
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
c5161f8853611c2f9557a26b0cf2c0690881ff07
| 15,118 |
ipynb
|
Jupyter Notebook
|
Python Data Science Toolbox -Part 1/Writing your own functions/08.Bringing it all together (2).ipynb
|
nazmusshakib121/Python-Programming
|
3ea852641cd5fe811228f27a780109a44174e8e5
|
[
"MIT"
] | null | null | null |
Python Data Science Toolbox -Part 1/Writing your own functions/08.Bringing it all together (2).ipynb
|
nazmusshakib121/Python-Programming
|
3ea852641cd5fe811228f27a780109a44174e8e5
|
[
"MIT"
] | null | null | null |
Python Data Science Toolbox -Part 1/Writing your own functions/08.Bringing it all together (2).ipynb
|
nazmusshakib121/Python-Programming
|
3ea852641cd5fe811228f27a780109a44174e8e5
|
[
"MIT"
] | null | null | null | 39.165803 | 239 | 0.431671 |
[
[
[
"Great job! You've now defined the functionality for iterating over entries in a column and building a dictionary with keys the names of languages and values the number of tweets in the given language.\n\nIn this exercise, you will define a function with the functionality you developed in the previous exercise, return the resulting dictionary from within the function, and call the function with the appropriate arguments.\n\nFor your convenience, the pandas package has been imported as pd and the 'tweets.csv' file has been imported into the tweets_df variable.",
"_____no_output_____"
],
[
"Define the function count_entries(), which has two parameters. The first parameter is df for the DataFrame and the second is col_name for the column name.",
"_____no_output_____"
],
[
"Complete the bodies of the if-else statements in the for loop: if the key is in the dictionary langs_count, add 1 to its current value, else add the key to langs_count and set its value to 1. Use the loop variable entry in your code.",
"_____no_output_____"
],
[
"Return the langs_count dictionary from inside the count_entries() function.",
"_____no_output_____"
],
[
"Call the count_entries() function by passing to it tweets_df and the name of the column, 'lang'. Assign the result of the call to the variable result.",
"_____no_output_____"
]
],
[
[
"# Import pandas\nimport pandas as pd\n\n# Import Twitter data as DataFrame: df\ntweets_df = pd.read_csv('tweets.csv')\ntweets_df.head()",
"_____no_output_____"
],
[
"# Define count_entries()\ndef count_entries(df, col_name):\n \"\"\"Return a dictionary with counts of \n occurrences as value for each key.\"\"\"\n\n # Initialize an empty dictionary: langs_count\n langs_count = {}\n\n # Extract column from DataFrame: col\n col = df[col_name]\n\n\n # Iterate over lang column in DataFrame\n for entry in col:\n\n # If the language is in langs_count, add 1\n if entry in langs_count.keys():\n langs_count[entry] += 1\n # Else add the language to langs_count, set the value to 1\n else:\n langs_count[entry] = 1\n\n # Return the langs_count dictionary\n return langs_count\n\n\n# Call count_entries(): result\nresult = count_entries(tweets_df, 'lang')\n\n# Print the result\nprint(result)",
"{'en': 97, 'et': 1, 'und': 2}\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
c5162494de23f331b571a5aecc5427e75dbb265e
| 853 |
ipynb
|
Jupyter Notebook
|
Notebooks/JuliaML.ipynb
|
BenjaminBorn/IntroToJulia
|
888969b4763e6d76b170a956d47c1ffb594585a3
|
[
"MIT"
] | 2 |
2020-09-26T11:17:00.000Z
|
2021-06-24T01:15:37.000Z
|
Notebooks/JuliaML.ipynb
|
BenjaminBorn/IntroToJulia
|
888969b4763e6d76b170a956d47c1ffb594585a3
|
[
"MIT"
] | null | null | null |
Notebooks/JuliaML.ipynb
|
BenjaminBorn/IntroToJulia
|
888969b4763e6d76b170a956d47c1ffb594585a3
|
[
"MIT"
] | 2 |
2019-06-14T14:20:37.000Z
|
2021-09-16T22:53:25.000Z
| 25.848485 | 228 | 0.609613 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
c5162684b5c7938df86ace88ad3d1747b20c9702
| 740 |
ipynb
|
Jupyter Notebook
|
presentation/.ipynb_checkpoints/FirstTry-checkpoint.ipynb
|
NemesisFLX/twitter.ai
|
a8fc4997f65e877e81a8c0b1713866b50cd0d817
|
[
"MIT"
] | null | null | null |
presentation/.ipynb_checkpoints/FirstTry-checkpoint.ipynb
|
NemesisFLX/twitter.ai
|
a8fc4997f65e877e81a8c0b1713866b50cd0d817
|
[
"MIT"
] | 6 |
2018-05-10T17:26:53.000Z
|
2018-05-16T16:31:09.000Z
|
presentation/.ipynb_checkpoints/FirstTry-checkpoint.ipynb
|
NemesisFLX/social.ai
|
a8fc4997f65e877e81a8c0b1713866b50cd0d817
|
[
"MIT"
] | null | null | null | 16.818182 | 39 | 0.509459 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"s = pd.Series([1,3,5,np.nan,6,8])",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
c5162f479e6b0af7ed529f71bce3f783299ba210
| 198,650 |
ipynb
|
Jupyter Notebook
|
perceptron-neural-network.ipynb
|
DS-Mind/perceptron
|
c6ac344174d902192c0d24047c9b4b07ee7b5693
|
[
"MIT"
] | null | null | null |
perceptron-neural-network.ipynb
|
DS-Mind/perceptron
|
c6ac344174d902192c0d24047c9b4b07ee7b5693
|
[
"MIT"
] | null | null | null |
perceptron-neural-network.ipynb
|
DS-Mind/perceptron
|
c6ac344174d902192c0d24047c9b4b07ee7b5693
|
[
"MIT"
] | null | null | null | 548.756906 | 149,124 | 0.94067 |
[
[
[
"# Artificial Neural Networks \n\n## About this notebook\n\nThis notebook kernel was created to help you understand more about machine learning. I intend to create tutorials with several machine learning algorithms from basic to advanced. I hope I can help you with this data science trail. For any information, you can contact me through the link below.\n\nContact me here: https://www.linkedin.com/in/vitorgamalemos/\n\n## Introduction \n\n<img src=\"https://media.springernature.com/original/springer-static/image/art%3A10.1007%2Fs40846-016-0191-3/MediaObjects/40846_2016_191_Fig1_HTML.gif\">\n\n<p style=\"text-align: justify;\">Artificial Neural Networks are mathematical models inspired by the human brain, specifically the ability to learn, process, and perform tasks. The Artificial Neural Networks are powerful tools that assist in solving complex problems linked mainly in the area of combinatorial optimization and machine learning. In this context, artificial neural networks have the most varied applications possible, as such models can adapt to the situations presented, ensuring a gradual increase in performance without any human interference. We can say that the Artificial Neural Networks are potent methods can give computers a new possibility, that is, a machine does not get stuck to preprogrammed rules and opens up various options to learn from its own mistakes.</p>",
"_____no_output_____"
],
[
"## Biologic Model\n\n<img src=\"https://www.neuroskills.com/images/photo-500x500-neuron.png\">\n<p style=\"text-align: justify;\">Artificial neurons are designed to mimic aspects of their biological counterparts. The neuron is one of the fundamental units that make up the entire brain structure of the central nervous system; such cells are responsible for transmitting information through the electrical potential difference in their membrane. In this context, a biological neuron can be divided as follows.</p>\n\n**Dendrites** – are thin branches located in the nerve cell. These cells act on receiving nerve input from other parts of our body.\n\n**Soma** – acts as a summation function. As positive and negative signals (exciting and inhibiting, respectively) arrive in the soma from the dendrites they are added together.\n\n**Axon** – gets its signal from the summation behavior which occurs inside the soma. It is formed by a single extended filament located throughout the neuron. The axon is responsible for sending nerve impulses to the external environment of a cell.",
"_____no_output_____"
],
[
"## Artificial Neuron as Mathematic Notation\nIn general terms, an input X is multiplied by a weight W and added a bias b producing the net activation. \n<img style=\"max-width:60%;max-height:60%;\" src=\"https://miro.medium.com/max/1290/1*-JtN9TWuoZMz7z9QKbT85A.png\">\n\nWe can summarize an artificial neuron with the following mathematical expression:\n$$\n\\hat{y} = f\\left(\\text{net}\\right)= f\\left(\\vec{w}\\cdot\\vec{x}+b\\right) = f\\left(\\sum_{i=1}^{n}{w_i x_i + b}\\right)\n$$",
"_____no_output_____"
],
[
"## The SigleLayer Perceptron\n\n<p style=\"text-align: justify;\">The Perceptron and its learning algorithm pioneered the research in neurocomputing. the perceptron is an algorithm for supervised learning of binary classifiers [1]. A binary classifier is a function which can decide whether or not an input, represented by a vector of numbers, belongs to some specific class. It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector.<p>\n \n<img src=\"https://www.edureka.co/blog/wp-content/uploads/2017/12/Perceptron-Learning-Algorithm_03.gif\">\n \n#### References\n \n- Freund, Y.; Schapire, R. E. (1999). \"Large margin classification using the perceptron algorithm\" (PDF). Machine Learning\n\n- Aizerman, M. A.; Braverman, E. M.; Rozonoer, L. I. (1964). \"Theoretical foundations of the potential function method in pattern recognition learning\". Automation and Remote Control. 25: 821–837.\n \n- Mohri, Mehryar and Rostamizadeh, Afshin (2013). Perceptron Mistake Bounds.",
"_____no_output_____"
],
[
"## The SingleLayer Perceptron Learning\nLearning goes by calculating the prediction of the perceptron:\n\n### Basic Neuron \n$$\n\\hat{y} = f\\left(\\vec{w}\\cdot\\vec{x} + b) = f( w_{1}x_{1} + w_2x_{2} + \\cdots + w_nx_{n}+b\\right)\\,\n$$\n\nAfter that, we update the weights and the bias using as:\n\n$$\n\\hat{w_i} = w_i + \\alpha (y - \\hat{y}) x_{i} \\,,\\ i=1,\\ldots,n\\,;\\\\\n$$\n$$\n\\hat{b} = b + \\alpha (y - \\hat{y})\\,.\n$$",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nclass SingleLayerPerceptron:\n def __init__(self, my_weights, my_bias, learningRate=0.05):\n self.weights = my_weights\n self.bias = my_bias\n self.learningRate = learningRate\n \n def activation(self, net):\n answer = 1 if net > 0 else 0\n return answer\n \n def neuron(self, inputs):\n neuronArchitecture = np.dot(self.weights, inputs) + self.bias\n return neuronArchitecture\n \n def neuron_propagate(self, inputs):\n processing = self.neuron(inputs)\n return self.activation(processing) \n \n def training(self, inputs, output):\n output_prev = self.neuron_propagate(inputs)\n self.weights = [W + X * self.learningRate * (output - output_prev)\n for (W, X) in zip(self.weights, inputs)]\n self.bias += self.learningRate * (output - output_prev)\n error_calculation = np.abs(output_prev - output)\n return error_calculation",
"_____no_output_____"
],
[
"data = pd.DataFrame(columns=('x1', 'x2'), data=np.random.uniform(size=(600,2)))\ndata.head()",
"_____no_output_____"
],
[
"def show_dataset(data, ax):\n data[data.y==1].plot(kind='scatter', ax=ax, x='x1', y='x2', color='blue')\n data[data.y==0].plot(kind='scatter', ax=ax, x='x1', y='x2', color='red')\n plt.grid()\n plt.title(' My Dataset')\n ax.set_xlim(-0.1,1.1)\n ax.set_ylim(-0.1,1.1)\n \ndef testing(inputs):\n answer = int(np.sum(inputs) > 1)\n return answer\n\ndata['y'] = data.apply(testing, axis=1)",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(10,10))\nshow_dataset(data, fig.gca())",
"_____no_output_____"
],
[
"InitialWeights = [0.1, 0.1]\nInitialBias = 0.01\nLearningRate = 0.1\nSLperceptron = SingleLayerPerceptron(InitialWeights, \n InitialBias,\n LearningRate)",
"_____no_output_____"
],
[
"import random, itertools\n\ndef showAll(perceptron, data, threshold, ax=None):\n if ax==None:\n fig = plt.figure(figsize=(5,4))\n ax = fig.gca()\n \n show_dataset(data, ax)\n show_threshold(perceptron, ax)\n title = 'training={}'.format(threshold + 1)\n ax.set_title(title)\n \ndef trainingData(SinglePerceptron, inputs):\n count = 0 \n for i, line in inputs.iterrows():\n count = count + SinglePerceptron.training(line[0:2], \n line[2])\n \n return count\n\ndef limit(neuron, inputs):\n weights_0 = neuron.weights[0]\n weights_1 = neuron.weights[1]\n bias = neuron.bias\n threshold = -weights_0 * inputs - bias\n threshold = threshold / weights_1\n return threshold\n\ndef show_threshold(SinglePerceptron, ax):\n xlim = plt.gca().get_xlim()\n ylim = plt.gca().get_ylim()\n \n x2 = [limit(SinglePerceptron, x1) for x1 in xlim]\n \n ax.plot(xlim, x2, color=\"yellow\")\n ax.set_xlim(-0.1,1.1)\n ax.set_ylim(-0.1,1.1)\n\nf, axarr = plt.subplots(3, 4, sharex=True, sharey=True, figsize=(12,12))\naxs = list(itertools.chain.from_iterable(axarr))\nuntil = 12\nfor interaction in range(until):\n showAll(SLperceptron, data, interaction, ax=axs[interaction])\n trainingData(SLperceptron, data)",
"_____no_output_____"
]
],
[
[
"Example using Multilayer Perceptron (no libraries): https://www.kaggle.com/vitorgamalemos/iris-flower-using-multilayer-perceptron/",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
c51644a5087d485315e8895361c0fc56ef8b5d1d
| 46,278 |
ipynb
|
Jupyter Notebook
|
Chapter08/chapter8_tutorials/smart_grasping_sandbox/smart_grasping_sandbox/notebooks/Grasp Quality.ipynb
|
PacktPublishing/Robot-Operating-System-Cookbook
|
d94ef672a483782922ca8b134f6de749af8e0a10
|
[
"MIT"
] | 53 |
2018-09-13T05:11:03.000Z
|
2022-02-28T04:09:58.000Z
|
Chapter08/chapter8_tutorials/smart_grasping_sandbox/smart_grasping_sandbox/notebooks/Grasp Quality.ipynb
|
PacktPublishing/Robot-Operating-System-Cookbook
|
d94ef672a483782922ca8b134f6de749af8e0a10
|
[
"MIT"
] | 2 |
2018-09-30T08:32:22.000Z
|
2019-04-12T13:37:43.000Z
|
Chapter08/chapter8_tutorials/smart_grasping_sandbox/smart_grasping_sandbox/notebooks/Grasp Quality.ipynb
|
PacktPublishing/Robot-Operating-System-Cookbook
|
d94ef672a483782922ca8b134f6de749af8e0a10
|
[
"MIT"
] | 31 |
2018-09-16T06:05:13.000Z
|
2021-09-10T18:10:37.000Z
| 95.615702 | 14,314 | 0.781624 |
[
[
[
"from keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.callbacks import TensorBoard\nfrom keras.layers import *\nimport numpy\n\nfrom sklearn.model_selection import train_test_split\n\n#ignoring the first row (header) \n# and the first column (unique experiment id, which I'm not using here)\ndataset = numpy.loadtxt(\"/results/shadow_robot_dataset.csv\", skiprows=1, usecols=range(1,30), delimiter=\",\")",
"Using TensorFlow backend.\n"
]
],
[
[
"# Loading the data\n\nEach row of my dataset contains the following:\n\n|0 | 1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24|25|26|27|28|29|\n|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|\n| experiment_number | robustness| H1_F1J2_pos | H1_F1J2_vel | H1_F1J2_effort | H1_F1J3_pos | H1_F1J3_vel | H1_F1J3_effort | H1_F1J1_pos | H1_F1J1_vel | H1_F1J1_effort | H1_F3J1_pos | H1_F3J1_vel | H1_F3J1_effort | H1_F3J2_pos | H1_F3J2_vel | H1_F3J2_effort | H1_F3J3_pos | H1_F3J3_vel | H1_F3J3_effort | H1_F2J1_pos | H1_F2J1_vel | H1_F2J1_effort | H1_F2J3_pos | H1_F2J3_vel | H1_F2J3_effort | H1_F2J2_pos | H1_F2J2_vel | H1_F2J2_effort | measurement_number|\n\nMy input vector contains the velocity and effort for each joint. I'm creating the vector `X` containing those below:",
"_____no_output_____"
]
],
[
[
"# Getting the header\nheader = \"\"\n\nwith open('/results/shadow_robot_dataset.csv', 'r') as f:\n header = f.readline()\n \nheader = header.strip(\"\\n\").split(',')\nheader = [i.strip(\" \") for i in header]\n\n# only use velocity and effort, not position\nsaved_cols = []\nfor index,col in enumerate(header[1:]):\n if (\"vel\" in col) or (\"eff\" in col):\n saved_cols.append(index)\n \nnew_X = []\nfor x in dataset:\n new_X.append([x[i] for i in saved_cols])\n \nX = numpy.array(new_X)\n",
"_____no_output_____"
]
],
[
[
"My output vector is the predicted grasp robustness. ",
"_____no_output_____"
]
],
[
[
"Y = dataset[:,0]",
"_____no_output_____"
]
],
[
[
"We are also splitting the dataset into a training set and a test set. \n\nThis gives us 4 sets: \n* `X_train` associated to its `Y_train`\n* `X_test` associated to its `Y_test`\n\nWe also discretize the output: 1 is a stable grasp and 0 is unstable. A grasp is considered stable if the robustness value is more than 100.",
"_____no_output_____"
]
],
[
[
"# fix random seed for reproducibility\n# and splitting the dataset\nseed = 7\nnumpy.random.seed(seed)\nX_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.20, random_state=seed)\n\n# this is a sensible grasp threshold for stability\nGOOD_GRASP_THRESHOLD = 50\n\n# we're also storing the best and worst grasps of the test set to do some sanity checks on them\nitemindex = numpy.where(Y_test>1.05*GOOD_GRASP_THRESHOLD)\nbest_grasps = X_test[itemindex[0]]\nitemindex = numpy.where(Y_test<=0.95*GOOD_GRASP_THRESHOLD)\nbad_grasps = X_test[itemindex[0]]\n\n# discretizing the grasp quality for stable or unstable grasps\nY_train = numpy.array([int(i>GOOD_GRASP_THRESHOLD) for i in Y_train])\nY_train = numpy.reshape(Y_train, (Y_train.shape[0],))\n\nY_test = numpy.array([int(i>GOOD_GRASP_THRESHOLD) for i in Y_test])\nY_test = numpy.reshape(Y_test, (Y_test.shape[0],))",
"_____no_output_____"
]
],
[
[
"# Creating the model\n\nI'm now creating a model to train. It's a very simple topology. Feel free to play with it and experiment with different model shapes.",
"_____no_output_____"
]
],
[
[
"# create model\nmodel = Sequential()\n\nmodel.add(Dense(20*len(X[0]), use_bias=True, input_dim=len(X[0]), activation='relu'))\nmodel.add(Dropout(0.5))\n\nmodel.add(Dense(1, activation='sigmoid'))\n\n# Compile model\nmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"# Training the model\n\nThe model training should be relatively quick. To speed it up you can use a GPU :)\n\nI'm using 80% of the data for training and 20% for validation.",
"_____no_output_____"
]
],
[
[
"model.fit(X_train, Y_train, validation_split=0.20, epochs=50,\n batch_size=500000)",
"Train on 635289 samples, validate on 158823 samples\nEpoch 1/50\n635289/635289 [==============================] - 21s - loss: 1.0522 - acc: 0.4108 - val_loss: 0.4919 - val_acc: 0.6370\nEpoch 2/50\n635289/635289 [==============================] - 6s - loss: 0.6931 - acc: 0.4742 - val_loss: 0.3576 - val_acc: 0.6560\nEpoch 3/50\n635289/635289 [==============================] - 6s - loss: 0.4839 - acc: 0.5830 - val_loss: 0.3343 - val_acc: 0.6545\nEpoch 4/50\n635289/635289 [==============================] - 6s - loss: 0.4019 - acc: 0.6293 - val_loss: 0.3379 - val_acc: 0.6544\nEpoch 5/50\n635289/635289 [==============================] - 6s - loss: 0.3755 - acc: 0.6446 - val_loss: 0.3456 - val_acc: 0.6544\nEpoch 6/50\n635289/635289 [==============================] - 6s - loss: 0.3702 - acc: 0.6497 - val_loss: 0.3523 - val_acc: 0.6544\nEpoch 7/50\n635289/635289 [==============================] - 6s - loss: 0.3698 - acc: 0.6528 - val_loss: 0.3572 - val_acc: 0.7986\nEpoch 8/50\n635289/635289 [==============================] - 6s - loss: 0.3732 - acc: 0.8353 - val_loss: 0.3599 - val_acc: 0.9473\nEpoch 9/50\n635289/635289 [==============================] - 6s - loss: 0.3729 - acc: 0.9474 - val_loss: 0.3608 - val_acc: 0.9474\nEpoch 10/50\n635289/635289 [==============================] - 6s - loss: 0.3735 - acc: 0.9480 - val_loss: 0.3601 - val_acc: 0.9475\nEpoch 11/50\n635289/635289 [==============================] - 6s - loss: 0.3723 - acc: 0.9484 - val_loss: 0.3582 - val_acc: 0.9476\nEpoch 12/50\n635289/635289 [==============================] - 6s - loss: 0.3697 - acc: 0.9494 - val_loss: 0.3553 - val_acc: 0.9477\nEpoch 13/50\n635289/635289 [==============================] - 6s - loss: 0.3667 - acc: 0.9501 - val_loss: 0.3518 - val_acc: 0.9498\nEpoch 14/50\n635289/635289 [==============================] - 6s - loss: 0.3641 - acc: 0.9513 - val_loss: 0.3480 - val_acc: 0.9514\nEpoch 15/50\n635289/635289 [==============================] - 6s - loss: 0.3599 - acc: 0.9527 - val_loss: 0.3436 - val_acc: 0.9524\nEpoch 16/50\n635289/635289 [==============================] - 6s - loss: 0.3559 - acc: 0.9550 - val_loss: 0.3394 - val_acc: 0.9559\nEpoch 17/50\n635289/635289 [==============================] - 6s - loss: 0.3532 - acc: 0.9573 - val_loss: 0.3355 - val_acc: 0.9629\nEpoch 18/50\n635289/635289 [==============================] - 6s - loss: 0.3500 - acc: 0.9594 - val_loss: 0.3315 - val_acc: 0.9658\nEpoch 19/50\n635289/635289 [==============================] - 6s - loss: 0.3474 - acc: 0.9615 - val_loss: 0.3277 - val_acc: 0.9672\nEpoch 20/50\n635289/635289 [==============================] - 6s - loss: 0.3439 - acc: 0.9631 - val_loss: 0.3241 - val_acc: 0.9685\nEpoch 21/50\n635289/635289 [==============================] - 6s - loss: 0.3409 - acc: 0.9640 - val_loss: 0.3207 - val_acc: 0.9693\nEpoch 22/50\n635289/635289 [==============================] - 6s - loss: 0.3382 - acc: 0.9646 - val_loss: 0.3175 - val_acc: 0.9701\nEpoch 23/50\n635289/635289 [==============================] - 6s - loss: 0.3362 - acc: 0.9652 - val_loss: 0.3145 - val_acc: 0.9706\nEpoch 24/50\n635289/635289 [==============================] - 6s - loss: 0.3338 - acc: 0.9656 - val_loss: 0.3116 - val_acc: 0.9710\nEpoch 25/50\n635289/635289 [==============================] - 6s - loss: 0.3312 - acc: 0.9658 - val_loss: 0.3089 - val_acc: 0.9713\nEpoch 26/50\n635289/635289 [==============================] - 6s - loss: 0.3293 - acc: 0.9665 - val_loss: 0.3063 - val_acc: 0.9716\nEpoch 27/50\n635289/635289 [==============================] - 6s - loss: 0.3276 - acc: 0.9665 - val_loss: 0.3039 - val_acc: 0.9718\nEpoch 28/50\n635289/635289 [==============================] - 6s - loss: 0.3254 - acc: 0.9666 - val_loss: 0.3016 - val_acc: 0.9719\nEpoch 29/50\n635289/635289 [==============================] - 6s - loss: 0.3225 - acc: 0.9670 - val_loss: 0.2994 - val_acc: 0.9720\nEpoch 30/50\n635289/635289 [==============================] - 6s - loss: 0.3213 - acc: 0.9670 - val_loss: 0.2972 - val_acc: 0.9721\nEpoch 31/50\n635289/635289 [==============================] - 6s - loss: 0.3190 - acc: 0.9673 - val_loss: 0.2952 - val_acc: 0.9721\nEpoch 32/50\n635289/635289 [==============================] - 6s - loss: 0.3176 - acc: 0.9671 - val_loss: 0.2931 - val_acc: 0.9722\nEpoch 33/50\n635289/635289 [==============================] - 6s - loss: 0.3150 - acc: 0.9674 - val_loss: 0.2910 - val_acc: 0.9722\nEpoch 34/50\n635289/635289 [==============================] - 6s - loss: 0.3128 - acc: 0.9676 - val_loss: 0.2889 - val_acc: 0.9723\nEpoch 35/50\n635289/635289 [==============================] - 6s - loss: 0.3101 - acc: 0.9678 - val_loss: 0.2869 - val_acc: 0.9724\nEpoch 36/50\n635289/635289 [==============================] - 6s - loss: 0.3084 - acc: 0.9679 - val_loss: 0.2848 - val_acc: 0.9724\nEpoch 37/50\n635289/635289 [==============================] - 6s - loss: 0.3062 - acc: 0.9680 - val_loss: 0.2828 - val_acc: 0.9725\nEpoch 38/50\n635289/635289 [==============================] - 6s - loss: 0.3049 - acc: 0.9679 - val_loss: 0.2807 - val_acc: 0.9726\nEpoch 39/50\n635289/635289 [==============================] - 6s - loss: 0.3023 - acc: 0.9681 - val_loss: 0.2785 - val_acc: 0.9727\nEpoch 40/50\n635289/635289 [==============================] - 6s - loss: 0.3000 - acc: 0.9683 - val_loss: 0.2764 - val_acc: 0.9729\nEpoch 41/50\n635289/635289 [==============================] - 6s - loss: 0.2977 - acc: 0.9684 - val_loss: 0.2742 - val_acc: 0.9730\nEpoch 42/50\n635289/635289 [==============================] - 6s - loss: 0.2952 - acc: 0.9686 - val_loss: 0.2721 - val_acc: 0.9730\nEpoch 43/50\n635289/635289 [==============================] - 6s - loss: 0.2933 - acc: 0.9687 - val_loss: 0.2699 - val_acc: 0.9731\nEpoch 44/50\n635289/635289 [==============================] - 6s - loss: 0.2907 - acc: 0.9688 - val_loss: 0.2678 - val_acc: 0.9732\nEpoch 45/50\n635289/635289 [==============================] - 6s - loss: 0.2891 - acc: 0.9689 - val_loss: 0.2657 - val_acc: 0.9732\nEpoch 46/50\n635289/635289 [==============================] - 6s - loss: 0.2863 - acc: 0.9689 - val_loss: 0.2636 - val_acc: 0.9733\nEpoch 47/50\n635289/635289 [==============================] - 6s - loss: 0.2843 - acc: 0.9690 - val_loss: 0.2615 - val_acc: 0.9734\nEpoch 48/50\n635289/635289 [==============================] - 6s - loss: 0.2820 - acc: 0.9694 - val_loss: 0.2594 - val_acc: 0.9735\nEpoch 49/50\n635289/635289 [==============================] - 6s - loss: 0.2798 - acc: 0.9694 - val_loss: 0.2573 - val_acc: 0.9735\nEpoch 50/50\n635289/635289 [==============================] - 7s - loss: 0.2777 - acc: 0.9693 - val_loss: 0.2553 - val_acc: 0.9735\n"
]
],
[
[
"Now that the model is trained I'm saving it to be able to load it easily later on.",
"_____no_output_____"
]
],
[
[
"import h5py\nmodel.save(\"./model.h5\")",
"_____no_output_____"
]
],
[
[
"# Evaluating the model\n\nFirst let's see how this model performs on the test set - which hasn't been used during the training phase.",
"_____no_output_____"
]
],
[
[
"scores = model.evaluate(X_test, Y_test)\nprint(\"\\n%s: %.2f%%\" % (model.metrics_names[1], scores[1]*100))",
"197632/198529 [============================>.] - ETA: 0s\nacc: 97.33%\n"
]
],
[
[
"Now let's take a quick look at the good grasps we stored earlier. Are they correctly predicted as stable?",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(best_grasps)\n\n%matplotlib inline\nimport matplotlib.pyplot as plt\n\nplt.hist(predictions,\n color='#77D651',\n alpha=0.5,\n label='Good Grasps',\n bins=np.arange(0.0, 1.0, 0.03))\n\nplt.title('Histogram of grasp prediction')\nplt.ylabel('Number of grasps')\nplt.xlabel('Grasp quality prediction')\nplt.legend(loc='upper right')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Most of the grasps are correctly predicted as stable (the grasp quality prediction is more than 0.5)! Looking good.\n\nWhat about the unstable grasps?",
"_____no_output_____"
]
],
[
[
"predictions_bad_grasp = model.predict(bad_grasps)\n\n\n# Plot a histogram of defender size\nplt.hist(predictions_bad_grasp,\n color='#D66751',\n alpha=0.3,\n label='Bad Grasps',\n bins=np.arange(0.0, 1.0, 0.03))\n\nplt.title('Histogram of grasp prediction')\nplt.ylabel('Number of grasps')\nplt.xlabel('Grasp quality prediction')\nplt.legend(loc='upper right')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Most of the grasps are considered unstable - below 0.5 - with a few bad classification.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c5164e0a08af6b53a3caa863598f51ec9b302cee
| 69,144 |
ipynb
|
Jupyter Notebook
|
for-scripters/R/notebooks/jupyter-bridge-rcy3.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null |
for-scripters/R/notebooks/jupyter-bridge-rcy3.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null |
for-scripters/R/notebooks/jupyter-bridge-rcy3.ipynb
|
kozo2/cytoscape-automation
|
2252651795e0f38a46fd2e02afbb36a01e3c6bf3
|
[
"CC0-1.0"
] | null | null | null | 29.790607 | 584 | 0.517066 |
[
[
[
"# **Jupyer Bridge and RCy3**\n",
"_____no_output_____"
],
[
"You can open this notebook in the Google Colab from Github directly (File -> Open notebook -> Github). \n\nAlso you can download this notebook and upload it to the Google Colab (File -> Open notebook -> Upload).",
"_____no_output_____"
],
[
"<font color='red'> You do not need to run installation and getting started sections if you come from the basic Jupyter Bride and RCy3 tutorial, since you have already installed required packages and build the connection. </font>",
"_____no_output_____"
],
[
"## **Installation**",
"_____no_output_____"
]
],
[
[
"library(devtools)\ninstall_github(\"cytoscape/RCy3\")\nlibrary(RCy3)\nlibrary(RColorBrewer)",
"Loading required package: usethis\n\nDownloading GitHub repo cytoscape/RCy3@HEAD\n\n"
]
],
[
[
"## **Getting started**\n",
"_____no_output_____"
]
],
[
[
"browserClientJs <- getBrowserClientJs()\nIRdisplay::display_javascript(browserClientJs)",
"_____no_output_____"
],
[
"cytoscapeVersionInfo()",
"_____no_output_____"
],
[
"cytoscapePing()",
"You are connected to Cytoscape!\n\n"
]
],
[
[
"# **Differentially Expressed Genes Network Analysis**",
"_____no_output_____"
],
[
"## **Prerequisites**\n\nIf you haven’t already, install the [*STRINGApp*](http://apps.cytoscape.org/apps/stringapp) and [*filetransferApp*](https://apps.cytoscape.org/apps/filetransfer).",
"_____no_output_____"
],
[
"## **Background**\n\nOvarian serous cystadenocarcinoma is a type of epithelial ovarian cancer which accounts for ~90% of all ovarian cancers. The data used in this protocol are from [The Cancer Genome Atlas](https://www.cancer.gov/about-nci/organization/ccg/research/structural-genomics/tcga).\nThe Cancer Genome Atlas, in which multiple subtypes of serous cystadenocarcinoma were identified and characterized by mRNA expression.\n\nWe will focus on the differential gene expression between two subtypes, Mesenchymal and Immunoreactive.\n\nFor convenience, the data has already been analyzed and pre-filtered, using log fold change value and adjusted p-value.\n\n\n",
"_____no_output_____"
],
[
"## **Network Retrieval**\n\nMany public databases and multiple Cytoscape apps allow you to retrieve a network or pathway relevant to your data. For this workflow, we will use the STRING app. Some other options include:\n\n* [WikiPathways](https://www.wikipathways.org/index.php/WikiPathways)\n* [NDEx](http://www.ndexbio.org/#/)\n* [GeneMANIA](https://genemania.org/)\n\n\n\n\n",
"_____no_output_____"
],
[
"## **Retrieve Networks from STRING**\n\nTo identify a relevant network, we will query the STRING database in two different ways:\n\nQuery STRING protein with the list of differentially expressed genes.\n\nQuery STRING disease for a keyword; ovarian cancer.\n\nThe two examples are split into two separate workflows below.\n\n",
"_____no_output_____"
],
[
"## **Example 1: STRING Protein Query Up-regulated Genes**\n\nLoad the file containing the data for up-regulated genes, TCGA-Ovarian-MesenvsImmuno_UP_full.csv:",
"_____no_output_____"
]
],
[
[
"de.genes.up <- read.table(\"https://raw.githubusercontent.com/cytoscape/cytoscape-tutorials/gh-pages/protocols/data/TCGA-Ovarian-MesenvsImmuno-data-up.csv\", header = TRUE, sep = \"\\t\", quote=\"\\\"\", stringsAsFactors = FALSE)",
"_____no_output_____"
],
[
"string.cmd = paste('string protein query query=\"', paste(de.genes.up$Gene, collapse = '\\n'), '\" cutoff=0.4 species=\"Homo sapiens\"', sep = \"\")\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"The resulting network will load automatically and contains up-regulated genes recognized by STRING, and interactions between them with an evidence score of 0.4 or greater.\n\nThe networks consists of one large connected component, several smaller networks, and some unconnected nodes. We will select only the connected nodes to work with for the rest of this tutorial, by creating a subnetwork based on all edges:",
"_____no_output_____"
]
],
[
[
"createSubnetwork(edges='all', subnetwork.name='String de genes up')",
"_____no_output_____"
]
],
[
[
"## **Data Integration**\n\nNext we will import log fold changes and p-values from our TCGA dataset to create a visualization. Since the STRING network is a protein-protein network, it is annotated with protein identifiers (Uniprot and Ensembl protein), as well as HGNC gene symbols. Our data from TCGA has NCBI Gene identifiers (formerly Entrez), so before importing the data we are going to use the ID Mapper functionality in Cytoscape to map the network to NCBI Gene.",
"_____no_output_____"
]
],
[
[
"mapped.cols <- mapTableColumn('display name', 'Human', 'HGNC', 'Entrez Gene')",
"_____no_output_____"
]
],
[
[
"We can now import the differential gene expression data and integrate it with the network (node) table in Cytoscape. For importing the data we will use the following mapping:\n\n* Key Column for Network should be Entrez Gene, which is the column we just added.\n\n* Gene should be the key of the data(de.genes.full).\n\n\n",
"_____no_output_____"
]
],
[
[
"de.genes.full <- read.table(\"https://raw.githubusercontent.com/cytoscape/cytoscape-tutorials/gh-pages/protocols/data/TCGA-Ovarian-MesenvsImmuno_data.csv\", header = TRUE, sep = \",\", quote=\"\\\"\", stringsAsFactors = FALSE)\n\nloadTableData(de.genes.full,data.key.column=\"Gene\",table.key.column=\"Entrez Gene\")",
"_____no_output_____"
]
],
[
[
"You will notice two new columns (logFC and FDR.adjusted.Pvalue) in the Node Table.\n\n\n",
"_____no_output_____"
]
],
[
[
"tail(getTableColumnNames('node'))",
"_____no_output_____"
]
],
[
[
"## **Visualization**\n\nNext, we will create a visualization of the imported data on the network.",
"_____no_output_____"
]
],
[
[
"setVisualStyle(style.name=\"default\")\nsetNodeShapeDefault(new.shape=\"ELLIPSE\", style.name = \"default\")\nlockNodeDimensions(new.state=\"TRUE\", style.name = \"default\")\nsetNodeSizeDefault(new.size=\"50\", style.name = \"default\")\nsetNodeColorDefault(new.color=\"#D3D3D3\", style.name = \"default\")\nsetNodeBorderWidthDefault(new.width=\"2\", style.name = \"default\")\nsetNodeBorderColorDefault(new.color=\"#616060\", style.name = \"default\")\nsetNodeLabelMapping(table.column=\"display name\",style.name = \"default\")\nsetNodeFontSizeDefault(new.size=\"14\", style.name = \"default\")",
"_____no_output_____"
]
],
[
[
"Before we create a mapping for node color representing the range of fold changes, we need the min and max of the logFC column:",
"_____no_output_____"
]
],
[
[
"logFC.table.up <- getTableColumns('node', 'logFC')",
"_____no_output_____"
],
[
"logFC.up.min <- min(logFC.table.up, na.rm = T)\nlogFC.up.max <- max(logFC.table.up, na.rm = T)\nlogFC.up.center <- logFC.up.min + (logFC.up.max - logFC.up.min)/2",
"_____no_output_____"
],
[
"copyVisualStyle(from.style = \"default\", to.style = \"de genes up\")\nsetVisualStyle(style.name=\"de genes up\")\n\ndata.values = c(logFC.up.min, logFC.up.center, logFC.up.max)\nnode.colors <- c(brewer.pal(length(data.values), \"YlOrRd\"))\nsetNodeColorMapping('logFC', data.values, node.colors, style.name=\"de genes up\")",
"_____no_output_____"
]
],
[
[
"Applying a force-directed layout, the network will now look something like this:\n\n",
"_____no_output_____"
]
],
[
[
"layoutNetwork(paste('force-directed', \n 'defaultSpringCoefficient=0.00003',\n 'defaultSpringLength=50',\n 'defaultNodeMass=4',\n sep=' '))",
"_____no_output_____"
]
],
[
[
"## **Enrichment Analysis Options**\n\nNext, we are going to perform enrichment anlaysis uing the STRING app.\n\n",
"_____no_output_____"
],
[
"## **STRING Enrichment**\nThe STRING app has built-in enrichment analysis functionality, which includes enrichment for GO Process, GO Component, GO Function, InterPro, KEGG Pathways, and PFAM.\n\nFirst, we will run the enrichment on the whole network, against the genome:",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string retrieve enrichment allNetSpecies=\"Homo sapiens\", background=genome selectedNodesOnly=\"false\"'\ncommandsRun(string.cmd)\nstring.cmd = 'string show enrichment'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"When the enrichment analysis is complete, a new tab titled STRING Enrichment will open in the Table Panel.\n\nThe STRING app includes several options for filtering and displaying the enrichment results. The features are all available at the top of the STRING Enrichment tab.\n\nWe are going to filter the table to only show GO Process:",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string filter enrichment categories=\"GO Process\", overlapCutoff = \"0.5\", removeOverlapping = \"true\"'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"Next, we will add a split donut chart to the nodes representing the top terms:\n\n",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string show charts'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"## **STRING Protein Query: Down-regulated genes**\nWe are going to repeat the network search, data integration, visualization and enrichment analysis for the set of down-regulated genes by using the first column of [TCGA-Ovarian-MesenvsImmuno-data-down.csv](https://cytoscape.github.io/cytoscape-tutorials/protocols/data/TCGA-Ovarian-MesenvsImmuno-data-down.csv):",
"_____no_output_____"
]
],
[
[
"de.genes.down <- read.table(\"https://cytoscape.github.io/cytoscape-tutorials/protocols/data/TCGA-Ovarian-MesenvsImmuno-data-down.csv\", header = TRUE, sep = \"\\t\", quote=\"\\\"\", stringsAsFactors = FALSE)\nstring.cmd = paste('string protein query query=\"', paste(de.genes.down$Gene, collapse = '\\n'), '\" cutoff=0.4 species=\"Homo sapiens\"', sep = \"\")\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"## **Subnetwork**\nLet’s select only the connected nodes to work with for the rest of this tutorial, by creating a subnetwork based on all edges:",
"_____no_output_____"
]
],
[
[
"createSubnetwork(edges='all', subnetwork.name='String de genes down')",
"_____no_output_____"
]
],
[
[
"## **Data integration**\nAgain, the identifiers in the network needs to be mapped to Entrez Gene (NCBI gene):",
"_____no_output_____"
]
],
[
[
"mapped.cols <- mapTableColumn('display name', 'Human', 'HGNC', 'Entrez Gene')",
"_____no_output_____"
]
],
[
[
"We can now import the data:\n\n",
"_____no_output_____"
]
],
[
[
"loadTableData(de.genes.full,data.key.column=\"Gene\",table.key.column=\"Entrez Gene\")",
"_____no_output_____"
]
],
[
[
"## **Visualization**\nNext, we can create a visualization. Note that the default style has been altered in the previous example, so we can simply switch to default to get started:",
"_____no_output_____"
]
],
[
[
"setVisualStyle(style.name=\"default\")",
"_____no_output_____"
]
],
[
[
"The node fill color has to be redefined for down-regulated genes:\n\n",
"_____no_output_____"
]
],
[
[
"logFC.table.down <- getTableColumns('node', 'logFC')",
"_____no_output_____"
],
[
"logFC.dn.min <- min(logFC.table.down, na.rm = T)\nlogFC.dn.max <- max(logFC.table.down, na.rm = T)\nlogFC.dn.center <- logFC.dn.min + (logFC.dn.max - logFC.dn.min)/2",
"_____no_output_____"
],
[
"copyVisualStyle(from.style = \"default\", to.style = \"de genes down\")\nsetVisualStyle(style.name=\"de genes down\")\n\ndata.values = c(logFC.dn.min, logFC.dn.center, logFC.dn.max)\nnode.colors <- c(brewer.pal(length(data.values), \"Blues\"))\nsetNodeColorMapping('logFC', data.values, node.colors, style.name=\"de genes down\")",
"_____no_output_____"
]
],
[
[
"Apply a force-directed layout.\n\n",
"_____no_output_____"
]
],
[
[
"layoutNetwork(paste('force-directed', \n 'defaultSpringCoefficient=0.00003',\n 'defaultSpringLength=50',\n 'defaultNodeMass=4',\n sep=' '))",
"_____no_output_____"
]
],
[
[
"## **STRING Enrichment**\nNow we can perform STRING Enrichment analysis on the resulting network:",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string retrieve enrichment allNetSpecies=\"Homo sapiens\", background=genome selectedNodesOnly=\"false\"'\ncommandsRun(string.cmd)\nstring.cmd = 'string show enrichment'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"Filter the analysis results for non-redundant GO Process terms only.\n\n",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string filter enrichment categories=\"GO Process\", overlapCutoff = \"0.5\", removeOverlapping = \"true\"'\ncommandsRun(string.cmd)",
"_____no_output_____"
],
[
"string.cmd = 'string show charts'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"## **STRING Disease Query**\nSo far, we queried the STRING database with a set of genes we knew were differentially expressed. Next, we will query the STRING disease database to retrieve a network genes associated with ovarian cancer, which will be completely independent of our dataset.",
"_____no_output_____"
]
],
[
[
"string.cmd = 'string disease query disease=\"ovarian cancer\" cutoff=\"0.95\"'\ncommandsRun(string.cmd)",
"_____no_output_____"
]
],
[
[
"This will bring in the top 100 (default) ovarian cancer associated genes connected with a confidence score greater than 0.95. Again, lets extract out the connected nodes:",
"_____no_output_____"
]
],
[
[
"createSubnetwork(edges='all', subnetwork.name='String ovarian sub')",
"_____no_output_____"
]
],
[
[
"## **Data integration**\nNext we will import differential gene expression data from our TCGA dataset to create a visualization. Just like the previous example, we will need to do some identifier mapping to match the data to the network.",
"_____no_output_____"
]
],
[
[
"mapped.cols <- mapTableColumn(\"display name\",'Human','HGNC','Entrez Gene')",
"_____no_output_____"
]
],
[
[
"Here we set Human as species, HGNC as Map from, and Entrez Gene as To.\n\nWe can now import the data frame with the full data (already loaded the data in Example 1 above) into the node table in Cytoscape:",
"_____no_output_____"
]
],
[
[
"loadTableData(de.genes.full, data.key.column = \"Gene\", table = \"node\", table.key.column = \"Entrez Gene\")",
"_____no_output_____"
]
],
[
[
"## **Visualization**\nAgain, we can create a visualization:",
"_____no_output_____"
]
],
[
[
"setVisualStyle(style.name=\"default\")",
"_____no_output_____"
]
],
[
[
"Next, we need the min and max of the logFC column:\n\n",
"_____no_output_____"
]
],
[
[
"logFC.table.ovarian <- getTableColumns('node', 'logFC')",
"_____no_output_____"
],
[
"logFC.ov.min <- min(logFC.table.ovarian, na.rm = T)\nlogFC.ov.max <- max(logFC.table.ovarian, na.rm = T)\nlogFC.ov.center <- logFC.ov.min + (logFC.ov.max - logFC.ov.min)/2",
"_____no_output_____"
]
],
[
[
"Let’s create the mapping:\n\n",
"_____no_output_____"
]
],
[
[
"copyVisualStyle(from.style = \"default\", to.style = \"ovarian\")\nsetVisualStyle(style.name=\"ovarian\")\n\ndata.values = c(logFC.ov.min, logFC.ov.center, logFC.ov.max)\nnode.colors <- c(brewer.pal(length(data.values), \"RdBu\"))\nsetNodeColorMapping('logFC', data.values, node.colors, style.name=\"ovarian\")",
"_____no_output_____"
]
],
[
[
"Apply a force-directed layout.\n\n",
"_____no_output_____"
]
],
[
[
"layoutNetwork(paste('force-directed', \n 'defaultSpringCoefficient=0.00003',\n 'defaultSpringLength=50',\n 'defaultNodeMass=4',\n sep=' '))",
"_____no_output_____"
]
],
[
[
"The TCGA found several genes that were commonly mutated in ovarian cancer, so called “cancer drivers”. We can add information about these genes to the network visualization, by changing the visual style of these nodes. Three of the most important drivers are TP53, BRCA1 and BRCA2. We will add a thicker, colored border for these genes in the network.\n\nSelect all three driver genes by:",
"_____no_output_____"
]
],
[
[
"selectNodes(c(\"TP53\", \"BRCA1\", \"BRCA2\"), by.col = \"display name\")",
"_____no_output_____"
]
],
[
[
"Add a style bypass for node Border Width (5) and node Border Paint (bright pink):\n\n",
"_____no_output_____"
]
],
[
[
"setNodeBorderWidthBypass(getSelectedNodes(), 5)\nsetNodeBorderColorBypass(getSelectedNodes(), '#FF007F')",
"_____no_output_____"
]
],
[
[
"## **Exporting Networks**\nJupyter Bridge RCy3 does not support import and export files now.\n\nPlease use local Cytoscape to import and export files.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c5165241d6ea33a974c15b7a14b04ca12802d73d
| 50,335 |
ipynb
|
Jupyter Notebook
|
examples/models/keras_mnist/keras_mnist.ipynb
|
MarcoGorelli/seldon-core
|
fdab6ecc718d5c20aa2df3b90592c3b4a410bd0e
|
[
"Apache-2.0"
] | null | null | null |
examples/models/keras_mnist/keras_mnist.ipynb
|
MarcoGorelli/seldon-core
|
fdab6ecc718d5c20aa2df3b90592c3b4a410bd0e
|
[
"Apache-2.0"
] | null | null | null |
examples/models/keras_mnist/keras_mnist.ipynb
|
MarcoGorelli/seldon-core
|
fdab6ecc718d5c20aa2df3b90592c3b4a410bd0e
|
[
"Apache-2.0"
] | null | null | null | 45.51085 | 277 | 0.551604 |
[
[
[
"# Keras MNIST Model Deployment\n\n * Wrap a Tensorflow MNIST python model for use as a prediction microservice in seldon-core\n * Run locally on Docker to test\n * Deploy on seldon-core running on minikube\n \n## Dependencies\n\n * [Helm](https://github.com/kubernetes/helm)\n * [Minikube](https://github.com/kubernetes/minikube)\n * [S2I](https://github.com/openshift/source-to-image)\n\n```bash\npip install seldon-core\npip install keras\n```\n\n## Train locally\n ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport math\nimport datetime\n#from seldon.pipeline import PipelineSaver\nimport os\nimport tensorflow as tf\nfrom keras import backend\nfrom keras.models import Model,load_model\nfrom keras.layers import Dense,Input\nfrom keras.layers import Dropout\nfrom keras.layers import Flatten, Reshape\nfrom keras.constraints import maxnorm\nfrom keras.layers.convolutional import Convolution2D\nfrom keras.layers.convolutional import MaxPooling2D\n\nfrom keras.callbacks import TensorBoard\n\nclass MnistFfnn(object):\n\n def __init__(self,\n input_shape=(784,),\n nb_labels=10,\n optimizer='Adam',\n run_dir='tensorboardlogs_test'):\n \n self.model_name='MnistFfnn'\n self.run_dir=run_dir\n self.input_shape=input_shape\n self.nb_labels=nb_labels\n self.optimizer=optimizer\n self.build_graph()\n\n def build_graph(self):\n \n inp = Input(shape=self.input_shape,name='input_part')\n\n #keras layers\n with tf.name_scope('dense_1') as scope:\n h1 = Dense(256,\n activation='relu',\n W_constraint=maxnorm(3))(inp)\n drop1 = Dropout(0.2)(h1)\n\n with tf.name_scope('dense_2') as scope:\n h2 = Dense(128,\n activation='relu',\n W_constraint=maxnorm(3))(drop1)\n drop2 = Dropout(0.5)(h2)\n \n out = Dense(self.nb_labels,\n activation='softmax')(drop2)\n\n self.model = Model(inp,out)\n \n if self.optimizer == 'rmsprop':\n self.model.compile(loss='categorical_crossentropy',\n optimizer='rmsprop',\n metrics=['accuracy'])\n elif self.optimizer == 'Adam':\n self.model.compile(loss='categorical_crossentropy',\n optimizer='Adam',\n metrics=['accuracy'])\n \n print('graph builded')\n\n def fit(self,X,y=None,\n X_test=None,y_test=None,\n batch_size=128,\n nb_epochs=2,\n shuffle=True):\n \n now = datetime.datetime.now()\n tensorboard_logname = self.run_dir+'/{}_{}'.format(self.model_name,\n now.strftime('%Y.%m.%d_%H.%M')) \n tensorboard = TensorBoard(log_dir=tensorboard_logname)\n \n self.model.fit(X,y,\n validation_data=(X_test,y_test),\n callbacks=[tensorboard],\n batch_size=batch_size, \n nb_epoch=nb_epochs,\n shuffle = shuffle)\n return self\n \n def predict_proba(self,X):\n\n return self.model.predict_proba(X)\n \n def predict(self, X):\n probas = self.model.predict_proba(X)\n return([[p>0.5 for p in p1] for p1 in probas])\n \n def score(self, X, y=None):\n pass\n\n def get_class_id_map(self):\n return [\"proba\"]\n\nclass MnistConv(object):\n\n def __init__(self,\n input_shape=(784,),\n nb_labels=10,\n optimizer='Adam',\n run_dir='tensorboardlogs_test',\n saved_model_file='MnistClassifier.h5'):\n \n self.model_name='MnistConv'\n self.run_dir=run_dir\n self.input_shape=input_shape\n self.nb_labels=nb_labels\n self.optimizer=optimizer\n self.saved_model_file=saved_model_file\n self.build_graph()\n\n def build_graph(self):\n \n inp = Input(shape=self.input_shape,name='input_part')\n inp2 = Reshape((28,28,1))(inp) \n #keras layers\n with tf.name_scope('conv') as scope:\n conv = Convolution2D(32, 3, 3,\n input_shape=(32, 32, 3),\n border_mode='same',\n activation='relu',\n W_constraint=maxnorm(3))(inp2)\n drop_conv = Dropout(0.2)(conv)\n max_pool = MaxPooling2D(pool_size=(2, 2))(drop_conv)\n\n with tf.name_scope('dense') as scope:\n flat = Flatten()(max_pool) \n dense = Dense(128,\n activation='relu',\n W_constraint=maxnorm(3))(flat)\n drop_dense = Dropout(0.5)(dense)\n \n out = Dense(self.nb_labels,\n activation='softmax')(drop_dense)\n\n self.model = Model(inp,out)\n \n if self.optimizer == 'rmsprop':\n self.model.compile(loss='categorical_crossentropy',\n optimizer='rmsprop',\n metrics=['accuracy'])\n elif self.optimizer == 'Adam':\n self.model.compile(loss='categorical_crossentropy',\n optimizer='Adam',\n metrics=['accuracy'])\n \n print('graph builded')\n\n def fit(self,X,y=None,\n X_test=None,y_test=None,\n batch_size=128,\n nb_epochs=2,\n shuffle=True):\n \n now = datetime.datetime.now()\n tensorboard_logname = self.run_dir+'/{}_{}'.format(self.model_name,\n now.strftime('%Y.%m.%d_%H.%M')) \n tensorboard = TensorBoard(log_dir=tensorboard_logname)\n \n self.model.fit(X,y,\n validation_data=(X_test,y_test),\n callbacks=[tensorboard],\n batch_size=batch_size, \n nb_epoch=nb_epochs,\n shuffle = shuffle)\n #if not os.path.exists('saved_model'):\n # os.makedirs('saved_model')\n self.model.save(self.saved_model_file)\n return self\n \n def predict_proba(self,X):\n return self.model.predict_proba(X)\n \n def predict(self, X):\n probas = self.model.predict_proba(X)\n return([[p>0.5 for p in p1] for p1 in probas])\n \n def score(self, X, y=None):\n pass\n\n def get_class_id_map(self):\n return [\"proba\"]\n\n",
"Using TensorFlow backend.\n"
],
[
"from tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets('data/MNIST_data', one_hot=True)\nX_train = mnist.train.images\ny_train = mnist.train.labels\nX_test = mnist.test.images\ny_test = mnist.test.labels\nmc = MnistConv()\nmc.fit(X_train,y=y_train,\n X_test=X_test,y_test=y_test)\n\n",
"WARNING:tensorflow:From <ipython-input-2-dac8c42b25f0>:2: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use alternatives such as official/mnist/dataset.py from tensorflow/models.\nWARNING:tensorflow:From /home/clive/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease write your own downloading logic.\nWARNING:tensorflow:From /home/clive/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.data to implement this functionality.\nExtracting data/MNIST_data/train-images-idx3-ubyte.gz\nWARNING:tensorflow:From /home/clive/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.data to implement this functionality.\nExtracting data/MNIST_data/train-labels-idx1-ubyte.gz\nWARNING:tensorflow:From /home/clive/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use tf.one_hot on tensors.\nExtracting data/MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting data/MNIST_data/t10k-labels-idx1-ubyte.gz\nWARNING:tensorflow:From /home/clive/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use alternatives such as official/mnist/dataset.py from tensorflow/models.\n"
]
],
[
[
"Wrap model using s2i",
"_____no_output_____"
]
],
[
[
"!s2i build . seldonio/seldon-core-s2i-python3:0.12 keras-mnist:0.1",
"---> Installing application source...\n---> Installing dependencies ...\nLooking in links: /whl\nRequirement already satisfied: numpy>=1.8.2 in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 1)) (1.16.3)\nCollecting scipy>=0.13.3 (from -r requirements.txt (line 2))\n WARNING: Url '/whl' is ignored. It is either a non-existing path or lacks a specific scheme.\nDownloading https://files.pythonhosted.org/packages/7f/5f/c48860704092933bf1c4c1574a8de1ffd16bf4fde8bab190d747598844b2/scipy-1.2.1-cp36-cp36m-manylinux1_x86_64.whl (24.8MB)\nCollecting keras==2.1.3 (from -r requirements.txt (line 3))\n WARNING: Url '/whl' is ignored. It is either a non-existing path or lacks a specific scheme.\nDownloading https://files.pythonhosted.org/packages/08/ae/7f94a03cb3f74cdc8a0f5f86d1df5c1dd686acb9a9c2a421c64f8497358e/Keras-2.1.3-py2.py3-none-any.whl (319kB)\nRequirement already satisfied: tensorflow>=1.12.0 in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 4)) (1.13.1)\nRequirement already satisfied: h5py in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 5)) (2.9.0)\nRequirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/site-packages (from keras==2.1.3->-r requirements.txt (line 3)) (1.12.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/site-packages (from keras==2.1.3->-r requirements.txt (line 3)) (5.1)\nRequirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.7.1)\nRequirement already satisfied: absl-py>=0.1.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.7.1)\nRequirement already satisfied: tensorflow-estimator<1.14.0rc0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.13.0)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.0.9)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.20.1)\nRequirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (3.7.1)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.33.1)\nRequirement already satisfied: keras-applications>=1.0.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.0.7)\nRequirement already satisfied: gast>=0.2.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.2.2)\nRequirement already satisfied: tensorboard<1.14.0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.13.1)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.1.0)\nRequirement already satisfied: mock>=2.0.0 in /usr/local/lib/python3.6/site-packages (from tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (2.0.0)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/site-packages (from protobuf>=3.6.1->tensorflow>=1.12.0->-r requirements.txt (line 4)) (41.0.1)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.15.2)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (3.1)\nRequirement already satisfied: pbr>=0.11 in /usr/local/lib/python3.6/site-packages (from mock>=2.0.0->tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (5.2.0)\nInstalling collected packages: scipy, keras\nSuccessfully installed keras-2.1.3 scipy-1.2.1\nBuild completed successfully\n"
],
[
"!docker run --name \"mnist_predictor\" -d --rm -p 5000:5000 keras-mnist:0.1",
"6231efde4036974469fddd42585db66067e6a30bcfd40efe5cf474d385f0eeda\r\n"
]
],
[
[
"Send some random features that conform to the contract",
"_____no_output_____"
]
],
[
[
"!seldon-core-tester contract.json 0.0.0.0 5000 -p",
"----------------------------------------\nSENDING NEW REQUEST:\n\n[[0.387 0.103 0.152 0.129 0.211 0.088 0.659 0.028 0.663 0.666 0.134 0.396\n 0.704 0.089 0.407 0.896 0.734 0.375 0.109 0.796 0.917 0.186 0.736 0.013\n 0.565 0.256 0.405 0.205 0.317 0.342 0.02 0.748 0.496 0.376 0.405 0.712\n 0.775 0.904 0.277 0.973 0.004 0.996 0.692 0.802 0.967 0.361 0.222 0.358\n 0.73 0.032 0.516 0.945 0.734 0.012 0.807 0.558 0.604 0.978 0.111 0.772\n 0.276 0.484 0.645 0.73 0.953 0.306 0.049 0.299 0.872 0.197 0.389 0.191\n 0.604 0.431 0.498 0.091 0.366 0.834 0.266 0.256 0.827 0.996 0.071 0.522\n 0.108 0.063 0.607 0.126 0.97 0.758 0.99 0.961 0.285 0.547 0.633 0.788\n 0.619 0.694 0.157 0.91 0.992 0.276 0.422 0.978 0.108 0.272 0.605 0.375\n 0.964 0.257 0.215 0.583 0.594 0.162 0.118 0.518 0.026 0.687 0.98 0.666\n 0.233 0.998 0.678 0.379 0.778 0.149 0.889 0.911 0.019 0.183 0.471 0.272\n 0.513 0.628 0.769 0.062 0.706 0.029 0.31 0.322 0.341 0.492 0.124 0.154\n 0.643 0.145 0.966 0.874 0.364 0.009 0.611 0.073 0.73 0.712 0.926 0.541\n 0.96 0.055 0.105 0.869 0.958 0.892 0.437 0.477 0.477 0.09 0.929 0.708\n 0.839 0.629 0.395 0.878 0.278 0.88 0.078 0.525 0.521 0.292 0.3 0.971\n 0.002 0.89 0.968 0.19 0.946 0.784 0.926 0.017 0.748 0.287 0.76 0.786\n 0.201 0.926 0.173 0.399 0.764 0.249 0.228 0.027 0.125 0.271 0.776 0.82\n 0.007 0.685 0.87 0.997 0.115 0.972 0.439 0.761 0.666 0.793 0.72 0.399\n 0.361 0.951 0.366 0.942 0.014 0.617 0.634 0.148 0.33 0.943 0.784 0.04\n 0.514 0.823 0.346 0.428 0.376 0.908 0.584 0.238 0.929 0.149 0.392 0.898\n 0.358 0.088 0.853 0.016 0.278 0.474 0.892 0.957 0.358 0.058 0.655 0.682\n 0.32 0.322 0.367 0.069 0.274 0.587 0.662 0.281 0.377 0.281 0.989 0.989\n 0.787 0.893 0.051 0.839 0.428 0.088 0.62 0.084 0.951 0.663 0.68 0.069\n 0.208 0.186 0.976 0.657 0.955 0.452 0.429 0.71 0.819 0.091 0.228 0.427\n 0.995 0.546 0.724 0.022 0.39 0.425 0.871 0.136 0.554 0.383 0.466 0.852\n 0.673 0.021 0.957 0.573 0.587 0.579 0.149 0.787 0.303 0.484 0.876 0.766\n 0.167 0.743 0.327 0.486 0.357 0.381 0.403 0.047 0.02 0.823 0.009 0.494\n 0.919 0.474 0.369 0.364 0.208 0.762 0.942 0.68 0.463 0.369 0.146 0.591\n 0.028 0.957 0.937 0.133 0.124 0.587 0.506 0.556 0.156 0.078 0.507 0.425\n 0.634 0.147 0.151 0.278 0.467 0.119 0.682 0.486 0.627 0.599 0.837 0.117\n 0.686 0.939 0.014 0.801 0.64 0.079 0.811 0.947 0.203 0.294 0.516 0.566\n 0.237 0.514 0.696 0.121 0.57 0.334 0.206 0.002 0.735 0.951 0.673 0.524\n 0.548 0.737 0.429 0.141 0.173 0.574 0.024 0.359 0.287 0.467 0.199 0.654\n 0.682 0.237 0.874 0.909 0.417 0.311 0.764 0.833 0.566 0.207 0.572 0.798\n 0.852 0.542 0.863 0.626 0.473 0.137 0.582 0.441 0.562 0.939 0.042 0.209\n 0.763 0.315 0.833 0.923 0.565 0.056 0.002 0.833 0.157 0.905 0.221 0.993\n 0.863 0.312 0.752 0.875 0.02 0.54 0.96 0.901 0.831 0.384 0.589 0.704\n 0.161 0.591 0.068 0.656 0.713 0.347 0.775 0.903 0.137 0.846 0.497 0.394\n 0.4 0.264 0.095 0.839 0.746 0.955 0.843 0.352 0.413 0.531 0.83 0.176\n 0.89 0.114 0.06 0.012 0.56 0.443 0.78 0.946 0.922 0.178 0.76 0.547\n 0.683 0.418 0.83 0.773 0.434 0.236 0.503 0.759 0.102 0.243 0.33 0.054\n 0.629 0.014 0.612 0.257 0.281 0.519 0.619 0.385 0.759 0.513 0.753 0.862\n 0.318 0.002 0.114 0.457 0.568 0.006 0.019 0.722 0.328 0.135 0.353 0.856\n 0.434 0.839 0.123 0.864 0.173 0.307 0.711 0.767 0.528 0.2 0.195 0.854\n 0.993 0.374 0.804 0.389 0.248 0.208 0.437 0.806 0.7 0.16 0.548 0.628\n 0.768 0.278 0.62 0.17 0.603 0.716 0.294 0.426 0.655 0.373 0.229 0.666\n 0.464 0.437 0.598 0.553 0.06 0.342 0.541 0.677 0.03 0.02 0.576 0.85\n 0.829 0.696 0.069 0.321 0.945 0.218 0.768 0.84 0.735 0.93 0.107 0.962\n 0.883 0.106 0.348 0.081 0.335 0.037 0.595 0.083 0.457 0.382 0.825 0.614\n 0.925 0.959 0.689 0.988 0.604 0.937 0.8 0.191 0.633 0.744 0.999 0.812\n 0.883 0.31 0.745 0.344 0.086 0.257 0.315 0.411 0.694 0.296 0.257 0.84\n 0.381 0.237 0.28 0.842 0.535 0.439 0.191 0.814 0.224 0.813 0.901 0.797\n 0.855 0.86 0.106 0.763 0.137 0.055 0.08 0.515 0.578 0.892 0.311 0.522\n 0.31 0.145 0.171 0.684 0.682 0.577 0.294 0.278 0.485 0.867 0.205 0.483\n 0.405 0.728 0.596 0.584 0.4 0.276 0.707 0.398 0.16 0.551 0.362 0.471\n 0.031 0.125 0.254 0.224 0.091 0.948 0.941 0.383 0.506 0.324 0.125 0.049\n 0.148 0.168 0.269 0.818 0.69 0.936 0.234 0.336 0.718 0.929 0.908 0.596\n 0.208 0.042 0.657 0.26 0.577 0.691 0.953 0.193 0.772 0.245 0.296 0.527\n 0.262 0.545 0.394 0.899 0.975 0.824 0.877 0.933 0.725 0.035 0.496 0.102\n 0.313 0.287 0.894 0.046 0.574 0.766 0.761 0.493 0.25 0.454 0.475 0.272\n 0.838 0.843 0.595 0.182 0.497 0.049 0.294 0.926 0.018 0.448 0.494 0.008\n 0.667 0.392 0.659 0.703 0.113 0.435 0.411 0.011 0.851 0.214 0.364 0.074\n 0.279 0.743 0.49 0.183 0.157 0.263 0.669 0.583 0.406 0.81 0.093 0.562\n 0.525 0.631 0.786 0.74 0.156 0.797 0.251 0.599 0.959 0.553 0.343 0.167\n 0.729 0.814 0.368 0.616 0.946 0.036 0.889 0.112 0.584 0.462 0.673 0.082\n 0.538 0.901 0.973 0.161]]\nRECEIVED RESPONSE:\nmeta {\n}\ndata {\n names: \"t:0\"\n names: \"t:1\"\n names: \"t:2\"\n names: \"t:3\"\n names: \"t:4\"\n names: \"t:5\"\n names: \"t:6\"\n names: \"t:7\"\n names: \"t:8\"\n names: \"t:9\"\n ndarray {\n values {\n list_value {\n values {\n number_value: 0.00022297287068795413\n }\n values {\n number_value: 0.003534407587721944\n }\n values {\n number_value: 0.1571815013885498\n }\n values {\n number_value: 0.22603441774845123\n }\n values {\n number_value: 5.994380626361817e-05\n }\n values {\n number_value: 0.0454179011285305\n }\n values {\n number_value: 0.34811070561408997\n }\n values {\n number_value: 0.21694059669971466\n }\n values {\n number_value: 0.0018390808254480362\n }\n values {\n number_value: 0.0006583957583643496\n }\n }\n }\n }\n}\n\n\n"
],
[
"!docker rm mnist_predictor --force",
"mnist_predictor\r\n"
]
],
[
[
"# Test using Minikube\n\n**Due to a [minikube/s2i issue](https://github.com/SeldonIO/seldon-core/issues/253) you will need [s2i >= 1.1.13](https://github.com/openshift/source-to-image/releases/tag/v1.1.13)**",
"_____no_output_____"
]
],
[
[
"!minikube start --memory 4096 ",
"😄 minikube v1.0.0 on linux (amd64)\n🤹 Downloading Kubernetes v1.14.0 images in the background ...\n🔥 Creating virtualbox VM (CPUs=2, Memory=4096MB, Disk=20000MB) ...\n📶 \"minikube\" IP address is 192.168.99.100\n🐳 Configuring Docker as the container runtime ...\n🐳 Version of container runtime is 18.06.2-ce\n⌛ Waiting for image downloads to complete ...\n✨ Preparing Kubernetes environment ...\n🚜 Pulling images required by Kubernetes v1.14.0 ...\n🚀 Launching Kubernetes v1.14.0 using kubeadm ... \n⌛ Waiting for pods: apiserver proxy etcd scheduler controller dns\n🔑 Configuring cluster permissions ...\n🤔 Verifying component health .....\n💗 kubectl is now configured to use \"minikube\"\n🏄 Done! Thank you for using minikube!\n"
],
[
"!kubectl create clusterrolebinding kube-system-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default",
"clusterrolebinding.rbac.authorization.k8s.io/kube-system-cluster-admin created\r\n"
],
[
"!helm init",
"$HELM_HOME has been configured at /home/clive/.helm.\n\nTiller (the Helm server-side component) has been installed into your Kubernetes Cluster.\n\nPlease note: by default, Tiller is deployed with an insecure 'allow unauthenticated users' policy.\nTo prevent this, run `helm init` with the --tiller-tls-verify flag.\nFor more information on securing your installation see: https://docs.helm.sh/using_helm/#securing-your-helm-installation\nHappy Helming!\n"
],
[
"!kubectl rollout status deploy/tiller-deploy -n kube-system",
"Waiting for deployment \"tiller-deploy\" rollout to finish: 0 of 1 updated replicas are available...\ndeployment \"tiller-deploy\" successfully rolled out\n"
],
[
"!helm install ../../../helm-charts/seldon-core-operator --name seldon-core --set usageMetrics.enabled=true --namespace seldon-system",
"NAME: seldon-core\nLAST DEPLOYED: Fri May 3 19:38:47 2019\nNAMESPACE: seldon-system\nSTATUS: DEPLOYED\n\nRESOURCES:\n==> v1/ClusterRoleBinding\nNAME AGE\nseldon-operator-manager-rolebinding 0s\n\n==> v1/Service\nNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE\nseldon-operator-controller-manager-service ClusterIP 10.101.135.115 <none> 443/TCP 0s\n\n==> v1/StatefulSet\nNAME DESIRED CURRENT AGE\nseldon-operator-controller-manager 1 1 0s\n\n==> v1/Pod(related)\nNAME READY STATUS RESTARTS AGE\nseldon-operator-controller-manager-0 0/1 ContainerCreating 0 0s\n\n==> v1/Secret\nNAME TYPE DATA AGE\nseldon-operator-webhook-server-secret Opaque 0 0s\n\n==> v1beta1/CustomResourceDefinition\nNAME AGE\nseldondeployments.machinelearning.seldon.io 0s\n\n==> v1/ClusterRole\nseldon-operator-manager-role 0s\n\n\nNOTES:\nNOTES: TODO\n\n\n"
],
[
"!kubectl rollout status statefulset.apps/seldon-operator-controller-manager -n seldon-system",
"Waiting for 1 pods to be ready...\npartitioned roll out complete: 1 new pods have been updated...\n"
]
],
[
[
"## Setup Ingress\nPlease note: There are reported gRPC issues with ambassador (see https://github.com/SeldonIO/seldon-core/issues/473).",
"_____no_output_____"
]
],
[
[
"!helm install stable/ambassador --name ambassador --set crds.keep=false",
"NAME: ambassador\nLAST DEPLOYED: Fri May 3 19:40:12 2019\nNAMESPACE: default\nSTATUS: DEPLOYED\n\nRESOURCES:\n==> v1/Deployment\nNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE\nambassador 3 3 3 0 0s\n\n==> v1/Pod(related)\nNAME READY STATUS RESTARTS AGE\nambassador-5b89d44544-f7prg 0/1 ContainerCreating 0 0s\nambassador-5b89d44544-jkbtz 0/1 ContainerCreating 0 0s\nambassador-5b89d44544-mjgj8 0/1 ContainerCreating 0 0s\n\n==> v1/ServiceAccount\nNAME SECRETS AGE\nambassador 1 0s\n\n==> v1beta1/ClusterRole\nNAME AGE\nambassador 0s\n\n==> v1beta1/ClusterRoleBinding\nNAME AGE\nambassador 0s\n\n==> v1/Service\nNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE\nambassador-admins ClusterIP 10.100.85.59 <none> 8877/TCP 0s\nambassador LoadBalancer 10.109.230.160 <pending> 80:31635/TCP,443:30969/TCP 0s\n\n\nNOTES:\nCongratuations! You've successfully installed Ambassador.\n\nFor help, visit our Slack at https://d6e.co/slack or view the documentation online at https://www.getambassador.io.\n\nTo get the IP address of Ambassador, run the following commands:\nNOTE: It may take a few minutes for the LoadBalancer IP to be available.\n You can watch the status of by running 'kubectl get svc -w --namespace default ambassador'\n\n On GKE/Azure:\n export SERVICE_IP=$(kubectl get svc --namespace default ambassador -o jsonpath='{.status.loadBalancer.ingress[0].ip}')\n\n On AWS:\n export SERVICE_IP=$(kubectl get svc --namespace default ambassador -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')\n\n echo http://$SERVICE_IP:\n\n"
],
[
"!kubectl rollout status deployment.apps/ambassador",
"Waiting for deployment \"ambassador\" rollout to finish: 0 of 3 updated replicas are available...\nWaiting for deployment \"ambassador\" rollout to finish: 1 of 3 updated replicas are available...\nWaiting for deployment \"ambassador\" rollout to finish: 2 of 3 updated replicas are available...\ndeployment \"ambassador\" successfully rolled out\n"
],
[
"!eval $(minikube docker-env) && s2i build . seldonio/seldon-core-s2i-python3:0.12 keras-mnist:0.1",
"---> Installing application source...\n---> Installing dependencies ...\nLooking in links: /whl\nRequirement already satisfied: numpy>=1.8.2 in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 1)) (1.16.3)\nCollecting scipy>=0.13.3 (from -r requirements.txt (line 2))\n WARNING: Url '/whl' is ignored. It is either a non-existing path or lacks a specific scheme.\nDownloading https://files.pythonhosted.org/packages/7f/5f/c48860704092933bf1c4c1574a8de1ffd16bf4fde8bab190d747598844b2/scipy-1.2.1-cp36-cp36m-manylinux1_x86_64.whl (24.8MB)\nCollecting keras==2.1.3 (from -r requirements.txt (line 3))\n WARNING: Url '/whl' is ignored. It is either a non-existing path or lacks a specific scheme.\nDownloading https://files.pythonhosted.org/packages/08/ae/7f94a03cb3f74cdc8a0f5f86d1df5c1dd686acb9a9c2a421c64f8497358e/Keras-2.1.3-py2.py3-none-any.whl (319kB)\nRequirement already satisfied: tensorflow>=1.12.0 in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 4)) (1.13.1)\nRequirement already satisfied: h5py in /usr/local/lib/python3.6/site-packages (from -r requirements.txt (line 5)) (2.9.0)\nRequirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.6/site-packages (from keras==2.1.3->-r requirements.txt (line 3)) (1.12.0)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/site-packages (from keras==2.1.3->-r requirements.txt (line 3)) (5.1)\nRequirement already satisfied: gast>=0.2.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.2.2)\nRequirement already satisfied: keras-applications>=1.0.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.0.7)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.1.0)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.33.1)\nRequirement already satisfied: absl-py>=0.1.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.7.1)\nRequirement already satisfied: tensorboard<1.14.0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.13.1)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.0.9)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.20.1)\nRequirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.7.1)\nRequirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (3.7.1)\nRequirement already satisfied: tensorflow-estimator<1.14.0rc0,>=1.13.0 in /usr/local/lib/python3.6/site-packages (from tensorflow>=1.12.0->-r requirements.txt (line 4)) (1.13.0)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (3.1)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/site-packages (from tensorboard<1.14.0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (0.15.2)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/site-packages (from protobuf>=3.6.1->tensorflow>=1.12.0->-r requirements.txt (line 4)) (41.0.1)\nRequirement already satisfied: mock>=2.0.0 in /usr/local/lib/python3.6/site-packages (from tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (2.0.0)\nRequirement already satisfied: pbr>=0.11 in /usr/local/lib/python3.6/site-packages (from mock>=2.0.0->tensorflow-estimator<1.14.0rc0,>=1.13.0->tensorflow>=1.12.0->-r requirements.txt (line 4)) (5.2.0)\nInstalling collected packages: scipy, keras\nSuccessfully installed keras-2.1.3 scipy-1.2.1\nBuild completed successfully\n"
],
[
"!kubectl create -f keras_mnist_deployment.json",
"seldondeployment.machinelearning.seldon.io/seldon-deployment-example created\r\n"
],
[
"!kubectl rollout status deploy/keras-mnist-deployment-keras-mnist-predictor-8baf5cc",
"Waiting for deployment \"keras-mnist-deployment-keras-mnist-predictor-8baf5cc\" rollout to finish: 0 of 1 updated replicas are available...\ndeployment \"keras-mnist-deployment-keras-mnist-predictor-8baf5cc\" successfully rolled out\n"
],
[
"!seldon-core-api-tester contract.json `minikube ip` `kubectl get svc ambassador -o jsonpath='{.spec.ports[0].nodePort}'` \\\n seldon-deployment-example --namespace default -p",
"----------------------------------------\nSENDING NEW REQUEST:\n\n[[0.615 0.937 0.603 0.929 0.9 0.267 0.498 0.514 0.13 0.579 0.213 0.063\n 0.671 0.524 0.455 0.049 0.159 0.379 0.886 0.302 0.024 0.57 0.86 0.979\n 0.908 0.502 0.427 0.818 0.711 0.83 0.496 0.908 0.567 0.065 0.639 0.464\n 0.699 0.415 0.356 0.181 0.152 0.409 0.901 0.981 0.648 0.761 0.721 0.867\n 0.76 0.834 0.092 0.236 0.881 0.292 0.229 0.37 0.069 0.413 0.007 0.15\n 0.132 0.851 0.75 0.026 0.614 0.533 0.082 0.805 0.176 0.662 0.379 0.002\n 0.001 0.132 0.345 0.016 0.317 0.418 0.197 0.846 0.956 0.193 0.447 0.835\n 0.2 0.313 0.094 0.94 0.068 0.724 0.732 0.561 0.763 0.589 0.056 0.893\n 0.867 0.548 0.365 0.865 0.459 0.217 0.686 0.831 0.952 0.526 0.567 0.544\n 0.84 0.642 0.659 0.266 0.666 0.401 0.77 0.646 0.477 0.646 0.186 0.39\n 0.197 0.216 0.552 0.465 0.294 0.596 0.955 0.117 0.644 0.31 0.925 0.559\n 0.113 0.897 0.379 0.307 0.581 0.044 0.644 0.31 0.871 0.001 0.266 0.356\n 0.17 0.16 0.761 0.035 0.217 0.417 0.877 0.862 0.199 0.39 0.135 0.795\n 0.181 0.587 0.597 0.498 0.711 0.957 0.033 0.238 0.964 0.112 0.292 0.703\n 0.797 0.931 0.582 0.438 0.56 0.599 0.015 0.438 0.807 0.013 0.812 0.841\n 0.604 0.763 0.084 0.325 0.854 0.523 0.562 0.112 0.296 0.674 0.173 0.323\n 0.077 0.743 0.396 0.848 0.666 0.505 0.319 0.366 0.345 0.394 0.656 0.124\n 0.86 0.301 0.481 0.547 0.552 0.769 0.812 0.241 0.476 0.513 0.946 0.877\n 0.415 0.396 0.553 0.261 0.987 0.157 0.417 0.311 0. 0.49 0.315 0.051\n 0.847 0.848 0.595 0.707 0.536 0.604 0.844 0.149 0.499 0.763 0.474 0.795\n 0.95 0.829 0.193 0.032 0.753 0.15 0.759 0.269 0.186 0.084 0.373 0.728\n 0.316 0.919 0.052 0.722 0.434 0.314 0.215 0.394 0.814 0.973 0.08 0.378\n 0.47 0.29 0.626 0.737 0.714 0.04 0.243 0.474 0.649 0.812 0.565 0.544\n 0.716 0.521 0.831 0.638 0.294 0.441 0.55 0.975 0.409 0.126 0.767 0.761\n 0.121 0.998 0.389 0.057 0.009 0.933 0.947 0.727 0.376 0.297 0.108 0.104\n 0.516 0.014 0.844 0.044 0.804 0.292 0.985 0.933 0.091 0.643 0.238 0.249\n 0.023 0.065 0.65 0.453 0.658 0.053 0.725 0.939 0.732 0.65 0.59 0.835\n 0.537 0.829 0.649 0.414 0.396 0.805 0.46 0.098 0.707 0.39 0.441 0.567\n 0.961 0.361 0.203 0.04 0.528 0.553 0.591 0.682 0.137 0.661 0.401 0.132\n 0.16 0.421 0.13 0.567 0.054 0.802 0.784 0.301 0.708 0.409 0.171 0.745\n 0.5 0.475 0.813 0.397 0.486 0.406 0.841 0.792 0.77 0.216 0.122 0.126\n 0.774 0.458 0.363 0.233 0.765 0.616 0.473 0.029 0.16 0.09 0.699 0.19\n 0.891 0.857 0.626 0.132 0.994 0.415 0.53 0.918 0.095 0.589 0.685 0.184\n 0.355 0.829 0.519 0.164 0.636 0.042 0.869 0.507 0.756 0.535 0.72 0.881\n 0.526 0.632 0.583 0.838 0.838 0.917 0.369 0.466 0.884 0.015 0.591 0.214\n 0.053 0.944 0.946 0.652 0.341 0.697 0.229 0.35 0.275 0.729 0.856 0.066\n 0.196 0.095 0.421 0.462 0.769 0.424 0.704 0.963 0.446 0.574 0.379 0.151\n 0.247 0.04 0.325 0.853 0.046 0.286 0.85 0.909 0.236 0.867 0.022 0.936\n 0.039 0.096 0.062 0.516 0.317 0.551 0.058 0.504 0.503 0.795 0.576 0.093\n 0.529 0.409 0.37 0.444 0.113 0.113 0.037 0.967 0.278 0.339 0.343 0.979\n 0.341 0.843 0.836 0.678 0.775 0.935 0.104 0.505 0.839 0.421 0.838 0.644\n 0.078 0.365 0.521 0.754 0.511 0.195 0.606 0.088 0.932 0.74 0.703 0.132\n 0.172 0.962 0.261 0.786 0.642 0.207 0.899 0.405 0.493 0.58 0.541 0.684\n 0.616 0.878 0.39 0.834 0.505 0.765 0.292 0.658 0.373 0.961 0.69 0.094\n 0.318 0.657 0.466 0.58 0.975 0.559 0.114 0.667 0.46 0.719 0.447 0.383\n 0.106 0.55 0.331 0.614 0.47 0.107 0.939 0.526 0.32 0.667 0.064 0.738\n 0.755 0.598 0.96 0.268 0.646 0.774 0.951 0.519 0.645 0.767 0.188 0.003\n 0.202 0.962 0.272 0.798 0.278 0.072 0.128 0.629 0.025 0.78 0.911 0.335\n 0.178 0.854 0.568 0.276 0.76 0.52 0.55 0.934 0.735 0.421 0.805 0.979\n 0.039 0.711 0.144 0.685 0.655 0.913 0.621 0.848 0.397 0.249 0.825 0.336\n 0.601 0.631 0.868 0.54 0.788 0.542 0.588 0.036 0.01 0.412 0.114 0.244\n 0.026 0.362 0.551 0.982 0.508 0.718 0.889 0.701 0.385 0.701 0.183 0.694\n 0.238 0.745 0.749 0.595 0.835 0.495 0.018 0.698 0.36 0.64 0.723 0.724\n 0.417 0.962 0.857 0.908 0.308 0.011 0.397 0.599 0.443 0.399 0.224 0.973\n 0.69 0.254 0.777 0.756 0.91 0.973 0.999 0.17 0.824 0.087 0.238 0.821\n 0.96 0.336 0.922 0.822 0.595 0.439 0.311 0.304 0.389 0.835 0.904 0.408\n 0.992 0.593 0.906 0.84 0.749 0.706 0.401 0.86 0.137 0.559 0.205 0.948\n 0.446 0.58 0.762 0.738 0.566 0.149 0.725 0.238 0.484 0.027 0.758 0.409\n 0.98 0.028 0.433 0.911 0.893 0.346 0.502 0.311 0.154 0.606 0.979 0.89\n 0.276 0.388 0.404 0.666 0.273 0.088 0.193 0.557 0.009 0.293 0.479 0.3\n 0.919 0.212 0.119 0.669 0.893 0.926 0.853 0.671 0.739 0.007 0.241 0.633\n 0.185 0.709 0.99 0.175 0.623 0.523 0.864 0.948 0.779 0.161 0.645 0.778\n 0.377 0.593 0.531 0.668 0.551 0.363 0.798 0.444 0.808 0.691 0.15 0.915\n 0.502 0.858 0.373 0.568 0.301 0.339 0.035 0.333 0.763 0.789 0.541 0.964\n 0.578 0.575 0.875 0.267 0.128 0.64 0.068 0.633 0.723 0.19 0.768 0.446\n 0.387 0.946 0.366 0.947]]\nRECEIVED RESPONSE:\nmeta {\n puid: \"8t8gotatm360hcu7ldv5s9goeo\"\n requestPath {\n key: \"keras-mnist-classifier\"\n value: \"keras-mnist:0.1\"\n }\n}\ndata {\n names: \"t:0\"\n names: \"t:1\"\n names: \"t:2\"\n names: \"t:3\"\n names: \"t:4\"\n names: \"t:5\"\n names: \"t:6\"\n names: \"t:7\"\n names: \"t:8\"\n names: \"t:9\"\n ndarray {\n values {\n list_value {\n values {\n number_value: 1.9628670997917652e-05\n }\n values {\n number_value: 0.000876674719620496\n }\n values {\n number_value: 0.011045475490391254\n }\n values {\n number_value: 0.39959368109703064\n }\n values {\n number_value: 1.71219180629123e-05\n }\n values {\n number_value: 0.24513600766658783\n }\n values {\n number_value: 0.024894580245018005\n }\n values {\n number_value: 0.31388890743255615\n }\n values {\n number_value: 0.00057043950073421\n }\n values {\n number_value: 0.0039573488757014275\n }\n }\n }\n }\n}\n\n\n"
],
[
"!minikube delete",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5165d51e1ede064c0b3c63839e7018066e9bc4c
| 37,158 |
ipynb
|
Jupyter Notebook
|
Prog3 Time Dependent Schrodinger Eq in 1D Leap Frog Method.ipynb
|
jamesb6313/Quantum-Examples
|
5ddb05eea1dfa1444aff80b5b011692f45bdb062
|
[
"Apache-2.0"
] | null | null | null |
Prog3 Time Dependent Schrodinger Eq in 1D Leap Frog Method.ipynb
|
jamesb6313/Quantum-Examples
|
5ddb05eea1dfa1444aff80b5b011692f45bdb062
|
[
"Apache-2.0"
] | null | null | null |
Prog3 Time Dependent Schrodinger Eq in 1D Leap Frog Method.ipynb
|
jamesb6313/Quantum-Examples
|
5ddb05eea1dfa1444aff80b5b011692f45bdb062
|
[
"Apache-2.0"
] | null | null | null | 67.19349 | 241 | 0.602616 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
c516620a967117a56cd7c9b2814e0936f71638bb
| 2,884 |
ipynb
|
Jupyter Notebook
|
Coursera/Concurrency in Go/Week-4/Quiz/Module-4-Quiz.ipynb
|
manipiradi/Online-Courses-Learning
|
2a4ce7590d1f6d1dfa5cfde632660b562fcff596
|
[
"MIT"
] | 331 |
2019-10-22T09:06:28.000Z
|
2022-03-27T13:36:03.000Z
|
Coursera/Concurrency in Go/Week-4/Quiz/Module-4-Quiz.ipynb
|
manipiradi/Online-Courses-Learning
|
2a4ce7590d1f6d1dfa5cfde632660b562fcff596
|
[
"MIT"
] | 8 |
2020-04-10T07:59:06.000Z
|
2022-02-06T11:36:47.000Z
|
Coursera/Concurrency in Go/Week-4/Quiz/Module-4-Quiz.ipynb
|
manipiradi/Online-Courses-Learning
|
2a4ce7590d1f6d1dfa5cfde632660b562fcff596
|
[
"MIT"
] | 572 |
2019-07-28T23:43:35.000Z
|
2022-03-27T22:40:08.000Z
| 20.898551 | 278 | 0.523925 |
[
[
[
"#### 1. What line of code could be used to define a loop which iteratively reads from a channel ch1?",
"_____no_output_____"
],
[
"##### Ans: for i := range ch1",
"_____no_output_____"
],
[
"#### 2. What does the select keyword do?",
"_____no_output_____"
],
[
"##### Ans: Allows a choice of channels to wait on.",
"_____no_output_____"
],
[
"#### 3. What is the meaning of the default clause inside a select?",
"_____no_output_____"
],
[
"##### Ans: The default clause is executed if all case clauses are blocked.",
"_____no_output_____"
],
[
"#### 4. Suppose that there are two goroutines, g1 and g2, which share a variable x. X is initialized to 0. The only instruction executed by g1 is x = 4. The only instruction executed by g2 is x = x + 1. What is a possible value for x after both goroutines are complete?\n\nI. 0\n\nII. 1\n\nIII. 4\n\nIV. 5",
"_____no_output_____"
],
[
"##### Ans: II, III, IV, but not I.",
"_____no_output_____"
],
[
"#### 5. What is mutual exclusion?",
"_____no_output_____"
],
[
"##### Ans: When multiple goroutines cannot execute blocks of code concurrently.",
"_____no_output_____"
],
[
"#### 6. What is true about deadlock?\n\nI. It can always be detected by the Golang runtime\n\nII. Its caused by a circular dependency chain between goroutines\n\nIII. It can be caused by waiting on channels",
"_____no_output_____"
],
[
"##### Ans: II and III only.",
"_____no_output_____"
],
[
"#### 7. What is the method of the sync.mutex type which must be called at the beginning of a critical region?",
"_____no_output_____"
],
[
"##### Ans: Lock()",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
c5166e70ad6b45292cb481dc933866ea60114be0
| 13,736 |
ipynb
|
Jupyter Notebook
|
notebooks/Predictions with vectors.ipynb
|
reidcathcart/toxic_comments
|
ef04670a48c8194eae87df1ef25f811802f691cd
|
[
"MIT"
] | null | null | null |
notebooks/Predictions with vectors.ipynb
|
reidcathcart/toxic_comments
|
ef04670a48c8194eae87df1ef25f811802f691cd
|
[
"MIT"
] | null | null | null |
notebooks/Predictions with vectors.ipynb
|
reidcathcart/toxic_comments
|
ef04670a48c8194eae87df1ef25f811802f691cd
|
[
"MIT"
] | null | null | null | 33.584352 | 373 | 0.566249 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport datetime\nimport string\nfrom collections import Counter\nfrom scipy.sparse import hstack, csr_matrix",
"_____no_output_____"
],
[
"from nltk.tokenize import RegexpTokenizer, word_tokenize\nfrom nltk import ngrams\nfrom sklearn.svm import LinearSVC\nfrom sklearn.naive_bayes import MultinomialNB\nfrom sklearn.preprocessing import MultiLabelBinarizer\nfrom sklearn.multiclass import OneVsRestClassifier\nfrom sklearn.ensemble import GradientBoostingClassifier\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer, HashingVectorizer\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import roc_auc_score\nimport xgboost as xgb",
"C:\\Anaconda3\\lib\\site-packages\\sklearn\\cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n"
],
[
"df_train_initial = pd.read_csv('train.csv.zip')\ndf_test_initial = pd.read_csv('test.csv.zip')\ndf_sub = pd.read_csv('sample_submission.csv.zip')\n\ninitialcols = list(df_train_initial.columns[df_train_initial.dtypes == 'int64'])\n\nbadwords_short = pd.read_csv('badwords_short.txt',header=None)\nbadwords_short.rename(columns={0:'badwords_short'},inplace=True)\nbadwords_short['badwords_short'] = badwords_short['badwords_short'].str.lower()\nbadwords_short = badwords_short.drop_duplicates().reset_index(drop=True)\nbadwords_short_set = set(badwords_short['badwords_short'].str.replace('*',''))\n",
"_____no_output_____"
],
[
"tokenizer = RegexpTokenizer(r'\\w+')\n\ndef get_ngrams(message):\n only_words = tokenizer.tokenize(message)\n filtered_message = ' '.join(only_words)\n filtered_message_list = list(ngrams(filtered_message.split(),2))\n filtered_message_list.extend(list(ngrams(filtered_message.split(),3)))\n #filtered_message = [i for i in filtered_message if all(j.isnumeric()==False for j in i)]\n return filtered_message_list\n\ndef get_words(message):\n only_words = tokenizer.tokenize(message)\n return only_words\n\ndef get_puncts(message):\n only_puncts = [i for i in message.split() if all(j in string.punctuation for j in i)]\n return only_puncts\n\ndef get_badwords(message):\n only_bad=[]\n for word in badwords_short_set:\n count = message.lower().count(word)\n if count>0:\n for i in range(0,count):\n only_bad.append('found_in_badwords_short_'+word)\n return only_bad \n\nmodel= {}\ny_train= {}\ny_test = {}\npreds={}\npreds_sub={}\nproc={}\nvec={}\nvec_test={}\ncombined={}",
"_____no_output_____"
],
[
"def make_model(flags,test=True):\n \n if test==True:\n for col in flags:\n X_train, X_test, y_train[col], y_test[col] = train_test_split(df_train_initial.comment_text, \n df_train_initial[col], \n test_size=0.33, random_state=42)\n else:\n X_train = df_train_initial.comment_text.copy()\n X_test = df_test_initial.comment_text.copy()\n for col in flags:\n y_train[col] = df_train_initial[col].copy()\n \n proc['words'] = TfidfVectorizer(analyzer=get_words,min_df=3,strip_accents='unicode',sublinear_tf=1)\n proc['puncts']= TfidfVectorizer(analyzer=get_puncts,min_df=2,strip_accents='unicode',sublinear_tf=1)\n proc['ngrams']= TfidfVectorizer(analyzer=get_ngrams,min_df=4,strip_accents='unicode',sublinear_tf=1)\n proc['badwords']= TfidfVectorizer(analyzer=get_badwords,min_df=1,strip_accents='unicode',sublinear_tf=1)\n\n vec['words'] = proc['words'].fit_transform(X_train)\n vec['puncts'] = proc['puncts'].fit_transform(X_train)\n vec['ngrams'] = proc['ngrams'].fit_transform(X_train)\n vec['badwords'] = proc['badwords'].fit_transform(X_train)\n\n vec_test['words']=proc['words'].transform(X_test)\n vec_test['puncts']=proc['puncts'].transform(X_test)\n vec_test['ngrams']=proc['ngrams'].transform(X_test)\n vec_test['badwords']=proc['badwords'].transform(X_test)\n \n combined['train'] = hstack([vec['words'],vec['puncts'],vec['ngrams'],vec['badwords']])\n combined['test'] = hstack([vec_test['words'],vec_test['puncts'],vec_test['ngrams'],vec_test['badwords']])\n \n for col in flags: \n model[col]={}\n \n model[col]['lr'] = LogisticRegression(solver='sag',C=3,max_iter=200,n_jobs=-1)\n model[col]['lr'].fit(combined['train'],y_train[col].tolist())\n \n model[col]['xgb'] = xgb.XGBClassifier(n_estimators=300, max_depth=5,objective= 'binary:logistic', \n scale_pos_weight=1, seed=27, base_score = .2)\n model[col]['xgb'].fit(combined['train'],y_train[col].tolist(),eval_metric='auc')\n \n model[col]['gbc'] = GradientBoostingClassifier()\n model[col]['gbc'].fit(combined['train'],y_train[col].tolist())\n \n\n if test==True:\n preds[col]={}\n for i in model[col].keys():\n preds[col][i] = model[col][i].predict_proba(combined['test'])[:,1]\n print(col,i,'model predictions:\\n',roc_auc_score(y_test[col],preds[col][i]))\n allpreds+=preds[col][i]\n allpreds/=3\n print(col,'model predictions:\\n',roc_auc_score(y_test[col],allpreds))\n else:\n preds_sub[col]={}\n allpreds=np.zeros(combined['test'].shape[0])\n for i in model[col].keys():\n preds_sub[col][i] = model[col][i].predict_proba(combined['test'])[:,1]\n allpreds+=preds_sub[col][i]\n allpreds/=3\n df_sub[col] = allpreds\n print(col,'done')",
"_____no_output_____"
],
[
"make_model(initialcols,test=False)",
"C:\\Anaconda3\\lib\\site-packages\\ipykernel\\__main__.py:7: DeprecationWarning: generator 'ngrams' raised StopIteration\nC:\\Anaconda3\\lib\\site-packages\\ipykernel\\__main__.py:6: DeprecationWarning: generator 'ngrams' raised StopIteration\n"
],
[
"df_sub['toxic'] = preds_sub['toxic']['lr']\ndf_sub['severe_toxic'] = preds_sub['severe_toxic']['lr']\ndf_sub['obscene'] = preds_sub['obscene']['lr']\ndf_sub['threat'] = preds_sub['threat']['lr']\ndf_sub['insult'] = preds_sub['insult']['lr']\ndf_sub['identity_hate'] = preds_sub['identity_hate']['lr']",
"_____no_output_____"
],
[
"import pickle \nfor i in vec.keys():\n pickle.dump(vec[i], open(i+'_vector.sav', 'wb'))",
"_____no_output_____"
],
[
"df_sub.to_csv('df_sub_'+datetime.datetime.now().strftime('%Y%m%d%I%M')+'.csv',index=False)",
"_____no_output_____"
],
[
"# C:\\Anaconda3\\lib\\site-packages\\ipykernel\\__main__.py:7: DeprecationWarning: generator 'ngrams' raised StopIteration\n# toxic lr model predictions:\n# 0.973623915807\n# toxic xgb model predictions:\n# 0.957367570947\n# toxic gbc model predictions:\n# 0.920677283411\n# toxic model predictions:\n# 0.967328623644\n# severe_toxic lr model predictions:\n# 0.988066880563\n# severe_toxic xgb model predictions:\n# 0.981223988455\n# severe_toxic gbc model predictions:\n# 0.946132712332\n# severe_toxic model predictions:\n# 0.987947888331\n# obscene lr model predictions:\n# 0.98715018023\n# obscene xgb model predictions:\n# 0.983366581819\n# obscene gbc model predictions:\n# 0.966495202699\n# obscene model predictions:\n# 0.987547215406\n# threat lr model predictions:\n# 0.984074679767\n# threat xgb model predictions:\n# 0.965280067921\n# threat gbc model predictions:\n# 0.542049593889\n# threat model predictions:\n# 0.983671224789\n# insult lr model predictions:\n# 0.98025063686\n# insult xgb model predictions:\n# 0.972816999733\n# insult gbc model predictions:\n# 0.953063786142\n# insult model predictions:\n# 0.978857091119\n# identity_hate lr model predictions:\n# 0.977883100898\n# identity_hate xgb model predictions:\n# 0.970471305196\n# identity_hate gbc model predictions:\n# 0.876133030069\n# identity_hate model predictions:\n# 0.979015052878",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5166f22ddbef2e83552d7b07bbf9dc0f2b11778
| 5,011 |
ipynb
|
Jupyter Notebook
|
Image/canny_edge_detector.ipynb
|
OIEIEIO/earthengine-py-notebooks
|
5d6c5cdec0c73bf02020ee17d42c9e30d633349f
|
[
"MIT"
] | 1,008 |
2020-01-27T02:03:18.000Z
|
2022-03-24T10:42:14.000Z
|
Image/canny_edge_detector.ipynb
|
rafatieppo/earthengine-py-notebooks
|
99fbc4abd1fb6ba41e3d8a55f8911217353a3237
|
[
"MIT"
] | 8 |
2020-02-01T20:18:18.000Z
|
2021-11-23T01:48:02.000Z
|
Image/canny_edge_detector.ipynb
|
rafatieppo/earthengine-py-notebooks
|
99fbc4abd1fb6ba41e3d8a55f8911217353a3237
|
[
"MIT"
] | 325 |
2020-01-27T02:03:36.000Z
|
2022-03-25T20:33:33.000Z
| 36.311594 | 470 | 0.559569 |
[
[
[
"<table class=\"ee-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://github.com/giswqs/earthengine-py-notebooks/tree/master/Image/canny_edge_detector.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /> View source on GitHub</a></td>\n <td><a target=\"_blank\" href=\"https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/Image/canny_edge_detector.ipynb\"><img width=26px src=\"https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png\" />Notebook Viewer</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/Image/canny_edge_detector.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /> Run in Google Colab</a></td>\n</table>",
"_____no_output_____"
],
[
"## Install Earth Engine API and geemap\nInstall the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geemap](https://geemap.org). The **geemap** Python package is built upon the [ipyleaflet](https://github.com/jupyter-widgets/ipyleaflet) and [folium](https://github.com/python-visualization/folium) packages and implements several methods for interacting with Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, and `Map.centerObject()`.\nThe following script checks if the geemap package has been installed. If not, it will install geemap, which automatically installs its [dependencies](https://github.com/giswqs/geemap#dependencies), including earthengine-api, folium, and ipyleaflet.",
"_____no_output_____"
]
],
[
[
"# Installs geemap package\nimport subprocess\n\ntry:\n import geemap\nexcept ImportError:\n print('Installing geemap ...')\n subprocess.check_call([\"python\", '-m', 'pip', 'install', 'geemap'])",
"_____no_output_____"
],
[
"import ee\nimport geemap",
"_____no_output_____"
]
],
[
[
"## Create an interactive map \nThe default basemap is `Google Maps`. [Additional basemaps](https://github.com/giswqs/geemap/blob/master/geemap/basemaps.py) can be added using the `Map.add_basemap()` function. ",
"_____no_output_____"
]
],
[
[
"Map = geemap.Map(center=[40,-100], zoom=4)\nMap",
"_____no_output_____"
]
],
[
[
"## Add Earth Engine Python script ",
"_____no_output_____"
]
],
[
[
"# Add Earth Engine dataset\n# Canny Edge Detector example.\n\n# Load an image and compute NDVI from it.\nimage = ee.Image('LANDSAT/LT05/C01/T1_TOA/LT05_031034_20110619')\nndvi = image.normalizedDifference(['B4','B3'])\n\n# Detect edges in the composite.\ncanny = ee.Algorithms.CannyEdgeDetector(ndvi, 0.7)\n\n# Mask the image with itself to get rid of areas with no edges.\ncanny = canny.updateMask(canny)\n\nMap.setCenter(-101.05259, 37.93418, 13)\nMap.addLayer(ndvi, {'min': 0, 'max': 1}, 'Landsat NDVI')\nMap.addLayer(canny, {'min': 0, 'max': 1, 'palette': 'FF0000'}, 'Canny Edges')\n",
"_____no_output_____"
]
],
[
[
"## Display Earth Engine data layers ",
"_____no_output_____"
]
],
[
[
"Map.addLayerControl() # This line is not needed for ipyleaflet-based Map.\nMap",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
c51671e77ae925d0be5fb36de3de19b962422299
| 640,520 |
ipynb
|
Jupyter Notebook
|
examples/gmm.ipynb
|
masa-su/pixyz
|
be15a930285cab0110f804aa635f5ad4dbe311c2
|
[
"MIT"
] | 453 |
2018-11-11T07:30:15.000Z
|
2022-03-24T06:21:02.000Z
|
examples/gmm.ipynb
|
masa-su/pixyz
|
be15a930285cab0110f804aa635f5ad4dbe311c2
|
[
"MIT"
] | 31 |
2018-11-17T11:04:58.000Z
|
2021-12-14T12:16:37.000Z
|
examples/gmm.ipynb
|
masa-su/pixyz
|
be15a930285cab0110f804aa635f5ad4dbe311c2
|
[
"MIT"
] | 44 |
2018-11-13T01:28:28.000Z
|
2022-02-09T15:45:30.000Z
| 763.432658 | 36,292 | 0.951781 |
[
[
[
"# Gaussian Mixture Model",
"_____no_output_____"
]
],
[
[
"!pip install tqdm torchvision tensorboardX",
"_____no_output_____"
],
[
"from __future__ import print_function\nimport torch\nimport torch.utils.data\nimport numpy as np\n\nimport matplotlib.pyplot as plt\nfrom matplotlib import cm\nfrom mpl_toolkits.mplot3d import Axes3D\n\nseed = 0\ntorch.manual_seed(seed)\n\nif torch.cuda.is_available():\n device = \"cuda\"\nelse:\n device = \"cpu\"",
"_____no_output_____"
]
],
[
[
"### toy dataset",
"_____no_output_____"
]
],
[
[
"# https://angusturner.github.io/generative_models/2017/11/03/pytorch-gaussian-mixture-model.html\ndef sample(mu, var, nb_samples=500):\n \"\"\"\n Return a tensor of (nb_samples, features), sampled\n from the parameterized gaussian.\n :param mu: torch.Tensor of the means\n :param var: torch.Tensor of variances (NOTE: zero covars.)\n \"\"\"\n out = []\n for i in range(nb_samples):\n out += [\n torch.normal(mu, var.sqrt())\n ]\n return torch.stack(out, dim=0)\n\n\n# generate some clusters\ncluster1 = sample(\n torch.Tensor([1.5, 2.5]),\n torch.Tensor([1.2, .8]),\n nb_samples=150\n)\n\ncluster2 = sample(\n torch.Tensor([7.5, 7.5]),\n torch.Tensor([.75, .5]),\n nb_samples=50\n)\n\ncluster3 = sample(\n torch.Tensor([8, 1.5]),\n torch.Tensor([.6, .8]),\n nb_samples=100\n)\n\n\ndef plot_2d_sample(sample_dict):\n x = sample_dict[\"x\"][:,0].data.numpy()\n y = sample_dict[\"x\"][:,1].data.numpy()\n plt.plot(x, y, 'gx')\n\n plt.show()",
"_____no_output_____"
],
[
"# create the dummy dataset, by combining the clusters.\nsamples = torch.cat([cluster1, cluster2, cluster3])\nsamples = (samples-samples.mean(dim=0)) / samples.std(dim=0)\nsamples_dict = {\"x\": samples}\n\nplot_2d_sample(samples_dict)",
"_____no_output_____"
]
],
[
[
"## GMM",
"_____no_output_____"
]
],
[
[
"from pixyz.distributions import Normal, Categorical\nfrom pixyz.distributions.mixture_distributions import MixtureModel\nfrom pixyz.utils import print_latex\n\nz_dim = 3 # the number of mixture\nx_dim = 2\n\ndistributions = []\nfor i in range(z_dim):\n loc = torch.randn(x_dim)\n scale = torch.empty(x_dim).fill_(0.6)\n distributions.append(Normal(loc=loc, scale=scale, var=[\"x\"], name=\"p_%d\" %i))\n\nprobs = torch.empty(z_dim).fill_(1. / z_dim)\nprior = Categorical(probs=probs, var=[\"z\"], name=\"p_{prior}\")",
"_____no_output_____"
],
[
"p = MixtureModel(distributions=distributions, prior=prior)\nprint(p)\nprint_latex(p)",
"Distribution:\n p(x) = p_0(x|z=0)p_{prior}(z=0) + p_1(x|z=1)p_{prior}(z=1) + p_2(x|z=2)p_{prior}(z=2)\nNetwork architecture:\n MixtureModel(\n name=p, distribution_name=Mixture Model,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([])\n (distributions): ModuleList(\n (0): Normal(\n name=p_0, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n (1): Normal(\n name=p_1, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n (2): Normal(\n name=p_2, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n )\n (prior): Categorical(\n name=p_{prior}, distribution_name=Categorical,\n var=['z'], cond_var=[], input_var=[], features_shape=torch.Size([3])\n (probs): torch.Size([1, 3])\n )\n )\n"
],
[
"post = p.posterior()\nprint(post)\nprint_latex(post)",
"Distribution:\n p(z|x) = \\frac{p(z,x)}{p(x)}\nNetwork architecture:\n PosteriorMixtureModel(\n name=p, distribution_name=Mixture Model (Posterior),\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([])\n (p): MixtureModel(\n name=p, distribution_name=Mixture Model,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([])\n (distributions): ModuleList(\n (0): Normal(\n name=p_0, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n (1): Normal(\n name=p_1, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n (2): Normal(\n name=p_2, distribution_name=Normal,\n var=['x'], cond_var=[], input_var=[], features_shape=torch.Size([2])\n (loc): torch.Size([1, 2])\n (scale): torch.Size([1, 2])\n )\n )\n (prior): Categorical(\n name=p_{prior}, distribution_name=Categorical,\n var=['z'], cond_var=[], input_var=[], features_shape=torch.Size([3])\n (probs): torch.Size([1, 3])\n )\n )\n )\n"
],
[
"def get_density(N=200, x_range=(-5, 5), y_range=(-5, 5)):\n x = np.linspace(*x_range, N)\n y = np.linspace(*y_range, N)\n x, y = np.meshgrid(x, y)\n \n # get the design matrix\n points = np.concatenate([x.reshape(-1, 1), y.reshape(-1, 1)], axis=1)\n points = torch.from_numpy(points).float()\n \n pdf = p.prob().eval({\"x\": points}).data.numpy().reshape([N, N])\n \n return x, y, pdf",
"_____no_output_____"
],
[
"def plot_density_3d(x, y, loglike):\n fig = plt.figure(figsize=(10, 10)) \n ax = fig.gca(projection='3d')\n ax.plot_surface(x, y, loglike, rstride=3, cstride=3, linewidth=1, antialiased=True,\n cmap=cm.inferno)\n cset = ax.contourf(x, y, loglike, zdir='z', offset=-0.15, cmap=cm.inferno)\n\n # adjust the limits, ticks and view angle\n ax.set_zlim(-0.15,0.2)\n ax.set_zticks(np.linspace(0,0.2,5))\n ax.view_init(27, -21)\n plt.show()",
"_____no_output_____"
],
[
"def plot_density_2d(x, y, pdf):\n fig = plt.figure(figsize=(5, 5))\n \n plt.plot(samples_dict[\"x\"][:,0].data.numpy(), samples_dict[\"x\"][:,1].data.numpy(), 'gx')\n \n for d in distributions:\n plt.scatter(d.loc[0,0], d.loc[0,1], c='r', marker='o')\n \n cs = plt.contour(x, y, pdf, 10, colors='k', linewidths=2)\n plt.show()",
"_____no_output_____"
],
[
"eps = 1e-6\nmin_scale = 1e-6\n\n# plot_density_3d(*get_density())\nplot_density_2d(*get_density())\nprint(\"Epoch: {}, log-likelihood: {}\".format(0, p.log_prob().mean().eval(samples_dict)))\nfor epoch in range(20):\n # E-step\n posterior = post.prob().eval(samples_dict)\n\n # M-step\n N_k = posterior.sum(dim=1) # (n_mix,)\n \n # update probs\n probs = N_k / N_k.sum() # (n_mix,)\n prior.probs[0] = probs\n \n # update loc & scale\n loc = (posterior[:, None] @ samples[None]).squeeze(1) # (n_mix, n_dim)\n loc /= (N_k[:, None] + eps)\n\n cov = (samples[None, :, :] - loc[:, None, :]) ** 2 # Covariances are set to 0.\n var = (posterior[:, None, :] @ cov).squeeze(1) # (n_mix, n_dim)\n var /= (N_k[:, None] + eps)\n scale = var.sqrt()\n\n for i, d in enumerate(distributions):\n d.loc[0] = loc[i]\n d.scale[0] = scale[i]\n\n# plot_density_3d(*get_density())\n plot_density_2d(*get_density()) \n print(\"Epoch: {}, log-likelihood: {}\".format(epoch+1, p.log_prob().mean().eval({\"x\": samples}).mean()))",
"_____no_output_____"
],
[
"psudo_sample_dict = p.sample(batch_n=200)\nplot_2d_sample(samples_dict)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5167352ef9166df80b08c0f89b61f0a00a8dabe
| 29,538 |
ipynb
|
Jupyter Notebook
|
_notebooks/2021-10-26-evaluate-flicker8k-image-search.ipynb
|
thigm85/blog
|
0060c1dbc255db4c3c7fea9d64543211354d05d1
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2021-10-26-evaluate-flicker8k-image-search.ipynb
|
thigm85/blog
|
0060c1dbc255db4c3c7fea9d64543211354d05d1
|
[
"Apache-2.0"
] | 2 |
2020-05-11T19:34:30.000Z
|
2020-05-11T19:34:31.000Z
|
_notebooks/2021-10-26-evaluate-flicker8k-image-search.ipynb
|
thigm85/blog
|
0060c1dbc255db4c3c7fea9d64543211354d05d1
|
[
"Apache-2.0"
] | null | null | null | 30.171604 | 282 | 0.445088 |
[
[
[
"# Evaluate text-image search app with Flickr 8k dataset\n> Create labeled data, text processor and evaluate with Vespa python API\n\n- toc: true \n- badges: true\n- comments: true\n- categories: [text_image_search, clip_model, vespa, flicker8k]",
"_____no_output_____"
],
[
"This post creates a labeled dataset out of the Flicker 8k image-caption dataset, builds a text processor that uses a CLIP model to map a text query into the same 512-dimensional space used to represent images and evaluate different query models using the Vespa python API. ",
"_____no_output_____"
],
[
"Check the previous three posts for context:\n\n* [Flicker 8k dataset first exploration](https://thigm85.github.io/blog/flicker8k/dataset/image/nlp/2021/10/21/flicker8k-dataset-first-exploration.html)\n* [Understanding CLIP image pipeline](https://thigm85.github.io/blog/image%20processing/clip%20model/dual%20encoder/pil/2021/10/22/understanding-clip-image-pipeline.html)\n* [Vespa image search with PyTorch feeder](https://thigm85.github.io/blog/image%20processing/clip%20model/vespa/pytorch/pytorch%20dataset/2021/10/25/vespa-image-search-flicker8k.html)",
"_____no_output_____"
],
[
"## Create labeled data",
"_____no_output_____"
],
[
"An (image, caption) pair will be considered relevant for our purposes if all three experts agreed on a relevance score equal to 4.",
"_____no_output_____"
],
[
"### Load and check the expert judgments",
"_____no_output_____"
]
],
[
[
"from pandas import read_csv\n\nexperts = read_csv(\n os.path.join(os.environ[\"DATA_FOLDER\"], \"ExpertAnnotations.txt\"), \n sep = \"\\t\", \n header=None, \n names=[\"image_file_name\", \"caption_id\", \"expert_1\", \"expert_2\", \"expert_3\"]\n)",
"_____no_output_____"
],
[
"experts.head()",
"_____no_output_____"
]
],
[
[
"### Check cases where all experts agrees ",
"_____no_output_____"
]
],
[
[
"experts_agreement_bool = experts.apply(\n lambda x: x[\"expert_1\"] == x[\"expert_2\"] and x[\"expert_2\"] == x[\"expert_3\"], \n axis=1\n)\nexperts_agreement = experts[experts_agreement_bool][\n [\"image_file_name\", \"caption_id\", \"expert_1\"]\n].rename(columns={\"expert_1\":\"expert\"})",
"_____no_output_____"
],
[
"experts_agreement.head()",
"_____no_output_____"
],
[
"experts_agreement[\"expert\"].value_counts().sort_index()",
"_____no_output_____"
]
],
[
[
"### Load captions data",
"_____no_output_____"
]
],
[
[
"captions = read_csv(\n os.path.join(os.environ[\"DATA_FOLDER\"], \"Flickr8k.token.txt\"), \n sep=\"\\t\", \n header=None, \n names=[\"caption_id\", \"caption\"]\n)",
"_____no_output_____"
],
[
"captions.head()",
"_____no_output_____"
],
[
"def get_caption(caption_id, captions):\n return captions[captions[\"caption_id\"] == caption_id][\"caption\"].values[0]",
"_____no_output_____"
]
],
[
[
"### Relevant (image, text) pair",
"_____no_output_____"
]
],
[
[
"relevant_data = experts_agreement[experts_agreement[\"expert\"] == 4]\nrelevant_data.head(3)",
"_____no_output_____"
]
],
[
[
"### Create labeled data",
"_____no_output_____"
]
],
[
[
"from ntpath import basename\nfrom pandas import DataFrame\n\nlabeled_data = DataFrame(\n data={\n \"qid\": list(range(relevant_data.shape[0])),\n \"query\": [get_caption(\n caption_id=x, \n captions=captions\n ).replace(\" ,\", \"\").replace(\" .\", \"\") for x in list(relevant_data.caption_id)],\n \"doc_id\": [basename(x) for x in list(relevant_data.image_file_name)],\n \"relevance\": 1}\n)\nlabeled_data.head()",
"_____no_output_____"
]
],
[
[
"## From text to embeddings",
"_____no_output_____"
],
[
"Create a text processor to map a text string into the same 512-dimensional space used to embed the images.",
"_____no_output_____"
]
],
[
[
"import clip\nimport torch\n\nclass TextProcessor(object):\n def __init__(self, model_name):\n self.model, _ = clip.load(model_name)\n \n def embed(self, text):\n text_tokens = clip.tokenize(text)\n with torch.no_grad():\n text_features = model.encode_text(text_tokens).float()\n text_features /= text_features.norm(dim=-1, keepdim=True)\n return text_features.tolist()[0]",
"_____no_output_____"
]
],
[
[
"## Evaluate",
"_____no_output_____"
],
[
"Define search evaluation metrics:",
"_____no_output_____"
]
],
[
[
"from vespa.evaluation import MatchRatio, Recall, ReciprocalRank\n\neval_metrics = [\n MatchRatio(), \n Recall(at=5), \n Recall(at=100), \n ReciprocalRank(at=5), \n ReciprocalRank(at=100)\n]",
"_____no_output_____"
]
],
[
[
"Instantiate `TextProcessor` with a specific CLIP model.",
"_____no_output_____"
]
],
[
[
"text_processor = TextProcessor(model_name=\"ViT-B/32\")",
"_____no_output_____"
]
],
[
[
"Create a `QueryModel`'s to be evaluated. In this case we create two query models based on the `ViT-B/32` CLIP model, one that sends the `query` as it is and another that prepends the prompt \"A photo of \" to the query before sending it, as suggest in the original CLIP paper.",
"_____no_output_____"
]
],
[
[
"from vespa.query import QueryModel\n\ndef create_vespa_query(query, prompt = False):\n if prompt:\n query = \"A photo of \" + query.lower()\n return {\n 'yql': 'select * from sources * where ([{\"targetNumHits\":100}]nearestNeighbor(vit_b_32_image,vit_b_32_text));',\n 'hits': 100,\n 'ranking.features.query(vit_b_32_text)': text_processor.embed(query),\n 'ranking.profile': 'vit-b-32-similarity',\n 'timeout': 10\n }\n\nquery_model_1 = QueryModel(name=\"vit_b_32\", body_function=create_vespa_query)\nquery_model_2 = QueryModel(name=\"vit_b_32_prompt\", body_function=lambda x: create_vespa_query(x, prompt=True))",
"_____no_output_____"
]
],
[
[
"Create a connection to the Vespa instance:",
"_____no_output_____"
]
],
[
[
"app = Vespa(\n url=os.environ[\"VESPA_END_POINT\"],\n cert = os.environ[\"PRIVATE_CERTIFICATE_PATH\"]\n)",
"_____no_output_____"
]
],
[
[
"Evaluate the query models using the labeled data and metrics defined earlier. The labeled data uses the `image_file_name` and doc id.",
"_____no_output_____"
]
],
[
[
"from vespa.application import Vespa\n\nresult = app.evaluate(\n labeled_data=labeled_data, \n eval_metrics=eval_metrics, \n query_model=[query_model_1, query_model_2], \n id_field=\"image_file_name\"\n)",
"_____no_output_____"
]
],
[
[
"The results shows that there is a lot of improvements to be made on the pre-trained `ViT-B/32` CLIP model.",
"_____no_output_____"
]
],
[
[
"result",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
c5167a76f515f3f736e8d110d4b972abe4471a84
| 81,421 |
ipynb
|
Jupyter Notebook
|
4_RandomForestRegressor.ipynb
|
ljgoico/OULAD_Project
|
2c3277448305c42961b1574b3ea78fc5a34017b9
|
[
"OML"
] | 1 |
2021-05-14T19:17:54.000Z
|
2021-05-14T19:17:54.000Z
|
4_RandomForestRegressor.ipynb
|
ljgoico/OULAD_Project
|
2c3277448305c42961b1574b3ea78fc5a34017b9
|
[
"OML"
] | null | null | null |
4_RandomForestRegressor.ipynb
|
ljgoico/OULAD_Project
|
2c3277448305c42961b1574b3ea78fc5a34017b9
|
[
"OML"
] | null | null | null | 88.501087 | 22,676 | 0.743432 |
[
[
[
"# Import libraries",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.metrics import r2_score\nfrom sklearn.metrics import mean_absolute_error\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import GridSearchCV\nimport matplotlib.pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Read csv",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('Data/ml.csv')",
"_____no_output_____"
],
[
"#Check the columns\n\ndata.columns",
"_____no_output_____"
],
[
"#Number of rows and columns\n\ndata.shape",
"_____no_output_____"
],
[
"#Transform categorical variables to object\n\ndata['is_banked'] = data['is_banked'].apply(str)\ndata['code_module'] = data['code_module'].apply(str)\ndata['code_presentation'] = data['code_presentation'].apply(str)",
"_____no_output_____"
],
[
"#Dummies\n\nto_dummies = ['is_banked','code_module', 'code_presentation', 'gender', 'region',\n 'highest_education', 'imd_band', 'age_band', 'disability', 'final_result',]\n\ndata = pd.get_dummies(data, columns=to_dummies)",
"_____no_output_____"
],
[
"#Check columns\n\ndata.columns",
"_____no_output_____"
],
[
"#Separate target from the rest of columns\n\ndata_data = data[['date_submitted', 'num_of_prev_attempts', 'studied_credits',\n 'module_presentation_length', 'is_banked_0', 'is_banked_1',\n 'code_module_AAA', 'code_module_BBB', 'code_module_CCC',\n 'code_module_DDD', 'code_module_EEE', 'code_module_FFF',\n 'code_module_GGG', 'code_presentation_2013B', 'code_presentation_2013J',\n 'code_presentation_2014B', 'code_presentation_2014J', 'gender_F',\n 'gender_M', 'region_East Anglian Region', 'region_East Midlands Region',\n 'region_Ireland', 'region_London Region', 'region_North Region',\n 'region_North Western Region', 'region_Scotland',\n 'region_South East Region', 'region_South Region',\n 'region_South West Region', 'region_Wales',\n 'region_West Midlands Region', 'region_Yorkshire Region',\n 'highest_education_A Level or Equivalent',\n 'highest_education_HE Qualification',\n 'highest_education_Lower Than A Level',\n 'highest_education_No Formal quals',\n 'highest_education_Post Graduate Qualification', 'imd_band_0-10%',\n 'imd_band_10-20', 'imd_band_20-30%', 'imd_band_30-40%',\n 'imd_band_40-50%', 'imd_band_50-60%', 'imd_band_60-70%',\n 'imd_band_70-80%', 'imd_band_80-90%', 'imd_band_90-100%', 'imd_band_?',\n 'age_band_0-35', 'age_band_35-55', 'age_band_55<=', 'disability_N',\n 'disability_Y', 'final_result_Distinction', 'final_result_Fail',\n 'final_result_Pass', 'final_result_Withdrawn']]\n\ndata_target = data_ml[\"score\"]",
"_____no_output_____"
],
[
"# Split Train and Test\n\nfrom sklearn.model_selection import train_test_split\n\nX_train, X_test, y_train, y_test=train_test_split(data_data, data_target, test_size=0.3, random_state=42)",
"_____no_output_____"
],
[
"#Grid search for parameter selection for a Random Forest Regressor model\nparam_grid = {\n 'n_estimators': [100, 1000],\n 'max_features': ['auto','sqrt','log2'],\n 'max_depth': [25, 15]\n}",
"_____no_output_____"
],
[
"RFR = RandomForestRegressor(n_jobs=-1)\nGS = GridSearchCV(RFR, param_grid, cv=5, verbose = 3)",
"_____no_output_____"
],
[
"GS.fit(X_train, y_train)",
"Fitting 5 folds for each of 12 candidates, totalling 60 fits\n[CV] max_depth=25, max_features=auto, n_estimators=100 ...............\n"
],
[
"GS.best_params_",
"_____no_output_____"
],
[
"RFR = RandomForestRegressor(max_depth = 25, max_features='sqrt', n_estimators=1000)\nRFR.fit(X_train, y_train)",
"_____no_output_____"
],
[
"y_train_pred = RFR.predict(X_train)\ny_pred = RFR.predict(X_test)",
"_____no_output_____"
],
[
"r2 = r2_score(y_train, y_train_pred)\nmae = mean_absolute_error(y_train, y_train_pred)\nprint ('TRAIN MODEL METRICS:')\nprint('The R2 score is: ' + str(r2))\nprint('The MAE score is: ' + str(mae))\n\nplt.scatter(y_train, y_train_pred)\nplt.plot([0,100], [0,100], color='red')\nplt.show()",
"TRAIN MODEL METRICS:\nThe R2 score is: 0.7432713203286277\nThe MAE score is: 7.251468092215323\n"
],
[
"r2 = r2_score(y_test, y_pred)\nmae = mean_absolute_error(y_test, y_pred)\nprint ('TEST MODEL METRICS:')\nprint('The R2 score is: ' + str(r2))\nprint('The MAE score is: ' + str(mae))\n\nplt.scatter(y_test, y_pred)\nplt.plot([0,100], [0,100], color='red')\nplt.show()",
"TEST MODEL METRICS:\nThe R2 score is: 0.3215301604602927\nThe MAE score is: 11.612282578596071\n"
],
[
"data_ml.head()",
"_____no_output_____"
],
[
"data_ml.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 207156 entries, 0 to 207155\nData columns (total 58 columns):\ndate_submitted 207156 non-null int64\nscore 207156 non-null float64\nnum_of_prev_attempts 207156 non-null int64\nstudied_credits 207156 non-null int64\nmodule_presentation_length 207156 non-null int64\nis_banked_0 207156 non-null uint8\nis_banked_1 207156 non-null uint8\ncode_module_AAA 207156 non-null uint8\ncode_module_BBB 207156 non-null uint8\ncode_module_CCC 207156 non-null uint8\ncode_module_DDD 207156 non-null uint8\ncode_module_EEE 207156 non-null uint8\ncode_module_FFF 207156 non-null uint8\ncode_module_GGG 207156 non-null uint8\ncode_presentation_2013B 207156 non-null uint8\ncode_presentation_2013J 207156 non-null uint8\ncode_presentation_2014B 207156 non-null uint8\ncode_presentation_2014J 207156 non-null uint8\ngender_F 207156 non-null uint8\ngender_M 207156 non-null uint8\nregion_East Anglian Region 207156 non-null uint8\nregion_East Midlands Region 207156 non-null uint8\nregion_Ireland 207156 non-null uint8\nregion_London Region 207156 non-null uint8\nregion_North Region 207156 non-null uint8\nregion_North Western Region 207156 non-null uint8\nregion_Scotland 207156 non-null uint8\nregion_South East Region 207156 non-null uint8\nregion_South Region 207156 non-null uint8\nregion_South West Region 207156 non-null uint8\nregion_Wales 207156 non-null uint8\nregion_West Midlands Region 207156 non-null uint8\nregion_Yorkshire Region 207156 non-null uint8\nhighest_education_A Level or Equivalent 207156 non-null uint8\nhighest_education_HE Qualification 207156 non-null uint8\nhighest_education_Lower Than A Level 207156 non-null uint8\nhighest_education_No Formal quals 207156 non-null uint8\nhighest_education_Post Graduate Qualification 207156 non-null uint8\nimd_band_0-10% 207156 non-null uint8\nimd_band_10-20 207156 non-null uint8\nimd_band_20-30% 207156 non-null uint8\nimd_band_30-40% 207156 non-null uint8\nimd_band_40-50% 207156 non-null uint8\nimd_band_50-60% 207156 non-null uint8\nimd_band_60-70% 207156 non-null uint8\nimd_band_70-80% 207156 non-null uint8\nimd_band_80-90% 207156 non-null uint8\nimd_band_90-100% 207156 non-null uint8\nimd_band_? 207156 non-null uint8\nage_band_0-35 207156 non-null uint8\nage_band_35-55 207156 non-null uint8\nage_band_55<= 207156 non-null uint8\ndisability_N 207156 non-null uint8\ndisability_Y 207156 non-null uint8\nfinal_result_Distinction 207156 non-null uint8\nfinal_result_Fail 207156 non-null uint8\nfinal_result_Pass 207156 non-null uint8\nfinal_result_Withdrawn 207156 non-null uint8\ndtypes: float64(1), int64(4), uint8(53)\nmemory usage: 18.4 MB\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51687f4f9fb3815c86232161658fa94c5d99552
| 18,557 |
ipynb
|
Jupyter Notebook
|
QFT/QFT.ipynb
|
jackhyder/QuantumKatas
|
5337b3fe8baa6ce2913ea434844e6700fd45e9b1
|
[
"MIT"
] | null | null | null |
QFT/QFT.ipynb
|
jackhyder/QuantumKatas
|
5337b3fe8baa6ce2913ea434844e6700fd45e9b1
|
[
"MIT"
] | null | null | null |
QFT/QFT.ipynb
|
jackhyder/QuantumKatas
|
5337b3fe8baa6ce2913ea434844e6700fd45e9b1
|
[
"MIT"
] | null | null | null | 31.452542 | 254 | 0.53306 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
c5168f3793af2b154cae7c5c1654a24045c75a1b
| 5,234 |
ipynb
|
Jupyter Notebook
|
Chapter01/06 - Loading a Linear Learner Model with Apache MXNet in Python.ipynb
|
MARKOM/sagemaker-cookbook
|
e75fda9493421a013eba5d547d2838dedf46c176
|
[
"MIT"
] | 19 |
2021-09-14T05:23:52.000Z
|
2022-03-19T18:20:58.000Z
|
Chapter01/06 - Loading a Linear Learner Model with Apache MXNet in Python.ipynb
|
MARKOM/sagemaker-cookbook
|
e75fda9493421a013eba5d547d2838dedf46c176
|
[
"MIT"
] | null | null | null |
Chapter01/06 - Loading a Linear Learner Model with Apache MXNet in Python.ipynb
|
MARKOM/sagemaker-cookbook
|
e75fda9493421a013eba5d547d2838dedf46c176
|
[
"MIT"
] | 15 |
2021-10-07T03:41:44.000Z
|
2022-03-06T00:17:25.000Z
| 21.45082 | 324 | 0.530569 |
[
[
[
"# Loading a Linear Learner Model with Apache MXNet in Python",
"_____no_output_____"
],
[
"<img align=\"left\" width=\"130\" src=\"https://raw.githubusercontent.com/PacktPublishing/Amazon-SageMaker-Cookbook/master/Extra/cover-small-padded.png\"/>\n\nThis notebook contains the code to help readers work through one of the recipes of the book [Machine Learning with Amazon SageMaker Cookbook: 80 proven recipes for data scientists and developers to perform ML experiments and deployments](https://www.amazon.com/Machine-Learning-Amazon-SageMaker-Cookbook/dp/1800567030)",
"_____no_output_____"
],
[
"### How to do it...",
"_____no_output_____"
]
],
[
[
"%store -r model_data",
"_____no_output_____"
],
[
"model_data",
"_____no_output_____"
],
[
"import sagemaker \nsession = sagemaker.Session()",
"_____no_output_____"
],
[
"from sagemaker.s3 import S3Downloader",
"_____no_output_____"
],
[
"S3Downloader.download(s3_uri=model_data,\n local_path=\"tmp/\",\n sagemaker_session=session)",
"_____no_output_____"
],
[
"!ls tmp",
"_____no_output_____"
],
[
"!tar -xzvf tmp/model.tar.gz",
"_____no_output_____"
],
[
"!unzip model_algo-1 ",
"_____no_output_____"
],
[
"import mxnet\n\nfrom mxnet import gluon\nfrom json import load as json_load \nfrom json import dumps as json_dumps",
"_____no_output_____"
],
[
"sym_json = json_load(open('mx-mod-symbol.json')) \nsym_json_string = json_dumps(sym_json)\n\nmodel = gluon.nn.SymbolBlock( \n outputs=mxnet.sym.load_json(sym_json_string), \n inputs=mxnet.sym.var('data'))\n\nmodel.load_parameters('mx-mod-0000.params', allow_missing=True)",
"_____no_output_____"
],
[
"model.initialize()\n\ndef mxnet_predict(x, model=model):\n return model(mxnet.nd.array([x]))[0].asscalar()",
"_____no_output_____"
],
[
"mxnet_predict(42)",
"_____no_output_____"
],
[
"def extract_weight_and_bias(model):\n params = model.collect_params()\n weight = params['fc0_weight'].data()[0].asscalar() \n bias = params['fc0_bias'].data()[0].asscalar()\n \n return {\n \"weight\": weight, \n \"bias\": bias\n } ",
"_____no_output_____"
],
[
"weight_and_bias = extract_weight_and_bias(model)\nweight_and_bias",
"_____no_output_____"
],
[
"%store weight_and_bias",
"_____no_output_____"
],
[
"%%bash\n\nrm -f additional-params.json\nrm -f manifest.json\nrm -f model_algo-1\nrm -f mx-mod-symbol.json\nrm -f mx-mod-0000.params",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51699c8e0af4992490c2a39d282373e597552e3
| 117,536 |
ipynb
|
Jupyter Notebook
|
Understanding Python/Dataframe.ipynb
|
Gunjan933/machine-learning
|
fff15a87410ddddd8968c04cff20a0e868eca447
|
[
"MIT"
] | 1 |
2019-08-05T10:27:47.000Z
|
2019-08-05T10:27:47.000Z
|
Understanding Python/Dataframe.ipynb
|
swayamxd/machine-learning
|
eb12207c6b2643e7efd28ecd02a3f55e13523bce
|
[
"MIT"
] | null | null | null |
Understanding Python/Dataframe.ipynb
|
swayamxd/machine-learning
|
eb12207c6b2643e7efd28ecd02a3f55e13523bce
|
[
"MIT"
] | 1 |
2019-07-03T04:38:25.000Z
|
2019-07-03T04:38:25.000Z
| 66.217465 | 62,672 | 0.675487 |
[
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"emps = pd.DataFrame({'name':['ram','sam','jadu','madhu'],'age':[19,25,21,23],'salary':[23000,2100,22000,19000]})\nemps",
"_____no_output_____"
],
[
"emps.values",
"_____no_output_____"
],
[
"emps.index",
"_____no_output_____"
],
[
"emps.columns",
"_____no_output_____"
],
[
"emps2 = pd.DataFrame({'names': ['ram','sam','jadu','madhu'], 'age':np.random.randint(20,30,size=(4,)), 'salary':np.random.randint(20000,30000,size=(4,))}, columns=['salary','age','names'])\nemps2",
"_____no_output_____"
],
[
"emps2['age']",
"_____no_output_____"
],
[
"emps2['names'][[0,2]]",
"_____no_output_____"
],
[
"emps[1:]",
"_____no_output_____"
],
[
"emps2[['names','salary']]",
"_____no_output_____"
],
[
"emps2.iloc[[0,3],[1,2]]",
"_____no_output_____"
],
[
"emps2[emps2['salary']>24200]",
"_____no_output_____"
],
[
"from sklearn.datasets import fetch_california_housing\nhousing = fetch_california_housing()",
"_____no_output_____"
],
[
"housing.data",
"_____no_output_____"
],
[
"housing.feature_names",
"_____no_output_____"
],
[
"housing['data']",
"_____no_output_____"
],
[
"housing_df = pd.DataFrame(housing.data,columns=housing.feature_names)\nhousing_df",
"_____no_output_____"
],
[
"housing_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 20640 entries, 0 to 20639\nData columns (total 8 columns):\nMedInc 20640 non-null float64\nHouseAge 20640 non-null float64\nAveRooms 20640 non-null float64\nAveBedrms 20640 non-null float64\nPopulation 20640 non-null float64\nAveOccup 20640 non-null float64\nLatitude 20640 non-null float64\nLongitude 20640 non-null float64\ndtypes: float64(8)\nmemory usage: 1.3 MB\n"
],
[
"housing_df.describe()",
"_____no_output_____"
],
[
"%matplotlib inline\nhousing_df.hist(bins=50,figsize=(20,20))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5169f6135e74345f8f989fd411e40ec9ca7da4a
| 168,962 |
ipynb
|
Jupyter Notebook
|
M2_Convolutional_Neural_Network_in_TensorFlow/Week3/Exercises/Exercise7-TransferLearning/Exercise7-Question.ipynb
|
cmaroblesg/TensorFlow_Developer_DeepLearning.AI
|
42cf4cda6b50b23e53d596f894f2aa28d7d533e6
|
[
"MIT"
] | null | null | null |
M2_Convolutional_Neural_Network_in_TensorFlow/Week3/Exercises/Exercise7-TransferLearning/Exercise7-Question.ipynb
|
cmaroblesg/TensorFlow_Developer_DeepLearning.AI
|
42cf4cda6b50b23e53d596f894f2aa28d7d533e6
|
[
"MIT"
] | null | null | null |
M2_Convolutional_Neural_Network_in_TensorFlow/Week3/Exercises/Exercise7-TransferLearning/Exercise7-Question.ipynb
|
cmaroblesg/TensorFlow_Developer_DeepLearning.AI
|
42cf4cda6b50b23e53d596f894f2aa28d7d533e6
|
[
"MIT"
] | null | null | null | 102.27724 | 14,006 | 0.632562 |
[
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"# Import all the necessary files!\nimport os\nimport tensorflow as tf\nfrom tensorflow.keras import layers\nfrom tensorflow.keras import Model",
"_____no_output_____"
],
[
"# Download the inception v3 weights\n!wget --no-check-certificate \\\n https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \\\n -O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5\n\n# Import the inception model \nfrom tensorflow.keras.applications.inception_v3 import InceptionV3\n\n# Create an instance of the inception model from the local pre-trained weights\nlocal_weights_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'\n\npre_trained_model = InceptionV3(input_shape = (150, 150, 3),\n include_top = False,\n weights = None)\n\npre_trained_model.load_weights(local_weights_file)\n\n# Make all the layers in the pre-trained model non-trainable\nfor layer in pre_trained_model.layers:\n layer.trainable=False\n \n# Print the model summary\npre_trained_model.summary()\n\n# Expected Output is extremely large, but should end with:\n\n#batch_normalization_v1_281 (Bat (None, 3, 3, 192) 576 conv2d_281[0][0] \n#__________________________________________________________________________________________________\n#activation_273 (Activation) (None, 3, 3, 320) 0 batch_normalization_v1_273[0][0] \n#__________________________________________________________________________________________________\n#mixed9_1 (Concatenate) (None, 3, 3, 768) 0 activation_275[0][0] \n# activation_276[0][0] \n#__________________________________________________________________________________________________\n#concatenate_5 (Concatenate) (None, 3, 3, 768) 0 activation_279[0][0] \n# activation_280[0][0] \n#__________________________________________________________________________________________________\n#activation_281 (Activation) (None, 3, 3, 192) 0 batch_normalization_v1_281[0][0] \n#__________________________________________________________________________________________________\n#mixed10 (Concatenate) (None, 3, 3, 2048) 0 activation_273[0][0] \n# mixed9_1[0][0] \n# concatenate_5[0][0] \n# activation_281[0][0] \n#==================================================================================================\n#Total params: 21,802,784\n#Trainable params: 0\n#Non-trainable params: 21,802,784",
"--2021-05-21 05:30:14-- https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5\nResolving storage.googleapis.com (storage.googleapis.com)... 142.251.33.208, 172.217.8.16, 172.217.13.80, ...\nConnecting to storage.googleapis.com (storage.googleapis.com)|142.251.33.208|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 87910968 (84M) [application/x-hdf]\nSaving to: ‘/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5’\n\n/tmp/inception_v3_w 100%[===================>] 83.84M 183MB/s in 0.5s \n\n2021-05-21 05:30:15 (183 MB/s) - ‘/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5’ saved [87910968/87910968]\n\nModel: \"inception_v3\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) [(None, 150, 150, 3) 0 \n__________________________________________________________________________________________________\nconv2d (Conv2D) (None, 74, 74, 32) 864 input_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization (BatchNorma (None, 74, 74, 32) 96 conv2d[0][0] \n__________________________________________________________________________________________________\nactivation (Activation) (None, 74, 74, 32) 0 batch_normalization[0][0] \n__________________________________________________________________________________________________\nconv2d_1 (Conv2D) (None, 72, 72, 32) 9216 activation[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_1 (BatchNor (None, 72, 72, 32) 96 conv2d_1[0][0] \n__________________________________________________________________________________________________\nactivation_1 (Activation) (None, 72, 72, 32) 0 batch_normalization_1[0][0] \n__________________________________________________________________________________________________\nconv2d_2 (Conv2D) (None, 72, 72, 64) 18432 activation_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_2 (BatchNor (None, 72, 72, 64) 192 conv2d_2[0][0] \n__________________________________________________________________________________________________\nactivation_2 (Activation) (None, 72, 72, 64) 0 batch_normalization_2[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 35, 35, 64) 0 activation_2[0][0] \n__________________________________________________________________________________________________\nconv2d_3 (Conv2D) (None, 35, 35, 80) 5120 max_pooling2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_3 (BatchNor (None, 35, 35, 80) 240 conv2d_3[0][0] \n__________________________________________________________________________________________________\nactivation_3 (Activation) (None, 35, 35, 80) 0 batch_normalization_3[0][0] \n__________________________________________________________________________________________________\nconv2d_4 (Conv2D) (None, 33, 33, 192) 138240 activation_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_4 (BatchNor (None, 33, 33, 192) 576 conv2d_4[0][0] \n__________________________________________________________________________________________________\nactivation_4 (Activation) (None, 33, 33, 192) 0 batch_normalization_4[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, 16, 16, 192) 0 activation_4[0][0] \n__________________________________________________________________________________________________\nconv2d_8 (Conv2D) (None, 16, 16, 64) 12288 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_8 (BatchNor (None, 16, 16, 64) 192 conv2d_8[0][0] \n__________________________________________________________________________________________________\nactivation_8 (Activation) (None, 16, 16, 64) 0 batch_normalization_8[0][0] \n__________________________________________________________________________________________________\nconv2d_6 (Conv2D) (None, 16, 16, 48) 9216 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_9 (Conv2D) (None, 16, 16, 96) 55296 activation_8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_6 (BatchNor (None, 16, 16, 48) 144 conv2d_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_9 (BatchNor (None, 16, 16, 96) 288 conv2d_9[0][0] \n__________________________________________________________________________________________________\nactivation_6 (Activation) (None, 16, 16, 48) 0 batch_normalization_6[0][0] \n__________________________________________________________________________________________________\nactivation_9 (Activation) (None, 16, 16, 96) 0 batch_normalization_9[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d (AveragePooli (None, 16, 16, 192) 0 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_5 (Conv2D) (None, 16, 16, 64) 12288 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_7 (Conv2D) (None, 16, 16, 64) 76800 activation_6[0][0] \n__________________________________________________________________________________________________\nconv2d_10 (Conv2D) (None, 16, 16, 96) 82944 activation_9[0][0] \n__________________________________________________________________________________________________\nconv2d_11 (Conv2D) (None, 16, 16, 32) 6144 average_pooling2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_5 (BatchNor (None, 16, 16, 64) 192 conv2d_5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_7 (BatchNor (None, 16, 16, 64) 192 conv2d_7[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_10 (BatchNo (None, 16, 16, 96) 288 conv2d_10[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_11 (BatchNo (None, 16, 16, 32) 96 conv2d_11[0][0] \n__________________________________________________________________________________________________\nactivation_5 (Activation) (None, 16, 16, 64) 0 batch_normalization_5[0][0] \n__________________________________________________________________________________________________\nactivation_7 (Activation) (None, 16, 16, 64) 0 batch_normalization_7[0][0] \n__________________________________________________________________________________________________\nactivation_10 (Activation) (None, 16, 16, 96) 0 batch_normalization_10[0][0] \n__________________________________________________________________________________________________\nactivation_11 (Activation) (None, 16, 16, 32) 0 batch_normalization_11[0][0] \n__________________________________________________________________________________________________\nmixed0 (Concatenate) (None, 16, 16, 256) 0 activation_5[0][0] \n activation_7[0][0] \n activation_10[0][0] \n activation_11[0][0] \n__________________________________________________________________________________________________\nconv2d_15 (Conv2D) (None, 16, 16, 64) 16384 mixed0[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_15 (BatchNo (None, 16, 16, 64) 192 conv2d_15[0][0] \n__________________________________________________________________________________________________\nactivation_15 (Activation) (None, 16, 16, 64) 0 batch_normalization_15[0][0] \n__________________________________________________________________________________________________\nconv2d_13 (Conv2D) (None, 16, 16, 48) 12288 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_16 (Conv2D) (None, 16, 16, 96) 55296 activation_15[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_13 (BatchNo (None, 16, 16, 48) 144 conv2d_13[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_16 (BatchNo (None, 16, 16, 96) 288 conv2d_16[0][0] \n__________________________________________________________________________________________________\nactivation_13 (Activation) (None, 16, 16, 48) 0 batch_normalization_13[0][0] \n__________________________________________________________________________________________________\nactivation_16 (Activation) (None, 16, 16, 96) 0 batch_normalization_16[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_1 (AveragePoo (None, 16, 16, 256) 0 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_12 (Conv2D) (None, 16, 16, 64) 16384 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_14 (Conv2D) (None, 16, 16, 64) 76800 activation_13[0][0] \n__________________________________________________________________________________________________\nconv2d_17 (Conv2D) (None, 16, 16, 96) 82944 activation_16[0][0] \n__________________________________________________________________________________________________\nconv2d_18 (Conv2D) (None, 16, 16, 64) 16384 average_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_12 (BatchNo (None, 16, 16, 64) 192 conv2d_12[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_14 (BatchNo (None, 16, 16, 64) 192 conv2d_14[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_17 (BatchNo (None, 16, 16, 96) 288 conv2d_17[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_18 (BatchNo (None, 16, 16, 64) 192 conv2d_18[0][0] \n__________________________________________________________________________________________________\nactivation_12 (Activation) (None, 16, 16, 64) 0 batch_normalization_12[0][0] \n__________________________________________________________________________________________________\nactivation_14 (Activation) (None, 16, 16, 64) 0 batch_normalization_14[0][0] \n__________________________________________________________________________________________________\nactivation_17 (Activation) (None, 16, 16, 96) 0 batch_normalization_17[0][0] \n__________________________________________________________________________________________________\nactivation_18 (Activation) (None, 16, 16, 64) 0 batch_normalization_18[0][0] \n__________________________________________________________________________________________________\nmixed1 (Concatenate) (None, 16, 16, 288) 0 activation_12[0][0] \n activation_14[0][0] \n activation_17[0][0] \n activation_18[0][0] \n__________________________________________________________________________________________________\nconv2d_22 (Conv2D) (None, 16, 16, 64) 18432 mixed1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_22 (BatchNo (None, 16, 16, 64) 192 conv2d_22[0][0] \n__________________________________________________________________________________________________\nactivation_22 (Activation) (None, 16, 16, 64) 0 batch_normalization_22[0][0] \n__________________________________________________________________________________________________\nconv2d_20 (Conv2D) (None, 16, 16, 48) 13824 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_23 (Conv2D) (None, 16, 16, 96) 55296 activation_22[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_20 (BatchNo (None, 16, 16, 48) 144 conv2d_20[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_23 (BatchNo (None, 16, 16, 96) 288 conv2d_23[0][0] \n__________________________________________________________________________________________________\nactivation_20 (Activation) (None, 16, 16, 48) 0 batch_normalization_20[0][0] \n__________________________________________________________________________________________________\nactivation_23 (Activation) (None, 16, 16, 96) 0 batch_normalization_23[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_2 (AveragePoo (None, 16, 16, 288) 0 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_19 (Conv2D) (None, 16, 16, 64) 18432 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_21 (Conv2D) (None, 16, 16, 64) 76800 activation_20[0][0] \n__________________________________________________________________________________________________\nconv2d_24 (Conv2D) (None, 16, 16, 96) 82944 activation_23[0][0] \n__________________________________________________________________________________________________\nconv2d_25 (Conv2D) (None, 16, 16, 64) 18432 average_pooling2d_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_19 (BatchNo (None, 16, 16, 64) 192 conv2d_19[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_21 (BatchNo (None, 16, 16, 64) 192 conv2d_21[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_24 (BatchNo (None, 16, 16, 96) 288 conv2d_24[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_25 (BatchNo (None, 16, 16, 64) 192 conv2d_25[0][0] \n__________________________________________________________________________________________________\nactivation_19 (Activation) (None, 16, 16, 64) 0 batch_normalization_19[0][0] \n__________________________________________________________________________________________________\nactivation_21 (Activation) (None, 16, 16, 64) 0 batch_normalization_21[0][0] \n__________________________________________________________________________________________________\nactivation_24 (Activation) (None, 16, 16, 96) 0 batch_normalization_24[0][0] \n__________________________________________________________________________________________________\nactivation_25 (Activation) (None, 16, 16, 64) 0 batch_normalization_25[0][0] \n__________________________________________________________________________________________________\nmixed2 (Concatenate) (None, 16, 16, 288) 0 activation_19[0][0] \n activation_21[0][0] \n activation_24[0][0] \n activation_25[0][0] \n__________________________________________________________________________________________________\nconv2d_27 (Conv2D) (None, 16, 16, 64) 18432 mixed2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_27 (BatchNo (None, 16, 16, 64) 192 conv2d_27[0][0] \n__________________________________________________________________________________________________\nactivation_27 (Activation) (None, 16, 16, 64) 0 batch_normalization_27[0][0] \n__________________________________________________________________________________________________\nconv2d_28 (Conv2D) (None, 16, 16, 96) 55296 activation_27[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_28 (BatchNo (None, 16, 16, 96) 288 conv2d_28[0][0] \n__________________________________________________________________________________________________\nactivation_28 (Activation) (None, 16, 16, 96) 0 batch_normalization_28[0][0] \n__________________________________________________________________________________________________\nconv2d_26 (Conv2D) (None, 7, 7, 384) 995328 mixed2[0][0] \n__________________________________________________________________________________________________\nconv2d_29 (Conv2D) (None, 7, 7, 96) 82944 activation_28[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_26 (BatchNo (None, 7, 7, 384) 1152 conv2d_26[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_29 (BatchNo (None, 7, 7, 96) 288 conv2d_29[0][0] \n__________________________________________________________________________________________________\nactivation_26 (Activation) (None, 7, 7, 384) 0 batch_normalization_26[0][0] \n__________________________________________________________________________________________________\nactivation_29 (Activation) (None, 7, 7, 96) 0 batch_normalization_29[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_2 (MaxPooling2D) (None, 7, 7, 288) 0 mixed2[0][0] \n__________________________________________________________________________________________________\nmixed3 (Concatenate) (None, 7, 7, 768) 0 activation_26[0][0] \n activation_29[0][0] \n max_pooling2d_2[0][0] \n__________________________________________________________________________________________________\nconv2d_34 (Conv2D) (None, 7, 7, 128) 98304 mixed3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_34 (BatchNo (None, 7, 7, 128) 384 conv2d_34[0][0] \n__________________________________________________________________________________________________\nactivation_34 (Activation) (None, 7, 7, 128) 0 batch_normalization_34[0][0] \n__________________________________________________________________________________________________\nconv2d_35 (Conv2D) (None, 7, 7, 128) 114688 activation_34[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_35 (BatchNo (None, 7, 7, 128) 384 conv2d_35[0][0] \n__________________________________________________________________________________________________\nactivation_35 (Activation) (None, 7, 7, 128) 0 batch_normalization_35[0][0] \n__________________________________________________________________________________________________\nconv2d_31 (Conv2D) (None, 7, 7, 128) 98304 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_36 (Conv2D) (None, 7, 7, 128) 114688 activation_35[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_31 (BatchNo (None, 7, 7, 128) 384 conv2d_31[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_36 (BatchNo (None, 7, 7, 128) 384 conv2d_36[0][0] \n__________________________________________________________________________________________________\nactivation_31 (Activation) (None, 7, 7, 128) 0 batch_normalization_31[0][0] \n__________________________________________________________________________________________________\nactivation_36 (Activation) (None, 7, 7, 128) 0 batch_normalization_36[0][0] \n__________________________________________________________________________________________________\nconv2d_32 (Conv2D) (None, 7, 7, 128) 114688 activation_31[0][0] \n__________________________________________________________________________________________________\nconv2d_37 (Conv2D) (None, 7, 7, 128) 114688 activation_36[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_32 (BatchNo (None, 7, 7, 128) 384 conv2d_32[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_37 (BatchNo (None, 7, 7, 128) 384 conv2d_37[0][0] \n__________________________________________________________________________________________________\nactivation_32 (Activation) (None, 7, 7, 128) 0 batch_normalization_32[0][0] \n__________________________________________________________________________________________________\nactivation_37 (Activation) (None, 7, 7, 128) 0 batch_normalization_37[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_3 (AveragePoo (None, 7, 7, 768) 0 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_30 (Conv2D) (None, 7, 7, 192) 147456 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_33 (Conv2D) (None, 7, 7, 192) 172032 activation_32[0][0] \n__________________________________________________________________________________________________\nconv2d_38 (Conv2D) (None, 7, 7, 192) 172032 activation_37[0][0] \n__________________________________________________________________________________________________\nconv2d_39 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_30 (BatchNo (None, 7, 7, 192) 576 conv2d_30[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_33 (BatchNo (None, 7, 7, 192) 576 conv2d_33[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_38 (BatchNo (None, 7, 7, 192) 576 conv2d_38[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_39 (BatchNo (None, 7, 7, 192) 576 conv2d_39[0][0] \n__________________________________________________________________________________________________\nactivation_30 (Activation) (None, 7, 7, 192) 0 batch_normalization_30[0][0] \n__________________________________________________________________________________________________\nactivation_33 (Activation) (None, 7, 7, 192) 0 batch_normalization_33[0][0] \n__________________________________________________________________________________________________\nactivation_38 (Activation) (None, 7, 7, 192) 0 batch_normalization_38[0][0] \n__________________________________________________________________________________________________\nactivation_39 (Activation) (None, 7, 7, 192) 0 batch_normalization_39[0][0] \n__________________________________________________________________________________________________\nmixed4 (Concatenate) (None, 7, 7, 768) 0 activation_30[0][0] \n activation_33[0][0] \n activation_38[0][0] \n activation_39[0][0] \n__________________________________________________________________________________________________\nconv2d_44 (Conv2D) (None, 7, 7, 160) 122880 mixed4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_44 (BatchNo (None, 7, 7, 160) 480 conv2d_44[0][0] \n__________________________________________________________________________________________________\nactivation_44 (Activation) (None, 7, 7, 160) 0 batch_normalization_44[0][0] \n__________________________________________________________________________________________________\nconv2d_45 (Conv2D) (None, 7, 7, 160) 179200 activation_44[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_45 (BatchNo (None, 7, 7, 160) 480 conv2d_45[0][0] \n__________________________________________________________________________________________________\nactivation_45 (Activation) (None, 7, 7, 160) 0 batch_normalization_45[0][0] \n__________________________________________________________________________________________________\nconv2d_41 (Conv2D) (None, 7, 7, 160) 122880 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_46 (Conv2D) (None, 7, 7, 160) 179200 activation_45[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_41 (BatchNo (None, 7, 7, 160) 480 conv2d_41[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_46 (BatchNo (None, 7, 7, 160) 480 conv2d_46[0][0] \n__________________________________________________________________________________________________\nactivation_41 (Activation) (None, 7, 7, 160) 0 batch_normalization_41[0][0] \n__________________________________________________________________________________________________\nactivation_46 (Activation) (None, 7, 7, 160) 0 batch_normalization_46[0][0] \n__________________________________________________________________________________________________\nconv2d_42 (Conv2D) (None, 7, 7, 160) 179200 activation_41[0][0] \n__________________________________________________________________________________________________\nconv2d_47 (Conv2D) (None, 7, 7, 160) 179200 activation_46[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_42 (BatchNo (None, 7, 7, 160) 480 conv2d_42[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_47 (BatchNo (None, 7, 7, 160) 480 conv2d_47[0][0] \n__________________________________________________________________________________________________\nactivation_42 (Activation) (None, 7, 7, 160) 0 batch_normalization_42[0][0] \n__________________________________________________________________________________________________\nactivation_47 (Activation) (None, 7, 7, 160) 0 batch_normalization_47[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_4 (AveragePoo (None, 7, 7, 768) 0 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_40 (Conv2D) (None, 7, 7, 192) 147456 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_43 (Conv2D) (None, 7, 7, 192) 215040 activation_42[0][0] \n__________________________________________________________________________________________________\nconv2d_48 (Conv2D) (None, 7, 7, 192) 215040 activation_47[0][0] \n__________________________________________________________________________________________________\nconv2d_49 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_40 (BatchNo (None, 7, 7, 192) 576 conv2d_40[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_43 (BatchNo (None, 7, 7, 192) 576 conv2d_43[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_48 (BatchNo (None, 7, 7, 192) 576 conv2d_48[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_49 (BatchNo (None, 7, 7, 192) 576 conv2d_49[0][0] \n__________________________________________________________________________________________________\nactivation_40 (Activation) (None, 7, 7, 192) 0 batch_normalization_40[0][0] \n__________________________________________________________________________________________________\nactivation_43 (Activation) (None, 7, 7, 192) 0 batch_normalization_43[0][0] \n__________________________________________________________________________________________________\nactivation_48 (Activation) (None, 7, 7, 192) 0 batch_normalization_48[0][0] \n__________________________________________________________________________________________________\nactivation_49 (Activation) (None, 7, 7, 192) 0 batch_normalization_49[0][0] \n__________________________________________________________________________________________________\nmixed5 (Concatenate) (None, 7, 7, 768) 0 activation_40[0][0] \n activation_43[0][0] \n activation_48[0][0] \n activation_49[0][0] \n__________________________________________________________________________________________________\nconv2d_54 (Conv2D) (None, 7, 7, 160) 122880 mixed5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_54 (BatchNo (None, 7, 7, 160) 480 conv2d_54[0][0] \n__________________________________________________________________________________________________\nactivation_54 (Activation) (None, 7, 7, 160) 0 batch_normalization_54[0][0] \n__________________________________________________________________________________________________\nconv2d_55 (Conv2D) (None, 7, 7, 160) 179200 activation_54[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_55 (BatchNo (None, 7, 7, 160) 480 conv2d_55[0][0] \n__________________________________________________________________________________________________\nactivation_55 (Activation) (None, 7, 7, 160) 0 batch_normalization_55[0][0] \n__________________________________________________________________________________________________\nconv2d_51 (Conv2D) (None, 7, 7, 160) 122880 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_56 (Conv2D) (None, 7, 7, 160) 179200 activation_55[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_51 (BatchNo (None, 7, 7, 160) 480 conv2d_51[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_56 (BatchNo (None, 7, 7, 160) 480 conv2d_56[0][0] \n__________________________________________________________________________________________________\nactivation_51 (Activation) (None, 7, 7, 160) 0 batch_normalization_51[0][0] \n__________________________________________________________________________________________________\nactivation_56 (Activation) (None, 7, 7, 160) 0 batch_normalization_56[0][0] \n__________________________________________________________________________________________________\nconv2d_52 (Conv2D) (None, 7, 7, 160) 179200 activation_51[0][0] \n__________________________________________________________________________________________________\nconv2d_57 (Conv2D) (None, 7, 7, 160) 179200 activation_56[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_52 (BatchNo (None, 7, 7, 160) 480 conv2d_52[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_57 (BatchNo (None, 7, 7, 160) 480 conv2d_57[0][0] \n__________________________________________________________________________________________________\nactivation_52 (Activation) (None, 7, 7, 160) 0 batch_normalization_52[0][0] \n__________________________________________________________________________________________________\nactivation_57 (Activation) (None, 7, 7, 160) 0 batch_normalization_57[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_5 (AveragePoo (None, 7, 7, 768) 0 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_50 (Conv2D) (None, 7, 7, 192) 147456 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_53 (Conv2D) (None, 7, 7, 192) 215040 activation_52[0][0] \n__________________________________________________________________________________________________\nconv2d_58 (Conv2D) (None, 7, 7, 192) 215040 activation_57[0][0] \n__________________________________________________________________________________________________\nconv2d_59 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_50 (BatchNo (None, 7, 7, 192) 576 conv2d_50[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_53 (BatchNo (None, 7, 7, 192) 576 conv2d_53[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_58 (BatchNo (None, 7, 7, 192) 576 conv2d_58[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_59 (BatchNo (None, 7, 7, 192) 576 conv2d_59[0][0] \n__________________________________________________________________________________________________\nactivation_50 (Activation) (None, 7, 7, 192) 0 batch_normalization_50[0][0] \n__________________________________________________________________________________________________\nactivation_53 (Activation) (None, 7, 7, 192) 0 batch_normalization_53[0][0] \n__________________________________________________________________________________________________\nactivation_58 (Activation) (None, 7, 7, 192) 0 batch_normalization_58[0][0] \n__________________________________________________________________________________________________\nactivation_59 (Activation) (None, 7, 7, 192) 0 batch_normalization_59[0][0] \n__________________________________________________________________________________________________\nmixed6 (Concatenate) (None, 7, 7, 768) 0 activation_50[0][0] \n activation_53[0][0] \n activation_58[0][0] \n activation_59[0][0] \n__________________________________________________________________________________________________\nconv2d_64 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_64 (BatchNo (None, 7, 7, 192) 576 conv2d_64[0][0] \n__________________________________________________________________________________________________\nactivation_64 (Activation) (None, 7, 7, 192) 0 batch_normalization_64[0][0] \n__________________________________________________________________________________________________\nconv2d_65 (Conv2D) (None, 7, 7, 192) 258048 activation_64[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_65 (BatchNo (None, 7, 7, 192) 576 conv2d_65[0][0] \n__________________________________________________________________________________________________\nactivation_65 (Activation) (None, 7, 7, 192) 0 batch_normalization_65[0][0] \n__________________________________________________________________________________________________\nconv2d_61 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_66 (Conv2D) (None, 7, 7, 192) 258048 activation_65[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_61 (BatchNo (None, 7, 7, 192) 576 conv2d_61[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_66 (BatchNo (None, 7, 7, 192) 576 conv2d_66[0][0] \n__________________________________________________________________________________________________\nactivation_61 (Activation) (None, 7, 7, 192) 0 batch_normalization_61[0][0] \n__________________________________________________________________________________________________\nactivation_66 (Activation) (None, 7, 7, 192) 0 batch_normalization_66[0][0] \n__________________________________________________________________________________________________\nconv2d_62 (Conv2D) (None, 7, 7, 192) 258048 activation_61[0][0] \n__________________________________________________________________________________________________\nconv2d_67 (Conv2D) (None, 7, 7, 192) 258048 activation_66[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_62 (BatchNo (None, 7, 7, 192) 576 conv2d_62[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_67 (BatchNo (None, 7, 7, 192) 576 conv2d_67[0][0] \n__________________________________________________________________________________________________\nactivation_62 (Activation) (None, 7, 7, 192) 0 batch_normalization_62[0][0] \n__________________________________________________________________________________________________\nactivation_67 (Activation) (None, 7, 7, 192) 0 batch_normalization_67[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_6 (AveragePoo (None, 7, 7, 768) 0 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_60 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_63 (Conv2D) (None, 7, 7, 192) 258048 activation_62[0][0] \n__________________________________________________________________________________________________\nconv2d_68 (Conv2D) (None, 7, 7, 192) 258048 activation_67[0][0] \n__________________________________________________________________________________________________\nconv2d_69 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_60 (BatchNo (None, 7, 7, 192) 576 conv2d_60[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_63 (BatchNo (None, 7, 7, 192) 576 conv2d_63[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_68 (BatchNo (None, 7, 7, 192) 576 conv2d_68[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_69 (BatchNo (None, 7, 7, 192) 576 conv2d_69[0][0] \n__________________________________________________________________________________________________\nactivation_60 (Activation) (None, 7, 7, 192) 0 batch_normalization_60[0][0] \n__________________________________________________________________________________________________\nactivation_63 (Activation) (None, 7, 7, 192) 0 batch_normalization_63[0][0] \n__________________________________________________________________________________________________\nactivation_68 (Activation) (None, 7, 7, 192) 0 batch_normalization_68[0][0] \n__________________________________________________________________________________________________\nactivation_69 (Activation) (None, 7, 7, 192) 0 batch_normalization_69[0][0] \n__________________________________________________________________________________________________\nmixed7 (Concatenate) (None, 7, 7, 768) 0 activation_60[0][0] \n activation_63[0][0] \n activation_68[0][0] \n activation_69[0][0] \n__________________________________________________________________________________________________\nconv2d_72 (Conv2D) (None, 7, 7, 192) 147456 mixed7[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_72 (BatchNo (None, 7, 7, 192) 576 conv2d_72[0][0] \n__________________________________________________________________________________________________\nactivation_72 (Activation) (None, 7, 7, 192) 0 batch_normalization_72[0][0] \n__________________________________________________________________________________________________\nconv2d_73 (Conv2D) (None, 7, 7, 192) 258048 activation_72[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_73 (BatchNo (None, 7, 7, 192) 576 conv2d_73[0][0] \n__________________________________________________________________________________________________\nactivation_73 (Activation) (None, 7, 7, 192) 0 batch_normalization_73[0][0] \n__________________________________________________________________________________________________\nconv2d_70 (Conv2D) (None, 7, 7, 192) 147456 mixed7[0][0] \n__________________________________________________________________________________________________\nconv2d_74 (Conv2D) (None, 7, 7, 192) 258048 activation_73[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_70 (BatchNo (None, 7, 7, 192) 576 conv2d_70[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_74 (BatchNo (None, 7, 7, 192) 576 conv2d_74[0][0] \n__________________________________________________________________________________________________\nactivation_70 (Activation) (None, 7, 7, 192) 0 batch_normalization_70[0][0] \n__________________________________________________________________________________________________\nactivation_74 (Activation) (None, 7, 7, 192) 0 batch_normalization_74[0][0] \n__________________________________________________________________________________________________\nconv2d_71 (Conv2D) (None, 3, 3, 320) 552960 activation_70[0][0] \n__________________________________________________________________________________________________\nconv2d_75 (Conv2D) (None, 3, 3, 192) 331776 activation_74[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_71 (BatchNo (None, 3, 3, 320) 960 conv2d_71[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_75 (BatchNo (None, 3, 3, 192) 576 conv2d_75[0][0] \n__________________________________________________________________________________________________\nactivation_71 (Activation) (None, 3, 3, 320) 0 batch_normalization_71[0][0] \n__________________________________________________________________________________________________\nactivation_75 (Activation) (None, 3, 3, 192) 0 batch_normalization_75[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_3 (MaxPooling2D) (None, 3, 3, 768) 0 mixed7[0][0] \n__________________________________________________________________________________________________\nmixed8 (Concatenate) (None, 3, 3, 1280) 0 activation_71[0][0] \n activation_75[0][0] \n max_pooling2d_3[0][0] \n__________________________________________________________________________________________________\nconv2d_80 (Conv2D) (None, 3, 3, 448) 573440 mixed8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_80 (BatchNo (None, 3, 3, 448) 1344 conv2d_80[0][0] \n__________________________________________________________________________________________________\nactivation_80 (Activation) (None, 3, 3, 448) 0 batch_normalization_80[0][0] \n__________________________________________________________________________________________________\nconv2d_77 (Conv2D) (None, 3, 3, 384) 491520 mixed8[0][0] \n__________________________________________________________________________________________________\nconv2d_81 (Conv2D) (None, 3, 3, 384) 1548288 activation_80[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_77 (BatchNo (None, 3, 3, 384) 1152 conv2d_77[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_81 (BatchNo (None, 3, 3, 384) 1152 conv2d_81[0][0] \n__________________________________________________________________________________________________\nactivation_77 (Activation) (None, 3, 3, 384) 0 batch_normalization_77[0][0] \n__________________________________________________________________________________________________\nactivation_81 (Activation) (None, 3, 3, 384) 0 batch_normalization_81[0][0] \n__________________________________________________________________________________________________\nconv2d_78 (Conv2D) (None, 3, 3, 384) 442368 activation_77[0][0] \n__________________________________________________________________________________________________\nconv2d_79 (Conv2D) (None, 3, 3, 384) 442368 activation_77[0][0] \n__________________________________________________________________________________________________\nconv2d_82 (Conv2D) (None, 3, 3, 384) 442368 activation_81[0][0] \n__________________________________________________________________________________________________\nconv2d_83 (Conv2D) (None, 3, 3, 384) 442368 activation_81[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_7 (AveragePoo (None, 3, 3, 1280) 0 mixed8[0][0] \n__________________________________________________________________________________________________\nconv2d_76 (Conv2D) (None, 3, 3, 320) 409600 mixed8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_78 (BatchNo (None, 3, 3, 384) 1152 conv2d_78[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_79 (BatchNo (None, 3, 3, 384) 1152 conv2d_79[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_82 (BatchNo (None, 3, 3, 384) 1152 conv2d_82[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_83 (BatchNo (None, 3, 3, 384) 1152 conv2d_83[0][0] \n__________________________________________________________________________________________________\nconv2d_84 (Conv2D) (None, 3, 3, 192) 245760 average_pooling2d_7[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_76 (BatchNo (None, 3, 3, 320) 960 conv2d_76[0][0] \n__________________________________________________________________________________________________\nactivation_78 (Activation) (None, 3, 3, 384) 0 batch_normalization_78[0][0] \n__________________________________________________________________________________________________\nactivation_79 (Activation) (None, 3, 3, 384) 0 batch_normalization_79[0][0] \n__________________________________________________________________________________________________\nactivation_82 (Activation) (None, 3, 3, 384) 0 batch_normalization_82[0][0] \n__________________________________________________________________________________________________\nactivation_83 (Activation) (None, 3, 3, 384) 0 batch_normalization_83[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_84 (BatchNo (None, 3, 3, 192) 576 conv2d_84[0][0] \n__________________________________________________________________________________________________\nactivation_76 (Activation) (None, 3, 3, 320) 0 batch_normalization_76[0][0] \n__________________________________________________________________________________________________\nmixed9_0 (Concatenate) (None, 3, 3, 768) 0 activation_78[0][0] \n activation_79[0][0] \n__________________________________________________________________________________________________\nconcatenate (Concatenate) (None, 3, 3, 768) 0 activation_82[0][0] \n activation_83[0][0] \n__________________________________________________________________________________________________\nactivation_84 (Activation) (None, 3, 3, 192) 0 batch_normalization_84[0][0] \n__________________________________________________________________________________________________\nmixed9 (Concatenate) (None, 3, 3, 2048) 0 activation_76[0][0] \n mixed9_0[0][0] \n concatenate[0][0] \n activation_84[0][0] \n__________________________________________________________________________________________________\nconv2d_89 (Conv2D) (None, 3, 3, 448) 917504 mixed9[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_89 (BatchNo (None, 3, 3, 448) 1344 conv2d_89[0][0] \n__________________________________________________________________________________________________\nactivation_89 (Activation) (None, 3, 3, 448) 0 batch_normalization_89[0][0] \n__________________________________________________________________________________________________\nconv2d_86 (Conv2D) (None, 3, 3, 384) 786432 mixed9[0][0] \n__________________________________________________________________________________________________\nconv2d_90 (Conv2D) (None, 3, 3, 384) 1548288 activation_89[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_86 (BatchNo (None, 3, 3, 384) 1152 conv2d_86[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_90 (BatchNo (None, 3, 3, 384) 1152 conv2d_90[0][0] \n__________________________________________________________________________________________________\nactivation_86 (Activation) (None, 3, 3, 384) 0 batch_normalization_86[0][0] \n__________________________________________________________________________________________________\nactivation_90 (Activation) (None, 3, 3, 384) 0 batch_normalization_90[0][0] \n__________________________________________________________________________________________________\nconv2d_87 (Conv2D) (None, 3, 3, 384) 442368 activation_86[0][0] \n__________________________________________________________________________________________________\nconv2d_88 (Conv2D) (None, 3, 3, 384) 442368 activation_86[0][0] \n__________________________________________________________________________________________________\nconv2d_91 (Conv2D) (None, 3, 3, 384) 442368 activation_90[0][0] \n__________________________________________________________________________________________________\nconv2d_92 (Conv2D) (None, 3, 3, 384) 442368 activation_90[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_8 (AveragePoo (None, 3, 3, 2048) 0 mixed9[0][0] \n__________________________________________________________________________________________________\nconv2d_85 (Conv2D) (None, 3, 3, 320) 655360 mixed9[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_87 (BatchNo (None, 3, 3, 384) 1152 conv2d_87[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_88 (BatchNo (None, 3, 3, 384) 1152 conv2d_88[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_91 (BatchNo (None, 3, 3, 384) 1152 conv2d_91[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_92 (BatchNo (None, 3, 3, 384) 1152 conv2d_92[0][0] \n__________________________________________________________________________________________________\nconv2d_93 (Conv2D) (None, 3, 3, 192) 393216 average_pooling2d_8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_85 (BatchNo (None, 3, 3, 320) 960 conv2d_85[0][0] \n__________________________________________________________________________________________________\nactivation_87 (Activation) (None, 3, 3, 384) 0 batch_normalization_87[0][0] \n__________________________________________________________________________________________________\nactivation_88 (Activation) (None, 3, 3, 384) 0 batch_normalization_88[0][0] \n__________________________________________________________________________________________________\nactivation_91 (Activation) (None, 3, 3, 384) 0 batch_normalization_91[0][0] \n__________________________________________________________________________________________________\nactivation_92 (Activation) (None, 3, 3, 384) 0 batch_normalization_92[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_93 (BatchNo (None, 3, 3, 192) 576 conv2d_93[0][0] \n__________________________________________________________________________________________________\nactivation_85 (Activation) (None, 3, 3, 320) 0 batch_normalization_85[0][0] \n__________________________________________________________________________________________________\nmixed9_1 (Concatenate) (None, 3, 3, 768) 0 activation_87[0][0] \n activation_88[0][0] \n__________________________________________________________________________________________________\nconcatenate_1 (Concatenate) (None, 3, 3, 768) 0 activation_91[0][0] \n activation_92[0][0] \n__________________________________________________________________________________________________\nactivation_93 (Activation) (None, 3, 3, 192) 0 batch_normalization_93[0][0] \n__________________________________________________________________________________________________\nmixed10 (Concatenate) (None, 3, 3, 2048) 0 activation_85[0][0] \n mixed9_1[0][0] \n concatenate_1[0][0] \n activation_93[0][0] \n==================================================================================================\nTotal params: 21,802,784\nTrainable params: 0\nNon-trainable params: 21,802,784\n__________________________________________________________________________________________________\n"
],
[
"last_layer = pre_trained_model.get_layer('mixed7')\nprint('last layer output shape: ', last_layer.output_shape)\nlast_output = last_layer.output\n\n# Expected Output:\n# ('last layer output shape: ', (None, 7, 7, 768))",
"last layer output shape: (None, 7, 7, 768)\n"
],
[
"# Define a Callback class that stops training once accuracy reaches 99.9%\nclass myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if(logs.get('accuracy')>0.999):\n print(\"\\nReached 99.9% accuracy so cancelling training!\")\n self.model.stop_training = True",
"_____no_output_____"
],
[
"from tensorflow.keras.optimizers import RMSprop\n\n# Flatten the output layer to 1 dimension\nx = layers.Flatten()(last_output)\n# Add a fully connected layer with 1,024 hidden units and ReLU activation\nx = layers.Dense(1024, activation='relu')(x)\n# Add a dropout rate of 0.2\nx = layers.Dropout(0.2)(x) \n# Add a final sigmoid layer for classification\nx = layers.Dense (1, activation='sigmoid')(x) \n\nmodel = Model( pre_trained_model.input, x) \n\nmodel.compile(optimizer = RMSprop(lr=0.0001), \n loss = 'binary_crossentropy', \n metrics = ['accuracy'])\n\nmodel.summary()\n\n# Expected output will be large. Last few lines should be:\n\n# mixed7 (Concatenate) (None, 7, 7, 768) 0 activation_248[0][0] \n# activation_251[0][0] \n# activation_256[0][0] \n# activation_257[0][0] \n# __________________________________________________________________________________________________\n# flatten_4 (Flatten) (None, 37632) 0 mixed7[0][0] \n# __________________________________________________________________________________________________\n# dense_8 (Dense) (None, 1024) 38536192 flatten_4[0][0] \n# __________________________________________________________________________________________________\n# dropout_4 (Dropout) (None, 1024) 0 dense_8[0][0] \n# __________________________________________________________________________________________________\n# dense_9 (Dense) (None, 1) 1025 dropout_4[0][0] \n# ==================================================================================================\n# Total params: 47,512,481\n# Trainable params: 38,537,217\n# Non-trainable params: 8,975,264\n",
"Model: \"model\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) [(None, 150, 150, 3) 0 \n__________________________________________________________________________________________________\nconv2d (Conv2D) (None, 74, 74, 32) 864 input_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization (BatchNorma (None, 74, 74, 32) 96 conv2d[0][0] \n__________________________________________________________________________________________________\nactivation (Activation) (None, 74, 74, 32) 0 batch_normalization[0][0] \n__________________________________________________________________________________________________\nconv2d_1 (Conv2D) (None, 72, 72, 32) 9216 activation[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_1 (BatchNor (None, 72, 72, 32) 96 conv2d_1[0][0] \n__________________________________________________________________________________________________\nactivation_1 (Activation) (None, 72, 72, 32) 0 batch_normalization_1[0][0] \n__________________________________________________________________________________________________\nconv2d_2 (Conv2D) (None, 72, 72, 64) 18432 activation_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_2 (BatchNor (None, 72, 72, 64) 192 conv2d_2[0][0] \n__________________________________________________________________________________________________\nactivation_2 (Activation) (None, 72, 72, 64) 0 batch_normalization_2[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 35, 35, 64) 0 activation_2[0][0] \n__________________________________________________________________________________________________\nconv2d_3 (Conv2D) (None, 35, 35, 80) 5120 max_pooling2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_3 (BatchNor (None, 35, 35, 80) 240 conv2d_3[0][0] \n__________________________________________________________________________________________________\nactivation_3 (Activation) (None, 35, 35, 80) 0 batch_normalization_3[0][0] \n__________________________________________________________________________________________________\nconv2d_4 (Conv2D) (None, 33, 33, 192) 138240 activation_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_4 (BatchNor (None, 33, 33, 192) 576 conv2d_4[0][0] \n__________________________________________________________________________________________________\nactivation_4 (Activation) (None, 33, 33, 192) 0 batch_normalization_4[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, 16, 16, 192) 0 activation_4[0][0] \n__________________________________________________________________________________________________\nconv2d_8 (Conv2D) (None, 16, 16, 64) 12288 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_8 (BatchNor (None, 16, 16, 64) 192 conv2d_8[0][0] \n__________________________________________________________________________________________________\nactivation_8 (Activation) (None, 16, 16, 64) 0 batch_normalization_8[0][0] \n__________________________________________________________________________________________________\nconv2d_6 (Conv2D) (None, 16, 16, 48) 9216 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_9 (Conv2D) (None, 16, 16, 96) 55296 activation_8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_6 (BatchNor (None, 16, 16, 48) 144 conv2d_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_9 (BatchNor (None, 16, 16, 96) 288 conv2d_9[0][0] \n__________________________________________________________________________________________________\nactivation_6 (Activation) (None, 16, 16, 48) 0 batch_normalization_6[0][0] \n__________________________________________________________________________________________________\nactivation_9 (Activation) (None, 16, 16, 96) 0 batch_normalization_9[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d (AveragePooli (None, 16, 16, 192) 0 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_5 (Conv2D) (None, 16, 16, 64) 12288 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nconv2d_7 (Conv2D) (None, 16, 16, 64) 76800 activation_6[0][0] \n__________________________________________________________________________________________________\nconv2d_10 (Conv2D) (None, 16, 16, 96) 82944 activation_9[0][0] \n__________________________________________________________________________________________________\nconv2d_11 (Conv2D) (None, 16, 16, 32) 6144 average_pooling2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_5 (BatchNor (None, 16, 16, 64) 192 conv2d_5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_7 (BatchNor (None, 16, 16, 64) 192 conv2d_7[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_10 (BatchNo (None, 16, 16, 96) 288 conv2d_10[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_11 (BatchNo (None, 16, 16, 32) 96 conv2d_11[0][0] \n__________________________________________________________________________________________________\nactivation_5 (Activation) (None, 16, 16, 64) 0 batch_normalization_5[0][0] \n__________________________________________________________________________________________________\nactivation_7 (Activation) (None, 16, 16, 64) 0 batch_normalization_7[0][0] \n__________________________________________________________________________________________________\nactivation_10 (Activation) (None, 16, 16, 96) 0 batch_normalization_10[0][0] \n__________________________________________________________________________________________________\nactivation_11 (Activation) (None, 16, 16, 32) 0 batch_normalization_11[0][0] \n__________________________________________________________________________________________________\nmixed0 (Concatenate) (None, 16, 16, 256) 0 activation_5[0][0] \n activation_7[0][0] \n activation_10[0][0] \n activation_11[0][0] \n__________________________________________________________________________________________________\nconv2d_15 (Conv2D) (None, 16, 16, 64) 16384 mixed0[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_15 (BatchNo (None, 16, 16, 64) 192 conv2d_15[0][0] \n__________________________________________________________________________________________________\nactivation_15 (Activation) (None, 16, 16, 64) 0 batch_normalization_15[0][0] \n__________________________________________________________________________________________________\nconv2d_13 (Conv2D) (None, 16, 16, 48) 12288 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_16 (Conv2D) (None, 16, 16, 96) 55296 activation_15[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_13 (BatchNo (None, 16, 16, 48) 144 conv2d_13[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_16 (BatchNo (None, 16, 16, 96) 288 conv2d_16[0][0] \n__________________________________________________________________________________________________\nactivation_13 (Activation) (None, 16, 16, 48) 0 batch_normalization_13[0][0] \n__________________________________________________________________________________________________\nactivation_16 (Activation) (None, 16, 16, 96) 0 batch_normalization_16[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_1 (AveragePoo (None, 16, 16, 256) 0 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_12 (Conv2D) (None, 16, 16, 64) 16384 mixed0[0][0] \n__________________________________________________________________________________________________\nconv2d_14 (Conv2D) (None, 16, 16, 64) 76800 activation_13[0][0] \n__________________________________________________________________________________________________\nconv2d_17 (Conv2D) (None, 16, 16, 96) 82944 activation_16[0][0] \n__________________________________________________________________________________________________\nconv2d_18 (Conv2D) (None, 16, 16, 64) 16384 average_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_12 (BatchNo (None, 16, 16, 64) 192 conv2d_12[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_14 (BatchNo (None, 16, 16, 64) 192 conv2d_14[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_17 (BatchNo (None, 16, 16, 96) 288 conv2d_17[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_18 (BatchNo (None, 16, 16, 64) 192 conv2d_18[0][0] \n__________________________________________________________________________________________________\nactivation_12 (Activation) (None, 16, 16, 64) 0 batch_normalization_12[0][0] \n__________________________________________________________________________________________________\nactivation_14 (Activation) (None, 16, 16, 64) 0 batch_normalization_14[0][0] \n__________________________________________________________________________________________________\nactivation_17 (Activation) (None, 16, 16, 96) 0 batch_normalization_17[0][0] \n__________________________________________________________________________________________________\nactivation_18 (Activation) (None, 16, 16, 64) 0 batch_normalization_18[0][0] \n__________________________________________________________________________________________________\nmixed1 (Concatenate) (None, 16, 16, 288) 0 activation_12[0][0] \n activation_14[0][0] \n activation_17[0][0] \n activation_18[0][0] \n__________________________________________________________________________________________________\nconv2d_22 (Conv2D) (None, 16, 16, 64) 18432 mixed1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_22 (BatchNo (None, 16, 16, 64) 192 conv2d_22[0][0] \n__________________________________________________________________________________________________\nactivation_22 (Activation) (None, 16, 16, 64) 0 batch_normalization_22[0][0] \n__________________________________________________________________________________________________\nconv2d_20 (Conv2D) (None, 16, 16, 48) 13824 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_23 (Conv2D) (None, 16, 16, 96) 55296 activation_22[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_20 (BatchNo (None, 16, 16, 48) 144 conv2d_20[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_23 (BatchNo (None, 16, 16, 96) 288 conv2d_23[0][0] \n__________________________________________________________________________________________________\nactivation_20 (Activation) (None, 16, 16, 48) 0 batch_normalization_20[0][0] \n__________________________________________________________________________________________________\nactivation_23 (Activation) (None, 16, 16, 96) 0 batch_normalization_23[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_2 (AveragePoo (None, 16, 16, 288) 0 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_19 (Conv2D) (None, 16, 16, 64) 18432 mixed1[0][0] \n__________________________________________________________________________________________________\nconv2d_21 (Conv2D) (None, 16, 16, 64) 76800 activation_20[0][0] \n__________________________________________________________________________________________________\nconv2d_24 (Conv2D) (None, 16, 16, 96) 82944 activation_23[0][0] \n__________________________________________________________________________________________________\nconv2d_25 (Conv2D) (None, 16, 16, 64) 18432 average_pooling2d_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_19 (BatchNo (None, 16, 16, 64) 192 conv2d_19[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_21 (BatchNo (None, 16, 16, 64) 192 conv2d_21[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_24 (BatchNo (None, 16, 16, 96) 288 conv2d_24[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_25 (BatchNo (None, 16, 16, 64) 192 conv2d_25[0][0] \n__________________________________________________________________________________________________\nactivation_19 (Activation) (None, 16, 16, 64) 0 batch_normalization_19[0][0] \n__________________________________________________________________________________________________\nactivation_21 (Activation) (None, 16, 16, 64) 0 batch_normalization_21[0][0] \n__________________________________________________________________________________________________\nactivation_24 (Activation) (None, 16, 16, 96) 0 batch_normalization_24[0][0] \n__________________________________________________________________________________________________\nactivation_25 (Activation) (None, 16, 16, 64) 0 batch_normalization_25[0][0] \n__________________________________________________________________________________________________\nmixed2 (Concatenate) (None, 16, 16, 288) 0 activation_19[0][0] \n activation_21[0][0] \n activation_24[0][0] \n activation_25[0][0] \n__________________________________________________________________________________________________\nconv2d_27 (Conv2D) (None, 16, 16, 64) 18432 mixed2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_27 (BatchNo (None, 16, 16, 64) 192 conv2d_27[0][0] \n__________________________________________________________________________________________________\nactivation_27 (Activation) (None, 16, 16, 64) 0 batch_normalization_27[0][0] \n__________________________________________________________________________________________________\nconv2d_28 (Conv2D) (None, 16, 16, 96) 55296 activation_27[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_28 (BatchNo (None, 16, 16, 96) 288 conv2d_28[0][0] \n__________________________________________________________________________________________________\nactivation_28 (Activation) (None, 16, 16, 96) 0 batch_normalization_28[0][0] \n__________________________________________________________________________________________________\nconv2d_26 (Conv2D) (None, 7, 7, 384) 995328 mixed2[0][0] \n__________________________________________________________________________________________________\nconv2d_29 (Conv2D) (None, 7, 7, 96) 82944 activation_28[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_26 (BatchNo (None, 7, 7, 384) 1152 conv2d_26[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_29 (BatchNo (None, 7, 7, 96) 288 conv2d_29[0][0] \n__________________________________________________________________________________________________\nactivation_26 (Activation) (None, 7, 7, 384) 0 batch_normalization_26[0][0] \n__________________________________________________________________________________________________\nactivation_29 (Activation) (None, 7, 7, 96) 0 batch_normalization_29[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_2 (MaxPooling2D) (None, 7, 7, 288) 0 mixed2[0][0] \n__________________________________________________________________________________________________\nmixed3 (Concatenate) (None, 7, 7, 768) 0 activation_26[0][0] \n activation_29[0][0] \n max_pooling2d_2[0][0] \n__________________________________________________________________________________________________\nconv2d_34 (Conv2D) (None, 7, 7, 128) 98304 mixed3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_34 (BatchNo (None, 7, 7, 128) 384 conv2d_34[0][0] \n__________________________________________________________________________________________________\nactivation_34 (Activation) (None, 7, 7, 128) 0 batch_normalization_34[0][0] \n__________________________________________________________________________________________________\nconv2d_35 (Conv2D) (None, 7, 7, 128) 114688 activation_34[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_35 (BatchNo (None, 7, 7, 128) 384 conv2d_35[0][0] \n__________________________________________________________________________________________________\nactivation_35 (Activation) (None, 7, 7, 128) 0 batch_normalization_35[0][0] \n__________________________________________________________________________________________________\nconv2d_31 (Conv2D) (None, 7, 7, 128) 98304 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_36 (Conv2D) (None, 7, 7, 128) 114688 activation_35[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_31 (BatchNo (None, 7, 7, 128) 384 conv2d_31[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_36 (BatchNo (None, 7, 7, 128) 384 conv2d_36[0][0] \n__________________________________________________________________________________________________\nactivation_31 (Activation) (None, 7, 7, 128) 0 batch_normalization_31[0][0] \n__________________________________________________________________________________________________\nactivation_36 (Activation) (None, 7, 7, 128) 0 batch_normalization_36[0][0] \n__________________________________________________________________________________________________\nconv2d_32 (Conv2D) (None, 7, 7, 128) 114688 activation_31[0][0] \n__________________________________________________________________________________________________\nconv2d_37 (Conv2D) (None, 7, 7, 128) 114688 activation_36[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_32 (BatchNo (None, 7, 7, 128) 384 conv2d_32[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_37 (BatchNo (None, 7, 7, 128) 384 conv2d_37[0][0] \n__________________________________________________________________________________________________\nactivation_32 (Activation) (None, 7, 7, 128) 0 batch_normalization_32[0][0] \n__________________________________________________________________________________________________\nactivation_37 (Activation) (None, 7, 7, 128) 0 batch_normalization_37[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_3 (AveragePoo (None, 7, 7, 768) 0 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_30 (Conv2D) (None, 7, 7, 192) 147456 mixed3[0][0] \n__________________________________________________________________________________________________\nconv2d_33 (Conv2D) (None, 7, 7, 192) 172032 activation_32[0][0] \n__________________________________________________________________________________________________\nconv2d_38 (Conv2D) (None, 7, 7, 192) 172032 activation_37[0][0] \n__________________________________________________________________________________________________\nconv2d_39 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_30 (BatchNo (None, 7, 7, 192) 576 conv2d_30[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_33 (BatchNo (None, 7, 7, 192) 576 conv2d_33[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_38 (BatchNo (None, 7, 7, 192) 576 conv2d_38[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_39 (BatchNo (None, 7, 7, 192) 576 conv2d_39[0][0] \n__________________________________________________________________________________________________\nactivation_30 (Activation) (None, 7, 7, 192) 0 batch_normalization_30[0][0] \n__________________________________________________________________________________________________\nactivation_33 (Activation) (None, 7, 7, 192) 0 batch_normalization_33[0][0] \n__________________________________________________________________________________________________\nactivation_38 (Activation) (None, 7, 7, 192) 0 batch_normalization_38[0][0] \n__________________________________________________________________________________________________\nactivation_39 (Activation) (None, 7, 7, 192) 0 batch_normalization_39[0][0] \n__________________________________________________________________________________________________\nmixed4 (Concatenate) (None, 7, 7, 768) 0 activation_30[0][0] \n activation_33[0][0] \n activation_38[0][0] \n activation_39[0][0] \n__________________________________________________________________________________________________\nconv2d_44 (Conv2D) (None, 7, 7, 160) 122880 mixed4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_44 (BatchNo (None, 7, 7, 160) 480 conv2d_44[0][0] \n__________________________________________________________________________________________________\nactivation_44 (Activation) (None, 7, 7, 160) 0 batch_normalization_44[0][0] \n__________________________________________________________________________________________________\nconv2d_45 (Conv2D) (None, 7, 7, 160) 179200 activation_44[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_45 (BatchNo (None, 7, 7, 160) 480 conv2d_45[0][0] \n__________________________________________________________________________________________________\nactivation_45 (Activation) (None, 7, 7, 160) 0 batch_normalization_45[0][0] \n__________________________________________________________________________________________________\nconv2d_41 (Conv2D) (None, 7, 7, 160) 122880 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_46 (Conv2D) (None, 7, 7, 160) 179200 activation_45[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_41 (BatchNo (None, 7, 7, 160) 480 conv2d_41[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_46 (BatchNo (None, 7, 7, 160) 480 conv2d_46[0][0] \n__________________________________________________________________________________________________\nactivation_41 (Activation) (None, 7, 7, 160) 0 batch_normalization_41[0][0] \n__________________________________________________________________________________________________\nactivation_46 (Activation) (None, 7, 7, 160) 0 batch_normalization_46[0][0] \n__________________________________________________________________________________________________\nconv2d_42 (Conv2D) (None, 7, 7, 160) 179200 activation_41[0][0] \n__________________________________________________________________________________________________\nconv2d_47 (Conv2D) (None, 7, 7, 160) 179200 activation_46[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_42 (BatchNo (None, 7, 7, 160) 480 conv2d_42[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_47 (BatchNo (None, 7, 7, 160) 480 conv2d_47[0][0] \n__________________________________________________________________________________________________\nactivation_42 (Activation) (None, 7, 7, 160) 0 batch_normalization_42[0][0] \n__________________________________________________________________________________________________\nactivation_47 (Activation) (None, 7, 7, 160) 0 batch_normalization_47[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_4 (AveragePoo (None, 7, 7, 768) 0 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_40 (Conv2D) (None, 7, 7, 192) 147456 mixed4[0][0] \n__________________________________________________________________________________________________\nconv2d_43 (Conv2D) (None, 7, 7, 192) 215040 activation_42[0][0] \n__________________________________________________________________________________________________\nconv2d_48 (Conv2D) (None, 7, 7, 192) 215040 activation_47[0][0] \n__________________________________________________________________________________________________\nconv2d_49 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_40 (BatchNo (None, 7, 7, 192) 576 conv2d_40[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_43 (BatchNo (None, 7, 7, 192) 576 conv2d_43[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_48 (BatchNo (None, 7, 7, 192) 576 conv2d_48[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_49 (BatchNo (None, 7, 7, 192) 576 conv2d_49[0][0] \n__________________________________________________________________________________________________\nactivation_40 (Activation) (None, 7, 7, 192) 0 batch_normalization_40[0][0] \n__________________________________________________________________________________________________\nactivation_43 (Activation) (None, 7, 7, 192) 0 batch_normalization_43[0][0] \n__________________________________________________________________________________________________\nactivation_48 (Activation) (None, 7, 7, 192) 0 batch_normalization_48[0][0] \n__________________________________________________________________________________________________\nactivation_49 (Activation) (None, 7, 7, 192) 0 batch_normalization_49[0][0] \n__________________________________________________________________________________________________\nmixed5 (Concatenate) (None, 7, 7, 768) 0 activation_40[0][0] \n activation_43[0][0] \n activation_48[0][0] \n activation_49[0][0] \n__________________________________________________________________________________________________\nconv2d_54 (Conv2D) (None, 7, 7, 160) 122880 mixed5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_54 (BatchNo (None, 7, 7, 160) 480 conv2d_54[0][0] \n__________________________________________________________________________________________________\nactivation_54 (Activation) (None, 7, 7, 160) 0 batch_normalization_54[0][0] \n__________________________________________________________________________________________________\nconv2d_55 (Conv2D) (None, 7, 7, 160) 179200 activation_54[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_55 (BatchNo (None, 7, 7, 160) 480 conv2d_55[0][0] \n__________________________________________________________________________________________________\nactivation_55 (Activation) (None, 7, 7, 160) 0 batch_normalization_55[0][0] \n__________________________________________________________________________________________________\nconv2d_51 (Conv2D) (None, 7, 7, 160) 122880 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_56 (Conv2D) (None, 7, 7, 160) 179200 activation_55[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_51 (BatchNo (None, 7, 7, 160) 480 conv2d_51[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_56 (BatchNo (None, 7, 7, 160) 480 conv2d_56[0][0] \n__________________________________________________________________________________________________\nactivation_51 (Activation) (None, 7, 7, 160) 0 batch_normalization_51[0][0] \n__________________________________________________________________________________________________\nactivation_56 (Activation) (None, 7, 7, 160) 0 batch_normalization_56[0][0] \n__________________________________________________________________________________________________\nconv2d_52 (Conv2D) (None, 7, 7, 160) 179200 activation_51[0][0] \n__________________________________________________________________________________________________\nconv2d_57 (Conv2D) (None, 7, 7, 160) 179200 activation_56[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_52 (BatchNo (None, 7, 7, 160) 480 conv2d_52[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_57 (BatchNo (None, 7, 7, 160) 480 conv2d_57[0][0] \n__________________________________________________________________________________________________\nactivation_52 (Activation) (None, 7, 7, 160) 0 batch_normalization_52[0][0] \n__________________________________________________________________________________________________\nactivation_57 (Activation) (None, 7, 7, 160) 0 batch_normalization_57[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_5 (AveragePoo (None, 7, 7, 768) 0 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_50 (Conv2D) (None, 7, 7, 192) 147456 mixed5[0][0] \n__________________________________________________________________________________________________\nconv2d_53 (Conv2D) (None, 7, 7, 192) 215040 activation_52[0][0] \n__________________________________________________________________________________________________\nconv2d_58 (Conv2D) (None, 7, 7, 192) 215040 activation_57[0][0] \n__________________________________________________________________________________________________\nconv2d_59 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_5[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_50 (BatchNo (None, 7, 7, 192) 576 conv2d_50[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_53 (BatchNo (None, 7, 7, 192) 576 conv2d_53[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_58 (BatchNo (None, 7, 7, 192) 576 conv2d_58[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_59 (BatchNo (None, 7, 7, 192) 576 conv2d_59[0][0] \n__________________________________________________________________________________________________\nactivation_50 (Activation) (None, 7, 7, 192) 0 batch_normalization_50[0][0] \n__________________________________________________________________________________________________\nactivation_53 (Activation) (None, 7, 7, 192) 0 batch_normalization_53[0][0] \n__________________________________________________________________________________________________\nactivation_58 (Activation) (None, 7, 7, 192) 0 batch_normalization_58[0][0] \n__________________________________________________________________________________________________\nactivation_59 (Activation) (None, 7, 7, 192) 0 batch_normalization_59[0][0] \n__________________________________________________________________________________________________\nmixed6 (Concatenate) (None, 7, 7, 768) 0 activation_50[0][0] \n activation_53[0][0] \n activation_58[0][0] \n activation_59[0][0] \n__________________________________________________________________________________________________\nconv2d_64 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_64 (BatchNo (None, 7, 7, 192) 576 conv2d_64[0][0] \n__________________________________________________________________________________________________\nactivation_64 (Activation) (None, 7, 7, 192) 0 batch_normalization_64[0][0] \n__________________________________________________________________________________________________\nconv2d_65 (Conv2D) (None, 7, 7, 192) 258048 activation_64[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_65 (BatchNo (None, 7, 7, 192) 576 conv2d_65[0][0] \n__________________________________________________________________________________________________\nactivation_65 (Activation) (None, 7, 7, 192) 0 batch_normalization_65[0][0] \n__________________________________________________________________________________________________\nconv2d_61 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_66 (Conv2D) (None, 7, 7, 192) 258048 activation_65[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_61 (BatchNo (None, 7, 7, 192) 576 conv2d_61[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_66 (BatchNo (None, 7, 7, 192) 576 conv2d_66[0][0] \n__________________________________________________________________________________________________\nactivation_61 (Activation) (None, 7, 7, 192) 0 batch_normalization_61[0][0] \n__________________________________________________________________________________________________\nactivation_66 (Activation) (None, 7, 7, 192) 0 batch_normalization_66[0][0] \n__________________________________________________________________________________________________\nconv2d_62 (Conv2D) (None, 7, 7, 192) 258048 activation_61[0][0] \n__________________________________________________________________________________________________\nconv2d_67 (Conv2D) (None, 7, 7, 192) 258048 activation_66[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_62 (BatchNo (None, 7, 7, 192) 576 conv2d_62[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_67 (BatchNo (None, 7, 7, 192) 576 conv2d_67[0][0] \n__________________________________________________________________________________________________\nactivation_62 (Activation) (None, 7, 7, 192) 0 batch_normalization_62[0][0] \n__________________________________________________________________________________________________\nactivation_67 (Activation) (None, 7, 7, 192) 0 batch_normalization_67[0][0] \n__________________________________________________________________________________________________\naverage_pooling2d_6 (AveragePoo (None, 7, 7, 768) 0 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_60 (Conv2D) (None, 7, 7, 192) 147456 mixed6[0][0] \n__________________________________________________________________________________________________\nconv2d_63 (Conv2D) (None, 7, 7, 192) 258048 activation_62[0][0] \n__________________________________________________________________________________________________\nconv2d_68 (Conv2D) (None, 7, 7, 192) 258048 activation_67[0][0] \n__________________________________________________________________________________________________\nconv2d_69 (Conv2D) (None, 7, 7, 192) 147456 average_pooling2d_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_60 (BatchNo (None, 7, 7, 192) 576 conv2d_60[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_63 (BatchNo (None, 7, 7, 192) 576 conv2d_63[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_68 (BatchNo (None, 7, 7, 192) 576 conv2d_68[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_69 (BatchNo (None, 7, 7, 192) 576 conv2d_69[0][0] \n__________________________________________________________________________________________________\nactivation_60 (Activation) (None, 7, 7, 192) 0 batch_normalization_60[0][0] \n__________________________________________________________________________________________________\nactivation_63 (Activation) (None, 7, 7, 192) 0 batch_normalization_63[0][0] \n__________________________________________________________________________________________________\nactivation_68 (Activation) (None, 7, 7, 192) 0 batch_normalization_68[0][0] \n__________________________________________________________________________________________________\nactivation_69 (Activation) (None, 7, 7, 192) 0 batch_normalization_69[0][0] \n__________________________________________________________________________________________________\nmixed7 (Concatenate) (None, 7, 7, 768) 0 activation_60[0][0] \n activation_63[0][0] \n activation_68[0][0] \n activation_69[0][0] \n__________________________________________________________________________________________________\nflatten (Flatten) (None, 37632) 0 mixed7[0][0] \n__________________________________________________________________________________________________\ndense (Dense) (None, 1024) 38536192 flatten[0][0] \n__________________________________________________________________________________________________\ndropout (Dropout) (None, 1024) 0 dense[0][0] \n__________________________________________________________________________________________________\ndense_1 (Dense) (None, 1) 1025 dropout[0][0] \n==================================================================================================\nTotal params: 47,512,481\nTrainable params: 38,537,217\nNon-trainable params: 8,975,264\n__________________________________________________________________________________________________\n"
],
[
"# Get the Horse or Human dataset\n!wget --no-check-certificate https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip -O /tmp/horse-or-human.zip\n\n# Get the Horse or Human Validation dataset\n!wget --no-check-certificate https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip -O /tmp/validation-horse-or-human.zip \n \nfrom tensorflow.keras.preprocessing.image import ImageDataGenerator\n\nimport os\nimport zipfile\n\nlocal_zip = '//tmp/horse-or-human.zip'\nzip_ref = zipfile.ZipFile(local_zip, 'r')\nzip_ref.extractall('/tmp/training')\nzip_ref.close()\n\nlocal_zip = '//tmp/validation-horse-or-human.zip'\nzip_ref = zipfile.ZipFile(local_zip, 'r')\nzip_ref.extractall('/tmp/validation')\nzip_ref.close()",
"--2021-05-21 05:30:18-- https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip\nResolving storage.googleapis.com (storage.googleapis.com)... 142.250.31.128, 142.250.73.208, 142.250.73.240, ...\nConnecting to storage.googleapis.com (storage.googleapis.com)|142.250.31.128|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 149574867 (143M) [application/zip]\nSaving to: ‘/tmp/horse-or-human.zip’\n\n/tmp/horse-or-human 100%[===================>] 142.65M 212MB/s in 0.7s \n\n2021-05-21 05:30:19 (212 MB/s) - ‘/tmp/horse-or-human.zip’ saved [149574867/149574867]\n\n--2021-05-21 05:30:19-- https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip\nResolving storage.googleapis.com (storage.googleapis.com)... 172.217.164.176, 172.253.115.128, 172.253.122.128, ...\nConnecting to storage.googleapis.com (storage.googleapis.com)|172.217.164.176|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 11480187 (11M) [application/zip]\nSaving to: ‘/tmp/validation-horse-or-human.zip’\n\n/tmp/validation-hor 100%[===================>] 10.95M --.-KB/s in 0.1s \n\n2021-05-21 05:30:19 (109 MB/s) - ‘/tmp/validation-horse-or-human.zip’ saved [11480187/11480187]\n\n"
],
[
"# Define our example directories and files\ntrain_dir = '/tmp/training'\nvalidation_dir = '/tmp/validation'\n\ntrain_horses_dir = os.path.join(train_dir,'horses')\ntrain_humans_dir = os.path.join(train_dir,'humans')\nvalidation_horses_dir = os.path.join(validation_dir,'horses')\nvalidation_humans_dir = os.path.join(validation_dir,'humans')\n\ntrain_horses_fnames = os.listdir(train_horses_dir)\ntrain_humans_fnames = os.listdir(train_humans_dir)\nvalidation_horses_fnames = os.listdir(validation_horses_dir)\nvalidation_humans_fnames = os.listdir(validation_humans_dir)\n\nprint(len(train_horses_fnames))\nprint(len(train_humans_fnames))\nprint(len(validation_horses_fnames))\nprint(len(validation_humans_fnames))\n\n# Expected Output:\n# 500\n# 527\n# 128\n# 128",
"500\n527\n128\n128\n"
],
[
"# Add our data-augmentation parameters to ImageDataGenerator\ntrain_datagen = ImageDataGenerator(rescale = 1.0/255.,\n rotation_range = 40,\n width_shift_range = 0.2,\n height_shift_range = 0.2,\n shear_range = 0.2,\n zoom_range = 0.2,\n horizontal_flip = True)\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator(rescale = 1.0/255)\n\n# Flow training images in batches of 20 using train_datagen generator\ntrain_generator = train_datagen.flow_from_directory(train_dir,\n batch_size = 20,\n class_mode = 'binary', \n target_size = (150, 150)) \n\n# Flow validation images in batches of 20 using test_datagen generator\nvalidation_generator = test_datagen.flow_from_directory( validation_dir,\n batch_size = 20,\n class_mode = 'binary',\n target_size = (150, 150))\n\n# Expected Output:\n# Found 1027 images belonging to 2 classes.\n# Found 256 images belonging to 2 classes.",
"Found 1027 images belonging to 2 classes.\nFound 256 images belonging to 2 classes.\n"
],
[
"# Run this and see how many epochs it should take before the callback\n# fires, and stops training at 99.9% accuracy\n# (It should take less than 100 epochs)\n\ncallbacks = myCallback()\nhistory = model.fit(train_generator,\n validation_data = validation_generator,\n steps_per_epoch = 100,\n epochs = 100,\n validation_steps = 50,\n verbose = 2,\n callbacks=[callbacks])",
"Epoch 1/100\nWARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 10000 batches). You may need to use the repeat() function when building your dataset.\nWARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least `steps_per_epoch * epochs` batches (in this case, 50 batches). You may need to use the repeat() function when building your dataset.\n100/100 - 11s - loss: 0.0274 - accuracy: 0.9922 - val_loss: 0.0214 - val_accuracy: 0.9961\n"
],
[
"import matplotlib.pyplot as plt\nacc = history.history['accuracy']\nval_acc = history.history['val_accuracy']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'r', label='Training accuracy')\nplt.plot(epochs, val_acc, 'b', label='Validation accuracy')\nplt.title('Training and validation accuracy')\nplt.legend(loc=0)\nplt.figure()\n\n\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5169fbbdfc8e3fec10def9de53a6a5ca935898e
| 445,857 |
ipynb
|
Jupyter Notebook
|
datagen/Characters_Notebook2.ipynb
|
ayush1120/OLAM
|
d2f1445c0e4e9ba4d3ca68d8cd77f193138fe689
|
[
"MIT"
] | null | null | null |
datagen/Characters_Notebook2.ipynb
|
ayush1120/OLAM
|
d2f1445c0e4e9ba4d3ca68d8cd77f193138fe689
|
[
"MIT"
] | null | null | null |
datagen/Characters_Notebook2.ipynb
|
ayush1120/OLAM
|
d2f1445c0e4e9ba4d3ca68d8cd77f193138fe689
|
[
"MIT"
] | null | null | null | 71.211787 | 200,663 | 0.423806 |
[
[
[
"import os\nimport pandas as pd",
"_____no_output_____"
],
[
"filePath = os.path.join(os.getcwd(), 'hindi_corpus_2012_12_19', 'Hi_Newspapers.txt')\ndata = pd.read_csv(filePath, delimiter='\\t', names=['source', 'date', 'unnamed_1', 'unnamed_2', 'text'])",
"_____no_output_____"
],
[
"filePath2 = os.path.join(os.getcwd(), 'hindi_corpus_2012_12_19', 'Hi_Blogs.txt')\ndata2 = pd.read_csv(filePath2, delimiter='\\t', names=['source', 'date', 'unnamed_1', 'unnamed_2', 'text'])",
"_____no_output_____"
],
[
"filePath3 = os.path.join(os.getcwd(), 'hindi_corpus_2012_12_19', 'x_test.txt')\ndata3 = pd.read_csv(filePath3, delimiter='\\t', names=['source', 'date', 'unnamed_1', 'unnamed_2', 'text'])",
"_____no_output_____"
],
[
"data.loc[:,['source', 'date', 'text']]",
"_____no_output_____"
],
[
"data2.loc[:,['source', 'date', 'text']]",
"_____no_output_____"
],
[
"data3.loc[:,['source', 'date', 'text']]",
"_____no_output_____"
],
[
"sample = data.text.loc[1]",
"_____no_output_____"
],
[
"sample.strip()",
"_____no_output_____"
],
[
"from textGenerator import TextProcess\ntextProcessor = TextProcess()",
"_____no_output_____"
],
[
"import nltk\nfrom nltk.tokenize import RegexpTokenizer\nfrom nltk.stem import WordNetLemmatizer,PorterStemmer\nfrom nltk.corpus import stopwords\nimport re",
"_____no_output_____"
],
[
"lemmatizer = WordNetLemmatizer()\nstemmer = PorterStemmer() \n\ndef preprocess(sentence):\n sentence=str(sentence)\n sentence = sentence.lower()\n sentence=sentence.replace('{html}',\"\") \n cleanr = re.compile('<.*?>')\n cleantext = re.sub(cleanr, '', sentence)\n rem_url=re.sub(r'http\\S+', '',cleantext)\n # rem_num = re.sub('[0-9]+', '', rem_url)\n # tokenizer = RegexpTokenizer(r'\\w+')\n # tokens = tokenizer.tokenize(rem_num) \n # filtered_words = [w for w in tokens if len(w) > 2 if not w in stopwords.words('english')]\n # stem_words=[stemmer.stem(w) for w in filtered_words]\n # lemma_words=[lemmatizer.lemmatize(w) for w in stem_words]\n # return \" \".join(filtered_words)\n return rem_url",
"_____no_output_____"
],
[
"preprocess(sample)",
"_____no_output_____"
],
[
"from textGenerator import TextGenerator\ntextgen = TextGenerator()\nsample = textgen.getRandomText()\n# preprocess(sample)\nsample",
"_____no_output_____"
],
[
"temp = sample\n",
"_____no_output_____"
],
[
"sample = temp\npreprocess(sample)\n# print(f\"Sample : {sample}\")\nsample = sample.strip()\n# print(f\"Sample : {sample}\")\nsample = sample.splitlines()\nprint(f\"Sample : {sample}\")\nsample = sample[0]\nsample = sample.split()\nprint(f\"Sample : {sample}\")\n# word = sample[-5]\n# print(f\"Word : {word}\")",
"Sample : ['परिवार के सदस्यों के बीच यदि मतभेद हो तो आए दिन विवाद होते रहते हैं। यह मतभेद अक्सर पति-पत्नी के बीच होते हैं। कई बार इनके कारण बड़ा विवाद भी हो जाता है। इसका असर परिवार के अन्य सदस्यों पर भी पड़ता है। कई बार आप यह समझ ही नहीं पाते कि इस समस्या से कैसे छुटकारा पाएं ?']\nSample : ['परिवार', 'के', 'सदस्यों', 'के', 'बीच', 'यदि', 'मतभेद', 'हो', 'तो', 'आए', 'दिन', 'विवाद', 'होते', 'रहते', 'हैं।', 'यह', 'मतभेद', 'अक्सर', 'पति-पत्नी', 'के', 'बीच', 'होते', 'हैं।', 'कई', 'बार', 'इनके', 'कारण', 'बड़ा', 'विवाद', 'भी', 'हो', 'जाता', 'है।', 'इसका', 'असर', 'परिवार', 'के', 'अन्य', 'सदस्यों', 'पर', 'भी', 'पड़ता', 'है।', 'कई', 'बार', 'आप', 'यह', 'समझ', 'ही', 'नहीं', 'पाते', 'कि', 'इस', 'समस्या', 'से', 'कैसे', 'छुटकारा', 'पाएं', '?']\n"
],
[
"def isEndOfLine(x):\n if u'\\u0964' <= x <= u'\\u0965' :\n return True\n return False\n \n\ndef isMatra(x):\n if (u'\\u0901' <= x <= u'\\u0903' or \n u'\\u093C' <= x <= u'\\u094F' or\n u'\\u0951' <= x <= u'\\u0954' or\n u'\\u0951' <= x <= u'\\u0954' or\n u'\\u0962' <= x <= u'\\u0963'):\n return True\n return False\ndef isVowel(x):\n if (u'\\u0905' <= x <= u'\\u0914' or \n u'\\u0960' <= x <= u'\\u0961'):\n return True\n return False\ndef isConsonant(x):\n if (u'\\u0915' <= x <= u'\\u0939' or \n u'\\u0958' <= x <= u'\\u095F'):\n return True\n return False\n\ndef isOM(x):\n if x == u'\\u0950' :\n return True\n return False\n \n ",
"_____no_output_____"
],
[
"pd1 =data.text\npd2 =data2.text\nnew_sample = pd.concat([pd1, pd2], ignore_index=True)\n\nnew_sample.head()\n",
"_____no_output_____"
]
],
[
[
"\n\n",
"_____no_output_____"
]
],
[
[
"vowel=0\nconsonant=0\nmatra=0\neofLine=0\nOM=0\nvowel_matra=0\nhalf_vowel=0\nconsonant_matra=0\nconstant_half_matra=0;\nword_start_matra=0\nhalf_consonant_vowel=0\nhalf_consonant_matra=0\ndictionary_vowel = {}\ndictionary_consonant = {} \nwords_with_half_consonant_following_vowel={}\nwords_with_half_consonant_following_matra={}\nwords_with_vowels_following_matra={}\nconstant_and_vowel_combination={}\nwords_starting_with_matra = []\nwords_having_half_vowel=[]\n\nwordCount = 0\nfor para in new_sample:\n words = para.split()\n for word in words:\n characters = list(word)\n wordCount += 1\n# if(isMatra(characters[0])):\n# word_start_matra+=1\n for index, char in enumerate(characters):\n if(isMatra(char)):\n matra = matra+1\n if(index==0):\n word_start_matra += 1\n words_starting_with_matra.append(word)\n \n elif(isVowel(char)):\n if(index+1 < len(characters)):\n if(isMatra(characters[index+1])):\n vowel_matra=vowel_matra+1\n if word in words_with_vowels_following_matra: \n words_with_vowels_following_matra[word] += 1\n else: \n words_with_vowels_following_matra.update({word: 1}) \n \n if(characters[index+1] == u'\\u094D'):\n half_vowel+=1\n words_having_half_vowel.append(word)\n if char in dictionary_vowel: \n dictionary_vowel[char] += 1\n else: \n dictionary_vowel.update({char: 1}) \n vowel=vowel+1\n elif(isConsonant(char)):\n if(index+1 < len(characters)):\n if(isMatra(characters[index+1])):\n consonant_matra=consonant_matra+1\n if(index+2 < len(characters)): \n if(characters[index+1] == u'\\u094D'):\n if(isVowel(characters[index+2])):\n half_consonant_vowel+=1\n if word in words_with_half_consonant_following_vowel: \n words_with_half_consonant_following_vowel[word] += 1\n else: \n words_with_half_consonant_following_vowel.update({word: 1}) \n if(isMatra(characters[index+2])):\n half_consonant_matra+=1\n if word in words_with_half_consonant_following_matra: \n words_with_half_consonant_following_matra[word] += 1\n else: \n words_with_half_consonant_following_matra.update({word: 1})\n if char in dictionary_consonant: \n dictionary_consonant[char] += 1\n else: \n dictionary_consonant.update({char: 1}) \n \n consonant = consonant+1\n elif(isEndOfLine(char)):\n eofLine = eofLine+1\n elif(isOM(char)):\n OM = OM+1",
"_____no_output_____"
],
[
"print(f\"Matra : {matra}\")\nprint(f\"Vowel : {vowel}\")\nprint(f\"Consonant : {consonant}\")\nprint(f\"end of line : {eofLine}\")\nprint(f\"OM : {OM}\")\nprint(f\"Word starting with a Matra : {word_start_matra}\")\nprint(f\"Vowels followed by a matra : {vowel_matra}\")\nprint(f\"Consonant followed by a matra : {consonant_matra}\")\nprint(f\"half vowel : {half_vowel}\")\nprint(f\"Number of words : {wordCount}\")\nprint(f\"half cononants followed by a matra : {half_consonant_matra}\")\nprint(f\"half cononants followed by a Vowel: {half_consonant_vowel}\")\nprint(f\"Words having half vowel: {words_having_half_vowel}\")\nprint(f\"Words starting with a matra : {words_starting_with_matra}\")\nprint(f\"Words with vowels followed by a matra : {words_with_vowels_following_matra}\")\n",
"Matra : 20007689\nVowel : 2295243\nConsonant : 29407930\nend of line : 507007\nOM : 275\nWord starting with a Matra : 756\nVowels followed by a matra : 140669\nConsonant followed by a matra : 18186346\nhalf vowel : 18\nNumber of words : 13532910\nhalf cononants followed by a matra : 856\nhalf cononants followed by a Vowel: 474\nWords having half vowel: ['जकिउ्द्दीन', 'कोइ्रü', 'गइ्र', 'कोइ्र्र', 'हुइ्र्र', 'जाए्गा।', 'हुइ्र्र', 'सुरमइ्रर्', 'जुलार्इ्र', 'कोइ्र', 'उ्देश्य', 'राष्अ्रपति', 'आइ्र', 'स्काउ्ट्स', 'चढार्इ्', '‘‘देखो-श्-अ्!’’', 'कोई्र', 'हेडलाइ्ट्स']\nWords starting with a matra : ['ा', 'ा', 'ॅषिकेश', 'ः', 'ंठहराव', 'ूबाजार', 'ंऔर', 'ेबाद', 'ः', '्', 'ारण', 'ंकिया', 'ाएंगे', 'ः', 'ः', 'ंलचर', 'ः', 'ा', 'ै', '़िखलाड़ी', 'ः', 'ः', 'ेवाले', 'ः', 'ाा,', 'ाराखंड', 'ा', 'ंिवश्वविख्यात', 'ः', 'ंने', 'ंको', 'ंदे', 'ः', 'ा', 'ा', 'ा’', 'ा', 'ा', 'ाीय', 'ेसे', 'ा', 'ा', 'ार', 'ाकम', 'ंने', 'ा', 'ः', 'ः', 'ः', 'ः', 'ा', 'ंसुस्ती', '़49', 'ः', 'ः', 'ो', 'े', 'े', 'ै', 'ंचार', 'ों', 'ः', 'ीका,', '्रदमुक', 'ा', 'ा', 'ः', 'ॉॉ', 'ेसी', 'ौर', 'ांसी', '़कर', 'ः', 'ः', 'ा', 'ः(4', 'िउच्च', 'ाीगंगानगर', 'ाीय,', 'ः', 'ोंच', 'ंकांग्रेस', 'ारोबार', 'ेबीएसई', 'ः', 'ः', 'ेमें', 'ेयह', 'ा', 'ा', 'ा', 'ः', 'ंआरोपियों', 'ेवेबसाइट', '़कर', 'ः', 'ंने', 'ः', 'ः', 'ः', 'ः', 'ः', 'ः', 'ः', 'ः', 'ि1कसे', 'ः', 'ंमंजूरिया', 'ः', 'ः', 'ः', 'ा', '्र', '्र', 'ः', 'ः', 'ै', 'ै', 'ः', 'ः', 'ंने', 'ः', 'ं।', '्रेलवे', 'ै', 'ंबड़ौदा', '्', 'ंगंगवार', 'ंने', 'ः', 'ंिवभागों', 'ार', 'ंपिछले', 'ः', 'ः', 'ंही', 'े', 'ः', 'ा', 'ः', 'ः', 'ः', 'ः', 'ंअंतिम', 'ः', 'ः', 'ः', 'ार्रवाई', 'ः', 'ः', 'ीन', 'ः', 'ा', 'ी', 'ायर', 'ेकी', 'े', 'े', 'ं।', 'ंपर', 'ः', 'ांट', 'ांट', 'ांट', '्र', 'ंकि', 'ः', 'ंसोने', 'ः', 'ंयह', 'ुपसंद', 'ः', 'ः', 'ः', 'ेस', '्रदमुक', 'ी', 'ी', 'ोप-', 'ृ1,452', 'ार्य', '्रदमुक', 'ः', 'ंने', 'ेकला,', 'ंऔर', 'ी', 'ः', 'ः', 'ंने', 'ोमवर्क', 'ः', 'ांग', '्रआकलनों', 'ेकेविन', 'ः', 'ं', 'ः', 'ः(20', 'ंिचंताजनक', 'ः', 'ः', 'ंिवश्व', 'ः', 'ेबताया', 'ारी', 'ा', 'ांतिकारी', 'ंवह', 'ंसिह,', '्', '्दक्षिण', '्', '्', '्', '्', '्एफएमसीजी', '्', '्', '्', 'ः', 'ोई', 'ा', 'ः', 'ारखाने', 'ं15', 'ा', 'ा', 'ेक्वांटो', 'ंएमसीए', 'ंने', 'ः', 'ंिवधेयक', 'ः', 'ः', 'ः', '्रछट', 'ः', 'ंिजनके', '्िमलीं', 'ंिचंता', 'ंशामिल', 'ंसे', 'ः', 'ार्मासिस्टों', 'ाम', 'ंसे', 'ंवरीयता', 'ंझुकने', 'ंकारोबार', 'ं', 'ः', 'े', 'ः', 'ी', 'िायों', 'ा', 'ोर्ट', 'ो', 'ो', 'ंसे', 'ोम', 'ाृंखला', 'ंसावधानियां', 'ोध', 'ी।', 'ः', 'ः', 'ंइन्हीं', 'ः', 'ः', 'ार', 'ो', 'ः', 'ुकमार', 'ा', 'ः', '्', 'ी', 'ः', 'ः', 'ा', 'ेबेहतर', 'ंसीडी', 'ंबद', 'ो', 'ंिसंह', 'ंयह', 'ंगिरावट', 'ंवोट', 'ंटी-20', 'ंयही', 'ंकारोबार', 'ः', 'ोंड्स', 'ो', 'ा', '्रहाल', 'ा', '्िदन)', 'ौर', 'ः', 'े', 'ः', 'ः', 'ंके', 'ंवर्षो', 'ा', 'ो', '्', 'ायत', 'ः', 'ः', 'ौलपुर,जैसलमेर,बारां,प्रतापगढ़', 'ंसे', 'ंिंवधेयक', 'ंवीआईपी', 'ः', 'ंआत्म', 'ों', 'ा', 'ंिचदंबरम', 'ंपर', 'ः', 'ी', 'ः', 'ोड़', 'ः', 'ोध', 'ुईंया', 'ोक्ता', '्र-कारपेट', 'ेप्रभावी', 'िमली', 'ः', 'ोंकलिन', 'ोंकलिन', 'ै', 'ै', 'ेने', 'ावा', 'ंिवधेयक', '़', 'ाना', 'ंट्वीट', 'ंिसंह,', 'ंिवभाग', 'ंशुक्रवार', 'ैजैसे', 'ाियान्वनयन', 'ाियान्वयन', 'ंची', 'ः', 'ेकहा', 'ंइस', 'ाल', 'ंनिवेशकों', 'ंिमलेगा।', 'ा', 'ः', 'ः', 'ी', 'ः', 'ी', '्', '्', '्', '्', '्', '्', 'ंिसन्हा', 'ः', 'ः', 'ः', '्र', 'ंहुआ', 'ाीय', '्', '्', '्', 'िपट्रर', 'ेलेना-देना', 'ः', 'ः', 'ारी', 'े', 'ः', 'ा', 'ंसिंह,', 'ंसिर्फ', 'ांति', 'ेकी', 'ः', '्र', 'ः', 'ः', 'ः', 'ः', 'ः', 'ः', 'ः', 'ंहैं.', 'ः', 'िध', 'ॅ', 'ाकी', 'ंजरूरत', '्समय', 'ै।', 'ंच', 'ाचार', 'िखलाफ', 'ामक', 'ा', 'ंयही', 'ु', 'ेमूँगफनी', 'िकवह', 'ी', 'े', 'ा', 'ंहै', 'ंप', 'ेइस', 'ंतो', 'ंसंगमरमर', 'िशक्षण', 'िशक्षक', 'ः', 'िभगाती', 'ंतो', 'ाय-पान', 'ः', 'ंसेवा', 'ं', 'ः', 'िक', 'ाकरना', 'ाा,', 'ी', 'ंहोगा', 'ेकर', 'ी', '॔मित्रातापूर्ण', 'े', 'ंकी', 'ााटी', 'ाुमावदार', 'ंतो', '्भी', 'ऽ', 'ंतो', 'ंतब', 'ाले', 'ंबताइये', 'ंिसंह', 'ानावाला', 'ेछुपाने', 'ंमें', 'ेविषय', 'िफर', '़लाई', '़लाई', '़', '़', '़', '़के', 'ः', 'ो', 'ेके', 'ा', 'ेचलिए,', 'ं', 'ों', 'ारदाता', 'ं।', '़ढ़की', 'ंमें', 'ः', 'ः', 'िक', 'ः', 'ंहै', 'ः', 'ः', '्कान', '्बीमारी', 'ऽ', 'ंके', 'ा', 'ः', 'ंहैं', '्तथा', 'ंजरूरत', 'ा', 'ंपरा', 'िदया।जब', 'ं', 'ंहैं।', 'ी', 'ं', 'ंतो', 'ंिचंता', 'ऽ', '्सुबह', 'ें', 'ंिसह', 'ःई', 'ूूू।ंिेजदमूेपदकपं।दमज', '्में', 'ऽ', 'ंिचंतन', 'ंतो', '़बीच', '़', '़', '़', '्रपद्रेश।', 'ाी', 'े', 'िं', 'ंने', 'िाकई', 'ंको', 'ुचकी', '्सरकार', '़', '़', '़', 'ै?', 'ंगमंजदा', 'िफक्रो', 'ी', 'ी', 'ंसार', 'ः', 'िफल्म', 'ा', 'िक', 'ऽ', 'ंतो', 'ंपर', 'ेकदम', 'ााषा', 'ंको', 'ऽ', 'े', 'ेट', 'ः', 'ः', 'ं', 'ौलए', 'ा', 'ंलिखा', 'ं', 'ाखुशियॉँ', 'ऽ', '॔निशंक’', '॔हिन्दी', '॔ताकी', '॔सफलता', '॔वटवृक्ष’', 'ार्यक्रमों', '़िखला़फ', '़फर्ज़', '़िखला़फ', 'ं।', 'ः', 'ी', 'ंफिर', 'ौन', 'ि\\u200dकए', 'ंतम', 'ूम', 'ंतम', 'ेवसक', 'ंिहंदू', 'ः', '्सही', 'ा', 'िा', 'ः', 'िाचडी', 'ैबपमदबम', 'ंदक', 'िंवटल', 'ेसे', 'ालोआन', 'ै', '़जरी', 'ी', 'ंनही', 'ंतो', 'िजम्मेदारी', 'ः', 'ः', 'ाते', 'े', 'ेमें', 'ः', 'ंतो', 'ंजहां', 'ः', 'ंसद्गति', 'ंिहसंक', 'ंसमस्याओं', 'ंऐसे', 'ंतो', 'ंचल', 'े', 'ा', 'ंप्रायश्चित', 'ेयह', 'ेलेकिन', 'ंकाटी', 'ऽहं', 'ँँँँँअविनाश', 'ँँँँँ', 'ा', 'ंतो', 'ेष्ेष्य', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ऽ', 'ूुघ', 'ः', 'ंबाधा', 'ंदूसरी', 'ी', 'ीीी', 'ः', 'ोगों', 'ः', 'िकवे', 'िकवह', 'ंएहि', 'िऔर', 'ाा,', 'ुर्ख', 'ाा', '़खूबसूरत', '़', '़', '़', 'ोलन', 'िलए', 'िम', \"ा'\", 'ारतीय', 'ि', 'ाचार', 'िजसे', 'िकए', 'ंहो', 'िफल्में', 'ै।', 'ंको', 'ंइंसान', 'ंतो', 'ाोष', 'ााओं', '्थईं।', 'ं', 'ंनहीं', '॔तू', '॔तेरा', 'ा', 'ः', 'ंकी', 'ाँचे', 'ं,', 'ंपर', 'ंसे', 'ऽ', 'ृ', 'ित', 'ा', 'ेसा', 'ंडदाता', 'ंतो', 'ंग', 'ऽ', 'ेसा', 'ेसे', 'ोगिक', 'ंफरीदा,', 'ुसकी', '़हाया', 'ंग', '़हाया', 'ऽ', '्में', 'ुसके', 'ः', 'ो', 'ऽ', 'िदनांक-', 'ऽ', 'ऽ....।’', 'िसरे', 'िदया', 'ाचार', 'िखलाफ', 'ाचार', 'ेश्य)', 'े', 'िथत', 'िलए', '्बदहजनी', '़', 'ऽ', 'ंसोंचता,', 'ंग', 'ंग', '़', '़', '़', 'ंिसंह', 'ा', 'ः', '॔॔यदि', '्यों', 'ंिजदगी', 'ंिवंसेज', '़', '़', '़', 'िजब्बार', 'िफल्मों', 'िंवटल', 'े', \"ऽ..ऽ...स्ट...।''\", 'ऽ', 'ाीसगढ़', 'ंने', '॔विनम्र’', '॔तीन', '॔सपफलता’', 'ं', 'ऽ', '्रसेमीनार', 'िफरकती', 'िक्रयेट', 'ंके', 'ि\\u200dकताब', 'ऽशुभम्।', 'ुसे', 'िसतारों', 'ाा', 'िफक्रो']\nWords with vowels followed by a matra : {'जाएंगे।': 1214, 'महिलाएं': 892, 'सर...अंदर': 1, 'एंटीऑक्सिडेंट': 3, 'डिस्काउंट': 86, 'उपभोक्ताओं': 463, 'कार्यकर्ताओं': 879, 'अंत': 1553, 'ऊंची': 473, 'अंग्रेज': 195, 'अंग्रेजों': 433, 'एंड': 1136, 'आंकड़ों': 238, 'जाएंगे,': 147, 'मुद्राएंलगेंगी.': 1, 'अंतरराष्ट्रीय': 1463, 'इंटरपोल': 30, 'पहलुओं': 246, 'लगाएंगे।': 26, 'आंकड़ों': 316, 'नेताओं': 2668, 'आंदोलन': 3086, 'इंकार': 611, 'इंग्लैंड': 1177, 'एंबोन': 1, 'अंतरिक्ष': 528, 'अंदाज': 650, '‘इंगलिश': 5, 'अंगरेजी': 229, 'अंश.': 10, 'संस्थाओं': 550, 'समस्याएं': 406, 'संवाददाताओं': 469, 'ऊंची)': 1, 'इंजिनियर्स': 5, 'महिलाओं': 2627, 'आंखों': 1152, 'युवाओं': 855, 'आंतकी': 8, 'इंटरनेट': 848, 'घबराएं': 13, 'चयनकर्ताओं': 159, 'आंखें': 591, 'आं': 2, 'इंद्र': 123, 'दवाओं': 316, 'गईं': 362, 'अंबानी': 209, 'ऊंचाइयों': 31, 'फाउंडेशन': 208, 'फाउंडेशन,': 4, 'इंस्टीच्यूट': 20, 'अंतर्गत': 627, 'इंतजार': 1283, 'अंगदान': 67, 'शोधकर्ताओं': 197, 'अंधेरे': 390, 'अंग्रेजी': 1315, 'समस्याओं': 1007, 'साइंस(भू-': 1, 'चिंताएं': 81, 'लाएं।': 17, 'इंदर': 49, 'आंकड़ा': 269, 'एंड्रॉयड': 115, 'इंस्टीटयूट': 10, 'संभावनाएं': 227, 'इंडिया,': 95, 'इंजीनियरों': 69, 'एयरलाइंस': 267, 'अंसारी': 312, 'ऊंचा।': 2, 'दिखाएंगे।': 12, 'अंगूठी': 59, 'जाएं,': 160, \"'एंग्री\": 2, 'सीमाएं': 103, 'हुआंगनिहे': 1, 'वस्तुओं': 419, 'आंकड़े': 286, 'अंजान': 60, 'आएंगे।': 232, 'अंतिम': 2490, 'अवधारणाओं': 33, 'आंतरिक': 336, 'इंजीनियरिंग': 358, 'शाखाओं': 108, 'अंजाम': 767, 'अंबर': 23, 'साजिशकर्ताओं': 14, 'इंडिया': 2440, 'छात्र-छात्राओं,': 2, 'एंड्रॉएड': 2, 'आॢथक': 40, 'बाध्यताएं': 2, 'कुओं': 28, 'गोइंग': 10, 'इंडस्ट्री': 595, 'इंटरटेनमेंट': 7, 'अकाउंट': 297, 'घटनाओं': 792, 'इंफ्रास्ट्रक्चर': 82, 'साइंटिस्ट्स': 9, 'एेंड': 5, 'इंडस्ट्रीज': 158, 'सूचनाओं': 139, 'अंडर': 115, 'इंडियन': 760, 'डिजाइंस': 42, \"'अंग्रेजी\": 3, 'इंच': 273, 'कन्याओं': 74, 'घटनाएं': 433, 'चिंताओं': 123, 'पुरुष-महिलाएं': 2, 'उंगलियां': 61, 'जाऊं': 191, 'आऊं।': 12, 'आऊंगा।': 20, 'अंदरखाने': 19, 'इंस्पेक्टर': 248, \"जाएं।'\": 4, 'आंतिम': 2, 'काउंटी': 58, 'अंगवस्त्र': 5, 'इंतानोन': 2, 'अंक': 2800, 'विदेश-यात्राएं': 1, 'सीमाओं': 211, 'इंजेक्शनों': 1, 'अंतर': 980, 'इंट्रो': 5, 'ऊंचाई': 353, 'सुविधाएं': 428, 'हुईं': 200, 'अंदाजा': 376, 'इंदौरा': 37, 'करवाएंगे।': 21, 'आंकड़ा': 98, 'जाएं': 430, 'जाएं।': 496, 'लिएंडर': 117, 'डब्ल्यूआएिसपीए': 1, 'इंडोनिशिया': 3, 'अंतर्राष्ट्रीय': 350, 'अंतत:': 270, \"दिखाएंगे।''\": 1, 'चढ़ाएं।': 42, 'छटाएं': 2, 'एंड्रयू': 41, 'इंडोर': 33, 'उठाएंगे।': 44, 'बाएं': 159, 'दाएं': 93, 'उठाएं।': 28, 'ऐंटिडिप्रेसेंट': 1, 'दवाएं': 186, 'काउंसलिंग': 54, 'कक्षाओं': 84, 'कविताओं': 526, 'लगाएं।': 171, 'मिलाएं।': 21, 'बेइंतहा': 22, 'इंदिरा': 651, 'ईंधन': 178, 'आंसूगैस,': 1, 'काउंटर,': 2, 'थलसेनाओं': 3, 'राउंड': 225, 'परंपराओं': 136, 'यात्राओं': 117, 'इंजॉय': 36, 'पाएंगी।': 27, 'जाएंगी।': 284, 'एंटो': 1, 'एंटनी': 146, 'इंटरनेशनल': 258, 'इंग्लिश': 186, 'अंश': 382, 'सेवाओं': 367, 'स्पर्धाओं': 19, 'गईं।': 414, 'क्लाइंट': 31, 'अंदर': 2409, 'गोपिकाएं': 3, \"इंडिया'\": 24, 'आएंगी.': 20, 'विक्रेताओं': 42, 'योजनाओं': 831, 'अंदरूनी': 152, 'अंगों': 180, 'डिस्काउंट्स': 3, 'अपेक्षाओं': 64, 'विद्याओं': 11, 'सुख-सुविधाएं': 11, 'जाऊंगा.’': 1, 'बाधाएं': 58, 'इंसुलिन': 40, 'सूरमाओं': 6, 'ग्राउंड': 121, 'खिलाएं।': 17, 'शाखाएं': 50, 'ब्लाइंड': 12, 'एंटनी,': 16, 'एंटरटेनमेंट': 50, 'पाएंगे,': 36, 'धातुओं': 100, 'कोशिकाओं': 105, 'एंटी': 129, '‘ओंकारा’': 1, 'आऊंगी.': 3, 'वेस्टइंडीज': 286, 'आंख': 496, 'इंटरेस्ट': 75, 'एलएंडटी1.02': 1, 'आंसू': 515, 'क्वालीफाईंग': 8, 'इंटरव्यूज': 3, 'बढ़ाएंगे।': 12, 'परियोजनाओं': 352, 'आंकड़े': 166, 'एंट्री': 226, 'अकाउंटधारक': 2, 'इंद्रजीत': 24, 'इंटर': 163, 'धनपशुओं': 3, 'संस्थाओं,': 17, 'मर्यादाओं,': 2, '17763.59अंक': 1, 'ऊंचे': 329, 'एंव': 66, 'अंपायर': 78, 'अंपायरों': 37, 'नजरअंदाज': 213, 'आंत': 27, 'बोइंग': 43, 'योजनाएं': 275, 'इंटीग्रेटेड': 19, 'अंडमान': 38, 'आंदोलनों': 237, 'एंडोर्स': 8, \"'इंडिया\": 28, 'उंगलिया': 7, 'ऐंटि-लॉक': 1, 'काउंसिल': 248, 'चुकाएं।': 1, 'इंसाफ,': 2, 'एंडी': 79, 'आएंगी': 33, 'लगाएंगी।': 6, 'चर्चाओं': 91, 'एंट्रेंस': 15, 'इंश्योरेंस': 345, 'अमाउंट': 21, 'परियोजनाएं': 84, 'इंजन': 362, 'सफलताएं-विफलताएं,': 2, 'अंधेरी': 97, 'बनाएंगे': 29, 'आएं,': 17, 'इंवेस्टमेंट': 16, 'इंस्पेक्टर)': 1, 'अनुसंधानकर्ताओं': 31, 'अंतरिम': 112, 'आंगनबाड़ी': 95, 'इंडोनेशिया': 105, 'आंग': 44, 'करदाताओं': 33, 'लगाईं': 12, 'छात्राओं': 262, 'खिलाऊंगी.': 1, 'ज्वाइंट': 40, 'जाएंगे': 406, 'इंतजाम': 457, 'इंडियंस': 70, 'चलाएंगे।': 14, 'ए़': 5, 'अंहकार': 13, 'योजनाओं,': 8, 'ग्राउंड्स': 2, 'बाधाओं': 90, 'घोषणाएं': 55, 'ऊँ।।': 6, 'अंतर्द्वद': 2, 'संभावनाओं': 225, 'अंतराल': 246, 'एंग्लो-फ्रेंच': 1, 'मतदाताओं': 411, 'इंस्टिट्यूट': 53, 'सूचनाएं': 143, 'शुभकामनाओं': 37, 'अंबेसडर': 9, 'सुविधाओं': 395, 'इंस्टीट्यूट': 208, 'अंकेक्षण': 9, '‘इंटरनेशनल': 4, 'याचिकाओं': 94, 'आएंगे,': 45, 'आएंगी।': 97, 'बैठाएं।': 4, 'अंकों': 401, 'इंसानों': 150, 'चाहिएं?': 4, 'इंदौर।': 23, 'धारणाएं': 21, \"लाएं।'\": 1, 'अंतरधन': 1, 'निर्माताओं': 127, 'अंजलि': 84, 'अंदर-': 1, 'विषमताओं': 10, 'रेखाएं': 64, 'इंसान': 1425, 'पाएं।': 40, 'इंसाइक्लोपीडिया': 5, 'विजेताओं': 63, 'इंदू': 12, 'अंधकार': 181, 'अंकुश': 248, '‘प्लेइंग': 2, 'पाएंगे': 153, 'महीलाओं': 3, 'खाएं,': 12, 'अंबे': 5, 'अंबेडकर': 115, 'क्षुद्रताओं': 4, 'कथाओं': 110, 'इंडेक्स': 183, 'सेनाओं': 125, 'आत्मकथाएं': 5, 'इंडस्ट्रियल': 77, 'इंडिपेंडेंट': 27, 'अभिनेताओं': 67, 'आएंगे.': 17, 'नीति-निर्माताओं': 4, 'कराएंगे': 15, 'देवताओं': 299, 'पाएंगे।': 213, 'कराएं': 28, 'धुआं': 97, 'छात्र-छात्रओं': 23, 'प्रयोगशालाओं': 14, 'अंदेशा': 86, 'कथाएं': 58, 'अंधेरा': 211, 'चबाएं।': 2, 'पीएं।': 40, 'इंफ्राटेल': 11, 'इंडस': 7, 'पाउंड': 90, 'अंचल': 206, 'सभाओं': 126, 'उंगली': 224, 'करवाएं।': 23, 'साइंस': 273, 'पेईंग': 2, 'एंजल्स': 2, 'क्लाइंट्स': 17, 'अंगूठे': 77, 'आंका': 40, 'अपेक्षाएं': 56, 'बिंदुओं': 95, 'इंजेक्शन': 88, 'अंतिदि': 1, 'ईंट': 110, 'इंद्राणी': 11, 'जाऊंगा,': 16, 'बढ़ाऊंगा.': 3, 'अंधेर': 25, 'हत्याएं': 47, 'ऊंची-ऊंची': 26, 'ाएंगे': 1, 'कंगारुओं': 12, 'घर-आंगन': 10, 'आएं': 116, '‘महत्त्वाकांक्षाओं’': 1, 'तेंदुएं': 1, 'बनाएं,': 28, 'अंबुज': 3, 'अंबिका': 74, 'हटाएं': 5, 'कक्षाएं': 50, 'नेताओं-कार्यकर्ताओं': 8, 'इंफोसिस,': 8, 'इंडस्ट्रीज,': 17, 'प्वाइंट,': 5, 'जीवाणुओं': 18, 'विषाणुओं': 5, 'आार्थिक': 2, 'इंचार्ज': 76, 'पॉइंट्स': 152, 'अंचलों': 30, 'मान्यताएं': 35, 'बेअंत': 14, 'इंजीनियरिंग।': 7, 'इंदौर': 200, 'जमालउा': 1, 'अंसारी,': 140, 'एंजलीना': 6, 'सेवाएं': 266, 'आलोचनाओं': 81, 'दुर्घटनाओं': 85, 'आंदालन': 1, 'इंदीवर': 11, 'जाऊंगा।ज्': 1, 'शिशुओं': 73, 'ऊँ': 167, 'आंबेडकर,': 4, 'ऊंचा': 260, 'चलाऊंगा।’’': 1, 'लाएं।’’': 1, 'इंटरनैट': 20, 'एंजेलो': 44, 'माइंडसेट’': 5, 'बनवाएं।': 3, 'जाऊं।': 34, 'इंगलिश': 29, 'इंस्टीटय़ूट': 14, 'इंजीनियर': 307, 'अंदाज,': 7, 'अंजली': 30, 'अंबेडकरनगर': 4, 'इंगलैंड': 170, 'एंडरसन': 85, 'ईं।': 1, 'बालिकाएं': 17, 'नईं': 11, 'आंध्र': 276, 'माताओं': 44, 'इंजिनियर': 35, 'चाकुओं': 9, 'हुईं।': 138, 'आईं।': 91, 'दोहराएं।': 8, 'बताएं': 148, 'कराएं।': 60, 'ऐंजिलिस:': 1, 'ऐंजेलिना': 1, 'कलाओं': 84, 'अंदोरमेडा': 1, 'आकाशगंगाओं': 20, 'बनाएं': 132, 'बढ़ाएं': 13, 'अंग': 527, 'दुआओं': 45, 'पशुओं': 210, 'प्रतियोगिताओं': 98, 'भावनाएं': 149, 'आईं।’': 1, 'गाइडलाइंस': 28, 'माइंडसेट': 6, 'विधवाओं': 46, 'अंतरदृष्टि': 2, 'आलराउंडरों': 4, 'भावनाओं': 529, 'साईं': 104, 'याचिकाएं': 36, 'अंडर-19': 48, 'विशेषताएं': 45, 'एंबीयंस': 1, 'आएंगे': 135, 'हिन्दुओं': 219, 'साउंड': 84, 'बैकग्राउंड': 51, 'अर्थव्यवस्थाओं': 66, 'अंत?': 2, 'बाप-दादाओं': 6, 'जाऊंगा': 98, \"दिखाऊंगा।'\": 1, 'आएं।': 97, 'अंत्येष्टि': 30, 'जांचकर्ताओं': 42, 'इंसेमीनिशन:': 1, 'परंपराएं': 25, 'मुद्राओं': 73, 'एंटीगा': 1, 'एंब्रॉयडरी': 6, 'एंब्रॉयडेड': 1, 'साधुओं': 47, 'लाइंस': 59, 'एंप्लॉयीज': 13, '(अंगूठी)': 1, 'अंगार': 21, 'हेडलाइंस': 5, 'खाएं।': 68, 'अंकित': 229, 'अंजीर': 31, 'ऊंटकटारों': 1, 'अंगूर।': 1, 'प्रतिक्रियाएं': 62, 'अंक:': 4, 'स्पध्र्दाओं': 5, 'अनिश्चितताओं': 11, 'काउंसेलर': 3, 'नाइंटीज': 8, 'इंटीरियर': 38, 'इंटरनैशनल': 182, 'अंजनी': 21, 'चर्चाएं': 40, 'परियोजाओं': 2, 'वाहिकाओं': 7, 'श्रध्दालुओं': 32, 'जाएं.': 36, 'अंगरेजी,': 10, 'लॉबिइंग': 1, 'अंडे': 162, 'प्रतिबद्धताओं': 23, 'महिलाओं,': 25, 'काउंटर': 179, 'शिकायतकर्ताओं': 10, 'आकांक्षाएं': 21, 'अंगुली': 100, 'फाउंडर': 18, 'अंडरवियर,': 2, 'भूमिकाओं': 55, 'आंटियों': 3, '‘युवाओं': 2, 'नुमाइंदों': 16, 'महिलाएं,': 19, 'आइंस्टीन': 41, 'साउंडलेस': 1, 'अंधाधुन': 1, 'अंकारा': 1, 'एंजाइम': 17, 'इंस्ट्रक्शंस': 2, 'इंटीमेट': 13, 'प्रक्रियाओं': 105, 'अनियमितताओं': 85, 'लाएंगे': 14, 'अंक-': 19, '‘अंदर’': 1, 'भाषाओं': 440, 'जनसभाएं': 7, 'जनसभाओं': 32, 'वक्ताओं': 104, 'अंशु': 60, 'अंकुर': 67, 'अंग्रेजी,': 28, 'इंटरसिटी': 12, 'इंजिनियरों': 7, 'अंत्ययात्रा': 2, 'आंखों,': 3, 'लेखिकाओं': 36, 'आंखे': 143, 'अंशिफ': 1, 'एंग्लो': 8, 'योग्यताओं': 40, 'योजनाआंे': 1, 'फ्लाइंग': 24, 'इंस्टूमेंट': 1, 'क्रियाओं': 67, 'धोएं।': 10, 'पाईं,': 6, 'अंगद': 36, 'अंतररात्मा': 3, 'इच्छाओं': 126, 'प्वाइंट': 142, 'आंकी': 50, 'आंदोलनकारियों': 69, 'आंशका': 9, 'खुलवाएं।': 2, 'इं': 1, 'आकांक्षाओं': 64, 'लगाएं': 95, 'अभियंताओं': 63, 'बनाएं।': 85, 'इंडिया’': 44, 'एंकरिंग': 8, 'एंजिलिस': 34, 'इंडीपेंडेंटली': 1, 'री-इंट्री': 1, 'चंपूओं': 1, 'अंचलाधिकारी': 14, 'जन-आंदोलनों': 12, 'ड्राइंगरुम': 1, 'असफलताओं': 30, 'इंट्रोडक्शन': 4, 'आशंकाओं': 57, 'कुएं': 162, 'मान्यताओं': 120, 'इंटरव्यू': 382, 'इंफेक्शन्स': 1, 'एकाउंट': 87, 'नियोक्ताओं': 19, 'इंजमाम': 13, \"अंडरअचीवर'\": 1, 'लगाएं.': 45, 'कराएंगे।': 35, 'आलराउंडर': 59, 'अंदरुनी': 16, 'सभाएं': 42, 'वितरिकाओं': 6, 'इंजनों': 27, 'इंजर्ड': 1, 'अंबाराम': 1, 'अंडर-17': 11, 'एंग': 11, 'इंश्योरेंस,': 18, 'एंबुलेंस': 92, 'काउंसेलिंग': 10, 'इंसाफ': 102, 'आंकलन': 63, 'जाएं-': 4, 'माउंटेनियरिंग': 10, 'हुई़.': 2, 'एंटोनिम्स,': 1, '‘इंगलिश-विंगलिश’': 1, 'बालाओं': 12, 'नायिकाओं': 36, 'उंची': 59, 'सुअंसा': 1, 'काउंसिलर': 15, 'इंगेज': 2, 'हुईं,': 50, 'भूमिकाएं': 64, 'अंत्येष्टि!': 1, 'इंटरेक्ट': 3, 'चाहिएं।': 25, 'आशाएं': 30, '‘अंदरूनी’': 1, 'इंटरनल': 41, '‘‘अंतत:': 1, 'एंटीबॉयोटिक': 2, 'सजाएं': 20, 'एंट्री,': 15, 'गर्इं।': 21, 'अंतरात्मा': 76, 'आॅटो-रिक्शा': 2, 'रेस्तरांओं': 4, '‘अंगना': 1, '(अंडरअचीवर)': 1, 'अंगुलिकाओं': 6, 'अंतरित': 5, 'व्यवस्थाओं': 95, 'इंद्रनील': 6, 'अंतरप्रांतीय': 1, 'अल्ट्रासाउंड': 22, 'आंसुओं': 264, 'सेवाओं,': 7, 'हाई-इंटेनसिटी': 1, 'सुनाएंगे।': 7, 'औंधे': 38, 'उपभोक्\\u200dताओं': 7, 'ऐंड': 198, 'इंफर्मेशन': 5, 'एलऐंडटी': 4, 'अंडर-16': 10, '(एसएंडपी)': 3, 'कामनाओं,': 4, 'एंट्रेस': 6, 'ऐंबैसडर': 5, 'दशाओं': 14, 'आंगन': 210, 'इंजीनियरिंग)': 1, 'इंडीज': 80, 'काउंटरों': 22, '‘‘इंटरनेट': 3, 'उपयोगकर्ताओं': 15, 'विधानसभाओं': 35, 'काउंसलर': 40, 'पाईं।': 18, 'बताएँगे': 18, 'अवस्थाओं': 45, 'आँध्रप्रदेश': 3, 'इंदिरागांधी': 3, 'प्लेइंग': 8, 'साइंटिस्ट': 17, 'लगाएं?’': 1, 'संभावनाएं’': 1, 'पीड़ाओं': 8, 'प्रेतबाधाओं': 1, 'इंफ्रास्ट्रक्चर,': 9, 'स्कीइंग': 20, 'चलाएं।': 12, 'आंकड़ों,': 1, 'आंशिक': 106, 'अव्यवस्थाओं': 12, 'हुईं.': 49, 'श्रद्धालुओं': 273, 'इंतजामों': 22, 'कविताएं': 247, 'अपॉइंटमेंट': 4, 'माइंस': 66, 'उठाएं': 17, 'अदाओं': 34, 'अंगेस्ट': 17, 'सफलताएं': 33, 'मंगवाएं,': 1, 'जाएंगी.': 16, 'बनाएंगी': 7, 'शुभकामनाएं': 115, 'अंधे': 106, 'इंद्रप्रस्थ': 17, 'फ़ाउंडेशन,': 1, 'इंटरप्राइजेज': 11, 'जाएंगे.': 80, 'इंकजेट': 1, 'आत्माओं': 31, 'हुईं.”': 1, 'ऊंच': 4, 'अंधाधुंध': 77, 'एप्लाइंसेज': 3, 'अंगरेजों': 37, 'मंगाएं': 1, 'अंतहीन': 67, 'उंचा': 30, 'रिबाउंड': 6, 'पाइंट्स': 15, 'अंबाटोली,': 1, 'विचाराधाराओं': 4, 'विचारधाराओं': 36, 'अंगीकार': 39, 'प्रतिमाएं': 41, \"जाऊंगी।'\": 2, 'वस्तुएं': 98, 'योद्धाओं': 38, 'राजाओं': 168, 'छात्र-छात्राओं': 94, 'साइंसेज': 20, \"'इंगुश\": 1, \"काउंसिल'\": 2, 'इंगुशेतिया': 1, 'धुएं': 84, 'बताएंगे,': 5, 'चलाएं': 11, 'जॉइंट': 45, '‘इंतीफादा’': 2, 'लगाएंगे?': 1, 'कुमाऊं': 46, 'अंतरराष्टीय': 7, 'कोशिकाएं': 40, 'ओरिएंटेड': 7, 'रखामाइंस': 1, 'फाऊंडेशन': 3, 'शत्रुओं': 86, 'बनाएंगे।': 36, 'कदमकुआं': 8, 'राजनेताओं': 254, 'अनुशंषाओं': 1, 'इंचौली': 2, 'बचाएं।': 3, 'आॅपरेशन': 18, 'शिक्षिकाओं': 23, 'रोगाणुओं': 3, 'क्रियाएं': 33, 'कामनाएं': 22, 'एंप्लॉईज': 6, 'अंशुमन': 24, 'गईं,': 87, 'राजा-महाराजाओं': 5, 'पकाएं।': 15, 'आंवला,': 19, 'आंच': 167, 'योजनाएँ': 14, 'देवी-देवताओं,': 4, 'जीव-जंतुओं': 15, 'एंजेलिस।': 2, 'पाउंड,': 3, 'समयअंतराल': 1, 'अंडर-14': 12, 'अंजना': 57, 'प्रतिस्पर्धाओं': 9, 'एंटरटेनमैंट': 1, 'अंब्रेला': 1, 'पाऊं।': 5, 'इंटरेक्शन': 3, 'इंटक': 37, 'आंकडे': 30, 'आशंकाएं': 45, 'संरचनाओं': 40, 'अंटार्कटिक': 20, 'हिंदुओं': 196, 'गुस्साएं': 4, 'प्रार्थनाओं': 22, 'अंधविश्वास': 106, 'अंबाला': 36, 'इंजीनियरिंग),': 1, 'इंटेलीजेंस': 17, 'धाराओं': 123, 'मनाऊं।': 2, 'औंस': 153, 'इंकलाबी': 18, 'इंफोसिस': 75, 'अंगुलियों': 51, 'कॉलेज-इंस्टीट्यूट': 2, 'इंग्लैड': 10, 'भू-माफ़ियाओं': 1, 'सहायिकाएं': 2, 'सहायिकाओं': 7, 'धूमकेतुओं': 3, 'कौओं': 25, 'अंतरबैंक': 19, 'एंटीबायोटिक्स': 19, 'संवेदनाओं': 68, 'समानताएं': 20, 'मुद्राएं': 33, 'इंटेलिजन': 3, 'जाऊंगा.': 22, 'इंट्री': 59, 'जगराओं': 2, 'जाऊंगी।': 26, 'ऊंचाईयां': 8, 'काउंसलिंग.': 2, 'काउंसिलिंग': 29, 'सेवाएं,': 12, 'वस्तुएं,': 12, 'ऐंटिऑक्सिडेंट': 2, 'अंगरेज': 15, '‘अंडरअचीवर’': 4, 'न्यूरोसाइंटिस्ट': 2, 'अल्ट्रासाउंड,': 1, 'इंटरनेट,': 20, 'अंधेरा,': 10, 'इंटेलिजेंस': 39, 'भुजाओं': 28, 'जाएंगे।’’': 5, 'अंगूर': 37, 'आंगूचा,': 1, 'इंवेस्टर': 2, 'पाए़।': 1, 'ओढ़ाएं।': 2, 'आंबेडकर': 121, 'अंकोरवाट': 12, 'इंद्रियों': 58, 'वासनाएं': 7, 'माइंड': 51, 'आंकडा': 15, \"'आंशिक'\": 1, 'अंशदान': 30, 'आॅडिट': 2, 'एंटिना': 3, 'आइंसटाइन': 2, 'ब्रेकप्वाइंट': 2, 'श्रद्धालूओं': 1, 'एकाउंटेंट': 21, 'अंगुल': 13, 'एंटी-ऑक्सिडेंट्स,': 1, 'प्वाइंटेड': 2, 'गुरुओं': 58, 'ऊंटगाड़ी': 2, 'निविदाओं': 9, 'एंबैसडर': 2, 'प्रतियोगिताएं': 30, 'सेनाएं': 29, 'अॢपत': 2, 'ऊंचा,': 4, 'अंक-6': 2, 'ऊंचाइयां': 12, 'मनाएं।': 7, 'इंडो': 8, 'राष्ट्रीय-अंतरराष्ट्रीय': 5, 'प्रतिभाएं': 35, 'व्यस्तताओं': 20, 'पॉइंट': 95, 'इंवेंट': 1, 'इंस्पायर': 5, 'ऐंड्रॉयड': 5, 'इंद्रियों,': 1, 'आईं': 154, '5243.60अंक': 1, '‘इंडिया': 18, 'इंप्रेस': 13, 'एंजिलिस:': 16, 'छात्रओं': 65, 'दावाकर्ताओं': 1, 'ऐंटि': 6, 'इंक्वायरी': 16, 'हुआंग': 2, 'भाषाएं': 79, 'इंज्वाय': 9, 'नौकाएं': 11, 'अकाउंट्स': 25, 'इंडिविजुअल': 20, 'लाउंड्री': 13, 'इंकार-': 1, 'लोककथाएं': 6, 'लोककथाओं': 20, 'एंटोनियो': 12, 'प्राथमिकताओं': 31, 'इंदौर:': 5, 'आंडबर': 1, 'बताएं,': 25, 'ओंकारेश्वर': 25, '‘कलाओं': 1, 'आंवले': 43, 'अंधी': 83, 'इंडियाज': 9, '(अंधेरा)': 3, 'अंधकारमय': 22, 'जनसमस्याओं': 16, 'माउंटेन्स’': 1, 'इंस्टॉल': 16, '‘इंस्पायर’': 2, 'रोएंदार': 3, 'बाउंड्री': 27, 'अंबा': 11, '‘एनकाऊंटर': 2, 'समझाएं': 19, 'जाओं,': 2, 'ऊंचे-ऊंचे': 24, 'इंद्रियदाताओं': 2, 'दाताओं': 8, 'इंद्रिय': 22, 'इंद्रियदान': 2, 'अकाऊंट': 5, 'बताउंगा..': 1, 'परंपराएं।’': 1, 'ऊंट': 76, 'आॅफ': 87, 'आॅपरेटरों': 8, 'बाबुओं': 40, 'एंसेबली': 1, 'इंट्रड्यूस': 1, 'सुख-सुविधाओं': 22, 'जाएंगी': 86, 'आंखें,': 18, 'डाइंग,': 2, 'लीलाओं': 14, 'बालक-बालिकाएं': 1, 'ऐंगल।': 1, 'ऐंगल': 6, 'लगाएं)': 3, 'नेतओं,': 1, 'इंस्टीट्यूशंस': 3, 'स्तेइंत्ज': 2, 'दुर्घटानाओं': 1, \"'लिएंडर\": 2, 'अंशकालीन': 3, 'जिआंगसू': 1, 'हुर्इं': 4, 'बताएं?': 21, 'आंसूगैस': 5, 'परिघटनाओं': 3, 'बढ़ाएंगे?': 1, 'श्रृद्धालुओं': 4, 'अंडा': 79, 'योग्यताएं': 11, 'आपदाओं': 31, 'दिलाएं': 5, 'सुनाएं।': 3, 'इंजीनियरिंग,': 39, 'एकाउंटिंग,': 5, 'एंथनी': 10, 'इंद्रा': 15, 'इंफ्रा': 20, 'धर्मगुरुओं': 13, 'शंकाएं': 13, 'घोषणाओं': 54, 'औपचारिकताओं': 16, 'परीक्षाओं': 105, 'अधिवक्ताओं': 36, 'इंफोलाइन': 4, 'साईंबाबा': 4, 'इंक': 37, 'एंजेल': 4, 'अंडरवर्ल्ड': 33, 'एंग्लोइंडियन': 2, 'एंगलोइंडियन': 6, 'ऐंबियंस': 3, 'क्लाइंबिंग': 2, 'इंडियाटाइम्स': 1, 'कन्याएं': 15, 'इंफॉर्मेशन': 15, 'इंटरफेस': 20, 'विंदुओं': 4, 'इंस्ट्रक्टर': 6, 'कराएं,': 13, 'एंजाइम्स': 4, '5214.85अंक': 1, '5234.55अंक': 1, 'बचावकर्ताओं': 2, 'टाउंसविल': 2, 'ऊना-अम्ब-इंदौरा': 1, 'इंदु': 40, 'औपचारिकताएं': 39, 'धातुएं': 5, 'अंडों': 41, 'एंडोवमेंट': 1, 'पैरामाउंट': 4, 'नाइंसाफी': 24, 'एंब्रॉयडरी,': 1, 'अंतर्राष्टीय': 6, 'प्रथाओं': 4, 'मास्टरमाइंड': 23, 'अंजिक्य': 7, 'छात्राएं': 61, 'विधानसभाएं': 4, 'हवाओं': 237, 'भावनाओें': 1, 'लाएं': 24, 'अंकल': 183, 'माउंट': 49, 'माउंटेन-': 1, 'माउंटेन': 10, 'ऊर्जाएं': 4, 'ऊंटला': 1, 'फैलाएं।': 9, 'निभाऊंगी.': 1, 'धारणाओं': 51, 'गुरूओं': 20, 'इंग्लैंड,': 32, 'सफलताओं': 22, 'संख्याओं': 15, 'संख्याएं': 3, 'इंक्लेव': 4, 'को-फाउंडर': 3, '‘इंदौरा': 1, 'लाएं,': 6, 'अंकुरित': 46, 'साईंबाबा)': 1, 'आंद्रे': 18, 'योजनाएं।': 2, 'उंचे': 31, 'इंटरनेशल': 6, 'अदाएं': 15, 'अंगवास': 1, 'दिखाएं': 18, 'चलाएं.': 3, 'चर्चाऐं': 1, 'लगाएंगे': 22, 'मेटलर्जिकल/फाउंड्री': 1, 'साइंस/': 2, 'घटाईं।': 1, 'खटखटाएंगे।': 6, 'अंतस': 56, 'लाएंगी.': 3, 'शिक्षाओं': 35, 'शिक्षाएं': 7, 'इंटरपर्सनल': 2, 'कविताएं,': 12, 'अंककी': 1, 'इंस्टॉलमेंट': 4, 'एंजेलीना': 7, 'इंग्लैंड-यूरो': 1, 'विवाहिताओं': 2, 'बैठकें-सभाएं': 1, 'अंको': 20, 'ठहराएं।': 1, 'बताएंगे': 48, 'अंधा': 82, 'पलायनकर्ताओं': 1, 'सहकारिताओं': 1, 'एंटीबायोटिक': 31, 'मांएं': 8, 'एकाउंटिंग': 2, 'इंधन': 15, 'आइओेसी': 1, 'दखलअंदाजी': 11, '(राउंड': 1, 'दिशाएं': 22, 'इंप्लॉइज': 2, 'बाउंस': 18, 'ऑलराउंड': 7, 'क्वॉलिफाइंग': 12, 'चलाईं': 6, 'ऐंटि-बायोटिक': 1, 'इंडिपेंडेंस': 4, 'इंदों': 2, 'आंकड़े?': 1, 'बनाऊं।': 5, 'अर्थव्यवस्थाओं,': 1, 'उठाएंगे': 20, 'रोईं,': 2, 'आवेदनकर्ताओं': 2, 'इंजनियरिंग': 2, 'अंगरक्षक': 40, 'खोएं': 4, 'एंजिलिस।': 2, 'लाएंगी।': 3, 'हत्याओं': 60, 'आंशुमान': 1, 'बताएं.': 6, 'इंजेक्शन,': 2, 'लताओं': 10, 'चयतकर्ताओं': 1, 'प्राथमिकताएं': 25, 'इंस्ट्रूमेंट्स': 8, 'ऐंजिलिस': 3, 'अपहर्ताओं': 23, 'चढ़ाएं': 16, 'लाएंगी': 5, 'अंतर्निहित': 27, 'बाधाएं-मुश्कलें': 1, 'आंदोलनकारी': 64, 'एंडोस्कोपी': 3, 'अपहरणकर्ताओं': 8, 'इंसानी': 90, 'रहनुमाओं': 12, \"आएं।'\": 1, 'मतदाताआें': 2, \"इंटरनल'\": 1, 'अघिवक्ताओं': 6, 'फ़ाउंडेशन': 17, \"जाएंगे।'\": 10, 'इंडिगो': 26, 'आंत्रशोथ': 3, 'दिखाएं।': 23, 'बनाऊंगी.': 1, 'नेताओं,': 48, 'इंटर्नशिप': 20, 'एंब्रोसिओ': 2, 'माफियाओं': 52, 'मांओं': 17, 'जनभावनाओं': 17, 'धुआंधार': 32, 'अंडर-25': 4, 'एंबेसी': 4, '(इंडियन': 14, 'एंडोर्समेंट': 4, 'दिखाऊंगा.': 2, 'माइंडेड': 2, 'समझाएंगे।': 2, '(आंध्र': 6, 'अंतर्राज्यीय': 5, 'एंकर': 59, 'उपभोओं': 1, 'कम्पाउंड': 18, 'आजमाएंगे': 1, 'अंतर्रात्मा': 4, 'आंगू': 1, 'अंतरिक्षयान': 12, 'सजाएं।': 8, 'अंगरडिहा': 2, 'वैरिएंट्स': 5, 'वैरिएंट': 24, 'स्पॢशकाएं': 1, 'अंडा,': 16, 'ऐहउँ': 1, 'जाएंगी।’': 3, 'अंबरीश': 13, 'जाएं!': 7, 'भावनाओं-कल्पनाओं': 2, 'छात्र-छात्राएं': 23, 'उल्लंघनकर्ताओं': 2, 'निभाऊं.': 1, 'इंडोनेशिया,': 25, 'पॉइंटस्': 1, 'दुरावस्थाओं': 1, 'बंधुओं': 107, 'अंतमलन': 1, 'मेधाएं': 1, 'खाएं': 77, \"बताएंगे।'\": 2, 'अंदाज़में': 1, 'अंजन': 12, 'ऊंचें': 2, 'एंड्रायड': 11, 'इंज्वॉय': 19, 'अंडाणु': 20, 'समस्याओं,': 5, 'सेवाआें': 4, 'जगाएंगे।': 3, 'एंटी-ऑक्सीडेंट': 2, 'अंबवानी': 2, 'माताएं': 35, 'ओंकारनाथ': 14, 'सफलताएं,': 2, 'अंतर्गत्': 2, 'बिताएं।': 11, 'नौकाएं,': 2, 'ऊचाइंयों': 1, 'इंडिकॉम': 4, 'मिलाकर,आंखों': 1, '‘बोइंग’': 1, '‘बोइंग': 1, '‘‘बोइंग': 1, 'दबाएं।': 13, 'कनाडा-इंडिया': 1, 'आऊंगा': 27, 'आंकना': 13, 'गिनाईं': 3, 'आंवला': 38, '‘अराउंड': 1, 'इंडिया...': 1, 'सभाओं,': 6, 'जाऊं?': 19, 'एंडेड': 2, 'एंथोनी': 13, 'रिवाइंड': 5, 'अंगरेजीदा': 1, 'अंडे,': 8, 'हुईं?': 3, 'इच्छाएं': 50, 'राउंड-2': 1, 'अंबार': 36, 'कार्यकत्र्ताओं': 23, 'इंटीग्रेटिंग': 2, 'ऑलराउंडर': 41, 'कल्पनाओं': 46, 'अंततः': 268, '‘अंक’': 5, 'उत्पादनकर्ताओं': 1, 'प्रस्तोताओं': 21, 'दानदाताओं': 13, 'आंधी': 146, 'इक्षाओं,': 1, 'सफलताओं,': 3, 'समस्\\u200dयाओं': 13, 'आंकने': 19, 'बिताऊंगी': 1, 'एंजेल्स': 10, 'आंगन,': 2, 'अलाउंस': 11, 'इंडक्शन': 11, 'फूल-मालाओं': 2, '\"इंगलिश': 1, 'आऊं,': 5, 'आऊं': 18, 'ऐंजेलो': 1, 'अंगुलीमाल': 2, 'अव्यवस्थाएं': 5, 'आत्महत्याएं': 13, 'मतदााताओं': 1, '‘‘उपभोक्ताओं': 1, 'व्यक्तिओं': 2, 'आँतों': 13, 'अंकों)': 1, 'एंजेलिना': 6, 'एंट्रिक्स': 8, 'हेपेटाइिटस': 2, 'बाउंटी’': 2, 'बाउंटी': 4, 'श्रोताओं': 112, 'आॅव': 1, '-अंशुल': 1, 'समस्याएं,': 6, 'राउंडर': 8, 'गैस्ट्रोइंटेस्टाइन': 1, 'अंधता': 3, 'अंजू': 63, 'राईं': 1, 'जाऊंगा।': 72, 'उल्लुओं': 21, 'गुफाओं': 45, 'अवधारणाएं,': 2, 'धाराएं': 44, 'एनकाउंटर': 41, 'व्यवस्थाएं': 43, 'र्इंट,': 1, '‘र्इंटें’,': 1, 'गुफ़ाओं': 6, 'जाएंगे?': 29, 'इंडोस्कोपी': 3, 'सेविकाओं': 13, 'परीक्षाएं': 62, 'आशाओं': 59, 'आॅब्जर्वर': 2, 'बोइंग,': 3, 'ऐंटि-रेबीज': 2, 'इंस्पेक्टर,': 10, 'अनियमितताएं': 34, 'महिलाएं।': 3, 'इंड': 5, 'अंगवाली': 3, 'इंडिगो,': 2, 'एयरलाइंस,': 6, 'रचनाएं,': 6, 'जाएं’.': 1, 'उंचाइयों': 2, 'अंडरवुड': 3, 'प्रवक्ताओं': 15, 'रेखाओं': 62, 'जिज्ञासाओं': 19, '‘‘अंधा': 1, 'निभाऊं,': 1, 'अंजी': 2, 'अंश)': 4, 'दिशाओं': 98, 'ललनाओं': 1, 'इंडस्ट्रियल,': 3, 'अंजुमन': 35, 'काउंसिलर्स': 1, 'प्रतिमाओं': 64, 'इंच)': 8, 'जाएंगी.’’': 1, '‘इंग्लैंड': 1, 'आॅक्सफोर्ड': 4, 'जटिलताएं': 7, 'कराएंगे.': 9, 'अकाउंट..': 1, 'हसीनाओं': 10, 'वीकएंड': 7, 'होउंगी.’’रानी': 1, 'इंजिनियरिंग': 50, 'अंगूठा': 49, 'अंतराष्ट्रीय': 30, 'हवाएं': 79, 'इंस्पायर्ड': 8, 'बालिकाओं': 31, 'प्रशिक्षुओं': 13, 'खाऊंगा.': 2, 'अंदुजार': 1, 'इंप्रूव': 7, 'प्रार्थनाएं': 25, 'पालिकाओं,': 2, 'जन-आंदोलन': 11, 'बताएं,जिसके': 1, 'दिखाएं-या': 1, 'बहाएं।': 3, 'अंतरंग': 51, 'ईंट,': 6, 'छाएंगे': 4, 'घटाएं': 14, 'अट््टालिकाओं': 2, 'इंद्रधनुष': 24, 'पिएं।': 16, 'मनाएंगे।': 14, 'लगाएं,': 18, 'मुस्कराएं': 1, 'इंग्लिश,': 7, 'हुर्इं,': 4, 'अंकल,': 11, 'माउंटबेटन': 16, 'इंवेस्ट': 4, 'जाएंगेे।': 1, 'मुंबईः': 15, 'अंगने': 1, 'इंप्रेशन': 12, 'इंद्राज': 5, 'अंडरग्राउंड': 46, 'सेमीफइानल': 1, 'लहराऊं।': 1, 'आंद्रिया': 7, 'अंसाजे': 4, 'अंतरे': 15, 'विडंबनाओं': 11, 'बिठाएं': 3, 'छात्रएं': 17, 'उपयोक्ताओं': 9, 'इंसुलेटर': 3, 'इंटेनसिटी': 3, 'ऋचाओं': 18, 'इंस्टीट्यूशन': 6, 'इंट्रेस्\\u200dटेड': 1, 'प्वाइंट-टू-प्वाइंट': 2, 'दुआएं': 72, 'अंतरआत्मा': 4, 'बताएंगे।': 23, 'बहुएं': 21, 'साइंस,': 25, 'केनजिटाइटिस(आंख': 1, 'इजरायल-इंडिया': 1, 'सम्भावनाएं': 18, 'कराएं.': 10, 'दक्ष-सेवाओं': 1, 'अंबाती': 7, 'लामाओं': 1, 'माउंटेड': 2, 'अंदर-अंदर': 14, 'आवश्यकताओं': 96, 'कोआॅपरेशन': 1, 'पालिकाओं': 7, 'कलादीर्घाओं': 2, 'दिलाएं’,': 1, 'इंडियन्स': 17, 'सम्भावनाओं': 17, 'इंद्रकांत': 10, 'समीक्षाएं': 13, '‘इंतकाम’,': 1, 'एंग्री': 20, 'मिलाएं,': 4, 'मिलाएं': 15, \"'अंदाज'\": 2, \"एंट्री',\": 1, 'एंवायरमेंट': 2, 'इंद्रकुमार': 9, 'गईं.': 53, 'पाईं.': 5, '‘अंग्रेजी': 1, '‘इंडेंजर्ड': 3, '‘इंग्लिश’,': 1, 'इंस्टेंट': 2, 'अकाउंटिंग': 7, 'बनाएं.': 13, 'अंगारक': 1, 'ऐंठने': 12, 'एंजॉय': 43, 'इंडोनेशियाई': 17, 'आस्थाओं': 27, 'अंहई': 1, 'अंधार’': 1, 'संवादाताओं': 3, 'अंडर-11': 3, 'भालुओं': 5, 'कुआं': 49, 'आयकरदाताओं': 4, 'इंगेजमेंट': 3, 'हटाएंगे।’’': 1, 'बिन्दुओं': 33, 'अंधापन': 5, 'अंतर्मन': 50, 'मुंबई-अंबेजोगाई': 1, 'पाएंगे.': 20, 'इंप्रोवाइज्ड': 1, 'ओंकार': 62, 'बाध्यताओं': 7, 'पाएं,हालांकि': 1, 'आंदोलनरत': 21, 'परिभाषाओं': 21, \"'साउंड\": 2, 'बढाएं।': 2, 'अंर्तसबंधों': 2, 'अंसतुलित': 2, 'अपनाएं-': 5, 'अंजलि,': 3, 'विद्रूपताओं': 6, 'अनिश्चिंतताओं': 1, 'डाकुओं': 37, 'आज्ञाओं': 3, 'कुव्यवस्थाएं': 1, 'अंबाटी': 2, 'अंत:करण': 18, 'इंप्लाइज': 7, 'वास्तविकताओं': 13, 'जलाएं।': 15, 'पहुंचाएंगे': 3, 'अंजुमने': 2, 'एंबेसडर': 23, 'काउंसिल,': 2, 'इंटरसेप्टर': 8, 'अंसतुष्टी': 1, 'योजनाएं,': 6, 'समानताओं': 7, '40अंकों': 1, 'नगरपालिकाओं': 3, 'रचनाओं': 333, 'लगवाऊंगा-दीपक': 1, 'अभियंताओं,': 4, 'इंफसोसि': 1, 'आंचलिक': 26, \"उठाऊंगा।'\": 1, 'इंस्पेक्टरों': 7, 'अंश..': 22, 'रूआंसे': 3, 'सेवाओंं': 1, 'ऋणदाताओं': 3, 'एंजियोप्लास्टी': 9, 'क्षमताओं': 82, 'अंतर-मंत्रिस्तरीय': 1, 'ऎेसे': 2, 'ऊँचाई': 87, 'हुईं.इनके': 1, 'एंगल': 33, 'एंटरप्राइजेस': 2, 'अंडरवियर': 9, '‘इंडियन': 15, 'इंडीज)': 1, 'रोइंग': 3, 'इनकमटैक्सइंडियाईफाइलिंग': 2, 'बदलाओं': 2, 'अंदाज़': 115, 'इंडियाफर्स्ट': 3, 'अंधरीगादर': 2, 'तक-अंबानी': 1, 'अपनाएं': 22, 'चाहिएं': 19, 'एंटीऑक्सीडेंट': 5, 'यात्राएं': 80, 'वेरिएंट्स': 1, 'संस्थाएं': 144, 'ईंच)': 1, 'इंजिन': 24, 'एलएंडटी': 17, 'इंग्लंड': 2, 'अलाउंस:': 3, 'इंश्योरर': 1, 'ओरिएंटल': 5, 'एंजाइना,': 3, '‘बाउंस': 1, 'अंत्यपरीक्षण': 5, 'अंशुमन,': 4, 'अंकगणित': 11, 'इंडियन!': 1, 'इंटरप्राइजेज,': 7, 'इंटरनेशनल,': 7, 'अंडाल': 10, 'आईं,': 23, 'पाईं': 20, 'अंतर्वस्तु': 18, 'बसाएं।': 1, 'इंफ्राटेक': 5, 'इंडेन': 8, 'हुआ़': 3, 'आंदियन': 1, 'एंबु': 1, 'फरमाएं': 7, 'अंडरटेकिंग': 18, 'आंदोलनों,': 7, 'विपदाओं': 8, 'अंधारी’': 1, 'महत्वाकांक्षाओं,': 1, 'जटिलताओं': 31, 'तेंदुओं': 5, \"लगाऊंगा।'\": 1, 'अंशदाताओं': 2, 'बुलाएं।': 5, 'आंख/': 1, 'बिछाएं।': 5, 'ऐं': 24, 'मर्यादाओं': 44, 'अंधा।': 2, 'इंतज़ार': 307, 'आंध्रप्रदेश': 51, 'बताईं।': 5, 'इंडस्ट्रिलिस्ट': 1, 'आडिएंस’': 1, 'पदयात्राएं': 5, 'अंतर्किया': 1, 'पाईं.फिल्म': 1, 'अर्थव्यवस्थाएं': 20, 'बताऊं,': 10, 'बैकग्राउंडवाले': 1, 'इंफोटेल': 1, 'इंफ्रा,जेपी': 1, 'एमएंडएम,': 2, 'एंटीक': 7, 'कामनाओं': 53, 'अंतरप्रांतिय': 1, 'अंतर-मंत्रालयीय': 3, 'फॉलोइंग': 5, 'नायक-नायिकाओं': 2, \"'इंग्लिश\": 6, 'नैतिकताओं': 8, 'इंताज': 1, 'विशेषताओं': 65, 'बनार्इं,': 1, 'इंफ़ॉर्मेशन': 1, 'मालाओं': 13, 'आंकडा,': 1, 'ओंडा': 1, 'इंस्पैक्टर': 30, 'इंस्टिट्यूशन': 4, 'पराकाष्ठाओं': 2, 'इंवांस': 1, 'इंतिखाब': 3, 'जाउंगी.’’': 1, 'इंटरेस्टिंग': 12, 'विविधताओं': 19, 'इंजरीज': 3, 'कार्यशालाओं': 13, 'कार्यकताओं': 9, 'आऊंगी..अभी': 1, 'अंतर्मुखी': 19, 'अंतर्गत’': 1, 'आएंगें।': 1, '(ब्लाइंट': 1, \"इंडियंस'\": 2, 'अल्ट्रासाउंट': 5, 'सेनाएंं': 1, 'दिलाऊं?': 1, 'अंशुमान': 21, 'बाउंसरों': 8, 'बालक-बालिकाओं': 3, 'इंटरटेंमेंट': 2, 'आंदोलित': 34, 'इच्छाओं,': 4, 'इंद्रियां': 16, 'इंटरफेथ': 1, 'अंगूर,': 14, '(अंतिका': 1, 'आंते': 2, 'इंडस्टरीज': 8, 'अंश।': 6, 'एंजिलर': 3, 'एंडोमेंट': 4, 'बकायाकर्ताओं': 1, 'अराउंड': 2, 'भुजाएं,': 3, 'पकाएं': 8, 'एंटिलेस': 1, 'अंडरस्टैंडिंग': 9, 'सुनाएंगी।': 2, 'सेमीफ्इानल': 1, 'क्षमताएं': 17, 'एंसिया': 1, 'उत्तरपुस्तिकाओं': 3, 'अकाउंटिबिलिटी': 2, 'कुशलताएं': 1, 'इंफो': 5, \"एक्सपीरिएंस'\": 1, 'सरगनाओं': 14, 'एंगेल': 2, 'गुआंगदोंग': 4, 'इंटर,': 3, 'जकिउ्द्दीन': 1, 'अंदेस': 1, 'नुमाइंदगी': 15, 'एंटीआक्सिडेंट)': 1, 'बनाएंगी.': 2, 'दौड़ाएं': 7, 'अंगरखा': 20, 'इंकार,': 2, \"साइंस'\": 2, 'औंकार': 1, 'एंसलम्स,': 1, 'आॅक्सीजन': 4, 'रोईं।': 2, 'अंतहीनता': 1, 'एंबुलेस': 4, 'प्रतियोतिाएं': 1, 'आंगनबाड़ी': 12, 'अंतरविश्वविद्यालय': 2, 'कुआं,': 7, 'इंटरनाकोनल': 1, 'इंडेक्स,': 3, 'खिंचवाएं।': 1, 'सरअंजाम': 1, 'सभ्यताओं': 47, 'एेसे': 5, 'अंडाणुओं': 4, 'बाजुओं': 15, 'इंटेंसिव': 2, 'अंसतोष': 3, 'अंगीभूत': 4, 'पिलाएंगी,': 1, 'अनिच्छाओं': 1, 'पाएंगी?': 4, 'बनाऊंगा.': 3, 'इंजीनियरिंग/': 3, 'ऐेसे': 4, 'टीएंडडी': 4, 'भारत-इंगलैंड': 2, 'नौकाओं': 23, 'इंदल': 1, 'अंकेक्षक': 3, 'अंतर्विरोध-': 1, 'ओरिएंटे’': 1, \"एंट्री'\": 4, 'एंकर,': 2, 'इंदौर,': 20, 'पात्रताएं': 2, 'सब-इंस्पेक्टर': 9, 'रि-इंट्री': 1, 'सहअभिनेताओं,': 1, 'बर्मामाइंस': 9, 'ऑंत,': 1, 'अपॉइंट': 3, 'अंदर.': 2, 'इंजिनियर,': 3, 'एफिशिएंसी': 4, 'अंडरस्टेंडिंग': 1, 'आंदोलनात्मक': 3, 'संभवानाएं': 1, 'बैकग्राउंड,': 1, 'आंकिए/': 1, 'जिज्ञासाएं': 4, 'नलिकाओं,': 1, 'आंतों': 27, 'एंटी-ऑक्सिडेंट': 3, 'इंस्ट्रूूमेंट्स': 1, 'इंस्ट्र्ूमेंट्स': 1, 'मांसलताओं': 1, 'संपूर्णताओं': 1, 'कंपाउंडर': 13, 'इंटरमीडिएट': 44, 'जमाओं': 5, 'इंफारेड,': 1, 'सुईंया': 2, 'आत्महत्याओं': 16, 'इंसास': 5, 'अनुशसाएं': 1, 'ऐंठना': 3, 'पाएं': 55, 'हिन्दुओं,': 5, 'इंतजामी': 1, 'इंडो-वेस्टर्न': 5, 'इंस्ट्र्क्टर': 1, 'आंकडो': 1, 'पत्र-पत्रिकाओं': 77, 'अंसारी(20)': 1, 'एंजेसियों': 4, 'कार्र्यकत्ताओं': 15, 'घटनाएं,': 10, 'इंटर्नल': 1, 'न्यूफोउंडलैंड': 1, 'इंट्रेस्ट': 11, 'इंदिरापुरम-वसुंधरा': 1, 'इंदिरापुरम,': 3, 'कार्यकत्तर्ााओं': 10, '(इंडिया': 7, 'एकाउंट्स': 9, 'आंकते': 14, 'कार्यकत्ताओं': 2, 'इंग्लैण्ड': 59, 'बीपीएल-अंत्योदय': 1, 'डिस्काऊंट': 2, 'अंडरग्रैजुएट': 3, 'इंजॉयमेंट।': 1, 'ङ्क्षहदुओं': 4, 'दाएं-बाएं': 22, 'एलएंडटी,': 8, 'होउंगी': 5, 'अंतरराज्यीय': 10, 'दाईं': 29, 'बाईं।': 1, 'इंफेक्शन': 39, 'इंदिराजी': 10, 'एंड्र्यू': 6, 'क्रिकइंफो': 5, 'आंसू,': 15, 'फाउंटेन्स': 1, 'साइंट्स्टि': 1, 'माइंस-': 1, '-इंसाफ': 1, 'कार्यशालाओे': 1, 'अंजू,': 5, 'आएंगे।’’': 5, 'इंतेहा': 2, 'गौएं': 3, 'इंस्टिटयूशनल': 1, 'इंटिग्रिटी': 2, 'संवाददाताआें': 1, 'इंस्टीट्यूशनल': 2, 'एंप्लॉयर': 8, 'एंजल': 3, 'भडकाएं.’’': 1, 'निभाएंगे.': 5, 'व्यथाओं': 3, 'रिमाइंडर': 13, 'प्रतिभाओं': 114, 'प्रत्युत्तरदाताओं': 1, 'अंतरजातीय': 14, 'इंवेस्टमेंट्स': 1, 'मनोकामनाओं': 9, 'डाउंस': 8, 'ईंटों': 28, 'इंस्\\u200dपेक्\\u200dटर': 2, 'आत्महत्याएं,': 1, 'समस्याएं.': 2, 'अंतर्राष्टï्रीय': 4, 'अकाउंटेंसी': 1, 'अकाउंटेंट्स):': 1, 'एकाउंटेंसी': 3, 'अकाउंटेंट्स': 2, 'इंस्टिट्यूट:': 12, 'बिताएंगे।': 8, 'इंतकाल': 12, 'दस्युओं': 4, 'इंपैक्ट': 8, 'इंदिरापुरम': 15, 'इंजीनियर्स': 22, 'एंडलॉ': 8, 'कंपाउंड': 16, 'इंटरमीडिएटरी': 2, 'प्रदाताओं': 7, 'अंबरनाथ': 1, 'आंचल': 97, 'अपनाएं,': 6, 'भुईंटोली': 12, 'एंटरप्राइजेज': 5, 'अंडर-रिकवरी': 1, 'कार्यकर्र्ताओं': 1, 'राउंडअप': 1, 'वार्ताओं': 11, 'अंकिता': 68, 'केंचुओं': 1, 'इंफाल।': 3, 'इंफाल': 12, 'रिफाइंड': 17, 'ड्राइंग': 46, 'फूलमालाओं': 4, 'ऐंठन': 15, 'अस्मिताओं': 12, 'साइंस)': 3, 'न्यूरोसाइंस': 6, 'अंडरवल्र्ड': 4, '(काउंटी),': 1, 'एंड्रिया': 1, 'जनसेवाओं': 1, 'गुआंग': 1, \"पॉइंट्स'\": 1, \"'युवाओं\": 3, 'प्वॉइंट': 10, 'इंगिलश': 2, 'आंचलिकता': 1, 'एंटरटेन': 8, 'गया-इंडस्ट्री': 1, 'अंतिम-16': 5, 'पत्रिकाओं': 165, '‘भैयाओं’': 1, 'अंकपत्रों': 3, 'एसएंडपी': 34, 'इंट्रेस्टिंग': 2, 'निभाएं': 7, 'केग/एंजिलीना': 1, 'इंपोर्ट्स': 1, 'कार्ययोजनाओं': 1, 'अंश-': 11, 'खुशबुओं': 14, 'अंगीठी': 14, 'इंटरेक्टिव': 2, 'अदाएं...': 1, \"जाएं।'हाजी\": 1, 'गोराईं': 1, 'साइंटिफिक': 15, 'आऊंगी।': 11, \"'इंडियाज\": 1, 'आंध्रा': 8, 'कुंओं': 2, 'खाएं.': 7, 'निभाएंगे?': 2, \"'एकाउंट्स\": 1, 'अंगुस': 1, 'ऐंटि-ऑक्सीडेंट': 1, 'आंवलें': 2, \"इंबेलिम'\": 1, 'आकाशगंगाएं।': 1, 'निहारिकाएं': 1, 'अंगड़ाइयां': 1, 'इंटिमेट': 5, 'जामकर्ताओं': 2, 'अंगूठी,': 8, 'भुजाएं': 13, 'अुर्जन': 1, 'अंक-7': 2, 'महात्माओं': 11, 'एंजेलिस)': 1, 'बीइंग': 9, 'आजमाएं': 4, 'नेताओं-कार्यकर्ता': 1, 'बढ़ाएंगी।': 5, 'माताएं,': 2, 'अंबिकेश': 12, 'अध्यापिकाओं': 5, 'प्रतिस्पार्धओं': 1, 'पाएं.': 10, 'कर्ताधर्ताओं': 7, 'परिभाषाएं': 22, 'लड्डुओं': 12, 'गोपिकाओं': 6, 'इंडस्ट्र्रीज': 1, 'इंडोनेशिया’': 1, 'एंजिल्स': 12, 'जाएंगी,': 29, 'इंग्रेडिएंट्स': 4, 'कराएंगे,': 4, 'लाभकर्ताओं': 1, 'एंजेला': 13, 'एंटी-ओक्सिडेंट': 3, 'दिखाऐं': 1, '‘‘आंकड़े': 1, 'इंटेलिजेंट': 10, 'आंसर': 13, 'पापाओं': 3, \"'वेस्टइंडीज\": 3, 'आईं.': 10, 'पेशवाओं': 3, 'एंप्लॉयज': 1, 'श्रृंखलाएं': 5, 'साइंस’': 3, 'एन्काउंटर्स’': 1, 'अंतध्र्यान': 3, 'अदाकाराएं': 3, 'अंकल!': 3, 'संस्थाएं.': 3, 'अंजनिपुत्र': 1, 'विधाओं': 72, 'सिनेमाओं': 2, 'ऊंटडा': 1, 'आर्इं': 3, 'बताएं!': 2, 'काऊंट': 1, 'एफीशिएंट': 1, 'मियांओं': 1, 'भिजवाएंगी,': 1, 'इंफीरियर': 1, 'अपनाएं.': 2, 'इंप्रेशन।': 1, 'इंटरएक्टिव': 5, \"जाएं'।\": 1, 'ग्राउंड,': 6, 'ड्रॉइंग': 8, \"अंकल'\": 1, 'बाउंसी': 1, 'आऊंगा.': 9, 'काउंंसिल': 1, 'अंर्तध्यान': 4, 'उड़ाएंगे।’': 1, 'साइंसिस': 1, \"आएंगे।'\": 3, 'क्वालीफाइंग': 36, 'माएं': 8, 'अंशुमा': 6, 'अपनाएं।': 14, 'ऊंचाईयों': 18, 'काउंटरटैरेरिज्म': 1, 'इंसटेंट': 2, 'बरसाईं': 3, 'विधवाएं': 5, 'इंद्रलोक': 3, 'पिताओं': 18, 'कोमलताओं': 3, 'कतराएं': 1, 'आएंगे.’': 1, 'उफपभोक्ताओं': 1, 'कुआंगली': 1, 'अंधरी': 2, 'इंटीग्रिटी': 8, 'निर्मताओं': 1, 'इंजरी': 12, '(प्लेइंग': 2, 'अंध': 41, 'इंग्लिश-विंग्लिश': 5, 'काउंटर्स,': 1, 'उकसाएं।': 1, 'आंदोलन-आलोचना': 1, 'जाएं?': 11, 'बढ़ाएं': 1, 'सुखाएं।': 3, 'इंपोर्टेड': 4, 'आंकडों': 32, 'इंजार्च': 1, 'इंप्राटैक': 6, '‘ऐंद्रिय’': 1, 'ऐंद्रिय': 2, 'ऐंद्रिक': 3, 'अंतर,': 7, 'एंडला': 5, 'योगदान-(घटाएं)': 1, 'गायिकाओं': 10, 'री-एंट्री': 2, 'संभावनाओं-आशंकाओं': 2, 'प्रस्थापनाएं': 1, 'खाएंगे': 16, 'बिइंग': 2, 'इंटेलीजेंट': 3, 'आंसर-की': 3, 'अंगदी': 1, 'इंस्ताबूल': 1, 'दानकर्ताओं': 2, 'इंटेसिव': 2, 'आंख,': 17, 'ऊंट-घोड़ों': 1, 'परंपराओं,': 3, 'इंडिया)': 9, 'अणुओं': 22, 'जलाएं': 20, 'अंबष्ठ,': 2, 'काऊंटर': 14, 'कमाएं': 3, '‘इंडेपेंडेंट': 1, 'दिलाएं.': 1, 'आपदाएं': 10, 'दुर्घटनाएं': 39, 'इंचार्ज,': 2, 'अमेरिइंडियन,': 1, 'एंब्रयोलॉजी': 1, 'भावनाओं’': 1, 'इंतजार:': 3, 'देवी-देवताओं': 99, 'जाएेंगे।': 1, \"'फाउंडेशन\": 1, 'वेरिएंट': 12, 'आकांओं': 1, 'माइंड्स’': 1, 'मनीषाएं,': 1, 'लालसाओं': 15, 'आत्माएं': 15, 'अंतररराष्ट्रीय': 3, 'भूमाफियाओं': 5, 'शंकालुओं': 1, 'इंटक,': 2, 'उठाएंगी।': 8, 'एंजेलिक': 2, 'दौड़ाएं।': 1, 'बुलाएंगे।': 6, 'अंटोनियो': 2, 'एंपरर': 2, 'नींबुओं': 1, 'इंडियाबुल्स,': 2, 'कमाएंगे।': 4, '5694अंक': 1, 'इंतज़ामात': 1, 'एंगलीन': 3, 'साइंसेज,': 1, 'इंडेक्स’': 2, 'अंडरपास': 10, 'एयरलाइंस’': 1, 'अलाऊंस’': 1, 'छात्रओं,': 1, 'चिन्ताओं': 15, 'अँधेरे': 195, 'जाऊं,': 34, 'उठाऊंगा.’’': 1, 'इंद्रलोक,': 1, 'इंतजामात': 4, 'मुखियाओं': 9, 'इंटरवियू': 2, 'इंजवॉय': 1, 'पाऊंगा!': 1, 'अंदरखाते': 7, 'उपभोक्तओं': 3, 'सिखाएं।': 5, 'जगाएं': 6, 'वार्ताएं': 6, 'पछताएंगी': 1, 'पिएं.': 3, 'समर्थक-नेताओं': 1, 'बिंदुओं-': 1, 'अंबोली': 3, \"'इंकलाब\": 1, 'एंड्र्यूज़': 2, 'एंड्र्यूज़,': 1, 'कराएंगी।': 6, 'संवाददताओं': 2, 'अंगरक्षकों': 8, 'परिक्षाएं': 5, 'अंगुलियां': 20, 'तहरीक-ए-इंसाफ': 9, 'अंपायरिंग': 10, 'परियोनजाएं': 1, 'गुआंगजू': 1, 'इंपोर्टेट': 1, 'लटकाएं।': 4, 'संरचनाएं': 4, 'भिक्षुओं': 29, '‘अंडरएचीवर’': 1, 'लाउंजरी': 1, 'लाउंडरी': 1, 'बिछाएं.': 1, 'लड्डओं': 1, 'ईंटे': 6, 'ईंटें': 14, 'इंटरफेज': 1, 'फाउंडेशन’': 4, 'सईंया': 2, '‘एंग्लो-सैक्शन’': 1, '‘एंग्लो-सैक्सन’': 1, 'इंटेल': 19, 'जॉइंट्स': 4, 'ज्वाइंट्स': 1, 'पशुओं,': 1, 'वस्तुओं,': 7, 'दान-दाताओं': 1, 'इंतिहा': 9, 'लाऊं?': 2, 'पॉइं\\u200cर्ट्स': 1, 'गंवाया.एंडरसन': 1, 'श्रद्घालुओं': 3, 'भूमिकएं': 2, 'आंख-कान': 3, 'अंतिल,': 3, 'अंतिरिक्त': 1, '-माउंट': 1, 'ऐंटि-एलर्जिक': 1, 'बनाएंगे!': 1, 'आएंगी!': 2, 'अंश....': 3, 'अंजली,': 3, 'संवेदनाएं।': 1, 'लड़ाएंगे।': 1, 'इंदौर।इंदौर': 2, 'बनाएंगे,': 6, 'निभाएंगे': 5, 'एंडा': 2, 'एंडसरन': 2, 'आंकें।': 1, 'मिसअंडरस्टैंडिंग': 1, 'आंगनवाड़ी': 10, 'विनिर्माताओं': 3, 'पॉइंट,': 4, 'कम्पाउंड,': 1, 'इंग': 4, 'प्राथमिकताआें': 1, '(एंकर': 1, 'लड़कियां-महिलाएं': 1, 'एंटविस्ल': 1, 'जमाएंगी': 1, 'इंसपेक्टर': 16, 'अपनाएं?': 1, 'विज्ञापनदाताओं': 10, 'कराएंगी.': 2, 'बनाएं:': 1, 'होऊंगी.': 1, 'उपसीमाएं': 2, 'यात्राएं,': 3, '‘इंटरेस्टिंग’': 2, 'इंटरेस्ंिटग': 2, 'पुस्तिकाएं': 6, 'अंत्योदय': 10, '-एंट्रिक्स': 1, 'एंटी-आक्सीडेंट': 3, 'हटाएं,': 1, 'एकाउंटेंट,': 3, '(इंटरनेट)': 1, 'सुनाऊं': 3, 'अंडरवेट': 3, 'योजनाऎं': 1, \"पाएंगे।'\": 7, 'अंदेशे': 5, 'पाऊं': 23, 'बढ़ाएं।': 17, 'अंधेरी-घाटकोपर': 1, '(साइंस': 1, 'निभाएंगे।': 22, 'आइंस्टाइन': 76, 'पर्यवेक्षिकाओं': 1, '(बेइंग': 1, 'जाऊंगी.': 11, 'ऊँची': 131, \"'आंदोलन'\": 3, 'इंटरनेशनलश': 1, 'इंटरचैंजेबल': 1, 'इंस्टीट्यूट’': 2, 'आशाएं-आकांक्षाएं': 2, 'इंटररनैशनल': 1, 'अंडरकरंट': 3, 'विपदाएं': 6, 'औंटा': 1, 'अंकुरों': 4, 'सुविधाओं,': 12, 'जर्नलिस्ट(इंडिया)': 1, 'समास्याओं': 1, '(एमआरसीओजी)-इंग्लैंड': 1, 'उास्तरीय': 1, '(अंडर': 1, 'इंकम': 6, 'अनुशंसाओं': 9, 'कछुओं': 7, 'इंफ्लेमेशन)': 1, 'कार्यकर्ताओें': 2, 'अंतर-मंत्रालयी': 4, 'पेइंचिंग,': 1, 'अंडरपास-70': 1, 'पाइंट': 17, 'अंतर-सरकारी': 1, 'मौलानाओं': 8, 'जाउंगा': 17, 'जाउंगा.’’': 1, 'आंदोलन,': 32, 'लीलाएं': 9, 'इंसान,': 14, 'धारणाओं,': 1, 'अंधश्रद्धा': 8, \"इंटरनेशनल'\": 1, \"'अ़ब\": 1, 'इंटरक्लिक': 2, 'इंटन': 1, 'मातओं': 1, 'बनाऊंगा': 9, 'अंतररष्ट्रीय': 2, 'अंसार': 10, 'इंपीरियन': 1, 'उठाऊंगा।': 3, 'इंटरी': 1, 'प्वॉइंट’': 1, 'चेतनाएं': 1, 'टैगलाइंस': 1, 'बहलाएंगे,': 1, 'इंसान।': 3, 'परम्पराओं': 80, 'ङ्क्षबदुओं': 1, 'उंचाई': 51, 'देवलुओं': 4, 'आॅफिस': 13, 'जाउंगा.': 5, 'जाऐंगे।': 3, 'एंकलेट्स': 3, 'लॉबीइंग': 5, 'एंटोनेला': 1, 'पहुंचाएं।': 9, 'महत्वाकांक्षाएं': 10, 'विधायिकाओं': 5, 'विधायिकाएं': 1, 'अंता': 2, 'शंकाओं': 29, 'एंकल': 2, 'आंखमिचौली': 4, '‘‘इंजीनियरिंग': 1, 'ईंधन,': 2, 'अंतर्विरोधों': 36, \"'इंशाअल्ला,\": 1, 'दिलाएंगी.': 1, 'यातनाएं': 33, 'एयरइंडिया': 6, 'धर्मशालाएं': 4, 'याचिकाकर्ताओं': 18, 'गिनाईं.': 1, 'अंडर-68': 1, 'अंडर-64': 1, 'अंबेडकरनगर-प्रतीक्षारत': 1, 'एक्सपीरीएंस': 1, 'आजमाएंगे।': 2, 'खलीफाओं': 4, 'बजाएंगे': 4, 'अंतर्ध्वनित': 1, 'पूजा’,‘अंधेरे': 1, 'जाचकर्ताओं': 2, 'उपशाखाओं': 1, 'आंतक': 7, 'इंक्लाइन': 1, 'बहुओं': 43, 'अंडरआर्म': 1, 'गुआंगझू': 2, 'नवदुर्गाओं': 5, 'मुआंग': 1, 'आंत्रप्रनरशिप': 1, 'अंतिम-4': 1, '‘योजनाओं': 1, 'इंटरफेस।': 1, 'जंतुओं': 23, '‘‘अंतरात्मा': 1, 'एंट्रीज': 1, 'एंक्जाइटी': 1, 'कक्षाओं,': 1, 'चलाएंगे.': 5, 'इंटर्न': 9, 'लाएंगे?': 3, 'हटाएंगे': 2, 'अंतिम-आठ': 3, 'डीपीओं': 1, 'डीटीओं': 1, 'एसडीओं': 1, 'धोइंदा': 1, 'निभाएं।': 9, 'आलराउंड': 2, 'इंद्र,': 5, 'वितरिकाएं': 1, 'जाने-अंजाने': 4, 'अंशावतार': 6, 'अंधेपन': 8, 'टोइंग': 1, 'एंटीना': 11, 'इंटरनेषनल': 1, 'हैरतअंगेज': 25, 'फ्लुएंट': 2, 'नुमाइंदा': 7, 'इंडीपेंडेंट': 2, 'इंटरप्राइज': 5, 'एंट्रिक्स-देवास': 10, 'एंजलेक': 1, 'आंजना': 6, 'मनाउंगा.': 1, 'अंशकालिक': 5, 'एेसा': 4, 'की‘इंग्लिश,': 1, 'भारत-इंग्लैंड': 5, 'आंखे.': 1, '(अंतिम': 6, '(अकाउंट्स': 1, 'धौलाकुआं': 6, 'अं': 1, 'इंस्टिट्यूशनल': 3, 'कंपाउंडिंग': 2, 'इंटरफ़ेस': 3, 'इंटिग्रेटेड': 6, 'दुआएं..': 1, 'एयरलइान': 1, 'एंटॉप': 1, 'अध्ययनकर्ताओं': 7, 'बताऊंगा,': 4, 'अंतरालों': 4, 'अंगो': 15, 'इंच।': 4, 'टुडे-हेडलाइंस': 1, 'अंडरव\\u200cर्ल्ड': 13, 'अंतिरक्षयान': 1, 'अंतरिक्षयान,': 1, 'इंडेवर': 3, 'कराऊं?': 1, 'ऐंटर': 1, 'इंदरमीत': 1, 'पुस्तिकाओं': 12, 'होलिकाएं': 1, 'इंडस्ट्रीज़': 7, 'अंदाज़': 63, 'संस्\\u200dथाओं': 4, 'ज्\\u200dवाइंट': 1, 'रंगशालाएं': 1, 'नगरपालिकाएं,': 1, 'ऊँचे': 109, 'माऊंटेन': 2, 'बढ़ाऊं,': 1, 'कईं': 26, 'इंप्लायमेंट': 5, 'ऐंठकर': 3, 'अंगिका,': 4, 'अंगिका': 9, 'आलोचनाएं': 21, 'इंड-स्विफ्ट,': 1, 'इंस्टीट्यूश्नल': 1, 'एंप्लॉयी': 5, 'आपूर्तिकर्ताओं': 9, 'उठार्इं।': 1, 'पाऊंगा.': 15, 'अंगरेजीवाले': 1, '16899.77अंक': 1, '6598.48अंक': 1, '5126.30अंक': 1, 'पॉइंटस': 2, 'बनाऊं': 7, 'इंडिफलिंग': 1, '(इएंडवाइ)': 1, 'अंतीचक': 1, 'ऊंगली': 13, 'एंबुलैंस': 5, 'जुटाएंगे': 1, 'एंड्रोजेन': 2, 'बताउंगी': 4, 'अंजुली': 4, '-ओरिएंटेशन': 2, 'जाऊं.': 14, 'आंतकवाद': 6, '‘अंकल्स': 2, 'नौकरीपेशाओं': 1, 'दिलवाएंगे-': 1, 'एंप्लॉई': 4, 'एंप्लॉइज': 3, 'सार्इंनाथ': 1, 'चाहिए़': 5, 'अंकन': 19, 'महत्वाकांक्षाओं': 20, 'समस्याएं।': 3, '‘अंतिम’।': 1, 'सुझाएंगी,': 1, 'अंखुवा': 1, 'इंस्टीट्यूट,': 3, 'अंधेरों': 74, 'इंद्रपूजन': 3, 'एंटरप्रिन्योर्स': 1, '(अनइंटरपटेड)': 1, 'अंतरराष्ट्रीयता': 1, 'अंक-9': 2, 'इंडियाना': 5, 'अंग्रेजीकरण,': 1, 'अंग्रेजीकरण': 1, 'पाऊंगी?': 2, 'इंडिया-': 4, 'पीसीएंडपीएनडीटी': 1, 'करवाएं.': 3, 'इंटेल,': 2, 'इंडस्ट्रीयल': 10, 'पाएं,': 8, 'पाएंगें': 1, 'इंदिरानगर,': 2, 'अंजुम': 22, 'पाऊंगा': 24, 'गर्इं': 8, 'मात्रिकाएं': 1, 'आॅपरेटर': 3, 'एमएंडएम': 2, 'आंदोलन’': 10, 'कार्यकार्ताओं': 2, '(आंसू)': 1, 'संवाददातओं': 3, '(अंग': 1, 'इंटिरियर,': 1, 'इंसानियत': 137, 'युवाओं-बच्चों': 1, 'एंड्रू': 2, 'आईआईअी': 1, 'गिराऊंगी.': 1, 'नलिकाओं': 4, 'कृतियों-कलाओं': 1, 'इंफ्रास्ट्र्कर': 1, 'जिंताओं': 2, 'है.अंकित': 1, 'आंधी-तूफान': 3, 'एंटर': 10, 'प्रेमिकाओं': 9, '(इंटरनेशनल': 3, 'इंटेस्टाइन)': 1, 'प्रतिद्वंद्विताओं': 2, 'कर्ार्यत्ताओं': 1, 'गाथाओं': 9, 'कविताएं’': 2, 'फाइटोन्यूट्रिएंट': 1, 'नलिकाएं': 4, 'अंकिता,': 4, 'शिक्षक-शिक्षिकाएं': 3, 'आकाओं': 46, 'विषेशताओं,सुंदर': 1, 'सभाएॅ': 1, 'शिवाइंटर': 1, 'आंचलिया': 2, 'विक्रेताओं-के्रताओं': 2, 'ऑइंटमेंट': 3, 'न्यूट्रिएंट': 4, 'ऐंटिबॉडीज': 1, 'आमसभाओं': 1, 'परछाईं': 28, 'उंत्पादन': 1, 'एंकलेट्स,': 2, 'दुर्बलताओं': 10, 'अंतराज': 1, 'ऊंदालिया': 1, 'एंडोथिलियल': 1, 'घर-आंगन,': 2, 'विद्याएं': 6, 'इंजीनियर,': 22, 'प्रक्रियाएं': 35, '(ईंधन': 1, 'जलाएंगे।': 3, 'लगाऊंगा।': 4, 'अंतर्कलह': 9, 'इंडोक्रानोलॉजी': 1, 'शुक्राणुओं': 15, 'श्रृंखलाओं': 8, 'एंफेटेमाइन': 1, 'अनाऊंस': 1, 'छुटकू-ऐंठू': 1, 'इंगित': 79, 'स्वाधीनता-आंदोलन': 1, 'इंडेक्सेस': 4, 'अंतर्निष्ठ': 1, 'लड़ाकुओं': 1, 'अंडरआर्म्स': 1, 'में‘इंडियाज': 1, 'जीडी-इंटरव्यू': 1, 'अंर्तध्वनि': 1, 'एकाउंटेंट्स': 4, 'इंटरप्रीटर': 1, 'अकाउंटेंट': 10, 'ज्ञानी-महात्माओं': 1, 'कारखानाओं': 1, 'आंधी-बारिश': 1, 'अंत:वस्त्र': 4, 'इंवेंट्स': 1, 'सर्टिफाइंग': 1, \"'महिलाओं\": 2, 'फैलाएं,': 1, '‘इंतजार': 1, 'माऊंट': 4, 'इंग्\\u200dलैंड': 3, 'इंजाइम': 1, 'मलिाएं': 1, 'बनाएं,जिससे': 1, 'दबाएं,': 2, 'अंकुरण': 11, 'लगाऊंगा।’': 1, '(करदाताओं': 1, 'विफलताओं': 15, 'अंधेपन,': 1, 'उूंची': 1, 'प्रसूताओं': 3, 'काउंसलेट': 2, 'आंजनेय': 2, 'जाएं...': 3, 'एैसी': 4, 'बताएं।': 55, 'ऊंटों': 12, 'इंडिपेंडेंस’': 1, 'आलुओं': 6, 'होएंगा?': 1, 'होएंगा,': 2, 'आएंगा': 1, 'आएंगा।': 1, 'नियंत्रणकर्ताओं': 1, 'उभय-अवधारणाओं': 1, 'राउंडर.': 1, 'वाइंडिंग-अप': 2, 'अंक-2': 2, 'र्इंटे': 2, 'उंगलियों': 87, 'फोरक्लोजरइंडिया': 1, 'बोलीदाताओं': 1, 'आंगनबाडिय़ों': 2, 'अंकसूची': 3, 'शालाओं': 4, 'खेल-भावनाओं': 1, 'लव-इंटरेस्ट': 1, 'सीएंड': 1, 'हाईएंड': 3, 'इंथानोन': 12, 'इंसेक्ट': 2, 'बजाएं।': 3, 'अंताक्षरी': 6, 'इंट्रोड्यूस': 8, 'इंफ़ॉरमेशन': 1, 'आंकड़ो': 1, 'चलाएं,': 3, 'आंक': 14, 'अंधेरी,': 1, 'ऊर्जाओं': 5, 'उूर्जा': 1, 'नाइंस': 3, 'इंडियंस,': 3, 'अंतरमन': 10, 'अंगूठियां,': 1, 'जाइंट': 5, 'डाकुओं,': 1, 'नौसेनाओं': 2, '‘इंग्लिश-विंग्लिश’': 2, 'इंद्रियजीवी': 2, 'श्राविकाओं': 1, 'गइंü,': 1, 'आइंü।': 1, 'एंथ्रोपोलॉजी,': 2, 'इंजन,': 11, 'पटकथाएं': 5, 'गुआंतानामो': 1, 'अंदाज-ए-बयां': 2, 'एंड्रीयू': 1, 'ओंटारियो': 2, 'आएंगे?': 10, 'इंद्रियसुख': 2, 'इंडी': 1, 'इंडला': 1, 'जताएं': 2, \"'आंसर\": 5, 'जन-सभाओं': 1, 'इंफ्रास्ट्रर': 2, 'आॅक्सीटोसिन': 1, \"जाएंगे,'\": 1, 'बढ़ाएंगे': 6, 'इंपोरियम': 1, 'बनवाएं': 3, '9-इंद्रादेवी': 1, 'ऐंटि-फंगल': 1, 'ऑलराउंडरों': 4, 'जाएंगे।।': 2, 'चुकाएंगे।\\x10अपनी': 1, 'सम्भावनाएं,': 1, 'निराशाओं': 11, 'आंचल,': 3, 'उंचे-उंचे': 4, 'रक्तकोशिकाएं': 1, 'एंजाइना': 5, 'बोइंग-767': 1, 'एक्सपीडिएंसी': 1, 'यचिकाओं': 1, '(इंट्रोड्यूसर)': 1, 'इंट्रोड्यूसर': 1, 'इंट्रोय़ूसर': 1, 'आंटी': 124, 'इंद': 4, 'अंतरक्षियात्री': 1, 'फसाऊं?': 1, 'इंडिकेशन': 2, 'एंबॉलिम': 1, 'गोसाईंघाटी': 1, 'बाजुएं': 2, 'बिताएं.': 2, 'ओंदा': 1, ':ओंदा': 1, 'इंदुभूषण': 6, 'सेतुओं': 3, 'टापुओं': 8, 'अंडकोष': 5, 'प्रतिबद्घताएं': 1, 'विधाएं': 10, 'रैडिएंट': 2, 'उठाएंगी.': 1, '‘र्इंटें-2’': 1, 'र्इंटों': 1, 'आएंगी/': 1, 'र्इंटें/': 1, 'बताएंगी': 7, 'इंस्परेशन': 1, 'लाइंस,': 4, 'इंडिका': 28, 'सरिताएं': 2, 'पइआं': 1, 'जाएं...।': 1, \"बचाएंगे।'\": 1, 'अंबाकोठी': 1, 'अंसल': 11, 'इंफोमीडिया,': 1, 'जनसुविधाओं': 4, 'दिलवाऊंगा।': 1, 'इंटीरियर्स': 2, 'परिक्षाओं': 2, 'लोकभाषाओं': 8, 'रचनाएं': 132, 'ऐंजला': 1, 'छेउंग': 1, 'अंडरग्रेजुएट': 3, \"'ऊँ\": 4, 'चढ़ाएं,': 3, 'निभाएंगी।': 9, 'पाएंगी': 19, 'बढ़ाएं,': 2, 'श्रद्वालुओं': 3, 'पंरपराएं': 1, 'बताऊंगा': 21, 'शिथिलताओं': 1, 'ओंकारा,': 2, 'संरचनाओं,': 1, 'पिऊंगी': 2, 'कामनाएं,': 3, 'लगाएंगे.': 2, 'सुझाएंगे.': 1, 'बनाऊंगा।': 3, 'दिखाऊंगा।': 5, 'आँव': 1, 'अंदर,': 10, 'भिन्नताएं': 1, 'चलाईं।': 2, 'उठाऊंगा,': 3, 'घुसपैठिओं': 1, 'समझाएंगे': 5, \"'अंकोरवाट'\": 1, 'छात्रनेताओं': 2, 'गोप-गोपिकाओं': 1, 'कुमाऊंनी,': 2, '4-प्वाइंट': 1, 'ऐंटी': 1, 'अंबिकश': 1, 'गर्इं?': 1, 'इंट्रस्ट': 1, 'इंटरकॉम': 3, 'छात्राओं,': 1, 'अंबुजा': 4, 'इंडोर,': 1, 'जलाएं.': 1, 'ऐंग': 1, \"'चयनकर्ताओं\": 2, 'इंस्टाग्राम': 2, 'डलवाऊंगी': 1, 'वीजाओं': 3, 'पाएंगे?': 22, 'अनुदानदताओं': 1, 'इंप्रूवमेंट': 1, 'एंड्यू': 1, 'दिखाएंगे': 13, '16.07अंक': 1, 'अंतर-7.54': 1, 'लिआंग': 5, 'गुआंगली': 5, 'इंडैक्स': 8, 'आंख-मिचौली': 6, 'एंजियोप्लास्ट': 1, 'करवाईं': 2, 'लगाईं।': 2, 'आंवटन': 8, \"'इंडियन\": 12, 'इंस्पीरेशन': 1, 'मुस्कराईं।': 1, 'लाईं।': 3, 'एंजला': 3, 'अंबेरा': 1, 'अंतरलिप्तता': 1, 'गुजाइंश': 2, 'मनोकामानाओं': 1, 'उठाएंगी': 3, 'अंडमान-निकोबार': 22, 'अंडर-7': 1, \"निभाएंगे।'\": 1, 'अंग्रेजीदां': 19, 'अंग्रेजियत': 8, 'अंक,': 15, 'ऐंकलेट्स,': 1, 'आंखो': 49, 'पहुंचाएंगे।': 8, 'बिताएं,': 4, 'इंडवेर': 1, '‘ईएसपीएनक्रिकइंफो’': 1, 'लगवाऊंगी।': 2, 'आंखें/': 1, 'क्रियाएं/': 1, 'ऎंठन': 2, 'इंपोर्ट': 11, 'सिखाएंगे': 6, 'अंत:क्रिया': 3, 'माइंडफुल': 2, 'माइंड,': 1, 'एंज्वॉय': 3, 'अ़ब': 6, 'ऊंघना': 1, 'इंजिनियरिंग,': 6, 'निविदाएं': 9, 'बनाएंगी।': 7, 'रीइंबर्समेंट': 1, 'ऐंटी-बायोटिक्स': 1, 'बताएंगी.': 1, 'नाइीरिया': 1, \"एनकाउंटर्स'\": 1, 'कार्ययोजनाएं': 1, 'गाउंस,': 1, 'गाउंस': 3, 'संचिकाएं': 3, 'अनाउंस': 6, 'अंतर्दशा': 10, 'चटाएं।': 3, 'औैर': 4, 'बुलाएंगे': 4, 'चलाएंगे': 10, 'काऊंसलर': 1, 'एंटरटेनिंग': 3, 'आंगनवाडिय़ों': 1, 'एंडिंग': 5, 'पहुंचाऊंगा.': 1, 'एंटरेटेनमेंट': 1, 'रणइंदर': 1, 'अंतर्राष्ट्रीयम': 1, 'जाऐं': 2, 'विफलताएं': 1, '(इंटेलेुअल': 1, 'इंफोटेक': 3, 'आंकडे़': 5, 'अंश:': 5, 'ऊंचीं': 1, 'इंक्रीमेंट': 4, 'डिपुओं': 10, 'गर्इं,': 7, 'मादाएं': 2, 'यात्रओं': 4, 'एंडू': 1, 'इंडिया-येल': 2, 'प्रतिक्रियाओं': 44, '-इंजन,': 1, 'समस्याओं-चुनौतियों': 1, \"फाउंडेशन'\": 4, 'उकतार्इं': 1, 'इंवर्टर': 1, 'इंडोनेशियन,': 1, 'पत्रिकाएं': 27, 'पीएंगे': 2, 'इंटेलिजेंस,': 2, 'अदाकाराओं': 3, 'तमाशा’,‘खलनायिका’,‘किंगअंकल’,‘कन्यादान’': 1, 'टर्नअराउंड': 2, 'अंतिल': 2, 'वेस्स्टइंडीज': 1, 'प्रेरणाओं': 6, 'संस्थाएं-': 1, 'ऐंठता': 2, 'क्लाइंट्स:': 1, 'इंटरवेल': 3, 'इंद्रदेव': 12, 'है.इंग्लैंड': 1, 'इंतजाम,': 1, 'भरवाईं': 2, '‘आत्माओं’': 1, \"इंस्टिंक्ट'\": 3, 'अंत्याक्षरी': 2, 'लौटाएंगे': 2, 'वासनाओं': 21, 'इंद्रनाथ': 11, 'इंटरलॉकिंग': 1, 'इंटरव्यूअर': 4, 'दलाईलामाओं': 1, 'स्नायुओं': 6, 'इतराऊं': 3, 'एंटीरियर': 2, 'आजमाएं।': 4, 'पाईं।’’': 1, 'इंफार्मेशन': 4, '(इंडिया)': 4, 'एसएचआे': 1, 'अंडरपास-76': 1, 'आाशियाने': 1, 'इंसपीरेशन': 1, 'इंगरसोल': 1, 'इंडिया-ए': 3, 'एंटीसेप्टिक': 7, 'एंटी-एलर्जी': 1, 'नुमाइंदे': 27, 'अनैतिकताओं': 2, 'हुई़': 3, 'इंद्री': 4, 'एयरलाइंसों': 3, 'आॅस्कर': 7, 'बीडीओे': 1, 'इंग्लिशबाजार': 2, 'इंस्पिरेशन': 4, 'निभाएंगी.': 1, 'सिखाएं': 6, 'कौओं,': 1, 'उूंचा': 1, 'इंटैलीजैंस': 3, 'इंशा': 22, 'कीटाणुओं': 8, 'इंफाल।।': 1, '‘‘इंडिया': 3, 'ऐंटेना': 3, 'कलाओं,': 4, 'यूएस-इंडिया': 2, 'इंजिनयिरंग': 1, 'इंगलिश-विंगलिश': 1, 'नाम-अंशु': 1, 'संस्थाओं)': 1, 'इंदप्रस्थ': 4, 'फुलाएंगे,': 1, 'घटनाएं5': 1, 'अपनाएंगे।': 7, 'दलबदलुओं': 2, 'असुविधाओं': 11, 'जाएंं।': 1, 'संरक्षणकर्ताओं': 2, 'एंटबेलम’': 1, 'फंसाएं।': 1, 'रेखाओं,': 2, 'इंतकामी': 1, 'मात्राओं': 12, 'एंटेनिया': 1, 'काउंसिल)': 2, 'आॅल': 7, 'ग्राउंड)': 1, 'एंटरप्रेन्योरशिप,': 1, 'अकाउंटिंग,': 3, 'इंटेरेक्टिव': 1, 'सदाएं': 4, 'इंसुलेटर्स': 2, 'एअरलाइंस': 2, 'नेताओं-मंत्रियों-अफसरों': 1, '(नेताओं/मंत्रियों/अफसरों)': 1, 'बाबूओं': 4, 'श्रीसाईं': 1, 'आत्माओं,': 3, '‘अंतरराष्ट्रीय': 2, 'सूचनाआें': 2, 'इंटीमेसी': 2, 'इंटीमम': 2, 'अंतरंगता': 10, 'अंतरतम': 10, 'इंकलाब': 23, 'इंदौरी,': 1, 'इंदौरी': 10, 'लड्डूओं': 3, 'करवाएंगी।': 2, 'ओंझल': 1, 'शिक्षा-संस्थाओं': 1, 'हसीनाएं': 5, '‘‘संस्थाओं': 1, '(अंजलि': 1, '‘अंधकार': 2, \"अंतर'\": 3, 'इंतजाम-अधिक': 1, 'जाएंगे1000': 1, 'इंतजामलोगों': 1, 'इंतजामयातायात': 1, 'प्रतियोगिताएं,': 1, 'आंकड़ें': 4, '‘इंटीरियर': 1, 'शुक्रणाओं': 1, 'यातनाओं': 14, 'मान्यताओं-परंपराओं': 2, 'प्रस्थापनाओं': 2, 'जेएंडके': 1, \"इंपीरिया'\": 1, 'डाइआॅक्साइड,': 1, 'आॅक्साइड,': 1, \"करवाएंगे।'\": 1, 'मान्यताएं,': 3, 'लगवाएं।': 2, 'आंते,': 1, 'ईंटें,': 1, 'सुरक्षा-योजनाओं': 1, 'अंडरस्टैंडिग।': 1, 'इंतेजार': 7, 'ग्राउंड्समैन': 3, '(बैकग्राउंड,': 1, 'आक्रांताओं': 6, 'मूल्यों-मान्यताओं': 2, 'देवआस्थाओं': 1, 'इंजिनीयरिंग-मेडिकल': 1, 'इंगलिश,': 1, 'लाइंस)': 1, 'सेविका-सहायिकाओं': 1, \"'फ्लाइंग\": 1, 'शुभ-मंगलकामनाएं': 1, 'मैन’,‘फ्लाइंग': 1, 'आएंगे!': 2, 'उठाएं,': 7, 'थे.इंडियन': 1, 'अंग्रेजी)': 2, 'इंटरप्रेटेशन': 3, 'इंटेस्टाइनल': 1, '(आंत': 1, 'एंटोलिया': 1, 'राऊंड': 4, 'पॉइंट्स)': 3, 'ग्लोइंग': 3, 'वेताओं': 1, 'अंचलाधिकारियों': 1, 'दिलाएंगे।': 9, 'तारिकाओं': 1, 'एंगेस्ट': 1, 'अंग्रेज़ी': 146, 'दुविधाओं': 5, 'प्रथाओं’’': 1, \"'अंतरात्मा'\": 1, 'इंप्लांट': 3, 'अंधियारा': 9, 'एंट्रीः': 1, 'आंगनबाडिय़ों': 1, 'इंटरवल': 29, 'साउंडट्रैक': 3, 'खाएंगे,': 6, 'अंशू,': 1, '‘‘वनप्वॉइंटनथिंग’’': 1, \"ऐंड'\": 1, '(इंडेक्स': 2, 'अंशों': 29, '‘इंटरनेट': 3, 'अंडाणु-कोशिका': 1, 'इंस्टीटच्यूट': 4, 'आंध्र-ओड़िशा': 1, 'जाएं।’’': 2, 'एंजिल्स:': 3, 'इंजीनियर्स,': 3, 'इंडस्ट्री,': 9, 'ऐंठ': 19, 'इंदौर।।': 3, 'एक्स-एंप्लॉई': 1, 'दिलाउंगा।’’': 1, 'बैंक-इंश्यूरेंस': 2, 'हिंदी/अंगरेजी': 1, 'जाऊंगी': 25, 'मनाएं)': 1, 'इंप्लोजन,': 2, 'पशुओंं,': 2, 'अंगुठियां': 2, 'एंटरटेनमेंट,': 6, 'बताएंगे?': 4, '‘‘इंग्लैंड': 1, 'अंटू': 16, 'एंटी-ग्लेर,': 1, 'एंटी-स्क्रैच,': 1, 'एंटी-ग्लेर': 1, 'एंटरटेनमेंट...': 1, 'हसीनाऐं': 1, 'हसिनाऐं': 1, 'इंतहा': 10, 'बदइंतजामी,': 1, 'आंखें..,': 1, 'साइंसेस,': 3, 'इंवायरमेंट': 2, 'इंडस्ट्रजी': 1, '(इंटिग्रेटेड': 1, 'निभाएं.': 5, 'कत्ताओं': 1, 'बचाओं': 10, 'नायिकाएं': 14, 'बाउंड्रीवॉल,': 2, 'बाउंड्रीवॉल': 2, 'समस्\\u200dयाएं': 8, 'अकांक्षाएं': 2, '..आईंस्टीन': 1, 'होऊं': 5, 'ऐंटि-सोशल': 1, 'प्लेग्राउंड': 3, 'वार्ताओं,': 1, 'इंद्रदवन': 6, 'आंखोें': 1, 'इंडेमोल': 2, 'निष्ठाओं': 4, 'एंगलिक': 1, 'जाऊंगा?': 5, 'संवेदनाएं': 26, 'इंफैंटा': 1, 'बढ़ाएंगे,': 5, 'गवाएं।': 1, 'जाएंगे।’': 10, 'एलाइंमेंट': 1, 'जलाएं,': 5, 'अंशु,': 3, 'इंटरफेरॉन': 1, 'एंटीबॉडीज': 1, 'ब्लाइंडली': 1, 'दुबईः': 2, '’अंशुमाली': 2, 'अंबिकापुर': 2, 'एंड्री': 1, 'आंकें': 1, 'इंडिपेंटेंड': 2, 'दिचाऊं': 4, 'एंडोस्कोपिक': 3, 'प्रस्तोताओं,': 1, 'इंडो-नेपाल': 1, 'इंटरप्रेटर': 2, 'गईं?': 12, 'डिस्काउंटेड': 1, 'आंधी,': 7, 'खिलाएं,': 6, 'आंकें,': 1, 'आंग्लोंग': 1, 'ऐंप्लिफायर': 1, 'राउंडटेबल': 1, 'इंडस्टीज,': 1, 'धारणाएं,': 2, 'यूजी(अंडग्राउंड),नार्थ': 2, 'भुईंया': 1, 'एंड््रयू': 1, 'एंटीलिया': 1, 'व्याख्याएं': 19, 'कलाओं-कृतियों': 1, 'अंग,': 7, 'इंद्रधनु': 2, 'इंटाली': 1, 'इंफ्रास्टर': 1, 'परंपराएं,': 2, 'श्रृखंलाएं': 1, 'बाऊंसरों': 1, 'इंडो-कनेडियन': 1, 'खाद्य-वस्तुओं': 1, 'बोएं।': 1, 'पढ़ाएं': 3, 'आंकड़े...': 2, 'अंट': 7, 'ईंट-भट्ठा': 2, 'इंद्रपुरी': 4, \"'इंटेलीजेंस'\": 1, 'अवस्थाएं': 10, 'अैर': 3, '‘साइंस’': 1, 'ओरिएंटिड': 1, '(इंग्लिश': 2, 'एयरलाईंस': 2, 'आंधी-पानी': 3, 'अंडरराइटर्स': 2, 'इंग्रीडिएंट्स': 4, 'ऐंबिट': 1, 'खाएंगी': 4, 'ताराओं': 2, 'कारबीआंगलोंग': 1, 'मोह-अंधकार': 1, 'शियाओं': 10, 'इंडस्ट्रियलिस्ट': 2, 'ईंगलू': 9, 'अंत’': 6, 'वेश्याओं': 20, 'बनाउंगा.’’': 2, 'पाऊंगा,': 10, 'इंकारकर': 1, 'पाऊंगी।': 12, 'समाज-इंसान': 1, 'उपभोक्ताओें': 1, 'यात्रएं': 1, 'बनाईं': 9, 'अंबलिकल': 1, 'इंदौरा,': 1, 'मीरा-भाईंदर': 2, 'अंडाल:': 2, 'डिफिशिएंसी': 2, 'अंतर्विरोधों,': 2, 'यातनाएं.': 1, 'बनाएंगी,': 3, 'असुरक्षाओं': 4, 'अंध-उपभोक्तावाद': 1, 'चैकिएं': 1, 'महिलओं': 7, 'अंडर-कंस्ट्रक्शन': 2, 'इंस्टिट्यूशंस': 1, 'संस्थाएं,': 12, 'इंडिज,': 1, 'इंडिज': 2, 'कल्पनाएं': 13, 'कराएंगे।’’': 1, 'मनोकामनाएं': 27, '‘कंबाइंड': 2, 'समझाएं।': 2, 'अंसुम,': 1, 'अंतरण': 4, 'शिक्षिकाएं': 4, 'घने-अंधेरे': 1, 'एंटी-हीरो': 1, 'हुईं-': 1, \"इंडस्ट्री'\": 1, \"एंथनी',\": 1, 'विडंबनाएं': 5, \"'पालतुओं'\": 1, 'जनसंवेदनाओं': 1, 'मर्यादाएं': 24, 'एंडरसन,': 6, 'आंतकवादियों': 4, 'सुझाएं।': 2, 'सुनाएं.': 1, 'इंटरस्कूल': 2, 'महत्वाकाक्षाएं': 2, 'विघिवेत्ताओं': 1, '‘आॅपरेशन': 3, 'इंटरलॉक्यूटर्स': 1, 'महिलाएँ': 36, 'एंथम': 1, 'एंगेल्स,': 1, 'इंवेस्टिेगेंशन': 1, 'इंटरस्फिंकटर': 1, 'अभिनेताओं,': 4, 'असफलताएं': 6, 'इतराएंगे।': 1, 'इंडिया:': 7, 'अंशधारकों': 6, 'एंटन’': 1, 'नाचें-गाएं,': 1, 'तंबुओं': 1, 'कटवाएं,': 1, 'पीएं,': 3, 'इंस्ट्रूमैंट': 1, 'अंयत्र': 1, 'इंटेटेनर': 1, \"'इंग्लिश-विंग्लिश'\": 1, 'अंधड़': 1, 'जिएंगे।': 2, '(इंडोनेशिया)': 1, 'अर्थ-व्यवस्थाओं': 2, 'अंतिम-32': 1, 'एक्सपिरिएंस': 1, 'एंक्लेट,': 1, 'मनाएंगे': 8, 'इंस्ट्रुमेंट्स': 1, 'इंट्रव्यू': 1, 'अंतरध्यान': 1, 'गुआंगसी': 1, 'घुआंग': 1, 'ऐंटिएचआईवी': 1, 'अंकोलाजिस्ट,': 1, 'अंतज्र्ञान': 2, 'अंतदृष्टि': 2, 'ऐेसा': 1, 'विन्दुओं': 1, 'आॅफर': 3, 'याचिकाकर्ताआं': 1, 'हुर्इं।': 5, ':अंदर': 1, 'इंडिपेनडेंट': 1, 'महिलाएं-बच्चे': 2, 'इंडस्टी': 1, 'एंटी-बैक्टीरियल': 1, 'इंटकवेल': 2, 'खोजकर्ताओं': 2, 'इंटनैशनल': 3, 'निपटाएंगे': 1, 'गोविंदाओं': 2, 'इंस्ट्रमेंट': 1, 'योग्यतओं': 1, 'अंचलकर्मी': 1, 'आॅटो': 4, 'एि': 1, 'आंरभिक': 1, 'मैट्रिक-इंटर': 1, 'अंतरा': 16, \"बताऊँ'\": 1, 'आंध्र,': 6, 'भावनाएं।': 1, 'ऊंचाई:': 1, 'अंक)': 7, '‘यूएस...इंडिया': 1, 'बचाएं': 10, 'ंअंतिम': 1, 'खिलाऊंगा.': 2, 'बुलाऊंगा.’': 1, 'एंटीडेंड्रफ': 1, 'एंड्रयड': 1, 'खिलाएं': 9, 'समझाईं।': 1, 'ऐंटिथेफ्ट': 1, 'अंबिकेष': 2, 'एंंड': 1, 'सिंगल-इंजन': 1, 'बनाएं-': 1, 'हिचकिचाएं।': 1, 'एकाउंटबिलिटी': 1, 'अंडाकार': 5, 'इंस्ट्रूमेंटेशन': 3, 'इंडस्टरी': 2, 'अंशर': 1, 'डिस्कॉउंट': 1, 'आंधवाड़ी': 1, 'इंश्योरैंस,': 1, 'आॅपरेशनों': 1, 'ज्वॉइंट': 2, 'सोएं।': 7, 'सत्ताएं': 9, 'इंडेक्सेशन': 4, 'तथ्यों/सूचनाओं': 1, 'लुभाएंगी': 1, ':सीएंडएसआई:': 1, 'आंगन’,': 1, 'व्यवहारिकताओं': 1, 'अर्थव्यव्स्थाओं': 1, 'अनुसंशाओं': 1, 'दिखलाऊं': 4, 'अुनवाद,': 1, 'वक्ताओं-प्रयोक्ताओं': 2, 'पत्रिकाओं,': 5, 'बाउंसर': 9, 'खाएंगी।': 1, 'अंतरराष्\\u200dट्रीय': 6, 'एंबुलेन्स': 1, 'भू-माफियाओं': 5, 'पांचकुआं': 1, 'एंटरटेनर': 3, 'ए़िड़यों': 1, 'अंकतालिका,': 1, 'पाऊंगा।': 20, 'इंटेरियर': 2, 'दुर्धटनाएं,': 1, 'ओंग': 1, 'एक्सपीरिएंस': 3, 'जिएं': 5, 'इंस्टीट्यूट्स': 3, 'ईंडीयुम': 1, 'आंतो': 10, 'खिलाएंगे': 5, 'ओझा-बाबाओं': 1, 'इंदो': 3, 'एंजलिक': 2, \"आएं'।\": 1, 'जीऊं।': 1, 'अंत्येष्टी': 2, '‘अंदाज’': 1, 'छटाओं': 2, 'अंबाला,': 5, 'अंदर-बाहर': 9, 'माइंडिड': 1, 'इंजीनिय¨रग': 1, 'लाएंगे।': 19, 'इंवेस्टिगेटिंग': 1, '‘ग्रेहाउंड': 1, 'सईं': 1, 'जुगनुओं': 13, 'अंधविश्वासों': 22, 'अंगारा': 16, 'हरफनमौलाओं': 4, 'इंटरस्टिंग': 1, 'ड्रॉइंगरूम': 1, 'घुंघरुओं': 5, 'प्वाइंट्स': 4, 'अंटी': 14, 'भिजवाएं,': 1, 'आंदोलन।': 4, 'बदइंतजामी': 3, 'इंगेजिंग': 1, 'काइंड': 3, 'कंबाइंड': 2, 'अंत।': 7, 'बनाऊं.': 3, '‘आॅस्कर’': 1, '‘इंटरटेनमेंट’': 1, 'दीपमालिकाओं': 2, 'काउंसिल्स': 1, 'कांस्टीचुएंसी’': 1, 'गणनाएं': 6, '2.अंग्रेज': 1, 'कौआं': 1, 'उठाएंगे?': 2, 'अंश,': 4, 'आंनद': 15, '(इंटेलीजेंस)': 1, 'अंगुठी': 2, 'बेसहाराओं': 3, ',कुप्रथाओं': 1, 'जितवाएं': 1, 'हरवाएं,': 1, 'ईंट-पत्थर': 6, 'शुभकामनाएं।': 17, 'लाउंज': 11, 'बयोसाइंस': 1, 'ई़': 1, 'भावनाओं,बल्कि': 1, 'अंतराल,': 2, 'मचाएं।': 1, 'आँखों': 1340, 'च्यूइंग': 11, '‘अंतरिम': 1, 'एंडोस्कोप': 1, 'आॅर्डर': 4, 'क्वालिफाइंग': 10, 'एंग्लो-हिंदू': 1, 'आइंसटीन': 2, 'इंसटीट्यूट': 1, 'नेताओं-': 3, '(एलएंडटी)': 1, 'पाएंगी.': 7, 'मानसिकताओं': 6, 'तर्इं': 3, 'इंक्युबेटरों': 1, 'लालकुआं': 2, 'पाऊंगी': 8, 'इंटरव्यू-': 1, 'अंधदौड़': 1, 'असफ़लताएं': 1, 'अंजनिया': 1, 'ओवर-एंबेलिश्ड': 1, 'बाईं': 38, 'आंगनबाडी': 2, 'ड्राइाूट': 1, 'बांगलादेश-इंडिया-पाकिस्तान)': 1, 'सब-प्वाइंट': 1, 'एंग्जाइटी': 13, 'अंत-अंत': 8, 'अंश:-': 1, '-इंटर': 1, 'अंकित,': 5, 'जाएंगीं।’': 1, 'पटकथाओं': 4, 'इंटरटेन': 5, 'ग्राइंडर,': 1, 'शिष्य-शिष्याओं': 2, 'अंडरकवर': 2, 'व्याख्याओं,': 1, 'अंर्तगत': 8, 'कुंठाओं': 16, 'आंवटित': 2, 'आंगनबॉड़ी,': 1, 'अभिलाषाओं': 13, '‘इंटैलीजैंस': 2, 'आँख': 529, 'इंगवार्ड': 1, 'अंचलाधिकार': 1, 'इंग्राडिएंट्स': 2, 'इंफ़ेक्शन': 3, 'महाराजाओं': 6, 'ऐंथनी': 2, 'ऐंड्रेसकिस': 1, 'बाउंड': 3, 'जीऊंगी': 2, 'जाऊंगी।’’': 1, 'गिनाईं।': 5, 'गणनाओं': 12, 'अंतत': 12, 'अंति': 1, 'शाखाओं,': 2, 'आंशिक,': 2, 'पाठशालाओं': 6, 'अंततोगत्वा': 12, 'एंग्लो-सैक्सन': 2, 'एंटीबॉडी': 8, 'एंड्रेड': 1, 'जलदस्युओं': 1, '17.40अंक': 1, 'इंटरकॉन्टिनेंटल': 2, 'इंटर-कॉन्टिनेंटल': 2, 'एंड्रीयूज': 1, 'वक्ताआें': 1, 'बिठाएंगे': 2, 'इंटेस्टाइन': 2, 'बोइंग-787': 1, 'अंतर्हस्तक्षेपी': 1, 'इंसपैक्टर': 1, 'अंटार्कटिका': 11, 'नेताओं-अफ़सरों': 1, 'ऊंझा': 3, '(पीएंडए)': 1, \"उठाएं।'\": 1, 'अंजाना-अंजानी': 2, 'फिजाओं': 18, 'विधाएं,': 1, 'लटकाएं.': 1, 'महिलाएं?': 1, 'बाबुओं,': 2, 'लहराएंगे.': 1, 'अंदाजे': 4, 'प्रतिक्रियाएं...': 1, 'एंक्लेव': 2, 'ओरिएंेटेड': 1, 'ओरिऐंटेड': 1, 'अपेक्षाओंको': 1, 'ची..सिउंग': 1, 'एंड्रेस': 1, 'एंडेमोल': 1, 'भुईंया,': 2, 'नागकन्याएं': 1, 'नागकन्याओं': 1, 'ऊर्जाएं,दोनों': 1, '‘बेजेंटाइंस’,': 1, 'इंपासिबिल': 1, 'आंद्रेई': 2, 'कनूइंगि': 1, 'वेतन-सुविधाओं': 1, 'पाएंगे।’’': 2, 'ऊंचाई,': 3, 'ऐंगुलर,': 1, 'ऐंगुलर': 1, 'आंद्रेस': 3, 'अंतिसंवेदनशील': 1, 'आर्इं।': 1, 'एंडोक्रायोनोलोजी': 1, 'ऐंबैसडर।': 1, 'जाएंगी।होल्कर': 1, 'बनगईं।': 1, 'बंटाएं।': 1, 'आईएलएंडएफस': 1, 'दुर्भावनाओं': 4, 'चुइंमगम': 1, 'सुविधाएं:': 2, 'बोईंग': 5, 'इंडियाफ़र्स्ट': 1, 'अंतरमहाद्वीपीय': 1, 'जुटाईं': 2, '‘इंग्लिश': 5, 'बिछाएंगे': 1, 'घुमाएं।': 6, 'जमाएं।': 1, 'अंकल-आंटी': 2, 'करवाएंगे': 9, 'हिचकिचाएंगे।': 1, 'चिंताएं,': 2, 'एलाइंस': 1, 'कलिकाएं': 1, 'युवाओं,': 11, 'आंगनबाड़ी,': 1, 'अपनाएं...': 1, 'इंकमटैक्स': 3, 'अर्थच्छायाएं': 1, '‘फाउंडेशन': 2, 'उठाऊं.': 2, 'एंबेसेडर': 2, 'विशिष्टताएं': 3, 'इंश्योरैंस': 6, 'स्व.इंदिरा': 1, 'आंद्रियास': 1, 'आंगनों': 6, 'भाईंदर': 1, 'पिएं': 5, 'सदस्याओं': 1, 'आेच्छी': 1, 'इंटरनेट-आधारित': 1, 'अॢजत': 3, 'बजाएं,': 3, 'आउंगी।': 2, 'भगाएं.': 1, 'एंडरसन।': 1, '(इंस्ंिटक्ट)': 1, 'अन-एंप्लॉयमेंट': 1, 'ऐंटि-डंपिंग': 1, 'सुविधाएं-': 1, 'जटाओं': 15, 'अंतरिक्षयात्री': 11, 'आरएंड': 2, 'परमाणुओं': 17, '5715.80अंक': 1, 'कार्यकर्ताओंं': 1, 'प्रकाशनाएं': 1, 'प्रयोगकर्ताओं': 5, \"इंस्टीटयूट'\": 2, 'आंगनबाड़ी,': 4, 'संध्याओं': 6, 'अंडर-12': 1, 'कराएँ।': 4, 'बिड़ला-अंबानी': 1, '4.7-इंच': 1, 'अंबाकोना': 1, 'अंडरपैंट': 1, 'अंडमानी': 1, 'चिंताओं-सरोकारों': 1, 'एंबेस्डर': 2, '6147.67अंक': 1, '6596.40अंक': 1, 'साइंसेज’': 2, \"'इंदिरा\": 1, \"इंदिरा'\": 1, 'लाएंगे,': 3, 'अंशा': 5, 'अंकतालिका': 8, 'इंटरैक्शन': 1, 'भिगोएं': 1, 'कुमाऊं-गढ़वाल': 2, 'दवाओं,': 2, 'एंबुलेंसों': 3, 'माउंटेनरिंग': 2, 'खाएंगे।': 9, 'अंनियंत्रित': 1, 'ऐंपियर': 1, 'इंटीमेशन': 3, 'अंजुम,': 4, 'इंतखाब': 1, 'छुड़ाएं': 1, 'ईंख': 4, '‘इंटर-सर्विसेज': 1, 'आॅटोमेटेड': 1, 'अपराधकथाएं': 1, '(गोइंदवाल)': 1, 'श्रावक-श्राविकाओं': 1, 'आक्राताओं': 2, 'अंतरजिला': 2, 'ऊँट': 33, '(चयनकर्ताओं)': 2, 'चढ़ाएं।': 2, 'इंजैक्शन': 12, 'निमार्ताओं': 2, 'र्इंधन': 4, 'पाउंगा.': 2, '‘इंटेलीजेंट': 1, 'रुआंसे': 4, 'अंतर्धान': 5, 'काउंट्स’': 2, 'भटकाएं।’’': 1, 'जाएंगी.वह': 1, 'दल-इंडियन': 1, '(फाउंडर,': 1, 'अंतरजाल': 9, '(इंटिग्रेटिड': 1, 'महिलाआंे': 1, 'ऑडिएंस': 11, 'गोशालाओं': 2, 'अंझरी': 1, 'आंखें।': 3, \"लगाएं।'\": 1, 'जिआंग': 1, 'गुक्आिंग': 1, 'अंडर-22': 3, 'रोएं': 4, 'जिआंग्सी': 1, 'डीपुओं': 1, 'इंजेक्ट': 4, 'एंडर्सन': 1, 'मिटाएंगे।': 1, 'अंतर-क्षेत्रीय': 1, 'इंदौरा/भरमाड़:': 1, 'इंजुरी': 6, '6901.99अंक': 1, 'आंशंकाओं': 2, 'एंबैलिश्ड': 1, 'दिलाएं।': 2, 'तईं': 10, 'अंतर्विरोध': 45, 'बचाऊं।': 2, 'कराउं.’’': 1, 'कोइ्रü': 1, 'विविधताएं': 2, 'है.आंध्र': 1, 'अंडर-15': 3, 'कार्यशालाओं,': 1, 'अंतर-7.98': 1, 'चुराएं...’': 1, 'आंद्रीव': 2, 'एयरलाइंस)': 2, 'साईंस': 14, 'बनाएं..': 1, 'इंटरव्यू,': 3, 'सख्ंयताओं': 1, 'अंतप्रवाह': 1, 'इंदनानी,': 1, 'साइंटिफ़िक': 3, 'ब्रिटिश-इंडियन': 1, 'एंड’': 2, 'बनाएंगे.’’': 1, 'योग्यताएं’’': 1, \"कराएं।'\": 4, 'बाबाओं': 53, 'अकाउंट।': 1, 'संचार-कलाएं,': 1, 'पीएं.': 1, 'संस्थाएं)': 1, 'सद्भावनाएं': 3, 'है.शोधकर्ताओं': 1, 'दिलाईं': 1, 'गुआंगुआ': 1, 'अंकुर,': 6, 'आएं.': 9, 'अगमकुआं': 5, 'अॅाटो': 1, 'साइंस/इन्फॉर्मेशन': 1, '‘आइंस्टाइन्स': 1, 'छायाओं': 3, '‘अंधुलिनी': 1, '‘एंटरटेन’': 1, 'देवताओं,': 5, 'सहायताएं': 1, 'प्रसूताएं': 1, 'पहरूओं': 1, 'विभिन्नताओं': 5, '-अंक': 1, 'इंवेंटर': 1, 'पहनाऊंगा।': 1, '‘आंख': 1, 'जाएंगें।': 5, 'इंटर्जी': 1, 'विके्रताओं': 2, 'इंट्रोवर्ट': 2, 'इंडिया-शो': 1, 'बनाएंगे?': 1, 'इंडियल': 1, 'हुआंगनान': 2, 'एलाउंस': 6, 'अंगदान:': 1, 'वजर्नाओं': 1, 'अंशुल': 3, 'इंसान’': 1, 'कार्यकत्तर्ााओं-नेताओं': 2, 'आरएंडडी': 2, 'एसएंडटी': 1, '‘एंग्जाइटी': 2, 'नाइंटिगेल': 1, 'उठाएंगे.': 7, 'कणिकाओं': 2, 'अंगेजों': 4, 'आंतकवादी': 10, 'अंकतालिकाओं': 4, 'ऎंठ': 2, 'फ्लूएंसी': 1, 'गया...अंतिम': 2, 'एंग्जाइटी,': 1, 'एंजलो': 1, 'आएं?': 3, 'बार्इं': 1, 'दार्इं': 1, 'इंग्लिश।': 1, 'घटनाओं,': 8, 'ओंकाड़ा': 1, \"'इंस्पेक्टर\": 1, 'जाएंगे?’’': 1, 'आशकाओं': 1, 'इंद्रजीत,': 3, 'जमाएं': 2, '‘फ्लाइंग': 1, 'आएंगी,': 10, 'आंतकियों': 3, 'पाइंटस': 1, 'इंच्छापुरी,': 1, 'इंड्स्ट्रियल': 1, 'इंटरप्राइज़ेज': 1, 'आत्मकथाएं,': 1, 'इंट्राडे': 3, 'पॉइंट्स।': 3, 'ईंच': 5, '(मतदाताओं': 1, '(कोशिकाएं': 1, 'ज्वालाएं': 4, 'इंरव्यू': 1, 'इंजीनियरिंग/मैकेनिकल': 1, 'अनुयायिओं': 3, 'प्रांतीयताओं': 1, 'अंडर-13': 2, 'पाउंगा': 10, 'खिचवाएंगे,': 1, 'क्रिकइंफोडॉट': 1, 'इंस्पेक्शन’': 2, 'एंटी-एड्स': 1, 'समरूपताओं': 1, 'प्रतिरूपताओं': 1, 'ऊंच-नीच': 16, 'विधवाओं,': 2, 'उूंचाई': 1, 'अंधेपन,आवेग': 1, 'सत्ताओं': 19, 'गुआंगझाउ': 1, '‘मॉम-एंड': 1, 'आंकड़ा-': 1, 'इंस्ट्रमेंटेशन': 2, 'इंस्ट्रमेंटेशन/': 1, 'इंफोसॉफ्ट,': 1, 'अंजोर.': 1, 'वेश्याएं': 7, 'अप्वाइंटमेंट': 2, 'इंफ्रारैड': 2, 'इंदूबाला': 1, 'पहनाएं।': 3, 'बालाएं': 5, 'उ़डें': 1, 'बढाएंगे': 1, 'भक्ति-आंदोलन': 3, \"'अंडर\": 3, 'इंजॉयमेंट': 1, \"माइंड'\": 2, 'परमपराएं': 1, 'मनाएंगे।’’': 1, '(इंदिरा': 1, 'संवादताओं': 1, 'छिपाईं।': 1, 'भावभंगिमाएं': 1, 'आंखों-ही-आंखों': 4, '‘अंदाज’,': 1, 'एंट्री’': 1, 'कुएं,': 1, 'बोस-आइंस्टीन': 1, 'काउंटरवेलिंग': 3, '‘अंग्रेज': 1, 'एंडीज': 1, 'चढ़ाईं।': 1, 'अंगारे': 25, 'पूजाइंदिरापुरम': 1, 'ऊँच-नीच,': 4, 'आॅनलाइन': 6, 'लगएं': 1, 'भावभंगिमाओं': 4, 'काउंटिंग': 4, 'इंवाइट': 4, 'ऋतुओं': 21, 'चलाएंगे,': 4, 'सजाएं.': 3, 'काउंसिलर।': 1, 'होऊंगा।': 2, 'अंजाम?': 1, 'पाठशालाएं': 3, 'कर्जदाताओं': 4, 'पीएंडएम': 1, 'अंतोनिस': 1, 'इंवोसिंग': 1, 'निपटाएं।': 5, '(इंडियन)': 1, 'इंटलेक्चुअल': 7, 'अंबानी।': 4, '84.30अंक': 1, 'होऊंगा': 9, 'अंगड़ाइयां': 1, 'प्रसंस्करणकर्ताओं': 1, 'इंस्टीच्यूट,': 2, \"'आइंस्टाइन\": 1, 'हैं.अनुसंधानकर्ताओं': 1, \"'पेइंग\": 1, 'एंबीशन': 1, 'इंटरलाकिंग': 4, 'एनजीओं': 4, 'साइंसेस),': 1, 'साइंसेस)': 1, 'इंडोर्समेंट/क्लॉज': 1, 'एंटी-रेबीज': 2, 'अंगुरी': 1, 'सकेंगे.इंटरनेट': 1, 'ओंगबी,': 1, 'आऊंगी': 7, 'अनयिमितताओं': 1, 'जाउंगी।': 3, 'उंबेंगे।': 1, 'शिक्षक-शिक्षिकाओं': 5, 'नवविवाहिताओं': 2, '(इंटर)': 2, 'एंड्स': 3, 'जाउंगी.': 4, 'अंताल्या': 2, 'इंसपेक्टर,': 1, '‘‘लिआंग': 2, 'ऐंटिसिख': 1, 'बीपीओे': 1, 'सुविधाएं,': 7, 'पर्वतमालाओं': 2, 'इंद्राशीष': 6, 'ऑलराउंडराें': 1, 'अंतरर्राष्ट्रीय': 2, \"पाएं।'\": 1, 'पीएंडजी': 1, 'ओंबले': 5, 'आॅवर': 3, 'अंगरेजी-हिंदी': 1, 'पॉइंटों': 1, 'च्युइंग': 1, 'एसाइंमेंट्स': 1, 'अंगोला,': 1, 'एं': 5, 'इंग्लिस': 1, 'अीम': 1, 'संकल्पनाओं': 3, 'अपूर्णताओं,': 1, 'चेतनाओं': 5, 'पुरुष-महिलाओं': 1, 'अदाएं,': 2, 'असुविधाएं': 3, 'पाउंगा.’’': 1, 'छात्राऔं': 1, 'अंगुष्ट': 1, 'अंगुठे': 5, 'तम्बुओं': 2, 'ऐंटिबायॉटिक': 2, 'ग्राऊंड': 6, 'इंजीनियरिंग/सेरेमिक्स': 1, 'घबराएंगी।': 1, 'अर्थंव्यवस्थाओं': 1, 'दुर्घनाओं': 1, 'संभाव्यताओं': 1, 'प्रतिज्ञाएं': 3, 'एंड्रॉइड': 1, 'कार्यकर्ताओं,': 7, '।।अंतरराष्ट्रीय': 1, 'एंड्रॉयड,': 3, 'केअंदर': 2, 'इंडस्टीज': 9, 'आंतरी': 1, 'स्वर्ण-मुद्राओं': 1, 'स्वर्ण-मुद्राएं': 1, 'माइंस,': 1, 'मनाएंगे..परिवार': 1, \"बढ़ाएंगे।'\": 1, 'एंथ्रेक्स': 1, 'इंप्लांटोलाजी': 1, 'इंप्लाटोलोजिस्ट': 1, 'रीकाउंटिंग': 1, 'इंटरटेंमेंट,': 1, 'इंडिया’ने': 1, 'इंडिया’की': 3, 'पंजगाईं': 1, 'दबाएं': 3, 'फ़ाऊंटेनहेड': 1, 'जाऊंगी,': 5, 'अंधानुकरण': 10, 'अंग्रजी': 12, 'एंवायरन्मेंटल': 1, 'आंध्रप्रदेश,': 8, '5614.80अंक': 1, 'इंडिया.': 5, 'इंडस्टीज.': 1, 'इंतहान': 1, '‘‘आंध्र': 1, 'बढाएं.': 1, 'आंके': 5, 'गए।शोधकर्ताओं': 1, 'इंटरव्यूवाले': 1, 'प्रतिछायाएं': 1, 'नियोक्ताओं,': 1, 'अंकोला': 1, 'अर्थव्यवस्थाओं..': 1, 'अपहरणकार्ताओं': 1, 'भूइंया': 2, 'इंकलाब,': 1, '(एंग्जाइटी)': 1, 'अंबूजा': 1, 'साईंनाथ.': 1, 'इंस्टिटयूट': 2, 'उूपर': 1, 'गवांऊंगा।': 1, 'अंडरवाटर': 2, 'कराऊंगा।': 4, 'पहलुओं,': 3, 'राजनेताओं,': 11, 'उपपरंपराओं': 1, 'सभ्यताएं': 7, 'आंती': 2, 'अंबालाल': 1, 'इंफॉमेंशन': 1, 'लगवाएं.': 2, '(साइंटिस्ट-बी)': 1, 'गोराईं,': 2, 'पाओं': 4, 'म्याइंग': 1, \"'अंतिम\": 4, 'अंतर्यामी': 10, 'सेवाएं)': 4, 'तारिकाएं': 1, 'सुनाएंगे': 1, 'इंडिगों': 1, 'बचाओ-बचाओं': 1, 'उंमग': 1, 'लाइनपरियोजनाओं': 1, 'एंडोमॉर्फ': 2, 'उठाएंगे,': 3, 'इंटरनेल': 1, 'अंगौता': 2, 'अंत्येष्टियां': 1, 'अट्टालिकाओं': 5, 'लोकसभाओं': 2, 'आवश्यकताएं': 15, 'इंड्रस्ट्रियल': 2, 'लीलाएं,': 1, 'हाथ-आंख': 1, 'सिनो-इंडियन': 1, 'जाएंगे.\"': 2, 'ऐंटि-ऑक्सिडेंट्स': 1, 'जाएंगें,': 2, '19486.80अंक': 1, 'इंडियट्स': 1, '18537.01अंक': 2, 'करवाएं': 13, 'जिताएं:': 1, 'जिताएं।': 1, 'जिएंगे': 3, 'कीआकांक्षाओं': 1, 'जाएंगे’,': 1, 'अंतर्चेतना,': 1, 'श्रदालुओं': 1, 'अंडर-19-': 1, 'मनोभावनाओं': 2, 'विशिष्टताओं': 10, 'हटाएं।': 2, 'एंटीसिपेशन': 1, 'अंजूमन': 1, ':आॅटो': 1, 'आाखिरी': 1, 'इंतजार,': 5, '-एंड्रॉयड': 1, 'नगवाईं': 1, 'आॅडियो-विजुअल': 1, 'आॅडियो': 1, 'बिठाएंगे।': 1, '‘मुद्राएं’': 1, 'इंदुप्रकाश': 1, 'कराउंगा।': 1, 'एंग्लो-सैक्शन': 1, '(इंटक)': 1, 'एंतोन': 1, 'शरमाएं': 1, 'सुनाईं।': 3, 'ओएंड्रिला': 1, 'एेंठन': 1, 'न्यूफाउंडलैंड': 1, 'अंदानेप्पा': 1, 'ऊचाईंयों': 1, 'जनआंदोलन': 12, 'इंटरसेप्ट': 4, 'गायक-गायिकाओं': 4, 'ऊंटनी': 5, 'इंडियाना,': 2, 'एंजाइटी': 4, 'दरियाओं': 4, 'अंदन': 1, 'पहुंचाउंगा।’': 1, 'अव्यवस्थाएं,': 1, '(डिसइंटीग्रेट)': 1, 'अंतुले,': 1, 'अंदराज': 1, 'कलाएं': 7, 'योजनाएॅ': 1, \"जाएंगी।'\": 3, '5287.95अंक': 1, 'अंकीय': 3, 'चलाऊंगा।’': 1, 'अप्पलाइंसिज': 1, 'ऐंटि-करप्शन': 2, '(ऐंटि-करप्शन)': 1, 'ऐंजिलिस।।': 1, \"'विफलताओं\": 1, 'दिखाएंगी।': 5, 'इंडीज),': 1, 'सुपरइंपोजिशन': 1, 'शिलाओं': 4, 'खाने,सुरक्षा,दवाओं': 1, 'अंतर्राजीय': 1, 'चिन्ताएं': 5, 'विधानसाभाएं': 1, 'अंर्त्धयान': 1, 'अकाउंटेबिलिटी': 1, 'इंफर्टीलिटी': 1, 'अंत:वासियों': 1, 'हेलीस्कीइंग': 1, 'इंश्योर्ड': 2, 'अंजा': 1, 'आंकड़ें': 5, 'हत्याएं,': 4, 'अंदाज।': 3, 'छात्राआें': 2, '\\u200bकिड्सवेबइंडिया': 1, 'अंथोनी': 1, '‘इंपावर': 1, '‘इंफॉर्मेशन’': 1, '‘इंफॉरमेशन’': 1, 'पेचकर्ताओं': 1, 'इंदुवाला,': 1, 'एंटोनी': 9, 'ईंट-भट्ठे,': 1, 'काउंट': 12, 'इंस्पैक्शन': 1, 'जाएंगी?': 8, 'आंलंपिक': 1, 'दिखाईं': 8, 'इंफ्रारेड': 5, 'एंटन': 2, 'केशरी,अंक': 1, '‘‘अंतर': 2, 'इंसुलेटेड': 1, 'चढाएं': 1, 'आंदर': 4, 'आंका।': 1, 'एंट्री-लेवल': 1, 'इंजीनियरो': 2, 'फाउंटेन': 7, 'ऊं': 4, \"दिलवाएं'\": 1, 'परपराएं': 1, '(आंध्रप्रदेश)': 3, 'धाराएं,': 1, 'अंत्येष्ठि': 1, 'परियोनाओं': 1, 'इंवेस्टीगेटिव': 1, \"जाऊं।'\": 1, 'इंटेजीबल': 1, 'लगाउंगा': 3, 'जाएंगे’’': 1, 'संसाधन-सुविधाओं': 1, 'अेथॉरिटी': 1, 'इंवेट': 3, 'अंतरों': 8, 'जुएं': 4, 'महिलाएं:': 2, 'अंगेलिक': 1, 'गैस्ट्रोइंटेरोलॉजी': 1, 'कार्यकर्ताआंे': 1, 'ट्राइऐंगल': 1, 'लव-ट्राइऐंगल': 1, 'ऋचाएं': 6, 'इंसां': 6, '‘अंतिम': 3, 'इंफ़ोसिस': 2, 'इनएफिशिएंट': 1, 'बायोइंस्ट्रूमेंटेशन,': 1, 'इंटरपोल,': 1, 'ग्रोइंग': 2, 'गवाऊंगा.': 1, 'बताएं।’': 1, 'एंगेज': 2, 'अपनाएंगे': 5, 'अंबरसरी': 1, 'आंदोलनधर्मी': 1, 'एंटीवायरल': 1, 'अंग्रेजी-वर्चस्व': 4, '(ऊँ': 2, 'इंद्रियादिकं': 1, 'मतदताओं': 1, 'दौड़ाएंगे।': 1, 'टकराईं': 2, 'साईंनाथ-रेड': 1, 'इंस्ट्रक्शन': 7, 'बतार्इं': 1, 'इंजीनियर:': 2, 'एकाउंट’': 1, 'धुओं': 2, 'विभीषिकाओं': 2, 'असमानताएं': 6, 'भिन्नताओं': 6, 'तालिकाओं': 2, 'इंट्रींसिक': 1, 'इंवेस्टर्स': 1, \"'इंद्र\": 2, 'अकाउंट,': 3, 'आदि-अंत': 3, 'एंफ़ीबियंस': 1, 'ऎंठे': 2, 'अंतवस्त्र': 1, \"'अंपायर\": 1, 'लौटाएं।': 2, 'ओंटोरियो': 1, 'एंटरप्राइज': 3, 'इंदिराकाल': 1, 'मुडवाएंगी.': 1, '`अंदाज`,': 2, 'रामलीलाओं': 7, 'ऊंखलिया': 2, 'कक्षाएं,': 3, 'उंगिलयों': 1, 'ऊंघती': 3, 'मद----परियोजनाएं---जरूरत': 1, 'इंटेरेस्ट': 2, 'योजनाआें': 1, '3-अंदर': 1, 'खिंचावाईं।': 1, 'आँकड़ों': 21, 'ऐंटिबॉडी': 2, 'इंदराज': 2, 'अंतरानुशासन': 1, 'बढ़ाएंगे.': 4, 'गुरिल्लाओं': 1, 'जिएं।': 2, 'आंकड़ाें': 1, 'होऊंगा,': 4, 'ग्राइंडर': 4, 'उपेक्षाओं': 5, 'अंतर-विद्यालय': 1, 'इंटरटेनर': 1, 'आपदओं': 1, 'इंडियान': 1, 'इंट्रिसिकली': 1, 'इंदरसिंह': 2, 'एंटी-एजिंग': 1, 'सूचनाओं-तथ्यों': 1, 'थपथपाएं.': 1, 'गिनवाएं।': 1, 'राजाओं-महाराजाओं': 4, 'बर्बरताओं': 1, 'श्रंखलाओं': 2, 'ओेर': 1, 'इंटिग्रेटिड': 1, 'अंत,': 17, 'आपदाएं,': 2, 'निवेशकर्ताओं': 2, \"बनाउंगी'\": 1, 'मनाएंगे.': 4, 'अंडर-51': 1, 'अंडर-48': 1, \"'एंटी\": 3, 'रेडिएंट': 4, 'रिडिफाइंड': 1, '-अंदरूनी': 1, 'उत्तरदाताओं': 1, 'गइं।': 1, \"ओंकार'\": 1, 'आॉडियो': 1, \"'इंशा\": 1, 'इंटरनेैशनल': 1, '281.09अंक': 1, 'जरिएः': 1, 'आॅफिसेज’': 1, 'आॅफिसेज': 1, 'अंबिया': 1, \"'अंडर-23\": 1, 'जुटाएं': 6, '‘‘अंत': 1, 'लीजिए़': 1, \"जाएंगे'।\": 2, 'बाइंग': 3, 'सूचनाएं,': 2, 'महिलाओंे': 1, 'लड़वाएंगे।': 1, \"'कॉन्स्टीट्यूएंसी'\": 1, 'माताओं,': 3, '18762.87अंक': 1, '7.29अंक': 1, 'आंदोलन-': 2, '‘एंड': 2, 'इंफेक्शंस': 2, 'एंकरों': 4, 'विधानसभाएं,': 2, \"'इंग्लैंड\": 2, 'स्टेट्स-इंडिया': 1, 'पिलाएं।': 2, \"इंक्वायरी'\": 2, 'अमेरिका-एंड': 1, 'एंट्रैंस': 1, 'साइंस/जमा': 1, 'अंगुलिया': 4, 'अनिश्चितताएं': 1, '(दवाओं': 1, 'आंदोलनकारी.': 1, 'अंटू,': 1, '‘इंडियाज': 1, 'अंधविश्वासी': 14, 'अंशिका': 1, 'फउंडेशनों-संस्थानों': 1, 'एंद्राका': 2, 'लखनउः': 1, 'ऊंगलियों': 5, '‘आॅफ': 1, 'अंतरराष्ट्रीयय': 1, 'अंत:': 5, '6744.53अंक': 1, 'कोल्हुओं': 1, 'असमानताओं': 6, 'एंटीगुआ': 1, 'एंतिल': 1, 'मिनदानाओं': 1, 'बताउं': 6, 'चाहिएं,': 3, 'इअिोबामा': 1, 'एंतोनियो': 2, 'घटनाआंे': 1, 'सूरजमल-ओंकारमल,': 1, 'इंटैलिजेंट': 1, 'निभाईं': 3, 'जाऊं)': 1, 'दिखाएं.’’भारत': 1, 'ऐंकर': 5, 'वीजे-ऐंकर': 1, 'पीड़िताओं': 1, 'धर्मशालाओं,': 1, 'करवाएंगे.': 1, 'फ्लोइंग': 1, 'इंपॉर्टेंस': 1, 'दिखाऊं': 3, 'एंड्राइड/लिनक्स': 1, 'अंसारी-वरिष्ठ': 1, 'अंदाओं': 2, 'स्केलिंग/अंक': 1, 'अंग्र्रेजी,': 1, 'अंातरिक': 1, 'बिताऊं।': 1, 'आौर': 1, 'बहाएंगे,': 1, 'अंचल,': 2, 'आंगनवाड़ियों': 1, 'साइंटिस्टों': 2, 'हिंदी-इंग्लिश,': 1, 'इंसपिरेशन?': 1, 'अंधविश्वाासों': 1, 'अंबानी,': 10, 'एंटीमाइक्रोबीयलपेप्टाइड': 1, 'इंस्टिट्यूट्स': 4, 'ओंकारेश्वर,': 1, 'पहुंचाएं,': 3, 'इंस्ट्रयूमेंटल': 2, 'ऐंजिलीना': 2, 'अदकाराओं': 1, 'भावनाओं,': 4, 'पाऊं,': 8, 'हैं-अंतरराष्ट्रीय': 1, 'अंक),': 1, 'एंमआर': 1, 'कहलाएंगे।': 4, 'व्याख्याताओं': 8, 'अंसार,': 1, 'परम्पराएं': 13, 'बेबाएं': 1, \"जाऊंगा।'\": 4, 'एंठने': 3, 'ऐंबेसडर': 1, 'शुभकामनाएं.': 5, 'लाएंगे.': 3, 'साइंटिक': 1, 'साइंसेस': 4, 'बाउंड्रीज': 1, 'दबाऊंगा': 2, 'जाउंगा।’’': 1, 'ग्रामसभाओं': 2, 'बेटलग्राउंड': 1, 'उठाऊंगी': 1, 'अंजर': 1, 'मिलाएंगे।': 3, '‘इंदिरा': 3, '‘सईंया': 1, 'दिखाउंगा।': 1, '-इंजरी': 1, 'क्लाइंबिंग,': 1, 'एंगलिंग,': 1, 'आकाशगंगाएं,': 1, 'अंतरराष्ट्रीयकरण': 1, 'आंसरशीट': 4, 'आंसरशीटस': 1, 'सीएंडसी-बीएससी': 2, 'अंशाति,': 1, 'आंइस्टीन': 1, 'जाएंगे’': 1, 'लाइवसाइंस': 2, 'हाइड्रोइंफोर्मेटिक्स’': 1, 'इश्यूओं': 1, 'पहुलओं': 1, 'भाव-ऊंचे': 1, 'इंदिरा,': 2, 'इंडिरूा': 1, 'इंसेफ्लाइटिस': 1, '‘इंस्टिट्यूशनल': 1, 'एंग्लोफोन': 1, 'इंडिया-फर्स्ट': 2, '।।महिलाओं': 1, 'आंके।': 2, 'लघुकथाएं': 3, 'इंटरवेंशन': 1, 'अंजनवेल': 1, 'इंफोसिस(-1.1': 1, '-ऊंचाई': 1, 'जुआं': 3, 'मनाएंगे,भाजपा': 1, 'मनाएंगे,ठीक': 1, 'महिलाएं,कर्मचारी': 1, 'इंडीवर': 1, 'फाईंस': 1, 'तिआंजिन': 1, 'बजाईं।': 3, 'भालुओं,': 1, 'डायइंट्री': 1, 'उठाईं।': 3, 'चाहिएः': 3, 'इंडिया-948': 1, 'गूढ़ताओं': 1, 'इंजीनियरों,': 4, '(इंचार्ज)': 2, 'नाइंथ': 2, \"प्वाइंट'\": 1, 'जताएंगे।': 3, 'षड्यंत्रकर्ताओं': 1, 'दिखाईं।': 3, 'लहराऊंगा.': 1, \"प्वाइंट्स'\": 1, 'इंफोर्समेंट': 3, 'अंडरवर्ल्\\u200dड': 3, \"कहा,'महिलाओं\": 1, \"'अंदाजा\": 1, '(इंटरनली': 1, \"'नेताओं\": 1, 'छायाएं': 3, 'सीखाएं।': 1, 'एंक्वायरी': 3, 'अंडरएस्टिमेट': 1, 'एंपावर्ड': 2, 'आएं।’’': 1, 'नचाएं।': 1, 'छिपाऊंगा': 1, 'एंटीना,': 1, 'एैज': 1, 'एंजिलबर्ट': 6, 'खिलाएंगी।': 1, '(इंटरनल': 1, 'मनाकोमनाएं': 1, 'इंस्टॉल्ड': 1, \"'अंतरिम\": 1, 'बलाएं,': 1, 'ओंकोलॉजिस्ट': 1, 'ड्राइंग,': 3, 'संकीर्णताओं': 9, 'बताऊं': 59, 'इंस्टीटय़ूशंस': 2, 'बनाऊं।’’': 1, 'एंजिलिस,': 1, 'इंद्रवा': 1, \"खाऊंगा.''\": 1, 'दिलाएंगे': 3, '‘इंडियास': 1, 'पीएंडटी': 2, 'अंबाबाद': 2, 'सुलझाएं,': 1, 'लेखक-बंधुओं': 1, 'स्वास्थ्य-सुविधाओं': 1, 'पीड़िताओं': 2, 'अंजु': 15, 'विषमताएं': 6, 'ओझाओं': 2, 'साइंटिस्ट,': 1, 'औपचारिक्ताएं': 1, 'आांदेई': 1, 'तुड़वाएंगे': 1, '3-इंच': 1, 'बंधुओं-': 2, 'पहुलुओं': 1, 'ऐंजल': 1, 'जाएंगे?’': 4, 'हटवाएंगे': 1, 'सेवाएं.': 1, 'सार्इं': 1, 'अंदाज)': 1, 'अंगा': 1, 'इंदोरिया': 2, 'इंद्रपास,': 1, 'अंगूरी': 17, 'इंटरस्ट': 2, '-नेताओं': 1, 'बताएंगी।': 4, 'बिताऊंगा,': 1, 'उपभोक्ताओं,': 4, 'अर्थव्यवस्थाओं-': 1, 'वि.इंग्लैंड': 1, 'एंजिलिसः': 1, 'कीप्वाइंट': 1, 'अंदराबी': 2, 'अंगीकृत': 3, 'बददुआओं': 2, '‘इंडिपेंडेंट’': 1, 'डीआरएंडआरडी': 1, 'एकाउंटेट': 1, 'प्रोफिशिएंसी': 1, '73.95अंक': 1, 'इंद्रिय-निग्रह।': 1, 'हटाएंगे।': 1, 'धमकाएंगे।': 1, 'सुविधााओं': 1, 'चिताएं': 6, 'इंड्रस्टी': 1, 'ऐम्बएंट': 1, \"बचाएं।'\": 1, 'खाएँ,': 1, '’’इंग्लैंड': 1, '‘सफलताओं’': 1, 'इंदुलाल': 3, 'दर्शाएं': 1, 'अंगौता,': 1, 'इंग्लैंड-भारत': 1, 'एंटरप्रेनर': 2, 'अंदलीब': 2, 'पाठकों-श्रोताओं': 9, 'अंकोलाजिस्ट': 1, 'अंकुड़ी': 1, 'इंदासर,': 1, 'जमाकर्ताओं': 3, 'अध्यापक-अध्यापिकाएं': 1, 'इंजोप्लास्टिक,': 1, 'एयरलाइंनों': 1, 'गौओं': 9, 'बढ़ाएंगे': 1, 'इंद्रधनुषी': 14, 'ऐंड्रयू': 1, 'एंज्\\u200dवॉय': 1, 'ओंकार।': 1, 'व्यवसायिओं': 1, 'अनुसंधानकत्र्ताओं': 2, 'आॅपरेटिंग': 1, 'श्वेइंस्टीगर': 4, \"'श्वेइंस्टीगर\": 1, 'छह-अंडर': 1, 'इंसेंटिव': 4, \"एंड'\": 3, '16877.35अंक': 1, 'एफिशिएंट': 3, 'सखाओं': 2, 'खाईं।': 1, 'रिलाएंस': 5, 'अंधत्व': 6, 'देवताएं': 1, 'अंतरदर्शन': 1, 'मानसिकताएं': 1, 'भाषाएं,': 3, 'इंडियाफोरेंसिक': 1, 'ऑरिएंटेड': 2, '‘‘अंतरराष्ट्रीय': 1, 'अंधाधंुध': 2, 'वरीयताओं': 3, 'एंटी-आॅक्सीडेंट': 2, 'वस्तुओं’': 1, 'परियाजनाएं': 1, 'इंजीनियर.': 1, 'ऊंचाहार': 1, 'इंडो-कनाडियन': 1, 'मनाऊंगी.': 1, 'कराएंगे।अभी': 1, 'च्पशुओं': 1, 'ऐंड्रू': 2, 'इंसानीयत': 2, 'आँत': 7, 'अपेक्षाएं।': 1, 'हुए़.': 1, 'इंतजार.और': 1, 'चर्चाओं,': 2, 'अंतर्राष्ट्रिय': 1, '?लाइंग': 1, 'इंडीकेटर': 3, 'प्रभुओं': 4, 'काऊंटरों': 2, 'आडिएंस': 1, 'इंटरैस्ट': 2, 'बचाएंगे': 3, 'हईं,': 1, 'अंतर्राष्\\u200dट्रीय': 2, 'गायिकाएं': 1, 'पहुंचेगा.अनुसंधानकर्ताओं': 1, 'इंपे्रस्ड': 1, 'मिसअंडरस्टैंडिंग’': 1, 'एंजाइमों': 6, 'एंजलिना': 1, '17195.51अंक': 1, '39.15अंक': 1, '43.52अंक': 1, '38.45अंक': 1, '6764.62अंक': 1, '-आशाएं': 1, 'एंटासिड': 2, 'हईं': 3, 'पाथफाइंडर': 4, 'इंट्रोडक्ट्री': 1, 'ऊंडल': 1, '78.69अंक': 1, 'एंटीआक्सीडेंट': 3, 'हुआंगयान': 2, 'फिराएं': 1, 'याएं': 1, \"'बाउंस\": 1, 'आंजनेयाय': 1, 'इंजतार': 2, 'लॉसएंजिल्स': 1, '\"महिलाओं': 1, '(अंडरराइटिंग': 2, 'काउंसिल’': 3, 'इंस्ट्रेक्टर,': 1, 'इंस्ट्रेक्टर': 1, 'अध्येताओं': 7, '(आॅलिगार्की)': 1, 'अभिकल्पनाओं': 1, \"'आंख\": 1, 'दोहराएंगे।': 3, 'अंंक': 1, 'सांप्रदायिकताएं,': 1, 'कट्टरताएं': 1, 'पाउंड्स': 1, 'अंकपत्र': 2, 'अकाउंटिग': 2, 'अंगोरा': 2, 'उड़ाएंगे,': 1, 'अंतर्कलह,': 2, 'खाईं': 8, 'पाऊंगी.': 2, 'गंवाएंगे।’’': 1, 'उर्जाओं': 1, 'खिलाऊंगी': 1, 'महिलाओें': 1, 'हटाओं': 2, '(इंटर': 1, 'वायुसेनाएं': 1, 'कथाएं,': 2, 'पढ़ाएंगे।': 1, 'सिखाएंगे।': 4, 'खटखटाएंगी।': 1, 'एंटिवायरस,': 1, 'एंटिस्पाईवेयर': 1, 'माफ़ियाओं': 4, 'अंबष्ट': 2, 'एंजेंसियों': 1, 'अंकोला,': 1, 'लुभाएंगी।': 1, 'ऊँचा': 102, 'बताईं,': 2, 'हाई-एंड': 2, 'काऊंटिंग': 1, 'कविताएं।': 5, 'गाएंगे,': 2, 'एंटएसिड': 1, 'अवधारणाओं,': 1, 'छलनाओं-प्रपंचनाओं,': 2, 'अंजाना': 7, \"'भावनाओं\": 1, 'इंटरसेल': 3, 'थानाअंतर्गत': 1, 'महिलाऐं': 9, 'संख्याएं,': 1, 'इंटरेस्ट,': 1, 'डिस्काउंट,': 2, 'आईं:': 1, '(एमएंडएम)': 1, 'एएंड9': 1, 'इंतकाल,': 1, 'अंदेर्सन': 1, 'अंतर’': 1, 'उपमाओं': 10, '(एमएंडआर)': 1, 'एंगरी': 7, 'इंगलैंड-': 1, 'इंफेक्टेड': 3, 'एंजलिस।': 1, 'सुविधआओं': 1, 'इंस्टिट्यूट,': 3, 'आंखंे': 2, 'निरंकुशताएं': 1, 'न्यूट्रिएंट्स': 3, 'ऐंटि-ऑक्सिडेंट': 3, 'पुण्यात्माओं': 4, 'साधनाएं': 5, 'टिशुओं': 2, 'राजाओं-महाराजाओं-सामंतों': 2, 'लिटाएं': 2, 'ब्लाइंट': 1, 'परिसेवाएं': 1, 'अंडा-मांस-मछली': 1, 'कर्मशालाओं': 1, 'एम.एच.अंसारी': 1, 'कराएंगी': 1, 'दिलवाएंगे।': 2, 'पाऊंगा’': 1, 'अभियन्ताओं': 1, 'पीड़ाओं': 3, '(अंडाकार)': 1, 'आइंदा': 9, 'डॉ.आंबेडकर': 1, 'वस्तुआें': 2, 'पाएंगें।': 1, '(रिज्वाइंडर)': 1, 'मलालाएं': 2, 'इंटेक्स': 1, 'इंफिनिटी': 1, \"इंडिपेंडेंट'\": 2, 'अंजाब': 1, 'बीएंडके': 2, \"एंजलो'\": 1, 'इंडो-तिब्बत': 2, 'इंडीज,': 3, 'अंग्रेज़ों': 38, 'अंग्रेजी।': 2, 'पहुचाएंगे।': 1, 'महिलाओं)': 1, 'इंटेक': 3, 'आंकेगी।': 1, 'अंवेषण': 2, 'एंड्रॉयड4': 1, 'इंफ्लेमेटरी': 1, 'इंस्टिट््यूट': 1, 'निभाऊंगा।': 1, 'जाओं': 7, 'जाएंगे।जिन': 1, 'इंतजाम.': 1, 'कराएंगे..': 1, 'एंबियंस': 3, 'बंधुओं,': 3, 'इंटेलीजेंस,': 1, 'ऐंबैसी': 1, '‘गुआंगमिंग': 1, 'इंटरसिटी,': 1, 'स्थापनाएं': 7, 'जाऐंगे': 1, 'सीएंडडीएस': 1, 'औपचरिकताएं': 1, 'इंतज़ार': 119, \"'इंटरक्लिक'\": 1, 'ऊँच-नीच': 12, 'महत्\\u200dवाकांक्षाओं': 2, 'है.अंतरबैंक': 1, 'ऋचाएं,': 1, 'खोएंगे।': 1, 'भगाएंगे।': 1, 'दुआंगानोंग': 1, 'एंटोनिया': 3, 'साजिशकत्र्ताओं': 1, 'क्रूरताओं': 4, 'भुइंया': 1, 'अंतरातारकीय': 2, 'औंकरलाल': 1, 'जुगनुओं,': 1, '(अंडररिकवरी)': 1, 'काउंंिसल': 1, 'अधिसूचनाएं': 2, 'इंटैग्रल': 1, 'इंद्रजीतसिंह': 1, 'इंजीनियंरिंग': 2, 'इंटेस्टाइन,': 1, 'फ्लाईओेवर': 1, 'इंडिया’,': 6, 'बताऊंगा।': 5, 'पकाएं,': 1, 'सबइंस्पेक्टरों': 3, '(परियोजनाएं)': 1, 'कष्ट-पीड़ाओं': 1, \"'अंगदान\": 1, 'इच्छाएं,': 4, 'अंदाज-2003': 1, '‘अंधेरे': 4, 'लिएंड्रो': 1, 'आंबटन': 2, 'आएंगे:': 1, 'अंडरपैंट्स': 1, 'छात्राएं,': 1, 'बो.एंडरसन': 1, 'प्रखंड-अंचल': 1, 'सिखाएं.': 1, 'अांत्रशोथ': 1, 'आाोश': 1, 'बीएंड': 1, 'इंफ्रा,': 2, 'इंटरप्राईस': 1, 'एंटीजेल': 1, 'इंजीयरिंग': 1, 'मिलाऊंगा': 1, 'वैस्टइंडीज': 4, 'एंटरनेनमेंट': 1, 'होना,आंखों': 1, 'कम्बाइंस': 1, 'अंडरगार्मेंट': 1, 'इंटरेंस': 1, 'कंपाउंडर,': 1, 'एंतोनेता': 1, 'इंटिग्रल': 1, '(महिलाओं': 1, 'अंतविर्रोध': 2, 'अंतविर्रोधों': 2, 'टीएंडई': 1, 'गाएं.': 1, 'गाएंगे': 3, 'गाएंगे.': 2, 'पाएं!': 2, 'लहराएं': 1, '‘अंदाज’,‘दाग’,‘फुटपाथ’,‘देवदास’,‘मुगल-ए-आजम’,‘गंगा': 1, 'संववाददाताओं': 1, \"'इंटरेस्ट\": 2, 'एंजलिया': 1, 'एंडाला': 1, 'करवाएंगे,': 2, 'नुमाइंदों,': 2, 'इंटरकोर्स': 1, 'इंजीनियर-इन-चीफ': 1, 'करवाईं।': 2, 'पिएं,': 4, 'ऊंच-नीच,': 4, \"बनाएं।'\": 1, 'लाऊं,': 4, 'जाएंगे.’’': 2, '(साइंटिस्ट': 1, 'एंटन,': 1, 'इंस्पिरेशन?': 1, 'अंतरसंबंधों': 1, 'एंटी-क्लॉक': 1, 'आंसू’': 1, 'एंटीबायोटिक.': 1, 'दाउंने,': 1, 'पाठशालाएं-मदरसे': 1, 'एंग्लिकन': 2, 'ऊँकार': 2, 'हटवाएं': 1, 'आउंगा.’’': 1, 'अंतर्बाधा)-': 1, 'सीमाबद्धताओं': 1, 'लाउंड्रिंग': 1, 'कर्ताओं': 20, 'पूजाएं': 2, 'एंटनी।': 1, 'वर्जनाएं,': 1, 'वंचनाएं,': 1, 'इंस्ट्रूमेंट': 4, 'नो-एंट्री': 1, 'इंवॉल्व': 1, 'इंजीनियर...नासा': 1, 'महानताओं': 1, 'गिराएं': 1, 'ब्रिलिएंट': 3, 'धोएं,': 5, 'व्यूइंग': 1, 'इंज्यूरी': 1, 'अंडररेटेड': 2, 'अपहर्ताओं-': 1, 'चक्षुओं': 4, 'एमऐंडएम,': 1, 'एलऐंडटी,': 1, 'अंगारीवाड़ा': 1, 'जाएंगे;': 1, 'हटाऊं': 1, 'प्रतिकियाएं': 1, 'शोधकत्र्ताओं': 3, 'मनाएं': 15, 'राष्ट्र-निर्माताओं': 2, 'अंतु': 1, 'अंडरलाइन': 1, 'बिज्जुओं': 1, 'अंजीर,': 1, 'संत-महात्माओं': 4, 'इंरनेशनल': 1, \"'अंधेरीचा\": 1, '(फ्लाइंग': 1, 'बनाईं।': 4, 'मेंआंदोलन': 1, 'आंख”': 1, 'मंशाओं': 6, 'रेस्तराओं': 5, 'र्इंट': 2, \"परीक्षाएं?'\": 1, 'अंतर्धारा': 7, 'चिंताओं,': 2, 'इंसाफ।': 2, 'सोईं': 2, 'कमाएंगी।': 1, 'इंदियों': 1, 'ममगाईं': 1, 'बचाएंगे।': 3, 'अंधभक्त': 3, 'ऐंगलीन': 1, 'करवाऊं': 4, 'फेमकाउंट': 5, 'काउंटियों': 1, 'इंडस्\\u200dट्री': 4, 'हिंदुओं-सिखों': 1, 'इंदुरानी': 2, 'शकाओं': 1, \"'साउंडट्रैक'\": 1, \"इंवेस्टिगेशन'\": 1, 'कहा-अंकल': 1, 'इंफ्लुएंस': 2, 'एंड्रियू': 1, 'बाध्याताओं': 1, 'पहुंचाऊंगा': 3, 'एंजर्स': 1, 'इंस्टैट': 1, 'ई-फआंर्म': 1, 'मतदाताआेे': 1, 'ऊंट,': 5, 'साइंटिफिकली': 1, 'अवधारणाएं': 10, 'अंशू': 1, 'इंटेलेक्चुएल': 2, 'योजनाओं/कार्यक्रमों': 1, 'भाषणकत्र्ताओं': 1, 'दखलअंदाजी,': 2, 'सेंगाओंकार': 1, 'अनाउंसमेंट': 4, 'ऐं,': 1, 'एंटि-ऑक्सिडेंट': 1, 'अंजलाबीन': 1, 'बताऊंगा।’': 3, 'इंकलाबी।': 1, \"इंटरव्यू'\": 2, 'इंटेंट,': 1, 'उठाऊंगी।': 1, 'बढ़ाईं': 1, 'इंडिकेटर': 1, 'सुनाऊं?': 1, 'अंडाकोष': 1, 'आईपीआरओ.इंडिया': 1, 'अंतर.सरकारी': 1, 'प्राथमिकताएं’': 1, 'एंजिलिना': 2, 'इंतज़ाम': 39, 'अंतिम-अंतिम': 2, 'गैस्ट्रोएंट्रोलॉजिस्ट': 1, 'कार्यकर्ताएं': 1, 'ईंट-मिट्टी': 1, \"दोहराएं।'\": 1, 'मुआ़.़.़.!’': 1, 'सुविधाएँ': 44, 'इंसेप्शन': 1, 'अंकवार': 2, \"बढ़ाऊंगा।'\": 1, '-इंडियन': 2, 'बंटवाएं।': 1, 'ड्रॉइंग-रूम': 1, 'आस्थाएं': 8, 'अर्थव्यवस्थाएं,': 1, 'लोग,काउंटर': 1, '(इंग्लैंड': 2, 'कंप्यूटर-इंटरनेट': 1, 'लोकगाथाएं': 1, 'इंद्रपूजा': 1, 'बजाएंगे।': 3, 'अंश...': 1, '(इंजन': 1, 'सोऊंगा।': 1, 'अंझी': 1, 'इंजंस': 1, 'कूपंसकोडइंडियाडॉटनेट': 1, 'एनाउंसर': 2, 'खाऊंगा।': 3, 'आंडरिला': 1, '(इंडोनेशिया,': 1, 'आॅटोरिक्शा': 1, 'काउंसि,': 1, 'अंशकालीनों': 1, 'अंग्रेजों,': 4, 'उठाएं.': 3, 'एंबुलेंस,': 1, 'जन-आंदोलनकारियों': 2, 'इंद्रियां,': 1, 'इंडियाबुल्स': 2, 'माउंटेन्स': 1, 'अंजुना': 2, 'एंटी-इन्कंबेंसी': 1, 'उूर्जा,': 1, 'अंतरिक्ष,': 3, 'उंखलिया': 2, 'को.एंड': 1, 'बेसधातुओं': 1, 'हिंदुओं,': 1, '(अंधेरे': 1, 'अलाउंस,': 1, 'एंजिलिक': 1, 'चाचाओं': 6, \"इंटरटेनमेंट'\": 1, 'अंधेरा?': 1, 'रेस्तराओं,': 1, 'आत्म-हत्याएं': 2, \"इंजीनियरिंग'\": 1, \"अंपायर'\": 1, 'अंवधारणा': 1, 'इंग्रिडेंट': 1, 'आंतरिक-': 1, 'इंडिकस': 3, 'नेकलाइंस': 2, 'अंगरेज,': 1, 'अंशदानों': 1, 'बेंगलुरु.लिएंडर': 1, 'अकाउंटों': 2, 'इंटरनेट-बैंकिंग': 1, 'एंगा': 1, 'उठाउंगा.': 1, 'मेहताओं': 1, \"इंडियन'\": 2, 'इंजतामों': 2, 'अंत:वस्त्रों': 1, 'फलाएं': 1, 'आऐंगे.': 2, 'घुमाएं,': 1, 'पढ़ाएंगे?': 1, 'आउंगी.': 2, 'दिखाएं,': 4, 'अंचु': 1, 'ओएंनजीसी': 1, 'गोसाईं': 5, 'ऊंच्चाई': 1, 'अंवश्य': 1, 'एंबूलेंस': 2, 'इंटेलेक्चुअल': 7, 'एंग्लो-इंडियन': 8, 'भिजवाएंगे': 1, 'अकाउंट्स,': 1, 'पादुकाएं': 3, 'एकाउंटेबिलिटी': 2, 'इंद्रिय-सुख': 1, 'इंडियारिजल्ट्स.कॉम,': 1, 'इंटीग्रेशन': 1, 'मुड़वाऊंगी.': 1, 'संभावनाएं,': 2, 'अंतर’,': 1, 'निभाएंगी,': 2, 'मैकइंटायरी': 1, 'कोरिएंडर': 1, 'बुलाएं': 4, 'करवाएं,': 2, 'कटिबद्धताएं': 1, 'इंद्रबीर': 1, 'इंजीनियरिंग-कृषि।': 1, 'कम्पाउंडर': 1, 'तंतुओं': 11, 'इंका.': 1, 'भुइंया,': 1, 'ऐँड': 1, 'दोहराऊंगी.': 1, '(वीकएंड': 1, 'इंसेटिव': 1, 'बसाएंगे,': 2, 'एंंडरसन': 1, 'भिजवाएं।': 3, 'आईंसटाइन,': 1, 'आईंस्टाइन': 1, 'संहिताओं': 6, 'पाएंगी,': 4, 'अंडरएचीवर': 1, '‘महिलाएं:': 1, 'एंटरप्राईजेज': 1, 'मिलवाएं.': 1, 'अंतरराष्ट्रीय,': 1, 'परम्पराएं,': 2, \"'इंग्लिया\": 1, 'एकाउंटस': 1, 'धोएं': 3, 'आंसू-': 1, 'पत्निओं': 1, 'इंडिया-पाक': 1, 'आकार-अंग': 1, 'मनाउंगा।': 1, 'बधाईः': 1, 'एंटीबायेटिक': 1, 'है.’’इंग्लैंड': 1, 'इंफ्रास्टक्चर': 1, 'इंफेंट्री': 2, 'घुमाएं': 2, 'अंगे्रजों': 5, 'प्रयोगशालाएं,': 1, 'इंडिया.कॉम': 2, 'हैं.आंकड़ों': 1, 'इंटरब्यू': 1, 'इंटेशन': 2, 'जाएंज्जे': 1, 'इंफोकॉम': 1, 'अंतर्विकास': 1, 'इंजन.': 1, 'अंपानी': 1, 'ऐंजलिना': 1, 'टिकाएं।': 3, 'आंक.डे': 1, 'काउंसेलरों': 1, 'थेइंद्रकांत': 1, 'लाउंड्री’': 1, 'मतदाताओं,': 3, 'अंतर्राट्रीय': 1, 'जाउं': 10, 'एंड्रे': 1, 'निभाएंगी': 1, 'इंटीरियर,': 2, 'अांकड़ों': 1, '‘रचनाओं’': 1, '‘रचनाएं’': 1, '91.55अंक': 1, '5727.45अंक': 1, 'इंडोक्रायोनोलॉजी': 1, 'एंड्रयूज': 2, 'सम्मस्याओं': 1, 'ऊंचायी': 1, '‘इंटरेस्टिंग': 1, 'मंगवाएंगे।': 1, '(आंदोलन': 1, 'अंतरराष्ट्र्रीय': 1, '5.10अंक': 1, 'अंत:स्त्रवी': 1, 'कुअंर': 2, 'ओंटारिया': 1, 'इंस्तांबुल': 1, \"''इंडिया\": 2, 'इंट्रोवर्ट्स': 1, 'इंश्योरेंस)': 1, 'एसऐंडपी': 1, 'चाईं': 2, 'आॅर्गनाईजेशन': 1, 'समझाऊं?': 1, 'आॅस्ट्रेलिया': 1, 'ए़जी': 1, 'इंग्लैंडःएलिस्टेयर': 1, 'एंडरसन.': 1, 'एंजलिस:': 1, 'एंजिलस': 1, 'ऐंकलेट्स': 1, '-इंडिया': 1, 'टे.एंड': 1, '(ऊंट': 1, 'ऊंकारसिंह': 1, 'महत्त्वाकांक्षाएं': 3, \"हैं।'महिलाओं\": 1, 'रचाएंगे।': 2, 'नहाएंगे।': 1, 'बिताएंगे': 2, 'एंक्लेव,': 1, 'क्रुईंगला': 2, 'धोएं.': 2, 'भक्ताओं': 2, 'इंटनेशनल': 2, 'अंताफ,': 1, 'सिखाऊं.': 1, 'इंग्लैंड.एक': 1, 'इंडॉमेंट': 1, '‘‘आंटी': 1, 'एंजलिस': 2, '‘ममताओं’': 1, \"'छात्र-छात्राओं\": 1, \"'अंडररेटेड'\": 1, 'महुओं': 2, 'एंथ्रोपोलॉजिस्ट': 1, 'इंवेस्टीगेशन’': 1, \"हराऊंगी।'\": 1, 'साधनाओं': 8, 'तंत्रिकाएं': 2, \"लड़ाऊं'\": 1, 'हाउस-इंजीनियर': 1, 'चढाएं।': 1, 'हाइपर-ऐंड्रोजिनिज्म': 1, '(सूचनाओं)': 1, 'लाऊंगा': 3, 'आंएगे।': 2, 'धुआं-धुआं': 2, 'अवैधताओं': 1, 'सीखाएं': 1, 'इंसिपिरेशन': 1, 'अंपायर:-': 1, 'सुलझार्इं': 1, 'जिओसाइंस': 1, 'अंगुलिकाएं': 2, 'आऊंगी,': 2, 'कीआंतरिक': 1, 'इंग्लिशमाउंट': 2, 'फाइंड': 2, 'मैनकाइंड': 1, 'अंजार': 1, \"बताऊं।'\": 1, 'आएंंं।’’': 1, 'चिंताआें': 2, 'एंप्लॉयर्स': 2, 'धराओं': 1, 'चुनाओं': 3, 'इंपोर्टेंट': 3, 'मिलाएं.': 1, 'इंटैग्रिटी': 1, 'नहाएं': 5, 'गुआंजली': 1, 'नियंताओं': 3, 'इंद्रोका': 1, 'राउंड्स': 1, 'परियोजनाओं’’': 1, 'अंतर्राश्ट्रीय': 2, 'इन्फेसिस.एलएंडटी,': 1, 'लगाएंगी': 1, '(इच्छाओं': 1, '‘संभावनाओं’': 1, \"ठुकराएंगी।'\": 1, 'बताउंगा.’’घोष': 1, 'एंट्री:': 1, 'आउटगोइंग': 2, 'बोरोइंग': 1, 'अंक-3': 1, 'यात्राओं,': 1, 'फूलमालाएं,': 1, '(अंगों)': 1, 'बिछाएं,': 1, 'भावनाओं...': 1, 'इंदरमल': 1, 'माइंड्स': 1, 'पार्इं!': 1, 'व्याख्याओं': 15, 'सुविधाएॅ': 1, 'इंफर्मोशन': 1, 'चाहिएं,अन्यथा': 1, 'अंतरानुशासनिकता': 1, 'बताऊंगा.': 4, 'चलाईं,': 1, 'एंटीबैक्टीरियल': 1, 'एंटीफंगल': 1, '-महिलाएं': 1, 'एंकरेज': 1, 'ऐंटिकरप्शन': 2, 'इंडोकॉन': 1, 'निभाएंगे,': 3, '‘यूएस-इंडिया': 1, 'बनाएंगे.': 2, 'इंकार।': 1, 'प्रौद्योगिकी-महिलाओं': 1, 'सिखाएं..': 1, 'एंज्वाय': 3, '‘‘अंदाजा': 1, '‘‘अंतिम': 1, 'लालसाएं': 5, 'कराईं': 1, 'टाइम-बाउंड': 1, 'संभावनाएँ': 4, 'आंद्रेया': 1, 'वेरिएंट,': 1, 'अंकल्स': 1, 'अंडो': 5, 'महिलाओंं': 1, 'परित्यक्ताओं': 1, ',विधवाओं': 1, 'विचित्रताओं': 1, 'घटनाएं।': 2, 'चुकाएं': 2, 'पाऊंगी,': 2, 'लाऊं।’': 1, 'लगवाएं': 1, 'प्रथाओं,': 1, \"'माइंडगेम'\": 1, 'एंग्लांइडियन': 1, 'एंगलोइडियन': 1, 'एगंलोइंडियन': 1, 'अंगदानी': 1, 'मचाएंगी।': 1, 'पुरूष्ा-महिलाएं': 1, 'कार्यक्षमताओं': 2, 'योजनाएंर्': 1, 'कंसाइंमेंट': 1, '‘इंटरप्रोनोयर’': 1, 'नहाएं,': 1, 'हैरअंगेज': 1, 'उलझाएं।': 1, 'महाविद्याओं': 7, 'विडंबनाओं,': 1, 'आकांक्षाओं,': 2, 'डिजाइंड,': 1, 'बढ़ाऊंगा': 2, 'इंटू': 2, 'न्यूट्राइंट्स': 1, 'धातुओं,': 2, 'समीक्षाओं': 7, 'इंटरनेशलन': 2, 'कॉउंसिल': 1, \"'मास्टरमाइंड'\": 1, 'अंदोलन': 3, 'एंगवांत': 1, 'धुआं।': 1, \"इंपैक्ट'\": 1, '‘इं': 1, 'ुईंया': 1, 'इंगितों': 2, 'प्वाइंट)': 2, '‘बिरला-टाटा-अंबानी-बाटा’': 1, 'अंगादी': 1, 'इंडंस्ट्रीज,': 1, 'आॅस्ट्रेलियन’': 1, 'आॅस्ट्रेलियाई': 1, \"'इंटेलिजेंट\": 1, 'पॉइँट्स': 1, 'अंतमें': 3, 'अंतर-धर्म': 2, 'अध्यापक/अध्यापिकाएं': 1, '(इंद्रपुरी': 1, '(इंद्रपुरी,': 1, 'शर्माएंगे': 1, 'कुईं,': 1, 'अंसारा,': 1, 'संचिकाओं': 1, 'इंडिविजुअल्स': 1, 'इंग्रीडिएंट्स-': 2, \"क्रिकइंफो'\": 1, 'चुआं': 1, 'लखनऊ,मेरठ,इंदौर': 1, 'देवाताओं': 1, 'संवेदनाएं,': 3, 'बाऊंस': 2, 'इंजीनयरिंग': 2, 'इंडेम्निटी': 1, 'अंतरबैंकिंग': 1, 'निर्माणकर्ताओं': 4, 'गाएं-': 1, \"कराएंगे।'\": 1, 'राजनेताओं-राजनीति': 1, '‘अंगार’,': 1, 'अंचू': 1, 'दुविधाएं,': 1, 'कॉपीइंग,': 1, 'सिखाऊंगा,': 1, \"सिखाऊंगा।'\": 1, 'इंटरव्यू?': 1, 'नहाएं।': 3, 'लाऊंगा।': 5, 'मुर्गा.’अंगरेजी': 1, 'जाएं।’': 7, 'अंक।': 5, 'आईंना:': 2, 'ऑटोइंफोज': 1, 'धर्मगुुरूओं': 1, 'काउंसलिंग।': 1, 'बताएंगे.': 1, '\"युवाओं': 1, 'आॅरगेनाइजेशन': 1, 'नकारात्मकताओं': 1, 'भावनाएं,': 6, 'टिकाएं': 2, 'एंतोने': 1, 'वेस्याएं': 1, 'पैराग्लाइंडिंग': 1, 'लिखवाएं।': 1, 'माउंग': 1, 'फैशनएंडयूडॉटकॉम,': 1, 'ओंगबुमरुंगपान': 1, 'वीकएंड्स': 1, 'इंजन्स': 1, 'जीवजन्तुओं': 1, \"'अंडरस्टैंड\": 1, 'नेताआं': 1, 'अंधविश्वास,': 7, 'इंजीनियङ्क्षरग': 1, 'अंडरस्टैंडिग': 2, 'पटुओं': 1, 'इंस्टीट्यूअ': 1, 'खाएँ।': 1, 'मैकइंटोश': 1, 'लगाऊं': 11, 'बढ़ाऊं?': 1, 'इंप्लाइमेंट': 1, 'जोनुन्तलुआंगा': 1, 'राउंड.': 1, 'अंदरुण': 1, 'ऊंघते': 2, 'एंडूय': 1, 'कलाएं,': 2, 'अंदाजे-बयां': 1, '‘अलाएंस': 1, 'इंसाफ’': 1, 'रिफाइंड,': 2, 'बताऊं!': 2, 'विशेषताएं-': 1, 'दवाओं)': 1, \"'निर्माताओं\": 1, 'दिलाएंगे,': 2, 'अंडरगारमेंट': 3, 'कार्यकर्त्ताओं': 10, 'स्व-घोषणाओं': 1, 'ईपीएफइंडिया': 1, 'डिपूओं': 1, 'अंबली': 1, 'मिलीएंपियर': 1, 'उलेमाओं': 2, 'दुर्गाओं': 1, 'इंटैक': 1, 'जटिलताएं,': 1, 'बढ़ाएंगी': 4, 'कतराएं।': 1, 'दस्तावेज-योजनाएं,': 1, 'इंडरव्यू': 1, 'भिगोएं।': 1, 'इंस्टेंट-ऑन': 1, 'श्रधालुओं': 1, 'इंटरव्यूह': 2, \"'उंगली'\": 1, 'बनाएंगे।कांग्रेस': 1, 'इंसाक': 1, 'उंठे': 1, 'उठाउंगा.’’': 1, 'ङ्क्षचताओं': 1, '‘आंखों': 3, 'अध्यापक-अध्यापिकाओं': 1, 'चलाऊंगा।': 2, 'एस.डी.ओं': 1, 'अमाउंट्स': 2, 'इंफोर्मेशन': 2, 'अांखों': 1, 'मनाएंगे,': 1, 'एंडर्स': 2, 'खिलाएंगी.': 1, \"दिखाएंगे।'\": 1, 'वैलेंटाइंस': 3, 'अंडरस्र्टैड': 1, 'आंदोलन)': 2, 'अंतरधार्मिक': 1, 'एंजेलिका.': 1, 'कार्यकर्तांओं': 1, 'नौसेनाएं': 1, '-इंटरव्यू': 1, 'एकाउंट,': 1, 'अंदाज़ा': 26, 'आंशिका': 1, 'अंकारा:': 1, 'करकेइंग्लैंड': 1, 'रंजन(साउंड)': 1, 'इंकर': 1, 'सुविधाएं।': 2, 'दिलाएं,': 1, 'चट्ढाओं': 1, 'इंट्रोडच्यूस': 1, 'नीज...एंड': 1, 'बैक...एंड': 1, 'माइंड।': 1, 'उठाएं?': 2, 'इंगलैण्ड': 17, 'युआनजिआंग': 1, 'खटखटाएंगे': 1, '192.08अंकों': 1, '(एचएसईं)': 1, 'संप्रभुताओं': 1, 'राष्ट्रीयताओं': 4, 'संप्रभुताएं-राष्ट्रीयताएं': 2, 'संप्रभुताओं-राष्ट्रीयताओं': 2, '‘एंटी-सेक्युलरिस्ट': 1, \"खाएं।'\": 1, 'आजमाएं.': 3, 'फ्राइंगपैन': 1, 'बुलाएं,': 1, \"'ऊँ'\": 5, 'अंकारा।': 1, \"'इंट्रा-कम्पनी\": 1, 'अंगवस्त्र,': 2, 'शाखाएँ': 13, 'इंजीनीयर': 2, 'एप्लाएंसेज': 1, 'आंगड़ापोता': 1, 'गाएंगे।': 1, 'अंग-प्रत्यंग': 3, 'बिलबाओः': 1, 'आंगनबॉड़ी': 2, 'शिलाएं': 2, 'ईंधनों': 2, 'ऊंगलियां': 5, 'रचनाओं,': 2, 'कविताओं,': 4, 'एंपियन': 1, \"आएंगी।'\": 2, 'बढ़ाईं।': 1, 'प्राथमिकताएं/': 1, 'आरेजाउू': 1, 'अंग्रेजसिंह,': 1, 'अंधियारे': 13, 'दिलाएंगी': 1, '-काउंटरों': 1, 'इंपार्टेट': 1, 'इंटरमेडिएट': 1, 'गुड़ियाओं': 1, 'एक्सपीरिएंस)': 1, 'दिखाएं.': 4, 'बाउंम': 1, 'इंट्रा-डे': 2, 'डुबोएं।': 1, 'अराजकताओं': 2, '‘परंपराओं': 1, 'गणेश-अंबिका': 1, 'तटरेखाओं': 1, '‘‘अंकल': 1, 'कराऊंगी।': 1, 'समझाएं.': 1, 'दादाओं': 6, 'कोल्हूओं': 1, 'बनाऊंगा,': 3, 'चटकाऊंगा।': 1, 'अंसभव': 1, 'फरमाएं।': 1, 'इंजीनियरिंग-': 1, 'धुआं,': 3, 'अंतीम': 1, 'फाइंडिंग्स': 1, 'आाम': 1, 'इंटरटेनमेंट,': 2, 'इंटरप्राइजेस': 1, 'इंडो-जापान': 1, 'सोएं': 7, 'इंडस्ट्रीयल,': 1, 'बनाउंगा': 1, 'हिंदूओं': 4, 'साइनो-इंडियन': 1, 'अंर्तराष्ट्रीय': 3, 'उठाएंगी,': 1, 'भाषाओं-संस्कृतियों': 1, 'एंब्रोज': 2, 'अंजूसिंह': 1, 'अभियोक्ताओं': 2, '(इंस्पेक्टर': 1, 'एंस्च': 1, 'जगाएं।': 1, 'आॅडिटोरियम': 1, '‘अंकुर’': 1, 'लाउंज,': 3, 'एंड-शॉपिंग': 1, 'दिखाएंगी': 1, 'ओंकोलाजी': 1, 'इंटरनेट,फोन,कैमरा': 1, 'बताएंगे।’’': 1, 'इंटल': 4, 'लगवाएंगे।': 2, 'गुनगुनाएंगे': 1, 'इंक्युबेटर': 4, 'भावनाएँ': 11, 'आएंगे,उन': 1, 'साइंस),': 1, 'तुलनाओं': 1, 'एंजल्सि': 1, 'तंत्रिकाओं': 4, 'इमरानाएं': 1, 'गुड़ियाएं': 1, 'लाएंगी?': 1, 'घटाएं-': 1, 'पीएंगे।': 1, 'एमऐंडएम': 1, 'आंखिन': 2, 'फूलमालाएं': 1, 'उंडेल': 7, 'मुल्लाओं': 6, 'चबाएं': 3, '-छात्रओं': 1, 'ऐंकरिंग': 1, 'मनोरंजनकत्र्ताओं': 1, \"'एंड\": 2, \"'इंस्टेंट'\": 1, 'ऐंटिटेररिस्ट': 1, \"दबाएं।'\": 1, 'इंद्रभूषण': 1, 'अप्सराओं': 9, '‘अंगूरी’': 1, 'इंटैलिजेंस': 1, '5635.90अंक': 1, '6663.34अंक': 1, 'एंबिट': 1, 'अॢवडसन': 1, 'अंकलेश्वर,': 1, 'बखनाओं': 1, 'नेताओं-ठेकेदारों': 1, 'इंटरमिनिस्टिरिअल': 1, 'झुलाएं।': 1, 'आलूओं': 1, 'एप्लाइंसेज:': 1, 'एफिशिएंसी)द्वारा': 1, 'गुफाएं,': 3, 'इंडिकेटर,': 1, 'इंका': 6, 'ञ्चअंतरराष्ट्रीय': 1, 'सीमाओं,': 2, 'ईंट-पत्थरों': 2, 'अंकेश': 1, 'कूएं': 1, 'छुड़ाएं।': 2, 'इंतजाम।': 3, 'आंबडेकर': 1, 'एंप्लॉयड': 2, 'करवाएं।\\x10': 1, 'दारोगा-इंस्पेक्टर': 2, 'बरसाईं.': 1, 'क्लाइंटों': 2, 'परियोजनाओं,': 3, 'इंटरवेन्शन': 1, 'फ्राइंग': 2, 'गाऊंगी.': 1, \"'अंधेरी\": 1, '‘ईंट': 1, 'लौटाएंगे।': 1, '-इंटक,': 1, \"'बैंकग्राउंड\": 1, 'क्वाइंट': 1, '-अंतर': 2, 'नगरपालिकाएं': 1, 'पत्र-पत्रिकाएं,': 1, 'एंजिल्स।': 1, 'हिंदी-अंगरेजी': 2, 'इंफोर्मेक्टिस,': 1, 'अंतरंग,': 1, 'अंत:संघटन': 1, 'करवाएंगी,': 1, 'आऊंगा,': 6, 'मंत्रियों-अंजली': 1, 'आॅपरेटर)': 1, '‘बाउंडिंग': 1, 'विधाएं)': 1, 'इच्\\u200dछाओं': 3, 'सूक्ष्मताओं': 1, 'हिंसाओं': 1, 'अंकाें': 1, 'स्थापनाओं': 8, '‘काउंसिल': 1, 'है.अंधेरे': 1, 'अप्वॉइंट': 1, 'हैरतअंगेज,': 1, 'बुलीइंग': 1, 'राय,अंचलाधिकारी': 1, '(टीएंडएफएस)': 1, 'वाउंस': 1, 'बैटलग्राउंड': 1, 'याओं': 2, 'बढ़ाएं.': 1, 'इंटरर्नशिप': 1, 'प्रशाखाओं': 4, '-आंखें': 1, 'इंसानियत,': 7, 'पाऊंगा?': 4, 'सराउंड': 1, 'अंजमुन': 1, 'अंजमन': 1, 'अंजुमनों': 1, 'अंगे्रजी': 4, '‘आॅर्गनाइजर’': 1, 'सुविधएं': 3, 'ईंट-भट्टा': 2, 'श्रद्धालओं': 1, 'अंतर्विरोध,': 4, 'आंगनवाड़ी': 2, 'दोहराएं.': 1, 'पहनाएंगी।': 1, 'पाइंट्स’': 1, 'प्वाएंट': 1, 'अंदेशा।': 1, 'अंधासुर': 1, \"'अंधेरा\": 2, 'इंटरवेंशनल': 1, \"'अंबेडकर\": 1, 'हिंदी-अंग्रेजी': 3, 'तमन्नाओं': 4, 'देवास-एंट्रिक्स': 2, 'इंजीनियिरग': 1, 'छात्र-छात्रएं': 1, 'सताएंगी।': 1, 'खुदाओं': 3, '(कविताएं),': 1, 'इंजीनियरिंग-अमेरिका।': 1, 'अंबाजी': 1, 'इंकलाइन': 1, 'इंगट': 2, 'अंगरेजियत': 1, 'जलाईं': 1, 'सक्रियताओं': 5, 'इंटरलाकिंग,': 1, 'इंफैंट्री': 2, 'एंटीकार्सिनोजेनिक': 1, 'आमसभाएं': 1, 'सांत्वनाएं': 1, 'वेदनाओं': 5, 'एंटिक': 4, 'भारत..इंग्लैंड': 1, 'मादाओं': 3, 'अंबाला।।': 1, 'इंद्रकांत,': 1, 'अंदाज.': 1, 'अंदाज़ा': 26, \"'एंट्रिक्स-देवास\": 1, 'खुला।अंदर': 1, 'अंदर!': 1, 'इंडसइंड': 4, 'अंगाड़ी': 2, 'इंजीनियर्स)': 1, 'इंवेन्चर': 1, 'अंत:प्रवाह': 1, 'इंफ्लेशन': 4, 'दुघर्टनाओं': 1, 'टीजोएंग': 1, 'एंबिशस': 1, \"महिलाओं'\": 1, 'इंफाल-': 1, 'इंफाल-जिरिबाम-सिल्चर': 1, '(तकनीकी/पीएंडडी)': 1, '(तकनीकी/आरडीएंडटी)': 1, 'दिखाएंगी,': 1, 'अपेक्षाएं.': 1, \"'इंडिया'\": 1, 'इंटरटेनमेंट’': 1, 'अंतर)': 1, '(इंडोनेशिया):': 1, 'अंडरटोन': 2, 'इंटरप्रिटेशन': 2, '(इंटरसेल)': 1, 'अंडर-137': 1, 'च्वीइंगम': 1, 'र्ताओं': 1, 'जमाएं,': 1, 'इंडेक्स‘': 1, 'शुभाकामनाएं': 1, 'अभियंताओं)': 1, 'गुफाएं।': 1, 'इंडो-कैनेडियन': 1, 'लाइफसाइंस': 1, 'ऊंचागांव,': 1, 'लगाएं।जब': 1, 'जन-प्रक्रियाएं': 1, 'इंडिया:-': 1, 'सब-इंजीनियर': 3, 'ऐंबुलेंस': 1, 'वधुओं': 1, 'बुलाईं।': 1, 'दोहराऊंगा।': 1, 'लड़खड़ाऊंगा': 1, \"'परंपराएं\": 1, 'इंपीरियल': 3, 'इंडिका,': 1, 'एंटीऑक्सीडेंट्स': 2, 'डाइंग': 2, 'भारत-इंगलैण्ड': 1, 'अनाउंसर': 2, 'इंडिया(पीसीआई)': 1, 'सेल्फ-एंप्लॉयड': 1, 'अपनाएंगे.': 1, \"इंपासिबल'\": 1, 'अंिभलेखागार': 1, '-अंबिका': 1, 'हाउंड': 1, 'खननकर्ताओं': 2, 'बचाएंगी।': 2, 'गइ्र': 1, 'एंबेलिशमेंट': 1, 'दोहराएंगी': 1, 'दिलवाएंगे': 2, 'जीरीबाम-इंफाल': 1, 'कथाओं,': 3, 'इंडिया0.70': 1, 'घटनओं': 2, 'आंदोलन:': 2, 'चलाऊंगा': 3, 'इंट्रेंस': 4, 'विदेश-यात्राओं': 1, 'हुएं': 2, 'अकाऊंटिंग': 1, 'इंस्टैंट': 2, 'उा': 1, 'व्याख्यताओं': 1, 'दाउंदकर': 1, 'ऊंचाई--5.34': 1, \"'अंतरराष्ट्रीय\": 1, 'ऐंठे': 5, 'श.फ.ब.अंजुम,': 1, 'औार': 2, 'एंटीबायोटिक,': 2, 'भाषाओं,': 2, 'एंटार्कटिक': 1, 'जुटाएंगे।': 1, 'अंडरडॉग': 2, 'ऐंटि-एलजिर्क': 1, 'रीएंट्री': 1, '-छात्राएं': 1, 'अंबादास': 1, 'इंवेट्स': 1, 'फूल-मालाएं': 2, '‘लोकदेवताओं’': 1, 'आत्माओं’': 1, 'साहियाओं': 1, 'फ्लैओं': 1, 'पकाऊंगी': 1, 'उेरेन': 1, 'इंडिसेज': 1, \"'इंफोसिस\": 1, 'मल्लिकाओं': 1, 'इंडो-तिब्बतन': 1, 'अंजनी,': 1, 'उंडीमिशिया': 1, 'इंजेक्टेबल': 1, 'इंटरनैशनल)': 1, 'अंतरानुशासनिक': 1, 'अंत:दृष्टि': 1, 'अंका': 1, 'एंट्रिक्टस-देवास': 1, 'शुभकामनाएं....': 1, 'इंटरचेंज-छह': 2, 'कनफ्लूएंस': 1, 'एंटिनों': 1, 'चिंताएं?': 1, 'बाबाओं,': 4, 'गुरुओं,': 3, 'महागुरुओं,': 1, 'उलेमाओं-इमामों': 1, 'एमाउंट-': 1, 'इंस्टीटय़ूट': 2, 'एंटीबायटिक': 3, 'एयरलाइंस।': 1, 'साधानाएं': 1, 'अनिमियताताएं': 1, 'अंतरकलह': 2, 'लासएंजिलिस': 1, 'इंडियन,': 4, 'इंडो-': 2, 'पशुओं-पक्षियों': 1, 'दिखाएंगी.': 1, 'पहनाएंगी.': 1, 'अुनसार': 1, 'अंडरसहारे,': 1, 'सांईं': 4, 'मझिआंव': 1, 'अंग-भंग': 2, 'बनाउं.': 1, 'कल्पनाओं,': 6, 'अंंडरवर्ल्ड': 1, 'धुएँ': 22, 'अँधेरा’': 1, 'जाऊँ,': 15, 'डाकूओं': 2, 'श्रेष्ठताओं': 1, 'पवित्रताओं': 2, 'ऊँगली': 59, 'ड्राइंगरूम': 15, 'अंग-अंग': 22, \"कराएं'?\": 1, 'विचारधाराएँ;': 1, 'पल्लैऊं': 2, 'अँगरेज़': 6, 'चम्पूओं': 1, 'अंधों': 9, 'आत्मकथाओं': 15, 'पाउंगा।': 5, 'अंशु’': 1, 'छइंहा': 2, 'जाएँ,': 41, 'परियोजनाएँ': 2, 'जाऊँ': 72, 'औं': 2, 'आँखें': 645, 'आँसू': 191, 'आंधे': 2, 'जाऊँगा': 55, 'ऊँचे-पुरे': 1, 'आंदोलन-फांदोलन,हमारी': 1, 'समस्याएँ': 35, 'आएंगे?...': 1, 'ऊँचाई,': 1, 'अँधेरा': 141, 'जटाएँ': 2, 'कान्ग्रेसिओं': 5, 'अंशतः': 3, 'इंडो-ग्रीक,': 1, 'कुदशाओं': 1, 'कुआँ': 18, 'अदीबों,नेताओं,बुद्धिजीवियों,शोषकों': 1, 'समिधाएँ': 2, 'पिलाएं': 1, 'बचाएं,': 3, 'ऊंची-नीची': 5, 'त्रिउंड,': 1, 'कुएँ': 48, 'अंग्रेजो': 39, 'परेडग्राउंड': 1, 'होऊँगा,': 1, 'सुदार्श्नाओं': 1, 'फैन-फॉलोइंग': 1, 'उँगलियों': 63, 'गोईं': 2, 'दाएँ-बाँए': 1, 'जाऊँगी': 25, 'आएँ।': 5, 'अंतर्राश्टीय': 1, 'छुएं': 4, 'आंय-बांय-सांय': 1, 'औृ': 1, 'उँचाई': 2, 'आँच': 39, 'ऋतुएँ': 2, 'उँगली': 41, 'राजाओं,': 4, 'वर्गों-महिलाओं': 1, 'दिखाएंगे,': 1, 'दवाएं,': 2, 'आँपरेशन': 1, 'गई.अंगूठा': 1, 'म्याऊँ': 1, 'जाएँ.': 41, 'शोधकर्ताओँ': 1, 'अध्यापिकाएँ': 2, 'मजनुओं': 1, 'मनाउं': 2, 'अंजाम,': 2, 'ऊँजी': 1, 'ऊँठ': 2, 'जाएँ।': 46, 'चिल्लाएंगे।': 1, 'झुकाऊँगा': 1, 'भिगोएंगे।': 1, 'पहलूओं': 10, 'आँगन': 226, \"इंदिरा'।\": 1, 'घटानाओं': 1, 'एंशिएंट': 2, 'बताओं': 7, 'गंगाएं': 3, 'बड़बडाएं': 1, 'कराएँगे।': 1, 'आँखे': 123, 'जगाईं,': 1, 'जाएँ': 285, 'पहनाएंगे': 2, 'ऑंख': 13, 'अंगूठा,': 2, 'असफलताओं,': 1, 'दिखाएंगे.\"': 1, 'एंटिबायोटिक': 1, 'जाऊँ...’:': 1, 'आँचल': 133, 'साइंसदानों': 17, 'अँगूठियों': 1, 'ओैर': 19, 'अंगीठियां': 1, 'बहाएंगे।': 1, 'खुजाऊँ,': 1, 'खुजाऊँ।': 1, 'एंट्रोपी': 1, 'बिठाऊँ': 1, 'आंसू,हँसी,....': 1, 'साथीओं': 1, 'कुऍं': 2, '‘अंबेडकर': 1, 'लाऊँ,': 4, 'सुनाऊं.': 1, 'दफ़नाएंगे': 1, 'अंतर्जातीय': 5, 'कविताएँ': 88, 'कविताएँ’': 2, 'परिकल्पनाओं': 4, 'एंटीऑक्\\u200dसीडेंट्स': 1, 'बेइंतिहा': 6, 'एंगेल्स': 11, 'अंत!': 4, 'दिखाएँ': 10, 'उल्काओं': 1, 'होउंगी…और': 1, 'अँगोछा': 5, 'नहाऊँ,': 1, 'नहाएँ।': 1, 'धुआँ': 38, 'भंगिमाएं': 5, 'जाएंगे,क्या': 1, '.८०%मरीजाओं': 1, 'आंख-मिचैनी': 1, 'उठाएँ': 8, 'अँधेरा....': 1, 'अंधाधूंध': 4, 'मान्यताओं,': 4, 'अंतर्जाल': 31, 'बताएंगे।’': 3, 'अँधा': 26, 'जाएँगे।': 36, 'अँधेरा,': 9, 'हिन्दूओं': 26, 'स्पर्धाएं': 1, 'इंटरनेश्नल': 1, \"समस्याएँ'\": 1, 'आँधियों': 18, 'वेइंतिसीएते': 1, 'सारमिएंतो': 1, 'प्रताड़नाओं': 1, 'चयन-कर्ताओं': 1, 'होऊंगी': 2, '\"अंजली\"': 1, 'अ़बस': 1, 'अंदेशा)': 1, '‘आंदोलन’': 2, 'अंधेरा!': 2, 'शोधकर्ताओं,': 1, 'कराएँ': 4, 'जाऊँगा.हाँजे': 1, 'लिए.आंखें': 1, 'ऊँचा,': 2, 'बोला-आओं': 1, 'परिचारिकाओं': 4, 'सर-आँखों': 4, 'अश्रुओं': 11, 'भवनाएँ': 1, 'इंडिया\"': 6, 'सेवाएँ,': 2, 'साइंसी': 1, 'था...कुआँ': 1, 'उठाऊँ,': 1, 'चलाऊं...': 2, 'एंड....’': 1, 'सुनाऊँ': 9, 'उद्भावनाओं': 4, 'इंदुम्बन': 2, 'समझाऊं': 10, 'पाखंड-अंधविश्वासों': 1, 'होओं,वहां': 1, 'अंधे-लालची-धंधेबाज-कर्रप्ट-और': 1, 'लगाऊँगा।': 1, 'जाउंगी': 34, 'आँखें...': 3, 'अंसारे': 1, 'इंद्रधनुष।': 2, 'अंगुलियाँ': 13, 'ऊंपर': 1, 'आऊँगा': 12, 'बेइंसाफी': 3, \"'इंटरप्राइज़'\": 1, \"इंटरप्राइज़'\": 1, 'माइंडसेट.': 1, 'अँट': 1, 'जाऊँगा...।’': 1, 'समस्याआें': 4, 'एंजॉयमेंट': 2, 'दिलाऊँ': 2, 'बहन,(ऊँगलियां': 1, 'अप्सराएं': 10, 'आॅफ़': 2, 'आॅक्सफ़ोर्ड': 1, 'आऊँ': 27, 'ऊँगली,सीखा': 1, 'उँगलियाँ,': 3, 'धोऊँ': 2, 'कविताएँ,': 2, 'अन्तश्चेतनाओं': 1, 'जाऊँगा,': 23, 'जाऊँगी।”': 1, 'खाऊँगा': 4, 'रचनाएँ': 86, 'थे-अँग्रेजी': 1, 'आिद': 2, 'गाऊंगी': 1, 'सोऊँ': 1, 'जीविकाआें': 1, 'खडाऊं': 5, 'साइंसदान': 10, 'अंधरे': 4, 'अंतर्भूत': 3, 'अंतर्धार्मिक': 3, 'जाएँगी?': 1, 'भाषाओँ': 26, 'अँगूठी': 7, 'ऑंखें': 52, '\"ठेठ-सभाएँ\"': 1, 'आँखमिचौली': 2, 'गर्मिओं': 7, 'अंतड़ियों': 4, 'अनेकताओं': 1, \"इंदी'\": 1, 'अंडर-अचीवर': 3, 'पत्र-पत्रिकाएँ': 3, 'कोइ्र्र': 1, 'हुइ्र्र': 2, 'इंटरनेट,प्रेस,फिल्म,वीडियो': 1, 'आउंगी': 7, 'घटनाओं/दुर्घटनाओं': 2, 'अंतर्संबंध,': 1, 'अँग्रेजी': 18, 'बोली—जाओं,': 1, 'अँखुआया': 1, 'बुलाऊँ।': 1, 'अंशो': 4, 'बदइंतज़ामी': 1, 'अंजाम\\u200b': 1, '...अंधेर': 1, 'मैअंत': 1, '???????????अंग्रेज': 1, 'जाएँगी': 27, '......अंत': 1, 'लाएंगी,': 1, 'आंदोलनो': 5, 'जाऊँगा”': 1, 'अँगुलियों': 13, 'सूईओं': 1, 'दुवाएं': 1, 'इंजहार': 1, 'लाएँगे,': 2, 'करवाऊंगा,': 1, 'लगवाऊंगा।': 1, 'भिजवाऊंगा।': 1, 'को.मल्लिकाओं': 1, 'अंगेज': 3, 'कमाएं,': 2, 'आवश्यक्ताओं': 3, 'परीकथाओं': 5, 'जीऊँगी,': 3, 'आऊँगी,': 5, 'नवविवाहिताएं': 1, 'कन्दराओं': 2, 'आंग्ल-भारतीयों': 1, 'चढ़ाएंगे': 1, 'अक्षरों,मत्राओं,': 2, 'मात्रिकाओं': 1, 'अंशधर': 1, 'आऊँगा।': 11, 'जाएँ।’’': 1, 'गाऊंगा...': 1, 'बनाऊँ': 4, 'अँधेरों': 11, 'सुनाएँ': 6, 'आँखें,': 23, 'बाजुआें': 2, 'हवाआें': 3, 'हुइंर्,': 1, 'ऊंटवाले': 2, 'पाउंगी': 9, 'गोरखाओं': 3, 'अंग्रजो': 3, 'इंफैक्शन,': 1, 'इंफैक्शन': 1, 'इंटरनेट,ब्लॉग.अखबार': 1, 'लाऊँ?': 2, 'घटाओं': 18, 'आंधियाँ....': 1, 'अंतर्सत्यों': 1, 'इंतनी': 2, 'कार्य-कर्ताओं': 3, 'जाऊँ।': 17, 'कार्यशालाएं': 6, 'अंगडाई': 16, 'इंटों': 3, 'लौटाऊं,': 1, 'बनाएँ': 8, 'शुभकामनाएँ': 15, 'मनाऊं': 3, \"बताऊं?''\": 1, 'कुमाऊँनी': 1, 'गेहुआँ': 1, 'आँखो': 29, 'परिकल्पनाएं': 4, 'बताऊँ।': 1, 'बताऊँ': 39, 'इंडिया,6-10-1926)': 1, 'कल्\\u200dपनाएं': 1, 'लडाईं।': 1, 'धोएँ': 1, 'अंकज्ञान': 1, 'कि-महिलाएं': 1, 'महिलाआें': 4, 'खाऊंगी.': 1, 'पकाएँ': 1, 'पीएँ।': 1, 'लगाऊंगा': 5, 'अंगड़ाई': 14, 'सेवाएँ': 19, 'खाऊँगा।': 3, 'उंगलियाँ': 32, 'बीटाएंडोरफिन': 1, 'रहा...आँखों': 1, 'आंटा': 3, 'जाऊँगा...': 5, 'कविताअें': 1, 'आएँगी,': 2, 'रिवाईंड': 1, 'फाउंडेशनों': 8, 'एंथोजैक्सिन': 1, 'अंतःप्रज्ञा': 1, 'चनैलह्यइंग्लिश': 1, 'पट्टिकाएं': 2, 'है।आइंस्टाइन': 2, 'चिकित्साएं,': 1, 'ऑंकलन': 1, 'आॅर्डर!': 1, 'ऊंचे-': 1, \"दिखाऊँगा''\": 1, 'अर्थव्यवस्थाआें': 1, 'इंडिपेंडेंट’': 2, 'साईंसिज,': 1, 'अँधियारे': 4, 'जाएंगे.यानी': 1, 'जाऊँगी।’': 1, 'अंतर्गगन': 1, 'अँधेरी': 55, 'ओैजारों': 1, 'अंकुश।': 1, 'अंगोछा': 3, 'लक्ष्मण-रेखाएं': 1, 'ऑंखों': 33, 'कुंऐं': 2, 'इंटरमिशन': 1, 'परिकथाओं': 1, 'कौऔं': 1, 'महात्वाकांक्षाएं,': 1, 'स्वप्न,अंक': 1, 'अंगड़ाई': 20, 'पहुंचाएं!': 1, 'धाराएँ': 13, 'थरुओं': 1, 'है...ऊंची': 1, 'वस्तुएँ': 17, 'अँगूठे': 9, 'आँधी': 39, 'आँसुओं': 114, 'अंधेरो': 9, 'अंतर−संबंध': 1, 'इंद्रमणि': 9, 'अंकल’': 2, 'दिखाऊंगा': 3, 'अंदर।': 4, 'बनाएँ।': 3, 'दिखाएँ।': 2, 'दोहराएँ।': 1, 'मोहतरमाओं': 3, 'आंसुओ': 18, 'एंगेज्मेंट': 1, 'अवस्\\u200dथाएं': 1, 'काऊं': 4, '*काऊं...': 1, 'डलवाएं..क्यों': 1, 'भाषाएँ': 35, 'रोउं': 1, 'सुलाऊँ!': 1, 'पाएंगीं': 2, 'आँकते': 3, 'गाएँ': 6, 'आलोचनाओें': 1, 'संकीर्णताओं,': 1, 'व्\\u200dयाख्\\u200dयाओं': 1, 'इच्छाएँ': 11, 'अंग्रजों': 7, 'बताओं,': 2, 'सजाऊं': 1, 'विजेताओें': 2, 'ऊँघती': 2, 'बजवाईं.उस': 1, 'बिताईं': 2, 'आॅडिषन': 2, 'अंखियों': 4, 'है,,उंगलियों': 1, 'पकाया,,,माताओं': 1, 'आऊं?\"': 1, 'घटनाएँ': 51, 'तालाबों-कुओं': 1, 'देवताअें': 1, 'अंतर्द्वंदों': 1, 'छुपाउंगा।': 1, 'बताउंगा।': 3, 'नेशनलइंटरग्रेसन': 1, 'हसाएंगे': 1, 'सत्ताएँ': 1, 'आया.आँखों': 1, 'भाई-बंधुओं': 2, 'बताउं,': 1, 'इंटे': 1, 'गाऊँ': 5, 'लडाऊं॥३॥': 1, 'बजाऊँगा?': 1, 'पाऊँगा': 19, 'नेताओँ': 4, 'क्रियाएँ': 5, 'अंकन,ब्रह्माण्ड': 1, 'ठहराएं,': 2, 'आंसूं': 21, 'हईं!\"': 1, 'आत्माऎं': 1, 'माशुकाओं': 1, 'जाएँगे।”': 1, 'जलाएँ': 1, 'अंगुलियाँ.': 1, 'घटना-अंश': 1, 'छात्राएँ': 2, 'इंतजा़र': 1, 'अकाउंट....और': 1, 'कूँएँ': 1, 'चित्र-कथाओं': 1, 'सदेच्छाएं': 1, 'अंजाने': 11, 'आजमाएं:': 1, 'ऊंघ': 7, 'है...कुएँ': 1, 'आकाशगंगाएँ': 2, 'इंडियाप्लाजा': 3, 'सरकारी-सेवाओं': 1, 'पाउँगा': 7, 'खाओ-पीओेे': 1, 'जुगाड़ुओं': 1, 'पाऊँगी': 20, 'महत्वकांषाओं': 1, 'अंशुमाला': 3, 'शुभकामनाएं!': 6, 'लगाईं,': 3, 'आऐंगे': 1, 'ड्राईंग': 7, 'अंतद्वंद्वों': 2, 'गिनाऊं,': 1, 'एंतोईने': 1, 'खाएं?मीडिया': 1, 'ऊँगलियाँ': 2, 'पाएँगे': 17, 'अँगना': 4, 'लगाओं': 1, 'माओं': 8, 'इंतजारे': 1, 'पाऊँ': 20, 'अवस्थाएं,': 1, 'धर्म-गुरूओं': 1, 'लाऊं': 14, 'रचनाएं-': 1, 'फोटुओं': 4, 'अंतर्द्वंद्व': 3, 'अंग्र्रेजी': 3, 'पुरोधाओं': 6, 'प्वाईंट....': 1, 'साईंदयाल': 5, 'ऊँचा-पूरा': 1, 'गवाईं,': 2, 'आं?': 1, 'नीचताएं-तुच्छताएं-संकीर्णताएं': 3, 'दुष्टताएं': 1, 'आंखिर': 3, 'अंधविश्\\u200dवास': 3, 'ऍंधेरा': 1, 'जलाएँगे।': 1, 'इंस्टीट्च्यूट': 1, 'वृद्धों-महिलाओं': 1, 'बताउंगी।': 1, 'एँटिबायटिक': 4, 'जाएँगे': 59, 'खाऍं': 2, 'चुराऍंगे': 2, 'खाऍंगे।': 3, 'दुआऍं': 5, 'आऍंगे।': 2, 'ऑंएगी': 2, 'अंजुल': 1, 'घटाएँ': 4, 'लड़ाएंगे,': 1, 'लड़वाएं,': 1, '....अंतर्जालीय': 1, 'आंगिक': 2, 'मान्यताएँ,': 2, 'धारणाएँ': 6, 'अदाएँ': 6, 'बहुऍं': 2, 'चाहिएँ': 4, 'आाखिर': 1, 'समाएँ': 1, 'आँसुओ': 4, 'चर्चाएँ': 10, 'पनघटों/कुओं': 1, 'ईंधन--3.74': 1, \"'आंय'\": 1, 'आऊँ,': 8, ',अभिनेताओं': 1, 'उपमाएँ': 3, 'अंतरनिहित': 1, 'देखा....आँखों': 1, 'अंतर्बाह्य': 2, 'अंगना': 12, 'ऐंसा': 6, 'संभवनाएं': 1, 'अम्बिएंस': 2, 'दरोगाओं': 2, 'जाऊँगा।': 18, 'आंखेँ': 2, 'अंक?': 1, 'सहलाऊंगा': 1, 'इंद्रसेन': 1, 'सुनाऊंगी.': 1, 'ऊँची-ऊँची': 8, 'जाएँगे;': 2, 'सत्यकथाओं': 1, 'कथाएँ': 30, 'दिशाएँ': 6, 'अंधक': 5, 'ऐं!': 1, 'प्रक्रियाएँ': 8, 'जाएंगे,,,जिस': 1, \"हुईं।''\": 1, 'फरमाएँ': 1, 'आंसु': 2, 'इंटरव्\\u200dयू': 5, 'इंग्लिशमैन': 1, 'आँगन।।': 1, 'ख़ताएं': 1, 'जाएँगी.': 10, 'शुभकामनाएं,': 2, 'मागऊँ': 1, 'इंडो-फ्रेंच': 1, 'साहित्य-रचनाओं': 1, 'मालाएं': 8, 'दारोगाओं': 3, 'संजोएं': 1, 'इंग्रेजी': 1, 'अंतर्विरोधी': 2, 'क्षणिकाएं': 5, 'क्षणिकाओं': 6, 'उँगलियाँ': 39, 'जीव-जन्तुओं,': 1, 'जीव-जन्तुओं': 3, 'अंतरण।': 1, '(माउंटबेटन': 1, 'निष्ठाएं': 3, 'मनाएंगे.\"': 1, 'रूआंसी': 2, 'घबराईं': 1, 'सुनाऊं!!': 3, 'सीमाएँ': 21, 'कल्पनाएँ': 17, 'गईं!': 1, 'बताऊँगा।)': 1, 'ऊँगली...कैनवास': 1, 'उँगलियाँ...कि': 1, 'मनोदशाओं': 3, 'जाएँगे,': 14, 'ईंतजार': 1, 'उठाऊं': 3, 'मिलाऊँ': 2, 'लाऊँगीं': 1, 'कोशाओं': 10, \"अंडरस्टैंड?',\": 1, 'कंदराओं,': 1, 'रोऊं': 2, 'आंजुरी': 1, 'अंग्रेज़ी': 17, 'कविताएँमैं': 1, 'निभाऊं': 1, 'इंडिरा': 1, 'अँडमान': 1, 'निभाईं,': 2, 'ईंटो': 3, 'हुओं': 17, 'गरियाएं': 1, 'इंटरपासिंग': 1, 'समाजचेताओं,': 1, '\"\"\"\"सभ्यताओं': 2, 'परंपराएंसभी': 1, 'अंगूर..को': 1, 'अंकल\"': 1, 'गौरव-गाथाएँ': 1, '‘ता-आंग’': 1, 'पीएंगें': 1, 'चबाएंगा': 1, 'लगाएंगें।': 1, 'जाऊँगा.लेकिन': 1, 'आंए-बांए': 1, 'अंतस—अनुसंधान': 1, 'गुफाओं’’': 1, 'एंड्रोमेडा': 1, 'जाऊँगा।”': 3, 'अंग्रेज,': 1, 'नृत्यांगनाएँ': 1, \"जाऊं?''-मैंने\": 1, 'अधिकारिओं': 3, 'गईं?इसी': 1, 'माँएं': 3, 'आँख’': 1, 'अंतर्क्रियाओं': 6, 'संकल्पनाएं': 2, 'अंतर्संबंधता': 1, 'रमाएंगे।': 1, 'शाखाओं-प्रशाखाओं': 2, 'अन्नाओं': 2, 'इंफ़ॉर्म्ड': 1, 'यतिओं': 1, 'अंतश्चेतना': 2, 'बाधाएँ': 8, 'विडबंनाओं': 1, '*आँखोँ': 1, 'पॉइंट्स\"': 1, 'माता-पिताओं': 3, 'ऊँघते..': 1, 'दादाओं,': 1, 'परदादाओं': 1, 'सद्भावनाओं': 2, ',भंगिमाएं': 1, 'लौटाएं': 1, 'अंसग': 1, 'प्रतिभाओंसे': 1, 'इंक्वायरी।’': 1, 'बहलाएंगी!': 1, 'अंशमात्र': 6, 'आएँगी': 9, 'पेइंग': 9, 'विशेषताएँ': 8, 'अंधकारपूर्ण': 6, '-कोशाओं': 1, 'लोकयात्राओं': 1, ',आंतरिक,और': 1, 'आँखें’': 1, 'दिशाओं/कोणों': 1, 'झुकाएँ,': 1, 'सिमाएं': 1, 'दहाईं': 2, 'चिंताएँ': 7, 'ईंजन': 6, 'इंफैट्री': 1, 'अंडरअचीवर': 12, 'आलराऊंडर': 1, 'मचाएंगे': 2, 'अंतर्राज्य': 1, 'सिखाएंगी।': 2, 'भावधाराओं': 1, 'आँखोंवाला': 1, 'प्रयोक्ताओं': 6, 'जिंताएं': 1, 'इंटेलीजेंट,': 1, 'सामानताओं': 1, 'बताऊं?': 7, 'आउंगा,': 3, 'मलपूओं': 1, '‘ऊं': 3, 'बुलाऊंगी।': 1, '(एमएंडएच)': 1, 'एंसीलरी': 1, 'बौखलाएं,': 1, 'जाऍं,': 5, 'अंगरेज़ी': 33, 'फाइटोन्यूट्रिएंट्स': 1, 'प्रकृति-शिशुओं': 1, 'मुस्कुराएं,': 1, 'लाओं।': 1, 'अंतर्वैयक्तिक': 2, 'इंटरपरेट': 1, 'इंजानियरिंग': 2, 'पिट/अंडरआर्म': 1, 'उँची': 3, 'कुंठाएं': 10, 'आंदोलन,पुनरूत्थानवाद,ब्रजभाषा,खड़ीबोली': 1, 'इंदौरी।': 1, 'अंतर्गणेश': 1, 'चिताओं': 14, '...अंतरात्मा': 1, 'जाएंगीए': 1, 'आवश्यकताओं,': 1, 'ऊँचनींच': 1, 'महत्वकांक्षाओं': 3, 'माईंड': 2, 'ऊँचाईयों': 2, 'गईँ।': 1, 'गाएंगी?': 1, 'अंतर्तम': 3, 'उठाऐं।': 2, 'ठुकराऐं': 1, 'नाईं': 19, 'आंदोलनकर्ता': 1, 'इंन्द्रिय': 1, 'भों-ओं-ओं!': 2, 'साइंसिज़': 1, 'बताऊंगी': 3, 'नाइंसाफ़ी': 4, 'इंसाफ़': 19, 'साइंया': 2, 'उप-कथाएं': 1, 'पत्रकारों-संपादकों-एंकरों': 1, 'अंगडाई.': 1, 'अँग्रेज़ी': 5, '32.आंकडों': 1, 'अंतर?': 1, 'आईंस्टाईन': 1, \"'अंकल'\": 2, 'गएँ': 14, 'नोटिफाइंग': 1, ',ऊंघ': 1, '2.कविताएं': 1, '(एंजियोप्लास्टी': 1, 'स्टेन्टइंग': 1, 'उठाऊंगा.': 1, 'पत्रिकाएँ': 29, \"'काशिराज-कन्याओँ\": 1, 'सवेंदनाओं': 1, 'इंची': 4, 'देव-देवताओं': 1, 'पोइंट': 2, 'आंदोलनांे': 1, 'हत्याएँ': 4, 'टिसुओं': 1, '=आंसु;': 1, '*अंतरा-१...सच': 1, 'अंगिरस': 1, 'जाएंगीं.': 3, 'आशाओँ': 1, 'आशाएँ': 10, 'लगाऊँ।”': 1, 'माँओं': 9, 'आँख़ें.': 1, 'सुनाऊँगा': 1, 'जाऊंगा।’': 5, 'बुलाएँ?': 1, 'आंखफोड़ाऊ': 1, '‘ऊंगली’': 1, 'ऑसूओं': 1, 'फाइंडर‘': 1, 'नेताओं-अफसरों': 1, 'अंतरतर,': 1, 'आएँगे': 17, 'तरफाएं': 1, 'बुराईयों,कुप्रथाओं': 1, 'ओंठों': 3, 'कारगर.इंटरनेट': 1, 'अँगोछे': 7, 'अंतरावलंबन': 2, 'आंख-मुंह': 1, 'इंतज़ार.': 2, 'विकलाँगताएँ': 5, 'इंक़लाब': 8, 'औंधा': 7, 'जाऊंगी.बहती': 1, 'जाऊंगी.फिर': 1, 'जाएंगे.एक': 1, 'कराऊंगी.': 1, 'अंतरखगोलीय': 2, 'अंत्यंत': 1, 'उड़ाएं': 1, 'उड़ाएं।': 1, 'इंडिया\"को': 1, 'बजाएंगी': 1, 'आँकड़े': 6, 'अंधियारी,': 1, 'बाएं-दाएं': 4, 'फिज़ाओं': 2, 'अंडररिकवरी': 3, 'बताएँ': 10, 'ललचाऊँ,': 1, 'जाएँ??”': 1, 'काऊंसलिंग': 3, 'अंतरीक्ष': 1, 'अंखिया': 2, 'गाऊंगा': 3, 'इंफ़ैंट्री': 1, 'कराऊंगा': 2, 'अंजामे': 1, 'आंत्रकृमि': 1, 'बंदउँ': 1, \"जाएंगी?''\": 1, 'तपस्याएँ': 1, 'धर्मगुरूओं': 2, 'विलक्षणताओं': 1, 'नजरअंदाज़': 1, 'आंकड़ा)': 1, 'जाऊं...??': 2, 'इंत़जार': 1, 'नेता-इंस्पेक्टर': 1, 'गाऊंगी-': 1, 'खिलाएंगे।': 1, 'लाऊँ।': 2, 'आऊंगी।’': 1, 'पहलुओंकी': 3, 'ज्वालाओं': 4, 'मनौकामनाएं': 1, 'सुविधाआें': 3, 'सजाऊँ': 4, 'माइंड–जब': 1, 'ओऽमप्रकाश': 7, 'बताऊँगा।': 2, '‘अंशुमाली’,': 1, 'उल्माओं': 1, 'उलमाओं': 3, 'अँजुरी': 4, 'कहलाऊँ': 2, 'घुमन्तुओं': 1, 'अंधियारीपाठ,': 1, 'अंजोरीपाठ,': 1, 'पाएंगे,जब': 1, '.दवाओं': 1, 'ओंकार,': 2, 'घटनाऐं': 7, \"'गोसाईंबगानेर\": 1, 'खोऊँ?,किसे': 1, 'पाऊँ?': 1, 'श्रृंखलाएं.': 1, 'जाउंगा,': 4, 'जाउंगा;': 2, 'अंदेशे,': 1, 'एंटरटेन्मेंट': 1, \"पाईं।'\": 1, 'सेनाएँ': 1, 'आँधी-ओ-तूफाँ': 1, 'खाएँ': 5, 'आएँ': 20, 'आओं': 3, 'बन्धुओं': 9, 'घटनाऍं': 1, 'इंक्स': 1, 'इंजी०': 1, 'इंस्टालेशन': 4, '“ऊंट,': 1, 'बुलाऊं?': 1, 'अंदाज़।': 1, 'चुकाएं,': 1, 'पहुंचाएं.': 2, 'इंद्रजाल': 1, 'एंड-टू': 1, 'एंड.”': 1, 'अंक-अगस्त': 1, 'गोईं!': 1, 'आंतरिकता': 2, 'अंबाळा': 1, 'कक्षाएँ': 9, 'अभिनेताओं-अभिनेत्रियों,राजनितिज्ञों': 1, 'अंगरेजी।': 1, 'इंदिरा-विंदीरा': 1, 'प्रतिक्रिताएं': 1, 'विषय-वस्तुओं': 1, 'हुईं......': 1, 'अंधा-अंधा': 2, 'फाउंडेशन\",': 1, 'जाउँ।': 1, 'पाउंगी?': 2, 'अँधियारी': 2, 'इंसा': 11, 'एकाऊंट': 2, '\"अँधा\"': 1, 'आंय': 1, 'इंडीपैडैंट': 1, 'अाते': 1, 'प्रतिक्रियाएँ': 5, 'अंगूठों': 3, 'आँकडे': 4, 'इंतिजाम': 1, 'जन्तुओं': 17, 'नज़रअंदाज': 1, 'अभिलाषाएं': 5, 'व्\\u200dयवस्\\u200dथाएं': 2, 'अंपने': 2, 'दिखाऊँ': 3, 'अंकुरित,': 1, '‘‘अंधेर': 1, '(क्लाइंट': 1, 'अंतर्संबंध': 4, 'जुग्नुओं': 1, 'छूईं।': 2, 'बताऊँगा': 2, 'संहिताएं,': 2, 'प्रार्थनाएं,': 1, 'इंटर-नेट': 2, 'नज़रअंदाज': 3, 'वेस्ट-इंडीज': 1, 'क़तअ़': 1, 'तअ़ल्लुक़': 1, 'सुचनाओं': 2, 'लड़ाएं': 3, 'अंतर्कथा': 1, 'ताकते-बेदादे-इंतजार': 1, 'बतियाएं': 1, 'बनाउंगी': 1, 'अंदमान': 5, 'बुलाएं\"': 1, 'सफलताएं।': 1, 'अखबारों,पत्रिकाओं': 1, 'घर-आँगन': 7, 'ऋतुएं,': 1, 'दशाएं': 2, 'माऊंटिंग': 1, \"बतलाऊँ!'\": 1, '“इंडिया': 1, \"जाऊँ?'\": 1, 'आँगन-आँगन': 4, 'अल्पनाएँ': 1, 'महाराष्ट्र-आँध्रप्रदेश': 1, '..आँखों': 2, 'ऊंचे-नीचे': 2, 'पीड़ाएं,': 2, 'कुंठाएं,': 1, 'अंगिरा': 3, 'आॅक्सफेम': 1, 'गुफाएं': 13, 'पीड़ाओं,': 1, 'कराएँ.': 3, 'अंधश्रद्धाओं': 2, 'पाऊँ।': 8, 'एंटवर्प': 1, 'बतलाऊं': 3, 'बसाएँगे।': 1, 'नेताओं/अफसरों': 2, 'कामनाएँ': 2, 'आऊँगा,': 2, 'धुआँ-सा': 1, 'वस्तुऐं': 4, 'गईं,’': 1, 'आँखें?': 1, 'मंगलकामनाएं.................': 1, 'उपमाएं': 7, 'अंतरगत': 1, 'हुआं': 5, '\"अँधेरे': 1, 'दौड़ाउंगा': 1, 'होगा...आँख': 1, 'म्याऊँ-म्याऊँ': 2, 'प्रतिभाएं.': 1, '(ऐंगेल्स,': 1, 'ऐंटीडयूहरिंग)।': 1, \"अँ''\": 1, 'पाउँगा...': 1, ',अंगूर': 1, 'जाऊं...': 3, 'इंडिया’’': 1, 'पहुंचाएंगी।': 1, 'विकलाँगताओं': 8, 'हुआ.अंग्रेजों': 1, 'करवाएँ,': 2, 'अपनाएँ': 1, 'आऊँ.': 3, 'कुंठाओं,': 1, 'साईंनाथ': 1, 'इंजेक्टर': 1, 'जड़ताओं': 1, 'रोएं?': 1, 'संस्थाएँ': 16, 'आँसू,': 10, \"'एंट्री'\": 1, 'खिजाएँ': 2, 'माशूकाएं': 1, 'वस्\\u200dतुओं': 12, 'धुआं...': 1, 'विफलताओं,': 1, 'अंगूरों': 10, 'आँखवाले': 1, \"'अंकुश\": 1, 'भुमकाओं': 1, '-अंशु': 1, 'कहलाऊं': 1, 'बाल-कविताओं': 3, 'बाल-कविताएँ': 1, 'धुँऐं': 2, 'शिराएं': 3, 'अंबावानी': 1, 'दिखाऊँगा।': 3, 'अंधेरापन': 1, 'इंस्टाल': 14, 'घर-आँगन-चौबारे': 1, 'बनाऊँ,': 2, 'अंगडाइया': 1, 'छाऊँगा': 1, 'कलाएँ': 6, 'नृत्यांगनाओं': 1, 'संकीर्णताएं': 5, '..ऊँचा,': 1, 'इंजीनियर...।': 1, 'करवाएँ': 2, 'अति-महत्वाकांक्षाओं': 1, 'लिटाऊँ': 1, '।आँखों': 1, 'रोएँदार': 1, 'पताकाओं': 1, 'दंतकथाओं': 4, 'भग्गुओं': 1, 'एंटीबॉडीज़': 1, 'इंपरिजनमेंट': 1, 'बलाएँ': 3, 'गुप्तअंगो': 1, 'आंट': 7, 'औंधी': 6, 'में...उँगलियाँ': 1, '(ऊँची': 1, 'शुभकामनाएँ,': 1, 'अँधियारा': 12, 'यात्राएँ': 7, 'आंतों,': 1, 'ऊंचे,': 2, 'उॅचा': 1, 'संस्कारों,रत्नों,धातुओं': 1, 'जाऍंगे?': 2, 'नायिकाएँ': 1, 'अट्टालिकाएं': 2, 'मान्यताआं': 1, 'अंगडाइयाँ': 1, 'बजाएं': 7, 'पताकाएं': 2, 'वर्जनाएं': 8, 'है...इंसान': 2, 'इंदिरा-आवास': 1, 'आऊँगा।’': 1, 'संश्लिष्टताओं': 1, 'अंटते.': 1, 'बताऊं।': 4, 'अंदाज़े': 4, 'पादुकाओं': 2, 'गणीकाओं': 1, 'सुरक्षा-सेवाओं': 1, 'दिवाओं': 1, 'रोऊँ': 6, 'ऍंधेरी': 1, 'अंत:कवच': 1, 'अंतर।': 7, 'आंचर\"': 1, 'हिलाएंगे': 3, 'खाऊँगा.': 2, 'उंडेला': 2, 'जाउँगी।': 2, 'क्षमताओं,': 2, 'नज़रअंदाज़': 16, 'शुभकामनाऐं': 1, 'जाऊँगी,': 7, 'आंखन': 2, \"'आंखन\": 2, ',बाएँ': 1, '(पत्र-पत्रिकाओं': 1, '“आंटी,': 1, 'जाओे': 1, \"जाऊँगी।'\": 3, 'उत्सुकताओं': 2, 'फाउंडेषन,': 1, 'लाईं': 8, 'इंटरनेटी': 6, 'बस्तिओं': 2, 'अंधारी': 1, 'इंजिनों': 5, 'अंतर्राष्ट्रीयकरण': 2, 'दुनियाओं': 5, '.अंतिम': 1, 'दवाएँ': 4, 'ऊंघनें': 1, 'अंबाडे': 1, ',इंजेक्सन': 1, '*आँधियाँ': 1, 'अंदर*': 1, 'योग्यताओंवाले': 1, 'विशेषताएं,': 1, 'अपहृताओं': 1, 'मनाऊँ': 6, 'लगवाएंगे': 1, \"जाएँगे।'\": 1, 'गाऊँगा': 2, 'एंकरवा': 2, 'इंस्ट्रकसन': 1, 'लेखिकाएं': 10, 'रूंआंसा': 1, 'अंधेरें': 1, 'इंदु।': 1, 'वक्ताओं/कलाकारों': 1, 'अंतःपुर': 2, 'ऊंघाए,': 1, 'होऊं.': 6, 'अंड़स': 1, 'नीति-नियंताओं': 3, 'करवाएं..:': 1, 'आशाओं,': 1, 'नीहारिकाओं': 1, 'कविताऐं': 2, 'सिचाईं': 1, 'सिविललाइंस': 1, '(छात्र-छात्राएं)': 1, 'अंबेदकर': 3, 'एंजोलो': 1, 'रहनुमाओं,': 1, 'सूक्ष्मताएं': 1, 'एंटीऑक्सीडेँट्स': 1, 'इंडियावालों': 1, 'माताओं-पिताओं': 4, 'फैलाएं...': 1, '‘इंडिया’': 4, 'इं\\u200dडस': 1, 'सभ्\\u200dयताएं': 1, 'एंटीरिफ्लेक्टिव': 1, 'गुडि़याएँ': 1, 'इंजीनिय्रर्स': 1, 'अंख': 1, 'आंदोलकारियों': 1, 'परमपराओं': 2, 'फरमाएं.': 1, 'पशुऒं': 1, 'दवाएं,हारमोन': 1, 'अंग्रेज़ों': 6, 'आत्महत्याएँ': 4, 'रेखांओं': 1, 'मात्राएं': 4, 'अंधक्षेत्रीयतावादी': 1, 'ऐंगल्स': 1, 'अप्सराआें': 1, 'एंजायम': 1, 'विरचनाओं': 1, '१७-अंगिरा,': 1, 'कुप्रथाओं': 6, 'चाहिएँ।': 8, 'आऊं;': 1, 'अंडरलाईन': 1, 'इंडिया,17-12-1925)': 1, 'इंडिया,23-4-1931)': 1, 'जाऊँगी,न': 1, 'दिलाऊँगी': 1, 'गुनगुनाएँ।\"': 1, 'साईंदास': 9, 'आंखां': 2, 'अंजुरियों': 2, '(आंशिक': 1, 'अंतःस्\\u200dथापित': 1, 'रचनाएं.': 1, 'ओंस': 5, 'इंसल्ट': 2, 'अंक’': 2, '(कुमाऊँ': 1, 'सुअंक': 1, 'अ़लैहि': 7, 'अंधविश्वासी,': 2, 'अ़न्हा': 3, 'अंबानियों': 2, 'इंगलिष': 1, 'आऊँगा।उधर': 1, 'खिलाऊँ।साधो': 1, 'खिलाऊँगा।': 1, 'आऊंगा.चूहे': 1, 'बुलाऊं.वह': 1, 'दाएँ': 5, 'मेघ-मालाएँ': 1, 'पाएंगें.': 1, 'अंग्रेज़ी,': 1, 'बनवाऊँ': 1, 'आऊंगा।’': 4, 'आभाएँ': 1, 'खाऊँ': 6, 'आँहें': 3, 'पत्रिकाआें': 3, 'ऑंचल': 2, 'संवेदनाओं,': 2, 'आऊँगी': 6, 'पाएंगी/': 1, 'बुलाऊँगा': 2, 'तारे,ऊँचे': 1, 'अंध-प्रशंसक': 1, 'बिन्दुएँ': 1, 'मांगी…आंख': 1, 'इंतेक़ाल': 3, 'अाॅख': 1, 'एंडोट्रेकियल': 1, 'सुरक्षाओं’': 1, 'ओँकार,': 1, 'दिलाओं': 1, 'अंधभक्ति': 2, 'इंदिरा’': 1, '-देवताओं': 2, 'आँक': 4, 'माईं': 3, 'प्रवंचिकाएँ,': 1, 'अंतकाले': 1, 'पहुंचाएंगे....??और': 1, 'महाविधाओं': 4, 'महाविधाएँ': 1, '(आंसर-शीट)': 1, 'आंसर-शीट': 1, 'पत्रिकाओं-अनुभूति,': 1, 'मात्राएँ': 2, 'बिछाऊंगी।': 1, 'लगाऊंगा,': 1, 'अाखिर': 1, 'घबराओं': 1, 'शहनाइंयां': 1, 'गाऊंगा,': 2, 'विचारधाराएं': 7, 'प्रेमगाथाएं': 1, 'कपोलकल्पनाएं': 1, 'कोरवाओं': 1, 'इंस्टीट्\\u200cयूट': 2, 'बोस-आंइस्टीन': 1, 'ऊँचा-नीचा,': 1, 'अंधड़': 7, 'आंखि': 3, 'गोकुल-इंद्रनाथ': 1, 'मिलाएंगी': 1, 'लडका,अल्टासाउंड': 1, 'आँख।': 1, 'अंतःकरण': 10, 'देवकथाओं': 1, '‘‘इंस्पेक्टर': 1, 'महि\\u200dलाओं': 3, 'जाएँगे.': 5, 'आएँ,': 2, 'होऊँगा।': 2, 'कुएं..': 1, 'वेश्याएँ...)': 1, 'आंगण': 1, 'एंड्रीन': 2, 'आंदोलन,स्त्री': 1, 'एंड्रीनी': 1, 'आंदोलनवाली': 1, 'लोक-आंदोलन': 1, 'दोहराएँ': 1, 'चाहिएं.': 2, 'मनाऊंगा,': 2, 'ऊँटों': 4, 'इंजीनिअर': 1, 'ऊँचाइयाँ': 8, 'ऊँचा-नीचापन': 1, 'अंतरस्\\u200dथ': 3, 'निभाएं,': 1, 'आंदोलन’’': 1, 'चिल्लाओं': 3, 'इंतेहान': 1, 'जाएँ.....': 1, 'सबइंस्पेक्टर': 3, 'गईं;': 3, 'अंशांत।।58।।': 1, 'आंकड़े…..पिछले': 1, 'भड़काएं,': 1, 'निर्माताओं(Constructor': 1, 'सोऊँ..': 1, 'जाऊँ..': 3, 'अौर': 5, \"''इंडियन\": 10, 'जाएँ.जल्द': 1, 'उंगुलियों': 2, 'चिल्लाएं': 2, '-ओंकारश्री': 1, 'अंदाज़,': 1, 'इंटरटेंटमेंट': 1, 'कविताओं-कहानियों,': 1, 'मनअ़-ए-क़दम-बोस': 3, 'आँखोँ': 2, 'मुद्राएँ': 6, 'है।...इंदिरा': 1, ',बालों,उँगलियों': 1, 'अंतर-राष्ट्रीय': 1, 'व्याख्याएँ': 3, 'खिलाईं': 1, 'अंग्रेजी,उर्दू,': 1, 'जाऊँगी...': 2, 'बढाएंगे।': 2, '...बाएं': 1, 'जाएंगे.रिलायन्स': 1, 'अंतिम,': 2, 'इंस्ट्ीटयूट': 1, 'उंवार-उंवार।।': 2, '(प्रिएंबल)': 1, 'दवाईंयां': 1, 'विशेषताएँ,': 1, 'आवश्यकताएँ': 4, 'क्षमताएँ': 1, 'एंथ्रापोलॉजी': 1, 'बचाएँ': 8, 'मैक्कैसलएंड': 1, 'आएँगे।': 9, 'पीऊँगा.-': 1, 'खेलग्राउंड': 1, 'डेसी.......अंग्रेज': 1, 'भेटाएंगे........': 1, 'जाऍं।': 6, 'ऑंखे': 10, 'भाषाएँ।': 1, 'बजाऊं?”': 1, 'उर-अंतर': 1, 'जूआं': 1, 'निराशाएं': 3, 'ऐंग्लो-अमेरीकन': 3, 'बाएँ': 23, 'अँग्रेजों': 15, 'इंडिया-पाकिस्तान': 1, 'mom(मोम)...आंटी': 1, 'जाएँगें': 1, 'आंचि।।': 1, 'इंन्कार': 1, 'इंतज़ाम-ए-सल्तनत': 1, '‘अंधेरा': 1, 'पाऊंगा।’': 2, 'दिशाऍं': 1, '‘शुभकामनाएं’': 1, 'आंटिया': 1, 'हईंजा’': 1, 'डाइंगरूम': 1, 'पिएंपानी,': 1, 'अंतःवासी': 1, 'ऐंचातानी': 1, \"सुनाऊँ।''\": 1, 'गाऊं': 4, 'अंतरधारा': 1, 'सफलताएँ': 2, 'सुविधाएं/ऐश्वर्य': 1, 'ईं': 3, 'ईंणै': 1, 'आँधी-तूफ़ान': 1, 'निभाऊंगा': 1, '‘अंकल': 1, 'आंधियां': 8, 'पाएँगी।': 2, 'हैलीस्कीइंग': 1, 'एंगर‘': 1, '\"इंडिया': 4, 'आंगन।': 1, 'जाउंगी...': 1, '.....आँखों': 1, 'धूंऐं': 1, 'आँगन,': 5, 'कुमाऊँ': 8, 'आकांछाओं': 1, 'ऋतुएं': 6, 'शैय्याओं': 1, \"नोएंजल्स'\": 1, 'इंजुरी,': 1, 'धर्मशालाऐं': 1, 'जाएं।इससे': 1, 'पाऊँ,': 7, 'इंस्\\u200dटीच्\\u200dयूट': 1, 'इंफाल,': 1, 'गेहुएं': 1, 'अँग्रेज,': 1, 'एंटीऑक्सीडेन्ट्स': 2, 'अंधाधुन्ध': 1, '...इंतज़ार': 1, 'दुश्चिंताओं': 2, 'एंटीइन्फ्लेमेटरी': 1, 'बनवाईं।': 1, 'पाठ-शालाएं': 1, 'पात्रताएँ': 1, 'बढाएँ;': 1, 'आँख,मूंह,नाक,कान': 1, 'बातों-घटनाओं': 1, '‘साईं!': 1, 'साईं!!’’': 1, 'लाऊँ': 17, 'जाऍंगे': 2, 'मराठी-इंग्रजी': 3, 'सेवईं': 3, 'इनकाउंटर': 11, 'अँखियों': 5, 'गुल्म-लताओं': 1, 'गउऍं': 1, 'जे.एंड': 1, 'छुपाऊं': 4, 'लगाऊँ': 5, 'मनाऊंगा': 1, 'जन-समस्याओं': 2, 'जाए्गा।': 1, 'अंतरजनपदीय': 2, 'शक्तिओं': 2, 'अंह-विमर्शात्मक': 1, 'जाऊंगा...\"': 2, 'यात्नाएं': 1, 'अंगीकार,': 1, 'कविताएँ।': 1, 'पीउंगा': 1, 'अँगरेजों': 1, 'एंसलम': 1, 'हल्की-परछाईं': 1, 'घुमाऊंगा।': 1, 'आँख,': 7, 'वेब/ई-पत्रिकाओं': 1, 'जाऊँ!': 3, 'ऊँघ': 5, 'राज्य-सत्ताओं': 1, 'अंग्रेज़ियत': 3, 'अंग्रेज़ीदां': 1, 'आँखोंसे': 1, 'जाएँ.गुरु': 1, 'महात्वाकांक्षाओं': 2, '(अंतर्राष्ट्रीय': 3, 'कुरआॅन': 1, 'गायिकाएँ': 2, 'तंत्र-मन्त्र-साधनाओं': 1, 'मातृभाषाओं': 3, 'अन्य-सुविधाएँ': 1, 'इंदुमति': 3, 'आंदोलनकभी': 1, 'समीक्षाएँ': 3, 'कमाएँ.': 1, 'चलाऊंगा...\"': 1, 'पाऊंगा...': 1, ',अंदर': 1, 'पुरावस्तुओं': 3, 'एंटीडोट': 1, 'अंगागिभाव': 1, 'अंगी': 1, 'जाऊँगी।': 13, 'भार-ऊँचाई': 1, 'आंकिये': 3, 'इंडो-इरानियन': 2, 'अंग्रेजीमे': 2, 'जाऊँगा.': 2, 'इंसाँ': 5, 'एंडोस्कोपी,': 2, 'गएं': 3, 'बनाएंगें।': 1, 'आऊँगी।': 3, 'शोधकर्ताआें': 4, 'ऑंकती': 1, 'बतलाऊँ': 3, 'प्रोनाउंसियेशन': 1, 'अप्सराएँ': 3, 'शुभकामनाएँ!': 1, 'अंक...क्यों': 1, 'निर्देशिकाओं': 1, 'इंतिजार': 6, 'समझाएंगे?': 1, 'आंख…': 1, 'वास्तविकताएं': 2, 'फाउंड': 1, 'सोएं,': 2, 'संवेेदनाओं': 1, 'इंसानो': 2, 'इंकलाब’': 1, 'अंधियारी': 7, 'नज़रअंदाज़': 8, 'अंबिके,': 1, 'अंबालिके': 1, 'कसमसाईं': 1, 'पाएँ': 9, 'व्यस्तताएं': 4, 'जगाऊँ': 1, 'वान्छओं': 2, 'जाएँगी।': 8, 'अँगारा': 1, 'अँगार': 1, 'आऊँ।': 3, '‘आॅपरेशन’': 1, 'घटनाओं-हादसों': 1, 'पाऊँगा।': 4, '६-इंडियन': 1, 'ओं': 1, 'भुजाएँ': 2, 'नागराजाओं': 1, 'अंकित\"': 1, 'खाउंगा': 2, '-पिउंगा': 1, 'जाएंगे.दूरी': 1, 'ऐंसी': 4, 'नेतृत्वकर्ताओं': 5, 'मैअ़यार': 6, 'आंकड़ो': 13, \"''अंकल\": 2, 'बताऊँगा...................': 1, 'निपटाएँ': 1, 'बतियाएंगे।’': 1, 'बहकाऊँ': 1, 'दागीओं': 1, 'कथाऍं': 1, 'ऑंच': 2, 'धूआँ': 2, \"संभावनाएं'\": 1, 'इंडिक': 1, 'सुनाउंगी': 1, 'सम्भावनाएँ': 6, 'शृंखलाओं': 2, 'इंटरल्यूड्स': 3, 'अभिलाषाएँ,': 1, 'रेखाएँ': 6, 'दिखलाएँगे': 1, 'जेल-देवताओं': 1, 'खिलाऊँगी”': 1, 'लगवाऊँ': 1, 'तलुओं': 5, 'सिखाऊंगा': 2, 'नीहारिकाएं,': 1, 'अंग-विच्छेदन': 1, 'बेइंतेहा': 3, 'इंजिन...': 1, 'इंतजार.........।': 1, 'अंजुरी': 14, 'पुरखाओं': 4, '...........आँखों': 1, 'आंबेडकरवादी': 1, 'प्रतिभाएँ,': 1, 'पिऐं,': 1, 'आंकाक्षाएं': 2, 'लाऊँगा': 2, 'खाऊँ...': 1, 'फाऊंडेशन-मेघालासिय': 2, 'नेताओं/मंत्रियों': 1, 'कमाएंगे': 4, 'खिलाएंगे,': 1, 'चलाउंगा।': 4, 'मुतालेअ़ा': 3, 'ऊँगलियों': 3, 'आँसूओं': 8, 'ओंकार-मान्धाता': 1, '(इंटेलिजेंस': 1, '.आँखें': 1, 'अंग़्रेज़ी': 1, 'लघुकथाओं': 12, 'अंदरही': 1, 'ए़तबार': 1, 'माउँटबैटन': 1, 'वर्जनाओं': 6, 'अंड़े': 2, 'जाएा': 2, 'दुवाओं': 2, 'औेर': 12, 'बनाउंगा/गी': 1, 'अंिहंसा': 1, 'ऐंठ-ऐंठकर': 2, 'बताईं': 7, 'आँगनवाड़ियों': 5, 'आँगनवाड़ी': 8, 'आँगनवाडी': 1, 'सुनाऊँ!!': 1, 'साऊंड़': 1, 'मेवाओं': 1, 'परीक्षाएँ': 7, 'गीत-कविताएँ': 1, 'दवाईंयॉं': 1, 'नहीं.आँखों(हेडलाईट)का': 1, 'आँगना,': 1, 'अवधारणाओं,सामाजिक': 1, 'अंतर्ध्वनि': 2, 'एंटीबायोटिकश्': 1, ',वंचिताओँ': 1, 'ऊंह': 1, 'आैर': 4, 'हाइकुओं': 1, 'कविताएं…जिनमें': 1, 'समझाऊँ..ये': 2, 'इन्फलूएंजा': 1, '--इंटेल,': 1, 'शुभकामनाएँ)': 1, 'अभिलाक्षणिकताओं': 1, 'आंग्ल': 3, 'अध्यक्षाओं': 2, 'बनाऊँगा,': 1, 'काउंटर-इनर्सजेंसी': 1, 'आत्माएँ': 5, 'है,आाखिरी': 1, 'ओएंस,': 1, 'श्रृखलाओं': 3, 'चयूइंग': 1, 'दायें-बाएं': 2, 'जाएँ;': 1, 'पाऊंगा....।': 1, 'अंकिचनों': 1, 'जाएंगे।”': 2, 'अंतर्ध्यान।': 1, 'करवाएंगे।’': 1, 'अंडरअचिवर,': 1, 'संस्थओँ': 1, 'महिलओँ': 1, 'उंनकी': 1, 'आँसूंओं': 2, 'अंतर्जगत': 2, 'रुआंसा': 5, 'दुआंओं': 2, 'बताएं.ताकि': 1, 'इंतिज़ाम': 1, 'अँगुली-सन्धि': 1, 'अंतरात्मा,': 1, 'गाऊंगा।': 2, 'प्रयोगशालाएं': 1, 'ईंटा': 1, 'पाएँगे।': 11, ',अंडा': 1, 'इंतज़ाम?': 1, 'अंतर्मुख': 2, 'हवाएँ': 18, 'परम्\\u200dपराओं': 3, 'सिखाईं।': 2, \"आएँगे...'\": 1, 'आंदोंलन': 1, 'लगाएंगे,': 1, 'अंगरेज़ों': 1, 'अंकः': 1, 'रचनाएं।': 1, 'मिलेगा...इंतजार': 1, 'उॉलर': 1, \"गुसाईं'।\": 1, 'जाउंगी...लेकिन': 1, 'जाउंगी..ऐसे': 1, 'जाउंगी..बट': 1, 'जाउंगी...यु': 1, 'जीवाणुओं,बीमारियों': 1, 'चिड़ियाएँ': 3, 'कंबल,अंडा,मांस,शराब': 1, 'शंकाएँ': 1, 'अंतर्जातिक': 1, 'सोमलाओं': 4, 'अं….': 1, 'कंदराओं': 8, '‘आंगनवाड़ी!’': 1, 'अंगड...शक्ति,': 1, 'शुभकामनाएँ!!!*': 1, 'खाऊंगा': 3, 'प्रतिमाएँ': 5, 'इंद्रावती': 4, 'अंगलीला': 1, 'पषुओं': 2, 'गईं...फिजा': 1, \"ड्राइंग'\": 1, 'वेधशालाओं': 1, 'भारियाओं': 3, 'इंटरनेट.': 1, 'आश्रयदाताओं': 1, 'सुनाऊंगी,': 1, 'है.अंग्रेजी': 1, 'आँखें।': 3, 'आसुओं': 7, 'अंगूठियों': 3, 'जाता...अंग्रेजी': 1, 'योजना-परियोजनाओं': 1, 'संवेदनाएँ': 9, 'गाएं': 9, 'ऐंठन,': 2, 'जाएे।': 3, 'आर्थिकताओं': 1, 'असफलताएँ': 2, 'बताऊँ...': 2, 'दुविधाएं': 2, 'आऊंगा.क्या': 1, 'पाऊंगा,यह': 1, 'दवाऐं,': 1, 'आँचल।”': 1, 'राष्ट्रीय-अंतर्राष्ट्रीय': 3, 'ईंटों।': 1, 'घबराएँ': 4, '‘सुविधाओं’': 1, 'ऊँचाइयों': 15, 'आऽऽह': 1, 'अंदरून': 1, 'गईं।’': 1, '‘सार्इंस': 1, 'इंस्टिटच्यूट': 1, '....मतदाताओं': 1, '....युवाओं': 1, 'आंख-नाक': 2, 'इंटेलेक्\\u200dचुअलाइज': 1, 'पाऊं!': 1, 'अँगरेजी': 6, 'चर्चाएँ,': 1, '\\u200dइंदु': 1, 'मनाएंगी।': 1, 'बताएंगे?जहाँ': 1, '‘इंकलाब’': 1, 'रचनाओँ': 1, 'अंग.': 1, 'अंतरिक्षयानों': 1, 'अंतरिक्षयात्रियों': 3, 'रचनाएँ,': 2, 'सोऊंगा': 1, 'दुश्भावनाओं': 1, 'कुमाओं': 1, '.तरु-बालाओं': 1, 'रूप-रेखाएं,': 1, 'टाईंम': 2, 'पाऊँगा,': 3, 'आँखों,': 2, 'आंटी।': 3, 'व्यथाएँ,': 1, '(अंतरराष्ट्रीय': 2, 'रचनाऐं': 2, 'अंक-कथाकार': 1, 'ठहराएंगे?': 1, 'लगाएं?': 2, 'ओंकरानाथ-': 1, 'आॅर्थोडाॅक्स': 1, 'नाइंसाफियां': 1, 'आएँगे?': 1, 'जाऍंगे,': 2, 'दिखाऊँगा': 2, \"'अंकल,\": 1, 'आँखें........जाने': 1, 'बनाओं': 2, 'जाऍंगी;': 1, 'लाऊं।': 2, 'टीकाओं': 1, 'मटकाएंगी': 1, 'सुनाऊं।': 2, ';इंडियन': 1, 'खाएँगे': 3, 'समस्यओं': 1, \"'सुनउं\": 1, 'इंस्ट्रूमेंटल': 2, 'स्थिरताएं': 1, 'जलाऊँ': 3, 'उँढ़ेला': 1, 'आँकने': 5, 'एकाऊँट': 7, 'पीडाओं': 3, 'गुफाओं,': 2, 'इंस्टिंक्ट”': 1, 'दुरात्माओं': 1, 'अंतद्र्वंद्वों': 1, '(आकाशगंगाओं': 1, 'आंउ।': 1, 'आँधी,': 4, '’इंडियन': 1, 'वेतन-भत्तों-सुविधाओं': 1, 'बढ़ाएं...': 1, 'उंगलियां.': 1, 'बनाएंगें': 1, 'काउंसिंग': 1, 'ऑंसू': 8, 'अंतर्क्रिया': 5, 'चाऊंकिया': 1, 'पाईं...।': 1, 'एंटीहाइपरतेंसिव': 1, 'आशाऍं': 2, 'पीड़ाएं': 3, 'आंए': 1, 'ऊँची-नीची': 2, 'शैतानी-आंख': 2, 'कलीसियाओं': 1, 'जाएं.मेरा': 1, 'आ॓र': 1, 'गईं.देश': 2, 'आजाऊं': 1, '80%महिलाओं': 1, 'इंटरनेशन': 1, 'परिचर्चाओं': 4, 'अंकगणित,': 2, \"गोसाईं।'\": 1, \"फाऊंडेशन'\": 1, '“आंसुओं': 2, 'इंतिहान': 2, 'रचयिताओं': 2, 'समानधर्माओं': 1, 'जाएंगे।\"': 3, 'सुनाऊंगी': 2, \"'हूँ-ऊँ-ऊँ-रे\": 2, 'जाएंगीं': 3, 'पार्श्वगायिकाओं': 1, '(इंद्रियों': 1, 'चेष्टाओं': 3, 'खुशबुएँ': 7, 'लगाएं...': 1, 'अँगीठी': 2, 'सजाओं': 2, 'कराऊँ;': 1, 'एमाउंट': 1, 'जिएँ': 5, 'अंचरा': 4, 'उूर्द': 2, 'सजाएँ,': 1, 'ओऽ...': 1, 'काइंतजाम': 1, 'लाबिइंग': 6, 'मांऑं': 1, 'छुड़ाएंगे,': 1, 'प्रतिकूलताओं': 2, 'जिताएंगे।': 1, 'एंगिल': 8, 'बहसों/चर्चाओं': 2, 'शिखाएं': 1, 'प्यार,जलवा,नाज़,अदाएं,मौज,मस्ती': 1, 'फिराऊँ': 1, 'लगाओंगे': 1, 'आंरभ': 2, 'चाहिऐं?': 1, 'जाऊं...मगर': 1, 'अंब्रैला': 2, 'भगाएंगे.डटकर': 1, 'तमन्नाएं': 2, 'शिष्याओं': 1, 'हिचकिचाएंगे': 1, 'होअंधियार': 1, 'इंपॉसिबल': 1, 'अंग-प्रत्यंगों': 1, 'हीआएंगी।': 1, 'अंगारों': 17, 'डाले,अंचल': 1, 'आंटी,': 4, 'अंतबिंदुओ': 1, 'अंतबिंदु(end': 1, 'अंतबिदु': 1, 'अंतर्निर्मित': 1, 'घुमाएँ': 1, 'अंड-पिंड': 1, 'खुशबुएं': 2, 'छायाओं,': 1, 'अंतर्वासना': 1, 'कविताओँ': 4, 'अंग।।': 1, 'विवशताओं': 2, 'काल-अंतराल': 6, 'अंकों(x,y,z,t)': 1, 'विवधताओं': 1, 'भंगिमाओं': 8, 'रहेंगे......अंधेरे': 1, 'ईंजिन': 1, 'आकृति-मुद्राएँ': 1, 'धूप-चांदनी-अंधेरा,': 1, 'सांकेतिक-मुद्राओं': 1, 'कटआॅफ': 1, 'समझाऊं!': 1, 'अंधकार!': 2, 'कनयाओं': 1, 'अंजान.': 1, 'निभाएंगे.”': 1, 'जाएंगे...': 1, 'बतलाएं,': 1, 'बतलाएं': 4, 'प्रतिभाएं,': 2, 'शम्मएँ': 1, 'मान्यताऐं': 1, 'इंसाफ़': 3, 'लाओंगे।': 1, 'रिश्ते,इंसानी': 1, 'अंतर्दृष्टि': 9, 'रोहिंगाओं': 1, 'अंशुमाली': 4, 'समस्याएँ,': 1, 'जाएंगी.”': 1, 'वेदनाएं': 3, 'विचारनिष्ठाओं': 1, 'सुनवाईं.': 1, 'लगाऊं।': 1, 'इंशाअल्ला': 1, 'इंटेलिजेण्ट': 1, 'अंतस्\\u200c': 1, 'फ़रमाएंगे-नज़्ममेरे': 1, 'ऑंधी': 5, 'अंक.': 1, 'अंचिता': 24, 'प्रति\\u200dक्रि\\u200dयाएं': 1, '‘अंकल!': 1, 'ऊँच': 5, 'ज़रीना-आंखे': 1, 'ऊंचा-लंबा': 1, 'उँह': 3, 'हवाओंने': 1, 'इंतीहा': 1, 'सेवाओं(?)': 1, 'अंट-शंट।': 1, 'एॅव': 3, 'हरियाएंगे।': 1, 'हरियाएंगे': 1, '1859)अंग्रेज': 1, 'बेरिओं': 1, 'है...ड्राईंग': 1, '‘हिंदी-इंग्लिश-मिक्स्चर’': 1, 'इंतेहाई': 1, 'बेइंतहाई': 1, 'इंटरैक्ट': 1, 'पत्र-पत्रिकाएं': 8, 'आज्ञाएँ': 1, 'लोकप्रियताओं': 1, 'बताऊँ!': 1, 'उल्काएँ': 1, 'अँगुली': 9, 'माईंजी': 9, 'जाओंगे।': 2, 'गदाएं': 1, 'फाउंटेन,': 1, 'जताएँगे': 1, 'एंड्': 1, 'अंततः,': 2, 'उठाऊँ': 2, 'इंटरलांकिंग,': 1, \"'इंसाफ\": 1, '‘अंजनी’,': 1, 'तृष्णाओं': 4, 'अपेक्षाएँ': 2, 'आँधियाँ': 3, 'क्लाईंट्स': 1, 'आरएंडपी': 1, 'जाएँ.क्यूंकि': 1, 'अंादोलनों': 1, 'साहित्यकाराएं': 1, 'परिकल्\\u200dपनाएं,': 1, 'इंजीर,': 1, 'कुआंरी': 1, 'अंतर्ध्यान': 6, 'अलिओं': 1, 'चढ्ढाओं': 1, 'एस.एंड.पी': 1, 'अंनजान': 1, 'आंखेंं': 1, 'पाईंट': 1, 'अंधी,': 2, 'बिठाऊं': 2, 'घुंघरूओं': 1, 'आंधी...': 1, 'कुआं।': 1, 'श्रंखलाएं।': 1, 'आंखें’': 1, 'सबइंस्पेटर': 1, 'आँकड़ा': 5, 'अँकता': 1, 'इंगित,': 2, 'इंस्टीच्यूशनों': 1, '.अंगोला': 1, '(इंटिमेसी)': 1, 'मन(माइंड)': 2, 'इंग्लॅण्ड': 2, 'अंदाज...': 1, 'अंकशायिनी': 6, 'आऊँ-पर': 1, 'इँसानी': 2, 'हाफ़िज़-मुल्लाओं': 1, '**ऊँचे': 1, 'माफियाओं-अफसरों': 1, 'उँटनी,': 1, 'स्कीइंग,': 1, 'अँगड़ाई': 7, '.,..आँखों': 1, 'आवश्यकताओं”': 1, 'खिंचवाऐं': 1, 'ठहराऊं': 1, 'बालिकाएँ': 2, '“अंतराल/अंतरिक्ष”': 2, 'अंतड़ियां': 6, 'विचारधाराएँ': 3, 'अंदाज़\"': 1, 'बताऊंगी।': 2, \"पाऊं।'\": 2, 'समस्याएँ/बाधायें': 1, 'समालोचनाएँ': 2, 'एंकरिया': 5, 'ऐंठते': 6, 'आरजुओं': 8, 'रक्तधाराऍं': 1, 'होऊं?’': 1, 'जन्मपत्रिकाओं': 1, 'समानताएँ': 2, 'जाऊंगा..': 3, '“हवाओं': 1, 'रज्जुओं': 1, 'करवाएं.लेकिन': 1, 'खिलाएँ,': 1, 'पिलाएँ': 1, 'बताएँ।': 1, 'लेखकों-लेखिकाओं': 1, 'इंटैलिजेंस)': 1, 'अंटसंट': 1, 'जाएंगे....': 1, 'माताएँ': 4, '(अंतर्मुखी': 1, 'शिक्षाएँ': 2, 'भिन्नताएँ': 2, 'आंसू...': 2, 'सभ्यताओं,': 1, 'डराएंगी,लेकिन': 1, 'धरवाएंगे': 1, 'पढ़ाऊं।': 1, 'आँखें...वर्जिन': 1, 'नैतिकताएं': 3, 'आकाशगंगाएं': 6, 'कंडेंस,आँखों': 1, 'इंतज़ाम': 5, 'बलाओं': 5, 'अंग्रेज़': 14, 'इंजीनियर)': 1, 'सप्तमातृकाओं': 1, 'ऊँचा।': 2, 'बे-धुआं': 1, 'आएँ,आना': 1, 'आँका,': 1, 'वेस्टइंडीज़': 3, 'एंटीग्वा,': 1, 'जंघाएं': 2, 'अवस्थाएँ': 2, 'ऍंगरेजी': 1, 'कोईं': 2, 'आँका': 9, 'जाऊँगा,”': 3, 'उठाईं': 3, 'अंगेंजी': 1, 'वीरगाथाएं': 1, 'अंतर्राष्ट्र्ीय': 2, 'कुमाऊँ”': 1, 'इंडिया”': 1, 'जाएंगें': 2, 'है..........कविताओं': 1, 'इंजन,पावर': 1, 'इंस्पेक्शन': 5, 'अभिव्यंजनाओं': 2, '(अंडर-अचीवर)': 1, 'प्रेतात्माएं': 2, 'कोशिकाएँ..': 1, 'इंस्टीच्यूशंस.\"': 1, '-इंदौर': 1, 'महाविद्याएं': 2, 'हुस्ने-सदरे-अंजुमन': 1, 'अँखियाँ': 7, 'होऊँगा-': 1, 'आंदोलन.': 1, '१)आँखों': 2, 'ऑंगन': 3, 'रेखाएं!!': 2, 'दुलराएँ.': 1, 'पहलु\\u200cओं': 1, 'समस्या\\u200cओं': 1, 'है.नेताओं': 1, 'उँचाइयो': 1, 'धुआँधुआँ': 2, 'कहलाऊंगा': 1, 'असफलताएं,': 1, 'अंगोछा,': 1, 'नेत्र-आँख': 1, 'तन्मात्राओं': 1, 'अंजुरी-भर': 1, 'अंकुआ': 1, 'ओलियाओं': 1, 'बेटिओं': 2, 'हिन्दी-अंग्रेज़ी': 1, 'आँसू-आँसू': 2, 'पुरूषों-महिलाओं': 1, 'अंगभंग': 2, 'अंतरगता': 1, 'अंत:स्फुरणा': 1, 'परसाईं': 1, 'दाहिने-बाएँ': 1, 'जिज्ञासुओं,': 1, 'आंकड़े,': 1, 'ओै\"': 2, \"'अंदाज\": 1, 'हुएँ': 5, 'आं..आं..': 2, ',कारी-अंधियारी': 1, 'धोषणाएं,': 1, 'एंजिन': 2, 'इंटीग्रेटर': 1, 'नेताओँ।': 1, 'अँधरे': 1, 'आवश्कताएं': 1, 'आंधियाँ': 5, 'धर्म-गुरुओं': 1, 'अंगहीनता': 1, 'अंदर/कुत्ता': 1, 'समस्\\u200dयाओं,': 1, 'इंडलिनक्स': 1, 'पड़ा/सुविधाओं': 1, 'श्रृंखलाएँ': 2, 'उपत्यकाएँ': 2, 'सिखाएँ': 3, 'काना-अंधा': 1, 'हैं-इंडोनेशिया,': 1, 'ऊँट-कटेली': 1, \"'अंडाकारÓ\": 1, 'एैसा': 4, 'कार्यकरताओं': 1, 'अंतर्भुक्त': 1, 'अंहकार।': 1, 'उँगलियाँ।': 1, 'हैं,सीमाओं': 1, 'पिऊँगा।”': 1, 'एनाउंस': 4, 'आंसूं,': 1, 'यातनाओं,': 1, 'पराधीनताओं': 1, 'अंबर,आग,': 1, 'आँकड़े': 19, 'आँखें.': 4, 'और,आँखें': 1, 'अंगड़ी,': 1, 'जल-धाराओं': 2, 'आएँगे,': 8, 'हुईं..': 1, 'सजाऊंगा': 2, 'कुवासनाओं': 2, 'बाधाऍं': 1, 'कार्यकताओं,': 1, 'गोशालाएँ': 1, 'बताएँ,': 1, 'होऊँ।': 4, 'पऊंगी': 1, 'पिलाएंगे': 1, 'अंगूरी,': 1, 'हिन्\\u200dदुओं': 4, 'ऊंचनीच': 3, 'एंड्रूज': 2, 'बैठाएं': 1, 'गौशालाओं,': 1, 'उपजाऊँ': 1, 'इतराएँ': 1, 'अंतर्जालीय': 1, 'पटकथाऐं': 1, 'अंधेरगर्दी': 6, 'अंतर:मन': 1, 'शाखाऍं': 1, 'सूईं': 2, 'ऊँट।': 1, 'आंटे': 7, 'एंटी-कोएगुलेंट्स': 1, 'आवश्यकताएंरोटी,': 1, '(आंध्रप्रदेश),': 1, 'मनसाओं': 1, 'सिखाऊं': 1, '-अंबरीश': 1, '...मुक्तसरआँगन': 1, 'इंतजार।कर': 1, 'इंजेक्षन': 1, 'लगे.काउंटर': 1, 'अध्येताओं,': 1, 'इंडीपैन्डैन्ट': 1, 'कराईं।': 1, 'अंगन्रेश': 1, 'छवाँईं': 1, 'लीजिएगा...एं': 1, 'बैंक,अंतर्राष्ट्रीय': 1, 'इंर्फामेशन': 1, 'संस्थाएँ,': 4, '‘अंगार’': 1, 'अंतर्बोध': 10, 'साऊँड': 2, 'रोऊं।': 1, 'आषंकाओं': 1, 'अंतर्जनपदीय': 1, 'कराएँगे.': 2, 'आँधियारे': 1, 'हटाओं।': 1, 'आंचल’': 1, 'समझाऊँ': 8, 'मातहओं': 1, 'अंधकार।': 2, 'हवाओं,': 1, 'हवाएँ।': 1, 'महत्त्वकाँक्षाओं': 1, 'अंहाकार': 1, 'है।अंहकार': 1, 'चर्चाओँ': 1, 'समाजसेविओं,': 1, 'बुद्धिजीविओं,': 1, 'पदाधिकारिओं': 1, 'अंबी': 1, 'धर्मशालाओं': 1, 'आकांक्षाएँ': 2, 'लाऊँगी': 2, 'सोऊंगा,': 2, 'इंसेफेलाइटिस': 9, 'जाएं?’': 1, 'अापसी': 1, 'बनाऊँगी': 2, 'इंडो-पाक': 1, 'पहुचाएं,जिससे': 1, 'जगाएं।-Khabron': 1, 'आंखॉ': 1, 'दीर्घाओं': 1, 'आएँगी।': 2, 'ऊंकारदास': 1, 'प्रश्नाकुलताओं': 1, 'अंधविष्वासी': 1, 'जीवन-जन्तुओं': 1, 'हुआं?': 1, 'होऊं.सन': 1, 'बचाऊँ!': 1, 'बुद्धिजीविओं': 1, 'उँचे': 2, 'रोऊँ,': 1, 'कहलाएंगे': 2, 'हटाउंगी': 1, '\\u200b\\u200bपरियोजनाओं': 1, 'गुनगुनाएँ': 1, 'खाएं:': 1, 'औीर': 1, 'जाएंगे...!!!': 1, 'अंदोलनों': 2, 'हत्याओं,': 1, 'भाभाओं': 1, 'अंद्रेएव्ना': 2, 'हुईं;': 1, '\"अंतिमहक्कलम\")': 1, 'शत्रुओंके': 1, 'एंेकाउंटेट': 2, 'छात्राऐं': 1, 'हैडलाईंस': 1, 'गएं।': 2, 'बताऊं.': 4, 'डॉक्टर-इंजीनियर': 1, 'अंक-अक्टूबर': 2, 'हस्तरेखाएं': 2, 'हस्तरेखाओं': 1, 'बताएँगे।': 2, 'वर्जनओं': 1, \"'अँगुलियों'\": 1, 'गोपिओं': 1, 'उपभोगकर्ताओं': 1, 'इँद्रधनुष': 1, 'धुआँ,': 2, 'ललचाऊँ': 2, 'अंधकार,': 3, 'दुर्घटनाएँ': 4, 'बुद्धुओं': 2, 'जाऊँगा..': 3, 'अंधेरे,': 1, 'ऊँचे-बुजुर्ग': 1, 'अंजीरों': 1, 'ऍफ़.एंड': 1, 'काण्डाओं': 1, '\"अंतिम': 1, 'खताएं': 2, 'पीऊँगी’': 1, 'उपभोक्ताओं-दोनों': 1, 'अंहिसा': 3, 'कार्यकर्ताओं-नेताओं': 2, 'लें...ऊँची': 1, 'आवश्कयताएं': 1, 'आँखि,': 1, 'भोजपुरी—आँखि)': 1, 'जन्तुआें': 1, 'अंकशास्त्री': 3, 'निष्फलताओं': 1, 'इंटरमीडियेट': 2, 'एंजियोग्राफी': 2, 'चढ़ाएं': 1, 'आये.इंजीनियर,': 1, 'हवाओं!': 1, 'दिशाएं,': 1, 'अंतराम': 1, 'आलोचनाओं,': 1, 'लूएं': 2, 'कथाओं’': 1, 'सिवईं': 1, 'लाईं.': 1, 'आंदोलनकारी।': 1, 'आॅस्ट्रिया': 2, 'ज्ञाताओं': 1, 'आएंगे..पर': 1, 'लाउंगी': 1, 'इंतज़ार,': 7, 'परिभाषाएँ': 2, 'अँखुआते': 1, 'जल-क्रिड़ाएं': 1, 'गुसांईं': 2, 'धन-पशुओं': 2, 'देवताओंके': 1, 'वाटिकाओं': 2, 'समस्याआें,': 1, 'टाटा,अंबानी,नीरा': 1, 'समझाऊँ।': 1, 'शाखाऐं': 1, 'एंटरेंस': 1, 'अंतरिक्षयात्रा': 1, 'फाउंडेसन': 1, 'इंज': 1, 'मंडराएं': 1, 'अंगड़ाईयों': 1, 'अंधकार...': 1, 'छुपाऊँ': 2, 'आँखे\"': 1, '\"रचनाएं': 1, 'थे,आँखों': 1, 'स्मृतिओं': 2, 'होउॅ': 1, 'पराओं': 1, 'विषयवस्तुओं': 1, 'कमाएँगे': 1, 'अंदेसा': 2, 'अँगुलियाँ': 2, 'महत्त्वाकांक्षाओं': 4, \"पढ़ाऊंगा।''\": 1, 'लोककलाओं': 2, 'पिऊंगा।': 1, 'आँतरिकता': 1, 'पाउंगी...दुनिया': 1, 'इंकारनामा': 1, 'धुआँ-धुआँ': 2, 'बुलाऊँ': 2, 'ऐंगेल्स': 6, 'पाएंगे---जो': 1, 'बनाऊं?': 2, 'धुआंयी': 1, 'लगवाउंगी': 1, 'अंतस:': 1, 'बढ़ाओं,': 1, 'नेताओं,दलालों': 1, 'अंडे-टमाटरों': 2, 'सुनाएं': 8, '‘साइंस': 1, \"''अंदर\": 1, 'अंादोलन': 4, 'चेतनाएं,': 1, 'अंर्तवस्तु': 1, 'जानिएं।': 1, 'अंतरराष्\\u200dट्रीय।': 1, 'हुआँ-हुआँ': 2, 'ऊँघता': 2, 'अंजान..': 1, 'ब्रिलिएंट...वैभव': 1, 'जाऊं....': 2, 'इंतना': 1, 'खाऊँ?': 1, 'कार्यकर्ताओं’': 2, 'बतलाएँगे,': 1, 'बहाऊँ': 1, 'वामलोचनाओं': 1, 'परियोजनाआें': 2, 'सुनाएंगे’': 1, 'बहलाऊँ': 1, '-फुसलाऊँ': 1, '‘अंकन’,': 1, 'जाएँगे)।': 1, '.हिन्दुओं': 1, 'गईँ': 11, 'घटाएंगे।': 1, 'अंडे।': 2, 'सकें/अँधेरे': 1, 'अंगः': 1, 'अंकगणतीय': 1, 'अंदेशो': 1, 'अंतरिक्षों': 1, '/आँखों': 1, 'अंग-प्रत्यंग।': 1, 'पाएंगे?\"': 1, 'आँचल,': 2, 'जाऊं’': 1, 'ही..आँचल': 1, 'ए.के.एंटनी': 2, 'अंधेरनगरी': 1, 'घुघंरूओं': 1, 'अंत:चेतना': 1, 'बन्धुओंको': 1, 'सूचाओं': 1, 'अंघविश्वास': 1, 'आइंस्टाइन-बोस': 1, 'हाड़ौती-अंचल': 1, 'इंटरनेशनल‘': 4, 'जाउँ': 1, 'लाऊँगी,': 1, '(देवताओं)': 1, 'तपस्\\u200dयाएं': 1, 'संपदाओं': 3, 'पाएं-': 1, 'बुझाएं।': 1, 'एंटरप्रायज': 3, 'आँके।': 1, 'सिखाएंमुझ': 1, 'आंगन;': 1, 'दुर्बलताएँ': 2, 'विषमताएँ': 1, 'अंतर-वैयक्तिक': 3, 'अंधा,': 1, '‘अंदाज': 1, '(अंत': 1, 'रुआंसी': 6, 'दिखलाईं,': 1, 'बुलाउंगा।': 1, '‘आंसर': 1, 'खोइंछे': 1, 'धुआँ-': 1, 'ओंठ': 7, 'इंग्लैन्ड': 1, ',अनाउंसमेंट': 1, 'बरसाओं': 1, '--आँखों': 1, 'माऊंटबेटन': 3, 'बिल,छेद,कंदराएं,': 1, 'पंक्तिओं': 1, 'टीकाएं': 1, 'विचारधाराओं,': 1, 'दिखाऊंगा?\"': 1, 'ऊँघते': 2, 'सुरमइ्रर्': 1, 'धुंएँ': 1, 'अंचिता...': 1, 'युद्धगाथाओं': 1, \"'इंडिपेंडेंट\": 1, 'अंगिरस्तमः': 1, 'भविष्यवक्ताओं': 4, 'फिजाएं': 1, 'अंजान,': 3, 'इंतहाँ': 1, 'अंगीरा': 2, 'गईं.राज': 1, 'लड़किओं': 1, 'बुढियाएं।': 1, 'बुढियाओं': 1, 'काम-इच्छाओं': 1, 'मिटाएं': 3, 'अपनाओं': 2, 'बताऐं': 1, 'प्वाईंट)': 1, 'अंधियारी-सी': 1, 'ऊंगुली': 1, 'आंतरीक': 1, 'ऐंठा': 1, 'मौलाविओं': 1, 'टकराएँगे': 1, 'गिनाऊं।': 1, 'दिलवाऊंगा.': 1, 'अपनाऊंगी': 1, 'शुभ-कामनाएं': 1, 'अंगुलिमाल': 3, 'मिआउं': 1, 'अंगप्रदर्शन': 1, '‘आँधियाँ’': 1, 'लाऊंज': 1, 'पाउँगा..?': 1, 'जाऐं।वैसा': 1, 'पाऐँगे?': 1, 'पाएंगे।’': 3, 'जिताएँ': 1, 'एेसी': 2, 'आऊँगी।”': 3, '‘‘ऐंहें!': 1, 'झुकाएंगे।': 1, 'अन्ना-आंदोलन': 6, 'आँखोंमें': 3, 'छोटी-अंजू': 1, 'जाऊं..': 2, 'इंतेज़ार': 5, 'पिएंगे,': 1, 'पिएंगे': 3, '-आंवले': 1, 'ऎंठती': 1, 'आपदाओं,': 1, 'पीडाएं': 2, 'ऊँचे-ऊँचे': 14, 'ऐंठती': 2, 'इंदरकोट': 1, 'पाएँगे?': 2, 'एंल्फ्रेड': 1, 'दनदनाएंगे': 1, 'अंतर-': 1, 'आँसू-भरे': 1, 'औंहाते': 1, 'सुरक्षाएं': 1, 'घ्ाटनाओं': 3, 'अंध-विश्वास': 2, 'आंकती': 2, '‘अंकुर’,': 1, 'सस्थाएं': 1, 'पुरातत्ववेत्ताओं': 1, 'भुजाऐं': 1, 'आंखर': 1, 'इंगति': 1, '-संवेदनाओं': 1, 'रॉंग-इंटरप्रिटेशन': 1, 'आँकी': 2, 'क्षमताऐं': 1, 'पापात्माऐं': 1, 'सुदर्शनाएं': 1, 'थ्रोइंग,': 1, 'हवौएँ': 1, 'लाएँगे...': 1, 'बनाएँगे।': 1, 'राशिओं': 3, 'अंग्रेजी,सिन्धी,': 1, 'गौंओं': 1, 'अंगरेज़ी': 2, 'छपवाऊंगी।': 1, 'लाबीइंग': 4, '‘अंडरप्ले’': 1, 'अंबेडकरवादी': 2, 'अंतरसांप्रदायिकता-': 1, 'अकाऊँट': 5, 'उठाएंगे?क्या': 1, 'कहलाऊं,': 2, 'अंधड़।': 1, 'अँधेरा।': 1, 'जाऍंगे।': 3, 'आऍं': 2, 'उंदर': 1, 'सुनाऊँगी': 2, 'पुष्पाएं': 1, 'हईंजा': 1, 'भूमिकाएँ': 10, 'जाएँगे.”': 1, \"बताऊं?'\": 1, 'ज्वालाऐं': 1, 'फ्लाईंग': 6, 'फ़्लाइंग': 1, 'अंद्रेएव्का': 1, 'गनपॉइंट': 1, 'है,एैसे': 1, 'अंगवस्त्रम': 1, 'आंदोलनको': 1, 'उंची-उंची': 2, 'जुलार्इ्र': 1, 'जाऊंगा\"': 1, 'करवाएँ।': 2, 'अंतरा,': 1, 'थाऊँदा।”': 1, 'भावनाआें': 5, 'मनोभावनाएं': 1, '‘इंद्र': 1, 'रचनाओंका': 1, 'आंकडा़': 1, 'आऊँ।\"': 2, 'अंग्रेज़': 1, 'प्रथाएं': 6, 'एंडोर्फिन': 1, 'समसयओं': 1, 'उंगलियों,': 1, 'आँजा': 1, 'शुभकानाएं।': 1, '(अँगूठे': 1, '‘आँखों': 1, 'आंगनो': 1, 'दिखाएंगें': 2, 'तम्मानाएं': 1, 'सुनाईं': 3, 'अंतस्तल': 3, 'आउंगा': 3, 'नौकाएँ': 2, 'अंड-बंड': 2, 'बताऊँ?': 3, 'पाऐंगे।': 1, 'काईं': 1, 'सीमा-रेखाएँ': 1, 'स्पाइंग': 3, 'व्\\u200dयाख्\\u200dयाएं': 2, 'संभावनाएँ’': 1, 'अंग्रेज़ी,': 1, 'काउंसुलावास': 2, 'इंतहां': 1, 'कर्यकर्ताओं': 2, 'बोलाईं?': 1, 'कन्याओं,': 1, 'बालाओं,': 1, 'था.इंदिराजी': 1, 'पाएंगी.परन्तु': 1, 'हटवाएं।': 1, 'डूइंन.आप': 1, 'खाऎं।': 1, 'अंडमानवासियों': 1, 'रोआं-रोआं': 2, 'आंखों-आंखों': 8, 'हैं.बाबाओं': 1, 'आँकलन': 3, 'एंटिला': 4, 'घबराएं,': 1, 'अंखियन': 2, 'ऊॅंच-नीच': 1, 'साउंडबाईट': 1, \"इंस्टिट्यूट'\": 1, 'विधावाओं': 1, 'संभावनाआें': 2, 'लोकयातिओं': 2, 'अंतरसम्बंधों': 1, \"आऊंगी'\": 1, 'प्रार्थानाओं': 1, 'इंदूवाला': 1, 'मूर्खताओं': 1, 'गुफाओं-तलहटियों': 1, \"जाऊंगा?''\": 1, 'चर्चा-परिचर्चाएं': 1, 'घुँघरूओं': 1, 'आंतें': 3, 'सोऊंगा।’': 1, 'अक्षमताओं': 2, 'दिखाऊंगा।))': 1, 'एंपायर': 2, 'मूढ़ताओं': 1, 'होऊँ': 6, 'लेखकों-कार्यकर्ताओं': 1, 'ऊँचाईयाँ': 1, 'अंह.\"': 1, 'जंतुआें': 1, '!इंद्र': 1, 'हिन्दी,अंग्रेज़ी': 1, 'मान्\\u200dयताओं': 1, 'छपवाईं?': 1, 'जाता...हवाएं': 1, 'अँगारे-से': 1, 'लोककलाएं': 1, 'जाऊंगा.”': 1, '‘आंतरिक': 4, 'अंबेडकर,': 4, 'पत्रि\\u200dकाओं': 1, '(अंग्रेजी': 4, 'थे....दुआएँ': 1, 'अंश,उल्टी': 1, '\"एंटरटेनमेंट': 1, 'इंडीपैंडेस': 2, 'अंजामो': 1, 'दुर्धटनाएं': 1, 'बढ़ाऊं।': 1, 'अग्निशिखाओं': 1, 'आैसतन': 1, 'चरमराईं!': 1, 'दिखाएं*': 1, 'लहराएं*।': 1, 'गाऊँगी,': 1, '‘आइंदा': 1, 'जाएँगी,': 5, 'जीव-जतुंओं,': 1, 'गउएँ': 2, 'पथराएँगे': 1, 'आँखें...कुछ': 1, 'आत्\\u200dमहत्\\u200dयाओं': 1, '।कविताएं': 1, 'नुचवाऊँ': 1, 'उगाऊं': 1, 'एसपीओं': 3, 'आंखओं': 2, 'समस्याएं:': 1, 'दिखाओं।\"': 1, 'आशंकाओं,': 1, 'जगाएंगे': 1, 'चढ़ाऊँगी': 1, 'परम्\\u200dपराएं': 1, 'क्षणिकाएँ': 7, 'अंग्रेज़ो': 2, 'करवाउंगा': 1, 'संवेदनाएँ।': 1, 'र्गइं': 3, 'ईंट-गारों': 1, 'एैसे': 5, 'आंखिरी': 2, 'दिग्बन्धुओं': 1, 'उठाएँ।': 3, '‘डॉन’-इंगलिष': 1, 'है?अंदरसे': 1, 'आंवयुक्त': 1, 'आंत,': 3, 'अपनेक्षाएं': 1, 'पीऊं': 1, 'ऊँख': 1, 'वेर्सिओं': 2, 'सुनाईं.': 1, 'इंतेज़ाम': 2, 'थपथपाएं': 1, 'आएँगे.': 4, '...आँखों': 1, '‘अंधायुग’': 1, 'स्वतंत्रताओं': 1, 'Gentओं,': 1, 'बेवफ़ाओं': 1, 'होऊं।....इस': 1, 'पढ़ाऊँगा।': 1, \"जाएँगे!''\": 1, 'होजाएंगे': 1, 'लडडुओं': 1, 'अंकन-पट': 1, 'खाऊं': 2, 'प्रोफाउंड': 1, 'भरमाऊँ': 1, 'वेद-शाखाएँ,': 1, 'पाएंगे?ये': 1, 'इंसेट': 1, 'प्रधानताएं,': 1, 'वस्\\u200dतुएं': 8, 'इंतज़ार,': 3, '‘इंटरव्यू’': 1, 'ऑंसू-भरी': 1, 'अंबार।': 2, 'शुभेच्\\u200dछुओं': 1, 'जाएँ।”': 1, '‘दुद्धुओं‘': 1, 'शरामऊँगी': 1, 'दारोग़ाओं': 1, ',क्षमताओं,प्रकार्यों': 1, 'जाऊँगा...मंहगाई': 1, 'इंटरेस्टिंग।': 1, 'उंझा': 1, 'सताएं': 5, 'आंनदू': 1, 'निहारिकाओं': 1, 'अँधारते': 1, 'घटनाआें': 1, \"'पावरप्वाइंट'\": 1, 'चेष्टाएँ,': 1, 'इंद्रद्युम्न': 6, 'इंजिनो': 2, 'इंस्टिंक्ट:': 1, 'आँज': 1, 'लगाउॅ।': 1, 'उँडेलने': 1, 'अंश...उसी': 1, 'अंत:विषय': 1, 'गाथाएं': 5, 'चिल्लाऊं': 2, '\"आँख': 3, 'अंतस्थल': 3, 'कविताएं...': 2, 'दिखाऊँगी': 1, 'इंक्यावन': 1, 'आंदा...’’': 1, '(हिन्दुओं)': 2, 'शंकाएं,': 1, '.ऊंचा-पूरा': 1, 'बोएं': 2, 'लिएः-': 1, 'था/आँख': 1, 'जायगी/व्याख्याओं': 1, 'गई.बताऊँ?': 1, 'अंताक्षरियों': 1, 'तन्हाईओं': 2, 'खाएंगे-': 1, 'पएंगे।': 1, 'ईसाईओं': 1, 'खाएं?': 1, 'अँगूठा': 4, 'कोइ्र': 1, 'अंतिरिक्षिय': 2, 'आंख-मिचौनी': 3, 'थे...आंगन': 2, 'उ़डा': 1, ',आँखों': 4, 'अंकुश,': 3, 'ऊँट-पटाँग': 1, 'आउं': 2, 'जुआं,रोते': 1, 'उँआ': 1, 'अंकज्योतिष:': 1, 'बनाऊँ?': 1, 'अंबेदकरवादियों,': 1, '(ऊँचे': 1, 'पिताओं,': 1, 'आँवला': 5, 'आँवले': 3, 'इंटरस्टेट': 1, 'पोर्न-इंडस्ट्री': 1, 'अँगरेज': 2, '‘अंधा’': 2, 'अंर्तजाल': 1, '‘सभ्यताओं': 1, '.आँखों': 2, 'अंधे-बहरे': 3, 'सम्वेदनाओं': 2, 'छायाएँ': 1, 'खाऊँगा-बोलो,': 1, 'आऊँगा।’’': 1, 'नहीं....हिंदी-अंग्रेजी': 1, 'सुविधाएँ।': 1, 'गेसुओं': 2, \"जाएंगे।''\": 1, 'अंपायर।': 1, 'उंगलियां।': 1, 'मनावऊँ,': 1, 'पावउँ': 1, 'पिछलग्गुओं': 2, 'सामाजिकरेखाएं': 1, 'जाएँ..': 1, 'आँशु': 2, 'चुकाएँगे।': 2, \"पढ़ाऊंगा।'\": 1, '“अंताक्षरी”': 1, 'बुलाऊंगा': 1, 'चर्चाओं/बहसों': 1, 'ड्ाइंगरूम': 1, 'उंन': 1, 'जाऊँगा।’’': 1, 'है,अंतर्द्वंद्व,पीड़ा': 1, 'पाएंगे,इससे': 1, 'इंतजार...': 2, 'कुऐं': 1, '-एंटी': 1, 'मिलेंगे-बतियाएंगे।’': 1, 'दुनिया,अंतर्मन': 1, 'आंगन’': 1, 'बताएं-': 1, 'आँखों-देखा': 1, 'आॅलराउंडर': 2, 'आंटते': 1, 'जाएँगे...।': 1, 'कविताऍं': 1, 'भावानाओं': 2, 'योजनओं': 1, 'अंर्तकथाओं': 2, ',पत्रिकाओं': 2, 'है...योजनाओं': 1, 'अंक‘': 1, '-ऊँची': 1, 'सुवधाओं': 1, 'जिऊँ': 1, 'तारिआँ': 1, 'इंड्स्ट्री': 1, 'पवित्रात्माओं': 1, 'हूँ,अंतरिक्ष': 1, 'आजाएँगे।': 1, 'तर्कनाएं': 1, 'बुलाऊंगी': 1, 'शुभकामनाएँ।': 2, 'अंधियार': 1, 'उॅची': 2, 'पाईं...\"': 1, 'एनाउंसमेंट': 2, 'कुँओं': 2, 'कहाऊँ': 1, \"इंडिया।''\": 1, \"''नही.इंदु\": 1, 'अंधियाला': 3, 'आएं“': 1, 'व्यवस्थाएँ': 2, 'अंतरलैंगिक': 1, 'पहनाऊं': 1, 'अंतरंता': 1, 'करो....ऊँचा': 1, 'ऍं,': 1, 'कहलाऊँ,': 1, 'लाऊँगा।': 1, 'करमचरिओं': 1, \"लेख-'अंधेरे\": 2, 'है,अंडे': 1, 'अंडरब्रिज': 4, 'भाएंगे': 2, 'घबराउंगा': 1, 'अंतः': 2, '।अकाउंटेंट': 1, 'कार्यकर्ताओंकी': 1, 'अंतरजात': 2, \"अकाउंट्स'\": 1, 'चित्रशालाओं': 1, 'हृदय-आँगन': 1, 'एकाऊंट्स': 1, 'फाउंड़ेशन': 1, '‘ऊंहूं’’': 1, 'आंधियों': 5, 'गिनाएं।': 1, 'फ़ोटुओं': 3, 'क्रीडाएं': 1, 'साईंस’': 1, 'चंडीगढ़/अंबाला,': 1, 'अंतराग्नि': 3, ',अंजना': 1, 'अासक्ति': 1, 'तीर्थयात्राएं': 1, 'आंघे': 1, 'शुभकामनाएं...': 1, 'आंवों': 1, 'सेनाओं,': 1, 'टहलुओं,': 1, '“अंकल': 1, 'अपनेबाएँ': 1, 'घटनाएं).': 1, 'फ़िज़ाएं': 1, 'मेघमालाओं': 2, 'रेखाएँ-जिनको': 1, \"आंदोलन'\": 7, 'अंबेडकर,सरोजनी': 1, 'अंतर्जालियों': 2, 'एंथ्रोपोलॉजी': 1, 'सम्वेदनाएं': 1, 'जुएँ': 3, 'वस्तुओँ': 2, 'पिएँगे': 2, 'सिंडीकेटों-माफियाओं': 1, 'जाएँ?': 3, '..ऊंचे': 1, '-ऊँचे': 2, 'तईं.': 1, 'आंगीक': 1, 'जन-आकांक्षाओं': 1, 'शिक्षासंस्थाओं': 1, 'तमन्नाएँ': 1, 'अँग्रेज': 6, 'अंतर्गत.': 1, 'वासिओं': 1, 'बनाऐंगे।': 1, 'आ...ऊं....र्इ...': 1, 'रोएंगे': 1, 'सराउंडिंग': 1, 'गाऊंगी।': 2, '*अंधत्व': 1, 'अंतस्\\u200dतल': 1, 'पहुंचे...अंकन...जिसकी': 1, 'निभाऊंगा’': 1, 'जाउॅ।': 1, 'बढ़ाईं': 1, 'इक्षाएं': 1, \"''अंग्रेज़ों\": 1, 'सिंधियाओं': 1, 'संवादिकाओं': 3, 'ठहराएँ,': 2, 'नईं,': 1, 'बनवाऊँगौ': 1, '‘बाउंसर’': 1, 'बाउंसर’,क्या': 1, 'जाऊंगा।अपने': 1, 'जनआकांक्षाओं': 2, 'पिट्ठुओं': 2, 'आंकेगा': 1, 'अँदाज़': 2, 'रुआंसा.': 1, '\"एंग्री': 1, 'उंच-नीच': 4, 'अंबेडकरी': 2, 'सविधाएं': 1, 'संवेदनाओँ': 2, 'तिलकहरुओं': 1, 'चुइंग-गम': 5, 'सीएंडवी': 4, 'वीक-एंड': 1, 'ऐंसे,': 1, 'इठलाएंगे': 1, 'मुन्नीआं,': 1, 'एैश्वर्य': 1, \"आएंगे?''\": 1, 'अभिलाषाएं,': 2, 'आकांक्षाएं,': 2, 'लालसाएं,': 1, 'पिलाऊंगा': 1, 'पिलाऊंगा।': 1, 'ऍंगूठा': 1, 'जाऊं?’': 1, 'ऐंठ-ऐंठ': 2, \"जाऊंगा'\": 1, 'ईँधन': 1, 'चीखें-चिल्लाएं': 1, 'आइं': 1, 'र्गइं।': 1, 'म्याऊं-म्याऊं': 2, 'अँगरेज़।': 1, 'पानिओं': 1, 'आंचल!': 1, 'कंगारूओं': 2, '‘अंबुबाची’': 2, 'अंबुबाची': 1, 'बताएं?’': 1, 'उत्तेजनाओं': 1, 'हिलाएं': 3, '-समझाऊं': 1, 'नेहरू-आंबेदकर': 1, 'इंशान': 2, 'शंकाओं,': 1, 'लघु-पत्रिकाएँ': 1, 'हिन्\\u200dदुओं,': 2, 'उतारूओं': 1, 'गुस्सालुओं': 1, 'इंटरफियरेंस': 1, 'खाऊंगी।': 1, 'इंगलेडिया': 1, 'एमपीइंफो': 1, 'गाथाएँ,': 1, 'ओंकार-भक्त': 1, 'अंधविश्वास-रूढ़िवादिता': 1, 'अंगरेज़“': 1, 'गणिकाओं': 2, 'खाउंगा।': 1, '(इंग्लैण्ड)': 1, 'इंगलेंड': 3, 'धँसाएँ': 1, 'अंडरस्टूड': 1, 'अैार': 1, 'आंसू..♥♥♥♥♥♥♥♥♥♥♥': 1, '(एसऐंडपी)': 1, 'जनआंदोलनों': 3, 'पढ़ाऊं।’': 1, '\"अंग्रेजी': 1, 'गाएँगे': 2, 'बुआएं': 1, 'बच्चों-बहुओं': 1, 'पखेरुओं': 1, 'लोकभाषाओं-बोलियों': 1, 'अंदाज़-ए-बयां,': 1, '“खाऊं': 1, 'खुजाऊं...\"': 1, 'जाउंगा।': 4, 'आउँगा।': 2, 'अंश-अंश': 2, 'दुष्\\u200dटात्माओं': 1, 'प्रस्तिताओं': 1, 'पाऊँगा?': 3, 'अँगुलि': 1, 'है....अंग्रेजी': 1, 'मन्थराएँ': 1, 'दुर्घटनाएं.जुलूस': 1, 'उदियाओं': 1, 'अंगद,': 3, 'लगाएंगे?’': 1, 'गाथाएँ': 1, 'पीसवाएं': 1, 'अंग्रेज्री': 2, 'अंचिता।': 1, '16-आंवले': 1, \"लाऊँगा।'\": 1, 'एंकात': 1, 'अंत:सर': 1, \"'अंतर्ध्यान'\": 1, 'जाउँगा': 1, 'अवधारणाएँ': 1, 'अंतव्यक्तिक': 1, 'आऊं.': 1, 'उठाएंगे।वित्त': 1, 'आँधी-तूफान': 2, '‘आँधी-तूफान': 1, 'संक्रियाएं': 2, 'आंदोलन,रैनेसां': 1, 'बढ़ाएंगें': 1, 'समस्याऐं': 1, 'इंसान...': 1, 'अंतजार्तीय': 1, 'शिशुओँ': 1, 'ड्राइंग-रूम': 6, 'धरती-अंबर': 1, 'इंदरसेन': 1, '\"अंतस': 1, 'ऐंद्रिकता': 1, 'दुआएँ': 7, 'अभिलाषाएं!!': 1, 'उंको': 1, 'अंग्नरेश': 1, 'इंद्रहार': 3, 'आउंगी,': 1, 'आउंगी.............': 1, 'उॅकारजी': 1, 'तंत्रिका-प्रक्रियाओं': 1, 'शुभकामनाएँ.': 1, 'खाएंगे.': 1, 'लोकपरंपराओं': 1, 'अंतरविरोधों': 1, 'पाऊंगा?’': 1, 'सम्भावनाआंे': 2, 'अनायुओं': 1, \"''ओरिएंटल\": 1, \"आंदोलन'',\": 1, 'आंच,': 2, 'बुझांऊं': 1, 'प्रतिबध्दताओं': 1, 'पिऊँदा,': 1, 'आऊँदा।”': 1, 'होऊँगा।”': 1, '’आंदोलन': 1, '\"अंकों\"': 1, 'आंखा': 1, 'जिज्ञासुओं': 4, 'संवदेनाओं': 1, 'आइंस्टिन': 1, 'सोऊँगी।”': 1, 'ख़ुशबुओं,': 1, 'अंगूठियों,': 1, ',हिन्दूओं': 2, 'डाक-सेवाएं': 1, \"'इंस्टेंट\": 1, '’अंतर्राष्ट्रीय': 2, \"आँख'\": 1, 'हाथ,पैर,आँख,कान,से': 1, 'आँखमिचोली': 1, ',सुविधाएं': 1, 'पत्रकाओं': 1, 'उंदती,': 1, 'जुगनूओं': 2, 'लगवाएँ।': 1, 'ट्रस्ट,इंडिया': 1, 'दोहराऊं।': 1, 'फर्मा-रवाओं': 1, 'अंधविश्वासों-रूढि़यों': 1, 'आँचबसा': 1, 'इंतजारी': 1, 'अल्बर्टआइंसटीनकहते': 1, \"इंतज़ार'\": 1, 'संचार-कलाएं,5.शांति': 1, 'अपेक्षाओं-आकांक्षाओं': 2, 'विधाताओं': 4, 'बनाऊंगी': 2, 'चुराऊंगी': 1, 'ईँट': 2, 'अंदाजों': 3, 'खाएँगे?’’': 1, 'उठाएँ।\"': 1, 'लाओं,': 1, '(आँखें': 1, 'अंाखें': 1, 'भैयाओं': 1, 'जाउँगा,...': 1, 'बाज़ुओं': 2, 'तैराऍं': 1, 'इंस्टालमेंट': 1, 'जाएंगे/......': 1, 'जाएंगे/': 3, 'चलाएं...': 1, 'फाइंटिंग': 1, 'विभिन्नताएं': 2, 'शीतमनाओं': 1, 'करवाएँगे': 2, 'एंटीवायरस': 9, 'अँगरेज़': 4, 'कुलाह(ऊँची': 1, 'जाएंगे।इससे': 1, 'उगाऊँ': 1, 'अनियमिताओं': 1, 'महात्वाकांक्षाएं': 2, '\"कथाओं': 1, 'बरासओं..': 1, 'बरसाओं...': 1, '3.गर्म-हवाएं': 1, '8.कविताएं-1,': 1, '9.कविताएं-2,': 1, 'चबाएँ': 1, 'इंटर-मिनिस्टीरियल': 1, 'अंकगणितीय': 1, '/आंधी': 1, 'बढ़ाऊंगी': 1, 'व्यूफाइंडर': 1, 'जाईं,': 1, 'गौशालाओं': 1, 'माएँ': 6, 'प्रतिमाएँ,': 1, 'सोएं?': 1, 'इंग्रिड': 3, 'उंन्होने': 1, 'आतुओं': 1, 'इंद्रियोन्\\u200dमुख': 1, 'बद्दुआओं': 1, 'आंखोँ': 2, 'आइंस्टीन,': 1, 'कहीं,आंगन': 1, 'पाईं?': 2, 'अंव': 1, 'लिखवाएं': 1, 'धोएँ।': 2, \"जाऊंगा.'\": 2, 'मिलाईं': 2, 'होऊंगा.': 2, '.साइंसदानों': 4, \"'ईंट\": 1, 'जाऊंगी।\"': 1, 'ब्\\u200dलैक-एंड-व्\\u200dहाइट': 1, 'बतलाएंगे,': 3, 'बतलाएंगे': 1, 'बतलाएंगे।': 1, 'मंगलकामनाएं': 1, 'अंडरग्राऊंड': 6, 'इंटरनेट,फेसबुक': 1, 'कटाएँ': 1, 'शोध-कर्ताओं': 1, 'दिलाऊं': 1, '\"एंक': 1, 'एंकसांथ': 1, 'उंतालता': 1, 'वसुओं': 2, 'उँची-': 1, 'मलिनताओं': 1, 'फहराएंगे...': 1, '(उंगलियां': 1, 'एकाउँट': 3, 'उपयोजनाओं': 1, 'बरपाऊंगा,': 1, '’कामनाओं': 1, 'हॆं.अंग्रेजी': 1, 'इंटरेस्टिंग.': 1, 'लंबी-ऊंची': 1, '(आकाशगंगाओं)': 1, \"जाऊंगी.'\": 1, 'इंजीनियर-ठेकेदार': 1, 'मुस्\\u200dकाऍं': 1, 'ताल-तलैय्यों,जीव-जंतुओं': 1, 'पर,इंटरनेट': 1, 'न्यायवेत्ताओं': 1, 'अंतत;': 1, 'गईं-': 1, 'खिलखिलाओं': 1, 'विद्वत्ताओं': 1, 'अँधे': 2, 'अँधों': 1, 'आंधी-तूफ़ान': 1, 'में...इंद्रनाथ': 1, 'धुंओं': 3, 'अंतमे': 1, 'जाउॅगा': 2, 'परसंप्रभुताओं': 1, 'उंगिलयां': 1, 'आंदुल': 1, 'यौवनाएं': 2, 'मचाएं': 4, 'खुशबुएँ...कभी': 1, 'अंशज,': 1, 'काला,नेताओँ': 1, 'सेवाओं-': 1, 'अंतरराष्ट्रीयता\"': 1, 'जाऊं....!!': 1, 'श्रृंखलाएं,': 1, 'पुरासम्पदाएं,': 1, 'गुफ़ाएं-कंदराएं,': 2, 'रामकथाओं': 4, 'इस्तेमालकर्ताओं': 1, 'अंकूर': 1, 'अंत...इससे': 1, 'खाऊंगा,': 2, 'मनोदशाएं': 2, 'कराऊँ': 2, 'अवहेलनाओं': 1, 'प्रतिभाएँ': 2, 'एंगेजमेंट': 5, 'इंन्द्रधनुष': 1, 'योजनाओं”': 1, 'भव्यताएं': 1, 'बताउँ,': 1, 'डा.अंबेडकर': 2, 'कहा-इंसान': 1, 'आँखें,कान,हाथ,पैर...पांच': 1, 'दबाऐंगे': 1, 'आक्रान्ताओं': 1, 'लिनिएंसी': 1, 'ऋतुएँ,': 1, 'भगाएँ': 1, 'अंकशास्त्र': 9, 'जाऊँ?”': 1, 'मराठाओं,': 1, '\"बन्दउँ': 1, 'जमाएंगे।': 1, 'हवाऐं': 1, \"'हुडुकचुल्लुओं'\": 1, 'आऐं': 1, 'इंसाफी': 2, 'मानव-सभ्यताएं': 1, 'बनवाएंगे': 1, 'लिखवाएंगे': 2, 'आरजूओं': 1, 'एंपुल': 1, 'आँख,कान': 1, 'संरचनाएँ': 1, 'पाठकों/श्रोताओं': 1, 'आंकणा': 1, 'जाऍं': 5, 'साधनाएँ': 1, \"''अंधेर\": 1, 'मरीचिकाएँ': 1, 'अंगार-सी': 1, 'गाईं।': 1, 'ऊंचापूरा': 1, 'मुंह-अँधेरे': 1, '/रचनाओं': 1, 'बाबाओं/बापूओं/स्वामियों': 6, 'बनवाऊंगा।': 1, 'अंगूठानुमा': 1, 'घटनाओं/मुद्दों': 1, 'हवाएं,अमावास': 1, 'ड्राईंग्स': 1, 'एंडेवर': 3, 'दिखाऊं:': 1, 'दौड़ाएंगे': 2, 'इंग्लिस्तान': 1, 'धुआँरे': 1, '!आँखें': 1, ',आँसू': 1, 'अंतरग्नि': 1, 'अंतर्नभ': 1, 'मज्बूरिओं': 1, 'होउंगा।': 2, 'इंस्टिक्ट': 1, 'टू-द-पाइंट': 1, 'शीलाओं': 1, 'आंवला(सिध्दीदात्री)': 1, 'इंडोलॉजी': 2, \"खाऊँगी।'\": 1, 'हिन्दुआो': 1, 'घुमाऊंगा,': 1, 'ट्राइंग': 1, 'अॅापेरा,': 1, '‘अंतर्राष्ट्रीय': 1, 'अपनाऐं': 1, 'समझाऊं?’': 2, \"प्राथमिकताएँ'\": 1, 'कईओं': 1, 'हसाउंगी': 1, '.अंग': 1, 'इंजीनियरी': 3, 'चिड़ियाओं': 1, 'आँसूं': 8, 'आतंकवादिओं': 2, 'एंठन,': 1, 'चबाईं': 2, 'अंगन': 1, 'उंगलियो': 1, 'विक्रेताओं,': 2, 'चोपड़ाएं': 1, 'वृध्दाओं': 2, 'इंजील': 2, 'खिज़ाओं': 2, 'काउंसल': 1, 'आॅलियोलक्स': 1, 'अंक;': 1, 'इंद्रमणि—यदि': 1, 'सम्भावनाएँ।': 1, 'सदभावनाएँ': 1, 'अमानुषिकताओं': 1, 'इंतकाम': 1, 'के...मंशाओं': 1, '‘के-आऊँ': 1, 'जाएँ.ना': 1, 'मल्लिकाएँ': 1, 'पाएँगी': 2, 'जाएँ.इधर': 1, 'जलधाराओं': 1, 'जलधाराएं': 1, 'पीएँ,': 3, 'जाएँ”': 4, 'बताऐंगे': 2, 'आँकता': 2, 'तअ़ाला': 4, 'तूफ़ान,बाजुओं': 1, 'इंडीजॉब्स': 1, 'आऊँगा?': 1, 'बसाऊँगा।': 1, 'अंगे्रज': 2, ',सुनाऊँ,': 1, 'अंखियाँ': 1, 'अंगडाइयां': 1, 'उ्देश्य': 1, 'समस्याएं-': 1, 'आँख,इन': 1, 'धूएं': 1, 'उठाएं-': 1, 'ईंघन': 1, '♥♥♥♥♥♥♥♥आशाओं': 1, 'इंटरव्यूज़': 1, 'छुड़ाऊँगा': 1, 'सद्गुरुओं': 1, 'शहरी(इंदिरा': 1, 'अंडकोषों': 1, 'स्वाभिमान,अंहकार,कर्म,भावनाएं': 2, 'आएंगें,': 1, 'बाललीलाऐं': 1, 'धूल-धुआं,': 1, \"''इंतहाÓÓ\": 1, 'हूँ.अंत': 1, \"चाहिएँ।''\": 1, 'जीऊँगी.': 1, 'बुलाएँ।': 1, 'सुईं': 2, 'अ़हद': 2, '‘इंटरव्यू': 1, 'अन्योन्यक्रियाएं,': 1, 'अंतर्गुथित': 1, 'वृष्णओं': 1, 'नेताओं...': 1, 'खाऊँगी.': 1, 'समझाउं': 2, 'अंतर.निहित': 1, 'है.इंदौर': 1, 'आँदोलन।': 1, 'मानताओं': 1, 'बिताऊं': 2, 'जगाओं,': 1, 'हिन्दी-इंगलिष': 1, \"'इंसान\": 1, '(अंक-22,': 1, 'जीवनधाराओं': 1, 'दूर्वाओं': 1, 'इंतज़ारमें': 1, 'पाऊँगी।': 3, 'इंद्रियबोध': 1, 'अंतरिक्षों,': 1, 'पाऊँगी.': 1, 'तर्क-समीक्षाओं': 1, 'ऐऽ..सुनो': 1, \"'हूँ-ऊँ-ऊँ!'\": 2, 'आवश्यकाओं': 1, 'जिज्ञाषाएं!!': 1, 'खाएंगें?': 1, 'निर्वसनाएँ,': 1, 'निर्वसनाओं': 1, 'निर्वसनाएँ': 1, '.राजाओं': 1, 'एंटिऑक्सीडेंट्स': 1, 'इंग्लेंड': 1, 'ईंटगारों': 1, 'इंगवले,': 1, 'हो,इंतज़ार': 1, ':कुमाऊं': 1, 'उंकड़': 1, 'हैं-‘कुएं': 1, 'ओ़बी़': 1, 'अंतःकरण,': 1, 'सदस्यताओं,': 1, 'परीक्षाएं,': 1, 'विचारधराओं': 1, 'अंधड': 1, 'इँट': 1, 'संज्ञाओं': 3, \"'अंचल',\": 1, 'जाएँ,भूखो': 1, 'आँखिन': 1, 'इंस्टाल्ड': 1, \"''इंकलाब\": 1, 'अंतर्संबंधों': 2, 'अंग-विन्यास': 1, 'मनाएँ': 2, 'भ्रष्ट-सत्ताएँ': 1, 'एंजियोजेनिक': 2, 'एंटीओक्सिडेंट': 1, 'इंटेसिटी': 1, 'अंतत,': 1, 'बतलाएँगें': 1, 'लहलहाएंगे': 1, 'निभाऊं...': 1, 'बनाएंगे।”': 1, 'अंदाज़-ऐ-हया': 1, 'बजाउंगी': 1, 'अंगीकरण,': 1, 'हाफ़िज़-मुल्लाओं': 1, 'बिताएं:': 1, 'विषय-विस्तुओं': 1, 'इंटरव्यू.': 2, 'इंदिरानगर': 4, 'अंगरों': 1, 'अंडवृद्धि,': 1, 'होऊं?': 2, '\"आंटी-आंटी\"': 2, 'चाहिएं???': 1, 'आउँगा': 2, 'बताऊँ..\"बड़े': 1, 'पाऊँ...”,': 1, 'पार्श्वगायिकाएँ': 1, 'राष्ट्रीय-अंतर्राष्ट्रीय,': 1, 'हटाऊंगी।': 1, \"'अंतर्राष्ट्रीय\": 5, 'जलाएँ!': 1, '...अंत': 2, 'की(अंजलि': 1, 'लाऊँगी।': 1, 'होउंगी...उस': 1, 'आंसूओं': 6, 'विलास-वस्तुओं': 1, 'मचाएँ': 1, 'टकराईं।': 2, 'गईं-लूट,': 2, 'झंझओं': 1, \"'दोर्लाओं'\": 1, 'इंतहा।': 1, 'आधुनिकताओं': 1, 'अत्याधुनिकताओं': 1, 'दन्तकथाओं': 1, 'बढ़ाएँगे।': 1, 'कथाएँ.': 1, 'कैलामाइंन': 1, 'अंडा,टमाटर': 1, 'चुराएंगे?': 1, 'मनाएं,': 2, 'अंर्तमुखी': 1, 'अंदाज़-ए-बयां': 2, 'अंधेरी-सी': 1, 'इंडिया।': 3, '‘इंटरनेट,': 1, 'अंतवस्तु': 1, 'घबराएंगे': 2, 'आऐंगे।': 1, 'ओंमकार': 1, 'उड़ाएं;': 1, 'ऊंचाई।': 1, 'देशनाओं': 3, 'इंसान-इंसान': 4, 'जाएँगी?\"': 1, 'स्वयंवराओं': 1, 'पाएँ,': 2, \"'परंपराओं'\": 1, 'हैं--अंर्स्ट': 1, 'इंपीरियलिज्म’,': 2, 'छाओं': 5, 'फिल्म-इंडस्ट्री': 1, 'सक्रियताएं': 1, 'जाऊंगा!’': 1, 'जाएंगा।': 1, 'पाएं...तब': 1, 'भाग्य-अंक,': 1, '\"अंजना': 1, 'यातनाएँ': 5, 'आएगा/आएँगी।': 1, '(रचनाओं': 1, 'कराईं.': 1, 'बहाऊँगी': 1, 'जाऊँगा.असित': 1, 'बढ़ाएंगे।’': 1, 'इंफोटैक': 1, 'इंटरप्राजिज': 1, 'मनाऊँ,': 1, 'आँकना': 1, 'इंलुएंस': 4, 'नहाऊंगा।': 1, 'एंड्रोयिड': 1, 'युत,आंनद': 1, 'इंट': 1, 'भगाऊँ': 1, 'मनोकामनाएँ': 2, 'बैंक-शाखाओं': 1, 'नाइंसाफी,': 1, 'छात्राएं...': 1, 'आंठवीं': 1, 'गाऊंगा.': 1, 'आंदोलनकारीयों': 1, 'इंडेक्स)': 1, 'उपमाएं,': 1, '“कुएं”': 1, 'सजाएँ': 6, 'जाएँगी...': 1, \"मालाएं.'\": 1, 'साउंडप्रूफ': 1, 'अंदुरनी,': 1, 'इंटोक्राइन': 1, 'जाएँगा।': 1, 'अंगेज़': 1, 'इंन्जीनियर': 1, 'अंधेंरे': 2, 'इंजीनियरिंग’': 2, 'बताऊँ,क्यों': 1, 'दबाओं': 2, 'अल्ट्रासाऊंड': 10, '‘आएंगे': 2, 'आॅलआउट': 1, 'आँतों,': 2, 'इंतज़ारकी': 1, 'ललनाएं': 1, 'चढ़ाएँगे.': 1, 'दक्षताओं': 1, 'जाऊँगा।\"': 1, 'जाएँगे”': 1, \"'बाउंड्री\": 1, 'अमरिकाओं': 1, 'हटाऊँ?': 1, 'अंतर्वस्त्र': 2, 'पुस्तक-पुस्तिकाएं': 1, 'अंतद्र्वन्द्व': 1, 'झपकाएं,': 1, 'संभावनाओं,': 2, 'यथार्थ-संभावनाओं': 2, '(बाएं': 1, 'जाऐं।': 2, 'इंसानियत..': 1, 'झुकाऊँ': 1, 'सहराओं': 4, 'हटाऊँगा': 1, 'आँखे-': 1, 'अंर्तराज्यीय': 1, 'बुराईओं': 1, 'आंगणियै': 1, 'इनफ्लूएंजा': 3, 'इनफ्लूएंजा-': 1, 'इंक्यूबेटर': 1, 'अंजाम।': 2, 'इच्\\u200dछाएँ': 1, 'दिखाऊंगा,': 1, 'धर्म-कथाएँ': 1, 'अंधभक्तों': 2, \"विधाएं'\": 1, 'अंतरें': 1, 'कुअंर—वहां': 1, 'चिल्लाएंगे,': 1, 'जिऊँगी।': 1, 'नेनुआं': 1, 'आइंस्\\u200dटीन': 2, 'आएंगे...यही': 1, 'लताएँ,': 1, 'अंबिकापुर.': 1, 'सोऊं।': 1, \"'बॉडी-मास-इंडेक्स'\": 1, 'अंतर्द्वंद': 5, 'जड़ताओं': 1, 'एैरे-गैरे': 1, 'जनआंदोलनो': 1, 'ओंकारदास': 2, 'ऊंचा-नीचा': 1, 'अंधियारों': 3, 'गुसाईं,': 1, 'जाएँ.या': 1, 'जाएँ.किसी': 1, 'गलतिओं': 2, 'जाऊँगा।‘': 1, 'बाएँ,': 1, 'गंवाएंगे।': 1, 'मंहगाईं': 1, 'अंधियरी': 1, 'पहनाएं': 1, 'बिन्दूओं': 1, 'छिपाऊँ,': 1, 'फडफडाउंगा': 1, 'आँसओ': 1, 'बजाएँगे': 1, 'आंकि': 1, 'महबूबाओं': 1, 'जंघाओं': 6, 'उम्मीदें-आकांक्षाएं': 1, '”इंसाफ“': 3, 'महत्\\u200dवकांक्षाएं': 1, 'गरिमाओं': 1, 'उंधियू': 1, 'पाएंगे/': 1, 'लगाउं।': 1, 'लगाएं...लेकिन': 1, 'बजाउंगा': 1, 'युवतियों/महिलाओं': 1, 'जाएँ.लेकिन': 1, 'अट्टालिकाओं,': 2, 'इंडीजीनस': 1, 'रचाएं': 1, 'अंतर्विरोधी,': 2, 'इंटरनशनैल': 1, 'आइंस्टाइन.': 1, 'आँख-कान-नाक': 1, 'उॅट': 4, 'आत्महत्याओं,भूख': 1, 'आँटी...सच्ची': 1, 'अंकल...शायद': 1, 'अंतकरण': 2, 'साईंस.': 1, 'शब्द-ऋचाओं': 1, 'गईं.....': 1, 'कार्यशालाएँ': 1, 'अनियमितताऐं': 1, 'आंखे,': 4, 'लघुकथाएँ’': 2, 'तन्तुओं': 1, 'अंकल-दोस्त': 1, 'बतलाएँ': 3, 'कार्यषालाएं': 1, 'अंसतुलन': 1, 'दलबदलुओं,': 1, 'इंतजामो': 1, 'अंधेरा।': 1, 'अपेक्षाएं’': 1, 'अंतर्विवशता': 1, 'जीजाओं': 1, 'इंटेंस': 1, 'राजव्यवस्थाएं': 1, '(एंटी': 1, 'इंटलेक्च्युअलिज्म)': 1, 'कीआँखे': 1, 'घुमाएंगे': 1, 'पहरुओं': 1, 'मानस-चक्षुओं': 1, 'आँत,': 1, 'अपसराएं,': 2, 'अंबेडकर।': 1, 'द्रष्टाओं': 2, 'सजाउं': 1, 'भाषाओंकी': 1, '‘‘इंडियन': 2, 'जाऊँ॥2॥॥': 1, 'संज्ञाएं': 1, 'आँखॉ': 1, 'उँगलीयों': 1, 'खाल्डीओं,': 1, 'हिब्रुओं,': 1, 'लताओं-पत्तियों': 1, 'अंधेंरों': 1, 'इंवेस्टिगेशन': 1, 'इंस्पेक्टर्स)': 1, 'दवाएॅ': 1, 'अंगराज': 2, 'आँसू....': 1, 'लाएंगे;': 1, 'अंगुष्ठ': 1, 'ऋृषि,': 1, 'अंगड़ाईयां': 1, 'अंत।।11।।': 1, 'बाएं-दांए': 1, 'प्राय:कविताओं': 1, 'अन्तर्गत-गुफाओं': 1, 'लघुकथाएं(1976)सं-सतीश': 1, 'लघुकथाएं(1977)सं-नरेन्द्र': 1, 'लघुकथाएं(1979)': 1, 'उ़फ़!': 1, 'अम्माएं': 1, ',शुभकामनाएं': 1, '....परम्पराओं': 1, 'ऊंघा': 2, 'राष्अ्रपति': 1, 'काली-अँधेरी,': 1, 'महात्माओं,': 1, 'रोऊंगी': 2, 'छुपाएंगे': 1, '‘ग्राउंड': 1, 'राष्ट्राध्यक्षों/राजनेताओं': 1, '‘अंटारेस‘': 1, 'भावनाओंकी': 1, '\"अंधेरी': 1, 'कविताएं\"': 1, '-अंगना': 1, 'जाउंगी...जिंदगी': 1, 'गल्लैऊं': 1, 'पाऊँगी...': 1, 'देखिएः-': 1, 'धातुएँ)': 1, 'हुईँ': 1, 'सर्वहाराओं': 1, 'अंगप्रभा': 1, 'करवाएंगे...मैंने': 1, \"जाएँगे'\": 1, 'गोरी-अंग्रेज़': 1, 'प्रतिज्ञाएँ': 1, 'परिस्थितिओं': 2, 'पहुँचाऊँ': 1, 'विशेषताएॅ': 1, 'बाधाएॅ': 1, 'घटाएं।': 1, 'अंतरिक्षमसुं': 1, 'साइंसदाँ': 1, 'लालाओं': 2, 'चौंधियाएं,': 1, 'जाएंगी...': 1, 'अंहिंसा': 2, 'अंतर-बाह्य': 1, '‘इनकाउंटर': 2, 'दिलवाएं...?': 2, 'अंतर्द्वंद्वों': 1, 'व्यंजनाओं': 1, 'जाऊं....!': 2, 'अंितंम': 1, 'खड़ाऊँ': 1, 'खड़ाऊँ?\"': 1, 'दोहराएं(डंडा': 1, 'सताएँ': 1, 'दिलाउंगी': 2, 'ढेरों-चर्चाएं': 1, 'अँखियन': 1, 'भाव-भंगिमाएं': 2, 'आँखोंवाले': 1, 'इंर्ट': 2, 'ठहराएंगे': 1, \"जाएंगे।''उन्होंने\": 1, 'अंज़ाम': 3, 'मूर्खताएं': 1, 'प्रसुताओं': 1, 'गोलिओं': 1, 'डिटरजेंट,यूरिया,सोडा,शैंपू,रिफाइंड': 1, 'आॅयल,': 1, 'शैंपू,रिफाइंड': 1, 'आॅयल,पानी': 1, 'शिशुआें': 2, 'अंतर्राष्टÑीय': 2, 'कोआॅपरेटिव': 1, 'राजाज्ञाओं': 1, 'इंवॉल्वमेंट': 1, 'काउंसलावास': 1, '(MDLR)एयरलाइंस': 1, \"जाऊं?'\": 1, 'बनाएंगे।’': 1, 'सिखाऊंगा,कि': 1, 'पार्टियों-नेताओं': 1, 'इंडियन‘': 1, 'चढ़ाएं-': 1, 'कविताएँ....या': 1, 'सिर-आँखों': 1, 'कहलाउंगा!!!': 1, '...आँगन': 1, \"अंकल।''\": 1, '-प्वाइंट।': 1, 'सरिताएँ': 1, 'इंस्टीट्यूशनलाइज़': 1, 'आएँगे?\"': 1, 'लाऊँगा,': 1, 'जाएँ.और': 3, 'सभ्यंताएं': 1, 'अंजनारूप': 1, 'वफाओं': 3, 'इंर्ट...': 1, '\"ऐंकर': 1, 'चिपकाएं।': 2, 'अंदाज़े': 1, 'झाएं': 2, 'एक्सप्रेसइंडिया': 1, 'एक्सपेरिएंस': 1, 'फ्रेजाइंजी': 1, 'लगाईं,लेनिन': 1, 'चढ़ाऊंगा': 1, 'निष्ठापूर्वकनिभाएं': 1, 'जाऊंगा..।’': 1, 'बताउंगा': 4, 'इंटिग्रेटिव': 1, 'बैगाओं': 5, 'उंच': 7, 'खपाऊं??': 1, 'अल्\\u200dपनाएं': 1, 'छुड़ाएँ': 1, \"बंटाऊंगी!'\": 1, 'अंगेज’र': 2, 'आंखी': 2, 'हम(अनपढ़,अंगूठा': 1, 'अंतर्दृष्टि,': 2, 'कायाओं': 1, 'अंसंभव': 1, 'जाउं,': 3, 'संवेदनाऐं': 1, ',ईंट': 1, 'जेल-यात्राएं': 1, 'नजर-अंदाज': 1, 'बोईं': 1, ',इंज.एस.एस.शर्मा': 1, 'दुहराएंगे?': 1, 'ऐंठी,': 1, 'शमाएँ': 2, 'ऐंग्लो-अमेरिकन': 2, 'अंडे-बच्चे': 4, 'बढाऊं॥२॥': 1, 'इंजीनियरिग': 1, 'अंतस्तल.': 1, 'आकाशगंगाएँ,': 1, 'अंघा': 1, 'जाएँगे।’’': 3, 'माउंड': 1, 'अंतर्यात्रा': 2, 'बताऊँ...सैकड़ों': 1, '17.इंटरनेट': 1, 'अंतर्सम्बन्ध': 2, 'बाल-कविताएं': 1, 'आएँगी)': 1, 'उगाएंगे!': 1, 'महाऋृषियांे': 1, 'अंगीरा,': 2, 'कटुताओँ': 1, 'आॅयल': 1, 'अंत:पुर': 2, 'जलाऊं': 2, '‘अंडरपास’': 1, 'फ़रमाईं': 1, 'एंटीवारसों': 1, 'शेर्पाओं': 1, \"'ऊं'\": 1, \"हैं,'ऊं'\": 1, '(अंकित': 1, 'आएंगे।\"': 1, 'इंटरेस्टेड': 2, 'आंकाक्षाओं': 4, 'ईंगेज': 1, 'कठमुल्लाओं': 1, 'सभ्\\u200dयताओं': 1, 'अंदाज़-ए-इश्क': 1, 'गईं...': 5, 'प्रजाओं': 1, 'इंटेग्रीटि': 1, 'होउंगा,': 1, 'अँखियां': 2, '‘ऊँची': 1, 'अँजोर': 1, 'तनाओं': 1, 'लाउंडरिंग': 1, 'खड़खड़ाएंगी': 1, 'समझाऊँ?': 1, 'करवाऊँ': 1, 'सुनाऊंगा.': 1, 'रोऊँगी': 1, 'इंजक्शन': 1, 'दंतकथाएं': 1, 'दीपमालाएँ': 1, 'इंटिलिजेंस': 2, 'अंटावा,': 1, 'भाषाओं-': 1, 'सुझाएँ,': 1, 'अंधविश्वासियों': 1, 'ईंध्ना': 1, 'वस्\\u200dतुओं,': 1, 'अंतर्निर्भरता': 1, 'लाऍंगें—': 1, 'छटाएँ': 1, 'टकराएँ': 1, 'बाइंड': 1, 'बाधओं': 2, 'एनकाऊँटरकी': 1, 'अंवेषी': 1, 'समझाओं,': 2, 'प्रेम-चक्षुओं': 1, 'अाग': 1, 'सिखाईं': 1, 'आकाशगंगाओं,': 2, 'नुमाइंदो': 1, '\"आंटी': 1, 'थर्राएँ': 1, 'पापिष्\\u200dठाओं': 1, 'प्रार्थना-सभाओं': 1, 'रंगों-रेखाओं,': 1, 'धर्मात्माओं': 2, 'अँचार': 1, 'अभिलाषाआें': 1, 'प्रथाएँ': 1, 'अंगकोरवाट': 1, 'अकाउंटस': 1, 'भ्रष्टाचार,नेताओं': 1, 'अंतःक्रियाओं': 2, 'विधवाएं।': 1, 'भविष्यद्वक्ताओं': 2, 'कराउंगा': 1, 'अँजुर': 1, 'उंके': 1, \"बनाऊं?''\": 1, 'इंतज़ार...': 2, 'ऊंदरू': 1, '-अंजनी': 1, 'इंसान.इंसान': 2, 'मछुओं': 1, 'अंगडाईयाँ': 1, 'आंगिरस': 1, 'बुर्जुआनेताओं': 1, 'लिएः': 1, 'छूएंगे': 1, 'जाउंगी...फिर': 1, 'इंस्ट्रक्ट': 1, 'लाऊं।।': 1, 'ओंकारस्वरूप': 1, 'आंधारे/': 1, 'मंगलकामनाएं-': 1, 'डराएंगे।': 1, 'रहइं': 1, 'बहुएं,': 2, 'अंबर,': 1, 'एंटीबायटिक्स': 1, ',आँधी': 2, 'बेचैनी-तड़फ-अंतर्मन': 1, 'आँहे': 1, 'आँकड़ा': 1, 'सदइच्छाओं': 1, 'मुर्तिओं': 1, 'कुआँ,': 1, 'फैलाईं': 1, 'ऊँटो': 4, 'कहलाएंगी': 1, 'बचाऊंगी,': 2, \"बचाऊंगी।''\": 1, 'निविदाकर्ताओं': 1, 'बाउँड्री': 1, '\"संवेदनाओं': 1, 'धर्मगुरुओं,': 2, 'अंशः': 1, \"'अंधेर'\": 1, 'समाचारपत्रों/पत्रिकाओं': 2, '..अंगार': 1, 'बतलाऊँ?': 1, 'अंतरराष्टï्रीय': 2, 'लताएँ': 5, \"अंतरावलंबन''\": 1, '‘अँगना': 1, 'अंग्ड़ाई,': 1, 'जंभाऊंगा,': 1, 'आंको': 1, 'उंलियों': 1, 'आईं-': 1, ',अंह': 1, '(ओं': 1, 'संपदाआें': 2, 'ऊँची,': 3, 'प्रबंधन-कर्ताओं': 1, 'जाएँ।)': 1, 'जाएँ,आपको': 1, 'अँधियार': 1, 'अंगोला': 4, 'कुम्हलाएँगे.': 1, 'इंप्रैशन': 1, 'आंखें.....': 1, 'खडाउओं': 1, 'हो!!आँखों': 1, 'अँधेरे’': 1, 'भुओं': 1, 'ऊँघने': 1, 'इंजीनियरिंग,एमबीए': 1, 'इंद्रियच्युत': 1, 'इंद्रियातीत': 2, 'जाऊँगा’': 1, 'अंगनाई': 5, 'जताएँ।': 1, 'सदिच्छाएँ': 1, 'प्रशंसिकाओं': 1, 'परिसीमाओं': 1, \"'अंगूठी'\": 1, 'निअराएँ।': 1, 'पाएँ।।': 1, 'ताडनाओं': 1, 'अंग-प्रोक्षण': 1, 'नाइंसाफियों': 3, 'गँवाएँ?’’': 1, 'कुमाऊंनी': 10, 'धनियाएं': 2, 'धनियाओं': 1, 'प्रतियोंगिताओं': 1, 'जन्मदाताओं': 1, 'अपनाएँ,': 2, 'जटिलताऐं': 1, 'इंडीजुवल': 1, 'नाटिकाओं': 2, 'कामनाएँ!': 1, 'एंड्यूरेंस)': 1, '--भाईंदर': 1, 'लगाएँ।': 4, \"'हूँ-ऊँ-ऊँ\": 2, 'खामोशिओं': 1, 'हॆ.’कामनाओं': 1, 'आँखें..': 2, 'तांत्रिक-ओझाओं': 1, 'आँसू)': 1, '‘अकविता-आंदोलन‘': 1, 'जीउँ': 1, 'अंगुलियो': 1, 'चलाएंगी': 2, 'आँखें,ख्वाब': 1, 'श्रृध्दालुओं': 1, 'इंडिपेन्डेंट': 3, 'इंडिपेन्डेंटÓ': 1, 'बादइंटरव्यू': 1, 'अंकसु': 1, 'बहकाऊँगा': 2, 'फंसऊँगा': 1, 'फडवाएंगे': 1, 'अंतर्लीन-सी': 1, 'गिराऊं।': 3, 'आईं?': 2, 'नेताऔं': 1, 'लहराऊं': 1, 'ऐंड़ने': 1, 'खाएंगे?': 1, 'खिलाऊंगा\"': 1, 'दुखाऊँ': 1, 'घटनाएं)।': 1, 'गिनाऊँ': 1, 'इंस्टीटॅयूट': 1, 'लाऊंगा...': 1, 'ओ़र': 1, 'अँगों': 1, 'गिड़गिड़ाएं,': 1, 'इंण्डिया,': 1, 'है...आँखों': 1, 'जाएँ...उन्हें': 1, '..........अंत': 1, 'नहाउंगी': 1, '............अंत': 1, 'अंधानुसरण': 3, 'देखूं...आँखें': 1, 'संभावानाएं': 1, 'विचित्रताएं,': 1, 'आंका.': 1, 'प्रशंसाओं': 1, 'सुपरनोवाओं': 2, 'एंटीबोडिज': 1, 'सम्मानदाताओं': 1, 'इंसान!!': 1, 'बाउंड,': 1, 'सजाऊंगी': 2, 'जटिलताआें': 1, 'परीक्षाआें': 1, 'नताओं': 1, 'रिझाऊँ': 1, 'अंलकार': 1, 'छात्र.छात्राओं': 1, 'अवास्तविकताएं': 1, 'ट्टूओं': 1, 'शिलाएँ,': 1, 'आँख-मिचौली': 3, 'इंक्वायरी।': 1, 'दिखाएँ’’।': 1, 'महिलाओँ': 6, 'झुकाएं': 1, 'ब्लाइंड’': 1, 'ऊंघने': 3, 'अंगूर-': 1, 'इंद्रधनुषीय': 1, 'आकांक्षओं': 1, 'जनाकांक्षाओं': 2, 'गुफओं': 1, 'दिखलाऊँ': 4, 'जाऊंगा...।': 1, 'उंनती': 1, 'इंडिविजुल': 1, 'अवस्\\u200dथाओं': 1, 'औंकात': 1, 'लियाअ़बुदून‘': 1, 'संस्थाऐं': 2, 'मिलाएँगे': 1, '‘‘अंधाधुंध': 1, 'अंक-१७': 1, 'वाक़िअ़ात': 2, 'बअ़ज़': 1, 'अनवाअ़': 1, 'दुआऐं': 2, '(कविताओं': 2, 'मान्यताएँ': 2, 'इठलाऊँ': 1, 'घूँघरूओं,': 1, 'कुआँरे': 1, 'अँग्रज़ों': 1, 'अँग्रेज़ों': 1, 'चबवाएँ': 1, 'इंस्टिंक्ट': 3, 'लम्बा-उंचा': 2, 'आँवें': 1, 'सेविकाएँ': 3, 'काउंट,': 3, 'जनअपेक्षाएं': 1, 'कोअंदर': 1, 'कोसगईं,': 1, 'अप्सराएं,': 1, 'विज्ञापनदताओं': 1, 'छिपकलीओं': 1, 'आंदी': 1, 'रि\\u200dतुऐं,': 1, 'फैलाईं,': 1, 'अँटाने': 1, 'आँफ': 2, 'आंकड़े।': 1, 'गोपान्गनाओं': 2, 'आँजने': 2, 'जाऊँगा..मगर': 1, 'लोकभाषाएं': 2, 'विमाएं': 1, 'समाएंगे,': 1, 'भाषओं': 2, 'जाऊंगा!': 1, 'जनभाषाओं': 2, 'पिलाऊंगी': 1, 'आॅटोबायोग्राफी': 1, 'महागाथाओं': 2, 'बिखराएंगे': 1, 'बुझाएंगे': 1, 'विशेष्ताओं': 1, 'अंसख्य': 1, 'पीएं': 2, 'जाएँ............': 1, 'अंतर-मनन': 1, 'हौऊं,': 1, 'गुनगुनाऊंगा': 2, 'हवाआंे': 1, 'आएँगी-जायेंगी।': 1, 'कमाऊं': 2, 'बुलाऊं': 1, 'आइ्र': 1, 'सजाऊँगा,': 1, 'इंजी॰': 1, 'विषेशताएँ': 1, 'अंतर्ब्रम्हांड': 1, 'माइंड।\"': 1, 'लताएं,': 1, 'गुण-विशेषताएं': 1, 'इंसान.': 3, 'बेइंतहाँ': 2, 'आंसू.?': 1, 'पोर्टब्लेयर,अंदमान': 1, 'खाईं,': 2, 'आंदोलन--जैसे': 1, 'आंदोलन--हमेशा': 1, 'दिखाउंगी': 1, 'मुनुज्ञओं': 1, 'कराएंगी?': 1, 'वनिताओं': 1, 'बसाऊं': 1, 'अंगराई': 2, 'मधुरताओं': 1, 'माधुरताओं': 1, 'सजाऊँगी,': 1, 'समझाईं': 1, 'अंत:प्रेरणा': 1, 'धाराएँ,': 2, 'गोदावरी-लजाऊँ': 1, 'स्थानीयनेताओं': 1, 'माएं।': 1, 'फैलाएं-': 1, 'आँकड़ों': 4, 'ईंट-रेत': 2, 'जाएं।।': 1, 'साथिओं': 1, 'हुएं!’': 1, 'आइंन्सटाइन': 1, '..गवईं': 1, 'सहायताओं': 1, 'लिखाएँगे।': 1, 'अनुयाओं': 1, \"'अंगुली\": 1, 'वहशतअंगेज़': 1, 'चंद्रमाओं': 1, 'संस्थाओं/बैंकों': 1, 'कराएंगी।भारत': 1, \"जाऊंगा।''\": 1, 'एंटीबॉयोटिक्स': 1, 'अंग्रेज़ी-हिंदी': 1, 'इंडिया*': 1, 'जोअंबेडकर': 1, '‘एंडेवर‘': 1, 'खाऊँगी': 2, 'पाएँगे,': 2, 'बनजाएंगे': 1, 'सक्रियताएँ।': 2, 'आंह्णह्णह्ण': 2, 'योजनाएं’': 1, 'एलाइंड': 1, 'समस्याओं’': 1, 'ओंगन': 1, 'जि\\u200dएं,': 1, 'है,अंग्रेजी': 1, 'भाई-बन्धुओं': 1, 'लगाऊँगी': 2, 'सीमाएं,': 2, \"'अंकुर',\": 1, 'है।इंडेक्स': 1, 'अभिलाषाएं-इच्छाएं': 2, 'मजनूओं': 1, 'लैलाओं': 1, 'आदाएं': 1, 'लाएंगें।': 1, 'पाऊंगी...ये': 1, 'अभिक्रियाओं': 2, 'फ़रमाएँ...ये': 1, 'तिक्तताओं': 1, 'दिखाएँगे': 2, 'कुआँनहीं': 1, 'कुआँभी': 1, 'कामनाएं।': 1, 'परम्पराएँ': 4, 'सभ्यताएँ': 2, 'ऐअे....रामचंद्र': 1, '\"कोशिशकाएं': 1, 'आँधारि\"': 1, 'साईं,': 1, 'बचाऊँ': 2, 'भुलाऊं': 2, 'सम्पदाओं': 1, 'ड्रॉइंग-कक्ष': 1, 'आर्इं,': 1, 'जाऊंगी’': 1, 'समझाउंगी': 1, 'अंतर्वेषण': 2, 'अंतर्द्वन्धों': 1, 'जुआँ': 1, 'आंतर': 1, 'झल्लाएं': 1, '(अंडाणु': 1, 'झाईं': 1, 'आशाओं-आकाकंक्षाओं': 2, 'अंध-कूप': 1, 'अंशाणु': 4, 'इंसान?': 1, 'जिएं,': 1, 'उंडेले': 1, 'अंधड़,': 1, 'इंसुलेशन': 1, '‘‘हिंदुओं': 1, 'अंतरद्वंद': 2, 'था.पत्र-पत्रिकाएँ': 1, 'गईं.अहिंसा': 1, 'चौंधियाएं': 1, 'नवीनताओं': 2, 'श्रोताओं।': 1, 'दाएं,': 1, 'बाएं।': 1, 'छात्र-नेताओं': 1, 'अंसारीजी': 1, 'नईं।': 1, 'प्रेरणाएं': 4, 'अनशन-आंदोलन': 1, 'अज्ञानताओं': 1, 'कार्यकर्ताआें': 1, 'खोएंगी': 1, 'इंतिजार,मगर': 1, 'अंधराष्ट्रवादी': 1, 'चाहिए.ट्रेनिंग/इंटर्नशिप': 1, 'पत्रिकाआंे': 1, '(दिशाओं': 1, 'अंशुमान्': 1, '4.अंधा-युग।': 1, 'रंग-संस्थाओं': 1, 'स्वर्ण-मुद्राएँ': 1, 'अभिलाक्षणिकताएं,': 2, 'इंतज़ार-ए': 1, 'बतलाऊंगी': 1, 'कुलगुरुओं': 1, 'एंथनी’': 1, 'अंतरव्यथा(नीचे': 1, 'नोए़डा': 1, 'रुकवाएं': 1, 'दिलवाएं।': 3, 'कोडाओं': 1, '(प्रेइंगमेंटीस)': 1, 'नर-देवताओं': 1, 'बिरसा-मुण्डाओं': 1, 'इंजिनिअर': 1, 'आइंस्टाइन,': 1, 'ऊँचाइयां': 2, 'सुविधाऐं': 1, '(अंदाज)': 1, 'अंतर्यामी,': 1, 'ऐंबेसी': 1, \"'अंक'\": 1, 'नवीनताएँ': 1, 'अंधमय,': 2, 'गांडुओं': 1, 'एंडक्रोनोस': 1, 'फुएंते': 1, 'घटनाएं‘': 1, 'अंतबिंदु': 2, 'अंतःप्रतिच्छेदन': 1, \"'ऊंचा'\": 1, 'अंतर-राज्यीय': 1, 'गलिओं': 1, 'एंबिगुअस': 1, 'आॅन...तो': 1, 'अ़खबार': 4, 'है-इंस्पेक्शन': 1, 'है।समस्याओं': 1, 'ईच्छाओं': 2, 'आंध्र-प्रदेश': 2, 'अंश’': 1, ',आकांक्षाओं': 1, 'अंषकालिन': 5, 'अंट-शंट': 3, 'आंटी...': 1, 'खाऊं।': 2, 'ऐंद्रजालिक': 1, 'समस्या्ओं': 1, 'अगुआ,नेतृत्व-कर्ताओं-': 1, 'महानुभावाओं': 1, 'इंसाफ़\")': 1, 'प्रेमिकाएं': 1, ',बाबूओं': 1, 'आंद्रेज,': 1, 'शिक्षा-नियंताओं': 1, 'विडम्बनाएं': 3, 'जाएे': 1, 'धुआँधार': 1, 'कला-विधाओं': 1, 'गुफ़ाएं': 2, 'परवाह!ग्राउंड': 1, 'मार्क्स-एंगेल्स': 2, 'सराओं': 1, 'सीमाओँ': 1, 'अंदेशों': 1, 'तड़पाउंगी': 1, 'अंधभक्त।': 1, 'बुलाउूं': 1, 'कहलावाएंगे।': 1, 'रथ-यात्राएं,ईंट-पूजन,शस्त्र-खरीद': 2, '.अंत': 2, 'बिताऊँगा': 1, 'ऊंखिया': 1, '..अंत': 1, '.कुएं': 1, 'विभीषिकाएं,': 1, 'अंजानी': 3, 'निपटाऊं,': 1, 'उडा़एं।': 1, 'कहाऊंगा': 1, '\"आँखें': 1, 'इंडिया”,': 2, 'विधाओं,': 1, 'ईंट-पत्\\u200dथर': 1, 'पाएंगे।़’’': 1, 'गया...अँधेरे': 1, '-आंसू': 1, ',आंसू': 1, 'रूपककथाएँ': 1, 'पासर्इंट': 1, 'आत्माऍं': 1, 'शुभकामनाऍं': 1, 'इंटेलिजेंस’': 1, 'सइंतेगा,': 1, 'वर्जनाओं,': 1, 'नजरअंजाद': 1, 'घुँघरुओं-सी': 2, 'बनाएं।-विनय': 1, 'जाऊं????': 1, 'कटवाएँगे।': 1, \"'उदभावनाएं'\": 1, 'संस्कृतिओं': 1, 'वधुएं': 2, 'सरिताओं': 1, '‘अट्ठारहबाँअंतर्राष्ट्रीय': 1, 'अंतस्संबंध': 1, 'नित्यक्रियाओं': 1, 'बढाऊं??': 1, 'शुभकामनाएँ...और': 1, 'अंडरवर्ड': 1, 'अंतर्दशाये': 1, 'इंद्र-धनुष': 1, 'अंतगर्त': 1, 'आाशा': 1, 'ईंतजाम': 1, 'अंकोर': 3, 'इंटरप्ले': 1, 'बहुलताओं,विविधताओं': 2, \"'.पंक,इंच,बंडा\": 1, 'अंत....': 1, 'अाकर्षण': 1, 'उत्कण्ठाओं': 1, 'काटी......आंटा': 1, 'देखा.....श्रद्धालुओं': 1, 'श्रद्रालुओं': 1, 'अंति\\u200dम': 1, 'बस...........अंतिम': 1, 'झुकाईं।': 1, 'इंडियाÓ।': 1, 'बटवाऊँगा।': 1, '………अंतिम': 1, 'पाएँ?': 1, 'ईंट-गारा': 1, 'अंतमर्थन': 1, 'ऊँगलियो': 1, 'माफियाओं,': 1, 'ओंकोप्लास्टिक': 1, 'तंबूओं': 1, 'जनाक्षाओं': 1, 'अंधी-बहरी': 1, 'अंतःप्रकृति': 1, 'उल्लूओं': 1, 'बताऊं...क्या': 1, 'सदिओं': 2, 'एंम्पलाइज': 1, 'जुआंरी': 1, 'डा.आंबेडकर': 1, 'है.उंच-नीच': 2, 'अँधियारों': 1, 'खोऊँगी,': 1, 'आँदोलन': 3, 'ऊँचाई.': 1, 'होएंगे.': 1, 'खोदवाएं': 1, 'अंताश्ररी': 1, 'कोशिकाआें': 2, 'साईंमय': 1, 'पाउंगी.': 1, 'आईं!!!': 1, 'हुआ—अंकित': 1, 'सामाजिकताओं/निजताओं,': 2, 'अंधेरा...ट्रेन': 1, 'द्वार-आँगन': 1, 'लैला-मजनूओं': 1, '‘‘हिन्दुओं': 1, 'परामर्शदाताओं': 6, 'उत्तर-पुस्तिकाओं': 2, 'भारी....कविताओं': 1, 'लक्ष्मणरेखाएं': 1, '\"महिलाएं': 1, 'सुनाएँ।यह': 1, ',,अँधेरा': 1, ',,आँखों': 1, 'सुनाएंगी': 2, 'जाऊँ?': 3, 'आईएं': 1, 'सीमओं': 2, '&अंतर्विरोधों': 1, 'कि्रयाओं': 2, 'इंदि्रयों': 3, ',लताएं': 1, 'कि्रयाएं': 1, ',पत्थरतोड़ाओं': 1, 'एंटीने': 3, 'एंजायटी': 2, 'अंटी,': 1, 'जाऊँगा।जीवन': 1, 'अंतर्देशीय': 1, 'इंपसमक': 1, 'ओंप्रकाश': 1, '...ऊंची': 1, 'इंडोनेशाई': 1, 'इीसीबी': 1, 'उड़ाईं।': 1, 'शैयाओं': 1, 'बुलाएँ,': 1, 'अंग्रेजी,फ्रेंच': 1, \"'इंडो-सोवियत\": 1, 'उपगोयगकर्ताओं': 1, 'आँगनबाड़ी': 2, 'कुआँर': 1, 'लाऊंगी।': 2, 'विघ्न-बाधाओं': 1, 'खाऊं,': 1, 'आंबले': 1, 'इंस्टीस्टूयट': 1, 'दिखाएँ.साथ': 1, 'जिऐं।': 1, 'गाऐं,': 1, 'बजाऐं।': 1, '---आंनदपुर': 1, '‘आंखन': 1, 'आंन': 2, ',संवेदनाओं': 1, 'अंतर्मुख-साधक': 1, 'आ॓फ': 1, 'अॅलोपेथिक': 1, '\"इंडिक\"': 1, 'सिखाएँ,': 2, 'आँसुओँ': 2, 'अंकशास्त्रप्राचीन': 1, 'अंतःप्रेरणा': 2, 'अंतिका': 2, 'परेशानियाँ,चिंताओं': 1, 'दोहराऊंगा': 1, 'एंट्री।': 1, 'इंद्रधनूषी': 1, 'अंगभीर': 1, 'सन्देश्टाओं': 1, 'कविताएं....।´´': 1, 'बंग-बंधुओं': 1, 'घुएं': 1, 'इंजोय': 2, 'जलाऊँगी': 1, 'अँधियारा।': 1, 'फ़ाउंडर': 1, 'बनाउंगा.': 1, 'अंजोरिया': 1, 'अंजोर': 1, 'अंगनवा': 2, 'दो-इंची': 1, 'चार-इंची': 1, 'अंग्रेजी-भाषी': 1, 'है।अंग्रेज़ी': 1, 'कुहाओं': 1, 'अंतर्मनुष्य': 1, 'था।आंध्रप्रदेश': 1, 'पुरातत्त्ववेत्ताओं': 1, 'बिंन्दुओं': 1, 'अंग्रेजीभाषी': 1, 'लाईं,': 1, 'इंच-इंच': 4, 'चढ़ाऊँ': 1, 'हैरतअंगेज़': 3, \"आंधी'\": 2, 'अँधेरेमें': 1, 'नहाउं...।': 1, 'टकराएंगे': 1, 'आंख(Cat’s': 1, 'था...उँगलियों': 1, 'अंतर्राष्ट्रीयय': 1, 'अंड': 4, 'हिन्दुआें': 2, 'मंत्रियों-नेताओं': 1, 'अंदर/': 1, 'रहन्नुमाओं': 1, 'लाऊँगी...।”': 1, 'जलाऊंगा।': 1, \"'अंचल',बच्चन\": 1, 'कविताएं(हालावादी': 1, 'एपोइंटमेन्ट': 1, 'अंतर्निरीक्षण': 1, ',अंत': 1, 'शिराओं': 11, 'मंशाएं': 1, 'इंशाअल्लाह,': 1, 'मऊआँ': 1, 'अँधेरें': 1, 'प्रयोगषालाएं': 1, 'धर्ताओं': 1, 'इतराऊँ': 1, 'मिटाऊंगा': 1, 'प्रेत-आत्माओं': 1, 'युवाओं-': 1, 'बहाऊं': 2, '4.ओंकारेश्वर': 1, 'हैं।ओंकारेश्वर': 1, 'ओंकारलिंग': 1, 'हुइंü,': 1, 'जाएँ\"।': 1, 'अंकावली': 1, 'अँतड़ियों': 1, 'आंगनवाड़ी,': 1, \"हुईं?'\": 1, 'आंगने': 1, 'चढ़ाईं,': 1, 'अंशत:': 1, 'जुगनुएं': 1, '(अंधे)': 1, 'र्इंटल': 1, 'मुस्काऊँ': 1, 'खुशिओं': 1, 'जाउॅ': 1, '!इंसान': 1, 'अंचलों,': 1, 'कर्नाटक-आंध्र': 1, 'म्याऊं': 1, '-म्याऊं': 1, 'सासुओं': 1, '-परिचारिकाओं': 1, 'नेतओं': 1, 'बिताऊँ': 1, 'अंडी': 2, 'आऊँ...और': 1, 'है..युवाओं': 1, 'योगदानकर्ताओं': 6, \"ऊँ'\": 1, 'बताएं..': 1, 'इत्तलाएं': 1, '....ओंटारियो(अमेरिका': 1, 'ऋचाएँ': 1, 'प्रधानाध्यापिकाएं': 1, 'लोकधारणाओं': 1, 'कुठाएं': 1, 'काम-कुंठाओं': 1, 'विशेषताओं,उनकी': 1, 'उपयोगिताओं': 1, 'शिल्पकलाओं': 2, 'शिल्पकलाएं': 1, 'जाऊंगी।’': 1, 'मिलाएँ': 1, \"खाएँगी।''\": 1, 'इंद्रियाँ': 2, 'सरिताएं,': 1, 'तुच्छताओं': 1, 'जाऊंगा..।': 1, 'प्दवितउंजपबे': 1, 'पिलाऊँगी।”': 1, 'विषमताओँ': 2, 'ऊंघते---ऊंघते....': 2, 'धूआं': 1, 'आशाएं,': 1, 'अंतराज्यीय': 1, 'गुनगुनाऊँगा': 1, 'इन्फ्लुएंस': 1, 'उंगरी': 2, 'इंदिरा।': 1, 'डगमगाऊं': 1, 'कोने-अंतरे': 2, 'बनाऊं..': 1, 'भरमाएं.': 1, 'लाऍं।': 1, ',रोशनी-अँधेरा': 1, 'सीहवाओं': 1, 'बुलाएंगे,': 2, 'मैग्निफाइंग': 1, 'बुलाएंगे.': 1, 'अंतोनिच,': 1, 'पकाऊं': 1, 'पहुचाउंगा': 1, 'आएंगे-': 1, 'खिंचवाएंगे,': 1, 'बजाईं': 1, 'आँखवाले,': 1, 'सीमाऎं': 1, 'प्रतियोगिताओं,': 1, 'अंधेरेमे': 1, '...अंजना': 2, 'भड़ओं': 1, 'शोकसभाएं': 1, 'लाईंस': 1, 'बचाएं।ह': 1, 'लगाईं--\"अबे': 1, 'इंडिया-गेट': 1, 'इंडियागेट': 1, '.ऊँची': 1, 'इंर्धन/इमारती': 1, 'इंडिअन': 1, 'इंस्ट्यिूट': 1, '‘महिलाओं': 1, 'अंटोनी': 1, 'कहा-शरमाऊँ': 1, 'पाएंगे.”': 1, 'इंर्धन': 1, 'उदात्तताओं': 1, 'पीड़ाएँ': 1, '“अंधी': 1, 'जीवन-रेखाएं': 1, 'पुओं': 1, 'बताऐंगे।': 1, 'सिखलाएं': 1, 'सिखलाएं,': 1, 'अंतर्दाह': 1, '.अंतर': 1, ',क्षणिकाएँ,हाइकु': 1, 'पाएंगे..': 1, 'इंदुकला': 1, 'भिगोऊँगी': 1, 'संस्थाओं/व्यवस्थाओं': 2, 'उंब-या,': 1, 'नृत्य-नाटिकाएं': 1, 'हुआा': 1, 'कम्प्यूटर-इंटरनेट': 1, 'रोओं': 2, 'इंद्रेश': 1, 'इंटीग्रेट': 1, 'अंगभंगी,': 1, 'एकाउंट!': 1, 'इंग्लिश.': 2, 'अंडरइस्टिमेट': 1, 'देवताआंें': 1, 'आँगन–आँगन': 2, 'अंगना,': 1, 'हैं,बाबाओं': 1, 'उंगलियाँ,': 3, \"जाइंट',\": 1, 'इंप्रेशंस': 1, 'मंगाऊं?': 2, 'लाईंने': 1, 'इंश्योरेन्स': 1, 'दिखाएंगे?': 1, 'तंत्रिकाएं,': 1, 'दंतकथाएं,': 1, 'गाथाएं,': 2, '(इंट्रासाइटोप्लास्मिक': 1, 'इंजेक्शन)': 1, 'आँसु': 1, 'अंतरिक्षा': 1, 'गूपियुओं': 1, 'मिएँ': 1, 'आँचलिक': 1, 'लोक-कथाओं': 1, '......आँगन': 1, 'पथराएँ......': 1, 'रोऊं?': 2, 'निश्चिन्तताओं': 1, 'ग़ज़लें,कविताएं': 1, 'सहलाऊं': 1, 'आउंस': 1, 'पाएंगे?’': 1, 'इंजीनियरिगं': 1, 'कराया।अंतत:': 1, 'एैनी': 1, 'विधाओँ': 1, 'अंगरेज़': 11, '‘अंतर्मन’': 1, 'वस्तुएं,सफ़ेद': 1, 'आंखें.': 1, 'जाऊंगा...': 3, 'जाऊंगी...’': 1, 'खाऊंगी...': 1, 'जाऊंगीं...।’': 1, 'इंसिक्योरिटी': 2, 'गुफा-कंदराओं': 1, 'माहिलाओं': 3, 'अलोचनाएं': 1, 'ऊंचाइया': 1, 'ब्लैक-एंड': 1, 'क्रुरताओं': 1, '\"आंसू': 1, 'इंजी),': 1, 'तुलनाएं': 1, 'अंडरविकलीज़': 1, 'रचानाओं': 1, 'अंतरग': 1, 'अंतरिक्ष-यान': 1, 'लगाएँगे': 1, 'बहाउंगी': 1, 'अंचलखेड़ा': 1, '!कविताओं': 1, 'अंगारमोती': 1, \"पिएंगे।'\": 1, 'शुआओं': 1, 'खिलाऊंगा,': 1, 'बुलाऊंगा.': 1, 'अँधेर': 1, 'बेइंतेहां': 1, 'अंशु।': 1, 'आआे': 1, 'सुनाउं': 1, 'सुनाउं?': 1, 'लगवाऊं।': 1, 'राजाओं-राजकुमारों': 1, 'हुएुए': 1, 'बहुएँ': 6, 'प्रकियाओं': 1, 'छुपाएं': 1, 'विष-कन्याओं': 1, 'सक्रियताएँ': 1, 'बचाएं.': 1, 'अंतर्गत,': 2, 'नज़र-अंदाज़': 2, 'अंधविश्वासों,': 2, 'हिलाएं।': 1, 'छपवाएंगे।': 1, 'बताऊंगी,': 1, 'आँचल...': 1, 'आंवला।': 1, 'ऐंठी': 1, '..रिलाएंस': 1, 'दिखाऊँ।': 1, 'जाऊं;': 1, 'उठाएंगा।': 1, 'रिलाइंस': 1, '‘इंडिया:': 2, 'इंडस्ट्रीयलिस्ट': 2, 'उ़र्फ…': 1, 'अटटालिकाओं': 1, 'महराजाओं,अँगरेज़': 2, 'सूईंयों': 2, 'नाजुकताएं': 1, 'महाराणाओं': 1, 'आंसूओ': 1, 'दबाएँ': 1, '(काउंसिलिंग-हीलिंग': 1, 'आउंछू.': 1, 'इठलाऊं': 1, 'अंगरो': 1, 'पाइंट-': 1, 'मरीचिकाओं': 1, 'खिसकाएं।': 1, 'भाई-बंधुओं-भाभियों': 1, 'झुकाऊंगा....': 1, 'अपनाउँगी': 1, 'बिताएंगे.': 1, 'माँऎं': 1, 'भावनाएं!!': 1, 'खिलाउि़यों': 1, 'जाऊं-न-जाऊं': 2, 'आत्माएं,': 1, 'प्रेरणाएं,': 1, 'है...उँगलियों': 1, 'पुरआब=आंसूओ': 1, 'काइंडली': 1, 'वस्तुऎं': 1, 'पाएंगे.\"': 1, 'सिखाऊँगा': 1, 'मनुओं': 3, 'बताऊँ,': 1, 'गिटपिटाईं': 1, 'जाएंगें...अभी': 1, 'लगी.हिन्दुओं': 1, 'निभाएं!': 1, 'चेतनाएं..': 1, '.साईंक्रिटिक': 1, 'छुड़ाऊं': 1, 'बिताऊं।\"': 1, 'शिक्षिकाएं,': 1, \"आऊं?''\": 1, 'सुनाएंगे,': 1, '\"अंधे': 1, 'आँखें\"': 1, 'छपवाउंगा': 1, 'पाऊंगी।’': 1, 'प्वाईंट': 3, 'गीतिकाओं': 1, 'चुराऊँ': 2, 'जीवविज्ञान-वेत्ताओं': 1, 'अंतरदृग': 1, 'वईं': 1, \"'यईं\": 1, 'पाएंगे.तो': 1, 'बहलाऊँ।': 1, 'ईंटल': 1, 'है...एंडी': 1, 'दिखाऊंगा?': 1, 'अभिलाक्षणिकताएं': 1, 'इंद्रमणि—': 1, 'शालाएँ': 1, 'अँगरेज़ी': 1, 'आंख-मिचैली': 1, 'पुत्रवधुओं': 1, 'पाएँ.': 3, 'इंडयूस्ड': 1, 'गाएंगी': 1, 'दोहराएंगे,': 1, 'उंगलियाँ....': 1, 'अंत...': 2, 'बिंदूओं': 1, 'इंच,': 1, 'पुकारू,बुलाउं': 1, 'अँखुवे': 1, 'चुकाएँ': 1, \"एँ...?'\": 1, 'निभाएँ': 1, 'कामनाऍं': 1, ',शिशुओं': 1, 'इंफलेमेंट्री': 1, 'कराउंगा).': 1, 'वुक़अ़त': 1, 'अँगूठी,': 1, 'है......आँख': 1, 'छात्र/छात्राओं-': 1, 'अंधविष्वासपूर्ण': 1, '(इंडिक),': 1, 'क्षणिकाएँ(': 1, 'उपेक्षाकर,वर्जनाओं': 1, 'अपनाइएं': 1, 'आँखें..?': 1, 'दुष्परंपराओं': 1, 'अवाओं': 1, 'दिखाएंगे?\"': 1, 'बधाओं': 1, 'बहुएँ।': 1, 'अंशदायी': 1, 'दि\\u200dशाओं': 1, 'वृद्धाएं': 1, 'अ़फवाहें': 1, 'कराऊं?’': 1, 'जाउं।': 1, 'अस्मिताएं': 1, '......आँखों': 1, 'अंत्यानुप्रास': 1, 'अंबरीष': 1, 'गुइंया': 1, 'दुर्घटनाएँ,': 1, 'आकस्मिकताओं': 1, 'ददाओं': 2, 'आास': 1, 'पाऊंगा।\"': 1, 'माक्र्स-एंगेल्स,': 1, 'बदलवाएं।': 1, 'कुण्ठाओं': 1, 'इंस्पेक्टरः-': 1, '`आंख': 1, 'मचाएँ।': 1, 'खड़ाऊँ': 2, 'जताउूं?': 1, '‘जल-कणिकाओं’': 1, 'शबे-इंतजार': 1, 'संहिताएं': 1, 'प्रताड़नाओं': 2, 'जाउंगी,': 3, 'समझाऊंगा': 1, 'कोसगईं': 1, 'आॅलराउण्डर': 1, 'दिनचर्याओं': 1, 'कुंइित': 1, 'शिराएँ': 2, 'गईं’’': 1, 'इंजीनियर,वकील': 1, 'आरज़ुओं': 2, '‘‘रंग-अंकुर’': 1, '.अंडाणु': 1, 'पीऊंगा।\"': 1, 'अंबैस्डर': 1, 'नजरअंदाजगी': 1, 'परिक्रमाएं': 1, 'अंटा': 1, 'अंगूठियाँ,': 1, \"'आँटी\": 2, ',अंतर': 1, 'छुएं।': 1, 'पहुंचाऊँ': 1, 'लटाएं': 2, 'बिसराऊं': 1, 'आंकता': 2, 'कहानियां-कविताएं-किताबें': 1, 'जिऊँगी': 1, 'इंतजार।': 2, 'मुस्कुराउँगी,': 1, '..विभिन्नताओं': 1, 'रुलाएं': 1, 'पाऊँगी-': 1, 'इंस्\\u200dपेक्टर': 1, '‘इनकाउंटर’': 3, 'बहलाऊं,': 1, 'मिलवाएंगे': 1, 'ख़लाओं': 1, 'अंध-विश्वास,': 1, 'मामूओं': 1, 'आऊं?’': 1, 'मन-आत्माएँ': 1, '(अंधी-बहरी': 1, 'अंगार(सच)': 1, ',अंतस्': 1, 'छुपाएँ': 2, 'प्रेमकथाएँ': 1, 'वसाएं': 3, 'ंसमस्याओं': 1, 'लाएँगे': 3, '”बहुएं': 1, \"जाएं।''\": 1, 'बाललीलाओं': 1, 'कमाऊँगा...तो': 1, 'आंककर': 3, 'अभिनेताओं,तकनीशियनों,लेखकों': 1, 'लगाएँ;': 1, 'क्लाईंट': 1, 'जनसभाएं।': 1, 'लगाऊँ।': 1, 'इंडिक्स': 3, 'अंगभूतों': 1, 'परंपराएँ': 2, 'लोकभाषाएँ,': 1, 'ग्राउंडनट': 1, 'जाऊं..और': 1, 'दिलाएँगे': 1, 'अंग्रेजी-शासन': 2, 'इंजन।': 1, 'काम-कथाएं': 1, '\\u200eअंतिम': 1, 'थी.आँगन': 1, 'छुड़ाऊंगा।': 1, 'लगाएँगे।': 1, 'दाहने-बाऍं': 1, 'बाऍं,': 1, 'ढाएँगे': 1, 'दिशाएँ,': 1, 'इंटरमीडिएट,': 1, \"'ओंकोप्लास्टिक\": 1, 'अँग्रेज़ो': 1, 'पक्षिओं': 1, 'अंक-अर्द्धवार्षिक': 1, 'अंधविश्वासि\\u200dयों': 1, 'ऑंखों-ऑंखों': 2, 'उंटों': 1, \"जलाऊँगी।'\": 1, 'फाउंडेशंस': 1, '‘इंटरनेशनल’': 1, '(अंतर्राष्ट्रीय)': 1, 'अंकल...': 1, ',विडंबनाओं': 1, '‘आऊंगा।': 1, 'आँख,तुम': 1, 'नजरअंदाजी': 1, 'एंग्लोइन्डियन': 1, 'इंद्रजाल,': 1, 'लगाउंगी.”': 1, '\"ऊं\"': 1, 'खटखटाएं': 1, 'मनाएंगे......क्योंकि': 1, 'रहें..बैकग्राउंड': 1, 'चिढ़ाएं': 1, 'बंटाएं,': 1, 'वस्तुऐं-गेंहूं,': 1, 'वस्तुऐं-यहां': 1, 'आंकठ': 1, 'उपत्यकाओं': 2, 'बताऊँगा।!': 1, 'लुढ़काएं,': 1, 'इंटरव्यू।': 1, 'इंटरसेक्शन': 1, 'एंजायिंग': 1, 'उंगलबाजी': 1, 'मांइंड': 1, 'एंजेसियां,': 1, 'रामलीलाएं': 1, 'bankओं': 1, 'अंतर्': 1, 'उठाऊंगी...तो': 1, \"अंत'\": 1, '‘अंकुश’का': 1, 'ऊंचायी,सागर': 1, 'अंतर्द्वद्व': 1, 'अंतः-चक्षु': 1, 'पिऊँ': 1, 'जाउंगी..\"': 1, '‘‘अंडर': 1, ',अंगडाई': 1, 'गिनाऊँ,फेहरिश्त': 1, '“अंतराल': 1, 'आऊं..फिर': 1, \"इंडिया'.\": 1, 'इंडिया,8-6-1921)': 1, 'इंडिया,3-3-27)': 1, 'इंडिया,15-9-1927)': 1, 'इंडिया,25-6-1931)': 1, 'इंडिया,4-2-1926)': 1, \"अंकुर'\": 1, 'इंतजामिया': 1, \"'ऐं!\": 1, 'यात्राएं।': 2, 'मुंडाओं': 1, 'कराएं)': 1, 'मिलवाउंगा।': 1, 'रोऊँगा।': 1, 'झिलमिलाएंगे': 1, '`इंसर्ट`': 1, 'झूमे-गाएं..': 1, 'इंटर-व्यू': 1, 'मुस्कुराएं।': 1, 'ऊंटपटांग': 1, 'रे!इंटर': 1, 'उंनका': 1, 'उंनसे': 1, 'पुराकथाओं': 2, 'इंस्टिट्\\u200cयूटों': 1, 'इंजनस्\\u200c': 1, 'हवाएं,': 2, 'सोएंगे,': 1, 'बतियाएंगे': 1, \"'आँख'\": 1, 'जगाऊंगी': 1, 'इंतेहाँ': 1, 'भूमाफियाओं,': 1, 'अँग्रेज़': 2, 'काव्य-परंपराओं': 1, 'दिखलाऊंगा,': 1, 'इंडियाÓ': 1, 'इंसान!': 1, 'होम-साइंस': 1, 'कथाएँ,': 2, 'दख़लअंदाज़ी': 1, 'नज़र-अंदाज़': 1, 'मनाएं..': 1, 'मालाएँ,ऊँची-नीची': 2, 'रूआंबांधा,': 1, 'लड़ाएँगे,.......': 1, \"'अँधा\": 2, 'अँकुआ,': 1, 'कुमाऊंनि,': 1, 'रोशनी-अँधेरा,': 1, 'विडम्बनाओं': 2, \"कविताएं'\": 1, 'प्रस्तर-प्रतिमाओं': 1, 'बहाउॅ।': 1, 'चाचियाँ,मामियां,बुआएं': 1, 'ईंकी': 1, 'आंदेस': 1, '\"इंकलाब!': 1, 'बुढऊं': 1, 'शुभ-भावनाओं': 1, 'होमसाइंस': 1, 'सूचनाएँ': 1, 'हुएँ.': 1, 'राजनेताआंे': 1, 'उंघते': 2, 'इंतजार?': 1, 'मलिकाएं': 1, 'रंगीन-रेखाओं': 1, 'अंबार,': 1, 'उंगलिओं': 4, 'इंडीब्लॉगीज,': 1, 'गा.अंत': 1, 'अकड़ओं': 1, 'लगाऊँगा': 2, 'अंचलो': 1, 'उठा...अंदर': 1, 'अखबार-पत्रिकाओं': 1, 'पाएँ।': 3, 'एंड्रीयोमेट्रीयोसि\\u200dस,': 1, 'ये...ऊँगली': 1, '‘एनकाउंटर': 1, 'पंरपराओं,': 1, 'ब्रोइंग': 1, 'जाएं।\"': 1, 'आैपचारिक': 1, 'सुविधओं': 1, \"'आंचल\": 1, 'प्रवंचनाओं': 1, 'बाऊंड्री': 1, 'लाओं': 2, 'ब्योएंस,': 1, 'इंस्टन्ट': 1, 'बतार्इं।': 1, 'दवाऐं': 2, 'ऋषिकाएँ': 1, 'ऋषिकाओं': 1, 'इंडिपेंडेट': 1, 'इंसान-': 1, \"'काउंटर\": 1, 'ऊंचा-लंबा,': 1, 'विषेषताएँ': 1, '‘ओं': 1, 'खाएँगे।': 1, 'अंतरमंडलीय': 1, 'जाएँगी.-मैंने': 1, 'जाएं!’': 1, 'राजनेताओं-उद्योगपतियों': 1, 'जाऊं।’': 2, 'अनियमित्ताओं': 1, '\"अंगारा\"': 1, 'इंद्रियपरक': 1, 'अंदरवाला': 1, 'माँएँ': 1, 'है..ऊँ': 1, 'रोईं': 2, 'कुंआं...और': 1, 'मॅंगवाएंगें': 1, 'रचनाएँ-': 1, 'अँगारे': 1, 'बार्इंडिंग': 1, 'एंथनी)': 1, 'सुझाएँ!': 1, 'संभावनाऐं': 1, 'बिछुओं': 2, 'आलोचनाएँ': 2, 'शासन-सत्ताओं,': 1, 'शंका-आशंकाओं': 1, 'आंतंकियो': 1, '........इंतज़ार': 1, 'होऊं।': 1, 'करवाएंगी': 1, 'जाऊंगा।\"': 1, 'मलिक\"अंसारो': 1, '\"ऊँचा': 1, 'विशिष्टताएं,': 1, 'एंफीथिएटर': 1, 'समस्याएं,उसका': 1, 'डेराओं': 1, 'अंतरमुखी': 1, 'अंतर्वर्ती': 1, 'क्रियाओं)': 1, 'परियोजनाऐं': 1, 'जुआँरी': 1, 'दिखएंगे': 1, 'सिखाएंगे।’': 1, 'अंगोपांग': 1, 'मचाऊँगी,': 1, 'मचाऊँगी': 1, 'आस्तिकाओं': 1, 'रोएँ': 2, 'अंतर्कुंभक,जालंधर': 1, '‘सजाएँ': 1, 'गाएँगे,': 1, 'जाएँ...वो': 1, 'गोवधशालाएँ': 1, 'है-दिशाएं।': 1, 'उपदिशाएं': 1, 'विदिशाएं': 1, 'विदिशाओं': 1, 'ऑंकुस': 1, 'जाउंगी?...हाँ': 1, 'विशेषताओं,': 1, 'इंजीनियर।': 2, 'करवाऊंगी।’': 1, 'गुलाबी,गेहुआं,सांवला,भूरा,गंदुमी,गोरा,काला,बादामी': 1, 'अंधेरा-ही-अंधेरा': 2, 'है,अंधेरे': 1, 'कोशाएं': 1, 'गलतीओं': 1, 'आईँ': 4, 'शीउंग': 2, 'है।आंकड़े': 1, 'होउंगा': 1, 'पत्रिकाएँ!': 1, 'प्वाईंट्स': 3, 'मुस्कुराओं': 1, 'पावरप्\\u200dवाइंट': 1, 'इंस्\\u200dटाग्राम': 1, 'फाउंडेशन)': 1, 'उडाओं': 1, 'कमाओं': 1, 'ओंकारोश्वर,': 1, 'मुस्कुराएँ': 1, 'जाऊंगा।’’': 1, 'बताऊंगी.पहचान': 1, 'जाऊंगा....': 1, 'रुआँसे': 1, 'इंटरव्यू...': 1, 'स्काउ्ट्स': 1, 'कला-आंदोलनों': 1, 'अंतरराष्ट्रीयतावाद': 1, '(डाइंग': 1, 'साइंसिज': 1, 'ठहराऊँगा।': 1, 'करवाएँगे।': 1, 'रक्तदाताओं': 1, 'रेखाएँ..': 1, 'ऐंटोनिया': 1, 'अंधायुग': 1, 'अंधकारसुरसूदन': 1, 'बनाऊँ.': 1, 'अंस': 2, 'प्रतिबद्धताएं': 1, 'प्रेरणाएं.': 1, 'इंदूभूषण': 1, ',इंटरनेट': 1, 'पत्र-पत्रिकाओं,': 1, 'अंदोहनाक': 1, 'है...इंटरमिटेन्टली.': 1, 'बताएं।?’': 1, 'बताऊंगी।”': 1, 'सप्तमातृकाएं': 1, 'आंध्र-ओडिशा': 1, 'स्व.बेअंत': 1, 'पुरूष-महिलाएं': 1, 'शायद...दुआएं': 1, 'आंदोलित,': 1, 'अकांक्षाएँ': 1, 'मिलाऊंगा।’': 1, 'कृतज्ञताएं': 1, 'अंदाजना': 1, 'पाएँगे।’’': 1, 'दाऊँदा।': 2, 'दाऊँगा।”': 1, 'बजाओं': 1, 'नैतिकताएँ': 1, 'ईंस्ट': 1, 'किओं': 3, 'राजकुमारिओं': 1, 'इंतज़ाम!’': 1, 'चलाएंगे..': 1, \"बताएं।'सोनिया\": 1, 'बनवाईं': 1, 'खाईं...इसे': 1, 'किटाणुओं': 1, 'लघु-कथाएं': 1, 'इंशाअल्लाह......': 1, 'प्रेमिओं': 1, 'रुअंसे': 1, 'फाऊंडेसन': 1, 'को-इंसीडेंस।': 1, \"आंदोलन'चल\": 1, \"'ओंकार'\": 1, 'गरियाऐंगे': 1, 'अंगुठा': 1, 'पड़ा,साईं,कृष्ण,आद्य': 1, 'इंडिपेंडन्स': 1, 'मिम्बअ़': 2, 'उपभाषाएं': 1, 'मचाऍंगे।': 1, 'है...बैकग्राउंड': 1, 'करवाऊँगा': 1, 'देवी-देव्त्ताओं': 1, 'बताएँगे,': 2, 'प्रेरणाएं।': 1, 'पात्र-पत्रिकाओं': 1, 'पीऍंगे।': 1, 'दुष्\\u200dटात्माएं': 1, 'सहजाताओं': 1, 'मसीहाओं,': 1, 'इंटैलेक्चुअल': 1, '-सुविधाओं': 1, 'बाइंडिंग': 1, 'दिखाएंगे?’': 1, 'आॅडिशन': 5, 'शुभकामनाँऎं': 1, 'पाएंगे?”': 1, 'अंतर्राष्ट्ीय': 1, 'अगुआओं': 2, 'इंडिया,13-10-21)': 1, 'इंडिया,23-3-1921)': 1, 'जटिलताएँ': 4, \"''इंसान\": 1, 'अम्माओं': 1, 'ऐँठे.': 1, 'क़तर-ए-आंसू,': 1, ',क्षणिकाएं': 1, '-अंग्रेजी': 1, 'शुभ-कामनाएँ.': 1, 'ऊँचे-२': 1, 'अट्ट्टलिकाओं': 1, 'चिंताएं।': 1, 'दुश्चिंताएं': 1, 'अंतरात्मा...': 1, 'चिं\\u200dताओं': 1, 'अंतिरम': 1, 'फाउंडेशन\"': 1, 'घटनाएं,कुछ': 1, 'समस्याएं...': 1, 'मालवकन्याएं': 1, 'इंटरव्यु': 2, 'चिन्ताएँ': 2, 'प्राक्कल्पनाएँ': 1, 'सिखाऊँगी': 1, 'चिंताएं.....।': 1, 'पकाएंगे।': 1, 'आईं।\"': 1, 'घूमाऊंगा,': 1, 'गईं..': 1, 'किउंकि': 1, 'व्यञ्जनाएं': 1, 'खड़ाऊं': 1, 'फ़ाउंडेशन': 4, 'कंदराएं': 1, 'आंतकित': 1, 'अंधेरों-आँधियों': 2, 'बरपाएंगे,': 1, 'रखवाएंगे।': 1, 'इंटरटेनर,': 1, 'हुईं-मंत्रिमंडलीय': 1, 'दायें-बाएँ': 1, 'नुमाइंदे,': 1, 'बताएँगे.': 1, 'पढाएं': 1, 'अंग्ररेजों': 1, 'आंसू।': 2, 'ओेैर': 1, 'एकाऊंटेंट': 1, 'कल्पनाऍं': 1, 'भंगिमाएँ': 1, 'पहुचाएंगे.': 1, 'उंगलीमार': 1, 'देवप्रतिमाएं': 1, 'आऊँगी.': 1, 'जाऊँगी.': 2, 'जगाऊं': 1, 'धारणाएँ।': 1, 'कुशाओं': 1, ',घटनाएं': 1, 'शुभकामनाओं,': 1, 'आंसुंओं': 2, \"'फालोइंग'\": 1, 'बिछाऊं': 1, 'अंाकड़ों': 1, 'इंतिहाई': 1, 'थी?अंत': 1, 'अंग्रेज।': 1, ',,,इंसान': 1, 'लाल-आँखे': 1, 'आंके,': 1, 'विपदाएँ': 2, '(अंक,': 1, 'दाहिने-बाएं,': 2, 'श्रंखलाएं': 1, 'शालाएं': 1, 'त्रुटिओं': 1, 'बजवाऊँ...।': 1, 'अबलाओं': 2, 'सुनाएँगे।’': 1, 'पूर्वापेक्षाएं': 1, 'घटनाएं/हम': 1, 'आएं/इससे': 1, 'हम/घटनाओं': 1, 'कर,हवाओं': 1, 'असमनाताएं': 1, 'छाएँगे,': 1, 'वीरकथाएं': 1, 'अंकतालिकाएं': 2, ',ऊँचे': 1, 'आंसुओं,': 2, 'जनसुविधाएं': 1, 'अभिलाषाओं,': 1, 'छायाओँ': 1, ',इंडियन': 2, ',इंडिया': 1, 'आएं....उनकी': 1, ',अंजुरी': 1, 'जाएंगे.......': 1, 'अनुशंषाएं': 1, 'फरमाएं-': 1, 'अंतर्लयता': 1, 'जाओं-पैमाना': 1, 'मान्ताओं': 1, 'बढाएँ': 1, 'आंकड़ेबाजी': 2, \"आऊं।''\": 1, 'विकलाँगताएँ\"': 1, '“फ्लाईंग': 1, 'में..समस्याओं': 1, 'जाओंगे': 1, 'अभिमन्युओं': 1, 'मनाएं.': 1, 'बचाएँ.और': 1, 'विध्न-बाधाएं': 1, 'उंह!': 1, 'ओंकारा': 2, 'इंजिनीयर,': 1, 'आंसमा': 1, 'कविताएं.': 1, 'चिलाऊंगा': 1, 'इंच-पत्थर': 1, 'मनाएँगे': 1, 'काउंट्स': 2, 'दफ़नाऊँगी': 1, 'गवईं': 1, 'पाएंगे।दिखने': 1, 'अंर्तजातीय': 1, 'अंगरेजी)': 1, 'आंटियां': 2, 'अधीनताओं': 1, 'आवश्यकताएँ:': 1, 'अंत्येष्टि-क्रिया': 1, 'कथाओं,पषु-पक्षिओं': 2, 'संहिताएँ': 1, 'संहिताएँ-': 1, 'कण्डिकाएँ': 1, 'लगाऊंगी।': 1, '(चरित्रवान-युवाओं': 1, 'बिताईं।': 1, 'मल्लिकाएं': 1, 'आंद्राखड्ड': 1, 'जाएंगे।‘-उसने': 1, 'माआेवादी': 1, 'पट्टिकाओं': 1, 'अंजाम-ए-उल्फत': 1, 'जीओं': 2, 'बताएं.मैंने': 1, 'जाऊंगा...रोज': 1, 'ब्लैक-एंड-व्\\u200dहाइट': 1, '\"सुकून-आंगन\"': 1, 'भूमिकाएं।': 1, 'कोशिकाओँ': 1, 'अंतःसंघर्ष': 1, 'एंटीथीसिस': 1, 'इंसेफलाइटिस': 1, 'बाउंसर,दोपहर': 1, 'जी…अंधेरा': 1, '-पत्रिकाओं': 4, 'इंदिया': 1, 'दुर्घटनाएं,': 2, '।अंशुमान': 1, 'इंस्\\u200dटॉल': 1, 'गउएँ,': 1, 'चढार्इ्': 1, 'ईंगलिश': 1, 'अंतररास्ट्रीय': 3, 'अंगारे।': 1, 'इंशाअल्लाह': 1, 'रोएँ-रोएँ': 4, '“कुएँ': 1, 'आंभी': 6, 'जाएंगे?\"': 1, 'जाऊंगा,मेरे': 1, 'नरसंहार:अंग्रेजों': 1, 'दोहराऊं': 1, 'मदेरणाओं': 1, 'मनाउंगी': 1, 'इंनका': 1, 'टीम-इंडिया': 1, 'ऊँच-': 1, 'एक्साइंिटंग': 1, 'संंभावनाएं': 1, 'ऋचाओं-मंत्रों': 1, 'सम्स्याओं': 1, 'अंगुरिया': 1, 'थे।अंतःकरण': 1, 'प्रताड़ओं': 1, 'घुआँ': 1, 'प्रार्थना-सभाएं': 1, 'निषिद्धताओं': 1, 'अंधाधुन।': 1, 'ख़ुशबुओं': 1, '\"इंकार:': 1, '\"इंजेक्शन': 1, 'आंदोलन’,': 1, 'शुभकामनाएँ.....।': 1, 'फैलाएँ': 1, 'बलाएँ,': 1, 'इंटलैक्ट': 1, 'इंदरपत': 1, 'आँटी': 1, 'बनाऊँगा।': 1, 'इ़ज़्ज़त': 1, '\"ऊँ\"': 1, 'अंतनिर्हित': 1, 'अंजानो': 1, 'गुदगुदाइं': 1, 'करते...अंबरीश': 1, 'जाओं।\"': 1, 'अजनबिओंका': 1, 'बनाऊँगी\"।': 1, 'जंघाएँ': 1, 'मुस्कुराऊं': 1, 'तमन्नओं': 1, 'इंर्धन,': 2, 'ंइंसान': 1, 'दाएं-बांए': 1, 'पीएँ': 1, 'अंतर्राष्टीय्र': 1, 'शुभकामनाएँ,मकर': 1, 'नइँ,': 1, 'छुपाऊं।': 1, 'अंग्रेज़ीदाँ,': 1, 'वेरिएंटों': 1, 'साँईं': 1, 'जाऊं!\"इस': 1, 'पहुंचाएंगे,': 1, 'आंखोने': 1, 'नहाऊंगा': 1, 'धोऊंगा..': 1, 'लगाऊँ,': 2, 'अध्\\u200dयेताओं': 1, 'पाएंगे—पाएंगे': 2, 'बताएं।–गुरुप्रसाद': 1, 'एंसिलियरी': 1, 'अंतःकथा': 1, 'देंवताओं': 1, 'अंदाज़-ए-बयानी': 1, 'सार्इंस': 1, ';अंदर': 1, 'लगाऊं?': 1, 'आंगन,नम': 1, 'अंत:गर्भाशय': 1, '-अंधविश्वास': 1, 'ऊँट,': 3, 'ााओं': 1, 'हेडराइंटिग': 1, 'हेडराइंटिंग': 1, 'लिऊंग': 1, 'निर्भीकताओं': 1, '्थईं।': 1, 'आक्रमणकर्ताओं': 1, 'चमकाऊँगा': 1, 'समालोचनाओं': 1, 'विभाषाओँ': 1, 'सिर-आंखों': 4, 'पेईंग-गेस्ट': 1, '\"बाउंसरों\"': 5, 'महानुभाओं': 1, 'बढ़ाऊं?': 1, 'जाऊं.........': 1, 'भाखड़ाओं': 1, 'अंनत': 1, 'पात्र-पत्रिकाओं,': 1, 'ड्राईंगरुम': 1, 'कराऊं': 1, 'अंग.रोज़': 1, 'आऊंगा,,': 1, 'इंशोरनस': 1, 'सिखाएँगे': 2, 'अनिवार्यताएँ': 1, 'एप्वाइंटमेंट': 1, 'उंडेलो': 1, 'कल्पनाएँ,': 1, 'आंगन-सा।': 1, 'जाएँगीं': 1, 'कविताएँ..': 1, 'उंउं': 2, 'इंटीरिअर': 1, 'एंजीना': 1, 'उपासनाओं': 1, '‘ऊँ’': 1, 'दिलाएंगे।\"': 1, 'प्रतिष्ठाताओं': 1, 'अंतिमयात्रा': 1, 'कृतिघ्न्ताओं': 1, 'शिराएँ...धवल': 1, 'वैष्याओं': 1, 'दिलाऊँ।': 1, ',अंगूठा': 1, 'सताऊं': 1, 'अँकुराये': 1, 'एंडिंग।': 1, 'अंगरक्षक,': 1, 'गाऊँगी': 1, 'ताउम्र...आँखों': 1, 'कहा-’’अंकल': 1, 'अंध,': 1, 'उपभक्ताओं': 1, 'आशंकाएँ': 1, 'भी...इंतज़ार': 1, 'आंगन-आंगन': 2, 'छुपाएंगे?’': 1, 'आॅडियंस)': 1, 'बताऊंगा’।': 1, 'एंजेल...मैं': 1, ',तंतुओं': 1, 'विशेषताएँ:': 1, 'इंस्टिंक्ट)': 1, 'अंगुलियाँ,': 1, 'लौटाऊं': 1, 'बताएँगे?': 1, 'दिखाएं..!!\"': 1, 'बताएंगे..': 1, '“अंध-विश्वासों”': 1, '....अंगरेजी': 1, 'इंडिया;नोट': 1, 'अंदर?': 1, 'सरिताएँ!': 1, 'अंवेर': 1, 'धुआँ।': 1, 'सदिच्छाओं,': 1, 'इंडिया)।': 1, 'कार्यकर्ताओं/प्रतिनिधियों': 1, 'पीएंडए': 2, '\"इंदिरा': 1, 'मोबाइल-अंकल--और': 1, 'कराएंगी,': 1, 'नइँ': 1, 'गेंसुओं': 1, 'आँगन।': 1, 'साऊंड़...)': 1, 'वस्तुओं,संस्कृति': 1, 'मुड़-जाएं': 1, 'अंधविश्\\u200dवासी': 1, 'आँधी.पानी': 1, 'आख्याओं': 1, 'आंकिक': 1, 'गईः': 1, '‘अल्ट्रासाउंड’': 1, 'इंद्रियनिग्रह': 1, 'बापुओं,': 1, 'निपटाउंगी.': 1, 'दुहराऊँगी': 1, 'ओ़क्झेलिक': 1, 'दिखाऊँगी?”': 1, 'अंडाशय': 1, 'अपदाओं': 1, 'अंलकृत': 1, 'आऊँगी;': 1, 'आॅख': 1, 'जीएं': 2, 'बुलाएँगे”': 1, 'जाएँ.वे': 1, 'है.इंडियन': 1, 'पढ़ाएं,': 2, 'व्यंजनाएं': 1, 'कड़ियाँबनाएँ.': 1, 'नीचताओं': 1, 'प्रतिद्वन्दिताओं': 1, 'ऊँचे,': 1, 'प्रतिभाओं,': 1, '\"साउंड': 1, 'ऊँचे-नीचे': 1, 'इंटरफेयर': 1, 'प्रकाश-अंधकार-मिश्रित': 1, 'आंकड़े,': 1, 'जाएँगी.इस': 1, \"इंसानों'\": 1, 'आंतक,': 1, 'बुलाएँगे.': 1, 'पाएं...काव्या-सौम्या': 1, 'संज्ञाएँ': 1, 'अल्ट्रासऊंड': 1, 'युआंन,': 1, 'विदेलाओं': 2, 'घोषणाएँ': 3, 'इंटरैक्टिव': 1, '(आंखें': 1, 'निगरानीकर्ताओं': 1, 'जाएं।गौरतलब': 1, 'विचारधाराओँ': 1, 'अंगेजी': 3, 'समाऊँ': 1, 'अंगूठियां।': 1, 'जाऊँ..??': 1, 'अंधालय': 1, 'परम्पराओं,विशेषतोओं': 2, '‘इंग्लैण्ड': 1, 'जाऊँगी...’': 1, 'अीाी': 1, 'सत्य-अंहिसा': 1, 'परीकथाएँ': 1, 'था...आँखें': 1, 'बताऊँगी।”': 1, 'निंदिअै,': 1, '(अंधवाड़ी),': 1, 'अंदर/एक': 1, 'नवयौवनाओं': 1, 'आईँ,': 1, 'राजभाषाएँ': 1, 'कबाओं': 1, 'छवियों-अपेक्षाओं-पूर्वाग्रहों': 1, 'अंतत:,': 1, 'बरसाऊंगा': 1, 'बटाएं।': 1, 'जाउंगी\"।': 1, '/कविताओं': 1, 'आंकडेÞ': 1, 'हुईं!': 1, 'अंतर्देशी।': 1, 'था.अंतिम': 1, 'बताऊँ...वो': 1, 'इंतजार...सब': 1, 'उड़ाएंगे।': 1, \"'छाया''प्रतिध्वनी''आकाशदीप''आंधी'कथा\": 1, \"'इंद्रजाल'\": 1, 'माइंजी': 3, 'अंबाबाड़ी': 1, 'अंधधुंध': 1, 'इंसानियात': 1, 'समझाएँ': 1, 'लम्पटताएं': 1, 'प्वाइंटों': 2, 'जिवाणुओं': 2, 'एंब्रॉडर,': 1, 'राजनेताओंसे': 1, 'साइंसदां': 1, 'बनाएंगा': 1, 'अंशदाता': 1, 'आँसू/': 2, \"थे''पिएंगे,\": 1, \"मंगवाऊं?''\": 1, 'आऍंगे?': 1, 'नव-दुर्गाएँ,': 1, 'मनाऊंगी': 1, 'ऐंग्री': 1, '“बाबाओं': 1, 'युवाआें': 1, 'यौनवर्जनाओं': 1, 'बताऊं?’': 1, 'औंर': 1, 'लगाऍं,': 2, 'इंस्पेकटर': 1, 'गाऊँगी।’': 1, 'सदाओं': 1, 'तालिकाएं': 1, 'पाउँगी,': 1, 'मनोवांछाओं': 1, 'खाऊं-पीऊं,': 2, 'इंडि\\u200dया': 1, 'कविताएं)अच्छा': 1, 'आँसुओं-धुला': 2, 'बिताएं।\"': 1, 'तमाशाओं': 1, 'आँधर': 1, 'कहोगे-इंतज़ार': 1, 'खिंचाएं': 1, \"'आईं!\": 1, 'एंटिटी': 1, 'कष्ट-आंनद': 1, 'प्रतिकूलताओँ': 2, 'पाएंगे!': 1, '\"तोहऊँ': 1, 'फिल्म-नायिकाएँ': 1, '-बच्चिओं': 1, \"'आंनदम्'\": 1, 'आइं।': 1, 'चुआं,': 2, 'बेंदरचुआं,': 1, 'घुंईचुआं,': 1, 'बेहरचुआं,': 1, 'जामचुआं,': 1, 'औंरापानी,': 1, 'भेडिओं': 1, 'आंदोलनः': 1, \"बताएंगे...''\": 1, 'दीपमालिकाऐं': 1, 'बद्दुआऐं': 1, 'बड़ाईं': 1, 'इंटेलीजेण्ट': 1, 'मंगवाएं.': 1, '“इंडियन': 1, 'रिमाईंड': 1, 'आधे-आँगन': 1, 'अंर्तमन': 1, 'मनोभाओं': 1, 'पढ़ाएंगे': 1, 'चलाऊँगा': 1, 'माफ़ियाओं': 1, '...अंतर्राष्ट्रीय': 1, 'राजसत्तओं': 1, 'बनाऊँगा': 1, 'दृष्टाओं': 1, 'मंगलकामनाएं!!!': 1, '‘आंटी': 1, '(ऋचाएं)': 1, 'उपत्\\u200dयकाएं': 1, 'अंकलों': 1, 'आँखे,': 1, 'रुढियों/अंधविश्वासों': 1, 'बनवाऊंगा,': 1, 'अंतरसंबंध': 2, 'सजाऊंगा!': 2, 'इंग्लेड': 1, 'अंतराल(Space)': 2, 'लोकगाथाओं': 2, 'नायिकाओं,': 1, 'अनैतिकताएं': 1, 'एंबीयंट': 1, 'आँख्याँ,': 1, 'अंअजन': 1, 'शृंखलाएँ': 1, 'झलमलाएं!': 1, 'शोधकर्ताआेंने': 1, 'दवाएं.': 1, 'पीएंगे,': 2, \"'अंधा\": 2, \"'अंधी'\": 1, 'जबकिघटनाएं': 1, '(बाबूओं)': 1, 'उपभोक्ताओॆ': 1, \"'अं'\": 1, 'लता-तरुओं': 1, 'प्रतिबद्धताएं’': 1, 'आजीविकाएं': 2, '‘अँधेरा’': 1, 'दाएँ-बाएँ': 2, 'किराएं': 1, 'आऊँ।...तुम': 1, 'अंधता,': 1, 'अंतःवैयक्तिक': 1, 'धोएं!': 1, 'जाएंगे!': 1, 'भाईं': 1, ',आँख': 2, 'परछाईँ': 1, 'होऊं,': 1, '(अंततः': 1, 'आँकरो': 1, '(पशुओं': 2, 'हैं),अंधा': 1, 'बताएं)': 1, 'उठाएं,तो': 1, 'आँतड़ियों': 1, 'अंडा-मांस': 1, 'अंगार-शय्या': 1, 'इंडीब्लॉगर': 1, 'अप्रासंगिकताएं': 1, 'आँगन!': 2, 'अंबेसेडर': 1, 'नक्सलिओं': 1, 'इंस्ट्रक्श': 1, 'आॅप्शन': 1, 'स्पधार्ओं': 1, 'बतलाएं।': 2, 'ई-पत्रिकाएँ(आनलाइन': 1, 'ई-पत्रिकाओं': 4, ',इंग्लैंड': 1, 'ऐंठा,': 1, 'मिटाऊँ': 2, 'काऊँटर': 2, 'आॅक्यूपाई': 1, 'धाराओं,': 1, 'यात्राएं),': 1, 'करवाउँगी': 1, 'रेशा...उँगलियाँ': 1, 'जाऊं...इतना': 1, 'त्वचाओं': 1, 'साउंड,': 1, 'साउंड.': 1, 'कन्याएँ': 1, 'होओ...........हत्याओं': 1, 'चढ़ाऊँगी': 1, 'कहलवाएं': 1, 'आंधी.आंधी': 2, 'एवईं': 1, 'आँख-नाक': 1, 'बेटियों-बहुओं': 1, 'पाएंगी...': 1, 'श्रद्धाओं': 1, '‘अंकुश’': 1, 'इंतजारमें,': 1, 'इंदुलकर': 2, 'बिसराऊँ': 1, 'दुहराएँगे,': 1, '(इंटरजेकशन)': 1, 'कि,आंदोलन': 1, 'अंतरचक्षु': 1, 'विज्ञानवेत्ताओं': 1, 'जन्मादाताओं': 1, 'बनाऊंगा’’': 1, 'ट्टुओं': 1, 'इंडिस्ट्रक्टिबल': 1, 'एटीएंडटी': 1, 'एंजिल्\\u200dस': 1, 'इंस्\\u200dटीट्युट': 1, 'बनवाऊंगा..मुर्गियां': 1, '‘ईंदलदेव’': 1, 'आईं)': 1, 'रिपोर्टरों/एंकरों': 1, 'साईंधाम': 1, 'चुराएंगे': 1, 'जाएँ...।': 1, 'सभाओं,संगोष्ठियों': 1, '(इंशाअल्लाह)।': 1, 'अंगडाई,': 1, 'करें.सफलताओं': 1, 'इंवेस्टीगेशन': 1, 'जाएं,लेकिन': 1, 'इंटेलिजेंट!': 1, 'सीखाएंगे।': 1, 'गइै': 1, 'उद्धारकर्ताओंके': 1, 'भड़ुओं': 1, 'आँखॉ-आँखॉ': 2, 'जाएँ|': 1, 'एंकर्स': 1, 'ठगा..अंगरेजी': 1, 'अँखें': 1, 'ऊँचे!': 1, 'लोक-परम्पराएँ,': 1, 'अंग्रेज.': 1, 'चुआंगू': 1, '“ऊंट-पटांग”': 1, \"लाऊँगा।''\": 1, 'खाऊंगी': 1, 'भईंस-गोबर': 1, '(‘इंटरनेट,': 1, 'गोसाईं’);': 1, 'दोहराएं,': 1, 'अंतर्चिंतन': 1, 'आँतविकार,': 1, 'संभवनाओं': 1, 'रचनात्मकताओं': 1, 'ऊर्जाएँ': 1, 'पाओंगे।': 1, 'साउंड-प्रूफ': 1, 'गुर्राएंगे': 1, 'अन्तर्क्रियाओं': 1, 'पाऊँ।।': 1, 'सुनाऊंगा,': 1, 'बताऊँ,कैसे': 1, ',माताओं': 1, 'जाएं..क्या': 1, '‘भावनाओं': 1, \"जाऊँगा..'\": 1, 'क्लाइंट,': 1, 'जताऊं': 1, 'अंबरेला': 1, 'सभ्याताओं': 1, 'योजनाऐं': 1, 'निएंडरथल': 1, 'पिएँगे।': 1, '-इंजीनियरिंग': 1, 'सर्वेक्षणकर्ताओं': 1, 'खुजाऊँ...': 1, 'जाएंगी,लगेगा': 1, 'बतलाऊँ,': 1, 'अंब': 1, 'हिंदुओं,मुसलमानों,हरिजन': 1, 'एंट्रिक्स..देवास': 1, 'आऊं?': 1, 'ऋंगार': 1, 'जीऊँगी।': 1, \"'उँह\": 1, 'एंटी,': 1, 'हिंदी-अंगरेज़ी': 1, 'इंग्लैण्ड,': 1, 'भूगर्भवेत्ताओं': 1, 'है-‘माउंटेनियरिंग': 1, 'अंधाधुन्द': 2, 'जाओं;': 1, 'गईं.”': 2, 'है.कन्याएं': 1, 'इंचार्ज़': 1, 'रिवाज-प्रथाएं': 1, 'इंशाजी': 1, 'मामाओं': 1, 'अ-हिंदुओं': 1, 'अंकल..': 1, 'पाएँगे।धोनी': 1, '“इंडीपेन्डेन्स': 2, 'रचियताओं': 1, 'अंगूठियां': 1, 'दिएं,ये': 1, 'इंडिया,27-8-1925)': 1, 'दफाओं': 1, '.एंजाइना': 1, 'जिएंगे?': 1, '‘‘देखो-श्-अ्!’’': 1, 'अंतर्राष्टरीय': 1, 'आँखों,गालों': 1, 'इंण्डिया': 1, 'टट्टुओं': 1, 'हईं!': 1, 'आलोचनाऍं': 2, 'इंतिज़ार': 1, 'करना,आंतरिक': 1, 'अंतकाल': 2, 'सम्मोह्नकर्ताओं': 1, 'सुनाऊँ?': 1, 'चढ़ाऊँगी।’': 1, 'विरूपताओं': 1, 'असमर्थताएँ': 1, '.इंदिरा': 1, 'इंचार्जों': 1, 'अँखियाँ...': 1, 'अंखुए': 1, 'इंसानके': 1, 'अंग्रेजोसे': 1, 'ऐंठते,': 1, 'सदगुरूओं': 3, 'जाएंगे।उन्होंने': 1, 'औंटाया': 1, 'ईंजीनियर...': 1, 'आॅक्सिजन': 1, 'अंधशाला': 1, 'आंदोलकारी': 1, 'इंडीपेंडेंस': 2, \"उठाएंगे!''\": 1, 'इंफॉर्म्ड': 1, 'इंजिनीयर': 1, 'अंततःअधिनायकवादी': 1, 'आँखॊं': 1, 'अंहकारी': 1, 'बाजुएँ': 1, ',बेल,एंसट्राम,आवंटी': 1, 'अंतर्निवि\\xadट': 1, 'गैर-हिंदुओं': 1, 'बढ़ाएं?': 1, 'बढ़ाएँ.': 1, 'यहूदिओं': 1, 'जुटाऊँगा': 1, 'लहराएँगे': 1, \"जाऊँगा।''\": 1, 'अंक-जुलाई': 1, 'उठाएँगे': 1, 'अलसाएं': 1, 'पाएँगे.': 1, 'पाउँगा?': 1, 'ल़डवाएं।': 1, 'पहुंचाऊंगा।': 1, 'हत्याओं/आत्महत्याओं': 2, 'नीम-अँधेरे': 1, 'बुलाएँगे,लीलाबाईने': 1, 'आँगनबाड़ी': 1, 'पत्रा-पत्रिाकाएँ': 1, 'आँफिस': 1, 'इंडीयाना': 1, 'अव्यवथाएं': 1, 'फिजाएँ': 1, 'थी...हवाएँ': 1, 'स्मारिकाओं': 1, 'चिड़ियाएँ': 1, 'साहित्यिक-रचनाओं': 1, 'अफसर,नेताओं': 1, 'सज़ाएं': 2, 'आयोजनकर्ताओं': 1, 'अंगूंठे': 1, 'आत्माऐं': 7, 'जाऐंगी': 1, \"आऊंगा।''\": 1, 'डराऊँ।': 1, 'व्यस्तताओं,': 1, \"'अंकुर'\": 1, 'अंशत': 1, \"लगाउंगा।''\": 1, 'आँसू-जल!': 1, 'सुधार-आंदोलनों': 1, ',महिलाओं': 1, 'होऊँ,': 1, 'आंकड़े/सर्वे': 2, 'आउंगी....(कनिष्क': 1, 'ग़िजाओं': 1, 'रिझाऊँ!': 1, 'मिटाऊँगी': 1, 'सज़ाएँ': 1, 'इंडोर्समेंट': 1, 'लगाएँ?': 1, 'ऎंठकर': 1, '“बैगाओं': 1, 'लहराएं।': 1, 'घुमाएंगे।': 1, 'घुमाएंगे।’': 1, 'रोएंगे।': 1, 'बताऊंगा...': 1, \"'इंकलाब'\": 1, 'इंडियन\"': 2, 'भारत-बेस्तइंडीज': 1, 'अागे': 1, 'घातकताओं': 1, 'नेताओं-अधिकारियों': 1, 'पहनाऊँगी': 1, 'रचना-अंश': 1, 'लिएँ': 1, 'दगा,आशाओं': 1, 'जाएंगे-': 1, 'जाऍंगी।': 1, 'मुक्तिदाताओं': 1, 'बताउं..!!': 1, 'नागाओं': 1, 'लाईंसेस': 1, 'सुनाऊँ,': 1, 'कवितओं': 1, 'है,सज़ाएँ': 1, 'अंर्तविरोध': 1, 'गौशालाएं': 1, 'अलग..आजाद...अंदाज..': 1, ',इंजिनीयर': 1, 'रओं': 1, 'ऐं’’': 1, 'धुऐं': 1, 'नाइंटीज’': 1, 'राजे-महाराजाओं': 1, 'अँधेरा).मैं': 1, 'मसीहाओं': 1, 'उंड़ेली': 1, '“अंग्रेजी': 1, 'कुओं,': 1, 'इंजीनिर': 1, 'जाएंगे,इस': 1, 'है.आंसू': 1, 'मृतात्माओं': 1, 'बसाएँगे': 2, 'जाऊंगा.’’': 1, '-अंबर': 1, 'गढ़ाऐँ': 1, 'मंडराएंगे': 1, 'सुनाउं,': 1, 'अंत:श्\\u200dवास': 1, 'अंत:श्वास': 1, 'इंडोस्कोप': 1, 'अर्थ्व्यवस्थाओं': 1, 'आऊँ?': 1, 'गाथाएं।': 1, 'यन्त्रणाएँ': 1, '\"एंग्लों': 1, 'नाईं.': 1, 'हड़बड़ाईं': 1, 'जनआंदोलनकारी': 1, 'फ़जा़ओं': 1, 'शिक्षाएं,': 1, 'बाईँ': 1, '‘फिजाओं’': 1, 'लिपियों-भाषाओं': 1, 'आऊंगा!': 1, 'इंतिज़ामात': 1, 'करवाऊंगा': 1, 'आंखे.....जो': 1, 'संदेष्टाओं': 2, 'चढ़ाएंगे?': 1, 'आँख.': 1, 'ऊँचायी': 1, ',अँगुली': 1, 'रीफाईंड': 1, 'अंत\"': 1, 'अंतर्लीन': 1, 'इंदिरासागर': 1, 'इंडियन-मुजाहिदीन,': 1, 'बुलाएँ': 3, 'जाएंगें...': 1, 'आशाएँ,': 1, 'चक्षृओं': 1, 'एंड्रियोमेट्रियोसिस': 1, 'बताऊँगा….': 1, 'वफ़ाओं': 2, 'मेंअंग्रेजों': 1, 'समाएं': 1, 'गुसाईं': 2, 'अँधकार': 1, 'अंबानी-टाटा,': 1, 'सत्यसाँईं': 1, '(इंटरनेट': 1, 'ओंधे': 2, 'बददुआएं': 1, 'इंजीनिअरों': 1, 'च्यूइंगम': 1, 'चढाएं,': 2, 'वस्\\u200dतुएं,': 1, 'अनियमितताओं,': 1, 'महत्वाकांक्षाएं,': 1, 'अंगर': 1, 'बजाऊँ..': 1, 'अँसुवन': 1, 'बैठाऊंगा': 1, '’अंदर': 1, 'खिलाऍं,': 1, 'अटखेलिओं': 1, 'बद्लाओं': 1, 'अंहि': 1, 'अंडरअचीवर।': 1, '(प्रेमिओं': 1, '‘अंडर': 1, 'दिखाएँगे...।': 1, 'गतिविधिओं': 1, \"'अंजान'(जो\": 1, 'छिपाऊं,': 1, 'बतओंगे': 1, '‘‘आँधी-तूफान': 1, 'बनाईं.': 1, 'इंन्सान': 1, 'अंग...': 1, 'कविताएँअमित': 1, 'रूपरेखाओं': 1, 'दौडाएं': 1, 'था.अंग्रेजी': 1, \"'इंस्टैंट'\": 1, 'एंजल्स,': 1, '...........इंतज़ार': 1, 'अंतर-खोज': 1, 'बैकग्राउंड।': 1, 'इंप्लाएमेंट': 2, 'अंतीं': 1, 'आऊंगी?': 1, 'आरजुएँ': 1, 'लाएँ': 1, 'उंब-या': 1, 'अमावस्याएं,': 1, 'अमावस्याओं': 1, 'अंदरे': 1, 'परिपक्वताओं': 1, 'अंधों....': 1, '७०%मरिज़ाओं': 1, '२५%ओंकोप्लास्टिक': 1, 'अध्\\u200dययनकर्ताओं': 1, 'आऊँगा...राजकृष्ण': 1, 'बारबालाओं': 1, 'बारबालाएं': 1, 'अंधराष्ट्रवाद': 1, 'पाएंगी.कुछ': 1, 'अर्हताएं': 1, 'चुकाऊंगा,': 1, 'चंपुओं': 1, 'रक्तवाहिकाओं': 1, 'गईं.’': 1, 'भिजवाएंगे.': 1, 'भांति,आलुओं': 1, \"जाऊं.'\": 1, '-\"अंकल': 1, 'लताएं': 1, 'अंदाज़ों': 1, 'धुआं,जलने': 1, 'उचाइंयों': 1, '-इंसानी': 1, '.नेताओं': 1, 'बजवाएं': 1, 'संवाददातापओं': 1, '-आँगन': 1, 'शबे-इंतजार=प्रतीक्षा': 1, 'जाऊँगी?': 1, 'जाऊँगी?”': 1, 'सुलझाएंगे?': 1, 'ऐक्ष्वाकुओं': 1, 'अंधक,': 1, 'एँल्बम': 1, 'कविता/ओं': 1, 'पाऊँगा।।': 1, 'झुकाएं।': 2, \"'उंन्हे\": 1, 'इंदौर.': 1, 'अंडा।': 1, 'कविताओं-': 1, 'डालें.एंटीवायरस': 1, 'निराशाएं,': 1, 'शर्माएं': 1, 'सोएँ': 1, 'जाएं...जिसके': 1, 'अंडरटेकिंग्स': 1, 'लेखिकाएँ': 1, 'आएंगे!’': 1, 'है.संभावनाएं': 1, '-आंखों': 1, 'छपवाईं।': 1, 'बनाएँ।संवाद': 1, 'बचाऊंगा।': 1, 'आॅखों': 3, 'कराऊं।': 2, '“अंगूठे”': 1, 'शर्माओंगी': 1, 'इंद्रदीप': 2, 'जाऊं\"': 2, 'उड़ाएं': 1, 'जिजीविषाओं': 2, 'लतिकाएं': 1, 'इंदीवरजी': 1, 'रेलयात्राएं': 1, 'आपत्तियों,चिंताओं,दुखों': 1, 'ऋषिओं': 1, ',नेताओं': 1, 'पहलओं': 1, '.अंततः': 1, 'चेताऊं,': 1, '\"ऊंची': 1, 'आंगुतकों': 1, 'जाउँगी': 1, 'एंटीला': 1, 'दर्शाएंगी।': 1, 'बंसल-अंसल,': 1, 'इंटेलिजेंट,': 1, 'ऐफिशिएंट,': 1, 'समाईं।': 1, 'विद्याएं?': 1, 'खाएं...।': 1, 'बचाऊँ?’’': 1, 'अंतर्संबध': 1, 'भाएं।': 1, 'राजमाताएं,': 1, 'इंग्लैंण्ड': 1, 'दाएं-बाएं,': 2, 'चित्रकथाओं': 1, 'राजाओं-नवाबों': 1, '‘अंशुमान': 1, 'इंटरनेट-फेसबुक-ब्लॉग': 1, 'अंदर!”': 1, 'इंस्टापेपर,': 1, 'इंजीनिया': 1, 'धुंआं': 1, 'अंग्रेज़ी-काव्यानुवादों': 1, 'ऊंघता': 1, 'इंटिरियर': 1, 'कंम्\\u200dबाइंड': 1, 'बॉलोइंग': 1, 'अंतराष्\\u200dट्रीय': 1, 'खाएं’': 1, 'दौड़ाएं': 1, '(अंबेडकर': 1, 'है.वृद्धावस्था,अंगों-प्रत्यंगों': 1, 'इंटरकट': 1, 'दुबोऊंगा': 1, 'अंगड़ाइयाँ': 1, 'जाएगा।आंदोलन': 1, 'रहे।आंदोलन': 1, '\"इंटरटेनमेंट\"': 1, 'पहुँचाएँ': 1, 'समस्याआंे': 1, \"--''सफलताओं\": 1, 'एंटीसिपेटरी': 1, 'युवाओं-छात्रों': 1, \"अंतर्निर्भरता'\": 1, 'माओं,': 1, 'गौएँ': 1, 'चराईं,': 1, 'एंबूलेन्\\u200dस': 1, 'रामशिलाएं': 1, '\"ग्राउंड': 1, 'जाएं,वही': 1, 'मिलाऊं?': 1, 'बताएँ..का': 1, 'रुंआँसा': 1, ',अंधे': 1, 'पढाकुओं': 1, 'बुर्जुओं': 1, 'अंतरग्रथित': 1, 'अप्वाइंट': 1, 'घटनाएं...': 1, 'शुभेच्छाएं': 1, 'एंडॉरसमेंट': 1, 'खिलाऊँ': 1, 'काल-निशाएँ': 1, 'घटनाएं.': 1, 'बाजूओं': 1, 'आसुंओं': 3, 'जॉंऊं।': 1, '(इंह्ह': 1, 'ॠतुएं': 1, 'चाहिएँ,': 1, \"आँचल',\": 1, 'अपेक्षाऐं': 2, 'कहलाएंगे....': 1, 'अ़खबारों': 3, 'अवस्थाओँ': 1, 'घोद्गाणाओं': 1, 'ढोईं....नीचे': 1, 'इंटरकोर्स’': 1, 'है.आरजुओं': 1, 'उंगुलियां': 1, 'अंगूली': 1, 'लुभाएँ': 1, 'मधुशालाएँ': 1, 'इंटवा': 1, 'प्रेमिकाएं,': 1, 'मिक्स़र-ग्राइंडर': 1, 'हो,अंदर': 1, 'इछ्छ्याओं': 2, 'पाएं...इतिहास': 1, 'अंसिफ': 1, 'महिलाऍं': 1, 'उंगलियां,': 1, '\"एंटी': 1, 'उमराओं': 1, '\"अंकल/आंटी,': 2, 'अँकल': 1, 'ओँखें': 1, 'चर्म-चक्षुओं': 1, 'आएँ..का': 1, 'करें/कराऍं।': 1, 'एंज़ाइम': 1, 'कुटियाओं': 1, 'आजकल....कविताएं': 1, 'इंहह!': 1, 'जाऍं;': 1, '-धुआं': 1, 'देहरी-आँगन': 1, 'अंगोछे': 1, 'एनाऊंसर': 1, 'बचाऊँ,': 1, 'आंग्ल-अमरीकी': 1, 'परियोजनाआें,': 1, '…अंग्रेजी': 1, 'जाएँगे...': 2, \"'अंजुमन'\": 1, 'अस्मिताओं‘': 1, 'सूनी,ईंट-गारे': 1, 'इंद्रासन': 1, 'लगवाएंगे?': 1, 'आएँगी.': 1, 'लगवाऊंगी': 1, 'नाख़ुदाओं': 1, 'एंटीबॉडी-': 1, 'उंचाइयां': 1, 'इंटैलैक्चुअल': 1, 'गुनगुनाएं': 2, 'पोथिओं': 1, 'नया,निर्मल,अंकुरित': 1, 'अंगीठियाँ': 1, 'अंधेर-उजालों': 1, 'काव्य-धाराओं': 1, 'इंटीग्रेशन,': 1, 'अंखरखे': 1, 'अंततःराजनीति': 1, 'नचाऊँगी...’,': 1, 'खाएँगे,': 1, 'आँगन-अलंकरण,': 1, 'समझाउं,तेरी': 1, 'च्यूंईंगम': 1, 'जटाआें': 1, 'रोआें': 1, 'धाराआें': 1, 'जुटाएगा,कथाओं-कीर्तनों': 1, 'सभाएं-जुलूस': 1, 'भाईओं': 1, 'संभावनाएं।': 1, 'सकुचाउंगी': 1, 'सिपाहियों-दरोगाओं': 1, 'कहाएंगे।': 1, 'युवानांअंतपुरसधर्माणा': 1, 'स्थापनाएँ': 1, 'शिक्षण-संस्थाओं': 1, 'सुविधाऐं-': 1, 'कोई्र': 1, ',इंसानियत': 1, 'लेखन-प्रतिभाओं': 1, 'औपचारिकताएँ': 1, 'छात्रााओं': 1, 'है.अंगरेजी': 1, 'सीमारेखाओं': 1, 'प़क्षधरताओं,': 1, 'जड़ताएँ': 1, 'इंगलैंड,': 1, 'इंटर-साइंस': 2, 'देव-प्रतिमाएं': 1, 'आंधी-पतझारों': 1, 'कुअें': 1, 'प;रतिस्पर्धाओं': 1, 'आंखें,प्यार': 1, 'दि\\u200dशाएं....': 1, '“प्रतिभाओं': 1, '..........आँख': 1, 'अंगरखे': 1, 'आइंख': 1, 'अंतरखगोल': 1, 'अंक!': 1, 'धर्मध्वजाओं': 1, 'लघुकथाऍं': 1, 'जाएँ)': 1, 'अवतारों-नायकों-मसीहाओं': 1, 'पहुंचाऊं': 1, 'बनवाएँगे': 1, 'सीमाऐं': 1, 'अंतरपट': 1, 'जुटाएंगे?': 1, 'बोएंगे?': 1, 'अंक-जुलाई-सितम्बर': 1, 'गवाएं': 1, 'अंतड़ियाँ': 1, 'उंक्के': 1, '(बताएं': 1, 'अंखियो': 2, 'करवाऊंगा.': 1, 'जाएं;': 2, 'वार्ताऐं': 1, 'आंदेालन': 1, 'धातुएँ': 1, \"'इंतज़ार\": 1, 'निभाऐंगे': 1, 'धातुएँ.': 1, 'आऊं?मैने': 1, \"'अंकगणित'\": 1, 'उंही': 1, 'पकड़ाईं': 1, 'है.क्वालिफाइंग': 1, 'प्रस्तावनाओं': 1, 'होऊँ...': 1, 'अंकुर..': 1, 'अंतदृष्\\u200dटि': 1, 'सजाईं': 1, 'बालिकाएं,': 1, 'ग़लतफ़हमिओं': 1, 'कलोनिओं': 1, 'मृतात्माएँ': 1, 'चिल्लाएंगे': 1, 'बनाईं,': 1, 'एंट्री-2': 1, 'संवेदनाएं.': 1, 'ऑंसुओ': 1, 'अंधेरे।': 1, 'लाऊंगी': 1, 'इंडोसन-निप्पन-जापानी': 1, 'पैरोकारो-सामंतो-नेताओं': 1, 'महिलाएॅ': 1, 'अंत:सलिला': 1, 'बाताऊं': 1, 'इंजीनियर,कुशल': 1, 'आंसूं,जो': 1, 'प्रतिज्ञाओं': 1, 'साधुओं,कर्मवीरों': 1, 'कराएँ.कमेंट्स': 1, 'इंद्रिय,': 1, 'एँड़ियों': 1, 'धर्म,संप्रदाय,ऊंच,नीच': 1, 'आईं,यदि': 1, '(छोटी)ऊँगली': 1, 'चाहिएं।‘': 1, 'हिन्\\u200dदी,संस्\\u200dकृत,अंग्रेजी': 1, 'रईंसाना': 1, 'अंसतुष्ट': 1, 'नेताआंे': 1, 'बिताएं': 1, 'अंग्रेजो,': 1, 'जाएँ.चाहे': 1, 'सूईंयां': 1, '...अंगूठा': 1, 'जताएंगे': 1, \"बनाएंगे।'\": 1, 'शास्त्रवेताओं': 1, 'अंडरइश्टैंड': 1, 'गईं)': 1, 'मिटाऊं': 1, 'समझाऊँगी।': 1, 'वस्तुओँमेँ': 1, 'अवस्थाओँमेँ': 1, 'रहस्य,संभावनाएं': 1, 'धर्मषालाएं': 2, 'लघु-पत्रिकाओं': 1, 'अंखवे': 1, 'दग़ाओं': 1, 'छुईं': 1, 'अ़जीज': 1, 'लगाएँ': 1, 'विकरालताओं': 1, \"बताऊँ।''\": 1, 'आंखे।': 1, 'जाऊँ.': 2, 'अंजवाया': 1, 'आॅन': 1, \"'इंका\": 1, 'अंगुल-अंगुल': 2, 'गाएँ,': 1, 'आँख-मिचैनी': 1, 'अंतरऱाष्ट्रीय': 1, 'अभिलाषाएँ': 1, 'खटखटाऊं': 1, 'बटाएं': 1, 'अँधेरे,': 1, '-इंग्लेंड': 1, 'हुईं...फिर': 1, 'औंढ़े': 1, 'बनाएँगे.': 1, '(ऊंचाई)का': 1, 'इंटेल,एलजी,सैमसंग': 1, 'आंटी!': 1, 'अकाऊंट्स': 1, 'मान्\\u200dयताएं': 1, 'मृत-पशुओं': 4, 'थे.हिन्दुओं': 1, 'संगीत-प्रतिभाओं': 1, 'जाऊँ...’': 1, 'छात्रा-छात्राओं': 1, 'माउंटबैटन': 1, 'आऊंगा.लेकिन': 1, 'लंकाओं': 1, 'सीताओं': 1, 'आंदमी': 1, 'सजाएँ\"': 1, 'सजाएँ\"|': 1, 'जाउंगा...नाश्ता': 1, 'आँखों-आँखों': 2, 'संजोंएं': 1, 'अििधकारियों': 1, 'अा': 1, 'अाई': 1, 'वालिइंटियर': 1, 'आओँ': 1, 'सतगुरूओं,': 1, 'चुआंÓ': 1, '....अंतिम': 1, '“अंकल,': 1, 'जाएंगी।आवश्यक': 1, \"इंसान'\": 1, '(चाईंबासा),': 1, '‘ताअ़बुदुल्लाह': 1, 'रथ-यात्राएं': 1, 'जाएँ,जितने': 1, 'भावनाएँ,': 1, 'संस्थाओं,परंपराओं': 2, 'हुईं.इन्हीं': 1, 'अ़फग़ानिस्तान': 1, 'पत्रिकाओं-अखबारों': 1, 'कराऊंगा,': 1, '“एैसा': 1, 'इंट्रा': 1, 'अंतह': 1, 'शुभकामनाएंे......': 1, 'रूकूअ़': 1, 'अंतर-आत्मा': 1, 'प्रेमिकाएं...तुम्हारी': 1, 'प्रेमिकाएं...सब...डाह': 1, \"'आँचर'\": 1, 'जाऊं....आस-पास': 1, 'खुशबुओं-सी': 1, 'मित्रों,अंत': 1, 'शुभकामनाएं.....': 1, 'सभ्यताआें': 1, 'अंग्रेज़ी-कुछ': 1, 'अंटकर': 1, 'जन्मदाताओं,': 1, 'बंधवाएं।': 1, 'जाएँ..??': 1, 'बुलाऊँगी।': 1, 'बुलाओं': 1, 'अंतनिर्मित': 1, 'कुएँ।': 1, 'अदभुतताओं': 1, '(अंगरेज़ी),': 1, 'अंगरेज़ी)': 1, 'इंक्रेडिबल': 1, 'आऊँगा”': 1, 'जाएंगे।मैं': 1, 'निभाओं।': 1, 'देती…आंख': 1, 'व्यस्ताओं': 1, 'ऐंसे': 1, 'market)जाएँ': 1, 'कंदराएं,': 1, 'आएँगे।“': 1, 'अधिसीमाओं': 1, '(अंग्रेजों': 1, 'अंधविद्यालय': 1, 'ट्राएंगल': 1, 'घहड़ाएं': 1, '९-आंध्र': 1, 'मनुष्यत्व-अंकुरणकारी': 1, 'अंकल’’': 1, 'अंगारें': 1, 'ऋचाएं,लोकगीत,': 1, 'कक्षाआें': 1, 'गिराएँ': 1, '\"इंडिया\"': 1, 'टापूओं': 1, 'पढ़ाएं.': 1, 'जाये.समस्याओं': 1, 'पुण्यात्माएँ': 1, 'दलितों-अंत्यजों': 1, 'समस्\\u200dयाएँ': 1, 'कविताएँ;': 1, 'पूजाओं': 1, 'अंगर,': 1, '‘अंग-विशेष’': 1, 'इंकम्बेंसी,': 1, 'समाएंगी': 1, '........आँधियों': 1, 'आँधी...': 1, 'चोपायों(पशुओं)': 1, 'बेइंसाफ़ी': 1, 'माऍं': 1, '\"बाउंसर\"': 1, 'विद्यार्थिओं': 1, 'जाऊंगा/': 1, 'शकुन्तलाओं': 1, 'मत्स्यगंधाओं': 1, ',अंतरावस्था': 1, 'अंतर्सम्बंध': 1, 'आंगवाड़ी,': 1, 'सिखलाएँ': 1, 'क्रियाआें': 1, 'इंटलपोल': 1, 'घुमाएँ.': 1, 'अंगभूत': 1, 'प़ित्रकाओं': 1, 'नीचे,अंदर': 1, 'फ़ोटुएं': 1, 'बजाऊं': 1, 'रूल्ज़-एंड-रेगुलेशन': 1, '(इंटीलिजेंस': 1, 'जाएंगीं।': 1, 'हताशाएं': 1, 'उंगी': 1, 'उँगलबाज': 1, 'ऐंजिल्स': 1, 'साइंटिस्ट’': 1, 'कन्\\u200dयाओं': 1, 'कहानिओं,': 1, \"जाऊंगी''-\": 1, 'ऑडिएंशेज,एंड': 2, 'संवादनाएं': 1, 'सब-इंस्पेक्टर,': 1, 'कणिकाएं': 2, 'माताऐं': 1, 'आँचर': 1, 'पकाएंगे': 1, 'इंटरप््रााईजेज': 1, 'कमाएंगे.': 1, 'महिलएं': 1, 'आंभृणि': 1, 'अंगिया': 1, 'जाएं।.’': 1, 'बनवाईं-': 1, 'उँडेल': 1, 'अंतरांशों': 1, 'इंतज़ामात,': 1, 'अंजनु': 1, 'पंखुरिओं': 1, 'दशाऐं': 1, 'अंगार-सदृश': 1, 'टाइॅम्स': 1, 'घर-आंगन,बैठक-चौबारों': 1, 'अंबेडकरनगर,': 1, 'अंधविश्\\u200dवासों': 1, ',अंतर्जाल': 1, '-सुविधाएं': 1, 'होंगे-आँखें': 1, 'शासकों-राजाओंं': 1, 'प्रतीक्षाएं': 1, 'भाऊंगी': 1, 'अंतद्र्वंद्व': 1, 'महत्त्चकांक्षाओं': 1, 'अन्तर्जातीय-अंतरवर्णीय': 1, 'जाऊँगा।’': 1, 'बिदुओं': 1, 'अंगलीकन': 1, 'मकसद...आँख': 1, 'युवाओें': 1, 'वस्तूओं': 1, 'अंडरवीयर-बनियान': 1, 'लगाउं': 1, 'आँखें—ऑपरेशन': 1, 'बढ़ाएंगे...': 1, 'व्यापारिओं': 1, '‘सत्य-कथाओं’': 1, 'गाउंगी': 2, 'र्इंटें': 1, 'अंतराल.': 1, 'गाईं': 1, 'लगाऊंगा!यह': 1, 'जाऊंगा.मैं': 1, 'प्रेरणाएँ': 1, 'अंथाती,': 1, 'पशुआें': 1, 'उंगुली': 1, 'अंसुअन': 2, '‘यूएस-इंग्लिश’': 1, '----आंसू': 1, 'हुईं।इन': 1, 'आईं।चर्चा': 1, 'महिलाएँ..घर': 1, '..अंतिम': 1, '‘ओ़फ़!': 1, 'अंश-)': 1, 'गईं????': 1, 'पिचकाएं।': 1, 'हेडलाइ्ट्स': 1, 'बजाऊंगा...!': 1, 'गाऊंगा...!': 1, 'तक,घर-आंगन,कोने-कोने,': 1, 'अंशिक': 1, 'इंसेफेलाइटिस,': 1, 'सम्\\u200dपर्क-अंतर्जाल': 1, 'अंकुर.....': 1, 'आउं....': 1, 'रोऊंगा': 1, 'बजाएँगे,': 1, 'गाएँगे;': 1, 'आउंगा..और': 1, ',समस्याओं': 1, 'दिलाउंगा...': 1, 'दुनियाएं': 1, \"'सुनीताओंÓ\": 1, 'मुर्झाऊंगा': 1, 'शंकाऍं': 1, 'दूस्याएँ': 1, 'आंमत्रण': 1, 'फ़ाईंड': 1, 'र्हुइं।': 1, 'जाएँगे-मेरे': 1, 'इंतेज़ाम': 1, 'अंतिम।': 1, 'अंक-जुलाई-अगस्त': 1, '(अंगुली': 1, 'जलाएंगे.': 1, 'भिड़वाओं।': 2, 'फ़रमाएंगे।': 1, 'होऊँ..?': 1, 'आऊँ…?': 1, 'जाएंगा': 1, 'अंबर!': 1, 'कुचेष्टाएं': 1, 'पॉइंट\"': 1, 'हैं...इंसान': 1, '-सुविधाएँ': 1, 'जाऐंगे,': 1, 'मनोकामनाऐं': 1, 'ऐंडर्सन': 2, 'परीकथाएं': 1, 'छूऊंगा': 1, 'बनाऊं,': 2, 'अंगिरा।चारों': 1, 'स्\\u200dनायुओं': 1, 'अंगुशताना,': 1, 'पाएँगी,': 1, \"'हिंदी...इंग्लिश?'\": 1, 'रामकथाएं': 1, 'आऋैर': 1, 'लड़ाएँगे': 1, 'अंदाज़-ए-उल्फ़त': 1, 'उपकथाएँ': 1, 'वीजाएं': 1, 'दोहराएं': 1, 'अंगराग': 1, 'पापमाओं': 1, 'दिलवाईं।': 1, 'एलाऊंस': 1, 'लगाना,इंट्रो': 1, 'आेआरजी': 1, 'रचाऊँ': 1, 'कण्ठनलिकाओं': 1, 'अंदाज़।': 1, 'भूईंया': 1, 'होएं': 1, 'ईंधन)': 1, 'क्रेताओं': 1, 'नदी-जलधाराओं': 1, 'प्रेतात्\\u200dमाओं': 1, '‘आँधी': 1, 'जिताएंगे': 1, 'ठहराएंगा।': 1, 'जलविन्दुओं': 1, 'आऽऽऽ': 1, 'घाटाएं': 1, 'कुशंकाओं': 1, 'बढाएं': 1, 'इंट्री.': 1, 'निभाएँ।': 1, 'सम्भानाओं': 1, 'कमाऊंगा': 1, 'अंटे': 1, \"एकाउंट'\": 1, 'अंकल-अंकल!': 2, 'अंडाशयों': 3, 'पाउँगा,': 1, 'आंटी(अल': 2, 'अंधगति': 1, 'आंसू!': 1, 'एैयाशी': 1, 'पाएंगे.सावित्रीबाई': 1, 'चलाऊं': 1, 'पिचकाएँगे': 1, '’इंदर...': 1, 'इंदर...': 1, 'इंदर...।’': 1, 'इंदर...?’': 1, 'गईं..।': 1, 'इंदर..': 1, 'एंट्रो': 1, 'साइन्साइ़': 1, \"में,'इंग्लिश\": 1, 'लगाएँ,': 1, 'इंटरप्रेट': 1, 'बेवफाओं': 1, 'इंजिनियरी': 1, 'थे...आँगन': 1, 'अँधेरा...एकदम': 1, 'इंतज़ार..': 1, 'चील-कौओं': 1, 'रुआँसी': 1, 'गाऊं,': 1, 'बजाऊं,': 1, 'रिझाऊं': 1, 'पहलुआंे': 1, 'दिलवाऐं।': 1, 'लड़ाईं': 1, 'अंतोनियो': 1, 'वक्ताओं,': 1, 'अभिलाषओं': 1, 'कुरीतिओं': 1, 'लघुकथाएँ’(2001)': 1, 'लघुकथाएँ’(2005)': 1, 'लघुकथाएँ': 1, 'अंकुआने': 1, 'योग्याताओं': 1, 'बताईं!': 1, 'इंवेटर': 1, 'इंग्लैंड’': 1, 'माईंडगेम': 1, 'पाऊं.': 1, 'व्यवहार,उम्मीदें,दिनचर्या,महत्वाकांक्षाएं': 1, 'सान्त्वनाएं': 1, '(आंखन': 1, 'विरोधकर्ताओं': 1, 'पालतुओं': 1, 'धारणाएँ,': 1, 'आएंगे...’': 1, 'उंगली,': 1, 'गाएँगे।': 1, 'महिलाओं/लड़कियों/बच्चियों': 1, 'उगाएंगे।': 1, 'चिड़ियाएं': 1, 'एंटी-सोशल': 1, 'जताऊँ': 1, 'वंचनाओं': 1, '.अँगड़ाई': 1, '.दिशाओँ': 1, 'हैं.सरिताएं': 1, ',हवाओं': 1, '.तरु-लताओं': 1, 'इंटरनेसनल।': 1, 'पहनाएं,': 1, 'फ़अ़ल': 1, 'क्या,ऊँचे-से-ऊँचे': 2, 'ख़ुदाओं': 1, 'हटाएँ?': 1, 'ख्वाजासराओं': 1, 'राजनैताओं': 1, \"बताऊं!''\": 1, 'सा,साधुओं': 1, \"आँख',\": 1, \"आंखें।''\": 1, '\"अंकल\"': 1, 'बांधाओं': 1, 'एँजेलो': 1, 'मालाएँ': 2, 'मंगवाएं': 1, 'मातृभाषा(ओं)': 1, 'भाषा(ओं)': 1, 'आँख-कान': 1, 'चेष्टाएं': 1, '*सफलताएं': 1, '(अंग)': 1, 'डुबाएंगे': 1, 'इंछ': 1, 'इंतज़ार..........खबर': 1, 'इंग्लैंड।': 1, 'आॅरेंज': 1, 'संवेदनसओं': 1, 'जलाएंगे': 2, 'गाउंगा': 1, \"गाएं।'\": 1, 'फ़िज़ाओं': 1, 'देत्याओं': 1, 'आंज': 1, 'फालोइंग': 1, 'अवस्थाओं,': 1, 'सभाएं,': 1, 'अंबैसी': 1, 'अंग्रेजी-शासकों': 1, 'नेताओं,पूंजीपतियों,साम्राज्यवादी': 1, 'इंटीग्रेटीड': 2, '(अंजनि-पर्वत': 1, ',इंटीरियर': 1, 'अंधेरा-': 1, 'ही-अंधेरा': 1, 'हथेलिओं': 1, 'स्वाद...आँखों': 1, 'अपाइंटमैंट': 1, 'विशिष्\\u200dटताएँ': 1, 'कहानिओं': 1, 'भार्याओं': 1, 'अंतर्गतमलो': 1, '.कोशाओं': 1, 'बताएं।–अमित': 1, 'जाएंगे...ख़ुशी': 1, 'आ़हत': 1, 'अंत’’': 1, 'अंगुली।': 1, 'चिताएँ': 1, 'जगाईं': 1, 'अंकुन': 1, \"'खडाऊं'\": 1, 'इंडस्ट्री।': 1, 'प्रतियोगिताएँ': 1, 'सुनाएँगे।\"': 1, 'एंटीना/': 1, 'आईं.मंडप': 1, 'विवशताएँ': 1, 'आेंकारेश्वर': 1, 'यात्राएॅ': 1, 'मुस्कराएंगे।': 1, 'लहराएँ': 1, 'कीटाणुओं,': 1, 'बचाएँ।': 1, 'चेष्ठाएं': 1, 'कर,अंततः': 1, 'संस्थाओँ': 1, 'रक्त-नलिकाओं': 1, 'खुजाऊंगा..': 1, 'थी।महिलाएं': 1, 'आंदोलनसे': 1, 'धमकाएं': 1, 'जागा...अंगड़ाई': 1, 'मिलाएं...': 1, 'हो....दुवाओं': 1, 'अंध-आस्था': 1, 'भगाएँगे': 1, 'मध्यबिन्दुओं': 1, 'आऊंगा.जिस': 1, 'बिताऊं,': 1, 'ग्राउंड.': 1, ',इंसाफ': 1, 'हैं.हिन्दुओं': 1, 'देवताओं,ईश्वर': 1, 'बुलाएँगे.7.': 1, 'समाचारपत्रों,पत्रिकाओं,': 1, 'बताउंगा’': 1, 'संवेदनशीलताओं’': 1, 'आंखों-नाक': 1, 'अँगेजी': 1, 'ओंडच': 1, 'मनोदुर्बलताओं': 1, 'आंकड़ो/सुचनाओ': 1, 'निभाएँगे': 1, 'उपभोग-इच्छाएं': 1, 'विधिवेत्ताओं': 1, 'बोएंगे': 1, 'राष्ट्र-नेताओं': 1, 'मराठाओं': 1, 'अँधाधुंध': 1, 'घुमाऊंगा': 1, 'मजमूअ़ा': 1, 'मुतालेअ़': 1, 'अंतरगृही': 1, 'दिखलाएँ': 1, 'मित्रताएं': 1, 'अंग।': 1, 'श्रोताओे': 1, 'विद्रूपताआें': 1, 'राष्ट्रीयताएं': 2, 'परंपराएं“': 1, 'आंग्लभाषी': 1, 'अंड़ों': 1, 'कुटिलताओं': 1, 'इंडो-अमेरिकन': 1, 'इंद्रयोनि': 1, 'एंटेना': 2, 'जुगुनुओं': 1, 'पत्र-पत्रिकाएँ,': 1, 'आंसू...तुम्हें': 1, 'पहुँचाएं': 1, 'एंकरों,': 1, 'दशा-महादशाओं': 1, 'इंम्तिहाँ': 1, 'परिक्रमाएँ': 1, 'मिलाऊं': 1, 'आंजहाँनी': 1, 'मअ़ज़र्रत': 1, \"फाउंडेशन',\": 1, 'लाएँ,': 1, 'इंतज़ाम,': 1, 'आकाश’,‘अंकुर’,‘भूमिका’,‘माया': 1, 'इंडियेन': 1, 'अंत:स': 1, 'मनाएँगे।': 1, 'आउंगा।': 1, 'थे...अंत': 1, 'बुलाईं.': 1, 'गईं.इन': 1, 'अंतर्संघर्ष': 1, 'मिथक/व्यवस्थाएं': 1, 'कीहत्याएं': 1, 'पिऊँगा': 1, 'पीऊँ।': 1, 'पाएंगे;': 1, 'संख्याएँ,': 1, 'संख्याएँ': 1, 'बिहाइंड': 1, 'नाताओं': 1, 'चिल्लाऊंगी,': 1, '\\u200b\\u200bइंड्सट्रीयल': 1, 'काऊंसिल': 1, 'संवेदनशीलताओं': 1, 'अंडरपास-76,': 1, 'लगेगा,खुशबुओं': 1, 'उँचान': 1, 'बताऊं,हमारे': 1, 'याचिकाएँ': 1, 'संघर्षकर्ताओं': 1, 'वस्तुएं।': 1, 'ज़फ़ाओं': 1, 'दिखाऊंगी': 1, 'शस्त्रविद्याएँ': 1, 'कुरूपताओं': 1, 'अंतराल(Space': 1, 'वीरांगनाओं': 1, 'पाउंगी’।': 1, 'क्लाइंडेमाइसिन': 1, 'ऐंटिऐक्नी': 1, 'ऐंटीबायॉटिक': 1, ',ऊँची': 1, 'जाएँ-उस': 1, 'चढ़ाउंगी': 1, 'चिल्लाईं–': 1, 'आँसू.खून.पसीने': 1, 'पढ़ाएं।': 1, 'इंजिन-छाप': 1, 'हईं।': 1, 'महोदय(एंकर': 1, 'प्रेम-कविताएँ,': 1, 'शोकान्तिकाएँ': 1, 'अँधेरे-पाख': 1, 'मातृभाषाएँ': 1, 'कौओं,चील': 1, ',’ओंर’ही': 1, '‘इंटेलिजेंट’': 1, 'एफीसिएंसी': 1, 'बसाएं': 1}\n"
],
[
"for allKeys in dictionary_vowel: \n print(f\"Frequency of {allKeys} : {dictionary_vowel[allKeys]}\")",
"Frequency of अ : 429904\nFrequency of औ : 205808\nFrequency of ऐ : 34538\nFrequency of उ : 304315\nFrequency of ए : 410350\nFrequency of इ : 294766\nFrequency of आ : 337944\nFrequency of ई : 187285\nFrequency of ऊ : 14706\nFrequency of ओ : 62414\nFrequency of ऑ : 10063\nFrequency of ऋ : 2121\nFrequency of ऎ : 822\nFrequency of ॠ : 38\nFrequency of ऍ : 157\nFrequency of ऌ : 3\nFrequency of ऒ : 9\n"
],
[
"for allKeys in dictionary_consonant: \n print(f\"Frequency of {allKeys} : {dictionary_consonant[allKeys]}\")",
"Frequency of प : 1254359\nFrequency of र : 3336110\nFrequency of व : 973866\nFrequency of क : 3623226\nFrequency of स : 2110400\nFrequency of त : 1768862\nFrequency of न : 2238889\nFrequency of म : 1736874\nFrequency of ह : 2146189\nFrequency of य : 1207779\nFrequency of द : 1006684\nFrequency of ख : 312081\nFrequency of ल : 1425704\nFrequency of ड़ : 43471\nFrequency of ब : 899384\nFrequency of भ : 419506\nFrequency of च : 454628\nFrequency of श : 448619\nFrequency of ट : 436552\nFrequency of ड : 310843\nFrequency of ग : 787541\nFrequency of ज : 925475\nFrequency of थ : 332103\nFrequency of छ : 127886\nFrequency of फ : 215071\nFrequency of घ : 70504\nFrequency of झ : 58741\nFrequency of ध : 245538\nFrequency of ढ : 48425\nFrequency of ण : 129405\nFrequency of ठ : 78913\nFrequency of ष : 196826\nFrequency of ढ़ : 6863\nFrequency of ऩ : 1073\nFrequency of ञ : 13551\nFrequency of ङ : 1195\nFrequency of य़ : 503\nFrequency of ळ : 121\nFrequency of क़ : 1502\nFrequency of ग़ : 560\nFrequency of ख़ : 877\nFrequency of ज़ : 6391\nFrequency of ऱ : 236\nFrequency of फ़ : 4604\n"
],
[
"for allKeys in words_with_half_consonant_following_vowel: \n print(f\"{allKeys} : {words_with_half_consonant_following_vowel[allKeys]}\")",
"मेंच्अच्छा : 1\nडिस्ऑर्डर : 23\nहुर्ई। : 2\nच्ए : 5\nगर्इं। : 21\nहुर्इं : 4\nर्इंट, : 1\n‘र्इंटें’, : 1\nकार्रवार्ई : 1\nप्रतिच्अच्छी : 1\nहुर्इं, : 4\nबनार्इं, : 1\nसेमीफ्इानल : 1\nकुर्आन : 2\nलम्बार्ई : 1\nआर्इं : 3\nरूप्ए : 2\nकिसीच्उच्च : 1\nइतनाच्अच्छे : 1\nगर्ई। : 5\nवाक्ओवर : 1\nउठार्इं। : 1\nसार्इंनाथ : 1\nगर्इं : 8\nज्एगा। : 1\nरुप्ए : 1\nसुनार्ई : 1\nर्इंटे : 2\n‘र्इंटें-2’ : 1\nर्इंटों : 1\nर्इंटें/ : 1\nगर्इं? : 1\nगर्इं, : 7\nउकतार्इं : 1\nपुनर्अदायगी : 2\nलुक्ओर, : 1\nएप्एमसीजी : 3\nगर्ई, : 1\nप्रत्एक : 1\nहुर्इं। : 5\nतर्इं : 3\nकेच्अच्छे : 1\nएफ्एमसीजी.बैकिंग : 1\nकेच्इच्छुक : 1\nआर्इं। : 1\nर्इंधन : 4\nगुक्आिंग : 1\nएक्सचेंज.एनएसर्ई.का : 1\nरियलटी.एप्एमसीजी : 1\nबार्इं : 1\nदार्इं : 1\nमनोनितच्उच्चायुक्त : 1\nसदस्ईय : 1\nच्एक : 2\nच्अच्छा : 1\nर्अघ्य : 1\nमैक्इनतोश : 1\nबतार्इं : 1\n’कुर्आन‘ : 2\nएफ्एमसीजी,पीएसयू : 1\nपुनर्उद्धार : 1\nर्ईधन : 3\nच्अगर : 1\nसार्इं : 1\nर्आपूत्ति : 1\nस्लीप-डिस्ऑर्डर : 1\nदाउच्च्उ : 1\nपुनर्उत्पाद : 1\nकेच्उच्च : 2\nएसबीर्आ : 1\nमेंच्अच्छी-खासी : 1\nर्इंट : 2\nश्ऋर : 1\nपुनर्उत्थान : 1\nसुलझार्इं : 1\nसद्आचरण, : 1\nपार्इं! : 1\nहार्ई : 1\nडिस्अप्रूवल : 1\nनैर्ऋत्य : 2\nच्अब : 1\nएय्ऋर : 1\nक्रोन्ए, : 1\nइतनीच्अच्छी : 1\nनेच्अच्छी : 1\nचेन्न्ई : 1\nहुर्इ : 20\nगर्इ। : 22\nगर्इ : 26\nजार्इये। : 1\nस्एच्। : 1\nदानम्अध्य्न : 1\nगर्इ, : 2\nढ़ार्इ : 2\nकोर्इ : 42\nभार्इ : 3\nरिप्लार्इ : 1\nअदरवार्इज : 1\nआर्इ : 7\nसार्इबर : 1\nहुर्इ। : 8\nप्रोफार्इल : 2\nसमार्इ। : 1\nकर्इ : 13\nमोटर-सार्इकिल : 1\nशम्अ : 2\nसफार्ई : 1\nवाक़र्इ : 1\nच्च्इन्द्रजीतज्ज् : 1\nसुर्इ-धागा : 1\nआर्इ। : 6\nकोर्ई : 1\nदिखलार्इ : 3\nब्आत : 1\nकचरा-सफार्इ : 1\n‘सार्इंस : 1\nनर्इ : 3\nकीच्इच्छा : 1\nजतार्इ। : 1\nदिखार्इ : 8\nबनार्इ : 3\nहार्इकोर्ट : 1\nकरार्इ : 1\nहीरोर्इन : 1\nपार्इप-लार्इन : 2\nपुनर्उपनिवेशीकरण : 1\nवाकर्इ : 2\nचिद्अर्पिता : 1\nबतार्इ : 1\nमर्ई : 1\nअच्छार्इ : 2\nमढर्इ : 1\nकर्ई : 1\nअमरार्इ : 2\nबधार्इ : 1\nसच्चार्इ : 1\nजुलार्इ्र : 1\nसच्चार्इ : 1\nटार्इट : 1\nपार्इ : 2\nकायर्ई : 1\nएम्ओयु : 1\nबीस-बार्इस : 1\nचढ़ार्इ : 1\nआ...ऊं....र्इ... : 1\nप्रार्इवेट : 1\nसुर्इ : 1\nर्इमानदार : 1\nछार्इ : 1\nर्इष्वर : 1\nव्ओ : 1\nराष्अ्रपति : 1\nर्इश्वर : 2\nकठिनार्इयों : 2\nख्इरडा, : 1\nआरम्अभिक : 1\nसद्उपयोग : 2\nआर्अपीसी : 1\nसार्इड : 1\nसुर्इ-धागे : 1\n‘फ़िटिंग-टार्इट’ : 1\nखिचवार्इ : 1\nआर्इं, : 1\nचिनार्इ : 2\nहुर्इपहुँच : 1\nपासर्इंट : 1\nगहरार्इ : 3\nमुस्कुरार्इ। : 1\nकुनमुनार्इ। : 1\nसार्इट : 1\nलड़खड़ार्इ : 1\nदुहार्इ : 1\nसुनार्इ : 2\nर्इंटल : 1\nनिर्ऋति, : 1\nमिठार्इ : 1\nरंगार्इ : 2\nउठार्इ। : 1\nमहंगार्इ : 1\nसद्इच्छा : 1\nबतार्इं। : 1\nबार्इंडिंग : 1\nहैण्ण्ण्इमरोज़ : 1\nपिटार्इ : 1\nव्ऑइस : 1\nचढार्इ् : 1\nसार्इंस : 1\nनिंदार्इ, : 1\nगुडार्इ, : 1\nकटार्इ : 1\nएसएम्एस : 1\nर्इमानदारी : 1\nस्पधार्ओं : 1\nसोर्इ : 1\nलड़ार्इ : 1\n“ोखार्इन : 1\nपार्इ? : 1\nउबकार्इ : 1\nर्इच्छा : 1\nहुर्इ, : 1\nजलार्इ : 1\nमिठार्इयाँ : 1\nरेलवे-लार्इन : 1\nस्थार्इ : 1\nएफडीआर्इ : 1\nकलार्इ : 1\nसद्उपदेश, : 1\nर्इंटें : 1\nबिलसपुरहिन-’’अइसर्इ : 1\nजबरर्इ : 1\nगर्इ? : 1\nसफार्इ : 1\n"
],
[
"for allKeys in words_with_half_consonant_following_matra: \n print(f\" {allKeys} : {words_with_half_consonant_following_matra[allKeys]}\")",
" जलर्ापूत्ति : 10\n वष्ाीüय : 11\n सुसज्ज्ाित : 3\n मुट््ठीभर : 2\n केन््रद : 9\n पुरूष्ाों : 5\n पाष्ाüद : 4\n मुद््दों : 9\n क्िलंटन : 1\n कट््टे : 1\n क््योंकि : 1\n विशेष्ा : 10\n श्ुारूआती : 1\n कट््टरता : 3\n शतर्ें : 2\n पुराविद्ों : 1\n गद््दी : 1\n थ्ौली : 3\n घोçष्ात : 2\n हष्ाü, : 2\n राष्ट््रीय : 1\n थ्ीा। : 2\n उच्च्ंचा : 1\n श्ृंखला : 1\n घोष्ाणा : 7\n श्ेवता : 1\n बच्चच्ें : 2\n गुड््डा : 1\n चड््ढी : 1\n मद््देनजर : 4\n गिट््टी, : 1\n ‘चट््टानें’, : 1\n ‘मिट््टी’ : 1\n मुद््दा : 10\n षड्ंगी : 1\n स्टेफ्ी : 1\n नम्ब्ार : 1\n अट््टालिकाओं : 2\n विशेष्ाज्ञों : 4\n राष्ट््रपति : 1\n शीष्ाüक : 2\n पट््टडकल : 1\n छद््म : 2\n स््ट्रीमिंग : 1\n परिष्ाद, : 2\n आकçष्ाüत : 2\n वष्ाü : 20\n पीयूष्ा : 1\n शेष्ा : 8\n मुद््दे : 8\n ब्ा्रह्मपोल : 1\n कृçष्ा : 11\n स्ान : 6\n उद््देश्यों : 2\n उद््देश्य : 7\n उद््देश्य-प्राप्ति : 1\n श्ृंगार : 2\n शिक्षाविद्ों, : 1\n नेता-कार्यकत्तर्ाा : 1\n क्िवटल : 3\n पाठ््यपुस्तकों : 1\n नेटवकिर्ंग : 2\n स्ट्ेटस : 1\n इंस्ट्र्ूमेंट्स : 1\n विष्ाय : 7\n स्ेह : 2\n कार्यकत्तर्ााओं : 10\n फीçल्ंडग : 1\n मच्े : 1\n बढ़ाउच्च्ंगा : 1\n कार्यश्ौली : 1\n सुभाष्ा : 5\n इफ्ेटक्ट : 1\n नवसुसज्ज्ाित : 1\n दोष्ा : 1\n औष्ाघि : 7\n थ्ौले : 2\n रफ़्तार : 2\n राजगद््दी : 2\n मनीष्ा : 4\n दोष्ाी : 7\n वाçष्ाüक : 2\n पुरूष्ा : 5\n बलव्ािंदर : 1\n ज्योतिçष्ायों : 1\n इंटरेस्ंिटग : 2\n संतोष्ा : 1\n धज्ज्ाियां : 5\n रिपोटर््स : 1\n जाउच्च्ंगा। : 2\n पाउच्च्ंगा। : 2\n अड््डे : 2\n अवाडर््स : 1\n बिल्ंिडग : 4\n श्ाकराचार्य : 1\n श्रृख्ांला : 1\n कनेक््शन : 1\n विष्ायक : 3\n विशेष्ाज्ञ : 2\n अभिभाष्ाक : 1\n परिष्ाद : 14\n अच्छच्े : 1\n पाष्ाüदों : 3\n पट््टी : 5\n स्ातक : 4\n कोष्ााध्यक्ष : 1\n अड््डों : 2\n कर्ार्यत्ताओं : 1\n उच्च्ंचाई : 3\n केन््रदीय : 4\n ज़्यादा : 4\n (अजेर्ंटीना), : 1\n खानर्ापूत्ति : 1\n महाप्रबध्ांक : 1\n होउच्च्ं : 1\n विष्ायाध्यापकों : 1\n कार्यकत्तर्ाा : 7\n उम्मीद़्वारों : 1\n महाविद्यालय/स्ातकोत्तर : 1\n रेड््डी, : 1\n इकट््ठे : 2\n स्ात्कोत्तर : 1\n हड््िडयां : 2\n फिक्ंिसग : 1\n होउच्च्ंगा : 2\n स्िवफ्ट : 1\n काप्ी : 1\n हम्ेब्रम : 1\n केन््रदों : 2\n ट््िवटर, : 1\n ट््वीट : 1\n स्ातकोत्तर : 2\n छुट््टी : 2\n सवाचर््च्च : 1\n वष्ाोü : 3\n एंड््रयू : 1\n डिस्े : 2\n चचऱ्ा : 1\n शक्ित : 1\n पोष्ााहार : 1\n ब्रह्मभट््ट : 1\n भ्ी : 4\n आशीष्ा : 1\n दिसम्ब्ार : 1\n इक्जीक्ूयटिव : 1\n भ्ौरव : 3\n सघ्ांर्ष : 1\n धब्ब्ाा : 1\n आथर््िाक : 1\n आउच्च्ंगा।’’ : 1\n उज्ौन : 2\n दागपुट्ट्ी : 1\n चन््रद : 1\n सट््टात्मक : 1\n श्ौल : 1\n शोष्ाण : 1\n अन्वेष्ाण : 1\n उच्च्ंची : 7\n कोष्ा : 2\n (इंस्ंिटक्ट) : 1\n çब्ाछीवाड़ा : 1\n शतोर्ं : 2\n स्ेहलता : 1\n çक्ंवटल : 1\n हुईर्ं। : 1\n प्रदश्ेा : 1\n श्ाकर : 2\n सख्ंयताओं : 1\n ट्ेवल्स : 1\n व्यक्ित : 1\n कार्यकत्तर्ााओं-नेताओं : 1\n उज्ौनिया : 1\n भट््टाचार्यने : 1\n दोçष्ायों : 3\n सदर््यूकोव : 1\n çब्ा्रटिश : 1\n पोस्ंटिग : 1\n परर्िवत्तनकारी : 1\n प्रैक्िटस : 1\n भट््ट : 3\n मिट््टी : 13\n परर्िवत्तन : 2\n प््ररस्ताव : 1\n वष्ाोüं : 1\n शॉटर््स : 1\n अड््डा : 1\n खद््दरधारी : 1\n नवम्ब्ार: : 2\n व्यक्ितगत : 1\n उल्ल्ेाखनीय : 1\n बताउच्च्ंगा......यदि : 1\n बताउच्च्ंगा : 1\n मुक्ित : 1\n हुड््डा : 2\n ज्ौसा : 1\n ख्ेाल : 1\n शीष्ाü : 2\n भत्तर्ाी : 1\n शख़्स : 1\n स्ेहा : 1\n ब्ौंकों : 1\n परफामर्ेंस : 1\n मानुष्ा : 1\n बज्ो : 1\n अवशेष्ा : 1\n मुट््ठी : 1\n हैçब्ाटाट्स : 1\n मुद््दा, : 1\n दासमुंश्ी : 1\n फमर्ाा : 3\n नवम्ब्ार : 1\n फिल्ंिडग : 2\n औष्ाधालय : 1\n ड््यूटी : 1\n çब्ा्रज : 1\n अब्ुदर : 1\n इस्तीप्े : 2\n संब्ाल : 1\n ब्ा्रीड : 1\n अद्धवाçष्ाüक : 1\n आलच्ेच्य : 1\n वक़्त : 14\n हटर््ज : 3\n इंस्टिट््यूट : 1\n भतर््सना : 1\n कृष्ण्ौया : 1\n कट््टरपंथी : 1\n पोस्ंिटग : 1\n वगोर्ं : 1\n भूख्ाड : 1\n क्िवजाट, : 1\n स्पोटर््स : 2\n प्रतिवष्ाü : 1\n पदाथोर्ं : 1\n कम्युनिकेश्ांस, : 1\n मेगाहटर््ज : 1\n ख्ेाला। : 1\n नरेन््रद : 2\n संघष्ाü : 4\n द्वेष्ाता : 1\n दर्ुव्यवहार : 2\n चिट््ठी : 1\n पट््टे : 1\n फ्ेड : 1\n ‘उद््घाटनों, : 1\n पुरूष्ा-महिलाएं : 1\n भीष्ाण : 1\n औष्ाधि : 1\n दिसम्ंबर : 1\n प्रबध्ंाक : 1\n द््यूरास : 1\n श्ांभु : 1\n सुखिऱ्यों : 1\n कंट््रोल : 1\n दूçष्ात : 1\n उल्ल्ेाख : 1\n थ्ौरेपी : 1\n वष्ााüें : 1\n स्ेह, : 1\n च्े : 1\n हष्ाü : 1\n भूष्ाण : 1\n पद््म : 1\n नसीरुद््दीन : 1\n हेमस्ंिट्रग : 1\n माद््दा : 1\n आध्ुनिक : 3\n निदर्ेशित : 1\n निदर्ेशक : 20\n रूप्ा : 4\n ग्ुारुत्वाकर्षण : 1\n तीव््राता : 3\n पदाथर्ों : 1\n श्ोयरधारकोंं : 1\n औकर्ुट : 1\n निदर्ेशकों : 10\n निदर्ेशन : 1\n ख्ुालता : 1\n फ्लेक्िसबिलिटी : 1\n दफ़्तर..... : 1\n ध्ंध्े : 2\n गांध्ी : 3\n सस्ंकृतियों : 1\n भट््टाचार्य : 3\n ‘टर्र्र््रेक्टर : 1\n रूपेण्ा : 1\n क्ार्यालय : 1\n ज़्यादातर : 1\n धमोर्ं : 2\n सवर्ोच्चता : 1\n घ्ाायल : 1\n गांध्ीवादी : 2\n गांध्ीवादियों : 1\n स्क्ूल : 1\n अर्ंतात्मा : 1\n ठ्ठ्ठ््ठाक, : 1\n ध्ूर्त : 1\n इंस्ट्ीटयूट : 1\n उत्तराख्ंड : 3\n रविन््रद : 1\n निश्ंिचत : 5\n कफर््यू’ : 1\n रुक़्न : 1\n नक़्क़ाद : 1\n मुगऱ्ी : 1\n पुनर्ःलिखे : 1\n निश्ंिचतता : 1\n मुदद्े : 1\n विरोध्ी : 4\n घ्ाोर : 1\n ट्ांसफर : 1\n बार्ंबार : 1\n अंतर्राष्ट्र्ीय : 2\n कांग्ेस : 1\n क्ुल : 1\n ज़्यादा। : 1\n ट्ांसपरेंसी : 1\n नज़्ााकत : 1\n ख्ुाशियोंे : 1\n ब्ा्रह्म : 5\n तरक़्क़ी : 1\n इनक़्लाब : 1\n शेड््स : 1\n ल्ेकिन : 4\n स्ंातान : 1\n घ्ाटनाओं : 3\n बश्ंाकार : 1\n राध्ेाश्याम : 1\n रेडड्ी : 1\n धनाड््यों : 1\n राबटर््सगंज, : 1\n ख्ंिाच : 1\n श्ुाबा : 2\n ज्ुाबान : 1\n ध़्ाड : 1\n गुगोर्ं : 1\n बंध्ंध्यो : 1\n प्ंाद्रह : 1\n इण्डस्ट्ीज : 1\n बेइज़्ज़त : 1\n ड्ाइंगरूम : 1\n अब्ब्ूा : 1\n रक़्स : 1\n बंध्ंधे,े,जाके : 1\n श्ंकर : 1\n भट््टा : 1\n आख्ािर : 1\n बेरोज्ागार : 1\n हाउसेज्ा : 1\n कुत्ुत्तों : 1\n घ्ोरा : 1\n घ्ोर : 1\n राग-द्वेष्ा : 1\n हुक़्म : 1\n ड्ाईवर : 1\n 1.धमर्ेंद्र : 1\n ज्योतिष्ााचार्य। : 1\n ग्ंगा : 1\n उम््रा : 2\n श्ंाकर : 1\n दुव्घर््यवहार, : 1\n ‘‘ग्ंगाजल : 1\n जीवन.संघषर्ों : 1\n इज़्ज़त : 1\n छुट््टी!दस : 1\n नक़्श : 1\n संघषर्् : 1\n निबर्ुद्धि : 1\n र्ंगीली : 1\n अद््भुत : 1\n उद्ेश्य : 1\n ख््राुश्चेव : 1\n म्ुनिरका- : 1\n अर्थशास़्ित्रयों : 1\n उम्म्ीदवार : 1\n मैजिस्ट्ेट : 3\n प्रश्ंवाचक : 1\n ख्ूाब : 1\n स्ंवय : 2\n हज्ज्ज्ज्ाार : 1\n थ्ो : 1\n राष्ट्ीय : 2\n ध्ंाधे : 1\n लोहापट््टी : 1\n ढ्ँढ़ : 1\n घ्ंटे : 1\n थ्ीा : 1\n पुर्षाथर््ा : 1\n प्र्िरतिषत : 1\n दजऱ् : 1\n ट्ेनिंग : 1\n गड़्मड़ : 1\n ख्ुादाई : 1\n पचांर्े : 1\n सास्ंकृतिक : 1\n प््रायासों : 1\n प््रासिद्ध : 1\n प््रााविडेंट : 1\n परमश्ेवर! : 1\n ...‘पेैड्ो’ : 1\n छिन्न-भिन्ेन : 1\n त्ंज़ीम : 1\n अक़्ली : 2\n वैन्ैन्ट : 1\n क्लियोपेट्ा, : 1\n प्राब्ॅलम : 1\n बशतर्े : 1\n प्ाशुपालन : 1\n क़ब्ज़्ाा : 1\n सीध्े : 1\n स्व्ीकार : 2\n ेष्ेष्य : 1\n मिट््टी, : 1\n अत्ंयत : 1\n अंतर्राष्ट्ीय : 1\n अट्ाहास : 1\n पेट्ोल : 1\n न्यूट्ीषिन : 1\n ‘दूध्ूध’ : 1\n लम्ऽऽबी : 1\n देशबंध्ुा : 1\n घ्ाटित : 1\n घ्ार : 1\n पाशर््व : 1\n प्रश्ंचिन्ह : 1\n ऑपॅपरेष्ेषन’ : 1\n देश्ी : 1\n सेष्ी : 1\n विमशर््ा’ : 1\n प्राण-वाक्् : 1\n सुब्रह््मण्यम : 1\n मजिस्ट्ेट : 1\n निश्ंचितता : 1\n महामंत्र्ी : 1\n दूध्ूध : 1\n मनीष्ाी : 1\n नक़्क़ादों : 1\n है.निदर्ेशक : 1\n गांध्ी, : 1\n शक़्लें : 1\n बुजष्ुर्ग : 1\n ट्ंासफर : 1\n प््राषिक्षण : 1\n प््राषासन : 1\n बहुस्ंस्कृतिवाद : 1\n वर्चसर््स्व : 1\n कफर््यू : 1\n शक़्ल : 1\n नुक़्ते : 1\n क्ष्े. : 1\n रिकाडऱ्स : 1\n बच्च्े : 1\n पावरलिफ्ंिटग : 1\n वषर्ों : 1\n पूणर््ातय: : 1\n ध्ार्मेंद्र, : 1\n ख्ेाली : 1\n च्ंद्र : 1\n इलेक्ट्ानिक : 1\n इंटरप््रााईजेज : 1\n घ्ाुसाया : 1\n श्ंाख : 1\n देख्ेा : 1\n उपाध्ि : 1\n मिजऱ्ापुर : 1\n वषोर्ं : 1\n छ्ःओटी : 1\n प्रा्रोत्ेत्साहित : 1\n पालन-पोष्ाण : 1\n (ब्ा्रह्म) : 1\n विध्ेयक : 1\n कलारूप्ा : 1\n मैंट्ो : 1\n राष्ट्र्ीय : 1\n एफटर््स : 1\n ज़्पारोशिया : 1\n"
],
[
"def isValidWord():\n pass",
"_____no_output_____"
],
[
"def isEndOfLine(x):\n if u'\\u0964' <= x <= u'\\u0965' :\n return True\n return False\n \n\ndef isMatra(x):\n if (u'\\u0901' <= x <= u'\\u0903' or \n u'\\u093C' <= x <= u'\\u094F' or\n u'\\u0951' <= x <= u'\\u0954' or\n u'\\u0951' <= x <= u'\\u0954' or\n u'\\u0962' <= x <= u'\\u0963'):\n return True\n return False\ndef isVowel(x):\n if (u'\\u0905' <= x <= u'\\u0914' or \n u'\\u0960' <= x <= u'\\u0961'):\n return True\n return False\ndef isConsonant(x):\n if (u'\\u0915' <= x <= u'\\u0939' or \n u'\\u0958' <= x <= u'\\u095F'):\n return True\n return False\n\ndef isOM(x):\n if x == u'\\u0950' :\n return True\n return False\n \n ",
"_____no_output_____"
],
[
"sample = 'येदयुरप्पा, उनके बेटे और सांसद बी वाई राघवेन्द्र, बी वाई विजयेन्द्र, दामाद आर एन सोहन कुमार कोर्ट में मौजूद थे। कोर्ट ने 16 नवंबर को इन्हें मौजूद होने के लिए समन जारी किया था। अदालत ने यह भी कहा कि मामले में जांच खत्म हो चुकी है।'\nsample.split()[7]",
"_____no_output_____"
],
[
"detectChars = {}\n\ndef detectCharsFunc(word):\n chars = list(word) \n a = ''\n enum_iter = enumerate(chars)\n flag = 0\n for index, char in enum_iter:\n if(isVowel(char) or isConsonant(char)):\n flag=0\n if a is not '':\n if a in detectChars: \n detectChars[a] += 1\n else: \n detectChars.update({a: 1})\n a = char\n elif(isMatra(char)):\n a += char\n if char==u'\\u094D':\n flag += 1\n if flag>1:\n flag = 0\n while (index+1 < len(chars) and isMatra(chars[index+1])):\n index, char = next(enum_iter)\n a += char\n if a in detectChars: \n detectChars[a] += 1\n else: \n detectChars.update({a: 1})\n a = ''\n continue\n\n if (index+1 >= len(chars)):\n continue\n index, char = next(enum_iter)\n a += char\n else:\n flag = 0\n if a in detectChars: \n detectChars[a] += 1\n else: \n detectChars.update({a: 1}) \ndetectCharsFunc(word)\ndetectChars\n",
"_____no_output_____"
],
[
"for para in new_sample:\n words = para.split()\n for word in words:\n detectCharsFunc(word)",
"_____no_output_____"
],
[
"detectChars\n ",
"_____no_output_____"
],
[
"detectConsonants_Matra={}\ndef detectConsonantMatra(word):\n chars = list(word) \n# print(f'chars:{chars}')\n a = ''\n enum_iter = enumerate(chars)\n flag = 0\n for index, char in enum_iter:\n a =''\n if(isConsonant(char)):\n a+=char\n i=0;\n while (index+1 < len(chars) and isMatra(chars[index+1])):\n index, char = next(enum_iter)\n a += char\n i+=1\n if a in detectConsonants_Matra: \n continue\n elif(i!=0): \n detectConsonants_Matra.update({a: i})\n \n\n",
"_____no_output_____"
],
[
"for para in new_sample:\n words = para.split()\n for word in words:\n detectConsonantMatra(word)",
"_____no_output_____"
],
[
"detectConsonants_Matra",
"_____no_output_____"
],
[
"df1=pd.DataFrame.from_dict(dictionary_vowel, orient='index',columns=[ 'Frequency'])\nprint(df1.index)\n\n\nind=[]\nind=list(df1.index)\nindi = [ 'u' + f\"'\\\\u\" + f\"{str(ord(x))}'\" for x in list(df1.index)]\n\n",
"Index(['अ', 'औ', 'ऐ', 'उ', 'ए', 'इ', 'आ', 'ई', 'ऊ', 'ओ', 'ऑ', 'ऋ', 'ऎ', 'ॠ',\n 'ऍ', 'ऌ', 'ऒ'],\n dtype='object')\n"
],
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom matplotlib import font_manager as fm, rcParams\nimport matplotlib.pyplot as plt\nfrom matplotlib.font_manager import FontProperties\nsns.set(font=\"Meiryo\")",
"_____no_output_____"
],
[
"df1.to_csv('vowel_freq.csv')",
"_____no_output_____"
],
[
"Data1 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/vowel_freq.csv\")",
"_____no_output_____"
],
[
"Data1.index\nData1\n\n",
"_____no_output_____"
],
[
"sns.barplot(y='Frequency',x=Data1.index,data=Data1.iloc[0:750,:])",
"_____no_output_____"
],
[
"df2=pd.DataFrame.from_dict(dictionary_consonant, orient='index',columns=[ 'Frequency'])\nprint(df2.index)\ndf2.to_csv('consonant_freq.csv',index = True)\nData2 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/consonant_freq.csv\")\nData2\n\n",
"Index(['प', 'र', 'व', 'क', 'स', 'त', 'न', 'म', 'ह', 'य', 'द', 'ख', 'ल', 'ड़',\n 'ब', 'भ', 'च', 'श', 'ट', 'ड', 'ग', 'ज', 'थ', 'छ', 'फ', 'घ', 'झ', 'ध',\n 'ढ', 'ण', 'ठ', 'ष', 'ढ़', 'ऩ', 'ञ', 'ङ', 'य़', 'ळ', 'क़', 'ग़', 'ख़', 'ज़',\n 'ऱ', 'फ़'],\n dtype='object')\n"
],
[
"sns.set(font=\"Meiryo\",font_scale=0.5)\nsns.barplot(y='Frequency',x=Data2.index,data=Data2.iloc[0:1500,:])",
"_____no_output_____"
],
[
"df3=pd.DataFrame.from_dict(words_with_half_consonant_following_vowel, orient='index',columns=[ 'Frequency'])\nprint(df3.index)\ndf3=df3.sort_values(by=['Frequency'],ascending=False)\ndf3.to_csv('half_cononant_vowel.csv',index = True)\n",
"Index(['मेंच्अच्छा', 'डिस्ऑर्डर', 'हुर्ई।', 'च्ए', 'गर्इं।', 'हुर्इं',\n 'र्इंट,', '‘र्इंटें’,', 'कार्रवार्ई', 'प्रतिच्अच्छी',\n ...\n 'रेलवे-लार्इन', 'स्थार्इ', 'एफडीआर्इ', 'कलार्इ', 'सद्उपदेश,', 'र्इंटें',\n 'बिलसपुरहिन-’’अइसर्इ', 'जबरर्इ', 'गर्इ?', 'सफार्इ'],\n dtype='object', length=212)\n"
],
[
"Data3 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/half_cononant_vowel.csv\")\nData3=Data3[0:20]\nData3",
"_____no_output_____"
],
[
"sns.set(font=\"Meiryo\",font_scale=0.9)\nsns.barplot(y='Frequency',x=Data3.index,data=Data3.iloc[0:1500,:])",
"_____no_output_____"
],
[
"df4=pd.DataFrame.from_dict(words_with_half_consonant_following_matra, orient='index',columns=[ 'Frequency'])\nprint(df4.index)\ndf4=df4.sort_values(by=['Frequency'],ascending=False)\ndf4.to_csv('half_cononant_matra.csv',index = True)\n",
"Index(['जलर्ापूत्ति', 'वष्ाीüय', 'सुसज्ज्ाित', 'मुट््ठीभर', 'केन््रद',\n 'पुरूष्ाों', 'पाष्ाüद', 'मुद््दों', 'क्िलंटन', 'कट््टे',\n ...\n 'छ्ःओटी', 'प्रा्रोत्ेत्साहित', 'पालन-पोष्ाण', '(ब्ा्रह्म)', 'विध्ेयक',\n 'कलारूप्ा', 'मैंट्ो', 'राष्ट्र्ीय', 'एफटर््स', 'ज़्पारोशिया'],\n dtype='object', length=476)\n"
],
[
"Data4 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/half_cononant_matra.csv\")\nData4=Data4[0:20]\nData4",
"_____no_output_____"
],
[
"sns.set(font=\"Meiryo\",font_scale=0.9)\nsns.barplot(y='Frequency',x=Data4.index,data=Data4.iloc[0:1500,:])",
"_____no_output_____"
],
[
"df5=pd.DataFrame.from_dict(detectChars, orient='index',columns=[ 'Frequency'])\nprint(df5.index)\ndf5=df5.sort_values(by=['Frequency'],ascending=False)\n# df5.to_csv('detectChars.csv',index = True)\nData5 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/detectChars.csv\")\nData5=Data5[0:20]\nData5",
"Index(['का', 'पू', 'र्व', 'पा', 'कि', 'स्ता', 'नी', 'क', 'प्ता', 'न',\n ...\n 'ट्.', 'दे्व', 'निंं', 'र्पः', 'ठ्या', 'ह्लो', 'च्चोे', 'त्न्', 'त्साा',\n 'ड़्ड'],\n dtype='object', length=8491)\n"
],
[
"sns.set(font=\"Meiryo\",font_scale=0.9)\nsns.barplot(y='Frequency',x=Data5.index,data=Data5.iloc[0:1500,:])",
"_____no_output_____"
],
[
"df6=pd.DataFrame.from_dict(detectConsonants_Matra, orient='index',columns=[ 'Frequency'])\nprint(df6.index)\ndf6=df6.sort_values(by=['Frequency'],ascending=False)\n# df6.to_csv('detectConsonants_Matra.csv',index = True)\nData6 = pd.read_csv(r\"/Users/shivanitripathi/Documents/study material/DS/OLAM/datagen/detectConsonants_Matra.csv\")\nData6=Data6[0:20]\nData6",
"Index(['पू', 'र्', 'पा', 'कि', 'स्', 'ता', 'नी', 'प्', 'ने', 'हा',\n ...\n 'झाा', 'पँू', 'विँ', 'ठिि', 'बंे', 'हाँं', 'नुे', 'किृ', 'ळौ', 'निंं'],\n dtype='object', length=2957)\n"
],
[
"sns.set(font=\"Meiryo\",font_scale=0.9)\nsns.barplot(y='Frequency',x=Data6.index,data=Data6.iloc[0:1500,:])",
"_____no_output_____"
],
[
"encoder_dict= {\n \"ऀ\":\"0\",\n \"ँ\":\"1\",\n \"ं\":\"2\",\n \"ः\":\"3\",\n \"ऄ\":\"4\",\n \"अ\":\"5\",\n \"आ\":\"6\",\n \"इ\":\"7\",\n \"ई\":\"8\",\n \"उ\":\"9\",\n \"ऊ\":\"10\",\n \"ऋ\":\"11\",\n \"ऌ\":\"12\",\n \"ऍ\":\"13\",\n \"ऎ\":\"14\",\n \"ए\":\"15\",\n \"ऐ\":\"16\",\n \"ऑ\":\"17\",\n \"ऒ\":\"18\",\n \"ओ\":\"19\",\n \"औ\":\"20\",\n \"क\":\"21\",\n \"ख\":\"22\",\n \"ग\":\"23\",\n \"घ\":\"24\",\n \"ङ\":\"25\",\n \"च\":\"26\",\n \"छ\":\"27\",\n \"ज\":\"28\",\n \"झ\":\"29\",\n \"ञ\":\"30\",\n \"ट\":\"31\",\n \"ठ\":\"32\",\n \"ड\":\"33\",\n \"ढ\":\"34\",\n \"ण\":\"35\",\n \"त\":\"36\",\n \"थ\":\"37\",\n \"द\":\"38\",\n \"ध\":\"39\",\n \"न\":\"40\",\n \"ऩ\":\"41\",\n \"प\":\"42\",\n \"फ\":\"43\",\n \"ब\":\"44\",\n \"भ\":\"45\",\n \"म\":\"46\",\n \"य\":\"47\",\n \"र\":\"48\",\n \"ऱ\":\"49\",\n \"ल\":\"50\",\n \"ळ\":\"51\",\n \"ऴ\":\"52\",\n \"व\":\"53\",\n \"श\":\"54\",\n \"ष\":\"55\",\n \"स\":\"56\",\n \"ा\":\"57\",\n \"ि\":\"58\",\n \"ी\":\"59\",\n \"ु\":\"60\",\n \"ू\":\"61\",\n \"ृ\":\"62\",\n \"ॄ\":\"63\",\n \"ॆ\":\"64\",\n \"े\":\"65\",\n \"ै\":\"66\",\n \"ॉ\":\"67\",\n \"ॊ\":\"68\",\n \"ो\":\"69\",\n \"ौ\":\"70\",\n \"्\":\"71\",\n \"ॎ\":\"72\",\n \"ॐ\":\"73\",\n \"ॏ\":\"74\",\n \"।\":\"75\",\n \"॥\":\"76\",\n \"०\":\"77\",\n \"१\":\"78\",\n \"२\":\"79\",\n \"३\":\"80\",\n \"४\":\"81\",\n \"५\":\"82\",\n \"६\":\"83\",\n \"७\":\"84\",\n \"८\":\"85\",\n \"९\":\"86\",\n \"ॕ\":\"87\",\n \"ॖ\":\"88\",\n \"ॗ\":\"89\",\n \"॰\":\"90\",\n \"ॱ\":\"91\",\n \"ॲ\":\"92\",\n \"ॳ\":\"93\",\n \"ॴ\":\"94\",\n \"ॵ\":\"95\",\n \"ॶ\":\"96\",\n \"ॷ\":\"97\",\n \"ॸ\":\"98\",\n \"ॹ\":\"99\",\n \"ॺ\":\"100\",\n \"ॻ\":\"101\",\n \"ॼ\":\"102\",\n \"ॽ\":\"103\",\n \"ॾ\":\"104\",\n \"ॿ\":\"105\",\n \"क़\":\"106\",\n \"ख़\":\"107\",\n \"ग़\":\"108\",\n \"ज़\":\"109\",\n \"ड़\":\"110\",\n \"ढ़\":\"111\",\n \"फ़\":\"112\",\n \"य़\":\"113\",\n \"ॠ\":\"114\",\n \"ॡ\":\"115\",\n \"ॢ\":\"116\",\n \"ॣ\":\"117\"\n}",
"_____no_output_____"
],
[
"\nfrom textGenerator import TextGenerator\n# textGen = TextGenerator(filePath=os.path.join('hindiTexts.csv'))\ntextGen = TextGenerator()\ndata = textGen.data['text']\nprint(data[0])",
"पूर्व पाकिस्तानी कप्तान अकरम ने कहा कि यदि खिलाड़ी दबाव भूलना भी चाहे तो दर्शक, क्रिकेट प्रेमी और मीडिया ऐसा नहीं करने देता है। उन्होंने कहा, ‘‘ लोग कहते हैं कि एशेज में बहुत दबाव होता है लेकिन भारत पाकिस्तान के मैचों में जितना दबाव होता उतना किसी अन्य के साथ खेलने में नहीं होता है। हर खिलाड़ी इन मैचों में अच्छा प्रदर्शन करना चाहता है। ’’\n"
],
[
"chr(97)",
"_____no_output_____"
],
[
"encoder_dict",
"_____no_output_____"
],
[
"k = 118\nfor i in range (ord('0'), ord('9')+1):\n print(i, chr(i))\n encoder_dict[chr(i)] = k\n k = k+1",
"48 0\n49 1\n50 2\n51 3\n52 4\n53 5\n54 6\n55 7\n56 8\n57 9\n"
],
[
"k = 128 \nfor i in range (ord('A'), ord('Z')+1):\n print(i, chr(i))\n encoder_dict[chr(i)] = k\n k = k+1",
"65 A\n66 B\n67 C\n68 D\n69 E\n70 F\n71 G\n72 H\n73 I\n74 J\n75 K\n76 L\n77 M\n78 N\n79 O\n80 P\n81 Q\n82 R\n83 S\n84 T\n85 U\n86 V\n87 W\n88 X\n89 Y\n90 Z\n"
],
[
"chr(ord('z') - ord('a') + ord('A'))",
"_____no_output_____"
],
[
"import json",
"_____no_output_____"
],
[
"with open('characterClasses.json', 'w') as fp:\n json.dump(encoder_dict, fp)",
"_____no_output_____"
],
[
"characters = list(encoder_dict.keys())[:154]\nclassesCharacter = {} \nfor i in range(0,154):\n classesCharacter[i] = characters[i]\n\nprint(classesCharacter)",
"{0: 'ऀ', 1: 'ँ', 2: 'ं', 3: 'ः', 4: 'ऄ', 5: 'अ', 6: 'आ', 7: 'इ', 8: 'ई', 9: 'उ', 10: 'ऊ', 11: 'ऋ', 12: 'ऌ', 13: 'ऍ', 14: 'ऎ', 15: 'ए', 16: 'ऐ', 17: 'ऑ', 18: 'ऒ', 19: 'ओ', 20: 'औ', 21: 'क', 22: 'ख', 23: 'ग', 24: 'घ', 25: 'ङ', 26: 'च', 27: 'छ', 28: 'ज', 29: 'झ', 30: 'ञ', 31: 'ट', 32: 'ठ', 33: 'ड', 34: 'ढ', 35: 'ण', 36: 'त', 37: 'थ', 38: 'द', 39: 'ध', 40: 'न', 41: 'ऩ', 42: 'प', 43: 'फ', 44: 'ब', 45: 'भ', 46: 'म', 47: 'य', 48: 'र', 49: 'ऱ', 50: 'ल', 51: 'ळ', 52: 'ऴ', 53: 'व', 54: 'श', 55: 'ष', 56: 'स', 57: 'ा', 58: 'ि', 59: 'ी', 60: 'ु', 61: 'ू', 62: 'ृ', 63: 'ॄ', 64: 'ॆ', 65: 'े', 66: 'ै', 67: 'ॉ', 68: 'ॊ', 69: 'ो', 70: 'ौ', 71: '्', 72: 'ॎ', 73: 'ॐ', 74: 'ॏ', 75: '।', 76: '॥', 77: '०', 78: '१', 79: '२', 80: '३', 81: '४', 82: '५', 83: '६', 84: '७', 85: '८', 86: '९', 87: 'ॕ', 88: 'ॖ', 89: 'ॗ', 90: '॰', 91: 'ॱ', 92: 'ॲ', 93: 'ॳ', 94: 'ॴ', 95: 'ॵ', 96: 'ॶ', 97: 'ॷ', 98: 'ॸ', 99: 'ॹ', 100: 'ॺ', 101: 'ॻ', 102: 'ॼ', 103: 'ॽ', 104: 'ॾ', 105: 'ॿ', 106: 'क़', 107: 'ख़', 108: 'ग़', 109: 'ज़', 110: 'ड़', 111: 'ढ़', 112: 'फ़', 113: 'य़', 114: 'ॠ', 115: 'ॡ', 116: 'ॢ', 117: 'ॣ', 118: '0', 119: '1', 120: '2', 121: '3', 122: '4', 123: '5', 124: '6', 125: '7', 126: '8', 127: '9', 128: 'a', 129: 'b', 130: 'c', 131: 'd', 132: 'e', 133: 'f', 134: 'g', 135: 'h', 136: 'i', 137: 'j', 138: 'k', 139: 'l', 140: 'm', 141: 'n', 142: 'o', 143: 'p', 144: 'q', 145: 'r', 146: 's', 147: 't', 148: 'u', 149: 'v', 150: 'w', 151: 'x', 152: 'y', 153: 'z'}\n"
],
[
"with open ('characterToClasses.json', 'w') as fp:\n json.dump(classesCharacter, fp)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c516ac83ead28faa6f42e69c4f72210a37a318fa
| 403,762 |
ipynb
|
Jupyter Notebook
|
ml-clustering-and-retrieval/week-2/1_nearest-neighbors-lsh-implementation_blank.ipynb
|
zomansud/coursera
|
8b63eda4194241edc0c493fb74ca6834c9d0792d
|
[
"MIT"
] | null | null | null |
ml-clustering-and-retrieval/week-2/1_nearest-neighbors-lsh-implementation_blank.ipynb
|
zomansud/coursera
|
8b63eda4194241edc0c493fb74ca6834c9d0792d
|
[
"MIT"
] | null | null | null |
ml-clustering-and-retrieval/week-2/1_nearest-neighbors-lsh-implementation_blank.ipynb
|
zomansud/coursera
|
8b63eda4194241edc0c493fb74ca6834c9d0792d
|
[
"MIT"
] | 1 |
2021-08-10T20:05:24.000Z
|
2021-08-10T20:05:24.000Z
| 118.963465 | 44,996 | 0.802517 |
[
[
[
"# Locality Sensitive Hashing",
"_____no_output_____"
],
[
"Locality Sensitive Hashing (LSH) provides for a fast, efficient approximate nearest neighbor search. The algorithm scales well with respect to the number of data points as well as dimensions.\n\nIn this assignment, you will\n* Implement the LSH algorithm for approximate nearest neighbor search\n* Examine the accuracy for different documents by comparing against brute force search, and also contrast runtimes\n* Explore the role of the algorithm’s tuning parameters in the accuracy of the method",
"_____no_output_____"
],
[
"**Note to Amazon EC2 users**: To conserve memory, make sure to stop all the other notebooks before running this notebook.",
"_____no_output_____"
],
[
"## Import necessary packages",
"_____no_output_____"
],
[
"The following code block will check if you have the correct version of GraphLab Create. Any version later than 1.8.5 will do. To upgrade, read [this page](https://turi.com/download/upgrade-graphlab-create.html).",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport graphlab\nfrom scipy.sparse import csr_matrix\nfrom sklearn.metrics.pairwise import pairwise_distances\nimport time\nfrom copy import copy\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n'''Check GraphLab Create version'''\nfrom distutils.version import StrictVersion\nassert (StrictVersion(graphlab.version) >= StrictVersion('1.8.5')), 'GraphLab Create must be version 1.8.5 or later.'\n\n'''compute norm of a sparse vector\n Thanks to: Jaiyam Sharma'''\ndef norm(x):\n sum_sq=x.dot(x.T)\n norm=np.sqrt(sum_sq)\n return(norm)",
"This non-commercial license of GraphLab Create for academic use is assigned to [email protected] and will expire on September 18, 2017.\n"
]
],
[
[
"## Load in the Wikipedia dataset",
"_____no_output_____"
]
],
[
[
"wiki = graphlab.SFrame('people_wiki.gl/')",
"_____no_output_____"
]
],
[
[
"For this assignment, let us assign a unique ID to each document.",
"_____no_output_____"
]
],
[
[
"wiki = wiki.add_row_number()\nwiki",
"_____no_output_____"
]
],
[
[
"## Extract TF-IDF matrix",
"_____no_output_____"
],
[
"We first use GraphLab Create to compute a TF-IDF representation for each document.",
"_____no_output_____"
]
],
[
[
"wiki['tf_idf'] = graphlab.text_analytics.tf_idf(wiki['text'])\nwiki",
"_____no_output_____"
]
],
[
[
"For the remainder of the assignment, we will use sparse matrices. Sparse matrices are [matrices](https://en.wikipedia.org/wiki/Matrix_(mathematics%29 ) that have a small number of nonzero entries. A good data structure for sparse matrices would only store the nonzero entries to save space and speed up computation. SciPy provides a highly-optimized library for sparse matrices. Many matrix operations available for NumPy arrays are also available for SciPy sparse matrices.\n\nWe first convert the TF-IDF column (in dictionary format) into the SciPy sparse matrix format.",
"_____no_output_____"
]
],
[
[
"def sframe_to_scipy(column):\n \"\"\" \n Convert a dict-typed SArray into a SciPy sparse matrix.\n \n Returns\n -------\n mat : a SciPy sparse matrix where mat[i, j] is the value of word j for document i.\n mapping : a dictionary where mapping[j] is the word whose values are in column j.\n \"\"\"\n # Create triples of (row_id, feature_id, count).\n x = graphlab.SFrame({'X1':column})\n \n # 1. Add a row number.\n x = x.add_row_number()\n # 2. Stack will transform x to have a row for each unique (row, key) pair.\n x = x.stack('X1', ['feature', 'value'])\n\n # Map words into integers using a OneHotEncoder feature transformation.\n f = graphlab.feature_engineering.OneHotEncoder(features=['feature'])\n\n # We first fit the transformer using the above data.\n f.fit(x)\n\n # The transform method will add a new column that is the transformed version\n # of the 'word' column.\n x = f.transform(x)\n\n # Get the feature mapping.\n mapping = f['feature_encoding']\n\n # Get the actual word id.\n x['feature_id'] = x['encoded_features'].dict_keys().apply(lambda x: x[0])\n\n # Create numpy arrays that contain the data for the sparse matrix.\n i = np.array(x['id'])\n j = np.array(x['feature_id'])\n v = np.array(x['value'])\n width = x['id'].max() + 1\n height = x['feature_id'].max() + 1\n\n # Create a sparse matrix.\n mat = csr_matrix((v, (i, j)), shape=(width, height))\n\n return mat, mapping",
"_____no_output_____"
]
],
[
[
"The conversion should take a few minutes to complete.",
"_____no_output_____"
]
],
[
[
"start=time.time()\ncorpus, mapping = sframe_to_scipy(wiki['tf_idf'])\nend=time.time()\nprint end-start",
"44.1307430267\n"
]
],
[
[
"**Checkpoint**: The following code block should return 'Check passed correctly', indicating that your matrix contains TF-IDF values for 59071 documents and 547979 unique words. Otherwise, it will return Error.",
"_____no_output_____"
]
],
[
[
"assert corpus.shape == (59071, 547979)\nprint 'Check passed correctly!'",
"Check passed correctly!\n"
]
],
[
[
"## Train an LSH model",
"_____no_output_____"
],
[
"LSH performs an efficient neighbor search by randomly partitioning all reference data points into different bins. Today we will build a popular variant of LSH known as random binary projection, which approximates cosine distance. There are other variants we could use for other choices of distance metrics.\n\nThe first step is to generate a collection of random vectors from the standard Gaussian distribution.",
"_____no_output_____"
]
],
[
[
"def generate_random_vectors(num_vector, dim):\n return np.random.randn(dim, num_vector)",
"_____no_output_____"
]
],
[
[
"To visualize these Gaussian random vectors, let's look at an example in low-dimensions. Below, we generate 3 random vectors each of dimension 5.",
"_____no_output_____"
]
],
[
[
"# Generate 3 random vectors of dimension 5, arranged into a single 5 x 3 matrix.\nnp.random.seed(0) # set seed=0 for consistent results\ngenerate_random_vectors(num_vector=3, dim=5)",
"_____no_output_____"
]
],
[
[
"We now generate random vectors of the same dimensionality as our vocubulary size (547979). Each vector can be used to compute one bit in the bin encoding. We generate 16 vectors, leading to a 16-bit encoding of the bin index for each document.",
"_____no_output_____"
]
],
[
[
"# Generate 16 random vectors of dimension 547979\nnp.random.seed(0)\nrandom_vectors = generate_random_vectors(num_vector=16, dim=547979)\nrandom_vectors.shape",
"_____no_output_____"
]
],
[
[
"Next, we partition data points into bins. Instead of using explicit loops, we'd like to utilize matrix operations for greater efficiency. Let's walk through the construction step by step.\n\nWe'd like to decide which bin document 0 should go. Since 16 random vectors were generated in the previous cell, we have 16 bits to represent the bin index. The first bit is given by the sign of the dot product between the first random vector and the document's TF-IDF vector.",
"_____no_output_____"
]
],
[
[
"doc = corpus[0, :] # vector of tf-idf values for document 0\ndoc.dot(random_vectors[:, 0]) >= 0 # True if positive sign; False if negative sign",
"_____no_output_____"
]
],
[
[
"Similarly, the second bit is computed as the sign of the dot product between the second random vector and the document vector.",
"_____no_output_____"
]
],
[
[
"doc.dot(random_vectors[:, 1]) >= 0 # True if positive sign; False if negative sign",
"_____no_output_____"
]
],
[
[
"We can compute all of the bin index bits at once as follows. Note the absence of the explicit `for` loop over the 16 vectors. Matrix operations let us batch dot-product computation in a highly efficent manner, unlike the `for` loop construction. Given the relative inefficiency of loops in Python, the advantage of matrix operations is even greater.",
"_____no_output_____"
]
],
[
[
"doc.dot(random_vectors) >= 0 # should return an array of 16 True/False bits",
"_____no_output_____"
],
[
"np.array(doc.dot(random_vectors) >= 0, dtype=int) # display index bits in 0/1's",
"_____no_output_____"
]
],
[
[
"All documents that obtain exactly this vector will be assigned to the same bin. We'd like to repeat the identical operation on all documents in the Wikipedia dataset and compute the corresponding bin indices. Again, we use matrix operations so that no explicit loop is needed.",
"_____no_output_____"
]
],
[
[
"corpus[0:2].dot(random_vectors) >= 0 # compute bit indices of first two documents",
"_____no_output_____"
],
[
"corpus.dot(random_vectors) >= 0 # compute bit indices of ALL documents",
"_____no_output_____"
]
],
[
[
"We're almost done! To make it convenient to refer to individual bins, we convert each binary bin index into a single integer: \n```\nBin index integer\n[0,0,0,0,0,0,0,0,0,0,0,0] => 0\n[0,0,0,0,0,0,0,0,0,0,0,1] => 1\n[0,0,0,0,0,0,0,0,0,0,1,0] => 2\n[0,0,0,0,0,0,0,0,0,0,1,1] => 3\n...\n[1,1,1,1,1,1,1,1,1,1,0,0] => 65532\n[1,1,1,1,1,1,1,1,1,1,0,1] => 65533\n[1,1,1,1,1,1,1,1,1,1,1,0] => 65534\n[1,1,1,1,1,1,1,1,1,1,1,1] => 65535 (= 2^16-1)\n```\nBy the [rules of binary number representation](https://en.wikipedia.org/wiki/Binary_number#Decimal), we just need to compute the dot product between the document vector and the vector consisting of powers of 2:",
"_____no_output_____"
]
],
[
[
"doc = corpus[0, :] # first document\nindex_bits = (doc.dot(random_vectors) >= 0)\npowers_of_two = (1 << np.arange(15, -1, -1))\nprint index_bits\nprint powers_of_two\nprint index_bits.dot(powers_of_two)",
"[[ True True False False False True True False True True True False\n False True False True]]\n[32768 16384 8192 4096 2048 1024 512 256 128 64 32 16\n 8 4 2 1]\n[50917]\n"
]
],
[
[
"Since it's the dot product again, we batch it with a matrix operation:",
"_____no_output_____"
]
],
[
[
"index_bits = corpus.dot(random_vectors) >= 0\nindex_bits.dot(powers_of_two)",
"_____no_output_____"
]
],
[
[
"This array gives us the integer index of the bins for all documents.\n\nNow we are ready to complete the following function. Given the integer bin indices for the documents, you should compile a list of document IDs that belong to each bin. Since a list is to be maintained for each unique bin index, a dictionary of lists is used.\n\n1. Compute the integer bin indices. This step is already completed.\n2. For each document in the dataset, do the following:\n * Get the integer bin index for the document.\n * Fetch the list of document ids associated with the bin; if no list yet exists for this bin, assign the bin an empty list.\n * Add the document id to the end of the list.\n",
"_____no_output_____"
]
],
[
[
"def train_lsh(data, num_vector=16, seed=None):\n \n dim = data.shape[1]\n if seed is not None:\n np.random.seed(seed)\n random_vectors = generate_random_vectors(num_vector, dim)\n \n powers_of_two = 1 << np.arange(num_vector-1, -1, -1)\n \n table = {}\n \n # Partition data points into bins\n bin_index_bits = (data.dot(random_vectors) >= 0)\n \n # Encode bin index bits into integers\n bin_indices = bin_index_bits.dot(powers_of_two)\n \n # Update `table` so that `table[i]` is the list of document ids with bin index equal to i.\n for data_index, bin_index in enumerate(bin_indices):\n if bin_index not in table:\n # If no list yet exists for this bin, assign the bin an empty list.\n table[bin_index] = []\n # Fetch the list of document ids associated with the bin and add the document id to the end.\n table[bin_index].append(data_index)\n \n model = {'data': data,\n 'bin_index_bits': bin_index_bits,\n 'bin_indices': bin_indices,\n 'table': table,\n 'random_vectors': random_vectors,\n 'num_vector': num_vector}\n \n return model",
"_____no_output_____"
]
],
[
[
"**Checkpoint**. ",
"_____no_output_____"
]
],
[
[
"model = train_lsh(corpus, num_vector=16, seed=143)\ntable = model['table']\nif 0 in table and table[0] == [39583] and \\\n 143 in table and table[143] == [19693, 28277, 29776, 30399]:\n print 'Passed!'\nelse:\n print 'Check your code.'",
"Passed!\n"
]
],
[
[
"**Note.** We will be using the model trained here in the following sections, unless otherwise indicated.",
"_____no_output_____"
],
[
"## Inspect bins",
"_____no_output_____"
],
[
"Let us look at some documents and see which bins they fall into.",
"_____no_output_____"
]
],
[
[
"wiki[wiki['name'] == 'Barack Obama']",
"_____no_output_____"
]
],
[
[
"**Quiz Question**. What is the document `id` of Barack Obama's article?\n\n**Quiz Question**. Which bin contains Barack Obama's article? Enter its integer index.",
"_____no_output_____"
]
],
[
[
"model['bin_indices'][wiki[wiki['name'] == 'Barack Obama']['id']] #obama bin index",
"_____no_output_____"
]
],
[
[
"Recall from the previous assignment that Joe Biden was a close neighbor of Barack Obama.",
"_____no_output_____"
]
],
[
[
"wiki[wiki['name'] == 'Joe Biden']",
"_____no_output_____"
]
],
[
[
"**Quiz Question**. Examine the bit representations of the bins containing Barack Obama and Joe Biden. In how many places do they agree?\n\n1. 16 out of 16 places (Barack Obama and Joe Biden fall into the same bin)\n2. 14 out of 16 places\n3. 12 out of 16 places\n4. 10 out of 16 places\n5. 8 out of 16 places",
"_____no_output_____"
]
],
[
[
"obama_bits = np.array(model['bin_index_bits'][wiki[wiki['name'] == 'Barack Obama']['id']], dtype=int)\nprint obama_bits\n\nbiden_bits = np.array(model['bin_index_bits'][wiki[wiki['name'] == 'Joe Biden']['id']], dtype=int)\nprint biden_bits",
"[[1 1 0 0 0 1 0 0 0 0 0 1 0 0 1 0]]\n[[1 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0]]\n"
],
[
"print \"# of similar bits = 14 \" + str(len(obama_bits[0]) - np.bitwise_xor(obama_bits[0], biden_bits[0]).sum()) ",
"# of similar bits = 14 14\n"
]
],
[
[
"Compare the result with a former British diplomat, whose bin representation agrees with Obama's in only 8 out of 16 places.",
"_____no_output_____"
]
],
[
[
"wiki[wiki['name']=='Wynn Normington Hugh-Jones']",
"_____no_output_____"
],
[
"print np.array(model['bin_index_bits'][22745], dtype=int) # list of 0/1's\nprint model['bin_indices'][22745] # integer format\nmodel['bin_index_bits'][35817] == model['bin_index_bits'][22745]",
"[0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0]\n4660\n"
]
],
[
[
"How about the documents in the same bin as Barack Obama? Are they necessarily more similar to Obama than Biden? Let's look at which documents are in the same bin as the Barack Obama article.",
"_____no_output_____"
]
],
[
[
"model['table'][model['bin_indices'][35817]] # all document ids in the same bin as barack obama",
"_____no_output_____"
]
],
[
[
"There are four other documents that belong to the same bin. Which documents are they?",
"_____no_output_____"
]
],
[
[
"doc_ids = list(model['table'][model['bin_indices'][35817]])\ndoc_ids.remove(35817) # display documents other than Obama\n\ndocs = wiki.filter_by(values=doc_ids, column_name='id') # filter by id column\ndocs",
"_____no_output_____"
]
],
[
[
"It turns out that Joe Biden is much closer to Barack Obama than any of the four documents, even though Biden's bin representation differs from Obama's by 2 bits.",
"_____no_output_____"
]
],
[
[
"def cosine_distance(x, y):\n xy = x.dot(y.T)\n dist = xy/(norm(x)*norm(y))\n return 1-dist[0,0]\n\nobama_tf_idf = corpus[35817,:]\nbiden_tf_idf = corpus[24478,:]\n\nprint '================= Cosine distance from Barack Obama'\nprint 'Barack Obama - {0:24s}: {1:f}'.format('Joe Biden',\n cosine_distance(obama_tf_idf, biden_tf_idf))\nfor doc_id in doc_ids:\n doc_tf_idf = corpus[doc_id,:]\n print 'Barack Obama - {0:24s}: {1:f}'.format(wiki[doc_id]['name'],\n cosine_distance(obama_tf_idf, doc_tf_idf))",
"================= Cosine distance from Barack Obama\nBarack Obama - Joe Biden : 0.703139\nBarack Obama - Mark Boulware : 0.950867\nBarack Obama - John Wells (politician) : 0.975966\nBarack Obama - Francis Longstaff : 0.978256\nBarack Obama - Madurai T. Srinivasan : 0.993092\n"
]
],
[
[
"**Moral of the story**. Similar data points will in general _tend to_ fall into _nearby_ bins, but that's all we can say about LSH. In a high-dimensional space such as text features, we often get unlucky with our selection of only a few random vectors such that dissimilar data points go into the same bin while similar data points fall into different bins. **Given a query document, we must consider all documents in the nearby bins and sort them according to their actual distances from the query.**",
"_____no_output_____"
],
[
"## Query the LSH model",
"_____no_output_____"
],
[
"Let us first implement the logic for searching nearby neighbors, which goes like this:\n```\n1. Let L be the bit representation of the bin that contains the query documents.\n2. Consider all documents in bin L.\n3. Consider documents in the bins whose bit representation differs from L by 1 bit.\n4. Consider documents in the bins whose bit representation differs from L by 2 bits.\n...\n```",
"_____no_output_____"
],
[
"To obtain candidate bins that differ from the query bin by some number of bits, we use `itertools.combinations`, which produces all possible subsets of a given list. See [this documentation](https://docs.python.org/3/library/itertools.html#itertools.combinations) for details.\n```\n1. Decide on the search radius r. This will determine the number of different bits between the two vectors.\n2. For each subset (n_1, n_2, ..., n_r) of the list [0, 1, 2, ..., num_vector-1], do the following:\n * Flip the bits (n_1, n_2, ..., n_r) of the query bin to produce a new bit vector.\n * Fetch the list of documents belonging to the bin indexed by the new bit vector.\n * Add those documents to the candidate set.\n```\n\nEach line of output from the following cell is a 3-tuple indicating where the candidate bin would differ from the query bin. For instance,\n```\n(0, 1, 3)\n```\nindicates that the candiate bin differs from the query bin in first, second, and fourth bits.",
"_____no_output_____"
]
],
[
[
"from itertools import combinations",
"_____no_output_____"
],
[
"num_vector = 16\nsearch_radius = 3\n\nfor diff in combinations(range(num_vector), search_radius):\n print diff",
"(0, 1, 2)\n(0, 1, 3)\n(0, 1, 4)\n(0, 1, 5)\n(0, 1, 6)\n(0, 1, 7)\n(0, 1, 8)\n(0, 1, 9)\n(0, 1, 10)\n(0, 1, 11)\n(0, 1, 12)\n(0, 1, 13)\n(0, 1, 14)\n(0, 1, 15)\n(0, 2, 3)\n(0, 2, 4)\n(0, 2, 5)\n(0, 2, 6)\n(0, 2, 7)\n(0, 2, 8)\n(0, 2, 9)\n(0, 2, 10)\n(0, 2, 11)\n(0, 2, 12)\n(0, 2, 13)\n(0, 2, 14)\n(0, 2, 15)\n(0, 3, 4)\n(0, 3, 5)\n(0, 3, 6)\n(0, 3, 7)\n(0, 3, 8)\n(0, 3, 9)\n(0, 3, 10)\n(0, 3, 11)\n(0, 3, 12)\n(0, 3, 13)\n(0, 3, 14)\n(0, 3, 15)\n(0, 4, 5)\n(0, 4, 6)\n(0, 4, 7)\n(0, 4, 8)\n(0, 4, 9)\n(0, 4, 10)\n(0, 4, 11)\n(0, 4, 12)\n(0, 4, 13)\n(0, 4, 14)\n(0, 4, 15)\n(0, 5, 6)\n(0, 5, 7)\n(0, 5, 8)\n(0, 5, 9)\n(0, 5, 10)\n(0, 5, 11)\n(0, 5, 12)\n(0, 5, 13)\n(0, 5, 14)\n(0, 5, 15)\n(0, 6, 7)\n(0, 6, 8)\n(0, 6, 9)\n(0, 6, 10)\n(0, 6, 11)\n(0, 6, 12)\n(0, 6, 13)\n(0, 6, 14)\n(0, 6, 15)\n(0, 7, 8)\n(0, 7, 9)\n(0, 7, 10)\n(0, 7, 11)\n(0, 7, 12)\n(0, 7, 13)\n(0, 7, 14)\n(0, 7, 15)\n(0, 8, 9)\n(0, 8, 10)\n(0, 8, 11)\n(0, 8, 12)\n(0, 8, 13)\n(0, 8, 14)\n(0, 8, 15)\n(0, 9, 10)\n(0, 9, 11)\n(0, 9, 12)\n(0, 9, 13)\n(0, 9, 14)\n(0, 9, 15)\n(0, 10, 11)\n(0, 10, 12)\n(0, 10, 13)\n(0, 10, 14)\n(0, 10, 15)\n(0, 11, 12)\n(0, 11, 13)\n(0, 11, 14)\n(0, 11, 15)\n(0, 12, 13)\n(0, 12, 14)\n(0, 12, 15)\n(0, 13, 14)\n(0, 13, 15)\n(0, 14, 15)\n(1, 2, 3)\n(1, 2, 4)\n(1, 2, 5)\n(1, 2, 6)\n(1, 2, 7)\n(1, 2, 8)\n(1, 2, 9)\n(1, 2, 10)\n(1, 2, 11)\n(1, 2, 12)\n(1, 2, 13)\n(1, 2, 14)\n(1, 2, 15)\n(1, 3, 4)\n(1, 3, 5)\n(1, 3, 6)\n(1, 3, 7)\n(1, 3, 8)\n(1, 3, 9)\n(1, 3, 10)\n(1, 3, 11)\n(1, 3, 12)\n(1, 3, 13)\n(1, 3, 14)\n(1, 3, 15)\n(1, 4, 5)\n(1, 4, 6)\n(1, 4, 7)\n(1, 4, 8)\n(1, 4, 9)\n(1, 4, 10)\n(1, 4, 11)\n(1, 4, 12)\n(1, 4, 13)\n(1, 4, 14)\n(1, 4, 15)\n(1, 5, 6)\n(1, 5, 7)\n(1, 5, 8)\n(1, 5, 9)\n(1, 5, 10)\n(1, 5, 11)\n(1, 5, 12)\n(1, 5, 13)\n(1, 5, 14)\n(1, 5, 15)\n(1, 6, 7)\n(1, 6, 8)\n(1, 6, 9)\n(1, 6, 10)\n(1, 6, 11)\n(1, 6, 12)\n(1, 6, 13)\n(1, 6, 14)\n(1, 6, 15)\n(1, 7, 8)\n(1, 7, 9)\n(1, 7, 10)\n(1, 7, 11)\n(1, 7, 12)\n(1, 7, 13)\n(1, 7, 14)\n(1, 7, 15)\n(1, 8, 9)\n(1, 8, 10)\n(1, 8, 11)\n(1, 8, 12)\n(1, 8, 13)\n(1, 8, 14)\n(1, 8, 15)\n(1, 9, 10)\n(1, 9, 11)\n(1, 9, 12)\n(1, 9, 13)\n(1, 9, 14)\n(1, 9, 15)\n(1, 10, 11)\n(1, 10, 12)\n(1, 10, 13)\n(1, 10, 14)\n(1, 10, 15)\n(1, 11, 12)\n(1, 11, 13)\n(1, 11, 14)\n(1, 11, 15)\n(1, 12, 13)\n(1, 12, 14)\n(1, 12, 15)\n(1, 13, 14)\n(1, 13, 15)\n(1, 14, 15)\n(2, 3, 4)\n(2, 3, 5)\n(2, 3, 6)\n(2, 3, 7)\n(2, 3, 8)\n(2, 3, 9)\n(2, 3, 10)\n(2, 3, 11)\n(2, 3, 12)\n(2, 3, 13)\n(2, 3, 14)\n(2, 3, 15)\n(2, 4, 5)\n(2, 4, 6)\n(2, 4, 7)\n(2, 4, 8)\n(2, 4, 9)\n(2, 4, 10)\n(2, 4, 11)\n(2, 4, 12)\n(2, 4, 13)\n(2, 4, 14)\n(2, 4, 15)\n(2, 5, 6)\n(2, 5, 7)\n(2, 5, 8)\n(2, 5, 9)\n(2, 5, 10)\n(2, 5, 11)\n(2, 5, 12)\n(2, 5, 13)\n(2, 5, 14)\n(2, 5, 15)\n(2, 6, 7)\n(2, 6, 8)\n(2, 6, 9)\n(2, 6, 10)\n(2, 6, 11)\n(2, 6, 12)\n(2, 6, 13)\n(2, 6, 14)\n(2, 6, 15)\n(2, 7, 8)\n(2, 7, 9)\n(2, 7, 10)\n(2, 7, 11)\n(2, 7, 12)\n(2, 7, 13)\n(2, 7, 14)\n(2, 7, 15)\n(2, 8, 9)\n(2, 8, 10)\n(2, 8, 11)\n(2, 8, 12)\n(2, 8, 13)\n(2, 8, 14)\n(2, 8, 15)\n(2, 9, 10)\n(2, 9, 11)\n(2, 9, 12)\n(2, 9, 13)\n(2, 9, 14)\n(2, 9, 15)\n(2, 10, 11)\n(2, 10, 12)\n(2, 10, 13)\n(2, 10, 14)\n(2, 10, 15)\n(2, 11, 12)\n(2, 11, 13)\n(2, 11, 14)\n(2, 11, 15)\n(2, 12, 13)\n(2, 12, 14)\n(2, 12, 15)\n(2, 13, 14)\n(2, 13, 15)\n(2, 14, 15)\n(3, 4, 5)\n(3, 4, 6)\n(3, 4, 7)\n(3, 4, 8)\n(3, 4, 9)\n(3, 4, 10)\n(3, 4, 11)\n(3, 4, 12)\n(3, 4, 13)\n(3, 4, 14)\n(3, 4, 15)\n(3, 5, 6)\n(3, 5, 7)\n(3, 5, 8)\n(3, 5, 9)\n(3, 5, 10)\n(3, 5, 11)\n(3, 5, 12)\n(3, 5, 13)\n(3, 5, 14)\n(3, 5, 15)\n(3, 6, 7)\n(3, 6, 8)\n(3, 6, 9)\n(3, 6, 10)\n(3, 6, 11)\n(3, 6, 12)\n(3, 6, 13)\n(3, 6, 14)\n(3, 6, 15)\n(3, 7, 8)\n(3, 7, 9)\n(3, 7, 10)\n(3, 7, 11)\n(3, 7, 12)\n(3, 7, 13)\n(3, 7, 14)\n(3, 7, 15)\n(3, 8, 9)\n(3, 8, 10)\n(3, 8, 11)\n(3, 8, 12)\n(3, 8, 13)\n(3, 8, 14)\n(3, 8, 15)\n(3, 9, 10)\n(3, 9, 11)\n(3, 9, 12)\n(3, 9, 13)\n(3, 9, 14)\n(3, 9, 15)\n(3, 10, 11)\n(3, 10, 12)\n(3, 10, 13)\n(3, 10, 14)\n(3, 10, 15)\n(3, 11, 12)\n(3, 11, 13)\n(3, 11, 14)\n(3, 11, 15)\n(3, 12, 13)\n(3, 12, 14)\n(3, 12, 15)\n(3, 13, 14)\n(3, 13, 15)\n(3, 14, 15)\n(4, 5, 6)\n(4, 5, 7)\n(4, 5, 8)\n(4, 5, 9)\n(4, 5, 10)\n(4, 5, 11)\n(4, 5, 12)\n(4, 5, 13)\n(4, 5, 14)\n(4, 5, 15)\n(4, 6, 7)\n(4, 6, 8)\n(4, 6, 9)\n(4, 6, 10)\n(4, 6, 11)\n(4, 6, 12)\n(4, 6, 13)\n(4, 6, 14)\n(4, 6, 15)\n(4, 7, 8)\n(4, 7, 9)\n(4, 7, 10)\n(4, 7, 11)\n(4, 7, 12)\n(4, 7, 13)\n(4, 7, 14)\n(4, 7, 15)\n(4, 8, 9)\n(4, 8, 10)\n(4, 8, 11)\n(4, 8, 12)\n(4, 8, 13)\n(4, 8, 14)\n(4, 8, 15)\n(4, 9, 10)\n(4, 9, 11)\n(4, 9, 12)\n(4, 9, 13)\n(4, 9, 14)\n(4, 9, 15)\n(4, 10, 11)\n(4, 10, 12)\n(4, 10, 13)\n(4, 10, 14)\n(4, 10, 15)\n(4, 11, 12)\n(4, 11, 13)\n(4, 11, 14)\n(4, 11, 15)\n(4, 12, 13)\n(4, 12, 14)\n(4, 12, 15)\n(4, 13, 14)\n(4, 13, 15)\n(4, 14, 15)\n(5, 6, 7)\n(5, 6, 8)\n(5, 6, 9)\n(5, 6, 10)\n(5, 6, 11)\n(5, 6, 12)\n(5, 6, 13)\n(5, 6, 14)\n(5, 6, 15)\n(5, 7, 8)\n(5, 7, 9)\n(5, 7, 10)\n(5, 7, 11)\n(5, 7, 12)\n(5, 7, 13)\n(5, 7, 14)\n(5, 7, 15)\n(5, 8, 9)\n(5, 8, 10)\n(5, 8, 11)\n(5, 8, 12)\n(5, 8, 13)\n(5, 8, 14)\n(5, 8, 15)\n(5, 9, 10)\n(5, 9, 11)\n(5, 9, 12)\n(5, 9, 13)\n(5, 9, 14)\n(5, 9, 15)\n(5, 10, 11)\n(5, 10, 12)\n(5, 10, 13)\n(5, 10, 14)\n(5, 10, 15)\n(5, 11, 12)\n(5, 11, 13)\n(5, 11, 14)\n(5, 11, 15)\n(5, 12, 13)\n(5, 12, 14)\n(5, 12, 15)\n(5, 13, 14)\n(5, 13, 15)\n(5, 14, 15)\n(6, 7, 8)\n(6, 7, 9)\n(6, 7, 10)\n(6, 7, 11)\n(6, 7, 12)\n(6, 7, 13)\n(6, 7, 14)\n(6, 7, 15)\n(6, 8, 9)\n(6, 8, 10)\n(6, 8, 11)\n(6, 8, 12)\n(6, 8, 13)\n(6, 8, 14)\n(6, 8, 15)\n(6, 9, 10)\n(6, 9, 11)\n(6, 9, 12)\n(6, 9, 13)\n(6, 9, 14)\n(6, 9, 15)\n(6, 10, 11)\n(6, 10, 12)\n(6, 10, 13)\n(6, 10, 14)\n(6, 10, 15)\n(6, 11, 12)\n(6, 11, 13)\n(6, 11, 14)\n(6, 11, 15)\n(6, 12, 13)\n(6, 12, 14)\n(6, 12, 15)\n(6, 13, 14)\n(6, 13, 15)\n(6, 14, 15)\n(7, 8, 9)\n(7, 8, 10)\n(7, 8, 11)\n(7, 8, 12)\n(7, 8, 13)\n(7, 8, 14)\n(7, 8, 15)\n(7, 9, 10)\n(7, 9, 11)\n(7, 9, 12)\n(7, 9, 13)\n(7, 9, 14)\n(7, 9, 15)\n(7, 10, 11)\n(7, 10, 12)\n(7, 10, 13)\n(7, 10, 14)\n(7, 10, 15)\n(7, 11, 12)\n(7, 11, 13)\n(7, 11, 14)\n(7, 11, 15)\n(7, 12, 13)\n(7, 12, 14)\n(7, 12, 15)\n(7, 13, 14)\n(7, 13, 15)\n(7, 14, 15)\n(8, 9, 10)\n(8, 9, 11)\n(8, 9, 12)\n(8, 9, 13)\n(8, 9, 14)\n(8, 9, 15)\n(8, 10, 11)\n(8, 10, 12)\n(8, 10, 13)\n(8, 10, 14)\n(8, 10, 15)\n(8, 11, 12)\n(8, 11, 13)\n(8, 11, 14)\n(8, 11, 15)\n(8, 12, 13)\n(8, 12, 14)\n(8, 12, 15)\n(8, 13, 14)\n(8, 13, 15)\n(8, 14, 15)\n(9, 10, 11)\n(9, 10, 12)\n(9, 10, 13)\n(9, 10, 14)\n(9, 10, 15)\n(9, 11, 12)\n(9, 11, 13)\n(9, 11, 14)\n(9, 11, 15)\n(9, 12, 13)\n(9, 12, 14)\n(9, 12, 15)\n(9, 13, 14)\n(9, 13, 15)\n(9, 14, 15)\n(10, 11, 12)\n(10, 11, 13)\n(10, 11, 14)\n(10, 11, 15)\n(10, 12, 13)\n(10, 12, 14)\n(10, 12, 15)\n(10, 13, 14)\n(10, 13, 15)\n(10, 14, 15)\n(11, 12, 13)\n(11, 12, 14)\n(11, 12, 15)\n(11, 13, 14)\n(11, 13, 15)\n(11, 14, 15)\n(12, 13, 14)\n(12, 13, 15)\n(12, 14, 15)\n(13, 14, 15)\n"
]
],
[
[
"With this output in mind, implement the logic for nearby bin search:",
"_____no_output_____"
]
],
[
[
"def search_nearby_bins(query_bin_bits, table, search_radius=2, initial_candidates=set()):\n \"\"\"\n For a given query vector and trained LSH model, return all candidate neighbors for\n the query among all bins within the given search radius.\n \n Example usage\n -------------\n >>> model = train_lsh(corpus, num_vector=16, seed=143)\n >>> q = model['bin_index_bits'][0] # vector for the first document\n \n >>> candidates = search_nearby_bins(q, model['table'])\n \"\"\"\n num_vector = len(query_bin_bits)\n powers_of_two = 1 << np.arange(num_vector-1, -1, -1)\n \n # Allow the user to provide an initial set of candidates.\n candidate_set = copy(initial_candidates)\n \n for different_bits in combinations(range(num_vector), search_radius): \n # Flip the bits (n_1,n_2,...,n_r) of the query bin to produce a new bit vector.\n ## Hint: you can iterate over a tuple like a list\n alternate_bits = copy(query_bin_bits)\n for i in different_bits:\n alternate_bits[i] = 0 if alternate_bits[i] == 1 else 1\n \n # Convert the new bit vector to an integer index\n nearby_bin = alternate_bits.dot(powers_of_two)\n \n # Fetch the list of documents belonging to the bin indexed by the new bit vector.\n # Then add those documents to candidate_set\n # Make sure that the bin exists in the table!\n # Hint: update() method for sets lets you add an entire list to the set\n if nearby_bin in table:\n # Update candidate_set with the documents in this bin.\n candidate_set.update(table[nearby_bin])\n \n return candidate_set",
"_____no_output_____"
]
],
[
[
"**Checkpoint**. Running the function with `search_radius=0` should yield the list of documents belonging to the same bin as the query.",
"_____no_output_____"
]
],
[
[
"obama_bin_index = model['bin_index_bits'][35817] # bin index of Barack Obama\ncandidate_set = search_nearby_bins(obama_bin_index, model['table'], search_radius=0)\nif candidate_set == set([35817, 21426, 53937, 39426, 50261]):\n print 'Passed test'\nelse:\n print 'Check your code'\nprint 'List of documents in the same bin as Obama: 35817, 21426, 53937, 39426, 50261'",
"Passed test\nList of documents in the same bin as Obama: 35817, 21426, 53937, 39426, 50261\n"
]
],
[
[
"**Checkpoint**. Running the function with `search_radius=1` adds more documents to the fore.",
"_____no_output_____"
]
],
[
[
"candidate_set = search_nearby_bins(obama_bin_index, model['table'], search_radius=1, initial_candidates=candidate_set)\nif candidate_set == set([39426, 38155, 38412, 28444, 9757, 41631, 39207, 59050, 47773, 53937, 21426, 34547,\n 23229, 55615, 39877, 27404, 33996, 21715, 50261, 21975, 33243, 58723, 35817, 45676,\n 19699, 2804, 20347]):\n print 'Passed test'\nelse:\n print 'Check your code'",
"Passed test\n"
]
],
[
[
"**Note**. Don't be surprised if few of the candidates look similar to Obama. This is why we add as many candidates as our computational budget allows and sort them by their distance to the query.",
"_____no_output_____"
],
[
"Now we have a function that can return all the candidates from neighboring bins. Next we write a function to collect all candidates and compute their true distance to the query.",
"_____no_output_____"
]
],
[
[
"def query(vec, model, k, max_search_radius):\n \n data = model['data']\n table = model['table']\n random_vectors = model['random_vectors']\n num_vector = random_vectors.shape[1]\n \n \n # Compute bin index for the query vector, in bit representation.\n bin_index_bits = (vec.dot(random_vectors) >= 0).flatten()\n \n # Search nearby bins and collect candidates\n candidate_set = set()\n for search_radius in xrange(max_search_radius+1):\n candidate_set = search_nearby_bins(bin_index_bits, table, search_radius, initial_candidates=candidate_set)\n \n # Sort candidates by their true distances from the query\n nearest_neighbors = graphlab.SFrame({'id':candidate_set})\n candidates = data[np.array(list(candidate_set)),:]\n nearest_neighbors['distance'] = pairwise_distances(candidates, vec, metric='cosine').flatten()\n \n return nearest_neighbors.topk('distance', k, reverse=True), len(candidate_set)",
"_____no_output_____"
]
],
[
[
"Let's try it out with Obama:",
"_____no_output_____"
]
],
[
[
"query(corpus[35817,:], model, k=10, max_search_radius=3)",
"_____no_output_____"
]
],
[
[
"To identify the documents, it's helpful to join this table with the Wikipedia table:",
"_____no_output_____"
]
],
[
[
"query(corpus[35817,:], model, k=10, max_search_radius=3)[0].join(wiki[['id', 'name']], on='id').sort('distance')",
"_____no_output_____"
]
],
[
[
"We have shown that we have a working LSH implementation!",
"_____no_output_____"
],
[
"# Experimenting with your LSH implementation",
"_____no_output_____"
],
[
"In the following sections we have implemented a few experiments so that you can gain intuition for how your LSH implementation behaves in different situations. This will help you understand the effect of searching nearby bins and the performance of LSH versus computing nearest neighbors using a brute force search.",
"_____no_output_____"
],
[
"## Effect of nearby bin search",
"_____no_output_____"
],
[
"How does nearby bin search affect the outcome of LSH? There are three variables that are affected by the search radius:\n* Number of candidate documents considered\n* Query time\n* Distance of approximate neighbors from the query",
"_____no_output_____"
],
[
"Let us run LSH multiple times, each with different radii for nearby bin search. We will measure the three variables as discussed above.",
"_____no_output_____"
]
],
[
[
"wiki[wiki['name']=='Barack Obama']",
"_____no_output_____"
],
[
"num_candidates_history = []\nquery_time_history = []\nmax_distance_from_query_history = []\nmin_distance_from_query_history = []\naverage_distance_from_query_history = []\n\nfor max_search_radius in xrange(17):\n start=time.time()\n result, num_candidates = query(corpus[35817,:], model, k=10,\n max_search_radius=max_search_radius)\n end=time.time()\n query_time = end-start\n \n print 'Radius:', max_search_radius\n print result.join(wiki[['id', 'name']], on='id').sort('distance')\n \n average_distance_from_query = result['distance'][1:].mean()\n max_distance_from_query = result['distance'][1:].max()\n min_distance_from_query = result['distance'][1:].min()\n \n num_candidates_history.append(num_candidates)\n query_time_history.append(query_time)\n average_distance_from_query_history.append(average_distance_from_query)\n max_distance_from_query_history.append(max_distance_from_query)\n min_distance_from_query_history.append(min_distance_from_query)",
"Radius: 0\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 21426 | 0.950866757525 | Mark Boulware |\n| 39426 | 0.97596600411 | John Wells (politician) |\n| 50261 | 0.978256163041 | Francis Longstaff |\n| 53937 | 0.993092148424 | Madurai T. Srinivasan |\n+-------+--------------------+-------------------------+\n[5 rows x 3 columns]\n\nRadius: 1\n+-------+--------------------+-------------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 41631 | 0.947459482005 | Binayak Sen |\n| 21426 | 0.950866757525 | Mark Boulware |\n| 33243 | 0.951765770113 | Janice Lachance |\n| 33996 | 0.960859054157 | Rufus Black |\n| 28444 | 0.961080585824 | John Paul Phelan |\n| 20347 | 0.974129605472 | Gianni De Fraja |\n| 39426 | 0.97596600411 | John Wells (politician) |\n| 34547 | 0.978214931987 | Nathan Murphy (Australian ... |\n| 50261 | 0.978256163041 | Francis Longstaff |\n+-------+--------------------+-------------------------------+\n[10 rows x 3 columns]\n\nRadius: 2\n+-------+--------------------+---------------------+\n| id | distance | name |\n+-------+--------------------+---------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 9267 | 0.898377208819 | Vikramaditya Khanna |\n| 55909 | 0.899340396322 | Herman Cain |\n| 6949 | 0.925713001103 | Harrison J. Goldin |\n| 23524 | 0.926397988994 | Paul Bennecke |\n| 5823 | 0.928498260316 | Adeleke Mamora |\n| 37262 | 0.93445433211 | Becky Cain |\n| 10121 | 0.936896394645 | Bill Bradley |\n| 54782 | 0.937809202206 | Thomas F. Hartnett |\n+-------+--------------------+---------------------+\n[10 rows x 3 columns]\n\nRadius: 3\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 56008 | 0.856848127628 | Nathan Cullen |\n| 37199 | 0.874668698194 | Barry Sullivan (lawyer) |\n| 40353 | 0.890034225981 | Neil MacBride |\n| 9267 | 0.898377208819 | Vikramaditya Khanna |\n| 55909 | 0.899340396322 | Herman Cain |\n| 9165 | 0.900921029925 | Raymond F. Clevenger |\n| 57958 | 0.903003263483 | Michael J. Malbin |\n| 49872 | 0.909532800353 | Lowell Barron |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 4\n+-------+--------------------+--------------------+\n| id | distance | name |\n+-------+--------------------+--------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 36452 | 0.833985493688 | Bill Clinton |\n| 24848 | 0.839406735668 | John C. Eastman |\n| 43155 | 0.840839007484 | Goodwin Liu |\n| 42965 | 0.849077676943 | John O. Brennan |\n| 56008 | 0.856848127628 | Nathan Cullen |\n| 38495 | 0.857573828556 | Barney Frank |\n| 18752 | 0.858899032522 | Dan W. Reicher |\n| 2092 | 0.874643264756 | Richard Blumenthal |\n+-------+--------------------+--------------------+\n[10 rows x 3 columns]\n\nRadius: 5\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46811 | 0.800197384104 | Jeff Sessions |\n| 14754 | 0.826854025897 | Mitt Romney |\n| 36452 | 0.833985493688 | Bill Clinton |\n| 40943 | 0.834534928232 | Jonathan Alter |\n| 55044 | 0.837013236281 | Wesley Clark |\n| 24848 | 0.839406735668 | John C. Eastman |\n| 43155 | 0.840839007484 | Goodwin Liu |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 6\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 46811 | 0.800197384104 | Jeff Sessions |\n| 48693 | 0.809192212293 | Artur Davis |\n| 23737 | 0.810164633465 | John D. McCormick |\n| 4032 | 0.814554748671 | Kenneth D. Thompson |\n| 28447 | 0.823228984384 | George W. Bush |\n| 14754 | 0.826854025897 | Mitt Romney |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 7\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 46811 | 0.800197384104 | Jeff Sessions |\n| 48693 | 0.809192212293 | Artur Davis |\n| 23737 | 0.810164633465 | John D. McCormick |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 8\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 46811 | 0.800197384104 | Jeff Sessions |\n| 48693 | 0.809192212293 | Artur Davis |\n| 23737 | 0.810164633465 | John D. McCormick |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 9\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 46811 | 0.800197384104 | Jeff Sessions |\n| 39357 | 0.809050776238 | John McCain |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 10\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n| 46811 | 0.800197384104 | Jeff Sessions |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 11\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n| 46811 | 0.800197384104 | Jeff Sessions |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 12\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 6796 | 0.788039072943 | Eric Holder |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 13\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 6796 | 0.788039072943 | Eric Holder |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 14\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 6796 | 0.788039072943 | Eric Holder |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 15\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 6796 | 0.788039072943 | Eric Holder |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\nRadius: 16\n+-------+--------------------+-------------------------+\n| id | distance | name |\n+-------+--------------------+-------------------------+\n| 35817 | -6.66133814775e-16 | Barack Obama |\n| 24478 | 0.703138676734 | Joe Biden |\n| 38376 | 0.742981902328 | Samantha Power |\n| 57108 | 0.758358397887 | Hillary Rodham Clinton |\n| 38714 | 0.770561227601 | Eric Stern (politician) |\n| 46140 | 0.784677504751 | Robert Gibbs |\n| 6796 | 0.788039072943 | Eric Holder |\n| 44681 | 0.790926415366 | Jesse Lee (politician) |\n| 18827 | 0.798322602893 | Henry Waxman |\n| 2412 | 0.799466360042 | Joe the Plumber |\n+-------+--------------------+-------------------------+\n[10 rows x 3 columns]\n\n"
]
],
[
[
"Notice that the top 10 query results become more relevant as the search radius grows. Let's plot the three variables:",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(7,4.5))\nplt.plot(num_candidates_history, linewidth=4)\nplt.xlabel('Search radius')\nplt.ylabel('# of documents searched')\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(query_time_history, linewidth=4)\nplt.xlabel('Search radius')\nplt.ylabel('Query time (seconds)')\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(average_distance_from_query_history, linewidth=4, label='Average of 10 neighbors')\nplt.plot(max_distance_from_query_history, linewidth=4, label='Farthest of 10 neighbors')\nplt.plot(min_distance_from_query_history, linewidth=4, label='Closest of 10 neighbors')\nplt.xlabel('Search radius')\nplt.ylabel('Cosine distance of neighbors')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"Some observations:\n* As we increase the search radius, we find more neighbors that are a smaller distance away.\n* With increased search radius comes a greater number documents that have to be searched. Query time is higher as a consequence.\n* With sufficiently high search radius, the results of LSH begin to resemble the results of brute-force search.",
"_____no_output_____"
],
[
"**Quiz Question**. What was the smallest search radius that yielded the correct nearest neighbor, namely Joe Biden?\n\n\n**Quiz Question**. Suppose our goal was to produce 10 approximate nearest neighbors whose average distance from the query document is within 0.01 of the average for the true 10 nearest neighbors. For Barack Obama, the true 10 nearest neighbors are on average about 0.77. What was the smallest search radius for Barack Obama that produced an average distance of 0.78 or better?",
"_____no_output_____"
]
],
[
[
"print \"radius = 2\"\n\nprint \"10\"\naverage_distance_from_query_history",
"radius = 2\n10\n"
]
],
[
[
"## Quality metrics for neighbors",
"_____no_output_____"
],
[
"The above analysis is limited by the fact that it was run with a single query, namely Barack Obama. We should repeat the analysis for the entirety of data. Iterating over all documents would take a long time, so let us randomly choose 10 documents for our analysis.\n\nFor each document, we first compute the true 25 nearest neighbors, and then run LSH multiple times. We look at two metrics:\n\n* Precision@10: How many of the 10 neighbors given by LSH are among the true 25 nearest neighbors?\n* Average cosine distance of the neighbors from the query\n\nThen we run LSH multiple times with different search radii.",
"_____no_output_____"
]
],
[
[
"def brute_force_query(vec, data, k):\n num_data_points = data.shape[0]\n \n # Compute distances for ALL data points in training set\n nearest_neighbors = graphlab.SFrame({'id':range(num_data_points)})\n nearest_neighbors['distance'] = pairwise_distances(data, vec, metric='cosine').flatten()\n \n return nearest_neighbors.topk('distance', k, reverse=True)",
"_____no_output_____"
]
],
[
[
"The following cell will run LSH with multiple search radii and compute the quality metrics for each run. Allow a few minutes to complete.",
"_____no_output_____"
]
],
[
[
"max_radius = 17\nprecision = {i:[] for i in xrange(max_radius)}\naverage_distance = {i:[] for i in xrange(max_radius)}\nquery_time = {i:[] for i in xrange(max_radius)}\n\nnp.random.seed(0)\nnum_queries = 10\nfor i, ix in enumerate(np.random.choice(corpus.shape[0], num_queries, replace=False)):\n print('%s / %s' % (i, num_queries))\n ground_truth = set(brute_force_query(corpus[ix,:], corpus, k=25)['id'])\n # Get the set of 25 true nearest neighbors\n \n for r in xrange(1,max_radius):\n start = time.time()\n result, num_candidates = query(corpus[ix,:], model, k=10, max_search_radius=r)\n end = time.time()\n\n query_time[r].append(end-start)\n # precision = (# of neighbors both in result and ground_truth)/10.0\n precision[r].append(len(set(result['id']) & ground_truth)/10.0)\n average_distance[r].append(result['distance'][1:].mean())",
"0 / 10\n1 / 10\n2 / 10\n3 / 10\n4 / 10\n5 / 10\n6 / 10\n7 / 10\n8 / 10\n9 / 10\n"
],
[
"plt.figure(figsize=(7,4.5))\nplt.plot(range(1,17), [np.mean(average_distance[i]) for i in xrange(1,17)], linewidth=4, label='Average over 10 neighbors')\nplt.xlabel('Search radius')\nplt.ylabel('Cosine distance')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(range(1,17), [np.mean(precision[i]) for i in xrange(1,17)], linewidth=4, label='Precison@10')\nplt.xlabel('Search radius')\nplt.ylabel('Precision')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(range(1,17), [np.mean(query_time[i]) for i in xrange(1,17)], linewidth=4, label='Query time')\nplt.xlabel('Search radius')\nplt.ylabel('Query time (seconds)')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"The observations for Barack Obama generalize to the entire dataset.",
"_____no_output_____"
],
[
"## Effect of number of random vectors",
"_____no_output_____"
],
[
"Let us now turn our focus to the remaining parameter: the number of random vectors. We run LSH with different number of random vectors, ranging from 5 to 20. We fix the search radius to 3.\n\nAllow a few minutes for the following cell to complete.",
"_____no_output_____"
]
],
[
[
"precision = {i:[] for i in xrange(5,20)}\naverage_distance = {i:[] for i in xrange(5,20)}\nquery_time = {i:[] for i in xrange(5,20)}\nnum_candidates_history = {i:[] for i in xrange(5,20)}\nground_truth = {}\n\nnp.random.seed(0)\nnum_queries = 10\ndocs = np.random.choice(corpus.shape[0], num_queries, replace=False)\n\nfor i, ix in enumerate(docs):\n ground_truth[ix] = set(brute_force_query(corpus[ix,:], corpus, k=25)['id'])\n # Get the set of 25 true nearest neighbors\n\nfor num_vector in xrange(5,20):\n print('num_vector = %s' % (num_vector))\n model = train_lsh(corpus, num_vector, seed=143)\n \n for i, ix in enumerate(docs):\n start = time.time()\n result, num_candidates = query(corpus[ix,:], model, k=10, max_search_radius=3)\n end = time.time()\n \n query_time[num_vector].append(end-start)\n precision[num_vector].append(len(set(result['id']) & ground_truth[ix])/10.0)\n average_distance[num_vector].append(result['distance'][1:].mean())\n num_candidates_history[num_vector].append(num_candidates)",
"num_vector = 5\nnum_vector = 6\nnum_vector = 7\nnum_vector = 8\nnum_vector = 9\nnum_vector = 10\nnum_vector = 11\nnum_vector = 12\nnum_vector = 13\nnum_vector = 14\nnum_vector = 15\nnum_vector = 16\nnum_vector = 17\nnum_vector = 18\nnum_vector = 19\n"
],
[
"plt.figure(figsize=(7,4.5))\nplt.plot(range(5,20), [np.mean(average_distance[i]) for i in xrange(5,20)], linewidth=4, label='Average over 10 neighbors')\nplt.xlabel('# of random vectors')\nplt.ylabel('Cosine distance')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(range(5,20), [np.mean(precision[i]) for i in xrange(5,20)], linewidth=4, label='Precison@10')\nplt.xlabel('# of random vectors')\nplt.ylabel('Precision')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(range(5,20), [np.mean(query_time[i]) for i in xrange(5,20)], linewidth=4, label='Query time (seconds)')\nplt.xlabel('# of random vectors')\nplt.ylabel('Query time (seconds)')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()\n\nplt.figure(figsize=(7,4.5))\nplt.plot(range(5,20), [np.mean(num_candidates_history[i]) for i in xrange(5,20)], linewidth=4,\n label='# of documents searched')\nplt.xlabel('# of random vectors')\nplt.ylabel('# of documents searched')\nplt.legend(loc='best', prop={'size':15})\nplt.rcParams.update({'font.size':16})\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"We see a similar trade-off between quality and performance: as the number of random vectors increases, the query time goes down as each bin contains fewer documents on average, but on average the neighbors are likewise placed farther from the query. On the other hand, when using a small enough number of random vectors, LSH becomes very similar brute-force search: Many documents appear in a single bin, so searching the query bin alone covers a lot of the corpus; then, including neighboring bins might result in searching all documents, just as in the brute-force approach.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
c516b12b3ec8841d515ace0ee8e2a03e289a8830
| 23,641 |
ipynb
|
Jupyter Notebook
|
Notebooks/cannabis_clean_wrangle.ipynb
|
med-cab-1/data_engineer
|
7fa99c7ae45642cd2ce0b47ec02b7a51532c4dfc
|
[
"MIT"
] | null | null | null |
Notebooks/cannabis_clean_wrangle.ipynb
|
med-cab-1/data_engineer
|
7fa99c7ae45642cd2ce0b47ec02b7a51532c4dfc
|
[
"MIT"
] | null | null | null |
Notebooks/cannabis_clean_wrangle.ipynb
|
med-cab-1/data_engineer
|
7fa99c7ae45642cd2ce0b47ec02b7a51532c4dfc
|
[
"MIT"
] | null | null | null | 32.743767 | 155 | 0.375619 |
[
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"df = pd.read_csv(\"kaggle_cannabis.csv\")",
"_____no_output_____"
],
[
"print(df.shape)\ndf.head(3)",
"(2351, 6)\n"
],
[
"# checking for missing values\ndf.isnull().sum()",
"_____no_output_____"
],
[
"# dropping missing values\ndf1 = df.dropna()\ndf1.isnull().sum()",
"_____no_output_____"
],
[
"print(df1.shape)\ndf1.head(3)",
"(2277, 6)\n"
],
[
"# Fixing formatting\ndf1['Effects'] = df1['Effects'].str.lower()\ndf1['Flavor'] = df1['Flavor'].str.lower()\ndf1['Description'] = df1['Description'].str.lower()\ndf1['Strain'] = df1['Strain'].str.lower()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n after removing the cwd from sys.path.\n/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"\n"
],
[
"#make the data PostgreSQL friendly\ndf[\"Description\"] = df[\"Description\"].str.replace(\"'\", '')\ndf.Effects = df.Effects.str.replace(\",\", \", \")\ndf.Flavor = df.Flavor.str.replace(\",\", \", \")\ndf.replace(np.nan, '', inplace=True)",
"_____no_output_____"
],
[
"# sorting the values by the ratings\ndf1 = df1.sort_values(by=['Rating'], ascending=False)",
"_____no_output_____"
],
[
"df1 = df1.dropna().reset_index().drop(columns=['index']).reset_index()",
"_____no_output_____"
],
[
"# df1 = df1.reset_index()",
"_____no_output_____"
],
[
"df1.head()",
"_____no_output_____"
],
[
"# checking the ratings values\ndf1['Rating'].min(), df1['Rating'].max(), len(df1['Rating'])",
"_____no_output_____"
],
[
"df1.dtypes",
"_____no_output_____"
],
[
"df1.head(1)",
"_____no_output_____"
],
[
"df1.to_csv('cannabis_new')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c516b13d862412a3313378f778b4771a5cf7232b
| 277,510 |
ipynb
|
Jupyter Notebook
|
Lab_2.ipynb
|
gdg-ml-team/ioExtended
|
c7ba682e61275b3119096a264a0d97749b763468
|
[
"MIT"
] | 2 |
2019-06-22T10:17:55.000Z
|
2019-06-22T10:22:53.000Z
|
Lab_2.ipynb
|
gdg-ml-team/ioExtended
|
c7ba682e61275b3119096a264a0d97749b763468
|
[
"MIT"
] | null | null | null |
Lab_2.ipynb
|
gdg-ml-team/ioExtended
|
c7ba682e61275b3119096a264a0d97749b763468
|
[
"MIT"
] | null | null | null | 611.255507 | 138,626 | 0.931988 |
[
[
[
"<a href=\"https://colab.research.google.com/github/gdg-ml-team/ioExtended/blob/master/Lab_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"!pip install -q tensorflow_hub",
"_____no_output_____"
],
[
"from __future__ import absolute_import, division, print_function\n\nimport matplotlib.pylab as plt\n\nimport tensorflow as tf\nimport tensorflow_hub as hub\n\nfrom tensorflow.keras import layers\n\ntf.VERSION",
"_____no_output_____"
],
[
"data_root = tf.keras.utils.get_file(\n 'flower_photos','https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',\n untar=True)",
"_____no_output_____"
],
[
"image_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1/255)\nimage_data = image_generator.flow_from_directory(str(data_root))",
"Found 3670 images belonging to 5 classes.\n"
],
[
"for image_batch,label_batch in image_data:\n print(\"Image batch shape: \", image_batch.shape)\n print(\"Labe batch shape: \", label_batch.shape)\n break",
"Image batch shape: (32, 256, 256, 3)\nLabe batch shape: (32, 5)\n"
],
[
"classifier_url = \"https://tfhub.dev/google/imagenet/mobilenet_v2_100_224/classification/2\" #@param {type:\"string\"}",
"_____no_output_____"
],
[
"def classifier(x):\n classifier_module = hub.Module(classifier_url)\n return classifier_module(x)\n \nIMAGE_SIZE = hub.get_expected_image_size(hub.Module(classifier_url))",
"_____no_output_____"
],
[
"classifier_layer = layers.Lambda(classifier, input_shape = IMAGE_SIZE+[3])\nclassifier_model = tf.keras.Sequential([classifier_layer])\nclassifier_model.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nlambda_1 (Lambda) (None, 1001) 0 \n=================================================================\nTotal params: 0\nTrainable params: 0\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"image_data = image_generator.flow_from_directory(str(data_root), target_size=IMAGE_SIZE)\nfor image_batch,label_batch in image_data:\n print(\"Image batch shape: \", image_batch.shape)\n print(\"Labe batch shape: \", label_batch.shape)\n break",
"Found 3670 images belonging to 5 classes.\nImage batch shape: (32, 224, 224, 3)\nLabe batch shape: (32, 5)\n"
],
[
"import tensorflow.keras.backend as K\nsess = K.get_session()\ninit = tf.global_variables_initializer()\n\nsess.run(init)",
"_____no_output_____"
],
[
"import numpy as np\nimport PIL.Image as Image\n\ngrace_hopper = tf.keras.utils.get_file('image.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg')\ngrace_hopper = Image.open(grace_hopper).resize(IMAGE_SIZE)\ngrace_hopper ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"grace_hopper = np.array(grace_hopper)/255.0\ngrace_hopper.shape",
"_____no_output_____"
],
[
"result = classifier_model.predict(grace_hopper[np.newaxis, ...])\nresult.shape",
"_____no_output_____"
],
[
"predicted_class = np.argmax(result[0], axis=-1)\npredicted_class",
"_____no_output_____"
],
[
"labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')\nimagenet_labels = np.array(open(labels_path).read().splitlines())",
"_____no_output_____"
],
[
"plt.imshow(grace_hopper)\nplt.axis('off')\npredicted_class_name = imagenet_labels[predicted_class]\n_ = plt.title(\"Prediction: \" + predicted_class_name)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c516b84ef25e0c725f7e9344b73e0f4a056c7d91
| 22,602 |
ipynb
|
Jupyter Notebook
|
12.elemzes/elemzes.ipynb
|
mittelholcz/python2020
|
13b223eb77edfdc61be678052e65570e4a7abc0f
|
[
"ECL-2.0"
] | null | null | null |
12.elemzes/elemzes.ipynb
|
mittelholcz/python2020
|
13b223eb77edfdc61be678052e65570e4a7abc0f
|
[
"ECL-2.0"
] | null | null | null |
12.elemzes/elemzes.ipynb
|
mittelholcz/python2020
|
13b223eb77edfdc61be678052e65570e4a7abc0f
|
[
"ECL-2.0"
] | 1 |
2021-02-11T20:08:19.000Z
|
2021-02-11T20:08:19.000Z
| 33.484444 | 496 | 0.555393 |
[
[
[
"# e-magyar elemzés\n\n---\n\n(2021. 04. 16.)\n\nMittelholcz Iván",
"_____no_output_____"
],
[
"## 1. Az e-magyar használata",
"_____no_output_____"
],
[
"Az elemzendő szöveg:",
"_____no_output_____"
]
],
[
[
"!cat orkeny.txt",
"_____no_output_____"
]
],
[
[
"Az e-magyar legfrissebb verziójának letöltése:",
"_____no_output_____"
]
],
[
[
"!docker pull mtaril/emtsv:latest",
"_____no_output_____"
]
],
[
[
"Az *orkeny.txt* elemzése, az eredmény kiírása az *orkény.tsv* fájlba:",
"_____no_output_____"
]
],
[
[
"!docker run --rm -i mtaril/emtsv:latest tok,morph,pos,ner,conv-morph,dep <orkeny.txt >orkeny.tsv",
"_____no_output_____"
]
],
[
[
"Magyarázatok:\n\n- `!docker run --rm -i mtaril/emtsv:latest`: Az *e-magyar* futtatása\n- `tok,morph,pos,ner`: a használt modulok felsorolása\n - `tok`: tokenizálás\n - `morph`: morfológiai elemzés\n - `pos`: szófaji egyértelműsítés\n - `ner`: névelem felismerés\n- `<orkeny.txt`: Az elemzendő szöveg beolvasása az *orkeny.txt* fájlból.\n- `>orkeny.tsv`: Az elemzés kiírása az *orkeny.tsv* fájlba.",
"_____no_output_____"
],
[
"## 2. Az elemzés beolvasása *pandas DataFrame*-be\n\nA TSV fájl beolvasásánál használt új paraméterek:\n\n- `dtype=str`: A stringet tartalmazó cellákat alapból is stringnek szokta értelmezni a pandas, de ha biztosra akarunk menni, nem árt, ha kifejezetten megkérjük erre.\n- `keep_default_na=False`: Ha ezt *False*-ra állítjuk, meghagyja az üres stringeket üres stringeknek és nem fogja azokat *NaN*-ként értelmezni. Ez a *wsafter* sor helyes beolvasásához kell.\n- `skip_blank_lines=False`: A *Pandas* alapból átugorja az üres sorokat. Az e-magyar viszont az üres sorokat használja a mondatok elhatárolására, ezért meg kell mondani a *Pandas*-nak, hogy ne dobja ki az üres sorokat.\n\nRészleteket a `df.read_csv()` [dokumentációjában](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html).",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndf = pd.read_csv('orkeny.tsv', sep='\\t', dtype=str, keep_default_na=False, skip_blank_lines=False)\ndf.head(50)",
"_____no_output_____"
]
],
[
[
"Oszlopok:\n\n- *form*: A tokenizáló modul (*tok*) kimenete. A szövegben található tokeneket (szóalakokat, írásjeleket) tartalmazza.\n- *wsafter*: Szintén a tokenizáló kimenete. A tokenek után található *whitespace* karaktereket tartalmazza.\n- *anas*: A morfológiai elemző kimenete (*morph*). Szögletes zárójelpáron belül tartalmazza a lehetséges morfológiai elemzések listáját. Használt morfológiai kódok leírása [itt](https://e-magyar.hu/hu/textmodules/emmorph_codelist).\n- *lemma*: A szófaji egyértelműsítő kimenete (*pos*). A legvalószínűbb morfológiai elemzéshez tartozó lemmát tartalmazza. \n- *xpostag*: Szintén a szófaji egyértelműsítő kimenete (*pos*). A legvalószínűbb morfológiai elemzést tartalmazza. \n- *NER-BIO*: A tulajdonnév felismerő modul kimenete (*ner*). Leírása [itt](https://e-magyar.hu/hu/textmodules/emner).",
"_____no_output_____"
],
[
"## 3. Elemzesek\n\n\n### 3.1. Felhasználási esetek\n\n#### Feladatok, amikhez egyszerre elég egy sort (*row*) figyelembe venni\n\n- Szűrni bizonyos pos-tagekre, pl. keressük a múltidejű igéket.\n- Adott lemmahalmaz múltidejű előfordulásai.\n- Több morfológiai jegy figyelembevétele: pl. adott lemmahalmaz múltidejű előfordulásai egyeszám elsőszemélyben ill. többesszám elsőszemélyben.\n\nA végén számolni kéne ezeket: az összes tokenszámhoz, vagy szószámhoz, vagy az összes igéhez képest milyen arányban fordulnak elő ezek az alakok.\n\n#### Feladatok, amikhez több sort kell figyelembe venni\n\n- Van-e személyes névmás az ige mellett? Pl. \"éldegéltem\" vs. \"én éldegéltem\".\n- Főnévnek van-e jelzője?\n- Igének van-e határozószava?\n- Tagmondat szintű elemzés: keressük azon tagmondatokat, amikben van kötőszó, de nincs múltidejű igealak.\n\nEzeket megint arányítani kell: az összes főnévből mennyinek van jelzője, az összes igéből mennyinek van határozója.\n\n#### Feladatok, amikhez az eredeti szöveget kell módosítani\n\n- Potenciálisan többszavas kifejezések keresése ([emterm](https://github.com/dlt-rilmta/emterm)!).\n- Szövegbe visszaírni elemzések eredményét XML-szerűen, pl. <érzelmi_kifejezés>...</érzelmi_kifejezés>",
"_____no_output_____"
],
[
"### 3.2. Egy soros feladatok megoldása",
"_____no_output_____"
]
],
[
[
"# multideju igek aranya\n\ndef is_not_punct(row):\n pos = row['xpostag']\n return not pos.startswith('[Punct]')\n\ndef is_verb(row):\n pos = row['xpostag']\n return pos.startswith('[/V]')\n\ndef is_past_verb(row):\n pos = row['xpostag']\n return pos.startswith('[/V][Pst.')\n\nmask0 = df.apply(is_not_punct, axis=1)\nmask1 = df.apply(is_verb, axis=1)\nmask2 = df.apply(is_past_verb, axis=1)\n\ncount_word = len(df[mask0])\ncount_verb = len(df[mask1])\ncount_past_verb = len(df[mask2])\n\nprint('multideju igek / osszes token: ', count_past_verb/len(df))\nprint('multideju igek / osszes szo: ', count_past_verb/count_word)\nprint('multideju igek / osszes ige: ', count_past_verb/count_verb)\ndf[mask2]",
"_____no_output_____"
],
[
"# egyesszam 3. szemelyu igek\n\ndef is_3sg_verb(row):\n pos = row['xpostag']\n return pos.startswith('[/V]') and '3Sg' in pos\n\nmask3 = df.apply(is_3sg_verb, axis=1)\n\ncount_3sg_verb = len(df[mask3])\n\nprint('3sg igek / osszes token: ', count_3sg_verb/len(df))\nprint('3sg igek / osszes szo: ', count_3sg_verb/count_word)\nprint('3sg igek / osszes ige: ', count_3sg_verb/count_verb)\ndf[mask3]",
"_____no_output_____"
],
[
"# adott lemmahalmaz keresése\n\ndef is_lemma_in_set(row):\n lemma = row['lemma']\n lemmaset = {'iszik', 'van'}\n pos = row['xpostag']\n is_in_lemmaset = lemma in lemmaset\n is_3sg = '3Sg' in pos\n return is_in_lemmaset and is_3sg\n\nmask4 = df.apply(is_lemma_in_set, axis=1)\n\ncount_lemmaset = len(df[mask4])\n\nprint('halmazban levo igek / osszes token: ', count_lemmaset/len(df))\nprint('halmazban levo igek / osszes szo: ', count_lemmaset/count_word)\nprint('halmazban levo igek / osszes ige: ', count_lemmaset/count_verb)\n\ndf[mask4]",
"_____no_output_____"
]
],
[
[
"### 3.3. Több soros feladatok megoldása\n\nAlgoritmus: Ha csak egy elem távolságba kell ellátni, akkor érdemes egy segédváltozóban eltárolni a ciklus előző elemének az értékét, vagy a vele kapcsolatos feltétel értékét.",
"_____no_output_____"
]
],
[
[
"# Rávezetés 1.: Keressük a maganhángzóval kezdődő gyümölcsöket.\n# elvárt eredmény: ['alma', 'eper']\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\nresult = []\nfor word in l:\n if word[0] in {'a', 'e', 'i', 'o', 'u'}:\n result.append(word)\nprint(result)",
"_____no_output_____"
],
[
"# Rávezetés 2.: Menjünk végig egy listán úgy, hogy az aktuális elem mellett írjuk ki az előzőt is.\n# Az első sorban az előző elem hiányozni fog.\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\nprevious = ''\nfor current in l:\n print(previous, current)\n previous = current # a ciklusmag végén mindig frissítjük az előző elemet az aktuálissal",
"_____no_output_____"
],
[
"# Rávezetés 3.: Keressük azokat a gyümölcsöket, amik magánhangzóval kezdődő gyümölcs után következnek.\n# elvárt eredmény: ['barack', 'fuge']\n# A segédváltozóban nem az előző elemet tároljuk, csak azt, hogy az előző elem magánhangzóval kezdődőtt-e.\n\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\nresult = []\nprevious_startswith_vowel = False\nfor current in l:\n if previous_startswith_vowel:\n result.append(current)\n previous_startswith_vowel = current[0] in {'a', 'e', 'i', 'o', 'u'}\nprint(result)",
"_____no_output_____"
]
],
[
[
"Hogy a fentieket alkalmazni tudjuk *DataFrame* esetében is, ahhoz végig kell tudnunk iterálni a *DataFrame* sorain. Ezt az [`.iterrows()`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iterrows.html) metódust használva tudjuk megtenni. A metódus minden sort egy *tuple*-ként ad vissza, aminek az első eleme az *index* (sorszám), a második a sor maga, mint [*Series*](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html#pandas.Series).",
"_____no_output_____"
]
],
[
[
"# Van-e névelő a főnév előtt?\n\ndef is_noun(row):\n return row['xpostag'].startswith('[/N')\n\nmask5 = df.apply(is_noun, axis=1)\n\nmask6 = []\nis_prev_article = False\nfor index, row in df.iterrows():\n is_current_noun = row['xpostag'].startswith('[/N')\n mask6.append(is_current_noun and is_prev_article)\n is_prev_article = row['xpostag'] in {'[/Det|Art.Def]', '[/Det|Art.NDef]'}\n\nprint('névelős főnév / összes főnév: ', len(df[mask6])/len(df[mask5]))\n \n#df['noun_with_article'] = mask5\n#df.head(50)\ndf[mask6]",
"_____no_output_____"
]
],
[
[
"Algoritmus: Ha nem csak a szomszédos elemet kell látnunk, hanem elemet is, akkor érdemes egy *ablakkal* (*frame*-mel) végigmenni a listán.",
"_____no_output_____"
]
],
[
[
"# Rávezetés 1.: Menjünk végig egy 3 elemet tartalmazó ablakkal a listán.\n\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\nlength = 3\nframe = []\n\nfor i in l:\n frame.append(i)\n if len(frame) < length: # meg tul rovid a frame\n continue\n if len(frame) > length: # mar tul hosszu a frame\n frame.pop(0)\n print(frame)",
"_____no_output_____"
],
[
"# Rávezetés 2.: Ál-elemekkel kiegészített lista.\n# Ha a frame-ek első elemei vizsgáljuk (mert arra vagyunk kíváncsiak, van-e utána olyan, ami érdekes),\n# akkor a fenti módon sosem jutunk oda, hogy az 'eper' vagy a 'füge' első elem legyen.\n# Ha a frame-ek utolsó elemeit vizsgáljuk (mert arra vagyunk kíváncsiak, van-e előtte olyan, ami érdekes),\n# akkor a fenti módon sosem jutunk oda, hogy az 'alma' vagy a 'barack' utolsó elem legyen.\n# Az első esetben a lista végét kell kiegészíteni álelemekkel (None),\n# a második esetben a lista elejére kell álelemeket beszúrni.\n\n\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\n# álelemek a lista végén\nlength = 3\nframe = []\n\nfor i in l + [None]*(length-1):\n frame.append(i)\n if len(frame) < length: # meg tul rovid a frame\n continue\n if len(frame) > length: # mar tul hosszu a frame\n frame.pop(0)\n print(frame)\n\nprint('--------')\n\n# álelemek a lista elején\nlength = 3\nframe = []\n\nfor i in [None]*(length-1) + l:\n frame.append(i)\n if len(frame) < length: # meg tul rovid a frame\n continue\n if len(frame) > length: # mar tul hosszu a frame\n frame.pop(0)\n print(frame)",
"_____no_output_____"
],
[
"# Rávezetés 3.: Keressük azokat az elemeket, amik után az első vagy második elem magánhangzóval kezdődik.\n# Az aktuális elemtől jobbra keresünk bizonyos tulajdonságú elemeket --> a listát jobbról egészítjük ki álelemekkel.\n\nl = ['alma', 'barack', 'citrom', 'dinnye', 'eper', 'füge']\n\nlength = 3\nframe = []\nvowels = {'a', 'e', 'i', 'o', 'u'}\n\nresult = []\nfor i in l + [None] * (length -1):\n frame.append(i)\n if len(frame) < length:\n continue\n if len(frame) > length:\n frame.pop(0)\n for x in frame[1:]:\n if x is None: # ha None-ba botlunk, akkor skippeljük\n continue\n if x[0] in vowels:\n result.append(frame[0])\n \nprint(result)",
"_____no_output_____"
],
[
"# Feladat: keressük az igekötők után lévő igéket.\n# Az eredményből csak az ('El', 'patkoltak') pár lesz a jó. Finomítás később.\n\nlength = 10\nframe = []\nresult = []\nmylist = [row for index, row in df.iterrows()] + [None] * (length - 1)\n\n# vegigmegyunk az álelemekkel kiegészített sorokon\nfor row in mylist:\n # frissitjuk a frame-et\n frame.append(row)\n if len(frame) < length:\n continue\n if len(frame) > length:\n frame.pop(0)\n # igekoto-e az elso elem? Ha igen, akkor megnezzuk, hogy utana valamelyik szo ige-e\n if frame[0]['xpostag'] == '[/Prev]':\n for frow in frame[1:]: # A frame-beli sorokat frow-nak nevezzuk el.\n if frow is None:\n continue\n if frow['xpostag'].startswith('[/V]'):\n # iget talaltunk, igekotot + iget hozzaadjuk az eredmenyhez\n result.append((frame[0]['form'], frow['form']))\n break # megvan az ige, abbahagyjuk a keresest\nprint(result)",
"_____no_output_____"
],
[
"# Finomítás: Mondathatár után ne keressünk igét, mert az biztos nem az előző mondat igekötőjéhez fog tartozni.\n# A mondathatárt a TSV üres sora jelöli. Ez a dataframe-ben olyan sor lesz, amiben minden cella egy üres string.\n# (Elég a \"form\" cellát ellenőrizni, az nem lehet üres.)\n# Az eredményekből a ('meg', 'akadt') pár még mindig rossz. Ezt a frame rövidebbre vételével lehet kiszűrni.\n\nlength = 10\nframe = []\nresult = []\nmylist = [row for index, row in df.iterrows()] + [None] * (length - 1)\n\n# vegigmegyunk az álelemekkel kiegészített sorokon\nfor row in mylist:\n # frissitjuk a frame-et\n frame.append(row)\n if len(frame) < length:\n continue\n if len(frame) > length:\n frame.pop(0)\n # igekoto-e az elso elem? Ha igen, akkor megnezzuk, hogy utana valamelyik szo ige-e\n if frame[0]['xpostag'] == '[/Prev]':\n for frow in frame[1:]:\n if frow is None:\n continue\n # Mondathatár vizsgálata: ha a form nem tartalmaz semmit, akkor utána új mondat jön.\n if len(frow['form']) == 0:\n break\n if frow['xpostag'].startswith('[/V]'):\n # iget talaltunk, igekotot + iget hozzaadjuk az eredmenyhez\n result.append((frame[0]['form'], frow['form']))\n break # megvan az ige, abbahagyjuk a keresest\nprint(result)",
"_____no_output_____"
],
[
"# Finomítás: A feladat ugyan az, mint az elobb, de most uj oszlopot csinalunk a dataframe-nek.\n# Az uj oszlop default egy kotojelet tartalmaz, de az igekotoknel a feltetelezett iget irjuk bele.\n\nlength = 3\nframe = []\nresult = []\nmylist = [row for i, row in df.iterrows()] + [None] * (length - 1)\n\nfor row in mylist:\n frame.append(row)\n if len(frame) < length:\n continue\n if len(frame) > length:\n frame.pop(0)\n res = '-'\n if frame[0]['xpostag'] == '[/Prev]':\n for frow in frame[1:]:\n if frow is None:\n continue\n if len(frow['form']) == 0:\n continue\n if frow['xpostag'].startswith('[/V]'):\n res = frow['lemma']\n break\n result.append(res)\n\ndf['preverb'] = result\n# kiirjuk a kerdeses reszt\ndf.iloc[120:128, :]",
"_____no_output_____"
]
],
[
[
"### 3.4. Elemzés visszaírása az eredeti szövegbe",
"_____no_output_____"
]
],
[
[
"# eredeti szöveg kiírása:\n# - minden sor 'form' és 'wsafter' celláját összeragasztjuk és hozzáadjuk ez eredmény listához\n# - az eredmény lista elemeit a join metódussal egyesítjük egyetlen szöveggé\n# - a szövegben lévő '\\\\n'-eket lecseréljük igazi sortörésekre \n\ntext = []\nfor index, row in df.iterrows():\n text.append(row['form'] + row['wsafter'])\ntext = ''.join(text)\ntext = text.replace('\\\\n', '\\n')\nprint(text)",
"_____no_output_____"
],
[
"# Feladat: NER-BIO oszlop xml-esítése.\n# Itt is a form és wsafter cellákat ragasztjuk össze és adjuk egy listához, de nézzük a ner cellákat is.\n# - ha egy ner cella B-vel kezdődik (pl. B-ORG), akkor nyitunk egy <ORG> címkét és csak utána írjuk a form cellát.\n# - ha egy ner cella E-vel kezdődik (pl. E-ORG), akkor a form cella után lezárjuk a címkét (</ORG>)\n# - a szövegben nincs példa az egy elemű címkékre (pl. 1-ORG), de azt is kezeljük\n\ntext = []\nfor index, row in df.iterrows():\n form = row['form']\n ws = row['wsafter']\n ner = row['NER-BIO']\n if ner.startswith('B'):\n # named entity kezdodik, xml tag-et nyitunk:\n form = f'<{ner[2:]}>{form}'\n elif ner.startswith('E'):\n # named entity vegzodik, xml tag-et zarunk:\n form = f'{form}</{ner[2:]}>'\n elif ner.startswith('1'):\n # egy elemu named entity, xml tag-ebe tesszuk:\n form = f'<{ner[2:]}>{form}</{ner[2:]}>'\n text.append(form+ws)\ntext = ''.join(text)\ntext = text.replace('\\\\n', '\\n')\nprint(text)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c516c504428242b4583344d792047d4a844ec6aa
| 65,662 |
ipynb
|
Jupyter Notebook
|
mnist_classification.ipynb
|
SanghunOh/test_deeplearning
|
27d05d3a9758f7f54c933c7e9cb8c0052372f70c
|
[
"Apache-2.0"
] | null | null | null |
mnist_classification.ipynb
|
SanghunOh/test_deeplearning
|
27d05d3a9758f7f54c933c7e9cb8c0052372f70c
|
[
"Apache-2.0"
] | null | null | null |
mnist_classification.ipynb
|
SanghunOh/test_deeplearning
|
27d05d3a9758f7f54c933c7e9cb8c0052372f70c
|
[
"Apache-2.0"
] | 1 |
2021-08-13T04:29:54.000Z
|
2021-08-13T04:29:54.000Z
| 97.133136 | 22,350 | 0.768131 |
[
[
[
"<a href=\"https://colab.research.google.com/github/SanghunOh/test_deeplearning/blob/main/mnist_classification.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras.datasets.mnist import load_data",
"_____no_output_____"
],
[
"(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz')\nx_train.shape, y_train.shape, x_test.shape, y_test.shape",
"_____no_output_____"
],
[
"# y_train[4], x_train[4],\ny_train[50000], x_train[50000]",
"_____no_output_____"
],
[
"# x_train[50000]/255",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nplt.imshow(x_train[50000])\nprint(y_train[50000], type(y_train[50000]))",
"3 <class 'numpy.uint8'>\n"
],
[
"x_train = x_train.reshape(-1,28*28) / 255\nx_train.shape",
"_____no_output_____"
],
[
"x_test = x_test.reshape(-1, 28*28) / 255\nx_test.shape",
"_____no_output_____"
],
[
"y_train[2:10], y_train.shape",
"_____no_output_____"
],
[
"import numpy as np\nnp.unique(y_train)",
"_____no_output_____"
]
],
[
[
"# apply model ",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf",
"_____no_output_____"
],
[
"model = tf.keras.models.Sequential()\n\nmodel.add(tf.keras.Input(shape=(784,))) # input layer\nmodel.add(tf.keras.layers.Dense(64, activation='relu')) # hidden layer\nmodel.add(tf.keras.layers.Dense(64, activation='relu')) # hidden layer\n# 3이상 --> softmax, binary --> sigmoid\nmodel.add(tf.keras.layers.Dense(10, activation='softmax')) # output layer \n\n# regression --> loss : mse\n# binary classification --> loss : binary crossentropy\n# over 3 classification --> loss : categorical crossentropy(sparse_categorical_crossentropy)\nmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])",
"WARNING:tensorflow:Please add `keras.layers.InputLayer` instead of `keras.Input` to Sequential model. `keras.Input` is intended to be used by Functional model.\n"
],
[
"hist = model.fit(x_train, y_train, epochs=100, validation_split=0.3)",
"_____no_output_____"
]
],
[
[
"# evaluation",
"_____no_output_____"
]
],
[
[
"hist.history.keys()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n\nplt.plot(hist.history['loss'])\nplt.plot(hist.history['val_loss'], 'b-')\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(hist.history['acc'])\nplt.plot(hist.history['val_acc'], 'r-')\nplt.show()",
"_____no_output_____"
]
],
[
[
"# service",
"_____no_output_____"
]
],
[
[
"# x_test[30]",
"_____no_output_____"
],
[
"import numpy as np\n# np.set_printoptions(precision=8)\n\npred = model.predict(x_test[30:31])\npred, np.argmax(pred)",
"_____no_output_____"
],
[
"model.save('./model_save')",
"INFO:tensorflow:Assets written to: ./model_save/assets\n"
],
[
"model.save('./model_save01.h5')",
"_____no_output_____"
],
[
"model_load = tf.keras.models.load_model('./model_save01.h5')\nmodel_load",
"_____no_output_____"
],
[
"load_pred = model_load.predict(x_test[30:31])\nload_pred, np.argmax(load_pred)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c516c5bda9eab69e491f38cf1d12cb89860e0f6c
| 35,431 |
ipynb
|
Jupyter Notebook
|
notebooks/02_NumPy.ipynb
|
loftwah/practicalAI
|
25a35683673ff6289c5119916de837d0b8310ba0
|
[
"MIT"
] | 2 |
2020-01-29T06:34:08.000Z
|
2020-03-11T15:09:42.000Z
|
notebooks/02_NumPy.ipynb
|
loftwah/practicalAI
|
25a35683673ff6289c5119916de837d0b8310ba0
|
[
"MIT"
] | 1 |
2022-02-10T06:59:25.000Z
|
2022-02-10T06:59:25.000Z
|
notebooks/02_NumPy.ipynb
|
loftwah/practicalAI
|
25a35683673ff6289c5119916de837d0b8310ba0
|
[
"MIT"
] | 2 |
2019-12-11T11:30:33.000Z
|
2020-05-05T03:28:10.000Z
| 28.758929 | 413 | 0.420677 |
[
[
[
"<a href=\"https://practicalai.me\"><img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/rounded_logo.png\" width=\"100\" align=\"left\" hspace=\"20px\" vspace=\"20px\"></a>\n\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/numpy.png\" width=\"200\" vspace=\"30px\" align=\"right\">\n\n<div align=\"left\">\n<h1>NumPy</h1>\n\nIn this lesson we will learn the basics of numerical analysis using the NumPy package.\n</div>",
"_____no_output_____"
],
[
"<table align=\"center\">\n <td>\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/rounded_logo.png\" width=\"25\"><a target=\"_blank\" href=\"https://practicalai.me\"> View on practicalAI</a>\n </td>\n <td>\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/colab_logo.png\" width=\"25\"><a target=\"_blank\" href=\"https://colab.research.google.com/github/practicalAI/practicalAI/blob/master/notebooks/02_NumPy.ipynb\"> Run in Google Colab</a>\n </td>\n <td>\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/github_logo.png\" width=\"22\"><a target=\"_blank\" href=\"https://github.com/practicalAI/practicalAI/blob/master/notebooks/02_NumPy.ipynb\"> View code on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Set up",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"# Set seed for reproducibility\nnp.random.seed(seed=1234)",
"_____no_output_____"
]
],
[
[
"# Basics",
"_____no_output_____"
],
[
"Let's take a took at how to create tensors with NumPy.\n* **Tensor**: collection of values \n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/tensors.png\" width=\"650\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Scalar\nx = np.array(6) # scalar\nprint (\"x: \", x)\n# Number of dimensions\nprint (\"x ndim: \", x.ndim)\n# Dimensions\nprint (\"x shape:\", x.shape)\n# Size of elements\nprint (\"x size: \", x.size)\n# Data type\nprint (\"x dtype: \", x.dtype)",
"x: 6\nx ndim: 0\nx shape: ()\nx size: 1\nx dtype: int64\n"
],
[
"# Vector\nx = np.array([1.3 , 2.2 , 1.7])\nprint (\"x: \", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype) # notice the float datatype",
"x: [1.3 2.2 1.7]\nx ndim: 1\nx shape: (3,)\nx size: 3\nx dtype: float64\n"
],
[
"# Matrix\nx = np.array([[1,2], [3,4]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)",
"x:\n [[1 2]\n [3 4]]\nx ndim: 2\nx shape: (2, 2)\nx size: 4\nx dtype: int64\n"
],
[
"# 3-D Tensor\nx = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)",
"x:\n [[[1 2]\n [3 4]]\n\n [[5 6]\n [7 8]]]\nx ndim: 3\nx shape: (2, 2, 2)\nx size: 8\nx dtype: int64\n"
]
],
[
[
"NumPy also comes with several functions that allow us to create tensors quickly.",
"_____no_output_____"
]
],
[
[
"# Functions\nprint (\"np.zeros((2,2)):\\n\", np.zeros((2,2)))\nprint (\"np.ones((2,2)):\\n\", np.ones((2,2)))\nprint (\"np.eye((2)):\\n\", np.eye((2))) # identity matrix \nprint (\"np.random.random((2,2)):\\n\", np.random.random((2,2)))",
"np.zeros((2,2)):\n [[0. 0.]\n [0. 0.]]\nnp.ones((2,2)):\n [[1. 1.]\n [1. 1.]]\nnp.eye((2)):\n [[1. 0.]\n [0. 1.]]\nnp.random.random((2,2)):\n [[0.19151945 0.62210877]\n [0.43772774 0.78535858]]\n"
]
],
[
[
"# Indexing",
"_____no_output_____"
],
[
"Keep in mind that when indexing the row and column, indices start at 0. And like indexing with lists, we can use negative indices as well (where -1 is the last item).",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/indexing.png\" width=\"300\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Indexing\nx = np.array([1, 2, 3])\nprint (\"x: \", x)\nprint (\"x[0]: \", x[0])\nx[0] = 0\nprint (\"x: \", x)",
"x: [1 2 3]\nx[0]: 1\nx: [0 2 3]\n"
],
[
"# Slicing\nx = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\nprint (x)\nprint (\"x column 1: \", x[:, 1]) \nprint (\"x row 0: \", x[0, :]) \nprint (\"x rows 0,1 & cols 1,2: \\n\", x[0:2, 1:3]) ",
"[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nx column 1: [ 2 6 10]\nx row 0: [1 2 3 4]\nx rows 0,1 & cols 1,2: \n [[2 3]\n [6 7]]\n"
],
[
"# Integer array indexing\nprint (x)\nrows_to_get = np.array([0, 1, 2])\nprint (\"rows_to_get: \", rows_to_get)\ncols_to_get = np.array([0, 2, 1])\nprint (\"cols_to_get: \", cols_to_get)\n# Combine sequences above to get values to get\nprint (\"indexed values: \", x[rows_to_get, cols_to_get]) # (0, 0), (1, 2), (2, 1)",
"[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nrows_to_get: [0 1 2]\ncols_to_get: [0 2 1]\nindexed values: [ 1 7 10]\n"
],
[
"# Boolean array indexing\nx = np.array([[1, 2], [3, 4], [5, 6]])\nprint (\"x:\\n\", x)\nprint (\"x > 2:\\n\", x > 2)\nprint (\"x[x > 2]:\\n\", x[x > 2])",
"x:\n [[1 2]\n [3 4]\n [5 6]]\nx > 2:\n [[False False]\n [ True True]\n [ True True]]\nx[x > 2]:\n [3 4 5 6]\n"
]
],
[
[
"# Arithmetic\n",
"_____no_output_____"
]
],
[
[
"# Basic math\nx = np.array([[1,2], [3,4]], dtype=np.float64)\ny = np.array([[1,2], [3,4]], dtype=np.float64)\nprint (\"x + y:\\n\", np.add(x, y)) # or x + y\nprint (\"x - y:\\n\", np.subtract(x, y)) # or x - y\nprint (\"x * y:\\n\", np.multiply(x, y)) # or x * y",
"x + y:\n [[2. 4.]\n [6. 8.]]\nx - y:\n [[0. 0.]\n [0. 0.]]\nx * y:\n [[ 1. 4.]\n [ 9. 16.]]\n"
]
],
[
[
"### Dot product",
"_____no_output_____"
],
[
"One of the most common NumPy operations we’ll use in machine learning is matrix multiplication using the dot product. We take the rows of our first matrix (2) and the columns of our second matrix (2) to determine the dot product, giving us an output of `[2 X 2]`. The only requirement is that the inside dimensions match, in this case the frist matrix has 3 columns and the second matrix has 3 rows. \n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/dot.gif\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Dot product\na = np.array([[1,2,3], [4,5,6]], dtype=np.float64) # we can specify dtype\nb = np.array([[7,8], [9,10], [11, 12]], dtype=np.float64)\nc = a.dot(b)\nprint (f\"{a.shape} · {b.shape} = {c.shape}\")\nprint (c)",
"(2, 3) · (3, 2) = (2, 2)\n[[ 58. 64.]\n [139. 154.]]\n"
]
],
[
[
"### Axis operations",
"_____no_output_____"
],
[
"We can also do operations across a specific axis.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/axis.gif\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Sum across a dimension\nx = np.array([[1,2],[3,4]])\nprint (x)\nprint (\"sum all: \", np.sum(x)) # adds all elements\nprint (\"sum axis=0: \", np.sum(x, axis=0)) # sum across rows\nprint (\"sum axis=1: \", np.sum(x, axis=1)) # sum across columns",
"[[1 2]\n [3 4]]\nsum all: 10\nsum axis=0: [4 6]\nsum axis=1: [3 7]\n"
],
[
"# Min/max\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"min: \", x.min())\nprint (\"max: \", x.max())\nprint (\"min axis=0: \", x.min(axis=0))\nprint (\"min axis=1: \", x.min(axis=1))",
"min: 1\nmax: 6\nmin axis=0: [1 2 3]\nmin axis=1: [1 4]\n"
]
],
[
[
"### Broadcasting",
"_____no_output_____"
],
[
"Here, we’re adding a vector with a scalar. Their dimensions aren’t compatible as is but how does NumPy still gives us the right result? This is where broadcasting comes in. The scalar is *broadcast* across the vector so that they have compatible shapes.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/broadcasting.png\" width=\"300\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Broadcasting\nx = np.array([1,2]) # vector\ny = np.array(3) # scalar\nz = x + y\nprint (\"z:\\n\", z)",
"z:\n [4 5]\n"
]
],
[
[
"# Advanced",
"_____no_output_____"
],
[
"### Transposing",
"_____no_output_____"
],
[
"We often need to change the dimensions of our tensors for operations like the dot product. If we need to switch two dimensions, we can transpose \nthe tensor.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/transpose.png\" width=\"400\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Transposing\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.transpose(x, (1,0)) # flip dimensions at index 0 and 1\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)",
"x:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny:\n [[1 4]\n [2 5]\n [3 6]]\ny.shape: (3, 2)\n"
]
],
[
[
"### Reshaping",
"_____no_output_____"
],
[
"Sometimes, we'll need to alter the dimensions of the matrix. Reshaping allows us to transform a tensor into different permissible shapes -- our reshaped tensor has the same amount of values in the tensor. (1X6 = 2X3). We can also use `-1` on a dimension and NumPy will infer the dimension based on our input tensor.\n\nThe way reshape works is by looking at each dimension of the new tensor and separating our original tensor into that many units. So here the dimension at index 0 of the new tensor is 2 so we divide our original tensor into 2 units, and each of those has 3 values.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape.png\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Reshaping\nx = np.array([[1,2,3,4,5,6]])\nprint (x)\nprint (\"x.shape: \", x.shape)\ny = np.reshape(x, (2, 3))\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape)\nz = np.reshape(x, (2, -1))\nprint (\"z: \\n\", z)\nprint (\"z.shape: \", z.shape)",
"[[1 2 3 4 5 6]]\nx.shape: (1, 6)\ny: \n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\nz: \n [[1 2 3]\n [4 5 6]]\nz.shape: (2, 3)\n"
]
],
[
[
"### Unintended reshaping",
"_____no_output_____"
],
[
"Though reshaping is very convenient to manipulate tensors, we must be careful of their pitfalls as well. Let's look at the example below. Suppose we have `x`, which has the shape `[2 X 3 X 4]`. \n```\n[[[ 1 1 1 1]\n [ 2 2 2 2]\n [ 3 3 3 3]]\n [[10 10 10 10]\n [20 20 20 20]\n [30 30 30 30]]]\n```\nWe want to reshape x so that it has shape `[3 X 8]` which we'll get by moving the dimension at index 0 to become the dimension at index 1 and then combining the last two dimensions. But when we do this, we want our output \n\nto look like:\n✅\n```\n[[ 1 1 1 1 10 10 10 10]\n [ 2 2 2 2 20 20 20 20]\n [ 3 3 3 3 30 30 30 30]]\n```\nand not like:\n❌\n```\n[[ 1 1 1 1 2 2 2 2]\n [ 3 3 3 3 10 10 10 10]\n [20 20 20 20 30 30 30 30]]\n ```\neven though they both have the same shape `[3X8]`.",
"_____no_output_____"
]
],
[
[
"x = np.array([[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],\n [[10, 10, 10, 10], [20, 20, 20, 20], [30, 30, 30, 30]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)",
"x:\n [[[ 1 1 1 1]\n [ 2 2 2 2]\n [ 3 3 3 3]]\n\n [[10 10 10 10]\n [20 20 20 20]\n [30 30 30 30]]]\nx.shape: (2, 3, 4)\n"
]
],
[
[
"When we naively do a reshape, we get the right shape but the values are not what we're looking for.",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape_wrong.png\" width=\"600\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Unintended reshaping\nz_incorrect = np.reshape(x, (x.shape[1], -1))\nprint (\"z_incorrect:\\n\", z_incorrect)\nprint (\"z_incorrect.shape: \", z_incorrect.shape)",
"z_incorrect:\n [[ 1 1 1 1 2 2 2 2]\n [ 3 3 3 3 10 10 10 10]\n [20 20 20 20 30 30 30 30]]\nz_incorrect.shape: (3, 8)\n"
]
],
[
[
"Instead, if we transpose the tensor and then do a reshape, we get our desired tensor. Transpose allows us to put our two vectors that we want to combine together and then we use reshape to join them together.\nAlways create a dummy example like this when you’re unsure about reshaping. Blindly going by the tensor shape can lead to lots of issues downstream.",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/practicalAI/images/master/images/02_Numpy/reshape_right.png\" width=\"600\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Intended reshaping\ny = np.transpose(x, (1,0,2))\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)\nz_correct = np.reshape(y, (y.shape[0], -1))\nprint (\"z_correct:\\n\", z_correct)\nprint (\"z_correct.shape: \", z_correct.shape)",
"y:\n [[[ 1 1 1 1]\n [10 10 10 10]]\n\n [[ 2 2 2 2]\n [20 20 20 20]]\n\n [[ 3 3 3 3]\n [30 30 30 30]]]\ny.shape: (3, 2, 4)\nz_correct:\n [[ 1 1 1 1 10 10 10 10]\n [ 2 2 2 2 20 20 20 20]\n [ 3 3 3 3 30 30 30 30]]\nz_correct.shape: (3, 8)\n"
]
],
[
[
"### Adding/removing dimensions",
"_____no_output_____"
],
[
"We can also easily add and remove dimensions to our tensors and we'll want to do this to make tensors compatible for certain operations.",
"_____no_output_____"
]
],
[
[
"# Adding dimensions\nx = np.array([[1,2,3],[4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.expand_dims(x, 1) # expand dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are added",
"x:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny: \n [[[1 2 3]]\n\n [[4 5 6]]]\ny.shape: (2, 1, 3)\n"
],
[
"# Removing dimensions\nx = np.array([[[1,2,3]],[[4,5,6]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.squeeze(x, 1) # squeeze dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are gone",
"x:\n [[[1 2 3]]\n\n [[4 5 6]]]\nx.shape: (2, 1, 3)\ny: \n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\n"
]
],
[
[
"# Additional resources",
"_____no_output_____"
],
[
"* **NumPy reference manual**: We don't have to memorize anything here and we will be taking a closer look at NumPy in the later lessons. If you want to learn more checkout the [NumPy reference manual](https://docs.scipy.org/doc/numpy-1.15.1/reference/).",
"_____no_output_____"
],
[
"---\n<div align=\"center\">\n\nSubscribe to our <a href=\"https://practicalai.me/#newsletter\">newsletter</a> and follow us on social media to get the latest updates!\n\n<a class=\"ai-header-badge\" target=\"_blank\" href=\"https://github.com/practicalAI/practicalAI\">\n <img src=\"https://img.shields.io/github/stars/practicalAI/practicalAI.svg?style=social&label=Star\"></a> \n <a class=\"ai-header-badge\" target=\"_blank\" href=\"https://www.linkedin.com/company/practicalai-me\">\n <img src=\"https://img.shields.io/badge/style--5eba00.svg?label=LinkedIn&logo=linkedin&style=social\"></a> \n <a class=\"ai-header-badge\" target=\"_blank\" href=\"https://twitter.com/practicalAIme\">\n <img src=\"https://img.shields.io/twitter/follow/practicalAIme.svg?label=Follow&style=social\">\n </a>\n </div>\n\n</div>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
c516c973a2cd79c2ab877671dc8267fa62fd5afb
| 8,141 |
ipynb
|
Jupyter Notebook
|
Kaggle Courses/Intro to Machine Learning/exercise-underfitting-and-overfitting.ipynb
|
stevekwon211/SteveKwon-Kaggle-Struggle
|
306c53df67ff1b20b9d097e9737d2fd95576ccea
|
[
"Apache-2.0"
] | 1 |
2021-01-26T06:08:28.000Z
|
2021-01-26T06:08:28.000Z
|
Kaggle Courses/Intro to Machine Learning/exercise-underfitting-and-overfitting.ipynb
|
stevekwon211/SteveKwon-Kaggle-Struggle
|
306c53df67ff1b20b9d097e9737d2fd95576ccea
|
[
"Apache-2.0"
] | null | null | null |
Kaggle Courses/Intro to Machine Learning/exercise-underfitting-and-overfitting.ipynb
|
stevekwon211/SteveKwon-Kaggle-Struggle
|
306c53df67ff1b20b9d097e9737d2fd95576ccea
|
[
"Apache-2.0"
] | null | null | null | 8,141 | 8,141 | 0.726692 |
[
[
[
"**This notebook is an exercise in the [Introduction to Machine Learning](https://www.kaggle.com/learn/intro-to-machine-learning) course. You can reference the tutorial at [this link](https://www.kaggle.com/dansbecker/underfitting-and-overfitting).**\n\n---\n",
"_____no_output_____"
],
[
"## Recap\nYou've built your first model, and now it's time to optimize the size of the tree to make better predictions. Run this cell to set up your coding environment where the previous step left off.",
"_____no_output_____"
]
],
[
[
"# Code you have previously used to load data\nimport pandas as pd\nfrom sklearn.metrics import mean_absolute_error\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.tree import DecisionTreeRegressor\n\n\n# Path of the file to read\niowa_file_path = '../input/home-data-for-ml-course/train.csv'\n\nhome_data = pd.read_csv(iowa_file_path)\n# Create target object and call it y\ny = home_data.SalePrice\n# Create X\nfeatures = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']\nX = home_data[features]\n\n# Split into validation and training data\ntrain_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)\n\n# Specify Model\niowa_model = DecisionTreeRegressor(random_state=1)\n# Fit Model\niowa_model.fit(train_X, train_y)\n\n# Make validation predictions and calculate mean absolute error\nval_predictions = iowa_model.predict(val_X)\nval_mae = mean_absolute_error(val_predictions, val_y)\nprint(\"Validation MAE: {:,.0f}\".format(val_mae))\n\n# Set up code checking\nfrom learntools.core import binder\nbinder.bind(globals())\nfrom learntools.machine_learning.ex5 import *\nprint(\"\\nSetup complete\")",
"Validation MAE: 29,653\n\nSetup complete\n"
]
],
[
[
"# Exercises\nYou could write the function `get_mae` yourself. For now, we'll supply it. This is the same function you read about in the previous lesson. Just run the cell below.",
"_____no_output_____"
]
],
[
[
"def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):\n model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)\n model.fit(train_X, train_y)\n preds_val = model.predict(val_X)\n mae = mean_absolute_error(val_y, preds_val)\n return(mae)",
"_____no_output_____"
]
],
[
[
"## Step 1: Compare Different Tree Sizes\nWrite a loop that tries the following values for *max_leaf_nodes* from a set of possible values.\n\nCall the *get_mae* function on each value of max_leaf_nodes. Store the output in some way that allows you to select the value of `max_leaf_nodes` that gives the most accurate model on your data.",
"_____no_output_____"
]
],
[
[
"candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]\n# Write loop to find the ideal tree size from candidate_max_leaf_nodes\nfor max_leaf_nodes in candidate_max_leaf_nodes:\n my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)\n print(\"Max leaf nodes: %d \\t\\t Mean Absolute Error: %d\" %(max_leaf_nodes, my_mae))\n \n# Store the best value of max_leaf_nodes (it will be either 5, 25, 50, 100, 250 or 500)\nbest_tree_size = 100\n\n# Check your answer\nstep_1.check()",
"Max leaf nodes: 5 \t\t Mean Absolute Error: 35044\nMax leaf nodes: 25 \t\t Mean Absolute Error: 29016\nMax leaf nodes: 50 \t\t Mean Absolute Error: 27405\nMax leaf nodes: 100 \t\t Mean Absolute Error: 27282\nMax leaf nodes: 250 \t\t Mean Absolute Error: 27893\nMax leaf nodes: 500 \t\t Mean Absolute Error: 29454\n"
],
[
"# The lines below will show you a hint or the solution.\n# step_1.hint() \n# step_1.solution()",
"_____no_output_____"
]
],
[
[
"## Step 2: Fit Model Using All Data\nYou know the best tree size. If you were going to deploy this model in practice, you would make it even more accurate by using all of the data and keeping that tree size. That is, you don't need to hold out the validation data now that you've made all your modeling decisions.",
"_____no_output_____"
]
],
[
[
"# Fill in argument to make optimal size and uncomment\nfinal_model = DecisionTreeRegressor(max_leaf_nodes=100, random_state=0)\n\n# fit the final model and uncomment the next two lines\nfinal_model.fit(X, y)\n\n# Check your answer\nstep_2.check()",
"_____no_output_____"
],
[
"# step_2.hint()\n# step_2.solution()",
"_____no_output_____"
]
],
[
[
"You've tuned this model and improved your results. But we are still using Decision Tree models, which are not very sophisticated by modern machine learning standards. In the next step you will learn to use Random Forests to improve your models even more.\n\n# Keep Going\n\nYou are ready for **[Random Forests](https://www.kaggle.com/dansbecker/random-forests).**\n",
"_____no_output_____"
],
[
"---\n\n\n\n\n*Have questions or comments? Visit the [Learn Discussion forum](https://www.kaggle.com/learn-forum/161285) to chat with other Learners.*",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
c516d054f1632113ef981aedb2d73f0493c05677
| 709 |
ipynb
|
Jupyter Notebook
|
helloGithub.ipynb
|
Xsenopl/dw_matrix
|
d071203cdbcf5ee9fe28f9129f8df655fac6378e
|
[
"MIT"
] | null | null | null |
helloGithub.ipynb
|
Xsenopl/dw_matrix
|
d071203cdbcf5ee9fe28f9129f8df655fac6378e
|
[
"MIT"
] | null | null | null |
helloGithub.ipynb
|
Xsenopl/dw_matrix
|
d071203cdbcf5ee9fe28f9129f8df655fac6378e
|
[
"MIT"
] | null | null | null | 709 | 709 | 0.699577 |
[
[
[
"print(\"Hello Githubbb\")",
"Hello Githubbb\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
c516eeaf8e14669d12dd454775b79911d29a77e1
| 208,607 |
ipynb
|
Jupyter Notebook
|
Untitled.ipynb
|
Sathyakumarnsk/custom_object_detection
|
b4c1a6de2d7617185a7da3e9f0c4ebc83c7c7a6a
|
[
"MIT"
] | null | null | null |
Untitled.ipynb
|
Sathyakumarnsk/custom_object_detection
|
b4c1a6de2d7617185a7da3e9f0c4ebc83c7c7a6a
|
[
"MIT"
] | null | null | null |
Untitled.ipynb
|
Sathyakumarnsk/custom_object_detection
|
b4c1a6de2d7617185a7da3e9f0c4ebc83c7c7a6a
|
[
"MIT"
] | null | null | null | 113.066125 | 799 | 0.717148 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Sathyakumarnsk/custom_object_detection/blob/master/Untitled.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"%tensorflow_version 1.x",
"TensorFlow 1.x selected.\n"
],
[
"import tensorflow\nprint(tensorflow.__version__)",
"1.15.2\n"
],
[
"!git clone https://github.com/tensorflow/models.git",
"Cloning into 'models'...\nremote: Enumerating objects: 33, done.\u001b[K\nremote: Counting objects: 100% (33/33), done.\u001b[K\nremote: Compressing objects: 100% (32/32), done.\u001b[K\nremote: Total 44959 (delta 5), reused 28 (delta 1), pack-reused 44926\u001b[K\nReceiving objects: 100% (44959/44959), 550.72 MiB | 36.36 MiB/s, done.\nResolving deltas: 100% (30726/30726), done.\n"
],
[
"%cd models/research\n!pwd",
"/content/models/research\n/content/models/research\n"
],
[
"# Compile protos.\n!protoc object_detection/protos/*.proto --python_out=.\n# Install TensorFlow Object Detection API.\n!cp object_detection/packages/tf2/setup.py .\n\n",
"_____no_output_____"
],
[
"pip install -U pip",
"Collecting pip\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/4e/5f/528232275f6509b1fff703c9280e58951a81abe24640905de621c9f81839/pip-20.2.3-py2.py3-none-any.whl (1.5MB)\n\u001b[K |████████████████████████████████| 1.5MB 5.3MB/s \n\u001b[?25hInstalling collected packages: pip\n Found existing installation: pip 19.3.1\n Uninstalling pip-19.3.1:\n Successfully uninstalled pip-19.3.1\nSuccessfully installed pip-20.2.3\n"
],
[
"!python -m pip install --use-feature=2020-resolver .",
"Processing /content/models/research\nRequirement already satisfied: pillow in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (7.0.0)\nRequirement already satisfied: lxml in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (4.2.6)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (3.2.2)\nRequirement already satisfied: Cython in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (0.29.21)\nRequirement already satisfied: contextlib2 in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (0.5.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: pycocotools in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (2.0.2)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.4.1)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.0.5)\nCollecting tf-slim\n Downloading tf_slim-1.1.0-py2.py3-none-any.whl (352 kB)\n\u001b[K |████████████████████████████████| 352 kB 4.8 MB/s \n\u001b[?25hRequirement already satisfied: absl-py>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from tf-slim->object-detection==0.1) (0.10.0)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (3.2.2)\nRequirement already satisfied: Cython in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (0.29.21)\nRequirement already satisfied: setuptools>=18.0 in /usr/local/lib/python3.6/dist-packages (from pycocotools->object-detection==0.1) (50.3.0)\nCollecting tf-models-official\n Downloading tf_models_official-2.3.0-py2.py3-none-any.whl (840 kB)\n\u001b[K |████████████████████████████████| 840 kB 15.4 MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.4.1)\nRequirement already satisfied: Cython in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (0.29.21)\nRequirement already satisfied: tensorflow-hub>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (0.9.0)\nRequirement already satisfied: google-api-python-client>=1.6.7 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.7.12)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: tensorflow-datasets in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (2.1.0)\nRequirement already satisfied: dataclasses in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (0.7)\nRequirement already satisfied: pillow in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (7.0.0)\nRequirement already satisfied: pandas in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.0.5)\nRequirement already satisfied: google-cloud-bigquery>=0.31.0 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.21.0)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (3.2.2)\nRequirement already satisfied: psutil>=5.4.3 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (5.4.8)\nRequirement already satisfied: tensorflow-addons in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (0.8.3)\nRequirement already satisfied: pyyaml in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (3.13)\nRequirement already satisfied: kaggle>=1.3.9 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.5.8)\nRequirement already satisfied: gin-config in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (0.3.0)\nCollecting tensorflow>=2.3.0\n Downloading tensorflow-2.3.1-cp36-cp36m-manylinux2010_x86_64.whl (320.4 MB)\n\u001b[K |████████████████████████████████| 320.4 MB 34 kB/s \n\u001b[?25hRequirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.3.0)\nRequirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.12.1)\nRequirement already satisfied: gast==0.3.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.3.3)\nRequirement already satisfied: google-pasta>=0.1.8 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.2.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.35.1)\nRequirement already satisfied: absl-py>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from tf-slim->object-detection==0.1) (0.10.0)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.32.0)\nRequirement already satisfied: astunparse==1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.6.3)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: h5py<2.11.0,>=2.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.10.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: keras-preprocessing<1.2,>=1.1.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.1.2)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.1.0)\nCollecting tensorboard<3,>=2.3.0\n Downloading tensorboard-2.3.0-py3-none-any.whl (6.8 MB)\n\u001b[K |████████████████████████████████| 6.8 MB 68.7 MB/s \n\u001b[?25hRequirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.23.0)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.2.2)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.35.1)\nRequirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.7.0)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.17.2)\nRequirement already satisfied: setuptools>=18.0 in /usr/local/lib/python3.6/dist-packages (from pycocotools->object-detection==0.1) (50.3.0)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.0.1)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: absl-py>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from tf-slim->object-detection==0.1) (0.10.0)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.32.0)\nRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.4.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (0.35.1)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nCollecting tensorflow-estimator<2.4.0,>=2.3.0\n Downloading tensorflow_estimator-2.3.0-py2.py3-none-any.whl (459 kB)\n\u001b[K |████████████████████████████████| 459 kB 67.1 MB/s \n\u001b[?25hRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.17.2)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.3.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.24.3)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.10)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.0.4)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2020.6.20)\nCollecting py-cpuinfo>=3.3.0\n Downloading py-cpuinfo-7.0.0.tar.gz (95 kB)\n\u001b[K |████████████████████████████████| 95 kB 5.9 MB/s \n\u001b[?25hCollecting tensorflow-model-optimization>=0.2.1\n Downloading tensorflow_model_optimization-0.5.0-py2.py3-none-any.whl (172 kB)\n\u001b[K |████████████████████████████████| 172 kB 59.9 MB/s \n\u001b[?25hRequirement already satisfied: dm-tree~=0.1.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow-model-optimization>=0.2.1->tf-models-official->object-detection==0.1) (0.1.5)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.23.0)\nRequirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.1.0)\nCollecting avro-python3\n Downloading avro-python3-1.10.0.tar.gz (37 kB)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: setuptools>=18.0 in /usr/local/lib/python3.6/dist-packages (from pycocotools->object-detection==0.1) (50.3.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.6/dist-packages (from markdown>=2.6.8->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.7.0)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (0.16.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (0.24.0)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.1.0)\nRequirement already satisfied: absl-py>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from tf-slim->object-detection==0.1) (0.10.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (4.41.1)\nRequirement already satisfied: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (0.3.2)\nRequirement already satisfied: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (2.3)\nRequirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.12.1)\nRequirement already satisfied: attrs>=18.1.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (20.2.0)\nRequirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.23.0)\nRequirement already satisfied: typeguard in /usr/local/lib/python3.6/dist-packages (from tensorflow-addons->tf-models-official->object-detection==0.1) (2.7.1)\nRequirement already satisfied: absl-py>=0.2.2 in /usr/local/lib/python3.6/dist-packages (from tf-slim->object-detection==0.1) (0.10.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: googleapis-common-protos<2,>=1.52.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow-datasets->tf-models-official->object-detection==0.1) (1.52.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nCollecting apache-beam\n Downloading apache_beam-2.24.0-cp36-cp36m-manylinux2010_x86_64.whl (8.6 MB)\n\u001b[K |████████████████████████████████| 8.6 MB 29.1 MB/s \n\u001b[?25hRequirement already satisfied: pymongo<4.0.0,>=3.8.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (3.11.0)\nRequirement already satisfied: pytz>=2018.3 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2018.9)\nRequirement already satisfied: python-dateutil<3,>=2.8.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2.8.1)\nRequirement already satisfied: httplib2<0.18.0,>=0.8 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (0.17.4)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.32.0)\nRequirement already satisfied: typing-extensions<3.8.0,>=3.7.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (3.7.4.3)\nRequirement already satisfied: crcmod<2.0,>=1.7 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (1.7)\nRequirement already satisfied: pydot<2,>=1.2.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (1.3.0)\nCollecting requests<3,>=2.21.0\n Downloading requests-2.24.0-py2.py3-none-any.whl (61 kB)\n\u001b[K |████████████████████████████████| 61 kB 452 kB/s \n\u001b[?25hRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.24.3)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2.10)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.0.4)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2020.6.20)\nCollecting future\n Downloading future-0.18.2.tar.gz (829 kB)\n\u001b[K |████████████████████████████████| 829 kB 50.6 MB/s \n\u001b[?25hCollecting dill\n Downloading dill-0.3.1.1.tar.gz (151 kB)\n\u001b[K |████████████████████████████████| 151 kB 62.9 MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nCollecting pyarrow<0.18.0,>=0.15.1\n Downloading pyarrow-0.17.1-cp36-cp36m-manylinux2014_x86_64.whl (63.8 MB)\n\u001b[K |████████████████████████████████| 63.8 MB 23 kB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nCollecting avro-python3\n Downloading avro-python3-1.9.2.1.tar.gz (37 kB)\nCollecting oauth2client<4,>=2.0.1\n Downloading oauth2client-3.0.0.tar.gz (77 kB)\n\u001b[K |████████████████████████████████| 77 kB 5.8 MB/s \n\u001b[?25hRequirement already satisfied: httplib2<0.18.0,>=0.8 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (0.17.4)\nRequirement already satisfied: pyasn1>=0.1.7 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (0.4.8)\nRequirement already satisfied: pyasn1-modules>=0.0.5 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (0.2.8)\nRequirement already satisfied: rsa>=3.1.4 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (4.6)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: pyparsing>=2.1.4 in /usr/local/lib/python3.6/dist-packages (from pydot<2,>=1.2.0->apache-beam->object-detection==0.1) (2.4.7)\nCollecting mock<3.0.0,>=1.0.1\n Downloading mock-2.0.0-py2.py3-none-any.whl (56 kB)\n\u001b[K |████████████████████████████████| 56 kB 4.6 MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nCollecting hdfs<3.0.0,>=2.1.0\n Downloading hdfs-2.5.8.tar.gz (41 kB)\n\u001b[K |████████████████████████████████| 41 kB 843 kB/s \n\u001b[?25hRequirement already satisfied: docopt in /usr/local/lib/python3.6/dist-packages (from hdfs<3.0.0,>=2.1.0->apache-beam->object-detection==0.1) (0.6.2)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: pyasn1>=0.1.7 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (0.4.8)\nRequirement already satisfied: pyasn1>=0.1.7 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (0.4.8)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->object-detection==0.1) (0.10.0)\nRequirement already satisfied: python-dateutil<3,>=2.8.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2.8.1)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->object-detection==0.1) (1.2.0)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: pyparsing>=2.1.4 in /usr/local/lib/python3.6/dist-packages (from pydot<2,>=1.2.0->apache-beam->object-detection==0.1) (2.4.7)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: python-dateutil<3,>=2.8.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2.8.1)\nRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: pytz>=2018.3 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2018.9)\nCollecting sentencepiece\n Downloading sentencepiece-0.1.91-cp36-cp36m-manylinux1_x86_64.whl (1.1 MB)\n\u001b[K |████████████████████████████████| 1.1 MB 56.2 MB/s \n\u001b[?25hRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (2020.6.20)\nRequirement already satisfied: slugify in /usr/local/lib/python3.6/dist-packages (from kaggle>=1.3.9->tf-models-official->object-detection==0.1) (0.0.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow-datasets->tf-models-official->object-detection==0.1) (4.41.1)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests<3,>=2.21.0->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.24.3)\nRequirement already satisfied: python-slugify in /usr/local/lib/python3.6/dist-packages (from kaggle>=1.3.9->tf-models-official->object-detection==0.1) (4.0.1)\nRequirement already satisfied: python-dateutil<3,>=2.8.0 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2.8.1)\nRequirement already satisfied: uritemplate<4dev,>=3.0.0 in /usr/local/lib/python3.6/dist-packages (from google-api-python-client>=1.6.7->tf-models-official->object-detection==0.1) (3.0.1)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.17.2)\nRequirement already satisfied: google-auth-httplib2>=0.0.3 in /usr/local/lib/python3.6/dist-packages (from google-api-python-client>=1.6.7->tf-models-official->object-detection==0.1) (0.0.4)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: httplib2<0.18.0,>=0.8 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (0.17.4)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.17.2)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: httplib2<0.18.0,>=0.8 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (0.17.4)\nCollecting opencv-python-headless\n Downloading opencv_python_headless-4.4.0.44-cp36-cp36m-manylinux2014_x86_64.whl (36.7 MB)\n\u001b[K |████████████████████████████████| 36.7 MB 36 kB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.6/dist-packages (from tf-models-official->object-detection==0.1) (1.18.5)\nRequirement already satisfied: text-unidecode>=1.3 in /usr/local/lib/python3.6/dist-packages (from python-slugify->kaggle>=1.3.9->tf-models-official->object-detection==0.1) (1.3)\nRequirement already satisfied: setuptools>=18.0 in /usr/local/lib/python3.6/dist-packages (from pycocotools->object-detection==0.1) (50.3.0)\nRequirement already satisfied: pyasn1-modules>=0.0.5 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (0.2.8)\nRequirement already satisfied: rsa>=3.1.4 in /usr/local/lib/python3.6/dist-packages (from oauth2client<4,>=2.0.1->apache-beam->object-detection==0.1) (4.6)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from google-auth<2,>=1.6.3->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (4.1.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.6/dist-packages (from importlib-metadata->markdown>=2.6.8->tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.1.0)\nCollecting fastavro<0.24,>=0.21.4\n Downloading fastavro-0.23.6-cp36-cp36m-manylinux2010_x86_64.whl (1.4 MB)\n\u001b[K |████████████████████████████████| 1.4 MB 72.2 MB/s \n\u001b[?25hRequirement already satisfied: pytz>=2018.3 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2018.9)\nCollecting pbr>=0.11\n Downloading pbr-5.5.0-py2.py3-none-any.whl (106 kB)\n\u001b[K |████████████████████████████████| 106 kB 74.9 MB/s \n\u001b[?25hRequirement already satisfied: google-cloud-core<2.0dev,>=1.0.3 in /usr/local/lib/python3.6/dist-packages (from google-cloud-bigquery>=0.31.0->tf-models-official->object-detection==0.1) (1.0.3)\nRequirement already satisfied: google-resumable-media!=0.4.0,<0.5.0dev,>=0.3.1 in /usr/local/lib/python3.6/dist-packages (from google-cloud-bigquery>=0.31.0->tf-models-official->object-detection==0.1) (0.4.1)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: google-api-core<2.0.0dev,>=1.14.0 in /usr/local/lib/python3.6/dist-packages (from google-cloud-core<2.0dev,>=1.0.3->google-cloud-bigquery>=0.31.0->tf-models-official->object-detection==0.1) (1.16.0)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from object-detection==0.1) (1.15.0)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.6/dist-packages (from tensorboard<3,>=2.3.0->tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (1.17.2)\nRequirement already satisfied: setuptools>=18.0 in /usr/local/lib/python3.6/dist-packages (from pycocotools->object-detection==0.1) (50.3.0)\nRequirement already satisfied: googleapis-common-protos<2,>=1.52.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow-datasets->tf-models-official->object-detection==0.1) (1.52.0)\nRequirement already satisfied: protobuf>=3.9.2 in /usr/local/lib/python3.6/dist-packages (from tensorflow>=2.3.0->tf-models-official->object-detection==0.1) (3.12.4)\nRequirement already satisfied: pytz>=2018.3 in /usr/local/lib/python3.6/dist-packages (from apache-beam->object-detection==0.1) (2018.9)\nBuilding wheels for collected packages: object-detection, py-cpuinfo, future, dill, avro-python3, oauth2client, hdfs\n Building wheel for object-detection (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for object-detection: filename=object_detection-0.1-py3-none-any.whl size=1578914 sha256=ed85b06087105166affa6c060f7b8e63ae2665db228a6bde3bc859528dab9a1c\n Stored in directory: /tmp/pip-ephem-wheel-cache-zsvwqg1y/wheels/16/63/fd/1293066bf448f757979af1b45c59b0e33b46f12d4454d12fde\n Building wheel for py-cpuinfo (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for py-cpuinfo: filename=py_cpuinfo-7.0.0-py3-none-any.whl size=20070 sha256=586c6c12207194d5134ad2ecb9432ac029023eb8e6de96249c2ad76c7ff42ecb\n Stored in directory: /root/.cache/pip/wheels/46/6d/cc/73a126dc2e09fe56fcec0a7386d255762611fbed1c86d3bbcc\n Building wheel for future (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for future: filename=future-0.18.2-py3-none-any.whl size=491059 sha256=f1d7393ef69666aa2bd6b0ae2250fc533d93b0cba2f3a3ed4034aec8654bf3e7\n Stored in directory: /root/.cache/pip/wheels/6e/9c/ed/4499c9865ac1002697793e0ae05ba6be33553d098f3347fb94\n Building wheel for dill (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dill: filename=dill-0.3.1.1-py3-none-any.whl size=78532 sha256=1310886b1e455ab5ea07700a3625afd18225ed2010972a44e3470654e36c5390\n Stored in directory: /root/.cache/pip/wheels/09/84/74/d2b4feb9ac9488bc83c475cb2cbe8e8b7d9cea8320d32f3787\n Building wheel for avro-python3 (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for avro-python3: filename=avro_python3-1.9.2.1-py3-none-any.whl size=43513 sha256=377d78a4f04d4a47fa8d0882fe521061e4b66ca3d2a143f73276abde7d25c2fa\n Stored in directory: /root/.cache/pip/wheels/4e/08/0c/727bff8f20fedbdeb8a2c5214e460b214d41c10dc879cf6dac\n Building wheel for oauth2client (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for oauth2client: filename=oauth2client-3.0.0-py3-none-any.whl size=106382 sha256=64e6d2882a1cd09c487649885aaa3d20dfcb2322a7eca09987d4be966d2221ee\n Stored in directory: /root/.cache/pip/wheels/85/84/41/0db9b5f02fab88d266e64a52c5a468a3a70f6d331e75ec0e49\n Building wheel for hdfs (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for hdfs: filename=hdfs-2.5.8-py3-none-any.whl size=33213 sha256=17eb063bea9f93ae6c2a4f38315072985e620de5670bb8d6e601fea723911645\n Stored in directory: /root/.cache/pip/wheels/3e/0c/c3/26ad975f80274d6bf73ed4d8facd055648f452428bc1623283\nSuccessfully built object-detection py-cpuinfo future dill avro-python3 oauth2client hdfs\nInstalling collected packages: requests, tensorflow-estimator, tensorboard, pbr, future, dill, tf-slim, tensorflow-model-optimization, tensorflow, sentencepiece, pyarrow, py-cpuinfo, opencv-python-headless, oauth2client, mock, hdfs, fastavro, avro-python3, tf-models-official, apache-beam, object-detection\n Attempting uninstall: requests\n Found existing installation: requests 2.23.0\n Uninstalling requests-2.23.0:\n Successfully uninstalled requests-2.23.0\n Attempting uninstall: tensorflow-estimator\n Found existing installation: tensorflow-estimator 1.15.1\n Uninstalling tensorflow-estimator-1.15.1:\n Successfully uninstalled tensorflow-estimator-1.15.1\n Attempting uninstall: tensorboard\n Found existing installation: tensorboard 1.15.0\n Uninstalling tensorboard-1.15.0:\n Successfully uninstalled tensorboard-1.15.0\n Attempting uninstall: future\n Found existing installation: future 0.16.0\n Uninstalling future-0.16.0:\n Successfully uninstalled future-0.16.0\n Attempting uninstall: dill\n Found existing installation: dill 0.3.2\n Uninstalling dill-0.3.2:\n Successfully uninstalled dill-0.3.2\n Attempting uninstall: tensorflow\n Found existing installation: tensorflow 1.15.2\n Uninstalling tensorflow-1.15.2:\n Successfully uninstalled tensorflow-1.15.2\n Attempting uninstall: pyarrow\n Found existing installation: pyarrow 0.14.1\n Uninstalling pyarrow-0.14.1:\n Successfully uninstalled pyarrow-0.14.1\n Attempting uninstall: oauth2client\n Found existing installation: oauth2client 4.1.3\n Uninstalling oauth2client-4.1.3:\n Successfully uninstalled oauth2client-4.1.3\n\u001b[31mERROR: pydrive 1.3.1 requires oauth2client>=4.0.0, but you'll have oauth2client 3.0.0 which is incompatible.\nmultiprocess 0.70.10 requires dill>=0.3.2, but you'll have dill 0.3.1.1 which is incompatible.\ngoogle-colab 1.0.0 requires requests~=2.23.0, but you'll have requests 2.24.0 which is incompatible.\ndatascience 0.10.6 requires folium==0.2.1, but you'll have folium 0.8.3 which is incompatible.\u001b[0m\nSuccessfully installed apache-beam-2.24.0 avro-python3-1.9.2.1 dill-0.3.1.1 fastavro-0.23.6 future-0.18.2 hdfs-2.5.8 mock-2.0.0 oauth2client-3.0.0 object-detection-0.1 opencv-python-headless-4.4.0.44 pbr-5.5.0 py-cpuinfo-7.0.0 pyarrow-0.17.1 requests-2.24.0 sentencepiece-0.1.91 tensorboard-2.3.0 tensorflow-2.3.1 tensorflow-estimator-2.3.0 tensorflow-model-optimization-0.5.0 tf-models-official-2.3.0 tf-slim-1.1.0\n"
],
[
"tensorflow.__version__",
"_____no_output_____"
],
[
"!python object_detection/builders/model_builder_tf1_test.py",
"_____no_output_____"
],
[
"%pwd",
"_____no_output_____"
],
[
"%%bash\ncd /content/models/research/object_detection/trainer\n# From tensorflow/models/research/\nwget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz\nwget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz\ntar -xvf images.tar.gz\ntar -xvf annotations.tar.gz",
"_____no_output_____"
],
[
"%cd /content/models/research/object_detection/trainer",
"/content/models/research/object_detection/trainer\n"
],
[
"# From tensorflow/models/research/\n!python /content/models/research/object_detection/dataset_tools/create_pet_tf_record.py \\\n --label_map_path=./pet_label_map.pbtxt \\\n --data_dir=`pwd` \\\n --output_dir=`pwd`",
"_____no_output_____"
],
[
"",
"/content/models/research\n"
],
[
"%cd ../../object_detection/",
"/content/models/research/object_detection\n"
],
[
"!wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz\n!tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz",
"--2020-09-26 03:24:33-- http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz\nResolving storage.googleapis.com (storage.googleapis.com)... 74.125.20.128, 74.125.195.128, 74.125.28.128, ...\nConnecting to storage.googleapis.com (storage.googleapis.com)|74.125.20.128|:80... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 595490113 (568M) [application/x-tar]\nSaving to: ‘faster_rcnn_resnet101_coco_11_06_2017.tar.gz’\n\nfaster_rcnn_resnet1 100%[===================>] 567.90M 95.0MB/s in 7.4s \n\n2020-09-26 03:24:41 (76.4 MB/s) - ‘faster_rcnn_resnet101_coco_11_06_2017.tar.gz’ saved [595490113/595490113]\n\nfaster_rcnn_resnet101_coco_11_06_2017/\nfaster_rcnn_resnet101_coco_11_06_2017/model.ckpt.index\nfaster_rcnn_resnet101_coco_11_06_2017/model.ckpt.meta\nfaster_rcnn_resnet101_coco_11_06_2017/frozen_inference_graph.pb\nfaster_rcnn_resnet101_coco_11_06_2017/model.ckpt.data-00000-of-00001\nfaster_rcnn_resnet101_coco_11_06_2017/graph.pbtxt\n"
],
[
"mv -v /content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/* /content/models/research/object_detection/trainer/",
"renamed '/content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/frozen_inference_graph.pb' -> '/content/models/research/object_detection/trainer/frozen_inference_graph.pb'\nrenamed '/content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/graph.pbtxt' -> '/content/models/research/object_detection/trainer/graph.pbtxt'\nrenamed '/content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.data-00000-of-00001' -> '/content/models/research/object_detection/trainer/model.ckpt.data-00000-of-00001'\nrenamed '/content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.index' -> '/content/models/research/object_detection/trainer/model.ckpt.index'\nrenamed '/content/models/research/object_detection/faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.meta' -> '/content/models/research/object_detection/trainer/model.ckpt.meta'\n"
],
[
"",
"/content/models/research/object_detection\n/content/models/research\n"
],
[
"tensorflow.__version__\n!pwd",
"/content/models/research/object_detection\n"
],
[
"!python3 ./train.py --logtostderr --train_dir=./trainer/ --pipeline_config_path=./trainer/faster_rcnn_resnet101_pets.config",
"2020-09-26 04:01:04.430584: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/absl/app.py:251: main (from __main__) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse object_detection/model_main.py.\nW0926 04:01:06.200358 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/absl/app.py:251: main (from __main__) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse object_detection/model_main.py.\n2020-09-26 04:01:06.232995: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1\n2020-09-26 04:01:06.267000: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.267615: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties: \npciBusID: 0000:00:04.0 name: Tesla T4 computeCapability: 7.5\ncoreClock: 1.59GHz coreCount: 40 deviceMemorySize: 14.73GiB deviceMemoryBandwidth: 298.08GiB/s\n2020-09-26 04:01:06.267657: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\n2020-09-26 04:01:06.270246: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10\n2020-09-26 04:01:06.272266: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10\n2020-09-26 04:01:06.272613: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10\n2020-09-26 04:01:06.275154: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10\n2020-09-26 04:01:06.276182: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10\n2020-09-26 04:01:06.282525: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7\n2020-09-26 04:01:06.282652: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.283243: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.283793: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0\n2020-09-26 04:01:06.284103: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\n2020-09-26 04:01:06.289987: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 2200000000 Hz\n2020-09-26 04:01:06.290175: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1555640 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n2020-09-26 04:01:06.290216: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n2020-09-26 04:01:06.400160: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.400838: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1555800 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:\n2020-09-26 04:01:06.400871: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Tesla T4, Compute Capability 7.5\n2020-09-26 04:01:06.401104: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.401649: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties: \npciBusID: 0000:00:04.0 name: Tesla T4 computeCapability: 7.5\ncoreClock: 1.59GHz coreCount: 40 deviceMemorySize: 14.73GiB deviceMemoryBandwidth: 298.08GiB/s\n2020-09-26 04:01:06.401695: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\n2020-09-26 04:01:06.401749: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10\n2020-09-26 04:01:06.401776: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10\n2020-09-26 04:01:06.401800: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10\n2020-09-26 04:01:06.401820: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10\n2020-09-26 04:01:06.401838: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10\n2020-09-26 04:01:06.401858: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7\n2020-09-26 04:01:06.401945: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.402788: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:06.403522: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0\n2020-09-26 04:01:06.403633: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1\n2020-09-26 04:01:07.117499: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-09-26 04:01:07.117557: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0 \n2020-09-26 04:01:07.117569: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N \n2020-09-26 04:01:07.117797: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:07.118422: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-09-26 04:01:07.118915: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\n2020-09-26 04:01:07.118955: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 13936 MB memory) -> physical GPU (device: 0, name: Tesla T4, pci bus id: 0000:00:04.0, compute capability: 7.5)\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/legacy/trainer.py:265: create_global_step (from tf_slim.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.create_global_step\nW0926 04:01:07.139197 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/legacy/trainer.py:265: create_global_step (from tf_slim.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.create_global_step\nWARNING:tensorflow:num_readers has been reduced to 10 to match input file shards.\nW0926 04:01:07.161178 140348406654848 dataset_builder.py:83] num_readers has been reduced to 10 to match input file shards.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:100: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_deterministic`.\nW0926 04:01:07.167158 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:100: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_deterministic`.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:175: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.map()\nW0926 04:01:07.197758 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:175: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.map()\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:48: DatasetV1.make_initializable_iterator (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis is a deprecated API that should only be used in TF 1 graph mode and legacy TF 2 graph mode available through `tf.compat.v1`. In all other situations -- namely, eager mode and inside `tf.function` -- you can consume dataset elements using `for elem in dataset: ...` or by explicitly creating iterator via `iterator = iter(dataset)` and fetching its elements via `values = next(iterator)`. Furthermore, this API is not available in TF 2. During the transition from TF 1 to TF 2 you can use `tf.compat.v1.data.make_initializable_iterator(dataset)` to create a TF 1 graph mode style iterator for a dataset created through TF 2 APIs. Note that this should be a transient state of your code base as there are in general no guarantees about the interoperability of TF 1 and TF 2 code.\nW0926 04:01:08.569184 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/builders/dataset_builder.py:48: DatasetV1.make_initializable_iterator (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis is a deprecated API that should only be used in TF 1 graph mode and legacy TF 2 graph mode available through `tf.compat.v1`. In all other situations -- namely, eager mode and inside `tf.function` -- you can consume dataset elements using `for elem in dataset: ...` or by explicitly creating iterator via `iterator = iter(dataset)` and fetching its elements via `values = next(iterator)`. Furthermore, this API is not available in TF 2. During the transition from TF 1 to TF 2 you can use `tf.compat.v1.data.make_initializable_iterator(dataset)` to create a TF 1 graph mode style iterator for a dataset created through TF 2 APIs. Note that this should be a transient state of your code base as there are in general no guarantees about the interoperability of TF 1 and TF 2 code.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/core/batcher.py:101: batch (from tensorflow.python.training.input) is deprecated and will be removed in a future version.\nInstructions for updating:\nQueue-based input pipelines have been replaced by `tf.data`. Use `tf.data.Dataset.batch(batch_size)` (or `padded_batch(...)` if `dynamic_pad=True`).\nW0926 04:01:08.601567 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/core/batcher.py:101: batch (from tensorflow.python.training.input) is deprecated and will be removed in a future version.\nInstructions for updating:\nQueue-based input pipelines have been replaced by `tf.data`. Use `tf.data.Dataset.batch(batch_size)` (or `padded_batch(...)` if `dynamic_pad=True`).\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/input.py:752: QueueRunner.__init__ (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nW0926 04:01:08.604455 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/input.py:752: QueueRunner.__init__ (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/input.py:752: add_queue_runner (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nW0926 04:01:08.605165 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/training/input.py:752: add_queue_runner (from tensorflow.python.training.queue_runner_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nTo construct input pipelines, use the `tf.data` module.\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0926 04:01:11.851781 140348406654848 convolutional_keras_box_predictor.py:154] depth of additional conv before box predictor: 0\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/utils/shape_utils.py:237: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nUse fn_output_signature instead\nW0926 04:01:12.574667 140348406654848 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/object_detection/utils/shape_utils.py:237: calling map_fn (from tensorflow.python.ops.map_fn) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nUse fn_output_signature instead\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:201: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nW0926 04:01:12.941462 140348406654848 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:201: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/object_detection/utils/model_util.py:57: Tensor.experimental_ref (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse ref() instead.\nW0926 04:01:12.956940 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/object_detection/utils/model_util.py:57: Tensor.experimental_ref (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse ref() instead.\nWARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:201: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\nW0926 04:01:13.477464 140348406654848 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/util/dispatch.py:201: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\n/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/indexed_slices.py:433: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.\n \"Converting sparse IndexedSlices to a dense Tensor of unknown shape. \"\nW0926 04:01:19.081314 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalBoxHead_0/BoxEncodingPredictor/bias] is not available in checkpoint\nW0926 04:01:19.081487 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalBoxHead_0/BoxEncodingPredictor/bias/Momentum] is not available in checkpoint\nW0926 04:01:19.081550 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalBoxHead_0/BoxEncodingPredictor/kernel] is not available in checkpoint\nW0926 04:01:19.081601 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalBoxHead_0/BoxEncodingPredictor/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.081652 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalClassHead_0/ClassPredictor/bias] is not available in checkpoint\nW0926 04:01:19.081703 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalClassHead_0/ClassPredictor/bias/Momentum] is not available in checkpoint\nW0926 04:01:19.081756 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalClassHead_0/ClassPredictor/kernel] is not available in checkpoint\nW0926 04:01:19.081804 140348406654848 variables_helper.py:156] Variable [FirstStageBoxPredictor/ConvolutionalClassHead_0/ClassPredictor/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.081851 140348406654848 variables_helper.py:156] Variable [FirstStageRPNFeatures/RPNConv/bias] is not available in checkpoint\nW0926 04:01:19.081961 140348406654848 variables_helper.py:156] Variable [FirstStageRPNFeatures/RPNConv/bias/Momentum] is not available in checkpoint\nW0926 04:01:19.082018 140348406654848 variables_helper.py:156] Variable [FirstStageRPNFeatures/RPNConv/kernel] is not available in checkpoint\nW0926 04:01:19.082072 140348406654848 variables_helper.py:156] Variable [FirstStageRPNFeatures/RPNConv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.082132 140348406654848 variables_helper.py:156] Variable [conv1_bn/beta] is not available in checkpoint\nW0926 04:01:19.082189 140348406654848 variables_helper.py:156] Variable [conv1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.082265 140348406654848 variables_helper.py:156] Variable [conv1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.082320 140348406654848 variables_helper.py:156] Variable [conv1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.082373 140348406654848 variables_helper.py:156] Variable [conv1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.082427 140348406654848 variables_helper.py:156] Variable [conv1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.082480 140348406654848 variables_helper.py:156] Variable [conv1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.082533 140348406654848 variables_helper.py:156] Variable [conv1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.082586 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/beta] is not available in checkpoint\nW0926 04:01:19.082639 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.082693 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/gamma] is not available in checkpoint\nW0926 04:01:19.082746 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.082799 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.082852 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.082905 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_conv/kernel] is not available in checkpoint\nW0926 04:01:19.082958 140348406654848 variables_helper.py:156] Variable [conv2_block1_0_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.083011 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.083074 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.083126 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.083174 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.083238 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.083287 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.083335 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.083382 140348406654848 variables_helper.py:156] Variable [conv2_block1_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.083430 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.083477 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.083524 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.083571 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.083622 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.083669 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.083717 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.083770 140348406654848 variables_helper.py:156] Variable [conv2_block1_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.083818 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.083865 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.083912 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.083959 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.084007 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.084054 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.084101 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.084153 140348406654848 variables_helper.py:156] Variable [conv2_block1_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.084214 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.084268 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.084318 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.084367 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.084416 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.084464 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.084513 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.084562 140348406654848 variables_helper.py:156] Variable [conv2_block2_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.084619 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.084665 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.084711 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.084757 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.084802 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.084848 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.084893 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.084939 140348406654848 variables_helper.py:156] Variable [conv2_block2_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.084984 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.085030 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.085077 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.085126 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.085173 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.085230 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.085277 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.085323 140348406654848 variables_helper.py:156] Variable [conv2_block2_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.085368 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.085413 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.085459 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.085504 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.085549 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.085594 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.085640 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.085685 140348406654848 variables_helper.py:156] Variable [conv2_block3_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.085731 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.085775 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.085820 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.085866 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.085911 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.085956 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.086001 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.086046 140348406654848 variables_helper.py:156] Variable [conv2_block3_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.086091 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.086141 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.086186 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.086247 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.086293 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.086339 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.086384 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.086429 140348406654848 variables_helper.py:156] Variable [conv2_block3_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.086474 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/beta] is not available in checkpoint\nW0926 04:01:19.086519 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.086567 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/gamma] is not available in checkpoint\nW0926 04:01:19.086612 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.086661 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.086706 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.086752 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_conv/kernel] is not available in checkpoint\nW0926 04:01:19.086798 140348406654848 variables_helper.py:156] Variable [conv3_block1_0_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.086844 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.086889 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.086934 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.086979 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.087024 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.087069 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.087119 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.087164 140348406654848 variables_helper.py:156] Variable [conv3_block1_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.087218 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.087265 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.087310 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.087355 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.087400 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.165870 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.166084 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.166193 140348406654848 variables_helper.py:156] Variable [conv3_block1_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.166305 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.166380 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.166451 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.166518 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.166583 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.166665 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.166735 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.166801 140348406654848 variables_helper.py:156] Variable [conv3_block1_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.166863 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.166927 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.166991 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.167061 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.167131 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.167196 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.167285 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.167350 140348406654848 variables_helper.py:156] Variable [conv3_block2_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.167413 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.167477 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.167541 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.167604 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.167697 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.167763 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.167828 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.167891 140348406654848 variables_helper.py:156] Variable [conv3_block2_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.167954 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.168017 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.168093 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.168158 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.168236 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.168304 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.168368 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.168431 140348406654848 variables_helper.py:156] Variable [conv3_block2_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.168494 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.168557 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.168628 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.168696 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.168760 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.168824 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.168886 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.168948 140348406654848 variables_helper.py:156] Variable [conv3_block3_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.169011 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.169074 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.169150 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.169239 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.169309 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.169373 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.169436 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.169499 140348406654848 variables_helper.py:156] Variable [conv3_block3_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.169561 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.169632 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.169700 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.169764 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.169827 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.169890 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.169953 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.170033 140348406654848 variables_helper.py:156] Variable [conv3_block3_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.170100 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.170167 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.170290 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.170359 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.170444 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.170526 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.170607 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.170680 140348406654848 variables_helper.py:156] Variable [conv3_block4_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.170742 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.170799 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.170860 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.170927 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.170995 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.171064 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.171135 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.171223 140348406654848 variables_helper.py:156] Variable [conv3_block4_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.171300 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.171372 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.171453 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.171519 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.171586 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.171671 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.171734 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.171797 140348406654848 variables_helper.py:156] Variable [conv3_block4_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.171859 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.171921 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.171984 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.172049 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.172111 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.172175 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.172256 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.172323 140348406654848 variables_helper.py:156] Variable [conv4_block10_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.172388 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.172450 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.172514 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.172577 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.172652 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.172718 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.172781 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.172843 140348406654848 variables_helper.py:156] Variable [conv4_block10_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.172926 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.172992 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.173058 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.173134 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.173197 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.173282 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.173345 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.173408 140348406654848 variables_helper.py:156] Variable [conv4_block10_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.173471 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.173534 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.173597 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.173671 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.173735 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.173797 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.173859 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.173923 140348406654848 variables_helper.py:156] Variable [conv4_block11_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.173986 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.174050 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.174112 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.174190 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.174270 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.174331 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.174392 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.174453 140348406654848 variables_helper.py:156] Variable [conv4_block11_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.174516 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.174580 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.174660 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.174726 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.174790 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.174853 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.174917 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.174979 140348406654848 variables_helper.py:156] Variable [conv4_block11_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.175041 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.175104 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.175168 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.175249 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.175317 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.175380 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.175464 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.175530 140348406654848 variables_helper.py:156] Variable [conv4_block12_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.175598 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.175686 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.175751 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.175815 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.175877 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.175939 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.176002 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.176066 140348406654848 variables_helper.py:156] Variable [conv4_block12_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.176132 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.176196 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.176279 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.176344 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.176407 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.176470 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.176534 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.176596 140348406654848 variables_helper.py:156] Variable [conv4_block12_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.176677 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.176743 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.176806 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.176869 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.176932 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.176995 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.177058 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.177120 140348406654848 variables_helper.py:156] Variable [conv4_block13_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.177186 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.177269 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.177335 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.177398 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.177461 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.177523 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.177585 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.177659 140348406654848 variables_helper.py:156] Variable [conv4_block13_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.177725 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.177789 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.177854 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.177916 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.177979 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.178049 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.178134 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.178217 140348406654848 variables_helper.py:156] Variable [conv4_block13_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.178306 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.178369 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.178432 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.178494 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.178556 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.178630 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.178698 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.178762 140348406654848 variables_helper.py:156] Variable [conv4_block14_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.178827 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.178890 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.178952 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.179014 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.179077 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.179140 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.179216 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.179284 140348406654848 variables_helper.py:156] Variable [conv4_block14_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.179344 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.179399 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.179460 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.179521 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.179583 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.179659 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.179726 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.179790 140348406654848 variables_helper.py:156] Variable [conv4_block14_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.179855 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.179918 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.179982 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.180045 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.180108 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.180173 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.180257 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.180325 140348406654848 variables_helper.py:156] Variable [conv4_block15_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.180389 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.180454 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.180518 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.180582 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.180657 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.180723 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.180787 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.180850 140348406654848 variables_helper.py:156] Variable [conv4_block15_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.180914 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.180978 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.181041 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.181104 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.181169 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.181251 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.181319 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.181382 140348406654848 variables_helper.py:156] Variable [conv4_block15_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.181445 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.181507 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.181570 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.181642 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.181707 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.181769 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.181831 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.181948 140348406654848 variables_helper.py:156] Variable [conv4_block16_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.182024 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.182098 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.182173 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.182270 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.182346 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.182420 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.182493 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.182566 140348406654848 variables_helper.py:156] Variable [conv4_block16_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.182649 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.182724 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.182798 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.182870 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.182943 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.183027 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.183103 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.183167 140348406654848 variables_helper.py:156] Variable [conv4_block16_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.183248 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.183314 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.183387 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.183449 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.183515 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.183578 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.183652 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.183716 140348406654848 variables_helper.py:156] Variable [conv4_block17_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.183777 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.183838 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.183898 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.183959 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.184020 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.184082 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.184142 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.184246 140348406654848 variables_helper.py:156] Variable [conv4_block17_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.184315 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.184381 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.184447 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.184513 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.184587 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.184664 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.184730 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.184794 140348406654848 variables_helper.py:156] Variable [conv4_block17_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.184857 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.184920 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.184982 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.185044 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.185107 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.185169 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.185249 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.185316 140348406654848 variables_helper.py:156] Variable [conv4_block18_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.185378 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.185441 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.185502 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.185563 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.185635 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.185702 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.185764 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.185827 140348406654848 variables_helper.py:156] Variable [conv4_block18_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.185889 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.185951 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.186013 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.186074 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.186138 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.186199 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.186281 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.186343 140348406654848 variables_helper.py:156] Variable [conv4_block18_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.186405 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.186468 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.186531 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.186593 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.186667 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.186731 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.186794 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.186856 140348406654848 variables_helper.py:156] Variable [conv4_block19_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.186922 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.187002 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.187076 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.187138 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.187217 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.187287 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.187349 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.187412 140348406654848 variables_helper.py:156] Variable [conv4_block19_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.187474 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.187536 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.187597 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.187672 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.187736 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.187798 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.187860 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.187922 140348406654848 variables_helper.py:156] Variable [conv4_block19_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.187984 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/beta] is not available in checkpoint\nW0926 04:01:19.188054 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.188120 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/gamma] is not available in checkpoint\nW0926 04:01:19.188181 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.188264 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.188328 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.188390 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_conv/kernel] is not available in checkpoint\nW0926 04:01:19.188454 140348406654848 variables_helper.py:156] Variable [conv4_block1_0_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.188516 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.188579 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.188654 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.188718 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.188780 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.188842 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.188905 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.188967 140348406654848 variables_helper.py:156] Variable [conv4_block1_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.189028 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.189090 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.189152 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.189231 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.189300 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.189363 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.189424 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.189486 140348406654848 variables_helper.py:156] Variable [conv4_block1_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.189548 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.189611 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.189686 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.189749 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.189810 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.189871 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.189934 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.189997 140348406654848 variables_helper.py:156] Variable [conv4_block1_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.190058 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.190120 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.190183 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.190265 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.190330 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.190393 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.190455 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.190517 140348406654848 variables_helper.py:156] Variable [conv4_block20_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.190578 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.190652 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.190716 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.190778 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.190839 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.190901 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.190962 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.191024 140348406654848 variables_helper.py:156] Variable [conv4_block20_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.191086 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.191149 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.191226 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.191294 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.191356 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.191417 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.191478 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.191539 140348406654848 variables_helper.py:156] Variable [conv4_block20_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.191600 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.191675 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.191739 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.191800 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.191862 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.191922 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.191984 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.192047 140348406654848 variables_helper.py:156] Variable [conv4_block21_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.192108 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.192178 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.192260 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.192324 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.192386 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.192448 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.192509 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.192571 140348406654848 variables_helper.py:156] Variable [conv4_block21_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.192644 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.192711 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.192773 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.192835 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.192897 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.192959 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.193020 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.193082 140348406654848 variables_helper.py:156] Variable [conv4_block21_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.193144 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.193222 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.193289 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.193352 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.193414 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.193476 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.193537 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.193598 140348406654848 variables_helper.py:156] Variable [conv4_block22_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.193672 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.193734 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.193796 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.193858 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.193920 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.193982 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.194044 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.194106 140348406654848 variables_helper.py:156] Variable [conv4_block22_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.194167 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.194248 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.194313 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.194375 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.194437 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.194500 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.194561 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.194633 140348406654848 variables_helper.py:156] Variable [conv4_block22_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.194699 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.194761 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.194824 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.194885 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.194946 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.195008 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.195071 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.195133 140348406654848 variables_helper.py:156] Variable [conv4_block23_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.195196 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.195278 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.195341 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.195404 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.195466 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.195528 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.195590 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.195667 140348406654848 variables_helper.py:156] Variable [conv4_block23_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.195730 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.195791 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.195854 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.195915 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.195977 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.196038 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.196099 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.196162 140348406654848 variables_helper.py:156] Variable [conv4_block23_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.196240 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.196305 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.196368 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.196429 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.196491 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.196552 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.196622 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.196690 140348406654848 variables_helper.py:156] Variable [conv4_block2_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.196752 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.196815 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.196877 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.196937 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.196999 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.197059 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.197121 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.197184 140348406654848 variables_helper.py:156] Variable [conv4_block2_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.197267 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.197333 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.197395 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.197458 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.197520 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.197583 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.197660 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.197726 140348406654848 variables_helper.py:156] Variable [conv4_block2_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.197788 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.197850 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.197914 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.197975 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.198042 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.198106 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.198168 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.198247 140348406654848 variables_helper.py:156] Variable [conv4_block3_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.198313 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.198377 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.198439 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.198501 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.198563 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.198638 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.198704 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.198767 140348406654848 variables_helper.py:156] Variable [conv4_block3_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.198829 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.198892 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.198953 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.199014 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.199076 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.199137 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.199199 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.199280 140348406654848 variables_helper.py:156] Variable [conv4_block3_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.199342 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.199404 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.199465 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.199528 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.199590 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.199663 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.199727 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.199789 140348406654848 variables_helper.py:156] Variable [conv4_block4_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.199849 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.199911 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.199973 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.200034 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.200096 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.200160 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.200238 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.200304 140348406654848 variables_helper.py:156] Variable [conv4_block4_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.200367 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.200428 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.200490 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.200553 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.200623 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.200690 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.200752 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.200814 140348406654848 variables_helper.py:156] Variable [conv4_block4_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.200875 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.200937 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.201000 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.201062 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.201124 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.201185 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.201265 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.201329 140348406654848 variables_helper.py:156] Variable [conv4_block5_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.201390 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.201452 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.201515 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.201578 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.201653 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.201717 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.201781 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.201844 140348406654848 variables_helper.py:156] Variable [conv4_block5_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.201947 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.202023 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.202096 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.202169 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.202263 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.202339 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.202411 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.202485 140348406654848 variables_helper.py:156] Variable [conv4_block5_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.202558 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.202642 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.202719 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.202792 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.202866 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.202941 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.203015 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.203089 140348406654848 variables_helper.py:156] Variable [conv4_block6_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.203152 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.203229 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.203296 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.203359 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.203421 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.203483 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.203545 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.203607 140348406654848 variables_helper.py:156] Variable [conv4_block6_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.203684 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.203746 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.203808 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.203870 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.203934 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.203996 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.204059 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.204120 140348406654848 variables_helper.py:156] Variable [conv4_block6_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.204183 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.204265 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.204329 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.204391 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.204473 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.204540 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.204625 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.204692 140348406654848 variables_helper.py:156] Variable [conv4_block7_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.204755 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.204816 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.204876 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.204936 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.204999 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.205061 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.205122 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.205185 140348406654848 variables_helper.py:156] Variable [conv4_block7_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.205266 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.205350 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.205416 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.205482 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.205549 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.205624 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.205694 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.205769 140348406654848 variables_helper.py:156] Variable [conv4_block7_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.205830 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.205893 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.205955 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.206017 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.206113 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.206220 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.206284 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.206347 140348406654848 variables_helper.py:156] Variable [conv4_block8_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.206408 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.206469 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.206531 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.206593 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.206666 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.206730 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.206792 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.206854 140348406654848 variables_helper.py:156] Variable [conv4_block8_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.206916 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.206978 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.207039 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.207101 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.207164 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.207249 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.207316 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.207379 140348406654848 variables_helper.py:156] Variable [conv4_block8_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.207440 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.207503 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.207565 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.207636 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.207701 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.207764 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.207826 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.207888 140348406654848 variables_helper.py:156] Variable [conv4_block9_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.207950 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.208013 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.208081 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.208132 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.208188 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.208262 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.208323 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.208384 140348406654848 variables_helper.py:156] Variable [conv4_block9_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.208444 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.208506 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.208568 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.208642 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.208707 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.208769 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.208831 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.208894 140348406654848 variables_helper.py:156] Variable [conv4_block9_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.208956 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/beta] is not available in checkpoint\nW0926 04:01:19.209018 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.209080 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/gamma] is not available in checkpoint\nW0926 04:01:19.209142 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.209219 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.209286 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.209348 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_conv/kernel] is not available in checkpoint\nW0926 04:01:19.209410 140348406654848 variables_helper.py:156] Variable [conv5_block1_0_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.209471 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.209533 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.209596 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.209671 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.209735 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.209796 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.209858 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.209919 140348406654848 variables_helper.py:156] Variable [conv5_block1_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.209980 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.210041 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.210103 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.210165 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.210242 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.210307 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.210369 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.210431 140348406654848 variables_helper.py:156] Variable [conv5_block1_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.210492 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.210553 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.210624 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.210692 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.210755 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.210815 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.210876 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.210938 140348406654848 variables_helper.py:156] Variable [conv5_block1_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.211001 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.211062 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.211125 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.211187 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.211269 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.211333 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.211395 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.211457 140348406654848 variables_helper.py:156] Variable [conv5_block2_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.211519 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.211579 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.211654 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.211719 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.211782 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.211843 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.211905 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.211967 140348406654848 variables_helper.py:156] Variable [conv5_block2_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.212027 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.212090 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.212151 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.212229 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.212297 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.212360 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.212423 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.212485 140348406654848 variables_helper.py:156] Variable [conv5_block2_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.212547 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/beta] is not available in checkpoint\nW0926 04:01:19.212609 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.212684 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/gamma] is not available in checkpoint\nW0926 04:01:19.212746 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.212809 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.212872 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.212935 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_conv/kernel] is not available in checkpoint\nW0926 04:01:19.212998 140348406654848 variables_helper.py:156] Variable [conv5_block3_1_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.213060 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/beta] is not available in checkpoint\nW0926 04:01:19.213121 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.213185 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/gamma] is not available in checkpoint\nW0926 04:01:19.213265 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.213329 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.213391 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.213453 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_conv/kernel] is not available in checkpoint\nW0926 04:01:19.213514 140348406654848 variables_helper.py:156] Variable [conv5_block3_2_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.213576 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/beta] is not available in checkpoint\nW0926 04:01:19.213651 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/beta/Momentum] is not available in checkpoint\nW0926 04:01:19.213715 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/gamma] is not available in checkpoint\nW0926 04:01:19.213777 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/gamma/Momentum] is not available in checkpoint\nW0926 04:01:19.213840 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/moving_mean] is not available in checkpoint\nW0926 04:01:19.213903 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_bn/moving_variance] is not available in checkpoint\nW0926 04:01:19.213965 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_conv/kernel] is not available in checkpoint\nW0926 04:01:19.214026 140348406654848 variables_helper.py:156] Variable [conv5_block3_3_conv/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.214087 140348406654848 variables_helper.py:156] Variable [global_step] is not available in checkpoint\nW0926 04:01:19.214151 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_box_head/BoxEncodingPredictor_dense/bias] is not available in checkpoint\nW0926 04:01:19.214230 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_box_head/BoxEncodingPredictor_dense/bias/Momentum] is not available in checkpoint\nW0926 04:01:19.214299 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_box_head/BoxEncodingPredictor_dense/kernel] is not available in checkpoint\nW0926 04:01:19.214362 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_box_head/BoxEncodingPredictor_dense/kernel/Momentum] is not available in checkpoint\nW0926 04:01:19.214425 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_class_head/ClassPredictor_dense/bias] is not available in checkpoint\nW0926 04:01:19.214479 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_class_head/ClassPredictor_dense/bias/Momentum] is not available in checkpoint\nW0926 04:01:19.214537 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_class_head/ClassPredictor_dense/kernel] is not available in checkpoint\nW0926 04:01:19.214596 140348406654848 variables_helper.py:156] Variable [mask_rcnn_keras_box_predictor/mask_rcnn_class_head/ClassPredictor_dense/kernel/Momentum] is not available in checkpoint\nTraceback (most recent call last):\n File \"./train.py\", line 186, in <module>\n tf.app.run()\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/platform/app.py\", line 40, in run\n _run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)\n File \"/usr/local/lib/python3.6/dist-packages/absl/app.py\", line 300, in run\n _run_main(main, args)\n File \"/usr/local/lib/python3.6/dist-packages/absl/app.py\", line 251, in _run_main\n sys.exit(main(argv))\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/deprecation.py\", line 324, in new_func\n return func(*args, **kwargs)\n File \"./train.py\", line 182, in main\n graph_hook_fn=graph_rewriter_fn)\n File \"/usr/local/lib/python3.6/dist-packages/object_detection/legacy/trainer.py\", line 397, in train\n init_saver = tf.train.Saver(available_var_map)\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py\", line 836, in __init__\n self.build()\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py\", line 848, in build\n self._build(self._filename, build_save=True, build_restore=True)\n File \"/usr/local/lib/python3.6/dist-packages/tensorflow/python/training/saver.py\", line 873, in _build\n raise ValueError(\"No variables to save\")\nValueError: No variables to save\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51708f768a51e2d869381abe2833f33e463c6a1
| 51,371 |
ipynb
|
Jupyter Notebook
|
OSQuery/OSQueryColab.ipynb
|
jgamblin/JupyterWorkshop
|
7cae1e68e874c1c12c1ee997611eac6ccba474f8
|
[
"MIT"
] | 5 |
2021-11-15T16:21:57.000Z
|
2021-11-21T05:35:52.000Z
|
OSQuery/OSQueryColab.ipynb
|
jgamblin/JupyterWorkshop
|
7cae1e68e874c1c12c1ee997611eac6ccba474f8
|
[
"MIT"
] | null | null | null |
OSQuery/OSQueryColab.ipynb
|
jgamblin/JupyterWorkshop
|
7cae1e68e874c1c12c1ee997611eac6ccba474f8
|
[
"MIT"
] | 2 |
2021-11-15T11:34:12.000Z
|
2022-01-02T20:14:00.000Z
| 45.022787 | 154 | 0.324463 |
[
[
[
"! apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 1484120AC4E9F8A1A577AEEE97A80C63C9D8B80B\n! apt-get install software-properties-common -y\n! add-apt-repository 'deb [arch=amd64] https://pkg.osquery.io/deb deb main'\n! apt-get update -y\n! apt-get install osquery -y",
"Executing: /tmp/apt-key-gpghome.lQM9PFD9sC/gpg.1.sh --keyserver keyserver.ubuntu.com --recv-keys 1484120AC4E9F8A1A577AEEE97A80C63C9D8B80B\ngpg: key 97A80C63C9D8B80B: \"osquery (osquery) <[email protected]>\" not changed\ngpg: Total number processed: 1\ngpg: unchanged: 1\nReading package lists... Done\nBuilding dependency tree \nReading state information... Done\nsoftware-properties-common is already the newest version (0.96.24.32.14).\nThe following package was automatically installed and is no longer required:\n libnvidia-common-460\nUse 'apt autoremove' to remove it.\n0 upgraded, 0 newly installed, 0 to remove and 61 not upgraded.\nHit:1 http://security.ubuntu.com/ubuntu bionic-security InRelease\nHit:2 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease\nIgn:3 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease\nHit:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease\nIgn:5 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease\nHit:6 http://archive.ubuntu.com/ubuntu bionic InRelease\nHit:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release\nHit:8 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release\nHit:9 https://pkg.osquery.io/deb deb InRelease\nHit:10 http://archive.ubuntu.com/ubuntu bionic-updates InRelease\nHit:11 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease\nHit:12 http://archive.ubuntu.com/ubuntu bionic-backports InRelease\nHit:13 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease\nHit:14 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease\nReading package lists... Done\nHit:1 http://security.ubuntu.com/ubuntu bionic-security InRelease\nIgn:2 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease\nHit:3 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease\nHit:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease\nHit:5 http://archive.ubuntu.com/ubuntu bionic InRelease\nIgn:6 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease\nHit:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release\nHit:8 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release\nHit:9 http://archive.ubuntu.com/ubuntu bionic-updates InRelease\nHit:10 https://pkg.osquery.io/deb deb InRelease\nHit:11 http://archive.ubuntu.com/ubuntu bionic-backports InRelease\nHit:12 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease\nHit:13 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease\nHit:14 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease\nReading package lists... Done\nReading package lists... Done\nBuilding dependency tree \nReading state information... Done\nosquery is already the newest version (5.0.1-1.linux).\nThe following package was automatically installed and is no longer required:\n libnvidia-common-460\nUse 'apt autoremove' to remove it.\n0 upgraded, 0 newly installed, 0 to remove and 61 not upgraded.\n"
],
[
"# ! osqueryi --json 'select * from deb_packages' > packages.json\n! osqueryi --json 'select * from apps' > packages.json\nimport pandas as pd\n\npackages_df = pd.read_json('packages.json')\npackages_df.head(10)",
"_____no_output_____"
],
[
"! osqueryi --json 'SELECT * FROM system_info;' > system_info.json\nsystem_df = pd.read_json('system_info.json')\nsystem_df",
"_____no_output_____"
],
[
"! osqueryi --json 'select * from suid_bin ;' > suid.json\nsuid_df = pd.read_json('suid.json')\nsuid_df",
"_____no_output_____"
],
[
"! osqueryi --json 'select * from listening_ports' > ports.json\nports_df = pd.read_json('ports.json')\nports_df[ports_df.port > 1]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
c51711329171daf7e1d81c5f0adce3157cfc9e3a
| 3,628 |
ipynb
|
Jupyter Notebook
|
data_vocabulary.ipynb
|
Pit-Storm/watch-your-data
|
8e86f75b06ce185b1e43004f929b633eed6823ac
|
[
"MIT"
] | null | null | null |
data_vocabulary.ipynb
|
Pit-Storm/watch-your-data
|
8e86f75b06ce185b1e43004f929b633eed6823ac
|
[
"MIT"
] | null | null | null |
data_vocabulary.ipynb
|
Pit-Storm/watch-your-data
|
8e86f75b06ce185b1e43004f929b633eed6823ac
|
[
"MIT"
] | null | null | null | 24.849315 | 91 | 0.51075 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"#df_news.to_pickle(\"data/data_preprocessed.pickle\")\n\ndf_news = pd.read_pickle(\"data/data_preprocessed.pickle\")",
"_____no_output_____"
]
],
[
[
"### Replace rare words with ```<unk>``` \n\nKeeping only 40k most frequent words",
"_____no_output_____"
]
],
[
[
"def create_word_freq(tokenlist, wordfreq):\n \"\"\"\n Create the word frequency list\n \n return: dict containing rokens with freq\n *args: list of tokens and deict of wordfreq\n \"\"\"\n \n for token in tokenlist:\n if token in wordfreq:\n wordfreq[token] += 1\n else:\n wordfreq[token] = 1\n return wordfreq\n\ntokenfreq = {}\n\nfor row in df_news.itertuples(index=False,name=\"tuple\"):\n tokenfreq = create_word_freq(row[1],tokenfreq)\n tokenfreq = create_word_freq(row[2],tokenfreq)\n\ntokenfreq = {k: v for k, v in sorted(tokenfreq.items(), key=lambda item: item[1])}\n\nprint(\"The Corpus has {} different tokens.\".format(len(tokenfreq)))\ntokenfreq = set(list(tokenfreq.keys())[-40000:])\nprint(\"We kept only the 40k most frequent.\")",
"_____no_output_____"
],
[
"def repl_rare(tokenlist):\n \"\"\"\n replace rare words with <unk>\n \n return: tokenlist\n *args: tokenlist\n \"\"\"\n for idx in range(len(tokenlist)):\n if tokenlist[idx] not in tokenfreq:\n tokenlist[idx] = \"<unk>\"\n return tokenlist\n\ndf_news[\"Headline\"] = df_news[\"Headline\"].apply(repl_rare)\ndf_news[\"Content\"] = df_news[\"Content\"].apply(repl_rare)",
"_____no_output_____"
]
],
[
[
"### Adding ```<eos>``` to the end of content list",
"_____no_output_____"
]
],
[
[
"def add_eos(tokenlist):\n \"\"\"\n adds <eos> token to end of list\n \"\"\"\n tokenlist.append(\"<eos>\")\n return tokenlist\n\ndf_news[\"Headline\"] = df_news[\"Headline\"].apply(add_eos)\ndf_news[\"Content\"] = df_news[\"Content\"].apply(add_eos)",
"_____no_output_____"
],
[
"df_news.to_pickle(\"data/data_vocab.pickle\")\n\n#df_news = pd.read_pickle(\"data/data_preprocessed.pickle\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c5171574577318cd205c6a389b28078ddff3c795
| 683,153 |
ipynb
|
Jupyter Notebook
|
texts_analysis.ipynb
|
ShalyginaA/artificial-or-real
|
57b8ace7703279b8ff5653b31c015855d99667ee
|
[
"MIT"
] | null | null | null |
texts_analysis.ipynb
|
ShalyginaA/artificial-or-real
|
57b8ace7703279b8ff5653b31c015855d99667ee
|
[
"MIT"
] | null | null | null |
texts_analysis.ipynb
|
ShalyginaA/artificial-or-real
|
57b8ace7703279b8ff5653b31c015855d99667ee
|
[
"MIT"
] | null | null | null | 44.531191 | 1,408 | 0.519118 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"sns.set(color_codes=True)",
"_____no_output_____"
],
[
"# makes inline plots to have better quality\n%config InlineBackend.figure_format = 'svg'\n\n# Set the default style\nplt.style.use(\"seaborn\") ",
"_____no_output_____"
]
],
[
[
"### Read the data and rename columns ",
"_____no_output_____"
]
],
[
[
"df = pd.read_excel(\"texts_data.xlsx\")",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"len(df.columns)",
"_____no_output_____"
],
[
"df.drop(['Unnamed: 0'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"column_names = ['Timestamp', 'score', 'gender', 'age', 'education', 'country', 'know_ai', 'similar_tests', 'english']",
"_____no_output_____"
],
[
"wc_columns = []\nfor i in range(1,9):\n column_names.append(\"q\" + str(i))\n column_names.append(\"wc\" + str(i))\n wc_columns.append(\"wc\" + str(i))",
"_____no_output_____"
],
[
"df.columns = column_names",
"_____no_output_____"
],
[
"#string score to score\ndef total_score(string):\n return int(string[0])\n#string percentage to float\ndef p2f(x):\n return x.str.rstrip('%').astype('float')/100",
"_____no_output_____"
],
[
"df['score'] = df['score'].apply(total_score)\ndf[wc_columns] = df[wc_columns].apply(p2f, axis=1)",
"_____no_output_____"
],
[
"#q1-q4: simple questions\n#q5-q8: comparison questions\ndf.head()",
"_____no_output_____"
]
],
[
[
"### Plots",
"_____no_output_____"
],
[
"#### 1. Time graph (for all data)",
"_____no_output_____"
]
],
[
[
"df_images = pd.read_excel(\"images_data.xlsx\")\ndf_sounds = pd.read_excel(\"sounds_data.xlsx\")\n\ndf_images['date'] = pd.to_datetime(df_images['Timestamp']).dt.date\ndf_sounds['date'] = pd.to_datetime(df_sounds['Timestamp']).dt.date",
"_____no_output_____"
],
[
"df['date'] = pd.to_datetime(df['Timestamp']).dt.date",
"/home/anastasiia/anaconda3/lib/python3.6/site-packages/dateutil/parser/_parser.py:1206: UnknownTimezoneWarning: tzname EET identified but not understood. Pass `tzinfos` argument in order to correctly return a timezone-aware datetime. In a future version, this will raise an exception.\n category=UnknownTimezoneWarning)\n"
],
[
"df_all = pd.concat([df.date, df_sounds.date, df_images.date], axis=1)\ndf_all.columns = ['texts', 'sounds', 'images']",
"_____no_output_____"
],
[
"hist1 = df_all.texts.value_counts().plot()\nhist2 = df_all.sounds.value_counts().plot()\nhist3 = df_all.images.value_counts().plot()\nplt.title('Response number by date')\nplt.legend(prop={'size': 12}, frameon=True, facecolor='white')\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 2. Age distribution",
"_____no_output_____"
]
],
[
[
"sns.countplot(pd.cut(df['age'],\n bins=[0,20,30,40,50,100], \n labels=[\"<20\",\"20-30\",\"30-40\",\"40-50\",\">50\"]), \n color=\"royalblue\")\nplt.title('Age distribution, texts')\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 3. Worked on/studied AI",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(5,5.5))\nax.pie(df['know_ai'].value_counts(),explode=(0.05,0),labels=[\"didn't work on/study AI\",'worked on/studied AI'], autopct='%1.1f%%',\n shadow=True, startangle=90)\nplt.title(\"Texts\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 4. Passed similar tests before",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(5,5.5))\nax.pie(df['similar_tests'].value_counts(),explode=(0.05,0),labels=[\"didn't pass similar tests before\",\"passed similar tests before\"], autopct='%1.1f%%',\n shadow=True, startangle=90)\nplt.title(\"Texts\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 5. Country of origin pie plot",
"_____no_output_____"
]
],
[
[
"temp_df = df['country'].value_counts()\ntemp_df2 = temp_df.head(4)\nif len(temp_df) > 4:\n temp_df2['Others'.format(len(temp_df) - 4)] = sum(temp_df[4:])",
"_____no_output_____"
],
[
"temp_df2",
"_____no_output_____"
],
[
"list(temp_df2.index)",
"_____no_output_____"
],
[
"#country of origin pie plot\nfig, ax = plt.subplots(figsize=(7,6.5))\nax.pie(temp_df2, autopct='%1.1f%%',\n shadow=True, startangle=90, textprops={'fontsize': 10}, labels = list(temp_df2.index))\nplt.title(\"Country of origin\")\nplt.show()",
"_____no_output_____"
],
[
"# country of origin historgam\nhist = sns.countplot(x = 'country',\n data = df,\n order = df['country'].value_counts().index,\n color = \"royalblue\")\nhist.set_xticklabels(hist.get_xticklabels(), rotation=90)\nplt.title(\"Country of origin, images\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 6. English level",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(5,5.5))\nax.pie(df['english'].value_counts(),explode=(0.07,0.07,0.07,0.07),labels=[\"Proficient/Advanced\",\n \"Upper-Intermediate/Intermediate\",\n \"Elementary/Beginner\",\n \"Native\"],\n autopct='%1.1f%%',\n shadow=True, startangle=90)\nplt.title(\"English level, texts\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 7. Scores distribution",
"_____no_output_____"
]
],
[
[
"hist = sns.countplot(x = 'score',\n data = df,\n color = \"royalblue\")\nhist.set_xticklabels(hist.get_xticklabels(), rotation=90)\nplt.title(\"Scores distribution, texts\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"******************",
"_____no_output_____"
],
[
"#### Map question columns into 0/1",
"_____no_output_____"
]
],
[
[
"#dictionaries for mapping\n\n# q1, q4\nd1 = {\"Probably AI\" : 1,\n \"Definitely AI\": 1,\n \"I don't know\": 0,\n \"Probably human\": 0,\n \"Definitely human\": 0}\n\n#q2, q3\nd2 = {\"Probably AI\" : 0,\n \"Definitely AI\": 0,\n \"I don't know\": 0,\n \"Probably human\": 1,\n \"Definitely human\": 1}\n\n#q5, q6, q7\nd4 = {\"Definitely A=AI, B=human\": 1,\n \"Probably A=AI, B=human\": 1,\n \"I don't know\": 0,\n \"Definitely A=human, B=AI\": 0,\n \"Probably A=human, B=AI\": 0}\n\n#q8\nd3 = {\"Definitely A=AI, B=human\": 0,\n \"Probably A=AI, B=human\": 0,\n \"I don't know\": 0,\n \"Definitely A=human, B=AI\": 1,\n \"Probably A=human, B=AI\": 1}",
"_____no_output_____"
],
[
"df_mapped = df.copy()\n\ncolumns1 = [\"q1\", \"q4\"]\nfor col in columns1:\n df_mapped[col] = df[col].map(d1)\n \ncolumns2 = [\"q2\", \"q3\"]\nfor col in columns2:\n df_mapped[col] = df[col].map(d2)\n\ncolumns3 = [\"q5\", \"q6\", \"q7\"]\nfor col in columns3:\n df_mapped[col] = df[col].map(d3)\n\ncolumns4 = [\"q8\"]\nfor col in columns4:\n df_mapped[col] = df[col].map(d4)",
"_____no_output_____"
],
[
"df_mapped.head()",
"_____no_output_____"
]
],
[
[
"****************************",
"_____no_output_____"
]
],
[
[
"simple_questions = ['q1','q2','q3','q4']\ncomparison_questions = ['q5','q6','q7','q8']",
"_____no_output_____"
],
[
"df_mapped['simple_sum'] = df_mapped[simple_questions].sum(axis=1)\ndf_mapped['comparison_sum'] = df_mapped[comparison_questions].sum(axis=1)",
"_____no_output_____"
]
],
[
[
"#### 8. Scores distribution, simple questions vs comparison questions",
"_____no_output_____"
]
],
[
[
"simple_average = np.round(np.sum(df_mapped['simple_sum'])/df_mapped.shape[0],2)\ncomparison_average = np.round(np.sum(df_mapped['comparison_sum'])/df_mapped.shape[0],2)",
"_____no_output_____"
],
[
"fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10,5))\n\nhist1 = sns.countplot(x = 'simple_sum',\n data = df_mapped,\n color = \"royalblue\",\n ax = ax1)\nax1.set_xlabel('score')\nax1.set_title('Simple questions, average: ' + str(simple_average))\n\nhist2 = sns.countplot(x = 'comparison_sum',\n data = df_mapped,\n color = \"royalblue\",\n ax = ax2)\nax2.set_xlabel('score')\nax2.set_title('Comparison questions, average: ' + str(comparison_average))\n\nfig.suptitle(\"Scores distribution, texts\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### 9. Question average score vs wisdom of the crowd",
"_____no_output_____"
]
],
[
[
"score_columns = [column for column in df_mapped.columns if column.startswith('q')]",
"_____no_output_____"
],
[
"score_columns",
"_____no_output_____"
],
[
"questions_average = np.sum(df_mapped[score_columns], axis = 0)/df_mapped.shape[0]",
"_____no_output_____"
],
[
"questions_average = np.round(questions_average*100,2)",
"_____no_output_____"
],
[
"questions_average",
"_____no_output_____"
],
[
"wc_to_invert = ['wc1', 'wc4', 'wc8']",
"_____no_output_____"
],
[
"#invert wisdom of the crowd columns when needed\ndf_mapped_inverted = df_mapped.copy()\ndf_mapped_inverted[wc_to_invert] = np.array([[1]*3]*df_mapped.shape[0]) - df_mapped[wc_to_invert]",
"_____no_output_____"
],
[
"wc_average = np.sum(df_mapped_inverted[wc_columns], axis = 0)/df_mapped.shape[0]\nwc_average = np.round(wc_average*100,2)",
"_____no_output_____"
],
[
"wc_average",
"_____no_output_____"
],
[
"N = 8\nind = np.arange(N) # the x locations for the groups\nwidth = 0.3 # the width of the bars\n\nfig = plt.figure(figsize=(10,5))\nax = fig.add_subplot(111)\n\nbars_q = ax.bar(ind, questions_average, width, color='r')\nbars_wc = ax.bar(ind+width, wc_average, width, color='b')\n\nax.set_ylabel('%')\nax.set_xticks(ind+width)\nax.set_xticklabels(score_columns)\nax.legend( (bars_q[0], bars_wc[0]), ('Question average', 'W-of-C average') , frameon=True, facecolor='white')\n\n\nplt.title(\"Percent of correct answers vs Wisdom-of-the-Crowd score, texts\")\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"#### 10. Scores by English level",
"_____no_output_____"
]
],
[
[
"df_mapped.english.value_counts()",
"_____no_output_____"
],
[
"adv_eng_df = df_mapped[df_mapped.english.isin(['Proficient/Advanced', 'Native'])]\nnot_adv_eng_df = df_mapped[~df_mapped.english.isin(['Proficient/Advanced', 'Native'])]",
"_____no_output_____"
],
[
"eng_score_aver = np.round(np.sum(adv_eng_df['score'])/adv_eng_df.shape[0],2)\nnot_eng_score_aver = np.round(np.sum(not_know_ai_df['score'])/not_know_ai_df.shape[0],2)",
"_____no_output_____"
],
[
"ai_score_aver",
"_____no_output_____"
],
[
"not_ai_score_aver",
"_____no_output_____"
],
[
"adv_eng_average = np.sum(adv_eng_df[score_columns], axis = 0)/adv_eng_df.shape[0]\nadv_eng_average = np.round(adv_eng_average*100,2)\nadv_eng_average",
"_____no_output_____"
],
[
"not_adv_eng_average = np.sum(not_adv_eng_df[score_columns], axis = 0)/not_adv_eng_df.shape[0]\nnot_adv_eng_average = np.round(not_adv_eng_average*100,2)\nnot_adv_eng_average",
"_____no_output_____"
],
[
"N = 8\nind = np.arange(N) # the x locations for the groups\nwidth = 0.3 # the width of the bars\n\nfig = plt.figure(figsize=(10,5))\nax = fig.add_subplot(111)\n\nbars_adv = ax.bar(ind, adv_eng_average, width, color='r')\nbars_not_adv = ax.bar(ind+width, not_adv_eng_average, width, color='b')\n\nax.set_ylabel('%')\nax.set_xticks(ind+width)\nax.set_xticklabels(score_columns)\nax.legend( (bars_adv[0], bars_not_adv[0]), ('Advanced/Native English level', 'Intermediate and less') , frameon=True, facecolor='white')\n\n\nplt.title(\"Score based on English level, texts\")\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"#### 11. Scores by knowledge of AI",
"_____no_output_____"
]
],
[
[
"df_mapped.know_ai.value_counts()",
"_____no_output_____"
],
[
"know_ai_df = df_mapped[df_mapped.know_ai=='Yes']\nnot_know_ai_df = df_mapped[df_mapped.know_ai=='No']",
"_____no_output_____"
],
[
"ai_score_aver = np.round(np.sum(know_ai_df['score'])/know_ai_df.shape[0],2)\nnot_ai_score_aver = np.round(np.sum(not_know_ai_df['score'])/not_know_ai_df.shape[0],2)",
"_____no_output_____"
],
[
"ai_score_aver",
"_____no_output_____"
],
[
"not_ai_score_aver",
"_____no_output_____"
],
[
"know_ai_average = np.sum(know_ai_df[score_columns], axis = 0)/know_ai_df.shape[0]\nknow_ai_average = np.round(know_ai_average*100,2)\n\nnot_know_ai_average = np.sum(not_know_ai_df[score_columns], axis = 0)/not_know_ai_df.shape[0]\nnot_know_ai_average = np.round(not_know_ai_average*100,2)",
"_____no_output_____"
],
[
"N = 8\nind = np.arange(N) # the x locations for the groups\nwidth = 0.3 # the width of the bars\n\nfig = plt.figure(figsize=(10,5))\nax = fig.add_subplot(111)\n\nbars_ai = ax.bar(ind, know_ai_average, width, color='r')\nbars_not_ai = ax.bar(ind+width, not_know_ai_average, width, color='b')\n\nax.set_ylabel('%')\nax.set_xticks(ind+width)\nax.set_xticklabels(score_columns)\nax.legend( (bars_ai[0], bars_not_ai[0]), ('Worked with AI, average score: ' + str(ai_score_aver), 'Did not work with AI, average score: ' + str(not_ai_score_aver)) , frameon=True, facecolor='white')\n\n\nplt.title(\"Score by knowledge of AI, texts\")\nplt.show()\n",
"_____no_output_____"
],
[
"not_adv_eng_average = np.sum(not_adv_eng_df[score_columns], axis = 0)/not_adv_eng_df.shape[0]\nnot_adv_eng_average = np.round(not_adv_eng_average*100,2)\nnot_adv_eng_average",
"_____no_output_____"
]
],
[
[
"#### 12. Scores by education level",
"_____no_output_____"
]
],
[
[
"df_mapped.education.value_counts()",
"_____no_output_____"
],
[
"masters_and_higher_df = df_mapped[df_mapped.education.isin([\"Master's\", \"PhD\"])]\nbachelor_and_lower_df = df_mapped[~df_mapped.education.isin([\"Master's\", \"PhD\"])]",
"_____no_output_____"
],
[
"masters_and_higher_average = np.sum(masters_and_higher_df[score_columns], axis = 0)/masters_and_higher_df.shape[0]\nmasters_and_higher_average = np.round(masters_and_higher_average*100,2)\n\nbachelor_and_lower_average = np.sum(bachelor_and_lower_df[score_columns], axis = 0)/bachelor_and_lower_df.shape[0]\nbachelor_and_lower_average = np.round(bachelor_and_lower_average*100,2)",
"_____no_output_____"
],
[
"higher_score_aver = np.round(np.sum(masters_and_higher_df['score'])/masters_and_higher_df.shape[0],2)\nlower_score_aver = np.round(np.sum(bachelor_and_lower_df['score'])/bachelor_and_lower_df.shape[0],2)",
"_____no_output_____"
],
[
"N = 8\nind = np.arange(N) # the x locations for the groups\nwidth = 0.3 # the width of the bars\n\nfig = plt.figure(figsize=(10,5))\nax = fig.add_subplot(111)\n\nbars_higher = ax.bar(ind, masters_and_higher_average, width, color='r')\nbars_lower = ax.bar(ind+width, bachelor_and_lower_average, width, color='b')\n\nax.set_ylabel('%')\nax.set_xticks(ind+width)\nax.set_xticklabels(score_columns)\nax.legend( (bars_higher[0], bars_lower[0]), (\"Master's/PhD, average score: \" + str(higher_score_aver), \"Bachelor's/High School, average score: \" + str(lower_score_aver)) , frameon=True, facecolor='white')\n\n\nplt.title(\"Score by education level, texts\")\nplt.show()\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
c51736bcffa00478d0164171751be9f45738917e
| 3,817 |
ipynb
|
Jupyter Notebook
|
staging/arrays_strings/reverse_words/reverse_words_challenge.ipynb
|
filippovitale/interactive-coding-challenges
|
8380a7aa98618c3cc9c0271c30bd320937d431ad
|
[
"Apache-2.0"
] | null | null | null |
staging/arrays_strings/reverse_words/reverse_words_challenge.ipynb
|
filippovitale/interactive-coding-challenges
|
8380a7aa98618c3cc9c0271c30bd320937d431ad
|
[
"Apache-2.0"
] | null | null | null |
staging/arrays_strings/reverse_words/reverse_words_challenge.ipynb
|
filippovitale/interactive-coding-challenges
|
8380a7aa98618c3cc9c0271c30bd320937d431ad
|
[
"Apache-2.0"
] | 1 |
2020-01-05T11:28:00.000Z
|
2020-01-05T11:28:00.000Z
| 24.467949 | 274 | 0.542835 |
[
[
[
"<small> <i> This notebook was prepared by Marco Guajardo. For license visit [github](https://github.com/donnemartin/interactive-coding-challenges) </i> </small>\n.",
"_____no_output_____"
],
[
"# Challenge Notebook\n",
"_____no_output_____"
],
[
"## Problem: Given a string of words, return a string with the words in reverse",
"_____no_output_____"
],
[
"* [Constraits](#Constraint)\n* [Test Cases](#Test-Cases)\n* [Algorithm](#Algorithm)\n* [Code](#Code)\n* [Unit Test](#Unit-Test)\n* [Solution Notebook](#Solution-Notebook)",
"_____no_output_____"
],
[
"## Constraints\n* Can we assume the string is ASCII?\n * Yes\n* Is whitespace important?\n * no the whitespace does not change\n* Is this case sensitive?\n * yes\n* What if the string is empty?\n * return None\n* Is the order of words important?\n * yes\n",
"_____no_output_____"
],
[
"## Test Cases\n* Empty string -> None\n* \"the sun is very hot\" -> \"eht nus si yrev toh\"\n",
"_____no_output_____"
],
[
"## Algorithm\n* Refer to the [Solution](https://github.com/donnemartin/interactive-coding-challenges/blob/master/arrays_strings/reverse_words/reverse_words_solution.ipynb) if you are stuck and need a hint, the solution notebook's algorithm discussion might be a good place to start.",
"_____no_output_____"
],
[
"## Code ",
"_____no_output_____"
]
],
[
[
"def reverse_words (S):\n #TODO: implement me\n pass ",
"_____no_output_____"
]
],
[
[
"## Unit Test\n<b> The following unit test is expected to fail until you solve challenge </b>",
"_____no_output_____"
]
],
[
[
"from nose.tools import assert_equal\n\nclass UnitTest (object):\n def testReverseWords(self):\n assert_equal(func('the sun is hot'), 'eht nus si toh')\n assert_equal(func(''), None)\n assert_equal(func('123 456 789'), '321 654 987')\n assert_equal(func('magic'), 'cigam')\n print('Success: reverse_words')\n \ndef main():\n test = UnitTest()\n test.testReverseWords()\n\nif __name__==\"__main__\":\n main()",
"_____no_output_____"
]
],
[
[
"## Solution Notebook\n* Review the [Solution Notebook](https://github.com/donnemartin/interactive-coding-challenges/blob/master/arrays_strings/reverse_words/reverse_words_solution.ipynb) for discussion on algorithms and code solutions.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c517372beca93eaea4c047766bbae77ad9f3781c
| 1,002,165 |
ipynb
|
Jupyter Notebook
|
code/notebooks/miscellaneous.ipynb
|
Subhasishbasak/emoji_analysis
|
76407ac7a755bf25ecee995f6d6c9be6bb467bf5
|
[
"MIT"
] | 2 |
2020-05-15T10:46:21.000Z
|
2021-01-09T20:18:59.000Z
|
code/notebooks/miscellaneous.ipynb
|
Subhasishbasak/emoji_analysis
|
76407ac7a755bf25ecee995f6d6c9be6bb467bf5
|
[
"MIT"
] | 5 |
2020-05-06T20:34:04.000Z
|
2020-05-16T16:09:25.000Z
|
code/notebooks/miscellaneous.ipynb
|
Subhasishbasak/emoji_analysis
|
76407ac7a755bf25ecee995f6d6c9be6bb467bf5
|
[
"MIT"
] | 1 |
2020-05-13T14:21:55.000Z
|
2020-05-13T14:21:55.000Z
| 880.637083 | 131,512 | 0.952538 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport emoji\nimport pickle\nimport cv2\nimport matplotlib.pyplot as plt\nimport os",
"_____no_output_____"
],
[
"sentiment_data = pd.read_csv(\"../../resource/Emoji_Sentiment_Ranking/Emoji_Sentiment_Data_v1.0.csv\")",
"_____no_output_____"
],
[
"sentiment_data.head()",
"_____no_output_____"
],
[
"def clean(x):\n x = x.replace(\" \", \"-\").lower()\n return str(x)\n\nsentiment_data['Unicode name'] = sentiment_data['Unicode name'].apply(clean)",
"_____no_output_____"
],
[
"sentiment_data.head()",
"_____no_output_____"
],
[
"score_dict = {}\nfor i in range(len(sentiment_data)) : \n score_dict[sentiment_data.loc[i, \"Unicode name\"]] = [sentiment_data.loc[i, \"Negative\"]/sentiment_data.loc[i, \"Occurrences\"],\n sentiment_data.loc[i, \"Neutral\"]/sentiment_data.loc[i, \"Occurrences\"],\n sentiment_data.loc[i, \"Positive\"]/sentiment_data.loc[i, \"Occurrences\"]]",
"_____no_output_____"
],
[
"score_dict['angry-face']",
"_____no_output_____"
]
],
[
[
"### Dumping name_2_score as pickle file",
"_____no_output_____"
]
],
[
[
"with open('../../lib/score_dict.pickle', 'wb') as handle:\n pickle.dump(score_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)",
"_____no_output_____"
],
[
"with open('../../lib/score_dict.pickle', 'rb') as handle:\n score_dict = pickle.load(handle)\n",
"_____no_output_____"
]
],
[
[
"### First transform the screenshot to process-able image",
"_____no_output_____"
],
[
"#### for that we need to import the module `ss_to_image` first",
"_____no_output_____"
]
],
[
[
"import os,sys,inspect\ncurrentdir = os.path.dirname(os.path.abspath(inspect.getfile(inspect.currentframe())))\nparentdir = os.path.dirname(currentdir)\nsys.path.insert(0,parentdir) \n\nprint(currentdir)\nprint(parentdir)\n",
"/media/subhasish/Professional/emoji_project/code/notebooks\n/media/subhasish/Professional/emoji_project/code\n"
],
[
"sys.path\n",
"_____no_output_____"
],
[
"from utils.ss_to_image import final_crop",
"_____no_output_____"
],
[
"cropped_image = final_crop('../../resource/screenshots/Rohan.jpeg')\nimg = cropped_image",
"_____no_output_____"
],
[
"plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Image pre-processing",
"_____no_output_____"
]
],
[
[
"img.shape",
"_____no_output_____"
]
],
[
[
"#### Resizing image : dim = (560, 280) / ALREADY DONE THO..",
"_____no_output_____"
]
],
[
[
"dim = (560,280)\nresized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA) ",
"_____no_output_____"
],
[
"plt.imshow(cv2.cvtColor(resized, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
],
[
"resized.shape",
"_____no_output_____"
],
[
"n_col = resized.shape[1]//2\n \nimg_left = resized[:, :n_col]\nprint(\"img_left\",img_left.shape)\n\nimg_right = resized[:, n_col:]\nprint(\"img_right\",img_right.shape)",
"img_left (280, 280, 3)\nimg_right (280, 280, 3)\n"
],
[
"plt.imshow(cv2.cvtColor(img_left, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
],
[
"plt.imshow(cv2.cvtColor(img_right, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
],
[
"i = 1\nj = 0\ntemp = img_right[i*70:(i+1)*70,j*70:(j+1)*70]\nplt.imshow(cv2.cvtColor(temp, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Final code for image processing",
"_____no_output_____"
]
],
[
[
"# takes input the image outputs the extracted emojis as np-arrays\ndef image_2_emoji(file_path):\n \n def to_half(image):\n \n n_col = image.shape[1]//2\n\n img_left = image[:, :n_col]\n img_right = image[:, n_col:]\n\n return (img_left, img_right)\n\n def extract_from_half(image):\n \n emoji_list = []\n for i in range(4):\n for j in range(4):\n temp = image[i*70:(i+1)*70,j*70:(j+1)*70]\n emoji_list.append(temp)\n return emoji_list\n \n img = cv2.imread(file_path)\n \n dim = (560,280)\n resized = cv2.resize(img, dim, interpolation = cv2.INTER_AREA) \n \n halfed = to_half(resized)\n \n output = extract_from_half(halfed[0])\n output += extract_from_half(halfed[1])\n \n return output",
"_____no_output_____"
],
[
"template = cv2.imread('../../resource/emoji_database/smiling-face-with-sunglasses_1f60e.png')\n\ndim = (50,50)\ntemplate = cv2.resize(template, dim, interpolation = cv2.INTER_AREA) \n\nplt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Each emoji after extraction has shape (70 $\\times$ 70)\n### Each template has size shape (50 $\\times$ 50)",
"_____no_output_____"
]
],
[
[
"# Takes file_path of the screenshot as input and outputs the predicted list of names of the emojis\ndef emoji_2_name(file_path, method = 'cv2.TM_SQDIFF_NORMED'):\n \n '''\n available methods : 'cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',\n 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED'\n '''\n \n methods = eval(method)\n emoji_list = image_2_emoji(file_path)\n emoji_name_list = [0]*len(emoji_list)\n output = [0]*len(emoji_list)\n \n for i in os.listdir('../resource/emoji_database'):\n \n template = cv2.imread('../resource/emoji_database/' + str(i))\n dim = (50,50)\n template = cv2.resize(template, dim, interpolation = cv2.INTER_AREA) \n\n for j in range(len(emoji_list)):\n \n res = cv2.matchTemplate(emoji_list[j][:, :, 0] ,template[:, :, 0],methods)\n\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n try:\n if emoji_name_list[j][0]>min_val:\n emoji_name_list[j] = (min_val, i)\n except TypeError:\n emoji_name_list[j] = (min_val, i)\n output[j] = emoji_name_list[j][1].split('_')[0]\n \n #return emoji_name_list \n return output\n ",
"_____no_output_____"
]
],
[
[
"#### Function to compute the sentiment score from the screenshots ",
"_____no_output_____"
]
],
[
[
"# takes the creenshot as input and returns the score\ndef name_2_score(file_path):\n \n output = None\n emoji_name_list = image_2_name(file_path)\n for i in emoji_name_list:\n try:\n output = np.add(output,np.array(score_dict[i]))\n except TypeError:\n output = np.array(score_dict[i])\n except KeyError:\n pass\n \n return output/np.sum(output)",
"_____no_output_____"
]
],
[
[
"## ROUGH",
"_____no_output_____"
]
],
[
[
"import cv2\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\nimg = cv2.imread('../../resource/screenshots/Arka.jpeg',0)\n#img = im2_right[:, :, 2] \nimg2 = img.copy()\ntemplate = cv2.imread('../../resource/emoji_database/face-savouring-delicious-food_1f60b.png',0)\n#template = template[:, :, 2] \nw, h = template.shape[::-1]\n\n# All the 6 methods for comparison in a list\nmethods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',\n 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']\n\nfor meth in methods:\n img = img2.copy()\n method = eval(meth)\n\n # Apply template Matching\n res = cv2.matchTemplate(img,template,method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n\n # If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum\n if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:\n top_left = min_loc\n else:\n top_left = max_loc\n bottom_right = (top_left[0] + w, top_left[1] + h)\n\n cv2.rectangle(img,top_left, bottom_right, 255, 2)\n\n plt.subplot(121),plt.imshow(res,cmap = 'gray')\n plt.title('Matching Result'), plt.xticks([]), plt.yticks([])\n plt.subplot(122),plt.imshow(img,cmap = 'gray')\n plt.title('Detected Point'), plt.xticks([]), plt.yticks([])\n plt.suptitle(meth)\n\n plt.show()",
"_____no_output_____"
],
[
"res.shape",
"_____no_output_____"
],
[
"from PIL import Image\nfrom matplotlib import pyplot",
"_____no_output_____"
],
[
"cv2.imshow(res, map = 'gray')",
"_____no_output_____"
],
[
"\n\nplt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))\nplt.show()",
"_____no_output_____"
],
[
"plt.imshow(cv2.cvtColor(res, cv2.COLOR_BGR2RGB))\nplt.show()",
"Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\n"
],
[
"img",
"_____no_output_____"
],
[
"for i in template:\n for j in range(len(i)):\n if i[j]==0:\n i[j]=26\n \n \n ",
"_____no_output_____"
],
[
"template",
"_____no_output_____"
],
[
"min_val, max_val, min_loc, max_loc",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517390e27e0d384770a6c00e991c432514c1c28
| 186,421 |
ipynb
|
Jupyter Notebook
|
AIR_IMPURITY DATA SET ANALYSIS (1).ipynb
|
patrasoumyaranjan1999/air-impurity-data-set-analysis-using-machine-learning
|
3845e3adb86c0e614580b0db13ebc86cf65bcb95
|
[
"MIT"
] | null | null | null |
AIR_IMPURITY DATA SET ANALYSIS (1).ipynb
|
patrasoumyaranjan1999/air-impurity-data-set-analysis-using-machine-learning
|
3845e3adb86c0e614580b0db13ebc86cf65bcb95
|
[
"MIT"
] | null | null | null |
AIR_IMPURITY DATA SET ANALYSIS (1).ipynb
|
patrasoumyaranjan1999/air-impurity-data-set-analysis-using-machine-learning
|
3845e3adb86c0e614580b0db13ebc86cf65bcb95
|
[
"MIT"
] | null | null | null | 57.644094 | 84,680 | 0.634939 |
[
[
[
"import pandas as pd\ndf=pd.read_excel(\"D:/DATA SCIENCE NOTE/AirQualityUCI.xlsx\")\ndf",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"df.keys()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df[\"RH\"].max()",
"_____no_output_____"
],
[
"df[\"RH\"].min()",
"_____no_output_____"
],
[
"len(df.loc[df[\"RH\"]==-200])",
"_____no_output_____"
],
[
"df[\"T\"].min()",
"_____no_output_____"
],
[
"df[\"T\"].max()",
"_____no_output_____"
],
[
"df[\"CO(GT)\"].min()",
"_____no_output_____"
],
[
"df[\"CO(GT)\"].max()",
"_____no_output_____"
],
[
"#REplace-200 by nan value of the dataset\nimport numpy as np\ndf.replace(-200,np.nan,inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"#find the missing values\ndf.isnull().sum()",
"_____no_output_____"
],
[
"#hence NHMC(GT) has more columns has more than 90% missing value\ndf.drop(\"NMHC(GT)\",axis=1,inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"#remove the date and time\ndf.drop(columns=[\"Date\",\"Time\"],inplace=True)\ndf.shape",
"_____no_output_____"
],
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"df.mean()",
"_____no_output_____"
],
[
"#replace the missing value by the mean of that column\ndf.replace(np.nan,df.mean(),inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"#display the corelation\ndf.corr()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\nsns.heatmap(df.corr(),annot=True,linewidth=5,linecolor=\"Black\")\nplt.figure(figsize=(20,13))",
"_____no_output_____"
],
[
"#divide the dataset into 2 parts\nX=df.drop(columns=[\"RH\"])\nY=df[\"RH\"]\nX",
"_____no_output_____"
],
[
"Y",
"_____no_output_____"
],
[
"#scale down the values of X by using StandardScaler\nfrom sklearn.preprocessing import StandardScaler\nsc=StandardScaler()\nX=sc.fit_transform(X)\nX",
"_____no_output_____"
],
[
"#split the dataset into 2 parts\nfrom sklearn.model_selection import train_test_split\nX_train,X_test,Y_train,Y_test=train_test_split(X,Y,test_size=0.2)\nX_train.shape",
"_____no_output_____"
],
[
"X_test.shape",
"_____no_output_____"
],
[
"Y_train.shape",
"_____no_output_____"
],
[
"Y_test.shape",
"_____no_output_____"
]
],
[
[
"# create the model of LINEAR REGRESSION",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\nL=LinearRegression()\n#train the model\nL.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"#test the model\nY_pred_LR=L.predict(X_test)\nY_pred_LR",
"_____no_output_____"
],
[
"Y_test.values",
"_____no_output_____"
],
[
"#find the mean squared error(mse)\nfrom sklearn.metrics import mean_squared_error\nmse=mean_squared_error(Y_pred_LR,Y_test)\nmse\n",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nrse=r2_score(Y_pred_LR,Y_test)\nrse",
"_____no_output_____"
]
],
[
[
"\n# implementation of KNN model",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsRegressor\nK=KNeighborsRegressor(n_neighbors=5)\nK.fit(X_train,Y_train)\n",
"_____no_output_____"
],
[
"Y_pred_KNN=K.predict(X_test)\nY_pred_KNN",
"_____no_output_____"
],
[
"Y_test.values\n",
"_____no_output_____"
],
[
"#find the mse\nfrom sklearn.metrics import mean_squared_error\nmse=mean_squared_error(Y_pred_KNN,Y_test)\nmse",
"_____no_output_____"
],
[
"#find the rse\nfrom sklearn.metrics import r2_score\nrse=r2_score(Y_pred_KNN,Y_test)\nrse",
"_____no_output_____"
]
],
[
[
"# implementatiin DECISSION TREE REGRESSOR",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeRegressor\nD=DecisionTreeRegressor()\nD.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"Y_pred_Tree=D.predict(X_test)\nY_pred_Tree",
"_____no_output_____"
],
[
"Y_test.values",
"_____no_output_____"
],
[
"#find the mse value\nfrom sklearn.metrics import mean_squared_error\nmse=mean_squared_error(Y_pred_Tree,Y_test)\nmse",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nrse=r2_score(Y_pred_Tree,Y_test)\nrse",
"_____no_output_____"
],
[
"#here we concluded that decision tree regressor beacuse mse value is:1.39,and rse value is 99%\n",
"_____no_output_____"
],
[
"#now we find the decision tree is the best model for this data set .because error value is less \n#in this tree model.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517397bb122a3b2e8a97c12fb45fadee5a85354
| 3,296 |
ipynb
|
Jupyter Notebook
|
notebooks/pipelines/longterm/01.00_run_pipeline.ipynb
|
martinlarsalbert/datadriven-energieffektivisering-av-fartyg
|
2fc65d611ff6d9497cb916b43477af9511912220
|
[
"MIT"
] | 2 |
2021-04-19T09:04:51.000Z
|
2021-11-14T19:41:15.000Z
|
notebooks/pipelines/longterm/01.00_run_pipeline.ipynb
|
martinlarsalbert/datadriven-energieffektivisering-av-fartyg
|
2fc65d611ff6d9497cb916b43477af9511912220
|
[
"MIT"
] | null | null | null |
notebooks/pipelines/longterm/01.00_run_pipeline.ipynb
|
martinlarsalbert/datadriven-energieffektivisering-av-fartyg
|
2fc65d611ff6d9497cb916b43477af9511912220
|
[
"MIT"
] | null | null | null | 23.71223 | 79 | 0.521845 |
[
[
[
"## Short",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('../')\nimport runner",
"_____no_output_____"
],
[
"parameters = {\n 'name':'tycho_short_parquet',\n 'n_rows':None,\n }\n\nrunner.run_experiment(name='tycho_short_parquet', parameters=parameters)",
"2021-06-17 14:17:58,567 - step:01.1_data_trip_id.ipynb\n2021-06-17 14:17:58,569 - Already run, skipping...\n2021-06-17 14:17:58,569 - step:02.1_trip_statistics.ipynb\n2021-06-17 14:17:58,570 - Already run, skipping...\n2021-06-17 14:17:58,570 - step:02.2_clean_trip_statistics.ipynb\n2021-06-17 14:17:58,570 - Already run, skipping...\n2021-06-17 14:17:58,571 - step:03.1_explore_trip_statistics.ipynb\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
]
] |
c5173c69b9ddfee0708c95f84d831b89278b0f1f
| 632,943 |
ipynb
|
Jupyter Notebook
|
hw_9/hw9_notebook.ipynb
|
ncinko/python-ay250-homeworks
|
c8bdac59c1b45d046823109c40883e9557296541
|
[
"MIT"
] | null | null | null |
hw_9/hw9_notebook.ipynb
|
ncinko/python-ay250-homeworks
|
c8bdac59c1b45d046823109c40883e9557296541
|
[
"MIT"
] | null | null | null |
hw_9/hw9_notebook.ipynb
|
ncinko/python-ay250-homeworks
|
c8bdac59c1b45d046823109c40883e9557296541
|
[
"MIT"
] | 1 |
2018-04-18T01:16:04.000Z
|
2018-04-18T01:16:04.000Z
| 666.255789 | 488,086 | 0.934285 |
[
[
[
"# Importing the data",
"_____no_output_____"
]
],
[
[
"from pandas import read_csv #Let's us read in the comma-separated text file\nimport matplotlib.pyplot as plt #Our go-to module for plotting\n\ndata = read_csv('data.csv')\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\n\nax.scatter(data['red_pos_X'], data['red_pos_Y'] , color = 'red', edgecolors = 'black', s = 15)\nax.scatter(data['blue_pos_X'], data['blue_pos_Y'] , color = 'blue', edgecolors = 'black', s =15)\nax.set_xlabel('x position')\nax.set_ylabel('y position')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"# a) Posterior distributions of speed",
"_____no_output_____"
],
[
"Looking ahead to part (c), let's describe our velocities using (speed, angle) notation rather than (v_x, v_y). (This will make equating the speeds easier.) That is, for a given object, its position will be described by $x(t) = x_0 + (v\\cos\\theta)t$ and $y(t) = y_0 + (v\\sin\\theta)t$.",
"_____no_output_____"
],
[
"We have to choose some prior distributions for our model, but we don't really know much about these moving objects. I'll take the velocities to be 'normally' distributed about 0; the priors for speed will be PyMC3's HalfNormal distribution, <s>and the priors for the angle will be a Uniform distribution around the full circle.</s> Evidently uniform priors are not the best thing to use, and the sampling runs quickly with Normal/HalfNormal distributions, so everything will be given a (Half)Normal distribution with a sufficiently large standard deviation. See https://docs.pymc.io/api/distributions/continuous.html for a list of available continuous distributions.",
"_____no_output_____"
],
[
"### Setting up the model",
"_____no_output_____"
]
],
[
[
"import pymc3 as pm #Our main 'hammer' according to the Bayesian Methods for Hackers notebook\nimport numpy as np #Grab some trig functions \n\ndef modelData(data, samespeed): \n \"\"\"This function takes the array of .csv data, along with a boolean value indicating\n whether or not the blue/red speeds are to be fixed equal to each other. All variables\n in the model are given (Half)Normal distributions, and the model is then run using the\n NUTS sampling algorithm. The function then returns the trace.\"\"\"\n with pm.Model() as model:\n #HalfNormal distributions keep these distributions positive\n v_r = pm.HalfNormal('v_r', sd = 0.1)\n if samespeed == True:\n v_b = v_r #blue and red speeds are the same\n else:\n v_b = pm.HalfNormal('v_b', sd = 0.1)\n\n sigma = pm.HalfNormal('sigma', sd = 1.0)\n\n #Normal distributions make the NUTS algorithm run more smoothly\n theta_r = pm.Normal('theta_r', mu = 0, sd = 1.0)\n theta_b = pm.Normal('theta_b', mu = 0, sd = 1.0)\n x0_r = pm.Normal('x0_r', mu = 0, sd = 1.0)\n y0_r = pm.Normal('y0_r', mu = 0, sd = 1.0)\n x0_b = pm.Normal('x0_b', mu = 0, sd = 1.0) \n y0_b = pm.Normal('y0_b', mu = 0, sd = 1.0)\n\n\n #The expected (x,y) values for the red and blue objects\n x_r_expected = x0_r + v_r*np.cos(theta_r)*data['t']\n y_r_expected = y0_r + v_r*np.sin(theta_r)*data['t']\n x_b_expected = x0_b + v_b*np.cos(theta_b)*data['t']\n y_b_expected = y0_b + v_b*np.sin(theta_b)*data['t']\n\n #Likelihood distributions for the normally-distributed (x,y) positions\n x_r = pm.Normal('x_r_likelihood', mu = x_r_expected, sd = sigma, observed = (data['red_pos_X']))\n y_r = pm.Normal('y_r_likelihood', mu = y_r_expected, sd = sigma, observed = (data['red_pos_Y']))\n x_b = pm.Normal('x_b_likelihood', mu = x_b_expected, sd = sigma, observed = (data['blue_pos_X']))\n y_b = pm.Normal('y_b_likelihood', mu = y_b_expected, sd = sigma, observed = (data['blue_pos_Y']))\n \n #Running the NUTS algorithm\n with model:\n step = pm.NUTS()\n trace = pm.sample(10000, step = step, njobs = 4)\n \n return trace",
"_____no_output_____"
]
],
[
[
"### Saving/Loading results\n\nThanks to [this post](https://stackoverflow.com/questions/44764932/can-a-pymc3-trace-be-loaded-and-values-accessed-without-the-original-model-in-me), the traces from NUTS can be saved and retrieved later using Pickle.",
"_____no_output_____"
]
],
[
[
"import pickle\n\ndef saveTrace(model, trace, filename):\n with open(filename, 'wb') as buff:\n pickle.dump({'model': model, 'trace': trace}, buff)\n\ndef openTrace(filename):\n with open(filename, 'rb') as buff:\n temp_data = pickle.load(buff) \n\n return temp_data['trace']",
"_____no_output_____"
]
],
[
[
"### Example in running the model\nFirst get the trace:",
"_____no_output_____"
]
],
[
[
"trace = modelData(data, True) #all of the data, the objects are assumed to be moving at the same speed",
"Multiprocess sampling (4 chains in 4 jobs)\nNUTS: [y0_b, x0_b, y0_r, x0_r, theta_b, theta_r, sigma_log__, v_r_log__]\nThe acceptance probability does not match the target. It is 0.895400714613, but should be close to 0.8. Try to increase the number of tuning steps.\nThe acceptance probability does not match the target. It is 0.890944099234, but should be close to 0.8. Try to increase the number of tuning steps.\nThe acceptance probability does not match the target. It is 0.900973630623, but should be close to 0.8. Try to increase the number of tuning steps.\nThe acceptance probability does not match the target. It is 0.885040436037, but should be close to 0.8. Try to increase the number of tuning steps.\n"
]
],
[
[
"Then save it with the appropriate file name:",
"_____no_output_____"
]
],
[
[
"saveTrace(model, trace, 'sameV_alldata.pkl')",
"_____no_output_____"
]
],
[
[
"The other three cases, are as follows (the above case is for part c):",
"_____no_output_____"
]
],
[
[
"trace2 = modelData(data, False)\nsaveTrace(model, trace2, 'diffV_alldata.pkl')\n\ntrace3 = modelData(data[:100], True)\nsaveTrace(model, trace3, 'sameV_100data.pkl')\n\ntrace4 = modelData(data[:100], False)\nsaveTrace(model, trace4, 'diffV_100data.pkl')",
"_____no_output_____"
]
],
[
[
"To save time, we can then load them all later",
"_____no_output_____"
]
],
[
[
"trace = openTrace('sameV_alldata.pkl')\ntrace2 = openTrace('diffV_alldata.pkl')\ntrace3 = openTrace('sameV_100data.pkl')\ntrace4 = openTrace('diffV_100data.pkl')",
"_____no_output_____"
]
],
[
[
"If we want to look at the results of the sampling algorithm,",
"_____no_output_____"
]
],
[
[
"pm.traceplot(trace2[1000:][::5]); #burn first 1000 steps and 'prune' the result by taking every 5th step\nplt.show()\npm.summary(trace2)",
"_____no_output_____"
]
],
[
[
"### Plotting the posterior distributions for speed",
"_____no_output_____"
]
],
[
[
"def plotPosterior(trace):\n bin_width = 1e-6\n \"\"\"This function takes a trace and plots the distribution of red/blue speeds\n as a histogram. If the speeds were taken to be equal, just the red speed is \n plotted (this is handled by excepting a KeyError for the missing 'v_b' value).\"\"\"\n fig = plt.figure()\n ax = fig.add_subplot(1, 1, 1)\n ax.ticklabel_format(style = 'sci', axis = 'x', scilimits = (0,0)) #scientific notation on x-axis\n ax.set_xlabel('speed')\n ax.set_ylabel('frequency')\n v_r = trace['v_r'][1000:][::5] #rembember to 'burn and prune' the results\n try:\n v_b = trace['v_b'][1000:][::5]\n mu = \"{:.3E}\".format(np.mean(v_b))\n sigma = \"{:.3E}\".format(np.sqrt(np.var(v_b)))\n ax.hist(v_b, color='blue', alpha = 0.4, bins=np.arange(min(v_b), max(v_b) + bin_width, bin_width), label = f'$\\mu$, $\\sigma$ = {mu}, {sigma}')\n except KeyError: \n pass\n mu = \"{:.3E}\".format(np.mean(v_r))\n sigma = \"{:.3E}\".format(np.sqrt(np.var(v_r)))\n ax.hist(v_r, color='red', alpha = 0.4, bins=np.arange(min(v_r), max(v_r) + bin_width, bin_width), label = f'$\\mu$, $\\sigma$ = {mu}, {sigma}')\n plt.legend(loc='upper left')\n \n plt.show()",
"_____no_output_____"
]
],
[
[
"For example, using the above function, we plot our answer to part (a). As the filename used to save/load 'trace2' suggests, the full data set was used and the speeds were assumed to be different.",
"_____no_output_____"
]
],
[
[
"plotPosterior(trace2)",
"_____no_output_____"
]
],
[
[
"# b) Confidence interval",
"_____no_output_____"
],
[
"These posterior distributions can be converted to distributions for the 'zero-crossing' time $t_0$ by solving $y(t_0) = 0$. This gives $t_0 = -\\frac{y_0}{v\\sin\\theta}$.",
"_____no_output_____"
]
],
[
[
"def plotCrossingTimes(trace):\n \"\"\"This function takes a trace and plots the distribution of the 'zero-crossing time'\n for each object. If the speeds were taken to be equal, the 'v_b' distribution is set \n equal to the 'v_r' distribution (this is handled by excepting a KeyError for the missing 'v_b' value).\"\"\"\n v_r = trace['v_r'][1000:][::5]\n y0_r = trace['y0_r'][1000:][::5]\n theta_r = trace['theta_r'][1000:][::5]\n \n try:\n v_b = trace['v_b'][1000:][::5]\n except KeyError:\n v_b = trace['v_r'][1000:][::5]\n y0_b = trace['y0_b'][1000:][::5]\n theta_b = trace['theta_b'][1000:][::5]\n\n #Solving for the crossing times\n t0_r = -y0_r/v_r/np.sin(theta_r)\n t0_b = -y0_b/v_b/np.sin(theta_b)\n \n fig = plt.figure()\n ax = fig.add_subplot(1, 1, 1)\n ax.set_xlabel('time (crossing y = 0)')\n ax.set_ylabel('frequency')\n ax.hist(t0_r, color='red', alpha = 1.0)\n ax.hist(t0_b, color='blue', alpha = 1.0)\n \n plt.show()",
"_____no_output_____"
],
[
"plotCrossingTimes(trace2)",
"_____no_output_____"
]
],
[
[
"As you can see, the blue object crosses $y = 0$ at a much later time than the red object. The Y value of the blue object is < 0 for times left of the blue curve. So, we are justified in using the distribution of 'crossing' times for the blue object to find our 90% confidence interval.",
"_____no_output_____"
]
],
[
[
"def findConfidenceInterval(trace):\n '''This function takes a trace and finds a 90% confidence interval for\n the time at which both objects have crossed Y = 0. It does this two ways:\n (1) fitting a Gaussian to the blue distribution and using the common +/- 1.645\n standard deviations from the mean (2) using the np.percentile() function directly\n on the distribution. If the speeds were taken to be equal, the 'v_b' distribution is set \n equal to the 'v_r' distribution (this is handled by excepting a KeyError for the missing 'v_b' value).'''\n try:\n v_b = trace['v_b'][1000:][::5]\n except KeyError:\n v_b = trace['v_r'][1000:][::5]\n y0_b = trace['y0_b'][1000:][::5]\n theta_b = trace['theta_b'][1000:][::5]\n\n t0_b = -y0_b/v_b/np.sin(theta_b)\n \n mean = np.mean(t0_b)\n sigma = np.sqrt(np.var(t0_b)) \n print('The (5%, 95%) confidence interval is')\n print('%.3f, %.3f by fitting a Gaussian' % (mean - 1.645*sigma, mean + 1.645*sigma))\n print('%.3f, %.3f using np.percentile()' % (np.percentile(t0_b, 5), np.percentile(t0_b, 95)))\n \n ",
"_____no_output_____"
],
[
"findConfidenceInterval(trace2)",
"The (5%, 95%) confidence interval is\n572.910, 576.563 by fitting a Gaussian\n572.909, 576.558 using np.percentile()\n"
]
],
[
[
"# c) Same speed",
"_____no_output_____"
],
[
"Repeating everything is now straightforward; make sure the traces have either been generated or loaded.",
"_____no_output_____"
]
],
[
[
"plotPosterior(trace)\nfindConfidenceInterval(trace)",
"_____no_output_____"
]
],
[
[
"# d) Repeat with smaller N",
"_____no_output_____"
],
[
"### Different speeds",
"_____no_output_____"
]
],
[
[
"plotPosterior(trace4)\nfindConfidenceInterval(trace4)",
"_____no_output_____"
]
],
[
[
"### Same speed",
"_____no_output_____"
]
],
[
[
"plotPosterior(trace3)\nfindConfidenceInterval(trace3)",
"_____no_output_____"
]
],
[
[
"As you'd expect, the confidence intervals became a bit larger with smaller $N$. In Bayesian language, we'd say that we are less certain in the time at which both objects have crossed Y=0. This makes sense with a smaller data set. Note also that the $\\sigma$ associated with our posterior speed distributions has more than doubled, so we are also less certain in the speeds of the objects.",
"_____no_output_____"
],
[
"# Summarizing everything",
"_____no_output_____"
],
[
"Let's first modify our plotting function to allow the part (c) speed distributions to be plotted on the same histogram as the 'different speed' distributions. The 'same speed' distribution will be plotted in green.",
"_____no_output_____"
]
],
[
[
"def plotOverlayedPosterior(trace, trace2):\n bin_width = 1e-6\n \"\"\"This function takes a trace and plots the distribution of red/blue speeds\n as a histogram. If the speeds were taken to be equal, just the red speed is \n plotted (this is handled by excepting a KeyError for the missing 'v_b' value).\n It then takes a second trace (where the speeds are the same) and also plots its\n speed distribution in green\"\"\"\n fig = plt.figure(figsize = (7,6))\n ax = fig.add_subplot(1, 1, 1)\n ax.ticklabel_format(style = 'sci', axis = 'x', scilimits = (0,0)) #scientific notation on x-axis\n ax.set_xlabel('speed')\n ax.set_ylabel('frequency')\n v_r = trace['v_r'][1000:][::5] #rembember to 'burn and prune' the results\n v_same = trace2['v_r'][1000:][::5] #rembember to 'burn and prune' the results\n try:\n v_b = trace['v_b'][1000:][::5]\n mu = \"{:.3E}\".format(np.mean(v_b))\n sigma = \"{:.3E}\".format(np.sqrt(np.var(v_b)))\n ax.hist(v_b, color='blue', alpha = 0.4, bins=np.arange(min(v_b), max(v_b) + bin_width, bin_width), label = f'$\\mu$, $\\sigma$ = {mu}, {sigma}')\n except KeyError: \n pass\n mu = \"{:.3E}\".format(np.mean(v_r))\n sigma = \"{:.3E}\".format(np.sqrt(np.var(v_r)))\n ax.hist(v_r, color='red', alpha = 0.4, bins=np.arange(min(v_r), max(v_r) + bin_width, bin_width), label = f'$\\mu$, $\\sigma$ = {mu}, {sigma}')\n mu = \"{:.3E}\".format(np.mean(v_same))\n sigma = \"{:.3E}\".format(np.sqrt(np.var(v_same)))\n ax.hist(v_same, color='green', alpha = 0.4, bins=np.arange(min(v_same), max(v_same) + bin_width, bin_width), label = f'$\\mu$, $\\sigma$ = {mu}, {sigma}')\n plt.legend(loc='upper left')\n \n plt.show()",
"_____no_output_____"
]
],
[
[
"### Using the full data set",
"_____no_output_____"
]
],
[
[
"plotOverlayedPosterior(trace2,trace)",
"_____no_output_____"
],
[
"print('When the speeds have different distributions')\nfindConfidenceInterval(trace2)\nprint('\\nWhen the speeds are taken to be equal')\nfindConfidenceInterval(trace)",
"When the speeds have different distributions\nThe (5%, 95%) confidence interval is\n572.910, 576.563 by fitting a Gaussian\n572.909, 576.558 using np.percentile()\n\nWhen the speeds are taken to be equal\nThe (5%, 95%) confidence interval is\n573.096, 576.659 by fitting a Gaussian\n573.100, 576.641 using np.percentile()\n"
]
],
[
[
"### Using the first 100 measurements",
"_____no_output_____"
]
],
[
[
"plotOverlayedPosterior(trace4,trace3)",
"_____no_output_____"
],
[
"print('When the speeds have different distributions')\nfindConfidenceInterval(trace4)\nprint('\\nWhen the speeds are taken to be equal')\nfindConfidenceInterval(trace3)",
"When the speeds have different distributions\nThe (5%, 95%) confidence interval is\n570.126, 586.016 by fitting a Gaussian\n570.148, 586.064 using np.percentile()\n\nWhen the speeds are taken to be equal\nThe (5%, 95%) confidence interval is\n572.698, 584.738 by fitting a Gaussian\n572.621, 584.762 using np.percentile()\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c5174043d9b524366100dd9f121f477be281a358
| 186,940 |
ipynb
|
Jupyter Notebook
|
tutorials/.ipynb_checkpoints/ex1_ZARC-checkpoint.ipynb
|
frank-ccc/BHT
|
a04628e239920bb0bdcaf856469cb4000df077eb
|
[
"MIT"
] | 2 |
2020-08-13T05:31:27.000Z
|
2020-12-01T10:43:27.000Z
|
tutorials/.ipynb_checkpoints/ex1_ZARC-checkpoint.ipynb
|
frank-ccc/BHT
|
a04628e239920bb0bdcaf856469cb4000df077eb
|
[
"MIT"
] | null | null | null |
tutorials/.ipynb_checkpoints/ex1_ZARC-checkpoint.ipynb
|
frank-ccc/BHT
|
a04628e239920bb0bdcaf856469cb4000df077eb
|
[
"MIT"
] | 4 |
2020-08-12T03:18:28.000Z
|
2020-09-21T03:32:21.000Z
| 248.921438 | 25,816 | 0.915994 |
[
[
[
"# Computing the Bayesian Hilbert Transform-DRT",
"_____no_output_____"
],
[
"In this tutorial example, we will show how the developed BHT-DRT method works using a simple ZARC model. The equivalent circuit consists one ZARC model, *i.e*., a resistor in parallel with a CPE element.",
"_____no_output_____"
]
],
[
[
"# import the libraries\nimport numpy as np\nfrom math import pi, log10\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# core library\nimport Bayes_HT\nimport importlib\nimportlib.reload(Bayes_HT)",
"_____no_output_____"
],
[
"# plot standards\nplt.rc('font', family='serif', size=15)\nplt.rc('text', usetex=True)\nplt.rc('xtick', labelsize=15)\nplt.rc('ytick', labelsize=15)",
"_____no_output_____"
]
],
[
[
"## 1) Define the synthetic impedance experiment $Z_{\\rm exp}(\\omega)$",
"_____no_output_____"
],
[
"### 1.1) Define the frequency range",
"_____no_output_____"
]
],
[
[
"N_freqs = 81\nfreq_min = 10**-4 # Hz\nfreq_max = 10**4 # Hz\nfreq_vec = np.logspace(log10(freq_min), log10(freq_max), num=N_freqs, endpoint=True)\ntau_vec = np.logspace(-log10(freq_max), -log10(freq_min), num=N_freqs, endpoint=True)\nomega_vec = 2.*pi*freq_vec",
"_____no_output_____"
]
],
[
[
"### 1.2) Define the circuit parameters for the two ZARCs",
"_____no_output_____"
]
],
[
[
"R_ct = 50 # Ohm\nR_inf = 10. # Ohm\nphi = 0.8\ntau_0 = 1. # sec",
"_____no_output_____"
]
],
[
[
"### 1.3) Generate exact impedance $Z_{\\rm exact}(\\omega)$ as well as the stochastic experiment $Z_{\\rm exp}(\\omega)$, here $Z_{\\rm exp}(\\omega)=Z_{\\rm exact}(\\omega)+\\sigma_n(\\varepsilon_{\\rm re}+i\\varepsilon_{\\rm im})$",
"_____no_output_____"
]
],
[
[
"# generate exact\nT = tau_0**phi/R_ct\nZ_exact = R_inf + 1./(1./R_ct+T*(1j*2.*pi*freq_vec)**phi)\n\n# random\nrng = np.random.seed(121295)\nsigma_n_exp = 0.8 # Ohm\nZ_exp = Z_exact + sigma_n_exp*(np.random.normal(0, 1, N_freqs)+1j*np.random.normal(0, 1, N_freqs))",
"_____no_output_____"
]
],
[
[
"### 1.4) show the impedance in Nyquist plot",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nplt.plot(Z_exact.real, -Z_exact.imag, linewidth=4, color='black', label='exact')\nplt.plot(np.real(Z_exp), -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')\nplt.plot(np.real(Z_exp[0:70:20]), -np.imag(Z_exp[0:70:20]), 's', markersize=8, color=\"black\")\nplt.plot(np.real(Z_exp[30]), -np.imag(Z_exp[30]), 's', markersize=8, color=\"black\")\n\nplt.annotate(r'$10^{-4}$', xy=(np.real(Z_exp[0]), -np.imag(Z_exp[0])), \n xytext=(np.real(Z_exp[0])-15, -np.imag(Z_exp[0])), \n arrowprops=dict(arrowstyle='-',connectionstyle='arc'))\nplt.annotate(r'$10^{-1}$', xy=(np.real(Z_exp[20]), -np.imag(Z_exp[20])), \n xytext=(np.real(Z_exp[20])-5, 10-np.imag(Z_exp[20])), \n arrowprops=dict(arrowstyle='-',connectionstyle='arc'))\nplt.annotate(r'$1$', xy=(np.real(Z_exp[30]), -np.imag(Z_exp[30])), \n xytext=(np.real(Z_exp[30]), 8-np.imag(Z_exp[30])), \n arrowprops=dict(arrowstyle='-',connectionstyle='arc'))\nplt.annotate(r'$10$', xy=(np.real(Z_exp[40]), -np.imag(Z_exp[40])), \n xytext=(np.real(Z_exp[40]), 8-np.imag(Z_exp[40])), \n arrowprops=dict(arrowstyle='-',connectionstyle='arc'))\nplt.annotate(r'$10^2$', xy=(np.real(Z_exp[60]), -np.imag(Z_exp[60])), \n xytext=(np.real(Z_exp[60])+5, -np.imag(Z_exp[60])), \n arrowprops=dict(arrowstyle='-',connectionstyle='arc'))\nplt.legend(frameon=False, fontsize = 15)\nplt.axis('scaled')\n\nplt.xlim(5, 70)\nplt.ylim(-2, 32)\nplt.xticks(range(5, 70, 10))\nplt.yticks(range(0, 40, 10))\nplt.xlabel(r'$Z_{\\rm re}/\\Omega$', fontsize = 20)\nplt.ylabel(r'$-Z_{\\rm im}/\\Omega$', fontsize = 20)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 2) Calculate the DRT impedance $Z_{\\rm DRT}(\\omega)$ and the Hilbert transformed impedance $Z_{\\rm H}(\\omega)$",
"_____no_output_____"
],
[
"### 2.1) optimize the hyperparamters",
"_____no_output_____"
]
],
[
[
"# set the intial parameters\nsigma_n = 1\nsigma_beta = 20\nsigma_lambda = 100\n\ntheta_0 = np.array([sigma_n, sigma_beta, sigma_lambda])\ndata_real, data_imag, scores = Bayes_HT.HT_est(theta_0, Z_exp, freq_vec, tau_vec)",
"sigma_n; sigma_beta; sigma_lambda\n8.07576e-01 19.998508 99.999899 \n7.67919e-01 19.891836 99.992062 \n7.61233e-01 19.635013 99.973366 \n7.55739e-01 19.090800 99.933660 \n7.50780e-01 17.975445 99.851742 \n7.49009e-01 15.531850 99.668509 \n7.56260e-01 15.741292 99.674711 \n7.63912e-01 15.639933 99.648666 \n7.63957e-01 15.673127 99.640903 \n7.63984e-01 15.702439 99.613967 \n7.64011e-01 15.732748 99.558007 \n7.64043e-01 15.770266 99.448787 \n7.64085e-01 15.822560 99.236093 \n7.64144e-01 15.901025 98.819714 \n7.64232e-01 16.024980 98.002129 \n7.64360e-01 16.227507 96.393159 \n7.64548e-01 16.567962 93.238301 \n7.67402e-01 23.043777 25.880260 \n7.67433e-01 23.113920 25.140417 \n7.68609e-01 22.301051 25.090725 \n7.68236e-01 20.485546 25.856902 \n7.67165e-01 19.104197 26.477246 \n7.66305e-01 18.776957 26.565019 \n7.66305e-01 18.848337 26.523488 \n7.66301e-01 18.845745 26.524648 \n7.66301e-01 18.845512 26.524639 \nWarning: Desired error not necessarily achieved due to precision loss.\n Current function value: 128.140790\n Iterations: 26\n Function evaluations: 551\n Gradient evaluations: 108\nsigma_n; sigma_beta; sigma_lambda\n8.50878e-01 19.997300 99.999839 \n9.09171e-01 19.758177 99.985734 \n9.02681e-01 19.521073 99.971692 \n8.95999e-01 18.976186 99.939364 \n8.88501e-01 17.799700 99.869186 \n8.81524e-01 15.086970 99.704186 \n8.88834e-01 15.596642 99.727137 \n8.92828e-01 15.480367 99.710847 \n8.95266e-01 15.414949 99.692885 \n8.96097e-01 15.410943 99.644569 \n8.96811e-01 15.408919 99.550734 \n9.01023e-01 15.401526 98.649862 \n9.05983e-01 15.402074 96.905737 \n9.11740e-01 15.417222 93.850842 \n1.00809e+00 15.911628 26.921163 \n9.86411e-01 16.493377 35.680385 \n9.82432e-01 17.266974 31.153934 \n9.73600e-01 18.469821 21.069636 \n9.21272e-01 19.513760 23.133536 \n8.92282e-01 20.017605 20.879858 \n8.96440e-01 19.547004 22.730150 \n8.99132e-01 19.250877 22.571741 \n8.97073e-01 18.817668 22.458340 \n8.95993e-01 18.816108 22.448388 \n8.95904e-01 18.817904 22.447747 \n8.95897e-01 18.819029 22.445779 \n8.95897e-01 18.819029 22.445779 \n8.95898e-01 18.819034 22.445767 \n8.95900e-01 18.819029 22.445778 \n8.95903e-01 18.819026 22.445784 \n8.95904e-01 18.819021 22.445795 \n8.95904e-01 18.819021 22.445795 \n8.95904e-01 18.819021 22.445795 \n8.95904e-01 18.819021 22.445795 \n8.95905e-01 18.819021 22.445794 \n8.95905e-01 18.819020 22.445794 \n8.95905e-01 18.819020 22.445794 \n8.95905e-01 18.819021 22.445794 \n8.95905e-01 18.819021 22.445794 \nWarning: Desired error not necessarily achieved due to precision loss.\n Current function value: 145.508415\n Iterations: 39\n Function evaluations: 857\n Gradient evaluations: 169\n"
]
],
[
[
"### 2.2) Calculate the real part of the $Z_{\\rm DRT}(\\omega)$ and the imaginary part of the $Z_{\\rm H}(\\omega)$",
"_____no_output_____"
],
[
"#### 2.2.1) Bayesian regression to obtain the real part of impedance for both mean and covariance",
"_____no_output_____"
]
],
[
[
"mu_Z_re = data_real.get('mu_Z')\ncov_Z_re = np.diag(data_real.get('Sigma_Z'))\n\n# the mean and covariance of $R_\\infty$\nmu_R_inf = data_real.get('mu_gamma')[0]\ncov_R_inf = np.diag(data_real.get('Sigma_gamma'))[0]",
"_____no_output_____"
]
],
[
[
"#### 2.2.2) Calculate the real part of DRT impedance for both mean and covariance",
"_____no_output_____"
]
],
[
[
"mu_Z_DRT_re = data_real.get('mu_Z_DRT')\ncov_Z_DRT_re = np.diag(data_real.get('Sigma_Z_DRT'))",
"_____no_output_____"
]
],
[
[
"#### 2.2.3) Calculate the imaginary part of HT impedance for both mean and covariance",
"_____no_output_____"
]
],
[
[
"mu_Z_H_im = data_real.get('mu_Z_H')\ncov_Z_H_im = np.diag(data_real.get('Sigma_Z_H'))",
"_____no_output_____"
]
],
[
[
"#### 2.2.4) Estimate the $\\sigma_n$",
"_____no_output_____"
]
],
[
[
"sigma_n_re = data_real.get('theta')[0]",
"_____no_output_____"
]
],
[
[
"### 2.3) Calculate the imaginary part of the $Z_{\\rm DRT}(\\omega)$ and the real part of the $Z_{\\rm H}(\\omega)$",
"_____no_output_____"
]
],
[
[
"# 2.3.1 Bayesian regression\nmu_Z_im = data_imag.get('mu_Z')\ncov_Z_im = np.diag(data_imag.get('Sigma_Z'))\n\n# the mean and covariance of the inductance $L_0$\nmu_L_0 = data_imag.get('mu_gamma')[0]\ncov_L_0 = np.diag(data_imag.get('Sigma_gamma'))[0]\n\n# 2.3.2 DRT part\nmu_Z_DRT_im = data_imag.get('mu_Z_DRT')\ncov_Z_DRT_im = np.diag(data_imag.get('Sigma_Z_DRT'))\n\n# 2.3.3 HT prediction\nmu_Z_H_re = data_imag.get('mu_Z_H')\ncov_Z_H_re = np.diag(data_imag.get('Sigma_Z_H'))\n\n# 2.3.4 estimated sigma_n\nsigma_n_im = data_imag.get('theta')[0]",
"_____no_output_____"
]
],
[
[
"## 3) Plot the BHT_DRT",
"_____no_output_____"
],
[
"### 3.1) plot the real parts of impedance for both Bayesian regression and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"band = np.sqrt(cov_Z_re)\nplt.fill_between(freq_vec, mu_Z_re-3*band, mu_Z_re+3*band, facecolor='lightgrey')\nplt.semilogx(freq_vec, mu_Z_re, linewidth=4, color='black', label='mean')\nplt.semilogx(freq_vec, Z_exp.real, 'o', markersize=8, color='red', label='synth exp')\nplt.xlim(1E-4, 1E4)\nplt.ylim(5, 65)\nplt.xscale('log')\nplt.yticks(range(5, 70, 10))\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$Z_{\\rm re}/\\Omega$', fontsize=20)\nplt.legend(frameon=False, fontsize = 15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.2 plot the imaginary parts of impedance for both Bayesian regression and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"band = np.sqrt(cov_Z_im)\nplt.fill_between(freq_vec, -mu_Z_im-3*band, -mu_Z_im+3*band, facecolor='lightgrey')\nplt.semilogx(freq_vec, -mu_Z_im, linewidth=4, color='black', label='mean')\nplt.semilogx(freq_vec, -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')\nplt.xlim(1E-4, 1E4)\nplt.ylim(-3, 30)\nplt.xscale('log')\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$-Z_{\\rm im}/\\Omega$', fontsize=20)\nplt.legend(frameon=False, fontsize = 15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.3) plot the real parts of impedance for both Hilbert transform and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"mu_Z_H_re_agm = mu_R_inf + mu_Z_H_re \nband_agm = np.sqrt(cov_R_inf + cov_Z_H_re + sigma_n_im**2)\nplt.fill_between(freq_vec, mu_Z_H_re_agm-3*band_agm, mu_Z_H_re_agm+3*band_agm, facecolor='lightgrey')\nplt.semilogx(freq_vec, mu_Z_H_re_agm, linewidth=4, color='black', label='mean')\nplt.semilogx(freq_vec, Z_exp.real, 'o', markersize=8, color='red', label='synth exp')\nplt.xlim(1E-4, 1E4)\nplt.ylim(-3, 70)\nplt.xscale('log')\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$\\left(R_\\infty + Z_{\\rm H, re}\\right)/\\Omega$', fontsize=20)\nplt.legend(frameon=False, fontsize = 15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.4) plot the imaginary parts of impedance for both Hilbert transform and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"mu_Z_H_im_agm = omega_vec*mu_L_0 + mu_Z_H_im\nband_agm = np.sqrt((omega_vec**2)*cov_L_0 + cov_Z_H_im + sigma_n_re**2)\nplt.fill_between(freq_vec, -mu_Z_H_im_agm-3*band_agm, -mu_Z_H_im_agm+3*band_agm, facecolor='lightgrey')\nplt.semilogx(freq_vec, -mu_Z_H_im_agm, linewidth=4, color='black', label='mean')\nplt.semilogx(freq_vec, -Z_exp.imag, 'o', markersize=8, color='red', label='synth exp')\nplt.xlim(1E-4, 1E4)\nplt.ylim(-3, 30)\nplt.xscale('log')\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$-\\left(\\omega L_0 + Z_{\\rm H, im}\\right)/\\Omega$', fontsize=20)\nplt.legend(frameon=False, fontsize = 15)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.5) plot the difference between real parts of impedance for Hilbert transform and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"difference_re = mu_R_inf + mu_Z_H_re - Z_exp.real \nband = np.sqrt(cov_R_inf + cov_Z_H_re + sigma_n_im**2)\nplt.fill_between(freq_vec, -3*band, 3*band, facecolor='lightgrey')\nplt.plot(freq_vec, difference_re, 'o', markersize=8, color='red')\nplt.xlim(1E-4, 1E4)\nplt.ylim(-10, 10)\nplt.xscale('log')\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$\\left(R_\\infty + Z_{\\rm H, re} - Z_{\\rm exp, re}\\right)/\\Omega$', fontsize=20)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.6) plot the density distribution of residuals for the real part",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(1)\na = sns.kdeplot(difference_re, shade=True, color='grey')\na = sns.rugplot(difference_re, color='black')\na.set_xlabel(r'$\\left(R_\\infty + Z_{\\rm H, re} - Z_{\\rm exp, re}\\right)/\\Omega$',fontsize=20)\na.set_ylabel(r'pdf',fontsize=20)\na.tick_params(labelsize=15)\nplt.xlim(-5, 5)\nplt.ylim(0, 0.5)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.7) plot the difference between imaginary parts of impedance for Hilbert transform and the synthetic experiment",
"_____no_output_____"
]
],
[
[
"difference_im = omega_vec*mu_L_0 + mu_Z_H_im - Z_exp.imag \nband = np.sqrt((omega_vec**2)*cov_L_0 + cov_Z_H_im + sigma_n_re**2)\nplt.fill_between(freq_vec, -3*band, 3*band, facecolor='lightgrey')\nplt.plot(freq_vec, difference_im, 'o', markersize=8, color='red')\nplt.xlim(1E-4, 1E4)\nplt.ylim(-10, 10)\nplt.xscale('log')\nplt.xlabel(r'$f/{\\rm Hz}$', fontsize=20)\nplt.ylabel(r'$\\left(\\omega L_0 + Z_{\\rm H, im} - Z_{\\rm exp, im}\\right)/\\Omega$', fontsize=20)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.8) plot the density distribution of residuals for the imaginary part",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(2)\na = sns.kdeplot(difference_im, shade=True, color='grey')\na = sns.rugplot(difference_im, color='black')\na.set_xlabel(r'$\\left(\\omega L_0 + Z_{\\rm H, im} - Z_{\\rm exp, im}\\right)/\\Omega$',fontsize=20)\na.set_ylabel(r'pdf',fontsize=20)\na.tick_params(labelsize=15)\nplt.xlim(-5, 5)\nplt.ylim(0, 0.5)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
c517457166d011bfde3c62f3178d3a2eb3f67f24
| 83,936 |
ipynb
|
Jupyter Notebook
|
notebooks/archive/fundamental_backtest_basic.ipynb
|
Blokas23/TradingStrategies
|
5dcff80f49e79a8c3d157ca885c64897e006d8b5
|
[
"MIT"
] | 1 |
2021-04-19T12:42:58.000Z
|
2021-04-19T12:42:58.000Z
|
notebooks/archive/fundamental_backtest_basic.ipynb
|
iewaij/tseu
|
fdb8f106e687ebefc82b25ae6bbda0206004c056
|
[
"MIT"
] | null | null | null |
notebooks/archive/fundamental_backtest_basic.ipynb
|
iewaij/tseu
|
fdb8f106e687ebefc82b25ae6bbda0206004c056
|
[
"MIT"
] | null | null | null | 244 | 41,412 | 0.919403 |
[
[
[
"from functools import reduce\nimport numpy as np\nimport pandas as pd\nfrom pandas.tseries.offsets import DateOffset\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.ensemble import RandomForestClassifier\nfrom xgboost import XGBClassifier\nfrom xgboost import XGBRegressor\nfrom ta import add_all_ta_features\npd.set_option(\"display.max_rows\", None)\npd.set_option(\"display.max_columns\", None)\nnp.seterr(divide=\"ignore\", invalid=\"ignore\");",
"_____no_output_____"
]
],
[
[
"## Model without Rebalace",
"_____no_output_____"
]
],
[
[
"def build_momentum(df):\n df[\"mom_6m\"] = np.log(df.close)-np.log(df.close.shift(6))\n df[\"mom_1m\"] = np.log(df.close)-np.log(df.close.shift(1))\n df[\"log_return\"] = np.log(df.close.shift(-3)) - np.log(df.close)\n return df.loc[df.prccd > 5, [\"mcap\", \"mom_6m\", \"mom_1m\", \"log_return\"]].dropna()",
"_____no_output_____"
],
[
"def be_extreme(df):\n \"\"\"Retain the 20% values that are the smallest and the 20% that are the largest.\"\"\"\n top = df.log_return.quantile(0.8)\n low = df.log_return.quantile(0.2)\n return df[(df.log_return < low) | (df.log_return > top)]",
"_____no_output_____"
],
[
"df = pd.read_parquet(\"../data/merged_data_alpha.6.parquet\")\ndf_basic = df[[\"mcap\", \"prccd\", \"close\"]]\ndf_mom = df_basic.groupby(\"gvkey\").apply(build_momentum)",
"_____no_output_____"
],
[
"df_train = df_mom.xs(slice(\"2002-01-01\", \"2012-01-01\"), level=\"date\", drop_level=False).groupby(\"date\").apply(be_extreme)\ndf_test = df_mom.xs(slice(\"2012-01-01\", \"2016-01-01\"), level=\"date\", drop_level=False)",
"_____no_output_____"
],
[
"X_train = df_train.drop(\"log_return\", axis=1).to_numpy()\ny_train = df_train[\"log_return\"].to_numpy()\nX_test = df_test.drop(\"log_return\", axis=1).to_numpy()\ny_test = df_test[\"log_return\"].to_numpy()",
"_____no_output_____"
],
[
"xgb_reg = XGBRegressor(n_estimators=100, max_depth=5, n_jobs=-1)\nxgb_fit = xgb_reg.fit(X_train, y_train)\nprint(xgb_reg.score(X_train, y_train))\nprint(xgb_reg.score(X_test, y_test))",
"0.1415069676696865\n-0.09907491765126553\n"
],
[
"xgb_clf = XGBClassifier(n_estimators=100, max_depth=3, n_jobs=-1)\nxgb_fit = xgb_clf.fit(X_train, np.sign(y_train))\nprint(xgb_clf.score(X_train, np.sign(y_train)))\nprint(xgb_clf.score(X_test, np.sign(y_test)))",
"[15:31:01] WARNING: /Users/travis/build/dmlc/xgboost/src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.\n"
]
],
[
[
"## Model with Rebalance",
"_____no_output_____"
]
],
[
[
"def be_extreme(df):\n \"\"\"Retain the 20% values that are the smallest and the 20% that are the largest.\"\"\"\n top = df.y.quantile(0.8)\n low = df.y.quantile(0.2)\n return df[(df.y < low) | (df.y > top)]",
"_____no_output_____"
],
[
"def be_balance(df):\n \"\"\"Returns minus a cross-sectional median\"\"\"\n median = df.log_return.quantile(0.5)\n df[\"y\"] = df.log_return - median\n return df",
"_____no_output_____"
],
[
"df_train = df_mom.xs(slice(\"2002-01-01\", \"2012-01-01\"), level=\"date\", drop_level=False).groupby(\"date\").apply(be_balance).groupby(\"date\").apply(be_extreme)\ndf_test = df_mom.xs(slice(\"2012-01-01\", \"2016-01-01\"), level=\"date\", drop_level=False).groupby(\"date\").apply(be_balance)\nX_train = df_train.drop([\"log_return\", \"y\"], axis=1).to_numpy()\ny_train = df_train[\"y\"].to_numpy()\nX_test = df_test.drop([\"log_return\", \"y\"], axis=1).to_numpy()\ny_test = df_test[\"y\"].to_numpy()",
"_____no_output_____"
],
[
"df_train.plot.scatter(x=\"mom_6m\", y=\"y\")",
"_____no_output_____"
],
[
"df_train.plot.scatter(x=\"mcap\", y=\"y\")",
"_____no_output_____"
],
[
"xgb_reg = XGBRegressor(n_estimators=100, max_depth=3, n_jobs=-1)\nxgb_fit = xgb_reg.fit(X_train, y_train)\nprint(xgb_reg.score(X_train, y_train))\nprint(xgb_reg.score(X_test, y_test))",
"0.06752312762195656\n-0.01972114326287744\n"
],
[
"xgb_clf = XGBClassifier(n_estimators=100, max_depth=3, n_jobs=-1)\nxgb_fit = xgb_clf.fit(X_train, np.sign(y_train))\nprint(xgb_clf.score(X_train, np.sign(y_train)))\nprint(xgb_clf.score(X_test, np.sign(y_test)))",
"[15:31:07] WARNING: /Users/travis/build/dmlc/xgboost/src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.\n"
]
],
[
[
"The algorithm improves after rebalancing.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
c517493d51c6704941071f88f5e10d2510cb9adf
| 1,950 |
ipynb
|
Jupyter Notebook
|
02_Basic Statistics (L2)/assignment_2.ipynb
|
kunalk3/eR_task
|
4d717680576bc62793c42840e772a28fb3f6c223
|
[
"MIT"
] | 1 |
2021-02-25T13:58:57.000Z
|
2021-02-25T13:58:57.000Z
|
02_Basic Statistics (L2)/assignment_2.ipynb
|
kunalk3/eR_task
|
4d717680576bc62793c42840e772a28fb3f6c223
|
[
"MIT"
] | null | null | null |
02_Basic Statistics (L2)/assignment_2.ipynb
|
kunalk3/eR_task
|
4d717680576bc62793c42840e772a28fb3f6c223
|
[
"MIT"
] | null | null | null | 24.683544 | 127 | 0.498462 |
[
[
[
"'''\nQu 1. Look at the data given below. \n Plot the data, find the outliers and find out μ, σ, σ^2\n'''",
"_____no_output_____"
],
[
"import pandas as pd\n\n# initialize data\ndata = {'Name od company':['Allied Signal', 'Bankers Trust', 'General Mills', 'ITT Industries', 'J.P.Morgan & Co.', \n 'Lehman Brothers', 'Marriott', 'MCI', 'Merrill Lynch', 'Microsoft', 'Morgan Stanley',\n 'Sun Microsystems', 'Travelers', 'US Airways', 'Warner-Lambert'],\n 'Measure X':[24.23, 25.53, 25.41, 24.14, 29.62, 28.25, 25.81, 24.39, 40.26, 32.95, 91.36, 25.99, 39.42, 26.71,\n 35.00]}\n# create dataframes\ndf = pd.DataFrame(data)\nprint(df)",
"_____no_output_____"
],
[
"print('Mean:', df['Measure X'].mean())\nprint('Std. dev:', df['Measure X'].std()) \nprint('Variance:', df['Measure X'].var())",
"_____no_output_____"
],
[
"# Outlier\nimport seaborn as sns\nsns.boxplot(x = df['Measure X'])",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
c5174e9533705b3cec0f533f448fdac3cc09b085
| 544,441 |
ipynb
|
Jupyter Notebook
|
Python_Nub/RecommendationSystems.ipynb
|
Nub-Team/Noob_Computation
|
becf36a920e840ef7a3294d7c9aefedcb3222edf
|
[
"Apache-2.0"
] | null | null | null |
Python_Nub/RecommendationSystems.ipynb
|
Nub-Team/Noob_Computation
|
becf36a920e840ef7a3294d7c9aefedcb3222edf
|
[
"Apache-2.0"
] | null | null | null |
Python_Nub/RecommendationSystems.ipynb
|
Nub-Team/Noob_Computation
|
becf36a920e840ef7a3294d7c9aefedcb3222edf
|
[
"Apache-2.0"
] | null | null | null | 87.671659 | 30,255 | 0.661548 |
[
[
[
"<i>Recommendation Systems</i><br>\r\n--\r\nAuthor by : \r\n* Nub-T\r\n* D. Johanes",
"_____no_output_____"
]
],
[
[
"!wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip",
"_____no_output_____"
],
[
"import os\r\nimport zipfile\r\nCUR_DIR = os.path.abspath(os.path.curdir)\r\nmovie_zip = zipfile.ZipFile(CUR_DIR + '/ml-latest-small.zip')\r\nmovie_zip.extractall()",
"_____no_output_____"
],
[
"import pandas as pd\r\nimport numpy as np\r\nfrom scipy import sparse, linalg",
"_____no_output_____"
],
[
"links = pd.read_csv(CUR_DIR + '/ml-latest-small/links.csv')\r\nmovies = pd.read_csv(CUR_DIR + '/ml-latest-small/movies.csv')\r\nratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\ntags = pd.read_csv(CUR_DIR + '/ml-latest-small/tags.csv')",
"_____no_output_____"
],
[
"# Content base Filtering",
"_____no_output_____"
],
[
"movies_genres = pd.concat([movies.loc[:,['movieId','title']],movies.genres.str.split('|', expand=False)], axis=1)\r\nmovies_genres = movies_genres.explode('genres')\r\nmovies_genres = pd.get_dummies(movies_genres,columns=['genres'])\r\nmovies_genres = movies_genres.groupby(['movieId'], as_index=False).sum()",
"_____no_output_____"
],
[
"assert movies_genres.iloc[:,1:].max().max() == 1\r\nmovies_genres.head()",
"_____no_output_____"
],
[
"ratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')",
"_____no_output_____"
],
[
"C = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean",
"_____no_output_____"
],
[
"b_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item",
"_____no_output_____"
],
[
"b_item",
"_____no_output_____"
],
[
"b_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')",
"_____no_output_____"
],
[
"b_user",
"_____no_output_____"
],
[
"ratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user\r\nurm = ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values",
"_____no_output_____"
],
[
"shrink_term = 3\r\nmovies_genres_mat = sparse.csr_matrix(movies_genres.iloc[:,1:].values)\r\n\r\nmovie_norms = np.sqrt(movies_genres_mat.sum(axis=1)).reshape(-1,1)\r\nxy, yx = np.meshgrid(movie_norms, movie_norms)\r\nxy, yx = np.array(xy), np.array(yx)",
"_____no_output_____"
],
[
"cbf_similarity_mat = movies_genres_mat.dot(movies_genres_mat.transpose())\r\ncbf_similarity_mat = np.array(cbf_similarity_mat / (xy * yx + shrink_term))\r\nnp.fill_diagonal(cbf_similarity_mat, 0.)",
"_____no_output_____"
],
[
"cbf_similarity_mat",
"_____no_output_____"
],
[
"movies['idx'] = movies.index",
"_____no_output_____"
],
[
"def get_similar_movies(k, movie_name):\r\n movie_idx = movies.set_index('title').loc[movie_name,'idx']\r\n movie_idxs = np.argsort(cbf_similarity_mat[movie_idx,:])[-k:]\r\n return movies.loc[np.flip(movie_idxs),['title','genres']]",
"_____no_output_____"
],
[
"def cbf_get_rating_given_user(u_ix, item_ix, k):\r\n movie_idxs = np.argsort(cbf_similarity_mat[item_ix,:])[-k:].squeeze()\r\n subusers_items = urm[u_ix,movie_idxs].squeeze()\r\n masked_subusers_items = np.ma.array(subusers_items, mask=subusers_items == 0.) \r\n weights = cbf_similarity_mat[item_ix, movie_idxs].squeeze()\r\n\r\n w_avg = np.ma.average(a=masked_subusers_items, weights=weights)\r\n return np.where(w_avg == np.ma.masked, 0., w_avg), masked_subusers_items, weights",
"_____no_output_____"
],
[
"cbf_get_rating_given_user(0,0,100)",
"_____no_output_____"
],
[
"get_similar_movies(10, 'Toy Story 2 (1999)')",
"_____no_output_____"
],
[
"# Collaborative Filtering\r\n\r\nimport seaborn as sns\r\nimport matplotlib.pyplot as plt\r\n%matplotlib inline\r\n\r\nfig = plt.figure(figsize=(10,10))\r\nsns.distplot(ratings.rating, bins=50)\r\nfig.show()",
"/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"ratings.groupby('movieId').agg({'userId':'count'}).sort_values('userId',ascending=False).loc[:500,:].plot.bar()",
"_____no_output_____"
],
[
"ratings.groupby('movieId').agg({'rating':np.mean}).sort_values('rating',ascending=False).plot.hist()",
"_____no_output_____"
],
[
"ratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\n\r\nC = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean\r\n\r\nb_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item\r\n\r\nb_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')\r\n\r\nratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user",
"_____no_output_____"
],
[
"b_user",
"_____no_output_____"
],
[
"urm = ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values\r\n\r\nuser_bias = urm.mean(axis=1, keepdims=True)\r\nurm_diff = ((urm - user_bias) / np.std(urm, axis=1, keepdims=True)) / np.sqrt(urm.shape[1]) # With this trick I can do dot product for pearson corr\r\ncf_user_similarity_mat = urm_diff.dot(urm_diff.T)\r\nnp.fill_diagonal(cf_user_similarity_mat, 0.)",
"_____no_output_____"
],
[
"def ucf_get_rating_given_user(u_ix, item_ix, k):\r\n u_ixs = np.argsort(cf_user_similarity_mat[u_ix,:])[-k:].squeeze()\r\n subusers_item = urm_diff[u_ixs,item_ix].squeeze()\r\n masked_subusers_item = np.ma.array(subusers_item, mask=subusers_item == 0) \r\n weights = cf_user_similarity_mat[u_ixs, item_ix].squeeze()\r\n w_avg = np.ma.average(a=masked_subusers_item, weights=weights) + user_bias[u_ix]\r\n return np.where(w_avg == np.ma.masked, 0., w_avg), masked_subusers_item, weights\r\n\r\nucf_get_rating_given_user(25,15,100)",
"_____no_output_____"
],
[
"urm = ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values\r\n\r\nuser_bias = urm.mean(axis=1, keepdims=True)\r\nurm_diff = urm - user_bias\r\nurm_diff = urm_diff / np.sqrt((urm_diff ** 2).sum(axis=0, keepdims=True)) \r\ncf_item_similarity_mat = urm_diff.T.dot(urm_diff)\r\nnp.fill_diagonal(cf_item_similarity_mat, 0.)",
"_____no_output_____"
],
[
"def icf_get_rating_given_user(u_ix, item_ix, k):\r\n i_ixs = np.argsort(cf_item_similarity_mat[item_ix,:])[-k:]\r\n user_subitems = urm[u_ix,i_ixs].squeeze()\r\n masked_user_subitems = np.ma.array(user_subitems, mask=user_subitems == 0.) \r\n weights = cf_item_similarity_mat[item_ix, i_ixs].squeeze()\r\n w_avg = np.ma.average(a=masked_user_subitems, weights=weights)\r\n return np.where(w_avg == np.ma.masked, 0., w_avg), masked_user_subitems, weights",
"_____no_output_____"
],
[
"icf_get_rating_given_user(0,55,200)",
"_____no_output_____"
],
[
"# Optimize using CF\r\n\r\nratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\n\r\nC = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean\r\n\r\nb_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item\r\n\r\nb_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')\r\n\r\nratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user",
"_____no_output_____"
],
[
"total_mean",
"_____no_output_____"
],
[
"import tensorflow as tf\r\n\r\[email protected]\r\ndef masked_mse(y_pred, y_true, mask, weights, lamb):\r\n y_pred_masked = tf.gather_nd(y_pred,tf.where(mask))\r\n y_true_masked = tf.gather_nd(y_true,tf.where(mask))\r\n return tf.losses.mean_squared_error(y_true_masked, y_pred_masked) + lamb * tf.norm(weights)",
"_____no_output_____"
],
[
"urm = ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values\r\nurm = tf.constant(urm, dtype=tf.float32)\r\n\r\nsim_matrix = tf.Variable(tf.random.uniform(shape=[urm.shape[1], urm.shape[1]]), trainable=True)\r\nepochs = 600\r\nopti = tf.optimizers.Adam(0.01)\r\n\r\nmask = tf.not_equal(urm, 0.)\r\nloss = masked_mse\r\nmses = []\r\nfor e in range(epochs):\r\n with tf.GradientTape() as gt:\r\n gt.watch(sim_matrix)\r\n preds = tf.matmul(urm, sim_matrix)\r\n preds = tf.clip_by_value(preds, 0., 5.)\r\n\r\n mse = loss(preds, urm, mask, sim_matrix, 0.9)\r\n grads = gt.gradient(mse, sim_matrix)\r\n opti.apply_gradients(grads_and_vars=zip([grads], [sim_matrix])) \r\n mses.append(loss(preds, urm, mask, sim_matrix, 0.))\r\n print(f'Epoch:{e} - Loss: {mses[-1]}')",
"Epoch:0 - Loss: 2.613279342651367\nEpoch:1 - Loss: 2.613279342651367\nEpoch:2 - Loss: 2.613279342651367\nEpoch:3 - Loss: 2.613279342651367\nEpoch:4 - Loss: 2.613279342651367\nEpoch:5 - Loss: 2.613279342651367\nEpoch:6 - Loss: 2.613279342651367\nEpoch:7 - Loss: 2.613279342651367\nEpoch:8 - Loss: 2.613279342651367\nEpoch:9 - Loss: 2.613279342651367\nEpoch:10 - Loss: 2.613279342651367\nEpoch:11 - Loss: 2.613279342651367\nEpoch:12 - Loss: 2.613279342651367\nEpoch:13 - Loss: 2.613279342651367\nEpoch:14 - Loss: 2.613279342651367\nEpoch:15 - Loss: 2.613279342651367\nEpoch:16 - Loss: 2.613279342651367\nEpoch:17 - Loss: 2.613279342651367\nEpoch:18 - Loss: 2.613279342651367\nEpoch:19 - Loss: 2.613279342651367\nEpoch:20 - Loss: 2.613279342651367\nEpoch:21 - Loss: 2.613279342651367\nEpoch:22 - Loss: 2.613279342651367\nEpoch:23 - Loss: 2.613279342651367\nEpoch:24 - Loss: 2.613279342651367\nEpoch:25 - Loss: 2.613279342651367\nEpoch:26 - Loss: 2.613279342651367\nEpoch:27 - Loss: 2.613279342651367\nEpoch:28 - Loss: 2.613279342651367\nEpoch:29 - Loss: 2.613279342651367\nEpoch:30 - Loss: 2.613279342651367\nEpoch:31 - Loss: 2.613276958465576\nEpoch:32 - Loss: 2.613259792327881\nEpoch:33 - Loss: 2.613237142562866\nEpoch:34 - Loss: 2.6132023334503174\nEpoch:35 - Loss: 2.6131584644317627\nEpoch:36 - Loss: 2.613110065460205\nEpoch:37 - Loss: 2.6130716800689697\nEpoch:38 - Loss: 2.613042116165161\nEpoch:39 - Loss: 2.6130123138427734\nEpoch:40 - Loss: 2.6129627227783203\nEpoch:41 - Loss: 2.6128907203674316\nEpoch:42 - Loss: 2.6127896308898926\nEpoch:43 - Loss: 2.6126203536987305\nEpoch:44 - Loss: 2.6123850345611572\nEpoch:45 - Loss: 2.6121487617492676\nEpoch:46 - Loss: 2.6119120121002197\nEpoch:47 - Loss: 2.6116299629211426\nEpoch:48 - Loss: 2.6113204956054688\nEpoch:49 - Loss: 2.611032485961914\nEpoch:50 - Loss: 2.610743522644043\nEpoch:51 - Loss: 2.610334873199463\nEpoch:52 - Loss: 2.6098690032958984\nEpoch:53 - Loss: 2.6093742847442627\nEpoch:54 - Loss: 2.6087629795074463\nEpoch:55 - Loss: 2.60790753364563\nEpoch:56 - Loss: 2.6066856384277344\nEpoch:57 - Loss: 2.6053144931793213\nEpoch:58 - Loss: 2.6037161350250244\nEpoch:59 - Loss: 2.6019065380096436\nEpoch:60 - Loss: 2.5998055934906006\nEpoch:61 - Loss: 2.5972280502319336\nEpoch:62 - Loss: 2.5943093299865723\nEpoch:63 - Loss: 2.5907199382781982\nEpoch:64 - Loss: 2.5863749980926514\nEpoch:65 - Loss: 2.581526279449463\nEpoch:66 - Loss: 2.576016902923584\nEpoch:67 - Loss: 2.569898843765259\nEpoch:68 - Loss: 2.563971519470215\nEpoch:69 - Loss: 2.5564332008361816\nEpoch:70 - Loss: 2.54665470123291\nEpoch:71 - Loss: 2.535766363143921\nEpoch:72 - Loss: 2.5248873233795166\nEpoch:73 - Loss: 2.5129470825195312\nEpoch:74 - Loss: 2.4985899925231934\nEpoch:75 - Loss: 2.4808833599090576\nEpoch:76 - Loss: 2.459094762802124\nEpoch:77 - Loss: 2.4360156059265137\nEpoch:78 - Loss: 2.4063847064971924\nEpoch:79 - Loss: 2.3703513145446777\nEpoch:80 - Loss: 2.326416492462158\nEpoch:81 - Loss: 2.278470039367676\nEpoch:82 - Loss: 2.2242069244384766\nEpoch:83 - Loss: 2.1465301513671875\nEpoch:84 - Loss: 2.0742135047912598\nEpoch:85 - Loss: 2.3134405612945557\nEpoch:86 - Loss: 2.955437183380127\nEpoch:87 - Loss: 3.249049186706543\nEpoch:88 - Loss: 3.1094748973846436\nEpoch:89 - Loss: 3.1199283599853516\nEpoch:90 - Loss: 3.149266004562378\nEpoch:91 - Loss: 3.1606478691101074\nEpoch:92 - Loss: 3.145237684249878\nEpoch:93 - Loss: 3.1078884601593018\nEpoch:94 - Loss: 3.071863889694214\nEpoch:95 - Loss: 3.0271809101104736\nEpoch:96 - Loss: 2.9581239223480225\nEpoch:97 - Loss: 2.894139289855957\nEpoch:98 - Loss: 2.80055570602417\nEpoch:99 - Loss: 2.6840462684631348\nEpoch:100 - Loss: 2.529674768447876\nEpoch:101 - Loss: 2.404740810394287\nEpoch:102 - Loss: 2.328268051147461\nEpoch:103 - Loss: 2.2797691822052\nEpoch:104 - Loss: 2.332228899002075\nEpoch:105 - Loss: 2.4532837867736816\nEpoch:106 - Loss: 2.5571200847625732\nEpoch:107 - Loss: 2.5251591205596924\nEpoch:108 - Loss: 2.508052110671997\nEpoch:109 - Loss: 2.399142265319824\nEpoch:110 - Loss: 2.30558705329895\nEpoch:111 - Loss: 2.225710868835449\nEpoch:112 - Loss: 2.170778751373291\nEpoch:113 - Loss: 2.2231483459472656\nEpoch:114 - Loss: 2.358616590499878\nEpoch:115 - Loss: 2.6110687255859375\nEpoch:116 - Loss: 2.7888689041137695\nEpoch:117 - Loss: 2.8331997394561768\nEpoch:118 - Loss: 2.715470552444458\nEpoch:119 - Loss: 2.5888466835021973\nEpoch:120 - Loss: 2.4915378093719482\nEpoch:121 - Loss: 2.405266046524048\nEpoch:122 - Loss: 2.398768663406372\nEpoch:123 - Loss: 2.514643907546997\nEpoch:124 - Loss: 2.672067165374756\nEpoch:125 - Loss: 2.7904534339904785\nEpoch:126 - Loss: 2.7922797203063965\nEpoch:127 - Loss: 2.6955881118774414\nEpoch:128 - Loss: 2.5762505531311035\nEpoch:129 - Loss: 2.509546995162964\nEpoch:130 - Loss: 2.570674419403076\nEpoch:131 - Loss: 2.667459487915039\nEpoch:132 - Loss: 2.8162827491760254\nEpoch:133 - Loss: 2.8279762268066406\nEpoch:134 - Loss: 2.776742935180664\nEpoch:135 - Loss: 2.708421230316162\nEpoch:136 - Loss: 2.648160219192505\nEpoch:137 - Loss: 2.673020124435425\nEpoch:138 - Loss: 2.7082107067108154\nEpoch:139 - Loss: 2.7554197311401367\nEpoch:140 - Loss: 2.779386281967163\nEpoch:141 - Loss: 2.7394561767578125\nEpoch:142 - Loss: 2.713902711868286\nEpoch:143 - Loss: 2.696983814239502\nEpoch:144 - Loss: 2.7841978073120117\nEpoch:145 - Loss: 2.7647621631622314\nEpoch:146 - Loss: 2.781435251235962\nEpoch:147 - Loss: 2.7868494987487793\nEpoch:148 - Loss: 2.762326955795288\nEpoch:149 - Loss: 2.7538130283355713\nEpoch:150 - Loss: 2.772033214569092\nEpoch:151 - Loss: 2.8110108375549316\nEpoch:152 - Loss: 2.7810637950897217\nEpoch:153 - Loss: 2.7674448490142822\nEpoch:154 - Loss: 2.7691915035247803\nEpoch:155 - Loss: 2.7774131298065186\nEpoch:156 - Loss: 2.7981133460998535\nEpoch:157 - Loss: 2.806396007537842\nEpoch:158 - Loss: 2.803683280944824\nEpoch:159 - Loss: 2.7682297229766846\nEpoch:160 - Loss: 2.79742169380188\nEpoch:161 - Loss: 2.763068914413452\nEpoch:162 - Loss: 2.8197078704833984\nEpoch:163 - Loss: 2.775240659713745\nEpoch:164 - Loss: 2.8031165599823\nEpoch:165 - Loss: 2.8468174934387207\nEpoch:166 - Loss: 2.7962706089019775\nEpoch:167 - Loss: 2.817808151245117\nEpoch:168 - Loss: 2.804271697998047\nEpoch:169 - Loss: 2.7964484691619873\nEpoch:170 - Loss: 2.7567801475524902\nEpoch:171 - Loss: 2.7702879905700684\nEpoch:172 - Loss: 2.803748846054077\nEpoch:173 - Loss: 2.7976367473602295\nEpoch:174 - Loss: 2.798489570617676\nEpoch:175 - Loss: 2.8176043033599854\nEpoch:176 - Loss: 2.7930197715759277\nEpoch:177 - Loss: 2.7972629070281982\nEpoch:178 - Loss: 2.7664434909820557\nEpoch:179 - Loss: 2.7255618572235107\nEpoch:180 - Loss: 2.7288453578948975\nEpoch:181 - Loss: 2.757657289505005\nEpoch:182 - Loss: 2.8055782318115234\nEpoch:183 - Loss: 2.768425226211548\nEpoch:184 - Loss: 2.749586582183838\nEpoch:185 - Loss: 2.7391743659973145\nEpoch:186 - Loss: 2.762237071990967\nEpoch:187 - Loss: 2.7480287551879883\nEpoch:188 - Loss: 2.7919058799743652\nEpoch:189 - Loss: 2.7517950534820557\nEpoch:190 - Loss: 2.7562878131866455\nEpoch:191 - Loss: 2.7275071144104004\nEpoch:192 - Loss: 2.7502169609069824\nEpoch:193 - Loss: 2.756761074066162\nEpoch:194 - Loss: 2.741589069366455\nEpoch:195 - Loss: 2.753300428390503\nEpoch:196 - Loss: 2.733062505722046\nEpoch:197 - Loss: 2.728703737258911\nEpoch:198 - Loss: 2.7011563777923584\nEpoch:199 - Loss: 2.7388110160827637\nEpoch:200 - Loss: 2.7096707820892334\nEpoch:201 - Loss: 2.742753744125366\nEpoch:202 - Loss: 2.760375499725342\nEpoch:203 - Loss: 2.725066661834717\nEpoch:204 - Loss: 2.6975550651550293\nEpoch:205 - Loss: 2.7422640323638916\nEpoch:206 - Loss: 2.7128548622131348\nEpoch:207 - Loss: 2.734285831451416\nEpoch:208 - Loss: 2.78586745262146\nEpoch:209 - Loss: 2.762176275253296\nEpoch:210 - Loss: 2.7437002658843994\nEpoch:211 - Loss: 2.7479796409606934\nEpoch:212 - Loss: 2.727048635482788\nEpoch:213 - Loss: 2.7074854373931885\nEpoch:214 - Loss: 2.726207971572876\nEpoch:215 - Loss: 2.748605489730835\nEpoch:216 - Loss: 2.715571641921997\nEpoch:217 - Loss: 2.7173094749450684\nEpoch:218 - Loss: 2.706939697265625\nEpoch:219 - Loss: 2.704880952835083\nEpoch:220 - Loss: 2.7033345699310303\nEpoch:221 - Loss: 2.68733549118042\nEpoch:222 - Loss: 2.7226383686065674\nEpoch:223 - Loss: 2.7336153984069824\nEpoch:224 - Loss: 2.6977813243865967\nEpoch:225 - Loss: 2.6961705684661865\nEpoch:226 - Loss: 2.6883156299591064\nEpoch:227 - Loss: 2.6972172260284424\nEpoch:228 - Loss: 2.713015556335449\nEpoch:229 - Loss: 2.7431282997131348\nEpoch:230 - Loss: 2.704216480255127\nEpoch:231 - Loss: 2.6940197944641113\nEpoch:232 - Loss: 2.701540470123291\nEpoch:233 - Loss: 2.7075626850128174\nEpoch:234 - Loss: 2.725489377975464\nEpoch:235 - Loss: 2.7055249214172363\nEpoch:236 - Loss: 2.7081828117370605\nEpoch:237 - Loss: 2.6731936931610107\nEpoch:238 - Loss: 2.7002980709075928\nEpoch:239 - Loss: 2.6839981079101562\nEpoch:240 - Loss: 2.7024643421173096\nEpoch:241 - Loss: 2.7126777172088623\nEpoch:242 - Loss: 2.6602301597595215\nEpoch:243 - Loss: 2.710968494415283\nEpoch:244 - Loss: 2.7091012001037598\nEpoch:245 - Loss: 2.6814777851104736\nEpoch:246 - Loss: 2.6548213958740234\nEpoch:247 - Loss: 2.698336362838745\nEpoch:248 - Loss: 2.714677095413208\nEpoch:249 - Loss: 2.6814610958099365\nEpoch:250 - Loss: 2.7086024284362793\nEpoch:251 - Loss: 2.659766912460327\nEpoch:252 - Loss: 2.6352763175964355\nEpoch:253 - Loss: 2.6386570930480957\nEpoch:254 - Loss: 2.6973440647125244\nEpoch:255 - Loss: 2.679487943649292\nEpoch:256 - Loss: 2.6786904335021973\nEpoch:257 - Loss: 2.6658642292022705\nEpoch:258 - Loss: 2.683126449584961\nEpoch:259 - Loss: 2.686997890472412\nEpoch:260 - Loss: 2.6950523853302\nEpoch:261 - Loss: 2.6582190990448\nEpoch:262 - Loss: 2.673722267150879\nEpoch:263 - Loss: 2.6589250564575195\nEpoch:264 - Loss: 2.700416326522827\nEpoch:265 - Loss: 2.7004480361938477\nEpoch:266 - Loss: 2.6547350883483887\nEpoch:267 - Loss: 2.664667844772339\nEpoch:268 - Loss: 2.641105890274048\nEpoch:269 - Loss: 2.698713541030884\nEpoch:270 - Loss: 2.6882667541503906\nEpoch:271 - Loss: 2.7236714363098145\nEpoch:272 - Loss: 2.692481517791748\nEpoch:273 - Loss: 2.6652045249938965\nEpoch:274 - Loss: 2.656660556793213\nEpoch:275 - Loss: 2.682109832763672\nEpoch:276 - Loss: 2.646392345428467\nEpoch:277 - Loss: 2.6550140380859375\nEpoch:278 - Loss: 2.6912238597869873\nEpoch:279 - Loss: 2.6714529991149902\nEpoch:280 - Loss: 2.6732895374298096\nEpoch:281 - Loss: 2.6946499347686768\nEpoch:282 - Loss: 2.6823878288269043\nEpoch:283 - Loss: 2.666128158569336\nEpoch:284 - Loss: 2.652785539627075\nEpoch:285 - Loss: 2.6796092987060547\nEpoch:286 - Loss: 2.667551040649414\nEpoch:287 - Loss: 2.6748664379119873\nEpoch:288 - Loss: 2.7010669708251953\nEpoch:289 - Loss: 2.695089340209961\nEpoch:290 - Loss: 2.6729488372802734\nEpoch:291 - Loss: 2.6453216075897217\nEpoch:292 - Loss: 2.653048276901245\nEpoch:293 - Loss: 2.6818981170654297\nEpoch:294 - Loss: 2.6676087379455566\nEpoch:295 - Loss: 2.680147171020508\nEpoch:296 - Loss: 2.6316404342651367\nEpoch:297 - Loss: 2.644205331802368\nEpoch:298 - Loss: 2.66447377204895\nEpoch:299 - Loss: 2.6835789680480957\nEpoch:300 - Loss: 2.68257999420166\nEpoch:301 - Loss: 2.6494452953338623\nEpoch:302 - Loss: 2.646090030670166\nEpoch:303 - Loss: 2.657640218734741\nEpoch:304 - Loss: 2.6546106338500977\nEpoch:305 - Loss: 2.701030731201172\nEpoch:306 - Loss: 2.664449691772461\nEpoch:307 - Loss: 2.668696880340576\nEpoch:308 - Loss: 2.6643826961517334\nEpoch:309 - Loss: 2.66020131111145\nEpoch:310 - Loss: 2.6749603748321533\nEpoch:311 - Loss: 2.6615614891052246\nEpoch:312 - Loss: 2.6722071170806885\nEpoch:313 - Loss: 2.6576359272003174\nEpoch:314 - Loss: 2.6937170028686523\nEpoch:315 - Loss: 2.6735658645629883\nEpoch:316 - Loss: 2.638397455215454\nEpoch:317 - Loss: 2.632795810699463\nEpoch:318 - Loss: 2.6727347373962402\nEpoch:319 - Loss: 2.669121265411377\nEpoch:320 - Loss: 2.6795620918273926\nEpoch:321 - Loss: 2.6568222045898438\nEpoch:322 - Loss: 2.6427860260009766\nEpoch:323 - Loss: 2.6574673652648926\nEpoch:324 - Loss: 2.6738529205322266\nEpoch:325 - Loss: 2.6673121452331543\nEpoch:326 - Loss: 2.6393861770629883\nEpoch:327 - Loss: 2.6262712478637695\nEpoch:328 - Loss: 2.6140620708465576\nEpoch:329 - Loss: 2.6544535160064697\nEpoch:330 - Loss: 2.6657655239105225\nEpoch:331 - Loss: 2.664992570877075\nEpoch:332 - Loss: 2.617743730545044\nEpoch:333 - Loss: 2.6413092613220215\nEpoch:334 - Loss: 2.663600444793701\nEpoch:335 - Loss: 2.647911548614502\nEpoch:336 - Loss: 2.6637091636657715\nEpoch:337 - Loss: 2.6281282901763916\nEpoch:338 - Loss: 2.629539966583252\nEpoch:339 - Loss: 2.628355026245117\nEpoch:340 - Loss: 2.6618452072143555\nEpoch:341 - Loss: 2.6578662395477295\nEpoch:342 - Loss: 2.6608543395996094\nEpoch:343 - Loss: 2.648059606552124\nEpoch:344 - Loss: 2.637321710586548\nEpoch:345 - Loss: 2.6141631603240967\nEpoch:346 - Loss: 2.638012409210205\nEpoch:347 - Loss: 2.627553701400757\nEpoch:348 - Loss: 2.676414966583252\nEpoch:349 - Loss: 2.661519765853882\nEpoch:350 - Loss: 2.624436616897583\nEpoch:351 - Loss: 2.6323909759521484\nEpoch:352 - Loss: 2.626446008682251\nEpoch:353 - Loss: 2.659865617752075\nEpoch:354 - Loss: 2.6678144931793213\nEpoch:355 - Loss: 2.643897294998169\nEpoch:356 - Loss: 2.621072292327881\nEpoch:357 - Loss: 2.6152007579803467\nEpoch:358 - Loss: 2.6390533447265625\nEpoch:359 - Loss: 2.65325665473938\nEpoch:360 - Loss: 2.6641170978546143\nEpoch:361 - Loss: 2.648965358734131\nEpoch:362 - Loss: 2.6193106174468994\nEpoch:363 - Loss: 2.62754487991333\nEpoch:364 - Loss: 2.6347877979278564\nEpoch:365 - Loss: 2.6299338340759277\nEpoch:366 - Loss: 2.6126351356506348\nEpoch:367 - Loss: 2.622786045074463\nEpoch:368 - Loss: 2.630147695541382\nEpoch:369 - Loss: 2.6213271617889404\nEpoch:370 - Loss: 2.652996778488159\nEpoch:371 - Loss: 2.619246244430542\nEpoch:372 - Loss: 2.6107616424560547\nEpoch:373 - Loss: 2.628584384918213\nEpoch:374 - Loss: 2.5905022621154785\nEpoch:375 - Loss: 2.617915391921997\nEpoch:376 - Loss: 2.6375017166137695\nEpoch:377 - Loss: 2.6315786838531494\nEpoch:378 - Loss: 2.6407017707824707\nEpoch:379 - Loss: 2.6066629886627197\nEpoch:380 - Loss: 2.5998353958129883\nEpoch:381 - Loss: 2.618147850036621\nEpoch:382 - Loss: 2.6391468048095703\nEpoch:383 - Loss: 2.646267890930176\nEpoch:384 - Loss: 2.6093831062316895\nEpoch:385 - Loss: 2.6300220489501953\nEpoch:386 - Loss: 2.6360373497009277\nEpoch:387 - Loss: 2.622286796569824\nEpoch:388 - Loss: 2.654279947280884\nEpoch:389 - Loss: 2.6187968254089355\nEpoch:390 - Loss: 2.645954132080078\nEpoch:391 - Loss: 2.63596773147583\nEpoch:392 - Loss: 2.6125760078430176\nEpoch:393 - Loss: 2.6292941570281982\nEpoch:394 - Loss: 2.6349592208862305\nEpoch:395 - Loss: 2.6294150352478027\nEpoch:396 - Loss: 2.6370179653167725\nEpoch:397 - Loss: 2.6376607418060303\nEpoch:398 - Loss: 2.6453263759613037\nEpoch:399 - Loss: 2.624107837677002\nEpoch:400 - Loss: 2.6302778720855713\nEpoch:401 - Loss: 2.6412720680236816\nEpoch:402 - Loss: 2.638200044631958\nEpoch:403 - Loss: 2.629952907562256\nEpoch:404 - Loss: 2.59702205657959\nEpoch:405 - Loss: 2.6262006759643555\nEpoch:406 - Loss: 2.6416757106781006\nEpoch:407 - Loss: 2.6549248695373535\nEpoch:408 - Loss: 2.646773338317871\nEpoch:409 - Loss: 2.666801691055298\nEpoch:410 - Loss: 2.636591911315918\nEpoch:411 - Loss: 2.6445727348327637\nEpoch:412 - Loss: 2.614048480987549\nEpoch:413 - Loss: 2.607105016708374\nEpoch:414 - Loss: 2.6289432048797607\nEpoch:415 - Loss: 2.635528326034546\nEpoch:416 - Loss: 2.6439199447631836\nEpoch:417 - Loss: 2.616630792617798\nEpoch:418 - Loss: 2.6306874752044678\nEpoch:419 - Loss: 2.630148410797119\nEpoch:420 - Loss: 2.6143341064453125\nEpoch:421 - Loss: 2.6165435314178467\nEpoch:422 - Loss: 2.60917067527771\nEpoch:423 - Loss: 2.6400794982910156\nEpoch:424 - Loss: 2.6293742656707764\nEpoch:425 - Loss: 2.6196773052215576\nEpoch:426 - Loss: 2.6313865184783936\nEpoch:427 - Loss: 2.6157734394073486\nEpoch:428 - Loss: 2.630833148956299\nEpoch:429 - Loss: 2.618619680404663\nEpoch:430 - Loss: 2.5961251258850098\nEpoch:431 - Loss: 2.6004538536071777\nEpoch:432 - Loss: 2.634641647338867\nEpoch:433 - Loss: 2.625905752182007\nEpoch:434 - Loss: 2.6536448001861572\nEpoch:435 - Loss: 2.6006722450256348\nEpoch:436 - Loss: 2.613964080810547\nEpoch:437 - Loss: 2.6125311851501465\nEpoch:438 - Loss: 2.606483221054077\nEpoch:439 - Loss: 2.639953136444092\nEpoch:440 - Loss: 2.6345200538635254\nEpoch:441 - Loss: 2.6305336952209473\nEpoch:442 - Loss: 2.5760154724121094\nEpoch:443 - Loss: 2.604818344116211\nEpoch:444 - Loss: 2.637467622756958\nEpoch:445 - Loss: 2.6436307430267334\nEpoch:446 - Loss: 2.6406571865081787\nEpoch:447 - Loss: 2.6310389041900635\nEpoch:448 - Loss: 2.619168758392334\nEpoch:449 - Loss: 2.6225900650024414\nEpoch:450 - Loss: 2.6016414165496826\nEpoch:451 - Loss: 2.6234726905822754\nEpoch:452 - Loss: 2.644998550415039\nEpoch:453 - Loss: 2.622159957885742\nEpoch:454 - Loss: 2.6217753887176514\nEpoch:455 - Loss: 2.595534086227417\nEpoch:456 - Loss: 2.6448707580566406\nEpoch:457 - Loss: 2.6504127979278564\nEpoch:458 - Loss: 2.642853021621704\nEpoch:459 - Loss: 2.61391019821167\nEpoch:460 - Loss: 2.6173532009124756\nEpoch:461 - Loss: 2.6250498294830322\nEpoch:462 - Loss: 2.618112802505493\nEpoch:463 - Loss: 2.633113384246826\nEpoch:464 - Loss: 2.6099467277526855\nEpoch:465 - Loss: 2.6196129322052\nEpoch:466 - Loss: 2.611658811569214\nEpoch:467 - Loss: 2.608186721801758\nEpoch:468 - Loss: 2.6254630088806152\nEpoch:469 - Loss: 2.6297614574432373\nEpoch:470 - Loss: 2.6145403385162354\nEpoch:471 - Loss: 2.6173787117004395\nEpoch:472 - Loss: 2.621741533279419\nEpoch:473 - Loss: 2.62955904006958\nEpoch:474 - Loss: 2.6262080669403076\nEpoch:475 - Loss: 2.6142685413360596\nEpoch:476 - Loss: 2.6034560203552246\nEpoch:477 - Loss: 2.5962636470794678\nEpoch:478 - Loss: 2.6005468368530273\nEpoch:479 - Loss: 2.631183385848999\nEpoch:480 - Loss: 2.6209983825683594\nEpoch:481 - Loss: 2.628624677658081\nEpoch:482 - Loss: 2.583601474761963\nEpoch:483 - Loss: 2.601170063018799\nEpoch:484 - Loss: 2.631730079650879\nEpoch:485 - Loss: 2.6134274005889893\nEpoch:486 - Loss: 2.6069750785827637\nEpoch:487 - Loss: 2.6063387393951416\nEpoch:488 - Loss: 2.601588249206543\nEpoch:489 - Loss: 2.619061231613159\nEpoch:490 - Loss: 2.627687931060791\nEpoch:491 - Loss: 2.595754623413086\nEpoch:492 - Loss: 2.606755256652832\nEpoch:493 - Loss: 2.5945069789886475\nEpoch:494 - Loss: 2.6202127933502197\nEpoch:495 - Loss: 2.5921101570129395\nEpoch:496 - Loss: 2.6005823612213135\nEpoch:497 - Loss: 2.6247036457061768\nEpoch:498 - Loss: 2.6293749809265137\nEpoch:499 - Loss: 2.6376123428344727\nEpoch:500 - Loss: 2.62833833694458\nEpoch:501 - Loss: 2.6235506534576416\nEpoch:502 - Loss: 2.6165921688079834\nEpoch:503 - Loss: 2.616743326187134\nEpoch:504 - Loss: 2.585397958755493\nEpoch:505 - Loss: 2.6260592937469482\nEpoch:506 - Loss: 2.6612355709075928\nEpoch:507 - Loss: 2.624699592590332\nEpoch:508 - Loss: 2.598811388015747\nEpoch:509 - Loss: 2.6160695552825928\nEpoch:510 - Loss: 2.608823299407959\nEpoch:511 - Loss: 2.639390230178833\nEpoch:512 - Loss: 2.621062994003296\nEpoch:513 - Loss: 2.6130223274230957\nEpoch:514 - Loss: 2.605778932571411\nEpoch:515 - Loss: 2.602062940597534\nEpoch:516 - Loss: 2.6156249046325684\nEpoch:517 - Loss: 2.6135847568511963\nEpoch:518 - Loss: 2.6151907444000244\nEpoch:519 - Loss: 2.607412576675415\nEpoch:520 - Loss: 2.6011688709259033\nEpoch:521 - Loss: 2.6195085048675537\nEpoch:522 - Loss: 2.6167514324188232\nEpoch:523 - Loss: 2.633312702178955\nEpoch:524 - Loss: 2.6022002696990967\nEpoch:525 - Loss: 2.641948938369751\nEpoch:526 - Loss: 2.614447593688965\nEpoch:527 - Loss: 2.6028671264648438\nEpoch:528 - Loss: 2.5897209644317627\nEpoch:529 - Loss: 2.613232135772705\nEpoch:530 - Loss: 2.6123673915863037\nEpoch:531 - Loss: 2.621772289276123\nEpoch:532 - Loss: 2.611823797225952\nEpoch:533 - Loss: 2.6009175777435303\nEpoch:534 - Loss: 2.606156826019287\nEpoch:535 - Loss: 2.6129817962646484\nEpoch:536 - Loss: 2.6319947242736816\nEpoch:537 - Loss: 2.6244897842407227\nEpoch:538 - Loss: 2.611097812652588\nEpoch:539 - Loss: 2.6043848991394043\nEpoch:540 - Loss: 2.5979831218719482\nEpoch:541 - Loss: 2.6138148307800293\nEpoch:542 - Loss: 2.6194467544555664\nEpoch:543 - Loss: 2.630070924758911\nEpoch:544 - Loss: 2.6232783794403076\nEpoch:545 - Loss: 2.6195459365844727\nEpoch:546 - Loss: 2.609923839569092\nEpoch:547 - Loss: 2.6228573322296143\nEpoch:548 - Loss: 2.606684923171997\nEpoch:549 - Loss: 2.5951743125915527\nEpoch:550 - Loss: 2.6158390045166016\nEpoch:551 - Loss: 2.6111812591552734\nEpoch:552 - Loss: 2.6142969131469727\nEpoch:553 - Loss: 2.630042791366577\nEpoch:554 - Loss: 2.6271469593048096\nEpoch:555 - Loss: 2.6195788383483887\nEpoch:556 - Loss: 2.6188371181488037\nEpoch:557 - Loss: 2.6082897186279297\nEpoch:558 - Loss: 2.627915620803833\nEpoch:559 - Loss: 2.6219000816345215\nEpoch:560 - Loss: 2.5963423252105713\nEpoch:561 - Loss: 2.5937511920928955\nEpoch:562 - Loss: 2.6358890533447266\nEpoch:563 - Loss: 2.608320713043213\nEpoch:564 - Loss: 2.608564853668213\nEpoch:565 - Loss: 2.6240298748016357\nEpoch:566 - Loss: 2.626755952835083\nEpoch:567 - Loss: 2.610520124435425\nEpoch:568 - Loss: 2.6157195568084717\nEpoch:569 - Loss: 2.6290318965911865\nEpoch:570 - Loss: 2.634085178375244\nEpoch:571 - Loss: 2.6324849128723145\nEpoch:572 - Loss: 2.6118266582489014\nEpoch:573 - Loss: 2.616396903991699\nEpoch:574 - Loss: 2.6265933513641357\nEpoch:575 - Loss: 2.620164155960083\nEpoch:576 - Loss: 2.6398329734802246\nEpoch:577 - Loss: 2.6194911003112793\nEpoch:578 - Loss: 2.5925955772399902\nEpoch:579 - Loss: 2.6135005950927734\nEpoch:580 - Loss: 2.624580144882202\nEpoch:581 - Loss: 2.645054817199707\nEpoch:582 - Loss: 2.6268365383148193\nEpoch:583 - Loss: 2.617997884750366\nEpoch:584 - Loss: 2.598167896270752\nEpoch:585 - Loss: 2.6032793521881104\nEpoch:586 - Loss: 2.60957407951355\nEpoch:587 - Loss: 2.5987870693206787\nEpoch:588 - Loss: 2.6120715141296387\nEpoch:589 - Loss: 2.6032090187072754\nEpoch:590 - Loss: 2.6010701656341553\nEpoch:591 - Loss: 2.607015609741211\nEpoch:592 - Loss: 2.5974626541137695\nEpoch:593 - Loss: 2.6176209449768066\nEpoch:594 - Loss: 2.627821445465088\nEpoch:595 - Loss: 2.6006884574890137\nEpoch:596 - Loss: 2.5979883670806885\nEpoch:597 - Loss: 2.6138815879821777\nEpoch:598 - Loss: 2.629605293273926\nEpoch:599 - Loss: 2.625037431716919\n"
],
[
"plt.plot(mses)",
"_____no_output_____"
],
[
"tf.clip_by_value(urm @ sim_matrix, 0., 5.)",
"_____no_output_____"
],
[
"masked_mse(tf.clip_by_value(urm @ sim_matrix, 0., 5.), urm, mask, sim_matrix, 0.)",
"_____no_output_____"
],
[
"k=tf.keras",
"_____no_output_____"
],
[
"ratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\n\r\nC = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean\r\n\r\nb_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item\r\n\r\nb_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')\r\n\r\nratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user",
"_____no_output_____"
],
[
"b_item",
"_____no_output_____"
],
[
"urm = tf.constant(ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values, dtype=tf.float32)",
"_____no_output_____"
],
[
"mask = tf.not_equal(urm, tf.constant(0., dtype=tf.float32))\r\nnon_zero_rating_ixs = tf.where(mask)\r\nnon_zero_ratings = tf.gather_nd(urm, non_zero_rating_ixs)\r\n\r\nsplit = 0.90\r\nsplit_ix = int(split * non_zero_rating_ixs.shape[0])\r\n\r\nnon_zero_rating_ixs_shuffled = tf.random.shuffle(tf.range(non_zero_ratings.shape))\r\n\r\ntrain_urm_ratings = tf.gather(non_zero_ratings, non_zero_rating_ixs_shuffled[:split_ix])\r\ntrain_urm_ratings_ixs = tf.gather(non_zero_rating_ixs, non_zero_rating_ixs_shuffled[:split_ix])\r\ntest_urm_ratings = tf.gather(non_zero_ratings, non_zero_rating_ixs_shuffled[split_ix:])\r\ntest_urm_ratings_ixs = tf.gather(non_zero_rating_ixs, non_zero_rating_ixs_shuffled[split_ix:])\r\n\r\ntrain_urm = tf.scatter_nd(train_urm_ratings_ixs, train_urm_ratings, urm.shape)\r\ntest_urm = tf.scatter_nd(test_urm_ratings_ixs, test_urm_ratings, urm.shape)",
"_____no_output_____"
],
[
"test_urm_ratings_ixs",
"_____no_output_____"
],
[
"@tf.function\r\ndef masked_mse(y_pred, y_true, mask, weights_1, lamb1, weights_2, lamb2):\r\n y_pred_masked = tf.boolean_mask(y_pred, mask)\r\n y_true_masked = tf.boolean_mask(y_true, mask)\r\n return tf.losses.mean_squared_error(y_true_masked, y_pred_masked) + lamb1 * tf.norm(weights_1) + lamb2 * tf.norm(weights_2)",
"_____no_output_____"
],
[
"emb_dim = 30\r\nuser_emb = tf.Variable(tf.random.uniform(shape=(urm.shape[0],emb_dim)), trainable=True)\r\nitem_emb = tf.Variable(tf.random.uniform(shape=(urm.shape[1],emb_dim)), trainable=True)\r\n\r\nmask = tf.not_equal(train_urm, tf.constant(0, dtype=tf.float32))\r\ntest_mask = tf.not_equal(test_urm, 0.)\r\n\r\nepochs = 400\r\nopti = tf.optimizers.Adam()\r\nloss = masked_mse\r\ntrain_mses = []\r\ntest_mses = []\r\n\r\nfor e in range(epochs):\r\n with tf.GradientTape(watch_accessed_variables=False) as gt1:\r\n \r\n gt1.watch(user_emb)\r\n with tf.GradientTape(watch_accessed_variables=False) as gt2:\r\n\r\n gt2.watch(item_emb)\r\n\r\n preds = tf.matmul(user_emb, item_emb, transpose_b=True)\r\n mse = loss(preds, train_urm, mask, user_emb, 0.5, item_emb, 0.4)\r\n \r\n grads = gt1.gradient(mse, user_emb)\r\n opti.apply_gradients(grads_and_vars=zip([grads], [user_emb])) \r\n\r\n grads = gt2.gradient(mse, item_emb)\r\n opti.apply_gradients(grads_and_vars=zip([grads], [item_emb]))\r\n\r\n test_mses.append(masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True), test_urm, test_mask, 0.,0.,0.,0.))\r\n train_mses.append(masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True), train_urm, mask, 0.,0.,0.,0.))\r\n print(f'Epoch: {e} - Train Loss: {train_mses[-1]} - Test Loss: {test_mses[-1]}')",
"Epoch: 0 - Train Loss: 16.956300735473633 - Test Loss: 16.799762725830078\nEpoch: 1 - Train Loss: 16.762908935546875 - Test Loss: 16.607070922851562\nEpoch: 2 - Train Loss: 16.56734848022461 - Test Loss: 16.412214279174805\nEpoch: 3 - Train Loss: 16.36725425720215 - Test Loss: 16.212841033935547\nEpoch: 4 - Train Loss: 16.162073135375977 - Test Loss: 16.00840187072754\nEpoch: 5 - Train Loss: 15.95179271697998 - Test Loss: 15.7988862991333\nEpoch: 6 - Train Loss: 15.736639022827148 - Test Loss: 15.584519386291504\nEpoch: 7 - Train Loss: 15.51695728302002 - Test Loss: 15.365650177001953\nEpoch: 8 - Train Loss: 15.293163299560547 - Test Loss: 15.142688751220703\nEpoch: 9 - Train Loss: 15.065713882446289 - Test Loss: 14.916098594665527\nEpoch: 10 - Train Loss: 14.835090637207031 - Test Loss: 14.68635368347168\nEpoch: 11 - Train Loss: 14.601786613464355 - Test Loss: 14.453948974609375\nEpoch: 12 - Train Loss: 14.366297721862793 - Test Loss: 14.219379425048828\nEpoch: 13 - Train Loss: 14.129108428955078 - Test Loss: 13.983124732971191\nEpoch: 14 - Train Loss: 13.890693664550781 - Test Loss: 13.745662689208984\nEpoch: 15 - Train Loss: 13.651512145996094 - Test Loss: 13.507447242736816\nEpoch: 16 - Train Loss: 13.41199779510498 - Test Loss: 13.268914222717285\nEpoch: 17 - Train Loss: 13.172562599182129 - Test Loss: 13.030471801757812\nEpoch: 18 - Train Loss: 12.93359661102295 - Test Loss: 12.792508125305176\nEpoch: 19 - Train Loss: 12.695454597473145 - Test Loss: 12.555378913879395\nEpoch: 20 - Train Loss: 12.45847225189209 - Test Loss: 12.319416046142578\nEpoch: 21 - Train Loss: 12.222952842712402 - Test Loss: 12.084922790527344\nEpoch: 22 - Train Loss: 11.989173889160156 - Test Loss: 11.8521728515625\nEpoch: 23 - Train Loss: 11.75738525390625 - Test Loss: 11.621418952941895\nEpoch: 24 - Train Loss: 11.527814865112305 - Test Loss: 11.39288330078125\nEpoch: 25 - Train Loss: 11.300660133361816 - Test Loss: 11.166766166687012\nEpoch: 26 - Train Loss: 11.076101303100586 - Test Loss: 10.943244934082031\nEpoch: 27 - Train Loss: 10.854290962219238 - Test Loss: 10.722472190856934\nEpoch: 28 - Train Loss: 10.635366439819336 - Test Loss: 10.504583358764648\nEpoch: 29 - Train Loss: 10.419445037841797 - Test Loss: 10.289693832397461\nEpoch: 30 - Train Loss: 10.206623077392578 - Test Loss: 10.077901840209961\nEpoch: 31 - Train Loss: 9.996984481811523 - Test Loss: 9.86928939819336\nEpoch: 32 - Train Loss: 9.790597915649414 - Test Loss: 9.663923263549805\nEpoch: 33 - Train Loss: 9.587515830993652 - Test Loss: 9.461857795715332\nEpoch: 34 - Train Loss: 9.387782096862793 - Test Loss: 9.263134956359863\nEpoch: 35 - Train Loss: 9.191425323486328 - Test Loss: 9.06778335571289\nEpoch: 36 - Train Loss: 8.998467445373535 - Test Loss: 8.875825881958008\nEpoch: 37 - Train Loss: 8.808920860290527 - Test Loss: 8.687272071838379\nEpoch: 38 - Train Loss: 8.622787475585938 - Test Loss: 8.502126693725586\nEpoch: 39 - Train Loss: 8.44006633758545 - Test Loss: 8.320384979248047\nEpoch: 40 - Train Loss: 8.26074504852295 - Test Loss: 8.142036437988281\nEpoch: 41 - Train Loss: 8.084808349609375 - Test Loss: 7.967066287994385\nEpoch: 42 - Train Loss: 7.912234783172607 - Test Loss: 7.79545259475708\nEpoch: 43 - Train Loss: 7.74299955368042 - Test Loss: 7.627171039581299\nEpoch: 44 - Train Loss: 7.577073574066162 - Test Loss: 7.462191104888916\nEpoch: 45 - Train Loss: 7.414424896240234 - Test Loss: 7.30048131942749\nEpoch: 46 - Train Loss: 7.255014896392822 - Test Loss: 7.142005443572998\nEpoch: 47 - Train Loss: 7.098809242248535 - Test Loss: 6.986725330352783\nEpoch: 48 - Train Loss: 6.945764064788818 - Test Loss: 6.834601879119873\nEpoch: 49 - Train Loss: 6.795839309692383 - Test Loss: 6.6855902671813965\nEpoch: 50 - Train Loss: 6.648991107940674 - Test Loss: 6.539649963378906\nEpoch: 51 - Train Loss: 6.50517463684082 - Test Loss: 6.396733283996582\nEpoch: 52 - Train Loss: 6.364341735839844 - Test Loss: 6.256795883178711\nEpoch: 53 - Train Loss: 6.226449012756348 - Test Loss: 6.119791030883789\nEpoch: 54 - Train Loss: 6.091445446014404 - Test Loss: 5.985671043395996\nEpoch: 55 - Train Loss: 5.959285259246826 - Test Loss: 5.854388236999512\nEpoch: 56 - Train Loss: 5.829919815063477 - Test Loss: 5.725894451141357\nEpoch: 57 - Train Loss: 5.703301429748535 - Test Loss: 5.600141525268555\nEpoch: 58 - Train Loss: 5.579380035400391 - Test Loss: 5.477081775665283\nEpoch: 59 - Train Loss: 5.458108901977539 - Test Loss: 5.356665134429932\nEpoch: 60 - Train Loss: 5.3394389152526855 - Test Loss: 5.2388458251953125\nEpoch: 61 - Train Loss: 5.223322868347168 - Test Loss: 5.123574733734131\nEpoch: 62 - Train Loss: 5.109713077545166 - Test Loss: 5.010805130004883\nEpoch: 63 - Train Loss: 4.998561859130859 - Test Loss: 4.900489807128906\nEpoch: 64 - Train Loss: 4.8898234367370605 - Test Loss: 4.792582035064697\nEpoch: 65 - Train Loss: 4.783450126647949 - Test Loss: 4.687036514282227\nEpoch: 66 - Train Loss: 4.679398059844971 - Test Loss: 4.583806991577148\nEpoch: 67 - Train Loss: 4.577620983123779 - Test Loss: 4.482848167419434\nEpoch: 68 - Train Loss: 4.478073596954346 - Test Loss: 4.384116172790527\nEpoch: 69 - Train Loss: 4.38071346282959 - Test Loss: 4.287568092346191\nEpoch: 70 - Train Loss: 4.285496234893799 - Test Loss: 4.193159580230713\nEpoch: 71 - Train Loss: 4.192379951477051 - Test Loss: 4.10084867477417\nEpoch: 72 - Train Loss: 4.101322174072266 - Test Loss: 4.010592937469482\nEpoch: 73 - Train Loss: 4.012281894683838 - Test Loss: 3.9223523139953613\nEpoch: 74 - Train Loss: 3.9252185821533203 - Test Loss: 3.836085081100464\nEpoch: 75 - Train Loss: 3.8400917053222656 - Test Loss: 3.7517523765563965\nEpoch: 76 - Train Loss: 3.7568628787994385 - Test Loss: 3.6693153381347656\nEpoch: 77 - Train Loss: 3.6754934787750244 - Test Loss: 3.5887343883514404\nEpoch: 78 - Train Loss: 3.595944404602051 - Test Loss: 3.5099732875823975\nEpoch: 79 - Train Loss: 3.5181801319122314 - Test Loss: 3.4329934120178223\nEpoch: 80 - Train Loss: 3.4421634674072266 - Test Loss: 3.357759952545166\nEpoch: 81 - Train Loss: 3.367858648300171 - Test Loss: 3.2842366695404053\nEpoch: 82 - Train Loss: 3.2952311038970947 - Test Loss: 3.212388515472412\nEpoch: 83 - Train Loss: 3.22424578666687 - Test Loss: 3.142181158065796\nEpoch: 84 - Train Loss: 3.1548690795898438 - Test Loss: 3.0735814571380615\nEpoch: 85 - Train Loss: 3.087068557739258 - Test Loss: 3.006556272506714\nEpoch: 86 - Train Loss: 3.0208115577697754 - Test Loss: 2.941073179244995\nEpoch: 87 - Train Loss: 2.9560656547546387 - Test Loss: 2.8771002292633057\nEpoch: 88 - Train Loss: 2.8928005695343018 - Test Loss: 2.8146069049835205\nEpoch: 89 - Train Loss: 2.8309850692749023 - Test Loss: 2.7535626888275146\nEpoch: 90 - Train Loss: 2.77059006690979 - Test Loss: 2.6939377784729004\nEpoch: 91 - Train Loss: 2.7115859985351562 - Test Loss: 2.6357030868530273\nEpoch: 92 - Train Loss: 2.6539440155029297 - Test Loss: 2.578829288482666\nEpoch: 93 - Train Loss: 2.5976359844207764 - Test Loss: 2.523289680480957\nEpoch: 94 - Train Loss: 2.5426347255706787 - Test Loss: 2.4690561294555664\nEpoch: 95 - Train Loss: 2.4889132976531982 - Test Loss: 2.4161014556884766\nEpoch: 96 - Train Loss: 2.4364449977874756 - Test Loss: 2.3643999099731445\nEpoch: 97 - Train Loss: 2.385204553604126 - Test Loss: 2.3139259815216064\nEpoch: 98 - Train Loss: 2.3351664543151855 - Test Loss: 2.264653444290161\nEpoch: 99 - Train Loss: 2.2863054275512695 - Test Loss: 2.2165586948394775\nEpoch: 100 - Train Loss: 2.238598108291626 - Test Loss: 2.169616937637329\nEpoch: 101 - Train Loss: 2.1920204162597656 - Test Loss: 2.123804807662964\nEpoch: 102 - Train Loss: 2.1465492248535156 - Test Loss: 2.07909893989563\nEpoch: 103 - Train Loss: 2.102161407470703 - Test Loss: 2.0354766845703125\nEpoch: 104 - Train Loss: 2.058835506439209 - Test Loss: 1.9929161071777344\nEpoch: 105 - Train Loss: 2.0165488719940186 - Test Loss: 1.9513953924179077\nEpoch: 106 - Train Loss: 1.9752812385559082 - Test Loss: 1.9108930826187134\nEpoch: 107 - Train Loss: 1.9350106716156006 - Test Loss: 1.871388554573059\nEpoch: 108 - Train Loss: 1.8957175016403198 - Test Loss: 1.8328614234924316\nEpoch: 109 - Train Loss: 1.8573814630508423 - Test Loss: 1.7952916622161865\nEpoch: 110 - Train Loss: 1.8199831247329712 - Test Loss: 1.7586597204208374\nEpoch: 111 - Train Loss: 1.7835031747817993 - Test Loss: 1.7229467630386353\nEpoch: 112 - Train Loss: 1.7479232549667358 - Test Loss: 1.688133955001831\nEpoch: 113 - Train Loss: 1.71322500705719 - Test Loss: 1.654203176498413\nEpoch: 114 - Train Loss: 1.6793901920318604 - Test Loss: 1.621135950088501\nEpoch: 115 - Train Loss: 1.6464014053344727 - Test Loss: 1.5889153480529785\nEpoch: 116 - Train Loss: 1.6142412424087524 - Test Loss: 1.5575239658355713\nEpoch: 117 - Train Loss: 1.5828936100006104 - Test Loss: 1.5269453525543213\nEpoch: 118 - Train Loss: 1.5523414611816406 - Test Loss: 1.4971626996994019\nEpoch: 119 - Train Loss: 1.5225690603256226 - Test Loss: 1.4681600332260132\nEpoch: 120 - Train Loss: 1.4935604333877563 - Test Loss: 1.4399218559265137\nEpoch: 121 - Train Loss: 1.4653003215789795 - Test Loss: 1.4124325513839722\nEpoch: 122 - Train Loss: 1.437773585319519 - Test Loss: 1.3856772184371948\nEpoch: 123 - Train Loss: 1.4109655618667603 - Test Loss: 1.3596409559249878\nEpoch: 124 - Train Loss: 1.384861707687378 - Test Loss: 1.3343093395233154\nEpoch: 125 - Train Loss: 1.359447956085205 - Test Loss: 1.3096685409545898\nEpoch: 126 - Train Loss: 1.3347105979919434 - Test Loss: 1.285704493522644\nEpoch: 127 - Train Loss: 1.310636043548584 - Test Loss: 1.2624038457870483\nEpoch: 128 - Train Loss: 1.2872110605239868 - Test Loss: 1.239753246307373\nEpoch: 129 - Train Loss: 1.2644227743148804 - Test Loss: 1.2177398204803467\nEpoch: 130 - Train Loss: 1.2422585487365723 - Test Loss: 1.1963510513305664\nEpoch: 131 - Train Loss: 1.2207058668136597 - Test Loss: 1.1755743026733398\nEpoch: 132 - Train Loss: 1.199752688407898 - Test Loss: 1.1553975343704224\nEpoch: 133 - Train Loss: 1.1793874502182007 - Test Loss: 1.135809063911438\nEpoch: 134 - Train Loss: 1.1595978736877441 - Test Loss: 1.1167972087860107\nEpoch: 135 - Train Loss: 1.1403732299804688 - Test Loss: 1.0983506441116333\nEpoch: 136 - Train Loss: 1.1217020750045776 - Test Loss: 1.0804580450057983\nEpoch: 137 - Train Loss: 1.1035736799240112 - Test Loss: 1.0631088018417358\nEpoch: 138 - Train Loss: 1.085977554321289 - Test Loss: 1.0462920665740967\nEpoch: 139 - Train Loss: 1.0689030885696411 - Test Loss: 1.0299975872039795\nEpoch: 140 - Train Loss: 1.0523401498794556 - Test Loss: 1.0142152309417725\nEpoch: 141 - Train Loss: 1.0362786054611206 - Test Loss: 0.9989349246025085\nEpoch: 142 - Train Loss: 1.0207090377807617 - Test Loss: 0.9841469526290894\nEpoch: 143 - Train Loss: 1.0056219100952148 - Test Loss: 0.9698415994644165\nEpoch: 144 - Train Loss: 0.9910076260566711 - Test Loss: 0.9560098648071289\nEpoch: 145 - Train Loss: 0.9768571853637695 - Test Loss: 0.942642331123352\nEpoch: 146 - Train Loss: 0.9631617069244385 - Test Loss: 0.9297302961349487\nEpoch: 147 - Train Loss: 0.9499123692512512 - Test Loss: 0.9172648191452026\nEpoch: 148 - Train Loss: 0.9371008276939392 - Test Loss: 0.9052374362945557\nEpoch: 149 - Train Loss: 0.92471843957901 - Test Loss: 0.8936397433280945\nEpoch: 150 - Train Loss: 0.9127570986747742 - Test Loss: 0.8824634552001953\nEpoch: 151 - Train Loss: 0.9012089371681213 - Test Loss: 0.8717007637023926\nEpoch: 152 - Train Loss: 0.8900659680366516 - Test Loss: 0.8613437414169312\nEpoch: 153 - Train Loss: 0.8793207406997681 - Test Loss: 0.8513845801353455\nEpoch: 154 - Train Loss: 0.8689655065536499 - Test Loss: 0.8418159484863281\nEpoch: 155 - Train Loss: 0.8589931130409241 - Test Loss: 0.8326303958892822\nEpoch: 156 - Train Loss: 0.8493962287902832 - Test Loss: 0.8238208293914795\nEpoch: 157 - Train Loss: 0.8401678800582886 - Test Loss: 0.8153800368309021\nEpoch: 158 - Train Loss: 0.831301212310791 - Test Loss: 0.8073011636734009\nEpoch: 159 - Train Loss: 0.8227896094322205 - Test Loss: 0.7995776534080505\nEpoch: 160 - Train Loss: 0.8146263360977173 - Test Loss: 0.7922027707099915\nEpoch: 161 - Train Loss: 0.8068049550056458 - Test Loss: 0.7851700782775879\nEpoch: 162 - Train Loss: 0.799319326877594 - Test Loss: 0.7784731984138489\nEpoch: 163 - Train Loss: 0.792163074016571 - Test Loss: 0.7721061706542969\nEpoch: 164 - Train Loss: 0.7853302955627441 - Test Loss: 0.7660626173019409\nEpoch: 165 - Train Loss: 0.7788151502609253 - Test Loss: 0.7603369355201721\nEpoch: 166 - Train Loss: 0.772611677646637 - Test Loss: 0.7549231052398682\nEpoch: 167 - Train Loss: 0.766714334487915 - Test Loss: 0.7498155832290649\nEpoch: 168 - Train Loss: 0.7611176371574402 - Test Loss: 0.7450088858604431\nEpoch: 169 - Train Loss: 0.7558161020278931 - Test Loss: 0.7404974102973938\nEpoch: 170 - Train Loss: 0.7508044838905334 - Test Loss: 0.7362759113311768\nEpoch: 171 - Train Loss: 0.7460775375366211 - Test Loss: 0.7323393225669861\nEpoch: 172 - Train Loss: 0.7416303753852844 - Test Loss: 0.7286823987960815\nEpoch: 173 - Train Loss: 0.737457811832428 - Test Loss: 0.7253001928329468\nEpoch: 174 - Train Loss: 0.7335551381111145 - Test Loss: 0.7221879363059998\nEpoch: 175 - Train Loss: 0.7299174666404724 - Test Loss: 0.7193407416343689\nEpoch: 176 - Train Loss: 0.7265402674674988 - Test Loss: 0.7167540192604065\nEpoch: 177 - Train Loss: 0.7234190702438354 - Test Loss: 0.7144231796264648\nEpoch: 178 - Train Loss: 0.7205492854118347 - Test Loss: 0.7123438119888306\nEpoch: 179 - Train Loss: 0.7179266810417175 - Test Loss: 0.7105115056037903\nEpoch: 180 - Train Loss: 0.7155468463897705 - Test Loss: 0.7089217901229858\nEpoch: 181 - Train Loss: 0.7134057879447937 - Test Loss: 0.7075709700584412\nEpoch: 182 - Train Loss: 0.7114992737770081 - Test Loss: 0.7064544558525085\nEpoch: 183 - Train Loss: 0.7098234295845032 - Test Loss: 0.7055685520172119\nEpoch: 184 - Train Loss: 0.7083743214607239 - Test Loss: 0.7049091458320618\nEpoch: 185 - Train Loss: 0.7071480751037598 - Test Loss: 0.704472541809082\nEpoch: 186 - Train Loss: 0.7061410546302795 - Test Loss: 0.7042548060417175\nEpoch: 187 - Train Loss: 0.7053495645523071 - Test Loss: 0.7042525410652161\nEpoch: 188 - Train Loss: 0.704770028591156 - Test Loss: 0.704461932182312\nEpoch: 189 - Train Loss: 0.7043988108634949 - Test Loss: 0.7048795223236084\nEpoch: 190 - Train Loss: 0.7042327523231506 - Test Loss: 0.7055017948150635\nEpoch: 191 - Train Loss: 0.7042683362960815 - Test Loss: 0.7063255310058594\nEpoch: 192 - Train Loss: 0.7045022249221802 - Test Loss: 0.7073473930358887\nEpoch: 193 - Train Loss: 0.704931378364563 - Test Loss: 0.708564043045044\nEpoch: 194 - Train Loss: 0.7055525183677673 - Test Loss: 0.7099724411964417\nEpoch: 195 - Train Loss: 0.7063627243041992 - Test Loss: 0.7115694284439087\nEpoch: 196 - Train Loss: 0.7073588371276855 - Test Loss: 0.7133520841598511\nEpoch: 197 - Train Loss: 0.7085379958152771 - Test Loss: 0.7153172492980957\nEpoch: 198 - Train Loss: 0.7098972797393799 - Test Loss: 0.7174621820449829\nEpoch: 199 - Train Loss: 0.7114338874816895 - Test Loss: 0.7197840809822083\nEpoch: 200 - Train Loss: 0.7131451368331909 - Test Loss: 0.7222800850868225\nEpoch: 201 - Train Loss: 0.7150282263755798 - Test Loss: 0.7249473929405212\nEpoch: 202 - Train Loss: 0.7170805931091309 - Test Loss: 0.7277836203575134\nEpoch: 203 - Train Loss: 0.7192996740341187 - Test Loss: 0.7307859063148499\nEpoch: 204 - Train Loss: 0.7216827869415283 - Test Loss: 0.7339518666267395\nEpoch: 205 - Train Loss: 0.7242276668548584 - Test Loss: 0.737278938293457\nEpoch: 206 - Train Loss: 0.7269317507743835 - Test Loss: 0.7407646179199219\nEpoch: 207 - Train Loss: 0.7297927737236023 - Test Loss: 0.7444067001342773\nEpoch: 208 - Train Loss: 0.7328084111213684 - Test Loss: 0.7482028007507324\nEpoch: 209 - Train Loss: 0.7359762787818909 - Test Loss: 0.7521504163742065\nEpoch: 210 - Train Loss: 0.7392942905426025 - Test Loss: 0.7562476396560669\nEpoch: 211 - Train Loss: 0.7427602410316467 - Test Loss: 0.7604920864105225\nEpoch: 212 - Train Loss: 0.7463720440864563 - Test Loss: 0.7648816108703613\nEpoch: 213 - Train Loss: 0.7501275539398193 - Test Loss: 0.7694142460823059\nEpoch: 214 - Train Loss: 0.7540248036384583 - Test Loss: 0.7740877866744995\nEpoch: 215 - Train Loss: 0.7580617070198059 - Test Loss: 0.7789004445075989\nEpoch: 216 - Train Loss: 0.7622365355491638 - Test Loss: 0.7838500738143921\nEpoch: 217 - Train Loss: 0.7665471434593201 - Test Loss: 0.7889347672462463\nEpoch: 218 - Train Loss: 0.7709918022155762 - Test Loss: 0.7941526770591736\nEpoch: 219 - Train Loss: 0.7755687236785889 - Test Loss: 0.7995020747184753\nEpoch: 220 - Train Loss: 0.7802760004997253 - Test Loss: 0.8049810528755188\nEpoch: 221 - Train Loss: 0.7851120233535767 - Test Loss: 0.8105877637863159\nEpoch: 222 - Train Loss: 0.7900750637054443 - Test Loss: 0.816320538520813\nEpoch: 223 - Train Loss: 0.7951633334159851 - Test Loss: 0.8221778869628906\nEpoch: 224 - Train Loss: 0.8003753423690796 - Test Loss: 0.828157901763916\nEpoch: 225 - Train Loss: 0.8057095408439636 - Test Loss: 0.8342592120170593\nEpoch: 226 - Train Loss: 0.811164140701294 - Test Loss: 0.8404800295829773\nEpoch: 227 - Train Loss: 0.8167377710342407 - Test Loss: 0.8468188643455505\nEpoch: 228 - Train Loss: 0.822428822517395 - Test Loss: 0.8532741069793701\nEpoch: 229 - Train Loss: 0.8282361626625061 - Test Loss: 0.8598445653915405\nEpoch: 230 - Train Loss: 0.8341580033302307 - Test Loss: 0.8665286898612976\nEpoch: 231 - Train Loss: 0.8401930928230286 - Test Loss: 0.8733248114585876\nEpoch: 232 - Train Loss: 0.8463400602340698 - Test Loss: 0.8802318572998047\nEpoch: 233 - Train Loss: 0.8525975942611694 - Test Loss: 0.8872482776641846\nEpoch: 234 - Train Loss: 0.8589642643928528 - Test Loss: 0.894372820854187\nEpoch: 235 - Train Loss: 0.8654389977455139 - Test Loss: 0.9016042351722717\nEpoch: 236 - Train Loss: 0.8720203638076782 - Test Loss: 0.9089412689208984\nEpoch: 237 - Train Loss: 0.8787071108818054 - Test Loss: 0.9163824915885925\nEpoch: 238 - Train Loss: 0.8854982256889343 - Test Loss: 0.9239267110824585\nEpoch: 239 - Train Loss: 0.8923924565315247 - Test Loss: 0.9315729141235352\nEpoch: 240 - Train Loss: 0.8993886709213257 - Test Loss: 0.9393198490142822\nEpoch: 241 - Train Loss: 0.9064856767654419 - Test Loss: 0.9471664428710938\nEpoch: 242 - Train Loss: 0.9136824011802673 - Test Loss: 0.9551116228103638\nEpoch: 243 - Train Loss: 0.9209778308868408 - Test Loss: 0.9631540179252625\nEpoch: 244 - Train Loss: 0.9283708930015564 - Test Loss: 0.9712929129600525\nEpoch: 245 - Train Loss: 0.9358605742454529 - Test Loss: 0.979526937007904\nEpoch: 246 - Train Loss: 0.9434458017349243 - Test Loss: 0.9878553152084351\nEpoch: 247 - Train Loss: 0.9511256217956543 - Test Loss: 0.9962769746780396\nEpoch: 248 - Train Loss: 0.9588992595672607 - Test Loss: 1.0047909021377563\nEpoch: 249 - Train Loss: 0.9667654633522034 - Test Loss: 1.0133962631225586\nEpoch: 250 - Train Loss: 0.9747236371040344 - Test Loss: 1.0220919847488403\nEpoch: 251 - Train Loss: 0.9827725887298584 - Test Loss: 1.0308771133422852\nEpoch: 252 - Train Loss: 0.9909117221832275 - Test Loss: 1.0397510528564453\nEpoch: 253 - Train Loss: 0.9991398453712463 - Test Loss: 1.0487124919891357\nEpoch: 254 - Train Loss: 1.0074564218521118 - Test Loss: 1.0577609539031982\nEpoch: 255 - Train Loss: 1.015860676765442 - Test Loss: 1.0668954849243164\nEpoch: 256 - Train Loss: 1.0243514776229858 - Test Loss: 1.0761152505874634\nEpoch: 257 - Train Loss: 1.0329283475875854 - Test Loss: 1.0854194164276123\nEpoch: 258 - Train Loss: 1.0415903329849243 - Test Loss: 1.0948071479797363\nEpoch: 259 - Train Loss: 1.0503368377685547 - Test Loss: 1.1042777299880981\nEpoch: 260 - Train Loss: 1.0591669082641602 - Test Loss: 1.11383056640625\nEpoch: 261 - Train Loss: 1.0680800676345825 - Test Loss: 1.1234647035598755\nEpoch: 262 - Train Loss: 1.077075481414795 - Test Loss: 1.133179783821106\nEpoch: 263 - Train Loss: 1.0861526727676392 - Test Loss: 1.1429743766784668\nEpoch: 264 - Train Loss: 1.0953106880187988 - Test Loss: 1.1528488397598267\nEpoch: 265 - Train Loss: 1.1045490503311157 - Test Loss: 1.1628016233444214\nEpoch: 266 - Train Loss: 1.113867163658142 - Test Loss: 1.1728323698043823\nEpoch: 267 - Train Loss: 1.123264193534851 - Test Loss: 1.1829406023025513\nEpoch: 268 - Train Loss: 1.1327396631240845 - Test Loss: 1.1931254863739014\nEpoch: 269 - Train Loss: 1.1422929763793945 - Test Loss: 1.2033864259719849\nEpoch: 270 - Train Loss: 1.151923656463623 - Test Loss: 1.2137229442596436\nEpoch: 271 - Train Loss: 1.1616308689117432 - Test Loss: 1.2241344451904297\nEpoch: 272 - Train Loss: 1.1714143753051758 - Test Loss: 1.234620213508606\nEpoch: 273 - Train Loss: 1.181273341178894 - Test Loss: 1.2451798915863037\nEpoch: 274 - Train Loss: 1.1912075281143188 - Test Loss: 1.255812644958496\nEpoch: 275 - Train Loss: 1.2012163400650024 - Test Loss: 1.266518235206604\nEpoch: 276 - Train Loss: 1.211298942565918 - Test Loss: 1.2772960662841797\nEpoch: 277 - Train Loss: 1.2214553356170654 - Test Loss: 1.2881455421447754\nEpoch: 278 - Train Loss: 1.2316848039627075 - Test Loss: 1.2990663051605225\nEpoch: 279 - Train Loss: 1.2419867515563965 - Test Loss: 1.3100578784942627\nEpoch: 280 - Train Loss: 1.2523610591888428 - Test Loss: 1.3211194276809692\nEpoch: 281 - Train Loss: 1.2628068923950195 - Test Loss: 1.3322508335113525\nEpoch: 282 - Train Loss: 1.2733240127563477 - Test Loss: 1.3434516191482544\nEpoch: 283 - Train Loss: 1.283912181854248 - Test Loss: 1.3547213077545166\nEpoch: 284 - Train Loss: 1.2945704460144043 - Test Loss: 1.366059422492981\nEpoch: 285 - Train Loss: 1.3052990436553955 - Test Loss: 1.3774654865264893\nEpoch: 286 - Train Loss: 1.3160970211029053 - Test Loss: 1.3889392614364624\nEpoch: 287 - Train Loss: 1.3269644975662231 - Test Loss: 1.4004801511764526\nEpoch: 288 - Train Loss: 1.3379006385803223 - Test Loss: 1.4120879173278809\nEpoch: 289 - Train Loss: 1.348905324935913 - Test Loss: 1.4237622022628784\nEpoch: 290 - Train Loss: 1.3599783182144165 - Test Loss: 1.435502290725708\nEpoch: 291 - Train Loss: 1.3711189031600952 - Test Loss: 1.4473081827163696\nEpoch: 292 - Train Loss: 1.3823269605636597 - Test Loss: 1.4591796398162842\nEpoch: 293 - Train Loss: 1.3936020135879517 - Test Loss: 1.4711159467697144\nEpoch: 294 - Train Loss: 1.4049440622329712 - Test Loss: 1.483116865158081\nEpoch: 295 - Train Loss: 1.4163525104522705 - Test Loss: 1.4951820373535156\nEpoch: 296 - Train Loss: 1.427827000617981 - Test Loss: 1.507311224937439\nEpoch: 297 - Train Loss: 1.4393675327301025 - Test Loss: 1.519504189491272\nEpoch: 298 - Train Loss: 1.4509735107421875 - Test Loss: 1.531760334968567\nEpoch: 299 - Train Loss: 1.4626449346542358 - Test Loss: 1.5440796613693237\nEpoch: 300 - Train Loss: 1.4743810892105103 - Test Loss: 1.5564616918563843\nEpoch: 301 - Train Loss: 1.4861820936203003 - Test Loss: 1.5689061880111694\nEpoch: 302 - Train Loss: 1.4980475902557373 - Test Loss: 1.5814129114151\nEpoch: 303 - Train Loss: 1.509977102279663 - Test Loss: 1.5939815044403076\nEpoch: 304 - Train Loss: 1.5219707489013672 - Test Loss: 1.6066118478775024\nEpoch: 305 - Train Loss: 1.5340280532836914 - Test Loss: 1.619303584098816\nEpoch: 306 - Train Loss: 1.5461487770080566 - Test Loss: 1.6320563554763794\nEpoch: 307 - Train Loss: 1.5583326816558838 - Test Loss: 1.6448700428009033\nEpoch: 308 - Train Loss: 1.5705797672271729 - Test Loss: 1.657744288444519\nEpoch: 309 - Train Loss: 1.5828893184661865 - Test Loss: 1.6706792116165161\nEpoch: 310 - Train Loss: 1.5952616930007935 - Test Loss: 1.6836739778518677\nEpoch: 311 - Train Loss: 1.607696294784546 - Test Loss: 1.6967289447784424\nEpoch: 312 - Train Loss: 1.6201932430267334 - Test Loss: 1.7098435163497925\nEpoch: 313 - Train Loss: 1.6327519416809082 - Test Loss: 1.723017692565918\nEpoch: 314 - Train Loss: 1.6453725099563599 - Test Loss: 1.7362512350082397\nEpoch: 315 - Train Loss: 1.6580545902252197 - Test Loss: 1.7495439052581787\nEpoch: 316 - Train Loss: 1.6707980632781982 - Test Loss: 1.7628953456878662\nEpoch: 317 - Train Loss: 1.6836026906967163 - Test Loss: 1.7763055562973022\nEpoch: 318 - Train Loss: 1.696468472480774 - Test Loss: 1.7897745370864868\nEpoch: 319 - Train Loss: 1.709395170211792 - Test Loss: 1.803301453590393\nEpoch: 320 - Train Loss: 1.7223825454711914 - Test Loss: 1.8168870210647583\nEpoch: 321 - Train Loss: 1.735430359840393 - Test Loss: 1.8305304050445557\nEpoch: 322 - Train Loss: 1.748538613319397 - Test Loss: 1.8442314863204956\nEpoch: 323 - Train Loss: 1.7617071866989136 - Test Loss: 1.8579905033111572\nEpoch: 324 - Train Loss: 1.7749359607696533 - Test Loss: 1.8718068599700928\nEpoch: 325 - Train Loss: 1.7882243394851685 - Test Loss: 1.8856810331344604\nEpoch: 326 - Train Loss: 1.8015729188919067 - Test Loss: 1.8996118307113647\nEpoch: 327 - Train Loss: 1.81498122215271 - Test Loss: 1.913599967956543\nEpoch: 328 - Train Loss: 1.8284486532211304 - Test Loss: 1.9276450872421265\nEpoch: 329 - Train Loss: 1.8419759273529053 - Test Loss: 1.9417471885681152\nEpoch: 330 - Train Loss: 1.855562448501587 - Test Loss: 1.955905556678772\nEpoch: 331 - Train Loss: 1.8692080974578857 - Test Loss: 1.9701205492019653\nEpoch: 332 - Train Loss: 1.8829129934310913 - Test Loss: 1.9843920469284058\nEpoch: 333 - Train Loss: 1.8966768980026245 - Test Loss: 1.9987199306488037\nEpoch: 334 - Train Loss: 1.9104995727539062 - Test Loss: 2.01310396194458\nEpoch: 335 - Train Loss: 1.924381136894226 - Test Loss: 2.0275440216064453\nEpoch: 336 - Train Loss: 1.9383212327957153 - Test Loss: 2.0420401096343994\nEpoch: 337 - Train Loss: 1.9523200988769531 - Test Loss: 2.056591749191284\nEpoch: 338 - Train Loss: 1.9663774967193604 - Test Loss: 2.071199655532837\nEpoch: 339 - Train Loss: 1.9804930686950684 - Test Loss: 2.085862636566162\nEpoch: 340 - Train Loss: 1.9946671724319458 - Test Loss: 2.100581407546997\nEpoch: 341 - Train Loss: 2.008899688720703 - Test Loss: 2.1153557300567627\nEpoch: 342 - Train Loss: 2.0231900215148926 - Test Loss: 2.13018536567688\nEpoch: 343 - Train Loss: 2.037538528442383 - Test Loss: 2.1450700759887695\nEpoch: 344 - Train Loss: 2.051945209503174 - Test Loss: 2.1600100994110107\nEpoch: 345 - Train Loss: 2.0664095878601074 - Test Loss: 2.1750054359436035\nEpoch: 346 - Train Loss: 2.080932140350342 - Test Loss: 2.1900553703308105\nEpoch: 347 - Train Loss: 2.0955123901367188 - Test Loss: 2.20516037940979\nEpoch: 348 - Train Loss: 2.1101505756378174 - Test Loss: 2.220320463180542\nEpoch: 349 - Train Loss: 2.1248459815979004 - Test Loss: 2.235535144805908\nEpoch: 350 - Train Loss: 2.139599323272705 - Test Loss: 2.2508046627044678\nEpoch: 351 - Train Loss: 2.1544103622436523 - Test Loss: 2.2661285400390625\nEpoch: 352 - Train Loss: 2.169278860092163 - Test Loss: 2.2815074920654297\nEpoch: 353 - Train Loss: 2.1842048168182373 - Test Loss: 2.296940565109253\nEpoch: 354 - Train Loss: 2.199187994003296 - Test Loss: 2.3124284744262695\nEpoch: 355 - Train Loss: 2.214229106903076 - Test Loss: 2.327970504760742\nEpoch: 356 - Train Loss: 2.2293272018432617 - Test Loss: 2.343567132949829\nEpoch: 357 - Train Loss: 2.2444825172424316 - Test Loss: 2.359218120574951\nEpoch: 358 - Train Loss: 2.259695291519165 - Test Loss: 2.37492299079895\nEpoch: 359 - Train Loss: 2.274965286254883 - Test Loss: 2.3906822204589844\nEpoch: 360 - Train Loss: 2.290292739868164 - Test Loss: 2.406496047973633\nEpoch: 361 - Train Loss: 2.3056766986846924 - Test Loss: 2.422363519668579\nEpoch: 362 - Train Loss: 2.3211183547973633 - Test Loss: 2.4382851123809814\nEpoch: 363 - Train Loss: 2.3366169929504395 - Test Loss: 2.454261064529419\nEpoch: 364 - Train Loss: 2.352172613143921 - Test Loss: 2.4702906608581543\nEpoch: 365 - Train Loss: 2.3677854537963867 - Test Loss: 2.4863741397857666\nEpoch: 366 - Train Loss: 2.383455276489258 - Test Loss: 2.502511978149414\nEpoch: 367 - Train Loss: 2.399182081222534 - Test Loss: 2.5187034606933594\nEpoch: 368 - Train Loss: 2.414966106414795 - Test Loss: 2.5349490642547607\nEpoch: 369 - Train Loss: 2.4308066368103027 - Test Loss: 2.55124831199646\nEpoch: 370 - Train Loss: 2.446704626083374 - Test Loss: 2.567601442337036\nEpoch: 371 - Train Loss: 2.4626593589782715 - Test Loss: 2.58400821685791\nEpoch: 372 - Train Loss: 2.478671073913574 - Test Loss: 2.600468873977661\nEpoch: 373 - Train Loss: 2.4947397708892822 - Test Loss: 2.616983413696289\nEpoch: 374 - Train Loss: 2.5108654499053955 - Test Loss: 2.6335513591766357\nEpoch: 375 - Train Loss: 2.527047872543335 - Test Loss: 2.6501734256744385\nEpoch: 376 - Train Loss: 2.5432872772216797 - Test Loss: 2.66684889793396\nEpoch: 377 - Train Loss: 2.5595836639404297 - Test Loss: 2.6835782527923584\nEpoch: 378 - Train Loss: 2.575936794281006 - Test Loss: 2.7003610134124756\nEpoch: 379 - Train Loss: 2.5923471450805664 - Test Loss: 2.7171974182128906\nEpoch: 380 - Train Loss: 2.608814001083374 - Test Loss: 2.7340877056121826\nEpoch: 381 - Train Loss: 2.625338077545166 - Test Loss: 2.7510316371917725\nEpoch: 382 - Train Loss: 2.6419191360473633 - Test Loss: 2.76802921295166\nEpoch: 383 - Train Loss: 2.6585566997528076 - Test Loss: 2.7850804328918457\nEpoch: 384 - Train Loss: 2.6752512454986572 - Test Loss: 2.802184820175171\nEpoch: 385 - Train Loss: 2.692003011703491 - Test Loss: 2.8193435668945312\nEpoch: 386 - Train Loss: 2.7088115215301514 - Test Loss: 2.836555242538452\nEpoch: 387 - Train Loss: 2.725677251815796 - Test Loss: 2.85382080078125\nEpoch: 388 - Train Loss: 2.7425994873046875 - Test Loss: 2.8711397647857666\nEpoch: 389 - Train Loss: 2.7595789432525635 - Test Loss: 2.8885128498077393\nEpoch: 390 - Train Loss: 2.7766153812408447 - Test Loss: 2.9059391021728516\nEpoch: 391 - Train Loss: 2.7937088012695312 - Test Loss: 2.9234189987182617\nEpoch: 392 - Train Loss: 2.810859203338623 - Test Loss: 2.9409525394439697\nEpoch: 393 - Train Loss: 2.828066825866699 - Test Loss: 2.9585399627685547\nEpoch: 394 - Train Loss: 2.8453309535980225 - Test Loss: 2.9761807918548584\nEpoch: 395 - Train Loss: 2.8626527786254883 - Test Loss: 2.99387526512146\nEpoch: 396 - Train Loss: 2.880031108856201 - Test Loss: 3.0116231441497803\nEpoch: 397 - Train Loss: 2.8974668979644775 - Test Loss: 3.0294251441955566\nEpoch: 398 - Train Loss: 2.9149599075317383 - Test Loss: 3.047280788421631\nEpoch: 399 - Train Loss: 2.932509660720825 - Test Loss: 3.065189838409424\n"
],
[
"import matplotlib.pyplot as plt\r\n\r\nplt.plot(train_mses)\r\nplt.plot(test_mses)",
"_____no_output_____"
],
[
"masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True), train_urm, mask,0.,0.,0.,0.)",
"_____no_output_____"
],
[
"test_mask = tf.not_equal(test_urm, 0.)\r\nmasked_mse(tf.matmul(user_emb, item_emb, transpose_b=True), test_urm, test_mask, 0.,0.,0.,0.)",
"_____no_output_____"
],
[
"tf.boolean_mask(tf.matmul(user_emb, item_emb, transpose_b=True), test_mask)",
"_____no_output_____"
],
[
"tf.boolean_mask(test_urm, test_mask)",
"_____no_output_____"
],
[
"ratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\n\r\nC = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean\r\n\r\nb_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item\r\n\r\nb_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')\r\n\r\nratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user",
"_____no_output_____"
],
[
"@tf.function\r\ndef masked_mse(y_pred, y_true, mask, weights_1, lamb1, weights_2, lamb2):\r\n y_pred_masked = tf.boolean_mask(y_pred, mask)\r\n y_true_masked = tf.boolean_mask(y_true, mask)\r\n return tf.losses.mean_squared_error(y_true_masked, y_pred_masked) + lamb1 * tf.norm(weights_1) + lamb2 * tf.norm(weights_2)",
"_____no_output_____"
],
[
"mask = tf.not_equal(urm, tf.constant(0., dtype=tf.float32))\r\nnon_zero_rating_ixs = tf.where(mask)\r\nnon_zero_ratings = tf.gather_nd(urm, non_zero_rating_ixs)\r\n\r\nsplit = 0.90\r\nsplit_ix = int(split * non_zero_rating_ixs.shape[0])\r\n\r\nnon_zero_rating_ixs_shuffled = tf.random.shuffle(tf.range(non_zero_ratings.shape))\r\n\r\ntrain_urm_ratings = tf.gather(non_zero_ratings, non_zero_rating_ixs_shuffled[:split_ix])\r\ntrain_urm_ratings_ixs = tf.gather(non_zero_rating_ixs, non_zero_rating_ixs_shuffled[:split_ix])\r\ntest_urm_ratings = tf.gather(non_zero_ratings, non_zero_rating_ixs_shuffled[split_ix:])\r\ntest_urm_ratings_ixs = tf.gather(non_zero_rating_ixs, non_zero_rating_ixs_shuffled[split_ix:])\r\n\r\ntrain_urm = tf.scatter_nd(train_urm_ratings_ixs, train_urm_ratings, urm.shape)\r\ntest_urm = tf.scatter_nd(test_urm_ratings_ixs, test_urm_ratings, urm.shape)",
"_____no_output_____"
],
[
"non_zero_rating_ixs",
"_____no_output_____"
],
[
"emb_dim = 30\r\nuser_emb = tf.Variable(tf.random.uniform(shape=(urm.shape[0],emb_dim)), trainable=True)\r\nitem_emb = tf.Variable(tf.random.uniform(shape=(urm.shape[1],emb_dim)), trainable=True)\r\nuser_bias = tf.Variable(tf.random.uniform(shape=(urm.shape[0],1)), trainable=True)\r\nitem_bias = tf.Variable(tf.random.uniform(shape=(1, urm.shape[1])), trainable=True)\r\nmean_rating = tf.Variable(tf.random.uniform(shape=(1,1)), trainable=True)\r\n\r\nmask = tf.not_equal(train_urm, tf.constant(0, dtype=tf.float32))\r\ntest_mask = tf.not_equal(test_urm, 0.)",
"_____no_output_____"
],
[
"epochs = 3000\r\nopti = tf.optimizers.Adam()\r\nloss = masked_mse\r\ntrain_mses = []\r\ntest_mses = []\r\n\r\nfor e in range(epochs): \r\n\r\n with tf.GradientTape(watch_accessed_variables=False) as gt1:\r\n\r\n gt1.watch(item_emb)\r\n gt1.watch(user_emb)\r\n gt1.watch(item_bias)\r\n gt1.watch(user_bias)\r\n gt1.watch(mean_rating)\r\n\r\n global_effects = user_bias + item_bias + mean_rating\r\n preds = (tf.matmul(user_emb, item_emb, transpose_b=True)) + global_effects\r\n preds = tf.clip_by_value(preds, 0., 5.)\r\n\r\n mse = loss(preds, train_urm, mask, user_emb, 0.5, item_emb, 0.6)\r\n \r\n grads = gt1.gradient([mse], [user_emb, item_emb, item_bias, user_bias, mean_rating])\r\n opti.apply_gradients(grads_and_vars=zip(grads, [user_emb, item_emb, item_bias, user_bias, mean_rating])) \r\n\r\n test_mses.append(masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True) + global_effects, test_urm, test_mask, 0.,0.,0.,0.))\r\n train_mses.append(masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True) + global_effects, train_urm, mask, 0.,0.,0.,0.))\r\n print(f'Epoch: {e} - Train Loss: {train_mses[-1]} - Test Loss: {test_mses[-1]}')",
"Epoch: 0 - Train Loss: 34.83883285522461 - Test Loss: 34.7446403503418\nEpoch: 1 - Train Loss: 34.482784271240234 - Test Loss: 34.38923645019531\nEpoch: 2 - Train Loss: 34.129051208496094 - Test Loss: 34.03615188598633\nEpoch: 3 - Train Loss: 33.778133392333984 - Test Loss: 33.685874938964844\nEpoch: 4 - Train Loss: 33.42972946166992 - Test Loss: 33.33810806274414\nEpoch: 5 - Train Loss: 33.08396911621094 - Test Loss: 32.99298858642578\nEpoch: 6 - Train Loss: 32.74095916748047 - Test Loss: 32.65060806274414\nEpoch: 7 - Train Loss: 32.40068435668945 - Test Loss: 32.31096649169922\nEpoch: 8 - Train Loss: 32.06315612792969 - Test Loss: 31.974061965942383\nEpoch: 9 - Train Loss: 31.72873878479004 - Test Loss: 31.640277862548828\nEpoch: 10 - Train Loss: 31.396987915039062 - Test Loss: 31.309162139892578\nEpoch: 11 - Train Loss: 31.067955017089844 - Test Loss: 30.980762481689453\nEpoch: 12 - Train Loss: 30.741579055786133 - Test Loss: 30.655025482177734\nEpoch: 13 - Train Loss: 30.417842864990234 - Test Loss: 30.33193016052246\nEpoch: 14 - Train Loss: 30.09674072265625 - Test Loss: 30.0114688873291\nEpoch: 15 - Train Loss: 29.778268814086914 - Test Loss: 29.693649291992188\nEpoch: 16 - Train Loss: 29.462419509887695 - Test Loss: 29.378448486328125\nEpoch: 17 - Train Loss: 29.149187088012695 - Test Loss: 29.065868377685547\nEpoch: 18 - Train Loss: 28.838497161865234 - Test Loss: 28.75583267211914\nEpoch: 19 - Train Loss: 28.530376434326172 - Test Loss: 28.4483585357666\nEpoch: 20 - Train Loss: 28.22482681274414 - Test Loss: 28.143461227416992\nEpoch: 21 - Train Loss: 27.92179298400879 - Test Loss: 27.84107208251953\nEpoch: 22 - Train Loss: 27.621126174926758 - Test Loss: 27.541040420532227\nEpoch: 23 - Train Loss: 27.322891235351562 - Test Loss: 27.243431091308594\nEpoch: 24 - Train Loss: 27.027053833007812 - Test Loss: 26.948225021362305\nEpoch: 25 - Train Loss: 26.7336483001709 - Test Loss: 26.655437469482422\nEpoch: 26 - Train Loss: 26.442672729492188 - Test Loss: 26.365089416503906\nEpoch: 27 - Train Loss: 26.154104232788086 - Test Loss: 26.0771484375\nEpoch: 28 - Train Loss: 25.86789894104004 - Test Loss: 25.791566848754883\nEpoch: 29 - Train Loss: 25.584075927734375 - Test Loss: 25.50836181640625\nEpoch: 30 - Train Loss: 25.302608489990234 - Test Loss: 25.227510452270508\nEpoch: 31 - Train Loss: 25.02349281311035 - Test Loss: 24.948999404907227\nEpoch: 32 - Train Loss: 24.74671173095703 - Test Loss: 24.67281723022461\nEpoch: 33 - Train Loss: 24.472211837768555 - Test Loss: 24.398902893066406\nEpoch: 34 - Train Loss: 24.199962615966797 - Test Loss: 24.127227783203125\nEpoch: 35 - Train Loss: 23.929868698120117 - Test Loss: 23.857707977294922\nEpoch: 36 - Train Loss: 23.66194725036621 - Test Loss: 23.590354919433594\nEpoch: 37 - Train Loss: 23.396135330200195 - Test Loss: 23.325105667114258\nEpoch: 38 - Train Loss: 23.132442474365234 - Test Loss: 23.061973571777344\nEpoch: 39 - Train Loss: 22.870885848999023 - Test Loss: 22.80095863342285\nEpoch: 40 - Train Loss: 22.611417770385742 - Test Loss: 22.54203224182129\nEpoch: 41 - Train Loss: 22.35405921936035 - Test Loss: 22.28521728515625\nEpoch: 42 - Train Loss: 22.09877586364746 - Test Loss: 22.030479431152344\nEpoch: 43 - Train Loss: 21.84543800354004 - Test Loss: 21.777694702148438\nEpoch: 44 - Train Loss: 21.59404182434082 - Test Loss: 21.526844024658203\nEpoch: 45 - Train Loss: 21.344558715820312 - Test Loss: 21.277912139892578\nEpoch: 46 - Train Loss: 21.096973419189453 - Test Loss: 21.030879974365234\nEpoch: 47 - Train Loss: 20.851242065429688 - Test Loss: 20.785701751708984\nEpoch: 48 - Train Loss: 20.607406616210938 - Test Loss: 20.54241180419922\nEpoch: 49 - Train Loss: 20.365434646606445 - Test Loss: 20.30097770690918\nEpoch: 50 - Train Loss: 20.125242233276367 - Test Loss: 20.06131362915039\nEpoch: 51 - Train Loss: 19.886533737182617 - Test Loss: 19.823110580444336\nEpoch: 52 - Train Loss: 19.649471282958984 - Test Loss: 19.5865421295166\nEpoch: 53 - Train Loss: 19.41400718688965 - Test Loss: 19.351533889770508\nEpoch: 54 - Train Loss: 19.18025016784668 - Test Loss: 19.11822509765625\nEpoch: 55 - Train Loss: 18.948223114013672 - Test Loss: 18.886646270751953\nEpoch: 56 - Train Loss: 18.717899322509766 - Test Loss: 18.65675926208496\nEpoch: 57 - Train Loss: 18.489334106445312 - Test Loss: 18.42860984802246\nEpoch: 58 - Train Loss: 18.262479782104492 - Test Loss: 18.20216178894043\nEpoch: 59 - Train Loss: 18.037275314331055 - Test Loss: 17.977354049682617\nEpoch: 60 - Train Loss: 17.813703536987305 - Test Loss: 17.754167556762695\nEpoch: 61 - Train Loss: 17.5917911529541 - Test Loss: 17.532634735107422\nEpoch: 62 - Train Loss: 17.371490478515625 - Test Loss: 17.312713623046875\nEpoch: 63 - Train Loss: 17.152807235717773 - Test Loss: 17.094409942626953\nEpoch: 64 - Train Loss: 16.935762405395508 - Test Loss: 16.87773895263672\nEpoch: 65 - Train Loss: 16.720258712768555 - Test Loss: 16.6626033782959\nEpoch: 66 - Train Loss: 16.506258010864258 - Test Loss: 16.4489688873291\nEpoch: 67 - Train Loss: 16.29368019104004 - Test Loss: 16.236772537231445\nEpoch: 68 - Train Loss: 16.082489013671875 - Test Loss: 16.025968551635742\nEpoch: 69 - Train Loss: 15.8726806640625 - Test Loss: 15.816560745239258\nEpoch: 70 - Train Loss: 15.664304733276367 - Test Loss: 15.60858154296875\nEpoch: 71 - Train Loss: 15.457350730895996 - Test Loss: 15.402026176452637\nEpoch: 72 - Train Loss: 15.25180721282959 - Test Loss: 15.196867942810059\nEpoch: 73 - Train Loss: 15.047616004943848 - Test Loss: 14.993061065673828\nEpoch: 74 - Train Loss: 14.844844818115234 - Test Loss: 14.790664672851562\nEpoch: 75 - Train Loss: 14.643462181091309 - Test Loss: 14.589627265930176\nEpoch: 76 - Train Loss: 14.443520545959473 - Test Loss: 14.389992713928223\nEpoch: 77 - Train Loss: 14.245052337646484 - Test Loss: 14.191807746887207\nEpoch: 78 - Train Loss: 14.048056602478027 - Test Loss: 13.995079040527344\nEpoch: 79 - Train Loss: 13.852505683898926 - Test Loss: 13.79979133605957\nEpoch: 80 - Train Loss: 13.65842342376709 - Test Loss: 13.605966567993164\nEpoch: 81 - Train Loss: 13.465733528137207 - Test Loss: 13.413516998291016\nEpoch: 82 - Train Loss: 13.274415016174316 - Test Loss: 13.222423553466797\nEpoch: 83 - Train Loss: 13.084474563598633 - Test Loss: 13.03269100189209\nEpoch: 84 - Train Loss: 12.895873069763184 - Test Loss: 12.844273567199707\nEpoch: 85 - Train Loss: 12.708586692810059 - Test Loss: 12.65715217590332\nEpoch: 86 - Train Loss: 12.522622108459473 - Test Loss: 12.471343994140625\nEpoch: 87 - Train Loss: 12.338013648986816 - Test Loss: 12.28690242767334\nEpoch: 88 - Train Loss: 12.15476131439209 - Test Loss: 12.103821754455566\nEpoch: 89 - Train Loss: 11.972796440124512 - Test Loss: 11.92203426361084\nEpoch: 90 - Train Loss: 11.792044639587402 - Test Loss: 11.741467475891113\nEpoch: 91 - Train Loss: 11.612505912780762 - Test Loss: 11.56212043762207\nEpoch: 92 - Train Loss: 11.43424129486084 - Test Loss: 11.384037017822266\nEpoch: 93 - Train Loss: 11.257231712341309 - Test Loss: 11.20720386505127\nEpoch: 94 - Train Loss: 11.081482887268066 - Test Loss: 11.03162956237793\nEpoch: 95 - Train Loss: 10.906988143920898 - Test Loss: 10.857316017150879\nEpoch: 96 - Train Loss: 10.733778953552246 - Test Loss: 10.684283256530762\nEpoch: 97 - Train Loss: 10.561860084533691 - Test Loss: 10.512530326843262\nEpoch: 98 - Train Loss: 10.39124870300293 - Test Loss: 10.342081069946289\nEpoch: 99 - Train Loss: 10.221906661987305 - Test Loss: 10.172904968261719\nEpoch: 100 - Train Loss: 10.053873062133789 - Test Loss: 10.005058288574219\nEpoch: 101 - Train Loss: 9.887190818786621 - Test Loss: 9.838553428649902\nEpoch: 102 - Train Loss: 9.72179126739502 - Test Loss: 9.67332649230957\nEpoch: 103 - Train Loss: 9.557703018188477 - Test Loss: 9.509404182434082\nEpoch: 104 - Train Loss: 9.394968032836914 - Test Loss: 9.346840858459473\nEpoch: 105 - Train Loss: 9.233577728271484 - Test Loss: 9.185627937316895\nEpoch: 106 - Train Loss: 9.073528289794922 - Test Loss: 9.02575969696045\nEpoch: 107 - Train Loss: 8.914813041687012 - Test Loss: 8.86722469329834\nEpoch: 108 - Train Loss: 8.757428169250488 - Test Loss: 8.710010528564453\nEpoch: 109 - Train Loss: 8.601370811462402 - Test Loss: 8.554132461547852\nEpoch: 110 - Train Loss: 8.44668197631836 - Test Loss: 8.399629592895508\nEpoch: 111 - Train Loss: 8.293363571166992 - Test Loss: 8.246500015258789\nEpoch: 112 - Train Loss: 8.14144229888916 - Test Loss: 8.094791412353516\nEpoch: 113 - Train Loss: 7.990915298461914 - Test Loss: 7.944491386413574\nEpoch: 114 - Train Loss: 7.841794013977051 - Test Loss: 7.795602798461914\nEpoch: 115 - Train Loss: 7.694004535675049 - Test Loss: 7.648052215576172\nEpoch: 116 - Train Loss: 7.547634124755859 - Test Loss: 7.5019330978393555\nEpoch: 117 - Train Loss: 7.402740478515625 - Test Loss: 7.357303142547607\nEpoch: 118 - Train Loss: 7.259368419647217 - Test Loss: 7.2142014503479\nEpoch: 119 - Train Loss: 7.117517471313477 - Test Loss: 7.072615146636963\nEpoch: 120 - Train Loss: 6.9771904945373535 - Test Loss: 6.932554721832275\nEpoch: 121 - Train Loss: 6.83840799331665 - Test Loss: 6.7940497398376465\nEpoch: 122 - Train Loss: 6.701157569885254 - Test Loss: 6.65708065032959\nEpoch: 123 - Train Loss: 6.565371036529541 - Test Loss: 6.5215959548950195\nEpoch: 124 - Train Loss: 6.43113374710083 - Test Loss: 6.387663841247559\nEpoch: 125 - Train Loss: 6.298485279083252 - Test Loss: 6.255331039428711\nEpoch: 126 - Train Loss: 6.167455196380615 - Test Loss: 6.124622344970703\nEpoch: 127 - Train Loss: 6.0380425453186035 - Test Loss: 5.995543003082275\nEpoch: 128 - Train Loss: 5.910236358642578 - Test Loss: 5.86807918548584\nEpoch: 129 - Train Loss: 5.784031391143799 - Test Loss: 5.742227554321289\nEpoch: 130 - Train Loss: 5.659428596496582 - Test Loss: 5.6179938316345215\nEpoch: 131 - Train Loss: 5.536467552185059 - Test Loss: 5.495415687561035\nEpoch: 132 - Train Loss: 5.415167808532715 - Test Loss: 5.374510765075684\nEpoch: 133 - Train Loss: 5.295534610748291 - Test Loss: 5.255286693572998\nEpoch: 134 - Train Loss: 5.177567481994629 - Test Loss: 5.137734889984131\nEpoch: 135 - Train Loss: 5.061297416687012 - Test Loss: 5.021881103515625\nEpoch: 136 - Train Loss: 4.946706295013428 - Test Loss: 4.907707214355469\nEpoch: 137 - Train Loss: 4.833795070648193 - Test Loss: 4.795220851898193\nEpoch: 138 - Train Loss: 4.722551345825195 - Test Loss: 4.684412002563477\nEpoch: 139 - Train Loss: 4.612974643707275 - Test Loss: 4.57526969909668\nEpoch: 140 - Train Loss: 4.505091667175293 - Test Loss: 4.467825412750244\nEpoch: 141 - Train Loss: 4.398919105529785 - Test Loss: 4.362094402313232\nEpoch: 142 - Train Loss: 4.294460296630859 - Test Loss: 4.258084297180176\nEpoch: 143 - Train Loss: 4.191731929779053 - Test Loss: 4.155808448791504\nEpoch: 144 - Train Loss: 4.090743541717529 - Test Loss: 4.055276393890381\nEpoch: 145 - Train Loss: 3.9914891719818115 - Test Loss: 3.9564831256866455\nEpoch: 146 - Train Loss: 3.8939671516418457 - Test Loss: 3.859431505203247\nEpoch: 147 - Train Loss: 3.7981624603271484 - Test Loss: 3.764098644256592\nEpoch: 148 - Train Loss: 3.7040815353393555 - Test Loss: 3.6704912185668945\nEpoch: 149 - Train Loss: 3.611713171005249 - Test Loss: 3.578603744506836\nEpoch: 150 - Train Loss: 3.5210447311401367 - Test Loss: 3.4884214401245117\nEpoch: 151 - Train Loss: 3.432084560394287 - Test Loss: 3.399949789047241\nEpoch: 152 - Train Loss: 3.344848394393921 - Test Loss: 3.3132050037384033\nEpoch: 153 - Train Loss: 3.259345531463623 - Test Loss: 3.2282068729400635\nEpoch: 154 - Train Loss: 3.1755857467651367 - Test Loss: 3.1449642181396484\nEpoch: 155 - Train Loss: 3.0935676097869873 - Test Loss: 3.0634727478027344\nEpoch: 156 - Train Loss: 3.0132858753204346 - Test Loss: 2.983726739883423\nEpoch: 157 - Train Loss: 2.9347293376922607 - Test Loss: 2.9057130813598633\nEpoch: 158 - Train Loss: 2.857896089553833 - Test Loss: 2.8294286727905273\nEpoch: 159 - Train Loss: 2.7827727794647217 - Test Loss: 2.7548584938049316\nEpoch: 160 - Train Loss: 2.7093472480773926 - Test Loss: 2.6819894313812256\nEpoch: 161 - Train Loss: 2.6376097202301025 - Test Loss: 2.6108131408691406\nEpoch: 162 - Train Loss: 2.5675511360168457 - Test Loss: 2.541318655014038\nEpoch: 163 - Train Loss: 2.4991581439971924 - Test Loss: 2.4734926223754883\nEpoch: 164 - Train Loss: 2.4324076175689697 - Test Loss: 2.4073104858398438\nEpoch: 165 - Train Loss: 2.3672757148742676 - Test Loss: 2.3427491188049316\nEpoch: 166 - Train Loss: 2.3037447929382324 - Test Loss: 2.279789686203003\nEpoch: 167 - Train Loss: 2.2417969703674316 - Test Loss: 2.218414068222046\nEpoch: 168 - Train Loss: 2.181417942047119 - Test Loss: 2.158601999282837\nEpoch: 169 - Train Loss: 2.1225996017456055 - Test Loss: 2.1003458499908447\nEpoch: 170 - Train Loss: 2.0653228759765625 - Test Loss: 2.043627977371216\nEpoch: 171 - Train Loss: 2.0095646381378174 - Test Loss: 1.9884257316589355\nEpoch: 172 - Train Loss: 1.9552973508834839 - Test Loss: 1.9347116947174072\nEpoch: 173 - Train Loss: 1.9025037288665771 - Test Loss: 1.8824681043624878\nEpoch: 174 - Train Loss: 1.851158618927002 - Test Loss: 1.8316706418991089\nEpoch: 175 - Train Loss: 1.8012419939041138 - Test Loss: 1.7823009490966797\nEpoch: 176 - Train Loss: 1.7527323961257935 - Test Loss: 1.7343316078186035\nEpoch: 177 - Train Loss: 1.7056056261062622 - Test Loss: 1.687739372253418\nEpoch: 178 - Train Loss: 1.6598397493362427 - Test Loss: 1.6425014734268188\nEpoch: 179 - Train Loss: 1.6154134273529053 - Test Loss: 1.5985984802246094\nEpoch: 180 - Train Loss: 1.5723050832748413 - Test Loss: 1.5560065507888794\nEpoch: 181 - Train Loss: 1.5304869413375854 - Test Loss: 1.5146980285644531\nEpoch: 182 - Train Loss: 1.4899306297302246 - Test Loss: 1.4746445417404175\nEpoch: 183 - Train Loss: 1.4506146907806396 - Test Loss: 1.4358221292495728\nEpoch: 184 - Train Loss: 1.4125126600265503 - Test Loss: 1.3982067108154297\nEpoch: 185 - Train Loss: 1.3755967617034912 - Test Loss: 1.361768126487732\nEpoch: 186 - Train Loss: 1.3398411273956299 - Test Loss: 1.326478362083435\nEpoch: 187 - Train Loss: 1.3052211999893188 - Test Loss: 1.2923123836517334\nEpoch: 188 - Train Loss: 1.2717082500457764 - Test Loss: 1.2592437267303467\nEpoch: 189 - Train Loss: 1.239274501800537 - Test Loss: 1.2272454500198364\nEpoch: 190 - Train Loss: 1.2078975439071655 - Test Loss: 1.1962950229644775\nEpoch: 191 - Train Loss: 1.1775511503219604 - Test Loss: 1.1663674116134644\nEpoch: 192 - Train Loss: 1.1482082605361938 - Test Loss: 1.1374343633651733\nEpoch: 193 - Train Loss: 1.1198437213897705 - Test Loss: 1.1094708442687988\nEpoch: 194 - Train Loss: 1.0924338102340698 - Test Loss: 1.0824552774429321\nEpoch: 195 - Train Loss: 1.06595778465271 - Test Loss: 1.0563676357269287\nEpoch: 196 - Train Loss: 1.0403943061828613 - Test Loss: 1.0311874151229858\nEpoch: 197 - Train Loss: 1.0157161951065063 - Test Loss: 1.0068880319595337\nEpoch: 198 - Train Loss: 0.9918984174728394 - Test Loss: 0.9834432005882263\nEpoch: 199 - Train Loss: 0.9689154624938965 - Test Loss: 0.9608277082443237\nEpoch: 200 - Train Loss: 0.9467399716377258 - Test Loss: 0.9390155673027039\nEpoch: 201 - Train Loss: 0.9253460168838501 - Test Loss: 0.9179820418357849\nEpoch: 202 - Train Loss: 0.9047109484672546 - Test Loss: 0.8977039456367493\nEpoch: 203 - Train Loss: 0.8848092555999756 - Test Loss: 0.8781566619873047\nEpoch: 204 - Train Loss: 0.8656131625175476 - Test Loss: 0.8593130111694336\nEpoch: 205 - Train Loss: 0.8470973968505859 - Test Loss: 0.8411468863487244\nEpoch: 206 - Train Loss: 0.8292377591133118 - Test Loss: 0.8236342072486877\nEpoch: 207 - Train Loss: 0.81201171875 - Test Loss: 0.8067525029182434\nEpoch: 208 - Train Loss: 0.7953994870185852 - Test Loss: 0.7904821634292603\nEpoch: 209 - Train Loss: 0.779380738735199 - Test Loss: 0.7748034000396729\nEpoch: 210 - Train Loss: 0.7639368772506714 - Test Loss: 0.7596969604492188\nEpoch: 211 - Train Loss: 0.749047040939331 - Test Loss: 0.7451425194740295\nEpoch: 212 - Train Loss: 0.7346917986869812 - Test Loss: 0.7311195731163025\nEpoch: 213 - Train Loss: 0.7208513021469116 - Test Loss: 0.7176089286804199\nEpoch: 214 - Train Loss: 0.7075088620185852 - Test Loss: 0.7045940160751343\nEpoch: 215 - Train Loss: 0.6946460604667664 - Test Loss: 0.6920567750930786\nEpoch: 216 - Train Loss: 0.682248055934906 - Test Loss: 0.6799821853637695\nEpoch: 217 - Train Loss: 0.67029869556427 - Test Loss: 0.6683540940284729\nEpoch: 218 - Train Loss: 0.6587833166122437 - Test Loss: 0.657157301902771\nEpoch: 219 - Train Loss: 0.6476873159408569 - Test Loss: 0.6463772654533386\nEpoch: 220 - Train Loss: 0.6369954943656921 - Test Loss: 0.635998547077179\nEpoch: 221 - Train Loss: 0.6266928911209106 - Test Loss: 0.6260058879852295\nEpoch: 222 - Train Loss: 0.6167658567428589 - Test Loss: 0.6163860559463501\nEpoch: 223 - Train Loss: 0.6072006225585938 - Test Loss: 0.6071252226829529\nEpoch: 224 - Train Loss: 0.5979833602905273 - Test Loss: 0.5982099175453186\nEpoch: 225 - Train Loss: 0.5891024470329285 - Test Loss: 0.5896286368370056\nEpoch: 226 - Train Loss: 0.5805466175079346 - Test Loss: 0.581369936466217\nEpoch: 227 - Train Loss: 0.5723053812980652 - Test Loss: 0.573422908782959\nEpoch: 228 - Train Loss: 0.5643686056137085 - Test Loss: 0.5657769441604614\nEpoch: 229 - Train Loss: 0.5567264556884766 - Test Loss: 0.5584220290184021\nEpoch: 230 - Train Loss: 0.5493675470352173 - Test Loss: 0.5513473749160767\nEpoch: 231 - Train Loss: 0.542281448841095 - Test Loss: 0.5445427298545837\nEpoch: 232 - Train Loss: 0.5354578495025635 - Test Loss: 0.5379975438117981\nEpoch: 233 - Train Loss: 0.5288878679275513 - Test Loss: 0.5317029356956482\nEpoch: 234 - Train Loss: 0.522563099861145 - Test Loss: 0.5256505012512207\nEpoch: 235 - Train Loss: 0.5164749026298523 - Test Loss: 0.5198314785957336\nEpoch: 236 - Train Loss: 0.510615348815918 - Test Loss: 0.5142379403114319\nEpoch: 237 - Train Loss: 0.5049759745597839 - Test Loss: 0.5088616013526917\nEpoch: 238 - Train Loss: 0.4995501935482025 - Test Loss: 0.5036954879760742\nEpoch: 239 - Train Loss: 0.49433010816574097 - Test Loss: 0.498731791973114\nEpoch: 240 - Train Loss: 0.48930826783180237 - Test Loss: 0.49396368861198425\nEpoch: 241 - Train Loss: 0.48447856307029724 - Test Loss: 0.48938438296318054\nEpoch: 242 - Train Loss: 0.4798341691493988 - Test Loss: 0.4849872291088104\nEpoch: 243 - Train Loss: 0.4753687381744385 - Test Loss: 0.4807661175727844\nEpoch: 244 - Train Loss: 0.47107627987861633 - Test Loss: 0.47671470046043396\nEpoch: 245 - Train Loss: 0.4669512212276459 - Test Loss: 0.47282716631889343\nEpoch: 246 - Train Loss: 0.46298837661743164 - Test Loss: 0.46909794211387634\nEpoch: 247 - Train Loss: 0.4591822326183319 - Test Loss: 0.46552154421806335\nEpoch: 248 - Train Loss: 0.45552748441696167 - Test Loss: 0.46209245920181274\nEpoch: 249 - Train Loss: 0.4520191252231598 - Test Loss: 0.45880571007728577\nEpoch: 250 - Train Loss: 0.4486522972583771 - Test Loss: 0.45565590262413025\nEpoch: 251 - Train Loss: 0.44542235136032104 - Test Loss: 0.4526383578777313\nEpoch: 252 - Train Loss: 0.4423249661922455 - Test Loss: 0.44974857568740845\nEpoch: 253 - Train Loss: 0.43935534358024597 - Test Loss: 0.44698166847229004\nEpoch: 254 - Train Loss: 0.43650922179222107 - Test Loss: 0.4443334639072418\nEpoch: 255 - Train Loss: 0.433782696723938 - Test Loss: 0.441800057888031\nEpoch: 256 - Train Loss: 0.431171715259552 - Test Loss: 0.43937748670578003\nEpoch: 257 - Train Loss: 0.42867231369018555 - Test Loss: 0.4370621144771576\nEpoch: 258 - Train Loss: 0.4262809753417969 - Test Loss: 0.4348503351211548\nEpoch: 259 - Train Loss: 0.42399415373802185 - Test Loss: 0.4327385425567627\nEpoch: 260 - Train Loss: 0.42180854082107544 - Test Loss: 0.43072372674942017\nEpoch: 261 - Train Loss: 0.41972100734710693 - Test Loss: 0.4288027584552765\nEpoch: 262 - Train Loss: 0.4177282154560089 - Test Loss: 0.42697256803512573\nEpoch: 263 - Train Loss: 0.41582727432250977 - Test Loss: 0.42523011565208435\nEpoch: 264 - Train Loss: 0.414014995098114 - Test Loss: 0.4235726594924927\nEpoch: 265 - Train Loss: 0.41228869557380676 - Test Loss: 0.42199739813804626\nEpoch: 266 - Train Loss: 0.41064557433128357 - Test Loss: 0.4205019176006317\nEpoch: 267 - Train Loss: 0.4090830981731415 - Test Loss: 0.41908350586891174\nEpoch: 268 - Train Loss: 0.4075985550880432 - Test Loss: 0.41773971915245056\nEpoch: 269 - Train Loss: 0.4061894714832306 - Test Loss: 0.41646808385849\nEpoch: 270 - Train Loss: 0.40485358238220215 - Test Loss: 0.4152663052082062\nEpoch: 271 - Train Loss: 0.40358880162239075 - Test Loss: 0.41413232684135437\nEpoch: 272 - Train Loss: 0.40239307284355164 - Test Loss: 0.413064181804657\nEpoch: 273 - Train Loss: 0.4012643098831177 - Test Loss: 0.41205963492393494\nEpoch: 274 - Train Loss: 0.4002005159854889 - Test Loss: 0.4111168384552002\nEpoch: 275 - Train Loss: 0.3991999328136444 - Test Loss: 0.41023412346839905\nEpoch: 276 - Train Loss: 0.39826059341430664 - Test Loss: 0.40940871834754944\nEpoch: 277 - Train Loss: 0.3973808288574219 - Test Loss: 0.4086395502090454\nEpoch: 278 - Train Loss: 0.39655885100364685 - Test Loss: 0.4079252779483795\nEpoch: 279 - Train Loss: 0.39579302072525024 - Test Loss: 0.40726444125175476\nEpoch: 280 - Train Loss: 0.39508193731307983 - Test Loss: 0.4066556692123413\nEpoch: 281 - Train Loss: 0.39442408084869385 - Test Loss: 0.4060976207256317\nEpoch: 282 - Train Loss: 0.3938180208206177 - Test Loss: 0.4055885672569275\nEpoch: 283 - Train Loss: 0.3932623267173767 - Test Loss: 0.40512731671333313\nEpoch: 284 - Train Loss: 0.39275550842285156 - Test Loss: 0.4047127366065979\nEpoch: 285 - Train Loss: 0.3922964632511139 - Test Loss: 0.4043436050415039\nEpoch: 286 - Train Loss: 0.3918839991092682 - Test Loss: 0.4040188193321228\nEpoch: 287 - Train Loss: 0.39151695370674133 - Test Loss: 0.40373730659484863\nEpoch: 288 - Train Loss: 0.3911941647529602 - Test Loss: 0.4034980535507202\nEpoch: 289 - Train Loss: 0.39091458916664124 - Test Loss: 0.403300017118454\nEpoch: 290 - Train Loss: 0.39067721366882324 - Test Loss: 0.40314221382141113\nEpoch: 291 - Train Loss: 0.3904811441898346 - Test Loss: 0.4030238389968872\nEpoch: 292 - Train Loss: 0.39032524824142456 - Test Loss: 0.40294376015663147\nEpoch: 293 - Train Loss: 0.3902086019515991 - Test Loss: 0.40290117263793945\nEpoch: 294 - Train Loss: 0.39013031125068665 - Test Loss: 0.4028952717781067\nEpoch: 295 - Train Loss: 0.3900894522666931 - Test Loss: 0.4029251039028168\nEpoch: 296 - Train Loss: 0.3900851905345917 - Test Loss: 0.40298992395401\nEpoch: 297 - Train Loss: 0.39011669158935547 - Test Loss: 0.4030890166759491\nEpoch: 298 - Train Loss: 0.3901832401752472 - Test Loss: 0.4032215476036072\nEpoch: 299 - Train Loss: 0.3902839124202728 - Test Loss: 0.40338629484176636\nEpoch: 300 - Train Loss: 0.39041799306869507 - Test Loss: 0.40358278155326843\nEpoch: 301 - Train Loss: 0.3905846178531647 - Test Loss: 0.4038103222846985\nEpoch: 302 - Train Loss: 0.39078304171562195 - Test Loss: 0.40406835079193115\nEpoch: 303 - Train Loss: 0.39101260900497437 - Test Loss: 0.4043561518192291\nEpoch: 304 - Train Loss: 0.391272634267807 - Test Loss: 0.4046730697154999\nEpoch: 305 - Train Loss: 0.39156240224838257 - Test Loss: 0.4050186276435852\nEpoch: 306 - Train Loss: 0.3918813467025757 - Test Loss: 0.4053920805454254\nEpoch: 307 - Train Loss: 0.3922288417816162 - Test Loss: 0.40579286217689514\nEpoch: 308 - Train Loss: 0.39260420203208923 - Test Loss: 0.40622052550315857\nEpoch: 309 - Train Loss: 0.3930068910121918 - Test Loss: 0.40667441487312317\nEpoch: 310 - Train Loss: 0.3934363126754761 - Test Loss: 0.40715402364730835\nEpoch: 311 - Train Loss: 0.3938919007778168 - Test Loss: 0.40765878558158875\nEpoch: 312 - Train Loss: 0.3943731188774109 - Test Loss: 0.40818822383880615\nEpoch: 313 - Train Loss: 0.39487937092781067 - Test Loss: 0.40874171257019043\nEpoch: 314 - Train Loss: 0.3954101800918579 - Test Loss: 0.4093188941478729\nEpoch: 315 - Train Loss: 0.39596500992774963 - Test Loss: 0.4099191725254059\nEpoch: 316 - Train Loss: 0.3965432941913605 - Test Loss: 0.4105420708656311\nEpoch: 317 - Train Loss: 0.3971446454524994 - Test Loss: 0.41118723154067993\nEpoch: 318 - Train Loss: 0.3977685272693634 - Test Loss: 0.411854088306427\nEpoch: 319 - Train Loss: 0.39841461181640625 - Test Loss: 0.4125422537326813\nEpoch: 320 - Train Loss: 0.3990822732448578 - Test Loss: 0.4132513403892517\nEpoch: 321 - Train Loss: 0.39977115392684937 - Test Loss: 0.4139808714389801\nEpoch: 322 - Train Loss: 0.40048083662986755 - Test Loss: 0.4147305190563202\nEpoch: 323 - Train Loss: 0.4012109339237213 - Test Loss: 0.41549983620643616\nEpoch: 324 - Train Loss: 0.40196099877357483 - Test Loss: 0.41628843545913696\nEpoch: 325 - Train Loss: 0.4027306139469147 - Test Loss: 0.4170958995819092\nEpoch: 326 - Train Loss: 0.4035194218158722 - Test Loss: 0.41792187094688416\nEpoch: 327 - Train Loss: 0.4043269157409668 - Test Loss: 0.41876596212387085\nEpoch: 328 - Train Loss: 0.405152827501297 - Test Loss: 0.41962775588035583\nEpoch: 329 - Train Loss: 0.40599676966667175 - Test Loss: 0.42050689458847046\nEpoch: 330 - Train Loss: 0.4068582355976105 - Test Loss: 0.42140305042266846\nEpoch: 331 - Train Loss: 0.40773701667785645 - Test Loss: 0.422315776348114\nEpoch: 332 - Train Loss: 0.4086326062679291 - Test Loss: 0.42324480414390564\nEpoch: 333 - Train Loss: 0.40954476594924927 - Test Loss: 0.4241897761821747\nEpoch: 334 - Train Loss: 0.41047313809394836 - Test Loss: 0.4251503646373749\nEpoch: 335 - Train Loss: 0.4114173352718353 - Test Loss: 0.4261262118816376\nEpoch: 336 - Train Loss: 0.4123770296573639 - Test Loss: 0.4271170496940613\nEpoch: 337 - Train Loss: 0.41335195302963257 - Test Loss: 0.42812252044677734\nEpoch: 338 - Train Loss: 0.4143417775630951 - Test Loss: 0.42914238572120667\nEpoch: 339 - Train Loss: 0.4153461456298828 - Test Loss: 0.4301762580871582\nEpoch: 340 - Train Loss: 0.41636478900909424 - Test Loss: 0.43122389912605286\nEpoch: 341 - Train Loss: 0.4173974096775055 - Test Loss: 0.43228501081466675\nEpoch: 342 - Train Loss: 0.4184436798095703 - Test Loss: 0.43335938453674316\nEpoch: 343 - Train Loss: 0.41950342059135437 - Test Loss: 0.4344465434551239\nEpoch: 344 - Train Loss: 0.42057618498802185 - Test Loss: 0.4355463981628418\nEpoch: 345 - Train Loss: 0.42166173458099365 - Test Loss: 0.4366585314273834\nEpoch: 346 - Train Loss: 0.4227598309516907 - Test Loss: 0.43778273463249207\nEpoch: 347 - Train Loss: 0.4238702356815338 - Test Loss: 0.43891870975494385\nEpoch: 348 - Train Loss: 0.42499253153800964 - Test Loss: 0.44006624817848206\nEpoch: 349 - Train Loss: 0.42612653970718384 - Test Loss: 0.4412250518798828\nEpoch: 350 - Train Loss: 0.4272719919681549 - Test Loss: 0.442394882440567\nEpoch: 351 - Train Loss: 0.42842864990234375 - Test Loss: 0.4435754418373108\nEpoch: 352 - Train Loss: 0.4295961558818817 - Test Loss: 0.44476646184921265\nEpoch: 353 - Train Loss: 0.4307743310928345 - Test Loss: 0.44596773386001587\nEpoch: 354 - Train Loss: 0.4319629669189453 - Test Loss: 0.44717904925346375\nEpoch: 355 - Train Loss: 0.43316176533699036 - Test Loss: 0.4484001398086548\nEpoch: 356 - Train Loss: 0.43437036871910095 - Test Loss: 0.4496307075023651\nEpoch: 357 - Train Loss: 0.4355887174606323 - Test Loss: 0.4508706033229828\nEpoch: 358 - Train Loss: 0.43681639432907104 - Test Loss: 0.45211952924728394\nEpoch: 359 - Train Loss: 0.43805330991744995 - Test Loss: 0.45337721705436707\nEpoch: 360 - Train Loss: 0.43929919600486755 - Test Loss: 0.454643577337265\nEpoch: 361 - Train Loss: 0.44055378437042236 - Test Loss: 0.4559182822704315\nEpoch: 362 - Train Loss: 0.44181689620018005 - Test Loss: 0.4572010636329651\nEpoch: 363 - Train Loss: 0.4430882930755615 - Test Loss: 0.45849183201789856\nEpoch: 364 - Train Loss: 0.44436773657798767 - Test Loss: 0.4597904086112976\nEpoch: 365 - Train Loss: 0.445654958486557 - Test Loss: 0.46109631657600403\nEpoch: 366 - Train Loss: 0.4469498097896576 - Test Loss: 0.46240949630737305\nEpoch: 367 - Train Loss: 0.4482520818710327 - Test Loss: 0.4637298285961151\nEpoch: 368 - Train Loss: 0.44956153631210327 - Test Loss: 0.4650568962097168\nEpoch: 369 - Train Loss: 0.45087796449661255 - Test Loss: 0.4663906693458557\nEpoch: 370 - Train Loss: 0.45220112800598145 - Test Loss: 0.4677308201789856\nEpoch: 371 - Train Loss: 0.45353081822395325 - Test Loss: 0.4690772294998169\nEpoch: 372 - Train Loss: 0.45486685633659363 - Test Loss: 0.47042953968048096\nEpoch: 373 - Train Loss: 0.4562089443206787 - Test Loss: 0.4717877507209778\nEpoch: 374 - Train Loss: 0.4575570523738861 - Test Loss: 0.4731515049934387\nEpoch: 375 - Train Loss: 0.4589109420776367 - Test Loss: 0.4745207726955414\nEpoch: 376 - Train Loss: 0.4602702558040619 - Test Loss: 0.4758951663970947\nEpoch: 377 - Train Loss: 0.46163487434387207 - Test Loss: 0.4772745370864868\nEpoch: 378 - Train Loss: 0.4630047380924225 - Test Loss: 0.47865885496139526\nEpoch: 379 - Train Loss: 0.46437951922416687 - Test Loss: 0.4800477623939514\nEpoch: 380 - Train Loss: 0.4657590985298157 - Test Loss: 0.4814411401748657\nEpoch: 381 - Train Loss: 0.4671432375907898 - Test Loss: 0.48283877968788147\nEpoch: 382 - Train Loss: 0.4685317277908325 - Test Loss: 0.48424047231674194\nEpoch: 383 - Train Loss: 0.4699244797229767 - Test Loss: 0.4856460988521576\nEpoch: 384 - Train Loss: 0.4713212251663208 - Test Loss: 0.4870555102825165\nEpoch: 385 - Train Loss: 0.4727218449115753 - Test Loss: 0.4884684085845947\nEpoch: 386 - Train Loss: 0.47412610054016113 - Test Loss: 0.4898846745491028\nEpoch: 387 - Train Loss: 0.47553393244743347 - Test Loss: 0.4913041591644287\nEpoch: 388 - Train Loss: 0.4769449830055237 - Test Loss: 0.4927266240119934\nEpoch: 389 - Train Loss: 0.47835925221443176 - Test Loss: 0.4941519498825073\nEpoch: 390 - Train Loss: 0.47977644205093384 - Test Loss: 0.4955799877643585\nEpoch: 391 - Train Loss: 0.48119643330574036 - Test Loss: 0.4970104694366455\nEpoch: 392 - Train Loss: 0.4826190173625946 - Test Loss: 0.4984433054924011\nEpoch: 393 - Train Loss: 0.4840441644191742 - Test Loss: 0.4998783767223358\nEpoch: 394 - Train Loss: 0.48547157645225525 - Test Loss: 0.5013154149055481\nEpoch: 395 - Train Loss: 0.48690110445022583 - Test Loss: 0.5027543306350708\nEpoch: 396 - Train Loss: 0.4883325695991516 - Test Loss: 0.5041949152946472\nEpoch: 397 - Train Loss: 0.48976588249206543 - Test Loss: 0.5056370496749878\nEpoch: 398 - Train Loss: 0.4912007749080658 - Test Loss: 0.5070804357528687\nEpoch: 399 - Train Loss: 0.4926372170448303 - Test Loss: 0.508525013923645\nEpoch: 400 - Train Loss: 0.4940749406814575 - Test Loss: 0.5099706649780273\nEpoch: 401 - Train Loss: 0.4955137372016907 - Test Loss: 0.5114171504974365\nEpoch: 402 - Train Loss: 0.4969536364078522 - Test Loss: 0.5128644108772278\nEpoch: 403 - Train Loss: 0.49839428067207336 - Test Loss: 0.5143120884895325\nEpoch: 404 - Train Loss: 0.4998355805873871 - Test Loss: 0.5157603025436401\nEpoch: 405 - Train Loss: 0.5012774467468262 - Test Loss: 0.5172085762023926\nEpoch: 406 - Train Loss: 0.5027195811271667 - Test Loss: 0.5186570286750793\nEpoch: 407 - Train Loss: 0.5041619539260864 - Test Loss: 0.5201054215431213\nEpoch: 408 - Train Loss: 0.5056043863296509 - Test Loss: 0.5215535759925842\nEpoch: 409 - Train Loss: 0.5070466995239258 - Test Loss: 0.5230013728141785\nEpoch: 410 - Train Loss: 0.5084887742996216 - Test Loss: 0.5244485139846802\nEpoch: 411 - Train Loss: 0.5099304914474487 - Test Loss: 0.5258951783180237\nEpoch: 412 - Train Loss: 0.5113715529441833 - Test Loss: 0.5273408889770508\nEpoch: 413 - Train Loss: 0.5128119587898254 - Test Loss: 0.5287857055664062\nEpoch: 414 - Train Loss: 0.5142515897750854 - Test Loss: 0.530229389667511\nEpoch: 415 - Train Loss: 0.5156901478767395 - Test Loss: 0.5316718220710754\nEpoch: 416 - Train Loss: 0.5171276330947876 - Test Loss: 0.5331128835678101\nEpoch: 417 - Train Loss: 0.5185638070106506 - Test Loss: 0.5345523357391357\nEpoch: 418 - Train Loss: 0.5199986696243286 - Test Loss: 0.5359901785850525\nEpoch: 419 - Train Loss: 0.5214318633079529 - Test Loss: 0.5374261736869812\nEpoch: 420 - Train Loss: 0.5228633880615234 - Test Loss: 0.5388602018356323\nEpoch: 421 - Train Loss: 0.5242931246757507 - Test Loss: 0.5402920842170715\nEpoch: 422 - Train Loss: 0.5257207751274109 - Test Loss: 0.5417217016220093\nEpoch: 423 - Train Loss: 0.5271463394165039 - Test Loss: 0.5431490540504456\nEpoch: 424 - Train Loss: 0.5285696983337402 - Test Loss: 0.5445738434791565\nEpoch: 425 - Train Loss: 0.5299906730651855 - Test Loss: 0.5459959506988525\nEpoch: 426 - Train Loss: 0.5314090251922607 - Test Loss: 0.5474152565002441\nEpoch: 427 - Train Loss: 0.5328247547149658 - Test Loss: 0.548831582069397\nEpoch: 428 - Train Loss: 0.5342375636100769 - Test Loss: 0.5502448081970215\nEpoch: 429 - Train Loss: 0.5356475710868835 - Test Loss: 0.5516549944877625\nEpoch: 430 - Train Loss: 0.5370543599128723 - Test Loss: 0.5530617237091064\nEpoch: 431 - Train Loss: 0.5384581089019775 - Test Loss: 0.5544649362564087\nEpoch: 432 - Train Loss: 0.539858341217041 - Test Loss: 0.5558646321296692\nEpoch: 433 - Train Loss: 0.5412551164627075 - Test Loss: 0.5572605133056641\nEpoch: 434 - Train Loss: 0.5426483154296875 - Test Loss: 0.5586525201797485\nEpoch: 435 - Train Loss: 0.5440376996994019 - Test Loss: 0.5600404739379883\nEpoch: 436 - Train Loss: 0.5454232692718506 - Test Loss: 0.5614243745803833\nEpoch: 437 - Train Loss: 0.5468047261238098 - Test Loss: 0.5628039836883545\nEpoch: 438 - Train Loss: 0.5481821298599243 - Test Loss: 0.5641792416572571\nEpoch: 439 - Train Loss: 0.5495551824569702 - Test Loss: 0.5655498504638672\nEpoch: 440 - Train Loss: 0.5509238243103027 - Test Loss: 0.5669159293174744\nEpoch: 441 - Train Loss: 0.5522879958152771 - Test Loss: 0.5682771801948547\nEpoch: 442 - Train Loss: 0.5536474585533142 - Test Loss: 0.5696335434913635\nEpoch: 443 - Train Loss: 0.5550021529197693 - Test Loss: 0.5709847807884216\nEpoch: 444 - Train Loss: 0.5563518404960632 - Test Loss: 0.572330892086029\nEpoch: 445 - Train Loss: 0.5576965808868408 - Test Loss: 0.5736717581748962\nEpoch: 446 - Train Loss: 0.5590360760688782 - Test Loss: 0.5750071406364441\nEpoch: 447 - Train Loss: 0.5603703260421753 - Test Loss: 0.5763370394706726\nEpoch: 448 - Train Loss: 0.5616991519927979 - Test Loss: 0.5776612162590027\nEpoch: 449 - Train Loss: 0.5630224347114563 - Test Loss: 0.5789797306060791\nEpoch: 450 - Train Loss: 0.5643399953842163 - Test Loss: 0.5802921652793884\nEpoch: 451 - Train Loss: 0.5656517744064331 - Test Loss: 0.5815986394882202\nEpoch: 452 - Train Loss: 0.5669576525688171 - Test Loss: 0.5828989744186401\nEpoch: 453 - Train Loss: 0.5682574510574341 - Test Loss: 0.5841930508613586\nEpoch: 454 - Train Loss: 0.5695511698722839 - Test Loss: 0.5854806900024414\nEpoch: 455 - Train Loss: 0.5708385109901428 - Test Loss: 0.5867618322372437\nEpoch: 456 - Train Loss: 0.572119414806366 - Test Loss: 0.5880363583564758\nEpoch: 457 - Train Loss: 0.5733938813209534 - Test Loss: 0.5893041491508484\nEpoch: 458 - Train Loss: 0.5746616125106812 - Test Loss: 0.5905649662017822\nEpoch: 459 - Train Loss: 0.5759226679801941 - Test Loss: 0.5918188691139221\nEpoch: 460 - Train Loss: 0.5771767497062683 - Test Loss: 0.593065619468689\nEpoch: 461 - Train Loss: 0.578423798084259 - Test Loss: 0.5943050980567932\nEpoch: 462 - Train Loss: 0.5796636343002319 - Test Loss: 0.5955373048782349\nEpoch: 463 - Train Loss: 0.5808963179588318 - Test Loss: 0.5967618823051453\nEpoch: 464 - Train Loss: 0.5821216106414795 - Test Loss: 0.5979790091514587\nEpoch: 465 - Train Loss: 0.5833393931388855 - Test Loss: 0.5991883277893066\nEpoch: 466 - Train Loss: 0.5845495462417603 - Test Loss: 0.6003899574279785\nEpoch: 467 - Train Loss: 0.585752010345459 - Test Loss: 0.6015835404396057\nEpoch: 468 - Train Loss: 0.5869466662406921 - Test Loss: 0.602769136428833\nEpoch: 469 - Train Loss: 0.5881332159042358 - Test Loss: 0.6039465665817261\nEpoch: 470 - Train Loss: 0.5893118381500244 - Test Loss: 0.6051155924797058\nEpoch: 471 - Train Loss: 0.5904820561408997 - Test Loss: 0.6062763333320618\nEpoch: 472 - Train Loss: 0.5916440486907959 - Test Loss: 0.6074285507202148\nEpoch: 473 - Train Loss: 0.5927976965904236 - Test Loss: 0.6085720658302307\nEpoch: 474 - Train Loss: 0.5939426422119141 - Test Loss: 0.6097068786621094\nEpoch: 475 - Train Loss: 0.5950790643692017 - Test Loss: 0.6108328700065613\nEpoch: 476 - Train Loss: 0.5962067246437073 - Test Loss: 0.6119499802589417\nEpoch: 477 - Train Loss: 0.5973255038261414 - Test Loss: 0.6130579113960266\nEpoch: 478 - Train Loss: 0.5984352231025696 - Test Loss: 0.6141567826271057\nEpoch: 479 - Train Loss: 0.5995358824729919 - Test Loss: 0.6152462959289551\nEpoch: 480 - Train Loss: 0.6006271839141846 - Test Loss: 0.6163262724876404\nEpoch: 481 - Train Loss: 0.6017091274261475 - Test Loss: 0.6173967123031616\nEpoch: 482 - Train Loss: 0.6027815937995911 - Test Loss: 0.6184576153755188\nEpoch: 483 - Train Loss: 0.6038444638252258 - Test Loss: 0.6195086240768433\nEpoch: 484 - Train Loss: 0.604897677898407 - Test Loss: 0.6205497980117798\nEpoch: 485 - Train Loss: 0.605941116809845 - Test Loss: 0.6215810775756836\nEpoch: 486 - Train Loss: 0.6069745421409607 - Test Loss: 0.6226022243499756\nEpoch: 487 - Train Loss: 0.6079980731010437 - Test Loss: 0.6236132979393005\nEpoch: 488 - Train Loss: 0.6090114116668701 - Test Loss: 0.6246139407157898\nEpoch: 489 - Train Loss: 0.6100145578384399 - Test Loss: 0.6256042718887329\nEpoch: 490 - Train Loss: 0.6110072731971741 - Test Loss: 0.6265840530395508\nEpoch: 491 - Train Loss: 0.6119896769523621 - Test Loss: 0.6275533437728882\nEpoch: 492 - Train Loss: 0.6129614114761353 - Test Loss: 0.628511905670166\nEpoch: 493 - Train Loss: 0.613922655582428 - Test Loss: 0.6294597387313843\nEpoch: 494 - Train Loss: 0.6148729920387268 - Test Loss: 0.6303965449333191\nEpoch: 495 - Train Loss: 0.6158124804496765 - Test Loss: 0.63132244348526\nEpoch: 496 - Train Loss: 0.6167410612106323 - Test Loss: 0.6322372555732727\nEpoch: 497 - Train Loss: 0.6176585555076599 - Test Loss: 0.6331408023834229\nEpoch: 498 - Train Loss: 0.6185649037361145 - Test Loss: 0.6340330839157104\nEpoch: 499 - Train Loss: 0.6194599270820618 - Test Loss: 0.6349140405654907\nEpoch: 500 - Train Loss: 0.6203435659408569 - Test Loss: 0.6357833743095398\nEpoch: 501 - Train Loss: 0.6212158203125 - Test Loss: 0.6366412043571472\nEpoch: 502 - Train Loss: 0.6220763921737671 - Test Loss: 0.6374872922897339\nEpoch: 503 - Train Loss: 0.622925341129303 - Test Loss: 0.638321578502655\nEpoch: 504 - Train Loss: 0.6237624883651733 - Test Loss: 0.6391440629959106\nEpoch: 505 - Train Loss: 0.6245877146720886 - Test Loss: 0.6399545669555664\nEpoch: 506 - Train Loss: 0.625400960445404 - Test Loss: 0.6407528519630432\nEpoch: 507 - Train Loss: 0.6262021660804749 - Test Loss: 0.6415389776229858\nEpoch: 508 - Train Loss: 0.6269911527633667 - Test Loss: 0.6423128247261047\nEpoch: 509 - Train Loss: 0.6277678608894348 - Test Loss: 0.6430743932723999\nEpoch: 510 - Train Loss: 0.6285321712493896 - Test Loss: 0.6438234448432922\nEpoch: 511 - Train Loss: 0.6292840838432312 - Test Loss: 0.6445600390434265\nEpoch: 512 - Train Loss: 0.6300234198570251 - Test Loss: 0.6452838182449341\nEpoch: 513 - Train Loss: 0.6307499408721924 - Test Loss: 0.6459948420524597\nEpoch: 514 - Train Loss: 0.6314637660980225 - Test Loss: 0.6466931700706482\nEpoch: 515 - Train Loss: 0.6321648955345154 - Test Loss: 0.6473785042762756\nEpoch: 516 - Train Loss: 0.6328528523445129 - Test Loss: 0.6480507850646973\nEpoch: 517 - Train Loss: 0.6335276961326599 - Test Loss: 0.6487098932266235\nEpoch: 518 - Train Loss: 0.6341895461082458 - Test Loss: 0.649355947971344\nEpoch: 519 - Train Loss: 0.6348381638526917 - Test Loss: 0.6499886512756348\nEpoch: 520 - Train Loss: 0.6354734301567078 - Test Loss: 0.6506080031394958\nEpoch: 521 - Train Loss: 0.6360952258110046 - Test Loss: 0.6512137651443481\nEpoch: 522 - Train Loss: 0.6367034316062927 - Test Loss: 0.6518060564994812\nEpoch: 523 - Train Loss: 0.6372982263565063 - Test Loss: 0.6523848176002502\nEpoch: 524 - Train Loss: 0.6378791928291321 - Test Loss: 0.6529496312141418\nEpoch: 525 - Train Loss: 0.6384463310241699 - Test Loss: 0.6535006761550903\nEpoch: 526 - Train Loss: 0.6389997005462646 - Test Loss: 0.6540378928184509\nEpoch: 527 - Train Loss: 0.6395391225814819 - Test Loss: 0.6545612215995789\nEpoch: 528 - Train Loss: 0.6400644183158875 - Test Loss: 0.6550703048706055\nEpoch: 529 - Train Loss: 0.6405755281448364 - Test Loss: 0.6555652618408203\nEpoch: 530 - Train Loss: 0.6410725712776184 - Test Loss: 0.6560461521148682\nEpoch: 531 - Train Loss: 0.6415552496910095 - Test Loss: 0.6565125584602356\nEpoch: 532 - Train Loss: 0.6420235633850098 - Test Loss: 0.6569647789001465\nEpoch: 533 - Train Loss: 0.6424773931503296 - Test Loss: 0.6574023365974426\nEpoch: 534 - Train Loss: 0.6429166197776794 - Test Loss: 0.6578254103660583\nEpoch: 535 - Train Loss: 0.6433413028717041 - Test Loss: 0.6582339406013489\nEpoch: 536 - Train Loss: 0.6437512040138245 - Test Loss: 0.6586276888847351\nEpoch: 537 - Train Loss: 0.6441463828086853 - Test Loss: 0.6590067148208618\nEpoch: 538 - Train Loss: 0.6445266008377075 - Test Loss: 0.6593708992004395\nEpoch: 539 - Train Loss: 0.6448920369148254 - Test Loss: 0.659720242023468\nEpoch: 540 - Train Loss: 0.6452422738075256 - Test Loss: 0.6600544452667236\nEpoch: 541 - Train Loss: 0.645577609539032 - Test Loss: 0.6603737473487854\nEpoch: 542 - Train Loss: 0.645897626876831 - Test Loss: 0.6606778502464294\nEpoch: 543 - Train Loss: 0.6462023854255676 - Test Loss: 0.6609667539596558\nEpoch: 544 - Train Loss: 0.6464919447898865 - Test Loss: 0.6612404584884644\nEpoch: 545 - Train Loss: 0.6467660665512085 - Test Loss: 0.6614987850189209\nEpoch: 546 - Train Loss: 0.6470247507095337 - Test Loss: 0.6617416739463806\nEpoch: 547 - Train Loss: 0.647267758846283 - Test Loss: 0.6619690656661987\nEpoch: 548 - Train Loss: 0.6474952697753906 - Test Loss: 0.66218101978302\nEpoch: 549 - Train Loss: 0.6477071642875671 - Test Loss: 0.6623773574829102\nEpoch: 550 - Train Loss: 0.6479034423828125 - Test Loss: 0.6625580191612244\nEpoch: 551 - Train Loss: 0.6480836868286133 - Test Loss: 0.6627229452133179\nEpoch: 552 - Train Loss: 0.6482481360435486 - Test Loss: 0.6628721356391907\nEpoch: 553 - Train Loss: 0.6483966708183289 - Test Loss: 0.663005530834198\nEpoch: 554 - Train Loss: 0.6485292315483093 - Test Loss: 0.6631229519844055\nEpoch: 555 - Train Loss: 0.6486457586288452 - Test Loss: 0.6632245182991028\nEpoch: 556 - Train Loss: 0.648746132850647 - Test Loss: 0.6633099317550659\nEpoch: 557 - Train Loss: 0.6488304138183594 - Test Loss: 0.6633794903755188\nEpoch: 558 - Train Loss: 0.6488984227180481 - Test Loss: 0.6634327173233032\nEpoch: 559 - Train Loss: 0.6489501595497131 - Test Loss: 0.6634699702262878\nEpoch: 560 - Train Loss: 0.6489856243133545 - Test Loss: 0.6634909510612488\nEpoch: 561 - Train Loss: 0.6490046977996826 - Test Loss: 0.663495659828186\nEpoch: 562 - Train Loss: 0.6490073204040527 - Test Loss: 0.6634841561317444\nEpoch: 563 - Train Loss: 0.6489933729171753 - Test Loss: 0.6634562015533447\nEpoch: 564 - Train Loss: 0.6489629149436951 - Test Loss: 0.6634117960929871\nEpoch: 565 - Train Loss: 0.6489158868789673 - Test Loss: 0.6633509993553162\nEpoch: 566 - Train Loss: 0.6488522887229919 - Test Loss: 0.6632736921310425\nEpoch: 567 - Train Loss: 0.6487718224525452 - Test Loss: 0.6631798148155212\nEpoch: 568 - Train Loss: 0.6486746668815613 - Test Loss: 0.6630693674087524\nEpoch: 569 - Train Loss: 0.6485608220100403 - Test Loss: 0.6629423499107361\nEpoch: 570 - Train Loss: 0.6484301686286926 - Test Loss: 0.6627987027168274\nEpoch: 571 - Train Loss: 0.648282527923584 - Test Loss: 0.6626383066177368\nEpoch: 572 - Train Loss: 0.6481181383132935 - Test Loss: 0.6624612212181091\nEpoch: 573 - Train Loss: 0.6479367613792419 - Test Loss: 0.6622673273086548\nEpoch: 574 - Train Loss: 0.6477383971214294 - Test Loss: 0.6620566844940186\nEpoch: 575 - Train Loss: 0.6475231051445007 - Test Loss: 0.6618292331695557\nEpoch: 576 - Train Loss: 0.6472907066345215 - Test Loss: 0.6615848541259766\nEpoch: 577 - Train Loss: 0.6470412611961365 - Test Loss: 0.6613236665725708\nEpoch: 578 - Train Loss: 0.6467747092247009 - Test Loss: 0.6610456109046936\nEpoch: 579 - Train Loss: 0.6464909911155701 - Test Loss: 0.6607505679130554\nEpoch: 580 - Train Loss: 0.6461901068687439 - Test Loss: 0.660438597202301\nEpoch: 581 - Train Loss: 0.6458721160888672 - Test Loss: 0.6601096391677856\nEpoch: 582 - Train Loss: 0.6455368995666504 - Test Loss: 0.6597636342048645\nEpoch: 583 - Train Loss: 0.6451844573020935 - Test Loss: 0.6594007611274719\nEpoch: 584 - Train Loss: 0.6448147892951965 - Test Loss: 0.6590207815170288\nEpoch: 585 - Train Loss: 0.6444277763366699 - Test Loss: 0.6586236953735352\nEpoch: 586 - Train Loss: 0.6440234780311584 - Test Loss: 0.6582095623016357\nEpoch: 587 - Train Loss: 0.6436018347740173 - Test Loss: 0.6577783823013306\nEpoch: 588 - Train Loss: 0.6431629657745361 - Test Loss: 0.6573300957679749\nEpoch: 589 - Train Loss: 0.6427067518234253 - Test Loss: 0.6568647623062134\nEpoch: 590 - Train Loss: 0.64223313331604 - Test Loss: 0.6563822627067566\nEpoch: 591 - Train Loss: 0.6417422890663147 - Test Loss: 0.6558827757835388\nEpoch: 592 - Train Loss: 0.6412338614463806 - Test Loss: 0.6553659439086914\nEpoch: 593 - Train Loss: 0.640708327293396 - Test Loss: 0.6548321843147278\nEpoch: 594 - Train Loss: 0.6401652693748474 - Test Loss: 0.6542811989784241\nEpoch: 595 - Train Loss: 0.6396048069000244 - Test Loss: 0.6537132263183594\nEpoch: 596 - Train Loss: 0.6390270590782166 - Test Loss: 0.6531280875205994\nEpoch: 597 - Train Loss: 0.6384318470954895 - Test Loss: 0.6525257229804993\nEpoch: 598 - Train Loss: 0.6378193497657776 - Test Loss: 0.6519063115119934\nEpoch: 599 - Train Loss: 0.6371894478797913 - Test Loss: 0.6512698531150818\nEpoch: 600 - Train Loss: 0.6365422010421753 - Test Loss: 0.6506162881851196\nEpoch: 601 - Train Loss: 0.6358775496482849 - Test Loss: 0.6499456167221069\nEpoch: 602 - Train Loss: 0.6351956129074097 - Test Loss: 0.6492579579353333\nEpoch: 603 - Train Loss: 0.6344963312149048 - Test Loss: 0.6485531330108643\nEpoch: 604 - Train Loss: 0.633779764175415 - Test Loss: 0.647831380367279\nEpoch: 605 - Train Loss: 0.6330457925796509 - Test Loss: 0.6470925211906433\nEpoch: 606 - Train Loss: 0.6322946548461914 - Test Loss: 0.6463367938995361\nEpoch: 607 - Train Loss: 0.6315261721611023 - Test Loss: 0.6455639600753784\nEpoch: 608 - Train Loss: 0.6307405829429626 - Test Loss: 0.6447743773460388\nEpoch: 609 - Train Loss: 0.6299376487731934 - Test Loss: 0.6439676880836487\nEpoch: 610 - Train Loss: 0.6291176080703735 - Test Loss: 0.6431441903114319\nEpoch: 611 - Train Loss: 0.6282803416252136 - Test Loss: 0.6423038840293884\nEpoch: 612 - Train Loss: 0.6274259686470032 - Test Loss: 0.6414466500282288\nEpoch: 613 - Train Loss: 0.626554548740387 - Test Loss: 0.640572726726532\nEpoch: 614 - Train Loss: 0.6256659626960754 - Test Loss: 0.639681875705719\nEpoch: 615 - Train Loss: 0.6247604489326477 - Test Loss: 0.6387743949890137\nEpoch: 616 - Train Loss: 0.623837947845459 - Test Loss: 0.637850284576416\nEpoch: 617 - Train Loss: 0.6228983998298645 - Test Loss: 0.6369094848632812\nEpoch: 618 - Train Loss: 0.6219419836997986 - Test Loss: 0.6359520554542542\nEpoch: 619 - Train Loss: 0.620968759059906 - Test Loss: 0.634978175163269\nEpoch: 620 - Train Loss: 0.6199786067008972 - Test Loss: 0.6339877247810364\nEpoch: 621 - Train Loss: 0.6189718246459961 - Test Loss: 0.6329808831214905\nEpoch: 622 - Train Loss: 0.6179481744766235 - Test Loss: 0.6319575309753418\nEpoch: 623 - Train Loss: 0.6169079542160034 - Test Loss: 0.6309179067611694\nEpoch: 624 - Train Loss: 0.6158509850502014 - Test Loss: 0.6298620104789734\nEpoch: 625 - Train Loss: 0.6147776246070862 - Test Loss: 0.6287898421287537\nEpoch: 626 - Train Loss: 0.6136876344680786 - Test Loss: 0.6277014017105103\nEpoch: 627 - Train Loss: 0.6125813126564026 - Test Loss: 0.6265970468521118\nEpoch: 628 - Train Loss: 0.6114585995674133 - Test Loss: 0.6254765391349792\nEpoch: 629 - Train Loss: 0.6103195548057556 - Test Loss: 0.6243399977684021\nEpoch: 630 - Train Loss: 0.6091642379760742 - Test Loss: 0.6231876015663147\nEpoch: 631 - Train Loss: 0.6079928278923035 - Test Loss: 0.622019350528717\nEpoch: 632 - Train Loss: 0.6068053245544434 - Test Loss: 0.6208354830741882\nEpoch: 633 - Train Loss: 0.6056017279624939 - Test Loss: 0.6196357607841492\nEpoch: 634 - Train Loss: 0.6043822169303894 - Test Loss: 0.6184203624725342\nEpoch: 635 - Train Loss: 0.6031468510627747 - Test Loss: 0.6171894073486328\nEpoch: 636 - Train Loss: 0.6018956303596497 - Test Loss: 0.6159431338310242\nEpoch: 637 - Train Loss: 0.6006286144256592 - Test Loss: 0.6146813035011292\nEpoch: 638 - Train Loss: 0.5993461012840271 - Test Loss: 0.6134042143821716\nEpoch: 639 - Train Loss: 0.5980479717254639 - Test Loss: 0.6121119856834412\nEpoch: 640 - Train Loss: 0.596734344959259 - Test Loss: 0.6108046174049377\nEpoch: 641 - Train Loss: 0.5954053997993469 - Test Loss: 0.6094821095466614\nEpoch: 642 - Train Loss: 0.5940611958503723 - Test Loss: 0.6081447005271912\nEpoch: 643 - Train Loss: 0.5927017331123352 - Test Loss: 0.6067923903465271\nEpoch: 644 - Train Loss: 0.5913271903991699 - Test Loss: 0.6054252982139587\nEpoch: 645 - Train Loss: 0.589937686920166 - Test Loss: 0.6040435433387756\nEpoch: 646 - Train Loss: 0.5885332822799683 - Test Loss: 0.6026473045349121\nEpoch: 647 - Train Loss: 0.587114155292511 - Test Loss: 0.6012365818023682\nEpoch: 648 - Train Loss: 0.5856802463531494 - Test Loss: 0.5998113751411438\nEpoch: 649 - Train Loss: 0.5842316746711731 - Test Loss: 0.5983719825744629\nEpoch: 650 - Train Loss: 0.5827688574790955 - Test Loss: 0.596918523311615\nEpoch: 651 - Train Loss: 0.5812915563583374 - Test Loss: 0.5954509377479553\nEpoch: 652 - Train Loss: 0.5798001289367676 - Test Loss: 0.5939695239067078\nEpoch: 653 - Train Loss: 0.5782945156097412 - Test Loss: 0.5924742221832275\nEpoch: 654 - Train Loss: 0.5767748355865479 - Test Loss: 0.590965211391449\nEpoch: 655 - Train Loss: 0.5752412676811218 - Test Loss: 0.5894425511360168\nEpoch: 656 - Train Loss: 0.5736938714981079 - Test Loss: 0.5879064798355103\nEpoch: 657 - Train Loss: 0.57213294506073 - Test Loss: 0.5863571166992188\nEpoch: 658 - Train Loss: 0.5705584287643433 - Test Loss: 0.5847944617271423\nEpoch: 659 - Train Loss: 0.5689705014228821 - Test Loss: 0.5832188129425049\nEpoch: 660 - Train Loss: 0.5673693418502808 - Test Loss: 0.5816300511360168\nEpoch: 661 - Train Loss: 0.5657549500465393 - Test Loss: 0.5800284743309021\nEpoch: 662 - Train Loss: 0.5641275644302368 - Test Loss: 0.5784142017364502\nEpoch: 663 - Train Loss: 0.5624872446060181 - Test Loss: 0.5767871737480164\nEpoch: 664 - Train Loss: 0.5608342289924622 - Test Loss: 0.5751478672027588\nEpoch: 665 - Train Loss: 0.5591685771942139 - Test Loss: 0.5734961032867432\nEpoch: 666 - Train Loss: 0.5574905276298523 - Test Loss: 0.5718322396278381\nEpoch: 667 - Train Loss: 0.5558000206947327 - Test Loss: 0.5701562762260437\nEpoch: 668 - Train Loss: 0.5540973544120789 - Test Loss: 0.5684685111045837\nEpoch: 669 - Train Loss: 0.5523827075958252 - Test Loss: 0.5667688250541687\nEpoch: 670 - Train Loss: 0.5506560802459717 - Test Loss: 0.5650575160980225\nEpoch: 671 - Train Loss: 0.5489176511764526 - Test Loss: 0.5633347034454346\nEpoch: 672 - Train Loss: 0.5471675992012024 - Test Loss: 0.5616005659103394\nEpoch: 673 - Train Loss: 0.5454062223434448 - Test Loss: 0.5598552227020264\nEpoch: 674 - Train Loss: 0.5436333417892456 - Test Loss: 0.5580987930297852\nEpoch: 675 - Train Loss: 0.5418494343757629 - Test Loss: 0.5563315749168396\nEpoch: 676 - Train Loss: 0.5400546193122864 - Test Loss: 0.5545536279678345\nEpoch: 677 - Train Loss: 0.5382488369941711 - Test Loss: 0.5527649521827698\nEpoch: 678 - Train Loss: 0.5364323258399963 - Test Loss: 0.5509659051895142\nEpoch: 679 - Train Loss: 0.5346053838729858 - Test Loss: 0.5491566061973572\nEpoch: 680 - Train Loss: 0.5327679514884949 - Test Loss: 0.547336995601654\nEpoch: 681 - Train Loss: 0.5309203863143921 - Test Loss: 0.545507550239563\nEpoch: 682 - Train Loss: 0.529062807559967 - Test Loss: 0.543668270111084\nEpoch: 683 - Train Loss: 0.5271952748298645 - Test Loss: 0.5418193340301514\nEpoch: 684 - Train Loss: 0.5253179669380188 - Test Loss: 0.5399608016014099\nEpoch: 685 - Train Loss: 0.5234312415122986 - Test Loss: 0.5380930304527283\nEpoch: 686 - Train Loss: 0.5215350985527039 - Test Loss: 0.5362160801887512\nEpoch: 687 - Train Loss: 0.519629716873169 - Test Loss: 0.5343301892280579\nEpoch: 688 - Train Loss: 0.5177152752876282 - Test Loss: 0.5324352979660034\nEpoch: 689 - Train Loss: 0.5157918930053711 - Test Loss: 0.5305318236351013\nEpoch: 690 - Train Loss: 0.5138598680496216 - Test Loss: 0.5286197662353516\nEpoch: 691 - Train Loss: 0.511919379234314 - Test Loss: 0.5266994833946228\nEpoch: 692 - Train Loss: 0.509970486164093 - Test Loss: 0.5247709155082703\nEpoch: 693 - Train Loss: 0.5080134868621826 - Test Loss: 0.5228345394134521\nEpoch: 694 - Train Loss: 0.5060484409332275 - Test Loss: 0.5208902359008789\nEpoch: 695 - Train Loss: 0.5040756464004517 - Test Loss: 0.5189383029937744\nEpoch: 696 - Train Loss: 0.502095103263855 - Test Loss: 0.5169788002967834\nEpoch: 697 - Train Loss: 0.5001071095466614 - Test Loss: 0.5150120258331299\nEpoch: 698 - Train Loss: 0.49811187386512756 - Test Loss: 0.5130382180213928\nEpoch: 699 - Train Loss: 0.4961094260215759 - Test Loss: 0.5110573172569275\nEpoch: 700 - Train Loss: 0.49410003423690796 - Test Loss: 0.5090696215629578\nEpoch: 701 - Train Loss: 0.49208393692970276 - Test Loss: 0.507075309753418\nEpoch: 702 - Train Loss: 0.4900612533092499 - Test Loss: 0.505074679851532\nEpoch: 703 - Train Loss: 0.48803219199180603 - Test Loss: 0.5030676126480103\nEpoch: 704 - Train Loss: 0.48599687218666077 - Test Loss: 0.501054584980011\nEpoch: 705 - Train Loss: 0.4839556813240051 - Test Loss: 0.4990357458591461\nEpoch: 706 - Train Loss: 0.4819086790084839 - Test Loss: 0.4970111548900604\nEpoch: 707 - Train Loss: 0.47985589504241943 - Test Loss: 0.49498093128204346\nEpoch: 708 - Train Loss: 0.4777977466583252 - Test Loss: 0.49294552206993103\nEpoch: 709 - Train Loss: 0.47573426365852356 - Test Loss: 0.4909048080444336\nEpoch: 710 - Train Loss: 0.47366568446159363 - Test Loss: 0.48885905742645264\nEpoch: 711 - Train Loss: 0.4715922176837921 - Test Loss: 0.48680856823921204\nEpoch: 712 - Train Loss: 0.4695141017436981 - Test Loss: 0.4847535192966461\nEpoch: 713 - Train Loss: 0.46743133664131165 - Test Loss: 0.4826938211917877\nEpoch: 714 - Train Loss: 0.46534425020217896 - Test Loss: 0.48062998056411743\nEpoch: 715 - Train Loss: 0.46325305104255676 - Test Loss: 0.47856205701828003\nEpoch: 716 - Train Loss: 0.46115797758102417 - Test Loss: 0.4764902591705322\nEpoch: 717 - Train Loss: 0.45905888080596924 - Test Loss: 0.4744146168231964\nEpoch: 718 - Train Loss: 0.45695623755455017 - Test Loss: 0.4723353981971741\nEpoch: 719 - Train Loss: 0.45485013723373413 - Test Loss: 0.4702528119087219\nEpoch: 720 - Train Loss: 0.4527408480644226 - Test Loss: 0.4681670069694519\nEpoch: 721 - Train Loss: 0.45062848925590515 - Test Loss: 0.4660781919956207\nEpoch: 722 - Train Loss: 0.44851335883140564 - Test Loss: 0.4639867842197418\nEpoch: 723 - Train Loss: 0.44639554619789124 - Test Loss: 0.46189260482788086\nEpoch: 724 - Train Loss: 0.44427525997161865 - Test Loss: 0.45979592204093933\nEpoch: 725 - Train Loss: 0.44215261936187744 - Test Loss: 0.45769694447517395\nEpoch: 726 - Train Loss: 0.4400279223918915 - Test Loss: 0.4555959403514862\nEpoch: 727 - Train Loss: 0.43790119886398315 - Test Loss: 0.4534929394721985\nEpoch: 728 - Train Loss: 0.43577277660369873 - Test Loss: 0.4513881802558899\nEpoch: 729 - Train Loss: 0.43364277482032776 - Test Loss: 0.44928184151649475\nEpoch: 730 - Train Loss: 0.4315113127231598 - Test Loss: 0.4471741020679474\nEpoch: 731 - Train Loss: 0.4293787479400635 - Test Loss: 0.4450652003288269\nEpoch: 732 - Train Loss: 0.42724522948265076 - Test Loss: 0.44295534491539\nEpoch: 733 - Train Loss: 0.42511072754859924 - Test Loss: 0.44084447622299194\nEpoch: 734 - Train Loss: 0.4229755997657776 - Test Loss: 0.4387330114841461\nEpoch: 735 - Train Loss: 0.42084014415740967 - Test Loss: 0.4366210699081421\nEpoch: 736 - Train Loss: 0.41870418190956116 - Test Loss: 0.43450862169265747\nEpoch: 737 - Train Loss: 0.4165681302547455 - Test Loss: 0.4323960542678833\nEpoch: 738 - Train Loss: 0.41443219780921936 - Test Loss: 0.4302836060523987\nEpoch: 739 - Train Loss: 0.41229644417762756 - Test Loss: 0.4281712472438812\nEpoch: 740 - Train Loss: 0.41016116738319397 - Test Loss: 0.4260592460632324\nEpoch: 741 - Train Loss: 0.40802642703056335 - Test Loss: 0.423947811126709\nEpoch: 742 - Train Loss: 0.40589240193367004 - Test Loss: 0.4218370318412781\nEpoch: 743 - Train Loss: 0.4037593901157379 - Test Loss: 0.4197271168231964\nEpoch: 744 - Train Loss: 0.40162742137908936 - Test Loss: 0.4176182746887207\nEpoch: 745 - Train Loss: 0.39949673414230347 - Test Loss: 0.41551053524017334\nEpoch: 746 - Train Loss: 0.3973674774169922 - Test Loss: 0.4134041666984558\nEpoch: 747 - Train Loss: 0.39523983001708984 - Test Loss: 0.41129928827285767\nEpoch: 748 - Train Loss: 0.39311400055885315 - Test Loss: 0.4091961979866028\nEpoch: 749 - Train Loss: 0.3909900486469269 - Test Loss: 0.4070948660373688\nEpoch: 750 - Train Loss: 0.3888682425022125 - Test Loss: 0.4049955904483795\nEpoch: 751 - Train Loss: 0.38674861192703247 - Test Loss: 0.4028984308242798\nEpoch: 752 - Train Loss: 0.38463157415390015 - Test Loss: 0.40080365538597107\nEpoch: 753 - Train Loss: 0.3825170397758484 - Test Loss: 0.39871129393577576\nEpoch: 754 - Train Loss: 0.3804052174091339 - Test Loss: 0.39662161469459534\nEpoch: 755 - Train Loss: 0.3782964050769806 - Test Loss: 0.39453473687171936\nEpoch: 756 - Train Loss: 0.37619057297706604 - Test Loss: 0.39245080947875977\nEpoch: 757 - Train Loss: 0.3740880787372589 - Test Loss: 0.3903699815273285\nEpoch: 758 - Train Loss: 0.37198886275291443 - Test Loss: 0.3882923126220703\nEpoch: 759 - Train Loss: 0.36989328265190125 - Test Loss: 0.3862181603908539\nEpoch: 760 - Train Loss: 0.367801308631897 - Test Loss: 0.3841475248336792\nEpoch: 761 - Train Loss: 0.3657131791114807 - Test Loss: 0.3820805847644806\nEpoch: 762 - Train Loss: 0.36362898349761963 - Test Loss: 0.3800174295902252\nEpoch: 763 - Train Loss: 0.3615490198135376 - Test Loss: 0.3779582977294922\nEpoch: 764 - Train Loss: 0.35947319865226746 - Test Loss: 0.3759032189846039\nEpoch: 765 - Train Loss: 0.35740190744400024 - Test Loss: 0.37385252118110657\nEpoch: 766 - Train Loss: 0.3553350269794464 - Test Loss: 0.3718060255050659\nEpoch: 767 - Train Loss: 0.3532729148864746 - Test Loss: 0.36976414918899536\nEpoch: 768 - Train Loss: 0.3512157201766968 - Test Loss: 0.3677270710468292\nEpoch: 769 - Train Loss: 0.3491634130477905 - Test Loss: 0.36569464206695557\nEpoch: 770 - Train Loss: 0.34711623191833496 - Test Loss: 0.3636672794818878\nEpoch: 771 - Train Loss: 0.34507429599761963 - Test Loss: 0.3616449236869812\nEpoch: 772 - Train Loss: 0.3430376946926117 - Test Loss: 0.35962772369384766\nEpoch: 773 - Train Loss: 0.34100663661956787 - Test Loss: 0.3576158881187439\nEpoch: 774 - Train Loss: 0.3389812409877777 - Test Loss: 0.35560959577560425\nEpoch: 775 - Train Loss: 0.3369615375995636 - Test Loss: 0.35360872745513916\nEpoch: 776 - Train Loss: 0.33494776487350464 - Test Loss: 0.3516136407852173\nEpoch: 777 - Train Loss: 0.3329399824142456 - Test Loss: 0.3496243953704834\nEpoch: 778 - Train Loss: 0.33093830943107605 - Test Loss: 0.3476410210132599\nEpoch: 779 - Train Loss: 0.3289428949356079 - Test Loss: 0.34566372632980347\nEpoch: 780 - Train Loss: 0.32695382833480835 - Test Loss: 0.3436926305294037\nEpoch: 781 - Train Loss: 0.3249712288379669 - Test Loss: 0.34172776341438293\nEpoch: 782 - Train Loss: 0.32299521565437317 - Test Loss: 0.33976930379867554\nEpoch: 783 - Train Loss: 0.32102593779563904 - Test Loss: 0.33781740069389343\nEpoch: 784 - Train Loss: 0.3190634548664093 - Test Loss: 0.33587202429771423\nEpoch: 785 - Train Loss: 0.3171078860759735 - Test Loss: 0.3339334726333618\nEpoch: 786 - Train Loss: 0.315159410238266 - Test Loss: 0.3320017457008362\nEpoch: 787 - Train Loss: 0.31321796774864197 - Test Loss: 0.3300769031047821\nEpoch: 788 - Train Loss: 0.31128382682800293 - Test Loss: 0.32815903425216675\nEpoch: 789 - Train Loss: 0.30935704708099365 - Test Loss: 0.3262484669685364\nEpoch: 790 - Train Loss: 0.30743759870529175 - Test Loss: 0.3243449330329895\nEpoch: 791 - Train Loss: 0.3055257797241211 - Test Loss: 0.3224489092826843\nEpoch: 792 - Train Loss: 0.30362164974212646 - Test Loss: 0.3205602467060089\nEpoch: 793 - Train Loss: 0.3017251193523407 - Test Loss: 0.3186790645122528\nEpoch: 794 - Train Loss: 0.29983648657798767 - Test Loss: 0.31680554151535034\nEpoch: 795 - Train Loss: 0.2979556620121002 - Test Loss: 0.31493961811065674\nEpoch: 796 - Train Loss: 0.29608291387557983 - Test Loss: 0.3130815327167511\nEpoch: 797 - Train Loss: 0.2942183017730713 - Test Loss: 0.311231404542923\nEpoch: 798 - Train Loss: 0.2923617660999298 - Test Loss: 0.3093891739845276\nEpoch: 799 - Train Loss: 0.2905135452747345 - Test Loss: 0.3075549900531769\nEpoch: 800 - Train Loss: 0.2886735498905182 - Test Loss: 0.30572885274887085\nEpoch: 801 - Train Loss: 0.2868420481681824 - Test Loss: 0.30391091108322144\nEpoch: 802 - Train Loss: 0.28501901030540466 - Test Loss: 0.3021013140678406\nEpoch: 803 - Train Loss: 0.28320443630218506 - Test Loss: 0.3003000020980835\nEpoch: 804 - Train Loss: 0.28139856457710266 - Test Loss: 0.2985071539878845\nEpoch: 805 - Train Loss: 0.2796013653278351 - Test Loss: 0.2967226207256317\nEpoch: 806 - Train Loss: 0.2778129279613495 - Test Loss: 0.29494670033454895\nEpoch: 807 - Train Loss: 0.27603334188461304 - Test Loss: 0.29317954182624817\nEpoch: 808 - Train Loss: 0.2742626368999481 - Test Loss: 0.2914210557937622\nEpoch: 809 - Train Loss: 0.2725008726119995 - Test Loss: 0.2896711528301239\nEpoch: 810 - Train Loss: 0.27074819803237915 - Test Loss: 0.28793013095855713\nEpoch: 811 - Train Loss: 0.26900461316108704 - Test Loss: 0.28619810938835144\nEpoch: 812 - Train Loss: 0.26727011799812317 - Test Loss: 0.2844749689102173\nEpoch: 813 - Train Loss: 0.2655448615550995 - Test Loss: 0.28276076912879944\nEpoch: 814 - Train Loss: 0.2638288140296936 - Test Loss: 0.28105559945106506\nEpoch: 815 - Train Loss: 0.2621220648288727 - Test Loss: 0.2793594300746918\nEpoch: 816 - Train Loss: 0.26042473316192627 - Test Loss: 0.2776726186275482\nEpoch: 817 - Train Loss: 0.2587367594242096 - Test Loss: 0.2759949266910553\nEpoch: 818 - Train Loss: 0.2570582926273346 - Test Loss: 0.2743264436721802\nEpoch: 819 - Train Loss: 0.2553893029689789 - Test Loss: 0.2726672291755676\nEpoch: 820 - Train Loss: 0.25372985005378723 - Test Loss: 0.27101749181747437\nEpoch: 821 - Train Loss: 0.2520800232887268 - Test Loss: 0.26937711238861084\nEpoch: 822 - Train Loss: 0.2504397928714752 - Test Loss: 0.26774609088897705\nEpoch: 823 - Train Loss: 0.24880924820899963 - Test Loss: 0.26612451672554016\nEpoch: 824 - Train Loss: 0.24718840420246124 - Test Loss: 0.2645125091075897\nEpoch: 825 - Train Loss: 0.24557726085186005 - Test Loss: 0.26291000843048096\nEpoch: 826 - Train Loss: 0.24397598206996918 - Test Loss: 0.2613171637058258\nEpoch: 827 - Train Loss: 0.24238437414169312 - Test Loss: 0.25973382592201233\nEpoch: 828 - Train Loss: 0.24080276489257812 - Test Loss: 0.25816020369529724\nEpoch: 829 - Train Loss: 0.2392309606075287 - Test Loss: 0.25659623742103577\nEpoch: 830 - Train Loss: 0.23766911029815674 - Test Loss: 0.25504207611083984\nEpoch: 831 - Train Loss: 0.2361171543598175 - Test Loss: 0.25349757075309753\nEpoch: 832 - Train Loss: 0.23457515239715576 - Test Loss: 0.251962810754776\nEpoch: 833 - Train Loss: 0.23304308950901031 - Test Loss: 0.25043785572052\nEpoch: 834 - Train Loss: 0.2315211147069931 - Test Loss: 0.24892276525497437\nEpoch: 835 - Train Loss: 0.23000913858413696 - Test Loss: 0.24741753935813904\nEpoch: 836 - Train Loss: 0.22850728034973145 - Test Loss: 0.24592219293117523\nEpoch: 837 - Train Loss: 0.22701546549797058 - Test Loss: 0.24443672597408295\nEpoch: 838 - Train Loss: 0.22553370893001556 - Test Loss: 0.242961123585701\nEpoch: 839 - Train Loss: 0.2240619957447052 - Test Loss: 0.24149543046951294\nEpoch: 840 - Train Loss: 0.22260044515132904 - Test Loss: 0.24003972113132477\nEpoch: 841 - Train Loss: 0.22114905714988708 - Test Loss: 0.2385939061641693\nEpoch: 842 - Train Loss: 0.21970775723457336 - Test Loss: 0.23715811967849731\nEpoch: 843 - Train Loss: 0.21827664971351624 - Test Loss: 0.2357323169708252\nEpoch: 844 - Train Loss: 0.2168557345867157 - Test Loss: 0.23431655764579773\nEpoch: 845 - Train Loss: 0.21544502675533295 - Test Loss: 0.23291082680225372\nEpoch: 846 - Train Loss: 0.21404443681240082 - Test Loss: 0.23151499032974243\nEpoch: 847 - Train Loss: 0.21265409886837006 - Test Loss: 0.23012931644916534\nEpoch: 848 - Train Loss: 0.21127401292324066 - Test Loss: 0.2287537306547165\nEpoch: 849 - Train Loss: 0.20990407466888428 - Test Loss: 0.22738811373710632\nEpoch: 850 - Train Loss: 0.20854443311691284 - Test Loss: 0.22603259980678558\nEpoch: 851 - Train Loss: 0.20719492435455322 - Test Loss: 0.22468708455562592\nEpoch: 852 - Train Loss: 0.20585574209690094 - Test Loss: 0.22335180640220642\nEpoch: 853 - Train Loss: 0.20452673733234406 - Test Loss: 0.22202648222446442\nEpoch: 854 - Train Loss: 0.20320796966552734 - Test Loss: 0.22071126103401184\nEpoch: 855 - Train Loss: 0.20189915597438812 - Test Loss: 0.2194058746099472\nEpoch: 856 - Train Loss: 0.20060096681118011 - Test Loss: 0.21811078488826752\nEpoch: 857 - Train Loss: 0.1993122398853302 - Test Loss: 0.21682536602020264\nEpoch: 858 - Train Loss: 0.19803394377231598 - Test Loss: 0.2155500203371048\nEpoch: 859 - Train Loss: 0.19676701724529266 - Test Loss: 0.2142856866121292\nEpoch: 860 - Train Loss: 0.195510134100914 - Test Loss: 0.21303144097328186\nEpoch: 861 - Train Loss: 0.19426491856575012 - Test Loss: 0.21178855001926422\nEpoch: 862 - Train Loss: 0.19303052127361298 - Test Loss: 0.21055656671524048\nEpoch: 863 - Train Loss: 0.1918075680732727 - Test Loss: 0.20933577418327332\nEpoch: 864 - Train Loss: 0.19059565663337708 - Test Loss: 0.20812588930130005\nEpoch: 865 - Train Loss: 0.18939493596553802 - Test Loss: 0.20692704617977142\nEpoch: 866 - Train Loss: 0.18820519745349884 - Test Loss: 0.2057390809059143\nEpoch: 867 - Train Loss: 0.1870262622833252 - Test Loss: 0.20456181466579437\nEpoch: 868 - Train Loss: 0.1858581006526947 - Test Loss: 0.20339523255825043\nEpoch: 869 - Train Loss: 0.18470045924186707 - Test Loss: 0.20223906636238098\nEpoch: 870 - Train Loss: 0.18355320394039154 - Test Loss: 0.20109319686889648\nEpoch: 871 - Train Loss: 0.182416170835495 - Test Loss: 0.199957475066185\nEpoch: 872 - Train Loss: 0.18128927052021027 - Test Loss: 0.1988317370414734\nEpoch: 873 - Train Loss: 0.18017227947711945 - Test Loss: 0.19771592319011688\nEpoch: 874 - Train Loss: 0.17906509339809418 - Test Loss: 0.19660978019237518\nEpoch: 875 - Train Loss: 0.17796772718429565 - Test Loss: 0.19551332294940948\nEpoch: 876 - Train Loss: 0.17687994241714478 - Test Loss: 0.19442638754844666\nEpoch: 877 - Train Loss: 0.17580178380012512 - Test Loss: 0.1933489441871643\nEpoch: 878 - Train Loss: 0.1747330278158188 - Test Loss: 0.1922808438539505\nEpoch: 879 - Train Loss: 0.17367370426654816 - Test Loss: 0.19122202694416046\nEpoch: 880 - Train Loss: 0.1726236343383789 - Test Loss: 0.19017238914966583\nEpoch: 881 - Train Loss: 0.17158280313014984 - Test Loss: 0.18913191556930542\nEpoch: 882 - Train Loss: 0.17055098712444305 - Test Loss: 0.1881004124879837\nEpoch: 883 - Train Loss: 0.16952820122241974 - Test Loss: 0.1870778203010559\nEpoch: 884 - Train Loss: 0.16851429641246796 - Test Loss: 0.18606403470039368\nEpoch: 885 - Train Loss: 0.16750922799110413 - Test Loss: 0.18505901098251343\nEpoch: 886 - Train Loss: 0.16651281714439392 - Test Loss: 0.18406257033348083\nEpoch: 887 - Train Loss: 0.16552500426769257 - Test Loss: 0.18307463824748993\nEpoch: 888 - Train Loss: 0.1645456999540329 - Test Loss: 0.18209517002105713\nEpoch: 889 - Train Loss: 0.16357485949993134 - Test Loss: 0.18112404644489288\nEpoch: 890 - Train Loss: 0.16261228919029236 - Test Loss: 0.18016113340854645\nEpoch: 891 - Train Loss: 0.16165798902511597 - Test Loss: 0.17920641601085663\nEpoch: 892 - Train Loss: 0.16071180999279022 - Test Loss: 0.1782597452402115\nEpoch: 893 - Train Loss: 0.15977375209331512 - Test Loss: 0.1773211508989334\nEpoch: 894 - Train Loss: 0.15884365141391754 - Test Loss: 0.17639043927192688\nEpoch: 895 - Train Loss: 0.1579214632511139 - Test Loss: 0.17546755075454712\nEpoch: 896 - Train Loss: 0.15700706839561462 - Test Loss: 0.17455241084098816\nEpoch: 897 - Train Loss: 0.15610043704509735 - Test Loss: 0.17364494502544403\nEpoch: 898 - Train Loss: 0.15520144999027252 - Test Loss: 0.17274507880210876\nEpoch: 899 - Train Loss: 0.15431000292301178 - Test Loss: 0.1718526929616928\nEpoch: 900 - Train Loss: 0.15342606604099274 - Test Loss: 0.17096774280071259\nEpoch: 901 - Train Loss: 0.15254950523376465 - Test Loss: 0.17009010910987854\nEpoch: 902 - Train Loss: 0.15168027579784393 - Test Loss: 0.1692197471857071\nEpoch: 903 - Train Loss: 0.15081825852394104 - Test Loss: 0.16835655272006989\nEpoch: 904 - Train Loss: 0.14996343851089478 - Test Loss: 0.16750049591064453\nEpoch: 905 - Train Loss: 0.14911572635173798 - Test Loss: 0.16665145754814148\nEpoch: 906 - Train Loss: 0.14827503263950348 - Test Loss: 0.16580939292907715\nEpoch: 907 - Train Loss: 0.1474413275718689 - Test Loss: 0.16497430205345154\nEpoch: 908 - Train Loss: 0.1466144323348999 - Test Loss: 0.16414594650268555\nEpoch: 909 - Train Loss: 0.14579439163208008 - Test Loss: 0.16332437098026276\nEpoch: 910 - Train Loss: 0.14498107135295868 - Test Loss: 0.162509486079216\nEpoch: 911 - Train Loss: 0.14417444169521332 - Test Loss: 0.1617012470960617\nEpoch: 912 - Train Loss: 0.14337439835071564 - Test Loss: 0.16089951992034912\nEpoch: 913 - Train Loss: 0.14258088171482086 - Test Loss: 0.16010427474975586\nEpoch: 914 - Train Loss: 0.14179378747940063 - Test Loss: 0.15931545197963715\nEpoch: 915 - Train Loss: 0.14101311564445496 - Test Loss: 0.15853296220302582\nEpoch: 916 - Train Loss: 0.14023873209953308 - Test Loss: 0.15775670111179352\nEpoch: 917 - Train Loss: 0.13947060704231262 - Test Loss: 0.15698666870594025\nEpoch: 918 - Train Loss: 0.13870865106582642 - Test Loss: 0.15622279047966003\nEpoch: 919 - Train Loss: 0.13795283436775208 - Test Loss: 0.15546496212482452\nEpoch: 920 - Train Loss: 0.13720309734344482 - Test Loss: 0.15471318364143372\nEpoch: 921 - Train Loss: 0.1364593356847763 - Test Loss: 0.15396733582019806\nEpoch: 922 - Train Loss: 0.13572145998477936 - Test Loss: 0.15322737395763397\nEpoch: 923 - Train Loss: 0.13498952984809875 - Test Loss: 0.15249326825141907\nEpoch: 924 - Train Loss: 0.13426338136196136 - Test Loss: 0.1517648994922638\nEpoch: 925 - Train Loss: 0.1335429847240448 - Test Loss: 0.15104226768016815\nEpoch: 926 - Train Loss: 0.13282832503318787 - Test Loss: 0.15032534301280975\nEpoch: 927 - Train Loss: 0.13211922347545624 - Test Loss: 0.14961394667625427\nEpoch: 928 - Train Loss: 0.13141576945781708 - Test Loss: 0.1489081084728241\nEpoch: 929 - Train Loss: 0.13071778416633606 - Test Loss: 0.14820776879787445\nEpoch: 930 - Train Loss: 0.13002526760101318 - Test Loss: 0.14751280844211578\nEpoch: 931 - Train Loss: 0.12933816015720367 - Test Loss: 0.14682325720787048\nEpoch: 932 - Train Loss: 0.12865643203258514 - Test Loss: 0.14613904058933258\nEpoch: 933 - Train Loss: 0.12797997891902924 - Test Loss: 0.14546003937721252\nEpoch: 934 - Train Loss: 0.12730878591537476 - Test Loss: 0.1447863131761551\nEpoch: 935 - Train Loss: 0.12664273381233215 - Test Loss: 0.14411768317222595\nEpoch: 936 - Train Loss: 0.12598183751106262 - Test Loss: 0.1434541493654251\nEpoch: 937 - Train Loss: 0.1253260374069214 - Test Loss: 0.14279568195343018\nEpoch: 938 - Train Loss: 0.1246752068400383 - Test Loss: 0.142142191529274\nEpoch: 939 - Train Loss: 0.12402942031621933 - Test Loss: 0.14149369299411774\nEpoch: 940 - Train Loss: 0.12338852882385254 - Test Loss: 0.14085006713867188\nEpoch: 941 - Train Loss: 0.12275252491235733 - Test Loss: 0.140211284160614\nEpoch: 942 - Train Loss: 0.12212136387825012 - Test Loss: 0.13957732915878296\nEpoch: 943 - Train Loss: 0.12149496376514435 - Test Loss: 0.13894811272621155\nEpoch: 944 - Train Loss: 0.12087330222129822 - Test Loss: 0.1383236050605774\nEpoch: 945 - Train Loss: 0.12025630474090576 - Test Loss: 0.13770373165607452\nEpoch: 946 - Train Loss: 0.1196439266204834 - Test Loss: 0.13708847761154175\nEpoch: 947 - Train Loss: 0.11903614550828934 - Test Loss: 0.1364777535200119\nEpoch: 948 - Train Loss: 0.11843295395374298 - Test Loss: 0.13587161898612976\nEpoch: 949 - Train Loss: 0.11783420294523239 - Test Loss: 0.1352698802947998\nEpoch: 950 - Train Loss: 0.11723994463682175 - Test Loss: 0.1346726268529892\nEpoch: 951 - Train Loss: 0.11665008217096329 - Test Loss: 0.13407975435256958\nEpoch: 952 - Train Loss: 0.11606454849243164 - Test Loss: 0.1334911584854126\nEpoch: 953 - Train Loss: 0.11548332870006561 - Test Loss: 0.13290686905384064\nEpoch: 954 - Train Loss: 0.11490638554096222 - Test Loss: 0.1323268562555313\nEpoch: 955 - Train Loss: 0.11433367431163788 - Test Loss: 0.13175104558467865\nEpoch: 956 - Train Loss: 0.11376514285802841 - Test Loss: 0.13117936253547668\nEpoch: 957 - Train Loss: 0.11320076882839203 - Test Loss: 0.130611851811409\nEpoch: 958 - Train Loss: 0.11264052987098694 - Test Loss: 0.13004843890666962\nEpoch: 959 - Train Loss: 0.11208437383174896 - Test Loss: 0.12948909401893616\nEpoch: 960 - Train Loss: 0.11153217405080795 - Test Loss: 0.12893369793891907\nEpoch: 961 - Train Loss: 0.11098401993513107 - Test Loss: 0.12838232517242432\nEpoch: 962 - Train Loss: 0.11043976992368698 - Test Loss: 0.12783482670783997\nEpoch: 963 - Train Loss: 0.10989944636821747 - Test Loss: 0.1272912472486496\nEpoch: 964 - Train Loss: 0.10936300456523895 - Test Loss: 0.12675152719020844\nEpoch: 965 - Train Loss: 0.10883037745952606 - Test Loss: 0.1262156069278717\nEpoch: 966 - Train Loss: 0.1083015501499176 - Test Loss: 0.1256834715604782\nEpoch: 967 - Train Loss: 0.1077764630317688 - Test Loss: 0.12515504658222198\nEpoch: 968 - Train Loss: 0.10725510120391846 - Test Loss: 0.12463035434484482\nEpoch: 969 - Train Loss: 0.1067374050617218 - Test Loss: 0.12410929054021835\nEpoch: 970 - Train Loss: 0.10622338205575943 - Test Loss: 0.12359190732240677\nEpoch: 971 - Train Loss: 0.10571293532848358 - Test Loss: 0.12307805567979813\nEpoch: 972 - Train Loss: 0.10520608723163605 - Test Loss: 0.12256781756877899\nEpoch: 973 - Train Loss: 0.10470277816057205 - Test Loss: 0.12206108868122101\nEpoch: 974 - Train Loss: 0.10420295596122742 - Test Loss: 0.12155784666538239\nEpoch: 975 - Train Loss: 0.10370665043592453 - Test Loss: 0.12105809897184372\nEpoch: 976 - Train Loss: 0.10321374237537384 - Test Loss: 0.12056174129247665\nEpoch: 977 - Train Loss: 0.10272426903247833 - Test Loss: 0.12006878107786179\nEpoch: 978 - Train Loss: 0.10223811864852905 - Test Loss: 0.11957915127277374\nEpoch: 979 - Train Loss: 0.10175532102584839 - Test Loss: 0.11909285932779312\nEpoch: 980 - Train Loss: 0.10127582401037216 - Test Loss: 0.11860985308885574\nEpoch: 981 - Train Loss: 0.10079962760210037 - Test Loss: 0.1181301400065422\nEpoch: 982 - Train Loss: 0.10032663494348526 - Test Loss: 0.11765363812446594\nEpoch: 983 - Train Loss: 0.099856898188591 - Test Loss: 0.11718035489320755\nEpoch: 984 - Train Loss: 0.09939032793045044 - Test Loss: 0.11671023815870285\nEpoch: 985 - Train Loss: 0.09892692416906357 - Test Loss: 0.11624325811862946\nEpoch: 986 - Train Loss: 0.09846661984920502 - Test Loss: 0.11577940732240677\nEpoch: 987 - Train Loss: 0.09800942242145538 - Test Loss: 0.11531861871480942\nEpoch: 988 - Train Loss: 0.09755527973175049 - Test Loss: 0.1148608922958374\nEpoch: 989 - Train Loss: 0.09710415452718735 - Test Loss: 0.11440616101026535\nEpoch: 990 - Train Loss: 0.09665605425834656 - Test Loss: 0.11395446211099625\nEpoch: 991 - Train Loss: 0.09621092677116394 - Test Loss: 0.11350570619106293\nEpoch: 992 - Train Loss: 0.09576874226331711 - Test Loss: 0.1130598932504654\nEpoch: 993 - Train Loss: 0.09532947838306427 - Test Loss: 0.11261700838804245\nEpoch: 994 - Train Loss: 0.09489309787750244 - Test Loss: 0.11217697709798813\nEpoch: 995 - Train Loss: 0.09445958584547043 - Test Loss: 0.11173982918262482\nEpoch: 996 - Train Loss: 0.09402891993522644 - Test Loss: 0.11130549013614655\nEpoch: 997 - Train Loss: 0.0936010479927063 - Test Loss: 0.11087395995855331\nEpoch: 998 - Train Loss: 0.09317599982023239 - Test Loss: 0.11044523119926453\nEpoch: 999 - Train Loss: 0.09275365620851517 - Test Loss: 0.11001922190189362\nEpoch: 1000 - Train Loss: 0.09233409911394119 - Test Loss: 0.10959596931934357\nEpoch: 1001 - Train Loss: 0.0919172465801239 - Test Loss: 0.10917540639638901\nEpoch: 1002 - Train Loss: 0.09150303900241852 - Test Loss: 0.10875753313302994\nEpoch: 1003 - Train Loss: 0.09109149128198624 - Test Loss: 0.10834226757287979\nEpoch: 1004 - Train Loss: 0.09068258851766586 - Test Loss: 0.10792965441942215\nEpoch: 1005 - Train Loss: 0.09027627855539322 - Test Loss: 0.10751963406801224\nEpoch: 1006 - Train Loss: 0.0898725762963295 - Test Loss: 0.10711219906806946\nEpoch: 1007 - Train Loss: 0.08947142958641052 - Test Loss: 0.10670731216669083\nEpoch: 1008 - Train Loss: 0.0890728011727333 - Test Loss: 0.10630496591329575\nEpoch: 1009 - Train Loss: 0.08867674320936203 - Test Loss: 0.10590516030788422\nEpoch: 1010 - Train Loss: 0.08828313648700714 - Test Loss: 0.10550781339406967\nEpoch: 1011 - Train Loss: 0.08789204061031342 - Test Loss: 0.1051129475235939\nEpoch: 1012 - Train Loss: 0.08750332146883011 - Test Loss: 0.10472049564123154\nEpoch: 1013 - Train Loss: 0.08711704611778259 - Test Loss: 0.10433045029640198\nEpoch: 1014 - Train Loss: 0.08673319220542908 - Test Loss: 0.10394283384084702\nEpoch: 1015 - Train Loss: 0.08635172247886658 - Test Loss: 0.10355760902166367\nEpoch: 1016 - Train Loss: 0.08597259968519211 - Test Loss: 0.10317470133304596\nEpoch: 1017 - Train Loss: 0.08559582382440567 - Test Loss: 0.10279414802789688\nEpoch: 1018 - Train Loss: 0.08522133529186249 - Test Loss: 0.10241588205099106\nEpoch: 1019 - Train Loss: 0.08484915643930435 - Test Loss: 0.10203992575407028\nEpoch: 1020 - Train Loss: 0.08447927981615067 - Test Loss: 0.10166626423597336\nEpoch: 1021 - Train Loss: 0.08411160856485367 - Test Loss: 0.10129479318857193\nEpoch: 1022 - Train Loss: 0.08374617248773575 - Test Loss: 0.10092557966709137\nEpoch: 1023 - Train Loss: 0.0833829939365387 - Test Loss: 0.10055858641862869\nEpoch: 1024 - Train Loss: 0.08302199840545654 - Test Loss: 0.1001937985420227\nEpoch: 1025 - Train Loss: 0.0826631560921669 - Test Loss: 0.09983114898204803\nEpoch: 1026 - Train Loss: 0.08230649679899216 - Test Loss: 0.09947068244218826\nEpoch: 1027 - Train Loss: 0.08195196092128754 - Test Loss: 0.09911234676837921\nEpoch: 1028 - Train Loss: 0.08159954100847244 - Test Loss: 0.09875611960887909\nEpoch: 1029 - Train Loss: 0.08124922215938568 - Test Loss: 0.0984019786119461\nEpoch: 1030 - Train Loss: 0.08090096712112427 - Test Loss: 0.09804990887641907\nEpoch: 1031 - Train Loss: 0.0805547833442688 - Test Loss: 0.09769990295171738\nEpoch: 1032 - Train Loss: 0.08021067827939987 - Test Loss: 0.09735198318958282\nEpoch: 1033 - Train Loss: 0.07986856997013092 - Test Loss: 0.09700603783130646\nEpoch: 1034 - Train Loss: 0.07952846586704254 - Test Loss: 0.09666211903095245\nEpoch: 1035 - Train Loss: 0.07919035851955414 - Test Loss: 0.09632018208503723\nEpoch: 1036 - Train Loss: 0.07885423302650452 - Test Loss: 0.09598023444414139\nEpoch: 1037 - Train Loss: 0.0785200372338295 - Test Loss: 0.09564220905303955\nEpoch: 1038 - Train Loss: 0.07818779349327087 - Test Loss: 0.09530612826347351\nEpoch: 1039 - Train Loss: 0.07785750925540924 - Test Loss: 0.09497200697660446\nEpoch: 1040 - Train Loss: 0.07752909511327744 - Test Loss: 0.09463976323604584\nEpoch: 1041 - Train Loss: 0.07720258831977844 - Test Loss: 0.09430942684412003\nEpoch: 1042 - Train Loss: 0.07687793672084808 - Test Loss: 0.09398093074560165\nEpoch: 1043 - Train Loss: 0.07655516266822815 - Test Loss: 0.0936543196439743\nEpoch: 1044 - Train Loss: 0.07623421400785446 - Test Loss: 0.093329519033432\nEpoch: 1045 - Train Loss: 0.07591510564088821 - Test Loss: 0.09300658851861954\nEpoch: 1046 - Train Loss: 0.07559780031442642 - Test Loss: 0.09268543124198914\nEpoch: 1047 - Train Loss: 0.07528230547904968 - Test Loss: 0.09236610680818558\nEpoch: 1048 - Train Loss: 0.07496859133243561 - Test Loss: 0.0920485407114029\nEpoch: 1049 - Train Loss: 0.0746566504240036 - Test Loss: 0.09173274785280228\nEpoch: 1050 - Train Loss: 0.07434644550085068 - Test Loss: 0.09141869843006134\nEpoch: 1051 - Train Loss: 0.07403796911239624 - Test Loss: 0.09110637754201889\nEpoch: 1052 - Train Loss: 0.07373122125864029 - Test Loss: 0.09079579263925552\nEpoch: 1053 - Train Loss: 0.07342617958784103 - Test Loss: 0.09048691391944885\nEpoch: 1054 - Train Loss: 0.07312285155057907 - Test Loss: 0.09017972648143768\nEpoch: 1055 - Train Loss: 0.07282119244337082 - Test Loss: 0.08987422287464142\nEpoch: 1056 - Train Loss: 0.07252119481563568 - Test Loss: 0.08957036584615707\nEpoch: 1057 - Train Loss: 0.07222286611795425 - Test Loss: 0.08926820755004883\nEpoch: 1058 - Train Loss: 0.07192617654800415 - Test Loss: 0.08896767348051071\nEpoch: 1059 - Train Loss: 0.07163108885288239 - Test Loss: 0.08866873383522034\nEpoch: 1060 - Train Loss: 0.07133761793375015 - Test Loss: 0.0883714109659195\nEpoch: 1061 - Train Loss: 0.07104572653770447 - Test Loss: 0.0880756825208664\nEpoch: 1062 - Train Loss: 0.07075544446706772 - Test Loss: 0.08778154104948044\nEpoch: 1063 - Train Loss: 0.07046676427125931 - Test Loss: 0.08748901635408401\nEpoch: 1064 - Train Loss: 0.07017961889505386 - Test Loss: 0.08719802647829056\nEpoch: 1065 - Train Loss: 0.06989400088787079 - Test Loss: 0.08690855652093887\nEpoch: 1066 - Train Loss: 0.06960994005203247 - Test Loss: 0.08662064373493195\nEpoch: 1067 - Train Loss: 0.06932739913463593 - Test Loss: 0.08633426576852798\nEpoch: 1068 - Train Loss: 0.06904637813568115 - Test Loss: 0.08604937791824341\nEpoch: 1069 - Train Loss: 0.06876685470342636 - Test Loss: 0.0857660248875618\nEpoch: 1070 - Train Loss: 0.06848882138729095 - Test Loss: 0.08548413962125778\nEpoch: 1071 - Train Loss: 0.06821225583553314 - Test Loss: 0.08520373702049255\nEpoch: 1072 - Train Loss: 0.06793714314699173 - Test Loss: 0.08492478728294373\nEpoch: 1073 - Train Loss: 0.06766347587108612 - Test Loss: 0.08464726060628891\nEpoch: 1074 - Train Loss: 0.0673912763595581 - Test Loss: 0.08437123149633408\nEpoch: 1075 - Train Loss: 0.06712047010660172 - Test Loss: 0.08409658074378967\nEpoch: 1076 - Train Loss: 0.06685110926628113 - Test Loss: 0.08382337540388107\nEpoch: 1077 - Train Loss: 0.06658315658569336 - Test Loss: 0.0835515707731247\nEpoch: 1078 - Train Loss: 0.06631660461425781 - Test Loss: 0.08328118920326233\nEpoch: 1079 - Train Loss: 0.0660514235496521 - Test Loss: 0.0830121710896492\nEpoch: 1080 - Train Loss: 0.06578762084245682 - Test Loss: 0.0827445238828659\nEpoch: 1081 - Train Loss: 0.06552516669034958 - Test Loss: 0.08247823268175125\nEpoch: 1082 - Train Loss: 0.06526407599449158 - Test Loss: 0.08221330493688583\nEpoch: 1083 - Train Loss: 0.06500432640314102 - Test Loss: 0.08194972574710846\nEpoch: 1084 - Train Loss: 0.06474592536687851 - Test Loss: 0.08168748766183853\nEpoch: 1085 - Train Loss: 0.06448885053396225 - Test Loss: 0.08142657577991486\nEpoch: 1086 - Train Loss: 0.06423305720090866 - Test Loss: 0.08116695284843445\nEpoch: 1087 - Train Loss: 0.06397858262062073 - Test Loss: 0.0809086412191391\nEpoch: 1088 - Train Loss: 0.06372540444135666 - Test Loss: 0.08065163344144821\nEpoch: 1089 - Train Loss: 0.06347351521253586 - Test Loss: 0.08039591461420059\nEpoch: 1090 - Train Loss: 0.06322287768125534 - Test Loss: 0.08014144003391266\nEpoch: 1091 - Train Loss: 0.0629734992980957 - Test Loss: 0.0798882395029068\nEpoch: 1092 - Train Loss: 0.06272538751363754 - Test Loss: 0.07963629066944122\nEpoch: 1093 - Train Loss: 0.06247851625084877 - Test Loss: 0.07938560098409653\nEpoch: 1094 - Train Loss: 0.062232863157987595 - Test Loss: 0.07913611084222794\nEpoch: 1095 - Train Loss: 0.06198844313621521 - Test Loss: 0.07888787984848022\nEpoch: 1096 - Train Loss: 0.061745259910821915 - Test Loss: 0.078640878200531\nEpoch: 1097 - Train Loss: 0.06150326505303383 - Test Loss: 0.0783950611948967\nEpoch: 1098 - Train Loss: 0.06126248463988304 - Test Loss: 0.07815045118331909\nEpoch: 1099 - Train Loss: 0.06102287396788597 - Test Loss: 0.0779070258140564\nEpoch: 1100 - Train Loss: 0.060784440487623215 - Test Loss: 0.07766477018594742\nEpoch: 1101 - Train Loss: 0.060547199100255966 - Test Loss: 0.07742370665073395\nEpoch: 1102 - Train Loss: 0.06031111255288124 - Test Loss: 0.0771838128566742\nEpoch: 1103 - Train Loss: 0.06007619947195053 - Test Loss: 0.07694508880376816\nEpoch: 1104 - Train Loss: 0.05984240397810936 - Test Loss: 0.07670747488737106\nEpoch: 1105 - Train Loss: 0.05960976704955101 - Test Loss: 0.07647103071212769\nEpoch: 1106 - Train Loss: 0.0593782439827919 - Test Loss: 0.07623569667339325\nEpoch: 1107 - Train Loss: 0.05914784595370293 - Test Loss: 0.07600148022174835\nEpoch: 1108 - Train Loss: 0.05891856551170349 - Test Loss: 0.07576839625835419\nEpoch: 1109 - Train Loss: 0.0586903914809227 - Test Loss: 0.07553642243146896\nEpoch: 1110 - Train Loss: 0.05846332758665085 - Test Loss: 0.07530555874109268\nEpoch: 1111 - Train Loss: 0.05823735147714615 - Test Loss: 0.07507577538490295\nEpoch: 1112 - Train Loss: 0.0580124594271183 - Test Loss: 0.07484707981348038\nEpoch: 1113 - Train Loss: 0.057788629084825516 - Test Loss: 0.07461944967508316\nEpoch: 1114 - Train Loss: 0.05756586790084839 - Test Loss: 0.0743928775191307\nEpoch: 1115 - Train Loss: 0.05734415352344513 - Test Loss: 0.07416737824678421\nEpoch: 1116 - Train Loss: 0.057123519480228424 - Test Loss: 0.07394294440746307\nEpoch: 1117 - Train Loss: 0.05690392106771469 - Test Loss: 0.07371953874826431\nEpoch: 1118 - Train Loss: 0.05668536201119423 - Test Loss: 0.07349719852209091\nEpoch: 1119 - Train Loss: 0.056467827409505844 - Test Loss: 0.0732758641242981\nEpoch: 1120 - Train Loss: 0.05625132843852043 - Test Loss: 0.07305557280778885\nEpoch: 1121 - Train Loss: 0.0560358464717865 - Test Loss: 0.07283630222082138\nEpoch: 1122 - Train Loss: 0.05582134798169136 - Test Loss: 0.0726180151104927\nEpoch: 1123 - Train Loss: 0.055607881397008896 - Test Loss: 0.072400763630867\nEpoch: 1124 - Train Loss: 0.05539538711309433 - Test Loss: 0.0721844807267189\nEpoch: 1125 - Train Loss: 0.055183906108140945 - Test Loss: 0.07196922600269318\nEpoch: 1126 - Train Loss: 0.05497339367866516 - Test Loss: 0.07175492495298386\nEpoch: 1127 - Train Loss: 0.054763857275247574 - Test Loss: 0.07154161483049393\nEpoch: 1128 - Train Loss: 0.054555293172597885 - Test Loss: 0.0713292732834816\nEpoch: 1129 - Train Loss: 0.05434770509600639 - Test Loss: 0.07111790776252747\nEpoch: 1130 - Train Loss: 0.054141055792570114 - Test Loss: 0.07090747356414795\nEpoch: 1131 - Train Loss: 0.053935352712869644 - Test Loss: 0.07069800794124603\nEpoch: 1132 - Train Loss: 0.05373060703277588 - Test Loss: 0.07048948109149933\nEpoch: 1133 - Train Loss: 0.053526800125837326 - Test Loss: 0.07028190046548843\nEpoch: 1134 - Train Loss: 0.05332392454147339 - Test Loss: 0.07007525861263275\nEpoch: 1135 - Train Loss: 0.05312196910381317 - Test Loss: 0.0698695257306099\nEpoch: 1136 - Train Loss: 0.052920930087566376 - Test Loss: 0.06966472417116165\nEpoch: 1137 - Train Loss: 0.052720796316862106 - Test Loss: 0.06946083158254623\nEpoch: 1138 - Train Loss: 0.05252157896757126 - Test Loss: 0.06925784796476364\nEpoch: 1139 - Train Loss: 0.052323248237371445 - Test Loss: 0.06905575096607208\nEpoch: 1140 - Train Loss: 0.052125826478004456 - Test Loss: 0.06885457038879395\nEpoch: 1141 - Train Loss: 0.0519292838871479 - Test Loss: 0.06865426152944565\nEpoch: 1142 - Train Loss: 0.051733631640672684 - Test Loss: 0.06845486164093018\nEpoch: 1143 - Train Loss: 0.0515388585627079 - Test Loss: 0.06825631856918335\nEpoch: 1144 - Train Loss: 0.051344964653253555 - Test Loss: 0.06805867701768875\nEpoch: 1145 - Train Loss: 0.051151927560567856 - Test Loss: 0.0678618848323822\nEpoch: 1146 - Train Loss: 0.050959765911102295 - Test Loss: 0.06766597181558609\nEpoch: 1147 - Train Loss: 0.050768449902534485 - Test Loss: 0.06747091561555862\nEpoch: 1148 - Train Loss: 0.05057799071073532 - Test Loss: 0.06727669388055801\nEpoch: 1149 - Train Loss: 0.050388362258672714 - Test Loss: 0.06708332896232605\nEpoch: 1150 - Train Loss: 0.050199586898088455 - Test Loss: 0.06689080595970154\nEpoch: 1151 - Train Loss: 0.050011638551950455 - Test Loss: 0.06669911742210388\nEpoch: 1152 - Train Loss: 0.04982452094554901 - Test Loss: 0.06650825589895248\nEpoch: 1153 - Train Loss: 0.049638234078884125 - Test Loss: 0.06631822884082794\nEpoch: 1154 - Train Loss: 0.049452755600214005 - Test Loss: 0.06612902134656906\nEpoch: 1155 - Train Loss: 0.04926808923482895 - Test Loss: 0.06594061106443405\nEpoch: 1156 - Train Loss: 0.049084242433309555 - Test Loss: 0.0657530277967453\nEpoch: 1157 - Train Loss: 0.048901185393333435 - Test Loss: 0.06556624174118042\nEpoch: 1158 - Train Loss: 0.04871894791722298 - Test Loss: 0.0653802677989006\nEpoch: 1159 - Train Loss: 0.048537496477365494 - Test Loss: 0.06519508361816406\nEpoch: 1160 - Train Loss: 0.04835681989789009 - Test Loss: 0.0650106817483902\nEpoch: 1161 - Train Loss: 0.048176925629377365 - Test Loss: 0.06482706218957901\nEpoch: 1162 - Train Loss: 0.04799782484769821 - Test Loss: 0.06464424729347229\nEpoch: 1163 - Train Loss: 0.04781949520111084 - Test Loss: 0.06446219235658646\nEpoch: 1164 - Train Loss: 0.047641921788454056 - Test Loss: 0.06428088992834091\nEpoch: 1165 - Train Loss: 0.04746513068675995 - Test Loss: 0.06410037726163864\nEpoch: 1166 - Train Loss: 0.047289103269577026 - Test Loss: 0.06392063200473785\nEpoch: 1167 - Train Loss: 0.047113820910453796 - Test Loss: 0.06374162435531616\nEpoch: 1168 - Train Loss: 0.046939294785261154 - Test Loss: 0.06356339156627655\nEpoch: 1169 - Train Loss: 0.046765509992837906 - Test Loss: 0.06338588893413544\nEpoch: 1170 - Train Loss: 0.046592459082603455 - Test Loss: 0.06320912390947342\nEpoch: 1171 - Train Loss: 0.04642016813158989 - Test Loss: 0.06303312629461288\nEpoch: 1172 - Train Loss: 0.046248603612184525 - Test Loss: 0.06285785883665085\nEpoch: 1173 - Train Loss: 0.04607776552438736 - Test Loss: 0.06268331408500671\nEpoch: 1174 - Train Loss: 0.04590766131877899 - Test Loss: 0.06250949949026108\nEpoch: 1175 - Train Loss: 0.04573826491832733 - Test Loss: 0.062336403876543045\nEpoch: 1176 - Train Loss: 0.04556959867477417 - Test Loss: 0.062164027243852615\nEpoch: 1177 - Train Loss: 0.04540165141224861 - Test Loss: 0.061992380768060684\nEpoch: 1178 - Train Loss: 0.04523438960313797 - Test Loss: 0.06182142347097397\nEpoch: 1179 - Train Loss: 0.04506782442331314 - Test Loss: 0.061651162803173065\nEpoch: 1180 - Train Loss: 0.04490198194980621 - Test Loss: 0.06148161366581917\nEpoch: 1181 - Train Loss: 0.0447368286550045 - Test Loss: 0.06131276860833168\nEpoch: 1182 - Train Loss: 0.0445723719894886 - Test Loss: 0.06114461272954941\nEpoch: 1183 - Train Loss: 0.04440861940383911 - Test Loss: 0.06097717583179474\nEpoch: 1184 - Train Loss: 0.04424551501870155 - Test Loss: 0.060810383409261703\nEpoch: 1185 - Train Loss: 0.044083114713430405 - Test Loss: 0.060644298791885376\nEpoch: 1186 - Train Loss: 0.043921396136283875 - Test Loss: 0.06047889217734337\nEpoch: 1187 - Train Loss: 0.04376034066081047 - Test Loss: 0.06031416356563568\nEpoch: 1188 - Train Loss: 0.043599966913461685 - Test Loss: 0.06015009805560112\nEpoch: 1189 - Train Loss: 0.04344024881720543 - Test Loss: 0.05998671054840088\nEpoch: 1190 - Train Loss: 0.04328121244907379 - Test Loss: 0.05982399359345436\nEpoch: 1191 - Train Loss: 0.043122805655002594 - Test Loss: 0.05966191366314888\nEpoch: 1192 - Train Loss: 0.04296506941318512 - Test Loss: 0.059500500559806824\nEpoch: 1193 - Train Loss: 0.04280797764658928 - Test Loss: 0.0593397431075573\nEpoch: 1194 - Train Loss: 0.042651545256376266 - Test Loss: 0.05917963758111\nEpoch: 1195 - Train Loss: 0.0424957349896431 - Test Loss: 0.059020161628723145\nEpoch: 1196 - Train Loss: 0.04234058037400246 - Test Loss: 0.058861326426267624\nEpoch: 1197 - Train Loss: 0.042186055332422256 - Test Loss: 0.058703139424324036\nEpoch: 1198 - Train Loss: 0.04203217849135399 - Test Loss: 0.05854560807347298\nEpoch: 1199 - Train Loss: 0.04187891259789467 - Test Loss: 0.05838867276906967\nEpoch: 1200 - Train Loss: 0.04172626882791519 - Test Loss: 0.058232370764017105\nEpoch: 1201 - Train Loss: 0.04157426208257675 - Test Loss: 0.058076705783605576\nEpoch: 1202 - Train Loss: 0.04142286628484726 - Test Loss: 0.057921648025512695\nEpoch: 1203 - Train Loss: 0.041272085160017014 - Test Loss: 0.05776720866560936\nEpoch: 1204 - Train Loss: 0.04112192988395691 - Test Loss: 0.05761340633034706\nEpoch: 1205 - Train Loss: 0.040972381830215454 - Test Loss: 0.057460203766822815\nEpoch: 1206 - Train Loss: 0.040823422372341156 - Test Loss: 0.05730760097503662\nEpoch: 1207 - Train Loss: 0.04067506641149521 - Test Loss: 0.05715559422969818\nEpoch: 1208 - Train Loss: 0.0405273400247097 - Test Loss: 0.05700422078371048\nEpoch: 1209 - Train Loss: 0.04038017988204956 - Test Loss: 0.056853413581848145\nEpoch: 1210 - Train Loss: 0.040233634412288666 - Test Loss: 0.05670322850346565\nEpoch: 1211 - Train Loss: 0.040087658911943436 - Test Loss: 0.056553613394498825\nEpoch: 1212 - Train Loss: 0.039942286908626556 - Test Loss: 0.05640460178256035\nEpoch: 1213 - Train Loss: 0.039797477424144745 - Test Loss: 0.05625614523887634\nEpoch: 1214 - Train Loss: 0.039653267711400986 - Test Loss: 0.05610830336809158\nEpoch: 1215 - Train Loss: 0.039509616792201996 - Test Loss: 0.055961012840270996\nEpoch: 1216 - Train Loss: 0.03936655819416046 - Test Loss: 0.05581432580947876\nEpoch: 1217 - Train Loss: 0.0392240546643734 - Test Loss: 0.0556681826710701\nEpoch: 1218 - Train Loss: 0.03908213973045349 - Test Loss: 0.05552263557910919\nEpoch: 1219 - Train Loss: 0.03894076496362686 - Test Loss: 0.05537763610482216\nEpoch: 1220 - Train Loss: 0.03879997879266739 - Test Loss: 0.05523322895169258\nEpoch: 1221 - Train Loss: 0.03865973651409149 - Test Loss: 0.055089354515075684\nEpoch: 1222 - Train Loss: 0.03852006793022156 - Test Loss: 0.05494605749845505\nEpoch: 1223 - Train Loss: 0.038380932062864304 - Test Loss: 0.054803311824798584\nEpoch: 1224 - Train Loss: 0.03824237361550331 - Test Loss: 0.054661136120557785\nEpoch: 1225 - Train Loss: 0.038104347884655 - Test Loss: 0.05451948940753937\nEpoch: 1226 - Train Loss: 0.03796686977148056 - Test Loss: 0.05437839776277542\nEpoch: 1227 - Train Loss: 0.037829939275979996 - Test Loss: 0.05423784628510475\nEpoch: 1228 - Train Loss: 0.03769353777170181 - Test Loss: 0.05409783497452736\nEpoch: 1229 - Train Loss: 0.037557680159807205 - Test Loss: 0.05395837128162384\nEpoch: 1230 - Train Loss: 0.03742237016558647 - Test Loss: 0.0538194514811039\nEpoch: 1231 - Train Loss: 0.037287577986717224 - Test Loss: 0.05368104949593544\nEpoch: 1232 - Train Loss: 0.03715331479907036 - Test Loss: 0.05354318767786026\nEpoch: 1233 - Train Loss: 0.03701959177851677 - Test Loss: 0.05340585857629776\nEpoch: 1234 - Train Loss: 0.03688637539744377 - Test Loss: 0.05326903238892555\nEpoch: 1235 - Train Loss: 0.03675369173288345 - Test Loss: 0.05313275754451752\nEpoch: 1236 - Train Loss: 0.03662153333425522 - Test Loss: 0.05299700051546097\nEpoch: 1237 - Train Loss: 0.03648987039923668 - Test Loss: 0.05286174640059471\nEpoch: 1238 - Train Loss: 0.036358751356601715 - Test Loss: 0.052727021276950836\nEpoch: 1239 - Train Loss: 0.03622811660170555 - Test Loss: 0.052592795342206955\nEpoch: 1240 - Train Loss: 0.036097992211580276 - Test Loss: 0.05245908722281456\nEpoch: 1241 - Train Loss: 0.035968393087387085 - Test Loss: 0.05232589691877365\nEpoch: 1242 - Train Loss: 0.03583928942680359 - Test Loss: 0.052193205803632736\nEpoch: 1243 - Train Loss: 0.035710692405700684 - Test Loss: 0.05206102877855301\nEpoch: 1244 - Train Loss: 0.03558257967233658 - Test Loss: 0.05192933231592178\nEpoch: 1245 - Train Loss: 0.035454973578453064 - Test Loss: 0.05179814621806145\nEpoch: 1246 - Train Loss: 0.03532785177230835 - Test Loss: 0.05166744440793991\nEpoch: 1247 - Train Loss: 0.035201236605644226 - Test Loss: 0.05153724551200867\nEpoch: 1248 - Train Loss: 0.0350751094520092 - Test Loss: 0.051407549530267715\nEpoch: 1249 - Train Loss: 0.034949466586112976 - Test Loss: 0.05127833038568497\nEpoch: 1250 - Train Loss: 0.03482430800795555 - Test Loss: 0.051149602979421616\nEpoch: 1251 - Train Loss: 0.03469962626695633 - Test Loss: 0.05102135241031647\nEpoch: 1252 - Train Loss: 0.03457542508840561 - Test Loss: 0.05089358240365982\nEpoch: 1253 - Train Loss: 0.034451715648174286 - Test Loss: 0.05076630041003227\nEpoch: 1254 - Train Loss: 0.03432847559452057 - Test Loss: 0.050639502704143524\nEpoch: 1255 - Train Loss: 0.03420570120215416 - Test Loss: 0.050513170659542084\nEpoch: 1256 - Train Loss: 0.03408340737223625 - Test Loss: 0.05038731172680855\nEpoch: 1257 - Train Loss: 0.03396157547831535 - Test Loss: 0.05026192590594292\nEpoch: 1258 - Train Loss: 0.03384021669626236 - Test Loss: 0.05013700947165489\nEpoch: 1259 - Train Loss: 0.03371931239962578 - Test Loss: 0.050012554973363876\nEpoch: 1260 - Train Loss: 0.033598873764276505 - Test Loss: 0.04988855868577957\nEpoch: 1261 - Train Loss: 0.03347890079021454 - Test Loss: 0.04976503551006317\nEpoch: 1262 - Train Loss: 0.03335938602685928 - Test Loss: 0.049641985446214676\nEpoch: 1263 - Train Loss: 0.03324032947421074 - Test Loss: 0.0495193749666214\nEpoch: 1264 - Train Loss: 0.033121731132268906 - Test Loss: 0.04939722642302513\nEpoch: 1265 - Train Loss: 0.03300357237458229 - Test Loss: 0.049275532364845276\nEpoch: 1266 - Train Loss: 0.032885853201150894 - Test Loss: 0.04915427789092064\nEpoch: 1267 - Train Loss: 0.032768599689006805 - Test Loss: 0.04903348162770271\nEpoch: 1268 - Train Loss: 0.03265180066227913 - Test Loss: 0.048913151025772095\nEpoch: 1269 - Train Loss: 0.032535430043935776 - Test Loss: 0.0487932451069355\nEpoch: 1270 - Train Loss: 0.032419510185718536 - Test Loss: 0.04867379367351532\nEpoch: 1271 - Train Loss: 0.03230402618646622 - Test Loss: 0.048554785549640656\nEpoch: 1272 - Train Loss: 0.03218897059559822 - Test Loss: 0.04843619838356972\nEpoch: 1273 - Train Loss: 0.03207436203956604 - Test Loss: 0.04831806570291519\nEpoch: 1274 - Train Loss: 0.03196018561720848 - Test Loss: 0.04820036515593529\nEpoch: 1275 - Train Loss: 0.031846433877944946 - Test Loss: 0.048083096742630005\nEpoch: 1276 - Train Loss: 0.03173312172293663 - Test Loss: 0.04796626791357994\nEpoch: 1277 - Train Loss: 0.03162023052573204 - Test Loss: 0.0478498600423336\nEpoch: 1278 - Train Loss: 0.031507767736911774 - Test Loss: 0.04773388430476189\nEpoch: 1279 - Train Loss: 0.03139573335647583 - Test Loss: 0.04761833697557449\nEpoch: 1280 - Train Loss: 0.03128410503268242 - Test Loss: 0.04750319942831993\nEpoch: 1281 - Train Loss: 0.031172899529337883 - Test Loss: 0.047388482838869095\nEpoch: 1282 - Train Loss: 0.031062118709087372 - Test Loss: 0.04727419465780258\nEpoch: 1283 - Train Loss: 0.030951743945479393 - Test Loss: 0.0471603199839592\nEpoch: 1284 - Train Loss: 0.030841801315546036 - Test Loss: 0.04704686999320984\nEpoch: 1285 - Train Loss: 0.030732261016964912 - Test Loss: 0.04693383350968361\nEpoch: 1286 - Train Loss: 0.03062313050031662 - Test Loss: 0.04682121053338051\nEpoch: 1287 - Train Loss: 0.030514415353536606 - Test Loss: 0.04670899361371994\nEpoch: 1288 - Train Loss: 0.030406096950173378 - Test Loss: 0.046597182750701904\nEpoch: 1289 - Train Loss: 0.030298184603452682 - Test Loss: 0.046485785394907\nEpoch: 1290 - Train Loss: 0.030190693214535713 - Test Loss: 0.04637480154633522\nEpoch: 1291 - Train Loss: 0.030083591118454933 - Test Loss: 0.04626421257853508\nEpoch: 1292 - Train Loss: 0.029976891353726387 - Test Loss: 0.04615402966737747\nEpoch: 1293 - Train Loss: 0.02987057715654373 - Test Loss: 0.0460442379117012\nEpoch: 1294 - Train Loss: 0.029764678329229355 - Test Loss: 0.04593485966324806\nEpoch: 1295 - Train Loss: 0.029659157618880272 - Test Loss: 0.045825861394405365\nEpoch: 1296 - Train Loss: 0.02955404669046402 - Test Loss: 0.0457172766327858\nEpoch: 1297 - Train Loss: 0.02944931574165821 - Test Loss: 0.04560907185077667\nEpoch: 1298 - Train Loss: 0.02934497594833374 - Test Loss: 0.045501261949539185\nEpoch: 1299 - Train Loss: 0.029241016134619713 - Test Loss: 0.04539383947849274\nEpoch: 1300 - Train Loss: 0.02913745865225792 - Test Loss: 0.045286815613508224\nEpoch: 1301 - Train Loss: 0.029034268110990524 - Test Loss: 0.04518016427755356\nEpoch: 1302 - Train Loss: 0.02893148548901081 - Test Loss: 0.045073915272951126\nEpoch: 1303 - Train Loss: 0.028829067945480347 - Test Loss: 0.04496804624795914\nEpoch: 1304 - Train Loss: 0.028727032244205475 - Test Loss: 0.04486255347728729\nEpoch: 1305 - Train Loss: 0.02862536907196045 - Test Loss: 0.04475743696093559\nEpoch: 1306 - Train Loss: 0.028524085879325867 - Test Loss: 0.044652700424194336\nEpoch: 1307 - Train Loss: 0.028423182666301727 - Test Loss: 0.04454834759235382\nEpoch: 1308 - Train Loss: 0.028322642669081688 - Test Loss: 0.044444359838962555\nEpoch: 1309 - Train Loss: 0.028222480788826942 - Test Loss: 0.04434075951576233\nEpoch: 1310 - Train Loss: 0.028122693300247192 - Test Loss: 0.04423752799630165\nEpoch: 1311 - Train Loss: 0.028023267164826393 - Test Loss: 0.04413466528058052\nEpoch: 1312 - Train Loss: 0.027924207970499992 - Test Loss: 0.04403216764330864\nEpoch: 1313 - Train Loss: 0.027825510129332542 - Test Loss: 0.043930042535066605\nEpoch: 1314 - Train Loss: 0.027727177366614342 - Test Loss: 0.04382827877998352\nEpoch: 1315 - Train Loss: 0.027629217132925987 - Test Loss: 0.04372689127922058\nEpoch: 1316 - Train Loss: 0.027531607076525688 - Test Loss: 0.0436258539557457\nEpoch: 1317 - Train Loss: 0.027434365823864937 - Test Loss: 0.04352518916130066\nEpoch: 1318 - Train Loss: 0.027337484061717987 - Test Loss: 0.04342488572001457\nEpoch: 1319 - Train Loss: 0.027240952476859093 - Test Loss: 0.04332493245601654\nEpoch: 1320 - Train Loss: 0.027144769206643105 - Test Loss: 0.04322533309459686\nEpoch: 1321 - Train Loss: 0.027048947289586067 - Test Loss: 0.043126098811626434\nEpoch: 1322 - Train Loss: 0.026953475549817085 - Test Loss: 0.04302721843123436\nEpoch: 1323 - Train Loss: 0.026858346536755562 - Test Loss: 0.042928680777549744\nEpoch: 1324 - Train Loss: 0.026763571426272392 - Test Loss: 0.04283049702644348\nEpoch: 1325 - Train Loss: 0.026669148355722427 - Test Loss: 0.04273267835378647\nEpoch: 1326 - Train Loss: 0.026575064286589622 - Test Loss: 0.04263519123196602\nEpoch: 1327 - Train Loss: 0.026481330394744873 - Test Loss: 0.04253805801272392\nEpoch: 1328 - Train Loss: 0.026387939229607582 - Test Loss: 0.04244127497076988\nEpoch: 1329 - Train Loss: 0.0262948889285326 - Test Loss: 0.0423448272049427\nEpoch: 1330 - Train Loss: 0.02620217576622963 - Test Loss: 0.04224872961640358\nEpoch: 1331 - Train Loss: 0.02610979974269867 - Test Loss: 0.04215296730399132\nEpoch: 1332 - Train Loss: 0.026017773896455765 - Test Loss: 0.04205755516886711\nEpoch: 1333 - Train Loss: 0.025926070287823677 - Test Loss: 0.04196247085928917\nEpoch: 1334 - Train Loss: 0.02583470568060875 - Test Loss: 0.04186772555112839\nEpoch: 1335 - Train Loss: 0.025743680074810982 - Test Loss: 0.041773322969675064\nEpoch: 1336 - Train Loss: 0.02565298043191433 - Test Loss: 0.0416792556643486\nEpoch: 1337 - Train Loss: 0.02556261233985424 - Test Loss: 0.041585516184568405\nEpoch: 1338 - Train Loss: 0.025472570210695267 - Test Loss: 0.04149210825562477\nEpoch: 1339 - Train Loss: 0.025382855907082558 - Test Loss: 0.0413990244269371\nEpoch: 1340 - Train Loss: 0.02529347874224186 - Test Loss: 0.04130628705024719\nEpoch: 1341 - Train Loss: 0.025204414501786232 - Test Loss: 0.04121386632323265\nEpoch: 1342 - Train Loss: 0.025115683674812317 - Test Loss: 0.04112177714705467\nEpoch: 1343 - Train Loss: 0.025027265772223473 - Test Loss: 0.04103000462055206\nEpoch: 1344 - Train Loss: 0.024939175695180893 - Test Loss: 0.04093856364488602\nEpoch: 1345 - Train Loss: 0.024851396679878235 - Test Loss: 0.04084743186831474\nEpoch: 1346 - Train Loss: 0.024763941764831543 - Test Loss: 0.04075663164258003\nEpoch: 1347 - Train Loss: 0.02467680536210537 - Test Loss: 0.040666159242391586\nEpoch: 1348 - Train Loss: 0.024589980021119118 - Test Loss: 0.040575988590717316\nEpoch: 1349 - Train Loss: 0.024503473192453384 - Test Loss: 0.04048614948987961\nEpoch: 1350 - Train Loss: 0.024417290464043617 - Test Loss: 0.04039663448929787\nEpoch: 1351 - Train Loss: 0.024331409484148026 - Test Loss: 0.0403074212372303\nEpoch: 1352 - Train Loss: 0.024245833978056908 - Test Loss: 0.04021851345896721\nEpoch: 1353 - Train Loss: 0.02416057139635086 - Test Loss: 0.04012992978096008\nEpoch: 1354 - Train Loss: 0.024075627326965332 - Test Loss: 0.040041666477918625\nEpoch: 1355 - Train Loss: 0.02399098128080368 - Test Loss: 0.039953697472810745\nEpoch: 1356 - Train Loss: 0.023906633257865906 - Test Loss: 0.03986603021621704\nEpoch: 1357 - Train Loss: 0.023822598159313202 - Test Loss: 0.039778683334589005\nEpoch: 1358 - Train Loss: 0.023738877847790718 - Test Loss: 0.03969164937734604\nEpoch: 1359 - Train Loss: 0.023655448108911514 - Test Loss: 0.03960491344332695\nEpoch: 1360 - Train Loss: 0.02357231080532074 - Test Loss: 0.03951847180724144\nEpoch: 1361 - Train Loss: 0.023489482700824738 - Test Loss: 0.039432343095541\nEpoch: 1362 - Train Loss: 0.02340696007013321 - Test Loss: 0.039346519857645035\nEpoch: 1363 - Train Loss: 0.02332473173737526 - Test Loss: 0.039260998368263245\nEpoch: 1364 - Train Loss: 0.023242786526679993 - Test Loss: 0.03917576000094414\nEpoch: 1365 - Train Loss: 0.0231611505150795 - Test Loss: 0.0390908308327198\nEpoch: 1366 - Train Loss: 0.02307981252670288 - Test Loss: 0.03900621086359024\nEpoch: 1367 - Train Loss: 0.022998761385679245 - Test Loss: 0.03892187401652336\nEpoch: 1368 - Train Loss: 0.022917991504073143 - Test Loss: 0.03883783146739006\nEpoch: 1369 - Train Loss: 0.022837525233626366 - Test Loss: 0.03875407949090004\nEpoch: 1370 - Train Loss: 0.022757353261113167 - Test Loss: 0.03867064416408539\nEpoch: 1371 - Train Loss: 0.022677462548017502 - Test Loss: 0.038587480783462524\nEpoch: 1372 - Train Loss: 0.02259785309433937 - Test Loss: 0.038504600524902344\nEpoch: 1373 - Train Loss: 0.02251853421330452 - Test Loss: 0.03842201456427574\nEpoch: 1374 - Train Loss: 0.022439494729042053 - Test Loss: 0.03833971545100212\nEpoch: 1375 - Train Loss: 0.022360745817422867 - Test Loss: 0.03825771063566208\nEpoch: 1376 - Train Loss: 0.022282276302576065 - Test Loss: 0.03817598894238472\nEpoch: 1377 - Train Loss: 0.022204093635082245 - Test Loss: 0.038094550371170044\nEpoch: 1378 - Train Loss: 0.02212618663907051 - Test Loss: 0.03801339492201805\nEpoch: 1379 - Train Loss: 0.022048555314540863 - Test Loss: 0.03793251886963844\nEpoch: 1380 - Train Loss: 0.0219712071120739 - Test Loss: 0.03785192593932152\nEpoch: 1381 - Train Loss: 0.02189413458108902 - Test Loss: 0.037771616131067276\nEpoch: 1382 - Train Loss: 0.021817339584231377 - Test Loss: 0.03769158944487572\nEpoch: 1383 - Train Loss: 0.02174081839621067 - Test Loss: 0.037611834704875946\nEpoch: 1384 - Train Loss: 0.021664578467607498 - Test Loss: 0.037532366812229156\nEpoch: 1385 - Train Loss: 0.021588603034615517 - Test Loss: 0.037453167140483856\nEpoch: 1386 - Train Loss: 0.021512899547815323 - Test Loss: 0.037374235689640045\nEpoch: 1387 - Train Loss: 0.021437471732497215 - Test Loss: 0.037295594811439514\nEpoch: 1388 - Train Loss: 0.021362310275435448 - Test Loss: 0.037217214703559875\nEpoch: 1389 - Train Loss: 0.02128741517663002 - Test Loss: 0.037139106541872025\nEpoch: 1390 - Train Loss: 0.021212788298726082 - Test Loss: 0.03706126660108566\nEpoch: 1391 - Train Loss: 0.021138429641723633 - Test Loss: 0.036983709782361984\nEpoch: 1392 - Train Loss: 0.021064339205622673 - Test Loss: 0.036906417459249496\nEpoch: 1393 - Train Loss: 0.020990503951907158 - Test Loss: 0.0368293859064579\nEpoch: 1394 - Train Loss: 0.02091694250702858 - Test Loss: 0.036752622574567795\nEpoch: 1395 - Train Loss: 0.020843636244535446 - Test Loss: 0.03667612373828888\nEpoch: 1396 - Train Loss: 0.0207706019282341 - Test Loss: 0.03659990802407265\nEpoch: 1397 - Train Loss: 0.0206978190690279 - Test Loss: 0.036523934453725815\nEpoch: 1398 - Train Loss: 0.020625300705432892 - Test Loss: 0.03644823655486107\nEpoch: 1399 - Train Loss: 0.020553037524223328 - Test Loss: 0.036372795701026917\nEpoch: 1400 - Train Loss: 0.02048102766275406 - Test Loss: 0.03629760816693306\nEpoch: 1401 - Train Loss: 0.02040928229689598 - Test Loss: 0.03622269630432129\nEpoch: 1402 - Train Loss: 0.0203377865254879 - Test Loss: 0.03614803031086922\nEpoch: 1403 - Train Loss: 0.020266545936465263 - Test Loss: 0.03607362508773804\nEpoch: 1404 - Train Loss: 0.020195569843053818 - Test Loss: 0.03599948808550835\nEpoch: 1405 - Train Loss: 0.02012483775615692 - Test Loss: 0.03592560067772865\nEpoch: 1406 - Train Loss: 0.020054353401064873 - Test Loss: 0.03585195913910866\nEpoch: 1407 - Train Loss: 0.019984126091003418 - Test Loss: 0.03577858582139015\nEpoch: 1408 - Train Loss: 0.019914142787456512 - Test Loss: 0.03570545092225075\nEpoch: 1409 - Train Loss: 0.019844401627779007 - Test Loss: 0.03563256934285164\nEpoch: 1410 - Train Loss: 0.019774919375777245 - Test Loss: 0.035559944808483124\nEpoch: 1411 - Train Loss: 0.01970568485558033 - Test Loss: 0.035487569868564606\nEpoch: 1412 - Train Loss: 0.019636688753962517 - Test Loss: 0.035415444523096085\nEpoch: 1413 - Train Loss: 0.019567938521504402 - Test Loss: 0.035343561321496964\nEpoch: 1414 - Train Loss: 0.019499443471431732 - Test Loss: 0.03527194261550903\nEpoch: 1415 - Train Loss: 0.019431184977293015 - Test Loss: 0.035200562328100204\nEpoch: 1416 - Train Loss: 0.01936316303908825 - Test Loss: 0.035129424184560776\nEpoch: 1417 - Train Loss: 0.01929539255797863 - Test Loss: 0.035058535635471344\nEpoch: 1418 - Train Loss: 0.019227853044867516 - Test Loss: 0.034987885504961014\nEpoch: 1419 - Train Loss: 0.019160550087690353 - Test Loss: 0.034917473793029785\nEpoch: 1420 - Train Loss: 0.01909349299967289 - Test Loss: 0.03484731167554855\nEpoch: 1421 - Train Loss: 0.01902666874229908 - Test Loss: 0.03477738797664642\nEpoch: 1422 - Train Loss: 0.01896008849143982 - Test Loss: 0.03470771387219429\nEpoch: 1423 - Train Loss: 0.018893741071224213 - Test Loss: 0.03463826701045036\nEpoch: 1424 - Train Loss: 0.01882762461900711 - Test Loss: 0.034569062292575836\nEpoch: 1425 - Train Loss: 0.01876174844801426 - Test Loss: 0.03450010344386101\nEpoch: 1426 - Train Loss: 0.018696099519729614 - Test Loss: 0.034431375563144684\nEpoch: 1427 - Train Loss: 0.01863069459795952 - Test Loss: 0.03436289355158806\nEpoch: 1428 - Train Loss: 0.01856551319360733 - Test Loss: 0.03429463878273964\nEpoch: 1429 - Train Loss: 0.018500560894608498 - Test Loss: 0.034226614981889725\nEpoch: 1430 - Train Loss: 0.018435833975672722 - Test Loss: 0.034158822149038315\nEpoch: 1431 - Train Loss: 0.0183713398873806 - Test Loss: 0.03409126400947571\nEpoch: 1432 - Train Loss: 0.018307078629732132 - Test Loss: 0.034023940563201904\nEpoch: 1433 - Train Loss: 0.018243037164211273 - Test Loss: 0.033956848084926605\nEpoch: 1434 - Train Loss: 0.01817922294139862 - Test Loss: 0.033889979124069214\nEpoch: 1435 - Train Loss: 0.018115635961294174 - Test Loss: 0.033823344856500626\nEpoch: 1436 - Train Loss: 0.018052278086543083 - Test Loss: 0.03375694155693054\nEpoch: 1437 - Train Loss: 0.017989138141274452 - Test Loss: 0.033690765500068665\nEpoch: 1438 - Train Loss: 0.01792621985077858 - Test Loss: 0.033624809235334396\nEpoch: 1439 - Train Loss: 0.017863530665636063 - Test Loss: 0.03355908766388893\nEpoch: 1440 - Train Loss: 0.017801063135266304 - Test Loss: 0.03349359333515167\nEpoch: 1441 - Train Loss: 0.01773880049586296 - Test Loss: 0.03342830389738083\nEpoch: 1442 - Train Loss: 0.01767677068710327 - Test Loss: 0.03336325287818909\nEpoch: 1443 - Train Loss: 0.01761496253311634 - Test Loss: 0.03329842910170555\nEpoch: 1444 - Train Loss: 0.017553364858031273 - Test Loss: 0.033233821392059326\nEpoch: 1445 - Train Loss: 0.017491985112428665 - Test Loss: 0.03316942974925041\nEpoch: 1446 - Train Loss: 0.017430834472179413 - Test Loss: 0.0331052765250206\nEpoch: 1447 - Train Loss: 0.017369884997606277 - Test Loss: 0.0330413319170475\nEpoch: 1448 - Train Loss: 0.017309153452515602 - Test Loss: 0.032977595925331116\nEpoch: 1449 - Train Loss: 0.017248637974262238 - Test Loss: 0.03291408717632294\nEpoch: 1450 - Train Loss: 0.017188336700201035 - Test Loss: 0.03285079821944237\nEpoch: 1451 - Train Loss: 0.017128244042396545 - Test Loss: 0.03278771787881851\nEpoch: 1452 - Train Loss: 0.01706835813820362 - Test Loss: 0.03272485360503197\nEpoch: 1453 - Train Loss: 0.017008692026138306 - Test Loss: 0.03266220912337303\nEpoch: 1454 - Train Loss: 0.016949230805039406 - Test Loss: 0.03259977698326111\nEpoch: 1455 - Train Loss: 0.01688998192548752 - Test Loss: 0.0325375534594059\nEpoch: 1456 - Train Loss: 0.016830936074256897 - Test Loss: 0.032475546002388\nEpoch: 1457 - Train Loss: 0.016772106289863586 - Test Loss: 0.03241375833749771\nEpoch: 1458 - Train Loss: 0.016713479533791542 - Test Loss: 0.03235217183828354\nEpoch: 1459 - Train Loss: 0.01665506325662136 - Test Loss: 0.03229079768061638\nEpoch: 1460 - Train Loss: 0.016596844419836998 - Test Loss: 0.03222963586449623\nEpoch: 1461 - Train Loss: 0.0165388360619545 - Test Loss: 0.0321686789393425\nEpoch: 1462 - Train Loss: 0.016481023281812668 - Test Loss: 0.03210793063044548\nEpoch: 1463 - Train Loss: 0.016423417255282402 - Test Loss: 0.03204738348722458\nEpoch: 1464 - Train Loss: 0.01636602357029915 - Test Loss: 0.031987059861421585\nEpoch: 1465 - Train Loss: 0.016308819875121117 - Test Loss: 0.03192692622542381\nEpoch: 1466 - Train Loss: 0.0162518173456192 - Test Loss: 0.031867001205682755\nEpoch: 1467 - Train Loss: 0.016195023432374 - Test Loss: 0.03180728480219841\nEpoch: 1468 - Train Loss: 0.01613842509686947 - Test Loss: 0.03174777328968048\nEpoch: 1469 - Train Loss: 0.016082022339105606 - Test Loss: 0.03168845921754837\nEpoch: 1470 - Train Loss: 0.016025815159082413 - Test Loss: 0.031629350036382675\nEpoch: 1471 - Train Loss: 0.015969812870025635 - Test Loss: 0.0315704420208931\nEpoch: 1472 - Train Loss: 0.015914004296064377 - Test Loss: 0.03151173144578934\nEpoch: 1473 - Train Loss: 0.01585838571190834 - Test Loss: 0.031453218311071396\nEpoch: 1474 - Train Loss: 0.01580297388136387 - Test Loss: 0.03139491751790047\nEpoch: 1475 - Train Loss: 0.01574775017797947 - Test Loss: 0.03133680671453476\nEpoch: 1476 - Train Loss: 0.01569271646440029 - Test Loss: 0.03127888962626457\nEpoch: 1477 - Train Loss: 0.01563788391649723 - Test Loss: 0.0312211774289608\nEpoch: 1478 - Train Loss: 0.015583241358399391 - Test Loss: 0.031163664534687996\nEpoch: 1479 - Train Loss: 0.015528785064816475 - Test Loss: 0.031106336042284966\nEpoch: 1480 - Train Loss: 0.015474521555006504 - Test Loss: 0.031049208715558052\nEpoch: 1481 - Train Loss: 0.015420442447066307 - Test Loss: 0.03099226765334606\nEpoch: 1482 - Train Loss: 0.015366566367447376 - Test Loss: 0.030935537070035934\nEpoch: 1483 - Train Loss: 0.01531287282705307 - Test Loss: 0.030878989025950432\nEpoch: 1484 - Train Loss: 0.015259371139109135 - Test Loss: 0.030822638422250748\nEpoch: 1485 - Train Loss: 0.015206051990389824 - Test Loss: 0.030766475945711136\nEpoch: 1486 - Train Loss: 0.015152915380895138 - Test Loss: 0.030710494145751\nEpoch: 1487 - Train Loss: 0.01509997621178627 - Test Loss: 0.030654726549983025\nEpoch: 1488 - Train Loss: 0.015047215856611729 - Test Loss: 0.030599134042859077\nEpoch: 1489 - Train Loss: 0.014994639903306961 - Test Loss: 0.030543731525540352\nEpoch: 1490 - Train Loss: 0.014942247420549393 - Test Loss: 0.0304885134100914\nEpoch: 1491 - Train Loss: 0.0148900356143713 - Test Loss: 0.03043348155915737\nEpoch: 1492 - Train Loss: 0.014838016591966152 - Test Loss: 0.03037865087389946\nEpoch: 1493 - Train Loss: 0.014786175452172756 - Test Loss: 0.030324000865221024\nEpoch: 1494 - Train Loss: 0.01473451592028141 - Test Loss: 0.03026953712105751\nEpoch: 1495 - Train Loss: 0.01468303520232439 - Test Loss: 0.030215254053473473\nEpoch: 1496 - Train Loss: 0.014631730504333973 - Test Loss: 0.030161147937178612\nEpoch: 1497 - Train Loss: 0.01458060648292303 - Test Loss: 0.03010723367333412\nEpoch: 1498 - Train Loss: 0.014529665000736713 - Test Loss: 0.030053507536649704\nEpoch: 1499 - Train Loss: 0.014478906989097595 - Test Loss: 0.029999960213899612\nEpoch: 1500 - Train Loss: 0.014428314752876759 - Test Loss: 0.02994658797979355\nEpoch: 1501 - Train Loss: 0.01437790784984827 - Test Loss: 0.029893405735492706\nEpoch: 1502 - Train Loss: 0.014327670447528362 - Test Loss: 0.02984039857983589\nEpoch: 1503 - Train Loss: 0.014277607202529907 - Test Loss: 0.029787572100758553\nEpoch: 1504 - Train Loss: 0.014227727428078651 - Test Loss: 0.02973492443561554\nEpoch: 1505 - Train Loss: 0.014178019016981125 - Test Loss: 0.0296824611723423\nEpoch: 1506 - Train Loss: 0.014128479175269604 - Test Loss: 0.02963016927242279\nEpoch: 1507 - Train Loss: 0.014079117216169834 - Test Loss: 0.029578054323792458\nEpoch: 1508 - Train Loss: 0.01402992382645607 - Test Loss: 0.029526114463806152\nEpoch: 1509 - Train Loss: 0.013980901800096035 - Test Loss: 0.029474355280399323\nEpoch: 1510 - Train Loss: 0.013932054862380028 - Test Loss: 0.02942277304828167\nEpoch: 1511 - Train Loss: 0.013883375562727451 - Test Loss: 0.029371358454227448\nEpoch: 1512 - Train Loss: 0.013834867626428604 - Test Loss: 0.02932012267410755\nEpoch: 1513 - Train Loss: 0.013786524534225464 - Test Loss: 0.029269056394696236\nEpoch: 1514 - Train Loss: 0.013738350011408329 - Test Loss: 0.029218165203928947\nEpoch: 1515 - Train Loss: 0.013690349645912647 - Test Loss: 0.029167456552386284\nEpoch: 1516 - Train Loss: 0.013642514124512672 - Test Loss: 0.029116909950971603\nEpoch: 1517 - Train Loss: 0.01359484251588583 - Test Loss: 0.029066534712910652\nEpoch: 1518 - Train Loss: 0.013547345995903015 - Test Loss: 0.029016336426138878\nEpoch: 1519 - Train Loss: 0.013500004075467587 - Test Loss: 0.028966302052140236\nEpoch: 1520 - Train Loss: 0.013452829793095589 - Test Loss: 0.028916433453559875\nEpoch: 1521 - Train Loss: 0.013405823148787022 - Test Loss: 0.028866741806268692\nEpoch: 1522 - Train Loss: 0.013358972035348415 - Test Loss: 0.028817206621170044\nEpoch: 1523 - Train Loss: 0.013312290422618389 - Test Loss: 0.028767846524715424\nEpoch: 1524 - Train Loss: 0.013265769928693771 - Test Loss: 0.028718650341033936\nEpoch: 1525 - Train Loss: 0.013219408690929413 - Test Loss: 0.02866961807012558\nEpoch: 1526 - Train Loss: 0.013173215091228485 - Test Loss: 0.02862076461315155\nEpoch: 1527 - Train Loss: 0.013127180747687817 - Test Loss: 0.028572067618370056\nEpoch: 1528 - Train Loss: 0.013081304728984833 - Test Loss: 0.028523540124297142\nEpoch: 1529 - Train Loss: 0.013035589829087257 - Test Loss: 0.02847517654299736\nEpoch: 1530 - Train Loss: 0.012990031391382217 - Test Loss: 0.028426973149180412\nEpoch: 1531 - Train Loss: 0.012944634072482586 - Test Loss: 0.028378935530781746\nEpoch: 1532 - Train Loss: 0.012899397872388363 - Test Loss: 0.028331061825156212\nEpoch: 1533 - Train Loss: 0.012854315340518951 - Test Loss: 0.02828334830701351\nEpoch: 1534 - Train Loss: 0.012809391133487225 - Test Loss: 0.028235798701643944\nEpoch: 1535 - Train Loss: 0.012764621526002884 - Test Loss: 0.02818840742111206\nEpoch: 1536 - Train Loss: 0.01272000465542078 - Test Loss: 0.028141170740127563\nEpoch: 1537 - Train Loss: 0.012675545178353786 - Test Loss: 0.02809409610927105\nEpoch: 1538 - Train Loss: 0.012631237506866455 - Test Loss: 0.02804717980325222\nEpoch: 1539 - Train Loss: 0.012587086297571659 - Test Loss: 0.028000425547361374\nEpoch: 1540 - Train Loss: 0.012543091550469398 - Test Loss: 0.027953829616308212\nEpoch: 1541 - Train Loss: 0.012499246746301651 - Test Loss: 0.027907393872737885\nEpoch: 1542 - Train Loss: 0.01245555654168129 - Test Loss: 0.027861109003424644\nEpoch: 1543 - Train Loss: 0.012412016279995441 - Test Loss: 0.02781498059630394\nEpoch: 1544 - Train Loss: 0.012368623167276382 - Test Loss: 0.02776901051402092\nEpoch: 1545 - Train Loss: 0.012325383722782135 - Test Loss: 0.027723191305994987\nEpoch: 1546 - Train Loss: 0.012282292358577251 - Test Loss: 0.02767753042280674\nEpoch: 1547 - Train Loss: 0.012239353731274605 - Test Loss: 0.02763202041387558\nEpoch: 1548 - Train Loss: 0.012196565978229046 - Test Loss: 0.027586670592427254\nEpoch: 1549 - Train Loss: 0.012153924442827702 - Test Loss: 0.027541473507881165\nEpoch: 1550 - Train Loss: 0.01211143471300602 - Test Loss: 0.027496429160237312\nEpoch: 1551 - Train Loss: 0.012069090269505978 - Test Loss: 0.0274515338242054\nEpoch: 1552 - Train Loss: 0.012026890181005001 - Test Loss: 0.027406789362430573\nEpoch: 1553 - Train Loss: 0.011984840035438538 - Test Loss: 0.027362197637557983\nEpoch: 1554 - Train Loss: 0.01194293238222599 - Test Loss: 0.027317756786942482\nEpoch: 1555 - Train Loss: 0.011901171877980232 - Test Loss: 0.027273468673229218\nEpoch: 1556 - Train Loss: 0.011859563179314137 - Test Loss: 0.02722932957112789\nEpoch: 1557 - Train Loss: 0.011818093247711658 - Test Loss: 0.027185343205928802\nEpoch: 1558 - Train Loss: 0.011776769533753395 - Test Loss: 0.027141505852341652\nEpoch: 1559 - Train Loss: 0.0117355827242136 - Test Loss: 0.027097798883914948\nEpoch: 1560 - Train Loss: 0.011694538407027721 - Test Loss: 0.02705424837768078\nEpoch: 1561 - Train Loss: 0.011653642170131207 - Test Loss: 0.027010846883058548\nEpoch: 1562 - Train Loss: 0.011612879112362862 - Test Loss: 0.02696758322417736\nEpoch: 1563 - Train Loss: 0.011572265066206455 - Test Loss: 0.02692447602748871\nEpoch: 1564 - Train Loss: 0.011531789787113667 - Test Loss: 0.0268815066665411\nEpoch: 1565 - Train Loss: 0.011491452343761921 - Test Loss: 0.02683868445456028\nEpoch: 1566 - Train Loss: 0.011451263912022114 - Test Loss: 0.026796016842126846\nEpoch: 1567 - Train Loss: 0.011411205865442753 - Test Loss: 0.026753487065434456\nEpoch: 1568 - Train Loss: 0.011371289379894733 - Test Loss: 0.026711096987128258\nEpoch: 1569 - Train Loss: 0.01133151538670063 - Test Loss: 0.026668855920433998\nEpoch: 1570 - Train Loss: 0.011291870847344398 - Test Loss: 0.026626750826835632\nEpoch: 1571 - Train Loss: 0.011252370662987232 - Test Loss: 0.026584796607494354\nEpoch: 1572 - Train Loss: 0.011213008314371109 - Test Loss: 0.02654298208653927\nEpoch: 1573 - Train Loss: 0.011173776350915432 - Test Loss: 0.026501303538680077\nEpoch: 1574 - Train Loss: 0.0111346784979105 - Test Loss: 0.02645976096391678\nEpoch: 1575 - Train Loss: 0.011095723137259483 - Test Loss: 0.026418369263410568\nEpoch: 1576 - Train Loss: 0.011056897230446339 - Test Loss: 0.026377107948064804\nEpoch: 1577 - Train Loss: 0.011018207296729088 - Test Loss: 0.02633598819375038\nEpoch: 1578 - Train Loss: 0.01097965519875288 - Test Loss: 0.0262950100004673\nEpoch: 1579 - Train Loss: 0.010941228829324245 - Test Loss: 0.026254165917634964\nEpoch: 1580 - Train Loss: 0.010902942158281803 - Test Loss: 0.02621346525847912\nEpoch: 1581 - Train Loss: 0.010864786803722382 - Test Loss: 0.026172900572419167\nEpoch: 1582 - Train Loss: 0.010826761834323406 - Test Loss: 0.02613246999680996\nEpoch: 1583 - Train Loss: 0.0107888700440526 - Test Loss: 0.026092179119586945\nEpoch: 1584 - Train Loss: 0.010751107707619667 - Test Loss: 0.026052018627524376\nEpoch: 1585 - Train Loss: 0.010713479481637478 - Test Loss: 0.026011997833848\nEpoch: 1586 - Train Loss: 0.010675977915525436 - Test Loss: 0.025972111150622368\nEpoch: 1587 - Train Loss: 0.010638605803251266 - Test Loss: 0.02593235671520233\nEpoch: 1588 - Train Loss: 0.010601365007460117 - Test Loss: 0.02589274011552334\nEpoch: 1589 - Train Loss: 0.010564250871539116 - Test Loss: 0.02585325576364994\nEpoch: 1590 - Train Loss: 0.010527268052101135 - Test Loss: 0.025813907384872437\nEpoch: 1591 - Train Loss: 0.010490414686501026 - Test Loss: 0.025774694979190826\nEpoch: 1592 - Train Loss: 0.01045368704944849 - Test Loss: 0.025735609233379364\nEpoch: 1593 - Train Loss: 0.010417080484330654 - Test Loss: 0.0256966445595026\nEpoch: 1594 - Train Loss: 0.010380606167018414 - Test Loss: 0.02565782703459263\nEpoch: 1595 - Train Loss: 0.010344257578253746 - Test Loss: 0.025619132444262505\nEpoch: 1596 - Train Loss: 0.010308031924068928 - Test Loss: 0.025580570101737976\nEpoch: 1597 - Train Loss: 0.01027193944901228 - Test Loss: 0.02554214373230934\nEpoch: 1598 - Train Loss: 0.010235965251922607 - Test Loss: 0.025503845885396004\nEpoch: 1599 - Train Loss: 0.010200112126767635 - Test Loss: 0.025465665385127068\nEpoch: 1600 - Train Loss: 0.010164386592805386 - Test Loss: 0.025427618995308876\nEpoch: 1601 - Train Loss: 0.010128787718713284 - Test Loss: 0.02538970485329628\nEpoch: 1602 - Train Loss: 0.010093308985233307 - Test Loss: 0.02535191737115383\nEpoch: 1603 - Train Loss: 0.010057955048978329 - Test Loss: 0.02531426213681698\nEpoch: 1604 - Train Loss: 0.010022723115980625 - Test Loss: 0.025276729837059975\nEpoch: 1605 - Train Loss: 0.009987609460949898 - Test Loss: 0.02523932047188282\nEpoch: 1606 - Train Loss: 0.009952615015208721 - Test Loss: 0.025202034041285515\nEpoch: 1607 - Train Loss: 0.009917744435369968 - Test Loss: 0.025164877995848656\nEpoch: 1608 - Train Loss: 0.009882993064820766 - Test Loss: 0.025127844884991646\nEpoch: 1609 - Train Loss: 0.009848363697528839 - Test Loss: 0.025090942159295082\nEpoch: 1610 - Train Loss: 0.009813857264816761 - Test Loss: 0.025054164230823517\nEpoch: 1611 - Train Loss: 0.009779466316103935 - Test Loss: 0.02501750737428665\nEpoch: 1612 - Train Loss: 0.009745188988745213 - Test Loss: 0.024980967864394188\nEpoch: 1613 - Train Loss: 0.009711036458611488 - Test Loss: 0.02494455873966217\nEpoch: 1614 - Train Loss: 0.00967700220644474 - Test Loss: 0.024908270686864853\nEpoch: 1615 - Train Loss: 0.009643081575632095 - Test Loss: 0.024872105568647385\nEpoch: 1616 - Train Loss: 0.009609280154109001 - Test Loss: 0.024836061522364616\nEpoch: 1617 - Train Loss: 0.009575595147907734 - Test Loss: 0.02480013482272625\nEpoch: 1618 - Train Loss: 0.009542028419673443 - Test Loss: 0.02476433292031288\nEpoch: 1619 - Train Loss: 0.009508575312793255 - Test Loss: 0.024728653952479362\nEpoch: 1620 - Train Loss: 0.009475236758589745 - Test Loss: 0.024693094193935394\nEpoch: 1621 - Train Loss: 0.009442011825740337 - Test Loss: 0.02465764991939068\nEpoch: 1622 - Train Loss: 0.009408908896148205 - Test Loss: 0.02462233230471611\nEpoch: 1623 - Train Loss: 0.009375912137329578 - Test Loss: 0.024587126448750496\nEpoch: 1624 - Train Loss: 0.009343034587800503 - Test Loss: 0.02455204166471958\nEpoch: 1625 - Train Loss: 0.00931027252227068 - Test Loss: 0.024517083540558815\nEpoch: 1626 - Train Loss: 0.009277617558836937 - Test Loss: 0.024482233449816704\nEpoch: 1627 - Train Loss: 0.009245081804692745 - Test Loss: 0.02444750815629959\nEpoch: 1628 - Train Loss: 0.00921265222132206 - Test Loss: 0.024412894621491432\nEpoch: 1629 - Train Loss: 0.009180338121950626 - Test Loss: 0.024378396570682526\nEpoch: 1630 - Train Loss: 0.009148137643933296 - Test Loss: 0.024344023317098618\nEpoch: 1631 - Train Loss: 0.009116041474044323 - Test Loss: 0.024309754371643066\nEpoch: 1632 - Train Loss: 0.009084059856832027 - Test Loss: 0.024275608360767365\nEpoch: 1633 - Train Loss: 0.009052186273038387 - Test Loss: 0.024241570383310318\nEpoch: 1634 - Train Loss: 0.00902042631059885 - Test Loss: 0.02420765534043312\nEpoch: 1635 - Train Loss: 0.008988779038190842 - Test Loss: 0.024173857644200325\nEpoch: 1636 - Train Loss: 0.008957237005233765 - Test Loss: 0.024140166118741035\nEpoch: 1637 - Train Loss: 0.008925799280405045 - Test Loss: 0.0241065863519907\nEpoch: 1638 - Train Loss: 0.008894476108253002 - Test Loss: 0.024073125794529915\nEpoch: 1639 - Train Loss: 0.008863260969519615 - Test Loss: 0.024039780721068382\nEpoch: 1640 - Train Loss: 0.008832150138914585 - Test Loss: 0.024006539955735207\nEpoch: 1641 - Train Loss: 0.008801144547760487 - Test Loss: 0.023973409086465836\nEpoch: 1642 - Train Loss: 0.008770253509283066 - Test Loss: 0.023940401151776314\nEpoch: 1643 - Train Loss: 0.008739463053643703 - Test Loss: 0.023907499387860298\nEpoch: 1644 - Train Loss: 0.008708777837455273 - Test Loss: 0.02387470193207264\nEpoch: 1645 - Train Loss: 0.008678200654685497 - Test Loss: 0.023842021822929382\nEpoch: 1646 - Train Loss: 0.008647731505334377 - Test Loss: 0.02380945347249508\nEpoch: 1647 - Train Loss: 0.008617368526756763 - Test Loss: 0.02377699501812458\nEpoch: 1648 - Train Loss: 0.008587106131017208 - Test Loss: 0.023744642734527588\nEpoch: 1649 - Train Loss: 0.008556947112083435 - Test Loss: 0.0237123966217041\nEpoch: 1650 - Train Loss: 0.008526895195245743 - Test Loss: 0.023680265992879868\nEpoch: 1651 - Train Loss: 0.008496949449181557 - Test Loss: 0.023648245260119438\nEpoch: 1652 - Train Loss: 0.008467105217278004 - Test Loss: 0.023616326972842216\nEpoch: 1653 - Train Loss: 0.00843735970556736 - Test Loss: 0.023584512993693352\nEpoch: 1654 - Train Loss: 0.008407722227275372 - Test Loss: 0.02355281449854374\nEpoch: 1655 - Train Loss: 0.008378186263144016 - Test Loss: 0.023521224036812782\nEpoch: 1656 - Train Loss: 0.00834874901920557 - Test Loss: 0.023489734157919884\nEpoch: 1657 - Train Loss: 0.008319413289427757 - Test Loss: 0.02345835044980049\nEpoch: 1658 - Train Loss: 0.0082901855930686 - Test Loss: 0.023427076637744904\nEpoch: 1659 - Train Loss: 0.008261052891612053 - Test Loss: 0.02339591085910797\nEpoch: 1660 - Train Loss: 0.008232018910348415 - Test Loss: 0.02336484007537365\nEpoch: 1661 - Train Loss: 0.008203087374567986 - Test Loss: 0.023333881050348282\nEpoch: 1662 - Train Loss: 0.008174258284270763 - Test Loss: 0.02330303005874157\nEpoch: 1663 - Train Loss: 0.00814552791416645 - Test Loss: 0.023272277787327766\nEpoch: 1664 - Train Loss: 0.0081168906763196 - Test Loss: 0.023241626098752022\nEpoch: 1665 - Train Loss: 0.008088357746601105 - Test Loss: 0.023211084306240082\nEpoch: 1666 - Train Loss: 0.00805992353707552 - Test Loss: 0.023180648684501648\nEpoch: 1667 - Train Loss: 0.00803158525377512 - Test Loss: 0.023150306195020676\nEpoch: 1668 - Train Loss: 0.008003342896699905 - Test Loss: 0.02312006987631321\nEpoch: 1669 - Train Loss: 0.007975203916430473 - Test Loss: 0.02308993972837925\nEpoch: 1670 - Train Loss: 0.00794715341180563 - Test Loss: 0.0230599045753479\nEpoch: 1671 - Train Loss: 0.00791920442134142 - Test Loss: 0.023029973730444908\nEpoch: 1672 - Train Loss: 0.007891352288424969 - Test Loss: 0.023000145331025124\nEpoch: 1673 - Train Loss: 0.007863594219088554 - Test Loss: 0.022970419377088547\nEpoch: 1674 - Train Loss: 0.007835933938622475 - Test Loss: 0.02294079028069973\nEpoch: 1675 - Train Loss: 0.007808367721736431 - Test Loss: 0.02291126176714897\nEpoch: 1676 - Train Loss: 0.007780898828059435 - Test Loss: 0.02288183942437172\nEpoch: 1677 - Train Loss: 0.00775351794436574 - Test Loss: 0.02285250648856163\nEpoch: 1678 - Train Loss: 0.007726236246526241 - Test Loss: 0.0228232741355896\nEpoch: 1679 - Train Loss: 0.007699048612266779 - Test Loss: 0.022794144228100777\nEpoch: 1680 - Train Loss: 0.007671949453651905 - Test Loss: 0.022765103727579117\nEpoch: 1681 - Train Loss: 0.007644945289939642 - Test Loss: 0.022736165672540665\nEpoch: 1682 - Train Loss: 0.007618033792823553 - Test Loss: 0.022707324475049973\nEpoch: 1683 - Train Loss: 0.007591217756271362 - Test Loss: 0.02267858386039734\nEpoch: 1684 - Train Loss: 0.007564492058008909 - Test Loss: 0.022649938240647316\nEpoch: 1685 - Train Loss: 0.007537860423326492 - Test Loss: 0.02262139320373535\nEpoch: 1686 - Train Loss: 0.007511320058256388 - Test Loss: 0.02259294129908085\nEpoch: 1687 - Train Loss: 0.007484869100153446 - Test Loss: 0.022564584389328957\nEpoch: 1688 - Train Loss: 0.007458506617695093 - Test Loss: 0.022536320611834526\nEpoch: 1689 - Train Loss: 0.007432239595800638 - Test Loss: 0.022508155554533005\nEpoch: 1690 - Train Loss: 0.00740605965256691 - Test Loss: 0.022480081766843796\nEpoch: 1691 - Train Loss: 0.007379972841590643 - Test Loss: 0.022452110424637794\nEpoch: 1692 - Train Loss: 0.007353974971920252 - Test Loss: 0.022424230352044106\nEpoch: 1693 - Train Loss: 0.007328064180910587 - Test Loss: 0.02239643968641758\nEpoch: 1694 - Train Loss: 0.007302241865545511 - Test Loss: 0.022368744015693665\nEpoch: 1695 - Train Loss: 0.0072765108197927475 - Test Loss: 0.02234114333987236\nEpoch: 1696 - Train Loss: 0.007250865921378136 - Test Loss: 0.022313633933663368\nEpoch: 1697 - Train Loss: 0.007225312292575836 - Test Loss: 0.022286219522356987\nEpoch: 1698 - Train Loss: 0.007199844345450401 - Test Loss: 0.022258896380662918\nEpoch: 1699 - Train Loss: 0.007174463476985693 - Test Loss: 0.022231662645936012\nEpoch: 1700 - Train Loss: 0.007149169221520424 - Test Loss: 0.022204522043466568\nEpoch: 1701 - Train Loss: 0.007123963441699743 - Test Loss: 0.022177476435899734\nEpoch: 1702 - Train Loss: 0.007098843809217215 - Test Loss: 0.022150514647364616\nEpoch: 1703 - Train Loss: 0.007073812186717987 - Test Loss: 0.022123655304312706\nEpoch: 1704 - Train Loss: 0.0070488653145730495 - Test Loss: 0.02209688164293766\nEpoch: 1705 - Train Loss: 0.007024003192782402 - Test Loss: 0.02207019366323948\nEpoch: 1706 - Train Loss: 0.00699922489002347 - Test Loss: 0.02204359881579876\nEpoch: 1707 - Train Loss: 0.006974535528570414 - Test Loss: 0.022017095237970352\nEpoch: 1708 - Train Loss: 0.006949929054826498 - Test Loss: 0.02199067920446396\nEpoch: 1709 - Train Loss: 0.006925409194082022 - Test Loss: 0.021964354440569878\nEpoch: 1710 - Train Loss: 0.006900973152369261 - Test Loss: 0.02193811908364296\nEpoch: 1711 - Train Loss: 0.006876619998365641 - Test Loss: 0.021911971271038055\nEpoch: 1712 - Train Loss: 0.006852349732071161 - Test Loss: 0.021885912865400314\nEpoch: 1713 - Train Loss: 0.006828164681792259 - Test Loss: 0.02185993641614914\nEpoch: 1714 - Train Loss: 0.006804061587899923 - Test Loss: 0.021834053099155426\nEpoch: 1715 - Train Loss: 0.006780040450394154 - Test Loss: 0.021808257326483727\nEpoch: 1716 - Train Loss: 0.006756104528903961 - Test Loss: 0.02178254909813404\nEpoch: 1717 - Train Loss: 0.006732249166816473 - Test Loss: 0.02175692468881607\nEpoch: 1718 - Train Loss: 0.006708478555083275 - Test Loss: 0.021731393411755562\nEpoch: 1719 - Train Loss: 0.006684785708785057 - Test Loss: 0.02170593850314617\nEpoch: 1720 - Train Loss: 0.0066611748188734055 - Test Loss: 0.021680576726794243\nEpoch: 1721 - Train Loss: 0.006637650076299906 - Test Loss: 0.021655304357409477\nEpoch: 1722 - Train Loss: 0.006614199373871088 - Test Loss: 0.02163011021912098\nEpoch: 1723 - Train Loss: 0.006590832490473986 - Test Loss: 0.021605001762509346\nEpoch: 1724 - Train Loss: 0.006567544769495726 - Test Loss: 0.021579978987574577\nEpoch: 1725 - Train Loss: 0.006544339936226606 - Test Loss: 0.021555043756961823\nEpoch: 1726 - Train Loss: 0.0065212128683924675 - Test Loss: 0.021530192345380783\nEpoch: 1727 - Train Loss: 0.006498165428638458 - Test Loss: 0.02150542102754116\nEpoch: 1728 - Train Loss: 0.006475195754319429 - Test Loss: 0.021480735391378403\nEpoch: 1729 - Train Loss: 0.006452302914112806 - Test Loss: 0.021456129848957062\nEpoch: 1730 - Train Loss: 0.006429496221244335 - Test Loss: 0.021431611850857735\nEpoch: 1731 - Train Loss: 0.006406761705875397 - Test Loss: 0.021407179534435272\nEpoch: 1732 - Train Loss: 0.006384104490280151 - Test Loss: 0.02138282172381878\nEpoch: 1733 - Train Loss: 0.0063615282997488976 - Test Loss: 0.02135854959487915\nEpoch: 1734 - Train Loss: 0.006339032202959061 - Test Loss: 0.021334365010261536\nEpoch: 1735 - Train Loss: 0.0063166129402816296 - Test Loss: 0.021310264244675636\nEpoch: 1736 - Train Loss: 0.006294265389442444 - Test Loss: 0.021286236122250557\nEpoch: 1737 - Train Loss: 0.006271999794989824 - Test Loss: 0.02126229554414749\nEpoch: 1738 - Train Loss: 0.006249808240681887 - Test Loss: 0.021238431334495544\nEpoch: 1739 - Train Loss: 0.006227693520486355 - Test Loss: 0.021214652806520462\nEpoch: 1740 - Train Loss: 0.006205654237419367 - Test Loss: 0.021190950646996498\nEpoch: 1741 - Train Loss: 0.006183694116771221 - Test Loss: 0.0211673341691494\nEpoch: 1742 - Train Loss: 0.006161804310977459 - Test Loss: 0.02114379033446312\nEpoch: 1743 - Train Loss: 0.00613999180495739 - Test Loss: 0.021120330318808556\nEpoch: 1744 - Train Loss: 0.0061182547360658646 - Test Loss: 0.02109695039689541\nEpoch: 1745 - Train Loss: 0.0060965935699641705 - Test Loss: 0.02107365056872368\nEpoch: 1746 - Train Loss: 0.006075005512684584 - Test Loss: 0.021050430834293365\nEpoch: 1747 - Train Loss: 0.006053491495549679 - Test Loss: 0.021027283743023872\nEpoch: 1748 - Train Loss: 0.006032050121575594 - Test Loss: 0.021004218608140945\nEpoch: 1749 - Train Loss: 0.0060106851160526276 - Test Loss: 0.020981229841709137\nEpoch: 1750 - Train Loss: 0.005989391356706619 - Test Loss: 0.020958319306373596\nEpoch: 1751 - Train Loss: 0.005968174431473017 - Test Loss: 0.02093549072742462\nEpoch: 1752 - Train Loss: 0.005947025492787361 - Test Loss: 0.020912734791636467\nEpoch: 1753 - Train Loss: 0.005925951991230249 - Test Loss: 0.02089005894958973\nEpoch: 1754 - Train Loss: 0.005904949735850096 - Test Loss: 0.02086745575070381\nEpoch: 1755 - Train Loss: 0.005884023383259773 - Test Loss: 0.02084493450820446\nEpoch: 1756 - Train Loss: 0.005863162688910961 - Test Loss: 0.020822487771511078\nEpoch: 1757 - Train Loss: 0.005842380225658417 - Test Loss: 0.020800119265913963\nEpoch: 1758 - Train Loss: 0.005821665748953819 - Test Loss: 0.02077782340347767\nEpoch: 1759 - Train Loss: 0.005801019724458456 - Test Loss: 0.020755602046847343\nEpoch: 1760 - Train Loss: 0.005780449602752924 - Test Loss: 0.020733458921313286\nEpoch: 1761 - Train Loss: 0.005759947933256626 - Test Loss: 0.020711390301585197\nEpoch: 1762 - Train Loss: 0.005739519372582436 - Test Loss: 0.020689398050308228\nEpoch: 1763 - Train Loss: 0.005719160661101341 - Test Loss: 0.020667482167482376\nEpoch: 1764 - Train Loss: 0.005698871333152056 - Test Loss: 0.020645638927817345\nEpoch: 1765 - Train Loss: 0.00567864952608943 - Test Loss: 0.020623870193958282\nEpoch: 1766 - Train Loss: 0.005658500827848911 - Test Loss: 0.02060217410326004\nEpoch: 1767 - Train Loss: 0.005638419650495052 - Test Loss: 0.020580554381012917\nEpoch: 1768 - Train Loss: 0.005618406925350428 - Test Loss: 0.020559003576636314\nEpoch: 1769 - Train Loss: 0.00559846218675375 - Test Loss: 0.02053752727806568\nEpoch: 1770 - Train Loss: 0.005578592419624329 - Test Loss: 0.020516132935881615\nEpoch: 1771 - Train Loss: 0.005558783188462257 - Test Loss: 0.020494800060987473\nEpoch: 1772 - Train Loss: 0.005539047531783581 - Test Loss: 0.020473549142479897\nEpoch: 1773 - Train Loss: 0.005519379395991564 - Test Loss: 0.020452365279197693\nEpoch: 1774 - Train Loss: 0.005499778315424919 - Test Loss: 0.020431257784366608\nEpoch: 1775 - Train Loss: 0.005480242893099785 - Test Loss: 0.020410215482115746\nEpoch: 1776 - Train Loss: 0.00546077499166131 - Test Loss: 0.020389247685670853\nEpoch: 1777 - Train Loss: 0.005441376939415932 - Test Loss: 0.020368356257677078\nEpoch: 1778 - Train Loss: 0.005422044079750776 - Test Loss: 0.020347531884908676\nEpoch: 1779 - Train Loss: 0.005402781069278717 - Test Loss: 0.020326783880591393\nEpoch: 1780 - Train Loss: 0.005383579526096582 - Test Loss: 0.020306099206209183\nEpoch: 1781 - Train Loss: 0.005364446435123682 - Test Loss: 0.02028549090027809\nEpoch: 1782 - Train Loss: 0.005345378536731005 - Test Loss: 0.020264949649572372\nEpoch: 1783 - Train Loss: 0.005326378159224987 - Test Loss: 0.020244481042027473\nEpoch: 1784 - Train Loss: 0.005307439714670181 - Test Loss: 0.020224077627062798\nEpoch: 1785 - Train Loss: 0.005288568791002035 - Test Loss: 0.02020374685525894\nEpoch: 1786 - Train Loss: 0.00526976166293025 - Test Loss: 0.020183486863970757\nEpoch: 1787 - Train Loss: 0.0052510215900838375 - Test Loss: 0.020163295790553093\nEpoch: 1788 - Train Loss: 0.005232345778495073 - Test Loss: 0.0201431754976511\nEpoch: 1789 - Train Loss: 0.005213732831180096 - Test Loss: 0.020123116672039032\nEpoch: 1790 - Train Loss: 0.005195183679461479 - Test Loss: 0.020103134214878082\nEpoch: 1791 - Train Loss: 0.005176699720323086 - Test Loss: 0.020083215087652206\nEpoch: 1792 - Train Loss: 0.005158279091119766 - Test Loss: 0.02006336860358715\nEpoch: 1793 - Train Loss: 0.005139920860528946 - Test Loss: 0.02004358172416687\nEpoch: 1794 - Train Loss: 0.005121625028550625 - Test Loss: 0.02002386562526226\nEpoch: 1795 - Train Loss: 0.005103394389152527 - Test Loss: 0.020004218444228172\nEpoch: 1796 - Train Loss: 0.005085225682705641 - Test Loss: 0.019984640181064606\nEpoch: 1797 - Train Loss: 0.005067119374871254 - Test Loss: 0.019965127110481262\nEpoch: 1798 - Train Loss: 0.005049076862633228 - Test Loss: 0.01994568295776844\nEpoch: 1799 - Train Loss: 0.0050310962833464146 - Test Loss: 0.01992630586028099\nEpoch: 1800 - Train Loss: 0.005013176240026951 - Test Loss: 0.019906990230083466\nEpoch: 1801 - Train Loss: 0.004995317198336124 - Test Loss: 0.019887741655111313\nEpoch: 1802 - Train Loss: 0.004977521486580372 - Test Loss: 0.019868560135364532\nEpoch: 1803 - Train Loss: 0.004959786776453257 - Test Loss: 0.019849441945552826\nEpoch: 1804 - Train Loss: 0.004942111670970917 - Test Loss: 0.01983039081096649\nEpoch: 1805 - Train Loss: 0.004924497101455927 - Test Loss: 0.01981140486896038\nEpoch: 1806 - Train Loss: 0.004906945396214724 - Test Loss: 0.019792484119534492\nEpoch: 1807 - Train Loss: 0.004889452829957008 - Test Loss: 0.01977362670004368\nEpoch: 1808 - Train Loss: 0.004872020334005356 - Test Loss: 0.019754832610487938\nEpoch: 1809 - Train Loss: 0.004854647442698479 - Test Loss: 0.01973610371351242\nEpoch: 1810 - Train Loss: 0.0048373364843428135 - Test Loss: 0.019717440009117126\nEpoch: 1811 - Train Loss: 0.004820084199309349 - Test Loss: 0.019698841497302055\nEpoch: 1812 - Train Loss: 0.004802891053259373 - Test Loss: 0.01968030259013176\nEpoch: 1813 - Train Loss: 0.00478575611487031 - Test Loss: 0.019661827012896538\nEpoch: 1814 - Train Loss: 0.004768683109432459 - Test Loss: 0.019643418490886688\nEpoch: 1815 - Train Loss: 0.004751667845994234 - Test Loss: 0.019625073298811913\nEpoch: 1816 - Train Loss: 0.00473471125587821 - Test Loss: 0.019606787711381912\nEpoch: 1817 - Train Loss: 0.004717811942100525 - Test Loss: 0.019588565453886986\nEpoch: 1818 - Train Loss: 0.004700973629951477 - Test Loss: 0.01957041025161743\nEpoch: 1819 - Train Loss: 0.004684192128479481 - Test Loss: 0.019552314653992653\nEpoch: 1820 - Train Loss: 0.00466747023165226 - Test Loss: 0.019534284248948097\nEpoch: 1821 - Train Loss: 0.004650806076824665 - Test Loss: 0.019516311585903168\nEpoch: 1822 - Train Loss: 0.004634195938706398 - Test Loss: 0.01949840411543846\nEpoch: 1823 - Train Loss: 0.004617647267878056 - Test Loss: 0.01948055624961853\nEpoch: 1824 - Train Loss: 0.004601153079420328 - Test Loss: 0.019462769851088524\nEpoch: 1825 - Train Loss: 0.00458471430465579 - Test Loss: 0.019445041194558144\nEpoch: 1826 - Train Loss: 0.004568334668874741 - Test Loss: 0.019427377730607986\nEpoch: 1827 - Train Loss: 0.0045520104467868805 - Test Loss: 0.019409772008657455\nEpoch: 1828 - Train Loss: 0.004535744898021221 - Test Loss: 0.019392231479287148\nEpoch: 1829 - Train Loss: 0.004519535228610039 - Test Loss: 0.019374748691916466\nEpoch: 1830 - Train Loss: 0.0045033772476017475 - Test Loss: 0.01935732364654541\nEpoch: 1831 - Train Loss: 0.004487279802560806 - Test Loss: 0.01933996193110943\nEpoch: 1832 - Train Loss: 0.004471234977245331 - Test Loss: 0.019322656095027924\nEpoch: 1833 - Train Loss: 0.004455244168639183 - Test Loss: 0.019305408000946045\nEpoch: 1834 - Train Loss: 0.0044393111020326614 - Test Loss: 0.01928822696208954\nEpoch: 1835 - Train Loss: 0.0044234320521354675 - Test Loss: 0.01927109621465206\nEpoch: 1836 - Train Loss: 0.0044076102785766125 - Test Loss: 0.019254034385085106\nEpoch: 1837 - Train Loss: 0.0043918415904045105 - Test Loss: 0.01923702284693718\nEpoch: 1838 - Train Loss: 0.004376124124974012 - Test Loss: 0.01922006905078888\nEpoch: 1839 - Train Loss: 0.004360465798527002 - Test Loss: 0.019203180447220802\nEpoch: 1840 - Train Loss: 0.0043448577634990215 - Test Loss: 0.019186345860362053\nEpoch: 1841 - Train Loss: 0.004329302813857794 - Test Loss: 0.01916956715285778\nEpoch: 1842 - Train Loss: 0.004313803743571043 - Test Loss: 0.019152848049998283\nEpoch: 1843 - Train Loss: 0.004298357293009758 - Test Loss: 0.019136186689138412\nEpoch: 1844 - Train Loss: 0.004282963462173939 - Test Loss: 0.01911957748234272\nEpoch: 1845 - Train Loss: 0.004267624579370022 - Test Loss: 0.0191030316054821\nEpoch: 1846 - Train Loss: 0.004252337384968996 - Test Loss: 0.01908653974533081\nEpoch: 1847 - Train Loss: 0.0042371004819869995 - Test Loss: 0.019070101901888847\nEpoch: 1848 - Train Loss: 0.004221920855343342 - Test Loss: 0.01905372366309166\nEpoch: 1849 - Train Loss: 0.0042067901231348515 - Test Loss: 0.01903740130364895\nEpoch: 1850 - Train Loss: 0.004191710148006678 - Test Loss: 0.019021132960915565\nEpoch: 1851 - Train Loss: 0.004176684655249119 - Test Loss: 0.019004924222826958\nEpoch: 1852 - Train Loss: 0.004161710850894451 - Test Loss: 0.01898876763880253\nEpoch: 1853 - Train Loss: 0.0041467901319265366 - Test Loss: 0.018972672522068024\nEpoch: 1854 - Train Loss: 0.004131919704377651 - Test Loss: 0.018956627696752548\nEpoch: 1855 - Train Loss: 0.004117098171263933 - Test Loss: 0.01894063875079155\nEpoch: 1856 - Train Loss: 0.004102332517504692 - Test Loss: 0.018924709409475327\nEpoch: 1857 - Train Loss: 0.004087614361196756 - Test Loss: 0.018908832222223282\nEpoch: 1858 - Train Loss: 0.004072946030646563 - Test Loss: 0.018893005326390266\nEpoch: 1859 - Train Loss: 0.004058330785483122 - Test Loss: 0.018877239897847176\nEpoch: 1860 - Train Loss: 0.004043765366077423 - Test Loss: 0.018861524760723114\nEpoch: 1861 - Train Loss: 0.0040292516350746155 - Test Loss: 0.01884586736559868\nEpoch: 1862 - Train Loss: 0.00401478772982955 - Test Loss: 0.018830260261893272\nEpoch: 1863 - Train Loss: 0.004000369925051928 - Test Loss: 0.018814703449606895\nEpoch: 1864 - Train Loss: 0.003986004739999771 - Test Loss: 0.018799206241965294\nEpoch: 1865 - Train Loss: 0.003971688449382782 - Test Loss: 0.01878375932574272\nEpoch: 1866 - Train Loss: 0.003957422915846109 - Test Loss: 0.018768370151519775\nEpoch: 1867 - Train Loss: 0.003943203017115593 - Test Loss: 0.01875302568078041\nEpoch: 1868 - Train Loss: 0.003929035272449255 - Test Loss: 0.01873774081468582\nEpoch: 1869 - Train Loss: 0.003914914559572935 - Test Loss: 0.01872250624001026\nEpoch: 1870 - Train Loss: 0.003900845069438219 - Test Loss: 0.01870732754468918\nEpoch: 1871 - Train Loss: 0.003886820748448372 - Test Loss: 0.018692195415496826\nEpoch: 1872 - Train Loss: 0.0038728464860469103 - Test Loss: 0.01867711916565895\nEpoch: 1873 - Train Loss: 0.0038589199539273977 - Test Loss: 0.018662091344594955\nEpoch: 1874 - Train Loss: 0.003845043247565627 - Test Loss: 0.018647123128175735\nEpoch: 1875 - Train Loss: 0.0038312117103487253 - Test Loss: 0.018632199615240097\nEpoch: 1876 - Train Loss: 0.0038174265064299107 - Test Loss: 0.01861732453107834\nEpoch: 1877 - Train Loss: 0.0038036915939301252 - Test Loss: 0.018602507188916206\nEpoch: 1878 - Train Loss: 0.0037900025490671396 - Test Loss: 0.018587734550237656\nEpoch: 1879 - Train Loss: 0.003776363329961896 - Test Loss: 0.01857302151620388\nEpoch: 1880 - Train Loss: 0.003762770676985383 - Test Loss: 0.018558355048298836\nEpoch: 1881 - Train Loss: 0.0037492215633392334 - Test Loss: 0.01854373700916767\nEpoch: 1882 - Train Loss: 0.003735723439604044 - Test Loss: 0.018529172986745834\nEpoch: 1883 - Train Loss: 0.0037222695536911488 - Test Loss: 0.018514657393097878\nEpoch: 1884 - Train Loss: 0.0037088606040924788 - Test Loss: 0.0185001902282238\nEpoch: 1885 - Train Loss: 0.0036955007817596197 - Test Loss: 0.01848577708005905\nEpoch: 1886 - Train Loss: 0.003682186361402273 - Test Loss: 0.01847141422331333\nEpoch: 1887 - Train Loss: 0.003668916877359152 - Test Loss: 0.018457097932696342\nEpoch: 1888 - Train Loss: 0.003655695356428623 - Test Loss: 0.018442831933498383\nEpoch: 1889 - Train Loss: 0.0036425187718123198 - Test Loss: 0.018428616225719452\nEpoch: 1890 - Train Loss: 0.0036293852608650923 - Test Loss: 0.01841445080935955\nEpoch: 1891 - Train Loss: 0.0036163011100143194 - Test Loss: 0.01840033195912838\nEpoch: 1892 - Train Loss: 0.0036032593343406916 - Test Loss: 0.01838626340031624\nEpoch: 1893 - Train Loss: 0.0035902622621506453 - Test Loss: 0.018372241407632828\nEpoch: 1894 - Train Loss: 0.0035773117560893297 - Test Loss: 0.018358269706368446\nEpoch: 1895 - Train Loss: 0.0035644054878503084 - Test Loss: 0.018344346433877945\nEpoch: 1896 - Train Loss: 0.003551542991772294 - Test Loss: 0.018330469727516174\nEpoch: 1897 - Train Loss: 0.0035387245006859303 - Test Loss: 0.018316641449928284\nEpoch: 1898 - Train Loss: 0.0035259525757282972 - Test Loss: 0.018302863463759422\nEpoch: 1899 - Train Loss: 0.003513224422931671 - Test Loss: 0.01828913390636444\nEpoch: 1900 - Train Loss: 0.003500539343804121 - Test Loss: 0.01827544905245304\nEpoch: 1901 - Train Loss: 0.003487897804006934 - Test Loss: 0.01826181448996067\nEpoch: 1902 - Train Loss: 0.003475301433354616 - Test Loss: 0.01824822835624218\nEpoch: 1903 - Train Loss: 0.003462748834863305 - Test Loss: 0.01823468506336212\nEpoch: 1904 - Train Loss: 0.003450238611549139 - Test Loss: 0.018221192061901093\nEpoch: 1905 - Train Loss: 0.0034377712290734053 - Test Loss: 0.018207743763923645\nEpoch: 1906 - Train Loss: 0.0034253469202667475 - Test Loss: 0.018194343894720078\nEpoch: 1907 - Train Loss: 0.003412964753806591 - Test Loss: 0.018180986866354942\nEpoch: 1908 - Train Loss: 0.0034006298519670963 - Test Loss: 0.018167681992053986\nEpoch: 1909 - Train Loss: 0.0033883319701999426 - Test Loss: 0.01815441995859146\nEpoch: 1910 - Train Loss: 0.003376081120222807 - Test Loss: 0.018141204491257668\nEpoch: 1911 - Train Loss: 0.0033638698514550924 - Test Loss: 0.018128035590052605\nEpoch: 1912 - Train Loss: 0.0033517004922032356 - Test Loss: 0.018114911392331123\nEpoch: 1913 - Train Loss: 0.003339574672281742 - Test Loss: 0.018101831898093224\nEpoch: 1914 - Train Loss: 0.0033274907618761063 - Test Loss: 0.018088800832629204\nEpoch: 1915 - Train Loss: 0.003315447364002466 - Test Loss: 0.018075810745358467\nEpoch: 1916 - Train Loss: 0.003303447738289833 - Test Loss: 0.01806286908686161\nEpoch: 1917 - Train Loss: 0.0032914895564317703 - Test Loss: 0.018049970269203186\nEpoch: 1918 - Train Loss: 0.003279569558799267 - Test Loss: 0.01803711988031864\nEpoch: 1919 - Train Loss: 0.0032676951959729195 - Test Loss: 0.01802431233227253\nEpoch: 1920 - Train Loss: 0.0032558590173721313 - Test Loss: 0.01801155135035515\nEpoch: 1921 - Train Loss: 0.0032440631184726954 - Test Loss: 0.01799883134663105\nEpoch: 1922 - Train Loss: 0.0032323100604116917 - Test Loss: 0.017986156046390533\nEpoch: 1923 - Train Loss: 0.0032205975148826838 - Test Loss: 0.017973527312278748\nEpoch: 1924 - Train Loss: 0.0032089250162243843 - Test Loss: 0.017960939556360245\nEpoch: 1925 - Train Loss: 0.003197292098775506 - Test Loss: 0.017948396503925323\nEpoch: 1926 - Train Loss: 0.003185701323673129 - Test Loss: 0.017935901880264282\nEpoch: 1927 - Train Loss: 0.003174150362610817 - Test Loss: 0.017923444509506226\nEpoch: 1928 - Train Loss: 0.003162637585774064 - Test Loss: 0.0179110337048769\nEpoch: 1929 - Train Loss: 0.003151169279590249 - Test Loss: 0.017898667603731155\nEpoch: 1930 - Train Loss: 0.003139738691970706 - Test Loss: 0.017886346206068993\nEpoch: 1931 - Train Loss: 0.003128347685560584 - Test Loss: 0.017874063923954964\nEpoch: 1932 - Train Loss: 0.003116999054327607 - Test Loss: 0.017861831933259964\nEpoch: 1933 - Train Loss: 0.003105689538642764 - Test Loss: 0.017849642783403397\nEpoch: 1934 - Train Loss: 0.0030944189056754112 - Test Loss: 0.017837490886449814\nEpoch: 1935 - Train Loss: 0.0030831899493932724 - Test Loss: 0.01782538741827011\nEpoch: 1936 - Train Loss: 0.0030719994101673365 - Test Loss: 0.01781332492828369\nEpoch: 1937 - Train Loss: 0.003060846356675029 - Test Loss: 0.017801303416490555\nEpoch: 1938 - Train Loss: 0.0030497354455292225 - Test Loss: 0.017789330333471298\nEpoch: 1939 - Train Loss: 0.003038660855963826 - Test Loss: 0.017777396366000175\nEpoch: 1940 - Train Loss: 0.0030276253819465637 - Test Loss: 0.017765501514077187\nEpoch: 1941 - Train Loss: 0.0030166292563080788 - Test Loss: 0.01775364950299263\nEpoch: 1942 - Train Loss: 0.003005671314895153 - Test Loss: 0.017741844058036804\nEpoch: 1943 - Train Loss: 0.00299475179053843 - Test Loss: 0.017730077728629112\nEpoch: 1944 - Train Loss: 0.0029838697519153357 - Test Loss: 0.017718354240059853\nEpoch: 1945 - Train Loss: 0.0029730272945016623 - Test Loss: 0.017706668004393578\nEpoch: 1946 - Train Loss: 0.0029622220899909735 - Test Loss: 0.017695026472210884\nEpoch: 1947 - Train Loss: 0.00295145227573812 - Test Loss: 0.017683424055576324\nEpoch: 1948 - Train Loss: 0.0029407236725091934 - Test Loss: 0.017671864479780197\nEpoch: 1949 - Train Loss: 0.0029300302267074585 - Test Loss: 0.017660344019532204\nEpoch: 1950 - Train Loss: 0.0029193733353167772 - Test Loss: 0.017648864537477493\nEpoch: 1951 - Train Loss: 0.002908754860982299 - Test Loss: 0.017637426033616066\nEpoch: 1952 - Train Loss: 0.002898173639550805 - Test Loss: 0.017626028507947922\nEpoch: 1953 - Train Loss: 0.002887628274038434 - Test Loss: 0.01761467009782791\nEpoch: 1954 - Train Loss: 0.0028771196957677603 - Test Loss: 0.017603352665901184\nEpoch: 1955 - Train Loss: 0.0028666488360613585 - Test Loss: 0.01759207248687744\nEpoch: 1956 - Train Loss: 0.0028562142979353666 - Test Loss: 0.017580833286046982\nEpoch: 1957 - Train Loss: 0.002845813287422061 - Test Loss: 0.017569633200764656\nEpoch: 1958 - Train Loss: 0.0028354523237794638 - Test Loss: 0.017558475956320763\nEpoch: 1959 - Train Loss: 0.002825123257935047 - Test Loss: 0.017547354102134705\nEpoch: 1960 - Train Loss: 0.0028148340061306953 - Test Loss: 0.01753627136349678\nEpoch: 1961 - Train Loss: 0.002804579446092248 - Test Loss: 0.01752523146569729\nEpoch: 1962 - Train Loss: 0.0027943605091422796 - Test Loss: 0.017514226958155632\nEpoch: 1963 - Train Loss: 0.002784176729619503 - Test Loss: 0.01750326342880726\nEpoch: 1964 - Train Loss: 0.002774027641862631 - Test Loss: 0.01749233528971672\nEpoch: 1965 - Train Loss: 0.002763913944363594 - Test Loss: 0.017481448128819466\nEpoch: 1966 - Train Loss: 0.002753834705799818 - Test Loss: 0.017470596358180046\nEpoch: 1967 - Train Loss: 0.0027437948156148195 - Test Loss: 0.017459789291024208\nEpoch: 1968 - Train Loss: 0.0027337847277522087 - Test Loss: 0.017449015751481056\nEpoch: 1969 - Train Loss: 0.002723813522607088 - Test Loss: 0.017438281327486038\nEpoch: 1970 - Train Loss: 0.0027138744480907917 - Test Loss: 0.017427586019039154\nEpoch: 1971 - Train Loss: 0.002703969832509756 - Test Loss: 0.017416926100850105\nEpoch: 1972 - Train Loss: 0.002694101072847843 - Test Loss: 0.017406301572918892\nEpoch: 1973 - Train Loss: 0.00268426607362926 - Test Loss: 0.01739571802318096\nEpoch: 1974 - Train Loss: 0.0026744648348540068 - Test Loss: 0.017385171726346016\nEpoch: 1975 - Train Loss: 0.0026646980550140142 - Test Loss: 0.017374662682414055\nEpoch: 1976 - Train Loss: 0.002654966665431857 - Test Loss: 0.017364192754030228\nEpoch: 1977 - Train Loss: 0.00264526903629303 - Test Loss: 0.017353756353259087\nEpoch: 1978 - Train Loss: 0.0026356030721217394 - Test Loss: 0.01734335720539093\nEpoch: 1979 - Train Loss: 0.0026259738951921463 - Test Loss: 0.017332997173070908\nEpoch: 1980 - Train Loss: 0.00261637382209301 - Test Loss: 0.017322668805718422\nEpoch: 1981 - Train Loss: 0.0026068114675581455 - Test Loss: 0.01731238327920437\nEpoch: 1982 - Train Loss: 0.0025972817093133926 - Test Loss: 0.017302131280303\nEpoch: 1983 - Train Loss: 0.0025877852458506823 - Test Loss: 0.017291920259594917\nEpoch: 1984 - Train Loss: 0.0025783211458474398 - Test Loss: 0.01728174276649952\nEpoch: 1985 - Train Loss: 0.002568890107795596 - Test Loss: 0.017271598801016808\nEpoch: 1986 - Train Loss: 0.0025594914332032204 - Test Loss: 0.01726149208843708\nEpoch: 1987 - Train Loss: 0.002550124889239669 - Test Loss: 0.01725142076611519\nEpoch: 1988 - Train Loss: 0.0025407925713807344 - Test Loss: 0.017241384834051132\nEpoch: 1989 - Train Loss: 0.0025314930826425552 - Test Loss: 0.01723138615489006\nEpoch: 1990 - Train Loss: 0.0025222254917025566 - Test Loss: 0.017221421003341675\nEpoch: 1991 - Train Loss: 0.0025129893328994513 - Test Loss: 0.017211491242051125\nEpoch: 1992 - Train Loss: 0.002503787400200963 - Test Loss: 0.01720159873366356\nEpoch: 1993 - Train Loss: 0.00249461573548615 - Test Loss: 0.01719173975288868\nEpoch: 1994 - Train Loss: 0.0024854771327227354 - Test Loss: 0.017181916162371635\nEpoch: 1995 - Train Loss: 0.0024763704277575016 - Test Loss: 0.017172129824757576\nEpoch: 1996 - Train Loss: 0.0024672949220985174 - Test Loss: 0.017162375152111053\nEpoch: 1997 - Train Loss: 0.0024582529440522194 - Test Loss: 0.017152659595012665\nEpoch: 1998 - Train Loss: 0.0024492403026670218 - Test Loss: 0.017142973840236664\nEpoch: 1999 - Train Loss: 0.0024402583949267864 - Test Loss: 0.017133323475718498\nEpoch: 2000 - Train Loss: 0.002431311644613743 - Test Loss: 0.017123712226748466\nEpoch: 2001 - Train Loss: 0.0024223916698247194 - Test Loss: 0.017114127054810524\nEpoch: 2002 - Train Loss: 0.002413506619632244 - Test Loss: 0.017104579135775566\nEpoch: 2003 - Train Loss: 0.002404650440439582 - Test Loss: 0.017095066606998444\nEpoch: 2004 - Train Loss: 0.0023958247620612383 - Test Loss: 0.017085587605834007\nEpoch: 2005 - Train Loss: 0.0023870314471423626 - Test Loss: 0.017076140269637108\nEpoch: 2006 - Train Loss: 0.002378268400207162 - Test Loss: 0.017066728323698044\nEpoch: 2007 - Train Loss: 0.002369535621255636 - Test Loss: 0.017057349905371666\nEpoch: 2008 - Train Loss: 0.0023608331102877855 - Test Loss: 0.017048006877303123\nEpoch: 2009 - Train Loss: 0.0023521629627794027 - Test Loss: 0.017038695514202118\nEpoch: 2010 - Train Loss: 0.0023435226175934076 - Test Loss: 0.0170294176787138\nEpoch: 2011 - Train Loss: 0.0023349104449152946 - Test Loss: 0.017020173370838165\nEpoch: 2012 - Train Loss: 0.002326331799849868 - Test Loss: 0.017010964453220367\nEpoch: 2013 - Train Loss: 0.0023177789989858866 - Test Loss: 0.01700177974998951\nEpoch: 2014 - Train Loss: 0.0023092597257345915 - Test Loss: 0.016992637887597084\nEpoch: 2015 - Train Loss: 0.0023007700219750404 - Test Loss: 0.016983525827527046\nEpoch: 2016 - Train Loss: 0.0022923077922314405 - Test Loss: 0.016974443569779396\nEpoch: 2017 - Train Loss: 0.0022838767617940903 - Test Loss: 0.016965394839644432\nEpoch: 2018 - Train Loss: 0.0022754750680178404 - Test Loss: 0.016956381499767303\nEpoch: 2019 - Train Loss: 0.00226710201241076 - Test Loss: 0.016947396099567413\nEpoch: 2020 - Train Loss: 0.0022587606217712164 - Test Loss: 0.01693844608962536\nEpoch: 2021 - Train Loss: 0.002250446006655693 - Test Loss: 0.01692952588200569\nEpoch: 2022 - Train Loss: 0.002242160029709339 - Test Loss: 0.016920635476708412\nEpoch: 2023 - Train Loss: 0.002233906416222453 - Test Loss: 0.016911782324314117\nEpoch: 2024 - Train Loss: 0.002225677715614438 - Test Loss: 0.016902955248951912\nEpoch: 2025 - Train Loss: 0.002217481378465891 - Test Loss: 0.016894163563847542\nEpoch: 2026 - Train Loss: 0.0022093113511800766 - Test Loss: 0.01688540354371071\nEpoch: 2027 - Train Loss: 0.002201169729232788 - Test Loss: 0.016876671463251114\nEpoch: 2028 - Train Loss: 0.002193058142438531 - Test Loss: 0.016867972910404205\nEpoch: 2029 - Train Loss: 0.002184974728152156 - Test Loss: 0.016859306022524834\nEpoch: 2030 - Train Loss: 0.0021769190207123756 - Test Loss: 0.016850670799613\nEpoch: 2031 - Train Loss: 0.0021688914857804775 - Test Loss: 0.016842061653733253\nEpoch: 2032 - Train Loss: 0.002160891890525818 - Test Loss: 0.016833489760756493\nEpoch: 2033 - Train Loss: 0.0021529218647629023 - Test Loss: 0.01682494580745697\nEpoch: 2034 - Train Loss: 0.002144978614524007 - Test Loss: 0.016816431656479836\nEpoch: 2035 - Train Loss: 0.0021370621398091316 - Test Loss: 0.016807951033115387\nEpoch: 2036 - Train Loss: 0.0021291763987392187 - Test Loss: 0.016799500212073326\nEpoch: 2037 - Train Loss: 0.0021213144063949585 - Test Loss: 0.016791075468063354\nEpoch: 2038 - Train Loss: 0.0021134831476956606 - Test Loss: 0.016782686114311218\nEpoch: 2039 - Train Loss: 0.00210567913018167 - Test Loss: 0.01677432470023632\nEpoch: 2040 - Train Loss: 0.002097900491207838 - Test Loss: 0.016765989363193512\nEpoch: 2041 - Train Loss: 0.0020901502575725317 - Test Loss: 0.016757691279053688\nEpoch: 2042 - Train Loss: 0.0020824274979531765 - Test Loss: 0.016749421134591103\nEpoch: 2043 - Train Loss: 0.002074731281027198 - Test Loss: 0.016741177067160606\nEpoch: 2044 - Train Loss: 0.002067063469439745 - Test Loss: 0.016732966527342796\nEpoch: 2045 - Train Loss: 0.002059420570731163 - Test Loss: 0.016724783927202225\nEpoch: 2046 - Train Loss: 0.002051803981885314 - Test Loss: 0.01671662926673889\nEpoch: 2047 - Train Loss: 0.0020442174281924963 - Test Loss: 0.016708508133888245\nEpoch: 2048 - Train Loss: 0.0020366539247334003 - Test Loss: 0.016700414940714836\nEpoch: 2049 - Train Loss: 0.002029120223596692 - Test Loss: 0.016692349687218666\nEpoch: 2050 - Train Loss: 0.002021610736846924 - Test Loss: 0.016684314236044884\nEpoch: 2051 - Train Loss: 0.0020141275599598885 - Test Loss: 0.01667630672454834\nEpoch: 2052 - Train Loss: 0.002006672089919448 - Test Loss: 0.016668327152729034\nEpoch: 2053 - Train Loss: 0.0019992422312498093 - Test Loss: 0.016660382971167564\nEpoch: 2054 - Train Loss: 0.0019918386824429035 - Test Loss: 0.016652461141347885\nEpoch: 2055 - Train Loss: 0.001984460512176156 - Test Loss: 0.016644567251205444\nEpoch: 2056 - Train Loss: 0.0019771079532802105 - Test Loss: 0.01663670502603054\nEpoch: 2057 - Train Loss: 0.0019697826355695724 - Test Loss: 0.016628872603178024\nEpoch: 2058 - Train Loss: 0.0019624829292297363 - Test Loss: 0.016621064394712448\nEpoch: 2059 - Train Loss: 0.0019552065059542656 - Test Loss: 0.01661328598856926\nEpoch: 2060 - Train Loss: 0.001947958953678608 - Test Loss: 0.016605539247393608\nEpoch: 2061 - Train Loss: 0.0019407332874834538 - Test Loss: 0.016597812995314598\nEpoch: 2062 - Train Loss: 0.0019335360266268253 - Test Loss: 0.016590118408203125\nEpoch: 2063 - Train Loss: 0.0019263626309111714 - Test Loss: 0.01658245176076889\nEpoch: 2064 - Train Loss: 0.0019192136824131012 - Test Loss: 0.016574811190366745\nEpoch: 2065 - Train Loss: 0.0019120913930237293 - Test Loss: 0.016567198559641838\nEpoch: 2066 - Train Loss: 0.0019049940165132284 - Test Loss: 0.01655961573123932\nEpoch: 2067 - Train Loss: 0.0018979213200509548 - Test Loss: 0.016552060842514038\nEpoch: 2068 - Train Loss: 0.0018908728379756212 - Test Loss: 0.016544528305530548\nEpoch: 2069 - Train Loss: 0.0018838493851944804 - Test Loss: 0.016537027433514595\nEpoch: 2070 - Train Loss: 0.0018768515437841415 - Test Loss: 0.01652955450117588\nEpoch: 2071 - Train Loss: 0.0018698780331760645 - Test Loss: 0.016522105783224106\nEpoch: 2072 - Train Loss: 0.0018629278056323528 - Test Loss: 0.01651468314230442\nEpoch: 2073 - Train Loss: 0.0018560043536126614 - Test Loss: 0.01650729402899742\nEpoch: 2074 - Train Loss: 0.0018491018563508987 - Test Loss: 0.016499923542141914\nEpoch: 2075 - Train Loss: 0.0018422267166897655 - Test Loss: 0.016492586582899094\nEpoch: 2076 - Train Loss: 0.0018353754421696067 - Test Loss: 0.016485275700688362\nEpoch: 2077 - Train Loss: 0.0018285464029759169 - Test Loss: 0.01647798717021942\nEpoch: 2078 - Train Loss: 0.0018217412289232016 - Test Loss: 0.01647072285413742\nEpoch: 2079 - Train Loss: 0.0018149618990719318 - Test Loss: 0.016463488340377808\nEpoch: 2080 - Train Loss: 0.0018082058522850275 - Test Loss: 0.016456279903650284\nEpoch: 2081 - Train Loss: 0.001801472739316523 - Test Loss: 0.0164490956813097\nEpoch: 2082 - Train Loss: 0.0017947652377188206 - Test Loss: 0.016441943123936653\nEpoch: 2083 - Train Loss: 0.0017880807863548398 - Test Loss: 0.016434814780950546\nEpoch: 2084 - Train Loss: 0.0017814182210713625 - Test Loss: 0.01642770878970623\nEpoch: 2085 - Train Loss: 0.0017747804522514343 - Test Loss: 0.016420632600784302\nEpoch: 2086 - Train Loss: 0.0017681658500805497 - Test Loss: 0.016413580626249313\nEpoch: 2087 - Train Loss: 0.0017615742981433868 - Test Loss: 0.016406554728746414\nEpoch: 2088 - Train Loss: 0.0017550059128552675 - Test Loss: 0.016399554908275604\nEpoch: 2089 - Train Loss: 0.00174846185836941 - Test Loss: 0.016392581164836884\nEpoch: 2090 - Train Loss: 0.0017419406212866306 - Test Loss: 0.016385633498430252\nEpoch: 2091 - Train Loss: 0.0017354408046230674 - Test Loss: 0.016378704458475113\nEpoch: 2092 - Train Loss: 0.0017289650859311223 - Test Loss: 0.01637180708348751\nEpoch: 2093 - Train Loss: 0.0017225120682269335 - Test Loss: 0.01636493392288685\nEpoch: 2094 - Train Loss: 0.0017160814022645354 - Test Loss: 0.016358084976673126\nEpoch: 2095 - Train Loss: 0.0017096750671043992 - Test Loss: 0.016351263970136642\nEpoch: 2096 - Train Loss: 0.00170328957028687 - Test Loss: 0.0163444634526968\nEpoch: 2097 - Train Loss: 0.0016969264252111316 - Test Loss: 0.016337687149643898\nEpoch: 2098 - Train Loss: 0.0016905867960304022 - Test Loss: 0.016330938786268234\nEpoch: 2099 - Train Loss: 0.001684269867837429 - Test Loss: 0.01632421463727951\nEpoch: 2100 - Train Loss: 0.0016779747093096375 - Test Loss: 0.016317512840032578\nEpoch: 2101 - Train Loss: 0.0016717020189389586 - Test Loss: 0.016310837119817734\nEpoch: 2102 - Train Loss: 0.0016654526116326451 - Test Loss: 0.01630418933928013\nEpoch: 2103 - Train Loss: 0.0016592234605923295 - Test Loss: 0.016297562047839165\nEpoch: 2104 - Train Loss: 0.0016530161956325173 - Test Loss: 0.016290957108139992\nEpoch: 2105 - Train Loss: 0.0016468324465677142 - Test Loss: 0.016284383833408356\nEpoch: 2106 - Train Loss: 0.001640670234337449 - Test Loss: 0.016277829185128212\nEpoch: 2107 - Train Loss: 0.0016345293261110783 - Test Loss: 0.016271300613880157\nEpoch: 2108 - Train Loss: 0.001628410303965211 - Test Loss: 0.016264794394373894\nEpoch: 2109 - Train Loss: 0.0016223143320530653 - Test Loss: 0.01625831425189972\nEpoch: 2110 - Train Loss: 0.0016162398969754577 - Test Loss: 0.016251858323812485\nEpoch: 2111 - Train Loss: 0.0016101852525025606 - Test Loss: 0.016245422884821892\nEpoch: 2112 - Train Loss: 0.0016041535418480635 - Test Loss: 0.016239015385508537\nEpoch: 2113 - Train Loss: 0.001598142902366817 - Test Loss: 0.016232630237936974\nEpoch: 2114 - Train Loss: 0.0015921532176434994 - Test Loss: 0.01622626557946205\nEpoch: 2115 - Train Loss: 0.0015861850697547197 - Test Loss: 0.01621992699801922\nEpoch: 2116 - Train Loss: 0.001580239157192409 - Test Loss: 0.016213612630963326\nEpoch: 2117 - Train Loss: 0.0015743128024041653 - Test Loss: 0.016207322478294373\nEpoch: 2118 - Train Loss: 0.0015684071695432067 - Test Loss: 0.016201047226786613\nEpoch: 2119 - Train Loss: 0.0015625241212546825 - Test Loss: 0.01619480550289154\nEpoch: 2120 - Train Loss: 0.0015566613292321563 - Test Loss: 0.01618858426809311\nEpoch: 2121 - Train Loss: 0.0015508192591369152 - Test Loss: 0.01618238352239132\nEpoch: 2122 - Train Loss: 0.0015449976781383157 - Test Loss: 0.01617620512843132\nEpoch: 2123 - Train Loss: 0.0015391980996355414 - Test Loss: 0.01617005467414856\nEpoch: 2124 - Train Loss: 0.001533418893814087 - Test Loss: 0.01616392284631729\nEpoch: 2125 - Train Loss: 0.0015276584308594465 - Test Loss: 0.016157811507582664\nEpoch: 2126 - Train Loss: 0.0015219199704006314 - Test Loss: 0.016151728108525276\nEpoch: 2127 - Train Loss: 0.001516201300546527 - Test Loss: 0.01614566519856453\nEpoch: 2128 - Train Loss: 0.001510503119789064 - Test Loss: 0.016139624640345573\nEpoch: 2129 - Train Loss: 0.0015048246132209897 - Test Loss: 0.01613360457122326\nEpoch: 2130 - Train Loss: 0.001499167992733419 - Test Loss: 0.016127610579133034\nEpoch: 2131 - Train Loss: 0.0014935294166207314 - Test Loss: 0.01612163707613945\nEpoch: 2132 - Train Loss: 0.0014879109803587198 - Test Loss: 0.016115684062242508\nEpoch: 2133 - Train Loss: 0.0014823134988546371 - Test Loss: 0.016109757125377655\nEpoch: 2134 - Train Loss: 0.0014767360407859087 - Test Loss: 0.016103848814964294\nEpoch: 2135 - Train Loss: 0.0014711781404912472 - Test Loss: 0.016097964718937874\nEpoch: 2136 - Train Loss: 0.0014656393323093653 - Test Loss: 0.016092099249362946\nEpoch: 2137 - Train Loss: 0.0014601218281313777 - Test Loss: 0.016086259856820107\nEpoch: 2138 - Train Loss: 0.0014546236488968134 - Test Loss: 0.01608043909072876\nEpoch: 2139 - Train Loss: 0.001449143746867776 - Test Loss: 0.016074640676379204\nEpoch: 2140 - Train Loss: 0.0014436831697821617 - Test Loss: 0.01606886088848114\nEpoch: 2141 - Train Loss: 0.0014382448280230165 - Test Loss: 0.016063107177615166\nEpoch: 2142 - Train Loss: 0.0014328226679936051 - Test Loss: 0.016057372093200684\nEpoch: 2143 - Train Loss: 0.0014274225104600191 - Test Loss: 0.016051659360527992\nEpoch: 2144 - Train Loss: 0.0014220403973013163 - Test Loss: 0.01604596897959709\nEpoch: 2145 - Train Loss: 0.0014166771434247494 - Test Loss: 0.016040300950407982\nEpoch: 2146 - Train Loss: 0.0014113340293988585 - Test Loss: 0.016034651547670364\nEpoch: 2147 - Train Loss: 0.0014060098910704255 - Test Loss: 0.01602902263402939\nEpoch: 2148 - Train Loss: 0.0014007044956088066 - Test Loss: 0.016023417934775352\nEpoch: 2149 - Train Loss: 0.0013954180758446455 - Test Loss: 0.016017833724617958\nEpoch: 2150 - Train Loss: 0.0013901501661166549 - Test Loss: 0.016012268140912056\nEpoch: 2151 - Train Loss: 0.0013849007664248347 - Test Loss: 0.016006721183657646\nEpoch: 2152 - Train Loss: 0.0013796701095998287 - Test Loss: 0.016001198440790176\nEpoch: 2153 - Train Loss: 0.0013744579628109932 - Test Loss: 0.01599569246172905\nEpoch: 2154 - Train Loss: 0.0013692653737962246 - Test Loss: 0.015990210697054863\nEpoch: 2155 - Train Loss: 0.0013640915276482701 - Test Loss: 0.015984753146767616\nEpoch: 2156 - Train Loss: 0.0013589360751211643 - Test Loss: 0.015979310497641563\nEpoch: 2157 - Train Loss: 0.0013537987833842635 - Test Loss: 0.01597389206290245\nEpoch: 2158 - Train Loss: 0.0013486793031916022 - Test Loss: 0.01596848852932453\nEpoch: 2159 - Train Loss: 0.0013435782166197896 - Test Loss: 0.015963109210133553\nEpoch: 2160 - Train Loss: 0.0013384963385760784 - Test Loss: 0.015957752242684364\nEpoch: 2161 - Train Loss: 0.0013334323884919286 - Test Loss: 0.01595241203904152\nEpoch: 2162 - Train Loss: 0.0013283849693834782 - Test Loss: 0.015947090461850166\nEpoch: 2163 - Train Loss: 0.001323356875218451 - Test Loss: 0.015941791236400604\nEpoch: 2164 - Train Loss: 0.0013183465925976634 - Test Loss: 0.015936510637402534\nEpoch: 2165 - Train Loss: 0.0013133538886904716 - Test Loss: 0.015931250527501106\nEpoch: 2166 - Train Loss: 0.0013083789963275194 - Test Loss: 0.01592600904405117\nEpoch: 2167 - Train Loss: 0.0013034229632467031 - Test Loss: 0.015920789912343025\nEpoch: 2168 - Train Loss: 0.0012984831118956208 - Test Loss: 0.015915589407086372\nEpoch: 2169 - Train Loss: 0.0012935609556734562 - Test Loss: 0.015910403802990913\nEpoch: 2170 - Train Loss: 0.0012886574259027839 - Test Loss: 0.015905240550637245\nEpoch: 2171 - Train Loss: 0.0012837713584303856 - Test Loss: 0.015900099650025368\nEpoch: 2172 - Train Loss: 0.0012789025204256177 - Test Loss: 0.015894977375864983\nEpoch: 2173 - Train Loss: 0.0012740509118884802 - Test Loss: 0.01588987186551094\nEpoch: 2174 - Train Loss: 0.0012692171148955822 - Test Loss: 0.01588478311896324\nEpoch: 2175 - Train Loss: 0.001264400314539671 - Test Loss: 0.015879720449447632\nEpoch: 2176 - Train Loss: 0.0012596020242199302 - Test Loss: 0.015874674543738365\nEpoch: 2177 - Train Loss: 0.001254820846952498 - Test Loss: 0.01586964540183544\nEpoch: 2178 - Train Loss: 0.0012500553857535124 - Test Loss: 0.01586463488638401\nEpoch: 2179 - Train Loss: 0.0012453082017600536 - Test Loss: 0.01585964672267437\nEpoch: 2180 - Train Loss: 0.0012405778979882598 - Test Loss: 0.01585467718541622\nEpoch: 2181 - Train Loss: 0.0012358644744381309 - Test Loss: 0.015849724411964417\nEpoch: 2182 - Train Loss: 0.001231167814694345 - Test Loss: 0.015844788402318954\nEpoch: 2183 - Train Loss: 0.0012264890829101205 - Test Loss: 0.015839876607060432\nEpoch: 2184 - Train Loss: 0.001221825834363699 - Test Loss: 0.015834981575608253\nEpoch: 2185 - Train Loss: 0.0012171793496236205 - Test Loss: 0.015830103307962418\nEpoch: 2186 - Train Loss: 0.001212550327181816 - Test Loss: 0.015825239941477776\nEpoch: 2187 - Train Loss: 0.0012079381849616766 - Test Loss: 0.015820400789380074\nEpoch: 2188 - Train Loss: 0.0012033421080559492 - Test Loss: 0.015815580263733864\nEpoch: 2189 - Train Loss: 0.0011987625621259212 - Test Loss: 0.015810778364539146\nEpoch: 2190 - Train Loss: 0.0011941990815103054 - Test Loss: 0.015805987641215324\nEpoch: 2191 - Train Loss: 0.001189652131870389 - Test Loss: 0.015801221132278442\nEpoch: 2192 - Train Loss: 0.001185122411698103 - Test Loss: 0.015796475112438202\nEpoch: 2193 - Train Loss: 0.001180608756840229 - Test Loss: 0.015791742131114006\nEpoch: 2194 - Train Loss: 0.001176110003143549 - Test Loss: 0.015787025913596153\nEpoch: 2195 - Train Loss: 0.0011716285953298211 - Test Loss: 0.01578233391046524\nEpoch: 2196 - Train Loss: 0.0011671631364151835 - Test Loss: 0.01577765680849552\nEpoch: 2197 - Train Loss: 0.0011627136263996363 - Test Loss: 0.015772994607686996\nEpoch: 2198 - Train Loss: 0.0011582797160372138 - Test Loss: 0.015768352895975113\nEpoch: 2199 - Train Loss: 0.0011538631515577435 - Test Loss: 0.01576372981071472\nEpoch: 2200 - Train Loss: 0.0011494607897475362 - Test Loss: 0.015759123489260674\nEpoch: 2201 - Train Loss: 0.001145074376836419 - Test Loss: 0.01575453393161297\nEpoch: 2202 - Train Loss: 0.0011407046113163233 - Test Loss: 0.015749961137771606\nEpoch: 2203 - Train Loss: 0.0011363503290340304 - Test Loss: 0.015745408833026886\nEpoch: 2204 - Train Loss: 0.001132011879235506 - Test Loss: 0.01574087329208851\nEpoch: 2205 - Train Loss: 0.0011276885634288192 - Test Loss: 0.015736350789666176\nEpoch: 2206 - Train Loss: 0.0011233807308599353 - Test Loss: 0.015731846913695335\nEpoch: 2207 - Train Loss: 0.0011190882651135325 - Test Loss: 0.015727363526821136\nEpoch: 2208 - Train Loss: 0.0011148122139275074 - Test Loss: 0.01572289504110813\nEpoch: 2209 - Train Loss: 0.0011105515295639634 - Test Loss: 0.015718447044491768\nEpoch: 2210 - Train Loss: 0.0011063046986237168 - Test Loss: 0.01571400836110115\nEpoch: 2211 - Train Loss: 0.0011020743986591697 - Test Loss: 0.015709595754742622\nEpoch: 2212 - Train Loss: 0.0010978591162711382 - Test Loss: 0.01570519432425499\nEpoch: 2213 - Train Loss: 0.0010936586186289787 - Test Loss: 0.01570081152021885\nEpoch: 2214 - Train Loss: 0.0010894732549786568 - Test Loss: 0.015696443617343903\nEpoch: 2215 - Train Loss: 0.001085302559658885 - Test Loss: 0.01569209061563015\nEpoch: 2216 - Train Loss: 0.0010811483953148127 - Test Loss: 0.01568775810301304\nEpoch: 2217 - Train Loss: 0.0010770076187327504 - Test Loss: 0.01568344235420227\nEpoch: 2218 - Train Loss: 0.001072881743311882 - Test Loss: 0.015679141506552696\nEpoch: 2219 - Train Loss: 0.0010687715839594603 - Test Loss: 0.015674853697419167\nEpoch: 2220 - Train Loss: 0.0010646763257682323 - Test Loss: 0.015670588240027428\nEpoch: 2221 - Train Loss: 0.001060595503076911 - Test Loss: 0.015666335821151733\nEpoch: 2222 - Train Loss: 0.0010565294651314616 - Test Loss: 0.01566210202872753\nEpoch: 2223 - Train Loss: 0.0010524779791012406 - Test Loss: 0.015657881274819374\nEpoch: 2224 - Train Loss: 0.001048441044986248 - Test Loss: 0.01565368101000786\nEpoch: 2225 - Train Loss: 0.0010444193612784147 - Test Loss: 0.015649497509002686\nEpoch: 2226 - Train Loss: 0.0010404124623164535 - Test Loss: 0.015645327046513557\nEpoch: 2227 - Train Loss: 0.0010364186018705368 - Test Loss: 0.015641171485185623\nEpoch: 2228 - Train Loss: 0.001032440341077745 - Test Loss: 0.01563703641295433\nEpoch: 2229 - Train Loss: 0.0010284761665388942 - Test Loss: 0.015632914379239082\nEpoch: 2230 - Train Loss: 0.0010245265439152718 - Test Loss: 0.015628809109330177\nEpoch: 2231 - Train Loss: 0.0010205908911302686 - Test Loss: 0.015624716877937317\nEpoch: 2232 - Train Loss: 0.0010166693245992064 - Test Loss: 0.015620642341673374\nEpoch: 2233 - Train Loss: 0.0010127628920599818 - Test Loss: 0.0156165836378932\nEpoch: 2234 - Train Loss: 0.0010088696144521236 - Test Loss: 0.015612540766596794\nEpoch: 2235 - Train Loss: 0.0010049901902675629 - Test Loss: 0.015608512796461582\nEpoch: 2236 - Train Loss: 0.0010011257836595178 - Test Loss: 0.015604499727487564\nEpoch: 2237 - Train Loss: 0.0009972754633054137 - Test Loss: 0.015600506216287613\nEpoch: 2238 - Train Loss: 0.0009934387635439634 - Test Loss: 0.015596526674926281\nEpoch: 2239 - Train Loss: 0.0009896159172058105 - Test Loss: 0.015592561103403568\nEpoch: 2240 - Train Loss: 0.0009858066914603114 - Test Loss: 0.0155886085703969\nEpoch: 2241 - Train Loss: 0.0009820112027227879 - Test Loss: 0.015584672801196575\nEpoch: 2242 - Train Loss: 0.0009782303823158145 - Test Loss: 0.015580754727125168\nEpoch: 2243 - Train Loss: 0.0009744621347635984 - Test Loss: 0.01557685062289238\nEpoch: 2244 - Train Loss: 0.0009707074495963752 - Test Loss: 0.015572960488498211\nEpoch: 2245 - Train Loss: 0.0009669674327597022 - Test Loss: 0.015569085255265236\nEpoch: 2246 - Train Loss: 0.0009632411529310048 - Test Loss: 0.015565229579806328\nEpoch: 2247 - Train Loss: 0.0009595282026566565 - Test Loss: 0.01556138601154089\nEpoch: 2248 - Train Loss: 0.0009558286401443183 - Test Loss: 0.01555755827575922\nEpoch: 2249 - Train Loss: 0.0009521427564322948 - Test Loss: 0.015553743578493595\nEpoch: 2250 - Train Loss: 0.0009484699694439769 - Test Loss: 0.015549943782389164\nEpoch: 2251 - Train Loss: 0.0009448106284253299 - Test Loss: 0.015546157956123352\nEpoch: 2252 - Train Loss: 0.0009411654900759459 - Test Loss: 0.015542389824986458\nEpoch: 2253 - Train Loss: 0.0009375336230732501 - Test Loss: 0.015538637526333332\nEpoch: 2254 - Train Loss: 0.0009339136304333806 - Test Loss: 0.015534895472228527\nEpoch: 2255 - Train Loss: 0.0009303081315010786 - Test Loss: 0.01553117111325264\nEpoch: 2256 - Train Loss: 0.0009267153800465167 - Test Loss: 0.01552746444940567\nEpoch: 2257 - Train Loss: 0.0009231356089003384 - Test Loss: 0.015523766167461872\nEpoch: 2258 - Train Loss: 0.000919568701647222 - Test Loss: 0.015520084649324417\nEpoch: 2259 - Train Loss: 0.0009160148329101503 - Test Loss: 0.015516416169703007\nEpoch: 2260 - Train Loss: 0.0009124738862738013 - Test Loss: 0.015512765385210514\nEpoch: 2261 - Train Loss: 0.0009089467930607498 - Test Loss: 0.015509127639234066\nEpoch: 2262 - Train Loss: 0.0009054329129867256 - Test Loss: 0.015505504794418812\nEpoch: 2263 - Train Loss: 0.0009019309072755277 - Test Loss: 0.015501894988119602\nEpoch: 2264 - Train Loss: 0.0008984431042335927 - Test Loss: 0.01549830287694931\nEpoch: 2265 - Train Loss: 0.0008949681068770587 - Test Loss: 0.015494721941649914\nEpoch: 2266 - Train Loss: 0.0008915059152059257 - Test Loss: 0.015491156838834286\nEpoch: 2267 - Train Loss: 0.0008880566456355155 - Test Loss: 0.015487604774534702\nEpoch: 2268 - Train Loss: 0.0008846213459037244 - Test Loss: 0.015484072268009186\nEpoch: 2269 - Train Loss: 0.0008811972802504897 - Test Loss: 0.01548055000603199\nEpoch: 2270 - Train Loss: 0.0008777859038673341 - Test Loss: 0.015477042645215988\nEpoch: 2271 - Train Loss: 0.0008743878570385277 - Test Loss: 0.015473547391593456\nEpoch: 2272 - Train Loss: 0.0008710024412721395 - Test Loss: 0.01547006331384182\nEpoch: 2273 - Train Loss: 0.0008676282595843077 - Test Loss: 0.01546659879386425\nEpoch: 2274 - Train Loss: 0.0008642683387733996 - Test Loss: 0.0154631482437253\nEpoch: 2275 - Train Loss: 0.0008609188953414559 - Test Loss: 0.01545970793813467\nEpoch: 2276 - Train Loss: 0.0008575833635404706 - Test Loss: 0.01545628160238266\nEpoch: 2277 - Train Loss: 0.000854258076287806 - Test Loss: 0.015452866442501545\nEpoch: 2278 - Train Loss: 0.0008509469917044044 - Test Loss: 0.015449469909071922\nEpoch: 2279 - Train Loss: 0.0008476480725221336 - Test Loss: 0.015446086414158344\nEpoch: 2280 - Train Loss: 0.0008443600963801146 - Test Loss: 0.015442713163793087\nEpoch: 2281 - Train Loss: 0.000841083936393261 - Test Loss: 0.015439353883266449\nEpoch: 2282 - Train Loss: 0.0008378208731301129 - Test Loss: 0.015436011366546154\nEpoch: 2283 - Train Loss: 0.0008345695096068084 - Test Loss: 0.015432680957019329\nEpoch: 2284 - Train Loss: 0.000831330253276974 - Test Loss: 0.015429362654685974\nEpoch: 2285 - Train Loss: 0.0008281024056486785 - Test Loss: 0.015426057390868664\nEpoch: 2286 - Train Loss: 0.0008248864323832095 - Test Loss: 0.015422762371599674\nEpoch: 2287 - Train Loss: 0.0008216832065954804 - Test Loss: 0.015419485978782177\nEpoch: 2288 - Train Loss: 0.0008184915059246123 - Test Loss: 0.01541622169315815\nEpoch: 2289 - Train Loss: 0.0008153105736710131 - Test Loss: 0.015412968583405018\nEpoch: 2290 - Train Loss: 0.0008121414575725794 - Test Loss: 0.015409727580845356\nEpoch: 2291 - Train Loss: 0.0008089850307442248 - Test Loss: 0.015406499616801739\nEpoch: 2292 - Train Loss: 0.0008058400126174092 - Test Loss: 0.01540328748524189\nEpoch: 2293 - Train Loss: 0.0008027065778151155 - Test Loss: 0.015400088392198086\nEpoch: 2294 - Train Loss: 0.0007995847263373435 - Test Loss: 0.015396898612380028\nEpoch: 2295 - Train Loss: 0.0007964741671457887 - Test Loss: 0.015393724665045738\nEpoch: 2296 - Train Loss: 0.000793374958448112 - Test Loss: 0.01539055909961462\nEpoch: 2297 - Train Loss: 0.0007902883226051927 - Test Loss: 0.015387413091957569\nEpoch: 2298 - Train Loss: 0.0007872117566876113 - Test Loss: 0.015384276397526264\nEpoch: 2299 - Train Loss: 0.0007841463666409254 - Test Loss: 0.01538114808499813\nEpoch: 2300 - Train Loss: 0.0007810929673723876 - Test Loss: 0.015378037467598915\nEpoch: 2301 - Train Loss: 0.0007780509768053889 - Test Loss: 0.01537493709474802\nEpoch: 2302 - Train Loss: 0.0007750200456939638 - Test Loss: 0.01537184976041317\nEpoch: 2303 - Train Loss: 0.0007720005232840776 - Test Loss: 0.015368775464594364\nEpoch: 2304 - Train Loss: 0.0007689919439144433 - Test Loss: 0.015365712344646454\nEpoch: 2305 - Train Loss: 0.0007659943657927215 - Test Loss: 0.015362662263214588\nEpoch: 2306 - Train Loss: 0.0007630079635418952 - Test Loss: 0.015359622426331043\nEpoch: 2307 - Train Loss: 0.0007600325043313205 - Test Loss: 0.015356597490608692\nEpoch: 2308 - Train Loss: 0.0007570679299533367 - Test Loss: 0.015353584662079811\nEpoch: 2309 - Train Loss: 0.0007541151135228574 - Test Loss: 0.0153505839407444\nEpoch: 2310 - Train Loss: 0.000751173123717308 - Test Loss: 0.01534759346395731\nEpoch: 2311 - Train Loss: 0.0007482410874217749 - Test Loss: 0.015344616025686264\nEpoch: 2312 - Train Loss: 0.0007453206344507635 - Test Loss: 0.015341649763286114\nEpoch: 2313 - Train Loss: 0.0007424108334816992 - Test Loss: 0.015338699333369732\nEpoch: 2314 - Train Loss: 0.0007395116263069212 - Test Loss: 0.015335758216679096\nEpoch: 2315 - Train Loss: 0.0007366230129264295 - Test Loss: 0.015332828275859356\nEpoch: 2316 - Train Loss: 0.0007337449351325631 - Test Loss: 0.015329907648265362\nEpoch: 2317 - Train Loss: 0.0007308773929253221 - Test Loss: 0.015327000990509987\nEpoch: 2318 - Train Loss: 0.000728021317627281 - Test Loss: 0.015324109233915806\nEpoch: 2319 - Train Loss: 0.0007251757779158652 - Test Loss: 0.01532122865319252\nEpoch: 2320 - Train Loss: 0.0007223395514301956 - Test Loss: 0.015318354591727257\nEpoch: 2321 - Train Loss: 0.0007195136277005076 - Test Loss: 0.015315493568778038\nEpoch: 2322 - Train Loss: 0.000716698938049376 - Test Loss: 0.015312645584344864\nEpoch: 2323 - Train Loss: 0.0007138947257772088 - Test Loss: 0.015309811569750309\nEpoch: 2324 - Train Loss: 0.0007111006416380405 - Test Loss: 0.0153069868683815\nEpoch: 2325 - Train Loss: 0.0007083166856318712 - Test Loss: 0.015304172411561012\nEpoch: 2326 - Train Loss: 0.0007055428577587008 - Test Loss: 0.015301368199288845\nEpoch: 2327 - Train Loss: 0.0007027792744338512 - Test Loss: 0.015298575162887573\nEpoch: 2328 - Train Loss: 0.0007000265177339315 - Test Loss: 0.015295795165002346\nEpoch: 2329 - Train Loss: 0.0006972840055823326 - Test Loss: 0.015293029136955738\nEpoch: 2330 - Train Loss: 0.0006945506320334971 - Test Loss: 0.015290268696844578\nEpoch: 2331 - Train Loss: 0.0006918271537870169 - Test Loss: 0.015287521295249462\nEpoch: 2332 - Train Loss: 0.0006891143857501447 - Test Loss: 0.015284785069525242\nEpoch: 2333 - Train Loss: 0.0006864116876386106 - Test Loss: 0.015282061882317066\nEpoch: 2334 - Train Loss: 0.0006837190594524145 - Test Loss: 0.015279347077012062\nEpoch: 2335 - Train Loss: 0.0006810360937379301 - Test Loss: 0.015276646241545677\nEpoch: 2336 - Train Loss: 0.00067836296511814 - Test Loss: 0.015273953787982464\nEpoch: 2337 - Train Loss: 0.0006756994989700615 - Test Loss: 0.015271272510290146\nEpoch: 2338 - Train Loss: 0.0006730457535013556 - Test Loss: 0.015268598683178425\nEpoch: 2339 - Train Loss: 0.0006704018451273441 - Test Loss: 0.015265941619873047\nEpoch: 2340 - Train Loss: 0.0006677685305476189 - Test Loss: 0.015263295732438564\nEpoch: 2341 - Train Loss: 0.0006651447038166225 - Test Loss: 0.015260658226907253\nEpoch: 2342 - Train Loss: 0.0006625296082347631 - Test Loss: 0.015258029103279114\nEpoch: 2343 - Train Loss: 0.0006599242333322763 - Test Loss: 0.015255410224199295\nEpoch: 2344 - Train Loss: 0.000657329277601093 - Test Loss: 0.01525280624628067\nEpoch: 2345 - Train Loss: 0.0006547438097186387 - Test Loss: 0.015250214375555515\nEpoch: 2346 - Train Loss: 0.0006521677132695913 - Test Loss: 0.015247629024088383\nEpoch: 2347 - Train Loss: 0.0006496009882539511 - Test Loss: 0.015245053917169571\nEpoch: 2348 - Train Loss: 0.0006470437510870397 - Test Loss: 0.015242490917444229\nEpoch: 2349 - Train Loss: 0.0006444960017688572 - Test Loss: 0.015239935368299484\nEpoch: 2350 - Train Loss: 0.0006419584387913346 - Test Loss: 0.015237394720315933\nEpoch: 2351 - Train Loss: 0.0006394300144165754 - Test Loss: 0.015234862454235554\nEpoch: 2352 - Train Loss: 0.0006369101465679705 - Test Loss: 0.015232340432703495\nEpoch: 2353 - Train Loss: 0.0006343995337374508 - Test Loss: 0.015229826793074608\nEpoch: 2354 - Train Loss: 0.0006318988744169474 - Test Loss: 0.015227324329316616\nEpoch: 2355 - Train Loss: 0.0006294073536992073 - Test Loss: 0.015224834904074669\nEpoch: 2356 - Train Loss: 0.0006269252044148743 - Test Loss: 0.015222354792058468\nEpoch: 2357 - Train Loss: 0.000624452019110322 - Test Loss: 0.015219885855913162\nEpoch: 2358 - Train Loss: 0.0006219879142008722 - Test Loss: 0.015217425301671028\nEpoch: 2359 - Train Loss: 0.0006195328896865249 - Test Loss: 0.015214972198009491\nEpoch: 2360 - Train Loss: 0.00061708694556728 - Test Loss: 0.015212531201541424\nEpoch: 2361 - Train Loss: 0.0006146499654278159 - Test Loss: 0.015210099518299103\nEpoch: 2362 - Train Loss: 0.0006122227059677243 - Test Loss: 0.015207681804895401\nEpoch: 2363 - Train Loss: 0.0006098043522797525 - Test Loss: 0.015205271542072296\nEpoch: 2364 - Train Loss: 0.0006073941476643085 - Test Loss: 0.015202868729829788\nEpoch: 2365 - Train Loss: 0.0006049929070286453 - Test Loss: 0.015200476162135601\nEpoch: 2366 - Train Loss: 0.0006026012124493718 - Test Loss: 0.01519809477031231\nEpoch: 2367 - Train Loss: 0.0006002182490192354 - Test Loss: 0.015195724554359913\nEpoch: 2368 - Train Loss: 0.0005978441331535578 - Test Loss: 0.015193362720310688\nEpoch: 2369 - Train Loss: 0.0005954787484370172 - Test Loss: 0.015191011130809784\nEpoch: 2370 - Train Loss: 0.0005931222112849355 - Test Loss: 0.015188668854534626\nEpoch: 2371 - Train Loss: 0.0005907741142436862 - Test Loss: 0.015186335891485214\nEpoch: 2372 - Train Loss: 0.0005884348065592349 - Test Loss: 0.015184009447693825\nEpoch: 2373 - Train Loss: 0.0005861044046469033 - Test Loss: 0.01518169604241848\nEpoch: 2374 - Train Loss: 0.0005837833741679788 - Test Loss: 0.015179394744336605\nEpoch: 2375 - Train Loss: 0.0005814707837998867 - Test Loss: 0.015177101828157902\nEpoch: 2376 - Train Loss: 0.000579166051466018 - Test Loss: 0.01517481543123722\nEpoch: 2377 - Train Loss: 0.0005768698174506426 - Test Loss: 0.015172538347542286\nEpoch: 2378 - Train Loss: 0.0005745835369452834 - Test Loss: 0.01517027523368597\nEpoch: 2379 - Train Loss: 0.0005723044159822166 - Test Loss: 0.015168020501732826\nEpoch: 2380 - Train Loss: 0.0005700351321138442 - Test Loss: 0.015165774151682854\nEpoch: 2381 - Train Loss: 0.0005677728331647813 - Test Loss: 0.015163535252213478\nEpoch: 2382 - Train Loss: 0.0005655206041410565 - Test Loss: 0.015161307528614998\nEpoch: 2383 - Train Loss: 0.000563275592867285 - Test Loss: 0.01515908446162939\nEpoch: 2384 - Train Loss: 0.0005610405933111906 - Test Loss: 0.015156880021095276\nEpoch: 2385 - Train Loss: 0.0005588140920735896 - Test Loss: 0.015154681168496609\nEpoch: 2386 - Train Loss: 0.0005565952160395682 - Test Loss: 0.015152490697801113\nEpoch: 2387 - Train Loss: 0.0005543847801163793 - Test Loss: 0.015150308609008789\nEpoch: 2388 - Train Loss: 0.0005521834245882928 - Test Loss: 0.015148136764764786\nEpoch: 2389 - Train Loss: 0.0005499901599250734 - Test Loss: 0.015145973302423954\nEpoch: 2390 - Train Loss: 0.0005478053353726864 - Test Loss: 0.015143821947276592\nEpoch: 2391 - Train Loss: 0.0005456287181004882 - Test Loss: 0.015141678974032402\nEpoch: 2392 - Train Loss: 0.0005434600752778351 - Test Loss: 0.015139542520046234\nEpoch: 2393 - Train Loss: 0.0005412998143583536 - Test Loss: 0.015137418173253536\nEpoch: 2394 - Train Loss: 0.0005391476443037391 - Test Loss: 0.015135297551751137\nEpoch: 2395 - Train Loss: 0.0005370035651139915 - Test Loss: 0.015133187174797058\nEpoch: 2396 - Train Loss: 0.0005348672857508063 - Test Loss: 0.015131089836359024\nEpoch: 2397 - Train Loss: 0.000532739155460149 - Test Loss: 0.015128999017179012\nEpoch: 2398 - Train Loss: 0.0005306196981109679 - Test Loss: 0.015126919373869896\nEpoch: 2399 - Train Loss: 0.00052850809879601 - Test Loss: 0.015124845318496227\nEpoch: 2400 - Train Loss: 0.0005264036008156836 - Test Loss: 0.01512277964502573\nEpoch: 2401 - Train Loss: 0.0005243070190772414 - Test Loss: 0.01512072142213583\nEpoch: 2402 - Train Loss: 0.0005222195759415627 - Test Loss: 0.015118677169084549\nEpoch: 2403 - Train Loss: 0.0005201385356485844 - Test Loss: 0.01511663943529129\nEpoch: 2404 - Train Loss: 0.0005180668085813522 - Test Loss: 0.015114610083401203\nEpoch: 2405 - Train Loss: 0.0005160011351108551 - Test Loss: 0.015112590044736862\nEpoch: 2406 - Train Loss: 0.0005139445420354605 - Test Loss: 0.015110575594007969\nEpoch: 2407 - Train Loss: 0.0005118942935951054 - Test Loss: 0.015108567662537098\nEpoch: 2408 - Train Loss: 0.0005098528927192092 - Test Loss: 0.01510657649487257\nEpoch: 2409 - Train Loss: 0.0005078192334622145 - Test Loss: 0.015104589983820915\nEpoch: 2410 - Train Loss: 0.0005057924427092075 - Test Loss: 0.015102609992027283\nEpoch: 2411 - Train Loss: 0.0005037731607444584 - Test Loss: 0.015100640244781971\nEpoch: 2412 - Train Loss: 0.0005017619696445763 - Test Loss: 0.015098676085472107\nEpoch: 2413 - Train Loss: 0.0004997584619559348 - Test Loss: 0.015096721239387989\nEpoch: 2414 - Train Loss: 0.0004977622302249074 - Test Loss: 0.015094776637852192\nEpoch: 2415 - Train Loss: 0.0004957736236974597 - Test Loss: 0.015092841349542141\nEpoch: 2416 - Train Loss: 0.0004937922931276262 - Test Loss: 0.015090912580490112\nEpoch: 2417 - Train Loss: 0.0004918181803077459 - Test Loss: 0.015088990330696106\nEpoch: 2418 - Train Loss: 0.0004898514598608017 - Test Loss: 0.015087077394127846\nEpoch: 2419 - Train Loss: 0.0004878921899944544 - Test Loss: 0.015085170976817608\nEpoch: 2420 - Train Loss: 0.0004859402251895517 - Test Loss: 0.015083272010087967\nEpoch: 2421 - Train Loss: 0.0004839955654460937 - Test Loss: 0.015081385150551796\nEpoch: 2422 - Train Loss: 0.00048205803614109755 - Test Loss: 0.015079505741596222\nEpoch: 2423 - Train Loss: 0.00048012856859713793 - Test Loss: 0.01507763285189867\nEpoch: 2424 - Train Loss: 0.0004782062896993011 - Test Loss: 0.01507576834410429\nEpoch: 2425 - Train Loss: 0.00047629058826714754 - Test Loss: 0.015073910355567932\nEpoch: 2426 - Train Loss: 0.0004743820463772863 - Test Loss: 0.015072060748934746\nEpoch: 2427 - Train Loss: 0.0004724821192212403 - Test Loss: 0.01507022138684988\nEpoch: 2428 - Train Loss: 0.0004705880128312856 - Test Loss: 0.015068390406668186\nEpoch: 2429 - Train Loss: 0.00046870228834450245 - Test Loss: 0.015066566877067089\nEpoch: 2430 - Train Loss: 0.000466822471935302 - Test Loss: 0.015064749866724014\nEpoch: 2431 - Train Loss: 0.00046495095011778176 - Test Loss: 0.015062939375638962\nEpoch: 2432 - Train Loss: 0.0004630851617548615 - Test Loss: 0.015061136335134506\nEpoch: 2433 - Train Loss: 0.0004612278426066041 - Test Loss: 0.01505934726446867\nEpoch: 2434 - Train Loss: 0.00045937745016999543 - Test Loss: 0.015057561919093132\nEpoch: 2435 - Train Loss: 0.00045753337326459587 - Test Loss: 0.01505578588694334\nEpoch: 2436 - Train Loss: 0.0004556963103823364 - Test Loss: 0.015054015442728996\nEpoch: 2437 - Train Loss: 0.0004538667853921652 - Test Loss: 0.0150522505864501\nEpoch: 2438 - Train Loss: 0.0004520442453213036 - Test Loss: 0.015050496906042099\nEpoch: 2439 - Train Loss: 0.0004502278461586684 - Test Loss: 0.015048747882246971\nEpoch: 2440 - Train Loss: 0.0004484191013034433 - Test Loss: 0.015047009103000164\nEpoch: 2441 - Train Loss: 0.00044661725405603647 - Test Loss: 0.015045279636979103\nEpoch: 2442 - Train Loss: 0.0004448221006896347 - Test Loss: 0.015043554827570915\nEpoch: 2443 - Train Loss: 0.0004430336703080684 - Test Loss: 0.015041837468743324\nEpoch: 2444 - Train Loss: 0.00044125207932665944 - Test Loss: 0.01504012756049633\nEpoch: 2445 - Train Loss: 0.0004394770658109337 - Test Loss: 0.015038423240184784\nEpoch: 2446 - Train Loss: 0.00043770953197963536 - Test Loss: 0.015036731958389282\nEpoch: 2447 - Train Loss: 0.00043594787712208927 - Test Loss: 0.015035046264529228\nEpoch: 2448 - Train Loss: 0.00043419297435320914 - Test Loss: 0.015033365227282047\nEpoch: 2449 - Train Loss: 0.0004324453475419432 - Test Loss: 0.015031692571938038\nEpoch: 2450 - Train Loss: 0.0004307043273001909 - Test Loss: 0.0150300282984972\nEpoch: 2451 - Train Loss: 0.00042896915692836046 - Test Loss: 0.01502836961299181\nEpoch: 2452 - Train Loss: 0.0004272404476068914 - Test Loss: 0.015026714652776718\nEpoch: 2453 - Train Loss: 0.00042551965452730656 - Test Loss: 0.015025075525045395\nEpoch: 2454 - Train Loss: 0.000423804041929543 - Test Loss: 0.015023438259959221\nEpoch: 2455 - Train Loss: 0.00042209605453535914 - Test Loss: 0.015021810308098793\nEpoch: 2456 - Train Loss: 0.00042039333493448794 - Test Loss: 0.015020187944173813\nEpoch: 2457 - Train Loss: 0.0004186982405371964 - Test Loss: 0.015018573962152004\nEpoch: 2458 - Train Loss: 0.00041700821020640433 - Test Loss: 0.015016963705420494\nEpoch: 2459 - Train Loss: 0.0004153258341830224 - Test Loss: 0.01501536089926958\nEpoch: 2460 - Train Loss: 0.00041364922071807086 - Test Loss: 0.015013767406344414\nEpoch: 2461 - Train Loss: 0.0004119789809919894 - Test Loss: 0.015012180432677269\nEpoch: 2462 - Train Loss: 0.0004103155224584043 - Test Loss: 0.015010600909590721\nEpoch: 2463 - Train Loss: 0.0004086584085598588 - Test Loss: 0.01500902883708477\nEpoch: 2464 - Train Loss: 0.0004070067952852696 - Test Loss: 0.015007460489869118\nEpoch: 2465 - Train Loss: 0.00040536152664572 - Test Loss: 0.015005899593234062\nEpoch: 2466 - Train Loss: 0.00040372295188717544 - Test Loss: 0.015004347078502178\nEpoch: 2467 - Train Loss: 0.00040209069265984 - Test Loss: 0.015002800151705742\nEpoch: 2468 - Train Loss: 0.00040046460344456136 - Test Loss: 0.015001262538135052\nEpoch: 2469 - Train Loss: 0.0003988446551375091 - Test Loss: 0.014999731443822384\nEpoch: 2470 - Train Loss: 0.00039723081863485277 - Test Loss: 0.014998205006122589\nEpoch: 2471 - Train Loss: 0.0003956230648327619 - Test Loss: 0.014996686019003391\nEpoch: 2472 - Train Loss: 0.00039402139373123646 - Test Loss: 0.014995172619819641\nEpoch: 2473 - Train Loss: 0.00039242583443410695 - Test Loss: 0.014993663877248764\nEpoch: 2474 - Train Loss: 0.00039083624142222106 - Test Loss: 0.014992167241871357\nEpoch: 2475 - Train Loss: 0.0003892532258760184 - Test Loss: 0.014990677125751972\nEpoch: 2476 - Train Loss: 0.00038767626392655075 - Test Loss: 0.014989192597568035\nEpoch: 2477 - Train Loss: 0.0003861045988742262 - Test Loss: 0.014987712725996971\nEpoch: 2478 - Train Loss: 0.0003845389874186367 - Test Loss: 0.01498623751103878\nEpoch: 2479 - Train Loss: 0.00038297977880574763 - Test Loss: 0.01498477254062891\nEpoch: 2480 - Train Loss: 0.0003814264782704413 - Test Loss: 0.014983310364186764\nEpoch: 2481 - Train Loss: 0.0003798784746322781 - Test Loss: 0.014981858432292938\nEpoch: 2482 - Train Loss: 0.00037833754322491586 - Test Loss: 0.014980414882302284\nEpoch: 2483 - Train Loss: 0.0003768012684304267 - Test Loss: 0.014978974126279354\nEpoch: 2484 - Train Loss: 0.00037527194945141673 - Test Loss: 0.014977540820837021\nEpoch: 2485 - Train Loss: 0.0003737472288776189 - Test Loss: 0.014976111240684986\nEpoch: 2486 - Train Loss: 0.0003722294932231307 - Test Loss: 0.014974690042436123\nEpoch: 2487 - Train Loss: 0.0003707162686623633 - Test Loss: 0.014973272569477558\nEpoch: 2488 - Train Loss: 0.00036920991260558367 - Test Loss: 0.01497186254709959\nEpoch: 2489 - Train Loss: 0.0003677088243421167 - Test Loss: 0.014970462769269943\nEpoch: 2490 - Train Loss: 0.000366213294910267 - Test Loss: 0.01496906578540802\nEpoch: 2491 - Train Loss: 0.00036472405190579593 - Test Loss: 0.014967676252126694\nEpoch: 2492 - Train Loss: 0.0003632405132520944 - Test Loss: 0.01496629323810339\nEpoch: 2493 - Train Loss: 0.0003617619804572314 - Test Loss: 0.014964913949370384\nEpoch: 2494 - Train Loss: 0.00036028906470164657 - Test Loss: 0.014963541179895401\nEpoch: 2495 - Train Loss: 0.000358822348061949 - Test Loss: 0.01496217306703329\nEpoch: 2496 - Train Loss: 0.00035736136487685144 - Test Loss: 0.01496081706136465\nEpoch: 2497 - Train Loss: 0.00035590602783486247 - Test Loss: 0.014959464780986309\nEpoch: 2498 - Train Loss: 0.00035445630783215165 - Test Loss: 0.014958119951188564\nEpoch: 2499 - Train Loss: 0.0003530121175572276 - Test Loss: 0.014956778846681118\nEpoch: 2500 - Train Loss: 0.0003515735443215817 - Test Loss: 0.014955444261431694\nEpoch: 2501 - Train Loss: 0.0003501405590213835 - Test Loss: 0.014954112470149994\nEpoch: 2502 - Train Loss: 0.00034871307434514165 - Test Loss: 0.01495278999209404\nEpoch: 2503 - Train Loss: 0.00034729097387753427 - Test Loss: 0.014951474964618683\nEpoch: 2504 - Train Loss: 0.00034587489790283144 - Test Loss: 0.014950167387723923\nEpoch: 2505 - Train Loss: 0.0003444644680712372 - Test Loss: 0.014948863536119461\nEpoch: 2506 - Train Loss: 0.0003430590149946511 - Test Loss: 0.014947566203773022\nEpoch: 2507 - Train Loss: 0.0003416591207496822 - Test Loss: 0.014946271665394306\nEpoch: 2508 - Train Loss: 0.000340265134582296 - Test Loss: 0.014944986440241337\nEpoch: 2509 - Train Loss: 0.00033887673635035753 - Test Loss: 0.014943704940378666\nEpoch: 2510 - Train Loss: 0.0003374934021849185 - Test Loss: 0.014942432753741741\nEpoch: 2511 - Train Loss: 0.00033611649996601045 - Test Loss: 0.014941166155040264\nEpoch: 2512 - Train Loss: 0.0003347439633216709 - Test Loss: 0.01493990421295166\nEpoch: 2513 - Train Loss: 0.0003333778295200318 - Test Loss: 0.014938647858798504\nEpoch: 2514 - Train Loss: 0.0003320159448776394 - Test Loss: 0.014937397092580795\nEpoch: 2515 - Train Loss: 0.0003306604630779475 - Test Loss: 0.01493615098297596\nEpoch: 2516 - Train Loss: 0.00032930908491835 - Test Loss: 0.014934910461306572\nEpoch: 2517 - Train Loss: 0.00032796410960145295 - Test Loss: 0.014933675527572632\nEpoch: 2518 - Train Loss: 0.0003266239073127508 - Test Loss: 0.014932449907064438\nEpoch: 2519 - Train Loss: 0.0003252887399867177 - Test Loss: 0.014931228943169117\nEpoch: 2520 - Train Loss: 0.000323959335219115 - Test Loss: 0.014930013567209244\nEpoch: 2521 - Train Loss: 0.0003226350818295032 - Test Loss: 0.014928803779184818\nEpoch: 2522 - Train Loss: 0.0003213154268451035 - Test Loss: 0.014927598647773266\nEpoch: 2523 - Train Loss: 0.0003200008941348642 - Test Loss: 0.014926397241652012\nEpoch: 2524 - Train Loss: 0.0003186919493600726 - Test Loss: 0.01492520235478878\nEpoch: 2525 - Train Loss: 0.0003173881850671023 - Test Loss: 0.01492401584982872\nEpoch: 2526 - Train Loss: 0.00031608936842530966 - Test Loss: 0.014922835864126682\nEpoch: 2527 - Train Loss: 0.0003147955285385251 - Test Loss: 0.014921657741069794\nEpoch: 2528 - Train Loss: 0.0003135066945105791 - Test Loss: 0.014920487068593502\nEpoch: 2529 - Train Loss: 0.0003122227790299803 - Test Loss: 0.014919321984052658\nEpoch: 2530 - Train Loss: 0.0003109439858235419 - Test Loss: 0.014918157830834389\nEpoch: 2531 - Train Loss: 0.0003096699365414679 - Test Loss: 0.014917002059519291\nEpoch: 2532 - Train Loss: 0.0003084006893914193 - Test Loss: 0.014915850944817066\nEpoch: 2533 - Train Loss: 0.0003071364772040397 - Test Loss: 0.014914706349372864\nEpoch: 2534 - Train Loss: 0.00030587753280997276 - Test Loss: 0.014913570135831833\nEpoch: 2535 - Train Loss: 0.000304623506963253 - Test Loss: 0.014912436716258526\nEpoch: 2536 - Train Loss: 0.00030337373027577996 - Test Loss: 0.014911305159330368\nEpoch: 2537 - Train Loss: 0.0003021288139279932 - Test Loss: 0.014910181984305382\nEpoch: 2538 - Train Loss: 0.0003008891362696886 - Test Loss: 0.014909062534570694\nEpoch: 2539 - Train Loss: 0.0002996542025357485 - Test Loss: 0.014907948672771454\nEpoch: 2540 - Train Loss: 0.00029842357616871595 - Test Loss: 0.014906838536262512\nEpoch: 2541 - Train Loss: 0.0002971976646222174 - Test Loss: 0.014905733987689018\nEpoch: 2542 - Train Loss: 0.00029597754473797977 - Test Loss: 0.014904635027050972\nEpoch: 2543 - Train Loss: 0.00029476112104021013 - Test Loss: 0.014903544448316097\nEpoch: 2544 - Train Loss: 0.0002935503434855491 - Test Loss: 0.014902455732226372\nEpoch: 2545 - Train Loss: 0.0002923431165982038 - Test Loss: 0.014901372604072094\nEpoch: 2546 - Train Loss: 0.00029114162316545844 - Test Loss: 0.014900295063853264\nEpoch: 2547 - Train Loss: 0.00028994379681535065 - Test Loss: 0.014899219386279583\nEpoch: 2548 - Train Loss: 0.00028875155840069056 - Test Loss: 0.014898153021931648\nEpoch: 2549 - Train Loss: 0.0002875628706533462 - Test Loss: 0.014897085726261139\nEpoch: 2550 - Train Loss: 0.00028637979994527996 - Test Loss: 0.014896029606461525\nEpoch: 2551 - Train Loss: 0.0002852013858500868 - Test Loss: 0.014894979074597359\nEpoch: 2552 - Train Loss: 0.00028402707539498806 - Test Loss: 0.014893931336700916\nEpoch: 2553 - Train Loss: 0.00028285730513744056 - Test Loss: 0.014892888255417347\nEpoch: 2554 - Train Loss: 0.0002816927735693753 - Test Loss: 0.0148918516933918\nEpoch: 2555 - Train Loss: 0.000280532956821844 - Test Loss: 0.014890817925333977\nEpoch: 2556 - Train Loss: 0.000279377301922068 - Test Loss: 0.014889787882566452\nEpoch: 2557 - Train Loss: 0.0002782261581160128 - Test Loss: 0.014888763427734375\nEpoch: 2558 - Train Loss: 0.00027708010748028755 - Test Loss: 0.014887748286128044\nEpoch: 2559 - Train Loss: 0.00027593859704211354 - Test Loss: 0.014886734075844288\nEpoch: 2560 - Train Loss: 0.00027480177232064307 - Test Loss: 0.014885728247463703\nEpoch: 2561 - Train Loss: 0.00027366940048523247 - Test Loss: 0.014884726144373417\nEpoch: 2562 - Train Loss: 0.0002725414524320513 - Test Loss: 0.014883727766573429\nEpoch: 2563 - Train Loss: 0.0002714181027840823 - Test Loss: 0.01488273311406374\nEpoch: 2564 - Train Loss: 0.00027029908960685134 - Test Loss: 0.014881744980812073\nEpoch: 2565 - Train Loss: 0.00026918502408079803 - Test Loss: 0.014880763366818428\nEpoch: 2566 - Train Loss: 0.00026807538233697414 - Test Loss: 0.014879787340760231\nEpoch: 2567 - Train Loss: 0.00026696958229877055 - Test Loss: 0.014878814108669758\nEpoch: 2568 - Train Loss: 0.000265868118731305 - Test Loss: 0.014877845533192158\nEpoch: 2569 - Train Loss: 0.00026477142819203436 - Test Loss: 0.01487688347697258\nEpoch: 2570 - Train Loss: 0.00026367910322733223 - Test Loss: 0.014875924214720726\nEpoch: 2571 - Train Loss: 0.00026259050355292857 - Test Loss: 0.014874966815114021\nEpoch: 2572 - Train Loss: 0.0002615061239339411 - Test Loss: 0.014874013140797615\nEpoch: 2573 - Train Loss: 0.0002604264300316572 - Test Loss: 0.014873066917061806\nEpoch: 2574 - Train Loss: 0.0002593510434962809 - Test Loss: 0.014872126281261444\nEpoch: 2575 - Train Loss: 0.000258279760600999 - Test Loss: 0.014871192164719105\nEpoch: 2576 - Train Loss: 0.0002572127559687942 - Test Loss: 0.014870261773467064\nEpoch: 2577 - Train Loss: 0.0002561498258728534 - Test Loss: 0.014869333244860172\nEpoch: 2578 - Train Loss: 0.00025509099941700697 - Test Loss: 0.014868409372866154\nEpoch: 2579 - Train Loss: 0.00025403627660125494 - Test Loss: 0.014867491088807583\nEpoch: 2580 - Train Loss: 0.0002529856574255973 - Test Loss: 0.014866575598716736\nEpoch: 2581 - Train Loss: 0.00025193902547471225 - Test Loss: 0.014865663833916187\nEpoch: 2582 - Train Loss: 0.00025089658447541296 - Test Loss: 0.014864755794405937\nEpoch: 2583 - Train Loss: 0.00024985859636217356 - Test Loss: 0.014863857999444008\nEpoch: 2584 - Train Loss: 0.0002488242171239108 - Test Loss: 0.014862961135804653\nEpoch: 2585 - Train Loss: 0.00024779376690275967 - Test Loss: 0.014862067997455597\nEpoch: 2586 - Train Loss: 0.0002467677986714989 - Test Loss: 0.014861179515719414\nEpoch: 2587 - Train Loss: 0.0002457458758726716 - Test Loss: 0.014860296621918678\nEpoch: 2588 - Train Loss: 0.00024472741642966866 - Test Loss: 0.014859415590763092\nEpoch: 2589 - Train Loss: 0.0002437129005556926 - Test Loss: 0.014858539216220379\nEpoch: 2590 - Train Loss: 0.00024270279391203076 - Test Loss: 0.014857664704322815\nEpoch: 2591 - Train Loss: 0.00024169670359697193 - Test Loss: 0.014856795780360699\nEpoch: 2592 - Train Loss: 0.00024069452774710953 - Test Loss: 0.014855935238301754\nEpoch: 2593 - Train Loss: 0.00023969625181052834 - Test Loss: 0.014855078421533108\nEpoch: 2594 - Train Loss: 0.0002387019048910588 - Test Loss: 0.01485422533005476\nEpoch: 2595 - Train Loss: 0.00023771135602146387 - Test Loss: 0.014853375032544136\nEpoch: 2596 - Train Loss: 0.00023672476527281106 - Test Loss: 0.014852529391646385\nEpoch: 2597 - Train Loss: 0.0002357420016778633 - Test Loss: 0.014851686544716358\nEpoch: 2598 - Train Loss: 0.00023476302158087492 - Test Loss: 0.014850848354399204\nEpoch: 2599 - Train Loss: 0.00023378791229333729 - Test Loss: 0.014850011095404625\nEpoch: 2600 - Train Loss: 0.00023281660105567425 - Test Loss: 0.014849180355668068\nEpoch: 2601 - Train Loss: 0.0002318490733159706 - Test Loss: 0.01484835147857666\nEpoch: 2602 - Train Loss: 0.00023088534362614155 - Test Loss: 0.014847530983388424\nEpoch: 2603 - Train Loss: 0.00022992538288235664 - Test Loss: 0.014846714213490486\nEpoch: 2604 - Train Loss: 0.00022896952577866614 - Test Loss: 0.014845903031527996\nEpoch: 2605 - Train Loss: 0.0002280173939652741 - Test Loss: 0.014845091849565506\nEpoch: 2606 - Train Loss: 0.0002270685654366389 - Test Loss: 0.014844285324215889\nEpoch: 2607 - Train Loss: 0.00022612346219830215 - Test Loss: 0.014843481592833996\nEpoch: 2608 - Train Loss: 0.00022518241894431412 - Test Loss: 0.014842684380710125\nEpoch: 2609 - Train Loss: 0.00022424498456530273 - Test Loss: 0.014841888099908829\nEpoch: 2610 - Train Loss: 0.00022331094078253955 - Test Loss: 0.014841095544397831\nEpoch: 2611 - Train Loss: 0.0002223808114649728 - Test Loss: 0.014840311370790005\nEpoch: 2612 - Train Loss: 0.00022145439288578928 - Test Loss: 0.014839530922472477\nEpoch: 2613 - Train Loss: 0.00022053155407775193 - Test Loss: 0.014838753268122673\nEpoch: 2614 - Train Loss: 0.0002196124114561826 - Test Loss: 0.014837978407740593\nEpoch: 2615 - Train Loss: 0.00021869690681342036 - Test Loss: 0.014837206341326237\nEpoch: 2616 - Train Loss: 0.00021778482187073678 - Test Loss: 0.014836439862847328\nEpoch: 2617 - Train Loss: 0.0002168763312511146 - Test Loss: 0.014835675247013569\nEpoch: 2618 - Train Loss: 0.0002159713621949777 - Test Loss: 0.014834916219115257\nEpoch: 2619 - Train Loss: 0.0002150699874619022 - Test Loss: 0.01483415812253952\nEpoch: 2620 - Train Loss: 0.00021417198877315968 - Test Loss: 0.014833403751254082\nEpoch: 2621 - Train Loss: 0.00021327803551685065 - Test Loss: 0.01483265683054924\nEpoch: 2622 - Train Loss: 0.0002123871527146548 - Test Loss: 0.014831915497779846\nEpoch: 2623 - Train Loss: 0.0002114998351316899 - Test Loss: 0.014831174165010452\nEpoch: 2624 - Train Loss: 0.00021061633015051484 - Test Loss: 0.014830438420176506\nEpoch: 2625 - Train Loss: 0.0002097364340443164 - Test Loss: 0.014829704537987709\nEpoch: 2626 - Train Loss: 0.00020885959384031594 - Test Loss: 0.014828975312411785\nEpoch: 2627 - Train Loss: 0.00020798624609597027 - Test Loss: 0.014828247018158436\nEpoch: 2628 - Train Loss: 0.00020711668184958398 - Test Loss: 0.014827524311840534\nEpoch: 2629 - Train Loss: 0.00020625069737434387 - Test Loss: 0.014826803468167782\nEpoch: 2630 - Train Loss: 0.00020538810349535197 - Test Loss: 0.014826091006398201\nEpoch: 2631 - Train Loss: 0.00020452892931643873 - Test Loss: 0.014825383201241493\nEpoch: 2632 - Train Loss: 0.0002036731457337737 - Test Loss: 0.01482467446476221\nEpoch: 2633 - Train Loss: 0.0002028207090916112 - Test Loss: 0.014823971316218376\nEpoch: 2634 - Train Loss: 0.000201971604838036 - Test Loss: 0.01482327375560999\nEpoch: 2635 - Train Loss: 0.0002011259348364547 - Test Loss: 0.014822574332356453\nEpoch: 2636 - Train Loss: 0.00020028348080813885 - Test Loss: 0.014821881428360939\nEpoch: 2637 - Train Loss: 0.0001994444610318169 - Test Loss: 0.014821189455688\nEpoch: 2638 - Train Loss: 0.00019860867178067565 - Test Loss: 0.014820503070950508\nEpoch: 2639 - Train Loss: 0.00019777609850279987 - Test Loss: 0.014819818548858166\nEpoch: 2640 - Train Loss: 0.00019694690126925707 - Test Loss: 0.01481914147734642\nEpoch: 2641 - Train Loss: 0.00019612093456089497 - Test Loss: 0.014818466268479824\nEpoch: 2642 - Train Loss: 0.00019529864948708564 - Test Loss: 0.014817794784903526\nEpoch: 2643 - Train Loss: 0.00019447958038654178 - Test Loss: 0.014817128889262676\nEpoch: 2644 - Train Loss: 0.00019366329070180655 - Test Loss: 0.014816462993621826\nEpoch: 2645 - Train Loss: 0.00019285024609416723 - Test Loss: 0.0148157998919487\nEpoch: 2646 - Train Loss: 0.0001920407376019284 - Test Loss: 0.014815140515565872\nEpoch: 2647 - Train Loss: 0.00019123448873870075 - Test Loss: 0.014814483933150768\nEpoch: 2648 - Train Loss: 0.00019043088832404464 - Test Loss: 0.014813830144703388\nEpoch: 2649 - Train Loss: 0.00018963048933073878 - Test Loss: 0.014813181012868881\nEpoch: 2650 - Train Loss: 0.0001888337719719857 - Test Loss: 0.014812532812356949\nEpoch: 2651 - Train Loss: 0.00018804016872309148 - Test Loss: 0.014811892993748188\nEpoch: 2652 - Train Loss: 0.00018724963592831045 - Test Loss: 0.014811254106462002\nEpoch: 2653 - Train Loss: 0.0001864621153799817 - Test Loss: 0.014810621738433838\nEpoch: 2654 - Train Loss: 0.00018567778170108795 - Test Loss: 0.014809989370405674\nEpoch: 2655 - Train Loss: 0.00018489648937247694 - Test Loss: 0.014809361658990383\nEpoch: 2656 - Train Loss: 0.00018411832570564002 - Test Loss: 0.014808733016252518\nEpoch: 2657 - Train Loss: 0.00018334317428525537 - Test Loss: 0.0148081099614501\nEpoch: 2658 - Train Loss: 0.00018257112242281437 - Test Loss: 0.014807489700615406\nEpoch: 2659 - Train Loss: 0.00018180205370299518 - Test Loss: 0.014806872233748436\nEpoch: 2660 - Train Loss: 0.00018103599722962826 - Test Loss: 0.01480625756084919\nEpoch: 2661 - Train Loss: 0.00018027298210654408 - Test Loss: 0.014805649407207966\nEpoch: 2662 - Train Loss: 0.00017951343033928424 - Test Loss: 0.014805044047534466\nEpoch: 2663 - Train Loss: 0.0001787568035069853 - Test Loss: 0.014804445207118988\nEpoch: 2664 - Train Loss: 0.00017800279601942748 - Test Loss: 0.014803842641413212\nEpoch: 2665 - Train Loss: 0.00017725177167449147 - Test Loss: 0.014803246594965458\nEpoch: 2666 - Train Loss: 0.00017650407971814275 - Test Loss: 0.014802653342485428\nEpoch: 2667 - Train Loss: 0.00017575932724867016 - Test Loss: 0.014802061952650547\nEpoch: 2668 - Train Loss: 0.000175017150468193 - Test Loss: 0.01480147335678339\nEpoch: 2669 - Train Loss: 0.00017427785496693105 - Test Loss: 0.014800887554883957\nEpoch: 2670 - Train Loss: 0.00017354181909468025 - Test Loss: 0.014800303615629673\nEpoch: 2671 - Train Loss: 0.0001728087809169665 - Test Loss: 0.014799724332988262\nEpoch: 2672 - Train Loss: 0.00017207856581080705 - Test Loss: 0.014799150638282299\nEpoch: 2673 - Train Loss: 0.00017135124653577805 - Test Loss: 0.014798578806221485\nEpoch: 2674 - Train Loss: 0.0001706267794361338 - Test Loss: 0.01479801069945097\nEpoch: 2675 - Train Loss: 0.00016990517906378955 - Test Loss: 0.014797445386648178\nEpoch: 2676 - Train Loss: 0.0001691864599706605 - Test Loss: 0.014796881936490536\nEpoch: 2677 - Train Loss: 0.00016847059305291623 - Test Loss: 0.014796322211623192\nEpoch: 2678 - Train Loss: 0.0001677574764471501 - Test Loss: 0.014795764349400997\nEpoch: 2679 - Train Loss: 0.00016704727022442967 - Test Loss: 0.014795208349823952\nEpoch: 2680 - Train Loss: 0.00016633991617709398 - Test Loss: 0.01479465514421463\nEpoch: 2681 - Train Loss: 0.00016563525423407555 - Test Loss: 0.014794103801250458\nEpoch: 2682 - Train Loss: 0.0001649334153626114 - Test Loss: 0.014793556183576584\nEpoch: 2683 - Train Loss: 0.00016423439956270158 - Test Loss: 0.014793016016483307\nEpoch: 2684 - Train Loss: 0.000163538075867109 - Test Loss: 0.014792478643357754\nEpoch: 2685 - Train Loss: 0.00016284495359286666 - Test Loss: 0.014791942201554775\nEpoch: 2686 - Train Loss: 0.00016215452342294157 - Test Loss: 0.014791407622396946\nEpoch: 2687 - Train Loss: 0.00016146639245562255 - Test Loss: 0.01479087769985199\nEpoch: 2688 - Train Loss: 0.00016078112821560353 - Test Loss: 0.014790348708629608\nEpoch: 2689 - Train Loss: 0.000160098890773952 - Test Loss: 0.014789823442697525\nEpoch: 2690 - Train Loss: 0.00015941938909236342 - Test Loss: 0.014789300039410591\nEpoch: 2691 - Train Loss: 0.00015874215750955045 - Test Loss: 0.014788779430091381\nEpoch: 2692 - Train Loss: 0.00015806771989446133 - Test Loss: 0.01478826068341732\nEpoch: 2693 - Train Loss: 0.00015739622176624835 - Test Loss: 0.014787742868065834\nEpoch: 2694 - Train Loss: 0.00015672743029426783 - Test Loss: 0.014787229709327221\nEpoch: 2695 - Train Loss: 0.00015606101078446954 - Test Loss: 0.01478672120720148\nEpoch: 2696 - Train Loss: 0.00015539790911134332 - Test Loss: 0.014786217361688614\nEpoch: 2697 - Train Loss: 0.00015473674284294248 - Test Loss: 0.014785715378820896\nEpoch: 2698 - Train Loss: 0.00015407893806695938 - Test Loss: 0.014785216189920902\nEpoch: 2699 - Train Loss: 0.0001534229813842103 - Test Loss: 0.014784716069698334\nEpoch: 2700 - Train Loss: 0.00015277040074579418 - Test Loss: 0.014784223400056362\nEpoch: 2701 - Train Loss: 0.00015211982827167958 - Test Loss: 0.014783729799091816\nEpoch: 2702 - Train Loss: 0.00015147248632274568 - Test Loss: 0.014783239923417568\nEpoch: 2703 - Train Loss: 0.00015082709433045238 - Test Loss: 0.014782750979065895\nEpoch: 2704 - Train Loss: 0.0001501849910710007 - Test Loss: 0.014782264828681946\nEpoch: 2705 - Train Loss: 0.00014954482321627438 - Test Loss: 0.014781780540943146\nEpoch: 2706 - Train Loss: 0.00014890792954247445 - Test Loss: 0.014781305566430092\nEpoch: 2707 - Train Loss: 0.0001482735387980938 - Test Loss: 0.014780830591917038\nEpoch: 2708 - Train Loss: 0.00014764146180823445 - Test Loss: 0.014780357480049133\nEpoch: 2709 - Train Loss: 0.0001470118440920487 - Test Loss: 0.014779886230826378\nEpoch: 2710 - Train Loss: 0.00014638509310316294 - Test Loss: 0.01477942056953907\nEpoch: 2711 - Train Loss: 0.00014576088869944215 - Test Loss: 0.014778953976929188\nEpoch: 2712 - Train Loss: 0.00014513877977151424 - Test Loss: 0.014778491109609604\nEpoch: 2713 - Train Loss: 0.00014451926108449697 - Test Loss: 0.01477802824229002\nEpoch: 2714 - Train Loss: 0.00014390243450179696 - Test Loss: 0.014777570962905884\nEpoch: 2715 - Train Loss: 0.0001432881545042619 - Test Loss: 0.014777114614844322\nEpoch: 2716 - Train Loss: 0.00014267598453443497 - Test Loss: 0.01477666012942791\nEpoch: 2717 - Train Loss: 0.00014206663763616234 - Test Loss: 0.01477621216326952\nEpoch: 2718 - Train Loss: 0.00014145970635581762 - Test Loss: 0.014775766059756279\nEpoch: 2719 - Train Loss: 0.00014085524890106171 - Test Loss: 0.014775322750210762\nEpoch: 2720 - Train Loss: 0.00014025323616806418 - Test Loss: 0.014774881303310394\nEpoch: 2721 - Train Loss: 0.00013965368270874023 - Test Loss: 0.014774441719055176\nEpoch: 2722 - Train Loss: 0.00013905655941925943 - Test Loss: 0.014774003066122532\nEpoch: 2723 - Train Loss: 0.0001384618371957913 - Test Loss: 0.014773569069802761\nEpoch: 2724 - Train Loss: 0.0001378695305902511 - Test Loss: 0.014773136004805565\nEpoch: 2725 - Train Loss: 0.000137279654154554 - Test Loss: 0.014772704802453518\nEpoch: 2726 - Train Loss: 0.00013669213512912393 - Test Loss: 0.01477227546274662\nEpoch: 2727 - Train Loss: 0.0001361069589620456 - Test Loss: 0.014771849848330021\nEpoch: 2728 - Train Loss: 0.00013552421296481043 - Test Loss: 0.014771425165235996\nEpoch: 2729 - Train Loss: 0.00013494407176040113 - Test Loss: 0.014771007001399994\nEpoch: 2730 - Train Loss: 0.00013436593872029334 - Test Loss: 0.014770589768886566\nEpoch: 2731 - Train Loss: 0.00013379020674619824 - Test Loss: 0.014770175330340862\nEpoch: 2732 - Train Loss: 0.00013321705046109855 - Test Loss: 0.014769763685762882\nEpoch: 2733 - Train Loss: 0.00013264620793052018 - Test Loss: 0.014769354835152626\nEpoch: 2734 - Train Loss: 0.00013207734446041286 - Test Loss: 0.01476894598454237\nEpoch: 2735 - Train Loss: 0.00013151078019291162 - Test Loss: 0.014768540859222412\nEpoch: 2736 - Train Loss: 0.00013094680616632104 - Test Loss: 0.01476813480257988\nEpoch: 2737 - Train Loss: 0.00013038502947892994 - Test Loss: 0.014767734333872795\nEpoch: 2738 - Train Loss: 0.00012982524640392512 - Test Loss: 0.014767332933843136\nEpoch: 2739 - Train Loss: 0.00012926773342769593 - Test Loss: 0.014766937121748924\nEpoch: 2740 - Train Loss: 0.0001287127670366317 - Test Loss: 0.014766540378332138\nEpoch: 2741 - Train Loss: 0.00012816005619242787 - Test Loss: 0.014766150154173374\nEpoch: 2742 - Train Loss: 0.00012760967365466058 - Test Loss: 0.014765762723982334\nEpoch: 2743 - Train Loss: 0.000127061503008008 - Test Loss: 0.014765375293791294\nEpoch: 2744 - Train Loss: 0.00012651560246013105 - Test Loss: 0.014764990657567978\nEpoch: 2745 - Train Loss: 0.0001259720156667754 - Test Loss: 0.01476460974663496\nEpoch: 2746 - Train Loss: 0.00012543061166070402 - Test Loss: 0.014764231629669666\nEpoch: 2747 - Train Loss: 0.0001248914486495778 - Test Loss: 0.014763851650059223\nEpoch: 2748 - Train Loss: 0.00012435448297765106 - Test Loss: 0.014763474464416504\nEpoch: 2749 - Train Loss: 0.0001238197583006695 - Test Loss: 0.014763101004064083\nEpoch: 2750 - Train Loss: 0.0001232872309628874 - Test Loss: 0.014762728475034237\nEpoch: 2751 - Train Loss: 0.00012275685730855912 - Test Loss: 0.01476235780864954\nEpoch: 2752 - Train Loss: 0.00012222865188959986 - Test Loss: 0.014761989936232567\nEpoch: 2753 - Train Loss: 0.00012170259287813678 - Test Loss: 0.014761628583073616\nEpoch: 2754 - Train Loss: 0.0001211789931403473 - Test Loss: 0.014761267229914665\nEpoch: 2755 - Train Loss: 0.00012065747432643548 - Test Loss: 0.014760908670723438\nEpoch: 2756 - Train Loss: 0.00012013778177788481 - Test Loss: 0.014760551042854786\nEpoch: 2757 - Train Loss: 0.00011962023563683033 - Test Loss: 0.014760195277631283\nEpoch: 2758 - Train Loss: 0.00011910506873391569 - Test Loss: 0.014759843237698078\nEpoch: 2759 - Train Loss: 0.0001185919827548787 - Test Loss: 0.014759492129087448\nEpoch: 2760 - Train Loss: 0.00011808067938545719 - Test Loss: 0.014759141020476818\nEpoch: 2761 - Train Loss: 0.00011757150787161663 - Test Loss: 0.014758792705833912\nEpoch: 2762 - Train Loss: 0.00011706461373250932 - Test Loss: 0.014758446253836155\nEpoch: 2763 - Train Loss: 0.00011655984417302534 - Test Loss: 0.014758101664483547\nEpoch: 2764 - Train Loss: 0.000116056835395284 - Test Loss: 0.014757758006453514\nEpoch: 2765 - Train Loss: 0.00011555586388567463 - Test Loss: 0.014757417142391205\nEpoch: 2766 - Train Loss: 0.00011505718430271372 - Test Loss: 0.014757082797586918\nEpoch: 2767 - Train Loss: 0.00011456052743596956 - Test Loss: 0.01475675031542778\nEpoch: 2768 - Train Loss: 0.00011406590783735737 - Test Loss: 0.014756416901946068\nEpoch: 2769 - Train Loss: 0.00011357331095496193 - Test Loss: 0.014756087213754654\nEpoch: 2770 - Train Loss: 0.0001130826713051647 - Test Loss: 0.014755760319530964\nEpoch: 2771 - Train Loss: 0.00011259403254371136 - Test Loss: 0.014755435287952423\nEpoch: 2772 - Train Loss: 0.00011210735101485625 - Test Loss: 0.014755108393728733\nEpoch: 2773 - Train Loss: 0.00011162261944264174 - Test Loss: 0.014754786156117916\nEpoch: 2774 - Train Loss: 0.00011113992513855919 - Test Loss: 0.0147544639185071\nEpoch: 2775 - Train Loss: 0.0001106591516872868 - Test Loss: 0.014754144474864006\nEpoch: 2776 - Train Loss: 0.00011018034274457023 - Test Loss: 0.014753826893866062\nEpoch: 2777 - Train Loss: 0.00010970341827487573 - Test Loss: 0.014753512106835842\nEpoch: 2778 - Train Loss: 0.00010922847286565229 - Test Loss: 0.014753195457160473\nEpoch: 2779 - Train Loss: 0.00010875571751967072 - Test Loss: 0.014752887189388275\nEpoch: 2780 - Train Loss: 0.00010828487575054169 - Test Loss: 0.014752579852938652\nEpoch: 2781 - Train Loss: 0.00010781571472762153 - Test Loss: 0.014752272516489029\nEpoch: 2782 - Train Loss: 0.00010734840907389298 - Test Loss: 0.014751969836652279\nEpoch: 2783 - Train Loss: 0.00010688332986319438 - Test Loss: 0.014751666225492954\nEpoch: 2784 - Train Loss: 0.00010642007691785693 - Test Loss: 0.014751366339623928\nEpoch: 2785 - Train Loss: 0.00010595849744277075 - Test Loss: 0.014751066453754902\nEpoch: 2786 - Train Loss: 0.00010549873695708811 - Test Loss: 0.014750770293176174\nEpoch: 2787 - Train Loss: 0.00010504115198273212 - Test Loss: 0.014750473201274872\nEpoch: 2788 - Train Loss: 0.00010458540782565251 - Test Loss: 0.014750177972018719\nEpoch: 2789 - Train Loss: 0.0001041312498273328 - Test Loss: 0.014749884605407715\nEpoch: 2790 - Train Loss: 0.0001036789471982047 - Test Loss: 0.01474959310144186\nEpoch: 2791 - Train Loss: 0.0001032287473208271 - Test Loss: 0.01474930252879858\nEpoch: 2792 - Train Loss: 0.00010278038098476827 - Test Loss: 0.014749014750123024\nEpoch: 2793 - Train Loss: 0.00010233367356704548 - Test Loss: 0.014748731628060341\nEpoch: 2794 - Train Loss: 0.00010188938904320821 - Test Loss: 0.014748452231287956\nEpoch: 2795 - Train Loss: 0.0001014464651234448 - Test Loss: 0.014748170040547848\nEpoch: 2796 - Train Loss: 0.00010100594226969406 - Test Loss: 0.014747895300388336\nEpoch: 2797 - Train Loss: 0.00010056671453639865 - Test Loss: 0.014747616834938526\nEpoch: 2798 - Train Loss: 0.00010012988786911592 - Test Loss: 0.01474734116345644\nEpoch: 2799 - Train Loss: 9.969435632228851e-05 - Test Loss: 0.014747069217264652\nEpoch: 2800 - Train Loss: 9.926117490977049e-05 - Test Loss: 0.01474679633975029\nEpoch: 2801 - Train Loss: 9.88293468253687e-05 - Test Loss: 0.014746527187526226\nEpoch: 2802 - Train Loss: 9.839981066761538e-05 - Test Loss: 0.014746258035302162\nEpoch: 2803 - Train Loss: 9.797159145819023e-05 - Test Loss: 0.014745988883078098\nEpoch: 2804 - Train Loss: 9.754557686392218e-05 - Test Loss: 0.014745722524821758\nEpoch: 2805 - Train Loss: 9.712086466606706e-05 - Test Loss: 0.014745457097887993\nEpoch: 2806 - Train Loss: 9.669837163528427e-05 - Test Loss: 0.014745197258889675\nEpoch: 2807 - Train Loss: 9.627770486986265e-05 - Test Loss: 0.014744941145181656\nEpoch: 2808 - Train Loss: 9.585847874404863e-05 - Test Loss: 0.014744684100151062\nEpoch: 2809 - Train Loss: 9.54409915721044e-05 - Test Loss: 0.014744429849088192\nEpoch: 2810 - Train Loss: 9.502546890871599e-05 - Test Loss: 0.014744175598025322\nEpoch: 2811 - Train Loss: 9.461167792323977e-05 - Test Loss: 0.014743926003575325\nEpoch: 2812 - Train Loss: 9.419932030141354e-05 - Test Loss: 0.014743673615157604\nEpoch: 2813 - Train Loss: 9.378868708154187e-05 - Test Loss: 0.014743424952030182\nEpoch: 2814 - Train Loss: 9.338001109426841e-05 - Test Loss: 0.014743177220225334\nEpoch: 2815 - Train Loss: 9.297303040511906e-05 - Test Loss: 0.01474293228238821\nEpoch: 2816 - Train Loss: 9.25674830796197e-05 - Test Loss: 0.014742685481905937\nEpoch: 2817 - Train Loss: 9.216358012054116e-05 - Test Loss: 0.014742441475391388\nEpoch: 2818 - Train Loss: 9.176160529023036e-05 - Test Loss: 0.014742199331521988\nEpoch: 2819 - Train Loss: 9.136122389463708e-05 - Test Loss: 0.014741957187652588\nEpoch: 2820 - Train Loss: 9.096234134631231e-05 - Test Loss: 0.014741717837750912\nEpoch: 2821 - Train Loss: 9.05653287190944e-05 - Test Loss: 0.014741484075784683\nEpoch: 2822 - Train Loss: 9.016992407850921e-05 - Test Loss: 0.014741250313818455\nEpoch: 2823 - Train Loss: 8.977617835626006e-05 - Test Loss: 0.01474101934581995\nEpoch: 2824 - Train Loss: 8.938404789660126e-05 - Test Loss: 0.01474078930914402\nEpoch: 2825 - Train Loss: 8.899356180336326e-05 - Test Loss: 0.01474055927246809\nEpoch: 2826 - Train Loss: 8.860469824867323e-05 - Test Loss: 0.014740332029759884\nEpoch: 2827 - Train Loss: 8.821747178444639e-05 - Test Loss: 0.014740104787051678\nEpoch: 2828 - Train Loss: 8.783186785876751e-05 - Test Loss: 0.01473988126963377\nEpoch: 2829 - Train Loss: 8.74478864716366e-05 - Test Loss: 0.014739657752215862\nEpoch: 2830 - Train Loss: 8.706548396730796e-05 - Test Loss: 0.01473943516612053\nEpoch: 2831 - Train Loss: 8.668471855344251e-05 - Test Loss: 0.014739212580025196\nEpoch: 2832 - Train Loss: 8.630548109067604e-05 - Test Loss: 0.014738994650542736\nEpoch: 2833 - Train Loss: 8.592789527028799e-05 - Test Loss: 0.014738774858415127\nEpoch: 2834 - Train Loss: 8.555181557312608e-05 - Test Loss: 0.014738558791577816\nEpoch: 2835 - Train Loss: 8.517727110302076e-05 - Test Loss: 0.014738340862095356\nEpoch: 2836 - Train Loss: 8.480456745019183e-05 - Test Loss: 0.014738132245838642\nEpoch: 2837 - Train Loss: 8.443317346973345e-05 - Test Loss: 0.014737923629581928\nEpoch: 2838 - Train Loss: 8.406329288845882e-05 - Test Loss: 0.014737713150680065\nEpoch: 2839 - Train Loss: 8.369518036488444e-05 - Test Loss: 0.014737505465745926\nEpoch: 2840 - Train Loss: 8.332856668857858e-05 - Test Loss: 0.01473730243742466\nEpoch: 2841 - Train Loss: 8.29632772365585e-05 - Test Loss: 0.014737095683813095\nEpoch: 2842 - Train Loss: 8.259950845967978e-05 - Test Loss: 0.014736891724169254\nEpoch: 2843 - Train Loss: 8.223743498092517e-05 - Test Loss: 0.014736691489815712\nEpoch: 2844 - Train Loss: 8.187684579752386e-05 - Test Loss: 0.014736490324139595\nEpoch: 2845 - Train Loss: 8.151753718266264e-05 - Test Loss: 0.014736289158463478\nEpoch: 2846 - Train Loss: 8.115969103528187e-05 - Test Loss: 0.014736092649400234\nEpoch: 2847 - Train Loss: 8.080360566964373e-05 - Test Loss: 0.014735894277691841\nEpoch: 2848 - Train Loss: 8.044904825510457e-05 - Test Loss: 0.014735697768628597\nEpoch: 2849 - Train Loss: 8.009579323697835e-05 - Test Loss: 0.014735504053533077\nEpoch: 2850 - Train Loss: 7.974403706612065e-05 - Test Loss: 0.014735308475792408\nEpoch: 2851 - Train Loss: 7.939420902403072e-05 - Test Loss: 0.01473512127995491\nEpoch: 2852 - Train Loss: 7.904548692749813e-05 - Test Loss: 0.014734933152794838\nEpoch: 2853 - Train Loss: 7.869862020015717e-05 - Test Loss: 0.014734748750925064\nEpoch: 2854 - Train Loss: 7.835281576262787e-05 - Test Loss: 0.014734562486410141\nEpoch: 2855 - Train Loss: 7.80089249019511e-05 - Test Loss: 0.014734379015862942\nEpoch: 2856 - Train Loss: 7.76660381234251e-05 - Test Loss: 0.014734196476638317\nEpoch: 2857 - Train Loss: 7.732505036983639e-05 - Test Loss: 0.014734015800058842\nEpoch: 2858 - Train Loss: 7.698505942244083e-05 - Test Loss: 0.014733835123479366\nEpoch: 2859 - Train Loss: 7.664688746444881e-05 - Test Loss: 0.01473365630954504\nEpoch: 2860 - Train Loss: 7.630969776073471e-05 - Test Loss: 0.014733477495610714\nEpoch: 2861 - Train Loss: 7.597435615025461e-05 - Test Loss: 0.014733300544321537\nEpoch: 2862 - Train Loss: 7.564004044979811e-05 - Test Loss: 0.01473312359303236\nEpoch: 2863 - Train Loss: 7.530747097916901e-05 - Test Loss: 0.014732951298356056\nEpoch: 2864 - Train Loss: 7.497587648686022e-05 - Test Loss: 0.014732775278389454\nEpoch: 2865 - Train Loss: 7.464614463970065e-05 - Test Loss: 0.01473260298371315\nEpoch: 2866 - Train Loss: 7.431730773532763e-05 - Test Loss: 0.014732430689036846\nEpoch: 2867 - Train Loss: 7.399030437227339e-05 - Test Loss: 0.01473226398229599\nEpoch: 2868 - Train Loss: 7.366466161329299e-05 - Test Loss: 0.014732101000845432\nEpoch: 2869 - Train Loss: 7.334013207582757e-05 - Test Loss: 0.014731934294104576\nEpoch: 2870 - Train Loss: 7.301699952222407e-05 - Test Loss: 0.014731770381331444\nEpoch: 2871 - Train Loss: 7.269538764376193e-05 - Test Loss: 0.01473161019384861\nEpoch: 2872 - Train Loss: 7.237512909341604e-05 - Test Loss: 0.014731450006365776\nEpoch: 2873 - Train Loss: 7.205602742033079e-05 - Test Loss: 0.014731287956237793\nEpoch: 2874 - Train Loss: 7.17382354196161e-05 - Test Loss: 0.014731128700077534\nEpoch: 2875 - Train Loss: 7.142201502574608e-05 - Test Loss: 0.014730971306562424\nEpoch: 2876 - Train Loss: 7.110711885616183e-05 - Test Loss: 0.014730814844369888\nEpoch: 2877 - Train Loss: 7.079329952830449e-05 - Test Loss: 0.014730657450854778\nEpoch: 2878 - Train Loss: 7.0480840804521e-05 - Test Loss: 0.014730502851307392\nEpoch: 2879 - Train Loss: 7.016988092800602e-05 - Test Loss: 0.014730348251760006\nEpoch: 2880 - Train Loss: 6.98602307238616e-05 - Test Loss: 0.014730195514857769\nEpoch: 2881 - Train Loss: 6.955164280952886e-05 - Test Loss: 0.014730042777955532\nEpoch: 2882 - Train Loss: 6.924432091182098e-05 - Test Loss: 0.01472989097237587\nEpoch: 2883 - Train Loss: 6.893855606904253e-05 - Test Loss: 0.014729740098118782\nEpoch: 2884 - Train Loss: 6.863405724288896e-05 - Test Loss: 0.014729594811797142\nEpoch: 2885 - Train Loss: 6.833083898527548e-05 - Test Loss: 0.014729452319443226\nEpoch: 2886 - Train Loss: 6.802890857215971e-05 - Test Loss: 0.014729308895766735\nEpoch: 2887 - Train Loss: 6.772828055545688e-05 - Test Loss: 0.014729166403412819\nEpoch: 2888 - Train Loss: 6.74290131428279e-05 - Test Loss: 0.014729023911058903\nEpoch: 2889 - Train Loss: 6.713101174682379e-05 - Test Loss: 0.014728885143995285\nEpoch: 2890 - Train Loss: 6.683426909148693e-05 - Test Loss: 0.014728745445609093\nEpoch: 2891 - Train Loss: 6.653874879702926e-05 - Test Loss: 0.014728606678545475\nEpoch: 2892 - Train Loss: 6.624452362302691e-05 - Test Loss: 0.014728468842804432\nEpoch: 2893 - Train Loss: 6.595152808586136e-05 - Test Loss: 0.014728332869708538\nEpoch: 2894 - Train Loss: 6.565982039319351e-05 - Test Loss: 0.014728196896612644\nEpoch: 2895 - Train Loss: 6.536934233736247e-05 - Test Loss: 0.014728063717484474\nEpoch: 2896 - Train Loss: 6.508009391836822e-05 - Test Loss: 0.014727928675711155\nEpoch: 2897 - Train Loss: 6.479208241216838e-05 - Test Loss: 0.014727797359228134\nEpoch: 2898 - Train Loss: 6.450526416301727e-05 - Test Loss: 0.014727665111422539\nEpoch: 2899 - Train Loss: 6.421969010261819e-05 - Test Loss: 0.014727533794939518\nEpoch: 2900 - Train Loss: 6.393533840309829e-05 - Test Loss: 0.01472740713506937\nEpoch: 2901 - Train Loss: 6.365236913552508e-05 - Test Loss: 0.014727282337844372\nEpoch: 2902 - Train Loss: 6.337060040095821e-05 - Test Loss: 0.014727158471941948\nEpoch: 2903 - Train Loss: 6.308985757641494e-05 - Test Loss: 0.014727034606039524\nEpoch: 2904 - Train Loss: 6.281023524934426e-05 - Test Loss: 0.014726911671459675\nEpoch: 2905 - Train Loss: 6.25320099061355e-05 - Test Loss: 0.014726790599524975\nEpoch: 2906 - Train Loss: 6.225497054401785e-05 - Test Loss: 0.014726671390235424\nEpoch: 2907 - Train Loss: 6.197886250447482e-05 - Test Loss: 0.014726552180945873\nEpoch: 2908 - Train Loss: 6.17039404460229e-05 - Test Loss: 0.014726432040333748\nEpoch: 2909 - Train Loss: 6.143034988781437e-05 - Test Loss: 0.014726312831044197\nEpoch: 2910 - Train Loss: 6.115793075878173e-05 - Test Loss: 0.01472619641572237\nEpoch: 2911 - Train Loss: 6.088645022828132e-05 - Test Loss: 0.014726080000400543\nEpoch: 2912 - Train Loss: 6.061610110918991e-05 - Test Loss: 0.014725964516401291\nEpoch: 2913 - Train Loss: 6.034708712832071e-05 - Test Loss: 0.014725848101079464\nEpoch: 2914 - Train Loss: 6.0079211834818125e-05 - Test Loss: 0.014725733548402786\nEpoch: 2915 - Train Loss: 5.9812282415805385e-05 - Test Loss: 0.014725619927048683\nEpoch: 2916 - Train Loss: 5.954646985628642e-05 - Test Loss: 0.01472550630569458\nEpoch: 2917 - Train Loss: 5.9281937865307555e-05 - Test Loss: 0.014725394546985626\nEpoch: 2918 - Train Loss: 5.9018559113610536e-05 - Test Loss: 0.01472529023885727\nEpoch: 2919 - Train Loss: 5.8756257203640416e-05 - Test Loss: 0.014725182205438614\nEpoch: 2920 - Train Loss: 5.849506487720646e-05 - Test Loss: 0.014725077897310257\nEpoch: 2921 - Train Loss: 5.823499304824509e-05 - Test Loss: 0.0147249735891819\nEpoch: 2922 - Train Loss: 5.7975972595158964e-05 - Test Loss: 0.014724869281053543\nEpoch: 2923 - Train Loss: 5.771805444965139e-05 - Test Loss: 0.01472476590424776\nEpoch: 2924 - Train Loss: 5.7461274991510436e-05 - Test Loss: 0.014724665321409702\nEpoch: 2925 - Train Loss: 5.720550689147785e-05 - Test Loss: 0.01472456380724907\nEpoch: 2926 - Train Loss: 5.69508301850874e-05 - Test Loss: 0.014724462293088436\nEpoch: 2927 - Train Loss: 5.669723032042384e-05 - Test Loss: 0.014724362641572952\nEpoch: 2928 - Train Loss: 5.644474731525406e-05 - Test Loss: 0.014724262058734894\nEpoch: 2929 - Train Loss: 5.619325747829862e-05 - Test Loss: 0.014724165201187134\nEpoch: 2930 - Train Loss: 5.594289905275218e-05 - Test Loss: 0.0147240674123168\nEpoch: 2931 - Train Loss: 5.569358836510219e-05 - Test Loss: 0.01472396869212389\nEpoch: 2932 - Train Loss: 5.544528903556056e-05 - Test Loss: 0.014723874628543854\nEpoch: 2933 - Train Loss: 5.519803016795777e-05 - Test Loss: 0.014723777770996094\nEpoch: 2934 - Train Loss: 5.495184086612426e-05 - Test Loss: 0.014723684638738632\nEpoch: 2935 - Train Loss: 5.4706641094526276e-05 - Test Loss: 0.014723590575158596\nEpoch: 2936 - Train Loss: 5.446249997476116e-05 - Test Loss: 0.01472349651157856\nEpoch: 2937 - Train Loss: 5.421961031970568e-05 - Test Loss: 0.014723407104611397\nEpoch: 2938 - Train Loss: 5.3977491916157305e-05 - Test Loss: 0.014723317697644234\nEpoch: 2939 - Train Loss: 5.3736457630293444e-05 - Test Loss: 0.014723232947289944\nEpoch: 2940 - Train Loss: 5.349663115339354e-05 - Test Loss: 0.01472314540296793\nEpoch: 2941 - Train Loss: 5.325773963704705e-05 - Test Loss: 0.01472306065261364\nEpoch: 2942 - Train Loss: 5.301974670146592e-05 - Test Loss: 0.01472297590225935\nEpoch: 2943 - Train Loss: 5.278276148601435e-05 - Test Loss: 0.01472289115190506\nEpoch: 2944 - Train Loss: 5.254689676803537e-05 - Test Loss: 0.01472280640155077\nEpoch: 2945 - Train Loss: 5.231207251199521e-05 - Test Loss: 0.014722723513841629\nEpoch: 2946 - Train Loss: 5.207807771512307e-05 - Test Loss: 0.014722641557455063\nEpoch: 2947 - Train Loss: 5.18450397066772e-05 - Test Loss: 0.014722559601068497\nEpoch: 2948 - Train Loss: 5.161313674761914e-05 - Test Loss: 0.01472247950732708\nEpoch: 2949 - Train Loss: 5.13822706125211e-05 - Test Loss: 0.014722398482263088\nEpoch: 2950 - Train Loss: 5.1152183004887775e-05 - Test Loss: 0.014722318388521671\nEpoch: 2951 - Train Loss: 5.092305946163833e-05 - Test Loss: 0.014722239226102829\nEpoch: 2952 - Train Loss: 5.069512553745881e-05 - Test Loss: 0.014722161926329136\nEpoch: 2953 - Train Loss: 5.046813748776913e-05 - Test Loss: 0.014722083695232868\nEpoch: 2954 - Train Loss: 5.0241938879480585e-05 - Test Loss: 0.014722004532814026\nEpoch: 2955 - Train Loss: 5.001671888749115e-05 - Test Loss: 0.014721929095685482\nEpoch: 2956 - Train Loss: 4.979258301318623e-05 - Test Loss: 0.014721858315169811\nEpoch: 2957 - Train Loss: 4.956940756528638e-05 - Test Loss: 0.014721786603331566\nEpoch: 2958 - Train Loss: 4.9347207095706835e-05 - Test Loss: 0.01472171675413847\nEpoch: 2959 - Train Loss: 4.912587610306218e-05 - Test Loss: 0.014721645973622799\nEpoch: 2960 - Train Loss: 4.8905538278631866e-05 - Test Loss: 0.014721577987074852\nEpoch: 2961 - Train Loss: 4.868613905273378e-05 - Test Loss: 0.014721508137881756\nEpoch: 2962 - Train Loss: 4.846765659749508e-05 - Test Loss: 0.014721442013978958\nEpoch: 2963 - Train Loss: 4.825010182685219e-05 - Test Loss: 0.014721374958753586\nEpoch: 2964 - Train Loss: 4.8033500206656754e-05 - Test Loss: 0.014721308834850788\nEpoch: 2965 - Train Loss: 4.7817782615311444e-05 - Test Loss: 0.014721241779625416\nEpoch: 2966 - Train Loss: 4.7602989070583135e-05 - Test Loss: 0.014721173793077469\nEpoch: 2967 - Train Loss: 4.73891559522599e-05 - Test Loss: 0.014721112325787544\nEpoch: 2968 - Train Loss: 4.717618867289275e-05 - Test Loss: 0.014721045270562172\nEpoch: 2969 - Train Loss: 4.696411997429095e-05 - Test Loss: 0.014720981940627098\nEpoch: 2970 - Train Loss: 4.675298623624258e-05 - Test Loss: 0.014720918610692024\nEpoch: 2971 - Train Loss: 4.654270378523506e-05 - Test Loss: 0.014720854349434376\nEpoch: 2972 - Train Loss: 4.633333082892932e-05 - Test Loss: 0.014720792882144451\nEpoch: 2973 - Train Loss: 4.612488919519819e-05 - Test Loss: 0.014720732346177101\nEpoch: 2974 - Train Loss: 4.591726610669866e-05 - Test Loss: 0.014720669947564602\nEpoch: 2975 - Train Loss: 4.571058525471017e-05 - Test Loss: 0.014720611274242401\nEpoch: 2976 - Train Loss: 4.5504788431571797e-05 - Test Loss: 0.014720551669597626\nEpoch: 2977 - Train Loss: 4.5300093916011974e-05 - Test Loss: 0.014720495790243149\nEpoch: 2978 - Train Loss: 4.509616701398045e-05 - Test Loss: 0.014720441773533821\nEpoch: 2979 - Train Loss: 4.4893000449519604e-05 - Test Loss: 0.014720386825501919\nEpoch: 2980 - Train Loss: 4.469071427593008e-05 - Test Loss: 0.014720333740115166\nEpoch: 2981 - Train Loss: 4.448946492630057e-05 - Test Loss: 0.014720282517373562\nEpoch: 2982 - Train Loss: 4.4289088691584766e-05 - Test Loss: 0.014720231294631958\nEpoch: 2983 - Train Loss: 4.4089447328587994e-05 - Test Loss: 0.014720178209245205\nEpoch: 2984 - Train Loss: 4.3890679080504924e-05 - Test Loss: 0.014720126986503601\nEpoch: 2985 - Train Loss: 4.3692885810742155e-05 - Test Loss: 0.014720076695084572\nEpoch: 2986 - Train Loss: 4.3495943828020245e-05 - Test Loss: 0.014720028266310692\nEpoch: 2987 - Train Loss: 4.3299700337229297e-05 - Test Loss: 0.014719977043569088\nEpoch: 2988 - Train Loss: 4.310432996135205e-05 - Test Loss: 0.014719928614795208\nEpoch: 2989 - Train Loss: 4.290997458156198e-05 - Test Loss: 0.014719880186021328\nEpoch: 2990 - Train Loss: 4.271641228115186e-05 - Test Loss: 0.014719831757247448\nEpoch: 2991 - Train Loss: 4.252351209288463e-05 - Test Loss: 0.014719783328473568\nEpoch: 2992 - Train Loss: 4.233145227772184e-05 - Test Loss: 0.014719737693667412\nEpoch: 2993 - Train Loss: 4.214034925098531e-05 - Test Loss: 0.014719691127538681\nEpoch: 2994 - Train Loss: 4.1950079321395606e-05 - Test Loss: 0.01471964456140995\nEpoch: 2995 - Train Loss: 4.1760493331821635e-05 - Test Loss: 0.014719598926603794\nEpoch: 2996 - Train Loss: 4.15717477153521e-05 - Test Loss: 0.014719555154442787\nEpoch: 2997 - Train Loss: 4.1384046198800206e-05 - Test Loss: 0.014719515107572079\nEpoch: 2998 - Train Loss: 4.119689765502699e-05 - Test Loss: 0.014719473198056221\nEpoch: 2999 - Train Loss: 4.101084778085351e-05 - Test Loss: 0.014719436876475811\n"
],
[
"import matplotlib.pyplot as plt\r\n\r\nplt.plot(train_mses)\r\nplt.plot(test_mses)",
"_____no_output_____"
],
[
"print(masked_mse(tf.matmul(user_emb, item_emb, transpose_b=True) + global_effects, train_urm, mask,0.,0.,0.,0.))",
"tf.Tensor(4.1010848e-05, shape=(), dtype=float32)\n"
],
[
"test_mask = tf.not_equal(test_urm, 0.)\r\nmasked_mse(tf.matmul(user_emb, item_emb, transpose_b=True) + global_effects, test_urm, test_mask, 0.,0.,0.,0.)",
"_____no_output_____"
],
[
"print(tf.boolean_mask(tf.matmul(user_emb, item_emb, transpose_b=True) + global_effects, test_mask))\r\nprint(tf.boolean_mask(urm, test_mask))",
"tf.Tensor([5.0182815 3.7925973 5.0045686 ... 3.2204056 3.504787 4.144094 ], shape=(10084,), dtype=float32)\ntf.Tensor([5.0187025 3.7919607 5.0068946 ... 3.2200649 3.501555 4.1439705], shape=(10084,), dtype=float32)\n"
],
[
"# Hybrid Linear Combination\r\n\r\ndef get_hybrid_rating_given_user(u_ix, item_ix, k, alpha, beta):\r\n return alpha * cbf_get_rating_given_user(u_ix, item_ix, k)[0] + \\\r\n beta * ucf_get_rating_given_user(u_ix, item_ix, k)[0]",
"_____no_output_____"
],
[
"ratings = pd.read_csv(CUR_DIR + '/ml-latest-small/ratings.csv')\r\n\r\nC = 3\r\ntotal_mean = ratings.rating.mean()\r\nratings['normalized_rating'] = ratings.rating - total_mean\r\n\r\nb_item = ratings.groupby('movieId').normalized_rating.sum() / (ratings.groupby('movieId').userId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_item, columns=['b_item']), left_on='movieId', right_index=True, how='inner')\r\nratings['norm_item_rating'] = ratings.normalized_rating - ratings.b_item\r\n\r\nb_user = ratings.groupby('userId').norm_item_rating.sum() / (ratings.groupby('userId').movieId.count() + C)\r\nratings = ratings.merge(pd.DataFrame(b_user, columns=['b_user']), left_on='userId', right_index=True, how='inner')\r\n\r\nratings['normr_user_item_rating'] = total_mean + ratings.b_item + ratings.b_user\r\nurm = ratings.pivot(index='userId', columns='movieId', values='normr_user_item_rating').fillna(0.).values\r\n\r\nget_hybrid_rating_given_user(25,15,100, 0.9, 1.9)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51758f08e1c57cf1d082d932f38697a617cfcfa
| 2,610 |
ipynb
|
Jupyter Notebook
|
ejercicios/datasets/Untitled.ipynb
|
jaimevalero/python-machine-learning-book-2nd-edition
|
6438c86e75f991afe7375a2969a5289455e2fb5a
|
[
"MIT"
] | 5 |
2018-05-18T17:11:22.000Z
|
2019-04-26T16:24:07.000Z
|
ejercicios/datasets/Untitled.ipynb
|
jaimevalero/python-machine-learning-book-2nd-edition
|
6438c86e75f991afe7375a2969a5289455e2fb5a
|
[
"MIT"
] | null | null | null |
ejercicios/datasets/Untitled.ipynb
|
jaimevalero/python-machine-learning-book-2nd-edition
|
6438c86e75f991afe7375a2969a5289455e2fb5a
|
[
"MIT"
] | 4 |
2018-05-07T19:04:29.000Z
|
2018-09-20T15:51:25.000Z
| 34.342105 | 460 | 0.568199 |
[
[
[
"import lantern as l\nl.VariableInspector()",
"_____no_output_____"
],
[
"l.VariableInspector()\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
c51774e676864b7db6b7f917b9b45abc39f8ae35
| 18,298 |
ipynb
|
Jupyter Notebook
|
assignments/assignment12/FittingModelsEx01.ipynb
|
ajhenrikson/phys202-2015-work
|
05fcf7c0cab66b290ed081d344942f7fff308095
|
[
"MIT"
] | null | null | null |
assignments/assignment12/FittingModelsEx01.ipynb
|
ajhenrikson/phys202-2015-work
|
05fcf7c0cab66b290ed081d344942f7fff308095
|
[
"MIT"
] | null | null | null |
assignments/assignment12/FittingModelsEx01.ipynb
|
ajhenrikson/phys202-2015-work
|
05fcf7c0cab66b290ed081d344942f7fff308095
|
[
"MIT"
] | null | null | null | 70.648649 | 12,750 | 0.826648 |
[
[
[
"# Fitting Models Exercise 1",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport scipy.optimize as opt",
"_____no_output_____"
]
],
[
[
"## Fitting a quadratic curve",
"_____no_output_____"
],
[
"For this problem we are going to work with the following model:\n\n$$ y_{model}(x) = a x^2 + b x + c $$\n\nThe true values of the model parameters are as follows:",
"_____no_output_____"
]
],
[
[
"a_true = 0.5\nb_true = 2.0\nc_true = -4.0",
"_____no_output_____"
]
],
[
[
"First, generate a dataset using this model using these parameters and the following characteristics:\n\n* For your $x$ data use 30 uniformly spaced points between $[-5,5]$.\n* Add a noise term to the $y$ value at each point that is drawn from a normal distribution with zero mean and standard deviation 2.0. Make sure you add a different random number to each point (see the `size` argument of `np.random.normal`).\n\nAfter you generate the data, make a plot of the raw data (use points).",
"_____no_output_____"
]
],
[
[
"xdata=np.linspace(-5,5,30)\ndy=2\nsigma=np.random.normal(0,dy,30)\nydata=a_true*xdata**2+b_true*xdata+c_true+sigma",
"_____no_output_____"
],
[
"assert True # leave this cell for grading the raw data generation and plot",
"_____no_output_____"
]
],
[
[
"Now fit the model to the dataset to recover estimates for the model's parameters:\n\n* Print out the estimates and uncertainties of each parameter.\n* Plot the raw data and best fit of the model.",
"_____no_output_____"
]
],
[
[
"def modl(x,a,b,c):\n y=a**2+b*x+c\n return y\ndef derivs(theta,x,y,dy):\n a=theta[0]\n b=theta[1]\n c=theta[2]\n return (y-a*x**2-b*x-c/dy)",
"_____no_output_____"
],
[
"assert True # leave this cell for grading the fit; should include a plot and printout of the parameters+errors",
"_____no_output_____"
],
[
"bestfit=opt.leastsq(derivs,np.array((1,2,-5)),args=(xdata,ydata,dy),full_output=True)\nthetabest=bestfit[0]\nthetacov=bestfit[1]",
"_____no_output_____"
],
[
"plt.errorbar(xdata,ydata,dy,fmt='b.')\nxfit=np.linspace(-5,5,100)\nyfit=thetabest[0]*xfit**2+thetabest[1]*xfit+thetabest[2]\nplt.plot(xfit,yfit)\nplt.title('Quad Fit')\nplt.xlabel('x')\nplt.ylabel('y')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
c517a9c78a94599ce9e97004e091a16323d0589e
| 320,796 |
ipynb
|
Jupyter Notebook
|
KorstiaanW_tn_en_Baseline.ipynb
|
KorstiaanW/masakhane-mt
|
6600d63da4886b44d6dd35c73be70891556dfaeb
|
[
"MIT"
] | null | null | null |
KorstiaanW_tn_en_Baseline.ipynb
|
KorstiaanW/masakhane-mt
|
6600d63da4886b44d6dd35c73be70891556dfaeb
|
[
"MIT"
] | null | null | null |
KorstiaanW_tn_en_Baseline.ipynb
|
KorstiaanW/masakhane-mt
|
6600d63da4886b44d6dd35c73be70891556dfaeb
|
[
"MIT"
] | null | null | null | 109.412005 | 999 | 0.612716 |
[
[
[
"<a href=\"https://colab.research.google.com/github/KorstiaanW/masakhane-mt/blob/master/KorstiaanW_tn_en_Baseline.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Masakhane - Reverse Machine Translation for African Languages (Using JoeyNMT)",
"_____no_output_____"
],
[
"> ## NB\n>### - The purpose of this Notebook is to build models that translate African languages(target language) *into* English(source language). This will allow us to in future be able to make translations from one African language to the other. If you'd like to translate *from* English, please use [this](https://github.com/masakhane-io/masakhane-mt/blob/master/starter_notebook.ipynb) starter notebook instead.\n\n>### - We call this reverse training because normally we build models that make translations from the source language(English) to the target language. But in this case we are doing the reverse; building models that make translations from the target language to the source(English)",
"_____no_output_____"
],
[
"## Note before beginning:\n### - The idea is that you should be able to make minimal changes to this in order to get SOME result for your own translation corpus. \n\n### - The tl;dr: Go to the **\"TODO\"** comments which will tell you what to update to get up and running\n\n### - If you actually want to have a clue what you're doing, read the text and peek at the links\n\n### - With 100 epochs, it should take around 7 hours to run in Google Colab\n\n### - Once you've gotten a result for your language, please attach and email your notebook that generated it to [email protected]\n\n### - If you care enough and get a chance, doing a brief background on your language would be amazing. See examples in [(Martinus, 2019)](https://arxiv.org/abs/1906.05685)",
"_____no_output_____"
],
[
"## Retrieve your data & make a parallel corpus\n\nIf you are wanting to use the JW300 data referenced on the Masakhane website or in our GitHub repo, you can use `opus-tools` to convert the data into a convenient format. `opus_read` from that package provides a convenient tool for reading the native aligned XML files and to convert them to TMX format. The tool can also be used to fetch relevant files from OPUS on the fly and to filter the data as necessary. [Read the documentation](https://pypi.org/project/opustools-pkg/) for more details.\n\nOnce you have your corpus files in TMX format (an xml structure which will include the sentences in your target language and your source language in a single file), we recommend reading them into a pandas dataframe. Thankfully, Jade wrote a silly `tmx2dataframe` package which converts your tmx file to a pandas dataframe. ",
"_____no_output_____"
],
[
"Submitted by Tebello Lebesa 2388016\n\nSumbitted by Korstiaan Wapenaar 1492459",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\n"
],
[
"# TODO: Set your source and target languages. Keep in mind, these traditionally use language codes as found here:\n# These will also become the suffix's of all vocab and corpus files used throughout\nimport os\nsource_language = \"en\"\ntarget_language = \"tn\" \nlc = False # If True, lowercase the data.\nseed = 42 # Random seed for shuffling.\ntag = \"baseline\" # Give a unique name to your folder - this is to ensure you don't rewrite any models you've already submitted\n\nos.environ[\"src\"] = source_language # Sets them in bash as well, since we often use bash scripts\nos.environ[\"tgt\"] = target_language\nos.environ[\"tag\"] = tag\n\n# This will save it to a folder in our gdrive instead!\n!mkdir -p \"/content/drive/My Drive/masakhane/$tgt-$src-$tag\"\nos.environ[\"gdrive_path\"] = \"/content/drive/My Drive/masakhane/%s-%s-%s\" % (target_language, source_language, tag)",
"_____no_output_____"
],
[
"!echo $gdrive_path",
"/content/drive/My Drive/masakhane/tn-en-baseline\n"
],
[
"# Install opus-tools\n! pip install opustools-pkg",
"Collecting opustools-pkg\n Downloading opustools_pkg-0.0.52-py3-none-any.whl (80 kB)\n\u001b[?25l\r\u001b[K |████ | 10 kB 19.9 MB/s eta 0:00:01\r\u001b[K |████████ | 20 kB 22.0 MB/s eta 0:00:01\r\u001b[K |████████████▏ | 30 kB 16.3 MB/s eta 0:00:01\r\u001b[K |████████████████▏ | 40 kB 14.8 MB/s eta 0:00:01\r\u001b[K |████████████████████▎ | 51 kB 5.3 MB/s eta 0:00:01\r\u001b[K |████████████████████████▎ | 61 kB 5.8 MB/s eta 0:00:01\r\u001b[K |████████████████████████████▎ | 71 kB 5.4 MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 80 kB 4.2 MB/s \n\u001b[?25hInstalling collected packages: opustools-pkg\nSuccessfully installed opustools-pkg-0.0.52\n"
],
[
"# Downloading our corpus\n! opus_read -d JW300 -s $src -t $tgt -wm moses -w jw300.$src jw300.$tgt -q\n\n# extract the corpus file\n! gunzip JW300_latest_xml_$src-$tgt.xml.gz",
"\nAlignment file /proj/nlpl/data/OPUS/JW300/latest/xml/en-tn.xml.gz not found. The following files are available for downloading:\n\n 8 MB https://object.pouta.csc.fi/OPUS-JW300/v1c/xml/en-tn.xml.gz\n 274 MB https://object.pouta.csc.fi/OPUS-JW300/v1c/xml/en.zip\n 111 MB https://object.pouta.csc.fi/OPUS-JW300/v1c/xml/tn.zip\n\n 393 MB Total size\n./JW300_latest_xml_en-tn.xml.gz ... 100% of 8 MB\n./JW300_latest_xml_en.zip ... 100% of 274 MB\n./JW300_latest_xml_tn.zip ... 100% of 111 MB\n"
],
[
"# Download the global test set.\n! wget https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-any.en\n \n# And the specific test set for this language pair.\nos.environ[\"trg\"] = target_language \nos.environ[\"src\"] = source_language \n\n! wget https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-$trg.en \n! mv test.en-$trg.en test.en\n! wget https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-$trg.$trg \n! mv test.en-$trg.$trg test.$trg",
"--2021-10-10 16:52:13-- https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-any.en\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.111.133, 185.199.109.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 277791 (271K) [text/plain]\nSaving to: ‘test.en-any.en’\n\n\rtest.en-any.en 0%[ ] 0 --.-KB/s \rtest.en-any.en 100%[===================>] 271.28K --.-KB/s in 0.03s \n\n2021-10-10 16:52:13 (8.48 MB/s) - ‘test.en-any.en’ saved [277791/277791]\n\n--2021-10-10 16:52:13-- https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-tn.en\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 206185 (201K) [text/plain]\nSaving to: ‘test.en-tn.en’\n\ntest.en-tn.en 100%[===================>] 201.35K --.-KB/s in 0.03s \n\n2021-10-10 16:52:13 (7.82 MB/s) - ‘test.en-tn.en’ saved [206185/206185]\n\n--2021-10-10 16:52:14-- https://raw.githubusercontent.com/juliakreutzer/masakhane/master/jw300_utils/test/test.en-tn.tn\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 238522 (233K) [text/plain]\nSaving to: ‘test.en-tn.tn’\n\ntest.en-tn.tn 100%[===================>] 232.93K --.-KB/s in 0.03s \n\n2021-10-10 16:52:14 (8.90 MB/s) - ‘test.en-tn.tn’ saved [238522/238522]\n\n"
],
[
"# Read the test data to filter from train and dev splits.\n# Store english portion in set for quick filtering checks.\nen_test_sents = set()\nfilter_test_sents = \"test.en-any.en\"\nj = 0\nwith open(filter_test_sents) as f:\n for line in f:\n en_test_sents.add(line.strip())\n j += 1\nprint('Loaded {} global test sentences to filter from the training/dev data.'.format(j))",
"Loaded 3571 global test sentences to filter from the training/dev data.\n"
],
[
"import pandas as pd\n\n# TMX file to dataframe\nsource_file = 'jw300.' + source_language\ntarget_file = 'jw300.' + target_language\n\nsource = []\ntarget = []\nskip_lines = [] # Collect the line numbers of the source portion to skip the same lines for the target portion.\nwith open(source_file) as f:\n for i, line in enumerate(f):\n # Skip sentences that are contained in the test set.\n if line.strip() not in en_test_sents:\n source.append(line.strip())\n else:\n skip_lines.append(i) \nwith open(target_file) as f:\n for j, line in enumerate(f):\n # Only add to corpus if corresponding source was not skipped.\n if j not in skip_lines:\n target.append(line.strip())\n \nprint('Loaded data and skipped {}/{} lines since contained in test set.'.format(len(skip_lines), i))\n \ndf = pd.DataFrame(zip(source, target), columns=['source_sentence', 'target_sentence'])\n# if you get TypeError: data argument can't be an iterator is because of your zip version run this below\n#df = pd.DataFrame(list(zip(source, target)), columns=['source_sentence', 'target_sentence'])\ndf.head(3)",
"Loaded data and skipped 5312/869198 lines since contained in test set.\n"
]
],
[
[
"## Pre-processing and export\n\nIt is generally a good idea to remove duplicate translations and conflicting translations from the corpus. In practice, these public corpora include some number of these that need to be cleaned.\n\nIn addition we will split our data into dev/test/train and export to the filesystem.",
"_____no_output_____"
]
],
[
[
"# drop duplicate translations\ndf_pp = df.drop_duplicates()\n\n# drop conflicting translations\n# (this is optional and something that you might want to comment out \n# depending on the size of your corpus)\ndf_pp.drop_duplicates(subset='source_sentence', inplace=True)\ndf_pp.drop_duplicates(subset='target_sentence', inplace=True)\n\n# Shuffle the data to remove bias in dev set selection.\ndf_pp = df_pp.sample(frac=1, random_state=seed).reset_index(drop=True)",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:7: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n import sys\n/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:8: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
],
[
"# Install fuzzy wuzzy to remove \"almost duplicate\" sentences in the\n# test and training sets.\n! pip install fuzzywuzzy\n! pip install python-Levenshtein\nimport time\nfrom fuzzywuzzy import process\nimport numpy as np\nfrom os import cpu_count\nfrom functools import partial\nfrom multiprocessing import Pool\n\n\n# reset the index of the training set after previous filtering\ndf_pp.reset_index(drop=False, inplace=True)\n\n# Remove samples from the training data set if they \"almost overlap\" with the\n# samples in the test set.\n\n# Filtering function. Adjust pad to narrow down the candidate matches to\n# within a certain length of characters of the given sample.\ndef fuzzfilter(sample, candidates, pad):\n candidates = [x for x in candidates if len(x) <= len(sample)+pad and len(x) >= len(sample)-pad] \n if len(candidates) > 0:\n return process.extractOne(sample, candidates)[1]\n else:\n return np.nan",
"Collecting fuzzywuzzy\n Downloading fuzzywuzzy-0.18.0-py2.py3-none-any.whl (18 kB)\nInstalling collected packages: fuzzywuzzy\nSuccessfully installed fuzzywuzzy-0.18.0\nCollecting python-Levenshtein\n Downloading python-Levenshtein-0.12.2.tar.gz (50 kB)\n\u001b[K |████████████████████████████████| 50 kB 3.1 MB/s \n\u001b[?25hRequirement already satisfied: setuptools in /usr/local/lib/python3.7/dist-packages (from python-Levenshtein) (57.4.0)\nBuilding wheels for collected packages: python-Levenshtein\n Building wheel for python-Levenshtein (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for python-Levenshtein: filename=python_Levenshtein-0.12.2-cp37-cp37m-linux_x86_64.whl size=149866 sha256=41caf7fc00b0f21a7b260ee9d6ba066226718d0ff1b000bfc6df6c467e118cd0\n Stored in directory: /root/.cache/pip/wheels/05/5f/ca/7c4367734892581bb5ff896f15027a932c551080b2abd3e00d\nSuccessfully built python-Levenshtein\nInstalling collected packages: python-Levenshtein\nSuccessfully installed python-Levenshtein-0.12.2\n"
],
[
"# start_time = time.time()\n# ### iterating over pandas dataframe rows is not recomended, let use multi processing to apply the function\n\n# with Pool(cpu_count()-1) as pool:\n# scores = pool.map(partial(fuzzfilter, candidates=list(en_test_sents), pad=5), df_pp['source_sentence'])\n# hours, rem = divmod(time.time() - start_time, 3600)\n# minutes, seconds = divmod(rem, 60)\n# print(\"done in {}h:{}min:{}seconds\".format(hours, minutes, seconds))\n\n# # Filter out \"almost overlapping samples\"\n# df_pp = df_pp.assign(scores=scores)\n# df_pp = df_pp[df_pp['scores'] < 95]",
"_____no_output_____"
],
[
"# This section does the split between train/dev for the parallel corpora then saves them as separate files\n# We use 1000 dev test and the given test set.\nimport csv\n\n# Do the split between dev/train and create parallel corpora\nnum_dev_patterns = 1000\n\n# Optional: lower case the corpora - this will make it easier to generalize, but without proper casing.\nif lc: # Julia: making lowercasing optional\n df_pp[\"source_sentence\"] = df_pp[\"source_sentence\"].str.lower()\n df_pp[\"target_sentence\"] = df_pp[\"target_sentence\"].str.lower()\n\n# Julia: test sets are already generated\ndev = df_pp.tail(num_dev_patterns) # Herman: Error in original\nstripped = df_pp.drop(df_pp.tail(num_dev_patterns).index)\n\nwith open(\"train.\"+source_language, \"w\") as src_file, open(\"train.\"+target_language, \"w\") as trg_file:\n for index, row in stripped.iterrows():\n src_file.write(row[\"source_sentence\"]+\"\\n\")\n trg_file.write(row[\"target_sentence\"]+\"\\n\")\n \nwith open(\"dev.\"+source_language, \"w\") as src_file, open(\"dev.\"+target_language, \"w\") as trg_file:\n for index, row in dev.iterrows():\n src_file.write(row[\"source_sentence\"]+\"\\n\")\n trg_file.write(row[\"target_sentence\"]+\"\\n\")\n\n#stripped[[\"source_sentence\"]].to_csv(\"train.\"+source_language, header=False, index=False) # Herman: Added `header=False` everywhere\n#stripped[[\"target_sentence\"]].to_csv(\"train.\"+target_language, header=False, index=False) # Julia: Problematic handling of quotation marks.\n\n#dev[[\"source_sentence\"]].to_csv(\"dev.\"+source_language, header=False, index=False)\n#dev[[\"target_sentence\"]].to_csv(\"dev.\"+target_language, header=False, index=False)\n\n# Doublecheck the format below. There should be no extra quotation marks or weird characters.\n! head train.*\n! head dev.*",
"==> train.en <==\n( Read Mark 12 : 28-30 . )\n□ What is “ the day of Jehovah ” ?\nImmediate and lasting rewards do come from listening to and applying the counsel of God ’ s Word as we work at cultivating reasonable expectations .\nNote how the Bible helps us to respect their knowledge and experience , take their feelings into account , and assist them to remain spiritually active .\nFlying an Air Force VIP jet over Parliament House , Canberra\nHe should “ do all things for God ’ s glory ” and not become a cause for stumbling .\nInstead , Jehovah had prepared a perfect human body for Jesus to offer as a sacrifice .\nIt ’ s like a big freckle on your hand .\nSo Jesus warned his disciples : “ Keep your eyes open ; look out for the leaven of the Pharisees and the leaven of Herod . ”\nFor example , Greek philosopher Aristotle pictured man at the top of a line evolving from lower animal life .\n\n==> train.tn <==\n( Bala Mareko 12 : 28 - 30 . )\n□ “ Motlha oa ga Yehofa ” ke eng ?\nRe tla bona dituelo tsa gone jaanong le tse di nnetseng ruri fa re reetsa le go dirisa kgakololo ya Lefoko la Modimo fa re ntse re lwela go nna le ditebelelo tse di lekalekaneng .\nRe tla bona kafa Baebele e re thusang ka teng gore re tlotle kitso ya bone le maitemogelo a ba nang le one , re akanyetse maikutlo a bone , mme gape re ba thuse gore ba nne le seabe ka metlha mo ditirong tsa Bokeresete .\nKe fofisa Sefofane sa Sesole sa batho ba maemo a a kwa godimo , mo godimo ga Ntlo ya Palamente , kwa Canberra\nO tshwanetse go “ [ dira ] dilo tsotlhe kgalaletsong ya Modimo ” mme a se nne lebaka la go kgopisa ba bangwe .\nGo na le moo , Jehofa o ne a baakanyeditse Jesu mmele o o itekanetseng wa motho gore a o ntshe go nna setlhabelo .\nGo tshwana fela le lebadi le legolo le le mo seatleng sa gago .\nKa jalo , Jesu o ne a tlhagisa barutwa ba gagwe jaana : “ Nnang lo butse matlho , itiseng mo sebedisong sa Bafarasai le mo sebedisong sa ga Herode . ”\nKa sekai , ramatlhajana wa Mogerika ebong Aristotle o ne a bona batho e le setlhoa sa mokoloko o o simologileng mo ditsheding tsa maemo a a kwa tlase .\n==> dev.en <==\nAnd when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\nComing Back to Lovech\nOn one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n“ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\nRather , he would study it , extracting from it every detail and nuance .\nOr perhaps you thought that you and your mate would spend most of your time together or that the two of you would work out every disagreement in a smooth , mature manner .\nAt best they are viewed as cheap labor , just waiting to be ruthlessly exploited .\nHe and I wanted to serve together as full-time evangelizers , so we began to spend time together . ”\nHe spoke swelling things to those whose favor he needed — all to acquire a coveted position of authority .\nMay that be your experience as a person who continually follows Jehovah fully .\n\n==> dev.tn <==\nMme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\nKe Boela Lovech\nMo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n“ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\nGo na le moo , o ne a tla le bala ka kelotlhoko , gore a utlwe sengwe le sengwe se se mo go lone .\nGongwe o ka tswa o ne o akanya gore wena le molekane wa gago lo tla dirisa nako e ntsi lo le mmogo kana loobabedi lo tla kgona go rarabolola kgotlhang nngwe le nngwe ka tsela e e motlhofo e e bontshang gore lo godile sentle .\nMme fa ba re ba ba tshotse tota ke fa ba ba leba jaaka babereki ba ba duelwang madi a a kwa tlase , ba eleng gore ba emetse fela gore ba jewe ntsoma ka tsela e e botlhoko .\nNna le ene re ne re batla go dira mmogo re le bareri ba nako e e tletseng , ka jalo re ne ra simolola go fetsa nako e rileng re le mmogo . ”\nO ne a raya batho ba a neng a batla gore ba mo eme nokeng dilo tse dikgolo — e le fela gore a bone maemo a go etelela pele .\nEkete le wena o ka nna le maitemogelo a a ntseng jalo a go nna motho yo o tswelelang a sala Jehofa morago ka botlalo .\n"
]
],
[
[
"\n\n---\n\n\n## Installation of JoeyNMT\n\nJoeyNMT is a simple, minimalist NMT package which is useful for learning and teaching. Check out the documentation for JoeyNMT [here](https://joeynmt.readthedocs.io) ",
"_____no_output_____"
]
],
[
[
"# Install JoeyNMT\n! git clone https://github.com/joeynmt/joeynmt.git\n! cd joeynmt; pip3 install .\n# Install Pytorch with GPU support v1.7.1.\n! pip install torch==1.9.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html",
"Cloning into 'joeynmt'...\nremote: Enumerating objects: 3224, done.\u001b[K\nremote: Counting objects: 100% (273/273), done.\u001b[K\nremote: Compressing objects: 100% (139/139), done.\u001b[K\nremote: Total 3224 (delta 157), reused 206 (delta 134), pack-reused 2951\u001b[K\nReceiving objects: 100% (3224/3224), 8.17 MiB | 14.96 MiB/s, done.\nResolving deltas: 100% (2185/2185), done.\nProcessing /content/joeynmt\n\u001b[33m DEPRECATION: A future pip version will change local packages to be built in-place without first copying to a temporary directory. We recommend you use --use-feature=in-tree-build to test your packages with this new behavior before it becomes the default.\n pip 21.3 will remove support for this functionality. You can find discussion regarding this at https://github.com/pypa/pip/issues/7555.\u001b[0m\nRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (0.16.0)\nRequirement already satisfied: pillow in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (7.1.2)\nRequirement already satisfied: numpy>=1.19.5 in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (1.19.5)\nRequirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (57.4.0)\nRequirement already satisfied: torch>=1.9.0 in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (1.9.0+cu111)\nRequirement already satisfied: tensorboard>=1.15 in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (2.6.0)\nRequirement already satisfied: torchtext>=0.10.0 in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (0.10.0)\nCollecting sacrebleu>=2.0.0\n Downloading sacrebleu-2.0.0-py3-none-any.whl (90 kB)\n\u001b[K |████████████████████████████████| 90 kB 4.5 MB/s \n\u001b[?25hCollecting subword-nmt\n Downloading subword_nmt-0.3.7-py2.py3-none-any.whl (26 kB)\nRequirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (3.2.2)\nRequirement already satisfied: seaborn in /usr/local/lib/python3.7/dist-packages (from joeynmt==1.3) (0.11.2)\nCollecting pyyaml>=5.1\n Downloading PyYAML-5.4.1-cp37-cp37m-manylinux1_x86_64.whl (636 kB)\n\u001b[K |████████████████████████████████| 636 kB 29.2 MB/s \n\u001b[?25hCollecting pylint>=2.9.6\n Downloading pylint-2.11.1-py3-none-any.whl (392 kB)\n\u001b[K |████████████████████████████████| 392 kB 90.9 MB/s \n\u001b[?25hCollecting six==1.12\n Downloading six-1.12.0-py2.py3-none-any.whl (10 kB)\nCollecting wrapt==1.11.1\n Downloading wrapt-1.11.1.tar.gz (27 kB)\nCollecting typing-extensions>=3.10.0\n Downloading typing_extensions-3.10.0.2-py3-none-any.whl (26 kB)\nCollecting platformdirs>=2.2.0\n Downloading platformdirs-2.4.0-py3-none-any.whl (14 kB)\nRequirement already satisfied: toml>=0.7.1 in /usr/local/lib/python3.7/dist-packages (from pylint>=2.9.6->joeynmt==1.3) (0.10.2)\nCollecting mccabe<0.7,>=0.6\n Downloading mccabe-0.6.1-py2.py3-none-any.whl (8.6 kB)\nCollecting astroid<2.9,>=2.8.0\n Downloading astroid-2.8.2-py3-none-any.whl (246 kB)\n\u001b[K |████████████████████████████████| 246 kB 74.2 MB/s \n\u001b[?25hCollecting isort<6,>=4.2.5\n Downloading isort-5.9.3-py3-none-any.whl (106 kB)\n\u001b[K |████████████████████████████████| 106 kB 82.7 MB/s \n\u001b[?25hCollecting typed-ast<1.5,>=1.4.0\n Downloading typed_ast-1.4.3-cp37-cp37m-manylinux1_x86_64.whl (743 kB)\n\u001b[K |████████████████████████████████| 743 kB 76.5 MB/s \n\u001b[?25hCollecting lazy-object-proxy>=1.4.0\n Downloading lazy_object_proxy-1.6.0-cp37-cp37m-manylinux1_x86_64.whl (55 kB)\n\u001b[K |████████████████████████████████| 55 kB 4.7 MB/s \n\u001b[?25hRequirement already satisfied: regex in /usr/local/lib/python3.7/dist-packages (from sacrebleu>=2.0.0->joeynmt==1.3) (2019.12.20)\nCollecting portalocker\n Downloading portalocker-2.3.2-py2.py3-none-any.whl (15 kB)\nRequirement already satisfied: tabulate>=0.8.9 in /usr/local/lib/python3.7/dist-packages (from sacrebleu>=2.0.0->joeynmt==1.3) (0.8.9)\nCollecting colorama\n Downloading colorama-0.4.4-py2.py3-none-any.whl (16 kB)\nRequirement already satisfied: protobuf>=3.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (3.17.3)\nRequirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (0.6.1)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (1.0.1)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (0.37.0)\nRequirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (1.8.0)\nRequirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (2.23.0)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (1.35.0)\nRequirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (0.12.0)\nRequirement already satisfied: grpcio>=1.24.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (1.41.0)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (3.3.4)\nRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.7/dist-packages (from tensorboard>=1.15->joeynmt==1.3) (0.4.6)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.15->joeynmt==1.3) (4.2.4)\nRequirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.15->joeynmt==1.3) (0.2.8)\nRequirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard>=1.15->joeynmt==1.3) (4.7.2)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.7/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=1.15->joeynmt==1.3) (1.3.0)\nRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from markdown>=2.6.8->tensorboard>=1.15->joeynmt==1.3) (4.8.1)\nRequirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.7/dist-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard>=1.15->joeynmt==1.3) (0.4.8)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.15->joeynmt==1.3) (2021.5.30)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.15->joeynmt==1.3) (2.10)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.15->joeynmt==1.3) (1.24.3)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests<3,>=2.21.0->tensorboard>=1.15->joeynmt==1.3) (3.0.4)\nRequirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.7/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard>=1.15->joeynmt==1.3) (3.1.1)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from torchtext>=0.10.0->joeynmt==1.3) (4.62.3)\nRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->markdown>=2.6.8->tensorboard>=1.15->joeynmt==1.3) (3.6.0)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->joeynmt==1.3) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->joeynmt==1.3) (1.3.2)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->joeynmt==1.3) (2.8.2)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib->joeynmt==1.3) (0.10.0)\nRequirement already satisfied: scipy>=1.0 in /usr/local/lib/python3.7/dist-packages (from seaborn->joeynmt==1.3) (1.4.1)\nRequirement already satisfied: pandas>=0.23 in /usr/local/lib/python3.7/dist-packages (from seaborn->joeynmt==1.3) (1.1.5)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.23->seaborn->joeynmt==1.3) (2018.9)\nBuilding wheels for collected packages: joeynmt, wrapt\n Building wheel for joeynmt (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for joeynmt: filename=joeynmt-1.3-py3-none-any.whl size=86029 sha256=6011da6dd28f7ad24bf77c2b5187402188985af099eb751ac9ba16566baa7d8d\n Stored in directory: /tmp/pip-ephem-wheel-cache-31uyk62q/wheels/0a/f4/bf/6c9d3b8efbfece6cd209f865be37382b02e7c3584df2e28ca4\n Building wheel for wrapt (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for wrapt: filename=wrapt-1.11.1-cp37-cp37m-linux_x86_64.whl size=68439 sha256=89f5d179ac5e698a6bf024bac0ecd6c835ae675301a836503595fa5dba785cc5\n Stored in directory: /root/.cache/pip/wheels/4e/58/9d/da8bad4545585ca52311498ff677647c95c7b690b3040171f8\nSuccessfully built joeynmt wrapt\nInstalling collected packages: typing-extensions, six, wrapt, typed-ast, lazy-object-proxy, portalocker, platformdirs, mccabe, isort, colorama, astroid, subword-nmt, sacrebleu, pyyaml, pylint, joeynmt\n Attempting uninstall: typing-extensions\n Found existing installation: typing-extensions 3.7.4.3\n Uninstalling typing-extensions-3.7.4.3:\n Successfully uninstalled typing-extensions-3.7.4.3\n Attempting uninstall: six\n Found existing installation: six 1.15.0\n Uninstalling six-1.15.0:\n Successfully uninstalled six-1.15.0\n Attempting uninstall: wrapt\n Found existing installation: wrapt 1.12.1\n Uninstalling wrapt-1.12.1:\n Successfully uninstalled wrapt-1.12.1\n Attempting uninstall: pyyaml\n Found existing installation: PyYAML 3.13\n Uninstalling PyYAML-3.13:\n Successfully uninstalled PyYAML-3.13\n\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\ntensorflow 2.6.0 requires six~=1.15.0, but you have six 1.12.0 which is incompatible.\ntensorflow 2.6.0 requires typing-extensions~=3.7.4, but you have typing-extensions 3.10.0.2 which is incompatible.\ntensorflow 2.6.0 requires wrapt~=1.12.1, but you have wrapt 1.11.1 which is incompatible.\ngoogle-colab 1.0.0 requires six~=1.15.0, but you have six 1.12.0 which is incompatible.\ngoogle-api-python-client 1.12.8 requires six<2dev,>=1.13.0, but you have six 1.12.0 which is incompatible.\ngoogle-api-core 1.26.3 requires six>=1.13.0, but you have six 1.12.0 which is incompatible.\ndatascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.\nalbumentations 0.1.12 requires imgaug<0.2.7,>=0.2.5, but you have imgaug 0.2.9 which is incompatible.\u001b[0m\nSuccessfully installed astroid-2.8.2 colorama-0.4.4 isort-5.9.3 joeynmt-1.3 lazy-object-proxy-1.6.0 mccabe-0.6.1 platformdirs-2.4.0 portalocker-2.3.2 pylint-2.11.1 pyyaml-5.4.1 sacrebleu-2.0.0 six-1.12.0 subword-nmt-0.3.7 typed-ast-1.4.3 typing-extensions-3.10.0.2 wrapt-1.11.1\nLooking in links: https://download.pytorch.org/whl/torch_stable.html\n\u001b[31mERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu101 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2, 0.4.1, 0.4.1.post2, 1.0.0, 1.0.1, 1.0.1.post2, 1.1.0, 1.2.0, 1.2.0+cpu, 1.2.0+cu92, 1.3.0, 1.3.0+cpu, 1.3.0+cu100, 1.3.0+cu92, 1.3.1, 1.3.1+cpu, 1.3.1+cu100, 1.3.1+cu92, 1.4.0, 1.4.0+cpu, 1.4.0+cu100, 1.4.0+cu92, 1.5.0, 1.5.0+cpu, 1.5.0+cu101, 1.5.0+cu92, 1.5.1, 1.5.1+cpu, 1.5.1+cu101, 1.5.1+cu92, 1.6.0, 1.6.0+cpu, 1.6.0+cu101, 1.6.0+cu92, 1.7.0, 1.7.0+cpu, 1.7.0+cu101, 1.7.0+cu110, 1.7.0+cu92, 1.7.1, 1.7.1+cpu, 1.7.1+cu101, 1.7.1+cu110, 1.7.1+cu92, 1.7.1+rocm3.7, 1.7.1+rocm3.8, 1.8.0, 1.8.0+cpu, 1.8.0+cu101, 1.8.0+cu111, 1.8.0+rocm3.10, 1.8.0+rocm4.0.1, 1.8.1, 1.8.1+cpu, 1.8.1+cu101, 1.8.1+cu102, 1.8.1+cu111, 1.8.1+rocm3.10, 1.8.1+rocm4.0.1, 1.9.0, 1.9.0+cpu, 1.9.0+cu102, 1.9.0+cu111, 1.9.0+rocm4.0.1, 1.9.0+rocm4.1, 1.9.0+rocm4.2, 1.9.1, 1.9.1+cpu, 1.9.1+cu102, 1.9.1+cu111, 1.9.1+rocm4.0.1, 1.9.1+rocm4.1, 1.9.1+rocm4.2)\u001b[0m\n\u001b[31mERROR: No matching distribution found for torch==1.9.0+cu101\u001b[0m\n"
]
],
[
[
"# Preprocessing the Data into Subword BPE Tokens\n\n- One of the most powerful improvements for agglutinative languages (a feature of most Bantu languages) is using BPE tokenization [ (Sennrich, 2015) ](https://arxiv.org/abs/1508.07909).\n\n- It was also shown that by optimizing the umber of BPE codes we significantly improve results for low-resourced languages [(Sennrich, 2019)](https://www.aclweb.org/anthology/P19-1021) [(Martinus, 2019)](https://arxiv.org/abs/1906.05685)\n\n- Below we have the scripts for doing BPE tokenization of our data. We use 4000 tokens as recommended by [(Sennrich, 2019)](https://www.aclweb.org/anthology/P19-1021). You do not need to change anything. Simply running the below will be suitable. ",
"_____no_output_____"
]
],
[
[
"# One of the huge boosts in NMT performance was to use a different method of tokenizing. \n# Usually, NMT would tokenize by words. However, using a method called BPE gave amazing boosts to performance\n\n# Do subword NMT\nfrom os import path\nos.environ[\"src\"] = source_language # Sets them in bash as well, since we often use bash scripts\nos.environ[\"tgt\"] = target_language\n\n# Learn BPEs on the training data.\nos.environ[\"data_path\"] = path.join(\"joeynmt\", \"data\",target_language + source_language ) # Herman! \n! subword-nmt learn-joint-bpe-and-vocab --input train.$src train.$tgt -s 4000 -o bpe.codes.4000 --write-vocabulary vocab.$src vocab.$tgt\n\n# Apply BPE splits to the development and test data.\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$src < train.$src > train.bpe.$src\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$tgt < train.$tgt > train.bpe.$tgt\n\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$src < dev.$src > dev.bpe.$src\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$tgt < dev.$tgt > dev.bpe.$tgt\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$src < test.$src > test.bpe.$src\n! subword-nmt apply-bpe -c bpe.codes.4000 --vocabulary vocab.$tgt < test.$tgt > test.bpe.$tgt\n\n# Create directory, move everyone we care about to the correct location\n! mkdir -p $data_path\n! cp train.* $data_path\n! cp test.* $data_path\n! cp dev.* $data_path\n! cp bpe.codes.4000 $data_path\n! ls $data_path\n\n# Also move everything we care about to a mounted location in google drive (relevant if running in colab) at gdrive_path\n! cp train.* \"$gdrive_path\"\n! cp test.* \"$gdrive_path\"\n! cp dev.* \"$gdrive_path\"\n! cp bpe.codes.4000 \"$gdrive_path\"\n! ls \"$gdrive_path\"\n\n# Create that vocab using build_vocab\n! sudo chmod 777 joeynmt/scripts/build_vocab.py\n! joeynmt/scripts/build_vocab.py joeynmt/data/$tgt$src/train.bpe.$src joeynmt/data/$tgt$src/train.bpe.$tgt --output_path joeynmt/data/$tgt$src/vocab.txt\n\n# Some output\n! echo \"BPE Setswana Sentences\"\n! tail -n 5 test.bpe.$tgt\n! echo \"Combined BPE Vocab\"\n! tail -n 10 joeynmt/data/$tgt$src/vocab.txt # Herman",
"bpe.codes.4000\tdev.en\t test.bpe.tn test.tn\t train.en\ndev.bpe.en\tdev.tn\t test.en\t train.bpe.en train.tn\ndev.bpe.tn\ttest.bpe.en test.en-any.en train.bpe.tn\nbpe.codes.4000\tdev.en\ttest.bpe.en test.en-any.en test.tn\t train.en\ndev.bpe.en\tdev.tn\ttest.bpe.tn test.en-any.en.1 train.bpe.en train.tn\ndev.bpe.tn\tmodels\ttest.en test.en-any.en.2 train.bpe.tn\nBPE Setswana Sentences\nSeo se ile sa dira gore ke its@@ iwe ke le motho yo o sa ikanyeg@@ eng .\nFa ke sena go ithuta boammaaruri , ke ne ka gana go tswelela ka mokgwa oo tota le fa tiro eo e ne e n@@ tu@@ ela bon@@ tle tota .\nKe tlhom@@ ela bo@@ morwa@@ ake ba babedi sekao se se molemo e bile ke kgon@@ ne go tshwan@@ ele@@ gela go newa di@@ tshiamelo mo phuthegong .\nBa@@ tlhatlho@@ bi ba le@@ kge@@ tho mmogo le batho ba bangwe ba ke gwe@@ b@@ is@@ anang le bone , ba n@@ k@@ itse ke le motho yo o ikanyegang . ”\nRu@@ the o ne a fudu@@ gela kwa Iseraele kwa a neng a ka kgona go obamela Modimo wa boammaaruri gone .\nCombined BPE Vocab\n{\nEkeso@@\nî\n◀\n̆\nastes\nŝ@@\nÙ@@\nΟ@@\nÒ@@\n"
],
[
"# Also move everything we care about to a mounted location in google drive (relevant if running in colab) at gdrive_path\n! cp train.* \"$gdrive_path\"\n! cp test.* \"$gdrive_path\"\n! cp dev.* \"$gdrive_path\"\n! cp bpe.codes.4000 \"$gdrive_path\"\n! ls \"$gdrive_path\"",
"bpe.codes.4000\tdev.en\ttest.bpe.en test.en-any.en test.tn\t train.en\ndev.bpe.en\tdev.tn\ttest.bpe.tn test.en-any.en.1 train.bpe.en train.tn\ndev.bpe.tn\tmodels\ttest.en test.en-any.en.2 train.bpe.tn\n"
]
],
[
[
"# Creating the JoeyNMT Config\n\nJoeyNMT requires a yaml config. We provide a template below. We've also set a number of defaults with it, that you may play with!\n\n- We used Transformer architecture \n- We set our dropout to reasonably high: 0.3 (recommended in [(Sennrich, 2019)](https://www.aclweb.org/anthology/P19-1021))\n\nThings worth playing with:\n- The batch size (also recommended to change for low-resourced languages)\n- The number of epochs (we've set it at 30 just so it runs in about an hour, for testing purposes)\n- The decoder options (beam_size, alpha)\n- Evaluation metrics (BLEU versus Crhf4)",
"_____no_output_____"
]
],
[
[
"# This creates the config file for our JoeyNMT system. It might seem overwhelming so we've provided a couple of useful parameters you'll need to update\n# (You can of course play with all the parameters if you'd like!)\n\nname = '%s%s' % (target_language, source_language)\n# gdrive_path = os.environ[\"gdrive_path\"]\n\n# Create the config\nconfig = \"\"\"\nname: \"{target_language}{source_language}_reverse_transformer\"\n\ndata:\n src: \"{target_language}\"\n trg: \"{source_language}\"\n train: \"data/{name}/train.bpe\"\n dev: \"data/{name}/dev.bpe\"\n test: \"data/{name}/test.bpe\"\n level: \"bpe\"\n lowercase: False\n max_sent_length: 100\n src_vocab: \"data/{name}/vocab.txt\"\n trg_vocab: \"data/{name}/vocab.txt\"\n\ntesting:\n beam_size: 5\n alpha: 1.0\n\ntraining:\n #load_model: \"{gdrive_path}/models/{name}_transformer/1.ckpt\" # if uncommented, load a pre-trained model from this checkpoint\n random_seed: 42\n optimizer: \"adam\"\n normalization: \"tokens\"\n adam_betas: [0.9, 0.999] \n scheduling: \"Noam scheduling\" # TODO: try switching from plateau to Noam scheduling. plateau to Noam scheduling\n patience: 5 # For plateau: decrease learning rate by decrease_factor if validation score has not improved for this many validation rounds.\n learning_rate_factor: 0.5 # factor for Noam scheduler (used with Transformer)\n learning_rate_warmup: 1000 # warmup steps for Noam scheduler (used with Transformer)\n decrease_factor: 0.7\n loss: \"crossentropy\"\n learning_rate: 0.0003\n learning_rate_min: 0.00000001\n weight_decay: 0.0\n label_smoothing: 0.1\n batch_size: 4096\n batch_type: \"token\"\n eval_batch_size: 3600\n eval_batch_type: \"token\"\n batch_multiplier: 1\n early_stopping_metric: \"ppl\"\n epochs: 3 # TODO: Decrease for when playing around and checking of working. Around 30 is sufficient to check if its working at all. 5 - 3\n validation_freq: 1000 # TODO: Set to at least once per epoch.\n logging_freq: 100\n eval_metric: \"bleu\"\n model_dir: \"models/{name}_reverse_transformer\"\n overwrite: True # TODO: Set to True if you want to overwrite possibly existing models. \n shuffle: True\n use_cuda: True\n max_output_length: 100\n print_valid_sents: [0, 1, 2, 3]\n keep_last_ckpts: 3\n\nmodel:\n initializer: \"xavier\"\n bias_initializer: \"zeros\"\n init_gain: 1.0\n embed_initializer: \"xavier\"\n embed_init_gain: 1.0\n tied_embeddings: True\n tied_softmax: True\n encoder:\n type: \"transformer\"\n num_layers: 6\n num_heads: 4 # TODO: Increase to 8 for larger data. 4 - 8\n embeddings:\n embedding_dim: 256 # TODO: Increase to 512 for larger data. 256 -512\n scale: True\n dropout: 0.2\n # typically ff_size = 4 x hidden_size\n hidden_size: 256 # TODO: Increase to 512 for larger data. 256 - 512\n ff_size: 2048 # TODO: Increase to 2048 for larger data. 1024 - 2048\n dropout: 0.3\n decoder:\n type: \"transformer\"\n num_layers: 6\n num_heads: 4 # TODO: Increase to 8 for larger data. 4 - 8\n embeddings:\n embedding_dim: 256 # TODO: Increase to 512 for larger data. 256 - 512\n scale: True\n dropout: 0.2\n # typically ff_size = 4 x hidden_size\n hidden_size: 256 # TODO: Increase to 512 for larger data. 256 - 512\n ff_size: 2048 # TODO: Increase to 2048 for larger data. 1024 - 2048\n dropout: 0.3\n\"\"\".format(name=name, gdrive_path=os.environ[\"gdrive_path\"], source_language=source_language, target_language=target_language)\nwith open(\"joeynmt/configs/transformer_reverse_{name}.yaml\".format(name=name),'w') as f:\n f.write(config)",
"_____no_output_____"
]
],
[
[
"# Train the Model\n\nThis single line of joeynmt runs the training using the config we made above",
"_____no_output_____"
]
],
[
[
"# Train the model\n# You can press Ctrl-C to stop. And then run the next cell to save your checkpoints! \n!cd joeynmt; python3 -m joeynmt train configs/transformer_reverse_$tgt$src.yaml",
"2021-10-10 16:58:41,141 - INFO - root - Hello! This is Joey-NMT (version 1.3).\n2021-10-10 16:58:41,193 - INFO - joeynmt.data - Loading training data...\n2021-10-10 16:58:56,797 - INFO - joeynmt.data - Building vocabulary...\n2021-10-10 16:58:57,092 - INFO - joeynmt.data - Loading dev data...\n2021-10-10 16:58:57,142 - INFO - joeynmt.data - Loading test data...\n2021-10-10 16:58:57,207 - INFO - joeynmt.data - Data loaded.\n2021-10-10 16:58:57,208 - INFO - joeynmt.model - Building an encoder-decoder model...\n2021-10-10 16:58:57,604 - INFO - joeynmt.model - Enc-dec model built.\n2021-10-10 16:58:58,628 - INFO - joeynmt.training - Total params: 18506752\n2021-10-10 16:58:58,630 - WARNING - joeynmt.training - `keep_last_ckpts` option is outdated. Please use `keep_best_ckpts`, instead.\n2021-10-10 16:59:10,089 - INFO - joeynmt.helpers - cfg.name : tnen_reverse_transformer\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.src : tn\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.trg : en\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.train : data/tnen/train.bpe\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.dev : data/tnen/dev.bpe\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.test : data/tnen/test.bpe\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.level : bpe\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.lowercase : False\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.max_sent_length : 100\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.src_vocab : data/tnen/vocab.txt\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.data.trg_vocab : data/tnen/vocab.txt\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.testing.beam_size : 5\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.testing.alpha : 1.0\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.random_seed : 42\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.optimizer : adam\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.normalization : tokens\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.adam_betas : [0.9, 0.999]\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.scheduling : Noam scheduling\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.patience : 5\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.learning_rate_factor : 0.5\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.learning_rate_warmup : 1000\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.decrease_factor : 0.7\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.loss : crossentropy\n2021-10-10 16:59:10,090 - INFO - joeynmt.helpers - cfg.training.learning_rate : 0.0003\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.learning_rate_min : 1e-08\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.weight_decay : 0.0\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.label_smoothing : 0.1\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.batch_size : 4096\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.batch_type : token\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.eval_batch_size : 3600\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.eval_batch_type : token\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.batch_multiplier : 1\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.early_stopping_metric : ppl\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.epochs : 3\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.validation_freq : 1000\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.logging_freq : 100\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.eval_metric : bleu\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.model_dir : models/tnen_reverse_transformer\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.overwrite : True\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.shuffle : True\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.use_cuda : True\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.max_output_length : 100\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.print_valid_sents : [0, 1, 2, 3]\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.training.keep_last_ckpts : 3\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.initializer : xavier\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.bias_initializer : zeros\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.init_gain : 1.0\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.embed_initializer : xavier\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.embed_init_gain : 1.0\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.tied_embeddings : True\n2021-10-10 16:59:10,091 - INFO - joeynmt.helpers - cfg.model.tied_softmax : True\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.type : transformer\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.num_layers : 6\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.num_heads : 4\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.embeddings.embedding_dim : 256\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.embeddings.scale : True\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.embeddings.dropout : 0.2\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.hidden_size : 256\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.ff_size : 2048\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.encoder.dropout : 0.3\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.type : transformer\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.num_layers : 6\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.num_heads : 4\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.embeddings.embedding_dim : 256\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.embeddings.scale : True\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.embeddings.dropout : 0.2\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.hidden_size : 256\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.ff_size : 2048\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - cfg.model.decoder.dropout : 0.3\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - Data set sizes: \n\ttrain 771547,\n\tvalid 1000,\n\ttest 2714\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - First training example:\n\t[SRC] ( Bala Mareko 12 : 28 - 30 . )\n\t[TRG] ( Read Mark 12 : 2@@ 8@@ -@@ 30 . )\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - First 10 words (src): (0) <unk> (1) <pad> (2) <s> (3) </s> (4) . (5) , (6) a (7) go (8) ba (9) le\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - First 10 words (trg): (0) <unk> (1) <pad> (2) <s> (3) </s> (4) . (5) , (6) a (7) go (8) ba (9) le\n2021-10-10 16:59:10,092 - INFO - joeynmt.helpers - Number of Src words (types): 4464\n2021-10-10 16:59:10,093 - INFO - joeynmt.helpers - Number of Trg words (types): 4464\n2021-10-10 16:59:10,093 - INFO - joeynmt.training - Model(\n\tencoder=TransformerEncoder(num_layers=6, num_heads=4),\n\tdecoder=TransformerDecoder(num_layers=6, num_heads=4),\n\tsrc_embed=Embeddings(embedding_dim=256, vocab_size=4464),\n\ttrg_embed=Embeddings(embedding_dim=256, vocab_size=4464))\n2021-10-10 16:59:10,096 - INFO - joeynmt.training - Train stats:\n\tdevice: cuda\n\tn_gpu: 1\n\t16-bits training: False\n\tgradient accumulation: 1\n\tbatch size per device: 4096\n\ttotal batch size (w. parallel & accumulation): 4096\n2021-10-10 16:59:10,096 - INFO - joeynmt.training - EPOCH 1\n2021-10-10 16:59:25,196 - INFO - joeynmt.training - Epoch 1, Step: 100, Batch Loss: 5.654608, Tokens per Sec: 9177, Lr: 0.000300\n2021-10-10 16:59:39,164 - INFO - joeynmt.training - Epoch 1, Step: 200, Batch Loss: 5.410481, Tokens per Sec: 9817, Lr: 0.000300\n2021-10-10 16:59:53,076 - INFO - joeynmt.training - Epoch 1, Step: 300, Batch Loss: 5.211629, Tokens per Sec: 9834, Lr: 0.000300\n2021-10-10 17:00:06,946 - INFO - joeynmt.training - Epoch 1, Step: 400, Batch Loss: 5.071335, Tokens per Sec: 10030, Lr: 0.000300\n2021-10-10 17:00:20,617 - INFO - joeynmt.training - Epoch 1, Step: 500, Batch Loss: 4.754916, Tokens per Sec: 9900, Lr: 0.000300\n2021-10-10 17:00:34,348 - INFO - joeynmt.training - Epoch 1, Step: 600, Batch Loss: 4.720602, Tokens per Sec: 10104, Lr: 0.000300\n2021-10-10 17:00:48,097 - INFO - joeynmt.training - Epoch 1, Step: 700, Batch Loss: 4.557406, Tokens per Sec: 10087, Lr: 0.000300\n2021-10-10 17:01:01,997 - INFO - joeynmt.training - Epoch 1, Step: 800, Batch Loss: 4.531649, Tokens per Sec: 9899, Lr: 0.000300\n2021-10-10 17:01:15,900 - INFO - joeynmt.training - Epoch 1, Step: 900, Batch Loss: 4.417782, Tokens per Sec: 10055, Lr: 0.000300\n2021-10-10 17:01:29,778 - INFO - joeynmt.training - Epoch 1, Step: 1000, Batch Loss: 4.397320, Tokens per Sec: 10013, Lr: 0.000300\n2021-10-10 17:01:53,580 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:01:53,580 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:01:53,581 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:01:53,590 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:01:53,978 - INFO - joeynmt.training - Example #0\n2021-10-10 17:01:53,978 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:01:53,978 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tHypothesis: We can be be be be to be to be to be to be to be to be to be to be to be to be to be .\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - Example #1\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tHypothesis: What is the Saly\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - Example #2\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - \tHypothesis: In the Bible , the Bible ’ s Witnesses was a Bible ’ s Witnesses of the Bible ’ s Witnesses ’ s Witnesses ’ s Witnesses and the United States of the United States of the United States .\n2021-10-10 17:01:53,979 - INFO - joeynmt.training - Example #3\n2021-10-10 17:01:53,980 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:01:53,980 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:01:53,980 - INFO - joeynmt.training - \tHypothesis: “ The Bible was a stt , ” was a stt , and the world , and the world ’ s Witnesses was a world .\n2021-10-10 17:01:53,980 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 1000: bleu: 1.45, loss: 126182.5625, ppl: 80.3479, duration: 24.2019s\n2021-10-10 17:02:07,790 - INFO - joeynmt.training - Epoch 1, Step: 1100, Batch Loss: 4.336116, Tokens per Sec: 10144, Lr: 0.000300\n2021-10-10 17:02:21,709 - INFO - joeynmt.training - Epoch 1, Step: 1200, Batch Loss: 4.291130, Tokens per Sec: 10112, Lr: 0.000300\n2021-10-10 17:02:35,589 - INFO - joeynmt.training - Epoch 1, Step: 1300, Batch Loss: 4.178442, Tokens per Sec: 9910, Lr: 0.000300\n2021-10-10 17:02:49,513 - INFO - joeynmt.training - Epoch 1, Step: 1400, Batch Loss: 4.149624, Tokens per Sec: 9738, Lr: 0.000300\n2021-10-10 17:03:03,273 - INFO - joeynmt.training - Epoch 1, Step: 1500, Batch Loss: 3.991884, Tokens per Sec: 10099, Lr: 0.000300\n2021-10-10 17:03:17,033 - INFO - joeynmt.training - Epoch 1, Step: 1600, Batch Loss: 4.066360, Tokens per Sec: 10049, Lr: 0.000300\n2021-10-10 17:03:30,830 - INFO - joeynmt.training - Epoch 1, Step: 1700, Batch Loss: 4.130277, Tokens per Sec: 10017, Lr: 0.000300\n2021-10-10 17:03:44,648 - INFO - joeynmt.training - Epoch 1, Step: 1800, Batch Loss: 3.999448, Tokens per Sec: 9989, Lr: 0.000300\n2021-10-10 17:03:58,612 - INFO - joeynmt.training - Epoch 1, Step: 1900, Batch Loss: 3.975065, Tokens per Sec: 9804, Lr: 0.000300\n2021-10-10 17:04:12,525 - INFO - joeynmt.training - Epoch 1, Step: 2000, Batch Loss: 4.026957, Tokens per Sec: 10066, Lr: 0.000300\n2021-10-10 17:04:37,518 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:04:37,518 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:04:37,518 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:04:37,523 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:04:37,906 - INFO - joeynmt.training - Example #0\n2021-10-10 17:04:37,906 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tHypothesis: But we are a person of the same , we will be a person , and we will be a person to be a person .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - Example #1\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tHypothesis: It is the Frrrrrle\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - Example #2\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - \tHypothesis: In the time , the other times , the apostle Paul ’ s Witnesses were been been been been been been been been been been been been been been been been been a .\n2021-10-10 17:04:37,907 - INFO - joeynmt.training - Example #3\n2021-10-10 17:04:37,908 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:04:37,908 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:04:37,908 - INFO - joeynmt.training - \tHypothesis: “ The fataty , ” was a few , ” he was a few of the time , ” he was a few than they were been been been been been been been .\n2021-10-10 17:04:37,908 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 2000: bleu: 3.26, loss: 110310.7812, ppl: 46.2763, duration: 25.3823s\n2021-10-10 17:04:51,825 - INFO - joeynmt.training - Epoch 1, Step: 2100, Batch Loss: 3.799799, Tokens per Sec: 10068, Lr: 0.000300\n2021-10-10 17:05:05,724 - INFO - joeynmt.training - Epoch 1, Step: 2200, Batch Loss: 3.897146, Tokens per Sec: 10169, Lr: 0.000300\n2021-10-10 17:05:19,642 - INFO - joeynmt.training - Epoch 1, Step: 2300, Batch Loss: 3.752156, Tokens per Sec: 9875, Lr: 0.000300\n2021-10-10 17:05:33,553 - INFO - joeynmt.training - Epoch 1, Step: 2400, Batch Loss: 3.654819, Tokens per Sec: 10045, Lr: 0.000300\n2021-10-10 17:05:47,430 - INFO - joeynmt.training - Epoch 1, Step: 2500, Batch Loss: 3.846561, Tokens per Sec: 9924, Lr: 0.000300\n2021-10-10 17:06:01,221 - INFO - joeynmt.training - Epoch 1, Step: 2600, Batch Loss: 3.891648, Tokens per Sec: 10023, Lr: 0.000300\n2021-10-10 17:06:15,067 - INFO - joeynmt.training - Epoch 1, Step: 2700, Batch Loss: 3.605246, Tokens per Sec: 10054, Lr: 0.000300\n2021-10-10 17:06:29,092 - INFO - joeynmt.training - Epoch 1, Step: 2800, Batch Loss: 3.608232, Tokens per Sec: 9932, Lr: 0.000300\n2021-10-10 17:06:43,009 - INFO - joeynmt.training - Epoch 1, Step: 2900, Batch Loss: 3.788059, Tokens per Sec: 10110, Lr: 0.000300\n2021-10-10 17:06:56,849 - INFO - joeynmt.training - Epoch 1, Step: 3000, Batch Loss: 3.570333, Tokens per Sec: 9995, Lr: 0.000300\n2021-10-10 17:07:17,809 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:07:17,810 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:07:17,810 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:07:17,815 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - Example #0\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - \tHypothesis: But we will be a fill , we will be a person , and we will be a real way to be a person .\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - Example #1\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:07:18,196 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tHypothesis: I ’ s Frrying\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - Example #2\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tHypothesis: In the time , some of the apostle Paul ’ s words have been been been been been been been been been been been been been been been been been been been been a source of the Pray .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - Example #3\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - \tHypothesis: “ The flecation of the fill , ” said , and the fley of the nations , and they were not to be a perfect .\n2021-10-10 17:07:18,197 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 3000: bleu: 6.42, loss: 98919.2109, ppl: 31.1444, duration: 21.3482s\n2021-10-10 17:07:32,160 - INFO - joeynmt.training - Epoch 1, Step: 3100, Batch Loss: 3.711189, Tokens per Sec: 9988, Lr: 0.000300\n2021-10-10 17:07:45,986 - INFO - joeynmt.training - Epoch 1, Step: 3200, Batch Loss: 3.552640, Tokens per Sec: 9991, Lr: 0.000300\n2021-10-10 17:07:59,880 - INFO - joeynmt.training - Epoch 1, Step: 3300, Batch Loss: 3.564120, Tokens per Sec: 9831, Lr: 0.000300\n2021-10-10 17:08:13,816 - INFO - joeynmt.training - Epoch 1, Step: 3400, Batch Loss: 3.552412, Tokens per Sec: 10114, Lr: 0.000300\n2021-10-10 17:08:27,732 - INFO - joeynmt.training - Epoch 1, Step: 3500, Batch Loss: 3.332840, Tokens per Sec: 10078, Lr: 0.000300\n2021-10-10 17:08:41,512 - INFO - joeynmt.training - Epoch 1, Step: 3600, Batch Loss: 3.498365, Tokens per Sec: 9897, Lr: 0.000300\n2021-10-10 17:08:55,412 - INFO - joeynmt.training - Epoch 1, Step: 3700, Batch Loss: 3.451744, Tokens per Sec: 9956, Lr: 0.000300\n2021-10-10 17:09:09,245 - INFO - joeynmt.training - Epoch 1, Step: 3800, Batch Loss: 3.415224, Tokens per Sec: 10227, Lr: 0.000300\n2021-10-10 17:09:23,038 - INFO - joeynmt.training - Epoch 1, Step: 3900, Batch Loss: 3.257262, Tokens per Sec: 10061, Lr: 0.000300\n2021-10-10 17:09:36,958 - INFO - joeynmt.training - Epoch 1, Step: 4000, Batch Loss: 3.371293, Tokens per Sec: 10003, Lr: 0.000300\n2021-10-10 17:09:57,589 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:09:57,589 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:09:57,589 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:09:57,594 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:09:57,987 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/1000.ckpt\n2021-10-10 17:09:58,011 - INFO - joeynmt.training - Example #0\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tHypothesis: But if we are not to be a mighty , we will be able to be a good way and to be a good .\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - Example #1\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tHypothesis: I Fird\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - Example #2\n2021-10-10 17:09:58,012 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - \tHypothesis: In the time , some of the apostle Paul ’ s words have been been given to the apostle Paul ’ s miles [ 50 km ] to be a source of Awake !\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - Example #3\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - \tHypothesis: “ The front of the front , ” he was not a fley , and they were not to be the dead .\n2021-10-10 17:09:58,013 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 4000: bleu: 8.69, loss: 91479.9453, ppl: 24.0475, duration: 21.0551s\n2021-10-10 17:10:11,938 - INFO - joeynmt.training - Epoch 1, Step: 4100, Batch Loss: 3.265278, Tokens per Sec: 9991, Lr: 0.000300\n2021-10-10 17:10:25,774 - INFO - joeynmt.training - Epoch 1, Step: 4200, Batch Loss: 3.415808, Tokens per Sec: 9992, Lr: 0.000300\n2021-10-10 17:10:39,784 - INFO - joeynmt.training - Epoch 1, Step: 4300, Batch Loss: 3.359226, Tokens per Sec: 9989, Lr: 0.000300\n2021-10-10 17:10:53,658 - INFO - joeynmt.training - Epoch 1, Step: 4400, Batch Loss: 3.274698, Tokens per Sec: 10081, Lr: 0.000300\n2021-10-10 17:11:07,430 - INFO - joeynmt.training - Epoch 1, Step: 4500, Batch Loss: 3.287345, Tokens per Sec: 9868, Lr: 0.000300\n2021-10-10 17:11:21,233 - INFO - joeynmt.training - Epoch 1, Step: 4600, Batch Loss: 3.157068, Tokens per Sec: 10094, Lr: 0.000300\n2021-10-10 17:11:35,056 - INFO - joeynmt.training - Epoch 1, Step: 4700, Batch Loss: 3.363083, Tokens per Sec: 9961, Lr: 0.000300\n2021-10-10 17:11:48,933 - INFO - joeynmt.training - Epoch 1, Step: 4800, Batch Loss: 3.093253, Tokens per Sec: 10047, Lr: 0.000300\n2021-10-10 17:12:02,775 - INFO - joeynmt.training - Epoch 1, Step: 4900, Batch Loss: 3.236108, Tokens per Sec: 9835, Lr: 0.000300\n2021-10-10 17:12:16,540 - INFO - joeynmt.training - Epoch 1, Step: 5000, Batch Loss: 3.259668, Tokens per Sec: 10020, Lr: 0.000300\n2021-10-10 17:12:37,300 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:12:37,300 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:12:37,300 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:12:37,306 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:12:37,683 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/2000.ckpt\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - Example #0\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - \tHypothesis: But if we are not to be a mighty of the water , we will be able to be a time and to be able to be a lot .\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - Example #1\n2021-10-10 17:12:37,708 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tHypothesis: I Helse to School\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - Example #2\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tHypothesis: In the time , some of the elders have been found in the apostle Paul ’ s people in the first 250 miles [ 30 m ] in the Muuan .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - Example #3\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - \tHypothesis: “ The great crowd was not a source of the croll , and the front of all of all of all the people .\n2021-10-10 17:12:37,709 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 5000: bleu: 10.50, loss: 86265.7422, ppl: 20.0609, duration: 21.1692s\n2021-10-10 17:12:51,582 - INFO - joeynmt.training - Epoch 1, Step: 5100, Batch Loss: 3.264165, Tokens per Sec: 10021, Lr: 0.000300\n2021-10-10 17:13:05,438 - INFO - joeynmt.training - Epoch 1, Step: 5200, Batch Loss: 3.200047, Tokens per Sec: 10057, Lr: 0.000300\n2021-10-10 17:13:19,259 - INFO - joeynmt.training - Epoch 1, Step: 5300, Batch Loss: 3.118136, Tokens per Sec: 10130, Lr: 0.000300\n2021-10-10 17:13:33,075 - INFO - joeynmt.training - Epoch 1, Step: 5400, Batch Loss: 3.072191, Tokens per Sec: 10184, Lr: 0.000300\n2021-10-10 17:13:46,937 - INFO - joeynmt.training - Epoch 1, Step: 5500, Batch Loss: 2.940107, Tokens per Sec: 10019, Lr: 0.000300\n2021-10-10 17:14:00,778 - INFO - joeynmt.training - Epoch 1, Step: 5600, Batch Loss: 3.210019, Tokens per Sec: 10247, Lr: 0.000300\n2021-10-10 17:14:14,718 - INFO - joeynmt.training - Epoch 1, Step: 5700, Batch Loss: 3.126306, Tokens per Sec: 9967, Lr: 0.000300\n2021-10-10 17:14:28,470 - INFO - joeynmt.training - Epoch 1, Step: 5800, Batch Loss: 3.216937, Tokens per Sec: 10017, Lr: 0.000300\n2021-10-10 17:14:42,267 - INFO - joeynmt.training - Epoch 1, Step: 5900, Batch Loss: 3.089858, Tokens per Sec: 10135, Lr: 0.000300\n2021-10-10 17:14:56,185 - INFO - joeynmt.training - Epoch 1, Step: 6000, Batch Loss: 2.886971, Tokens per Sec: 9948, Lr: 0.000300\n2021-10-10 17:15:15,913 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:15:15,913 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:15:15,913 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:15:15,918 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:15:16,307 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/3000.ckpt\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - Example #0\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tHypothesis: But if we are not easy to be a mighty , we will not be important and be able to be able to be .\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - Example #1\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - \tHypothesis: I Help to the Fink\n2021-10-10 17:15:16,331 - INFO - joeynmt.training - Example #2\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the elders have been given the apostle Paul ’ s first miles [ 50 km ] from the Asia ] in the Prich .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - Example #3\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - \tHypothesis: “ The schooling of the wink , the wink , and the most of all of all of all of them .\n2021-10-10 17:15:16,332 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 6000: bleu: 12.46, loss: 82152.5234, ppl: 17.3882, duration: 20.1465s\n2021-10-10 17:15:30,218 - INFO - joeynmt.training - Epoch 1, Step: 6100, Batch Loss: 3.217391, Tokens per Sec: 9790, Lr: 0.000300\n2021-10-10 17:15:44,022 - INFO - joeynmt.training - Epoch 1, Step: 6200, Batch Loss: 3.115761, Tokens per Sec: 10236, Lr: 0.000300\n2021-10-10 17:15:57,947 - INFO - joeynmt.training - Epoch 1, Step: 6300, Batch Loss: 2.985588, Tokens per Sec: 10104, Lr: 0.000300\n2021-10-10 17:16:11,878 - INFO - joeynmt.training - Epoch 1, Step: 6400, Batch Loss: 2.941866, Tokens per Sec: 9738, Lr: 0.000300\n2021-10-10 17:16:25,764 - INFO - joeynmt.training - Epoch 1, Step: 6500, Batch Loss: 3.060092, Tokens per Sec: 9884, Lr: 0.000300\n2021-10-10 17:16:39,765 - INFO - joeynmt.training - Epoch 1, Step: 6600, Batch Loss: 2.896182, Tokens per Sec: 9871, Lr: 0.000300\n2021-10-10 17:16:53,552 - INFO - joeynmt.training - Epoch 1, Step: 6700, Batch Loss: 3.038348, Tokens per Sec: 9974, Lr: 0.000300\n2021-10-10 17:17:07,708 - INFO - joeynmt.training - Epoch 1, Step: 6800, Batch Loss: 3.130677, Tokens per Sec: 9807, Lr: 0.000300\n2021-10-10 17:17:21,602 - INFO - joeynmt.training - Epoch 1, Step: 6900, Batch Loss: 2.907236, Tokens per Sec: 10061, Lr: 0.000300\n2021-10-10 17:17:35,705 - INFO - joeynmt.training - Epoch 1, Step: 7000, Batch Loss: 3.047904, Tokens per Sec: 9706, Lr: 0.000300\n2021-10-10 17:17:55,705 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:17:55,705 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:17:55,705 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:17:55,711 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:17:56,109 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/4000.ckpt\n2021-10-10 17:17:56,134 - INFO - joeynmt.training - Example #0\n2021-10-10 17:17:56,134 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tHypothesis: But if we understand the water of the water will be , we will see that we will not be important and be able to drink .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - Example #1\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tHypothesis: I Frive\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - Example #2\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul ’ s fellow believers were killed by the miles [ 50 km ] from the Amal .\n2021-10-10 17:17:56,135 - INFO - joeynmt.training - Example #3\n2021-10-10 17:17:56,136 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:17:56,136 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:17:56,136 - INFO - joeynmt.training - \tHypothesis: “ The stats were not sleep , the smoking , and the flesh were all of them .\n2021-10-10 17:17:56,136 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 7000: bleu: 13.81, loss: 78422.2812, ppl: 15.2735, duration: 20.4300s\n2021-10-10 17:18:10,126 - INFO - joeynmt.training - Epoch 1, Step: 7100, Batch Loss: 2.885946, Tokens per Sec: 10001, Lr: 0.000300\n2021-10-10 17:18:24,270 - INFO - joeynmt.training - Epoch 1, Step: 7200, Batch Loss: 3.074751, Tokens per Sec: 9844, Lr: 0.000300\n2021-10-10 17:18:38,266 - INFO - joeynmt.training - Epoch 1, Step: 7300, Batch Loss: 2.888007, Tokens per Sec: 9932, Lr: 0.000300\n2021-10-10 17:18:52,159 - INFO - joeynmt.training - Epoch 1, Step: 7400, Batch Loss: 2.984877, Tokens per Sec: 10035, Lr: 0.000300\n2021-10-10 17:19:06,131 - INFO - joeynmt.training - Epoch 1, Step: 7500, Batch Loss: 2.990601, Tokens per Sec: 9803, Lr: 0.000300\n2021-10-10 17:19:19,987 - INFO - joeynmt.training - Epoch 1, Step: 7600, Batch Loss: 2.866169, Tokens per Sec: 10057, Lr: 0.000300\n2021-10-10 17:19:33,905 - INFO - joeynmt.training - Epoch 1, Step: 7700, Batch Loss: 3.001849, Tokens per Sec: 9825, Lr: 0.000300\n2021-10-10 17:19:47,897 - INFO - joeynmt.training - Epoch 1, Step: 7800, Batch Loss: 2.935211, Tokens per Sec: 10101, Lr: 0.000300\n2021-10-10 17:20:01,836 - INFO - joeynmt.training - Epoch 1, Step: 7900, Batch Loss: 2.785452, Tokens per Sec: 10076, Lr: 0.000300\n2021-10-10 17:20:15,780 - INFO - joeynmt.training - Epoch 1, Step: 8000, Batch Loss: 2.957135, Tokens per Sec: 9865, Lr: 0.000300\n2021-10-10 17:20:37,497 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:20:37,497 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:20:37,497 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:20:37,503 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:20:37,892 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/5000.ckpt\n2021-10-10 17:20:37,919 - INFO - joeynmt.training - Example #0\n2021-10-10 17:20:37,919 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tHypothesis: But if we understand the water of water will be a lot of our lives , we will see the importance of drinking and will not want to drink .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - Example #1\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tHypothesis: I Have to Be a Shepherd\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - Example #2\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tHypothesis: In one time , some of the other friends of the apostle Paul had been born in the miles [ 50 km ] from Eden in the Mamb .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - Example #3\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - \tHypothesis: “ It was born , the winter of the winter , and the flawth of all were not .\n2021-10-10 17:20:37,920 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 8000: bleu: 15.35, loss: 75613.9375, ppl: 13.8529, duration: 22.1402s\n2021-10-10 17:20:51,844 - INFO - joeynmt.training - Epoch 1, Step: 8100, Batch Loss: 2.870221, Tokens per Sec: 9837, Lr: 0.000300\n2021-10-10 17:21:05,709 - INFO - joeynmt.training - Epoch 1, Step: 8200, Batch Loss: 2.768867, Tokens per Sec: 10038, Lr: 0.000300\n2021-10-10 17:21:19,622 - INFO - joeynmt.training - Epoch 1, Step: 8300, Batch Loss: 3.042747, Tokens per Sec: 9780, Lr: 0.000300\n2021-10-10 17:21:33,660 - INFO - joeynmt.training - Epoch 1, Step: 8400, Batch Loss: 3.119140, Tokens per Sec: 9927, Lr: 0.000300\n2021-10-10 17:21:47,512 - INFO - joeynmt.training - Epoch 1, Step: 8500, Batch Loss: 2.829927, Tokens per Sec: 10147, Lr: 0.000300\n2021-10-10 17:22:01,546 - INFO - joeynmt.training - Epoch 1, Step: 8600, Batch Loss: 2.982260, Tokens per Sec: 9942, Lr: 0.000300\n2021-10-10 17:22:15,533 - INFO - joeynmt.training - Epoch 1, Step: 8700, Batch Loss: 2.883412, Tokens per Sec: 9990, Lr: 0.000300\n2021-10-10 17:22:29,352 - INFO - joeynmt.training - Epoch 1, Step: 8800, Batch Loss: 2.863246, Tokens per Sec: 9933, Lr: 0.000300\n2021-10-10 17:22:43,318 - INFO - joeynmt.training - Epoch 1, Step: 8900, Batch Loss: 2.834056, Tokens per Sec: 9900, Lr: 0.000300\n2021-10-10 17:22:57,298 - INFO - joeynmt.training - Epoch 1, Step: 9000, Batch Loss: 2.687692, Tokens per Sec: 9841, Lr: 0.000300\n2021-10-10 17:23:18,733 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:23:18,733 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:23:18,734 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:23:18,739 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:23:19,135 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/6000.ckpt\n2021-10-10 17:23:19,161 - INFO - joeynmt.training - Example #0\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of the water of life will be able to see the importance of the importance of drinking and will also want to drink .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - Example #1\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tHypothesis: I Hearn\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - Example #2\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul ’ s brothers were left a miles [ 50 km ] from East in Miiiie .\n2021-10-10 17:23:19,162 - INFO - joeynmt.training - Example #3\n2021-10-10 17:23:19,163 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:23:19,163 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:23:19,163 - INFO - joeynmt.training - \tHypothesis: “ The front was made , not the sound , and the fall of all the people were dead .\n2021-10-10 17:23:19,163 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 9000: bleu: 16.03, loss: 72726.8672, ppl: 12.5301, duration: 21.8649s\n2021-10-10 17:23:32,985 - INFO - joeynmt.training - Epoch 1, Step: 9100, Batch Loss: 2.807886, Tokens per Sec: 9732, Lr: 0.000300\n2021-10-10 17:23:46,890 - INFO - joeynmt.training - Epoch 1, Step: 9200, Batch Loss: 2.767649, Tokens per Sec: 9954, Lr: 0.000300\n2021-10-10 17:24:00,809 - INFO - joeynmt.training - Epoch 1, Step: 9300, Batch Loss: 2.478835, Tokens per Sec: 9999, Lr: 0.000300\n2021-10-10 17:24:14,727 - INFO - joeynmt.training - Epoch 1, Step: 9400, Batch Loss: 2.855491, Tokens per Sec: 9976, Lr: 0.000300\n2021-10-10 17:24:28,900 - INFO - joeynmt.training - Epoch 1, Step: 9500, Batch Loss: 2.695379, Tokens per Sec: 9771, Lr: 0.000300\n2021-10-10 17:24:42,910 - INFO - joeynmt.training - Epoch 1, Step: 9600, Batch Loss: 2.655593, Tokens per Sec: 10097, Lr: 0.000300\n2021-10-10 17:24:57,009 - INFO - joeynmt.training - Epoch 1, Step: 9700, Batch Loss: 2.815083, Tokens per Sec: 10021, Lr: 0.000300\n2021-10-10 17:25:10,906 - INFO - joeynmt.training - Epoch 1, Step: 9800, Batch Loss: 2.706918, Tokens per Sec: 10014, Lr: 0.000300\n2021-10-10 17:25:24,797 - INFO - joeynmt.training - Epoch 1, Step: 9900, Batch Loss: 2.424981, Tokens per Sec: 9889, Lr: 0.000300\n2021-10-10 17:25:38,678 - INFO - joeynmt.training - Epoch 1, Step: 10000, Batch Loss: 2.665458, Tokens per Sec: 10042, Lr: 0.000300\n2021-10-10 17:25:57,443 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:25:57,443 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:25:57,443 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:25:57,449 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:25:57,836 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/7000.ckpt\n2021-10-10 17:25:57,863 - INFO - joeynmt.training - Example #0\n2021-10-10 17:25:57,863 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:25:57,863 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:25:57,863 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of the world will be done , we will not see the most important and will also be able to drink .\n2021-10-10 17:25:57,863 - INFO - joeynmt.training - Example #1\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tHypothesis: I Way the Pregion\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - Example #2\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul had been raised by the miles [ 50 km ] from Eiver , where the Miiiiiley is a measure .\n2021-10-10 17:25:57,864 - INFO - joeynmt.training - Example #3\n2021-10-10 17:25:57,865 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:25:57,865 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:25:57,865 - INFO - joeynmt.training - \tHypothesis: “ The source of the source of the source , the source of the flesh , and the one of all the people were .\n2021-10-10 17:25:57,865 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 10000: bleu: 17.21, loss: 70534.7969, ppl: 11.6108, duration: 19.1870s\n2021-10-10 17:26:11,829 - INFO - joeynmt.training - Epoch 1, Step: 10100, Batch Loss: 2.586971, Tokens per Sec: 10119, Lr: 0.000300\n2021-10-10 17:26:25,635 - INFO - joeynmt.training - Epoch 1, Step: 10200, Batch Loss: 2.604633, Tokens per Sec: 10095, Lr: 0.000300\n2021-10-10 17:26:39,506 - INFO - joeynmt.training - Epoch 1, Step: 10300, Batch Loss: 2.767893, Tokens per Sec: 9963, Lr: 0.000300\n2021-10-10 17:26:53,308 - INFO - joeynmt.training - Epoch 1, Step: 10400, Batch Loss: 2.769896, Tokens per Sec: 10111, Lr: 0.000300\n2021-10-10 17:27:07,277 - INFO - joeynmt.training - Epoch 1, Step: 10500, Batch Loss: 2.655937, Tokens per Sec: 9905, Lr: 0.000300\n2021-10-10 17:27:21,190 - INFO - joeynmt.training - Epoch 1, Step: 10600, Batch Loss: 2.816471, Tokens per Sec: 10121, Lr: 0.000300\n2021-10-10 17:27:35,109 - INFO - joeynmt.training - Epoch 1, Step: 10700, Batch Loss: 2.639119, Tokens per Sec: 10016, Lr: 0.000300\n2021-10-10 17:27:48,948 - INFO - joeynmt.training - Epoch 1, Step: 10800, Batch Loss: 2.657701, Tokens per Sec: 10081, Lr: 0.000300\n2021-10-10 17:28:02,749 - INFO - joeynmt.training - Epoch 1, Step: 10900, Batch Loss: 2.654588, Tokens per Sec: 10031, Lr: 0.000300\n2021-10-10 17:28:16,802 - INFO - joeynmt.training - Epoch 1, Step: 11000, Batch Loss: 2.483727, Tokens per Sec: 9976, Lr: 0.000300\n2021-10-10 17:28:34,730 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:28:34,730 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:28:34,730 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:28:34,736 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:28:35,134 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/8000.ckpt\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - Example #0\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tHypothesis: But if we understand the water of water will be done , we will not see the most important way to drink and will also want to drink drinking .\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - Example #1\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - \tHypothesis: I Without the Prich\n2021-10-10 17:28:35,159 - INFO - joeynmt.training - Example #2\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul ’ s brothers have been walked with 50 miles [ 50 km ] from Eiiius in Miiiiiito met him .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - Example #3\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - \tHypothesis: “ It was not a source of the flashing , and the flashing of all the people who were in the face .\n2021-10-10 17:28:35,160 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 11000: bleu: 18.71, loss: 68509.1953, ppl: 10.8213, duration: 18.3578s\n2021-10-10 17:28:49,104 - INFO - joeynmt.training - Epoch 1, Step: 11100, Batch Loss: 2.714690, Tokens per Sec: 9937, Lr: 0.000300\n2021-10-10 17:29:03,083 - INFO - joeynmt.training - Epoch 1, Step: 11200, Batch Loss: 2.764172, Tokens per Sec: 10153, Lr: 0.000300\n2021-10-10 17:29:16,947 - INFO - joeynmt.training - Epoch 1, Step: 11300, Batch Loss: 2.626076, Tokens per Sec: 9890, Lr: 0.000300\n2021-10-10 17:29:30,772 - INFO - joeynmt.training - Epoch 1, Step: 11400, Batch Loss: 2.739626, Tokens per Sec: 10219, Lr: 0.000300\n2021-10-10 17:29:44,643 - INFO - joeynmt.training - Epoch 1, Step: 11500, Batch Loss: 2.786689, Tokens per Sec: 10117, Lr: 0.000300\n2021-10-10 17:29:58,510 - INFO - joeynmt.training - Epoch 1, Step: 11600, Batch Loss: 2.521538, Tokens per Sec: 10201, Lr: 0.000300\n2021-10-10 17:30:12,334 - INFO - joeynmt.training - Epoch 1, Step: 11700, Batch Loss: 2.711964, Tokens per Sec: 10102, Lr: 0.000300\n2021-10-10 17:30:26,296 - INFO - joeynmt.training - Epoch 1, Step: 11800, Batch Loss: 2.490960, Tokens per Sec: 10200, Lr: 0.000300\n2021-10-10 17:30:40,193 - INFO - joeynmt.training - Epoch 1, Step: 11900, Batch Loss: 2.591709, Tokens per Sec: 10205, Lr: 0.000300\n2021-10-10 17:30:54,008 - INFO - joeynmt.training - Epoch 1, Step: 12000, Batch Loss: 2.582632, Tokens per Sec: 9952, Lr: 0.000300\n2021-10-10 17:31:14,562 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:31:14,563 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:31:14,563 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:31:14,568 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:31:14,976 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/9000.ckpt\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - Example #0\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tHypothesis: But if we understand the water of the living will be done , we will not see the most important thing and will also want to drink .\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - Example #1\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:31:15,002 - INFO - joeynmt.training - \tHypothesis: I Fribuse\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - Example #2\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Bible ’ s lovers have been walked with a miles [ 50 km ] from Eiath to Miiito meet .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - Example #3\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - \tHypothesis: “ The fourth was made , the window , and the fall of all the people were .\n2021-10-10 17:31:15,003 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 12000: bleu: 18.81, loss: 66658.0078, ppl: 10.1469, duration: 20.9950s\n2021-10-10 17:31:28,834 - INFO - joeynmt.training - Epoch 1, Step: 12100, Batch Loss: 2.539070, Tokens per Sec: 10030, Lr: 0.000300\n2021-10-10 17:31:42,730 - INFO - joeynmt.training - Epoch 1, Step: 12200, Batch Loss: 2.654794, Tokens per Sec: 9969, Lr: 0.000300\n2021-10-10 17:31:56,602 - INFO - joeynmt.training - Epoch 1, Step: 12300, Batch Loss: 2.642098, Tokens per Sec: 10042, Lr: 0.000300\n2021-10-10 17:32:10,479 - INFO - joeynmt.training - Epoch 1, Step: 12400, Batch Loss: 2.601283, Tokens per Sec: 9834, Lr: 0.000300\n2021-10-10 17:32:24,437 - INFO - joeynmt.training - Epoch 1, Step: 12500, Batch Loss: 2.781003, Tokens per Sec: 10226, Lr: 0.000300\n2021-10-10 17:32:38,523 - INFO - joeynmt.training - Epoch 1, Step: 12600, Batch Loss: 2.444286, Tokens per Sec: 9943, Lr: 0.000300\n2021-10-10 17:32:52,510 - INFO - joeynmt.training - Epoch 1, Step: 12700, Batch Loss: 2.445865, Tokens per Sec: 9942, Lr: 0.000300\n2021-10-10 17:33:06,591 - INFO - joeynmt.training - Epoch 1, Step: 12800, Batch Loss: 2.641857, Tokens per Sec: 10086, Lr: 0.000300\n2021-10-10 17:33:20,664 - INFO - joeynmt.training - Epoch 1, Step: 12900, Batch Loss: 2.412566, Tokens per Sec: 9939, Lr: 0.000300\n2021-10-10 17:33:34,513 - INFO - joeynmt.training - Epoch 1, Step: 13000, Batch Loss: 2.510840, Tokens per Sec: 9774, Lr: 0.000300\n2021-10-10 17:33:54,113 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:33:54,113 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:33:54,113 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:33:54,119 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:33:54,516 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/10000.ckpt\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - Example #0\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of life will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - Example #1\n2021-10-10 17:33:54,543 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tHypothesis: I Help to Love\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - Example #2\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul ’ s brothers have been walked about 50 miles [ 50 km ] from Eigogoreto the Mito meet .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - Example #3\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - \tHypothesis: “ It was not translated , not the fire , but the fight of all the people who were .\n2021-10-10 17:33:54,544 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 13000: bleu: 20.43, loss: 65412.3906, ppl: 9.7169, duration: 20.0313s\n2021-10-10 17:34:08,553 - INFO - joeynmt.training - Epoch 1, Step: 13100, Batch Loss: 2.600287, Tokens per Sec: 10025, Lr: 0.000300\n2021-10-10 17:34:22,520 - INFO - joeynmt.training - Epoch 1, Step: 13200, Batch Loss: 2.426045, Tokens per Sec: 9962, Lr: 0.000300\n2021-10-10 17:34:36,485 - INFO - joeynmt.training - Epoch 1, Step: 13300, Batch Loss: 2.515554, Tokens per Sec: 9894, Lr: 0.000300\n2021-10-10 17:34:50,516 - INFO - joeynmt.training - Epoch 1, Step: 13400, Batch Loss: 2.585913, Tokens per Sec: 9966, Lr: 0.000300\n2021-10-10 17:35:04,461 - INFO - joeynmt.training - Epoch 1, Step: 13500, Batch Loss: 2.637033, Tokens per Sec: 9984, Lr: 0.000300\n2021-10-10 17:35:18,544 - INFO - joeynmt.training - Epoch 1, Step: 13600, Batch Loss: 2.646212, Tokens per Sec: 9994, Lr: 0.000300\n2021-10-10 17:35:32,466 - INFO - joeynmt.training - Epoch 1, Step: 13700, Batch Loss: 2.360912, Tokens per Sec: 10059, Lr: 0.000300\n2021-10-10 17:35:46,324 - INFO - joeynmt.training - Epoch 1, Step: 13800, Batch Loss: 2.463607, Tokens per Sec: 9951, Lr: 0.000300\n2021-10-10 17:36:00,198 - INFO - joeynmt.training - Epoch 1, Step: 13900, Batch Loss: 2.594020, Tokens per Sec: 10005, Lr: 0.000300\n2021-10-10 17:36:14,058 - INFO - joeynmt.training - Epoch 1, Step: 14000, Batch Loss: 2.422567, Tokens per Sec: 9881, Lr: 0.000300\n2021-10-10 17:36:31,886 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:36:31,886 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:36:31,886 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:36:31,892 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:36:32,284 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/11000.ckpt\n2021-10-10 17:36:32,310 - INFO - joeynmt.training - Example #0\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of the water will be doing , we will never see the importance of drinking and will also want to drink .\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - Example #1\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tHypothesis: I Love to Love\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - Example #2\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:36:32,311 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Christian friends of the apostle Paul had walked up a miles [ 50 km ] from Eiath to Mito to meet .\n2021-10-10 17:36:32,312 - INFO - joeynmt.training - Example #3\n2021-10-10 17:36:32,312 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:36:32,312 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:36:32,312 - INFO - joeynmt.training - \tHypothesis: “ The fall was made , the fall of the camp , the crushing , and all of them were living .\n2021-10-10 17:36:32,312 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 14000: bleu: 20.79, loss: 64002.3711, ppl: 9.2521, duration: 18.2534s\n2021-10-10 17:36:46,135 - INFO - joeynmt.training - Epoch 1, Step: 14100, Batch Loss: 2.528666, Tokens per Sec: 9922, Lr: 0.000300\n2021-10-10 17:37:00,120 - INFO - joeynmt.training - Epoch 1, Step: 14200, Batch Loss: 2.441280, Tokens per Sec: 9754, Lr: 0.000300\n2021-10-10 17:37:14,185 - INFO - joeynmt.training - Epoch 1, Step: 14300, Batch Loss: 2.504504, Tokens per Sec: 10070, Lr: 0.000300\n2021-10-10 17:37:28,275 - INFO - joeynmt.training - Epoch 1, Step: 14400, Batch Loss: 2.491087, Tokens per Sec: 9768, Lr: 0.000300\n2021-10-10 17:37:42,184 - INFO - joeynmt.training - Epoch 1, Step: 14500, Batch Loss: 2.494852, Tokens per Sec: 9998, Lr: 0.000300\n2021-10-10 17:37:56,081 - INFO - joeynmt.training - Epoch 1, Step: 14600, Batch Loss: 2.656476, Tokens per Sec: 9886, Lr: 0.000300\n2021-10-10 17:38:10,099 - INFO - joeynmt.training - Epoch 1, Step: 14700, Batch Loss: 2.531868, Tokens per Sec: 9930, Lr: 0.000300\n2021-10-10 17:38:24,125 - INFO - joeynmt.training - Epoch 1, Step: 14800, Batch Loss: 2.318296, Tokens per Sec: 10053, Lr: 0.000300\n2021-10-10 17:38:38,107 - INFO - joeynmt.training - Epoch 1, Step: 14900, Batch Loss: 2.618590, Tokens per Sec: 9926, Lr: 0.000300\n2021-10-10 17:38:52,071 - INFO - joeynmt.training - Epoch 1, Step: 15000, Batch Loss: 2.455672, Tokens per Sec: 10024, Lr: 0.000300\n2021-10-10 17:39:10,953 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:39:10,953 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:39:10,954 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:39:10,959 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:39:11,352 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/12000.ckpt\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - Example #0\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of water will do , we will not see the most important important thing to drink and will also want to drink .\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - Example #1\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:39:11,378 - INFO - joeynmt.training - \tHypothesis: I Love to Love\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - Example #2\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Christian friends have been walking in the miles [ 50 km ] from Eiath to Mito meet him .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - Example #3\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - \tHypothesis: “ It was made up , the camp of the camp , and the floud of all who were .\n2021-10-10 17:39:11,379 - INFO - joeynmt.training - Validation result (greedy) at epoch 1, step 15000: bleu: 21.82, loss: 62576.0781, ppl: 8.8046, duration: 19.3077s\n2021-10-10 17:39:25,330 - INFO - joeynmt.training - Epoch 1, Step: 15100, Batch Loss: 2.644012, Tokens per Sec: 9966, Lr: 0.000300\n2021-10-10 17:39:39,226 - INFO - joeynmt.training - Epoch 1, Step: 15200, Batch Loss: 2.375915, Tokens per Sec: 10224, Lr: 0.000300\n2021-10-10 17:39:53,158 - INFO - joeynmt.training - Epoch 1, Step: 15300, Batch Loss: 2.401255, Tokens per Sec: 10094, Lr: 0.000300\n2021-10-10 17:40:07,109 - INFO - joeynmt.training - Epoch 1, Step: 15400, Batch Loss: 2.530723, Tokens per Sec: 10071, Lr: 0.000300\n2021-10-10 17:40:20,988 - INFO - joeynmt.training - Epoch 1, Step: 15500, Batch Loss: 2.316025, Tokens per Sec: 10090, Lr: 0.000300\n2021-10-10 17:40:34,823 - INFO - joeynmt.training - Epoch 1, Step: 15600, Batch Loss: 2.473889, Tokens per Sec: 10041, Lr: 0.000300\n2021-10-10 17:40:48,750 - INFO - joeynmt.training - Epoch 1, Step: 15700, Batch Loss: 2.378470, Tokens per Sec: 10045, Lr: 0.000300\n2021-10-10 17:41:02,591 - INFO - joeynmt.training - Epoch 1, Step: 15800, Batch Loss: 2.619327, Tokens per Sec: 9787, Lr: 0.000300\n2021-10-10 17:41:14,507 - INFO - joeynmt.training - Epoch 1: total training loss 49308.74\n2021-10-10 17:41:14,508 - INFO - joeynmt.training - EPOCH 2\n2021-10-10 17:41:17,662 - INFO - joeynmt.training - Epoch 2, Step: 15900, Batch Loss: 2.378689, Tokens per Sec: 6614, Lr: 0.000300\n2021-10-10 17:41:31,568 - INFO - joeynmt.training - Epoch 2, Step: 16000, Batch Loss: 2.594733, Tokens per Sec: 10144, Lr: 0.000300\n2021-10-10 17:41:52,706 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:41:52,706 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:41:52,706 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:41:52,712 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:41:53,104 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/13000.ckpt\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - Example #0\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of water will do , we will not see the most important thing to drink and will also want to drink .\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - Example #1\n2021-10-10 17:41:53,131 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tHypothesis: I Love to Look\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - Example #2\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Christian friends of the apostle Paul had walked about about about 50 miles [ 50 km ] from Eiath to the Mileto meet .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - Example #3\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - \tHypothesis: “ It was made a sleep , the window , and the floud of all who were .\n2021-10-10 17:41:53,132 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 16000: bleu: 21.32, loss: 61077.4297, ppl: 8.3576, duration: 21.5635s\n2021-10-10 17:42:07,038 - INFO - joeynmt.training - Epoch 2, Step: 16100, Batch Loss: 2.527231, Tokens per Sec: 9783, Lr: 0.000300\n2021-10-10 17:42:20,908 - INFO - joeynmt.training - Epoch 2, Step: 16200, Batch Loss: 2.501658, Tokens per Sec: 9823, Lr: 0.000300\n2021-10-10 17:42:34,825 - INFO - joeynmt.training - Epoch 2, Step: 16300, Batch Loss: 2.327776, Tokens per Sec: 9953, Lr: 0.000300\n2021-10-10 17:42:48,632 - INFO - joeynmt.training - Epoch 2, Step: 16400, Batch Loss: 2.418102, Tokens per Sec: 9881, Lr: 0.000300\n2021-10-10 17:43:02,537 - INFO - joeynmt.training - Epoch 2, Step: 16500, Batch Loss: 2.366061, Tokens per Sec: 10025, Lr: 0.000300\n2021-10-10 17:43:16,418 - INFO - joeynmt.training - Epoch 2, Step: 16600, Batch Loss: 2.232424, Tokens per Sec: 10129, Lr: 0.000300\n2021-10-10 17:43:30,334 - INFO - joeynmt.training - Epoch 2, Step: 16700, Batch Loss: 2.413372, Tokens per Sec: 9862, Lr: 0.000300\n2021-10-10 17:43:44,204 - INFO - joeynmt.training - Epoch 2, Step: 16800, Batch Loss: 2.309558, Tokens per Sec: 10009, Lr: 0.000300\n2021-10-10 17:43:58,074 - INFO - joeynmt.training - Epoch 2, Step: 16900, Batch Loss: 2.208057, Tokens per Sec: 10130, Lr: 0.000300\n2021-10-10 17:44:11,947 - INFO - joeynmt.training - Epoch 2, Step: 17000, Batch Loss: 2.317603, Tokens per Sec: 9922, Lr: 0.000300\n2021-10-10 17:44:32,290 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:44:32,290 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:44:32,290 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:44:32,297 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:44:32,694 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/14000.ckpt\n2021-10-10 17:44:32,723 - INFO - joeynmt.training - Example #0\n2021-10-10 17:44:32,723 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tHypothesis: And when we understand that the water will serve , we will not find the importance of drinking and will also want to drink .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - Example #1\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tHypothesis: I Love Love\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - Example #2\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful friends of the apostle Paul had walked about about 50 miles [ 50 km ] from Eigoto Mileto meet him .\n2021-10-10 17:44:32,724 - INFO - joeynmt.training - Example #3\n2021-10-10 17:44:32,725 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:44:32,725 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:44:32,725 - INFO - joeynmt.training - \tHypothesis: “ It was transferred , the window , and the animals of all those who were .\n2021-10-10 17:44:32,725 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 17000: bleu: 22.46, loss: 60196.6172, ppl: 8.1056, duration: 20.7779s\n2021-10-10 17:44:46,721 - INFO - joeynmt.training - Epoch 2, Step: 17100, Batch Loss: 2.335266, Tokens per Sec: 9927, Lr: 0.000300\n2021-10-10 17:45:00,603 - INFO - joeynmt.training - Epoch 2, Step: 17200, Batch Loss: 2.112263, Tokens per Sec: 9951, Lr: 0.000300\n2021-10-10 17:45:14,485 - INFO - joeynmt.training - Epoch 2, Step: 17300, Batch Loss: 2.343539, Tokens per Sec: 10113, Lr: 0.000300\n2021-10-10 17:45:28,361 - INFO - joeynmt.training - Epoch 2, Step: 17400, Batch Loss: 2.322982, Tokens per Sec: 9963, Lr: 0.000300\n2021-10-10 17:45:42,221 - INFO - joeynmt.training - Epoch 2, Step: 17500, Batch Loss: 2.386677, Tokens per Sec: 9813, Lr: 0.000300\n2021-10-10 17:45:56,097 - INFO - joeynmt.training - Epoch 2, Step: 17600, Batch Loss: 2.485045, Tokens per Sec: 10219, Lr: 0.000300\n2021-10-10 17:46:10,057 - INFO - joeynmt.training - Epoch 2, Step: 17700, Batch Loss: 2.245244, Tokens per Sec: 9943, Lr: 0.000300\n2021-10-10 17:46:23,866 - INFO - joeynmt.training - Epoch 2, Step: 17800, Batch Loss: 2.372415, Tokens per Sec: 10045, Lr: 0.000300\n2021-10-10 17:46:37,722 - INFO - joeynmt.training - Epoch 2, Step: 17900, Batch Loss: 2.383636, Tokens per Sec: 10085, Lr: 0.000300\n2021-10-10 17:46:51,711 - INFO - joeynmt.training - Epoch 2, Step: 18000, Batch Loss: 2.393405, Tokens per Sec: 9944, Lr: 0.000300\n2021-10-10 17:47:09,830 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:47:09,830 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:47:09,830 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:47:09,836 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:47:10,225 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/15000.ckpt\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - Example #0\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tHypothesis: But when we understand what the water will do , we will not see the most important thing to drink and we will want to drink .\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - Example #1\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - \tHypothesis: I Love Love\n2021-10-10 17:47:10,249 - INFO - joeynmt.training - Example #2\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Christian friends of the apostle Paul had traveled to a midst of miles [ 50 km ] from Eito Mito meet with him .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - Example #3\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - \tHypothesis: “ The cloud was made , the cloud , and the television of all those who were .\n2021-10-10 17:47:10,250 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 18000: bleu: 23.67, loss: 59383.4531, ppl: 7.8797, duration: 18.5385s\n2021-10-10 17:47:24,192 - INFO - joeynmt.training - Epoch 2, Step: 18100, Batch Loss: 2.099269, Tokens per Sec: 9916, Lr: 0.000300\n2021-10-10 17:47:38,086 - INFO - joeynmt.training - Epoch 2, Step: 18200, Batch Loss: 2.322279, Tokens per Sec: 9827, Lr: 0.000300\n2021-10-10 17:47:52,095 - INFO - joeynmt.training - Epoch 2, Step: 18300, Batch Loss: 2.373856, Tokens per Sec: 10186, Lr: 0.000300\n2021-10-10 17:48:06,080 - INFO - joeynmt.training - Epoch 2, Step: 18400, Batch Loss: 2.304965, Tokens per Sec: 9932, Lr: 0.000300\n2021-10-10 17:48:19,850 - INFO - joeynmt.training - Epoch 2, Step: 18500, Batch Loss: 2.200218, Tokens per Sec: 10134, Lr: 0.000300\n2021-10-10 17:48:33,765 - INFO - joeynmt.training - Epoch 2, Step: 18600, Batch Loss: 2.353125, Tokens per Sec: 10003, Lr: 0.000300\n2021-10-10 17:48:47,678 - INFO - joeynmt.training - Epoch 2, Step: 18700, Batch Loss: 2.261370, Tokens per Sec: 10049, Lr: 0.000300\n2021-10-10 17:49:01,567 - INFO - joeynmt.training - Epoch 2, Step: 18800, Batch Loss: 2.348484, Tokens per Sec: 10109, Lr: 0.000300\n2021-10-10 17:49:15,496 - INFO - joeynmt.training - Epoch 2, Step: 18900, Batch Loss: 2.251022, Tokens per Sec: 10200, Lr: 0.000300\n2021-10-10 17:49:29,356 - INFO - joeynmt.training - Epoch 2, Step: 19000, Batch Loss: 2.380957, Tokens per Sec: 10105, Lr: 0.000300\n2021-10-10 17:49:47,611 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:49:47,611 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:49:47,611 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:49:47,617 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:49:48,000 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/16000.ckpt\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - Example #0\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tHypothesis: But when we understand the water of living will do , we will not see the most important thing to drink and also want to drink .\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - Example #1\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:49:48,025 - INFO - joeynmt.training - \tHypothesis: I Love Love\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - Example #2\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the Christian friends of the apostle Paul had walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - Example #3\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:49:48,026 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:49:48,027 - INFO - joeynmt.training - \tHypothesis: “ It was made up , no punishment , and the sleeping of all who were .\n2021-10-10 17:49:48,027 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 19000: bleu: 23.31, loss: 58540.3594, ppl: 7.6521, duration: 18.6700s\n2021-10-10 17:50:01,931 - INFO - joeynmt.training - Epoch 2, Step: 19100, Batch Loss: 2.079177, Tokens per Sec: 9930, Lr: 0.000300\n2021-10-10 17:50:15,964 - INFO - joeynmt.training - Epoch 2, Step: 19200, Batch Loss: 2.384826, Tokens per Sec: 9895, Lr: 0.000300\n2021-10-10 17:50:29,800 - INFO - joeynmt.training - Epoch 2, Step: 19300, Batch Loss: 2.424232, Tokens per Sec: 9961, Lr: 0.000300\n2021-10-10 17:50:43,817 - INFO - joeynmt.training - Epoch 2, Step: 19400, Batch Loss: 2.332895, Tokens per Sec: 9992, Lr: 0.000300\n2021-10-10 17:50:57,725 - INFO - joeynmt.training - Epoch 2, Step: 19500, Batch Loss: 2.363232, Tokens per Sec: 10062, Lr: 0.000300\n2021-10-10 17:51:11,547 - INFO - joeynmt.training - Epoch 2, Step: 19600, Batch Loss: 2.287678, Tokens per Sec: 10060, Lr: 0.000300\n2021-10-10 17:51:25,559 - INFO - joeynmt.training - Epoch 2, Step: 19700, Batch Loss: 2.267950, Tokens per Sec: 9850, Lr: 0.000300\n2021-10-10 17:51:39,437 - INFO - joeynmt.training - Epoch 2, Step: 19800, Batch Loss: 2.192162, Tokens per Sec: 9985, Lr: 0.000300\n2021-10-10 17:51:53,388 - INFO - joeynmt.training - Epoch 2, Step: 19900, Batch Loss: 2.350035, Tokens per Sec: 9875, Lr: 0.000300\n2021-10-10 17:52:07,250 - INFO - joeynmt.training - Epoch 2, Step: 20000, Batch Loss: 2.202635, Tokens per Sec: 9968, Lr: 0.000300\n2021-10-10 17:52:25,546 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:52:25,546 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:52:25,546 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:52:25,551 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:52:25,946 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/17000.ckpt\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - Example #0\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - Example #1\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tHypothesis: I Love Love\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - Example #2\n2021-10-10 17:52:25,974 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the apostle Paul ’ s companions have been walked with a hundreds of miles [ 50 km ] from Eileto Mito to meet him .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - Example #3\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - \tHypothesis: “ It was made up , not the sleep , and the sleep of all those who were .\n2021-10-10 17:52:25,975 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 20000: bleu: 24.51, loss: 57893.0117, ppl: 7.4818, duration: 18.7246s\n2021-10-10 17:52:39,740 - INFO - joeynmt.training - Epoch 2, Step: 20100, Batch Loss: 2.275442, Tokens per Sec: 9987, Lr: 0.000300\n2021-10-10 17:52:53,661 - INFO - joeynmt.training - Epoch 2, Step: 20200, Batch Loss: 2.144047, Tokens per Sec: 9842, Lr: 0.000300\n2021-10-10 17:53:07,531 - INFO - joeynmt.training - Epoch 2, Step: 20300, Batch Loss: 2.100185, Tokens per Sec: 9942, Lr: 0.000300\n2021-10-10 17:53:21,386 - INFO - joeynmt.training - Epoch 2, Step: 20400, Batch Loss: 2.366673, Tokens per Sec: 9983, Lr: 0.000300\n2021-10-10 17:53:35,216 - INFO - joeynmt.training - Epoch 2, Step: 20500, Batch Loss: 2.407998, Tokens per Sec: 10071, Lr: 0.000300\n2021-10-10 17:53:49,036 - INFO - joeynmt.training - Epoch 2, Step: 20600, Batch Loss: 2.275151, Tokens per Sec: 9909, Lr: 0.000300\n2021-10-10 17:54:02,939 - INFO - joeynmt.training - Epoch 2, Step: 20700, Batch Loss: 2.241833, Tokens per Sec: 9978, Lr: 0.000300\n2021-10-10 17:54:16,663 - INFO - joeynmt.training - Epoch 2, Step: 20800, Batch Loss: 2.186196, Tokens per Sec: 10073, Lr: 0.000300\n2021-10-10 17:54:30,421 - INFO - joeynmt.training - Epoch 2, Step: 20900, Batch Loss: 2.068994, Tokens per Sec: 10219, Lr: 0.000300\n2021-10-10 17:54:44,303 - INFO - joeynmt.training - Epoch 2, Step: 21000, Batch Loss: 2.121050, Tokens per Sec: 10004, Lr: 0.000300\n2021-10-10 17:55:02,334 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:55:02,334 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:55:02,334 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:55:02,340 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:55:02,732 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/18000.ckpt\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - Example #0\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tHypothesis: But when we understand what the living water will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - Example #1\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tHypothesis: I Love Lot\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - Example #2\n2021-10-10 17:55:02,756 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful friends of the apostle Paul had walked about a miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - Example #3\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - \tHypothesis: “ It was made a cell , the cloud , and the tree of all those who were .\n2021-10-10 17:55:02,757 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 21000: bleu: 24.87, loss: 56888.7109, ppl: 7.2252, duration: 18.4532s\n2021-10-10 17:55:16,552 - INFO - joeynmt.training - Epoch 2, Step: 21100, Batch Loss: 2.241100, Tokens per Sec: 9996, Lr: 0.000300\n2021-10-10 17:55:30,502 - INFO - joeynmt.training - Epoch 2, Step: 21200, Batch Loss: 2.309985, Tokens per Sec: 10039, Lr: 0.000300\n2021-10-10 17:55:44,326 - INFO - joeynmt.training - Epoch 2, Step: 21300, Batch Loss: 2.189127, Tokens per Sec: 10016, Lr: 0.000300\n2021-10-10 17:55:58,111 - INFO - joeynmt.training - Epoch 2, Step: 21400, Batch Loss: 2.299753, Tokens per Sec: 10052, Lr: 0.000300\n2021-10-10 17:56:11,980 - INFO - joeynmt.training - Epoch 2, Step: 21500, Batch Loss: 2.283839, Tokens per Sec: 9894, Lr: 0.000300\n2021-10-10 17:56:25,822 - INFO - joeynmt.training - Epoch 2, Step: 21600, Batch Loss: 2.435302, Tokens per Sec: 10053, Lr: 0.000300\n2021-10-10 17:56:39,740 - INFO - joeynmt.training - Epoch 2, Step: 21700, Batch Loss: 2.214674, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 17:56:53,628 - INFO - joeynmt.training - Epoch 2, Step: 21800, Batch Loss: 2.386527, Tokens per Sec: 10030, Lr: 0.000300\n2021-10-10 17:57:07,519 - INFO - joeynmt.training - Epoch 2, Step: 21900, Batch Loss: 2.176718, Tokens per Sec: 10036, Lr: 0.000300\n2021-10-10 17:57:21,459 - INFO - joeynmt.training - Epoch 2, Step: 22000, Batch Loss: 2.106091, Tokens per Sec: 10217, Lr: 0.000300\n2021-10-10 17:57:39,988 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 17:57:39,988 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 17:57:39,988 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 17:57:39,994 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 17:57:40,380 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/19000.ckpt\n2021-10-10 17:57:40,407 - INFO - joeynmt.training - Example #0\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tHypothesis: But when we understand the way of living water will do , we will not see the most important value of drinking and will also want to drink .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - Example #1\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tHypothesis: I Love Lot\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - Example #2\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful friends of the apostle Paul walked about a miles [ 50 km ] from Ephesus to Mileto to meet him .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - Example #3\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - \tHypothesis: “ It was made up , the sound of the sound , and the touch of all those who were .\n2021-10-10 17:57:40,408 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 22000: bleu: 25.25, loss: 56083.4062, ppl: 7.0257, duration: 18.9488s\n2021-10-10 17:57:54,378 - INFO - joeynmt.training - Epoch 2, Step: 22100, Batch Loss: 2.274431, Tokens per Sec: 9855, Lr: 0.000300\n2021-10-10 17:58:08,276 - INFO - joeynmt.training - Epoch 2, Step: 22200, Batch Loss: 2.362981, Tokens per Sec: 10109, Lr: 0.000300\n2021-10-10 17:58:22,119 - INFO - joeynmt.training - Epoch 2, Step: 22300, Batch Loss: 2.349352, Tokens per Sec: 9857, Lr: 0.000300\n2021-10-10 17:58:36,105 - INFO - joeynmt.training - Epoch 2, Step: 22400, Batch Loss: 2.042896, Tokens per Sec: 10044, Lr: 0.000300\n2021-10-10 17:58:50,036 - INFO - joeynmt.training - Epoch 2, Step: 22500, Batch Loss: 2.267240, Tokens per Sec: 9894, Lr: 0.000300\n2021-10-10 17:59:04,017 - INFO - joeynmt.training - Epoch 2, Step: 22600, Batch Loss: 2.166953, Tokens per Sec: 10116, Lr: 0.000300\n2021-10-10 17:59:17,888 - INFO - joeynmt.training - Epoch 2, Step: 22700, Batch Loss: 2.194158, Tokens per Sec: 9825, Lr: 0.000300\n2021-10-10 17:59:31,859 - INFO - joeynmt.training - Epoch 2, Step: 22800, Batch Loss: 2.234727, Tokens per Sec: 10043, Lr: 0.000300\n2021-10-10 17:59:45,727 - INFO - joeynmt.training - Epoch 2, Step: 22900, Batch Loss: 2.355744, Tokens per Sec: 9868, Lr: 0.000300\n2021-10-10 17:59:59,538 - INFO - joeynmt.training - Epoch 2, Step: 23000, Batch Loss: 2.130964, Tokens per Sec: 9925, Lr: 0.000300\n2021-10-10 18:00:18,129 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:00:18,129 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:00:18,129 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:00:18,136 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:00:18,520 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/20000.ckpt\n2021-10-10 18:00:18,544 - INFO - joeynmt.training - Example #0\n2021-10-10 18:00:18,544 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:00:18,544 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tHypothesis: But when we understand what our lives will do , we will not see the most important value of drinking and also want to drink .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - Example #1\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tHypothesis: I Love Lovech\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - Example #2\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the apostle Paul ’ s lovers have walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - Example #3\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - \tHypothesis: “ It was taken to the catch , the window , and the rest of all those who were .\n2021-10-10 18:00:18,545 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 23000: bleu: 25.81, loss: 55436.6641, ppl: 6.8695, duration: 19.0073s\n2021-10-10 18:00:32,467 - INFO - joeynmt.training - Epoch 2, Step: 23100, Batch Loss: 2.024996, Tokens per Sec: 9890, Lr: 0.000300\n2021-10-10 18:00:46,200 - INFO - joeynmt.training - Epoch 2, Step: 23200, Batch Loss: 2.311018, Tokens per Sec: 9949, Lr: 0.000300\n2021-10-10 18:01:00,116 - INFO - joeynmt.training - Epoch 2, Step: 23300, Batch Loss: 2.234103, Tokens per Sec: 9924, Lr: 0.000300\n2021-10-10 18:01:13,892 - INFO - joeynmt.training - Epoch 2, Step: 23400, Batch Loss: 2.233852, Tokens per Sec: 10089, Lr: 0.000300\n2021-10-10 18:01:27,630 - INFO - joeynmt.training - Epoch 2, Step: 23500, Batch Loss: 2.315796, Tokens per Sec: 9913, Lr: 0.000300\n2021-10-10 18:01:41,531 - INFO - joeynmt.training - Epoch 2, Step: 23600, Batch Loss: 2.285094, Tokens per Sec: 10125, Lr: 0.000300\n2021-10-10 18:01:55,314 - INFO - joeynmt.training - Epoch 2, Step: 23700, Batch Loss: 2.069260, Tokens per Sec: 10094, Lr: 0.000300\n2021-10-10 18:02:09,216 - INFO - joeynmt.training - Epoch 2, Step: 23800, Batch Loss: 2.054610, Tokens per Sec: 10220, Lr: 0.000300\n2021-10-10 18:02:23,136 - INFO - joeynmt.training - Epoch 2, Step: 23900, Batch Loss: 2.209172, Tokens per Sec: 9973, Lr: 0.000300\n2021-10-10 18:02:37,115 - INFO - joeynmt.training - Epoch 2, Step: 24000, Batch Loss: 2.146525, Tokens per Sec: 9986, Lr: 0.000300\n2021-10-10 18:02:54,607 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:02:54,607 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:02:54,607 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:02:54,613 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:02:54,991 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/21000.ckpt\n2021-10-10 18:02:55,016 - INFO - joeynmt.training - Example #0\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - Example #1\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tHypothesis: I Love Lot\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - Example #2\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the apostle Paul ’ s dear friends have walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:02:55,017 - INFO - joeynmt.training - Example #3\n2021-10-10 18:02:55,018 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:02:55,018 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:02:55,018 - INFO - joeynmt.training - \tHypothesis: “ The sleeping was made , the clouds of the sword , and the whole of them .\n2021-10-10 18:02:55,018 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 24000: bleu: 25.50, loss: 54890.4453, ppl: 6.7403, duration: 17.9027s\n2021-10-10 18:03:08,799 - INFO - joeynmt.training - Epoch 2, Step: 24100, Batch Loss: 2.196375, Tokens per Sec: 9970, Lr: 0.000300\n2021-10-10 18:03:22,676 - INFO - joeynmt.training - Epoch 2, Step: 24200, Batch Loss: 2.264002, Tokens per Sec: 9862, Lr: 0.000300\n2021-10-10 18:03:36,574 - INFO - joeynmt.training - Epoch 2, Step: 24300, Batch Loss: 2.161167, Tokens per Sec: 10095, Lr: 0.000300\n2021-10-10 18:03:50,628 - INFO - joeynmt.training - Epoch 2, Step: 24400, Batch Loss: 2.337445, Tokens per Sec: 9926, Lr: 0.000300\n2021-10-10 18:04:04,596 - INFO - joeynmt.training - Epoch 2, Step: 24500, Batch Loss: 2.132469, Tokens per Sec: 10058, Lr: 0.000300\n2021-10-10 18:04:18,385 - INFO - joeynmt.training - Epoch 2, Step: 24600, Batch Loss: 2.284099, Tokens per Sec: 10181, Lr: 0.000300\n2021-10-10 18:04:32,258 - INFO - joeynmt.training - Epoch 2, Step: 24700, Batch Loss: 2.273267, Tokens per Sec: 10075, Lr: 0.000300\n2021-10-10 18:04:46,213 - INFO - joeynmt.training - Epoch 2, Step: 24800, Batch Loss: 2.030794, Tokens per Sec: 10027, Lr: 0.000300\n2021-10-10 18:05:00,156 - INFO - joeynmt.training - Epoch 2, Step: 24900, Batch Loss: 2.075187, Tokens per Sec: 9961, Lr: 0.000300\n2021-10-10 18:05:13,889 - INFO - joeynmt.training - Epoch 2, Step: 25000, Batch Loss: 2.303748, Tokens per Sec: 10043, Lr: 0.000300\n2021-10-10 18:05:32,569 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:05:32,570 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:05:32,570 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:05:32,576 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:05:32,958 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/22000.ckpt\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - Example #0\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - \tHypothesis: But when we understand what the water will do , we will not see the most important thing to drink and will also want to drink .\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - Example #1\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:05:32,983 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tHypothesis: I Forget Lovech\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - Example #2\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful friends of the apostle Paul walked on a half miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - Example #3\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - \tHypothesis: “ It was made the sleep , the winter , and the cover of all those who were .\n2021-10-10 18:05:32,984 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 25000: bleu: 26.21, loss: 54494.3828, ppl: 6.6481, duration: 19.0951s\n2021-10-10 18:05:46,880 - INFO - joeynmt.training - Epoch 2, Step: 25100, Batch Loss: 2.135945, Tokens per Sec: 10139, Lr: 0.000300\n2021-10-10 18:06:00,730 - INFO - joeynmt.training - Epoch 2, Step: 25200, Batch Loss: 2.145694, Tokens per Sec: 10063, Lr: 0.000300\n2021-10-10 18:06:14,545 - INFO - joeynmt.training - Epoch 2, Step: 25300, Batch Loss: 2.227857, Tokens per Sec: 10126, Lr: 0.000300\n2021-10-10 18:06:28,445 - INFO - joeynmt.training - Epoch 2, Step: 25400, Batch Loss: 2.402470, Tokens per Sec: 9922, Lr: 0.000300\n2021-10-10 18:06:42,367 - INFO - joeynmt.training - Epoch 2, Step: 25500, Batch Loss: 2.176313, Tokens per Sec: 10000, Lr: 0.000300\n2021-10-10 18:06:56,306 - INFO - joeynmt.training - Epoch 2, Step: 25600, Batch Loss: 2.282737, Tokens per Sec: 10084, Lr: 0.000300\n2021-10-10 18:07:10,206 - INFO - joeynmt.training - Epoch 2, Step: 25700, Batch Loss: 1.964579, Tokens per Sec: 10072, Lr: 0.000300\n2021-10-10 18:07:23,978 - INFO - joeynmt.training - Epoch 2, Step: 25800, Batch Loss: 2.034355, Tokens per Sec: 9918, Lr: 0.000300\n2021-10-10 18:07:37,870 - INFO - joeynmt.training - Epoch 2, Step: 25900, Batch Loss: 1.953404, Tokens per Sec: 9932, Lr: 0.000300\n2021-10-10 18:07:51,731 - INFO - joeynmt.training - Epoch 2, Step: 26000, Batch Loss: 2.308923, Tokens per Sec: 10058, Lr: 0.000300\n2021-10-10 18:08:10,145 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:08:10,145 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:08:10,145 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:08:10,150 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:08:10,531 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/23000.ckpt\n2021-10-10 18:08:10,556 - INFO - joeynmt.training - Example #0\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tHypothesis: But when we understand what the living water will do , we will not see the value of drinking and will also want to drink .\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - Example #1\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tHypothesis: I Look Lovech\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - Example #2\n2021-10-10 18:08:10,557 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the faithful associates of the apostle Paul took a small top of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - Example #3\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - \tHypothesis: “ The cells were exposed , the cells , and the cover of all those who were .\n2021-10-10 18:08:10,558 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 26000: bleu: 26.24, loss: 53838.3398, ppl: 6.4982, duration: 18.8263s\n2021-10-10 18:08:24,415 - INFO - joeynmt.training - Epoch 2, Step: 26100, Batch Loss: 2.250172, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:08:38,331 - INFO - joeynmt.training - Epoch 2, Step: 26200, Batch Loss: 2.191309, Tokens per Sec: 10178, Lr: 0.000300\n2021-10-10 18:08:52,266 - INFO - joeynmt.training - Epoch 2, Step: 26300, Batch Loss: 2.106799, Tokens per Sec: 10152, Lr: 0.000300\n2021-10-10 18:09:06,140 - INFO - joeynmt.training - Epoch 2, Step: 26400, Batch Loss: 2.082134, Tokens per Sec: 9870, Lr: 0.000300\n2021-10-10 18:09:19,967 - INFO - joeynmt.training - Epoch 2, Step: 26500, Batch Loss: 2.041553, Tokens per Sec: 9889, Lr: 0.000300\n2021-10-10 18:09:33,912 - INFO - joeynmt.training - Epoch 2, Step: 26600, Batch Loss: 2.136860, Tokens per Sec: 10053, Lr: 0.000300\n2021-10-10 18:09:47,758 - INFO - joeynmt.training - Epoch 2, Step: 26700, Batch Loss: 2.116478, Tokens per Sec: 10245, Lr: 0.000300\n2021-10-10 18:10:01,681 - INFO - joeynmt.training - Epoch 2, Step: 26800, Batch Loss: 2.155962, Tokens per Sec: 9993, Lr: 0.000300\n2021-10-10 18:10:15,468 - INFO - joeynmt.training - Epoch 2, Step: 26900, Batch Loss: 2.343928, Tokens per Sec: 9980, Lr: 0.000300\n2021-10-10 18:10:29,340 - INFO - joeynmt.training - Epoch 2, Step: 27000, Batch Loss: 2.179948, Tokens per Sec: 10190, Lr: 0.000300\n2021-10-10 18:10:48,527 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:10:48,527 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:10:48,527 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:10:48,533 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:10:48,910 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/24000.ckpt\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - Example #0\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water of life will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - Example #1\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - Example #2\n2021-10-10 18:10:48,935 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful friends of the apostle Paul had walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - Example #3\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - \tHypothesis: “ The clouds were made , the window , and the cover of all those who were there .\n2021-10-10 18:10:48,936 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 27000: bleu: 26.92, loss: 53182.0859, ppl: 6.3517, duration: 19.5956s\n2021-10-10 18:11:02,807 - INFO - joeynmt.training - Epoch 2, Step: 27100, Batch Loss: 2.187025, Tokens per Sec: 10121, Lr: 0.000300\n2021-10-10 18:11:16,596 - INFO - joeynmt.training - Epoch 2, Step: 27200, Batch Loss: 2.103814, Tokens per Sec: 10189, Lr: 0.000300\n2021-10-10 18:11:30,450 - INFO - joeynmt.training - Epoch 2, Step: 27300, Batch Loss: 2.017248, Tokens per Sec: 10162, Lr: 0.000300\n2021-10-10 18:11:44,233 - INFO - joeynmt.training - Epoch 2, Step: 27400, Batch Loss: 2.122421, Tokens per Sec: 10075, Lr: 0.000300\n2021-10-10 18:11:58,176 - INFO - joeynmt.training - Epoch 2, Step: 27500, Batch Loss: 2.148218, Tokens per Sec: 10046, Lr: 0.000300\n2021-10-10 18:12:12,127 - INFO - joeynmt.training - Epoch 2, Step: 27600, Batch Loss: 2.076077, Tokens per Sec: 10096, Lr: 0.000300\n2021-10-10 18:12:26,045 - INFO - joeynmt.training - Epoch 2, Step: 27700, Batch Loss: 2.109702, Tokens per Sec: 10125, Lr: 0.000300\n2021-10-10 18:12:39,953 - INFO - joeynmt.training - Epoch 2, Step: 27800, Batch Loss: 2.185456, Tokens per Sec: 10138, Lr: 0.000300\n2021-10-10 18:12:53,679 - INFO - joeynmt.training - Epoch 2, Step: 27900, Batch Loss: 2.417077, Tokens per Sec: 9968, Lr: 0.000300\n2021-10-10 18:13:07,442 - INFO - joeynmt.training - Epoch 2, Step: 28000, Batch Loss: 2.141473, Tokens per Sec: 9994, Lr: 0.000300\n2021-10-10 18:13:25,663 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:13:25,663 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:13:25,663 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:13:25,669 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:13:26,057 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/25000.ckpt\n2021-10-10 18:13:26,081 - INFO - joeynmt.training - Example #0\n2021-10-10 18:13:26,081 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:13:26,081 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:13:26,081 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water of life will serve , we will not see the importance of drinking but also want to drink .\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - Example #1\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - Example #2\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:13:26,082 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful associates of the apostle Paul had walked a midddle of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - Example #3\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - \tHypothesis: “ The climb was made , the cloud , and the coast of all those who were .\n2021-10-10 18:13:26,083 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 28000: bleu: 27.40, loss: 52850.7266, ppl: 6.2789, duration: 18.6409s\n2021-10-10 18:13:40,078 - INFO - joeynmt.training - Epoch 2, Step: 28100, Batch Loss: 2.214673, Tokens per Sec: 9920, Lr: 0.000300\n2021-10-10 18:13:53,955 - INFO - joeynmt.training - Epoch 2, Step: 28200, Batch Loss: 2.078556, Tokens per Sec: 10075, Lr: 0.000300\n2021-10-10 18:14:07,717 - INFO - joeynmt.training - Epoch 2, Step: 28300, Batch Loss: 2.078411, Tokens per Sec: 9987, Lr: 0.000300\n2021-10-10 18:14:21,595 - INFO - joeynmt.training - Epoch 2, Step: 28400, Batch Loss: 2.258502, Tokens per Sec: 10175, Lr: 0.000300\n2021-10-10 18:14:35,385 - INFO - joeynmt.training - Epoch 2, Step: 28500, Batch Loss: 2.031138, Tokens per Sec: 10235, Lr: 0.000300\n2021-10-10 18:14:49,259 - INFO - joeynmt.training - Epoch 2, Step: 28600, Batch Loss: 1.995497, Tokens per Sec: 10118, Lr: 0.000300\n2021-10-10 18:15:03,044 - INFO - joeynmt.training - Epoch 2, Step: 28700, Batch Loss: 2.297553, Tokens per Sec: 10009, Lr: 0.000300\n2021-10-10 18:15:17,011 - INFO - joeynmt.training - Epoch 2, Step: 28800, Batch Loss: 2.240839, Tokens per Sec: 9978, Lr: 0.000300\n2021-10-10 18:15:31,035 - INFO - joeynmt.training - Epoch 2, Step: 28900, Batch Loss: 2.158037, Tokens per Sec: 9891, Lr: 0.000300\n2021-10-10 18:15:44,846 - INFO - joeynmt.training - Epoch 2, Step: 29000, Batch Loss: 2.127482, Tokens per Sec: 9963, Lr: 0.000300\n2021-10-10 18:16:02,981 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:16:02,982 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:16:02,982 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:16:02,987 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:16:03,377 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/26000.ckpt\n2021-10-10 18:16:03,401 - INFO - joeynmt.training - Example #0\n2021-10-10 18:16:03,401 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:16:03,401 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:16:03,401 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 18:16:03,401 - INFO - joeynmt.training - Example #1\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - Example #2\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tHypothesis: In one occasion , some of the faithful associates of the apostle Paul walked about a midle of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - Example #3\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - \tHypothesis: “ The cells were sleeply discovered , the cloud , and the whole of the people .\n2021-10-10 18:16:03,402 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 29000: bleu: 27.69, loss: 52299.3125, ppl: 6.1597, duration: 18.5559s\n2021-10-10 18:16:17,225 - INFO - joeynmt.training - Epoch 2, Step: 29100, Batch Loss: 2.262763, Tokens per Sec: 9899, Lr: 0.000300\n2021-10-10 18:16:31,098 - INFO - joeynmt.training - Epoch 2, Step: 29200, Batch Loss: 1.911950, Tokens per Sec: 10116, Lr: 0.000300\n2021-10-10 18:16:44,881 - INFO - joeynmt.training - Epoch 2, Step: 29300, Batch Loss: 2.022499, Tokens per Sec: 9991, Lr: 0.000300\n2021-10-10 18:16:58,747 - INFO - joeynmt.training - Epoch 2, Step: 29400, Batch Loss: 1.927156, Tokens per Sec: 10208, Lr: 0.000300\n2021-10-10 18:17:12,597 - INFO - joeynmt.training - Epoch 2, Step: 29500, Batch Loss: 2.190295, Tokens per Sec: 9911, Lr: 0.000300\n2021-10-10 18:17:26,488 - INFO - joeynmt.training - Epoch 2, Step: 29600, Batch Loss: 2.062475, Tokens per Sec: 9982, Lr: 0.000300\n2021-10-10 18:17:40,417 - INFO - joeynmt.training - Epoch 2, Step: 29700, Batch Loss: 1.969772, Tokens per Sec: 9917, Lr: 0.000300\n2021-10-10 18:17:54,161 - INFO - joeynmt.training - Epoch 2, Step: 29800, Batch Loss: 1.818613, Tokens per Sec: 10081, Lr: 0.000300\n2021-10-10 18:18:08,024 - INFO - joeynmt.training - Epoch 2, Step: 29900, Batch Loss: 2.064332, Tokens per Sec: 9759, Lr: 0.000300\n2021-10-10 18:18:21,859 - INFO - joeynmt.training - Epoch 2, Step: 30000, Batch Loss: 2.015635, Tokens per Sec: 10008, Lr: 0.000300\n2021-10-10 18:18:39,811 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:18:39,811 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:18:39,812 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:18:39,817 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:18:40,222 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/27000.ckpt\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - Example #0\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the importance of drinking and also want to drink .\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - Example #1\n2021-10-10 18:18:40,248 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - Example #2\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul had walked about a half miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - Example #3\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - \tHypothesis: “ The screams were made , the cattle , and the whole of those who were present .\n2021-10-10 18:18:40,249 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 30000: bleu: 27.88, loss: 52082.3867, ppl: 6.1134, duration: 18.3902s\n2021-10-10 18:18:54,202 - INFO - joeynmt.training - Epoch 2, Step: 30100, Batch Loss: 2.442043, Tokens per Sec: 9899, Lr: 0.000300\n2021-10-10 18:19:08,078 - INFO - joeynmt.training - Epoch 2, Step: 30200, Batch Loss: 2.108574, Tokens per Sec: 10162, Lr: 0.000300\n2021-10-10 18:19:21,913 - INFO - joeynmt.training - Epoch 2, Step: 30300, Batch Loss: 2.216369, Tokens per Sec: 9987, Lr: 0.000300\n2021-10-10 18:19:35,797 - INFO - joeynmt.training - Epoch 2, Step: 30400, Batch Loss: 1.871041, Tokens per Sec: 10282, Lr: 0.000300\n2021-10-10 18:19:49,695 - INFO - joeynmt.training - Epoch 2, Step: 30500, Batch Loss: 2.121447, Tokens per Sec: 10029, Lr: 0.000300\n2021-10-10 18:20:03,519 - INFO - joeynmt.training - Epoch 2, Step: 30600, Batch Loss: 2.268383, Tokens per Sec: 10147, Lr: 0.000300\n2021-10-10 18:20:17,328 - INFO - joeynmt.training - Epoch 2, Step: 30700, Batch Loss: 2.041761, Tokens per Sec: 10106, Lr: 0.000300\n2021-10-10 18:20:31,155 - INFO - joeynmt.training - Epoch 2, Step: 30800, Batch Loss: 2.218953, Tokens per Sec: 10305, Lr: 0.000300\n2021-10-10 18:20:44,952 - INFO - joeynmt.training - Epoch 2, Step: 30900, Batch Loss: 2.088216, Tokens per Sec: 9897, Lr: 0.000300\n2021-10-10 18:20:58,804 - INFO - joeynmt.training - Epoch 2, Step: 31000, Batch Loss: 1.965414, Tokens per Sec: 9956, Lr: 0.000300\n2021-10-10 18:21:16,837 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:21:16,837 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:21:16,837 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:21:16,843 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:21:17,232 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/28000.ckpt\n2021-10-10 18:21:17,257 - INFO - joeynmt.training - Example #0\n2021-10-10 18:21:17,257 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water of life will do , we will not see the value of drinking but also want to drink .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - Example #1\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - Example #2\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the faithful friends of the apostle Paul walked a small top of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:21:17,258 - INFO - joeynmt.training - Example #3\n2021-10-10 18:21:17,259 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:21:17,259 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:21:17,259 - INFO - joeynmt.training - \tHypothesis: “ The square was made , the celebration of the telephone , and the touch of all the people .\n2021-10-10 18:21:17,259 - INFO - joeynmt.training - Validation result (greedy) at epoch 2, step 31000: bleu: 27.96, loss: 51469.4727, ppl: 5.9846, duration: 18.4540s\n2021-10-10 18:21:31,113 - INFO - joeynmt.training - Epoch 2, Step: 31100, Batch Loss: 2.018025, Tokens per Sec: 10048, Lr: 0.000300\n2021-10-10 18:21:45,068 - INFO - joeynmt.training - Epoch 2, Step: 31200, Batch Loss: 1.949871, Tokens per Sec: 10078, Lr: 0.000300\n2021-10-10 18:21:59,009 - INFO - joeynmt.training - Epoch 2, Step: 31300, Batch Loss: 2.246894, Tokens per Sec: 10107, Lr: 0.000300\n2021-10-10 18:22:13,005 - INFO - joeynmt.training - Epoch 2, Step: 31400, Batch Loss: 2.177929, Tokens per Sec: 9768, Lr: 0.000300\n2021-10-10 18:22:26,789 - INFO - joeynmt.training - Epoch 2, Step: 31500, Batch Loss: 2.254878, Tokens per Sec: 9900, Lr: 0.000300\n2021-10-10 18:22:40,594 - INFO - joeynmt.training - Epoch 2, Step: 31600, Batch Loss: 2.119123, Tokens per Sec: 10112, Lr: 0.000300\n2021-10-10 18:22:54,513 - INFO - joeynmt.training - Epoch 2, Step: 31700, Batch Loss: 2.010700, Tokens per Sec: 10117, Lr: 0.000300\n2021-10-10 18:23:03,108 - INFO - joeynmt.training - Epoch 2: total training loss 34911.64\n2021-10-10 18:23:03,108 - INFO - joeynmt.training - EPOCH 3\n2021-10-10 18:23:09,311 - INFO - joeynmt.training - Epoch 3, Step: 31800, Batch Loss: 2.068009, Tokens per Sec: 8388, Lr: 0.000300\n2021-10-10 18:23:23,190 - INFO - joeynmt.training - Epoch 3, Step: 31900, Batch Loss: 2.045819, Tokens per Sec: 10137, Lr: 0.000300\n2021-10-10 18:23:37,006 - INFO - joeynmt.training - Epoch 3, Step: 32000, Batch Loss: 2.076019, Tokens per Sec: 10180, Lr: 0.000300\n2021-10-10 18:23:56,286 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:23:56,286 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:23:56,286 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:23:56,292 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:23:56,676 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/29000.ckpt\n2021-10-10 18:23:56,700 - INFO - joeynmt.training - Example #0\n2021-10-10 18:23:56,700 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:23:56,700 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:23:56,700 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the importance of drinking and will also want to drink .\n2021-10-10 18:23:56,700 - INFO - joeynmt.training - Example #1\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - Example #2\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tHypothesis: On one occasion , some loving companions of the apostle Paul walked a seven miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - Example #3\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:23:56,701 - INFO - joeynmt.training - \tHypothesis: “ It was made up , the cell of the cell , the snare , and the whole of the people were present .\n2021-10-10 18:23:56,702 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 32000: bleu: 28.27, loss: 51181.9492, ppl: 5.9251, duration: 19.6951s\n2021-10-10 18:24:10,709 - INFO - joeynmt.training - Epoch 3, Step: 32100, Batch Loss: 2.042233, Tokens per Sec: 9923, Lr: 0.000300\n2021-10-10 18:24:24,490 - INFO - joeynmt.training - Epoch 3, Step: 32200, Batch Loss: 2.016007, Tokens per Sec: 9883, Lr: 0.000300\n2021-10-10 18:24:38,385 - INFO - joeynmt.training - Epoch 3, Step: 32300, Batch Loss: 1.929759, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:24:52,232 - INFO - joeynmt.training - Epoch 3, Step: 32400, Batch Loss: 1.883950, Tokens per Sec: 9965, Lr: 0.000300\n2021-10-10 18:25:06,136 - INFO - joeynmt.training - Epoch 3, Step: 32500, Batch Loss: 1.898288, Tokens per Sec: 10152, Lr: 0.000300\n2021-10-10 18:25:20,149 - INFO - joeynmt.training - Epoch 3, Step: 32600, Batch Loss: 2.110570, Tokens per Sec: 9894, Lr: 0.000300\n2021-10-10 18:25:34,043 - INFO - joeynmt.training - Epoch 3, Step: 32700, Batch Loss: 2.084391, Tokens per Sec: 10032, Lr: 0.000300\n2021-10-10 18:25:47,656 - INFO - joeynmt.training - Epoch 3, Step: 32800, Batch Loss: 1.969644, Tokens per Sec: 10061, Lr: 0.000300\n2021-10-10 18:26:01,657 - INFO - joeynmt.training - Epoch 3, Step: 32900, Batch Loss: 2.004416, Tokens per Sec: 9855, Lr: 0.000300\n2021-10-10 18:26:15,596 - INFO - joeynmt.training - Epoch 3, Step: 33000, Batch Loss: 2.073905, Tokens per Sec: 10112, Lr: 0.000300\n2021-10-10 18:26:33,588 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:26:33,588 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:26:33,588 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:26:33,594 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:26:33,979 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/30000.ckpt\n2021-10-10 18:26:34,006 - INFO - joeynmt.training - Example #0\n2021-10-10 18:26:34,006 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:26:34,006 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:26:34,006 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the value of drinking and also want to drink .\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - Example #1\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tHypothesis: I Way Lovech\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - Example #2\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the brothers Paul ’ s dear friends have walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:26:34,007 - INFO - joeynmt.training - Example #3\n2021-10-10 18:26:34,008 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:26:34,008 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:26:34,008 - INFO - joeynmt.training - \tHypothesis: “ The season was put , the cloud , and the snare of all the present .\n2021-10-10 18:26:34,008 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 33000: bleu: 28.08, loss: 50917.1719, ppl: 5.8708, duration: 18.4119s\n2021-10-10 18:26:47,949 - INFO - joeynmt.training - Epoch 3, Step: 33100, Batch Loss: 2.051121, Tokens per Sec: 9842, Lr: 0.000300\n2021-10-10 18:27:01,798 - INFO - joeynmt.training - Epoch 3, Step: 33200, Batch Loss: 1.978353, Tokens per Sec: 9960, Lr: 0.000300\n2021-10-10 18:27:15,513 - INFO - joeynmt.training - Epoch 3, Step: 33300, Batch Loss: 1.748485, Tokens per Sec: 10027, Lr: 0.000300\n2021-10-10 18:27:29,248 - INFO - joeynmt.training - Epoch 3, Step: 33400, Batch Loss: 2.192412, Tokens per Sec: 10047, Lr: 0.000300\n2021-10-10 18:27:43,235 - INFO - joeynmt.training - Epoch 3, Step: 33500, Batch Loss: 1.821099, Tokens per Sec: 10068, Lr: 0.000300\n2021-10-10 18:27:57,160 - INFO - joeynmt.training - Epoch 3, Step: 33600, Batch Loss: 1.894230, Tokens per Sec: 10020, Lr: 0.000300\n2021-10-10 18:28:10,977 - INFO - joeynmt.training - Epoch 3, Step: 33700, Batch Loss: 2.067996, Tokens per Sec: 10022, Lr: 0.000300\n2021-10-10 18:28:24,644 - INFO - joeynmt.training - Epoch 3, Step: 33800, Batch Loss: 2.329060, Tokens per Sec: 9975, Lr: 0.000300\n2021-10-10 18:28:38,517 - INFO - joeynmt.training - Epoch 3, Step: 33900, Batch Loss: 2.133287, Tokens per Sec: 10057, Lr: 0.000300\n2021-10-10 18:28:52,251 - INFO - joeynmt.training - Epoch 3, Step: 34000, Batch Loss: 1.925297, Tokens per Sec: 10071, Lr: 0.000300\n2021-10-10 18:29:10,331 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:29:10,331 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:29:10,331 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:29:10,336 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:29:10,723 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/31000.ckpt\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - Example #0\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the importance of drinking and also want to drink .\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - Example #1\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - Example #2\n2021-10-10 18:29:10,755 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the dear friends of the apostle Paul walked a small top of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - Example #3\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - \tHypothesis: “ The cattle was taken , the cloud of the cloud , and the whole of the people .\n2021-10-10 18:29:10,756 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 34000: bleu: 28.72, loss: 50570.4844, ppl: 5.8004, duration: 18.5050s\n2021-10-10 18:29:24,708 - INFO - joeynmt.training - Epoch 3, Step: 34100, Batch Loss: 1.790401, Tokens per Sec: 10084, Lr: 0.000300\n2021-10-10 18:29:38,582 - INFO - joeynmt.training - Epoch 3, Step: 34200, Batch Loss: 1.933846, Tokens per Sec: 10118, Lr: 0.000300\n2021-10-10 18:29:52,413 - INFO - joeynmt.training - Epoch 3, Step: 34300, Batch Loss: 1.875998, Tokens per Sec: 9967, Lr: 0.000300\n2021-10-10 18:30:06,342 - INFO - joeynmt.training - Epoch 3, Step: 34400, Batch Loss: 2.122011, Tokens per Sec: 10050, Lr: 0.000300\n2021-10-10 18:30:20,220 - INFO - joeynmt.training - Epoch 3, Step: 34500, Batch Loss: 2.020377, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:30:34,126 - INFO - joeynmt.training - Epoch 3, Step: 34600, Batch Loss: 1.929458, Tokens per Sec: 10073, Lr: 0.000300\n2021-10-10 18:30:47,985 - INFO - joeynmt.training - Epoch 3, Step: 34700, Batch Loss: 2.179698, Tokens per Sec: 10140, Lr: 0.000300\n2021-10-10 18:31:01,934 - INFO - joeynmt.training - Epoch 3, Step: 34800, Batch Loss: 2.029736, Tokens per Sec: 9987, Lr: 0.000300\n2021-10-10 18:31:15,805 - INFO - joeynmt.training - Epoch 3, Step: 34900, Batch Loss: 2.041309, Tokens per Sec: 9846, Lr: 0.000300\n2021-10-10 18:31:29,749 - INFO - joeynmt.training - Epoch 3, Step: 35000, Batch Loss: 1.791162, Tokens per Sec: 9942, Lr: 0.000300\n2021-10-10 18:31:48,097 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:31:48,098 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:31:48,098 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:31:48,104 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:31:48,487 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/32000.ckpt\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - Example #0\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not find the importance of drinking but we will want to drink .\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - Example #1\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 18:31:48,513 - INFO - joeynmt.training - Example #2\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tHypothesis: On another occasion , some of the faithful friends of the apostle Paul took a third of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - Example #3\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - \tHypothesis: “ The square were made up , the windroppping , and the cover of all those present .\n2021-10-10 18:31:48,514 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 35000: bleu: 28.53, loss: 50189.2969, ppl: 5.7241, duration: 18.7647s\n2021-10-10 18:32:02,549 - INFO - joeynmt.training - Epoch 3, Step: 35100, Batch Loss: 1.949219, Tokens per Sec: 9781, Lr: 0.000300\n2021-10-10 18:32:16,342 - INFO - joeynmt.training - Epoch 3, Step: 35200, Batch Loss: 1.954309, Tokens per Sec: 9973, Lr: 0.000300\n2021-10-10 18:32:30,104 - INFO - joeynmt.training - Epoch 3, Step: 35300, Batch Loss: 1.982354, Tokens per Sec: 10175, Lr: 0.000300\n2021-10-10 18:32:43,994 - INFO - joeynmt.training - Epoch 3, Step: 35400, Batch Loss: 2.273927, Tokens per Sec: 10047, Lr: 0.000300\n2021-10-10 18:32:57,848 - INFO - joeynmt.training - Epoch 3, Step: 35500, Batch Loss: 2.081658, Tokens per Sec: 9863, Lr: 0.000300\n2021-10-10 18:33:11,606 - INFO - joeynmt.training - Epoch 3, Step: 35600, Batch Loss: 2.082301, Tokens per Sec: 10134, Lr: 0.000300\n2021-10-10 18:33:25,384 - INFO - joeynmt.training - Epoch 3, Step: 35700, Batch Loss: 1.879775, Tokens per Sec: 9850, Lr: 0.000300\n2021-10-10 18:33:39,282 - INFO - joeynmt.training - Epoch 3, Step: 35800, Batch Loss: 1.894253, Tokens per Sec: 10105, Lr: 0.000300\n2021-10-10 18:33:53,091 - INFO - joeynmt.training - Epoch 3, Step: 35900, Batch Loss: 1.822135, Tokens per Sec: 10049, Lr: 0.000300\n2021-10-10 18:34:07,013 - INFO - joeynmt.training - Epoch 3, Step: 36000, Batch Loss: 2.077337, Tokens per Sec: 9916, Lr: 0.000300\n2021-10-10 18:34:26,524 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:34:26,524 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:34:26,524 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:34:26,530 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:34:26,915 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/33000.ckpt\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - Example #0\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the value of drinking and also want to drink .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - Example #1\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tHypothesis: I Way Lovech\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - Example #2\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - \tHypothesis: On one occasion , some of the dear friends of the apostle Paul walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:34:26,942 - INFO - joeynmt.training - Example #3\n2021-10-10 18:34:26,943 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:34:26,943 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:34:26,943 - INFO - joeynmt.training - \tHypothesis: “ The papers were made , the clouds of the clouds , and the cooking of all those present .\n2021-10-10 18:34:26,943 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 36000: bleu: 29.13, loss: 49669.1133, ppl: 5.6215, duration: 19.9298s\n2021-10-10 18:34:40,840 - INFO - joeynmt.training - Epoch 3, Step: 36100, Batch Loss: 2.040991, Tokens per Sec: 10127, Lr: 0.000300\n2021-10-10 18:34:54,687 - INFO - joeynmt.training - Epoch 3, Step: 36200, Batch Loss: 1.933728, Tokens per Sec: 9962, Lr: 0.000300\n2021-10-10 18:35:08,386 - INFO - joeynmt.training - Epoch 3, Step: 36300, Batch Loss: 1.992523, Tokens per Sec: 10240, Lr: 0.000300\n2021-10-10 18:35:22,300 - INFO - joeynmt.training - Epoch 3, Step: 36400, Batch Loss: 1.782499, Tokens per Sec: 10120, Lr: 0.000300\n2021-10-10 18:35:36,192 - INFO - joeynmt.training - Epoch 3, Step: 36500, Batch Loss: 2.091286, Tokens per Sec: 10174, Lr: 0.000300\n2021-10-10 18:35:50,140 - INFO - joeynmt.training - Epoch 3, Step: 36600, Batch Loss: 1.926049, Tokens per Sec: 9991, Lr: 0.000300\n2021-10-10 18:36:03,901 - INFO - joeynmt.training - Epoch 3, Step: 36700, Batch Loss: 2.059632, Tokens per Sec: 9950, Lr: 0.000300\n2021-10-10 18:36:17,812 - INFO - joeynmt.training - Epoch 3, Step: 36800, Batch Loss: 1.887103, Tokens per Sec: 10056, Lr: 0.000300\n2021-10-10 18:36:31,702 - INFO - joeynmt.training - Epoch 3, Step: 36900, Batch Loss: 1.962435, Tokens per Sec: 10313, Lr: 0.000300\n2021-10-10 18:36:45,607 - INFO - joeynmt.training - Epoch 3, Step: 37000, Batch Loss: 2.055488, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:37:04,198 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:37:04,198 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:37:04,198 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:37:04,204 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:37:04,594 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/34000.ckpt\n2021-10-10 18:37:04,620 - INFO - joeynmt.training - Example #0\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the importance of drinking and also want to drink .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - Example #1\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tHypothesis: I Lovech\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - Example #2\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul have walked about 50 miles [ 50 km ] from Ephesus to Mileto to meet him .\n2021-10-10 18:37:04,621 - INFO - joeynmt.training - Example #3\n2021-10-10 18:37:04,622 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:37:04,622 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:37:04,622 - INFO - joeynmt.training - \tHypothesis: “ The season was remembered , the cloud , and the cook of all those who were present .\n2021-10-10 18:37:04,622 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 37000: bleu: 29.08, loss: 49537.5859, ppl: 5.5959, duration: 19.0144s\n2021-10-10 18:37:18,628 - INFO - joeynmt.training - Epoch 3, Step: 37100, Batch Loss: 2.042917, Tokens per Sec: 9774, Lr: 0.000300\n2021-10-10 18:37:32,526 - INFO - joeynmt.training - Epoch 3, Step: 37200, Batch Loss: 1.998875, Tokens per Sec: 10035, Lr: 0.000300\n2021-10-10 18:37:46,272 - INFO - joeynmt.training - Epoch 3, Step: 37300, Batch Loss: 1.883306, Tokens per Sec: 10066, Lr: 0.000300\n2021-10-10 18:38:00,146 - INFO - joeynmt.training - Epoch 3, Step: 37400, Batch Loss: 1.969604, Tokens per Sec: 9998, Lr: 0.000300\n2021-10-10 18:38:13,882 - INFO - joeynmt.training - Epoch 3, Step: 37500, Batch Loss: 1.961437, Tokens per Sec: 10199, Lr: 0.000300\n2021-10-10 18:38:27,815 - INFO - joeynmt.training - Epoch 3, Step: 37600, Batch Loss: 2.143653, Tokens per Sec: 9809, Lr: 0.000300\n2021-10-10 18:38:41,702 - INFO - joeynmt.training - Epoch 3, Step: 37700, Batch Loss: 1.969104, Tokens per Sec: 9840, Lr: 0.000300\n2021-10-10 18:38:55,579 - INFO - joeynmt.training - Epoch 3, Step: 37800, Batch Loss: 2.116809, Tokens per Sec: 10175, Lr: 0.000300\n2021-10-10 18:39:09,312 - INFO - joeynmt.training - Epoch 3, Step: 37900, Batch Loss: 1.985059, Tokens per Sec: 10236, Lr: 0.000300\n2021-10-10 18:39:23,125 - INFO - joeynmt.training - Epoch 3, Step: 38000, Batch Loss: 1.973351, Tokens per Sec: 10013, Lr: 0.000300\n2021-10-10 18:39:41,705 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:39:41,705 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:39:41,705 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:39:41,711 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:39:42,093 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/35000.ckpt\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - Example #0\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tHypothesis: But when we understand what the living water will do , we will not see the importance of drinking but also want to drink .\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - Example #1\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 18:39:42,117 - INFO - joeynmt.training - Example #2\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - Example #3\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - \tHypothesis: “ The cattle was made , the cloud of the flouds , and the coat of all those who were present .\n2021-10-10 18:39:42,118 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 38000: bleu: 29.52, loss: 49273.5977, ppl: 5.5448, duration: 18.9925s\n2021-10-10 18:39:55,951 - INFO - joeynmt.training - Epoch 3, Step: 38100, Batch Loss: 1.903373, Tokens per Sec: 10002, Lr: 0.000300\n2021-10-10 18:40:09,870 - INFO - joeynmt.training - Epoch 3, Step: 38200, Batch Loss: 1.852714, Tokens per Sec: 10139, Lr: 0.000300\n2021-10-10 18:40:23,829 - INFO - joeynmt.training - Epoch 3, Step: 38300, Batch Loss: 1.980691, Tokens per Sec: 10016, Lr: 0.000300\n2021-10-10 18:40:37,662 - INFO - joeynmt.training - Epoch 3, Step: 38400, Batch Loss: 1.919226, Tokens per Sec: 9975, Lr: 0.000300\n2021-10-10 18:40:51,504 - INFO - joeynmt.training - Epoch 3, Step: 38500, Batch Loss: 2.092162, Tokens per Sec: 10058, Lr: 0.000300\n2021-10-10 18:41:05,399 - INFO - joeynmt.training - Epoch 3, Step: 38600, Batch Loss: 2.179053, Tokens per Sec: 10066, Lr: 0.000300\n2021-10-10 18:41:19,235 - INFO - joeynmt.training - Epoch 3, Step: 38700, Batch Loss: 1.896655, Tokens per Sec: 10196, Lr: 0.000300\n2021-10-10 18:41:32,913 - INFO - joeynmt.training - Epoch 3, Step: 38800, Batch Loss: 2.004767, Tokens per Sec: 9981, Lr: 0.000300\n2021-10-10 18:41:46,812 - INFO - joeynmt.training - Epoch 3, Step: 38900, Batch Loss: 1.915368, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:42:00,526 - INFO - joeynmt.training - Epoch 3, Step: 39000, Batch Loss: 1.998612, Tokens per Sec: 9896, Lr: 0.000300\n2021-10-10 18:42:19,343 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:42:19,343 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:42:19,343 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:42:19,349 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:42:19,738 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/36000.ckpt\n2021-10-10 18:42:19,764 - INFO - joeynmt.training - Example #0\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tHypothesis: But when we understand what life will do , we will not see the importance of drinking but also want to drink .\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - Example #1\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:42:19,765 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - Example #2\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul walked a small top of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - Example #3\n2021-10-10 18:42:19,766 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:42:19,767 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:42:19,767 - INFO - joeynmt.training - \tHypothesis: “ The cells were taken , the clouds , and the top of all those there were .\n2021-10-10 18:42:19,767 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 39000: bleu: 29.65, loss: 48842.4414, ppl: 5.4623, duration: 19.2404s\n2021-10-10 18:42:33,565 - INFO - joeynmt.training - Epoch 3, Step: 39100, Batch Loss: 1.782042, Tokens per Sec: 9978, Lr: 0.000300\n2021-10-10 18:42:47,343 - INFO - joeynmt.training - Epoch 3, Step: 39200, Batch Loss: 2.068702, Tokens per Sec: 10134, Lr: 0.000300\n2021-10-10 18:43:01,315 - INFO - joeynmt.training - Epoch 3, Step: 39300, Batch Loss: 1.991406, Tokens per Sec: 9899, Lr: 0.000300\n2021-10-10 18:43:15,184 - INFO - joeynmt.training - Epoch 3, Step: 39400, Batch Loss: 2.011262, Tokens per Sec: 9882, Lr: 0.000300\n2021-10-10 18:43:28,943 - INFO - joeynmt.training - Epoch 3, Step: 39500, Batch Loss: 1.938933, Tokens per Sec: 10029, Lr: 0.000300\n2021-10-10 18:43:42,708 - INFO - joeynmt.training - Epoch 3, Step: 39600, Batch Loss: 1.957666, Tokens per Sec: 10038, Lr: 0.000300\n2021-10-10 18:43:56,579 - INFO - joeynmt.training - Epoch 3, Step: 39700, Batch Loss: 1.767985, Tokens per Sec: 9902, Lr: 0.000300\n2021-10-10 18:44:10,379 - INFO - joeynmt.training - Epoch 3, Step: 39800, Batch Loss: 1.651956, Tokens per Sec: 9997, Lr: 0.000300\n2021-10-10 18:44:24,146 - INFO - joeynmt.training - Epoch 3, Step: 39900, Batch Loss: 2.023867, Tokens per Sec: 10095, Lr: 0.000300\n2021-10-10 18:44:37,993 - INFO - joeynmt.training - Epoch 3, Step: 40000, Batch Loss: 1.682558, Tokens per Sec: 10009, Lr: 0.000300\n2021-10-10 18:44:56,156 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:44:56,156 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:44:56,156 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:44:56,162 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:44:56,550 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/37000.ckpt\n2021-10-10 18:44:56,574 - INFO - joeynmt.training - Example #0\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tHypothesis: And if we understand what life will do , we will not see the most important of drinking and also want to drink .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - Example #1\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - Example #2\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul walked a small total of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - Example #3\n2021-10-10 18:44:56,575 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:44:56,576 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:44:56,576 - INFO - joeynmt.training - \tHypothesis: “ The season was brought , the clouds of the cell , and the cover of all those who were present .\n2021-10-10 18:44:56,576 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 40000: bleu: 29.62, loss: 48639.2734, ppl: 5.4238, duration: 18.5826s\n2021-10-10 18:45:10,540 - INFO - joeynmt.training - Epoch 3, Step: 40100, Batch Loss: 1.799951, Tokens per Sec: 9993, Lr: 0.000300\n2021-10-10 18:45:24,322 - INFO - joeynmt.training - Epoch 3, Step: 40200, Batch Loss: 1.816161, Tokens per Sec: 10147, Lr: 0.000300\n2021-10-10 18:45:38,095 - INFO - joeynmt.training - Epoch 3, Step: 40300, Batch Loss: 1.795152, Tokens per Sec: 10055, Lr: 0.000300\n2021-10-10 18:45:52,048 - INFO - joeynmt.training - Epoch 3, Step: 40400, Batch Loss: 1.743682, Tokens per Sec: 10086, Lr: 0.000300\n2021-10-10 18:46:05,897 - INFO - joeynmt.training - Epoch 3, Step: 40500, Batch Loss: 1.736402, Tokens per Sec: 9797, Lr: 0.000300\n2021-10-10 18:46:19,716 - INFO - joeynmt.training - Epoch 3, Step: 40600, Batch Loss: 1.969497, Tokens per Sec: 10183, Lr: 0.000300\n2021-10-10 18:46:33,579 - INFO - joeynmt.training - Epoch 3, Step: 40700, Batch Loss: 1.836353, Tokens per Sec: 9970, Lr: 0.000300\n2021-10-10 18:46:47,444 - INFO - joeynmt.training - Epoch 3, Step: 40800, Batch Loss: 1.864252, Tokens per Sec: 10046, Lr: 0.000300\n2021-10-10 18:47:01,192 - INFO - joeynmt.training - Epoch 3, Step: 40900, Batch Loss: 1.947629, Tokens per Sec: 10130, Lr: 0.000300\n2021-10-10 18:47:15,070 - INFO - joeynmt.training - Epoch 3, Step: 41000, Batch Loss: 1.719854, Tokens per Sec: 10044, Lr: 0.000300\n2021-10-10 18:47:33,437 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:47:33,437 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:47:33,437 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:47:33,443 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:47:33,825 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/38000.ckpt\n2021-10-10 18:47:33,849 - INFO - joeynmt.training - Example #0\n2021-10-10 18:47:33,849 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tHypothesis: But when we understand what the water of life will serve us , we will not see the importance of drinking and will also want to drink .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - Example #1\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - Example #2\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tHypothesis: In one occasion , some loving friends of the apostle Paul have walked about 50 miles [ 50 km ] from Ephesus to Mileto to meet him .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - Example #3\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - \tHypothesis: “ The flock was brought up , the window , and the eye of all those who were present .\n2021-10-10 18:47:33,850 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 41000: bleu: 29.95, loss: 48457.8086, ppl: 5.3897, duration: 18.7800s\n2021-10-10 18:47:47,758 - INFO - joeynmt.training - Epoch 3, Step: 41100, Batch Loss: 1.966212, Tokens per Sec: 10145, Lr: 0.000300\n2021-10-10 18:48:01,630 - INFO - joeynmt.training - Epoch 3, Step: 41200, Batch Loss: 1.806029, Tokens per Sec: 10030, Lr: 0.000300\n2021-10-10 18:48:15,510 - INFO - joeynmt.training - Epoch 3, Step: 41300, Batch Loss: 1.935231, Tokens per Sec: 9864, Lr: 0.000300\n2021-10-10 18:48:29,302 - INFO - joeynmt.training - Epoch 3, Step: 41400, Batch Loss: 2.037904, Tokens per Sec: 9932, Lr: 0.000300\n2021-10-10 18:48:43,004 - INFO - joeynmt.training - Epoch 3, Step: 41500, Batch Loss: 1.887793, Tokens per Sec: 10057, Lr: 0.000300\n2021-10-10 18:48:56,881 - INFO - joeynmt.training - Epoch 3, Step: 41600, Batch Loss: 1.780562, Tokens per Sec: 10068, Lr: 0.000300\n2021-10-10 18:49:10,698 - INFO - joeynmt.training - Epoch 3, Step: 41700, Batch Loss: 1.930511, Tokens per Sec: 10031, Lr: 0.000300\n2021-10-10 18:49:24,646 - INFO - joeynmt.training - Epoch 3, Step: 41800, Batch Loss: 1.888705, Tokens per Sec: 9980, Lr: 0.000300\n2021-10-10 18:49:38,478 - INFO - joeynmt.training - Epoch 3, Step: 41900, Batch Loss: 1.777530, Tokens per Sec: 10051, Lr: 0.000300\n2021-10-10 18:49:52,465 - INFO - joeynmt.training - Epoch 3, Step: 42000, Batch Loss: 2.064550, Tokens per Sec: 10078, Lr: 0.000300\n2021-10-10 18:50:11,350 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:50:11,350 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:50:11,350 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:50:11,356 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:50:11,758 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/39000.ckpt\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - Example #0\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not see the value of drinking and will also want to drink .\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - Example #1\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:50:11,785 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tHypothesis: I Follow Lovech\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - Example #2\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul walked a small town of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - Example #3\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - \tHypothesis: “ The cattle was brought , the cloud , and the eye of all those present .\n2021-10-10 18:50:11,786 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 42000: bleu: 30.09, loss: 48158.2109, ppl: 5.3339, duration: 19.3205s\n2021-10-10 18:50:25,586 - INFO - joeynmt.training - Epoch 3, Step: 42100, Batch Loss: 1.975612, Tokens per Sec: 10075, Lr: 0.000300\n2021-10-10 18:50:39,342 - INFO - joeynmt.training - Epoch 3, Step: 42200, Batch Loss: 1.982908, Tokens per Sec: 10203, Lr: 0.000300\n2021-10-10 18:50:53,285 - INFO - joeynmt.training - Epoch 3, Step: 42300, Batch Loss: 1.704525, Tokens per Sec: 9916, Lr: 0.000300\n2021-10-10 18:51:07,105 - INFO - joeynmt.training - Epoch 3, Step: 42400, Batch Loss: 1.867386, Tokens per Sec: 10097, Lr: 0.000300\n2021-10-10 18:51:21,038 - INFO - joeynmt.training - Epoch 3, Step: 42500, Batch Loss: 1.740445, Tokens per Sec: 9989, Lr: 0.000300\n2021-10-10 18:51:34,819 - INFO - joeynmt.training - Epoch 3, Step: 42600, Batch Loss: 1.950732, Tokens per Sec: 10228, Lr: 0.000300\n2021-10-10 18:51:48,751 - INFO - joeynmt.training - Epoch 3, Step: 42700, Batch Loss: 1.997052, Tokens per Sec: 9937, Lr: 0.000300\n2021-10-10 18:52:02,667 - INFO - joeynmt.training - Epoch 3, Step: 42800, Batch Loss: 1.916195, Tokens per Sec: 10076, Lr: 0.000300\n2021-10-10 18:52:16,494 - INFO - joeynmt.training - Epoch 3, Step: 42900, Batch Loss: 2.007994, Tokens per Sec: 9891, Lr: 0.000300\n2021-10-10 18:52:30,370 - INFO - joeynmt.training - Epoch 3, Step: 43000, Batch Loss: 2.016331, Tokens per Sec: 10147, Lr: 0.000300\n2021-10-10 18:52:49,702 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:52:49,702 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:52:49,702 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:52:50,101 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/40000.ckpt\n2021-10-10 18:52:50,129 - INFO - joeynmt.training - Example #0\n2021-10-10 18:52:50,129 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:52:50,129 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:52:50,129 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water of life will do , we will not see the importance of drinking but also want to drink .\n2021-10-10 18:52:50,129 - INFO - joeynmt.training - Example #1\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tHypothesis: I Forget Lovech\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - Example #2\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - Example #3\n2021-10-10 18:52:50,130 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:52:50,131 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:52:50,131 - INFO - joeynmt.training - \tHypothesis: “ It was taken to the cell , the cloud , and the eager of all those present .\n2021-10-10 18:52:50,131 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 43000: bleu: 29.95, loss: 48158.5938, ppl: 5.3339, duration: 19.7604s\n2021-10-10 18:53:03,830 - INFO - joeynmt.training - Epoch 3, Step: 43100, Batch Loss: 1.809808, Tokens per Sec: 10122, Lr: 0.000300\n2021-10-10 18:53:17,722 - INFO - joeynmt.training - Epoch 3, Step: 43200, Batch Loss: 1.976417, Tokens per Sec: 10080, Lr: 0.000300\n2021-10-10 18:53:31,697 - INFO - joeynmt.training - Epoch 3, Step: 43300, Batch Loss: 1.979404, Tokens per Sec: 10002, Lr: 0.000300\n2021-10-10 18:53:45,522 - INFO - joeynmt.training - Epoch 3, Step: 43400, Batch Loss: 1.928611, Tokens per Sec: 10112, Lr: 0.000300\n2021-10-10 18:53:59,464 - INFO - joeynmt.training - Epoch 3, Step: 43500, Batch Loss: 1.933224, Tokens per Sec: 10108, Lr: 0.000300\n2021-10-10 18:54:13,423 - INFO - joeynmt.training - Epoch 3, Step: 43600, Batch Loss: 1.990884, Tokens per Sec: 10036, Lr: 0.000300\n2021-10-10 18:54:27,333 - INFO - joeynmt.training - Epoch 3, Step: 43700, Batch Loss: 2.006536, Tokens per Sec: 9927, Lr: 0.000300\n2021-10-10 18:54:41,272 - INFO - joeynmt.training - Epoch 3, Step: 43800, Batch Loss: 1.789778, Tokens per Sec: 10002, Lr: 0.000300\n2021-10-10 18:54:55,043 - INFO - joeynmt.training - Epoch 3, Step: 43900, Batch Loss: 1.931412, Tokens per Sec: 10036, Lr: 0.000300\n2021-10-10 18:55:08,958 - INFO - joeynmt.training - Epoch 3, Step: 44000, Batch Loss: 1.989033, Tokens per Sec: 9926, Lr: 0.000300\n2021-10-10 18:55:28,220 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:55:28,220 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:55:28,220 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:55:28,226 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 18:55:28,610 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/41000.ckpt\n2021-10-10 18:55:28,635 - INFO - joeynmt.training - Example #0\n2021-10-10 18:55:28,635 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:55:28,635 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:55:28,635 - INFO - joeynmt.training - \tHypothesis: But if we understand what the living water will do , we will not only see the importance of drinking but also want to drink .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - Example #1\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tHypothesis: I Follow Lovech\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - Example #2\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul have walked a small of about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - Example #3\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:55:28,636 - INFO - joeynmt.training - \tHypothesis: “ The cells were made , the windows , the cooking , and the eat of all those present .\n2021-10-10 18:55:28,637 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 44000: bleu: 30.03, loss: 47611.5195, ppl: 5.2335, duration: 19.6785s\n2021-10-10 18:55:42,534 - INFO - joeynmt.training - Epoch 3, Step: 44100, Batch Loss: 1.845599, Tokens per Sec: 10156, Lr: 0.000300\n2021-10-10 18:55:56,365 - INFO - joeynmt.training - Epoch 3, Step: 44200, Batch Loss: 1.924816, Tokens per Sec: 10080, Lr: 0.000300\n2021-10-10 18:56:10,292 - INFO - joeynmt.training - Epoch 3, Step: 44300, Batch Loss: 1.996691, Tokens per Sec: 10000, Lr: 0.000300\n2021-10-10 18:56:24,104 - INFO - joeynmt.training - Epoch 3, Step: 44400, Batch Loss: 1.727630, Tokens per Sec: 9963, Lr: 0.000300\n2021-10-10 18:56:37,858 - INFO - joeynmt.training - Epoch 3, Step: 44500, Batch Loss: 2.052135, Tokens per Sec: 10065, Lr: 0.000300\n2021-10-10 18:56:51,732 - INFO - joeynmt.training - Epoch 3, Step: 44600, Batch Loss: 1.708970, Tokens per Sec: 10052, Lr: 0.000300\n2021-10-10 18:57:05,564 - INFO - joeynmt.training - Epoch 3, Step: 44700, Batch Loss: 1.978328, Tokens per Sec: 10149, Lr: 0.000300\n2021-10-10 18:57:19,623 - INFO - joeynmt.training - Epoch 3, Step: 44800, Batch Loss: 1.888260, Tokens per Sec: 10086, Lr: 0.000300\n2021-10-10 18:57:33,376 - INFO - joeynmt.training - Epoch 3, Step: 44900, Batch Loss: 1.856740, Tokens per Sec: 9915, Lr: 0.000300\n2021-10-10 18:57:47,341 - INFO - joeynmt.training - Epoch 3, Step: 45000, Batch Loss: 1.897039, Tokens per Sec: 9978, Lr: 0.000300\n2021-10-10 18:58:05,840 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 18:58:05,840 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 18:58:05,840 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 18:58:06,246 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/43000.ckpt\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - Example #0\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tHypothesis: But when we understand what the living water will do , we will not see the need to drink and will also want to drink .\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - Example #1\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 18:58:06,271 - INFO - joeynmt.training - \tHypothesis: I Was Lovech\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - Example #2\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear companions of the apostle Paul have walked about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - Example #3\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - \tHypothesis: “ The cells were made , the cells of the cells , and the eat of all those present .\n2021-10-10 18:58:06,272 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 45000: bleu: 30.59, loss: 47705.8711, ppl: 5.2507, duration: 18.9305s\n2021-10-10 18:58:20,013 - INFO - joeynmt.training - Epoch 3, Step: 45100, Batch Loss: 1.885184, Tokens per Sec: 9774, Lr: 0.000300\n2021-10-10 18:58:33,922 - INFO - joeynmt.training - Epoch 3, Step: 45200, Batch Loss: 1.831518, Tokens per Sec: 9977, Lr: 0.000300\n2021-10-10 18:58:47,687 - INFO - joeynmt.training - Epoch 3, Step: 45300, Batch Loss: 2.161468, Tokens per Sec: 10144, Lr: 0.000300\n2021-10-10 18:59:01,651 - INFO - joeynmt.training - Epoch 3, Step: 45400, Batch Loss: 1.812405, Tokens per Sec: 9944, Lr: 0.000300\n2021-10-10 18:59:15,525 - INFO - joeynmt.training - Epoch 3, Step: 45500, Batch Loss: 1.662724, Tokens per Sec: 9930, Lr: 0.000300\n2021-10-10 18:59:29,379 - INFO - joeynmt.training - Epoch 3, Step: 45600, Batch Loss: 1.775449, Tokens per Sec: 10102, Lr: 0.000300\n2021-10-10 18:59:43,177 - INFO - joeynmt.training - Epoch 3, Step: 45700, Batch Loss: 2.049054, Tokens per Sec: 9933, Lr: 0.000300\n2021-10-10 18:59:57,074 - INFO - joeynmt.training - Epoch 3, Step: 45800, Batch Loss: 1.851314, Tokens per Sec: 10053, Lr: 0.000300\n2021-10-10 19:00:10,937 - INFO - joeynmt.training - Epoch 3, Step: 45900, Batch Loss: 1.807860, Tokens per Sec: 10141, Lr: 0.000300\n2021-10-10 19:00:24,798 - INFO - joeynmt.training - Epoch 3, Step: 46000, Batch Loss: 1.894998, Tokens per Sec: 9943, Lr: 0.000300\n2021-10-10 19:00:43,934 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:00:43,934 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:00:43,934 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:00:43,941 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 19:00:44,328 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/42000.ckpt\n2021-10-10 19:00:44,354 - INFO - joeynmt.training - Example #0\n2021-10-10 19:00:44,354 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 19:00:44,354 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 19:00:44,354 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the importance of drinking but also want to drink .\n2021-10-10 19:00:44,354 - INFO - joeynmt.training - Example #1\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tHypothesis: I Was Lovech\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - Example #2\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul had walked about 50 miles [ 50 km ] from Ephesus to Mileto meet with him .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - Example #3\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - \tHypothesis: “ The chickens were made , no elephants , and the eat of all the existence .\n2021-10-10 19:00:44,355 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 46000: bleu: 30.50, loss: 47308.3984, ppl: 5.1786, duration: 19.5572s\n2021-10-10 19:00:58,269 - INFO - joeynmt.training - Epoch 3, Step: 46100, Batch Loss: 1.853889, Tokens per Sec: 10096, Lr: 0.000300\n2021-10-10 19:01:12,210 - INFO - joeynmt.training - Epoch 3, Step: 46200, Batch Loss: 1.821321, Tokens per Sec: 9974, Lr: 0.000300\n2021-10-10 19:01:26,133 - INFO - joeynmt.training - Epoch 3, Step: 46300, Batch Loss: 1.732705, Tokens per Sec: 10038, Lr: 0.000300\n2021-10-10 19:01:39,924 - INFO - joeynmt.training - Epoch 3, Step: 46400, Batch Loss: 1.992208, Tokens per Sec: 10111, Lr: 0.000300\n2021-10-10 19:01:53,664 - INFO - joeynmt.training - Epoch 3, Step: 46500, Batch Loss: 1.762646, Tokens per Sec: 9959, Lr: 0.000300\n2021-10-10 19:02:07,548 - INFO - joeynmt.training - Epoch 3, Step: 46600, Batch Loss: 1.895002, Tokens per Sec: 10034, Lr: 0.000300\n2021-10-10 19:02:21,421 - INFO - joeynmt.training - Epoch 3, Step: 46700, Batch Loss: 1.788276, Tokens per Sec: 10174, Lr: 0.000300\n2021-10-10 19:02:35,287 - INFO - joeynmt.training - Epoch 3, Step: 46800, Batch Loss: 1.945603, Tokens per Sec: 10003, Lr: 0.000300\n2021-10-10 19:02:49,110 - INFO - joeynmt.training - Epoch 3, Step: 46900, Batch Loss: 1.818265, Tokens per Sec: 10055, Lr: 0.000300\n2021-10-10 19:03:03,005 - INFO - joeynmt.training - Epoch 3, Step: 47000, Batch Loss: 1.729321, Tokens per Sec: 10077, Lr: 0.000300\n2021-10-10 19:03:23,831 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:03:23,831 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:03:23,831 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:03:23,837 - INFO - joeynmt.training - Hooray! New best validation result [ppl]!\n2021-10-10 19:03:24,259 - INFO - joeynmt.helpers - delete models/tnen_reverse_transformer/45000.ckpt\n2021-10-10 19:03:24,287 - INFO - joeynmt.training - Example #0\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tSource: Mme fa re tlhaloganya se metsi a a tshelang a tla re direlang sone , ga re kitla re bona fela botlhokwa jwa go a nwa mme gape re tla batla go a nwa .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tReference: And when we understand what the living waters can mean for us , not only will we see the need to partake of them but we will also want to drink them .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tHypothesis: But if we understand what the water will do , we will not see the value of drinking but also want to drink .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - Example #1\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tSource: Ke Boela Lovech\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tReference: Coming Back to Lovech\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tHypothesis: I Find Lovech\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - Example #2\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tSource: Mo lekgetlhong lengwe , ditsala dingwe tse di rategang tsa ga moaposetoloi Paulo di ile tsa tsamaya sekgala sa dikilometara tse di ka nnang 50 go tswa kwa Efeso go ya kwa Mileto go ya go kopana le ene .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tReference: On one occasion , dear friends of the apostle Paul traveled about 30 miles [ 50 km ] from Ephesus to Miletus to meet him .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tHypothesis: On one occasion , some dear friends of the apostle Paul have traveled about 50 miles [ 50 km ] from Ephesus to Mileto meet him .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - Example #3\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tSource: “ Go ne ga isiwa manoko a kola , ga tlhajwa phelehu , ya apewa mme ya jewa ke botlhe ba ba neng ba le teng .\n2021-10-10 19:03:24,288 - INFO - joeynmt.training - \tReference: “ Kola nuts were offered , and a ram was slaughtered , boiled , and eaten by all those present .\n2021-10-10 19:03:24,289 - INFO - joeynmt.training - \tHypothesis: “ The seasons were made , the shortage of the clouds , and the cooking of all the attendants .\n2021-10-10 19:03:24,289 - INFO - joeynmt.training - Validation result (greedy) at epoch 3, step 47000: bleu: 30.67, loss: 47000.2148, ppl: 5.1234, duration: 21.2834s\n2021-10-10 19:03:38,099 - INFO - joeynmt.training - Epoch 3, Step: 47100, Batch Loss: 1.790086, Tokens per Sec: 10117, Lr: 0.000300\n2021-10-10 19:03:51,981 - INFO - joeynmt.training - Epoch 3, Step: 47200, Batch Loss: 1.854407, Tokens per Sec: 9995, Lr: 0.000300\n2021-10-10 19:04:05,844 - INFO - joeynmt.training - Epoch 3, Step: 47300, Batch Loss: 1.828321, Tokens per Sec: 10187, Lr: 0.000300\n2021-10-10 19:04:19,749 - INFO - joeynmt.training - Epoch 3, Step: 47400, Batch Loss: 1.956179, Tokens per Sec: 10221, Lr: 0.000300\n2021-10-10 19:04:33,581 - INFO - joeynmt.training - Epoch 3, Step: 47500, Batch Loss: 1.990606, Tokens per Sec: 10011, Lr: 0.000300\n2021-10-10 19:04:47,416 - INFO - joeynmt.training - Epoch 3, Step: 47600, Batch Loss: 1.942025, Tokens per Sec: 10018, Lr: 0.000300\n2021-10-10 19:04:53,119 - INFO - joeynmt.training - Epoch 3: total training loss 31018.94\n2021-10-10 19:04:53,119 - INFO - joeynmt.training - Training ended after 3 epochs.\n2021-10-10 19:04:53,119 - INFO - joeynmt.training - Best validation result (greedy) at step 47000: 5.12 ppl.\n2021-10-10 19:04:53,137 - INFO - joeynmt.prediction - Process device: cuda, n_gpu: 1, batch_size per device: 3600\n2021-10-10 19:04:53,137 - INFO - joeynmt.prediction - Loading model from models/tnen_reverse_transformer/47000.ckpt\n2021-10-10 19:04:53,321 - INFO - joeynmt.model - Building an encoder-decoder model...\n2021-10-10 19:04:53,580 - INFO - joeynmt.model - Enc-dec model built.\n2021-10-10 19:04:53,654 - INFO - joeynmt.prediction - Decoding on dev set (data/tnen/dev.bpe.en)...\n2021-10-10 19:05:23,910 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:05:23,911 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:05:23,911 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:05:23,917 - INFO - joeynmt.prediction - dev bleu[13a]: 31.46 [Beam search decoding with beam size = 5 and alpha = 1.0]\n2021-10-10 19:05:23,918 - INFO - joeynmt.prediction - Translations saved to: models/tnen_reverse_transformer/00047000.hyps.dev\n2021-10-10 19:05:23,918 - INFO - joeynmt.prediction - Decoding on test set (data/tnen/test.bpe.en)...\n2021-10-10 19:06:08,474 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:06:08,475 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:06:08,475 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:06:08,488 - INFO - joeynmt.prediction - test bleu[13a]: 37.96 [Beam search decoding with beam size = 5 and alpha = 1.0]\n2021-10-10 19:06:08,489 - INFO - joeynmt.prediction - Translations saved to: models/tnen_reverse_transformer/00047000.hyps.test\n"
],
[
"# Copy the created models from the notebook storage to google drive for persistant storage \n!cp -r joeynmt/models/${tgt}${src}_reverse_transformer/* \"$gdrive_path/models/${tgt}${src}_reverse_transformer/\"",
"_____no_output_____"
],
[
"# Output our validation accuracy\n! cat \"$gdrive_path/models/${tgt}${src}_reverse_transformer/validations.txt\"",
"Steps: 1000\tLoss: 126182.56250\tPPL: 80.34786\tbleu: 1.45442\tLR: 0.00030000\t*\nSteps: 2000\tLoss: 110310.78125\tPPL: 46.27628\tbleu: 3.26133\tLR: 0.00030000\t*\nSteps: 3000\tLoss: 98919.21094\tPPL: 31.14442\tbleu: 6.42067\tLR: 0.00030000\t*\nSteps: 4000\tLoss: 91479.94531\tPPL: 24.04749\tbleu: 8.68640\tLR: 0.00030000\t*\nSteps: 5000\tLoss: 86265.74219\tPPL: 20.06094\tbleu: 10.50495\tLR: 0.00030000\t*\nSteps: 6000\tLoss: 82152.52344\tPPL: 17.38818\tbleu: 12.45765\tLR: 0.00030000\t*\nSteps: 7000\tLoss: 78422.28125\tPPL: 15.27351\tbleu: 13.81173\tLR: 0.00030000\t*\nSteps: 8000\tLoss: 75613.93750\tPPL: 13.85292\tbleu: 15.34764\tLR: 0.00030000\t*\nSteps: 9000\tLoss: 72726.86719\tPPL: 12.53012\tbleu: 16.02968\tLR: 0.00030000\t*\nSteps: 10000\tLoss: 70534.79688\tPPL: 11.61079\tbleu: 17.21468\tLR: 0.00030000\t*\nSteps: 11000\tLoss: 68509.19531\tPPL: 10.82134\tbleu: 18.71070\tLR: 0.00030000\t*\nSteps: 12000\tLoss: 66658.00781\tPPL: 10.14691\tbleu: 18.81253\tLR: 0.00030000\t*\nSteps: 13000\tLoss: 65412.39062\tPPL: 9.71692\tbleu: 20.42745\tLR: 0.00030000\t*\nSteps: 14000\tLoss: 64002.37109\tPPL: 9.25213\tbleu: 20.78946\tLR: 0.00030000\t*\nSteps: 15000\tLoss: 62576.07812\tPPL: 8.80459\tbleu: 21.81592\tLR: 0.00030000\t*\nSteps: 16000\tLoss: 61077.42969\tPPL: 8.35765\tbleu: 21.31980\tLR: 0.00030000\t*\nSteps: 17000\tLoss: 60196.61719\tPPL: 8.10562\tbleu: 22.46356\tLR: 0.00030000\t*\nSteps: 18000\tLoss: 59383.45312\tPPL: 7.87971\tbleu: 23.66806\tLR: 0.00030000\t*\nSteps: 19000\tLoss: 58540.35938\tPPL: 7.65212\tbleu: 23.31496\tLR: 0.00030000\t*\nSteps: 20000\tLoss: 57893.01172\tPPL: 7.48185\tbleu: 24.51057\tLR: 0.00030000\t*\nSteps: 21000\tLoss: 56888.71094\tPPL: 7.22515\tbleu: 24.87310\tLR: 0.00030000\t*\nSteps: 22000\tLoss: 56083.40625\tPPL: 7.02570\tbleu: 25.25078\tLR: 0.00030000\t*\nSteps: 23000\tLoss: 55436.66406\tPPL: 6.86951\tbleu: 25.80573\tLR: 0.00030000\t*\nSteps: 24000\tLoss: 54890.44531\tPPL: 6.74030\tbleu: 25.50434\tLR: 0.00030000\t*\nSteps: 25000\tLoss: 54494.38281\tPPL: 6.64814\tbleu: 26.20500\tLR: 0.00030000\t*\nSteps: 26000\tLoss: 53838.33984\tPPL: 6.49824\tbleu: 26.24285\tLR: 0.00030000\t*\nSteps: 27000\tLoss: 53182.08594\tPPL: 6.35168\tbleu: 26.91832\tLR: 0.00030000\t*\nSteps: 28000\tLoss: 52850.72656\tPPL: 6.27893\tbleu: 27.40164\tLR: 0.00030000\t*\nSteps: 29000\tLoss: 52299.31250\tPPL: 6.15972\tbleu: 27.69016\tLR: 0.00030000\t*\nSteps: 30000\tLoss: 52082.38672\tPPL: 6.11345\tbleu: 27.87664\tLR: 0.00030000\t*\nSteps: 31000\tLoss: 51469.47266\tPPL: 5.98457\tbleu: 27.96221\tLR: 0.00030000\t*\nSteps: 32000\tLoss: 51181.94922\tPPL: 5.92505\tbleu: 28.27321\tLR: 0.00030000\t*\nSteps: 33000\tLoss: 50917.17188\tPPL: 5.87077\tbleu: 28.08357\tLR: 0.00030000\t*\nSteps: 34000\tLoss: 50570.48438\tPPL: 5.80044\tbleu: 28.72083\tLR: 0.00030000\t*\nSteps: 35000\tLoss: 50189.29688\tPPL: 5.72409\tbleu: 28.52615\tLR: 0.00030000\t*\nSteps: 36000\tLoss: 49669.11328\tPPL: 5.62151\tbleu: 29.12522\tLR: 0.00030000\t*\nSteps: 37000\tLoss: 49537.58594\tPPL: 5.59587\tbleu: 29.07765\tLR: 0.00030000\t*\nSteps: 38000\tLoss: 49273.59766\tPPL: 5.54475\tbleu: 29.52465\tLR: 0.00030000\t*\nSteps: 39000\tLoss: 48842.44141\tPPL: 5.46227\tbleu: 29.64597\tLR: 0.00030000\t*\nSteps: 40000\tLoss: 48639.27344\tPPL: 5.42382\tbleu: 29.61812\tLR: 0.00030000\t*\nSteps: 41000\tLoss: 48457.80859\tPPL: 5.38972\tbleu: 29.95469\tLR: 0.00030000\t*\nSteps: 42000\tLoss: 48158.21094\tPPL: 5.33388\tbleu: 30.08509\tLR: 0.00030000\t*\nSteps: 43000\tLoss: 48158.59375\tPPL: 5.33395\tbleu: 29.95472\tLR: 0.00030000\t\nSteps: 44000\tLoss: 47611.51953\tPPL: 5.23347\tbleu: 30.02836\tLR: 0.00030000\t*\nSteps: 45000\tLoss: 47705.87109\tPPL: 5.25066\tbleu: 30.58518\tLR: 0.00030000\t\nSteps: 46000\tLoss: 47308.39844\tPPL: 5.17861\tbleu: 30.50380\tLR: 0.00030000\t*\nSteps: 47000\tLoss: 47000.21484\tPPL: 5.12343\tbleu: 30.67280\tLR: 0.00030000\t*\n"
],
[
"# Test our model\n! cd joeynmt; python3 -m joeynmt test \"$gdrive_path/models/${tgt}${src}_reverse_transformer/config.yaml\"",
"2021-10-10 19:06:23,899 - INFO - root - Hello! This is Joey-NMT (version 1.3).\n2021-10-10 19:06:23,900 - INFO - joeynmt.data - Building vocabulary...\n2021-10-10 19:06:24,236 - INFO - joeynmt.data - Loading dev data...\n2021-10-10 19:06:24,248 - INFO - joeynmt.data - Loading test data...\n2021-10-10 19:06:24,310 - INFO - joeynmt.data - Data loaded.\n2021-10-10 19:06:24,327 - INFO - joeynmt.prediction - Process device: cuda, n_gpu: 1, batch_size per device: 3600\n2021-10-10 19:06:24,327 - INFO - joeynmt.prediction - Loading model from models/tnen_reverse_transformer/47000.ckpt\n2021-10-10 19:06:27,424 - INFO - joeynmt.model - Building an encoder-decoder model...\n2021-10-10 19:06:27,748 - INFO - joeynmt.model - Enc-dec model built.\n2021-10-10 19:06:27,835 - INFO - joeynmt.prediction - Decoding on dev set (data/tnen/dev.bpe.en)...\n2021-10-10 19:06:57,927 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:06:57,927 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:06:57,927 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:06:57,931 - INFO - joeynmt.prediction - dev bleu[13a]: 31.46 [Beam search decoding with beam size = 5 and alpha = 1.0]\n2021-10-10 19:06:57,931 - INFO - joeynmt.prediction - Decoding on test set (data/tnen/test.bpe.en)...\n2021-10-10 19:07:41,733 - WARNING - sacrebleu - That's 100 lines that end in a tokenized period ('.')\n2021-10-10 19:07:41,733 - WARNING - sacrebleu - It looks like you forgot to detokenize your test data, which may hurt your score.\n2021-10-10 19:07:41,733 - WARNING - sacrebleu - If you insist your data is detokenized, or don't care, you can suppress this message with the `force` parameter.\n2021-10-10 19:07:41,743 - INFO - joeynmt.prediction - test bleu[13a]: 37.96 [Beam search decoding with beam size = 5 and alpha = 1.0]\n"
],
[
"while True:pass",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517ac0536f18ff51e47b7b936df91f26e933fec
| 262,957 |
ipynb
|
Jupyter Notebook
|
notebooks/07-dataframe-wrangling-with-pandas.ipynb
|
yaojenkuo/ntnu-fall-2020
|
5c2b3df1eae8e81cd05b883d20691ee40e349530
|
[
"MIT"
] | 3 |
2020-09-14T02:29:39.000Z
|
2020-09-28T08:13:53.000Z
|
notebooks/07-dataframe-wrangling-with-pandas.ipynb
|
yaojenkuo/ntnu-fall-2020
|
5c2b3df1eae8e81cd05b883d20691ee40e349530
|
[
"MIT"
] | null | null | null |
notebooks/07-dataframe-wrangling-with-pandas.ipynb
|
yaojenkuo/ntnu-fall-2020
|
5c2b3df1eae8e81cd05b883d20691ee40e349530
|
[
"MIT"
] | 5 |
2020-09-21T02:26:32.000Z
|
2021-01-11T04:10:32.000Z
| 33.489175 | 518 | 0.34811 |
[
[
[
"# Python Data Science\n\n> Dataframe Wrangling with Pandas\n\nKuo, Yao-Jen from [DATAINPOINT](https://www.datainpoint.com/)",
"_____no_output_____"
]
],
[
[
"import requests\nimport json\nfrom datetime import date\nfrom datetime import timedelta",
"_____no_output_____"
]
],
[
[
"## TL; DR\n\n> In this lecture, we will talk about essential data wrangling skills in `pandas`.",
"_____no_output_____"
],
[
"## Essential Data Wrangling Skills in `pandas`",
"_____no_output_____"
],
[
"## What is `pandas`?\n\n> Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more.\n\nSource: <https://github.com/pandas-dev/pandas>",
"_____no_output_____"
],
[
"## Why `pandas`?\n\nPython used to have a weak spot in its analysis capability due to it did not have an appropriate structure handling the common tabular datasets. Pythonists had to switch to a more data-centric language like R or Matlab during the analysis stage until the presence of `pandas`.",
"_____no_output_____"
],
[
"## Import Pandas with `import` command\n\nPandas is officially aliased as `pd`.",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"## If Pandas is not installed, we will encounter a `ModuleNotFoundError`\n\n```\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\nModuleNotFoundError: No module named 'pandas'\n```",
"_____no_output_____"
],
[
"## Use `pip install` at Terminal to install pandas\n\n```bash\npip install pandas\n```",
"_____no_output_____"
],
[
"## Check version and its installation file path\n\n- `__version__` attribute\n- `__file__` attribute",
"_____no_output_____"
]
],
[
[
"print(pd.__version__)\nprint(pd.__file__)",
"1.1.3\n/opt/conda/lib/python3.8/site-packages/pandas/__init__.py\n"
]
],
[
[
"## What does `pandas` mean?\n\n\n\nSource: <https://giphy.com/>",
"_____no_output_____"
],
[
"## Turns out its naming has nothing to do with panda the animal, it refers to three primary class customed by its author [Wes McKinney](https://wesmckinney.com/)\n\n- **Pan**el(Deprecated since version 0.20.0)\n- **Da**taFrame\n- **S**eries",
"_____no_output_____"
],
[
"## In order to master `pandas`, it is vital to understand the relationships between `Index`, `ndarray`, `Series`, and `DataFrame`\n\n- An `Index` and a `ndarray` assembles a `Series`\n- A couple of `Series` that sharing the same `Index` can then form a `DataFrame`",
"_____no_output_____"
],
[
"## `Index` from Pandas\n\nThe simpliest way to create an `Index` is using `pd.Index()`.",
"_____no_output_____"
]
],
[
[
"prime_indices = pd.Index([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])\nprint(type(prime_indices))",
"<class 'pandas.core.indexes.numeric.Int64Index'>\n"
]
],
[
[
"## An `Index` is like a combination of `tuple` and `set`\n\n- It is immutable.\n- It has the characteristics of a set.",
"_____no_output_____"
]
],
[
[
"# It is immutable\nprime_indices = pd.Index([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])\n#prime_indices[-1] = 31",
"_____no_output_____"
],
[
"# It has the characteristics of a set\nodd_indices = pd.Index(range(1, 30, 2))\nprint(prime_indices.intersection(odd_indices)) # prime_indices & odd_indices\nprint(prime_indices.union(odd_indices)) # prime_indices | odd_indices\nprint(prime_indices.symmetric_difference(odd_indices)) # prime_indices ^ odd_indices\nprint(prime_indices.difference(odd_indices))\nprint(odd_indices.difference(prime_indices))",
"Int64Index([3, 5, 7, 11, 13, 17, 19, 23, 29], dtype='int64')\nInt64Index([1, 2, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29], dtype='int64')\nInt64Index([1, 2, 9, 15, 21, 25, 27], dtype='int64')\nInt64Index([2], dtype='int64')\nInt64Index([1, 9, 15, 21, 25, 27], dtype='int64')\n"
]
],
[
[
"## `Series` from Pandas\n\nThe simpliest way to create an `Series` is using `pd.Series()`.",
"_____no_output_____"
]
],
[
[
"prime_series = pd.Series([2, 3, 5, 7, 11, 13, 17, 19, 23, 29])\nprint(type(prime_series))",
"<class 'pandas.core.series.Series'>\n"
]
],
[
[
"## A `Series` is a combination of `Index` and `ndarray`",
"_____no_output_____"
]
],
[
[
"print(type(prime_series.index))\nprint(type(prime_series.values))",
"<class 'pandas.core.indexes.range.RangeIndex'>\n<class 'numpy.ndarray'>\n"
]
],
[
[
"## `DataFrame` from Pandas\n\nThe simpliest way to create an `DataFrame` is using `pd.DataFrame()`.",
"_____no_output_____"
]
],
[
[
"movie_df = pd.DataFrame()\nmovie_df[\"title\"] = [\"The Shawshank Redemption\", \"The Dark Knight\", \"Schindler's List\", \"Forrest Gump\", \"Inception\"]\nmovie_df[\"imdb_rating\"] = [9.3, 9.0, 8.9, 8.8, 8.7]\nprint(type(movie_df))",
"<class 'pandas.core.frame.DataFrame'>\n"
]
],
[
[
"## A `DataFrame` is a combination of multiple `Series` sharing the same `Index`",
"_____no_output_____"
]
],
[
[
"print(type(movie_df.index))\nprint(type(movie_df[\"title\"]))\nprint(type(movie_df[\"imdb_rating\"]))",
"<class 'pandas.core.indexes.range.RangeIndex'>\n<class 'pandas.core.series.Series'>\n<class 'pandas.core.series.Series'>\n"
]
],
[
[
"## Review of the definition of modern data science\n\n> Modern data science is a huge field, it invovles applications and tools like importing, tidying, transformation, visualization, modeling, and communication. Surrounding all these is programming.\n\n\n\nSource: [R for Data Science](https://r4ds.had.co.nz/)",
"_____no_output_____"
],
[
"## Key functionalities analysts rely on `pandas` are\n\n- Importing\n- Tidying\n- Transforming",
"_____no_output_____"
],
[
"## Tidying and transforming together is also known as WRANGLING\n\n\n\nSource: <https://giphy.com/>",
"_____no_output_____"
],
[
"## Importing",
"_____no_output_____"
],
[
"## `pandas` has massive functions importing tabular data\n\n- Flat text file\n- Database table\n- Spreadsheet\n- Array of JSONs\n- HTML `<table></table>` tags\n- ...etc.\n\nSource: <https://pandas.pydata.org/pandas-docs/stable/user_guide/io.html>",
"_____no_output_____"
],
[
"## Using `read_csv` function for flat text files",
"_____no_output_____"
]
],
[
[
"from datetime import date\nfrom datetime import timedelta\n\ndef get_covid19_latest_daily_report():\n \"\"\"\n Get latest daily report(world) from:\n https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_daily_reports\n \"\"\"\n data_date = date.today()\n data_date_delta = timedelta(days=1)\n daily_report_url_no_date = \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/{}.csv\"\n while True:\n data_date_str = date.strftime(data_date, '%m-%d-%Y')\n daily_report_url = daily_report_url_no_date.format(data_date_str)\n try:\n print(\"嘗試載入{}的每日報告\".format(data_date_str)) \n daily_report = pd.read_csv(daily_report_url)\n print(\"檔案存在,擷取了{}的每日報告\".format(data_date_str))\n break\n except:\n print(\"{}的檔案還沒有上傳\".format(data_date_str))\n data_date -= data_date_delta # data_date = data_date - data_date_delta\n return daily_report",
"_____no_output_____"
],
[
"daily_report = get_covid19_latest_daily_report()",
"嘗試載入12-13-2020的每日報告\n12-13-2020的檔案還沒有上傳\n嘗試載入12-12-2020的每日報告\n12-12-2020的檔案還沒有上傳\n嘗試載入12-11-2020的每日報告\n檔案存在,擷取了12-11-2020的每日報告\n"
]
],
[
[
"## Using `read_sql` function for database tables\n\n```python\nimport sqlite3\n\nconn = sqlite3.connect('YOUR_DATABASE.db')\nsql_query = \"\"\"\nSELECT * \n FROM YOUR_TABLE\n LIMIT 100;\n\"\"\"\npd.read_sql(sql_query, conn)\n```",
"_____no_output_____"
],
[
"## Using `read_excel` function for spreadsheets\n\n```python\nexcel_file_path = \"PATH/TO/YOUR/EXCEL/FILE\"\npd.read_excel(excel_file_path)\n```",
"_____no_output_____"
],
[
"## Using `read_json` function for array of JSONs\n\n```python\njson_file_path = \"PATH/TO/YOUR/JSON/FILE\"\npd.read_json(json_file_path)\n```",
"_____no_output_____"
],
[
"## What is JSON?\n\n> JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. It is based on a subset of the JavaScript Programming Language. JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.\n\nSource: <https://www.json.org/json-en.html>",
"_____no_output_____"
],
[
"## Using `read_html` function for HTML `<table></table>` tags\n\n> The `<table>` tag defines an HTML table. An HTML table consists of one `<table>` element and one or more `<tr>`, `<th>`, and `<td>` elements. The `<tr>` element defines a table row, the `<th>` element defines a table header, and the `<td>` element defines a table cell.\n\nSource: <https://www.w3schools.com/default.asp>",
"_____no_output_____"
]
],
[
[
"request_url = \"https://www.imdb.com/chart/top\"\nhtml_tables = pd.read_html(request_url)\nprint(type(html_tables))\nprint(len(html_tables))",
"<class 'list'>\n1\n"
],
[
"html_tables[0]",
"_____no_output_____"
]
],
[
[
"## Basic attributes and methods",
"_____no_output_____"
],
[
"## Basic attributes of a `DataFrame` object\n\n- `shape`\n- `dtypes`\n- `index`\n- `columns`",
"_____no_output_____"
]
],
[
[
"print(daily_report.shape)\nprint(daily_report.dtypes)\nprint(daily_report.index)\nprint(daily_report.columns)",
"(3976, 14)\nFIPS float64\nAdmin2 object\nProvince_State object\nCountry_Region object\nLast_Update object\nLat float64\nLong_ float64\nConfirmed int64\nDeaths int64\nRecovered int64\nActive float64\nCombined_Key object\nIncident_Rate float64\nCase_Fatality_Ratio float64\ndtype: object\nRangeIndex(start=0, stop=3976, step=1)\nIndex(['FIPS', 'Admin2', 'Province_State', 'Country_Region', 'Last_Update',\n 'Lat', 'Long_', 'Confirmed', 'Deaths', 'Recovered', 'Active',\n 'Combined_Key', 'Incident_Rate', 'Case_Fatality_Ratio'],\n dtype='object')\n"
]
],
[
[
"## Basic methods of a `DataFrame` object\n\n- `head(n)`\n- `tail(n)`\n- `describe`\n- `info`\n- `set_index`\n- `reset_index`",
"_____no_output_____"
],
[
"## `head(n)` returns the top n observations with header",
"_____no_output_____"
]
],
[
[
"daily_report.head() # n is default to 5",
"_____no_output_____"
]
],
[
[
"## `tail(n)` returns the bottom n observations with header",
"_____no_output_____"
]
],
[
[
"daily_report.tail(3)",
"_____no_output_____"
]
],
[
[
"## `describe` returns the descriptive summary for numeric columns",
"_____no_output_____"
]
],
[
[
"daily_report.describe()",
"_____no_output_____"
]
],
[
[
"## `info` returns the concise information of the dataframe",
"_____no_output_____"
]
],
[
[
"daily_report.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 3976 entries, 0 to 3975\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 FIPS 3263 non-null float64\n 1 Admin2 3268 non-null object \n 2 Province_State 3806 non-null object \n 3 Country_Region 3976 non-null object \n 4 Last_Update 3976 non-null object \n 5 Lat 3890 non-null float64\n 6 Long_ 3890 non-null float64\n 7 Confirmed 3976 non-null int64 \n 8 Deaths 3976 non-null int64 \n 9 Recovered 3976 non-null int64 \n 10 Active 3974 non-null float64\n 11 Combined_Key 3976 non-null object \n 12 Incident_Rate 3890 non-null float64\n 13 Case_Fatality_Ratio 3934 non-null float64\ndtypes: float64(6), int64(3), object(5)\nmemory usage: 435.0+ KB\n"
]
],
[
[
"## `set_index` replaces current `Index` with a specific variable",
"_____no_output_____"
]
],
[
[
"daily_report.set_index('Combined_Key')",
"_____no_output_____"
]
],
[
[
"## `reset_index` resets current `Index` with default `RangeIndex` ",
"_____no_output_____"
]
],
[
[
"daily_report.set_index('Combined_Key').reset_index()",
"_____no_output_____"
]
],
[
[
"## Basic Dataframe Wrangling",
"_____no_output_____"
],
[
"## Basic wrangling is like writing SQL queries\n\n- Selecting: `SELECT FROM`\n- Filtering: `WHERE`\n- Subsetting: `SELECT FROM WHERE`\n- Indexing\n- Sorting: `ORDER BY`\n- Deriving\n- Summarizing\n- Summarizing and Grouping: `GROUP BY`",
"_____no_output_____"
],
[
"## Selecting a column as `Series`",
"_____no_output_____"
]
],
[
[
"print(daily_report['Country_Region'])\nprint(type(daily_report['Country_Region']))",
"0 Afghanistan\n1 Albania\n2 Algeria\n3 Andorra\n4 Angola\n ... \n3971 Vietnam\n3972 West Bank and Gaza\n3973 Yemen\n3974 Zambia\n3975 Zimbabwe\nName: Country_Region, Length: 3976, dtype: object\n<class 'pandas.core.series.Series'>\n"
]
],
[
[
"## Selecting a column as `DataFrame`",
"_____no_output_____"
]
],
[
[
"print(type(daily_report[['Country_Region']]))\ndaily_report[['Country_Region']]",
"<class 'pandas.core.frame.DataFrame'>\n"
]
],
[
[
"## Selecting multiple columns as `DataFrame`, for sure",
"_____no_output_____"
]
],
[
[
"cols = ['Country_Region', 'Province_State']\ndaily_report[cols]",
"_____no_output_____"
]
],
[
[
"## Filtering rows with conditional statements",
"_____no_output_____"
]
],
[
[
"is_taiwan = daily_report['Country_Region'] == 'Taiwan*'\ndaily_report[is_taiwan]",
"_____no_output_____"
]
],
[
[
"## Subsetting columns and rows simultaneously",
"_____no_output_____"
]
],
[
[
"cols_to_select = ['Country_Region', 'Confirmed']\nrows_to_filter = daily_report['Country_Region'] == 'Taiwan*'\ndaily_report[rows_to_filter][cols_to_select]",
"_____no_output_____"
]
],
[
[
"## Indexing `DataFrame` with\n\n- `loc[]`\n- `iloc[]`",
"_____no_output_____"
],
[
"## `loc[]` is indexing `DataFrame` with `Index` ",
"_____no_output_____"
]
],
[
[
"print(daily_report.loc[3388, ['Country_Region', 'Confirmed']]) # as Series\ndaily_report.loc[[3388], ['Country_Region', 'Confirmed']] # as DataFrame",
"Country_Region US\nConfirmed 35\nName: 3388, dtype: object\n"
]
],
[
[
"## `iloc[]` is indexing `DataFrame` with absolute position",
"_____no_output_____"
]
],
[
[
"print(daily_report.iloc[3388, [3, 7]]) # as Series\ndaily_report.iloc[[3388], [3, 7]] # as DataFrame",
"Country_Region US\nConfirmed 35\nName: 3388, dtype: object\n"
]
],
[
[
"## Sorting `DataFrame` with\n\n- `sort_values`\n- `sort_index`",
"_____no_output_____"
],
[
"## `sort_values` sorts `DataFrame` with specific columns",
"_____no_output_____"
]
],
[
[
"daily_report.sort_values(['Country_Region', 'Confirmed'])",
"_____no_output_____"
]
],
[
[
"## `sort_index` sorts `DataFrame` with the `Index` of `DataFrame`",
"_____no_output_____"
]
],
[
[
"daily_report.sort_index(ascending=False)",
"_____no_output_____"
]
],
[
[
"## Deriving new variables from `DataFrame`\n\n- Simple operations\n- `pd.cut`\n- `map` with a `dict`\n- `map` with a function(or a lambda expression)",
"_____no_output_____"
],
[
"## Deriving new variable with simple operations",
"_____no_output_____"
]
],
[
[
"active = daily_report['Confirmed'] - daily_report['Deaths'] - daily_report['Recovered']\nprint(active)",
"0 8030\n1 21750\n2 28956\n3 560\n4 6898\n ... \n3971 118\n3972 24525\n3973 93\n3974 467\n3975 1532\nLength: 3976, dtype: int64\n"
]
],
[
[
"## Deriving categorical from numerical with `pd.cut`",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ncut_bins = [0, 1000, 10000, 100000, np.Inf]\ncut_labels = ['Less than 1000', 'Between 1000 and 10000', 'Between 10000 and 100000', 'Above 100000']\nconfirmed_categorical = pd.cut(daily_report['Confirmed'], bins=cut_bins, labels=cut_labels, right=False)\nprint(confirmed_categorical)",
"0 Between 10000 and 100000\n1 Between 10000 and 100000\n2 Between 10000 and 100000\n3 Between 1000 and 10000\n4 Between 10000 and 100000\n ... \n3971 Between 1000 and 10000\n3972 Above 100000\n3973 Between 1000 and 10000\n3974 Between 10000 and 100000\n3975 Between 10000 and 100000\nName: Confirmed, Length: 3976, dtype: category\nCategories (4, object): ['Less than 1000' < 'Between 1000 and 10000' < 'Between 10000 and 100000' < 'Above 100000']\n"
]
],
[
[
"## Deriving categorical from categorical with `map`\n\n- Passing a `dict`\n- Passing a function(or lambda expression)",
"_____no_output_____"
]
],
[
[
"# Passing a dict\ncountry_name = {\n 'Taiwan*': 'Taiwan'\n}\ndaily_report_tw = daily_report[is_taiwan]\ndaily_report_tw['Country_Region'].map(country_name)",
"_____no_output_____"
],
[
"# Passing a function\ndef is_us(x):\n if x == 'US':\n return 'US'\n else:\n return 'Not US'\ndaily_report['Country_Region'].map(is_us)",
"_____no_output_____"
],
[
"# Passing a lambda expression)\ndaily_report['Country_Region'].map(lambda x: 'US' if x == 'US' else 'Not US')",
"_____no_output_____"
]
],
[
[
"## Summarizing `DataFrame` with aggregate methods",
"_____no_output_____"
]
],
[
[
"daily_report['Confirmed'].sum()",
"_____no_output_____"
]
],
[
[
"## Summarizing and grouping `DataFrame` with aggregate methods",
"_____no_output_____"
]
],
[
[
"daily_report.groupby('Country_Region')['Confirmed'].sum()",
"_____no_output_____"
]
],
[
[
"## More Dataframe Wrangling Operations",
"_____no_output_____"
],
[
"## Other common `Dataframe` wranglings including\n\n- Dealing with missing values\n- Dealing with text values\n- Reshaping dataframes\n- Merging and joining dataframes",
"_____no_output_____"
],
[
"## Dealing with missing values\n\n- Using `isnull` or `notnull` to check if `np.NaN` exists\n- Using `dropna` to drop rows with `np.NaN`\n- Using `fillna` to fill `np.NaN` with specific values",
"_____no_output_____"
]
],
[
[
"print(daily_report['Province_State'].size)\nprint(daily_report['Province_State'].isnull().sum())\nprint(daily_report['Province_State'].notnull().sum())",
"3976\n170\n3806\n"
],
[
"print(daily_report.dropna().shape)\nprint(daily_report['FIPS'].fillna(0))",
"(3193, 14)\n0 0.0\n1 0.0\n2 0.0\n3 0.0\n4 0.0\n ... \n3971 0.0\n3972 0.0\n3973 0.0\n3974 0.0\n3975 0.0\nName: FIPS, Length: 3976, dtype: float64\n"
]
],
[
[
"## Splitting strings with `str.split` as a `Series`",
"_____no_output_____"
]
],
[
[
"split_pattern = ', '\ndaily_report['Combined_Key'].str.split(split_pattern)",
"_____no_output_____"
]
],
[
[
"## Splitting strings with `str.split` as a `DataFrame`",
"_____no_output_____"
]
],
[
[
"split_pattern = ', '\ndaily_report['Combined_Key'].str.split(split_pattern, expand=True)",
"_____no_output_____"
]
],
[
[
"## Replacing strings with `str.replace`",
"_____no_output_____"
]
],
[
[
"daily_report['Combined_Key'].str.replace(\", \", ';')",
"_____no_output_____"
]
],
[
[
"## Testing for strings that match or contain a pattern with `str.contains`",
"_____no_output_____"
]
],
[
[
"print(daily_report['Country_Region'].str.contains('land').sum())\ndaily_report[daily_report['Country_Region'].str.contains('land')]",
"26\n"
]
],
[
[
"## Reshaping dataframes from wide to long format with `pd.melt`\n\nA common problem is that a dataset where some of the column names are not names of variables, but values of a variable.",
"_____no_output_____"
]
],
[
[
"ts_confirmed_global_url = \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv\"\nts_confirmed_global = pd.read_csv(ts_confirmed_global_url)\nts_confirmed_global",
"_____no_output_____"
]
],
[
[
"## We can pivot the columns into a new pair of variables\n\nTo describe that operation we need four parameters:\n\n- The set of columns whose names are not values\n- The set of columns whose names are values\n- The name of the variable to move the column names to\n- The name of the variable to move the column values to",
"_____no_output_____"
],
[
"## In this example, the four parameters are\n\n- `id_vars`: `['Province/State', 'Country/Region', 'Lat', 'Long']`\n- `value_vars`: The columns from `1/22/20` to the last column\n- `var_name`: Let's name it `Date`\n- `value_name`: Let's name it `Confirmed`",
"_____no_output_____"
]
],
[
[
"idVars = ['Province/State', 'Country/Region', 'Lat', 'Long']\nts_confirmed_global_long = pd.melt(ts_confirmed_global,\n id_vars=idVars,\n var_name='Date',\n value_name='Confirmed')\nts_confirmed_global_long",
"_____no_output_____"
]
],
[
[
"## Merging and joining dataframes\n\n- `merge` on column names\n- `join` on index",
"_____no_output_____"
],
[
"## Using `merge` function to join dataframes on columns",
"_____no_output_____"
]
],
[
[
"left_df = daily_report[daily_report['Country_Region'].isin(['Taiwan*', 'Japan'])]\nright_df = ts_confirmed_global_long[ts_confirmed_global_long['Country/Region'].isin(['Taiwan*', 'Korea, South'])]\n# default: inner join\npd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region')",
"_____no_output_____"
],
[
"# left join\npd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region', how='left')",
"_____no_output_____"
],
[
"# right join\npd.merge(left_df, right_df, left_on='Country_Region', right_on='Country/Region', how='right')",
"_____no_output_____"
]
],
[
[
"## Using `join` method to join dataframes on index",
"_____no_output_____"
]
],
[
[
"left_df = daily_report[daily_report['Country_Region'].isin(['Taiwan*', 'Japan'])]\nright_df = ts_confirmed_global_long[ts_confirmed_global_long['Country/Region'].isin(['Taiwan*', 'Korea, South'])]\nleft_df = left_df.set_index('Country_Region')\nright_df = right_df.set_index('Country/Region')",
"_____no_output_____"
],
[
"# default: left join\nleft_df.join(right_df, lsuffix='_x', rsuffix='_y')",
"_____no_output_____"
],
[
"# inner join\nleft_df.join(right_df, lsuffix='_x', rsuffix='_y', how='inner')",
"_____no_output_____"
],
[
"# inner join\nleft_df.join(right_df, lsuffix='_x', rsuffix='_y', how='inner')",
"_____no_output_____"
],
[
"# right join\nleft_df.join(right_df, lsuffix='_x', rsuffix='_y', how='right')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
c517ad6461502bccc4bbb89b4c2c0b6f3e1f94b7
| 29,358 |
ipynb
|
Jupyter Notebook
|
scipy_and_numpy/numpy/01_funciones_utiles.ipynb
|
pystudent1913/python-machine-learning
|
888e29094cde40155af8bea0507ee1c154cc2050
|
[
"MIT"
] | null | null | null |
scipy_and_numpy/numpy/01_funciones_utiles.ipynb
|
pystudent1913/python-machine-learning
|
888e29094cde40155af8bea0507ee1c154cc2050
|
[
"MIT"
] | null | null | null |
scipy_and_numpy/numpy/01_funciones_utiles.ipynb
|
pystudent1913/python-machine-learning
|
888e29094cde40155af8bea0507ee1c154cc2050
|
[
"MIT"
] | null | null | null | 36.066339 | 911 | 0.415764 |
[
[
[
"import numpy as np\n\n## ahora veremos como mostrar la forma de los arrays creados con numpy\n\n# creando un array 3D\narr_3d = np.zeros((3,3,3))\n\n# y lo imprimimos\nprint(arr_3d)\n\n# vemos su forma\nprint(\"la forma es: {}\".format(arr_3d.shape))",
"[[[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]]\nla forma es: (3, 3, 3)\n"
],
[
"# ahora veremos como convertir una lista de python a un array en numpy\n\n# primero creamos una lista \nlista = [1,2,3,45,5,6,7,8,8]\nlista_array = np.array(lista)\n\nprint(lista_array)\nprint(lista_array.shape)",
"[ 1 2 3 45 5 6 7 8 8]\n(9,)\n"
],
[
"# crear un array de inicializando con ceros\narray_ceros = np.zeros(10)\nprint(array_ceros)\narray_ceros_dimensiones = np.zeros((5,2,3))\nprint(array_ceros_dimensiones)\n\nprint(\"y la forma es: {}\".format(array_ceros_dimensiones.shape))",
"[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n[[[0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]]\n\n [[0. 0. 0.]\n [0. 0. 0.]]]\ny la forma es: (5, 2, 3)\n"
],
[
"# crear un array dando un rango\n# para dar el rango hay opciones como en una lista normal\n# si dejas un numero solo -> (numero) : ira desde el cero hasta en (numero - 1)\n# si pones dos numeros -> (numero_inicial, numero_final) : desde el inicial hasta el (final - 1)\n# si pones tres numeros -> (numero_inicial, numero_final, intervalo): va como el anterior pero el tercer valor en la razon a la que va a aumentar\n# ahora veremos los ejemplos\narray_rango_1 = np.arange(100)\narray_rango_2 = np.arange(0,100)\narray_rango_3 = np.arange(0,100,2)\nprint(array_rango_1)\nprint(array_rango_2)\nprint(array_rango_3)",
"_____no_output_____"
],
[
"# si quieres hallar los espacios entre dos numeros, usaremos linspace\n# .linspace(inicio, fin, numero_de_espacios)\narray_espacios = np.linspace(0,10,100)\nprint(array_espacios)",
"_____no_output_____"
],
[
"# ahora veremos la diferencia entre un array normal y otro convertido a un entero\ncube_normal = np.zeros((3,3,3)) + 1\ncube_integer = np.zeros((3,3,3)).astype(int) + 1\ncube_float = np.ones((3, 3, 3)).astype(np.float16)\n\n# podran notar el punto decimal que se aplica por defecto\nprint(\"Cubo normal creado: \\n{}\".format(cube_normal))\nprint(\"Cubo de integers creado: \\n{}\".format(cube_integer))\nprint(\"Cubo de flotantes creado: \\n{}\".format(cube_float))",
"Cubo normal creado: \n[[[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]\n\n [[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]\n\n [[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]]\nCubo de integers creado: \n[[[1 1 1]\n [1 1 1]\n [1 1 1]]\n\n [[1 1 1]\n [1 1 1]\n [1 1 1]]\n\n [[1 1 1]\n [1 1 1]\n [1 1 1]]]\nCubo de flotantes creado: \n[[[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]\n\n [[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]\n\n [[1. 1. 1.]\n [1. 1. 1.]\n [1. 1. 1.]]]\n"
],
[
"# tambien podemos usar tipos de datos desde numpy\narray_entero = np.zeros(3, dtype=int)\nprint(\"el array de enteros con tipo de datos de python: \\n{}\".format(array_entero))\n\narray_flotante = np.zeros(3, dtype=np.float32)\nprint(\"el array de enteros con tipo de datos de numpy: \\n{}\".format(array_flotante))\n# y porque usamos np.float32? porque en python no existe nativamente exactamente float32",
"el array de enteros con tipo de datos de python: \n[0 0 0]\nel array de enteros con tipo de datos de numpy: \n[0. 0. 0.]\n"
],
[
"# ahora veremos algo interesante\n\n# creamos un array de 1000 elementos \narr_1d = np.arange(1000)\nprint(arr_1d)\n\n# y los podemos reformar a una matriz 3d y numpy se encarga de manera automatica de esto\narr_3d_1 = arr_1d.reshape((10,10,10))\nprint(arr_3d_1)\n\n# y tambien puede ser cambiado de esta forma\narr_3d_2 = np.reshape(arr1s, (10, 10, 10))\nprint(arr_3d_2)",
"[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17\n 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35\n 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53\n 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71\n 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89\n 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107\n 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125\n 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143\n 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161\n 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179\n 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197\n 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215\n 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233\n 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251\n 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269\n 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287\n 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305\n 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323\n 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341\n 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359\n 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377\n 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395\n 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413\n 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431\n 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449\n 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467\n 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485\n 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503\n 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521\n 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539\n 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557\n 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575\n 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593\n 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611\n 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629\n 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647\n 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665\n 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683\n 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701\n 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719\n 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737\n 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755\n 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773\n 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791\n 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809\n 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827\n 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845\n 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863\n 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881\n 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899\n 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917\n 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935\n 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953\n 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971\n 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989\n 990 991 992 993 994 995 996 997 998 999]\n[[[ 0 1 2 3 4 5 6 7 8 9]\n [ 10 11 12 13 14 15 16 17 18 19]\n [ 20 21 22 23 24 25 26 27 28 29]\n [ 30 31 32 33 34 35 36 37 38 39]\n [ 40 41 42 43 44 45 46 47 48 49]\n [ 50 51 52 53 54 55 56 57 58 59]\n [ 60 61 62 63 64 65 66 67 68 69]\n [ 70 71 72 73 74 75 76 77 78 79]\n [ 80 81 82 83 84 85 86 87 88 89]\n [ 90 91 92 93 94 95 96 97 98 99]]\n\n [[100 101 102 103 104 105 106 107 108 109]\n [110 111 112 113 114 115 116 117 118 119]\n [120 121 122 123 124 125 126 127 128 129]\n [130 131 132 133 134 135 136 137 138 139]\n [140 141 142 143 144 145 146 147 148 149]\n [150 151 152 153 154 155 156 157 158 159]\n [160 161 162 163 164 165 166 167 168 169]\n [170 171 172 173 174 175 176 177 178 179]\n [180 181 182 183 184 185 186 187 188 189]\n [190 191 192 193 194 195 196 197 198 199]]\n\n [[200 201 202 203 204 205 206 207 208 209]\n [210 211 212 213 214 215 216 217 218 219]\n [220 221 222 223 224 225 226 227 228 229]\n [230 231 232 233 234 235 236 237 238 239]\n [240 241 242 243 244 245 246 247 248 249]\n [250 251 252 253 254 255 256 257 258 259]\n [260 261 262 263 264 265 266 267 268 269]\n [270 271 272 273 274 275 276 277 278 279]\n [280 281 282 283 284 285 286 287 288 289]\n [290 291 292 293 294 295 296 297 298 299]]\n\n [[300 301 302 303 304 305 306 307 308 309]\n [310 311 312 313 314 315 316 317 318 319]\n [320 321 322 323 324 325 326 327 328 329]\n [330 331 332 333 334 335 336 337 338 339]\n [340 341 342 343 344 345 346 347 348 349]\n [350 351 352 353 354 355 356 357 358 359]\n [360 361 362 363 364 365 366 367 368 369]\n [370 371 372 373 374 375 376 377 378 379]\n [380 381 382 383 384 385 386 387 388 389]\n [390 391 392 393 394 395 396 397 398 399]]\n\n [[400 401 402 403 404 405 406 407 408 409]\n [410 411 412 413 414 415 416 417 418 419]\n [420 421 422 423 424 425 426 427 428 429]\n [430 431 432 433 434 435 436 437 438 439]\n [440 441 442 443 444 445 446 447 448 449]\n [450 451 452 453 454 455 456 457 458 459]\n [460 461 462 463 464 465 466 467 468 469]\n [470 471 472 473 474 475 476 477 478 479]\n [480 481 482 483 484 485 486 487 488 489]\n [490 491 492 493 494 495 496 497 498 499]]\n\n [[500 501 502 503 504 505 506 507 508 509]\n [510 511 512 513 514 515 516 517 518 519]\n [520 521 522 523 524 525 526 527 528 529]\n [530 531 532 533 534 535 536 537 538 539]\n [540 541 542 543 544 545 546 547 548 549]\n [550 551 552 553 554 555 556 557 558 559]\n [560 561 562 563 564 565 566 567 568 569]\n [570 571 572 573 574 575 576 577 578 579]\n [580 581 582 583 584 585 586 587 588 589]\n [590 591 592 593 594 595 596 597 598 599]]\n\n [[600 601 602 603 604 605 606 607 608 609]\n [610 611 612 613 614 615 616 617 618 619]\n [620 621 622 623 624 625 626 627 628 629]\n [630 631 632 633 634 635 636 637 638 639]\n [640 641 642 643 644 645 646 647 648 649]\n [650 651 652 653 654 655 656 657 658 659]\n [660 661 662 663 664 665 666 667 668 669]\n [670 671 672 673 674 675 676 677 678 679]\n [680 681 682 683 684 685 686 687 688 689]\n [690 691 692 693 694 695 696 697 698 699]]\n\n [[700 701 702 703 704 705 706 707 708 709]\n [710 711 712 713 714 715 716 717 718 719]\n [720 721 722 723 724 725 726 727 728 729]\n [730 731 732 733 734 735 736 737 738 739]\n [740 741 742 743 744 745 746 747 748 749]\n [750 751 752 753 754 755 756 757 758 759]\n [760 761 762 763 764 765 766 767 768 769]\n [770 771 772 773 774 775 776 777 778 779]\n [780 781 782 783 784 785 786 787 788 789]\n [790 791 792 793 794 795 796 797 798 799]]\n\n [[800 801 802 803 804 805 806 807 808 809]\n [810 811 812 813 814 815 816 817 818 819]\n [820 821 822 823 824 825 826 827 828 829]\n [830 831 832 833 834 835 836 837 838 839]\n [840 841 842 843 844 845 846 847 848 849]\n [850 851 852 853 854 855 856 857 858 859]\n [860 861 862 863 864 865 866 867 868 869]\n [870 871 872 873 874 875 876 877 878 879]\n [880 881 882 883 884 885 886 887 888 889]\n [890 891 892 893 894 895 896 897 898 899]]\n\n [[900 901 902 903 904 905 906 907 908 909]\n [910 911 912 913 914 915 916 917 918 919]\n [920 921 922 923 924 925 926 927 928 929]\n [930 931 932 933 934 935 936 937 938 939]\n [940 941 942 943 944 945 946 947 948 949]\n [950 951 952 953 954 955 956 957 958 959]\n [960 961 962 963 964 965 966 967 968 969]\n [970 971 972 973 974 975 976 977 978 979]\n [980 981 982 983 984 985 986 987 988 989]\n [990 991 992 993 994 995 996 997 998 999]]]\n"
],
[
"arr4d = np.zeros((10, 10, 10, 10))\nprint(arr4d)\n\narr1d = arr4d.ravel()\nprint(arr1d)\nprint(\"la forma es: {}\".format(arr1d.shape))",
"[[[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]\n\n\n [[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]\n\n\n [[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]\n\n\n ...\n\n\n [[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]\n\n\n [[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]\n\n\n [[[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n ...\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n\n [[0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n ...\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]]]\n[0. 0. 0. ... 0. 0. 0.]\nla forma es: (10000,)\n"
],
[
"recarr = np.zeros((2,), dtype=('i4,f4,a10'))\ntoadd = [(1,2.,'Hello'),(2,3.,\"World\")]\nrecarr[:] = toadd\nprint(recarr)\nrecarr = np.zeros((2,), dtype=('i4,f4,a10'))\nprint(recarr)\n\ncol1 = np.arange(2) + 1\ncol2 = np.arange(2, dtype=np.float32)\ncol3 = ['Hello', 'World']\n\nprint(col1)\nprint(col2)\nprint(col3)",
"[(1, 2., b'Hello') (2, 3., b'World')]\n[(0, 0., b'') (0, 0., b'')]\n[1 2]\n[0. 1.]\n['Hello', 'World']\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517c20e5b626f3c9073b30d463835cceba6dbb0
| 50,447 |
ipynb
|
Jupyter Notebook
|
1-Training/AzureServiceClassifier_Training.ipynb
|
maxluk/bert-azureml-training
|
8bc5be5b94c5c2aeb34cfb3135a3c5fee0076196
|
[
"MIT"
] | 1 |
2020-01-17T10:11:03.000Z
|
2020-01-17T10:11:03.000Z
|
1-Training/AzureServiceClassifier_Training.ipynb
|
maxluk/bert-azureml-training
|
8bc5be5b94c5c2aeb34cfb3135a3c5fee0076196
|
[
"MIT"
] | null | null | null |
1-Training/AzureServiceClassifier_Training.ipynb
|
maxluk/bert-azureml-training
|
8bc5be5b94c5c2aeb34cfb3135a3c5fee0076196
|
[
"MIT"
] | 2 |
2020-01-16T22:24:10.000Z
|
2020-01-16T22:39:11.000Z
| 42.787956 | 666 | 0.631078 |
[
[
[
"Copyright (c) Microsoft Corporation. All rights reserved.\n\nLicensed under the MIT License.",
"_____no_output_____"
],
[
"# Part 1: Training Tensorflow 2.0 Model on Azure Machine Learning Service\n\n## Overview of the part 1\nThis notebook is Part 1 (Preparing Data and Model Training) of a two part workshop that demonstrates an end-to-end workflow using Tensorflow 2.0 on Azure Machine Learning service. The different components of the workshop are as follows:\n\n- Part 1: [Model Training](https://github.com/microsoft/bert-stack-overflow/blob/master/1-Training/AzureServiceClassifier_Training.ipynb)\n- Part 2: [Inferencing and Deploying a Model](https://github.com/microsoft/bert-stack-overflow/blob/master/2-Inferencing/AzureServiceClassifier_Inferencing.ipynb)\n\n**This notebook will cover the following topics:**\n\n- Stackoverflow question tagging problem\n- Introduction to Transformer and BERT deep learning models\n- Registering cleaned up training data as a Dataset\n- Training the model on GPU cluster\n- Monitoring training progress with built-in Tensorboard dashboard \n- Automated search of best hyper-parameters of the model\n- Registering the trained model for future deployment",
"_____no_output_____"
],
[
"## Prerequisites\nThis notebook is designed to be run in Azure ML Notebook VM. See [readme](https://github.com/microsoft/bert-stack-overflow/blob/master/README.md) file for instructions on how to create Notebook VM and open this notebook in it.",
"_____no_output_____"
],
[
"### Check Azure Machine Learning Python SDK version\n\nThis tutorial requires version 1.0.69 or higher. Let's check the version of the SDK:",
"_____no_output_____"
]
],
[
[
"import azureml.core\n\nprint(\"Azure Machine Learning Python SDK version:\", azureml.core.VERSION)",
"_____no_output_____"
]
],
[
[
"## Stackoverflow Question Tagging Problem \nIn this workshop we will use powerful language understanding model to automatically route Stackoverflow questions to the appropriate support team on the example of Azure services.\n\nOne of the key tasks to ensuring long term success of any Azure service is actively responding to related posts in online forums such as Stackoverflow. In order to keep track of these posts, Microsoft relies on the associated tags to direct questions to the appropriate support team. While Stackoverflow has different tags for each Azure service (azure-web-app-service, azure-virtual-machine-service, etc), people often use the generic **azure** tag. This makes it hard for specific teams to track down issues related to their product and as a result, many questions get left unanswered. \n\n**In order to solve this problem, we will build a model to classify posts on Stackoverflow with the appropriate Azure service tag.**\n\nWe will be using a BERT (Bidirectional Encoder Representations from Transformers) model which was published by researchers at Google AI Reasearch. Unlike prior language representation models, BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of natural language processing (NLP) tasks without substantial architecture modifications.\n\n## Why use BERT model?\n[Introduction of BERT model](https://arxiv.org/pdf/1810.04805.pdf) changed the world of NLP. Many NLP problems that before relied on specialized models to achive state of the art performance are now solved with BERT better and with more generic approach.\n\nIf we look at the leaderboards on such popular NLP problems as GLUE and SQUAD, most of the top models are based on BERT:\n* [GLUE Benchmark Leaderboard](https://gluebenchmark.com/leaderboard/)\n* [SQuAD Benchmark Leaderboard](https://rajpurkar.github.io/SQuAD-explorer/)\n\nRecently, Allen Institue for AI announced new language understanding system called Aristo [https://allenai.org/aristo/](https://allenai.org/aristo/). The system has been developed for 20 years, but it's performance was stuck at 60% on 8th grade science test. The result jumped to 90% once researchers adopted BERT as core language understanding component. With BERT Aristo now solves the test with A grade. ",
"_____no_output_____"
],
[
"## Quick Overview of How BERT model works\n\nThe foundation of BERT model is Transformer model, which was introduced in [Attention Is All You Need paper](https://arxiv.org/abs/1706.03762). Before that event the dominant way of processing language was Recurrent Neural Networks (RNNs). Let's start our overview with RNNs.\n\n## RNNs\n\nRNNs were powerful way of processing language due to their ability to memorize its previous state and perform sophisticated inference based on that.\n\n<img src=\"https://miro.medium.com/max/400/1*L38xfe59H5tAgvuIjKoWPg.png\" alt=\"Drawing\" style=\"width: 100px;\"/>\n\n_Taken from [1](https://towardsdatascience.com/transformers-141e32e69591)_\n\nApplied to language translation task, the processing dynamics looked like this.\n\n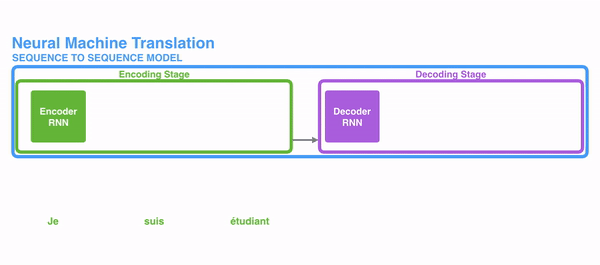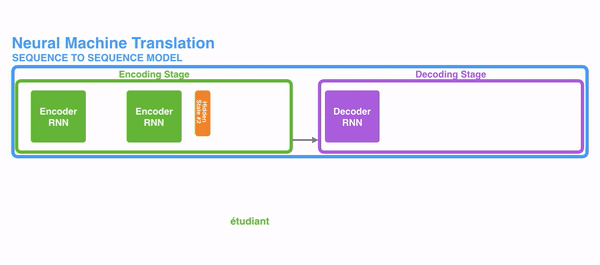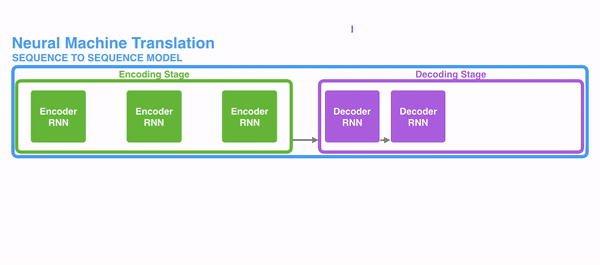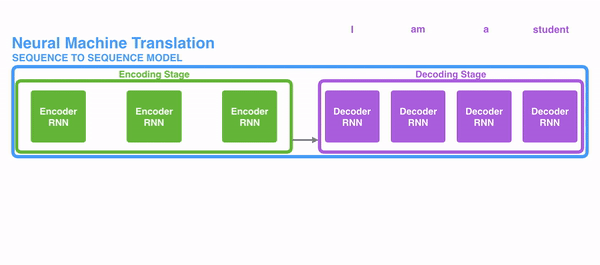\n_Taken from [2](https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/)_\n \nBut RNNs suffered from 2 disadvantes:\n1. Sequential computation put a limit on parallelization, which limited effectiveness of larger models.\n2. Long term relationships between words were harder to detect.",
"_____no_output_____"
],
[
"## Transformers\n\nTransformers were designed to address these two limitations of RNNs.\n\n<img src=\"https://miro.medium.com/max/2436/1*V2435M1u0tiSOz4nRBfl4g.png\" alt=\"Drawing\" style=\"width: 500px;\"/>\n\n_Taken from [3](http://jalammar.github.io/illustrated-transformer/)_\n\nIn each Encoder layer Transformer performs Self-Attention operation which detects relationships between all word embeddings in one matrix multiplication operation. \n\n<img src=\"https://miro.medium.com/max/2176/1*fL8arkEFVKA3_A7VBgapKA.gif\" alt=\"Drawing\" style=\"width: 500px;\"/>\n\n_Taken from [4](https://towardsdatascience.com/deconstructing-bert-part-2-visualizing-the-inner-workings-of-attention-60a16d86b5c1)_\n",
"_____no_output_____"
],
[
"## BERT Model\n\nBERT is a very large network with multiple layers of Transformers (12 for BERT-base, and 24 for BERT-large). The model is first pre-trained on large corpus of text data (WikiPedia + books) using un-superwised training (predicting masked words in a sentence). During pre-training the model absorbs significant level of language understanding.\n\n<img src=\"http://jalammar.github.io/images/bert-output-vector.png\" alt=\"Drawing\" style=\"width: 700px;\"/>\n\n_Taken from [5](http://jalammar.github.io/illustrated-bert/)_\n\nPre-trained network then can easily be fine-tuned to solve specific language task, like answering questions, or categorizing spam emails.\n\n<img src=\"http://jalammar.github.io/images/bert-classifier.png\" alt=\"Drawing\" style=\"width: 700px;\"/>\n\n_Taken from [5](http://jalammar.github.io/illustrated-bert/)_\n\nThe end-to-end training process of the stackoverflow question tagging model looks like this:\n\n\n",
"_____no_output_____"
],
[
"## What is Azure Machine Learning Service?\nAzure Machine Learning service is a cloud service that you can use to develop and deploy machine learning models. Using Azure Machine Learning service, you can track your models as you build, train, deploy, and manage them, all at the broad scale that the cloud provides.\n\n\n\n#### How can we use it for training machine learning models?\nTraining machine learning models, particularly deep neural networks, is often a time- and compute-intensive task. Once you've finished writing your training script and running on a small subset of data on your local machine, you will likely want to scale up your workload.\n\nTo facilitate training, the Azure Machine Learning Python SDK provides a high-level abstraction, the estimator class, which allows users to easily train their models in the Azure ecosystem. You can create and use an Estimator object to submit any training code you want to run on remote compute, whether it's a single-node run or distributed training across a GPU cluster.",
"_____no_output_____"
],
[
"## Connect To Workspace\n\nThe [workspace](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.workspace(class)?view=azure-ml-py) is the top-level resource for Azure Machine Learning, providing a centralized place to work with all the artifacts you create when you use Azure Machine Learning. The workspace holds all your experiments, compute targets, models, datastores, etc.\n\nYou can [open ml.azure.com](https://ml.azure.com) to access your workspace resources through a graphical user interface of **Azure Machine Learning studio**.\n\n\n\n**You will be asked to login in the next step. Use your Microsoft AAD credentials.**",
"_____no_output_____"
]
],
[
[
"from azureml.core import Workspace\n\nworkspace = Workspace.from_config()\nprint('Workspace name: ' + workspace.name, \n 'Azure region: ' + workspace.location, \n 'Subscription id: ' + workspace.subscription_id, \n 'Resource group: ' + workspace.resource_group, sep = '\\n')",
"_____no_output_____"
]
],
[
[
"## Create Compute Target\n\nA [compute target](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.computetarget?view=azure-ml-py) is a designated compute resource/environment where you run your training script or host your service deployment. This location may be your local machine or a cloud-based compute resource. Compute targets can be reused across the workspace for different runs and experiments. \n\nFor this tutorial, we will create an auto-scaling [Azure Machine Learning Compute](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute?view=azure-ml-py) cluster, which is a managed-compute infrastructure that allows the user to easily create a single or multi-node compute. To create the cluster, we need to specify the following parameters:\n\n- `vm_size`: The is the type of GPUs that we want to use in our cluster. For this tutorial, we will use **Standard_NC12s_v2 (NVIDIA P100) GPU Machines** .\n- `idle_seconds_before_scaledown`: This is the number of seconds before a node will scale down in our auto-scaling cluster. We will set this to **6000** seconds. \n- `min_nodes`: This is the minimum numbers of nodes that the cluster will have. To avoid paying for compute while they are not being used, we will set this to **0** nodes.\n- `max_modes`: This is the maximum number of nodes that the cluster will scale up to. Will will set this to **2** nodes.\n\n**When jobs are submitted to the cluster it takes approximately 5 minutes to allocate new nodes** ",
"_____no_output_____"
]
],
[
[
"from azureml.core.compute import AmlCompute, ComputeTarget\n\ncluster_name = 'p100cluster'\ncompute_config = AmlCompute.provisioning_configuration(vm_size='Standard_NC12s_v2', \n idle_seconds_before_scaledown=6000,\n min_nodes=0, \n max_nodes=2)\n\ncompute_target = ComputeTarget.create(workspace, cluster_name, compute_config)\ncompute_target.wait_for_completion(show_output=True)",
"_____no_output_____"
]
],
[
[
"To ensure our compute target was created successfully, we can check it's status.",
"_____no_output_____"
]
],
[
[
"compute_target.get_status().serialize()",
"_____no_output_____"
]
],
[
[
"#### If the compute target has already been created, then you (and other users in your workspace) can directly run this cell.",
"_____no_output_____"
]
],
[
[
"compute_target = workspace.compute_targets['p100cluster']",
"_____no_output_____"
]
],
[
[
"## Prepare Data Using Apache Spark\n\nTo train our model, we used the Stackoverflow data dump from [Stack exchange archive](https://archive.org/download/stackexchange). Since the Stackoverflow _posts_ dataset is 12GB, we prepared the data using [Apache Spark](https://spark.apache.org/) framework on a scalable Spark compute cluster in [Azure Databricks](https://azure.microsoft.com/en-us/services/databricks/). \n\nFor the purpose of this tutorial, we have processed the data ahead of time and uploaded it to an [Azure Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/) container. The full data processing notebook can be found in the _spark_ folder.\n\n* **ACTION**: Open and explore [data preparation notebook](spark/stackoverflow-data-prep.ipynb).\n",
"_____no_output_____"
],
[
"## Register Datastore",
"_____no_output_____"
],
[
"A [Datastore](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py) is used to store connection information to a central data storage. This allows you to access your storage without having to hard code this (potentially confidential) information into your scripts. \n\nIn this tutorial, the data was been previously prepped and uploaded into a central [Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/) container. We will register this container into our workspace as a datastore using a [shared access signature (SAS) token](https://docs.microsoft.com/en-us/azure/storage/common/storage-sas-overview). ",
"_____no_output_____"
]
],
[
[
"from azureml.core import Datastore, Dataset\n\ndatastore_name = 'tfworld'\ncontainer_name = 'azureml-blobstore-7c6bdd88-21fa-453a-9c80-16998f02935f'\naccount_name = 'tfworld6818510241'\nsas_token = '?sv=2019-02-02&ss=bfqt&srt=sco&sp=rl&se=2021-01-01T06:07:44Z&st=2020-01-11T22:00:44Z&spr=https&sig=geV1mc46gEv9yLBsWjnlJwij%2Blg4qN53KFyyK84tn3Q%3D'\n\ndatastore = Datastore.register_azure_blob_container(workspace=workspace, \n datastore_name=datastore_name, \n container_name=container_name,\n account_name=account_name, \n sas_token=sas_token)",
"_____no_output_____"
]
],
[
[
"#### If the datastore has already been registered, then you (and other users in your workspace) can directly run this cell.",
"_____no_output_____"
]
],
[
[
"datastore = workspace.datastores['tfworld']",
"_____no_output_____"
]
],
[
[
"#### What if my data wasn't already hosted remotely?\nAll workspaces also come with a blob container which is registered as a default datastore. This allows you to easily upload your own data to a remote storage location. You can access this datastore and upload files as follows:\n```\ndatastore = workspace.get_default_datastore()\nds.upload(src_dir='<LOCAL-PATH>', target_path='<REMOTE-PATH>')\n```\n",
"_____no_output_____"
],
[
"## Register Dataset\n\nAzure Machine Learning service supports first class notion of a Dataset. A [Dataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.dataset.dataset?view=azure-ml-py) is a resource for exploring, transforming and managing data in Azure Machine Learning. The following Dataset types are supported:\n\n* [TabularDataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.tabulardataset?view=azure-ml-py) represents data in a tabular format created by parsing the provided file or list of files.\n\n* [FileDataset](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.filedataset?view=azure-ml-py) references single or multiple files in datastores or from public URLs.\n\nWe can use visual tools in Azure ML studio to register and explore dataset. In this workshop we will skip this step to save time. After the workshop please explore visual way of creating dataset as your homework. Use the guide below as guiding steps. \n\n* **Homework**: After workshop follow [create-dataset](images/create-dataset.ipynb) guide to create Tabular Dataset from our training data using visual tools in studio.",
"_____no_output_____"
],
[
"#### Use created dataset in code",
"_____no_output_____"
]
],
[
[
"from azureml.core import Dataset\n\n# Get a dataset by name\ntabular_ds = Dataset.get_by_name(workspace=workspace, name='Stackoverflow dataset')\n\n# Load a TabularDataset into pandas DataFrame\ndf = tabular_ds.to_pandas_dataframe()\n\ndf.head(10)",
"_____no_output_____"
]
],
[
[
"## Register Dataset using SDK\n\nIn addition to UI we can register datasets using SDK. In this workshop we will register second type of Datasets using code - File Dataset. File Dataset allows specific folder in our datastore that contains our data files to be registered as a Dataset.\n\nThere is a folder within our datastore called **azure-service-data** that contains all our training and testing data. We will register this as a dataset.",
"_____no_output_____"
]
],
[
[
"azure_dataset = Dataset.File.from_files(path=(datastore, 'azure-service-classifier/data'))\n\nazure_dataset = azure_dataset.register(workspace=workspace,\n name='Azure Services Dataset',\n description='Dataset containing azure related posts on Stackoverflow')",
"_____no_output_____"
]
],
[
[
"#### If the dataset has already been registered, then you (and other users in your workspace) can directly run this cell.",
"_____no_output_____"
]
],
[
[
"azure_dataset = workspace.datasets['Azure Services Dataset']",
"_____no_output_____"
]
],
[
[
"## Explore Training Code",
"_____no_output_____"
],
[
"In this workshop the training code is provided in [train.py](./train.py) and [model.py](./model.py) files. The model is based on popular [huggingface/transformers](https://github.com/huggingface/transformers) libary. Transformers library provides performant implementation of BERT model with high level and easy to use APIs based on Tensorflow 2.0.\n\n\n\n* **ACTION**: Explore _train.py_ and _model.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)\n* NOTE: You can also explore the files using Jupyter or Jupyter Lab UI.",
"_____no_output_____"
],
[
"## Test Locally\n\nLet's try running the script locally to make sure it works before scaling up to use our compute cluster. To do so, you will need to install the transformers libary.",
"_____no_output_____"
]
],
[
[
"%pip install transformers==2.0.0",
"_____no_output_____"
]
],
[
[
"We have taken a small partition of the dataset and included it in this repository. Let's take a quick look at the format of the data.",
"_____no_output_____"
]
],
[
[
"data_dir = './data'",
"_____no_output_____"
],
[
"import os \nimport pandas as pd\ndata = pd.read_csv(os.path.join(data_dir, 'train.csv'), header=None)\ndata.head(5)",
"_____no_output_____"
]
],
[
[
"Now we know what the data looks like, let's test out our script!",
"_____no_output_____"
]
],
[
[
"import sys\n!{sys.executable} train.py --data_dir {data_dir} --max_seq_length 128 --batch_size 16 --learning_rate 3e-5 --steps_per_epoch 5 --num_epochs 1 --export_dir ../outputs/model",
"_____no_output_____"
]
],
[
[
"## Homework: Debugging in TensorFlow 2.0 Eager Mode\n\nEager mode is new feature in TensorFlow 2.0 which makes understanding and debugging models easy. You can use VS Code Remote feature to connect to Notebook VM and perform debugging in the cloud environment.\n\n#### More info: Configuring VS Code Remote connection to Notebook VM\n\n* Homework: Install [Microsoft VS Code](https://code.visualstudio.com/) on your local machine.\n\n* Homework: Follow this [configuration guide](https://github.com/danielsc/azureml-debug-training/blob/master/Setting%20up%20VSCode%20Remote%20on%20an%20AzureML%20Notebook%20VM.md) to setup VS Code Remote connection to Notebook VM.",
"_____no_output_____"
],
[
"On a CPU machine training on a full dataset will take approximatly 1.5 hours. Although it's a small dataset, it still takes a long time. Let's see how we can speed up the training by using latest NVidia V100 GPUs in the Azure cloud. ",
"_____no_output_____"
],
[
"## Perform Experiment\n\nNow that we have our compute target, dataset, and training script working locally, it is time to scale up so that the script can run faster. We will start by creating an [experiment](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.experiment.experiment?view=azure-ml-py). An experiment is a grouping of many runs from a specified script. All runs in this tutorial will be performed under the same experiment. ",
"_____no_output_____"
]
],
[
[
"from azureml.core import Experiment\n\nexperiment_name = 'azure-service-classifier' \nexperiment = Experiment(workspace, name=experiment_name)",
"_____no_output_____"
]
],
[
[
"#### Create TensorFlow Estimator\n\nThe Azure Machine Learning Python SDK Estimator classes allow you to easily construct run configurations for your experiments. They allow you too define parameters such as the training script to run, the compute target to run it on, framework versions, additional package requirements, etc. \n\nYou can also use a generic [Estimator](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.estimator.estimator?view=azure-ml-py) to submit training scripts that use any learning framework you choose.\n\nFor popular libaries like PyTorch and Tensorflow you can use their framework specific estimators. We will use the [TensorFlow Estimator](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.dnn.tensorflow?view=azure-ml-py) for our experiment.",
"_____no_output_____"
]
],
[
[
"from azureml.train.dnn import TensorFlow\n\nestimator1 = TensorFlow(source_directory='.',\n entry_script='train_logging.py',\n compute_target=compute_target,\n script_params = {\n '--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),\n '--max_seq_length': 128,\n '--batch_size': 32,\n '--learning_rate': 3e-5,\n '--steps_per_epoch': 150,\n '--num_epochs': 3,\n '--export_dir':'./outputs/model'\n },\n framework_version='2.0',\n use_gpu=True,\n pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])",
"_____no_output_____"
]
],
[
[
"A quick description for each of the parameters we have just defined:\n\n- `source_directory`: This specifies the root directory of our source code. \n- `entry_script`: This specifies the training script to run. It should be relative to the source_directory.\n- `compute_target`: This specifies to compute target to run the job on. We will use the one created earlier.\n- `script_params`: This specifies the input parameters to the training script. Please note:\n\n 1) *azure_dataset.as_named_input('azureservicedata').as_mount()* mounts the dataset to the remote compute and provides the path to the dataset on our datastore. \n \n 2) All outputs from the training script must be outputted to an './outputs' directory as this is the only directory that will be saved to the run. \n \n \n- `framework_version`: This specifies the version of TensorFlow to use. Use Tensorflow.get_supported_verions() to see all supported versions.\n- `use_gpu`: This will use the GPU on the compute target for training if set to True.\n- `pip_packages`: This allows you to define any additional libraries to install before training.",
"_____no_output_____"
],
[
"#### 1) Submit a Run \n\nWe can now train our model by submitting the estimator object as a [run](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.run.run?view=azure-ml-py).",
"_____no_output_____"
]
],
[
[
"run1 = experiment.submit(estimator1)",
"_____no_output_____"
]
],
[
[
"We can view the current status of the run and stream the logs from within the notebook.",
"_____no_output_____"
]
],
[
[
"from azureml.widgets import RunDetails\nRunDetails(run1).show()",
"_____no_output_____"
]
],
[
[
"You cancel a run at anytime which will stop the run and scale down the nodes in the compute target.",
"_____no_output_____"
]
],
[
[
"run1.cancel()",
"_____no_output_____"
]
],
[
[
"While we wait for the run to complete, let's go over how a Run is executed in Azure Machine Learning.\n\n",
"_____no_output_____"
],
[
"#### 2) Monitoring metrics with Azure ML SDK \n\nTo monitor performance of our model we log those metrics using a few lines of code in our training script:\n\n```python\n# 1) Import SDK Run object\nfrom azureml.core.run import Run\n\n# 2) Get current service context\nrun = Run.get_context()\n\n# 3) Log the metrics that we want\nrun.log('val_accuracy', float(logs.get('val_accuracy')))\nrun.log('accuracy', float(logs.get('accuracy')))\n```",
"_____no_output_____"
],
[
"#### 3) Monitoring metrics with Tensorboard\n\nTensorboard is a popular Deep Learning Training visualization tool and it's built-in into TensorFlow framework. We can easily add tracking of the metrics in Tensorboard format by adding Tensorboard callback to the **fit** function call.\n```python\n # Add callback to record Tensorboard events\n model.fit(train_dataset, epochs=FLAGS.num_epochs, \n steps_per_epoch=FLAGS.steps_per_epoch, validation_data=valid_dataset, \n callbacks=[\n AmlLogger(),\n tf.keras.callbacks.TensorBoard(update_freq='batch')]\n )\n```\n\n* **ACTION**: Explore _train_logging.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)\n\n#### Launch Tensorboard\nAzure ML service provides built-in integration with Tensorboard through **tensorboard** package.\n\nWhile the run is in progress (or after it has completed), we can start Tensorboard with the run as its target, and it will begin streaming logs.",
"_____no_output_____"
]
],
[
[
"from azureml.tensorboard import Tensorboard\n\n# The Tensorboard constructor takes an array of runs, so be sure and pass it in as a single-element array here\ntb = Tensorboard([run1])\n\n# If successful, start() returns a string with the URI of the instance.\ntb.start()",
"_____no_output_____"
]
],
[
[
"#### Stop Tensorboard\nWhen you're done, make sure to call the stop() method of the Tensorboard object, or it will stay running even after your job completes.",
"_____no_output_____"
]
],
[
[
"tb.stop()",
"_____no_output_____"
]
],
[
[
"## Check the model performance\n\nLast training run produced model of decent accuracy. Let's test it out and see what it does. First, let's check what files our latest training run produced and download the model files.\n\n#### Download model files",
"_____no_output_____"
]
],
[
[
"run1.get_file_names()",
"_____no_output_____"
],
[
"run1.download_files(prefix='outputs/model')\n\n# If you haven't finished training the model then just download pre-made model from datastore\ndatastore.download('./',prefix=\"azure-service-classifier/model\")",
"_____no_output_____"
]
],
[
[
"#### Instantiate the model\n\nNext step is to import our model class and instantiate fine-tuned model from the model file.",
"_____no_output_____"
]
],
[
[
"from model import TFBertForMultiClassification\nfrom transformers import BertTokenizer\nimport tensorflow as tf\ndef encode_example(text, max_seq_length):\n # Encode inputs using tokenizer\n inputs = tokenizer.encode_plus(\n text,\n add_special_tokens=True,\n max_length=max_seq_length\n )\n input_ids, token_type_ids = inputs[\"input_ids\"], inputs[\"token_type_ids\"]\n # The mask has 1 for real tokens and 0 for padding tokens. Only real tokens are attended to.\n attention_mask = [1] * len(input_ids)\n # Zero-pad up to the sequence length.\n padding_length = max_seq_length - len(input_ids)\n input_ids = input_ids + ([0] * padding_length)\n attention_mask = attention_mask + ([0] * padding_length)\n token_type_ids = token_type_ids + ([0] * padding_length)\n \n return input_ids, attention_mask, token_type_ids\n \nlabels = ['azure-web-app-service', 'azure-storage', 'azure-devops', 'azure-virtual-machine', 'azure-functions']\n# Load model and tokenizer\nloaded_model = TFBertForMultiClassification.from_pretrained('azure-service-classifier/model', num_labels=len(labels))\ntokenizer = BertTokenizer.from_pretrained('bert-base-cased')\nprint(\"Model loaded from disk.\")",
"_____no_output_____"
]
],
[
[
"#### Define prediction function\n\nUsing the model object we can interpret new questions and predict what Azure service they talk about. To do that conveniently we'll define **predict** function.",
"_____no_output_____"
]
],
[
[
"# Prediction function\ndef predict(question):\n input_ids, attention_mask, token_type_ids = encode_example(question, 128)\n predictions = loaded_model.predict({\n 'input_ids': tf.convert_to_tensor([input_ids], dtype=tf.int32),\n 'attention_mask': tf.convert_to_tensor([attention_mask], dtype=tf.int32),\n 'token_type_ids': tf.convert_to_tensor([token_type_ids], dtype=tf.int32)\n })\n prediction = labels[predictions[0].argmax().item()]\n probability = predictions[0].max()\n result = {\n 'prediction': str(labels[predictions[0].argmax().item()]),\n 'probability': str(predictions[0].max())\n }\n print('Prediction: {}'.format(prediction))\n print('Probability: {}'.format(probability))",
"_____no_output_____"
]
],
[
[
"#### Experiment with our new model\n\nNow we can easily test responses of the model to new inputs. \n* **ACTION**: Invent your own input for one of the 5 services our model understands: 'azure-web-app-service', 'azure-storage', 'azure-devops', 'azure-virtual-machine', 'azure-functions'.",
"_____no_output_____"
]
],
[
[
"# Route question\npredict(\"How can I specify Service Principal in devops pipeline when deploying virtual machine\")",
"_____no_output_____"
],
[
"# Now more tricky case - the opposite\npredict(\"How can virtual machine trigger devops pipeline\")",
"_____no_output_____"
]
],
[
[
"## Distributed Training Across Multiple GPUs\n\nDistributed training allows us to train across multiple nodes if your cluster allows it. Azure Machine Learning service helps manage the infrastructure for training distributed jobs. All we have to do is add the following parameters to our estimator object in order to enable this:\n\n- `node_count`: The number of nodes to run this job across. Our cluster has a maximum node limit of 2, so we can set this number up to 2.\n- `process_count_per_node`: The number of processes to enable per node. The nodes in our cluster have 2 GPUs each. We will set this value to 2 which will allow us to distribute the load on both GPUs. Using multi-GPUs nodes is benefitial as communication channel bandwidth on local machine is higher.\n- `distributed_training`: The backend to use for our distributed job. We will be using an MPI (Message Passing Interface) backend which is used by Horovod framework.\n\nWe use [Horovod](https://github.com/horovod/horovod), which is a framework that allows us to easily modifying our existing training script to be run across multiple nodes/GPUs. The distributed training script is saved as *train_horovod.py*.\n\n* **ACTION**: Explore _train_horovod.py_ using [Azure ML studio > Notebooks tab](images/azuremlstudio-notebooks-explore.png)",
"_____no_output_____"
],
[
"We can submit this run in the same way that we did with the others, but with the additional parameters.",
"_____no_output_____"
]
],
[
[
"from azureml.train.dnn import Mpi\n\nestimator3 = TensorFlow(source_directory='./',\n entry_script='train_horovod.py',compute_target=compute_target,\n script_params = {\n '--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),\n '--max_seq_length': 128,\n '--batch_size': 32,\n '--learning_rate': 3e-5,\n '--steps_per_epoch': 150,\n '--num_epochs': 3,\n '--export_dir':'./outputs/model'\n },\n framework_version='2.0',\n node_count=1,\n distributed_training=Mpi(process_count_per_node=2),\n use_gpu=True,\n pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])\n\nrun3 = experiment.submit(estimator3)",
"_____no_output_____"
]
],
[
[
"Once again, we can view the current details of the run. ",
"_____no_output_____"
]
],
[
[
"from azureml.widgets import RunDetails\nRunDetails(run3).show()",
"_____no_output_____"
]
],
[
[
"Once the run completes note the time it took. It should be around 5 minutes. As you can see, by moving to the cloud GPUs and using distibuted training we managed to reduce training time of our model from more than an hour to 5 minutes. This greatly improves speed of experimentation and innovation.",
"_____no_output_____"
],
[
"## Tune Hyperparameters Using Hyperdrive\n\nSo far we have been putting in default hyperparameter values, but in practice we would need tune these values to optimize the performance. Azure Machine Learning service provides many methods for tuning hyperparameters using different strategies.\n\nThe first step is to choose the parameter space that we want to search. We have a few choices to make here :\n\n- **Parameter Sampling Method**: This is how we select the combinations of parameters to sample. Azure Machine Learning service offers [RandomParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.randomparametersampling?view=azure-ml-py), [GridParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.gridparametersampling?view=azure-ml-py), and [BayesianParameterSampling](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.bayesianparametersampling?view=azure-ml-py). We will use the `GridParameterSampling` method.\n- **Parameters To Search**: We will be searching for optimal combinations of `learning_rate` and `num_epochs`.\n- **Parameter Expressions**: This defines the [functions that can be used to describe a hyperparameter search space](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.parameter_expressions?view=azure-ml-py), which can be discrete or continuous. We will be using a `discrete set of choices`.\n\nThe following code allows us to define these options.",
"_____no_output_____"
]
],
[
[
"from azureml.train.hyperdrive import GridParameterSampling\nfrom azureml.train.hyperdrive.parameter_expressions import choice\n\n\nparam_sampling = GridParameterSampling( {\n '--learning_rate': choice(3e-5, 3e-4),\n '--num_epochs': choice(3, 4)\n }\n)",
"_____no_output_____"
]
],
[
[
"The next step is to a define how we want to measure our performance. We do so by specifying two classes:\n\n- **[PrimaryMetricGoal](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.primarymetricgoal?view=azure-ml-py)**: We want to `MAXIMIZE` the `val_accuracy` that is logged in our training script.\n- **[BanditPolicy](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.banditpolicy?view=azure-ml-py)**: A policy for early termination so that jobs which don't show promising results will stop automatically.",
"_____no_output_____"
]
],
[
[
"from azureml.train.hyperdrive import BanditPolicy\nfrom azureml.train.hyperdrive import PrimaryMetricGoal\n\nprimary_metric_name='val_accuracy'\nprimary_metric_goal=PrimaryMetricGoal.MAXIMIZE\n\nearly_termination_policy = BanditPolicy(slack_factor = 0.1, evaluation_interval=1, delay_evaluation=2)",
"_____no_output_____"
]
],
[
[
"We define an estimator as usual, but this time without the script parameters that we are planning to search.",
"_____no_output_____"
]
],
[
[
"estimator4 = TensorFlow(source_directory='./',\n entry_script='train_logging.py',\n compute_target=compute_target,\n script_params = {\n '--data_dir': azure_dataset.as_named_input('azureservicedata').as_mount(),\n '--max_seq_length': 128,\n '--batch_size': 32,\n '--steps_per_epoch': 150,\n '--export_dir':'./outputs/model',\n },\n framework_version='2.0',\n use_gpu=True,\n pip_packages=['transformers==2.0.0', 'azureml-dataprep[fuse,pandas]==1.1.29'])",
"_____no_output_____"
]
],
[
[
"Finally, we add all our parameters in a [HyperDriveConfig](https://docs.microsoft.com/en-us/python/api/azureml-train-core/azureml.train.hyperdrive.hyperdriveconfig?view=azure-ml-py) class and submit it as a run. ",
"_____no_output_____"
]
],
[
[
"from azureml.train.hyperdrive import HyperDriveConfig\n\nhyperdrive_run_config = HyperDriveConfig(estimator=estimator4,\n hyperparameter_sampling=param_sampling, \n policy=early_termination_policy,\n primary_metric_name=primary_metric_name, \n primary_metric_goal=PrimaryMetricGoal.MAXIMIZE,\n max_total_runs=10,\n max_concurrent_runs=2)\n\nrun4 = experiment.submit(hyperdrive_run_config)",
"_____no_output_____"
]
],
[
[
"When we view the details of our run this time, we will see information and metrics for every run in our hyperparameter tuning.",
"_____no_output_____"
]
],
[
[
"from azureml.widgets import RunDetails\nRunDetails(run4).show()",
"_____no_output_____"
]
],
[
[
"We can retrieve the best run based on our defined metric.",
"_____no_output_____"
]
],
[
[
"best_run = run4.get_best_run_by_primary_metric()",
"_____no_output_____"
]
],
[
[
"## Register Model\n\nA registered [model](https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.model(class)?view=azure-ml-py) is a reference to the directory or file that make up your model. After registering a model, you and other people in your workspace can easily gain access to and deploy your model without having to run the training script again. \n\nWe need to define the following parameters to register a model:\n\n- `model_name`: The name for your model. If the model name already exists in the workspace, it will create a new version for the model.\n- `model_path`: The path to where the model is stored. In our case, this was the *export_dir* defined in our estimators.\n- `description`: A description for the model.\n\nLet's register the best run from our hyperparameter tuning.",
"_____no_output_____"
]
],
[
[
"model = best_run.register_model(model_name='azure-service-classifier', \n model_path='./outputs/model',\n datasets=[('train, test, validation data', azure_dataset)],\n description='BERT model for classifying azure services on stackoverflow posts.')",
"_____no_output_____"
]
],
[
[
"We have registered the model with Dataset reference. \n* **ACTION**: Check dataset to model link in **Azure ML studio > Datasets tab > Azure Service Dataset**.",
"_____no_output_____"
],
[
"In the [next tutorial](), we will perform inferencing on this model and deploy it to a web service.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
c517ca3c7ea1d9bc999b51712233bae0586d274a
| 14,037 |
ipynb
|
Jupyter Notebook
|
Chapter_00.ipynb
|
hmanikantan/Python-Repo
|
dffd63c586b4db6238e385be6bb4dc58273799ee
|
[
"MIT"
] | 4 |
2021-07-13T06:54:06.000Z
|
2021-07-13T18:25:35.000Z
|
Chapter_00.ipynb
|
hmanikantan/Python-Repo
|
dffd63c586b4db6238e385be6bb4dc58273799ee
|
[
"MIT"
] | null | null | null |
Chapter_00.ipynb
|
hmanikantan/Python-Repo
|
dffd63c586b4db6238e385be6bb4dc58273799ee
|
[
"MIT"
] | 2 |
2020-09-30T17:59:39.000Z
|
2022-01-23T03:39:12.000Z
| 72.73057 | 1,074 | 0.717746 |
[
[
[
"# Introduction\n© Harishankar Manikantan, maintained on GitHub at [hmanikantan/ECH60](https://github.com/hmanikantan/ECH60) and published under an [MIT license](https://github.com/hmanikantan/ECH60/blob/master/LICENSE).\n\nReturn to [Course Home Page](https://hmanikantan.github.io/ECH60/)\n",
"_____no_output_____"
],
[
"**[Context and Scope](#scope) <br>**\n\n**[Getting used to Python](#install)**\n* [Installing and Using Python](#start)\n* [Useful tips](#tips)",
"_____no_output_____"
],
[
"<a id='scope'></a>\n\n\n## Context and Scope\n\nThis set of tutorials are written at an introductory level for an engineering or physical sciences major. It is ideal for someone who has completed college level courses in linear algebra, calculus and differential equations. While prior experience with programming is a certain advantage, it is not expected. At UC Davis, this is aimed at sophomore level Chemical and Biochemical Engineers and Materials Scientists: examples and the language used here might reflect this. At the same time, this is not meant to be an exhaustive course in Python or in numerical methods.\n\nThe objective of the module is to get the reader to appreciate and apply Python to basic scientific calculations. While computational efficiency and succinct programming are certainly factors that become important to advanced coders, the focus here is on learning the methods. Brevity will often be forsaken for clarity in what follows. The goal is to flatten the learning curve as much as possible for a beginner.\n\nIn the same vein, most of the 'application' chapters (fitting, root finding, calculus and differential equations) introduces classic numerical methods built from first principles but then also provides the inbuilt Python routine to do the same. These 'black-box' approaches are often more efficient because they are written by experts in the most efficient and optimal manner. The hope is that the reader learns and appreciates the methods and the algorithms behind these approaches, while also learning to use the easiest and most efficient tools to get the job done.\n\nThese are casual notes based on a course taught at UC Davis and are certainly not free of errors. Typos and coding gaffes are sure to have escaped my attention, and I take full responsibility for errors. For those comfortable with GitHub, I welcome pull requests for modifications. Or just send me an [email](mailto:[email protected]) with any mistakes you spot, and I will be greateful. Outside of technical accuracy, I have taken an approach that favors a pedagogic development of topics, one that I hoped would least intimidate an engineer in training with no prior experience in coding. Criticism and feedback on stylistic changes in this spirit are also welcome. \n\nI recommend the following wonderful books that have guided aspects of the course that I teach with these notes. \n* [A Student's Guide to Python for Physical Modeling, Jesse M. Kinder & Philip Nelson, Princeton University Press](https://press.princeton.edu/books/hardcover/9780691180564/a-students-guide-to-python-for-physical-modeling)\n* [Numerical Methods for Engineers and Scientists, Amos Gilat & Vish Subramaniam, Wiley](https://www.wiley.com/en-us/Numerical+Methods+for+Engineers+and+Scientists%2C+3rd+Edition-p-9781118554937)\n* [Numerical Methods in Engineering with Python 3, Jaan Kiusalaas, Cambridge University Press](https://doi.org/10.1017/CBO9781139523899)\n\nWhile any of these books provide a fantastic introduction to the topic, I believe that interactive tutorials using the Jupyter framework provide an engaging complement to learning numerical methods. Yet I was unable to find a set of pedagogic and interactive code notebooks that covered the range of topics suitable for this level of instruction. I have hoped to fill this gap. If you are new to coding, the best way to learn is to download these notebooks from the GitHub repository (linked at the course [home page](https://hmanikantan.github.io/ECH60/)), and edit and execute every code cell in these chapters as you read through them. Details on installing and using Python are below.\n\nMy ECH 60 students beta tested these tutorials, and their learning styles, feedback and comments crafted the structure of this series. And finally, the world of Python is a fantastic testament to the power of open-source science and learning. I thank the countless selfless nameless strangers whose stackoverflow comments have informed me, and whose coding styles have inadvertently creeped in to my interpretation of the code and style in what follows. And I thank the generous online notes of [John Kitchin](https://kitchingroup.cheme.cmu.edu/pycse/pycse.html), [Patrick Walls](https://www.math.ubc.ca/~pwalls/math-python/), [Vivi Andasari](http://people.bu.edu/andasari/courses/numericalpython/python.html), [Charles Jekel](https://github.com/cjekel/Introduction-to-Python-Numerical-Analysis-for-Engineers-and-Scientist), and [Jeffrey Kantor](https://github.com/jckantor) whose works directly or indirectly inspired and influenced what follows. I am happy to contribute to this collective knowledge base, free for anyone to adapt, build on, and make it their own.\n",
"_____no_output_____"
],
[
"<a id='install'></a>\n\n\n## Getting Used to Python\n\nPython is a popular, powerful and free prgramming language that is rapidly becoming one of [the most widely used computational tools](https://stackoverflow.blog/2017/09/06/incredible-growth-python/) in science and engineering. Python is notable for its minimalist syntax, clear and logical flow of code, efficient organization, readily and freely available 'plug and play' modules for every kind of advanced scientific computation, and the massive online community of support. This makes Python easy to learn for beginners, and extremely convenient to adapt for those transitioning from other languages.\n\n<a id='start'></a>\n\n\n### Installing and Using Python \n\nPython is free to download and use. The [Anaconda distribution](https://www.anaconda.com) is a user-friendly way to get Python on your computer. Anaconda is free and easy to install on all platforms. It installs the Python language, and related useful packages like Jupyter and Spyder.\n\n#### Jupyter \nThe Jupyter environment allows interactive computations and runs on any browser. This file you are reading is written using Jupyter, and each such file is saved with a `.ipynb` extension. To open an ipynb file, first open Jupyter from the Anaconda launch screen. Once you have Jupyter up and runnning, navigate to the folder where you saved the file and double click to open. Alternatively, you can launch Jupyter by typing `jupyter notebook` in your terminal prompt. Note that you can only open files after you launch Jupyter and navigate to the folder containing your ipynb file. You cannot simply double click, or use a 'right click and open with' option.\n\nJupyter allows us to write and edit plain text (like the one you are reading) and code. This paragraph and the ones above are 'mark down' text: meaning, Jupyter treats them as plain text. From within Jupyter, double click anywhere on the text to go into 'edit' mode. When you are done changing anything, hit `shift+enter` to exit to the 'view' mode. \n\nYou can toggle between markdown and code using the drop down in the menu above. Code cells look like the following",
"_____no_output_____"
]
],
[
[
"print('Hello')",
"Hello\n"
]
],
[
[
"Single click on a code cell to select it, edit it, and hit `shift+enter` to execute that bit of code. For example, the following code cell evaluates the sum of two numbers when you execute it. Try it, type in any two numbers, see what happens.",
"_____no_output_____"
]
],
[
[
"# add two numbers\n2+40",
"_____no_output_____"
]
],
[
[
"The `#` sign is useful to write comments in Python, and are not executed.\n\nPlay around with all editable code cells in these tutorials so you get comfortable. The more you practice, the faster you will get comfortable with coding and Python.\n\nJupyter allows LaTeX as well in the markdown cells: so you can write things like $\\alpha+i \\sqrt{\\beta}=e^{i\\theta}$. You can also play around with fonts, colors, sizes, hyperlinks, and text organization. This makes Jupyter a great environment for teaching, learning, tutorials, assignments, and academic reports. This entire course is written and tested in the Jupyter environment.",
"_____no_output_____"
],
[
"#### Spyder\n\nAn integrated development environment (IDE) like Spyder is more apt for longer projects. Spyder has features like variable explorer, script editor, live debugging, history log, and more. For those comfortable with Matlab or R, adapting to Spyder is an easy learning curve. The ipynb files will not open in a usable manner in Spyder (or any other Python IDE) as it contains markdown text in addition to code. However, every bit of code that we will learn in what follows works in Spyder or a similar IDE. When using Spyder, save the code as 'script' files with a `.py` extension. This is the traditional or standard Python format: just code, no markdown.\n\nAnother big advantage with `.py` files is modularity: bit of code written in one file can be easily accessed in another. This makes the traditional `.py` Python format more suitable for large-scale and collaborative projects. Nevertheless, for pedagogic reasons, we will continue with Jupyter notebooks and the `.ipynb` files for this course: as you learn Python, you are heavily encouraged to get comfortable with and port all the code you develop into Spyder.\n\n#### Python, more generally\n\nOf course, Anaconda (and it's inbuilt environments like Jupyter and Spyder) are not the only ways to interact with Python. You can install just the Python language directly from [Python.org](https://www.python.org/downloads/), write a bit of Python code in any text editor, save it as a `.py` file, and run it on your terminal using `python filename.py`. Python is an _interpreted_ language, meaning you do not need to compile it to execute it (unlike C, C++, Fortran etc) and you can run the scripts directly.\n",
"_____no_output_____"
],
[
"<a id='tips'></a>\n\n\n### Useful Tips\n\nWhether you are a beginner to coding or a seasoned coder transitioning from another language, the following (non-exhaustive) tips are useful to bear in mind as you learn Python:\n\n* Blocks of code in Python are identified by indentation. We will see this when we start with loops and conditional and functions in Chapter 1: indents (and a preliminary colon) identify lines of code that go together. As you learn to go through and Python code, it is good practice to ensure an 'indentation discipline'. That's the only way Python knows which bits of code belong together.\n\n* All but the most basic Python operations will need imported _modules_. Modules are collections of code written in an efficient manner, and are easily 'loaded' into your code by using the `import` statement. For example, a common module that you will find yourself using in pretty much every engineering code is `numpy` (Chapter 1), which you would import using the line `import numpy`. This doesn't have to be in the beginning of the code, as long as it is executed before you use something that belongs to `numpy`. \n\n* Individual code cells in Jupyter are executed independent of the rest of the notebook. So, make sure to execute the `import` line for necessary modules before you execute a code cell that needs that module or you will see an error.\n\n* If you need to import a data file or an image, Python looks for that file in the current folder unless you provide a full path. The same goes when you save an image or export a data file: the exported file is saved in the current directly unless explicitly stated.\n\n* Notebook files with an `.ipynb` extension can only be opened, edited or renamed from within the Jupyter framework. Opening these files in a text editor or another application, even when possible, does not display the markdown or code in a comprehensible manner.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
c517ccf9e7e87c739b1d777e41b98243a8b59d60
| 84,615 |
ipynb
|
Jupyter Notebook
|
assignment1/softmax.ipynb
|
lumialengine/CS231n
|
6b42e069b6f1ee7ee5424afa74844fc5d23c4c59
|
[
"MIT"
] | 4 |
2018-01-06T08:24:48.000Z
|
2019-01-14T11:52:22.000Z
|
assignment1/softmax.ipynb
|
lumialengine/CS231n
|
6b42e069b6f1ee7ee5424afa74844fc5d23c4c59
|
[
"MIT"
] | null | null | null |
assignment1/softmax.ipynb
|
lumialengine/CS231n
|
6b42e069b6f1ee7ee5424afa74844fc5d23c4c59
|
[
"MIT"
] | null | null | null | 209.962779 | 69,062 | 0.883791 |
[
[
[
"# Softmax exercise\n\n*Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the [assignments page](http://vision.stanford.edu/teaching/cs231n/assignments.html) on the course website.*\n\nThis exercise is analogous to the SVM exercise. You will:\n\n- implement a fully-vectorized **loss function** for the Softmax classifier\n- implement the fully-vectorized expression for its **analytic gradient**\n- **check your implementation** with numerical gradient\n- use a validation set to **tune the learning rate and regularization** strength\n- **optimize** the loss function with **SGD**\n- **visualize** the final learned weights\n",
"_____no_output_____"
]
],
[
[
"import random\nimport numpy as np\nfrom cs231n.data_utils import load_CIFAR10\nimport matplotlib.pyplot as plt\n\nfrom __future__ import print_function\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n# for auto-reloading extenrnal modules\n# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000, num_dev=500):\n \"\"\"\n Load the CIFAR-10 dataset from disk and perform preprocessing to prepare\n it for the linear classifier. These are the same steps as we used for the\n SVM, but condensed to a single function. \n \"\"\"\n # Load the raw CIFAR-10 data\n cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'\n X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)\n \n # subsample the data\n mask = list(range(num_training, num_training + num_validation))\n X_val = X_train[mask]\n y_val = y_train[mask]\n mask = list(range(num_training))\n X_train = X_train[mask]\n y_train = y_train[mask]\n mask = list(range(num_test))\n X_test = X_test[mask]\n y_test = y_test[mask]\n mask = np.random.choice(num_training, num_dev, replace=False)\n X_dev = X_train[mask]\n y_dev = y_train[mask]\n \n # Preprocessing: reshape the image data into rows\n X_train = np.reshape(X_train, (X_train.shape[0], -1))\n X_val = np.reshape(X_val, (X_val.shape[0], -1))\n X_test = np.reshape(X_test, (X_test.shape[0], -1))\n X_dev = np.reshape(X_dev, (X_dev.shape[0], -1))\n \n # Normalize the data: subtract the mean image\n mean_image = np.mean(X_train, axis = 0)\n X_train -= mean_image\n X_val -= mean_image\n X_test -= mean_image\n X_dev -= mean_image\n \n # add bias dimension and transform into columns\n X_train = np.hstack([X_train, np.ones((X_train.shape[0], 1))])\n X_val = np.hstack([X_val, np.ones((X_val.shape[0], 1))])\n X_test = np.hstack([X_test, np.ones((X_test.shape[0], 1))])\n X_dev = np.hstack([X_dev, np.ones((X_dev.shape[0], 1))])\n \n return X_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev\n\n\n# Invoke the above function to get our data.\nX_train, y_train, X_val, y_val, X_test, y_test, X_dev, y_dev = get_CIFAR10_data()\nprint('Train data shape: ', X_train.shape)\nprint('Train labels shape: ', y_train.shape)\nprint('Validation data shape: ', X_val.shape)\nprint('Validation labels shape: ', y_val.shape)\nprint('Test data shape: ', X_test.shape)\nprint('Test labels shape: ', y_test.shape)\nprint('dev data shape: ', X_dev.shape)\nprint('dev labels shape: ', y_dev.shape)",
"Train data shape: (49000, 3073)\nTrain labels shape: (49000,)\nValidation data shape: (1000, 3073)\nValidation labels shape: (1000,)\nTest data shape: (1000, 3073)\nTest labels shape: (1000,)\ndev data shape: (500, 3073)\ndev labels shape: (500,)\n"
]
],
[
[
"## Softmax Classifier\n\nYour code for this section will all be written inside **cs231n/classifiers/softmax.py**. \n",
"_____no_output_____"
]
],
[
[
"# First implement the naive softmax loss function with nested loops.\n# Open the file cs231n/classifiers/softmax.py and implement the\n# softmax_loss_naive function.\n\nfrom cs231n.classifiers.softmax import softmax_loss_naive\nimport time\n\n# Generate a random softmax weight matrix and use it to compute the loss.\nW = np.random.randn(3073, 10) * 0.0001\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)\n\n# As a rough sanity check, our loss should be something close to -log(0.1).\nprint('loss: %f' % loss)\nprint('sanity check: %f' % (-np.log(0.1)))",
"loss: 2.417958\nsanity check: 2.302585\n"
]
],
[
[
"## Inline Question 1:\nWhy do we expect our loss to be close to -log(0.1)? Explain briefly.**\n\n**Your answer:** *Fill this in*\n",
"_____no_output_____"
]
],
[
[
"# Complete the implementation of softmax_loss_naive and implement a (naive)\n# version of the gradient that uses nested loops.\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 0.0)\n\n# As we did for the SVM, use numeric gradient checking as a debugging tool.\n# The numeric gradient should be close to the analytic gradient.\nfrom cs231n.gradient_check import grad_check_sparse\nf = lambda w: softmax_loss_naive(w, X_dev, y_dev, 0.0)[0]\ngrad_numerical = grad_check_sparse(f, W, grad, 10)\n\n# similar to SVM case, do another gradient check with regularization\nloss, grad = softmax_loss_naive(W, X_dev, y_dev, 5e1)\nf = lambda w: softmax_loss_naive(w, X_dev, y_dev, 5e1)[0]\ngrad_numerical = grad_check_sparse(f, W, grad, 10)",
"numerical: 1.541164 analytic: 1.541164, relative error: 7.123159e-08\nnumerical: -3.007297 analytic: -3.007297, relative error: 2.730143e-08\nnumerical: 0.783258 analytic: 0.783258, relative error: 7.952695e-08\nnumerical: -0.849591 analytic: -0.849591, relative error: 4.319073e-08\nnumerical: -0.743468 analytic: -0.743468, relative error: 5.394534e-10\nnumerical: 0.508246 analytic: 0.508246, relative error: 6.439240e-08\nnumerical: -1.915112 analytic: -1.915112, relative error: 9.022549e-09\nnumerical: 2.924842 analytic: 2.924842, relative error: 3.382662e-09\nnumerical: -2.442379 analytic: -2.442379, relative error: 8.094909e-09\nnumerical: -0.252703 analytic: -0.252703, relative error: 2.499480e-08\nnumerical: -0.800072 analytic: -0.800072, relative error: 8.015305e-08\nnumerical: -1.661064 analytic: -1.661064, relative error: 1.488001e-08\nnumerical: -3.044407 analytic: -3.044407, relative error: 4.600609e-09\nnumerical: -3.093792 analytic: -3.093792, relative error: 2.272946e-08\nnumerical: -0.713167 analytic: -0.713167, relative error: 4.665315e-08\nnumerical: -0.335343 analytic: -0.335344, relative error: 3.045860e-08\nnumerical: 0.756957 analytic: 0.756957, relative error: 1.552388e-08\nnumerical: -1.504907 analytic: -1.504907, relative error: 6.796556e-08\nnumerical: -0.522326 analytic: -0.522326, relative error: 5.245924e-08\nnumerical: -1.275013 analytic: -1.275013, relative error: 1.102205e-08\n"
],
[
"# Now that we have a naive implementation of the softmax loss function and its gradient,\n# implement a vectorized version in softmax_loss_vectorized.\n# The two versions should compute the same results, but the vectorized version should be\n# much faster.\ntic = time.time()\nloss_naive, grad_naive = softmax_loss_naive(W, X_dev, y_dev, 0.000005)\ntoc = time.time()\nprint('naive loss: %e computed in %fs' % (loss_naive, toc - tic))\n\nfrom cs231n.classifiers.softmax import softmax_loss_vectorized\ntic = time.time()\nloss_vectorized, grad_vectorized = softmax_loss_vectorized(W, X_dev, y_dev, 0.000005)\ntoc = time.time()\nprint('vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))\n\n# As we did for the SVM, we use the Frobenius norm to compare the two versions\n# of the gradient.\ngrad_difference = np.linalg.norm(grad_naive - grad_vectorized, ord='fro')\nprint('Loss difference: %f' % np.abs(loss_naive - loss_vectorized))\nprint('Gradient difference: %f' % grad_difference)",
"naive loss: 2.417958e+00 computed in 0.056040s\nvectorized loss: 2.417958e+00 computed in 0.012995s\nLoss difference: 0.000000\nGradient difference: 0.000000\n"
],
[
"# Use the validation set to tune hyperparameters (regularization strength and\n# learning rate). You should experiment with different ranges for the learning\n# rates and regularization strengths; if you are careful you should be able to\n# get a classification accuracy of over 0.35 on the validation set.\nfrom cs231n.classifiers import Softmax\nresults = {}\nbest_val = -1\nbest_softmax = None\nlearning_rates = [1e-7, 5e-7]\nregularization_strengths = [2.5e4, 5e4]\n\n################################################################################\n# TODO: #\n# Use the validation set to set the learning rate and regularization strength. #\n# This should be identical to the validation that you did for the SVM; save #\n# the best trained softmax classifer in best_softmax. #\n################################################################################\n#pass\nfor lr in learning_rates:\n for reg in regularization_strengths:\n softmax = Softmax()\n softmax.train(X_train, y_train, lr, reg, num_iters=1500)\n y_train_pred = softmax.predict(X_train)\n train_acc = np.mean(y_train == y_train_pred)\n y_val_pred = softmax.predict(X_val)\n val_acc = np.mean(y_val == y_val_pred)\n if val_acc > best_val:\n best_val = val_acc\n best_softmax = softmax\n results[(lr, reg)] = train_acc, val_acc\n################################################################################\n# END OF YOUR CODE #\n################################################################################\n \n# Print out results.\nfor lr, reg in sorted(results):\n train_accuracy, val_accuracy = results[(lr, reg)]\n print('lr %e reg %e train accuracy: %f val accuracy: %f' % (\n lr, reg, train_accuracy, val_accuracy))\n \nprint('best validation accuracy achieved during cross-validation: %f' % best_val)",
"lr 1.000000e-07 reg 2.500000e+04 train accuracy: 0.348837 val accuracy: 0.362000\nlr 1.000000e-07 reg 5.000000e+04 train accuracy: 0.334571 val accuracy: 0.351000\nlr 5.000000e-07 reg 2.500000e+04 train accuracy: 0.342286 val accuracy: 0.349000\nlr 5.000000e-07 reg 5.000000e+04 train accuracy: 0.326327 val accuracy: 0.332000\nbest validation accuracy achieved during cross-validation: 0.362000\n"
],
[
"# evaluate on test set\n# Evaluate the best softmax on test set\ny_test_pred = best_softmax.predict(X_test)\ntest_accuracy = np.mean(y_test == y_test_pred)\nprint('softmax on raw pixels final test set accuracy: %f' % (test_accuracy, ))",
"softmax on raw pixels final test set accuracy: 0.364000\n"
],
[
"# Visualize the learned weights for each class\nw = best_softmax.W[:-1,:] # strip out the bias\nw = w.reshape(32, 32, 3, 10)\n\nw_min, w_max = np.min(w), np.max(w)\n\nclasses = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']\nfor i in range(10):\n plt.subplot(2, 5, i + 1)\n \n # Rescale the weights to be between 0 and 255\n wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)\n plt.imshow(wimg.astype('uint8'))\n plt.axis('off')\n plt.title(classes[i])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
c517cf836568a638ba319c1f21d2d69eb5ba6c77
| 265,139 |
ipynb
|
Jupyter Notebook
|
ETL PROJECT.ipynb
|
darrenlefort/ETL-Project
|
c2779f8d7f8e086025e89e9579163d76bc65f3fe
|
[
"Apache-2.0"
] | null | null | null |
ETL PROJECT.ipynb
|
darrenlefort/ETL-Project
|
c2779f8d7f8e086025e89e9579163d76bc65f3fe
|
[
"Apache-2.0"
] | null | null | null |
ETL PROJECT.ipynb
|
darrenlefort/ETL-Project
|
c2779f8d7f8e086025e89e9579163d76bc65f3fe
|
[
"Apache-2.0"
] | null | null | null | 71.29309 | 113,628 | 0.615179 |
[
[
[
"# __Proposal__\n\nWe are facing a serious situation of COVID-19 pandemic, for which governments have implemented contingency plans with various effectiveness. We are trying to create a database for further analysis of the effectiveness of the contingency plans and measures governments have chosen.",
"_____no_output_____"
],
[
"# __Finding Data__\n\nSource 1: We picked our first data source of covid 19 daily data from the following API, where the Data is sourced from Johns Hopkins CSSE. “https://api.covid19api.com/all\" The data in this dataset is basically total cases, total deaths and total recovered reported daily.\n\nSource 2: We pulled the contingency plans from OXFORD COVID-19 Government Response Tracker(OxCGRT). We downloaded our second dataset as a CSV file from https://data.humdata.org/dataset/oxford-covid-19-government-response-tracker. The Oxford COVID-19 Government Response Tracker (OxCGRT) systematically collects information on several different common policy responses that governments have taken to respond to the pandemic on 17 indicators such as school closures and travel restrictions. It now has data from more than 180 countries. The data is also used to inform a ‘Lockdown rollback checklist’ which looks at how closely countries meet four of the six World Health Organisation recommendations for relaxing ‘lockdown’.\n\nSource 3: We downloaded an EXCEL file from https://data.humdata.org/dataset/acaps-covid19-government-measures-dataset. the source is ACAPS which is an independent information provider, free from the bias or vested interests of a specific enterprise, sector, or region. ACAPS consulted government, media, United Nations, and other organisations sources. The #COVID19 Government Measures Dataset puts together all the measures implemented by governments worldwide in response to the Coronavirus pandemic. The data in this dataset is not updated daily but the major events and limitations placed are described in a column as comments. the analysts could use these data to explain and assess the effect they had on the decline or increase in the number of cases and deaths.",
"_____no_output_____"
],
[
"# -----------------------------------------__E__xtract-----------------------------------------",
"_____no_output_____"
]
],
[
[
"# Dependencies\nimport requests\nimport pandas as pd \nimport datetime\nfrom sqlalchemy import create_engine",
"_____no_output_____"
]
],
[
[
"## __Source 1: Following the API calling we then created a dataframe in pandas__",
"_____no_output_____"
]
],
[
[
"# Source 1: we picked our first data source of covid 19 daily data from the following API\n# Source 1: Calling the API\nurl = \"https://api.covid19api.com/all\"\nresponse1 = requests.get(url).json()\nresponse1\n\ncountry = []\ndate = []\ntotal_cases = []\ntotal_deaths = []\ntotal_recovered = []\n\nfor row in response1:\n country.append(row['Country'])\n date.append(row[\"Date\"])\n total_cases.append(row['Confirmed'])\n total_deaths.append(row['Deaths'])\n total_recovered.append(row['Recovered'])\n\n #creating the dataframe\ncovid_df = pd.DataFrame({\n 'Country': country,\n 'Date': date,\n 'TotalCases': total_cases,\n 'TotalDeaths': total_deaths,\n 'TotalRecovered': total_recovered\n})\ncovid_df.head()",
"_____no_output_____"
]
],
[
[
"## __Source 2: after downloading the CSV file we imported the csv file into another dataframe__",
"_____no_output_____"
]
],
[
[
"## we pulled the contingency plans from OXFORD COVID-19 Government Response Tracker(OxCGRT) \n## the website https://data.humdata.org/dataset/oxford-covid-19-government-response-tracker\n\n# Source 2: read from csv file\ngovernment_df=pd.read_csv('Resources/government_contingency.csv')\ngovernment_df",
"C:\\Users\\dlefo\\anaconda3\\envs\\PythonData\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3063: DtypeWarning: Columns (2) have mixed types.Specify dtype option on import or set low_memory=False.\n interactivity=interactivity, compiler=compiler, result=result)\n"
]
],
[
[
"The COVID19 Government Measures Dataset puts together all the measures implemented by governments worldwide in response to the Coronavirus pandemic. Data collection includes secondary data review. The researched information available falls into five categories:\nSocial distancing\nMovement restrictions\nPublic health measures\nSocial and economic measures\nLockdowns\nEach category is broken down into several types of measures.\nACAPS consulted government, media, United Nations, and other organisations sources.\nFor any comments, please contact us at [email protected]\nPlease note note that some measures together with non-compliance policies may not be recorded and the exact date of implementation may not be accurate in some cases, due to the different way of reporting of the primary data sources we used.",
"_____no_output_____"
],
[
"## __Source 3: We imported only one sheet from the EXCEL file we downloaded__",
"_____no_output_____"
]
],
[
[
"# Source3: read from excel file\nxlFile = pd.ExcelFile(r'Resources/acaps_covid19_government_measures_dataset.xlsx')\nspecial_measures_df = pd.read_excel(xlFile, sheet_name='Database')\nspecial_measures_df",
"_____no_output_____"
]
],
[
[
"# -----------------------------------------__T__ransform-----------------------------------------",
"_____no_output_____"
],
[
"## Source 1:\n### -change the date formats\n### -cleaning the data\n### -dropping the duplicates",
"_____no_output_____"
]
],
[
[
"# Source1: changing the date format\ncovid_df.loc[:,'Date']=pd.to_datetime(covid_df.loc[:,\"Date\"]).apply(lambda x: x.date())\ncovid_df['Date']=covid_df['Date'].apply(lambda x: pd.to_datetime(str(x)))\ncovid_df.head()\n# Source1: discovering the uncleanness\ncovid_df.shape\n# # the shape shows that the data is not consistent so there must be redundancies\ndays=len(covid_df['Date'].value_counts())\ndays\ndate_percountry=covid_df['Country'].value_counts()\ndate_percountry\n \n# # deleting the multiple rows for the same date\ncountries=covid_df['Country'].unique()\nfor c in countries:\n if date_percountry[c]>days:\n country_df=covid_df.loc[(covid_df[\"Country\"]==c)]\n max_df=country_df.groupby('Date').max().reset_index()\n new_df=covid_df.loc[(covid_df[\"Country\"]!=c)]\n frames=[new_df,max_df]\n new_covid_df = pd.concat(frames)\nclean_covid_df=new_covid_df.copy()\n\nclean_covid_df\nclean_covid_df.shape\n#there are still some duplicate data\nclean_covid_df['Date'].value_counts()\n# there are more than 186 (number of countries) dates where all so we must delete the duplicate dates for the same country\nclean_covid_df=clean_covid_df.drop_duplicates(subset=['Date','Country'])\n#now the shape shows that the data is totally clean\n# so we will write this to a csv to save time\nclean_covid_df.to_csv('Resources/covid_from_API.CSV')\nclean_covid_df",
"_____no_output_____"
]
],
[
[
"## __Source 2:__\n### -Deleting the extra header\n### -Renaming the columns to replace of unwanted spaces with _ and unify the format\n### -Converting the date format\n### -Picking useful columns\n### -Dropping NAN values and Duplicates by country name and date",
"_____no_output_____"
]
],
[
[
"#Source 2:\n# delete the first row\nclean_government_df= government_df.loc[government_df['CountryName']!='#country']\n# determine the date data type\ngovernment_df['Date'].dtype\n# converting the date format from object to date\nclean_government_df['Date']=clean_government_df['Date'].apply(lambda x: pd.to_datetime(str(x), format='%Y%m%d'))\n",
"C:\\Users\\dlefo\\anaconda3\\envs\\PythonData\\lib\\site-packages\\ipykernel_launcher.py:7: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n import sys\n"
],
[
"# renaming the columns\nclean_government_df.columns=['CountryName','CountryCode','Date','C1_School_closing','C1_Flag','C2_Workplace_closing','C2_Flag','C3_Cancel_public_events','C3_Flag','C4_Restrictions_on_gatherings','C4_Flag','C5_Close_public_transport','C5_Flag','C6_Stay_at_home_requirements','C6_Flag','C7_Restrictions_on_internal_movement','C7_Flag','C8_International_travel_controls','E1_Income_support','E1_Flag','E2_Debt_contract_relief','E3_Fiscal_measures','E4_International_support','H1_Public_information_campaigns','H1_Flag','H2_Testing_policy','H3_Contact_tracing','H4_Emergency_investment_in_healthcare','H5_Investment_in_vaccines','M1_Wildcard','ConfirmedCases','ConfirmedDeaths','StringencyIndex','StringencyIndexForDisplay','StringencyLegacyIndex','StringencyLegacyIndexForDisplay','GovernmentResponseIndex','GovernmentResponseIndexForDisplay','ContainmentHealthIndex','ContainmentHealthIndexForDisplay','EconomicSupportIndex','EconomicSupportIndexForDisplay']",
"_____no_output_____"
],
[
"clean_government_df.head()",
"_____no_output_____"
],
[
"# picking 24 columns out of 42\nclean_government_df=clean_government_df[['CountryName',\n'Date',\n'C1_School_closing',\n'C2_Workplace_closing',\n'C3_Cancel_public_events',\n'C4_Restrictions_on_gatherings',\n'C5_Close_public_transport',\n'C6_Stay_at_home_requirements',\n'C7_Restrictions_on_internal_movement',\n'C8_International_travel_controls',\n'E1_Income_support',\n'E2_Debt_contract_relief',\n'E3_Fiscal_measures',\n'E4_International_support',\n'H1_Public_information_campaigns',\n'H2_Testing_policy',\n'H3_Contact_tracing',\n'H4_Emergency_investment_in_healthcare',\n'H5_Investment_in_vaccines',\n'StringencyIndex',\n'StringencyLegacyIndex',\n'GovernmentResponseIndex',\n'ContainmentHealthIndex',\n'EconomicSupportIndex'\n]]\n",
"_____no_output_____"
],
[
"clean_government_df",
"_____no_output_____"
],
[
"#dropping the nan values to get rid of the unfilled data which is mostly the last week \nclean_government_df=clean_government_df.dropna()\n",
"_____no_output_____"
],
[
"clean_government_df=clean_government_df.drop_duplicates(subset=['CountryName','Date'])",
"_____no_output_____"
],
[
"clean_government_df",
"_____no_output_____"
],
[
"clean_government_df['CountryName'].value_counts()",
"_____no_output_____"
]
],
[
[
"## __Source 3__\n### -columns selection based on data completeness and analysis potential\n### -changed date format to match source 1\n### -checked COUNTRY counts",
"_____no_output_____"
]
],
[
[
"# Source 3: Choosing useful columns\nclean_special_measures_df=special_measures_df[['COUNTRY','DATE_IMPLEMENTED','REGION','LOG_TYPE','CATEGORY','MEASURE','TARGETED_POP_GROUP','COMMENTS','SOURCE','SOURCE_TYPE','LINK']]",
"_____no_output_____"
],
[
"clean_special_measures_df",
"_____no_output_____"
],
[
"# Source 3: changing the date format\nclean_special_measures_df.loc[:,'DATE_IMPLEMENTED']=pd.to_datetime(clean_special_measures_df.loc[:,\"DATE_IMPLEMENTED\"]).apply(lambda x: x.date())\nclean_special_measures_df['DATE_IMPLEMENTED']=clean_special_measures_df['DATE_IMPLEMENTED'].apply(lambda x: pd.to_datetime(str(x)))\nclean_special_measures_df.head()",
"C:\\Users\\dlefo\\anaconda3\\envs\\PythonData\\lib\\site-packages\\pandas\\core\\indexing.py:1048: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n self.obj[item_labels[indexer[info_axis]]] = value\nC:\\Users\\dlefo\\anaconda3\\envs\\PythonData\\lib\\site-packages\\ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n"
],
[
"clean_special_measures_df['COUNTRY'].value_counts()",
"_____no_output_____"
]
],
[
[
"## __Ensure source 2 and 3 foreign key values exist in source 1 primary keys__",
"_____no_output_____"
],
[
"__Note:__ The table covid_statistics was deemed to hold the primary statistical results for analysis. A cleaning method was required to eliminate Country's and Date's that did not exist within the covid_statistics dataframe. The use of Left JOINS between government_measures_stringency and government_measures_keydate, independently, with the covid_statistics dataframe achieved the desired result. The independent dataframes will allow flexibility for the Data Analyst to perform various operations.",
"_____no_output_____"
],
[
"### Merge and clean source 1 to source 2 droping all source 1 columns and null values in foreign key columns in source 2.",
"_____no_output_____"
]
],
[
[
"merge1_2=pd.merge(clean_covid_df, clean_government_df, left_on=['Country','Date'],right_on=['CountryName','Date'], how='left')\nmerge1_2=merge1_2.drop(columns=['Country','TotalCases','TotalDeaths','TotalRecovered'])\nmerge1_2=merge1_2[merge1_2['CountryName'].notna()]\nmerge1_2=merge1_2[merge1_2['Date'].notna()]\nmerge1_2.head()",
"_____no_output_____"
]
],
[
[
"### Merge and clean source 1 to source 3 droping all source 1 columns and null values in foreign key columns in source 3.",
"_____no_output_____"
]
],
[
[
"merge1_3=pd.merge(clean_covid_df, clean_special_measures_df, left_on=['Country','Date'],right_on=['COUNTRY','DATE_IMPLEMENTED'], how='left')\nmerge1_3=merge1_3.drop(columns=['Country','Date','TotalCases','TotalDeaths','TotalRecovered'])\nmerge1_3=merge1_3.dropna()\nmerge1_3.head()",
"_____no_output_____"
]
],
[
[
"# -----------------------------------------__L__oad-----------------------------------------",
"_____no_output_____"
],
[
"### Choosing Postgresql as database\n#### -Postgresql was chosen due to the nature of the data being related by country and date. This relationship supports the structure of relational databases.",
"_____no_output_____"
],
[
"## __Creating a ERD diagram__",
"_____no_output_____"
],
[
"### ERD Postgresql Code",
"_____no_output_____"
]
],
[
[
"# Exported from QuickDBD: https://www.quickdatabasediagrams.com/\n\n# CREATE TABLE \"covid_statistics\" (\n# \"Country\" VARCHAR NOT NULL,\n# \"Date\" DATE NOT NULL,\n# \"TotalCases\" INT NOT NULL,\n# \"TotalDeaths\" INT NOT NULL,\n# \"TotalRecovered\" INT NOT NULL,\n# CONSTRAINT \"pk_covid_statistics\" PRIMARY KEY (\n# \"Country\",\"Date\"\n# )\n# );\n\n# CREATE TABLE \"government_measures_stringency\" (\n# \"CountryName\" VARCHAR NOT NULL,\n# \"Date\" DATE NOT NULL,\n# \"C1_School_closing\" BIGINT NULL,\n# \"C2_Workplace_closing\" BIGINT NULL,\n# \"C3_Cancel_public_events\" BIGINT NULL,\n# \"C4_Restrictions_on_gatherings\" BIGINT NULL,\n# \"C5_Close_public_transport\" BIGINT NULL,\n# \"C6_Stay_at_home_requirements\" BIGINT NULL,\n# \"C7_Restrictions_on_internal_movement\" BIGINT NULL,\n# \"C8_International_travel_controls\" BIGINT NULL,\n# \"E1_Income_support\" BIGINT NULL,\n# \"E2_Debt_contract_relief\" BIGINT NULL,\n# \"E3_Fiscal_measures\" BIGINT NULL,\n# \"E4_International_support\" BIGINT NULL,\n# \"H1_Public_information_campaigns\" BIGINT NULL,\n# \"H2_Testing_policy\" BIGINT NULL,\n# \"H3_Contact_tracing\" BIGINT NULL,\n# \"H4_Emergency_investment_in_healthcare\" BIGINT NULL,\n# \"H5_Investment_in_vaccines\" BIGINT NULL,\n# \"StringencyIndex\" BIGINT NULL,\n# \"StringencyLegacyIndex\" BIGINT NULL,\n# \"GovernmentResponseIndex\" BIGINT NULL,\n# \"ContainmentHealthIndex\" BIGINT NULL,\n# \"EconomicSupportIndex\" BIGINT NULL\n# );\n\n# CREATE TABLE \"government_measures_keydate\" (\n# \"id\" SERIAL NOT NULL,\n# \"COUNTRY\" VARCHAR NOT NULL,\n# \"DATE_IMPLEMENTED\" DATE NOT NULL,\n# \"REGION\" VARCHAR NULL,\n# \"LOG_TYPE\" VARCHAR NULL,\n# \"CATEGORY\" VARCHAR NULL,\n# \"MEASURE\" VARCHAR NULL,\n# \"TARGETED_POP_GROUP\" VARCHAR NULL,\n# \"COMMENTS\" VARCHAR NULL,\n# \"SOURCE\" VARCHAR NULL,\n# \"SOURCE_TYPE\" VARCHAR NULL,\n# \"LINK\" VARCHAR NULL\n# );\n\n# ALTER TABLE \"government_measures_stringency\" ADD CONSTRAINT \"fk_government_measures_stringency_CountryName_Date\" FOREIGN KEY(\"CountryName\", \"Date\")\n# REFERENCES \"covid_statistics\" (\"Country\", \"Date\");\n\n# ALTER TABLE \"government_measures_keydate\" ADD CONSTRAINT \"fk_government_measures_keydate_COUNTRY_DATE_IMPLEMENTED\" FOREIGN KEY(\"COUNTRY\", \"DATE_IMPLEMENTED\")\n# REFERENCES \"covid_statistics\" (\"Country\", \"Date\");",
"_____no_output_____"
]
],
[
[
"### ERD Image\n",
"_____no_output_____"
],
[
"## __Connect to local database__",
"_____no_output_____"
]
],
[
[
"import ETLconfig\nfrom ETLconfig import rds_connection_string",
"_____no_output_____"
],
[
"engine = create_engine(f'postgresql+psycopg2://{rds_connection_string}')",
"_____no_output_____"
]
],
[
[
"## __Check for tables__",
"_____no_output_____"
]
],
[
[
"engine.table_names()",
"_____no_output_____"
]
],
[
[
"## __Use pandas to load dataframe(s) into database__",
"_____no_output_____"
]
],
[
[
"clean_covid_df.to_sql(name='covid_statistics', con=engine, if_exists='append',index=False)",
"_____no_output_____"
],
[
"merge1_2.to_sql(name='government_measures_stringency', con=engine, if_exists='append',index=False)",
"_____no_output_____"
],
[
"merge1_3.to_sql(name='government_measures_keydate', con=engine, if_exists='append',index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
c517cfd32616bc32a6ec3cb7df6bb0e591dec6fe
| 53,795 |
ipynb
|
Jupyter Notebook
|
Copy_of_LS_DS_213_assignment.ipynb
|
thecodinguru/DS-Unit-2-Linear-Models
|
7dc88be4a61361ca8a0b6954bfc6dd6222cde0c5
|
[
"MIT"
] | null | null | null |
Copy_of_LS_DS_213_assignment.ipynb
|
thecodinguru/DS-Unit-2-Linear-Models
|
7dc88be4a61361ca8a0b6954bfc6dd6222cde0c5
|
[
"MIT"
] | null | null | null |
Copy_of_LS_DS_213_assignment.ipynb
|
thecodinguru/DS-Unit-2-Linear-Models
|
7dc88be4a61361ca8a0b6954bfc6dd6222cde0c5
|
[
"MIT"
] | null | null | null | 34.661727 | 319 | 0.378251 |
[
[
[
"<a href=\"https://colab.research.google.com/github/thecodinguru/DS-Unit-2-Linear-Models/blob/master/Copy_of_LS_DS_213_assignment.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Lambda School Data Science\n\n*Unit 2, Sprint 1, Module 3*\n\n---",
"_____no_output_____"
],
[
"# Ridge Regression\n\n## Assignment\n\nWe're going back to our other **New York City** real estate dataset. Instead of predicting apartment rents, you'll predict property sales prices.\n\nBut not just for condos in Tribeca...\n\n- [ ] Use a subset of the data where `BUILDING_CLASS_CATEGORY` == `'01 ONE FAMILY DWELLINGS'` and the sale price was more than 100 thousand and less than 2 million.\n- [ ] Do train/test split. Use data from January — March 2019 to train. Use data from April 2019 to test.\n- [ ] Do one-hot encoding of categorical features.\n- [ ] Do feature selection with `SelectKBest`.\n- [ ] Fit a ridge regression model with multiple features. Use the `normalize=True` parameter (or do [feature scaling](https://scikit-learn.org/stable/modules/preprocessing.html) beforehand — use the scaler's `fit_transform` method with the train set, and the scaler's `transform` method with the test set)\n- [ ] Get mean absolute error for the test set.\n- [ ] As always, commit your notebook to your fork of the GitHub repo.\n\nThe [NYC Department of Finance](https://www1.nyc.gov/site/finance/taxes/property-rolling-sales-data.page) has a glossary of property sales terms and NYC Building Class Code Descriptions. The data comes from the [NYC OpenData](https://data.cityofnewyork.us/browse?q=NYC%20calendar%20sales) portal.\n\n\n## Stretch Goals\n\nDon't worry, you aren't expected to do all these stretch goals! These are just ideas to consider and choose from.\n\n- [ ] Add your own stretch goal(s) !\n- [ ] Instead of `Ridge`, try `LinearRegression`. Depending on how many features you select, your errors will probably blow up! 💥\n- [ ] Instead of `Ridge`, try [`RidgeCV`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeCV.html).\n- [ ] Learn more about feature selection:\n - [\"Permutation importance\"](https://www.kaggle.com/dansbecker/permutation-importance)\n - [scikit-learn's User Guide for Feature Selection](https://scikit-learn.org/stable/modules/feature_selection.html)\n - [mlxtend](http://rasbt.github.io/mlxtend/) library\n - scikit-learn-contrib libraries: [boruta_py](https://github.com/scikit-learn-contrib/boruta_py) & [stability-selection](https://github.com/scikit-learn-contrib/stability-selection)\n - [_Feature Engineering and Selection_](http://www.feat.engineering/) by Kuhn & Johnson.\n- [ ] Try [statsmodels](https://www.statsmodels.org/stable/index.html) if you’re interested in more inferential statistical approach to linear regression and feature selection, looking at p values and 95% confidence intervals for the coefficients.\n- [ ] Read [_An Introduction to Statistical Learning_](http://faculty.marshall.usc.edu/gareth-james/ISL/ISLR%20Seventh%20Printing.pdf), Chapters 1-3, for more math & theory, but in an accessible, readable way.\n- [ ] Try [scikit-learn pipelines](https://scikit-learn.org/stable/modules/compose.html).",
"_____no_output_____"
]
],
[
[
"%%capture\nimport sys\n\n# If you're on Colab:\nif 'google.colab' in sys.modules:\n DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Applied-Modeling/master/data/'\n !pip install category_encoders==2.*\n\n# If you're working locally:\nelse:\n DATA_PATH = '../data/'\n \n# Ignore this Numpy warning when using Plotly Express:\n# FutureWarning: Method .ptp is deprecated and will be removed in a future version. Use numpy.ptp instead.\nimport warnings\nwarnings.filterwarnings(action='ignore', category=FutureWarning, module='numpy')",
"_____no_output_____"
],
[
"import pandas as pd\nimport pandas_profiling\n\n# Read New York City property sales data\ndf = pd.read_csv(DATA_PATH+'condos/NYC_Citywide_Rolling_Calendar_Sales.csv')\n\n# Change column names: replace spaces with underscores\ndf.columns = [col.replace(' ', '_') for col in df]\n\n# SALE_PRICE was read as strings.\n# Remove symbols, convert to integer\ndf['SALE_PRICE'] = (\n df['SALE_PRICE']\n .str.replace('$','')\n .str.replace('-','')\n .str.replace(',','')\n .astype(int)\n)",
"_____no_output_____"
],
[
"# BOROUGH is a numeric column, but arguably should be a categorical feature,\n# so convert it from a number to a string\ndf['BOROUGH'] = df['BOROUGH'].astype(str)",
"_____no_output_____"
],
[
"# Reduce cardinality for NEIGHBORHOOD feature\n\n# Get a list of the top 10 neighborhoods\ntop10 = df['NEIGHBORHOOD'].value_counts()[:10].index\n\n# At locations where the neighborhood is NOT in the top 10, \n# replace the neighborhood with 'OTHER'\ndf.loc[~df['NEIGHBORHOOD'].isin(top10), 'NEIGHBORHOOD'] = 'OTHER'",
"_____no_output_____"
],
[
"#Let's explore our data\nprint(df.shape)\ndf.head()",
"(23040, 21)\n"
],
[
"# Use a subset of the data where BUILDING_CLASS_CATEGORY == '01 ONE FAMILY DWELLINGS' \n# and the sale price was more than 100 thousand and less than 2 million.\n\ndf_single = df[(df['BUILDING_CLASS_CATEGORY']== '01 ONE FAMILY DWELLINGS') & \n (df['SALE_PRICE'] < 2000000) & (df['SALE_PRICE'] > 100000)]\n\nprint(df_single.info())\ndf_single.head()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 3151 entries, 44 to 23035\nData columns (total 21 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 BOROUGH 3151 non-null object \n 1 NEIGHBORHOOD 3151 non-null object \n 2 BUILDING_CLASS_CATEGORY 3151 non-null object \n 3 TAX_CLASS_AT_PRESENT 3151 non-null object \n 4 BLOCK 3151 non-null int64 \n 5 LOT 3151 non-null int64 \n 6 EASE-MENT 0 non-null float64\n 7 BUILDING_CLASS_AT_PRESENT 3151 non-null object \n 8 ADDRESS 3151 non-null object \n 9 APARTMENT_NUMBER 1 non-null object \n 10 ZIP_CODE 3151 non-null float64\n 11 RESIDENTIAL_UNITS 3151 non-null float64\n 12 COMMERCIAL_UNITS 3151 non-null float64\n 13 TOTAL_UNITS 3151 non-null float64\n 14 LAND_SQUARE_FEET 3151 non-null object \n 15 GROSS_SQUARE_FEET 3151 non-null float64\n 16 YEAR_BUILT 3151 non-null float64\n 17 TAX_CLASS_AT_TIME_OF_SALE 3151 non-null int64 \n 18 BUILDING_CLASS_AT_TIME_OF_SALE 3151 non-null object \n 19 SALE_PRICE 3151 non-null int64 \n 20 SALE_DATE 3151 non-null object \ndtypes: float64(7), int64(4), object(10)\nmemory usage: 541.6+ KB\nNone\n"
],
[
"# I'll assign Sales Price as our target\n\ny = df_single['SALE_PRICE']\n\ny.shape",
"_____no_output_____"
],
[
"# I'll put the rest of the features into a dataframe.\n# Also, I'll need to drop our target from the dataframe\n\nX = df_single.drop('SALE_PRICE', axis = 1)\nX.shape",
"_____no_output_____"
],
[
"#Setting training data to January — March 2019 to train. Setting testing data from April 2019\n\nX_train = X[(X['SALE_DATE'] >= '01/01/2019') & (X['SALE_DATE'] < '04/01/2019')]\ny_train = y[y.index.isin(X_train.index)]\n\nX_test = X[X['SALE_DATE'] >= '04/01/2019']\ny_test = y[y.index.isin(X_test.index)]\n\nprint(X_train.shape)\nprint(X_test.shape)",
"(2507, 20)\n(644, 20)\n"
]
],
[
[
"#Encoding",
"_____no_output_____"
]
],
[
[
"#Explore our categorical data\n\nprint(df_single.info())\ndf_single.describe(exclude='number')",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 3151 entries, 44 to 23035\nData columns (total 21 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 BOROUGH 3151 non-null object \n 1 NEIGHBORHOOD 3151 non-null object \n 2 BUILDING_CLASS_CATEGORY 3151 non-null object \n 3 TAX_CLASS_AT_PRESENT 3151 non-null object \n 4 BLOCK 3151 non-null int64 \n 5 LOT 3151 non-null int64 \n 6 EASE-MENT 0 non-null float64\n 7 BUILDING_CLASS_AT_PRESENT 3151 non-null object \n 8 ADDRESS 3151 non-null object \n 9 APARTMENT_NUMBER 1 non-null object \n 10 ZIP_CODE 3151 non-null float64\n 11 RESIDENTIAL_UNITS 3151 non-null float64\n 12 COMMERCIAL_UNITS 3151 non-null float64\n 13 TOTAL_UNITS 3151 non-null float64\n 14 LAND_SQUARE_FEET 3151 non-null object \n 15 GROSS_SQUARE_FEET 3151 non-null float64\n 16 YEAR_BUILT 3151 non-null float64\n 17 TAX_CLASS_AT_TIME_OF_SALE 3151 non-null int64 \n 18 BUILDING_CLASS_AT_TIME_OF_SALE 3151 non-null object \n 19 SALE_PRICE 3151 non-null int64 \n 20 SALE_DATE 3151 non-null object \ndtypes: float64(7), int64(4), object(10)\nmemory usage: 541.6+ KB\nNone\n"
],
[
"# I need to create a subset of just the categorical data\n# Also need to drop NaN values in Apartment Number\n\ndf_single_train = df_single.select_dtypes(exclude='number').drop('APARTMENT_NUMBER', axis = 1)\n\ndf_single_train.head()",
"_____no_output_____"
],
[
"#One Hot Encoder\n# 1. Import the class\nfrom sklearn.preprocessing import OneHotEncoder",
"_____no_output_____"
],
[
"# 2. Instantiate\nohe = OneHotEncoder(sparse=False)",
"_____no_output_____"
],
[
"# 3. Fit the transformer to the categorical data\nohe.fit(df_single_train)",
"_____no_output_____"
],
[
"# 4. Transform the data\ndf_single_trans = ohe.transform(df_single_train)",
"_____no_output_____"
],
[
"#Check if it worked\nprint(type(df_single_trans))\n\ndf_single_trans",
"<class 'numpy.ndarray'>\n"
]
],
[
[
"#SIngle KBest Feature Selection",
"_____no_output_____"
]
],
[
[
"# 1. Import the class\nfrom sklearn.feature_selection import SelectKBest",
"_____no_output_____"
],
[
"# 2. Instantiate\nselector = SelectKBest(k=5)",
"_____no_output_____"
],
[
"# 3. Fitting and transforming data\n# Excluding Ease-ment because of NaNs\nX_train = X_train.select_dtypes(include='number').drop('EASE-MENT', axis = 1)\nX_test = X_test.select_dtypes(include='number').drop('EASE-MENT', axis = 1)",
"_____no_output_____"
],
[
"X_train_selected = selector.fit_transform(X_train, y_train)",
"/usr/local/lib/python3.6/dist-packages/sklearn/feature_selection/_univariate_selection.py:114: UserWarning: Features [8] are constant.\n UserWarning)\n/usr/local/lib/python3.6/dist-packages/sklearn/feature_selection/_univariate_selection.py:115: RuntimeWarning: invalid value encountered in true_divide\n f = msb / msw\n"
],
[
"X_test_selected = selector.transform(X_test)",
"_____no_output_____"
],
[
"print(X_train.shape)\nprint(X_train_selected.shape)",
"(2507, 9)\n(2507, 5)\n"
],
[
"#4. Create a mask to view selected features\nmask = selector.get_support()\n\n#Putting the values back into columns\nX_train.columns[mask]",
"_____no_output_____"
]
],
[
[
"#Ridge Regression",
"_____no_output_____"
]
],
[
[
"#Start with a Baseline\n\nmean_y = y_train.mean()\n\nprint(f'Baseline mean (January — March 2019): ${mean_y:.2f}')",
"Baseline mean (January — March 2019): $621573.74\n"
],
[
"# Lets see how much error is in our baseline train data\n# Train Error\nfrom sklearn.metrics import mean_absolute_error\n\ny_pred = [y_train.mean()] * len(y_train)\n\nmae = mean_absolute_error(y_train, y_pred)\nprint(f'Train Error (January — March 2019): ${mae:.2f}')",
"Train Error (January — March 2019): $214721.53\n"
],
[
"# Lets see how much error is in our baseline test data\n# Test Error\n\ny_pred = [y_train.mean()] * len(y_test)\nmae = mean_absolute_error(y_test, y_pred)\nprint(f'Test Error (From April 2019): ${mae:.2f}')",
"Test Error (From April 2019): $211564.20\n"
],
[
"#Ridge Regression\n#1. Import model\nfrom sklearn.linear_model import Ridge",
"_____no_output_____"
],
[
"#2. Instantiate a class\nmodel = Ridge(normalize=True)",
"_____no_output_____"
],
[
"#3. Fit the model to training data from SelectKBest\nmodel.fit(X_train_selected, y_train)",
"_____no_output_____"
],
[
"#4. Apply model to test data\ny_pred = model.predict(X_test_selected)",
"_____no_output_____"
],
[
"#5. Print out metrics\nfrom sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score\n\n#print(f'Test Error (From April 2019): ${mae:.2f}')\n\nprint(f'MAE: {mean_absolute_error(y_test, y_pred):.2f}')\nprint(f'MSE: {mean_squared_error(y_test, y_pred):.2f}')\nprint(f'R2: {r2_score(y_test, y_pred):.2f}')",
"MAE: 191852.19\nMSE: 75268378144.36\nR2: 0.15\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517dc7b3cf18d12a7133575228edeec7cd94f44
| 2,780 |
ipynb
|
Jupyter Notebook
|
notebooks/magic.ipynb
|
eparcs/crawlab
|
00dffd7b67a5e851d255dac2b183a2dfda13dc41
|
[
"MIT"
] | 4 |
2018-09-17T19:26:38.000Z
|
2019-06-20T11:02:38.000Z
|
notebooks/magic.ipynb
|
yparcs/crawlab
|
00dffd7b67a5e851d255dac2b183a2dfda13dc41
|
[
"MIT"
] | null | null | null |
notebooks/magic.ipynb
|
yparcs/crawlab
|
00dffd7b67a5e851d255dac2b183a2dfda13dc41
|
[
"MIT"
] | null | null | null | 22.601626 | 125 | 0.528777 |
[
[
[
"%load_ext crawlab",
"_____no_output_____"
],
[
"import scrapy",
"_____no_output_____"
],
[
"%fetch https://www.google.com.br",
"_____no_output_____"
],
[
"%xpath //a > assuntos\n%xpath //title/text() > titulo\n%xpath //b/text() > importante\n\n%item titulo=titulo.extract_first(), importante=importante.extract_first(), assuntos=assuntos.extract()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
c517e378f946aa4d373a46540401122528d58f41
| 16,000 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
NicholasGoh/real_estate_app
|
01fd83ebe7dffbd42fb3cc8ce1e8c9c0d6285ac0
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
NicholasGoh/real_estate_app
|
01fd83ebe7dffbd42fb3cc8ce1e8c9c0d6285ac0
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
NicholasGoh/real_estate_app
|
01fd83ebe7dffbd42fb3cc8ce1e8c9c0d6285ac0
|
[
"MIT"
] | null | null | null | 34.408602 | 569 | 0.396375 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport altair as alt\nimport datetime",
"_____no_output_____"
],
[
"df = pd.read_csv('transactions.csv')\ndf.head()",
"_____no_output_____"
],
[
"def to_date(x):\n # format is in mmyy\n x = str(x)\n year = x[-2:]\n month = x[:2] if len(x) == 4 else x[0]\n return datetime.datetime(2000 + int(year), int(month), 1)",
"_____no_output_____"
],
[
"df.contractDate = df.contractDate.apply(to_date)\ndf.head()",
"_____no_output_____"
],
[
"json = 'transactions.json'\n# save df as json so can plot without a memory error\ndf.to_json(json, orient='records')",
"_____no_output_____"
],
[
"# can drag ard, zoom in and out\nalt.Chart(json).mark_point().encode(\n x='contractDate:T',\n y='price:Q',\n color='region:N'\n).interactive()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517e9289bdb72c00293c760c072384845f4170b
| 18,776 |
ipynb
|
Jupyter Notebook
|
Spam dectection.ipynb
|
rahulsd18/spamfilter
|
043d38ba1f09fa30dad84d13b5bc42bfd4cef5b7
|
[
"Apache-2.0"
] | null | null | null |
Spam dectection.ipynb
|
rahulsd18/spamfilter
|
043d38ba1f09fa30dad84d13b5bc42bfd4cef5b7
|
[
"Apache-2.0"
] | null | null | null |
Spam dectection.ipynb
|
rahulsd18/spamfilter
|
043d38ba1f09fa30dad84d13b5bc42bfd4cef5b7
|
[
"Apache-2.0"
] | null | null | null | 38.008097 | 1,373 | 0.546496 |
[
[
[
"### Importing the required modules/packages",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport re\nimport nltk\nimport string\nimport scipy as sp\n\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestClassifier\nfrom nltk.corpus import stopwords\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.model_selection import KFold, cross_val_score\nfrom sklearn.metrics import precision_recall_fscore_support as score\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.ensemble import GradientBoostingClassifier\nfrom sklearn import metrics\nfrom textblob import TextBlob, Word\nfrom nltk.stem.snowball import SnowballStemmer\nfrom sklearn.pipeline import Pipeline\n\n\n\nfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer\n\n# Naive Bayes\nfrom sklearn.naive_bayes import MultinomialNB \n\n# Logistic Regression\nfrom sklearn.linear_model import LogisticRegression\n\n",
"_____no_output_____"
]
],
[
[
"### Loading file and looking into the dimensions of data",
"_____no_output_____"
]
],
[
[
"raw_data = pd.read_csv(\"SMSSpamCollection.tsv\",sep='\\t',names=['label','text'])\npd.set_option('display.max_colwidth',100)\nraw_data.head()",
"_____no_output_____"
],
[
"print(raw_data.shape)\npd.crosstab(raw_data['label'],columns = 'label',normalize=True)",
"(5572, 2)\n"
],
[
"# Create Test Train Fit\n\n# Define X and y.\nX = raw_data.text\ny = raw_data.label\n\n# Split the new DataFrame into training and testing sets.\nX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=99, test_size= 0.3)",
"_____no_output_____"
]
],
[
[
" # Create Features using Count Vectorize",
"_____no_output_____"
]
],
[
[
"# Use CountVectorizer to create document-term matrices from X_train and X_test.\nvect = CountVectorizer()\nX_train_dtm = vect.fit_transform(X_train)\nX_test_dtm = vect.transform(X_test)",
"_____no_output_____"
],
[
"# Rows are documents, columns are terms (aka \"tokens\" or \"features\", individual words in this situation).\nX_train_dtm.shape",
"_____no_output_____"
],
[
"# Last 50 features\nprint((vect.get_feature_names()[-50:]))",
"['yetty', 'yetunde', 'yi', 'yijue', 'ym', 'ymca', 'yo', 'yoga', 'yogasana', 'yor', 'yorge', 'you', 'youdoing', 'youi', 'young', 'younger', 'youphone', 'your', 'youre', 'yourinclusive', 'yourjob', 'yours', 'yourself', 'youuuuu', 'youwanna', 'yowifes', 'yoyyooo', 'yr', 'yrs', 'ystrday', 'yummmm', 'yummy', 'yun', 'yunny', 'yuo', 'yuou', 'yup', 'zaher', 'zealand', 'zebra', 'zed', 'zeros', 'zhong', 'zindgi', 'zoe', 'zogtorius', 'zoom', 'zouk', 'zyada', 'èn']\n"
],
[
"# Show vectorizer options.\nvect",
"_____no_output_____"
],
[
"# Don't convert to lowercase. For now we want to keep the case value to original and run initial test/train and predict.\nvect = CountVectorizer(lowercase=False)\nX_train_dtm = vect.fit_transform(X_train)\nX_train_dtm.shape\nvect.get_feature_names()[-10:]",
"_____no_output_____"
],
[
"# Convert the Classifer to Dense Classifier for Pipeline\nclass DenseTransformer(TransformerMixin):\n\n def transform(self, X, y=None, **fit_params):\n return X.todense()\n\n def fit_transform(self, X, y=None, **fit_params):\n self.fit(X, y, **fit_params)\n return self.transform(X)\n\n def fit(self, X, y=None, **fit_params):\n return self",
"_____no_output_____"
]
],
[
[
"# Use Naive Bayes to predict the ham vs spam label.",
"_____no_output_____"
]
],
[
[
"# Use default options for CountVectorizer.\nvect = CountVectorizer()\n\n# Create document-term matrices.\nX_train_dtm = vect.fit_transform(X_train)\nX_test_dtm = vect.transform(X_test)\n\n# Use Naive Bayes to predict the star rating.\nnb = MultinomialNB()\nnb.fit(X_train_dtm, y_train)\ny_pred_class = nb.predict(X_test_dtm)\n\n# Calculate accuracy.\nprint((metrics.accuracy_score(y_test, y_pred_class)))",
"0.9899497487437185\n"
],
[
"from sklearn.naive_bayes import GaussianNB\ngnb = GaussianNB()\n\n# Create a pipeline with the items needed for execution:\npipeline = Pipeline([\n ('vectorizer', CountVectorizer()), \n ('to_dense', DenseTransformer()), \n ('classifier', GaussianNB())\n])\n\n\nGNBlearn = gnb.fit(X_train_dtm, y_train)\n\nprob_class = gnb.class_prior_\nprint(\"Probability of each class: \")\nprint(data.target_names)\nprint(prob_class)\n\nprint()\n\nfeature_mean = gnb.theta_\nprint(\"Means of attribute of every class: \")\nprint(pd.DataFrame(data = np.c_[feature_mean], columns = data.feature_names))\n\nprint()\n\nfeature_variance = gnb.sigma_\nprint(\"Variance of attribute of every class: \")\nprint(pd.DataFrame(data = np.c_[feature_variance], columns = data.feature_names))\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c517f523ce24d5bed1653db2ba94be787e572dff
| 8,959 |
ipynb
|
Jupyter Notebook
|
week-2/week-2-2-homework.ipynb
|
adrianblanco/lede-algorithms
|
8f26b6ed014ee13cea0dc3f5298384fae37e0926
|
[
"CC-BY-3.0"
] | 166 |
2018-07-18T17:03:12.000Z
|
2022-03-04T19:07:46.000Z
|
week-2/week-2-2-homework.ipynb
|
103percent/lede-algorithms
|
16c504348c94235e524b42ab5bd407e335d48e2a
|
[
"CC-BY-3.0"
] | null | null | null |
week-2/week-2-2-homework.ipynb
|
103percent/lede-algorithms
|
16c504348c94235e524b42ab5bd407e335d48e2a
|
[
"CC-BY-3.0"
] | 51 |
2018-07-18T21:47:14.000Z
|
2021-05-14T14:30:17.000Z
| 38.78355 | 362 | 0.596718 |
[
[
[
"## Week 2-2 - Visualizing General Social Survey data\n\nYour mission is to analyze a data set of social attitudes by turning it into vectors, then visualizing the result.\n\n### 1. Choose a topic and get your data\n\nWe're going to be working with data from the General Social Survey, which asks Americans thousands of questions ever year, over decades. This is an enormous data set and there have been very many stories written from its data. The first thing you need to do is decide which questions and which years you are going to try to analyze.\n\nUse their [data explorer](https://gssdataexplorer.norc.org/) to see what's available, and ultimately download an Excel file with the data. \n\n- Click the `Search Varibles` button.\n- You will need at least a dozen or two related variables. Try selecting some using their `Filter by Module / Subject` interface.\n- When you've made your selection, click the `+ All` button to add all listed variables, then choose `Extract Data` under the `Actions` menu.\n- Then you have a multi-step process. Step 1 is just naming your extract\n- Step 2: select variables *again!* Click `Add All` in the upper right of the \"Variable Cart\" in the \"Choose Variables\" step.\n- Step 3: Skip it. You could use this to filter the data in various ways. \n- Step 4: Click `Select certain years` to pick one year of data, then check `Excel Workbook (data + metadata)` as the output format.\n- Click `Create Extract` and wait a minute or two on the \"Extracts\" page until the spinner stops and turns into a download link.\n\nYou'll end up with an compressed file in tar.gz format, which you should be able to decompressed by double-clicking on it. Inside is an Excel file. Open it in Excel (or your favorite spreadsheet program) and resave it as a CSV.\n\n\n\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.decomposition import PCA\nimport matplotlib.pyplot as plt\nimport math",
"_____no_output_____"
],
[
"# load your data set here\ngss = pd.read_csv(...)\n",
"_____no_output_____"
]
],
[
[
"### 3. Turn people into vectors\nI know, it sounds cruel. We're trying to group people, but computers can only group vectors, so there we are. \n\nTranslating the spreadsheet you downloaded from GSS Explorer into vectors is a multistep process. Generally, each row of the spreadsheet is one person, and each column is one qeustion. \n\n- First, we need to throw away any extra rows and columns: headers, questions with no data, etc.\n- Many GSS questions already have numerical answers. These usually don't require any work.\n- But you'll need to turn categorical variables into numbers.\n\nBasically, you have to remove or convert every value that isn't a number. Because this is survey data, we can turn most questions into an integer scale. The cleanup might use functions like this:",
"_____no_output_____"
]
],
[
[
"# drop the last two rows, which are just notes and do not contain data\ngss = gss.iloc[0:-2,:]\n",
"_____no_output_____"
],
[
"# Here's a bunch of cleanup code. It probably won't be quite right for your data.\n# The goal is to convert all values to small integers, to make them easy to plot with colors below.\n\n# First, replace all of the \"Not Applicable\" values with None\ngss = gss.replace({'Not applicable' : None, \n 'No answer' : None, \n 'Don\\'t know' : None,\n 'Dont know' : None})\n\n# Manually code likert scales \ngss = gss.replace({'Strongly disagree':-2, 'Disagree':-1, 'Neither agree nor disagree':0, 'Agree':1, 'Strongly agree':2})\n\n# yes/no -> 1/-1\ngss = gss.replace({'Yes':1, 'No':-1})\n\n# Some frequency scales should have numeric coding too\ngss = gss.replace({'Not at all in the past year' : 0, \n 'Once in the past year' : 1,\n 'At least 2 or 3 times in the past year' : 2, \n 'Once a month' : 3,\n 'Once a week' : 4,\n 'More than once a week':5}) \n\ngss = gss.replace({ 'Never or almost never' : 0, \n 'Once in a while' : 1,\n 'Some days' : 2, \n 'Most days' : 3,\n 'Every day' : 4,\n 'Many times a day' : 5}) \n\n# Drop some columns that don't contain useful information\ngss = gss.drop(['Respondent id number',\n 'Ballot used for interview',\n 'Gss year for this respondent'], axis=1)\n\n# Turn invalid numeric entries into zeros\ngss = gss.replace({np.nan:0.0})\n",
"_____no_output_____"
]
],
[
[
"### 4. Plot those vectors!\nFor this assignment, we'll use the PCA projection algorithm to make 2D (or 3D!) pictures of the set of vectors. Once you have the vectors, it should be easy to make a PCA plot using the steps we followed in class.\n ",
"_____no_output_____"
]
],
[
[
"# make a PCA plot here\n",
"_____no_output_____"
]
],
[
[
"### 5. Add color to help interpretation\nCongratulations, you have a picture of a blob of dots. Hopefully, that blob has some structure representing clusters of similar people. To understand what the plot is telling us, it really helps to take one of the original variables and use it to assign colors to the points. \n\nSo: pick one of the questions that you think will separate people into natural groups. Use it to set the color of the dots in your scatterplot. By repeating this with different questions, or combining questions (like two binary questions giving rise to a four color scheme) you should be able to figure out what the structure of the clusters represents. \n",
"_____no_output_____"
]
],
[
[
"# map integer columns to colors\ndef col2colors(colvals):\n # gray for zero, then a rainbow.\n # This is set up so yes = 1 = red and no = -1 = indigo\n my_colors = ['gray', 'red','orange','yellow','lightgreen','cyan','blue','indigo']\n \n # We may have integers higher than len(my_colors) or less than zero\n # So use the mod operator (%) to make values \"wrap around\" when they go off the end of the list\n column_ints = colvals.astype(int) % len(my_colors)\n \n # map each index to the corresponding color\n return column_ints.apply(lambda x: my_colors[x])\n\n",
"_____no_output_____"
],
[
"# Make a plot using colors from a particular column\n\n# Make another plot using colors from another column\n\n# ... repeat and see if you can figure out what each axis means\n",
"_____no_output_____"
]
],
[
[
"### 6. Tell us what it means?\nWhat did you learn from this exercise? Did you find the standard left-right divide? Or urban-rural? Early adopters vs. luddites? People with vs. without children? \n\nWhat did you learn? What could end up in a story? \n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
c517f9aa7c566341c6dff11d76b3a7f167a1ab69
| 3,503 |
ipynb
|
Jupyter Notebook
|
data-extraction/python-spark/LaunchSparkJobs.ipynb
|
gabrielclimb/intro-to-ml-with-kubeflow-examples
|
cc5cf30212a88f1c5c97d4c65e6d35824f468669
|
[
"Apache-2.0"
] | 150 |
2019-01-13T09:47:34.000Z
|
2022-03-27T18:43:39.000Z
|
data-extraction/python-spark/LaunchSparkJobs.ipynb
|
gabrielclimb/intro-to-ml-with-kubeflow-examples
|
cc5cf30212a88f1c5c97d4c65e6d35824f468669
|
[
"Apache-2.0"
] | 28 |
2019-03-20T09:31:19.000Z
|
2021-11-13T10:16:58.000Z
|
data-extraction/python-spark/LaunchSparkJobs.ipynb
|
gabrielclimb/intro-to-ml-with-kubeflow-examples
|
cc5cf30212a88f1c5c97d4c65e6d35824f468669
|
[
"Apache-2.0"
] | 63 |
2019-01-13T01:45:54.000Z
|
2022-03-18T04:28:56.000Z
| 24.326389 | 103 | 0.460748 |
[
[
[
"!pip3 install --upgrade --user kfp",
"_____no_output_____"
],
[
"import kfp",
"_____no_output_____"
],
[
"import kfp.dsl as dsl",
"_____no_output_____"
],
[
"# Use Kubeflow's built in Spark operator\n#tag::launch_operator[]\nresource = {\n \"apiVersion\": \"sparkoperator.k8s.io/v1beta2\",\n \"kind\": \"SparkApplication\",\n \"metadata\": {\n \"name\": \"boop\",\n \"namespace\": \"kubeflow\"\n },\n \"spec\": {\n \"type\": \"Python\",\n \"mode\": \"cluster\",\n \"image\": \"gcr.io/boos-demo-projects-are-rad/kf-steps/kubeflow/myspark\",\n \"imagePullPolicy\": \"Always\",\n \"mainApplicationFile\": \"local:///job/job.py\", # See the Dockerfile OR use GCS/S3/...\n \"sparkVersion\": \"2.4.5\",\n \"restartPolicy\": {\n \"type\": \"Never\"\n },\n \"driver\": {\n \"cores\": 1, \n \"coreLimit\": \"1200m\", \n \"memory\": \"512m\", \n \"labels\": {\n \"version\": \"2.4.5\", \n }, \n \"serviceAccount\": \"spark-operatoroperator-sa\", # also try spark-operatoroperator-sa\n },\n \"executor\": {\n \"cores\": 1,\n \"instances\": 2,\n \"memory\": \"512m\" \n }, \n \"labels\": {\n \"version\": \"2.4.5\"\n }, \n }\n}\n\[email protected](\n name=\"local Pipeline\",\n description=\"No need to ask why.\"\n)\ndef local_pipeline():\n\n rop = dsl.ResourceOp(\n name=\"boop\",\n k8s_resource=resource,\n action=\"create\",\n success_condition=\"status.applicationState.state == COMPLETED\"\n )\n#end::launch_operator[]\n\nimport kfp.compiler as compiler\n\ncompiler.Compiler().compile(local_pipeline,\"boop.zip\")",
"_____no_output_____"
],
[
"client = kfp.Client()",
"_____no_output_____"
],
[
"my_experiment = client.create_experiment(name='boop-test-2')\nmy_run = client.run_pipeline(my_experiment.id, 'boop-test', \n 'boop.zip')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c517fc100d68b32b259708cfaf81ade6e64ba000
| 260,831 |
ipynb
|
Jupyter Notebook
|
Titanic (2).ipynb
|
hashmat3525/Titanic
|
1a15bbf8afeff7aa522a916653984da4e92bfc8a
|
[
"MIT"
] | 3 |
2019-10-30T08:56:35.000Z
|
2019-10-31T08:50:52.000Z
|
Titanic (2).ipynb
|
hashmat3525/Titanic
|
1a15bbf8afeff7aa522a916653984da4e92bfc8a
|
[
"MIT"
] | null | null | null |
Titanic (2).ipynb
|
hashmat3525/Titanic
|
1a15bbf8afeff7aa522a916653984da4e92bfc8a
|
[
"MIT"
] | 1 |
2019-10-31T08:51:10.000Z
|
2019-10-31T08:51:10.000Z
| 101.451186 | 49,656 | 0.748462 |
[
[
[
"import numpy as np\nimport pandas as pd\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import preprocessing\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn import svm\nfrom sklearn.metrics import precision_score, recall_score\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"#reading train.csv\ndata = pd.read_csv('train.csv')\n# show the actaul data\ndata",
"_____no_output_____"
],
[
"# show the first few rows\ndata.head(10)",
"_____no_output_____"
],
[
"# count the null values \nnull_values = data.isnull().sum()\nnull_values",
"_____no_output_____"
],
[
"plt.plot(null_values)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Data Processing",
"_____no_output_____"
]
],
[
[
"def handle_non_numerical_data(df):\n \n columns = df.columns.values\n\n for column in columns:\n text_digit_vals = {}\n def convert_to_int(val):\n return text_digit_vals[val]\n\n #print(column,df[column].dtype)\n if df[column].dtype != np.int64 and df[column].dtype != np.float64:\n \n column_contents = df[column].values.tolist()\n #finding just the uniques\n unique_elements = set(column_contents)\n # great, found them. \n x = 0\n for unique in unique_elements:\n if unique not in text_digit_vals:\n text_digit_vals[unique] = x\n x+=1\n df[column] = list(map(convert_to_int,df[column]))\n\n return df\n",
"_____no_output_____"
],
[
"y_target = data['Survived']\n# Y_target.reshape(len(Y_target),1)\nx_train = data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare','Embarked', 'Ticket']]\n\nx_train = handle_non_numerical_data(x_train)\nx_train.head()\n",
"c:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\ipykernel_launcher.py:22: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n"
],
[
"fare = pd.DataFrame(x_train['Fare'])\n# Normalizing\nmin_max_scaler = preprocessing.MinMaxScaler()\nnewfare = min_max_scaler.fit_transform(fare)\nx_train['Fare'] = newfare\nx_train",
"c:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"\n"
],
[
"null_values = x_train.isnull().sum()\nnull_values",
"_____no_output_____"
],
[
"plt.plot(null_values)\nplt.show()",
"_____no_output_____"
],
[
"# Fill the NAN values with the median values in the datasets\nx_train['Age'] = x_train['Age'].fillna(x_train['Age'].mean())\nprint(\"Number of NULL values\" , x_train['Age'].isnull().sum())\nprint(x_train.head(3))",
"Number of NULL values 0\n Pclass Age Sex SibSp Parch Fare Embarked Ticket\n0 3 22.0 1 1 0 0.014151 3 315\n1 1 38.0 0 1 0 0.139136 2 68\n2 3 26.0 0 0 0 0.015469 3 620\n"
],
[
"x_train['Sex'] = x_train['Sex'].replace('male', 0)\nx_train['Sex'] = x_train['Sex'].replace('female', 1)\n# print(type(x_train))\ncorr = x_train.corr()\ncorr.style.background_gradient()",
"c:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\nc:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
],
[
"def plot_corr(df,size=10):\n\n\n corr = df.corr()\n fig, ax = plt.subplots(figsize=(size, size))\n ax.matshow(corr)\n plt.xticks(range(len(corr.columns)), corr.columns);\n plt.yticks(range(len(corr.columns)), corr.columns);\n# plot_corr(x_train)\nx_train.corr()\ncorr.style.background_gradient()",
"_____no_output_____"
],
[
"# Dividing the data into train and test data set\nX_train, X_test, Y_train, Y_test = train_test_split(x_train, y_target, test_size = 0.4, random_state = 40)",
"_____no_output_____"
],
[
"clf = RandomForestClassifier()\nclf.fit(X_train, Y_train)",
"c:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\sklearn\\ensemble\\forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.\n \"10 in version 0.20 to 100 in 0.22.\", FutureWarning)\n"
],
[
"print(clf.predict(X_test))\nprint(\"Accuracy: \",clf.score(X_test, Y_test))",
"[0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 1 1 0 0 1 0 0 0 0 0 0 1 0\n 0 1 1 0 0 0 1 1 0 0 0 0 0 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 1 1 0 0 1 1 0 0\n 0 0 0 1 0 0 1 0 1 0 1 1 1 1 1 1 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0\n 1 0 0 0 0 1 0 0 1 0 0 1 0 1 1 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 0 0 0 1 1 0 0\n 1 0 0 0 1 1 0 0 1 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 1 0\n 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0 1 0 0 1 0 1 0 1 0 1 0 0 0 0 0 0 1 1 1 1 1\n 0 1 0 1 1 0 0 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0\n 1 0 0 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0\n 0 0 0 0 0 0 1 1 0 1 0 1 1 0 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 0 0 0 1 0 1 0 1\n 1 0 0 1 0 1 1 0 0 1 1 0 1 0 0 0 0 1 1 1 1 0 1 0]\nAccuracy: 0.803921568627451\n"
],
[
"## Testing the model.\ntest_data = pd.read_csv('test.csv')\ntest_data.head(3)\n# test_data.isnull().sum()",
"_____no_output_____"
],
[
"### Preprocessing on the test data\ntest_data = test_data[['Pclass', 'Age', 'Sex', 'SibSp', 'Parch', 'Fare', 'Ticket', 'Embarked']]\ntest_data = handle_non_numerical_data(test_data)\n\nfare = pd.DataFrame(test_data['Fare'])\nmin_max_scaler = preprocessing.MinMaxScaler()\nnewfare = min_max_scaler.fit_transform(fare)\ntest_data['Fare'] = newfare\ntest_data['Fare'] = test_data['Fare'].fillna(test_data['Fare'].median())\ntest_data['Age'] = test_data['Age'].fillna(test_data['Age'].median())\ntest_data['Sex'] = test_data['Sex'].replace('male', 0)\ntest_data['Sex'] = test_data['Sex'].replace('female', 1)\nprint(test_data.head())\n",
" Pclass Age Sex SibSp Parch Fare Ticket Embarked\n0 3 34.5 1 0 0 0.015282 126 0\n1 3 47.0 0 1 0 0.013663 123 2\n2 2 62.0 1 0 0 0.018909 181 0\n3 3 27.0 1 0 0 0.016908 218 2\n4 3 22.0 0 1 1 0.023984 21 2\n"
],
[
"print(clf.predict(test_data))",
"[0 0 0 1 1 0 1 0 0 0 0 0 1 0 1 1 0 0 0 1 0 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0\n 0 1 1 0 1 0 1 1 0 1 0 1 0 1 0 1 1 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 0 0 0 1\n 1 0 0 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0\n 1 1 0 1 0 0 1 0 1 1 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0\n 1 0 1 0 0 0 0 0 1 0 0 1 1 1 1 0 0 0 0 0 1 0 0 0 0 0 0 1 1 0 1 1 0 0 1 0 1\n 0 1 0 0 0 0 0 1 0 1 0 0 0 0 0 1 1 0 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 1 0\n 1 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1\n 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 1 0 0 0 0 0 0 1 1 0 0 0 0\n 1 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 1 1 0\n 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 0 0 0 0 0 1 0 0 1 0 1 1 1 1 0 0 1 1 0\n 0 1 0 0 1 1 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 0 1 0 1 1 0 0 0\n 0 1 1 1 1 1 0 1 0 0 0]\n"
],
[
"from sklearn.model_selection import cross_val_predict\npredictions = cross_val_predict(clf, X_train, Y_train, cv=3)\nprint(\"Precision:\", precision_score(Y_train, predictions))\nprint(\"Recall:\",recall_score(Y_train, predictions))",
"Precision: 0.7653631284916201\nRecall: 0.6618357487922706\n"
],
[
"from sklearn.metrics import precision_recall_curve\n\n# getting the probabilities of our predictions\ny_scores = clf.predict_proba(X_train)\ny_scores = y_scores[:,1]\n\nprecision, recall, threshold = precision_recall_curve(Y_train, y_scores)\ndef plot_precision_and_recall(precision, recall, threshold):\n plt.plot(threshold, precision[:-1], \"r-\", label=\"precision\", linewidth=5)\n plt.plot(threshold, recall[:-1], \"b\", label=\"recall\", linewidth=5)\n plt.xlabel(\"threshold\", fontsize=19)\n plt.legend(loc=\"upper right\", fontsize=19)\n plt.ylim([0, 1])\n\nplt.figure(figsize=(14, 7))\nplot_precision_and_recall(precision, recall, threshold)\nplt.axis([0.3,0.8,0.8,1])\nplt.show()",
"_____no_output_____"
],
[
"def plot_precision_vs_recall(precision, recall):\n plt.plot(recall, precision, \"g--\", linewidth=2.5)\n plt.ylabel(\"recall\", fontsize=19)\n plt.xlabel(\"precision\", fontsize=19)\n plt.axis([0, 1.5, 0, 1.5])\n\nplt.figure(figsize=(14, 7))\nplot_precision_vs_recall(precision, recall)\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_predict\nfrom sklearn.metrics import confusion_matrix\npredictions = cross_val_predict(clf, X_train, Y_train, cv=3)\nconfusion_matrix(Y_train, predictions)",
"_____no_output_____"
]
],
[
[
"True positive: 293 (We predicted a positive result and it was positive)\nTrue negative: 143 (We predicted a negative result and it was negative)\nFalse positive: 34 (We predicted a positive result and it was negative)\nFalse negative: 64 (We predicted a negative result and it was positive)",
"_____no_output_____"
],
[
"### data v",
"_____no_output_____"
]
],
[
[
"import seaborn as sns\nsurvived = 'survived'\nnot_survived = 'not survived'\nfig, axes = plt.subplots(nrows=1, ncols=2,figsize=(10, 4))\nwomen = data[data['Sex']=='female']\nmen = data[data['Sex']=='male']\nax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[0], kde =False)\nax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[0], kde =False)\nax.legend()\nax.set_title('Female')\nax = sns.distplot(men[men['Survived']==1].Age.dropna(), bins=18, label = survived, ax = axes[1], kde = False)\nax = sns.distplot(men[men['Survived']==0].Age.dropna(), bins=40, label = not_survived, ax = axes[1], kde = False)\nax.legend()\n_ = ax.set_title('Male')",
"_____no_output_____"
],
[
"FacetGrid = sns.FacetGrid(data, row='Embarked', size=4.5, aspect=1.6)\nFacetGrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette=None, order=None, hue_order=None )\nFacetGrid.add_legend()",
"c:\\users\\nemgeree armanonah\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\seaborn\\axisgrid.py:230: UserWarning: The `size` paramter has been renamed to `height`; please update your code.\n warnings.warn(msg, UserWarning)\n"
]
],
[
[
"#### Embarked seems to be correlated with survival, depending on the gender.\nWomen on port Q and on port S have a higher chance of survival. The inverse is true, if they are at port C. Men have a high survival probability if they are on port C, but a low probability if they are on port Q or S.",
"_____no_output_____"
]
],
[
[
"sns.barplot('Pclass', 'Survived', data=data, color=\"darkturquoise\")\nplt.show()",
"_____no_output_____"
],
[
"sns.barplot('Embarked', 'Survived', data=data, color=\"teal\")\nplt.show()",
"_____no_output_____"
],
[
"sns.barplot('Sex', 'Survived', data=data, color=\"aquamarine\")\nplt.show()",
"_____no_output_____"
],
[
"print(clf.predict(X_test))\nprint(\"Accuracy: \",clf.score(X_test, Y_test))",
"[0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 0 1 0 0 0 1 1 1 1 1 0 0 1 0 0 0 0 0 0 1 0\n 0 1 1 0 0 0 1 1 0 0 0 0 0 1 0 1 1 1 1 0 1 1 0 0 0 0 1 0 1 1 1 0 0 1 1 0 0\n 0 0 0 1 0 0 1 0 1 0 1 1 1 1 1 1 0 1 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0\n 1 0 0 0 0 1 0 0 1 0 0 1 0 1 1 0 0 0 1 1 1 1 0 0 0 1 0 0 1 0 0 0 0 1 1 0 0\n 1 0 0 0 1 1 0 0 1 0 1 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 1 0\n 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 0 1 0 0 1 0 1 0 1 0 1 0 0 0 0 0 0 1 1 1 1 1\n 0 1 0 1 1 0 0 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0\n 1 0 0 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0\n 0 0 0 0 0 0 1 1 0 1 0 1 1 0 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 0 0 0 1 0 1 0 1\n 1 0 0 1 0 1 1 0 0 1 1 0 1 0 0 0 0 1 1 1 1 0 1 0]\nAccuracy: 0.803921568627451\n"
],
[
"data",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
c517fe386478a79f09cd3eeff8b7f940388ad3b8
| 279,337 |
ipynb
|
Jupyter Notebook
|
Real_world_examples/Scalable_machine_learning/1_Extract_training_data.ipynb
|
RichardScottOZ/dea-notebooks
|
76f206cfdbbaf38f10d393b985eb1220fa977f3f
|
[
"Apache-2.0"
] | 1 |
2021-08-16T02:10:46.000Z
|
2021-08-16T02:10:46.000Z
|
Real_world_examples/Scalable_machine_learning/1_Extract_training_data.ipynb
|
RichardScottOZ/dea-notebooks
|
76f206cfdbbaf38f10d393b985eb1220fa977f3f
|
[
"Apache-2.0"
] | null | null | null |
Real_world_examples/Scalable_machine_learning/1_Extract_training_data.ipynb
|
RichardScottOZ/dea-notebooks
|
76f206cfdbbaf38f10d393b985eb1220fa977f3f
|
[
"Apache-2.0"
] | null | null | null | 23.722887 | 687 | 0.347623 |
[
[
[
"# Extracting training data from the ODC <img align=\"right\" src=\"../../Supplementary_data/dea_logo.jpg\">\n\n* [**Sign up to the DEA Sandbox**](https://docs.dea.ga.gov.au/setup/sandbox.html) to run this notebook interactively from a browser\n* **Compatibility:** Notebook currently compatible with the `DEA Sandbox` environment\n* **Products used:** \n[ls8_nbart_geomedian_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_geomedian_annual/extents),\n[ls8_nbart_tmad_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_tmad_annual/extents),\n[fc_percentile_albers_annual](https://explorer.sandbox.dea.ga.gov.au/products/fc_percentile_albers_annual/extents)",
"_____no_output_____"
],
[
"## Background\n\n**Training data** is the most important part of any supervised machine learning workflow. The quality of the training data has a greater impact on the classification than the algorithm used. Large and accurate training data sets are preferable: increasing the training sample size results in increased classification accuracy ([Maxell et al 2018](https://www.tandfonline.com/doi/full/10.1080/01431161.2018.1433343)). A review of training data methods in the context of Earth Observation is available [here](https://www.mdpi.com/2072-4292/12/6/1034) \n\nWhen creating training labels, be sure to capture the **spectral variability** of the class, and to use imagery from the time period you want to classify (rather than relying on basemap composites). Another common problem with training data is **class imbalance**. This can occur when one of your classes is relatively rare and therefore the rare class will comprise a smaller proportion of the training set. When imbalanced data is used, it is common that the final classification will under-predict less abundant classes relative to their true proportion.\n\nThere are many platforms to use for gathering training labels, the best one to use depends on your application. GIS platforms are great for collection training data as they are highly flexible and mature platforms; [Geo-Wiki](https://www.geo-wiki.org/) and [Collect Earth Online](https://collect.earth/home) are two open-source websites that may also be useful depending on the reference data strategy employed. Alternatively, there are many pre-existing training datasets on the web that may be useful, e.g. [Radiant Earth](https://www.radiant.earth/) manages a growing number of reference datasets for use by anyone.\n",
"_____no_output_____"
],
[
"## Description\nThis notebook will extract training data (feature layers, in machine learning parlance) from the `open-data-cube` using labelled geometries within a geojson. The default example will use the crop/non-crop labels within the `'data/crop_training_WA.geojson'` file. This reference data was acquired and pre-processed from the USGS's Global Food Security Analysis Data portal [here](https://croplands.org/app/data/search?page=1&page_size=200) and [here](https://e4ftl01.cr.usgs.gov/MEASURES/GFSAD30VAL.001/2008.01.01/).\n\nTo do this, we rely on a custom `dea-notebooks` function called `collect_training_data`, contained within the [dea_tools.classification](../../Tools/dea_tools/classification.py) script. The principal goal of this notebook is to familarise users with this function so they can extract the appropriate data for their use-case. The default example also highlights extracting a set of useful feature layers for generating a cropland mask forWA.\n\n1. Preview the polygons in our training data by plotting them on a basemap\n2. Extract training data from the datacube using `collect_training_data`'s inbuilt feature layer parameters\n3. Extract training data from the datacube using a **custom defined feature layer function** that we can pass to `collect_training_data`\n4. Export the training data to disk for use in subsequent scripts\n\n***",
"_____no_output_____"
],
[
"## Getting started\n\nTo run this analysis, run all the cells in the notebook, starting with the \"Load packages\" cell. ",
"_____no_output_____"
],
[
"### Load packages\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport os\nimport sys\nimport datacube\nimport numpy as np\nimport xarray as xr\nimport subprocess as sp\nimport geopandas as gpd\nfrom odc.io.cgroups import get_cpu_quota\nfrom datacube.utils.geometry import assign_crs\n\nsys.path.append('../../Scripts')\nfrom dea_plotting import map_shapefile\nfrom dea_bandindices import calculate_indices\nfrom dea_classificationtools import collect_training_data\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")",
"/env/lib/python3.6/site-packages/geopandas/_compat.py:88: UserWarning: The Shapely GEOS version (3.7.2-CAPI-1.11.0 ) is incompatible with the GEOS version PyGEOS was compiled with (3.9.0-CAPI-1.16.2). Conversions between both will be slow.\n shapely_geos_version, geos_capi_version_string\n/env/lib/python3.6/site-packages/datacube/storage/masking.py:8: DeprecationWarning: datacube.storage.masking has moved to datacube.utils.masking\n category=DeprecationWarning)\n"
]
],
[
[
"## Analysis parameters\n\n* `path`: The path to the input vector file from which we will extract training data. A default geojson is provided.\n* `field`: This is the name of column in your shapefile attribute table that contains the class labels. **The class labels must be integers**\n",
"_____no_output_____"
]
],
[
[
"path = 'data/crop_training_WA.geojson' \nfield = 'class'",
"_____no_output_____"
]
],
[
[
"### Find the number of CPUs",
"_____no_output_____"
]
],
[
[
"ncpus = round(get_cpu_quota())\nprint('ncpus = ' + str(ncpus))",
"ncpus = 7\n"
]
],
[
[
"## Preview input data\n\nWe can load and preview our input data shapefile using `geopandas`. The shapefile should contain a column with class labels (e.g. 'class'). These labels will be used to train our model. \n\n> Remember, the class labels **must** be represented by `integers`.\n",
"_____no_output_____"
]
],
[
[
"# Load input data shapefile\ninput_data = gpd.read_file(path)\n\n# Plot first five rows\ninput_data.head()",
"_____no_output_____"
],
[
"# Plot training data in an interactive map\nmap_shapefile(input_data, attribute=field)",
"_____no_output_____"
]
],
[
[
"## Extracting training data\n\nThe function `collect_training_data` takes our geojson containing class labels and extracts training data (features) from the datacube over the locations specified by the input geometries. The function will also pre-process our training data by stacking the arrays into a useful format and removing any `NaN` or `inf` values. \n\n`Collect_training_data` has the ability to generate many different types of **feature layers**. Relatively simple layers can be calculated using pre-defined parameters within the function, while more complex layers can be computed by passing in a `custom_func`. To begin with, let's try generating feature layers using the pre-defined methods.\n\nThe in-built feature layer parameters are described below:\n\n* `product`: The name of the product to extract from the datacube. In this example we use a Landsat 8 geomedian composite from 2019, `'ls8_nbart_geomedian_annual'`\n* `time`: The time range from which to extract data\n* `calc_indices`: This parameter provides a method for calculating a number of remote sensing indices (e.g. `['NDWI', 'NDVI']`). Any of the indices found in the [dea_tools.bandindices](../../Tools/dea_tools/bandindices.py) script can be used here\n* `drop`: If this variable is set to `True`, and 'calc_indices' are supplied, the spectral bands will be dropped from the dataset leaving only the band indices as data variables in the dataset.\n* `reduce_func`: The classification models we're applying here require our training data to be in two dimensions (ie. `x` & `y`). If our data has a time-dimension (e.g. if we load in an annual time-series of satellite images) then we need to collapse the time dimension. `reduce_func` is simply the summary statistic used to collapse the temporal dimension. Options are 'mean', 'median', 'std', 'max', 'min', and 'geomedian'. In the default example we are loading a geomedian composite, so there is no time dimension to reduce.\n* `zonal_stats`: An optional string giving the names of zonal statistics to calculate across each polygon. Default is `None` (all pixel values are returned). Supported values are 'mean', 'median', 'max', and 'min'.\n* `return_coords` : If `True`, then the training data will contain two extra columns 'x_coord' and 'y_coord' corresponding to the x,y coordinate of each sample. This variable can be useful for handling spatial autocorrelation between samples later on in the ML workflow when we conduct k-fold cross validation.\n\n> Note: `collect_training_data` also has a number of additional parameters for handling ODC I/O read failures, where polygons that return an excessive number of null values can be resubmitted to the multiprocessing queue. Check out the [docs](https://github.com/GeoscienceAustralia/dea-notebooks/blob/68d3526f73779f3316c5e28001c69f556c0d39ae/Tools/dea_tools/classification.py#L661) to learn more. \n\nIn addition to the parameters required for `collect_training_data`, we also need to set up a few parameters for the Open Data Cube query, such as `measurements` (the bands to load from the satellite), the `resolution` (the cell size), and the `output_crs` (the output projection). ",
"_____no_output_____"
]
],
[
[
"# Set up our inputs to collect_training_data\nproducts = ['ls8_nbart_geomedian_annual']\ntime = ('2014')\nreduce_func = None\ncalc_indices = ['NDVI', 'MNDWI']\ndrop = False\nzonal_stats = 'median'\nreturn_coords = True\n\n# Set up the inputs for the ODC query\nmeasurements = ['blue', 'green', 'red', 'nir', 'swir1', 'swir2']\nresolution = (-30, 30)\noutput_crs = 'epsg:3577'",
"_____no_output_____"
]
],
[
[
"Generate a datacube query object from the parameters above:",
"_____no_output_____"
]
],
[
[
"query = {\n 'time': time,\n 'measurements': measurements,\n 'resolution': resolution,\n 'output_crs': output_crs,\n 'group_by': 'solar_day',\n}",
"_____no_output_____"
]
],
[
[
"Now let's run the `collect_training_data` function. We will limit this run to only a subset of all samples (first 100) as here we are only demonstrating the use of the function. Futher on in the notebook we will rerun this function but with all the polygons in the training data.\n\n> **Note**: With supervised classification, its common to have many, many labelled geometries in the training data. `collect_training_data` can parallelize across the geometries in order to speed up the extracting of training data. Setting `ncpus>1` will automatically trigger the parallelization. However, its best to set `ncpus=1` to begin with to assist with debugging before triggering the parallelization. You can also limit the number of polygons to run when checking code. For example, passing in `gdf=input_data[0:5]` will only run the code over the first 5 polygons.",
"_____no_output_____"
]
],
[
[
"column_names, model_input = collect_training_data(gdf=input_data[0:100],\n products=products,\n dc_query=query,\n ncpus=ncpus,\n return_coords=return_coords,\n field=field,\n calc_indices=calc_indices,\n reduce_func=reduce_func,\n drop=drop,\n zonal_stats=zonal_stats)",
"Calculating indices: ['NDVI', 'MNDWI']\nTaking zonal statistic: median\nCollecting training data in parallel mode\n"
]
],
[
[
"The function returns two numpy arrays, the first (`column_names`) contains a list of the names of the feature layers we've computed:",
"_____no_output_____"
]
],
[
[
"print(column_names)",
"['class', 'blue', 'green', 'red', 'nir', 'swir1', 'swir2', 'NDVI', 'MNDWI', 'x_coord', 'y_coord']\n"
]
],
[
[
"The second array (`model_input`) contains the data from our labelled geometries. The first item in the array is the class integer (e.g. in the default example 1. 'crop', or 0. 'noncrop'), the second set of items are the values for each feature layer we computed:",
"_____no_output_____"
]
],
[
[
"print(np.array_str(model_input, precision=2, suppress_small=True))",
"[[ 1. 809. 1249. ... -0.45 -1447515.\n -3510225. ]\n [ 1. 950. 1506. ... -0.4 -1430025.\n -3532245. ]\n [ 1. 1089. 1526. ... -0.45 -1368555.\n -3603855. ]\n ...\n [ 1. 843. 1171. ... -0.47 -1300185.\n -3646395. ]\n [ 1. 827. 1120. ... -0.52 -1544385.\n -3460635. ]\n [ 1. 816. 1087. ... -0.46 -1305465.\n -3660765. ]]\n"
]
],
[
[
"## Custom feature layers\n\nThe feature layers that are most relevant for discriminating the classes of your classification problem may be more complicated than those provided in the `collect_training_data` function. In this case, we can pass a custom feature layer function through the `custom_func` parameter. Below, we will use a custom function to recollect training data (overwriting the previous example above). \n\n* `custom_func`: A custom function for generating feature layers. If this parameter is set, all other options (excluding 'zonal_stats'), will be ignored. The result of the 'custom_func' must be a single xarray dataset containing 2D coordinates (i.e x and y with no time dimension). The custom function has access to the datacube dataset extracted using the `dc_query` params. To load other datasets, you can use the `like=ds.geobox` parameter in `dc.load`\n\nFirst, lets define a custom feature layer function. This function is fairly basic and replicates some of what the `collect_training_data` function can do, but you can build these custom functions as complex as you like. We will calculate some band indices on the Landsat 8 geomedian, append the ternary median aboslute deviation dataset from the same year: [ls8_nbart_tmad_annual](https://explorer.sandbox.dea.ga.gov.au/products/ls8_nbart_tmad_annual/extents), and append fractional cover percentiles for the photosynthetic vegetation band, also from the same year: [fc_percentile_albers_annual](https://explorer.sandbox.dea.ga.gov.au/products/fc_percentile_albers_annual/extents).",
"_____no_output_____"
]
],
[
[
"def custom_reduce_function(ds):\n \n # Calculate some band indices\n da = calculate_indices(ds,\n index=['NDVI', 'LAI', 'MNDWI'],\n drop=False,\n collection='ga_ls_2')\n \n # Connect to datacube to add TMADs product\n dc = datacube.Datacube(app='custom_feature_layers')\n \n # Add TMADs dataset\n tmad = dc.load(product='ls8_nbart_tmad_annual',\n measurements=['sdev','edev','bcdev'],\n like=ds.geobox, #will match geomedian extent\n time='2014' #same as geomedian\n )\n \n # Add Fractional cover percentiles\n fc = dc.load(product='fc_percentile_albers_annual',\n measurements=['PV_PC_10','PV_PC_50','PV_PC_90'], #only the PV band\n like=ds.geobox, #will match geomedian extent\n time='2014' #same as geomedian\n )\n\n # Merge results into single dataset \n result = xr.merge([da, tmad, fc],compat='override')\n\n return result.squeeze()",
"_____no_output_____"
]
],
[
[
"Now, we can pass this function to `collect_training_data`. We will redefine our intial parameters to align with the new custom function. Remember, passing in a `custom_func` to `collect_training_data` means many of the other feature layer parameters are ignored.\n",
"_____no_output_____"
]
],
[
[
"# Set up our inputs to collect_training_data\nproducts = ['ls8_nbart_geomedian_annual']\ntime = ('2014')\nzonal_stats = 'median'\nreturn_coords = True\n\n# Set up the inputs for the ODC query\nmeasurements = ['blue', 'green', 'red', 'nir', 'swir1', 'swir2']\n\nresolution = (-30, 30)\noutput_crs = 'epsg:3577'",
"_____no_output_____"
],
[
"# Generate a new datacube query object\nquery = {\n 'time': time,\n 'measurements': measurements,\n 'resolution': resolution,\n 'output_crs': output_crs,\n 'group_by': 'solar_day',\n}",
"_____no_output_____"
]
],
[
[
"Below we collect training data from the datacube using the custom function. This will take around 5-6 minutes to run all 430 samples on the default sandbox as it only has two cpus.",
"_____no_output_____"
]
],
[
[
"%%time\ncolumn_names, model_input = collect_training_data(\n gdf=input_data,\n products=products,\n dc_query=query,\n ncpus=ncpus,\n return_coords=return_coords,\n field=field,\n zonal_stats=zonal_stats,\n custom_func=custom_reduce_function)",
"Reducing data using user supplied custom function\nTaking zonal statistic: median\nCollecting training data in parallel mode\n"
],
[
"print(column_names)\nprint('')\nprint(np.array_str(model_input, precision=2, suppress_small=True))",
"['class', 'blue', 'green', 'red', 'nir', 'swir1', 'swir2', 'NDVI', 'LAI', 'MNDWI', 'sdev', 'edev', 'bcdev', 'PV_PC_10', 'PV_PC_50', 'PV_PC_90', 'x_coord', 'y_coord']\n\n[[ 1. 1005. 1464. ... 68. -1393035. -3614685.]\n [ 1. 952. 1407. ... 71. -1319175. -3597135.]\n [ 1. 1089. 1526. ... 69. -1368555. -3603855.]\n ...\n [ 0. 579. 1070. ... 11. -1690725. -2826555.]\n [ 0. 667. 1049. ... 22. -516825. -3463935.]\n [ 0. 519. 744. ... 48. -698085. -1657005.]]\n"
]
],
[
[
"## Separate coordinate data\n\nBy setting `return_coords=True` in the `collect_training_data` function, our training data now has two extra columns called `x_coord` and `y_coord`. We need to separate these from our training dataset as they will not be used to train the machine learning model. Instead, these variables will be used to help conduct Spatial K-fold Cross validation (SKVC) in the notebook `3_Evaluate_optimize_fit_classifier`. For more information on why this is important, see this [article](https://www.tandfonline.com/doi/abs/10.1080/13658816.2017.1346255?journalCode=tgis20).",
"_____no_output_____"
]
],
[
[
"# Select the variables we want to use to train our model\ncoord_variables = ['x_coord', 'y_coord']\n\n# Extract relevant indices from the processed shapefile\nmodel_col_indices = [column_names.index(var_name) for var_name in coord_variables]\n\n# Export to coordinates to file\nnp.savetxt(\"results/training_data_coordinates.txt\", model_input[:, model_col_indices])\n",
"_____no_output_____"
]
],
[
[
"## Export training data\n\nOnce we've collected all the training data we require, we can write the data to disk. This will allow us to import the data in the next step(s) of the workflow.\n",
"_____no_output_____"
]
],
[
[
"# Set the name and location of the output file\noutput_file = \"results/test_training_data.txt\"",
"_____no_output_____"
],
[
"# Grab all columns except the x-y coords\nmodel_col_indices = [column_names.index(var_name) for var_name in column_names[0:-2]]\n\n# Export files to disk\nnp.savetxt(output_file, model_input[:, model_col_indices], header=\" \".join(column_names[0:-2]), fmt=\"%4f\")",
"_____no_output_____"
]
],
[
[
"## Recommended next steps\n\nTo continue working through the notebooks in this `Scalable Machine Learning on the ODC` workflow, go to the next notebook `2_Inspect_training_data.ipynb`.\n\n1. **Extracting training data from the ODC (this notebook)**\n2. [Inspecting training data](2_Inspect_training_data.ipynb)\n3. [Evaluate, optimize, and fit a classifier](3_Evaluate_optimize_fit_classifier.ipynb)\n4. [Classifying satellite data](4_Classify_satellite_data.ipynb)\n5. [Object-based filtering of pixel classifications](5_Object-based_filtering.ipynb)\n",
"_____no_output_____"
],
[
"***\n\n## Additional information\n\n**License:** The code in this notebook is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0). \nDigital Earth Australia data is licensed under the [Creative Commons by Attribution 4.0](https://creativecommons.org/licenses/by/4.0/) license.\n\n**Contact:** If you need assistance, please post a question on the [Open Data Cube Slack channel](http://slack.opendatacube.org/) or on the [GIS Stack Exchange](https://gis.stackexchange.com/questions/ask?tags=open-data-cube) using the `open-data-cube` tag (you can view previously asked questions [here](https://gis.stackexchange.com/questions/tagged/open-data-cube)).\nIf you would like to report an issue with this notebook, you can file one on [Github](https://github.com/GeoscienceAustralia/dea-notebooks).\n\n**Last modified:** March 2021\n\n**Compatible datacube version:** ",
"_____no_output_____"
]
],
[
[
"print(datacube.__version__)",
"1.8.4.dev52+g07bc51a5\n"
]
],
[
[
"## Tags\nBrowse all available tags on the DEA User Guide's [Tags Index](https://docs.dea.ga.gov.au/genindex.html)",
"_____no_output_____"
]
],
[
[
"**Tags** :index:`Landsat 8 geomedian`, :index:`Landsat 8 TMAD`, :index:`machine learning`, :index:`collect_training_data`, :index:`Fractional Cover`",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
]
] |
c51808d0deb959110afeed7532d9ec4043b16447
| 6,581 |
ipynb
|
Jupyter Notebook
|
matplotlib/bar/bar.ipynb
|
ageller/IDEAS_FSS-Vis_2017
|
e026e2a02f12fd6b69d49c6d55c7de79c9e766a4
|
[
"MIT"
] | 1 |
2017-09-26T19:05:46.000Z
|
2017-09-26T19:05:46.000Z
|
matplotlib/bar/bar.ipynb
|
ageller/IDEAS_FSS-Vis_2017
|
e026e2a02f12fd6b69d49c6d55c7de79c9e766a4
|
[
"MIT"
] | null | null | null |
matplotlib/bar/bar.ipynb
|
ageller/IDEAS_FSS-Vis_2017
|
e026e2a02f12fd6b69d49c6d55c7de79c9e766a4
|
[
"MIT"
] | null | null | null | 26.011858 | 113 | 0.518158 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib\nfrom matplotlib import pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Read in the data\n\n*I'm using pandas*",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('bar.csv')\ndata",
"_____no_output_____"
]
],
[
[
"## Here is the default bar chart from python",
"_____no_output_____"
]
],
[
[
"f,ax = plt.subplots()\n\nind = np.arange(len(data)) # the x locations for the bars\nwidth = 0.5 # the width of the bars\nrects = ax.bar(ind, data['Value'], width)",
"_____no_output_____"
]
],
[
[
"## Add some labels",
"_____no_output_____"
]
],
[
[
"f,ax = plt.subplots()\n\nind = np.arange(len(data)) # the x locations for the bars\nwidth = 0.5 # the width of the bars\nrects = ax.bar(ind, data['Value'], width)\n\n# add some text for labels, title and axes ticks\nax.set_ylabel('Percent')\nax.set_title('Percentage of Poor Usage')\nax.set_xticks(ind)\nax.set_xticklabels(data['Label'])\n",
"_____no_output_____"
]
],
[
[
"## Rotate the plot and add gridlines",
"_____no_output_____"
]
],
[
[
"f,ax = plt.subplots()\n\nind = np.arange(len(data)) # the x locations for the bars\nwidth = 0.5 # the width of the bars\nrects = ax.barh(ind, data['Value'], width, zorder=2)\n\n# add some text for labels, title and axes ticks\nax.set_xlabel('Percent')\nax.set_title('Percentage of Poor Usage')\nax.set_yticks(ind)\nax.set_yticklabels(data['Label'])\n\n#add a grid behind the plot\nax.grid(color='gray', linestyle='-', linewidth=1, zorder = 1)\n",
"_____no_output_____"
]
],
[
[
"## Sort the data, and add the percentage values to each bar",
"_____no_output_____"
]
],
[
[
"f,ax = plt.subplots()\n\n#sort the data (nice aspect of pandas dataFrames)\ndata.sort_values('Value', inplace=True)\n\nind = np.arange(len(data)) # the x locations for the bars\nwidth = 0.5 # the width of the bars\nrects = ax.barh(ind, data['Value'], width, zorder=2)\n\n# add some text for labels, title and axes ticks\nax.set_xlabel('Percent')\nax.set_title('Percentage of Poor Usage')\nax.set_yticks(ind)\nax.set_yticklabels(data['Label'])\n\n#add a grid behind the plot\nax.grid(color='gray', linestyle='-', linewidth=1, zorder = 1)\n\n#I grabbed this from here : https://matplotlib.org/examples/api/barchart_demo.html\n#and tweaked it slightly \nfor r in rects:\n h = r.get_height()\n w = r.get_width()\n y = r.get_y()\n if (w > 1):\n x = w - 0.5\n else:\n x = w + 0.5\n ax.text(x, y ,'%.1f%%' % w, ha='center', va='bottom', zorder = 3) \n \n",
"_____no_output_____"
]
],
[
[
"## Clean this up a bit\n* I don't want the grid lines anymore\n* Make the font larger\n* Let's change the colors, and highlight one of them\n* Save the plot",
"_____no_output_____"
]
],
[
[
"#this will change the font globally, but you could also change the fontsize for each label independently\nfont = {'size' : 20}\nmatplotlib.rc('font', **font) \n\nf,ax = plt.subplots(figsize=(10,8))\n\n#sort the data (nice aspect of pandas dataFrames)\ndata.sort_values('Value', inplace=True)\n\nind = np.arange(len(data)) # the x locations for the bars\nwidth = 0.5 # the width of the bars\nrects = ax.barh(ind, data['Value'], width, zorder=2)\n\n# add some text for labels, title and axes ticks\nax.set_title('Percentage of Poor Usage', fontsize = 30)\nax.set_yticks(ind)\nax.set_yticklabels(data['Label'])\n\n#remove all the axes, ticks and lower x label\naoff = ['right', 'left', 'top', 'bottom']\nfor x in aoff:\n ax.spines[x].set_visible(False)\nax.tick_params(length=0)\nax.set_xticklabels([' ']*len(data))\n\n\n#I grabbed this from here : https://matplotlib.org/examples/api/barchart_demo.html\n#and tweaked it slightly \nhighlight = [4]\nfor i, r in enumerate(rects):\n h = r.get_height()\n w = r.get_width()\n y = r.get_y()\n if (w >= 10):\n x = w - 0.75\n elif (w > 1):\n x = w - 0.6\n else:\n x = w + 0.5\n r.set_color('gray')\n if (i in highlight):\n r.set_color('orange')\n ax.text(x, y ,'%.1f%%' % w, ha='center', va='bottom', zorder = 3) \n\n \nf.savefig('bar.pdf',format='pdf', bbox_inches = 'tight') \n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
c5180abd2871a15d8813ff3967a03e72b0a1a8b9
| 25,084 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/advanced_lane_finding-checkpoint.ipynb
|
bparkhe/advanced-lane-finding
|
58b1be17a6e0ae13398d8bd6e059a540fdaa8d70
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/advanced_lane_finding-checkpoint.ipynb
|
bparkhe/advanced-lane-finding
|
58b1be17a6e0ae13398d8bd6e059a540fdaa8d70
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/advanced_lane_finding-checkpoint.ipynb
|
bparkhe/advanced-lane-finding
|
58b1be17a6e0ae13398d8bd6e059a540fdaa8d70
|
[
"MIT"
] | null | null | null | 43.173838 | 227 | 0.573872 |
[
[
[
"Advanced Lane Finding Project\n===\n\n### Run the code in the cell below to extract object points and image points for camera calibration. ",
"_____no_output_____"
]
],
[
[
"# Code block: Import \n# Import all necessary libraries\n\nimport numpy as np\nimport cv2\nimport glob\nimport matplotlib.pyplot as plt\nimport pickle\nimport matplotlib.image as mpimg\n%matplotlib inline\n%matplotlib qt",
"_____no_output_____"
],
[
"# Code block: Camera Calibration\n\n# prepare object points, like (0,0,0), (1,0,0), (2,0,0) ....,(6,5,0)\nobjp = np.zeros((6*9,3), np.float32)\nobjp[:,:2] = np.mgrid[0:9, 0:6].T.reshape(-1,2)\n\n# Arrays to store object points and image points from all the images.\nobjpoints = [] # 3d points in real world space\nimgpoints = [] # 2d points in image plane.\n\n# Make a list of calibration images\nimages = glob.glob('camera_cal/calibration*.jpg')\n\n# Step through the list and search for chessboard corners\nfor idx, fname in enumerate(images):\n img = cv2.imread(fname)\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n # Find the chessboard corners\n ret, corners = cv2.findChessboardCorners(gray, (9,6), None)\n # If found, add object points, image points\n if ret == True:\n objpoints.append(objp)\n imgpoints.append(corners)\n #Draw and display the corners\n #cv2.drawChessboardCorners(img, (8,6), corners, ret)\n\n \n\n# Test undistortion on an image\nimg = cv2.imread('test_images/calibration1.jpg')\nimg_size = (img.shape[1], img.shape[0])\n\n# Do camera calibration given object points and image points\nret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_size,None,None)\n\n# Save the camera calibration result for later use\ndist_pickle = {}\ndist_pickle[\"mtx\"] = mtx\ndist_pickle[\"dist\"] = dist\npickle.dump( dist_pickle, open(\"output_images/wide_dist_pickle.p\",\"wb\"))",
"_____no_output_____"
]
],
[
[
"### If the above cell ran sucessfully, you should now have `objpoints` and `imgpoints` needed for camera calibration. Run the cell below to calibrate, calculate distortion coefficients, and test undistortion on an image!",
"_____no_output_____"
]
],
[
[
"# Code block: Functions\n\n#1. Color and Gradient thresholding\ndef thresholding(img, s_thresh=(210, 255), sx_thresh=(20, 100)):\n \n img = np.copy(img)\n # Convert to HLS color space and separate the V channel\n hls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)\n l_channel = hls[:,:,1]\n s_channel = hls[:,:,2]\n # Sobel x\n sobelx = cv2.Sobel(l_channel, cv2.CV_64F, 1, 0) # Take the derivative in x\n abs_sobelx = np.absolute(sobelx) # Absolute x derivative to accentuate lines away from horizontal\n scaled_sobel = np.uint8(255*abs_sobelx/np.max(abs_sobelx))\n \n # Threshold x gradient\n sxbinary = np.zeros_like(scaled_sobel)\n sxbinary[(scaled_sobel >= sx_thresh[0]) & (scaled_sobel <= sx_thresh[1])] = 1\n \n # Threshold color channel\n s_binary = np.zeros_like(s_channel)\n s_binary[(s_channel >= s_thresh[0]) & (s_channel <= s_thresh[1])] = 1\n s_binary = s_binary | sxbinary\n # Stack each channel\n color_binary = np.dstack((s_binary, s_binary, s_binary)) * 255\n return color_binary\n\n\n#2. Finding lanes without prior information\n\ndef find_lane_pixels(binary_warped):\n # Take a histogram of the bottom half of the image\n histogram = np.sum(binary_warped[binary_warped.shape[0]//2:,:], axis=0)\n # Create an output image to draw on and visualize the result\n out_img = binary_warped#np.dstack((binary_warped, binary_warped, binary_warped))\n # Find the peak of the left and right halves of the histogram\n # These will be the starting point for the left and right lines\n midpoint = np.int(histogram.shape[0]//2)\n leftx_base = np.argmax(histogram[:midpoint],0)[0]\n rightx_base = np.argmax(histogram[midpoint:],0)[0] + midpoint\n #print(leftx_base)\n # HYPERPARAMETERS\n # Choose the number of sliding windows\n nwindows = 9\n # Set the width of the windows +/- margin\n margin = 50\n # Set minimum number of pixels found to recenter window\n minpix = 50\n \n # Set height of windows - based on nwindows above and image shape\n window_height = np.int(binary_warped.shape[0]//nwindows)\n # Identify the x and y positions of all nonzero pixels in the image\n nonzero = binary_warped.nonzero()\n nonzeroy = np.array(nonzero[0])\n nonzerox = np.array(nonzero[1])\n # Current positions to be updated later for each window in nwindows\n leftx_current = leftx_base\n rightx_current = rightx_base\n\n # Create empty lists to receive left and right lane pixel indices\n left_lane_inds = []\n right_lane_inds = []\n\n # Step through the windows one by one\n for window in range(nwindows):\n # Identify window boundaries in x and y (and right and left)\n win_y_low = binary_warped.shape[0] - (window+1)*window_height\n win_y_high = binary_warped.shape[0] - window*window_height\n ### TO-DO: Find the four below boundaries of the window ###\n win_xleft_low = leftx_current - margin # Update this\n win_xleft_high = leftx_current + margin # Update this\n win_xright_low = rightx_current - margin # Update this\n win_xright_high = rightx_current + margin # Update this\n #print(win_xleft_low,win_xleft_high,win_y_low,win_y_high)\n # Draw the windows on the visualization image\n cv2.rectangle(out_img,(win_xleft_low,win_y_low),(win_xleft_high,win_y_high),(0,255,0), 4) \n cv2.rectangle(out_img,(win_xright_low,win_y_low),(win_xright_high,win_y_high),(0,255,0), 4) \n \n ### TO-DO: Identify the nonzero pixels in x and y within the window ###\n #good_y = nonzerox[(nonzeroy>win_y_low) & (nonzeroy<win_y_high)]\n #good_left_inds = good_y[(good_y>win_xleft_low) & (good_y<win_xleft_high)]\n #good_right_inds = good_y[(good_y>win_xright_low) & (good_y<win_xright_high)]\n\n good_y = (nonzeroy>win_y_low) & (nonzeroy<win_y_high)\n good_left_inds = np.flatnonzero((nonzerox>win_xleft_low) & (nonzerox<win_xleft_high) & good_y)\n good_right_inds = np.flatnonzero((nonzerox>win_xright_low) & (nonzerox<win_xright_high) & good_y)\n \n # Append these indices to the lists\n left_lane_inds.append(good_left_inds)\n right_lane_inds.append(good_right_inds)\n #print(good_left_inds)\n ### TO-DO: If you found > minpix pixels, recenter next window ###\n ### (`right` or `leftx_current`) on their mean position ###\n if len(good_left_inds)>minpix:\n leftx_current = np.int(np.mean(nonzerox[good_left_inds]))\n else:\n pass\n if len(good_right_inds)>minpix:\n rightx_current = np.int(np.mean(nonzerox[good_right_inds]))\n else: \n pass # Remove this when you add your function\n #print(left_lane_inds)\n # Concatenate the arrays of indices (previously was a list of lists of pixels)\n try:\n left_lane_inds = np.concatenate(left_lane_inds)\n right_lane_inds = np.concatenate(right_lane_inds)\n except ValueError:\n # Avoids an error if the above is not implemented fully\n pass\n \n # Extract left and right line pixel positions\n leftx = nonzerox[left_lane_inds]\n lefty = nonzeroy[left_lane_inds] \n rightx = nonzerox[right_lane_inds]\n righty = nonzeroy[right_lane_inds]\n\n return leftx, lefty, rightx, righty, out_img\n\n\n#3. Fit Polynomial to points foud using windows\ndef fit_polynomial(binary_warped):\n # Find our lane pixels first\n leftx, lefty, rightx, righty, out_img = find_lane_pixels(binary_warped)\n\n ### TO-DO: Fit a second order polynomial to each using `np.polyfit` ###\n left_fit = np.polyfit(lefty,leftx,2)\n right_fit = np.polyfit(righty,rightx,2)\n\n # Generate x and y values for plotting\n ploty = np.linspace(0, binary_warped.shape[0]-1, binary_warped.shape[0] )\n try:\n left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n except TypeError:\n # Avoids an error if `left` and `right_fit` are still none or incorrect\n print('The function failed to fit a line!')\n left_fitx = 1*ploty**2 + 1*ploty\n right_fitx = 1*ploty**2 + 1*ploty\n\n ## Visualization ##\n # Colors in the left and right lane regions\n out_img[lefty, leftx] = [255, 0, 0]\n out_img[righty, rightx] = [0, 0, 255]\n\n # Plots the left and right polynomials on the lane lines\n #plt.plot(left_fitx, ploty, color='yellow')\n #plt.plot(right_fitx, ploty, color='yellow')\n\n return out_img,left_fitx,right_fitx,ploty,left_fit,right_fit\n\n\n#4. Fit Polynomial to existing coefficients\ndef fit_poly(img_shape, leftx, lefty, rightx, righty):\n ### TO-DO: Fit a second order polynomial to each with np.polyfit() ###\n left_fit = np.polyfit(lefty, leftx, 2)\n right_fit = np.polyfit(righty, rightx, 2)\n # Generate x and y values for plotting\n ploty = np.linspace(0, img_shape[0]-1, img_shape[0])\n ### TO-DO: Calc both polynomials using ploty, left_fit and right_fit ###\n left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n \n return left_fitx, right_fitx, ploty,left_fit,right_fit\n\n#5. Search near polynomials of existing coefficients\ndef search_around_poly(binary_warped,left_fit,right_fit):\n # HYPERPARAMETER\n # Choose the width of the margin around the previous polynomial to search\n # The quiz grader expects 100 here, but feel free to tune on your own!\n margin = 100\n\n # Grab activated pixels\n nonzero = binary_warped.nonzero()\n nonzeroy = np.array(nonzero[0])\n nonzerox = np.array(nonzero[1])\n \n ### TO-DO: Set the area of search based on activated x-values ###\n ### within the +/- margin of our polynomial function ###\n ### Hint: consider the window areas for the similarly named variables ###\n ### in the previous quiz, but change the windows to our new search area ###\n left_lane_inds = ((nonzerox > (left_fit[0]*(nonzeroy**2) + left_fit[1]*nonzeroy + \n left_fit[2] - margin)) & (nonzerox < (left_fit[0]*(nonzeroy**2) + \n left_fit[1]*nonzeroy + left_fit[2] + margin)))\n right_lane_inds = ((nonzerox > (right_fit[0]*(nonzeroy**2) + right_fit[1]*nonzeroy + \n right_fit[2] - margin)) & (nonzerox < (right_fit[0]*(nonzeroy**2) + \n right_fit[1]*nonzeroy + right_fit[2] + margin)))\n leftx = nonzerox[left_lane_inds]\n lefty = nonzeroy[left_lane_inds] \n rightx = nonzerox[right_lane_inds]\n righty = nonzeroy[right_lane_inds]\n\n \n if len(leftx) <50 | len(rightx)<50:\n ploty = np.linspace(0, img_shape[0]-1, img_shape[0])\n ### TO-DO: Calc both polynomials using ploty, left_fit and right_fit ###\n left_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n right_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n else:\n # Again, extract left and right line pixel positions\n \n # Fit new polynomials\n left_fitx, right_fitx, ploty,left_fit,right_fit = fit_poly(binary_warped.shape, leftx, lefty, rightx, righty)\n\n \n ## Visualization ##\n # Create an image to draw on and an image to show the selection window\n out_img = np.dstack((binary_warped, binary_warped, binary_warped))*255\n window_img = np.zeros_like(out_img)\n # Color in left and right line pixels\n #out_img[nonzeroy[left_lane_inds], nonzerox[left_lane_inds]] = [255, 0, 0]\n #out_img[nonzeroy[right_lane_inds], nonzerox[right_lane_inds]] = [0, 0, 255]\n\n # Generate a polygon to illustrate the search window area\n # And recast the x and y points into usable format for cv2.fillPoly()\n left_line_window1 = np.array([np.transpose(np.vstack([left_fitx-margin, ploty]))])\n left_line_window2 = np.array([np.flipud(np.transpose(np.vstack([left_fitx+margin, \n ploty])))])\n left_line_pts = np.hstack((left_line_window1, left_line_window2))\n right_line_window1 = np.array([np.transpose(np.vstack([right_fitx-margin, ploty]))])\n right_line_window2 = np.array([np.flipud(np.transpose(np.vstack([right_fitx+margin, \n ploty])))])\n right_line_pts = np.hstack((right_line_window1, right_line_window2))\n\n # Draw the lane onto the warped blank image\n #cv2.fillPoly(window_img, np.int_([left_line_pts]), (0,255, 0))\n #cv2.fillPoly(window_img, np.int_([right_line_pts]), (0,255, 0))\n #result = cv2.addWeighted(out_img, 1, window_img, 0.3, 0)\n \n # Plot the polynomial lines onto the image\n #plt.plot(left_fitx, ploty, color='yellow')\n #plt.plot(right_fitx, ploty, color='yellow')\n ## End visualization steps ##\n \n return out_img,left_fitx,right_fitx,left_fit,right_fit,ploty\n\n\n#6. Get coefficient values for data in meters\ndef generate_data(ploty,left_fitx,right_fitx,ym_per_pix, xm_per_pix):\n left_fit_cr = np.polyfit(ploty*ym_per_pix, left_fitx*xm_per_pix, 2)\n right_fit_cr = np.polyfit(ploty*ym_per_pix, right_fitx*xm_per_pix, 2)\n \n return ploty*ym_per_pix, left_fit_cr, right_fit_cr\n\n\n#7. Calculate Radius of curvature and center offset\n\ndef measure_curvature_real(ploty,left_fitx,right_fitx):\n '''\n Calculates the curvature of polynomial functions in meters.\n '''\n \n # Define conversions in x and y from pixels space to meters\n ym_per_pix = 30/720 # meters per pixel in y dimension\n xm_per_pix = 3.7/700 # meters per pixel in x dimension\n \n center_offset = 640- (left_fitx[-1] + right_fitx[-1])/2\n center_offset = center_offset*xm_per_pix\n \n \n # Start by generating our fake example data\n # Make sure to feed in your real data instead in your project!\n ploty, left_fit_cr, right_fit_cr = generate_data(ploty,left_fitx,right_fitx,ym_per_pix, xm_per_pix)\n \n # Define y-value where we want radius of curvature\n # We'll choose the maximum y-value, corresponding to the bottom of the image\n y_eval = np.max(ploty)\n \n ##### TO-DO: Implement the calculation of R_curve (radius of curvature) #####\n left_curverad = ((1+(2*left_fit_cr[0]*y_eval + left_fit_cr[1])**2)**1.5)//(2*abs(left_fit_cr[0])) ## Implement the calculation of the left line here\n right_curverad = ((1+(2*right_fit_cr[0]*y_eval + right_fit_cr[1])**2)**1.5)//(2*abs(right_fit_cr[0])) ## Implement the calculation of the right line here\n avg_curverad = (left_curverad + right_curverad)/2\n return avg_curverad, center_offset\n\n\ndef unwarp_to_original(result,ploty,left_fitx,right_fitx,Minv,undist):\n ##Unwarp to original\n warp_zero = np.zeros_like(result).astype(np.uint8)\n color_warp = np.dstack((warp_zero, warp_zero, warp_zero))\n # Recast the x and y points into usable format for cv2.fillPoly()\n pts_left = np.array([np.transpose(np.vstack([left_fitx, ploty]))])\n pts_right = np.array([np.flipud(np.transpose(np.vstack([right_fitx, ploty])))])\n pts = np.hstack((pts_left, pts_right))\n # Draw the lane onto the warped blank image\n cv2.fillPoly(warp_zero, np.int_([pts]), (0,255, 0))\n # Warp the blank back to original image space using inverse perspective matrix (Minv)\n newwarp = cv2.warpPerspective(warp_zero, Minv, (undist.shape[1], undist.shape[0]))\n \n return newwarp",
"_____no_output_____"
],
[
"# Code block: Pipeline\n\n\n# Initialize Coeffcients for lane lines\nleft_fit = np.array([0,0,0])\nright_fit = np.array([0,0,0])\n\n# Pipeline for video input.output\ndef process_image(image):\n \n global left_fit,right_fit\n copy_image = np.copy(image)\n \n img_size = (1280,720)\n undist = cv2.undistort(copy_image, mtx, dist, None, mtx)\n my_img = np.zeros_like(undist)\n pts = np.array([[255,650],[505,500],[802,500],[1100,650]], np.int32)\n pts = pts.reshape((-1,1,2))\n cv2.polylines(my_img,[pts],True,(0,255,255),2)\n combo = cv2.addWeighted(undist, 1,my_img, 0, 0) \n \n offset = 50\n src = np.float32(pts)\n #print(img_size)\n # For destination points, I'm arbitrarily choosing some points to be\n # a nice fit for displaying our warped result \n # again, not exact, but close enough for our purposes\n dst = np.float32([[offset, img_size[1]-offset],[offset, offset*8], [img_size[0]-offset, offset*8], \n [img_size[0]-offset, img_size[1]-offset]])\n # Given src and dst points, calculate the perspective transform matrix\n M = cv2.getPerspectiveTransform(src, dst)\n Minv = cv2.getPerspectiveTransform(dst,src)\n # Warp the image using OpenCV warpPerspective()\n warped = cv2.warpPerspective(combo, M, img_size)\n \n \n \n result = thresholding(warped)\n \n # Look for lane indices\n if right_fit.any() ==0:\n # If initial values unchanged or polynomial ceases to exist, \n # use histogram to find new lane indices\n opt_img,left_fitx,right_fitx,ploty,left_fit,right_fit = fit_polynomial(result)\n else:\n # If polynomila coefficiant exist from prvious run, search around them \n opt_img,left_fitx,right_fitx,left_fit,right_fit,ploty = search_around_poly(result,left_fit,right_fit)\n \n #Unwarp to original\n newwarp = unwarp_to_original(result,ploty,left_fitx,right_fitx,Minv,undist)\n \n # Combine the result with the original image\n result = cv2.addWeighted(undist, 1, newwarp, 0.3, 0)\n \n # Calculate radius of curvature and center postion\n avg_curverad, center_offset= measure_curvature_real(ploty,left_fitx,right_fitx)\n \n \n # Print the values of curvature and offset the video\n font = cv2.FONT_HERSHEY_SIMPLEX\n bottomLeftCornerOfText = (100,100)\n fontScale = 1\n fontColor = (255,255,255)\n lineType = 2\n T = 'Radius Of Curvature = ' + str(avg_curverad) + 'mtrs, Center Offset = ' + str(round(center_offset,4)) + 'mtrs'\n cv2.putText(result,T, \n bottomLeftCornerOfText, \n font, \n fontScale,\n fontColor,\n lineType)\n\n \n return result\n\n#image = 'test_images/test5.jpg'\n#result = process_image(image)\n#plt.imshow(result)\n#plt.show()",
"_____no_output_____"
],
[
"# Code block: Process Video\n\n# Import everything needed to edit/save/watch video clips\nfrom moviepy.editor import VideoFileClip\nfrom IPython.display import HTML\nproject_output = 'project_video_output_3.mp4'\n\nclip1 = VideoFileClip(\"project_video.mp4\").subclip(30,45)\n\n#clip1 = VideoFileClip(\"project_video.mp4\")\nwhite_clip = clip1.fl_image(process_image) #NOTE: this function expects color images!!\n%time white_clip.write_videofile(project_output, audio=False)",
"[MoviePy] >>>> Building video project_video_output_3.mp4\n[MoviePy] Writing video project_video_output_3.mp4\n"
],
[
"# Code block: Output\n\nHTML(\"\"\"\n<video width=\"960\" height=\"540\" controls>\n <source src=\"{0}\">\n</video>\n\"\"\".format(project_output))\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
c5181baadf884418066e007fdb227b145a3bdaa5
| 4,301 |
ipynb
|
Jupyter Notebook
|
training-job-launcher-pypkg-test.ipynb
|
d3rpd3rp/repro-samples
|
e3ae18cc21e6755f7c2426d6b35164ea86e91424
|
[
"Apache-2.0"
] | null | null | null |
training-job-launcher-pypkg-test.ipynb
|
d3rpd3rp/repro-samples
|
e3ae18cc21e6755f7c2426d6b35164ea86e91424
|
[
"Apache-2.0"
] | null | null | null |
training-job-launcher-pypkg-test.ipynb
|
d3rpd3rp/repro-samples
|
e3ae18cc21e6755f7c2426d6b35164ea86e91424
|
[
"Apache-2.0"
] | null | null | null | 25.152047 | 104 | 0.518717 |
[
[
[
"**Proposed use:**\nTesting python package installation against AI Platform Training",
"_____no_output_____"
]
],
[
[
"#auth notebook\nexport GOOGLE_APPLICATION_CREDENTIALS=\"PATH\"",
"_____no_output_____"
],
[
"#define args & filenames\n#ASSIGN/REPLACE VALUES HERE\nJOB_NAME_PREFIX=\"\"\nPIP_PKG_NAME_LIST=[\"pkg1\", \"pkg2\", \"pkg3\"]\nJOB_DIR=\"gs://BUCKET_NAME/PATH\"\nRUNTIME_VERSION=\"\"\nPYTHON_VERSION=\"\"\nREGION=\"\"",
"_____no_output_____"
],
[
"%%bash\nmkdir -p trainer\necho -n \"\" trainer/__init__.py",
"_____no_output_____"
],
[
"import os, time\n\nt = time.localtime()\nt_str = time.strftime(\"%H%M%S\", t)\nJOB_NAME=JOB_NAME_PREFIX + t_str\n\nif os.path.exists('requirements.txt'):\n os.remove('requirements.txt')\nif os.path.exists('trainer/' + 'train.py'):\n os.remove('trainer/' + 'train.py')\nwith open('requirements.txt', 'a') as reqfile, open('trainer/' + 'train.py', 'a') as trainfile:\n if len(PIP_PKG_NAME_LIST) == 0:\n reqfile.write(\"\")\n elif len(PIP_PKG_NAME_LIST) == 1:\n reqfile.write(PIP_PKG_NAME_LIST[0])\n trainfile.write(\"import\" + \" \" + PIP_PKG_NAME_LIST[0])\n reqfile.write(\"\\n\")\n trainfile.write(\"\\n\")\n else:\n trainfile.write(\"import\" + \" \")\n for index in range(0,len(PIP_PKG_NAME_LIST)):\n reqfile.write(PIP_PKG_NAME_LIST[index])\n trainfile.write(PIP_PKG_NAME_LIST[index] + \" \")\n if index < len(PIP_PKG_NAME_LIST) - 1:\n reqfile.write(\"\\n\")\n trainfile.write(\"\\n\")\nreqfile.close()\ntrainfile.close()",
"_____no_output_____"
],
[
"%%writefile -a trainer/train.py\n\n\nif __name__ == '__main__':\n \n print(\"hello world!\")",
"_____no_output_____"
],
[
"pip install -r requirements.txt",
"_____no_output_____"
],
[
"!gcloud ai-platform local train \\\n --package-path trainer \\\n --module-name trainer.train \\\n --job-dir local-training-output",
"_____no_output_____"
],
[
"!gcloud ai-platform jobs submit training $JOB_NAME \\\n --job-dir $JOB_DIR \\\n --package-path trainer \\\n --module-name trainer.train \\\n --runtime-version $RUNTIME_VERSION \\\n --python-version $PYTHON_VERSION \\\n --region $REGION",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5182c19e2d451f966ba2817dc32f968c3171c7d
| 24,433 |
ipynb
|
Jupyter Notebook
|
examples/test_ex3p1.ipynb
|
philippwulff/robotics_calc
|
8365ed3931206ca3788086e261d800ebe21ef86b
|
[
"MIT"
] | null | null | null |
examples/test_ex3p1.ipynb
|
philippwulff/robotics_calc
|
8365ed3931206ca3788086e261d800ebe21ef86b
|
[
"MIT"
] | null | null | null |
examples/test_ex3p1.ipynb
|
philippwulff/robotics_calc
|
8365ed3931206ca3788086e261d800ebe21ef86b
|
[
"MIT"
] | null | null | null | 50.481405 | 2,828 | 0.502026 |
[
[
[
"%load_ext autoreload\n%autoreload 2\n\nfrom utils import build_transf, full_homo_transf, prop_velo, prop_force_torque, comp_jacobian\nfrom sympy import sqrt\nimport sympy as sy",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
]
],
[
[
"# Exercise 3 Problem 1\n\nDenavit-Hartenberg Parameters are from problem 1 of exercise 3.",
"_____no_output_____"
]
],
[
[
"dh_params = [[0, 0, 0, \"theta_1\"],\n [0, 1, 0, \"theta_2\"],\n [45, 0, sqrt(2), \"theta_3\"],\n [0, sqrt(2), 0, \"theta_4\"]]",
"_____no_output_____"
]
],
[
[
"## Homogeneous transforms",
"_____no_output_____"
]
],
[
[
"transforms = build_transf(dh_params, verbose=True)",
"_____no_output_____"
],
[
"full_transform = full_homo_transf(transforms)",
"_____no_output_____"
]
],
[
[
"## Propagate linear-angular velocities",
"_____no_output_____"
]
],
[
[
"joint_points = [sy.Matrix([0, 0, 0]),\n sy.Matrix([1, 0, 0]),\n sy.Matrix([0, -1, 1]),\n sy.Matrix([sqrt(2), 0, 0])]\nv, omega, joint_params = prop_velo(dh_params, joint_points)",
"_____no_output_____"
]
],
[
[
"We can read off the Jacobian from the linear-angular velocities.\n\nOr use the next function to calculate it explicitly:",
"_____no_output_____"
]
],
[
[
"J = comp_jacobian(dh_params, joint_points, verbose=False)",
"_____no_output_____"
],
[
"config = {\n sy.Symbol(\"theta_1\"): 0,\n sy.Symbol(\"theta_2\"): 90/180 * sy.pi,\n sy.Symbol(\"theta_3\"): -90/180 * sy.pi,\n sy.Symbol(\"theta_4\"): 0,\n}\n\nJ_config = sy.simplify(J.subs(config))\nJ_config",
"_____no_output_____"
]
],
[
[
"Calculate the joint torques needed to support the external force-torque vector.",
"_____no_output_____"
]
],
[
[
"sy.N(J_config.T @ sy.Matrix([0, 6, 0, 7, 0, 8]))",
"_____no_output_____"
]
],
[
[
"## Propagate force-torque vector\n\nThe force-torque vector at the end-effector is from the exercise.",
"_____no_output_____"
]
],
[
[
"prop_force_torque(dh_params, joint_points, sympy.Matrix([0, 6, 0, 7, 0, 8]))",
"_____no_output_____"
]
],
[
[
"We can now read off the joint torques acting on the revolute joints from the Z-components of the torque vectors at each link.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c51845c466059505a23689bfd1976a9d15b34120
| 85,130 |
ipynb
|
Jupyter Notebook
|
notebooks/Covid-19-India.ipynb
|
ravioshankar/pungi
|
3dabf777c8722821b3c30f45bd5c59d55affddee
|
[
"MIT"
] | 2 |
2020-06-29T22:43:29.000Z
|
2020-07-06T20:39:34.000Z
|
notebooks/Covid-19-India.ipynb
|
ravioshankar/pungi
|
3dabf777c8722821b3c30f45bd5c59d55affddee
|
[
"MIT"
] | null | null | null |
notebooks/Covid-19-India.ipynb
|
ravioshankar/pungi
|
3dabf777c8722821b3c30f45bd5c59d55affddee
|
[
"MIT"
] | null | null | null | 22.209757 | 182 | 0.28339 |
[
[
[
"import sys\nsys.path.append('../src')\nimport numpy as np \nimport pandas as pd \nimport matplotlib.pyplot as plt\nimport plotly.graph_objects as go\nimport plotly.express as px\npd.set_option('display.max_rows', None)\nimport datetime\nfrom plotly.subplots import make_subplots\nfrom covid19.config import covid_19_data\n",
"_____no_output_____"
],
[
"data = covid_19_data",
"_____no_output_____"
],
[
"data[[\"Confirmed\",\"Deaths\",\"Recovered\"]] =data[[\"Confirmed\",\"Deaths\",\"Recovered\"]].astype(int)",
"_____no_output_____"
],
[
"data['Active_case'] = data['Confirmed'] - data['Deaths'] - data['Recovered']",
"_____no_output_____"
],
[
"Data_India = data [(data['Country/Region'] == 'India') ].reset_index(drop=True)\nData_India_op= Data_India.groupby([\"ObservationDate\",\"Country/Region\"])[[\"Confirmed\",\"Deaths\",\"Recovered\",\"Active_case\"]].sum().reset_index().reset_index(drop=True)",
"_____no_output_____"
],
[
"fig = go.Figure()\nfig.add_trace(go.Scatter(x=Data_India_op[\"ObservationDate\"], y=Data_India_op['Confirmed'],\n mode=\"lines+text\",\n name='Confirmed cases',\n marker_color='orange',\n ))\n\nfig.add_annotation(\n x=\"03/24/2020\",\n y=Data_India_op['Confirmed'].max(),\n text=\"COVID-19 pandemic lockdown in India\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"red\"\n ),\n)\n\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"03/24/2020\",\n y0=Data_India_op['Confirmed'].max(),\n x1=\"03/24/2020\",\n \n line=dict(\n color=\"red\",\n width=3\n )\n))\nfig.add_annotation(\n x=\"04/24/2020\",\n y=Data_India_op['Confirmed'].max()-30000,\n text=\"Month after lockdown\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"#00FE58\"\n ),\n)\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"04/24/2020\",\n y0=Data_India_op['Confirmed'].max(),\n x1=\"04/24/2020\",\n \n line=dict(\n color=\"#00FE58\",\n width=3\n )\n))\nfig\nfig.update_layout(\n title='Evolution of Confirmed cases over time in India',\n template='plotly_dark'\n\n)\n\nfig.show()",
"_____no_output_____"
],
[
"fig = go.Figure()\nfig.add_trace(go.Scatter(x=Data_India_op[\"ObservationDate\"], y=Data_India_op['Active_case'],\n mode=\"lines+text\",\n name='Active cases',\n marker_color='#00FE58',\n ))\n\nfig.add_annotation(\n x=\"03/24/2020\",\n y=Data_India_op['Active_case'].max(),\n text=\"COVID-19 pandemic lockdown in India\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"red\"\n ),\n)\n\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"03/24/2020\",\n y0=Data_India_op['Active_case'].max(),\n x1=\"03/24/2020\",\n \n line=dict(\n color=\"red\",\n width=3\n )\n))\n\n\nfig.add_annotation(\n x=\"04/24/2020\",\n y=Data_India_op['Active_case'].max()-20000,\n text=\"Month after lockdown\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"rgb(255,217,47)\"\n ),\n)\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"04/24/2020\",\n y0=Data_India_op['Active_case'].max(),\n x1=\"04/24/2020\",\n \n line=dict(\n color=\"rgb(255,217,47)\",\n width=3\n )\n))\nfig.update_layout(\n title='Evolution of Active cases over time in India',\n template='plotly_dark'\n\n)\n\nfig.show()",
"_____no_output_____"
],
[
"fig = go.Figure()\nfig.add_trace(go.Scatter(x=Data_India_op[\"ObservationDate\"], y=Data_India_op['Recovered'],\n mode=\"lines+text\",\n name='Recovered cases',\n marker_color='rgb(229,151,232)',\n ))\n\nfig.add_annotation(\n x=\"03/24/2020\",\n y=Data_India_op['Recovered'].max(),\n text=\"COVID-19 pandemic lockdown in India\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"red\"\n ),\n)\n\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"03/24/2020\",\n y0=Data_India_op['Recovered'].max(),\n x1=\"03/24/2020\",\n \n line=dict(\n color=\"red\",\n width=3\n )\n))\n\n\nfig.add_annotation(\n x=\"04/24/2020\",\n y=Data_India_op['Recovered'].max()-20000,\n text=\"Month after lockdown\",\n font=dict(\n family=\"Courier New, monospace\",\n size=16,\n color=\"rgb(103,219,165)\"\n ),\n)\n\nfig.add_shape(\n # Line Vertical\n dict(\n type=\"line\",\n x0=\"04/24/2020\",\n y0=Data_India_op['Recovered'].max(),\n x1=\"04/24/2020\",\n \n line=dict(\n color=\"rgb(103,219,165)\",\n width=3\n )\n))\nfig.update_layout(\n title='Evolution of Recovered cases over time in India',\n template='plotly_dark'\n\n)\n\nfig.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5185267731e6541af3f2c933840e042327928d0
| 440,927 |
ipynb
|
Jupyter Notebook
|
notebooks/ATT&CK_DataSources.ipynb
|
2xyo/ATTACK-Python-Client
|
6a286aaa736f453f29a4e54fa37d30beb5fed0af
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/ATT&CK_DataSources.ipynb
|
2xyo/ATTACK-Python-Client
|
6a286aaa736f453f29a4e54fa37d30beb5fed0af
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/ATT&CK_DataSources.ipynb
|
2xyo/ATTACK-Python-Client
|
6a286aaa736f453f29a4e54fa37d30beb5fed0af
|
[
"BSD-3-Clause"
] | null | null | null | 98.973513 | 114,950 | 0.79845 |
[
[
[
"# **MITRE ATT&CK PYTHON CLIENT**: Data Sources\n------------------",
"_____no_output_____"
],
[
"## Goals:\n* Access ATT&CK data sources in STIX format via a public TAXII server\n* Learn to interact with ATT&CK data all at once\n* Explore and idenfity patterns in the data retrieved\n* Learn more about ATT&CK data sources",
"_____no_output_____"
],
[
"## 1. ATT&CK Python Client Installation",
"_____no_output_____"
],
[
"You can install it via PIP: **pip install attackcti**",
"_____no_output_____"
],
[
"## 2. Import ATT&CK API Client",
"_____no_output_____"
]
],
[
[
"from attackcti import attack_client",
"_____no_output_____"
]
],
[
[
"## 3. Import Extra Libraries",
"_____no_output_____"
]
],
[
[
"from pandas import *\nfrom pandas.io.json import json_normalize\n\nimport numpy as np\n\nimport altair as alt\n\nimport itertools\n",
"_____no_output_____"
]
],
[
[
"## 4. Initialize ATT&CK Client Class",
"_____no_output_____"
]
],
[
[
"lift = attack_client()",
"_____no_output_____"
]
],
[
[
"## 5. Getting Information About Techniques",
"_____no_output_____"
],
[
"Getting ALL ATT&CK Techniques",
"_____no_output_____"
]
],
[
[
"all_techniques = lift.get_all_techniques()",
"_____no_output_____"
]
],
[
[
"Showing the first technique in our list",
"_____no_output_____"
]
],
[
[
"all_techniques[0]",
"_____no_output_____"
]
],
[
[
"Normalizing semi-structured JSON data into a flat table via **pandas.io.json.json_normalize**\n* Reference: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.io.json.json_normalize.html",
"_____no_output_____"
]
],
[
[
"techniques_normalized = json_normalize(all_techniques)",
"_____no_output_____"
],
[
"techniques_normalized[0:1]",
"_____no_output_____"
]
],
[
[
"## 6. Re-indexing Dataframe",
"_____no_output_____"
]
],
[
[
"techniques = techniques_normalized.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)",
"_____no_output_____"
],
[
"techniques.head()",
"_____no_output_____"
],
[
"print('A total of ',len(techniques),' techniques')",
"A total of 478 techniques\n"
]
],
[
[
"## 7. Techniques With and Without Data Sources",
"_____no_output_____"
],
[
"Using **altair** python library we can start showing a few charts stacking the number of techniques with or without data sources.\nReference: https://altair-viz.github.io/",
"_____no_output_____"
]
],
[
[
"data_source_distribution = pandas.DataFrame({\n 'Techniques': ['Without DS','With DS'],\n 'Count of Techniques': [techniques['data_sources'].isna().sum(),techniques['data_sources'].notna().sum()]})\nbars = alt.Chart(data_source_distribution).mark_bar().encode(x='Techniques',y='Count of Techniques',color='Techniques').properties(width=200,height=300)\ntext = bars.mark_text(align='center',baseline='middle',dx=0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"What is the distribution of techniques based on ATT&CK Matrix?",
"_____no_output_____"
]
],
[
[
"data = techniques\ndata['Num_Tech'] = 1\ndata['Count_DS'] = data['data_sources'].str.len()\ndata['Ind_DS'] = np.where(data['Count_DS']>0,'With DS','Without DS')\ndata_2 = data.groupby(['matrix','Ind_DS'])['technique'].count()\ndata_3 = data_2.to_frame().reset_index()\ndata_3",
"_____no_output_____"
],
[
"alt.Chart(data_3).mark_bar().encode(x='technique', y='Ind_DS', color='matrix').properties(height = 200)",
"_____no_output_____"
]
],
[
[
"What are those mitre-attack techniques without data sources?",
"_____no_output_____"
]
],
[
[
"data[(data['matrix']=='mitre-attack') & (data['Ind_DS']=='Without DS')]",
"_____no_output_____"
]
],
[
[
"### Techniques without data sources",
"_____no_output_____"
]
],
[
[
"techniques_without_data_sources=techniques[techniques.data_sources.isnull()].reset_index(drop=True)",
"_____no_output_____"
],
[
"techniques_without_data_sources.head()",
"_____no_output_____"
],
[
"print('There are ',techniques['data_sources'].isna().sum(),' techniques without data sources (',\"{0:.0%}\".format(techniques['data_sources'].isna().sum()/len(techniques)),' of ',len(techniques),' techniques)')",
"There are 259 techniques without data sources ( 54% of 478 techniques)\n"
]
],
[
[
"### Techniques With Data Sources",
"_____no_output_____"
]
],
[
[
"techniques_with_data_sources=techniques[techniques.data_sources.notnull()].reset_index(drop=True)",
"_____no_output_____"
],
[
"techniques_with_data_sources.head()",
"_____no_output_____"
],
[
"print('There are ',techniques['data_sources'].notna().sum(),' techniques with data sources (',\"{0:.0%}\".format(techniques['data_sources'].notna().sum()/len(techniques)),' of ',len(techniques),' techniques)')",
"There are 219 techniques with data sources ( 46% of 478 techniques)\n"
]
],
[
[
"## 8. Grouping Techniques With Data Sources By Matrix",
"_____no_output_____"
],
[
"Let's create a graph to represent the number of techniques per matrix:",
"_____no_output_____"
]
],
[
[
"matrix_distribution = pandas.DataFrame({\n 'Matrix': list(techniques_with_data_sources.groupby(['matrix'])['matrix'].count().keys()),\n 'Count of Techniques': techniques_with_data_sources.groupby(['matrix'])['matrix'].count().tolist()})\nbars = alt.Chart(matrix_distribution).mark_bar().encode(y='Matrix',x='Count of Techniques').properties(width=300,height=100)\ntext = bars.mark_text(align='center',baseline='middle',dx=10,dy=0).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"All the techniques belong to **mitre-attack** matrix which is the main **Enterprise** matrix. Reference: https://attack.mitre.org/wiki/Main_Page ",
"_____no_output_____"
],
[
"## 9. Grouping Techniques With Data Sources by Platform",
"_____no_output_____"
],
[
"First, we need to split the **platform** column values because a technique might be mapped to more than one platform",
"_____no_output_____"
]
],
[
[
"techniques_platform=techniques_with_data_sources\n\nattributes_1 = ['platform'] # In attributes we are going to indicate the name of the columns that we need to split\n\nfor a in attributes_1:\n s = techniques_platform.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n # \"s\" is going to be a column of a frame with every value of the list inside each cell of the column \"a\"\n s.name = a\n # We name \"s\" with the same name of \"a\".\n techniques_platform=techniques_platform.drop(a, axis=1).join(s).reset_index(drop=True)\n # We drop the column \"a\" from \"techniques_platform\", and then join \"techniques_platform\" with \"s\"\n\n# Let's re-arrange the columns from general to specific\ntechniques_platform_2=techniques_platform.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)",
"_____no_output_____"
]
],
[
[
"We can now show techniques with data sources mapped to one platform at the time",
"_____no_output_____"
]
],
[
[
"techniques_platform_2.head()",
"_____no_output_____"
]
],
[
[
"Let's create a visualization to show the number of techniques grouped by platform:",
"_____no_output_____"
]
],
[
[
"platform_distribution = pandas.DataFrame({\n 'Platform': list(techniques_platform_2.groupby(['platform'])['platform'].count().keys()),\n 'Count of Techniques': techniques_platform_2.groupby(['platform'])['platform'].count().tolist()})\nbars = alt.Chart(platform_distribution,height=300).mark_bar().encode(x ='Platform',y='Count of Techniques',color='Platform').properties(width=200)\ntext = bars.mark_text(align='center',baseline='middle',dx=0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"In the bar chart above we can see that there are more techniques with data sources mapped to the Windows platform.",
"_____no_output_____"
],
[
"## 10. Grouping Techniques With Data Sources by Tactic",
"_____no_output_____"
],
[
"Again, first we need to split the tactic column values because a technique might be mapped to more than one tactic:",
"_____no_output_____"
]
],
[
[
"techniques_tactic=techniques_with_data_sources\n\nattributes_2 = ['tactic'] # In attributes we are going to indicate the name of the columns that we need to split\n\nfor a in attributes_2:\n s = techniques_tactic.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n # \"s\" is going to be a column of a frame with every value of the list inside each cell of the column \"a\"\n s.name = a\n # We name \"s\" with the same name of \"a\".\n techniques_tactic = techniques_tactic.drop(a, axis=1).join(s).reset_index(drop=True)\n # We drop the column \"a\" from \"techniques_tactic\", and then join \"techniques_tactic\" with \"s\"\n\n# Let's re-arrange the columns from general to specific\ntechniques_tactic_2=techniques_tactic.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)\n",
"_____no_output_____"
]
],
[
[
"We can now show techniques with data sources mapped to one tactic at the time",
"_____no_output_____"
]
],
[
[
"techniques_tactic_2.head()",
"_____no_output_____"
]
],
[
[
"Let's create a visualization to show the number of techniques grouped by tactic:",
"_____no_output_____"
]
],
[
[
"tactic_distribution = pandas.DataFrame({\n 'Tactic': list(techniques_tactic_2.groupby(['tactic'])['tactic'].count().keys()),\n 'Count of Techniques': techniques_tactic_2.groupby(['tactic'])['tactic'].count().tolist()}).sort_values(by='Count of Techniques',ascending=True)\nbars = alt.Chart(tactic_distribution,width=800,height=300).mark_bar().encode(x ='Tactic',y='Count of Techniques',color='Tactic').properties(width=400)\ntext = bars.mark_text(align='center',baseline='middle',dx=0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"Defende-evasion and Persistence are tactics with the highest nummber of techniques with data sources",
"_____no_output_____"
],
[
"## 11. Grouping Techniques With Data Sources by Data Source",
"_____no_output_____"
],
[
"We need to split the data source column values because a technique might be mapped to more than one data source:",
"_____no_output_____"
]
],
[
[
"techniques_data_source=techniques_with_data_sources\n\nattributes_3 = ['data_sources'] # In attributes we are going to indicate the name of the columns that we need to split\n\nfor a in attributes_3:\n s = techniques_data_source.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n # \"s\" is going to be a column of a frame with every value of the list inside each cell of the column \"a\"\n s.name = a\n # We name \"s\" with the same name of \"a\".\n techniques_data_source = techniques_data_source.drop(a, axis=1).join(s).reset_index(drop=True)\n # We drop the column \"a\" from \"techniques_data_source\", and then join \"techniques_data_source\" with \"s\"\n\n# Let's re-arrange the columns from general to specific\ntechniques_data_source_2 = techniques_data_source.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)\n\n# We are going to edit some names inside the dataframe to improve the consistency:\ntechniques_data_source_3 = techniques_data_source_2.replace(['Process monitoring','Application logs'],['Process Monitoring','Application Logs'])",
"_____no_output_____"
]
],
[
[
"We can now show techniques with data sources mapped to one data source at the time",
"_____no_output_____"
]
],
[
[
"techniques_data_source_3.head()",
"_____no_output_____"
]
],
[
[
"Let's create a visualization to show the number of techniques grouped by data sources:",
"_____no_output_____"
]
],
[
[
"data_source_distribution = pandas.DataFrame({\n 'Data Source': list(techniques_data_source_3.groupby(['data_sources'])['data_sources'].count().keys()),\n 'Count of Techniques': techniques_data_source_3.groupby(['data_sources'])['data_sources'].count().tolist()})\nbars = alt.Chart(data_source_distribution,width=800,height=300).mark_bar().encode(x ='Data Source',y='Count of Techniques',color='Data Source').properties(width=1200)\ntext = bars.mark_text(align='center',baseline='middle',dx=0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"A few interesting things from the bar chart above:\n* Process Monitoring, File Monitoring, and Process Command-line parameters are the Data Sources with the highest number of techniques\n* There are some data source names that include string references to Windows such as PowerShell, Windows and wmi",
"_____no_output_____"
],
[
"## 12. Most Relevant Groups Of Data Sources Per Technique",
"_____no_output_____"
],
[
"### Number Of Data Sources Per Technique",
"_____no_output_____"
],
[
"Although identifying the data sources with the highest number of techniques is a good start, they usually do not work alone. You might be collecting **Process Monitoring** already but you might be still missing a lot of context from a data perspective.",
"_____no_output_____"
]
],
[
[
"data_source_distribution_2 = pandas.DataFrame({\n 'Techniques': list(techniques_data_source_3.groupby(['technique'])['technique'].count().keys()),\n 'Count of Data Sources': techniques_data_source_3.groupby(['technique'])['technique'].count().tolist()})\n\ndata_source_distribution_3 = pandas.DataFrame({\n 'Number of Data Sources': list(data_source_distribution_2.groupby(['Count of Data Sources'])['Count of Data Sources'].count().keys()),\n 'Count of Techniques': data_source_distribution_2.groupby(['Count of Data Sources'])['Count of Data Sources'].count().tolist()})\n\nbars = alt.Chart(data_source_distribution_3).mark_bar().encode(x ='Number of Data Sources',y='Count of Techniques').properties(width=500)\ntext = bars.mark_text(align='center',baseline='middle',dx=0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"The image above shows you the number data sources needed per techniques according to ATT&CK:\n* There are 71 techniques that require 3 data sources as enough context to validate the detection of them according to ATT&CK\n* Only one technique has 12 data sources\n* One data source only applies to 19 techniques",
"_____no_output_____"
],
[
"Let's create subsets of data sources with the data source column defining and using a python function:",
"_____no_output_____"
]
],
[
[
"# https://stackoverflow.com/questions/26332412/python-recursive-function-to-display-all-subsets-of-given-set\ndef subs(l):\n res = []\n for i in range(1, len(l) + 1):\n for combo in itertools.combinations(l, i):\n res.append(list(combo))\n return res",
"_____no_output_____"
]
],
[
[
"Before applying the function, we need to use lowercase data sources names and sort data sources names to improve consistency:",
"_____no_output_____"
]
],
[
[
"df = techniques_with_data_sources[['data_sources']]",
"_____no_output_____"
],
[
"for index, row in df.iterrows():\n row[\"data_sources\"]=[x.lower() for x in row[\"data_sources\"]]\n row[\"data_sources\"].sort()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"Let's apply the function and split the subsets column:",
"_____no_output_____"
]
],
[
[
"df['subsets']=df['data_sources'].apply(subs)",
"C:\\Users\\lucho\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"We need to split the subsets column values:",
"_____no_output_____"
]
],
[
[
"techniques_with_data_sources_preview = df",
"_____no_output_____"
],
[
"attributes_4 = ['subsets']\n\nfor a in attributes_4:\n s = techniques_with_data_sources_preview.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n s.name = a\n techniques_with_data_sources_preview = techniques_with_data_sources_preview.drop(a, axis=1).join(s).reset_index(drop=True)\n \ntechniques_with_data_sources_subsets = techniques_with_data_sources_preview.reindex(['data_sources','subsets'], axis=1)\n",
"_____no_output_____"
],
[
"techniques_with_data_sources_subsets.head()",
"_____no_output_____"
]
],
[
[
"Let's add three columns to analyse the dataframe: subsets_name (Changing Lists to Strings), subsets_number_elements ( Number of data sources per subset) and number_data_sources_per_technique",
"_____no_output_____"
]
],
[
[
"techniques_with_data_sources_subsets['subsets_name']=techniques_with_data_sources_subsets['subsets'].apply(lambda x: ','.join(map(str, x)))\ntechniques_with_data_sources_subsets['subsets_number_elements']=techniques_with_data_sources_subsets['subsets'].str.len()\ntechniques_with_data_sources_subsets['number_data_sources_per_technique']=techniques_with_data_sources_subsets['data_sources'].str.len()",
"_____no_output_____"
],
[
"techniques_with_data_sources_subsets.head()",
"_____no_output_____"
]
],
[
[
"As it was described above, we need to find grups pf data sources, so we are going to filter out all the subsets with only one data source:",
"_____no_output_____"
]
],
[
[
"subsets = techniques_with_data_sources_subsets\n\nsubsets_ok=subsets[subsets.subsets_number_elements != 1]",
"_____no_output_____"
],
[
"subsets_ok.head()",
"_____no_output_____"
]
],
[
[
"Finally, we calculate the most relevant groups of data sources (Top 15):",
"_____no_output_____"
]
],
[
[
"subsets_graph = subsets_ok.groupby(['subsets_name'])['subsets_name'].count().to_frame(name='subsets_count').sort_values(by='subsets_count',ascending=False)[0:15]",
"_____no_output_____"
],
[
"subsets_graph",
"_____no_output_____"
],
[
"subsets_graph_2 = pandas.DataFrame({\n 'Data Sources': list(subsets_graph.index),\n 'Count of Techniques': subsets_graph['subsets_count'].tolist()})\n\nbars = alt.Chart(subsets_graph_2).mark_bar().encode(x ='Data Sources', y ='Count of Techniques', color='Data Sources').properties(width=500)\ntext = bars.mark_text(align='center',baseline='middle',dx= 0,dy=-5).encode(text='Count of Techniques')\nbars + text",
"_____no_output_____"
]
],
[
[
"Group (Process Monitoring - Process Command-line parameters) is the is the group of data sources with the highest number of techniques. This group of data sources are suggested to hunt 78 techniques",
"_____no_output_____"
],
[
"## 14. Let's Split all the Information About Techniques With Data Sources Defined: Matrix, Platform, Tactic and Data Source",
"_____no_output_____"
],
[
"Let's split all the relevant columns of the dataframe:",
"_____no_output_____"
]
],
[
[
"techniques_data = techniques_with_data_sources\n\nattributes = ['platform','tactic','data_sources'] # In attributes we are going to indicate the name of the columns that we need to split\n\nfor a in attributes:\n s = techniques_data.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n # \"s\" is going to be a column of a frame with every value of the list inside each cell of the column \"a\"\n s.name = a\n # We name \"s\" with the same name of \"a\".\n techniques_data=techniques_data.drop(a, axis=1).join(s).reset_index(drop=True)\n # We drop the column \"a\" from \"techniques_data\", and then join \"techniques_data\" with \"s\"\n\n# Let's re-arrange the columns from general to specific\ntechniques_data_2=techniques_data.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)\n\n# We are going to edit some names inside the dataframe to improve the consistency:\ntechniques_data_3 = techniques_data_2.replace(['Process monitoring','Application logs'],['Process Monitoring','Application Logs'])\n\ntechniques_data_3.head()",
"_____no_output_____"
]
],
[
[
"Do you remember data sources names with a reference to Windows? After splitting the dataframe by platforms, tactics and data sources, are there any macOC or linux techniques that consider windows data sources? Let's identify those rows:",
"_____no_output_____"
]
],
[
[
"# After splitting the rows of the dataframe, there are some values that relate windows data sources with platforms like linux and masOS.\n# We need to identify those rows\nconditions = [(techniques_data_3['platform']=='Linux')&(techniques_data_3['data_sources'].str.contains('windows',case=False)== True),\n (techniques_data_3['platform']=='macOS')&(techniques_data_3['data_sources'].str.contains('windows',case=False)== True),\n (techniques_data_3['platform']=='Linux')&(techniques_data_3['data_sources'].str.contains('powershell',case=False)== True),\n (techniques_data_3['platform']=='macOS')&(techniques_data_3['data_sources'].str.contains('powershell',case=False)== True),\n (techniques_data_3['platform']=='Linux')&(techniques_data_3['data_sources'].str.contains('wmi',case=False)== True),\n (techniques_data_3['platform']=='macOS')&(techniques_data_3['data_sources'].str.contains('wmi',case=False)== True)]\n# In conditions we indicate a logical test\n\nchoices = ['NO OK','NO OK','NO OK','NO OK','NO OK','NO OK']\n# In choices, we indicate the result when the logical test is true\n\ntechniques_data_3['Validation'] = np.select(conditions,choices,default='OK')\n# We add a column \"Validation\" to \"techniques_data_3\" with the result of the logical test. The default value is going to be \"OK\"",
"_____no_output_____"
]
],
[
[
"What is the inconsistent data?",
"_____no_output_____"
]
],
[
[
"techniques_analysis_data_no_ok = techniques_data_3[techniques_data_3.Validation == 'NO OK']\n# Finally, we are filtering all the values with NO OK\n\ntechniques_analysis_data_no_ok.head()",
"_____no_output_____"
],
[
"print('There are ',len(techniques_analysis_data_no_ok),' rows with inconsistent data')",
"There are 32 rows with inconsistent data\n"
]
],
[
[
"What is the impact of this inconsistent data from a platform and data sources perspective?",
"_____no_output_____"
]
],
[
[
"df = techniques_with_data_sources\n\nattributes = ['platform','data_sources']\n\nfor a in attributes:\n s = df.apply(lambda x: pandas.Series(x[a]),axis=1).stack().reset_index(level=1, drop=True)\n s.name = a\n df=df.drop(a, axis=1).join(s).reset_index(drop=True)\n \ndf_2=df.reindex(['matrix','platform','tactic','technique','technique_id','data_sources'], axis=1)\ndf_3 = df_2.replace(['Process monitoring','Application logs'],['Process Monitoring','Application Logs'])\n\nconditions = [(df_3['data_sources'].str.contains('windows',case=False)== True),\n (df_3['data_sources'].str.contains('powershell',case=False)== True),\n (df_3['data_sources'].str.contains('wmi',case=False)== True)]\n\nchoices = ['Windows','Windows','Windows']\n\ndf_3['Validation'] = np.select(conditions,choices,default='Other')\ndf_3['Num_Tech'] = 1\ndf_4 = df_3[df_3.Validation == 'Windows']\ndf_5 = df_4.groupby(['data_sources','platform'])['technique'].nunique()\ndf_6 = df_5.to_frame().reset_index()",
"_____no_output_____"
],
[
"alt.Chart(df_6).mark_bar().encode(x=alt.X('technique', stack=\"normalize\"), y='data_sources', color='platform').properties(height=200)",
"_____no_output_____"
]
],
[
[
"There are techniques that consider Windows Error Reporting, Windows Registry, and Windows event logs as data sources and they also consider platforms like Linux and masOS. We do not need to consider this rows because those data sources can only be managed at a Windows environment. These are the techniques that we should not consider in our data base:",
"_____no_output_____"
]
],
[
[
"techniques_analysis_data_no_ok[['technique','data_sources']].drop_duplicates().sort_values(by='data_sources',ascending=True)",
"_____no_output_____"
]
],
[
[
"Without considering this inconsistent data, the final dataframe is:",
"_____no_output_____"
]
],
[
[
"techniques_analysis_data_ok = techniques_data_3[techniques_data_3.Validation == 'OK']\ntechniques_analysis_data_ok.head()",
"_____no_output_____"
],
[
"print('There are ',len(techniques_analysis_data_ok),' rows of data that you can play with')",
"There are 1790 rows of data that you can play with\n"
]
],
[
[
"## 15. Getting Techniques by Data Sources",
"_____no_output_____"
],
[
"This function gets techniques' information that includes specific data sources",
"_____no_output_____"
]
],
[
[
"from attackcti import attack_client\nlift = attack_client()",
"_____no_output_____"
],
[
"data_source = 'PROCESS MONITORING'",
"_____no_output_____"
],
[
"results = lift.get_techniques_by_datasources(data_source)",
"_____no_output_____"
],
[
"len(results)",
"_____no_output_____"
],
[
"data_sources_list = ['pRoceSS MoniTorinG','process commAnd-linE parameters']",
"_____no_output_____"
],
[
"results2 = lift.get_techniques_by_datasources(data_sources_list)",
"_____no_output_____"
],
[
"len(results2)",
"_____no_output_____"
],
[
"results2[1]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51872608053eb9b90f79675ccc520d63f34af39
| 203,937 |
ipynb
|
Jupyter Notebook
|
notebooks/0-Introduction.ipynb
|
voytekresearch/BandRatios
|
ce06cdd3066c45730bff7f48e82835bd4c0e0fdc
|
[
"MIT"
] | 6 |
2021-03-29T20:58:32.000Z
|
2022-03-20T10:38:35.000Z
|
notebooks/0-Introduction.ipynb
|
voytekresearch/BandRatios
|
ce06cdd3066c45730bff7f48e82835bd4c0e0fdc
|
[
"MIT"
] | 1 |
2020-01-11T05:30:38.000Z
|
2020-01-11T05:30:39.000Z
|
notebooks/0-Introduction.ipynb
|
voytekresearch/BandRatios
|
ce06cdd3066c45730bff7f48e82835bd4c0e0fdc
|
[
"MIT"
] | 7 |
2020-03-18T13:22:38.000Z
|
2022-02-06T12:05:11.000Z
| 374.884191 | 84,452 | 0.931484 |
[
[
[
"# Introduction to Band Ratios & Spectral Features",
"_____no_output_____"
],
[
"The BandRatios project explore properties of band ratio measures.\n\nBand ratio measures are an analysis measure in which the ratio of power between frequency bands is calculated. \n\nBy 'spectral features' we mean features we can measure from the power spectra, such as periodic components (oscillations), that we can describe with their center frequency, power and bandwidth, and the aperiodic component, which we can describe with their exponent and offset value. These parameters will be further explored and explained later on. \n\nIn this introductory notebook, we walk through how band ratio measures and spectral features are calculated.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_context('poster')\n\nfrom fooof import FOOOF\nfrom fooof.sim import gen_power_spectrum\nfrom fooof.analysis import get_band_peak_fm\nfrom fooof.plts import plot_spectrum, plot_spectrum_shading",
"_____no_output_____"
],
[
"# Import custom project code\nimport sys\nsys.path.append('../bratios')\nfrom ratios import *\nfrom paths import FIGS_PATHS as fp\nfrom paths import DATA_PATHS as dp",
"_____no_output_____"
],
[
"# Settings\nSAVE_FIG = False",
"_____no_output_____"
]
],
[
[
"## What is a Band Ratio\n\nThis project explores frequency band ratios, a metric used in spectral analysis since at least the 1960's to characterize cognitive functions such as vigilance, aging, memory among other. In clinical work, band ratios have also been used as a biomarker for diagnosing and monitoring of ADHD, diseases of consciousness, and nervous system disorders such as Parkinson's disease.\n\nGiven a power spectrum, a band ratio is the ratio of average power within a band between two frequency ranges. \n\nTypically, band ratio measures are calculated as:\n\n$ \\frac{avg(low\\ band\\ power)}{avg(high\\ band\\ power} $\n\nThe following cell generates a power spectrum and highlights the frequency ranges used to calculate a theta/beta band ratio.",
"_____no_output_____"
]
],
[
[
"# Settings\ntheta_band = [4, 8]\nbeta_band = [20, 30]\nfreq_range = [1, 35]\n\n# Define default simulation values\nap_def = [0, 1]\ntheta_def = [6, 0.25, 1]\nalpha_def = [10, 0.4, 0.75]\nbeta_def = [25, 0.2, 1.5]",
"_____no_output_____"
],
[
"# Plot Settings\nline_color = 'black'\nshade_colors = ['#057D2E', '#0365C0']",
"_____no_output_____"
],
[
"# Generate a simulated power spectrum\nfs, ps = gen_power_spectrum(freq_range, ap_def,\n [theta_def, alpha_def, beta_def])\n\n# Plot the power spectrum, shading the frequency bands used for the ratio\nplot_spectrum_shading(fs, ps, [theta_band, beta_band],\n color=line_color, shade_colors=shade_colors,\n log_powers=True, linewidth=3.5)\n\n# Plot aesthetics\nax = plt.gca()\nfor it in [ax.xaxis.label, ax.yaxis.label]:\n it.set_fontsize(26)\nax.set_xlim([0, 35])\nax.set_ylim([-1.6, 0])\n\nif SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'Ratio-example', 'pdf'))",
"_____no_output_____"
]
],
[
[
"# Calculate theta/beta ratios ",
"_____no_output_____"
],
[
"### Average Power Ratio\n\nThe typical way of calculating band ratios is to take average power in the low-band and divide it by the average power from the high-band. \n\nAverage power is calculated as the sum of all discrete power values divided by number on power values in that band.",
"_____no_output_____"
]
],
[
[
"# Calculate the theta / beta ratio for our simulated power spectrum\nratio = calc_band_ratio(fs, ps, theta_band, beta_band)\nprint('Theta-beta ratio is: {:1.4f}'.format(ratio))",
"Theta-beta ratio is: 4.9890\n"
]
],
[
[
"And there you have it - our first computed frequency band ratio!",
"_____no_output_____"
],
[
"# The FOOOF Model\n\nTo measure spectral features from power spectra, which we can then compare to ratio measures, we will use the [FOOOF](https://github.com/fooof-tools/fooof) library.\n\nBriefly, the FOOOF algorithm parameterizes neural power spectra, measuring both periodic (oscillatory) and aperiodic features. \n\nEach identified oscillation is parameterized as a peak, fit as a gaussian, which provides us with a measures of the center frequency, power and bandwidth of peak.\n\nThe aperiodic component is measured by a function of the form $ 1/f^\\chi $, in which this $ \\chi $ value is referred to as the aperiodic exponent. \n\nThis exponent is equivalent the the negative slope of the power spectrum, when plotted in log-log. \n\nMore details on FOOOF can be found in the associated [paper](https://doi.org/10.1101/299859) and/or on the documentation [site](https://fooof-tools.github.io/fooof/).",
"_____no_output_____"
]
],
[
[
"# Load power spectra from an example subject\npsd = np.load(dp.make_file_path(dp.eeg_psds, 'A00051886_ec_psds', 'npz'))\n\n# Unpack the loaded power spectra, and select a spectrum to fit\nfreqs = psd['arr_0']\npowers = psd['arr_1'][0][50]",
"_____no_output_____"
],
[
"# Initialize a FOOOF object\nfm = FOOOF(verbose=False)\n\n# Fit the FOOOF model\nfm.fit(freqs, powers)",
"_____no_output_____"
],
[
"# Plot the power spectrum, with the FOOOF model\nfm.plot()\n\n# Plot aesthetic updates\nax = plt.gca()\nax.set_ylabel('log(Power)', {'fontsize':35})\nax.set_xlabel('Frequency', {'fontsize':35})\nplt.legend(prop={'size': 24})\nfor line, width in zip(ax.get_lines(), [3, 5, 5]):\n line.set_linewidth(width)\nax.set_xlim([0, 35]);\n\nif SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'FOOOF-example', 'pdf'))",
"_____no_output_____"
]
],
[
[
"In the plot above, the the FOOOF model fit, in red, is plotted over the original data, in black.\n\nThe blue dashed line is the fit of the aperiodic component of the data. The aperiodic exponent describes the steepness of this line.\n\nFor all future notebooks, the aperiodic exponent reflects values that are simulated and/or measured with the FOOOF model, reflecting the blue line. \n\nPeriodic spectral features are simulation values and/or model fit values from the FOOOF model that measure oscillatory peaks over and above the blue dashed line. ",
"_____no_output_____"
],
[
"#### Helper settings & functions for the next section",
"_____no_output_____"
]
],
[
[
"# Settings\nf_theta = 6\nf_beta = 25",
"_____no_output_____"
],
[
"# Functions\ndef style_plot(ax):\n \"\"\"Helper function to style plots.\"\"\"\n \n ax.get_legend().remove()\n ax.grid(False)\n for line in ax.get_lines():\n line.set_linewidth(3.5)\n ax.set_xticks([])\n ax.set_yticks([])\n \ndef add_lines(ax, fs, ps, f_val):\n \"\"\"Helper function to add vertical lines to power spectra plots.\"\"\"\n \n y_lims = ax.get_ylim()\n ax.plot([f_val, f_val], [y_lims[0], np.log10(ps[fs==f_val][0])],\n 'g--', markersize=12, alpha=0.75)\n ax.set_ylim(y_lims)",
"_____no_output_____"
]
],
[
[
"### Comparing Ratios With and Without Periodic Activity\n\nIn the next section, we will explore power spectra with and without periodic activity within specified bands. \n\nWe will use simulations to explore how ratio measures relate to the presence or absence or periodic activity, and how this relates to the analyses we will be performing, comparing ratio measures to spectral features.",
"_____no_output_____"
]
],
[
[
"# Generate simulated power spectrum, with and without a theta & beta oscillations\nfs, ps0 = gen_power_spectrum(freq_range, ap_def,\n [theta_def, alpha_def, beta_def])\nfs, ps1 = gen_power_spectrum(freq_range, ap_def,\n [alpha_def, beta_def])\nfs, ps2 = gen_power_spectrum(freq_range, ap_def,\n [theta_def, alpha_def])\nfs, ps3 = gen_power_spectrum(freq_range, ap_def,\n [alpha_def])",
"_____no_output_____"
],
[
"# Initialize some FOOOF models\nfm0 = FOOOF(verbose=False)\nfm1 = FOOOF(verbose=False)\nfm2 = FOOOF(verbose=False)\nfm3 = FOOOF(verbose=False)",
"_____no_output_____"
],
[
"# Fit FOOOF models\nfm0.fit(fs, ps0)\nfm1.fit(fs, ps1)\nfm2.fit(fs, ps2)\nfm3.fit(fs, ps3)",
"_____no_output_____"
],
[
"# Create a plot with the spectra\nfig, axes = plt.subplots(1, 4, figsize=(18, 4))\ntitles = ['Theta & Beta', 'Beta Only', 'Theta Only', 'Neither']\n\nfor cur_fm, cur_ps, cur_title, cur_ax in zip(\n [fm0, fm1, fm2, fm3], [ps0, ps1, ps2, ps3], titles, axes):\n \n # Create the \n cur_fm.plot(ax=cur_ax)\n cur_ax.set_title(cur_title)\n style_plot(cur_ax)\n add_lines(cur_ax, fs, cur_ps, f_theta)\n add_lines(cur_ax, fs, cur_ps, f_beta)\n\n# Save out the FOOOF figure\nif SAVE_FIG: plt.savefig(fp.make_file_path(fp.demo, 'PeakComparisons', 'pdf'))",
"_____no_output_____"
]
],
[
[
"Note that in the plots above, we have plotted the power spectra, with the aperiodic component parameterized in blue, and the potential location of peaks is indicated in green.\n\nKeep in mind that under the FOOOF model idea, there is only evidence for an oscillation if there is band specific power over and above the aperiodic activity.\n\nIn the first power spectrum, for example, we see clear peaks in both theta and beta. However, in subsequent power spectra, we have created spectra without theta, without theta, and without either (or, alternatively put, spectra in which the FOOOF model would say there is no evidence of peaks in these bands). \n\nWe can actually check our model parameterizations, to see if and when theta and beta peaks were detected, over and above the aperiodic, was measured. ",
"_____no_output_____"
]
],
[
[
"# Check if there are extracted thetas in the model parameterizations\nprint('Detected Theta Values:')\nprint('\\tTheta & Beta: \\t', get_band_peak_fm(fm0, theta_band))\nprint('\\tBeta Only: \\t', get_band_peak_fm(fm1, theta_band))\nprint('\\tTheta Only: \\t', get_band_peak_fm(fm2, theta_band))\nprint('\\tNeither: \\t', get_band_peak_fm(fm3, theta_band))",
"Detected Theta Values:\n\tTheta & Beta: \t [6.01988395 0.24165648 1.85385149]\n\tBeta Only: \t [nan nan nan]\n\tTheta Only: \t [6.00830117 0.24049592 1.93199763]\n\tNeither: \t [nan nan nan]\n"
]
],
[
[
"Now, just because there is no evidence of, for example, theta activity specifically, does not mean there is no power in the 4-8 Hz range. \n\nWe can see this in the power spectra, as the aperiodic component also contributes power across all frequencies. \n\nThis means that, due to the way that band ratio measures are calculated, the theta-beta ratio in power spectra without any actual theta activity (or beta) will still measure a value. ",
"_____no_output_____"
]
],
[
[
"print('Theta / Beta Ratio of Theta & Beta: \\t{:1.4f}'.format(\n calc_band_ratio(fm0.freqs, fm0.power_spectrum, theta_band, beta_band)))\nprint('Theta / Beta Ratio of Beta Only: \\t{:1.4f}'.format(\n calc_band_ratio(fm1.freqs, fm1.power_spectrum, theta_band, beta_band)))\nprint('Theta / Beta Ratio of Theta Only: \\t{:1.4f}'.format(\n calc_band_ratio(fm2.freqs, fm2.power_spectrum, theta_band, beta_band)))\nprint('Theta / Beta Ratio of Neither: \\t{:1.4f}'.format(\n calc_band_ratio(fm3.freqs, fm3.power_spectrum, theta_band, beta_band)))",
"Theta / Beta Ratio of Theta & Beta: \t0.4776\nTheta / Beta Ratio of Beta Only: \t0.5781\nTheta / Beta Ratio of Theta Only: \t0.4545\nTheta / Beta Ratio of Neither: \t0.5504\n"
]
],
[
[
"As we can see above, as compared to the 'Theta & Beta' PSD, the theta / beta ratio of the 'Beta Only' PSD is higher (which we might interpret as reflecting less theta or more beta activity), and the theta / beta ratio of the 'Theta Only' PSD is lower (which we might interpret as reflecting more theta or less beta activity).\n\nHowever, we know that these are not really the best interpretations, in so far as we would like to say that these differences reflect the lack of theta and beta, and not merely a change in their power. \n\nIn the extreme case, with no theta or beta peaks at all, we still measure a (quite high) value for the theta / beta ratio, though in this case it entirely reflects aperiodic activity. It is important to note that the measure is not zero (or undefined) as we might expect or want in cases in which there is no oscillatory activity, over and above the aperiodic component.",
"_____no_output_____"
],
[
"### Summary\n\nIn this notebook, we have explored band ratio measures, and spectral features, using the FOOOF model.\n\nOne thing to keep in mind, for the upcoming analyses in this project is that when we compare a ratio value to periodic power, we do so to the isolated periodic power - periodic power over and above the aperiodic power - and we can only calculate this when there is actually power over and above the aperiodic component.\n\nThat is to say, revisiting the plots above, the periodic activity we are interested in is not the green line, which is total power, but rather is section of the green line above the blue line (the aperiodic adjusted power measured by FOOOF). This means that to compare ratio values to periodic power, we can only calculate this, and only do so, when we measure periodic power within the specified band.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
c51873fc9c470096f921f7caffa96afcd3cc808e
| 25,893 |
ipynb
|
Jupyter Notebook
|
tests/ds000133_preprocessing.ipynb
|
apalombit/Slice_Order_Explorer
|
9b40ec4a4e0ac4545720faffd266a11626b93e41
|
[
"MIT"
] | null | null | null |
tests/ds000133_preprocessing.ipynb
|
apalombit/Slice_Order_Explorer
|
9b40ec4a4e0ac4545720faffd266a11626b93e41
|
[
"MIT"
] | null | null | null |
tests/ds000133_preprocessing.ipynb
|
apalombit/Slice_Order_Explorer
|
9b40ec4a4e0ac4545720faffd266a11626b93e41
|
[
"MIT"
] | null | null | null | 33.847059 | 172 | 0.433051 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import os, sys\nimport nibabel as nb\nimport numpy as np\n\nfrom nipype import Node, Workflow\nfrom nipype.interfaces.fsl import SliceTimer, MCFLIRT, Smooth, ExtractROI\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nfrom sklearn.utils import shuffle\n\nimport glob\nimport shutil",
"_____no_output_____"
],
[
"def writer(MyList, tgtf):\n MyFile=open(tgtf,'w')\n MyList=map(lambda x:x+'\\n', MyList)\n MyFile.writelines(MyList)\n MyFile.close()\n\ndef f_kendall(timeseries_matrix):\n\n \"\"\"\n Calculates the Kendall's coefficient of concordance for a number of\n time-series in the input matrix\n Parameters\n ----------\n timeseries_matrix : ndarray\n A matrix of ranks of a subset subject's brain voxels\n Returns\n -------\n kcc : float\n Kendall's coefficient of concordance on the given input matrix\n \"\"\"\n\n import numpy as np\n nk = timeseries_matrix.shape\n\n n = nk[0]\n k = nk[1]\n\n sr = np.sum(timeseries_matrix, 1)\n sr_bar = np.mean(sr)\n s = np.sum(np.power(sr, 2)) - n*np.power(sr_bar, 2)\n kcc = 12 *s/np.power(k, 2)/(np.power(n, 3) - n)\n return kcc\n\ndef compute_reho(in_file, mask_file, cluster_size = 7, out_file = None):\n\n \"\"\"\n Computes the ReHo Map, by computing tied ranks of the timepoints,\n followed by computing Kendall's coefficient concordance(KCC) of a\n timeseries with its neighbours\n Parameters\n ----------\n in_file : nifti file\n 4D EPI File\n mask_file : nifti file\n Mask of the EPI File(Only Compute ReHo of voxels in the mask)\n out_file : nifti file\n Where to save result\n cluster_size : integer\n for a brain voxel the number of neighbouring brain voxels to use for\n KCC.\n Returns\n -------\n out_file : nifti file\n ReHo map of the input EPI image\n \"\"\"\n\n res_fname = (in_file)\n res_mask_fname = (mask_file)\n CUTNUMBER = 10\n\n if not (cluster_size == 27 or cluster_size == 19 or cluster_size == 7 or cluster_size == 18):\n cluster_size = 27\n\n nvoxel = cluster_size\n\n res_img = nb.load(res_fname)\n res_mask_img = nb.load(res_mask_fname)\n\n res_data = res_img.get_data()\n res_mask_data = res_mask_img.get_data()\n\n print(res_data.shape)\n (n_x, n_y, n_z, n_t) = res_data.shape\n\n # \"flatten\" each volume of the timeseries into one big array instead of\n # x,y,z - produces (timepoints, N voxels) shaped data array\n res_data = np.reshape(res_data, (n_x*n_y*n_z, n_t), order='F').T\n\n # create a blank array of zeroes of size n_voxels, one for each time point\n Ranks_res_data = np.tile((np.zeros((1, (res_data.shape)[1]))),\n [(res_data.shape)[0], 1])\n\n # divide the number of total voxels by the cutnumber (set to 10)\n # ex. end up with a number in the thousands if there are tens of thousands\n # of voxels\n segment_length = np.ceil(float((res_data.shape)[1])/float(CUTNUMBER))\n\n for icut in range(0, CUTNUMBER):\n\n segment = None\n\n # create a Numpy array of evenly spaced values from the segment\n # starting point up until the segment_length integer\n if not (icut == (CUTNUMBER - 1)):\n segment = np.array(np.arange(icut * segment_length,\n (icut+1) * segment_length))\n else:\n segment = np.array(np.arange(icut * segment_length,\n (res_data.shape[1])))\n\n segment = np.int64(segment[np.newaxis])\n\n # res_data_piece is a chunk of the original timeseries in_file, but\n # aligned with the current segment index spacing\n res_data_piece = res_data[:, segment[0]]\n nvoxels_piece = res_data_piece.shape[1]\n\n # run a merge sort across the time axis, re-ordering the flattened\n # volume voxel arrays\n res_data_sorted = np.sort(res_data_piece, 0, kind='mergesort')\n sort_index = np.argsort(res_data_piece, axis=0, kind='mergesort')\n\n # subtract each volume from each other\n db = np.diff(res_data_sorted, 1, 0)\n\n # convert any zero voxels into \"True\" flag\n db = db == 0\n\n # return an n_voxel (n voxels within the current segment) sized array\n # of values, each value being the sum total of TRUE values in \"db\"\n sumdb = np.sum(db, 0)\n\n temp_array = np.array(np.arange(0, n_t))\n temp_array = temp_array[:, np.newaxis]\n\n sorted_ranks = np.tile(temp_array, [1, nvoxels_piece])\n\n if np.any(sumdb[:]):\n\n tie_adjust_index = np.flatnonzero(sumdb)\n\n for i in range(0, len(tie_adjust_index)):\n\n ranks = sorted_ranks[:, tie_adjust_index[i]]\n\n ties = db[:, tie_adjust_index[i]]\n\n tieloc = np.append(np.flatnonzero(ties), n_t + 2)\n maxties = len(tieloc)\n tiecount = 0\n\n while(tiecount < maxties -1):\n tiestart = tieloc[tiecount]\n ntied = 2\n while(tieloc[tiecount + 1] == (tieloc[tiecount] + 1)):\n tiecount += 1\n ntied += 1\n\n ranks[tiestart:tiestart + ntied] = np.ceil(np.float32(np.sum(ranks[tiestart:tiestart + ntied ]))/np.float32(ntied))\n tiecount += 1\n\n sorted_ranks[:, tie_adjust_index[i]] = ranks\n\n del db, sumdb\n sort_index_base = np.tile(np.multiply(np.arange(0, nvoxels_piece), n_t), [n_t, 1])\n sort_index += sort_index_base\n del sort_index_base\n\n ranks_piece = np.zeros((n_t, nvoxels_piece))\n\n ranks_piece = ranks_piece.flatten(order='F')\n sort_index = sort_index.flatten(order='F')\n sorted_ranks = sorted_ranks.flatten(order='F')\n\n ranks_piece[sort_index] = np.array(sorted_ranks)\n\n ranks_piece = np.reshape(ranks_piece, (n_t, nvoxels_piece), order='F')\n\n del sort_index, sorted_ranks\n\n Ranks_res_data[:, segment[0]] = ranks_piece\n\n sys.stdout.write('.')\n\n Ranks_res_data = np.reshape(Ranks_res_data, (n_t, n_x, n_y, n_z), order='F')\n\n K = np.zeros((n_x, n_y, n_z))\n\n mask_cluster = np.ones((3, 3, 3))\n\n if nvoxel == 19:\n mask_cluster[0, 0, 0] = 0\n mask_cluster[0, 2, 0] = 0\n mask_cluster[2, 0, 0] = 0\n mask_cluster[2, 2, 0] = 0\n mask_cluster[0, 0, 2] = 0\n mask_cluster[0, 2, 2] = 0\n mask_cluster[2, 0, 2] = 0\n mask_cluster[2, 2, 2] = 0\n \n elif nvoxel == 18:\n # null mid disk and disky-shaped\n mask_cluster[0, 0, 0] = 0\n mask_cluster[0, 2, 0] = 0\n mask_cluster[2, 0, 0] = 0\n mask_cluster[2, 2, 0] = 0\n mask_cluster[0, 0, 2] = 0\n mask_cluster[0, 2, 2] = 0\n mask_cluster[2, 0, 2] = 0\n mask_cluster[2, 2, 2] = 0\n mask_cluster[1, 0, 0] = 0\n mask_cluster[1, 0, 1] = 0\n mask_cluster[1, 0, 2] = 0\n mask_cluster[1, 2, 0] = 0\n mask_cluster[1, 2, 1] = 0\n mask_cluster[1, 2, 2] = 0\n mask_cluster[1, 1, 0] = 0\n mask_cluster[1, 1, 2] = 0\n\n elif nvoxel == 7:\n\n mask_cluster[0, 0, 0] = 0\n mask_cluster[0, 1, 0] = 0\n mask_cluster[0, 2, 0] = 0\n mask_cluster[0, 0, 1] = 0\n mask_cluster[0, 2, 1] = 0\n mask_cluster[0, 0, 2] = 0\n mask_cluster[0, 1, 2] = 0\n mask_cluster[0, 2, 2] = 0\n mask_cluster[1, 0, 0] = 0\n mask_cluster[1, 2, 0] = 0\n mask_cluster[1, 0, 2] = 0\n mask_cluster[1, 2, 2] = 0\n mask_cluster[2, 0, 0] = 0\n mask_cluster[2, 1, 0] = 0\n mask_cluster[2, 2, 0] = 0\n mask_cluster[2, 0, 1] = 0\n mask_cluster[2, 2, 1] = 0\n mask_cluster[2, 0, 2] = 0\n mask_cluster[2, 1, 2] = 0\n mask_cluster[2, 2, 2] = 0\n\n for i in range(1, n_x - 1):\n for j in range(1, n_y -1):\n for k in range(1, n_z -1):\n\n block = Ranks_res_data[:, i-1:i+2, j-1:j+2, k-1:k+2]\n mask_block = res_mask_data[i-1:i+2, j-1:j+2, k-1:k+2]\n\n if not(int(mask_block[1, 1, 1]) == 0):\n\n if nvoxel == 19 or nvoxel == 7 or nvoxel == 18:\n mask_block = np.multiply(mask_block, mask_cluster)\n\n R_block = np.reshape(block, (block.shape[0], 27),\n order='F')\n mask_R_block = R_block[:, np.argwhere(np.reshape(mask_block, (1, 27), order='F') > 0)[:, 1]]\n\n K[i, j, k] = f_kendall(mask_R_block)\n\n img = nb.Nifti1Image(K, header=res_img.get_header(),\n affine=res_img.get_affine())\n \n if out_file is not None:\n reho_file = out_file\n else:\n reho_file = os.path.join(os.getcwd(), 'ReHo.nii.gz')\n img.to_filename(reho_file)\n \n return reho_file",
"_____no_output_____"
],
[
"base = \"/Volumes/G_drive/Backup_06062020/ds000133/\"\norder_path = base + \"/SlTi/\"\n\nsbjpatt = \"\"\nsess = \"ses-pre/func\"\nfmriname = \"_ses-pre_task-rest_run-01_bold.nii.gz\"",
"_____no_output_____"
],
[
"TR = 1.67136\nfwhm = 3\ndummy = 10\nn_sl = 30\nrh = 18 #27",
"_____no_output_____"
],
[
"# https://en.wikibooks.org/wiki/SPM/Slice_Timing\n\nos.makedirs(order_path, mode=777, exist_ok=True)\n\n# seq asc 1 2 3 4\nslice_order = list(np.arange(1, n_sl+1).astype(str))\nwriter(slice_order, order_path + 'slti_1.txt') \n\n# seq desc 4 3 2 1\nslice_order = list(reversed(list(np.arange(1, n_sl+1).astype(str))))\nwriter(slice_order, order_path + 'slti_2.txt') \n\n# int asc 1 3 2 4\nslice_order = list(np.arange(1, n_sl+1, 2).astype(str)) + list(np.arange(2, n_sl+1, 2).astype(str))\nwriter(slice_order, order_path + 'slti_3.txt') \n\n# int asc 4 2 3 1\nslice_order = list(reversed(list(np.arange(1, n_sl+1, 2).astype(str)) + list(np.arange(2, n_sl+1, 2).astype(str))))\nwriter(slice_order, order_path + 'slti_4.txt') \n\n# int2 asc 2 4 1 3\nslice_order = list(np.arange(2, n_sl+1, 2).astype(str)) + list(np.arange(1, n_sl+1, 2).astype(str))\nwriter(slice_order, order_path + 'slti_5.txt') \n\n# int2 dsc 3 1 4 2\nslice_order = list(reversed(list(np.arange(2, n_sl+1, 2).astype(str)) + list(np.arange(1, n_sl+1, 2).astype(str))))\nwriter(slice_order, order_path + 'slti_6.txt') \n\nfor rr in np.arange(7,27):\n slice_order = list(shuffle(np.arange(1, n_sl+1).astype(str), random_state=rr))\n writer(slice_order, order_path + 'slti_{}.txt'.format(rr)) # random permutation of slices ",
"_____no_output_____"
],
[
"rehos = []\nfor sbj in sorted([sbj.split(\"/\")[-1].replace(\"sub-\",\"\") for sbj in glob.glob(base + \"sub-{}*\".format(sbjpatt))]):\n fmri_nii = base + \"sub-{}/{}/\".format(sbj,sess) + \"sub-{}{}\".format(sbj,fmriname)\n for opt in np.arange(1, 17):\n #if (opt in [5,6] and n_sl%2==0): \n # skip Siemens interleaved even cases unless n_sl is really even\n \n proc_ref = '{}_preproc_{}'.format(sbj,opt)\n extract = Node(ExtractROI(t_min=dummy, t_size=-1, output_type='NIFTI_GZ'), name=\"extract\")\n slicetimer = Node(SliceTimer(custom_order = order_path + \"slti_{}.txt\".format(opt), time_repetition=TR), name=\"slicetimer\")\n mcflirt = Node(MCFLIRT(mean_vol=True, save_plots=True), name=\"mcflirt\")\n smooth = Node(Smooth(fwhm=fwhm), name=\"smooth\")\n preproc01 = Workflow(name=proc_ref, base_dir=base)\n preproc01.connect([(extract, slicetimer, [('roi_file', 'in_file')]),\n (slicetimer, mcflirt, [('slice_time_corrected_file', 'in_file')]),\n (mcflirt, smooth, [('out_file', 'in_file')])])\n extract.inputs.in_file = fmri_nii\n preproc01.run('MultiProc', plugin_args={'n_procs': 1})\n \n basepath = base + \"/{}/smooth/\".format(proc_ref)\n proc_f = basepath + fmri_nii.split(\"/\")[-1].replace(\".nii.gz\",\"\") + \"_roi_st_mcf_smooth.nii.gz\"\n in_f = basepath + \"meanvol\"\n out_f = basepath + \"meanvol_bet\"\n !fslmaths {proc_f} -Tmean {in_f}\n !bet {in_f} {out_f} -m\n \n rehos.append([sbj, opt, compute_reho(proc_f, in_f + \"_bet\" + \"_mask.nii.gz\", rh, out_file = base + \"/\" + sbj + \"_\" + str(opt) + \"_ReHo.nii.gz\")])\n shutil.rmtree(base + \"/{}/\".format(proc_ref))",
"_____no_output_____"
],
[
"rehos = [[ff.split(\"/\")[-1].split(\"_\")[0], ff.split(\"/\")[-1].split(\"_\")[1], ff] for ff in glob.glob(base+\"*_ReHo.nii.gz\")]",
"_____no_output_____"
],
[
"thr = 0.05\nres = pd.DataFrame(columns=['sbj', 'ord', 'rehoavg', 'rehopct'])\nfor nii in rehos:\n img = nb.load(nii[-1]).get_fdata()\n img = img.ravel()\n img = img[img>thr] \n if int(nii[1]) < 7:\n res = res.append({\"sbj\":nii[0], \"ord\":nii[1], \"rehoavg\":np.nanmean(img), \"rehopct\":np.percentile(img,90)}, ignore_index = True)\n else:\n res = res.append({\"sbj\":nii[0], \"ord\":\"0\", \"rehoavg\":np.nanmean(img), \"rehopct\":np.percentile(img,90)}, ignore_index = True)",
"_____no_output_____"
],
[
"metric = \"rehopct\"\n\nsignif = pd.DataFrame(columns=['sbj', 'ord', 'reho', 'tt'])\nfor sbj in np.unique(res.sbj.values):\n rsel = res[res.sbj == sbj].sort_values([\"rehopct\",\"rehoavg\"])\n \n for oo in np.arange(0,7):\n oo = str(oo)\n t2 = (np.nanmean(rsel[rsel.ord == oo][metric].values - np.nanmean(rsel[rsel.ord == \"0\"][metric].values))) / \\\n np.nanstd(rsel[rsel.ord == \"0\"][metric].values)\n signif = signif.append({\"sbj\":sbj, \n \"ord\":oo, \n \"reho\":round(np.nanmean(rsel[rsel.ord == oo][metric].values),3), \n \"tt\": round(np.abs(t2), 3)}, ignore_index = True)\n\nsignif = signif[(signif.ord != \"3\")] # exclude impossible cases\n\nlls = []\nfor sbj in np.unique(res.sbj.values):\n rsel = signif[signif.sbj == sbj].sort_values([\"reho\",\"sbj\"])\n lls.append(rsel[rsel.sbj==sbj].iloc[-1:].ord.values[:])",
"_____no_output_____"
],
[
"x = np.array(lls).astype(int).ravel()\ny = np.bincount(x)\nii = np.nonzero(y)[0]\nprint(\"ord_id, counts\")\nnp.vstack((ii,y[ii])).T",
"ord_id, counts\n"
],
[
"signif.sort_values([\"sbj\", \"tt\"]).head(20)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51883230ac7655f82de21b73517b7e249ce50f6
| 187,596 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/test_simulators-checkpoint.ipynb
|
prashantramnani/nn_likelihoods
|
94e7a1d8fdf8c4e635eeaa66a7e941aa6b226f41
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/test_simulators-checkpoint.ipynb
|
prashantramnani/nn_likelihoods
|
94e7a1d8fdf8c4e635eeaa66a7e941aa6b226f41
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/test_simulators-checkpoint.ipynb
|
prashantramnani/nn_likelihoods
|
94e7a1d8fdf8c4e635eeaa66a7e941aa6b226f41
|
[
"MIT"
] | null | null | null | 86.290708 | 28,756 | 0.706854 |
[
[
[
"# Environ\nimport scipy as scp\nimport tensorflow as tf\nfrom scipy.stats import gamma\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.neighbors import KernelDensity\nimport random\nimport multiprocessing as mp\nimport psutil\nimport pickle\nimport os\nimport re\nimport time\n\n# import dataset_generator as dg\n# import make_data_lba as mdlba\n# from tqdm import tqdm\n\n# Own\n#import ddm_data_simulation as ds\nimport cddm_data_simulation as cds\nimport kde_training_utilities as kde_util\nimport kde_class as kde\nimport boundary_functions as bf\n\nfrom cdwiener import batch_fptd\nfrom cdwiener import fptd",
"_____no_output_____"
],
[
"# DDM\nnow = time.time()\nrepeats = 1000\nmy_means = np.zeros(repeats)\n\nv_vec = np.random.uniform(low = -3, high = 3, size = 1000)\na_vec = np.random.uniform(low = 0.5, high = 2.5, size = 1000)\nw_vec = np.random.uniform(low = 0.2, high = 0.8, size = 1000)\n\n\nfor i in range(repeats):\n out = cds.ddm_flexbound(v = v_vec[i], \n a = a_vec[i],\n w = w_vec[i],\n ndt = 0.0,\n delta_t = 0.001, \n s = 1, #np.sqrt(2),\n max_t = 20,\n n_samples = 30000,\n boundary_fun = bf.constant,\n boundary_multiplicative = True, \n boundary_params = {})\n #boundary_params = {\"theta\": 0.01})\n if i % 100 == 0:\n print(i)\n \n my_means[i] = np.mean(out[0][out[1] == 1])\n \nprint(time.time() - now)",
"0\n"
],
[
"np.random.uniform(low= -1, high = 2, size = 1000)",
"_____no_output_____"
],
[
"plt.hist(out[0] * out[1], bins = np.linspace(-15, 15, 100), density = True)",
"_____no_output_____"
],
[
"out = cds.ddm_sdv(v = -3,\n a = 2.5, \n w = 0.3,\n ndt = 1,\n sdv = 0,\n s = 1,\n boundary_fun = bf.constant, \n delta_t = 0.001,\n n_samples = 100000)",
"_____no_output_____"
],
[
"out[0] * out[1]",
"_____no_output_____"
],
[
"my_bins = np.arange(- 512, 513) * 20 / 1024",
"_____no_output_____"
],
[
"analy_out = batch_fptd(t = my_bins.copy(),\n v = 3,\n a = 5,\n w = 0.7,\n ndt = 1,\n sdv = 0,\n eps = 1e-50)",
"_____no_output_____"
],
[
"(analy_out <= 1e-48).nonzero()\n",
"_____no_output_____"
],
[
"analy_out[500:550]",
"_____no_output_____"
],
[
"plt.plot(my_bins, analy_out)",
"_____no_output_____"
],
[
"plt.hist(out[0] * out[1], \n bins = np.arange(-512, 513) * 20/1024 , \n alpha = 0.2, \n color = 'red', \n density = 1)\n\nplt.plot(my_bins, analy_out)",
"_____no_output_____"
],
[
"cumsum = 0\nfor i in range(1, analy_out.shape[0], 1):\n cumsum += ((analy_out[i - 1] + analy_out[i]) / 2) * (my_bins[1] - my_bins[0])",
"_____no_output_____"
],
[
"cumsum",
"_____no_output_____"
],
[
"np.exp(25)",
"_____no_output_____"
],
[
"analy_out.shape",
"_____no_output_____"
],
[
"plt.hist(out[0][out[1][:, 0] == -1, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'red')\nplt.hist(out[0][out[1][:, 0] == 1, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'green')",
"_____no_output_____"
],
[
"# DDM \nrepeats = 1\ncolors = ['green', 'red']\nmy_means = np.zeros(repeats)\ncnt = 0\nfor i in np.linspace(2, 1.01, 2):\n out = cds.levy_flexbound(v = 0, \n a = 2.5,\n w = 0.5,\n alpha_diff = i,\n ndt = 0.5,\n delta_t = 0.001, \n max_t = 20,\n n_samples = 10000,\n boundary_fun = bf.constant,\n boundary_multiplicative = True, \n boundary_params = {})\n #boundary_params = {\"theta\": 0.01})\n plt.hist(out[0] * out[1], bins = np.linspace(-15, 15, 100), density = True, alpha = 0.2, color = colors[cnt])\n print(i)\n cnt += 1\n \n #my_means[i] = np.mean(out[0][out[1] == 1])\nplt.show()",
"2.0\n1.01\n"
],
[
"def bin_simulator_output(out = [0, 0],\n bin_dt = 0.04,\n n_bins = 0,\n eps_correction = 1e-7, # min p for a bin\n params = ['v', 'a', 'w', 'ndt']\n ): # ['v', 'a', 'w', 'ndt', 'angle']\n\n # Generate bins\n if n_bins == 0:\n n_bins = int(out[2]['max_t'] / bin_dt)\n bins = np.linspace(0, out[2]['max_t'], n_bins)\n else: \n bins = np.linspace(0, out[2]['max_t'], n_bins)\n bins = np.append(bins, [100])\n print(bins)\n counts = []\n cnt = 0\n counts = np.zeros( (n_bins, len(out[2]['possible_choices']) ) )\n counts_size = counts.shape[0] * counts.shape[1]\n \n for choice in out[2]['possible_choices']:\n counts[:, cnt] = np.histogram(out[0][out[1] == choice], bins = bins)[0] / out[2]['n_samples']\n cnt += 1\n \n # Apply correction for empty bins\n n_small = 0\n n_big = 0\n n_small = np.sum(counts < eps_correction)\n n_big = counts_size - n_small \n \n if eps_correction > 0:\n counts[counts <= eps_correction] = eps_correction\n counts[counts > eps_correction] -= (eps_correction * (n_small / n_big))\n\n return ([out[2][param] for param in params], # features\n counts, # labels\n {'max_t': out[2]['max_t'], \n 'bin_dt': bin_dt, \n 'n_samples': out[2]['n_samples']} # meta data\n )\n\n\ndef bin_simulator_output(self, \n out = [0, 0],\n bin_dt = 0.04,\n nbins = 0): # ['v', 'a', 'w', 'ndt', 'angle']\n \n # Generate bins\n if nbins == 0:\n nbins = int(out[2]['max_t'] / bin_dt)\n bins = np.zeros(nbins + 1)\n bins[:nbins] = np.linspace(0, out[2]['max_t'], nbins)\n bins[nbins] = np.inf\n else: \n bins = np.zeros(nbins + 1)\n bins[:nbins] = np.linspace(0, out[2]['max_t'], nbins)\n bins[nbins] = np.inf\n\n cnt = 0\n counts = np.zeros( (nbins, len(out[2]['possible_choices']) ) )\n\n for choice in out[2]['possible_choices']:\n counts[:, cnt] = np.histogram(out[0][out[1] == choice], bins = bins)[0] / out[2]['n_samples']\n cnt += 1\n return counts",
"_____no_output_____"
],
[
"#%%timeit -n 1 -r 5\na, b = bin_simulator_output(out = out)",
"_____no_output_____"
],
[
"%%timeit -n 5 -r 1\nout = cds.ornstein_uhlenbeck(v = 0.0,\n a = 1.5,\n w = 0.5,\n g = 0,\n ndt = 0.92,\n delta_t = 0.001,\n boundary_fun = bf.constant,\n n_samples = 100000)",
"36.2 s ± 0 ns per loop (mean ± std. dev. of 1 run, 5 loops each)\n"
],
[
"binned_sims = bin_simulator_output(out = out,\n n_bins = 256,\n eps_correction = 1e-7,\n params = ['v', 'a', 'w', 'g', 'ndt'])",
"_____no_output_____"
],
[
"%%timeit -n 5 -r 1\nout = cds.ddm_flexbound_seq2(v_h = 0,\n v_l_1 = 0,\n v_l_2 = 0,\n a = 1.5,\n w_h = 0.5,\n w_l_1 = 0.5,\n w_l_2 = 0.5,\n ndt = 0.5,\n s = 1,\n delta_t = 0.001,\n max_t = 20,\n n_samples = 100000,\n print_info = True,\n boundary_fun = bf.constant, # function of t (and potentially other parameters) that takes in (t, *args)\n boundary_multiplicative = True,\n boundary_params = {})",
"1min 10s ± 0 ns per loop (mean ± std. dev. of 1 run, 5 loops each)\n"
],
[
"%%timeit -n 5 -r 1\nout = cds.ddm_flexbound_par2(v_h = 0,\n v_l_1 = 0,\n v_l_2 = 0,\n a = 1.5,\n w_h = 0.5,\n w_l_1 = 0.5,\n w_l_2 = 0.5,\n ndt = 0.5,\n s = 1,\n delta_t = 0.001,\n max_t = 20,\n n_samples = 100000,\n print_info = True,\n boundary_fun = bf.constant, # function of t (and potentially other parameters) that takes in (t, *args)\n boundary_multiplicative = True,\n boundary_params = {})",
"1min 9s ± 0 ns per loop (mean ± std. dev. of 1 run, 5 loops each)\n"
],
[
"%%timeit -n 5 -r 1 \nout = cds.ddm_flexbound_mic2(v_h = 0.0,\n v_l_1 = 0.0,\n v_l_2 = 0.0,\n a = 1.5,\n w_h = 0.5,\n w_l_1 = 0.5,\n w_l_2 = 0.5,\n d = 1.0, \n ndt = 0.5,\n s = 1,\n delta_t = 0.001,\n max_t = 20,\n n_samples = 100000,\n print_info = True,\n boundary_fun = bf.constant, # function of t (and potentially other parameters) that takes in (t, *args)\n boundary_multiplicative = True,\n boundary_params = {})",
"1min 12s ± 0 ns per loop (mean ± std. dev. of 1 run, 5 loops each)\n"
],
[
"plt.hist(out[0][out[1][:, 0] == 0, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'red')\nplt.hist(out[0][out[1][:, 0] == 1, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'green')\n#plt.hist(out[0][out[1][:, 0] == 2, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'red')\n#plt.hist(out[0][out[1][:, 0] == 3, 0], bins = np.arange(512) * 20/512 , alpha = 0.2, color = 'green')",
"_____no_output_____"
],
[
"import pickle\nimport os\n",
"_____no_output_____"
],
[
"os.listdir('/media/data_cifs/afengler/data/kde/ddm_seq2/training_data_binned_1_nbins_512_n_100000')",
"_____no_output_____"
],
[
"tt = pickle.load(open('/media/data_cifs/afengler/data/kde/ddm_mic2/training_data_binned_1_nbins_512_n_100000/ddm_mic2_nchoices_2_train_data_binned_1_nbins_512_n_100000_999.pickle', 'rb'))",
"_____no_output_____"
],
[
"tt[1][0][:,0]",
"_____no_output_____"
],
[
"plt.plot(tt[1][2, :,0])\nplt.plot(tt[1][2, :,1])\nplt.plot(tt[1][2, :,2])\nplt.plot(tt[1][2, :,3])",
"_____no_output_____"
],
[
"print(np.mean(out[0][out[1][:, 0] == 0, 0]))\nprint(np.mean(out[0][out[1][:, 0] == 1, 0]))\n#print(np.mean(out[0][out[1][:, 0] == 2, 0]))\n#print(np.mean(out[0][out[1][:, 0] == 3, 0]))",
"1.9529729\n1.9603328\n"
],
[
"print(np.shape(out[0][out[1][:, 0] == 0, 0]))\nprint(np.shape(out[0][out[1][:, 0] == 1, 0]))\n#print(np.shape(out[0][out[1][:, 0] == 2, 0]))\n#print(np.shape(out[0][out[1][:, 0] == 3, 0]))",
"(24981,)\n(24776,)\n"
],
[
"np.sort(out[0][out[1][:,0] == 1, 0])",
"_____no_output_____"
],
[
"plt.hist(out[0][out[1][:, 0] == 0, 0], bins = 50, alpha = 0.5, color = 'green')\nplt.hist(out[0][out[1][:, 0] == 1, 0], bins = 50, alpha = 0.2, color = 'green')\nplt.hist(out[0][out[1][:, 0] == 2, 0], bins = 50, alpha = 0.2, color = 'blue')\nplt.hist(out[0][out[1][:, 0] == 3, 0], bins = 50, alpha = 0.2, color = 'red')",
"_____no_output_____"
],
[
"print(np.max(out[0][out[1][:, 0] == 0, 0]))\nprint(np.max(out[0][out[1][:, 0] == 1, 0]))\nprint(np.max(out[0][out[1][:, 0] == 2, 0]))\nprint(np.max(out[0][out[1][:, 0] == 3, 0]))",
"20.500637\n17.52927\n14.810153\n16.616772\n"
],
[
"binned_sims = bin_simulator_output(out = out,\n n_bins = 256,\n eps_correction = 1e-7,\n params = ['v', 'a', 'w', 'g', 'ndt'])",
"_____no_output_____"
],
[
"plt.plot(binned_sims[1][:, 1])\nplt.plot(binned_sims[1][:, 0])",
"_____no_output_____"
],
[
"binned_sims[1][255, 1]",
"_____no_output_____"
],
[
"files_ = os.listdir('/media/data_cifs/afengler/data/kde/ddm/base_simulations_20000')",
"_____no_output_____"
],
[
"labels = np.zeros((250000, 500, 2))\nfeatures = np.zeros((250000, 3))\n\ncnt = 0\ni = 0\nfile_dim = 100\nfor file_ in files_[:1000]:\n if file_[:8] == 'ddm_flex':\n out = pickle.load(open('/media/data_cifs/afengler/data/kde/ddm/base_simulations_20000/' + file_, 'rb'))\n features[cnt], labels[cnt] = bin_simulator_output(out = out)\n if cnt % file_dim == 0:\n print(cnt)\n pickle.dump((labels[(i * file_dim):((i + 1) * file_dim)], features[(i * file_dim):((i + 1) * file_dim)]), open('/media/data_cifs/afengler/data/kde/ddm/base_simulations_20000_binned/dataset_' + str(i), 'wb'))\n i += 1\n cnt += 1\n",
"_____no_output_____"
],
[
"# FULL DDM \nrepeats = 50\nmy_means = np.zeros(repeats)\nfor i in range(repeats):\n out = cds.full_ddm(v = 0, \n a = 0.96,\n w = 0.5,\n ndt = 0.5,\n dw = 0.0,\n sdv = 0.0,\n dndt = 0.5,\n delta_t = 0.01, \n max_t = 20,\n n_samples = 10000,\n boundary_fun = bf.constant,\n boundary_multiplicative = True, \n boundary_params = {})\n print(i)\n \n my_means[i] = np.mean(out[0][out[1] == 1])",
"_____no_output_____"
],
[
"plt.hist(out[0] * out[1], bins = 50)",
"_____no_output_____"
],
[
"int(50 / out[2]['delta_t'] + 1)",
"_____no_output_____"
],
[
"# LCA \nrepeats = 1\nmy_means = np.zeros(repeats)\nfor i in range(repeats):\n out = cds.lca(v = np.array([0, 0], dtype = np.float32), \n a = 2, \n w = np.array([0.5, 0.5], dtype = np.float32), \n ndt = np.array([1.0, 1.0], dtype = np.float32),\n g = -1.0,\n b = 1.0,\n delta_t = 0.01, \n max_t = 40,\n n_samples = 10000,\n boundary_fun = bf.constant,\n boundary_multiplicative = True, \n boundary_params = {})\n print(i)\n my_means[i] = np.mean(out[0][out[1] == 1])",
"_____no_output_____"
],
[
"out[1][out[1] == 0] = -1\nplt.hist(out[0] * out[1], bins = 50)",
"_____no_output_____"
],
[
"# LCA \nrepeats = 10\nmy_means = np.zeros(repeats)\nfor i in range(repeats):\n out = cds.ddm_flexbound(v = 0.0, \n a = 1.5, \n w = 0.5, \n ndt = 0.1,\n delta_t = 0.01, \n max_t = 40,\n n_samples = 10000,\n boundary_fun = bf.constant,\n boundary_multiplicative = True, \n boundary_params = {})\n print(i)\n my_means[i] = np.mean(out[0][out[1] == 1])",
"_____no_output_____"
],
[
"def foo(name, *args, **kwargs):\n print (\"args: \", args)\n print (\"Type of args: \", type(args))\n if len(args)>2:\n args = args[0], args[1] #- Created Same name variable.\n print (\"Temp args:\", args)",
"_____no_output_____"
],
[
"my_keys = []\nfor key in test_dat.keys():\n if key[0] == 'v':\n my_keys.append(key)\nnp.array(test_dat.loc[1, ['v_0', 'v_1']])",
"_____no_output_____"
],
[
"my_dat = mdlba.make_data_rt_choice(target_folder = my_target_folder)",
"_____no_output_____"
],
[
"np.max(my_dat['log_likelihood'])",
"_____no_output_____"
],
[
"data = np.concatenate([out[0], out[1]], axis = 1)",
"_____no_output_____"
],
[
"###\ncds.race_model(boundary_fun = bf.constant,\n n_samples = 100000)",
"_____no_output_____"
],
[
"np.quantile(np.random.uniform(size = (10000,4)), q = [0.05, 0.10, 0.9, 0.95], axis = 0)",
"_____no_output_____"
],
[
"tuple(map(tuple, a))",
"_____no_output_____"
],
[
"tuple(np.apply_along_axis(my_func, 0, a, key_vec))",
"_____no_output_____"
],
[
"dict(zip(a[0,:], ['a' ,'b', 'c']))",
"_____no_output_____"
],
[
"def my_func(x = 0, key_vec = ['a' ,'b', 'c']):\n return dict(zip(key_vec, x))",
"_____no_output_____"
],
[
"my_func_init = my_func(key_vec = ['d', 'e', 'f'])",
"_____no_output_____"
],
[
"test = yaml.load(open('config_files/config_data_generator.yaml'))",
"_____no_output_____"
],
[
"from multiprocessing import Pool\n\ndef myfunc(a):\n return a ** 2\npbar = tqdm(total = 100)\ndef update():\n pbar.update\n\na = tuple()\nfor i in range(pbar.total):\n a += ((1, ), )\n \npool = Pool(4)\npool.starmap(myfunc, a, callback = update)\npool.close()\npool.join()",
"\n\n\n\n\n 0%| | 0/100 [00:00<?, ?it/s]\u001b[A\u001b[A\u001b[A\u001b[A\u001b[A"
],
[
"def my_fun(*args):\n print(args)",
"_____no_output_____"
],
[
"help(dg.make_dataset_r_dgp)",
"_____no_output_____"
],
[
"def zip_dict(x = [], \n key_vec = ['a', 'b', 'c']):\n return dict(zip(key_vec, x))",
"_____no_output_____"
],
[
"my_dg = dg.data_generator(file_id = 'TEST')",
"_____no_output_____"
],
[
"out = my_dg.make_dataset_perturbation_experiment(save = False)",
"_____no_output_____"
],
[
"out = my_dg.make_dataset_uniform(save = False)",
"_____no_output_____"
],
[
"my_dg.param_grid_perturbation_experiment()",
"_____no_output_____"
],
[
"param_grid = my_dg.param_grid_uniform()",
"_____no_output_____"
],
[
"%%timeit -n 1 -r 1\ntt = my_dg.generate_data_grid_parallel(param_grid = param_grid)",
"_____no_output_____"
],
[
"3**3",
"_____no_output_____"
],
[
"a = np.random.choice(10, size = (1000,1))",
"_____no_output_____"
],
[
"for i in zip([1,2,3], [1, 2, 3], [1]):\n print( i )",
"(1, 1, 1)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c518afd1de12a7885274fd0d09a596175c262c8e
| 45,211 |
ipynb
|
Jupyter Notebook
|
labs/bayesian-curve-fitting/bayesian-curve-fitting.ipynb
|
anujpra/pattern-recognition-lab
|
f032f1f2a9309b13ef50848a2560b49c5d677835
|
[
"MIT"
] | 3 |
2021-02-22T04:45:43.000Z
|
2021-11-28T14:49:24.000Z
|
labs/bayesian-curve-fitting/bayesian-curve-fitting.ipynb
|
anujpra/pattern-recognition-lab
|
f032f1f2a9309b13ef50848a2560b49c5d677835
|
[
"MIT"
] | null | null | null |
labs/bayesian-curve-fitting/bayesian-curve-fitting.ipynb
|
anujpra/pattern-recognition-lab
|
f032f1f2a9309b13ef50848a2560b49c5d677835
|
[
"MIT"
] | 1 |
2021-04-13T05:00:58.000Z
|
2021-04-13T05:00:58.000Z
| 270.724551 | 40,364 | 0.914047 |
[
[
[
"# Bayesian Curve Fitting\n\n### Overview\nThe predictive distribution resulting from a Baysian treatment of polynominal curve fittting using an $M = 9$ polynominal, with the fixed parameters $\\alpha = 5×10^{-3}$ and $\\beta = 11.1$ (Corresponding to known noise variance), in which the red curve denotes the mean of the predictive distribution and the red region corresponds to $±1$ standard deviation around the mean.\n\n### Procedure\n\n1. The predictive distribution tis written in the form\n\\begin{equation*}\n p(t| x, {\\bf x}, {\\bf t}) = N(t| m(x), s^2(x)) (1.69).\n\\end{equation*}\n\n2. The basis function is defined as $\\phi_i(x) = x^i$ for $i = 0,...M$.\n\n3. The mean and variance are given by\n\n\\begin{equation*}m(x) = \\beta\\phi(x)^{\\bf T}{\\bf S} \\sum_{n=1}^N \\phi(x_n)t_n(1.70)\\end{equation*}\n\n\\begin{equation*} s^2(x) = \\beta^{-1} + \\phi(x)^{\\bf T} {\\bf S} \\phi(x)(1.71)\\end{equation*}\n\n\\begin{equation*}{\\bf S}^{-1} = \\alpha {\\bf I} + \\beta \\sum_{n=1}^N \\phi(x_n)\\phi(x_n)^{\\bf T}(1.72)\\end{equation*}\n\n4. Inprement these equation and visualize the predictive distribution in the raneg of $0.0<x<1.0$.\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom numpy.linalg import inv\nimport pandas as pd\nfrom pylab import *\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"#From p31 the authors define phi as following\ndef phi(x):\n return np.array([x ** i for i in range(M + 1)]).reshape((M + 1, 1))\n\n#(1.70) Mean of predictive distribution\ndef mean(x, x_train, y_train, S): #m\n sum = np.array(zeros((M+1, 1)))\n for n in range(len(x_train)):\n sum += np.dot(phi(x_train[n]), y_train[n])\n return Beta * phi(x).T.dot(S).dot(sum)\n \n#(1.71) Variance of predictive distribution\ndef var(x, S): #s2\n return 1.0/Beta + phi(x).T.dot(S).dot(phi(x))\n\n#(1.72)\ndef S(x_train, y_train):\n I = np.identity(M + 1)\n Sigma = np.zeros((M + 1, M + 1))\n for n in range(len(x_train)):\n Sigma += np.dot(phi(x_train[n]), phi(x_train[n]).T)\n S_inv = alpha * I + Beta * Sigma\n return inv(S_inv)",
"_____no_output_____"
],
[
"alpha = 0.005\nBeta = 11.1\nM = 9\n\n#Sine curve\nx_real = np.arange(0, 1, 0.01)\ny_real = np.sin(2*np.pi*x_real)\n\n##Training Data\nN=10\nx_train = np.linspace(0, 1, 10)\n\n#Set \"small level of random noise having a Gaussian distribution\"\nloc = 0\nscale = 0.3\ny_train = np.sin(2* np.pi * x_train) + np.random.normal(loc, scale, N)\n\n\nresult = S(x_train, y_train)\n\n#Seek predictive distribution corespponding to entire x\nmu = [mean(x, x_train, y_train, result)[0,0] for x in x_real]\nvariance = [var(x, result)[0,0] for x in x_real]\nSD = np.sqrt(variance)\nupper = mu + SD\nlower = mu - SD\n\n\nplt.figure(figsize=(10, 7))\nplot(x_train, y_train, 'bo')\nplot(x_real, y_real, 'g-')\nplot(x_real, mu, 'r-')\nfill_between(x_real, upper, lower, color='pink')\nxlim(0.0, 1.0)\nylim(-2, 2)\ntitle(\"Figure 1.17\") ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
c518b1e93ab1629cb892d52469d801a53942c9a7
| 172,015 |
ipynb
|
Jupyter Notebook
|
run/resnet-56/resnet56_prune.ipynb
|
mmendiet/gate-decorator-pruning
|
ebff861626296638619f48cdf0ff8bf3c5eccc2f
|
[
"Apache-2.0"
] | 192 |
2019-09-18T10:02:16.000Z
|
2022-03-24T16:31:18.000Z
|
run/resnet-56/resnet56_prune.ipynb
|
mmendiet/gate-decorator-pruning
|
ebff861626296638619f48cdf0ff8bf3c5eccc2f
|
[
"Apache-2.0"
] | 25 |
2019-09-24T10:53:51.000Z
|
2022-01-18T07:13:52.000Z
|
run/resnet-56/resnet56_prune.ipynb
|
mmendiet/gate-decorator-pruning
|
ebff861626296638619f48cdf0ff8bf3c5eccc2f
|
[
"Apache-2.0"
] | 33 |
2019-09-19T02:21:58.000Z
|
2022-03-31T10:04:20.000Z
| 33.821274 | 164 | 0.338784 |
[
[
[
"''' setting before run. every notebook should include this code. '''\nimport os\nos.environ[\"CUDA_DEVICE_ORDER\"]=\"PCI_BUS_ID\"\nos.environ[\"CUDA_VISIBLE_DEVICES\"]=\"0\"\n\nimport sys\n\n_r = os.getcwd().split('/')\n_p = '/'.join(_r[:_r.index('gate-decorator-pruning')+1])\nprint('Change dir from %s to %s' % (os.getcwd(), _p))\nos.chdir(_p)\nsys.path.append(_p)\n\nfrom config import parse_from_dict\nparse_from_dict({\n \"base\": {\n \"task_name\": \"resnet56_cifar10_ticktock\",\n \"cuda\": True,\n \"seed\": 0,\n \"checkpoint_path\": \"\",\n \"epoch\": 0,\n \"multi_gpus\": True,\n \"fp16\": False\n },\n \"model\": {\n \"name\": \"cifar.resnet56\",\n \"num_class\": 10,\n \"pretrained\": False\n },\n \"train\": {\n \"trainer\": \"normal\",\n \"max_epoch\": 160,\n \"optim\": \"sgd\",\n \"steplr\": [\n [80, 0.1],\n [120, 0.01],\n [160, 0.001]\n ],\n \"weight_decay\": 5e-4,\n \"momentum\": 0.9,\n \"nesterov\": False\n },\n \"data\": {\n \"type\": \"cifar10\",\n \"shuffle\": True,\n \"batch_size\": 128,\n \"test_batch_size\": 128,\n \"num_workers\": 4\n },\n \"loss\": {\n \"criterion\": \"softmax\"\n },\n \"gbn\": {\n \"sparse_lambda\": 1e-3,\n \"flops_eta\": 0,\n \"lr_min\": 1e-3,\n \"lr_max\": 1e-2,\n \"tock_epoch\": 10,\n \"T\": 10,\n \"p\": 0.002\n }\n})\nfrom config import cfg",
"Change dir from /root/code/gate-decorator-pruning/run/resnet-56 to /root/code/gate-decorator-pruning\nParsing config file...\n** Assert in demo mode. **\n"
],
[
"import torch\nimport torch.nn as nn\nimport numpy as np\nimport torch.optim as optim\n\nfrom logger import logger\nfrom main import set_seeds, recover_pack, adjust_learning_rate, _step_lr, _sgdr\nfrom models import get_model\nfrom utils import dotdict\n\nfrom prune.universal import Meltable, GatedBatchNorm2d, Conv2dObserver, IterRecoverFramework, FinalLinearObserver\nfrom prune.utils import analyse_model, finetune",
"_____no_output_____"
],
[
"set_seeds()\npack = recover_pack()\n\nmodel_dict = torch.load('./ckps/resnet56_cifair10_baseline.ckp', map_location='cpu' if not cfg.base.cuda else 'cuda')\npack.net.module.load_state_dict(model_dict)",
"==> Preparing Cifar10 data..\nFiles already downloaded and verified\nFiles already downloaded and verified\n"
],
[
"GBNs = GatedBatchNorm2d.transform(pack.net)\nfor gbn in GBNs:\n gbn.extract_from_bn()",
"_____no_output_____"
],
[
"pack.optimizer = optim.SGD(\n pack.net.parameters() ,\n lr=2e-3,\n momentum=cfg.train.momentum,\n weight_decay=cfg.train.weight_decay,\n nesterov=cfg.train.nesterov\n)",
"_____no_output_____"
]
],
[
[
"----",
"_____no_output_____"
]
],
[
[
"import uuid\n\ndef bottleneck_set_group(net):\n layers = [\n net.module.layer1,\n net.module.layer2,\n net.module.layer3\n ]\n for m in layers:\n masks = []\n if m == net.module.layer1:\n masks.append(pack.net.module.bn1)\n for mm in m.modules():\n if mm.__class__.__name__ == 'BasicBlock':\n if len(mm.shortcut._modules) > 0:\n masks.append(mm.shortcut._modules['1'])\n masks.append(mm.bn2)\n\n group_id = uuid.uuid1()\n for mk in masks:\n mk.set_groupid(group_id)\n\nbottleneck_set_group(pack.net)",
"_____no_output_____"
],
[
"def clone_model(net):\n model = get_model()\n gbns = GatedBatchNorm2d.transform(model.module)\n model.load_state_dict(net.state_dict())\n return model, gbns",
"_____no_output_____"
],
[
"cloned, _ = clone_model(pack.net)\nBASE_FLOPS, BASE_PARAM = analyse_model(cloned.module, torch.randn(1, 3, 32, 32).cuda())\nprint('%.3f MFLOPS' % (BASE_FLOPS / 1e6))\nprint('%.3f M' % (BASE_PARAM / 1e6))\ndel cloned",
"127.932 MFLOPS\n0.856 M\n"
],
[
"def eval_prune(pack):\n cloned, _ = clone_model(pack.net)\n _ = Conv2dObserver.transform(cloned.module)\n cloned.module.linear = FinalLinearObserver(cloned.module.linear)\n cloned_pack = dotdict(pack.copy())\n cloned_pack.net = cloned\n Meltable.observe(cloned_pack, 0.001)\n Meltable.melt_all(cloned_pack.net)\n flops, params = analyse_model(cloned_pack.net.module, torch.randn(1, 3, 32, 32).cuda())\n del cloned\n del cloned_pack\n \n return flops, params",
"_____no_output_____"
]
],
[
[
"----",
"_____no_output_____"
]
],
[
[
"pack.trainer.test(pack)",
"_____no_output_____"
],
[
"pack.tick_trainset = pack.train_loader\nprune_agent = IterRecoverFramework(pack, GBNs, sparse_lambda = cfg.gbn.sparse_lambda, flops_eta = cfg.gbn.flops_eta, minium_filter = 3)",
"_____no_output_____"
],
[
"LOGS = []\nflops_save_points = set([40, 38, 35, 32, 30])\n\niter_idx = 0\nprune_agent.tock(lr_min=cfg.gbn.lr_min, lr_max=cfg.gbn.lr_max, tock_epoch=cfg.gbn.tock_epoch)\nwhile True:\n left_filter = prune_agent.total_filters - prune_agent.pruned_filters\n num_to_prune = int(left_filter * cfg.gbn.p)\n info = prune_agent.prune(num_to_prune, tick=True, lr=cfg.gbn.lr_min)\n flops, params = eval_prune(pack)\n info.update({\n 'flops': '[%.2f%%] %.3f MFLOPS' % (flops/BASE_FLOPS * 100, flops / 1e6),\n 'param': '[%.2f%%] %.3f M' % (params/BASE_PARAM * 100, params / 1e6)\n })\n LOGS.append(info)\n print('Iter: %d,\\t FLOPS: %s,\\t Param: %s,\\t Left: %d,\\t Pruned Ratio: %.2f %%,\\t Train Loss: %.4f,\\t Test Acc: %.2f' % \n (iter_idx, info['flops'], info['param'], info['left'], info['total_pruned_ratio'] * 100, info['train_loss'], info['after_prune_test_acc']))\n \n iter_idx += 1\n if iter_idx % cfg.gbn.T == 0:\n print('Tocking:')\n prune_agent.tock(lr_min=cfg.gbn.lr_min, lr_max=cfg.gbn.lr_max, tock_epoch=cfg.gbn.tock_epoch)\n\n flops_ratio = flops/BASE_FLOPS * 100\n for point in [i for i in list(flops_save_points)]:\n if flops_ratio <= point:\n torch.save(pack.net.module.state_dict(), './logs/resnet56_cifar10_ticktock/%s.ckp' % str(point))\n flops_save_points.remove(point)\n\n if len(flops_save_points) == 0:\n break",
"100%|█████████████████████████████████████████████████████████████| 391/391 [00:33<00:00, 11.69it/s]\n 0%| | 0/391 [00:00<?, ?it/s]"
]
],
[
[
"### You can see how to fine-tune and get the pruned network in the finetune.ipynb",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
c518b51b0665d0221316c8d9b449a98878e31a19
| 1,358 |
ipynb
|
Jupyter Notebook
|
contributors/Dillon_Ragar/pit_data_processing.ipynb
|
GiuliaMazzotti/hot-pow
|
6c964b5b2af8897e9b998f5c804b8d8cfd80a3ea
|
[
"BSD-3-Clause"
] | null | null | null |
contributors/Dillon_Ragar/pit_data_processing.ipynb
|
GiuliaMazzotti/hot-pow
|
6c964b5b2af8897e9b998f5c804b8d8cfd80a3ea
|
[
"BSD-3-Clause"
] | null | null | null |
contributors/Dillon_Ragar/pit_data_processing.ipynb
|
GiuliaMazzotti/hot-pow
|
6c964b5b2af8897e9b998f5c804b8d8cfd80a3ea
|
[
"BSD-3-Clause"
] | 1 |
2021-08-22T09:14:53.000Z
|
2021-08-22T09:14:53.000Z
| 20.268657 | 72 | 0.527982 |
[
[
[
"import glob\nimport pandas as pd\n\n# get data file names\npath =r'/home/jovyan/hot-pow/contributors/Zachary_Miller/pits/'\nfilenames = glob.glob(path + \"/*.csv\")\n\ndfs = []\nfor filename in filenames:\n dfs.append(pd.read_csv(filename))\n\n# Concatenate all data into one DataFrame\n#big_frame = pd.concat(dfs, ignore_index=True)",
"_____no_output_____"
],
[
"for df in dfs:\n ",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
c518b767137a1230ddfa493d94cd608c585250dd
| 85,686 |
ipynb
|
Jupyter Notebook
|
notebooks/WhenToStopFuzzing.ipynb
|
darkrsw/fuzzingbook
|
3ed5a4ba14dd2837dff2c4b8c6d222c102dea338
|
[
"MIT"
] | null | null | null |
notebooks/WhenToStopFuzzing.ipynb
|
darkrsw/fuzzingbook
|
3ed5a4ba14dd2837dff2c4b8c6d222c102dea338
|
[
"MIT"
] | null | null | null |
notebooks/WhenToStopFuzzing.ipynb
|
darkrsw/fuzzingbook
|
3ed5a4ba14dd2837dff2c4b8c6d222c102dea338
|
[
"MIT"
] | null | null | null | 32.322143 | 785 | 0.591894 |
[
[
[
"# When To Stop Fuzzing\n\nIn the past chapters, we have discussed several fuzzing techniques. Knowing _what_ to do is important, but it is also important to know when to _stop_ doing things. In this chapter, we will learn when to _stop fuzzing_ – and use a prominent example for this purpose: The *Enigma* machine that was used in the second world war by the navy of Nazi Germany to encrypt communications, and how Alan Turing and I.J. Good used _fuzzing techniques_ to crack ciphers for the Naval Enigma machine.",
"_____no_output_____"
],
[
"Turing did not only develop the foundations of computer science, the Turing machine. Together with his assistant I.J. Good, he also invented estimators of the probability of an event occuring that has never previously occured. We show how the Good-Turing estimator can be used to quantify the *residual risk* of a fuzzing campaign that finds no vulnerabilities. Meaning, we show how it estimates the probability of discovering a vulnerability when no vulnerability has been observed before throughout the fuzzing campaign.\n\nWe discuss means to speed up [coverage-based fuzzers](Coverage.ipynb) and introduce a range of estimation and extrapolation methodologies to assess and extrapolate fuzzing progress and residual risk.\n\n**Prerequisites**\n\n* _The chapter on [Coverage](Coverage.ipynb) discusses how to use coverage information for an executed test input to guide a coverage-based mutational greybox fuzzer_.\n* Some knowledge of statistics is helpful.",
"_____no_output_____"
]
],
[
[
"import bookutils",
"_____no_output_____"
],
[
"import Fuzzer\nimport Coverage",
"_____no_output_____"
]
],
[
[
"## The Enigma Machine\n\nIt is autumn in the year of 1938. Turing has just finished his PhD at Princeton University demonstrating the limits of computation and laying the foundation for the theory of computer science. Nazi Germany is rearming. It has reoccupied the Rhineland and annexed Austria against the treaty of Versailles. It has just annexed the Sudetenland in Czechoslovakia and begins preparations to take over the rest of Czechoslovakia despite an agreement just signed in Munich.\n\nMeanwhile, the British intelligence is building up their capability to break encrypted messages used by the Germans to communicate military and naval information. The Germans are using [Enigma machines](https://en.wikipedia.org/wiki/Enigma_machine) for encryption. Enigma machines use a series of electro-mechanical rotor cipher machines to protect military communication. Here is a picture of an Enigma machine:",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"By the time Turing joined the British Bletchley park, the Polish intelligence reverse engineered the logical structure of the Enigma machine and built a decryption machine called *Bomba* (perhaps because of the ticking noise they made). A bomba simulates six Enigma machines simultaneously and tries different decryption keys until the code is broken. The Polish bomba might have been the very _first fuzzer_.\n\nTuring took it upon himself to crack ciphers of the Naval Enigma machine, which were notoriously hard to crack. The Naval Enigma used, as part of its encryption key, a three letter sequence called *trigram*. These trigrams were selected from a book, called *Kenngruppenbuch*, which contained all trigrams in a random order.",
"_____no_output_____"
],
[
"### The Kenngruppenbuch\n\nLet's start with the Kenngruppenbuch (K-Book).\n\nWe are going to use the following Python functions.\n* `random.shuffle(elements)` - shuffle *elements* and put items in random order.\n* `random.choices(elements, weights)` - choose an item from *elements* at random. An element with twice the *weight* is twice as likely to be chosen.\n* `log(a)` - returns the natural logarithm of a.\n* `a ** b` - means `a` to the power of `b` (a.k.a. [power operator](https://docs.python.org/3/reference/expressions.html#the-power-operator))",
"_____no_output_____"
]
],
[
[
"import string",
"_____no_output_____"
],
[
"import numpy\nfrom numpy import log",
"_____no_output_____"
],
[
"import random",
"_____no_output_____"
]
],
[
[
"We start with creating the set of trigrams:",
"_____no_output_____"
]
],
[
[
"letters = list(string.ascii_letters[26:]) # upper-case characters\ntrigrams = [str(a + b + c) for a in letters for b in letters for c in letters]",
"_____no_output_____"
],
[
"random.shuffle(trigrams)",
"_____no_output_____"
],
[
"trigrams[:10]",
"_____no_output_____"
]
],
[
[
"These now go into the Kenngruppenbuch. However, it was observed that some trigrams were more likely chosen than others. For instance, trigrams at the top-left corner of any page, or trigrams on the first or last few pages were more likely than one somewhere in the middle of the book or page. We reflect this difference in distribution by assigning a _probability_ to each trigram, using Benford's law as introduced in [Probabilistic Fuzzing](ProbabilisticGrammarFuzzer.ipynb).",
"_____no_output_____"
],
[
"Recall, that Benford's law assigns the $i$-th digit the probability $\\log_{10}\\left(1 + \\frac{1}{i}\\right)$ where the base 10 is chosen because there are 10 digits $i\\in [0,9]$. However, Benford's law works for an arbitrary number of \"digits\". Hence, we assign the $i$-th trigram the probability $\\log_b\\left(1 + \\frac{1}{i}\\right)$ where the base $b$ is the number of all possible trigrams $b=26^3$. ",
"_____no_output_____"
]
],
[
[
"k_book = {} # Kenngruppenbuch\n\nfor i in range(1, len(trigrams) + 1):\n trigram = trigrams[i - 1]\n # choose weights according to Benford's law\n k_book[trigram] = log(1 + 1 / i) / log(26**3 + 1)",
"_____no_output_____"
]
],
[
[
"Here's a random trigram from the Kenngruppenbuch:",
"_____no_output_____"
]
],
[
[
"random_trigram = random.choices(list(k_book.keys()), weights=list(k_book.values()))[0]\nrandom_trigram",
"_____no_output_____"
]
],
[
[
"And this is its probability:",
"_____no_output_____"
]
],
[
[
"k_book[random_trigram]",
"_____no_output_____"
]
],
[
[
"### Fuzzing the Enigma\n\nIn the following, we introduce an extremely simplified implementation of the Naval Enigma based on the trigrams from the K-book. Of course, the encryption mechanism of the actual Enigma machine is much more sophisticated and worthy of a much more detailed investigation. We encourage the interested reader to follow up with further reading listed in the Background section.\n\nThe personell at Bletchley Park can only check whether an encoded message is encoded with a (guessed) trigram.\nOur implementation `naval_enigma()` takes a `message` and a `key` (i.e., the guessed trigram). If the given key matches the (previously computed) key for the message, `naval_enigma()` returns `True`.",
"_____no_output_____"
]
],
[
[
"from Fuzzer import RandomFuzzer\nfrom Fuzzer import Runner",
"_____no_output_____"
],
[
"class EnigmaMachine(Runner):\n def __init__(self, k_book):\n self.k_book = k_book\n self.reset()\n\n def reset(self):\n \"\"\"Resets the key register\"\"\"\n self.msg2key = {}\n\n def internal_msg2key(self, message):\n \"\"\"Internal helper method. \n Returns the trigram for an encoded message.\"\"\"\n if message not in self.msg2key:\n # Simulating how an officer chooses a key from the Kenngruppenbuch\n # to encode the message.\n self.msg2key[message] = \\\n random.choices(list(self.k_book.keys()),\n weights=list(self.k_book.values()))[0]\n trigram = self.msg2key[message]\n return trigram\n\n def naval_enigma(self, message, key):\n \"\"\"Returns true if 'message' is encoded with 'key'\"\"\"\n if key == self.internal_msg2key(message):\n return True\n else:\n return False",
"_____no_output_____"
]
],
[
[
"To \"fuzz\" the `naval_enigma()`, our job will be to come up with a key that matches a given (encrypted) message. Since the keys only have three characters, we have a good chance to achieve this in much less than a second. (Of course, longer keys will be much harder to find via random fuzzing.)",
"_____no_output_____"
]
],
[
[
"class EnigmaMachine(EnigmaMachine):\n def run(self, tri):\n \"\"\"PASS if cur_msg is encoded with trigram tri\"\"\"\n if self.naval_enigma(self.cur_msg, tri):\n outcome = self.PASS\n else:\n outcome = self.FAIL\n\n return (tri, outcome)",
"_____no_output_____"
]
],
[
[
"Now we can use the `EnigmaMachine` to check whether a certain message is encoded with a certain trigram.",
"_____no_output_____"
]
],
[
[
"enigma = EnigmaMachine(k_book)\nenigma.cur_msg = \"BrEaK mE. L0Lzz\"\nenigma.run(\"AAA\")",
"_____no_output_____"
]
],
[
[
"The simplest way to crack an encoded message is by brute forcing. Suppose, at Bletchley park they would try random trigrams until a message is broken.",
"_____no_output_____"
]
],
[
[
"class BletchleyPark(object):\n def __init__(self, enigma):\n self.enigma = enigma\n self.enigma.reset()\n self.enigma_fuzzer = RandomFuzzer(\n min_length=3,\n max_length=3,\n char_start=65,\n char_range=26)\n \n def break_message(self, message):\n \"\"\"Returning the trigram for an encoded message\"\"\"\n self.enigma.cur_msg = message\n while True:\n (trigram, outcome) = self.enigma_fuzzer.run(self.enigma)\n if outcome == self.enigma.PASS:\n break\n return trigram",
"_____no_output_____"
]
],
[
[
"How long does it take Bletchley park to find the key using this brute forcing approach?",
"_____no_output_____"
]
],
[
[
"from Timer import Timer",
"_____no_output_____"
],
[
"enigma = EnigmaMachine(k_book)\nbletchley = BletchleyPark(enigma)\n\nwith Timer() as t:\n trigram = bletchley.break_message(\"BrEaK mE. L0Lzz\")",
"_____no_output_____"
]
],
[
[
"Here's the key for the current message:",
"_____no_output_____"
]
],
[
[
"trigram",
"_____no_output_____"
]
],
[
[
"And no, this did not take long:",
"_____no_output_____"
]
],
[
[
"'%f seconds' % t.elapsed_time()",
"_____no_output_____"
],
[
"'Bletchley cracks about %d messages per second' % (1/t.elapsed_time())",
"_____no_output_____"
]
],
[
[
"### Turing's Observations\nOkay, lets crack a few messages and count the number of times each trigram is observed.",
"_____no_output_____"
]
],
[
[
"from collections import defaultdict",
"_____no_output_____"
],
[
"n = 100 # messages to crack",
"_____no_output_____"
],
[
"observed = defaultdict(int)\nfor msg in range(0, n):\n trigram = bletchley.break_message(msg)\n observed[trigram] += 1\n\n# list of trigrams that have been observed\ncounts = [k for k, v in observed.items() if int(v) > 0]\n\nt_trigrams = len(k_book)\no_trigrams = len(counts)",
"_____no_output_____"
],
[
"\"After cracking %d messages, we observed %d out of %d trigrams.\" % (\n n, o_trigrams, t_trigrams)",
"_____no_output_____"
],
[
"singletons = len([k for k, v in observed.items() if int(v) == 1])",
"_____no_output_____"
],
[
"\"From the %d observed trigrams, %d were observed only once.\" % (\n o_trigrams, singletons)",
"_____no_output_____"
]
],
[
[
"Given a sample of previously used entries, Turing wanted to _estimate the likelihood_ that the current unknown entry was one that had been previously used, and further, to estimate the probability distribution over the previously used entries. This lead to the development of the estimators of the missing mass and estimates of the true probability mass of the set of items occuring in the sample. Good worked with Turing during the war and, with Turing’s permission, published the analysis of the bias of these estimators in 1953.",
"_____no_output_____"
],
[
"Suppose, after finding the keys for n=100 messages, we have observed the trigram \"ABC\" exactly $X_\\text{ABC}=10$ times. What is the probability $p_\\text{ABC}$ that \"ABC\" is the key for the next message? Empirically, we would estimate $\\hat p_\\text{ABC}=\\frac{X_\\text{ABC}}{n}=0.1$. We can derive the empirical estimates for all other trigrams that we have observed. However, it becomes quickly evident that the complete probability mass is distributed over the *observed* trigrams. This leaves no mass for *unobserved* trigrams, i.e., the probability of discovering a new trigram. This is called the missing probability mass or the discovery probability.",
"_____no_output_____"
],
[
"Turing and Good derived an estimate of the *discovery probability* $p_0$, i.e., the probability to discover an unobserved trigram, as the number $f_1$ of trigrams observed exactly once divided by the total number $n$ of messages cracked:\n$$\np_0 = \\frac{f_1}{n}\n$$\nwhere $f_1$ is the number of singletons and $n$ is the number of cracked messages.",
"_____no_output_____"
],
[
"Lets explore this idea for a bit. We'll extend `BletchleyPark` to crack `n` messages and record the number of trigrams observed as the number of cracked messages increases.",
"_____no_output_____"
]
],
[
[
"class BletchleyPark(BletchleyPark):\n def break_message(self, message):\n \"\"\"Returning the trigram for an encoded message\"\"\"\n # For the following experiment, we want to make it practical\n # to break a large number of messages. So, we remove the\n # loop and just return the trigram for a message.\n #\n # enigma.cur_msg = message\n # while True:\n # (trigram, outcome) = self.enigma_fuzzer.run(self.enigma)\n # if outcome == self.enigma.PASS:\n # break\n trigram = enigma.internal_msg2key(message)\n return trigram\n\n def break_n_messages(self, n):\n \"\"\"Returns how often each trigram has been observed, \n and #trigrams discovered for each message.\"\"\"\n observed = defaultdict(int)\n timeseries = [0] * n\n\n # Crack n messages and record #trigrams observed as #messages increases\n cur_observed = 0\n for cur_msg in range(0, n):\n trigram = self.break_message(cur_msg)\n\n observed[trigram] += 1\n if (observed[trigram] == 1):\n cur_observed += 1\n timeseries[cur_msg] = cur_observed\n\n return (observed, timeseries)",
"_____no_output_____"
]
],
[
[
"Let's crack 2000 messages and compute the GT-estimate.",
"_____no_output_____"
]
],
[
[
"n = 2000 # messages to crack",
"_____no_output_____"
],
[
"bletchley = BletchleyPark(enigma)\n(observed, timeseries) = bletchley.break_n_messages(n)",
"_____no_output_____"
]
],
[
[
"Let us determine the Good-Turing estimate of the probability that the next trigram has not been observed before:",
"_____no_output_____"
]
],
[
[
"singletons = len([k for k, v in observed.items() if int(v) == 1])\ngt = singletons / n\ngt",
"_____no_output_____"
]
],
[
[
"We can verify the Good-Turing estimate empirically and compute the empirically determined probability that the next trigram has not been observed before. To do this, we repeat the following experiment `repeats=1000` times, reporting the average: If the next message is a new trigram, return 1, otherwise return 0. Note that here, we do not record the newly discovered trigrams as observed.",
"_____no_output_____"
]
],
[
[
"repeats = 1000 # experiment repetitions ",
"_____no_output_____"
],
[
"newly_discovered = 0\nfor cur_msg in range(n, n + repeats):\n trigram = bletchley.break_message(cur_msg)\n if(observed[trigram] == 0):\n newly_discovered += 1\n\nnewly_discovered / repeats",
"_____no_output_____"
]
],
[
[
"Looks pretty accurate, huh? The difference between estimates is reasonably small, probably below 0.03. However, the Good-Turing estimate did not nearly require as much computational resources as the empirical estimate. Unlike the empirical estimate, the Good-Turing estimate can be computed during the campaign. Unlike the empirical estimate, the Good-Turing estimate requires no additional, redundant repetitions.",
"_____no_output_____"
],
[
"In fact, the Good-Turing (GT) estimator often performs close to the best estimator for arbitrary distributions ([Try it here!](#Kenngruppenbuch)). Of course, the concept of *discovery* is not limited to trigrams. The GT estimator is also used in the study of natural languages to estimate the likelihood that we haven't ever heard or read the word we next encounter. The GT estimator is used in ecology to estimate the likelihood of discovering a new, unseen species in our quest to catalog all _species_ on earth. Later, we will see how it can be used to estimate the probability to discover a vulnerability when none has been observed, yet (i.e., residual risk).",
"_____no_output_____"
],
[
"Alan Turing was interested in the _complement_ $(1-GT)$ which gives the proportion of _all_ messages for which the Brits have already observed the trigram needed for decryption. For this reason, the complement is also called sample coverage. The *sample coverage* quantifies how much we know about decryption of all messages given the few messages we have already decrypted. ",
"_____no_output_____"
],
[
"The probability that the next message can be decrypted with a previously discovered trigram is:",
"_____no_output_____"
]
],
[
[
"1 - gt",
"_____no_output_____"
]
],
[
[
"The *inverse* of the GT-estimate (1/GT) is a _maximum likelihood estimate_ of the expected number of messages that we can decrypt with previously observed trigrams before having to find a new trigram to decrypt the message. In our setting, the number of messages for which we can expect to reuse previous trigrams before having to discover a new trigram is:",
"_____no_output_____"
]
],
[
[
"1 / gt",
"_____no_output_____"
]
],
[
[
"But why is GT so accurate? Intuitively, despite a large sampling effort (i.e., cracking $n$ messages), there are still $f_1$ trigrams that have been observed only once. We could say that such \"singletons\" are very rare trigrams. Hence, the probability that the next messages is encoded with such a rare but observed trigram gives a good upper bound on the probability that the next message is encoded with an evidently much rarer, unobserved trigram. Since Turing's observation 80 years ago, an entire statistical theory has been developed around the hypothesis that rare, observed \"species\" are good predictors of unobserved species.\n\nLet's have a look at the distribution of rare trigrams.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"frequencies = [v for k, v in observed.items() if int(v) > 0]\nfrequencies.sort(reverse=True)\n# Uncomment to see how often each discovered trigram has been observed\n# print(frequencies)\n\n# frequency of rare trigrams\nplt.figure(num=None, figsize=(12, 4), dpi=80, facecolor='w', edgecolor='k')\nplt.subplot(1, 2, 1)\nplt.hist(frequencies, range=[1, 21], bins=numpy.arange(1, 21) - 0.5)\nplt.xticks(range(1, 21))\nplt.xlabel('# of occurances (e.g., 1 represents singleton trigrams)')\nplt.ylabel('Frequency of occurances')\nplt.title('Figure 1. Frequency of Rare Trigrams')\n\n# trigram discovery over time\nplt.subplot(1, 2, 2)\nplt.plot(timeseries)\nplt.xlabel('# of messages cracked')\nplt.ylabel('# of trigrams discovered')\nplt.title('Figure 2. Trigram Discovery Over Time');",
"_____no_output_____"
],
[
"# Statistics for most and least often observed trigrams\nsingletons = len([v for k, v in observed.items() if int(v) == 1])\ntotal = len(frequencies)\n\nprint(\"%3d of %3d trigrams (%.3f%%) have been observed 1 time (i.e., are singleton trigrams).\"\n % (singletons, total, singletons * 100 / total))\n\nprint(\"%3d of %3d trigrams ( %.3f%%) have been observed %d times.\"\n % (1, total, 1 / total, frequencies[0]))",
"_____no_output_____"
]
],
[
[
"The *majority of trigrams* have been observed only once, as we can see in Figure 1 (left). In other words, the majority of observed trigrams are \"rare\" singletons. In Figure 2 (right), we can see that discovery is in full swing. The trajectory seems almost linear. However, since there is a finite number of trigrams (26^3 = 17,576) trigram discovery will slow down and eventually approach an asymptote (the total number of trigrams).\n\n### Boosting the Performance of BletchleyPark\nSome trigrams have been observed very often. We call these \"abundant\" trigrams.",
"_____no_output_____"
]
],
[
[
"print(\"Trigram : Frequency\")\nfor trigram in sorted(observed, key=observed.get, reverse=True):\n if observed[trigram] > 10:\n print(\" %s : %d\" % (trigram, observed[trigram]))",
"_____no_output_____"
]
],
[
[
"We'll speed up the code breaking by _trying the abundant trigrams first_. \n\nFirst, we'll find out how many messages can be cracked by the existing brute forcing strategy at Bledgley park, given a maximum number of attempts. We'll also track the number of messages cracked over time (`timeseries`).",
"_____no_output_____"
]
],
[
[
"class BletchleyPark(BletchleyPark):\n def __init__(self, enigma):\n super().__init__(enigma)\n self.cur_attempts = 0\n self.cur_observed = 0\n self.observed = defaultdict(int)\n self.timeseries = [None] * max_attempts * 2\n\n def break_message(self, message):\n \"\"\"Returns the trigram for an encoded message, and\n track #trigrams observed as #attempts increases.\"\"\"\n self.enigma.cur_msg = message\n while True:\n self.cur_attempts += 1 # NEW\n (trigram, outcome) = self.enigma_fuzzer.run(self.enigma)\n self.timeseries[self.cur_attempts] = self.cur_observed # NEW\n if outcome == self.enigma.PASS: \n break\n return trigram\n\n def break_max_attempts(self, max_attempts):\n \"\"\"Returns #messages successfully cracked after a given #attempts.\"\"\"\n cur_msg = 0\n n_messages = 0\n\n while True:\n trigram = self.break_message(cur_msg)\n\n # stop when reaching max_attempts\n if self.cur_attempts >= max_attempts:\n break\n\n # update observed trigrams\n n_messages += 1\n self.observed[trigram] += 1\n if (self.observed[trigram] == 1):\n self.cur_observed += 1\n self.timeseries[self.cur_attempts] = self.cur_observed\n cur_msg += 1\n return n_messages",
"_____no_output_____"
]
],
[
[
"`original` is the number of messages cracked by the bruteforcing strategy, given 100k attempts. Can we beat this?",
"_____no_output_____"
]
],
[
[
"max_attempts = 100000",
"_____no_output_____"
],
[
"bletchley = BletchleyPark(enigma)\noriginal = bletchley.break_max_attempts(max_attempts)\noriginal",
"_____no_output_____"
]
],
[
[
"Now, we'll create a boosting strategy by trying trigrams first that we have previously observed most often.",
"_____no_output_____"
]
],
[
[
"class BoostedBletchleyPark(BletchleyPark):\n def break_message(self, message):\n \"\"\"Returns the trigram for an encoded message, and\n track #trigrams observed as #attempts increases.\"\"\"\n self.enigma.cur_msg = message\n\n # boost cracking by trying observed trigrams first\n for trigram in sorted(self.prior, key=self.prior.get, reverse=True):\n self.cur_attempts += 1\n (_, outcome) = self.enigma.run(trigram)\n self.timeseries[self.cur_attempts] = self.cur_observed\n if outcome == self.enigma.PASS:\n return trigram\n\n # else fall back to normal cracking\n return super().break_message(message)",
"_____no_output_____"
]
],
[
[
"`boosted` is the number of messages cracked by the boosted strategy.",
"_____no_output_____"
]
],
[
[
"boostedBletchley = BoostedBletchleyPark(enigma)\nboostedBletchley.prior = observed\nboosted = boostedBletchley.break_max_attempts(max_attempts)\nboosted",
"_____no_output_____"
]
],
[
[
"We see that the boosted technique cracks substantially more messages. It is worthwhile to record how often each trigram is being used as key and try them in the order of their occurence.\n\n***Try it***. *For practical reasons, we use a large number of previous observations as prior (`boostedBletchley.prior = observed`). You can try to change the code such that the strategy uses the trigram frequencies (`self.observed`) observed **during** the campaign itself to boost the campaign. You will need to increase `max_attempts` and wait for a long while.*",
"_____no_output_____"
],
[
"Let's compare the number of trigrams discovered over time.",
"_____no_output_____"
]
],
[
[
"# print plots\nline_old, = plt.plot(bletchley.timeseries, label=\"Bruteforce Strategy\")\nline_new, = plt.plot(boostedBletchley.timeseries, label=\"Boosted Strategy\")\nplt.legend(handles=[line_old, line_new])\nplt.xlabel('# of cracking attempts')\nplt.ylabel('# of trigrams discovered')\nplt.title('Trigram Discovery Over Time');",
"_____no_output_____"
]
],
[
[
"We see that the boosted fuzzer is constantly superior over the random fuzzer.",
"_____no_output_____"
],
[
"## Estimating the Probability of Path Discovery\n\n<!-- ## Residual Risk: Probability of Failure after an Unsuccessful Fuzzing Campaign -->\n<!-- Residual risk is not formally defined in this section, so I made the title a bit more generic -- AZ -->\n\nSo, what does Turing's observation for the Naval Enigma have to do with fuzzing _arbitrary_ programs? Turing's assistant I.J. Good extended and published Turing's work on the estimation procedures in Biometrica, a journal for theoretical biostatistics that still exists today. Good did not talk about trigrams. Instead, he calls them \"species\". Hence, the GT estimator is presented to estimate how likely it is to discover a new species, given an existing sample of individuals (each of which belongs to exactly one species). \n\nNow, we can associate program inputs to species, as well. For instance, we could define the path that is exercised by an input as that input's species. This would allow us to _estimate the probability that fuzzing discovers a new path._ Later, we will see how this discovery probability estimate also estimates the likelihood of discovering a vulnerability when we have not seen one, yet (residual risk).",
"_____no_output_____"
],
[
"Let's do this. We identify the species for an input by computing a hash-id over the set of statements exercised by that input. In the [Coverage](Coverage.ipynb) chapter, we have learned about the [Coverage class](Coverage.ipynb#A-Coverage-Class) which collects coverage information for an executed Python function. As an example, the function [`cgi_decode()`](Coverage.ipynb#A-CGI-Decoder) was introduced. The function `cgi_decode()` takes a string encoded for a website URL and decodes it back to its original form.\n\nHere's what `cgi_decode()` does and how coverage is computed.",
"_____no_output_____"
]
],
[
[
"from Coverage import Coverage, cgi_decode",
"_____no_output_____"
],
[
"encoded = \"Hello%2c+world%21\"\nwith Coverage() as cov:\n decoded = cgi_decode(encoded)",
"_____no_output_____"
],
[
"decoded",
"_____no_output_____"
],
[
"print(cov.coverage());",
"_____no_output_____"
]
],
[
[
"### Trace Coverage\nFirst, we will introduce the concept of execution traces, which are a coarse abstraction of the execution path taken by an input. Compared to the definition of path, a trace ignores the sequence in which statements are exercised or how often each statement is exercised.\n\n* `pickle.dumps()` - serializes an object by producing a byte array from all the information in the object\n* `hashlib.md5()` - produces a 128-bit hash value from a byte array",
"_____no_output_____"
]
],
[
[
"import pickle\nimport hashlib",
"_____no_output_____"
],
[
"def getTraceHash(cov):\n pickledCov = pickle.dumps(cov.coverage())\n hashedCov = hashlib.md5(pickledCov).hexdigest()\n return hashedCov",
"_____no_output_____"
]
],
[
[
"Remember our model for the Naval Enigma machine? Each message must be decrypted using exactly one trigram while multiple messages may be decrypted by the same trigram. Similarly, we need each input to yield exactly one trace hash while multiple inputs can yield the same trace hash.",
"_____no_output_____"
],
[
"Let's see whether this is true for our `getTraceHash()` function.",
"_____no_output_____"
]
],
[
[
"inp1 = \"a+b\"\ninp2 = \"a+b+c\"\ninp3 = \"abc\"\n\nwith Coverage() as cov1:\n cgi_decode(inp1)\nwith Coverage() as cov2:\n cgi_decode(inp2)\nwith Coverage() as cov3:\n cgi_decode(inp3)",
"_____no_output_____"
]
],
[
[
"The inputs `inp1` and `inp2` execute the same statements:",
"_____no_output_____"
]
],
[
[
"inp1, inp2",
"_____no_output_____"
],
[
"cov1.coverage() - cov2.coverage()",
"_____no_output_____"
]
],
[
[
"The difference between both coverage sets is empty. Hence, the trace hashes should be the same:",
"_____no_output_____"
]
],
[
[
"getTraceHash(cov1)",
"_____no_output_____"
],
[
"getTraceHash(cov2)",
"_____no_output_____"
],
[
"assert getTraceHash(cov1) == getTraceHash(cov2)",
"_____no_output_____"
]
],
[
[
"In contrast, the inputs `inp1` and `inp3` execute _different_ statements:",
"_____no_output_____"
]
],
[
[
"inp1, inp3",
"_____no_output_____"
],
[
"cov1.coverage() - cov3.coverage()",
"_____no_output_____"
]
],
[
[
"Hence, the trace hashes should be different, too:",
"_____no_output_____"
]
],
[
[
"getTraceHash(cov1)",
"_____no_output_____"
],
[
"getTraceHash(cov3)",
"_____no_output_____"
],
[
"assert getTraceHash(cov1) != getTraceHash(cov3)",
"_____no_output_____"
]
],
[
[
"### Measuring Trace Coverage over Time\nIn order to measure trace coverage for a `function` executing a `population` of fuzz inputs, we slightly adapt the `population_coverage()` function from the [Chapter on Coverage](Coverage.ipynb#Coverage-of-Basic-Fuzzing).",
"_____no_output_____"
]
],
[
[
"def population_trace_coverage(population, function):\n cumulative_coverage = []\n all_coverage = set()\n cumulative_singletons = []\n cumulative_doubletons = []\n singletons = set()\n doubletons = set()\n\n for s in population:\n with Coverage() as cov:\n try:\n function(s)\n except BaseException:\n pass\n cur_coverage = set([getTraceHash(cov)])\n\n # singletons and doubletons -- we will need them later\n doubletons -= cur_coverage\n doubletons |= singletons & cur_coverage\n singletons -= cur_coverage\n singletons |= cur_coverage - (cur_coverage & all_coverage)\n cumulative_singletons.append(len(singletons))\n cumulative_doubletons.append(len(doubletons))\n\n # all and cumulative coverage\n all_coverage |= cur_coverage\n cumulative_coverage.append(len(all_coverage))\n\n return all_coverage, cumulative_coverage, cumulative_singletons, cumulative_doubletons",
"_____no_output_____"
]
],
[
[
"Let's see whether our new function really contains coverage information only for *two* traces given our three inputs for `cgi_decode`.",
"_____no_output_____"
]
],
[
[
"all_coverage = population_trace_coverage([inp1, inp2, inp3], cgi_decode)[0]\nassert len(all_coverage) == 2",
"_____no_output_____"
]
],
[
[
"Unfortunately, the `cgi_decode()` function is too simple. Instead, we will use the original Python [HTMLParser](https://docs.python.org/3/library/html.parser.html) as our test subject.",
"_____no_output_____"
]
],
[
[
"from Fuzzer import RandomFuzzer\nfrom Coverage import population_coverage\nfrom html.parser import HTMLParser",
"_____no_output_____"
],
[
"trials = 50000 # number of random inputs generated",
"_____no_output_____"
]
],
[
[
"Let's run a random fuzzer for $n=50000$ times and plot trace coverage over time.",
"_____no_output_____"
]
],
[
[
"# create wrapper function\ndef my_parser(inp):\n parser = HTMLParser() # resets the HTMLParser object for every fuzz input\n parser.feed(inp)",
"_____no_output_____"
],
[
"# create random fuzzer\nfuzzer = RandomFuzzer(min_length=1, max_length=100,\n char_start=32, char_range=94)\n\n# create population of fuzz inputs\npopulation = []\nfor i in range(trials):\n population.append(fuzzer.fuzz())\n\n# execute and measure trace coverage\ntrace_timeseries = population_trace_coverage(population, my_parser)[1]\n\n# execute and measure code coverage\ncode_timeseries = population_coverage(population, my_parser)[1]\n\n# plot trace coverage over time\nplt.figure(num=None, figsize=(12, 4), dpi=80, facecolor='w', edgecolor='k')\nplt.subplot(1, 2, 1)\nplt.plot(trace_timeseries)\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of traces exercised')\nplt.title('Trace Coverage Over Time')\n\n# plot code coverage over time\nplt.subplot(1, 2, 2)\nplt.plot(code_timeseries)\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of statements covered')\nplt.title('Code Coverage Over Time');",
"_____no_output_____"
]
],
[
[
"Above, we can see trace coverage (left) and code coverage (right) over time. Here are our observations.\n1. **Trace coverage is more robust**. There are less sudden jumps in the graph compared to code coverage.\n2. **Trace coverage is more fine grained.** There are more traces than statements covered in the end (y-axis).\n3. **Trace coverage grows more steadily**. Code coverage exercises more than half the statements it has exercised after 50k inputs with the first input. Instead, the number of traces covered grows slowly and steadily since each input can yield only one execution trace.\n\nIt is for this reason that one of the most prominent and successful fuzzers today, american fuzzy lop (AFL), uses a similar *measure of progress* (a hash computed over the branches exercised by the input).",
"_____no_output_____"
],
[
"### Evaluating the Discovery Probability Estimate\n\nLet's find out how the Good-Turing estimator performs as estimate of discovery probability when we are fuzzing to discover execution traces rather than trigrams. \n\nTo measure the empirical probability, we execute the same population of inputs (n=50000) and measure in regular intervals (`measurements=100` intervals). During each measurement, we repeat the following experiment `repeats=500` times, reporting the average: If the next input yields a new trace, return 1, otherwise return 0. Note that during these repetitions, we do not record the newly discovered traces as observed.",
"_____no_output_____"
]
],
[
[
"repeats = 500 # experiment repetitions\nmeasurements = 100 # experiment measurements",
"_____no_output_____"
],
[
"emp_timeseries = []\nall_coverage = set()\nstep = int(trials / measurements)\n\nfor i in range(0, trials, step):\n if i - step >= 0:\n for j in range(step):\n inp = population[i - j]\n with Coverage() as cov:\n try:\n my_parser(inp)\n except BaseException:\n pass\n all_coverage |= set([getTraceHash(cov)])\n\n discoveries = 0\n for _ in range(repeats):\n inp = fuzzer.fuzz()\n with Coverage() as cov:\n try:\n my_parser(inp)\n except BaseException:\n pass\n if getTraceHash(cov) not in all_coverage:\n discoveries += 1\n emp_timeseries.append(discoveries / repeats)",
"_____no_output_____"
]
],
[
[
"Now, we compute the Good-Turing estimate over time.",
"_____no_output_____"
]
],
[
[
"gt_timeseries = []\nsingleton_timeseries = population_trace_coverage(population, my_parser)[2]\nfor i in range(1, trials + 1, step):\n gt_timeseries.append(singleton_timeseries[i - 1] / i)",
"_____no_output_____"
]
],
[
[
"Let's go ahead and plot both time series.",
"_____no_output_____"
]
],
[
[
"line_emp, = plt.semilogy(emp_timeseries, label=\"Empirical\")\nline_gt, = plt.semilogy(gt_timeseries, label=\"Good-Turing\")\nplt.legend(handles=[line_emp, line_gt])\nplt.xticks(range(0, measurements + 1, int(measurements / 5)),\n range(0, trials + 1, int(trials / 5)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('discovery probability')\nplt.title('Discovery Probability Over Time');",
"_____no_output_____"
]
],
[
[
"Again, the Good-Turing estimate appears to be *highly accurate*. In fact, the empirical estimator has a much lower precision as indicated by the large swings. You can try and increase the number of repetitions (`repeats`) to get more precision for the empirical estimates, however, at the cost of waiting much longer.",
"_____no_output_____"
],
[
"### Discovery Probability Quantifies Residual Risk\n\nAlright. You have gotten a hold of a couple of powerful machines and used them to fuzz a software system for several months without finding any vulnerabilities. Is the system vulnerable?\n\nWell, who knows? We cannot say for sure; there is always some residual risk. Testing is not verification. Maybe the next test input that is generated reveals a vulnerability.\n\nLet's say *residual risk* is the probability that the next test input reveals a vulnerability that has not been found, yet. Böhme \\cite{Boehme2018stads} has shown that the Good-Turing estimate of the discovery probability is also an estimate of the maximum residual risk.",
"_____no_output_____"
],
[
"**Proof sketch (Residual Risk)**. Here is a proof sketch that shows that an estimator of discovery probability for an arbitrary definition of species gives an upper bound on the probability to discover a vulnerability when none has been found: Suppose, for each \"old\" species A (here, execution trace), we derive two \"new\" species: Some inputs belonging to A expose a vulnerability while others belonging to A do not. We know that _only_ species that do not expose a vulnerability have been discovered. Hence, _all_ species exposing a vulnerability and _some_ species that do not expose a vulnerability remain undiscovered. Hence, the probability to discover a new species gives an upper bound on the probability to discover (a species that exposes) a vulnerability. **QED**.",
"_____no_output_____"
],
[
"An estimate of the discovery probability is useful in many other ways.\n\n1. **Discovery probability**. We can estimate, at any point during the fuzzing campaign, the probability that the next input belongs to a previously unseen species (here, that it yields a new execution trace, i.e., exercises a new set of statements).\n2. **Complement of discovery probability**. We can estimate the proportion of *all* inputs the fuzzer can generate for which we have already seen the species (here, execution traces). In some sense, this allows us to quantify the *progress of the fuzzing campaign towards completion*: If the probability to discovery a new species is too low, we might as well abort the campaign.\n3. **Inverse of discovery probability**. We can predict the number of test inputs needed, so that we can expect the discovery of a new species (here, execution trace).",
"_____no_output_____"
],
[
"## How Do We Know When to Stop Fuzzing?\n\nIn fuzzing, we have measures of progress such as [code coverage](Coverage.ipynb) or [grammar coverage](GrammarCoverageFuzzer.ipynb). Suppose, we are interested in covering all statements in the program. The _percentage_ of statements that have already been covered quantifies how \"far\" we are from completing the fuzzing campaign. However, sometimes we know only the _number_ of species $S(n)$ (here, statements) that have been discovered after generating $n$ fuzz inputs. The percentage $S(n)/S$ can only be computed if we know the _total number_ of species $S$. Even then, not all species may be feasible.",
"_____no_output_____"
],
[
"### A Success Estimator\n\nIf we do not _know_ the total number of species, then let's at least _estimate_ it: As we have seen before, species discovery slows down over time. In the beginning, many new species are discovered. Later, many inputs need to be generated before discovering the next species. In fact, given enough time, the fuzzing campaign approaches an _asymptote_. It is this asymptote that we can estimate.",
"_____no_output_____"
],
[
"In 1984, Anne Chao, a well-known theoretical bio-statistician, has developed an estimator $\\hat S$ which estimates the asymptotic total number of species $S$:\n\\begin{align}\n\\hat S_\\text{Chao1} = \\begin{cases}\nS(n) + \\frac{f_1^2}{2f_2} & \\text{if $f_2>0$}\\\\\nS(n) + \\frac{f_1(f_1-1)}{2} & \\text{otherwise}\n\\end{cases}\n\\end{align}\n* where $f_1$ and $f_2$ is the number of singleton and doubleton species, respectively (that have been observed exactly once or twice, resp.), and \n* where $S(n)$ is the number of species that have been discovered after generating $n$ fuzz inputs.",
"_____no_output_____"
],
[
"So, how does Chao's estimate perform? To investigate this, we generate `trials=400000` fuzz inputs using a fuzzer setting that allows us to see an asymptote in a few seconds: We measure trace coverage. After half-way into our fuzzing campaign (`trials`/2=100000), we generate Chao's estimate $\\hat S$ of the asymptotic total number of species. Then, we run the remainer of the campaign to see the \"empirical\" asymptote.",
"_____no_output_____"
]
],
[
[
"trials = 400000\nfuzzer = RandomFuzzer(min_length=2, max_length=4,\n char_start=32, char_range=32)\npopulation = []\nfor i in range(trials):\n population.append(fuzzer.fuzz())\n\n_, trace_ts, f1_ts, f2_ts = population_trace_coverage(population, my_parser)",
"_____no_output_____"
],
[
"time = int(trials / 2)\ntime",
"_____no_output_____"
],
[
"f1 = f1_ts[time]\nf2 = f2_ts[time]\nSn = trace_ts[time]\nif f2 > 0:\n hat_S = Sn + f1 * f1 / (2 * f2)\nelse:\n hat_S = Sn + f1 * (f1 - 1) / 2",
"_____no_output_____"
]
],
[
[
"After executing `time` fuzz inputs (half of all), we have covered this many traces:",
"_____no_output_____"
]
],
[
[
"time",
"_____no_output_____"
],
[
"Sn",
"_____no_output_____"
]
],
[
[
"We can estimate there are this many traces in total:",
"_____no_output_____"
]
],
[
[
"hat_S",
"_____no_output_____"
]
],
[
[
"Hence, we have achieved this percentage of the estimate:",
"_____no_output_____"
]
],
[
[
"100 * Sn / hat_S",
"_____no_output_____"
]
],
[
[
"After executing `trials` fuzz inputs, we have covered this many traces:",
"_____no_output_____"
]
],
[
[
"trials",
"_____no_output_____"
],
[
"trace_ts[trials - 1]",
"_____no_output_____"
]
],
[
[
"The accuracy of Chao's estimator is quite reasonable. It isn't always accurate -- particularly at the beginning of a fuzzing campaign when the [discovery probability](WhenIsEnough.ipynb#Measuring-Trace-Coverage-over-Time) is still very high. Nevertheless, it demonstrates the main benefit of reporting a percentage to assess the progress of a fuzzing campaign towards completion.\n\n***Try it***. *Try setting `trials` to 1 million and `time` to `int(trials / 4)`.*",
"_____no_output_____"
],
[
"### Extrapolating Fuzzing Success\n<!-- ## Cost-Benefit Analysis: Extrapolating the Number of Species Discovered -->\n\nSuppose you have run the fuzzer for a week, which generated $n$ fuzz inputs and discovered $S(n)$ species (here, covered $S(n)$ execution traces). Instead, of running the fuzzer for another week, you would like to *predict* how many more species you would discover. In 2003, Anne Chao and her team developed an extrapolation methodology to do just that. We are interested in the number $S(n+m^*)$ of species discovered if $m^*$ more fuzz inputs were generated:\n\n\\begin{align}\n\\hat S(n + m^*) = S(n) + \\hat f_0 \\left[1-\\left(1-\\frac{f_1}{n\\hat f_0 + f_1}\\right)^{m^*}\\right]\n\\end{align}\n* where $\\hat f_0=\\hat S - S(n)$ is an estimate of the number $f_0$ of undiscovered species, and \n* where $f_1$ is the number of singleton species, i.e., those we have observed exactly once. \n\nThe number $f_1$ of singletons, we can just keep track of during the fuzzing campaign itself. The estimate of the number $\\hat f_0$ of undiscovered species, we can simply derive using Chao's estimate $\\hat S$ and the number of observed species $S(n)$.\n\nLet's see how Chao's extrapolator performs by comparing the predicted number of species to the empirical number of species.",
"_____no_output_____"
]
],
[
[
"prediction_ts = [None] * time\nf0 = hat_S - Sn\n\nfor m in range(trials - time):\n assert (time * f0 + f1) != 0 , 'time:%s f0:%s f1:%s' % (time, f0,f1)\n prediction_ts.append(Sn + f0 * (1 - (1 - f1 / (time * f0 + f1)) ** m))",
"_____no_output_____"
],
[
"plt.figure(num=None, figsize=(12, 3), dpi=80, facecolor='w', edgecolor='k')\nplt.subplot(1, 3, 1)\nplt.plot(trace_ts, color='white')\nplt.plot(trace_ts[:time])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of traces exercised')\n\nplt.subplot(1, 3, 2)\nline_cur, = plt.plot(trace_ts[:time], label=\"Ongoing fuzzing campaign\")\nline_pred, = plt.plot(prediction_ts, linestyle='--',\n color='black', label=\"Predicted progress\")\nplt.legend(handles=[line_cur, line_pred])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of traces exercised')\n\nplt.subplot(1, 3, 3)\nline_emp, = plt.plot(trace_ts, color='grey', label=\"Actual progress\")\nline_cur, = plt.plot(trace_ts[:time], label=\"Ongoing fuzzing campaign\")\nline_pred, = plt.plot(prediction_ts, linestyle='--',\n color='black', label=\"Predicted progress\")\nplt.legend(handles=[line_emp, line_cur, line_pred])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of traces exercised');",
"_____no_output_____"
]
],
[
[
"The prediction from Chao's extrapolator looks quite accurate. We make a prediction at `time=trials/4`. Despite an extrapolation by 3 times (i.e., at trials), we can see that the predicted value (black, dashed line) closely matches the empirical value (grey, solid line).\n\n***Try it***. Again, try setting `trials` to 1 million and `time` to `int(trials / 4)`.",
"_____no_output_____"
],
[
"## Lessons Learned\n\n* One can measure the _progress_ of a fuzzing campaign (as species over time, i.e., $S(n)$).\n* One can measure the _effectiveness_ of a fuzzing campaign (as asymptotic total number of species $S$).\n* One can estimate the _effectiveness_ of a fuzzing campaign using the Chao1-estimator $\\hat S$.\n* One can extrapolate the _progress_ of a fuzzing campaign, $\\hat S(n+m^*)$.\n* One can estimate the _residual risk_ (i.e., the probability that a bug exists that has not been found) using the Good-Turing estimator $GT$ of the species discovery probability.",
"_____no_output_____"
],
[
"## Next Steps\n\nThis chapter is the last in the book! If you want to continue reading, have a look at the [Appendices](99_Appendices.ipynb). Otherwise, _make use of what you have learned and go and create great fuzzers and test generators!_",
"_____no_output_____"
],
[
"## Background\n\n* A **statistical framework for fuzzing**, inspired from ecology. Marcel Böhme. [STADS: Software Testing as Species Discovery](https://mboehme.github.io/paper/TOSEM18.pdf). ACM TOSEM 27(2):1--52\n* Estimating the **discovery probability**: I.J. Good. 1953. [The population frequencies of species and the\nestimation of population parameters](https://www.jstor.org/stable/2333344). Biometrika 40:237–264.\n* Estimating the **asymptotic total number of species** when each input can belong to exactly one species: Anne Chao. 1984. [Nonparametric estimation of the number of classes in a population](https://www.jstor.org/stable/4615964). Scandinavian Journal of Statistics 11:265–270\n* Estimating the **asymptotic total number of species** when each input can belong to one or more species: Anne Chao. 1987. [Estimating the population size for capture-recapture data with unequal catchability](https://www.jstor.org/stable/2531532). Biometrics 43:783–791\n* **Extrapolating** the number of discovered species: Tsung-Jen Shen, Anne Chao, and Chih-Feng Lin. 2003. [Predicting the Number of New Species in Further Taxonomic Sampling](http://chao.stat.nthu.edu.tw/wordpress/paper/2003_Ecology_84_P798.pdf). Ecology 84, 3 (2003), 798–804.",
"_____no_output_____"
],
[
"## Exercises\nI.J. Good and Alan Turing developed an estimator for the case where each input belongs to exactly one species. For instance, each input yields exactly one execution trace (see function [`getTraceHash`](#Trace-Coverage)). However, this is not true in general. For instance, each input exercises multiple statements and branches in the source code. Generally, each input can belong to one *or more* species. \n\nIn this extended model, the underlying statistics are quite different. Yet, all estimators that we have discussed in this chapter turn out to be almost identical to those for the simple, single-species model. For instance, the Good-Turing estimator $C$ is defined as \n$$C=\\frac{Q_1}{n}$$ \nwhere $Q_1$ is the number of singleton species and $n$ is the number of generated test cases.\nThroughout the fuzzing campaign, we record for each species the *incidence frequency*, i.e., the number of inputs that belong to that species. Again, we define a species $i$ as *singleton species* if we have seen exactly one input that belongs to species $i$.",
"_____no_output_____"
],
[
"### Exercise 1: Estimate and Evaluate the Discovery Probability for Statement Coverage\n\nIn this exercise, we create a Good-Turing estimator for the simple fuzzer.",
"_____no_output_____"
],
[
"#### Part 1: Population Coverage\n\nImplement a function `population_stmt_coverage()` as in [the section on estimating discovery probability](#Estimating-the-Discovery-Probability) that monitors the number of singletons and doubletons over time, i.e., as the number $i$ of test inputs increases.",
"_____no_output_____"
]
],
[
[
"from Coverage import population_coverage, Coverage\n...",
"_____no_output_____"
]
],
[
[
"**Solution.** Here we go:",
"_____no_output_____"
]
],
[
[
"def population_stmt_coverage(population, function):\n cumulative_coverage = []\n all_coverage = set()\n cumulative_singletons = []\n cumulative_doubletons = []\n singletons = set()\n doubletons = set()\n\n for s in population:\n with Coverage() as cov:\n try:\n function(s)\n except BaseException:\n pass\n cur_coverage = cov.coverage()\n\n # singletons and doubletons\n doubletons -= cur_coverage\n doubletons |= singletons & cur_coverage\n singletons -= cur_coverage\n singletons |= cur_coverage - (cur_coverage & all_coverage)\n cumulative_singletons.append(len(singletons))\n cumulative_doubletons.append(len(doubletons))\n\n # all and cumulative coverage\n all_coverage |= cur_coverage\n cumulative_coverage.append(len(all_coverage))\n\n return all_coverage, cumulative_coverage, cumulative_singletons, cumulative_doubletons",
"_____no_output_____"
]
],
[
[
"#### Part 2: Population\n\nUse the random `fuzzer(min_length=1, max_length=1000, char_start=0, char_range=255)` from [the chapter on Fuzzers](Fuzzer.ipynb) to generate a population of $n=10000$ fuzz inputs.",
"_____no_output_____"
]
],
[
[
"from Fuzzer import RandomFuzzer\nfrom html.parser import HTMLParser\n...",
"_____no_output_____"
]
],
[
[
"**Solution.** This is fairly straightforward:",
"_____no_output_____"
]
],
[
[
"trials = 2000 # increase to 10000 for better convergences. Will take a while..",
"_____no_output_____"
]
],
[
[
"We create a wrapper function...",
"_____no_output_____"
]
],
[
[
"def my_parser(inp):\n parser = HTMLParser() # resets the HTMLParser object for every fuzz input\n parser.feed(inp)",
"_____no_output_____"
]
],
[
[
"... and a random fuzzer:",
"_____no_output_____"
]
],
[
[
"fuzzer = RandomFuzzer(min_length=1, max_length=1000,\n char_start=0, char_range=255)",
"_____no_output_____"
]
],
[
[
"We fill the population:",
"_____no_output_____"
]
],
[
[
"population = []\nfor i in range(trials):\n population.append(fuzzer.fuzz())",
"_____no_output_____"
]
],
[
[
"#### Part 3: Estimating Probabilities\n\nExecute the generated inputs on the Python HTML parser (`from html.parser import HTMLParser`) and estimate the probability that the next input covers a previously uncovered statement (i.e., the discovery probability) using the Good-Turing estimator.",
"_____no_output_____"
],
[
"**Solution.** Here we go:",
"_____no_output_____"
]
],
[
[
"measurements = 100 # experiment measurements\nstep = int(trials / measurements)\n\ngt_timeseries = []\nsingleton_timeseries = population_stmt_coverage(population, my_parser)[2]\nfor i in range(1, trials + 1, step):\n gt_timeseries.append(singleton_timeseries[i - 1] / i)",
"_____no_output_____"
]
],
[
[
"#### Part 4: Empirical Evaluation\n\nEmpirically evaluate the accuracy of the Good-Turing estimator (using $10000$ repetitions) of the probability to cover new statements using the experimental procedure at the end of [the section on estimating discovery probability](#Estimating-the-Discovery-Probability).",
"_____no_output_____"
],
[
"**Solution.** This is as above:",
"_____no_output_____"
]
],
[
[
"# increase to 10000 for better precision (less variance). Will take a while..\nrepeats = 100",
"_____no_output_____"
],
[
"emp_timeseries = []\nall_coverage = set()\nfor i in range(0, trials, step):\n if i - step >= 0:\n for j in range(step):\n inp = population[i - j]\n with Coverage() as cov:\n try:\n my_parser(inp)\n except BaseException:\n pass\n all_coverage |= cov.coverage()\n\n discoveries = 0\n for _ in range(repeats):\n inp = fuzzer.fuzz()\n with Coverage() as cov:\n try:\n my_parser(inp)\n except BaseException:\n pass\n # If intersection not empty, a new stmt was (dis)covered\n if cov.coverage() - all_coverage:\n discoveries += 1\n emp_timeseries.append(discoveries / repeats)",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nline_emp, = plt.semilogy(emp_timeseries, label=\"Empirical\")\nline_gt, = plt.semilogy(gt_timeseries, label=\"Good-Turing\")\nplt.legend(handles=[line_emp, line_gt])\nplt.xticks(range(0, measurements + 1, int(measurements / 5)),\n range(0, trials + 1, int(trials / 5)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('discovery probability')\nplt.title('Discovery Probability Over Time');",
"_____no_output_____"
]
],
[
[
"### Exercise 2: Extrapolate and Evaluate Statement Coverage\n\nIn this exercise, we use Chao's extrapolation method to estimate the success of fuzzing.",
"_____no_output_____"
],
[
"#### Part 1: Create Population\n\nUse the random `fuzzer(min_length=1, max_length=1000, char_start=0, char_range=255)` to generate a population of $n=400000$ fuzz inputs.",
"_____no_output_____"
],
[
"**Solution.** Here we go:",
"_____no_output_____"
]
],
[
[
"trials = 400 # Use 400000 for actual solution. This takes a while!",
"_____no_output_____"
],
[
"population = []\nfor i in range(trials):\n population.append(fuzzer.fuzz())\n\n_, stmt_ts, Q1_ts, Q2_ts = population_stmt_coverage(population, my_parser)",
"_____no_output_____"
]
],
[
[
"#### Part 2: Compute Estimate\n\nCompute an estimate of the total number of statements $\\hat S$ after $n/4=100000$ fuzz inputs were generated. In the extended model, $\\hat S$ is computed as\n\\begin{align}\n\\hat S_\\text{Chao1} = \\begin{cases}\nS(n) + \\frac{Q_1^2}{2Q_2} & \\text{if $Q_2>0$}\\\\\nS(n) + \\frac{Q_1(Q_1-1)}{2} & \\text{otherwise}\n\\end{cases}\n\\end{align}\n * where $Q_1$ and $Q_2$ is the number of singleton and doubleton statements, respectively (i.e., statements that have been exercised by exactly one or two fuzz inputs, resp.), and \n * where $S(n)$ is the number of statements that have been (dis)covered after generating $n$ fuzz inputs.",
"_____no_output_____"
],
[
"**Solution.** Here we go:",
"_____no_output_____"
]
],
[
[
"time = int(trials / 4)\nQ1 = Q1_ts[time]\nQ2 = Q2_ts[time]\nSn = stmt_ts[time]\n\nif Q2 > 0:\n hat_S = Sn + Q1 * Q1 / (2 * Q2)\nelse:\n hat_S = Sn + Q1 * (Q1 - 1) / 2\n\nprint(\"After executing %d fuzz inputs, we have covered %d **(%.1f %%)** statements.\\n\" % (time, Sn, 100 * Sn / hat_S) +\n \"After executing %d fuzz inputs, we estimate there are %d statements in total.\\n\" % (time, hat_S) +\n \"After executing %d fuzz inputs, we have covered %d statements.\" % (trials, stmt_ts[trials - 1]))",
"_____no_output_____"
]
],
[
[
"#### Part 3: Compute and Evaluate Extrapolator\n\nCompute and evaluate Chao's extrapolator by comparing the predicted number of statements to the empirical number of statements.",
"_____no_output_____"
],
[
"**Solution.** Here's our solution:",
"_____no_output_____"
]
],
[
[
"prediction_ts = [None] * time\nQ0 = hat_S - Sn\n\nfor m in range(trials - time):\n prediction_ts.append(Sn + Q0 * (1 - (1 - Q1 / (time * Q0 + Q1)) ** m))",
"_____no_output_____"
],
[
"plt.figure(num=None, figsize=(12, 3), dpi=80, facecolor='w', edgecolor='k')\nplt.subplot(1, 3, 1)\nplt.plot(stmt_ts, color='white')\nplt.plot(stmt_ts[:time])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of statements exercised')\n\nplt.subplot(1, 3, 2)\nline_cur, = plt.plot(stmt_ts[:time], label=\"Ongoing fuzzing campaign\")\nline_pred, = plt.plot(prediction_ts, linestyle='--',\n color='black', label=\"Predicted progress\")\nplt.legend(handles=[line_cur, line_pred])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of statements exercised')\n\nplt.subplot(1, 3, 3)\nline_emp, = plt.plot(stmt_ts, color='grey', label=\"Actual progress\")\nline_cur, = plt.plot(stmt_ts[:time], label=\"Ongoing fuzzing campaign\")\nline_pred, = plt.plot(prediction_ts, linestyle='--',\n color='black', label=\"Predicted progress\")\nplt.legend(handles=[line_emp, line_cur, line_pred])\nplt.xticks(range(0, trials + 1, int(time)))\nplt.xlabel('# of fuzz inputs')\nplt.ylabel('# of statements exercised');",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
c518c45a6557d43df0d7fca13aa75cc748ae5540
| 402,317 |
ipynb
|
Jupyter Notebook
|
examples/cfd/07_cavity_flow.ipynb
|
garg-aayush/devito
|
b1e8fffdee7d6b556ff19a372d69ed1aebee675a
|
[
"MIT"
] | 1 |
2020-01-31T10:35:49.000Z
|
2020-01-31T10:35:49.000Z
|
examples/cfd/07_cavity_flow.ipynb
|
pnmoralesh/Devito
|
1e619c0208ecf5f3817d614cd49b8df89d0beb22
|
[
"MIT"
] | 52 |
2020-10-12T19:29:09.000Z
|
2022-03-10T14:05:22.000Z
|
examples/cfd/07_cavity_flow.ipynb
|
ArthurGiannotta/devito
|
f25850ec1683031145c9405e2ab11acedb1ea5b5
|
[
"MIT"
] | 1 |
2020-06-02T03:31:11.000Z
|
2020-06-02T03:31:11.000Z
| 581.382948 | 138,428 | 0.933624 |
[
[
[
"# Cavity flow with Navier-Stokes",
"_____no_output_____"
],
[
"The final two steps will both solve the Navier–Stokes equations in two dimensions, but with different boundary conditions.\n\nThe momentum equation in vector form for a velocity field v⃗ \n\nis:\n\n$$ \\frac{\\partial \\overrightarrow{v}}{\\partial t} + (\\overrightarrow{v} \\cdot \\nabla ) \\overrightarrow{v} = -\\frac{1}{\\rho}\\nabla p + \\nu \\nabla^2 \\overrightarrow{v}$$\n\nThis represents three scalar equations, one for each velocity component (u,v,w). But we will solve it in two dimensions, so there will be two scalar equations.\n\nRemember the continuity equation? This is where the Poisson equation for pressure comes in!",
"_____no_output_____"
],
[
"Here is the system of differential equations: two equations for the velocity components u,v and one equation for pressure:\n\n$$ \\frac{\\partial u}{\\partial t} + u \\frac{\\partial u}{\\partial x} + v \\frac{\\partial u}{\\partial y}= -\\frac{1}{\\rho}\\frac{\\partial p}{\\partial x} + \\nu \\left[ \\frac{\\partial^2 u}{\\partial x^2} +\\frac{\\partial^2 u}{\\partial y^2} \\right] $$\n\n$$ \\frac{\\partial v}{\\partial t} + u \\frac{\\partial v}{\\partial x} + v \\frac{\\partial v}{\\partial y}= -\\frac{1}{\\rho}\\frac{\\partial p}{\\partial y} + \\nu \\left[ \\frac{\\partial^2 v}{\\partial x^2} +\\frac{\\partial^2 v}{\\partial y^2} \\right] $$\n\n$$\n\\frac{\\partial^2 p}{\\partial x^2} +\\frac{\\partial^2 p}{\\partial y^2} =\n\\rho \\left[\\frac{\\partial}{\\partial t} \\left(\\frac{\\partial u}{\\partial x} + \\frac{\\partial v}{\\partial y} \\right) - \\left(\\frac{\\partial u}{\\partial x}\\frac{\\partial u}{\\partial x}+2\\frac{\\partial u}{\\partial y}\\frac{\\partial v}{\\partial x}+\\frac{\\partial v}{\\partial y}\\frac{\\partial v}{\\partial y} \\right) \\right]\n$$\n\nFrom the previous steps, we already know how to discretize all these terms. Only the last equation is a little unfamiliar. But with a little patience, it will not be hard!\n",
"_____no_output_____"
],
[
"Our stencils look like this:\nFirst the momentum equation in the u direction\n$$\n\\begin{split}\nu_{i,j}^{n+1} = u_{i,j}^{n} & - u_{i,j}^{n} \\frac{\\Delta t}{\\Delta x} \\left(u_{i,j}^{n}-u_{i-1,j}^{n}\\right) - v_{i,j}^{n} \\frac{\\Delta t}{\\Delta y} \\left(u_{i,j}^{n}-u_{i,j-1}^{n}\\right) \\\\\n& - \\frac{\\Delta t}{\\rho 2\\Delta x} \\left(p_{i+1,j}^{n}-p_{i-1,j}^{n}\\right) \\\\\n& + \\nu \\left(\\frac{\\Delta t}{\\Delta x^2} \\left(u_{i+1,j}^{n}-2u_{i,j}^{n}+u_{i-1,j}^{n}\\right) + \\frac{\\Delta t}{\\Delta y^2} \\left(u_{i,j+1}^{n}-2u_{i,j}^{n}+u_{i,j-1}^{n}\\right)\\right)\n\\end{split}\n$$\nSecond the momentum equation in the v direction\n$$\n\\begin{split}\nv_{i,j}^{n+1} = v_{i,j}^{n} & - u_{i,j}^{n} \\frac{\\Delta t}{\\Delta x} \\left(v_{i,j}^{n}-v_{i-1,j}^{n}\\right) - v_{i,j}^{n} \\frac{\\Delta t}{\\Delta y} \\left(v_{i,j}^{n}-v_{i,j-1}^{n})\\right) \\\\\n& - \\frac{\\Delta t}{\\rho 2\\Delta y} \\left(p_{i,j+1}^{n}-p_{i,j-1}^{n}\\right) \\\\\n& + \\nu \\left(\\frac{\\Delta t}{\\Delta x^2} \\left(v_{i+1,j}^{n}-2v_{i,j}^{n}+v_{i-1,j}^{n}\\right) + \\frac{\\Delta t}{\\Delta y^2} \\left(v_{i,j+1}^{n}-2v_{i,j}^{n}+v_{i,j-1}^{n}\\right)\\right)\n\\end{split}\n$$\nFinally the pressure-Poisson equation\n$$\\begin{split}\np_{i,j}^{n} = & \\frac{\\left(p_{i+1,j}^{n}+p_{i-1,j}^{n}\\right) \\Delta y^2 + \\left(p_{i,j+1}^{n}+p_{i,j-1}^{n}\\right) \\Delta x^2}{2\\left(\\Delta x^2+\\Delta y^2\\right)} \\\\\n& -\\frac{\\rho\\Delta x^2\\Delta y^2}{2\\left(\\Delta x^2+\\Delta y^2\\right)} \\\\\n& \\times \\left[\\frac{1}{\\Delta t}\\left(\\frac{u_{i+1,j}-u_{i-1,j}}{2\\Delta x}+\\frac{v_{i,j+1}-v_{i,j-1}}{2\\Delta y}\\right)-\\frac{u_{i+1,j}-u_{i-1,j}}{2\\Delta x}\\frac{u_{i+1,j}-u_{i-1,j}}{2\\Delta x}\\right. \\\\ \n& \\left. -2\\frac{u_{i,j+1}-u_{i,j-1}}{2\\Delta y}\\frac{v_{i+1,j}-v_{i-1,j}}{2\\Delta x}-\\frac{v_{i,j+1}-v_{i,j-1}}{2\\Delta y}\\frac{v_{i,j+1}-v_{i,j-1}}{2\\Delta y} \\right] \n\\end{split}\n$$\n\nThe initial condition is $u,v,p=0$\n\neverywhere, and the boundary conditions are:\n\n$u=1$ at $y=1$ (the \"lid\");\n\n$u,v=0$ on the other boundaries;\n\n$\\frac{\\partial p}{\\partial y}=0$ at $y=0,1$;\n\n$\\frac{\\partial p}{\\partial x}=0$ at $x=0,1$\n\n$p=0$ at $(0,0)$\n\nInterestingly these boundary conditions describe a well known problem in the Computational Fluid Dynamics realm, where it is known as the lid driven square cavity flow problem.",
"_____no_output_____"
],
[
"## Numpy Implementation",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot, cm\n%matplotlib inline",
"_____no_output_____"
],
[
"nx = 41\nny = 41\nnt = 1000\nnit = 50\nc = 1\ndx = 1. / (nx - 1)\ndy = 1. / (ny - 1)\nx = np.linspace(0, 1, nx)\ny = np.linspace(0, 1, ny)\nY, X = np.meshgrid(x, y)\n\nrho = 1\nnu = .1\ndt = .001\n\nu = np.zeros((nx, ny))\nv = np.zeros((nx, ny))\np = np.zeros((nx, ny)) ",
"_____no_output_____"
]
],
[
[
"The pressure Poisson equation that's written above can be hard to write out without typos. The function `build_up_b` below represents the contents of the square brackets, so that the entirety of the Poisson pressure equation is slightly more manageable.",
"_____no_output_____"
]
],
[
[
"def build_up_b(b, rho, dt, u, v, dx, dy):\n \n b[1:-1, 1:-1] = (rho * (1 / dt * \n ((u[2:, 1:-1] - u[0:-2, 1:-1]) / \n (2 * dx) + (v[1:-1, 2:] - v[1:-1, 0:-2]) / (2 * dy)) -\n ((u[2:, 1:-1] - u[0:-2, 1:-1]) / (2 * dx))**2 -\n 2 * ((u[1:-1, 2:] - u[1:-1, 0:-2]) / (2 * dy) *\n (v[2:, 1:-1] - v[0:-2, 1:-1]) / (2 * dx))-\n ((v[1:-1, 2:] - v[1:-1, 0:-2]) / (2 * dy))**2))\n\n return b",
"_____no_output_____"
]
],
[
[
"The function `pressure_poisson` is also defined to help segregate the different rounds of calculations. Note the presence of the pseudo-time variable nit. This sub-iteration in the Poisson calculation helps ensure a divergence-free field.",
"_____no_output_____"
]
],
[
[
"def pressure_poisson(p, dx, dy, b):\n pn = np.empty_like(p)\n pn = p.copy()\n \n for q in range(nit):\n pn = p.copy()\n p[1:-1, 1:-1] = (((pn[2:, 1:-1] + pn[0:-2, 1:-1]) * dy**2 + \n (pn[1:-1, 2:] + pn[1:-1, 0:-2]) * dx**2) /\n (2 * (dx**2 + dy**2)) -\n dx**2 * dy**2 / (2 * (dx**2 + dy**2)) * \n b[1:-1,1:-1])\n \n p[-1, :] = p[-2, :] # dp/dx = 0 at x = 2\n p[:, 0] = p[:, 1] # dp/dy = 0 at y = 0\n p[0, :] = p[1, :] # dp/dx = 0 at x = 0\n p[:, -1] = p[:, -2] # p = 0 at y = 2\n p[0, 0] = 0 \n \n return p, pn",
"_____no_output_____"
]
],
[
[
"Finally, the rest of the cavity flow equations are wrapped inside the function `cavity_flow`, allowing us to easily plot the results of the cavity flow solver for different lengths of time.",
"_____no_output_____"
]
],
[
[
"def cavity_flow(nt, u, v, dt, dx, dy, p, rho, nu):\n un = np.empty_like(u)\n vn = np.empty_like(v)\n b = np.zeros((nx, ny))\n \n for n in range(0,nt):\n un = u.copy()\n vn = v.copy()\n \n b = build_up_b(b, rho, dt, u, v, dx, dy)\n p = pressure_poisson(p, dx, dy, b)[0]\n pn = pressure_poisson(p, dx, dy, b)[1]\n \n u[1:-1, 1:-1] = (un[1:-1, 1:-1]-\n un[1:-1, 1:-1] * dt / dx *\n (un[1:-1, 1:-1] - un[0:-2, 1:-1]) -\n vn[1:-1, 1:-1] * dt / dy *\n (un[1:-1, 1:-1] - un[1:-1, 0:-2]) -\n dt / (2 * rho * dx) * (p[2:, 1:-1] - p[0:-2, 1:-1]) +\n nu * (dt / dx**2 *\n (un[2:, 1:-1] - 2 * un[1:-1, 1:-1] + un[0:-2, 1:-1]) +\n dt / dy**2 *\n (un[1:-1, 2:] - 2 * un[1:-1, 1:-1] + un[1:-1, 0:-2])))\n\n v[1:-1,1:-1] = (vn[1:-1, 1:-1] -\n un[1:-1, 1:-1] * dt / dx *\n (vn[1:-1, 1:-1] - vn[0:-2, 1:-1]) -\n vn[1:-1, 1:-1] * dt / dy *\n (vn[1:-1, 1:-1] - vn[1:-1, 0:-2]) -\n dt / (2 * rho * dy) * (p[1:-1, 2:] - p[1:-1, 0:-2]) +\n nu * (dt / dx**2 *\n (vn[2:, 1:-1] - 2 * vn[1:-1, 1:-1] + vn[0:-2, 1:-1]) +\n dt / dy**2 *\n (vn[1:-1, 2:] - 2 * vn[1:-1, 1:-1] + vn[1:-1, 0:-2])))\n\n u[:, 0] = 0\n u[0, :] = 0\n u[-1, :] = 0\n u[:, -1] = 1 # Set velocity on cavity lid equal to 1\n \n v[:, 0] = 0\n v[:, -1] = 0\n v[0, :] = 0\n v[-1, :] = 0\n \n return u, v, p, pn",
"_____no_output_____"
],
[
"#NBVAL_IGNORE_OUTPUT\nu = np.zeros((nx, ny))\nv = np.zeros((nx, ny))\np = np.zeros((nx, ny))\nb = np.zeros((nx, ny))\nnt = 1000\n# Store the output velocity and pressure fields in the variables a, b and c.\n# This is so they do not clash with the devito outputs below.\na, b, c, d = cavity_flow(nt, u, v, dt, dx, dy, p, rho, nu)\n\nfig = pyplot.figure(figsize=(11, 7), dpi=100)\npyplot.contourf(X, Y, c, alpha=0.5, cmap=cm.viridis)\npyplot.colorbar()\npyplot.contour(X, Y, c, cmap=cm.viridis)\npyplot.quiver(X[::2, ::2], Y[::2, ::2], a[::2, ::2], b[::2, ::2])\npyplot.xlabel('X')\npyplot.ylabel('Y');",
"_____no_output_____"
]
],
[
[
"### Validation",
"_____no_output_____"
],
[
"Marchi et al (2009)$^1$ compared numerical implementations of the lid driven cavity problem with their solution on a 1024 x 1024 nodes grid. We will compare a solution using both NumPy and Devito with the results of their paper below.\n\n1. https://www.scielo.br/scielo.php?pid=S1678-58782009000300004&script=sci_arttext",
"_____no_output_____"
]
],
[
[
"# Import u values at x=L/2 (table 6, column 2 rows 12-26) in Marchi et al.\nMarchi_Re10_u = np.array([[0.0625, -3.85425800e-2],\n [0.125, -6.96238561e-2],\n [0.1875, -9.6983962e-2],\n [0.25, -1.22721979e-1],\n [0.3125, -1.47636199e-1],\n [0.375, -1.71260757e-1],\n [0.4375, -1.91677043e-1],\n [0.5, -2.05164738e-1],\n [0.5625, -2.05770198e-1],\n [0.625, -1.84928116e-1],\n [0.6875, -1.313892353e-1],\n [0.75, -3.1879308e-2],\n [0.8125, 1.26912095e-1],\n [0.875, 3.54430364e-1],\n [0.9375, 6.50529292e-1]])\n# Import v values at y=L/2 (table 6, column 2 rows 27-41) in Marchi et al.\nMarchi_Re10_v = np.array([[0.0625, 9.2970121e-2],\n [0.125, 1.52547843e-1],\n [0.1875, 1.78781456e-1],\n [0.25, 1.76415100e-1],\n [0.3125, 1.52055820e-1],\n [0.375, 1.121477612e-1],\n [0.4375, 6.21048147e-2],\n [0.5, 6.3603620e-3],\n [0.5625,-5.10417285e-2],\n [0.625, -1.056157259e-1],\n [0.6875,-1.51622101e-1],\n [0.75, -1.81633561e-1],\n [0.8125,-1.87021651e-1],\n [0.875, -1.59898186e-1],\n [0.9375,-9.6409942e-2]])",
"_____no_output_____"
],
[
"#NBVAL_IGNORE_OUTPUT\n# Check results with Marchi et al 2009.\nnpgrid=[nx,ny]\n\nx_coord = np.linspace(0, 1, npgrid[0])\ny_coord = np.linspace(0, 1, npgrid[1])\n\nfig = pyplot.figure(figsize=(12, 6))\nax1 = fig.add_subplot(121)\nax1.plot(a[int(npgrid[0]/2),:],y_coord[:])\nax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')\nax1.set_xlabel('$u$')\nax1.set_ylabel('$y$')\nax1 = fig.add_subplot(122)\nax1.plot(x_coord[:],b[:,int(npgrid[1]/2)])\nax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')\nax1.set_xlabel('$x$')\nax1.set_ylabel('$v$')\n\npyplot.show()",
"_____no_output_____"
]
],
[
[
"## Devito Implementation",
"_____no_output_____"
]
],
[
[
"from devito import Grid\n\ngrid = Grid(shape=(nx, ny), extent=(1., 1.))\nx, y = grid.dimensions\nt = grid.stepping_dim",
"_____no_output_____"
]
],
[
[
"Reminder: here are our equations\n\n$$ \\frac{\\partial u}{\\partial t} + u \\frac{\\partial u}{\\partial x} + v \\frac{\\partial u}{\\partial y}= -\\frac{1}{\\rho}\\frac{\\partial p}{\\partial x} + \\nu \\left[ \\frac{\\partial^2 u}{\\partial x^2} +\\frac{\\partial^2 u}{\\partial y^2} \\right] $$\n\n$$ \\frac{\\partial v}{\\partial t} + u \\frac{\\partial v}{\\partial x} + v \\frac{\\partial v}{\\partial y}= -\\frac{1}{\\rho}\\frac{\\partial p}{\\partial y} + \\nu \\left[ \\frac{\\partial^2 v}{\\partial x^2} +\\frac{\\partial^2 v}{\\partial y^2} \\right] $$\n\n$$\n\\frac{\\partial^2 p}{\\partial x^2} +\\frac{\\partial^2 p}{\\partial y^2} =\n\\rho \\left[\\frac{\\partial}{\\partial t} \\left(\\frac{\\partial u}{\\partial x} + \\frac{\\partial v}{\\partial y} \\right) - \\left(\\frac{\\partial u}{\\partial x}\\frac{\\partial u}{\\partial x}+2\\frac{\\partial u}{\\partial y}\\frac{\\partial v}{\\partial x}+\\frac{\\partial v}{\\partial y}\\frac{\\partial v}{\\partial y} \\right) \\right]\n$$\n\nNote that p has no time dependence, so we are going to solve for p in pseudotime then move to the next time step and solve for u and v. This will require two operators, one for p (using p and pn) in pseudotime and one for u and v in time.\n\nAs shown in the Poisson equation tutorial, a TimeFunction can be used despite the lack of a time-dependence. This will cause Devito to allocate two grid buffers, which we can addressed directly via the terms pn and pn.forward. The internal time loop can be controlled by supplying the number of pseudotime steps (iterations) as a time argument to the operator.\n\nThe time steps are advanced through a Python loop where a separator operator calculates u and v.",
"_____no_output_____"
],
[
"Also note that we need to use first order spatial derivatives for the velocites and these derivatives are not the maximum spatial derivative order (2nd order) in these equations. This is the first time we have seen this in this tutorial series (previously we have only used a single spatial derivate order). \n\n To use a first order derivative of a devito function, we use the syntax `function.dxc` or `function.dyc` for the x and y derivatives respectively.",
"_____no_output_____"
]
],
[
[
"from devito import TimeFunction, Function, \\\nEq, solve, Operator, configuration\n\n# Build Required Functions and derivatives:\n# --------------------------------------\n# |Variable | Required Derivatives |\n# --------------------------------------\n# | u | dt, dx, dy, dx**2, dy**2 |\n# | v | dt, dx, dy, dx**2, dy**2 |\n# | p | dx, dy, dx**2, dy**2 |\n# | pn | dx, dy, dx**2, dy**2 |\n# --------------------------------------\nu = TimeFunction(name='u', grid=grid, space_order=2)\nv = TimeFunction(name='v', grid=grid, space_order=2)\np = TimeFunction(name='p', grid=grid, space_order=2)\n#Variables are automatically initalized at 0.\n\n# First order derivatives will be handled with p.dxc\neq_u =Eq(u.dt + u*u.dx + v*u.dy, -1./rho * p.dxc + nu*(u.laplace), subdomain=grid.interior)\neq_v =Eq(v.dt + u*v.dx + v*v.dy, -1./rho * p.dyc + nu*(v.laplace), subdomain=grid.interior)\neq_p =Eq(p.laplace,rho*(1./dt*(u.dxc+v.dyc)-(u.dxc*u.dxc)+2*(u.dyc*v.dxc)+(v.dyc*v.dyc)), subdomain=grid.interior)\n\n# NOTE: Pressure has no time dependence so we solve for the other pressure buffer.\nstencil_u =solve(eq_u , u.forward)\nstencil_v =solve(eq_v , v.forward)\nstencil_p=solve(eq_p, p)\n \nupdate_u =Eq(u.forward, stencil_u)\nupdate_v =Eq(v.forward, stencil_v)\nupdate_p =Eq(p.forward, stencil_p) \n\n# Boundary Conds. u=v=0 for all sides\nbc_u = [Eq(u[t+1, 0, y], 0)] \nbc_u += [Eq(u[t+1, nx-1, y], 0)] \nbc_u += [Eq(u[t+1, x, 0], 0)] \nbc_u += [Eq(u[t+1, x, ny-1], 1)] # except u=1 for y=2\nbc_v = [Eq(v[t+1, 0, y], 0)] \nbc_v += [Eq(v[t+1, nx-1, y], 0)] \nbc_v += [Eq(v[t+1, x, ny-1], 0)] \nbc_v += [Eq(v[t+1, x, 0], 0)] \n\nbc_p = [Eq(p[t+1, 0, y],p[t+1, 1,y])] # dpn/dx = 0 for x=0.\nbc_p += [Eq(p[t+1,nx-1, y],p[t+1,nx-2, y])] # dpn/dx = 0 for x=2.\nbc_p += [Eq(p[t+1, x, 0],p[t+1,x ,1])] # dpn/dy = 0 at y=0\nbc_p += [Eq(p[t+1, x, ny-1],p[t+1, x, ny-2])] # pn=0 for y=2\nbc_p += [Eq(p[t+1, 0, 0], 0)]\nbc=bc_u+bc_v\n\noptime=Operator([update_u, update_v]+bc_u+bc_v)\noppres=Operator([update_p]+bc_p)",
"_____no_output_____"
],
[
"# Silence non-essential outputs from the solver.\nconfiguration['log-level'] = 'ERROR'\n\n\n# This is the time loop.\nfor step in range(0,nt):\n if step>0:\n oppres(time_M = nit)\n optime(time_m=step, time_M=step, dt=dt)",
"_____no_output_____"
],
[
"#NBVAL_IGNORE_OUTPUT\nfig = pyplot.figure(figsize=(11,7), dpi=100)\n# Plotting the pressure field as a contour.\npyplot.contourf(X, Y, p.data[0], alpha=0.5, cmap=cm.viridis) \npyplot.colorbar()\n# Plotting the pressure field outlines.\npyplot.contour(X, Y, p.data[0], cmap=cm.viridis) \n# Plotting velocity field.\npyplot.quiver(X[::2,::2], Y[::2,::2], u.data[0,::2,::2], v.data[0,::2,::2]) \npyplot.xlabel('X')\npyplot.ylabel('Y');\n",
"_____no_output_____"
]
],
[
[
"### Validation",
"_____no_output_____"
]
],
[
[
"#NBVAL_IGNORE_OUTPUT\n# Again, check results with Marchi et al 2009.\nfig = pyplot.figure(figsize=(12, 6))\nax1 = fig.add_subplot(121)\nax1.plot(u.data[0,int(grid.shape[0]/2),:],y_coord[:])\nax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')\nax1.set_xlabel('$u$')\nax1.set_ylabel('$y$')\nax1 = fig.add_subplot(122)\nax1.plot(x_coord[:],v.data[0,:,int(grid.shape[0]/2)])\nax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')\nax1.set_xlabel('$x$')\nax1.set_ylabel('$v$')\n\npyplot.show()",
"_____no_output_____"
]
],
[
[
"\nThe Devito implementation produces results consistent with the benchmark solution. There is a small disparity in a few of the velocity values, but this is expected as the Devito 41 x 41 node grid is much coarser than the benchmark on a 1024 x 1024 node grid.\n",
"_____no_output_____"
],
[
"## Comparison",
"_____no_output_____"
]
],
[
[
"#NBVAL_IGNORE_OUTPUT\nfig = pyplot.figure(figsize=(12, 6))\nax1 = fig.add_subplot(121)\nax1.plot(a[int(npgrid[0]/2),:],y_coord[:])\nax1.plot(u.data[0,int(grid.shape[0]/2),:],y_coord[:],'--')\nax1.plot(Marchi_Re10_u[:,1],Marchi_Re10_u[:,0],'ro')\nax1.set_xlabel('$u$')\nax1.set_ylabel('$y$')\nax1 = fig.add_subplot(122)\nax1.plot(x_coord[:],b[:,int(npgrid[1]/2)])\nax1.plot(x_coord[:],v.data[0,:,int(grid.shape[0]/2)],'--')\nax1.plot(Marchi_Re10_v[:,0],Marchi_Re10_v[:,1],'ro')\nax1.set_xlabel('$x$')\nax1.set_ylabel('$v$')\nax1.legend(['numpy','devito','Marchi (2009)'])\n\npyplot.show()\n\n#Pressure norm check\ntol = 1e-3\nassert np.sum((c[:,:]-d[:,:])**2/ np.maximum(d[:,:]**2,1e-10)) < tol\nassert np.sum((p.data[0]-p.data[1])**2/np.maximum(p.data[0]**2,1e-10)) < tol",
"_____no_output_____"
]
],
[
[
"Overlaying all the graphs together shows how the Devito, NumPy and Marchi et al (2009)$^1$ \n solutions compare with each other. A final accuracy check is done which is to test whether the pressure norm has exceeded a specified tolerance.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c518c8b68454e6aa8ed06251bfed8825dae9981f
| 44,504 |
ipynb
|
Jupyter Notebook
|
lfm_movielens.ipynb
|
PanJianning/TutorML
|
f87cbcf4cdfc490338a995dce78a9fc6f5d518ae
|
[
"BSD-3-Clause"
] | 1 |
2018-08-14T06:55:40.000Z
|
2018-08-14T06:55:40.000Z
|
lfm_movielens.ipynb
|
PanJianning/TutorML
|
f87cbcf4cdfc490338a995dce78a9fc6f5d518ae
|
[
"BSD-3-Clause"
] | null | null | null |
lfm_movielens.ipynb
|
PanJianning/TutorML
|
f87cbcf4cdfc490338a995dce78a9fc6f5d518ae
|
[
"BSD-3-Clause"
] | null | null | null | 147.364238 | 34,912 | 0.873629 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport os\nimport matplotlib.pyplot as plt\nfrom TutorML.decomposition import LFM ",
"_____no_output_____"
],
[
"def load_movielens(train_path, test_path, basedir=None):\n if basedir:\n train_path = os.path.join(basedir,train_path)\n test_path = os.path.join(basedir,test_path)\n col_names = ['user_id','item_id','score','timestamp']\n use_cols = ['user_id','item_id','score']\n df_train = pd.read_csv(train_path,sep='\\t',header=None,\n names=col_names,usecols=use_cols)\n df_test = pd.read_csv(test_path,sep='\\t',header=None,\n names=col_names,usecols=use_cols)\n df_train.user_id -= 1\n df_train.item_id -= 1\n df_test.user_id -= 1\n df_test.item_id -=1\n return df_train, df_test",
"_____no_output_____"
],
[
"df_train, df_test = load_movielens(train_path='u1.base',test_path='u1.test',\n basedir='ml-100k/')",
"_____no_output_____"
],
[
"data = pd.concat([df_train,df_test]).reset_index().drop('index',axis=1)\nn_users = data.user_id.nunique()\nn_items = data.item_id.nunique()\ntrain_idx = np.ravel_multi_index(df_train[['user_id','item_id']].values.T,\n dims=(n_users,n_items))\ntest_idx = np.ravel_multi_index(df_test[['user_id','item_id']].values.T,\n dims=(n_users,n_items))",
"_____no_output_____"
],
[
"X = np.zeros(shape=(n_users*n_items,))\nmask = np.zeros(shape=(n_users*n_items))\n\nX[train_idx] = df_train['score']\nmask[train_idx] = 1\ny_test = df_test.score.values.ravel()\n\nX = X.reshape((n_users,n_items))\nmask = mask.reshape((n_users, n_items))",
"_____no_output_____"
],
[
"\"\"\"\nif you want to increace number of factors, \nyou should lower the learning rate too. otherwise nan or inf may appear\n\"\"\"\nlfm = LFM(n_factors=5,max_iter=1000,early_stopping=50,reg_lambda=2,\n learning_rate=1e-3,print_every=20)",
"_____no_output_____"
],
[
"lfm.fit(X,mask,test_data=(test_idx,y_test))",
"[Iter 020] train mse: 0.9766 test mse: 1.0839\n[Iter 040] train mse: 0.9299 test mse: 1.0321\n[Iter 060] train mse: 1.1823 test mse: 1.0349\n[Iter 080] train mse: 0.9006 test mse: 1.0224\n[Iter 100] train mse: 0.8708 test mse: 1.0178\n[Iter 120] train mse: 0.8476 test mse: 1.0146\n[Iter 140] train mse: 0.8296 test mse: 1.0103\n[Iter 160] train mse: 0.8122 test mse: 1.0048\n[Iter 180] train mse: 0.7957 test mse: 1.0030\n[Iter 200] train mse: 0.7841 test mse: 1.0063\n[Iter 220] train mse: 0.7733 test mse: 1.0010\n[Iter 240] train mse: 0.7665 test mse: 1.0022\n[Iter 260] train mse: 0.7593 test mse: 1.0025\n[Iter 280] train mse: 0.7530 test mse: 1.0050\n[EarlyStop] best test mse at iter 233: 1.0003\n"
],
[
"rounded_prediction_mse = lfm.mse_history",
"_____no_output_____"
],
[
"lfm = LFM(n_factors=2,max_iter=1000,early_stopping=50,reg_lambda=1,\n round_prediction=False, learning_rate=1e-3,print_every=20)\nlfm.fit(X,mask,test_data=(test_idx,y_test))",
"[Iter 020] train mse: 0.9552 test mse: 1.0978\n[Iter 040] train mse: 0.8654 test mse: 0.9728\n[Iter 060] train mse: 0.8435 test mse: 0.9464\n[Iter 080] train mse: 0.8326 test mse: 0.9375\n[Iter 100] train mse: 0.8249 test mse: 0.9334\n[Iter 120] train mse: 0.8458 test mse: 0.9309\n[Iter 140] train mse: 0.9049 test mse: 0.9312\n[Iter 160] train mse: 0.8134 test mse: 0.9275\n[Iter 180] train mse: 0.8055 test mse: 0.9278\n[Iter 200] train mse: 0.8077 test mse: 0.9314\n[Iter 220] train mse: 0.8017 test mse: 0.9261\n[Iter 240] train mse: 0.7911 test mse: 0.9149\n[Iter 260] train mse: 0.7857 test mse: 0.9070\n[Iter 280] train mse: 0.7829 test mse: 0.9021\n[Iter 300] train mse: 0.7783 test mse: 0.8990\n[Iter 320] train mse: 0.7729 test mse: 0.8968\n[Iter 340] train mse: 0.7684 test mse: 0.8950\n[Iter 360] train mse: 0.7648 test mse: 0.8932\n[Iter 380] train mse: 0.7617 test mse: 0.8912\n[Iter 400] train mse: 0.7589 test mse: 0.8892\n[Iter 420] train mse: 0.7565 test mse: 0.8874\n[Iter 440] train mse: 0.7544 test mse: 0.8858\n[Iter 460] train mse: 0.7526 test mse: 0.8844\n[Iter 480] train mse: 0.7511 test mse: 0.8833\n[Iter 500] train mse: 0.7499 test mse: 0.8823\n[Iter 520] train mse: 0.7488 test mse: 0.8815\n[Iter 540] train mse: 0.7478 test mse: 0.8807\n[Iter 560] train mse: 0.7470 test mse: 0.8801\n[Iter 580] train mse: 0.7463 test mse: 0.8796\n[Iter 600] train mse: 0.7456 test mse: 0.8791\n[Iter 620] train mse: 0.7451 test mse: 0.8787\n[Iter 640] train mse: 0.7446 test mse: 0.8783\n[Iter 660] train mse: 0.7442 test mse: 0.8780\n[Iter 680] train mse: 0.7438 test mse: 0.8777\n[Iter 700] train mse: 0.7435 test mse: 0.8774\n[Iter 720] train mse: 0.7432 test mse: 0.8772\n[Iter 740] train mse: 0.7429 test mse: 0.8770\n[Iter 760] train mse: 0.7427 test mse: 0.8769\n[Iter 780] train mse: 0.7425 test mse: 0.8767\n[Iter 800] train mse: 0.7423 test mse: 0.8766\n[Iter 820] train mse: 0.7421 test mse: 0.8765\n[Iter 840] train mse: 0.7419 test mse: 0.8764\n[Iter 860] train mse: 0.7418 test mse: 0.8764\n[Iter 880] train mse: 0.7416 test mse: 0.8763\n[Iter 900] train mse: 0.7415 test mse: 0.8763\n[Iter 920] train mse: 0.7414 test mse: 0.8763\n[Iter 940] train mse: 0.7413 test mse: 0.8762\n[Iter 960] train mse: 0.7412 test mse: 0.8762\n[Iter 980] train mse: 0.7411 test mse: 0.8762\n[Iter 1000] train mse: 0.7410 test mse: 0.8763\n"
],
[
"mse = lfm.mse_history",
"_____no_output_____"
],
[
"def plot(xy, start_it, title):\n n_iters = xy.shape[0]\n plt.plot(range(start_it,n_iters), xy[start_it:,0],label='train mse')\n plt.plot(range(start_it,n_iters), xy[start_it:,1],label='test mse')\n plt.title(title)\n plt.legend()\n plt.xlabel('iter')\nplt.figure(figsize=(12,4))\nplt.subplot(121)\nplot(rounded_prediction_mse, 20, 'Mse with prediction rounded')\nplt.subplot(122)\nplot(mse, 20, 'Mse with prediction unrounded')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c518e7c195cf94b54d471a411709c700a3419a45
| 33,722 |
ipynb
|
Jupyter Notebook
|
p2_continuous-control/Continuous_Control.ipynb
|
VVKot/deep-reinforcement-learning
|
0d1040a9942f238cd5b5a05908eb4155dd60bfc4
|
[
"MIT"
] | null | null | null |
p2_continuous-control/Continuous_Control.ipynb
|
VVKot/deep-reinforcement-learning
|
0d1040a9942f238cd5b5a05908eb4155dd60bfc4
|
[
"MIT"
] | null | null | null |
p2_continuous-control/Continuous_Control.ipynb
|
VVKot/deep-reinforcement-learning
|
0d1040a9942f238cd5b5a05908eb4155dd60bfc4
|
[
"MIT"
] | null | null | null | 80.868106 | 16,432 | 0.786045 |
[
[
[
"# Continuous Control\n\n---\n\nYou are welcome to use this coding environment to train your agent for the project. Follow the instructions below to get started!\n\n### 1. Start the Environment\n\nRun the next code cell to install a few packages. This line will take a few minutes to run!",
"_____no_output_____"
]
],
[
[
"!pip -q install ./python",
"\u001b[31mtensorflow 1.7.1 has requirement numpy>=1.13.3, but you'll have numpy 1.12.1 which is incompatible.\u001b[0m\r\n\u001b[31mipython 6.5.0 has requirement prompt-toolkit<2.0.0,>=1.0.15, but you'll have prompt-toolkit 2.0.10 which is incompatible.\u001b[0m\r\n"
]
],
[
[
"The environments corresponding to both versions of the environment are already saved in the Workspace and can be accessed at the file paths provided below. \n\nPlease select one of the two options below for loading the environment.",
"_____no_output_____"
]
],
[
[
"from unityagents import UnityEnvironment\nimport numpy as np\n\n# select this option to load version 1 (with a single agent) of the environment\n#env = UnityEnvironment(file_name='/data/Reacher_One_Linux_NoVis/Reacher_One_Linux_NoVis.x86_64')\n\n# select this option to load version 2 (with 20 agents) of the environment\nenv = UnityEnvironment(file_name='/data/Reacher_Linux_NoVis/Reacher.x86_64')",
"INFO:unityagents:\n'Academy' started successfully!\nUnity Academy name: Academy\n Number of Brains: 1\n Number of External Brains : 1\n Lesson number : 0\n Reset Parameters :\n\t\tgoal_speed -> 1.0\n\t\tgoal_size -> 5.0\nUnity brain name: ReacherBrain\n Number of Visual Observations (per agent): 0\n Vector Observation space type: continuous\n Vector Observation space size (per agent): 33\n Number of stacked Vector Observation: 1\n Vector Action space type: continuous\n Vector Action space size (per agent): 4\n Vector Action descriptions: , , , \n"
]
],
[
[
"Environments contain **_brains_** which are responsible for deciding the actions of their associated agents. Here we check for the first brain available, and set it as the default brain we will be controlling from Python.",
"_____no_output_____"
]
],
[
[
"# get the default brain\nbrain_name = env.brain_names[0]\nbrain = env.brains[brain_name]",
"_____no_output_____"
]
],
[
[
"### 2. Examine the State and Action Spaces\n\nRun the code cell below to print some information about the environment.",
"_____no_output_____"
]
],
[
[
"# reset the environment\nenv_info = env.reset(train_mode=True)[brain_name]\n\n# number of agents\nnum_agents = len(env_info.agents)\nprint('Number of agents:', num_agents)\n\n# size of each action\naction_size = brain.vector_action_space_size\nprint('Size of each action:', action_size)\n\n# examine the state space \nstates = env_info.vector_observations\nstate_size = states.shape[1]\nprint('There are {} agents. Each observes a state with length: {}'.format(states.shape[0], state_size))\nprint('The state for the first agent looks like:', states[0])",
"Number of agents: 20\nSize of each action: 4\nThere are 20 agents. Each observes a state with length: 33\nThe state for the first agent looks like: [ 0.00000000e+00 -4.00000000e+00 0.00000000e+00 1.00000000e+00\n -0.00000000e+00 -0.00000000e+00 -4.37113883e-08 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 -1.00000000e+01 0.00000000e+00\n 1.00000000e+00 -0.00000000e+00 -0.00000000e+00 -4.37113883e-08\n 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00\n 0.00000000e+00 0.00000000e+00 5.75471878e+00 -1.00000000e+00\n 5.55726624e+00 0.00000000e+00 1.00000000e+00 0.00000000e+00\n -1.68164849e-01]\n"
]
],
[
[
"### 3. It's Your Turn!\n\nNow it's your turn to train your own agent to solve the environment! A few **important notes**:\n- When training the environment, set `train_mode=True`, so that the line for resetting the environment looks like the following:\n```python\nenv_info = env.reset(train_mode=True)[brain_name]\n```\n- To structure your work, you're welcome to work directly in this Jupyter notebook, or you might like to start over with a new file! You can see the list of files in the workspace by clicking on **_Jupyter_** in the top left corner of the notebook.\n- In this coding environment, you will not be able to watch the agents while they are training. However, **_after training the agents_**, you can download the saved model weights to watch the agents on your own machine! ",
"_____no_output_____"
]
],
[
[
"env_info = env.reset(train_mode=True)[brain_name]",
"_____no_output_____"
]
],
[
[
"We need additional files to successfully create an agent, namely for the model, the agent itself, and workspace utilities to prevent Udacity's workspace from going into sleep while doing long-running learning.",
"_____no_output_____"
]
],
[
[
"!curl https://raw.githubusercontent.com/VVKot/deep-reinforcement-learning/master/p2_continuous-control/ddpg_agent.py --output ddpg_agent.py\n!curl https://raw.githubusercontent.com/VVKot/deep-reinforcement-learning/master/p2_continuous-control/model.py --output model.py\n!curl https://raw.githubusercontent.com/VVKot/deep-reinforcement-learning/master/p2_continuous-control/workspace_utils.py --output workspace_utils.py",
" % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 7922 100 7922 0 0 47431 0 --:--:-- --:--:-- --:--:-- 56585\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 2972 100 2972 0 0 22606 0 --:--:-- --:--:-- --:--:-- 23038\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 1549 100 1549 0 0 11252 0 --:--:-- --:--:-- --:--:-- 11474\n"
]
],
[
[
"After that, we can create an actual agent.\n\nThe agent is represented by two neural networks - Actor and Critic. Both of them are of equal size, with 512 neurons in each layer, and 4 layers. Network with 3 layers in my experience wasn't sufficient to achieve the task. Inner layers of both networks have leaky RELU activation function - in my experiments, it helped to converge faster compared to RELU/ELU. Since Actor has to produce values for actions, and we operate in continuos space where each action has to be a value from -1 to 1, is has a tanh activation function at the last layer. On the other hand, Critic produces Q values, that's why it does not have an activation function for the last layer at all. Both networks are trained using Adam optimizer. The choice of action is not greedy. Since we cannot use epsilon-greedy policy in continuous space, every action is changed slightly using Ornstein-Uhlenbeck noise.\n\nFor learning, the agent uses a ReplayBuffer, which samples from experiences of all 20 agents. Learning is stabilized by using fixed Q-targets and soft updates.\n\nChanged in hyperparameters which proved to be useful - decreasing the critic's learning rate(from 10^-3 to 10^-4) while increasing the soft update coefficient(from 10^-3 to 10^-2). In this way agent converged faster and in a more stable manner. Also, decreasing the theta parameter of the noise(from 0.15 to 0.7), i.e. increasing the noise, proved to be helpful for faster convergence.",
"_____no_output_____"
]
],
[
[
"from ddpg_agent import Agent\nagent = Agent(state_size, action_size, 0)",
"_____no_output_____"
]
],
[
[
"Let's train and agent",
"_____no_output_____"
]
],
[
[
"from collections import deque\nimport torch\nfrom workspace_utils import active_session\n\ndef ddpg(n_episodes=500,print_every=1):\n env_info = env.reset(train_mode=True)[brain_name]\n agent.reset()\n scores_deque = deque(maxlen=100)\n scores = []\n for i_episode in range(1, n_episodes+1):\n state = env_info.vector_observations\n score = np.zeros((num_agents,))\n num_step = 0\n while True:\n action = agent.act(state) # get next action\n env_info = env.step(action)[brain_name] # perform an action\n next_state = env_info.vector_observations # get next state\n reward = env_info.rewards # get received reward\n done = env_info.local_done # get information about episode termination\n \n agent.step(state, action, reward, next_state, done) # memorise an experience and, possibly, learn\n state = next_state # update the state\n score += np.array(reward) # record current score\n num_step += 1 # track number of steps\n if any(done):\n break \n scores_deque.append(np.mean(score))\n scores.append(np.mean(score))\n print('\\rEpisode {}\\tAverage Score: {:.2f}'.format(i_episode, np.mean(scores_deque)), end=\"\")\n torch.save(agent.actor_local.state_dict(), 'checkpoint_actor.pth')\n torch.save(agent.critic_local.state_dict(), 'checkpoint_critic.pth')\n if i_episode % print_every == 0:\n print('\\rEpisode {}\\tAverage Score: {:.2f}\\tmax_step:{}'.format(i_episode, np.mean(scores_deque), num_step))\n if np.mean(scores_deque) >= 30.0:\n print(\"Score is higher than 30.\")\n break\n return scores\n\nwith active_session(): # used to avoid workspace restart due to long-running learning process\n scores = ddpg()",
"Episode 1\tAverage Score: 0.71\tmax_step:1001\nEpisode 2\tAverage Score: 0.90\tmax_step:1001\nEpisode 3\tAverage Score: 1.43\tmax_step:1001\nEpisode 4\tAverage Score: 2.21\tmax_step:1001\nEpisode 5\tAverage Score: 2.87\tmax_step:1001\nEpisode 6\tAverage Score: 3.57\tmax_step:1001\nEpisode 7\tAverage Score: 4.38\tmax_step:1001\nEpisode 8\tAverage Score: 5.39\tmax_step:1001\nEpisode 9\tAverage Score: 6.44\tmax_step:1001\nEpisode 10\tAverage Score: 7.80\tmax_step:1001\nEpisode 11\tAverage Score: 9.36\tmax_step:1001\nEpisode 12\tAverage Score: 10.98\tmax_step:1001\nEpisode 13\tAverage Score: 12.61\tmax_step:1001\nEpisode 14\tAverage Score: 14.26\tmax_step:1001\nEpisode 15\tAverage Score: 15.68\tmax_step:1001\nEpisode 16\tAverage Score: 16.79\tmax_step:1001\nEpisode 17\tAverage Score: 17.88\tmax_step:1001\nEpisode 18\tAverage Score: 18.83\tmax_step:1001\nEpisode 19\tAverage Score: 19.76\tmax_step:1001\nEpisode 20\tAverage Score: 20.60\tmax_step:1001\nEpisode 21\tAverage Score: 21.40\tmax_step:1001\nEpisode 22\tAverage Score: 22.06\tmax_step:1001\nEpisode 23\tAverage Score: 22.66\tmax_step:1001\nEpisode 24\tAverage Score: 23.25\tmax_step:1001\nEpisode 25\tAverage Score: 23.80\tmax_step:1001\nEpisode 26\tAverage Score: 24.33\tmax_step:1001\nEpisode 27\tAverage Score: 24.78\tmax_step:1001\nEpisode 28\tAverage Score: 25.18\tmax_step:1001\nEpisode 29\tAverage Score: 25.53\tmax_step:1001\nEpisode 30\tAverage Score: 25.81\tmax_step:1001\nEpisode 31\tAverage Score: 26.06\tmax_step:1001\nEpisode 32\tAverage Score: 26.37\tmax_step:1001\nEpisode 33\tAverage Score: 26.64\tmax_step:1001\nEpisode 34\tAverage Score: 26.85\tmax_step:1001\nEpisode 35\tAverage Score: 27.04\tmax_step:1001\nEpisode 36\tAverage Score: 27.29\tmax_step:1001\nEpisode 37\tAverage Score: 27.51\tmax_step:1001\nEpisode 38\tAverage Score: 27.73\tmax_step:1001\nEpisode 39\tAverage Score: 27.96\tmax_step:1001\nEpisode 40\tAverage Score: 28.16\tmax_step:1001\nEpisode 41\tAverage Score: 28.33\tmax_step:1001\nEpisode 42\tAverage Score: 28.50\tmax_step:1001\nEpisode 43\tAverage Score: 28.72\tmax_step:1001\nEpisode 44\tAverage Score: 28.90\tmax_step:1001\nEpisode 45\tAverage Score: 29.07\tmax_step:1001\nEpisode 46\tAverage Score: 29.25\tmax_step:1001\nEpisode 47\tAverage Score: 29.39\tmax_step:1001\nEpisode 48\tAverage Score: 29.47\tmax_step:1001\nEpisode 49\tAverage Score: 29.58\tmax_step:1001\nEpisode 50\tAverage Score: 29.73\tmax_step:1001\nEpisode 51\tAverage Score: 29.87\tmax_step:1001\nEpisode 52\tAverage Score: 30.01\tmax_step:1001\nScore is higher than 30.\n"
]
],
[
[
"and visualize its performance:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\nplt.plot(scores, 'o-')\nplt.grid()\nplt.title('Reward Records')\nplt.xlabel('Episode')\nplt.ylabel('Reward')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Definitely, the most interesting challenge would be to train the network from the raw pixels. With regards to the current network - it seems that there is still some potential in hyperparameter tuning which can lead to even faster convergence. One of the things which still is also not great is reproducibility, for example, the initial seed significantly influences the learning process. With seed 42, agent is not able to converge being stuck around score 24. Additional techniques such as gradient clipping might be used to further improve the stability of the agent.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c518eff1351161f88d805cb36d3661940940bfda
| 428,264 |
ipynb
|
Jupyter Notebook
|
examples/ME321-Thermodynamics_II/03 - Chapter 10 Vapor Power Cycles/Ex10.2 Non-Ideal Rankine Cycle.ipynb
|
johnfmaddox/kilojoule
|
b4c146ded82e3ef51a0252ff48b1066a076e9aeb
|
[
"MIT"
] | null | null | null |
examples/ME321-Thermodynamics_II/03 - Chapter 10 Vapor Power Cycles/Ex10.2 Non-Ideal Rankine Cycle.ipynb
|
johnfmaddox/kilojoule
|
b4c146ded82e3ef51a0252ff48b1066a076e9aeb
|
[
"MIT"
] | null | null | null |
examples/ME321-Thermodynamics_II/03 - Chapter 10 Vapor Power Cycles/Ex10.2 Non-Ideal Rankine Cycle.ipynb
|
johnfmaddox/kilojoule
|
b4c146ded82e3ef51a0252ff48b1066a076e9aeb
|
[
"MIT"
] | null | null | null | 586.663014 | 179,980 | 0.851589 |
[
[
[
"# Example 10.2: Non-Ideal Rankine Cycle\n\n*John F. Maddox, Ph.D., P.E.<br>\nUniversity of Kentucky - Paducah Campus<br>\nME 321: Engineering Thermodynamics II<br>*",
"_____no_output_____"
],
[
"## Problem Statement\nA Rankine cycle operates with water as the working fluid with a turbine inlet pressure of 3 MPa, a condenser pressure of 15 kPa, and no superheat in the boiler. For For isentropic efficiencies of $\\eta_t=0.8$ and $\\eta_p=0.6$ and $\\dot{W}_\\text{Net}=1\\ \\mathrm{MW}$ Find:\n* (a) Mass flow rate of steam (kg/s)\n* (b) Boiler heat transfer (MW)\n* (c) Thermal efficiency of the cycle\n* (d) Sketch a $T$-$s$ diagram of the cycle\n\n",
"_____no_output_____"
],
[
"## Solution\n\n__[Video Explanation](https://uky.yuja.com/V/Video?v=3074261&node=10465193&a=1519284077&autoplay=1)__",
"_____no_output_____"
],
[
"### Python Initialization\nWe'll start by importing the libraries we will use for our analysis and initializing dictionaries to hold the properties we will be usings.",
"_____no_output_____"
]
],
[
[
"from kilojoule.templates.kSI_C import *\nwater = realfluid.Properties('Water')",
"_____no_output_____"
]
],
[
[
"### Given Parameters\nWe now define variables to hold our known values.",
"_____no_output_____"
]
],
[
[
"p[3] = Quantity(3.0,'MPa') # Turbine inlet pressure\np[1] = p[4] = Quantity(15.0,'kPa') # Condenser pressure\nWdot_net = Quantity(1,'MW') # Net power \neta_t = 0.8 # Turbine isentropic efficiency\neta_p = 0.6 # Pump isentropic efficiency\n \nSummary();",
"_____no_output_____"
]
],
[
[
"### Assumptions\n- Non-ideal work devices\n- No superheat: saturated vapor at boiler exit\n- Single phase into pump: saturated liquid at condenser exit\n- Isobaric heat exchagners\n- Negligible changes in kinetic energy\n- Negligible changes in potential energy",
"_____no_output_____"
]
],
[
[
"x[3] = 1 # No superheat\nx[1] = 0 # Single phase into pump\np[2] = p[3] # isobaric heat exchanger\n\nSummary();",
"_____no_output_____"
]
],
[
[
"#### (a) Mass flow rate",
"_____no_output_____"
]
],
[
[
"%%showcalc\n#### State 1)\nT[1] = water.T(p[1],x[1])\nv[1] = water.v(p[1],x[1])\nh[1] = water.h(p[1],x[1])\ns[1] = water.s(p[1],x[1])\n\n#### 1-2) Non-ideal compression\n# Isentropic compression\np['2s'] = p[2]\ns['2s'] = s[1]\nT['2s'] = water.T(p['2s'],s['2s'])\nh['2s'] = water.h(p['2s'],s['2s'])\nv['2s'] = water.v(p['2s'],s['2s'])\n# Actual compression\nh[2] = h[1] + (h['2s']-h[1])/eta_p\nT[2] = water.T(p[2],h=h[2])\nv[2] = water.v(p[2],h=h[2])\ns[2] = water.s(p[2],h=h[2])\nw_1_to_2 = h[1]-h[2]\n\n#### 2-3) Isobaric heat addition\nT[3] = water.T(p[3],x[3])\nv[3] = water.v(p[3],x[3])\nh[3] = water.h(p[3],x[3])\ns[3] = water.s(p[3],x[3])\n\n#### 3-4) Non-ideal expansion\n# Isentropic Expansion\np['4s'] = p[4]\ns['4s'] = s[3]\nT['4s']= water.T(p['4s'],s['4s'])\nv['4s']= water.v(p['4s'],s['4s'])\nh['4s'] = water.h(p['4s'],s['4s'])\nx['4s'] = water.x(p['4s'],s['4s'])\n# Actual expansion\nh[4] = h[3] - eta_t*(h[3]-h['4s'])\nT[4] = water.T(p[4],h=h[4])\nv[4] = water.v(p[4],h=h[4])\ns[4] = water.s(p[4],h=h[4])\nx[4] = water.x(p[4],h=h[4])\nw_3_to_4 = h[3]-h[4]\n\n#### Mass flow rate\nw_net = w_1_to_2 + w_3_to_4\nmdot = Wdot_net/w_net\nmdot.ito('kg/s')",
"_____no_output_____"
]
],
[
[
"#### (b) Boiler heat transfer (MW)",
"_____no_output_____"
]
],
[
[
"%%showcalc\n#### Boiler First Law\nq_2_to_3 = h[3]-h[2]\nQdot_in = mdot*q_2_to_3",
"_____no_output_____"
]
],
[
[
"#### (c) Thermal efficiency",
"_____no_output_____"
]
],
[
[
"%%showcalc\neta_th = Wdot_net/Qdot_in\neta_th.ito('')",
"_____no_output_____"
]
],
[
[
"#### (d) Diagrams",
"_____no_output_____"
]
],
[
[
"pv = water.pv_diagram()\n\nfor state in [1,2,3,4]:\n v[state] = water.v(p[state],h=h[state])\n\npv.plot_state(states[1],label_loc='west')\npv.plot_state(states[2],label_loc='north west')\npv.plot_state(states[3],label_loc='north east')\npv.plot_state(states[4],label_loc='south')\n\npv.plot_process(states[1],states[2],path='nonideal',label='pump')\npv.plot_process(states[2],states[3],path='isobaric',label='boiler')\npv.plot_process(states[3],states[4],path='nonideal',label='turbine')\npv.plot_process(states[4],states[1],path='isobaric',label='condenser');",
"_____no_output_____"
],
[
"Ts = water.Ts_diagram()\nTs.plot_isobar(p[3],label=f'{p[3]}',pos=.9)\nTs.plot_isobar(p[4],label=f'{p[4]}',pos=.9)\n\nTs.plot_state(states[1],label_loc='south east')\nTs.plot_state(states[2],label_loc='north west')\nTs.plot_state(states[3],label_loc='east')\nTs.plot_state(states[4],label_loc='east')\n \nTs.plot_process(states[1],states[2],path='isentropic',arrow=False)\nTs.plot_process(states[2],states[3],path='isobaric',label='boiler')\nTs.plot_process(states[3],states[4],path='isentropic',label='turbine')\nTs.plot_process(states[4],states[1],path='isobaric',label='condenser');\nTs.plot_process(states[3],states['4s'],path='isentropic',linestyle='dashed');",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c5190b2ef3722dc53147f290c7102d9dfb7e5f59
| 10,055 |
ipynb
|
Jupyter Notebook
|
3D Plots.ipynb
|
oscartong3/HSBC
|
be21a67c036f59783425b2fc04e15676a770fe7e
|
[
"MIT"
] | null | null | null |
3D Plots.ipynb
|
oscartong3/HSBC
|
be21a67c036f59783425b2fc04e15676a770fe7e
|
[
"MIT"
] | 1 |
2021-05-10T13:47:28.000Z
|
2021-05-10T13:47:28.000Z
|
3D Plots.ipynb
|
oscartong3/HSBC
|
be21a67c036f59783425b2fc04e15676a770fe7e
|
[
"MIT"
] | null | null | null | 30.014925 | 212 | 0.431427 |
[
[
[
"import plotly \nplotly.tools.set_credentials_file(username='saikt3', api_key='djHLW9i22srGSI0wMkVj')",
"_____no_output_____"
],
[
"import plotly.plotly as py\nimport plotly.graph_objs as go\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"impact_score = pd.read_excel('abnormal financial change fangyi.xlsx',sheet_name = 'abnormal changes')",
"_____no_output_____"
],
[
"impact_score.head()",
"_____no_output_____"
],
[
"impact2 = impact_score[impact_score['End Date']==pd.to_datetime('2019-03-31')]",
"_____no_output_____"
],
[
"x = impact2['Borrow Need'].fillna(0)\nz = impact2['Risk Score'].fillna(0)\ny = impact2['FX Need'].fillna(0)\nTotal = np.sqrt(x**2+y**2+(1-z)**2)",
"_____no_output_____"
],
[
"info = []\nfor i in range(len(impact2)):\n info.append('Name: '+impact2.iloc[i,1]+'\\nBorrow Need: '+np.str(impact2.iloc[i,9])\n +'\\nFX Need: '+np.str(impact2.iloc[i,11])+'\\nRisk Score: '+np.str(impact2.iloc[i,10]))",
"_____no_output_____"
],
[
"print(info[0])\n",
"Name: China Baoan Group Co Ltd\nDate: 2018-06-30 00:00:00\nBorrow Need: 0.5009899968921547\nFX Need: nan\nRisk Score: 0.2772762392489528\n"
],
[
"\ntrace1 = go.Scatter3d(\n x=x,\n y=y,\n z=z,\n text = info,\n hoverinfo ='text',\n mode='markers',\n marker=dict(\n size=5,\n color=Total, # set color to an array/list of desired values\n colorscale='Viridis', # choose a colorscale\n opacity=0.7,\n showscale= True,\n reversescale= True\n )\n)\n\ndata = [trace1]\nlayout = go.Layout(\n scene=dict(\n xaxis = dict(\n title='Borrow Need'),\n yaxis = dict(\n title='FX Need'),\n zaxis = dict(\n title='Risk Score'),),\n margin=dict(\n l=0,\n r=0,\n b=0,\n t=0\n )\n)\nfig = go.Figure(data=data, layout=layout)\npy.iplot(fig, filename='3d-scatter-colorscale')",
"High five! You successfully sent some data to your account on plotly. View your plot in your browser at https://plot.ly/~saikt3/0 or inside your plot.ly account where it is named '3d-scatter-colorscale'\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5190b4ebdbf3b998604af48dc26a8812dcd4281
| 603,348 |
ipynb
|
Jupyter Notebook
|
explanations_code/Image-Explanations.ipynb
|
nesl/Explainability-Study
|
b410aadc12a35c5c5047cd514b0a5f702bb09c4b
|
[
"MIT"
] | 14 |
2020-10-26T10:26:57.000Z
|
2022-03-30T17:39:41.000Z
|
explanations_code/Image-Explanations.ipynb
|
nesl/Explainability-Study
|
b410aadc12a35c5c5047cd514b0a5f702bb09c4b
|
[
"MIT"
] | null | null | null |
explanations_code/Image-Explanations.ipynb
|
nesl/Explainability-Study
|
b410aadc12a35c5c5047cd514b0a5f702bb09c4b
|
[
"MIT"
] | 2 |
2021-02-15T08:58:33.000Z
|
2021-03-16T12:06:05.000Z
| 388.755155 | 89,824 | 0.928093 |
[
[
[
"# Setup",
"_____no_output_____"
]
],
[
[
"from warnings import simplefilter \nsimplefilter(action='ignore', category=FutureWarning)\n\nfrom tensorflow.keras import backend as K\nfrom tensorflow.keras.models import Model, load_model, clone_model\nfrom tensorflow.keras.utils import to_categorical\nfrom tensorflow.keras.layers import Activation\nfrom sklearn.model_selection import train_test_split\n\nfrom sklearn.metrics import f1_score, accuracy_score, confusion_matrix\nimport itertools\nfrom random import randint\nfrom skimage.segmentation import slic, mark_boundaries, felzenszwalb, quickshift\nfrom matplotlib.colors import LinearSegmentedColormap\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport numpy as np\nimport os\nimport time\nimport cv2\nimport numpy as np\n\nimport shap\nfrom alibi.explainers import AnchorImage\nimport lime\nfrom lime import lime_image\nfrom lime.wrappers.scikit_image import SegmentationAlgorithm\n\nimport vis\nfrom vis.visualization import visualize_saliency\n\nfrom exmatchina import *\n",
"Using TensorFlow backend.\n"
],
[
"num_classes = 10\n\nclasses = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship','truck']\n\nclass_dict = {\n 'airplane': 0,\n 'automobile':1,\n 'bird':2,\n 'cat':3,\n 'deer':4,\n 'dog':5,\n 'frog':6,\n 'horse':7,\n 'ship':8,\n 'truck':9\n}\n\ninv_class_dict = {v: k for k, v in class_dict.items()}\n\n## These are the randomly generated indices that were used in our survey\n\n# all_idx = np.array([23, 26, 390, 429, 570, 649, 732, 739, 1081, 1163, 1175, 1289, 1310, 1323\n# , 1487, 1623, 1715, 1733, 1825, 1881, 1951, 2102, 2246, 2300, 2546, 2702, 2994, 3095\n# , 3308, 3488, 3727, 3862, 4190, 4299, 4370, 4417, 4448, 4526, 4537, 4559, 4604, 4672\n# , 4857, 5050, 5138, 5281, 5332, 5471, 5495, 5694, 5699, 5754, 5802, 5900, 6039, 6042\n# , 6046, 6127, 6285, 6478, 6649, 6678, 6795, 7023, 7087, 7254, 7295, 7301, 7471, 7524\n# , 7544, 7567, 7670, 7885, 7914, 7998, 8197, 8220, 8236, 8291, 8311, 8355, 8430, 8437\n# , 8510, 8646, 8662, 8755, 8875, 8896, 8990, 9106, 9134, 9169, 9436, 9603, 9739, 9772\n# , 9852, 9998])\n\nall_idx = [23, 26, 390, 429, 570] #Considering just 5 samples",
"_____no_output_____"
],
[
"x_train = np.load('../data/image/X_train.npy')\ny_train = np.load('../data/image/y_train.npy')\nx_test = np.load('../data/image/X_test.npy')\ny_test = np.load('../data/image/y_test.npy')\n\nprint(f'Number of Training samples: {x_train.shape[0]}')\nprint(f'Number of Test samples: {x_test.shape[0]}')\n\nprint(x_train.shape)\nprint(y_train.shape)\nprint(x_test.shape)\nprint(y_test.shape)",
"Number of Training samples: 50000\nNumber of Test samples: 10000\n(50000, 32, 32, 3)\n(50000,)\n(10000, 32, 32, 3)\n(10000,)\n"
],
[
"y_train = to_categorical(y_train,num_classes)\ny_test = to_categorical(y_test,num_classes)",
"_____no_output_____"
],
[
"model = load_model('../trained_models/image.hdf5')\nmodel.summary()",
"WARNING:tensorflow:From C:\\Users\\vikra\\.conda\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\init_ops.py:97: calling GlorotUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nWARNING:tensorflow:From C:\\Users\\vikra\\.conda\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\init_ops.py:97: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nWARNING:tensorflow:From C:\\Users\\vikra\\.conda\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\nInstructions for updating:\nIf using Keras pass *_constraint arguments to layers.\nWARNING:tensorflow:From C:\\Users\\vikra\\.conda\\envs\\tf2\\lib\\site-packages\\tensorflow_core\\python\\ops\\init_ops.py:97: calling Ones.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nModel: \"CNN\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nConv_1 (Conv2D) (None, 32, 32, 32) 896 \n_________________________________________________________________\nBn_1 (BatchNormalization) (None, 32, 32, 32) 128 \n_________________________________________________________________\nConv_2 (Conv2D) (None, 32, 32, 32) 9248 \n_________________________________________________________________\nBn_2 (BatchNormalization) (None, 32, 32, 32) 128 \n_________________________________________________________________\nMax_pool_1 (MaxPooling2D) (None, 16, 16, 32) 0 \n_________________________________________________________________\nDrop_1 (Dropout) (None, 16, 16, 32) 0 \n_________________________________________________________________\nConv_3 (Conv2D) (None, 16, 16, 64) 18496 \n_________________________________________________________________\nBn_3 (BatchNormalization) (None, 16, 16, 64) 256 \n_________________________________________________________________\nConv_4 (Conv2D) (None, 16, 16, 64) 36928 \n_________________________________________________________________\nBn_4 (BatchNormalization) (None, 16, 16, 64) 256 \n_________________________________________________________________\nMax_pool_2 (MaxPooling2D) (None, 8, 8, 64) 0 \n_________________________________________________________________\nDrop_2 (Dropout) (None, 8, 8, 64) 0 \n_________________________________________________________________\nConv_5 (Conv2D) (None, 8, 8, 128) 73856 \n_________________________________________________________________\nBn_5 (BatchNormalization) (None, 8, 8, 128) 512 \n_________________________________________________________________\nConv_6 (Conv2D) (None, 8, 8, 128) 147584 \n_________________________________________________________________\nBn_6 (BatchNormalization) (None, 8, 8, 128) 512 \n_________________________________________________________________\nMax_pool_3 (MaxPooling2D) (None, 4, 4, 128) 0 \n_________________________________________________________________\nDrop_3 (Dropout) (None, 4, 4, 128) 0 \n_________________________________________________________________\nFlatten_1 (Flatten) (None, 2048) 0 \n_________________________________________________________________\ndense (Dense) (None, 32) 65568 \n_________________________________________________________________\nBn_7 (BatchNormalization) (None, 32) 128 \n_________________________________________________________________\nDrop_4 (Dropout) (None, 32) 0 \n_________________________________________________________________\nlogits (Dense) (None, 10) 330 \n_________________________________________________________________\nprobs (Activation) (None, 10) 0 \n=================================================================\nTotal params: 354,826\nTrainable params: 353,866\nNon-trainable params: 960\n_________________________________________________________________\n"
],
[
"def calculate_metrics(model, X_test, y_test_binary):\n y_pred = np.argmax(model.predict(X_test), axis=1)\n y_true = np.argmax(y_test_binary, axis=1)\n mismatch = np.where(y_true != y_pred)\n cf_matrix = confusion_matrix(y_true, y_pred)\n accuracy = accuracy_score(y_true, y_pred)\n #micro_f1 = f1_score(y_true, y_pred, average='micro')\n macro_f1 = f1_score(y_true, y_pred, average='macro')\n return cf_matrix, accuracy, macro_f1, mismatch, y_pred\n\ndef plot_confusion_matrix(cm, classes,\n normalize=False,\n title='Confusion matrix',\n cmap=plt.cm.Blues):\n \"\"\"\n This function prints and plots the confusion matrix.\n Normalization can be applied by setting `normalize=True`.\n \"\"\"\n if normalize:\n cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]\n print(\"Normalized confusion matrix\")\n # print(cm)\n else:\n print('Confusion matrix, without normalization')\n # print(cm)\n\n plt.figure(figsize = (10,7))\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45, fontsize = 15)\n plt.yticks(tick_marks, classes, fontsize = 15)\n\n fmt = '.2f' if normalize else 'd'\n thresh = cm.max() / 2.\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, format(cm[i, j], fmt), fontsize = 15,\n horizontalalignment=\"center\",\n color=\"white\" if cm[i, j] > thresh else \"black\")\n\n plt.tight_layout()\n \n plt.ylabel('True label', fontsize = 12)\n plt.xlabel('Predicted label', fontsize = 12)\n ",
"_____no_output_____"
],
[
"cf_matrix, accuracy, macro_f1, mismatch, y_pred = calculate_metrics(model, x_test, y_test)\nprint('Accuracy : {}'.format(accuracy))\nprint('F1-score : {}'.format(macro_f1))\n\nplot_confusion_matrix(cf_matrix, classes,\n normalize=True,\n title='Confusion matrix',\n cmap=plt.cm.Blues)",
"Accuracy : 0.869\nF1-score : 0.8683100113942105\nNormalized confusion matrix\n"
]
],
[
[
"# LIME",
"_____no_output_____"
]
],
[
[
"explainer = lime_image.LimeImageExplainer()\n\nsegmentation_fn = SegmentationAlgorithm('felzenszwalb', scale=10,\n sigma=0.4, min_size=20)\n\nfor i in all_idx:\n image = x_test[i]\n to_explain = np.expand_dims(image,axis=0)\n class_idx = np.argmax(model.predict(to_explain))\n print(inv_class_dict[class_idx])\n \n # Hide color is the color for a superpixel turned OFF. \n # Alternatively, if it is NONE, the superpixel will be replaced by the average of its pixels\n explanation = explainer.explain_instance(image, model.predict,segmentation_fn = segmentation_fn,\n top_labels=5, hide_color=0, num_samples=1000)\n\n temp, mask = explanation.get_image_and_mask(explanation.top_labels[0],\n positive_only=True, num_features=5, hide_rest=True)\n \n #Plotting\n fig, axes1 = plt.subplots(1,2, figsize=(10,10))\n # fig.suptitle(inv_class_dict[y_test[i]])\n axes1[0].set_axis_off()\n axes1[1].set_axis_off()\n axes1[0].imshow(x_test[i], interpolation='nearest')\n axes1[1].imshow(mark_boundaries(temp, mask), interpolation='nearest')\n # plt.savefig(f'./image/image-{i}-lime',bbox_inches = 'tight', pad_inches = 0.5)\n plt.show()",
"truck\n"
]
],
[
[
"# Anchor Explanations",
"_____no_output_____"
]
],
[
[
"# Define a Prediction Function\npredict_fn = lambda x: model.predict(x)\n\nimage_shape = (32,32,3)\nsegmentation_fn = 'felzenszwalb'\nslic_kwargs = {'n_segments': 100, 'compactness': 1, 'sigma': .5, 'max_iter': 50}\nfelzenszwalb_kwargs = {'scale': 10, 'sigma': 0.4, 'min_size': 50}\n\nexplainer = AnchorImage(predict_fn, image_shape, segmentation_fn=segmentation_fn,\n segmentation_kwargs=felzenszwalb_kwargs, images_background=None)",
"_____no_output_____"
],
[
"for i in all_idx:\n\n image = x_test[i]\n to_explain = np.expand_dims(image,axis=0)\n class_idx = np.argmax(model.predict(to_explain))\n print(inv_class_dict[class_idx])\n \n explanation = explainer.explain(image, threshold=.99, p_sample=0.5, tau=0.15)\n \n ## Plotting\n fig, axes1 = plt.subplots(1,2, figsize=(10,10))\n # fig.suptitle(inv_class_dict[y_test[i]])\n axes1[0].set_axis_off()\n axes1[1].set_axis_off()\n axes1[0].imshow(x_test[i], interpolation='nearest')\n axes1[1].imshow(explanation['anchor'], interpolation='nearest')\n # plt.savefig(f'./image-{i}-anchor', bbox_inches = 'tight', pad_inches = 0.5)\n plt.show()",
"truck\n"
]
],
[
[
"# SHAP",
"_____no_output_____"
]
],
[
[
"background = x_train[np.random.choice(x_train.shape[0], 1000, replace=False)]\n\n# map input to specified layer \ndef map2layer(x, layer):\n feed_dict = dict(zip([model.layers[0].input], x.reshape((1,) + x.shape)))\n return K.get_session().run(model.layers[layer].input, feed_dict)\n\ndef get_shap_full(idx):\n layer = 14\n to_explain = np.expand_dims(x_test[idx],axis=0)\n class_idx = np.argmax(model.predict(to_explain))\n print(inv_class_dict[class_idx])\n\n # get shap values\n e = shap.GradientExplainer((model.layers[layer].input, model.layers[-1].output), map2layer(background, layer))\n shap_values,indexes = e.shap_values(map2layer(to_explain, layer), ranked_outputs=1)\n\n # use SHAP plot\n shap.image_plot(shap_values, to_explain, show=False)\n\n # plt.savefig('./image/image-' + str(idx) + '-shap.png', bbox_inches='tight')\n",
"_____no_output_____"
],
[
"for i in all_idx:\n get_shap_full(i)",
"truck\ncat\nautomobile\nfrog\nfrog\n"
]
],
[
[
"# Saliency Map",
"_____no_output_____"
]
],
[
[
"# Replace activation with linear\nnew_model = clone_model(model)\nnew_model.pop()\nnew_model.add(Activation('linear', name=\"linear_p\"))",
"_____no_output_____"
],
[
"new_model.summary()",
"Model: \"CNN\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nConv_1 (Conv2D) (None, 32, 32, 32) 896 \n_________________________________________________________________\nBn_1 (BatchNormalization) (None, 32, 32, 32) 128 \n_________________________________________________________________\nConv_2 (Conv2D) (None, 32, 32, 32) 9248 \n_________________________________________________________________\nBn_2 (BatchNormalization) (None, 32, 32, 32) 128 \n_________________________________________________________________\nMax_pool_1 (MaxPooling2D) (None, 16, 16, 32) 0 \n_________________________________________________________________\nDrop_1 (Dropout) (None, 16, 16, 32) 0 \n_________________________________________________________________\nConv_3 (Conv2D) (None, 16, 16, 64) 18496 \n_________________________________________________________________\nBn_3 (BatchNormalization) (None, 16, 16, 64) 256 \n_________________________________________________________________\nConv_4 (Conv2D) (None, 16, 16, 64) 36928 \n_________________________________________________________________\nBn_4 (BatchNormalization) (None, 16, 16, 64) 256 \n_________________________________________________________________\nMax_pool_2 (MaxPooling2D) (None, 8, 8, 64) 0 \n_________________________________________________________________\nDrop_2 (Dropout) (None, 8, 8, 64) 0 \n_________________________________________________________________\nConv_5 (Conv2D) (None, 8, 8, 128) 73856 \n_________________________________________________________________\nBn_5 (BatchNormalization) (None, 8, 8, 128) 512 \n_________________________________________________________________\nConv_6 (Conv2D) (None, 8, 8, 128) 147584 \n_________________________________________________________________\nBn_6 (BatchNormalization) (None, 8, 8, 128) 512 \n_________________________________________________________________\nMax_pool_3 (MaxPooling2D) (None, 4, 4, 128) 0 \n_________________________________________________________________\nDrop_3 (Dropout) (None, 4, 4, 128) 0 \n_________________________________________________________________\nFlatten_1 (Flatten) (None, 2048) 0 \n_________________________________________________________________\ndense (Dense) (None, 32) 65568 \n_________________________________________________________________\nBn_7 (BatchNormalization) (None, 32) 128 \n_________________________________________________________________\nDrop_4 (Dropout) (None, 32) 0 \n_________________________________________________________________\nlogits (Dense) (None, 10) 330 \n_________________________________________________________________\nlinear_p (Activation) (None, 10) 0 \n=================================================================\nTotal params: 354,826\nTrainable params: 353,866\nNon-trainable params: 960\n_________________________________________________________________\n"
],
[
"def plot_map(img_index, class_idx, grads):\n print(inv_class_dict[class_idx])\n fig, axes = plt.subplots(ncols=2,figsize=(8,6))\n axes[0].imshow(x_test[img_index])\n axes[0].axis('off')\n axes[1].imshow(x_test[img_index])\n axes[1].axis('off')\n i = axes[1].imshow(grads,cmap=\"jet\",alpha=0.6)\n fig.subplots_adjust(right=0.9)\n cbar_ax = fig.add_axes([1, 0.2, 0.04, 0.59])\n fig.colorbar(i, cax=cbar_ax)\n \n # plt.savefig('./image/image-' + str(img_index) + '-saliencymap.png', bbox_inches='tight', pad_inches=0.3)\n # plt.close(fig)\n\n plt.show()\n",
"_____no_output_____"
],
[
"def getSaliencyMap(img_index):\n \n to_explain = x_test[img_index].reshape(1,32,32,3)\n class_idx = np.argmax(model.predict(to_explain))\n\n grads = visualize_saliency(new_model,\n 14,\n filter_indices = None,\n seed_input = x_test[img_index])\n plot_map(img_index, class_idx , grads)",
"_____no_output_____"
],
[
"for i in all_idx:\n getSaliencyMap(i)",
"WARNING:tensorflow:From C:\\Users\\vikra\\.conda\\envs\\tf2\\lib\\site-packages\\keras\\backend\\tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.\n\ntruck\n"
]
],
[
[
"# Grad-Cam++",
"_____no_output_____"
]
],
[
[
"def get_gradcampp(idx):\n img = x_test[idx]\n cls_true = np.argmax(y_test[idx])\n \n x = np.expand_dims(img, axis=0)\n\n # get cam\n cls_pred, cam = grad_cam_plus_plus(model=model, x=x, layer_name=\"Conv_6\")\n print(inv_class_dict[cls_pred])\n\n # resize to to size of image\n heatmap = cv2.resize(cam, (img.shape[1], img.shape[0]))\n\n fig, axes = plt.subplots(ncols=2,figsize=(8,6))\n axes[0].imshow(img)\n axes[0].axis('off')\n axes[1].imshow(img)\n axes[1].axis('off')\n i = axes[1].imshow(heatmap,cmap=\"jet\",alpha=0.6)\n fig.subplots_adjust(right=0.9)\n cbar_ax = fig.add_axes([1, 0.2, 0.04, 0.60])\n fig.colorbar(i, cax=cbar_ax)\n\n # plt.savefig('./image/image-' + str(idx) + '-gradcampp.png', bbox_inches='tight', pad_inches=0.3)\n # plt.close(fig)\n plt.show()\n\ndef grad_cam_plus_plus(model, x, layer_name): \n cls = np.argmax(model.predict(x))\n y_c = model.output[0, cls]\n conv_output = model.get_layer(layer_name).output\n grads = K.gradients(y_c, conv_output)[0]\n\n first = K.exp(y_c) * grads\n second = K.exp(y_c) * grads * grads\n third = K.exp(y_c) * grads * grads * grads\n\n gradient_function = K.function([model.input], [y_c, first, second, third, conv_output, grads])\n y_c, conv_first_grad, conv_second_grad, conv_third_grad, conv_output, grads_val = gradient_function([x])\n global_sum = np.sum(conv_output[0].reshape((-1,conv_first_grad[0].shape[2])), axis=0)\n\n alpha_num = conv_second_grad[0]\n alpha_denom = conv_second_grad[0] * 2.0 + conv_third_grad[0] * global_sum.reshape((1, 1, conv_first_grad[0].shape[2]))\n alpha_denom = np.where(alpha_denom != 0.0, alpha_denom, np.ones(alpha_denom.shape))\n alphas = alpha_num / alpha_denom\n\n weights = np.maximum(conv_first_grad[0], 0.0)\n alpha_normalization_constant = np.sum(np.sum(alphas, axis=0), axis=0) # 0\n alphas /= alpha_normalization_constant.reshape((1, 1, conv_first_grad[0].shape[2])) # NAN\n deep_linearization_weights = np.sum((weights * alphas).reshape((-1, conv_first_grad[0].shape[2])), axis=0)\n\n cam = np.sum(deep_linearization_weights * conv_output[0], axis=2)\n cam = np.maximum(cam, 0)\n cam /= np.max(cam)\n\n return cls, cam",
"_____no_output_____"
],
[
"for i in all_idx:\n get_gradcampp(i)",
"truck\n"
]
],
[
[
"# ExMatchina",
"_____no_output_____"
]
],
[
[
"def plot_images(test, examples, label):\n # =======GENERATE STUDY EXAMPLES=========\n fig = plt.figure(figsize=(10,3))\n num_display = 4\n fig.add_subplot(1, num_display, 1).title.set_text(inv_class_dict[label])\n plt.imshow(test, interpolation='nearest')\n plt.axis('off')\n line = fig.add_subplot(1, 1, 1)\n line.plot([2.39,2.39],[0,1],'--')\n line.set_xlim(0,10)\n line.axis('off')\n for k in range(num_display-1):\n if k >= len(examples):\n continue\n fig.add_subplot(1,num_display,k+2).title.set_text(inv_class_dict[label])\n fig.add_subplot(1,num_display,k+2).title.set_color('#0067FF')\n plt.imshow(examples[k], interpolation='nearest')\n plt.axis('off')\n \n fig.tight_layout()\n plt.tight_layout()\n plt.show()\n # plt.savefig('./image-' + str(i) + '-example.png', bbox_inches='tight')",
"_____no_output_____"
],
[
"selected_layer = 'Flatten_1'\n\nexm = ExMatchina(model=model, layer=selected_layer, examples=x_train)",
"Getting activations...\nGetting labels...\nGenerating activation matrix...\n"
],
[
"for test_idx in all_idx:\n test_input = x_test[test_idx]\n label = exm.get_label_for(test_input)\n (examples, indices) = exm.return_nearest_examples(test_input)\n plot_images(test_input, examples, label)",
"Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
c5190c490f900c257d2c24fab8f083b7921be215
| 61,894 |
ipynb
|
Jupyter Notebook
|
disease/Yuxuan Li 7.ipynb
|
lamblamblamb/Peace-agreement
|
01298148ac6877e09f78531081906873e51c8826
|
[
"MIT"
] | 1 |
2020-11-28T07:08:02.000Z
|
2020-11-28T07:08:02.000Z
|
disease/Yuxuan Li 7.ipynb
|
lamblamblamb/Peace-agreement
|
01298148ac6877e09f78531081906873e51c8826
|
[
"MIT"
] | 13 |
2020-11-28T08:29:34.000Z
|
2020-12-07T07:06:26.000Z
|
disease/Yuxuan Li 7.ipynb
|
lamblamblamb/Peace-agreement
|
01298148ac6877e09f78531081906873e51c8826
|
[
"MIT"
] | null | null | null | 345.776536 | 11,656 | 0.945633 |
[
[
[
"import pandas as pd \nimport numpy as np \nimport matplotlib.pyplot as plt ",
"_____no_output_____"
],
[
"df = pd.read_csv('./peace agreement.csv')\ndf = df.iloc[:,:266]",
"_____no_output_____"
],
[
"cross_table = pd.pivot_table(data , index = ['event_type'], columns = ['location'],\n values = ['data_id'], aggfunc = len, fill_value = 0)\n\ncross_table = cross_table.T",
"_____no_output_____"
],
[
"for i, col in enumerate(cross_table):\n col = cols[1]\n values = cross_table[col].sort_values(ascending=False).head(10)\n labels = [c[1] for c in values.index]\n values.index = labels\n values.plot(kind = 'barh')\n plt.title(col)\n plt.xlabel('Freq')\n plt.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
c519170caba088b5380b34bb2f4bd79dbd21f093
| 12,735 |
ipynb
|
Jupyter Notebook
|
tutorial14.ipynb
|
dschwen/learn_python
|
9c49fc732dd99a632984a537c1b00d5ba1ffabaa
|
[
"CC-BY-3.0"
] | 1 |
2022-02-02T03:21:37.000Z
|
2022-02-02T03:21:37.000Z
|
tutorial14.ipynb
|
jrincayc/learn_python
|
9c49fc732dd99a632984a537c1b00d5ba1ffabaa
|
[
"CC-BY-3.0"
] | null | null | null |
tutorial14.ipynb
|
jrincayc/learn_python
|
9c49fc732dd99a632984a537c1b00d5ba1ffabaa
|
[
"CC-BY-3.0"
] | 1 |
2021-08-29T16:05:02.000Z
|
2021-08-29T16:05:02.000Z
| 32.906977 | 969 | 0.507028 |
[
[
[
"Here is a simple example of file IO:\n",
"_____no_output_____"
]
],
[
[
"#Write a file\nout_file = open(\"test.txt\", \"w\")\nout_file.write(\"This Text is going to out file\\nLook at it and see\\n\")\nout_file.close()\n\n#Read a file\nin_file = open(\"test.txt\", \"r\")\ntext = in_file.read()\nin_file.close()\n\nprint(text)",
"_____no_output_____"
]
],
[
[
"The output and the contents of the file test.txt are:\n",
"_____no_output_____"
]
],
[
[
"This Text is going to out file\nLook at it and see",
"_____no_output_____"
]
],
[
[
"Notice that it wrote a file called test.txt in the directory that you ran the program from. The `\\n` in the string tells Python to put a **n**ewline where it is.\n\n\nA overview of file IO is:\n\n1. Get a file object with the `open` function.\n2. Read or write to the file object (depending on if you open it with a \"r\" or \"w\")\n3. Close it\n\n\n\nThe first step is to get a file object. The way to do this is to use the `open` function. The format is `file_object = open(filename, mode)` where `file_object` is the variable to put the file object, `filename` is a string with the filename, and `mode` is either `\"r\"` to **r**ead a file or `\"w\"` to **w**rite a file. Next the file object's functions can be called. The two most common functions are `read` and `write`. The `write` function adds a string to the end of the file. The `read` function reads the next thing in the file and returns it as a string. If no argument is given it will return the whole file (as done in the example).\n\n\nNow here is a new version of the phone numbers program that we made earlier:\n",
"_____no_output_____"
]
],
[
[
"def print_numbers(numbers):\n print(\"Telephone Numbers:\")\n for x in numbers:\n print(\"Name: \", x, \" \\tNumber: \", numbers[x])\n print()\n\ndef add_number(numbers, name, number):\n numbers[name] = number\n\ndef lookup_number(numbers, name):\n if name in numbers:\n return \"The number is \"+numbers[name]\n else:\n return name+\" was not found\"\n\ndef remove_number(numbers, name):\n if name in numbers:\n del numbers[name]\n else:\n print(name, \" was not found\")\n\n\ndef load_numbers(numbers, filename):\n in_file = open(filename, \"r\")\n while True:\n in_line = in_file.readline()\n if in_line == \"\":\n break\n in_line = in_line[:-1]\n [name, number] = in_line.split(\",\")\n numbers[name] = number\n in_file.close()\n\ndef save_numbers(numbers, filename):\n out_file = open(filename, \"w\")\n for x in numbers:\n out_file.write(x+\",\"+numbers[x]+\"\\n\")\n out_file.close()\n\n\ndef print_menu():\n print('1. Print Phone Numbers')\n print('2. Add a Phone Number')\n print('3. Remove a Phone Number')\n print('4. Lookup a Phone Number')\n print('5. Load numbers')\n print('6. Save numbers')\n print('7. Quit')\n print()\n\nphone_list = {}\nmenu_choice = 0\nprint_menu()\nwhile menu_choice != 7:\n menu_choice = int(input(\"Type in a number (1-7):\"))\n if menu_choice == 1:\n print_numbers(phone_list)\n elif menu_choice == 2:\n print(\"Add Name and Number\")\n name = input(\"Name:\")\n phone = input(\"Number:\")\n add_number(phone_list, name, phone)\n elif menu_choice == 3:\n print(\"Remove Name and Number\")\n name = input(\"Name:\")\n remove_number(phone_list, name)\n elif menu_choice == 4:\n print(\"Lookup Number\")\n name = input(\"Name:\")\n print(lookup_number(phone_list, name))\n elif menu_choice == 5:\n filename = input(\"Filename to load:\")\n load_numbers(phone_list, filename)\n elif menu_choice == 6:\n filename = input(\"Filename to save:\")\n save_numbers(phone_list, filename)\n elif menu_choice == 7:\n pass\n else:\n print_menu()\nprint(\"Goodbye\")",
"_____no_output_____"
]
],
[
[
"Notice that it now includes saving and loading files. Here is some output of my running it twice:\n",
"_____no_output_____"
]
],
[
[
"1. Print Phone Numbers\n2. Add a Phone Number\n3. Remove a Phone Number\n4. Lookup a Phone Number\n5. Load numbers\n6. Save numbers\n7. Quit\n\nType in a number (1-7):2\nAdd Name and Number\nName:Jill\nNumber:1234\nType in a number (1-7):2\nAdd Name and Number\nName:Fred\nNumber:4321\nType in a number (1-7):1\nTelephone Numbers:\nName: Jill Number: 1234\nName: Fred Number: 4321\n\nType in a number (1-7):6\nFilename to save:numbers.txt\nType in a number (1-7):7\nGoodbye",
"_____no_output_____"
]
],
[
[
"\n",
"_____no_output_____"
]
],
[
[
"1. Print Phone Numbers\n2. Add a Phone Number\n3. Remove a Phone Number\n4. Lookup a Phone Number\n5. Load numbers\n6. Save numbers\n7. Quit\n\nType in a number (1-7):5\nFilename to load:numbers.txt\nType in a number (1-7):1\nTelephone Numbers:\nName: Jill Number: 1234\nName: Fred Number: 4321\n\nType in a number (1-7):7\nGoodbye",
"_____no_output_____"
]
],
[
[
"\n\nThe new portions of this program are:\n",
"_____no_output_____"
]
],
[
[
"def load_numbers(numbers, filename):\n in_file = open(filename, \"r\")\n while True:\n in_line = in_file.readline()\n if len(in_line) == 0:\n break\n in_line = in_line[:-1]\n [name, number] = in_line.split(\",\")\n numbers[name] = number\n in_file.close()",
"_____no_output_____"
]
],
[
[
"\n",
"_____no_output_____"
]
],
[
[
"def save_numbers(numbers, filename):\n out_file = open(filename, \"w\")\n for x in numbers:\n out_file.write(x+\",\"+numbers[x]+\"\\n\")\n out_file.close()",
"_____no_output_____"
]
],
[
[
"\n\nFirst we will look at the save portion of the program. First, it creates a file object with the command open(filename, \"w\"). Next, it goes through and creates a line for each of the phone numbers with the command `out_file.write(x+\",\"+numbers[x]+\"\\n\")`. This writes out a line that contains the name, a comma, the number and follows it by a newline.\n\n\nThe loading portion is a little more complicated. It starts by getting a file object. Then, it uses a while True: loop to keep looping until a `break` statement is encountered. Next, it gets a line with the line in\\_line = in\\_file.readline(). The `readline` function will return a empty string (len(string) == 0) when the end of the file is reached. The `if` statement checks for this and `break`s out of the `while` loop when that happens. Of course if the `readline` function did not return the newline at the end of the line there would be no way to tell if an empty string was an empty line or the end of the file so the newline is left in what `readline` returns. Hence we have to get rid of the newline. The line `in_line = in_line[:-1]` does this for us by dropping the last character. Next the line `[name, number] = string.split(in_line, \",\")` splits the line at the comma into a name and a number. This is then added to the `numbers` dictionary.\n\n\nExercises\n=========\n\n\n\nNow modify the grades program from notebook 10 (copied below) so that it uses file\nIO to keep a record of the students.\n",
"_____no_output_____"
]
],
[
[
"max_points = [25, 25, 50, 25, 100]\nassignments = ['hw ch 1', 'hw ch 2', 'quiz ', 'hw ch 3', 'test']\nstudents = {'#Max':max_points}\n\ndef print_menu():\n print(\"1. Add student\")\n print(\"2. Remove student\")\n print(\"3. Print grades\")\n print(\"4. Record grade\")\n print(\"5. Print Menu\")\n print(\"6. Exit\")\n\ndef print_all_grades():\n print('\\t', end=' ')\n for i in range(len(assignments)):\n print(assignments[i], '\\t', end=' ')\n print()\n keys = list(students.keys())\n keys.sort()\n for x in keys:\n print(x, '\\t', end=' ')\n grades = students[x]\n print_grades(grades)\n\ndef print_grades(grades):\n for i in range(len(grades)):\n print(grades[i], '\\t\\t', end=' ')\n print()\n\nprint_menu()\nmenu_choice = 0\nwhile menu_choice != 6:\n print()\n menu_choice = int(input(\"Menu Choice (1-6):\"))\n if menu_choice == 1:\n name = input(\"Student to add:\")\n students[name] = [0]*len(max_points)\n elif menu_choice == 2:\n name = input(\"Student to remove:\")\n if name in students:\n del students[name]\n else:\n print(\"Student: \", name, \" not found\")\n elif menu_choice == 3:\n print_all_grades()\n\n elif menu_choice == 4:\n print(\"Record Grade\")\n name = input(\"Student:\")\n if name in students:\n grades = students[name]\n print(\"Type in the number of the grade to record\")\n print(\"Type a 0 (zero) to exit\")\n for i in range(len(assignments)):\n print(i+1, ' ', assignments[i], '\\t', end=' ')\n print()\n print_grades(grades)\n which = 1234\n while which != -1:\n which = int(input(\"Change which Grade:\"))\n which = which-1\n if 0 <= which < len(grades):\n grade = int(input(\"Grade:\"))\n grades[which] = grade\n elif which != -1:\n print(\"Invalid Grade Number\")\n else:\n print(\"Student not found\")\n elif menu_choice != 6:\n print_menu()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"raw",
"markdown",
"raw",
"markdown",
"raw",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
]
] |
c519180acb98c2375a479baf5be01b1e415c8563
| 76,357 |
ipynb
|
Jupyter Notebook
|
stock_predictions.ipynb
|
henryboisdequin/Stock-Price-Prediction-
|
74cf4cf065379274099704760aa288ff10b50a86
|
[
"MIT"
] | null | null | null |
stock_predictions.ipynb
|
henryboisdequin/Stock-Price-Prediction-
|
74cf4cf065379274099704760aa288ff10b50a86
|
[
"MIT"
] | null | null | null |
stock_predictions.ipynb
|
henryboisdequin/Stock-Price-Prediction-
|
74cf4cf065379274099704760aa288ff10b50a86
|
[
"MIT"
] | null | null | null | 154.256566 | 30,026 | 0.813665 |
[
[
[
"import tensorflow as tf\nfrom tensorflow.keras.layers import Input, LSTM, GRU, SimpleRNN, Dense, MaxPooling1D\nfrom tensorflow.keras.models import Model\nfrom tensorflow.keras.optimizers import Adam, SGD\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.preprocessing import StandardScaler",
"_____no_output_____"
],
[
"df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/tesla-stock-price.csv')\nprint(\"Head: \", df.head())\nprint(\"Tail: \", df.tail())",
"Head: date close volume open high low\n0 11:34 270.49 4,787,699 264.50 273.88 262.2400\n1 2018/10/15 259.59 6189026.0000 259.06 263.28 254.5367\n2 2018/10/12 258.78 7189257.0000 261.00 261.99 252.0100\n3 2018/10/11 252.23 8128184.0000 257.53 262.25 249.0300\n4 2018/10/10 256.88 12781560.0000 264.61 265.51 247.7700\nTail: date close volume open high low\n752 2015/10/21 210.09 4177956.0000 211.99 214.8100 208.80\n753 2015/10/20 213.03 14877020.0000 227.72 228.6000 202.00\n754 2015/10/19 228.10 2506836.0000 226.50 231.1500 224.94\n755 2015/10/16 227.01 4327574.0000 223.04 230.4805 222.87\n756 2015/10/15 221.31 2835920.0000 216.43 221.7300 213.70\n"
],
[
"# understand data better\n\nprint(\"High in Blue, Low in Orange\")\ndf['high'].hist()\ndf['low'].hist()",
"High in Blue, Low in Orange\n"
],
[
"series = df['close'].values.reshape(-1, 1)",
"_____no_output_____"
],
[
"scaler = StandardScaler()\nscaler.fit(series[:len(series) // 2])\nseries = scaler.transform(series).flatten()",
"_____no_output_____"
],
[
"# covert to supervised learning dataset\nT = 10\nD = 1\nX = []\nY = []\nfor t in range(len(series) - T):\n x = series[t:t+T]\n X.append(x)\n y = series[t+T]\n Y.append(y)\n\nX = np.array(X).reshape(-1, T, 1) # convert to 3D\nY = np.array(Y)\nN = len(X)\nprint(\"X.shape: \", X.shape, \"Y.shape: \", Y.shape)",
"X.shape: (747, 10, 1) Y.shape: (747,)\n"
],
[
"# Build the model\ni = Input(shape=(T, 1))\nx = LSTM(5)(i)\nx = Dense(1)(x)\nmodel = Model(i, x)\nmodel.compile(loss='mse', optimizer=Adam(lr=0.1))\n\n# train the RNN model\nr = model.fit(\n X[:-N // 2], Y[:-N // 2],\n epochs=80,\n validation_data=(X[-N//2:], Y[-N//2:]),\n)",
"Epoch 1/80\n12/12 [==============================] - 0s 37ms/step - loss: 0.3286 - val_loss: 6.6904\nEpoch 2/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1317 - val_loss: 6.6030\nEpoch 3/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1216 - val_loss: 5.4149\nEpoch 4/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1173 - val_loss: 4.6129\nEpoch 5/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1228 - val_loss: 4.3501\nEpoch 6/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1134 - val_loss: 4.2301\nEpoch 7/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1115 - val_loss: 4.2742\nEpoch 8/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1177 - val_loss: 4.3308\nEpoch 9/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1300 - val_loss: 4.3941\nEpoch 10/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1216 - val_loss: 4.9013\nEpoch 11/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1119 - val_loss: 4.3266\nEpoch 12/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1121 - val_loss: 4.3389\nEpoch 13/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1144 - val_loss: 4.8317\nEpoch 14/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1123 - val_loss: 4.5440\nEpoch 15/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1135 - val_loss: 4.8252\nEpoch 16/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1108 - val_loss: 5.0993\nEpoch 17/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1176 - val_loss: 4.8871\nEpoch 18/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1138 - val_loss: 4.7910\nEpoch 19/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1192 - val_loss: 4.7083\nEpoch 20/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1193 - val_loss: 4.3454\nEpoch 21/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1144 - val_loss: 4.5743\nEpoch 22/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1124 - val_loss: 4.0458\nEpoch 23/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1259 - val_loss: 4.9257\nEpoch 24/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1105 - val_loss: 4.8262\nEpoch 25/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1080 - val_loss: 5.2163\nEpoch 26/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1069 - val_loss: 4.1806\nEpoch 27/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1181 - val_loss: 5.1179\nEpoch 28/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1160 - val_loss: 5.0873\nEpoch 29/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1124 - val_loss: 4.7859\nEpoch 30/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1150 - val_loss: 5.1390\nEpoch 31/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1239 - val_loss: 5.2615\nEpoch 32/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1128 - val_loss: 4.6668\nEpoch 33/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1119 - val_loss: 4.5143\nEpoch 34/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1138 - val_loss: 4.6016\nEpoch 35/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1204 - val_loss: 4.7128\nEpoch 36/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1179 - val_loss: 5.4115\nEpoch 37/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1260 - val_loss: 4.5211\nEpoch 38/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1149 - val_loss: 4.6702\nEpoch 39/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1232 - val_loss: 3.9770\nEpoch 40/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1077 - val_loss: 3.8249\nEpoch 41/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1096 - val_loss: 4.2100\nEpoch 42/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1065 - val_loss: 4.2327\nEpoch 43/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1087 - val_loss: 4.4419\nEpoch 44/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1105 - val_loss: 4.7745\nEpoch 45/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1067 - val_loss: 5.1191\nEpoch 46/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1142 - val_loss: 4.7091\nEpoch 47/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1180 - val_loss: 4.6562\nEpoch 48/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1102 - val_loss: 3.9936\nEpoch 49/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1074 - val_loss: 4.3102\nEpoch 50/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1148 - val_loss: 4.9163\nEpoch 51/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1151 - val_loss: 5.3792\nEpoch 52/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1161 - val_loss: 5.2537\nEpoch 53/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1121 - val_loss: 4.6752\nEpoch 54/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1030 - val_loss: 5.3632\nEpoch 55/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1108 - val_loss: 4.6240\nEpoch 56/80\n12/12 [==============================] - 0s 8ms/step - loss: 0.1050 - val_loss: 4.3611\nEpoch 57/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1021 - val_loss: 4.7931\nEpoch 58/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1073 - val_loss: 4.1374\nEpoch 59/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1223 - val_loss: 4.4484\nEpoch 60/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1169 - val_loss: 4.2401\nEpoch 61/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1074 - val_loss: 3.6890\nEpoch 62/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1066 - val_loss: 3.3266\nEpoch 63/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1024 - val_loss: 3.0613\nEpoch 64/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1091 - val_loss: 3.7681\nEpoch 65/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1066 - val_loss: 3.7990\nEpoch 66/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1053 - val_loss: 2.9785\nEpoch 67/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1088 - val_loss: 3.5945\nEpoch 68/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1049 - val_loss: 3.7648\nEpoch 69/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1039 - val_loss: 3.2523\nEpoch 70/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1101 - val_loss: 3.4060\nEpoch 71/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1074 - val_loss: 3.7574\nEpoch 72/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1119 - val_loss: 3.6339\nEpoch 73/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1083 - val_loss: 3.3161\nEpoch 74/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1047 - val_loss: 3.2385\nEpoch 75/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1037 - val_loss: 3.6610\nEpoch 76/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1043 - val_loss: 4.3874\nEpoch 77/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1108 - val_loss: 5.0016\nEpoch 78/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1213 - val_loss: 4.7699\nEpoch 79/80\n12/12 [==============================] - 0s 10ms/step - loss: 0.1126 - val_loss: 4.8303\nEpoch 80/80\n12/12 [==============================] - 0s 9ms/step - loss: 0.1134 - val_loss: 3.7428\n"
],
[
"# Loss of model over time\nplt.plot(r.history['loss'], label=\"Loss\")\nplt.plot(r.history['val_loss'], label=\"Testing Loss\")\nplt.legend()",
"_____no_output_____"
],
[
"# Forecast/Predictions\n\noutputs = model.predict(X)\nprint(outputs.shape)\npredictions = outputs[:,0]\n\nplt.plot(Y, label=\"Target\")\nplt.plot(predictions, label=\"Predictions\")\nplt.legend()",
"(747, 1)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5191ae82d1974a0a8cd03732a6e1037d78d4e77
| 31,652 |
ipynb
|
Jupyter Notebook
|
langevin-mfpt/ft-exp2d-automated.ipynb
|
xif-fr/BrownianMotion
|
1a5eae07419f97b91d2cebe11dd0b6ac7769ac33
|
[
"MIT"
] | null | null | null |
langevin-mfpt/ft-exp2d-automated.ipynb
|
xif-fr/BrownianMotion
|
1a5eae07419f97b91d2cebe11dd0b6ac7769ac33
|
[
"MIT"
] | null | null | null |
langevin-mfpt/ft-exp2d-automated.ipynb
|
xif-fr/BrownianMotion
|
1a5eae07419f97b91d2cebe11dd0b6ac7769ac33
|
[
"MIT"
] | null | null | null | 83.514512 | 18,540 | 0.774169 |
[
[
[
"Uses `langevin-survival.cpp` with `INPUT_DATA_FILE` flag to compute 2D MFPT from a file generated by `exp-data-diffus-analysis.ipynb`. The file contains $(x,y)$ positions, with only free diffusion phases, separated by `NaN`s when reset occurs. Parameters ($D$, $\\sigma$, FPS, $T_\\text{res}$...) are contained in the associated `.csv` file.\n\nThings to specify in `langevin-survival.cpp` :\n - `#define INPUT_DATA_FILE` obviously\n - `#define XTARG_ONE_VARIABLE`\n - `#undef ENABLE_SURVIVAL_PROBABILITIES_*`\n - `#define TARGET_2D_CYL`\n\nThen set `path_traj` and `path_params` below (outputs of `exp-data-diffus-analysis.ipynb`), and set desired $a$ and $b$'s in `a_and_b`. Because $T_r$ and $\\sigma$ are fixed by the data, there is only one possibility for $L$ and $R_\\text{tol}$, which will be set automatically.\n\nAlso choose how to define $\\sigma$ from $(\\sigma_x,\\sigma_y)$ if they are different, typically $\\sigma_x$ or $\\sqrt{(\\sigma_x^2+\\sigma_y^2)/2}$ (the target being along the $x$ axis).",
"_____no_output_____"
]
],
[
[
"# [1]\nimport numpy as np\nimport pandas as pd\nimport csv\nimport matplotlib.pyplot as plt\nimport pysimul\nfrom common import *\nfrom math import *",
"_____no_output_____"
],
[
"# [2]\npath_params = \"../dati_MFPT/20-01-10/qpd_Ttrap50ms_Ttot200ms_T0.03/qpd_Ttrap50ms_Ttot200ms_diffus.csv\"\npath_traj = \"../dati_MFPT/20-01-10/qpd_Ttrap50ms_Ttot200ms_T0.03/qpd_Ttrap50ms_Ttot200ms_traj_data.bin\"\ndf = pd.read_csv(path_params, sep=',', header=None)\ndf = df.set_index(0)\nparams = dict(df[1])\nprint(params)\nD = params['D']\nrT = params['reset_period']\nσ = sqrt(params['sigma_x']**2 + params['sigma_y']**2)/sqrt(2) #params['sigma_x'] # or\n\nreset_type = 'per'\npath = \"data-exp-2d-periodical/2D_meansigma/\" # output storage directory\ni_beg = 30\n\nparam_i = 0\na_and_b = [\n (0.3,1), (0.3,2), (0.3,3), (0.3,3.5), (0.3,4), (0.3,8),# (0.3,12),\n (0.5,1), (0.5,2), (0.5,3), (0.5,4), (0.5,6), (0.5,8),# (0.5,12),\n (0.6,2), (0.6,4), (0.6,12),\n (0.75,1), (0.75,2), (0.75,4), (0.75,8), (0.75,12),\n (0.9,2), (0.9,4), (0.9,8), (0.9,12),\n]",
"{'N_traj': 249.0, 'ratio_x_y': 0.9828440944231122, 'sigma_x': 0.033886043718504996, 'sigma_y': 0.041104072050447436, 'D': 0.12108261098743794, 'D_err': 0.010740436099068912, 'fps': 50000.0, 'reset_period': 0.03}\n"
],
[
"# [3]\nsimul = pysimul.PySimul()\n\na,b = a_and_b[param_i]\nprint(\"doing a =\",a,\", b =\",b)\nassert(a < 1)\nsimul['first_times_xtarg'] = L = b*σ\nsimul['2D-Rtol'] = Rtol = a * L\n\nsimul['file_path'] = path_traj\nsimul.start()\n\nif reset_type == 'poisson':\n th_tau_2d = fpt_2d_poisson_tau\n th_c = lambda L: fpt_poisson_c(α, D, L)\nelif reset_type == 'per':\n th_tau_2d = np.vectorize(lambda b,c,a: fpt_2d_periodical_tau(b,c,a, use_cache=\"th-cache-2d-periodical/\"))\n th_c = lambda L: fpt_periodic_c(rT, D, L)\nc = th_c(L)\n\nparam_i += 1\nended = False",
"_____no_output_____"
],
[
"# [4]\ndef timer_f ():\n global simul, ended\n if simul is None:\n return 1\n if simul['pause'] == 1 and not ended:\n ended = True\n return 2\n return 0",
"_____no_output_____"
],
[
"%%javascript\nvar sfml_event_poll_timer = setInterval(function() {\n Jupyter.notebook.kernel.execute(\"print(timer_f())\", { iopub : { output : function (data) {\n console.log(data.content.text)\n if (data.content.text == \"1\\n\" || data.content.text === undefined) {\n clearInterval(sfml_event_poll_timer);\n } else if (data.content.text == \"2\\n\") {\n Jupyter.notebook.execute_cells([7,8,9,3]);\n }\n }}})\n}, 1000);",
"_____no_output_____"
],
[
"# [6]\nparam_i-1, simul['n_trajectories']",
"_____no_output_____"
],
[
"# [7]\nsimul.explicit_lock()\n\ntime_conversion = (1/params['fps']) / simul['Delta_t']\nfirst_times = simul['first_times'] * time_conversion\nmfpt = np.mean(first_times)\nn_traj = len(first_times)\n\npath2 = path+str(param_i+i_beg)\nnp.savetxt(path2+\"-ft.csv\", first_times, fmt='%.2e')\n\nd = {\n 'D': D,\n 'x0sigma': σ, 'x0sigma_x': params['sigma_x'], 'x0sigma_y': params['sigma_y'],\n 'L': L, 'b': b, 'c': c,\n 'Rtol': Rtol, 'a': a,\n 'mfpt': mfpt, 'fpt_stdev': np.std(first_times),\n 'n_traj': n_traj,\n 'Delta_t': 1/params['fps'],\n}\n\nif reset_type == 'poisson':\n d['reset_rate'] = α\nelif reset_type == 'per':\n d['reset_period'] = rT\n\ndf = pd.DataFrame(list(d.items())).set_index(0)\ndf.to_csv(path2+\"-params.csv\", header=False, quoting=csv.QUOTE_NONE, sep=',')\n \nsimul.explicit_unlock()\ndf.T",
"_____no_output_____"
],
[
"# [8]\nplt.figure(figsize=(10,4))\nfpt_max = 5*mfpt\nplt.hist(first_times, bins=100, range=(0,fpt_max), weights=100/fpt_max*np.ones(n_traj)/n_traj, label=\"distribution ({} traj.)\".format(n_traj))\nplt.axvline(x=mfpt, color='purple', label=\"MFPT = {:.3f}\".format(mfpt))\n\n# comment if not wanted :\nmfpt_th = L**2/(4*D)*th_tau_2d(b,c,a)\nplt.axvline(x=mfpt_th, color='black', label=\"th. MFPT = {:.3f}\".format(mfpt_th))\n\nplt.yscale('log')\nplt.xlabel(\"first passage time\")\nif reset_type == 'poisson':\n plt.title(r\"FPT distribution for $b={:.2f}$, $c={:.2f}$ ($D={:.3f}$, $\\alpha={}$, $\\sigma_{{x_0}}={:.3e}$, $L={}$)\".format(b, c, D, α, σ, L))\nelif reset_type == 'per':\n plt.title(r\"FPT distribution for $b={:.2f}$, $c={:.2f}$ ($D={:.3f}$, $T_\\operatorname{{res}}={}$, $\\sigma_{{x_0}}={:.3e}$, $L={}$)\".format(b, c, D, rT, σ, L))\nplt.legend()\nplt.savefig(path2+\"-distrib.pdf\", bbox_inches='tight')",
"_____no_output_____"
],
[
"# [9]\nsimul.end()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5191fc38b89bec68289485eb65bad71ff7a0cfc
| 33,945 |
ipynb
|
Jupyter Notebook
|
_notebooks/2020-03-15-best-performing-sectors.ipynb
|
gitdhiman/blog
|
fc8de8b1ee6017bc3ae3ef65f67eddedeffac72b
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-03-15-best-performing-sectors.ipynb
|
gitdhiman/blog
|
fc8de8b1ee6017bc3ae3ef65f67eddedeffac72b
|
[
"Apache-2.0"
] | 1 |
2022-02-26T06:45:19.000Z
|
2022-02-26T06:45:19.000Z
|
_notebooks/2020-03-15-best-performing-sectors.ipynb
|
gitdhiman/blog
|
fc8de8b1ee6017bc3ae3ef65f67eddedeffac72b
|
[
"Apache-2.0"
] | 1 |
2020-12-03T20:13:24.000Z
|
2020-12-03T20:13:24.000Z
| 56.480865 | 770 | 0.507409 |
[
[
[
"# Identify sectors expected to perform well in near future\n> Find out beaten down sectors that are showing signs of reversal. \n\n- badges: true\n- categories: [personal-finance]\n",
"_____no_output_____"
],
[
"Here I find out the sectors that are delivering diminishing returns i.e. returns are decreasing on lower time frames compared to higher time frames. The second criterion is to shortlist sectors that took a maximum beating recently.",
"_____no_output_____"
]
],
[
[
"#hide\n%load_ext blackcellmagic",
"_____no_output_____"
],
[
"#hide\nfrom IPython.display import HTML\nimport pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv(\"https://www1.nseindia.com/content/indices/mir.csv\", header=None)",
"_____no_output_____"
],
[
"#hide\ncaption = df.iloc[0, 0]\ndf.columns = [\"Sector\", \"1m\", \"3m\", \"6m\", \"12m\"]\ndf = df[3:]\ndf.set_index(\"Sector\", inplace=True)\ndf[\"1m\"] = df[\"1m\"].astype(float) / 100\ndf[\"3m\"] = df[\"3m\"].astype(float) / 100\ndf[\"6m\"] = df[\"6m\"].astype(float) / 100\ndf[\"12m\"] = df[\"12m\"].astype(float) / 100\ndf[\"diminishing_returns\"] = False",
"_____no_output_____"
],
[
"mask_diminishing_returns = (\n (df[\"12m\"] > df[\"6m\"]) & (df[\"6m\"] > df[\"3m\"]) & (df[\"3m\"] > df[\"1m\"])\n)\ndf.loc[mask_diminishing_returns, \"diminishing_returns\"] = True\ndf = df.sort_values(\n by=[\"diminishing_returns\", \"12m\", \"6m\", \"3m\", \"1m\"], ascending=False\n)",
"_____no_output_____"
],
[
"#hide\ndef color_negative_red(val):\n color = \"red\" if val < 0 else \"black\"\n return \"color: %s\" % color\n\n\ndef hover(hover_color=\"#f0f0f0\"):\n return dict(selector=\"tr:hover\", props=[(\"background-color\", \"%s\" % hover_color)])\n\n\nstyles = [\n hover(),\n dict(selector=\"th\", props=[(\"font-size\", \"105%\"), (\"text-align\", \"left\")]),\n dict(selector=\"caption\", props=[(\"caption-side\", \"top\")]),\n]\n\nformat_dict = {\n \"1m\": \"{:.2%}\",\n \"3m\": \"{:.2%}\",\n \"6m\": \"{:.2%}\",\n \"12m\": \"{:.2%}\",\n}\n\nhtml = (\n df.style.format(format_dict)\n .set_table_styles(styles)\n .applymap(color_negative_red)\n .highlight_max(color=\"lightgreen\")\n .set_caption(caption)\n)",
"_____no_output_____"
],
[
"#collapse-hide\nhtml",
"_____no_output_____"
]
],
[
[
"Once you identify the beaten down sectors, you can check the stocks under those sectors. Both the sector and stocks should confirm the reversal.\n\n",
"_____no_output_____"
],
[
"As an investor, it is important to understand that there is a correlation between the economic cycle, stock market cycle and the performance of various sectors of the economy. \n\nDuring the early cycle, it is better to invest in interest-rate sensitive stocks like consumer discretionary, financials, real estate, industrial and transportation. You should avoid, communications, utilities, and energy sector stocks. \n\nDuring the middle of the cycle, you can invest in IT and capital goods stocks. Whereas you should avoid, metals and utilities during this phase. \n\nDuring the late cycle, you can invest in energy, metals, health care and the utilities and you can skip the IT and consumer discretionary stocks. \n\nBest sectors for investment during Economic Slowdown are FMCG, utilities and health care. Investment in Industrials, IT and Real Estate should be avoided during this time. \n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
c51921d929bd3089426ca4a7d21b448cb681998f
| 95,151 |
ipynb
|
Jupyter Notebook
|
demos/Day 2 - 02 Classification (credit default).ipynb
|
ramesh152/MachineLearningPractice
|
2b2ae0d648e0ddbc75fa37e23607c692dbe5b252
|
[
"Apache-2.0"
] | null | null | null |
demos/Day 2 - 02 Classification (credit default).ipynb
|
ramesh152/MachineLearningPractice
|
2b2ae0d648e0ddbc75fa37e23607c692dbe5b252
|
[
"Apache-2.0"
] | null | null | null |
demos/Day 2 - 02 Classification (credit default).ipynb
|
ramesh152/MachineLearningPractice
|
2b2ae0d648e0ddbc75fa37e23607c692dbe5b252
|
[
"Apache-2.0"
] | null | null | null | 60.375 | 14,580 | 0.66529 |
[
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn import *\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"/Users/abulbasar/anaconda3/lib/python3.6/site-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n/Users/abulbasar/anaconda3/lib/python3.6/site-packages/sklearn/grid_search.py:42: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. This module will be removed in 0.20.\n DeprecationWarning)\n/Users/abulbasar/anaconda3/lib/python3.6/site-packages/sklearn/learning_curve.py:22: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the functions are moved. This module will be removed in 0.20\n DeprecationWarning)\n"
],
[
"df = pd.read_csv(\"/data/credit-default.csv\")\ndf.head()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 21 columns):\nchecking_balance 1000 non-null object\nmonths_loan_duration 1000 non-null int64\ncredit_history 1000 non-null object\npurpose 1000 non-null object\namount 1000 non-null int64\nsavings_balance 1000 non-null object\nemployment_length 1000 non-null object\ninstallment_rate 1000 non-null int64\npersonal_status 1000 non-null object\nother_debtors 1000 non-null object\nresidence_history 1000 non-null int64\nproperty 1000 non-null object\nage 1000 non-null int64\ninstallment_plan 1000 non-null object\nhousing 1000 non-null object\nexisting_credits 1000 non-null int64\ndefault 1000 non-null int64\ndependents 1000 non-null int64\ntelephone 1000 non-null object\nforeign_worker 1000 non-null object\njob 1000 non-null object\ndtypes: int64(8), object(13)\nmemory usage: 164.1+ KB\n"
],
[
"df.default.value_counts()/len(df)",
"_____no_output_____"
],
[
"target = \"default\"\ny = np.where(df[target] == 2, 1, 0) #outcome variable\nX = df.copy() #feature matrix\ndel X[target]\nX = pd.get_dummies(X, drop_first=True)\n\nX_train, X_test, y_train, y_test = model_selection.train_test_split(X, y,\n test_size = 0.3, random_state = 1234)\nX_train.shape, X_test.shape\n\npipe = pipeline.Pipeline([\n (\"poly\", preprocessing.PolynomialFeatures(degree=1, include_bias=False)),\n (\"scaler\", preprocessing.StandardScaler()),\n (\"est\", linear_model.LogisticRegression())\n])\n\npipe.fit(X_train, y_train)\n\n\ny_test_prob = pipe.predict_proba(X_test)\ny_train_pred = pipe.predict(X_train)\ny_test_pred = pipe.predict(X_test)\n\nplot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))\n\n#print(\"training r2:\", metrics.r2_score(y_train, y_train_pred),\n# \"\\ntesting r2:\", metrics.r2_score(y_test, y_test_pred),\n# \"\\ntraining mse:\", metrics.mean_squared_error(y_train, y_train_pred),\n# \"\\ntesting mse:\", metrics.mean_squared_error(y_test, y_test_pred))",
"_____no_output_____"
],
[
"pd.DataFrame({\"actual\": y_test, \"predicted\": y_test_pred})",
"_____no_output_____"
],
[
"from mlxtend.plotting import plot_confusion_matrix",
"_____no_output_____"
],
[
"plot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))",
"_____no_output_____"
],
[
"(182 + 43)/len(X_test)",
"_____no_output_____"
],
[
"metrics.accuracy_score(y_test, y_test_pred)",
"_____no_output_____"
],
[
"y_test_prob",
"_____no_output_____"
],
[
"y_test_pred = np.where(y_test_prob[:, 1] > 0.5, 1, 0)\nplot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))",
"_____no_output_____"
],
[
"y_test_pred.shape",
"_____no_output_____"
],
[
"recall = 43/(43+51)\nrecall",
"_____no_output_____"
],
[
"precision = 43 / (43+24)\nprecision",
"_____no_output_____"
],
[
"y_test_pred = np.where(y_test_prob[:, 1] > 0.5, 1, 0)\nprint(\"accuracy\", metrics.accuracy_score(y_test, y_test_pred)\n,\"\\nrecall\", metrics.recall_score(y_test, y_test_pred)\n,\"\\nprecision\", metrics.precision_score(y_test, y_test_pred))\nplot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))",
"accuracy 0.75 \nrecall 0.4574468085106383 \nprecision 0.6417910447761194\n"
],
[
"y_test_pred = np.where(y_test_prob[:, 1] > 0.8, 1, 0)\nprint(\"accuracy\", metrics.accuracy_score(y_test, y_test_pred)\n,\"\\nrecall\", metrics.recall_score(y_test, y_test_pred)\n,\"\\nprecision\", metrics.precision_score(y_test, y_test_pred))\nplot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))",
"accuracy 0.71 \nrecall 0.09574468085106383 \nprecision 0.8181818181818182\n"
],
[
"y_test_pred = np.where(y_test_prob[:, 1] > 0.2, 1, 0)\nprint(\"accuracy\", metrics.accuracy_score(y_test, y_test_pred)\n,\"\\nrecall\", metrics.recall_score(y_test, y_test_pred)\n,\"\\nprecision\", metrics.precision_score(y_test, y_test_pred))\nplot_confusion_matrix(metrics.confusion_matrix(y_test, y_test_pred))",
"accuracy 0.6866666666666666 \nrecall 0.8191489361702128 \nprecision 0.5\n"
],
[
"fpr, tpr, thresholds = metrics.roc_curve(y_test, y_test_prob[:, 1])",
"_____no_output_____"
],
[
"plt.plot(fpr, tpr)\nplt.plot([0, 1], [0, 1], ls = \"--\")\nplt.xlabel(\"FPR\")\nplt.ylabel(\"TPR\")\nplt.title(\"ROC, auc: \"+ str(metrics.auc(fpr, tpr)))",
"_____no_output_____"
],
[
"%%time \n\ntarget = \"default\"\ny = np.where(df[target] == 2, 1, 0) #outcome variable\nX = df.copy() #feature matrix\ndel X[target]\nX = pd.get_dummies(X, drop_first=True)\n\nX_train, X_test, y_train, y_test = model_selection.train_test_split(X, y,\n test_size = 0.3, random_state = 1234)\nX_train.shape, X_test.shape\n\npipe = pipeline.Pipeline([\n (\"poly\", preprocessing.PolynomialFeatures(degree=1, include_bias=False)),\n (\"scaler\", preprocessing.StandardScaler()),\n (\"est\", linear_model.SGDClassifier(loss=\"log\",\n penalty = \"elasticnet\",\n learning_rate = \"invscaling\",\n eta0 = 0.01, \n max_iter = 2000,\n tol = 1e-4\n ))\n])\n\nparam_grid = {\n \"est__l1_ratio\": np.linspace(0, 1, 10),\n \"est__alpha\": np.linspace(0.08, 0.09, 10)\n}\n\ngsearch = model_selection.GridSearchCV(cv=5, \n estimator=pipe, \n n_jobs=1, \n param_grid=param_grid)\ngsearch.fit(X_train, y_train)\n\nest = gsearch.best_estimator_\n\ny_test_prob = est.predict_proba(X_test)\ny_train_pred = est.predict(X_train)\ny_test_pred = est.predict(X_test)\nprint(\"test accuracy\", metrics.accuracy_score(y_test, y_test_pred))\nprint(\"best params: \", gsearch.best_params_)",
"test accuracy 0.74\nbest params: {'est__alpha': 0.08, 'est__l1_ratio': 0.0}\nCPU times: user 17.4 s, sys: 27.2 ms, total: 17.4 s\nWall time: 17.4 s\n"
],
[
"gsearch.best_params_",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c51931613ce8b334b7fa4fd0c510ef39c629af62
| 59,296 |
ipynb
|
Jupyter Notebook
|
intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb
|
hovhanns/deep-learning-v2-pytorch
|
bcf27146bd85d07a12dbf303b05156f8899b7a29
|
[
"MIT"
] | null | null | null |
intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb
|
hovhanns/deep-learning-v2-pytorch
|
bcf27146bd85d07a12dbf303b05156f8899b7a29
|
[
"MIT"
] | null | null | null |
intro-to-pytorch/Part 2 - Neural Networks in PyTorch (Exercises).ipynb
|
hovhanns/deep-learning-v2-pytorch
|
bcf27146bd85d07a12dbf303b05156f8899b7a29
|
[
"MIT"
] | null | null | null | 63.896552 | 16,508 | 0.734012 |
[
[
[
"# Neural networks with PyTorch\n\nDeep learning networks tend to be massive with dozens or hundreds of layers, that's where the term \"deep\" comes from. You can build one of these deep networks using only weight matrices as we did in the previous notebook, but in general it's very cumbersome and difficult to implement. PyTorch has a nice module `nn` that provides a nice way to efficiently build large neural networks.",
"_____no_output_____"
]
],
[
[
"# Import necessary packages\n\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport numpy as np\nimport torch\n\nimport helper\n\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"\nNow we're going to build a larger network that can solve a (formerly) difficult problem, identifying text in an image. Here we'll use the MNIST dataset which consists of greyscale handwritten digits. Each image is 28x28 pixels, you can see a sample below\n\n<img src='assets/mnist.png'>\n\nOur goal is to build a neural network that can take one of these images and predict the digit in the image.\n\nFirst up, we need to get our dataset. This is provided through the `torchvision` package. The code below will download the MNIST dataset, then create training and test datasets for us. Don't worry too much about the details here, you'll learn more about this later.",
"_____no_output_____"
]
],
[
[
"### Run this cell\n\nfrom torchvision import datasets, transforms\n\n# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5,), (0.5,)),\n ])\n\n# Download and load the training data\ntrainset = datasets.MNIST('~/.pytorch/MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"We have the training data loaded into `trainloader` and we make that an iterator with `iter(trainloader)`. Later, we'll use this to loop through the dataset for training, like\n\n```python\nfor image, label in trainloader:\n ## do things with images and labels\n```\n\nYou'll notice I created the `trainloader` with a batch size of 64, and `shuffle=True`. The batch size is the number of images we get in one iteration from the data loader and pass through our network, often called a *batch*. And `shuffle=True` tells it to shuffle the dataset every time we start going through the data loader again. But here I'm just grabbing the first batch so we can check out the data. We can see below that `images` is just a tensor with size `(64, 1, 28, 28)`. So, 64 images per batch, 1 color channel, and 28x28 images.",
"_____no_output_____"
]
],
[
[
"dataiter = iter(trainloader)\nimages, labels = dataiter.next()\nprint(type(images))\nprint(images.shape)\nprint(labels.shape)",
"<class 'torch.Tensor'>\ntorch.Size([64, 1, 28, 28])\ntorch.Size([64])\n"
]
],
[
[
"This is what one of the images looks like. ",
"_____no_output_____"
]
],
[
[
"plt.imshow(images[1].numpy().squeeze(), cmap='Greys_r');",
"_____no_output_____"
]
],
[
[
"First, let's try to build a simple network for this dataset using weight matrices and matrix multiplications. Then, we'll see how to do it using PyTorch's `nn` module which provides a much more convenient and powerful method for defining network architectures.\n\nThe networks you've seen so far are called *fully-connected* or *dense* networks. Each unit in one layer is connected to each unit in the next layer. In fully-connected networks, the input to each layer must be a one-dimensional vector (which can be stacked into a 2D tensor as a batch of multiple examples). However, our images are 28x28 2D tensors, so we need to convert them into 1D vectors. Thinking about sizes, we need to convert the batch of images with shape `(64, 1, 28, 28)` to a have a shape of `(64, 784)`, 784 is 28 times 28. This is typically called *flattening*, we flattened the 2D images into 1D vectors.\n\nPreviously you built a network with one output unit. Here we need 10 output units, one for each digit. We want our network to predict the digit shown in an image, so what we'll do is calculate probabilities that the image is of any one digit or class. This ends up being a discrete probability distribution over the classes (digits) that tells us the most likely class for the image. That means we need 10 output units for the 10 classes (digits). We'll see how to convert the network output into a probability distribution next.\n\n> **Exercise:** Flatten the batch of images `images`. Then build a multi-layer network with 784 input units, 256 hidden units, and 10 output units using random tensors for the weights and biases. For now, use a sigmoid activation for the hidden layer. Leave the output layer without an activation, we'll add one that gives us a probability distribution next.",
"_____no_output_____"
]
],
[
[
"print(images.shape)\nprint(images.shape[0])\nprint(images.view(images.shape[0], -1).shape)",
"torch.Size([64, 1, 28, 28])\n64\ntorch.Size([64, 784])\n"
],
[
"## Your solution\ndef activation(x):\n return 1/(1 + torch.exp(-x))\ninputs = images.view(images.shape[0], -1)\nn_input = 784\nn_hidden = 256\nn_output = 10\n\nW1 = torch.randn(n_input, n_hidden)\n\nW2 = torch.randn(n_hidden, n_output)\n\nB1 = torch.randn((1, n_hidden))\nB2 = torch.randn((1, n_output))\nh = activation(torch.mm(inputs, W1) + B1)\nout = torch.mm(h, W2) + B2\nout.shape",
"_____no_output_____"
]
],
[
[
"Now we have 10 outputs for our network. We want to pass in an image to our network and get out a probability distribution over the classes that tells us the likely class(es) the image belongs to. Something that looks like this:\n<img src='assets/image_distribution.png' width=500px>\n\nHere we see that the probability for each class is roughly the same. This is representing an untrained network, it hasn't seen any data yet so it just returns a uniform distribution with equal probabilities for each class.\n\nTo calculate this probability distribution, we often use the [**softmax** function](https://en.wikipedia.org/wiki/Softmax_function). Mathematically this looks like\n\n$$\n\\Large \\sigma(x_i) = \\cfrac{e^{x_i}}{\\sum_k^K{e^{x_k}}}\n$$\n\nWhat this does is squish each input $x_i$ between 0 and 1 and normalizes the values to give you a proper probability distribution where the probabilites sum up to one.\n\n> **Exercise:** Implement a function `softmax` that performs the softmax calculation and returns probability distributions for each example in the batch. Note that you'll need to pay attention to the shapes when doing this. If you have a tensor `a` with shape `(64, 10)` and a tensor `b` with shape `(64,)`, doing `a/b` will give you an error because PyTorch will try to do the division across the columns (called broadcasting) but you'll get a size mismatch. The way to think about this is for each of the 64 examples, you only want to divide by one value, the sum in the denominator. So you need `b` to have a shape of `(64, 1)`. This way PyTorch will divide the 10 values in each row of `a` by the one value in each row of `b`. Pay attention to how you take the sum as well. You'll need to define the `dim` keyword in `torch.sum`. Setting `dim=0` takes the sum across the rows while `dim=1` takes the sum across the columns.",
"_____no_output_____"
]
],
[
[
"torch.sum(out, dim=1).view(-1,1).shape",
"_____no_output_____"
],
[
"def softmax(x):\n \n b = torch.sum(torch.exp(x), dim=1).view(-1, 1)\n return torch.exp(x) / b\n \n ## TODO: Implement the softmax function here\n\n# Here, out should be the output of the network in the previous excercise with shape (64,10)\nprobabilities = softmax(out)\n\n# Does it have the right shape? Should be (64, 10)\nprint(probabilities.shape)\n# Does it sum to 1?\nprint(probabilities.sum(dim=1))",
"torch.Size([64, 10])\ntensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000,\n 1.0000])\n"
]
],
[
[
"## Building networks with PyTorch\n\nPyTorch provides a module `nn` that makes building networks much simpler. Here I'll show you how to build the same one as above with 784 inputs, 256 hidden units, 10 output units and a softmax output.",
"_____no_output_____"
]
],
[
[
"from torch import nn",
"_____no_output_____"
],
[
"class Network(nn.Module):\n def __init__(self):\n super().__init__()\n \n # Inputs to hidden layer linear transformation\n self.hidden = nn.Linear(784, 256)\n # Output layer, 10 units - one for each digit\n self.output = nn.Linear(256, 10)\n \n # Define sigmoid activation and softmax output \n self.sigmoid = nn.Sigmoid()\n self.softmax = nn.Softmax(dim=1)\n \n def forward(self, x):\n # Pass the input tensor through each of our operations\n x = self.hidden(x)\n x = self.sigmoid(x)\n x = self.output(x)\n x = self.softmax(x)\n \n return x",
"_____no_output_____"
]
],
[
[
"Let's go through this bit by bit.\n\n```python\nclass Network(nn.Module):\n```\n\nHere we're inheriting from `nn.Module`. Combined with `super().__init__()` this creates a class that tracks the architecture and provides a lot of useful methods and attributes. It is mandatory to inherit from `nn.Module` when you're creating a class for your network. The name of the class itself can be anything.\n\n```python\nself.hidden = nn.Linear(784, 256)\n```\n\nThis line creates a module for a linear transformation, $x\\mathbf{W} + b$, with 784 inputs and 256 outputs and assigns it to `self.hidden`. The module automatically creates the weight and bias tensors which we'll use in the `forward` method. You can access the weight and bias tensors once the network (`net`) is created with `net.hidden.weight` and `net.hidden.bias`.\n\n```python\nself.output = nn.Linear(256, 10)\n```\n\nSimilarly, this creates another linear transformation with 256 inputs and 10 outputs.\n\n```python\nself.sigmoid = nn.Sigmoid()\nself.softmax = nn.Softmax(dim=1)\n```\n\nHere I defined operations for the sigmoid activation and softmax output. Setting `dim=1` in `nn.Softmax(dim=1)` calculates softmax across the columns.\n\n```python\ndef forward(self, x):\n```\n\nPyTorch networks created with `nn.Module` must have a `forward` method defined. It takes in a tensor `x` and passes it through the operations you defined in the `__init__` method.\n\n```python\nx = self.hidden(x)\nx = self.sigmoid(x)\nx = self.output(x)\nx = self.softmax(x)\n```\n\nHere the input tensor `x` is passed through each operation and reassigned to `x`. We can see that the input tensor goes through the hidden layer, then a sigmoid function, then the output layer, and finally the softmax function. It doesn't matter what you name the variables here, as long as the inputs and outputs of the operations match the network architecture you want to build. The order in which you define things in the `__init__` method doesn't matter, but you'll need to sequence the operations correctly in the `forward` method.\n\nNow we can create a `Network` object.",
"_____no_output_____"
]
],
[
[
"# Create the network and look at it's text representation\nmodel = Network()\nmodel",
"_____no_output_____"
]
],
[
[
"You can define the network somewhat more concisely and clearly using the `torch.nn.functional` module. This is the most common way you'll see networks defined as many operations are simple element-wise functions. We normally import this module as `F`, `import torch.nn.functional as F`.",
"_____no_output_____"
]
],
[
[
"import torch.nn.functional as F\n\nclass Network(nn.Module):\n def __init__(self):\n super().__init__()\n # Inputs to hidden layer linear transformation\n self.hidden = nn.Linear(784, 256)\n # Output layer, 10 units - one for each digit\n self.output = nn.Linear(256, 10)\n \n def forward(self, x):\n # Hidden layer with sigmoid activation\n x = F.sigmoid(self.hidden(x))\n # Output layer with softmax activation\n x = F.softmax(self.output(x), dim=1)\n \n return x",
"_____no_output_____"
]
],
[
[
"### Activation functions\n\nSo far we've only been looking at the sigmoid activation function, but in general any function can be used as an activation function. The only requirement is that for a network to approximate a non-linear function, the activation functions must be non-linear. Here are a few more examples of common activation functions: Tanh (hyperbolic tangent), and ReLU (rectified linear unit).\n\n<img src=\"assets/activation.png\" width=700px>\n\nIn practice, the ReLU function is used almost exclusively as the activation function for hidden layers.",
"_____no_output_____"
],
[
"### Your Turn to Build a Network\n\n<img src=\"assets/mlp_mnist.png\" width=600px>\n\n> **Exercise:** Create a network with 784 input units, a hidden layer with 128 units and a ReLU activation, then a hidden layer with 64 units and a ReLU activation, and finally an output layer with a softmax activation as shown above. You can use a ReLU activation with the `nn.ReLU` module or `F.relu` function.\n\nIt's good practice to name your layers by their type of network, for instance 'fc' to represent a fully-connected layer. As you code your solution, use `fc1`, `fc2`, and `fc3` as your layer names.",
"_____no_output_____"
]
],
[
[
"## Your solution here\n\nclass MyNetwork(nn.Module):\n def __init__(self):\n super().__init__()\n self.fc1 = nn.Linear(784, 128)\n self.fc2 = nn.Linear(128, 64)\n self.fc3 = nn.Linear(64,10)\n \n def forward(self, x):\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = F.softmax(self.fc3(x), dim=1)\n return x\n",
"_____no_output_____"
],
[
"model = MyNetwork()",
"_____no_output_____"
]
],
[
[
"### Initializing weights and biases\n\nThe weights and such are automatically initialized for you, but it's possible to customize how they are initialized. The weights and biases are tensors attached to the layer you defined, you can get them with `model.fc1.weight` for instance.",
"_____no_output_____"
]
],
[
[
"print(model.fc1.weight)\nprint(model.fc1.bias)",
"Parameter containing:\ntensor([[-0.0234, -0.0142, -0.0122, ..., 0.0266, 0.0294, 0.0062],\n [ 0.0190, 0.0230, -0.0273, ..., -0.0039, 0.0096, -0.0188],\n [ 0.0150, 0.0105, -0.0164, ..., 0.0258, -0.0023, 0.0049],\n ...,\n [ 0.0159, -0.0272, -0.0331, ..., 0.0070, -0.0008, 0.0220],\n [ 0.0340, -0.0029, -0.0151, ..., -0.0261, 0.0124, -0.0305],\n [-0.0235, 0.0301, 0.0268, ..., -0.0336, 0.0226, 0.0344]],\n requires_grad=True)\nParameter containing:\ntensor([ 3.5430e-02, -2.7568e-02, -3.8787e-03, -3.2276e-02, 2.0831e-02,\n 5.1944e-03, 3.3920e-02, 3.5375e-02, 6.0003e-03, 3.3555e-02,\n -5.7377e-03, -2.1918e-02, 2.5196e-02, -2.9223e-02, -1.0229e-02,\n -2.1008e-02, -1.9560e-03, -2.2531e-03, 2.9253e-02, 2.6678e-02,\n 8.9291e-04, 1.4880e-02, 9.5398e-03, 2.0634e-02, 2.5457e-02,\n -1.8483e-02, -2.2663e-02, 3.0557e-02, 3.1503e-02, 3.1342e-03,\n 3.4858e-02, 3.5519e-02, 8.2334e-03, 3.5116e-02, -3.1197e-02,\n -9.5050e-03, -3.2375e-03, 5.8201e-04, 2.3490e-02, 1.4370e-02,\n -3.1748e-02, 1.1279e-02, 3.2394e-02, 4.5131e-03, -1.7894e-03,\n 3.1733e-02, -6.1504e-03, -2.8532e-02, -2.5302e-02, 3.0130e-02,\n -2.1495e-02, -1.1413e-02, -9.2705e-03, 3.5650e-02, 1.1976e-02,\n 2.7696e-02, 3.0047e-02, 1.4895e-02, -3.0616e-02, -2.9595e-02,\n -3.1824e-02, -3.2921e-02, -1.2067e-02, -1.2658e-02, -2.2948e-03,\n 3.0626e-02, 1.4349e-04, -2.2277e-02, 3.0614e-02, -1.3623e-02,\n 2.2418e-02, 1.4597e-02, -6.2746e-04, -3.8849e-04, -1.9894e-02,\n 3.4237e-02, 2.3616e-02, 3.0216e-02, -9.8883e-03, 7.2047e-03,\n -2.6377e-02, 1.8049e-04, 3.2935e-02, 9.8985e-03, 1.9330e-02,\n -3.3015e-02, -9.3841e-03, 2.3701e-02, 2.9804e-02, -1.3836e-03,\n -2.9102e-02, 1.6457e-02, 2.7790e-03, 3.1382e-05, 3.3198e-03,\n -3.4114e-02, -1.4753e-02, -3.5110e-02, 1.9152e-02, -3.1663e-02,\n 1.4462e-02, 2.6422e-02, -2.2656e-02, 6.4981e-03, -1.6851e-02,\n -3.1353e-02, 2.7632e-02, 9.7598e-03, 1.2690e-03, 1.7122e-02,\n 2.3027e-02, 2.8829e-02, 8.0463e-03, -2.4731e-02, 1.4841e-02,\n 1.3668e-02, -3.5250e-02, -1.2129e-02, 3.4558e-02, -1.1547e-02,\n 1.6635e-03, -4.1779e-03, -1.8910e-02, 2.2902e-02, 3.6562e-03,\n 3.2834e-02, 9.1502e-03, 2.5613e-02], requires_grad=True)\n"
]
],
[
[
"For custom initialization, we want to modify these tensors in place. These are actually autograd *Variables*, so we need to get back the actual tensors with `model.fc1.weight.data`. Once we have the tensors, we can fill them with zeros (for biases) or random normal values.",
"_____no_output_____"
]
],
[
[
"# Set biases to all zeros\nmodel.fc1.bias.data.fill_(0)",
"_____no_output_____"
],
[
"# sample from random normal with standard dev = 0.01\nmodel.fc1.weight.data.normal_(std=0.01)",
"_____no_output_____"
]
],
[
[
"### Forward pass\n\nNow that we have a network, let's see what happens when we pass in an image.",
"_____no_output_____"
]
],
[
[
"# Grab some data \ndataiter = iter(trainloader)\nimages, labels = dataiter.next()\n\n# Resize images into a 1D vector, new shape is (batch size, color channels, image pixels) \nimages.resize_(64, 1, 784)\n# or images.resize_(images.shape[0], 1, 784) to automatically get batch size\n\n# Forward pass through the network\nimg_idx = 0\nps = model.forward(images[img_idx,:])\n\nimg = images[img_idx]\nhelper.view_classify(img.view(1, 28, 28), ps)",
"_____no_output_____"
]
],
[
[
"As you can see above, our network has basically no idea what this digit is. It's because we haven't trained it yet, all the weights are random!\n\n### Using `nn.Sequential`\n\nPyTorch provides a convenient way to build networks like this where a tensor is passed sequentially through operations, `nn.Sequential` ([documentation](https://pytorch.org/docs/master/nn.html#torch.nn.Sequential)). Using this to build the equivalent network:",
"_____no_output_____"
]
],
[
[
"# Hyperparameters for our network\ninput_size = 784\nhidden_sizes = [128, 64]\noutput_size = 10\n\n# Build a feed-forward network\nmodel = nn.Sequential(nn.Linear(input_size, hidden_sizes[0]),\n nn.ReLU(),\n nn.Linear(hidden_sizes[0], hidden_sizes[1]),\n nn.ReLU(),\n nn.Linear(hidden_sizes[1], output_size),\n nn.Softmax(dim=1))\nprint(model)\n\n# Forward pass through the network and display output\nimages, labels = next(iter(trainloader))\nimages.resize_(images.shape[0], 1, 784)\nps = model.forward(images[0,:])\nhelper.view_classify(images[0].view(1, 28, 28), ps)",
"Sequential(\n (0): Linear(in_features=784, out_features=128, bias=True)\n (1): ReLU()\n (2): Linear(in_features=128, out_features=64, bias=True)\n (3): ReLU()\n (4): Linear(in_features=64, out_features=10, bias=True)\n (5): Softmax(dim=1)\n)\n"
]
],
[
[
"Here our model is the same as before: 784 input units, a hidden layer with 128 units, ReLU activation, 64 unit hidden layer, another ReLU, then the output layer with 10 units, and the softmax output.\n\nThe operations are available by passing in the appropriate index. For example, if you want to get first Linear operation and look at the weights, you'd use `model[0]`.",
"_____no_output_____"
]
],
[
[
"print(model[0])\nmodel[0].weight",
"Linear(in_features=784, out_features=128, bias=True)\n"
]
],
[
[
"You can also pass in an `OrderedDict` to name the individual layers and operations, instead of using incremental integers. Note that dictionary keys must be unique, so _each operation must have a different name_.",
"_____no_output_____"
]
],
[
[
"from collections import OrderedDict\nmodel = nn.Sequential(OrderedDict([\n ('fc1', nn.Linear(input_size, hidden_sizes[0])),\n ('relu1', nn.ReLU()),\n ('fc2', nn.Linear(hidden_sizes[0], hidden_sizes[1])),\n ('relu2', nn.ReLU()),\n ('output', nn.Linear(hidden_sizes[1], output_size)),\n ('softmax', nn.Softmax(dim=1))]))\nmodel",
"_____no_output_____"
]
],
[
[
"Now you can access layers either by integer or the name",
"_____no_output_____"
]
],
[
[
"print(model[0])\nprint(model.fc1)",
"Linear(in_features=784, out_features=128, bias=True)\nLinear(in_features=784, out_features=128, bias=True)\n"
]
],
[
[
"In the next notebook, we'll see how we can train a neural network to accuractly predict the numbers appearing in the MNIST images.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c51932004f106cecdd8660c6520faffcaa517118
| 1,005 |
ipynb
|
Jupyter Notebook
|
hacker-rank/Python/Regex and Parsing/Group(), Groups() & Groupdict().ipynb
|
izan-majeed/archives
|
89af2a24f4a6f07bda8ee38d99ae8667d42727f4
|
[
"Apache-2.0"
] | null | null | null |
hacker-rank/Python/Regex and Parsing/Group(), Groups() & Groupdict().ipynb
|
izan-majeed/archives
|
89af2a24f4a6f07bda8ee38d99ae8667d42727f4
|
[
"Apache-2.0"
] | null | null | null |
hacker-rank/Python/Regex and Parsing/Group(), Groups() & Groupdict().ipynb
|
izan-majeed/archives
|
89af2a24f4a6f07bda8ee38d99ae8667d42727f4
|
[
"Apache-2.0"
] | null | null | null | 17.946429 | 48 | 0.500498 |
[
[
[
"import re\n\ntext = input()\npattern = r'([A-Za-z0-9])\\1+'\nresult = re.search(pattern, text)\nprint(result.group(1) if result else -1)",
"..12345678910111213141516171820212223\n1\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
c51937c34ef7b325f42c8367fd7b6729e01e801d
| 40,183 |
ipynb
|
Jupyter Notebook
|
notebooks/02-WorkflowStructure_Optional.ipynb
|
CBroz1/workflow-deeplabcut
|
6eaf3105d3c328ea029305277acf31b654422ee0
|
[
"MIT"
] | null | null | null |
notebooks/02-WorkflowStructure_Optional.ipynb
|
CBroz1/workflow-deeplabcut
|
6eaf3105d3c328ea029305277acf31b654422ee0
|
[
"MIT"
] | null | null | null |
notebooks/02-WorkflowStructure_Optional.ipynb
|
CBroz1/workflow-deeplabcut
|
6eaf3105d3c328ea029305277acf31b654422ee0
|
[
"MIT"
] | 2 |
2022-03-23T14:16:26.000Z
|
2022-03-23T19:33:30.000Z
| 41.468524 | 423 | 0.5137 |
[
[
[
"# DataJoint U24 - Workflow DeepLabCut",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"This notebook gives a brief overview and introduces some useful DataJoint tools to facilitate the exploration.\n\n+ DataJoint needs to be configured before running this notebook, if you haven't done so, refer to the [01-Configure](./01-Configure.ipynb) notebook.\n+ If you are familar with DataJoint and the workflow structure, proceed to the next notebook [03-Process](./03-Process.ipynb) directly to run the workflow.\n+ For a more thorough introduction of DataJoint functionings, please visit our [general tutorial site](http://codebook.datajoint.io/)",
"_____no_output_____"
],
[
"To load the local configuration, we will change the directory to the package root.",
"_____no_output_____"
]
],
[
[
"import os\nif os.path.basename(os.getcwd())=='notebooks': os.chdir('..')\nassert os.path.basename(os.getcwd())=='workflow-deeplabcut', (\"Please move to the \"\n + \"workflow directory\")",
"_____no_output_____"
]
],
[
[
"## Schemas and tables",
"_____no_output_____"
],
[
"By importing from `workflow_deeplabcut`, we'll run the activation functions that declare the tables in these schemas. If these tables are already declared, we'll gain access.",
"_____no_output_____"
]
],
[
[
"import datajoint as dj\nfrom workflow_deeplabcut.pipeline import lab, subject, session, train, model",
"Connecting [email protected]:3306\n"
]
],
[
[
"Each module contains a schema object that enables interaction with the schema in the database. For more information abotu managing the upstream tables, see our [session workflow](https://github.com/datajoint/workflow-session). In this case, lab is required because the pipeline adds a `Device` table to the lab schema to keep track of camera IDs. The pipeline also adds a `VideoRecording` table to the session schema.",
"_____no_output_____"
],
[
"`dj.list_schemas()` lists all schemas a user has access to in the current database",
"_____no_output_____"
]
],
[
[
"dj.list_schemas()",
"_____no_output_____"
]
],
[
[
"`<schema>.schema.list_tables()` will provide names for each table in the format used under the hood.",
"_____no_output_____"
]
],
[
[
"train.schema.list_tables()",
"_____no_output_____"
]
],
[
[
"`dj.Diagram()` plots tables and dependencies in a schema. To see additional upstream or downstream connections, add `- N` or `+ N` where N is the number of additional links.\n\nWhile the `model` schema is required for pose estimation, the `train` schema is optional, and can be used to manage model training within DataJoint",
"_____no_output_____"
]
],
[
[
"dj.Diagram(train) #- 1",
"_____no_output_____"
],
[
"dj.Diagram(model)",
"_____no_output_____"
]
],
[
[
"### Table tiers \n- **Manual table**: green box, manually inserted table, expect new entries daily, e.g. Subject, ProbeInsertion. \n- **Lookup table**: gray box, pre inserted table, commonly used for general facts or parameters. e.g. Strain, ClusteringMethod, ClusteringParamSet. \n- **Imported table**: blue oval, auto-processing table, the processing depends on the importing of external files. e.g. process of Clustering requires output files from kilosort2. \n- **Computed table**: red circle, auto-processing table, the processing does not depend on files external to the database, commonly used for \n- **Part table**: plain text, as an appendix to the master table, all the part entries of a given master entry represent a intact set of the master entry. e.g. Unit of a CuratedClustering.\n\n### Dependencies\n\n- **One-to-one primary**: thick solid line, share the exact same primary key, meaning the child table inherits all the primary key fields from the parent table as its own primary key. \n- **One-to-many primary**: thin solid line, inherit the primary key from the parent table, but have additional field(s) as part of the primary key as well\n- **secondary dependency**: dashed line, the child table inherits the primary key fields from parent table as its own secondary attribute.",
"_____no_output_____"
]
],
[
[
"# plot diagram of tables in multiple schemas\ndj.Diagram(subject.Subject) + dj.Diagram(session.Session) + dj.Diagram(model)",
"_____no_output_____"
],
[
"lab.schema.list_tables()",
"_____no_output_____"
],
[
"# plot diagram of selected tables and schemas\n(dj.Diagram(subject.Subject) + dj.Diagram(session.Session) \n + dj.Diagram(model.VideoRecording) + dj.Diagram(model.PoseEstimationTask)) ",
"_____no_output_____"
],
[
"# preview columns and contents in a table\nmodel.VideoRecording.File()",
"_____no_output_____"
]
],
[
[
"`describe()` shows table definition with foreign key references",
"_____no_output_____"
]
],
[
[
"train.TrainingTask.describe()",
"# Specification for a DLC model training instance\n-> train.VideoSet\n-> train.TrainingParamSet\ntraining_id : int \n---\nmodel_prefix=\"\" : varchar(32) \nproject_path=\"\" : varchar(255) # DLC's project_path in config relative to root\n\n"
]
],
[
[
"`heading` shows attribute definitions regardless of foreign key references",
"_____no_output_____"
]
],
[
[
"model.Model.heading",
"_____no_output_____"
]
],
[
[
"## Other Elements installed with the workflow\n\n[`lab`](https://github.com/datajoint/element-lab): lab management related information, such as Lab, User, Project, Protocol, Source.",
"_____no_output_____"
]
],
[
[
"dj.Diagram(lab)",
"_____no_output_____"
]
],
[
[
"[`subject`](https://github.com/datajoint/element-animal): general animal information, User, Genetic background, Death etc.",
"_____no_output_____"
]
],
[
[
"dj.Diagram(subject)",
"_____no_output_____"
],
[
"subject.Subject.describe();",
"# Animal Subject\nsubject : varchar(8) \n---\nsex : enum('M','F','U') \nsubject_birth_date : date \nsubject_description=\"\" : varchar(1024) \n\n"
]
],
[
[
"[`session`](https://github.com/datajoint/element-session): General information of experimental sessions.",
"_____no_output_____"
]
],
[
[
"dj.Diagram(session)",
"_____no_output_____"
],
[
"session.Session.describe()",
"-> subject.Subject\nsession_datetime : datetime \n\n"
]
],
[
[
"## Summary and next step\n\n- This notebook introduced the overall structures of the schemas and tables in the workflow and relevant tools to explore the schema structure and table definitions.\n\n- The [next notebook](./03-Process.ipynb) will introduce the detailed steps to run through `workflow-deeplabcut`.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
c5193bbb75b6639c2ae6c05fd4a9c537d8723c6e
| 704,125 |
ipynb
|
Jupyter Notebook
|
Exploratory_DA.ipynb
|
swaroop9ai9/Learning-development
|
c53bc084f41712397748538e8b3ad7bd4a416e07
|
[
"MIT"
] | 1 |
2020-06-20T14:21:24.000Z
|
2020-06-20T14:21:24.000Z
|
Exploratory_DA.ipynb
|
swaroop9ai9/Learning-development
|
c53bc084f41712397748538e8b3ad7bd4a416e07
|
[
"MIT"
] | null | null | null |
Exploratory_DA.ipynb
|
swaroop9ai9/Learning-development
|
c53bc084f41712397748538e8b3ad7bd4a416e07
|
[
"MIT"
] | null | null | null | 276.778695 | 196,546 | 0.90397 |
[
[
[
"# accessing documentation with ?\n# We can use help function to understand the documentation\nprint(help(len))\n# or we can use the ? operator\nlen?\n\n# The notation works for objects also \nL = [1,2,4,5]\nL.append?\nL?\n\n# This will also work for functions that we create ourselves, the ? returns the doc string in the function\ndef square(n):\n '''return the square of the number'''\n return n**2\n\nsquare?",
"Help on built-in function len in module builtins:\n\nlen(obj, /)\n Return the number of items in a container.\n\nNone\n"
],
[
"# Accessing the source code with ?? \nsquare??\n\n# Sometimes it might not return the source code because it might be written in an other language\nfrom collections import deque as d\nd??",
"_____no_output_____"
],
[
"# Wild Card matching\n# We can use the wild card * and type the known part to retrieve the unknown command\n# Example for looking at different type of warnings\n*Warning?\n# We can use this in functions also\nd.app*?",
"_____no_output_____"
],
[
"# Shortcuts in Ipython notebook\n''' Navigation shortcuts\nCtrl-a\tMove cursor to the beginning of the line\nCtrl-e\tMove cursor to the end of the line\nCtrl-b or the left arrow key\tMove cursor back one character\nCtrl-f or the right arrow key\tMove cursor forward one character \n\n Text Entry shortcuts\nBackspace key\tDelete previous character in line\nCtrl-d\tDelete next character in line\nCtrl-k\tCut text from cursor to end of line\nCtrl-u\tCut text from beginning of line to cursor\nCtrl-y\tYank (i.e. paste) text that was previously cut\nCtrl-t\tTranspose (i.e., switch) previous two characters \n\n Command History Shortcuts\nCtrl-p (or the up arrow key)\tAccess previous command in history\nCtrl-n (or the down arrow key)\tAccess next command in history\nCtrl-r\tReverse-search through command history \n\n Keystroke\tAction\nCtrl-l\tClear terminal screen\nCtrl-c\tInterrupt current Python command\nCtrl-d\tExit IPython session '''\n\n\n\n\n",
"_____no_output_____"
],
[
"# MAGIC COMMANDS\n# We can use %run to execute python (.py) file in notebook, any functions defined in the script can be used by the notebook\n# We can use %timeit to check the execution time for a single iteration or line command, for finding multiline command time execution we can use %%timeit\n%%timeit\nL = []\nfor i in range(10000):\n L.append(i**2)\n%timeit L = [n ** 2 for n in range(1000)] # Checking time for executing list comprehensions, we can see list comprehension execution is very efficient",
"1000 loops, best of 3: 255 µs per loop\n1000 loops, best of 3: 255 µs per loop\n1000 loops, best of 3: 253 µs per loop\n1000 loops, best of 3: 253 µs per loop\n1 loop, best of 3: 1.06 s per loop\n"
],
[
"# Input/ Output history commands\n# We can use In/ Out objects to print the Input and output objects in history, lets say we start the below session\nimport math\nmath.sin(2)\nmath.cos(2)\n# print(In), will print all the commands inputted in the current notebook\nprint(In) # returns a list of all the commands executed so far.\n# Similarly we can use 'OUT' to print the output of these functions\nprint(Out) # Returns a dictonary with input and output\n\n# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function\nmath.sin(2) + math.cos(2); # We usually use this ';' symbol especially if in case of matplolib\n\n\n# For accesing previous batch of inputs we can use %history command\n#%history?\n%history -n 1-4",
"['', 'help(len)', \"help(len)\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\", \"print(help(len))\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\", \"get_ipython().magic('pinfo len')\", \"print(help(len))\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\", \"print(help(len))\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\\n\\n# The notation works for objects also \\nL = [1,2,4,5]\\nget_ipython().magic('pinfo L.append')\", \"print(help(len))\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\\n\\n# The notation works for objects also \\nL = [1,2,4,5]\\nget_ipython().magic('pinfo L.append')\\nget_ipython().magic('pinfo L')\", \"print(help(len))\\n# or we can use the ? operator\\nget_ipython().magic('pinfo len')\\n\\n# The notation works for objects also \\nL = [1,2,4,5]\\nget_ipython().magic('pinfo L.append')\\nget_ipython().magic('pinfo L')\\n\\n# This will also work for functions that we create ourselves, the ? returns the doc string in the function\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\\n\\nget_ipython().magic('pinfo square')\", 'print(square??)', \"get_ipython().magic('pinfo2 square')\", \"get_ipython().magic('pinfo2 square')\\n\\n# Sometimes it might not return the source code because it might be written in an other language\\nget_ipython().magic('pinfo2 len')\", \"get_ipython().magic('pinfo2 square')\\n\\n# Sometimes it might not return the source code because it might be written in an other language\\nfrom collections import deque as d\\nget_ipython().magic('pinfo2 d')\", 'L. ', 'L.<TAB>', \"get_ipython().magic('psearch *Warning')\", \"get_ipython().magic('psearch *Warning')\", \"get_ipython().magic('psearch *Warning')\\n# We can use this in functions also\\nd.app*\", \"get_ipython().magic('psearch *Warning')\\n# We can use this in functions also\\nget_ipython().magic('psearch d.app*')\", \"get_ipython().magic('paste')\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\", \"get_ipython().magic('pastebin')\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\", \"get_ipython().magic('cpaste')\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\", \"get_ipython().magic('pastebin')\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\", \"get_ipython().magic('pastebin')\\ndef square(n):\\n '''return the square of the number'''\\n return n**2\\nsquare(100)\", '# We can use %run to execute python (.py) file in notebook', \"get_ipython().run_cell_magic('timeit', '', 'L = []\\\\nfor i in range(10000):\\\\n L.append(i**2)')\", \"get_ipython().run_cell_magic('timeit', '', 'L = []\\\\nfor i in range(10000):\\\\n L.append(i**2)\\\\n%timeit L = [n ** 2 for n in range(1000)] # Checking time for executing list comprehensions')\", 'import math\\nmath.sin(2)\\nmath.cos(2)', 'print(In)', \"import math\\nmath.sin(2)\\nmath.cos(2)\\n# print(In), will print all the commands inputted in the current notebook\\nprint(In)\\n# Similarly we can use 'OUT' to print the output of these functions\\nOut\", \"import math\\nmath.sin(2)\\nmath.cos(2)\\n# print(In), will print all the commands inputted in the current notebook\\nprint(In) # returns a list of all the commands executed so far.\\n# Similarly we can use 'OUT' to print the output of these functions\\nOut # Returns a dictonary with input and output\\n\\n# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function\\nmath.sin(2) + math.cos(2);\", \"import math\\nmath.sin(2)\\nmath.cos(2)\\n# print(In), will print all the commands inputted in the current notebook\\nprint(In) # returns a list of all the commands executed so far.\\n# Similarly we can use 'OUT' to print the output of these functions\\nprint(Out) # Returns a dictonary with input and output\\n\\n# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function\\nmath.sin(2) + math.cos(2);\", \"import math\\nmath.sin(2)\\nmath.cos(2)\\n# print(In), will print all the commands inputted in the current notebook\\nprint(In) # returns a list of all the commands executed so far.\\n# Similarly we can use 'OUT' to print the output of these functions\\nprint(Out) # Returns a dictonary with input and output\\n\\n# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function\\nmath.sin(2) + math.cos(2); # We usually use this ';' symbol especially if in case of matplolib\\n\\n\\n# For accesing previous batch of inputs we can use %history command\\nget_ipython().magic('pinfo %history')\", \"import math\\nmath.sin(2)\\nmath.cos(2)\\n# print(In), will print all the commands inputted in the current notebook\\nprint(In) # returns a list of all the commands executed so far.\\n# Similarly we can use 'OUT' to print the output of these functions\\nprint(Out) # Returns a dictonary with input and output\\n\\n# We can also supress outputs while executing so that we can make according changes if we want the function to execute, we simple place a semicolon in the end of the function\\nmath.sin(2) + math.cos(2); # We usually use this ';' symbol especially if in case of matplolib\\n\\n\\n# For accesing previous batch of inputs we can use %history command\\n#%history?\\nget_ipython().magic('history -n 1-4')\"]\n{23: 10000, 27: -0.4161468365471424}\n 1: help(len)\n 2:\nhelp(len)\n# or we can use the ? operator\nlen?\n 3:\nprint(help(len))\n# or we can use the ? operator\nlen?\n 4: len?\n"
],
[
"# Shell Commands\n# We can use '!' for executing os commands\n# Shell is a direct way to interact textually with computer\n!ls\n!pwd\n!echo \"printing from the shell\"\ncontents = !ls\nprint(contents)",
"sample_data\n/content\nprinting from the shell\n"
],
[
"# Errors and debugging\n# Controlling Exceptions: %xmode\n# Using %xmode we can control the length of content of error message\n%xmode Plain\ndef func2(x):\n a = x\n b = 0\n return a/b\nfunc2(4)",
"Exception reporting mode: Plain\n"
],
[
"# We can use '%xmode verbose' to have additional information reported regarding the error\n%xmode verbose\nfunc2(90)\n# We can apply the default mode to take things normal\n#%xmode Default",
"Exception reporting mode: Verbose\n"
],
[
"# Debugging\n# The standard tool for reading traceback is pdb(python debugger), ipdb(ipython version)\n# We can also use the %debug magic command, in case of an exception it will automatically open an interactive debugging shell\n# The ipdb prompt lets you explore the current state of the stack, explore the available variables, and even run Python commands!\n\n%debug\n# Other debugging commands in the shell\n'''list\tShow the current location in the file\nh(elp)\tShow a list of commands, or find help on a specific command\nq(uit)\tQuit the debugger and the program\nc(ontinue)\tQuit the debugger, continue in the program\nn(ext)\tGo to the next step of the program\n<enter>\tRepeat the previous command\np(rint)\tPrint variables\ns(tep)\tStep into a subroutine\nr(eturn)\tReturn out of a subroutine '''",
"> \u001b[0;32m<ipython-input-40-790b792d1d80>\u001b[0m(5)\u001b[0;36mfunc2\u001b[0;34m()\u001b[0m\n\u001b[0;32m 2 \u001b[0;31m\u001b[0;32mdef\u001b[0m \u001b[0mfunc2\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mx\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 3 \u001b[0;31m \u001b[0ma\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mx\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 4 \u001b[0;31m \u001b[0mb\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m----> 5 \u001b[0;31m \u001b[0;32mreturn\u001b[0m \u001b[0ma\u001b[0m\u001b[0;34m/\u001b[0m\u001b[0mb\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 6 \u001b[0;31m\u001b[0mfunc2\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m4\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\nipdb> 90\n90\nipdb> print(a)\n90\nipdb> print(b)\n0\nipdb> exit()\n"
],
[
"# We can use these commands to figureout the execution time for various snnipets and code\n'''%time: Time the execution of a single statement\n%timeit: Time repeated execution of a single statement for more accuracy\n%prun: Run code with the profiler\n%lprun: Run code with the line-by-line profiler\n%memit: Measure the memory use of a single statement\n%mprun: Run code with the line-by-line memory profiler'''",
"_____no_output_____"
],
[
"# Data Structures and Processing for Machine Learing\nimport numpy as np\nnp.__version__",
"_____no_output_____"
],
[
"# Data types in python\n# As we know python is dynamically typed language, but inside it is just complex 'c' lang structure disguised in python\n'''struct _longobject {\n long ob_refcnt;\n PyTypeObject *ob_type;\n size_t ob_size;\n long ob_digit[1];\n};\n\nob_refcnt, a reference count that helps Python silently handle memory allocation and deallocation\nob_type, which encodes the type of the variable\nob_size, which specifies the size of the following data members\nob_digit, which contains the actual integer value that we expect the Python variable to represent. ''' \n# usually all this additional information comes at a cost of memory and computation\n# A list if also a complex structure that can accomodate multiple data types, So we make use of a numpy array for manipulating integer data\n# Although a list might be flexible, but a numpy array is very efficient to store and manipulate data\n# We can make use of 'array' data structure make computationally effective manipulations\nimport array\nL = list(range(10))\narr = array.array('i',L) # 'i' is a type code indicating the elements of the array as integer\narr",
"_____no_output_____"
],
[
"import numpy as np\n# Creating array\nnp.array([1,2,3,4,5]) # Unlike list, numpy array need to have same data type\nnp.array([1, 2, 3, 4], dtype='float32') # We can explicitly declare the type using 'dtype' attribute",
"_____no_output_____"
],
[
"# nested lists result in multi-dimensional arrays\nnp.array([range(i, i + 3) for i in [2, 4, 6]])",
"_____no_output_____"
],
[
"# Create a length-10 integer array filled with zeros\nnp.zeros(10, dtype=int)",
"_____no_output_____"
],
[
"# Create a 3x5 floating-point array filled with ones\nnp.ones((3, 5), dtype=float)",
"_____no_output_____"
],
[
"# Create a 3x5 array filled with 3.14\nnp.full((3, 5), 3.14)",
"_____no_output_____"
],
[
"# Create an array filled with a linear sequence\n# Starting at 0, ending at 20, stepping by 2\n# (this is similar to the built-in range() function)\nnp.arange(0, 20, 2).reshape(5,2) # We can use reshape() to convert the shape as we want to",
"_____no_output_____"
],
[
"# Create an array of five values evenly spaced between 0 and 1\nnp.linspace(0, 1, 25)",
"_____no_output_____"
],
[
"# Create a 3x3 array of uniformly distributed\n# random values between 0 and 1\nnp.random.random((3, 3))",
"_____no_output_____"
],
[
"# Create a 3x3 array of normally distributed random values\n# with mean 0 and standard deviation 1\nnp.random.normal(0, 1, (3, 3))",
"_____no_output_____"
],
[
"# Create a 3x3 array of random integers in the interval [0, 10)\nnp.random.randint(0, 10000, (3, 3))",
"_____no_output_____"
],
[
"# Create a 3x3 identity matrix\nnp.eye(3)",
"_____no_output_____"
],
[
"# Create an uninitialized array of three integers\n# The values will be whatever happens to already exist at that memory location\nnp.empty(3)",
"_____no_output_____"
],
[
"# Numpy built in data types, numpy is built in 'C'. \n'''\nbool_\tBoolean (True or False) stored as a byte\nint_\tDefault integer type (same as C long; normally either int64 or int32)\nintc\tIdentical to C int (normally int32 or int64)\nintp\tInteger used for indexing (same as C ssize_t; normally either int32 or int64)\nint8\tByte (-128 to 127)\nint16\tInteger (-32768 to 32767)\nint32\tInteger (-2147483648 to 2147483647)\nint64\tInteger (-9223372036854775808 to 9223372036854775807)\nuint8\tUnsigned integer (0 to 255)\nuint16\tUnsigned integer (0 to 65535)\nuint32\tUnsigned integer (0 to 4294967295)\nuint64\tUnsigned integer (0 to 18446744073709551615)\nfloat_\tShorthand for float64.\nfloat16\tHalf precision float: sign bit, 5 bits exponent, 10 bits mantissa\nfloat32\tSingle precision float: sign bit, 8 bits exponent, 23 bits mantissa\nfloat64\tDouble precision float: sign bit, 11 bits exponent, 52 bits mantissa\ncomplex_\tShorthand for complex128.\ncomplex64\tComplex number, represented by two 32-bit floats\ncomplex128\tComplex number, represented by two 64-bit floats'''\n",
"_____no_output_____"
],
[
"# Numpy Array Attributes\nnp.random.seed(0) # seed for reproducibility\n# 3 array's with random integers and different dimensions\nx1 = np.random.randint(10, size=6) # One-dimensional array\nx2 = np.random.randint(10, size=(3, 4)) # Two-dimensional array\nx3 = np.random.randint(10, size=(3, 4, 5)) # Three-dimensional array",
"_____no_output_____"
],
[
"print(\"x3 ndim: \", x3.ndim) # number of dimensions\nprint(\"x3 shape:\", x3.shape) # size of dimension\nprint(\"x3 size: \", x3.size) # total size of array\nprint(\"dtype:\", x3.dtype) # Data type stored in numpy array\nprint(\"itemsize:\", x3.itemsize, \"bytes\") # itemsize of single item in bytes\nprint(\"nbytes:\", x3.nbytes, \"bytes\") # total array itemsize ,nbyted = itemsize*size",
"x3 ndim: 3\nx3 shape: (3, 4, 5)\nx3 size: 60\ndtype: int64\nitemsize: 8 bytes\nnbytes: 480 bytes\n"
],
[
"# Accesing elements (Single)\nprint(x1)\nprint(x1[0]) # prints the first element\nprint(x1[4]) # prints the fifth element\nprint(x1[-1]) # To index array from end (prints last element)\nprint(x1[-2]) # prints second last element\n\n# Multidimentional array can be accessed using a comma seperated tuple of indices\nprint(x2)\nprint(x2[0,0]) # array_name(row,column)\nprint(x2[2,0]) # 3rd row element(0,1,2), first column\nprint(x2[2,-1]) # 3rd row element, last column\nx2[0,0] = 90 # values can also be modified at any index\n# but if we change 'x1[0] = 9.9', it gets trucated and converted to 3 as 'x1' is declared as int32\n",
"[5 0 3 3 7 9]\n5\n7\n9\n7\n[[3 5 2 4]\n [7 6 8 8]\n [1 6 7 7]]\n3\n1\n7\n"
],
[
"# Accessing elements via slicing\n#x[start:stop:step]\nprint(x1)\nprint(x1[0:2]) # returns first 2 elements\nprint(x1[1:]) # returns all elements from 2nd position\nprint(x1[0:3:2]) # returns all elements from 0 to 2 position with step '2' (so 5,3)\nprint(x1[::2]) # every other element\nprint(x1[1::2]) # every other element, starting at index 1\n\n# If step is negative then it returns in reverse order, internally start and stop are swapped\nprint(x1[::-1]) # all elements, reversed\nprint(x1[3::-1]) # reversed from index 3 to starting, this includes 3\nprint(x1[4:1:-1]) # revered from index 4 up to 2nd element. \n\n# Multidimentional array\nprint(x2)\nprint(x2[:2,:3]) # returns array from start row up to 3rd row, and up to 4th column\nprint('\\n')\nprint(x2[:3, ::2]) # all rows, every other column as step value is 2\nprint(x2[::-1, ::-1]) # sub array dimensions can also be reveresed",
"[5 0 3 3 7 9]\n[5 0]\n[0 3 3 7 9]\n[5 3]\n[5 3 7]\n[0 3 9]\n[9 7 3 3 0 5]\n[3 3 0 5]\n[7 3 3]\n[[90 5 2 4]\n [ 7 6 8 8]\n [ 1 6 7 7]]\n[[90 5 2]\n [ 7 6 8]]\n\n\n[[90 2]\n [ 7 8]\n [ 1 7]]\n[[ 7 7 6 1]\n [ 8 8 6 7]\n [ 4 2 5 90]]\n"
],
[
"# Accesing array rows and columns\nprint(x2)\nprint(x2[:, 0]) # first column of x2\nprint(x2[0, :]) # first row of x2\nprint(x2[0]) # equivalent to x2[0, :], first row\n\n# When we copy sub array, to another array (internally it does not make copies it just returns a view, so on changing the subarray will make change in original array)\n# In order to actually create a copy we can use the 'copy()' method \nx2_sub_copy = x2[:2, :2].copy()\nprint(x2_sub_copy)",
"[[90 5 2 4]\n [ 7 6 8 8]\n [ 1 6 7 7]]\n[90 7 1]\n[90 5 2 4]\n[90 5 2 4]\n[[90 5]\n [ 7 6]]\n"
],
[
"# Reshaping array\ngrid = np.arange(1, 10).reshape((3, 3))\nprint(grid) # for this to work, the initial array needs to have the same shape\n",
"[[1 2 3]\n [4 5 6]\n [7 8 9]]\n"
],
[
"# Array Concatenation and Spliting\n# We can use np.concatenate, np.hstack, np.vstack\nx = np.array([1, 2, 3])\ny = np.array([3, 2, 1])\nnp.concatenate([x, y])\n# We can also concatenate more than one array at once\nz = [99, 99, 99]\nprint(np.concatenate([x, y, z]))\n\n# Concatenating 2d array \ngrid = np.array([[1, 2, 3],\n [4, 5, 6]])\ngrids = np.concatenate([grid,grid])\nprint(grids)\n# concatenate along the axis (zero-indexed)\nprint(np.concatenate([grid, grid], axis=1))\n\n# Using vstack and hstack\nx = np.array([1, 2, 3])\ngrid = np.array([[9, 8, 7],\n [6, 5, 4]])\n\n# vertically stack the arrays \nprint(np.vstack([x, grid])) # We simply stack vertically\nprint(np.hstack([grids,grids])) # We concatenate them horizontally sideways\n\n# Similarly we can use np.dstack to concatenate along the 3rd axis",
"[ 1 2 3 3 2 1 99 99 99]\n[[1 2 3]\n [4 5 6]\n [1 2 3]\n [4 5 6]]\n[[1 2 3 1 2 3]\n [4 5 6 4 5 6]]\n[[1 2 3]\n [9 8 7]\n [6 5 4]]\n[[1 2 3 1 2 3]\n [4 5 6 4 5 6]\n [1 2 3 1 2 3]\n [4 5 6 4 5 6]]\n"
],
[
"# Spliting is opposite to concatenation. We use np.vsplit, np.hsplit and np.split to split the array\nx = [1, 2, 3, 99, 99, 3, 2, 1]\nx1, x2, x3 = np.split(x, [3, 5]) # these are points where to split for 'n' points we get 'n+1' sub arrays\nprint(x1, x2, x3)\n\n# using np.vsplit\ngrid = np.arange(16).reshape((4, 4))\nprint('\\n')\nprint(grid)\nupper, lower = np.vsplit(grid, [2]) # its like a horizontal plane spliting at a point\nprint(upper)\nprint(lower)\n\n# using np.hsplit\nleft, right = np.hsplit(grid, [2])\nprint(left)\nprint(right) \n# Similarly we can use np.dsplit to split along the 3rd axis",
"[1 2 3] [99 99] [3 2 1]\n\n\n[[ 0 1 2 3]\n [ 4 5 6 7]\n [ 8 9 10 11]\n [12 13 14 15]]\n[[0 1 2 3]\n [4 5 6 7]]\n[[ 8 9 10 11]\n [12 13 14 15]]\n[[ 0 1]\n [ 4 5]\n [ 8 9]\n [12 13]]\n[[ 2 3]\n [ 6 7]\n [10 11]\n [14 15]]\n"
],
[
"# numpy for computation\n# Numpy is very fast when we use it for vectorised operations, generally implemented through \"Numpy Universal Functions\"\n# It makes repeated calculations on numpy very efficient\n\n# Slowness of python loops, the loops mostly implemented via cpython are slow due to dynamic and interpreted nature\n# Sometimes it is absurdly slow, especially while running loops\n \n# So for many types of operations numpy is quite efficient especially as it is statically typed and complied routine. (called vectorized operations)\n# vectorized operation is simple applying the operation on the array which is then applied on each element\n\n#Vectorized operations in NumPy are implemented via ufuncs, whose main purpose is to quickly execute repeated operations.\n#On values in NumPy arrays. Ufuncs are extremely flexible – before we saw an operation between a scalar and an array,\n# but we can also operate between two arrays\nprint(np.arange(5) / np.arange(1, 6))\n\n# Multi dimentional array\nx = np.arange(9).reshape((3, 3))\n2 ** x",
"[0. 0.5 0.66666667 0.75 0.8 ]\n"
],
[
"#Array arithmetic\n\n#NumPy's ufuncs feel very natural to use because they make use of Python's native arithmetic operators. \n#The standard addition, subtraction, multiplication, and division can all be used\nx = np.arange(4)\nprint(\"x =\", x)\nprint(\"x + 5 =\", x + 5)\nprint(\"x - 5 =\", x - 5)\nprint(\"x * 2 =\", x * 2)\nprint(\"x / 2 =\", x / 2)\nprint(\"x // 2 =\", x // 2) # floor division\nprint(\"-x = \", -x)\nprint(\"x ** 2 = \", x ** 2)\nprint(\"x % 2 = \", x % 2)\nprint(-(0.5*x + 1) ** 2) # These can be strung together as you wish\n\n\n# We can also call functions instead\n'''\n+\tnp.add\tAddition (e.g., 1 + 1 = 2)\n-\tnp.subtract\tSubtraction (e.g., 3 - 2 = 1)\n-\tnp.negative\tUnary negation (e.g., -2)\n*\tnp.multiply\tMultiplication (e.g., 2 * 3 = 6)\n/\tnp.divide\tDivision (e.g., 3 / 2 = 1.5)\n//\tnp.floor_divide\tFloor division (e.g., 3 // 2 = 1)\n**\tnp.power\tExponentiation (e.g., 2 ** 3 = 8)\n%\tnp.mod\tModulus/remainder (e.g., 9 % 4 = 1) '''\n\n\nx = np.array([-2, -1, 0, 1, 2])\nprint(abs(x))\n",
"x = [0 1 2 3]\nx + 5 = [5 6 7 8]\nx - 5 = [-5 -4 -3 -2]\nx * 2 = [0 2 4 6]\nx / 2 = [0. 0.5 1. 1.5]\nx // 2 = [0 0 1 1]\n-x = [ 0 -1 -2 -3]\nx ** 2 = [0 1 4 9]\nx % 2 = [0 1 0 1]\n[-1. -2.25 -4. -6.25]\n[2 1 0 1 2]\n"
],
[
"# Array trignometry\ntheta = np.linspace(0, np.pi, 3)\n\nprint(\"theta = \", theta)\nprint(\"sin(theta) = \", np.sin(theta))\nprint(\"cos(theta) = \", np.cos(theta))\nprint(\"tan(theta) = \", np.tan(theta))\nx = [-1, 0, 1]\nprint(\"x = \", x)\nprint(\"arcsin(x) = \", np.arcsin(x))\nprint(\"arccos(x) = \", np.arccos(x))\nprint(\"arctan(x) = \", np.arctan(x))\n\n# Exponents and logrithms\nx = [1, 2, 3]\nprint(\"x =\", x)\nprint(\"e^x =\", np.exp(x))\nprint(\"2^x =\", np.exp2(x))\nprint(\"3^x =\", np.power(3, x))\n\nx = [1, 2, 4, 10]\nprint(\"x =\", x)\nprint(\"ln(x) =\", np.log(x))\nprint(\"log2(x) =\", np.log2(x))\nprint(\"log10(x) =\", np.log10(x))\n\n",
"theta = [0. 1.57079633 3.14159265]\nsin(theta) = [0.0000000e+00 1.0000000e+00 1.2246468e-16]\ncos(theta) = [ 1.000000e+00 6.123234e-17 -1.000000e+00]\ntan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]\nx = [-1, 0, 1]\narcsin(x) = [-1.57079633 0. 1.57079633]\narccos(x) = [3.14159265 1.57079633 0. ]\narctan(x) = [-0.78539816 0. 0.78539816]\nx = [1, 2, 3]\ne^x = [ 2.71828183 7.3890561 20.08553692]\n2^x = [2. 4. 8.]\n3^x = [ 3 9 27]\nx = [1, 2, 4, 10]\nln(x) = [0. 0.69314718 1.38629436 2.30258509]\nlog2(x) = [0. 1. 2. 3.32192809]\nlog10(x) = [0. 0.30103 0.60205999 1. ]\n"
],
[
"# Special functions\nfrom scipy import special\n# Gamma functions (generalized factorials) and related functions\nx = [1, 5, 10]\nprint(\"gamma(x) =\", special.gamma(x))\nprint(\"ln|gamma(x)| =\", special.gammaln(x))\nprint(\"beta(x, 2) =\", special.beta(x, 2))\n\n# Error function (integral of Gaussian)\n# its complement, and its inverse\nx = np.array([0, 0.3, 0.7, 1.0])\nprint(\"erf(x) =\", special.erf(x))\nprint(\"erfc(x) =\", special.erfc(x))\nprint(\"erfinv(x) =\", special.erfinv(x))\n\n\n",
"gamma(x) = [1.0000e+00 2.4000e+01 3.6288e+05]\nln|gamma(x)| = [ 0. 3.17805383 12.80182748]\nbeta(x, 2) = [0.5 0.03333333 0.00909091]\nerf(x) = [0. 0.32862676 0.67780119 0.84270079]\nerfc(x) = [1. 0.67137324 0.32219881 0.15729921]\nerfinv(x) = [0. 0.27246271 0.73286908 inf]\n"
],
[
"# Aggregation min/max \nimport numpy as np\nL = np.random.random(100)\nsum(L)\n# Using np.sum()\nprint(np.sum(L))\n# The reason numpy is fast is because it executes the operations as compiled code\n",
"53.52667818144105\n"
],
[
"big_array = np.random.rand(1000000)\n%timeit sum(big_array)\n%timeit np.sum(big_array) # The difference between time of execution is in square order.\n# Max and Min in big_array\nmin(big_array), max(big_array)\nnp.min(big_array), np.max(big_array)\n%timeit min(big_array)\n%timeit np.min(big_array)",
"10 loops, best of 3: 159 ms per loop\n1000 loops, best of 3: 363 µs per loop\n10 loops, best of 3: 102 ms per loop\n1000 loops, best of 3: 416 µs per loop\n"
],
[
"# Multidimentional Array Aggregation\nM = np.random.random((3, 4))\nprint(M)\n# By default each aggregation the function will aggregate on the entire np.array\nM.sum()\n#Aggregation functions take an additional argument specifying the axis along which the aggregate is computed. \n#For example, we can find the minimum value within each column by specifying axis=0:\nM.min(axis=0)\n\n# Additional List of aggregation functions in python\n'''\nFunction Name\tNaN-safe Version\tDescription\nnp.sum\t np.nansum\t Compute sum of elements\nnp.prod\t np.nanprod\t Compute product of elements\nnp.mean\t np.nanmean\t Compute mean of elements\nnp.std\t np.nanstd\t Compute standard deviation\nnp.var\t np.nanvar\t Compute variance\nnp.min\t np.nanmin\t Find minimum value\nnp.max\t np.nanmax\t Find maximum value\nnp.argmin\t np.nanargmin\t Find index of minimum value\nnp.argmax\t np.nanargmax\t Find index of maximum value\nnp.median\t np.nanmedian\t Compute median of elements\nnp.percentile\t np.nanpercentile\t Compute rank-based statistics of elements\nnp.any\t N/A\t Evaluate whether any elements are true\nnp.all\t N/A \tEvaluate whether all elements are true '''",
"[[0.12187143 0.12172419 0.07083764 0.22112473]\n [0.05669852 0.88724085 0.59191918 0.4679162 ]\n [0.56922461 0.91640821 0.71129149 0.43453839]]\n"
],
[
"# Broadcasting for Computation in numpy arrays\n# For same size, binary operations are performed element by element wise\na = np.array([0, 1, 2])\nb = np.array([5, 5, 5])\nprint(a + b)\nprint(a+5)\n\n# Adding 1 dimentional array to 2 dimentional array.\nM = np.ones((3, 3))\nprint(M+a) # The 'a' is stretched, or broadcast across the second dimension in order to match the shape of M.\n",
"[5 6 7]\n[5 6 7]\n"
],
[
"# Masking in Numpy array's, we use masking for extracting, modifying, counting the values in an array based on a criteria\n# Ex: Counting all values greater than a certain value.\n # Comparision Operators as ufuncs\n x = np.array([1, 2, 3, 4, 5])\n print(x < 3) # less than\n print((2 * x) == (x ** 2))\n\n '''\n Operator\t Equivalent ufunc\t\tOperator\t Equivalent ufunc\n ==\t np.equal\t\t !=\t np.not_equal\n <\t np.less\t\t <=\t np.less_equal\n >\t np.greater\t\t >=\t np.greater_equal '''\n # how many values less than 3?\nprint(np.count_nonzero(x < 3))\n",
"[ True True False False False]\n[False True False False False]\n"
],
[
"# Fancy Indexing\nrand = np.random.RandomState(42)\n\nx = rand.randint(100, size=10)\nprint(x)\n# Accesing different elements\nprint([x[3], x[7], x[2]])\n# Alternatively we can also access the elements as \nind = [3, 7, 4]\nprint(x[ind])",
"[51 92 14 71 60 20 82 86 74 74]\n[71, 86, 14]\n[71 86 60]\n"
],
[
"# Sorting Array's\nx = np.array([2, 1, 4, 3, 5])\nprint(np.sort(x)) # Using builtin sort function we can sort the values of an array\n# Using argsort we can return the indices of these elements after sorting\nx = np.array([2, 1, 4, 3, 5])\ni = np.argsort(x)\nprint(i)\n# Soring elements row wise or column wise\nrand = np.random.RandomState(42)\nX = rand.randint(0, 10, (4, 6))\nprint(X)\n# sort each column of X\nprint(np.sort(X, axis=0))",
"[1 2 3 4 5]\n[1 0 3 2 4]\n[[6 3 7 4 6 9]\n [2 6 7 4 3 7]\n [7 2 5 4 1 7]\n [5 1 4 0 9 5]]\n[[2 1 4 0 1 5]\n [5 2 5 4 3 7]\n [6 3 7 4 6 7]\n [7 6 7 4 9 9]]\n"
],
[
"# Handling Missing Data\ndata = pd.Series([1, np.nan, 'hello', None])\ndata.isnull() # Using to detect missing values in a pandas data frame\ndata.dropna() # Drops the null values present in a data frame\n# We can drop null values along different axis \n# df.dropna(axis='columns')\n# df.dropna(axis='columns', how='all')\n# df.dropna(axis='rows', thresh=3) 'thresh' parameter specifies the minimum number of not null values to be kept\ndata = pd.Series([1, np.nan, 2, None, 3], index=list('abcde'))\ndata.fillna(0) # Fills null values with zero\n# forward-fill\ndata.fillna(method='ffill') # Fills the previous value in the series\n# back-fill\ndata.fillna(method='bfill')\n#data.fillna(method='ffill', axis=1) We can also specify the axis to fill",
"_____no_output_____"
],
[
"# Pivot tables in Pandas\nimport seaborn as sns\ntitanic = sns.load_dataset('titanic')\ntitanic.pivot_table('survived', index='sex', columns='class')",
"/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
],
[
"# Date and time tools for handling time series data\nfrom datetime import datetime\ndatetime(year=2015, month=7, day=4)",
"_____no_output_____"
],
[
"# Using date util module we can parse date in string format\nfrom dateutil import parser\ndate = parser.parse(\"4th of July, 2015\")\ndate",
"_____no_output_____"
],
[
"# Dates which are consecutive using arange\ndate = np.array('2015-07-04', dtype=np.datetime64)\nprint(date)\nprint(date + np.arange(12))",
"2015-07-04\n['2015-07-04' '2015-07-05' '2015-07-06' '2015-07-07' '2015-07-08'\n '2015-07-09' '2015-07-10' '2015-07-11' '2015-07-12' '2015-07-13'\n '2015-07-14' '2015-07-15']\n"
],
[
"# Datetime in pandas\nimport pandas as pd\ndate = pd.to_datetime(\"4th of July, 2015\")\nprint(date)\nprint(date.strftime('%A'))\n# Vectorized operations on the same object\nprint(date + pd.to_timedelta(np.arange(12), 'D'))",
"2015-07-04 00:00:00\nSaturday\nDatetimeIndex(['2015-07-04', '2015-07-05', '2015-07-06', '2015-07-07',\n '2015-07-08', '2015-07-09', '2015-07-10', '2015-07-11',\n '2015-07-12', '2015-07-13', '2015-07-14', '2015-07-15'],\n dtype='datetime64[ns]', freq=None)\n"
],
[
"# Visualizations\n# Simple Line plots\n%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn-whitegrid')\nimport numpy as np\nfig = plt.figure()\nax = plt.axes()\n\nx = np.linspace(0, 10, 1000)\nax.plot(x, np.sin(x));\nplt.plot(x, np.cos(x));",
"_____no_output_____"
],
[
"plt.plot(x, np.sin(x - 0), color='blue') # specify color by name\nplt.plot(x, np.sin(x - 1), color='g') # short color code (rgbcmyk)\nplt.plot(x, np.sin(x - 2), color='0.75') # Grayscale between 0 and 1\nplt.plot(x, np.sin(x - 3), color='#FFDD44') # Hex code (RRGGBB from 00 to FF)\nplt.plot(x, np.sin(x - 4), color=(1.0,0.2,0.3)) # RGB tuple, values 0 to 1\nplt.plot(x, np.sin(x - 5), color='chartreuse'); # all HTML color names supported",
"_____no_output_____"
],
[
"plt.plot(x, x + 0, linestyle='solid')\nplt.plot(x, x + 1, linestyle='dashed')\nplt.plot(x, x + 2, linestyle='dashdot')\nplt.plot(x, x + 3, linestyle='dotted');\n\n# For short, you can use the following codes:\nplt.plot(x, x + 4, linestyle='-') # solid\nplt.plot(x, x + 5, linestyle='--') # dashed\nplt.plot(x, x + 6, linestyle='-.') # dashdot\nplt.plot(x, x + 7, linestyle=':'); # dotted",
"_____no_output_____"
],
[
"plt.plot(x, x + 0, '-g') # solid green\nplt.plot(x, x + 1, '--c') # dashed cyan\nplt.plot(x, x + 2, '-.k') # dashdot black\nplt.plot(x, x + 3, ':r'); # dotted red",
"_____no_output_____"
],
[
"plt.plot(x, np.sin(x))\n\nplt.xlim(-1, 11)\nplt.ylim(-1.5, 1.5);",
"_____no_output_____"
],
[
"x = np.linspace(0, 10, 30)\ny = np.sin(x)\n\nplt.plot(x, y, 'o', color='black');",
"_____no_output_____"
],
[
"rng = np.random.RandomState(0)\nfor marker in ['o', '.', ',', 'x', '+', 'v', '^', '<', '>', 's', 'd']:\n plt.plot(rng.rand(5), rng.rand(5), marker,\n label=\"marker='{0}'\".format(marker))\nplt.legend(numpoints=1)\nplt.xlim(0, 1.8);",
"_____no_output_____"
],
[
"plt.plot(x, y, '-p', color='gray',\n markersize=15, linewidth=4,\n markerfacecolor='white',\n markeredgecolor='gray',\n markeredgewidth=2)\nplt.ylim(-1.2, 1.2);",
"_____no_output_____"
],
[
"rng = np.random.RandomState(0)\nx = rng.randn(100)\ny = rng.randn(100)\ncolors = rng.rand(100)\nsizes = 1000 * rng.rand(100)\n\nplt.scatter(x, y, c=colors, s=sizes, alpha=0.3,\n cmap='viridis')\nplt.colorbar(); # show color scale",
"_____no_output_____"
],
[
"from sklearn.datasets import load_iris\niris = load_iris()\nfeatures = iris.data.T\n\nplt.scatter(features[0], features[1], alpha=0.2,\n s=100*features[3], c=iris.target, cmap='viridis')\nplt.xlabel(iris.feature_names[0])\nplt.ylabel(iris.feature_names[1]);",
"_____no_output_____"
],
[
"# Contour Plots\ndef f(x, y):\n return np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)\nx = np.linspace(0, 5, 50)\ny = np.linspace(0, 5, 40)\n\nX, Y = np.meshgrid(x, y)\nZ = f(X, Y)\n\nplt.contour(X, Y, Z, colors='black');",
"_____no_output_____"
],
[
"plt.contour(X, Y, Z, 20, cmap='RdGy');",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5194897996666b94db42133be43c29eef662a1b
| 120,576 |
ipynb
|
Jupyter Notebook
|
1Kmeans/Kmeans.ipynb
|
yeltayzhastay/all_notebooks
|
20122b375aaef13b36ed4b2cd8028f7c1ed91465
|
[
"MIT"
] | null | null | null |
1Kmeans/Kmeans.ipynb
|
yeltayzhastay/all_notebooks
|
20122b375aaef13b36ed4b2cd8028f7c1ed91465
|
[
"MIT"
] | null | null | null |
1Kmeans/Kmeans.ipynb
|
yeltayzhastay/all_notebooks
|
20122b375aaef13b36ed4b2cd8028f7c1ed91465
|
[
"MIT"
] | null | null | null | 41.678534 | 16,984 | 0.478453 |
[
[
[
"import matplotlib.pyplot as plt\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.cluster import KMeans\nfrom sklearn.decomposition import PCA\nfrom sklearn.manifold import TSNE\nfrom pathlib import Path\n\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"random_state = 100",
"_____no_output_____"
],
[
"all_txt_files =[]\nfor file in Path(\"all_plus\").rglob(\"*.txt\"):\n all_txt_files.append(file.parent / file.name)\n# counts the length of the list\nall_docs = []\nfor txt_file in all_txt_files:\n with open(txt_file, encoding='utf-8') as f:\n txt_file_as_string = f.read()\n all_docs.append(txt_file_as_string)\n \nprint(len(all_docs))",
"75\n"
],
[
"exp_list = []\nfor i in range(1,16):\n exp_list.append(0)\nfor i in range(1,16):\n exp_list.append(1)\nfor i in range(1,16):\n exp_list.append(2)\nfor i in range(1,16):\n exp_list.append(3)\nfor i in range(1,16):\n exp_list.append(4)\n ",
"_____no_output_____"
],
[
"d = {\"text\": all_docs, \"label\": exp_list}\ndf = pd.DataFrame(d)\ndf",
"_____no_output_____"
],
[
"stop = ['маған', 'оған', 'саған', 'біздің', 'сіздің', 'оның', 'бізге', 'сізге', 'оларға', 'біздерге', 'сіздерге', 'оларға', 'менімен', 'сенімен', 'онымен', 'бізбен', 'сізбен', 'олармен', 'біздермен', 'сіздермен', 'менің', 'сенің', 'біздің', 'сіздің', 'оның', 'біздердің', 'сіздердің', 'олардың', 'маған', 'саған', 'оған', 'менен', 'сенен', 'одан', 'бізден', 'сізден', 'олардан', 'біздерден', 'сіздерден', 'олардан', 'айтпақшы', 'сонымен', 'сондықтан', 'бұл', 'осы', 'сол', 'анау', 'мынау', 'сонау', 'осынау', 'ана', 'мына', 'сона', 'әні', 'міне', 'өй', 'үйт', 'бүйт', 'біреу', 'кейбіреу', 'кейбір', 'қайсыбір', 'әрбір', 'бірнеше', 'бірдеме', 'бірнеше', 'әркім', 'әрне', 'әрқайсы', 'әрқалай', 'әлдекім','ах', 'ох', 'эх', 'ай', 'эй', 'ой', 'тағы', 'тағыда', 'әрине', 'жоқ', 'сондай', 'осындай', 'осылай', 'солай', 'мұндай', 'бұндай', 'мен', 'сен', 'ол', 'біз', 'біздер', 'олар', 'сіз', 'сіздер', 'әлдене', 'әлдеқайдан', 'әлденеше', 'әлдеқалай', 'әлдеқашан', 'алдақашан', 'еш', 'ешкім', 'ешбір', 'ештеме', 'дәнеңе', 'ешқашан', 'ешқандай', 'ешқайсы', 'емес', 'бәрі', 'барлық', 'барша', 'бар', 'күллі', 'бүкіл', 'түгел', 'өз', 'өзім', 'өзің', 'өзінің', 'өзіме', 'өзіне', 'өзімнің', 'өзі', 'өзге', 'менде', 'сенде', 'онда', 'менен', 'сенен\\tонан', 'одан', 'ау', 'па', 'ей', 'әй', 'е', 'уа', 'уау', 'уай', 'я', 'пай', 'ә', 'о', 'оһо', 'ой', 'ие', 'аһа', 'ау', 'беу', 'мәссаған', 'бәрекелді', 'әттегенай', 'жаракімалла', 'масқарай', 'астапыралла', 'япырмай', 'ойпырмай', 'кәне', 'кәнеки', 'ал', 'әйда', 'кәні', 'міне', 'әні', 'сорап', 'қош-қош', 'пфша', 'пішә', 'құрау-құрау', 'шәйт', 'шек', 'моһ', 'тәк', 'құрау', 'құр', 'кә', 'кәһ', 'күшім', 'күшім', 'мышы', 'пырс', 'әукім', 'алақай', 'паһ-паһ', 'бәрекелді', 'ура', 'әттең', 'әттеген-ай', 'қап', 'түге', 'пішту', 'шіркін', 'алатау', 'пай-пай', 'үшін', 'сайын', 'сияқты', 'туралы', 'арқылы', 'бойы', 'бойымен', 'шамалы', 'шақты', 'қаралы', 'ғұрлы', 'ғұрлым', 'шейін', 'дейін', 'қарай', 'таман', 'салым', 'тарта', 'жуық', 'таяу', 'гөрі', 'бері', 'кейін', 'соң', 'бұрын', 'бетер', 'қатар', 'бірге', 'қоса', 'арс', 'гүрс', 'дүрс', 'қорс', 'тарс', 'тырс', 'ырс', 'барқ', 'борт', 'күрт', 'кірт', 'морт', 'сарт', 'шырт', 'дүңк', 'күңк', 'қыңқ', 'мыңқ', 'маңқ', 'саңқ', 'шаңқ', 'шіңк', 'сыңқ', 'таңқ', 'тыңқ', 'ыңқ', 'болп', 'былп', 'жалп', 'желп', 'қолп', 'ірк', 'ырқ', 'сарт-сұрт', 'тарс-тұрс', 'арс-ұрс', 'жалт-жалт', 'жалт-жұлт', 'қалт-қалт', 'қалт-құлт', 'қаңқ-қаңқ', 'қаңқ-құңқ', 'шаңқ-шаңқ', 'шаңқ-шұңқ', 'арбаң-арбаң', 'бүгжең-бүгжең', 'арсалаң-арсалаң', 'ербелең-ербелең', 'батыр-бұтыр', 'далаң-далаң', 'тарбаң-тарбаң', 'қызараң-қызараң', 'қаңғыр-күңгір', 'қайқаң-құйқаң', 'митың-митың', 'салаң-сұлаң', 'ыржың-тыржың', 'бірақ', 'алайда', 'дегенмен', 'әйтпесе', 'әйткенмен', 'себебі', 'өйткені', 'сондықтан', 'үшін', 'сайын', 'сияқты', 'туралы', 'арқылы', 'бойы', 'бойымен', 'шамалы', 'шақты', 'қаралы', 'ғұрлы', 'ғұрлым', 'гөрі', 'бері', 'кейін', 'соң', 'бұрын', 'бетер', 'қатар', 'бірге', 'қоса', 'шейін', 'дейін', 'қарай', 'таман', 'салым', 'тарта', 'жуық', 'таяу', 'арнайы', 'осындай', 'ғана', 'қана', 'тек', 'әншейін', 'мен', 'да', 'бола', 'бір', 'де', 'сен', 'мені', 'сені', 'және', 'немесе', 'оны', 'еді', 'жатыр', 'деп', 'деді', 'тұр', 'тар', 'жаты', 'болып', ' ']\nvec = TfidfVectorizer(analyzer=\"word\", stop_words=stop,use_idf=True, smooth_idf=True, ngram_range=(1, 1))\nvec.fit_transform(df.text.values)\nfeatures = vec.transform(df.text.values)",
"c:\\users\\zhastay\\appdata\\local\\programs\\python\\python36\\lib\\site-packages\\sklearn\\feature_extraction\\text.py:385: UserWarning: Your stop_words may be inconsistent with your preprocessing. Tokenizing the stop words generated tokens ['арбаң', 'арсалаң', 'батыр', 'бүгжең', 'бұтыр', 'далаң', 'ербелең', 'жалт', 'жұлт', 'күңгір', 'митың', 'онан', 'паһ', 'салаң', 'сұлаң', 'сұрт', 'тарбаң', 'тыржың', 'тұрс', 'шұңқ', 'ыржың', 'қайқаң', 'қалт', 'қаңғыр', 'қаңқ', 'қош', 'қызараң', 'құйқаң', 'құлт', 'құңқ', 'ұрс', 'әттеген'] not in stop_words.\n 'stop_words.' % sorted(inconsistent))\n"
]
],
[
[
"# Результаты",
"_____no_output_____"
]
],
[
[
"df_idf = pd.DataFrame(vec.idf_, index=vec.get_feature_names(),columns=[\"idf_weights\"])\ndf_idf.sort_values(by=['idf_weights'], ascending=False)[0:20]",
"_____no_output_____"
],
[
"features",
"_____no_output_____"
],
[
"pd.DataFrame(features[i].T.todense(), index=vec.get_feature_names(), columns=[\"tfidf\", \"11\"]).sort_values(by=[\"tfidf\"],ascending=False)[:5]",
"_____no_output_____"
],
[
"tdf = []\nfor i in range(75):\n expp = pd.DataFrame(features[i].T.todense(), index=vec.get_feature_names(), columns=[\"tfidf\"]).sort_values(by=[\"tfidf\"],ascending=False)[:5]\n expp['doc_id'] = [i, i, i, i, i]\n tdf.append(expp)\n\ndfnw = pd.concat(tdf)",
"_____no_output_____"
],
[
"dfnw",
"_____no_output_____"
],
[
"N = 20\n\nidx = np.ravel(features.sum(axis=0).argsort(axis=1))[::1][:N]\n\ntop_10_words = np.array(vec.get_feature_names())[idx].tolist()\n\ntop_10_words",
"_____no_output_____"
],
[
"features[0]",
"_____no_output_____"
],
[
"features[0]\nnp.ravel(features.sum(axis=0).argsort(axis=1))[::1][:N]",
"_____no_output_____"
]
],
[
[
"# Кластеризация",
"_____no_output_____"
]
],
[
[
"cls = KMeans(\n n_clusters=num_clusters,\n random_state=random_state\n)\ncls.fit(features)",
"_____no_output_____"
],
[
"cls.predict(features)\ncls.labels_",
"_____no_output_____"
],
[
"pca = PCA(n_components=pca_num_components, random_state=random_state)\nreduced_features = pca.fit_transform(features.toarray())\n\nreduced_cluster_centers = pca.transform(cls.cluster_centers_)",
"_____no_output_____"
],
[
"centroids = cls.cluster_centers_\nsamplesCentroids = centroids[cls.labels_]",
"_____no_output_____"
],
[
"centoides = pd.DataFrame(centroids)\ncentoides",
"_____no_output_____"
],
[
"np.sum(centoides[1:2].values)",
"_____no_output_____"
],
[
"def calcul(doc, centoides):\n alllist = []\n for i in range(len(centoides)):\n docslist = []\n for j in range(len(doc)):\n sq = np.sum((doc[j:(j+1)].values - centoides[i:(i+1)].values)**2)\n docslist.append(sq)\n alllist.append(docslist)\n \n numpy_array = np.array(alllist)\n transpose = numpy_array.T\n\n transpose_list = transpose.tolist()\n return pd.DataFrame(transpose_list)",
"_____no_output_____"
],
[
"docci = pd.DataFrame(features.toarray())",
"_____no_output_____"
],
[
"calcula = calcul(docci, centoides)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df['Centroid1'] = calcula[0]\ndf['Centroid2'] = calcula[1]\ndf['Centroid3'] = calcula[2]\ndf['Centroid4'] = calcula[3]\ndf['Centroid5'] = calcula[4]\ndf",
"_____no_output_____"
]
],
[
[
"# Определение точности кластеризации",
"_____no_output_____"
]
],
[
[
"plt.scatter(reduced_features[:,0], reduced_features[:,1], c=cls.predict(features))\nplt.scatter(reduced_cluster_centers[:, 0], reduced_cluster_centers[:,1], marker='x', s=150, c='b')",
"_____no_output_____"
],
[
"from sklearn.metrics import homogeneity_score\nhomogeneity_score(df.label, cls.predict(features))",
"_____no_output_____"
],
[
"from sklearn.metrics import silhouette_score\nsilhouette_score(features, labels=cls.predict(features))",
"_____no_output_____"
]
],
[
[
"# Проверька данных",
"_____no_output_____"
]
],
[
[
"df['predic_label'] = cls.labels_",
"_____no_output_____"
],
[
"df[:15]",
"_____no_output_____"
],
[
"df[15:30]",
"_____no_output_____"
],
[
"df[30:45]",
"_____no_output_____"
],
[
"df[45:60]",
"_____no_output_____"
],
[
"df[60:75]",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5194ee5f474f536b60fa33d62d7ccdc5f45f2f4
| 415,968 |
ipynb
|
Jupyter Notebook
|
collecting_tweets_from_candidates.ipynb
|
iamgonzalez/Used-Words-Twitter-Candidates-Election-BR-22
|
5fb3179ae09c11927408e343b417dfaf4046eefc
|
[
"MIT"
] | 1 |
2022-03-19T23:07:51.000Z
|
2022-03-19T23:07:51.000Z
|
collecting_tweets_from_candidates.ipynb
|
iamgonzalez/Used-Words-Twitter-Candidates-Election-BR-22
|
5fb3179ae09c11927408e343b417dfaf4046eefc
|
[
"MIT"
] | null | null | null |
collecting_tweets_from_candidates.ipynb
|
iamgonzalez/Used-Words-Twitter-Candidates-Election-BR-22
|
5fb3179ae09c11927408e343b417dfaf4046eefc
|
[
"MIT"
] | null | null | null | 590.025532 | 38,230 | 0.948842 |
[
[
[
"# Imports",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import stopwords\nfrom nltk.tokenize import word_tokenize\nfrom pymongo import MongoClient\nimport csv\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport seaborn as sns\nimport spacy\nimport tweepy",
"_____no_output_____"
]
],
[
[
"# Help-Functions",
"_____no_output_____"
]
],
[
[
"def open_csv(csv_address):\n '''Loading CSV document with token bearer for conection with Twitter API'''\n with open(csv_address, 'r', encoding = 'utf8') as file:\n reader = csv.reader(file)\n data = list(reader)\n file.close()\n return data[0][1]\n\n\ndef conection_twitter(bearer_token):\n ''' Connecting with Twitter API'''\n # Access key\n client = tweepy.Client(bearer_token=bearer_token)\n return client\n\n\ndef mongo_connection(database_name):\n '''Connecting with Mongo DB and creating Database'''\n client = MongoClient('localhost', 27017)\n # Creating database or connecting\n db = client[database_name]\n return db\n\n\ndef load_tweet(candidate_dict:dict, client_twitter, data_base, maximum_results: int = 100):\n '''Using tweetpy API for loading tweets'''\n # Accessing a dictionary that contains name as key and id as value\n for key, value in candidate_dict.items():\n # Creating a collection in MongoDB using key in dictionary as name\n collection = data_base[key]\n \n # Collecting tweets ussing method .get_users_id from tweepy\n tweets = client_twitter.get_users_tweets(id= value,\n tweet_fields = ['created_at',\n 'lang',\n 'public_metrics',\n 'reply_settings',\n 'entities',\n 'referenced_tweets',\n 'in_reply_to_user_id'],\n expansions='referenced_tweets.id.author_id',\n max_results=maximum_results)\n \n # Using iteration to create variables that will receive data in each tweet, to insert a tweet into the MongoDB collection.\n for tweet in tweets.data:\n \n tweet_id = tweet.id\n user_id = value\n texto = tweet.text\n data = tweet.created_at\n likes = tweet.public_metrics['like_count']\n retweet_count = tweet.public_metrics['retweet_count']\n reply_count = tweet.public_metrics['reply_count']\n quote_count = tweet.public_metrics['quote_count']\n retweet_origen_id = tweet.referenced_tweets\n try:\n link = tweet.entities['urls'][0]['expanded_url']\n except:\n link = ('Null')\n \n # Error handling for Tweet Id already added, because mongo db does not accept repeated Ids\n try:\n collection.insert_one({\n '_id': tweet_id,\n 'user_id':user_id, \n 'texto': texto,\n 'data': data,\n 'likes': likes,\n 'retweet_count':retweet_count,\n 'reply_count': reply_count,\n 'quote_count': quote_count,\n 'retweet_origen_id': retweet_origen_id,\n 'link': link\n })\n except:\n pass\n\n\ndef extract_words(data):\n '''Extracting stopwords for text in tweets using spacy'''\n stop_words = stopwords.words('portuguese')\n texto = data['texto'].to_list()\n \n # Removing stopwords\n striped_phrase = []\n for element in texto:\n words = word_tokenize(element)\n for word in words:\n if word not in stop_words:\n word = word.strip(',:.#')\n word = word.replace('https', '')\n if len(word) >=3:\n striped_phrase.append(word)\n 'Removing whitespaces in a list'\n str_list = list(filter(None, striped_phrase)) \n return str_list\n\n\ndef create_label(word_list):\n '''Using trained pipelines for Portuguese linguage fron spacy library to create label on each word in the list'''\n nlp_lg = spacy.load(\"pt_core_news_lg\")\n #To instantiate the object it is necessary that it is in a string in text format\n str1 = \", \" \n #Adds an empty space to each word of the comma\n stem2 = str1.join(word_list)\n #Instance text as spacy object\n stem2 = nlp_lg(stem2)\n #Using a Comprehension list to create a selected list of text and label '''\n label_lg = [(X.text, X.label_) for X in stem2.ents]\n return label_lg\n\n\ndef create_df(word_label, term: str, max_rows: int):\n '''Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.'''\n upper = term.upper()\n df = pd.DataFrame(word_label, columns = ['Word','Entity'])\n #Entity filtering \n df_org = df.where(df['Entity'] == upper)\n #Creates a repeated word count\n df_org_count = df_org['Word'].value_counts()\n #Selecting the most commonly used words\n df = df_org_count[:max_rows]\n return df\n\n\ndef create_plot(df, title: str, size: tuple ):\n '''Creating a barplot'''\n title_save = title.replace(' ', '-').lower()\n \n path = 'images'\n \n plt.figure(figsize= size)\n sns.barplot(df.values, df.index, alpha=0.8)\n plt.title(title)\n plt.ylabel('Word from Tweet', fontsize=12)\n plt.xlabel('Count of Words', fontsize=12)\n \n plt.savefig(path + '/' + title_save + '.png', dpi = 300, transparent = True, bbox_inches='tight')\n \n plt.show()",
"_____no_output_____"
]
],
[
[
"# Dictionary with candidates",
"_____no_output_____"
]
],
[
[
"# Dict where key = User, Value = Id User\ncandidate_dict = {\n 'Bolsonaro':'128372940',\n 'Ciro': '33374761',\n 'Lula': '2670726740',\n 'Sergio_Moro': '1113094855281008641' \n}",
"_____no_output_____"
]
],
[
[
"# Creating connection to Twitter API",
"_____no_output_____"
]
],
[
[
"# Load a token from csv\ntoken = open_csv('C:/Users/Diego/OneDrive/Cursos e codigos/Codigos/twitter/bearertoken.csv')\n\n# Connecting with Twitter API\nclient_twitter = conection_twitter(token)",
"_____no_output_____"
]
],
[
[
"# Creating connection to MongoDB Database",
"_____no_output_____"
]
],
[
[
"# Creating connection to MongoDB Database\ndb = mongo_connection('data_twitter')",
"_____no_output_____"
]
],
[
[
"# Load tweets and insert then inside MongoDB Collections",
"_____no_output_____"
]
],
[
[
"# Load tweets and insert then inside MongoDB Collections\nload_tweet(candidate_dict = candidate_dict,\n client_twitter = client_twitter,\n data_base = db,\n maximum_results = 5)",
"_____no_output_____"
]
],
[
[
"# Connecting with Collections and Loading DataFrames from MongoDB",
"_____no_output_____"
]
],
[
[
"# Connecting with collections from MongoDb\ncollection_Bolsonaro = db.Bolsonaro\ncollection_Ciro = db.Ciro\ncollection_Lula = db.Lula\ncollection_SergioMoro = db.Sergio_Moro",
"_____no_output_____"
],
[
"# Loading DataFrames from MongoDB\ndf_bol = pd.DataFrame(collection_Bolsonaro.find())\ndf_cir = pd.DataFrame(collection_Ciro.find())\ndf_lul = pd.DataFrame(collection_Lula.find())\ndf_ser = pd.DataFrame(collection_SergioMoro.find())",
"_____no_output_____"
]
],
[
[
"# Operations in DataFrame",
"_____no_output_____"
]
],
[
[
"# Extracting words fron DataFrame and remove stopwords\nbol_words = extract_words(df_bol)\ncir_words = extract_words(df_cir)\nlul_words = extract_words(df_lul)\nser_words = extract_words(df_ser)",
"_____no_output_____"
],
[
"# Creating labels from the list, uning spacy\nbol_label = create_label(bol_words)\ncir_label = create_label(cir_words)\nlul_label = create_label(lul_words)\nser_label = create_label(ser_words)",
"_____no_output_____"
],
[
"# Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.\nbol_df_loc = create_df(bol_label, 'LOC', 30)\ncir_df_loc = create_df(cir_label, 'LOC', 30)\nlul_df_loc = create_df(lul_label, 'LOC', 30)\nser_df_loc = create_df(ser_label, 'LOC', 30)",
"_____no_output_____"
]
],
[
[
"# Views of the top location mentioned by each candidate",
"_____no_output_____"
]
],
[
[
"# Creating DataFrame with labels, term of occurrence, and total of DataFrame rows.\nbol_df_loc = create_df(bol_label, 'LOC', 30)\ncir_df_loc = create_df(cir_label, 'LOC', 30)\nlul_df_loc = create_df(lul_label, 'LOC', 30)\nser_df_loc = create_df(ser_label, 'LOC', 30)",
"_____no_output_____"
],
[
"# Creating plots from DataFrames \nbol_plot = create_plot(bol_df_loc, 'Top Location Mentioned By Bolsonaro', (20,10))\ncir_plot = create_plot(cir_df_loc, 'Top Location Mentioned By Ciro Gomes', (20,10))\nlul_plot = create_plot(lul_df_loc, 'Top Location Mentioned By Luiz Inácio Lula da Silva', (20,10))\nser_plot = create_plot(ser_df_loc, 'Top Location Mentioned By Sergio Moro', (20,10))",
"C:\\Users\\Diego\\AppData\\Roaming\\Python\\Python38\\site-packages\\seaborn\\_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n warnings.warn(\n"
]
],
[
[
"# Views of the top persons mentioned by each candidate",
"_____no_output_____"
]
],
[
[
"bol_df_loc = create_df(bol_label, 'PER', 30)\ncir_df_loc = create_df(cir_label, 'PER', 30)\nlul_df_loc = create_df(lul_label, 'PER', 30)\nser_df_loc = create_df(ser_label, 'PER', 30)",
"_____no_output_____"
],
[
"bol_plot = create_plot(bol_df_loc, 'Top Persons Mentioned By Bolsonaro', (20,10))\ncir_plot = create_plot(cir_df_loc, 'Top Persons Mentioned By Ciro Gomes', (20,10))\nlul_plot = create_plot(lul_df_loc, 'Top Persons Mentioned By Luiz Inácio Lula da Silva', (20,10))\nser_plot = create_plot(ser_df_loc, 'Top Persons Mentioned By Sergio Moro', (20,10))",
"C:\\Users\\Diego\\AppData\\Roaming\\Python\\Python38\\site-packages\\seaborn\\_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n warnings.warn(\n"
]
],
[
[
"# Views of the top organizations mentioned by each candidate",
"_____no_output_____"
]
],
[
[
"bol_df_loc = create_df(bol_label, 'ORG', 30)\ncir_df_loc = create_df(cir_label, 'ORG', 30)\nlul_df_loc = create_df(lul_label, 'ORG', 30)\nser_df_loc = create_df(ser_label, 'ORG', 30)",
"_____no_output_____"
],
[
"bol_plot = create_plot(bol_df_loc, 'Top Organization Mentioned By Bolsonaro', (20,10))\ncir_plot = create_plot(cir_df_loc, 'Top Organization Mentioned By Ciro Gomes', (20,10))\nlul_plot = create_plot(lul_df_loc, 'Top Organization Mentioned By Luiz Inácio Lula da Silva', (20,10))\nser_plot = create_plot(ser_df_loc, 'Top Organization Mentioned By Sergio Moro', (20,10))",
"C:\\Users\\Diego\\AppData\\Roaming\\Python\\Python38\\site-packages\\seaborn\\_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n warnings.warn(\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
c51960eb05e41ffb6e8a3455cdd22ca5fd5d154e
| 89,712 |
ipynb
|
Jupyter Notebook
|
Variacoes_de_ataques/Singulares_CNN/CNN(21.02).ipynb
|
AfonsoSeguro/IDS_Comportamental
|
83145f815b67b2d501eb3744367aaea9b5d11cba
|
[
"MIT"
] | null | null | null |
Variacoes_de_ataques/Singulares_CNN/CNN(21.02).ipynb
|
AfonsoSeguro/IDS_Comportamental
|
83145f815b67b2d501eb3744367aaea9b5d11cba
|
[
"MIT"
] | null | null | null |
Variacoes_de_ataques/Singulares_CNN/CNN(21.02).ipynb
|
AfonsoSeguro/IDS_Comportamental
|
83145f815b67b2d501eb3744367aaea9b5d11cba
|
[
"MIT"
] | 1 |
2021-09-05T13:56:36.000Z
|
2021-09-05T13:56:36.000Z
| 50.118436 | 16,544 | 0.535346 |
[
[
[
"import os\nimport numpy as np\nimport itertools\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom sklearn.utils import shuffle\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.model_selection import train_test_split\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"df15 = pd.read_csv(\"../Dataset/21-02-2018.csv\", low_memory = False)",
"_____no_output_____"
],
[
"df15 = df15.drop([0,1])",
"_____no_output_____"
],
[
"df15",
"_____no_output_____"
],
[
"df16Aux = pd.read_csv(\"../Dataset/02-03-2018.csv\", low_memory = False)",
"_____no_output_____"
],
[
"df16Aux = df16Aux.drop([0,1])",
"_____no_output_____"
],
[
"df16Aux",
"_____no_output_____"
],
[
"listOrd = df15.columns.tolist()",
"_____no_output_____"
],
[
"df16 = pd.DataFrame()\nfor colu in listOrd:\n df16[colu] = df16Aux[colu]",
"_____no_output_____"
],
[
"df16",
"_____no_output_____"
],
[
"df16Aux = None",
"_____no_output_____"
],
[
"input_label15 = np.array(df15.loc[:, df15.columns != \"Label\"]).astype(np.float)",
"_____no_output_____"
],
[
"output_label15 = np.array(df15[\"Label\"])",
"_____no_output_____"
],
[
"out = []\nfor o in output_label15:\n if(o == \"Benign\"):out.append(0)\n else: out.append(1)\noutput_label15 = out",
"_____no_output_____"
],
[
"input_label16 = np.array(df16.loc[:, df16.columns != \"Label\"]).astype(np.float)",
"_____no_output_____"
],
[
"output_label16 = np.array(df16[\"Label\"])",
"_____no_output_____"
],
[
"out = []\nfor o in output_label16:\n if(o == \"Benign\"):out.append(0)\n else: out.append(1)\noutput_label16 = out",
"_____no_output_____"
],
[
"dfAE = pd.concat([df15, df16])",
"_____no_output_____"
],
[
"input_labelAE = np.array(dfAE.loc[:, dfAE.columns != \"Label\"]).astype(np.float)",
"_____no_output_____"
],
[
"output_labelAE = np.array(dfAE[\"Label\"])",
"_____no_output_____"
],
[
"out = []\nfor o in output_labelAE:\n if(o == \"Benign\"):out.append(0)\n else: out.append(1)\noutput_labelAE = out",
"_____no_output_____"
],
[
"dfAE = None\ndf15 = None\ndf16 = None",
"_____no_output_____"
],
[
"scaler = MinMaxScaler(feature_range=(0,1))\nscaler.fit(input_labelAE)\ninput_label15 = scaler.transform(input_label15)\ninput_label16 = scaler.transform(input_label16)\ninput_labelAE = scaler.transform(input_labelAE)",
"_____no_output_____"
],
[
"input_labelAE, output_labelAE = shuffle(input_labelAE, output_labelAE)\ninput_label15, output_label15 = shuffle(input_label15, output_label15)\ninput_label16, output_label16 = shuffle(input_label16, output_label16)",
"_____no_output_____"
]
],
[
[
"## AutoEncoder",
"_____no_output_____"
]
],
[
[
"inp_train,inp_test,out_train,out_test = train_test_split(input_labelAE, input_labelAE, test_size=0.2)",
"_____no_output_____"
],
[
"input_model = keras.layers.Input(shape = (78,))\nenc = keras.layers.Dense(units = 64, activation = \"relu\", use_bias = True)(input_model)\nenc = keras.layers.Dense(units = 36, activation = \"relu\", use_bias = True)(enc)\nenc = keras.layers.Dense(units = 18, activation = \"relu\")(enc)\ndec = keras.layers.Dense(units = 36, activation = \"relu\", use_bias = True)(enc)\ndec = keras.layers.Dense(units = 64, activation = \"relu\", use_bias = True)(dec)\ndec = keras.layers.Dense(units = 78, activation = \"relu\", use_bias = True)(dec)\nauto_encoder = keras.Model(input_model, dec)",
"_____no_output_____"
],
[
"encoder = keras.Model(input_model, enc)\ndecoder_input = keras.layers.Input(shape = (18,))\ndecoder_layer = auto_encoder.layers[-3](decoder_input)\ndecoder_layer = auto_encoder.layers[-2](decoder_layer)\ndecoder_layer = auto_encoder.layers[-1](decoder_layer)\ndecoder = keras.Model(decoder_input, decoder_layer)",
"_____no_output_____"
],
[
"auto_encoder.compile(optimizer=keras.optimizers.Adam(learning_rate=0.00025), loss = \"mean_squared_error\", metrics = ['accuracy'])",
"_____no_output_____"
],
[
"train = auto_encoder.fit(x = np.array(inp_train), y = np.array(out_train),validation_split= 0.1, epochs = 10, verbose = 1, shuffle = True)",
"Epoch 1/10\n47095/47095 [==============================] - 48s 1ms/step - loss: 0.0117 - accuracy: 0.7586 - val_loss: 0.0103 - val_accuracy: 0.6130\nEpoch 2/10\n47095/47095 [==============================] - 45s 960us/step - loss: 0.0102 - accuracy: 0.7804 - val_loss: 0.0101 - val_accuracy: 0.8719loss: 0.0102 - - ETA: 0s - loss: 0.010\nEpoch 3/10\n47095/47095 [==============================] - 47s 1ms/step - loss: 0.0102 - accuracy: 0.7826 - val_loss: 0.0101 - val_accuracy: 0.5961acy - ETA: - ETA: - ETA: 5s - loss: 0.010 - ETA: 4s - loss: 0.0102 - accuracy: - ETA: 4s - loss: 0.0102 - accu - ETA: 3s - loss: 0.0102 - ac - ETA: 3s - loss: 0.0102 - accuracy: 0. -\nEpoch 4/10\n47095/47095 [==============================] - 45s 962us/step - loss: 0.0102 - accuracy: 0.7829 - val_loss: 0.0101 - val_accuracy: 0.7923\nEpoch 5/10\n47095/47095 [==============================] - 47s 988us/step - loss: 0.0102 - accuracy: 0.7834 - val_loss: 0.0101 - val_accuracy: 0.7891\nEpoch 6/10\n47095/47095 [==============================] - 46s 971us/step - loss: 0.0102 - accuracy: 0.7839 - val_loss: 0.0101 - val_accuracy: 0.8562\nEpoch 7/10\n47095/47095 [==============================] - 48s 1ms/step - loss: 0.0101 - accuracy: 0.7844 - val_loss: 0.0100 - val_accuracy: 0.9640loss: 0.0102 - accuracy: 0.7 - ETA: 43s - loss: 0.0102 - accuracy: 0. - ETA: 34s - loss: 0.0102 - accuracy: 0.78 - ETA: 34s - loss: 0.0102 - accuracy: 0. - ETA: 34s - loss: 0.0102 - accura - ETA: 33s - ETA: 7s - loss: 0.0102 - accura - ETA: 7s - l - ETA: 6s - loss: 0.0102 - accuracy - ETA: 6s - loss: 0.010 - ETA: 6s - loss: 0.0102 - accuracy: 0. - ETA: 6s - loss: 0.010 - ETA: 5s - loss: 0.0102 - accuracy: 0. -\nEpoch 8/10\n47095/47095 [==============================] - 47s 1ms/step - loss: 0.0100 - accuracy: 0.7839 - val_loss: 0.0100 - val_accuracy: 0.7077\nEpoch 9/10\n47095/47095 [==============================] - 48s 1ms/step - loss: 0.0100 - accuracy: 0.7829 - val_loss: 0.0100 - val_accuracy: 0.7052\nEpoch 10/10\n47095/47095 [==============================] - 48s 1ms/step - loss: 0.0100 - accuracy: 0.7828 - val_loss: 0.0100 - val_accuracy: 0.6559\n"
],
[
"predict = auto_encoder.predict(inp_test)",
"_____no_output_____"
],
[
"losses = keras.losses.mean_squared_error(out_test, predict).numpy()",
"_____no_output_____"
],
[
"total = 0\nfor loss in losses:\n total += loss\nprint(total / len(losses))",
"0.010032695569909789\n"
],
[
"input_labelAE = None\ninput_label15 = encoder.predict(input_label15).reshape(len(input_label15), 18, 1)\ninput_label16 = encoder.predict(input_label16).reshape(len(input_label16), 18, 1)",
"_____no_output_____"
]
],
[
[
"## Classificador",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n keras.layers.Conv1D(filters = 16, input_shape = (18,1), kernel_size = 3, padding = \"same\", activation = \"relu\", use_bias = True),\n keras.layers.MaxPool1D(pool_size = 3),\n keras.layers.Conv1D(filters = 8, kernel_size = 3, padding = \"same\", activation = \"relu\", use_bias = True),\n keras.layers.MaxPool1D(pool_size = 3),\n keras.layers.Flatten(),\n keras.layers.Dense(units = 2, activation = \"softmax\")\n ])",
"_____no_output_____"
],
[
"model.compile(optimizer= keras.optimizers.Adam(learning_rate= 0.00025), loss=\"sparse_categorical_crossentropy\", metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(x = np.array(input_label15), y = np.array(output_label15), validation_split= 0.1, epochs = 10, shuffle = True,verbose = 1)",
"Epoch 1/10\n29492/29492 [==============================] - 42s 1ms/step - loss: 0.0624 - accuracy: 0.9885 - val_loss: 5.8082e-04 - val_accuracy: 0.9999\nEpoch 2/10\n29492/29492 [==============================] - 41s 1ms/step - loss: 8.2366e-04 - accuracy: 0.9999 - val_loss: 4.3833e-04 - val_accuracy: 1.0000\nEpoch 3/10\n29492/29492 [==============================] - 41s 1ms/step - loss: 3.4517e-04 - accuracy: 0.9999 - val_loss: 2.2550e-04 - val_accuracy: 1.0000\nEpoch 4/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 2.0469e-04 - accuracy: 1.0000 - val_loss: 2.0910e-04 - val_accuracy: 1.0000\nEpoch 5/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 2.4514e-04 - accuracy: 1.0000 - val_loss: 1.9018e-04 - val_accuracy: 1.0000\nEpoch 6/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 1.4517e-04 - accuracy: 1.0000 - val_loss: 1.6735e-04 - val_accuracy: 1.0000\nEpoch 7/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 1.5353e-04 - accuracy: 1.0000 - val_loss: 1.5721e-04 - val_accuracy: 1.0000\nEpoch 8/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 1.0564e-04 - accuracy: 1.0000 - val_loss: 1.5042e-04 - val_accuracy: 1.0000\nEpoch 9/10\n29492/29492 [==============================] - 40s 1ms/step - loss: 1.1315e-04 - accuracy: 1.0000 - val_loss: 1.6405e-04 - val_accuracy: 1.0000\nEpoch 10/10\n29492/29492 [==============================] - 41s 1ms/step - loss: 8.2404e-05 - accuracy: 1.0000 - val_loss: 1.5585e-04 - val_accuracy: 1.0000\n"
],
[
"res = [np.argmax(resu) for resu in model.predict(input_label16)]",
"_____no_output_____"
],
[
"cm = confusion_matrix(y_true = np.array(output_label16).reshape(len(output_label16)), y_pred = np.array(res))",
"_____no_output_____"
],
[
"def plot_confusion_matrix(cm, classes, normaliza = False, title = \"Confusion matrix\", cmap = plt.cm.Blues):\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45)\n plt.yticks(tick_marks, classes)\n if normaliza:\n cm = cm.astype('float') / cm.sum(axis = 1)[:, np.newaxis]\n print(\"Normalized confusion matrix\")\n else:\n print(\"Confusion matrix, without normalization\")\n \n print(cm)\n \n thresh = cm.max() / 2\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, cm[i, j],\n horizontalalignment=\"center\",\n color=\"white\" if cm[i,j] > thresh else \"black\")\n \n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predicted label')",
"_____no_output_____"
],
[
"labels = [\"Benign\", \"Dos\"]\nplot_confusion_matrix(cm = cm, classes = labels, title = \"Dos IDS\")",
"Confusion matrix, without normalization\n[[494817 263517]\n [143272 142919]]\n"
],
[
"from sklearn.metrics import roc_curve\nfrom sklearn.metrics import roc_auc_score",
"_____no_output_____"
],
[
"output_label16 = np.array(output_label16).reshape(len(output_label16))\nres = np.array(res)\nfpr, tpr, _ = roc_curve(output_label16, res)\nauc = roc_auc_score(output_label16, res)",
"_____no_output_____"
],
[
"plt.plot(fpr, tpr, label=\"auc=\" + str(auc))\nplt.legend(loc=4)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c5197905779a54d551457fb77f7f423a74ad99df
| 49,963 |
ipynb
|
Jupyter Notebook
|
final_project/notebooks/01_food_inspections_data_prep.ipynb
|
jstremme/DATA512-Research
|
21650ed519bc27fc005721058e1000b7a4a9bc52
|
[
"MIT"
] | 2 |
2019-12-07T16:33:06.000Z
|
2020-04-30T22:45:25.000Z
|
final_project/notebooks/01_food_inspections_data_prep.ipynb
|
jstremme/DATA512-Research
|
21650ed519bc27fc005721058e1000b7a4a9bc52
|
[
"MIT"
] | null | null | null |
final_project/notebooks/01_food_inspections_data_prep.ipynb
|
jstremme/DATA512-Research
|
21650ed519bc27fc005721058e1000b7a4a9bc52
|
[
"MIT"
] | 1 |
2021-12-04T00:53:18.000Z
|
2021-12-04T00:53:18.000Z
| 27.943512 | 723 | 0.409263 |
[
[
[
"# Data Prep of Chicago Food Inspections Data\nThis notebook reads in the food inspections dataset containing records of food inspections in Chicago since 2010. This dataset is freely available through healthdata.gov, but must be provided with the odbl license linked below and provided within this repository. This notebook prepares the data for statistical analysis and modeling by creating features from categorical variables and enforcing a prevalence threshold for these categories. Note that in this way, rare features are not analyzed or used to create a model (to encourage generalizability), though the code is designed so that it would be easy to change or eliminate the prevalence threshold to run downstream analysis with a different feature set.\n\n### References\n- Data Source: https://healthdata.gov/dataset/food-inspections\n- License: http://opendefinition.org/licenses/odc-odbl/",
"_____no_output_____"
],
[
"### Set Global Seed",
"_____no_output_____"
]
],
[
[
"SEED = 666",
"_____no_output_____"
]
],
[
[
"### Imports",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"### Read Chicago Food Inspections Data\nCount records and columns.",
"_____no_output_____"
]
],
[
[
"food_inspections_df = pd.read_csv('../data/Food_Inspections.gz', compression='gzip')",
"_____no_output_____"
],
[
"food_inspections_df.shape",
"_____no_output_____"
]
],
[
[
"### Rename Columns",
"_____no_output_____"
]
],
[
[
"food_inspections_df.columns.tolist()",
"_____no_output_____"
],
[
"columns = ['inspection_id', 'dba_name', 'aka_name', 'license_number', 'facility_type',\n 'risk', 'address', 'city', 'state', 'zip', 'inspection_date', 'inspection_type',\n 'result', 'violation', 'latitude', 'longitude', 'location']",
"_____no_output_____"
],
[
"food_inspections_df.columns = columns",
"_____no_output_____"
]
],
[
[
"### Convert Zip Code to String\nAnd take only the first five digits, chopping off the decimal from reading the column as a float.",
"_____no_output_____"
]
],
[
[
"food_inspections_df['zip'] = food_inspections_df['zip'].astype(str).apply(lambda x: x.split('.')[0])",
"_____no_output_____"
]
],
[
[
"### Normalize Casing of Chicago\nAccept only proper spellings of the word Chicago with mixed casing accepted.",
"_____no_output_____"
]
],
[
[
"food_inspections_df['city'] = food_inspections_df['city'].apply(lambda x: 'CHICAGO'\n if str(x).upper() == 'CHICAGO'\n else x)",
"_____no_output_____"
]
],
[
[
"### Filter for Facilities in Chicago Illinois",
"_____no_output_____"
]
],
[
[
"loc_condition = (food_inspections_df['city'] == 'CHICAGO') & (food_inspections_df['state'] == 'IL')",
"_____no_output_____"
]
],
[
[
"### Drop Redundant Information\n- Only Chicago is considered\n- Only Illinois is considered\n- Location is encoded as separate latitute and longitude columns",
"_____no_output_____"
]
],
[
[
"food_inspections_df = food_inspections_df[loc_condition].drop(['city', 'state', 'location'], 1)",
"_____no_output_____"
],
[
"food_inspections_df.shape",
"_____no_output_____"
]
],
[
[
"### Create Codes Corresponding to Each Violation Type by Parsing Violation Text",
"_____no_output_____"
]
],
[
[
"def create_violation_code(violation_text):\n \n if violation_text != violation_text:\n return -1\n else:\n return int(violation_text.split('.')[0])",
"_____no_output_____"
],
[
"food_inspections_df['violation_code'] = food_inspections_df['violation'].apply(create_violation_code)",
"_____no_output_____"
]
],
[
[
"### Create Attribute Dataframes with the Unique Inspection ID for Lookups if Needed\n- Names\n- Licenses\n- Locations\n- Violations\n- Dates",
"_____no_output_____"
]
],
[
[
"names = ['inspection_id', 'dba_name', 'aka_name']\nnames_df = food_inspections_df[names]",
"_____no_output_____"
],
[
"licenses = ['inspection_id', 'license_number']\nlicenses_df = food_inspections_df[licenses]",
"_____no_output_____"
],
[
"locations = ['inspection_id', 'address', 'latitude', 'longitude']\nlocations_df = food_inspections_df[locations]",
"_____no_output_____"
],
[
"violations = ['inspection_id', 'violation', 'violation_code']\nviolations_df = food_inspections_df[violations]",
"_____no_output_____"
],
[
"dates = ['inspection_id', 'inspection_date']\ndates_df = food_inspections_df[dates]",
"_____no_output_____"
]
],
[
[
"### Drop Features Not Used in Statistical Analysis\nFeatures such as:\n\n- `DBA Name`\n- `AKA Name`\n- `License #`\n- `Address`\n- `Violations`\n- `Inspection Date`\n\nMay be examined following statistical analysis by joining on `Inspection ID`. **Note:** future iterations of this work may wish to consider:\n\n- Text from the the facility name\n- Street level information from the facility address\n- Prior inspections of the same facility by performing a temporal analysis of the data using `Inspection Date`",
"_____no_output_____"
]
],
[
[
"not_considered = ['dba_name', 'aka_name', 'license_number', 'address', 'violation', 'inspection_date']\nfood_inspections_df = food_inspections_df.drop(not_considered, 1)",
"_____no_output_____"
]
],
[
[
"### Create Dataframes of Count and Prevalence for Categorical Features\n- Facility types\n- Violation codes\n- Zip codes\n- Inspection types",
"_____no_output_____"
]
],
[
[
"facilities = food_inspections_df['facility_type'].value_counts()\nfacilities_df = pd.DataFrame({'facility_type':facilities.index, 'count':facilities.values})\nfacilities_df['prevalence'] = facilities_df['count'] / food_inspections_df.shape[0]",
"_____no_output_____"
],
[
"facilities_df.nlargest(10, 'count')",
"_____no_output_____"
],
[
"facilities_df.nsmallest(10, 'count')",
"_____no_output_____"
],
[
"violations = food_inspections_df['violation_code'].value_counts()\nviolations_df = pd.DataFrame({'violation_code':violations.index, 'count':violations.values})\nviolations_df['prevalence'] = violations_df['count'] / food_inspections_df.shape[0]",
"_____no_output_____"
],
[
"violations_df.nlargest(10, 'count')",
"_____no_output_____"
],
[
"violations_df.nsmallest(10, 'count')",
"_____no_output_____"
],
[
"zips = food_inspections_df['zip'].value_counts()\nzips_df = pd.DataFrame({'zip':zips.index, 'count':zips.values})\nzips_df['prevalence'] = zips_df['count'] / food_inspections_df.shape[0]",
"_____no_output_____"
],
[
"zips_df.nlargest(10, 'count')",
"_____no_output_____"
],
[
"zips_df.nsmallest(10, 'count')",
"_____no_output_____"
],
[
"inspections = food_inspections_df['inspection_type'].value_counts()\ninspections_df = pd.DataFrame({'inspection_type':inspections.index, 'count':inspections.values})\ninspections_df['prevalence'] = inspections_df['count'] / food_inspections_df.shape[0]",
"_____no_output_____"
],
[
"inspections_df.nlargest(10, 'count')",
"_____no_output_____"
],
[
"inspections_df.nsmallest(10, 'count')",
"_____no_output_____"
],
[
"results = food_inspections_df['result'].value_counts()\nresults_df = pd.DataFrame({'result':results.index, 'count':results.values})\nresults_df['prevalence'] = results_df['count'] / food_inspections_df.shape[0]",
"_____no_output_____"
],
[
"results_df.nlargest(10, 'count')",
"_____no_output_____"
]
],
[
[
"### Drop Violation Code for Now\nWe can join back using the Inspection ID to learn about types of violations, but we don't want to use any information about the violation itself to predict if a food inspection will pass or fail.",
"_____no_output_____"
]
],
[
[
"food_inspections_df = food_inspections_df.drop('violation_code', 1)",
"_____no_output_____"
]
],
[
[
"### Create Risk Group Feature\nIf the feature cannot be found in the middle of the text string as a value 1-3, return -1.",
"_____no_output_____"
]
],
[
[
"def create_risk_groups(risk_text):\n \n try: \n risk = int(risk_text.split(' ')[1])\n return risk\n except:\n return -1",
"_____no_output_____"
],
[
"food_inspections_df['risk'] = food_inspections_df['risk'].apply(create_risk_groups)",
"_____no_output_____"
]
],
[
[
"### Format Result\n- Encode Pass and Pass w/ Conditions as 0\n- Encode Fail as 1\n- Encode all others as -1 and filter out these results",
"_____no_output_____"
]
],
[
[
"def format_results(result):\n \n if result == 'Pass':\n return 0\n elif result == 'Pass w/ Conditions':\n return 0\n elif result == 'Fail':\n return 1\n else:\n return -1",
"_____no_output_____"
],
[
"food_inspections_df['result'] = food_inspections_df['result'].apply(format_results)\nfood_inspections_df = food_inspections_df[food_inspections_df['result'] != -1]",
"_____no_output_____"
],
[
"food_inspections_df.shape",
"_____no_output_____"
]
],
[
[
"### Filter for Categorical Features that Pass some Prevalence Threshold\nThis way we only consider fairly common attributes of historical food establishments and inspections so that our analysis will generalize to new establishments and inspections. **Note:** the prevalence threshold is set to **0.1%**.",
"_____no_output_____"
]
],
[
[
"categorical_features = ['facility_type', 'zip', 'inspection_type']",
"_____no_output_____"
],
[
"def prev_filter(df, feature, prevalence='prevalence', prevalence_threshold=0.001):\n \n return df[df[prevalence] > prevalence_threshold][feature].tolist()",
"_____no_output_____"
],
[
"feature_dict = dict(zip(categorical_features, [prev_filter(facilities_df, 'facility_type'),\n prev_filter(zips_df, 'zip'),\n prev_filter(inspections_df, 'inspection_type')]))",
"_____no_output_____"
]
],
[
[
"### Encode Rare Features with the 'DROP' String, to be Removed Later\nNote that by mapping all rare features to the 'DROP' attribute, we avoid having to one-hot-encode all rare features and then drop them after the fact. That would create an unnecessarily large feature matrix. Instead we one-hot encode features passing the prevalence threshold and then drop all rare features that were tagged with the 'DROP' string.",
"_____no_output_____"
]
],
[
[
"for feature in categorical_features:\n food_inspections_df[feature] = food_inspections_df[feature].apply(lambda x: \n x if x in feature_dict[feature]\n else 'DROP')",
"_____no_output_____"
],
[
"feature_df = pd.get_dummies(food_inspections_df,\n prefix=['{}'.format(feature) for feature in categorical_features],\n columns=categorical_features)",
"_____no_output_____"
],
[
"feature_df = feature_df[[col for col in feature_df.columns if 'DROP' not in col]]",
"_____no_output_____"
],
[
"feature_df.shape",
"_____no_output_____"
]
],
[
[
"### Drop Features with:\n- Risk level not recorded as 1, 2, or 3\n- Result not recorded as Pass, Pass w/ Conditions, or Fail\n- NA values (Some latitudes and longitudes are NA)",
"_____no_output_____"
]
],
[
[
"feature_df = feature_df[feature_df['risk'] != -1]\nfeature_df = feature_df[feature_df['result'] != -1]\nfeature_df = feature_df.dropna()",
"_____no_output_____"
],
[
"feature_df.shape",
"_____no_output_____"
]
],
[
[
"### Write the Feature Set to a Compressed CSV File to Load for Modeling and Analysis",
"_____no_output_____"
]
],
[
[
"feature_df.to_csv('../data/Food_Inspection_Features.gz', compression='gzip', index=False)",
"_____no_output_____"
]
],
[
[
"### Write off Zip Codes to Join with Census Data",
"_____no_output_____"
]
],
[
[
"zips_df.to_csv('../data/Zips.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
c51983f0df247a34baf9ae0af6d7a661c251d663
| 135,945 |
ipynb
|
Jupyter Notebook
|
weibull/Weibull_RRXY_MTF_Streamlined.ipynb
|
manual123/Nacho-Jupyter-Notebooks
|
e75523434b1a90313a6b44e32b056f63de8a7135
|
[
"MIT"
] | 2 |
2021-02-13T05:52:05.000Z
|
2022-02-08T09:52:35.000Z
|
weibull/Weibull_RRXY_MTF_Streamlined.ipynb
|
manual123/Nacho-Jupyter-Notebooks
|
e75523434b1a90313a6b44e32b056f63de8a7135
|
[
"MIT"
] | null | null | null |
weibull/Weibull_RRXY_MTF_Streamlined.ipynb
|
manual123/Nacho-Jupyter-Notebooks
|
e75523434b1a90313a6b44e32b056f63de8a7135
|
[
"MIT"
] | null | null | null | 367.418919 | 50,779 | 0.910214 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
c5198efef0d7cf10f359bf192228969aa1a3352c
| 18,985 |
ipynb
|
Jupyter Notebook
|
Comprehensive Evaluation & Decision-making Methods/Grey Relational Analysis.ipynb
|
FinCreWorld/Mathematical-Modeling-with-Python
|
d5206309bce32f2aa64fe94ab4e8a576add0e628
|
[
"MIT"
] | null | null | null |
Comprehensive Evaluation & Decision-making Methods/Grey Relational Analysis.ipynb
|
FinCreWorld/Mathematical-Modeling-with-Python
|
d5206309bce32f2aa64fe94ab4e8a576add0e628
|
[
"MIT"
] | 1 |
2021-08-21T09:36:54.000Z
|
2021-08-21T09:36:54.000Z
|
Comprehensive Evaluation & Decision-making Methods/Grey Relational Analysis.ipynb
|
FinCreWorld/Mathematical-Modeling-with-Python
|
d5206309bce32f2aa64fe94ab4e8a576add0e628
|
[
"MIT"
] | 3 |
2021-08-21T09:25:22.000Z
|
2021-08-29T12:04:49.000Z
| 30.18283 | 157 | 0.365762 |
[
[
[
"# 灰色关联分析法 Grey Relational Analysis\n\nFinCreWorld & xyfJASON\n\n## 1 简述\n\n> 参考资料:[数学建模笔记——评价类模型之灰色关联分析 - 小白的文章 - 知乎](https://zhuanlan.zhihu.com/p/161536409)\n\n灰色关联分析的研究对象是一个系统,系统的发展受多个因素的影响,我们想知道这些因素中哪些影响大、哪些影响小。\n\n如果把系统和因素都量化为数值,那么我们研究的就是多个序列的关联程度,或者换句话说,这些序列的**曲线几何形状的相似程度**。形状越相似,说明关联度越高。我们只需要量化各个因素的曲线 $\\{x_i\\}$ 与系统的曲线 $\\{x_0\\}$ 之间的相似程度,就能刻画出各个因素对系统的影响程度。\n\n也就是说,我们应用灰色关联分析法的时候,需要一个母序列(参考数列) $\\{x_0\\}$ 和若干子序列(比较数列) $\\{x_i\\}$。\n\n可是这和我们的主题——综合评价与决策有什么关系呢?在做评价类问题时,我们需要人为构造这个母序列——**将各个指标中最好的数据合并**作为「理想解」,然后计算各评价对象关于这个理想解的灰色关联度,关联度越高,评价对象越好。\n\n## 2 步骤\n\n1. 确定比较对象(评价对象)和参考数列(评价标准)\n\n 设有 $m$ 个评价对象,$n$ 个评价指标,则参考数列为 $x_0=\\{x_0(k)|k=1,2,\\cdots,n\\}$,比较数列为\n\n $$\n x_i=\\{x_i(k)|k=1,2,\\cdots,n\\},i=1,2,\\cdots,m\n $$\n \n 注意所有的指标都需要**正向化**。\n\n\n2. 确定各指标值对应的权重\n \n $$\n w=[w_1,\\cdots,w_n]\n $$\n\n\n3. 计算灰色关联系数\n \n $$\n \\xi_i(k)=\\frac{\\min\\limits_s\\min\\limits_t|x_0(t)-x_s(t)|+\\rho\\max\\limits_s\\max\\limits_t|x_0(t)-x_s(t)|}\n {|x_0(k)-x_i(k)|+\\rho\\max\\limits_s\\max\\limits_t|x_0(t)-x_s(t)|}\n $$\n \n 称 'minmin' 项为两级最小差,'maxmax' 项为两级最大差,$\\rho$ 为分辨系数,$\\rho$ 越大,分辨率越大\n\n\n4. 计算灰色加权关联度。其计算公式为\n \n $$\n r_i=\\sum\\limits_{k=1}^nw_i\\xi_i(k)\n $$\n \n $r_i$ 为第 $i$ 个评价对象对理想对象的灰色加权关联度。\n\n\n5. 评价分析\n\n 根据灰色加权关联度的大小,对各评价对象进行排序,可以建立评价对象的关联序,关联度越大,评价结果越好。",
"_____no_output_____"
],
[
"## 3 代码模板\n\n见同文件夹下的 `evaluation.py` 模块。",
"_____no_output_____"
],
[
"## 4 实例\n\n在 6 个待选的零部件供应商中选择一个合作伙伴,各待选供应商有关数据如下",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndf = pd.DataFrame([[ 0.83 , 0.9 , 0.99 , 0.92 , 0.87 , 0.95 ],\n [ 326 , 295 , 340 , 287 , 310 , 303 ],\n [ 21 , 38 , 25 , 19 , 27 , 10 ],\n [ 3.2 , 2.4 , 2.2 , 2 , 0.9 , 1.7 ],\n [ 0.2 , 0.25 , 0.12 , 0.33 , 0.2 , 0.09 ],\n [ 0.15 , 0.2 , 0.14 , 0.09 , 0.15 , 0.17 ],\n [ 250 , 180 , 300 , 200 , 150 , 175 ],\n [ 0.23 , 0.15 , 0.27 , 0.3 , 0.18 , 0.26 ],\n [ 0.87 , 0.95 , 0.99 , 0.89 , 0.82 , 0.94 ]])\ndf.columns = [['待选供应商']*6, list('123456')]\ndf.index = ['产品质量', '产品价格', '地理位置', '售后服务', '技术水平', '经济效益', '供应能力', '市场影响度', '交货情况']\ndf",
"_____no_output_____"
]
],
[
[
"其中产品质量、技术水平、供应能力、经济效益、交货情况、市场影响度指标为效益型指标,其标准化方式为\n\n$$\nstd = \\frac{ori - \\min(ori)}{\\max(ori) - \\min(ori)}\n$$\n\n而产品地位、地理位置、售后服务指标属于成本型指标,其标准化方式为\n\n$$\nstd = \\frac{\\max(ori) - ori}{\\max(ori) - \\min(ori)}\n$$",
"_____no_output_____"
]
],
[
[
"# 对数据进行预处理\nimport numpy as np\nfrom evaluation import positive_scale\n\nres = positive_scale(x=df.T.values, kind=np.array([0,1,1,1,0,0,0,0,0]))\ndf.iloc[:, :] = res.T\ndf",
"_____no_output_____"
],
[
"# 假设各项指标地位相同,权重相等\n# 计算关联度\nfrom evaluation import GreyRelationalAnalysis\n\nsolver = GreyRelationalAnalysis(x=df.values.T)\nR, r = solver.run()\nr",
"_____no_output_____"
],
[
"# 列表\ndf2 = pd.DataFrame(np.concatenate((R.T, r.reshape(1, -1)), axis=0))\ndf2.columns = [f'供应商{i}' for i in '123456']\ndf2.index = [*[f'指标{i}' for i in range(1, 10)], 'r']\ndf2",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
c51993985b6653955614315d4e9860317ac969e9
| 40,067 |
ipynb
|
Jupyter Notebook
|
site/en/tutorials/images/transfer_learning.ipynb
|
Hayyan-Arshad/docs
|
556c179c14b386d73bee63158feaf3c3c375fdda
|
[
"Apache-2.0"
] | 1 |
2021-11-07T18:53:52.000Z
|
2021-11-07T18:53:52.000Z
|
site/en/tutorials/images/transfer_learning.ipynb
|
agentdavidjoseph/docs
|
9fbb00bd50f962d5edfba09f426b761ae9283aec
|
[
"Apache-2.0"
] | null | null | null |
site/en/tutorials/images/transfer_learning.ipynb
|
agentdavidjoseph/docs
|
9fbb00bd50f962d5edfba09f426b761ae9283aec
|
[
"Apache-2.0"
] | null | null | null | 36.758716 | 553 | 0.563331 |
[
[
[
"##### Copyright 2019 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# Transfer learning and fine-tuning",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/images/transfer_learning\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/images/transfer_learning.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/images/transfer_learning.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/images/transfer_learning.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"In this tutorial, you will learn how to classify images of cats and dogs by using transfer learning from a pre-trained network.\n\nA pre-trained model is a saved network that was previously trained on a large dataset, typically on a large-scale image-classification task. You either use the pretrained model as is or use transfer learning to customize this model to a given task.\n\nThe intuition behind transfer learning for image classification is that if a model is trained on a large and general enough dataset, this model will effectively serve as a generic model of the visual world. You can then take advantage of these learned feature maps without having to start from scratch by training a large model on a large dataset.\n\nIn this notebook, you will try two ways to customize a pretrained model:\n\n1. Feature Extraction: Use the representations learned by a previous network to extract meaningful features from new samples. You simply add a new classifier, which will be trained from scratch, on top of the pretrained model so that you can repurpose the feature maps learned previously for the dataset.\n\n You do not need to (re)train the entire model. The base convolutional network already contains features that are generically useful for classifying pictures. However, the final, classification part of the pretrained model is specific to the original classification task, and subsequently specific to the set of classes on which the model was trained.\n\n1. Fine-Tuning: Unfreeze a few of the top layers of a frozen model base and jointly train both the newly-added classifier layers and the last layers of the base model. This allows us to \"fine-tune\" the higher-order feature representations in the base model in order to make them more relevant for the specific task.\n\nYou will follow the general machine learning workflow.\n\n1. Examine and understand the data\n1. Build an input pipeline, in this case using Keras ImageDataGenerator\n1. Compose the model\n * Load in the pretrained base model (and pretrained weights)\n * Stack the classification layers on top\n1. Train the model\n1. Evaluate model\n",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nimport os\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"## Data preprocessing",
"_____no_output_____"
],
[
"### Data download",
"_____no_output_____"
],
[
"In this tutorial, you will use a dataset containing several thousand images of cats and dogs. Download and extract a zip file containing the images, then create a `tf.data.Dataset` for training and validation using the `tf.keras.utils.image_dataset_from_directory` utility. You can learn more about loading images in this [tutorial](https://www.tensorflow.org/tutorials/load_data/images).",
"_____no_output_____"
]
],
[
[
"_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'\npath_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)\nPATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')\n\ntrain_dir = os.path.join(PATH, 'train')\nvalidation_dir = os.path.join(PATH, 'validation')\n\nBATCH_SIZE = 32\nIMG_SIZE = (160, 160)\n\ntrain_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,\n shuffle=True,\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE)",
"_____no_output_____"
],
[
"validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,\n shuffle=True,\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE)",
"_____no_output_____"
]
],
[
[
"Show the first nine images and labels from the training set:",
"_____no_output_____"
]
],
[
[
"class_names = train_dataset.class_names\n\nplt.figure(figsize=(10, 10))\nfor images, labels in train_dataset.take(1):\n for i in range(9):\n ax = plt.subplot(3, 3, i + 1)\n plt.imshow(images[i].numpy().astype(\"uint8\"))\n plt.title(class_names[labels[i]])\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"As the original dataset doesn't contain a test set, you will create one. To do so, determine how many batches of data are available in the validation set using `tf.data.experimental.cardinality`, then move 20% of them to a test set.",
"_____no_output_____"
]
],
[
[
"val_batches = tf.data.experimental.cardinality(validation_dataset)\ntest_dataset = validation_dataset.take(val_batches // 5)\nvalidation_dataset = validation_dataset.skip(val_batches // 5)",
"_____no_output_____"
],
[
"print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))\nprint('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))",
"_____no_output_____"
]
],
[
[
"### Configure the dataset for performance",
"_____no_output_____"
],
[
"Use buffered prefetching to load images from disk without having I/O become blocking. To learn more about this method see the [data performance](https://www.tensorflow.org/guide/data_performance) guide.",
"_____no_output_____"
]
],
[
[
"AUTOTUNE = tf.data.AUTOTUNE\n\ntrain_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)\nvalidation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)\ntest_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)",
"_____no_output_____"
]
],
[
[
"### Use data augmentation",
"_____no_output_____"
],
[
"When you don't have a large image dataset, it's a good practice to artificially introduce sample diversity by applying random, yet realistic, transformations to the training images, such as rotation and horizontal flipping. This helps expose the model to different aspects of the training data and reduce [overfitting](https://www.tensorflow.org/tutorials/keras/overfit_and_underfit). You can learn more about data augmentation in this [tutorial](https://www.tensorflow.org/tutorials/images/data_augmentation).",
"_____no_output_____"
]
],
[
[
"data_augmentation = tf.keras.Sequential([\n tf.keras.layers.RandomFlip('horizontal'),\n tf.keras.layers.RandomRotation(0.2),\n])",
"_____no_output_____"
]
],
[
[
"Note: These layers are active only during training, when you call `Model.fit`. They are inactive when the model is used in inference mode in `Model.evaluate` or `Model.fit`.",
"_____no_output_____"
],
[
"Let's repeatedly apply these layers to the same image and see the result.",
"_____no_output_____"
]
],
[
[
"for image, _ in train_dataset.take(1):\n plt.figure(figsize=(10, 10))\n first_image = image[0]\n for i in range(9):\n ax = plt.subplot(3, 3, i + 1)\n augmented_image = data_augmentation(tf.expand_dims(first_image, 0))\n plt.imshow(augmented_image[0] / 255)\n plt.axis('off')",
"_____no_output_____"
]
],
[
[
"### Rescale pixel values\n\nIn a moment, you will download `tf.keras.applications.MobileNetV2` for use as your base model. This model expects pixel values in `[-1, 1]`, but at this point, the pixel values in your images are in `[0, 255]`. To rescale them, use the preprocessing method included with the model.",
"_____no_output_____"
]
],
[
[
"preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input",
"_____no_output_____"
]
],
[
[
"Note: Alternatively, you could rescale pixel values from `[0, 255]` to `[-1, 1]` using `tf.keras.layers.Rescaling`.",
"_____no_output_____"
]
],
[
[
"rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)",
"_____no_output_____"
]
],
[
[
"Note: If using other `tf.keras.applications`, be sure to check the API doc to determine if they expect pixels in `[-1, 1]` or `[0, 1]`, or use the included `preprocess_input` function.",
"_____no_output_____"
],
[
"## Create the base model from the pre-trained convnets\nYou will create the base model from the **MobileNet V2** model developed at Google. This is pre-trained on the ImageNet dataset, a large dataset consisting of 1.4M images and 1000 classes. ImageNet is a research training dataset with a wide variety of categories like `jackfruit` and `syringe`. This base of knowledge will help us classify cats and dogs from our specific dataset.\n\nFirst, you need to pick which layer of MobileNet V2 you will use for feature extraction. The very last classification layer (on \"top\", as most diagrams of machine learning models go from bottom to top) is not very useful. Instead, you will follow the common practice to depend on the very last layer before the flatten operation. This layer is called the \"bottleneck layer\". The bottleneck layer features retain more generality as compared to the final/top layer.\n\nFirst, instantiate a MobileNet V2 model pre-loaded with weights trained on ImageNet. By specifying the **include_top=False** argument, you load a network that doesn't include the classification layers at the top, which is ideal for feature extraction.",
"_____no_output_____"
]
],
[
[
"# Create the base model from the pre-trained model MobileNet V2\nIMG_SHAPE = IMG_SIZE + (3,)\nbase_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,\n include_top=False,\n weights='imagenet')",
"_____no_output_____"
]
],
[
[
"This feature extractor converts each `160x160x3` image into a `5x5x1280` block of features. Let's see what it does to an example batch of images:",
"_____no_output_____"
]
],
[
[
"image_batch, label_batch = next(iter(train_dataset))\nfeature_batch = base_model(image_batch)\nprint(feature_batch.shape)",
"_____no_output_____"
]
],
[
[
"## Feature extraction\nIn this step, you will freeze the convolutional base created from the previous step and to use as a feature extractor. Additionally, you add a classifier on top of it and train the top-level classifier.",
"_____no_output_____"
],
[
"### Freeze the convolutional base",
"_____no_output_____"
],
[
"It is important to freeze the convolutional base before you compile and train the model. Freezing (by setting layer.trainable = False) prevents the weights in a given layer from being updated during training. MobileNet V2 has many layers, so setting the entire model's `trainable` flag to False will freeze all of them.",
"_____no_output_____"
]
],
[
[
"base_model.trainable = False",
"_____no_output_____"
]
],
[
[
"### Important note about BatchNormalization layers\n\nMany models contain `tf.keras.layers.BatchNormalization` layers. This layer is a special case and precautions should be taken in the context of fine-tuning, as shown later in this tutorial. \n\nWhen you set `layer.trainable = False`, the `BatchNormalization` layer will run in inference mode, and will not update its mean and variance statistics. \n\nWhen you unfreeze a model that contains BatchNormalization layers in order to do fine-tuning, you should keep the BatchNormalization layers in inference mode by passing `training = False` when calling the base model. Otherwise, the updates applied to the non-trainable weights will destroy what the model has learned.\n\nFor more details, see the [Transfer learning guide](https://www.tensorflow.org/guide/keras/transfer_learning).",
"_____no_output_____"
]
],
[
[
"# Let's take a look at the base model architecture\nbase_model.summary()",
"_____no_output_____"
]
],
[
[
"### Add a classification head",
"_____no_output_____"
],
[
"To generate predictions from the block of features, average over the spatial `5x5` spatial locations, using a `tf.keras.layers.GlobalAveragePooling2D` layer to convert the features to a single 1280-element vector per image.",
"_____no_output_____"
]
],
[
[
"global_average_layer = tf.keras.layers.GlobalAveragePooling2D()\nfeature_batch_average = global_average_layer(feature_batch)\nprint(feature_batch_average.shape)",
"_____no_output_____"
]
],
[
[
"Apply a `tf.keras.layers.Dense` layer to convert these features into a single prediction per image. You don't need an activation function here because this prediction will be treated as a `logit`, or a raw prediction value. Positive numbers predict class 1, negative numbers predict class 0.",
"_____no_output_____"
]
],
[
[
"prediction_layer = tf.keras.layers.Dense(1)\nprediction_batch = prediction_layer(feature_batch_average)\nprint(prediction_batch.shape)",
"_____no_output_____"
]
],
[
[
"Build a model by chaining together the data augmentation, rescaling, `base_model` and feature extractor layers using the [Keras Functional API](https://www.tensorflow.org/guide/keras/functional). As previously mentioned, use `training=False` as our model contains a `BatchNormalization` layer.",
"_____no_output_____"
]
],
[
[
"inputs = tf.keras.Input(shape=(160, 160, 3))\nx = data_augmentation(inputs)\nx = preprocess_input(x)\nx = base_model(x, training=False)\nx = global_average_layer(x)\nx = tf.keras.layers.Dropout(0.2)(x)\noutputs = prediction_layer(x)\nmodel = tf.keras.Model(inputs, outputs)",
"_____no_output_____"
]
],
[
[
"### Compile the model\n\nCompile the model before training it. Since there are two classes, use the `tf.keras.losses.BinaryCrossentropy` loss with `from_logits=True` since the model provides a linear output.",
"_____no_output_____"
]
],
[
[
"base_learning_rate = 0.0001\nmodel.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),\n loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.summary()",
"_____no_output_____"
]
],
[
[
"The 2.5 million parameters in MobileNet are frozen, but there are 1.2 thousand _trainable_ parameters in the Dense layer. These are divided between two `tf.Variable` objects, the weights and biases.",
"_____no_output_____"
]
],
[
[
"len(model.trainable_variables)",
"_____no_output_____"
]
],
[
[
"### Train the model\n\nAfter training for 10 epochs, you should see ~94% accuracy on the validation set.\n",
"_____no_output_____"
]
],
[
[
"initial_epochs = 10\n\nloss0, accuracy0 = model.evaluate(validation_dataset)",
"_____no_output_____"
],
[
"print(\"initial loss: {:.2f}\".format(loss0))\nprint(\"initial accuracy: {:.2f}\".format(accuracy0))",
"_____no_output_____"
],
[
"history = model.fit(train_dataset,\n epochs=initial_epochs,\n validation_data=validation_dataset)",
"_____no_output_____"
]
],
[
[
"### Learning curves\n\nLet's take a look at the learning curves of the training and validation accuracy/loss when using the MobileNetV2 base model as a fixed feature extractor.",
"_____no_output_____"
]
],
[
[
"acc = history.history['accuracy']\nval_acc = history.history['val_accuracy']\n\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nplt.figure(figsize=(8, 8))\nplt.subplot(2, 1, 1)\nplt.plot(acc, label='Training Accuracy')\nplt.plot(val_acc, label='Validation Accuracy')\nplt.legend(loc='lower right')\nplt.ylabel('Accuracy')\nplt.ylim([min(plt.ylim()),1])\nplt.title('Training and Validation Accuracy')\n\nplt.subplot(2, 1, 2)\nplt.plot(loss, label='Training Loss')\nplt.plot(val_loss, label='Validation Loss')\nplt.legend(loc='upper right')\nplt.ylabel('Cross Entropy')\nplt.ylim([0,1.0])\nplt.title('Training and Validation Loss')\nplt.xlabel('epoch')\nplt.show()",
"_____no_output_____"
]
],
[
[
"Note: If you are wondering why the validation metrics are clearly better than the training metrics, the main factor is because layers like `tf.keras.layers.BatchNormalization` and `tf.keras.layers.Dropout` affect accuracy during training. They are turned off when calculating validation loss.\n\nTo a lesser extent, it is also because training metrics report the average for an epoch, while validation metrics are evaluated after the epoch, so validation metrics see a model that has trained slightly longer.",
"_____no_output_____"
],
[
"## Fine tuning\nIn the feature extraction experiment, you were only training a few layers on top of an MobileNetV2 base model. The weights of the pre-trained network were **not** updated during training.\n\nOne way to increase performance even further is to train (or \"fine-tune\") the weights of the top layers of the pre-trained model alongside the training of the classifier you added. The training process will force the weights to be tuned from generic feature maps to features associated specifically with the dataset.\n\nNote: This should only be attempted after you have trained the top-level classifier with the pre-trained model set to non-trainable. If you add a randomly initialized classifier on top of a pre-trained model and attempt to train all layers jointly, the magnitude of the gradient updates will be too large (due to the random weights from the classifier) and your pre-trained model will forget what it has learned.\n\nAlso, you should try to fine-tune a small number of top layers rather than the whole MobileNet model. In most convolutional networks, the higher up a layer is, the more specialized it is. The first few layers learn very simple and generic features that generalize to almost all types of images. As you go higher up, the features are increasingly more specific to the dataset on which the model was trained. The goal of fine-tuning is to adapt these specialized features to work with the new dataset, rather than overwrite the generic learning.",
"_____no_output_____"
],
[
"### Un-freeze the top layers of the model\n",
"_____no_output_____"
],
[
"All you need to do is unfreeze the `base_model` and set the bottom layers to be un-trainable. Then, you should recompile the model (necessary for these changes to take effect), and resume training.",
"_____no_output_____"
]
],
[
[
"base_model.trainable = True",
"_____no_output_____"
],
[
"# Let's take a look to see how many layers are in the base model\nprint(\"Number of layers in the base model: \", len(base_model.layers))\n\n# Fine-tune from this layer onwards\nfine_tune_at = 100\n\n# Freeze all the layers before the `fine_tune_at` layer\nfor layer in base_model.layers[:fine_tune_at]:\n layer.trainable = False",
"_____no_output_____"
]
],
[
[
"### Compile the model\n\nAs you are training a much larger model and want to readapt the pretrained weights, it is important to use a lower learning rate at this stage. Otherwise, your model could overfit very quickly.",
"_____no_output_____"
]
],
[
[
"model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),\n optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.summary()",
"_____no_output_____"
],
[
"len(model.trainable_variables)",
"_____no_output_____"
]
],
[
[
"### Continue training the model",
"_____no_output_____"
],
[
"If you trained to convergence earlier, this step will improve your accuracy by a few percentage points.",
"_____no_output_____"
]
],
[
[
"fine_tune_epochs = 10\ntotal_epochs = initial_epochs + fine_tune_epochs\n\nhistory_fine = model.fit(train_dataset,\n epochs=total_epochs,\n initial_epoch=history.epoch[-1],\n validation_data=validation_dataset)",
"_____no_output_____"
]
],
[
[
"Let's take a look at the learning curves of the training and validation accuracy/loss when fine-tuning the last few layers of the MobileNetV2 base model and training the classifier on top of it. The validation loss is much higher than the training loss, so you may get some overfitting.\n\nYou may also get some overfitting as the new training set is relatively small and similar to the original MobileNetV2 datasets.\n",
"_____no_output_____"
],
[
"After fine tuning the model nearly reaches 98% accuracy on the validation set.",
"_____no_output_____"
]
],
[
[
"acc += history_fine.history['accuracy']\nval_acc += history_fine.history['val_accuracy']\n\nloss += history_fine.history['loss']\nval_loss += history_fine.history['val_loss']",
"_____no_output_____"
],
[
"plt.figure(figsize=(8, 8))\nplt.subplot(2, 1, 1)\nplt.plot(acc, label='Training Accuracy')\nplt.plot(val_acc, label='Validation Accuracy')\nplt.ylim([0.8, 1])\nplt.plot([initial_epochs-1,initial_epochs-1],\n plt.ylim(), label='Start Fine Tuning')\nplt.legend(loc='lower right')\nplt.title('Training and Validation Accuracy')\n\nplt.subplot(2, 1, 2)\nplt.plot(loss, label='Training Loss')\nplt.plot(val_loss, label='Validation Loss')\nplt.ylim([0, 1.0])\nplt.plot([initial_epochs-1,initial_epochs-1],\n plt.ylim(), label='Start Fine Tuning')\nplt.legend(loc='upper right')\nplt.title('Training and Validation Loss')\nplt.xlabel('epoch')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Evaluation and prediction",
"_____no_output_____"
],
[
"Finaly you can verify the performance of the model on new data using test set.",
"_____no_output_____"
]
],
[
[
"loss, accuracy = model.evaluate(test_dataset)\nprint('Test accuracy :', accuracy)",
"_____no_output_____"
]
],
[
[
"And now you are all set to use this model to predict if your pet is a cat or dog.",
"_____no_output_____"
]
],
[
[
"# Retrieve a batch of images from the test set\nimage_batch, label_batch = test_dataset.as_numpy_iterator().next()\npredictions = model.predict_on_batch(image_batch).flatten()\n\n# Apply a sigmoid since our model returns logits\npredictions = tf.nn.sigmoid(predictions)\npredictions = tf.where(predictions < 0.5, 0, 1)\n\nprint('Predictions:\\n', predictions.numpy())\nprint('Labels:\\n', label_batch)\n\nplt.figure(figsize=(10, 10))\nfor i in range(9):\n ax = plt.subplot(3, 3, i + 1)\n plt.imshow(image_batch[i].astype(\"uint8\"))\n plt.title(class_names[predictions[i]])\n plt.axis(\"off\")",
"_____no_output_____"
]
],
[
[
"## Summary\n\n* **Using a pre-trained model for feature extraction**: When working with a small dataset, it is a common practice to take advantage of features learned by a model trained on a larger dataset in the same domain. This is done by instantiating the pre-trained model and adding a fully-connected classifier on top. The pre-trained model is \"frozen\" and only the weights of the classifier get updated during training.\nIn this case, the convolutional base extracted all the features associated with each image and you just trained a classifier that determines the image class given that set of extracted features.\n\n* **Fine-tuning a pre-trained model**: To further improve performance, one might want to repurpose the top-level layers of the pre-trained models to the new dataset via fine-tuning.\nIn this case, you tuned your weights such that your model learned high-level features specific to the dataset. This technique is usually recommended when the training dataset is large and very similar to the original dataset that the pre-trained model was trained on.\n\nTo learn more, visit the [Transfer learning guide](https://www.tensorflow.org/guide/keras/transfer_learning).\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
c5199c7d27c5e76ea57eff192595aad0482e1ee2
| 45,189 |
ipynb
|
Jupyter Notebook
|
01_donnees_en_tables/05_traitement_donnees_en_table.ipynb
|
efloti/cours-nsi-premiere
|
5b05bc81e5f8d7df47bf5785068b4bf4d1e357bb
|
[
"CC0-1.0"
] | null | null | null |
01_donnees_en_tables/05_traitement_donnees_en_table.ipynb
|
efloti/cours-nsi-premiere
|
5b05bc81e5f8d7df47bf5785068b4bf4d1e357bb
|
[
"CC0-1.0"
] | null | null | null |
01_donnees_en_tables/05_traitement_donnees_en_table.ipynb
|
efloti/cours-nsi-premiere
|
5b05bc81e5f8d7df47bf5785068b4bf4d1e357bb
|
[
"CC0-1.0"
] | null | null | null | 29.886905 | 305 | 0.526743 |
[
[
[
"# Traitement des données en tables",
"_____no_output_____"
],
[
"[Vidéo d'accompagnement 2](https://vimeo.com/534400395)",
"_____no_output_____"
],
[
"Dans cette section, nous supposons disposer d'une table de n-uplets nommés (à l'aide de dictionnaires) et donc de la forme:\n\n```python\n[\n {\"descr1\": \"val1\", \"descr2\": \"val2\",...},\n {\"descr1\": \"val'1\", ...}, \n ...\n]\n```\n\nqui représente un **tableau** de données de la forme:\n\n| descr1 | descr2 | ... |\n| :-------------:|:-------------:|:-----:|\n| val1 | val2 | ... |\n| val'1 | ... | ... |\n| ... | ... | ... |",
"_____no_output_____"
],
[
"**Notre objectif est** d'apprendre à réaliser certaines **opérations incontournables** sur ce genre de données:\n- **«pré-traitements»**: adapter le **type** de certaines données,\n- **projection**: sélectionner certaines «**colonnes**» ou descripteurs,\n- **sélection**: sélectionner certaines «**lignes**» ou enregistrements,\n- **trier** les lignes ou enregistrements,\n- **fusionner**: produire un tableau sur la base de deux autres. ",
"_____no_output_____"
],
[
"Voici la table que nous utiliserons pour illustrer/tester ces opérations.",
"_____no_output_____"
]
],
[
[
"table_test = [\n {'n_client': '1212', 'nom': 'Lacasse' , 'prenom': 'Aubrey' , 'ville': 'Annecy' , 'position': '45.900000,6.116667'},\n {'n_client': '1343', 'nom': 'Primeau' , 'prenom': 'Angelette', 'ville': 'Tours' , 'position': '47.383333,0.683333'},\n {'n_client': '2454', 'nom': 'Gabriaux' , 'prenom': 'Julie' , 'ville': 'Bordeaux', 'position': '44.833333,-0.566667'},\n {'n_client': '895' , 'nom': 'Gaulin' , 'prenom': 'Dorene' , 'ville': 'Lyon' , 'position': '45.750000,4.850000'},\n {'n_client': '2324', 'nom': 'Jobin' , 'prenom': 'Aubrey' , 'ville': 'Bourges' , 'position': '47.083333,2.400000'},\n {'n_client': '34' , 'nom': 'Boncoeur' , 'prenom': 'Kari' , 'ville': 'Nantes' , 'position': '47.216667,-1.550000'},\n {'n_client': '1221', 'nom': 'Parizeau' , 'prenom': 'Olympia' , 'ville': 'Metz' , 'position': '49.133333,6.166667'},\n {'n_client': '1114', 'nom': 'Paiement' , 'prenom': 'Inès' , 'ville': 'Bordeaux', 'position': '44.833333,-0.566667'},\n {'n_client': '3435', 'nom': 'Chrétien' , 'prenom': 'Adèle' , 'ville': 'Moulin' , 'position': '46.566667,3.333333'},\n {'n_client': '5565', 'nom': 'Neufville', 'prenom': 'Ila' , 'ville': 'Toulouse', 'position': '43.600000,1.433333'},\n {'n_client': '2221', 'nom': 'Larivière', 'prenom': 'Alice' , 'ville': 'Tours' , 'position': '47.383333,0.683333'},\n]",
"_____no_output_____"
]
],
[
[
"#### Exercice 1",
"_____no_output_____"
],
[
"Quels sont les descripteurs de cette table? **réponse**: ______",
"_____no_output_____"
]
],
[
[
"# combien comporte-t-elle de lignes? de colonnes? réponses: ____",
"_____no_output_____"
]
],
[
[
"Quel est le type commun de toutes les valeurs? **réponse**: ______\n_____",
"_____no_output_____"
],
[
"## Complément Python: Parcours d'un dictionnaire",
"_____no_output_____"
],
[
"Lorsqu'on utilise la syntaxe `for <var> in <dictionnaire>`, la variable de boucle contient une nouvelle **clé** du dictionnaire à chaque *itération*.",
"_____no_output_____"
]
],
[
[
"test = {\"un\": 1, \"deux\": 2, \"3\": \"trois\"}\nfor var in test:\n print(var)",
"_____no_output_____"
]
],
[
[
"À partir de la clé, on peut facilement récupérer la valeur associée dans la paire clé-valeur avec la syntaxe `dico[cle]`:",
"_____no_output_____"
]
],
[
[
"test = {\"un\": 1, \"deux\": 2, \"3\": \"trois\"}\nfor var in test:\n print(test[var])",
"_____no_output_____"
]
],
[
[
"Mais il est plus pratique de récupérer directement **la clé et la valeur** dans la variable de boucle. On peut faire cela en utilisant la méthode `dict.items()` dans la boucle:",
"_____no_output_____"
]
],
[
[
"test = {\"un\": 1, \"deux\": 2, \"3\": \"trois\"}\nfor var in test.items():\n print(var)",
"_____no_output_____"
]
],
[
[
"Comme vous le constatez, à chaque itération la variable de boucle reçoit un *tuple de taille 2*, on peut récupérer directement chaque composante comme suit:",
"_____no_output_____"
]
],
[
[
"test = {\"un\": 1, \"deux\": 2, \"3\": \"trois\"}\nfor cle, val in test.items():\n print(f\"{cle} => {val}\")",
"_____no_output_____"
]
],
[
[
"**Retenir**\n\n> si `d` est un dictionnaire, `for cle, val in d.items()` récupère une nouvelle paire clé-valeur à chaque itération de la boucle.",
"_____no_output_____"
],
[
"On peut utiliser cela dans l'écriture en compréhension pour «transformer» un dictionnaire.",
"_____no_output_____"
]
],
[
[
"test = {\"entier\":\"13\", \"chaine\": \"python\", \"flottant\": \"3.14\", \"booleen\": \"Oui\", \"tuple_entiers\": \"4,5,6\"}",
"_____no_output_____"
]
],
[
[
"On peut vouloir «oublier» certaines paires:",
"_____no_output_____"
]
],
[
[
"{c: v for c, v in test.items() if c not in [\"chaine\", \"booleen\"]}",
"_____no_output_____"
]
],
[
[
"On peut vouloir *adapter* les **types** de certaines valeurs. Par exemple, dans le dictionnaire `test` la valeur associé à la clé \"entier\" est de type *str* et on voudrait un *int*:",
"_____no_output_____"
]
],
[
[
"def conv(c, v):\n if c == \"entier\":\n return int(v)\n else:\n return v\n\n{c: conv(c,v) for c, v in test.items()}",
"_____no_output_____"
]
],
[
[
"Il est très courant de vouloir faire cela; pour cette raison (et d'autres...) Python propose l'opérateur *ternaire* `e1 if cond else e2` qui produit la valeur `e1` si `cond` vaut «vrai» et produit `e2` sinon:",
"_____no_output_____"
]
],
[
[
"{ \n c: (float(v) if c == \"flottant\" else v) \n for c, v in test.items()\n}",
"_____no_output_____"
]
],
[
[
"Néanmoins, s'il y a trop de cas à traiter, l'écriture d'une fonction reste utile. Examinez attentivement cet exemple:",
"_____no_output_____"
]
],
[
[
"def adapter_types(c, v):\n if c == \"entier\":\n return int(v)\n elif c == \"flottant\":\n return float(v)\n elif c == \"booleen\":\n return (True if v == \"Oui\" else False)\n elif c == \"tuple_entiers\":\n # découper\n vs = v.split(',')\n # puis convertir chaque composante\n vs = [int(v) for v in vs]\n # puis tranformer la liste en tuple\n return tuple(vs)\n else:\n return v\n\n{c:adapter_types(c, v) for c, v in test.items()}",
"_____no_output_____"
]
],
[
[
"*Astuce*: il est possible d'utiliser une «compréhension de tuple» `tuple(...)` pour raccourcir le cas \"tuple_entiers\".\nPlus précisément, on pourrait remplacer cette partie par `return tuple( int(x) for x in v.split(',') )`. Essayez...",
"_____no_output_____"
],
[
"> **Retenir**: Si `d` est un dictionnaire, on peut utiliser l'écriture en compréhension pour le *transformer*; notamment «oublier» certaines paires clé valeur avec `if` ou ajuster le type de certaines valeurs sur la base de leur clé.",
"_____no_output_____"
],
[
"## Pré-traitement",
"_____no_output_____"
],
[
"Pour rappel notre table de test est:",
"_____no_output_____"
]
],
[
[
"table_test = [\n {'n_client': '1212', 'nom': 'Lacasse' , 'prenom': 'Aubrey' , 'ville': 'Annecy' , 'position': '45.900000,6.116667'},\n {'n_client': '1343', 'nom': 'Primeau' , 'prenom': 'Angelette', 'ville': 'Tours' , 'position': '47.383333,0.683333'},\n {'n_client': '2454', 'nom': 'Gabriaux' , 'prenom': 'Julie' , 'ville': 'Bordeaux', 'position': '44.833333,-0.566667'},\n {'n_client': '895' , 'nom': 'Gaulin' , 'prenom': 'Dorene' , 'ville': 'Lyon' , 'position': '45.750000,4.850000'},\n {'n_client': '2324', 'nom': 'Jobin' , 'prenom': 'Aubrey' , 'ville': 'Bourges' , 'position': '47.083333,2.400000'},\n {'n_client': '34' , 'nom': 'Boncoeur' , 'prenom': 'Kari' , 'ville': 'Nantes' , 'position': '47.216667,-1.550000'},\n {'n_client': '1221', 'nom': 'Parizeau' , 'prenom': 'Olympia' , 'ville': 'Metz' , 'position': '49.133333,6.166667'},\n {'n_client': '1114', 'nom': 'Paiement' , 'prenom': 'Inès' , 'ville': 'Bordeaux', 'position': '44.833333,-0.566667'},\n {'n_client': '3435', 'nom': 'Chrétien' , 'prenom': 'Adèle' , 'ville': 'Moulin' , 'position': '46.566667,3.333333'},\n {'n_client': '5565', 'nom': 'Neufville', 'prenom': 'Ila' , 'ville': 'Toulouse', 'position': '43.600000,1.433333'},\n {'n_client': '2221', 'nom': 'Larivière', 'prenom': 'Alice' , 'ville': 'Tours' , 'position': '47.383333,0.683333'},\n]",
"_____no_output_____"
]
],
[
[
"On observe que certains **descripteurs** pourrait avoir un **type** plus précis que `str`, par exemple le descripteur `n_client` gagnerait a être de type `int`.\n\nAméliorons cela à l'aide de *l'écriture en compréhension*:",
"_____no_output_____"
]
],
[
[
"table_test_2 = [ # liste en compréhension: produit une liste de ...\n { # ... dictionnaires ...\n c: int(v) if c == 'n_client' else v # conversion de la valeur si le descripteur est 'n_client'\n for c, v in enr.items() \n }\n # ... pour chaque enregistrement de la table d'origine.\n for enr in table_test\n]\n# observe bien la valeur du descripteur 'n_client'\ntable_test_2[:2]",
"_____no_output_____"
]
],
[
[
"C'est encore un peu difficile à lire probablement? l'opérateur ternaire `e1 if cond else e2` n'est pas encore parfaitement clair? ni l'écriture en compréhension?\n\nAlors voici l'équivalent dans une fonction avec une boucle imbriquée.",
"_____no_output_____"
]
],
[
[
"def conversion1(table):\n tc = [] # table à construire\n # pour chaque enregistrement\n for l in table:\n enr = {} # nouvel enregistrement\n # pour chaque paire clé-valeur de l'enregistrement courant\n for c, v in l.items():\n # doit-on convertir en int?\n if c == 'n_client':\n enr[c] = int(v)\n else:\n enr[c] = v\n # ajouter le nouvel enregistrement à la table en consruction\n tc.append(enr)\n return tc\n\nconversion1(table_test)",
"_____no_output_____"
]
],
[
[
"Mais il y a un autre descripteur qui pose problème: `position`\n\nSon type est `str` au format `'<float>,<float>'`\n\nNous voudrions que son type soit «`tuple` de `float`» c'est-à-dire passer par exemple de `'45.900000,6.116667'` à `(45.900000, 6.116667)`.",
"_____no_output_____"
],
[
"#### Exercice 2",
"_____no_output_____"
],
[
"En t'inspirant de la conversion résolue précédente, transforme le descripteur `position` en un tuple de 2 floats.",
"_____no_output_____"
]
],
[
[
"# avec une fonction\ndef conversion2(table):\n pass",
"_____no_output_____"
],
[
"# avec la syntaxe en compréhension (tu peux utiliser plusieurs étapes)\n",
"_____no_output_____"
]
],
[
[
"_________",
"_____no_output_____"
],
[
"## Projection",
"_____no_output_____"
],
[
"L'opération de **projection** consiste à «oublier» certaines «colonnes» du jeu de données.",
"_____no_output_____"
],
[
"On repart de la table ci-dessous:",
"_____no_output_____"
]
],
[
[
"table_test = [\n {'n_client': 1212, 'nom': 'Lacasse' , 'prenom': 'Aubrey' , 'ville': 'Annecy' , 'position': (45.900000,6.116667)},\n {'n_client': 1343, 'nom': 'Primeau' , 'prenom': 'Angelette', 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n {'n_client': 2454, 'nom': 'Gabriaux' , 'prenom': 'Julie' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 895 , 'nom': 'Gaulin' , 'prenom': 'Dorene' , 'ville': 'Lyon' , 'position': (45.750000,4.850000)},\n {'n_client': 2324, 'nom': 'Jobin' , 'prenom': 'Aubrey' , 'ville': 'Bourges' , 'position': (47.083333,2.400000)},\n {'n_client': 34 , 'nom': 'Boncoeur' , 'prenom': 'Kari' , 'ville': 'Nantes' , 'position': (47.216667,-1.550000)},\n {'n_client': 1221, 'nom': 'Parizeau' , 'prenom': 'Olympia' , 'ville': 'Metz' , 'position': (49.133333,6.166667)},\n {'n_client': 1114, 'nom': 'Paiement' , 'prenom': 'Inès' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 3435, 'nom': 'Chrétien' , 'prenom': 'Adèle' , 'ville': 'Moulin' , 'position': (46.566667,3.333333)},\n {'n_client': 5565, 'nom': 'Neufville', 'prenom': 'Ila' , 'ville': 'Toulouse', 'position': (43.600000,1.433333)},\n {'n_client': 2221, 'nom': 'Larivière', 'prenom': 'Alice' , 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n]",
"_____no_output_____"
]
],
[
[
"Le problème est le suivant: étant donnée une liste de **descripteurs** *à oublier* (car chaque descripteur correspond à une «colonne» du jeu de données), produire la table de donnée correspondante.",
"_____no_output_____"
],
[
"*Exemple*: si `a_oublier = ['n_client', 'prenom', 'position']` alors l'enregistrement:\n\n {'n_client': 1212, 'nom': 'Lacasse', 'prenom': 'Aubrey',\n 'ville': 'Annecy', 'position': (45.900000,6.116667)}\ndoit être transformé en \n\n {'nom': 'Lacasse', 'ville': 'Annecy'}`\net ainsi de suite pour chaque enregistrement.",
"_____no_output_____"
],
[
"Voici une solution qui utilise une fonction:",
"_____no_output_____"
]
],
[
[
"def projection_par_oubli(tableau, a_oublier):\n tsel = [] # pour notre nouveau tableau\n # pour chaque enregistrement\n for ligne in tableau:\n enr = {} # pour notre nouvel enregistrement\n # pour chaque paire clé-valeur de l'enregistrement courant\n for c, v in ligne.items():\n if not c in a_oublier:\n # on conserve cette paire\n enr[c] = v\n # ajoutons notre nouvel enregistrement\n tsel.append(enr)\n return tsel\n\nprojection_par_oubli(table_test, ['n_client', 'prenom', 'position'])",
"_____no_output_____"
]
],
[
[
"Mais il est bien plus simple d'utiliser l'*écriture en compréhension* dans ce cas...",
"_____no_output_____"
],
[
"#### Exercice 3",
"_____no_output_____"
],
[
"1. Peux-tu réaliser la même chose avec la notation en compréhension en complétant ce qui suit?",
"_____no_output_____"
]
],
[
[
"a_oublier = ['n_client', 'prenom', 'position']\n[\n { ... } \n for enr in table_test\n]",
"_____no_output_____"
],
[
"a_oublier = ['n_client', 'prenom', 'position']\n[\n { c: v for c, v in enr.items() if c not in a_oublier } \n for enr in table_test\n]",
"_____no_output_____"
]
],
[
[
"2. Écris une fonction `projection(tableau, a_conserver)` qui prend en argument le tableau de données et la liste des descripteurs **à conserver**; elle renvoie le tableau «projeté».",
"_____no_output_____"
]
],
[
[
"def projection(tableau, a_conserver):\n return [\n { c:v for c, v in enr.items() if c in a_conserver }\n for enr in tableau\n ]\n\n#test\nprojection(table_test, ['nom', 'ville'])",
"_____no_output_____"
]
],
[
[
"_____",
"_____no_output_____"
],
[
"## Sélection",
"_____no_output_____"
],
[
"On souhaite à présent transformer le tableau en ne conservant que les *enregistrements* qui respectent *un certain critère*; autrement dit on veut **sélectionner certaines lignes** (et abandonner les autres).",
"_____no_output_____"
]
],
[
[
"table_test = [\n {'n_client': 1212, 'nom': 'Lacasse' , 'prenom': 'Aubrey' , 'ville': 'Annecy' , 'position': (45.900000,6.116667)},\n {'n_client': 1343, 'nom': 'Primeau' , 'prenom': 'Angelette', 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n {'n_client': 2454, 'nom': 'Gabriaux' , 'prenom': 'Julie' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 895 , 'nom': 'Gaulin' , 'prenom': 'Dorene' , 'ville': 'Lyon' , 'position': (45.750000,4.850000)},\n {'n_client': 2324, 'nom': 'Jobin' , 'prenom': 'Aubrey' , 'ville': 'Bourges' , 'position': (47.083333,2.400000)},\n {'n_client': 34 , 'nom': 'Boncoeur' , 'prenom': 'Kari' , 'ville': 'Nantes' , 'position': (47.216667,-1.550000)},\n {'n_client': 1221, 'nom': 'Parizeau' , 'prenom': 'Olympia' , 'ville': 'Metz' , 'position': (49.133333,6.166667)},\n {'n_client': 1114, 'nom': 'Paiement' , 'prenom': 'Inès' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 3435, 'nom': 'Chrétien' , 'prenom': 'Adèle' , 'ville': 'Moulin' , 'position': (46.566667,3.333333)},\n {'n_client': 5565, 'nom': 'Neufville', 'prenom': 'Ila' , 'ville': 'Toulouse', 'position': (43.600000,1.433333)},\n {'n_client': 2221, 'nom': 'Larivière', 'prenom': 'Alice' , 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n]",
"_____no_output_____"
]
],
[
[
"Par exemple, on pourrait vouloir sélectionner les clients qui habitent à tours. Avec une fonction, cela donne:",
"_____no_output_____"
]
],
[
[
"def selection_exemple(tableau):\n tsel = []\n for enr in tableau:\n if enr['ville'] == 'Tours':\n tsel.append(enr)\n return tsel\n\nselection_exemple(table_test)",
"_____no_output_____"
]
],
[
[
"mais l'écriture en compréhension est bien plus simple!",
"_____no_output_____"
]
],
[
[
"[ enr for enr in table_test if enr['ville'] == 'Tours' ]",
"_____no_output_____"
]
],
[
[
"#### Exercice 4",
"_____no_output_____"
],
[
"1. Écris une fonction `selection2` qui renvoie le tableau en ne conservant que les enregistrements dont le numéro de client `\"n_client\"` est dans l'intervalle `[1000;3000]`.",
"_____no_output_____"
]
],
[
[
"def selection2(tableau):\n pass\n\nselection2(table_test)",
"_____no_output_____"
],
[
"def selection2(tableau):\n tsel = []\n for enr in tableau:\n if 1000 <= enr['n_client'] <= 3000:\n tsel.append(enr)\n return tsel\n\n# ou mieux!\ndef selection2_bis(tableau):\n return [e for e in tableau if 1000 <= e['n_client'] <= 3000]\n\nselection2(table_test)",
"_____no_output_____"
]
],
[
[
"2. Écris une fonction `selection3` qui sélectionne les enregistrements dont la longitude est positive - `\"position\": <(lat., long.)>` - et dont le `prenom` débute par un 'A'.\n\n *Note*: les caractères d'un `str` sont *indexés*. si `c=\"Python\"` alors `c[0]` vaut \"P\".",
"_____no_output_____"
]
],
[
[
"def selection3(tableau):\n pass\n\nselection3(table_test)",
"_____no_output_____"
],
[
"def selection3(tableau):\n tsel = []\n for enr in tableau:\n if enr['position'][1] >= 0 and enr['prenom'][0] == 'A':\n tsel.append(enr)\n return tsel\n\ndef selection3_bis(tableau):\n return [\n e for e in tableau\n if e['position'][0] >= 0 and e['prenom'][0] == 'A'\n ]\n\nselection3(table_test)",
"_____no_output_____"
]
],
[
[
"____",
"_____no_output_____"
],
[
"### Une fonction qui prend en argument une autre fonction!",
"_____no_output_____"
],
[
"Il est simple d'adapter le code précédent pour sélectionner selon un autre critère, mais il faut observer qu'*on fait toujours la même chose*:\n\n<pre>\n <strong>Pour</strong> chaque enregistrement du jeu de donnees:\n <strong>Si</strong> cet enregistrement vérifie le <strong>critère</strong>:\n l'ajouter a l'accumulateur\n</pre>\n\nSeul le **critère** change!",
"_____no_output_____"
],
[
"On peut faire bien mieux en suivant ces étapes:\n1. *Définir un* **filtre**: une fonction qui, *étant donné un enregistrement*, renvoie un **booléen**:\n - `True` si l'enregistrement respecte un certain critère, `False` autrement.\n2. *Adapter* la fonction de **sélection** de façon à ce qu'elle puisse *recevoir la fonction **filtre** en argument*.\n\nCommençons par l'**étape 2** :-o",
"_____no_output_____"
]
],
[
[
"def selection(tableau, filtre_fn):\n tsel = []\n for enr in tableau:\n # rappel: filtre_fn est une fonction qui\n # s'attend à recevoir un enregistrement\n # et qui renvoie `True` ou `False`\n if filtre_fn(enr):\n tsel.append(enr)\n return tsel",
"_____no_output_____"
]
],
[
[
"Pour l'**étape 1**, une «micro fonction» suffit bien souvent:",
"_____no_output_____"
]
],
[
[
"a_tours = lambda enregistrement: enregistrement['ville'] == 'Tours'",
"_____no_output_____"
]
],
[
[
"Finalement, on combine les deux:",
"_____no_output_____"
]
],
[
[
"selection(table_test, a_tours)",
"_____no_output_____"
]
],
[
[
"En fait, tout l'intérêt des «micro fonctions» `lambda`, parfois appelée *fonctions anonymes*, est de pouvoir les utiliser «en place»:",
"_____no_output_____"
]
],
[
[
"# sur plusieurs lignes pour plus de clarté; remettre sur une ligne. \nselection(\n table_test,\n # ici on attend une fonction et une lambda est une fonction!\n lambda e: e['ville'] == 'Tours'\n)",
"_____no_output_____"
]
],
[
[
"Si le filtre est plus compliqué, rien n'empêche d'utiliser une fonction «normale»",
"_____no_output_____"
]
],
[
[
"def filtre_tordu(enr):\n condition1 = enr['ville'] == 'Tours'\n condition2 = enr['nom'][0] in ['P', 'B']\n return condition1 or condition2\n\nselection(table_test, filtre_tordu)",
"_____no_output_____"
],
[
"# ... mais on peut encore utiliser une «micro-fonction» dans ce cas.\nselection(\n table_test,\n lambda e: e['ville'] == 'Tours' or e['nom'][0] in ['P', 'B']\n)",
"_____no_output_____"
]
],
[
[
"On peut même simplifier le code de la fonction `selection` en utilisant une compréhension:",
"_____no_output_____"
]
],
[
[
"def selection(tableau, filtre_fn):\n return [e for e in tableau if filtre_fn(e)]\n\nselection(\n table_test,\n lambda e: e['ville'] == 'Tours' or e['nom'][0] in ['P', 'B']\n)",
"_____no_output_____"
]
],
[
[
"#### Exercice 5",
"_____no_output_____"
],
[
"Utilise la fonction `selection` conjointement avec des «micros fonctions» pour résoudre les sélections de l'exercice 4; sélectionner les enregistrements dont:\n1. le numéro de client `\"n_client\"` est dans l'intervalle `[1000;3000]`,\n2. la longitude est positive - \"position\": <(lat., long.)> - et dont le prenom débute par un 'A'.",
"_____no_output_____"
]
],
[
[
"#1",
"_____no_output_____"
],
[
"#1\nselection(table_test, lambda e: 1000 <= e[\"n_client\"] <= 3000)",
"_____no_output_____"
],
[
"#2",
"_____no_output_____"
],
[
"#2\nselection(table_test, lambda e: e[\"position\"][1] >= 0 and e[\"prenom\"][0] == \"A\")",
"_____no_output_____"
]
],
[
[
"_____",
"_____no_output_____"
],
[
"Rencontrer pour la première fois «une fonction qui prend en argument une autre fonction» - parfois appelée **fonction d'ordre supérieur** - est souvent déroutant.\n\nPour «passer le cap», voici un exercice complémentaire.",
"_____no_output_____"
],
[
"#### Exercice 6 - ma première fonction d'ordre supérieur",
"_____no_output_____"
],
[
"Écrire une fonction `appliquer(liste, fn)` qui prend en argument:\n- une liste d'éléments de type 'a': ce type est arbitraire, l'important c'est que tous les éléments de la liste aient le même type,\n- une fonction `fn` qui prend en argument un élément de type 'a' et renvoie un élément de type 'b'.\n\nFinalement, la fonction `appliquer` renvoie une liste d'éléments de type 'b'.\n\n**En résumé**: `appliquer` reçois `liste: \"[a]\"` et `fn: \"a -> b\"` et elle produit `\"[b]\"`...\n\nPar *exemple*, `appliquer([\"1\", \"2\", \"3\"], int)` renvoie `[1, 2, 3]`\n\nAide-toi des assertions qui suivent et de l'exemple de la fonction `selection` pour résoudre le problème.",
"_____no_output_____"
]
],
[
[
"def appliquer(liste, fn):\n # à toi de jouer!",
"_____no_output_____"
],
[
"l = [1,2,3]\nf = lambda x: x**2 # f: int -> int\nassert appliquer(l, f) == [1,4,9]\nl = [\"un\", \"deux\", \"trois\"]\nf = lambda ch: len(ch) # f: str -> int\nassert appliquer(l, f) == [2,4,5]\nf = lambda ch: ch.upper() # f: str -> str\nassert appliquer(l, f) == [\"UN\", \"DEUX\", \"TROIS\"]",
"_____no_output_____"
]
],
[
[
"_____",
"_____no_output_____"
],
[
"## Trier le tableau selon un ou plusieurs descripteurs",
"_____no_output_____"
],
[
"[Vidéo d'accompagnement 3](https://vimeo.com/535451191)",
"_____no_output_____"
]
],
[
[
"table_test = [\n {'n_client': 1212, 'nom': 'Lacasse' , 'prenom': 'Aubrey' , 'ville': 'Annecy' , 'position': (45.900000,6.116667)},\n {'n_client': 1343, 'nom': 'Primeau' , 'prenom': 'Angelette', 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n {'n_client': 2454, 'nom': 'Gabriaux' , 'prenom': 'Julie' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 895 , 'nom': 'Gaulin' , 'prenom': 'Dorene' , 'ville': 'Lyon' , 'position': (45.750000,4.850000)},\n {'n_client': 2324, 'nom': 'Jobin' , 'prenom': 'Aubrey' , 'ville': 'Bourges' , 'position': (47.083333,2.400000)},\n {'n_client': 34 , 'nom': 'Boncoeur' , 'prenom': 'Kari' , 'ville': 'Nantes' , 'position': (47.216667,-1.550000)},\n {'n_client': 1221, 'nom': 'Parizeau' , 'prenom': 'Olympia' , 'ville': 'Metz' , 'position': (49.133333,6.166667)},\n {'n_client': 1114, 'nom': 'Paiement' , 'prenom': 'Inès' , 'ville': 'Bordeaux', 'position': (44.833333,-0.566667)},\n {'n_client': 3435, 'nom': 'Gabriaux' , 'prenom': 'Adèle' , 'ville': 'Moulin' , 'position': (46.566667,3.333333)},\n {'n_client': 5565, 'nom': 'Neufville', 'prenom': 'Ila' , 'ville': 'Toulouse', 'position': (43.600000,1.433333)},\n {'n_client': 2221, 'nom': 'Larivière', 'prenom': 'Alice' , 'ville': 'Tours' , 'position': (47.383333,0.683333)},\n]",
"_____no_output_____"
]
],
[
[
"Supposer que nous souhaitions **ordonner** les enregistrements selon leur descripteur `n_client` du plus petit numéro au plus grand.\n\nPour faire cela, nous utiliserons la fonction *prédéfinie* \\[ *builtin* \\] de python `sorted`.\n\nAppliquée à une liste de valeurs comparables, elle fait ce qu'on attend: ",
"_____no_output_____"
]
],
[
[
"sorted([3, 6, 2, 7, 1, 8])",
"_____no_output_____"
],
[
"sorted([\"un\", \"deux\", \"trois\", \"quatre\"]) # ordre du dictionnaire (lexicographique)",
"_____no_output_____"
],
[
"sorted([(1, 2), (2, 3), (2, 1), (1, 3)])",
"_____no_output_____"
]
],
[
[
"Mais comment pourrait-elle trier nos enregistrements? Il faudrait qu'elle puisse savoir par rapport à quel(s) descripteurs(s) on souhaite les trier.",
"_____no_output_____"
],
[
"Pour cette raison, la fonction `sorted` admet un deuxième *paramètre* optionnel `key`.\n\nOn peut l'utiliser pour préciser **une fonction** qui, à un «objet» de la liste, fait correspondre **la (ou les) valeurs par rapport à laquelle (auxquels) on souhaite effectuer le tri**.\n\nPar exemple, *pour trier nos enregistrements* **suivant le n° de client**, on va lui passer la fonction `lambda e: e[\"n_client\"]`:",
"_____no_output_____"
]
],
[
[
"sorted(table_test, key=lambda e: e['n_client'])",
"_____no_output_____"
]
],
[
[
"*Autre exemple*: si nous souhaitons trier les enregistrement (clients) suivant leur *nom*, **puis** leur *prénom*, notre fonction devra renvoyée un tuple avec ces valeurs dans le même ordre:",
"_____no_output_____"
]
],
[
[
"sorted(\n table_test,\n key=lambda e: (e['nom'], e['prenom']) # attention; parenthèses autour du tuples obligatoires\n)",
"_____no_output_____"
]
],
[
[
"Voyez-vous la différence si nous trions seulement sur le nom? (observez bien).",
"_____no_output_____"
],
[
"À «noms égaux» (voir \"Gabriaux\"), les enregistrements sont ordonnées suivant le \"prénom\" (donc \"Adèle\" avant \"Julie\" contrairement à l'ordre initial...)",
"_____no_output_____"
],
[
"#### Exercice 7",
"_____no_output_____"
],
[
"1. Trier la table selon la première lettre du prénom puis selon la longitude.\n\n *Rappel*: position=(lat,long)",
"_____no_output_____"
]
],
[
[
"sorted(table_test, key=lambda e: (e[\"prenom\"][0], e[\"position\"][1]))",
"_____no_output_____"
]
],
[
[
"2. Sachant que `sorted` possède un troisième paramètre optionnel nommé `reverse` et qui vaut `False` par défaut, trier la table selon le numéro de client dans l'ordre décroissant (plus grand en premier).",
"_____no_output_____"
]
],
[
[
"sorted(table_test, key=lambda e: e[\"n_client\"], reverse=True)",
"_____no_output_____"
]
],
[
[
"## Fusionner deux tableaux ayant un descripteur commun",
"_____no_output_____"
],
[
"En pratique, les données sont souvent «dispatchées» dans plusieurs tableaux. Par exemple, supposez qu'on trouve les deux «tableaux» qui suivent dans un jeu de données au format CSV.",
"_____no_output_____"
]
],
[
[
"«personnes.csv»\n id,nom,prenom,date_naissance\n 0,Durand,Jean-Pierre,23/05/1985\n 1,Dupont,Christophe,15/12/1967\n 2,Terta,Henry,12/06/1978\n\n«adresses.csv»\n rue,cp,ville,id_personne\n 32 rue Général De Gaulle,27315,Harquency,2\n 7 rue Georges Courteline,37000,Tours,0",
"_____no_output_____"
]
],
[
[
"Vous devinez peut-être que cela signifie par exemple: \n> Jean-Pierre Durand, né le 23/05/1985 *habite* au 7 rue Georges Courteline à Tours (37000).",
"_____no_output_____"
],
[
"On obtient cela en «rapprochant» les enregistrements des deux tableaux dont les valeurs associées aux descripteurs `id` et `id_personne` coincident. Cet opération de rapprochement est appelée **jointure** ou **fusion**.\n\nElle permet de produire un tableau sur la base de deux autres en s'appuyant sur des descripteurs «commun» aux deux tableaux.",
"_____no_output_____"
]
],
[
[
"personnes = [\n {\"id\": 0, \"nom\": \"Durand\", \"prenom\": \"Jean-Pierre\", \"date_naissance\": \"23/05/1985\"},\n {\"id\": 1, \"nom\": \"Dupont\", \"prenom\": \"Christophe\", \"date_naissance\": \"15/12/1967\"},\n {\"id\": 2, \"nom\": \"Terta\", \"prenom\": \"Henry\", \"date_naissance\": \"12/06/1978\"}\n]\n\nadresses = [\n {\"rue\": \"32 rue Général De Gaulle\", \"cp\": \"27315\", \"ville\": \"Harquency\", \"id_personne\": 2},\n {\"rue\": \"7 rue Georges Courteline\", \"cp\": \"37000\", \"ville\": \"Tours\", \"id_personne\": 0}\n]",
"_____no_output_____"
]
],
[
[
"#### Exercice 8",
"_____no_output_____"
],
[
"Écrire une fonction `fusionner(tab1, tab2, d1, d2)` qui à partir de deux tableaux (de n-uplets nommés), d'un descripteur du premier et d'un descripteur du second, renvoie un tableau qui «fusionne» les deux tableaux donnés.\n\nPlus précisément, chaque **couple d'enregistrements** des tableaux en entrée *ayant la même valeur pour les descripteurs `d1` et `d2`* produit un enregistrement pour le tableau en sortie. Les descripteurs du tableau en sortie sont les descripteurs des deux tableaux *hormis* `d1` et `d2`.\n\n*Par exemple*, `fusionner(personnes, adresses, \"id\", \"id_personne\")` produit:\n\n [{'nom': 'Durand',\n 'prenom': 'Jean-Pierre',\n 'date_naissance': '23/05/1985',\n 'rue': '7 rue Georges Courteline',\n 'cp': '37000',\n 'ville': 'Tours'},\n {'nom': 'Terta',\n 'prenom': 'Henry',\n 'date_naissance': '12/06/1978',\n 'rue': '32 rue Général De Gaulle',\n 'cp': '27315',\n 'ville': 'Harquency'}]",
"_____no_output_____"
],
[
"*Aide*: Utiliser deux boucles imbriquées pour considérer tous les couples d'enregistrements possibles; lorsque les enregistrements du couple possèdent la même valeur pour `d1` et `d2`, produire un nouveau dictionnaire en copiant les paires clés-valeurs adéquates, puis l'ajouter à l'accumulateur ...",
"_____no_output_____"
]
],
[
[
"def fusionner(tab1, tab2, d1, d2):\n tab = [] # l'accumulateur\n pass\n\nfusionner(personnes, adresses, \"id\", \"id_personne\")",
"_____no_output_____"
],
[
"def fusionner(tab1, tab2, d1, d2):\n tab = []\n for e1 in tab1:\n for e2 in tab2:\n if e1[d1] == e2[d2]:\n d = {}\n for c in e1:\n if c != d1:\n d[c] = e1[c]\n for c in e2:\n if c != d2:\n d[c] = e2[c]\n tab.append(d)\n return tab\n \nfusionner(personnes, adresses, \"id\", \"id_personne\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
c519a200d5cb5968654324e7b8b019d0a08d68c2
| 8,777 |
ipynb
|
Jupyter Notebook
|
deep_learning/reinforcement_learning/ReinforcementLearning_BasisConcept.ipynb
|
jiankaiwang/sophia.ml
|
b8cc450ed2a53417a3ff9431528dbbd7fcfcc6ea
|
[
"MIT"
] | 7 |
2019-05-03T01:18:56.000Z
|
2021-08-21T18:44:17.000Z
|
deep_learning/reinforcement_learning/ReinforcementLearning_BasisConcept.ipynb
|
jiankaiwang/sophia.ml
|
b8cc450ed2a53417a3ff9431528dbbd7fcfcc6ea
|
[
"MIT"
] | null | null | null |
deep_learning/reinforcement_learning/ReinforcementLearning_BasisConcept.ipynb
|
jiankaiwang/sophia.ml
|
b8cc450ed2a53417a3ff9431528dbbd7fcfcc6ea
|
[
"MIT"
] | 3 |
2019-01-17T03:53:31.000Z
|
2022-01-27T14:33:54.000Z
| 8,777 | 8,777 | 0.691238 |
[
[
[
"# Markov Decision Process (MDP)",
"_____no_output_____"
],
[
"# Discounted Future Return\n\n$$R_t = \\sum^{T}_{k=0}\\gamma^{t}r_{t+k+1}$$\n\n$$R_0 = \\gamma^{0} * r_{1} + \\gamma^{1} * r_{2} = r_{1} + \\gamma^{1} * r_{2}\\ (while\\ T\\ =\\ 1) $$\n$$R_1 = \\gamma^{1} * r_{2} =\\ (while\\ T\\ =\\ 1) $$\n$$so,\\ R_0 = r_{1} + R_1$$\n\nHigher $\\gamma$ stands for lower discounted value, and lower $\\gamma$ stands for higher discounted value (in normal, $\\gamma$ value is between 0.97 and 0.99).",
"_____no_output_____"
]
],
[
[
"def discount_rewards(rewards, gamma=0.98):\n discounted_returns = [0 for _ in rewards]\n discounted_returns[-1] = rewards[-1]\n for t in range(len(rewards)-2, -1, -1):\n discounted_returns[t] = rewards[t] + discounted_returns[t+1]*gamma\n return discounted_returns",
"_____no_output_____"
]
],
[
[
"If returns get higher when the time passes by, the Discounted Future Return method is not suggested.",
"_____no_output_____"
]
],
[
[
"print(discount_rewards([1,2,4]))",
"[6.8016, 5.92, 4]\n"
]
],
[
[
"If returns are the same or lesser when the time passes by, the Discounted Future Return method is suggested.",
"_____no_output_____"
]
],
[
[
"# about 2.94 fold\n# examples are like succeeding or failing\nprint(discount_rewards([1,1,1]))",
"[2.9404, 1.98, 1]\n"
],
[
"# about 3.31 fold\n# examples are like relating to the time-consuming\nprint(discount_rewards([1,0.9,0.8]))",
"[2.6503200000000002, 1.6840000000000002, 0.8]\n"
]
],
[
[
"# Explore and Exploit",
"_____no_output_____"
],
[
"## $\\epsilon$-Greedy strategy\n\nEach time the agent decides to take an action, it will consider one of which, the recommended one (exploit) or the random one (explore). The value $\\epsilon$ standing for the probability of taking random actions.",
"_____no_output_____"
]
],
[
[
"import random\nimport numpy as np",
"_____no_output_____"
],
[
"def epsilon_greedy_action(action_distribution, epsilon=1e-1):\n if random.random() < epsilon:\n return np.argmax(np.random.random(action_distribution.shape))\n else:\n return np.argmax(action_distribution)",
"_____no_output_____"
]
],
[
[
"here we assume there are 10 actions as well as their probabilities (fixed probabilities on each step making us easier to monitor the result) for the agent to take",
"_____no_output_____"
]
],
[
[
"action_distribution = np.random.random((1, 10))\nprint(action_distribution)\nprint(epsilon_greedy_action(action_distribution))",
"[[0.25634599 0.61871756 0.76904048 0.01270285 0.79426894 0.63050946\n 0.36007282 0.21638714 0.89302613 0.18750439]]\n8\n"
]
],
[
[
"## Annealing $\\epsilon$-Greedy strategy\n\nAt the beginning of training reinforcement learning, the agent knows nothing about the environment and the state or the feedback while taking an action as well. Thus we hope the agent takes more random actions (exploring) at the beginning of training. \n\nAfter a long training period, the agent knows the environment more and learns more the feedback given an action. Thus, we hope the agent takes an action based on its own experience (exploiting).\n\nWe provide a new idea to anneal (or decay) the $\\epsilon$ parameter in each time the agent takes an action. The classic annealing strategy is decaying $\\epsilon$ value from 0.99 to 0.01 in around 10000 steps.",
"_____no_output_____"
]
],
[
[
"def epsilon_greedy_annealed(action_distribution, training_percentage, epsilon_start=1.0, epsilon_end=1e-2):\n annealed_epsilon = epsilon_start * (1-training_percentage) + epsilon_end * training_percentage\n if random.random() < annealed_epsilon:\n # take random action\n return np.argmax(np.random.random(action_distribution.shape))\n else:\n # take the recommended action\n return np.argmax(action_distribution)",
"_____no_output_____"
]
],
[
[
"here we assume there are 10 actions as well as their probabilities (fixed probabilities on each step making us easier to monitor the result) for the agent to take",
"_____no_output_____"
]
],
[
[
"action_distribution = np.random.random((1, 10))\nprint(action_distribution)\n\nfor i in range(1, 99, 10):\n percentage = i / 100.0\n action = epsilon_greedy_annealed(action_distribution, percentage)\n print(\"percentage : {} and action is {}\".format(percentage, action))",
"[[0.02100268 0.45219792 0.11096445 0.83215913 0.73601745 0.2042438\n 0.60744428 0.11792413 0.13162112 0.86374139]]\npercentage : 0.01 and action is 6\npercentage : 0.11 and action is 7\npercentage : 0.21 and action is 5\npercentage : 0.31 and action is 9\npercentage : 0.41 and action is 6\npercentage : 0.51 and action is 7\npercentage : 0.61 and action is 9\npercentage : 0.71 and action is 9\npercentage : 0.81 and action is 9\npercentage : 0.91 and action is 9\n"
]
],
[
[
"# Learning to Earn Max Returns",
"_____no_output_____"
],
[
"## Policy Learning\n\nPolicy learning is the policy the agent learning to earn the maximum returns. For instance, if we ride a bicycle, when the bicycle is tilt to the left we try to give more power to the right side. The above strategy is called policy learning.",
"_____no_output_____"
],
[
"### Gradient Descent in Policy Learning\n\n$$arg\\ min_\\theta\\ -\\sum_{i}\\ R_{i}\\ log{p(y_{i}|x_{i}, \\theta)}$$\n\n$R_{i}$ is the discounted future return, $y_{i}$ is the action taken at time $i$.",
"_____no_output_____"
],
[
"## Value Learning\n\nValue learning is the agent learns the value from the state while taking an action. That is, value learning is to learn the value from a pair [state, action]. For example, if we ride a bicycle, we give higher or lower values to any combinations of [state, action], such a strategy is called value learning.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
c519b07757081916c86d560a7e10f1f9e90a9afc
| 368,574 |
ipynb
|
Jupyter Notebook
|
my_gesture_tshirts.ipynb
|
hiromasat/my_gesture_tshirts
|
232ca1bb460952963b728ff51de5884480953c83
|
[
"Apache-2.0"
] | null | null | null |
my_gesture_tshirts.ipynb
|
hiromasat/my_gesture_tshirts
|
232ca1bb460952963b728ff51de5884480953c83
|
[
"Apache-2.0"
] | null | null | null |
my_gesture_tshirts.ipynb
|
hiromasat/my_gesture_tshirts
|
232ca1bb460952963b728ff51de5884480953c83
|
[
"Apache-2.0"
] | null | null | null | 1,880.479592 | 271,108 | 0.963448 |
[
[
[
"from IPython.display import Image\nImage(\"./tshirts.png\")",
"_____no_output_____"
],
[
"%matplotlib inline\nimport numpy as np\nimport math\nimport matplotlib.pyplot as plt\n\n# graph matrix\nn_cols = 5\nn_rows = 3\n\n# generate x\n# 半径\nradius = 2*np.pi\nx_value = np.linspace(-radius, radius, 100)",
"_____no_output_____"
],
[
"# Graph作画関数\ndef graph(x, y, ax, f):\n ax.set_xlim([-radius, radius])\n ax.set_ylim([-radius, radius])\n ax.set_title(f)\n ax.grid(linewidth=1)\n ax.plot(x, y)",
"_____no_output_____"
],
[
"# 円の作画関数\ndef generate_xy_for_circle(x_value, a):\n \n # zeroのベクトルを生成\n x = np.zeros(len(x_value))\n y = np.zeros(len(x_value))\n \n for i in range(len(x_value)):\n x[i] = a * np.cos(x_value[i])\n y[i] = a * np.sin(x_value[i])\n\n return x, y",
"_____no_output_____"
],
[
"# 各関数を辞書型で作成\nfunc_dict={}\n\nfunc_dict[\"x\"] = x_value\nfunc_dict[\"x^2\"] = pow(x_value, 2)\nfunc_dict[\"x^3\"]= pow(x_value, 3)\nfunc_dict[\"sin x\"] = np.sin(x_value)\nfunc_dict[\"cos x\"] = np.cos(x_value)\nfunc_dict[\"tan x\"]=np.tan(x_value)\nfunc_dict[\"cot x\"] = 1/np.tan(x_value)\nfunc_dict[\"1/x\"] = 1/x_value\nfunc_dict[\"-1/x\"]= -1/x_value\nfunc_dict[\"|x|\"] = np.abs(x_value)\nfunc_dict[\"-|x|\"] = - np.abs(x_value)\nfunc_dict[\"-x\"]= -x_value\nfunc_dict[\"log x\"] = np.log(x_value)\nfunc_dict[\"a^x\"] = pow(radius, x_value)\nfunc_dict[\"x^2+y^2=a^2\"]= 0",
"/var/folders/6f/dzlpy9kd3xxgf9lphzpf8cqc0000gn/T/ipykernel_40874/4210085636.py:16: RuntimeWarning: invalid value encountered in log\n func_dict[\"log x\"] = np.log(x_value)\n"
],
[
"# 作画\nfig, ax = plt.subplots(nrows=3, ncols=5, figsize=(15, 10))\n\n# forループを一回で回せるようにflatten()を使用\nax = ax.flatten()\n\ni=0\nfor f in func_dict:\n \n x = np.zeros(len(x_value))\n y = np.zeros(len(x_value))\n \n # x yの値の取得\n if f == \"x^2+y^2=a^2\":\n x, y = generate_xy_for_circle(x_value, radius)\n else:\n x, y = x_value, func_dict[f]\n\n graph(x, y, ax[i], f)\n i=i+1",
"_____no_output_____"
],
[
"fig.savefig('my_gesture_tshirts.png')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c519b52423615d12579b5e65341cbdd60e1e14de
| 3,781 |
ipynb
|
Jupyter Notebook
|
notebook - Classification evaluation.ipynb
|
SaintlyVi/DLR_DB
|
71130189946c68e6875828fa1bd75cba38d3ce5f
|
[
"MIT"
] | null | null | null |
notebook - Classification evaluation.ipynb
|
SaintlyVi/DLR_DB
|
71130189946c68e6875828fa1bd75cba38d3ce5f
|
[
"MIT"
] | null | null | null |
notebook - Classification evaluation.ipynb
|
SaintlyVi/DLR_DB
|
71130189946c68e6875828fa1bd75cba38d3ce5f
|
[
"MIT"
] | null | null | null | 20.327957 | 195 | 0.501984 |
[
[
[
"from features.feature_extraction import *\nfrom evaluation.eval_classification import *\n\nfrom scipy.stats import ttest_rel\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"### Join classification runs",
"_____no_output_____"
]
],
[
[
"#joinResults('18_08_23_')",
"_____no_output_____"
]
],
[
[
"### Test Results",
"_____no_output_____"
]
],
[
[
"df, r = formatResults('class_results_archive/no CPI/classification_output', \n cats=['default+CGD','K2-P1','K2-P2','K2-P3','K2-P4','RHC-P1','RHC-P2','RHC-P3','Tabu-P1',\n 'Tabu-P2','Tabu-P3','Tabu-P4','BestFirst'])#filename='classification_results', cats=['HC-P1','HC-P2','HC-P3','HC-P4','K2-P1','K2-P2','K2-P3','K2-P4','BestFirst'])",
"_____no_output_____"
],
[
"pd.DataFrame(r.iloc[1,:-2]).T",
"_____no_output_____"
],
[
"percent_correct = df.pivot_table(index=['Key_Dataset','Key_Run','Key_Fold'], \n columns=['Key_Scheme','Options'], \n values='Percent_correct')",
"_____no_output_____"
],
[
"percent_correct = df.groupby(['Key_Dataset','Key_Run','Key_Scheme','Options'])['Percent_correct'].mean()",
"_____no_output_____"
],
[
"percent_correct.unstack(level=[2,3])",
"_____no_output_____"
],
[
"baseline = 'exp7_kmeans_unit_norm_features1BEST1'\nidx = pd.IndexSlice\npercent_correct.loc[idx[baseline,:,:],:]",
"_____no_output_____"
],
[
"ttest_rel(r.iloc[0], r.iloc[2])",
"_____no_output_____"
],
[
"pc",
"_____no_output_____"
],
[
"pc[3:6]",
"_____no_output_____"
],
[
"sf = describeFProfiles()",
"_____no_output_____"
],
[
"sf[:44]",
"_____no_output_____"
],
[
"sf[44:]",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c519b922c18f8288c482eb1067c2f02074b69d73
| 421,223 |
ipynb
|
Jupyter Notebook
|
notebook/DataStructure-lim-Copy1.ipynb
|
sgkang/DamGeophysics
|
c35cac2f33f1c84c99f6234da9af33fcd2eda88f
|
[
"MIT"
] | 2 |
2021-07-16T04:40:03.000Z
|
2022-01-05T08:12:30.000Z
|
notebook/DataStructure-lim-Copy1.ipynb
|
sgkang/DamGeophysics
|
c35cac2f33f1c84c99f6234da9af33fcd2eda88f
|
[
"MIT"
] | null | null | null |
notebook/DataStructure-lim-Copy1.ipynb
|
sgkang/DamGeophysics
|
c35cac2f33f1c84c99f6234da9af33fcd2eda88f
|
[
"MIT"
] | 2 |
2016-08-25T05:10:01.000Z
|
2019-09-28T08:18:14.000Z
| 311.325203 | 58,766 | 0.902975 |
[
[
[
"import pandas as pd\nimport sys\nimport matplotlib",
"_____no_output_____"
],
[
"print('Python version ' + sys.version)\nprint('Pandas version ' + pd.__version__)\nprint('Matplotlib version ' + matplotlib.__version__)",
"Python version 2.7.11 |Anaconda 2.5.0 (64-bit)| (default, Jan 29 2016, 14:26:21) [MSC v.1500 64 bit (AMD64)]\nPandas version 0.17.1\nMatplotlib version 1.5.1\n"
],
[
"names = ['Bob','Jessica','Mary','John','Mel']\nbirths = [968, 155, 77, 578, 973]",
"_____no_output_____"
],
[
"zip(names, births)",
"_____no_output_____"
],
[
"BabyDataSet = list (zip(names, births))\ndf = pd.DataFrame(data = BabyDataSet, columns=['Names', 'Births'])",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"water23 = pd.read_csv(\"../data/waterlevel/Water23.csv\", index_col='date')",
"_____no_output_____"
],
[
"water23",
"_____no_output_____"
],
[
"%pylab inline",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"#water23['upperlevel'].plot()\nfig = plt.figure(figsize=(12,4))\nax1 = plt.subplot(111)\nwater23['downlevel'].plot(ax=ax1)\nax1_1 = ax1.twinx()\nwater23['upperlevel'].plot(ax=ax1_1)\n#climate[\"Rainfall(mm)\"].plot.bar(figsize=(12,5))",
"_____no_output_____"
],
[
"climate = pd.read_csv(\"../data/waterlevel/ClimateWater.csv\", index_col='date')",
"_____no_output_____"
],
[
"#climate[\"WaterH1\"].hist(bins=100)\nwater23['upperlevel'].hist(bins=500)\n#water23['downlevel'].hist(bins=500)",
"_____no_output_____"
],
[
"pd=climate[\"WaterH1\"]",
"_____no_output_____"
],
[
"pd",
"_____no_output_____"
],
[
"pd.iloc[5]",
"_____no_output_____"
],
[
"climate[\"WaterH1\"].plot(figsize=(20,5))\nclimate[\"Rainfall(mm)\"].plot(figsize=(20,5))",
"_____no_output_____"
],
[
"climate[\"WaterH1\"].plot(figsize=(12,5))",
"_____no_output_____"
],
[
"water23['upperlevel'].plot(figsize=(12,5))\nwater23['downlevel'].plot()\n#climate[\"Rainfall(mm)\"].plot.bar(figsize=(12,5))",
"_____no_output_____"
],
[
"newindex = []\nfor ind in water23.index:\n newindex.append(ind.split()[0])",
"_____no_output_____"
],
[
"vals, inds = np.unique(newindex, return_inverse=True)",
"_____no_output_____"
],
[
"upperh = np.ones(vals.size)*np.nan\ndownh = np.ones(vals.size)*np.nan\nfor i in range (vals.size):\n active = inds==i\n upperh[i] = water23[\"upperlevel\"].values[active].sum() / active.sum()\n downh[i] = water23[\"downlevel\"].values[active].sum() / active.sum()",
"_____no_output_____"
],
[
"climate[\"WaterH1\"].plot(figsize=(20,3))\ngrid(True)",
"_____no_output_____"
],
[
"water23['upperlevel'].plot(figsize=(20,3))\ngrid(True)",
"_____no_output_____"
],
[
"water23['downlevel'].plot(figsize=(20,3))\ngrid(True)",
"_____no_output_____"
],
[
"climate.keys()",
"_____no_output_____"
],
[
"climate[\"Moisture(%)\"].plot(figsize=(20,3))\n",
"_____no_output_____"
],
[
"climate[\"SurfaceTemp(\\xa1\\xc6C)\"].plot(figsize=(20,3))\ngrid(True)",
"_____no_output_____"
],
[
"climate[\"Rainfall(mm)\"].plot(figsize=(20,3))\ngrid(True)",
"_____no_output_____"
],
[
"climate[\"Rainfall(mm)\"].plot(figsize=(20,3)).bar",
"_____no_output_____"
],
[
"plt.plot(downh)",
"_____no_output_____"
],
[
"waterdataset = list (zip(vals, upperh, downh))\ndf = pd.DataFrame(data = waterdataset, columns=['date', 'upperH', 'downH'])",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df['upperH'].plot()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
c519b9a2107ae06a9a3d37ea2482ad0d2e95cb16
| 8,529 |
ipynb
|
Jupyter Notebook
|
Numbers_and_operators/Numbers_and_operators.ipynb
|
Multiomics-Analytics-Group/PythonTsunami
|
fac131c140b7fda8c4687cdfa0fb15cd4cc8986b
|
[
"MIT"
] | 5 |
2020-11-07T14:49:29.000Z
|
2021-06-28T10:28:13.000Z
|
Numbers_and_operators/Numbers_and_operators.ipynb
|
Multiomics-Analytics-Group/PythonTsunami
|
fac131c140b7fda8c4687cdfa0fb15cd4cc8986b
|
[
"MIT"
] | 5 |
2020-11-06T18:46:31.000Z
|
2021-04-21T07:51:09.000Z
|
Numbers_and_operators/Numbers_and_operators.ipynb
|
Multiomics-Analytics-Group/PythonTsunami
|
fac131c140b7fda8c4687cdfa0fb15cd4cc8986b
|
[
"MIT"
] | 3 |
2021-04-15T06:57:43.000Z
|
2021-05-20T07:18:37.000Z
| 20.453237 | 289 | 0.503107 |
[
[
[
"<img src=\"../figures/HeaDS_logo_large_withTitle.png\" width=\"300\">\n\n<img src=\"../figures/tsunami_logo.PNG\" width=\"600\">\n\n[](https://colab.research.google.com/github/Center-for-Health-Data-Science/PythonTsunami/blob/intro/Numbers_and_operators/Numbers_and_operators.ipynb)",
"_____no_output_____"
],
[
"# Numerical Operators\n\n*Prepared by [Katarina Nastou](https://www.cpr.ku.dk/staff/?pure=en/persons/672471)*",
"_____no_output_____"
],
[
"## Objectives\n- understand differences between `int`s and `float`s\n- work with simple math operators\n- add comments to your code",
"_____no_output_____"
],
[
"## Numbers\nTwo main types of numbers:\n- Integers: `56, 3, -90`\n- Floating Points: `5.666, 0.0, -8.9`",
"_____no_output_____"
],
[
"## Operators \n- addition: `+`\n- subtraction: `-`\n- multiplication: `*`\n- division: `/`\n- exponentiation, power: `**`\n- modulo: `%`\n- integer division: `//` (what does it return?)",
"_____no_output_____"
]
],
[
[
"# playground",
"_____no_output_____"
]
],
[
[
"### Qestions: Ints and Floats\n- Question 1: Which of the following numbers is NOT a float? \n (a) 0 \n (b) 2.3 \n (c) 23.0 \n (d) -23.0 \n (e) 0.0",
"_____no_output_____"
],
[
"- Question 2: What type does the following expression result in? \n\n```python\n3.0 + 5\n```",
"_____no_output_____"
],
[
"### Operators 1\n- Question 3: How can we add parenthesis to the following expression to make it equal 100? \n```python\n1 + 9 * 10\n```\n \n- Question 4: What is the result of the following expression?\n```python\n3 + 14 * 2 + 4 * 5\n```\n- Question 5: What is the result of the following expression\n```python\n5 * 9 / 4 ** 3 - 6 * 7\n```",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
]
],
[
[
"### Comments\n- Question 6: What is the result of running this code? \n\n```python\n15 / 3 * 2 # + 1 \n```",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
]
],
[
[
"### Questions: Operators 2 \n\n- Question 7: Which of the following result in integers in Python? \n (a) 8 / 2\n (b) 3 // 2 \n (c) 4.5 * 2",
"_____no_output_____"
],
[
"- Question 8: What is the result of `18 // 3` ?",
"_____no_output_____"
],
[
"- Question 9: What is the result of `121 % 7` ?",
"_____no_output_____"
],
[
"## Exercise\n\nAsk the user for a number using the function [input()](https://www.askpython.com/python/examples/python-user-input) and then multiply that number by 2 and print out the value. Remember to store the input value into a variable, so that you can use it afterwards in the multiplication.",
"_____no_output_____"
],
[
"Modfify your previous calculator and ask for the second number (instead of x * 2 --> x * y).",
"_____no_output_____"
],
[
"Now get the square of the number that the user inputs",
"_____no_output_____"
],
[
"### Note\n\nCheck out also the [math library](https://docs.python.org/3/library/math.html) in Python. You can use this library for more complex operations with numbers. Just import the library and try it out:\n\n```python\n\nimport math\n\nprint(math.sqrt(25))\n\nprint(math.log10(10))\n```",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
c519bec369858cfef9d46e86452ee2528193de44
| 49,889 |
ipynb
|
Jupyter Notebook
|
examples/whisper_connectivity.ipynb
|
ScottHMcKean/pyfracman
|
c5d0d5e6207d6dc86e1fc7d19506996c0014f5bc
|
[
"MIT"
] | null | null | null |
examples/whisper_connectivity.ipynb
|
ScottHMcKean/pyfracman
|
c5d0d5e6207d6dc86e1fc7d19506996c0014f5bc
|
[
"MIT"
] | null | null | null |
examples/whisper_connectivity.ipynb
|
ScottHMcKean/pyfracman
|
c5d0d5e6207d6dc86e1fc7d19506996c0014f5bc
|
[
"MIT"
] | null | null | null | 103.289855 | 34,574 | 0.823248 |
[
[
[
"This notebook accompanies the Whisper Connected Fracture Analysis note.",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\n\nimport geopandas as gpd\nimport pandas as pd\nimport numpy as np\nfrom shapely.geometry import LineString\n\nfrom pyfracman.data import clean_columns\nfrom pyfracman.fab import parse_fab_file\nfrom pyfracman.frac_geo import flatten_frac, get_mid_z, get_fracture_set_stats\nfrom pyfracman.well_geo import (\n load_stage_location,\n load_survey_export, \n well_surveys_to_linestrings, \n stage_locs_to_gdf\n )",
"_____no_output_____"
],
[
"data_dir = Path(r\"C:\\Users\\scott.mckean\\Desktop\\Data Exports\")",
"_____no_output_____"
],
[
"# load fractures\nfrac_fpath = next(data_dir.rglob(\"Interpreted_Seismic_Lineaments.fab\"))\nfracs = parse_fab_file(frac_fpath)",
"_____no_output_____"
],
[
"### Load fractures ###\n\n# load fracture properties\n# parse average properties per fracture\n# must average for tesselated fractures\nif len(fracs.get('t_properties')) > 0:\n fracs['prop_list'] = [np.mean(x, axis=1) for x in fracs['t_properties']]\n prop_df = pd.DataFrame(fracs['prop_list'], columns = fracs['prop_dict'].values(), index=fracs['t_fid'])\nelse:\n prop_df = pd.DataFrame(fracs['prop_list'], columns = fracs['prop_dict'].values(), index=fracs['fid'])\n\nprop_df.index.set_names('fid', inplace=True)\n\n# load fracture geometry and flatten to 2D at midpoint of frac plane\nif len(fracs.get('t_nodes')) > 0:\n frac_linestrings = list(map(flatten_frac, fracs['t_nodes']))\n frac_mid_z = list(map(get_mid_z, fracs['t_nodes']))\nelse:\n frac_linestrings = list(map(flatten_frac, fracs['fracs']))\n frac_mid_z = list(map(get_mid_z, fracs['fracs']))\n\nfrac_gdf = gpd.GeoDataFrame(prop_df, geometry=frac_linestrings)",
"_____no_output_____"
],
[
"# for stochastic connections - don't need this yet\nconn_out = []\nfor conn_fpath in data_dir.rglob(\"*_Connections.txt\"):\n set_a = get_fracture_set_stats(conn_fpath, set_name='Stochastic Faults - Set A_1', set_alias='set_a')\n set_b = get_fracture_set_stats(conn_fpath, set_name='Stochastic Faults - Set B_1', set_alias='set_b')\n sets = set_a.merge(set_b, on=['stage_no','well','object'])\n conn_out.append(sets)\n\nstochastic_connections = pd.concat(conn_out)",
"_____no_output_____"
],
[
"### load stages and surveys ###\n# load surveys and convert to linestrings\nsurveys = pd.concat(\n [load_survey_export(well_path) for well_path in data_dir.glob(\"*_well.txt\")]\n)\nsurvey_linestrings = well_surveys_to_linestrings(surveys)\n\n# load stage locations and convert to GDF with points and linestring\nstage_locs = pd.concat(\n [load_stage_location(well_path) for well_path in data_dir.glob(\"*_intervals.txt\")]\n)\nstage_gdf = stage_locs_to_gdf(stage_locs)\n\n# get stage start times, with clean non-flowback for geometry merge\nstage_times = pd.read_parquet(data_dir / \"stage_times.parquet\")\nstage_times['stage_w_f'] = stage_times['stage'].copy()\nstage_times['stage'] = stage_times['stage_w_f'].astype(int)",
"_____no_output_____"
],
[
"# load manual connections\nmanual_map = pd.read_excel(data_dir / 'Stage - Event Array.xlsx', skiprows=1)\nconnections = manual_map.iloc[:,2:].apply(lambda x: x.dropna().unique().astype(int), axis=1)\nconnections.name = 'connections'\n\n# get well and stage\nwell_stg = manual_map.Stage.str.split(\"_\",expand=True)\nwell_stg.columns = ['well', 'stage']\nmanual_connections = pd.concat([well_stg, connections], axis=1)\nmanual_connections['stage_w_f'] = manual_connections['stage'].copy()\nmanual_connections['stage_w_f'] = manual_connections['stage_w_f'].str.replace('F',\".5\").astype(float)\nmanual_connections['stage'] = manual_connections['stage_w_f'].astype(int)\n\n# add stage geometry and start times\nmanual_connections = (manual_connections\n .merge(stage_times, on=['well','stage_w_f','stage'], how='left')\n .merge(stage_gdf, on=['well','stage'], how='left')\n .pipe(gpd.GeoDataFrame)\n )",
"_____no_output_____"
],
[
"# load manual f\nlineaments = pd.read_csv(data_dir / 'Seismic Lineament centres.csv')\nlineaments.columns = clean_columns(lineaments.columns)\nlineaments = gpd.GeoDataFrame(lineaments, geometry=gpd.points_from_xy(lineaments['x'], lineaments['y']))\nlineaments.head()",
"_____no_output_____"
],
[
"connections_out = []\nfor i, row in manual_connections.iterrows():\n for conn_fid in row.connections:\n # make one row per connection, with a single geometry\n stg_geom = row.geometry\n frac_geom = lineaments.query(\"id == @conn_fid\").geometry.iloc[0]\n conn_geom = LineString([stg_geom, frac_geom])\n conn_out = gpd.GeoDataFrame(\n row.to_frame().transpose()[['well','stage','well_stage','start_date','is_count']].reset_index(),\n geometry=[conn_geom]\n )\n conn_out['fid'] = conn_fid\n conn_out['start_date'] = conn_out.start_date.astype(str)\n connections_out.append(conn_out)",
"_____no_output_____"
],
[
"connections_out = pd.concat(connections_out)",
"_____no_output_____"
],
[
"connections_out.to_file(data_dir / 'manual_connections.shp')\nconnections_out.to_file(data_dir / 'manual_connections.geojson', driver='GeoJSON')",
"C:\\Users\\scott.mckean\\Miniconda3\\lib\\site-packages\\geopandas\\io\\file.py:299: FutureWarning: pandas.Int64Index is deprecated and will be removed from pandas in a future version. Use pandas.Index with the appropriate dtype instead.\n pd.Int64Index,\n"
],
[
"connections_out.query(\"well_stage == 'A6_28F'\")",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nfig, ax = plt.subplots()\nsurvey_linestrings.plot(ax = ax)\nfrac_gdf.plot(ax = ax, color='r')\nstage_gdf.set_geometry('stg_line').plot(ax = ax, color='k')\nconnections_out.plot(ax = ax, color='b')\nax.set_aspect('equal')\nplt.xlim(-250, 2000)\nplt.ylim(-1250, 1000)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.