['loan_status'].values\ny[0:5]",
"_____no_output_____"
]
],
[
[
"## Part 5: Normalizing Feature Set",
"_____no_output_____"
],
[
"It's important to normalize our feature set to a zero mean and variance to prevent individual feature from being over or underweighted and in order to generate interpretable, reliable predictions. We can do this using the scikit learn libraries StandardScaler, fit, and transform. ",
"_____no_output_____"
]
],
[
[
"# Normalize using scikit learn preprocessing libraries StandardScaler, fit, transform. \nX = preprocessing.StandardScaler().fit(X).transform(X)\nX[0:5]",
"/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/preprocessing/data.py:645: DataConversionWarning: Data with input dtype uint8, int64 were all converted to float64 by StandardScaler.\n return self.partial_fit(X, y)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/ipykernel/__main__.py:2: DataConversionWarning: Data with input dtype uint8, int64 were all converted to float64 by StandardScaler.\n from ipykernel import kernelapp as app\n"
]
],
[
[
"## Classification Models - Optimizing Algorithms, Train and Test Sets, and Evaluating Models",
"_____no_output_____"
],
[
"Let's build and compare 4 classification models: K Nearest Neighbor (KNN), Decision Tree, Support Vector Machine (SVM), and Logistic Regression. ",
"_____no_output_____"
],
[
"## Part 6: KNN",
"_____no_output_____"
]
],
[
[
"# Split into train and test sets \nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)\nprint ('Training set:', X_train.shape, y_train.shape)\nprint ('Test set:', X_test.shape, y_test.shape)",
"Training set: (276, 8) (276,)\nTest set: (70, 8) (70,)\n"
]
],
[
[
"Let's determine our optimal value of K for the number of nearest neighbors. A K value that is too low will capture too much noise (overfit) while one that is too large will be over-generalized. Below, we determine our optimal K value is 7, which has a cross-validation accuracy of 0.74.",
"_____no_output_____"
]
],
[
[
"# Determine optimal k value. \nbest_score = 0.0\nacc_list=[]\n\nfor k in range(3,15):\n \n clf_knn = KNeighborsClassifier(n_neighbors = k, algorithm='auto')\n \n # using 10-fold cross validation for scoring the classifier's accuracy\n scores = cross_val_score(clf_knn, X, y, cv=10)\n score = scores.mean()\n acc_list.append(score)\n \n if score > best_score:\n best_score=score\n best_clf = clf_knn\n best_k = k\n \nprint(\"Best K is :\",best_k,\"| Cross validation Accuracy :\",best_score)\nclf_knn = best_clf",
"Best K is : 7 | Cross validation Accuracy : 0.7438655462184873\n"
]
],
[
[
"Let's plot accuracy across varying K values. We see our optimal K value, the one with the highest accuracy, is 7.",
"_____no_output_____"
]
],
[
[
"# Plot accuracy of various K values. \nplt.plot(range(3,15),acc_list, c=\"r\")\nplt.xlabel('K')\nplt.ylabel('Cross-Validation Accuracy')\nplt.show()",
"_____no_output_____"
],
[
"# Train model using our algorithm above with optimal value of K of 7\nclf_knn.fit(X_train,y_train)",
"_____no_output_____"
],
[
"# Make predictions on test set using our model\ny_hat_knn = clf_knn.predict(X_test)\ny_hat_knn[0:5]",
"_____no_output_____"
]
],
[
[
"#### Evaluating KNN Performance",
"_____no_output_____"
],
[
"Let's calculate the confusion matrix to evaluate model performance. ",
"_____no_output_____"
]
],
[
[
"# Calculate confusion matrix\ncm = confusion_matrix(y_test, y_hat_knn,labels=[\"PAIDOFF\",\"COLLECTION\"]) \nprint(cm)",
"[[48 4]\n [13 5]]\n"
]
],
[
[
"We can plot a heatmap to make it easier to visualize and interpret:\n\nTop left is true negative (TN)\n<br>Top right is false positive (FP)\n<br>Bottom left is false negative (FN)\n<br>Bottom right is true postivie (TP)",
"_____no_output_____"
]
],
[
[
"# Plot heatmap of confusion matrix\nsns.heatmap(cm, annot=True)\nplt.xlabel(\"Predicted\")\nplt.ylabel(\"Actual\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's generate our confustion matrix report to evaluate model performance. Remember that:\n\nPrecision is the ratio of true postives to all positive predicted by model, Precision = TP / (TP + FP).\n\nRecall is the ratio of true positives to all positives actually in our data set, Recall = TP / (TP + FN).\n\nF1-score is the harmonic mean of preiciaion and recall. ",
"_____no_output_____"
]
],
[
[
"# Confusion matrix report\nnp.set_printoptions(precision=2)\nprint (classification_report(y_test, y_hat_knn))",
" precision recall f1-score support\n\n COLLECTION 0.56 0.28 0.37 18\n PAIDOFF 0.79 0.92 0.85 52\n\n micro avg 0.76 0.76 0.76 70\n macro avg 0.67 0.60 0.61 70\nweighted avg 0.73 0.76 0.73 70\n\n"
]
],
[
[
"We can also calculate jaccard similarity score and f1-score automaically using the jaccard_similarity_score and f1_score functions, respectively. Jaccard score is the intersection divided by the union of the two labeled sets (the test and fitted set). F1-score is the harmonic mean of preiciaion and recall as we saw above. ",
"_____no_output_____"
]
],
[
[
"# Jaccard similarity score for KNN model for test set\njaccard_knn = jaccard_similarity_score(y_test, y_hat_knn)\njaccard_knn",
"_____no_output_____"
],
[
"# F1 score for KNN model for test set\nf1_knn = f1_score(y_test, y_hat_knn, average='weighted')\nf1_knn",
"_____no_output_____"
]
],
[
[
"## Part 7: Decision Tree",
"_____no_output_____"
],
[
"Before we train and test our decision tree, let's determine our max depth that will yield the highest accuracy. When training our decision tree, we'll focus here on reducing entropy as much as possible (maximizing information gain) in each node of the tree. We see below that our max depth that will achieve the highest accuracy is 12. We see in our plot below that accuracy drops off after this point.",
"_____no_output_____"
]
],
[
[
"# Test max depths from 1 to 19\ndepth_range = range(1, 20)\n\n# Create empty array for jaccard and f1 scores \njaccard_similarity_score_ = []\nf1_score_ = []\n\n# Use for loop to train decision tree using increasing max depth values. \n# Make predictions using test set, append jaccard and F1 score to arrays created above\nfor d in depth_range:\n dec_tree = DecisionTreeClassifier(criterion = 'entropy', max_depth = d)\n dec_tree.fit(X_train, y_train)\n y_hat_tree = dec_tree.predict(X_test)\n jaccard_similarity_score_.append(jaccard_similarity_score(y_test, y_hat_tree))\n f1_score_.append(f1_score(y_test, y_hat_tree, average = 'weighted'))",
"/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n"
],
[
"# Create dataframe with jaccard and F1 accuaracy values to determine best max depth. We see the best max depth is d = 12. \nresult = pd.DataFrame([jaccard_similarity_score_, f1_score_], index = ['Jaccard', 'F1'], columns = ['d = 1','d = 2','d = 3','d = 4','d = 5','d = 6','d = 7','d = 8','d = 9','d = 10', 'd = 11', 'd = 12', 'd = 13', 'd = 14', 'd = 15', 'd = 16', 'd = 17', 'd = 18', 'd = 19'])\nresult.columns.name = 'Evaluation Metrics'\nresult",
"_____no_output_____"
],
[
"# Plot accuracy of various max depths, jaccard score in blue and F1 score in red. \nplt.plot(range(1,20),jaccard_similarity_score_)\nplt.plot(range(1,20),f1_score_, c='r')\nplt.xlabel('Max Depth')\nplt.ylabel('Accuracy')\nplt.show()",
"_____no_output_____"
],
[
"# Set tree algorithm to max depth 12\ndec_tree = DecisionTreeClassifier(criterion=\"entropy\", max_depth = 12)\ndec_tree",
"_____no_output_____"
],
[
"# Train decision tree\ndec_tree.fit(X_train,y_train)",
"_____no_output_____"
],
[
"# Make prediction on test set using our model\ny_hat_tree = dec_tree.predict(X_test)\ny_hat_tree[0:5]",
"_____no_output_____"
]
],
[
[
"Let's visualize our decision tree, which has a depth of 12 nodes. Keep in mind that values for our features are normalized. Our initial node is a criterion for weekend, which splits into criteria for a person's age and terms of loan. We can continue to follow the nodes and branches down, with each step maximizing reduction in entropy (maximizing information gain). ",
"_____no_output_____"
]
],
[
[
"# Visualize decision tree using tree.export_graphviz\ndot_data = tree.export_graphviz(dec_tree, out_file=None, \n feature_names=['Principal','terms','age','Gender','weekend','Bachelor','High School or Below','college'], \n class_names='loan_status', \n filled=True, rounded=True, \n special_characters=True) \n\ngraph = pydotplus.graph_from_dot_data(dot_data)\ngraph.set_size('\"8,8!\"') # We have 8 features in our feature set\ngvz_graph = graphviz.Source(graph.to_string())\n\ngvz_graph",
"_____no_output_____"
]
],
[
[
"#### Evaluating Decision Tree Performance",
"_____no_output_____"
],
[
"Let's calculate the confusion matrix to evaluate model performance.",
"_____no_output_____"
]
],
[
[
"# Calculate confusion matrix\ncm = confusion_matrix(y_test, y_hat_tree,labels=[\"PAIDOFF\",\"COLLECTION\"]) \nprint(cm)",
"[[48 4]\n [14 4]]\n"
]
],
[
[
"We can plot a heatmap to make it easier to visualize and interpret:\n\nTop left is true negative (TN)\n<br>Top right is false positive (FP)\n<br>Bottom left is false negative (FN)\n<br>Bottom right is true postivie (TP)",
"_____no_output_____"
]
],
[
[
"# Plot heatmap of confusion matrix\nsns.heatmap(cm, annot=True)\nplt.xlabel(\"Predicted\")\nplt.ylabel(\"Actual\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's generate our confustion matrix report to evaluate model performance. Remember that:\n\nPrecision is the ratio of true postives to all positive predicted by model, Precision = TP / (TP + FP).\n\nRecall is the ratio of true positives to all positives actually in our data set, Recall = TP / (TP + FN).\n\nF1-score is the harmonic mean of preiciaion and recall. ",
"_____no_output_____"
]
],
[
[
"# Confusion matrix report\nnp.set_printoptions(precision=2)\nprint (classification_report(y_test, y_hat_tree))",
" precision recall f1-score support\n\n COLLECTION 0.50 0.22 0.31 18\n PAIDOFF 0.77 0.92 0.84 52\n\n micro avg 0.74 0.74 0.74 70\n macro avg 0.64 0.57 0.57 70\nweighted avg 0.70 0.74 0.70 70\n\n"
]
],
[
[
"We can also calculate jaccard similarity score and f1-score automaically using the jaccard_similarity_score and f1_score functions, respectively. Jaccard score is the intersection divided by the union of the two labeled sets (the test and fitted set). F1-score is the harmonic mean of preiciaion and recall as we saw above.",
"_____no_output_____"
]
],
[
[
"# Jaccard similarity score for decision tree\njaccard_tree = jaccard_similarity_score(y_test, y_hat_tree)\njaccard_tree",
"_____no_output_____"
],
[
"# F1 score for decision tree\nf1_tree = f1_score(y_test, y_hat_tree, average='weighted')\nf1_tree",
"_____no_output_____"
]
],
[
[
"## Part 8: SVM",
"_____no_output_____"
],
[
"For our SVM, let's first determine which kernel function - linear, polynomial, radial basis function (rbf), or sigmoid - generates the highest accuracy. We see that all of the polynomial kernel function generates the highest F1 score of 0.69. ",
"_____no_output_____"
]
],
[
[
"# Determine optimal kernel function\n\n# Array of kernel functions\nkernel_func = ['sigmoid', 'poly', 'rbf', 'linear']\n\n# Empty array for accuracy score (F1 score)\naccuracy_score = []\n\n# For each kernel function, train SVM model, run prediction on test set, calculate F1 score and append it to accuracy_score array\nfor k in kernel_func:\n svc_model = SVC(kernel = k) \n svc_model.fit(X_train, y_train)\n y_hat_svm = svc_model.predict(X_test)\n accuracy_score.append(f1_score(y_test, y_hat_svm, average = 'weighted'))\n\naccuracy_score",
"/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/svm/base.py:196: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.\n \"avoid this warning.\", FutureWarning)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/svm/base.py:196: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.\n \"avoid this warning.\", FutureWarning)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/svm/base.py:196: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.\n \"avoid this warning.\", FutureWarning)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/metrics/classification.py:1143: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n"
],
[
"# Bar plot of accuracy score for each kernel function\n\ny_pos = np.arange(len(kernel_func))\nplt.bar(y_pos, accuracy_score, align='center', alpha = 0.6)\nplt.xticks(y_pos, kernel_func)\nplt.xlabel('Kernel Functions')\nplt.ylabel('Accuracy')",
"_____no_output_____"
],
[
"# Set SVM algorithm with polynomial kernel function\nsvc_model = SVC(kernel = 'poly')",
"_____no_output_____"
],
[
"# Train SVM model \nsvc_model.fit(X_train, y_train)\nsvc_model",
"/opt/conda/envs/Python36/lib/python3.6/site-packages/sklearn/svm/base.py:196: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.\n \"avoid this warning.\", FutureWarning)\n"
],
[
"# Make prediction on test set using our model\ny_hat_svm = svc_model.predict(X_test)\ny_hat_svm [0:5]",
"_____no_output_____"
]
],
[
[
"#### Evaluating SVM Performance",
"_____no_output_____"
],
[
"Let's calculate the confusion matrix to evaluate model performance.",
"_____no_output_____"
]
],
[
[
"# Calculate confusion matrix\ncm = confusion_matrix(y_test, y_hat_svm,labels=[\"PAIDOFF\",\"COLLECTION\"]) \nprint(cm)",
"[[51 1]\n [16 2]]\n"
]
],
[
[
"We can plot a heatmap to make it easier to visualize and interpret:\n\nTop left is true negative (TN)\n<br>Top right is false positive (FP)\n<br>Bottom left is false negative (FN)\n<br>Bottom right is true postivie (TP)",
"_____no_output_____"
]
],
[
[
"# Plot heatmap of confusion matrix\nsns.heatmap(cm, annot=True)\nplt.xlabel(\"Predicted\")\nplt.ylabel(\"Actual\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's generate our confustion matrix report to evaluate model performance. Remember that:\n\nPrecision is the ratio of true postives to all positive predicted by model, Precision = TP / (TP + FP).\n\nRecall is the ratio of true positives to all positives actually in our data set, Recall = TP / (TP + FN).\n\nF1-score is the harmonic mean of preiciaion and recall. ",
"_____no_output_____"
]
],
[
[
"# Confusion matrix report\nnp.set_printoptions(precision=2)\nprint (classification_report(y_test, y_hat_svm))",
" precision recall f1-score support\n\n COLLECTION 0.67 0.11 0.19 18\n PAIDOFF 0.76 0.98 0.86 52\n\n micro avg 0.76 0.76 0.76 70\n macro avg 0.71 0.55 0.52 70\nweighted avg 0.74 0.76 0.69 70\n\n"
]
],
[
[
"We can also calculate jaccard similarity score and f1-score automaically using the jaccard_similarity_score and f1_score functions, respectively. Jaccard score is the intersection divided by the union of the two labeled sets (the test and fitted set). F1-score is the harmonic mean of preiciaion and recall as we saw above.",
"_____no_output_____"
]
],
[
[
"# Jaccard similarity score for SVM\njaccard_svm = jaccard_similarity_score(y_test, y_hat_svm)\njaccard_svm",
"_____no_output_____"
],
[
"# F1 score for SVM\nf1_svm = f1_score(y_test, y_hat_svm, average='weighted')\nf1_svm",
"_____no_output_____"
]
],
[
[
"## Part 9: Logistic Regression",
"_____no_output_____"
],
[
"Logistic regression is best suited for binary categorical target variable like the one we have. Moreover, it offers the benefit of determining not just whether a customer will default or not, but the probabality that he or she will default. This is useful if knowing the likelihood that a customer will default is an important question for a bank to answer. For our logistic regression, let's first determine which combination of regularization (to account for overfitting) and numerical solver to find parameters - newton-cg, lbfgs, liblinear, sag, saga - generates the highest accuracy score (log loss score). We find below that our highest accuracy is with regularization C = 0.001 and solver liblinear. ",
"_____no_output_____"
]
],
[
[
"solvers = ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga']\nregularization_val = [0.1, 0.01, 0.001]\nindex = []\naccuracy_score = []\niterations = 0\n\nfor index1, c in enumerate(regularization_val):\n for index2, solver in enumerate(solvers):\n index.append(index1 + index2 *5)\n iterations +=1\n lr_model = LogisticRegression(C = c, solver = solver)\n lr_model.fit(X_train, y_train)\n y_hat_lr = lr_model.predict(X_test)\n y_prob = lr_model.predict_proba(X_test)\n print('Test {}: Accuracy at C = {} when Solver = {} is : {}'.format(iterations, c, solver, log_loss(y_test, y_prob) ))\n accuracy_score.append(log_loss(y_test, y_prob))\n \n print('\\n')",
"Test 1: Accuracy at C = 0.1 when Solver = newton-cg is : 0.5070167730906173\nTest 2: Accuracy at C = 0.1 when Solver = lbfgs is : 0.5070168606342651\nTest 3: Accuracy at C = 0.1 when Solver = liblinear is : 0.5117457077259853\nTest 4: Accuracy at C = 0.1 when Solver = sag is : 0.5070187154624726\nTest 5: Accuracy at C = 0.1 when Solver = saga is : 0.5070112885707856\n\n\nTest 6: Accuracy at C = 0.01 when Solver = newton-cg is : 0.5285217065161242\nTest 7: Accuracy at C = 0.01 when Solver = lbfgs is : 0.528521695422437\nTest 8: Accuracy at C = 0.01 when Solver = liblinear is : 0.5838106520220708\nTest 9: Accuracy at C = 0.01 when Solver = sag is : 0.5285236974285631\nTest 10: Accuracy at C = 0.01 when Solver = saga is : 0.5285223782106919\n\n\nTest 11: Accuracy at C = 0.001 when Solver = newton-cg is : 0.56269409127642\nTest 12: Accuracy at C = 0.001 when Solver = lbfgs is : 0.5626941386444698\nTest 13: Accuracy at C = 0.001 when Solver = liblinear is : 0.6723416199429343\nTest 14: Accuracy at C = 0.001 when Solver = sag is : 0.5626927038676494\nTest 15: Accuracy at C = 0.001 when Solver = saga is : 0.5626932139886323\n\n\n"
],
[
"# Visualize the above accuracy tests, with the peak at test 13, which corresponds to C = 0.001 and solver = liblinear\n\nlr_prob = lr_model.predict_proba(X_test)\nlog_loss(y_test, lr_prob)\nplt.plot(index, accuracy_score)\nplt.xlabel('Parameter Value')\nplt.ylabel('Testing Accuracy')",
"_____no_output_____"
],
[
"# Set logistic regression with optimal regularization of C = 0.001 and solver = 'liblinear'\nlr_model = LogisticRegression(C = 0.001, solver = 'liblinear')",
"_____no_output_____"
],
[
"# Train logistic regression model\nlr_model.fit(X_train, y_train)\nlr_model",
"_____no_output_____"
],
[
"# Make prediction on test set using our model\ny_hat_lr = lr_model.predict(X_test)",
"_____no_output_____"
],
[
"# Determine probabilities of loan classification using our test set. We'll need this for our logloss score. \ny_hat_lr_prob = lr_model.predict_proba(X_test)",
"_____no_output_____"
]
],
[
[
"#### Evaluating Logistic Regression Performance",
"_____no_output_____"
],
[
"Let's calculate the confusion matrix to evaluate model performance.",
"_____no_output_____"
]
],
[
[
"# Calculate confusion matrix\ncm = confusion_matrix(y_test, y_hat_lr,labels=[\"PAIDOFF\",\"COLLECTION\"]) \nprint(cm)",
"[[45 7]\n [14 4]]\n"
]
],
[
[
"We can plot a heatmap to make it easier to visualize and interpret:\n\nTop left is true negative (TN)\n<br>Top right is false positive (FP)\n<br>Bottom left is false negative (FN)\n<br>Bottom right is true postivie (TP)",
"_____no_output_____"
]
],
[
[
"# Plot heatmap of confusion matrix\nsns.heatmap(cm, annot=True)\nplt.xlabel(\"Predicted\")\nplt.ylabel(\"Actual\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's generate our confustion matrix report to evaluate model performance. Remember that:\n\nPrecision is the ratio of true postives to all positive predicted by model, Precision = TP / (TP + FP).\n\nRecall is the ratio of true positives to all positives actually in our data set, Recall = TP / (TP + FN).\n\nF1-score is the harmonic mean of preiciaion and recall. ",
"_____no_output_____"
]
],
[
[
"# Confusion matrix report\nnp.set_printoptions(precision=2)\nprint (classification_report(y_test, y_hat_lr))",
" precision recall f1-score support\n\n COLLECTION 0.36 0.22 0.28 18\n PAIDOFF 0.76 0.87 0.81 52\n\n micro avg 0.70 0.70 0.70 70\n macro avg 0.56 0.54 0.54 70\nweighted avg 0.66 0.70 0.67 70\n\n"
]
],
[
[
"We can also calculate jaccard similarity score, f1-score, and log loss automaically using the jaccard_similarity_score, f1_score, and log_loss functions, respectively. Jaccard score is the intersection divided by the union of the two labeled sets (the test and fitted set). F1-score is the harmonic mean of preiciaion and recall as we saw above.",
"_____no_output_____"
]
],
[
[
"# Jaccard similarity score for logistic regression\njaccard_lr = jaccard_similarity_score(y_test, y_hat_lr)\njaccard_lr",
"_____no_output_____"
],
[
"# F1 score for logistic regression\nf1_lr = f1_score(y_test, y_hat_lr, average='weighted')\nf1_lr",
"_____no_output_____"
],
[
"# Logloss for logistic regression\nlogloss_lr = log_loss(y_test, y_hat_lr_prob)\nlogloss_lr",
"_____no_output_____"
]
],
[
[
"## Part 10: Evaluating Model Performance Head-to-Head",
"_____no_output_____"
],
[
"Let's compare KNN, decision tree, SVM, and logistic regression head-to-head using our specified parameters for classifying loan status for this data set. Creating a data frame with our evaluation metrics, we see that KNN performs best while logistic regression is the weakest of the four. ",
"_____no_output_____"
]
],
[
[
"# Create dataframe with evaluation metrics\nevaluation = {\"Jaccard\":[jaccard_knn, jaccard_tree, jaccard_svm, jaccard_lr], \n \"F1-score\":[f1_knn, f1_tree, f1_svm, f1_lr],\n \"Log Loss\":[\"NA\", \"NA\", \"NA\", logloss_lr] \n }\neval_df = pd.DataFrame(evaluation, columns=[\"Jaccard\", \"F1-score\", \"Log Loss\"], index=[\"KNN\", \"Decision Tree\", \"SVM\", \"Logistic Regression\"])\neval_df.columns.name = \"Algorithm\"\neval_df",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4ad390b66991fcaeceb403bd6b6c54b93bf13704
| 38,437 |
ipynb
|
Jupyter Notebook
|
26-NeuralNetworks2/26-NeuralNetworks2.ipynb
|
nicholas-greger/2020-datascience-lectures
|
389d0a5b56f510677d3b09da400268a1991a5b0f
|
[
"MIT"
] | 26 |
2019-12-13T09:22:19.000Z
|
2021-03-06T05:21:41.000Z
|
26-NeuralNetworks2/26-NeuralNetworks2.ipynb
|
nicholas-greger/2020-datascience-lectures
|
389d0a5b56f510677d3b09da400268a1991a5b0f
|
[
"MIT"
] | null | null | null |
26-NeuralNetworks2/26-NeuralNetworks2.ipynb
|
nicholas-greger/2020-datascience-lectures
|
389d0a5b56f510677d3b09da400268a1991a5b0f
|
[
"MIT"
] | 43 |
2020-01-08T05:09:08.000Z
|
2021-12-19T11:23:40.000Z
| 36.433175 | 559 | 0.574785 |
[
[
[
"# Introduction to Data Science \n# Lecture 25: Neural Networks II\n*COMP 5360 / MATH 4100, University of Utah, http://datasciencecourse.net/*\n\nIn this lecture, we'll continue discussing Neural Networks. \n\nRecommended Reading:\n* A. Géron, [Hands-On Machine Learning with Scikit-Learn & TensorFlow](http://proquest.safaribooksonline.com/book/programming/9781491962282) (2017) \n* I. Goodfellow, Y. Bengio, and A. Courville, [Deep Learning](http://www.deeplearningbook.org/) (2016)\n* Y. LeCun, Y. Bengio, and G. Hinton, [Deep learning](https://www.nature.com/articles/nature14539), Nature (2015) \n",
"_____no_output_____"
],
[
"## Recap: Neural Networks\n\nLast time, we introduced *Neural Networks* and discussed how they can be used for classification and regression.\n\nThere are many different *network architectures* for Neural Networks, but our focus is on **Multi-layer Perceptrons**. Here, there is an *input layer*, typically drawn on the left hand side and an *output layer*, typically drawn on the right hand side. The middle layers are called *hidden layers*. \n\n\n<img src=\"Colored_neural_network.svg\" title=\"https://en.wikipedia.org/wiki/Artificial_neural_network#/media/File:Colored_neural_network.svg\" \nwidth=\"300\">\n\nGiven a set of features $X = x^0 = \\{x_1, x_2, ..., x_n\\}$ and a target $y$, a neural network works as follows. \n\n\nEach layer applies an affine transformation and an [activation function](https://en.wikipedia.org/wiki/Activation_function) (e.g., ReLU, hyperbolic tangent, or logistic) to the output of the previous layer: \n$$\nx^{j} = f ( A^{j} x^{j-1} + b^j ). \n$$\nAt the $j$-th hidden layer, the input is represented as the composition of $j$ such mappings. An additional function, *e.g.* [softmax](https://en.wikipedia.org/wiki/Softmax_function), is applied to the output layer to give the prediction, $\\hat y$, for classification or regression. \n\n<img src=\"activationFct.png\" \ntitle=\"see Géron, Ch. 10\" \nwidth=\"700\">\n",
"_____no_output_____"
],
[
"## Softmax function for classificaton \n\nThe *softmax function*, $\\sigma:\\mathbb{R}^K \\to (0,1)^K$ is defined by\n$$\n\\sigma(\\mathbf{z})_j = \\frac{e^{z_j}}{\\sum_{k=1}^K e^{z_k}}\n\\qquad \\qquad \\textrm{for } j=1, \\ldots, K.\n$$\nNote that each component is in the range $(0,1)$ and the values sum to 1. We interpret $\\sigma(\\mathbf{z})_j$ as the probability that $\\mathbf{z}$ is a member of class $j$. ",
"_____no_output_____"
],
[
"## Training a neural network\n\nNeural networks uses a loss function of the form \n$$\nLoss(\\hat{y},y,W) = \\frac{1}{2} \\sum_{i=1}^n g(\\hat{y}_i(W),y_i) + \\frac{\\alpha}{2} \\|W\\|_2^2\n$$\nHere, \n+ $y_i$ is the label for the $i$-th example, \n+ $\\hat{y}_i(W)$ is the predicted label for the $i$-th example, \n+ $g$ is a function that measures the error, typically $L^2$ difference for regression or cross-entropy for classification, and \n+ $\\alpha$ is a regularization parameter. \n\nStarting from initial random weights, the loss function is minimized by repeatedly updating these weights. Various **optimization methods** can be used, *e.g.*, \n+ gradient descent method \n+ quasi-Newton method,\n+ stochastic gradient descent, or \n+ ADAM. \n\nThere are various parameters associated with each method that must be tuned. \n\n**Back propagation** is a way of using the chain rule from calculus to compute the gradient of the $Loss$ function for optimization. ",
"_____no_output_____"
],
[
"## Neural Networks in scikit-learn\n\nIn the previous lecture, we used Neural Network implementations in scikit-learn to do both classification and regression:\n+ [multi-layer perceptron (MLP) classifier](http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html)\n+ [multi-layer perceptron (MLP) regressor](http://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPRegressor.html)\n\n\nHowever, there are several limitations to the scikit-learn implementation: \n- no GPU support\n- limited network architectures ",
"_____no_output_____"
],
[
"## Neural networks with TensorFlow\n\nToday, we'll use [TensorFlow](https://github.com/tensorflow/tensorflow) to train a Neural Network. \n\nTensorFlow is an open-source library designed for large-scale machine learning. ",
"_____no_output_____"
],
[
"### Installing TensorFlow\n\nInstructions for installing TensorFlow are available at [the tensorflow install page](https://www.tensorflow.org/install).\n\nIt is recommended that you use the command: \n```\npip install tensorflow\n```\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nprint(tf.__version__)\n\n# to make this notebook's output stable across runs\ndef reset_graph(seed=42):\n tf.reset_default_graph()\n tf.set_random_seed(seed)\n np.random.seed(seed)",
"1.13.2\n"
]
],
[
[
"TensorFlow represents computations by connecting op (operation) nodes into a computation graph.\n\n<img src=\"graph.png\" \ntitle=\"An example of computational graph\" \nwidth=\"400\">\n\nA TensorFlow program usually has two components:\n+ In the *construction phase*, a computational graph is built. During this phase, no computations are performed and the variables are not yet initialized. \n+ In the *execution phase*, the graph is evaluated, typically many times. In this phase, the each operation is given to a CPU or GPU, variables are initialized, and functions can be evaluted. ",
"_____no_output_____"
]
],
[
[
"# construction phase\nx = tf.Variable(3)\ny = tf.Variable(4)\nf = x*x*y + y + 2\n\n# execution phase\nwith tf.Session() as sess: # initializes a \"session\" \n x.initializer.run()\n y.initializer.run()\n print(f.eval())\n\n\n# alternatively all variables cab be initialized as follows\ninit = tf.global_variables_initializer()\nwith tf.Session() as sess: # initializes a \"session\" \n init.run() # initializes all the variables\n print(f.eval())\n",
"42\n42\n"
]
],
[
[
"### Autodiff\n\nTensorFlow can automatically compute the derivative of functions using [```gradients```](https://www.tensorflow.org/api_docs/python/tf/gradients). ",
"_____no_output_____"
]
],
[
[
"# construction phase\nx = tf.Variable(3.0)\ny = tf.Variable(4.0)\nf = x + 2*y*y + 2\ngrads = tf.gradients(f,[x,y])\n\n# execution phase\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer()) # initializes all variables\n print([g.eval() for g in grads])\n",
"[1.0, 16.0]\n"
]
],
[
[
"This is enormously helpful since training a NN requires the derivate of the loss function with respect to the parameters (and there are a lot of parameters). This is computed using backpropagation (chain rule) and TensorFlow does this work for you. ",
"_____no_output_____"
],
[
"**Exercise:** Use TensorFlow to compute the derivative of $f(x) = e^x$ at $x=2$.",
"_____no_output_____"
]
],
[
[
"# your code here\n",
"_____no_output_____"
]
],
[
[
"### Optimization methods\nTensorflow also has several built-in optimization methods.\n\nOther optimization methods in TensorFlow:\n+ [```tf.train.Optimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/Optimizer)\n+ [```tf.train.GradientDescentOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/GradientDescentOptimizer)\n+ [```tf.train.AdadeltaOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/AdadeltaOptimizer)\n+ [```tf.train.AdagradOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/AdagradOptimizer)\n+ [```tf.train.AdagradDAOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/AdagradDAOptimizer)\n+ [```tf.train.MomentumOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/MomentumOptimizer)\n+ [```tf.train.AdamOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/AdamOptimizer)\n+ [```tf.train.FtrlOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/FtrlOptimizer)\n+ [```tf.train.ProximalGradientDescentOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/ProximalGradientDescentOptimizer)\n+ [```tf.train.ProximalAdagradOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/ProximalAdagradOptimizer)\n+ [```tf.train.RMSPropOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/RMSPropOptimizer)\n\nFor more information, see the [TensorFlow training webpage](https://www.tensorflow.org/api_guides/python/train). \n\n\nLet's see how to use the [```GradientDescentOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/GradientDescentOptimizer). ",
"_____no_output_____"
]
],
[
[
"x = tf.Variable(3.0, trainable=True)\ny = tf.Variable(2.0, trainable=True)\nf = x*x + 100*y*y\nopt = tf.train.GradientDescentOptimizer(learning_rate=5e-3).minimize(f)\n\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for i in range(1000):\n if i%100 == 0: print(sess.run([x,y,f]))\n sess.run(opt)\n ",
"[3.0, 2.0, 409.0]\n[1.0980968, 0.0, 1.2058167]\n[0.40193906, 0.0, 0.161555]\n[0.14712274, 0.0, 0.0216451]\n[0.053851694, 0.0, 0.0029000049]\n[0.019711465, 0.0, 0.00038854184]\n[0.0072150305, 0.0, 5.2056665e-05]\n[0.0026409342, 0.0, 6.9745333e-06]\n[0.00096666755, 0.0, 9.344461e-07]\n[0.00035383157, 0.0, 1.2519678e-07]\n"
]
],
[
[
"Using another optimizer, such as the [```MomentumOptimizer```](https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/MomentumOptimizer), \nhas similiar syntax. ",
"_____no_output_____"
]
],
[
[
"x = tf.Variable(3.0, trainable=True)\ny = tf.Variable(2.0, trainable=True)\nf = x*x + 100*y*y\nopt = tf.train.MomentumOptimizer(learning_rate=1e-2,momentum=.5).minimize(f)\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for i in range(1000):\n if i%100 == 0: print(sess.run([x,y,f]))\n sess.run(opt)\n ",
"[3.0, 2.0, 409.0]\n[0.043930665, 2.0290405e-15, 0.0019299033]\n[0.0006126566, -1.547466e-30, 3.753481e-07]\n[8.544106e-06, 0.0, 7.300175e-11]\n[1.1915596e-07, 0.0, 1.4198143e-14]\n[1.6617479e-09, 0.0, 2.761406e-18]\n[2.3174716e-11, 0.0, 5.3706746e-22]\n[3.2319424e-13, 0.0, 1.0445451e-25]\n[4.5072626e-15, 0.0, 2.0315416e-29]\n[6.285822e-17, 0.0, 3.951156e-33]\n"
]
],
[
[
"**Exercise:** Use TensorFlow to find the minimum of the [Rosenbrock function](https://en.wikipedia.org/wiki/Rosenbrock_function): \n$$\nf(x,y) = (x-1)^2 + 100*(y-x^2)^2.\n$$\n",
"_____no_output_____"
]
],
[
[
"# your code here\n",
"_____no_output_____"
]
],
[
[
"## Classifying the MNIST handwritten digit dataset\n\nWe now use TensorFlow to classify the handwritten digits in the MNIST dataset. \n\n### Using plain TensorFlow\nWe'll first follow [Géron, Ch. 10](https://github.com/ageron/handson-ml/blob/master/10_introduction_to_artificial_neural_networks.ipynb) to build a NN using plain TensorFlow. \n\n\n\n#### Construction phase\n\n+ We specify the number of inputs and outputs and the size of each layer. Here the images are 28x28 and there are 10 classes (each corresponding to a digit). We'll choose 2 hidden layers, with 300 and 100 neurons respectively. \n\n+ Placeholder nodes are used to represent the training data and targets. We use the ```None``` keyword to leave the shape (of the training batch) unspecified. \n\n+ We add layers to the NN using the ```layers.dense()``` function. In each case, we specify the input, and the size of the layer. We also specify the activation function used in each layer. Here, we choose the ReLU function. \n\n+ We specify that the output of the NN will be a softmax function. The loss function is cross entropy. \n\n+ We then specify that we'll use the [GradientDescentOptimizer](https://www.tensorflow.org/api_docs/python/tf/train/GradientDescentOptimizer) \nwith a learning rate of 0.01. \n\n+ Finally, we specify how the model will be evaluated. The [```in_top_k```](https://www.tensorflow.org/api_docs/python/tf/nn/in_top_k) function checks to see if the targets are in the top k predictions. \n\nWe then initialize all of the variables and create an object to save the model using the [```saver()```](https://www.tensorflow.org/programmers_guide/saved_model) function. \n\n#### Execution phase\n\nAt each *epoch*, the code breaks the training batch into mini-batches of size 50. Cycling through the mini-batches, it uses gradient descent to train the NN. The accuracy for both the training and test datasets are evaluated. \n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np \nfrom sklearn.metrics import confusion_matrix\n\n# to make this notebook's output stable across runs\ndef reset_graph(seed=42):\n tf.reset_default_graph()\n tf.set_random_seed(seed)\n np.random.seed(seed)",
"_____no_output_____"
],
[
"# load the data\n(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()\nX_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0\nX_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0\ny_train = y_train.astype(np.int32)\ny_test = y_test.astype(np.int32)",
"_____no_output_____"
],
[
"# helper code\ndef shuffle_batch(X, y, batch_size):\n rnd_idx = np.random.permutation(len(X))\n n_batches = len(X) // batch_size\n for batch_idx in np.array_split(rnd_idx, n_batches):\n X_batch, y_batch = X[batch_idx], y[batch_idx]\n yield X_batch, y_batch\n",
"_____no_output_____"
],
[
"# construction phase\n\nn_inputs = 28*28 # MNIST\nn_hidden1 = 300\nn_hidden2 = 100\nn_outputs = 10\n\nreset_graph()\n\nX = tf.placeholder(tf.float32, shape=(None, n_inputs), name=\"X\")\ny = tf.placeholder(tf.int32, shape=(None), name=\"y\")\n\nwith tf.name_scope(\"dnn\"):\n hidden1 = tf.layers.dense(X, n_hidden1, name=\"hidden1\",activation=tf.nn.relu)\n hidden2 = tf.layers.dense(hidden1, n_hidden2, name=\"hidden2\",activation=tf.nn.relu)\n logits = tf.layers.dense(hidden2, n_outputs, name=\"outputs\")\n #y_proba = tf.nn.softmax(logits)\n\nwith tf.name_scope(\"loss\"):\n xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)\n loss = tf.reduce_mean(xentropy, name=\"loss\")\n\n\nlearning_rate = 0.01\nwith tf.name_scope(\"train\"):\n optimizer = tf.train.GradientDescentOptimizer(learning_rate)\n training_op = optimizer.minimize(loss)\n\nwith tf.name_scope(\"eval\"):\n correct = tf.nn.in_top_k(logits, y, 1)\n accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))\n ",
"WARNING:tensorflow:From <ipython-input-13-8eb9dd318214>:14: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.dense instead.\n"
],
[
"# execution phase\n\ninit = tf.global_variables_initializer()\nsaver = tf.train.Saver()\n\nn_epochs = 10\n#n_batches = 50\nbatch_size = 50\n\nwith tf.Session() as sess:\n init.run()\n for epoch in range(n_epochs):\n for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):\n sess.run(training_op, feed_dict={X: X_batch, y: y_batch})\n acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})\n acc_valid = accuracy.eval(feed_dict={X: X_test, y: y_test})\n print(epoch, \"Batch accuracy:\", acc_batch, \"Validation accuracy:\", acc_valid)\n\n save_path = saver.save(sess, \"./my_model_final.ckpt\")",
"0 Batch accuracy: 0.9 Validation accuracy: 0.9055\n1 Batch accuracy: 0.9 Validation accuracy: 0.9208\n2 Batch accuracy: 0.94 Validation accuracy: 0.9331\n3 Batch accuracy: 0.94 Validation accuracy: 0.9406\n4 Batch accuracy: 1.0 Validation accuracy: 0.9444\n5 Batch accuracy: 0.98 Validation accuracy: 0.9481\n6 Batch accuracy: 0.98 Validation accuracy: 0.9537\n7 Batch accuracy: 0.98 Validation accuracy: 0.9566\n8 Batch accuracy: 0.98 Validation accuracy: 0.9591\n9 Batch accuracy: 1.0 Validation accuracy: 0.9597\n"
]
],
[
[
"Since the NN has been saved, we can use it for classification using the [```saver.restore```](https://www.tensorflow.org/programmers_guide/saved_model) function. \n\nWe can also print the confusion matrix using [```confusion_matrix```](https://www.tensorflow.org/api_docs/python/tf/confusion_matrix). ",
"_____no_output_____"
]
],
[
[
"with tf.Session() as sess:\n saver.restore(sess, save_path)\n Z = logits.eval(feed_dict={X: X_test})\n y_pred = np.argmax(Z, axis=1)\n \nprint(confusion_matrix(y_test,y_pred))",
"WARNING:tensorflow:From /Applications/anaconda3/lib/python3.7/site-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\nINFO:tensorflow:Restoring parameters from ./my_model_final.ckpt\n[[ 969 0 1 1 0 3 1 2 2 1]\n [ 0 1115 2 2 0 1 4 2 9 0]\n [ 7 1 980 12 5 0 6 9 11 1]\n [ 1 0 2 984 0 1 0 10 7 5]\n [ 1 0 3 1 930 0 7 1 5 34]\n [ 10 2 1 25 3 820 10 1 14 6]\n [ 8 3 0 2 9 6 925 0 5 0]\n [ 0 10 12 4 2 0 0 984 2 14]\n [ 3 2 3 13 4 1 8 8 929 3]\n [ 5 7 0 13 11 2 1 5 4 961]]\n"
]
],
[
[
"### Using TensorFlow's Keras API \n\nNext, we'll use TensorFlow's Keras API to build a NN for the MNIST dataset. \n\n[Keras](https://keras.io/) is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. We'll use it with TensorFlow. ",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"(X_train, y_train),(X_test, y_test) = tf.keras.datasets.mnist.load_data()\nX_train, X_test = X_train / 255.0, X_test / 255.0",
"_____no_output_____"
],
[
"# set the model\nmodel = tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape=(28, 28)),\n tf.keras.layers.Dense(512, activation=tf.nn.relu),\n tf.keras.layers.Dropout(rate=0.2),\n tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n])\n\n# specifiy optimizer\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\n# train the model\nmodel.fit(X_train, y_train, epochs=5)",
"WARNING:tensorflow:From /Applications/anaconda3/lib/python3.7/site-packages/tensorflow/python/keras/layers/core.py:143: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\nEpoch 1/5\n60000/60000 [==============================] - 54s 892us/sample - loss: 0.2186 - acc: 0.9348\nEpoch 2/5\n60000/60000 [==============================] - 52s 867us/sample - loss: 0.0963 - acc: 0.9698\nEpoch 3/5\n60000/60000 [==============================] - 52s 874us/sample - loss: 0.0687 - acc: 0.9786\nEpoch 4/5\n60000/60000 [==============================] - 53s 882us/sample - loss: 0.0537 - acc: 0.9823\nEpoch 5/5\n60000/60000 [==============================] - 50s 838us/sample - loss: 0.0428 - acc: 0.9859\n"
],
[
"score = model.evaluate(X_test, y_test)\nnames = model.metrics_names\nfor ii in np.arange(len(names)):\n print(names[ii],score[ii])\n ",
"10000/10000 [==============================] - 2s 153us/sample - loss: 0.0719 - acc: 0.9791\nloss 0.07185092351303901\nacc 0.9791\n"
],
[
"model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nflatten (Flatten) (None, 784) 0 \n_________________________________________________________________\ndense (Dense) (None, 512) 401920 \n_________________________________________________________________\ndropout (Dropout) (None, 512) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 10) 5130 \n=================================================================\nTotal params: 407,050\nTrainable params: 407,050\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"y_pred = np.argmax(model.predict(X_test), axis=1)\nprint(confusion_matrix(y_test,y_pred))",
"[[ 974 1 0 0 0 0 3 1 0 1]\n [ 0 1124 3 2 0 1 2 0 3 0]\n [ 5 0 1018 2 1 0 1 1 3 1]\n [ 0 1 3 997 0 0 0 2 2 5]\n [ 1 0 1 1 971 0 3 0 0 5]\n [ 2 0 0 20 3 852 5 1 6 3]\n [ 2 3 0 1 7 3 940 0 2 0]\n [ 3 6 10 6 1 0 0 984 4 14]\n [ 4 0 7 6 1 3 3 3 945 2]\n [ 2 2 0 4 12 1 0 1 1 986]]\n"
]
],
[
[
"## Using a pre-trained network\n\nThere are many examples of pre-trained NN that can be accessed [here](https://www.tensorflow.org/api_docs/python/tf/keras/applications). \nThese NN are very large, having been trained on giant computers using massive datasets. \n\nIt can be very useful to initialize a NN using one of these. This is called [transfer learning](https://en.wikipedia.org/wiki/Transfer_learning). \n\n\nWe'll use a NN that was pretrained for image recognition. This NN was trained on the [ImageNet](http://www.image-net.org/) project, which contains > 14 million images belonging to > 20,000 classes (synsets). ",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nfrom tensorflow.keras.preprocessing import image\nfrom tensorflow.keras.applications import vgg16",
"_____no_output_____"
],
[
"vgg_model = tf.keras.applications.VGG16(weights='imagenet',include_top=True)\nvgg_model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 224, 224, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 224, 224, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 224, 224, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 112, 112, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 112, 112, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 112, 112, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 56, 56, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 56, 56, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 56, 56, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 56, 56, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 28, 28, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 14, 14, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 7, 7, 512) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 25088) 0 \n_________________________________________________________________\nfc1 (Dense) (None, 4096) 102764544 \n_________________________________________________________________\nfc2 (Dense) (None, 4096) 16781312 \n_________________________________________________________________\npredictions (Dense) (None, 1000) 4097000 \n=================================================================\nTotal params: 138,357,544\nTrainable params: 138,357,544\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"img_path = 'images/scout1.jpeg'\nimg = image.load_img(img_path, target_size=(224, 224))\n\nx = image.img_to_array(img)\nx = np.expand_dims(x, axis=0)\nx = vgg16.preprocess_input(x)\n\npreds = vgg_model.predict(x)\nprint('Predicted:', vgg16.decode_predictions(preds, top=5)[0])",
"Predicted: [('n02098105', 'soft-coated_wheaten_terrier', 0.3554158), ('n02105641', 'Old_English_sheepdog', 0.23714595), ('n02095314', 'wire-haired_fox_terrier', 0.13490717), ('n02091635', 'otterhound', 0.0611032), ('n02093991', 'Irish_terrier', 0.052789364)]\n"
]
],
[
[
"**Exercise:** Repeat the above steps for an image of your own.\n\n**Exercise:** There are several [other pre-trained networks in Keras](https://github.com/keras-team/keras-applications). Try these! ",
"_____no_output_____"
]
],
[
[
"# your code here\n",
"_____no_output_____"
]
],
[
[
"## Some NN topics that we didn't discuss\n+ Recurrent neural networks (RNN) for time series\n+ How NN can be used for unsupervised learning problems and [Reinforcement learning problems](https://en.wikipedia.org/wiki/Reinforcement_learning)\n+ Special layers in NN for image processing \n+ Using Tensorflow on a GPU \n+ ... ",
"_____no_output_____"
],
[
"## CPU vs. GPU\n\n[CPUs (Central processing units)](https://en.wikipedia.org/wiki/Central_processing_unit) have just a few cores. The number of processes that a CPU can do in parallel is limited. However, each cores is very fast and is good for sequential tasks. \n\n[GPUs (Graphics processing units)](https://en.wikipedia.org/wiki/Graphics_processing_unit) have thousands of cores, so can do many processes in parallel. GPU cores are typically slower and are more limited than CPU cores. However, for the right kind of computations (think matrix multiplication), GPUs are very fast. GPUs also have their own memory and caching systems, which further improves the speed of some computations, but also makes GPUs more difficult to program. (You have to use something like [CUDA](https://en.wikipedia.org/wiki/CUDA)). \n\nTensorFlow can use GPUs to significantly speed up the training NN. See the programmer's guide [here](https://www.tensorflow.org/programmers_guide/using_gpu). ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4ad391a77dbd8d275d88e7e28c4db4c16731cf7c
| 570,682 |
ipynb
|
Jupyter Notebook
|
JoshFiles/Pre-Hierarchical Scripts/RG fits-Vrard.ipynb
|
daw538/y4project
|
f8b7cb7c8ee0a5312a661a366e339371cf428533
|
[
"MIT"
] | null | null | null |
JoshFiles/Pre-Hierarchical Scripts/RG fits-Vrard.ipynb
|
daw538/y4project
|
f8b7cb7c8ee0a5312a661a366e339371cf428533
|
[
"MIT"
] | null | null | null |
JoshFiles/Pre-Hierarchical Scripts/RG fits-Vrard.ipynb
|
daw538/y4project
|
f8b7cb7c8ee0a5312a661a366e339371cf428533
|
[
"MIT"
] | null | null | null | 1,145.947791 | 490,396 | 0.94924 |
[
[
[
"# Red Giant Mode fitting\n\nFitting $nstars$ RG stars chosen at random using Vrard model.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport pystan\nimport random",
"_____no_output_____"
],
[
"#import output data\nnstars = 5\nIDs = []\nstardat = pd.read_csv('RGdata/output_1000stars.csv', delim_whitespace=False, header=0, usecols=range(1,4))\nfor i in range(nstars):\n IDs.append(random.choice(stardat['ID']))\n\nmodes = {} # dictionary with frequencies and errors\nfor i in IDs:\n modes[str(i)] = pd.read_csv('RGdata/modes_'+str(i)+'.csv', delim_whitespace=False, header=0, usecols=[0,7])\n modes[str(i)] = modes[str(i)].sort_values(by=['f0'])\n modes[str(i)] = modes[str(i)].set_index(np.arange(0,len(modes[str(i)]),1))\n modes[str(i)]['dnu'] = modes[str(i)].f0.diff(2).shift(-1)/2\n dnu_avg = np.mean(modes[str(i)].dnu)\n n_min = int(modes[str(i)].f0.min() / dnu_avg)\n n_obs = np.arange(n_min, n_min+len(modes[str(i)].f0), 1)\n modes[str(i)]['n'] = n_obs\n \nstardat= stardat.loc[stardat['ID'].isin(IDs)]",
"_____no_output_____"
]
],
[
[
"To find a ballpark figure before defining priors, will use model:\n\n$$\\nu(n)=(n+\\epsilon)\\langle\\Delta\\nu\\rangle+k(n_{max}-n)^2+\\mathcal{A}e^{-n/\\tau}sin(nw+\\phi)$$\n\nwhere $n_{max}= \\nu_{max}/\\Delta\\nu - \\epsilon$",
"_____no_output_____"
]
],
[
[
"def echelle(stardat, modes, ID, model=False, stanfit=[], stan_dnu=0):\n numax_obs = float(stardat.loc[stardat['ID'] == ID].Numax)\n numax_obs_err = float(stardat.loc[stardat['ID'] == ID].Numax_err)\n #dnu_obs = float(stardat.loc[stardat.ID == IDs[i]].Dnu_median_all)\n #dnu_obs = np.mean(np.diff(modes[str(IDs[i])].f0)) \n dnu_obs = np.mean(modes[str(ID)].f0.diff(2).shift(-1)/2)\n # Create dataframes for frequencies and calculate orders n\n l0modes = pd.DataFrame([modes[str(ID)].f0, modes[str(ID)].f0_err])\n l0modes = l0modes.T\n l0modes = l0modes.sort_values('f0', ascending=True)\n n_min = int(l0modes.f0.min() / dnu_obs)\n n_obs = np.arange(n_min, n_min+len(l0modes.f0), 1)\n l0modes['n'] = n_obs\n l0modes = l0modes.set_index(np.arange(0, len(l0modes.f0), 1))\n plt.scatter(l0modes.f0 % dnu_obs, l0modes.f0, label = str(ID))\n \n if model:\n label = 'Stan Fit '+str(ID)\n plt.plot(stanfit % stan_dnu, stanfit, label = label)\n \n plt.xlabel(r'Frequency modulo ($\\mu Hz$)')\n plt.ylabel(r'Frequency ($\\mu Hz$)')\n plt.legend()",
"_____no_output_____"
],
[
"def model(n, dnu, nmax, epsilon, alpha, A, G, phi):\n freqs = (n + epsilon + alpha/2 * (nmax - n)**2 + A*G/(2*np.pi) * np.sin((2*np.pi*(n-nmax))/G + phi))*dnu #* np.exp(-n/tau);\n return freqs",
"_____no_output_____"
],
[
"for i in IDs:\n #values from Vrard\n dnu_avg = np.mean(modes[str(i)].dnu)\n n = modes[str(i)].n\n #epsilon = 0.601 + 0.632*np.log(dnu_avg)\n epsilon = np.median((modes[str(i)].f0 % dnu_avg) / dnu_avg)\n numax_obs = float(stardat.loc[stardat['ID'] == i].Numax)\n nmax = numax_obs/dnu_avg - epsilon\n alpha = 0.015*dnu_avg**(-0.32)\n A = 0.06*dnu_avg**(-0.88) \n G = 3.08\n #tau = 8\n phi = 1.71\n f = model(n, dnu_avg, nmax, epsilon, alpha, A, G, phi)\n echelle(stardat, modes, i, True, f, dnu_avg)\n ",
"_____no_output_____"
],
[
"'''plt.scatter(l0modes.f0 % dnu_obs, l0modes.f0, label = 'Data') \nplt.plot(f % dnu_obs, f, label = 'Model')\nplt.xlabel(r'Frequency modulo ($\\mu Hz$)')\nplt.ylabel(r'Frequency ($\\mu Hz$)')\n#mod_err = (l0modes.f0 % dnu_obs)*np.sqrt((dnu_obs_err/dnu_obs)**2 + (l0modes.f0_err/l0modes.f0)**2)\nplt.errorbar(l0modes.f0 % dnu_obs, l0modes.f0, yerr = l0modes.f0_err, xerr = mod_err, ecolor = 'r', ls='none', label = 'Error')\nplt.legend()'''",
"_____no_output_____"
],
[
"code = '''\ndata {\n int N;\n real n[N];\n real freq[N];\n real freq_err[N];\n real dnu_guess;\n}\nparameters {\n real dnu;\n real nmax;\n real epsilon;\n real alpha;\n real<lower = 0> A;\n real<lower = 0> G;\n real<lower = -2.0*pi(), upper = 2.0*pi()> phi;\n //real<lower = 0> tau;\n}\nmodel {\n real mod[N];\n for (i in 1:N){\n mod[i] = (n[i] + epsilon + (alpha/2) * (nmax - n[i])^2 + \n A*G/(2*pi()) * sin((2*pi()*(n[i]-nmax))/G + phi))*dnu;\n }\n mod ~ normal(freq, freq_err);\n dnu ~ normal(dnu_guess, dnu_guess*0.001);\n epsilon ~ normal(0.601 + 0.632*log(dnu), 0.5);\n epsilon ~ uniform(-1.0, 2.0);\n nmax ~ normal(10, 4);\n alpha ~ lognormal(log(0.015*dnu^(-0.32)), 0.3);\n A ~ lognormal(log(0.06*dnu^(-0.88)), 0.4);\n G ~ normal(3.08, 0.8);\n // tau ~ normal(50, 10);\n}\ngenerated quantities{\n real fm[N];\n for (j in 1:N){\n fm[j] = (n[j] + epsilon + (alpha/2) * (nmax - n[j])^2 + \n A*G/(2*pi()) * sin((2*pi()*(n[j]-nmax))/G + phi))*dnu;\n }\n}\n'''\nsm = pystan.StanModel(model_code=code)",
"INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_1644777b2cefc7b2c6ca8418f8c28f73 NOW.\n/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/Cython/Compiler/Main.py:367: FutureWarning: Cython directive 'language_level' not set, using 2 for now (Py2). This will change in a later release! File: /var/folders/2_/b8v0t8pn1hj1p3r4lyfvvv2h0000gn/T/tmpus3k3gum/stanfit4anon_model_1644777b2cefc7b2c6ca8418f8c28f73_4007119050413793728.pyx\n tree = Parsing.p_module(s, pxd, full_module_name)\n"
],
[
"fits = {}\nfor i in IDs:\n dat_star = stardat.loc[stardat['ID'] == i]\n df_star = modes[str(i)]\n df_star = df_star.sort_values(by=['f0'])\n dnu_obs = np.mean(df_star.dnu)\n numax_obs = float(dat_star.loc[dat_star['ID'] == i].Numax)\n df_star = df_star.set_index(np.arange(0, len(df_star.f0), 1))\n nmax_guess = np.mean(df_star.n)\n epsilon_obs = np.median((df_star.f0 % dnu_obs) / dnu_obs)\n #epsilon_obs = 0.601 + 0.632*np.log(dnu_obs)\n alpha_obs = 0.015*dnu_obs**(-0.32)\n A_obs = 0.06*dnu_obs**(-0.88)\n \n data = {'N': len(df_star.f0), 'n': df_star.n.values, 'freq': df_star.f0.values,\n 'freq_err': df_star.f0_err.values, 'dnu_guess': dnu_obs}\n start = {'dnu': dnu_obs, 'epsilon': epsilon_obs, \n 'nmax': numax_obs/dnu_obs - epsilon_obs, 'alpha': alpha_obs, 'A': A_obs,\n 'G': 3, 'phi': -1.6}\n nchains=4\n fit = sm.sampling(data=data, iter=5000, chains=nchains, init=[start for n in range(nchains)])\n fits[str(i)] = fit\n output = pd.DataFrame({'dnu': fit['dnu'], 'nmax': fit['nmax'], 'epsilon': fit['epsilon'], \n 'alpha': fit['alpha'], 'A': fit['A'], 'G': fit['G'], 'phi': fit['phi']})\n #output.to_csv('samples_' + str(i) + '.csv')",
"WARNING:pystan:1 of 10000 iterations ended with a divergence (0.01%).\nWARNING:pystan:Try running with adapt_delta larger than 0.8 to remove the divergences.\n"
],
[
"for i in IDs:\n print('ID = ' + str(i))\n print(fits[str(i)])",
"ID = 2141928\nInference for Stan model: anon_model_1644777b2cefc7b2c6ca8418f8c28f73.\n4 chains, each with iter=5000; warmup=2500; thin=1; \npost-warmup draws per chain=2500, total post-warmup draws=10000.\n\n mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat\ndnu 4.08 5.9e-5 4.0e-3 4.07 4.08 4.08 4.08 4.09 4585 1.0\nnmax 7.69 3.0e-3 0.19 7.3 7.57 7.7 7.82 8.05 4116 1.0\nepsilon 0.94 1.3e-4 9.0e-3 0.92 0.93 0.94 0.94 0.96 4502 1.0\nalpha 0.01 2.0e-5 1.8e-3 7.9e-3 0.01 0.01 0.01 0.02 8426 1.0\nA 0.04 1.1e-4 8.6e-3 0.02 0.04 0.04 0.05 0.06 6382 1.0\nG 3.09 2.6e-3 0.2 2.7 2.96 3.08 3.21 3.51 6046 1.0\nphi -0.22 7.0e-3 0.46 -1.16 -0.51 -0.2 0.09 0.67 4330 1.0\nfm[1] 24.43 6.3e-4 0.05 24.33 24.39 24.43 24.46 24.52 5939 1.0\nfm[2] 28.4 2.0e-4 0.02 28.37 28.39 28.4 28.41 28.44 8591 1.0\nfm[3] 32.3 2.7e-4 0.02 32.26 32.29 32.3 32.32 32.35 7262 1.0\nfm[4] 36.49 1.8e-4 0.02 36.45 36.47 36.49 36.5 36.52 9695 1.0\nfm[5] 40.62 2.9e-4 0.03 40.57 40.6 40.62 40.64 40.67 7776 1.0\nfm[6] 44.66 3.8e-4 0.03 44.6 44.63 44.66 44.68 44.72 6708 1.0\nfm[7] 48.96 4.0e-4 0.04 48.88 48.93 48.96 48.98 49.04 10846 1.0\nlp__ -3.73 0.03 1.98 -8.53 -4.77 -3.36 -2.28 -0.95 3644 1.0\n\nSamples were drawn using NUTS at Thu Dec 13 14:27:22 2018.\nFor each parameter, n_eff is a crude measure of effective sample size,\nand Rhat is the potential scale reduction factor on split chains (at \nconvergence, Rhat=1).\nID = 7345200\nInference for Stan model: anon_model_1644777b2cefc7b2c6ca8418f8c28f73.\n4 chains, each with iter=5000; warmup=2500; thin=1; \npost-warmup draws per chain=2500, total post-warmup draws=10000.\n\n mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat\ndnu 3.84 5.4e-5 3.8e-3 3.84 3.84 3.84 3.85 3.85 5090 1.0\nnmax 7.67 6.7e-3 0.33 7.15 7.45 7.63 7.84 8.47 2447 1.0\nepsilon 0.91 1.4e-4 9.3e-3 0.89 0.9 0.91 0.92 0.93 4687 1.0\nalpha 0.01 4.2e-5 3.0e-3 6.8e-3 9.9e-3 0.01 0.01 0.02 4981 1.0\nA 0.03 7.9e-5 5.5e-3 0.02 0.02 0.03 0.03 0.04 4870 1.0\nG 4.34 7.7e-3 0.48 3.5 3.99 4.31 4.65 5.36 3912 1.0\nphi 0.35 7.8e-3 0.45 -0.57 0.07 0.36 0.64 1.21 3282 1.0\nfm[1] 22.9 3.3e-4 0.03 22.84 22.88 22.9 22.91 22.95 6815 1.0\nfm[2] 26.55 1.4e-4 0.01 26.52 26.54 26.55 26.56 26.58 9951 1.0\nfm[3] 30.36 1.2e-4 0.01 30.34 30.36 30.36 30.37 30.39 10539 1.0\nfm[4] 34.3 1.7e-4 0.02 34.26 34.28 34.3 34.31 34.33 9516 1.0\nfm[5] 38.18 2.5e-4 0.02 38.13 38.16 38.18 38.19 38.22 9143 1.0\nfm[6] 42.02 5.1e-4 0.04 41.94 41.99 42.02 42.04 42.09 5632 1.0\nlp__ -3.07 0.03 1.89 -7.8 -4.07 -2.73 -1.69 -0.42 3778 1.0\n\nSamples were drawn using NUTS at Thu Dec 13 14:27:24 2018.\nFor each parameter, n_eff is a crude measure of effective sample size,\nand Rhat is the potential scale reduction factor on split chains (at \nconvergence, Rhat=1).\nID = 6104786\nInference for Stan model: anon_model_1644777b2cefc7b2c6ca8418f8c28f73.\n4 chains, each with iter=5000; warmup=2500; thin=1; \npost-warmup draws per chain=2500, total post-warmup draws=10000.\n\n mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat\ndnu 13.83 2.6e-4 0.01 13.8 13.82 13.83 13.84 13.86 2867 1.0\nnmax 11.56 3.4e-3 0.18 11.23 11.44 11.56 11.67 11.92 2641 1.0\nepsilon 0.3 2.3e-4 0.01 0.28 0.29 0.3 0.31 0.32 2836 1.0\nalpha 7.8e-3 8.8e-6 6.9e-4 6.5e-3 7.3e-3 7.8e-3 8.3e-3 9.2e-3 6237 1.0\nA 0.01 3.5e-5 2.3e-3 9.4e-3 0.01 0.01 0.02 0.02 4493 1.0\nG 2.42 5.5e-3 0.27 1.86 2.26 2.42 2.6 2.97 2471 1.0\nphi -3.62 0.01 0.48 -4.47 -3.93 -3.65 -3.35 -2.58 2292 1.0\nfm[1] 129.03 2.1e-4 0.02 128.99 129.02 129.03 129.05 129.08 10295 1.0\nfm[2] 142.52 2.2e-4 0.02 142.49 142.51 142.52 142.54 142.56 6495 1.0\nfm[3] 156.37 1.7e-4 0.02 156.34 156.36 156.37 156.38 156.4 7565 1.0\nfm[4] 170.09 9.2e-5 9.5e-3 170.07 170.08 170.09 170.1 170.11 10823 1.0\nfm[5] 184.06 1.2e-3 0.07 183.93 184.01 184.06 184.11 184.18 3203 1.0\nfm[6] 198.12 3.9e-4 0.04 198.05 198.1 198.12 198.15 198.2 9342 1.0\nlp__ -7.86 0.04 1.91 -12.32 -8.98 -7.55 -6.42 -5.09 2557 1.0\n\nSamples were drawn using NUTS at Thu Dec 13 14:27:30 2018.\nFor each parameter, n_eff is a crude measure of effective sample size,\nand Rhat is the potential scale reduction factor on split chains (at \nconvergence, Rhat=1).\nID = 9080407\nInference for Stan model: anon_model_1644777b2cefc7b2c6ca8418f8c28f73.\n4 chains, each with iter=5000; warmup=2500; thin=1; \npost-warmup draws per chain=2500, total post-warmup draws=10000.\n\n mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat\ndnu 4.74 7.4e-5 4.7e-3 4.73 4.74 4.74 4.74 4.75 4098 1.0\nnmax 10.05 2.1e-3 0.14 9.8 9.95 10.04 10.13 10.34 4222 1.0\nepsilon 0.03 1.6e-4 0.01 6.7e-3 0.02 0.03 0.03 0.05 4037 1.0\nalpha 0.01 2.0e-5 1.6e-3 0.01 0.01 0.01 0.01 0.02 5900 1.0\nA 0.02 5.9e-5 4.5e-3 0.01 0.02 0.02 0.02 0.03 5833 1.0\nG 3.07 5.9e-3 0.39 2.43 2.79 3.02 3.29 3.98 4494 1.0\nphi 2.45 5.9e-3 0.39 1.76 2.18 2.43 2.69 3.27 4254 1.0\nfm[1] 33.64 1.4e-4 0.01 33.61 33.63 33.64 33.65 33.67 10881 1.0\nfm[2] 38.15 1.5e-4 0.01 38.12 38.14 38.15 38.16 38.17 7607 1.0\nfm[3] 42.84 9.3e-5 8.6e-3 42.82 42.83 42.84 42.85 42.86 8533 1.0\nfm[4] 47.56 1.3e-4 0.01 47.54 47.55 47.56 47.57 47.59 9720 1.0\nfm[5] 52.27 1.8e-4 0.02 52.24 52.26 52.27 52.28 52.3 7788 1.0\nfm[6] 57.15 5.4e-4 0.04 57.06 57.12 57.15 57.18 57.22 5601 1.0\nfm[7] 62.06 7.6e-4 0.06 61.95 62.02 62.06 62.1 62.17 5622 1.0\nlp__ -5.05 0.03 1.9 -9.75 -6.07 -4.71 -3.66 -2.33 3920 1.0\n\nSamples were drawn using NUTS at Thu Dec 13 14:27:34 2018.\nFor each parameter, n_eff is a crude measure of effective sample size,\nand Rhat is the potential scale reduction factor on split chains (at \nconvergence, Rhat=1).\nID = 11567572\nInference for Stan model: anon_model_1644777b2cefc7b2c6ca8418f8c28f73.\n4 chains, each with iter=5000; warmup=2500; thin=1; \npost-warmup draws per chain=2500, total post-warmup draws=10000.\n\n mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat\ndnu 5.23 8.8e-5 5.4e-3 5.22 5.23 5.23 5.24 5.25 3736 1.0\nnmax 10.58 3.5e-3 0.18 10.17 10.47 10.6 10.71 10.89 2727 1.0\nepsilon -0.02 1.9e-4 0.01 -0.05 -0.03 -0.02 -0.02-1.4e-3 3509 1.0\nalpha 0.01 4.0e-5 2.4e-3 8.9e-3 0.01 0.01 0.01 0.02 3557 1.0\nA 0.02 7.8e-5 5.3e-3 0.01 0.02 0.02 0.03 0.03 4604 1.0\nG 3.77 5.0e-3 0.31 3.21 3.55 3.75 3.97 4.44 3868 1.0\nphi 0.56 7.0e-3 0.37 -0.31 0.35 0.6 0.82 1.16 2772 1.0\nfm[1] 42.02 8.7e-4 0.05 41.92 41.98 42.02 42.05 42.13 3916 1.0\nfm[2] 47.02 2.0e-4 0.02 46.98 47.0 47.02 47.03 47.06 11136 1.0\nfm[3] 52.21 1.8e-4 0.02 52.17 52.2 52.21 52.22 52.25 9742 1.0\nfm[4] 57.53 2.0e-4 0.02 57.5 57.52 57.53 57.54 57.56 7327 1.0\nfm[5] 62.77 1.6e-4 0.02 62.74 62.76 62.77 62.78 62.81 9615 1.0\nfm[6] 68.06 3.4e-4 0.03 68.01 68.04 68.06 68.07 68.11 5347 1.0\nfm[7] 73.55 3.2e-4 0.04 73.49 73.53 73.55 73.58 73.62 12609 1.0\nlp__ -10.75 0.04 1.98 -15.51 -11.85 -10.42 -9.29 -7.95 3154 1.0\n\nSamples were drawn using NUTS at Thu Dec 13 14:27:37 2018.\nFor each parameter, n_eff is a crude measure of effective sample size,\nand Rhat is the potential scale reduction factor on split chains (at \nconvergence, Rhat=1).\n"
],
[
"for i in IDs:\n stanfit = model(modes[str(i)].n, fits[str(i)]['dnu'].mean(), fits[str(i)]['nmax'].mean(), fits[str(i)]['epsilon'].mean(), fits[str(i)]['alpha'].mean(), fits[str(i)]['A'].mean(), fits[str(i)]['G'].mean(), fits[str(i)]['phi'].mean())\n stan_dnu = fits[str(i)]['dnu'].mean()\n echelle(stardat, modes, i, True, stanfit, stan_dnu)",
"_____no_output_____"
],
[
"import corner\ndata = np.vstack([fit['dnu'], fit['nmax'], fit['epsilon'], fit['alpha'], fit['A'], fit['G'], fit['phi']]).T\ncorner.corner(data, labels=['dnu', 'nmax', 'epsilon', 'alpha', 'A', 'G', 'phi'])\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad39af600b3e6b1e2a24f7621b6cb73e137df2e
| 13,470 |
ipynb
|
Jupyter Notebook
|
Datasets/Terrain/us_ned_physio_diversity.ipynb
|
guy1ziv2/earthengine-py-notebooks
|
931f57c61c147fe6cff745c2a099a444716e69e4
|
[
"MIT"
] | 1 |
2020-07-14T10:45:09.000Z
|
2020-07-14T10:45:09.000Z
|
Datasets/Terrain/us_ned_physio_diversity.ipynb
|
Yesicaleo/earthengine-py-notebooks
|
b737a889d5023408cc5cec204f8bd5f9d51cdee8
|
[
"MIT"
] | null | null | null |
Datasets/Terrain/us_ned_physio_diversity.ipynb
|
Yesicaleo/earthengine-py-notebooks
|
b737a889d5023408cc5cec204f8bd5f9d51cdee8
|
[
"MIT"
] | 1 |
2021-08-12T12:19:37.000Z
|
2021-08-12T12:19:37.000Z
| 79.235294 | 8,264 | 0.840535 |
[
[
[
"<table class=\"ee-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://github.com/giswqs/earthengine-py-notebooks/tree/master/Datasets/Terrain/us_ned_physio_diversity.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /> View source on GitHub</a></td>\n <td><a target=\"_blank\" href=\"https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/Datasets/Terrain/us_ned_physio_diversity.ipynb\"><img width=26px src=\"https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png\" />Notebook Viewer</a></td>\n <td><a target=\"_blank\" href=\"https://mybinder.org/v2/gh/giswqs/earthengine-py-notebooks/master?filepath=Datasets/Terrain/us_ned_physio_diversity.ipynb\"><img width=58px src=\"https://mybinder.org/static/images/logo_social.png\" />Run in binder</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/Datasets/Terrain/us_ned_physio_diversity.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /> Run in Google Colab</a></td>\n</table>",
"_____no_output_____"
],
[
"## Install Earth Engine API\nInstall the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geehydro](https://github.com/giswqs/geehydro). The **geehydro** Python package builds on the [folium](https://github.com/python-visualization/folium) package and implements several methods for displaying Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, `Map.centerObject()`, and `Map.setOptions()`.\nThe magic command `%%capture` can be used to hide output from a specific cell.",
"_____no_output_____"
]
],
[
[
"# %%capture\n# !pip install earthengine-api\n# !pip install geehydro",
"_____no_output_____"
]
],
[
[
"Import libraries",
"_____no_output_____"
]
],
[
[
"import ee\nimport folium\nimport geehydro",
"_____no_output_____"
]
],
[
[
"Authenticate and initialize Earth Engine API. You only need to authenticate the Earth Engine API once. Uncomment the line `ee.Authenticate()` \nif you are running this notebook for this first time or if you are getting an authentication error. ",
"_____no_output_____"
]
],
[
[
"# ee.Authenticate()\nee.Initialize()",
"_____no_output_____"
]
],
[
[
"## Create an interactive map \nThis step creates an interactive map using [folium](https://github.com/python-visualization/folium). The default basemap is the OpenStreetMap. Additional basemaps can be added using the `Map.setOptions()` function. \nThe optional basemaps can be `ROADMAP`, `SATELLITE`, `HYBRID`, `TERRAIN`, or `ESRI`.",
"_____no_output_____"
]
],
[
[
"Map = folium.Map(location=[40, -100], zoom_start=4)\nMap.setOptions('HYBRID')",
"_____no_output_____"
]
],
[
[
"## Add Earth Engine Python script ",
"_____no_output_____"
]
],
[
[
"dataset = ee.Image('CSP/ERGo/1_0/US/physioDiversity')\nphysiographicDiversity = dataset.select('b1')\nphysiographicDiversityVis = {\n 'min': 0.0,\n 'max': 1.0,\n}\nMap.setCenter(-94.625, 39.825, 7)\nMap.addLayer(\n physiographicDiversity, physiographicDiversityVis,\n 'Physiographic Diversity')\n",
"_____no_output_____"
]
],
[
[
"## Display Earth Engine data layers ",
"_____no_output_____"
]
],
[
[
"Map.setControlVisibility(layerControl=True, fullscreenControl=True, latLngPopup=True)\nMap",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad3a0534456fbc34e895e377503cd2b54530226
| 100,634 |
ipynb
|
Jupyter Notebook
|
gradients/results/hessian-sim/analysis.ipynb
|
NunoEdgarGFlowHub/derivatives-of-variational-circuits
|
8c57b7971c339c350c01e1954e93fd92fd0e6fec
|
[
"Apache-2.0"
] | 7 |
2020-08-18T01:35:54.000Z
|
2021-02-25T00:04:42.000Z
|
gradients/results/hessian-sim/analysis.ipynb
|
NunoEdgarGFlowHub/derivatives-of-variational-circuits
|
8c57b7971c339c350c01e1954e93fd92fd0e6fec
|
[
"Apache-2.0"
] | null | null | null |
gradients/results/hessian-sim/analysis.ipynb
|
NunoEdgarGFlowHub/derivatives-of-variational-circuits
|
8c57b7971c339c350c01e1954e93fd92fd0e6fec
|
[
"Apache-2.0"
] | 4 |
2021-03-02T17:44:04.000Z
|
2022-02-10T15:10:04.000Z
| 205.795501 | 33,060 | 0.911292 |
[
[
[
"import sys\nimport pickle\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nsys.path.append(\"../..\")\nimport gradient_analyze as ga\nimport hp_file",
"_____no_output_____"
],
[
"filename = './results.pickle'\n\nwith open(filename, \"rb\") as file:\n results = pickle.load(file)",
"_____no_output_____"
],
[
"hess_exact = np.array([[ 0.794, 0.055, 0.109, -0.145, 0. ],\n [ 0.055, 0.794, -0.042, 0.056, -0. ],\n [ 0.109, -0.042, 0.794, 0.11 , 0. ],\n [-0.145, 0.056, 0.11 , 0.794, 0. ],\n [ 0. , -0. , 0. , 0. , -0. ]])",
"_____no_output_____"
],
[
"corr = lambda x: np.array(2 * x, dtype=\"float64\") - np.diag(np.diag(np.array(x, dtype=\"float64\")))\n\nga.calculate_new_quantity(['hess_ps'], 'hess_ps_corr', corr, results, hp_file)\nga.calculate_new_quantity(['hess_fd'], 'hess_fd_corr', corr, results, hp_file)",
"_____no_output_____"
],
[
"f = lambda x: np.sum((x - hess_exact) ** 2)\n\nga.calculate_new_quantity(['hess_ps_corr'], 'hess_ps_err', f, results, hp_file)\nga.calculate_new_quantity(['hess_fd_corr'], 'hess_fd_err', f, results, hp_file)",
"_____no_output_____"
],
[
"results_processed = ga.avg_quantities(['hess_ps_err', 'hess_fd_err'], results, hp_file)",
"_____no_output_____"
],
[
"results_processed_accessed = ga.access_quantities(['hess_ps_err', 'hess_fd_err'], results, hp_file)",
"_____no_output_____"
],
[
"n_shots = [10, 20, 41, 84, 119, 242, 492, 1000, 2031,\n 4125, 8192, 11938, 24245, 49239, 100000]\nn_shots = n_shots[7]\nn_shots",
"_____no_output_____"
],
[
"cols = plt.rcParams['axes.prop_cycle'].by_key()['color']",
"_____no_output_____"
],
[
"results_slice = ga.calculate_slice({\"n_shots\": n_shots}, results_processed)\nresults_slice_acc = ga.calculate_slice({\"n_shots\": n_shots}, results_processed_accessed)\nx, y_fd = ga.make_numpy(results_slice, \"h\", \"hess_fd_err\")\nx, y_ps = ga.make_numpy(results_slice, \"h\", \"hess_ps_err\")\n\nstds_fd = []\nstds_ps = []\n\nfor h in x:\n errors = list(ga.calculate_slice({\"h\": h}, results_slice_acc).values())[0]\n errors_fd = errors[\"hess_fd_err\"]\n errors_ps = errors[\"hess_ps_err\"]\n \n stds_fd.append(np.std(errors_fd))\n stds_ps.append(np.std(errors_ps))\n\nstds_fd = np.array(stds_fd)\nstds_ps = np.array(stds_ps)\n\nplt.fill_between(x, y_fd - stds_fd, y_fd + stds_fd, color=cols[0], alpha=0.2)\nplt.fill_between(x, y_ps - stds_ps, y_ps + stds_ps, color=cols[1], alpha=0.2)\nplt.plot(x, y_fd, label=\"finite-difference\", c=cols[0])\nplt.plot(x, y_ps, label=\"parameter-shift\", c=cols[1])\n# plt.axvline(np.pi / 2, c=\"black\", alpha=0.4, linestyle=\":\")\nplt.xlabel('step size', fontsize=20)\nplt.ylabel('MSE', fontsize=20)\nplt.xscale(\"log\")\nplt.tick_params(labelsize=15)\nplt.legend()\n\n# plt.savefig(\"tradeoff_1.pdf\")\nplt.yscale(\"log\")\n# plt.ylim(10**-5.25, 10**(-0.95))\nplt.tick_params(labelsize=15)\nplt.legend(fontsize=12)\n# plt.title(\"(A)\", loc=\"left\", fontsize=15)\nplt.tight_layout()\nplt.savefig(\"ps_vs_fd_hess.pdf\")",
"_____no_output_____"
],
[
"max_point = 8\ny_fit_low = np.log(y_fd[:max_point])\nx_fit_low = np.log(x[:max_point])\n\np = np.polyfit(x_fit_low, y_fit_low, 1)\nprint(p[0])\n\ny_fit_low = p[0] * np.log(x) + p[1]\ny_fit_low = np.exp(y_fit_low)",
"-3.948615578367928\n"
],
[
"min_point = 40\nmax_point = 50\ny_fit_high_ = np.log(y_fd[min_point:max_point])\nx_fit_high_ = np.log(x[min_point:max_point])\n\nppp = np.polyfit(x_fit_high_, y_fit_high_, 1)\nprint(ppp[0])\n\ny_fit_high_ = ppp[0] * np.log(x) + ppp[1]\ny_fit_high_ = np.exp(y_fit_high_)",
"3.2889869941077534\n"
],
[
"min_point = 80\nmax_point = 99\ny_fit_high = np.log(y_fd[min_point:max_point])\nx_fit_high = np.log(x[min_point:max_point])\n\npp = np.polyfit(x_fit_high, y_fit_high, 1)\nprint(pp[0])\n\ny_fit_high = pp[0] * np.log(x) + pp[1]\ny_fit_high = np.exp(y_fit_high)",
"2.3275174603063657\n"
],
[
"plt.plot(x, y_fd, '--bo', label=\"Finite difference\")\nplt.plot(x, y_fit_low, label=\"Power law fit with p={:.4f}\".format(p[0]))\n# plt.plot(x, y_fit_high, label=\"Power law fit with p={:.4f}\".format(pp[0]))\nplt.plot(x, y_fit_high_, label=\"Power law fit with p={:.4f}\".format(ppp[0]))\nplt.xlabel('Finite difference step size', fontsize=20)\nplt.ylabel('Mean squared error', fontsize=20)\nplt.xscale(\"log\")\nplt.tick_params(labelsize=15)\nplt.legend()\nplt.tight_layout()\nplt.savefig(\"tradeoff_1.pdf\")\nplt.yscale(\"log\")\nplt.ylim(10**-4, 0)",
"/home/tom/miniconda3/envs/derivatives-of-variational-circuits/lib/python3.7/site-packages/ipykernel_launcher.py:13: UserWarning: Attempted to set non-positive top ylim on a log-scaled axis.\nInvalid limit will be ignored.\n del sys.path[0]\n"
],
[
"n_shots_list = [10, 20, 41, 84, 119, 242, 492, 1000, 2031,\n 4125, 8192, 11938, 24245, 49239, 100000]\n\nerrs = []\nerr_fds = []\nerrs_vars = []\n\nfor n_shots in n_shots_list:\n results_slice = ga.calculate_slice({\"n_shots\": n_shots}, results_processed)\n results_slice_acc = ga.calculate_slice({\"n_shots\": n_shots}, results_processed_accessed)\n x, y_fd = ga.make_numpy(results_slice, \"h\", \"hess_fd_err\")\n x, y_ps = ga.make_numpy(results_slice, \"h\", \"hess_ps_err\")\n opt_arg = np.argmin(np.abs(x - np.pi / 2))\n opt_x = x[opt_arg]\n \n err = np.min(y_ps)\n opt_x = x[np.argmin(y_ps)]\n \n results_slice_acc_h = ga.calculate_slice({\"h\": opt_x}, results_slice_acc)\n results_slice_acc_h = list(results_slice_acc_h.values())[0][\"hess_ps_err\"]\n\n errs.append(err)\n \n err_fd = np.min(y_fd)\n err_fds.append(err_fd)\n \n errs_vars.append(np.std(results_slice_acc_h))",
"_____no_output_____"
],
[
"errs = np.array(errs)\nerrs_vars = np.array(errs_vars)",
"_____no_output_____"
],
[
"min_point = 0\nmax_point = -1\ny_fit_high = np.log(errs[min_point:max_point])\nx_fit_high = np.log(n_shots_list[min_point:max_point])\n\npp = np.polyfit(x_fit_high, y_fit_high, 1)\nprint(pp[0])\n\ny_fit_high = pp[0] * np.log(x) + pp[1]\ny_fit_high = np.exp(y_fit_high)",
"-1.0007730459228334\n"
],
[
"# plt.fill_between(n_shots_list, errs - errs_vars, errs + errs_vars, color=cols[0], alpha=0.2)\nplt.plot(n_shots_list, err_fds, label=\"finite-difference\")\nplt.plot(n_shots_list, errs, label=\"paramter-shift\")\nplt.xlabel('N', fontsize=20)\nplt.ylabel('MSE', fontsize=20)\nplt.tick_params(labelsize=15)\nplt.tight_layout()\nplt.yscale(\"log\")\nplt.xscale(\"log\")\nplt.tick_params(labelsize=15)\nplt.legend(fontsize=12)\n# plt.title(\"(B)\", loc=\"left\", fontsize=15)\nplt.tight_layout()\nplt.savefig(\"ps_vs_fd_N.pdf\")\n# # plt.ylim(10**-5.25, 10**(-0.95))",
"_____no_output_____"
],
[
"min_point = 0\nmax_point = -1\ny_fit_high = np.log(errs[min_point:max_point])\nx_fit_high = np.log(n_shots_list[min_point:max_point])\n\npp = np.polyfit(x_fit_high, y_fit_high, 1)\nprint(pp[0])\n\ny_fit_high = pp[0] * np.log(x) + pp[1]\ny_fit_high = np.exp(y_fit_high)",
"-1.0007730459228334\n"
],
[
"min_point = 10\nmax_point = -1\ny_fit_high = np.log(err_fds[min_point:max_point])\nx_fit_high = np.log(n_shots_list[min_point:max_point])\n\npp = np.polyfit(x_fit_high, y_fit_high, 1)\nprint(pp[0])\n\ny_fit_high = pp[0] * np.log(x) + pp[1]\ny_fit_high = np.exp(y_fit_high)",
"-0.5012673016787207\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad3a184d08c4ca71fd84819de7472530a2b95d2
| 74,656 |
ipynb
|
Jupyter Notebook
|
02_Filtering_&_Sorting/Euro12/Exercises_with_Solutions.ipynb
|
dhruv-agg/pyspark_practice
|
a091d21e7d5d15966d32f72237ef7e15f5266c90
|
[
"BSD-3-Clause"
] | 2 |
2021-08-12T05:46:02.000Z
|
2022-02-06T20:01:08.000Z
|
02_Filtering_&_Sorting/Euro12/Exercises_with_Solutions.ipynb
|
dhruv-agg/pyspark_practice
|
a091d21e7d5d15966d32f72237ef7e15f5266c90
|
[
"BSD-3-Clause"
] | null | null | null |
02_Filtering_&_Sorting/Euro12/Exercises_with_Solutions.ipynb
|
dhruv-agg/pyspark_practice
|
a091d21e7d5d15966d32f72237ef7e15f5266c90
|
[
"BSD-3-Clause"
] | null | null | null | 34.105071 | 185 | 0.258546 |
[
[
[
"# Ex2 - Filtering and Sorting Data\nCheck out [Euro 12 Exercises Video Tutorial](https://youtu.be/iqk5d48Qisg) to watch a data scientist go through the exercises",
"_____no_output_____"
],
[
"This time we are going to pull data directly from the internet.\n\n### Step 1. Import the necessary libraries",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"### Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/02_Filtering_%26_Sorting/Euro12/Euro_2012_stats_TEAM.csv). ",
"_____no_output_____"
],
[
"### Step 3. Assign it to a variable called euro12.",
"_____no_output_____"
]
],
[
[
"euro12 = pd.read_csv('https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/02_Filtering_%26_Sorting/Euro12/Euro_2012_stats_TEAM.csv', sep=',')\neuro12",
"_____no_output_____"
]
],
[
[
"### Step 4. Select only the Goal column.",
"_____no_output_____"
]
],
[
[
"euro12.Goals",
"_____no_output_____"
]
],
[
[
"### Step 5. How many team participated in the Euro2012?",
"_____no_output_____"
]
],
[
[
"euro12.shape[0]",
"_____no_output_____"
]
],
[
[
"### Step 6. What is the number of columns in the dataset?",
"_____no_output_____"
]
],
[
[
"euro12.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 16 entries, 0 to 15\nData columns (total 35 columns):\nTeam 16 non-null object\nGoals 16 non-null int64\nShots on target 16 non-null int64\nShots off target 16 non-null int64\nShooting Accuracy 16 non-null object\n% Goals-to-shots 16 non-null object\nTotal shots (inc. Blocked) 16 non-null int64\nHit Woodwork 16 non-null int64\nPenalty goals 16 non-null int64\nPenalties not scored 16 non-null int64\nHeaded goals 16 non-null int64\nPasses 16 non-null int64\nPasses completed 16 non-null int64\nPassing Accuracy 16 non-null object\nTouches 16 non-null int64\nCrosses 16 non-null int64\nDribbles 16 non-null int64\nCorners Taken 16 non-null int64\nTackles 16 non-null int64\nClearances 16 non-null int64\nInterceptions 16 non-null int64\nClearances off line 15 non-null float64\nClean Sheets 16 non-null int64\nBlocks 16 non-null int64\nGoals conceded 16 non-null int64\nSaves made 16 non-null int64\nSaves-to-shots ratio 16 non-null object\nFouls Won 16 non-null int64\nFouls Conceded 16 non-null int64\nOffsides 16 non-null int64\nYellow Cards 16 non-null int64\nRed Cards 16 non-null int64\nSubs on 16 non-null int64\nSubs off 16 non-null int64\nPlayers Used 16 non-null int64\ndtypes: float64(1), int64(29), object(5)\nmemory usage: 4.4+ KB\n"
]
],
[
[
"### Step 7. View only the columns Team, Yellow Cards and Red Cards and assign them to a dataframe called discipline",
"_____no_output_____"
]
],
[
[
"# filter only giving the column names\n\ndiscipline = euro12[['Team', 'Yellow Cards', 'Red Cards']]\ndiscipline",
"_____no_output_____"
]
],
[
[
"### Step 8. Sort the teams by Red Cards, then to Yellow Cards",
"_____no_output_____"
]
],
[
[
"discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)",
"_____no_output_____"
]
],
[
[
"### Step 9. Calculate the mean Yellow Cards given per Team",
"_____no_output_____"
]
],
[
[
"round(discipline['Yellow Cards'].mean())",
"_____no_output_____"
]
],
[
[
"### Step 10. Filter teams that scored more than 6 goals",
"_____no_output_____"
]
],
[
[
"euro12[euro12.Goals > 6]",
"_____no_output_____"
]
],
[
[
"### Step 11. Select the teams that start with G",
"_____no_output_____"
]
],
[
[
"euro12[euro12.Team.str.startswith('G')]",
"_____no_output_____"
]
],
[
[
"### Step 12. Select the first 7 columns",
"_____no_output_____"
]
],
[
[
"# use .iloc to slices via the position of the passed integers\n# : means all, 0:7 means from 0 to 7\n\neuro12.iloc[: , 0:7]",
"_____no_output_____"
]
],
[
[
"### Step 13. Select all columns except the last 3.",
"_____no_output_____"
]
],
[
[
"# use negative to exclude the last 3 columns\n\neuro12.iloc[: , :-3]",
"_____no_output_____"
]
],
[
[
"### Step 14. Present only the Shooting Accuracy from England, Italy and Russia",
"_____no_output_____"
]
],
[
[
"# .loc is another way to slice, using the labels of the columns and indexes\n\neuro12.loc[euro12.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad3b389516a592896cf8552b5d50855793d5d61
| 40,204 |
ipynb
|
Jupyter Notebook
|
notebooks/.ipynb_checkpoints/ML Pipeline Preparation-checkpoint.ipynb
|
aoless/disaster-response-project
|
87f46e2e08a3962e5758c41e864678e258a51a73
|
[
"MIT"
] | null | null | null |
notebooks/.ipynb_checkpoints/ML Pipeline Preparation-checkpoint.ipynb
|
aoless/disaster-response-project
|
87f46e2e08a3962e5758c41e864678e258a51a73
|
[
"MIT"
] | null | null | null |
notebooks/.ipynb_checkpoints/ML Pipeline Preparation-checkpoint.ipynb
|
aoless/disaster-response-project
|
87f46e2e08a3962e5758c41e864678e258a51a73
|
[
"MIT"
] | null | null | null | 42.588983 | 337 | 0.472242 |
[
[
[
"# ML Pipeline Preparation\nFollow the instructions below to help you create your ML pipeline.\n### 1. Import libraries and load data from database.\n- Import Python libraries\n- Load dataset from database with [`read_sql_table`](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_sql_table.html)\n- Define feature and target variables X and Y",
"_____no_output_____"
]
],
[
[
"# import libraries\nimport matplotlib.pyplot as plt\nimport nltk\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\n\nfrom joblib import load, dump\nfrom nltk.tokenize import word_tokenize\nfrom nltk.stem.wordnet import WordNetLemmatizer\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report\nfrom sklearn.multioutput import MultiOutputClassifier\nfrom sklearn.pipeline import Pipeline, FeatureUnion\nfrom sklearn.svm import LinearSVC\nfrom sqlalchemy import create_engine",
"_____no_output_____"
],
[
"nltk.download(\"punkt\")\nnltk.download(\"wordnet\")\nnltk.download('averaged_perceptron_tagger')",
"[nltk_data] Downloading package punkt to /home/oamadeus/nltk_data...\n[nltk_data] Package punkt is already up-to-date!\n[nltk_data] Downloading package wordnet to /home/oamadeus/nltk_data...\n[nltk_data] Package wordnet is already up-to-date!\n[nltk_data] Downloading package averaged_perceptron_tagger to\n[nltk_data] /home/oamadeus/nltk_data...\n[nltk_data] Package averaged_perceptron_tagger is already up-to-\n[nltk_data] date!\n"
],
[
"# load data from database\ndatabase_filepath = \"../disaster_response/data/DisasterResponse.db\"\nengine = create_engine(f\"sqlite:///{database_filepath}\")\n\nnum_of_feature_cols = 4\n\ndf = pd.read_sql_table(\"DisasterResponse\", engine)\n\nX = df[\"message\"]\nY = df[df.columns[num_of_feature_cols:]]",
"_____no_output_____"
],
[
"classes_names = Y.columns.tolist()",
"_____no_output_____"
]
],
[
[
"### 2. Write a tokenization function to process your text data",
"_____no_output_____"
]
],
[
[
"def tokenize(text):\n lemmatizer = WordNetLemmatizer()\n \n tokens = word_tokenize(text)\n clean_tokens = [lemmatizer.lemmatize(token.lower()) for token in tokens]\n return clean_tokens",
"_____no_output_____"
]
],
[
[
"### 3. Build a machine learning pipeline\nThis machine pipeline should take in the `message` column as input and output classification results on the other 36 categories in the dataset. You may find the [MultiOutputClassifier](http://scikit-learn.org/stable/modules/generated/sklearn.multioutput.MultiOutputClassifier.html) helpful for predicting multiple target variables.",
"_____no_output_____"
]
],
[
[
"pipeline = Pipeline([\n (\"c_vect\", CountVectorizer(tokenizer=tokenize, ngram_range=(1, 2), max_df=0.95)),\n (\"tfidf\", TfidfTransformer(use_idf=True, smooth_idf=True)),\n (\"clf\", MultiOutputClassifier(RandomForestClassifier(verbose=1, n_jobs=6))),\n])",
"_____no_output_____"
]
],
[
[
"### 4. Train pipeline\n- Split data into train and test sets\n- Train pipeline",
"_____no_output_____"
]
],
[
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \n\npipeline.fit(X_train, Y_train)",
"_____no_output_____"
]
],
[
[
"### 5. Test your model\nReport the f1 score, precision and recall for each output category of the dataset. You can do this by iterating through the columns and calling sklearn's `classification_report` on each.",
"_____no_output_____"
]
],
[
[
"def extract_macro_avg(report):\n for item in report.split(\"\\n\"):\n if \"macro avg\" in item:\n return float(item.strip().split()[4])",
"_____no_output_____"
],
[
"def show_scores(predicted_values):\n macro_avg_list = []\n \n for i in range(1, len(classes_names)):\n report = classification_report(Y_test.iloc[:, i].values, Y_pred[:, i], zero_division=1)\n macro_avg_list.append(extract_macro_avg(report))\n print(\"Category:\", classes_names[i], \"\\n\", report)\n \n overall_avg_score = sum(macro_avg_list) / len(macro_avg_list)\n print(f\"Overral average score: {overall_avg_score:.3}\")",
"_____no_output_____"
],
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \n\nY_pred = model.predict(X_test)\nshow_scores(Y_pred)",
"_____no_output_____"
]
],
[
[
"### 6. Improve your model\nUse grid search to find better parameters. ",
"_____no_output_____"
]
],
[
[
"parameters = {\n \"c_vect__ngram_range\": ((1, 1), (1, 2)),\n \"c_vect__max_df\": (0.75, 0.90, 1.0),\n \"c_vect__max_features\": (5000, 10000),\n \"tfidf__use_idf\": (True, False),\n \"tfidf__smooth_idf\": (True, False),\n \"tfidf__sublinear_tf\": (True, False),\n \"clf__estimator__n_estimators\": [300],\n}\n\ncv = GridSearchCV(pipeline, parameters)",
"_____no_output_____"
],
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \n\n### BE CAREFUL! This may take a very very long time to fit ###\n#cv.fit(X_train, Y_train)",
"_____no_output_____"
]
],
[
[
"### 7. Test your model\nShow the accuracy, precision, and recall of the tuned model. \n\nSince this project focuses on code quality, process, and pipelines, there is no minimum performance metric needed to pass. However, make sure to fine tune your models for accuracy, precision and recall to make your project stand out - especially for your portfolio!",
"_____no_output_____"
]
],
[
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \nmodel = load(\"../disaster_response/models/model.pkl\")\n\nY_pred = model.predict(X_test)\nshow_scores(Y_pred)",
"[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.5s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.5s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.6s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.6s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.5s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.5s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.3s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.3s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.4s finished\n[Parallel(n_jobs=6)]: Using backend ThreadingBackend with 6 concurrent workers.\n[Parallel(n_jobs=6)]: Done 38 tasks | elapsed: 0.1s\n[Parallel(n_jobs=6)]: Done 188 tasks | elapsed: 0.4s\n[Parallel(n_jobs=6)]: Done 200 out of 200 | elapsed: 0.5s finished\n"
]
],
[
[
"### 8. Try improving your model further. Here are a few ideas:\n* try other machine learning algorithms\n* add other features besides the TF-IDF",
"_____no_output_____"
]
],
[
[
"from sklearn.base import BaseEstimator, TransformerMixin\n\nclass PosCounter(BaseEstimator, TransformerMixin):\n \n def pos_tagger(self, text):\n tokenized = tokenize(text)\n\n tagged = nltk.pos_tag(tokenized)\n\n part_of_speech_list = []\n\n for word_tag_pair in tagged:\n tag = word_tag_pair[1]\n if tag[0] == \"V\":\n part_of_speech_list.append(\"verb\")\n elif tag[0] == \"N\":\n part_of_speech_list.append(\"noun\")\n elif tag[0] == \"J\":\n part_of_speech_list.append(\"adjective\")\n\n return part_of_speech_list\n \n def count_pos(self, l, pos):\n return l.count(pos)\n \n def fit(self, X, y=None):\n return self\n \n def transform(self, X):\n X = pd.DataFrame(X.apply(self.pos_tagger))\n \n for pos in (\"verb\", \"noun\", \"adjective\"):\n X[pos] = X[\"message\"].apply(lambda l: self.count_pos(l, pos))\n\n del X['message']\n \n return X",
"_____no_output_____"
],
[
"pc = PosCounter()\npc.transform(X)",
"_____no_output_____"
],
[
"pipeline = Pipeline([\n (\"features\", FeatureUnion([\n (\"nlp_pipeline\", Pipeline([\n (\"c_vect\", CountVectorizer(tokenizer=tokenize, ngram_range=(1, 2), max_df=0.95)),\n (\"tfidf\", TfidfTransformer(use_idf=True, smooth_idf=True)),\n ])),\n\n (\"pos_counter\", PosCounter()),\n ])),\n (\"clf\", MultiOutputClassifier(LinearSVC(verbose=2, max_iter=100000))),\n])",
"_____no_output_____"
],
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \n\npipeline.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42) \n\nY_pred = pipeline.predict(X_test)\nshow_scores(Y_pred)",
"_____no_output_____"
]
],
[
[
"### 9. Export your model as a pickle file",
"_____no_output_____"
],
[
"### 10. Use this notebook to complete `train.py`\nUse the template file attached in the Resources folder to write a script that runs the steps above to create a database and export a model based on a new dataset specified by the user.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4ad3b7562e714bbe798e2fb09ab1b2e4ceed00ab
| 267,483 |
ipynb
|
Jupyter Notebook
|
archive/2020-21_semester1/2020-10-onwards Colab/HappinessReport.ipynb
|
gabrielecalvo/Language4Water
|
45a0e72926d60e70a1e55d669792ddaf6c310d80
|
[
"MIT"
] | 2 |
2020-01-19T20:47:59.000Z
|
2022-03-28T11:59:28.000Z
|
archive/2020-21_semester1/2020-10-onwards Colab/HappinessReport.ipynb
|
gabrielecalvo/Language4Water
|
45a0e72926d60e70a1e55d669792ddaf6c310d80
|
[
"MIT"
] | null | null | null |
archive/2020-21_semester1/2020-10-onwards Colab/HappinessReport.ipynb
|
gabrielecalvo/Language4Water
|
45a0e72926d60e70a1e55d669792ddaf6c310d80
|
[
"MIT"
] | 1 |
2020-01-19T20:59:58.000Z
|
2020-01-19T20:59:58.000Z
| 267,483 | 267,483 | 0.866051 |
[
[
[
"# Dowloading data\nWe'll use a shell command to download the zipped data, unzip it into are working directory (folder).",
"_____no_output_____"
]
],
[
[
"!wget \"https://docs.google.com/uc?export=download&id=1h3YjfecYS8vJ4yXKE3oBwg3Am64kN4-x\" -O temp.zip && unzip -o temp.zip && rm temp.zip",
"--2020-10-25 09:30:20-- https://docs.google.com/uc?export=download&id=1h3YjfecYS8vJ4yXKE3oBwg3Am64kN4-x\nResolving docs.google.com (docs.google.com)... 64.233.189.113, 64.233.189.139, 64.233.189.102, ...\nConnecting to docs.google.com (docs.google.com)|64.233.189.113|:443... connected.\nHTTP request sent, awaiting response... 302 Moved Temporarily\nLocation: https://doc-0g-70-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/e3jqdbq6atsag8b761gsqnoevc5g576q/1603618200000/05823673623161676158/*/1h3YjfecYS8vJ4yXKE3oBwg3Am64kN4-x?e=download [following]\nWarning: wildcards not supported in HTTP.\n--2020-10-25 09:30:21-- https://doc-0g-70-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/e3jqdbq6atsag8b761gsqnoevc5g576q/1603618200000/05823673623161676158/*/1h3YjfecYS8vJ4yXKE3oBwg3Am64kN4-x?e=download\nResolving doc-0g-70-docs.googleusercontent.com (doc-0g-70-docs.googleusercontent.com)... 64.233.188.132, 2404:6800:4008:c06::84\nConnecting to doc-0g-70-docs.googleusercontent.com (doc-0g-70-docs.googleusercontent.com)|64.233.188.132|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 37002 (36K) [application/zip]\nSaving to: ‘temp.zip’\n\ntemp.zip 100%[===================>] 36.13K --.-KB/s in 0s \n\n2020-10-25 09:30:21 (107 MB/s) - ‘temp.zip’ saved [37002/37002]\n\nArchive: temp.zip\n creating: happiness_report/\n inflating: happiness_report/2015.csv \n inflating: happiness_report/2016.csv \n inflating: happiness_report/2017.csv \n inflating: happiness_report/2018.csv \n inflating: happiness_report/2019.csv \n"
]
],
[
[
"# Importing and Cleaning the Data",
"_____no_output_____"
]
],
[
[
"import pandas as pd # aliasing for convenience",
"_____no_output_____"
]
],
[
[
"## Importing data one file at a time",
"_____no_output_____"
],
[
"### Importing 2015 data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('happiness_report/2015.csv') # loading the data to a variable called \"df\"\ndf.head(3) # looking at the first 3 rows\ndf.tail(2) # looking at the last 2 rows",
"_____no_output_____"
]
],
[
[
"#### adding a year column\nTo add a column we can use the syntax:\n\n`df['new_col_name'] = values`\n\n**note**: if there was a column with the same name, it would be overwritten\n",
"_____no_output_____"
]
],
[
[
"df['year'] = 2015 # adding a column \ndf",
"_____no_output_____"
]
],
[
[
"### Importing 2016 data",
"_____no_output_____"
]
],
[
[
"df_2016 = pd.read_csv('happiness_report/2016.csv')\ndf_2016['year'] = 2016",
"_____no_output_____"
]
],
[
[
"### merging (stacking vertically) the two dataframes\n\n**note** if a column exists in one dataframe but not in the other, the values for the latter will be set to NaN (empty value)",
"_____no_output_____"
]
],
[
[
"list_of_df_to_merge = [df, df_2016]\ndf_merged = pd.concat(list_of_df_to_merge)\n\ndf_merged",
"_____no_output_____"
]
],
[
[
"## Interaction with the filesystem",
"_____no_output_____"
]
],
[
[
"# python library for OperatingSystem interaction\nimport os \n\n# list of files under the speficied folder\nos.listdir('happiness_report') ",
"_____no_output_____"
],
[
"# getting the full path given the folder and file\nos.path.join('happiness_report','2019.csv') ",
"_____no_output_____"
]
],
[
[
"## Loading and combining data from all files\n\nWe will:\n- initialise an empty list of dataframes\n- loop over the content of the `happiness_report` folder\n - get the filepath from the filename and folder name\n - load the data from the filepath\n - add a column to the dataframe so we can keep track of which file the data belongs to\n - add the dataframe to the list\n- merge all the dataframes (vertically)",
"_____no_output_____"
]
],
[
[
"fld_name = 'happiness_report'\ndf_list = []\nfor filename in os.listdir(fld_name):\n filepath = os.path.join(fld_name, filename)\n df = pd.read_csv(filepath)\n \n print(filename, ':', df.columns) # printing the column name for the file\n df['filename'] = filename\n df_list.append(df)\n\ndf_merged = pd.concat(df_list)",
"2018.csv : Index(['Overall rank', 'Country or region', 'Score', 'GDP per capita',\n 'Social support', 'Healthy life expectancy',\n 'Freedom to make life choices', 'Generosity',\n 'Perceptions of corruption'],\n dtype='object')\n2015.csv : Index(['Country', 'Region', 'Happiness Rank', 'Happiness Score',\n 'Standard Error', 'Economy (GDP per Capita)', 'Family',\n 'Health (Life Expectancy)', 'Freedom', 'Trust (Government Corruption)',\n 'Generosity', 'Dystopia Residual'],\n dtype='object')\n2017.csv : Index(['Country', 'Happiness.Rank', 'Happiness.Score', 'Whisker.high',\n 'Whisker.low', 'Economy..GDP.per.Capita.', 'Family',\n 'Health..Life.Expectancy.', 'Freedom', 'Generosity',\n 'Trust..Government.Corruption.', 'Dystopia.Residual'],\n dtype='object')\n2019.csv : Index(['Overall rank', 'Country or region', 'Score', 'GDP per capita',\n 'Social support', 'Healthy life expectancy',\n 'Freedom to make life choices', 'Generosity',\n 'Perceptions of corruption'],\n dtype='object')\n2016.csv : Index(['Country', 'Region', 'Happiness Rank', 'Happiness Score',\n 'Lower Confidence Interval', 'Upper Confidence Interval',\n 'Economy (GDP per Capita)', 'Family', 'Health (Life Expectancy)',\n 'Freedom', 'Trust (Government Corruption)', 'Generosity',\n 'Dystopia Residual'],\n dtype='object')\n"
]
],
[
[
"## Data cleaning\nBecause of inconsistency over the years of reporting, we need to do some data cleaning:\n- we want a `year` column which we can get from the filename\n- there are different naming for the Happiness score over the years: `Happiness Score`, `Happiness.Score`, `Score`. We want to unify them into one column.\n- the country column has the same issue: `Country`, `Country or region`",
"_____no_output_____"
]
],
[
[
"# `filename` column is a text (string) column, so we can use string methods to edit it\ncolumn_of_string_pairs = df_merged['filename'].str.split('.') # '2015.csv' is now ['2015', 'csv']\n\n# selecting only the fist element for each list\ncolumn_year_string = column_of_string_pairs.str[0] # ['2015', 'csv'] is now '2015'\n\n# converting the string to an integer (number)\ncolumn_of_years = (column_year_string).astype(int) # '2015' (string) is now 2015 (number)\n\ndf_merged['year'] = column_of_years",
"_____no_output_____"
]
],
[
[
"To fix the issue of change in naming, we can use:\n\n`colA.fillna(colB)`\n\nwhich checks if there are any empty valus in `colA` and fills them with the values in `colB` for the same row.\n",
"_____no_output_____"
]
],
[
[
"# checks if there are any empty valus in colA and fills them with the values in colB for the same row\ndf_merged['Happiness Score'] = df_merged['Happiness Score'].fillna(df_merged['Happiness.Score']).fillna(df_merged['Score'])\ndf_merged['Country'] = df_merged['Country or region'].fillna(df_merged['Country'])",
"_____no_output_____"
]
],
[
[
"## Data Reshaping and Plotting",
"_____no_output_____"
],
[
"### Trends of Happiness and Generosity over the years\nWe'll:\n- select only the columns we care about\n- group the data by `year` and take the mean\n- plot the Happiness and Generosity (in separate plots)",
"_____no_output_____"
]
],
[
[
"df_subset = df_merged[['year', 'Happiness Score', 'Generosity']]\nmean_by_year = df_subset.groupby('year').mean()\nmean_by_year",
"_____no_output_____"
],
[
"mean_by_year.plot(subplots=True, grid=True)\n# `subplots=True` will plot the two columns in two separate charts\n# `grid=True` will add the axis grid in the background",
"_____no_output_____"
]
],
[
[
"### Average Generosity and Happiness by year AND Country\nWe'll:\n- select only the columns we care about\n- group the data by `Country` and `year`\n- take the mean ",
"_____no_output_____"
]
],
[
[
"df = df_merged[['year', 'Happiness Score', 'Generosity', 'Country']]\nmean_by_country_and_year = df.groupby(['Country', 'year']).mean()\nmean_by_country_and_year",
"_____no_output_____"
]
],
[
[
"#### Finding the countries and years with highest and lowest Happiness",
"_____no_output_____"
]
],
[
[
"mean_by_country_and_year['Happiness Score'].idxmax() # highest",
"_____no_output_____"
],
[
"mean_by_country_and_year['Happiness Score'].idxmin() # lowest",
"_____no_output_____"
]
],
[
[
"#### Happiness by Country and Year",
"_____no_output_____"
]
],
[
[
"happiness_column = mean_by_country_and_year['Happiness Score'] \n\n# turning the single column with 2d-index into a table by moving the inner index to columns\nhappiness_table = happiness_column.unstack()\nhappiness_table",
"_____no_output_____"
],
[
"# for each year, plotting the values in each country\nhappiness_table.plot(figsize=(20,5),grid=True)",
"_____no_output_____"
]
],
[
[
"# (FYI) Interactive Chart\nYou can also create interactive charts by using a different library (bokeh).\n\nfor more examples: https://colab.research.google.com/notebooks/charts.ipynb",
"_____no_output_____"
]
],
[
[
"uk_happiness = happiness_column['United Kingdom']",
"_____no_output_____"
],
[
"from bokeh.plotting import figure, output_notebook, show\noutput_notebook()",
"_____no_output_____"
],
[
"x = uk_happiness.index\ny = uk_happiness.values\nfig = figure(title=\"UK Happiness\", x_axis_label='x', y_axis_label='y')\nfig.line(x, y, legend_label=\"UK\", line_width=2)\nshow(fig)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ad3ca1ca3a023a34f3a343b5ead98154142249b
| 468,402 |
ipynb
|
Jupyter Notebook
|
models/lol-prediction.ipynb
|
bcnishi/lol-worlds-2020
|
3449c286762146e8eb661b7005ccac6c1185212f
|
[
"MIT"
] | null | null | null |
models/lol-prediction.ipynb
|
bcnishi/lol-worlds-2020
|
3449c286762146e8eb661b7005ccac6c1185212f
|
[
"MIT"
] | null | null | null |
models/lol-prediction.ipynb
|
bcnishi/lol-worlds-2020
|
3449c286762146e8eb661b7005ccac6c1185212f
|
[
"MIT"
] | null | null | null | 79.877558 | 279,132 | 0.68875 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom sklearn.preprocessing import LabelEncoder, MinMaxScaler\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import accuracy_score, confusion_matrix, classification_report\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom imblearn.over_sampling import SMOTE",
"_____no_output_____"
],
[
"lcs_teams = pd.read_csv('../datasets/summer-playoffs/lcs/LCS 2020 Summer Playoffs - Team Stats - OraclesElixir.csv')\nlck_teams = pd.read_csv('../datasets/summer-playoffs/lck/LCK 2020 Summer Playoffs - Team Stats - OraclesElixir.csv')\nlec_teams = pd.read_csv('../datasets/summer-playoffs/lec/LEC 2020 Summer Playoffs - Team Stats - OraclesElixir.csv')\nlpl_teams = pd.read_csv('../datasets/summer-playoffs/lpl/LPL 2020 Summer Playoffs - Team Stats - OraclesElixir.csv')",
"_____no_output_____"
],
[
"summer_teams = pd.concat([lcs_teams,lck_teams,lec_teams,lpl_teams], axis=0, ignore_index=True)\nsummer_teams",
"_____no_output_____"
],
[
"#checking missing values\nsummer_teams.isnull().sum()",
"_____no_output_____"
],
[
"#Replacing missing values with '0%'\nsummer_teams.fillna('0%', inplace=True)",
"_____no_output_____"
],
[
"#split the dataframe by categorical and numerical variables\nst_cat = summer_teams.select_dtypes(object)\nst_num = summer_teams.select_dtypes(np.number)\nprint(st_num.head())\nprint(st_cat.head())",
" GP W L AGT K D KD CKPM GPR EGR MLR GD15 WPM CWPM \\\n0 3 0 3 34.7 22 60 0.37 0.79 -1.58 31.4 -31.4 -1798 3.34 1.29 \n1 11 5 6 34.1 159 155 1.03 0.84 -0.37 41.6 3.8 -297 3.21 1.18 \n2 3 0 3 31.5 20 43 0.47 0.67 -1.41 22.1 -22.1 -1832 2.63 1.18 \n3 11 5 6 34.3 138 157 0.88 0.78 -0.01 44.8 0.6 -497 3.35 1.35 \n4 17 10 7 36.0 212 193 1.10 0.66 -0.01 55.8 3.0 365 3.11 1.11 \n\n WCPM \n0 1.31 \n1 1.21 \n2 1.23 \n3 1.40 \n4 1.66 \n Team GSPD FB% FT% F3T% HLD% FD% DRG% ELD% FBN% BN% LNE% \\\n0 100 Thieves -7.0% 67% 33% 0% 50% 67% 46% 50% 0% 25% 49.2% \n1 Cloud9 0.2% 36% 45% 36% 45% 45% 39% 0% 36% 39% 50.2% \n2 Dignitas -11.4% 33% 67% 0% 33% 0% 46% 0% 0% 0% 50.0% \n3 Evil Geniuses -4.0% 45% 36% 64% 45% 55% 47% 67% 45% 50% 49.3% \n4 FlyQuest 1.9% 59% 47% 47% 56% 53% 60% 40% 71% 64% 50.4% \n\n JNG% \n0 44.4% \n1 49.5% \n2 46.6% \n3 51.9% \n4 49.7% \n"
],
[
"winners_teams = ['Team SoloMid','G2 Esports','Gen.G','LGD Gaming'] #winners from respective region",
"_____no_output_____"
],
[
"winners = lambda x: 1 if x in winners_teams else 0",
"_____no_output_____"
],
[
"st_cat['WINNER'] = st_cat['Team'].apply(winners) #create label\nst_cat",
"C:\\Users\\Beatriz\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"st_cat = st_cat.drop('Team', axis=1)",
"_____no_output_____"
],
[
"st_cat",
"_____no_output_____"
],
[
"y = st_cat['WINNER'] #the label we want to predict",
"_____no_output_____"
],
[
"st_cat = st_cat.drop('WINNER', axis=1)",
"_____no_output_____"
],
[
"#remove '%' symbol\ndef transform_percent(df):\n for c in range(len(df.columns)):\n for l in range(df.shape[0]):\n df.iloc[:,c][l] = df.iloc[:,c][l][:-1] \n return df ",
"_____no_output_____"
],
[
"transform_percent(st_cat)\nst_cat",
"_____no_output_____"
],
[
"#transform str features into float\nst_cat = st_cat.astype('float64') ",
"_____no_output_____"
],
[
"st_f = pd.concat([st_cat,st_num],axis=1)\nst_f",
"_____no_output_____"
],
[
"st_f = st_f.drop(['GP','W','L','K','D'], axis=1)",
"_____no_output_____"
],
[
"st_f",
"_____no_output_____"
],
[
"#plotting correlation\nplt.subplots(figsize=(15,10))\nsns.heatmap(st_f.corr(),annot = True,cmap='coolwarm');",
"_____no_output_____"
],
[
"#droping high correlated features\nst_f = st_f.drop(['EGR','GD15'], axis=1)",
"_____no_output_____"
],
[
"X = st_f",
"_____no_output_____"
],
[
"smt = SMOTE(k_neighbors=3)",
"_____no_output_____"
],
[
"X, y = smt.fit_sample(X, y)",
"_____no_output_____"
],
[
"X_train, X_val, y_train ,y_val = train_test_split(X, y, test_size = 0.2, random_state = 42)\nX_train.head()",
"_____no_output_____"
],
[
"print(X_train.shape)\nprint(X_val.shape)\nprint(y_train.shape)\nprint(y_val.shape)",
"(36, 20)\n(10, 20)\n(36,)\n(10,)\n"
],
[
"scaler = MinMaxScaler()\nX_train = scaler.fit_transform(X_train)\nX_val = scaler.fit_transform(X_val)",
"_____no_output_____"
],
[
"LR = LogisticRegression()\nDT = DecisionTreeClassifier(random_state=42) \nRF = RandomForestClassifier(n_estimators=100, random_state=42)",
"_____no_output_____"
],
[
"LR_fit = LR.fit(X_train, y_train)\nDT_fit = DT.fit(X_train, y_train)\nRF_fit = RF.fit(X_train, y_train)",
"_____no_output_____"
],
[
"LR_pred = LR_fit.predict(X_val)\nDT_pred = DT_fit.predict(X_val)\nRF_pred = RF_fit.predict(X_val)",
"_____no_output_____"
],
[
"print(\"Logistic Regression accuracy: %f \" % (accuracy_score(LR_pred, y_val)*100))\nprint(\"Decision Tree accuracy: %f \" % (accuracy_score(DT_pred, y_val)*100))\nprint(\"Random Forest accuracy: %f \" % (accuracy_score(RF_pred, y_val)*100))",
"Logistic Regression accuracy: 70.000000 \nDecision Tree accuracy: 60.000000 \nRandom Forest accuracy: 90.000000 \n"
],
[
"print(classification_report(RF_pred, y_val))",
" precision recall f1-score support\n\n 0 0.83 1.00 0.91 5\n 1 1.00 0.80 0.89 5\n\n accuracy 0.90 10\n macro avg 0.92 0.90 0.90 10\nweighted avg 0.92 0.90 0.90 10\n\n"
],
[
"worlds_teams = pd.read_csv('datasets/worlds/Worlds 2020 Play-In - Team Stats - OraclesElixir.csv')\nworlds_teams",
"_____no_output_____"
],
[
"wt = worlds_teams.drop(['Team','GP','W','L','K','D','EGR','GD15'], axis=1)",
"_____no_output_____"
],
[
"wt.isnull().sum()",
"_____no_output_____"
],
[
"wt.fillna('0%', inplace=True)",
"_____no_output_____"
],
[
"wt_cat = wt.select_dtypes(object)\nwt_num = wt.select_dtypes(np.number)",
"_____no_output_____"
],
[
"wt_cat",
"_____no_output_____"
],
[
"transform_percent(wt_cat)",
"_____no_output_____"
],
[
"wt_cat = wt_cat.astype('float64') ",
"_____no_output_____"
],
[
"wt_f = pd.concat([wt_cat,wt_num],axis=1)\nwt_f",
"_____no_output_____"
],
[
"X_test = scaler.fit_transform(wt_f)",
"_____no_output_____"
],
[
"RF_predw = RF_fit.predict(X_test)",
"_____no_output_____"
],
[
"pred = pd.concat([worlds_teams['Team'],pd.DataFrame(RF_predw)],axis=1)\npred",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad3dafe739d0f3c6c59060a780c7671bd9de6b5
| 232,720 |
ipynb
|
Jupyter Notebook
|
overview_val10/overview_junk/overview_11869-svm.ipynb
|
vevurka/mt-lob
|
70989bcb61f4cfa7884437e1cff2db2454b3ceff
|
[
"MIT"
] | 2 |
2019-04-17T02:19:22.000Z
|
2019-05-23T12:14:59.000Z
|
overview_val10/overview_junk/overview_11869-svm.ipynb
|
vevurka/mt-lob
|
70989bcb61f4cfa7884437e1cff2db2454b3ceff
|
[
"MIT"
] | 10 |
2020-01-28T22:32:13.000Z
|
2021-09-08T00:41:37.000Z
|
overview_val10/overview_junk/overview_11869-svm.ipynb
|
vevurka/mt-lob
|
70989bcb61f4cfa7884437e1cff2db2454b3ceff
|
[
"MIT"
] | 6 |
2018-12-05T22:17:05.000Z
|
2020-09-03T03:00:50.000Z
| 233.186373 | 33,000 | 0.88875 |
[
[
[
"%load_ext autoreload\n\n%autoreload 2\n%matplotlib inline\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn.cluster import KMeans\nfrom sklearn.svm import SVC\nfrom sklearn.metrics import roc_auc_score, roc_curve\n\nfrom mlxtend.plotting import plot_decision_regions\n\nfrom sklearn import preprocessing\nfrom sklearn.linear_model import LogisticRegression\n\nimport warnings\nimport numpy as np\nfrom collections import OrderedDict\n\nfrom lob_data_utils import lob, db_result, overview\nfrom lob_data_utils.svm_calculation import lob_svm\n\nsns.set_style('whitegrid')\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"data_length = 10000\nstock = '11869'",
"_____no_output_____"
],
[
"df, df_cv, df_test = lob.load_prepared_data(\n stock, data_dir='../queue_imbalance/data/prepared', cv=True, length=data_length)",
"_____no_output_____"
]
],
[
[
"## Logistic",
"_____no_output_____"
]
],
[
[
"log_clf = lob.logistic_regression(df, 0, len(df))\npred_train = log_clf.predict(df['queue_imbalance'].values.reshape(-1, 1))\npred_test = log_clf.predict(df_test['queue_imbalance'].values.reshape(-1, 1))\ndf['pred_log'] = pred_train\ndf_test['pred_log'] = pred_test\nlob.plot_roc(df, log_clf, stock=int(stock), label='train')\nlob.plot_roc(df_test, log_clf, stock=int(stock), label='test')",
"_____no_output_____"
],
[
"plt.figure(figsize=(16,2))\nplt.scatter(df['queue_imbalance'], np.zeros(len(df)), c=df['mid_price_indicator'])\nprint(len(df[df['mid_price_indicator'] ==1]), len(df))",
"3054 6000\n"
],
[
"lob.plot_learning_curve(log_clf, df['queue_imbalance'].values.reshape(-1, 1), df['mid_price_indicator'])",
"_____no_output_____"
]
],
[
[
"### Let's look inside",
"_____no_output_____"
]
],
[
[
"df_test[df_test['pred_log'] != df_test['mid_price_indicator']][['pred_log', 'mid_price_indicator']].plot(kind='kde')",
"_____no_output_____"
],
[
"print(len(df_test[df_test['pred_log'] != df_test['mid_price_indicator']]), len(df_test))\ndf_test[df_test['pred_log'] != df_test['mid_price_indicator']][['pred_log', 'mid_price_indicator', 'queue_imbalance']].head()",
"856 2000\n"
],
[
"pivot = min(df[df['pred_log'] == 1]['queue_imbalance'])\npivot",
"_____no_output_____"
],
[
"print('Amount of positive samples below the pivot and negative above the pivot for training data:')\nprint(len(df[df['queue_imbalance'] < pivot][df['pred_log'] == 1]), \n len(df[df['queue_imbalance'] >= pivot][df['pred_log'] == 0]))\n\nprint('Amount of positive samples below the pivot and negative above the pivot for testing data:')\nprint(len(df_test[df_test['queue_imbalance'] < pivot][df_test['pred_log'] == 1]), \n len(df_test[df_test['queue_imbalance'] >= pivot][df_test['pred_log'] == 0]))",
"Amount of positive samples below the pivot and negative above the pivot for training data:\n0 0\nAmount of positive samples below the pivot and negative above the pivot for testing data:\n0 0\n"
]
],
[
[
"So this classifier just finds a pivot. But why this particular one is choosen? Let's check what amount of data is below and above the pivot.",
"_____no_output_____"
]
],
[
[
"len(df[df['queue_imbalance'] < pivot]), len(df[df['queue_imbalance'] >= pivot])",
"_____no_output_____"
],
[
"df[df['queue_imbalance'] < pivot]['queue_imbalance'].plot(kind='kde')\ndf[df['queue_imbalance'] >= pivot]['queue_imbalance'].plot(kind='kde')\ndf['queue_imbalance'].plot(kind='kde')",
"_____no_output_____"
]
],
[
[
"## SVM",
"_____no_output_____"
]
],
[
[
"overview_data = overview.Overview(stock, data_length)\n\ngammas = [0.0005, 0.005, 1, 5, 50, 500, 5000]\ncs = [0.0005, 0.005, 1, 5.0, 50, 500, 1000]\ncoef0s = [0, 0.0005, 0.005, 1, 5, 50, 500, 5000]\n\ndf_svm_res = overview_data.write_svm_results(df, df_cv, gammas=gammas, cs=cs, coef0s=coef0s)\nunnamed_columns = [c for c in df_svm_res.columns if 'Unnamed' in c]\ndf_svm_res.drop(columns=unnamed_columns, inplace=True)\ndf_svm_res.sort_values(by='roc_cv_score').head()",
"Results read from file\n"
],
[
"df_svm_res[df_svm_res['svm'] == 'linear'].sort_values(by='roc_cv_score', ascending=False).head()",
"_____no_output_____"
],
[
"df_svm_res.sort_values(by='roc_cv_score', ascending=False).head()",
"_____no_output_____"
]
],
[
[
"## Different kernels visualization",
"_____no_output_____"
]
],
[
[
"X = df[['queue_imbalance']].values\ny = df['mid_price_indicator'].values.astype(np.integer)\n\nclf = SVC(kernel='sigmoid', C=0.005, gamma=500, coef0=5.0)\nclf.fit(df[['queue_imbalance']], df['mid_price_indicator'])\n\ndf['pred'] = clf.predict(df[['queue_imbalance']])\nplt.figure(figsize=(16,2))\nplot_decision_regions(X, y, clf=clf, legend='data')\nplt.xlabel('')\nplt.xlim(-1, 1)\nplt.title('Sigmoid Kernel')\nplt.legend()\nmin(df[df['pred'] == 1]['queue_imbalance']), max(df[df['pred'] == 0]['queue_imbalance']), clf.score(X, y)",
"_____no_output_____"
],
[
"X = df[['queue_imbalance']].values\ny = df['mid_price_indicator'].values.astype(np.integer)\n\nclf = SVC(kernel='rbf', C=0.005, gamma=50)\nclf.fit(df[['queue_imbalance']], df['mid_price_indicator'])\ndf['pred'] = clf.predict(df[['queue_imbalance']])\nplt.figure(figsize=(16,2))\nplot_decision_regions(X, y, clf=clf, legend='data')\nplt.xlim(-1, 1)\nplt.xlabel('')\nplt.title('Rbf')\nplt.legend()\nmin(df[df['pred'] == 1]['queue_imbalance']), max(df[df['pred'] == 0]['queue_imbalance']), clf.score(X, y)",
"_____no_output_____"
],
[
"X = df[['queue_imbalance']].values\ny = df['mid_price_indicator'].values.astype(np.integer)\n\nclf = SVC(kernel='linear', C=0.005)\nclf.fit(df[['queue_imbalance']], df['mid_price_indicator'])\ndf['pred'] = clf.predict(df[['queue_imbalance']])\nplt.figure(figsize=(16,2))\nplot_decision_regions(X, y, clf=clf, legend='data')\nplt.xlabel('')\nplt.xlim(-1, 1)\nplt.title('Linear')\nplt.legend()\nmin(df[df['pred'] == 1]['queue_imbalance']), max(df[df['pred'] == 0]['queue_imbalance']), clf.score(X, y)",
"_____no_output_____"
],
[
"## Some plotly visualizations",
"_____no_output_____"
],
[
"import plotly.offline as py\nimport plotly.figure_factory as ff\nimport plotly.graph_objs as go\n\nfrom plotly import tools\nfrom itertools import product\npy.init_notebook_mode(connected=True)\n\ntitles=['s']\n\nclf1 = SVC(kernel='rbf')\nclf1.fit(X, y)\nfig = tools.make_subplots(rows=1, cols=1,\n print_grid=False,\n subplot_titles=titles)\n\nx_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1\ny_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1\nxx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),\n np.arange(y_min, y_max, 0.1))\ny_ = np.arange(y_min, y_max, 0.1)\n\nZ = clf.predict(np.c_[xx.ravel(), yy.ravel()])\nZ = Z.reshape(xx.shape)\n\ntrace1 = go.Contour(x=xx[0], y=y_, \n z=Z,\n colorscale=[[0, 'purple'],\n [0.5, 'cyan'],\n [1, 'pink']],\n opacity=0.5,\n showscale=False)\ntrace2 = go.Scatter(x=X[:, 0], y=X[:, 1], \n showlegend=False,\n mode='markers',\n marker=dict(\n color=y,\n line=dict(color='black', width=1)))\n\nfig.append_trace(trace1, 1, 1)\nfig.append_trace(trace2, 1, 1)\n \nfig['layout'].update(hovermode='closest')\n\nfig['layout'][x].update(showgrid=False, zeroline=False)\n#fig['layout'][y].update(showgrid=False, zeroline=False)\n\npy.iplot(fig)",
"_____no_output_____"
],
[
"py.init_notebook_mode(connected=True)\n\nfrom ipywidgets import interact, interactive, fixed, interact_manual, widgets\n\n@interact(C=[1,2,3], gamma=[1,2,3], coef0=[1,2,3])\ndef _plot_lob(C, gamma, coef0):\n py_config = {'displayModeBar': False, 'showLink': False, 'editable': False}\n\n titles=['s']\n\n clf1 = SVC(kernel='rbf', C=C, gamma=gamma)\n clf1.fit(X, y)\n fig = tools.make_subplots(rows=1, cols=1,\n print_grid=False,\n subplot_titles=titles)\n\n x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1\n y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1\n xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),\n np.arange(y_min, y_max, 0.1))\n y_ = np.arange(y_min, y_max, 0.1)\n\n Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])\n Z = Z.reshape(xx.shape)\n\n trace1 = go.Contour(x=xx[0], y=y_, \n z=Z,\n colorscale=[[0, 'purple'],\n [0.5, 'cyan'],\n [1, 'pink']],\n opacity=0.5,\n showscale=False)\n trace2 = go.Scatter(x=X[:, 0], y=X[:, 1], \n showlegend=False,\n mode='markers',\n marker=dict(\n color=y,\n line=dict(color='black', width=1)))\n\n fig.append_trace(trace1, 1, 1)\n fig.append_trace(trace2, 1, 1)\n\n fig['layout'].update(hovermode='closest')\n\n fig['layout'][x].update(showgrid=False, zeroline=False)\n #fig['layout'][y].update(showgrid=False, zeroline=False)\n\n py.iplot(fig)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad3fa672e1ad0745db50f1817b1464abd8e7c79
| 217,547 |
ipynb
|
Jupyter Notebook
|
TensorFlowTutorial.ipynb
|
MBadriNarayanan/DeepLearningSpecializationCoursera
|
bbc3f96f229ab0716ffc2f5013fd35b5e33df9e1
|
[
"MIT"
] | null | null | null |
TensorFlowTutorial.ipynb
|
MBadriNarayanan/DeepLearningSpecializationCoursera
|
bbc3f96f229ab0716ffc2f5013fd35b5e33df9e1
|
[
"MIT"
] | null | null | null |
TensorFlowTutorial.ipynb
|
MBadriNarayanan/DeepLearningSpecializationCoursera
|
bbc3f96f229ab0716ffc2f5013fd35b5e33df9e1
|
[
"MIT"
] | 1 |
2021-01-19T18:44:23.000Z
|
2021-01-19T18:44:23.000Z
| 112.543714 | 118,292 | 0.830455 |
[
[
[
"# TensorFlow Tutorial\n\nWelcome to this week's programming assignment. Until now, you've always used numpy to build neural networks. Now we will step you through a deep learning framework that will allow you to build neural networks more easily. Machine learning frameworks like TensorFlow, PaddlePaddle, Torch, Caffe, Keras, and many others can speed up your machine learning development significantly. All of these frameworks also have a lot of documentation, which you should feel free to read. In this assignment, you will learn to do the following in TensorFlow: \n\n- Initialize variables\n- Start your own session\n- Train algorithms \n- Implement a Neural Network\n\nPrograming frameworks can not only shorten your coding time, but sometimes also perform optimizations that speed up your code. ",
"_____no_output_____"
],
[
"## <font color='darkblue'>Updates</font>\n\n#### If you were working on the notebook before this update...\n* The current notebook is version \"v3b\".\n* You can find your original work saved in the notebook with the previous version name (it may be either TensorFlow Tutorial version 3\" or \"TensorFlow Tutorial version 3a.) \n* To view the file directory, click on the \"Coursera\" icon in the top left of this notebook.\n\n#### List of updates\n* forward_propagation instruction now says 'A1' instead of 'a1' in the formula for Z2; \n and are updated to say 'A2' instead of 'Z2' in the formula for Z3.\n* create_placeholders instruction refer to the data type \"tf.float32\" instead of float.\n* in the model function, the x axis of the plot now says \"iterations (per fives)\" instead of iterations(per tens)\n* In the linear_function, comments remind students to create the variables in the order suggested by the starter code. The comments are updated to reflect this order.\n* The test of the cost function now creates the logits without passing them through a sigmoid function (since the cost function will include the sigmoid in the built-in tensorflow function).\n* In the 'model' function, the minibatch_cost is now divided by minibatch_size (instead of num_minibatches).\n* Updated print statements and 'expected output that are used to check functions, for easier visual comparison.\n",
"_____no_output_____"
],
[
"## 1 - Exploring the Tensorflow Library\n\nTo start, you will import the library:",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\nfrom tf_utils import load_dataset, random_mini_batches, convert_to_one_hot, predict\n\n%matplotlib inline\nnp.random.seed(1)",
"_____no_output_____"
]
],
[
[
"Now that you have imported the library, we will walk you through its different applications. You will start with an example, where we compute for you the loss of one training example. \n$$loss = \\mathcal{L}(\\hat{y}, y) = (\\hat y^{(i)} - y^{(i)})^2 \\tag{1}$$",
"_____no_output_____"
]
],
[
[
"y_hat = tf.constant(36, name='y_hat') # Define y_hat constant. Set to 36.\ny = tf.constant(39, name='y') # Define y. Set to 39\n\nloss = tf.Variable((y - y_hat)**2, name='loss') # Create a variable for the loss\n\ninit = tf.global_variables_initializer() # When init is run later (session.run(init)),\n # the loss variable will be initialized and ready to be computed\nwith tf.Session() as session: # Create a session and print the output\n session.run(init) # Initializes the variables\n print(session.run(loss)) # Prints the loss",
"9\n"
]
],
[
[
"Writing and running programs in TensorFlow has the following steps:\n\n1. Create Tensors (variables) that are not yet executed/evaluated. \n2. Write operations between those Tensors.\n3. Initialize your Tensors. \n4. Create a Session. \n5. Run the Session. This will run the operations you'd written above. \n\nTherefore, when we created a variable for the loss, we simply defined the loss as a function of other quantities, but did not evaluate its value. To evaluate it, we had to run `init=tf.global_variables_initializer()`. That initialized the loss variable, and in the last line we were finally able to evaluate the value of `loss` and print its value.\n\nNow let us look at an easy example. Run the cell below:",
"_____no_output_____"
]
],
[
[
"a = tf.constant(2)\nb = tf.constant(10)\nc = tf.multiply(a,b)\nprint(c)",
"Tensor(\"Mul:0\", shape=(), dtype=int32)\n"
]
],
[
[
"As expected, you will not see 20! You got a tensor saying that the result is a tensor that does not have the shape attribute, and is of type \"int32\". All you did was put in the 'computation graph', but you have not run this computation yet. In order to actually multiply the two numbers, you will have to create a session and run it.",
"_____no_output_____"
]
],
[
[
"sess = tf.Session()\nprint(sess.run(c))",
"20\n"
]
],
[
[
"Great! To summarize, **remember to initialize your variables, create a session and run the operations inside the session**. \n\nNext, you'll also have to know about placeholders. A placeholder is an object whose value you can specify only later. \nTo specify values for a placeholder, you can pass in values by using a \"feed dictionary\" (`feed_dict` variable). Below, we created a placeholder for x. This allows us to pass in a number later when we run the session. ",
"_____no_output_____"
]
],
[
[
"# Change the value of x in the feed_dict\n\nx = tf.placeholder(tf.int64, name = 'x')\nprint(sess.run(2 * x, feed_dict = {x: 3}))\nsess.close()",
"6\n"
]
],
[
[
"When you first defined `x` you did not have to specify a value for it. A placeholder is simply a variable that you will assign data to only later, when running the session. We say that you **feed data** to these placeholders when running the session. \n\nHere's what's happening: When you specify the operations needed for a computation, you are telling TensorFlow how to construct a computation graph. The computation graph can have some placeholders whose values you will specify only later. Finally, when you run the session, you are telling TensorFlow to execute the computation graph.",
"_____no_output_____"
],
[
"### 1.1 - Linear function\n\nLets start this programming exercise by computing the following equation: $Y = WX + b$, where $W$ and $X$ are random matrices and b is a random vector. \n\n**Exercise**: Compute $WX + b$ where $W, X$, and $b$ are drawn from a random normal distribution. W is of shape (4, 3), X is (3,1) and b is (4,1). As an example, here is how you would define a constant X that has shape (3,1):\n```python\nX = tf.constant(np.random.randn(3,1), name = \"X\")\n\n```\nYou might find the following functions helpful: \n- tf.matmul(..., ...) to do a matrix multiplication\n- tf.add(..., ...) to do an addition\n- np.random.randn(...) to initialize randomly\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_function\n\ndef linear_function():\n \"\"\"\n Implements a linear function: \n Initializes X to be a random tensor of shape (3,1)\n Initializes W to be a random tensor of shape (4,3)\n Initializes b to be a random tensor of shape (4,1)\n Returns: \n result -- runs the session for Y = WX + b \n \"\"\"\n \n np.random.seed(1)\n \n \"\"\"\n Note, to ensure that the \"random\" numbers generated match the expected results,\n please create the variables in the order given in the starting code below.\n (Do not re-arrange the order).\n \"\"\"\n ### START CODE HERE ### (4 lines of code)\n \n X = np.random.randn(3, 1)\n \n W = np.random.randn(4, 3)\n \n b = np.random.randn(4, 1)\n \n Y = tf.add(tf.matmul(W, X), b)\n \n ### END CODE HERE ### \n \n # Create the session using tf.Session() and run it with sess.run(...) on the variable you want to calculate\n \n ### START CODE HERE ###\n \n sess = tf.Session()\n \n result = sess.run(Y)\n \n ### END CODE HERE ### \n \n # close the session \n sess.close()\n\n return result",
"_____no_output_____"
],
[
"print( \"result = \\n\" + str(linear_function()))",
"result = \n[[-2.15657382]\n [ 2.95891446]\n [-1.08926781]\n [-0.84538042]]\n"
]
],
[
[
"*** Expected Output ***: \n\n```\nresult = \n[[-2.15657382]\n [ 2.95891446]\n [-1.08926781]\n [-0.84538042]]\n```",
"_____no_output_____"
],
[
"### 1.2 - Computing the sigmoid \nGreat! You just implemented a linear function. Tensorflow offers a variety of commonly used neural network functions like `tf.sigmoid` and `tf.softmax`. For this exercise lets compute the sigmoid function of an input. \n\nYou will do this exercise using a placeholder variable `x`. When running the session, you should use the feed dictionary to pass in the input `z`. In this exercise, you will have to (i) create a placeholder `x`, (ii) define the operations needed to compute the sigmoid using `tf.sigmoid`, and then (iii) run the session. \n\n** Exercise **: Implement the sigmoid function below. You should use the following: \n\n- `tf.placeholder(tf.float32, name = \"...\")`\n- `tf.sigmoid(...)`\n- `sess.run(..., feed_dict = {x: z})`\n\n\nNote that there are two typical ways to create and use sessions in tensorflow: \n\n**Method 1:**\n```python\nsess = tf.Session()\n# Run the variables initialization (if needed), run the operations\nresult = sess.run(..., feed_dict = {...})\nsess.close() # Close the session\n```\n**Method 2:**\n```python\nwith tf.Session() as sess: \n # run the variables initialization (if needed), run the operations\n result = sess.run(..., feed_dict = {...})\n # This takes care of closing the session for you :)\n```\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: sigmoid\n\ndef sigmoid(z):\n \"\"\"\n Computes the sigmoid of z\n \n Arguments:\n z -- input value, scalar or vector\n \n Returns: \n results -- the sigmoid of z\n \"\"\"\n \n ### START CODE HERE ### ( approx. 4 lines of code)\n # Create a placeholder for x. Name it 'x'.\n \n x = tf.placeholder(tf.float32,name = 'x')\n\n # compute sigmoid(x)\n \n sigmoid = tf.sigmoid(x)\n\n # Create a session, and run it. Please use the method 2 explained above. \n # You should use a feed_dict to pass z's value to x. \n \n with tf.Session() as sess :\n \n # Run session and call the output \"result\"\n \n result = sess.run(sigmoid, feed_dict = {x: z})\n\n ### END CODE HERE ###\n \n return result",
"_____no_output_____"
],
[
"print (\"sigmoid(0) = \" + str(sigmoid(0)))\nprint (\"sigmoid(12) = \" + str(sigmoid(12)))",
"sigmoid(0) = 0.5\nsigmoid(12) = 0.999994\n"
]
],
[
[
"*** Expected Output ***: \n\n<table> \n<tr> \n<td>\n**sigmoid(0)**\n</td>\n<td>\n0.5\n</td>\n</tr>\n<tr> \n<td>\n**sigmoid(12)**\n</td>\n<td>\n0.999994\n</td>\n</tr> \n\n</table> ",
"_____no_output_____"
],
[
"<font color='blue'>\n**To summarize, you how know how to**:\n1. Create placeholders\n2. Specify the computation graph corresponding to operations you want to compute\n3. Create the session\n4. Run the session, using a feed dictionary if necessary to specify placeholder variables' values. ",
"_____no_output_____"
],
[
"### 1.3 - Computing the Cost\n\nYou can also use a built-in function to compute the cost of your neural network. So instead of needing to write code to compute this as a function of $a^{[2](i)}$ and $y^{(i)}$ for i=1...m: \n$$ J = - \\frac{1}{m} \\sum_{i = 1}^m \\large ( \\small y^{(i)} \\log a^{ [2] (i)} + (1-y^{(i)})\\log (1-a^{ [2] (i)} )\\large )\\small\\tag{2}$$\n\nyou can do it in one line of code in tensorflow!\n\n**Exercise**: Implement the cross entropy loss. The function you will use is: \n\n\n- `tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)`\n\nYour code should input `z`, compute the sigmoid (to get `a`) and then compute the cross entropy cost $J$. All this can be done using one call to `tf.nn.sigmoid_cross_entropy_with_logits`, which computes\n\n$$- \\frac{1}{m} \\sum_{i = 1}^m \\large ( \\small y^{(i)} \\log \\sigma(z^{[2](i)}) + (1-y^{(i)})\\log (1-\\sigma(z^{[2](i)})\\large )\\small\\tag{2}$$\n\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: cost\n\ndef cost(logits, labels):\n \"\"\"\n Computes the cost using the sigmoid cross entropy\n \n Arguments:\n logits -- vector containing z, output of the last linear unit (before the final sigmoid activation)\n labels -- vector of labels y (1 or 0) \n \n Note: What we've been calling \"z\" and \"y\" in this class are respectively called \"logits\" and \"labels\" \n in the TensorFlow documentation. So logits will feed into z, and labels into y. \n \n Returns:\n cost -- runs the session of the cost (formula (2))\n \"\"\"\n \n ### START CODE HERE ### \n \n # Create the placeholders for \"logits\" (z) and \"labels\" (y) (approx. 2 lines)\n \n z = tf.placeholder(tf.float32,name = 'logits')\n \n y = tf.placeholder(tf.float32,name = 'labels')\n \n # Use the loss function (approx. 1 line)\n \n cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=z, labels=y)\n \n # Create a session (approx. 1 line). See method 1 above.\n \n sess = tf.Session()\n \n # Run the session (approx. 1 line).\n \n cost = sess.run(cost, feed_dict={z: logits, y: labels})\n \n # Close the session (approx. 1 line). See method 1 above.\n \n sess.close\n \n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"logits = np.array([0.2,0.4,0.7,0.9])\n\ncost = cost(logits, np.array([0,0,1,1]))\nprint (\"cost = \" + str(cost))",
"cost = [ 0.79813886 0.91301525 0.40318605 0.34115386]\n"
]
],
[
[
"** Expected Output** : \n\n```\ncost = [ 0.79813886 0.91301525 0.40318605 0.34115386]\n```",
"_____no_output_____"
],
[
"### 1.4 - Using One Hot encodings\n\nMany times in deep learning you will have a y vector with numbers ranging from 0 to C-1, where C is the number of classes. If C is for example 4, then you might have the following y vector which you will need to convert as follows:\n\n\n<img src=\"images/onehot.png\" style=\"width:600px;height:150px;\">\n\nThis is called a \"one hot\" encoding, because in the converted representation exactly one element of each column is \"hot\" (meaning set to 1). To do this conversion in numpy, you might have to write a few lines of code. In tensorflow, you can use one line of code: \n\n- tf.one_hot(labels, depth, axis) \n\n**Exercise:** Implement the function below to take one vector of labels and the total number of classes $C$, and return the one hot encoding. Use `tf.one_hot()` to do this. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: one_hot_matrix\n\ndef one_hot_matrix(labels, C):\n \"\"\"\n Creates a matrix where the i-th row corresponds to the ith class number and the jth column\n corresponds to the jth training example. So if example j had a label i. Then entry (i,j) \n will be 1. \n \n Arguments:\n labels -- vector containing the labels \n C -- number of classes, the depth of the one hot dimension\n \n Returns: \n one_hot -- one hot matrix\n \"\"\"\n \n ### START CODE HERE ###\n \n # Create a tf.constant equal to C (depth), name it 'C'. (approx. 1 line)\n \n C = tf.constant(C, name = 'C') \n \n # Use tf.one_hot, be careful with the axis (approx. 1 line)\n \n one_hot_matrix = tf.one_hot(labels,C,axis = 0)\n \n # Create the session (approx. 1 line)\n \n sess = tf.Session()\n \n # Run the session (approx. 1 line)\n \n one_hot = sess.run(one_hot_matrix)\n \n # Close the session (approx. 1 line). See method 1 above.\n \n sess.close()\n \n ### END CODE HERE ###\n \n return one_hot",
"_____no_output_____"
],
[
"labels = np.array([1,2,3,0,2,1])\none_hot = one_hot_matrix(labels, C = 4)\nprint (\"one_hot = \\n\" + str(one_hot))",
"one_hot = \n[[ 0. 0. 0. 1. 0. 0.]\n [ 1. 0. 0. 0. 0. 1.]\n [ 0. 1. 0. 0. 1. 0.]\n [ 0. 0. 1. 0. 0. 0.]]\n"
]
],
[
[
"**Expected Output**: \n\n```\none_hot = \n[[ 0. 0. 0. 1. 0. 0.]\n [ 1. 0. 0. 0. 0. 1.]\n [ 0. 1. 0. 0. 1. 0.]\n [ 0. 0. 1. 0. 0. 0.]]\n```",
"_____no_output_____"
],
[
"### 1.5 - Initialize with zeros and ones\n\nNow you will learn how to initialize a vector of zeros and ones. The function you will be calling is `tf.ones()`. To initialize with zeros you could use tf.zeros() instead. These functions take in a shape and return an array of dimension shape full of zeros and ones respectively. \n\n**Exercise:** Implement the function below to take in a shape and to return an array (of the shape's dimension of ones). \n\n - tf.ones(shape)\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: ones\n\ndef ones(shape):\n \"\"\"\n Creates an array of ones of dimension shape\n \n Arguments:\n shape -- shape of the array you want to create\n \n Returns: \n ones -- array containing only ones\n \"\"\"\n \n ### START CODE HERE ###\n \n # Create \"ones\" tensor using tf.ones(...). (approx. 1 line)\n \n ones = tf.ones(shape)\n \n # Create the session (approx. 1 line)\n \n sess = tf.Session()\n \n # Run the session to compute 'ones' (approx. 1 line)\n \n ones = sess.run(ones)\n \n # Close the session (approx. 1 line). See method 1 above.\n \n sess.close()\n \n ### END CODE HERE ###\n return ones",
"_____no_output_____"
],
[
"print (\"ones = \" + str(ones([3])))",
"ones = [ 1. 1. 1.]\n"
]
],
[
[
"**Expected Output:**\n\n<table> \n <tr> \n <td>\n **ones**\n </td>\n <td>\n [ 1. 1. 1.]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"# 2 - Building your first neural network in tensorflow\n\nIn this part of the assignment you will build a neural network using tensorflow. Remember that there are two parts to implement a tensorflow model:\n\n- Create the computation graph\n- Run the graph\n\nLet's delve into the problem you'd like to solve!\n\n### 2.0 - Problem statement: SIGNS Dataset\n\nOne afternoon, with some friends we decided to teach our computers to decipher sign language. We spent a few hours taking pictures in front of a white wall and came up with the following dataset. It's now your job to build an algorithm that would facilitate communications from a speech-impaired person to someone who doesn't understand sign language.\n\n- **Training set**: 1080 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (180 pictures per number).\n- **Test set**: 120 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (20 pictures per number).\n\nNote that this is a subset of the SIGNS dataset. The complete dataset contains many more signs.\n\nHere are examples for each number, and how an explanation of how we represent the labels. These are the original pictures, before we lowered the image resolutoion to 64 by 64 pixels.\n<img src=\"images/hands.png\" style=\"width:800px;height:350px;\"><caption><center> <u><font color='purple'> **Figure 1**</u><font color='purple'>: SIGNS dataset <br> <font color='black'> </center>\n\n\nRun the following code to load the dataset.",
"_____no_output_____"
]
],
[
[
"# Loading the dataset\nX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()",
"_____no_output_____"
]
],
[
[
"Change the index below and run the cell to visualize some examples in the dataset.",
"_____no_output_____"
]
],
[
[
"# Example of a picture\nindex = 78\nplt.imshow(X_train_orig[index])\nprint (\"y = \" + str(np.squeeze(Y_train_orig[:, index])))",
"y = 5\n"
]
],
[
[
"As usual you flatten the image dataset, then normalize it by dividing by 255. On top of that, you will convert each label to a one-hot vector as shown in Figure 1. Run the cell below to do so.",
"_____no_output_____"
]
],
[
[
"# Flatten the training and test images\nX_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T\nX_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T\n# Normalize image vectors\nX_train = X_train_flatten/255.\nX_test = X_test_flatten/255.\n# Convert training and test labels to one hot matrices\nY_train = convert_to_one_hot(Y_train_orig, 6)\nY_test = convert_to_one_hot(Y_test_orig, 6)\n\nprint (\"number of training examples = \" + str(X_train.shape[1]))\nprint (\"number of test examples = \" + str(X_test.shape[1]))\nprint (\"X_train shape: \" + str(X_train.shape))\nprint (\"Y_train shape: \" + str(Y_train.shape))\nprint (\"X_test shape: \" + str(X_test.shape))\nprint (\"Y_test shape: \" + str(Y_test.shape))",
"number of training examples = 1080\nnumber of test examples = 120\nX_train shape: (12288, 1080)\nY_train shape: (6, 1080)\nX_test shape: (12288, 120)\nY_test shape: (6, 120)\n"
]
],
[
[
"**Note** that 12288 comes from $64 \\times 64 \\times 3$. Each image is square, 64 by 64 pixels, and 3 is for the RGB colors. Please make sure all these shapes make sense to you before continuing.",
"_____no_output_____"
],
[
"**Your goal** is to build an algorithm capable of recognizing a sign with high accuracy. To do so, you are going to build a tensorflow model that is almost the same as one you have previously built in numpy for cat recognition (but now using a softmax output). It is a great occasion to compare your numpy implementation to the tensorflow one. \n\n**The model** is *LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX*. The SIGMOID output layer has been converted to a SOFTMAX. A SOFTMAX layer generalizes SIGMOID to when there are more than two classes. ",
"_____no_output_____"
],
[
"### 2.1 - Create placeholders\n\nYour first task is to create placeholders for `X` and `Y`. This will allow you to later pass your training data in when you run your session. \n\n**Exercise:** Implement the function below to create the placeholders in tensorflow.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: create_placeholders\n\ndef create_placeholders(n_x, n_y):\n \"\"\"\n Creates the placeholders for the tensorflow session.\n \n Arguments:\n n_x -- scalar, size of an image vector (num_px * num_px = 64 * 64 * 3 = 12288)\n n_y -- scalar, number of classes (from 0 to 5, so -> 6)\n \n Returns:\n X -- placeholder for the data input, of shape [n_x, None] and dtype \"tf.float32\"\n Y -- placeholder for the input labels, of shape [n_y, None] and dtype \"tf.float32\"\n \n Tips:\n - You will use None because it let's us be flexible on the number of examples you will for the placeholders.\n In fact, the number of examples during test/train is different.\n \"\"\"\n\n ### START CODE HERE ### (approx. 2 lines)\n \n X = tf.placeholder(tf.float32,[n_x,None],name = 'X')\n \n Y = tf.placeholder(tf.float32,[n_y,None],name = 'Y')\n \n ### END CODE HERE ###\n \n return X, Y",
"_____no_output_____"
],
[
"X, Y = create_placeholders(12288, 6)\nprint (\"X = \" + str(X))\nprint (\"Y = \" + str(Y))",
"X = Tensor(\"X:0\", shape=(12288, ?), dtype=float32)\nY = Tensor(\"Y:0\", shape=(6, ?), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **X**\n </td>\n <td>\n Tensor(\"Placeholder_1:0\", shape=(12288, ?), dtype=float32) (not necessarily Placeholder_1)\n </td>\n </tr>\n <tr> \n <td>\n **Y**\n </td>\n <td>\n Tensor(\"Placeholder_2:0\", shape=(6, ?), dtype=float32) (not necessarily Placeholder_2)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.2 - Initializing the parameters\n\nYour second task is to initialize the parameters in tensorflow.\n\n**Exercise:** Implement the function below to initialize the parameters in tensorflow. You are going use Xavier Initialization for weights and Zero Initialization for biases. The shapes are given below. As an example, to help you, for W1 and b1 you could use: \n\n```python\nW1 = tf.get_variable(\"W1\", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))\nb1 = tf.get_variable(\"b1\", [25,1], initializer = tf.zeros_initializer())\n```\nPlease use `seed = 1` to make sure your results match ours.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters():\n \"\"\"\n Initializes parameters to build a neural network with tensorflow. The shapes are:\n W1 : [25, 12288]\n b1 : [25, 1]\n W2 : [12, 25]\n b2 : [12, 1]\n W3 : [6, 12]\n b3 : [6, 1]\n \n Returns:\n parameters -- a dictionary of tensors containing W1, b1, W2, b2, W3, b3\n \"\"\"\n \n tf.set_random_seed(1) # so that your \"random\" numbers match ours\n \n ### START CODE HERE ### (approx. 6 lines of code)\n \n W1 = tf.get_variable(\"W1\", [25, 12288], initializer = tf.contrib.layers.xavier_initializer(seed=1))\n \n b1 = tf.get_variable(\"b1\", [25, 1], initializer = tf.zeros_initializer())\n \n W2 = tf.get_variable(\"W2\", [12, 25], initializer = tf.contrib.layers.xavier_initializer(seed=1))\n \n b2 = tf.get_variable(\"b2\", [12, 1], initializer = tf.zeros_initializer())\n \n W3 = tf.get_variable(\"W3\", [6, 12], initializer = tf.contrib.layers.xavier_initializer(seed=1))\n \n b3 = tf.get_variable(\"b3\", [6, 1], initializer = tf.zeros_initializer())\n \n ### END CODE HERE ###\n\n parameters = {\"W1\": W1,\n \"b1\": b1,\n \"W2\": W2,\n \"b2\": b2,\n \"W3\": W3,\n \"b3\": b3}\n \n return parameters",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nwith tf.Session() as sess:\n parameters = initialize_parameters()\n print(\"W1 = \" + str(parameters[\"W1\"]))\n print(\"b1 = \" + str(parameters[\"b1\"]))\n print(\"W2 = \" + str(parameters[\"W2\"]))\n print(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = <tf.Variable 'W1:0' shape=(25, 12288) dtype=float32_ref>\nb1 = <tf.Variable 'b1:0' shape=(25, 1) dtype=float32_ref>\nW2 = <tf.Variable 'W2:0' shape=(12, 25) dtype=float32_ref>\nb2 = <tf.Variable 'b2:0' shape=(12, 1) dtype=float32_ref>\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **W1**\n </td>\n <td>\n < tf.Variable 'W1:0' shape=(25, 12288) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **b1**\n </td>\n <td>\n < tf.Variable 'b1:0' shape=(25, 1) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **W2**\n </td>\n <td>\n < tf.Variable 'W2:0' shape=(12, 25) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **b2**\n </td>\n <td>\n < tf.Variable 'b2:0' shape=(12, 1) dtype=float32_ref >\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"As expected, the parameters haven't been evaluated yet.",
"_____no_output_____"
],
[
"### 2.3 - Forward propagation in tensorflow \n\nYou will now implement the forward propagation module in tensorflow. The function will take in a dictionary of parameters and it will complete the forward pass. The functions you will be using are: \n\n- `tf.add(...,...)` to do an addition\n- `tf.matmul(...,...)` to do a matrix multiplication\n- `tf.nn.relu(...)` to apply the ReLU activation\n\n**Question:** Implement the forward pass of the neural network. We commented for you the numpy equivalents so that you can compare the tensorflow implementation to numpy. It is important to note that the forward propagation stops at `z3`. The reason is that in tensorflow the last linear layer output is given as input to the function computing the loss. Therefore, you don't need `a3`!\n\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation\n\ndef forward_propagation(X, parameters):\n \"\"\"\n Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX\n \n Arguments:\n X -- input dataset placeholder, of shape (input size, number of examples)\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", \"W2\", \"b2\", \"W3\", \"b3\"\n the shapes are given in initialize_parameters\n\n Returns:\n Z3 -- the output of the last LINEAR unit\n \"\"\"\n \n # Retrieve the parameters from the dictionary \"parameters\" \n W1 = parameters['W1']\n b1 = parameters['b1']\n W2 = parameters['W2']\n b2 = parameters['b2']\n W3 = parameters['W3']\n b3 = parameters['b3']\n \n ### START CODE HERE ### (approx. 5 lines) # Numpy Equivalents:\n \n Z1 = tf.add(tf.matmul(W1, X), b1) # Z1 = np.dot(W1, X) + b1\n \n A1 = tf.nn.relu(Z1) # A1 = relu(Z1)\n \n Z2 = tf.add(tf.matmul(W2, A1), b2) # Z2 = np.dot(W2, a1) + b2\n \n A2 = tf.nn.relu(Z2) # A2 = relu(Z2)\n \n Z3 = tf.add(tf.matmul(W3, A2), b3) # Z3 = np.dot(W3,Z2) + b3\n \n ### END CODE HERE ###\n \n return Z3",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n X, Y = create_placeholders(12288, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n print(\"Z3 = \" + str(Z3))",
"Z3 = Tensor(\"Add_2:0\", shape=(6, ?), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **Z3**\n </td>\n <td>\n Tensor(\"Add_2:0\", shape=(6, ?), dtype=float32)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"You may have noticed that the forward propagation doesn't output any cache. You will understand why below, when we get to brackpropagation.",
"_____no_output_____"
],
[
"### 2.4 Compute cost\n\nAs seen before, it is very easy to compute the cost using:\n```python\ntf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = ..., labels = ...))\n```\n**Question**: Implement the cost function below. \n- It is important to know that the \"`logits`\" and \"`labels`\" inputs of `tf.nn.softmax_cross_entropy_with_logits` are expected to be of shape (number of examples, num_classes). We have thus transposed Z3 and Y for you.\n- Besides, `tf.reduce_mean` basically does the summation over the examples.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost \n\ndef compute_cost(Z3, Y):\n \"\"\"\n Computes the cost\n \n Arguments:\n Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)\n Y -- \"true\" labels vector placeholder, same shape as Z3\n \n Returns:\n cost - Tensor of the cost function\n \"\"\"\n \n # to fit the tensorflow requirement for tf.nn.softmax_cross_entropy_with_logits(...,...)\n logits = tf.transpose(Z3)\n labels = tf.transpose(Y)\n \n ### START CODE HERE ### (1 line of code)\n \n cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))\n \n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n X, Y = create_placeholders(12288, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n cost = compute_cost(Z3, Y)\n print(\"cost = \" + str(cost))",
"cost = Tensor(\"Mean:0\", shape=(), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **cost**\n </td>\n <td>\n Tensor(\"Mean:0\", shape=(), dtype=float32)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.5 - Backward propagation & parameter updates\n\nThis is where you become grateful to programming frameworks. All the backpropagation and the parameters update is taken care of in 1 line of code. It is very easy to incorporate this line in the model.\n\nAfter you compute the cost function. You will create an \"`optimizer`\" object. You have to call this object along with the cost when running the tf.session. When called, it will perform an optimization on the given cost with the chosen method and learning rate.\n\nFor instance, for gradient descent the optimizer would be:\n```python\noptimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)\n```\n\nTo make the optimization you would do:\n```python\n_ , c = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})\n```\n\nThis computes the backpropagation by passing through the tensorflow graph in the reverse order. From cost to inputs.\n\n**Note** When coding, we often use `_` as a \"throwaway\" variable to store values that we won't need to use later. Here, `_` takes on the evaluated value of `optimizer`, which we don't need (and `c` takes the value of the `cost` variable). ",
"_____no_output_____"
],
[
"### 2.6 - Building the model\n\nNow, you will bring it all together! \n\n**Exercise:** Implement the model. You will be calling the functions you had previously implemented.",
"_____no_output_____"
]
],
[
[
"def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,\n num_epochs = 1500, minibatch_size = 32, print_cost = True):\n \"\"\"\n Implements a three-layer tensorflow neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.\n \n Arguments:\n X_train -- training set, of shape (input size = 12288, number of training examples = 1080)\n Y_train -- test set, of shape (output size = 6, number of training examples = 1080)\n X_test -- training set, of shape (input size = 12288, number of training examples = 120)\n Y_test -- test set, of shape (output size = 6, number of test examples = 120)\n learning_rate -- learning rate of the optimization\n num_epochs -- number of epochs of the optimization loop\n minibatch_size -- size of a minibatch\n print_cost -- True to print the cost every 100 epochs\n \n Returns:\n parameters -- parameters learnt by the model. They can then be used to predict.\n \"\"\"\n \n ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables\n tf.set_random_seed(1) # to keep consistent results\n seed = 3 # to keep consistent results\n (n_x, m) = X_train.shape # (n_x: input size, m : number of examples in the train set)\n n_y = Y_train.shape[0] # n_y : output size\n costs = [] # To keep track of the cost\n \n # Create Placeholders of shape (n_x, n_y)\n ### START CODE HERE ### (1 line)\n \n X, Y = create_placeholders(n_x, n_y)\n \n ### END CODE HERE ###\n\n # Initialize parameters\n ### START CODE HERE ### (1 line)\n \n parameters = initialize_parameters()\n \n ### END CODE HERE ###\n \n # Forward propagation: Build the forward propagation in the tensorflow graph\n ### START CODE HERE ### (1 line)\n \n Z3 = forward_propagation(X, parameters)\n \n ### END CODE HERE ###\n \n # Cost function: Add cost function to tensorflow graph\n ### START CODE HERE ### (1 line)\n \n cost = compute_cost(Z3, Y)\n \n ### END CODE HERE ###\n \n # Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer.\n ### START CODE HERE ### (1 line)\n \n optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)\n \n ### END CODE HERE ###\n \n # Initialize all the variables\n init = tf.global_variables_initializer()\n\n # Start the session to compute the tensorflow graph\n with tf.Session() as sess:\n \n # Run the initialization\n sess.run(init)\n \n # Do the training loop\n for epoch in range(num_epochs):\n\n epoch_cost = 0. # Defines a cost related to an epoch\n num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set\n seed = seed + 1\n minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)\n\n for minibatch in minibatches:\n\n # Select a minibatch\n (minibatch_X, minibatch_Y) = minibatch\n \n # IMPORTANT: The line that runs the graph on a minibatch.\n # Run the session to execute the \"optimizer\" and the \"cost\", the feedict should contain a minibatch for (X,Y).\n ### START CODE HERE ### (1 line)\n \n _ , minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})\n \n ### END CODE HERE ###\n \n epoch_cost += minibatch_cost / minibatch_size\n\n # Print the cost every epoch\n if print_cost == True and epoch % 100 == 0:\n print (\"Cost after epoch %i: %f\" % (epoch, epoch_cost))\n if print_cost == True and epoch % 5 == 0:\n costs.append(epoch_cost)\n \n # plot the cost\n plt.plot(np.squeeze(costs))\n plt.ylabel('cost')\n plt.xlabel('iterations (per fives)')\n plt.title(\"Learning rate =\" + str(learning_rate))\n plt.show()\n\n # lets save the parameters in a variable\n parameters = sess.run(parameters)\n print (\"Parameters have been trained!\")\n\n # Calculate the correct predictions\n correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))\n\n # Calculate accuracy on the test set\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n\n print (\"Train Accuracy:\", accuracy.eval({X: X_train, Y: Y_train}))\n print (\"Test Accuracy:\", accuracy.eval({X: X_test, Y: Y_test}))\n \n return parameters",
"_____no_output_____"
]
],
[
[
"Run the following cell to train your model! On our machine it takes about 5 minutes. Your \"Cost after epoch 100\" should be 1.048222. If it's not, don't waste time; interrupt the training by clicking on the square (⬛) in the upper bar of the notebook, and try to correct your code. If it is the correct cost, take a break and come back in 5 minutes!",
"_____no_output_____"
]
],
[
[
"parameters = model(X_train, Y_train, X_test, Y_test)",
"Cost after epoch 0: 1.913693\nCost after epoch 100: 1.048222\nCost after epoch 200: 0.756012\nCost after epoch 300: 0.590844\nCost after epoch 400: 0.483423\nCost after epoch 500: 0.392928\nCost after epoch 600: 0.323629\nCost after epoch 700: 0.262100\nCost after epoch 800: 0.210199\nCost after epoch 900: 0.171622\nCost after epoch 1000: 0.145907\nCost after epoch 1100: 0.110942\nCost after epoch 1200: 0.088966\nCost after epoch 1300: 0.061226\nCost after epoch 1400: 0.053860\n"
]
],
[
[
"**Expected Output**:\n\n<table> \n <tr> \n <td>\n **Train Accuracy**\n </td>\n <td>\n 0.999074\n </td>\n </tr>\n <tr> \n <td>\n **Test Accuracy**\n </td>\n <td>\n 0.716667\n </td>\n </tr>\n\n</table>\n\nAmazing, your algorithm can recognize a sign representing a figure between 0 and 5 with 71.7% accuracy.\n\n**Insights**:\n- Your model seems big enough to fit the training set well. However, given the difference between train and test accuracy, you could try to add L2 or dropout regularization to reduce overfitting. \n- Think about the session as a block of code to train the model. Each time you run the session on a minibatch, it trains the parameters. In total you have run the session a large number of times (1500 epochs) until you obtained well trained parameters.",
"_____no_output_____"
],
[
"### 2.7 - Test with your own image (optional / ungraded exercise)\n\nCongratulations on finishing this assignment. You can now take a picture of your hand and see the output of your model. To do that:\n 1. Click on \"File\" in the upper bar of this notebook, then click \"Open\" to go on your Coursera Hub.\n 2. Add your image to this Jupyter Notebook's directory, in the \"images\" folder\n 3. Write your image's name in the following code\n 4. Run the code and check if the algorithm is right!",
"_____no_output_____"
]
],
[
[
"import scipy\nfrom PIL import Image\nfrom scipy import ndimage\n\n## START CODE HERE ## (PUT YOUR IMAGE NAME) \nmy_image = \"thumbs_up.jpg\"\n## END CODE HERE ##\n\n# We preprocess your image to fit your algorithm.\nfname = \"images/\" + my_image\nimage = np.array(ndimage.imread(fname, flatten=False))\nimage = image/255.\nmy_image = scipy.misc.imresize(image, size=(64,64)).reshape((1, 64*64*3)).T\nmy_image_prediction = predict(my_image, parameters)\n\nplt.imshow(image)\nprint(\"Your algorithm predicts: y = \" + str(np.squeeze(my_image_prediction)))",
"Your algorithm predicts: y = 3\n"
]
],
[
[
"You indeed deserved a \"thumbs-up\" although as you can see the algorithm seems to classify it incorrectly. The reason is that the training set doesn't contain any \"thumbs-up\", so the model doesn't know how to deal with it! We call that a \"mismatched data distribution\" and it is one of the various of the next course on \"Structuring Machine Learning Projects\".",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- Tensorflow is a programming framework used in deep learning\n- The two main object classes in tensorflow are Tensors and Operators. \n- When you code in tensorflow you have to take the following steps:\n - Create a graph containing Tensors (Variables, Placeholders ...) and Operations (tf.matmul, tf.add, ...)\n - Create a session\n - Initialize the session\n - Run the session to execute the graph\n- You can execute the graph multiple times as you've seen in model()\n- The backpropagation and optimization is automatically done when running the session on the \"optimizer\" object.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4ad409f8aa7769158fa487c9d16e1e4fdd739fcf
| 5,320 |
ipynb
|
Jupyter Notebook
|
tutorials/Spatial Coding/AttractorModel.ipynb
|
h-mayorquin/camp_india_2016
|
a8bf8db7778c39c7ca959a7f876c1aa85f2cae8b
|
[
"MIT"
] | 3 |
2019-04-10T07:38:55.000Z
|
2020-11-15T18:33:18.000Z
|
tutorials/Spatial Coding/AttractorModel.ipynb
|
h-mayorquin/camp_india_2016
|
a8bf8db7778c39c7ca959a7f876c1aa85f2cae8b
|
[
"MIT"
] | null | null | null |
tutorials/Spatial Coding/AttractorModel.ipynb
|
h-mayorquin/camp_india_2016
|
a8bf8db7778c39c7ca959a7f876c1aa85f2cae8b
|
[
"MIT"
] | null | null | null | 22.832618 | 77 | 0.464662 |
[
[
[
"### From Burak and Fiete, Plos Comp. Biol. 2009\n### Author: Harsha Gurnani",
"_____no_output_____"
],
[
"from numpy import *\nfrom scipy import *",
"_____no_output_____"
],
[
"### Setting up model\n\nnsedge = 128\nNN = nsedge**2 #no. of neurons\n\nposx = [ int(nn/nsedge)-nsedge/2 for nn in range(NN) ]\nposy = [ int(mod(nn,nsedge))-nsedge/2 for nn in range(NN) ]\n\npref_dirn = [0 for ii in range(NN)]\n\ndirns = [[0,1], [1,0],[0,-1], [-1,0]]\nfor ii in range(NN):\n shift=int(mod(mod(ii,8),4))\n ind= mod(shift+ int(mod(ii,4)),4)\n pref_dirn[ii] = ind\n \ntau=10/1000\ndt =0.5/1000",
"_____no_output_____"
],
[
"### Weight matrix\ndef get_baselineW(a, gamma, beta, dist2):\n return a*exp(-gamma*dist2) - exp(-beta*dist2)\n\nlambda_net=13\na = 1.0\nbeta =3/(lambda_net**2)\ngamma = 1.05*beta\nl = 0.5\n\nvec=zeros(2)\nWt = zeros([NN,NN])\nfor ii in range(NN):\n for jj in range(NN):\n x1,y1=posx[ii],posy[ii]\n x2,y2=posx[jj],posy[jj]\n pf=dirns[pref_dirn[jj]]\n vec[0] = x1 - x2 - l*pf[0]\n vec[1] = y1 - y2 -l*pf[1]\n dist2 = vec[0]**2 + vec[1]**2\n W = get_baselineW(a,gamma,beta,dist2)\n Wt[ii,jj] = W",
"_____no_output_____"
],
[
"### Velocity-modulated inputs\n\nB = zeros(NN)\ndef get_vel_input(NN,A,alpha,edir,vel):\n bv = zeros(NN)\n for ii in range(NN):\n pf = dirns[edir[ii]]\n comp = pf[0]*vel[0] + pf[1]*vel[1]\n bv[ii] = A[ii]*(1+alpha*comp)\n return bv\n ",
"_____no_output_____"
],
[
"A = [1 for ii in range(NN)]\nalpha=0.10315",
"_____no_output_____"
],
[
"def DiffEqnForRates( s, t, Wt, tau , vel) :\n '''\n eqns for ds/dt\n s: Firing rates of all neurons\n Wt : synaptic weight matrix\n B : Velocity-modulated input\n '''\n Ns= len(s)\n n = int(sqrt(Ns))\n dsdt = zeros(Ns)\n B = get_vel_input(Ns, A, alpha, pref_dirn, vel[t])\n for ii in range(Ns):\n syn_act = B[ii]\n for jj in range(Ns):\n syn_act += Wt[jj,ii]*s[jj]\n if syn_act < 0:\n syn_act = 0;\n dsdt[ii] = (syn_act - s[ii])/tau\n \n return dsdt",
"_____no_output_____"
],
[
"### Setting up simulations\ndt =0.5/1000\nt=10\ntrange=range(int(t/dt))\n\nvel=[(rand(2)-0.5)*0.8 for ii in trange]\ninit_t=int(0.25/dt)\nfor ii in range(init_t):\n vel[ii] = [1,0]*0.8\nfor ii in range(init_t, 2*init_t):\n vel[ii] = [cos(pi/5), sin(pi/5)]*0.8\nfor ii in range(2*init_t,3*init_t):\n vel[ii] = [cos(pi/2-pi/5), sin(pi/2-pi/5)]*0.8\n\nprint shape(vel)\n\ns0 = rand(NN)*5\nrates = scipy.integrate.odeint(DiffEqnForRates, s0, t, Wt, tau, vel)\nprint shape(rates)",
"_____no_output_____"
],
[
"### Get position from velocity\n### Plot rates versus position\n### Plot population response maps",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad433ec6f92a131d741577871b20eae405bad21
| 48,953 |
ipynb
|
Jupyter Notebook
|
notebooks/Ligeti - Desordre.ipynb
|
tiagoantao/abjad-ipython
|
a39c494ae38689bc25caaaa6cd840267eb91648c
|
[
"CC0-1.0"
] | 1 |
2015-05-14T22:20:52.000Z
|
2015-05-14T22:20:52.000Z
|
notebooks/Ligeti - Desordre.ipynb
|
tiagoantao/abjad-ipython
|
a39c494ae38689bc25caaaa6cd840267eb91648c
|
[
"CC0-1.0"
] | null | null | null |
notebooks/Ligeti - Desordre.ipynb
|
tiagoantao/abjad-ipython
|
a39c494ae38689bc25caaaa6cd840267eb91648c
|
[
"CC0-1.0"
] | null | null | null | 125.520513 | 29,616 | 0.84955 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4ad4375bd0edb11c2776f428af33683cde66d2f5
| 71,277 |
ipynb
|
Jupyter Notebook
|
3.ipynb
|
BobNobrain/matstat-labs
|
bf7c95b29a6dc8b65675a780871400fd729f9e35
|
[
"MIT"
] | null | null | null |
3.ipynb
|
BobNobrain/matstat-labs
|
bf7c95b29a6dc8b65675a780871400fd729f9e35
|
[
"MIT"
] | null | null | null |
3.ipynb
|
BobNobrain/matstat-labs
|
bf7c95b29a6dc8b65675a780871400fd729f9e35
|
[
"MIT"
] | 7 |
2018-11-18T06:31:49.000Z
|
2020-11-09T18:36:40.000Z
| 141.422619 | 38,308 | 0.874335 |
[
[
[
"# Лабораторная работа №3. Однофакторный дисперсионный анализ\n\n> Вариант № ??\n\n**Распределения**:\n\n$X_1$ ~ ?? (объём выборки $n_1$ — ?)\n\n$X_2$ ~ ?? (объём выборки $n_2$ — ?)\n\n$X_3$ ~ ?? (объём выборки $n_3$ — ?)",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nfrom scipy import stats\nimport matplotlib.pyplot as plt\nfrom statsmodels.distributions.empirical_distribution import ECDF\n\n# Немного магии для того, чтобы рисунки стали больше\nimport pylab\npylab.rcParams['figure.figsize'] = (24.0, 16.0)\nplt.rcParams.update({'font.size': 22})\n\n# Вспомогательные классы и функции, определённые тут же (см. репозиторий)\n# https://github.com/BobNobrain/matstat-labs/tree/master/s\nfrom s import Sample, PooledSample, BartlettHyp, OneWayAnovaHyp, LinearContrastHyp\nfrom s.utils import table, printf",
"_____no_output_____"
]
],
[
[
"## 1. Исходные данные",
"_____no_output_____"
]
],
[
[
"X1 = stats.norm(0, 1)\nX2 = stats.norm(0.01, 1.1)\nX3 = stats.norm(-0.02, 0.9)\n\nn1 = 100\nn2 = 200\nn3 = 150\n\nprint('Характеристики наблюдаемых случайных величин:')\ntable(\n ['СВ', 'Распределение', 'Параметры', '$m_i$', '$\\\\sigma_i^2$', '$n_i$'],\n [\n ['X1', 'N', '$m=0.0, \\\\sigma=1.0$', X1.mean(), X1.var(), n1],\n ['X2', 'N', '$m=0.1, \\\\sigma=1.1$', X2.mean(), X2.var(), n2],\n ['X3', 'N', '$m=-0.3, \\\\sigma=0.9$', X3.mean(), X3.var(), n3]\n ]\n)\nprintf('Количество случайных величин $k={}$', 3)\n ",
"Характеристики наблюдаемых случайных величин:\n"
],
[
"x1 = Sample.from_distribution(\"x1\", X1, count=n1)\nx2 = Sample.from_distribution(\"x2\", X2, count=n2)\nx3 = Sample.from_distribution(\"x3\", X3, count=n3)\n\nx_pooled = PooledSample(\"Pooled\", x1, x2, x3)\n\nprint('Выборочные характеристики:')\ntable(\n ['СВ', 'Среднее $\\\\overline{x_i}$', '$s^2_i$', '$s_i$'],\n [\n [\n s._name,\n round(s.mean(), 4),\n round(s.s() ** 2, 4),\n round(s.s(), 4)\n ] for s in [x1, x2, x3, x_pooled]\n ]\n)",
"Выборочные характеристики:\n"
]
],
[
[
"## 2. Визуальное представление выборок\n\nДиаграммы *Box-and-Whisker*:",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\n\nax.boxplot([x1.data(), x2.data(), x3.data()])\nax.set_title('Выборки')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 3. Проверка условия применимости дисперсионного анализа\n\nСтатистическая гипотеза $H_0: \\sigma_1^2 = \\sigma_2^2 = \\sigma_3^2$",
"_____no_output_____"
]
],
[
[
"print('Критерий Бартлетта')\n\nalpha = 0.05\n\nH0 = BartlettHyp(x_pooled)\ncriterion_value, interval, p_value, result = H0.full_test(x_pooled, alpha)\n\ntable(\n [\n 'Выборочное значение статистики критерия',\n 'p-value',\n 'Статистическое решение при $\\\\alpha={}$'.format(alpha),\n 'Ошибка статистического решения'\n ],\n [[\n round(criterion_value, 4),\n round(p_value, 4),\n 'H0' if result else 'H1',\n 'TODO'\n ]]\n)",
"Критерий Бартлетта\n"
]
],
[
[
"## 4. Однофакторный дисперсионный анализ",
"_____no_output_____"
]
],
[
[
"print('Таблица дисперсионного анализа')\n\n# http://datalearning.ru/index.php/textbook?cid=1&mid=5&topic=2, таблица 6.4\ntable(\n ['Источник вариации', 'Показатель вариации', 'Число степеней свободы', 'Несмещённая оценка'],\n [\n ['Группировочный признак', '', '', ''],\n ['Остаточные признаки', '', '', ''],\n ['Все признаки', '', '', '']\n ]\n)\n\neta2 = x_pooled.eta_squared()\nprintf('Эмпирический коэффициент детерминации $\\\\eta^2 = {}$', round(eta2, 4))\nprintf('Эмпирическое корреляционное отношение $\\\\eta = {}$', round(np.sqrt(eta2), 4))",
"Таблица дисперсионного анализа\n"
]
],
[
[
"Статистическая гипотеза $H_0: m_1 = m_2 = m_3$",
"_____no_output_____"
]
],
[
[
"alpha = 0.05\n\nanova = OneWayAnovaHyp(x_pooled)\ncriterion_value, (crit_left, crit_right), p_value, result = anova.full_test(x_pooled, alpha)\n\ntable(\n [\n 'Выборочное значение статистики критерия',\n 'p-value',\n 'Статистическое решение при $\\\\alpha={}$'.format(alpha),\n 'Ошибка статистического решения'\n ],\n [[\n round(criterion_value, 4),\n round(p_value, 4),\n 'H0' if result else 'H1',\n 'TODO'\n ]]\n)\n",
"_____no_output_____"
]
],
[
[
"## 5. Метод линейных контрастов",
"_____no_output_____"
]
],
[
[
"alpha = 0.05\n\ndef m_interval(sample):\n n = sample.n()\n delta = stats.t(n - 1).ppf(1 - alpha / 2) * sample.s() / np.sqrt(n)\n mean = sample.mean()\n return mean - delta, mean + delta\n \nfig, ax = plt.subplots()\nax.set_title('Доверительные интервалы для $m_{1..k}$')\n\nsamples = [x1, x2, x3]\nfor i in range(len(samples)):\n l, r = m_interval(samples[i])\n domain = [l, r]\n values = [i + 1, i + 1]\n ax.plot(\n domain,\n values,\n label='$m_{} \\\\in [{}; {}]$'.format(i + 1, round(l, 3), round(r, 3)),\n linewidth=4\n )\n ax.fill_between(domain, 0, values, alpha=.2)\n\nplt.legend()\nplt.show()\n\n# TODO: вынести в функцию и сделать для всех комбинаций\nH0 = LinearContrastHyp(x_pooled)\nc, (c_1, c_2), p_value, result = H0.full_test([1, -1, 0], alpha=alpha)\nprint(c_1, c_2)\n\ntable(\n [\n 'Гипотеза',\n 'Выборочное значение статистики критерия',\n 'p-value',\n 'Статистическое решение при $\\\\alpha={}$'.format(alpha),\n 'Ошибка статистического решения'\n ],\n [\n ['$m_1=m_2$', round(c, 4), round(p_value, 4), '$=$' if result else '$\\\\ne$', 'TODO'],\n ['$m_2=m_3$', '', '', '', ''],\n ['$m_1=m_3$', '', '', '', '']\n ]\n)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad44fb3772d7ade5d44ddf85ca2c28accf48023
| 881 |
ipynb
|
Jupyter Notebook
|
docs/content/0-install.ipynb
|
ecurtin2/ngboost
|
73d246d73719b39acd90fa8c5f208ae8022f4fa0
|
[
"Apache-2.0"
] | 1 |
2020-07-16T08:33:50.000Z
|
2020-07-16T08:33:50.000Z
|
docs/content/0-install.ipynb
|
ecurtin2/ngboost
|
73d246d73719b39acd90fa8c5f208ae8022f4fa0
|
[
"Apache-2.0"
] | null | null | null |
docs/content/0-install.ipynb
|
ecurtin2/ngboost
|
73d246d73719b39acd90fa8c5f208ae8022f4fa0
|
[
"Apache-2.0"
] | null | null | null | 19.577778 | 82 | 0.531215 |
[
[
[
"# Installation\n\nNGBoost is easy to install using pip:\n\n```\npip install --upgrade ngboost\n```\n\nalthough we recommend installing the most up-to-date version from github:\n\n```\npip install --upgrade git+https://github.com/stanfordmlgroup/ngboost.git\n```",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4ad47ac8f769470f6468fde2c1abb2214dc05715
| 63,707 |
ipynb
|
Jupyter Notebook
|
2. Custom and Distributed Training with TensorFlow/Week 3/C2W3_Assignment.ipynb
|
Abdelrahman350/TensorFlow-Advanced-Techniques-Specialization
|
72b9c8eec2ceb06ecc239b9ed6738fa0109fd284
|
[
"MIT"
] | null | null | null |
2. Custom and Distributed Training with TensorFlow/Week 3/C2W3_Assignment.ipynb
|
Abdelrahman350/TensorFlow-Advanced-Techniques-Specialization
|
72b9c8eec2ceb06ecc239b9ed6738fa0109fd284
|
[
"MIT"
] | null | null | null |
2. Custom and Distributed Training with TensorFlow/Week 3/C2W3_Assignment.ipynb
|
Abdelrahman350/TensorFlow-Advanced-Techniques-Specialization
|
72b9c8eec2ceb06ecc239b9ed6738fa0109fd284
|
[
"MIT"
] | null | null | null | 65.140082 | 31,576 | 0.771061 |
[
[
[
"# Horse or Human? In-graph training loop Assignment\n\nThis assignment lets you practice how to train a Keras model on the [horses_or_humans](https://www.tensorflow.org/datasets/catalog/horses_or_humans) dataset with the entire training process performed in graph mode. These steps include:\n- loading batches\n- calculating gradients\n- updating parameters\n- calculating validation accuracy\n- repeating the loop until convergence",
"_____no_output_____"
],
[
"## Setup\n\nImport TensorFlow 2.0:",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\nimport numpy as np",
"_____no_output_____"
],
[
"import tensorflow as tf\nimport tensorflow_datasets as tfds\nimport tensorflow_hub as hub\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### Prepare the dataset\n\nLoad the horses to human dataset, splitting 80% for the training set and 20% for the test set.",
"_____no_output_____"
]
],
[
[
"splits, info = tfds.load('horses_or_humans', as_supervised=True, with_info=True, split=['train[:80%]', 'train[80%:]', 'test'], data_dir='./data')\n\n(train_examples, validation_examples, test_examples) = splits\n\nnum_examples = info.splits['train'].num_examples\nnum_classes = info.features['label'].num_classes",
"_____no_output_____"
],
[
"BATCH_SIZE = 32\nIMAGE_SIZE = 224",
"_____no_output_____"
]
],
[
[
"## Pre-process an image (please complete this section)\n\nYou'll define a mapping function that resizes the image to a height of 224 by 224, and normalizes the pixels to the range of 0 to 1. Note that pixels range from 0 to 255.\n\n- You'll use the following function: [tf.image.resize](https://www.tensorflow.org/api_docs/python/tf/image/resize) and pass in the (height,width) as a tuple (or list).\n- To normalize, divide by a floating value so that the pixel range changes from [0,255] to [0,1].",
"_____no_output_____"
]
],
[
[
"# Create a autograph pre-processing function to resize and normalize an image\n### START CODE HERE ###\[email protected]\ndef map_fn(img, label):\n image_height = 224\n image_width = 224\n### START CODE HERE ###\n # resize the image\n img = tf.image.resize(img, (image_height, image_width))\n # normalize the image\n img /= 255.\n### END CODE HERE\n return img, label",
"_____no_output_____"
],
[
"## TEST CODE:\n\ntest_image, test_label = list(train_examples)[0]\n\ntest_result = map_fn(test_image, test_label)\n\nprint(test_result[0].shape)\nprint(test_result[1].shape)\n\ndel test_image, test_label, test_result",
"(224, 224, 3)\n()\n"
]
],
[
[
"**Expected Output:**\n\n```\n(224, 224, 3)\n()\n```",
"_____no_output_____"
],
[
"## Apply pre-processing to the datasets (please complete this section)\n\nApply the following steps to the training_examples:\n- Apply the `map_fn` to the training_examples\n- Shuffle the training data using `.shuffle(buffer_size=)` and set the buffer size to the number of examples.\n- Group these into batches using `.batch()` and set the batch size given by the parameter.\n\nHint: You can look at how validation_examples and test_examples are pre-processed to get a sense of how to chain together multiple function calls.",
"_____no_output_____"
]
],
[
[
"# Prepare train dataset by using preprocessing with map_fn, shuffling and batching\ndef prepare_dataset(train_examples, validation_examples, test_examples, num_examples, map_fn, batch_size):\n ### START CODE HERE ###\n train_ds = train_examples.map(map_fn).shuffle(128).batch(batch_size)\n ### END CODE HERE ###\n valid_ds = validation_examples.map(map_fn).batch(batch_size)\n test_ds = test_examples.map(map_fn).batch(batch_size)\n \n return train_ds, valid_ds, test_ds",
"_____no_output_____"
],
[
"train_ds, valid_ds, test_ds = prepare_dataset(train_examples, validation_examples, test_examples, num_examples, map_fn, BATCH_SIZE)",
"_____no_output_____"
],
[
"## TEST CODE:\n\ntest_train_ds = list(train_ds)\nprint(len(test_train_ds))\nprint(test_train_ds[0][0].shape)\n\ndel test_train_ds",
"26\n(32, 224, 224, 3)\n"
]
],
[
[
"**Expected Output:**\n\n```\n26\n(32, 224, 224, 3)\n```",
"_____no_output_____"
],
[
"### Define the model",
"_____no_output_____"
]
],
[
[
"MODULE_HANDLE = 'data/resnet_50_feature_vector'\nmodel = tf.keras.Sequential([\n hub.KerasLayer(MODULE_HANDLE, input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)),\n tf.keras.layers.Dense(num_classes, activation='softmax')\n])\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nkeras_layer (KerasLayer) (None, 2048) 23561152 \n_________________________________________________________________\ndense (Dense) (None, 2) 4098 \n=================================================================\nTotal params: 23,565,250\nTrainable params: 4,098\nNon-trainable params: 23,561,152\n_________________________________________________________________\n"
]
],
[
[
"## Define optimizer: (please complete these sections)\nDefine the [Adam optimizer](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam) that is in the tf.keras.optimizers module.",
"_____no_output_____"
]
],
[
[
"def set_adam_optimizer():\n ### START CODE HERE ###\n # Define the adam optimizer\n optimizer = tf.keras.optimizers.Adam()\n ### END CODE HERE ###\n return optimizer",
"_____no_output_____"
],
[
"## TEST CODE:\n\ntest_optimizer = set_adam_optimizer()\n\nprint(type(test_optimizer))\n\ndel test_optimizer",
"<class 'tensorflow.python.keras.optimizer_v2.adam.Adam'>\n"
]
],
[
[
"**Expected Output:**\n```\n<class 'tensorflow.python.keras.optimizer_v2.adam.Adam'>\n```",
"_____no_output_____"
],
[
"## Define the loss function (please complete this section)\n\nDefine the loss function as the [sparse categorical cross entropy](https://www.tensorflow.org/api_docs/python/tf/keras/losses/SparseCategoricalCrossentropy) that's in the tf.keras.losses module. Use the same function for both training and validation.",
"_____no_output_____"
]
],
[
[
"def set_sparse_cat_crossentropy_loss():\n ### START CODE HERE ###\n # Define object oriented metric of Sparse categorical crossentropy for train and val loss\n train_loss = tf.keras.losses.SparseCategoricalCrossentropy()\n val_loss = tf.keras.losses.SparseCategoricalCrossentropy()\n ### END CODE HERE ###\n return train_loss, val_loss",
"_____no_output_____"
],
[
"## TEST CODE:\n\ntest_train_loss, test_val_loss = set_sparse_cat_crossentropy_loss()\n\nprint(type(test_train_loss))\nprint(type(test_val_loss))\n\ndel test_train_loss, test_val_loss",
"<class 'tensorflow.python.keras.losses.SparseCategoricalCrossentropy'>\n<class 'tensorflow.python.keras.losses.SparseCategoricalCrossentropy'>\n"
]
],
[
[
"**Expected Output:**\n```\n<class 'tensorflow.python.keras.losses.SparseCategoricalCrossentropy'>\n<class 'tensorflow.python.keras.losses.SparseCategoricalCrossentropy'>\n```",
"_____no_output_____"
],
[
"## Define the acccuracy function (please complete this section)\nDefine the accuracy function as the [spare categorical accuracy](https://www.tensorflow.org/api_docs/python/tf/keras/metrics/SparseCategoricalAccuracy) that's contained in the tf.keras.metrics module. Use the same function for both training and validation.",
"_____no_output_____"
]
],
[
[
"def set_sparse_cat_crossentropy_accuracy():\n ### START CODE HERE ###\n # Define object oriented metric of Sparse categorical accuracy for train and val accuracy\n train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()\n val_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()\n ### END CODE HERE ###\n return train_accuracy, val_accuracy",
"_____no_output_____"
],
[
"## TEST CODE:\n\ntest_train_accuracy, test_val_accuracy = set_sparse_cat_crossentropy_accuracy()\n\nprint(type(test_train_accuracy))\nprint(type(test_val_accuracy))\n\ndel test_train_accuracy, test_val_accuracy",
"<class 'tensorflow.python.keras.metrics.SparseCategoricalAccuracy'>\n<class 'tensorflow.python.keras.metrics.SparseCategoricalAccuracy'>\n"
]
],
[
[
"**Expected Output:**\n```\n<class 'tensorflow.python.keras.metrics.SparseCategoricalAccuracy'>\n<class 'tensorflow.python.keras.metrics.SparseCategoricalAccuracy'>\n```",
"_____no_output_____"
],
[
"Call the three functions that you defined to set the optimizer, loss and accuracy",
"_____no_output_____"
]
],
[
[
"optimizer = set_adam_optimizer()\ntrain_loss, val_loss = set_sparse_cat_crossentropy_loss()\ntrain_accuracy, val_accuracy = set_sparse_cat_crossentropy_accuracy()",
"_____no_output_____"
]
],
[
[
"### Define the training loop (please complete this section)\n\nIn the training loop:\n- Get the model predictions: use the model, passing in the input `x`\n- Get the training loss: Call `train_loss`, passing in the true `y` and the predicted `y`.\n- Calculate the gradient of the loss with respect to the model's variables: use `tape.gradient` and pass in the loss and the model's `trainable_variables`.\n- Optimize the model variables using the gradients: call `optimizer.apply_gradients` and pass in a `zip()` of the two lists: the gradients and the model's `trainable_variables`.\n- Calculate accuracy: Call `train_accuracy`, passing in the true `y` and the predicted `y`.",
"_____no_output_____"
]
],
[
[
"# this code uses the GPU if available, otherwise uses a CPU\ndevice = '/gpu:0' if tf.test.is_gpu_available() else '/cpu:0'\nEPOCHS = 2\n\n# Custom training step\ndef train_one_step(model, optimizer, x, y, train_loss, train_accuracy):\n '''\n Trains on a batch of images for one step.\n \n Args:\n model (keras Model) -- image classifier\n optimizer (keras Optimizer) -- optimizer to use during training\n x (Tensor) -- training images\n y (Tensor) -- training labels\n train_loss (keras Loss) -- loss object for training\n train_accuracy (keras Metric) -- accuracy metric for training\n '''\n with tf.GradientTape() as tape:\n ### START CODE HERE ###\n # Run the model on input x to get predictions\n predictions = model(x)\n # Compute the training loss using `train_loss`, passing in the true y and the predicted y\n loss = train_loss(y, predictions)\n\n # Using the tape and loss, compute the gradients on model variables using tape.gradient\n grads = tape.gradient(loss, model.trainable_weights)\n \n # Zip the gradients and model variables, and then apply the result on the optimizer\n optimizer.apply_gradients(zip(grads , model.trainable_weights))\n\n # Call the train accuracy object on ground truth and predictions\n train_accuracy(y , predictions)\n ### END CODE HERE\n return loss",
"WARNING:tensorflow:From <ipython-input-18-82b8d7935a57>:2: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.config.list_physical_devices('GPU')` instead.\n"
],
[
"## TEST CODE:\n\ndef base_model():\n inputs = tf.keras.layers.Input(shape=(2))\n x = tf.keras.layers.Dense(64, activation='relu')(inputs)\n outputs = tf.keras.layers.Dense(1, activation='sigmoid')(x)\n model = tf.keras.Model(inputs=inputs, outputs=outputs)\n return model\n\ntest_model = base_model()\n\ntest_optimizer = set_adam_optimizer()\ntest_image = tf.ones((2,2))\ntest_label = tf.ones((1,))\ntest_train_loss, _ = set_sparse_cat_crossentropy_loss()\ntest_train_accuracy, _ = set_sparse_cat_crossentropy_accuracy()\n\ntest_result = train_one_step(test_model, test_optimizer, test_image, test_label, test_train_loss, test_train_accuracy)\nprint(test_result)\n\ndel test_result, test_model, test_optimizer, test_image, test_label, test_train_loss, test_train_accuracy",
"tf.Tensor(0.6931472, shape=(), dtype=float32)\n"
]
],
[
[
"**Expected Output:**\n\nYou will see a Tensor with the same shape and dtype. The value might be different.\n\n```\ntf.Tensor(0.6931472, shape=(), dtype=float32)\n```",
"_____no_output_____"
],
[
"## Define the 'train' function (please complete this section)\n\nYou'll first loop through the training batches to train the model. (Please complete these sections)\n- The `train` function will use a for loop to iteratively call the `train_one_step` function that you just defined.\n- You'll use `tf.print` to print the step number, loss, and train_accuracy.result() at each step. Remember to use tf.print when you plan to generate autograph code.\n\nNext, you'll loop through the batches of the validation set to calculation the validation loss and validation accuracy. (This code is provided for you). At each iteration of the loop:\n- Use the model to predict on x, where x is the input from the validation set.\n- Use val_loss to calculate the validation loss between the true validation 'y' and predicted y.\n- Use val_accuracy to calculate the accuracy of the predicted y compared to the true y.\n\nFinally, you'll print the validation loss and accuracy using tf.print. (Please complete this section)\n- print the final `loss`, which is the validation loss calculated by the last loop through the validation dataset.\n- Also print the val_accuracy.result().\n\n**HINT**\nIf you submit your assignment and see this error for your stderr output: \n```\nCannot convert 1e-07 to EagerTensor of dtype int64\n```\nPlease check your calls to train_accuracy and val_accuracy to make sure that you pass in the true and predicted values in the correct order (check the documentation to verify the order of parameters).",
"_____no_output_____"
]
],
[
[
"# Decorate this function with tf.function to enable autograph on the training loop\[email protected]\ndef train(model, optimizer, epochs, device, train_ds, train_loss, train_accuracy, valid_ds, val_loss, val_accuracy):\n '''\n Performs the entire training loop. Prints the loss and accuracy per step and epoch.\n \n Args:\n model (keras Model) -- image classifier\n optimizer (keras Optimizer) -- optimizer to use during training\n epochs (int) -- number of epochs\n train_ds (tf Dataset) -- the train set containing image-label pairs\n train_loss (keras Loss) -- loss function for training\n train_accuracy (keras Metric) -- accuracy metric for training\n valid_ds (Tensor) -- the val set containing image-label pairs\n val_loss (keras Loss) -- loss object for validation\n val_accuracy (keras Metric) -- accuracy metric for validation\n '''\n step = 0\n loss = 0.0\n for epoch in range(epochs):\n for x, y in train_ds:\n # training step number increments at each iteration\n step += 1\n with tf.device(device_name=device):\n ### START CODE HERE ###\n # Run one training step by passing appropriate model parameters\n # required by the function and finally get the loss to report the results\n loss = train_one_step(model, optimizer, x, y, train_loss, train_accuracy)\n ### END CODE HERE ###\n # Use tf.print to report your results.\n # Print the training step number, loss and accuracy\n tf.print('Step', step, \n ': train loss', loss, \n '; train accuracy', train_accuracy.result())\n\n with tf.device(device_name=device):\n for x, y in valid_ds:\n # Call the model on the batches of inputs x and get the predictions\n y_pred = model(x)\n loss = val_loss(y, y_pred)\n val_accuracy(y, y_pred)\n \n # Print the validation loss and accuracy\n ### START CODE HERE ###\n tf.print('val loss', loss, '; val accuracy', val_accuracy.result())\n ### END CODE HERE ###",
"_____no_output_____"
]
],
[
[
"Run the `train` function to train your model! You should see the loss generally decreasing and the accuracy increasing.\n\n**Note**: **Please let the training finish before submitting** and **do not** modify the next cell. It is required for grading. This will take around 5 minutes to run. ",
"_____no_output_____"
]
],
[
[
"train(model, optimizer, EPOCHS, device, train_ds, train_loss, train_accuracy, valid_ds, val_loss, val_accuracy)",
"Step 1 : train loss 1.39727843 ; train accuracy 0.1875\nStep 2 : train loss 0.776474118 ; train accuracy 0.359375\nStep 3 : train loss 0.771845341 ; train accuracy 0.40625\nStep 4 : train loss 0.570763588 ; train accuracy 0.4765625\nStep 5 : train loss 0.481995314 ; train accuracy 0.525\nStep 6 : train loss 0.311862648 ; train accuracy 0.59375\nStep 7 : train loss 0.19977437 ; train accuracy 0.651785731\nStep 8 : train loss 0.157444417 ; train accuracy 0.6953125\nStep 9 : train loss 0.139509737 ; train accuracy 0.722222209\nStep 10 : train loss 0.124969423 ; train accuracy 0.75\nStep 11 : train loss 0.0733243078 ; train accuracy 0.772727251\nStep 12 : train loss 0.042274069 ; train accuracy 0.791666687\nStep 13 : train loss 0.0618721023 ; train accuracy 0.807692289\nStep 14 : train loss 0.0496986061 ; train accuracy 0.821428597\nStep 15 : train loss 0.0401798487 ; train accuracy 0.833333313\nStep 16 : train loss 0.0269004535 ; train accuracy 0.84375\nStep 17 : train loss 0.0229306743 ; train accuracy 0.852941155\nStep 18 : train loss 0.0143860774 ; train accuracy 0.861111104\nStep 19 : train loss 0.0121200141 ; train accuracy 0.868421078\nStep 20 : train loss 0.0138575155 ; train accuracy 0.875\nStep 21 : train loss 0.0123870522 ; train accuracy 0.880952358\nStep 22 : train loss 0.0730450451 ; train accuracy 0.884943187\nStep 23 : train loss 0.0094801588 ; train accuracy 0.889945626\nStep 24 : train loss 0.00618610531 ; train accuracy 0.89453125\nStep 25 : train loss 0.00605348684 ; train accuracy 0.89875\nStep 26 : train loss 0.0113621019 ; train accuracy 0.901459873\nval loss 0.00875141565 ; val accuracy 1\nStep 27 : train loss 0.00788081065 ; train accuracy 0.905152202\nStep 28 : train loss 0.00737154856 ; train accuracy 0.908577859\nStep 29 : train loss 0.00642075436 ; train accuracy 0.911764681\nStep 30 : train loss 0.00554736657 ; train accuracy 0.914736867\nStep 31 : train loss 0.00591501314 ; train accuracy 0.917515278\nStep 32 : train loss 0.00501414482 ; train accuracy 0.920118332\nStep 33 : train loss 0.00398396514 ; train accuracy 0.922562122\nStep 34 : train loss 0.00239584711 ; train accuracy 0.924860835\nStep 35 : train loss 0.00902077463 ; train accuracy 0.927027047\nStep 36 : train loss 0.00367009081 ; train accuracy 0.929071784\nStep 37 : train loss 0.00383501407 ; train accuracy 0.93100512\nStep 38 : train loss 0.00409892481 ; train accuracy 0.932835817\nStep 39 : train loss 0.00883996207 ; train accuracy 0.934571862\nStep 40 : train loss 0.00420338847 ; train accuracy 0.936220467\nStep 41 : train loss 0.00385603867 ; train accuracy 0.937788\nStep 42 : train loss 0.00275801495 ; train accuracy 0.939280331\nStep 43 : train loss 0.00394644495 ; train accuracy 0.940702796\nStep 44 : train loss 0.0597604662 ; train accuracy 0.941344798\nStep 45 : train loss 0.00271444535 ; train accuracy 0.942657351\nStep 46 : train loss 0.00350449234 ; train accuracy 0.943912446\nStep 47 : train loss 0.00323135732 ; train accuracy 0.945113778\nStep 48 : train loss 0.00164620951 ; train accuracy 0.946264744\nStep 49 : train loss 0.00332479505 ; train accuracy 0.947368443\nStep 50 : train loss 0.00264814612 ; train accuracy 0.948427677\nStep 51 : train loss 0.0061004879 ; train accuracy 0.949445128\nStep 52 : train loss 0.00474204542 ; train accuracy 0.950121641\nval loss 0.00428403961 ; val accuracy 1\n"
]
],
[
[
"# Evaluation\n\nYou can now see how your model performs on test images. First, let's load the test dataset and generate predictions:",
"_____no_output_____"
]
],
[
[
"test_imgs = []\ntest_labels = []\n\npredictions = []\nwith tf.device(device_name=device):\n for images, labels in test_ds:\n preds = model(images)\n preds = preds.numpy()\n predictions.extend(preds)\n\n test_imgs.extend(images.numpy())\n test_labels.extend(labels.numpy())",
"_____no_output_____"
]
],
[
[
"Let's define a utility function for plotting an image and its prediction.",
"_____no_output_____"
]
],
[
[
"# Utilities for plotting\n\nclass_names = ['horse', 'human']\n\ndef plot_image(i, predictions_array, true_label, img):\n predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]\n plt.grid(False)\n plt.xticks([])\n plt.yticks([])\n\n img = np.squeeze(img)\n\n plt.imshow(img, cmap=plt.cm.binary)\n\n predicted_label = np.argmax(predictions_array)\n \n # green-colored annotations will mark correct predictions. red otherwise.\n if predicted_label == true_label:\n color = 'green'\n else:\n color = 'red'\n \n # print the true label first\n print(true_label)\n \n # show the image and overlay the prediction\n plt.xlabel(\"{} {:2.0f}% ({})\".format(class_names[predicted_label],\n 100*np.max(predictions_array),\n class_names[true_label]),\n color=color)\n\n",
"_____no_output_____"
]
],
[
[
"### Plot the result of a single image\n\nChoose an index and display the model's prediction for that image.",
"_____no_output_____"
]
],
[
[
"# Visualize the outputs \n\n# you can modify the index value here from 0 to 255 to test different images\nindex = 8 \nplt.figure(figsize=(6,3))\nplt.subplot(1,2,1)\nplot_image(index, predictions, test_labels, test_imgs)\nplt.show()",
"0\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad487bcc012fb249fc36f5c2fcbde1b0b53b1a3
| 7,893 |
ipynb
|
Jupyter Notebook
|
book/notebooks/simulation/Rejection-Sampling-MC.ipynb
|
matthewfeickert/Statistics-Notes
|
088181920b0f560fdd2ed593d3653f67baa56190
|
[
"MIT"
] | 18 |
2018-02-15T15:22:15.000Z
|
2022-02-18T07:28:57.000Z
|
book/notebooks/simulation/Rejection-Sampling-MC.ipynb
|
matthewfeickert/Statistics-Notes
|
088181920b0f560fdd2ed593d3653f67baa56190
|
[
"MIT"
] | 7 |
2018-05-08T22:51:03.000Z
|
2021-12-08T03:58:30.000Z
|
book/notebooks/simulation/Rejection-Sampling-MC.ipynb
|
matthewfeickert/Statistics-Notes
|
088181920b0f560fdd2ed593d3653f67baa56190
|
[
"MIT"
] | 4 |
2018-10-24T17:15:44.000Z
|
2020-04-13T00:27:06.000Z
| 28.189286 | 413 | 0.518687 |
[
[
[
"# Rejection Sampling",
"_____no_output_____"
],
[
"Rejection sampling, or \"accept-reject Monte Carlo\" is a Monte Carlo method used to generate obsrvations from distributions. As it is a Monte Carlo it can also be used for numerical integration.",
"_____no_output_____"
],
[
"## Monte Carlo Integration",
"_____no_output_____"
],
[
"### Example: Approximation of $\\pi$",
"_____no_output_____"
],
[
"Enclose a quadrant of a circle of radius $1$ in a square of side length $1$. Then uniformly sample points inside the bounds of the square in Cartesian coordinates. If the point lies inside the circle quadrant record this information. At the ends of many throws the ratio of points inside the circle to all points thrown will approximate the ratio of the area of the cricle quadrant to the area of the square",
"_____no_output_____"
],
[
"$$\n\\frac{\\text{points inside circle}}{\\text{all points thrown}} \\approx \\frac{\\text{area of circle quadrant}}{\\text{area of square}} = \\frac{\\pi r^2}{4\\, l^2} = \\frac{\\pi}{4},\n$$",
"_____no_output_____"
],
[
"thus, an approximation of $\\pi$ can be found to be",
"_____no_output_____"
],
[
"$$\n\\pi \\approx 4 \\cdot \\frac{\\text{points inside circle}}{\\text{all points thrown}}.\n$$",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"def approximate_pi(n_throws=10000, draw=True):\n n_circle_points = 0\n\n x_coord = np.random.uniform(0, 1, n_throws)\n y_coord = np.random.uniform(0, 1, n_throws)\n\n circle_x = []\n circle_y = []\n outside_x = []\n outside_y = []\n\n for x, y in zip(x_coord, y_coord):\n radius = np.sqrt(x ** 2 + y ** 2)\n if 1 > radius:\n n_circle_points += 1\n circle_x.append(x)\n circle_y.append(y)\n else:\n outside_x.append(x)\n outside_y.append(y)\n\n approx_pi = 4 * (n_circle_points / n_throws)\n print(f\"The approximation of pi after {n_throws} throws is: {approx_pi}\")\n\n if draw:\n plt.plot(circle_x, circle_y, \"ro\")\n plt.plot(outside_x, outside_y, \"bo\")\n plt.xlabel(r\"$x$\")\n plt.ylabel(r\"$y$\")\n plt.show()",
"_____no_output_____"
],
[
"approximate_pi()",
"_____no_output_____"
]
],
[
[
"## Sampling Distributions",
"_____no_output_____"
],
[
"To approximate a statistical distribution one can also use accept-reject Monte Carlo to approximate the distribution.",
"_____no_output_____"
],
[
"### Example: Approximation of Gaussian Distribution",
"_____no_output_____"
]
],
[
[
"import scipy.stats as stats",
"_____no_output_____"
]
],
[
[
"The Gaussian has a known analytic form",
"_____no_output_____"
],
[
"$$\nf\\left(\\vec{x}\\,\\middle|\\,\\mu, \\sigma\\right) = \\frac{1}{\\sqrt{2\\pi}\\, \\sigma} e^{-\\left(x-\\mu\\right)^2/2\\sigma^2}\n$$",
"_____no_output_____"
]
],
[
[
"x = np.linspace(-5.0, 5.0, num=10000)\nplt.plot(x, stats.norm.pdf(x, 0, 1), linewidth=2, color=\"black\")\n\n# Axes\n# plt.title('Plot of $f(x;\\mu,\\sigma)$')\nplt.xlabel(r\"$x$\")\nplt.ylabel(r\"$f(\\vec{x}|\\mu,\\sigma)$\")\n# dist_window_w = sigma * 2\nplt.xlim([-5, 5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Given this it is seen that the Gaussian's maximum is at its mean. For the standard Gaussian this is at $\\mu = 0$, and so it has a maximum at $1/\\sqrt{2\\pi}\\,\\sigma \\approx 0.39$. Thus, this can be the maximum height of a rectangle that we need to throw our points in.",
"_____no_output_____"
]
],
[
[
"def approximate_Guassian(n_throws=10000, x_range=[-5, 5], draw=True):\n n_accept = 0\n\n x_coord = np.random.uniform(x_range[0], x_range[1], n_throws)\n y_coord = np.random.uniform(0, stats.norm.pdf(0, 0, 1), n_throws)\n # Use Freedman–Diaconis rule\n # https://en.wikipedia.org/wiki/Freedman%E2%80%93Diaconis_rule\n h = 2 * stats.iqr(x_coord) / np.cbrt([n_throws])\n n_bins = int((x_range[1] - x_range[0]) / h)\n\n accept_x = []\n accept_y = []\n reject_x = []\n reject_y = []\n\n for x, y in zip(x_coord, y_coord):\n if stats.norm.pdf(x, 0, 1) > y:\n n_accept += 1\n accept_x.append(x)\n accept_y.append(y)\n else:\n reject_x.append(x)\n reject_y.append(y)\n\n if draw:\n fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(1.2 * 14, 1.2 * 4.5))\n\n x_space = np.linspace(x_range[0], x_range[1], num=10000)\n axes[0].plot(accept_x, accept_y, \"ro\")\n axes[0].plot(reject_x, reject_y, \"bo\")\n axes[0].plot(x_space, stats.norm.pdf(x_space, 0, 1), linewidth=2, color=\"black\")\n axes[0].set_xlabel(r\"$x$\")\n axes[0].set_ylabel(r\"$y$\")\n axes[0].set_title(r\"Sampled space of $f(\\vec{x}|\\mu,\\sigma)$\")\n\n hist_count, bins, _ = axes[1].hist(accept_x, n_bins, density=True)\n axes[1].set_xlabel(r\"$x$\")\n axes[1].set_ylabel(\"Arbitrary normalized units\")\n axes[1].set_title(r\"Normalized binned distribution of accepted toys\")\n\n plt.xlim(x_range)\n plt.show()",
"_____no_output_____"
],
[
"approximate_Guassian()",
"_____no_output_____"
]
],
[
[
"This exercise is trivial but for more complex functional forms with more difficult integrals it can be a powerful numerical technique.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4ad49974b5b11316a181d08fffcda6b06e01b309
| 15,704 |
ipynb
|
Jupyter Notebook
|
lijin-THU:notes-python/03-numpy/03.05-array-calculation-method.ipynb
|
Maecenas/python-getting-started
|
2739444e0f4aa692123dcd0c1b9a44218281f9b6
|
[
"MIT"
] | null | null | null |
lijin-THU:notes-python/03-numpy/03.05-array-calculation-method.ipynb
|
Maecenas/python-getting-started
|
2739444e0f4aa692123dcd0c1b9a44218281f9b6
|
[
"MIT"
] | null | null | null |
lijin-THU:notes-python/03-numpy/03.05-array-calculation-method.ipynb
|
Maecenas/python-getting-started
|
2739444e0f4aa692123dcd0c1b9a44218281f9b6
|
[
"MIT"
] | null | null | null | 15.350929 | 72 | 0.424605 |
[
[
[
"# 数组方法",
"_____no_output_____"
]
],
[
[
"%pylab",
"Using matplotlib backend: Qt4Agg\nPopulating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"## 求和",
"_____no_output_____"
]
],
[
[
"a = array([[1,2,3], \n [4,5,6]])",
"_____no_output_____"
]
],
[
[
"求所有元素的和:",
"_____no_output_____"
]
],
[
[
"sum(a)",
"_____no_output_____"
]
],
[
[
"指定求和的维度:",
"_____no_output_____"
],
[
"沿着第一维求和:",
"_____no_output_____"
]
],
[
[
"sum(a, axis=0)",
"_____no_output_____"
]
],
[
[
"沿着第二维求和:",
"_____no_output_____"
]
],
[
[
"sum(a, axis=1)",
"_____no_output_____"
]
],
[
[
"沿着最后一维求和:",
"_____no_output_____"
]
],
[
[
"sum(a, axis=-1)",
"_____no_output_____"
]
],
[
[
"或者使用 `sum` 方法:",
"_____no_output_____"
]
],
[
[
"a.sum()",
"_____no_output_____"
],
[
"a.sum(axis=0)",
"_____no_output_____"
],
[
"a.sum(axis=-1)",
"_____no_output_____"
]
],
[
[
"## 求积",
"_____no_output_____"
],
[
"求所有元素的乘积:",
"_____no_output_____"
]
],
[
[
"a.prod()",
"_____no_output_____"
]
],
[
[
"或者使用函数形式:",
"_____no_output_____"
]
],
[
[
"prod(a, axis=0)",
"_____no_output_____"
]
],
[
[
"## 求最大最小值",
"_____no_output_____"
]
],
[
[
"from numpy.random import rand\na = rand(3, 4)\n%precision 3\na",
"_____no_output_____"
]
],
[
[
"全局最小:",
"_____no_output_____"
]
],
[
[
"a.min()",
"_____no_output_____"
]
],
[
[
"沿着某个轴的最小:",
"_____no_output_____"
]
],
[
[
"a.min(axis=0)",
"_____no_output_____"
]
],
[
[
"全局最大:",
"_____no_output_____"
]
],
[
[
"a.max()",
"_____no_output_____"
]
],
[
[
"沿着某个轴的最大:",
"_____no_output_____"
]
],
[
[
"a.max(axis=-1)",
"_____no_output_____"
]
],
[
[
"## 最大最小值的位置",
"_____no_output_____"
],
[
"使用 `argmin, argmax` 方法:",
"_____no_output_____"
]
],
[
[
"a.argmin()",
"_____no_output_____"
],
[
"a.argmin(axis=0)",
"_____no_output_____"
]
],
[
[
"## 均值",
"_____no_output_____"
],
[
"可以使用 `mean` 方法:",
"_____no_output_____"
]
],
[
[
"a = array([[1,2,3],[4,5,6]])",
"_____no_output_____"
],
[
"a.mean()",
"_____no_output_____"
],
[
"a.mean(axis=-1)",
"_____no_output_____"
]
],
[
[
"也可以使用 `mean` 函数:",
"_____no_output_____"
]
],
[
[
"mean(a)",
"_____no_output_____"
]
],
[
[
"还可以使用 `average` 函数:",
"_____no_output_____"
]
],
[
[
"average(a, axis = 0)",
"_____no_output_____"
]
],
[
[
"`average` 函数还支持加权平均:",
"_____no_output_____"
]
],
[
[
"average(a, axis = 0, weights=[1,2])",
"_____no_output_____"
]
],
[
[
"## 标准差",
"_____no_output_____"
],
[
"用 `std` 方法计算标准差:",
"_____no_output_____"
]
],
[
[
"a.std(axis=1)",
"_____no_output_____"
]
],
[
[
"用 `var` 方法计算方差:",
"_____no_output_____"
]
],
[
[
"a.var(axis=1)",
"_____no_output_____"
]
],
[
[
"或者使用函数:",
"_____no_output_____"
]
],
[
[
"var(a, axis=1)",
"_____no_output_____"
],
[
"std(a, axis=1)",
"_____no_output_____"
]
],
[
[
"## clip 方法",
"_____no_output_____"
],
[
"将数值限制在某个范围:",
"_____no_output_____"
]
],
[
[
"a",
"_____no_output_____"
],
[
"a.clip(3,5)",
"_____no_output_____"
]
],
[
[
"小于3的变成3,大于5的变成5。",
"_____no_output_____"
],
[
"## ptp 方法",
"_____no_output_____"
],
[
"计算最大值和最小值之差:",
"_____no_output_____"
]
],
[
[
"a.ptp(axis=1)",
"_____no_output_____"
],
[
"a.ptp()",
"_____no_output_____"
]
],
[
[
"## round 方法",
"_____no_output_____"
],
[
"近似,默认到整数:",
"_____no_output_____"
]
],
[
[
"a = array([1.35, 2.5, 1.5])",
"_____no_output_____"
]
],
[
[
"这里,.5的近似规则为近似到偶数值,可以参考:\n\nhttps://en.wikipedia.org/wiki/Rounding#Round_half_to_odd",
"_____no_output_____"
]
],
[
[
"a.round()",
"_____no_output_____"
]
],
[
[
"近似到一位小数:",
"_____no_output_____"
]
],
[
[
"a.round(decimals=1)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad4af9c828a44fd3267c179443e980fbe9c6c21
| 952,771 |
ipynb
|
Jupyter Notebook
|
notebooks/topcount/atoti.ipynb
|
seanahmad/notebooks-1
|
c7609406973a4ac4ba33bd154a52fd53d94afb54
|
[
"Apache-2.0"
] | 1 |
2020-11-27T12:20:29.000Z
|
2020-11-27T12:20:29.000Z
|
notebooks/topcount/atoti.ipynb
|
shrikant9793/notebooks
|
051b6d9038c1100d5487c7b67e15feed8effd215
|
[
"Apache-2.0"
] | null | null | null |
notebooks/topcount/atoti.ipynb
|
shrikant9793/notebooks
|
051b6d9038c1100d5487c7b67e15feed8effd215
|
[
"Apache-2.0"
] | null | null | null | 29.522232 | 114,139 | 0.40362 |
[
[
[
"# Ways to visualize top count with atoti\n\nGiven different categories of items, we will explore how to achieve the following with atoti:\n- Visualize top 10 apps with the highest rating in table\n- Visualize top 10 categories with most number of apps rated 5 in Pie chart\n- Visualize top 10 apps for each category in subplots\n\nSee [pandas.ipynb](pandas.ipynb) to see how we can achieve the similar top count with Pandas.\n\n__Note on data:__\nWe are using the [Google Play Store Apps data](https://www.kaggle.com/lava18/google-play-store-apps) from Kaggle. Data has been processed to convert strings with millions and thousands abbreviations into numeric data.",
"_____no_output_____"
],
[
"## Top count with atoti",
"_____no_output_____"
]
],
[
[
"import atoti as tt\nfrom atoti.config import create_config\n\nconfig = create_config(metadata_db=\"./metadata.db\")\nsession = tt.create_session(config=config)",
"Welcome to atoti 0.4.3!\n\nBy using this community edition, you agree with the license available at https://www.atoti.io/eula.\nBrowse the official documentation at https://docs.atoti.io.\nJoin the community at https://www.atoti.io/register.\n\nYou can hide this message by setting the ATOTI_HIDE_EULA_MESSAGE environment variable to True.\n"
],
[
"playstore = session.read_csv(\n \"s3://data.atoti.io/notebooks/topcount/googleplaystore_cleaned.csv\",\n store_name=\"playstore\",\n keys=[\"App\", \"Category\", \"Genres\", \"Current Ver\"],\n sampling_mode=tt.sampling.FULL,\n types={\"Reviews\": tt.types.FLOAT, \"Installs\": tt.types.FLOAT},\n)\n\nplaystore.head()",
"_____no_output_____"
],
[
"cube = session.create_cube(playstore, \"Google Playstore\")\ncube.schema",
"_____no_output_____"
]
],
[
[
"### Top 10 apps with highest rating across categories\n\nUse the content editor to apply a top count filter on the pivot table.",
"_____no_output_____"
]
],
[
[
"cube.visualize(\"Top 10 apps with highest rating across categories\")",
"_____no_output_____"
]
],
[
[
"### Top 10 categories with the most number of apps rated 5",
"_____no_output_____"
]
],
[
[
"h = cube.hierarchies\nl = cube.levels\nm = cube.measures\nm",
"_____no_output_____"
]
],
[
[
"#### Number of apps rated 5\n\nCreate a measure that counts the number of apps rated 5 within categories and at levels below the category.",
"_____no_output_____"
]
],
[
[
"m[\"Count with rating 5\"] = tt.agg.sum(\n tt.where(m[\"Rating.MEAN\"] == 5, m[\"contributors.COUNT\"], 0),\n scope=tt.scope.origin(l[\"Category\"], l[\"App\"]),\n)",
"_____no_output_____"
]
],
[
[
"We can drill down to different levels from category and the count is computed on the fly.",
"_____no_output_____"
]
],
[
[
"cube.visualize(\"Categories with apps rated 5\")",
"_____no_output_____"
]
],
[
[
"Apply top count filter from **atoti editor** on the category by the `Count with rating 5` measure. The atoti editor is the atoti's Jupyterlab extension on the right with the <img src=\"https://data.atoti.io/notebooks/topcount/atoti_editor.png\" alt=\"a.\" width=\"50\"> icon.",
"_____no_output_____"
]
],
[
[
"cube.visualize(\"Top 10 categories with most number of apps rated 5\")",
"_____no_output_____"
]
],
[
[
"### Top 10 apps for each category\n\nSince we are performing top 10 apps filtering for each category, it's only right that we classify `App` under `Category`. \nIn this case, we create a multi-level hierarchy such as the following:",
"_____no_output_____"
]
],
[
[
"h[\"App Categories\"] = [l[\"Category\"], l[\"App\"]]\nh",
"_____no_output_____"
]
],
[
[
"This structure allows us to select at which level we want to apply the top count on from the atoti editor. \n<img src=\"https://data.atoti.io/notebooks/topcount/filter_by_level.png\" alt=\"Filter by level\" width=\"30%\">",
"_____no_output_____"
]
],
[
[
"cube.visualize(\"Top 10 apps with highest rating for each category\")",
"_____no_output_____"
]
],
[
[
"#### Creating subplot to visualize top count per category\n\nAgain, go to the atoti's Jupyterlab extension and click on the ellipsis to show the subplot controls. \n \n\nYou should be able to add `Category` level to the subplot section sliced by `Apps`. Apply filter on `App` level of the `App Categories`",
"_____no_output_____"
]
],
[
[
"cube.visualize(\"Top 10 apps within each categories\")",
"_____no_output_____"
]
],
[
[
"You can use the filter to select the categories that you want to view. \nAlternative, use `session.url` to access the web application to build an interactive dashboard with quick filters. Check out the link below.",
"_____no_output_____"
]
],
[
[
"session.url + \"/#/dashboard/767\"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad4b65a0cd898a03975057a7fde64e923806854
| 204,011 |
ipynb
|
Jupyter Notebook
|
examples/Example.ipynb
|
nttcom/HSICLassoVI
|
4d841feb25f24ae8af5ecfb7bf109dbb12afd2d5
|
[
"Unlicense"
] | null | null | null |
examples/Example.ipynb
|
nttcom/HSICLassoVI
|
4d841feb25f24ae8af5ecfb7bf109dbb12afd2d5
|
[
"Unlicense"
] | null | null | null |
examples/Example.ipynb
|
nttcom/HSICLassoVI
|
4d841feb25f24ae8af5ecfb7bf109dbb12afd2d5
|
[
"Unlicense"
] | null | null | null | 192.644948 | 48,852 | 0.875154 |
[
[
[
"from HSICLassoVI.models import api",
"_____no_output_____"
],
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport pandas as pd\nfrom sklearn.metrics import *",
"_____no_output_____"
]
],
[
[
"## Data1: Additive model",
"_____no_output_____"
]
],
[
[
"N, P = 1000, 256\nmean = np.zeros(P)\ncov = np.eye(P)\nnp.random.seed(1)",
"_____no_output_____"
]
],
[
[
"$$\ny\\in\\mathbb{R}^{1000}, X\\in\\mathbb{R}^{1000\\times256}\n$$",
"_____no_output_____"
]
],
[
[
"X = np.random.multivariate_normal(mean = mean, cov = cov, size = N)\ny = -2*np.sin(2*X[:,0]) + np.power(X[:,1],2) + X[:,2] + np.exp(-X[:,3]) + np.random.normal(loc=0, scale=1, size=N)",
"_____no_output_____"
]
],
[
[
"$$\ny=-2\\sin(2X_1)+X_2^2+X_3+\\exp(-X_4)+\\epsilon\n$$",
"_____no_output_____"
]
],
[
[
"data1 = pd.DataFrame(np.c_[y.reshape(-1,1),X], columns = ['y'] + [f'X{p+1}' for p in range(P)])\ndata1.describe()",
"_____no_output_____"
]
],
[
[
"### Proposed (HSIC)",
"_____no_output_____"
]
],
[
[
"model_PH1 = api.Proposed_HSIC_Lasso(lam = [np.inf, 1e-5])\nmodel_PH1.input(X,y,featname = data1.columns[1:])",
"_____no_output_____"
],
[
"model_PH1.regression_multi(kernels=['Gaussian'])",
"Block HSIC Lasso B = 20.\nM set to 3.\nUsing Gaussian kernel for the features and Gaussian kernel for the target.\n"
],
[
"plt.figure(figsize=[8,6], dpi=200)\nplt.bar(np.arange(20),model_PH1.get_index_score()[:20])\nplt.xticks(np.arange(20),model_PH1.get_features()[:20], rotation=40)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Proposed (NOCCO)",
"_____no_output_____"
]
],
[
[
"model_PN1 = api.Proposed_NOCCO_Lasso(lam = [np.inf, 5e-5], eps = 1e-3)\nmodel_PN1.input(X,y,featname = data1.columns[1:])",
"_____no_output_____"
],
[
"model_PN1.regression_multi(kernels=['Gaussian'])",
"Block HSIC Lasso B = 20.\nM set to 3.\nUsing Gaussian kernel for the features and Gaussian kernel for the target.\n"
],
[
"plt.figure(figsize=[8,6], dpi=200)\nplt.bar(np.arange(20),model_PN1.get_index_score()[:20])\nplt.xticks(np.arange(20),model_PN1.get_features()[:20], rotation=40)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Data2: Non-additive model",
"_____no_output_____"
]
],
[
[
"N, P = 1000, 1000\nmean = np.zeros(P)\ncov = np.eye(P)\nnp.random.seed(2)",
"_____no_output_____"
]
],
[
[
"$$\ny\\in\\mathbb{R}^{1000}, X\\in\\mathbb{R}^{1000\\times1000}\n$$",
"_____no_output_____"
]
],
[
[
"X = np.random.multivariate_normal(mean = mean, cov = cov, size = N)\ny = X[:,0] * np.exp(2 * X[:,1]) + X[:,2]**2 + np.random.normal(loc=0, scale=1, size=N)",
"_____no_output_____"
]
],
[
[
"$$\ny=X_1\\exp(2X_2)+X_3^2+\\epsilon\n$$",
"_____no_output_____"
]
],
[
[
"data2 = pd.DataFrame(np.c_[y.reshape(-1,1),X], columns = ['y'] + [f'X{p+1}' for p in range(P)])\ndata2.describe()",
"_____no_output_____"
]
],
[
[
"### Proposed (HSIC)",
"_____no_output_____"
]
],
[
[
"model_PH2 = api.Proposed_HSIC_Lasso(lam = [np.inf,4e-6])\nmodel_PH2.input(X,y,featname = data2.columns[1:])",
"_____no_output_____"
],
[
"model_PH2.regression_multi(kernels=['Gaussian'])",
"Block HSIC Lasso B = 20.\nM set to 3.\nUsing Gaussian kernel for the features and Gaussian kernel for the target.\n"
],
[
"plt.figure(figsize=[8,6], dpi=200)\nplt.bar(np.arange(20),model_PH2.get_index_score()[:20])\nplt.xticks(np.arange(20),model_PH2.get_features()[:20], rotation=40)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Proposed (NOCCO)",
"_____no_output_____"
]
],
[
[
"model_PN2 = api.Proposed_NOCCO_Lasso(lam = [np.inf,2e-5], eps = 1e-3)\nmodel_PN2.input(X,y,featname = data2.columns[1:])",
"_____no_output_____"
],
[
"model_PN2.regression_multi(kernels=['Gaussian'])",
"Block HSIC Lasso B = 20.\nM set to 3.\nUsing Gaussian kernel for the features and Gaussian kernel for the target.\n"
],
[
"plt.figure(figsize=[8,6], dpi=200)\nplt.bar(np.arange(20),model_PN2.get_index_score()[:20])\nplt.xticks(np.arange(20),model_PN2.get_features()[:20], rotation=40)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4ad4b993bd99c5c18d7a4acee2501ae38b3527da
| 52,412 |
ipynb
|
Jupyter Notebook
|
tutorials/W3D5_DeepLearning2/W3D5_Tutorial2.ipynb
|
mmyros/course-content
|
6b3751fa2aea1c101a9213c1fce2d0832231fa76
|
[
"CC-BY-4.0"
] | 2 |
2021-05-12T02:19:05.000Z
|
2021-05-12T13:49:29.000Z
|
tutorials/W3D5_DeepLearning2/W3D5_Tutorial2.ipynb
|
pattanaikay/course-content
|
b9c79974109a279121e6875cdcd2e69f39aeb2fb
|
[
"CC-BY-4.0",
"BSD-3-Clause"
] | 1 |
2020-07-21T20:37:28.000Z
|
2020-07-21T20:37:28.000Z
|
tutorials/W3D5_DeepLearning2/W3D5_Tutorial2.ipynb
|
pattanaikay/course-content
|
b9c79974109a279121e6875cdcd2e69f39aeb2fb
|
[
"CC-BY-4.0",
"BSD-3-Clause"
] | 1 |
2021-05-02T10:03:07.000Z
|
2021-05-02T10:03:07.000Z
| 32.09553 | 489 | 0.535469 |
[
[
[
"<a href=\"https://colab.research.google.com/github/NeuromatchAcademy/course-content/blob/master/tutorials/W3D5_DeepLearning2/W3D5_Tutorial2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Neuromatch Academy: Week 3, Day 5, Tutorial 2\n# Deep Learning 2: Autoencoder extensions\n\n__Content creators:__ Marco Brigham and the [CCNSS](https://www.ccnss.org/) team (2014-2018)\n\n__Content reviewers:__ Itzel Olivos, Karen Schroeder, Karolina Stosio, Kshitij Dwivedi, Spiros Chavlis, Michael Waskom",
"_____no_output_____"
],
[
"---\n# Tutorial Objectives\n\n## Architecture\nHow can we improve the internal representation of shallow autoencoder with 2D bottleneck layer? \n\nWe may try the following architecture changes:\n* Introducing additional hidden layers\n* Wrapping latent space as a sphere\n\n \n\n\n\nAdding hidden layers increases the number of learnable parameters to better use non-linear operations in encoding/decoding. Spherical geometry of latent space forces the network to use these additional degrees of freedom more efficiently.\n\nLet's dive deeper into the technical aspects of autoencoders and improve their internal representations to reach the levels required for the *MNIST cognitive task*.\n\nIn this tutorial, you will:\n- Increase the capacity of the network by introducing additional hidden layers\n- Understand the effect of constraints in the geometry of latent space",
"_____no_output_____"
]
],
[
[
"# @title Video 1: Extensions\nfrom IPython.display import YouTubeVideo\nvideo = YouTubeVideo(id=\"pgkrU9UqXiU\", width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"_____no_output_____"
]
],
[
[
"---\n# Setup\nPlease execute the cell(s) below to initialize the notebook environment.",
"_____no_output_____"
]
],
[
[
"# Imports\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport torch\nfrom torch import nn, optim\n\nfrom sklearn.datasets import fetch_openml",
"_____no_output_____"
],
[
"# @title Figure settings\n!pip install plotly --quiet\nimport plotly.graph_objects as go\nfrom plotly.colors import qualitative\n%config InlineBackend.figure_format = 'retina'\nplt.style.use(\"https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/nma.mplstyle\")",
"_____no_output_____"
],
[
"# @title Helper functions\n\n\ndef downloadMNIST():\n \"\"\"\n Download MNIST dataset and transform it to torch.Tensor\n\n Args:\n None\n\n Returns:\n x_train : training images (torch.Tensor) (60000, 28, 28)\n x_test : test images (torch.Tensor) (10000, 28, 28)\n y_train : training labels (torch.Tensor) (60000, )\n y_train : test labels (torch.Tensor) (10000, )\n \"\"\"\n X, y = fetch_openml('mnist_784', version=1, return_X_y=True)\n # Trunk the data\n n_train = 60000\n n_test = 10000\n\n train_idx = np.arange(0, n_train)\n test_idx = np.arange(n_train, n_train + n_test)\n\n x_train, y_train = X[train_idx], y[train_idx]\n x_test, y_test = X[test_idx], y[test_idx]\n\n # Transform np.ndarrays to torch.Tensor\n x_train = torch.from_numpy(np.reshape(x_train,\n (len(x_train),\n 28, 28)).astype(np.float32))\n x_test = torch.from_numpy(np.reshape(x_test,\n (len(x_test),\n 28, 28)).astype(np.float32))\n\n y_train = torch.from_numpy(y_train.astype(int))\n y_test = torch.from_numpy(y_test.astype(int))\n\n return (x_train, y_train, x_test, y_test)\n\n\ndef init_weights_kaiming_uniform(layer):\n \"\"\"\n Initializes weights from linear PyTorch layer\n with kaiming uniform distribution.\n\n Args:\n layer (torch.Module)\n Pytorch layer\n\n Returns:\n Nothing.\n \"\"\"\n # check for linear PyTorch layer\n if isinstance(layer, nn.Linear):\n # initialize weights with kaiming uniform distribution\n nn.init.kaiming_uniform_(layer.weight.data)\n\n\ndef init_weights_kaiming_normal(layer):\n \"\"\"\n Initializes weights from linear PyTorch layer\n with kaiming normal distribution.\n\n Args:\n layer (torch.Module)\n Pytorch layer\n\n Returns:\n Nothing.\n \"\"\"\n # check for linear PyTorch layer\n if isinstance(layer, nn.Linear):\n # initialize weights with kaiming normal distribution\n nn.init.kaiming_normal_(layer.weight.data)\n\n\ndef get_layer_weights(layer):\n \"\"\"\n Retrieves learnable parameters from PyTorch layer.\n\n Args:\n layer (torch.Module)\n Pytorch layer\n\n Returns:\n list with learnable parameters\n \"\"\"\n # initialize output list\n weights = []\n\n # check whether layer has learnable parameters\n if layer.parameters():\n # copy numpy array representation of each set of learnable parameters\n for item in layer.parameters():\n weights.append(item.detach().numpy())\n\n return weights\n\n\ndef print_parameter_count(net):\n \"\"\"\n Prints count of learnable parameters per layer from PyTorch network.\n\n Args:\n net (torch.Sequential)\n Pytorch network\n\n Returns:\n Nothing.\n \"\"\"\n\n params_n = 0\n\n # loop all layers in network\n for layer_idx, layer in enumerate(net):\n\n # retrieve learnable parameters\n weights = get_layer_weights(layer)\n params_layer_n = 0\n\n # loop list of learnable parameters and count them\n for params in weights:\n params_layer_n += params.size\n\n params_n += params_layer_n\n print(f'{layer_idx}\\t {params_layer_n}\\t {layer}')\n\n print(f'\\nTotal:\\t {params_n}')\n\n\ndef eval_mse(y_pred, y_true):\n \"\"\"\n Evaluates mean square error (MSE) between y_pred and y_true\n\n Args:\n y_pred (torch.Tensor)\n prediction samples\n\n v (numpy array of floats)\n ground truth samples\n\n Returns:\n MSE(y_pred, y_true)\n \"\"\"\n\n with torch.no_grad():\n criterion = nn.MSELoss()\n loss = criterion(y_pred, y_true)\n\n return float(loss)\n\n\ndef eval_bce(y_pred, y_true):\n \"\"\"\n Evaluates binary cross-entropy (BCE) between y_pred and y_true\n\n Args:\n y_pred (torch.Tensor)\n prediction samples\n\n v (numpy array of floats)\n ground truth samples\n\n Returns:\n BCE(y_pred, y_true)\n \"\"\"\n\n with torch.no_grad():\n criterion = nn.BCELoss()\n loss = criterion(y_pred, y_true)\n\n return float(loss)\n\n\ndef plot_row(images, show_n=10, image_shape=None):\n \"\"\"\n Plots rows of images from list of iterables (iterables: list, numpy array\n or torch.Tensor). Also accepts single iterable.\n Randomly selects images in each list element if item count > show_n.\n\n Args:\n images (iterable or list of iterables)\n single iterable with images, or list of iterables\n\n show_n (integer)\n maximum number of images per row\n\n image_shape (tuple or list)\n original shape of image if vectorized form\n\n Returns:\n Nothing.\n \"\"\"\n\n if not isinstance(images, (list, tuple)):\n images = [images]\n\n for items_idx, items in enumerate(images):\n\n items = np.array(items)\n if items.ndim == 1:\n items = np.expand_dims(items, axis=0)\n\n if len(items) > show_n:\n selected = np.random.choice(len(items), show_n, replace=False)\n items = items[selected]\n\n if image_shape is not None:\n items = items.reshape([-1]+list(image_shape))\n\n plt.figure(figsize=(len(items) * 1.5, 2))\n for image_idx, image in enumerate(items):\n\n plt.subplot(1, len(items), image_idx + 1)\n plt.imshow(image, cmap='gray', vmin=image.min(), vmax=image.max())\n plt.axis('off')\n\n plt.tight_layout()\n\n\ndef to_s2(u):\n \"\"\"\n Projects 3D coordinates to spherical coordinates (theta, phi) surface of\n unit sphere S2.\n theta: [0, pi]\n phi: [-pi, pi]\n\n Args:\n u (list, numpy array or torch.Tensor of floats)\n 3D coordinates\n\n Returns:\n Sperical coordinates (theta, phi) on surface of unit sphere S2.\n \"\"\"\n\n x, y, z = (u[:, 0], u[:, 1], u[:, 2])\n r = np.sqrt(x**2 + y**2 + z**2)\n theta = np.arccos(z / r)\n phi = np.arctan2(x, y)\n\n return np.array([theta, phi]).T\n\n\ndef to_u3(s):\n \"\"\"\n Converts from 2D coordinates on surface of unit sphere S2 to 3D coordinates\n (on surface of S2), i.e. (theta, phi) ---> (1, theta, phi).\n\n Args:\n s (list, numpy array or torch.Tensor of floats)\n 2D coordinates on unit sphere S_2\n\n Returns:\n 3D coordinates on surface of unit sphere S_2\n \"\"\"\n\n theta, phi = (s[:, 0], s[:, 1])\n x = np.sin(theta) * np.sin(phi)\n y = np.sin(theta) * np.cos(phi)\n z = np.cos(theta)\n\n return np.array([x, y, z]).T\n\n\ndef xy_lim(x):\n \"\"\"\n Return arguments for plt.xlim and plt.ylim calculated from minimum\n and maximum of x.\n\n Args:\n x (list, numpy array or torch.Tensor of floats)\n data to be plotted\n\n Returns:\n Nothing.\n \"\"\"\n\n x_min = np.min(x, axis=0)\n x_max = np.max(x, axis=0)\n\n x_min = x_min - np.abs(x_max - x_min) * 0.05 - np.finfo(float).eps\n x_max = x_max + np.abs(x_max - x_min) * 0.05 + np.finfo(float).eps\n\n return [x_min[0], x_max[0]], [x_min[1], x_max[1]]\n\n\ndef plot_generative(x, decoder_fn, image_shape, n_row=16, s2=False):\n \"\"\"\n Plots images reconstructed by decoder_fn from a 2D grid in\n latent space that is determined by minimum and maximum values in x.\n\n Args:\n x (list, numpy array or torch.Tensor of floats)\n 2D or 3D coordinates in latent space\n\n decoder_fn (integer)\n function returning vectorized images from 2D latent space coordinates\n\n image_shape (tuple or list)\n original shape of image\n\n n_row (integer)\n number of rows in grid\n\n s2 (boolean)\n convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)\n\n Returns:\n Nothing.\n \"\"\"\n\n if s2:\n x = to_s2(np.array(x))\n\n xlim, ylim = xy_lim(np.array(x))\n\n dx = (xlim[1] - xlim[0]) / n_row\n grid = [np.linspace(ylim[0] + dx / 2, ylim[1] - dx / 2, n_row),\n np.linspace(xlim[0] + dx / 2, xlim[1] - dx / 2, n_row)]\n\n canvas = np.zeros((image_shape[0] * n_row, image_shape[1] * n_row))\n\n cmap = plt.get_cmap('gray')\n\n for j, latent_y in enumerate(grid[0][::-1]):\n for i, latent_x in enumerate(grid[1]):\n\n latent = np.array([[latent_x, latent_y]], dtype=np.float32)\n\n if s2:\n latent = to_u3(latent)\n\n with torch.no_grad():\n x_decoded = decoder_fn(torch.from_numpy(latent))\n\n x_decoded = x_decoded.reshape(image_shape)\n\n canvas[j * image_shape[0]: (j + 1) * image_shape[0],\n i * image_shape[1]: (i + 1) * image_shape[1]] = x_decoded\n\n plt.imshow(canvas, cmap=cmap, vmin=canvas.min(), vmax=canvas.max())\n plt.axis('off')\n\n\ndef plot_latent(x, y, show_n=500, s2=False, fontdict=None, xy_labels=None):\n \"\"\"\n Plots digit class of each sample in 2D latent space coordinates.\n\n Args:\n x (list, numpy array or torch.Tensor of floats)\n 2D coordinates in latent space\n\n y (list, numpy array or torch.Tensor of floats)\n digit class of each sample\n\n n_row (integer)\n number of samples\n\n s2 (boolean)\n convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)\n\n fontdict (dictionary)\n style option for plt.text\n\n xy_labels (list)\n optional list with [xlabel, ylabel]\n\n Returns:\n Nothing.\n \"\"\"\n\n if fontdict is None:\n fontdict = {'weight': 'bold', 'size': 12}\n\n if s2:\n x = to_s2(np.array(x))\n\n cmap = plt.get_cmap('tab10')\n\n if len(x) > show_n:\n selected = np.random.choice(len(x), show_n, replace=False)\n x = x[selected]\n y = y[selected]\n\n for my_x, my_y in zip(x, y):\n plt.text(my_x[0], my_x[1], str(int(my_y)),\n color=cmap(int(my_y) / 10.),\n fontdict=fontdict,\n horizontalalignment='center',\n verticalalignment='center',\n alpha=0.8)\n\n xlim, ylim = xy_lim(np.array(x))\n plt.xlim(xlim)\n plt.ylim(ylim)\n\n if s2:\n if xy_labels is None:\n xy_labels = [r'$\\varphi$', r'$\\theta$']\n\n plt.xticks(np.arange(0, np.pi + np.pi / 6, np.pi / 6),\n ['0', '$\\pi/6$', '$\\pi/3$', '$\\pi/2$',\n '$2\\pi/3$', '$5\\pi/6$', '$\\pi$'])\n plt.yticks(np.arange(-np.pi, np.pi + np.pi / 3, np.pi / 3),\n ['$-\\pi$', '$-2\\pi/3$', '$-\\pi/3$', '0',\n '$\\pi/3$', '$2\\pi/3$', '$\\pi$'])\n\n if xy_labels is None:\n xy_labels = ['$Z_1$', '$Z_2$']\n\n plt.xlabel(xy_labels[0])\n plt.ylabel(xy_labels[1])\n\n\ndef plot_latent_generative(x, y, decoder_fn, image_shape, s2=False,\n title=None, xy_labels=None):\n \"\"\"\n Two horizontal subplots generated with encoder map and decoder grid.\n\n Args:\n x (list, numpy array or torch.Tensor of floats)\n 2D coordinates in latent space\n\n y (list, numpy array or torch.Tensor of floats)\n digit class of each sample\n\n decoder_fn (integer)\n function returning vectorized images from 2D latent space coordinates\n\n image_shape (tuple or list)\n original shape of image\n\n s2 (boolean)\n convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)\n\n title (string)\n plot title\n\n xy_labels (list)\n optional list with [xlabel, ylabel]\n\n Returns:\n Nothing.\n \"\"\"\n\n fig = plt.figure(figsize=(12, 6))\n\n if title is not None:\n fig.suptitle(title, y=1.05)\n\n ax = fig.add_subplot(121)\n ax.set_title('Encoder map', y=1.05)\n plot_latent(x, y, s2=s2, xy_labels=xy_labels)\n\n ax = fig.add_subplot(122)\n ax.set_title('Decoder grid', y=1.05)\n plot_generative(x, decoder_fn, image_shape, s2=s2)\n\n plt.tight_layout()\n plt.show()\n\n\ndef plot_latent_3d(my_x, my_y, show_text=True, show_n=500):\n \"\"\"\n Plot digit class or marker in 3D latent space coordinates.\n\n Args:\n my_x (list, numpy array or torch.Tensor of floats)\n 2D coordinates in latent space\n\n my_y (list, numpy array or torch.Tensor of floats)\n digit class of each sample\n\n show_text (boolean)\n whether to show text\n\n image_shape (tuple or list)\n original shape of image\n\n s2 (boolean)\n convert 3D coordinates (x, y, z) to spherical coordinates (theta, phi)\n\n title (string)\n plot title\n\n Returns:\n Nothing.\n \"\"\"\n\n layout = {'margin': {'l': 0, 'r': 0, 'b': 0, 't': 0},\n 'scene': {'xaxis': {'showspikes': False,\n 'title': 'z1'},\n 'yaxis': {'showspikes': False,\n 'title': 'z2'},\n 'zaxis': {'showspikes': False,\n 'title': 'z3'}}\n }\n\n selected_idx = np.random.choice(len(my_x), show_n, replace=False)\n\n colors = [qualitative.T10[idx] for idx in my_y[selected_idx]]\n\n x = my_x[selected_idx, 0]\n y = my_x[selected_idx, 1]\n z = my_x[selected_idx, 2]\n\n text = my_y[selected_idx]\n\n if show_text:\n\n trace = go.Scatter3d(x=x, y=y, z=z, text=text,\n mode='text',\n textfont={'color': colors, 'size': 12}\n )\n\n layout['hovermode'] = False\n\n else:\n\n trace = go.Scatter3d(x=x, y=y, z=z, text=text,\n hoverinfo='text', mode='markers',\n marker={'size': 5, 'color': colors, 'opacity': 0.8}\n )\n\n fig = go.Figure(data=trace, layout=layout)\n\n fig.show()\n\n\ndef runSGD(net, input_train, input_test, criterion='bce',\n n_epochs=10, batch_size=32, verbose=False):\n \"\"\"\n Trains autoencoder network with stochastic gradient descent with Adam\n optimizer and loss criterion. Train samples are shuffled, and loss is\n displayed at the end of each opoch for both MSE and BCE. Plots training loss\n at each minibatch (maximum of 500 randomly selected values).\n\n Args:\n net (torch network)\n ANN object (nn.Module)\n\n input_train (torch.Tensor)\n vectorized input images from train set\n\n input_test (torch.Tensor)\n vectorized input images from test set\n\n criterion (string)\n train loss: 'bce' or 'mse'\n\n n_epochs (boolean)\n number of full iterations of training data\n\n batch_size (integer)\n number of element in mini-batches\n\n verbose (boolean)\n print final loss\n\n Returns:\n Nothing.\n \"\"\"\n\n # Initialize loss function\n if criterion == 'mse':\n loss_fn = nn.MSELoss()\n elif criterion == 'bce':\n loss_fn = nn.BCELoss()\n else:\n print('Please specify either \"mse\" or \"bce\" for loss criterion')\n\n # Initialize SGD optimizer\n optimizer = optim.Adam(net.parameters())\n\n # Placeholder for loss\n track_loss = []\n\n print('Epoch', '\\t', 'Loss train', '\\t', 'Loss test')\n for i in range(n_epochs):\n\n shuffle_idx = np.random.permutation(len(input_train))\n batches = torch.split(input_train[shuffle_idx], batch_size)\n\n for batch in batches:\n\n output_train = net(batch)\n loss = loss_fn(output_train, batch)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n # Keep track of loss at each epoch\n track_loss += [float(loss)]\n\n loss_epoch = f'{i+1}/{n_epochs}'\n with torch.no_grad():\n output_train = net(input_train)\n loss_train = loss_fn(output_train, input_train)\n loss_epoch += f'\\t {loss_train:.4f}'\n\n output_test = net(input_test)\n loss_test = loss_fn(output_test, input_test)\n loss_epoch += f'\\t\\t {loss_test:.4f}'\n\n print(loss_epoch)\n\n if verbose:\n # Print loss\n loss_mse = f'\\nMSE\\t {eval_mse(output_train, input_train):0.4f}'\n loss_mse += f'\\t\\t {eval_mse(output_test, input_test):0.4f}'\n print(loss_mse)\n\n loss_bce = f'BCE\\t {eval_bce(output_train, input_train):0.4f}'\n loss_bce += f'\\t\\t {eval_bce(output_test, input_test):0.4f}'\n print(loss_bce)\n\n # Plot loss\n step = int(np.ceil(len(track_loss) / 500))\n x_range = np.arange(0, len(track_loss), step)\n plt.figure()\n plt.plot(x_range, track_loss[::step], 'C0')\n plt.xlabel('Iterations')\n plt.ylabel('Loss')\n plt.xlim([0, None])\n plt.ylim([0, None])\n plt.show()\n\n\nclass NormalizeLayer(nn.Module):\n \"\"\"\n pyTorch layer (nn.Module) that normalizes activations by their L2 norm.\n\n Args:\n None.\n\n Returns:\n Object inherited from nn.Module class.\n \"\"\"\n\n def __init__(self):\n super().__init__()\n\n def forward(self, x):\n return nn.functional.normalize(x, p=2, dim=1)",
"_____no_output_____"
]
],
[
[
"---\n# Section 1: Download and prepare MNIST dataset\nWe use the helper function `downloadMNIST` to download the dataset and transform it into `torch.Tensor` and assign train and test sets to (`x_train`, `y_train`) and (`x_test`, `y_test`).\n\nThe variable `input_size` stores the length of *vectorized* versions of the images `input_train` and `input_test` for training and test images.\n\n**Instructions:**\n* Please execute the cell below",
"_____no_output_____"
]
],
[
[
"# Download MNIST\nx_train, y_train, x_test, y_test = downloadMNIST()\n\nx_train = x_train / 255\nx_test = x_test / 255\n\nimage_shape = x_train.shape[1:]\n\ninput_size = np.prod(image_shape)\n\ninput_train = x_train.reshape([-1, input_size])\ninput_test = x_test.reshape([-1, input_size])\n\ntest_selected_idx = np.random.choice(len(x_test), 10, replace=False)\ntrain_selected_idx = np.random.choice(len(x_train), 10, replace=False)\n\nprint(f'shape image \\t \\t {image_shape}')\nprint(f'shape input_train \\t {input_train.shape}')\nprint(f'shape input_test \\t {input_test.shape}')",
"_____no_output_____"
]
],
[
[
"---\n# Section 2: Deeper autoencoder (2D)\nThe internal representation of shallow autoencoder with 2D latent space is similar to PCA, which shows that the autoencoder is not fully leveraging non-linear capabilities to model data. Adding capacity in terms of learnable parameters takes advantage of non-linear operations in encoding/decoding to capture non-linear patterns in data.\n\nAdding hidden layers enables us to introduce additional parameters, either layerwise or depthwise. The same amount $N$ of additional parameters can be added in a single layer or distributed among several layers. Adding several hidden layers reduces the compression/decompression ratio of each layer.",
"_____no_output_____"
],
[
"## Exercise 1: Build deeper autoencoder (2D)\nImplement this deeper version of the ANN autoencoder by adding four hidden layers. The number of units per layer in the encoder is the following:\n\n```\n784 -> 392 -> 64 -> 2\n```\n\nThe shallow autoencoder has a compression ratio of **784:2 = 392:1**. The first additional hidden layer has a compression ratio of **2:1**, followed by a hidden layer that sets the bottleneck compression ratio of **32:1**.\n\nThe choice of hidden layer size aims to reduce the compression rate in the bottleneck layer while increasing the count of trainable parameters. For example, if the compression rate of the first hidden layer doubles from **2:1** to **4:1**, the count of trainable parameters halves from 667K to 333K.\n\n \n\nThis deep autoencoder's performance may be further improved by adding additional hidden layers and by increasing the count of trainable parameters in each layer. These improvements have a diminishing return due to challenges associated with training under high parameter count and depth. One option explored in the *Bonus* section is to add a first hidden layer with 2x - 3x the input size. This size increase results in millions of parameters at the cost of longer training time.\n\n \n\nWeight initialization is particularly important in deep networks. The availability of large datasets and weight initialization likely drove the deep learning revolution of 2010. We'll implement Kaiming normal as follows:\n```\nmodel[:-2].apply(init_weights_kaiming_normal)\n```\n\n**Instructions:**\n* Add four additional layers and activation functions to the network\n* Adjust the definitions of `encoder` and `decoder`\n* Check learnable parameter count for this autoencoder by executing the last cell",
"_____no_output_____"
]
],
[
[
"encoding_size = 2\n\nmodel = nn.Sequential(\n nn.Linear(input_size, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), encoding_size * 32),\n #################################################\n ## TODO for students: add layers to build deeper autoencoder\n #################################################\n # Add activation function\n # ...,\n # Add another layer\n # nn.Linear(..., ...),\n # Add activation function\n # ...,\n # Add another layer\n # nn.Linear(..., ...),\n # Add activation function\n # ...,\n # Add another layer\n # nn.Linear(..., ...),\n # Add activation function\n # ...,\n # Add another layer\n # nn.Linear(..., ...),\n # Add activation function\n # ....\n )\n\nmodel[:-2].apply(init_weights_kaiming_normal)\n\nprint(f'Autoencoder \\n\\n {model}\\n')\n\n# Adjust the value n_l to split your model correctly\n# n_l = ...\n\n# uncomment when you fill the code\n# encoder = model[:n_l]\n# decoder = model[n_l:]\n# print(f'Encoder \\n\\n {encoder}\\n')\n# print(f'Decoder \\n\\n {decoder}')",
"_____no_output_____"
],
[
"# to_remove solution\nencoding_size = 2\n\nmodel = nn.Sequential(\n nn.Linear(input_size, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), encoding_size * 32),\n # Add activation function\n nn.PReLU(),\n # Add another layer\n nn.Linear(encoding_size * 32, encoding_size),\n # Add activation function\n nn.PReLU(),\n # Add another layer\n nn.Linear(encoding_size, encoding_size * 32),\n # Add activation function\n nn.PReLU(),\n # Add another layer\n nn.Linear(encoding_size * 32, int(input_size / 2)),\n # Add activation function\n nn.PReLU(),\n # Add another layer\n nn.Linear(int(input_size / 2), input_size),\n # Add activation function\n nn.Sigmoid()\n )\n\nmodel[:-2].apply(init_weights_kaiming_normal)\n\nprint(f'Autoencoder \\n\\n {model}\\n')\n\n# Adjust the value n_l to split your model correctly\nn_l = 6\n\n# uncomment when you fill the code\nencoder = model[:n_l]\ndecoder = model[n_l:]\nprint(f'Encoder \\n\\n {encoder}\\n')\nprint(f'Decoder \\n\\n {decoder}')",
"_____no_output_____"
]
],
[
[
"**Helper function:** `print_parameter_count`\n\nPlease uncomment the line below to inspect this function.",
"_____no_output_____"
]
],
[
[
"# help(print_parameter_count)",
"_____no_output_____"
]
],
[
[
"## Train the autoencoder\n\nTrain the network for `n_epochs=10` epochs with `batch_size=128`, and observe how the internal representation successfully captures additional digit classes.\n\nThe encoder map shows well-separated clusters that correspond to the associated digits in the decoder grid. The decoder grid also shows that the network is robust to digit skewness, i.e., digits leaning to the left or the right are recognized in the same digit class.\n\n**Instructions:**\n* Please execute the cells below\n\n",
"_____no_output_____"
]
],
[
[
"n_epochs = 10\nbatch_size = 128\n\nrunSGD(model, input_train, input_test, n_epochs=n_epochs,\n batch_size=batch_size)",
"_____no_output_____"
],
[
"with torch.no_grad():\n output_test = model(input_test)\n latent_test = encoder(input_test)\n\nplot_row([input_test[test_selected_idx], output_test[test_selected_idx]],\n image_shape=image_shape)\n\nplot_latent_generative(latent_test, y_test, decoder, image_shape=image_shape)",
"_____no_output_____"
]
],
[
[
"---\n# Section 3: Spherical latent space\n\nThe previous architecture generates representations that typically spread in different directions from coordinate $(z_1, z_2)=(0,0)$. This effect is due to the initialization of weights distributed randomly around `0`.\n\nAdding a third unit to the bottleneck layer defines a coordinate $(z_1, z_2, z_3)$ in 3D space. The latent space from such a network will still spread out from $(z_1, z_2, z_3)=(0, 0, 0)$.\n\nCollapsing the latent space on the surface of a sphere removes the possibility of spreading indefinitely from the origin $(0, 0, 0)$ in any direction since this will eventually lead back to the origin. This constraint generates a representation that fills the surface of the sphere.\n\n \n\n\n\n \n\n\nProjecting to the surface of the sphere is implemented by dividing the coordinates $(z_1, z_2, z_3)$ by their $L_2$ norm.\n\n$(z_1, z_2, z_3)\\longmapsto (s_1, s_2, s_3)=(z_1, z_2, z_3)/\\|(z_1, z_2, z_3)\\|_2=(z_1, z_2, z_3)/ \\sqrt{z_1^2+z_2^2+z_3^2}$\n\nThis mapping projects to the surface of the [$S_2$ sphere](https://en.wikipedia.org/wiki/N-sphere) with unit radius. (Why?)",
"_____no_output_____"
],
[
"## Section 3.1: Build and train autoencoder (3D)\n\nWe start by adding one unit to the bottleneck layer and visualize the latent space in 3D.\n\nPlease execute the cell below.",
"_____no_output_____"
]
],
[
[
"encoding_size = 3\n\nmodel = nn.Sequential(\n nn.Linear(input_size, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, encoding_size),\n nn.PReLU(),\n nn.Linear(encoding_size, encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), input_size),\n nn.Sigmoid()\n )\n\nmodel[:-2].apply(init_weights_kaiming_normal)\n\nencoder = model[:6]\ndecoder = model[6:]\n\nprint(f'Autoencoder \\n\\n {model}')",
"_____no_output_____"
]
],
[
[
"## Section 3.2: Train the autoencoder\n\nTrain the network for `n_epochs=10` epochs with `batch_size=128`. Observe how the internal representation spreads from the origin and reaches much lower loss due to the additional degree of freedom in the bottleneck layer.\n\n**Instructions:**\n* Please execute the cell below",
"_____no_output_____"
]
],
[
[
"n_epochs = 10\nbatch_size = 128\n\nrunSGD(model, input_train, input_test, n_epochs=n_epochs,\n batch_size=batch_size)",
"_____no_output_____"
]
],
[
[
"## Section 3.3: Visualize the latent space in 3D\n\n**Helper function**: `plot_latent_3d`\n\nPlease uncomment the line below to inspect this function.",
"_____no_output_____"
]
],
[
[
"# help(plot_latent_3d)",
"_____no_output_____"
],
[
"with torch.no_grad():\n latent_test = encoder(input_test)\n\nplot_latent_3d(latent_test, y_test)",
"_____no_output_____"
]
],
[
[
"### Exercise 2: Build deep autoencoder (2D) with latent spherical space\nWe now constrain the latent space to the surface of a sphere $S_2$.\n\n\n**Instructions:**\n* Add the custom layer `NormalizeLayer` after the bottleneck layer\n* Adjust the definitions of `encoder` and `decoder`\n* Experiment with keyword `show_text=False` for `plot_latent_3d`",
"_____no_output_____"
],
[
"**Helper function**: `NormalizeLayer`\n\nPlease uncomment the line below to inspect this function.",
"_____no_output_____"
]
],
[
[
"# help(NormalizeLayer)",
"_____no_output_____"
],
[
"encoding_size = 3\n\nmodel = nn.Sequential(\n nn.Linear(input_size, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, encoding_size),\n nn.PReLU(),\n #################################################\n ## TODO for students: add custom normalize layer\n #################################################\n # add the normalization layer\n # ...,\n nn.Linear(encoding_size, encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), input_size),\n nn.Sigmoid()\n )\n\nmodel[:-2].apply(init_weights_kaiming_normal)\n\nprint(f'Autoencoder \\n\\n {model}\\n')\n\n# Adjust the value n_l to split your model correctly\n# n_l = ...\n\n# uncomment when you fill the code\n# encoder = model[:n_l]\n# decoder = model[n_l:]\n# print(f'Encoder \\n\\n {encoder}\\n')\n# print(f'Decoder \\n\\n {decoder}')",
"_____no_output_____"
],
[
"# to_remove solution\nencoding_size = 3\n\nmodel = nn.Sequential(\n nn.Linear(input_size, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, encoding_size),\n nn.PReLU(),\n # add the normalization layer\n NormalizeLayer(),\n nn.Linear(encoding_size, encoding_size * 32),\n nn.PReLU(),\n nn.Linear(encoding_size * 32, int(input_size / 2)),\n nn.PReLU(),\n nn.Linear(int(input_size / 2), input_size),\n nn.Sigmoid()\n )\n\nmodel[:-2].apply(init_weights_kaiming_normal)\n\nprint(f'Autoencoder \\n\\n {model}\\n')\n\n# Adjust the value n_l to split your model correctly\nn_l = 7\n\n# uncomment when you fill the code\nencoder = model[:n_l]\ndecoder = model[n_l:]\nprint(f'Encoder \\n\\n {encoder}\\n')\nprint(f'Decoder \\n\\n {decoder}')",
"_____no_output_____"
]
],
[
[
"## Section 3.4: Train the autoencoder\nTrain the network for `n_epochs=10` epochs with `batch_size=128` and observe how loss raises again and is comparable to the model with 2D latent space.\n\n**Instructions:**\n* Please execute the cell below",
"_____no_output_____"
]
],
[
[
"n_epochs = 10\nbatch_size = 128\n\nrunSGD(model, input_train, input_test, n_epochs=n_epochs,\n batch_size=batch_size)",
"_____no_output_____"
],
[
"with torch.no_grad():\n latent_test = encoder(input_test)\n\nplot_latent_3d(latent_test, y_test)",
"_____no_output_____"
]
],
[
[
"## Section 3.5: Visualize latent space on surface of $S_2$\nThe 3D coordinates $(s_1, s_2, s_3)$ on the surface of the unit sphere $S_2$ can be mapped to [spherical coordinates](https://en.wikipedia.org/wiki/Spherical_coordinate_system) $(r, \\theta, \\phi)$, as follows:\n\n$$\n\\begin{aligned}\nr &= \\sqrt{s_1^2 + s_2^2 + s_3^2} \\\\\n\\phi &= \\arctan \\frac{s_2}{s_1} \\\\\n\\theta &= \\arccos\\frac{s_3}{r}\n\\end{aligned}\n$$\n\n\n\nWhat is the domain (numerical range) spanned by ($\\theta, \\phi)$?\n\nWe return to a 2D representation since the angles $(\\theta, \\phi)$ are the only degrees of freedom on the surface of the sphere. Add the keyword `s2=True` to `plot_latent_generative` to un-wrap the sphere's surface similar to a world map.\n\nTask: Check the numerical range of the plot axis to help identify $\\theta$ and $\\phi$, and visualize the unfolding of the 3D plot from the previous exercise.\n\n**Instructions:**\n* Please execute the cells below",
"_____no_output_____"
]
],
[
[
"with torch.no_grad():\n output_test = model(input_test)\n\nplot_row([input_test[test_selected_idx], output_test[test_selected_idx]],\n image_shape=image_shape)\n\nplot_latent_generative(latent_test, y_test, decoder,\n image_shape=image_shape, s2=True)",
"_____no_output_____"
]
],
[
[
"---\n# Summary\nWe learned two techniques to improve representation capacity: adding a few hidden layers and projecting latent space on the sphere $S_2$.\n\nThe expressive power of autoencoder improves with additional hidden layers. Projecting latent space on the surface of $S_2$ spreads out digits classes in a more visually pleasing way but may not always produce a lower loss.\n\n**Deep autoencoder architectures have rich internal representations to deal with sophisticated tasks such as the MNIST cognitive task.**\n\nWe now have powerful tools to explore how simple algorithms build robust models of the world by capturing relevant data patterns.",
"_____no_output_____"
]
],
[
[
"# @title Video 2: Wrap-up\nfrom IPython.display import YouTubeVideo\nvideo = YouTubeVideo(id=\"GnkmzCqEK3E\", width=854, height=480, fs=1)\nprint(\"Video available at https://youtube.com/watch?v=\" + video.id)\nvideo",
"_____no_output_____"
]
],
[
[
"---\n# Bonus",
"_____no_output_____"
],
[
"## Deep and thick autoencoder\nIn this exercise, we first expand the first hidden layer to double the input size, followed by compression to half the input size leading to 3.8M parameters. Please **do not train this network during tutorial** due to long training time.\n\n**Instructions:**\n* Please uncomment and execute the cells below",
"_____no_output_____"
]
],
[
[
"# encoding_size = 3\n\n# model = nn.Sequential(\n# nn.Linear(input_size, int(input_size * 2)),\n# nn.PReLU(),\n# nn.Linear(int(input_size * 2), int(input_size / 2)),\n# nn.PReLU(),\n# nn.Linear(int(input_size / 2), encoding_size * 32),\n# nn.PReLU(),\n# nn.Linear(encoding_size * 32, encoding_size),\n# nn.PReLU(),\n# NormalizeLayer(),\n# nn.Linear(encoding_size, encoding_size * 32),\n# nn.PReLU(),\n# nn.Linear(encoding_size * 32, int(input_size / 2)),\n# nn.PReLU(),\n# nn.Linear(int(input_size / 2), int(input_size * 2)),\n# nn.PReLU(),\n# nn.Linear(int(input_size * 2), input_size),\n# nn.Sigmoid()\n# )\n\n# model[:-2].apply(init_weights_kaiming_normal)\n\n# encoder = model[:9]\n# decoder = model[9:]\n\n# print_parameter_count(model)",
"_____no_output_____"
],
[
"# n_epochs = 5\n# batch_size = 128\n\n# runSGD(model, input_train, input_test, n_epochs=n_epochs,\n# batch_size=batch_size)\n\n# Visualization\n# with torch.no_grad():\n# output_test = model(input_test)\n\n# plot_row([input_test[test_selected_idx], output_test[test_selected_idx]],\n# image_shape=image_shape)\n\n# plot_latent_generative(latent_test, y_test, decoder,\n# image_shape=image_shape, s2=True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4ad4bec1562a69ab6d0c455f2e80456f1b6867f7
| 418,817 |
ipynb
|
Jupyter Notebook
|
triplet.ipynb
|
abinitio888/image_embedding
|
99fd44885e56cfb44a247b2ac92b65f5af17da7a
|
[
"MIT"
] | null | null | null |
triplet.ipynb
|
abinitio888/image_embedding
|
99fd44885e56cfb44a247b2ac92b65f5af17da7a
|
[
"MIT"
] | null | null | null |
triplet.ipynb
|
abinitio888/image_embedding
|
99fd44885e56cfb44a247b2ac92b65f5af17da7a
|
[
"MIT"
] | null | null | null | 437.635319 | 222,316 | 0.927312 |
[
[
[
"pip install cached_property",
"Collecting cached_property\r\n Downloading cached_property-1.5.2-py2.py3-none-any.whl (7.6 kB)\r\nInstalling collected packages: cached-property\r\nSuccessfully installed cached-property-1.5.2\r\n\u001b[33mWARNING: You are using pip version 20.3.1; however, version 21.0 is available.\r\nYou should consider upgrading via the '/opt/conda/bin/python -m pip install --upgrade pip' command.\u001b[0m\r\nNote: you may need to restart the kernel to use updated packages.\n"
],
[
"from PIL import Image\nfrom cached_property import cached_property\nfrom skimage import io\nfrom torch.autograd import Variable\nfrom torch.optim import lr_scheduler\nfrom torch.utils.data import Dataset\nfrom torchvision import transforms, datasets\nimport glob\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport os\nimport pandas as pd\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\n\nis_cuda = torch.cuda.is_available()\n%matplotlib inline\n\n\nclass FashionDataset(Dataset):\n def __init__(self, csv_file, target_column, root_dir, transform=None, is_train=True, training_size=0.8, is_debug=True):\n self.target_column = target_column\n self.training_size = training_size\n self.csv_file = csv_file\n self.root_dir = root_dir\n self.transform = transform\n self.train = is_train\n self.is_debug = is_debug\n self.train_df, self.test_df = self._get_df()\n \n if self.train: \n self.train_labels = self.train_df[self.target_column].to_list()\n self.labels_set = set(self.train_labels)\n print(f\"# of labels: {len(self.labels_set)}\")\n else:\n self.test_labels = self.test_df[self.target_column].to_list()\n self.labels_set = set(self.test_labels)\n print(f\"# of labels: {len(self.labels_set)}\")\n \n\n def _get_df(self):\n df = pd.read_csv(os.path.join(self.root_dir, self.csv_file), error_bad_lines=False, warn_bad_lines=False)\n df = df.sample(frac=1, random_state=29, axis=\"index\")\n df = df.dropna(axis=0, subset=[self.target_column])\n \n if self.is_debug:\n df = df.head(10000)\n \n image_ids = []\n for fd in glob.glob(os.path.join(self.root_dir, \"images/*.jpg\")):\n image_id = os.path.split(fd)[1][:-4]\n image_ids.append(int(image_id))\n # Take a inner set\n common_ids = set(df.id) & set(image_ids)\n \n print(\"Common ids: \", len(common_ids))\n df = df.loc[df.id.isin(common_ids)]\n \n # Split to training and test\n random_state = np.random.RandomState(29)\n df[\"is_train\"] = random_state.choice([True, False], size=df.shape[0], p=[self.training_size, 1-self.training_size])\n \n train_df = df.loc[(df.is_train==True)]\n self.train_df = self.filter_insufficient_labels(train_df, 5)\n \n # Only keep the labels in the training set.\n train_labels_set = set(self.train_df[self.target_column].to_list())\n test_df = df.loc[(df.is_train==False)]\n test_df = test_df.loc[(test_df[self.target_column].isin(train_labels_set))]\n self.test_df = self.filter_insufficient_labels(test_df, 1)\n \n return self.train_df, self.test_df\n \n \n def filter_insufficient_labels(self, df, thredhold):\n count_df = df.groupby(self.target_column).count().id.reset_index(name=\"counts\")\n df = df.merge(count_df, on=self.target_column, how=\"left\")\n return df.loc[(df.counts > thredhold)].reset_index()\n\n\n @cached_property\n def train_data(self):\n print(f\"is_training: {self.train}\")\n self.image_ids = self.train_df.id.to_list()\n return self._read_images()\n \n @cached_property\n def test_data(self):\n print(f\"is_training: {self.train}\")\n self.image_ids = self.test_df.id.to_list()\n return self._read_images()\n \n \n def _read_images(self):\n data = []\n for i in self.image_ids:\n filename = os.path.join(self.root_dir, \"images\", str(i) + \".jpg\")\n img = Image.open(filename).convert(\"L\")\n if self.transform:\n img = self.transform(img)\n data.append(img)\n data = torch.stack(data, dim=0)\n return data\n \n def __len__(self):\n if self.train:\n return len(self.train_df)\n else:\n return len(self.test_df)\n \n def __getitem__(self, idx):\n if self.train:\n filename = os.path.join(self.root_dir, \"images\", str(self.train_df.loc[idx].id) + \".jpg\")\n label = self.train_df.loc[idx][self.target_column]\n else:\n filename = os.path.join(self.root_dir, \"images\", str(self.test_df.loc[idx].id) + \".jpg\")\n label = self.test_df.loc[idx][self.target_column]\n \n sample = Image.open(filename).convert(\"L\")\n\n if self.transform:\n sample = self.transform(sample)\n \n return (sample, label)",
"_____no_output_____"
],
[
"class TripletDataset(Dataset):\n \"\"\"\n Train: For each sample (anchor) randomly chooses a positive and negative samples\n Test: Creates fixed triplets for testing\n \"\"\"\n\n def __init__(self, dataset):\n self.dataset = dataset\n self.train = self.dataset.train\n\n if self.train:\n self.train_labels = self.dataset.train_labels\n self.train_data = self.dataset.train_data\n self.labels_set = set(self.train_labels)\n self.label_to_indices = {label: np.where(np.array(self.train_labels) == label)[0]\n for label in self.labels_set}\n else:\n self.test_labels = self.dataset.test_labels\n self.test_data = self.dataset.test_data\n \n self.labels_set = set(self.test_labels)\n self.label_to_indices = {label: np.where(np.array(self.test_labels) == label)[0]\n for label in self.labels_set}\n\n random_state = np.random.RandomState(29)\n \n # Generate fixed triplets for testing len(self.test_data)\n triplets = [[i,\n random_state.choice(self.label_to_indices[self.test_labels[i]]),\n random_state.choice(self.label_to_indices[\n np.random.choice(\n list(self.labels_set - set([self.test_labels[i]]))\n )\n ])\n ]\n for i in range(len(self.test_data))] \n self.test_triplets = triplets\n\n def __getitem__(self, index):\n if self.train:\n img1, label1 = self.train_data[index], self.train_labels[index] \n positive_index = index\n# print(f\"Anchor: {index}\")\n while positive_index == index:\n positive_index = np.random.choice(self.label_to_indices[label1])\n# print(\"Randomly selecting the Postive sample...\")\n# print(f\"Positive: {positive_index}\")\n negative_label = np.random.choice(list(self.labels_set - set([label1])))\n negative_index = np.random.choice(self.label_to_indices[negative_label])\n# print(f\"Negative: {negative_index}\")\n img2 = self.train_data[positive_index]\n img3 = self.train_data[negative_index]\n else:\n img1 = self.test_data[self.test_triplets[index][0]]\n img2 = self.test_data[self.test_triplets[index][1]]\n img3 = self.test_data[self.test_triplets[index][2]]\n \n # (Anchor, Positive, Negative)\n return (img1, img2, img3), []\n\n def __len__(self):\n return len(self.dataset)",
"_____no_output_____"
],
[
"class EmbeddingNet(nn.Module):\n def __init__(self):\n super(EmbeddingNet, self).__init__()\n self.convnet = nn.Sequential(nn.Conv2d(1, 32, 5), nn.PReLU(),\n nn.MaxPool2d(2, stride=2),\n nn.Conv2d(32, 64, 5), nn.PReLU(),\n nn.MaxPool2d(2, stride=2))\n\n self.fc = nn.Sequential(nn.Linear(64 * 4 * 4, 256),\n nn.PReLU(),\n nn.Linear(256, 256),\n nn.PReLU(),\n nn.Linear(256, 2) # the embedding space is 2\n )\n\n def forward(self, x):\n output = self.convnet(x)\n output = output.view(output.size()[0], -1)\n output = self.fc(output)\n return output\n\n def get_embedding(self, x):\n return self.forward(x)\n \n \n \nclass TripletNet(nn.Module):\n def __init__(self, embedding_net):\n super(TripletNet, self).__init__()\n self.embedding_net = embedding_net\n\n def forward(self, x1, x2, x3):\n output1 = self.embedding_net(x1)\n output2 = self.embedding_net(x2)\n output3 = self.embedding_net(x3)\n return output1, output2, output3\n\n def get_embedding(self, x):\n return self.embedding_net(x)",
"_____no_output_____"
],
[
"def fit(train_loader, val_loader, model, loss_fn, optimizer, scheduler, n_epochs, is_cuda, log_interval, metrics=[],\n start_epoch=0):\n \"\"\"\n Trainer\n \"\"\"\n for epoch in range(0, start_epoch):\n scheduler.step()\n \n print(\"===> Start training...\")\n for epoch in range(start_epoch, n_epochs):\n scheduler.step()\n\n # Train stage\n train_loss, metrics = train_epoch(train_loader, model, loss_fn, optimizer, is_cuda, log_interval, metrics)\n message = 'Epoch: {}/{}. Train set: Average loss: {:.4f}'.format(epoch + 1, n_epochs, train_loss)\n for metric in metrics:\n message += '\\t{}: {}'.format(metric.name(), metric.value())\n \n # Validation stage \n val_loss, metrics = test_epoch(val_loader, model, loss_fn, is_cuda, metrics)\n val_loss /= len(val_loader)\n message += '\\nEpoch: {}/{}. Validation set: Average loss: {:.4f}'.format(epoch + 1, n_epochs, val_loss)\n for metric in metrics:\n message += '\\t{}: {}'.format(metric.name(), metric.value())\n\n print(message)\n print(\"===> Finish training!\")\n\n\ndef train_epoch(train_loader, model, loss_fn, optimizer, is_cuda, log_interval, metrics):\n for metric in metrics:\n metric.reset()\n\n model.train()\n losses = []\n total_loss = 0\n\n for batch_idx, (data, target) in enumerate(train_loader):\n target = target if len(target) > 0 else None\n if not type(data) in (tuple, list):\n data = (data,)\n if is_cuda:\n data = tuple(d.cuda() for d in data)\n if target is not None:\n target = target.cuda()\n\n \n optimizer.zero_grad()\n# data = [len(triplet)=3, batch_size, c, w, h]\n outputs = model(*data)\n\n if type(outputs) not in (tuple, list):\n outputs = (outputs,)\n\n loss_inputs = outputs\n if target is not None:\n target = (target,)\n loss_inputs += target\n\n loss_outputs = loss_fn(*loss_inputs)\n loss = loss_outputs[0] if type(loss_outputs) in (tuple, list) else loss_outputs\n losses.append(loss.item())\n total_loss += loss.item()\n loss.backward()\n optimizer.step()\n\n for metric in metrics:\n metric(outputs, target, loss_outputs)\n\n if batch_idx % log_interval == 0:\n message = 'Train: [{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(\n batch_idx * len(data[0]), len(train_loader.dataset),\n 100. * batch_idx / len(train_loader), np.mean(losses))\n for metric in metrics:\n message += '\\t{}: {}'.format(metric.name(), metric.value())\n\n print(message)\n losses = []\n\n total_loss /= (batch_idx + 1)\n return total_loss, metrics\n\n\ndef test_epoch(val_loader, model, loss_fn, is_cuda, metrics):\n with torch.no_grad():\n for metric in metrics:\n metric.reset()\n model.eval()\n val_loss = 0\n for batch_idx, (data, target) in enumerate(val_loader):\n target = target if len(target) > 0 else None\n if not type(data) in (tuple, list):\n data = (data,)\n if is_cuda:\n data = tuple(d.cuda() for d in data)\n if target is not None:\n target = target.cuda()\n\n outputs = model(*data)\n\n if type(outputs) not in (tuple, list):\n outputs = (outputs,)\n loss_inputs = outputs\n if target is not None:\n target = (target,)\n loss_inputs += target\n\n loss_outputs = loss_fn(*loss_inputs)\n loss = loss_outputs[0] if type(loss_outputs) in (tuple, list) else loss_outputs\n val_loss += loss.item()\n\n for metric in metrics:\n metric(outputs, target, loss_outputs)\n\n return val_loss, metrics",
"_____no_output_____"
],
[
"# Read raw dataset\nmean, std = 0.1307, 0.3081\ntransform = transforms.Compose([\n transforms.Resize((28, 28)),\n transforms.ToTensor(),\n# transforms.Normalize((mean,), (std,))\n])\n\ntarget_column = \"subCategory\"\nis_debug = True\nroot_dir=\"/kaggle/input/fashion-product-images-small/myntradataset\"\ntrain_dataset = FashionDataset(is_train=True, target_column=target_column, root_dir=root_dir, csv_file=\"styles.csv\", transform=transform, is_debug=is_debug)\nprint(train_dataset.train_data.shape)\ntest_dataset = FashionDataset(is_train=False, target_column=target_column, root_dir=root_dir, csv_file=\"styles.csv\", transform=transform, is_debug=is_debug)\nprint(test_dataset.test_data.shape)\n\n\n# Construct triplet dataset\ntriplet_train_dataset = TripletDataset(train_dataset)\ntriplet_test_dataset = TripletDataset(test_dataset)\n\n\n# Construct triplet dataset loader\nbatch_size = 128\nkwargs = {'num_workers': 10, 'pin_memory': True} if is_cuda else {}\ntriplet_train_loader = torch.utils.data.DataLoader(triplet_train_dataset, batch_size=batch_size, shuffle=True, **kwargs)\ntriplet_test_loader = torch.utils.data.DataLoader(triplet_test_dataset, batch_size=batch_size, shuffle=False, **kwargs)\n\n\n# Construct raw dataset loader for embedding and plotting\ntrain_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, **kwargs)\ntest_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, **kwargs)\n\n\n# Set up the network\n# from networks import EmbeddingNet, TripletNet\nembedding_net = EmbeddingNet()\nmodel = TripletNet(embedding_net)\nif is_cuda:\n model.cuda()\n\n# Set up the loss function\nloss_fn = nn.TripletMarginLoss(margin=1.0)\n\n# Set up the optimizer\noptimizer = optim.Adam(model.parameters(), lr=1e-3)\nscheduler = lr_scheduler.StepLR(optimizer, 8, gamma=0.1, last_epoch=-1)\n\n\n# Set training parameters\nn_epochs = 20\nlog_interval = 50\nfit(triplet_train_loader, triplet_test_loader, model, loss_fn, optimizer, scheduler, n_epochs, is_cuda, log_interval)",
"Common ids: 9999\n# of labels: 32\nis_training: True\ntorch.Size([7921, 1, 28, 28])\nCommon ids: 9999\n# of labels: 31\nis_training: False\ntorch.Size([2051, 1, 28, 28])\n===> Start training...\n"
],
[
"def plot_embeddings(embeddings, labels, classes, xlim=None, ylim=None):\n plt.figure(figsize=(8, 8))\n for i, c in enumerate(classes):\n inds = np.where(labels==c)[0]\n plt.scatter(embeddings[inds,0], embeddings[inds,1], alpha=0.5, color=colors[c])\n if xlim:\n plt.xlim(xlim[0], xlim[1])\n if ylim:\n plt.ylim(ylim[0], ylim[1])\n plt.legend(classes, bbox_to_anchor=(1, 1.))\n\n \ndef extract_embeddings(dataloader, dataset, model):\n with torch.no_grad():\n classes = dataset.labels_set\n model.eval()\n embeddings = np.zeros((len(dataloader.dataset), 2)) # the embedding space is 2\n labels = []\n k = 0\n for images, targets in dataloader:\n if is_cuda:\n images = images.cuda()\n embeddings[k:k+len(images)] = model.get_embedding(images).data.cpu().numpy()\n labels[k:k+len(images)] = list(targets)\n k += len(images)\n labels = np.array(labels)\n return embeddings, labels, classes",
"_____no_output_____"
],
[
"classes = train_dataset.labels_set\n\n\nrandom_state = np.random.RandomState(30)\ncolors = {}\nfor c in classes:\n r = lambda: random_state.randint(0, 255)\n color = '#%02X%02X%02X' % (r(),r(),r())\n colors[c] = color",
"_____no_output_____"
],
[
"train_embeddings, train_labels, classes = extract_embeddings(train_loader, train_dataset, model) \nplot_embeddings(train_embeddings, train_labels, classes)\n\nval_embeddings, val_labels, classes = extract_embeddings(test_loader, test_dataset, model)\nplot_embeddings(val_embeddings, val_labels, classes)",
"_____no_output_____"
],
[
"model",
"_____no_output_____"
],
[
"embedding_net",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad4c90735d1a4b36c1e07df9836b7e9727a92dc
| 120,137 |
ipynb
|
Jupyter Notebook
|
Prediction using Supervised ML/Task_01.ipynb
|
vedanti-github/Spark_Projects
|
cfc3402139cb829a896cda72324428176333d359
|
[
"MIT"
] | 1 |
2021-06-21T14:10:39.000Z
|
2021-06-21T14:10:39.000Z
|
Prediction using Supervised ML/Task_01.ipynb
|
vedanti-github/Spark_Projects
|
cfc3402139cb829a896cda72324428176333d359
|
[
"MIT"
] | null | null | null |
Prediction using Supervised ML/Task_01.ipynb
|
vedanti-github/Spark_Projects
|
cfc3402139cb829a896cda72324428176333d359
|
[
"MIT"
] | 1 |
2021-09-08T09:28:27.000Z
|
2021-09-08T09:28:27.000Z
| 114.853728 | 19,050 | 0.827314 |
[
[
[
"# Author : Vedanti Ekre\n\n# Email: [email protected]\n\n## Task 1 : Prediction using Supervised Machine Learning\n___\n## GRIP @ The Sparks Foundation\n____\n# Role : Data Science and Business Analytics [Batch May-2021]",
"_____no_output_____"
],
[
"## TABLE OF CONTENTS:\n\n1. [Introduction](#intro)\n2. [Importing the dependencies](#libs)\n3. [Loading the Data](#DL)\n4. [Understanding data](#UD)\n5. [Spliting data in Test and Train](#split)\n6. [Use Simple Linear Regression Model to do prediction](#LR)\n7. [Task](#PT)\n8. [Evaluate the model using MAE and MSE metrics](#Eval)\n9. [Conslusion](#conclu)\n\n",
"_____no_output_____"
],
[
"## **Introduction**<a class=\"anchor\" id=\"intro\"></a>\n● We have given Student dataset,which have only two features Hours and scores.<br>\n● Predict the percentage of an student based on the no. of study hours.<br>\n● This is a simple linear regression task as it involves just 2 variables.<br>\n● You can use R, Python, SAS Enterprise Miner or any other tool<br>\n● Data can be found at http://bit.ly/w-data",
"_____no_output_____"
],
[
"## Importing dependencies<a class=\"anchor\" id=\"libs\"></a>",
"_____no_output_____"
]
],
[
[
"#importing packages\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## **Loading the Data**<a class=\"anchor\" id=\"DL\"></a>",
"_____no_output_____"
]
],
[
[
"#importing datasets\nurl = \"http://bit.ly/w-data\"\ndata = pd.read_csv(url)",
"_____no_output_____"
]
],
[
[
"## **Understanding data**<a class=\"anchor\" id=\"UD\"></a>",
"_____no_output_____"
]
],
[
[
"display(data.head(3),data.tail(3))",
"_____no_output_____"
],
[
"print(type(data))\nprint('-'*45)\nprint('The data set has {} rows and {} columns'.format(data.shape[0],data.shape[1]))\nprint('-'*45)\nprint('Data types :') \nprint(data.dtypes.value_counts())\n#print('Total : ',data.dtypes.value_counts().sum())\nprint('-'*45)",
"<class 'pandas.core.frame.DataFrame'>\n---------------------------------------------\nThe data set has 25 rows and 2 columns\n---------------------------------------------\nData types :\nint64 1\nfloat64 1\ndtype: int64\n---------------------------------------------\n"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 25 entries, 0 to 24\nData columns (total 2 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Hours 25 non-null float64\n 1 Scores 25 non-null int64 \ndtypes: float64(1), int64(1)\nmemory usage: 528.0 bytes\n"
],
[
"# Checking for the missing values\ndata.isnull().sum()",
"_____no_output_____"
]
],
[
[
"### Observation :<br>\n - ```There is no missing or null value & hence we don't need to do data preprocessing```",
"_____no_output_____"
],
[
"## **Data Visualization**",
"_____no_output_____"
]
],
[
[
"x = data.iloc[:,:-1].values #spliting data in X & Y\ny = data.iloc[:,-1].values\nprint(x[:5])\nprint(y[:5])",
"[[2.5]\n [5.1]\n [3.2]\n [8.5]\n [3.5]]\n[21 47 27 75 30]\n"
],
[
"plt.xlabel('hours')\nplt.ylabel('scores')\nplt.scatter(x,y,color='red',marker='+')\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Observation :\n - ```From the graph we can safely assume a positive linear relation between the number of hours studied and percentage of score```",
"_____no_output_____"
],
[
"## **Spliting data in x_train , x_test and y_train , y_test** <a class=\"anchor\" id=\"split\"></a>",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split #spliting data in x_train , x_test & y_train,y_test \nx_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25, random_state = 0)",
"_____no_output_____"
]
],
[
[
"## **Apply Linear Regression on train data**",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\nlin_reg = LinearRegression()\nlin_reg.fit(x_train,y_train)",
"_____no_output_____"
],
[
"plt.xlabel('hours')\nplt.ylabel('scores')\nplt.scatter(x_train,y_train,color='purple',marker='+',label='scatter plot')\nplt.plot(x_train,lin_reg.predict(x_train),color='green',label='reg_line')\nplt.legend()\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## **Apply Linear Regression on test data** <a class=\"anchor\" id=\"LR\"></a>",
"_____no_output_____"
]
],
[
[
"plt.xlabel('hours')\nplt.ylabel('scores')\nplt.scatter(x_test,y_test,color='blue',marker='+',label='scatter plot')\nplt.plot(x_train,lin_reg.predict(x_train),color='purple',label='reg_line')\nplt.legend()\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### **Coefficents and y-intercept**",
"_____no_output_____"
]
],
[
[
"print('coefficents : ',lin_reg.coef_)\nprint('y-intercept : ',lin_reg.intercept_)",
"coefficents : [9.94167834]\ny-intercept : 1.932204253151646\n"
],
[
"y_pred = lin_reg.predict(x_test)\ny_pred",
"_____no_output_____"
]
],
[
[
"## Comparing Actual value with Predicted value",
"_____no_output_____"
]
],
[
[
"result = pd.DataFrame({'Actual values':y_test,'Predicted values':y_pred})\nresult",
"_____no_output_____"
],
[
"# Plotting the Bar graph to depict the difference between the actual and predicted value\n\nresult.plot(kind='bar',figsize=(9,9))\nplt.grid(which='major', linewidth='0.5', color='red')\nplt.grid(which='minor', linewidth='0.5', color='blue')\nplt.show()",
"_____no_output_____"
],
[
"diff = np.array(np.abs(y_test-y_pred))\ndiff",
"_____no_output_____"
]
],
[
[
"## Displot distribution of Actual value with Predicted value",
"_____no_output_____"
]
],
[
[
"sns.set_style('whitegrid')\nsns.kdeplot(diff,shade=True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"# **Task** <a class=\"anchor\" id=\"PT\"></a>\n## - What will be predicted score if a student studies for 9.25 hrs/ day?",
"_____no_output_____"
]
],
[
[
"import math\n# y = mx + c\nres = lin_reg.intercept_+9.25*lin_reg.coef_\nhr= 9.25\nprint(\"If student study for {} hrs/day student will get {}% score in exam\".format(hr,math.floor(res[0])))\nprint('-'*80)",
"If student study for 9.25 hrs/day student will get 93% score in exam\n"
]
],
[
[
"# Model Evaluation <a class=\"anchor\" id=\"Eval\"></a> ",
"_____no_output_____"
],
[
"## MAE :\n - MAE measures the differences between prediction and actual observation.<br>\n Formula is :<br>\n ",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics \nprint('Mean Absolute Error:', \n metrics.mean_absolute_error(y_test, y_pred)) ",
"Mean Absolute Error: 4.130879918502482\n"
]
],
[
[
"## MSE :\n- MSE simply refers to the mean of the squared difference between the predicted value and the observed value.<br>\nFormula : <br>",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics \nprint('Mean Squared Error:', \n metrics.mean_squared_error(y_test, y_pred)) ",
"Mean Absolute Error: 20.33292367497996\n"
]
],
[
[
"## **R-Square** :\n - R-squared is measure of how close the data are to the fitted regression line.<br>\n Formula : <br>",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import r2_score\nr2_score(y_test,y_pred)",
"_____no_output_____"
]
],
[
[
"# **Conclusion :**<br><a class=\"anchor\" id=\"conclu\"></a>\n- We have successfully created a Simple linear Regression model to predict score of the student given number of hours one studies.\n- By the MAE and MSE , we are not getting much difference in actual or predicted value , means error is less.\n- The Score of R-Square **0.93** quite close to **1**.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4ad4d0c3cc8628e22f6f4d58ddcffe8f9188e5cc
| 61,119 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Trabajo Final Pregunta 5-checkpoint.ipynb
|
efvillar/Trabajo_Final_Bases_Datos
|
cc38385890deee41e14ff93011d7e349bff13084
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Trabajo Final Pregunta 5-checkpoint.ipynb
|
efvillar/Trabajo_Final_Bases_Datos
|
cc38385890deee41e14ff93011d7e349bff13084
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Trabajo Final Pregunta 5-checkpoint.ipynb
|
efvillar/Trabajo_Final_Bases_Datos
|
cc38385890deee41e14ff93011d7e349bff13084
|
[
"MIT"
] | 2 |
2019-06-09T23:09:20.000Z
|
2019-06-11T00:19:17.000Z
| 30.498503 | 304 | 0.37373 |
[
[
[
"## Genere un conjunto de datos nuevos a partir de CSV con al menos 50mil registros y prediga cuáles serían las respuestas de una nueva encuestaenel 2018.(Adjunte el análisis y el algoritmo que le permitió generar los registros manteniendo la línea de tendencia con base en las encuestas anteriores)",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport os",
"_____no_output_____"
],
[
"data1 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_0_16000.json')\ndata2 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_16000_32000.json')\ndata3 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_32000_48000.json')\ndata4 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_48000_64000.json')\ndata5 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_64000_80000.json')\ndata6 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_80000_96000.json')\ndata7 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_96000_112000.json')\ndata8 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_112000_128000.json')\ndata9 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_128000_144000.json')\ndata10 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_144000_160000.json')\ndata11 = pd.read_json(r'.\\Base_Datos_Encuestas\\BD_Encuesta_160000_160111.json')\n",
"_____no_output_____"
],
[
"Total = pd.concat([data1, data2, data3, data4, data5, data6, data7, data8, data9, data10, data11], axis=0)",
"_____no_output_____"
],
[
"Total.columns.values",
"_____no_output_____"
],
[
"Total.head()",
"_____no_output_____"
]
],
[
[
"### Para crear los 50.000 registros del año 2018 se realizarán los siguientes pasos:\n\n1. Asumiendo que el comportamiento de 2018 es similar al comportamiento de 2017, se realiza una descripción general de los datos de 2017.\n\n2. Dado que desconocemos la distribución de probabilidad de la cual se generan los datos, se respetará la distribución de probabilidad empirica de la muestra de 2017.\n\n3. Se crea para cada variable una función generadora de datos que siga la distribución de probabilidad, la cual utiliza como variables de entrada variables contincuas de ditribución uniformes entre 0 y 1.\n\n4. se crea una función generadora de un registro que toma como insumos las funciones generadoras de datos\n\n5. Se crea una función de varios registros",
"_____no_output_____"
],
[
"## Pasos 1 y 2: ",
"_____no_output_____"
]
],
[
[
"data_2017 = Total.loc[Total[\"Year\"]==2017].reset_index()",
"_____no_output_____"
],
[
"data_2017.shape",
"_____no_output_____"
],
[
"Total.groupby('Year').count()",
"_____no_output_____"
],
[
"Prob_Lang=data_2017.groupby('Year').count()/data_2017.shape[0]",
"_____no_output_____"
],
[
"Prob_Lang",
"_____no_output_____"
]
],
[
[
"A continuación se extrae la probabilidad de ocurrencia de los lenguajes de programación en 2017",
"_____no_output_____"
]
],
[
[
"from collections import OrderedDict",
"_____no_output_____"
],
[
"P_JavaScript = Prob_Lang.JavaScript.item()\nP_JavaScript",
"_____no_output_____"
],
[
"P_AngularJS = Prob_Lang.AngularJS.item()\nP_C = Prob_Lang.C.item()\nP_CPlusPlus = Prob_Lang.CPlusPlus.item()\nP_CSS = Prob_Lang.CSS.item()\nP_CSharp = Prob_Lang.CSharp.item()\nP_HTML5 = Prob_Lang.HTML5.item()\nP_Java = Prob_Lang.Java.item()\nP_JavaScript = Prob_Lang.JavaScript.item()\nP_Nodejs = Prob_Lang.Nodejs.item()\nP_ObjectiveC = Prob_Lang.ObjectiveC.item()\nP_PHP = Prob_Lang.PHP.item()\nP_Perl = Prob_Lang.Perl.item()\nP_Python = Prob_Lang.Python.item()\nP_Ruby = Prob_Lang.Ruby.item()\nP_SQL = Prob_Lang.SQL.item()\nP_SQL_Server = Prob_Lang.SQL_Server.item()\nP_TypeScript = Prob_Lang.TypeScript.item()\nP_jQuery = Prob_Lang.jQuery.item()",
"_____no_output_____"
]
],
[
[
"Se crean diccionarios con los rangos de probabilidad de ocurrencia de los datos descriptivos de 2017 (dimensiones): país, edad, experiencia, genero, salario",
"_____no_output_____"
]
],
[
[
"temp1 = data_2017.Id_Country.value_counts()/data_2017.shape[0]\ntemp2 = data_2017.Id_Age.value_counts()/data_2017.shape[0]\ntemp3 = data_2017.Id_Experience.value_counts()/data_2017.shape[0]\ntemp4 = data_2017.Id_Gender.value_counts()/data_2017.shape[0]\ntemp5 = data_2017.Id_Salary.value_counts()/data_2017.shape[0]",
"_____no_output_____"
]
],
[
[
"La siguiene función toma como insumo la serie de Pandas y la transforma en un diccionario ordenado de Python",
"_____no_output_____"
]
],
[
[
"def dic_other_vars(temp1):\n #temp = df[col].value_counts()/data_2017.shape[0]\n temp = temp1.to_frame() #se convierte de serie de datos a data frame\n #print (temp)\n L=temp.index.tolist() # exporta el indice a una lista\n #print (L)\n #print (temp.loc[213].item())\n #dict_var = {}\n dict_var = OrderedDict() #se genera un diccionario ordenado vacío\n sum=0\n for key in L:\n #print (key)\n #print (temp.loc[key])\n dict_var[key]=sum+temp.loc[key].item()\n sum = sum + temp.loc[key].item()\n return dict_var",
"_____no_output_____"
]
],
[
[
"Se crean los diccionarios de probabilidades para las variables descriptivas",
"_____no_output_____"
]
],
[
[
"dict_Id_Country = dic_other_vars(temp1)\ndict_Id_Age = dic_other_vars(temp2)\ndict_Id_Experience = dic_other_vars(temp3)\ndict_Id_Gender = dic_other_vars(temp4)\ndict_Id_Salary = dic_other_vars(temp5)",
"_____no_output_____"
],
[
"dict_Id_Salary",
"_____no_output_____"
]
],
[
[
"Para el año 2017 la variable edad esta en NULL",
"_____no_output_____"
],
[
"## Paso 3: Funciones generadoras de datos por variable",
"_____no_output_____"
],
[
"Primero la función generadora de datos para los leguajes de programación",
"_____no_output_____"
]
],
[
[
"import random",
"_____no_output_____"
],
[
"random.random()",
"_____no_output_____"
],
[
"P_JavaScript",
"_____no_output_____"
],
[
"def gen_L_Prog(p_lang, label):\n '''se ingresa la probabilidad de occurrencia del lenguaje y la equiqueta que se quiere generar\n '''\n output=None\n temp_p = random.random() #prob entre 0 y 1 uniforme\n #print (temp_p)\n #print (temp_p<p_lang)\n if temp_p < p_lang:\n output = label\n else: \n pass\n return output ",
"_____no_output_____"
]
],
[
[
"Prueba de la funcion para 10 datos",
"_____no_output_____"
]
],
[
[
"for i in range(10):\n prueba = gen_L_Prog(P_JavaScript, \"JavaScript\")\n print (prueba)",
"None\nJavaScript\nJavaScript\nNone\nJavaScript\nNone\nJavaScript\nNone\nJavaScript\nNone\n"
]
],
[
[
"Ahora se definen las funciones para la generación de las otras variables descriptivas: país, edad, experiencia, genero, salario",
"_____no_output_____"
]
],
[
[
"dict_Id_Experience",
"_____no_output_____"
],
[
"def gen_V_Desc(Input_Dict):\n temp_p = random.random() #prob entre 0 y 1 uniforme\n #print (temp_p)\n output=None\n for k,v in Input_Dict.items():\n #print (k,v)\n if temp_p < v:\n output = k\n break\n return output",
"_____no_output_____"
]
],
[
[
"prueba de generación para experiencia",
"_____no_output_____"
]
],
[
[
"for i in range(5):\n prueba = gen_V_Desc(dict_Id_Experience)\n print (prueba)",
"4.0\n4.0\n5.0\n5.0\n6.0\n"
]
],
[
[
"prueba de generación para país",
"_____no_output_____"
]
],
[
[
"for i in range(5):\n prueba = gen_V_Desc(dict_Id_Country)\n print (prueba)",
"33.0\n212.0\n78.0\n213.0\n93.0\n"
]
],
[
[
"## 4. Función que genera un registro aleatorio con la distribución de probabilidad empírica de 2017",
"_____no_output_____"
]
],
[
[
"Total.columns.values",
"_____no_output_____"
],
[
"def registro ():\n temp = []\n temp.append(gen_L_Prog(P_AngularJS, \"AngularJS\"))\n temp.append(gen_L_Prog(P_C, \"C\"))\n temp.append(gen_L_Prog(P_CPlusPlus, \"CPlusPlus\"))\n temp.append(gen_L_Prog(P_CSS, \"CSS\"))\n temp.append(gen_L_Prog(P_CSharp, \"CSharp\"))\n temp.append(gen_L_Prog(P_HTML5, \"HTML5\"))\n temp.append(gen_V_Desc(dict_Id_Age))\n temp.append(gen_V_Desc(dict_Id_Country))\n temp.append(gen_V_Desc(dict_Id_Experience))\n temp.append(gen_V_Desc(dict_Id_Gender)) \n temp.append(gen_V_Desc(dict_Id_Salary)) \n temp.append(gen_L_Prog(P_Java, \"Java\"))\n temp.append(gen_L_Prog(P_JavaScript, \"JavaScript\"))\n temp.append(gen_L_Prog(P_Nodejs, \"Nodejs\"))\n temp.append(gen_L_Prog(P_ObjectiveC, \"Objective-C\"))\n temp.append(gen_L_Prog(P_PHP, \"PHP\"))\n temp.append(gen_L_Prog(P_Perl, \"Perl\"))\n temp.append(gen_L_Prog(P_Python, \"Python\"))\n temp.append(gen_L_Prog(P_Ruby, \"Ruby\"))\n temp.append(gen_L_Prog(P_SQL, \"SQL\"))\n temp.append(gen_L_Prog(P_SQL_Server, \"SQL_Server\"))\n temp.append(gen_L_Prog(P_TypeScript, \"TypeScript\"))\n temp.append(2018)\n temp.append(gen_L_Prog(P_jQuery, \"jQuery\"))\n return temp",
"_____no_output_____"
],
[
"print (registro())",
"[None, None, None, None, None, None, None, 196.0, 5.0, 4.0, 14.0, None, 'JavaScript', None, None, 'PHP', None, 'Python', None, None, None, None, 2018, None]\n"
]
],
[
[
"## 5. Función para generar N registros",
"_____no_output_____"
]
],
[
[
"def n_registros(n):\n data=[]\n for i in range(n):\n data.append(registro())\n return data ",
"_____no_output_____"
],
[
"tabla = n_registros(50000)",
"_____no_output_____"
],
[
"header = ['AngularJS', 'C', 'CPlusPlus', 'CSS', 'CSharp', 'HTML5', 'Id_Age',\n 'Id_Country', 'Id_Experience', 'Id_Gender', 'Id_Salary', 'Java',\n 'JavaScript', 'Nodejs', 'ObjectiveC', 'PHP', 'Perl', 'Python',\n 'Ruby', 'SQL', 'SQL_Server', 'TypeScript', 'Year', 'jQuery']\ntabla_df = pd.DataFrame(tabla, columns = header)",
"_____no_output_____"
],
[
"tabla_df.head()",
"_____no_output_____"
],
[
"tabla_df.tail()",
"_____no_output_____"
]
],
[
[
"### DATOS TABLA 2017",
"_____no_output_____"
]
],
[
[
"Prob_Lang=data_2017.groupby('Year').count()/data_2017.shape[0]\nProb_Lang",
"_____no_output_____"
]
],
[
[
"## DATOS SIMULADOS 2018",
"_____no_output_____"
]
],
[
[
"datos_tabla_df = tabla_df.groupby('Year').count()/tabla_df.shape[0]\ndatos_tabla_df",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4ad4da3d4cd78431b676ba28662ccbdee153c62c
| 42,550 |
ipynb
|
Jupyter Notebook
|
jordan_cp9_add_sub_maxstep.ipynb
|
sungjae-cho/arithmetic-jordan-net
|
3eeb9cfa0fdcae9d8655aaa5d6112a91e201ec5f
|
[
"MIT"
] | 1 |
2019-03-05T14:07:03.000Z
|
2019-03-05T14:07:03.000Z
|
jordan_cp9_add_sub_maxstep.ipynb
|
sungjae-cho/arithmetic-jordan-net
|
3eeb9cfa0fdcae9d8655aaa5d6112a91e201ec5f
|
[
"MIT"
] | null | null | null |
jordan_cp9_add_sub_maxstep.ipynb
|
sungjae-cho/arithmetic-jordan-net
|
3eeb9cfa0fdcae9d8655aaa5d6112a91e201ec5f
|
[
"MIT"
] | 1 |
2019-09-07T16:35:41.000Z
|
2019-09-07T16:35:41.000Z
| 41.512195 | 206 | 0.405311 |
[
[
[
"import run_info_utils",
"_____no_output_____"
],
[
"df = run_info_utils.get_df_run_info()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"# print(list(df.columns))",
"_____no_output_____"
],
[
"experiment_name = 'jordan_cp9_add_sub_maxstep'\ndf = df.loc[df['experiment_name'] == experiment_name]\n\ncols = ['run_id', 'operator', 'rnn_type', 'confidence_prob', 'operand_bits', 'hidden_activation', 'max_steps',\n'dev/last_carry-0_mean_correct_answer_step', \n'dev/last_carry-1_mean_correct_answer_step', \n'dev/last_carry-2_mean_correct_answer_step', \n'dev/last_carry-3_mean_correct_answer_step', \n'dev/last_carry-4_mean_correct_answer_step', \n'dev/last_mean_correct_answer_step', 'dev/last_accuracy']\ndf = df[cols]",
"_____no_output_____"
],
[
"df = df.loc[df['dev/last_accuracy'] == 1.0]",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df_add_jordan_9_relu_maxstep10 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 10')\ndf_sub_jordan_9_relu_maxstep10 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 10')\ndf_add_jordan_9_relu_maxstep20 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 20')\ndf_sub_jordan_9_relu_maxstep20 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 20')\ndf_add_jordan_9_relu_maxstep30 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 30')\ndf_sub_jordan_9_relu_maxstep30 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 30')\ndf_add_jordan_9_relu_maxstep40 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 40')\ndf_sub_jordan_9_relu_maxstep40 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 40')\ndf_add_jordan_9_relu_maxstep50 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 50')\ndf_sub_jordan_9_relu_maxstep50 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 50')\ndf_add_jordan_9_relu_maxstep60 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 60')\ndf_sub_jordan_9_relu_maxstep60 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 60')\ndf_add_jordan_9_relu_maxstep90 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"relu\"').query('max_steps == 90')\n\n\ndf_add_jordan_9_tanh_maxstep10 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 10')\ndf_sub_jordan_9_tanh_maxstep10 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 10')\ndf_add_jordan_9_tanh_maxstep20 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 20')\ndf_sub_jordan_9_tanh_maxstep20 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 20')\ndf_add_jordan_9_tanh_maxstep30 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 30')\ndf_sub_jordan_9_tanh_maxstep30 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 30')\ndf_add_jordan_9_tanh_maxstep40 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 40')\ndf_sub_jordan_9_tanh_maxstep40 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 40')\ndf_add_jordan_9_tanh_maxstep50 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 50')\ndf_sub_jordan_9_tanh_maxstep50 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 50')\ndf_add_jordan_9_tanh_maxstep60 = df.query('operator == \"add\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 60')\ndf_sub_jordan_9_tanh_maxstep60 = df.query('operator == \"subtract\"').query('rnn_type == \"jordan\"').query('confidence_prob == 0.9').query('hidden_activation == \"tanh\"').query('max_steps == 60')",
"_____no_output_____"
],
[
"print(df_add_jordan_9_relu_maxstep10.shape)\nprint(df_sub_jordan_9_relu_maxstep10.shape)\nprint(df_add_jordan_9_relu_maxstep20.shape)\nprint(df_sub_jordan_9_relu_maxstep20.shape)\nprint(df_add_jordan_9_relu_maxstep30.shape)\nprint(df_sub_jordan_9_relu_maxstep30.shape)\nprint(df_add_jordan_9_relu_maxstep40.shape)\nprint(df_sub_jordan_9_relu_maxstep40.shape)\nprint(df_add_jordan_9_relu_maxstep50.shape)\nprint(df_sub_jordan_9_relu_maxstep50.shape)\nprint(df_add_jordan_9_relu_maxstep60.shape)\nprint(df_sub_jordan_9_relu_maxstep60.shape)\nprint(df_add_jordan_9_relu_maxstep90.shape)",
"(100, 14)\n(30, 14)\n(100, 14)\n(30, 14)\n(100, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(102, 14)\n(30, 14)\n(102, 14)\n(30, 14)\n(60, 14)\n"
],
[
"print(df_add_jordan_9_tanh_maxstep10.shape)\nprint(df_sub_jordan_9_tanh_maxstep10.shape)\nprint(df_add_jordan_9_tanh_maxstep20.shape)\nprint(df_sub_jordan_9_tanh_maxstep20.shape)\nprint(df_add_jordan_9_tanh_maxstep30.shape)\nprint(df_sub_jordan_9_tanh_maxstep30.shape)\nprint(df_add_jordan_9_tanh_maxstep40.shape)\nprint(df_sub_jordan_9_tanh_maxstep40.shape)\nprint(df_add_jordan_9_tanh_maxstep50.shape)\nprint(df_sub_jordan_9_tanh_maxstep50.shape)\nprint(df_add_jordan_9_tanh_maxstep60.shape)\nprint(df_sub_jordan_9_tanh_maxstep60.shape)",
"(37, 14)\n(40, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n(30, 14)\n"
]
],
[
[
"# Result",
"_____no_output_____"
]
],
[
[
"df_add_jordan_9_relu_maxstep40.describe()",
"_____no_output_____"
],
[
"df_sub_jordan_9_relu_maxstep40.describe()",
"_____no_output_____"
]
],
[
[
"# Export as CSV",
"_____no_output_____"
],
[
"## Functionalize",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport data_utils \nfrom utils import create_dir\nfrom os.path import join\n\ndef get_csv_df(df, filename, experiment_name):\n # Get configurations\n n_rows = df.shape[0]\n operator = df['operator'].iloc[0]\n operand_digits = df['operand_bits'].iloc[0]\n carry_list = list(data_utils.import_carry_datasets(operand_digits, operator).keys())\n \n # Gather for each \n csv_df_list = list()\n for carries in carry_list:\n col = 'dev/last_carry-{}_mean_correct_answer_step'.format(carries)\n csv_df = pd.DataFrame(data={'mean_anwer_steps':df[col], 'carries':np.full((n_rows), carries)})\n csv_df_list.append(csv_df)\n csv_df = pd.concat(csv_df_list, ignore_index=True)\n \n # Change the order of columns\n csv_df = csv_df[['mean_anwer_steps', 'carries']]\n \n # Create dir\n dir_to_save = join('result_statistics', experiment_name)\n create_dir(dir_to_save)\n \n # Save the dataframe to a CSV file.\n csv_df.to_csv(join(dir_to_save, filename), index=False)",
"_____no_output_____"
],
[
"experiment_name = 'jordan_cp9_add_sub_maxstep'",
"_____no_output_____"
],
[
"get_csv_df(df_add_jordan_9_relu_maxstep10, 'df_add_jordan_9_relu_maxstep10.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep10, 'df_sub_jordan_9_relu_maxstep10.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep20, 'df_add_jordan_9_relu_maxstep20.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep20, 'df_sub_jordan_9_relu_maxstep20.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep30, 'df_add_jordan_9_relu_maxstep30.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep30, 'df_sub_jordan_9_relu_maxstep30.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep40, 'df_add_jordan_9_relu_maxstep40.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep40, 'df_sub_jordan_9_relu_maxstep40.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep50, 'df_add_jordan_9_relu_maxstep50.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep50, 'df_sub_jordan_9_relu_maxstep50.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep60, 'df_add_jordan_9_relu_maxstep60.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_relu_maxstep60, 'df_sub_jordan_9_relu_maxstep60.csv', experiment_name)\nget_csv_df(df_add_jordan_9_relu_maxstep90, 'df_add_jordan_9_relu_maxstep90.csv', experiment_name)",
"_____no_output_____"
],
[
"get_csv_df(df_add_jordan_9_tanh_maxstep10, 'df_add_jordan_9_tanh_maxstep10.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep10, 'df_sub_jordan_9_tanh_maxstep10.csv', experiment_name)\nget_csv_df(df_add_jordan_9_tanh_maxstep20, 'df_add_jordan_9_tanh_maxstep20.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep20, 'df_sub_jordan_9_tanh_maxstep20.csv', experiment_name)\nget_csv_df(df_add_jordan_9_tanh_maxstep30, 'df_add_jordan_9_tanh_maxstep30.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep30, 'df_sub_jordan_9_tanh_maxstep30.csv', experiment_name)\nget_csv_df(df_add_jordan_9_tanh_maxstep40, 'df_add_jordan_9_tanh_maxstep40.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep40, 'df_sub_jordan_9_tanh_maxstep40.csv', experiment_name)\nget_csv_df(df_add_jordan_9_tanh_maxstep50, 'df_add_jordan_9_tanh_maxstep50.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep50, 'df_sub_jordan_9_tanh_maxstep50.csv', experiment_name)\nget_csv_df(df_add_jordan_9_tanh_maxstep60, 'df_add_jordan_9_tanh_maxstep60.csv', experiment_name)\nget_csv_df(df_sub_jordan_9_tanh_maxstep60, 'df_sub_jordan_9_tanh_maxstep60.csv', experiment_name)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4ad4da52e82320f66a37f6d57c2e6708749dce44
| 30,574 |
ipynb
|
Jupyter Notebook
|
python_data_science/Week-4-Pandas/Introduction to Pandas.ipynb
|
bunnydev26/micromasters-edx
|
ed97e7f27985ac084cf74fc48b6221f0c2254533
|
[
"MIT"
] | null | null | null |
python_data_science/Week-4-Pandas/Introduction to Pandas.ipynb
|
bunnydev26/micromasters-edx
|
ed97e7f27985ac084cf74fc48b6221f0c2254533
|
[
"MIT"
] | null | null | null |
python_data_science/Week-4-Pandas/Introduction to Pandas.ipynb
|
bunnydev26/micromasters-edx
|
ed97e7f27985ac084cf74fc48b6221f0c2254533
|
[
"MIT"
] | null | null | null | 20.505701 | 233 | 0.517008 |
[
[
[
"<p style=\"font-family: Arial; font-size:3.75em;color:purple; font-style:bold\"><br>\nPandas</p><br>\n\n*pandas* is a Python library for data analysis. It offers a number of data exploration, cleaning and transformation operations that are critical in working with data in Python. \n\n*pandas* build upon *numpy* and *scipy* providing easy-to-use data structures and data manipulation functions with integrated indexing.\n\nThe main data structures *pandas* provides are *Series* and *DataFrames*. After a brief introduction to these two data structures and data ingestion, the key features of *pandas* this notebook covers are:\n* Generating descriptive statistics on data\n* Data cleaning using built in pandas functions\n* Frequent data operations for subsetting, filtering, insertion, deletion and aggregation of data\n* Merging multiple datasets using dataframes\n* Working with timestamps and time-series data\n\n**Additional Recommended Resources:**\n* *pandas* Documentation: http://pandas.pydata.org/pandas-docs/stable/\n* *Python for Data Analysis* by Wes McKinney\n* *Python Data Science Handbook* by Jake VanderPlas\n\nLet's get started with our first *pandas* notebook!",
"_____no_output_____"
],
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\"><br>\n\nImport Libraries\n</p>",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\">\nIntroduction to pandas Data Structures</p>\n<br>\n*pandas* has two main data structures it uses, namely, *Series* and *DataFrames*. \n\n<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\">\npandas Series</p>\n\n*pandas Series* one-dimensional labeled array. \n",
"_____no_output_____"
]
],
[
[
"ser = pd.Series([100, 'foo', 300, 'bar', 500], ['tom', 'bob', 'nancy', 'dan', 'eric'])",
"_____no_output_____"
],
[
"ser",
"_____no_output_____"
],
[
"ser.index",
"_____no_output_____"
],
[
"ser.loc[['nancy','bob']]",
"_____no_output_____"
],
[
"ser[[4, 3, 1]]",
"_____no_output_____"
],
[
"ser.iloc[2]",
"_____no_output_____"
],
[
"'bob' in ser",
"_____no_output_____"
],
[
"ser",
"_____no_output_____"
],
[
"ser * 2",
"_____no_output_____"
],
[
"ser[['nancy', 'eric']] ** 2",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\">\npandas DataFrame</p>\n\n*pandas DataFrame* is a 2-dimensional labeled data structure.",
"_____no_output_____"
],
[
"<p style=\"font-family: Arial; font-size:1.25em;color:#2462C0; font-style:bold\">\nCreate DataFrame from dictionary of Python Series</p>",
"_____no_output_____"
]
],
[
[
"d = {'one' : pd.Series([100., 200., 300.], index=['apple', 'ball', 'clock']),\n 'two' : pd.Series([111., 222., 333., 4444.], index=['apple', 'ball', 'cerill', 'dancy'])}",
"_____no_output_____"
],
[
"df = pd.DataFrame(d)\nprint(df)",
"_____no_output_____"
],
[
"df.index",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"pd.DataFrame(d, index=['dancy', 'ball', 'apple'])",
"_____no_output_____"
],
[
"pd.DataFrame(d, index=['dancy', 'ball', 'apple'], columns=['two', 'five'])",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.25em;color:#2462C0; font-style:bold\">\nCreate DataFrame from list of Python dictionaries</p>",
"_____no_output_____"
]
],
[
[
"data = [{'alex': 1, 'joe': 2}, {'ema': 5, 'dora': 10, 'alice': 20}]",
"_____no_output_____"
],
[
"pd.DataFrame(data)",
"_____no_output_____"
],
[
"pd.DataFrame(data, index=['orange', 'red'])",
"_____no_output_____"
],
[
"pd.DataFrame(data, columns=['joe', 'dora','alice'])",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.25em;color:#2462C0; font-style:bold\">\nBasic DataFrame operations</p>",
"_____no_output_____"
]
],
[
[
"df",
"_____no_output_____"
],
[
"df['one']",
"_____no_output_____"
],
[
"df['three'] = df['one'] * df['two']\ndf",
"_____no_output_____"
],
[
"df['flag'] = df['one'] > 250\ndf",
"_____no_output_____"
],
[
"three = df.pop('three')",
"_____no_output_____"
],
[
"three",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"del df['two']",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.insert(2, 'copy_of_one', df['one'])\ndf",
"_____no_output_____"
],
[
"df['one_upper_half'] = df['one'][:2]\ndf",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\">\nCase Study: Movie Data Analysis</p>\n<br>This notebook uses a dataset from the MovieLens website. We will describe the dataset further as we explore with it using *pandas*. \n\n## Download the Dataset\n\nPlease note that **you will need to download the dataset**. Although the video for this notebook says that the data is in your folder, the folder turned out to be too large to fit on the edX platform due to size constraints.\n\nHere are the links to the data source and location:\n* **Data Source:** MovieLens web site (filename: ml-20m.zip)\n* **Location:** https://grouplens.org/datasets/movielens/\n\nOnce the download completes, please make sure the data files are in a directory called *movielens* in your *Week-3-pandas* folder. \n\nLet us look at the files in this dataset using the UNIX command ls.\n",
"_____no_output_____"
]
],
[
[
"# Note: Adjust the name of the folder to match your local directory\n\n!ls ./movielens",
"_____no_output_____"
],
[
"!cat ./movielens/movies.csv | wc -l",
"_____no_output_____"
],
[
"!head -5 ./movielens/ratings.csv",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\">\nUse Pandas to Read the Dataset<br>\n</p>\n<br>\nIn this notebook, we will be using three CSV files:\n* **ratings.csv :** *userId*,*movieId*,*rating*, *timestamp*\n* **tags.csv :** *userId*,*movieId*, *tag*, *timestamp*\n* **movies.csv :** *movieId*, *title*, *genres* <br>\n\nUsing the *read_csv* function in pandas, we will ingest these three files.",
"_____no_output_____"
]
],
[
[
"movies = pd.read_csv('./movielens/movies.csv', sep=',')\nprint(type(movies))\nmovies.head(15)",
"_____no_output_____"
],
[
"# Timestamps represent seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970\n\ntags = pd.read_csv('./movielens/tags.csv', sep=',')\ntags.head()",
"_____no_output_____"
],
[
"ratings = pd.read_csv('./movielens/ratings.csv', sep=',', parse_dates=['timestamp'])\nratings.head()",
"_____no_output_____"
],
[
"# For current analysis, we will remove timestamp (we will come back to it!)\n\ndel ratings['timestamp']\ndel tags['timestamp']",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Data Structures </h1>",
"_____no_output_____"
],
[
"<h1 style=\"font-size:1.5em;color:#2467C0\">Series</h1>",
"_____no_output_____"
]
],
[
[
"#Extract 0th row: notice that it is infact a Series\n\nrow_0 = tags.iloc[0]\ntype(row_0)",
"_____no_output_____"
],
[
"print(row_0)",
"_____no_output_____"
],
[
"row_0.index",
"_____no_output_____"
],
[
"row_0['userId']",
"_____no_output_____"
],
[
"'rating' in row_0",
"_____no_output_____"
],
[
"row_0.name",
"_____no_output_____"
],
[
"row_0 = row_0.rename('first_row')\nrow_0.name",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:1.5em;color:#2467C0\">DataFrames </h1>",
"_____no_output_____"
]
],
[
[
"tags.head()",
"_____no_output_____"
],
[
"tags.index",
"_____no_output_____"
],
[
"tags.columns",
"_____no_output_____"
],
[
"# Extract row 0, 11, 2000 from DataFrame\n\ntags.iloc[ [0,11,2000] ]",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Descriptive Statistics</h1>\n\nLet's look how the ratings are distributed! ",
"_____no_output_____"
]
],
[
[
"ratings['rating'].describe()",
"_____no_output_____"
],
[
"ratings.describe()",
"_____no_output_____"
],
[
"ratings['rating'].mean()",
"_____no_output_____"
],
[
"ratings.mean()",
"_____no_output_____"
],
[
"ratings['rating'].min()",
"_____no_output_____"
],
[
"ratings['rating'].max()",
"_____no_output_____"
],
[
"ratings['rating'].std()",
"_____no_output_____"
],
[
"ratings['rating'].mode()",
"_____no_output_____"
],
[
"ratings.corr()",
"_____no_output_____"
],
[
"filter_1 = ratings['rating'] > 5\nprint(filter_1)\nfilter_1.any()",
"_____no_output_____"
],
[
"filter_2 = ratings['rating'] > 0\nfilter_2.all()",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Data Cleaning: Handling Missing Data</h1>",
"_____no_output_____"
]
],
[
[
"movies.shape",
"_____no_output_____"
],
[
"#is any row NULL ?\n\nmovies.isnull().any()",
"_____no_output_____"
]
],
[
[
"Thats nice ! No NULL values !",
"_____no_output_____"
]
],
[
[
"ratings.shape",
"_____no_output_____"
],
[
"#is any row NULL ?\n\nratings.isnull().any()",
"_____no_output_____"
]
],
[
[
"Thats nice ! No NULL values !",
"_____no_output_____"
]
],
[
[
"tags.shape",
"_____no_output_____"
],
[
"#is any row NULL ?\n\ntags.isnull().any()",
"_____no_output_____"
]
],
[
[
"We have some tags which are NULL.",
"_____no_output_____"
]
],
[
[
"tags = tags.dropna()",
"_____no_output_____"
],
[
"#Check again: is any row NULL ?\n\ntags.isnull().any()",
"_____no_output_____"
],
[
"tags.shape",
"_____no_output_____"
]
],
[
[
"Thats nice ! No NULL values ! Notice the number of lines have reduced.",
"_____no_output_____"
],
[
"<h1 style=\"font-size:2em;color:#2467C0\">Data Visualization</h1>",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nratings.hist(column='rating', figsize=(15,10))",
"_____no_output_____"
],
[
"ratings.boxplot(column='rating', figsize=(15,20))",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Slicing Out Columns</h1>\n ",
"_____no_output_____"
]
],
[
[
"tags['tag'].head()",
"_____no_output_____"
],
[
"movies[['title','genres']].head()",
"_____no_output_____"
],
[
"ratings[-10:]",
"_____no_output_____"
],
[
"tag_counts = tags['tag'].value_counts()\ntag_counts[-10:]",
"_____no_output_____"
],
[
"tag_counts[:10].plot(kind='bar', figsize=(15,10))",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Filters for Selecting Rows</h1>",
"_____no_output_____"
]
],
[
[
"is_highly_rated = ratings['rating'] >= 4.0\n\nratings[is_highly_rated][30:50]",
"_____no_output_____"
],
[
"is_animation = movies['genres'].str.contains('Animation')\n\nmovies[is_animation][5:15]",
"_____no_output_____"
],
[
"movies[is_animation].head(15)",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Group By and Aggregate </h1>",
"_____no_output_____"
]
],
[
[
"ratings_count = ratings[['movieId','rating']].groupby('rating').count()\nratings_count",
"_____no_output_____"
],
[
"average_rating = ratings[['movieId','rating']].groupby('movieId').mean()\naverage_rating.head()",
"_____no_output_____"
],
[
"movie_count = ratings[['movieId','rating']].groupby('movieId').count()\nmovie_count.head()",
"_____no_output_____"
],
[
"movie_count = ratings[['movieId','rating']].groupby('movieId').count()\nmovie_count.tail()",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Merge Dataframes</h1>",
"_____no_output_____"
]
],
[
[
"tags.head()",
"_____no_output_____"
],
[
"movies.head()",
"_____no_output_____"
],
[
"t = movies.merge(tags, on='movieId', how='inner')\nt.head()",
"_____no_output_____"
]
],
[
[
"More examples: http://pandas.pydata.org/pandas-docs/stable/merging.html",
"_____no_output_____"
],
[
"<p style=\"font-family: Arial; font-size:1.75em;color:#2462C0; font-style:bold\"><br>\n\n\nCombine aggreagation, merging, and filters to get useful analytics\n</p>",
"_____no_output_____"
]
],
[
[
"avg_ratings = ratings.groupby('movieId', as_index=False).mean()\ndel avg_ratings['userId']\navg_ratings.head()",
"_____no_output_____"
],
[
"box_office = movies.merge(avg_ratings, on='movieId', how='inner')\nbox_office.tail()",
"_____no_output_____"
],
[
"is_highly_rated = box_office['rating'] >= 4.0\n\nbox_office[is_highly_rated][-5:]",
"_____no_output_____"
],
[
"is_comedy = box_office['genres'].str.contains('Comedy')\n\nbox_office[is_comedy][:5]",
"_____no_output_____"
],
[
"box_office[is_comedy & is_highly_rated][-5:]",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Vectorized String Operations</h1>\n",
"_____no_output_____"
]
],
[
[
"movies.head()",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\"><br>\n\nSplit 'genres' into multiple columns\n\n<br> </p>",
"_____no_output_____"
]
],
[
[
"movie_genres = movies['genres'].str.split('|', expand=True)",
"_____no_output_____"
],
[
"movie_genres[:10]",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\"><br>\n\nAdd a new column for comedy genre flag\n\n<br> </p>",
"_____no_output_____"
]
],
[
[
"movie_genres['isComedy'] = movies['genres'].str.contains('Comedy')",
"_____no_output_____"
],
[
"movie_genres[:10]",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\"><br>\n\nExtract year from title e.g. (1995)\n\n<br> </p>",
"_____no_output_____"
]
],
[
[
"movies['year'] = movies['title'].str.extract('.*\\((.*)\\).*', expand=True)",
"_____no_output_____"
],
[
"movies.tail()",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\"><br>\n\nMore here: http://pandas.pydata.org/pandas-docs/stable/text.html#text-string-methods\n<br> </p>",
"_____no_output_____"
],
[
"<h1 style=\"font-size:2em;color:#2467C0\">Parsing Timestamps</h1>",
"_____no_output_____"
],
[
"Timestamps are common in sensor data or other time series datasets.\nLet us revisit the *tags.csv* dataset and read the timestamps!\n",
"_____no_output_____"
]
],
[
[
"tags = pd.read_csv('./movielens/tags.csv', sep=',')",
"_____no_output_____"
],
[
"tags.dtypes",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\">\n\nUnix time / POSIX time / epoch time records \ntime in seconds <br> since midnight Coordinated Universal Time (UTC) of January 1, 1970\n</p>",
"_____no_output_____"
]
],
[
[
"tags.head(5)",
"_____no_output_____"
],
[
"tags['parsed_time'] = pd.to_datetime(tags['timestamp'], unit='s')",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\">\n\nData Type datetime64[ns] maps to either <M8[ns] or >M8[ns] depending on the hardware\n\n</p>",
"_____no_output_____"
]
],
[
[
"\ntags['parsed_time'].dtype",
"_____no_output_____"
],
[
"tags.head(2)",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\">\n\nSelecting rows based on timestamps\n</p>",
"_____no_output_____"
]
],
[
[
"greater_than_t = tags['parsed_time'] > '2015-02-01'\n\nselected_rows = tags[greater_than_t]\n\ntags.shape, selected_rows.shape",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\">\n\nSorting the table using the timestamps\n</p>",
"_____no_output_____"
]
],
[
[
"tags.sort_values(by='parsed_time', ascending=True)[:10]",
"_____no_output_____"
]
],
[
[
"<h1 style=\"font-size:2em;color:#2467C0\">Average Movie Ratings over Time </h1>\n## Are Movie ratings related to the year of launch?",
"_____no_output_____"
]
],
[
[
"average_rating = ratings[['movieId','rating']].groupby('movieId', as_index=False).mean()\naverage_rating.tail()",
"_____no_output_____"
],
[
"joined = movies.merge(average_rating, on='movieId', how='inner')\njoined.head()\njoined.corr()",
"_____no_output_____"
],
[
"yearly_average = joined[['year','rating']].groupby('year', as_index=False).mean()\nyearly_average[:10]",
"_____no_output_____"
],
[
"yearly_average[-20:].plot(x='year', y='rating', figsize=(15,10), grid=True)",
"_____no_output_____"
]
],
[
[
"<p style=\"font-family: Arial; font-size:1.35em;color:#2462C0; font-style:bold\">\n\nDo some years look better for the boxoffice movies than others? <br><br>\n\nDoes any data point seem like an outlier in some sense?\n\n</p>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ad4e9b25a992eb29170d840935e78750d3d3c86
| 160,338 |
ipynb
|
Jupyter Notebook
|
Blogpostproject.ipynb
|
sarathchandratumuluri/Udacity_Datascience
|
d74d7461b90d3787f521062513ad499d37187e1a
|
[
"Apache-2.0"
] | null | null | null |
Blogpostproject.ipynb
|
sarathchandratumuluri/Udacity_Datascience
|
d74d7461b90d3787f521062513ad499d37187e1a
|
[
"Apache-2.0"
] | null | null | null |
Blogpostproject.ipynb
|
sarathchandratumuluri/Udacity_Datascience
|
d74d7461b90d3787f521062513ad499d37187e1a
|
[
"Apache-2.0"
] | null | null | null | 188.411281 | 38,300 | 0.876037 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sb\nimport string\n",
"_____no_output_____"
],
[
"df = pd.read_csv('./Documents/listings.csv')\ndf.head()\n\nHt = pd.read_csv('./Documents/Hawaii_Tourisim_Data.csv')\nHt",
"_____no_output_____"
],
[
"Ht['Value']=pd.to_numeric(Ht['Value']) # convert the data type to numeric \nvisitor_month=Ht.groupby('month',sort=False,as_index=False)['Value'].sum() #grouping by month and sorting to see the trend of visitors by month\nvisitor_month=visitor_month[visitor_month.month!='All'] # removing uncessary data",
"_____no_output_____"
],
[
"plt.bar(x=visitor_month[\"month\"],height=visitor_month[\"Value\"]) # plotting a bar chart sorted by month to identify trends",
"_____no_output_____"
],
[
"island_visitors=Ht.groupby(['State','Attribute'],sort=False)['Value'].sum() #grouping by month to see the trend of visitors by month\n#island_visitors\n",
"_____no_output_____"
],
[
"island_visitors=Ht.groupby(['State','Attribute'],sort=False)['Value'].sum().reset_index(name='Value') # reseting the index ",
"_____no_output_____"
],
[
"island_visitors1=island_visitors[island_visitors.Attribute=='Visitor arrivals'] # filtering to visitor arrivals attribute",
"_____no_output_____"
],
[
"island_visitors1['Pct'] = (island_visitors1.Value/island_visitors1.Value.sum())*100 # calculating the percentage of visitors by island\nisland_visitors1",
"<ipython-input-199-4e68a0d21d81>:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n island_visitors1['Pct'] = (island_visitors1.Value/island_visitors1.Value.sum())*100 # calculating the percentage of visitors by island\n"
],
[
"plt.bar(x=island_visitors1[\"State\"],height=island_visitors1[\"Pct\"]) # Plotting to visualize the trend\nplt.title(\"Islands comparision\")\nfig = plt.gcf() # Adjusting the size of the graph to increase visibility\nfig.set_size_inches(11,8)\n",
"_____no_output_____"
],
[
"Length_of_stay=Ht.groupby(['State','Attribute'])['Value'].mean() #Grouping by state and attribute to know the length of stay\n",
"_____no_output_____"
],
[
"Length_of_stay=Ht.groupby(['State','Attribute'],sort=False)['Value'].mean().reset_index(name='Value') # reseting the index\n",
"_____no_output_____"
],
[
"Length_of_stay=Length_of_stay[island_visitors.Attribute=='Length of stay(days)'] #Filtering to length of stay attribute\nLength_of_stay",
"_____no_output_____"
],
[
"plt.bar(x=Length_of_stay[\"State\"],height=Length_of_stay[\"Value\"]) # Plotting to visualize the trend\nplt.title(\"Length of stay comparision\")\nfig = plt.gcf()\nfig.set_size_inches(11,8)",
"_____no_output_____"
],
[
"airbnb_reviews = df.groupby(['neighbourhood_group_cleansed','neighbourhood_cleansed'])['host_id'].agg('count') # Groupby islands \n# and neighrbourhoods to see the number of airbnbs listed\n",
"_____no_output_____"
],
[
"airbnb_reviews = airbnb_reviews.unstack(level=0) # unstack them to create a heatmap dataset",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(11, 9)) # adjusting the size of the plot for better visibility\nsb.heatmap(airbnb_reviews) # generating a heatmap\nplt.show()",
"_____no_output_____"
],
[
"#Trying to filter the signs from the number and get number\n\ndf['price'] = df['price'].str.replace('$', '')\ndf['price'] = df['price'].str.replace(',', '')\ndf['price']=pd.to_numeric(df['price']) # convert the data type to numeric \nairbnb_price_variations = df.groupby(['neighbourhood_group_cleansed'])['price'].sum().reset_index(name='price')\n# grouping by price to understand the price variation across the airbnbs\n",
"_____no_output_____"
],
[
"sb.set(rc={'figure.figsize':(14,6)}) # adjusting the size of the plot\ndf[['neighbourhood_group_cleansed','price']] # creating the dataset for plotting box plot\nax = sb.boxplot(x=\"neighbourhood_group_cleansed\", y=\"price\", data=df[['neighbourhood_group_cleansed','price']],showfliers=False)\n# plotting the box plot by removing the outliers",
"_____no_output_____"
],
[
"airbnb_price_variations_sub = df.groupby(['neighbourhood_group_cleansed','neighbourhood_cleansed','host_id'])['price'].sum().reset_index(name='price') \n# Grouping by island and neighourhood to see the price variation",
"_____no_output_____"
],
[
"airbnb_price_variations_sub = airbnb_price_variations_sub[airbnb_price_variations_sub.neighbourhood_group_cleansed=='Hawaii']\n# Filtering to Hawaii islands",
"_____no_output_____"
],
[
"sb.set(rc={'figure.figsize':(14,6)})\nax = sb.boxplot(x=\"neighbourhood_cleansed\", y=\"price\", data=airbnb_price_variations_sub,showfliers=False)\n# Plotting the price variation in Hawaii islands ",
"_____no_output_____"
],
[
"Reviews_check=df.groupby(['neighbourhood_cleansed','host_id'])['review_scores_value','number_of_reviews'].mean().reset_index()\n# getting the review score value and number of reviews by neighbourhood\nReviews_check['review_score_normalized'] = Reviews_check.review_scores_value*Reviews_check.number_of_reviews\n# Normalizing the scores to get a good KPI to measure the success of airbnbs\nvaluesin = ['Kau','Puna']\nReviews_check=Reviews_check[Reviews_check.neighbourhood_cleansed.isin(valuesin)] # Filtering to Kau and Puna region\nReviews_check =Reviews_check.dropna() # Dropping 'na' values to filter the data to only those airbnbs that have valid scores\n#Reviews_check\nsb.set(rc={'figure.figsize':(14,6)})\nax = sb.boxplot(x=\"neighbourhood_cleansed\", y=\"review_score_normalized\", data=Reviews_check,showfliers=False)\n# Plotting to see the difference between the two regions",
"<ipython-input-170-c72b0d6c3563>:1: FutureWarning: Indexing with multiple keys (implicitly converted to a tuple of keys) will be deprecated, use a list instead.\n Reviews_check=df.groupby(['neighbourhood_cleansed','host_id'])['review_scores_value','number_of_reviews'].mean().reset_index()\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4ad4ecfa9a7f6d429239fa331939ee8ef3867fc2
| 15,480 |
ipynb
|
Jupyter Notebook
|
Python_Jupyter_Training/Week_3/.ipynb_checkpoints/4_Input_Output_CSV_Files-checkpoint.ipynb
|
brendo61-byte/pythonOnBoarding
|
f16fdb1107631591db157b7db8bb1ea8e0dc2e1b
|
[
"MIT"
] | 1 |
2019-11-10T00:13:18.000Z
|
2019-11-10T00:13:18.000Z
|
Python_Jupyter_Training/Week_3/4_Input_Output_CSV_Files.ipynb
|
brendo61-byte/pythonOnBoarding
|
f16fdb1107631591db157b7db8bb1ea8e0dc2e1b
|
[
"MIT"
] | null | null | null |
Python_Jupyter_Training/Week_3/4_Input_Output_CSV_Files.ipynb
|
brendo61-byte/pythonOnBoarding
|
f16fdb1107631591db157b7db8bb1ea8e0dc2e1b
|
[
"MIT"
] | null | null | null | 36 | 798 | 0.541408 |
[
[
[
"# What you will learn\n- What is a CSV file\n- Reading and writting on a csv file",
"_____no_output_____"
],
[
"### CSV = Comma seperated values\n\nChances are you have worked with .csv files before. There are simply values sperated by commas ...\n\n#### Note\n- All files used or created will be stored under week 3 in a folder called \"data\"\n\nHere is some exampe output:",
"_____no_output_____"
]
],
[
[
"data,timeStamp,dataType,units,sensorType,supervisorID\n35.18,03/22/2020-23:54:04,Humidity,%,BME280,2\n840.78,03/22/2020-23:54:04,Pressure,hPa,BME280,2\n1546.75,03/22/2020-23:54:04,Elevation,m,BME280,2\n176.6784452,03/22/2020-17:54:04,solar irradiance,w/m^2,ADC1115_Pyra,1\n0.035,03/22/2020-17:54:04,raw Voltage,V,ADC1115_Pyra,1\n17.25,03/22/2020-23:54:05,Temperature,C,BME280,2\n35.18,03/22/2020-23:54:05,Humidity,%,BME280,2\n840.84,03/22/2020-23:54:05,Pressure,hPa,BME280,2\n1546.24,03/22/2020-23:54:05,Elevation,m,BME280,2\n175.4164563,03/22/2020-17:54:06,solar irradiance,w/m^2,ADC1115_Pyra,1\n0.03475,03/22/2020-17:54:06,raw Voltage,V,ADC1115_Pyra,1\n17.23,03/22/2020-23:54:06,Temperature,C,BME280,2\n35.16,03/22/2020-23:54:06,Humidity,%,BME280,2\n840.73,03/22/2020-23:54:06,Pressure,hPa,BME280,2\n1547.14,03/22/2020-23:54:06,Elevation,m,BME280,2\n176.0474508,03/22/2020-17:54:07,solar irradiance,w/m^2,ADC1115_Pyra,1\n0.034875,03/22/2020-17:54:07,raw Voltage,V,ADC1115_Pyra,1\n17.24,03/22/2020-23:54:07,Temperature,C,BME280,2\n34.98,03/22/2020-23:54:07,Humidity,%,BME280,2\n840.67,03/22/2020-23:54:07,Pressure,hPa,BME280,2",
"_____no_output_____"
]
],
[
[
"If this kinda looks like data in excel that is because excel spread-sheets can be exported as .csv files.\n\nAbove each column for a given row has a distinction. The first row shown above are the column headers - i.e. the name of each column. We'll show how to work with this data but first the basics:\n\n## Reading a CSV file",
"_____no_output_____"
]
],
[
[
"import csv\nimport os\n\ndef run():\n with open(\"./data/example1.csv\", \"r\") as csvFile: # the \"r\" means read\n fileReader = csv.reader(csvFile)\n\n i = 0\n for row in fileReader:\n print(row)\n i += 1\n\n if i == 10:\n break\n \nif __name__==\"__main__\":\n run()",
"['data', 'timeStamp', 'dataType', 'units', 'sensorType', 'supervisorID']\n['218.3240787', '03/22/2020-17:38:38', 'solar irradiance', 'w/m^2', 'ADC1115_Pyra', '1']\n['0.04325', '03/22/2020-17:38:38', 'raw Voltage', 'V', 'ADC1115_Pyra', '1']\n['17.67', '03/22/2020-23:38:39', 'Temperature', 'C', 'BME280', '2']\n['35.05', '03/22/2020-23:38:39', 'Humidity', '%', 'BME280', '2']\n['840.43', '03/22/2020-23:38:39', 'Pressure', 'hPa', 'BME280', '2']\n['1550.4', '03/22/2020-23:38:39', 'Elevation', 'm', 'BME280', '2']\n['218.3240787', '03/22/2020-17:38:39', 'solar irradiance', 'w/m^2', 'ADC1115_Pyra', '1']\n['0.04325', '03/22/2020-17:38:39', 'raw Voltage', 'V', 'ADC1115_Pyra', '1']\n['17.68', '03/22/2020-23:38:40', 'Temperature', 'C', 'BME280', '2']\n"
]
],
[
[
"#### Note\n- The \"if i == 10\" break is just so all 5001 rows are not printed\n- the \"r\" tells the file to be opened for reading only",
"_____no_output_____"
],
[
"### What is the \"with open\"\n\nTo operate (meaning to read or to write) on a file that file has to be accessed. This involves opening the file. But what happens when you are done? That file needs to be closed. This is where \"with\" comes in. It is a context manager meaning that when you fall out of the with indentation the file will automatically be closed.\n\nYou cannot write to a file that another program is using - this is like two people trying to use the remote at the same time; chaoas and confusion will result. Context mangers allow clean closing of files without having to explicitly state that the file closes.\n\nWe could write the above code as seen below - but THIS IS BAD FORM!",
"_____no_output_____"
]
],
[
[
"# this is bad code\ncsvFile = open(\"./data/example1.csv\")\n\nfileReader = csv.reader(csvFile)\n\ni = 0\nfor row in fileReader:\n print(row)\n i += 1\n\n if i == 10:\n break\n\ncsvFile.close()",
"['data', 'timeStamp', 'dataType', 'units', 'sensorType', 'supervisorID']\n['218.3240787', '03/22/2020-17:38:38', 'solar irradiance', 'w/m^2', 'ADC1115_Pyra', '1']\n['0.04325', '03/22/2020-17:38:38', 'raw Voltage', 'V', 'ADC1115_Pyra', '1']\n['17.67', '03/22/2020-23:38:39', 'Temperature', 'C', 'BME280', '2']\n['35.05', '03/22/2020-23:38:39', 'Humidity', '%', 'BME280', '2']\n['840.43', '03/22/2020-23:38:39', 'Pressure', 'hPa', 'BME280', '2']\n['1550.4', '03/22/2020-23:38:39', 'Elevation', 'm', 'BME280', '2']\n['218.3240787', '03/22/2020-17:38:39', 'solar irradiance', 'w/m^2', 'ADC1115_Pyra', '1']\n['0.04325', '03/22/2020-17:38:39', 'raw Voltage', 'V', 'ADC1115_Pyra', '1']\n['17.68', '03/22/2020-23:38:40', 'Temperature', 'C', 'BME280', '2']\n"
]
],
[
[
"## Writing to a CSV file\n\nAbove we used \"r\" to read from a file. Well now that becomes \"w\" to write.\n\n#### Important\nIf you write to a file that already exists then the file will be overwritten. There will be no warning as with many office tools saying you are about to overwrite something.\n\nIf you with to add something to a csv file we will cover that below.",
"_____no_output_____"
]
],
[
[
"import csv\nimport os\nimport time\nimport random\n\nHEADERS = ['data', 'timeStamp', 'dataType']\n\ndef makeRow(): # random data to put in csv\n return [random.randint(0,101), time.time(), \"random Float\"]\n \n\ndef makeFile(): # makes a csv\n with open(\"./data/example2.csv\", \"w\") as csvFile: # the \"w\" means write\n fileWriter = csv.writer(csvFile)\n \n fileWriter.writerow(HEADERS)\n \n for i in range(10):\n fileWriter.writerow(makeRow())\n \n\ndef readFile(): # read from the csv you created to see it!\n with open(\"./data/example2.csv\", \"r\") as csvFile:\n fileReader = csv.reader(csvFile)\n\n for row in fileReader:\n print(row)\n \nif __name__==\"__main__\":\n makeFile()\n readFile()",
"['data', 'timeStamp', 'dataType']\n['100', '1586128830.8706567', 'random Float']\n['7', '1586128830.870685', 'random Float']\n['23', '1586128830.8707', 'random Float']\n['95', '1586128830.8707128', 'random Float']\n['17', '1586128830.8707256', 'random Float']\n['25', '1586128830.870738', 'random Float']\n['27', '1586128830.8707497', 'random Float']\n['1', '1586128830.8707626', 'random Float']\n['3', '1586128830.8707747', 'random Float']\n['50', '1586128830.870787', 'random Float']\n"
]
],
[
[
"#### Note\n- If you re-run the above bit of code you will notice that the all the values change\n- This is, again, because the \"w\" mode will overwrite your files!\n- Please don't accedently overwrite the results of an experiment have to redo it ... ",
"_____no_output_____"
],
[
"## From csv to list of dics\n\nOften it is good to organize data in a csv to a list of dics. This is easier to later operate on",
"_____no_output_____"
]
],
[
[
"# we'll take the values that you just created in the above code and turn them into the list of dics!\n\ndef csvToDict(csvData):\n headers = next(csvData) # next will push the iterable object one forword\n \n data = list(map(lambda row: dict(zip(headers, row)) , csvData))\n \n return data\n\n\ndef run(): # read from the csv you created to see it!\n with open(\"./data/example2.csv\", \"r\") as csvFile:\n fileReader = csv.reader(csvFile)\n listOfDics = csvToDict(fileReader)\n \n print(listOfDics)\n \n \nif __name__==\"__main__\":\n run()",
"[{'data': '77', 'timeStamp': '1586127437.9168706', 'dataType': 'random Float'}, {'data': '99', 'timeStamp': '1586127437.9168973', 'dataType': 'random Float'}, {'data': '71', 'timeStamp': '1586127437.9169118', 'dataType': 'random Float'}, {'data': '72', 'timeStamp': '1586127437.9169242', 'dataType': 'random Float'}, {'data': '9', 'timeStamp': '1586127437.9169366', 'dataType': 'random Float'}, {'data': '85', 'timeStamp': '1586127437.9169497', 'dataType': 'random Float'}, {'data': '75', 'timeStamp': '1586127437.9169614', 'dataType': 'random Float'}, {'data': '21', 'timeStamp': '1586127437.916973', 'dataType': 'random Float'}, {'data': '75', 'timeStamp': '1586127437.9169855', 'dataType': 'random Float'}, {'data': '47', 'timeStamp': '1586127437.9169977', 'dataType': 'random Float'}]\n"
]
],
[
[
"## Appending a csv file\n\nLet's take the csv file you created above and append it with 10 more rows",
"_____no_output_____"
]
],
[
[
"import csv\nimport os\nimport time\nimport random\n\nHEADERS = ['data', 'timeStamp', 'dataType']\n\ndef makeRow(): # random data to put in csv\n return [random.randint(0,101), time.time(), \"random Float\"]\n \n\ndef makeFile(): # makes a csv\n with open(\"./data/example2.csv\", \"a\") as csvFile: # the \"a\" means append\n fileWriter = csv.writer(csvFile)\n \n for i in range(10):\n fileWriter.writerow(makeRow())\n \n\ndef readFile(): # read from the csv you created to see it!\n with open(\"./data/example2.csv\", \"r\") as csvFile:\n fileReader = csv.reader(csvFile)\n\n for row in fileReader:\n print(row)\n \nif __name__==\"__main__\":\n makeFile()\n readFile()",
"['data', 'timeStamp', 'dataType']\n['100', '1586128830.8706567', 'random Float']\n['7', '1586128830.870685', 'random Float']\n['23', '1586128830.8707', 'random Float']\n['95', '1586128830.8707128', 'random Float']\n['17', '1586128830.8707256', 'random Float']\n['25', '1586128830.870738', 'random Float']\n['27', '1586128830.8707497', 'random Float']\n['1', '1586128830.8707626', 'random Float']\n['3', '1586128830.8707747', 'random Float']\n['50', '1586128830.870787', 'random Float']\n['29', '1586128842.588033', 'random Float']\n['31', '1586128842.5880682', 'random Float']\n['37', '1586128842.588084', 'random Float']\n['21', '1586128842.588097', 'random Float']\n['82', '1586128842.5881093', 'random Float']\n['56', '1586128842.5881224', 'random Float']\n['58', '1586128842.5881343', 'random Float']\n['22', '1586128842.5881467', 'random Float']\n['97', '1586128842.5881586', 'random Float']\n['57', '1586128842.588171', 'random Float']\n"
]
],
[
[
"#### Note\n- Yep, it is that simple to append. Just change \"w\" to \"a\"\n- If you try to append a file that does not exist then that file will be created for you",
"_____no_output_____"
],
[
"#### Note\n- There are some other options besides \"r\", \"w\", \"a\" but those three should work for now. Just know ther are a few more.\n - See here for details: https://docs.python.org/3/library/functions.html#open",
"_____no_output_____"
],
[
"# What you need to do\n\n- Read in the csv file from example1.csv\n- Turn it into a list of dicts\n- Replace all timeStamps with their equivalent time since epoch value\n- Find the mean of the timeStamps\n- Discard all data points that have timeStamps lower thean the that mean\n- Write all data points that have a sensorType of \"BME280\" to a .csv file called \"BME280\" that is in the \"data folder\"\n- Write all data points that have a sensorType of \"ADC1115_Pyra\" to a .csv file called \"ADC1115_Pyra\" that is in the \"data folder\"",
"_____no_output_____"
]
]
] |
[
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4ad4f3c8b1b58d8ae8c4096853f7698791ef5138
| 6,255 |
ipynb
|
Jupyter Notebook
|
docs/Training Tutorial.ipynb
|
jcaw/fastaudio
|
d6d61aaa0885bc8e39437e950b96f2015d09dabb
|
[
"MIT"
] | 1 |
2020-08-25T20:07:04.000Z
|
2020-08-25T20:07:04.000Z
|
docs/Training Tutorial.ipynb
|
jcaw/fastaudio
|
d6d61aaa0885bc8e39437e950b96f2015d09dabb
|
[
"MIT"
] | 7 |
2020-08-25T20:20:53.000Z
|
2020-08-27T01:48:00.000Z
|
docs/Training Tutorial.ipynb
|
jcaw/fastaudio
|
d6d61aaa0885bc8e39437e950b96f2015d09dabb
|
[
"MIT"
] | 1 |
2020-08-26T10:02:38.000Z
|
2020-08-26T10:02:38.000Z
| 22.828467 | 178 | 0.542766 |
[
[
[
"# Simple training tutorial\n\nThe objective of this tutorial is to show you the basics of the library and how it can be used to simplify the audio processing pipeline.\n\nThis page is generated from the corresponding jupyter notebook, that can be found on [this folder](https://github.com/fastaudio/fastaudio/tree/master/docs)",
"_____no_output_____"
],
[
"To install the library, uncomment and run this cell:",
"_____no_output_____"
]
],
[
[
"# !pip install git+https://github.com/fastaudio/fastaudio.git",
"_____no_output_____"
]
],
[
[
"**COLAB USERS: Before you continue and import the lib, go to the `Runtime` menu and select `Restart Runtime`.**",
"_____no_output_____"
]
],
[
[
"from fastai.vision.all import *\nfrom fastaudio.core.all import *\nfrom fastaudio.augment.all import *",
"_____no_output_____"
]
],
[
[
"# ESC-50: Dataset for Environmental Sound Classification",
"_____no_output_____"
]
],
[
[
"#The first time this will download a dataset that is ~650mb\npath = untar_data(URLs.ESC50, dest=\"ESC50\")",
"_____no_output_____"
]
],
[
[
"The audio files are inside a subfolder `audio/`",
"_____no_output_____"
]
],
[
[
"(path/\"audio\").ls()",
"_____no_output_____"
]
],
[
[
"And there's another folder `meta/` with some metadata about all the files and the labels",
"_____no_output_____"
]
],
[
[
"(path/\"meta\").ls()",
"_____no_output_____"
]
],
[
[
"Opening the metadata file",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(path/\"meta\"/\"esc50.csv\")\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Datablock and Basic End to End Training",
"_____no_output_____"
]
],
[
[
"# Helper function to split the data\ndef CrossValidationSplitter(col='fold', fold=1):\n \"Split `items` (supposed to be a dataframe) by fold in `col`\"\n def _inner(o):\n assert isinstance(o, pd.DataFrame), \"ColSplitter only works when your items are a pandas DataFrame\"\n col_values = o.iloc[:,col] if isinstance(col, int) else o[col]\n valid_idx = (col_values == fold).values.astype('bool')\n return IndexSplitter(mask2idxs(valid_idx))(o)\n return _inner",
"_____no_output_____"
]
],
[
[
"Creating the Audio to Spectrogram transform from a predefined config.",
"_____no_output_____"
]
],
[
[
"cfg = AudioConfig.BasicMelSpectrogram(n_fft=512)\na2s = AudioToSpec.from_cfg(cfg)",
"_____no_output_____"
]
],
[
[
"Creating the Datablock",
"_____no_output_____"
]
],
[
[
"auds = DataBlock(blocks=(AudioBlock, CategoryBlock), \n get_x=ColReader(\"filename\", pref=path/\"audio\"), \n splitter=CrossValidationSplitter(fold=1),\n batch_tfms = [a2s],\n get_y=ColReader(\"category\"))",
"_____no_output_____"
],
[
"dbunch = auds.dataloaders(df, bs=64)",
"_____no_output_____"
]
],
[
[
"Visualizing one batch of data. Notice that the title of each Spectrogram is the corresponding label.",
"_____no_output_____"
]
],
[
[
"dbunch.show_batch(figsize=(10, 5))",
"_____no_output_____"
]
],
[
[
"# Learner and Training",
"_____no_output_____"
],
[
"While creating the learner, we need to pass a special cnn_config to indicate that our input spectrograms only have one channel. Besides that, it's the usual vision learner.",
"_____no_output_____"
]
],
[
[
"learn = cnn_learner(dbunch, \n resnet18, \n config={\"n_in\":1}, #<- Only audio specific modification here\n loss_func=CrossEntropyLossFlat(),\n metrics=[accuracy])",
"_____no_output_____"
],
[
"from fastaudio.ci import skip_if_ci\n\n@skip_if_ci\ndef learn():\n learn.fine_tune(10)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4ad4fe7bafd9e77a058c759e0317960da64c6f74
| 23,728 |
ipynb
|
Jupyter Notebook
|
intro_to_statistics/Lesson 5 - Conditional Probability.ipynb
|
robinl3680/udacity-course
|
308daf62479f9bf6f4256eb19313631f1bb4c5da
|
[
"MIT"
] | 68 |
2016-07-28T07:24:57.000Z
|
2021-10-09T19:28:48.000Z
|
intro_to_statistics/Lesson 5 - Conditional Probability.ipynb
|
robinl3680/udacity-course
|
308daf62479f9bf6f4256eb19313631f1bb4c5da
|
[
"MIT"
] | null | null | null |
intro_to_statistics/Lesson 5 - Conditional Probability.ipynb
|
robinl3680/udacity-course
|
308daf62479f9bf6f4256eb19313631f1bb4c5da
|
[
"MIT"
] | 105 |
2016-10-19T03:56:33.000Z
|
2022-03-15T02:12:08.000Z
| 48.129817 | 1,866 | 0.653911 |
[
[
[
"# Table of Contents\n <p><div class=\"lev1\"><a href=\"#Dependent-Things\"><span class=\"toc-item-num\">1 </span>Dependent Things</a></div><div class=\"lev1\"><a href=\"#Cancer-Example\"><span class=\"toc-item-num\">2 </span>Cancer Example</a></div><div class=\"lev2\"><a href=\"#Question-1\"><span class=\"toc-item-num\">2.1 </span>Question 1</a></div><div class=\"lev2\"><a href=\"#Question-2\"><span class=\"toc-item-num\">2.2 </span>Question 2</a></div><div class=\"lev2\"><a href=\"#Question-3\"><span class=\"toc-item-num\">2.3 </span>Question 3</a></div><div class=\"lev2\"><a href=\"#Question-4\"><span class=\"toc-item-num\">2.4 </span>Question 4</a></div><div class=\"lev2\"><a href=\"#Question-5\"><span class=\"toc-item-num\">2.5 </span>Question 5</a></div><div class=\"lev2\"><a href=\"#Question-6\"><span class=\"toc-item-num\">2.6 </span>Question 6</a></div><div class=\"lev2\"><a href=\"#Question-7\"><span class=\"toc-item-num\">2.7 </span>Question 7</a></div><div class=\"lev1\"><a href=\"#Total-Probability\"><span class=\"toc-item-num\">3 </span>Total Probability</a></div><div class=\"lev1\"><a href=\"#Two-Coins\"><span class=\"toc-item-num\">4 </span>Two Coins</a></div><div class=\"lev2\"><a href=\"#Question-1\"><span class=\"toc-item-num\">4.1 </span>Question 1</a></div><div class=\"lev2\"><a href=\"#Question-2\"><span class=\"toc-item-num\">4.2 </span>Question 2</a></div><div class=\"lev2\"><a href=\"#Question-3\"><span class=\"toc-item-num\">4.3 </span>Question 3</a></div><div class=\"lev2\"><a href=\"#Question-4\"><span class=\"toc-item-num\">4.4 </span>Question 4</a></div><div class=\"lev1\"><a href=\"#Summary\"><span class=\"toc-item-num\">5 </span>Summary</a></div>",
"_____no_output_____"
],
[
"# Dependent Things",
"_____no_output_____"
],
[
"In real life, things depend on each other.\n\nSay you can be born smart or dumb and for the sake of simplicity, let's assume whether you're smart or dumb is just nature's flip of a coin. Now whether you become a professor at Standford is non-entirely independent. I would argue becoming a professor in Standford is generally not very likely, so probability might be 0.001 but it also depends on whether you're born smart or dumb. If you are born smart the probability might be larger, whereas if you're born dumb, the probability might be marked more smaller.\n\nNow this just is an example, but if you can think of the most two consecutive coin flips. The first is whether you are born smart or dumb. The second is whether you get a job on a certain time. And now if we take them in these two coin flips, they are not independent anymore. So whereas in our last unit, we assumed that the coin flips were independent, that is, the outcome of the first didn't affect the outcome of the second. From now on, we're going to study the more interesting cases where the outcome of the first does impact the outcome of the second, and to do so you need to use more variables to express these cases.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-27 at 8.49.53 AM.png\"/>",
"_____no_output_____"
],
[
"# Cancer Example",
"_____no_output_____"
],
[
"## Question 1",
"_____no_output_____"
],
[
"To do so, let's study a medical example--supposed there's a patient in the hospital who might suffer from a medical condition like cancer. Let's say the probability of having this cancer is 0.1. That means you can tell me what's the probability of being cancer free.\n\n**Answer**\n- The answer is 0.9 with just 1 minus the cancer.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-27 at 8.52.39 AM.png\"/>",
"_____no_output_____"
],
[
"## Question 2",
"_____no_output_____"
],
[
"Of course, in reality, we don't know whether a person suffers cancer, but we can run a test like a blood test. The outcome of it blood test may be positive or negative, but like any good test, it tells me something about the thing I really care about--whether the person has cancer or not.\n\nLet's say, if the person has the cancer, the test comes up positive with the probability of 0.9, and that implies if the person has cancer, the negative outcome will have 0.1 probability and that's because these two things have to add to 1.\n\nI've just given you a fairly complicated notation that says the outcome of the test depends on whether the person has cancer or not. We call this thing over here a conditional probability, and the way to understand this is a very funny notation. There's a bar in the middle, and the bar says what's the probability of the stuff on the left given that we assume the stuff on the right is actually the case.\n\nNow, in reality, we don't know whether the person has cancer or not, and in a later unit, we're going to reason about whether the person has cancer given a certain data set, but for now, we assume we have god-like capabilities. We can tell with absolute certainty that the person has cancer, and we can determine what the outcome of the test is. This is a test that isn't exactly deterministic--it makes mistakes, but it only makes a mistake in 10% of the cases, as illustrated by the 0.1 down here. \n\nNow, it turns out, I haven't fully specified the test. The same test might also be applied to a situation where the person does not have cancer. So this little thing over here is my shortcut of not having cancer. And now, let me say the probability of the test giving me a positive results--a false positive result when there's no cancer is 0.2. You can now tell me what's the probability of a negative outcome in case we know for a fact the person doesn't have cancer, so please tell me.",
"_____no_output_____"
],
[
"**Answer**\n\nAnd the answer is 0.8. As I'm sure you noticed in the case where there is cancer, the possible test outcomes add up to 1. In the where there isn't cancer, the possible test outcomes add up to 1. So 1 - 0.2 = 0.8.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.24.34 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487236390923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 3",
"_____no_output_____"
],
[
"Look at this, this is very nontrivial but armed with this, we can now build up the truth table for all the cases of the two different variables, cancer and non-cancer and positive and negative tests outcome.\n\nSo, let me write down cancer and test and let me go through different possibilities. We could have cancer or not, and the test may come up positive or negative. So, please give me the probability of the combination of those for the very first one, and as a hint, it's kind of the same as before where we multiply two things, but you have to find the right things to multiple in this table over here.",
"_____no_output_____"
],
[
"**Answer**\nAnd the answer is probability of cancer is 0.1, probability of test being positive given that he has cancer is the one over here--0.9, multiplying those two together gives us 0.09.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.31.47 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486789140923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 4",
"_____no_output_____"
],
[
"Moving to the next case--what do you think the probability is that the person does have cancer but the test comes back negative? What's the combined probability of these two cases?\n\n**Answer**\n\nAnd once again, we'd like to refer the corresponding numbers over here on the right side 0.1 for the cancer times the probability of getting a negative result conditioned on having cancer and that is 0.1 0.1, which is 0.01.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.34.42 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486977510923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 5",
"_____no_output_____"
],
[
"Moving on to the next two, we have:\n\n**Answer**:\n- **Cancer (N) - Test (P)**: Here the answer is 0.18 by multiplying the probability of not having cancer, which is 0.9, with the probability of getting a positive test result for a non-cancer patient 0.2. Multiplying 0.9 with 0.2 gives me 0.18.\n- **Cancer (N) - Test (N)**: Here you get 0.72, which is the product of not having cancer in the first place 0.9 and the probability of getting a negative test result under the condition of not having cancer.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.39.14 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486987400923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 6",
"_____no_output_____"
],
[
"Now quickly add all of those probabilities up.\n\n**Answer**\n\nAnd as usual, the answer is 1. That is, we study in the truth table all possible cases. and when we add up the probabilities, you should always get the answer of 1.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.41.53 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487214940923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 7",
"_____no_output_____"
],
[
"Now let me ask you a really tricky question. What is the probability of a positive test result? Can you sum or determine, irrespective of whether there's cancer or not, what is the probability you get a positive test result?\n\n** Answer**\n\nAnd the result, once again, is found in the truth table, which is why this table is so powerful. Let's look at where in the truth table we get a positive test result. I would say it is right here, right here. If you take corresponding probabilities of 0.09 and 0.18, and add them up, we get 0.27.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.44.52 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486987410923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"# Total Probability",
"_____no_output_____"
],
[
"Putting all of this into mathematical notation we've given the probability of having cancer and from there, it follows the probability of not having cancer. And they give me 2 conditional probability that are the test being positive. \n\nIf we have have cancer, from which we can now predict the probability of the test being negative of having cancer. And the probability of the test being positive can be cancer free which can complete the probability of a negative test result in the cancer-free case. So these things are just easily inferred by the 1 minus rule.\n\nThen when we read this, you complete the probability of a positive test result as the sum of a positive test result given cancer times the probability of cancer, which is our truth table entry for the combination of P and C plus the same given we don't have of cancer.\n\nNow this notation is confusing and complicated if we ever dive deep into probability, that's called total probability, but it's useful to know that this is very, very intuitive and to further develop intuition let me just give you another exercise of exactly the same type.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.50.03 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487202500923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"# Two Coins",
"_____no_output_____"
],
[
"## Question 1",
"_____no_output_____"
],
[
"This time around, we have a bag, and in the bag are 2 coins,coin 1 and coin 2. And in advance, we know that coin 1 is fair. So P of coin 1 of coming up heads is 0.5 whereas coin 2 is loaded, that is, P of coin 2 coming up heads is 0.9. Quickly, give me the following numbers of the probability of coming up tails for coin 1 and for coin 2.\n\n**Answer**\n\nAnd the answer is 0.5 for coin 1and 0.1 for coin 2, because these things have to add up to 1 for each of the coins.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 7.57.29 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487236400923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 2",
"_____no_output_____"
],
[
"So now what happens is, I'm going to remove one of the coins from this bag, and each coin, coin 1 or coin 2, is being picked with equal probability. Let me now flip that coin once, and I want you to tell me, what's the probability that this coin which could be 50% chance fair coin 1and 50% chance a loaded coin. What's the probability that this coin comes up heads? Again, this is an exercise in conditional probability.\n\n**Answer**\n\nAnd let’s do the truth table. You have a pick event followed by a flip event\n\n- We can pick coin 1 or coin 2. There is a 0.5 chance for each of the coins. Then we can flip and get heads or tails for the coin we've chosen. Now what are the probabilities?\n- I'd argue picking 1 at 0.5 and once I pick the fair coin, I know that the probability of heads is, once again, 0.5 which makes it 0.25 The same is true for picking the fair coin and expecting tails \n- But as we pick the unfair coin with a 0.5 chance we get a 0.9 chance of heads So 0.5 times 0.95 gives you 0.45 whereas the unfair coin, the probability of tails is 0.1 multiply by the probability of picking it at 0.5 gives us\n- Now when they ask you, what's the probability of heads we'll find that 2 of those cases indeed come up with heads so if you add 0.25 and 0.45 and we get 0.7. So this example is a 0.7 chance that we might generate heads.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 8.03.35 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486938400923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 3",
"_____no_output_____"
],
[
"Now let me up the ante by flipping this coin twice. Once again, I'm drawing a coin from this bag, and I pick one at 50% chance. I don't know which one I have picked. It might be fair or loaded. And in flipping it twice, I get first heads, and then tails. What's the probability that if I do the following, I draw a coin at random with the probabilities shown, and then I flip it twice, that same coin. I just draw it once and then flip it twice. What's the probability of seeing heads first and then tails? Again, you might derive this using truth tables.\n\n**Answer**\nThis is a non-trivial question, and the right way to do this is to go through the truth table, which I've drawn over here. There's 3 different things happening. We've taken initial pick of the coin, which can take coin 1 or coin 2 with equal probability, and then you go flip it for the first time, and there's heads or tails outcomes, and we flip it for the second time with the second outcome. So these different cases summarize my truth table.\n\nI now need to observe just the cases where head is followed by tail. This one right here and over here. Then we compute the probability for those 2 cases.\n- The probability of picking coin 1 is 0.5. For the fair coin, we get 0.5 for heads, followed by 0.5 for tails. They're together is 0.125.\n- Let's do it with the second case. There's a 0.5 chance of taking coin 2. Now that one comes up with heads at 0.9. It comes up with tails at 0.1. So multiply these together, gives us 0.045, a smaller number than up here.\n- Adding these 2 things together results in 0.17, which is the right answer to the question over here.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 8.09.25 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/486957990923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"## Question 4",
"_____no_output_____"
],
[
"Let me do this once again. There are 2 coins in the bag, coin 1 and coin 2. And as before, taking coin 1 at 0.5 probability. But now I'm telling you that coin 1 is loaded, so give you heads with probability of 1. Think of it as a coin that only has heads. And coin 2 is also loaded. It gives you heads with 0.6 probability. Now work out for me into this experiment, what's the probability of seeing tails twice?\n\n**Answer**\n\nAnd the answer is depressing. If you, once again, draw the truth table, you find, for the different combinations, that if you've drawn coin 1, you'd never see tails. So this case over here, which indeed has tails, tails. We have 0 probability.\n- We can work this out probability of drawing the first coin at 0.5, but the probability of tails given the first coin must be 0, because the probability of heads is 1, so 0.5 times 0 times 0, that is 0.\n- So the only case where you might see tails/tails is when you actually drew coin 2, and this has a probability of 0.5 times the probability of tails given that we drew the second coin, which is 0.4 times 0.4 again, and that's the same as 0.08 would have been the correct answer.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 8.34.08 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487015560923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
],
[
"# Summary",
"_____no_output_____"
],
[
"So there're important lessons in what we just learned, the key thing is we talked about conditional probabilities. We said that the outcome in a variable, like a test is actually not like the random coin flip but it depends on something else, like a disease. \n\nWhen we looked at this, we were able to predict what's the probability of a test outcome even if we don't know whether the person has a disease or not. And we did this using the truth table, and in the truth table, we summarized multiple lines.\n\n- For example, we multiplied the probability of a test outcome condition on this unknown variable, whether the person is diseased multiplied by the probability of the disease being present. Then we added a second row of the truth table, where our unobserved disease variable took the opposite value of not diseased.\n- Written this way, it looks really clumsy, but that's effectively what we did when we went to the truth table. So we now understand that certain coin flips are dependent on other coin flips, so if god, for example, flips the coin of us having a disease or not, then the medical test again has a random outcome, but its probability really depends on whether we have the disease or not. We have to consider this when we do probabilistic inference. In the next unit, we're going to ask the real question. Say we really care about whether we have a disease like cancer or not. What do you think the probability is, given that our doctor just gave us a positive test result?\n\nAnd I can tell you, you will be in for a surprise.",
"_____no_output_____"
],
[
"<img src=\"images/Screen Shot 2016-04-28 at 8.44.56 AM.png\"/>\n\n*Screenshot taken from [Udacity](https://classroom.udacity.com/courses/st101/lessons/48729372/concepts/487015560923)*\n\n<!--TEASER_END-->",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4ad50babe2f03b7a405185ef211c4f7468dab883
| 652,162 |
ipynb
|
Jupyter Notebook
|
m04_vid01_store_sales_prediction.ipynb
|
pedropscf/1-Rossman-Sales-Prediction
|
2152cd42f86b666c40ca9b942c23f0ff845af315
|
[
"MIT"
] | null | null | null |
m04_vid01_store_sales_prediction.ipynb
|
pedropscf/1-Rossman-Sales-Prediction
|
2152cd42f86b666c40ca9b942c23f0ff845af315
|
[
"MIT"
] | null | null | null |
m04_vid01_store_sales_prediction.ipynb
|
pedropscf/1-Rossman-Sales-Prediction
|
2152cd42f86b666c40ca9b942c23f0ff845af315
|
[
"MIT"
] | null | null | null | 190.190143 | 187,228 | 0.870839 |
[
[
[
"# 0.0. IMPORTS",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport inflection\nimport math\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nfrom IPython.display import Image\n\nimport datetime\n\nfrom scipy import stats",
"_____no_output_____"
]
],
[
[
"## 0.1. Helper Functions",
"_____no_output_____"
]
],
[
[
"def cramer_v(x, y):\n cm = pd.crosstab(x, y).as_matrix()\n n = cm.sum()\n r, k = cm.shape\n \n chi2 = stats.chi2_contingency(cm)[0]\n chi2_corrected = chi2 - ((k - 1)*(r - 1))/(n - 1)\n k_corrected = k - ((k - 1)**2)/(n - 1)\n r_corrected = r - ((r - 1)**2)/(n - 1)\n \n return np.sqrt((chi2_corrected/n) / (min(k_corrected - 1, r_corrected - 1)))",
"_____no_output_____"
]
],
[
[
"## 0.2. Loading Data",
"_____no_output_____"
]
],
[
[
"df_sales_raw = pd.read_csv('data/train.csv', low_memory=False)\ndf_store_raw = pd.read_csv('data/store.csv', low_memory=False)\n\n# merge dataframes\ndf_raw = pd.merge(df_sales_raw, df_store_raw, how='left', on='Store' )",
"_____no_output_____"
],
[
"df_raw.sample()",
"_____no_output_____"
]
],
[
[
"# 1.0. DESCRICAO DOS DADOS",
"_____no_output_____"
]
],
[
[
"# Original dataframe copy\ndf1 = df_raw.copy()",
"_____no_output_____"
]
],
[
[
"## 1.1. Rename columns",
"_____no_output_____"
]
],
[
[
"df1.columns",
"_____no_output_____"
],
[
"cols_old = ['Store', 'DayOfWeek', 'Date', 'Sales', 'Customers', 'Open', 'Promo',\n 'StateHoliday', 'SchoolHoliday', 'StoreType', 'Assortment',\n 'CompetitionDistance', 'CompetitionOpenSinceMonth',\n 'CompetitionOpenSinceYear', 'Promo2', 'Promo2SinceWeek',\n 'Promo2SinceYear', 'PromoInterval']\n\n# Changing write pattern to snakecase\n\nsnakecase = lambda x: inflection.underscore( x )\n\ncols_new = list( map( snakecase, cols_old ) )\n\n# Renaming\ndf1.columns = cols_new",
"_____no_output_____"
],
[
"df1.columns",
"_____no_output_____"
]
],
[
[
"## 1.2. Data Dimension",
"_____no_output_____"
]
],
[
[
"print( 'Number of rows: {}'.format(df1.shape[0]))\nprint( 'Number of rows: {}'.format(df1.shape[1]))",
"Number of rows: 1017209\nNumber of rows: 18\n"
]
],
[
[
"## 1.3. Data Types",
"_____no_output_____"
]
],
[
[
"df1.dtypes",
"_____no_output_____"
],
[
"df1['date'] = pd.to_datetime(df1['date'])\n\ndf1.dtypes",
"_____no_output_____"
]
],
[
[
"## 1.4. Check NA",
"_____no_output_____"
]
],
[
[
"df1.isna().sum()",
"_____no_output_____"
]
],
[
[
"## 1.5. Fillout NA",
"_____no_output_____"
]
],
[
[
"# First, we must analyze what every variable and data with NA values\n\n# competition_distance\n## Assumption: if it is NA, maybe it is because the store doesnt have an near competitor\n## What has been done: CONSIDER AN EXTREME DISTANT RANGE FROM NEAR COMPETITOR\n\ndf1['competition_distance'].max()\ndf1['competition_distance'] = df1['competition_distance'].apply( lambda x: 100000 if math.isnan(x) else x )\n\n# competition_open_since_month\n## Assumption: there are two main reasons that this data is NA: (i) the store doesnt have a near competitor or\n## (ii) the store has an near competitor, but it the opening data is unknown, either it is older than the store or data is unavailable\n## What has been done: CONSIDER THE SAME MONTH THAT THE STORE HAS BEEN OPEN (because it maybe older than the store)\n\n# Error: EDIT Solved\ndf1['competition_open_since_month'] = df1.apply( lambda x: x['date'].month if math.isnan(x['competition_open_since_month']) else x['competition_open_since_month'], axis=1)\n#Alternative: \n#df1.competition_open_since_month.fillna(df1.date.dt.month, inplace=True)\n\n# competition_open_since_year\n## Same ideia from variable above\n\n#Error: EDIT: Solved\ndf1['competition_open_since_year'] = df1.apply( lambda x: x['date'].year if math.isnan(x['competition_open_since_year']) else x['competition_open_since_year'], axis=1)\n#Alternative: \n#df1.competition_open_since_year.fillna(df1.date.dt.month, inplace=True)\n\n\n\n# promo2\n## Doesnt have any NA\n\n# promo2_since_week\n## Assumption: it is possible that the NA values are due to lack of participation/extension of any promotions.\n## What I think should have been done: ALL NA VALUES ARE CONSIDERED \"0\", AS THE STORE IS NOT EXTENDING PROMOTIONS\n## What has actually been done: CONSIDER THE SAME VALUE AS THE DATE\ndf1['promo2_since_week'] = df1.apply( lambda x: x['date'].month if math.isnan(x['promo2_since_week']) else x['promo2_since_week'], axis=1)\n\n\n# promo2_since_year\n## Same logic as above\ndf1['promo2_since_year'] = df1.apply( lambda x: x['date'].year if math.isnan(x['promo2_since_year']) else x['promo2_since_year'], axis=1)\n\n\n# promo_interval\n## The problem here is that, it is hard to understand the way it has been inserted.\n## What has been done: (i) Analyze the interval of the promo; (ii) Check if sale month is in promo_interval\n## if it is, (iii) apply value 1 to new column is_promo, else 0.\n## This way, it will be easy to check if sale is inside a promotion interval.\n\nmonth_map = {1: 'Jan', 2: 'Fev', 3: 'Mar', 4: 'Apr', 5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct', 11: 'Nov', 12: 'Dec', }\n\ndf1['promo_interval'].fillna(0, inplace=True)\ndf1['month_map'] = df1['date'].dt.month.map(month_map)\n\ndf1['is_promo'] = df1[['promo_interval', 'month_map']].apply( lambda x: 0 if x['promo_interval'] == 0 else 1 if x['month_map'] in x['promo_interval'].split(',') else 0, axis=1 )\n\ndf1.isna().sum()\n",
"_____no_output_____"
],
[
"df1.sample(5).T",
"_____no_output_____"
]
],
[
[
"## 1.6. Change Types",
"_____no_output_____"
]
],
[
[
"df1.dtypes",
"_____no_output_____"
],
[
"# Competion and promos since are portrayed as float types, while it should be int type.\n\ndf1['competition_open_since_month'] = df1['competition_open_since_month'].astype(int)\ndf1['competition_open_since_year'] = df1['competition_open_since_year'].astype(int)\ndf1['promo2_since_week'] = df1['promo2_since_week'].astype(int)\ndf1['promo2_since_year'] = df1['promo2_since_year'].astype(int)\n\ndf1.dtypes",
"_____no_output_____"
]
],
[
[
"## 1.7. Descriptive Statistical",
"_____no_output_____"
]
],
[
[
"num_attributes = df1.select_dtypes( include=['int64','float64'])\ncat_attributes = df1.select_dtypes( exclude=['int64','float64', 'datetime64[ns]'])\n\nnum_attributes.sample(5)",
"_____no_output_____"
]
],
[
[
"### 1.7.1. Numerical Attributes",
"_____no_output_____"
]
],
[
[
"# Central tendency - mean, median\n\nct1 = pd.DataFrame(num_attributes.apply(np.mean)).T\nct2 = pd.DataFrame(num_attributes.apply(np.median)).T\n\n# Dispersion - std, min, max, range, skew, kurtosis\n\nd1 = pd.DataFrame(num_attributes.apply(np.std)).T\nd2 = pd.DataFrame(num_attributes.apply(min)).T\nd3 = pd.DataFrame(num_attributes.apply(max)).T\nd4 = pd.DataFrame(num_attributes.apply(lambda x: x.max() - x.min())).T\nd5 = pd.DataFrame(num_attributes.apply(lambda x: x.skew())).T\nd6 = pd.DataFrame(num_attributes.apply(lambda x: x.kurtosis())).T\n\n# Concatenate\n\nn = pd.concat( [d2, d3, d4, ct1, ct2, d1, d5, d6] ).T.reset_index()\n \nn.columns = ['attributes', 'min', 'max', 'range', 'mean', 'median', 'std', 'skew', 'kurtosis']\n\nn",
"_____no_output_____"
],
[
"sns.distplot( df1['competition_distance'] )",
"_____no_output_____"
]
],
[
[
"### 1.7.2. Categorical Attributes",
"_____no_output_____"
]
],
[
[
"cat_attributes.apply( lambda x: x.unique().shape[0] )",
"_____no_output_____"
],
[
"filter1 = df1[(df1['state_holiday'] != '0') & (df1['sales'] > 0)]\nsns.boxplot(x='state_holiday', y='sales', data=filter1)",
"_____no_output_____"
],
[
"plt.subplot(1,3,1)\nsns.boxplot(x='state_holiday', y='sales', data=filter1)\n\nplt.subplot(1,3,2)\nsns.boxplot(x='store_type', y='sales', data=filter1)\n\nplt.subplot(1,3,3)\nsns.boxplot(x='assortment', y='sales', data=filter1)",
"_____no_output_____"
]
],
[
[
"# 2.0. FEATURE ENGINEERING",
"_____no_output_____"
]
],
[
[
"df2 = df1.copy()\n\ndf2.sample(5)",
"_____no_output_____"
],
[
"Image('img/MindMapHypothesis.png')",
"_____no_output_____"
]
],
[
[
"## 2.1. Hypothesis mental map",
"_____no_output_____"
],
[
"### 2.1.1. Stores Hypothesis",
"_____no_output_____"
],
[
"**1.** Stores with more employees **should** have more sales\n\n**2.** Stores with more product stock **should** have more sales\n\n**3.** Smaller stores **should** have less sales\n\n**4.** Bigger stores **should** have more sales\n\n**5.** Stores with more product options **should** have more sales",
"_____no_output_____"
],
[
"### 2.1.2. Product Hypothesis",
"_____no_output_____"
],
[
"**1.** Stores with more marketing investment **should** have more sales\n\n**2.** Stores that exposes more the products **should** sell more those products\n\n**3.** Stores with smaller product prices **should** have more sales of those products\n\n**4.** Stores with smaller product prices for the longest possible time **should** have more sales",
"_____no_output_____"
],
[
"### 2.1.3. Time Hypothesis",
"_____no_output_____"
],
[
"**1.** Stores with more holidays **should** have less sales\n\n**2.** Stores that opens at the first 6 months **should** have more sales\n\n**3.** Stores that opens at the weekends **should** have more sales",
"_____no_output_____"
],
[
"## 2.2. Hypothesis priorization",
"_____no_output_____"
],
[
"The hypothesis that should have prioritized are the ones with the data available at the start of the proccess\n\n**1.** Stores with more product options **should** have more sales\n\n**2.** Stores with closer competitors **should** have less sales\n\n**3.** Stores with competitors open for the longest time **should** have more sales\n\n\n**4.** Stores with more active promotions **should** have more sales\n\n**5.** Stores with more promotion days **should** have more sales\n\n**6.** Stores with consecutive promotions **should** have more sales\n\n\n**7.** Stores open at Xmas **should** have more sales\n\n**8.** Stores sales **should** grow through the years\n\n**9.** Stores **should** sell more at the second half of the year\n\n**10.** Stores **should** sell more after the tenth day of each month\n\n**11.** Stores **should** sell less at the weekends\n\n**12.** Stores **should** sell less at school holydays",
"_____no_output_____"
],
[
"## 2.3 Feature Engineering",
"_____no_output_____"
]
],
[
[
"#year\ndf2['year'] = df2['date'].dt.year\n\n#month\ndf2['month'] = df2['date'].dt.month\n\n#day\ndf2['day'] = df2['date'].dt.day\n\n#weekofyear\ndf2['week_of_year'] = df2['date'].dt.weekofyear\n\n#year week\ndf2['year_week'] = df2['date'].dt.strftime('%Y-%W')\n\n#competitionsince\ndf2['competition_since'] = df2.apply( lambda x: datetime.datetime(year=x['competition_open_since_year'], month=x['competition_open_since_month'], day=1), axis=1 )\ndf2['competition_time_month'] = ((df2['date'] - df2['competition_since']) / 30).apply(lambda x: x.days).astype(int)\n\n#promo since\ndf2['promo_since'] = df2['promo2_since_year'].astype(str) + '-' + df2['promo2_since_week'].astype(str)\ndf2['promo_since'] = df2['promo_since'].apply(lambda x: datetime.datetime.strptime(x + '-1', '%Y-%W-%w') - datetime.timedelta(days=7) )\ndf2['promo_time_week'] = ((df2['date'] - df2['promo_since']) / 7).apply(lambda x: x.days ).astype(int)\n\n#assortment\ndf2['assortment'] = df2['assortment'].apply( lambda x: 'basic' if x=='a' else 'extra' if x=='b' else 'extended')\n\n#state holiday\ndf2['state_holiday'] = df2['state_holiday'].apply( lambda x: 'public_holiday' if x=='a' else 'easter_holiday' if x=='b' else 'christmas' if x=='c' else 'regular_day')",
"_____no_output_____"
],
[
"df2.sample(5).T",
"_____no_output_____"
]
],
[
[
"# 3.0. VARIABLE FILTERING",
"_____no_output_____"
]
],
[
[
"df3 = df2.copy()",
"_____no_output_____"
]
],
[
[
"## 3.1. Line Filtering",
"_____no_output_____"
]
],
[
[
"df3 = df3[(df3['open'] != 0) & (df3['sales'] > 0)]",
"_____no_output_____"
]
],
[
[
"## 3.2. Column FIltering",
"_____no_output_____"
]
],
[
[
"cols_drop = ['customers', 'open', 'promo_interval', 'month_map']\n\ndf3 = df3.drop(cols_drop, axis = 1)",
"_____no_output_____"
]
],
[
[
"# 4.0. EXPLORATORY DATA ANALYSIS",
"_____no_output_____"
]
],
[
[
"df4 = df3.copy()",
"_____no_output_____"
]
],
[
[
"## 4.1. Univariate Analysis",
"_____no_output_____"
],
[
"### 4.1.1. Response Variable",
"_____no_output_____"
]
],
[
[
"sns.distplot(df4['sales'])\n\n# The more the graph seems like a bell curve, the better.\n# It is because some models and algorithms are based on normal shape curve\n# Applying functions such as log makes the graph looks more like the bell.",
"_____no_output_____"
]
],
[
[
"### 4.1.2. Numerical Variable",
"_____no_output_____"
]
],
[
[
"num_attributes.hist(bins=25)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 4.1.3 Categorical Variable",
"_____no_output_____"
]
],
[
[
"cat_attributes.sample(5)",
"_____no_output_____"
],
[
"\n\n# State holiday\nplt.subplot(3, 2, 1)\n#a = df4[df4['state_holiday'] != 'regular_day']\nsns.countplot(cat_attributes['state_holiday'])\n\nplt.subplot(3, 2, 2)\nsns.kdeplot( df4[df4['state_holiday'] == 'public_holiday']['sales'], label='public_holiday', shade=True)\nsns.kdeplot( df4[df4['state_holiday'] == 'easter_holiday']['sales'], label='easter_holiday', shade=True)\nsns.kdeplot( df4[df4['state_holiday'] == 'christmas']['sales'], label='christmas', shade=True)\n\n\n\n\n\n# Store type\nplt.subplot(3, 2, 3)\nsns.countplot(cat_attributes['store_type'])\n\nplt.subplot(3, 2, 4)\nsns.kdeplot( df4[df4['store_type'] == 'a']['sales'], label='a', shade=True)\nsns.kdeplot( df4[df4['store_type'] == 'b']['sales'], label='b', shade=True)\nsns.kdeplot( df4[df4['store_type'] == 'c']['sales'], label='c', shade=True)\nsns.kdeplot( df4[df4['store_type'] == 'd']['sales'], label='d', shade=True)\n\n# Assortment\nplt.subplot(3, 2, 5)\nsns.countplot(df4['assortment'])\n\nplt.subplot(3, 2, 6)\nsns.kdeplot( df4[df4['assortment'] == 'extended']['sales'], label='extended', shade=True)\nsns.kdeplot( df4[df4['assortment'] == 'basic']['sales'], label='basic', shade=True)\nsns.kdeplot( df4[df4['assortment'] == 'extra']['sales'], label='extra', shade=True)\n\n\n\n",
"_____no_output_____"
]
],
[
[
"## 4.2. Bivariate Analysis",
"_____no_output_____"
],
[
"### Hypothesis **1.** Stores with more product options **should** have more sales",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['assortment', 'sales']].groupby('assortment').sum().reset_index()\nsns.barplot(x='assortment', y='sales', data= aux1);\n\naux2 = df4[['year_week','assortment', 'sales']].groupby(['year_week','assortment']).sum().reset_index()\naux2.pivot(index='year_week', columns='assortment', values='sales').plot()\n#sns.barplot(x='assortment', y='sales', data= aux2);",
"_____no_output_____"
]
],
[
[
"**False** Results shows that the basic assortment store type, sells **more** than a store with more assortment",
"_____no_output_____"
],
[
"### Hypothesis **2.** Stores with closer competitors **should** have less sales",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['competition_distance', 'sales']].groupby('competition_distance').sum().reset_index()\n\nplt.subplot (1, 3, 1)\nbins = list(np.arange(0, 20000, 1000))\naux1['competition_distance_binned'] = pd.cut(aux1['competition_distance'], bins=bins)\n#sns.barplot(x='competition_distance_binned', y='sales', data= aux1);\nsns.scatterplot(x='competition_distance', y='sales', data=aux1)\n\nplt.subplot(1, 3, 2)\naux2 = aux1[['competition_distance_binned','sales']].groupby('competition_distance_binned').sum().reset_index()\nsns.barplot(x='competition_distance_binned', y='sales', data= aux2);\nplt.xticks(rotation=90)\n\nplt.subplot(1, 3, 3)\nx = sns.heatmap(aux1.corr(method='pearson'), annot=True)\nbottom, top = x.get_ylim()\nx.set_ylim(bottom+0.5, top-0.5);",
"_____no_output_____"
]
],
[
[
"**False** Stores with closer competitors actually sells **more** than stores with distant competitors",
"_____no_output_____"
],
[
"### Hypothesis **3.** Stores with competitors open for the longest time **should** have more sales",
"_____no_output_____"
]
],
[
[
"plt.subplot(1, 3, 1)\naux1 = df4[['competition_time_month', 'sales']].groupby('competition_time_month').sum().reset_index()\naux4 = aux1[(aux1['competition_time_month'] < 120 ) & (aux1['competition_time_month'] != 0) ]\nsns.barplot(x='competition_time_month', y='sales', data=aux4)\nplt.xticks(rotation=90);\n\nplt.subplot(1, 3, 2)\nsns.regplot(x='competition_time_month', y='sales', data=aux4)\n\nplt.subplot(1, 3, 3)\nx = sns.heatmap(aux4.corr(method='pearson'), annot=True)\nbottom, top = x.get_ylim()\nx.set_ylim(bottom+0.5, top-0.5);",
"_____no_output_____"
]
],
[
[
"**False** stores with longer competition sells **less**. However, the behavior of sales is different before competition starts and after it starts.",
"_____no_output_____"
],
[
"## 4.3. Multivariate Analysis",
"_____no_output_____"
],
[
"### 4.3.1. Numerical Attributes",
"_____no_output_____"
]
],
[
[
"correlation = num_attributes.corr(method='pearson')\nsns.heatmap(correlation, annot=True, fmt='.2f')",
"_____no_output_____"
]
],
[
[
"### 4.3.2. Categorical Attributes",
"_____no_output_____"
]
],
[
[
"from scipy import stats\n\ncategorical = df4.select_dtypes(include='object')\ncategorical.head()",
"_____no_output_____"
],
[
"cm = pd.crosstab(categorical['state_holiday'], categorical['store_type']).as_matrix()\n\n",
"<ipython-input-85-c0215fa5e443>:1: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.\n cm = pd.crosstab(categorical['state_holiday'], categorical['store_type']).as_matrix()\n"
],
[
"a1 = cramer_v(categorical['state_holiday'], categorical['state_holiday'])\na2 = cramer_v(categorical['state_holiday'], categorical['store_type'])\na3 = cramer_v(categorical['state_holiday'], categorical['assortment'])\n\na4 = cramer_v(categorical['store_type'], categorical['state_holiday'])\na5 = cramer_v(categorical['store_type'], categorical['store_type'])\na6 = cramer_v(categorical['store_type'], categorical['assortment'])\n\na7 = cramer_v(categorical['assortment'], categorical['state_holiday'])\na8 = cramer_v(categorical['assortment'], categorical['store_type'])\na9 = cramer_v(categorical['assortment'], categorical['assortment'])\n\nd = pd.DataFrame({'state_holiday': [a1, a2, a3],\n 'store_type': [a4, a5, a6],\n 'assortment': [a7, a8, a9] })",
"<ipython-input-84-cddd5d3c621c>:2: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.\n cm = pd.crosstab(x, y).as_matrix()\n"
],
[
"d = d.set_index(d.columns)\nd.head()",
"_____no_output_____"
],
[
"sns.heatmap(d, annot=True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4ad52017eb9ad3fd71951558daecaf7677698d3c
| 193,516 |
ipynb
|
Jupyter Notebook
|
Pandas/DSPD0110EN-Merge-and-Join.ipynb
|
reddyprasade/Data-Science-With-Python
|
b8e9b16691dc2f35a4d975946f8ca5cc0e0469d0
|
[
"Apache-2.0"
] | 14 |
2020-04-20T14:17:39.000Z
|
2021-12-30T11:39:48.000Z
|
Pandas/DSPD0110EN-Merge-and-Join.ipynb
|
reddyprasade/Data-Science-With-Python
|
b8e9b16691dc2f35a4d975946f8ca5cc0e0469d0
|
[
"Apache-2.0"
] | null | null | null |
Pandas/DSPD0110EN-Merge-and-Join.ipynb
|
reddyprasade/Data-Science-With-Python
|
b8e9b16691dc2f35a4d975946f8ca5cc0e0469d0
|
[
"Apache-2.0"
] | 3 |
2020-05-13T10:08:18.000Z
|
2020-09-01T16:40:32.000Z
| 29.571516 | 249 | 0.364967 |
[
[
[
"<h3 align=center> Combining Datasets: Merge and Join</h3>",
"_____no_output_____"
],
[
"One essential feature offered by Pandas is its high-performance, in-memory join and merge operations.\nIf you have ever worked with databases, you should be familiar with this type of data interaction.\nThe main interface for this is the ``pd.merge`` function, and we'll see few examples of how this can work in practice.\n\nFor convenience, we will start by redefining the ``display()`` functionality from the previous section:",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nclass display(object):\n \"\"\"Display HTML representation of multiple objects\"\"\"\n template = \"\"\"<div style=\"float: left; padding: 10px;\">\n <p style='font-family:\"Courier New\", Courier, monospace'>{0}</p>{1}\n </div>\"\"\"\n def __init__(self, *args):\n self.args = args\n \n def _repr_html_(self):\n return '\\n'.join(self.template.format(a, eval(a)._repr_html_())\n for a in self.args)\n \n def __repr__(self):\n return '\\n\\n'.join(a + '\\n' + repr(eval(a))\n for a in self.args)",
"_____no_output_____"
]
],
[
[
"## Relational Algebra\n\nThe behavior implemented in ``pd.merge()`` is a subset of what is known as *relational algebra*, which is a formal set of rules for manipulating relational data, and forms the conceptual foundation of operations available in most databases.\nThe strength of the relational algebra approach is that it proposes several primitive operations, which become the building blocks of more complicated operations on any dataset.\nWith this lexicon of fundamental operations implemented efficiently in a database or other program, a wide range of fairly complicated composite operations can be performed.\n\nPandas implements several of these fundamental building-blocks in the ``pd.merge()`` function and the related ``join()`` method of ``Series`` and ``Dataframe``s.\nAs we will see, these let you efficiently link data from different sources.",
"_____no_output_____"
],
[
"## Categories of Joins\n\nThe ``pd.merge()`` function implements a number of types of joins: the \n1. *one-to-one*, \n2. *many-to-one*, and \n3. *many-to-many* joins.\n\nAll three types of joins are accessed via an identical call to the ``pd.merge()`` interface; the type of join performed depends on the form of the input data.\nHere we will show simple examples of the three types of merges, and discuss detailed options further below.",
"_____no_output_____"
],
[
"### One-to-one joins\n\nPerhaps the simplest type of merge expresion is the one-to-one join, which is in many ways very similar to the column-wise concatenation seen in [Combining Datasets: Concat & Append](03.06-Concat-And-Append.ipynb).\nAs a concrete example, consider the following two ``DataFrames`` which contain information on several employees in a company:",
"_____no_output_____"
]
],
[
[
"df1 = pd.DataFrame({'employee': ['Raju', 'Rani', 'Ramesh', 'Ram'],\n 'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})\n\ndf2 = pd.DataFrame({'employee': ['Raju', 'Rani', 'Ramesh', 'Ram'],\n 'hire_date': [2004, 2008, 2012, 2014]})\ndisplay('df1', 'df2','pd.merge(df1, df2)')",
"_____no_output_____"
]
],
[
[
"To combine this information into a single ``DataFrame``, we can use the ``pd.merge()`` function:",
"_____no_output_____"
]
],
[
[
"df3 = pd.merge(df1, df2)\ndf3",
"_____no_output_____"
]
],
[
[
"The ``pd.merge()`` function recognizes that each ``DataFrame`` has an \"employee\" column, and automatically joins using this column as a key.\nThe result of the merge is a new ``DataFrame`` that combines the information from the two inputs.\nNotice that the order of entries in each column is not necessarily maintained: in this case, the order of the \"employee\" column differs between ``df1`` and ``df2``, and the ``pd.merge()`` function correctly accounts for this.\nAdditionally, keep in mind that the merge in general discards the index, except in the special case of merges by index (see the ``left_index`` and ``right_index`` keywords, discussed momentarily).",
"_____no_output_____"
],
[
"### Many-to-one joins",
"_____no_output_____"
],
[
"Many-to-one joins are joins in which one of the two key columns contains duplicate entries.\nFor the many-to-one case, the resulting ``DataFrame`` will preserve those duplicate entries as appropriate.\nConsider the following example of a many-to-one join:",
"_____no_output_____"
]
],
[
[
"df4 = pd.DataFrame({'group': ['Accounting', 'Engineering', 'HR'],\n 'supervisor': ['Carly', 'Guido', 'Steve']})\ndf4",
"_____no_output_____"
],
[
"pd.merge(df3, df4)",
"_____no_output_____"
],
[
"display('df3', 'df4', 'pd.merge(df3, df4)')",
"_____no_output_____"
]
],
[
[
"The resulting ``DataFrame`` has an aditional column with the \"supervisor\" information, where the information is repeated in one or more locations as required by the inputs.",
"_____no_output_____"
],
[
"### Many-to-many joins",
"_____no_output_____"
],
[
"Many-to-many joins are a bit confusing conceptually, but are nevertheless well defined.\nIf the key column in both the left and right array contains duplicates, then the result is a many-to-many merge.\nThis will be perhaps most clear with a concrete example.\nConsider the following, where we have a ``DataFrame`` showing one or more skills associated with a particular group.\nBy performing a many-to-many join, we can recover the skills associated with any individual person:",
"_____no_output_____"
]
],
[
[
"df5 = pd.DataFrame({'group': ['Accounting', 'Accounting',\n 'Engineering', 'Engineering', 'HR', 'Hdf4'],\n \n 'skills': ['math', 'spreadsheets', 'coding', 'linux',\n 'spreadsheets', 'organization']})\ndf5",
"_____no_output_____"
],
[
"display('df1', 'df5', \"pd.merge(df1, df5)\")",
"_____no_output_____"
],
[
"pd.merge(df1, df5)",
"_____no_output_____"
]
],
[
[
"These three types of joins can be used with other Pandas tools to implement a wide array of functionality.\nBut in practice, datasets are rarely as clean as the one we're working with here.\nIn the following section we'll consider some of the options provided by ``pd.merge()`` that enable you to tune how the join operations work.",
"_____no_output_____"
],
[
"## Specification of the Merge Key",
"_____no_output_____"
],
[
"We've already seen the default behavior of ``pd.merge()``: it looks for one or more matching column names between the two inputs, and uses this as the key.\nHowever, often the column names will not match so nicely, and ``pd.merge()`` provides a variety of options for handling this.",
"_____no_output_____"
],
[
"### The ``on`` keyword\n\nMost simply, you can explicitly specify the name of the key column using the ``on`` keyword, which takes a column name or a list of column names:",
"_____no_output_____"
]
],
[
[
"display('df1', 'df2', \"pd.merge(df1, df2, on='employee')\")",
"_____no_output_____"
],
[
"pd.merge(df1, df2, on='employee')",
"_____no_output_____"
]
],
[
[
"This option works only if both the left and right ``DataFrame``s have the specified column name.",
"_____no_output_____"
],
[
"### The ``left_on`` and ``right_on`` keywords\n\nAt times you may wish to merge two datasets with different column names; for example, we may have a dataset in which the employee name is labeled as \"name\" rather than \"employee\".\nIn this case, we can use the ``left_on`` and ``right_on`` keywords to specify the two column names:",
"_____no_output_____"
]
],
[
[
"df3 = pd.DataFrame({'name': ['Raju', 'Rani', 'Ramesh', 'Ram'],\n 'salary': [70000, 80000, 120000, 90000]})\n\n\ndisplay('df1', 'df3', 'pd.merge(df1, df3, left_on=\"employee\", right_on=\"name\")')",
"_____no_output_____"
]
],
[
[
"The result has a redundant column that we can drop if desired–for example, by using the ``drop()`` method of ``DataFrame``s:",
"_____no_output_____"
]
],
[
[
"pd.merge(df1, df3, left_on=\"employee\", right_on=\"name\").drop('name', axis=1) #Duplicat Col",
"_____no_output_____"
]
],
[
[
"### The ``left_index`` and ``right_index`` keywords\n\nSometimes, rather than merging on a column, you would instead like to merge on an index.\nFor example, your data might look like this:",
"_____no_output_____"
]
],
[
[
"df1a = df1.set_index('employee')\ndf2a = df2.set_index('employee')\ndisplay('df1a', 'df2a')",
"_____no_output_____"
]
],
[
[
"You can use the index as the key for merging by specifying the ``left_index`` and/or ``right_index`` flags in ``pd.merge()``:",
"_____no_output_____"
]
],
[
[
"display('df1a', 'df2a',\n \"pd.merge(df1a, df2a, left_index=True, right_index=True)\")",
"_____no_output_____"
],
[
"pd.merge(df1a, df2a, left_index=True, right_index=True)",
"_____no_output_____"
]
],
[
[
"For convenience, ``DataFrame``s implement the ``join()`` method, which performs a merge that defaults to joining on indices:",
"_____no_output_____"
]
],
[
[
"display('df1a', 'df2a', 'df1a.join(df2a)')",
"_____no_output_____"
]
],
[
[
"If you'd like to mix indices and columns, you can combine ``left_index`` with ``right_on`` or ``left_on`` with ``right_index`` to get the desired behavior:",
"_____no_output_____"
]
],
[
[
"display('df1a', 'df3', \"pd.merge(df1a, df3, left_index=True, right_on='name')\")",
"_____no_output_____"
]
],
[
[
"All of these options also work with multiple indices and/or multiple columns; the interface for this behavior is very intuitive.\nFor more information on this, see the [\"Merge, Join, and Concatenate\" section](http://pandas.pydata.org/pandas-docs/stable/merging.html) of the Pandas documentation.",
"_____no_output_____"
],
[
"## Specifying Set Arithmetic for Joins",
"_____no_output_____"
],
[
"In all the preceding examples we have glossed over one important consideration in performing a join: the type of set arithmetic used in the join.\nThis comes up when a value appears in one key column but not the other. Consider this example:",
"_____no_output_____"
]
],
[
[
"df6 = pd.DataFrame({'name': ['Peter', 'Paul', 'Mary'],\n 'food': ['fish', 'beans', 'bread']},\n columns=['name', 'food'])\n\ndf7 = pd.DataFrame({'name': ['Mary', 'Joseph','Paul'],\n 'drink': ['wine', 'beer','Water']},\n columns=['name', 'drink'])",
"_____no_output_____"
],
[
"display('df6', 'df7', 'pd.merge(df6, df7)')",
"_____no_output_____"
]
],
[
[
"Here we have merged two datasets that have only a single \"name\" entry in common: Mary.\nBy default, the result contains the *intersection* of the two sets of inputs; this is what is known as an *inner join*.\nWe can specify this explicitly using the ``how`` keyword, which defaults to ``\"inner\"``:",
"_____no_output_____"
]
],
[
[
"pd.merge(df6, df7, how='inner') # by Defautl inner to join the data",
"_____no_output_____"
],
[
"pd.merge(df6, df7, how='outer')",
"_____no_output_____"
]
],
[
[
"Other options for the ``how`` keyword are ``'outer'``, ``'left'``, and ``'right'``.\nAn *outer join* returns a join over the union of the input columns, and fills in all missing values with NAs:",
"_____no_output_____"
]
],
[
[
"display('df6', 'df7', \"pd.merge(df6, df7, how='outer')\")",
"_____no_output_____"
]
],
[
[
"The *left join* and *right join* return joins over the left entries and right entries, respectively.\nFor example:",
"_____no_output_____"
]
],
[
[
"display('df6', 'df7', \"pd.merge(df6, df7, how='left')\")",
"_____no_output_____"
],
[
"display('df6', 'df7', \"pd.merge(df6, df7, how='right')\")",
"_____no_output_____"
]
],
[
[
"The output rows now correspond to the entries in the left input. Using\n``how='right'`` works in a similar manner.\n\nAll of these options can be applied straightforwardly to any of the preceding join types.",
"_____no_output_____"
],
[
"## Overlapping Column Names: The ``suffixes`` Keyword",
"_____no_output_____"
],
[
"Finally, you may end up in a case where your two input ``DataFrame``s have conflicting column names.\nConsider this example:",
"_____no_output_____"
]
],
[
[
"df8 = pd.DataFrame({'name': ['Bob', 'Jake', 'Lisa', 'Sue'],\n 'rank': [1, 2, 3, 4]})\ndf9 = pd.DataFrame({'name': ['Bob', 'Jake', 'Lisa', 'Sue'],\n 'rank': [3, 1, 4, 2]})\ndisplay('df8', 'df9', 'pd.merge(df8, df9, on=\"name\")')",
"_____no_output_____"
]
],
[
[
"Because the output would have two conflicting column names, the merge function automatically appends a suffix ``_x`` or ``_y`` to make the output columns unique.\nIf these defaults are inappropriate, it is possible to specify a custom suffix using the ``suffixes`` keyword:",
"_____no_output_____"
]
],
[
[
"display('df8', 'df9', 'pd.merge(df8, df9, on=\"name\", suffixes=[\"_L\", \"_R\"])')",
"_____no_output_____"
]
],
[
[
"These suffixes work in any of the possible join patterns, and work also if there are multiple overlapping columns.",
"_____no_output_____"
],
[
"For more information on these patterns, see [Aggregation and Grouping](03.08-Aggregation-and-Grouping.ipynb) where we dive a bit deeper into relational algebra.\nAlso see the [Pandas \"Merge, Join and Concatenate\" documentation](http://pandas.pydata.org/pandas-docs/stable/merging.html) for further discussion of these topics.",
"_____no_output_____"
],
[
"## Example: US States Data\n\nMerge and join operations come up most often when combining data from different sources.\nHere we will consider an example of some data about US states and their populations.\nThe data files can be found at [DataSet](https://github.com/reddyprasade/Data-Sets-For-Machine-Learnig-and-Data-Science/tree/master/DataSets)",
"_____no_output_____"
],
[
"Let's take a look at the three datasets, using the Pandas ``read_csv()`` function:",
"_____no_output_____"
]
],
[
[
"pop = pd.read_csv('data/state-population.csv')\nareas = pd.read_csv('data/state-areas.csv')\nabbrevs = pd.read_csv('data/state-abbrevs.csv')\n\ndisplay('pop.head()', 'areas.head()', 'abbrevs.head()')",
"_____no_output_____"
],
[
"pop.shape,areas.shape,abbrevs.shape",
"_____no_output_____"
],
[
"pop.isna().sum()",
"_____no_output_____"
],
[
"areas.isna().sum()",
"_____no_output_____"
],
[
"abbrevs.isna().sum()",
"_____no_output_____"
]
],
[
[
"Given this information, say we want to compute a relatively straightforward result: rank US states and territories by their 2010 population density.\nWe clearly have the data here to find this result, but we'll have to combine the datasets to find the result.\n\nWe'll start with a many-to-one merge that will give us the full state name within the population ``DataFrame``.\nWe want to merge based on the ``state/region`` column of ``pop``, and the ``abbreviation`` column of ``abbrevs``.\nWe'll use ``how='outer'`` to make sure no data is thrown away due to mismatched labels.",
"_____no_output_____"
]
],
[
[
"merged = pd.merge(pop, abbrevs, how='outer',\n left_on='state/region', right_on='abbreviation')\nmerged.head()",
"_____no_output_____"
],
[
"merged.isna().sum()",
"_____no_output_____"
],
[
"merged.tail()",
"_____no_output_____"
],
[
"merged = merged.drop('abbreviation', 1) # drop duplicate info\nmerged.head()",
"_____no_output_____"
]
],
[
[
"Let's double-check whether there were any mismatches here, which we can do by looking for rows with nulls:",
"_____no_output_____"
]
],
[
[
"merged.isnull().any()",
"_____no_output_____"
],
[
"merged.isnull().sum()",
"_____no_output_____"
]
],
[
[
"Some of the ``population`` info is null; let's figure out which these are!",
"_____no_output_____"
]
],
[
[
"merged['population'].isnull().sum()",
"_____no_output_____"
],
[
"merged['state'].isnull().sum()",
"_____no_output_____"
],
[
"merged[merged['population'].isnull()]",
"_____no_output_____"
],
[
"merged[merged['state'].isnull()]",
"_____no_output_____"
]
],
[
[
"It appears that all the null population values are from Puerto Rico prior to the year 2000; this is likely due to this data not being available from the original source.\n\nMore importantly, we see also that some of the new ``state`` entries are also null, which means that there was no corresponding entry in the ``abbrevs`` key!\nLet's figure out which regions lack this match:",
"_____no_output_____"
]
],
[
[
"merged.loc[merged['state'].isnull(), 'state/region'].unique()",
"_____no_output_____"
]
],
[
[
"We can quickly infer the issue: our population data includes entries for Puerto Rico (PR) and the United States as a whole (USA), while these entries do not appear in the state abbreviation key.\nWe can fix these quickly by filling in appropriate entries:",
"_____no_output_____"
]
],
[
[
"merged.loc[merged['state/region'] == 'PR', 'state'] = 'Puerto Rico'\nmerged.loc[merged['state/region'] == 'USA', 'state'] = 'United States'\nmerged.isnull().any()",
"_____no_output_____"
],
[
"merged.isnull().sum()",
"_____no_output_____"
]
],
[
[
"No more nulls in the ``state`` column: we're all set!\n\nNow we can merge the result with the area data using a similar procedure.\nExamining our results, we will want to join on the ``state`` column in both:",
"_____no_output_____"
]
],
[
[
"final = pd.merge(merged, areas, on='state', how='left')\nfinal.head()",
"_____no_output_____"
]
],
[
[
"Again, let's check for nulls to see if there were any mismatches:",
"_____no_output_____"
]
],
[
[
"final.isnull().any()",
"_____no_output_____"
],
[
"final.isna().sum()",
"_____no_output_____"
]
],
[
[
"There are nulls in the ``area`` column; we can take a look to see which regions were ignored here:",
"_____no_output_____"
]
],
[
[
"final['state'][final['area (sq. mi)'].isnull()].unique()",
"_____no_output_____"
]
],
[
[
"We see that our ``areas`` ``DataFrame`` does not contain the area of the United States as a whole.\nWe could insert the appropriate value (using the sum of all state areas, for instance), but in this case we'll just drop the null values because the population density of the entire United States is not relevant to our current discussion:",
"_____no_output_____"
]
],
[
[
"final.dropna(inplace=True)\nfinal.head()",
"_____no_output_____"
],
[
"final.shape",
"_____no_output_____"
],
[
"final.isnull().info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 2476 entries, 0 to 2495\nData columns (total 6 columns):\n # Column Non-Null Count Dtype\n--- ------ -------------- -----\n 0 state/region 2476 non-null bool \n 1 ages 2476 non-null bool \n 2 year 2476 non-null bool \n 3 population 2476 non-null bool \n 4 state 2476 non-null bool \n 5 area (sq. mi) 2476 non-null bool \ndtypes: bool(6)\nmemory usage: 33.9 KB\n"
],
[
"final.isna().sum()",
"_____no_output_____"
]
],
[
[
"Now we have all the data we need. To answer the question of interest, let's first select the portion of the data corresponding with the year 2000, and the total population.\nWe'll use the ``query()`` function to do this quickly (this requires the ``numexpr`` package to be installed; see [High-Performance Pandas: ``eval()`` and ``query()``](03.12-Performance-Eval-and-Query.ipynb)):",
"_____no_output_____"
]
],
[
[
"data2010 = final.query(\"year == 2010 & ages == 'total'\") # SQL Select Stastement\ndata2010.head()",
"_____no_output_____"
]
],
[
[
"Now let's compute the population density and display it in order.\nWe'll start by re-indexing our data on the state, and then compute the result:",
"_____no_output_____"
]
],
[
[
"data2010.set_index('state', inplace=True)\ndata2010",
"_____no_output_____"
],
[
"density = data2010['population'] / data2010['area (sq. mi)']\ndensity.head()",
"_____no_output_____"
],
[
"density.sort_values(ascending=True, inplace=True)\ndensity.head()",
"_____no_output_____"
]
],
[
[
"The result is a ranking of US states plus Washington, DC, and Puerto Rico in order of their 2010 population density, in residents per square mile.\nWe can see that by far the densest region in this dataset is Washington, DC (i.e., the District of Columbia); among states, the densest is New Jersey.\n\nWe can also check the end of the list:",
"_____no_output_____"
]
],
[
[
"density.tail()",
"_____no_output_____"
],
[
"final.isnull().describe()",
"_____no_output_____"
]
],
[
[
"Converting the Data Frame into Pickle File Formate ",
"_____no_output_____"
]
],
[
[
"Data = pd.to_pickle(final,'Data/US_States_Data.plk')# Save the Data in the from of Pickled",
"_____no_output_____"
],
[
"final.to_csv('Data/US_States_Data.csv')# Save the Data Csv",
"_____no_output_____"
],
[
"unpickled_df = pd.read_pickle(\"Data/US_States_Data.plk\")\nunpickled_df",
"_____no_output_____"
]
],
[
[
"We see that the least dense state, by far, is Alaska, averaging slightly over one resident per square mile.\n\nThis type of messy data merging is a common task when trying to answer questions using real-world data sources.\nI hope that this example has given you an idea of the ways you can combine tools we've covered in order to gain insight from your data!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4ad523f7add94402be4324b1271060ba25966ae7
| 3,913 |
ipynb
|
Jupyter Notebook
|
notebooks/sandbox/Trying to load point cloud from PDAL to ipyvolume.ipynb
|
d-diaz/Lidar_Plot_Registration
|
1a71f8c5dd7c4f8436c983ede4a7d1131aa117d9
|
[
"BSD-3-Clause"
] | 5 |
2018-12-21T22:35:59.000Z
|
2021-12-21T20:12:21.000Z
|
notebooks/sandbox/Trying to load point cloud from PDAL to ipyvolume.ipynb
|
d-diaz/lidar_plot_registration
|
1a71f8c5dd7c4f8436c983ede4a7d1131aa117d9
|
[
"BSD-3-Clause"
] | 12 |
2018-11-28T19:10:29.000Z
|
2018-12-12T06:40:23.000Z
|
notebooks/sandbox/Trying to load point cloud from PDAL to ipyvolume.ipynb
|
d-diaz/lidar_plot_registration
|
1a71f8c5dd7c4f8436c983ede4a7d1131aa117d9
|
[
"BSD-3-Clause"
] | 4 |
2018-12-01T04:57:30.000Z
|
2021-07-25T14:38:35.000Z
| 26.619048 | 314 | 0.492717 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport geopandas as gpd\nimport pdal\nimport ipyvolume as ipv",
"_____no_output_____"
],
[
"pdal_json = \"\"\"\n{\n \"pipeline\": [\n \"../forest3d/tests/sample_data_for_testing/point_cloud.laz\"\n ]\n}\"\"\"",
"_____no_output_____"
],
[
"pipeline = pdal.Pipeline(pdal_json)\npipeline.validate() # check if our JSON and options were good\npipeline.loglevel = 8 #really noisy\ncount = pipeline.execute()\narrays = pipeline.arrays\nmetadata = pipeline.metadata\nlog = pipeline.log",
"_____no_output_____"
],
[
"arrays",
"_____no_output_____"
],
[
"len(arrays[0])",
"_____no_output_____"
],
[
"tree_scatter = ipv.quickscatter(x=arrays[0]['X'],\n y=arrays[0]['Y'],\n z=arrays[0]['Z'], marker='sphere', size=0.5, color='green')\nipv.pylab.xlim(arrays[0]['X'].min(),arrays[0]['X'].max())\nipv.pylab.ylim(arrays[0]['Y'].min(),arrays[0]['Y'].max())\nipv.pylab.zlim(arrays[0]['Z'].min(),arrays[0]['Z'].max())\nipv.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.